mirror of
https://github.com/LCTT/TranslateProject.git
synced 2024-12-26 21:30:55 +08:00
remove www.codementor.io
This commit is contained in:
parent
3d0be8766c
commit
2ae455bf4f
@ -1,363 +0,0 @@
|
||||
translating by lujun9972
|
||||
Advanced Python Debugging with pdb
|
||||
======
|
||||
|
||||
|
||||
|
||||
Python's built-in [`pdb`][1] module is extremely useful for interactive debugging, but has a bit of a learning curve. For a long time, I stuck to basic `print`-debugging and used `pdb` on a limited basis, which meant I missed out on a lot of features that would have made debugging faster and easier.
|
||||
|
||||
In this post I will show you a few tips I've picked up over the years to level up my interactive debugging skills.
|
||||
|
||||
## Print debugging vs. interactive debugging
|
||||
|
||||
First, why would you want to use an interactive debugger instead of inserting `print` or `logging` statements into your code?
|
||||
|
||||
With `pdb`, you have a lot more flexibility to run, resume, and alter the execution of your program without touching the underlying source. Once you get good at this, it means more time spent diving into issues and less time context switching back and forth between your editor and the command line.
|
||||
|
||||
Also, by not touching the underlying source code, you will have the ability to step into third party code (e.g. modules installed from PyPI) and the standard library.
|
||||
|
||||
## Post-mortem debugging
|
||||
|
||||
The first workflow I used after moving away from `print` debugging was `pdb`'s "post-mortem debugging" mode. This is where you run your program as usual, but whenever an unhandled exception is thrown, you drop down into the debugger to poke around in the program state. After that, you attempt to make a fix and repeat the process until the problem is resolved.
|
||||
|
||||
You can run an existing script with the post-mortem debugger by using Python's `-mpdb` option:
|
||||
```
|
||||
python3 -mpdb path/to/script.py
|
||||
|
||||
```
|
||||
|
||||
From here, you are dropped into a `(Pdb)` prompt. To start execution, you use the `continue` or `c` command. If the program executes successfully, you will be taken back to the `(Pdb)` prompt where you can restart the execution again. At this point, you can use `quit` / `q` or Ctrl+D to exit the debugger.
|
||||
|
||||
If the program throws an unhandled exception, you'll also see a `(Pdb)` prompt, but with the program execution stopped at the line that threw the exception. From here, you can run Python code and debugger commands at the prompt to inspect the current program state.
|
||||
|
||||
## Testing our basic workflow
|
||||
|
||||
To see how these basic debugging steps work, I'll be using this (buggy) program:
|
||||
```
|
||||
import random
|
||||
|
||||
MAX = 100
|
||||
|
||||
def main(num_loops=1000):
|
||||
for i in range(num_loops):
|
||||
num = random.randint(0, MAX)
|
||||
denom = random.randint(0, MAX)
|
||||
result = num / denom
|
||||
print("{} divided by {} is {:.2f}".format(num, denom, result))
|
||||
|
||||
if __name__ == "__main__":
|
||||
import sys
|
||||
arg = sys.argv[-1]
|
||||
if arg.isdigit():
|
||||
main(arg)
|
||||
else:
|
||||
main()
|
||||
|
||||
```
|
||||
|
||||
We're expecting the program to do some basic math operations on random numbers in a loop and print the result. Try running it normally and you will see one of the bugs:
|
||||
```
|
||||
$ python3 script.py
|
||||
2 divided by 30 is 0.07
|
||||
65 divided by 41 is 1.59
|
||||
0 divided by 70 is 0.00
|
||||
...
|
||||
38 divided by 26 is 1.46
|
||||
Traceback (most recent call last):
|
||||
File "script.py", line 16, in <module>
|
||||
main()
|
||||
File "script.py", line 7, in main
|
||||
result = num / denom
|
||||
ZeroDivisionError: division by zero
|
||||
|
||||
```
|
||||
|
||||
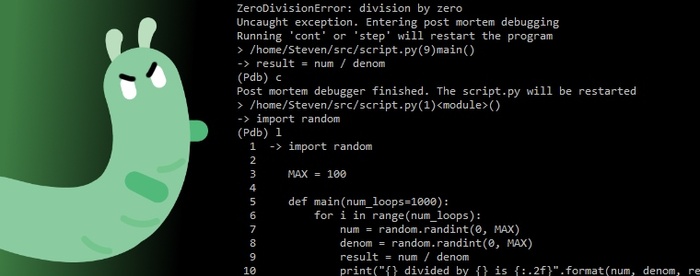
Let's try post-mortem debugging this error:
|
||||
```
|
||||
$ python3 -mpdb script.py
|
||||
> ./src/script.py(1)<module>()
|
||||
-> import random
|
||||
(Pdb) c
|
||||
49 divided by 46 is 1.07
|
||||
...
|
||||
Traceback (most recent call last):
|
||||
File "/usr/lib/python3.4/pdb.py", line 1661, in main
|
||||
pdb._runscript(mainpyfile)
|
||||
File "/usr/lib/python3.4/pdb.py", line 1542, in _runscript
|
||||
self.run(statement)
|
||||
File "/usr/lib/python3.4/bdb.py", line 431, in run
|
||||
exec(cmd, globals, locals)
|
||||
File "<string>", line 1, in <module>
|
||||
File "./src/script.py", line 1, in <module>
|
||||
import random
|
||||
File "./src/script.py", line 7, in main
|
||||
result = num / denom
|
||||
ZeroDivisionError: division by zero
|
||||
Uncaught exception. Entering post mortem debugging
|
||||
Running 'cont' or 'step' will restart the program
|
||||
> ./src/script.py(7)main()
|
||||
-> result = num / denom
|
||||
(Pdb) num
|
||||
76
|
||||
(Pdb) denom
|
||||
0
|
||||
(Pdb) random.randint(0, MAX)
|
||||
56
|
||||
(Pdb) random.randint(0, MAX)
|
||||
79
|
||||
(Pdb) random.randint(0, 1)
|
||||
0
|
||||
(Pdb) random.randint(1, 1)
|
||||
1
|
||||
|
||||
```
|
||||
|
||||
Once the post-mortem debugger kicks in, we can inspect all of the variables in the current frame and even run new code to help us figure out what's wrong and attempt to make a fix.
|
||||
|
||||
## Dropping into the debugger from Python code using `pdb.set_trace`
|
||||
|
||||
Another technique that I used early on, after starting to use `pdb`, was forcing the debugger to run at a certain line of code before an error occurred. This is a common next step after learning post-mortem debugging because it feels similar to debugging with `print` statements.
|
||||
|
||||
For example, in the above code, if we want to stop execution before the division operation, we could add a `pdb.set_trace` call to our program here:
|
||||
```
|
||||
import pdb; pdb.set_trace()
|
||||
result = num / denom
|
||||
|
||||
```
|
||||
|
||||
And then run our program without `-mpdb`:
|
||||
```
|
||||
$ python3 script.py
|
||||
> ./src/script.py(10)main()
|
||||
-> result = num / denom
|
||||
(Pdb) num
|
||||
94
|
||||
(Pdb) denom
|
||||
19
|
||||
|
||||
```
|
||||
|
||||
The problem with this method is that you have to constantly drop these statements into your source code, remember to remove them afterwards, and switch between running your code with `python` vs. `python -mpdb`.
|
||||
|
||||
Using `pdb.set_trace` gets the job done, but **breakpoints** are an even more flexible way to stop the debugger at any line (even third party or standard library code), without needing to modify any source code. Let's learn about breakpoints and a few other useful commands.
|
||||
|
||||
## Debugger commands
|
||||
|
||||
There are over 30 commands you can give to the interactive debugger, a list that can be seen by using the `help` command when at the `(Pdb)` prompt:
|
||||
```
|
||||
(Pdb) help
|
||||
|
||||
Documented commands (type help <topic>):
|
||||
========================================
|
||||
EOF c d h list q rv undisplay
|
||||
a cl debug help ll quit s unt
|
||||
alias clear disable ignore longlist r source until
|
||||
args commands display interact n restart step up
|
||||
b condition down j next return tbreak w
|
||||
break cont enable jump p retval u whatis
|
||||
bt continue exit l pp run unalias where
|
||||
|
||||
```
|
||||
|
||||
You can use `help <topic>` for more information on a given command.
|
||||
|
||||
Instead of walking through each command, I'll list out the ones I've found most useful and what arguments they take.
|
||||
|
||||
**Setting breakpoints** :
|
||||
|
||||
* `l(ist)`: displays the source code of the currently running program, with line numbers, for the 10 lines around the current statement.
|
||||
* `l 1,999`: displays the source code of lines 1-999. I regularly use this to see the source for the entire program. If your program only has 20 lines, it'll just show all 20 lines.
|
||||
* `b(reakpoint)`: displays a list of current breakpoints.
|
||||
* `b 10`: set a breakpoint at line 10. Breakpoints are referred to by a numeric ID, starting at 1.
|
||||
* `b main`: set a breakpoint at the function named `main`. The function name must be in the current scope. You can also set breakpoints on functions in other modules in the current scope, e.g. `b random.randint`.
|
||||
* `b script.py:10`: sets a breakpoint at line 10 in `script.py`. This gives you another way to set breakpoints in another module.
|
||||
* `clear`: clears all breakpoints.
|
||||
* `clear 1`: clear breakpoint 1.
|
||||
|
||||
|
||||
|
||||
**Stepping through execution** :
|
||||
|
||||
* `c(ontinue)`: execute until the program finishes, an exception is thrown, or a breakpoint is hit.
|
||||
* `s(tep)`: execute the next line, whatever it is (your code, stdlib, third party code, etc.). Use this when you want to step down into function calls you're interested in.
|
||||
* `n(ext)`: execute the next line in the current function (will not step into downstream function calls). Use this when you're only interested in the current function.
|
||||
* `r(eturn)`: execute the remaining lines in the current function until it returns. Use this to skip over the rest of the function and go up a level. For example, if you've stepped down into a function by mistake.
|
||||
* `unt(il) [lineno]`: execute until the current line exceeds the current line number. This is useful when you've stepped into a loop but want to let the loop continue executing without having to manually step through every iteration. Without any argument, this command behaves like `next` (with the loop skipping behavior, once you've stepped through the loop body once).
|
||||
|
||||
|
||||
|
||||
**Moving up and down the stack** :
|
||||
|
||||
* `w(here)`: shows an annotated view of the stack trace, with your current frame marked by `>`.
|
||||
* `u(p)`: move up one frame in the current stack trace. For example, when post-mortem debugging, you'll start off on the lowest level of the stack and typically want to move `up` a few times to help figure out what went wrong.
|
||||
* `d(own)`: move down one frame in the current stack trace.
|
||||
|
||||
|
||||
|
||||
**Additional commands and tips** :
|
||||
|
||||
* `pp <expression>`: This will "pretty print" the result of the given expression using the [`pprint`][2] module. Example:
|
||||
|
||||
|
||||
```
|
||||
(Pdb) stuff = "testing the pp command in pdb with a big list of strings"
|
||||
(Pdb) pp [(i, x) for (i, x) in enumerate(stuff.split())]
|
||||
[(0, 'testing'),
|
||||
(1, 'the'),
|
||||
(2, 'pp'),
|
||||
(3, 'command'),
|
||||
(4, 'in'),
|
||||
(5, 'pdb'),
|
||||
(6, 'with'),
|
||||
(7, 'a'),
|
||||
(8, 'big'),
|
||||
(9, 'list'),
|
||||
(10, 'of'),
|
||||
(11, 'strings')]
|
||||
|
||||
```
|
||||
|
||||
* `!<python code>`: sometimes the Python code you run in the debugger will be confused for a command. For example `c = 1` will trigger the `continue` command. To force the debugger to execute Python code, prefix the line with `!`, e.g. `!c = 1`.
|
||||
|
||||
* Pressing the Enter key at the `(Pdb)` prompt will execute the previous command again. This is most useful after the `s`/`n`/`r`/`unt` commands to quickly step through execution line-by-line.
|
||||
|
||||
* You can run multiple commands on one line by separating them with `;;`, e.g. `b 8 ;; c`.
|
||||
|
||||
* The `pdb` module can take multiple `-c` arguments on the command line to execute commands as soon as the debugger starts.
|
||||
|
||||
|
||||
|
||||
|
||||
Example:
|
||||
```
|
||||
python3 -mpdb -cc script.py # run the program without you having to enter an initial "c" at the prompt
|
||||
python3 -mpdb -c "b 8" -cc script.py # sets a breakpoint on line 8 and runs the program
|
||||
|
||||
```
|
||||
|
||||
## Restart behavior
|
||||
|
||||
Another thing that can shave time off debugging is understanding how `pdb`'s restart behavior works. You may have noticed that after execution stops, `pdb` will give a message like, "The program finished and will be restarted," or "The script will be restarted." When I first started using `pdb`, I would always quit and re-run `python -mpdb ...` to make sure that my code changes were getting picked up, which was unnecessary in most cases.
|
||||
|
||||
When `pdb` says it will restart the program, or when you use the `restart` command, code changes to the script you're debugging will be reloaded automatically. Breakpoints will still be set after reloading, but may need to be cleared and re-set due to line numbers shifting. Code changes to other imported modules will not be reloaded -- you will need to `quit` and re-run the `-mpdb` command to pick those up.
|
||||
|
||||
## Watches
|
||||
|
||||
One feature you may miss from other interactive debuggers is the ability to "watch" a variable change throughout the program's execution. `pdb` does not include a watch command by default, but you can get something similar by using `commands`, which lets you run arbitrary Python code whenever a breakpoint is hit.
|
||||
|
||||
To watch what happens to the `denom` variable in our example program:
|
||||
```
|
||||
$ python3 -mpdb script.py
|
||||
> ./src/script.py(1)<module>()
|
||||
-> import random
|
||||
(Pdb) b 9
|
||||
Breakpoint 1 at ./src/script.py:9
|
||||
(Pdb) commands
|
||||
(com) silent
|
||||
(com) print("DENOM: {}".format(denom))
|
||||
(com) c
|
||||
(Pdb) c
|
||||
DENOM: 77
|
||||
71 divided by 77 is 0.92
|
||||
DENOM: 27
|
||||
100 divided by 27 is 3.70
|
||||
DENOM: 10
|
||||
82 divided by 10 is 8.20
|
||||
DENOM: 20
|
||||
...
|
||||
|
||||
```
|
||||
|
||||
We first set a breakpoint (which is assigned ID 1), then use `commands` to start entering a block of commands. These commands function as if you had typed them at the `(Pdb)` prompt. They can be either Python code or additional `pdb` commands.
|
||||
|
||||
Once we start the `commands` block, the prompt changes to `(com)`. The `silent` command means the following commands will not be echoed back to the screen every time they're executed, which makes reading the output a little easier.
|
||||
|
||||
After that, we run a `print` statement to inspect the variable, similar to what we might do when `print` debugging. Finally, we end with a `c` to continue execution, which ends the command block. Typing `c` again at the `(Pdb)` prompt starts execution and we see our new `print` statement running.
|
||||
|
||||
If you'd rather stop execution instead of continuing, you can use `end` instead of `c` in the command block.
|
||||
|
||||
## Running pdb from the interpreter
|
||||
|
||||
Another way to run `pdb` is via the interpreter, which is useful when you're experimenting interactively and would like to drop into `pdb` without running a standalone script.
|
||||
|
||||
For post-mortem debugging, all you need is a call to `pdb.pm()` after an exception has occurred:
|
||||
```
|
||||
$ python3
|
||||
>>> import script
|
||||
>>> script.main()
|
||||
17 divided by 60 is 0.28
|
||||
...
|
||||
56 divided by 94 is 0.60
|
||||
Traceback (most recent call last):
|
||||
File "<stdin>", line 1, in <module>
|
||||
File "./src/script.py", line 9, in main
|
||||
result = num / denom
|
||||
ZeroDivisionError: division by zero
|
||||
>>> import pdb
|
||||
>>> pdb.pm()
|
||||
> ./src/script.py(9)main()
|
||||
-> result = num / denom
|
||||
(Pdb) num
|
||||
4
|
||||
(Pdb) denom
|
||||
0
|
||||
|
||||
```
|
||||
|
||||
If you want to step through normal execution instead, use the `pdb.run()` function:
|
||||
```
|
||||
$ python3
|
||||
>>> import script
|
||||
>>> import pdb
|
||||
>>> pdb.run("script.main()")
|
||||
> <string>(1)<module>()
|
||||
(Pdb) b script:6
|
||||
Breakpoint 1 at ./src/script.py:6
|
||||
(Pdb) c
|
||||
> ./src/script.py(6)main()
|
||||
-> for i in range(num_loops):
|
||||
(Pdb) n
|
||||
> ./src/script.py(7)main()
|
||||
-> num = random.randint(0, MAX)
|
||||
(Pdb) n
|
||||
> ./src/script.py(8)main()
|
||||
-> denom = random.randint(0, MAX)
|
||||
(Pdb) n
|
||||
> ./src/script.py(9)main()
|
||||
-> result = num / denom
|
||||
(Pdb) n
|
||||
> ./src/script.py(10)main()
|
||||
-> print("{} divided by {} is {:.2f}".format(num, denom, result))
|
||||
(Pdb) n
|
||||
66 divided by 70 is 0.94
|
||||
> ./src/script.py(6)main()
|
||||
-> for i in range(num_loops):
|
||||
|
||||
```
|
||||
|
||||
This one is a little trickier than `-mpdb` because you don't have the ability to step through an entire program. Instead, you'll need to manually set a breakpoint, e.g. on the first statement of the function you're trying to execute.
|
||||
|
||||
## Conclusion
|
||||
|
||||
Hopefully these tips have given you a few new ideas on how to use `pdb` more effectively. After getting a handle on these, you should be able to pick up the [other commands][3] and start customizing `pdb` via a `.pdbrc` file ([example][4]).
|
||||
|
||||
You can also look into other front-ends for debugging, like [pdbpp][5], [pudb][6], and [ipdb][7], or GUI debuggers like the one included in PyCharm. Happy debugging!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.codementor.io/stevek/advanced-python-debugging-with-pdb-g56gvmpfa
|
||||
|
||||
作者:[Steven Kryskalla][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.codementor.io/stevek
|
||||
[1]:https://docs.python.org/3/library/pdb.html
|
||||
[2]:https://docs.python.org/3/library/pprint.html
|
||||
[3]:https://docs.python.org/3/library/pdb.html#debugger-commands
|
||||
[4]:https://nedbatchelder.com/blog/200704/my_pdbrc.html
|
||||
[5]:https://pypi.python.org/pypi/pdbpp/
|
||||
[6]:https://pypi.python.org/pypi/pudb/
|
||||
[7]:https://pypi.python.org/pypi/ipdb
|
||||
@ -1,133 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Python Hello World and String Manipulation
|
||||
======
|
||||
|
||||
|
||||
|
||||
Before starting, I should mention that the [code][1] used in this blog post and in the [video][2] below is available on my github.
|
||||
|
||||
With that, let’s get started! If you get lost, I recommend opening the [video][3] below in a separate tab.
|
||||
|
||||
[Hello World and String Manipulation Video using Python][2]
|
||||
|
||||
#### ** Get Started (Prerequisites)
|
||||
|
||||
Install Anaconda (Python) on your operating system. You can either download anaconda from the [official site][4] and install on your own or you can follow these anaconda installation tutorials below.
|
||||
|
||||
Install Anaconda on Windows: [Link][5]
|
||||
|
||||
Install Anaconda on Mac: [Link][6]
|
||||
|
||||
Install Anaconda on Ubuntu (Linux): [Link][7]
|
||||
|
||||
#### Open a Jupyter Notebook
|
||||
|
||||
Open your terminal (Mac) or command line and type the following ([see 1:16 in the video to follow along][8]) to open a Jupyter Notebook:
|
||||
```
|
||||
jupyter notebook
|
||||
|
||||
```
|
||||
|
||||
#### Print Statements/Hello World
|
||||
|
||||
Type the following into a cell in Jupyter and type **shift + enter** to execute code.
|
||||
```
|
||||
# This is a one line comment
|
||||
print('Hello World!')
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
Output of printing ‘Hello World!’
|
||||
|
||||
#### Strings and String Manipulation
|
||||
|
||||
Strings are a special type of a python class. As objects, in a class, you can call methods on string objects using the .methodName() notation. The string class is available by default in python, so you do not need an import statement to use the object interface to strings.
|
||||
```
|
||||
# Create a variable
|
||||
# Variables are used to store information to be referenced
|
||||
# and manipulated in a computer program.
|
||||
firstVariable = 'Hello World'
|
||||
print(firstVariable)
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
Output of printing the variable firstVariable
|
||||
```
|
||||
# Explore what various string methods
|
||||
print(firstVariable.lower())
|
||||
print(firstVariable.upper())
|
||||
print(firstVariable.title())
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
Output of using .lower(), .upper() , and title() methods
|
||||
```
|
||||
# Use the split method to convert your string into a list
|
||||
print(firstVariable.split(' '))
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
Output of using the split method (in this case, split on space)
|
||||
```
|
||||
# You can add strings together.
|
||||
a = "Fizz" + "Buzz"
|
||||
print(a)
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
string concatenation
|
||||
|
||||
#### Look up what Methods Do
|
||||
|
||||
For new programmers, they often ask how you know what each method does. Python provides two ways to do this.
|
||||
|
||||
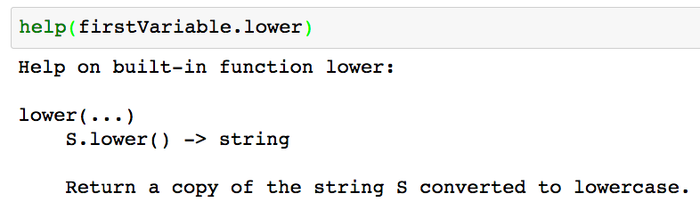
1. (works in and out of Jupyter Notebook) Use **help** to lookup what each method does.
|
||||
|
||||
|
||||
|
||||
![][9]
|
||||
Look up what each method does
|
||||
|
||||
2. (Jupyter Notebook exclusive) You can also look up what a method does by having a question mark after a method.
|
||||
|
||||
|
||||
```
|
||||
# To look up what each method does in jupyter (doesnt work outside of jupyter)
|
||||
firstVariable.lower?
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
Look up what each method does in Jupyter
|
||||
|
||||
#### Closing Remarks
|
||||
|
||||
Please let me know if you have any questions either here or in the comments section of the [youtube video][2]. The code in the post is also available on my [github][1]. Part 2 of the tutorial series is [Simple Math][10].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.codementor.io/mgalarny/python-hello-world-and-string-manipulation-gdgwd8ymp
|
||||
|
||||
作者:[Michael][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.codementor.io/mgalarny
|
||||
[1]:https://github.com/mGalarnyk/Python_Tutorials/blob/master/Python_Basics/Intro/Python3Basics_Part1.ipynb
|
||||
[2]:https://www.youtube.com/watch?v=JqGjkNzzU4s
|
||||
[3]:https://www.youtube.com/watch?v=kApPBm1YsqU
|
||||
[4]:https://www.continuum.io/downloads
|
||||
[5]:https://medium.com/@GalarnykMichael/install-python-on-windows-anaconda-c63c7c3d1444
|
||||
[6]:https://medium.com/@GalarnykMichael/install-python-on-mac-anaconda-ccd9f2014072
|
||||
[7]:https://medium.com/@GalarnykMichael/install-python-on-ubuntu-anaconda-65623042cb5a
|
||||
[8]:https://youtu.be/JqGjkNzzU4s?t=1m16s
|
||||
[9]:data:image/gif;base64,R0lGODlhAQABAAAAACH5BAEKAAEALAAAAAABAAEAAAICTAEAOw==
|
||||
[10]:https://medium.com/@GalarnykMichael/python-basics-2-simple-math-4ac7cc928738
|
||||
@ -1,51 +0,0 @@
|
||||
Translating by Torival Linear Regression Classifier from scratch using Numpy and Stochastic gradient descent as an optimization technique
|
||||
======
|
||||
|
||||
|
||||
|
||||
In statistics, linear regression is a linear approach for modelling the relationship between a scalar dependent variable y and one or more explanatory variables (or independent variables) denoted X. The case of one explanatory variable is called simple linear regression. For more than one explanatory variable, the process is called multiple linear regression.
|
||||
|
||||
As you may know the equation of line with a slope **m** and intercept **c** is given by **y=mx+c** .Now in our dataset **x** is a feature and **y** is the label that is the output.
|
||||
|
||||
Now we will start with some random values of m and c and by using our classifier we will adjust their values so that we obtain a line with the best fit.
|
||||
|
||||
Suppose we have a dataset with a single feature given by **X=[1,2,3,4,5,6,7,8,9,10]** and label/output being **Y=[1,4,9,16,25,36,49,64,81,100]**.We start with random value of **m** being **1** and **c** being **0**. Now starting with the first data point which is **x=1** we will calculate its corresponding output which is **y=m*x+c** - > **y=1-1+0** - > **y=1** .
|
||||
|
||||
Now this is our guess for the given input.Now we will subtract the calculated y which is our guess whith the actual output which is **y(original)=1** to calculate the error which is **y(guess)-y(original)** which can also be termed as our cost function when we take the square of its mean and our aim is to minimize this cost.
|
||||
|
||||
After each iteration through the data points we will change our values of **m** and **c** such that the obtained m and c gives the line with the best fit.Now how we can do this?
|
||||
|
||||
The answer is using **Gradient Descent Technique**.
|
||||
|
||||
![Gd_demystified.png][1]
|
||||
|
||||
In gradient descent we look to minimize the cost function and in order to minimize the cost function we need to minimize the error which is given by **error=y(guess)-y(original)**.
|
||||
|
||||
|
||||
Now error depends on two values **m** and **c** . Now if we take the partial derivative of error with respect to **m** and **c** we can get to know the oreintation i.e whether we need to increase the values of m and c or decrease them in order to obtain the line of best fit.
|
||||
|
||||
Now error depends on two values **m** and **c**.So on taking partial derivative of error with respect to **m** we get **x** and taking partial derivative of error with repsect to **c** we get a constant.
|
||||
|
||||
So if we apply two changes that is **m=m-error*x** and **c=c-error*1** after every iteration we can adjust the value of m and c to obtain the line with the best fit.
|
||||
|
||||
Now error can be negative as well as positive.When the error is negative it means our **m** and **c** are smaller than the actual **m** and **c** and hence we would need to increase their values and if the error is positive we would need to decrease their values that is what we are doing.
|
||||
|
||||
But wait we also need a constant called the learning_rate so that we don't increase or decrease the values of **m** and **c** with a steep rate .so we need to multiply **m=m-error * x * learning_rate** and **c=c-error * 1 * learning_rate** so as to make the process smooth.
|
||||
|
||||
So we need to update **m** to **m=m-error * x * learning_rate** and **c** to **c=c-error * 1 * learning_rate** to obtain the line with the best fit and this is our linear regreesion model using stochastic gradient descent meaning of stochastic being that we are updating the values of m and c in every iteration.
|
||||
|
||||
You can check the full code in python :[https://github.com/assassinsurvivor/MachineLearning/blob/master/Regression.py][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.codementor.io/prakharthapak/linear-regression-classifier-from-scratch-using-numpy-and-stochastic-gradient-descent-as-an-optimization-technique-gf5gm9yti
|
||||
|
||||
作者:[Prakhar Thapak][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.codementor.io/prakharthapak
|
||||
[1]:https://process.filestackapi.com/cache=expiry:max/5TXRH28rSo27kTNZLgdN
|
||||
[2]:https://www.codementor.io/prakharthapak/here
|
||||
@ -1,262 +0,0 @@
|
||||
Locust.io: Load-testing using vagrant
|
||||
======
|
||||
|
||||
|
||||
|
||||
What could possibly go wrong when you release an application to the public domain without testing? You could either wait to find out or you can just find out before releasing the product.
|
||||
|
||||
In this tutorial, we will be considering the art of load-testing, one of the several types of [non-functional test][1] required for a system.
|
||||
|
||||
According to wikipedia
|
||||
|
||||
> [Load testing][2] is the process of putting demand on a software system or computing device and measuring its response. Load testing is performed to determine a system's behavior under both normal and anticipated peak load conditions. It helps to identify the maximum operating capacity of an application as well as any bottlenecks and determine which element is causing degradation.
|
||||
|
||||
### What the heck is locust.io?
|
||||
[Locust][3] is an opensource load-testing tool that can be used to simulate millions of simultaneous users, it has other cool features that allows you to visualize the data generated from the test plus it has been proven & battle tested ![😃][4]
|
||||
|
||||
### Why Vagrant?
|
||||
Because [vagrant][5] allows us to build and maintain our near replica production environment with the right parameters for memory, CPU, storage, and disk i/o.
|
||||
|
||||
### Why VirtualBox?
|
||||
VirtualBox here will act as our hypervisor, the computer software that will create and run our virtual machine(s).
|
||||
|
||||
### So, what is the plan here?
|
||||
|
||||
* Download [Vagrant][6] and [VirtualBox][7]
|
||||
* Set up a near-production replica environment using ### vagrant** and **virtualbox [SOURCE_CODE_APPLICATION][8]
|
||||
* Set up locust to run our load test [SOURCE_CODE_LOCUST][9]
|
||||
* Execute test against our production replica environment and check performance
|
||||
|
||||
|
||||
|
||||
### Some context
|
||||
Vagrant uses "Provisioners" and "Providers" as building blocks to manage the development environments.
|
||||
|
||||
> Provisioners are tools that allow users to customize the configuration of virtual environments. Puppet and Chef are the two most widely used provisioners in the Vagrant ecosystem.
|
||||
> Providers are the services that Vagrant uses to set up and create virtual environments.
|
||||
|
||||
Reference can be found [here][10]
|
||||
|
||||
That said for our vagrant configuration we will be making use of the Vagrant Shell provisioner and VirtualBox for our provider, just a simple setup for now ![😉][11]
|
||||
|
||||
One more thing, the Machine, and software requirements are written in a file called "Vagrantfile" to execute necessary steps in order to create a development-ready box, so let's get down to business.
|
||||
|
||||
### A near production environment using Vagrant and Virtualbox
|
||||
I used a past project of mine, a very minimal Python/Django application I called Bookshelf to create a near-production environment. Here is the link to the [repository][8]
|
||||
|
||||
Let's create our environmnet using a vagrantfile.
|
||||
Use the command `vagrant init --minimal hashicorp/precise64` to create a vagrant file, where `hashicorp` is the username and `precise64` is the box name.
|
||||
|
||||
More about getting started with vagrant can be found [here][12]
|
||||
```
|
||||
# vagrant file
|
||||
|
||||
# set our environment to use our host private and public key to access the VM
|
||||
# as vagrant project provides an insecure key pair for SSH Public Key # Authentication so that vagrant ssh works
|
||||
# https://stackoverflow.com/questions/14715678/vagrant-insecure-by-default
|
||||
|
||||
private_key_path = File.join(Dir.home, ".ssh", "id_rsa")
|
||||
public_key_path = File.join(Dir.home, ".ssh", "id_rsa.pub")
|
||||
insecure_key_path = File.join(Dir.home, ".vagrant.d", "insecure_private_key")
|
||||
|
||||
private_key = IO.read(private_key_path)
|
||||
public_key = IO.read(public_key_path)
|
||||
|
||||
# Set the environment details here
|
||||
Vagrant.configure("2") do |config|
|
||||
config.vm.box = "hashicorp/precise64"
|
||||
config.vm.hostname = "bookshelf-dev"
|
||||
# using a private network here, so don't forget to update your /etc/host file.
|
||||
# 192.168.50.4 bookshelf.example
|
||||
config.vm.network "private_network", ip: "192.168.50.4"
|
||||
|
||||
config.ssh.insert_key = false
|
||||
config.ssh.private_key_path = [
|
||||
private_key_path,
|
||||
insecure_key_path # to provision the first time
|
||||
]
|
||||
|
||||
# reference: https://github.com/hashicorp/vagrant/issues/992 @dwickern
|
||||
# use host/personal public and private key for security reasons
|
||||
config.vm.provision :shell, :inline => <<-SCRIPT
|
||||
set -e
|
||||
mkdir -p /vagrant/.ssh/
|
||||
|
||||
echo '#{private_key}' > /vagrant/.ssh/id_rsa
|
||||
chmod 600 /vagrant/.ssh/id_rsa
|
||||
|
||||
echo '#{public_key}' > /vagrant/.ssh/authorized_keys
|
||||
chmod 600 /vagrant/.ssh/authorized_keys
|
||||
SCRIPT
|
||||
|
||||
# Use a shell provisioner here
|
||||
config.vm.provision "shell" do |s|
|
||||
s.path = ".provision/setup_env.sh"
|
||||
s.args = ["set_up_python"]
|
||||
end
|
||||
|
||||
|
||||
config.vm.provision "shell" do |s|
|
||||
s.path = ".provision/setup_nginx.sh"
|
||||
s.args = ["set_up_nginx"]
|
||||
end
|
||||
|
||||
if Vagrant.has_plugin?("vagrant-vbguest")
|
||||
config.vbguest.auto_update = false
|
||||
end
|
||||
|
||||
# set your environment parameters here
|
||||
config.vm.provider 'virtualbox' do |v|
|
||||
v.memory = 2048
|
||||
v.cpus = 2
|
||||
end
|
||||
|
||||
config.vm.post_up_message = "At this point use `vagrant ssh` to ssh into the development environment"
|
||||
end
|
||||
|
||||
```
|
||||
|
||||
Something to note here, notice the config `config.vm.network "private_network", ip: "192.168.50.4"` where I configured the Virtual machine network to use a private network "192.168.59.4", I edited my `/etc/hosts` file to map that IP address to the fully qualified domain name (FQDN) of the application called `bookshelf.example`. So, don't forget to edit your `/etc/hosts/` as well it should look like this
|
||||
```
|
||||
##
|
||||
# /etc/host
|
||||
# Host Database
|
||||
#
|
||||
# localhost is used to configure the loopback interface
|
||||
# when the system is booting. Do not change this entry.
|
||||
##
|
||||
127.0.0.1 localhost
|
||||
255.255.255.255 broadcasthost
|
||||
::1 localhost
|
||||
192.168.50.4 bookshelf.example
|
||||
|
||||
```
|
||||
|
||||
The provision scripts can be found in the `.provision` [folder][13] of the repository
|
||||
![provision_sd.png][14]
|
||||
|
||||
There you would see all the scripts used in the setup, the `start_app.sh` is used to run the application once you are in the virtual machine via ssh.
|
||||
|
||||
To start the process run `vagrant up && vagrant ssh`, this will start the application and take you via ssh into the VM, inside the VM navigate to the `/vagrant/` folder to start the app via the command `./start_app.sh`
|
||||
|
||||
With our application up and running, next would be to create a load testing script to run against our setup.
|
||||
|
||||
### NB: The current application setup here makes use of sqlite3 for the database config, you can change that to Postgres by uncommenting that in the settings file. Also, `setup_env.sh` provisions the environment to use Postgres.
|
||||
|
||||
To set up a more comprehensive and robust production replica environment I would suggest you reference the docs [here][15], you can also check out [vagrant][5] to understand and play with vagrant.
|
||||
|
||||
### Set up locust for load-testing
|
||||
In other to perform load testing we are going to make use of locust. Source code can be found [here][9]
|
||||
|
||||
First, we create our locust file
|
||||
```
|
||||
# locustfile.py
|
||||
|
||||
# script used against vagrant set up on bookshelf git repo
|
||||
# url to repo: https://github.com/andela-sjames/bookshelf
|
||||
|
||||
from locust import HttpLocust, TaskSet, task
|
||||
|
||||
class SampleTrafficTask(TaskSet):
|
||||
|
||||
@task(2)
|
||||
def index(self):
|
||||
self.client.get("/")
|
||||
|
||||
@task(1)
|
||||
def search_for_book_that_contains_string_space(self):
|
||||
self.client.get("/?q=space")
|
||||
|
||||
@task(1)
|
||||
def search_for_book_that_contains_string_man(self):
|
||||
self.client.get("/?q=man")
|
||||
|
||||
class WebsiteUser(HttpLocust):
|
||||
host = "http://bookshelf.example"
|
||||
task_set = SampleTrafficTask
|
||||
min_wait = 5000
|
||||
max_wait = 9000
|
||||
|
||||
```
|
||||
|
||||
Here is a simple locust file called `locustfile.py`, where we define a number of locust task grouped under the `TaskSet class`. Then we have the `HttpLocust class` which represents a user, where we define how long a simulated user should wait between executing tasks, as well as what TaskSet class should define the user’s “behavior”.
|
||||
|
||||
using the filename locustfile.py allows us to start the process by simply running the command `locust`. If you choose to give your file a different name then you just need to reference the path using `locust -f /path/to/the/locust/file` to start the script.
|
||||
|
||||
If you're getting excited and want to know more then the [quick start][16] guide will get up to speed.
|
||||
|
||||
### Execute test and check perfomance
|
||||
|
||||
It's time to see some action ![😮][17]
|
||||
|
||||
Bookshelf app:
|
||||
Run the application via `vagrant up && vagrant ssh` navigate to the `/vagrant` and run `./start_app.sh`
|
||||
|
||||
Vagrant allows you to shut down the running machine using `vagrant halt` and to destroy the machine and all the resources that were created with it using `vagrant destroy`. Use this [link][18] to know more about the vagrant command line.
|
||||
|
||||
![bookshelf_str.png][14]
|
||||
|
||||
Go to your browser and use the private_ip address `192.168.50.4` or preferably `http://bookshelf.example` what we set in our `/etc/host` file of the system
|
||||
`192.168.50.4 bookshelf.example`
|
||||
|
||||
![bookshelf_app_web.png][14]
|
||||
|
||||
Locust Swarm:
|
||||
Within your load-testing folder, activate your `virtualenv`, get your dependencies down via `pip install -r requirements.txt` and run `locust`
|
||||
|
||||
![locust_str.png][14]
|
||||
|
||||
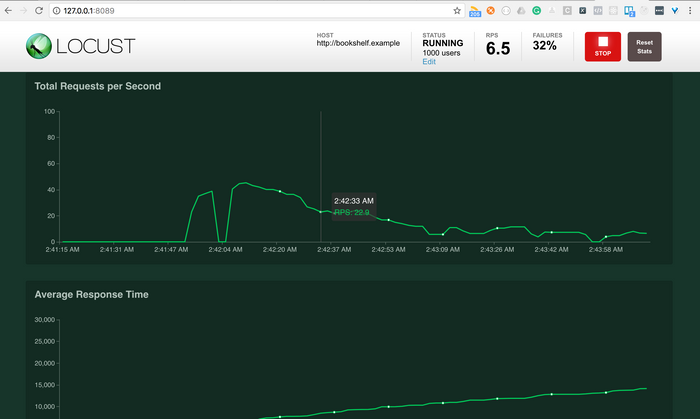
We're almost done:
|
||||
Now got to `http://127.0.0.1:8089/` on your browser
|
||||
![locust_rate.png][14]
|
||||
|
||||
Enter the number of users you want to simulate and the hatch rate (i.e how many users you want to be generated per second) and start swarming your development environment
|
||||
|
||||
**NB: You can also run locust against a development environment hosted via a cloud service if that is your use case. You don't have to confine yourself to vagrant.**
|
||||
|
||||
With the generated report and metric from the process, you should be able to make a well-informed decision on with regards to your system architecture or at least know the limit of your system and prepare for an anticipated event.
|
||||
|
||||
![locust_1.png][14]
|
||||
|
||||
![locust_a.png][14]
|
||||
|
||||
![locust_b.png][14]
|
||||
|
||||
![locust_error.png][14]
|
||||
|
||||
### Conclusion
|
||||
Congrats!!! if you made it to the end. As a recap, we were able to talk about what load-testing is, why you would want to perform a load test on your application and how to do it using locust and vagrant with a VirtualBox provider and a Shell provisioner. We also looked at the metrics and data generated from the test.
|
||||
|
||||
**NB: If you want a more concise vagrant production environment you can reference the docs [here][15].**
|
||||
|
||||
Thanks for reading and feel free to like/share this post.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.codementor.io/samueljames/locust-io-load-testing-using-vagrant-ffwnjger9
|
||||
|
||||
作者:[Samuel James][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[1]:https://en.wikipedia.org/wiki/Non-functional_testing
|
||||
[2]:https://en.wikipedia.org/wiki/Load_testing
|
||||
[3]:https://locust.io/
|
||||
[4]:https://twemoji.maxcdn.com/2/72x72/1f603.png
|
||||
[5]:https://www.vagrantup.com/intro/index.html
|
||||
[6]:https://www.vagrantup.com/downloads.html
|
||||
[7]:https://www.virtualbox.org/wiki/Downloads
|
||||
[8]:https://github.com/andela-sjames/bookshelf
|
||||
[9]:https://github.com/andela-sjames/load-testing
|
||||
[10]:https://en.wikipedia.org/wiki/Vagrant_(software)
|
||||
[11]:https://twemoji.maxcdn.com/2/72x72/1f609.png
|
||||
[12]:https://www.vagrantup.com/intro/getting-started/install.html
|
||||
[13]:https://github.com/andela-sjames/bookshelf/tree/master/.provision
|
||||
[14]:data:image/gif;base64,R0lGODlhAQABAAAAACH5BAEKAAEALAAAAAABAAEAAAICTAEAOw==
|
||||
[15]:http://vagrant-django.readthedocs.io/en/latest/intro.html
|
||||
[16]:https://docs.locust.io/en/latest/quickstart.html
|
||||
[17]:https://twemoji.maxcdn.com/2/72x72/1f62e.png
|
||||
[18]:https://www.vagrantup.com/docs/cli/
|
||||
@ -1,243 +0,0 @@
|
||||
Apache Beam: a Python example
|
||||
======
|
||||
|
||||

|
||||
|
||||
Nowadays, being able to handle huge amounts of data can be an interesting skill: analytics, user profiling, statistics — virtually any business that needs to extrapolate information from whatever data is, in one way or another, using some big data tools or platforms.
|
||||
|
||||
One of the most interesting tool is Apache Beam, a framework that gives us the instruments to generate procedures to transform, process, aggregate, and manipulate data for our needs.
|
||||
|
||||
Let’s try and see how we can use it in a very simple scenario.
|
||||
|
||||
### The context
|
||||
|
||||
Imagine that we have a database with information about users visiting a website, with each record containing:
|
||||
|
||||
* country of the visiting user
|
||||
* duration of the visit
|
||||
* user name
|
||||
|
||||
|
||||
|
||||
We want to create some reports containing:
|
||||
|
||||
1. for each country, the **number of users** visiting the website
|
||||
2. for each country, the **average visit time**
|
||||
|
||||
|
||||
|
||||
We will use **Apache Beam** , a Google SDK (previously called Dataflow) representing a **programming model** aimed at simplifying the mechanism of large-scale data processing.
|
||||
|
||||
It’s been donated to the Apache Foundation, and called Beam because it’s able to process data in whatever form you need: **batches** and **streams** (b-eam). It gives you the chance to define **pipelines** to process real-time data ( **streams** ) and historical data ( **batches** ).
|
||||
|
||||
The pipeline definition is totally disjointed by the context that you will use to run it, so Beam gives you the chance to choose one of the supported runners you can use:
|
||||
|
||||
* Beam model: local execution of your pipeline
|
||||
* Google Cloud Dataflow: dataflow as a service
|
||||
* Apache Flink
|
||||
* Apache Spark
|
||||
* Apache Gearpump
|
||||
* Apache Hadoop MapReduce
|
||||
* JStorm
|
||||
* IBM Streams
|
||||
|
||||
|
||||
|
||||
We will be running the beam model one, which basically executes everything on your local machine.
|
||||
|
||||
### The programming model
|
||||
|
||||
Though this is not going to be a deep explanation of the DataFlow programming model, it’s necessary to understand what a pipeline is: a set of manipulations being made on an input data set that provides a new set of data. More precisely, a pipeline is made of **transforms** applied to **collections.**
|
||||
|
||||
Straight from the [Apache Beam website][1]:
|
||||
|
||||
> A pipeline encapsulates your entire data processing task, from start to finish. This includes reading input data, transforming that data, and writing output data.
|
||||
|
||||
The pipeline gets data injected from the outside and represents it as **collections** (formally named `PCollection` s ), each of them being
|
||||
|
||||
> a potentially distributed, multi-element, data set
|
||||
|
||||
When one or more `Transform` s are applied to a `PCollection`, a brand new `PCollection` is generated (and for this reason the resulting `PCollection` s are **immutable** objects).
|
||||
|
||||
The first and last step of a pipeline are, of course, the ones that can read and write data to and from several kind of storages — you can find a list [here][2].
|
||||
|
||||
### The application
|
||||
|
||||
We will have the data in a `csv` file, so the first thing we need to do is to read the contents of the file and provide a structured representation of all of the rows.
|
||||
|
||||
A generic row of the `csv` file will be like the following:
|
||||
```
|
||||
United States Of America, 0.5, John Doe
|
||||
|
||||
```
|
||||
|
||||
with the columns being the country, the visit time in seconds, and the user name, respectively.
|
||||
|
||||
Given the data we want to provide, let’s see what our pipeline will be doing and how.
|
||||
|
||||
### Read the input data set
|
||||
|
||||
The first step will be to read the input file.
|
||||
```
|
||||
with apache_beam.Pipeline(options=options) as p:
|
||||
|
||||
rows = (
|
||||
p |
|
||||
ReadFromText(input_filename) |
|
||||
apache_beam.ParDo(Split())
|
||||
)
|
||||
|
||||
```
|
||||
|
||||
In the above context, `p` is an instance of `apache_beam.Pipeline` and the first thing that we do is to apply a built-in transform, `apache_beam.io.textio.ReadFromText` that will load the contents of the file into a `PCollection`. After this, we apply a specific logic, `Split`, to process every row in the input file and provide a more convenient representation (a dictionary, specifically).
|
||||
|
||||
Here’s the `Split` function:
|
||||
```
|
||||
class Split(apache_beam.DoFn):
|
||||
|
||||
def process(self, element):
|
||||
country, duration, user = element.split(",")
|
||||
|
||||
return [{
|
||||
'country': country,
|
||||
'duration': float(duration),
|
||||
'user': user
|
||||
}]
|
||||
|
||||
```
|
||||
|
||||
The `ParDo` transform is a core one, and, as per official Apache Beam documentation:
|
||||
|
||||
`ParDo` is useful for a variety of common data processing operations, including:
|
||||
|
||||
* **Filtering a data set.** You can use `ParDo` to consider each element in a `PCollection` and either output that element to a new collection or discard it.
|
||||
* **Formatting or type-converting each element in a data set.** If your input `PCollection` contains elements that are of a different type or format than you want, you can use `ParDo` to perform a conversion on each element and output the result to a new `PCollection`.
|
||||
* **Extracting parts of each element in a data set.** If you have a`PCollection` of records with multiple fields, for example, you can use a `ParDo` to parse out just the fields you want to consider into a new `PCollection`.
|
||||
* **Performing computations on each element in a data set.** You can use `ParDo` to perform simple or complex computations on every element, or certain elements, of a `PCollection` and output the results as a new `PCollection`.
|
||||
|
||||
|
||||
|
||||
Please read more of this [here][3].
|
||||
|
||||
### Grouping relevant information under proper keys
|
||||
|
||||
At this point, we have a list of valid rows, but we need to reorganize the information under keys that are the countries referenced by such rows. For example, if we have three rows like the following:
|
||||
|
||||
> Spain (ES), 2.2, John Doe> Spain (ES), 2.9, John Wayne> United Kingdom (UK), 4.2, Frank Sinatra
|
||||
|
||||
we need to rearrange the information like this:
|
||||
```
|
||||
{
|
||||
"Spain (ES)": [2.2, 2.9],
|
||||
"United kingdom (UK)": [4.2]
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
If we do this, we have all the information in good shape to make all the calculations we need.
|
||||
|
||||
Here we go:
|
||||
```
|
||||
timings = (
|
||||
rows |
|
||||
apache_beam.ParDo(CollectTimings()) |
|
||||
"Grouping timings" >> apache_beam.GroupByKey() |
|
||||
"Calculating average" >> apache_beam.CombineValues(
|
||||
apache_beam.combiners.MeanCombineFn()
|
||||
)
|
||||
)
|
||||
|
||||
users = (
|
||||
rows |
|
||||
apache_beam.ParDo(CollectUsers()) |
|
||||
"Grouping users" >> apache_beam.GroupByKey() |
|
||||
"Counting users" >> apache_beam.CombineValues(
|
||||
apache_beam.combiners.CountCombineFn()
|
||||
)
|
||||
)
|
||||
|
||||
```
|
||||
|
||||
The classes `CollectTimings` and `CollectUsers` basically filter the rows that are of interest for our goal. They also rearrange each of them in the right form, that is something like:
|
||||
|
||||
> (“Spain (ES)”, 2.2)
|
||||
|
||||
At this point, we are able to use the `GroupByKey` transform, that will create a single record that, incredibly, groups all of the info that shares the same keys:
|
||||
|
||||
> (“Spain (ES)”, (2.2, 2.9))
|
||||
|
||||
Note: the key is always the first element of the tuple.
|
||||
|
||||
The very last missing bit of the logic to apply is the one that has to process the values associated to each key. The built-in transform is `apache_beam.CombineValues`, which is pretty much self explanatory.
|
||||
|
||||
The logics that are applied are `apache_beam.combiners.MeanCombineFn` and `apache_beam.combiners.CountCombineFn` respectively: the former calculates the arithmetic mean, the latter counts the element of a set.
|
||||
|
||||
For the sake of completeness, here is the definition of the two classes `CollectTimings` and `CollectUsers`:
|
||||
```
|
||||
class CollectTimings(apache_beam.DoFn):
|
||||
|
||||
def process(self, element):
|
||||
"""
|
||||
Returns a list of tuples containing country and duration
|
||||
"""
|
||||
|
||||
result = [
|
||||
(element['country'], element['duration'])
|
||||
]
|
||||
return result
|
||||
|
||||
|
||||
class CollectUsers(apache_beam.DoFn):
|
||||
|
||||
def process(self, element):
|
||||
"""
|
||||
Returns a list of tuples containing country and user name
|
||||
"""
|
||||
result = [
|
||||
(element['country'], element['user'])
|
||||
]
|
||||
return result
|
||||
|
||||
```
|
||||
|
||||
Note: the operation of applying multiple times some transforms to a given `PCollection` generates multiple brand new collections. This is called **collection branching**. It’s very well represented here:
|
||||
|
||||
Source: <https://beam.apache.org/images/design-your-pipeline-multiple-pcollections.png>
|
||||
|
||||
Basically, now we have two sets of information — the average visit time for each country and the number of users for each country. What we're missing is a single structure containing all of the information we want.
|
||||
|
||||
Also, having made a pipeline branching, we need to recompose the data. We can do this by using `CoGroupByKey`, which is nothing less than a **join** made on two or more collections that have the same keys.
|
||||
|
||||
The last two transforms are ones that format the info into `csv` entries while the other writes them to a file.
|
||||
|
||||
After this, the resulting `output.txt` file will contain rows like this one:
|
||||
|
||||
`Italy (IT),36,2.23611111111`
|
||||
|
||||
meaning that 36 people visited the website from Italy, spending, on average, 2.23 seconds on the website.
|
||||
|
||||
### The input data
|
||||
|
||||
The data used for this simulation has been procedurally generated: 10,000 rows, with a maximum of 200 different users, spending between 1 and 5 seconds on the website. This was needed to have a rough estimate on the resulting values we obtained. A new article about **pipeline testing** will probably follow.
|
||||
|
||||
### GitHub repository
|
||||
|
||||
The GitHub repository for this article is [here][4].
|
||||
|
||||
The README.md file contains everything needed to try it locally.!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.codementor.io/brunoripa/apache-beam-a-python-example-gapr8smod
|
||||
|
||||
作者:[Bruno Ripa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.codementor.io/brunoripa
|
||||
[1]:https://href.li/?https://beam.apache.org
|
||||
[2]:https://href.li/?https://beam.apache.org/documentation/programming-guide/#pipeline-io
|
||||
[3]:https://beam.apache.org/documentation/programming-guide/#pardo
|
||||
[4]:https://github.com/brunoripa/beam-example
|
||||
Loading…
Reference in New Issue
Block a user