mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-03 23:40:14 +08:00
commit
2a92452d5c
@ -1,39 +1,41 @@
|
||||
如何在 Linux 上安装应用程序
|
||||
=====
|
||||
|
||||
> 学习在你的 Linux 计算机上摆弄那些软件。
|
||||
|
||||

|
||||
|
||||
图片提供:Internet Archive Book Images。由 Opensource.com 修改。CC BY-SA 4.0
|
||||
|
||||
如何在 Linux 上安装应用程序?与有许多操作系统一样,这个问题不止有一个答案。应用程序可以可以来自许多来源-几乎不可能数的清,并且每个开发团队都可以以他们认为最好的方式提供软件。知道如何安装你所得到的软件是成为操作系统强大用户的一部分。
|
||||
|
||||
如何在 Linux 上安装应用程序?因为有许多操作系统,这个问题不止有一个答案。应用程序可以可以来自许多来源 —— 几乎不可能数的清,并且每个开发团队都可以以他们认为最好的方式提供软件。知道如何安装你所得到的软件是成为操作系统高级用户的一部分。
|
||||
|
||||
### 仓库
|
||||
|
||||
十多年来,Linux 已经使用软件库来分发软件。在这种情况下,“仓库”是一个托管可安装软件包的公共服务器。Linux 发行版提供了一条命令,通常是该命令的图形界面,用于从服务器获取软件并将其安装到你的计算机。这是一个非常简单的概念,它已经成为所有主流手机操作系统的模型,最近,它也成为了两大闭源计算机操作系统的“应用商店”。
|
||||
十多年来,Linux 已经在使用软件库来分发软件。在这种情况下,“仓库”是一个托管可安装软件包的公共服务器。Linux 发行版提供了一条命令,以及该命令的图形界面,用于从服务器获取软件并将其安装到你的计算机。这是一个非常简单的概念,它已经成为所有主流手机操作系统的模式,最近,该模式也成为了两大闭源计算机操作系统的“应用商店”。
|
||||
|
||||
![Linux repository][2]
|
||||
|
||||
不是一个应用程序商店
|
||||
*不是应用程序商店*
|
||||
|
||||
从软件仓库安装是在 Linux 上安装应用程序的主要方法,它应该是你想要安装的任何应用程序的第一个地方。
|
||||
从软件仓库安装是在 Linux 上安装应用程序的主要方法,它应该是你寻找想要安装的任何应用程序的首选地方。
|
||||
|
||||
从软件仓库安装,通常需要一个命令,如:
|
||||
|
||||
从软件仓库安装,通常需要一个命令:
|
||||
```
|
||||
$ sudo dnf install inkscape
|
||||
```
|
||||
|
||||
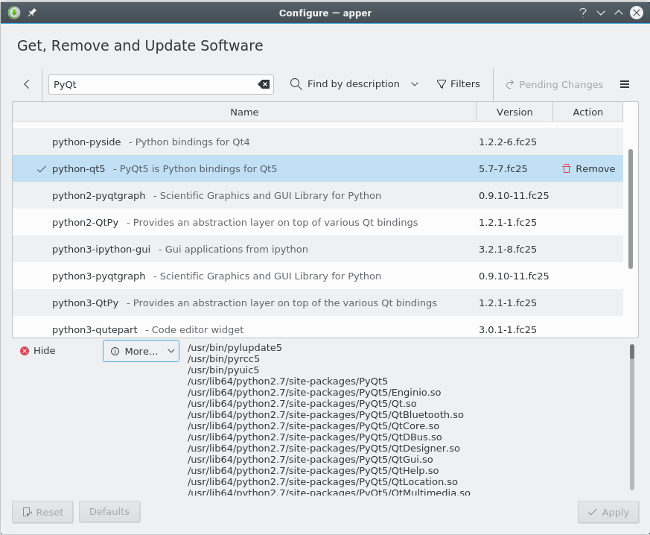
实际使用的命令取决于你所使用的 Linux 发行版。Fedora 使用 `dnf`,OpenSUSE 使用 `zypper`,Debian 和 Ubuntu 使用 `apt`,Slackware 使用 `sbopkg`,FreeBSD 使用 `pkg_add`,而基于 lllumos 的 Openlndiana 使用 `pkg`。无论你使用什么,命令通常包括搜索你想要安装应用程序的正确名称,因为有时候你认为的软件名称不是它官方或单独的名称:
|
||||
实际使用的命令取决于你所使用的 Linux 发行版。Fedora 使用 `dnf`,OpenSUSE 使用 `zypper`,Debian 和 Ubuntu 使用 `apt`,Slackware 使用 `sbopkg`,FreeBSD 使用 `pkg_add`,而基于 lllumos 的 Openlndiana 使用 `pkg`。无论你使用什么,该命令通常要搜索你想要安装应用程序的正确名称,因为有时候你认为的软件名称不是它官方或独有的名称:
|
||||
|
||||
```
|
||||
$ sudo dnf search pyqt
|
||||
|
||||
PyQt.x86_64 : Python bindings for Qt3
|
||||
|
||||
PyQt4.x86_64 : Python bindings for Qt4
|
||||
|
||||
python-qt5.x86_64 : PyQt5 is Python bindings for Qt5
|
||||
```
|
||||
|
||||
一旦你找到要安装的软件包的名称后,使用 `install` 子命令执行实际的下载和自动安装:
|
||||
|
||||
```
|
||||
$ sudo dnf install python-qt5
|
||||
```
|
||||
@ -44,18 +46,20 @@ $ sudo dnf install python-qt5
|
||||
|
||||
|
||||
|
||||
与底层命令一样,图形安装程序的名称取决于你正在运行的 Linux 发行版。相关应用程序通常使用软件或关键字进行标记,因此请在你的启动项或菜单中搜索这些条款,然后你将找到所需的内容。 由于开源是关于用户的选择,所以如果你不喜欢你的发行版提供的图形用户界面(GUI),那么你可以选择安装与否。 现在你知道如何做到这一点。
|
||||
与底层命令一样,图形安装程序的名称取决于你正在运行的 Linux 发行版。相关的应用程序通常使用“软件(software)”或“包(package)”等关键字进行标记,因此请在你的启动项或菜单中搜索这些词汇,然后你将找到所需的内容。 由于开源全由用户来选择,所以如果你不喜欢你的发行版提供的图形用户界面(GUI),那么你可以选择安装替代品。 你知道该如何做到这一点。
|
||||
|
||||
#### 额外仓库
|
||||
|
||||
你的 Linux 发行版为其打包的软件提供了标准仓库,通常也有额外的仓库。例如,[EPEL][3] 服务于 Red Hat Enterprise Linux 和 CentOS,[RPMFusion][4] 服务于 Fedora,Ubuntu 有各种级别的支持以及个人包存档(PPA),[Packman][5] 为 OpenSUSE 提供额外的软件以及 [SlackBuilds.org][6] 为 Slackware 提供社区构建脚本。
|
||||
|
||||
默认情况下,你的 Linux 操作系统设置为只查看其官方仓库,因此如果你想使用其他软件集合,则必须自己添加额外库。你通常可以像安装软件包一样安装仓库。实际上,当你安装例如 [GNU Ring][7] 视频聊天,[Vivaldi][8] web 浏览器,谷歌浏览器等许多软件时,你实际安装的是访问他们的私人仓库,从中将最新版本的应用程序安装到你的机器上。
|
||||
默认情况下,你的 Linux 操作系统设置为只查看其官方仓库,因此如果你想使用其他软件集合,则必须自己添加额外库。你通常可以像安装软件包一样安装仓库。实际上,当你安装例如 [GNU Ring][7] 视频聊天,[Vivaldi][8] web 浏览器,谷歌浏览器等许多软件时,你的实际安装是访问他们的私有仓库,从中将最新版本的应用程序安装到你的机器上。
|
||||
|
||||
![Installing a repo][10]
|
||||
|
||||
建立一个仓库
|
||||
*安装仓库*
|
||||
|
||||
你还可以通过编辑文本文件将仓库手动添加到你的软件包管理器的配置目录,或者运行命令来添加添加仓库。像往常一样,你使用的确切命令取决于 Linux 发行版本。例如,这是一个 `dnf` 命令,它将一个仓库添加到系统中:
|
||||
|
||||
你还可以通过编辑文本文件将仓库手动添加到软件包管理器的配置目录,或者运行命令来添加添加仓库。像往常一样,你使用的确切命令取决于 Linux 发行版本。例如,这是一个 `dnf` 命令,它将一个仓库添加到系统中:
|
||||
```
|
||||
$ sudo dnf config-manager --add-repo=http://example.com/pub/centos/7
|
||||
```
|
||||
@ -64,118 +68,111 @@ $ sudo dnf config-manager --add-repo=http://example.com/pub/centos/7
|
||||
|
||||
仓库模型非常流行,因为它提供了用户(你)和开发人员之间的链接。重要更新发布之后,系统会提示你接受更新,并且你可以从一个集中位置接受所有更新。
|
||||
|
||||
然而,有时候一个软件包没有附加的仓库可以使用。这些安装包有几种形式。
|
||||
然而,有时候一个软件包还没有放到仓库中时。这些安装包有几种形式。
|
||||
|
||||
#### Linux 包
|
||||
|
||||
有时候,开发人员会以通用的 Linux 打包格式分发软件,例如 RPM,DEB 或较新但非常流行的 FlatPak 或 Snap 格式。你无法使用此下载访问仓库;你可能会得到这个包。
|
||||
有时候,开发人员会以通用的 Linux 打包格式分发软件,例如 RPM、DEB 或较新但非常流行的 FlatPak 或 Snap 格式。你不是访问仓库下载的,你只是得到了这个包。
|
||||
|
||||
例如,视频编辑器 [Lightworks][11] 为 APT 用户提供了一个 `.deb` 文件,RPM 用户提供了 `.rpm` 文件。当你想要更新时,可以到网站下载最新的适合的文件。
|
||||
|
||||
这些一次性软件包可以使用从仓库进行安装时所用的所有工具进行安装。如果双击下载的软件包,图形安装程序将启动并逐步完成安装过程。
|
||||
这些一次性软件包可以使用从仓库进行安装时所用的一样的工具进行安装。如果双击下载的软件包,图形安装程序将启动并逐步完成安装过程。
|
||||
|
||||
或者,你可以从终端进行安装。这里的区别在于你从互联网下载的独立包文件不是来自仓库。这是一个“本地”安装,这意味着你的软件安装包不需要下载来安装。大多数软件包管理器都是透明处理的:
|
||||
|
||||
```
|
||||
$ sudo dnf install ~/Downloads/lwks-14.0.0-amd64.rpm
|
||||
```
|
||||
|
||||
在某些情况下,你需要采取额外的步骤才能使应用程序运行,因此请仔细阅读有关你正在安装软件的文档。
|
||||
|
||||
#### 通用安装
|
||||
#### 通用安装脚本
|
||||
|
||||
一些开发人员以几种通用格式发布他们的包。常见的扩展包括 `.run` 和 `.sh`。NVIDIA 显卡驱动程序,像 Nuke 和 Mari 这样的 Foundry visual FX 软件包以及来自 [GOG][12] 的许多无 DRM 游戏都是用这种安装程序。(译注:DRM 是数字版权管理。)
|
||||
一些开发人员以几种通用格式发布他们的包。常见的扩展名包括 `.run` 和 `.sh`。NVIDIA 显卡驱动程序、像 Nuke 和 Mari 这样的 Foundry visual FX 软件包以及来自 [GOG][12] 的许多非 DRM 游戏都是用这种安装程序。(LCTT 译注:DRM 是数字版权管理。)
|
||||
|
||||
这种安装模式依赖于开发人员提供安装“向导”。一些安装程序是图形化的,而另一些只是在终端中运行。
|
||||
|
||||
有两种方式来运行这些类型的安装程序。
|
||||
|
||||
1. 你可以直接从终端运行安装程序:
|
||||
1、 你可以直接从终端运行安装程序:
|
||||
|
||||
```
|
||||
|
||||
$ sh ./game/gog_warsow_x.y.z.sh
|
||||
```
|
||||
2. 另外,你可以通过标记其为可执行文件来运行它。要标记为安装程序可执行文件,右键单击它的图标并选择 **Properties**。
|
||||
|
||||
2、 另外,你可以通过标记其为可执行文件来运行它。要标记为安装程序可执行文件,右键单击它的图标并选择其属性。
|
||||
|
||||
![Giving an installer executable permission][14]
|
||||
|
||||
给安装程序可执行权限。
|
||||
*给安装程序可执行权限。*
|
||||
|
||||
一旦你允许其运行,双击图标就可以安装了。
|
||||
|
||||
![GOG installer][16]
|
||||
|
||||
GOG 安装程序
|
||||
*GOG 安装程序*
|
||||
|
||||
对于其余的安装程序,只需要按照屏幕上的说明进行操作。
|
||||
|
||||
#### AppImage 便携式应用程序
|
||||
|
||||
AppImage 格式对于 Linux 相对来说比较新,尽管它的概念是基于 NeXT 和 Rox 的。这个想法很简单:运行应用程序所需的一切都应该放在一个目录中,然后该目录被视为一个“应用程序”。要运行该应用程序,只需双击该图标即可运行。没有必要或期望应用程序安装在传统意义的地方;它只是从你在硬盘上的任何地方运行。
|
||||
AppImage 格式对于 Linux 相对来说比较新,尽管它的概念是基于 NeXT 和 Rox 的。这个想法很简单:运行应用程序所需的一切都应该放在一个目录中,然后该目录被视为一个“应用程序”。要运行该应用程序,只需双击该图标即可运行。不需要也要不应该把应用程序安装在传统意义的地方;它从你在硬盘上的任何地方运行都行。
|
||||
|
||||
尽管它可以作为独立应用运行,但 AppImage 通常提供一些系统集成。
|
||||
|
||||
![AppImage system integration][18]
|
||||
|
||||
AppImage 系统集成
|
||||
*AppImage 系统集成*
|
||||
|
||||
如果你接受此条件,则将本地 `.desktop` 文件安装到你的主目录。`.desktop` 文件是 Linux 桌面的应用程序菜单和 mimetype 系统使用的一个小配置文件。实质上,将桌面配置文件放置在主目录的应用程序列表中“安装”应用程序,而不实际安装它。你获得了安装某些东西的所有好处,以及能够在本地运行某些东西的好处,例如“便携式应用程序”。
|
||||
如果你接受此条件,则将一个本地的 `.desktop` 文件安装到你的主目录。`.desktop` 文件是 Linux 桌面的应用程序菜单和 mimetype 系统使用的一个小配置文件。实质上,只是将桌面配置文件放置在主目录的应用程序列表中“安装”应用程序,而不实际安装它。你获得了安装某些东西的所有好处,以及能够在本地运行某些东西的好处,即“便携式应用程序”。
|
||||
|
||||
#### 应用程序目录
|
||||
|
||||
有时,开发人员只需要编译一个应用程序,然后将结果发布到下载中,没有安装脚本,也没有打包。通常,这意味着你下载了一个 TAR 文件,然后 [解压缩][19],然后双击可执行文件(通常是你下载软件的名称)。
|
||||
|
||||
有时,开发人员只是编译一个应用程序,然后将结果发布到下载中,没有安装脚本,也没有打包。通常,这意味着你下载了一个 TAR 文件,然后 [解压缩][19],然后双击可执行文件(通常是你下载软件的名称)。
|
||||
|
||||
![Twine downloaded for Linux][21]
|
||||
|
||||
下载 Twine
|
||||
*下载 Twine*
|
||||
|
||||
当使用这种软件方式交付时,你可以将它放在你下载的地方,当你需要它时,你可以手动启动它,或者你可以自己进行快速但是麻烦的安装。这包括两个简单的步骤:
|
||||
|
||||
1. 将目录保存到一个标准位置,并在需要时手动启动它。
|
||||
2. 将目录保存到一个标准位置,并创建一个 `.desktop` 文件,将其集成到你的系统中。
|
||||
|
||||
如果你只是为自己安装应用程序,那么在你的主目录中保留 `bin` 目录(简称“二进制文件”)作为本地安装的应用程序和脚本的存储位置是传统意义上的。如果你的系统上有其他用户需要访问这些应用程序,传统上将二进制文件放置在 `/opt` 中。最后,这取决于你存储应用程序的位置。
|
||||
如果你只是为自己安装应用程序,那么传统上会在你的主目录中放个 `bin` (“<ruby>二进制文件<rt>binary</rt></ruby>” 的简称)目录作为本地安装的应用程序和脚本的存储位置。如果你的系统上有其他用户需要访问这些应用程序,传统上将二进制文件放置在 `/opt` 中。最后,这取决于你存储应用程序的位置。
|
||||
|
||||
下载通常以带版本名称的目录进行,如 `twine_2.13` 或者 `pcgen-v6.07.04`。由于可以合理地假设你将在某个时候更新应用程序,因此将版本号删除或创建目录的符号链接是个不错的主意。这样,即使你更新应用程序本身,为应用程序创建的启动程序也可以保持不变。
|
||||
下载通常以带版本名称的目录进行,如 `twine_2.13` 或者 `pcgen-v6.07.04`。由于假设你将在某个时候更新应用程序,因此将版本号删除或创建目录的符号链接是个不错的主意。这样,即使你更新应用程序本身,为应用程序创建的启动程序也可以保持不变。
|
||||
|
||||
要创建一个 `.desktop` 启动文件,打开一个文本编辑器并创建一个名为 `twine.desktop` 的文件。[桌面条目规范][22] 由 [FreeDesktop.org][23] 定义。这是一个简单的启动器,用于一个名为 Twine 的游戏开发 IDE,安装在系统范围的 `/opt` 目录中:
|
||||
要创建一个 `.desktop` 启动文件,打开一个文本编辑器并创建一个名为 `twine.desktop` 的文件。[桌面条目规范][22] 由 [FreeDesktop.org][23] 定义。下面是一个简单的启动器,用于一个名为 Twine 的游戏开发 IDE,安装在系统范围的 `/opt` 目录中:
|
||||
|
||||
```
|
||||
[Desktop Entry]
|
||||
|
||||
Encoding=UTF-8
|
||||
|
||||
Name=Twine
|
||||
|
||||
GenericName=Twine
|
||||
|
||||
Comment=Twine
|
||||
|
||||
Exec=/opt/twine/Twine
|
||||
|
||||
Icon=/usr/share/icons/oxygen/64x64/categories/applications-games.png
|
||||
|
||||
Terminal=false
|
||||
|
||||
Type=Application
|
||||
|
||||
Categories=Development;IDE;
|
||||
```
|
||||
|
||||
棘手的一行是 `Exec` 行。它必须包含一个有效的命令来启动应用程序。通常,它只是你下载的东西的完整路径,但在某些情况下,它更复杂一些。例如,Java 应用程序可能需要作为 Java 自身的参数启动。
|
||||
|
||||
```
|
||||
Exec=java -jar /path/to/foo.jar
|
||||
```
|
||||
|
||||
有时,一个项目包含一个可以运行的包装脚本,这样你就不必找出正确的命令:
|
||||
|
||||
```
|
||||
Exec=/opt/foo/foo-launcher.sh
|
||||
```
|
||||
|
||||
在这个 Twine 例子中,没有与下载捆绑的图标,因此示例 `.desktop` 文件指定了 KDE 桌面附带的通用游戏图标。你可以使用类似的解决方法,但如果你更具艺术性,这可以创建自己的图标,或者可以在 Internet 上搜索一个好的图标。只要 `Icon` 行指向一个有效的 PNG 或 SVG 文件,你的应用程序就会继承该图标。
|
||||
在这个 Twine 例子中,没有与该下载的软件捆绑的图标,因此示例 `.desktop` 文件指定了 KDE 桌面附带的通用游戏图标。你可以使用类似的解决方法,但如果你更具艺术性,可以创建自己的图标,或者可以在 Internet 上搜索一个好的图标。只要 `Icon` 行指向一个有效的 PNG 或 SVG 文件,你的应用程序就会以该图标为代表。
|
||||
|
||||
示例脚本还将应用程序类别主要设置为 Development,因此在 KDE, GNOME 和大多数其他应用程序菜单中,Twine 出现在开发类别下。
|
||||
示例脚本还将应用程序类别主要设置为 Development,因此在 KDE、GNOME 和大多数其他应用程序菜单中,Twine 出现在开发类别下。
|
||||
|
||||
为了让这个例子出现在应用程序菜单中,把 `twine.desktop` 文件放这到两个地方之一:
|
||||
|
||||
@ -186,7 +183,7 @@ Exec=/opt/foo/foo-launcher.sh
|
||||
|
||||
### 从源代码编译
|
||||
|
||||
最后,还有真正的通用格式安装格式:源代码。从源代码编译应用程序是学习如何构建应用程序,如何与系统交互以及如何定制应用程序的好方法。尽管如此,它绝不是一个按按钮式过程。它需要一个构建环境,通常需要安装依赖库和头文件,有时还要进行一些调试。
|
||||
最后,还有真正的通用格式安装格式:源代码。从源代码编译应用程序是学习如何构建应用程序,如何与系统交互以及如何定制应用程序的好方法。尽管如此,它绝不是一个点击按钮式过程。它需要一个构建环境,通常需要安装依赖库和头文件,有时还要进行一些调试。
|
||||
|
||||
要了解更多关于从源代码编译的内容,请阅读[我这篇文章][24]。
|
||||
|
||||
@ -194,9 +191,9 @@ Exec=/opt/foo/foo-launcher.sh
|
||||
|
||||
有些人认为安装软件是一个神奇的过程,只有开发人员理解,或者他们认为它“激活”了应用程序,就好像二进制可执行文件在“安装”之前无效。学习许多不同的安装方法会告诉你安装实际上只是“将文件从一个地方复制到系统中适当位置”的简写。 没有什么神秘的。只要你去了解每次安装,不是期望应该如何发生,并且寻找开发者为安装过程设置了什么,那么通常很容易,即使它与你的习惯不同。
|
||||
|
||||
重要的是安装人员对你很诚实。 如果你遇到未经你的同意尝试安装其他软件的安装程序(或者它可能会以混淆或误导的方式请求同意),或者尝试在没有明显原因的情况下对系统执行检查,则不要继续安装。
|
||||
重要的是安装器要诚实于你。 如果你遇到未经你的同意尝试安装其他软件的安装程序(或者它可能会以混淆或误导的方式请求同意),或者尝试在没有明显原因的情况下对系统执行检查,则不要继续安装。
|
||||
|
||||
好的软件是灵活的,诚实的,开放的。 现在你知道如何在你的计算机上获得好的软件。
|
||||
好的软件是灵活的、诚实的、开放的。 现在你知道如何在你的计算机上获得好软件了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -204,7 +201,7 @@ via: https://opensource.com/article/18/1/how-install-apps-linux
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
225
published/20180129 Parsing HTML with Python.md
Normal file
225
published/20180129 Parsing HTML with Python.md
Normal file
@ -0,0 +1,225 @@
|
||||
如何用 Python 解析 HTML
|
||||
======
|
||||
|
||||
用一些简单的脚本,可以很容易地清理文档和其它大量的 HTML 文件。但是首先你需要解析它们。
|
||||

|
||||
|
||||
图片由 Jason Baker 为 Opensource.com 所作。
|
||||
|
||||
作为 Scribus 文档团队的长期成员,我要随时了解最新的源代码更新,以便对文档进行更新和补充。 我最近在刚升级到 Fedora 27 系统的计算机上使用 Subversion 进行检出操作时,对于下载该文档所需要的时间我感到很惊讶,文档由 HTML 页面和相关图像组成。 我恐怕该项目的文档看起来比项目本身大得多,并且怀疑其中的一些内容是“僵尸”文档——不再使用的 HTML 文件以及 HTML 中无法访问到的图像。
|
||||
|
||||
我决定为自己创建一个项目来解决这个问题。 一种方法是搜索未使用的现有图像文件。 如果我可以扫描所有 HTML 文件中的图像引用,然后将该列表与实际图像文件进行比较,那么我可能会看到不匹配的文件。
|
||||
|
||||
这是一个典型的图像标签:
|
||||
|
||||
```
|
||||
<img src="images/edit_shapes.png" ALT="Edit examples" ALIGN=left>
|
||||
```
|
||||
|
||||
我对 `src=` 之后的第一组引号之间的部分很感兴趣。 在寻找了一些解决方案后,我找到一个名为 [BeautifulSoup][1] 的 Python 模块。 脚本的核心部分如下所示:
|
||||
|
||||
```
|
||||
soup = BeautifulSoup(all_text, 'html.parser')
|
||||
match = soup.findAll("img")
|
||||
if len(match) > 0:
|
||||
for m in match:
|
||||
imagelist.append(str(m))
|
||||
```
|
||||
|
||||
我们可以使用这个 `findAll` 方法来挖出图片标签。 这是一小部分输出:
|
||||
|
||||
```
|
||||
<img src="images/pdf-form-ht3.png"/><img src="images/pdf-form-ht4.png"/><img src="images/pdf-form-ht5.png"/><img src="images/pdf-form-ht6.png"/><img align="middle" alt="GSview - Advanced Options Panel" src="images/gsadv1.png" title="GSview - Advanced Options Panel"/><img align="middle" alt="Scribus External Tools Preferences" src="images/gsadv2.png" title="Scribus External Tools Preferences"/>
|
||||
```
|
||||
|
||||
到现在为止还挺好。我原以为下一步就可以搞定了,但是当我在脚本中尝试了一些字符串方法时,它返回了有关标记的错误而不是字符串的错误。 我将输出保存到一个文件中,并在 [KWrite][2] 中进行编辑。 KWrite 的一个好处是你可以使用正则表达式(regex)来做“查找和替换”操作,所以我可以用 `\n<img` 替换 `<img`,这样可以看得更清楚。 KWrite 的另一个好处是,如果你用正则表达式做了一个不明智的选择,你还可以撤消。
|
||||
|
||||
但我认为,肯定有比这更好的东西,所以我转而使用正则表达式,或者更具体地说 Python 的 `re` 模块。 这个新脚本的相关部分如下所示:
|
||||
|
||||
```
|
||||
match = re.findall(r'src="(.*)/>', all_text)
|
||||
if len(match)>0:
|
||||
for m in match:
|
||||
imagelist.append(m)
|
||||
```
|
||||
|
||||
它的一小部分输出如下所示:
|
||||
|
||||
```
|
||||
images/cmcanvas.png" title="Context Menu for the document canvas" alt="Context Menu for the document canvas" /></td></tr></table><br images/eps-imp1.png" title="EPS preview in a file dialog" alt="EPS preview in a file dialog" images/eps-imp5.png" title="Colors imported from an EPS file" alt="Colors imported from an EPS file" images/eps-imp4.png" title="EPS font substitution" alt="EPS font substitution" images/eps-imp2.png" title="EPS import progress" alt="EPS import progress" images/eps-imp3.png" title="Bitmap conversion failure" alt="Bitmap conversion failure"
|
||||
```
|
||||
|
||||
乍一看,它看起来与上面的输出类似,并且附带有去除图像的标签部分的好处,但是有令人费解的是还夹杂着表格标签和其他内容。 我认为这涉及到这个正则表达式 `src="(.*)/>`,这被称为*贪婪*,意味着它不一定停止在遇到 `/>` 的第一个实例。我应该补充一点,我也尝试过 `src="(.*)"`,这真的没有什么更好的效果,我不是一个正则表达式专家(只是做了这个),找了各种方法来改进这一点但是并没什么用。
|
||||
|
||||
做了一系列的事情之后,甚至尝试了 Perl 的 `HTML::Parser` 模块,最终我试图将这与我为 Scribus 编写的一些脚本进行比较,这些脚本逐个字符的分析文本内容,然后采取一些行动。 为了最终目的,我终于想出了所有这些方法,并且完全不需要正则表达式或 HTML 解析器。 让我们回到展示的那个 `img` 标签的例子。
|
||||
|
||||
```
|
||||
<img src="images/edit_shapes.png" ALT="Edit examples" ALIGN=left>
|
||||
```
|
||||
|
||||
我决定回到 `src=` 这一块。 一种方法是等待 `s` 出现,然后看下一个字符是否是 `r`,下一个是 `c`,下一个是否 `=`。 如果是这样,那就匹配上了! 那么两个双引号之间的内容就是我所需要的。 这种方法的问题在于需要连续识别上面这样的结构。 一种查看代表一行 HTML 文本的字符串的方法是:
|
||||
|
||||
```
|
||||
for c in all_text:
|
||||
```
|
||||
|
||||
但是这个逻辑太乱了,以至于不能持续匹配到前面的 `c`,还有之前的字符,更之前的字符,更更之前的字符。
|
||||
|
||||
最后,我决定专注于 `=` 并使用索引方法,以便我可以轻松地引用字符串中的任何先前或将来的字符。 这里是搜索部分:
|
||||
|
||||
```
|
||||
index = 3
|
||||
while index < linelength:
|
||||
if (all_text[index] == '='):
|
||||
if (all_text[index-3] == 's') and (all_text[index-2] == 'r') and (all_text[index-1] == 'c'):
|
||||
imagefound(all_text, imagelist, index)
|
||||
index += 1
|
||||
else:
|
||||
index += 1
|
||||
else:
|
||||
index += 1
|
||||
```
|
||||
|
||||
我用第四个字符开始搜索(索引从 0 开始),所以我在下面没有出现索引错误,并且实际上,在每一行的第四个字符之前不会有等号。 第一个测试是看字符串中是否出现了 `=`,如果没有,我们就会前进。 如果我们确实看到一个等号,那么我们会看前三个字符是否是 `s`、`r` 和 `c`。 如果全都匹配了,就调用函数 `imagefound`:
|
||||
|
||||
```
|
||||
def imagefound(all_text, imagelist, index):
|
||||
end = 0
|
||||
index += 2
|
||||
newimage = ''
|
||||
while end == 0:
|
||||
if (all_text[index] != '"'):
|
||||
newimage = newimage + all_text[index]
|
||||
index += 1
|
||||
else:
|
||||
newimage = newimage + '\n'
|
||||
imagelist.append(newimage)
|
||||
end = 1
|
||||
return
|
||||
```
|
||||
|
||||
我们给函数发送当前索引,它代表着 `=`。 我们知道下一个字符将会是 `"`,所以我们跳过两个字符,并开始向名为 `newimage` 的控制字符串添加字符,直到我们发现下一个 `"`,此时我们完成了一次匹配。 我们将字符串加一个换行符(`\n`)添加到列表 `imagelist` 中并返回(`return`),请记住,在剩余的这个 HTML 字符串中可能会有更多图片标签,所以我们马上回到搜索循环中。
|
||||
|
||||
以下是我们的输出现在的样子:
|
||||
|
||||
```
|
||||
images/text-frame-link.png
|
||||
images/text-frame-unlink.png
|
||||
images/gimpoptions1.png
|
||||
images/gimpoptions3.png
|
||||
images/gimpoptions2.png
|
||||
images/fontpref3.png
|
||||
images/font-subst.png
|
||||
images/fontpref2.png
|
||||
images/fontpref1.png
|
||||
images/dtp-studio.png
|
||||
```
|
||||
|
||||
啊,干净多了,而这只花费几秒钟的时间。 我本可以将索引前移 7 步来剪切 `images/` 部分,但我更愿意把这个部分保存下来,以确保我没有剪切掉图像文件名的第一个字母,这很容易用 KWrite 编辑成功 —— 你甚至不需要正则表达式。 做完这些并保存文件后,下一步就是运行我编写的另一个脚本 `sortlist.py`:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
# sortlist.py
|
||||
|
||||
import os
|
||||
|
||||
imagelist = []
|
||||
for line in open('/tmp/imagelist_parse4.txt').xreadlines():
|
||||
imagelist.append(line)
|
||||
|
||||
imagelist.sort()
|
||||
|
||||
outfile = open('/tmp/imagelist_parse4_sorted.txt', 'w')
|
||||
outfile.writelines(imagelist)
|
||||
outfile.close()
|
||||
```
|
||||
|
||||
这会读取文件内容,并存储为列表,对其排序,然后另存为另一个文件。 之后,我可以做到以下几点:
|
||||
|
||||
```
|
||||
ls /home/gregp/development/Scribus15x/doc/en/images/*.png > '/tmp/actual_images.txt'
|
||||
```
|
||||
|
||||
然后我需要在该文件上运行 `sortlist.py`,因为 `ls` 方法的排序与 Python 不同。 我原本可以在这些文件上运行比较脚本,但我更愿意以可视方式进行操作。 最后,我成功找到了 42 个图像,这些图像没有来自文档的 HTML 引用。
|
||||
|
||||
这是我的完整解析脚本:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
# parseimg4.py
|
||||
|
||||
import os
|
||||
|
||||
def imagefound(all_text, imagelist, index):
|
||||
end = 0
|
||||
index += 2
|
||||
newimage = ''
|
||||
while end == 0:
|
||||
if (all_text[index] != '"'):
|
||||
newimage = newimage + all_text[index]
|
||||
index += 1
|
||||
else:
|
||||
newimage = newimage + '\n'
|
||||
imagelist.append(newimage)
|
||||
end = 1
|
||||
return
|
||||
|
||||
htmlnames = []
|
||||
imagelist = []
|
||||
tempstring = ''
|
||||
filenames = os.listdir('/home/gregp/development/Scribus15x/doc/en/')
|
||||
for name in filenames:
|
||||
if name.endswith('.html'):
|
||||
htmlnames.append(name)
|
||||
#print htmlnames
|
||||
for htmlfile in htmlnames:
|
||||
all_text = open('/home/gregp/development/Scribus15x/doc/en/' + htmlfile).read()
|
||||
linelength = len(all_text)
|
||||
index = 3
|
||||
while index < linelength:
|
||||
if (all_text[index] == '='):
|
||||
if (all_text[index-3] == 's') and (all_text[index-2] == 'r') and
|
||||
(all_text[index-1] == 'c'):
|
||||
imagefound(all_text, imagelist, index)
|
||||
index += 1
|
||||
else:
|
||||
index += 1
|
||||
else:
|
||||
index += 1
|
||||
|
||||
outfile = open('/tmp/imagelist_parse4.txt', 'w')
|
||||
outfile.writelines(imagelist)
|
||||
outfile.close()
|
||||
imageno = len(imagelist)
|
||||
print str(imageno) + " images were found and saved"
|
||||
```
|
||||
|
||||
脚本名称为 `parseimg4.py`,这并不能真实反映我陆续编写的脚本数量(包括微调的和大改的以及丢弃并重新开始写的)。 请注意,我已经对这些目录和文件名进行了硬编码,但是很容易变得通用化,让用户输入这些信息。 同样,因为它们是工作脚本,所以我将输出发送到 `/tmp` 目录,所以一旦重新启动系统,它们就会消失。
|
||||
|
||||
这不是故事的结尾,因为下一个问题是:僵尸 HTML 文件怎么办? 任何未使用的文件都可能会引用图像,不能被前面的方法所找出。 我们有一个 `menu.xml` 文件作为联机手册的目录,但我还需要考虑 TOC(LCTT 译注:TOC 是 table of contents 的缩写)中列出的某些文件可能引用了不在 TOC 中的文件,是的,我确实找到了一些这样的文件。
|
||||
|
||||
最后我可以说,这是一个比图像搜索更简单的任务,而且开发的过程对我有很大的帮助。
|
||||
|
||||
### 关于作者
|
||||
|
||||
[][7]
|
||||
|
||||
Greg Pittman 是 Kentucky 州 Louisville 市的一名退休的神经学家,从二十世纪六十年代的 Fortran IV 语言开始长期以来对计算机和编程有着浓厚的兴趣。 当 Linux 和开源软件出现的时候,Greg 深受启发,去学习更多知识,并实现最终贡献的承诺。 他是 Scribus 团队的成员。[更多关于我][8]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/parsing-html-python
|
||||
|
||||
作者:[Greg Pittman][a]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/greg-p
|
||||
[1]:https://www.crummy.com/software/BeautifulSoup/
|
||||
[2]:https://www.kde.org/applications/utilities/kwrite/
|
||||
[7]:https://opensource.com/users/greg-p
|
||||
[8]:https://opensource.com/users/greg-p
|
||||
@ -1,19 +1,19 @@
|
||||
3种扩展 Kubernetes 能力的方式
|
||||
3 种扩展 Kubernetes 能力的方式
|
||||
======
|
||||
|
||||

|
||||
|
||||
Google 的工程总监 Chen Goldberg 在奥斯汀最近的[KubeCon 和 CloudNativeCon][1]上说,Kubernetes 的扩展能力是它的秘密武器。
|
||||
Google 的工程总监 Chen Goldberg 在最近的奥斯汀 [KubeCon 和 CloudNativeCon][1]上说,Kubernetes 的扩展能力是它的秘密武器。
|
||||
|
||||
在建立帮助工程师提高工作效率的工具的竞赛中,Goldberg 谈到他曾经领导过一个开发这样一个平台的团队。尽管平台最初有用,但它无法扩展,并且修改也很困难。
|
||||
|
||||
幸运的是,Goldberg 说,Kubernetes 没有这些问题。首先,Kubernetes 是一个自我修复系统,因为它使用的控制器实现了“_协调环_”(Reconciliation Loop)。在协调环中,控制器观察系统的当前状态并将其与所需状态进行比较。一旦它确定了这两个状态之间的差异,它就会努力实现所需的状态。这使得 Kubernetes 非常适合动态环境。
|
||||
幸运的是,Goldberg 说,Kubernetes 没有这些问题。首先,Kubernetes 是一个自我修复系统,因为它使用的控制器实现了“<ruby>协调环<rt>Reconciliation Loop</rt></ruby>”。在协调环中,控制器观察系统的当前状态并将其与所需状态进行比较。一旦它确定了这两个状态之间的差异,它就会努力实现所需的状态。这使得 Kubernetes 非常适合动态环境。
|
||||
|
||||
### 3种扩展 Kubernetes 的方式
|
||||
### 3 种扩展 Kubernetes 的方式
|
||||
|
||||
Goldberg 然后解释说,要建立控制器,你需要资源,也就是说,你需要扩展 Kubernetes。有三种方法可以做到这一点,从最灵活(但也更困难)到最简单的是:使用 Kube 聚合器,使用 API 服务器构建器或创建自定义资源定义(或 CRD)。
|
||||
Goldberg 然后解释说,要建立控制器,你需要资源,也就是说,你需要扩展 Kubernetes。有三种方法可以做到这一点,从最灵活(但也更困难)到最简单的依次是:使用 Kube 聚合器、使用 API 服务器构建器或创建<ruby>自定义资源定义<rt>Custom Resource Definition</rt></ruby>(CRD)。
|
||||
|
||||
后者允许即使使用最少的编码来扩展 Kubernetes 的功能。为了演示它是如何完成的,Goggle 软件工程师 Anthony Yeh 出席并展示了为 Kubernetes 添加一个状态集。 (状态集对象用于管理有状态应用,即需要存储应用状态的程序,跟踪例如用户身份及其个人设置。)使用 _catset_,在一个 100 行 JavaScript 的文件中实现的 CRD,Yeh 展示了如何将状态集添加到 Kubernetes 部署中。之前的扩展不是 CRD,需要 24 个文件和 3000 多行代码。
|
||||
后者甚至可以使用极少的代码来扩展 Kubernetes 的功能。为了演示它是如何完成的,Goggle 软件工程师 Anthony Yeh 上台展示了为 Kubernetes 添加一个状态集。 (状态集对象用于管理有状态应用,即需要存储应用状态的程序,跟踪例如用户身份及其个人设置。)使用 _catset_,在一个 100 行 JavaScript 的文件中实现的 CRD,Yeh 展示了如何将状态集添加到 Kubernetes 部署中。之前的扩展不是 CRD,需要 24 个文件和 3000 多行代码。
|
||||
|
||||
为解决 CRD 可靠性问题,Goldberg 表示,Kubernetes 已经启动了一项认证计划,允许公司在 Kubernetes 社区注册和认证其扩展。在一个月内,已有 30 多家公司报名参加该计划。
|
||||
|
||||
@ -31,7 +31,7 @@ via: https://www.linux.com/blog/event/kubecon/2018/2/3-ways-extend-power-kuberne
|
||||
|
||||
作者:[PAUL BROWN][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
Translating By MjSeven
|
||||
|
||||
How to Use DockerHub
|
||||
======
|
||||
|
||||
|
||||
@ -1,60 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Continuous integration in Fedora
|
||||
======
|
||||
|
||||

|
||||
Continuous Integration (CI) is the process of running tests for every change made to a project, integrated as if this were the new deliverable. If done consistently, it means that software is always ready to be released. CI is a very well established process across the entire IT industry as well as free and open source projects. Fedora has been a little behind on this, but we’re catching up. Read below to find out how.
|
||||
|
||||
### Why do we need this?
|
||||
|
||||
CI will improve Fedora all around. It provides a more stable and consistent operating system by revealing bugs as early as possible. It lets you add tests when you encounter an issue so it doesn’t happen again (avoid regressions). CI can run tests from the upstream project as well as Fedora-specific ones that test the integration of the application in the distribution.
|
||||
|
||||
Above all, consistent CI allows automation and reduced manual labor. It frees up our valuable volunteers and contributors to spend more time on new things for Fedora.
|
||||
|
||||
### How will it look?
|
||||
|
||||
For starters, we’ll run tests for every commit to git repositories of Fedora’s packages (dist-git). These tests are independent of the tests each of these packages run when built. However, they test the functionality of the package in an environment as close as possible to what Fedora’s users run. In addition to package-specific tests, Fedora also runs some distribution-wide tests, such as upgrade testing from F27 to F28 or rawhide.
|
||||
|
||||
Packages are “gated” based on test results: test failures prevent an update being pushed to users. However, sometimes tests fail for various reasons. Perhaps the tests themselves are wrong, or not up to date with the software. Or perhaps an infrastructure issue occurred and prevented the tests from running correctly. Maintainers will be able to re-trigger the tests or waive their results until the tests are updated.
|
||||
|
||||
Eventually, Fedora’s CI will run tests when a new pull-request is opened or updated on <https://src.fedoraproject.org>. This will give maintainers information about the impact of the proposed change on the stability of the package, and help them decide how to proceed.
|
||||
|
||||
### What do we have today?
|
||||
|
||||
Currently, a CI pipeline runs tests on packages that are part of Fedora Atomic Host. Other packages can have tests in dist-git, but they won’t be run automatically yet. Distribution specific tests already run on all of our packages. These test results are used to gate packages with failures.
|
||||
|
||||
### How do I get involved?
|
||||
|
||||
The best way to get started is to read the documentation about [Continuous Integration in Fedora][1]. You should get familiar with the [Standard Test Interface][2], which describes a lot of the terminology as well as how to write tests and use existing ones.
|
||||
|
||||
With this knowledge, if you’re a package maintainer you can start adding tests to your packages. You can run them on your local machine or in a virtual machine. (This latter is advisable for destructive tests!)
|
||||
|
||||
The Standard Test Interface makes testing consistent. As a result, you can easily add any tests to a package you like, and submit them to the maintainers in a pull-request on its [repository][3].
|
||||
|
||||
Reach out on #fedora-ci on irc.freenode.net with feedback, questions or for a general discussion on CI.
|
||||
|
||||
Photo by [Samuel Zeller][4] on [Unsplash][5]
|
||||
|
||||
#### Like this:
|
||||
|
||||
Like
|
||||
|
||||
Loading...
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/continuous-integration-fedora/
|
||||
|
||||
作者:[Pierre-Yves Chibon;Dominik Perpeet][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org
|
||||
[1]:http://fedoraproject.org/wiki/CI
|
||||
[2]:http://fedoraproject.org/wiki/CI/Standard_Test_Interface
|
||||
[3]:https://src.fedoraproject.org
|
||||
[4]:https://unsplash.com/photos/77oXlGwwOw0?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[5]:https://unsplash.com/search/photos/factory-line?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
How To Find If A CPU Supports Virtualization Technology (VT)
|
||||
======
|
||||
|
||||
|
||||
@ -1,219 +0,0 @@
|
||||
用Python解析HTML
|
||||
======
|
||||
|
||||

|
||||
|
||||
图片由Jason Baker为Opensource.com所作。
|
||||
|
||||
作为Scribus文档团队的长期成员,我随时了解最新的源代码更新,以便对文档进行更新和补充。 我最近在刚升级到Fedora 27系统的计算机上使用Subversion进行“checkout”操作时,对于文档下载所需要的时间我感到很惊讶,文档由HTML页面和相关图像组成。 我担心该项目的文档看起来比项目本身大得多,并且怀疑其中的一些内容是“僵尸”文档——不会再使用的HTML文件以及HTML中无法访问到的图像。
|
||||
|
||||
我决定为自己创建一个项目来解决这个问题。 一种方法是搜索未使用的现有图像文件。 如果我可以扫描所有HTML文件中的图像引用,然后将该列表与实际图像文件进行比较,那么我可能会看到不匹配的文件。
|
||||
|
||||
这是一个典型的图像标签:
|
||||
```
|
||||
<img src="images/edit_shapes.png" ALT="Edit examples" ALIGN=left>
|
||||
```
|
||||
|
||||
我对第一组引号之间的部分很感兴趣,在src =之后。 寻找解决方案后,我找到一个名为[BeautifulSoup][1]的Python模块。 脚本的核心部分如下所示:
|
||||
|
||||
```
|
||||
soup = BeautifulSoup(all_text, 'html.parser')
|
||||
match = soup.findAll("img")
|
||||
if len(match) > 0:
|
||||
for m in match:
|
||||
imagelist.append(str(m))
|
||||
```
|
||||
|
||||
我们可以使用这个`findAll` 方法来挖出图片标签。 这是一小部分输出:
|
||||
|
||||
```
|
||||
<img src="images/pdf-form-ht3.png"/><img src="images/pdf-form-ht4.png"/><img src="images/pdf-form-ht5.png"/><img src="images/pdf-form-ht6.png"/><img align="middle" alt="GSview - Advanced Options Panel" src="images/gsadv1.png" title="GSview - Advanced Options Panel"/><img align="middle" alt="Scribus External Tools Preferences" src="images/gsadv2.png" title="Scribus External Tools Preferences"/>
|
||||
```
|
||||
|
||||
到现在为止还挺好。我原以为下一步就可以搞定了,但是当我在脚本中尝试了一些字符串方法时,它返回了有关标记的错误而不是字符串的错误。 我将输出保存到一个文件中,并在[KWrite][2]中进行编辑。 KWrite的一个好处是你可以使用正则表达式(regex)来做“查找和替换”操作,所以我可以用`\n<img` 替换 `<img`,这样可以看得更清楚。 KWrite的另一个好处是,如果你用正则表达式做了一个不明智的选择,你还可以撤消。
|
||||
|
||||
但我认为,肯定有比这更好的东西,所以我转而使用正则表达式,或者更具体地说Python的 `re` 模块。 这个新脚本的相关部分如下所示:
|
||||
|
||||
```
|
||||
match = re.findall(r'src="(.*)/>', all_text)
|
||||
if len(match)>0:
|
||||
for m in match:
|
||||
imagelist.append(m)
|
||||
```
|
||||
|
||||
它的一小部分输出如下所示:
|
||||
```
|
||||
images/cmcanvas.png" title="Context Menu for the document canvas" alt="Context Menu for the document canvas" /></td></tr></table><br images/eps-imp1.png" title="EPS preview in a file dialog" alt="EPS preview in a file dialog" images/eps-imp5.png" title="Colors imported from an EPS file" alt="Colors imported from an EPS file" images/eps-imp4.png" title="EPS font substitution" alt="EPS font substitution" images/eps-imp2.png" title="EPS import progress" alt="EPS import progress" images/eps-imp3.png" title="Bitmap conversion failure" alt="Bitmap conversion failure"
|
||||
```
|
||||
|
||||
乍一看,它看起来与上面的输出类似,并且附带有修剪部分图像标签的好处,但是有令人费解的是还夹杂着表格标签和其他内容。 我认为这涉及到这个正则表达式`src="(.*)/>`,这被称为贪婪,意味着它不一定停止在遇到`/>`的第一个实例。我应该补充一点,我也尝试过`src="(.*)"`,这真的没有什么更好的效果,不是一个正则表达式专家(只是做了这个),我找了各种方法来改进这一点但是并没什么用。
|
||||
|
||||
做了一系列的事情之后,甚至尝试了Perl的`HTML::Parser`模块,最终我试图将这与我为Scribus编写的一些脚本进行比较,这些脚本逐个字符的分析文本内容,然后采取一些行动。 为了最终目的,我终于想出了所有这些方法,并且完全不需要正则表达式或HTML解析器。 让我们回到展示的那个`img`标签的例子。
|
||||
|
||||
```
|
||||
<img src="images/edit_shapes.png" ALT="Edit examples" ALIGN=left>
|
||||
```
|
||||
|
||||
我决定回到`src=`这一块。 一种方法是等待`s`出现,然后看下一个字符是否是`r`,下一个是`c`,下一个是否`=`。 如果是这样,那就匹配上了! 那么两个双引号之间的内容就是我所需要的。 这种方法的问题在于需要连续识别上面这样的结构。 一种查看代表一行HTML文本的字符串的方法是:
|
||||
|
||||
```
|
||||
for c in all_text:
|
||||
```
|
||||
|
||||
但是这个逻辑太乱了,以至于不能持续匹配到前面的`c`,还有之前的字符,更之前的字符,更更之前的字符。
|
||||
|
||||
最后,我决定专注于`=`并使用索引方法,以便我可以轻松地引用字符串中的任何先前或将来的字符。 这里是搜索部分:
|
||||
|
||||
```
|
||||
index = 3
|
||||
while index < linelength:
|
||||
if (all_text[index] == '='):
|
||||
if (all_text[index-3] == 's') and (all_text[index-2] == 'r') and (all_text[index-1] == 'c'):
|
||||
imagefound(all_text, imagelist, index)
|
||||
index += 1
|
||||
else:
|
||||
index += 1
|
||||
else:
|
||||
index += 1
|
||||
```
|
||||
|
||||
我用第四个字符开始搜索(索引从0开始),所以我在下面没有出现索引错误,并且实际上,在每一行的第四个字符之前不会有等号。 第一个测试是看字符串中是否出现了`=`,如果没有,我们就会前进。 如果我们确实看到一个等号,那么我们会看前三个字符是否是`s`,`r`和`c`。 如果全都匹配了,就调用函数`imagefound`:
|
||||
|
||||
```
|
||||
def imagefound(all_text, imagelist, index):
|
||||
end = 0
|
||||
index += 2
|
||||
newimage = ''
|
||||
while end == 0:
|
||||
if (all_text[index] != '"'):
|
||||
newimage = newimage + all_text[index]
|
||||
index += 1
|
||||
else:
|
||||
newimage = newimage + '\n'
|
||||
imagelist.append(newimage)
|
||||
end = 1
|
||||
return
|
||||
```
|
||||
|
||||
我们正在给函数发送当前索引,它代表着`=`。 我们知道下一个字符将会是`"`,所以我们跳过两个字符,并开始向名为`newimage`的控制字符串添加字符,直到我们发现下一个`"`,此时我们完成了一次匹配。 我们将字符串加一个`换行`符添加到列表`imagelist`中并`返回`,请记住,在剩余的这个HTML字符串中可能会有更多图片标签,所以我们马上回到搜索循环的中间。
|
||||
|
||||
以下是我们的输出现在的样子:
|
||||
```
|
||||
images/text-frame-link.png
|
||||
images/text-frame-unlink.png
|
||||
images/gimpoptions1.png
|
||||
images/gimpoptions3.png
|
||||
images/gimpoptions2.png
|
||||
images/fontpref3.png
|
||||
images/font-subst.png
|
||||
images/fontpref2.png
|
||||
images/fontpref1.png
|
||||
images/dtp-studio.png
|
||||
```
|
||||
|
||||
啊,干净多了,而这只花费几秒钟的时间。 我本可以将索引前移7步来剪切`images/`部分,但我更愿意把这个部分保存下来,确保我没有切片掉图像文件名的第一个字母,这很容易用KWrite编辑成功- - 你甚至不需要正则表达式。 做完这些并保存文件后,下一步就是运行我编写的另一个脚本`sortlist.py`:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
# sortlist.py
|
||||
|
||||
import os
|
||||
|
||||
imagelist = []
|
||||
for line in open('/tmp/imagelist_parse4.txt').xreadlines():
|
||||
imagelist.append(line)
|
||||
|
||||
imagelist.sort()
|
||||
|
||||
outfile = open('/tmp/imagelist_parse4_sorted.txt', 'w')
|
||||
outfile.writelines(imagelist)
|
||||
outfile.close()
|
||||
```
|
||||
|
||||
这会读取文件内容,并存储为列表,对其排序,然后另存为另一个文件。 之后,我可以做到以下几点:
|
||||
|
||||
```
|
||||
ls /home/gregp/development/Scribus15x/doc/en/images/*.png > '/tmp/actual_images.txt'
|
||||
```
|
||||
|
||||
然后我需要在该文件上运行`sortlist.py`,因为`ls`方法的排序与Python不同。 我原本可以在这些文件上运行比较脚本,但我更愿意以可视方式进行操作。 最后,我成功找到了42个图像,这些图像没有来自文档的HTML引用。
|
||||
|
||||
这是我的完整解析脚本:
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
# parseimg4.py
|
||||
|
||||
import os
|
||||
|
||||
def imagefound(all_text, imagelist, index):
|
||||
end = 0
|
||||
index += 2
|
||||
newimage = ''
|
||||
while end == 0:
|
||||
if (all_text[index] != '"'):
|
||||
newimage = newimage + all_text[index]
|
||||
index += 1
|
||||
else:
|
||||
newimage = newimage + '\n'
|
||||
imagelist.append(newimage)
|
||||
end = 1
|
||||
return
|
||||
|
||||
htmlnames = []
|
||||
imagelist = []
|
||||
tempstring = ''
|
||||
filenames = os.listdir('/home/gregp/development/Scribus15x/doc/en/')
|
||||
for name in filenames:
|
||||
if name.endswith('.html'):
|
||||
htmlnames.append(name)
|
||||
#print htmlnames
|
||||
for htmlfile in htmlnames:
|
||||
all_text = open('/home/gregp/development/Scribus15x/doc/en/' + htmlfile).read()
|
||||
linelength = len(all_text)
|
||||
index = 3
|
||||
while index < linelength:
|
||||
if (all_text[index] == '='):
|
||||
if (all_text[index-3] == 's') and (all_text[index-2] == 'r') and
|
||||
(all_text[index-1] == 'c'):
|
||||
imagefound(all_text, imagelist, index)
|
||||
index += 1
|
||||
else:
|
||||
index += 1
|
||||
else:
|
||||
index += 1
|
||||
|
||||
outfile = open('/tmp/imagelist_parse4.txt', 'w')
|
||||
outfile.writelines(imagelist)
|
||||
outfile.close()
|
||||
imageno = len(imagelist)
|
||||
print str(imageno) + " images were found and saved"
|
||||
```
|
||||
|
||||
脚本名称为`parseimg4.py`,这并不能真实反映我陆续编写的脚本数量,包括微调的和大改的以及丢弃并重新开始写的。 请注意,我已经对这些目录和文件名进行了硬编码,但是总结起来很容易,要求用户输入这些信息。 同样,因为它们是工作脚本,所以我将输出发送到 `/tmp`目录,所以一旦重新启动系统,它们就会消失。
|
||||
|
||||
这不是故事的结尾,因为下一个问题是:僵尸HTML文件怎么办? 任何未使用的文件都可能会引用到前面比对方法没有提取到的图像。 我们有一个`menu.xml`文件作为联机手册的目录,但我还需要考虑TOC(译者注:TOC是table of contents的缩写)中列出的某些文件可能引用了不在TOC中的文件,是的,我确实找到了一些这样的文件。
|
||||
|
||||
最后我可以说,这是一个比图像搜索更简单的任务,而且开发的过程对我有很大的帮助。
|
||||
|
||||
|
||||
### About the author
|
||||
|
||||
[][7] Greg Pittman - Greg是Kentucky州Louisville市的一名退休的神经学家,从二十世纪六十年代的Fortran IV语言开始长期以来对计算机和编程有着浓厚的兴趣。 当Linux和开源软件出现的时候,Greg深受启发,去学习更多只是,并实现最终贡献的承诺。 他是Scribus团队的成员。[更多关于我][8]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/parsing-html-python
|
||||
|
||||
作者:[Greg Pittman][a]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/greg-p
|
||||
[1]:https://www.crummy.com/software/BeautifulSoup/
|
||||
[2]:https://www.kde.org/applications/utilities/kwrite/
|
||||
[7]:https://opensource.com/users/greg-p
|
||||
[8]:https://opensource.com/users/greg-p
|
||||
53
translated/tech/20180312 Continuous integration in Fedora.md
Normal file
53
translated/tech/20180312 Continuous integration in Fedora.md
Normal file
@ -0,0 +1,53 @@
|
||||
在 Fedora 中持续集成
|
||||
======
|
||||
|
||||

|
||||
持续集成 (CI) 是为项目的每一项变更运行测试的过程,如同这是新的交付项目一样。如果持续执行,这意味着软件随时可以发布。 CI 是整个 IT 行业以及免费和开源项目非常成熟的流程。Fedora 在这方面有点落后,但我们正在赶上。阅读以下内容了解进展。
|
||||
|
||||
### 我们为什么需要这个?
|
||||
|
||||
CI 将全面改善 Fedora。它通过尽早揭示 bug 提供更稳定和一致的操作系统。它让你在遇到问题时添加测试,以免再次发生(避免回归)。CI 可以运行来自上游的项目测试,还有测试集成在发行版中 Fedora 特定的测试。
|
||||
|
||||
最重要的是,一致的 CI 能自动化并减少手工劳动。它释放了我们宝贵的志愿者和贡献者,让他们将更多时间花在 Fedora 的新事物上。
|
||||
|
||||
### 它看起来如何?
|
||||
|
||||
对于初学者,我们将对在 Fedora 包 (dist-git) 仓库的每个提交运行测试。这些测试独立于构建时运行的每个软件包的测试。但是,他们在尽可能接近 Fedora 用户运行环境的环境中测试软件包的功能。除了特定的软件包测试外,Fedora 还运行一些发行测试,例如从 F27 升级到 F28 或者全新安装。
|
||||
|
||||
软件包根据测试结果进行“控制”:测试失败会阻止将更新推送给用户。但是,有时由于各种原因,测试会失败。也许测试本身是错误的,或者不是最新的软件。或者可能发生基础架构问题,并阻止测试正常运行。维护人员能够重新触发测试或放弃测试结果,直到测试更新。
|
||||
|
||||
最终,当在 <https://src.fedoraproject.org> 上有合并请求或者更新时,Fedora 的 CI 将运行测试。这将使维护者了解建议的更改对包稳定性的影响,并帮助他们决定如何进行。
|
||||
|
||||
### 我们如今有什么?
|
||||
|
||||
目前,CI 管道在 Fedora Atomic Host 一部分软件包上运行测试。其他软件包可以在 dist-git 中进行测试,但它们不会自动运行。分发特定的测试已经在我们所有的软件包上运行。这些测试结果被用于过滤测试失败的软件包。
|
||||
|
||||
### 我该如何参与?
|
||||
|
||||
最好的入门方法是阅读关于[ Fedora 持续集成][1]的文档。你应该熟悉[标准测试接口][2],它描述了很多术语以及如何编写测试和使用现有的测试。
|
||||
|
||||
有了这些知识,如果你是一个软件包维护者,你可以开始添加测试到你的软件包。你可以在本地或虚拟机上运行它们。 (后者对于破坏性测试是明治的!)
|
||||
|
||||
标准测试接口使测试保持一致。因此,你可以轻松地将任何测试添加到你喜欢的包中,并在 [仓库][3] 提交合并请求给维护人员。
|
||||
|
||||
Reach out on #fedora-ci on irc.freenode.net with feedback, questions or for a general discussion on CI.
|
||||
在 irc.freenode.net 上与 #fedora-ci 联系,提供反馈,问题或关于 CI 的一般性讨论。
|
||||
|
||||
[Samuel Zeller][4] 在 [Unsplash][5] 上提供的照片
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/continuous-integration-fedora/
|
||||
|
||||
作者:[Pierre-Yves Chibon;Dominik Perpeet][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org
|
||||
[1]:http://fedoraproject.org/wiki/CI
|
||||
[2]:http://fedoraproject.org/wiki/CI/Standard_Test_Interface
|
||||
[3]:https://src.fedoraproject.org
|
||||
[4]:https://unsplash.com/photos/77oXlGwwOw0?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[5]:https://unsplash.com/search/photos/factory-line?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
Loading…
Reference in New Issue
Block a user