mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-15 01:50:08 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject into new
This commit is contained in:
commit
29d84d9051
@ -16,12 +16,8 @@ Linux DNS 查询剖析(第四部分)
|
||||
|
||||
在第四部分中,我将介绍容器如何完成 DNS 查询。你想的没错,也不是那么简单。
|
||||
|
||||
* * *
|
||||
|
||||
### 1) Docker 和 DNS
|
||||
|
||||
============================================================
|
||||
|
||||
在 [Linux DNS 查询剖析(第三部分)][3] 中,我们介绍了 `dnsmasq`,其工作方式如下:将 DNS 查询指向到 localhost 地址 `127.0.0.1`,同时启动一个进程监听 `53` 端口并处理查询请求。
|
||||
|
||||
在按上述方式配置 DNS 的主机上,如果运行了一个 Docker 容器,容器内的 `/etc/resolv.conf` 文件会是怎样的呢?
|
||||
@ -72,29 +68,29 @@ google.com. 112 IN A 172.217.23.14
|
||||
|
||||
在这个问题上,Docker 的解决方案是忽略所有可能的复杂情况,即无论主机中使用什么 DNS 服务器,容器内都使用 Google 的 DNS 服务器 `8.8.8.8` 和 `8.8.4.4` 完成 DNS 查询。
|
||||
|
||||
_我的经历:在 2013 年,我遇到了使用 Docker 以来的第一个问题,与 Docker 的这种 DNS 解决方案密切相关。我们公司的网络屏蔽了 `8.8.8.8` 和 `8.8.4.4`,导致容器无法解析域名。_
|
||||
_我的经历:在 2013 年,我遇到了使用 Docker 以来的第一个问题,与 Docker 的这种 DNS 解决方案密切相关。我们公司的网络屏蔽了 `8.8.8.8` 和 `8.8.4.4`,导致容器无法解析域名。_
|
||||
|
||||
这就是 Docker 容器的情况,但对于包括 Kubernetes 在内的容器 _<ruby>编排引擎<rt>orchestrators</rt></ruby>_,情况又有些不同。
|
||||
这就是 Docker 容器的情况,但对于包括 Kubernetes 在内的容器 <ruby>编排引擎<rt>orchestrators</rt></ruby>,情况又有些不同。
|
||||
|
||||
### 2) Kubernetes 和 DNS
|
||||
|
||||
在 Kubernetes 中,最小部署单元是 `pod`;`pod` 是一组相互协作的容器,共享 IP 地址(和其它资源)。
|
||||
在 Kubernetes 中,最小部署单元是 pod;它是一组相互协作的容器,共享 IP 地址(和其它资源)。
|
||||
|
||||
Kubernetes 面临的一个额外的挑战是,将 Kubernetes 服务请求(例如,`myservice.kubernetes.io`)通过对应的<ruby>解析器<rt>resolver</rt></ruby>,转发到具体服务地址对应的<ruby>内网地址<rt>private network</rt></ruby>。这里提到的服务地址被称为归属于“<ruby>集群域<rt>cluster domain</rt></ruby>”。集群域可由管理员配置,根据配置可以是 `cluster.local` 或 `myorg.badger` 等。
|
||||
|
||||
在 Kubernetes 中,你可以为 `pod` 指定如下四种 `pod` 内 DNS 查询的方式。
|
||||
在 Kubernetes 中,你可以为 pod 指定如下四种 pod 内 DNS 查询的方式。
|
||||
|
||||
* Default
|
||||
**Default**
|
||||
|
||||
在这种(名称容易让人误解)的方式中,`pod` 与其所在的主机采用相同的 DNS 查询路径,与前面介绍的主机 DNS 查询一致。我们说这种方式的名称容易让人误解,因为该方式并不是默认选项!`ClusterFirst` 才是默认选项。
|
||||
在这种(名称容易让人误解)的方式中,pod 与其所在的主机采用相同的 DNS 查询路径,与前面介绍的主机 DNS 查询一致。我们说这种方式的名称容易让人误解,因为该方式并不是默认选项!`ClusterFirst` 才是默认选项。
|
||||
|
||||
如果你希望覆盖 `/etc/resolv.conf` 中的条目,你可以添加到 `kubelet` 的配置中。
|
||||
|
||||
* ClusterFirst
|
||||
**ClusterFirst**
|
||||
|
||||
在 `ClusterFirst` 方式中,遇到 DNS 查询请求会做有选择的转发。根据配置的不同,有以下两种方式:
|
||||
|
||||
第一种方式配置相对古老但更简明,即采用一个规则:如果请求的域名不是集群域的子域,那么将其转发到 `pod` 所在的主机。
|
||||
第一种方式配置相对古老但更简明,即采用一个规则:如果请求的域名不是集群域的子域,那么将其转发到 pod 所在的主机。
|
||||
|
||||
第二种方式相对新一些,你可以在内部 DNS 中配置选择性转发。
|
||||
|
||||
@ -115,27 +111,27 @@ data:
|
||||
|
||||
在 `stubDomains` 条目中,可以为特定域名指定特定的 DNS 服务器;而 `upstreamNameservers` 条目则给出,待查询域名不是集群域子域情况下用到的 DNS 服务器。
|
||||
|
||||
这是通过在一个 `pod` 中运行我们熟知的 `dnsmasq` 实现的。
|
||||
这是通过在一个 pod 中运行我们熟知的 `dnsmasq` 实现的。
|
||||
|
||||

|
||||
|
||||
剩下两种选项都比较小众:
|
||||
|
||||
* ClusterFirstWithHostNet
|
||||
**ClusterFirstWithHostNet**
|
||||
|
||||
适用于 `pod` 使用主机网络的情况,例如绕开 Docker 网络配置,直接使用与 `pod` 对应主机相同的网络。
|
||||
适用于 pod 使用主机网络的情况,例如绕开 Docker 网络配置,直接使用与 pod 对应主机相同的网络。
|
||||
|
||||
* None
|
||||
**None**
|
||||
|
||||
`None` 意味着不改变 DNS,但强制要求你在 `pod` <ruby>规范文件<rt>specification</rt></ruby>的 `dnsConfig` 条目中指定 DNS 配置。
|
||||
|
||||
### CoreDNS 即将到来
|
||||
|
||||
除了上面提到的那些,一旦 `CoreDNS` 取代Kubernetes 中的 `kube-dns`,情况还会发生变化。`CoreDNS` 相比 `kube-dns` 具有可配置性更高、效率更高等优势。
|
||||
除了上面提到的那些,一旦 `CoreDNS` 取代 Kubernetes 中的 `kube-dns`,情况还会发生变化。`CoreDNS` 相比 `kube-dns` 具有可配置性更高、效率更高等优势。
|
||||
|
||||
如果想了解更多,参考[这里][5]。
|
||||
|
||||
如果你对 OpenShift 的网络感兴趣,我曾写过一篇[文章][6]可供你参考。但文章中 OpenShift 的版本是 `3.6`,可能有些过时。
|
||||
如果你对 OpenShift 的网络感兴趣,我曾写过一篇[文章][6]可供你参考。但文章中 OpenShift 的版本是 3.6,可能有些过时。
|
||||
|
||||
### 第四部分总结
|
||||
|
||||
@ -152,14 +148,14 @@ via: https://zwischenzugs.com/2018/08/06/anatomy-of-a-linux-dns-lookup-part-iv/
|
||||
|
||||
作者:[zwischenzugs][a]
|
||||
译者:[pinewall](https://github.com/pinewall)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://zwischenzugs.com/
|
||||
[1]:https://zwischenzugs.com/2018/06/08/anatomy-of-a-linux-dns-lookup-part-i/
|
||||
[2]:https://zwischenzugs.com/2018/06/18/anatomy-of-a-linux-dns-lookup-part-ii/
|
||||
[3]:https://zwischenzugs.com/2018/07/06/anatomy-of-a-linux-dns-lookup-part-iii/
|
||||
[1]:https://linux.cn/article-9943-1.html
|
||||
[2]:https://linux.cn/article-9949-1.html
|
||||
[3]:https://linux.cn/article-9972-1.html
|
||||
[4]:https://kubernetes.io/docs/tasks/administer-cluster/dns-custom-nameservers/#impacts-on-pods
|
||||
[5]:https://coredns.io/
|
||||
[6]:https://zwischenzugs.com/2017/10/21/openshift-3-6-dns-in-pictures/
|
||||
@ -0,0 +1,78 @@
|
||||
|
||||
Steam 让我们在 Linux 上玩 Windows 的游戏更加容易
|
||||
======
|
||||
|
||||
![Steam Wallpaper][1]
|
||||
|
||||
总所周知,[Linux 游戏][2]库中的游戏只有 Windows 游戏库中的一部分,实际上,许多人甚至都不会考虑将操作系统[转换为 Linux][3],原因很简单,因为他们喜欢的游戏,大多数都不能在这个平台上运行。
|
||||
|
||||
在撰写本文时,Steam 上已有超过 5000 种游戏可以在 Linux 上运行,而 Steam 上的游戏总数已经接近 27000 种了。现在 5000 种游戏可能看起来很多,但还没有达到 27000 种,确实没有。
|
||||
|
||||
虽然几乎所有的新的<ruby>独立游戏<rt>indie game</rt></ruby>都是在 Linux 中推出的,但我们仍然无法在这上面玩很多的 [3A 大作][4]。对我而言,虽然这其中有很多游戏我都很希望能有机会玩,但这从来都不是一个非黑即白的问题。因为我主要是玩独立游戏和[复古游戏][5],所以几乎所有我喜欢的游戏都可以在 Linux 系统上运行。
|
||||
|
||||
### 认识 Proton,Steam 的一个 WINE 复刻
|
||||
|
||||
现在,这个问题已经成为过去式了,因为本周 Valve [宣布][6]要对 Steam Play 进行一次更新,此次更新会将一个名为 Proton 的 Wine 复刻版本添加到 Linux 客户端中。是的,这个工具是开源的,Valve 已经在 [GitHub][7] 上开源了源代码,但该功能仍然处于测试阶段,所以你必须使用测试版的 Steam 客户端才能使用这项功能。
|
||||
|
||||
#### 使用 proton ,可以在 Linux 系统上通过 Steam 运行更多 Windows 游戏
|
||||
|
||||
这对我们这些 Linux 用户来说,实际上意味着什么?简单来说,这意味着我们可以在 Linux 电脑上运行全部 27000 种游戏,而无需配置像 [PlayOnLinux][8] 或 [Lutris][9] 这样的东西。我要告诉你的是,配置这些东西有时候会非常让人头疼。
|
||||
|
||||
对此更为复杂的答案是,某种原因听起来非常美好。虽然在理论上,你可以用这种方式在 Linux 上玩所有的 Windows 平台上的游戏。但只有一少部分游戏在推出时会正式支持 Linux。这少部分游戏包括 《DOOM》、《最终幻想 VI》、《铁拳 7》、《星球大战:前线 2》,和其他几个。
|
||||
|
||||
#### 你可以在 Linux 上玩所有的 Windows 游戏(理论上)
|
||||
|
||||
虽然目前该列表只有大约 30 个游戏,你可以点击“为所有游戏启用 Steam Play”复选框来强制使用 Steam 的 Proton 来安装和运行任意游戏。但你最好不要有太高的期待,它们的稳定性和性能表现不一定有你希望的那么好,所以请把期望值压低一点。
|
||||
|
||||
![Steam Play][10]
|
||||
|
||||
据[这份报告][13],已经有超过一千个游戏可以在 Linux 上玩了。按[此指南][14]来了解如何启用 Steam Play 测试版本。
|
||||
|
||||
#### 体验 Proton,没有我想的那么烂
|
||||
|
||||
例如,我安装了一些难度适中的游戏,使用 Proton 来进行安装。其中一个是《上古卷轴 4:湮没》,在我玩这个游戏的两个小时里,它只崩溃了一次,而且几乎是紧跟在游戏教程的自动保存点之后。
|
||||
|
||||
我有一块英伟达 Gtx 1050 Ti 的显卡。所以我可以使用 1080P 的高配置来玩这个游戏。而且我没有遇到除了这次崩溃之外的任何问题。我唯一真正感到不爽的只有它的帧数没有原本的高。在 90% 的时间里,游戏的帧数都在 60 帧以上,但我知道它的帧数应该能更高。
|
||||
|
||||
我安装和运行的其他所有游戏都运行得很完美,虽然我还没有较长时间地玩过它们中的任何一个。我安装的游戏中包括《森林》、《丧尸围城 4》和《刺客信条 2》。(你觉得我这是喜欢恐怖游戏吗?)
|
||||
|
||||
#### 为什么 Steam(仍然)要下注在 Linux 上?
|
||||
|
||||
现在,一切都很好,这件事为什么会发生呢?为什么 Valve 要花费时间,金钱和资源来做这样的事?我倾向于认为,他们这样做是因为他们懂得 Linux 社区的价值,但是如果要我老实地说,我不相信我们和它有任何的关系。
|
||||
|
||||
如果我一定要在这上面花钱,我想说 Valve 开发了 Proton,因为他们还没有放弃 [Steam Machine][11]。因为 [Steam OS][12] 是基于 Linux 的发行版,在这类东西上面投资可以获取最大的利润,Steam OS 上可用的游戏越多,就会有更多的人愿意购买 Steam Machine。
|
||||
|
||||
可能我是错的,但是我敢打赌啊,我们会在不远的未来看到新一批的 Steam Machine。可能我们会在一年内看到它们,也有可能我们再等五年都见不到,谁知道呢!
|
||||
|
||||
无论哪种方式,我所知道的是,我终于能兴奋地从我的 Steam 游戏库里玩游戏了。这个游戏库是多年来我通过各种慈善包、促销码和不定时地买的游戏慢慢积累的,只不过是想试试让它在 Lutris 中运行。
|
||||
|
||||
#### 为 Linux 上越来越多的游戏而激动?
|
||||
|
||||
你怎么看?你对此感到激动吗?或者说你会害怕只有很少的开发者会开发 Linux 平台上的游戏,因为现在几乎没有需求?Valve 喜欢 Linux 社区,还是说他们喜欢钱?请在下面的评论区告诉我们您的想法,然后重新搜索来查看更多类似这样的开源软件方面的文章。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/steam-play-proton/
|
||||
|
||||
作者:[Phillip Prado][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[hopefully2333](https://github.com/hopefully2333)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/phillip/
|
||||
[1]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/steam-wallpaper.jpeg
|
||||
[2]:https://itsfoss.com/linux-gaming-guide/
|
||||
[3]:https://itsfoss.com/reasons-switch-linux-windows-xp/
|
||||
[4]:https://itsfoss.com/triplea-game-review/
|
||||
[5]:https://itsfoss.com/play-retro-games-linux/
|
||||
[6]:https://steamcommunity.com/games/221410
|
||||
[7]:https://github.com/ValveSoftware/Proton/
|
||||
[8]:https://www.playonlinux.com/en/
|
||||
[9]:https://lutris.net/
|
||||
[10]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/SteamProton.jpg
|
||||
[11]:https://store.steampowered.com/sale/steam_machines
|
||||
[12]:https://itsfoss.com/valve-annouces-linux-based-gaming-operating-system-steamos/
|
||||
[13]:https://spcr.netlify.com/
|
||||
[14]:https://itsfoss.com/steam-play/
|
||||
@ -0,0 +1,173 @@
|
||||
每位 Ubuntu 18.04 用户都应该知道的快捷键
|
||||
======
|
||||
|
||||
了解快捷键能够提升您的生产力。这里有一些实用的 Ubuntu 快捷键助您像专业人士一样使用 Ubuntu。
|
||||
|
||||
您可以用键盘和鼠标组合来使用操作系统。
|
||||
|
||||
> 注意:本文中提到的键盘快捷键适用于 Ubuntu 18.04 GNOME 版。 通常,它们中的大多数(或者全部)也适用于其他的 Ubuntu 版本,但我不能够保证。
|
||||
|
||||
![Ubuntu keyboard shortcuts][1]
|
||||
|
||||
### 实用的 Ubuntu 快捷键
|
||||
|
||||
让我们来看一看 Ubuntu GNOME 必备的快捷键吧!通用的快捷键如 `Ctrl+C`(复制)、`Ctrl+V`(粘贴)或者 `Ctrl+S`(保存)不再赘述。
|
||||
|
||||
注意:Linux 中的 Super 键即键盘上带有 Windows 图标的键,本文中我使用了大写字母,但这不代表你需要按下 `shift` 键,比如,`T` 代表键盘上的 ‘t’ 键,而不代表 `Shift+t`。
|
||||
|
||||
#### 1、 Super 键:打开活动搜索界面
|
||||
|
||||
使用 `Super` 键可以打开活动菜单。如果你只能在 Ubuntu 上使用一个快捷键,那只能是 `Super` 键。
|
||||
|
||||
想要打开一个应用程序?按下 `Super` 键然后搜索应用程序。如果搜索的应用程序未安装,它会推荐来自应用中心的应用程序。
|
||||
|
||||
想要看看有哪些正在运行的程序?按下 `Super` 键,屏幕上就会显示所有正在运行的 GUI 应用程序。
|
||||
|
||||
想要使用工作区吗?只需按下 `Super` 键,您就可以在屏幕右侧看到工作区选项。
|
||||
|
||||
#### 2、 Ctrl+Alt+T:打开 Ubuntu 终端窗口
|
||||
|
||||
![Ubuntu Terminal Shortcut][2]
|
||||
|
||||
*使用 Ctrl+alt+T 来打开终端窗口*
|
||||
|
||||
想要打开一个新的终端,您只需使用快捷键 `Ctrl+Alt+T`。这是我在 Ubuntu 中最喜欢的键盘快捷键。 甚至在我的许多 FOSS 教程中,当需要打开终端窗口是,我都会提到这个快捷键。
|
||||
|
||||
#### 3、 Super+L 或 Ctrl+Alt+L:锁屏
|
||||
|
||||
当您离开电脑时锁定屏幕,是最基本的安全习惯之一。您可以使用 `Super+L` 快捷键,而不是繁琐地点击屏幕右上角然后选择锁定屏幕选项。
|
||||
|
||||
有些系统也会使用 `Ctrl+Alt+L` 键锁定屏幕。
|
||||
|
||||
#### 4、 Super+D or Ctrl+Alt+D:显示桌面
|
||||
|
||||
按下 `Super+D` 可以最小化所有正在运行的应用程序窗口并显示桌面。
|
||||
|
||||
再次按 `Super+D` 将重新打开所有正在运行的应用程序窗口,像之前一样。
|
||||
|
||||
您也可以使用 `Ctrl+Alt+D` 来实现此目的。
|
||||
|
||||
#### 5、 Super+A:显示应用程序菜单
|
||||
|
||||
您可以通过单击屏幕左下角的 9 个点打开 Ubuntu 18.04 GNOME 中的应用程序菜单。 但是一个更快捷的方法是使用 `Super+A` 快捷键。
|
||||
|
||||
它将显示应用程序菜单,您可以在其中查看或搜索系统上已安装的应用程序。
|
||||
|
||||
您可以使用 `Esc` 键退出应用程序菜单界面。
|
||||
|
||||
#### 6、 Super+Tab 或 Alt+Tab:在运行中的应用程序间切换
|
||||
|
||||
如果您运行的应用程序不止一个,则可以使用 `Super+Tab` 或 `Alt+Tab` 快捷键在应用程序之间切换。
|
||||
|
||||
按住 `Super` 键同时按下 `Tab` 键,即可显示应用程序切换器。 按住 `Super` 的同时,继续按下 `Tab` 键在应用程序之间进行选择。 当光标在所需的应用程序上时,松开 `Super` 和 `Tab` 键。
|
||||
|
||||
默认情况下,应用程序切换器从左向右移动。 如果要从右向左移动,可使用 `Super+Shift+Tab` 快捷键。
|
||||
|
||||
在这里您也可以用 `Alt` 键代替 `Super` 键。
|
||||
|
||||
> 提示:如果有多个应用程序实例,您可以使用 Super+` 快捷键在这些实例之间切换。
|
||||
|
||||
#### 7、 Super+箭头:移动窗口位置
|
||||
|
||||
<https://player.vimeo.com/video/289091549>
|
||||
|
||||
这个快捷键也适用于 Windows 系统。 使用应用程序时,按下 `Super+左箭头`,应用程序将贴合屏幕的左边缘,占用屏幕的左半边。
|
||||
|
||||
同样,按下 `Super+右箭头`会使应用程序贴合右边缘。
|
||||
|
||||
按下 `Super+上箭头`将最大化应用程序窗口,`Super+下箭头`将使应用程序恢复到其正常的大小。
|
||||
|
||||
#### 8、 Super+M:切换到通知栏
|
||||
|
||||
GNOME 中有一个通知栏,您可以在其中查看系统和应用程序活动的通知,这里也有一个日历。
|
||||
|
||||
![Notification Tray Ubuntu 18.04 GNOME][3]
|
||||
|
||||
*通知栏*
|
||||
|
||||
使用 `Super+M` 快捷键,您可以打开此通知栏。 如果再次按这些键,将关闭打开的通知托盘。
|
||||
|
||||
使用 `Super+V` 也可实现相同的功能。
|
||||
|
||||
#### 9、 Super+空格:切换输入法(用于多语言设置)
|
||||
|
||||
如果您使用多种语言,可能您的系统上安装了多个输入法。 例如,我需要在 Ubuntu 上同时使用[印地语] [4]和英语,所以我安装了印地语(梵文)输入法以及默认的英语输入法。
|
||||
|
||||
如果您也使用多语言设置,则可以使用 `Super+空格` 快捷键快速更改输入法。
|
||||
|
||||
#### 10、 Alt+F2:运行控制台
|
||||
|
||||
这适用于高级用户。 如果要运行快速命令,而不是打开终端并在其中运行命令,则可以使用 `Alt+F2` 运行控制台。
|
||||
|
||||
![Alt+F2 to run commands in Ubuntu][5]
|
||||
|
||||
*控制台*
|
||||
|
||||
当您使用只能在终端运行的应用程序时,这尤其有用。
|
||||
|
||||
#### 11、 Ctrl+Q:关闭应用程序窗口
|
||||
|
||||
如果您有正在运行的应用程序,可以使用 `Ctrl+Q` 快捷键关闭应用程序窗口。您也可以使用 `Ctrl+W` 来实现此目的。
|
||||
|
||||
`Alt+F4` 是关闭应用程序窗口更“通用”的快捷方式。
|
||||
|
||||
它不适用于一些应用程序,如 Ubuntu 中的默认终端。
|
||||
|
||||
#### 12、 Ctrl+Alt+箭头:切换工作区
|
||||
|
||||
![Workspace switching][6]
|
||||
|
||||
*切换工作区*
|
||||
|
||||
如果您是使用工作区的重度用户,可以使用 `Ctrl+Alt+上箭头`和 `Ctrl+Alt+下箭头`在工作区之间切换。
|
||||
|
||||
#### 13、 Ctrl+Alt+Del:注销
|
||||
|
||||
不!在 Linux 中使用著名的快捷键 `Ctrl+Alt+Del` 并不会像在 Windows 中一样打开任务管理器(除非您使用自定义快捷键)。
|
||||
|
||||
![Log Out Ubuntu][7]
|
||||
|
||||
*注销*
|
||||
|
||||
在普通的 GNOME 桌面环境中,您可以使用 `Ctrl+Alt+Del` 键打开关机菜单,但 Ubuntu 并不总是遵循此规范,因此当您在 Ubuntu 中使用 `Ctrl+Alt+Del` 键时,它会打开注销菜单。
|
||||
|
||||
### 在 Ubuntu 中使用自定义键盘快捷键
|
||||
|
||||
您不是只能使用默认的键盘快捷键,您可以根据需要创建自己的自定义键盘快捷键。
|
||||
|
||||
转到“设置->设备->键盘”,您将在这里看到系统的所有键盘快捷键。向下滚动到底部,您将看到“自定义快捷方式”选项。
|
||||
|
||||
![Add custom keyboard shortcut in Ubuntu][8]
|
||||
|
||||
您需要提供易于识别的快捷键名称、使用快捷键时运行的命令,以及您自定义的按键组合。
|
||||
|
||||
### Ubuntu 中你最喜欢的键盘快捷键是什么?
|
||||
|
||||
快捷键无穷无尽。如果需要,你可以看一看所有可能的 [GNOME 快捷键][9],看其中有没有你需要用到的快捷键。
|
||||
|
||||
您可以学习使用您经常使用应用程序的快捷键,这是很有必要的。例如,我使用 Kazam 进行[屏幕录制][10],键盘快捷键帮助我方便地暂停和开始录像。
|
||||
|
||||
您最喜欢、最离不开的 Ubuntu 快捷键是什么?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/ubuntu-shortcuts/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[XiatianSummer](https://github.com/XiatianSummer)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/ubuntu-keyboard-shortcuts.jpeg
|
||||
[2]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/ubuntu-terminal-shortcut.jpg
|
||||
[3]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/notification-tray-ubuntu-gnome.jpeg
|
||||
[4]: https://itsfoss.com/type-indian-languages-ubuntu/
|
||||
[5]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/console-alt-f2-ubuntu-gnome.jpeg
|
||||
[6]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/workspace-switcher-ubuntu.png
|
||||
[7]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/log-out-ubuntu.jpeg
|
||||
[8]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/custom-keyboard-shortcut.jpg
|
||||
[9]: https://wiki.gnome.org/Design/OS/KeyboardShortcuts
|
||||
[10]: https://itsfoss.com/best-linux-screen-recorders/
|
||||
@ -3,7 +3,7 @@
|
||||
|
||||

|
||||
|
||||
**APT**, 是 **A** dvanced **P** ackage **T** ool 的缩写,是基于 Debian 的系统的默认包管理器。我们可以使用 APT 安装、更新、升级和删除应用程序。最近,我一直遇到一个奇怪的错误。每当我尝试更新我的 Ubuntu 16.04 时,我都会收到此错误 - **“0% [Connecting to in.archive.ubuntu.com (2001:67c:1560:8001::14)]”** ,同时更新流程会卡住很长时间。我的网络连接没问题,我可以 ping 通所有网站,包括 Ubuntu 官方网站。在搜索了一番谷歌后,我意识到 Ubuntu 镜像有时无法通过 IPv6 访问。在我强制将 APT 包管理器在更新系统时使用 IPv4 代替 IPv6 访问 Ubuntu 镜像后,此问题得以解决。如果你遇到过此错误,可以按照以下说明解决。
|
||||
**APT**, 是 **A** dvanced **P** ackage **T** ool 的缩写,是基于 Debian 的系统的默认包管理器。我们可以使用 APT 安装、更新、升级和删除应用程序。最近,我一直遇到一个奇怪的错误。每当我尝试更新我的 Ubuntu 16.04 时,我都会收到此错误 - **“0% [Connecting to in.archive.ubuntu.com (2001:67c:1560:8001::14)]”** ,同时更新流程会卡住很长时间。我的网络连接没问题,我可以 ping 通所有网站,包括 Ubuntu 官方网站。在搜索了一番谷歌后,我意识到 Ubuntu 镜像站点有时无法通过 IPv6 访问。在我强制将 APT 包管理器在更新系统时使用 IPv4 代替 IPv6 访问 Ubuntu 镜像站点后,此问题得以解决。如果你遇到过此错误,可以按照以下说明解决。
|
||||
|
||||
### 强制 APT 包管理器在 Ubuntu 16.04 中使用 IPv4
|
||||
|
||||
@ -11,13 +11,12 @@
|
||||
|
||||
```
|
||||
$ sudo apt-get -o Acquire::ForceIPv4=true update
|
||||
|
||||
$ sudo apt-get -o Acquire::ForceIPv4=true upgrade
|
||||
```
|
||||
|
||||
瞧!这次更新很快就完成了。
|
||||
|
||||
你还可以使用以下命令在 **/etc/apt/apt.conf.d/99force-ipv4** 中添加以下行,以便将来对所有 **apt-get** 事务保持持久性:
|
||||
你还可以使用以下命令在 `/etc/apt/apt.conf.d/99force-ipv4` 中添加以下行,以便将来对所有 `apt-get` 事务保持持久性:
|
||||
|
||||
```
|
||||
$ echo 'Acquire::ForceIPv4 "true";' | sudo tee /etc/apt/apt.conf.d/99force-ipv4
|
||||
@ -25,7 +24,7 @@ $ echo 'Acquire::ForceIPv4 "true";' | sudo tee /etc/apt/apt.conf.d/99force-ipv4
|
||||
|
||||
**免责声明:**
|
||||
|
||||
我不知道最近是否有人遇到这个问题,但我今天在我的 Ubuntu 16.04 LTS 虚拟机中遇到了至少四五次这样的错误,我按照上面的说法解决了这个问题。我不确定这是推荐的解决方案。请浏览 Ubuntu 论坛来确保此方法合法。由于我只是一个 VM,我只将它用于测试和学习目的,我不介意这种方法的真实性。请自行承担使用风险。
|
||||
我不知道最近是否有人遇到这个问题,但我今天在我的 Ubuntu 16.04 LTS 虚拟机中遇到了至少四、五次这样的错误,我按照上面的说法解决了这个问题。我不确定这是推荐的解决方案。请浏览 Ubuntu 论坛来确保此方法合法。由于我只是一个 VM,我只将它用于测试和学习目的,我不介意这种方法的真实性。请自行承担使用风险。
|
||||
|
||||
希望这有帮助。还有更多的好东西。敬请关注!
|
||||
|
||||
@ -40,7 +39,7 @@ via: https://www.ostechnix.com/how-to-force-apt-package-manager-to-use-ipv4-in-u
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,74 @@
|
||||
CPU Power Manager – Control And Manage CPU Frequency In Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
If you are a laptop user, you probably know that power management on Linux isn’t really as good as on other OSes. While there are tools like **TLP** , [**Laptop Mode Tools** and **powertop**][1] to help reduce power consumption, overall battery life on Linux isn’t as good as Windows or Mac OS. Another way to reduce power consumption is to limit the frequency of your CPU. While this is something that has always been doable, it generally requires complicated terminal commands, making it inconvenient. But fortunately, there’s a gnome extension that helps you easily set and manage your CPU’s frequency – **CPU Power Manager**. CPU Power Manager uses the **intel_pstate** frequency scaling driver (supported by almost every Intel CPU) to control and manage CPU frequency in your GNOME desktop.
|
||||
|
||||
Another reason to use this extension is to reduce heating in your system. There are many systems out there which can get uncomfortably hot in normal usage. Limiting your CPU’s frequency could reduce heating. It will also decrease the wear and tear on your CPU and other components.
|
||||
|
||||
### Installing CPU Power Manager
|
||||
|
||||
First, go to the [**extension’s page**][2], and install the extension.
|
||||
|
||||
Once the extension has installed, you’ll get a CPU icon at the right side of the Gnome top bar. Click the icon, and you get an option to install the extension:
|
||||
|
||||

|
||||
|
||||
If you click **“Attempt Installation”** , you’ll get a password prompt. The extension needs root privileges to add policykit rule for controlling CPU frequency. This is what the prompt looks like:
|
||||
|
||||

|
||||
|
||||
Type in your password and Click **“Authenticate”** , and that finishes installation. The last action adds a policykit file – **mko.cpupower.setcpufreq.policy** at **/usr/share/polkit-1/actions**.
|
||||
|
||||
After installation is complete, if you click the CPU icon at the top right, you’ll get something like this:
|
||||
|
||||

|
||||
|
||||
### Features
|
||||
|
||||
* **See the current CPU frequency:** Obviously, you can use this window to see the frequency that your CPU is running at.
|
||||
* **Set maximum and minimum frequency:** With this extension, you can set maximum and minimum frequency limits in terms of percentage of max frequency. Once these limits are set, the CPU will operate only in this range of frequencies.
|
||||
* **Turn Turbo Boost On and Off:** This is my favorite feature. Most Intel CPU’s have “Turbo Boost” feature, whereby the one of the cores of the CPU is boosted past the normal maximum frequency for extra performance. While this can make your system more performant, it also increases power consumption a lot. So if you aren’t doing anything intensive, it’s nice to be able to turn off Turbo Boost and save power. In fact, in my case, I have Turbo Boost turned off most of the time.
|
||||
* **Make Profiles:** You can make profiles with max and min frequency that you can turn on/off easily instead of fiddling with max and frequencies.
|
||||
|
||||
|
||||
|
||||
### Preferences
|
||||
|
||||
You can also customize the extension via the preferences window:
|
||||
|
||||

|
||||
|
||||
As you can see, you can set whether CPU frequency is to be displayed, and whether to display it in **Mhz** or **Ghz**.
|
||||
|
||||
You can also edit and create/delete profiles:
|
||||
|
||||

|
||||
|
||||
You can set maximum and minimum frequencies, and turbo boost for each profile.
|
||||
|
||||
### Conclusion
|
||||
|
||||
As I said in the beginning, power management on Linux is not the best, and many people are always looking to eek out a few minutes more out of their Linux laptop. If you are one of those, check out this extension. This is a unconventional method to save power, but it does work. I certainly love this extension, and have been using it for a few months now.
|
||||
|
||||
What do you think about this extension? Put your thoughts in the comments below!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/cpu-power-manager-control-and-manage-cpu-frequency-in-linux/
|
||||
|
||||
作者:[EDITOR][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/editor/
|
||||
[1]: https://www.ostechnix.com/improve-laptop-battery-performance-linux/
|
||||
[2]: https://extensions.gnome.org/extension/945/cpu-power-manager/
|
||||
@ -0,0 +1,80 @@
|
||||
How to Install Cinnamon Desktop on Ubuntu
|
||||
======
|
||||
**This tutorial shows you how to install Cinnamon desktop environment on Ubuntu.**
|
||||
|
||||
[Cinnamon][1] is the default desktop environment of [Linux Mint][2]. Unlike Unity desktop environment in Ubuntu, Cinnamon is more traditional but elegant looking desktop environment with the bottom panel and app menu etc. Many Windows migrants [prefer Linux Mint over Ubuntu][3] because of Cinnamon desktop and its Windows-resembling user interface.
|
||||
|
||||
Now, you don’t need to [install Linux Mint][4] just for trying Cinnamon. In this tutorial, I’ll show you **how to install Cinnamon in Ubuntu 18.04, 16.04 and 14.04**.
|
||||
|
||||
You should note something before you install Cinnamon desktop on Ubuntu. Sometimes, installing additional desktop environments leads to conflict between the desktop environments. This may result in a broken session, broken applications and features etc. This is why you should be careful in making this choice.
|
||||
|
||||
### How to Install Cinnamon on Ubuntu
|
||||
|
||||
![How to install cinnamon desktop on Ubuntu Linux][5]
|
||||
|
||||
There used to be a-sort-of official PPA from Cinnamon team for Ubuntu but it doesn’t exist anymore. Don’t lose heart. There is an unofficial PPA available and it works perfectly. This PPA consists of the latest Cinnamon version.
|
||||
|
||||
Open a terminal and use the following commands:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:embrosyn/cinnamon
|
||||
sudo apt update && sudo apt install cinnamon
|
||||
|
||||
```
|
||||
|
||||
It will download files of around 150 MB in size (if I remember correctly). This also provides you with Nemo (Nautilus fork) and Cinnamon Control Center. This bonus stuff gives a closer feel of Linux Mint.
|
||||
|
||||
### Using Cinnamon desktop environment in Ubuntu
|
||||
|
||||
Once you have installed Cinnamon, log out of the current session. At the login screen, click on the Ubuntu symbol beside the username:
|
||||
|
||||

|
||||
|
||||
When you do this, it will give you all the desktop environments available for your system. No need to tell you that you have to choose Cinnamon:
|
||||
|
||||

|
||||
|
||||
Now you should be logged in to Ubuntu with Cinnamon desktop environment. Remember, you can do the same to switch back to Unity. Here is a quick screenshot of what it looked like to run **Cinnamon in Ubuntu** :
|
||||
|
||||

|
||||
|
||||
Looks completely like Linux Mint, isn’t it? I didn’t find any compatibility issue between Cinnamon and Unity. I switched back and forth between Unity and Cinnamon and both worked perfectly.
|
||||
|
||||
#### Remove Cinnamon from Ubuntu
|
||||
|
||||
It is understandable that you might want to uninstall Cinnamon. We will use PPA Purge for this purpose. Let’s install PPA Purge first:
|
||||
|
||||
```
|
||||
sudo apt-get install ppa-purge
|
||||
|
||||
```
|
||||
|
||||
Afterward, use the following command to purge the PPA:
|
||||
|
||||
```
|
||||
sudo ppa-purge ppa:embrosyn/cinnamon
|
||||
|
||||
```
|
||||
|
||||
In related articles, I suggest you to read more about [how to remove PPA in Linux][6].
|
||||
|
||||
I hope this post helps you to **install Cinnamon in Ubuntu**. Do share your experience with Cinnamon.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/install-cinnamon-on-ubuntu/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]: http://cinnamon.linuxmint.com/
|
||||
[2]: http://www.linuxmint.com/
|
||||
[3]: https://itsfoss.com/linux-mint-vs-ubuntu/
|
||||
[4]: https://itsfoss.com/guide-install-linux-mint-16-dual-boot-windows/
|
||||
[5]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/install-cinnamon-ubuntu.png
|
||||
[6]: https://itsfoss.com/how-to-remove-or-delete-ppas-quick-tip/
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by bayar199468
|
||||
7 Best eBook Readers for Linux
|
||||
======
|
||||
**Brief:** In this article, we are covering some of the best ebook readers for Linux. These apps give a better reading experience and some will even help in managing your ebooks.
|
||||
|
||||
@ -1,182 +0,0 @@
|
||||
How to Install and Use Wireshark on Debian 9 / Ubuntu 16.04 / 17.10
|
||||
============================================================
|
||||
|
||||
by [Pradeep Kumar][1] · Published November 29, 2017 · Updated November 29, 2017
|
||||
|
||||
[][2]
|
||||
|
||||
Wireshark is free and open source, cross platform, GUI based Network packet analyzer that is available for Linux, Windows, MacOS, Solaris etc. It captures network packets in real time & presents them in human readable format. Wireshark allows us to monitor the network packets up to microscopic level. Wireshark also has a command line utility called ‘tshark‘ that performs the same functions as Wireshark but through terminal & not through GUI.
|
||||
|
||||
Wireshark can be used for network troubleshooting, analyzing, software & communication protocol development & also for education purposed. Wireshark uses a library called ‘pcap‘ for capturing the network packets.
|
||||
|
||||
Wireshark comes with a lot of features & some those features are;
|
||||
|
||||
* Support for a hundreds of protocols for inspection,
|
||||
|
||||
* Ability to capture packets in real time & save them for later offline analysis,
|
||||
|
||||
* A number of filters to analyzing data,
|
||||
|
||||
* Data captured can be compressed & uncompressed on the fly,
|
||||
|
||||
* Various file formats for data analysis supported, output can also be saved to XML, CSV, plain text formats,
|
||||
|
||||
* data can be captured from a number of interfaces like ethernet, wifi, bluetooth, USB, Frame relay , token rings etc.
|
||||
|
||||
In this article, we will discuss how to install Wireshark on Ubuntu/Debain machines & will also learn to use Wireshark for capturing network packets.
|
||||
|
||||
#### Installation of Wireshark on Ubuntu 16.04 / 17.10
|
||||
|
||||
Wireshark is available with default Ubuntu repositories & can be simply installed using the following command. But there might be chances that you will not get the latest version of wireshark.
|
||||
|
||||
```
|
||||
linuxtechi@nixworld:~$ sudo apt-get update
|
||||
linuxtechi@nixworld:~$ sudo apt-get install wireshark -y
|
||||
```
|
||||
|
||||
So to install latest version of wireshark we have to enable or configure official wireshark repository.
|
||||
|
||||
Use the beneath commands one after the another to configure repository and to install latest version of Wireshark utility
|
||||
|
||||
```
|
||||
linuxtechi@nixworld:~$ sudo add-apt-repository ppa:wireshark-dev/stable
|
||||
linuxtechi@nixworld:~$ sudo apt-get update
|
||||
linuxtechi@nixworld:~$ sudo apt-get install wireshark -y
|
||||
```
|
||||
|
||||
Once the Wireshark is installed execute the below command so that non-root users can capture live packets of interfaces,
|
||||
|
||||
```
|
||||
linuxtechi@nixworld:~$ sudo setcap 'CAP_NET_RAW+eip CAP_NET_ADMIN+eip' /usr/bin/dumpcap
|
||||
```
|
||||
|
||||
#### Installation of Wireshark on Debian 9
|
||||
|
||||
Wireshark package and its dependencies are already present in the default debian 9 repositories, so to install latest and stable version of Wireshark on Debian 9, use the following command:
|
||||
|
||||
```
|
||||
linuxtechi@nixhome:~$ sudo apt-get update
|
||||
linuxtechi@nixhome:~$ sudo apt-get install wireshark -y
|
||||
```
|
||||
|
||||
During the installation, it will prompt us to configure dumpcap for non-superusers,
|
||||
|
||||
Select ‘yes’ and then hit enter.
|
||||
|
||||
[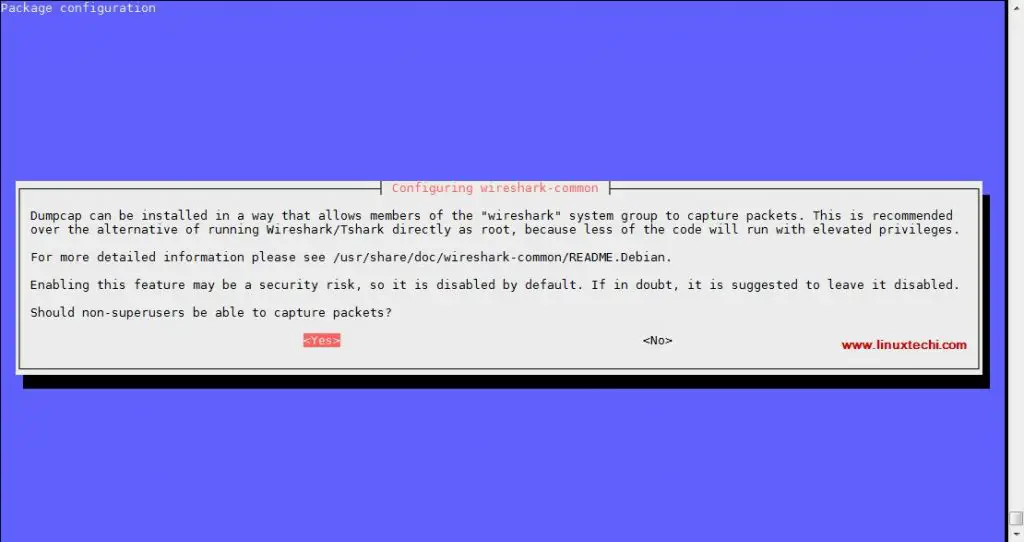][3]
|
||||
|
||||
Once the Installation is completed, execute the below command so that non-root users can also capture the live packets of the interfaces.
|
||||
|
||||
```
|
||||
linuxtechi@nixhome:~$ sudo chmod +x /usr/bin/dumpcap
|
||||
```
|
||||
|
||||
We can also use the latest source package to install the wireshark on Ubuntu/Debain & many other Linux distributions.
|
||||
|
||||
#### Installing Wireshark using source code on Debian / Ubuntu Systems
|
||||
|
||||
Firstly download the latest source package (which is 2.4.2 at the time for writing this article), use the following command,
|
||||
|
||||
```
|
||||
linuxtechi@nixhome:~$ wget https://1.as.dl.wireshark.org/src/wireshark-2.4.2.tar.xz
|
||||
```
|
||||
|
||||
Next extract the package & enter into the extracted directory,
|
||||
|
||||
```
|
||||
linuxtechi@nixhome:~$ tar -xf wireshark-2.4.2.tar.xz -C /tmp
|
||||
linuxtechi@nixhome:~$ cd /tmp/wireshark-2.4.2
|
||||
```
|
||||
|
||||
Now we will compile the code with the following commands,
|
||||
|
||||
```
|
||||
linuxtechi@nixhome:/tmp/wireshark-2.4.2$ ./configure --enable-setcap-install
|
||||
linuxtechi@nixhome:/tmp/wireshark-2.4.2$ make
|
||||
```
|
||||
|
||||
Lastly install the compiled packages to install Wireshark on the system,
|
||||
|
||||
```
|
||||
linuxtechi@nixhome:/tmp/wireshark-2.4.2$ sudo make install
|
||||
linuxtechi@nixhome:/tmp/wireshark-2.4.2$ sudo ldconfig
|
||||
```
|
||||
|
||||
Upon installation a separate group for Wireshark will also be created, we will now add our user to the group so that it can work with wireshark otherwise you might get ‘permission denied‘ error when starting wireshark.
|
||||
|
||||
To add the user to the wireshark group, execute the following command,
|
||||
|
||||
```
|
||||
linuxtechi@nixhome:~$ sudo usermod -a -G wireshark linuxtechi
|
||||
```
|
||||
|
||||
Now we can start wireshark either from GUI Menu or from terminal with this command,
|
||||
|
||||
```
|
||||
linuxtechi@nixhome:~$ wireshark
|
||||
```
|
||||
|
||||
#### Access Wireshark on Debian 9 System
|
||||
|
||||
[][4]
|
||||
|
||||
Click on Wireshark icon
|
||||
|
||||
[][5]
|
||||
|
||||
#### Access Wireshark on Ubuntu 16.04 / 17.10
|
||||
|
||||
[][6]
|
||||
|
||||
Click on Wireshark icon
|
||||
|
||||
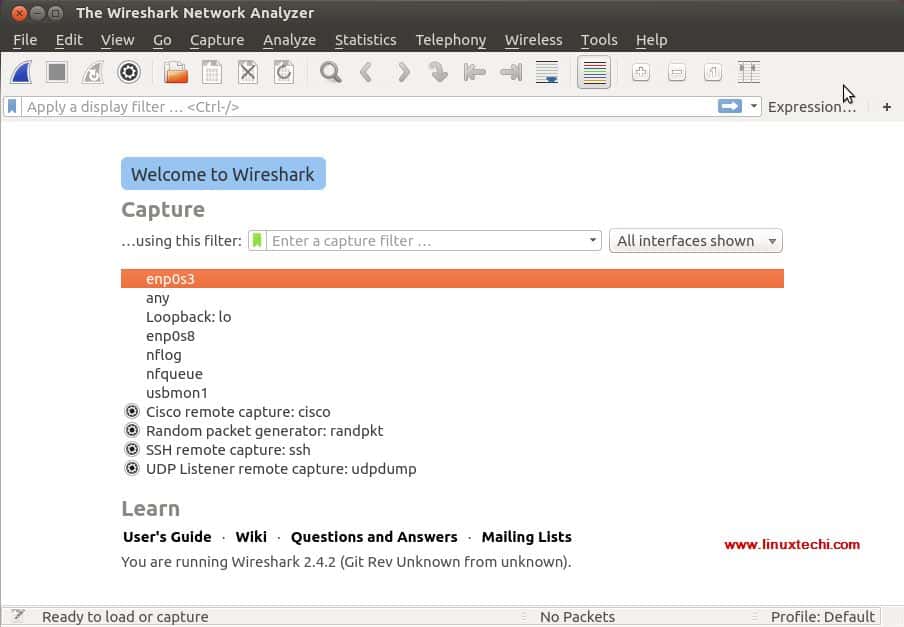
[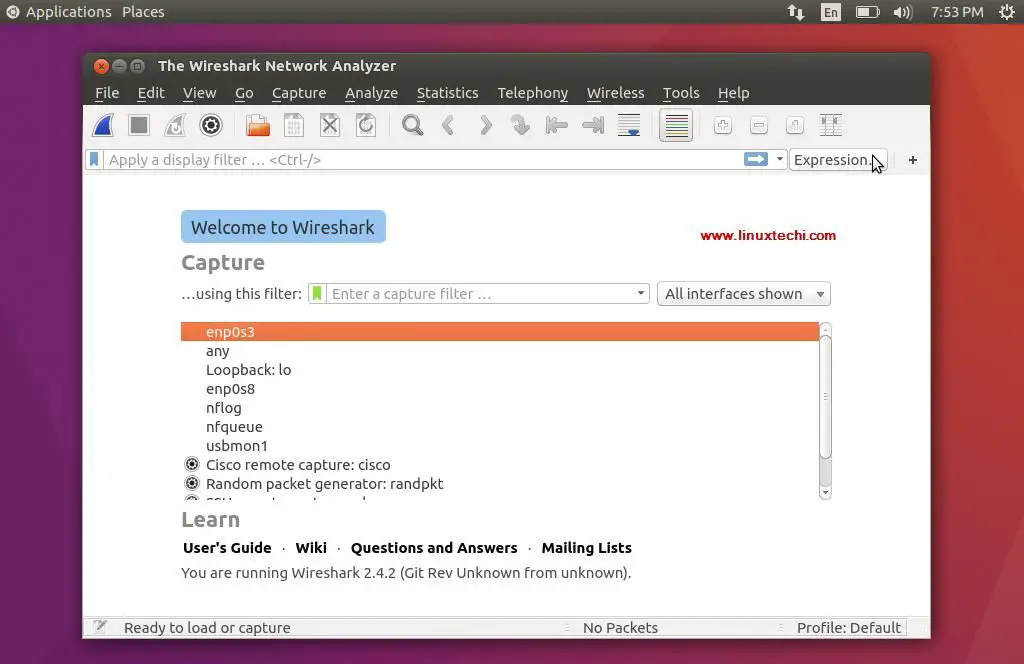][7]
|
||||
|
||||
#### Capturing and Analyzing packets
|
||||
|
||||
Once the wireshark has been started, we should be presented with the wireshark window, example is shown above for Ubuntu and Debian system.
|
||||
|
||||
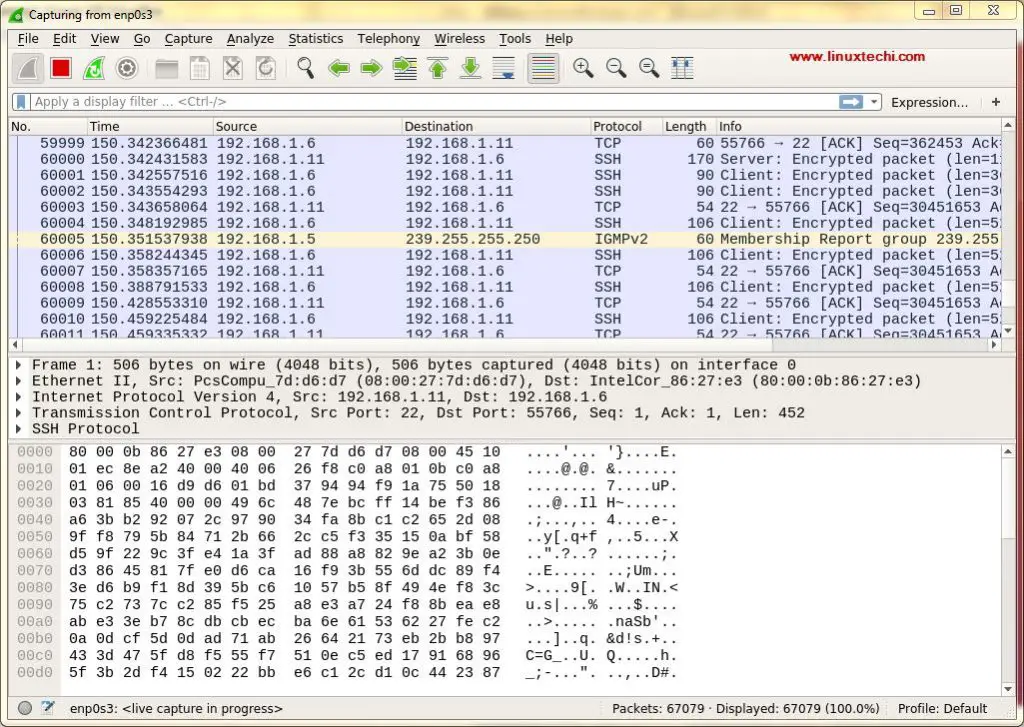
[][8]
|
||||
|
||||
All these are the interfaces from where we can capture the network packets. Based on the interfaces you have on your system, this screen might be different for you.
|
||||
|
||||
We are selecting ‘enp0s3’ for capturing the network traffic for that inteface. After selecting the inteface, network packets for all the devices on our network start to populate (refer to screenshot below)
|
||||
|
||||
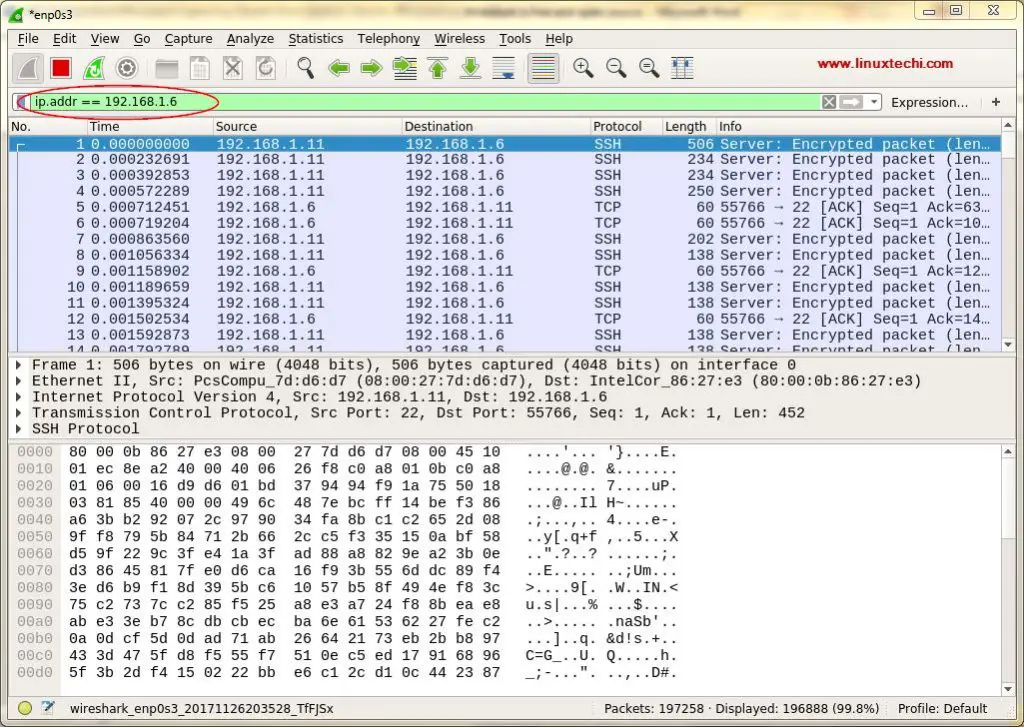
[][9]
|
||||
|
||||
First time we see this screen we might get overwhelmed by the data that is presented in this screen & might have thought how to sort out this data but worry not, one the best features of Wireshark is its filters.
|
||||
|
||||
We can sort/filter out the data based on IP address, Port number, can also used source & destination filters, packet size etc & can also combine 2 or more filters together to create more comprehensive searches. We can either write our filters in ‘Apply a Display Filter‘ tab , or we can also select one of already created rules. To select pre-built filter, click on ‘flag‘ icon , next to ‘Apply a Display Filter‘ tab,
|
||||
|
||||
[][10]
|
||||
|
||||
We can also filter data based on the color coding, By default, light purple is TCP traffic, light blue is UDP traffic, and black identifies packets with errors , to see what these codes mean, click View -> Coloring Rules, also we can change these codes.
|
||||
|
||||
[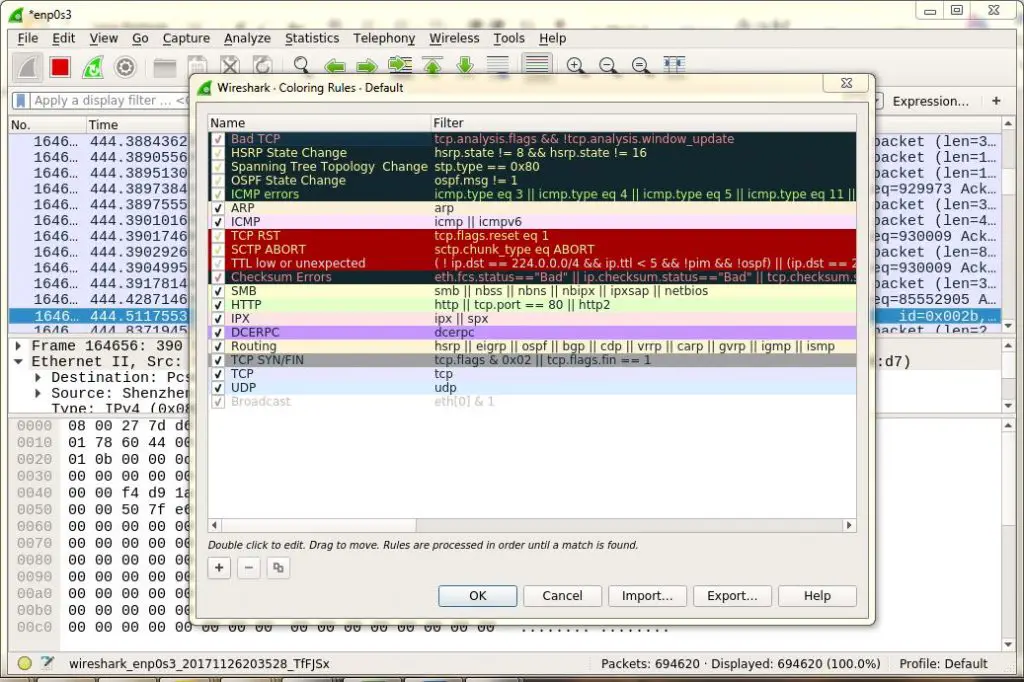][11]
|
||||
|
||||
After we have the results that we need, we can then click on any of the captured packets to get more details about that packet, this will show all the data about that network packet.
|
||||
|
||||
Wireshark is an extremely powerful tool takes some time to getting used to & make a command over it, this tutorial will help you get started. Please feel free to drop in your queries or suggestions in the comment box below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxtechi.com
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxtechi.com/author/pradeep/
|
||||
[1]:https://www.linuxtechi.com/author/pradeep/
|
||||
[2]:https://www.linuxtechi.com/wp-content/uploads/2017/11/wireshark-Debian-9-Ubuntu-16.04-17.10.jpg
|
||||
[3]:https://www.linuxtechi.com/wp-content/uploads/2017/11/Configure-Wireshark-Debian9.jpg
|
||||
[4]:https://www.linuxtechi.com/wp-content/uploads/2017/11/Access-wireshark-debian9.jpg
|
||||
[5]:https://www.linuxtechi.com/wp-content/uploads/2017/11/Wireshark-window-debian9.jpg
|
||||
[6]:https://www.linuxtechi.com/wp-content/uploads/2017/11/Access-wireshark-Ubuntu.jpg
|
||||
[7]:https://www.linuxtechi.com/wp-content/uploads/2017/11/Wireshark-window-Ubuntu.jpg
|
||||
[8]:https://www.linuxtechi.com/wp-content/uploads/2017/11/wireshark-Linux-system.jpg
|
||||
[9]:https://www.linuxtechi.com/wp-content/uploads/2017/11/Capturing-Packet-from-enp0s3-Ubuntu-Wireshark.jpg
|
||||
[10]:https://www.linuxtechi.com/wp-content/uploads/2017/11/Filter-in-wireshark-Ubuntu.jpg
|
||||
[11]:https://www.linuxtechi.com/wp-content/uploads/2017/11/Packet-Colouring-Wireshark.jpg
|
||||
@ -1,308 +0,0 @@
|
||||
translating by Flowsnow
|
||||
What is behavior-driven Python?
|
||||
======
|
||||

|
||||
Have you heard about [behavior-driven development][1] (BDD) and wondered what all the buzz is about? Maybe you've caught team members talking in "gherkin" and felt left out of the conversation. Or perhaps you're a Pythonista looking for a better way to test your code. Whatever the circumstance, learning about BDD can help you and your team achieve better collaboration and test automation, and Python's `behave` framework is a great place to start.
|
||||
|
||||
### What is BDD?
|
||||
|
||||
* Submitting forms on a website
|
||||
* Searching for desired results
|
||||
* Saving a document
|
||||
* Making REST API calls
|
||||
* Running command-line interface commands
|
||||
|
||||
|
||||
|
||||
In software, a behavior is how a feature operates within a well-defined scenario of inputs, actions, and outcomes. Products can exhibit countless behaviors, such as:
|
||||
|
||||
Defining a product's features based on its behaviors makes it easier to describe them, develop them, and test them. This is the heart of BDD: making behaviors the focal point of software development. Behaviors are defined early in development using a [specification by example][2] language. One of the most common behavior spec languages is [Gherkin][3], the Given-When-Then scenario format from the [Cucumber][4] project. Behavior specs are basically plain-language descriptions of how a behavior works, with a little bit of formal structure for consistency and focus. Test frameworks can easily automate these behavior specs by "gluing" step texts to code implementations.
|
||||
|
||||
Below is an example of a behavior spec written in Gherkin:
|
||||
```
|
||||
Scenario: Basic DuckDuckGo Search
|
||||
|
||||
Given the DuckDuckGo home page is displayed
|
||||
|
||||
When the user searches for "panda"
|
||||
|
||||
Then results are shown for "panda"
|
||||
|
||||
```
|
||||
|
||||
At a quick glance, the behavior is intuitive to understand. Except for a few keywords, the language is freeform. The scenario is concise yet meaningful. A real-world example illustrates the behavior. Steps declaratively indicate what should happen—without getting bogged down in the details of how.
|
||||
|
||||
The [main benefits of BDD][5] are good collaboration and automation. Everyone can contribute to behavior development, not just programmers. Expected behaviors are defined and understood from the beginning of the process. Tests can be automated together with the features they cover. Each test covers a singular, unique behavior in order to avoid duplication. And, finally, existing steps can be reused by new behavior specs, creating a snowball effect.
|
||||
|
||||
### Python's behave framework
|
||||
|
||||
`behave` is one of the most popular BDD frameworks in Python. It is very similar to other Gherkin-based Cucumber frameworks despite not holding the official Cucumber designation. `behave` has two primary layers:
|
||||
|
||||
1. Behavior specs written in Gherkin `.feature` files
|
||||
2. Step definitions and hooks written in Python modules that implement Gherkin steps
|
||||
|
||||
|
||||
|
||||
As shown in the example above, Gherkin scenarios use a three-part format:
|
||||
|
||||
1. Given some initial state
|
||||
2. When an action is taken
|
||||
3. Then verify the outcome
|
||||
|
||||
|
||||
|
||||
Each step is "glued" by decorator to a Python function when `behave` runs tests.
|
||||
|
||||
### Installation
|
||||
|
||||
As a prerequisite, make sure you have Python and `pip` installed on your machine. I strongly recommend using Python 3. (I also recommend using [`pipenv`][6], but the following example commands use the more basic `pip`.)
|
||||
|
||||
Only one package is required for `behave`:
|
||||
```
|
||||
pip install behave
|
||||
|
||||
```
|
||||
|
||||
Other packages may also be useful, such as:
|
||||
```
|
||||
pip install requests # for REST API calls
|
||||
|
||||
pip install selenium # for Web browser interactions
|
||||
|
||||
```
|
||||
|
||||
The [behavior-driven-Python][7] project on GitHub contains the examples used in this article.
|
||||
|
||||
### Gherkin features
|
||||
|
||||
The Gherkin syntax that `behave` uses is practically compliant with the official Cucumber Gherkin standard. A `.feature` file has Feature sections, which in turn have Scenario sections with Given-When-Then steps. Below is an example:
|
||||
```
|
||||
Feature: Cucumber Basket
|
||||
|
||||
As a gardener,
|
||||
|
||||
I want to carry many cucumbers in a basket,
|
||||
|
||||
So that I don’t drop them all.
|
||||
|
||||
|
||||
|
||||
@cucumber-basket
|
||||
|
||||
Scenario: Add and remove cucumbers
|
||||
|
||||
Given the basket is empty
|
||||
|
||||
When "4" cucumbers are added to the basket
|
||||
|
||||
And "6" more cucumbers are added to the basket
|
||||
|
||||
But "3" cucumbers are removed from the basket
|
||||
|
||||
Then the basket contains "7" cucumbers
|
||||
|
||||
```
|
||||
|
||||
There are a few important things to note here:
|
||||
|
||||
* Both the Feature and Scenario sections have [short, descriptive titles][8].
|
||||
* The lines immediately following the Feature title are comments ignored by `behave`. It is a good practice to put the user story there.
|
||||
* Scenarios and Features can have tags (notice the `@cucumber-basket` mark) for hooks and filtering (explained below).
|
||||
* Steps follow a [strict Given-When-Then order][9].
|
||||
* Additional steps can be added for any type using `And` and `But`.
|
||||
* Steps can be parametrized with inputs—notice the values in double quotes.
|
||||
|
||||
|
||||
|
||||
Scenarios can also be written as templates with multiple input combinations by using a Scenario Outline:
|
||||
```
|
||||
Feature: Cucumber Basket
|
||||
|
||||
|
||||
|
||||
@cucumber-basket
|
||||
|
||||
Scenario Outline: Add cucumbers
|
||||
|
||||
Given the basket has “<initial>” cucumbers
|
||||
|
||||
When "<more>" cucumbers are added to the basket
|
||||
|
||||
Then the basket contains "<total>" cucumbers
|
||||
|
||||
|
||||
|
||||
Examples: Cucumber Counts
|
||||
|
||||
| initial | more | total |
|
||||
|
||||
| 0 | 1 | 1 |
|
||||
|
||||
| 1 | 2 | 3 |
|
||||
|
||||
| 5 | 4 | 9 |
|
||||
|
||||
```
|
||||
|
||||
Scenario Outlines always have an Examples table, in which the first row gives column titles and each subsequent row gives an input combo. The row values are substituted wherever a column title appears in a step surrounded by angle brackets. In the example above, the scenario will be run three times because there are three rows of input combos. Scenario Outlines are a great way to avoid duplicate scenarios.
|
||||
|
||||
There are other elements of the Gherkin language, but these are the main mechanics. To learn more, read the Automation Panda articles [Gherkin by Example][10] and [Writing Good Gherkin][11].
|
||||
|
||||
### Python mechanics
|
||||
|
||||
Every Gherkin step must be "glued" to a step definition, a Python function that provides the implementation. Each function has a step type decorator with the matching string. It also receives a shared context and any step parameters. Feature files must be placed in a directory named `features/`, while step definition modules must be placed in a directory named `features/steps/`. Any feature file can use step definitions from any module—they do not need to have the same names. Below is an example Python module with step definitions for the cucumber basket features.
|
||||
```
|
||||
from behave import *
|
||||
|
||||
from cucumbers.basket import CucumberBasket
|
||||
|
||||
|
||||
|
||||
@given('the basket has "{initial:d}" cucumbers')
|
||||
|
||||
def step_impl(context, initial):
|
||||
|
||||
context.basket = CucumberBasket(initial_count=initial)
|
||||
|
||||
|
||||
|
||||
@when('"{some:d}" cucumbers are added to the basket')
|
||||
|
||||
def step_impl(context, some):
|
||||
|
||||
context.basket.add(some)
|
||||
|
||||
|
||||
|
||||
@then('the basket contains "{total:d}" cucumbers')
|
||||
|
||||
def step_impl(context, total):
|
||||
|
||||
assert context.basket.count == total
|
||||
|
||||
```
|
||||
|
||||
Three [step matchers][12] are available: `parse`, `cfparse`, and `re`. The default and simplest marcher is `parse`, which is shown in the example above. Notice how parametrized values are parsed and passed into the functions as input arguments. A common best practice is to put double quotes around parameters in steps.
|
||||
|
||||
Each step definition function also receives a [context][13] variable that holds data specific to the current scenario being run, such as `feature`, `scenario`, and `tags` fields. Custom fields may be added, too, to share data between steps. Always use context to share data—never use global variables!
|
||||
|
||||
`behave` also supports [hooks][14] to handle automation concerns outside of Gherkin steps. A hook is a function that will be run before or after a step, scenario, feature, or whole test suite. Hooks are reminiscent of [aspect-oriented programming][15]. They should be placed in a special `environment.py` file under the `features/` directory. Hook functions can check the current scenario's tags, as well, so logic can be selectively applied. The example below shows how to use hooks to set up and tear down a Selenium WebDriver instance for any scenario tagged as `@web`.
|
||||
```
|
||||
from selenium import webdriver
|
||||
|
||||
|
||||
|
||||
def before_scenario(context, scenario):
|
||||
|
||||
if 'web' in context.tags:
|
||||
|
||||
context.browser = webdriver.Firefox()
|
||||
|
||||
context.browser.implicitly_wait(10)
|
||||
|
||||
|
||||
|
||||
def after_scenario(context, scenario):
|
||||
|
||||
if 'web' in context.tags:
|
||||
|
||||
context.browser.quit()
|
||||
|
||||
```
|
||||
|
||||
Note: Setup and cleanup can also be done with [fixtures][16] in `behave`.
|
||||
|
||||
To offer an idea of what a `behave` project should look like, here's the example project's directory structure:
|
||||
|
||||
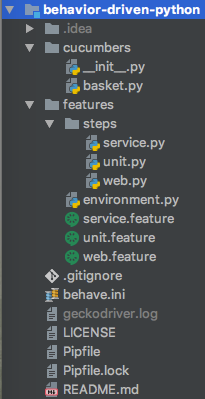
|
||||
|
||||
Any Python packages and custom modules can be used with `behave`. Use good design patterns to build a scalable test automation solution. Step definition code should be concise.
|
||||
|
||||
### Running tests
|
||||
|
||||
To run tests from the command line, change to the project's root directory and run the `behave` command. Use the `–help` option to see all available options.
|
||||
|
||||
Below are a few common use cases:
|
||||
```
|
||||
# run all tests
|
||||
|
||||
behave
|
||||
|
||||
|
||||
|
||||
# run the scenarios in a feature file
|
||||
|
||||
behave features/web.feature
|
||||
|
||||
|
||||
|
||||
# run all tests that have the @duckduckgo tag
|
||||
|
||||
behave --tags @duckduckgo
|
||||
|
||||
|
||||
|
||||
# run all tests that do not have the @unit tag
|
||||
|
||||
behave --tags ~@unit
|
||||
|
||||
|
||||
|
||||
# run all tests that have @basket and either @add or @remove
|
||||
|
||||
behave --tags @basket --tags @add,@remove
|
||||
|
||||
```
|
||||
|
||||
For convenience, options may be saved in [config][17] files.
|
||||
|
||||
### Other options
|
||||
|
||||
`behave` is not the only BDD test framework in Python. Other good frameworks include:
|
||||
|
||||
* `pytest-bdd` , a plugin for `pytest``behave`, it uses Gherkin feature files and step definition modules, but it also leverages all the features and plugins of `pytest`. For example, it can run Gherkin scenarios in parallel using `pytest-xdist`. BDD and non-BDD tests can also be executed together with the same filters. `pytest-bdd` also offers a more flexible directory layout.
|
||||
|
||||
* `radish` is a "Gherkin-plus" framework—it adds Scenario Loops and Preconditions to the standard Gherkin language, which makes it more friendly to programmers. It also offers rich command line options like `behave`.
|
||||
|
||||
* `lettuce` is an older BDD framework very similar to `behave`, with minor differences in framework mechanics. However, GitHub shows little recent activity in the project (as of May 2018).
|
||||
|
||||
|
||||
|
||||
Any of these frameworks would be good choices.
|
||||
|
||||
Also, remember that Python test frameworks can be used for any black box testing, even for non-Python products! BDD frameworks are great for web and service testing because their tests are declarative, and Python is a [great language for test automation][18].
|
||||
|
||||
This article is based on the author's [PyCon Cleveland 2018][19] talk, [Behavior-Driven Python][20].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/behavior-driven-python
|
||||
|
||||
作者:[Andrew Knight][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/andylpk247
|
||||
[1]:https://automationpanda.com/bdd/
|
||||
[2]:https://en.wikipedia.org/wiki/Specification_by_example
|
||||
[3]:https://automationpanda.com/2017/01/26/bdd-101-the-gherkin-language/
|
||||
[4]:https://cucumber.io/
|
||||
[5]:https://automationpanda.com/2017/02/13/12-awesome-benefits-of-bdd/
|
||||
[6]:https://docs.pipenv.org/
|
||||
[7]:https://github.com/AndyLPK247/behavior-driven-python
|
||||
[8]:https://automationpanda.com/2018/01/31/good-gherkin-scenario-titles/
|
||||
[9]:https://automationpanda.com/2018/02/03/are-gherkin-scenarios-with-multiple-when-then-pairs-okay/
|
||||
[10]:https://automationpanda.com/2017/01/27/bdd-101-gherkin-by-example/
|
||||
[11]:https://automationpanda.com/2017/01/30/bdd-101-writing-good-gherkin/
|
||||
[12]:http://behave.readthedocs.io/en/latest/api.html#step-parameters
|
||||
[13]:http://behave.readthedocs.io/en/latest/api.html#detecting-that-user-code-overwrites-behave-context-attributes
|
||||
[14]:http://behave.readthedocs.io/en/latest/api.html#environment-file-functions
|
||||
[15]:https://en.wikipedia.org/wiki/Aspect-oriented_programming
|
||||
[16]:http://behave.readthedocs.io/en/latest/api.html#fixtures
|
||||
[17]:http://behave.readthedocs.io/en/latest/behave.html#configuration-files
|
||||
[18]:https://automationpanda.com/2017/01/21/the-best-programming-language-for-test-automation/
|
||||
[19]:https://us.pycon.org/2018/
|
||||
[20]:https://us.pycon.org/2018/schedule/presentation/87/
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by qhwdw
|
||||
What's all the C Plus Fuss? Bjarne Stroustrup warns of dangerous future plans for his C++
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,6 @@
|
||||
Translating by MjSeven
|
||||
|
||||
|
||||
An introduction to the Django Python web app framework
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating by Flowsnow
|
||||
|
||||
How to build rpm packages
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
Backup Installed Packages And Restore Them On Freshly Installed Ubuntu
|
||||
======
|
||||
|
||||
|
||||
@ -0,0 +1,113 @@
|
||||
Distributed tracing in a microservices world
|
||||
======
|
||||
What is distributed tracing and why is it so important in a microservices environment?
|
||||
|
||||
|
||||
|
||||
[Microservices][1] have become the default choice for greenfield applications. After all, according to practitioners, microservices provide the type of decoupling required for a full digital transformation, allowing individual teams to innovate at a far greater speed than ever before.
|
||||
|
||||
Microservices are nothing more than regular distributed systems, only at a larger scale. Therefore, they exacerbate the well-known problems that any distributed system faces, like lack of visibility into a business transaction across process boundaries.
|
||||
|
||||
Given that it's extremely common to have multiple versions of a single service running in production at the same time—be it in a [A/B testing][2] scenario or as part of rolling out a new release following the [Canary release][3] technique—when we account for the fact that we are talking about hundreds of services, it's clear that what we have is chaos. It's almost impossible to map the interdependencies and understand the path of a business transaction across services and their versions.
|
||||
|
||||
### Observability
|
||||
|
||||
This chaos ends up being a good thing, as long as we can observe what's going on and diagnose the problems that will eventually occur.
|
||||
|
||||
A system is said to be observable when we can understand its state based on the [metrics, logs, and traces][4] it emits. Given that we are talking about distributed systems, knowing the state of a single instance of a single service isn't enough; we need to be able to aggregate the metrics for all instances of a given service, perhaps grouped by version. Metrics solutions like [Prometheus][5] are very popular in tackling this aspect of the observability problem. Similarly, we need logs to be stored in a central location, as it's impossible to analyze the logs from the individual instances of each service. [Logstash][6] is usually applied here, in combination with a backing storage like [Elasticsearch][7]. And finally, we need to get end-to-end traces to understand the path a given transaction has taken. This is where distributed tracing solutions come into play.
|
||||
|
||||
### Distributed tracing
|
||||
|
||||
In monolithic web applications, logging frameworks provide enough capabilities to do a basic root-cause analysis when something fails. A developer just needs to place log statements in the code. Information like "context" (usually "thread") and "timestamp" are automatically added to the log entry, making it easier to understand the execution of a given request and correlate the entries.
|
||||
|
||||
```
|
||||
Thread-1 2018-09-03T15:52:54+02:00 Request started
|
||||
Thread-2 2018-09-03T15:52:55+02:00 Charging credit card x321
|
||||
Thread-1 2018-09-03T15:52:55+02:00 Order submitted
|
||||
Thread-1 2018-09-03T15:52:56+02:00 Charging credit card x123
|
||||
Thread-1 2018-09-03T15:52:57+02:00 Changing order status
|
||||
Thread-1 2018-09-03T15:52:58+02:00 Dispatching event to inventory
|
||||
Thread-1 2018-09-03T15:52:59+02:00 Request finished
|
||||
```
|
||||
|
||||
We can safely say that the second log entry above is not related to the other entries, as it's being executed in a different thread.
|
||||
|
||||
In microservices architectures, logging alone fails to deliver the complete picture. Is this service the first one in the call chain? And what happened at the inventory service (where we apparently dispatched an event)?
|
||||
|
||||
A common strategy to answer this question is creating an identifier at the very first building block of our transaction and propagating this identifier across all the calls, probably by sending it as an HTTP header whenever a remote call is made.
|
||||
|
||||
In a central log collector, we could then see entries like the ones below. Note how we could log the correlation ID (the first column in our example), so we know that the second entry is not related to the other entries.
|
||||
|
||||
```
|
||||
abc123 Order 2018-09-03T15:52:58+02:00 Dispatching event to inventory
|
||||
def456 Order 2018-09-03T15:52:58+02:00 Dispatching event to inventory
|
||||
abc123 Inventory 2018-09-03T15:52:59+02:00 Received `order-submitted` event
|
||||
abc123 Inventory 2018-09-03T15:53:00+02:00 Checking inventory status
|
||||
abc123 Inventory 2018-09-03T15:53:01+02:00 Updating inventory
|
||||
abc123 Inventory 2018-09-03T15:53:02+02:00 Preparing order manifest
|
||||
```
|
||||
|
||||
This technique is one of the concepts at the core of any modern distributed tracing solution, but it's not really new; correlating log entries is decades old, probably as old as "distributed systems" itself.
|
||||
|
||||
What sets distributed tracing apart from regular logging is that the data structure that holds tracing data is more specialized, so we can also identify causality. Looking at the log entries above, it's hard to tell if the last step was caused by the previous entry, if they were performed concurrently, or if they share the same caller. Having a dedicated data structure also allows distributed tracing to record not only a message in a single point in time but also the start and end time of a given procedure.
|
||||
|
||||
![Trace showing spans][9]
|
||||
|
||||
Trace showing spans similar to the logs described above
|
||||
|
||||
[Click to enlarge][10]
|
||||
|
||||
Most of the modern distributed tracing tools are inspired by a 2010 [paper about Dapper][11], the distributed tracing solution used at Google. In that paper, the data structure described above was called a span, and you can see nine of them in the image above. This particular "forest" of spans is called a trace and is equivalent to the correlated log entries we've seen before.
|
||||
|
||||
The image above is a screenshot of a trace displayed in [Jaeger][12], an open source distributed tracing solution hosted by the [Cloud Native Computing Foundation (CNCF)][13]. It marks each service with a color to make it easier to see the process boundaries. Timing information can be easily visualized, both by looking at the macro timeline at the top of the screen or at the individual spans, giving a sense of how long each span takes and how impactful it is in this particular execution. It's also easy to observe when processes are asynchronous and therefore may outlive the initial request.
|
||||
|
||||
Like with logging, we need to annotate or instrument our code with the data we want to record. Unlike logging, we record spans instead of messages and do some demarcation to know when the span starts and finishes so we can get accurate timing information. As we would probably like to have our business code independent from a specific distributed tracing implementation, we can use an API such as [OpenTracing][14], leaving the decision about the concrete implementation as a packaging or runtime concern. Following is pseudo-Java code showing such demarcation.
|
||||
|
||||
```
|
||||
try (Scope scope = tracer.buildSpan("submitOrder").startActive(true)) {
|
||||
scope.span().setTag("order-id", "c85b7644b6b5");
|
||||
chargeCreditCard();
|
||||
changeOrderStatus();
|
||||
dispatchEventToInventory();
|
||||
}
|
||||
```
|
||||
|
||||
Given the nature of the distributed tracing concept, it's clear the code executed "between" our business services can also be part of the trace. For instance, we could [turn on][15] the distributed tracing integration for [Istio][16], a service mesh solution that helps in the communication between microservices, and we'll suddenly have a better picture about the network latency and routing decisions made at this layer. Another example is the work done in the OpenTracing community to provide instrumentation for popular stacks, frameworks, and APIs, such as Java's [JAX-RS][17], [Spring Cloud][18], or [JDBC][19]. This enables us to see how our business code interacts with the rest of the middleware, understand where a potential problem might be happening, and identify the best areas to improve. In fact, today's middleware instrumentation is so rich that it's common to get started with distributed tracing by using only the so-called "framework instrumentation," leaving the business code free from any tracing-related code.
|
||||
|
||||
While a microservices architecture is almost unavoidable nowadays for established companies to innovate faster and for ambitious startups to achieve web scale, it's easy to feel helpless while conducting a root cause analysis when something eventually fails and the right tools aren't available. The good news is tools like Prometheus, Logstash, OpenTracing, and Jaeger provide the pieces to bring observability to your application.
|
||||
|
||||
Juraci Paixão Kröhling will present [What are My Microservices Doing?][20] at [Open Source Summit Europe][21], October 22-24 in Edinburgh, Scotland.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/distributed-tracing-microservices-world
|
||||
|
||||
作者:[Juraci Paixão Kröhling][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jpkroehling
|
||||
[1]: https://en.wikipedia.org/wiki/Microservices
|
||||
[2]: https://en.wikipedia.org/wiki/A/B_testing
|
||||
[3]: https://martinfowler.com/bliki/CanaryRelease.html
|
||||
[4]: https://blog.twitter.com/engineering/en_us/a/2016/observability-at-twitter-technical-overview-part-i.html
|
||||
[5]: https://prometheus.io/
|
||||
[6]: https://github.com/elastic/logstash
|
||||
[7]: https://github.com/elastic/elasticsearch
|
||||
[8]: /file/409621
|
||||
[9]: https://opensource.com/sites/default/files/uploads/distributed-trace.png (Trace showing spans)
|
||||
[10]: /sites/default/files/uploads/trace.png
|
||||
[11]: https://ai.google/research/pubs/pub36356
|
||||
[12]: https://www.jaegertracing.io/
|
||||
[13]: https://www.cncf.io/
|
||||
[14]: http://opentracing.io/
|
||||
[15]: https://istio.io/docs/tasks/telemetry/distributed-tracing/
|
||||
[16]: https://istio.io/
|
||||
[17]: https://github.com/opentracing-contrib/java-jaxrs
|
||||
[18]: https://github.com/opentracing-contrib/java-spring-cloud
|
||||
[19]: https://github.com/opentracing-contrib/java-jdbc
|
||||
[20]: https://osseu18.sched.com/event/FxW3/what-are-my-microservices-doing-juraci-paixao-krohling-red-hat#
|
||||
[21]: https://osseu18.sched.com/
|
||||
@ -0,0 +1,108 @@
|
||||
Control your data with Syncthing: An open source synchronization tool
|
||||
======
|
||||
Decide how to store and share your personal information.
|
||||
|
||||

|
||||
|
||||
These days, some of our most important possessions—from pictures and videos of family and friends to financial and medical documents—are data. And even as cloud storage services are booming, so there are concerns about privacy and lack of control over our personal data. From the PRISM surveillance program to Google [letting app developers scan your personal emails][1], the news is full of reports that should give us all pause regarding the security of our personal information.
|
||||
|
||||
[Syncthing][2] can help put your mind at ease. An open source peer-to-peer file synchronization tool that runs on Linux, Windows, Mac, Android, and others (sorry, no iOS), Syncthing uses its own protocol, called [Block Exchange Protocol][3]. In brief, Syncthing lets you synchronize your data across many devices without owning a server.
|
||||
|
||||
### Linux
|
||||
|
||||
In this post, I will explain how to install and synchronize files between a Linux computer and an Android phone.
|
||||
|
||||
Syncthing is readily available for most popular distributions. Fedora 28 includes the latest version.
|
||||
|
||||
To install Syncthing in Fedora, you can either search for it in Software Center or execute the following command:
|
||||
|
||||
```
|
||||
sudo dnf install syncthing syncthing-gtk
|
||||
|
||||
```
|
||||
|
||||
Once it’s installed, open it. You’ll be welcomed by an assistant to help configure Syncthing. Click **Next** until it asks to configure the WebUI. The safest option is to keep the option **Listen on localhost**. That will disable the web interface and keep unauthorized users away.
|
||||
|
||||
![Syncthing in Setup WebUI dialog box][5]
|
||||
|
||||
Syncthing in Setup WebUI dialog box
|
||||
|
||||
Close the dialog. Now that Syncthing is installed, it’s time to share a folder, connect a device, and start syncing. But first, let’s continue with your other client.
|
||||
|
||||
### Android
|
||||
|
||||
Syncthing is available in Google Play and in F-Droid app stores.
|
||||
|
||||
|
||||
|
||||
Once the application is installed, you’ll be welcomed by a wizard. Grant Syncthing permissions to your storage. You might be asked to disable battery optimization for this application. It is safe to do so as we will optimize the app to synchronize only when plugged in and connected to a wireless network.
|
||||
|
||||
Click on the main menu icon and go to **Settings** , then **Run Conditions**. Tick **Always run in** **the background** , **Run only when charging** , and **Run only on wifi**. Now your Android client is ready to exchange files with your devices.
|
||||
|
||||
There are two important concepts to remember in Syncthing: folders and devices. Folders are what you want to share, but you must have a device to share with. Syncthing allows you to share individual folders with different devices. Devices are added by exchanging device IDs. A device ID is a unique, cryptographically secure identifier that is created when Syncthing starts for the first time.
|
||||
|
||||
### Connecting devices
|
||||
|
||||
Now let’s connect your Linux machine and your Android client.
|
||||
|
||||
In your Linux computer, open Syncthing, click on the **Settings** icon and click **Show ID**. A QR code will show up.
|
||||
|
||||
In your Android mobile, open Syncthing. In the main screen, click the **Devices** tab and press the **+** symbol. In the first field, press the QR code symbol to open the QR scanner.
|
||||
|
||||
Point your mobile camera to the computer QR code. The Device ID** **field will be populated with your desktop client Device ID. Give it a friendly name and save. Because adding a device goes two ways, you now need to confirm on the computer client that you want to add the Android mobile. It might take a couple of minutes for your computer client to ask for confirmation. When it does, click **Add**.
|
||||
|
||||

|
||||
|
||||
In the **New Device** window, you can verify and configure some options about your new device, like the **Device Name** and **Addresses**. If you keep dynamic, it will try to auto-discover the device IP, but if you want to force one, you can add it in this field. If you already created a folder (more on this later), you can also share it with this new device.
|
||||
|
||||
|
||||
|
||||
Your computer and Android are now paired and ready to exchange files. (If you have more than one computer or mobile phone, simply repeat these steps.)
|
||||
|
||||
### Sharing folders
|
||||
|
||||
Now that the devices you want to sync are already connected, it’s time to share a folder. You can share folders on your computer and the devices you add to that folder will get a copy.
|
||||
|
||||
To share a folder, go to **Settings** and click **Add Shared Folder** :
|
||||
|
||||
|
||||
|
||||
In the next window, enter the information of the folder you want to share:
|
||||
|
||||
|
||||
|
||||
You can use any label you want. **Folder ID** will be generated randomly and will be used to identify the folder between the clients. In **Path** , click **Browse** and locate the folder you want to share. If you want Syncthing to monitor the folder for changes (such as deletes, new files, etc.), click **Monitor filesystem for changes**.
|
||||
|
||||
Remember, when you share a folder, any change that happens on the other clients will be reflected on every single device. That means that if you share a folder containing pictures with other computers or mobile devices, changes in these other clients will be reflected everywhere. If this is not what you want, you can make your folder “Send Only” so it will send files to the clients, but the other clients’ changes won’t be synced.
|
||||
|
||||
When this is done, go to **Share with Devices** and select the hosts you want to sync with your folder:
|
||||
|
||||
All the devices you select will need to accept the share request; you will get a notification from the devices:
|
||||
|
||||
Just as when you shared the folder, you must configure the new shared folder:
|
||||
|
||||
|
||||
|
||||
Again, here you can define any label, but the ID must match each client. In the folder option, select the destination for the folder and its files. Remember that any change done in this folder will be reflected with every device allowed in the folder.
|
||||
|
||||
These are the steps to connect devices and share folders with Syncthing. It might take a few minutes to start copying, depending on your network settings or if you are not on the same network.
|
||||
|
||||
Syncthing offers many more great features and options. Try it—and take control of your data.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/take-control-your-data-syncthing
|
||||
|
||||
作者:[Michael Zamot][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mzamot
|
||||
[1]: https://gizmodo.com/google-says-it-doesnt-go-through-your-inbox-anymore-bu-1827299695
|
||||
[2]: https://syncthing.net/
|
||||
[3]: https://docs.syncthing.net/specs/bep-v1.html
|
||||
[4]: /file/410191
|
||||
[5]: https://opensource.com/sites/default/files/uploads/syncthing1.png (Syncthing in Setup WebUI dialog box)
|
||||
@ -1,3 +1,5 @@
|
||||
translating by Flowsnow
|
||||
|
||||
A Simple, Beautiful And Cross-platform Podcast App
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
HankChow translating
|
||||
|
||||
How To Find Out Which Port Number A Process Is Using In Linux
|
||||
======
|
||||
As a Linux administrator, you should know whether the corresponding service is binding/listening with correct port or not.
|
||||
|
||||
@ -1,131 +0,0 @@
|
||||
HankChow translating
|
||||
|
||||
Make The Output Of Ping Command Prettier And Easier To Read
|
||||
======
|
||||
|
||||

|
||||
|
||||
As we all know, the **ping** command is used to check if a target host is reachable or not. Using Ping command, we can send ICMP Echo request to our target host, and verify whether the destination host is up or down. If you use ping command often, I’d like to recommend you to try **“Prettyping”**. Prettyping is just a wrapper for the standard ping tool and makes the output of the ping command prettier, easier to read, colorful and compact. The prettyping runs the standard ping command in the background and parses the output with colors and unicode characters. It is free and open source tool written in **Bash** and **awk** and supports most Unix-like operating systems such as GNU/Linux, FreeBSD and Mac OS X. Prettyping is not only used to make the output of ping command prettier, but also ships with other notable features as listed below.
|
||||
|
||||
* Detects the lost or missing packets and marks them in the output.
|
||||
* Shows live statistics. The statistics are constantly updated after each response is received, while ping only shows after it ends.
|
||||
* Smart enough to handle “unknown messages” (like error messages) without messing up the output.
|
||||
* Avoids printing the repeated messages.
|
||||
* You can use most common ping parameters with Prettyping.
|
||||
* Can run as normal user.
|
||||
* Can be able to redirect the output to a file.
|
||||
* Requires no installation. Just download the binary, make it executable and run.
|
||||
* Fast and lightweight.
|
||||
* And, finally makes the output pretty, colorful and very intuitive.
|
||||
|
||||
|
||||
|
||||
### Installing Prettyping
|
||||
|
||||
Like I said already, Prettyping does not requires any installation. It is portable application! Just download the Prettyping binary file using command:
|
||||
|
||||
```
|
||||
$ curl -O https://raw.githubusercontent.com/denilsonsa/prettyping/master/prettyping
|
||||
```
|
||||
|
||||
Move the binary file to your $PATH, for example **/usr/local/bin**.
|
||||
|
||||
```
|
||||
$ sudo mv prettyping /usr/local/bin
|
||||
```
|
||||
|
||||
And, make it executable as like below:
|
||||
|
||||
```
|
||||
$ sudo chmod +x /usr/local/bin/prettyping
|
||||
```
|
||||
|
||||
It’s that simple.
|
||||
|
||||
### Let us Make The Output Of Ping Command Prettier And Easier To Read
|
||||
|
||||
Once installed, ping any host or IP address and see the ping command output in graphical way.
|
||||
|
||||
```
|
||||
$ prettyping ostechnix.com
|
||||
```
|
||||
|
||||
Here is the visually displayed ping output:
|
||||
|
||||

|
||||
|
||||
If you run Prettyping without any arguments, it will keep running until you manually stop it by pressing **Ctrl+c**.
|
||||
|
||||
Since Prettyping is just a wrapper to the ping command, you can use most common ping parameters. For instance, you can use **-c** flag to ping a host only a specific number of times, for example **5** :
|
||||
|
||||
```
|
||||
$ prettyping -c 5 ostechnix.com
|
||||
```
|
||||
|
||||
By default, prettynping displays the output in colored format. Don’t like the colored output? No problem! Use `--nocolor` option.
|
||||
|
||||
```
|
||||
$ prettyping --nocolor ostechnix.com
|
||||
```
|
||||
|
||||
Similarly, you can disable mult-color support using `--nomulticolor` option:
|
||||
|
||||
```
|
||||
$ prettyping --nomulticolor ostechnix.com
|
||||
```
|
||||
|
||||
To disable unicode characters, use `--nounicode` option:
|
||||
|
||||
|
||||
|
||||
This can be useful if your terminal does not support **UTF-8**. If you can’t fix the unicode (fonts) in your system, simply pass `--nounicode` option.
|
||||
|
||||
Prettyping can redirect the output to a file as well. The following command will write the output of `prettyping ostechnix.com` command in `ostechnix.txt` file.
|
||||
|
||||
```
|
||||
$ prettyping ostechnix.com | tee ostechnix.txt
|
||||
```
|
||||
|
||||
Prettyping has few more options which helps you to do various tasks, such as,
|
||||
|
||||
* Enable/disable the latency legend. (default value is: enabled)
|
||||
* Force the output designed to a terminal. (default: auto)
|
||||
* Use the last “n” pings at the statistics line. (default: 60)
|
||||
* Override auto-detection of terminal dimensions.
|
||||
* Override the awk interpreter. (default: awk)
|
||||
* Override the ping tool. (default: ping)
|
||||
|
||||
|
||||
|
||||
For more details, view the help section:
|
||||
|
||||
```
|
||||
$ prettyping --help
|
||||
```
|
||||
|
||||
Even though Prettyping doesn’t add any extra functionality, I personally like the following feature implementations in it:
|
||||
|
||||
* Live statistics – You can see all the live statistics all the time. The standard ping command will only shows the statistics after it ends.
|
||||
* Compact – You can see a longer timespan at your terminal.
|
||||
* Prettyping detects missing responses.
|
||||
|
||||
|
||||
|
||||
If you’re ever looking for a way to visually display the output of the ping command, Prettyping will definitely help. Give it a try, you won’t be disappointed.
|
||||
|
||||
And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/prettyping-make-the-output-of-ping-command-prettier-and-easier-to-read/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
@ -0,0 +1,208 @@
|
||||
9 Easiest Ways To Find Out Process ID (PID) In Linux
|
||||
======
|
||||
Everybody knows about PID, Exactly what is PID? Why you want PID? What are you going to do using PID? Are you having the same questions on your mind? If so, you are in the right place to get all the details.
|
||||
|
||||
Mainly, we are looking PID to kill an unresponsive program and it’s similar to Windows task manager. Linux GUI also offering the same feature but CLI is an efficient way to perform the kill operation.
|
||||
|
||||
### What Is Process ID?
|
||||
|
||||
PID stands for process identification number which is generally used by most operating system kernels such as Linux, Unix, macOS and Windows. It is a unique identification number that is automatically assigned to each process when it is created in an operating system. A process is a running instance of a program.
|
||||
|
||||
**Suggested Read :**
|
||||
**(#)** [How To Find Out Which Port Number A Process Is Using In Linux][1]
|
||||
**(#)** [3 Easy Ways To Kill Or Terminate A Process In Linux][2]
|
||||
|
||||
Each time process ID will be getting change to all the processes except init because init is always the first process on the system and is the ancestor of all other processes. It’s PID is 1.
|
||||
|
||||
The default maximum value of PIDs is `32,768`. The same has been verified by running the following command on your system `cat /proc/sys/kernel/pid_max`. On 32-bit systems 32768 is the maximum value but we can set to any value up to 2^22 (approximately 4 million) on 64-bit systems.
|
||||
|
||||
You may ask, why we need such amount of PIDs? because we can’t reused the PIDs immediately that’s why. Also in order to prevent possible errors.
|
||||
|
||||
The PID for the running processes on the system can be found by using the below nine methods such as pidof command, pgrep command, ps command, pstree command, ss command, netstat command, lsof command, fuser command and systemctl command.
|
||||
|
||||
This can be achieved using the below six methods.
|
||||
|
||||
* `pidof:` pidof — find the process ID of a running program.
|
||||
* `pgrep:` pgre – look up or signal processes based on name and other attributes.
|
||||
* `ps:` ps – report a snapshot of the current processes.
|
||||
* `pstree:` pstree – display a tree of processes.
|
||||
* `ss:` ss is used to dump socket statistics.
|
||||
* `netstat:` netstat is displays a list of open sockets.
|
||||
* `lsof:` lsof – list open files.
|
||||
* `fuser:` fuser – list process IDs of all processes that have one or more files open
|
||||
* `systemctl:` systemctl – Control the systemd system and service manager
|
||||
|
||||
|
||||
|
||||
In this tutorial we are going to find out the Apache process id to test this article. Make sure your need to input your process name instead of us.
|
||||
|
||||
### Method-1 : Using pidof Command
|
||||
|
||||
pidof used to find the process ID of a running program. It’s prints those id’s on the standard output. To demonstrate this, we are going to find out the Apache2 process id from Debian 9 (stretch) system.
|
||||
|
||||
```
|
||||
# pidof apache2
|
||||
3754 2594 2365 2364 2363 2362 2361
|
||||
|
||||
```
|
||||
|
||||
From the above output you may face difficulties to identify the Process ID because it’s shows all the PIDs (included Parent and Childs) aginst the process name. Hence we need to find out the parent PID (PPID), which is the one we are looking. It could be the first number. In my case it’s `3754` and it’s shorted in descending order.
|
||||
|
||||
### Method-2 : Using pgrep Command
|
||||
|
||||
pgrep looks through the currently running processes and lists the process IDs which match the selection criteria to stdout.
|
||||
|
||||
```
|
||||
# pgrep apache2
|
||||
2361
|
||||
2362
|
||||
2363
|
||||
2364
|
||||
2365
|
||||
2594
|
||||
3754
|
||||
|
||||
```
|
||||
|
||||
This also similar to the above output but it’s shorting the results in ascending order, which clearly says that the parent PID is the last one. In my case it’s `3754`.
|
||||
|
||||
**Note :** If you have more than one process id of the process, you may face trouble to identify the parent process id when using pidof & pgrep command.
|
||||
|
||||
### Method-3 : Using pstree Command
|
||||
|
||||
pstree shows running processes as a tree. The tree is rooted at either pid or init if pid is omitted. If a user name is specified in the pstree command then it’s shows all the process owned by the corresponding user.
|
||||
|
||||
pstree visually merges identical branches by putting them in square brackets and prefixing them with the repetition count.
|
||||
|
||||
```
|
||||
# pstree -p | grep "apache2"
|
||||
|-apache2(3754)-|-apache2(2361)
|
||||
| |-apache2(2362)
|
||||
| |-apache2(2363)
|
||||
| |-apache2(2364)
|
||||
| |-apache2(2365)
|
||||
| `-apache2(2594)
|
||||
|
||||
```
|
||||
|
||||
To get parent process alone, use the following format.
|
||||
|
||||
```
|
||||
# pstree -p | grep "apache2" | head -1
|
||||
|-apache2(3754)-|-apache2(2361)
|
||||
|
||||
```
|
||||
|
||||
pstree command is very simple because it’s segregating the Parent and Child processes separately but it’s not easy when using pidof & pgrep command.
|
||||
|
||||
### Method-4 : Using ps Command
|
||||
|
||||
ps displays information about a selection of the active processes. It displays the process ID (pid=PID), the terminal associated with the process (tname=TTY), the cumulated CPU time in [DD-]hh:mm:ss format (time=TIME), and the executable name (ucmd=CMD). Output is unsorted by default.
|
||||
|
||||
```
|
||||
# ps aux | grep "apache2"
|
||||
www-data 2361 0.0 0.4 302652 9732 ? S 06:25 0:00 /usr/sbin/apache2 -k start
|
||||
www-data 2362 0.0 0.4 302652 9732 ? S 06:25 0:00 /usr/sbin/apache2 -k start
|
||||
www-data 2363 0.0 0.4 302652 9732 ? S 06:25 0:00 /usr/sbin/apache2 -k start
|
||||
www-data 2364 0.0 0.4 302652 9732 ? S 06:25 0:00 /usr/sbin/apache2 -k start
|
||||
www-data 2365 0.0 0.4 302652 8400 ? S 06:25 0:00 /usr/sbin/apache2 -k start
|
||||
www-data 2594 0.0 0.4 302652 8400 ? S 06:55 0:00 /usr/sbin/apache2 -k start
|
||||
root 3754 0.0 1.4 302580 29324 ? Ss Dec11 0:23 /usr/sbin/apache2 -k start
|
||||
root 5648 0.0 0.0 12784 940 pts/0 S+ 21:32 0:00 grep apache2
|
||||
|
||||
```
|
||||
|
||||
From the above output we can easily identify the parent process id (PPID) based on the process start date. In my case apache2 process was started @ `Dec11` which is the parent and others are child’s. PID of apache2 is `3754`.
|
||||
|
||||
### Method-5: Using ss Command
|
||||
|
||||
ss is used to dump socket statistics. It allows showing information similar to netstat. It can display more TCP and state informations than other tools.
|
||||
|
||||
It can display stats for all kind of sockets such as PACKET, TCP, UDP, DCCP, RAW, Unix domain, etc.
|
||||
|
||||
```
|
||||
# ss -tnlp | grep apache2
|
||||
LISTEN 0 128 :::80 :::* users:(("apache2",pid=3319,fd=4),("apache2",pid=3318,fd=4),("apache2",pid=3317,fd=4))
|
||||
|
||||
```
|
||||
|
||||
### Method-6: Using netstat Command
|
||||
|
||||
netstat – Print network connections, routing tables, interface statistics, masquerade connections, and multicast memberships.
|
||||
By default, netstat displays a list of open sockets.
|
||||
|
||||
If you don’t specify any address families, then the active sockets of all configured address families will be printed. This program is obsolete. Replacement for netstat is ss.
|
||||
|
||||
```
|
||||
# netstat -tnlp | grep apache2
|
||||
tcp6 0 0 :::80 :::* LISTEN 3317/apache2
|
||||
|
||||
```
|
||||
|
||||
### Method-7: Using lsof Command
|
||||
|
||||
lsof – list open files. The Linux lsof command lists information about files that are open by processes running on the system.
|
||||
|
||||
```
|
||||
# lsof -i -P | grep apache2
|
||||
apache2 3317 root 4u IPv6 40518 0t0 TCP *:80 (LISTEN)
|
||||
apache2 3318 www-data 4u IPv6 40518 0t0 TCP *:80 (LISTEN)
|
||||
apache2 3319 www-data 4u IPv6 40518 0t0 TCP *:80 (LISTEN)
|
||||
|
||||
```
|
||||
|
||||
### Method-8: Using fuser Command
|
||||
|
||||
The fuser utility shall write to standard output the process IDs of processes running on the local system that have one or more named files open.
|
||||
|
||||
```
|
||||
# fuser -v 80/tcp
|
||||
USER PID ACCESS COMMAND
|
||||
80/tcp: root 3317 F.... apache2
|
||||
www-data 3318 F.... apache2
|
||||
www-data 3319 F.... apache2
|
||||
|
||||
```
|
||||
|
||||
### Method-9: Using systemctl Command
|
||||
|
||||
systemctl – Control the systemd system and service manager. This is the replacement of old SysV init system management and
|
||||
most of the modern Linux operating systems were adapted systemd.
|
||||
|
||||
```
|
||||
# systemctl status apache2
|
||||
● apache2.service - The Apache HTTP Server
|
||||
Loaded: loaded (/lib/systemd/system/apache2.service; disabled; vendor preset: enabled)
|
||||
Drop-In: /lib/systemd/system/apache2.service.d
|
||||
└─apache2-systemd.conf
|
||||
Active: active (running) since Tue 2018-09-25 10:03:28 IST; 3s ago
|
||||
Process: 3294 ExecStart=/usr/sbin/apachectl start (code=exited, status=0/SUCCESS)
|
||||
Main PID: 3317 (apache2)
|
||||
Tasks: 55 (limit: 4915)
|
||||
Memory: 7.9M
|
||||
CPU: 71ms
|
||||
CGroup: /system.slice/apache2.service
|
||||
├─3317 /usr/sbin/apache2 -k start
|
||||
├─3318 /usr/sbin/apache2 -k start
|
||||
└─3319 /usr/sbin/apache2 -k start
|
||||
|
||||
Sep 25 10:03:28 ubuntu systemd[1]: Starting The Apache HTTP Server...
|
||||
Sep 25 10:03:28 ubuntu systemd[1]: Started The Apache HTTP Server.
|
||||
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/9-methods-to-check-find-the-process-id-pid-ppid-of-a-running-program-in-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[1]: https://www.2daygeek.com/how-to-find-out-which-port-number-a-process-is-using-in-linux/
|
||||
[2]: https://www.2daygeek.com/kill-terminate-a-process-in-linux-using-kill-pkill-killall-command/
|
||||
@ -0,0 +1,78 @@
|
||||
Hegemon – A Modular System Monitor Application Written In Rust
|
||||
======
|
||||
|
||||
|
||||
|
||||
When it comes to monitor running processes in Unix-like systems, the most commonly used applications are **top** and **htop** , which is an enhanced version of top. My personal favorite is htop. However, the developers are releasing few alternatives to these applications every now and then. One such alternative to top and htop utilities is **Hegemon**. It is a modular system monitor application written using **Rust** programming language.
|
||||
|
||||
Concerning about the features of Hegemon, we can list the following:
|
||||
|
||||
* Hegemon will monitor the usage of CPU, memory and Swap.
|
||||
* It monitors the system’s temperature and fan speed.
|
||||
* The update interval time can be adjustable. The default value is 3 seconds.
|
||||
* We can reveal more detailed graph and additional information by expanding the data streams.
|
||||
* Unit tests
|
||||
* Clean interface
|
||||
* Free and open source.
|
||||
|
||||
|
||||
|
||||
### Installing Hegemon
|
||||
|
||||
Make sure you have installed **Rust 1.26** or later version. To install Rust in your Linux distribution, refer the following guide:
|
||||
|
||||
[Install Rust Programming Language In Linux][2]
|
||||
|
||||
Also, install [libsensors][1] library. It is available in the default repositories of most Linux distributions. For example, you can install it in RPM based systems such as Fedora using the following command:
|
||||
|
||||
```
|
||||
$ sudo dnf install lm_sensors-devel
|
||||
```
|
||||
|
||||
On Debian-based systems like Ubuntu, Linux Mint, it can be installed using command:
|
||||
|
||||
```
|
||||
$ sudo apt-get install libsensors4-dev
|
||||
```
|
||||
|
||||
Once you installed Rust and libsensors, install Hegemon using command:
|
||||
|
||||
```
|
||||
$ cargo install hegemon
|
||||
```
|
||||
|
||||
Once hegemon installed, start monitoring the running processes in your Linux system using command:
|
||||
|
||||
```
|
||||
$ hegemon
|
||||
```
|
||||
|
||||
Here is the sample output from my Arch Linux desktop.
|
||||
|
||||
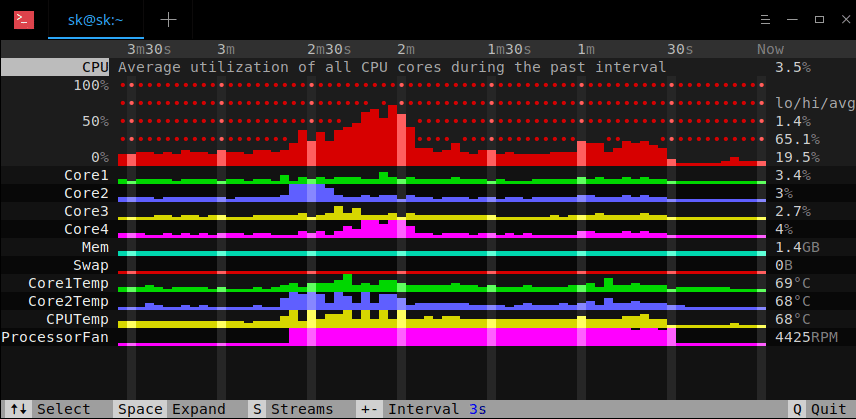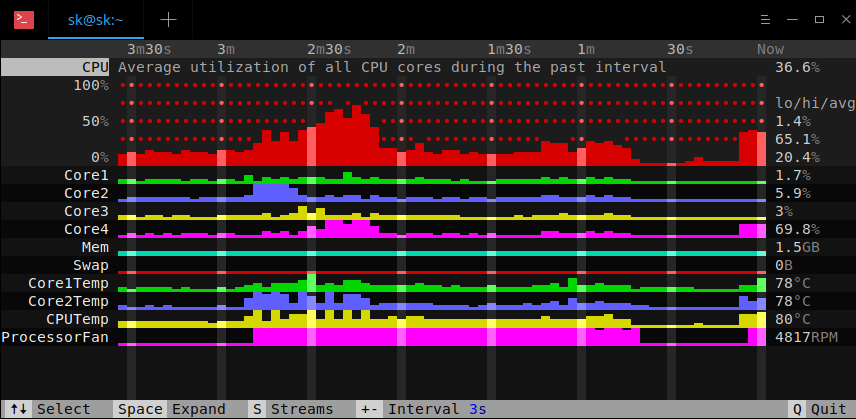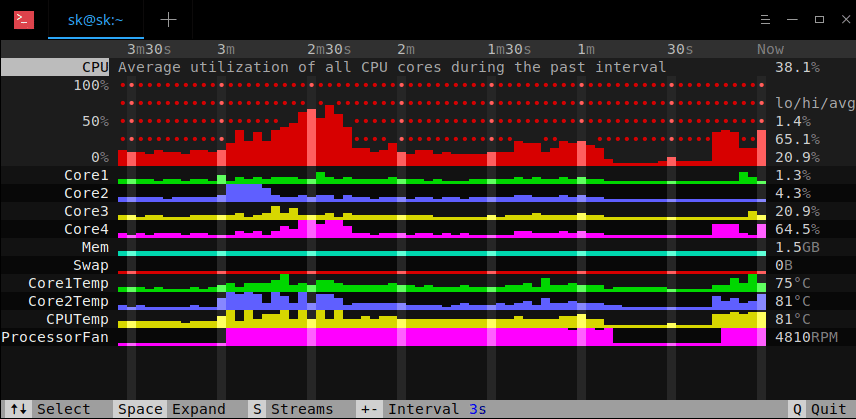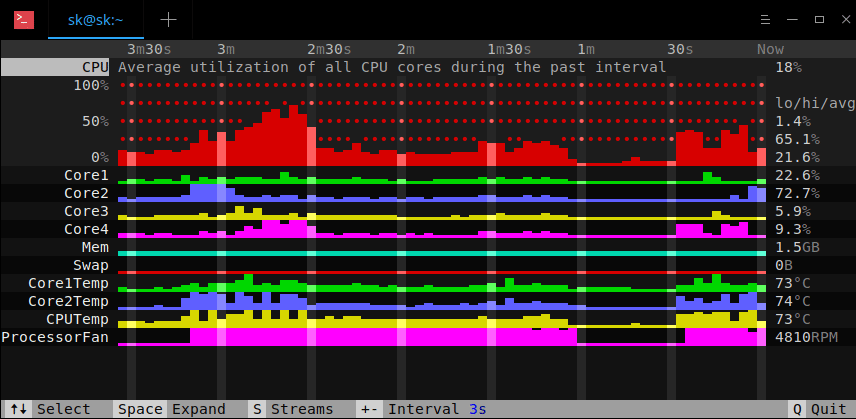
|
||||
|
||||
To exit, press **Q**.
|
||||
|
||||
|
||||
Please be mindful that hegemon is still in its early development stage and it is not complete replacement for **top** command. There might be bugs and missing features. If you came across any bugs, report them in the project’s github page. The developer is planning to bring more features in the upcoming versions. So, keep an eye on this project.
|
||||
|
||||
And, that’s all for now. Hope this helps. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/hegemon-a-modular-system-monitor-application-written-in-rust/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[1]: https://github.com/lm-sensors/lm-sensors
|
||||
[2]: https://www.ostechnix.com/install-rust-programming-language-in-linux/
|
||||
@ -0,0 +1,88 @@
|
||||
How to Boot Ubuntu 18.04 / Debian 9 Server in Rescue (Single User mode) / Emergency Mode
|
||||
======
|
||||
Booting a Linux Server into a single user mode or **rescue mode** is one of the important troubleshooting that a Linux admin usually follow while recovering the server from critical conditions. In Ubuntu 18.04 and Debian 9, single user mode is known as a rescue mode.
|
||||
|
||||
Apart from the rescue mode, Linux servers can be booted in **emergency mode** , the main difference between them is that, emergency mode loads a minimal environment with read only root file system file system, also it does not enable any network or other services. But rescue mode try to mount all the local file systems & try to start some important services including network.
|
||||
|
||||
In this article we will discuss how we can boot our Ubuntu 18.04 LTS / Debian 9 Server in rescue mode and emergency mode.
|
||||
|
||||
#### Booting Ubuntu 18.04 LTS Server in Single User / Rescue Mode:
|
||||
|
||||
Reboot your server and go to boot loader (Grub) screen and Select “ **Ubuntu** “, bootloader screen would look like below,
|
||||
|
||||

|
||||
|
||||
Press “ **e** ” and then go the end of line which starts with word “ **linux** ” and append “ **systemd.unit=rescue.target** “. Remove the word “ **$vt_handoff** ” if it exists.
|
||||
|
||||

|
||||
|
||||
Now Press Ctrl-x or F10 to boot,
|
||||
|
||||

|
||||
|
||||
Now press enter and then you will get the shell where all file systems will be mounted in read-write mode and do the troubleshooting. Once you are done with troubleshooting, you can reboot your server using “ **reboot** ” command.
|
||||
|
||||
#### Booting Ubuntu 18.04 LTS Server in emergency mode
|
||||
|
||||
Reboot the server and go the boot loader screen and select “ **Ubuntu** ” and then press “ **e** ” and go to the end of line which starts with word linux, and append “ **systemd.unit=emergency.target** ”
|
||||
|
||||

|
||||
|
||||
Now Press Ctlr-x or F10 to boot in emergency mode, you will get a shell and do the troubleshooting from there. As we had already discussed that in emergency mode, file systems will be mounted in read-only mode and also there will be no networking in this mode,
|
||||
|
||||

|
||||
|
||||
Use below command to mount the root file system in read-write mode,
|
||||
|
||||
```
|
||||
# mount -o remount,rw /
|
||||
|
||||
```
|
||||
|
||||
Similarly, you can remount rest of file systems in read-write mode .
|
||||
|
||||
#### Booting Debian 9 into Rescue & Emergency Mode
|
||||
|
||||
Reboot your Debian 9.x server and go to grub screen and select “ **Debian GNU/Linux** ”
|
||||
|
||||

|
||||
|
||||
Press “ **e** ” and go to end of line which starts with word linux and append “ **systemd.unit=rescue.target** ” to boot the system in rescue mode and to boot in emergency mode then append “ **systemd.unit=emergency.target** ”
|
||||
|
||||
#### Rescue mode :
|
||||
|
||||

|
||||
|
||||
Now press Ctrl-x or F10 to boot in rescue mode
|
||||
|
||||

|
||||
|
||||
Press Enter to get the shell and from there you can start troubleshooting.
|
||||
|
||||
#### Emergency Mode:
|
||||
|
||||

|
||||
|
||||
Now press ctrl-x or F10 to boot your system in emergency mode
|
||||
|
||||

|
||||
|
||||
Press enter to get the shell and use “ **mount -o remount,rw /** ” command to mount the root file system in read-write mode.
|
||||
|
||||
**Note:** In case root password is already set in Ubuntu 18.04 and Debian 9 Server then you must enter root password to get shell in rescue and emergency mode
|
||||
|
||||
That’s all from this article, please do share your feedback and comments in case you like this article.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxtechi.com/boot-ubuntu-18-04-debian-9-rescue-emergency-mode/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.linuxtechi.com/author/pradeep/
|
||||
@ -0,0 +1,300 @@
|
||||
An introduction to swap space on Linux systems
|
||||
======
|
||||
|
||||

|
||||
|
||||
Swap space is a common aspect of computing today, regardless of operating system. Linux uses swap space to increase the amount of virtual memory available to a host. It can use one or more dedicated swap partitions or a swap file on a regular filesystem or logical volume.
|
||||
|
||||
There are two basic types of memory in a typical computer. The first type, random access memory (RAM), is used to store data and programs while they are being actively used by the computer. Programs and data cannot be used by the computer unless they are stored in RAM. RAM is volatile memory; that is, the data stored in RAM is lost if the computer is turned off.
|
||||
|
||||
Hard drives are magnetic media used for long-term storage of data and programs. Magnetic media is nonvolatile; the data stored on a disk remains even when power is removed from the computer. The CPU (central processing unit) cannot directly access the programs and data on the hard drive; it must be copied into RAM first, and that is where the CPU can access its programming instructions and the data to be operated on by those instructions. During the boot process, a computer copies specific operating system programs, such as the kernel and init or systemd, and data from the hard drive into RAM, where it is accessed directly by the computer’s processor, the CPU.
|
||||
|
||||
### Swap space
|
||||
|
||||
Swap space is the second type of memory in modern Linux systems. The primary function of swap space is to substitute disk space for RAM memory when real RAM fills up and more space is needed.
|
||||
|
||||
For example, assume you have a computer system with 8GB of RAM. If you start up programs that don’t fill that RAM, everything is fine and no swapping is required. But suppose the spreadsheet you are working on grows when you add more rows, and that, plus everything else that's running, now fills all of RAM. Without swap space available, you would have to stop working on the spreadsheet until you could free up some of your limited RAM by closing down some other programs.
|
||||
|
||||
The kernel uses a memory management program that detects blocks, aka pages, of memory in which the contents have not been used recently. The memory management program swaps enough of these relatively infrequently used pages of memory out to a special partition on the hard drive specifically designated for “paging,” or swapping. This frees up RAM and makes room for more data to be entered into your spreadsheet. Those pages of memory swapped out to the hard drive are tracked by the kernel’s memory management code and can be paged back into RAM if they are needed.
|
||||
|
||||
The total amount of memory in a Linux computer is the RAM plus swap space and is referred to as virtual memory.
|
||||
|
||||
### Types of Linux swap
|
||||
|
||||
Linux provides for two types of swap space. By default, most Linux installations create a swap partition, but it is also possible to use a specially configured file as a swap file. A swap partition is just what its name implies—a standard disk partition that is designated as swap space by the `mkswap` command.
|
||||
|
||||
A swap file can be used if there is no free disk space in which to create a new swap partition or space in a volume group where a logical volume can be created for swap space. This is just a regular file that is created and preallocated to a specified size. Then the `mkswap` command is run to configure it as swap space. I don’t recommend using a file for swap space unless absolutely necessary.
|
||||
|
||||
### Thrashing
|
||||
|
||||
Thrashing can occur when total virtual memory, both RAM and swap space, become nearly full. The system spends so much time paging blocks of memory between swap space and RAM and back that little time is left for real work. The typical symptoms of this are obvious: The system becomes slow or completely unresponsive, and the hard drive activity light is on almost constantly.
|
||||
|
||||
If you can manage to issue a command like `free` that shows CPU load and memory usage, you will see that the CPU load is very high, perhaps as much as 30 to 40 times the number of CPU cores in the system. Another symptom is that both RAM and swap space are almost completely allocated.
|
||||
|
||||
After the fact, looking at SAR (system activity report) data can also show these symptoms. I install SAR on every system I work on and use it for post-repair forensic analysis.
|
||||
|
||||
### What is the right amount of swap space?
|
||||
|
||||
Many years ago, the rule of thumb for the amount of swap space that should be allocated on the hard drive was 2X the amount of RAM installed in the computer (of course, that was when most computers' RAM was measured in KB or MB). So if a computer had 64KB of RAM, a swap partition of 128KB would be an optimum size. This rule took into account the facts that RAM sizes were typically quite small at that time and that allocating more than 2X RAM for swap space did not improve performance. With more than twice RAM for swap, most systems spent more time thrashing than actually performing useful work.
|
||||
|
||||
RAM has become an inexpensive commodity and most computers these days have amounts of RAM that extend into tens of gigabytes. Most of my newer computers have at least 8GB of RAM, one has 32GB, and my main workstation has 64GB. My older computers have from 4 to 8 GB of RAM.
|
||||
|
||||
When dealing with computers having huge amounts of RAM, the limiting performance factor for swap space is far lower than the 2X multiplier. The Fedora 28 online Installation Guide, which can be found online at [Fedora Installation Guide][1], defines current thinking about swap space allocation. I have included below some discussion and the table of recommendations from that document.
|
||||
|
||||
The following table provides the recommended size of a swap partition depending on the amount of RAM in your system and whether you want sufficient memory for your system to hibernate. The recommended swap partition size is established automatically during installation. To allow for hibernation, however, you will need to edit the swap space in the custom partitioning stage.
|
||||
|
||||
_Table 1: Recommended system swap space in Fedora 28 documentation_
|
||||
|
||||
| **Amount of system RAM** | **Recommended swap space** | **Recommended swap with hibernation** |
|
||||
|--------------------------|-----------------------------|---------------------------------------|
|
||||
| less than 2 GB | 2 times the amount of RAM | 3 times the amount of RAM |
|
||||
| 2 GB - 8 GB | Equal to the amount of RAM | 2 times the amount of RAM |
|
||||
| 8 GB - 64 GB | 0.5 times the amount of RAM | 1.5 times the amount of RAM |
|
||||
| more than 64 GB | workload dependent | hibernation not recommended |
|
||||
|
||||
At the border between each range listed above (for example, a system with 2 GB, 8 GB, or 64 GB of system RAM), use discretion with regard to chosen swap space and hibernation support. If your system resources allow for it, increasing the swap space may lead to better performance.
|
||||
|
||||
Of course, most Linux administrators have their own ideas about the appropriate amount of swap space—as well as pretty much everything else. Table 2, below, contains my recommendations based on my personal experiences in multiple environments. These may not work for you, but as with Table 1, they may help you get started.
|
||||
|
||||
_Table 2: Recommended system swap space per the author_
|
||||
|
||||
| Amount of RAM | Recommended swap space |
|
||||
|---------------|------------------------|
|
||||
| ≤ 2GB | 2X RAM |
|
||||
| 2GB – 8GB | = RAM |
|
||||
| >8GB | 8GB |
|
||||
|
||||
One consideration in both tables is that as the amount of RAM increases, beyond a certain point adding more swap space simply leads to thrashing well before the swap space even comes close to being filled. If you have too little virtual memory while following these recommendations, you should add more RAM, if possible, rather than more swap space. As with all recommendations that affect system performance, use what works best for your specific environment. This will take time and effort to experiment and make changes based on the conditions in your Linux environment.
|
||||
|
||||
#### Adding more swap space to a non-LVM disk environment
|
||||
|
||||
Due to changing requirements for swap space on hosts with Linux already installed, it may become necessary to modify the amount of swap space defined for the system. This procedure can be used for any general case where the amount of swap space needs to be increased. It assumes sufficient available disk space is available. This procedure also assumes that the disks are partitioned in “raw” EXT4 and swap partitions and do not use logical volume management (LVM).
|
||||
|
||||
The basic steps to take are simple:
|
||||
|
||||
1. Turn off the existing swap space.
|
||||
|
||||
2. Create a new swap partition of the desired size.
|
||||
|
||||
3. Reread the partition table.
|
||||
|
||||
4. Configure the partition as swap space.
|
||||
|
||||
5. Add the new partition/etc/fstab.
|
||||
|
||||
6. Turn on swap.
|
||||
|
||||
|
||||
|
||||
|
||||
A reboot should not be necessary.
|
||||
|
||||
For safety's sake, before turning off swap, at the very least you should ensure that no applications are running and that no swap space is in use. The `free` or `top` commands can tell you whether swap space is in use. To be even safer, you could revert to run level 1 or single-user mode.
|
||||
|
||||
Turn off the swap partition with the command which turns off all swap space:
|
||||
|
||||
```
|
||||
swapoff -a
|
||||
|
||||
```
|
||||
|
||||
Now display the existing partitions on the hard drive.
|
||||
|
||||
```
|
||||
fdisk -l
|
||||
|
||||
```
|
||||
|
||||
This displays the current partition tables on each drive. Identify the current swap partition by number.
|
||||
|
||||
Start `fdisk` in interactive mode with the command:
|
||||
|
||||
```
|
||||
fdisk /dev/<device name>
|
||||
|
||||
```
|
||||
|
||||
For example:
|
||||
|
||||
```
|
||||
fdisk /dev/sda
|
||||
|
||||
```
|
||||
|
||||
At this point, `fdisk` is now interactive and will operate only on the specified disk drive.
|
||||
|
||||
Use the fdisk `p` sub-command to verify that there is enough free space on the disk to create the new swap partition. The space on the hard drive is shown in terms of 512-byte blocks and starting and ending cylinder numbers, so you may have to do some math to determine the available space between and at the end of allocated partitions.
|
||||
|
||||
Use the `n` sub-command to create a new swap partition. fdisk will ask you the starting cylinder. By default, it chooses the lowest-numbered available cylinder. If you wish to change that, type in the number of the starting cylinder.
|
||||
|
||||
The `fdisk` command now allows you to enter the size of the partitions in a number of formats, including the last cylinder number or the size in bytes, KB or MB. Type in 4000M, which will give about 4GB of space on the new partition (for example), and press Enter.
|
||||
|
||||
Use the `p` sub-command to verify that the partition was created as you specified it. Note that the partition will probably not be exactly what you specified unless you used the ending cylinder number. The `fdisk` command can only allocate disk space in increments on whole cylinders, so your partition may be a little smaller or larger than you specified. If the partition is not what you want, you can delete it and create it again.
|
||||
|
||||
Now it is necessary to specify that the new partition is to be a swap partition. The sub-command `t` allows you to specify the type of partition. So enter `t`, specify the partition number, and when it asks for the hex code partition type, type 82, which is the Linux swap partition type, and press Enter.
|
||||
|
||||
When you are satisfied with the partition you have created, use the `w` sub-command to write the new partition table to the disk. The `fdisk` program will exit and return you to the command prompt after it completes writing the revised partition table. You will probably receive the following message as `fdisk` completes writing the new partition table:
|
||||
|
||||
```
|
||||
The partition table has been altered!
|
||||
Calling ioctl() to re-read partition table.
|
||||
WARNING: Re-reading the partition table failed with error 16: Device or resource busy.
|
||||
The kernel still uses the old table.
|
||||
The new table will be used at the next reboot.
|
||||
Syncing disks.
|
||||
```
|
||||
|
||||
At this point, you use the `partprobe` command to force the kernel to re-read the partition table so that it is not necessary to perform a reboot.
|
||||
|
||||
```
|
||||
partprobe
|
||||
```
|
||||
|
||||
Now use the command `fdisk -l` to list the partitions and the new swap partition should be among those listed. Be sure that the new partition type is “Linux swap”.
|
||||
|
||||
It will be necessary to modify the /etc/fstab file to point to the new swap partition. The existing line may look like this:
|
||||
|
||||
```
|
||||
LABEL=SWAP-sdaX swap swap defaults 0 0
|
||||
|
||||
```
|
||||
|
||||
where `X` is the partition number. Add a new line that looks similar this, depending upon the location of your new swap partition:
|
||||
|
||||
```
|
||||
/dev/sdaY swap swap defaults 0 0
|
||||
|
||||
```
|
||||
|
||||
Be sure to use the correct partition number. Now you can perform the final step in creating the swap partition. Use the `mkswap` command to define the partition as a swap partition.
|
||||
|
||||
```
|
||||
mkswap /dev/sdaY
|
||||
|
||||
```
|
||||
|
||||
The final step is to turn swap on using the command:
|
||||
|
||||
```
|
||||
swapon -a
|
||||
|
||||
```
|
||||
|
||||
Your new swap partition is now online along with the previously existing swap partition. You can use the `free` or `top` commands to verify this.
|
||||
|
||||
#### Adding swap to an LVM disk environment
|
||||
|
||||
If your disk setup uses LVM, changing swap space will be fairly easy. Again, this assumes that space is available in the volume group in which the current swap volume is located. By default, the installation procedures for Fedora Linux in an LVM environment create the swap partition as a logical volume. This makes it easy because you can simply increase the size of the swap volume.
|
||||
|
||||
Here are the steps required to increase the amount of swap space in an LVM environment:
|
||||
|
||||
1. Turn off all swap.
|
||||
|
||||
2. Increase the size of the logical volume designated for swap.
|
||||
|
||||
3. Configure the resized volume as swap space.
|
||||
|
||||
4. Turn on swap.
|
||||
|
||||
|
||||
|
||||
|
||||
First, let’s verify that swap exists and is a logical volume using the `lvs` command (list logical volume).
|
||||
|
||||
```
|
||||
[root@studentvm1 ~]# lvs
|
||||
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
|
||||
home fedora_studentvm1 -wi-ao---- 2.00g
|
||||
pool00 fedora_studentvm1 twi-aotz-- 2.00g 8.17 2.93
|
||||
root fedora_studentvm1 Vwi-aotz-- 2.00g pool00 8.17
|
||||
swap fedora_studentvm1 -wi-ao---- 8.00g
|
||||
tmp fedora_studentvm1 -wi-ao---- 5.00g
|
||||
usr fedora_studentvm1 -wi-ao---- 15.00g
|
||||
var fedora_studentvm1 -wi-ao---- 10.00g
|
||||
[root@studentvm1 ~]#
|
||||
```
|
||||
|
||||
You can see that the current swap size is 8GB. In this case, we want to add 2GB to this swap volume. First, stop existing swap. You may have to terminate running programs if swap space is in use.
|
||||
|
||||
```
|
||||
swapoff -a
|
||||
|
||||
```
|
||||
|
||||
Now increase the size of the logical volume.
|
||||
|
||||
```
|
||||
[root@studentvm1 ~]# lvextend -L +2G /dev/mapper/fedora_studentvm1-swap
|
||||
Size of logical volume fedora_studentvm1/swap changed from 8.00 GiB (2048 extents) to 10.00 GiB (2560 extents).
|
||||
Logical volume fedora_studentvm1/swap successfully resized.
|
||||
[root@studentvm1 ~]#
|
||||
```
|
||||
|
||||
Run the `mkswap` command to make this entire 10GB partition into swap space.
|
||||
|
||||
```
|
||||
[root@studentvm1 ~]# mkswap /dev/mapper/fedora_studentvm1-swap
|
||||
mkswap: /dev/mapper/fedora_studentvm1-swap: warning: wiping old swap signature.
|
||||
Setting up swapspace version 1, size = 10 GiB (10737414144 bytes)
|
||||
no label, UUID=3cc2bee0-e746-4b66-aa2d-1ea15ef1574a
|
||||
[root@studentvm1 ~]#
|
||||
```
|
||||
|
||||
Turn swap back on.
|
||||
|
||||
```
|
||||
[root@studentvm1 ~]# swapon -a
|
||||
[root@studentvm1 ~]#
|
||||
```
|
||||
|
||||
Now verify the new swap space is present with the list block devices command. Again, a reboot is not required.
|
||||
|
||||
```
|
||||
[root@studentvm1 ~]# lsblk
|
||||
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
|
||||
sda 8:0 0 60G 0 disk
|
||||
|-sda1 8:1 0 1G 0 part /boot
|
||||
`-sda2 8:2 0 59G 0 part
|
||||
|-fedora_studentvm1-pool00_tmeta 253:0 0 4M 0 lvm
|
||||
| `-fedora_studentvm1-pool00-tpool 253:2 0 2G 0 lvm
|
||||
| |-fedora_studentvm1-root 253:3 0 2G 0 lvm /
|
||||
| `-fedora_studentvm1-pool00 253:6 0 2G 0 lvm
|
||||
|-fedora_studentvm1-pool00_tdata 253:1 0 2G 0 lvm
|
||||
| `-fedora_studentvm1-pool00-tpool 253:2 0 2G 0 lvm
|
||||
| |-fedora_studentvm1-root 253:3 0 2G 0 lvm /
|
||||
| `-fedora_studentvm1-pool00 253:6 0 2G 0 lvm
|
||||
|-fedora_studentvm1-swap 253:4 0 10G 0 lvm [SWAP]
|
||||
|-fedora_studentvm1-usr 253:5 0 15G 0 lvm /usr
|
||||
|-fedora_studentvm1-home 253:7 0 2G 0 lvm /home
|
||||
|-fedora_studentvm1-var 253:8 0 10G 0 lvm /var
|
||||
`-fedora_studentvm1-tmp 253:9 0 5G 0 lvm /tmp
|
||||
sr0 11:0 1 1024M 0 rom
|
||||
[root@studentvm1 ~]#
|
||||
```
|
||||
|
||||
You can also use the `swapon -s` command, or `top`, `free`, or any of several other commands to verify this.
|
||||
|
||||
```
|
||||
[root@studentvm1 ~]# free
|
||||
total used free shared buff/cache available
|
||||
Mem: 4038808 382404 2754072 4152 902332 3404184
|
||||
Swap: 10485756 0 10485756
|
||||
[root@studentvm1 ~]#
|
||||
```
|
||||
|
||||
Note that the different commands display or require as input the device special file in different forms. There are a number of ways in which specific devices are accessed in the /dev directory. My article, [Managing Devices in Linux][2], includes more information about the /dev directory and its contents.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/swap-space-linux-systems
|
||||
|
||||
作者:[David Both][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/dboth
|
||||
[1]: https://docs.fedoraproject.org/en-US/fedora/f28/install-guide/
|
||||
[2]: https://opensource.com/article/16/11/managing-devices-linux
|
||||
@ -0,0 +1,260 @@
|
||||
translating by Flowsnow
|
||||
|
||||
How to use the Scikit-learn Python library for data science projects
|
||||
======
|
||||
|
||||

|
||||
|
||||
The Scikit-learn Python library, initially released in 2007, is commonly used in solving machine learning and data science problems—from the beginning to the end. The versatile library offers an uncluttered, consistent, and efficient API and thorough online documentation.
|
||||
|
||||
### What is Scikit-learn?
|
||||
|
||||
[Scikit-learn][1] is an open source Python library that has powerful tools for data analysis and data mining. It's available under the BSD license and is built on the following machine learning libraries:
|
||||
|
||||
* **NumPy** , a library for manipulating multi-dimensional arrays and matrices. It also has an extensive compilation of mathematical functions for performing various calculations.
|
||||
* **SciPy** , an ecosystem consisting of various libraries for completing technical computing tasks.
|
||||
* **Matplotlib** , a library for plotting various charts and graphs.
|
||||
|
||||
|
||||
|
||||
Scikit-learn offers an extensive range of built-in algorithms that make the most of data science projects.
|
||||
|
||||
Here are the main ways the Scikit-learn library is used.
|
||||
|
||||
#### 1. Classification
|
||||
|
||||
The [classification][2] tools identify the category associated with provided data. For example, they can be used to categorize email messages as either spam or not.
|
||||
|
||||
* Support vector machines (SVMs)
|
||||
* Nearest neighbors
|
||||
* Random forest
|
||||
|
||||
|
||||
|
||||
#### 2. Regression
|
||||
|
||||
Classification algorithms in Scikit-learn include:
|
||||
|
||||
Regression involves creating a model that tries to comprehend the relationship between input and output data. For example, regression tools can be used to understand the behavior of stock prices.
|
||||
|
||||
Regression algorithms include:
|
||||
|
||||
* SVMs
|
||||
* Ridge regression
|
||||
* Lasso
|
||||
|
||||
|
||||
|
||||
#### 3. Clustering
|
||||
|
||||
The Scikit-learn clustering tools are used to automatically group data with the same characteristics into sets. For example, customer data can be segmented based on their localities.
|
||||
|
||||
Clustering algorithms include:
|
||||
|
||||
* K-means
|
||||
* Spectral clustering
|
||||
* Mean-shift
|
||||
|
||||
|
||||
|
||||
#### 4. Dimensionality reduction
|
||||
|
||||
Dimensionality reduction lowers the number of random variables for analysis. For example, to increase the efficiency of visualizations, outlying data may not be considered.
|
||||
|
||||
Dimensionality reduction algorithms include:
|
||||
|
||||
* Principal component analysis (PCA)
|
||||
* Feature selection
|
||||
* Non-negative matrix factorization
|
||||
|
||||
|
||||
|
||||
#### 5. Model selection
|
||||
|
||||
Model selection algorithms offer tools to compare, validate, and select the best parameters and models to use in your data science projects.
|
||||
|
||||
Model selection modules that can deliver enhanced accuracy through parameter tuning include:
|
||||
|
||||
* Grid search
|
||||
* Cross-validation
|
||||
* Metrics
|
||||
|
||||
|
||||
|
||||
#### 6. Preprocessing
|
||||
|
||||
The Scikit-learn preprocessing tools are important in feature extraction and normalization during data analysis. For example, you can use these tools to transform input data—such as text—and apply their features in your analysis.
|
||||
|
||||
Preprocessing modules include:
|
||||
|
||||
* Preprocessing
|
||||
* Feature extraction
|
||||
|
||||
|
||||
|
||||
### A Scikit-learn library example
|
||||
|
||||
Let's use a simple example to illustrate how you can use the Scikit-learn library in your data science projects.
|
||||
|
||||
We'll use the [Iris flower dataset][3], which is incorporated in the Scikit-learn library. The Iris flower dataset contains 150 details about three flower species:
|
||||
|
||||
* Setosa—labeled 0
|
||||
* Versicolor—labeled 1
|
||||
* Virginica—labeled 2
|
||||
|
||||
|
||||
|
||||
The dataset includes the following characteristics of each flower species (in centimeters):
|
||||
|
||||
* Sepal length
|
||||
* Sepal width
|
||||
* Petal length
|
||||
* Petal width
|
||||
|
||||
|
||||
|
||||
#### Step 1: Importing the library
|
||||
|
||||
Since the Iris dataset is included in the Scikit-learn data science library, we can load it into our workspace as follows:
|
||||
|
||||
```
|
||||
from sklearn import datasets
|
||||
iris = datasets.load_iris()
|
||||
```
|
||||
|
||||
These commands import the **datasets** module from **sklearn** , then use the **load_digits()** method from **datasets** to include the data in the workspace.
|
||||
|
||||
#### Step 2: Getting dataset characteristics
|
||||
|
||||
The **datasets** module contains several methods that make it easier to get acquainted with handling data.
|
||||
|
||||
In Scikit-learn, a dataset refers to a dictionary-like object that has all the details about the data. The data is stored using the **.data** key, which is an array list.
|
||||
|
||||
For instance, we can utilize **iris.data** to output information about the Iris flower dataset.
|
||||
|
||||
```
|
||||
print(iris.data)
|
||||
```
|
||||
|
||||
Here is the output (the results have been truncated):
|
||||
|
||||
```
|
||||
[[5.1 3.5 1.4 0.2]
|
||||
[4.9 3. 1.4 0.2]
|
||||
[4.7 3.2 1.3 0.2]
|
||||
[4.6 3.1 1.5 0.2]
|
||||
[5. 3.6 1.4 0.2]
|
||||
[5.4 3.9 1.7 0.4]
|
||||
[4.6 3.4 1.4 0.3]
|
||||
[5. 3.4 1.5 0.2]
|
||||
[4.4 2.9 1.4 0.2]
|
||||
[4.9 3.1 1.5 0.1]
|
||||
[5.4 3.7 1.5 0.2]
|
||||
[4.8 3.4 1.6 0.2]
|
||||
[4.8 3. 1.4 0.1]
|
||||
[4.3 3. 1.1 0.1]
|
||||
[5.8 4. 1.2 0.2]
|
||||
[5.7 4.4 1.5 0.4]
|
||||
[5.4 3.9 1.3 0.4]
|
||||
[5.1 3.5 1.4 0.3]
|
||||
```
|
||||
|
||||
Let's also use **iris.target** to give us information about the different labels of the flowers.
|
||||
|
||||
```
|
||||
print(iris.target)
|
||||
```
|
||||
|
||||
Here is the output:
|
||||
|
||||
```
|
||||
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
|
||||
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
|
||||
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
|
||||
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
|
||||
2 2]
|
||||
|
||||
```
|
||||
|
||||
If we use **iris.target_names** , we'll output an array of the names of the labels found in the dataset.
|
||||
|
||||
```
|
||||
print(iris.target_names)
|
||||
```
|
||||
|
||||
Here is the result after running the Python code:
|
||||
|
||||
```
|
||||
['setosa' 'versicolor' 'virginica']
|
||||
```
|
||||
|
||||
#### Step 3: Visualizing the dataset
|
||||
|
||||
We can use the [box plot][4] to produce a visual depiction of the Iris flower dataset. The box plot illustrates how the data is distributed over the plane through their quartiles.
|
||||
|
||||
Here's how to achieve this:
|
||||
|
||||
```
|
||||
import seaborn as sns
|
||||
box_data = iris.data #variable representing the data array
|
||||
box_target = iris.target #variable representing the labels array
|
||||
sns.boxplot(data = box_data,width=0.5,fliersize=5)
|
||||
sns.set(rc={'figure.figsize':(2,15)})
|
||||
```
|
||||
|
||||
Let's see the result:
|
||||
|
||||
|
||||
|
||||
On the horizontal axis:
|
||||
|
||||
* 0 is sepal length
|
||||
* 1 is sepal width
|
||||
* 2 is petal length
|
||||
* 3 is petal width
|
||||
|
||||
|
||||
|
||||
The vertical axis is dimensions in centimeters.
|
||||
|
||||
### Wrapping up
|
||||
|
||||
Here is the entire code for this simple Scikit-learn data science tutorial.
|
||||
|
||||
```
|
||||
from sklearn import datasets
|
||||
iris = datasets.load_iris()
|
||||
print(iris.data)
|
||||
print(iris.target)
|
||||
print(iris.target_names)
|
||||
import seaborn as sns
|
||||
box_data = iris.data #variable representing the data array
|
||||
box_target = iris.target #variable representing the labels array
|
||||
sns.boxplot(data = box_data,width=0.5,fliersize=5)
|
||||
sns.set(rc={'figure.figsize':(2,15)})
|
||||
```
|
||||
|
||||
Scikit-learn is a versatile Python library you can use to efficiently complete data science projects.
|
||||
|
||||
If you want to learn more, check out the tutorials on [LiveEdu][5], such as Andrey Bulezyuk's video on using the Scikit-learn library to create a [machine learning application][6].
|
||||
|
||||
Do you have any questions or comments? Feel free to share them below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/how-use-scikit-learn-data-science-projects
|
||||
|
||||
作者:[Dr.Michael J.Garbade][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/drmjg
|
||||
[1]: http://scikit-learn.org/stable/index.html
|
||||
[2]: https://blog.liveedu.tv/regression-versus-classification-machine-learning-whats-the-difference/
|
||||
[3]: https://en.wikipedia.org/wiki/Iris_flower_data_set
|
||||
[4]: https://en.wikipedia.org/wiki/Box_plot
|
||||
[5]: https://www.liveedu.tv/guides/data-science/
|
||||
[6]: https://www.liveedu.tv/andreybu/REaxr-machine-learning-model-python-sklearn-kera/oPGdP-machine-learning-model-python-sklearn-kera/
|
||||
@ -0,0 +1,183 @@
|
||||
在 Debian 9 / Ubuntu 16.04 / 17.10 中如何安装并使用 Wireshark
|
||||
======
|
||||
|
||||
作者 [Pradeep Kumar][1],首发于 2017 年 11 月 29 日,更新于 2017 年 11 月 29 日
|
||||
|
||||
[][2]
|
||||
|
||||
Wireshark 是免费的,开源的,跨平台的基于 GUI 的网络数据包分析器,可用于 Linux, Windows, MacOS, Solaris 等。它可以实时捕获网络数据包,并以人性化的格式呈现。Wireshark 允许我们监控网络数据包上升到微观层面。Wireshark 还有一个名为 `tshark` 的命令行实用程序,它与 Wireshark 执行相同的功能,但它是通过终端而不是 GUI。
|
||||
|
||||
Wireshark 可用于网络故障排除,分析,软件和通信协议开发以及用于教育目的。Wireshark 使用 `pcap` 库来捕获网络数据包。
|
||||
|
||||
Wireshark 具有许多功能:
|
||||
|
||||
* 支持数百项协议检查
|
||||
|
||||
* 能够实时捕获数据包并保存,以便以后进行离线分析
|
||||
|
||||
* 许多用于分析数据的过滤器
|
||||
|
||||
* 捕获的数据可以被压缩和解压缩(to 校正:on the fly 什么意思?)
|
||||
|
||||
* 支持各种文件格式的数据分析,输出也可以保存为 XML, CSV 和纯文本格式
|
||||
|
||||
* 数据可以从以太网,wifi,蓝牙,USB,帧中继,令牌环等多个接口中捕获
|
||||
|
||||
在本文中,我们将讨论如何在 Ubuntu/Debian 上安装 Wireshark,并将学习如何使用 Wireshark 捕获网络数据包。
|
||||
|
||||
#### 在 Ubuntu 16.04 / 17.10 上安装 Wireshark
|
||||
|
||||
Wireshark 在 Ubuntu 默认仓库中可用,只需使用以下命令即可安装。但有可能得不到最新版本的 wireshark。
|
||||
|
||||
```
|
||||
linuxtechi@nixworld:~$ sudo apt-get update
|
||||
linuxtechi@nixworld:~$ sudo apt-get install wireshark -y
|
||||
```
|
||||
|
||||
因此,要安装最新版本的 wireshark,我们必须启用或配置官方 wireshark 仓库。
|
||||
|
||||
使用下面的命令来配置仓库并安装最新版本的 wireshark 实用程序。
|
||||
|
||||
```
|
||||
linuxtechi@nixworld:~$ sudo add-apt-repository ppa:wireshark-dev/stable
|
||||
linuxtechi@nixworld:~$ sudo apt-get update
|
||||
linuxtechi@nixworld:~$ sudo apt-get install wireshark -y
|
||||
```
|
||||
|
||||
一旦安装了 wireshark,执行以下命令,以便非 root 用户也可以捕获接口的实时数据包。
|
||||
|
||||
```
|
||||
linuxtechi@nixworld:~$ sudo setcap 'CAP_NET_RAW+eip CAP_NET_ADMIN+eip' /usr/bin/dumpcap
|
||||
```
|
||||
|
||||
#### 在 Debian 9 上安装 Wireshark
|
||||
|
||||
Wireshark 包及其依赖项已存在于 debian 9 的默认仓库中,因此要在 Debian 9 上安装最新且稳定版本的 Wireshark,请使用以下命令:
|
||||
|
||||
```
|
||||
linuxtechi@nixhome:~$ sudo apt-get update
|
||||
linuxtechi@nixhome:~$ sudo apt-get install wireshark -y
|
||||
```
|
||||
|
||||
在安装过程中,它会提示我们为非超级用户配置 dumpcap,
|
||||
|
||||
选择 `yes` 并回车。
|
||||
|
||||
[][3]
|
||||
|
||||
安装完成后,执行以下命令,以便非 root 用户也可以捕获接口的实时数据包。
|
||||
|
||||
```
|
||||
linuxtechi@nixhome:~$ sudo chmod +x /usr/bin/dumpcap
|
||||
```
|
||||
|
||||
我们还可以使用最新的源代码包在 Ubuntu/Debian 和其它 Linux 发行版上安装 wireshark。
|
||||
|
||||
#### 在 Debian / Ubuntu 系统上使用源代码安装 Wireshark
|
||||
|
||||
首先下载最新的源代码包(写这篇文章时它的最新版本是 2.4.2),使用以下命令:
|
||||
|
||||
```
|
||||
linuxtechi@nixhome:~$ wget https://1.as.dl.wireshark.org/src/wireshark-2.4.2.tar.xz
|
||||
```
|
||||
|
||||
然后解压缩包,进入解压缩的目录:
|
||||
|
||||
```
|
||||
linuxtechi@nixhome:~$ tar -xf wireshark-2.4.2.tar.xz -C /tmp
|
||||
linuxtechi@nixhome:~$ cd /tmp/wireshark-2.4.2
|
||||
```
|
||||
|
||||
现在我们使用以下命令编译代码:
|
||||
|
||||
```
|
||||
linuxtechi@nixhome:/tmp/wireshark-2.4.2$ ./configure --enable-setcap-install
|
||||
linuxtechi@nixhome:/tmp/wireshark-2.4.2$ make
|
||||
```
|
||||
|
||||
最后安装已编译的软件包以便在系统上安装 Wireshark:
|
||||
|
||||
```
|
||||
linuxtechi@nixhome:/tmp/wireshark-2.4.2$ sudo make install
|
||||
linuxtechi@nixhome:/tmp/wireshark-2.4.2$ sudo ldconfig
|
||||
```
|
||||
|
||||
在安装后,它将创建一个单独的 Wireshark 组,我们现在将我们的用户添加到组中,以便它可以与 Wireshark 一起使用,否则在启动 wireshark 时可能会出现 `permission denied(权限被拒绝)`错误。
|
||||
|
||||
要将用户添加到 wireshark 组,执行以下命令:
|
||||
|
||||
```
|
||||
linuxtechi@nixhome:~$ sudo usermod -a -G wireshark linuxtechi
|
||||
```
|
||||
|
||||
现在我们可以使用以下命令从 GUI 菜单或终端启动 wireshark:
|
||||
|
||||
```
|
||||
linuxtechi@nixhome:~$ wireshark
|
||||
```
|
||||
|
||||
#### 在 Debian 9 系统上使用 Wireshark
|
||||
|
||||
[][4]
|
||||
|
||||
点击 Wireshark 图标
|
||||
|
||||
[][5]
|
||||
|
||||
#### 在 Ubuntu 16.04 / 17.10 上使用 Wireshark
|
||||
|
||||
[][6]
|
||||
|
||||
点击 Wireshark 图标
|
||||
|
||||
[][7]
|
||||
|
||||
#### 捕获并分析数据包
|
||||
|
||||
一旦 wireshark 启动,我们就会看到 wireshark 窗口,上面有 Ubuntu 和 Debian 系统的示例。
|
||||
|
||||
[][8]
|
||||
|
||||
所有这些都是我们可以捕获网络数据包的接口。根据你系统上的界面,此屏幕可能与你的不同。
|
||||
|
||||
我们选择 `enp0s3` 来捕获该接口的网络流量。选择接口后,在我们网络上所有设备的网络数据包开始填充(参考下面的屏幕截图):
|
||||
|
||||
[][9]
|
||||
|
||||
第一次看到这个屏幕,我们可能会被这个屏幕上显示的数据所淹没,并且可能已经想过如何整理这些数据,但不用担心,Wireshark 的最佳功能之一就是它的过滤器。
|
||||
|
||||
我们可以根据 IP 地址,端口号,也可以使用来源和目标过滤器,数据包大小等对数据进行排序和过滤,也可以将两个或多个过滤器组合在一起以创建更全面的搜索。我们也可以在 `Apply a Display Filter(应用显示过滤器)`选项卡中编写过滤规则,也可以选择已创建的规则。要选择之前构建的过滤器,请单击 `Apply a Display Filter(应用显示过滤器)`选项卡旁边的 `flag` 图标。
|
||||
|
||||
[][10]
|
||||
|
||||
我们还可以根据颜色编码过滤数据,默认情况下,浅紫色是 TCP 流量,浅蓝色是 UDP 流量,黑色标识有错误的数据包,看看这些编码是什么意思,点击 `View -> Coloring Rules`,我们也可以改变这些编码。
|
||||
|
||||
[][11]
|
||||
|
||||
在我们得到我们需要的结果之后,我们可以点击任何捕获的数据包以获得有关该数据包的更多详细信息,这将显示该网络数据包的所有数据。
|
||||
|
||||
Wireshark 是一个非常强大的工具,需要一些时间来习惯并对其进行命令操作,本教程将帮助你入门。请随时在下面的评论框中提出你的疑问或建议。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxtechi.com
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxtechi.com/author/pradeep/
|
||||
[1]:https://www.linuxtechi.com/author/pradeep/
|
||||
[2]:https://www.linuxtechi.com/wp-content/uploads/2017/11/wireshark-Debian-9-Ubuntu-16.04-17.10.jpg
|
||||
[3]:https://www.linuxtechi.com/wp-content/uploads/2017/11/Configure-Wireshark-Debian9.jpg
|
||||
[4]:https://www.linuxtechi.com/wp-content/uploads/2017/11/Access-wireshark-debian9.jpg
|
||||
[5]:https://www.linuxtechi.com/wp-content/uploads/2017/11/Wireshark-window-debian9.jpg
|
||||
[6]:https://www.linuxtechi.com/wp-content/uploads/2017/11/Access-wireshark-Ubuntu.jpg
|
||||
[7]:https://www.linuxtechi.com/wp-content/uploads/2017/11/Wireshark-window-Ubuntu.jpg
|
||||
[8]:https://www.linuxtechi.com/wp-content/uploads/2017/11/wireshark-Linux-system.jpg
|
||||
[9]:https://www.linuxtechi.com/wp-content/uploads/2017/11/Capturing-Packet-from-enp0s3-Ubuntu-Wireshark.jpg
|
||||
[10]:https://www.linuxtechi.com/wp-content/uploads/2017/11/Filter-in-wireshark-Ubuntu.jpg
|
||||
[11]:https://www.linuxtechi.com/wp-content/uploads/2017/11/Packet-Colouring-Wireshark.jpg
|
||||
237
translated/tech/20180528 What is behavior-driven Python.md
Normal file
237
translated/tech/20180528 What is behavior-driven Python.md
Normal file
@ -0,0 +1,237 @@
|
||||
什么是行为驱动的Python?
|
||||
======
|
||||

|
||||
|
||||
您是否听说过[行为驱动开发][1](BDD),并想知道所有的新奇事物是什么? 也许你已经发现了团队成员在使用“gherkin”了,并感到被排除在外无法参与其中。 或许你是一个Python爱好者,正在寻找更好的方法来测试你的代码。 无论在什么情况下,了解BDD都可以帮助您和您的团队实现更好的协作和测试自动化,而Python的`行为`框架是一个很好的起点。
|
||||
|
||||
### 什么是BDD?
|
||||
|
||||
* 在网站上提交表单
|
||||
* 搜索想要的结果
|
||||
* 保存文档
|
||||
* 进行REST API调用
|
||||
* 运行命令行界面命令
|
||||
|
||||
在软件中,行为是指在明确定义的输入,行为和结果场景中功能是如何运转的。 产品可以表现出无数的行为,例如:
|
||||
|
||||
根据产品的行为定义产品的功能可以更容易地描述产品,并对其进行开发和测试。 BDD的核心是:使行为成为软件开发的焦点。 在开发早期使用示例语言的规范来定义行为。 最常见的行为规范语言之一是Gherkin,Cucumber项目中的Given-When-Then场景格式。 行为规范基本上是对行为如何工作的简单语言描述,具有一致性和焦点的一些正式结构。 通过将步骤文本“粘合”到代码实现,测试框架可以轻松地自动化这些行为规范。
|
||||
|
||||
下面是用Gherkin编写的行为规范的示例:
|
||||
|
||||
根据产品的行为定义产品的功能可以更容易地描述产品,开发产品并对其进行测试。 这是BDD的核心:使行为成为软件开发的焦点。 在开发早期使用[示例规范][2]的语言来定义行为。 最常见的行为规范语言之一是[Gherkin][3],[Cucumber][4]项目中的Given-When-Then场景格式。 行为规范基本上是对行为如何工作的简单语言描述,具有一致性和焦点的一些正式结构。 通过将步骤文本“粘合”到代码实现,测试框架可以轻松地自动化这些行为规范。
|
||||
|
||||
下面是用Gherkin编写的行为规范的示例:
|
||||
|
||||
```
|
||||
Scenario: Basic DuckDuckGo Search
|
||||
Given the DuckDuckGo home page is displayed
|
||||
When the user searches for "panda"
|
||||
Then results are shown for "panda"
|
||||
```
|
||||
|
||||
快速浏览一下,行为是直观易懂的。 除少数关键字外,该语言为自由格式。 场景简洁而有意义。 一个真实的例子说明了这种行为。 步骤以声明的方式表明应该发生什么——而不会陷入如何如何的细节中。
|
||||
|
||||
[BDD的主要优点][5]是良好的协作和自动化。 每个人都可以为行为开发做出贡献,而不仅仅是程序员。 从流程开始就定义并理解预期的行为。 测试可以与它们涵盖的功能一起自动化。 每个测试都包含一个单一的,独特的行为,以避免重复。 最后,现有的步骤可以通过新的行为规范重用,从而产生雪球效果。
|
||||
|
||||
### Python的behave框架
|
||||
|
||||
`behave`是Python中最流行的BDD框架之一。 它与其他基于Gherkin的Cucumber框架非常相似,尽管没有得到官方的Cucumber定名。 `behave`有两个主要层:
|
||||
|
||||
1. 用Gherkin的`.feature`文件编写的行为规范
|
||||
2. 用Python模块编写的步骤定义和钩子,用于实现Gherkin步骤
|
||||
|
||||
如上例所示,Gherkin场景有三部分格式:
|
||||
|
||||
1. 鉴于一些初始状态
|
||||
2. 当行为发生时
|
||||
3. 然后验证结果
|
||||
|
||||
当`behave`运行测试时,每个步骤由装饰器“粘合”到Python函数。
|
||||
|
||||
### 安装
|
||||
|
||||
作为先决条件,请确保在你的计算机上安装了Python和`pip`。 我强烈建议使用Python 3.(我还建议使用[`pipenv`][6],但以下示例命令使用更基本的`pip`。)
|
||||
|
||||
`behave`框架只需要一个包:
|
||||
|
||||
```
|
||||
pip install behave
|
||||
```
|
||||
|
||||
其他包也可能有用,例如:
|
||||
```
|
||||
pip install requests # 用于调用REST API
|
||||
pip install selenium # 用于web浏览器交互
|
||||
```
|
||||
|
||||
GitHub上的[behavior-driven-Python][7]项目包含本文中使用的示例。
|
||||
|
||||
### Gherkin特点
|
||||
|
||||
`behave`框架使用的Gherkin语法实际上是符合官方的Cucumber Gherkin标准的。 `.feature`文件包含功能Feature部分,而Feature部分又包含具有Given-When-Then步骤的场景Scenario部分。 以下是一个例子:
|
||||
|
||||
```
|
||||
Feature: Cucumber Basket
|
||||
As a gardener,
|
||||
I want to carry many cucumbers in a basket,
|
||||
So that I don’t drop them all.
|
||||
|
||||
@cucumber-basket
|
||||
Scenario: Add and remove cucumbers
|
||||
Given the basket is empty
|
||||
When "4" cucumbers are added to the basket
|
||||
And "6" more cucumbers are added to the basket
|
||||
But "3" cucumbers are removed from the basket
|
||||
Then the basket contains "7" cucumbers
|
||||
```
|
||||
|
||||
这里有一些重要的事情需要注意:
|
||||
|
||||
- Feature和Scenario部分都有[简短的描述性标题][8]。
|
||||
- 紧跟在Feature标题后面的行是会被`behave`框架忽略掉的注释。将功能描述放在那里是一种很好的做法。
|
||||
- Scenarios和Features可以有标签(注意`@cucumber-basket`标记)用于钩子和过滤(如下所述)。
|
||||
- 步骤都遵循[严格的Given-When-Then顺序][9]。
|
||||
- 使用`And`和`Bu`t可以为任何类型添加附加步骤。
|
||||
- 可以使用输入对步骤进行参数化——注意双引号里的值。
|
||||
|
||||
通过使用场景大纲,场景也可以写为具有多个输入组合的模板:
|
||||
|
||||
```
|
||||
Feature: Cucumber Basket
|
||||
|
||||
@cucumber-basket
|
||||
Scenario Outline: Add cucumbers
|
||||
Given the basket has “<initial>” cucumbers
|
||||
When "<more>" cucumbers are added to the basket
|
||||
Then the basket contains "<total>" cucumbers
|
||||
|
||||
Examples: Cucumber Counts
|
||||
| initial | more | total |
|
||||
| 0 | 1 | 1 |
|
||||
| 1 | 2 | 3 |
|
||||
| 5 | 4 | 9 |
|
||||
```
|
||||
|
||||
场景大纲总是有一个Examples表,其中第一行给出列标题,后续每一行给出一个输入组合。 只要列标题出现在由尖括号括起的步骤中,行值就会被替换。 在上面的示例中,场景将运行三次,因为有三行输入组合。 场景大纲是避免重复场景的好方法。
|
||||
|
||||
Gherkin语言还有其他元素,但这些是主要的机制。 想了解更多信息,请阅读Automation Panda这个网站的文章[Gherkin by Example][10]和[Writing Good Gherkin][11]。
|
||||
|
||||
### Python机制
|
||||
|
||||
每个Gherkin步骤必须“粘合”到步骤定义,即提供了实现的Python函数。 每个函数都有一个带有匹配字符串的步骤类型装饰器。 它还接收共享的上下文和任何步骤参数。 功能文件必须放在名为`features/`的目录中,而步骤定义模块必须放在名为`features/steps/`的目录中。 任何功能文件都可以使用任何模块中的步骤定义——它们不需要具有相同的名称。 下面是一个示例Python模块,其中包含cucumber basket功能的步骤定义。
|
||||
|
||||
```
|
||||
from behave import *
|
||||
from cucumbers.basket import CucumberBasket
|
||||
|
||||
@given('the basket has "{initial:d}" cucumbers')
|
||||
def step_impl(context, initial):
|
||||
context.basket = CucumberBasket(initial_count=initial)
|
||||
|
||||
@when('"{some:d}" cucumbers are added to the basket')
|
||||
def step_impl(context, some):
|
||||
context.basket.add(some)
|
||||
|
||||
@then('the basket contains "{total:d}" cucumbers')
|
||||
def step_impl(context, total):
|
||||
assert context.basket.count == total
|
||||
```
|
||||
|
||||
可以使用三个[步骤匹配器][12]:`parse`,`cfparse`和`re`。默认和最简单的匹配器是`parse`,如上例所示。注意如何解析参数化值并将其作为输入参数传递给函数。一个常见的最佳实践是在步骤中给参数加双引号。
|
||||
|
||||
每个步骤定义函数还接收一个[上下文][13]变量,该变量保存当前正在运行的场景的数据,例如`feature`, `scenario`和`tags`字段。也可以添加自定义字段,用于在步骤之间共享数据。始终使用上下文来共享数据——永远不要使用全局变量!
|
||||
|
||||
`behave`框架还支持[钩子][14]来处理Gherkin步骤之外的自动化问题。钩子是一个将在步骤,场景,功能或整个测试套件之前或之后运行的功能。钩子让人联想到[面向方面的编程][15]。它们应放在`features/`目录下的特殊`environment.py`文件中。钩子函数也可以检查当前场景的标签,因此可以有选择地应用逻辑。下面的示例显示了如何使用钩子为标记为`@web`的任何场景生成和销毁一个Selenium WebDriver实例。
|
||||
|
||||
```
|
||||
from selenium import webdriver
|
||||
|
||||
def before_scenario(context, scenario):
|
||||
if 'web' in context.tags:
|
||||
context.browser = webdriver.Firefox()
|
||||
context.browser.implicitly_wait(10)
|
||||
|
||||
def after_scenario(context, scenario):
|
||||
if 'web' in context.tags:
|
||||
context.browser.quit()
|
||||
```
|
||||
|
||||
注意:也可以使用[fixtures][16]进行构建和清理。
|
||||
|
||||
要了解一个`behave`项目应该是什么样子,这里是示例项目的目录结构:
|
||||
|
||||

|
||||
|
||||
任何Python包和自定义模块都可以与`behave`框架一起使用。 使用良好的设计模式构建可扩展的测试自动化解决方案。步骤定义代码应简明扼要。
|
||||
|
||||
### 运行测试
|
||||
|
||||
要从命令行运行测试,请切换到项目的根目录并运行`behave`命令。 使用`-help`选项查看所有可用选项。
|
||||
|
||||
以下是一些常见用例:
|
||||
|
||||
```
|
||||
# run all tests
|
||||
behave
|
||||
|
||||
# run the scenarios in a feature file
|
||||
behave features/web.feature
|
||||
|
||||
# run all tests that have the @duckduckgo tag
|
||||
behave --tags @duckduckgo
|
||||
|
||||
# run all tests that do not have the @unit tag
|
||||
behave --tags ~@unit
|
||||
|
||||
# run all tests that have @basket and either @add or @remove
|
||||
behave --tags @basket --tags @add,@remove
|
||||
```
|
||||
|
||||
为方便起见,选项可以保存在[config][17]文件中。
|
||||
|
||||
### 其他选择
|
||||
|
||||
`behave`不是Python中唯一的BDD测试框架。其他好的框架包括:
|
||||
|
||||
- `pytest-bdd`,`pytest`的插件,和`behave`一样,它使用Gherkin功能文件和步骤定义模块,但它也利用了`pytest`的所有功能和插件。例如,它可以使用`pytest-xdist`并行运行Gherkin场景。 BDD和非BDD测试也可以与相同的过滤器一起执行。 `pytest-bdd`还提供更灵活的目录布局。
|
||||
- `radish`是一个“Gherkin增强版”框架——它将Scenario循环和前提条件添加到标准的Gherkin语言中,这使得它对程序员更友好。它还提供丰富的命令行选项,如`behave`。
|
||||
- `lettuce`是一种较旧的BDD框架,与`behave`非常相似,在框架机制方面存在细微差别。然而,GitHub最近显示该项目的活动很少(截至2018年5月)。
|
||||
|
||||
任何这些框架都是不错的选择。
|
||||
|
||||
另外,请记住,Python测试框架可用于任何黑盒测试,即使对于非Python产品也是如此! BDD框架非常适合Web和服务测试,因为它们的测试是声明性的,而Python是一种[很好的测试自动化语言][18]。
|
||||
|
||||
本文基于作者的[PyCon Cleveland 2018][19]演讲,[行为驱动的Python][20]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/behavior-driven-python
|
||||
|
||||
作者:[Andrew Knight][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/andylpk247
|
||||
[1]:https://automationpanda.com/bdd/
|
||||
[2]:https://en.wikipedia.org/wiki/Specification_by_example
|
||||
[3]:https://automationpanda.com/2017/01/26/bdd-101-the-gherkin-language/
|
||||
[4]:https://cucumber.io/
|
||||
[5]:https://automationpanda.com/2017/02/13/12-awesome-benefits-of-bdd/
|
||||
[6]:https://docs.pipenv.org/
|
||||
[7]:https://github.com/AndyLPK247/behavior-driven-python
|
||||
[8]:https://automationpanda.com/2018/01/31/good-gherkin-scenario-titles/
|
||||
[9]:https://automationpanda.com/2018/02/03/are-gherkin-scenarios-with-multiple-when-then-pairs-okay/
|
||||
[10]:https://automationpanda.com/2017/01/27/bdd-101-gherkin-by-example/
|
||||
[11]:https://automationpanda.com/2017/01/30/bdd-101-writing-good-gherkin/
|
||||
[12]:http://behave.readthedocs.io/en/latest/api.html#step-parameters
|
||||
[13]:http://behave.readthedocs.io/en/latest/api.html#detecting-that-user-code-overwrites-behave-context-attributes
|
||||
[14]:http://behave.readthedocs.io/en/latest/api.html#environment-file-functions
|
||||
[15]:https://en.wikipedia.org/wiki/Aspect-oriented_programming
|
||||
[16]:http://behave.readthedocs.io/en/latest/api.html#fixtures
|
||||
[17]:http://behave.readthedocs.io/en/latest/behave.html#configuration-files
|
||||
[18]:https://automationpanda.com/2017/01/21/the-best-programming-language-for-test-automation/
|
||||
[19]:https://us.pycon.org/2018/
|
||||
[20]:https://us.pycon.org/2018/schedule/presentation/87/
|
||||
@ -1,73 +0,0 @@
|
||||
|
||||
steam 让我们在 Linux 上玩 Windows 的游戏更加容易
|
||||
======
|
||||
![Steam Wallpaper][1]
|
||||
|
||||
总所周知,Linux 游戏库中的游戏只有 Windows 游戏库中的一部分,实际上,许多人甚至都不会考虑将操作系统转换为 Linux,原因很简单,因为他们喜欢的游戏,大多数都不能在这个平台上运行。
|
||||
|
||||
在撰写本文时,steam 上已有超过 5000 种游戏可以在 Linux 上运行,而 steam 上的游戏总数已经接近 27000 种了。现在 5000 种游戏可能看起来很多,但还没有达到 27000 种,确实没有。
|
||||
|
||||
虽然几乎所有的新的独立游戏都是在 Linux 中推出的,但我们仍然无法在这上面玩很多的 3A 大作。对我而言,虽然这其中有很多游戏我都很希望能有机会玩,但这从来都不是一个非黑即白的问题。因为我主要是玩独立游戏和复古游戏,所以几乎所有我喜欢的游戏都可以在 Linux 系统上运行。
|
||||
|
||||
### 认识 Proton,Steam 的一次 WINE 分叉。
|
||||
|
||||
现在,这个问题已经成为过去式了,因为本周 Valve 宣布要对 Steam Play 进行一次更新,此次更新会将一个名为 Proton 的分叉版本的 Wine 添加到 Linux 和 Mac 的客户端中。是的,这个工具是开源的,Valve 已经在 GitHub 上开源了源代码,但该功能仍然处于测试阶段,所以你必须使用测试版的 Steam 客户端才能使用这项功能。
|
||||
|
||||
#### 使用 proton ,可以在 Linux 系统上使用 Steam 运行更多的 Windows 上的游戏。
|
||||
|
||||
这对我们这些 Linux 用户来说,实际上意味着什么?简单来说,这意味着我们可以在 Linux 和 Mac 这两种操作系统的电脑上运行全部 27000 种游戏,而无需配置像 PlayOnLinux 或 Lutris 这样的服务。我要告诉你的是,配置这些东西有时候会非常让人头疼。
|
||||
|
||||
对此更为复杂的答案是,某种原因听起来非常美好。虽然在理论上,你可以用这种方式在 Linux 上玩所有的 Windows 平台上的游戏。但只有一少部分游戏在推出时会正式支持 Linux。这少部分游戏包括 DOOM,最终幻想 VI,铁拳 7,星球大战:前线 2,和其他几个。
|
||||
|
||||
#### 你可以在 Linux 上玩所有的 Windows 平台的游戏(理论上)
|
||||
|
||||
虽然目前该列表只有大约 30 个游戏,你可以点击“为所有游戏使用 Steam play 进行运行”复选框来强制使用 Steam 的 Proton 来安装和运行任意游戏。但你最好不要有太高的期待,它们的稳定性和性能表现不一定有你希望的那么好,所以请把期望值压低一点。
|
||||
|
||||
![Steam Play][10]
|
||||
|
||||
#### 体验 Proton,没有我想的那么烂。
|
||||
|
||||
例如,我安装了一些中等价格的游戏,使用 Proton 来进行安装。其中一个是上古卷轴 4:湮没,在我玩这个游戏的两个小时里,它只崩溃了一次,而且几乎是紧跟在游戏教程的自动保存点之后。
|
||||
|
||||
我有一块英伟达 Gtx 1050 Ti 的显卡。所以我可以使用 1080P 的高配置来玩这个游戏。而且我没有遇到除了这次崩溃之外的任何问题。我唯一真正感到不爽的只有它的帧数没有原本的高。在 90% 的时间里,游戏的帧数都在 60 帧以上,但我知道它的帧数应该能更高。
|
||||
|
||||
我安装和发布的其他所有游戏都运行得很完美,虽然我还没有较长时间地玩过它们中的任何一个。我安装的游戏中包括森林,丧尸围城 4,H1Z1,和刺客信条 2.(你能说我这是喜欢恐怖游戏吗?)。
|
||||
|
||||
#### 为什么 Steam(仍然)要下注在 Linux 上?
|
||||
|
||||
现在,一切都很好,这件事为什么会发生呢?为什么 Valve 要花费时间,金钱和资源来做这样的事?我倾向于认为,他们这样做是因为他们懂得 Linux 社区的价值,但是如果要我老实地说,我不相信我们和它有任何的关系。
|
||||
|
||||
如果我一定要在这上面花钱,我想说 Valve 开发了 Proton,因为他们还没有放弃 Steam 机器。因为 Steam OS 是基于 Linux 的发行版,在这类东西上面投资可以获取最大的利润,Steam OS 上可用的游戏越多,就会有更多的人愿意购买 Steam 的机器。
|
||||
|
||||
可能我是错的,但是我敢打赌啊,我们会在不远的未来看到新一批的 Steam 机器。可能我们会在一年内看到它们,也有可能我们再等五年都见不到,谁知道呢!
|
||||
|
||||
无论哪种方式,我所知道的是,我终于能兴奋地从我的 Steam 游戏库里玩游戏了。多年来我通过所有的收藏包,游戏促销,和不定时地买一个贱卖的游戏来以防万一,我想去尝试让它在 Lutris 中运行。
|
||||
|
||||
#### 为 Linux 上越来越多的游戏而激动?
|
||||
|
||||
你怎么看?你对此感到激动吗?或者说你会害怕只有很少的开发者会开发 Linux 平台上的游戏,因为现在几乎没有需求?Valve 喜欢 Linux 社区,还是说他们喜欢钱?请在下面的评论区告诉我们您的想法,然后重新搜索来查看更多类似这样的开源软件方面的文章。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/steam-play-proton/
|
||||
|
||||
作者:[Phillip Prado][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[hopefully2333](https://github.com/hopefully2333)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/phillip/
|
||||
[1]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/steam-wallpaper.jpeg
|
||||
[2]:https://itsfoss.com/linux-gaming-guide/
|
||||
[3]:https://itsfoss.com/reasons-switch-linux-windows-xp/
|
||||
[4]:https://itsfoss.com/triplea-game-review/
|
||||
[5]:https://itsfoss.com/play-retro-games-linux/
|
||||
[6]:https://steamcommunity.com/games/221410
|
||||
[7]:https://github.com/ValveSoftware/Proton/
|
||||
[8]:https://www.playonlinux.com/en/
|
||||
[9]:https://lutris.net/
|
||||
[10]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/SteamProton.jpg
|
||||
[11]:https://store.steampowered.com/sale/steam_machines
|
||||
[12]:https://itsfoss.com/valve-annouces-linux-based-gaming-operating-system-steamos/
|
||||
@ -1,172 +0,0 @@
|
||||
每位 Ubuntu 18.04 用户都应该知道的快捷键
|
||||
======
|
||||
了解快捷键能够提升您的生产力。这里有一些实用的 Ubuntu 快捷键助您像专业人士一样使用 Ubuntu。
|
||||
|
||||
您可以使用有键盘和鼠标组合的操作系统。
|
||||
|
||||
注意:本文中提到的键盘快捷键适用于 Ubuntu 18.04 GNOME 版。 通常,它们中的大多数(或者全部)也适用于其他的 Ubuntu 版本,但我不能够保证。
|
||||
|
||||
![Ubuntu keyboard shortcuts][1]
|
||||
|
||||
### 实用的 Ubuntu 快捷键
|
||||
|
||||
让我们来看一看 Ubuntu GNOME 必备的快捷键吧!通用的快捷键如 Ctrl+C(复制),Ctrl+V(粘贴)或者 Ctrl+S(保存)不再赘述。
|
||||
|
||||
注意:Linux 中的 Super 键即键盘上带有 Windows 图标的键,本文中我使用了大写字母,但这不代表你需要按下 shift 键,比如,T 代表键盘上的‘t’键,而不代表 Shift+t。
|
||||
|
||||
#### 1\. Super 键:打开活动搜索界面
|
||||
|
||||
使用 Super 键可以打开活动菜单。如果你只能在 Ubuntu 上使用一个快捷键,那只能是 Super 键。
|
||||
|
||||
想要打开一个应用程序?按下 Super 键然后搜索应用程序。如果搜索的应用程序未安装,它会推荐来自应用中心的应用程序。
|
||||
|
||||
想要看看有哪些正在运行的程序?按下 Super 键,屏幕上就会显示所有正在运行的 GUI 应用程序。
|
||||
|
||||
想要使用工作区吗?只需按下 Super 键,您就可以在屏幕右侧看到工作区选项。
|
||||
|
||||
#### 2\. Ctrl+Alt+T:打开 Ubuntu 终端窗口
|
||||
|
||||
![Ubuntu Terminal Shortcut][2]
|
||||
|
||||
*使用 Ctrl+alt+T 来打开终端窗口*
|
||||
|
||||
想要打开一个新的终端,您只需使用快捷键 Ctrl+Alt+T。这是我在 Ubuntu 中最喜欢的键盘快捷键。 甚至在我的许多 FOSS 教程中,当需要打开终端窗口是,我都会提到这个快捷键。
|
||||
|
||||
#### 3\. Super+L 或 Ctrl——Alt+L:锁屏
|
||||
|
||||
当您离开电脑时锁定屏幕,是最基本的安全习惯之一。您可以使用 Super + L 快捷键,而不是繁琐地点击屏幕右上角然后选择锁定屏幕选项。
|
||||
|
||||
有些系统也会使用 Ctrl+Alt+L 键锁定屏幕。
|
||||
|
||||
#### 4\. Super+D or Ctrl+Alt+D:显示桌面
|
||||
|
||||
按下 Super + D 可以最小化所有正在运行的应用程序窗口并显示桌面。
|
||||
|
||||
再次按 Super + D 将重新打开所有正在运行的应用程序窗口,像之前一样。
|
||||
|
||||
您也可以使用 Ctrl + Alt + D 来实现此目的。
|
||||
|
||||
#### 5\. Super+A:显示应用程序菜单
|
||||
|
||||
您可以通过单击屏幕左下角的 9个点打开 Ubuntu 18.04 GNOME 中的应用程序菜单。 但是一个更快捷的方法是使用 Super + A 快捷键。
|
||||
|
||||
它将显示应用程序菜单,您可以在其中查看或搜索系统上已安装的应用程序。
|
||||
|
||||
您可以使用 Esc 键退出应用程序菜单界面。
|
||||
|
||||
#### 6\. Super+Tab or Alt+Tab:在运行中的应用程序间切换
|
||||
|
||||
如果您运行的应用程序不止一个,则可以使用 Super + Tab 或 Alt + Tab 快捷键在应用程序之间切换。
|
||||
|
||||
按住 Super 键同时按下 Tab 键,即可显示应用程序切换器。 按住 Super 的同时,继续点击 Tab 键在应用程序之间进行选择。 当光标在所需的应用程序上时,松开 Super 和 Tab 键。
|
||||
|
||||
默认情况下,应用程序切换器从左向右移动。 如果要从右向左移动,可使用 Super + Shift + Tab 快捷键。
|
||||
|
||||
在这里您也可以用 Alt 键代替 Super 键。
|
||||
|
||||
提示:如果有多个应用程序实例,您可以使用 Super + \` 快捷键在这些实例之间切换。
|
||||
|
||||
#### 7\. Super+Arrow keys: 移动窗口位置
|
||||
|
||||
<https://player.vimeo.com/video/289091549>
|
||||
|
||||
这个快捷键也适用于 Windows 系统。 使用应用程序时,按下 Super 和左箭头键,应用程序将贴合屏幕的左边缘,占用屏幕的左半边。
|
||||
|
||||
同样,按下 Super 和右箭头键会使应用程序贴合右边缘。
|
||||
|
||||
按下 Super 和上箭头键将最大化应用程序窗口,超级和下箭头将使应用程序恢复到其正常的大小。
|
||||
|
||||
#### 8\. Super+M: 切换到通知栏
|
||||
|
||||
GNOME 中有一个通知栏,您可以在其中查看系统和应用程序活动的通知,这里也有一个日历。
|
||||
|
||||
![Notification Tray Ubuntu 18.04 GNOME][3]
|
||||
|
||||
*通知栏*
|
||||
|
||||
使用 Super + M 快捷键,您可以打开此通知栏。 如果再次按这些键,将关闭打开的通知托盘。
|
||||
|
||||
使用 Super+V 也可实现相同的功能。
|
||||
|
||||
#### 9\. Super+Space:切换输入法(用于多语言设置)
|
||||
|
||||
如果您使用多种语言,可能您的系统上安装了多个输入法。 例如,我需要在 Ubuntu 上同时使用[印地语] [4]和英语,所以我安装了印地语(梵文)输入法以及默认的英语输入法。
|
||||
|
||||
如果您也使用多语言设置,则可以使用 Super + Space 快捷键快速更改输入法。
|
||||
|
||||
#### 10\. Alt+F2:运行控制台
|
||||
|
||||
这适用于高级用户。 如果要运行快速命令,而不是打开终端并在其中运行命令,则可以使用 Alt + F2 运行控制台。
|
||||
|
||||
![Alt+F2 to run commands in Ubuntu][5]
|
||||
|
||||
*控制台*
|
||||
|
||||
当您使用只能在终端运行的应用程序时,这尤其有用。
|
||||
|
||||
#### 11\. Ctrl+Q:关闭应用程序窗口
|
||||
|
||||
如果您有正在运行的应用程序,可以使用 Ctrl + Q 快捷键关闭应用程序窗口。您也可以使用 Ctrl + W 来实现此目的。
|
||||
|
||||
Alt + F4 是关闭应用程序窗口更“通用”的快捷方式。
|
||||
|
||||
它不适用于一些应用程序,如 Ubuntu 中的默认终端。
|
||||
|
||||
#### 12\. Ctrl+Alt+arrow:切换工作区
|
||||
|
||||
![Workspace switching][6]
|
||||
|
||||
*切换工作区*
|
||||
|
||||
如果您是使用工作区的重度用户,可以使用 Ctrl + Alt + 上箭头和 Ctrl + Alt + 下箭头键在工作区之间切换。
|
||||
|
||||
#### 13\. Ctrl+Alt+Del:注销
|
||||
|
||||
不会!在 Linux 中使用著名的快捷键 Ctrl+Alt+Del 并不会像在 Windows 中一样打开任务管理器(除非您使用自定义快捷键)。
|
||||
|
||||
![Log Out Ubuntu][7]
|
||||
|
||||
*注销*
|
||||
|
||||
在普通的 GNOME 桌面环境中,您可以使用 Ctrl + Alt + Del 键打开关机菜单,但 Ubuntu 并不总是遵循此规范,因此当您在 Ubuntu 中使用 Ctrl + Alt + Del 键时,它会打开注销菜单。
|
||||
|
||||
### 在 Ubuntu 中使用自定义键盘快捷键
|
||||
|
||||
您不是只能使用默认的键盘快捷键,您可以根据需要创建自己的自定义键盘快捷键。
|
||||
|
||||
转到“设置->设备->键盘”,您将在这里看到系统的所有键盘快捷键。向下滚动到底部,您将看到“自定义快捷方式”选项。
|
||||
|
||||
![Add custom keyboard shortcut in Ubuntu][8]
|
||||
|
||||
您需要提供易于识别的快捷键名称、使用快捷键时运行的命令,以及您自定义的按键组合。
|
||||
|
||||
### Ubuntu 中你最喜欢的键盘快捷键是什么?
|
||||
|
||||
快捷键永无止境。如果需要,你可以看一看所有可能的 [GNOME 快捷键][9],看其中有没有你需要用到的快捷键。
|
||||
|
||||
您可以学习使用您经常使用应用程序的快捷键,这是很有必要的。例如,我使用 Kazam 进行[屏幕录制][10],键盘快捷键帮助我方便地暂停和开始录像。
|
||||
|
||||
您最喜欢、最离不开的 Ubuntu 快捷键是什么?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/ubuntu-shortcuts/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[XiatianSummer](https://github.com/XiatianSummer)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/ubuntu-keyboard-shortcuts.jpeg
|
||||
[2]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/ubuntu-terminal-shortcut.jpg
|
||||
[3]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/notification-tray-ubuntu-gnome.jpeg
|
||||
[4]: https://itsfoss.com/type-indian-languages-ubuntu/
|
||||
[5]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/console-alt-f2-ubuntu-gnome.jpeg
|
||||
[6]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/workspace-switcher-ubuntu.png
|
||||
[7]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/log-out-ubuntu.jpeg
|
||||
[8]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/custom-keyboard-shortcut.jpg
|
||||
[9]: https://wiki.gnome.org/Design/OS/KeyboardShortcuts
|
||||
[10]: https://itsfoss.com/best-linux-screen-recorders/
|
||||
@ -0,0 +1,128 @@
|
||||
如何让 Ping 的输出更简单易读
|
||||
======
|
||||
|
||||

|
||||
|
||||
众所周知,`ping` 命令可以用来检查目标主机是否可达。使用 `ping` 命令的时候,会发送一个 ICMP Echo 请求,通过目标主机的响应与否来确定目标主机的状态。如果你经常使用 `ping` 命令,你可以尝试一下 `prettyping`。Prettyping 只是将一个标准的 ping 工具增加了一层封装,在运行标准 ping 命令的同时添加了颜色和 unicode 字符解析输出,所以它的输出更漂亮紧凑、清晰易读。它是用 `bash` 和 `awk` 编写的免费开源工具,支持大部分类 Unix 操作系统,包括 GNU/Linux、FreeBSD 和 Mac OS X。Prettyping 除了美化 ping 命令的输出,还有很多值得注意的功能。
|
||||
|
||||
* 检测丢失的数据包并在输出中标记出来。
|
||||
* 显示实时数据。每次收到响应后,都会更新统计数据,而对于普通 ping 命令,只会在执行结束后统计。
|
||||
* 能够在输出结果不混乱的前提下灵活处理“未知信息”(例如错误信息)。
|
||||
* 能够避免输出重复的信息。
|
||||
* 兼容常用的 ping 工具命令参数。
|
||||
* 能够由普通用户执行。
|
||||
* 可以将输出重定向到文件中。
|
||||
* 不需要安装,只需要下载二进制文件,赋予可执行权限即可执行。
|
||||
* 快速且轻巧。
|
||||
* 输出结果清晰直观。
|
||||
|
||||
|
||||
|
||||
### 安装 Prettyping
|
||||
|
||||
如上所述,Prettyping 是一个绿色软件,不需要任何安装,只要使用以下命令下载 Prettyping 二进制文件:
|
||||
|
||||
```
|
||||
$ curl -O https://raw.githubusercontent.com/denilsonsa/prettyping/master/prettyping
|
||||
```
|
||||
|
||||
将二进制文件放置到 `$PATH`(例如 `/usr/local/bin`)中:
|
||||
|
||||
```
|
||||
$ sudo mv prettyping /usr/local/bin
|
||||
```
|
||||
|
||||
然后对其赋予可执行权限:
|
||||
|
||||
```
|
||||
$ sudo chmod +x /usr/local/bin/prettyping
|
||||
```
|
||||
|
||||
就可以使用了。
|
||||
|
||||
### 让 ping 的输出清晰易读
|
||||
|
||||
安装完成后,通过 `prettyping` 来 ping 任何主机或 IP 地址,就可以以图形方式查看输出。
|
||||
|
||||
```
|
||||
$ prettyping ostechnix.com
|
||||
```
|
||||
|
||||
输出效果大概会是这样:
|
||||
|
||||

|
||||
|
||||
如果你不带任何参数执行 `prettyping`,它就会一直运行直到被 ctrl + c 中断。
|
||||
|
||||
由于 Prettyping 只是一个对普通 ping 命令的封装,所以常用的 ping 参数也是有效的。例如使用 `-c 5` 来指定 ping 一台主机的 5 次:
|
||||
|
||||
```
|
||||
$ prettyping -c 5 ostechnix.com
|
||||
```
|
||||
|
||||
Prettyping 默认会使用彩色输出,如果你不喜欢彩色的输出,可以加上 `--nocolor` 参数:
|
||||
|
||||
```
|
||||
$ prettyping --nocolor ostechnix.com
|
||||
```
|
||||
|
||||
同样的,也可以用 `--nomulticolor` 参数禁用多颜色支持:
|
||||
|
||||
```
|
||||
$ prettyping --nomulticolor ostechnix.com
|
||||
```
|
||||
|
||||
使用 `--nounicode` 参数禁用 unicode 字符:
|
||||
|
||||

|
||||
|
||||
如果你的终端不支持 **UTF-8**,或者无法修复系统中的 unicode 字体,只需要加上 `--nounicode` 参数就能轻松解决。
|
||||
|
||||
Prettyping 支持将输出的内容重定向到文件中,例如执行以下这个命令会将 `prettyping ostechnix.com` 的输出重定向到 `ostechnix.txt` 中:
|
||||
|
||||
```
|
||||
$ prettyping ostechnix.com | tee ostechnix.txt
|
||||
```
|
||||
|
||||
Prettyping 还有很多选项帮助你完成各种任务,例如:
|
||||
|
||||
* 启用/禁用延时图例(默认启用)
|
||||
* 强制按照终端的格式输出(默认自动)
|
||||
* 在统计数据中统计最后的 n 次 ping(默认 60 次)
|
||||
* 覆盖对终端尺寸的检测
|
||||
* 覆盖 awk 解释器(默认不覆盖)
|
||||
* 覆盖 ping 工具(默认不覆盖)
|
||||
|
||||
|
||||
|
||||
查看帮助文档可以了解更多:
|
||||
|
||||
```
|
||||
$ prettyping --help
|
||||
```
|
||||
|
||||
尽管 prettyping 没有添加任何额外功能,但我个人喜欢它的这些优点:
|
||||
|
||||
* 实时统计 - 可以随时查看所有实时统计信息,标准 `ping` 命令只会在命令执行结束后才显示统计信息。
|
||||
* 紧凑的显示 - 可以在终端看到更长的时间跨度。
|
||||
* 检测丢失的数据包并显示出来。
|
||||
|
||||
|
||||
|
||||
如果你一直在寻找可视化显示 `ping` 命令输出的工具,那么 Prettyping 肯定会有所帮助。尝试一下,你不会失望的。
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/prettyping-make-the-output-of-ping-command-prettier-and-easier-to-read/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
|
||||
Loading…
Reference in New Issue
Block a user