mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-22 00:40:10 +08:00
commit
29d5118071
@ -1,9 +1,9 @@
|
||||
[GitHub 风格的 Markdown 的正式规范][8]
|
||||
《GitHub 风格的 Markdown 正式规范》发布
|
||||
====================
|
||||
|
||||
很庆幸,我们当初选择 Markdown 作为用户在 GitHub 上托管内容的标记语言,它为用户提供了强大且直接的方式 (不管是技术的还是非技术的) 来编写可以很好的渲染成 HTML 的纯文本文档。
|
||||
|
||||
其最主要的限制,就是缺乏在最模糊的语言细节上的标准。比如,使用多少个空格来进行行缩进、两个不同元素之间需要使用多少空行区分、大量繁琐细节往往造成不同的实现:相似的 Markdown 文档会因为选用的不同的语法解析器而渲染成大量不同的呈现效果。
|
||||
然而,其最主要的限制,就是缺乏在最模糊的语言细节上的标准。比如,使用多少个空格来进行行缩进、两个不同元素之间需要使用多少空行区分、大量繁琐细节往往造成不同的实现:相似的 Markdown 文档会因为选用的不同的语法解析器而渲染成相当不同的呈现效果。
|
||||
|
||||
五年前,我们在 [Sundown][13] 的基础之上开始构建 GitHub 自定义版本的 Markdown —— GFM (<ruby>GitHub 风格的 Markdown<rt>GitHub Flavored Markdown</rt></ruby>),这是我们特地为解决当时已有的 Markdown 解析器的不足而开发的一款解析器。
|
||||
|
||||
@ -11,19 +11,19 @@
|
||||
|
||||
该正式规范基于 [CommonMark][14],这是一个雄心勃勃的项目,旨在通过一个反映现实世界用法的方式来规范目前互联网上绝大多数网站使用的 Markdown 语法。CommonMark 允许人们以他们原有的习惯来使用 Markdown,同时为开发者提供一个综合规范和参考实例,从而实现跨平台的 Markdown 互操作和显示。
|
||||
|
||||
#### 规范
|
||||
### 规范
|
||||
|
||||
使用 CommonMark 规范并围绕它来重设我们当前用户内容堆栈需要不少努力。我们纠结的主要问题是该规范 (及其参考实现) 过多关注由原生 Perl 实现支持的 Markdown 通用子集。这还不包括那些 GitHub 上已经在用的扩展特性。最明显的就是缺少 _表格 (tables)、删除线 (strikethrough)、自动链接 (autolinks)_ 和 _任务列表 (task lists)_ 的支持。
|
||||
使用 CommonMark 规范并围绕它来重新加工我们当前用户内容需要不少努力。我们纠结的主要问题是该规范 (及其参考实现) 过多关注由原生 Perl 实现支持的 Markdown 通用子集。这还不包括那些 GitHub 上已经在用的扩展特性。最明显的就是缺少 表格 (tables)、删除线 (strikethrough)、自动链接 (autolinks) 和 任务列表 (task lists) 的支持。
|
||||
|
||||
为完全指定 GitHub 的 Markdown 版本 (也称为 GFM),我们必须要要正式定义这些特性的的语法和语意,这在以前从未做过。我们是在现存的 CommonMark 规范中来完成这一项工作的,同时还特意关注以确保我们的扩展是原有规范的一个严格且可选的超集。
|
||||
为完全描述 GitHub 的 Markdown 版本 (也称为 GFM),我们必须要要正式定义这些特性的的语法和语意,这在以前从未做过。我们是在现存的 CommonMark 规范中来完成这一项工作的,同时还特意关注以确保我们的扩展是原有规范的一个严格且可选的超集。
|
||||
|
||||
当评估 [GFM 规范][15] 的时候,你可以清楚的知道哪些是 GFM 特定规范的补充内容,因为它们都高亮显示了。并且你也会看到原有规范的所有部分都保存原样,因此,GFM 规范能够与其他任何实现兼容。
|
||||
当评估 [GFM 规范][15] 的时候,你可以清楚的知道哪些是 GFM 特定规范的补充内容,因为它们都高亮显示了。并且你也会看到原有规范的所有部分都保持原样,因此,GFM 规范能够与任何其他的实现保持兼容。
|
||||
|
||||
#### 实现
|
||||
### 实现
|
||||
|
||||
为确保我们网站中的 Markdown 渲染能够完美兼容 CommonMark 规范,GitHub 的 GFM 解析器的后端实现基于 `cmark` 来开发,这是 CommonMark 规范的一个参考实现,由 [John MacFarlane][16] 和 许多其他的 [出色的贡献者][17] 开发完成。
|
||||
为确保我们网站中的 Markdown 渲染能够完美兼容 CommonMark 规范,GitHub 的 GFM 解析器的后端实现基于 `cmark` 来开发,这是 CommonMark 规范的一个参考实现,由 [John MacFarlane][16] 和许多其他的 [出色的贡献者][17] 开发完成。
|
||||
|
||||
就像规范本身那样,`cmark` 是 Markdown 的严格子集解析器,所以我们还必须在现存解析器的基础上完成 GitHub 自定义扩展的解析功能。你可以通过 [`cmark` 的分支][18] 来查看变更记录;为了跟踪不断改进的上游项目,我们持续将我们的补丁变基到上游主线上去。我们希望,这些扩展的正式规范一旦确定,这些 patch 集同样可以应用到原始项目的上游变更中去。
|
||||
就像规范本身那样,`cmark` 是 Markdown 的严格子集解析器,所以我们还必须在现存解析器的基础上完成 GitHub 自定义扩展的解析功能。你可以通过 [`cmark` 的分支][18] 来查看变更记录;为了跟踪不断改进的上游项目,我们持续将我们的补丁变基到上游主线上去。我们希望,这些扩展的正式规范一旦确定,这些补丁集同样可以应用到原始项目的上游变更中去。
|
||||
|
||||
除了在 `cmark` 分支中实现 GFM 规范特性,我们也同时将许多目标相似的变更贡献到上游。绝大多数的贡献都主要围绕性能和安全。我们的后端每天都需要渲染大量的 Markdown 文档,所以我们主要关注这些操作可以尽可能的高效率完成,同时还要确保那些滥用的恶意 Markdown 文档无法攻击到我们的服务器。
|
||||
|
||||
@ -31,9 +31,9 @@
|
||||
|
||||
`cmark` 在性能方面则是有点粗糙:基于实现 Sundown 时我们所学到的性能技巧,我们向上游贡献了许多优化方案,但除去所有这些变更之外,当前版本的 `cmark` 仍然无法与 Sundown 本身匹敌:我们的基准测试表明,`cmark` 在绝大多数文档渲染的性能上要比 Sundown 低 20% 到 30%。
|
||||
|
||||
那句古老的优化谚语 _最快的代码就是不需要运行的代码 (the fastest code is the code that doesn’t run)_ 在此处同样适用:实际上,`cmark` 比 Sundown 要进行 _多一些操作_。在其他的功能上,`cmark` 支持 UTF8 字符集,对参考的支持、扩展的接口清理的效果更佳。最重要的是它如同 Sundown 那样,并不会将 Markdown _翻译成_ HTML。它实际上从 Markdown 源码中生成一个 AST (抽象语法树,Abstract Syntax Tree),然后我们就看将之转换和逐渐渲染成 HTML。
|
||||
那句古老的优化谚语 _最快的代码就是不需要运行的代码 (the fastest code is the code that doesn’t run)_ 在此处同样适用:实际上,`cmark` 比 Sundown 要_多进行一些操作_。在其他的功能上,`cmark` 支持 UTF8 字符集,对参考的支持、扩展的接口清理的效果更佳。最重要的是它如同 Sundown 那样,并不会将 Markdown _翻译成_ HTML。它实际上从 Markdown 源码中生成一个 AST (抽象语法树,Abstract Syntax Tree),然后我们就看将之转换和逐渐渲染成 HTML。
|
||||
|
||||
如果考虑下我们在 Sundown 的最初实现 (特别是文档中关于查询用户的 mention 和 issue 参考、插入任务列表等) 时的 HTML 语法剖析工作量,你会发现 `cmark` 基于 AST 的方法可以节约大量时间 _和_ 降低我们用户内容堆栈的复杂度。Markdown AST 是一个非常强大的工具,并且值得 `cmark` 生成它所付出的性能成本。
|
||||
如果考虑下我们在 Sundown 的最初实现 (特别是文档中关于查询用户的 mention 和 issue 引用、插入任务列表等) 时的 HTML 语法剖析工作量,你会发现 `cmark` 基于 AST 的方法可以节约大量时间 _和_ 降低我们用户内容堆栈的复杂度。Markdown AST 是一个非常强大的工具,并且值得 `cmark` 生成它所付出的性能成本。
|
||||
|
||||
### 迁移
|
||||
|
||||
@ -43,11 +43,11 @@
|
||||
|
||||
只有 1% 的文档存在少量的渲染问题,使得换用新实现并获取其更多出看起来是非常合理的权衡,但是是根据当前 GitHub 的规模,这个 1% 是非常多的内容以及很多的受影响用户。我们真的不想导致任何用户需要重新校对一个老旧的问题、看到先前可以渲染成 HTML 的内容又呈现为 ASCII 码 —— 尽管这明显不会导致任何原始内容的丢失,却是糟糕的用户体验。
|
||||
|
||||
因此,我们想出相应的方法来缓和迁移过程。首先,第一件我们做的事就是收集用户托管在我们网站上的两种不同类型 Markdown 的数据:用户的评论 (比如 Gists、issues、PR 等)以及在 git 仓库中的 Markdown 文档。
|
||||
因此,我们想出相应的方法来缓和迁移过程。首先,第一件我们做的事就是收集用户托管在我们网站上的两种不同类型 Markdown 的数据:用户的评论 (比如 Gist、issue、PR 等)以及在 git 仓库中的 Markdown 文档。
|
||||
|
||||
这两种内容有着本质上的区别:用户评论存储在我们的数据库中,这意味着他们的 Markdown 语法可以标准化 (比如添加或移除空格、修正缩进或则插入缺失的 Markdown 说明符,直到它们可正常渲染为止)。然而,那些存储在 Git 仓库中的 Markdown 文档则是 _根本_ 无法触及,因为这些内容已经散列成为 Git 存储模型的一部分。
|
||||
|
||||
幸运的是,我们发现绝大多数使用了复杂的 Markdown 特性的用户内容都是用户评论 (特别是 issue 主体和 PR 主体),而存储于仓库中的文档则大多数情况下都可以使用新旧渲染器正常进行渲染。
|
||||
幸运的是,我们发现绝大多数使用了复杂的 Markdown 特性的用户内容都是用户评论 (特别是 issue 主体和 PR 主体),而存储于仓库中的文档则大多数情况下都可以使用新的和旧的渲染器正常进行渲染。
|
||||
|
||||
因此,我们加快了标准化现存用户内容的语法的进程,以便使它们在新旧实现下渲染效果一致。
|
||||
|
||||
@ -55,19 +55,19 @@
|
||||
|
||||
除了转换之外,这还是一个高效的标准化过程,并且我们对此信心满满,毕竟完成这一任务的是我们在五年前就使用过的解析器。因此,所有的现存文档在保留其原始语意的情况下都能够进行明确的解析。
|
||||
|
||||
一旦升级 Sundown 来标准化输入文档并充分测试之后,我们就会做好开启转换进程的准备。最开始的一步,就是在新的 `cmark` 实现上为所有新用户内容进行反置转换,以便确保我们能有一个有限的分界点来进行过渡。实际上,几个月前我们就为网站上所有 **新的** 用户评论启用了 CommonMark,这一过程几乎没有引起任何人注意 —— 这是关于 CommonMark 团队出色工作的证明,通过一个最具现实世界用法的方式来正式规范 Markdown 语言。
|
||||
一旦升级 Sundown 来标准化输入文档并充分测试之后,我们就会做好开启转换进程的准备。最开始的一步,就是对所有新用户内容切换到新的 `cmark` 实现上,以便确保我们能有一个有限的分界点来进行过渡。实际上,几个月前我们就为网站上所有 **新的** 用户评论启用了 CommonMark,这一过程几乎没有引起任何人注意 —— 这是关于 CommonMark 团队出色工作的证明,通过一个最具现实世界用法的方式来正式规范 Markdown 语言。
|
||||
|
||||
在后端,我们开启 MySQL 转换来升级替代所有 Markdown 用户内容。在所有的评论进行标准化之后,在将其写回到数据库之前,我们将使用新实现来进行渲染并与旧实现的渲染结果进行对比,以确保 HTML 输出结果视觉上感觉相同,并且用户数据在任何情况下都不会被破坏。总而言之,只有不到 1% 的输入文档会受到标准进程的修改,这符合我们的的期望,同时再次证明 CommonMark 规范能够呈现语言的真实用法。
|
||||
|
||||
整个过程会持续好几天,最后的结果是网站上所有的 Markdown 用户内容会得到全面升级以符合新的 Markdown 标准,同时确保所有的最终渲染输出效果对用户视觉上感觉相同。
|
||||
|
||||
#### 结论
|
||||
### 结论
|
||||
|
||||
从今天 (LCTT 译注:原文发布于 2017 年 3 月 14 日,这里的今天应该是这个日期) 开始, 我们同样为所有存储在 Git 仓库中的 Markdown 内容启动 CommonMark 渲染。正如上文所述,所有的现存文档都不会进行标准化,因为我们所期望中的多数渲染效果都刚刚好。
|
||||
|
||||
能够让在 GitHub 上的所有 Markdown 内容符合一个动态变化且使用的标准,同时还可以为我的用户提供一个关于 GFM 如何进行解析和渲染 [清晰且权威的参考说明][19],我们是相当激动的。
|
||||
|
||||
我们还将致力于 CommonMark 规范,一直到在它正式发布之前消除最后一个 bug。我们也希望 GitHub.com 在 1.0 规范发布之后可以进行完美兼容。
|
||||
我们还将致力于 CommonMark 规范,一直到在它正式发布之前消除最后一个 bug。我们也希望 GitHub.com 在其 1.0 规范发布之后可以进行完美兼容。
|
||||
|
||||
作为结束,以下为想要学习 CommonMark 规范或则自己来编写实现的朋友提供一些有用的链接。
|
||||
|
||||
@ -89,7 +89,7 @@
|
||||
|
||||
via: https://githubengineering.com/a-formal-spec-for-github-markdown/
|
||||
|
||||
作者:[Yuki Izumi][a][Vicent Martí][b]
|
||||
作者:[Yuki Izumi][a], [Vicent Martí][b]
|
||||
译者:[GHLandy](https://github.com/GHLandy)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
@ -1,18 +1,17 @@
|
||||
如何在 Linux 中添加一块大于 2TB 的新磁盘
|
||||
============================================================
|
||||
|
||||
你有没有试过使用 [fdisk][1] 对大于 2TB 的硬盘进行分区,并且纳闷为什么会得到需要使用 GPT 的警告? 是的,你看到的没错。我们无法使用 fdisk 对大于 2TB 的硬盘进行分区。
|
||||
|
||||
你有没有试过使用 [fdisk][1] 对大于 2TB 的硬盘进行分区,并且想知道为什么会得到需要使用 GPT 的警告? 是的,你看到的没错。我们无法使用 fdisk 对大于 2TB 的硬盘进行分区。
|
||||
在这种情况下,我们可以使用 `parted` 命令。它的主要区别在于 fdisk 使用 DOS 分区表格式而 parted 使用 GPT 格式。
|
||||
|
||||
在这种情况下,我们可以使用 parted 命令。它的主要区别在于 fdisk 使用 DOS 分区表格式而 parted 使用 GPT 格式。
|
||||
|
||||
提示:你可以使用 gdisk 来代替 parted。
|
||||
提示:你可以使用 `gdisk` 来代替 `parted`。
|
||||
|
||||
在本文中,我们将介绍如何将大于 2TB 的新磁盘添加到现有的 Linux 服务器中(如 RHEL/CentOS 或 Debian/Ubuntu)中。
|
||||
|
||||
我使用的是 fdisk 和 parted 来进行此配置。
|
||||
我使用的是 `fdisk` 和 `parted` 来进行此配置。
|
||||
|
||||
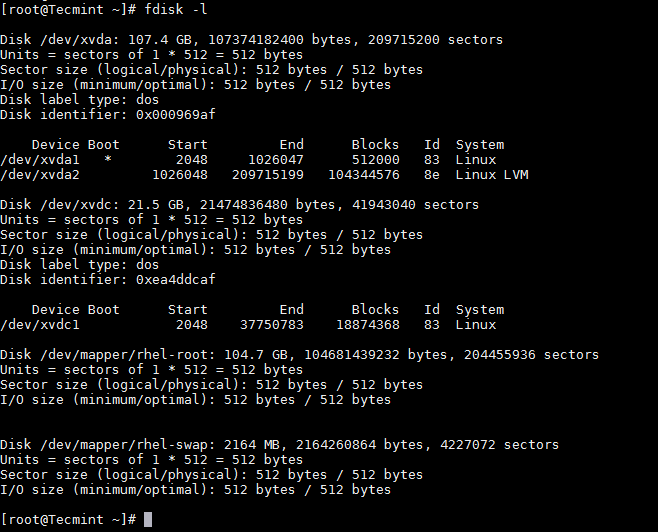
首先使用 fdisk 命令列出当前的分区详细信息,如图所示。
|
||||
首先使用 `fdisk` 命令列出当前的分区详细信息,如图所示。
|
||||
|
||||
```
|
||||
# fdisk -l
|
||||
@ -21,9 +20,9 @@
|
||||
|
||||
][2]
|
||||
|
||||
列出 Linux 分区表
|
||||
*列出 Linux 分区表*
|
||||
|
||||
为了本文的目的,我加了一块 20GB 的磁盘,这也可以是大于 2TB 的磁盘。在你加完磁盘后,使用相同的 fdisk 命令验证分区表。
|
||||
为了本文的目的,我加了一块 20GB 的磁盘,这也可以是大于 2TB 的磁盘。在你加完磁盘后,使用相同的 `fdisk` 命令验证分区表。
|
||||
|
||||
```
|
||||
# fdisk -l
|
||||
@ -32,9 +31,9 @@
|
||||

|
||||
][3]
|
||||
|
||||
列出新的分区表
|
||||
*列出新的分区表*
|
||||
|
||||
提示:如果你添加了一块物理磁盘,你可能会发现分区已经创建了。此种情况下,你可以在使用 parted 之前使用 fdisk 删除它。
|
||||
提示:如果你添加了一块物理磁盘,你可能会发现分区已经创建了。此种情况下,你可以在使用 `parted` 之前使用 `fdisk` 删除它。
|
||||
|
||||
```
|
||||
# fdisk /dev/xvdd
|
||||
@ -46,11 +45,11 @@
|
||||

|
||||
][4]
|
||||
|
||||
删除 Linux 分区
|
||||
*删除 Linux 分区*
|
||||
|
||||
重要:在删除分区时你需要小心点。这会擦除磁盘上的数据。
|
||||
**重要:在删除分区时你需要小心点。这会擦除磁盘上的数据。**
|
||||
|
||||
现在是使用 parted 命令分区新的磁盘了。
|
||||
现在是使用 `parted` 命令分区新的磁盘了。
|
||||
|
||||
```
|
||||
# parted /dev/xvdd
|
||||
@ -71,9 +70,9 @@
|
||||

|
||||
][5]
|
||||
|
||||
使用 parted 创建分区
|
||||
*使用 parted 创建分区*
|
||||
|
||||
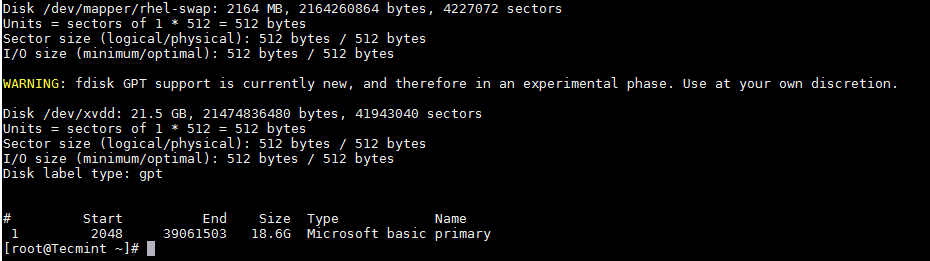
出于好奇,让我们用 fdisk 看看新的分区。
|
||||
出于好奇,让我们用 `fdisk` 看看新的分区。
|
||||
|
||||
```
|
||||
# fdisk /dev/xvdd
|
||||
@ -82,9 +81,9 @@
|
||||
|
||||
][6]
|
||||
|
||||
验证分区细节
|
||||
*验证分区细节*
|
||||
|
||||
现在格式化并挂载分区,并在 /etc/fstab 添加相同的信息,它控制在系统启动时挂载文件系统。
|
||||
现在格式化并挂载分区,并在 `/etc/fstab` 添加相同的信息,它控制在系统启动时挂载文件系统。
|
||||
|
||||
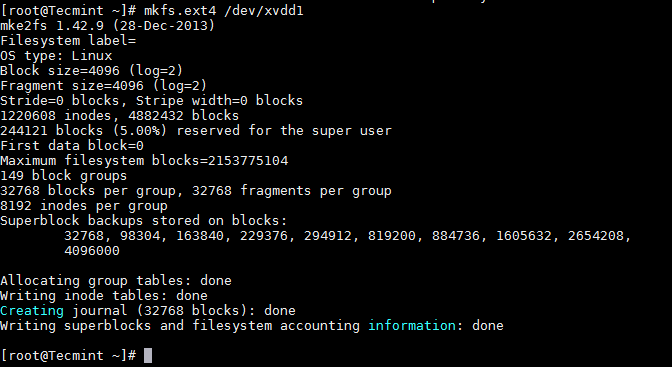
```
|
||||
# mkfs.ext4 /dev/xvdd1
|
||||
@ -93,15 +92,15 @@
|
||||
|
||||
][7]
|
||||
|
||||
格式化 Linux 分区
|
||||
*格式化 Linux 分区*
|
||||
|
||||
一旦分区格式化之后,是时候在 /data1 下挂载分区了。
|
||||
一旦分区格式化之后,是时候在 `/data1` 下挂载分区了。
|
||||
|
||||
```
|
||||
# mount /dev/xvdd1 /data1
|
||||
```
|
||||
|
||||
要永久挂载,在 /etc/fstab 添加条目。
|
||||
要永久挂载,在 `/etc/fstab` 添加条目。
|
||||
|
||||
```
|
||||
/dev/xvdd1 /data1 ext4 defaults 0 0
|
||||
@ -109,7 +108,7 @@
|
||||
|
||||
重要:要使用 GPT 分区格式需要内核支持。默认上 RHEL/CentOS 的内核已经支持 GPT,但是对于 Debian/Ubuntu,你需要在修改配置之后重新编译内核。
|
||||
|
||||
就是这样了!在本文中,我们向你展示了如何使用 parted 命令。与我们分享你的评论和反馈。
|
||||
就是这样了!在本文中,我们向你展示了如何使用 `parted` 命令。与我们分享你的评论和反馈。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -123,7 +122,7 @@ via: http://www.tecmint.com/add-disk-larger-than-2tb-to-an-existing-linux/
|
||||
|
||||
作者:[Lakshmi Dhandapani][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,21 +1,21 @@
|
||||
Pyinotify - 在 Linux 中实时监控文件系统更改
|
||||
pyinotify:在 Linux 中实时监控文件系统更改
|
||||
============================================================
|
||||
|
||||
Pyinotify 是一个简单而有用的 Python 模块,它可用于在 Linux 中实时[监控文件系统更改][1]。
|
||||
`Pyinotify` 是一个简单而有用的 Python 模块,它可用于在 Linux 中实时[监控文件系统更改][1]。
|
||||
|
||||
作为一名系统管理员,你可以用它来监视你感兴趣的目录的更改,如 Web 目录或程序数据存储目录及其他目录。
|
||||
|
||||
**建议阅读:** [fswatch - 监控 Linux 中的文件和目录更改或修改][2]
|
||||
|
||||
它取决于 inotify(内核 2.6.13 中包含的 Linux 内核功能),它是一个事件驱动的通知程序,其通知通过三个系统调用从内核空间导出到用户空间。
|
||||
它依赖于 `inotify`(在内核 2.6.13 中纳入的 Linux 内核功能),它是一个事件驱动的通知程序,其通知通过三个系统调用从内核空间导出到用户空间。
|
||||
|
||||
pyinotiy 的目的是绑定这三个系统调用,并在其上提供了一个通用和抽象的方法来操作这些功能。
|
||||
`pyinotiy` 的目的是绑定这三个系统调用,并在其上提供了一个通用和抽象的方法来操作这些功能。
|
||||
|
||||
在本文中,我们将向你展示如何在 Linux 中安装并使用 pyinotify 来实时监控文件系统更改或修改。
|
||||
在本文中,我们将向你展示如何在 Linux 中安装并使用 `pyinotify` 来实时监控文件系统更改或修改。
|
||||
|
||||
#### 依赖
|
||||
|
||||
要使用 pyinotify,你的系统必须运行:
|
||||
要使用 `pyinotify`,你的系统必须运行:
|
||||
|
||||
1. Linux kernel 2.6.13 或更高
|
||||
2. Python 2.4 或更高
|
||||
@ -29,7 +29,7 @@ pyinotiy 的目的是绑定这三个系统调用,并在其上提供了一个
|
||||
# python -V
|
||||
```
|
||||
|
||||
一旦依赖满足,我们会使用 pip 安装 pynotify。在大多数 Linux 发行版中,如果你使用的是 Python 2 >= 2.7.9 或者从 python.org 下载了 Python 3 >=3.4 的二进制,那么 pip 就已经安装了,否则,就按如下安装:
|
||||
一旦依赖满足,我们会使用 `pip` 安装 `pynotify`。在大多数 Linux 发行版中,如果你使用的是从 python.org 下载的 **Python 2 (>= 2.7.9)** 或者 **Python 3( >=3.4)** 的二进制,那么 `pip` 就已经安装了,否则,就按如下安装:
|
||||
|
||||
```
|
||||
# yum install python-pip [On CentOS based Distros]
|
||||
@ -37,13 +37,13 @@ pyinotiy 的目的是绑定这三个系统调用,并在其上提供了一个
|
||||
# dnf install python-pip [On Fedora 22+]
|
||||
```
|
||||
|
||||
现在安装 pyinotify:
|
||||
现在安装 `pyinotify`:
|
||||
|
||||
```
|
||||
# pip install pyinotify
|
||||
```
|
||||
|
||||
它会从默认仓库安装可用的版本,如果你想要最新的稳定版,考虑按如下从 git 仓库 clone 下来:
|
||||
它会从默认仓库安装可用的版本,如果你想要最新的稳定版,可以按如下从 git 仓库 clone 下来:
|
||||
|
||||
```
|
||||
# git clone https://github.com/seb-m/pyinotify.git
|
||||
@ -54,7 +54,7 @@ pyinotiy 的目的是绑定这三个系统调用,并在其上提供了一个
|
||||
|
||||
### 如何在 Linux 中使用 pyinotify
|
||||
|
||||
在下面的例子中,我以 root 用户(通过 ssh 登录)监视了任何用户 tecmint 家目录(/home/tecmint)下的改变,如截图所示:
|
||||
在下面的例子中,我以 root 用户(通过 ssh 登录)监视了用户 tecmint 的家目录(`/home/tecmint`)下的改变,如截图所示:
|
||||
|
||||
```
|
||||
# python -m pyinotify -v /home/tecmint
|
||||
@ -63,23 +63,23 @@ pyinotiy 的目的是绑定这三个系统调用,并在其上提供了一个
|
||||

|
||||
][3]
|
||||
|
||||
监视目录更改
|
||||
*监视目录更改*
|
||||
|
||||
接下来,我会观察到任何 web 目录 (/var/www/html/tecmint.com) 的更改:
|
||||
接下来,我会观察到任何 web 目录 (`/var/www/html/tecmint.com`) 的更改:
|
||||
|
||||
```
|
||||
# python -m pyinotify -v /var/www/html/tecmint.com
|
||||
```
|
||||
|
||||
要退出程序,只要点击 `[Ctrl+C]`。
|
||||
要退出程序,只要按下 `Ctrl+C`。
|
||||
|
||||
注意:当你在运行时没有指定要监视的目录是,`/tmp` 将作为默认目录。
|
||||
**注意**:当你在运行 `pyinotify` 时如果没有指定要监视的目录,`/tmp` 将作为默认目录。
|
||||
|
||||
在 Github 上了解更多 Pyinotify 信息:[https://github.com/seb-m/pyinotify][4]
|
||||
可以在 Github 上了解更多 Pyinotify 信息:[https://github.com/seb-m/pyinotify][4]。
|
||||
|
||||
就是这样了!在本文中,我们向你展示了如何安装及使用 pyinotify,一个有用的用于在 Linux 中监控文件系统更改的 Python 模块。
|
||||
就是这样了!在本文中,我们向你展示了如何安装及使用 `pyinotify`,一个在 Linux 中监控文件系统更改的有用的 Python 模块。
|
||||
|
||||
你有遇到类似的 Python 模块或者相关的[ Linux 工具/小程序][5]么?让我们在评论中了解,或许你也可以询问与这篇文章相关的问题。
|
||||
你有遇到类似的 Python 模块或者相关的 [Linux 工具/小程序][5]么?请在评论中让我们了解,或许你也可以询问与这篇文章相关的问题。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -0,0 +1,51 @@
|
||||
Ubuntu 17.04(Zesty Zapus)正式发布,可以下载使用了
|
||||
-------------------------------
|
||||
|
||||

|
||||
|
||||
今天,2017 年 4 月 13 日,Canonical 官方发布了 Ubuntu 17.04(Zesty Zapus)的最终版。自从去年十月发布 Ubuntu 16.10(Yakkety Yak)起,它已经开发了将近 6 个月。
|
||||
|
||||
如果直到今天,你一直在你的电脑上使用 Ubuntu 16.10,那么是时候升级到 Ubuntu 17.04 了,它是一个强大的发行版,“内外兼修”。它由最新的稳定的 Linux 4.10 内核驱动,并使用最新的基于 X.org 服务器 1.19.3 和 Mesa 17.0.3 的图形 Stack 进行配备。
|
||||
|
||||
上面提到的三个新技术,是那些使用 AMD 的 Radeon 显卡来玩游戏的人们需要立刻升级到 Ubuntu 17.04(Zesty Zapus)的唯一原因。但是 Ubuntu 17.04(Zesty Zapus)仅配备有最新的组件和应用程序。
|
||||
|
||||
Ubuntu 17.04(Zesty Zapus)的默认桌面环境仍然是 Unity 7,所以你钟爱的 Ubuntu 桌面环境此刻还没有消失。在未来的 Ubuntu 17.10 中,Unity 依然可用,Ubuntu 17.10 将在下个月开始开发。之后,从 Ubuntu 18.04 LTS 开始,[将默认使用 GNOME 桌面][1]。
|
||||
|
||||

|
||||
|
||||
*默认使用 Unity 7 桌面*
|
||||
|
||||
Ubuntu 17.04 有一些新的特性:
|
||||
|
||||
- 免驱动打印
|
||||
- 交换文件
|
||||
- 不再支持 32 位 PPC 架构
|
||||
|
||||
伴随其他有趣的技术一起装载在 Ubuntu 17.04 的最终发行版上,最值得一提的是交换文件,对于新安装的系统来说可以用它来替代交换分区。所以如果你从之前的 Ubuntu 发行版升级过来,这是唯一一个不适用的地方。
|
||||
|
||||
此外,默认的 DNS 解析器转换为了 `systemd-resolved`。IPP Everywhere 和苹果 AirPrint 打印机支持免驱动的开箱即用。绝大多数来自 GNOME 家族的包都升级到了 GNOME 3.24,只有 Nautilus 仍然保持在 GNOME 3.20.4 版本。
|
||||
|
||||
gconf 工具不再默认安装,因为它现在已经被 gsettings 所代替。而安装的应用大多数都是最新的,比如 LibreOffice 5.3 办公套件,Mozilla Firefox 52.0.1 Web 浏览器,以及 Mozilla Thunderbird 45.8.0 邮箱和新闻客户端。
|
||||
|
||||
|
||||
|
||||
*Nautilus 文件管理器*
|
||||
|
||||
从本次发行版本开始,不再支持 32 位 PowerPC(PPC)架构,以后的发行版也不再会支持。但是 PPC64el(PowerPC 64 位 Little Endian)会持续支持。现在,已经可以从我们网站上[下载 Ubuntu 17.04][2]的 64 位(amd64)和 32 位 ISO(i386)镜像。
|
||||
|
||||
其他的 Ubuntu 风味版本也在今天开始发行,包括 Ubuntu GNOME 17.04、Ubuntu MATE 17.04、Kubuntu 17.04、Xubuntu 17.04、Lubuntu 17.04、Ubuntu Kylin 17.04、Ubuntu Studio 17.04 以及 Ubuntu Budgie 17.04,这也是 Budgie 桌面作为官方的 Ubuntu 风味版本的首次亮相。
|
||||
|
||||
请注意,Ubuntu 17.04(Zesty Zapus)是一个短暂的分支,仅支持 9 个月的安全更新,即从今天到 2018 年 1 月中旬 。
|
||||
|
||||
--------------------------------------------------------
|
||||
via: http://news.softpedia.com/news/ubuntu-17-04-zesty-zapus-officially-released-available-to-download-now-514853.shtml
|
||||
|
||||
作者:[Marius Nestor][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/marius-nestor
|
||||
[1]:http://news.softpedia.com/news/canonical-to-stop-developing-unity-8-ubuntu-18-04-lts-ships-with-gnome-desktop-514604.shtml
|
||||
[2]:http://linux.softpedia.com/get/Linux-Distributions/Ubuntu-Wily-Werewolf-103744.shtml
|
||||
@ -1,204 +0,0 @@
|
||||
icltyh Translating
|
||||
Writing a Linux Debugger Part 2: Breakpoints
|
||||
============================================================
|
||||
|
||||
In the first part of this series we wrote a small process launcher as a base for our debugger. In this post we’ll learn how breakpoints work in x86 Linux and augment our tool with the ability to set them.
|
||||
|
||||
* * *
|
||||
|
||||
### Series index
|
||||
|
||||
These links will go live as the rest of the posts are released.
|
||||
|
||||
1. [Setup][1]
|
||||
2. [Breakpoints][2]
|
||||
3. Registers and memory
|
||||
4. Elves and dwarves
|
||||
5. Stepping, source and signals
|
||||
6. Stepping on dwarves
|
||||
7. Source-level breakpoints
|
||||
8. Stack unwinding
|
||||
9. Reading variables
|
||||
10. Next steps
|
||||
|
||||
* * *
|
||||
|
||||
### How is breakpoint formed?
|
||||
|
||||
There are two main kinds of breakpoints: hardware and software. Hardware breakpoints typically involve setting architecture-specific registers to produce your breaks for you, whereas software breakpoints involve modifying the code which is being executed on the fly. We’ll be focusing solely on software breakpoints for this article, as they are simpler and you can have as many as you want. On x86 you can only have four hardware breakpoints set at a given time, but they give you the power to make them fire on just reading from or writing to a given address rather than only executing code there.
|
||||
|
||||
I said above that software breakpoints are set by modifying the executing code on the fly, so the questions are:
|
||||
|
||||
* How do we modify the code?
|
||||
* What modifications do we make to set a breakpoint?
|
||||
* How is the debugger notified?
|
||||
|
||||
The answer to the first question is, of course, `ptrace`. We’ve previously used it to set up our program for tracing and continuing its execution, but we can also use it to read and write memory.
|
||||
|
||||
The modification we make has to cause the processor to halt and signal the program when the breakpoint address is executed. On x86 this is accomplished by overwriting the instruction at that address with the `int 3` instruction. x86 has an _interrupt vector table_ which the operating system can use to register handlers for various events, such as page faults, protection faults, and invalid opcodes. It’s kind of like registering error handling callbacks, but right down at the hardware level. When the processor executes the `int 3` instruction, control is passed to the breakpoint interrupt handler, which – in the case of Linux – signals the process with a `SIGTRAP`. You can see this process in the diagram below, where we overwrite the first byte of the `mov` instruction with `0xcc`, which is the instruction encoding for `int 3`.
|
||||
|
||||

|
||||
|
||||
The last piece of the puzzle is how the debugger is notified of the break. If you remember back in the previous post, we can use `waitpid` to listen for signals which are sent to the debugee. We can do exactly the same thing here: set the breakpoint, continue the program, call `waitpid` and wait until the `SIGTRAP`occurs. This breakpoint can then be communicated to the user, perhaps by printing the source location which has been reached, or changing the focused line in a GUI debugger.
|
||||
|
||||
* * *
|
||||
|
||||
### Implementing software breakpoints
|
||||
|
||||
We’ll implement a `breakpoint` class to represent a breakpoint on some location which we can enable or disable as we wish.
|
||||
|
||||
```
|
||||
class breakpoint {
|
||||
public:
|
||||
breakpoint(pid_t pid, std::intptr_t addr)
|
||||
: m_pid{pid}, m_addr{addr}, m_enabled{false}, m_saved_data{}
|
||||
{}
|
||||
|
||||
void enable();
|
||||
void disable();
|
||||
|
||||
auto is_enabled() const -> bool { return m_enabled; }
|
||||
auto get_address() const -> std::intptr_t { return m_addr; }
|
||||
|
||||
private:
|
||||
pid_t m_pid;
|
||||
std::intptr_t m_addr;
|
||||
bool m_enabled;
|
||||
uint64_t m_saved_data; //data which used to be at the breakpoint address
|
||||
};
|
||||
```
|
||||
|
||||
Most of this is just tracking of state; the real magic happens in the `enable` and `disable` functions.
|
||||
|
||||
As we’ve learned above, we need to replace the instruction which is currently at the given address with an `int 3`instruction, which is encoded as `0xcc`. We’ll also want to save out what used to be at that address so that we can restore the code later; we don’t want to just forget to execute the user’s code!
|
||||
|
||||
```
|
||||
void breakpoint::enable() {
|
||||
m_saved_data = ptrace(PTRACE_PEEKDATA, m_pid, m_addr, nullptr);
|
||||
uint64_t int3 = 0xcc;
|
||||
uint64_t data_with_int3 = ((m_saved_data & ~0xff) | int3); //set bottom byte to 0xcc
|
||||
ptrace(PTRACE_POKEDATA, m_pid, m_addr, data_with_int3);
|
||||
|
||||
m_enabled = true;
|
||||
}
|
||||
```
|
||||
|
||||
The `PTRACE_PEEKDATA` request to `ptrace` is how to read the memory of the traced process. We give it a process ID and an address, and it gives us back the 64 bits which are currently at that address. `(m_saved_data & ~0xff)` zeroes out the bottom byte of this data, then we bitwise `OR` that with our `int 3` instruction to set the breakpoint. Finally, we set the breakpoint by overwriting that part of memory with our new data with `PTRACE_POKEDATA`.
|
||||
|
||||
The implementation of `disable` is easier, as we simply need to restore the original data which we overwrote with `0xcc`.
|
||||
|
||||
```
|
||||
void breakpoint::disable() {
|
||||
ptrace(PTRACE_POKEDATA, m_pid, m_addr, m_saved_data);
|
||||
m_enabled = false;
|
||||
}
|
||||
```
|
||||
|
||||
* * *
|
||||
|
||||
### Adding breakpoints to the debugger
|
||||
|
||||
We’ll make three changes to our debugger class to support setting breakpoints through the user interface:
|
||||
|
||||
1. Add a breakpoint storage data structure to `debugger`
|
||||
2. Write a `set_breakpoint_at_address` function
|
||||
3. Add a `break` command to our `handle_command` function
|
||||
|
||||
I’ll store my breakpoints in a `std::unordered_map<std::intptr_t, breakpoint>` structure so that it’s easy and fast to check if a given address has a breakpoint on it and, if so, retrieve that breakpoint object.
|
||||
|
||||
```
|
||||
class debugger {
|
||||
//...
|
||||
void set_breakpoint_at_address(std::intptr_t addr);
|
||||
//...
|
||||
private:
|
||||
//...
|
||||
std::unordered_map<std::intptr_t,breakpoint> m_breakpoints;
|
||||
}
|
||||
```
|
||||
|
||||
In `set_breakpoint_at_address` we’ll create a new breakpoint, enable it, add it to the data structure, and print out a message for the user. If you like, you could factor out all message printing so that you can use the debugger as a library as well as a command-line tool, but I’ll mash it all together for simplicity.
|
||||
|
||||
```
|
||||
void debugger::set_breakpoint_at_address(std::intptr_t addr) {
|
||||
std::cout << "Set breakpoint at address 0x" << std::hex << addr << std::endl;
|
||||
breakpoint bp {m_pid, addr};
|
||||
bp.enable();
|
||||
m_breakpoints[addr] = bp;
|
||||
}
|
||||
```
|
||||
|
||||
Now we’ll augment our command handler to call our new function.
|
||||
|
||||
```
|
||||
void debugger::handle_command(const std::string& line) {
|
||||
auto args = split(line,' ');
|
||||
auto command = args[0];
|
||||
|
||||
if (is_prefix(command, "cont")) {
|
||||
continue_execution();
|
||||
}
|
||||
else if(is_prefix(command, "break")) {
|
||||
std::string addr {args[1], 2}; //naively assume that the user has written 0xADDRESS
|
||||
set_breakpoint_at_address(std::stol(addr, 0, 16));
|
||||
}
|
||||
else {
|
||||
std::cerr << "Unknown command\n";
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
I’ve simply removed the first two characters of the string and called `std::stol` on the result, but feel free to make the parsing more robust. `std::stol` optionally takes a radix to convert from, which is handy for reading in hexadecimal.
|
||||
|
||||
* * *
|
||||
|
||||
### Continuing from the breakpoint
|
||||
|
||||
If you try this out, you might notice that if you continue from the breakpoint, nothing happens. That’s because the breakpoint is still set in memory, so it’s just hit repeatedly. The simple solution is to just disable the breakpoint, single step, re-enable it, then continue. Unfortunately we’d also need to modify the program counter to point back before the breakpoint, so we’ll leave this until the next post where we’ll learn about manipulating registers.
|
||||
|
||||
* * *
|
||||
|
||||
### Testing it out
|
||||
|
||||
Of course, setting a breakpoint on some address isn’t very useful if you don’t know what address to set it at. In the future we’ll be adding the ability to set breakpoints on function names or source code lines, but for now, we can work it out manually.
|
||||
|
||||
A simple way to test out your debugger is to write a hello world program which writes to `std::cerr` (to avoid buffering) and set a breakpoint on the call to the output operator. If you continue the debugee then hopefully the execution will stop without printing anything. You can then restart the debugger and set a breakpoint just after the call, and you should see the message being printed successfully.
|
||||
|
||||
One way to find the address is to use `objdump`. If you open up a shell and execute `objdump -d <your program>`, then you should see the disassembly for your code. You should then be able to find the `main` function and locate the `call` instruction which you want to set the breakpoint on. For example, I built a hello world example, disassembled it, and got this as the disassembly for `main`:
|
||||
|
||||
```
|
||||
0000000000400936 <main>:
|
||||
400936: 55 push %rbp
|
||||
400937: 48 89 e5 mov %rsp,%rbp
|
||||
40093a: be 35 0a 40 00 mov $0x400a35,%esi
|
||||
40093f: bf 60 10 60 00 mov $0x601060,%edi
|
||||
400944: e8 d7 fe ff ff callq 400820 <_ZStlsISt11char_traitsIcEERSt13basic_ostreamIcT_ES5_PKc@plt>
|
||||
400949: b8 00 00 00 00 mov $0x0,%eax
|
||||
40094e: 5d pop %rbp
|
||||
40094f: c3 retq
|
||||
```
|
||||
|
||||
As you can see, we would want to set a breakpoint on `0x400944`to see no output, and `0x400949` to see the output.
|
||||
|
||||
* * *
|
||||
|
||||
### Finishing up
|
||||
|
||||
You should now have a debugger which can launch a program and allow the user to set breakpoints on memory addresses. Next time we’ll add the ability to read from and write to memory and registers. Again, let me know in the comments if you have any issues.
|
||||
|
||||
You can find the code for this post [here][3].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://blog.tartanllama.xyz/c++/2017/03/24/writing-a-linux-debugger-breakpoints/
|
||||
|
||||
作者:[Simon Brand ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://blog.tartanllama.xyz/
|
||||
[1]:http://blog.tartanllama.xyz/c++/2017/03/21/writing-a-linux-debugger-setup/
|
||||
[2]:http://blog.tartanllama.xyz/c++/2017/03/24/writing-a-linux-debugger-breakpoints/
|
||||
[3]:https://github.com/TartanLlama/minidbg/tree/tut_break
|
||||
@ -1,7 +1,7 @@
|
||||
ucasFL is Translating
|
||||
pyDash – A Web Based Linux Performance Monitoring Tool
|
||||
============================================================
|
||||
|
||||
|
||||
pydash is a lightweight [web-based monitoring tool for Linux][1] written in Python and [Django][2] plus Chart.js. It has been tested and can run on the following mainstream Linux distributions: CentOS, Fedora, Ubuntu, Debian, Arch Linux, Raspbian as well as Pidora.
|
||||
|
||||
You can use it to keep an eye on your Linux PC/server resources such as CPUs, RAM, network stats, processes including online users and more. The dashboard is developed entirely using Python libraries provided in the main Python distribution, therefore it has a few dependencies; you don’t need to install many packages or libraries to run it.
|
||||
@ -13,9 +13,9 @@ In this article, we will show you how to install pydash to monitor Linux server
|
||||
1. First install required packages: git and Python pip as follows:
|
||||
|
||||
```
|
||||
-------------- On Debian/Ubuntu --------------
|
||||
-------------- On Debian/Ubuntu --------------
|
||||
$ sudo apt-get install git python-pip
|
||||
-------------- On CentOS/RHEL --------------
|
||||
-------------- On CentOS/RHEL --------------
|
||||
# yum install epel-release
|
||||
# yum install git python-pip
|
||||
-------------- On Fedora 22+ --------------
|
||||
@ -43,7 +43,7 @@ $ sudo pip install virtualenv
|
||||
$ virtualenv pydashtest #give a name for your virtual environment like pydashtest
|
||||
```
|
||||
[
|
||||

|
||||

|
||||
][3]
|
||||
|
||||
Create Virtual Environment
|
||||
@ -56,7 +56,7 @@ Important: Take note the virtual environment’s bin directory path highlighted
|
||||
$ source /home/aaronkilik/pydash/pydashtest/bin/activate
|
||||
```
|
||||
[
|
||||

|
||||

|
||||
][4]
|
||||
|
||||
Active Virtual Environment
|
||||
@ -76,7 +76,7 @@ $ pip install -r requirements.txt
|
||||
$ vi pydash/settings.py
|
||||
```
|
||||
[
|
||||

|
||||

|
||||
][6]
|
||||
|
||||
Set Secret Key
|
||||
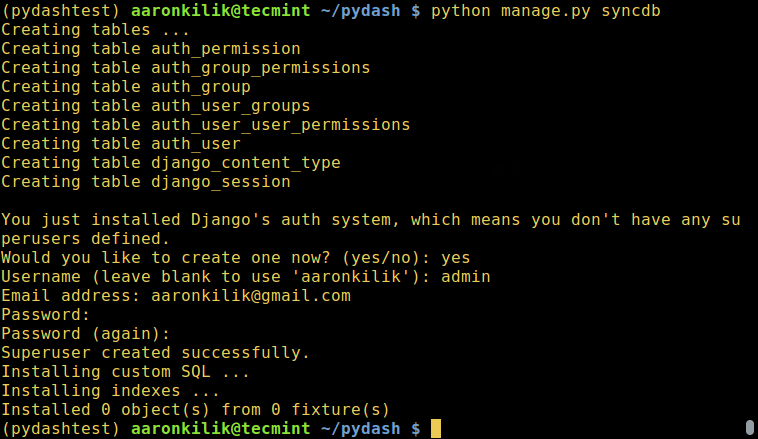
@ -99,7 +99,7 @@ Password: ###########
|
||||
Password (again): ############
|
||||
```
|
||||
[
|
||||
|
||||

|
||||
][7]
|
||||
|
||||
Create Project Database
|
||||
@ -113,7 +113,7 @@ $ python manage.py runserver
|
||||
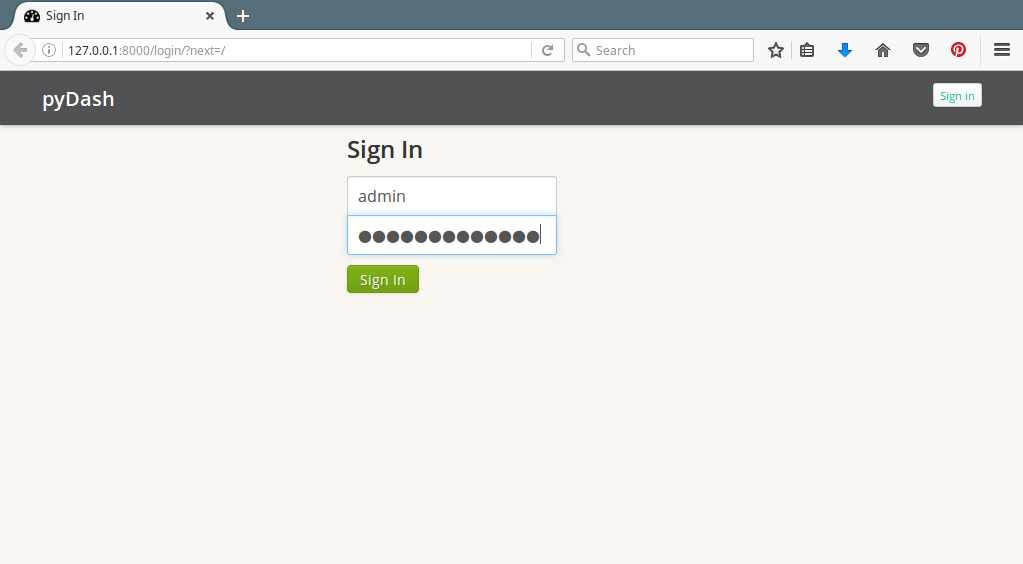
10. Next, open your web browser and type the URL: http://127.0.0.1:8000/ to get the web dashboard login interface. Enter the super user name and password you created while creating the database and installing Django’s auth system in step 8 and click Sign In.
|
||||
|
||||
[
|
||||
|
||||

|
||||
][8]
|
||||
|
||||
pyDash Login Interface
|
||||
@ -123,7 +123,7 @@ pyDash Login Interface
|
||||
Simply scroll down to view more sections.
|
||||
|
||||
[
|
||||

|
||||

|
||||
][9]
|
||||
|
||||
pyDash Server Performance Overview
|
||||
@ -131,7 +131,7 @@ pyDash Server Performance Overview
|
||||
12. Next, screenshot of the pydash showing a section for keeping track of interfaces, IP addresses, Internet traffic, disk read/writes, online users and netstats.
|
||||
|
||||
[
|
||||

|
||||

|
||||
][10]
|
||||
|
||||
pyDash Network Overview
|
||||
@ -139,7 +139,7 @@ pyDash Network Overview
|
||||
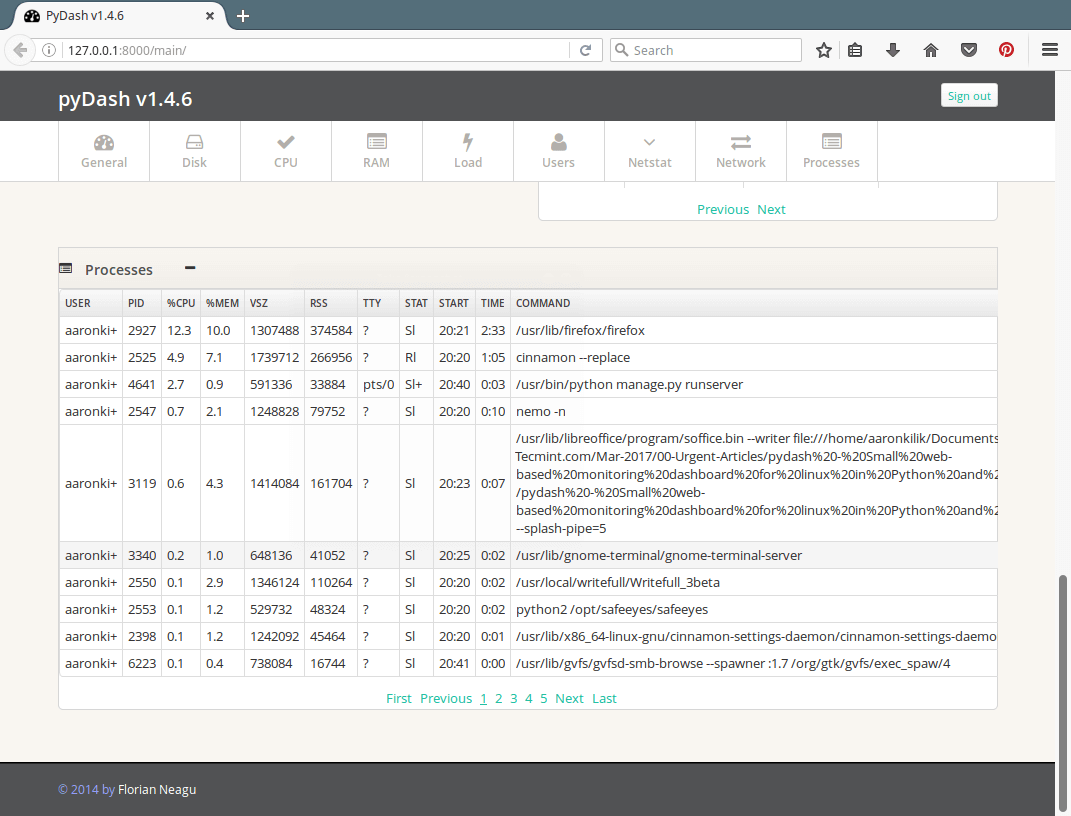
13. Next is a screenshot of the pydash main interface showing a section to keep an eye on active processes on the system.
|
||||
|
||||
[
|
||||
|
||||

|
||||
][11]
|
||||
|
||||
pyDash Active Linux Processes
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
ucasFL is Translating
|
||||
How To Enable Desktop Sharing In Ubuntu and Linux Mint
|
||||
============================================================
|
||||
|
||||
@ -11,7 +12,7 @@ In this article, we will show you how to enable desktop sharing in Ubuntu and Li
|
||||
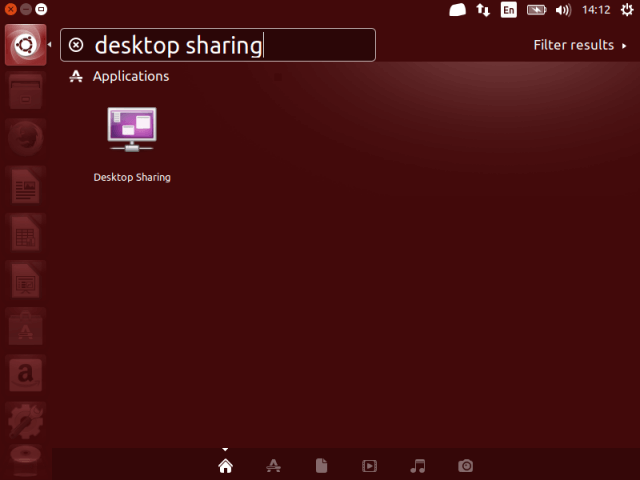
1. In the Ubuntu Dash or Linux Mint Menu, search for “desktop sharing” as shown in the following screenshot, once you get it, launch it.
|
||||
|
||||
[
|
||||
|
||||

|
||||
][1]
|
||||
|
||||
Search for Desktop Sharing in Ubuntu
|
||||
@ -21,7 +22,7 @@ Search for Desktop Sharing in Ubuntu
|
||||
Under sharing, check the option “Allow others users to view your desktop” to enable desktop sharing. Optionally, you can also permit other users to remotely control your desktops by checking the option “Allow others users to control your desktop”.
|
||||
|
||||
[
|
||||

|
||||

|
||||
][2]
|
||||
|
||||
Desktop Sharing Preferences
|
||||
@ -33,7 +34,7 @@ Again, another useful security feature is creating a certain shared password usi
|
||||
4. Concerning notifications, you can keep an eye on remote connections by choosing to show the notification area icon each time there is a remote connection to your desktops by selecting “Only when someone is connected”.
|
||||
|
||||
[
|
||||

|
||||

|
||||
][3]
|
||||
|
||||
Configure Desktop Sharing Set
|
||||
@ -47,7 +48,7 @@ You can test to ensure that it’s working using a remote connection application
|
||||
5. I will connect to my Ubuntu PC using VNC (Virtual Network Computing) protocol via [remmina remote connection application][4].
|
||||
|
||||
[
|
||||

|
||||

|
||||
][5]
|
||||
|
||||
Remmina Desktop Sharing Tool
|
||||
@ -55,7 +56,7 @@ Remmina Desktop Sharing Tool
|
||||
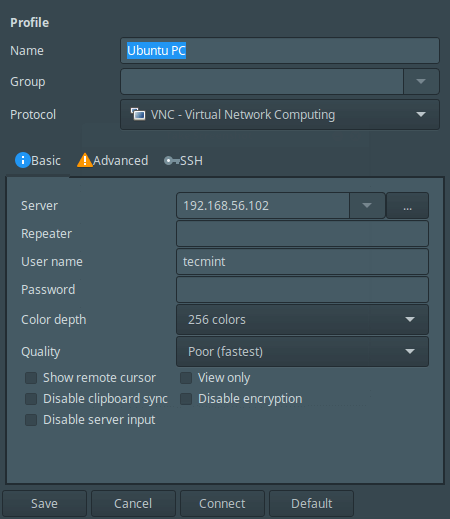
6. After clicking on Ubuntu PC item, I get the interface below to configure my connection settings.
|
||||
|
||||
[
|
||||
|
||||

|
||||
][6]
|
||||
|
||||
Remmina Desktop Sharing Preferences
|
||||
@ -63,7 +64,7 @@ Remmina Desktop Sharing Preferences
|
||||
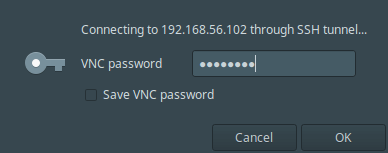
7. After performing all the settings, I will click Connect. Then provide the SSH password for the username and click OK.
|
||||
|
||||
[
|
||||
|
||||

|
||||
][7]
|
||||
|
||||
Enter SSH User Password
|
||||
@ -71,7 +72,7 @@ Enter SSH User Password
|
||||
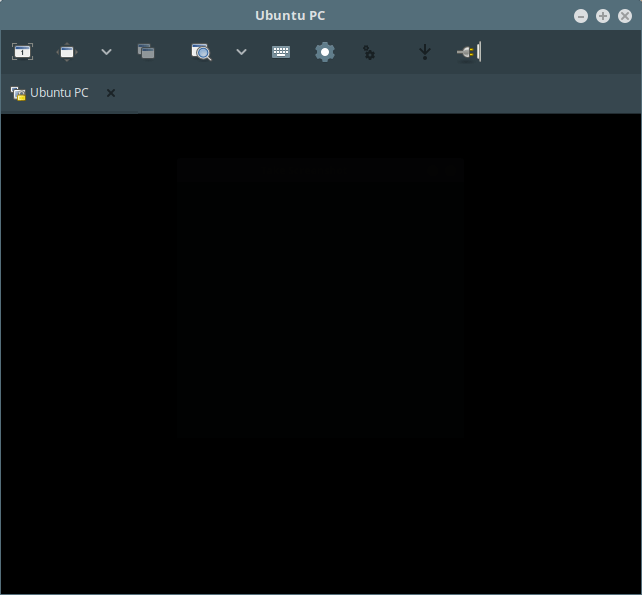
I have got this black screen after clicking OK because, on the remote machine, the connection has not been confirmed yet.
|
||||
|
||||
[
|
||||
|
||||

|
||||
][8]
|
||||
|
||||
Black Screen Before Confirmation
|
||||
@ -79,7 +80,7 @@ Black Screen Before Confirmation
|
||||
8. Now on the remote machine, I have to accept the remote access request by clicking on “Allow” as shown in the next screenshot.
|
||||
|
||||
[
|
||||

|
||||

|
||||
][9]
|
||||
|
||||
Allow Remote Desktop Sharing
|
||||
@ -87,7 +88,7 @@ Allow Remote Desktop Sharing
|
||||
9. After accepting the request, I have successfully connected, remotely to my Ubuntu desktop machine.
|
||||
|
||||
[
|
||||

|
||||

|
||||
][10]
|
||||
|
||||
Remote Ubuntu Desktop
|
||||
|
||||
211
sources/tech/20170406 Anbox - Android in a Box.md
Normal file
211
sources/tech/20170406 Anbox - Android in a Box.md
Normal file
@ -0,0 +1,211 @@
|
||||
# Anbox
|
||||
|
||||
Anbox is container based approach to boot a full Android system on a
|
||||
regular GNU Linux system like Ubuntu.
|
||||
|
||||
## Overview
|
||||
|
||||
Anbox uses Linux namespaces (user, pid, uts, net, mount, ipc) to run a
|
||||
full Android system in a container and provide Android applications on
|
||||
any GNU Linux based platform.
|
||||
|
||||
The Android inside the container has no direct access to any hardware.
|
||||
All hardware access is going through the anbox daemon on the host. We're
|
||||
reusing what Android implemented within the QEMU based emulator for Open
|
||||
GL ES accelerated rendering. The Android system inside the container uses
|
||||
different pipes to communicate with the host system and sends all hardware
|
||||
access commands through these.
|
||||
|
||||
For more details have a look at the following documentation pages:
|
||||
|
||||
* [Android Hardware OpenGL ES emulation design overview](https://android.googlesource.com/platform/external/qemu/+/emu-master-dev/android/android-emugl/DESIGN)
|
||||
* [Android QEMU fast pipes](https://android.googlesource.com/platform/external/qemu/+/emu-master-dev/android/docs/ANDROID-QEMU-PIPE.TXT)
|
||||
* [The Android "qemud" multiplexing daemon](https://android.googlesource.com/platform/external/qemu/+/emu-master-dev/android/docs/ANDROID-QEMUD.TXT)
|
||||
* [Android qemud services](https://android.googlesource.com/platform/external/qemu/+/emu-master-dev/android/docs/ANDROID-QEMUD-SERVICES.TXT)
|
||||
|
||||
Anbox is currently suited for the desktop use case but can be used on
|
||||
mobile operating systems like Ubuntu Touch, Sailfish OS or Lune OS too.
|
||||
However as the mapping of Android applications is currently desktop specific
|
||||
this needs additional work to supported stacked window user interfaces too.
|
||||
|
||||
The Android runtime environment ships with a minimal customized Android system
|
||||
image based on the [Android Open Source Project](https://source.android.com/).
|
||||
The used image is currently based on Android 7.1.1
|
||||
|
||||
## Installation
|
||||
|
||||
The installation process currently consists of a few steps which will
|
||||
add additional components to your host system. These include
|
||||
|
||||
* Out-of-tree kernel modules for binder and ashmem as no distribution kernel
|
||||
ships both enabled.
|
||||
* A udev rule to set correct permissions for /dev/binder and /dev/ashmem
|
||||
* A upstart job which starts the Anbox session manager as part of
|
||||
a user session.
|
||||
|
||||
To make this process as easy as possible we have bundled the necessary
|
||||
steps in a snap (see https://snapcraft.io) called "anbox-installer". The
|
||||
installer will perform all necessary steps. You can install it on a system
|
||||
providing support for snaps by running
|
||||
|
||||
```
|
||||
$ snap install --classic anbox-installer
|
||||
```
|
||||
|
||||
Alternatively you can fetch the installer script via
|
||||
|
||||
```
|
||||
$ wget https://raw.githubusercontent.com/anbox/anbox-installer/master/installer.sh -O anbox-installer
|
||||
```
|
||||
|
||||
Please note that we don't support any possible Linux distribution out there
|
||||
yet. Please have a look at the following chapter to see a list of supported
|
||||
distributions.
|
||||
|
||||
To proceed the installation process simply called
|
||||
|
||||
```
|
||||
$ anbox-installer
|
||||
```
|
||||
|
||||
This will guide you through the installation process.
|
||||
|
||||
**NOTE:** Anbox is currently in a **pre-alpha development state**. Don't expect a
|
||||
fully working system for a production system with all features you need. You will
|
||||
for sure see bugs and crashes. If you do so, please don't hestitate and report them!
|
||||
|
||||
**NOTE:** The Anbox snap currently comes **completely unconfined** and is because of
|
||||
this only available from the edge channel. Proper confinement is a thing we want
|
||||
to achieve in the future but due to the nature and complexity of Anbox this isn't
|
||||
a simple task.
|
||||
|
||||
## Supported Linux Distributions
|
||||
|
||||
At the moment we officially support the following Linux distributions:
|
||||
|
||||
* Ubuntu 16.04 (xenial)
|
||||
|
||||
Untested but likely to work:
|
||||
|
||||
* Ubuntu 14.04 (trusty)
|
||||
* Ubuntu 16.10 (yakkety)
|
||||
* Ubuntu 17.04 (zesty)
|
||||
|
||||
## Install and Run Android Applications
|
||||
|
||||
## Build from source
|
||||
|
||||
To build the Anbox runtime itself there is nothing special to know. We're using
|
||||
cmake as build system. A few build dependencies need to be present on your host
|
||||
system:
|
||||
|
||||
* libdbus
|
||||
* google-mock
|
||||
* google-test
|
||||
* libboost
|
||||
* libboost-filesystem
|
||||
* libboost-log
|
||||
* libboost-iostreams
|
||||
* libboost-program-options
|
||||
* libboost-system
|
||||
* libboost-test
|
||||
* libboost-thread
|
||||
* libcap
|
||||
* libdbus-cpp
|
||||
* mesa (libegl1, libgles2)
|
||||
* glib-2.0
|
||||
* libsdl2
|
||||
* libprotobuf
|
||||
* protobuf-compiler
|
||||
* lxc
|
||||
|
||||
On an Ubuntu system you can install all build dependencies with the following
|
||||
command:
|
||||
|
||||
```
|
||||
$ sudo apt install build-essential cmake cmake-data debhelper dbus google-mock \
|
||||
libboost-dev libboost-filesystem-dev libboost-log-dev libboost-iostreams-dev \
|
||||
libboost-program-options-dev libboost-system-dev libboost-test-dev \
|
||||
libboost-thread-dev libcap-dev libdbus-1-dev libdbus-cpp-dev libegl1-mesa-dev \
|
||||
libgles2-mesa-dev libglib2.0-dev libglm-dev libgtest-dev liblxc1 \
|
||||
libproperties-cpp-dev libprotobuf-dev libsdl2-dev lxc-dev pkg-config \
|
||||
protobuf-compiler
|
||||
```
|
||||
|
||||
Afterwards you can build Anbox with
|
||||
|
||||
```
|
||||
$ mkdir build
|
||||
$ cd build
|
||||
$ cmake ..
|
||||
$ make
|
||||
```
|
||||
|
||||
A simple
|
||||
|
||||
```
|
||||
$ make install
|
||||
```
|
||||
|
||||
will install the necessary bits into your system.
|
||||
|
||||
If you want to build the anbox snap instead you can do this with the following
|
||||
steps:
|
||||
|
||||
```
|
||||
$ mkdir android-images
|
||||
$ cp /path/to/android.img android-images/android.img
|
||||
$ snapcraft
|
||||
```
|
||||
|
||||
The result will be a .snap file you can install on a system supporting snaps
|
||||
|
||||
```
|
||||
$ snap install --dangerous --devmode anbox_1_amd64.snap
|
||||
```
|
||||
|
||||
## Run Anbox
|
||||
|
||||
Running Anbox from a local build requires a few more things you need to know
|
||||
about. Please have a look at the ["Runtime Setup"](docs/runtime-setup.md)
|
||||
documentation.
|
||||
|
||||
## documentation
|
||||
|
||||
You will find additional documentation for Anbox in the *docs* subdirectory
|
||||
of the project source.
|
||||
|
||||
Interesting things to have a look at
|
||||
|
||||
* [Runtime Setup](docs/runtime-setup.md)
|
||||
* [Build Android image](docs/build-android.md)
|
||||
|
||||
## Reporting bugs
|
||||
|
||||
If you have found an issue with Anbox, please [file a bug](https://github.com/anbox/anbox/issues/new).
|
||||
|
||||
## Get in Touch
|
||||
|
||||
If you want to get in contact with the developers please feel free to join the
|
||||
*#anbox* IRC channel on [FreeNode](https://freenode.net/).
|
||||
|
||||
## Copyright and Licensing
|
||||
|
||||
Anbox reuses code from other projects like the Android QEMU emulator. These
|
||||
projects are available in the external/ subdirectory with the licensing terms
|
||||
included.
|
||||
|
||||
The anbox source itself, if not stated differently in the relevant source files,
|
||||
is licensed under the terms of the GPLv3 license.
|
||||
|
||||
-----------------------------------------------
|
||||
|
||||
via: https://github.com/anbox/anbox/blob/master/README.md
|
||||
|
||||
作者:[ Anbox][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://anbox.io/
|
||||
@ -1,105 +0,0 @@
|
||||
How to install Asterisk on the Raspberry Pi
|
||||
============================================================
|
||||
|
||||
> Are you looking for a phone system for your small business or home office?
|
||||
|
||||
|
||||

|
||||
>Image credits : Dwight Sipler on [Flickr][8]
|
||||
|
||||
Are you looking for a phone system for your small business or home office? I've been interested in a scalable VoIP (Voice over IP) solution, and that's when I came across an implementation of [Asterisk][9] on the Raspberry Pi.
|
||||
|
||||
My curiosity was piqued and I was determined to give it a try, so I [downloaded][10] the software from [Asterisk][11] and then set about building the server using my Raspberry Pi 3.
|
||||
|
||||
### Getting started
|
||||
|
||||
First, I burned the downloaded image onto a MicroSD card; the suggested minimum is 4GB. After transferring the image to the MicroSD card and inserting it into the appropriate slot on the Raspberry Pi, I connected an Ethernet cable to the Pi and to an Ethernet port on my home router.
|
||||
|
||||
More on Raspberry Pi
|
||||
|
||||
* [Our latest on Raspberry Pi][1]
|
||||
* [What is Raspberry Pi?][2]
|
||||
* [Getting started with Raspberry Pi][3]
|
||||
* [Send us your Raspberry Pi projects and tutorials][4]
|
||||
|
||||
Next, I opened a terminal on my Linux computer and entered **ssh root@192.168.1.8**, which is the IP address of my server. I was prompted to log in as root on the **raspbx**. The default password is "raspberry." (For security reasons, be sure to change your passwords from the default settings if you plan to do more than just try it out.)
|
||||
|
||||
Once I was logged into the shell on the **raspbx,** I then needed to prepare the server for use. Following the [documentation][12] provided on the site, I created new host keys as directed by entering **regen-hostkeys** at the shell prompt. Then, I configured the time zone for the server by entering **configure-timezone** at the shell prompt. I configured the locale setting by entering, **dpkg-reconfigure locales** at the prompt. I also installed [Fail2Ban][13] to provide security on my server.
|
||||
|
||||
Now I was ready to test my configuration.
|
||||
|
||||
### Testing
|
||||
|
||||
I logged out of the **raspbx** shell and then opened a browser and pointed it at the IP address of my server. Loading the server IP address into the browser, I was presented with a lovely login page.
|
||||
|
||||
[FreePBX][14] provides a very nice web-based, open source graphical user interface, which I used to control and configure Asterisk (find on [GitHub][15]). (FreePBX is licensed under the GPL.) I used it to complete the rest of the configuration. The default login for FreePBX is**username:admin;password:admin**.
|
||||
|
||||

|
||||
|
||||
Once in, I navigated to the Application Menu, which is located at the upper left of the display. I clicked on the menu link and selected the second option, which is Applications, and selected the fourth option, which is labeled Extensions. From there I created a **New Chan_Sip** extension.
|
||||
|
||||
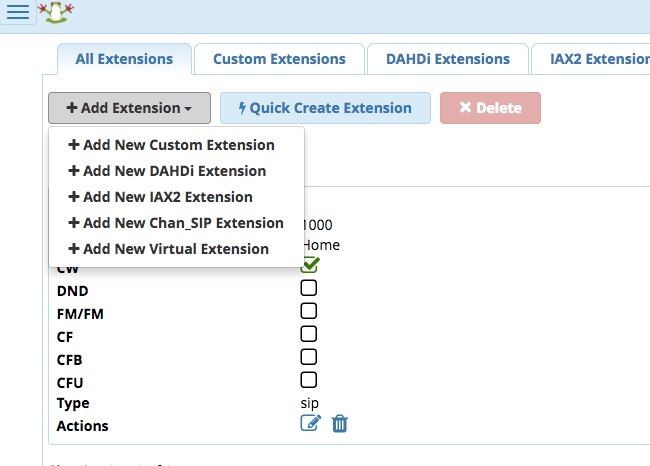
|
||||
|
||||
I configured a **Sip** extension user with a password. Passwords are either automatically generated or you can elect to create your own.
|
||||
|
||||
Now that I had a functioning extension I was anxious to try out my new VoIP server. I downloaded and installed [Yate Client][16], which I discovered in the process of building the server. After installing [Yate][17], I wanted to test the connectivity with the server. I discovered that I could connect to the server for an echo test using Yate and entering ***43**. I was really excited when I heard the instructions through the client.
|
||||
|
||||
|
||||
|
||||
I decided to create another **Sip** extension so that I could test the voicemail capabilities of the system. Once I completed that I used the Yate client to call that extension and leave a brief voice message. Then using Yate again, I called that extension and entered ***97** and retrieved the voice message. Then I wanted to see if I could use my new server to call an outside line. Returning to the menu, I chose the Connectivity option and added a Google Voice line.
|
||||
|
||||

|
||||
|
||||
Then I returned to the Connectivity menu and added Google Voice to the Outbound routes.
|
||||
|
||||

|
||||
|
||||
### Completing a call
|
||||
|
||||
Returning to the Yate client, I entered an outside line and successfully completed that call.
|
||||
|
||||
I'm convinced that this particular VoIP solution could easily work for a small office. According to the [Frequently Asked Questions][18] section of the RasPBX website, a typical Raspberry Pi system could support up to 10 concurrent calls on a Raspberry Pi 1.
|
||||
|
||||
Asterisk has many nuances and the FreePBX software easily leveraged them.
|
||||
|
||||
_For more information about the Asterisk on Raspberry Pi project, follow their[blog][5]. You can find additional information about [FreePBX source code][6] on their website._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Don Watkins - Educator, education technology specialist, entrepreneur, open source advocate. M.A. in Educational Psychology, MSED in Educational Leadership, Linux system administrator, CCNA, virtualization using Virtual Box. Follow me at @Don_Watkins .
|
||||
|
||||
----------
|
||||
|
||||
|
||||
via: https://opensource.com/article/17/4/asterisk-raspberry-pi-3
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/don-watkins
|
||||
[1]:https://opensource.com/tags/raspberry-pi?src=raspberry_pi_resource_menu
|
||||
[2]:https://opensource.com/resources/what-raspberry-pi?src=raspberry_pi_resource_menu
|
||||
[3]:https://opensource.com/article/16/12/getting-started-raspberry-pi?src=raspberry_pi_resource_menu
|
||||
[4]:https://opensource.com/article/17/2/raspberry-pi-submit-your-article?src=raspberry_pi_resource_menu
|
||||
[5]:http://www.raspberry-asterisk.org/blog/
|
||||
[6]:https://www.freepbx.org/development/source-code/
|
||||
[7]:https://opensource.com/article/17/4/asterisk-raspberry-pi-3?rate=zM9tOp0HEPyOUq31Np__W0QNnuAfWATkdkixOdSysDY
|
||||
[8]:http://www.flickr.com/photos/photofarmer/272567650/
|
||||
[9]:http://www.asterisk.org/
|
||||
[10]:http://download.raspberry-asterisk.org/raspbx-28-01-2017.zip
|
||||
[11]:http://www.raspberry-asterisk.org/downloads/
|
||||
[12]:http://www.raspberry-asterisk.org/documentation/
|
||||
[13]:http://www.raspberry-asterisk.org/documentation/#fail2ban
|
||||
[14]:https://www.freepbx.org/
|
||||
[15]:https://github.com/asterisk/asterisk/blob/master/LICENSE
|
||||
[16]:http://yateclient.yate.ro/index.php/Download/Download
|
||||
[17]:https://en.wikipedia.org/wiki/Yate_(telephony_engine)
|
||||
[18]:http://www.raspberry-asterisk.org/faq/
|
||||
[19]:https://opensource.com/user/15542/feed
|
||||
[20]:https://opensource.com/article/17/4/asterisk-raspberry-pi-3#comments
|
||||
[21]:https://opensource.com/users/don-watkins
|
||||
@ -1,4 +1,4 @@
|
||||
开发 Linux 调试器第一部分:起步
|
||||
开发 Linux 调试器第一部分:启动
|
||||
============================================================
|
||||
|
||||
任何写过 hello world 程序的人都应该使用过调试器(如果你还没有,那就停下手头的工作先学习一下吧)。但是,尽管这些工具已经得到了广泛的使用,却并没有太多的资源告诉你它们的工作原理以及如何开发[1][1],尤其是和其它类似编译器等工具链技术相比的时候。
|
||||
@ -211,7 +211,7 @@ void debugger::continue_execution() {
|
||||
|
||||
* * *
|
||||
|
||||
### 完成
|
||||
### 总结
|
||||
|
||||
现在你应该编译一些 C 或者 C++ 程序,然后用你的调试器运行它们,看它是否能在函数入口暂停、从调试器中继续执行。在下一篇文章中,我们会学习如何让我们的调试器设置断点。如果你遇到了任何问题,在下面的评论框中告诉我吧!
|
||||
|
||||
|
||||
@ -0,0 +1,202 @@
|
||||
开发 Linux 调试器第二部分:断点
|
||||
============================================================
|
||||
|
||||
在该系列的第一部分,我们写了一个小的进程启动器作为我们调试器的基础。在这篇博客中,我们会学习断点如何在 x86 Linux 上工作以及给我们工具添加设置断点的能力。
|
||||
|
||||
* * *
|
||||
|
||||
###系列文章索引
|
||||
|
||||
随着后面文章的发布,这些链接会逐渐生效。
|
||||
|
||||
1. [启动][2]
|
||||
2. [断点][3]
|
||||
3. 寄存器和内存
|
||||
4. Elves 和 dwarves
|
||||
5. 逐步、源码和信号
|
||||
6. Stepping on dwarves
|
||||
7. 源码层断点
|
||||
8. 调用栈
|
||||
9. 读取变量
|
||||
10. 下一步
|
||||
|
||||
* * *
|
||||
|
||||
### 断点如何形成?
|
||||
|
||||
有两种类型的断点:硬件和软件。硬件断点通常涉及设置和体系结构相关的寄存器来为你产生断点,而软件断点则涉及修改正在执行的代码。在这篇文章中我们只会关注软件断点,因为它们比较简单,而且足够完成你想要的功能。在 x86 机器上任一时刻你最多只能有 4 个硬件断点,但是它们能使你通过读取或者写入给定地址生效,而不是只有当执行到那里的时候。
|
||||
|
||||
我前面说软件断点是通过修改正在执行的代码实现的,那么问题就来了:
|
||||
|
||||
* 我们如何修改代码?
|
||||
* 为了设置断点我们要做什么修改?
|
||||
* 如何告知调试器?
|
||||
|
||||
第一个问题的答案显然是 `ptrace`。我们之前已经用它来启动我们的程序以便跟踪和继续它的执行,但我们也可以用它来读或者写内存。
|
||||
|
||||
当执行到断点时,我们的更改要让处理器暂停并给程序发送信号。在 x86 机器上这是通过 `int 3` 重写该地址上的指令实现的。x86 机器有个`interrupt vector table`(中断向量表),操作系统能用它来为多种事件注册处理程序,例如页故障、保护故障和无效操作码。它就像是注册错误处理回调函数,但是在硬件层面的。当处理器执行 `int 3` 指令时,控制权就被传递给断点中断处理器,对于 Linux 来说,就是给进程发送 `SIGTRAP` 信号。你可以在下图中看到这个进程,我们用 `0xcc`-`int 3` 的指令编码 - 覆盖了 `mov` 指令的第一个字节。
|
||||
|
||||

|
||||
|
||||
最后一个谜题是调试器如何被告知中断的。如果你回顾前面的文章,我们可以用 `waitpid` 来监听被发送给被调试程序的信号。这里我们也可以这样做:设置断点、继续执行程序、调用 `waitpid` 然后等待直到发生 `SIGTRAP`。然后就可以通过打印已运行到的源码位置、或改变有图形用户界面的调试器中关注的代码行从而将这个断点传达给用户。
|
||||
|
||||
* * *
|
||||
|
||||
### 实现软件断点
|
||||
|
||||
我们会实现一个 `breakpoint` 类来表示某个位置的断点,我们可以根据需要启用或者停用该断点。
|
||||
|
||||
```
|
||||
class breakpoint {
|
||||
public:
|
||||
breakpoint(pid_t pid, std::intptr_t addr)
|
||||
: m_pid{pid}, m_addr{addr}, m_enabled{false}, m_saved_data{}
|
||||
{}
|
||||
|
||||
void enable();
|
||||
void disable();
|
||||
|
||||
auto is_enabled() const -> bool { return m_enabled; }
|
||||
auto get_address() const -> std::intptr_t { return m_addr; }
|
||||
|
||||
private:
|
||||
pid_t m_pid;
|
||||
std::intptr_t m_addr;
|
||||
bool m_enabled;
|
||||
uint64_t m_saved_data; //data which used to be at the breakpoint address
|
||||
};
|
||||
```
|
||||
这里的大部分代码都是跟踪状态;真正神奇的地方是 `enable` 和 `disable` 函数。
|
||||
|
||||
正如我们上面学到的,我们要用 `int 3` 指令 - 编码为 `0xcc` - 替换当前指定地址的指令。我们还要保存该地址之前的值,以便后面恢复代码;我们不想忘了执行用户的代码。
|
||||
|
||||
```
|
||||
void breakpoint::enable() {
|
||||
m_saved_data = ptrace(PTRACE_PEEKDATA, m_pid, m_addr, nullptr);
|
||||
uint64_t int3 = 0xcc;
|
||||
uint64_t data_with_int3 = ((m_saved_data & ~0xff) | int3); //set bottom byte to 0xcc
|
||||
ptrace(PTRACE_POKEDATA, m_pid, m_addr, data_with_int3);
|
||||
|
||||
m_enabled = true;
|
||||
}
|
||||
```
|
||||
|
||||
`ptrace` 的 `PTRACE_PEEKDATA` 请求完成如何读取被跟踪进程的内存。我们给它一个进程 ID 和一个地址,然后它返回给我们该地址当前的 64 位内容。 `(m_saved_data & ~0xff)` 把这个数据的低位字节置零,然后我们用它和我们的 `int 3` 指令按位或 `OR` 来设置断点。然后我们通过 `PTRACE_POKEDATA` 用我们的新数据覆盖那部分内存来设置断点。
|
||||
|
||||
`disable` 的实现比较简单,我们只需要恢复用 `0xcc` 覆盖的原始数据。
|
||||
|
||||
```
|
||||
void breakpoint::disable() {
|
||||
ptrace(PTRACE_POKEDATA, m_pid, m_addr, m_saved_data);
|
||||
m_enabled = false;
|
||||
}
|
||||
```
|
||||
|
||||
* * *
|
||||
|
||||
### 在调试器中增加断点
|
||||
|
||||
为了支持通过用户界面设置断点,我们要在 debugger 类修改三个地方:
|
||||
|
||||
1. 给 `debugger` 添加断点存储数据结构
|
||||
2. 添加 `set_breakpoint_at_address` 函数
|
||||
3. 给我们的 `handle_command` 函数添加 `break` 命令
|
||||
|
||||
我会将我的断点保存到 `std::unordered_map<std::intptr_t, breakpoint>` 结构,以便能简单快速地判断一个给定的地址是否有断点,如果有的话,取回该 breakpoint 对象。
|
||||
|
||||
```
|
||||
class debugger {
|
||||
//...
|
||||
void set_breakpoint_at_address(std::intptr_t addr);
|
||||
//...
|
||||
private:
|
||||
//...
|
||||
std::unordered_map<std::intptr_t,breakpoint> m_breakpoints;
|
||||
}
|
||||
```
|
||||
|
||||
在 `set_breakpoint_at_address` 函数中我们会新建一个 breakpoint 对象、启用它、把它添加到数据结构里、并给用户打印一条信息。如果你喜欢的话,你可以重构所有的输出信息,从而你可以将调试器作为库或者命令行工具使用,为了简便,我把它们都整合到了一起。
|
||||
|
||||
```
|
||||
void debugger::set_breakpoint_at_address(std::intptr_t addr) {
|
||||
std::cout << "Set breakpoint at address 0x" << std::hex << addr << std::endl;
|
||||
breakpoint bp {m_pid, addr};
|
||||
bp.enable();
|
||||
m_breakpoints[addr] = bp;
|
||||
}
|
||||
```
|
||||
|
||||
现在我们会在我们的命令处理程序中增加对我们新函数的调用。
|
||||
|
||||
```
|
||||
void debugger::handle_command(const std::string& line) {
|
||||
auto args = split(line,' ');
|
||||
auto command = args[0];
|
||||
|
||||
if (is_prefix(command, "cont")) {
|
||||
continue_execution();
|
||||
}
|
||||
else if(is_prefix(command, "break")) {
|
||||
std::string addr {args[1], 2}; //naively assume that the user has written 0xADDRESS
|
||||
set_breakpoint_at_address(std::stol(addr, 0, 16));
|
||||
}
|
||||
else {
|
||||
std::cerr << "Unknown command\n";
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
我删除了字符串中的前两个字符并对结果调用 `std::stol`,为了让解析更加强壮,你也可以修改它。`std::stol` 可以将字符串按照所给基数转化为整数。
|
||||
|
||||
* * *
|
||||
|
||||
### 从断点继续执行
|
||||
|
||||
如果你尝试这样做,你可能会发现如果你从断点处继续执行,不会发生任何事情。这是因为断点仍然在内存中,因此一直被命中。简单的解决办法就是停用这个断点、运行到下一步、再次启用这个断点、然后继续执行。不幸的是我们还需要更改程序计数器指回断点前面,我们会将这部分内容留到下一篇博客学习了如何操作寄存器之后。
|
||||
|
||||
* * *
|
||||
|
||||
### 测试它
|
||||
|
||||
当然,如果你不知道要设置的地址,设置断点并非很有帮助。后面我们会学习如何在函数名或者代码行设置断点,但现在我们可以通过手动实现。
|
||||
|
||||
测试你调试器的简单方法是写一个 hello world 程序,这个程序输出到 `std::err`(为了避免缓存),并在调用输出操作符的地方设置断点。如果你继续执行被调试的程序,执行很可能会停止而不会输出任何东西。然后你可以重启调试器并在调用之后设置一个断点,现在你应该看到成功地输出了消息。
|
||||
|
||||
查找地址的一个方法是使用 `objdump`。如果你打开一个终端并执行 `objdump -d <your program>`,然后你应该看到你程序的反汇编代码。然后你就可以找到 `main` 函数并定位到你想设置断点的 `call` 指令。例如,我编译了一个 hello world 程序,反汇编它,然后得到了 `main` 的反汇编代码:
|
||||
|
||||
```
|
||||
0000000000400936 <main>:
|
||||
400936: 55 push %rbp
|
||||
400937: 48 89 e5 mov %rsp,%rbp
|
||||
40093a: be 35 0a 40 00 mov $0x400a35,%esi
|
||||
40093f: bf 60 10 60 00 mov $0x601060,%edi
|
||||
400944: e8 d7 fe ff ff callq 400820 <_ZStlsISt11char_traitsIcEERSt13basic_ostreamIcT_ES5_PKc@plt>
|
||||
400949: b8 00 00 00 00 mov $0x0,%eax
|
||||
40094e: 5d pop %rbp
|
||||
40094f: c3 retq
|
||||
```
|
||||
|
||||
正如你看到的,要没有输出,我们要在 `0x400944` 设置断点,要看到输出,要在 `0x400949` 设置断点。
|
||||
|
||||
* * *
|
||||
|
||||
### 总结
|
||||
|
||||
现在你应该有了一个可以启动程序、允许在内存地址上设置断点的调试器。后面我们会添加读写内存和寄存器的功能。再次说明,如果你有任何问题请在评论框中告诉我。
|
||||
|
||||
你可以在[这里][3] 找到该项目的代码。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://blog.tartanllama.xyz/c++/2017/03/24/writing-a-linux-debugger-breakpoints/
|
||||
|
||||
作者:[Simon Brand ][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://blog.tartanllama.xyz/
|
||||
[1]:http://blog.tartanllama.xyz/c++/2017/03/21/writing-a-linux-debugger-setup/
|
||||
[2]:http://blog.tartanllama.xyz/c++/2017/03/24/writing-a-linux-debugger-breakpoints/
|
||||
[3]:https://github.com/TartanLlama/minidbg/tree/tut_break
|
||||
@ -87,7 +87,7 @@ via: https://hackernoon.com/yes-python-is-slow-and-i-dont-care-13763980b5a1
|
||||
|
||||
作者:[Nick Humrich ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -109,4 +109,4 @@ via: https://hackernoon.com/yes-python-is-slow-and-i-dont-care-13763980b5a1
|
||||
[15]:https://wiki.python.org/moin/PythonSpeed/PerformanceTips
|
||||
[16]:https://www.eveonline.com/
|
||||
[17]:http://pypy.org/
|
||||
[18]:http://pythondevelopers.herokuapp.com/
|
||||
[18]:http://pythondevelopers.herokuapp.com/
|
||||
|
||||
@ -0,0 +1,105 @@
|
||||
如何在树莓派中安装 Asterisk
|
||||
============================================================
|
||||
|
||||
> 你是否在为小型企业或家庭办公室寻找电话系统?
|
||||
|
||||
|
||||

|
||||
>图片版权: Dwight Sipler 的 [Flickr][8]
|
||||
|
||||
你是否在为小型企业或家庭办公室寻找电话系统?我一直对可扩展 VoIP(Voice over IP)解决方案感兴趣,我在树莓派上找到 [Asterisk][9] 的一个实现。
|
||||
|
||||
我的好奇心被激起了,我决心尝试一下,所以我从 [Asterisk][11] 官网[下载][10]了它,然后使用我的树莓派 3 构建服务器。
|
||||
|
||||
### 准备开始
|
||||
|
||||
首先,我将下载的镜像刻录到 MicroSD 卡上。建议的最小值是 4GB。将镜像传输到 MicroSD 卡并插到树莓派上的相应插槽中后,我将网线连接到树莓派和家庭路由器上的以太网端口中。
|
||||
|
||||
更多关于树莓派的
|
||||
|
||||
* [我们最新的树莓派教程][1]
|
||||
* [什么是树莓派?][2]
|
||||
* [开始使用树莓派][3]
|
||||
* [给我们发送你的树莓派项目和教程][4]
|
||||
|
||||
接下来,我在 Linux 上打开一个终端,并输入 **ssh root@192.168.1.8**,这是我的服务器的IP地址。我被提示以 root 用户身份登录到 **raspbx** 上。默认密码是 “raspberry”。 (出于安全考虑,如果你打算再多试试,请务必更改默认密码。)
|
||||
|
||||
当我登录到了 raspbx 上的 shell 后,接下来我需要准备配置了。根据网站上提供的[文档][12],我在 shell 下输入 **regen-hostkeys** 来创建新的主机密钥。然后输入 **configure-timezone** 来配置服务器的时区。我通过在提示符下输入 **dpkg-reconfigure locales** 来配置区域设置。我也安装了 [Fail2Ban][13] 来提供服务器的安全性。
|
||||
|
||||
现在我准备测试我的配置。
|
||||
|
||||
### 测试
|
||||
|
||||
我从 **raspbx** shell 中登出,然后打开浏览器并输入我的服务器的 IP 地址。将服务器 IP 地址加载到浏览器中,我看到了一个可爱的登录页面。
|
||||
|
||||
[FreePBX][14] 提供了一个非常好的基于 Web 的开源图形用户界面,我用它来控制和配置 Asterisk(在 [GitHub][15] 上找到)。(FreePBX 是 GPL 许可的)。我用它来完成其余的配置。FreePBX 的默认登录账号为 **用户名:admin; 密码:admin**。
|
||||
|
||||

|
||||
|
||||
登录之后,我进入位于显示屏左上方的 “Application Menu”。点击菜单链接并选择了第二个选项,即 “Applications”,接着选择了第四个选项,其中标有 “Extensions”。从那里我选择创建一个 **New Chan_Sip** 分机。
|
||||
|
||||

|
||||
|
||||
我使用密码配置了一个 **sip** 分机用户。密码是自动生成的,也可以选择创建自己的密码。
|
||||
|
||||
现在我有了一个完整的分机,我急于尝试我的新的 VoIP 服务器。我下载并安装了[ Yate 客户端][16],这是在构建服务器的过程中发现的。安装 [Yate][17] 之后,我想测试与服务器的连接。我发现我可以使用 Yate 连接到服务器并输入 **43** 进行回声测试。当我听到客户端指示时,我感到很激动。
|
||||
|
||||

|
||||
|
||||
我决定创建另外一个 **sip** 分机,这样我就可以测试系统的语音信箱功能。 在完成后,我使用 Yate 客户端来呼叫这个分机,并留下了简短的语音留言。然后再次使用 Yate 呼叫该分机并输入 **97** 来检索语音留言。然后我想看看我是否可以使用我的新服务器来呼叫外线。返回到菜单,选择 “Connectivity” 选项,并添加了 Google Voice 号码。
|
||||
|
||||

|
||||
|
||||
接着我返回到 “Connectivity” 菜单将 Google Voice 添加到出站路由中。
|
||||
|
||||

|
||||
|
||||
### 完成一个电话
|
||||
|
||||
回到 Yate 客户端,我呼叫了一个外线并成功完成了这个电话。
|
||||
|
||||
我相信这个特定的 VoIP 解决方案可以轻松地为一个小型办公室工作。根据 RasPBX 网站的[常见问题][18]部分,典型的树莓派系统可以在树莓派 1 上支持多达 10 个并发呼叫。
|
||||
|
||||
Asterisk 有很多细微差别的功能,FreePBX 则可以很容易地利用它们。
|
||||
|
||||
_关于树莓派上的 Asterisk 的更多信息,请参考他们的[博客][5]。你可以在他们的网站上找到有关[ FreePBX 源代码][6]的其他信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Don Watkins - 教育家、教育技术专家、企业家、开源倡导者。教育心理学硕士、教育领导硕士、Linux 系统管理员、CCNA、使用 Virtual Box 虚拟化。关注我 @Don_Watkins。
|
||||
|
||||
----------
|
||||
|
||||
|
||||
via: https://opensource.com/article/17/4/asterisk-raspberry-pi-3
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/don-watkins
|
||||
[1]:https://opensource.com/tags/raspberry-pi?src=raspberry_pi_resource_menu
|
||||
[2]:https://opensource.com/resources/what-raspberry-pi?src=raspberry_pi_resource_menu
|
||||
[3]:https://opensource.com/article/16/12/getting-started-raspberry-pi?src=raspberry_pi_resource_menu
|
||||
[4]:https://opensource.com/article/17/2/raspberry-pi-submit-your-article?src=raspberry_pi_resource_menu
|
||||
[5]:http://www.raspberry-asterisk.org/blog/
|
||||
[6]:https://www.freepbx.org/development/source-code/
|
||||
[7]:https://opensource.com/article/17/4/asterisk-raspberry-pi-3?rate=zM9tOp0HEPyOUq31Np__W0QNnuAfWATkdkixOdSysDY
|
||||
[8]:http://www.flickr.com/photos/photofarmer/272567650/
|
||||
[9]:http://www.asterisk.org/
|
||||
[10]:http://download.raspberry-asterisk.org/raspbx-28-01-2017.zip
|
||||
[11]:http://www.raspberry-asterisk.org/downloads/
|
||||
[12]:http://www.raspberry-asterisk.org/documentation/
|
||||
[13]:http://www.raspberry-asterisk.org/documentation/#fail2ban
|
||||
[14]:https://www.freepbx.org/
|
||||
[15]:https://github.com/asterisk/asterisk/blob/master/LICENSE
|
||||
[16]:http://yateclient.yate.ro/index.php/Download/Download
|
||||
[17]:https://en.wikipedia.org/wiki/Yate_(telephony_engine)
|
||||
[18]:http://www.raspberry-asterisk.org/faq/
|
||||
[19]:https://opensource.com/user/15542/feed
|
||||
[20]:https://opensource.com/article/17/4/asterisk-raspberry-pi-3#comments
|
||||
[21]:https://opensource.com/users/don-watkins
|
||||
Loading…
Reference in New Issue
Block a user