mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-25 23:11:02 +08:00
commit
2994518324
125
published/20141223 Defending the Free Linux World.md
Normal file
125
published/20141223 Defending the Free Linux World.md
Normal file
@ -0,0 +1,125 @@
|
||||
守卫自由的 Linux 世界
|
||||
================================================================================
|
||||

|
||||
|
||||
**合作是开源的一部分。OIN 的 CEO Keith Bergelt 解释说,开放创新网络(Open Invention Network)模式允许众多企业和公司决定它们该在哪较量,在哪合作。随着开源的演变,“我们需要为合作创造渠道,否则我们将会有几百个团体把数十亿美元花费到同样的技术上。”**
|
||||
|
||||
[开放创新网络(Open Invention Network)][1],即 OIN,正在全球范围内开展让 Linux 远离专利诉讼的伤害的活动。它的努力得到了一千多个公司的热烈回应,它们的加入让这股力量成为了历史上最大的反专利管理组织。
|
||||
|
||||
开放创新网络以白帽子组织的身份创建于2005年,目的是保护 Linux 免受来自许可证方面的困扰。包括 Google、 IBM、 NEC、 Novell、 Philips、 [Red Hat][2] 和 Sony 这些成员的董事会给予了它可观的经济支持。世界范围内的多个组织通过签署自由 OIN 协议加入了这个社区。
|
||||
|
||||
创立开放创新网络的组织成员把它当作利用知识产权保护 Linux 的大胆尝试。它的商业模式非常的难以理解。它要求它的成员采用免版权许可证,并永远放弃由于 Linux 相关知识产权起诉其他成员的机会。
|
||||
|
||||
然而,从 Linux 收购风波——想想服务器和云平台——那时起,保护 Linux 知识产权的策略就变得越加的迫切。
|
||||
|
||||
在过去的几年里,Linux 的版图曾经历了一场变革。OIN 不必再向人们解释这个组织的定义,也不必再解释为什么 Linux 需要保护。据 OIN 的 CEO Keith Bergelt 说,现在 Linux 的重要性得到了全世界的关注。
|
||||
|
||||
“我们已经见到了一场人们了解到 OIN 如何让合作受益的文化变革,”他对 LinuxInsider 说。
|
||||
|
||||
### 如何运作 ###
|
||||
|
||||
开放创新网络使用专利权的方式创建了一个协作环境。这种方法有助于确保创新的延续。这已经使很多软件厂商、顾客、新型市场和投资者受益。
|
||||
|
||||
开放创新网络的专利证可以让任何公司、公共机构或个人免版权使用。这些权利的获得建立在签署者同意不会专为了维护专利而攻击 Linux 系统的基础上。
|
||||
|
||||
OIN 确保 Linux 的源代码保持开放的状态。这让编程人员、设备厂商、独立软件开发者和公共机构在投资和使用 Linux 时不用过多的担心知识产权的问题。这让对 Linux 进行重新打包、嵌入和使用的公司省了不少钱。
|
||||
|
||||
“随着版权许可证越来越广泛的使用,对 OIN 许可证的需求也变得更加的迫切。现在,人们正在寻找更加简单或更实用的解决方法”,Bergelt 说。
|
||||
|
||||
OIN 法律防御援助对成员是免费的。成员必须承诺不对 OIN 名单上的软件发起专利诉讼。为了保护他们的软件,他们也同意提供他们自己的专利。最终,这些保证将让几十万的交叉许可通过该网络相互连接起来,Bergelt 如此解释道。
|
||||
|
||||
### 填补法律漏洞 ###
|
||||
|
||||
“OIN 正在做的事情是非常必要的。它提供另一层 IP (知识产权)保护,”[休斯顿法律中心大学][3]的副教授 Greg R. Vetter 这样说道。
|
||||
|
||||
他回答 LinuxInsider 说,第二版 GPL 许可证被某些人认为提供了隐含的专利许可,但是律师们更喜欢明确的许可。
|
||||
|
||||
OIN 所提供的许可填补了这个空白。它还明确的覆盖了 Linux 内核。据 Vetter 说,明确的专利许可并不是 GPLv2 中的必要部分,但是这个部分被加入到了 GPLv3 中。(LCTT 译注:Linux 内核采用的是 GPLv2 的许可)
|
||||
|
||||
拿一个在 GPLv3 中写了10000行代码的代码编写者来说。随着时间推移,其他的代码编写者会贡献更多行的代码,也加入到了知识产权中。GPLv3 中的软件专利许可条款将基于所有参与的贡献者的专利,保护全部代码的使用,Vetter 如此说道。
|
||||
|
||||
### 并不完全一样 ###
|
||||
|
||||
专利权和许可证在法律结构上层层叠叠互相覆盖。弄清两者对开源软件的作用就像是穿越雷区。
|
||||
|
||||
Vetter 说“通常,许可证是授予建立在专利和版权法律上的额外权利的法律结构。许可证被认为是给予了人们做一些的可能会侵犯到其他人的知识产权权利的事的许可。”
|
||||
|
||||
Vetter 指出,很多自由开源许可证(例如 Mozilla 公共许可、GNU GPLv3 以及 Apache 软件许可)融合了某些互惠专利权的形式。Vetter 指出,像 BSD 和 MIT 这样旧的许可证不会提到专利。
|
||||
|
||||
一个软件的许可证让其他人可以在某种程度上使用这个编程人员创造的代码。版权对所属权的建立是自动的,只要某个人写或者画了某个原创的东西。然而,版权只覆盖了个别的表达方式和衍生的作品。他并没有涵盖代码的功能性或可用的想法。
|
||||
|
||||
专利涵盖了功能性。专利权还可以被许可。版权可能无法保护某人如何独立地开发对另一个人的代码的实现,但是专利填补了这个小瑕疵,Vetter 解释道。
|
||||
|
||||
### 寻找安全通道 ###
|
||||
|
||||
许可证和专利混合的法律性质可能会对开源开发者产生威胁。据 [Chaotic Moon Studios][4] 的创办者之一、 [IEEE][5] 计算机协会成员 William Hurley 说,对于某些人来说,即使是 GPL 也会成为威胁。
|
||||
|
||||
“在很久以前,开源是个完全不同的世界。被彼此间的尊重和把代码视为艺术而非资产的观点所驱动,那时的程序和代码比现在更加的开放。我相信很多为最好的愿景所做的努力几乎最后总是背负着意外的结果,”Hurley 这样告诉 LinuxInsider。
|
||||
|
||||
他暗示说,成员人数超越了1000人(的组织)可能会在知识产权保护重要性方面意见不一。这可能会继续搅混开源生态系统这滩浑水。
|
||||
|
||||
“最终,这些显现出了围绕着知识产权的常见的一些错误概念。拥有几千个开发者并不会减少风险——而是增加。给出了专利许可的开发者越多,它们看起来就越值钱,”Hurley 说。“它们看起来越值钱,有着类似专利的或者其他知识产权的人就越可能试图利用并从中榨取他们自己的经济利益。”
|
||||
|
||||
### 共享与竞争共存 ###
|
||||
|
||||
竞合策略是开源的一部分。OIN 模型让各个公司能够决定他们将在哪竞争以及在哪合作,Bergelt 解释道。
|
||||
|
||||
“开源演化中的许多改变已经把我们移到了另一个方向上。我们必须为合作创造渠道。否则我们将会有几百个团体把数十亿美元花费到同样的技术上,”他说。
|
||||
|
||||
手机产业的革新就是个很好的例子。各个公司放出了不同的标准。没有共享,没有合作,Bergelt 解释道。
|
||||
|
||||
他说:“这让我们在美国接触技术的能力落后了七到十年。我们接触设备的经验远远落后于世界其他地方的人。在我们用不上 CDMA (Code Division Multiple Access 码分多址访问通信技术)时对 GSM (Global System for Mobile Communications 全球移动通信系统) 还沾沾自喜。”
|
||||
|
||||
### 改变格局 ###
|
||||
|
||||
OIN 在去年经历了激增400个新许可的增长。这意味着着开源有了新趋势。
|
||||
|
||||
Bergelt 说:“市场到达了一个临界点,组织内的人们终于意识到直白地合作和竞争的需要。结果是两件事同时进行。这可能会变得复杂、费力。”
|
||||
|
||||
然而,这个由人们开始考虑合作和竞争的文化革新所驱动的转换过程是可以接受的。他解释说,这也是一个人们怎样拥抱开源的转变——尤其是在 Linux 这个开源社区的领导者项目。
|
||||
|
||||
还有一个迹象是,最具意义的新项目都没有在 GPLv3 许可下开发。
|
||||
|
||||
### 二个总比一个好 ###
|
||||
|
||||
“GPL 极为重要,但是事实是有一堆的许可模型正被使用着。在 Eclipse、Apache 和 Berkeley 许可中,专利问题的相对可解决性通常远远低于在 GPLv3 中的。”Bergelt 说。
|
||||
|
||||
GPLv3 对于解决专利问题是个自然的补充——但是 GPL 自身不足以独自解决围绕专利使用的潜在冲突。所以 OIN 的设计是以能够补充版权许可为目的的,他补充道。
|
||||
|
||||
然而,层层叠叠的专利和许可也许并没有带来多少好处。到最后,专利在几乎所有的案例中都被用于攻击目的——而不是防御目的,Bergelt 暗示说。
|
||||
|
||||
“如果你不准备对其他人采取法律行动,那么对于你的知识产权来说专利可能并不是最佳的法律保护方式”,他说。“我们现在生活在一个对软件——开放的和专有的——误会重重的世界里。这些软件还被错误而过时的专利系统所捆绑。我们每天在工业化和被扼杀的创新中挣扎”,他说。
|
||||
|
||||
### 法院是最后的手段###
|
||||
|
||||
想到 OIN 的出现抑制了诉讼的泛滥就感到十分欣慰,Bergelt 说,或者至少可以说 OIN 的出现扼制了特定的某些威胁。
|
||||
|
||||
“可以说我们让人们放下他们的武器。同时我们正在创建一种新的文化规范。一旦你入股这个模型中的非侵略专利,所产生的相关影响就是对合作的鼓励”,他说。
|
||||
|
||||
如果你愿意承诺合作,你的第一反应就会趋向于不急着起诉。相反的,你会想如何让我们允许你使用我们所拥有的东西并让它为你赚钱,而同时我们也能使用你所拥有的东西,Bergelt 解释道。
|
||||
|
||||
“OIN 是个多面的解决方式。它鼓励签署者创造双赢协议”,他说,“这让起诉成为最逼不得已的行为。那才是它的位置。”
|
||||
|
||||
### 底线###
|
||||
|
||||
Bergelt 坚信,OIN 的运作是为了阻止 Linux 受到专利伤害。在这个需要 Linux 的世界里没有诉讼的地方。
|
||||
|
||||
唯一临近的是与微软的移动之争,这关系到行业的发展前景(原文: The only thing that comes close are the mobile wars with Microsoft, which focus on elements high in the stack. 不太理解,请指正。)。那些来自法律的挑战可能是为了提高包括使用 Linux 产品的所属权的成本,Bergelt 说。
|
||||
|
||||
尽管如此“这些并不是有关 Linux 诉讼”,他说。“他们的重点并不在于 Linux 的核心。他们关注的是 Linux 系统里都有些什么。”
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxinsider.com/story/Defending-the-Free-Linux-World-81512.html
|
||||
|
||||
作者:Jack M. Germain
|
||||
译者:[H-mudcup](https://github.com/H-mudcup)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.openinventionnetwork.com/
|
||||
[2]:http://www.redhat.com/
|
||||
[3]:http://www.law.uh.edu/
|
||||
[4]:http://www.chaoticmoon.com/
|
||||
[5]:http://www.ieee.org/
|
||||
@ -0,0 +1,348 @@
|
||||
Shilpa Nair 分享的 RedHat Linux 包管理方面的面试经验
|
||||
========================================================================
|
||||
**Shilpa Nair 刚于2015年毕业。她之后去了一家位于 Noida,Delhi 的国家新闻电视台,应聘实习生的岗位。在她去年毕业季的时候,常逛 Tecmint 寻求作业上的帮助。从那时开始,她就常去 Tecmint。**
|
||||
|
||||

|
||||
|
||||
*有关 RPM 方面的 Linux 面试题*
|
||||
|
||||
所有的问题和回答都是 Shilpa Nair 根据回忆重写的。
|
||||
|
||||
> “大家好!我是来自 Delhi 的Shilpa Nair。我不久前才顺利毕业,正寻找一个实习的机会。在大学早期的时候,我就对 UNIX 十分喜爱,所以我也希望这个机会能适合我,满足我的兴趣。我被提问了很多问题,大部分都是关于 RedHat 包管理的基础问题。”
|
||||
|
||||
下面就是我被问到的问题,和对应的回答。我仅贴出了与 RedHat GNU/Linux 包管理相关的,也是主要被提问的。
|
||||
|
||||
### 1,Linux 里如何查找一个包安装与否?假设你需要确认 ‘nano’ 有没有安装,你怎么做? ###
|
||||
|
||||
**回答**:为了确认 nano 软件包有没有安装,我们可以使用 rpm 命令,配合 -q 和 -a 选项来查询所有已安装的包
|
||||
|
||||
# rpm -qa nano
|
||||
或
|
||||
# rpm -qa | grep -i nano
|
||||
|
||||
nano-2.3.1-10.el7.x86_64
|
||||
|
||||
同时包的名字必须是完整的,不完整的包名会返回到提示符,不打印任何东西,就是说这包(包名字不全)未安装。下面的例子会更好理解些:
|
||||
|
||||
我们通常使用 vim 替代 vi 命令。当时如果我们查找安装包 vi/vim 的时候,我们就会看到标准输出上没有任何结果。
|
||||
|
||||
# vi
|
||||
# vim
|
||||
|
||||
尽管如此,我们仍然可以像上面一样运行 vi/vim 命令来清楚地知道包有没有安装。只是因为我们不知道它的完整包名才不能找到的。如果我们不确切知道完整的文件名,我们可以使用通配符:
|
||||
|
||||
# rpm -qa vim*
|
||||
|
||||
vim-minimal-7.4.160-1.el7.x86_64
|
||||
|
||||
通过这种方式,我们可以获得任何软件包的信息,安装与否。
|
||||
|
||||
### 2. 你如何使用 rpm 命令安装 XYZ 软件包? ###
|
||||
|
||||
**回答**:我们可以使用 rpm 命令安装任何的软件包(*.rpm),像下面这样,选项 -i(安装),-v(冗余或者显示额外的信息)和 -h(在安装过程中,打印#号显示进度)。
|
||||
|
||||
# rpm -ivh peazip-1.11-1.el6.rf.x86_64.rpm
|
||||
|
||||
Preparing... ################################# [100%]
|
||||
Updating / installing...
|
||||
1:peazip-1.11-1.el6.rf ################################# [100%]
|
||||
|
||||
如果要升级一个早期版本的包,应加上 -U 选项,选项 -v 和 -h 可以确保我们得到用 # 号表示的冗余输出,这增加了可读性。
|
||||
|
||||
### 3. 你已经安装了一个软件包(假设是 httpd),现在你想看看软件包创建并安装的所有文件和目录,你会怎么做? ###
|
||||
|
||||
**回答**:使用选项 -l(列出所有文件)和 -q(查询)列出 httpd 软件包安装的所有文件(Linux 哲学:所有的都是文件,包括目录)。
|
||||
|
||||
# rpm -ql httpd
|
||||
|
||||
/etc/httpd
|
||||
/etc/httpd/conf
|
||||
/etc/httpd/conf.d
|
||||
...
|
||||
|
||||
### 4. 假如你要移除一个软件包,叫 postfix。你会怎么做? ###
|
||||
|
||||
**回答**:首先我们需要知道什么包安装了 postfix。查找安装 postfix 的包名后,使用 -e(擦除/卸载软件包)和 -v(冗余输出)两个选项来实现。
|
||||
|
||||
# rpm -qa postfix*
|
||||
|
||||
postfix-2.10.1-6.el7.x86_64
|
||||
|
||||
然后移除 postfix,如下:
|
||||
|
||||
# rpm -ev postfix-2.10.1-6.el7.x86_64
|
||||
|
||||
Preparing packages...
|
||||
postfix-2:3.0.1-2.fc22.x86_64
|
||||
|
||||
### 5. 获得一个已安装包的具体信息,如版本,发行号,安装日期,大小,总结和一个简短的描述。 ###
|
||||
|
||||
**回答**:我们通过使用 rpm 的选项 -qi,后面接包名,可以获得关于一个已安装包的具体信息。
|
||||
|
||||
举个例子,为了获得 openssh 包的具体信息,我需要做的就是:
|
||||
|
||||
# rpm -qi openssh
|
||||
|
||||
[root@tecmint tecmint]# rpm -qi openssh
|
||||
Name : openssh
|
||||
Version : 6.8p1
|
||||
Release : 5.fc22
|
||||
Architecture: x86_64
|
||||
Install Date: Thursday 28 May 2015 12:34:50 PM IST
|
||||
Group : Applications/Internet
|
||||
Size : 1542057
|
||||
License : BSD
|
||||
....
|
||||
|
||||
### 6. 假如你不确定一个指定包的配置文件在哪,比如 httpd。你如何找到所有 httpd 提供的配置文件列表和位置。 ###
|
||||
|
||||
**回答**: 我们需要用选项 -c 接包名,这会列出所有配置文件的名字和他们的位置。
|
||||
|
||||
# rpm -qc httpd
|
||||
|
||||
/etc/httpd/conf.d/autoindex.conf
|
||||
/etc/httpd/conf.d/userdir.conf
|
||||
/etc/httpd/conf.d/welcome.conf
|
||||
/etc/httpd/conf.modules.d/00-base.conf
|
||||
/etc/httpd/conf/httpd.conf
|
||||
/etc/sysconfig/httpd
|
||||
|
||||
相似地,我们可以列出所有相关的文档文件,如下:
|
||||
|
||||
# rpm -qd httpd
|
||||
|
||||
/usr/share/doc/httpd/ABOUT_APACHE
|
||||
/usr/share/doc/httpd/CHANGES
|
||||
/usr/share/doc/httpd/LICENSE
|
||||
...
|
||||
|
||||
我们也可以列出所有相关的证书文件,如下:
|
||||
|
||||
# rpm -qL openssh
|
||||
|
||||
/usr/share/licenses/openssh/LICENCE
|
||||
|
||||
忘了说明上面的选项 -d 和 -L 分别表示 “文档” 和 “证书”,抱歉。
|
||||
|
||||
### 7. 你找到了一个配置文件,位于‘/usr/share/alsa/cards/AACI.conf’,现在你不确定该文件属于哪个包。你如何查找出包的名字? ###
|
||||
|
||||
**回答**:当一个包被安装后,相关的信息就存储在了数据库里。所以使用选项 -qf(-f 查询包拥有的文件)很容易追踪谁提供了上述的包。
|
||||
|
||||
# rpm -qf /usr/share/alsa/cards/AACI.conf
|
||||
alsa-lib-1.0.28-2.el7.x86_64
|
||||
|
||||
类似地,我们可以查找(谁提供的)关于任何子包,文档和证书文件的信息。
|
||||
|
||||
### 8. 你如何使用 rpm 查找最近安装的软件列表? ###
|
||||
|
||||
**回答**:如刚刚说的,每一样被安装的文件都记录在了数据库里。所以这并不难,通过查询 rpm 的数据库,找到最近安装软件的列表。
|
||||
|
||||
我们通过运行下面的命令,使用选项 -last(打印出最近安装的软件)达到目的。
|
||||
|
||||
# rpm -qa --last
|
||||
|
||||
上面的命令会打印出所有安装的软件,最近安装的软件在列表的顶部。
|
||||
|
||||
如果我们关心的是找出特定的包,我们可以使用 grep 命令从列表中匹配包(假设是 sqlite ),简单如下:
|
||||
|
||||
# rpm -qa --last | grep -i sqlite
|
||||
|
||||
sqlite-3.8.10.2-1.fc22.x86_64 Thursday 18 June 2015 05:05:43 PM IST
|
||||
|
||||
我们也可以获得10个最近安装的软件列表,简单如下:
|
||||
|
||||
# rpm -qa --last | head
|
||||
|
||||
我们可以重定义一下,输出想要的结果,简单如下:
|
||||
|
||||
# rpm -qa --last | head -n 2
|
||||
|
||||
上面的命令中,-n 代表数目,后面接一个常数值。该命令是打印2个最近安装的软件的列表。
|
||||
|
||||
### 9. 安装一个包之前,你如果要检查其依赖。你会怎么做? ###
|
||||
|
||||
**回答**:检查一个 rpm 包(XYZ.rpm)的依赖,我们可以使用选项 -q(查询包),-p(指定包名)和 -R(查询/列出该包依赖的包,嗯,就是依赖)。
|
||||
|
||||
# rpm -qpR gedit-3.16.1-1.fc22.i686.rpm
|
||||
|
||||
/bin/sh
|
||||
/usr/bin/env
|
||||
glib2(x86-32) >= 2.40.0
|
||||
gsettings-desktop-schemas
|
||||
gtk3(x86-32) >= 3.16
|
||||
gtksourceview3(x86-32) >= 3.16
|
||||
gvfs
|
||||
libX11.so.6
|
||||
...
|
||||
|
||||
### 10. rpm 是不是一个前端的包管理工具呢? ###
|
||||
|
||||
**回答**:**不是!**rpm 是一个后端管理工具,适用于基于 Linux 发行版的 RPM (此处指 Redhat Package Management)。
|
||||
|
||||
[YUM][1],全称 Yellowdog Updater Modified,是一个 RPM 的前端工具。YUM 命令自动完成所有工作,包括解决依赖和其他一切事务。
|
||||
|
||||
最近,[DNF][2](YUM命令升级版)在Fedora 22发行版中取代了 YUM。尽管 YUM 仍然可以在 RHEL 和 CentOS 平台使用,我们也可以安装 dnf,与 YUM 命令共存使用。据说 DNF 较于 YUM 有很多提高。
|
||||
|
||||
知道更多总是好的,保持自我更新。现在我们移步到前端部分来谈谈。
|
||||
|
||||
### 11. 你如何列出一个系统上面所有可用的仓库列表。 ###
|
||||
|
||||
**回答**:简单地使用下面的命令,我们就可以列出一个系统上所有可用的仓库列表。
|
||||
|
||||
# yum repolist
|
||||
或
|
||||
# dnf repolist
|
||||
|
||||
Last metadata expiration check performed 0:30:03 ago on Mon Jun 22 16:50:00 2015.
|
||||
repo id repo name status
|
||||
*fedora Fedora 22 - x86_64 44,762
|
||||
ozonos Repository for Ozon OS 61
|
||||
*updates Fedora 22 - x86_64 - Updates
|
||||
|
||||
上面的命令仅会列出可用的仓库。如果你需要列出所有的仓库,不管可用与否,可以这样做。
|
||||
|
||||
# yum repolist all
|
||||
或
|
||||
# dnf repolist all
|
||||
|
||||
Last metadata expiration check performed 0:29:45 ago on Mon Jun 22 16:50:00 2015.
|
||||
repo id repo name status
|
||||
*fedora Fedora 22 - x86_64 enabled: 44,762
|
||||
fedora-debuginfo Fedora 22 - x86_64 - Debug disabled
|
||||
fedora-source Fedora 22 - Source disabled
|
||||
ozonos Repository for Ozon OS enabled: 61
|
||||
*updates Fedora 22 - x86_64 - Updates enabled: 5,018
|
||||
updates-debuginfo Fedora 22 - x86_64 - Updates - Debug
|
||||
|
||||
### 12. 你如何列出一个系统上所有可用并且安装了的包? ###
|
||||
|
||||
**回答**:列出一个系统上所有可用的包,我们可以这样做:
|
||||
|
||||
# yum list available
|
||||
或
|
||||
# dnf list available
|
||||
|
||||
ast metadata expiration check performed 0:34:09 ago on Mon Jun 22 16:50:00 2015.
|
||||
Available Packages
|
||||
0ad.x86_64 0.0.18-1.fc22 fedora
|
||||
0ad-data.noarch 0.0.18-1.fc22 fedora
|
||||
0install.x86_64 2.6.1-2.fc21 fedora
|
||||
0xFFFF.x86_64 0.3.9-11.fc22 fedora
|
||||
2048-cli.x86_64 0.9-4.git20141214.723738c.fc22 fedora
|
||||
2048-cli-nocurses.x86_64 0.9-4.git20141214.723738c.fc22 fedora
|
||||
....
|
||||
|
||||
而列出一个系统上所有已安装的包,我们可以这样做。
|
||||
|
||||
# yum list installed
|
||||
或
|
||||
# dnf list installed
|
||||
|
||||
Last metadata expiration check performed 0:34:30 ago on Mon Jun 22 16:50:00 2015.
|
||||
Installed Packages
|
||||
GeoIP.x86_64 1.6.5-1.fc22 @System
|
||||
GeoIP-GeoLite-data.noarch 2015.05-1.fc22 @System
|
||||
NetworkManager.x86_64 1:1.0.2-1.fc22 @System
|
||||
NetworkManager-libnm.x86_64 1:1.0.2-1.fc22 @System
|
||||
aajohan-comfortaa-fonts.noarch 2.004-4.fc22 @System
|
||||
....
|
||||
|
||||
而要同时满足两个要求的时候,我们可以这样做。
|
||||
|
||||
# yum list
|
||||
或
|
||||
# dnf list
|
||||
|
||||
Last metadata expiration check performed 0:32:56 ago on Mon Jun 22 16:50:00 2015.
|
||||
Installed Packages
|
||||
GeoIP.x86_64 1.6.5-1.fc22 @System
|
||||
GeoIP-GeoLite-data.noarch 2015.05-1.fc22 @System
|
||||
NetworkManager.x86_64 1:1.0.2-1.fc22 @System
|
||||
NetworkManager-libnm.x86_64 1:1.0.2-1.fc22 @System
|
||||
aajohan-comfortaa-fonts.noarch 2.004-4.fc22 @System
|
||||
acl.x86_64 2.2.52-7.fc22 @System
|
||||
....
|
||||
|
||||
### 13. 你会怎么在一个系统上面使用 YUM 或 DNF 分别安装和升级一个包与一组包? ###
|
||||
|
||||
**回答**:安装一个包(假设是 nano),我们可以这样做,
|
||||
|
||||
# yum install nano
|
||||
|
||||
而安装一组包(假设是 Haskell),我们可以这样做,
|
||||
|
||||
# yum groupinstall 'haskell'
|
||||
|
||||
升级一个包(还是 nano),我们可以这样做,
|
||||
|
||||
# yum update nano
|
||||
|
||||
而为了升级一组包(还是 haskell),我们可以这样做,
|
||||
|
||||
# yum groupupdate 'haskell'
|
||||
|
||||
### 14. 你会如何同步一个系统上面的所有安装软件到稳定发行版? ###
|
||||
|
||||
**回答**:我们可以一个系统上(假设是 CentOS 或者 Fedora)的所有包到稳定发行版,如下,
|
||||
|
||||
# yum distro-sync [在 CentOS/ RHEL]
|
||||
或
|
||||
# dnf distro-sync [在 Fedora 20之后版本]
|
||||
|
||||
似乎来面试之前你做了相当不多的功课,很好!在进一步交谈前,我还想问一两个问题。
|
||||
|
||||
### 15. 你对 YUM 本地仓库熟悉吗?你尝试过建立一个本地 YUM 仓库吗?让我们简单看看你会怎么建立一个本地 YUM 仓库。 ###
|
||||
|
||||
**回答**:首先,感谢你的夸奖。回到问题,我必须承认我对本地 YUM 仓库十分熟悉,并且在我的本地主机上也部署过,作为测试用。
|
||||
|
||||
1、 为了建立本地 YUM 仓库,我们需要安装下面三个包:
|
||||
|
||||
# yum install deltarpm python-deltarpm createrepo
|
||||
|
||||
2、 新建一个目录(假设 /home/$USER/rpm),然后复制 RedHat/CentOS DVD 上的 RPM 包到这个文件夹下
|
||||
|
||||
# mkdir /home/$USER/rpm
|
||||
# cp /path/to/rpm/on/DVD/*.rpm /home/$USER/rpm
|
||||
|
||||
3、 新建基本的库头文件如下。
|
||||
|
||||
# createrepo -v /home/$USER/rpm
|
||||
|
||||
4、 在路径 /etc/yum.repo.d 下创建一个 .repo 文件(如 abc.repo):
|
||||
|
||||
cd /etc/yum.repos.d && cat << EOF abc.repo
|
||||
[local-installation]name=yum-local
|
||||
baseurl=file:///home/$USER/rpm
|
||||
enabled=1
|
||||
gpgcheck=0
|
||||
EOF
|
||||
|
||||
**重要**:用你的用户名替换掉 $USER。
|
||||
|
||||
以上就是创建一个本地 YUM 仓库所要做的全部工作。我们现在可以从这里安装软件了,相对快一些,安全一些,并且最重要的是不需要 Internet 连接。
|
||||
|
||||
好了!面试过程很愉快。我已经问完了。我会将你推荐给 HR。你是一个年轻且十分聪明的候选者,我们很愿意你加入进来。如果你有任何问题,你可以问我。
|
||||
|
||||
**我**:谢谢,这确实是一次愉快的面试,我感到今天非常幸运,可以搞定这次面试...
|
||||
|
||||
显然,不会在这里结束。我问了很多问题,比如他们正在做的项目。我会担任什么角色,负责什么,,,balabalabala
|
||||
|
||||
小伙伴们,这之后的 3 天会经过 HR 轮,到时候所有问题到时候也会被写成文档。希望我当时表现不错。感谢你们所有的祝福。
|
||||
|
||||
谢谢伙伴们和 Tecmint,花时间来编辑我的面试经历。我相信 Tecmint 好伙伴们做了很大的努力,必要要赞一个。当我们与他人分享我们的经历的时候,其他人从我们这里知道了更多,而我们自己则发现了自己的不足。
|
||||
|
||||
这增加了我们的信心。如果你最近也有任何类似的面试经历,别自己蔵着。分享出来!让我们所有人都知道。你可以使用如下的表单来与我们分享你的经历。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-rpm-package-management-interview-questions/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[wi-cuckoo](https://github.com/wi-cuckoo)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
|
||||
[2]:https://linux.cn/article-5718-1.html
|
||||
690
published/20150728 Process of the Linux kernel building.md
Normal file
690
published/20150728 Process of the Linux kernel building.md
Normal file
@ -0,0 +1,690 @@
|
||||
你知道 Linux 内核是如何构建的吗?
|
||||
================================================================================
|
||||
|
||||
###介绍
|
||||
|
||||
我不会告诉你怎么在自己的电脑上去构建、安装一个定制化的 Linux 内核,这样的[资料](https://encrypted.google.com/search?q=building+linux+kernel#q=building+linux+kernel+from+source+code)太多了,它们会对你有帮助。本文会告诉你当你在内核源码路径里敲下`make` 时会发生什么。
|
||||
|
||||
当我刚刚开始学习内核代码时,[Makefile](https://github.com/torvalds/linux/blob/master/Makefile) 是我打开的第一个文件,这个文件看起来真令人害怕 :)。那时候这个 [Makefile](https://en.wikipedia.org/wiki/Make_%28software%29) 还只包含了`1591` 行代码,当我开始写本文时,内核已经是[4.2.0的第三个候选版本](https://github.com/torvalds/linux/commit/52721d9d3334c1cb1f76219a161084094ec634dc) 了。
|
||||
|
||||
这个 makefile 是 Linux 内核代码的根 makefile ,内核构建就始于此处。是的,它的内容很多,但是如果你已经读过内核源代码,你就会发现每个包含代码的目录都有一个自己的 makefile。当然了,我们不会去描述每个代码文件是怎么编译链接的,所以我们将只会挑选一些通用的例子来说明问题。而你不会在这里找到构建内核的文档、如何整洁内核代码、[tags](https://en.wikipedia.org/wiki/Ctags) 的生成和[交叉编译](https://en.wikipedia.org/wiki/Cross_compiler) 相关的说明,等等。我们将从`make` 开始,使用标准的内核配置文件,到生成了内核镜像 [bzImage](https://en.wikipedia.org/wiki/Vmlinux#bzImage) 结束。
|
||||
|
||||
如果你已经很了解 [make](https://en.wikipedia.org/wiki/Make_%28software%29) 工具那是最好,但是我也会描述本文出现的相关代码。
|
||||
|
||||
让我们开始吧!
|
||||
|
||||
|
||||
###编译内核前的准备
|
||||
|
||||
在开始编译前要进行很多准备工作。最主要的就是找到并配置好配置文件,`make` 命令要使用到的参数都需要从这些配置文件获取。现在就让我们深入内核的根 `makefile` 吧
|
||||
|
||||
内核的根 `Makefile` 负责构建两个主要的文件:[vmlinux](https://en.wikipedia.org/wiki/Vmlinux) (内核镜像可执行文件)和模块文件。内核的 [Makefile](https://github.com/torvalds/linux/blob/master/Makefile) 从定义如下变量开始:
|
||||
|
||||
```Makefile
|
||||
VERSION = 4
|
||||
PATCHLEVEL = 2
|
||||
SUBLEVEL = 0
|
||||
EXTRAVERSION = -rc3
|
||||
NAME = Hurr durr I'ma sheep
|
||||
```
|
||||
|
||||
这些变量决定了当前内核的版本,并且被使用在很多不同的地方,比如同一个 `Makefile` 中的 `KERNELVERSION` :
|
||||
|
||||
```Makefile
|
||||
KERNELVERSION = $(VERSION)$(if $(PATCHLEVEL),.$(PATCHLEVEL)$(if $(SUBLEVEL),.$(SUBLEVEL)))$(EXTRAVERSION)
|
||||
```
|
||||
|
||||
接下来我们会看到很多`ifeq` 条件判断语句,它们负责检查传递给 `make` 的参数。内核的 `Makefile` 提供了一个特殊的编译选项 `make help` ,这个选项可以生成所有的可用目标和一些能传给 `make` 的有效的命令行参数。举个例子,`make V=1` 会在构建过程中输出详细的编译信息,第一个 `ifeq` 就是检查传递给 make 的 `V=n` 选项。
|
||||
|
||||
```Makefile
|
||||
ifeq ("$(origin V)", "command line")
|
||||
KBUILD_VERBOSE = $(V)
|
||||
endif
|
||||
ifndef KBUILD_VERBOSE
|
||||
KBUILD_VERBOSE = 0
|
||||
endif
|
||||
|
||||
ifeq ($(KBUILD_VERBOSE),1)
|
||||
quiet =
|
||||
Q =
|
||||
else
|
||||
quiet=quiet_
|
||||
Q = @
|
||||
endif
|
||||
|
||||
export quiet Q KBUILD_VERBOSE
|
||||
```
|
||||
如果 `V=n` 这个选项传给了 `make` ,系统就会给变量 `KBUILD_VERBOSE` 选项附上 `V` 的值,否则的话`KBUILD_VERBOSE` 就会为 `0`。然后系统会检查 `KBUILD_VERBOSE` 的值,以此来决定 `quiet` 和`Q` 的值。符号 `@` 控制命令的输出,如果它被放在一个命令之前,这条命令的输出将会是 `CC scripts/mod/empty.o`,而不是`Compiling .... scripts/mod/empty.o`(LCTT 译注:CC 在 makefile 中一般都是编译命令)。在这段最后,系统导出了所有的变量。
|
||||
|
||||
下一个 `ifeq` 语句检查的是传递给 `make` 的选项 `O=/dir`,这个选项允许在指定的目录 `dir` 输出所有的结果文件:
|
||||
|
||||
```Makefile
|
||||
ifeq ($(KBUILD_SRC),)
|
||||
|
||||
ifeq ("$(origin O)", "command line")
|
||||
KBUILD_OUTPUT := $(O)
|
||||
endif
|
||||
|
||||
ifneq ($(KBUILD_OUTPUT),)
|
||||
saved-output := $(KBUILD_OUTPUT)
|
||||
KBUILD_OUTPUT := $(shell mkdir -p $(KBUILD_OUTPUT) && cd $(KBUILD_OUTPUT) \
|
||||
&& /bin/pwd)
|
||||
$(if $(KBUILD_OUTPUT),, \
|
||||
$(error failed to create output directory "$(saved-output)"))
|
||||
|
||||
sub-make: FORCE
|
||||
$(Q)$(MAKE) -C $(KBUILD_OUTPUT) KBUILD_SRC=$(CURDIR) \
|
||||
-f $(CURDIR)/Makefile $(filter-out _all sub-make,$(MAKECMDGOALS))
|
||||
|
||||
skip-makefile := 1
|
||||
endif # ifneq ($(KBUILD_OUTPUT),)
|
||||
endif # ifeq ($(KBUILD_SRC),)
|
||||
```
|
||||
|
||||
系统会检查变量 `KBUILD_SRC`,它代表内核代码的顶层目录,如果它是空的(第一次执行 makefile 时总是空的),我们会设置变量 `KBUILD_OUTPUT` 为传递给选项 `O` 的值(如果这个选项被传进来了)。下一步会检查变量 `KBUILD_OUTPUT` ,如果已经设置好,那么接下来会做以下几件事:
|
||||
|
||||
* 将变量 `KBUILD_OUTPUT` 的值保存到临时变量 `saved-output`;
|
||||
* 尝试创建给定的输出目录;
|
||||
* 检查创建的输出目录,如果失败了就打印错误;
|
||||
* 如果成功创建了输出目录,那么就在新目录重新执行 `make` 命令(参见选项`-C`)。
|
||||
|
||||
下一个 `ifeq` 语句会检查传递给 make 的选项 `C` 和 `M`:
|
||||
|
||||
```Makefile
|
||||
ifeq ("$(origin C)", "command line")
|
||||
KBUILD_CHECKSRC = $(C)
|
||||
endif
|
||||
ifndef KBUILD_CHECKSRC
|
||||
KBUILD_CHECKSRC = 0
|
||||
endif
|
||||
|
||||
ifeq ("$(origin M)", "command line")
|
||||
KBUILD_EXTMOD := $(M)
|
||||
endif
|
||||
```
|
||||
|
||||
第一个选项 `C` 会告诉 `makefile` 需要使用环境变量 `$CHECK` 提供的工具来检查全部 `c` 代码,默认情况下会使用[sparse](https://en.wikipedia.org/wiki/Sparse)。第二个选项 `M` 会用来编译外部模块(本文不做讨论)。
|
||||
|
||||
系统还会检查变量 `KBUILD_SRC`,如果 `KBUILD_SRC` 没有被设置,系统会设置变量 `srctree` 为`.`:
|
||||
|
||||
```Makefile
|
||||
ifeq ($(KBUILD_SRC),)
|
||||
srctree := .
|
||||
endif
|
||||
|
||||
objtree := .
|
||||
src := $(srctree)
|
||||
obj := $(objtree)
|
||||
|
||||
export srctree objtree VPATH
|
||||
```
|
||||
|
||||
这将会告诉 `Makefile` 内核的源码树就在执行 `make` 命令的目录,然后要设置 `objtree` 和其他变量为这个目录,并且将这些变量导出。接着就是要获取 `SUBARCH` 的值,这个变量代表了当前的系统架构(LCTT 译注:一般都指CPU 架构):
|
||||
|
||||
```Makefile
|
||||
SUBARCH := $(shell uname -m | sed -e s/i.86/x86/ -e s/x86_64/x86/ \
|
||||
-e s/sun4u/sparc64/ \
|
||||
-e s/arm.*/arm/ -e s/sa110/arm/ \
|
||||
-e s/s390x/s390/ -e s/parisc64/parisc/ \
|
||||
-e s/ppc.*/powerpc/ -e s/mips.*/mips/ \
|
||||
-e s/sh[234].*/sh/ -e s/aarch64.*/arm64/ )
|
||||
```
|
||||
|
||||
如你所见,系统执行 [uname](https://en.wikipedia.org/wiki/Uname) 得到机器、操作系统和架构的信息。因为我们得到的是 `uname` 的输出,所以我们需要做一些处理再赋给变量 `SUBARCH` 。获得 `SUBARCH` 之后就要设置`SRCARCH` 和 `hfr-arch`,`SRCARCH` 提供了硬件架构相关代码的目录,`hfr-arch` 提供了相关头文件的目录:
|
||||
|
||||
```Makefile
|
||||
ifeq ($(ARCH),i386)
|
||||
SRCARCH := x86
|
||||
endif
|
||||
ifeq ($(ARCH),x86_64)
|
||||
SRCARCH := x86
|
||||
endif
|
||||
|
||||
hdr-arch := $(SRCARCH)
|
||||
```
|
||||
|
||||
注意:`ARCH` 是 `SUBARCH` 的别名。如果没有设置过代表内核配置文件路径的变量 `KCONFIG_CONFIG`,下一步系统会设置它,默认情况下就是 `.config` :
|
||||
|
||||
```Makefile
|
||||
KCONFIG_CONFIG ?= .config
|
||||
export KCONFIG_CONFIG
|
||||
```
|
||||
|
||||
以及编译内核过程中要用到的 [shell](https://en.wikipedia.org/wiki/Shell_%28computing%29)
|
||||
|
||||
```Makefile
|
||||
CONFIG_SHELL := $(shell if [ -x "$$BASH" ]; then echo $$BASH; \
|
||||
else if [ -x /bin/bash ]; then echo /bin/bash; \
|
||||
else echo sh; fi ; fi)
|
||||
```
|
||||
|
||||
接下来就要设置一组和编译内核的编译器相关的变量。我们会设置主机的 `C` 和 `C++` 的编译器及相关配置项:
|
||||
|
||||
```Makefile
|
||||
HOSTCC = gcc
|
||||
HOSTCXX = g++
|
||||
HOSTCFLAGS = -Wall -Wmissing-prototypes -Wstrict-prototypes -O2 -fomit-frame-pointer -std=gnu89
|
||||
HOSTCXXFLAGS = -O2
|
||||
```
|
||||
|
||||
接下来会去适配代表编译器的变量 `CC`,那为什么还要 `HOST*` 这些变量呢?这是因为 `CC` 是编译内核过程中要使用的目标架构的编译器,但是 `HOSTCC` 是要被用来编译一组 `host` 程序的(下面我们就会看到)。
|
||||
|
||||
然后我们就看到变量 `KBUILD_MODULES` 和 `KBUILD_BUILTIN` 的定义,这两个变量决定了我们要编译什么东西(内核、模块或者两者):
|
||||
|
||||
```Makefile
|
||||
KBUILD_MODULES :=
|
||||
KBUILD_BUILTIN := 1
|
||||
|
||||
ifeq ($(MAKECMDGOALS),modules)
|
||||
KBUILD_BUILTIN := $(if $(CONFIG_MODVERSIONS),1)
|
||||
endif
|
||||
```
|
||||
|
||||
在这我们可以看到这些变量的定义,并且,如果们仅仅传递了 `modules` 给 `make`,变量 `KBUILD_BUILTIN` 会依赖于内核配置选项 `CONFIG_MODVERSIONS`。
|
||||
|
||||
下一步操作是引入下面的文件:
|
||||
|
||||
```Makefile
|
||||
include scripts/Kbuild.include
|
||||
```
|
||||
|
||||
文件 [Kbuild](https://github.com/torvalds/linux/blob/master/Documentation/kbuild/kbuild.txt) 或者又叫做 `Kernel Build System` 是一个用来管理构建内核及其模块的特殊框架。`kbuild` 文件的语法与 makefile 一样。文件[scripts/Kbuild.include](https://github.com/torvalds/linux/blob/master/scripts/Kbuild.include) 为 `kbuild` 系统提供了一些常规的定义。因为我们包含了这个 `kbuild` 文件,我们可以看到和不同工具关联的这些变量的定义,这些工具会在内核和模块编译过程中被使用(比如链接器、编译器、来自 [binutils](http://www.gnu.org/software/binutils/) 的二进制工具包 ,等等):
|
||||
|
||||
```Makefile
|
||||
AS = $(CROSS_COMPILE)as
|
||||
LD = $(CROSS_COMPILE)ld
|
||||
CC = $(CROSS_COMPILE)gcc
|
||||
CPP = $(CC) -E
|
||||
AR = $(CROSS_COMPILE)ar
|
||||
NM = $(CROSS_COMPILE)nm
|
||||
STRIP = $(CROSS_COMPILE)strip
|
||||
OBJCOPY = $(CROSS_COMPILE)objcopy
|
||||
OBJDUMP = $(CROSS_COMPILE)objdump
|
||||
AWK = awk
|
||||
...
|
||||
...
|
||||
...
|
||||
```
|
||||
|
||||
在这些定义好的变量后面,我们又定义了两个变量:`USERINCLUDE` 和 `LINUXINCLUDE`。他们包含了头文件的路径(第一个是给用户用的,第二个是给内核用的):
|
||||
|
||||
```Makefile
|
||||
USERINCLUDE := \
|
||||
-I$(srctree)/arch/$(hdr-arch)/include/uapi \
|
||||
-Iarch/$(hdr-arch)/include/generated/uapi \
|
||||
-I$(srctree)/include/uapi \
|
||||
-Iinclude/generated/uapi \
|
||||
-include $(srctree)/include/linux/kconfig.h
|
||||
|
||||
LINUXINCLUDE := \
|
||||
-I$(srctree)/arch/$(hdr-arch)/include \
|
||||
...
|
||||
```
|
||||
|
||||
以及给 C 编译器的标准标志:
|
||||
|
||||
```Makefile
|
||||
KBUILD_CFLAGS := -Wall -Wundef -Wstrict-prototypes -Wno-trigraphs \
|
||||
-fno-strict-aliasing -fno-common \
|
||||
-Werror-implicit-function-declaration \
|
||||
-Wno-format-security \
|
||||
-std=gnu89
|
||||
```
|
||||
|
||||
这并不是最终确定的编译器标志,它们还可以在其他 makefile 里面更新(比如 `arch/` 里面的 kbuild)。变量定义完之后,全部会被导出供其他 makefile 使用。
|
||||
|
||||
下面的两个变量 `RCS_FIND_IGNORE` 和 `RCS_TAR_IGNORE` 包含了被版本控制系统忽略的文件:
|
||||
|
||||
```Makefile
|
||||
export RCS_FIND_IGNORE := \( -name SCCS -o -name BitKeeper -o -name .svn -o \
|
||||
-name CVS -o -name .pc -o -name .hg -o -name .git \) \
|
||||
-prune -o
|
||||
export RCS_TAR_IGNORE := --exclude SCCS --exclude BitKeeper --exclude .svn \
|
||||
--exclude CVS --exclude .pc --exclude .hg --exclude .git
|
||||
```
|
||||
|
||||
这就是全部了,我们已经完成了所有的准备工作,下一个点就是如果构建`vmlinux`。
|
||||
|
||||
###直面内核构建
|
||||
|
||||
现在我们已经完成了所有的准备工作,根 makefile(注:内核根目录下的 makefile)的下一步工作就是和编译内核相关的了。在这之前,我们不会在终端看到 `make` 命令输出的任何东西。但是现在编译的第一步开始了,这里我们需要从内核根 makefile 的 [598](https://github.com/torvalds/linux/blob/master/Makefile#L598) 行开始,这里可以看到目标`vmlinux`:
|
||||
|
||||
```Makefile
|
||||
all: vmlinux
|
||||
include arch/$(SRCARCH)/Makefile
|
||||
```
|
||||
|
||||
不要操心我们略过的从 `export RCS_FIND_IGNORE.....` 到 `all: vmlinux.....` 这一部分 makefile 代码,他们只是负责根据各种配置文件(`make *.config`)生成不同目标内核的,因为之前我就说了这一部分我们只讨论构建内核的通用途径。
|
||||
|
||||
目标 `all:` 是在命令行如果不指定具体目标时默认使用的目标。你可以看到这里包含了架构相关的 makefile(在这里就指的是 [arch/x86/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/Makefile))。从这一时刻起,我们会从这个 makefile 继续进行下去。如我们所见,目标 `all` 依赖于根 makefile 后面声明的 `vmlinux`:
|
||||
|
||||
```Makefile
|
||||
vmlinux: scripts/link-vmlinux.sh $(vmlinux-deps) FORCE
|
||||
```
|
||||
|
||||
`vmlinux` 是 linux 内核的静态链接可执行文件格式。脚本 [scripts/link-vmlinux.sh](https://github.com/torvalds/linux/blob/master/scripts/link-vmlinux.sh) 把不同的编译好的子模块链接到一起形成了 vmlinux。
|
||||
|
||||
第二个目标是 `vmlinux-deps`,它的定义如下:
|
||||
|
||||
```Makefile
|
||||
vmlinux-deps := $(KBUILD_LDS) $(KBUILD_VMLINUX_INIT) $(KBUILD_VMLINUX_MAIN)
|
||||
```
|
||||
|
||||
它是由内核代码下的每个顶级目录的 `built-in.o` 组成的。之后我们还会检查内核所有的目录,`kbuild` 会编译各个目录下所有的对应 `$(obj-y)` 的源文件。接着调用 `$(LD) -r` 把这些文件合并到一个 `build-in.o` 文件里。此时我们还没有`vmlinux-deps`,所以目标 `vmlinux` 现在还不会被构建。对我而言 `vmlinux-deps` 包含下面的文件:
|
||||
|
||||
```
|
||||
arch/x86/kernel/vmlinux.lds arch/x86/kernel/head_64.o
|
||||
arch/x86/kernel/head64.o arch/x86/kernel/head.o
|
||||
init/built-in.o usr/built-in.o
|
||||
arch/x86/built-in.o kernel/built-in.o
|
||||
mm/built-in.o fs/built-in.o
|
||||
ipc/built-in.o security/built-in.o
|
||||
crypto/built-in.o block/built-in.o
|
||||
lib/lib.a arch/x86/lib/lib.a
|
||||
lib/built-in.o arch/x86/lib/built-in.o
|
||||
drivers/built-in.o sound/built-in.o
|
||||
firmware/built-in.o arch/x86/pci/built-in.o
|
||||
arch/x86/power/built-in.o arch/x86/video/built-in.o
|
||||
net/built-in.o
|
||||
```
|
||||
|
||||
下一个可以被执行的目标如下:
|
||||
|
||||
```Makefile
|
||||
$(sort $(vmlinux-deps)): $(vmlinux-dirs) ;
|
||||
$(vmlinux-dirs): prepare scripts
|
||||
$(Q)$(MAKE) $(build)=$@
|
||||
```
|
||||
|
||||
就像我们看到的,`vmlinux-dir` 依赖于两部分:`prepare` 和 `scripts`。第一个 `prepare` 定义在内核的根 `makefile` 中,准备工作分成三个阶段:
|
||||
|
||||
```Makefile
|
||||
prepare: prepare0
|
||||
prepare0: archprepare FORCE
|
||||
$(Q)$(MAKE) $(build)=.
|
||||
archprepare: archheaders archscripts prepare1 scripts_basic
|
||||
|
||||
prepare1: prepare2 $(version_h) include/generated/utsrelease.h \
|
||||
include/config/auto.conf
|
||||
$(cmd_crmodverdir)
|
||||
prepare2: prepare3 outputmakefile asm-generic
|
||||
```
|
||||
|
||||
第一个 `prepare0` 展开到 `archprepare` ,后者又展开到 `archheader` 和 `archscripts`,这两个变量定义在 `x86_64` 相关的 [Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/Makefile)。让我们看看这个文件。`x86_64` 特定的 makefile 从变量定义开始,这些变量都是和特定架构的配置文件 ([defconfig](https://github.com/torvalds/linux/tree/master/arch/x86/configs),等等)有关联。在定义了编译 [16-bit](https://en.wikipedia.org/wiki/Real_mode) 代码的编译选项之后,根据变量 `BITS` 的值,如果是 `32`, 汇编代码、链接器、以及其它很多东西(全部的定义都可以在[arch/x86/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/Makefile)找到)对应的参数就是 `i386`,而 `64` 就对应的是 `x86_84`。
|
||||
|
||||
第一个目标是 makefile 生成的系统调用列表(syscall table)中的 `archheaders` :
|
||||
|
||||
```Makefile
|
||||
archheaders:
|
||||
$(Q)$(MAKE) $(build)=arch/x86/entry/syscalls all
|
||||
```
|
||||
|
||||
第二个目标是 makefile 里的 `archscripts`:
|
||||
|
||||
```Makefile
|
||||
archscripts: scripts_basic
|
||||
$(Q)$(MAKE) $(build)=arch/x86/tools relocs
|
||||
```
|
||||
|
||||
我们可以看到 `archscripts` 是依赖于根 [Makefile](https://github.com/torvalds/linux/blob/master/Makefile)里的`scripts_basic` 。首先我们可以看出 `scripts_basic` 是按照 [scripts/basic](https://github.com/torvalds/linux/blob/master/scripts/basic/Makefile) 的 makefile 执行 make 的:
|
||||
|
||||
```Maklefile
|
||||
scripts_basic:
|
||||
$(Q)$(MAKE) $(build)=scripts/basic
|
||||
```
|
||||
|
||||
`scripts/basic/Makefile` 包含了编译两个主机程序 `fixdep` 和 `bin2` 的目标:
|
||||
|
||||
```Makefile
|
||||
hostprogs-y := fixdep
|
||||
hostprogs-$(CONFIG_BUILD_BIN2C) += bin2c
|
||||
always := $(hostprogs-y)
|
||||
|
||||
$(addprefix $(obj)/,$(filter-out fixdep,$(always))): $(obj)/fixdep
|
||||
```
|
||||
|
||||
第一个工具是 `fixdep`:用来优化 [gcc](https://gcc.gnu.org/) 生成的依赖列表,然后在重新编译源文件的时候告诉make。第二个工具是 `bin2c`,它依赖于内核配置选项 `CONFIG_BUILD_BIN2C`,并且它是一个用来将标准输入接口(LCTT 译注:即 stdin)收到的二进制流通过标准输出接口(即:stdout)转换成 C 头文件的非常小的 C 程序。你可能注意到这里有些奇怪的标志,如 `hostprogs-y` 等。这个标志用于所有的 `kbuild` 文件,更多的信息你可以从[documentation](https://github.com/torvalds/linux/blob/master/Documentation/kbuild/makefiles.txt) 获得。在我们这里, `hostprogs-y` 告诉 `kbuild` 这里有个名为 `fixed` 的程序,这个程序会通过和 `Makefile` 相同目录的 `fixdep.c` 编译而来。
|
||||
|
||||
执行 make 之后,终端的第一个输出就是 `kbuild` 的结果:
|
||||
|
||||
```
|
||||
$ make
|
||||
HOSTCC scripts/basic/fixdep
|
||||
```
|
||||
|
||||
当目标 `script_basic` 被执行,目标 `archscripts` 就会 make [arch/x86/tools](https://github.com/torvalds/linux/blob/master/arch/x86/tools/Makefile) 下的 makefile 和目标 `relocs`:
|
||||
|
||||
```Makefile
|
||||
$(Q)$(MAKE) $(build)=arch/x86/tools relocs
|
||||
```
|
||||
|
||||
包含了[重定位](https://en.wikipedia.org/wiki/Relocation_%28computing%29) 的信息的代码 `relocs_32.c` 和 `relocs_64.c` 将会被编译,这可以在`make` 的输出中看到:
|
||||
|
||||
```Makefile
|
||||
HOSTCC arch/x86/tools/relocs_32.o
|
||||
HOSTCC arch/x86/tools/relocs_64.o
|
||||
HOSTCC arch/x86/tools/relocs_common.o
|
||||
HOSTLD arch/x86/tools/relocs
|
||||
```
|
||||
|
||||
在编译完 `relocs.c` 之后会检查 `version.h`:
|
||||
|
||||
```Makefile
|
||||
$(version_h): $(srctree)/Makefile FORCE
|
||||
$(call filechk,version.h)
|
||||
$(Q)rm -f $(old_version_h)
|
||||
```
|
||||
|
||||
我们可以在输出看到它:
|
||||
|
||||
```
|
||||
CHK include/config/kernel.release
|
||||
```
|
||||
|
||||
以及在内核的根 Makefiel 使用 `arch/x86/include/generated/asm` 的目标 `asm-generic` 来构建 `generic` 汇编头文件。在目标 `asm-generic` 之后,`archprepare` 就完成了,所以目标 `prepare0` 会接着被执行,如我上面所写:
|
||||
|
||||
```Makefile
|
||||
prepare0: archprepare FORCE
|
||||
$(Q)$(MAKE) $(build)=.
|
||||
```
|
||||
|
||||
注意 `build`,它是定义在文件 [scripts/Kbuild.include](https://github.com/torvalds/linux/blob/master/scripts/Kbuild.include),内容是这样的:
|
||||
|
||||
```Makefile
|
||||
build := -f $(srctree)/scripts/Makefile.build obj
|
||||
```
|
||||
|
||||
或者在我们的例子中,它就是当前源码目录路径:`.`:
|
||||
|
||||
```Makefile
|
||||
$(Q)$(MAKE) -f $(srctree)/scripts/Makefile.build obj=.
|
||||
```
|
||||
|
||||
脚本 [scripts/Makefile.build](https://github.com/torvalds/linux/blob/master/scripts/Makefile.build) 通过参数 `obj` 给定的目录找到 `Kbuild` 文件,然后引入 `kbuild` 文件:
|
||||
|
||||
```Makefile
|
||||
include $(kbuild-file)
|
||||
```
|
||||
|
||||
并根据这个构建目标。我们这里 `.` 包含了生成 `kernel/bounds.s` 和 `arch/x86/kernel/asm-offsets.s` 的 [Kbuild](https://github.com/torvalds/linux/blob/master/Kbuild) 文件。在此之后,目标 `prepare` 就完成了它的工作。 `vmlinux-dirs` 也依赖于第二个目标 `scripts` ,它会编译接下来的几个程序:`filealias`,`mk_elfconfig`,`modpost` 等等。之后,`scripts/host-programs` 就可以开始编译我们的目标 `vmlinux-dirs` 了。
|
||||
|
||||
首先,我们先来理解一下 `vmlinux-dirs` 都包含了那些东西。在我们的例子中它包含了下列内核目录的路径:
|
||||
|
||||
```
|
||||
init usr arch/x86 kernel mm fs ipc security crypto block
|
||||
drivers sound firmware arch/x86/pci arch/x86/power
|
||||
arch/x86/video net lib arch/x86/lib
|
||||
```
|
||||
|
||||
我们可以在内核的根 [Makefile](https://github.com/torvalds/linux/blob/master/Makefile) 里找到 `vmlinux-dirs` 的定义:
|
||||
|
||||
```Makefile
|
||||
vmlinux-dirs := $(patsubst %/,%,$(filter %/, $(init-y) $(init-m) \
|
||||
$(core-y) $(core-m) $(drivers-y) $(drivers-m) \
|
||||
$(net-y) $(net-m) $(libs-y) $(libs-m)))
|
||||
|
||||
init-y := init/
|
||||
drivers-y := drivers/ sound/ firmware/
|
||||
net-y := net/
|
||||
libs-y := lib/
|
||||
...
|
||||
...
|
||||
...
|
||||
```
|
||||
|
||||
这里我们借助函数 `patsubst` 和 `filter`去掉了每个目录路径里的符号 `/`,并且把结果放到 `vmlinux-dirs` 里。所以我们就有了 `vmlinux-dirs` 里的目录列表,以及下面的代码:
|
||||
|
||||
```Makefile
|
||||
$(vmlinux-dirs): prepare scripts
|
||||
$(Q)$(MAKE) $(build)=$@
|
||||
```
|
||||
|
||||
符号 `$@` 在这里代表了 `vmlinux-dirs`,这就表明程序会递归遍历从 `vmlinux-dirs` 以及它内部的全部目录(依赖于配置),并且在对应的目录下执行 `make` 命令。我们可以在输出看到结果:
|
||||
|
||||
```
|
||||
CC init/main.o
|
||||
CHK include/generated/compile.h
|
||||
CC init/version.o
|
||||
CC init/do_mounts.o
|
||||
...
|
||||
CC arch/x86/crypto/glue_helper.o
|
||||
AS arch/x86/crypto/aes-x86_64-asm_64.o
|
||||
CC arch/x86/crypto/aes_glue.o
|
||||
...
|
||||
AS arch/x86/entry/entry_64.o
|
||||
AS arch/x86/entry/thunk_64.o
|
||||
CC arch/x86/entry/syscall_64.o
|
||||
```
|
||||
|
||||
每个目录下的源代码将会被编译并且链接到 `built-io.o` 里:
|
||||
|
||||
```
|
||||
$ find . -name built-in.o
|
||||
./arch/x86/crypto/built-in.o
|
||||
./arch/x86/crypto/sha-mb/built-in.o
|
||||
./arch/x86/net/built-in.o
|
||||
./init/built-in.o
|
||||
./usr/built-in.o
|
||||
...
|
||||
...
|
||||
```
|
||||
|
||||
好了,所有的 `built-in.o` 都构建完了,现在我们回到目标 `vmlinux` 上。你应该还记得,目标 `vmlinux` 是在内核的根makefile 里。在链接 `vmlinux` 之前,系统会构建 [samples](https://github.com/torvalds/linux/tree/master/samples), [Documentation](https://github.com/torvalds/linux/tree/master/Documentation) 等等,但是如上文所述,我不会在本文描述这些。
|
||||
|
||||
```Makefile
|
||||
vmlinux: scripts/link-vmlinux.sh $(vmlinux-deps) FORCE
|
||||
...
|
||||
...
|
||||
+$(call if_changed,link-vmlinux)
|
||||
```
|
||||
|
||||
你可以看到,调用脚本 [scripts/link-vmlinux.sh](https://github.com/torvalds/linux/blob/master/scripts/link-vmlinux.sh) 的主要目的是把所有的 `built-in.o` 链接成一个静态可执行文件,和生成 [System.map](https://en.wikipedia.org/wiki/System.map)。 最后我们来看看下面的输出:
|
||||
|
||||
```
|
||||
LINK vmlinux
|
||||
LD vmlinux.o
|
||||
MODPOST vmlinux.o
|
||||
GEN .version
|
||||
CHK include/generated/compile.h
|
||||
UPD include/generated/compile.h
|
||||
CC init/version.o
|
||||
LD init/built-in.o
|
||||
KSYM .tmp_kallsyms1.o
|
||||
KSYM .tmp_kallsyms2.o
|
||||
LD vmlinux
|
||||
SORTEX vmlinux
|
||||
SYSMAP System.map
|
||||
```
|
||||
|
||||
`vmlinux` 和`System.map` 生成在内核源码树根目录下。
|
||||
|
||||
```
|
||||
$ ls vmlinux System.map
|
||||
System.map vmlinux
|
||||
```
|
||||
|
||||
这就是全部了,`vmlinux` 构建好了,下一步就是创建 [bzImage](https://en.wikipedia.org/wiki/Vmlinux#bzImage).
|
||||
|
||||
###制作bzImage
|
||||
|
||||
`bzImage` 就是压缩了的 linux 内核镜像。我们可以在构建了 `vmlinux` 之后通过执行 `make bzImage` 获得`bzImage`。同时我们可以仅仅执行 `make` 而不带任何参数也可以生成 `bzImage` ,因为它是在 [arch/x86/kernel/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/Makefile) 里预定义的、默认生成的镜像:
|
||||
|
||||
```Makefile
|
||||
all: bzImage
|
||||
```
|
||||
|
||||
让我们看看这个目标,它能帮助我们理解这个镜像是怎么构建的。我已经说过了 `bzImage` 是被定义在 [arch/x86/kernel/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/Makefile),定义如下:
|
||||
|
||||
```Makefile
|
||||
bzImage: vmlinux
|
||||
$(Q)$(MAKE) $(build)=$(boot) $(KBUILD_IMAGE)
|
||||
$(Q)mkdir -p $(objtree)/arch/$(UTS_MACHINE)/boot
|
||||
$(Q)ln -fsn ../../x86/boot/bzImage $(objtree)/arch/$(UTS_MACHINE)/boot/$@
|
||||
```
|
||||
|
||||
在这里我们可以看到第一次为 boot 目录执行 `make`,在我们的例子里是这样的:
|
||||
|
||||
```Makefile
|
||||
boot := arch/x86/boot
|
||||
```
|
||||
|
||||
现在的主要目标是编译目录 `arch/x86/boot` 和 `arch/x86/boot/compressed` 的代码,构建 `setup.bin` 和 `vmlinux.bin`,最后用这两个文件生成 `bzImage`。第一个目标是定义在 [arch/x86/boot/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/boot/Makefile) 的 `$(obj)/setup.elf`:
|
||||
|
||||
```Makefile
|
||||
$(obj)/setup.elf: $(src)/setup.ld $(SETUP_OBJS) FORCE
|
||||
$(call if_changed,ld)
|
||||
```
|
||||
|
||||
我们已经在目录 `arch/x86/boot` 有了链接脚本 `setup.ld`,和扩展到 `boot` 目录下全部源代码的变量 `SETUP_OBJS` 。我们可以看看第一个输出:
|
||||
|
||||
```Makefile
|
||||
AS arch/x86/boot/bioscall.o
|
||||
CC arch/x86/boot/cmdline.o
|
||||
AS arch/x86/boot/copy.o
|
||||
HOSTCC arch/x86/boot/mkcpustr
|
||||
CPUSTR arch/x86/boot/cpustr.h
|
||||
CC arch/x86/boot/cpu.o
|
||||
CC arch/x86/boot/cpuflags.o
|
||||
CC arch/x86/boot/cpucheck.o
|
||||
CC arch/x86/boot/early_serial_console.o
|
||||
CC arch/x86/boot/edd.o
|
||||
```
|
||||
|
||||
下一个源码文件是 [arch/x86/boot/header.S](https://github.com/torvalds/linux/blob/master/arch/x86/boot/header.S),但是我们不能现在就编译它,因为这个目标依赖于下面两个头文件:
|
||||
|
||||
```Makefile
|
||||
$(obj)/header.o: $(obj)/voffset.h $(obj)/zoffset.h
|
||||
```
|
||||
|
||||
第一个头文件 `voffset.h` 是使用 `sed` 脚本生成的,包含用 `nm` 工具从 `vmlinux` 获取的两个地址:
|
||||
|
||||
```C
|
||||
#define VO__end 0xffffffff82ab0000
|
||||
#define VO__text 0xffffffff81000000
|
||||
```
|
||||
|
||||
这两个地址是内核的起始和结束地址。第二个头文件 `zoffset.h` 在 [arch/x86/boot/compressed/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/boot/compressed/Makefile) 可以看出是依赖于目标 `vmlinux`的:
|
||||
|
||||
```Makefile
|
||||
$(obj)/zoffset.h: $(obj)/compressed/vmlinux FORCE
|
||||
$(call if_changed,zoffset)
|
||||
```
|
||||
|
||||
目标 `$(obj)/compressed/vmlinux` 依赖于 `vmlinux-objs-y` —— 说明需要编译目录 [arch/x86/boot/compressed](https://github.com/torvalds/linux/tree/master/arch/x86/boot/compressed) 下的源代码,然后生成 `vmlinux.bin`、`vmlinux.bin.bz2`,和编译工具 `mkpiggy`。我们可以在下面的输出看出来:
|
||||
|
||||
```Makefile
|
||||
LDS arch/x86/boot/compressed/vmlinux.lds
|
||||
AS arch/x86/boot/compressed/head_64.o
|
||||
CC arch/x86/boot/compressed/misc.o
|
||||
CC arch/x86/boot/compressed/string.o
|
||||
CC arch/x86/boot/compressed/cmdline.o
|
||||
OBJCOPY arch/x86/boot/compressed/vmlinux.bin
|
||||
BZIP2 arch/x86/boot/compressed/vmlinux.bin.bz2
|
||||
HOSTCC arch/x86/boot/compressed/mkpiggy
|
||||
```
|
||||
|
||||
`vmlinux.bin` 是去掉了调试信息和注释的 `vmlinux` 二进制文件,加上了占用了 `u32` (LCTT 译注:即4-Byte)的长度信息的 `vmlinux.bin.all` 压缩后就是 `vmlinux.bin.bz2`。其中 `vmlinux.bin.all` 包含了 `vmlinux.bin` 和`vmlinux.relocs`(LCTT 译注:vmlinux 的重定位信息),其中 `vmlinux.relocs` 是 `vmlinux` 经过程序 `relocs` 处理之后的 `vmlinux` 镜像(见上文所述)。我们现在已经获取到了这些文件,汇编文件 `piggy.S` 将会被 `mkpiggy` 生成、然后编译:
|
||||
|
||||
```Makefile
|
||||
MKPIGGY arch/x86/boot/compressed/piggy.S
|
||||
AS arch/x86/boot/compressed/piggy.o
|
||||
```
|
||||
|
||||
这个汇编文件会包含经过计算得来的、压缩内核的偏移信息。处理完这个汇编文件,我们就可以看到 `zoffset` 生成了:
|
||||
|
||||
```Makefile
|
||||
ZOFFSET arch/x86/boot/zoffset.h
|
||||
```
|
||||
|
||||
现在 `zoffset.h` 和 `voffset.h` 已经生成了,[arch/x86/boot](https://github.com/torvalds/linux/tree/master/arch/x86/boot/) 里的源文件可以继续编译:
|
||||
|
||||
```Makefile
|
||||
AS arch/x86/boot/header.o
|
||||
CC arch/x86/boot/main.o
|
||||
CC arch/x86/boot/mca.o
|
||||
CC arch/x86/boot/memory.o
|
||||
CC arch/x86/boot/pm.o
|
||||
AS arch/x86/boot/pmjump.o
|
||||
CC arch/x86/boot/printf.o
|
||||
CC arch/x86/boot/regs.o
|
||||
CC arch/x86/boot/string.o
|
||||
CC arch/x86/boot/tty.o
|
||||
CC arch/x86/boot/video.o
|
||||
CC arch/x86/boot/video-mode.o
|
||||
CC arch/x86/boot/video-vga.o
|
||||
CC arch/x86/boot/video-vesa.o
|
||||
CC arch/x86/boot/video-bios.o
|
||||
```
|
||||
|
||||
所有的源代码会被编译,他们最终会被链接到 `setup.elf` :
|
||||
|
||||
```Makefile
|
||||
LD arch/x86/boot/setup.elf
|
||||
```
|
||||
|
||||
或者:
|
||||
|
||||
```
|
||||
ld -m elf_x86_64 -T arch/x86/boot/setup.ld arch/x86/boot/a20.o arch/x86/boot/bioscall.o arch/x86/boot/cmdline.o arch/x86/boot/copy.o arch/x86/boot/cpu.o arch/x86/boot/cpuflags.o arch/x86/boot/cpucheck.o arch/x86/boot/early_serial_console.o arch/x86/boot/edd.o arch/x86/boot/header.o arch/x86/boot/main.o arch/x86/boot/mca.o arch/x86/boot/memory.o arch/x86/boot/pm.o arch/x86/boot/pmjump.o arch/x86/boot/printf.o arch/x86/boot/regs.o arch/x86/boot/string.o arch/x86/boot/tty.o arch/x86/boot/video.o arch/x86/boot/video-mode.o arch/x86/boot/version.o arch/x86/boot/video-vga.o arch/x86/boot/video-vesa.o arch/x86/boot/video-bios.o -o arch/x86/boot/setup.elf
|
||||
```
|
||||
|
||||
最后的两件事是创建包含目录 `arch/x86/boot/*` 下的编译过的代码的 `setup.bin`:
|
||||
|
||||
```
|
||||
objcopy -O binary arch/x86/boot/setup.elf arch/x86/boot/setup.bin
|
||||
```
|
||||
|
||||
以及从 `vmlinux` 生成 `vmlinux.bin` :
|
||||
|
||||
```
|
||||
objcopy -O binary -R .note -R .comment -S arch/x86/boot/compressed/vmlinux arch/x86/boot/vmlinux.bin
|
||||
```
|
||||
|
||||
最最后,我们编译主机程序 [arch/x86/boot/tools/build.c](https://github.com/torvalds/linux/blob/master/arch/x86/boot/tools/build.c),它将会用来把 `setup.bin` 和 `vmlinux.bin` 打包成 `bzImage`:
|
||||
|
||||
```
|
||||
arch/x86/boot/tools/build arch/x86/boot/setup.bin arch/x86/boot/vmlinux.bin arch/x86/boot/zoffset.h arch/x86/boot/bzImage
|
||||
```
|
||||
|
||||
实际上 `bzImage` 就是把 `setup.bin` 和 `vmlinux.bin` 连接到一起。最终我们会看到输出结果,就和那些用源码编译过内核的同行的结果一样:
|
||||
|
||||
```
|
||||
Setup is 16268 bytes (padded to 16384 bytes).
|
||||
System is 4704 kB
|
||||
CRC 94a88f9a
|
||||
Kernel: arch/x86/boot/bzImage is ready (#5)
|
||||
```
|
||||
|
||||
|
||||
全部结束。
|
||||
|
||||
###结论
|
||||
|
||||
这就是本文的结尾部分。本文我们了解了编译内核的全部步骤:从执行 `make` 命令开始,到最后生成 `bzImage`。我知道,linux 内核的 makefile 和构建 linux 的过程第一眼看起来可能比较迷惑,但是这并不是很难。希望本文可以帮助你理解构建 linux 内核的整个流程。
|
||||
|
||||
|
||||
###链接
|
||||
|
||||
* [GNU make util](https://en.wikipedia.org/wiki/Make_%28software%29)
|
||||
* [Linux kernel top Makefile](https://github.com/torvalds/linux/blob/master/Makefile)
|
||||
* [cross-compilation](https://en.wikipedia.org/wiki/Cross_compiler)
|
||||
* [Ctags](https://en.wikipedia.org/wiki/Ctags)
|
||||
* [sparse](https://en.wikipedia.org/wiki/Sparse)
|
||||
* [bzImage](https://en.wikipedia.org/wiki/Vmlinux#bzImage)
|
||||
* [uname](https://en.wikipedia.org/wiki/Uname)
|
||||
* [shell](https://en.wikipedia.org/wiki/Shell_%28computing%29)
|
||||
* [Kbuild](https://github.com/torvalds/linux/blob/master/Documentation/kbuild/kbuild.txt)
|
||||
* [binutils](http://www.gnu.org/software/binutils/)
|
||||
* [gcc](https://gcc.gnu.org/)
|
||||
* [Documentation](https://github.com/torvalds/linux/blob/master/Documentation/kbuild/makefiles.txt)
|
||||
* [System.map](https://en.wikipedia.org/wiki/System.map)
|
||||
* [Relocation](https://en.wikipedia.org/wiki/Relocation_%28computing%29)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://github.com/0xAX/linux-insides/blob/master/Misc/how_kernel_compiled.md
|
||||
|
||||
译者:[oska874](https://github.com/oska874)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,10 +1,9 @@
|
||||
|
||||
在 Linux 中怎样将 MySQL 迁移到 MariaDB 上
|
||||
================================================================================
|
||||
|
||||
自从甲骨文收购 MySQL 后,很多 MySQL 的开发者和用户放弃了 MySQL 由于甲骨文对 MySQL 的开发和维护更多倾向于闭门的立场。在社区驱动下,促使更多人移到 MySQL 的另一个分支中,叫 MariaDB。在原有 MySQL 开发人员的带领下,MariaDB 的开发遵循开源的理念,并确保 [它的二进制格式与 MySQL 兼容][1]。Linux 发行版如 Red Hat 家族(Fedora,CentOS,RHEL),Ubuntu 和Mint,openSUSE 和 Debian 已经开始使用,并支持 MariaDB 作为 MySQL 的简易替换品。
|
||||
自从甲骨文收购 MySQL 后,由于甲骨文对 MySQL 的开发和维护更多倾向于闭门的立场,很多 MySQL 的开发者和用户放弃了 MySQL。在社区驱动下,促使更多人移到 MySQL 的另一个叫 MariaDB 的分支。在原有 MySQL 开发人员的带领下,MariaDB 的开发遵循开源的理念,并确保[它的二进制格式与 MySQL 兼容][1]。Linux 发行版如 Red Hat 家族(Fedora,CentOS,RHEL),Ubuntu 和 Mint,openSUSE 和 Debian 已经开始使用,并支持 MariaDB 作为 MySQL 的直接替换品。
|
||||
|
||||
如果想要将 MySQL 中的数据库迁移到 MariaDB 中,这篇文章就是你所期待的。幸运的是,由于他们的二进制兼容性,MySQL-to-MariaDB 迁移过程是非常简单的。如果你按照下面的步骤,将 MySQL 迁移到 MariaDB 会是无痛的。
|
||||
如果你想要将 MySQL 中的数据库迁移到 MariaDB 中,这篇文章就是你所期待的。幸运的是,由于他们的二进制兼容性,MySQL-to-MariaDB 迁移过程是非常简单的。如果你按照下面的步骤,将 MySQL 迁移到 MariaDB 会是无痛的。
|
||||
|
||||
### 准备 MySQL 数据库和表 ###
|
||||
|
||||
@ -69,7 +68,7 @@
|
||||
|
||||
### 安装 MariaDB ###
|
||||
|
||||
在 CentOS/RHEL 7和Ubuntu(14.04或更高版本)上,最新的 MariaDB 包含在其官方源。在 Fedora 上,自19版本后 MariaDB 已经替代了 MySQL。如果你使用的是旧版本或 LTS 类型如 Ubuntu 13.10 或更早的,你仍然可以通过添加其官方仓库来安装 MariaDB。
|
||||
在 CentOS/RHEL 7和Ubuntu(14.04或更高版本)上,最新的 MariaDB 已经包含在其官方源。在 Fedora 上,自19 版本后 MariaDB 已经替代了 MySQL。如果你使用的是旧版本或 LTS 类型如 Ubuntu 13.10 或更早的,你仍然可以通过添加其官方仓库来安装 MariaDB。
|
||||
|
||||
[MariaDB 网站][2] 提供了一个在线工具帮助你依据你的 Linux 发行版中来添加 MariaDB 的官方仓库。此工具为 openSUSE, Arch Linux, Mageia, Fedora, CentOS, RedHat, Mint, Ubuntu, 和 Debian 提供了 MariaDB 的官方仓库.
|
||||
|
||||
@ -103,7 +102,7 @@
|
||||
|
||||
$ sudo yum install MariaDB-server MariaDB-client
|
||||
|
||||
安装了所有必要的软件包后,你可能会被要求为 root 用户创建一个新密码。设置 root 的密码后,别忘了恢复备份的 my.cnf 文件。
|
||||
安装了所有必要的软件包后,你可能会被要求为 MariaDB 的 root 用户创建一个新密码。设置 root 的密码后,别忘了恢复备份的 my.cnf 文件。
|
||||
|
||||
$ sudo cp /opt/my.cnf /etc/mysql/
|
||||
|
||||
@ -111,7 +110,7 @@
|
||||
|
||||
$ sudo service mariadb start
|
||||
|
||||
或者:
|
||||
或:
|
||||
|
||||
$ sudo systemctl start mariadb
|
||||
|
||||
@ -141,13 +140,13 @@
|
||||
|
||||
### 结论 ###
|
||||
|
||||
如你在本教程中看到的,MySQL-to-MariaDB 的迁移并不难。MariaDB 相比 MySQL 有很多新的功能,你应该知道的。至于配置方面,在我的测试情况下,我只是将我旧的 MySQL 配置文件(my.cnf)作为 MariaDB 的配置文件,导入过程完全没有出现任何问题。对于配置文件,我建议你在迁移之前请仔细阅读MariaDB 配置选项的文件,特别是如果你正在使用 MySQL 的特殊配置。
|
||||
如你在本教程中看到的,MySQL-to-MariaDB 的迁移并不难。你应该知道,MariaDB 相比 MySQL 有很多新的功能。至于配置方面,在我的测试情况下,我只是将我旧的 MySQL 配置文件(my.cnf)作为 MariaDB 的配置文件,导入过程完全没有出现任何问题。对于配置文件,我建议你在迁移之前请仔细阅读 MariaDB 配置选项的文件,特别是如果你正在使用 MySQL 的特定配置。
|
||||
|
||||
如果你正在运行更复杂的配置有海量的数据库和表,包括群集或主从复制,看一看 Mozilla IT 和 Operations 团队的 [更详细的指南][3] ,或者 [官方的 MariaDB 文档][4]。
|
||||
如果你正在运行有海量的表、包括群集或主从复制的数据库的复杂配置,看一看 Mozilla IT 和 Operations 团队的 [更详细的指南][3] ,或者 [官方的 MariaDB 文档][4]。
|
||||
|
||||
### 故障排除 ###
|
||||
|
||||
1.在运行 mysqldump 命令备份数据库时出现以下错误。
|
||||
1、 在运行 mysqldump 命令备份数据库时出现以下错误。
|
||||
|
||||
$ mysqldump --all-databases --user=root --password --master-data > backupdb.sql
|
||||
|
||||
@ -155,7 +154,7 @@
|
||||
|
||||
mysqldump: Error: Binlogging on server not active
|
||||
|
||||
通过使用 "--master-data",你要在导出的输出中包含二进制日志信息,这对于数据库的复制和恢复是有用的。但是,二进制日志未在 MySQL 服务器启用。要解决这个错误,修改 my.cnf 文件,并在 [mysqld] 部分添加下面的选项。
|
||||
通过使用 "--master-data",你可以在导出的输出中包含二进制日志信息,这对于数据库的复制和恢复是有用的。但是,二进制日志未在 MySQL 服务器启用。要解决这个错误,修改 my.cnf 文件,并在 [mysqld] 部分添加下面的选项。
|
||||
|
||||
log-bin=mysql-bin
|
||||
|
||||
@ -176,8 +175,8 @@
|
||||
via: http://xmodulo.com/migrate-mysql-to-mariadb-linux.html
|
||||
|
||||
作者:[Kristophorus Hadiono][a]
|
||||
译者:[strugglingyouth](https://github.com/译者ID)
|
||||
校对:[strugglingyouth](https://github.com/校对者ID)
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,14 +1,6 @@
|
||||
|
||||
Linux 有问必答--如何解决 Linux 桌面上的 Wireshark GUI 死机
|
||||
Linux 有问必答:如何解决 Linux 上的 Wireshark 界面僵死
|
||||
================================================================================
|
||||
> **问题**: 当我试图在 Ubuntu 上的 Wireshark 中打开一个 pre-recorded 数据包转储时,它的 UI 突然死机,在我发起 Wireshark 的终端出现了下面的错误和警告。我该如何解决这个问题?
|
||||
|
||||
Wireshark 是一个基于 GUI 的数据包捕获和嗅探工具。该工具被网络管理员普遍使用,网络安全工程师或开发人员对于各种任务的 packet-level 网络分析是必需的,例如在网络故障,漏洞测试,应用程序调试,或逆向协议工程是必需的。 Wireshark 允许记录存活数据包,并通过便捷的图形用户界面浏览他们的协议首部和有效负荷。
|
||||
|
||||

|
||||
|
||||
这是 Wireshark 的 UI,尤其是在 Ubuntu 桌面下运行,有时会挂起或冻结出现以下错误,而你是向上或向下滚动分组列表视图时,就开始加载一个 pre-recorded 包转储文件。
|
||||
|
||||
> **问题**: 当我试图在 Ubuntu 上的 Wireshark 中打开一个 pre-recorded 数据包转储时,它的界面突然死机,在我运行 Wireshark 的终端出现了下面的错误和警告。我该如何解决这个问题?
|
||||
|
||||
(wireshark:3480): GLib-GObject-WARNING **: invalid unclassed pointer in cast to 'GObject'
|
||||
(wireshark:3480): GLib-GObject-CRITICAL **: g_object_set_qdata_full: assertion 'G_IS_OBJECT (object)' failed
|
||||
@ -22,6 +14,15 @@ Wireshark 是一个基于 GUI 的数据包捕获和嗅探工具。该工具被
|
||||
(wireshark:3480): GLib-GObject-CRITICAL **: g_object_get_qdata: assertion 'G_IS_OBJECT (object)' failed
|
||||
(wireshark:3480): Gtk-CRITICAL **: gtk_widget_set_name: assertion 'GTK_IS_WIDGET (widget)' failed
|
||||
|
||||
|
||||
Wireshark 是一个基于 GUI 的数据包捕获和嗅探工具。该工具被网络管理员普遍使用,网络安全工程师或开发人员对于各种任务的数据包级的网络分析是必需的,例如在网络故障,漏洞测试,应用程序调试,或逆向协议工程是必需的。 Wireshark 允许实时记录数据包,并通过便捷的图形用户界面浏览他们的协议首部和有效负荷。
|
||||
|
||||

|
||||
|
||||
这是 Wireshark 的 UI,尤其是在 Ubuntu 桌面下运行时,当你向上或向下滚动分组列表视图时,或开始加载一个 pre-recorded 包转储文件时,有时会挂起或冻结,并出现以下错误。
|
||||
|
||||

|
||||
|
||||
显然,这个错误是由 Wireshark 和叠加滚动条之间的一些不兼容造成的,在最新的 Ubuntu 桌面还没有被解决(例如,Ubuntu 15.04 的桌面)。
|
||||
|
||||
一种避免 Wireshark 的 UI 卡死的办法就是 **暂时禁用叠加滚动条**。在 Wireshark 上有两种方法来禁用叠加滚动条,这取决于你在桌面上如何启动 Wireshark 的。
|
||||
@ -46,7 +47,7 @@ Wireshark 是一个基于 GUI 的数据包捕获和嗅探工具。该工具被
|
||||
|
||||
Exec=env LIBOVERLAY_SCROLLBAR=0 wireshark %f
|
||||
|
||||
虽然这种解决方法将有利于所有桌面用户的 system-wide,但它将无法升级 Wireshark。如果你想保留修改的 .desktop 文件,如下所示将它复制到你的主目录。
|
||||
虽然这种解决方法可以在系统级帮助到所有桌面用户,但升级 Wireshark 就没用了。如果你想保留修改的 .desktop 文件,如下所示将它复制到你的主目录。
|
||||
|
||||
$ cp /usr/share/applications/wireshark.desktop ~/.local/share/applications/
|
||||
|
||||
@ -56,7 +57,7 @@ via: http://ask.xmodulo.com/fix-wireshark-gui-freeze-linux-desktop.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
LinuxCon: 服务器操作系统的转型
|
||||
================================================================================
|
||||
来自西雅图。容器迟早要改变世界,以及改变操作系统的角色。这是 Wim Coekaerts 带来的 LinuxCon 演讲主题,Coekaerts 是 Oracle 公司 Linux 与虚拟化工程的高级副总裁。
|
||||
西雅图报道。容器迟早要改变世界,以及改变操作系统的角色。这是 Wim Coekaerts 带来的 LinuxCon 演讲主题,Coekaerts 是 Oracle 公司 Linux 与虚拟化工程的高级副总裁。
|
||||
|
||||

|
||||
|
||||
@ -8,7 +8,7 @@ Coekaerts 在开始演讲的时候拿出一张关于“桌面之年”的幻灯
|
||||
|
||||
“你需要操作系统做什么事情?”,Coekaerts 回答现场观众:“只需一件事:运行一个应用。操作系统负责管理硬件和资源,来让你的应用运行起来。”
|
||||
|
||||
Coakaerts 说在 Docker 容器的帮助下,我们的注意力再次集中在应用上,而在 Oracle,我们将注意力放在如何让应用更好地运行在操作系统上。
|
||||
Coakaerts 补充说,在 Docker 容器的帮助下,我们的注意力再次集中在应用上,而在 Oracle,我们将注意力放在如何让应用更好地运行在操作系统上。
|
||||
|
||||
“许多人过去常常需要繁琐地安装应用,而现在的年轻人只需要按一个按钮就能让应用在他们的移动设备上运行起来”。
|
||||
|
||||
@ -20,7 +20,6 @@ Docker 的出现不代表虚拟机的淘汰,容器化过程需要经过很长
|
||||
|
||||
在这段时间内,容器会与虚拟机共存,并且我们需要一些工具,将应用在容器和虚拟机之间进行转换迁移。Coekaerts 举例说 Oracle 的 VirtualBox 就可以用来帮助用户运行 Docker,而它原来是被广泛用在桌面系统上的一项开源技术。现在 Docker 的 Kitematic 项目将在 Mac 上使用 VirtualBox 运行 Docker。
|
||||
|
||||
### The Open Compute Initiative and Write Once, Deploy Anywhere for Containers ###
|
||||
### 容器的开放计算计划和一次写随处部署 ###
|
||||
|
||||
一个能让容器成功的关键是“一次写,随处部署”的概念。而在容器之间的互操作领域,Linux 基金会的开放计算计划(OCI)扮演一个非常关键的角色。
|
||||
@ -43,7 +42,7 @@ via: http://www.serverwatch.com/server-news/linuxcon-the-changing-role-of-the-se
|
||||
|
||||
作者:[Sean Michael Kerner][a]
|
||||
译者:[bazz2](https://github.com/bazz2)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,14 +1,15 @@
|
||||
Linux 界将出现一个新的文件系统:bcachefs
|
||||
Linux 上将出现一个新的文件系统:bcachefs
|
||||
================================================================================
|
||||
这个有 5 年历史,由 Kent Oberstreet 创建,过去属于谷歌的文件系统,最近完成了关键的组件。Bcachefs 文件系统自称其性能和稳定性与 ext4 和 xfs 相同,而其他方面的功能又可以与 btrfs 和 zfs 相媲美。主要特性包括校验、压缩、多设备支持、缓存、快照与其他好用的特性。
|
||||
|
||||
Bcachefs 来自 **bcache**,这是一个块级缓存层,从 bcaceh 到一个功能完整的[写时复制][1]文件系统,堪称是一项质的转变。
|
||||
这个有 5 年历史,由 Kent Oberstreet 创建,过去属于谷歌的文件系统,最近完成了全部关键组件。Bcachefs 文件系统自称其性能和稳定性与 ext4 和 xfs 相同,而其他方面的功能又可以与 btrfs 和 zfs 相媲美。主要特性包括校验、压缩、多设备支持、缓存、快照与其他“漂亮”的特性。
|
||||
|
||||
在自己提出问题“为什么要出一个新的文件系统”中,Kent Oberstreet 作了以下回答:当我还在谷歌的时候,我与其他在 bcache 上工作的同事在偶然的情况下意识到我们正在使用的东西可以成为一个成熟文件系统的功能块,我们可以用 bcache 创建一个拥有干净而优雅设计的文件系统,而最重要的一点是,bcachefs 的主要目的就是在性能和稳定性上能与 ext4 和 xfs 匹敌,同时拥有 btrfs 和 zfs 的特性。
|
||||
Bcachefs 来自 **bcache**,这是一个块级缓存层。从 bcaceh 到一个功能完整的[写时复制][1]文件系统,堪称是一项质的转变。
|
||||
|
||||
对自己的问题“为什么要出一个新的文件系统”中,Kent Oberstreet 自问自答道:当我还在谷歌的时候,我与其他在 bcache 上工作的同事在偶然的情况下意识到我们正在使用的东西可以成为一个成熟文件系统的功能块,我们可以用 bcache 创建一个拥有干净而优雅设计的文件系统,而最重要的一点是,bcachefs 的主要目的就是在性能和稳定性上能与 ext4 和 xfs 匹敌,同时拥有 btrfs 和 zfs 的特性。
|
||||
|
||||
Overstreet 邀请人们在自己的系统上测试 bcachefs,可以通过邮件列表[通告]获取 bcachefs 的操作指南。
|
||||
|
||||
Linux 生态系统中文件系统几乎处于一家独大状态,Fedora 在第 16 版的时候就想用 btrfs 换掉 ext4 作为其默认文件系统,但是到现在(LCTT:都出到 Fedora 22 了)还在使用 ext4。而几乎所有 Debian 系的发行版(Ubuntu、Mint、elementary OS 等)也使用 ext4 作为默认文件系统,并且这些主流的发生版都没有替换默认文件系统的意思。
|
||||
Linux 生态系统中文件系统几乎处于一家独大状态,Fedora 在第 16 版的时候就想用 btrfs 换掉 ext4 作为其默认文件系统,但是到现在(LCTT:都出到 Fedora 22 了)还在使用 ext4。而几乎所有 Debian 系的发行版(Ubuntu、Mint、elementary OS 等)也使用 ext4 作为默认文件系统,并且这些主流的发行版都没有替换默认文件系统的意思。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -16,7 +17,7 @@ via: http://www.linuxveda.com/2015/08/22/linux-gain-new-file-system-bcachefs/
|
||||
|
||||
作者:[Paul Hill][a]
|
||||
译者:[bazz2](https://github.com/bazz2)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
Xtreme下载管理器升级全新用户界面
|
||||
Xtreme 下载管理器升级带来全新用户界面
|
||||
================================================================================
|
||||

|
||||
|
||||
@ -6,11 +6,11 @@ Xtreme下载管理器升级全新用户界面
|
||||
|
||||
Xtreme 下载管理器,也被称作 XDM 或 XDMAN,它是一个跨平台的下载管理器,可以用于 Linux、Windows 和 Mac OS X 系统之上。同时它兼容于主流的浏览器,如 Chrome, Firefox, Safari 等,因此当你从浏览器下载东西的时候可以直接使用 XDM 下载。
|
||||
|
||||
当你的网络连接超慢并且需要管理下载文件的时候,像 XDM 这种软件可以帮到你大忙。例如说你在一个慢的要死的网络速度下下载一个超大文件, XDM 可以帮助你暂停并且继续下载。
|
||||
当你的网络连接超慢并且需要管理下载文件的时候,像 XDM 这种软件可以帮到你大忙。例如说你在一个慢的要死的网络速度下下载一个超大文件,或者你想要暂停和恢复下载的话, XDM 可以帮助你。
|
||||
|
||||
XDM 的主要功能:
|
||||
|
||||
- 暂停和继续下载
|
||||
- 暂停和恢复下载
|
||||
- [从 YouTube 下载视频][3],其他视频网站同样适用
|
||||
- 强制聚合
|
||||
- 下载加速
|
||||
@ -23,11 +23,11 @@ XDM 的主要功能:
|
||||
|
||||

|
||||
|
||||
老版本XDM
|
||||
*老版本XDM*
|
||||
|
||||

|
||||
|
||||
新版本XDM
|
||||
*新版本XDM*
|
||||
|
||||
### 在基于 Ubuntu 的 Linux 发行版上安装 Xtreme下载管理器 ###
|
||||
|
||||
@ -48,15 +48,15 @@ XDM 的主要功能:
|
||||
|
||||
对于其他Linux发行版,可以通过以下连接下载:
|
||||
|
||||
- [Download Xtreme Download Manager][4]
|
||||
- [下载 Xtreme 下载管理器][4]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/xtreme-download-manager-install/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/mr-ping)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[mr-ping](https://github.com/mr-ping)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,248 @@
|
||||
RHCSA 系列(三): 如何管理 RHEL7 的用户和组
|
||||
================================================================================
|
||||
|
||||
和管理其它Linux服务器一样,管理一个 RHEL 7 服务器要求你能够添加、修改、暂停或删除用户帐户,并且授予他们执行其分配的任务所需的文件、目录、其它系统资源所必要的权限。
|
||||
|
||||

|
||||
|
||||
*RHCSA: 用户和组管理 – Part 3*
|
||||
|
||||
###管理用户帐户##
|
||||
|
||||
如果想要给RHEL 7 服务器添加账户,你需要以root用户执行如下两条命令之一:
|
||||
|
||||
# adduser [new_account]
|
||||
# useradd [new_account]
|
||||
|
||||
当添加新的用户帐户时,默认会执行下列操作。
|
||||
|
||||
- 它/她的主目录就会被创建(一般是"/home/用户名",除非你特别设置)
|
||||
- 一些隐藏文件 如`.bash_logout`, `.bash_profile` 以及 `.bashrc` 会被复制到用户的主目录,它们会为用户的回话提供环境变量。你可以进一步查看它们的相关细节。
|
||||
- 会为您的账号添加一个邮件池目录。
|
||||
- 会创建一个和用户名同样的组(LCTT 译注:除非你给新创建的用户指定了组)。
|
||||
|
||||
用户帐户的全部信息被保存在`/etc/passwd`文件。这个文件以如下格式保存了每一个系统帐户的所有信息(字段以“:”分割)
|
||||
|
||||
[username]:[x]:[UID]:[GID]:[Comment]:[Home directory]:[Default shell]
|
||||
|
||||
- `[username]` 和`[Comment]` 其意自明,就是用户名和备注
|
||||
- 第二个‘x’表示帐户的启用了密码保护(记录在`/etc/shadow`文件),密码用于登录`[username]`
|
||||
- `[UID]` 和`[GID]`是整数,它们表明了`[username]`的用户ID 和所属的主组ID
|
||||
|
||||
最后。
|
||||
|
||||
- `[Home directory]`显示`[username]`的主目录的绝对路径
|
||||
- `[Default shell]` 是当用户登录系统后使用的默认shell
|
||||
|
||||
另外一个你必须要熟悉的重要的文件是存储组信息的`/etc/group`。和`/etc/passwd`类似,也是每行一个记录,字段由“:”分割
|
||||
|
||||
[Group name]:[Group password]:[GID]:[Group members]
|
||||
|
||||
- `[Group name]` 是组名
|
||||
- 这个组是否使用了密码 (如果是"x"意味着没有)
|
||||
- `[GID]`: 和`/etc/passwd`中一样
|
||||
- `[Group members]`:用户列表,使用“,”隔开。里面包含组内的所有用户
|
||||
|
||||
添加过帐户后,任何时候你都可以通过 usermod 命令来修改用户账户信息,基本的语法如下:
|
||||
|
||||
# usermod [options] [username]
|
||||
|
||||
相关阅读
|
||||
|
||||
- [15 ‘useradd’ 命令示例][1]
|
||||
- [15 ‘usermod’ 命令示例][2]
|
||||
|
||||
#### 示例1 : 设置帐户的过期时间 ####
|
||||
|
||||
如果你的公司有一些短期使用的帐户或者你要在有限时间内授予访问,你可以使用 `--expiredate` 参数 ,后加YYYY-MM-DD 格式的日期。为了查看是否生效,你可以使用如下命令查看
|
||||
|
||||
# chage -l [username]
|
||||
|
||||
帐户更新前后的变动如下图所示
|
||||
|
||||
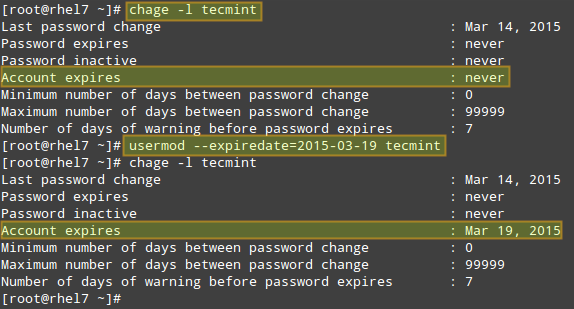
|
||||
|
||||
*修改用户信息*
|
||||
|
||||
#### 示例 2: 向组内追加用户 ####
|
||||
|
||||
除了创建用户时的主用户组,一个用户还能被添加到别的组。你需要使用 -aG或 -append -group 选项,后跟逗号分隔的组名。
|
||||
|
||||
#### 示例 3: 修改用户主目录或默认Shell ####
|
||||
|
||||
如果因为一些原因,你需要修改默认的用户主目录(一般为 /home/用户名),你需要使用 -d 或 -home 参数,后跟绝对路径来修改主目录。
|
||||
|
||||
如果有用户想要使用其它的shell来取代默认的bash(比如zsh)。使用 usermod ,并使用 -shell 的参数,后加新的shell的路径。
|
||||
|
||||
#### 示例 4: 展示组内的用户 ####
|
||||
|
||||
当把用户添加到组中后,你可以使用如下命令验证属于哪一个组
|
||||
|
||||
# groups [username]
|
||||
# id [username]
|
||||
|
||||
下面图片的演示了示例2到示例4
|
||||
|
||||

|
||||
|
||||
*添加用户到额外的组*
|
||||
|
||||
在上面的示例中:
|
||||
|
||||
# usermod --append --groups gacanepa,users --home /tmp --shell /bin/sh tecmint
|
||||
|
||||
如果想要从组内删除用户,取消 `--append` 选项,并使用 `--groups` 和你要用户属于的组的列表。
|
||||
|
||||
#### 示例 5: 通过锁定密码来停用帐户 ####
|
||||
|
||||
如果想要关闭帐户,你可以使用 -l(小写的L)或 -lock 选项来锁定用户的密码。这将会阻止用户登录。
|
||||
|
||||
#### 示例 6: 解锁密码 ####
|
||||
|
||||
当你想要重新启用帐户让它可以继续登录时,使用 -u 或 –unlock 选项来解锁用户的密码,就像示例5 介绍的那样
|
||||
|
||||
# usermod --unlock tecmint
|
||||
|
||||
下面的图片展示了示例5和示例6:
|
||||
|
||||

|
||||
|
||||
*锁定上锁用户*
|
||||
|
||||
#### 示例 7:删除组和用户 ####
|
||||
|
||||
如果要删除一个组,你需要使用 groupdel ,如果需要删除用户 你需要使用 userdel (添加 -r 可以删除主目录和邮件池的内容)。
|
||||
|
||||
# groupdel [group_name] # 删除组
|
||||
# userdel -r [user_name] # 删除用户,并删除主目录和邮件池
|
||||
|
||||
如果一些文件属于该组,删除组时它们不会也被删除。但是组拥有者的名字将会被设置为删除掉的组的GID。
|
||||
|
||||
### 列举,设置,并且修改标准 ugo/rwx 权限 ###
|
||||
|
||||
著名的 [ls 命令][3] 是管理员最好的助手. 当我们使用 -l 参数, 这个工具允许您以长格式(或详细格式)查看一个目录中的内容。
|
||||
|
||||
而且,该命令还可以用于单个文件中。无论哪种方式,在“ls”输出中的前10个字符表示每个文件的属性。
|
||||
|
||||
这10个字符序列的第一个字符用于表示文件类型:
|
||||
|
||||
- – (连字符): 一个标准文件
|
||||
- d: 一个目录
|
||||
- l: 一个符号链接
|
||||
- c: 字符设备(将数据作为字节流,例如终端)
|
||||
- b: 块设备(以块的方式处理数据,例如存储设备)
|
||||
|
||||
文件属性的接下来的九个字符,分为三个组,被称为文件模式,并注明读(r)、写(w)、和执行(x)权限授予文件的所有者、文件的所有组、和其它的用户(通常被称为“世界”)。
|
||||
|
||||
同文件上的读取权限允许文件被打开和读取一样,如果目录同时有执行权限时,就允许其目录内容被列出。此外,如果一个文件有执行权限,就允许它作为一个程序运行。
|
||||
|
||||
文件权限是通过chmod命令改变的,它的基本语法如下:
|
||||
|
||||
# chmod [new_mode] file
|
||||
|
||||
new_mode 是一个八进制数或表达式,用于指定新的权限。随意试试各种权限看看是什么效果。或者您已经有了一个更好的方式来设置文件的权限,你也可以用你自己的方式自由地试试。
|
||||
|
||||
八进制数可以基于二进制等价计算,可以从所需的文件权限的文件的所有者、所有组、和世界组合成。每种权限都等于2的幂(R = 2\^2,W = 2\^1,x = 2\^0),没有时即为0。例如:
|
||||
|
||||

|
||||
|
||||
*文件权限*
|
||||
|
||||
在八进制形式下设置文件的权限,如上图所示
|
||||
|
||||
# chmod 744 myfile
|
||||
|
||||
请用马上来对比一下我们以前的计算,在更改文件的权限后,我们的实际输出为:
|
||||
|
||||
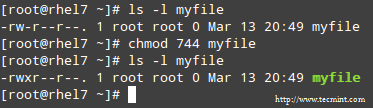
|
||||
|
||||
*长列表格式*
|
||||
|
||||
#### 示例 8: 寻找777权限的文件 ####
|
||||
|
||||
出于安全考虑,你应该确保在正常情况下,尽可能避免777权限(任何人可读、可写、可执行的文件)。虽然我们会在以后的教程中教你如何更有效地找到您的系统的具有特定权限的全部文件,你现在仍可以组合使用ls 和 grep来获取这种信息。
|
||||
|
||||
在下面的例子,我们会寻找 /etc 目录下的777权限文件。注意,我们要使用[第二章:文件和目录管理][4]中讲到的管道的知识:
|
||||
|
||||
# ls -l /etc | grep rwxrwxrwx
|
||||
|
||||

|
||||
|
||||
*查找所有777权限的文件*
|
||||
|
||||
#### 示例 9: 为所有用户指定特定权限 ####
|
||||
|
||||
shell脚本,以及一些二进制文件,所有用户都应该有权访问(不只是其相应的所有者和组),应该有相应的执行权限(我们会讨论特殊情况下的问题):
|
||||
|
||||
# chmod a+x script.sh
|
||||
|
||||
**注意**: 我们可以使用表达式设置文件模式,表示用户权限的字母如“u”,组所有者权限的字母“g”,其余的为“o” ,同时具有所有权限为“a”。权限可以通过`+` 或 `-` 来授予和收回。
|
||||
|
||||

|
||||
|
||||
*为文件设置执行权限*
|
||||
|
||||
长目录列表还用两列显示了该文件的所有者和所有组。此功能可作为系统中文件的第一级访问控制方法:
|
||||
|
||||
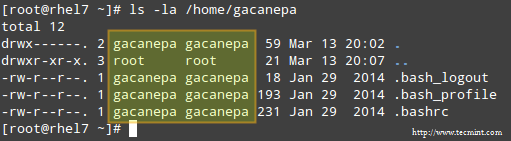
|
||||
|
||||
*检查文件的所有者和所有组*
|
||||
|
||||
改变文件的所有者,您应该使用chown命令。请注意,您可以在同时或分别更改文件的所有组:
|
||||
|
||||
# chown user:group file
|
||||
|
||||
你可以更改用户或组,或在同时更改两个属性,但是不要忘记冒号区分,如果你想要更新其它属性,让另外的部分为空:
|
||||
|
||||
# chown :group file # 仅改变所有组
|
||||
# chown user: file # 仅改变所有者
|
||||
|
||||
#### 示例 10:从一个文件复制权限到另一个文件####
|
||||
|
||||
|
||||
如果你想“克隆”一个文件的所有权到另一个,你可以这样做,使用–reference参数,如下:
|
||||
|
||||
# chown --reference=ref_file file
|
||||
|
||||
ref_file的所有信息会复制给 file
|
||||
|
||||

|
||||
|
||||
*复制文件属主信息*
|
||||
|
||||
### 设置 SETGID 协作目录 ###
|
||||
|
||||
假如你需要授予在一个特定的目录中拥有访问所有的文件的权限给一个特定的用户组,你有可能需要使用给目录设置setgid的方法。当setgid设置后,该真实用户的有效GID会变成属主的GID。
|
||||
|
||||
因此,任何访问该文件的用户会被授予该文件的属组的权限。此外,当setgid设置在一个目录中,新创建的文件继承组该目录的组,而且新创建的子目录也将继承父目录的setgid权限。
|
||||
|
||||
# chmod g+s [filename]
|
||||
|
||||
要以八进制形式设置 setgid,需要在基本权限前缀以2。
|
||||
|
||||
# chmod 2755 [directory]
|
||||
|
||||
### 总结 ###
|
||||
|
||||
扎实的用户和组管理知识,以及标准和特殊的 Linux权限管理,通过实践,可以帮你快速解决 RHEL 7 服务器的文件权限问题。
|
||||
|
||||
我向你保证,当你按照本文所概述的步骤和使用系统文档(在本系列的[第一章 回顾基础命令及系统文档][5]中讲到), 你将掌握基本的系统管理的能力。
|
||||
|
||||
请随时使用下面的评论框让我们知道你是否有任何问题或意见。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/rhcsa-exam-manage-users-and-groups/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[xiqingongzi](https://github.com/xiqingongzi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/add-users-in-linux/
|
||||
[2]:http://www.tecmint.com/usermod-command-examples/
|
||||
[3]:http://linux.cn/article-5349-1.html
|
||||
[4]:https://www.linux.cn/article-6155-1.html
|
||||
[5]:http://www.tecmint.com/rhcsa-exam-reviewing-essential-commands-system-documentation/
|
||||
@ -1,110 +0,0 @@
|
||||
Mosh Shell – A SSH Based Client for Connecting Remote Unix/Linux Systems
|
||||
================================================================================
|
||||
Mosh, which stands for Mobile Shell is a command-line application which is used for connecting to the server from a client computer, over the Internet. It can be used as SSH and contains more feature than Secure Shell. It is an application similar to SSH, but with additional features. The application is written originally by Keith Winstein for Unix like operating system and released under GNU GPL v3.
|
||||
|
||||

|
||||
|
||||
Mosh Shell SSH Client
|
||||
|
||||
#### Features of Mosh ####
|
||||
|
||||
- It is a remote terminal application that supports roaming.
|
||||
- Available for all major UNIX-like OS viz., Linux, FreeBSD, Solaris, Mac OS X and Android.
|
||||
- Intermittent Connectivity supported.
|
||||
- Provides intelligent local echo.
|
||||
- Line editing of user keystrokes supported.
|
||||
- Responsive design and Robust Nature over wifi, cellular and long-distance links.
|
||||
- Remain Connected even when IP changes. It usages UDP in place of TCP (used by SSH). TCP time out when connect is reset or new IP assigned but UDP keeps the connection open.
|
||||
- The Connection remains intact when you resume the session after a long time.
|
||||
- No network lag. Shows users typed key and deletions immediately without network lag.
|
||||
- Same old method to login as it was in SSH.
|
||||
- Mechanism to handle packet loss.
|
||||
|
||||
### Installation of Mosh Shell in Linux ###
|
||||
|
||||
On Debian, Ubuntu and Mint alike systems, you can easily install the Mosh package with the help of [apt-get package manager][1] as shown.
|
||||
|
||||
# apt-get update
|
||||
# apt-get install mosh
|
||||
|
||||
On RHEL/CentOS/Fedora based distributions, you need to turn on third party repository called [EPEL][2], in order to install mosh from this repository using [yum package manager][3] as shown.
|
||||
|
||||
# yum update
|
||||
# yum install mosh
|
||||
|
||||
On Fedora 22+ version, you need to use [dnf package manager][4] to install mosh as shown.
|
||||
|
||||
# dnf install mosh
|
||||
|
||||
### How do I use Mosh Shell? ###
|
||||
|
||||
1. Let’s try to login into remote Linux server using mosh shell.
|
||||
|
||||
$ mosh root@192.168.0.150
|
||||
|
||||

|
||||
|
||||
Mosh Shell Remote Connection
|
||||
|
||||
**Note**: Did you see I got an error in connecting since the port was not open in my remote CentOS 7 box. A quick but not recommended solution I performed was:
|
||||
|
||||
# systemctl stop firewalld [on Remote Server]
|
||||
|
||||
The preferred way is to open a port and update firewall rules. And then connect to mosh on a predefined port. For in-depth details on firewalld you may like to visit this post.
|
||||
|
||||
- [How to Configure Firewalld][5]
|
||||
|
||||
2. Let’s assume that the default SSH port 22 was changed to port 70, in this case you can define custom port with the help of ‘-p‘ switch with mosh.
|
||||
|
||||
$ mosh -p 70 root@192.168.0.150
|
||||
|
||||
3. Check the version of installed Mosh.
|
||||
|
||||
$ mosh --version
|
||||
|
||||

|
||||
|
||||
Check Mosh Version
|
||||
|
||||
4. You can close mosh session type ‘exit‘ on the prompt.
|
||||
|
||||
$ exit
|
||||
|
||||
5. Mosh supports a lot of options, which you may see as:
|
||||
|
||||
$ mosh --help
|
||||
|
||||

|
||||
|
||||
Mosh Shell Options
|
||||
|
||||
#### Cons of Mosh Shell ####
|
||||
|
||||
- Mosh requires additional prerequisite for example, allow direct connection via UDP, which was not required by SSH.
|
||||
- Dynamic port allocation in the range of 60000-61000. The first open fort is allocated. It requires one port per connection.
|
||||
- Default port allocation is a serious security concern, especially in production.
|
||||
- IPv6 connections supported, but roaming on IPv6 not supported.
|
||||
- Scrollback not supported.
|
||||
- No X11 forwarding supported.
|
||||
- No support for ssh-agent forwarding.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Mosh is a nice small utility which is available for download in the repository of most of the Linux Distributions. Though it has a few discrepancies specially security concern and additional requirement it’s features like remaining connected even while roaming is its plus point. My recommendation is Every Linux-er who deals with SSH should try this application and mind it, Mosh is worth a try.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-mosh-shell-ssh-client-in-linux/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/useful-basic-commands-of-apt-get-and-apt-cache-for-package-management/
|
||||
[2]:http://www.tecmint.com/how-to-enable-epel-repository-for-rhel-centos-6-5/
|
||||
[3]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
|
||||
[4]:http://www.tecmint.com/dnf-commands-for-fedora-rpm-package-management/
|
||||
[5]:http://www.tecmint.com/configure-firewalld-in-centos-7/
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by H-mudcup
|
||||
5 best open source board games to play online
|
||||
================================================================================
|
||||
I have always had a fascination with board games, in part because they are a device of social interaction, they challenge the mind and, most importantly, they are great fun to play. In my misspent youth, myself and a group of friends gathered together to escape the horrors of the classroom, and indulge in a little escapism. The time provided an outlet for tension and rivalry. Board games help teach diplomacy, how to make and break alliances, bring families and friends together, and learn valuable lessons.
|
||||
@ -191,4 +192,4 @@ via: http://www.linuxlinks.com/article/20150830011533893/BoardGames.html
|
||||
[2]:http://domination.sourceforge.net/
|
||||
[3]:http://www.pychess.org/
|
||||
[4]:http://sourceforge.net/projects/scrabble/
|
||||
[5]:http://www.gnubg.org/
|
||||
[5]:http://www.gnubg.org/
|
||||
|
||||
@ -1,126 +0,0 @@
|
||||
How learning data structures and algorithms make you a better developer
|
||||
================================================================================
|
||||
|
||||
> "I'm a huge proponent of designing your code around the data, rather than the other way around, and I think it's one of the reasons git has been fairly successful […] I will, in fact, claim that the difference between a bad programmer and a good one is whether he considers his code or his data structures more important."
|
||||
-- Linus Torvalds
|
||||
|
||||
---
|
||||
|
||||
> "Smart data structures and dumb code works a lot better than the other way around."
|
||||
-- Eric S. Raymond, The Cathedral and The Bazaar
|
||||
|
||||
Learning about data structures and algorithms makes you a stonking good programmer.
|
||||
|
||||
**Data structures and algorithms are patterns for solving problems.** The more of them you have in your utility belt, the greater variety of problems you'll be able to solve. You'll also be able to come up with more elegant solutions to new problems than you would otherwise be able to.
|
||||
|
||||
You'll understand, ***in depth***, how your computer gets things done. This informs any technical decisions you make, regardless of whether or not you're using a given algorithm directly. Everything from memory allocation in the depths of your operating system, to the inner workings of your RDBMS to how your networking stack manages to send data from one corner of Earth to another. All computers rely on fundamental data structures and algorithms, so understanding them better makes you understand the computer better.
|
||||
|
||||
Cultivate a broad and deep knowledge of algorithms and you'll have stock solutions to large classes of problems. Problem spaces that you had difficulty modelling before often slot neatly into well-worn data structures that elegantly handle the known use-cases. Dive deep into the implementation of even the most basic data structures and you'll start seeing applications for them in your day-to-day programming tasks.
|
||||
|
||||
You'll also be able to come up with novel solutions to the somewhat fruitier problems you're faced with. Data structures and algorithms have the habit of proving themselves useful in situations that they weren't originally intended for, and the only way you'll discover these on your own is by having a deep and intuitive knowledge of at least the basics.
|
||||
|
||||
But enough with the theory, have a look at some examples
|
||||
|
||||
###Figuring out the fastest way to get somewhere###
|
||||
Let's say we're creating software to figure out the shortest distance from one international airport to another. Assume we're constrained to following routes:
|
||||
|
||||

|
||||
|
||||
graph of destinations and the distances between them, how can we find the shortest distance say, from Helsinki to London? **Dijkstra's algorithm** is the algorithm that will definitely get us the right answer in the shortest time.
|
||||
|
||||
In all likelihood, if you ever came across this problem and knew that Dijkstra's algorithm was the solution, you'd probably never have to implement it from scratch. Just ***knowing*** about it would point you to a library implementation that solves the problem for you.
|
||||
|
||||
If you did dive deep into the implementation, you'd be working through one of the most important graph algorithms we know of. You'd know that in practice it's a little resource intensive so an extension called A* is often used in it's place. It gets used everywhere from robot guidance to routing TCP packets to GPS pathfinding.
|
||||
|
||||
###Figuring out the order to do things in###
|
||||
Let's say you're trying to model courses on a new Massive Open Online Courses platform (like Udemy or Khan Academy). Some of the courses depend on each other. For example, a user has to have taken Calculus before she's eligible for the course on Newtonian Mechanics. Courses can have multiple dependencies. Here's are some examples of what that might look like written out in YAML:
|
||||
|
||||
# Mapping from course name to requirements
|
||||
#
|
||||
# If you're a physcist or a mathematicisn and you're reading this, sincere
|
||||
# apologies for the completely made-up dependency tree :)
|
||||
courses:
|
||||
arithmetic: []
|
||||
algebra: [arithmetic]
|
||||
trigonometry: [algebra]
|
||||
calculus: [algebra, trigonometry]
|
||||
geometry: [algebra]
|
||||
mechanics: [calculus, trigonometry]
|
||||
atomic_physics: [mechanics, calculus]
|
||||
electromagnetism: [calculus, atomic_physics]
|
||||
radioactivity: [algebra, atomic_physics]
|
||||
astrophysics: [radioactivity, calculus]
|
||||
quantumn_mechanics: [atomic_physics, radioactivity, calculus]
|
||||
|
||||
Given those dependencies, as a user, I want to be able to pick any course and have the system give me an ordered list of courses that I would have to take to be eligible. So if I picked `calculus`, I'd want the system to return the list:
|
||||
|
||||
arithmetic -> algebra -> trigonometry -> calculus
|
||||
|
||||
Two important constraints on this that may not be self-evident:
|
||||
|
||||
- At every stage in the course list, the dependencies of the next course must be met.
|
||||
- We don't want any duplicate courses in the list.
|
||||
|
||||
This is an example of resolving dependencies and the algorithm we're looking for to solve this problem is called topological sort (tsort). Tsort works on a dependency graph like we've outlined in the YAML above. Here's what that would look like in a graph (where each arrow means `requires`):
|
||||
|
||||

|
||||
|
||||
topological sort does is take a graph like the one above and find an ordering in which all the dependencies are met at each stage. So if we took a sub-graph that only contained `radioactivity` and it's dependencies, then ran tsort on it, we might get the following ordering:
|
||||
|
||||
arithmetic
|
||||
algebra
|
||||
trigonometry
|
||||
calculus
|
||||
mechanics
|
||||
atomic_physics
|
||||
radioactivity
|
||||
|
||||
This meets the requirements set out by the use case we described above. A user just has to pick `radioactivity` and they'll get an ordered list of all the courses they have to work through before they're allowed to.
|
||||
|
||||
We don't even need to go into the details of how topological sort works before we put it to good use. In all likelihood, your programming language of choice probably has an implementation of it in the standard library. In the worst case scenario, your Unix probably has the `tsort` utility installed by default, run man `tsort` and have a play with it.
|
||||
|
||||
###Other places tsort get's used###
|
||||
|
||||
- **Tools like** `make` allow you to declare task dependencies. Topological sort is used under the hood to figure out what order the tasks should be executed in.
|
||||
- **Any programming language that has a `require` directive**, indicating that the current file requires the code in a different file to be run first. Here topological sort can be used to figure out what order the files should be loaded in so that each is only loaded once and all dependencies are met.
|
||||
- **Project management tools with Gantt charts**. A Gantt chart is a graph that outlines all the dependencies of a given task and gives you an estimate of when it will be complete based on those dependencies. I'm not a fan of Gantt charts, but it's highly likely that tsort will be used to draw them.
|
||||
|
||||
###Squeezing data with Huffman coding###
|
||||
[Huffman coding](http://en.wikipedia.org/wiki/Huffman_coding) is an algorithm used for lossless data compression. It works by analyzing the data you want to compress and creating a binary code for each character. More frequently occurring characters get smaller codes, so `e` might be encoded as `111` while `x` might be `10010`. The codes are created so that they can be concatenated without a delimeter and still be decoded accurately.
|
||||
|
||||
Huffman coding is used along with LZ77 in the DEFLATE algorithm which is used by gzip to compress things. gzip is used all over the place, in particular for compressing files (typically anything with a `.gz` extension) and for http requests/responses in transit.
|
||||
|
||||
Knowing how to implement and use Huffman coding has a number of benefits:
|
||||
|
||||
- You'll know why a larger compression context results in better compression overall (e.g. the more you compress, the better the compression ratio). This is one of the proposed benefits of SPDY: that you get better compression on multiple HTTP requests/responses.
|
||||
- You'll know that if you're compressing your javascript/css in transit anyway, it's completely pointless to run a minifier on them. Sames goes for PNG files, which use DEFLATE internally for compression already.
|
||||
- If you ever find yourself trying to forcibly decipher encrypted information , you may realize that since repeating data compresses better, the compression ratio of a given bit of ciphertext will help you determine it's [block cipher mode of operation](http://en.wikipedia.org/wiki/Block_cipher_mode_of_operation).
|
||||
|
||||
###Picking what to learn next is hard###
|
||||
Being a programmer involves learning constantly. To operate as a web developer you need to know markup languages, high level languages like ruby/python, regular expressions, SQL and JavaScript. You need to know the fine details of HTTP, how to drive a unix terminal and the subtle art of object oriented programming. It's difficult to navigate that landscape effectively and choose what to learn next.
|
||||
|
||||
I'm not a fast learner so I have to choose what to spend time on very carefully. As much as possible, I want to learn skills and techniques that are evergreen, that is, won't be rendered obsolete in a few years time. That means I'm hesitant to learn the javascript framework of the week or untested programming languages and environments.
|
||||
|
||||
As long as our dominant model of computation stays the same, data structures and algorithms that we use today will be used in some form or another in the future. You can safely spend time on gaining a deep and thorough knowledge of them and know that they will pay dividends for your entire career as a programmer.
|
||||
|
||||
###Sign up to the Happy Bear Software List###
|
||||
Find this article useful? For a regular dose of freshly squeezed technical content delivered straight to your inbox, **click on the big green button below to sign up to the Happy Bear Software mailing list.**
|
||||
|
||||
We'll only be in touch a few times per month and you can unsubscribe at any time.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.happybearsoftware.com/how-learning-data-structures-and-algorithms-makes-you-a-better-developer
|
||||
|
||||
作者:[Happy Bear][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.happybearsoftware.com/
|
||||
[1]:http://en.wikipedia.org/wiki/Huffman_coding
|
||||
[2]:http://en.wikipedia.org/wiki/Block_cipher_mode_of_operation
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,389 @@
|
||||
Superclass: 15 of the world’s best living programmers
|
||||
================================================================================
|
||||
When developers discuss who the world’s top programmer is, these names tend to come up a lot.
|
||||
|
||||

|
||||
|
||||
Image courtesy [tom_bullock CC BY 2.0][1]
|
||||
|
||||
It seems like there are lots of programmers out there these days, and lots of really good programmers. But which one is the very best?
|
||||
|
||||
Even though there’s no way to really say who the best living programmer is, that hasn’t stopped developers from frequently kicking the topic around. ITworld has solicited input and scoured coder discussion forums to see if there was any consensus. As it turned out, a handful of names did frequently get mentioned in these discussions.
|
||||
|
||||
Use the arrows above to read about 15 people commonly cited as the world’s best living programmer.
|
||||
|
||||

|
||||
|
||||
Image courtesy [NASA][2]
|
||||
|
||||
### Margaret Hamilton ###
|
||||
|
||||
**Main claim to fame: The brains behind Apollo’s flight control software**
|
||||
|
||||
Credentials: As the Director of the Software Engineering Division at Charles Stark Draper Laboratory, she headed up the team which [designed and built][3] the on-board [flight control software for NASA’s Apollo][4] and Skylab missions. Based on her Apollo work, she later developed the [Universal Systems Language][5] and [Development Before the Fact][6] paradigm. Pioneered the concepts of [asynchronous software, priority scheduling, and ultra-reliable software design][7]. Coined the term “[software engineering][8].” Winner of the [Augusta Ada Lovelace Award][9] in 1986 and [NASA’s Exceptional Space Act Award in 2003][10].
|
||||
|
||||
Quotes: “Hamilton invented testing , she pretty much formalised Computer Engineering in the US.” [ford_beeblebrox][11]
|
||||
|
||||
“I think before her (and without disrespect including Knuth) computer programming was (and to an extent remains) a branch of mathematics. However a flight control system for a spacecraft clearly moves programming into a different paradigm.” [Dan Allen][12]
|
||||
|
||||
“... she originated the term ‘software engineering’ — and offered a great example of how to do it.” [David Hamilton][13]
|
||||
|
||||
“What a badass” [Drukered][14]
|
||||
|
||||

|
||||
|
||||
Image courtesy [vonguard CC BY-SA 2.0][15]
|
||||
|
||||
### Donald Knuth ###
|
||||
|
||||
**Main claim to fame: Author of The Art of Computer Programming**
|
||||
|
||||
Credentials: Wrote the [definitive book on the theory of programming][16]. Created the TeX digital typesetting system. [First winner of the ACM’s Grace Murray Hopper Award][17] in 1971. Winner of the ACM’s [A. M. Turing][18] Award in 1974, the [National Medal of Science][19] in 1979 and the IEEE’s [John von Neumann Medal][20] in 1995. Named a [Fellow at the Computer History Museum][21] in 1998.
|
||||
|
||||
Quotes: “... wrote The Art of Computer Programming which is probably the most comprehensive work on computer programming ever.” [Anonymous][22]
|
||||
|
||||
“There is only one large computer program I have used in which there are to a decent approximation 0 bugs: Don Knuth's TeX. That's impressive.” [Jaap Weel][23]
|
||||
|
||||
“Pretty awesome if you ask me.” [Mitch Rees-Jones][24]
|
||||
|
||||

|
||||
|
||||
Image courtesy [Association for Computing Machinery][25]
|
||||
|
||||
### Ken Thompson ###
|
||||
|
||||
**Main claim to fame: Creator of Unix**
|
||||
|
||||
Credentials: Co-creator, [along with Dennis Ritchie][26], of Unix. Creator of the [B programming language][27], the [UTF-8 character encoding scheme][28], the ed [text editor][29], and co-developer of the Go programming language. Co-winner (along with Ritchie) of the [A.M. Turing Award][30] in 1983, [IEEE Computer Pioneer Award][31] in 1994, and the [National Medal of Technology][32] in 1998. Inducted as a [fellow of the Computer History Museum][33] in 1997.
|
||||
|
||||
Quotes: “... probably the most accomplished programmer ever. Unix kernel, Unix tools, world-champion chess program Belle, Plan 9, Go Language.” [Pete Prokopowicz][34]
|
||||
|
||||
“Ken's contributions, more than anyone else I can think of, were fundamental and yet so practical and timeless they are still in daily use.“ [Jan Jannink][35]
|
||||
|
||||

|
||||
|
||||
Image courtesy Jiel Beaumadier CC BY-SA 3.0
|
||||
|
||||
### Richard Stallman ###
|
||||
|
||||
**Main claim to fame: Creator of Emacs, GCC**
|
||||
|
||||
Credentials: Founded the [GNU Project][36] and created many of its core tools, such as [Emacs, GCC, GDB][37], and [GNU Make][38]. Also founded the [Free Software Foundation][39]. Winner of the ACM's [Grace Murray Hopper Award][40] in 1990 and the [EFF's Pioneer Award in 1998][41].
|
||||
|
||||
Quotes: “... there was the time when he single-handedly outcoded several of the best Lisp hackers around, in the Symbolics vs LMI fight.” [Srinivasan Krishnan][42]
|
||||
|
||||
“Through his amazing mastery of programming and force of will, he created a whole sub-culture in programming and computers.” [Dan Dunay][43]
|
||||
|
||||
“I might disagree on many things with the great man, but he is still one of the most important programmers, alive or dead” [Marko Poutiainen][44]
|
||||
|
||||
“Try to imagine Linux without the prior work on the GNu project. Stallman's the bomb, yo.” [John Burnette][45]
|
||||
|
||||

|
||||
|
||||
Image courtesy [D.Begley CC BY 2.0][46]
|
||||
|
||||
### Anders Hejlsberg ###
|
||||
|
||||
**Main claim to fame: Creator of Turbo Pascal**
|
||||
|
||||
Credentials: [The original author of what became Turbo Pascal][47], one of the most popular Pascal compilers and the first integrated development environment. Later, [led the building of Delphi][48], Turbo Pascal’s successor. [Chief designer and architect of C#][49]. Winner of [Dr. Dobb's Excellence in Programming Award][50] in 2001.
|
||||
|
||||
Quotes: “He wrote the [Pascal] compiler in assembly language for both of the dominant PC operating systems of the day (DOS and CPM). It was designed to compile, link and run a program in seconds rather than minutes.” [Steve Wood][51]
|
||||
|
||||
“I revere this guy - he created the development tools that were my favourite through three key periods along my path to becoming a professional software engineer.” [Stefan Kiryazov][52]
|
||||
|
||||

|
||||
|
||||
Image courtesy [vonguard CC BY-SA 2.0][53]
|
||||
|
||||
### Doug Cutting ###
|
||||
|
||||
**Main claim to fame: Creator of Lucene**
|
||||
|
||||
Credentials: [Developed the Lucene search engine, as well as Nutch][54], a web crawler, and [Hadoop][55], a set of tools for distributed processing of large data sets. A strong proponent of open-source (Lucene, Nutch and Hadoop are all open-source). Currently [a former director of the Apache Software Foundation][56].
|
||||
|
||||
Quotes: “... he is the same guy who has written an exceptional search framework(lucene/solr) and opened the big-data gateway to the world(hadoop).” [Rajesh Rao][57]
|
||||
|
||||
“His creation/work on Lucene and Hadoop (among other projects) has created a tremendous amount of wealth and employment for folks in the world….” [Amit Nithianandan][58]
|
||||
|
||||

|
||||
|
||||
Image courtesy [Association for Computing Machinery][59]
|
||||
|
||||
### Sanjay Ghemawat ###
|
||||
|
||||
**Main claim to fame: Key Google architect**
|
||||
|
||||
Credentials: [Helped to design and implement some of Google’s large distributed systems][60], including MapReduce, BigTable, Spanner and Google File System. [Created Unix’s ical][61] calendaring system. Elected to the [National Academy of Engineering][62] in 2009. Winner of the [ACM-Infosys Foundation Award in the Computing Sciences][63] in 2012.
|
||||
|
||||
Quote: “Jeff Dean's wingman.” [Ahmet Alp Balkan][64]
|
||||
|
||||

|
||||
|
||||
Image courtesy [Google][65]
|
||||
|
||||
### Jeff Dean ###
|
||||
|
||||
**Main claim to fame: The brains behind Google search indexing**
|
||||
|
||||
Credentials: Helped to design and implement [many of Google’s large-scale distributed systems][66], including website crawling, indexing and searching, AdSense, MapReduce, BigTable and Spanner. Elected to the [National Academy of Engineering][67] in 2009. 2012 winner of the ACM’s [SIGOPS Mark Weiser Award][68] and the [ACM-Infosys Foundation Award in the Computing Sciences][69].
|
||||
|
||||
Quotes: “... for bringing breakthroughs in data mining( GFS, Map and Reduce, Big Table ).” [Natu Lauchande][70]
|
||||
|
||||
“... conceived, built, and deployed MapReduce and BigTable, among a bazillion other things” [Erik Goldman][71]
|
||||
|
||||

|
||||
|
||||
Image courtesy [Krd CC BY-SA 4.0][72]
|
||||
|
||||
### Linus Torvalds ###
|
||||
|
||||
**Main claim to fame: Creator of Linux**
|
||||
|
||||
Credentials: Created the [Linux kernel][73] and [Git][74], an open source version control system. Winner of numerous awards and honors, including the [EFF Pioneer Award][75] in 1998, the [British Computer Society’s Lovelace Medal][76] in 2000, the [Millenium Technology Prize][77] in 2012 and the [IEEE Computer Society’s Computer Pioneer Award][78] in 2014. Also inducted into the [Computer History Museum’s Hall of Fellows][79] in 2008 and the [Internet Hall of Fame][80] in 2012.
|
||||
|
||||
Quotes: “To put into prospective what an achievement this is, he wrote the Linux kernel in a few years while the GNU Hurd (a GNU-developed kernel) has been under development for 25 years and has still yet to release a production-ready example.” [Erich Ficker][81]
|
||||
|
||||
“Torvalds is probably the programmer's programmer.” [Dan Allen][82]
|
||||
|
||||
“He's pretty darn good.” [Alok Tripathy][83]
|
||||
|
||||

|
||||
|
||||
Image courtesy [QuakeCon CC BY 2.0][84]
|
||||
|
||||
### John Carmack ###
|
||||
|
||||
**Main claim to fame: Creator of Doom**
|
||||
|
||||
Credentials: Cofounded id Software and [created such influential FPS games][85] as Wolfenstein 3D, Doom and Quake. Pioneered such ground-breaking computer graphic techniques [adaptive tile refresh][86], [binary space partitioning][87], and surface caching. Inducted into the [Academy of Interactive Arts and Sciences Hall of Fame][88] in 2001, [won Emmy awards][89] in the Engineering & Technology category in 2007 and 2008, and given a lifetime achievement award by the [Game Developers Choice Awards][90] in 2010.
|
||||
|
||||
Quotes: “He wrote his first rendering engine before he was 20 years old. The guy's a genius. I wish I were a quarter a programmer he is.” [Alex Dolinsky][91]
|
||||
|
||||
“... Wolfenstein 3D, Doom and Quake were revolutionary at the time and have influenced a generation of game designers.” [dniblock][92]
|
||||
|
||||
“He can write basically anything in a weekend....” [Greg Naughton][93]
|
||||
|
||||
“He is the Mozart of computer coding….” [Chris Morris][94]
|
||||
|
||||

|
||||
|
||||
Image courtesy [Duff][95]
|
||||
|
||||
### Fabrice Bellard ###
|
||||
|
||||
**Main claim to fame: Creator of QEMU**
|
||||
|
||||
Credentials: Created a [variety of well-known open-source software programs][96], including QEMU, a platform for hardware emulation and virtualization, FFmpeg, for handling multimedia data, the Tiny C Compiler and LZEXE, an executable file compressor. [Winner of the Obfuscated C Code Contest][97] in 2000 and 2001 and the [Google-O'Reilly Open Source Award][98] in 2011. Former world record holder for [calculating the most number of digits in Pi][99].
|
||||
|
||||
Quotes: “I find Fabrice Bellard's work remarkable and impressive.” [raphinou][100]
|
||||
|
||||
“Fabrice Bellard is the most productive programmer in the world....” [Pavan Yara][101]
|
||||
|
||||
“Hes like the Nikola Tesla of sofware engineering.” [Michael Valladolid][102]
|
||||
|
||||
“He's a prolific serial achiever since the 1980s.” M[ichael Biggins][103]
|
||||
|
||||

|
||||
|
||||
Image courtesy [Craig Murphy CC BY 2.0][104]
|
||||
|
||||
### Jon Skeet ###
|
||||
|
||||
**Main claim to fame: Legendary Stack Overflow contributor**
|
||||
|
||||
Credentials: Google engineer and author of [C# in Depth][105]. Holds [highest reputation score of all time on Stack Overflow][106], answering, on average, 390 questions per month.
|
||||
|
||||
Quotes: “Jon Skeet doesn't need a debugger, he just stares down the bug until the code confesses” [Steven A. Lowe][107]
|
||||
|
||||
“When Jon Skeet's code fails to compile the compiler apologises.” [Dan Dyer][108]
|
||||
|
||||
“Jon Skeet's code doesn't follow a coding convention. It is the coding convention.” [Anonymous][109]
|
||||
|
||||

|
||||
|
||||
Image courtesy [Philip Neustrom CC BY 2.0][110]
|
||||
|
||||
### Adam D'Angelo ###
|
||||
|
||||
**Main claim to fame: Co-founder of Quora**
|
||||
|
||||
Credentials: As an engineer at Facebook, [built initial infrastructure for its news feed][111]. Went on to become CTO and VP of engineering at Facebook, before leaving to co-found Quora. [Eighth place finisher at the USA Computing Olympiad][112] as a high school student in 2001. Member of [California Institute of Technology’s silver medal winning team][113] at the ACM International Collegiate Programming Contest in 2004. [Finalist in the Algorithm Coding Competition][114] of Topcoder Collegiate Challenge in 2005.
|
||||
|
||||
Quotes: “An "All-Rounder" Programmer.” [Anonymous][115]
|
||||
|
||||
"For every good thing I make he has like six." [Mark Zuckerberg][116]
|
||||
|
||||

|
||||
|
||||
Image courtesy [Facebook][117]
|
||||
|
||||
### Petr Mitrechev ###
|
||||
|
||||
**Main claim to fame: One of the top competitive programmers of all time**
|
||||
|
||||
Credentials: [Two-time gold medal winner][118] in the International Olympiad in Informatics (2000, 2002). In 2006, [won the Google Code Jam][119] and was also the [TopCoder Open Algorithm champion][120]. Also, two-time winner of the Facebook Hacker Cup ([2011][121], [2013][122]). At the time of this writing, [the second ranked algorithm competitor on TopCoder][123] (handle: Petr) and also [ranked second by Codeforces][124]
|
||||
|
||||
Quote: “He is an idol in competitive programming even here in India…” [Kavish Dwivedi][125]
|
||||
|
||||

|
||||
|
||||
Image courtesy [Ishandutta2007 CC BY-SA 3.0][126]
|
||||
|
||||
### Gennady Korotkevich ###
|
||||
|
||||
**Main claim to fame: Competitive programming prodigy**
|
||||
|
||||
Credentials: Youngest participant ever (age 11) and [6 time gold medalist][127] (2007-2012) in the International Olympiad in Informatics. Part of [the winning team][128] at the ACM International Collegiate Programming Contest in 2013 and winner of the [2014 Facebook Hacker Cup][129]. At the time of this writing, [ranked first by Codeforces][130] (handle: Tourist) and [first among algorithm competitors by TopCoder][131].
|
||||
|
||||
Quotes: “A programming prodigy!” [Prateek Joshi][132]
|
||||
|
||||
“Gennady is definitely amazing, and visible example of why I have a large development team in Belarus.” [Chris Howard][133]
|
||||
|
||||
“Tourist is genius” [Nuka Shrinivas Rao][134]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.itworld.com/article/2823547/enterprise-software/158256-superclass-14-of-the-world-s-best-living-programmers.html#slide1
|
||||
|
||||
作者:[Phil Johnson][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.itworld.com/author/Phil-Johnson/
|
||||
[1]:https://www.flickr.com/photos/tombullock/15713223772
|
||||
[2]:https://commons.wikimedia.org/wiki/File:Margaret_Hamilton_in_action.jpg
|
||||
[3]:http://klabs.org/home_page/hamilton.htm
|
||||
[4]:https://www.youtube.com/watch?v=DWcITjqZtpU&feature=youtu.be&t=3m12s
|
||||
[5]:http://www.htius.com/Articles/r12ham.pdf
|
||||
[6]:http://www.htius.com/Articles/Inside_DBTF.htm
|
||||
[7]:http://www.nasa.gov/home/hqnews/2003/sep/HQ_03281_Hamilton_Honor.html
|
||||
[8]:http://www.nasa.gov/50th/50th_magazine/scientists.html
|
||||
[9]:https://books.google.com/books?id=JcmV0wfQEoYC&pg=PA321&lpg=PA321&dq=ada+lovelace+award+1986&source=bl&ots=qGdBKsUa3G&sig=bkTftPAhM1vZ_3VgPcv-38ggSNo&hl=en&sa=X&ved=0CDkQ6AEwBGoVChMI3paoxJHWxwIVA3I-Ch1whwPn#v=onepage&q=ada%20lovelace%20award%201986&f=false
|
||||
[10]:http://history.nasa.gov/alsj/a11/a11Hamilton.html
|
||||
[11]:https://www.reddit.com/r/pics/comments/2oyd1y/margaret_hamilton_with_her_code_lead_software/cmrswof
|
||||
[12]:http://qr.ae/RFEZLk
|
||||
[13]:http://qr.ae/RFEZUn
|
||||
[14]:https://www.reddit.com/r/pics/comments/2oyd1y/margaret_hamilton_with_her_code_lead_software/cmrv9u9
|
||||
[15]:https://www.flickr.com/photos/44451574@N00/5347112697
|
||||
[16]:http://cs.stanford.edu/~uno/taocp.html
|
||||
[17]:http://awards.acm.org/award_winners/knuth_1013846.cfm
|
||||
[18]:http://amturing.acm.org/award_winners/knuth_1013846.cfm
|
||||
[19]:http://www.nsf.gov/od/nms/recip_details.jsp?recip_id=198
|
||||
[20]:http://www.ieee.org/documents/von_neumann_rl.pdf
|
||||
[21]:http://www.computerhistory.org/fellowawards/hall/bios/Donald,Knuth/
|
||||
[22]:http://www.quora.com/Who-are-the-best-programmers-in-Silicon-Valley-and-why/answers/3063
|
||||
[23]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Jaap-Weel
|
||||
[24]:http://qr.ae/RFE94x
|
||||
[25]:http://amturing.acm.org/photo/thompson_4588371.cfm
|
||||
[26]:https://www.youtube.com/watch?v=JoVQTPbD6UY
|
||||
[27]:https://www.bell-labs.com/usr/dmr/www/bintro.html
|
||||
[28]:http://doc.cat-v.org/bell_labs/utf-8_history
|
||||
[29]:http://c2.com/cgi/wiki?EdIsTheStandardTextEditor
|
||||
[30]:http://amturing.acm.org/award_winners/thompson_4588371.cfm
|
||||
[31]:http://www.computer.org/portal/web/awards/cp-thompson
|
||||
[32]:http://www.uspto.gov/about/nmti/recipients/1998.jsp
|
||||
[33]:http://www.computerhistory.org/fellowawards/hall/bios/Ken,Thompson/
|
||||
[34]:http://www.quora.com/Computer-Programming/Who-is-the-best-programmer-in-the-world-right-now/answer/Pete-Prokopowicz-1
|
||||
[35]:http://qr.ae/RFEWBY
|
||||
[36]:https://groups.google.com/forum/#!msg/net.unix-wizards/8twfRPM79u0/1xlglzrWrU0J
|
||||
[37]:http://www.emacswiki.org/emacs/RichardStallman
|
||||
[38]:https://www.gnu.org/gnu/thegnuproject.html
|
||||
[39]:http://www.emacswiki.org/emacs/FreeSoftwareFoundation
|
||||
[40]:http://awards.acm.org/award_winners/stallman_9380313.cfm
|
||||
[41]:https://w2.eff.org/awards/pioneer/1998.php
|
||||
[42]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Greg-Naughton/comment/4146397
|
||||
[43]:http://qr.ae/RFEaib
|
||||
[44]:http://www.quora.com/Software-Engineering/Who-are-some-of-the-greatest-currently-active-software-architects-in-the-world/answer/Marko-Poutiainen
|
||||
[45]:http://qr.ae/RFEUqp
|
||||
[46]:https://www.flickr.com/photos/begley/2979906130
|
||||
[47]:http://www.taoyue.com/tutorials/pascal/history.html
|
||||
[48]:http://c2.com/cgi/wiki?AndersHejlsberg
|
||||
[49]:http://www.microsoft.com/about/technicalrecognition/anders-hejlsberg.aspx
|
||||
[50]:http://www.drdobbs.com/windows/dr-dobbs-excellence-in-programming-award/184404602
|
||||
[51]:http://qr.ae/RFEZrv
|
||||
[52]:http://www.quora.com/Software-Engineering/Who-are-some-of-the-greatest-currently-active-software-architects-in-the-world/answer/Stefan-Kiryazov
|
||||
[53]:https://www.flickr.com/photos/vonguard/4076389963/
|
||||
[54]:http://www.wizards-of-os.org/archiv/sprecher/a_c/doug_cutting.html
|
||||
[55]:http://hadoop.apache.org/
|
||||
[56]:https://www.linkedin.com/in/cutting
|
||||
[57]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Shalin-Shekhar-Mangar/comment/2293071
|
||||
[58]:http://www.quora.com/Who-are-the-best-programmers-in-Silicon-Valley-and-why/answer/Amit-Nithianandan
|
||||
[59]:http://awards.acm.org/award_winners/ghemawat_1482280.cfm
|
||||
[60]:http://research.google.com/pubs/SanjayGhemawat.html
|
||||
[61]:http://www.quora.com/Google/Who-is-Sanjay-Ghemawat
|
||||
[62]:http://www8.nationalacademies.org/onpinews/newsitem.aspx?RecordID=02062009
|
||||
[63]:http://awards.acm.org/award_winners/ghemawat_1482280.cfm
|
||||
[64]:http://www.quora.com/Google/Who-is-Sanjay-Ghemawat/answer/Ahmet-Alp-Balkan
|
||||
[65]:http://research.google.com/people/jeff/index.html
|
||||
[66]:http://research.google.com/people/jeff/index.html
|
||||
[67]:http://www8.nationalacademies.org/onpinews/newsitem.aspx?RecordID=02062009
|
||||
[68]:http://news.cs.washington.edu/2012/10/10/uw-cse-ph-d-alum-jeff-dean-wins-2012-sigops-mark-weiser-award/
|
||||
[69]:http://awards.acm.org/award_winners/dean_2879385.cfm
|
||||
[70]:http://www.quora.com/Computer-Programming/Who-is-the-best-programmer-in-the-world-right-now/answer/Natu-Lauchande
|
||||
[71]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Cosmin-Negruseri/comment/28399
|
||||
[72]:https://commons.wikimedia.org/wiki/File:LinuxCon_Europe_Linus_Torvalds_05.jpg
|
||||
[73]:http://www.linuxfoundation.org/about/staff#torvalds
|
||||
[74]:http://git-scm.com/book/en/Getting-Started-A-Short-History-of-Git
|
||||
[75]:https://w2.eff.org/awards/pioneer/1998.php
|
||||
[76]:http://www.bcs.org/content/ConWebDoc/14769
|
||||
[77]:http://www.zdnet.com/blog/open-source/linus-torvalds-wins-the-tech-equivalent-of-a-nobel-prize-the-millennium-technology-prize/10789
|
||||
[78]:http://www.computer.org/portal/web/pressroom/Linus-Torvalds-Named-Recipient-of-the-2014-IEEE-Computer-Society-Computer-Pioneer-Award
|
||||
[79]:http://www.computerhistory.org/fellowawards/hall/bios/Linus,Torvalds/
|
||||
[80]:http://www.internethalloffame.org/inductees/linus-torvalds
|
||||
[81]:http://qr.ae/RFEeeo
|
||||
[82]:http://qr.ae/RFEZLk
|
||||
[83]:http://www.quora.com/Software-Engineering/Who-are-some-of-the-greatest-currently-active-software-architects-in-the-world/answer/Alok-Tripathy-1
|
||||
[84]:https://www.flickr.com/photos/quakecon/9434713998
|
||||
[85]:http://doom.wikia.com/wiki/John_Carmack
|
||||
[86]:http://thegamershub.net/2012/04/gaming-gods-john-carmack/
|
||||
[87]:http://www.shamusyoung.com/twentysidedtale/?p=4759
|
||||
[88]:http://www.interactive.org/special_awards/details.asp?idSpecialAwards=6
|
||||
[89]:http://www.itworld.com/article/2951105/it-management/a-fly-named-for-bill-gates-and-9-other-unusual-honors-for-tech-s-elite.html#slide8
|
||||
[90]:http://www.gamechoiceawards.com/archive/lifetime.html
|
||||
[91]:http://qr.ae/RFEEgr
|
||||
[92]:http://www.itworld.com/answers/topic/software/question/whos-best-living-programmer#comment-424562
|
||||
[93]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Greg-Naughton
|
||||
[94]:http://money.cnn.com/2003/08/21/commentary/game_over/column_gaming/
|
||||
[95]:http://dufoli.wordpress.com/2007/06/23/ammmmaaaazing-night/
|
||||
[96]:http://bellard.org/
|
||||
[97]:http://www.ioccc.org/winners.html#B
|
||||
[98]:http://www.oscon.com/oscon2011/public/schedule/detail/21161
|
||||
[99]:http://bellard.org/pi/pi2700e9/
|
||||
[100]:https://news.ycombinator.com/item?id=7850797
|
||||
[101]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Erik-Frey/comment/1718701
|
||||
[102]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Erik-Frey/comment/2454450
|
||||
[103]:http://qr.ae/RFEjhZ
|
||||
[104]:https://www.flickr.com/photos/craigmurphy/4325516497
|
||||
[105]:http://www.amazon.co.uk/gp/product/1935182471?ie=UTF8&tag=developetutor-21&linkCode=as2&camp=1634&creative=19450&creativeASIN=1935182471
|
||||
[106]:http://stackexchange.com/leagues/1/alltime/stackoverflow
|
||||
[107]:http://meta.stackexchange.com/a/9156
|
||||
[108]:http://meta.stackexchange.com/a/9138
|
||||
[109]:http://meta.stackexchange.com/a/9182
|
||||
[110]:https://www.flickr.com/photos/philipn/5326344032
|
||||
[111]:http://www.crunchbase.com/person/adam-d-angelo
|
||||
[112]:http://www.exeter.edu/documents/Exeter_Bulletin/fall_01/oncampus.html
|
||||
[113]:http://icpc.baylor.edu/community/results-2004
|
||||
[114]:https://www.topcoder.com/tc?module=Static&d1=pressroom&d2=pr_022205
|
||||
[115]:http://qr.ae/RFfOfe
|
||||
[116]:http://www.businessinsider.com/in-new-alleged-ims-mark-zuckerberg-talks-about-adam-dangelo-2012-9#ixzz369FcQoLB
|
||||
[117]:https://www.facebook.com/hackercup/photos/a.329665040399024.91563.133954286636768/553381194694073/?type=1
|
||||
[118]:http://stats.ioinformatics.org/people/1849
|
||||
[119]:http://googlepress.blogspot.com/2006/10/google-announces-winner-of-global-code_27.html
|
||||
[120]:http://community.topcoder.com/tc?module=SimpleStats&c=coder_achievements&d1=statistics&d2=coderAchievements&cr=10574855
|
||||
[121]:https://www.facebook.com/notes/facebook-hacker-cup/facebook-hacker-cup-finals/208549245827651
|
||||
[122]:https://www.facebook.com/hackercup/photos/a.329665040399024.91563.133954286636768/553381194694073/?type=1
|
||||
[123]:http://community.topcoder.com/tc?module=AlgoRank
|
||||
[124]:http://codeforces.com/ratings
|
||||
[125]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Venkateswaran-Vicky/comment/1960855
|
||||
[126]:http://commons.wikimedia.org/wiki/File:Gennady_Korot.jpg
|
||||
[127]:http://stats.ioinformatics.org/people/804
|
||||
[128]:http://icpc.baylor.edu/regionals/finder/world-finals-2013/standings
|
||||
[129]:https://www.facebook.com/hackercup/posts/10152022955628845
|
||||
[130]:http://codeforces.com/ratings
|
||||
[131]:http://community.topcoder.com/tc?module=AlgoRank
|
||||
[132]:http://www.quora.com/Computer-Programming/Who-is-the-best-programmer-in-the-world-right-now/answer/Prateek-Joshi
|
||||
[133]:http://www.quora.com/Computer-Programming/Who-is-the-best-programmer-in-the-world-right-now/answer/Prateek-Joshi/comment/4720779
|
||||
[134]:http://www.quora.com/Computer-Programming/Who-is-the-best-programmer-in-the-world-right-now/answer/Prateek-Joshi/comment/4880549
|
||||
@ -0,0 +1,149 @@
|
||||
The Free Software Foundation: 30 years in
|
||||
================================================================================
|
||||

|
||||
|
||||
Welcome back, folks, to a new Six Degrees column. As usual, please send your thoughts on this piece to the comment box and your suggestions for future columns to [my inbox][1].
|
||||
|
||||
Now, I have to be honest with you all, this column went a little differently than I expected.
|
||||
|
||||
A few weeks ago when thinking what to write, I mused over the notion of a piece about the [Free Software Foundation][2] celebrating its 30 year anniversary and how relevant and important its work is in today's computing climate.
|
||||
|
||||
To add some meat I figured I would interview [John Sullivan][3], executive director of the FSF. My plan was typical of many of my pieces: thread together an interesting narrative and quote pieces of the interview to give it color.
|
||||
|
||||
Well, that all went out the window when John sent me a tremendously detailed, thoughtful, and descriptive interview. I decided therefore to present it in full as the main event, and to add some commentary throughout. Thus, this is quite a long column, but I think it paints a fascinating picture of a fascinating organization. I recommend you grab a cup of something delicious and settle in for a solid read.
|
||||
|
||||
### The sands of change ###
|
||||
|
||||
The Free Software Foundation was founded in 1985. To paint a picture of what computing was like back then, the [Amiga 1000][4] was released, C++ was becoming a dominant language, [Aldus PageMaker][5] was announced, and networking was just starting to grow. Oh, and that year [Careless Whisper][6] by Wham! was a major hit.
|
||||
|
||||
Things have changed a lot in 30 years. Back in 1985 the FSF was primarily focused on building free pieces of software that were primarily useful to nerdy computer people. These days we have software, services, social networks, and more to consider.
|
||||
|
||||
I first wanted to get a sense of what John feels are most prominent risks to software freedom today.
|
||||
|
||||
"I think there's widespread agreement on the biggest risks for computer user freedom today, but maybe not on the names for them."
|
||||
|
||||
"The first is what we might as well just call 'tiny computers everywhere.' The free software movement has succeeded to the point where laptops, desktops, and servers can run fully free operating systems doing anything users of proprietary systems can do. There are still a few holes, but they'll be closed. The challenge that remains in this area is to cut through the billion dollar marketing budgets and legal regimes working against us to actually get the systems into users hands."
|
||||
|
||||
"However, we have a serious problem on the set of computers whose primary common trait is that they are very small. Even though a car is not especially small, the computers in it are, so I include that form factor in this category, along with phones, tablets, glasses, watches, and so on. While these computers often have a basis in free software—for example, using the kernel Linux along with other free software like Android or GNU—their primary uses are to run proprietary applications and be shims for services that replace local computing with computing done on a server over which the user has no control. Since these devices serve vital functions, with some being primary means of communication for huge populations, some sitting very close to our bodies and our actual vital functions, some bearing responsibility for our physical safety, it is imperative that they run fully free systems under their users' control. Right now, they don't."
|
||||
|
||||
John feels the risk here is not just the platforms and form factors, but the services integrates into them.
|
||||
|
||||
"The services many of these devices talk to are the second major threat we face. It does us little good booting into a free system if we do our actual work and entertainment on companies' servers running software we have no access to at all. The point of free software is that we can see, modify, and share code. The existence of those freedoms even for nontechnical users provides a shield that prevents companies from controlling us. None of these freedoms exist for users of Facebook or Salesforce or Google Docs. Even more worrisome, we see a trend where people are accepting proprietary restrictions imposed on their local machines in order to have access to certain services. Browsers—including Firefox—are now automatically installing a DRM plugin in order to appease Netflix and other video giants. We need to work harder at developing free software decentralized replacements for media distribution that can actually empower users, artists, and user-artists, and for other services as well. For Facebook we have GNU social, pump.io, Diaspora, Movim, and others. For Salesforce, we have CiviCRM. For Google Docs, we have Etherpad. For media, we have GNU MediaGoblin. But all of these projects need more help, and many services don't have any replacement contenders yet."
|
||||
|
||||
It is interesting that John mentions finding free software equivalents for common applications and services today. The FSF maintains a list of "High Priority Projects" that are designed to fill this gap. Unfortunately the capabilities of these projects varies tremendously and in an age where social media is so prominent, the software is only part of the problem: the real challenge is getting people to use it.
|
||||
|
||||
This all begs the question of where the FSF fit in today's modern computing world. I am a fan of the FSF. I think the work they do is valuable and I contribute financially to support it too. They are an important organization for building an open computing culture, but all organizations need to grow, adjust, and adapt, particularly ones in the technology space.
|
||||
|
||||
I wanted to get a better sense of what the FSF is doing today that it wasn't doing at it's inception.
|
||||
|
||||
"We're speaking to a much larger audience than we were 30 years ago, and to a much broader audience. It's no longer just hackers and developers and researchers that need to know about free software. Everyone using a computer does, and it's quickly becoming the case that everyone uses a computer."
|
||||
|
||||
John went on to provide some examples of these efforts.
|
||||
|
||||
"We're doing coordinated public advocacy campaigns on issues of concern to the free software movement. Earlier in our history, we expressed opinions on these things, and took action on a handful, but in the last ten years we've put more emphasis on formulating and carrying out coherent campaigns. We've made especially significant noise in the area of Digital Restrictions Management (DRM) with Defective by Design, which I believe played a role in getting iTunes music off DRM (now of course, Apple is bringing DRM back with Apple Music). We've made attractive and useful introductory materials for people new to free software, like our [User Liberation animated video][7] and our [Email Self-Defense Guide][8].
|
||||
|
||||
We're also endorsing hardware that [respects users' freedoms][9]. Hardware distributors whose devices have been certified by the FSF to contain and require only free software can display a logo saying so. Expanding the base of free software users and the free software movement has two parts: convincing people to care, and then making it possible for them to act on that. Through this initiative, we encourage manufacturers and distributors to do the right thing, and we make it easy for users who have started to care about free software to buy what they need without suffering through hours and hours of research. We've certified a home WiFi router, 3D printers, laptops, and USB WiFi adapters, with more on the way.
|
||||
|
||||
We're collecting all of the free software we can find in our [Free Software Directory][10]. We still have a long way to go on this—we're at only about 15,500 packages right now, and we can imagine many improvements to the design and function of the site—but I think this resource has great potential for helping users find the free software they need, especially users who aren't yet using a full GNU/Linux system. With the dangers inherent in downloading random programs off the Internet, there is a definite need for a curated collection like this. It also happens to provide a wealth of machine-readable data of use to researchers.
|
||||
|
||||
We're acting as the fiscal sponsor for several specific free software projects, enabling them to raise funds for development. Most of these projects are part of GNU (which we continue to provide many kinds of infrastructure for), but we also sponsor [Replicant][11], a fully free fork of Android designed to give users the free-est mobile devices currently possible.
|
||||
|
||||
We're helping developers use free software licenses properly, and we're following up on complaints about companies that aren't following the terms of the GPL. We help them fix their mistakes and distribute properly. RMS was in fact doing similar work with the precursors of the GPL very early on, but it's now an ongoing part of our work.
|
||||
|
||||
Most of the specific things the FSF does now it wasn't doing 30 years ago, but the vision is little changed from the original paperwork—we aim to create a world where everything users want to do on any computer can be done using free software; a world where users control their computers and not the other way around."
|
||||
|
||||
### A cult of personality ###
|
||||
|
||||
There is little doubt in anyone's minds about the value the FSF brings. As John just highlighted, its efforts span not just the creation and licensing of free software, but also recognizing, certifying, and advocating a culture of freedom in technology.
|
||||
|
||||
The head of the FSF is the inimitable Richard M. Stallman, commonly referred to as RMS.
|
||||
|
||||
RMS is a curious character. He has demonstrated an unbelievable level of commitment to his ideas, philosophy, and ethical devotion to freedom in software.
|
||||
|
||||
While he is sometimes mocked online for his social awkwardness, be it things said in his speeches, his bizarre travel requirements, or other sometimes cringeworthy moments, RMS's perspectives on software and freedom are generally rock-solid. He takes a remarkably consistent approach to his perspectives and he is clearly a careful thinker about not just his own thoughts but the wider movement he is leading. My only criticism is that I think from time to time he somewhat over-eggs the pudding with the voracity of his words. But hey, given his importance in our world, I would rather take an extra egg than no pudding for anyone. O.K., I get that the whole pudding thing here was strained...
|
||||
|
||||
So RMS is a key part of the FSF, but the organization is also much more than that. There are employees, a board, and many contributors. I was curious to see how much of a role RMS plays these days in the FSF. John shared this with me.
|
||||
|
||||
"RMS is the FSF's President, and does that work without receiving a salary from the FSF. He continues his grueling global speaking schedule, advocating for free software and computer user freedom in dozens of countries each year. In the course of that, he meets with government officials as well as local activists connected with all varieties of social movements. He also raises funds for the FSF and inspires many people to volunteer."
|
||||
|
||||
"In between engagements, he does deep thinking on issues facing the free software movement, and anticipates new challenges. Often this leads to new articles—he wrote a 3-part series for Wired earlier this year about free software and free hardware designs—or new ideas communicated to the FSF's staff as the basis for future projects."
|
||||
|
||||
As we delved into the cult of personality, I wanted to tap John's perspectives on how wide the free software movement has grown.
|
||||
|
||||
I remember being at the [Open Source Think Tank][12] (an event that brings together execs from various open source organizations) and there was a case study where attendees were asked to recommend license choice for a particular project. The vast majority of break-out groups recommended the Apache Software License (APL) over the GNU Public License (GPL).
|
||||
|
||||
This stuck in my mind as since then I have noticed that many companies seem to have opted for open licenses other than the GPL. I was curious to see if John had noticed a trend towards the APL as opposed to the GPL.
|
||||
|
||||
"Has there been? I'm not so sure. I gave a presentation at FOSDEM a few years ago called 'Is Copyleft Being Framed?' that showed some of the problems with the supposed data behind claims of shifts in license adoption. I'll be publishing an article soon on this, but here's some of the major problems:
|
||||
|
||||
|
||||
- Free software license choices do not exist in a vacuum. The number of people choosing proprietary software licenses also needs to be considered in order to draw the kinds of conclusions that people want to draw. I find it much more likely that lax permissive license choices (such as the Apache License or 3-clause BSD) are trading off with proprietary license choices, rather than with the GPL.
|
||||
- License counters often, ironically, don't publish the software they use to collect that data as free software. That means we can't inspect their methods or reproduce their results. Some people are now publishing the code they use, but certainly any that don't should be completely disregarded. Science has rules.
|
||||
- What counts as a thing with a license? Are we really counting an app under the APL that makes funny noises as 1:1 with GNU Emacs under GPLv3? If not, how do we decide which things to treat as equals? Are we only looking at software that actually works? Are we making sure not to double- and triple- count programs that exist on multiple hosting sites, and what about ports for different OSes?
|
||||
|
||||
The question is interesting to ponder, but every conclusion I've seen so far has been extremely premature in light of the actual data. I'd much rather see a survey of developers asking about why they chose particular licenses for their projects than any more of these attempts to programmatically ascertain the license of programs and then ascribe human intentions on to patterns in that data.
|
||||
|
||||
Copyleft is as vital as it ever was. Permissively licensed software is still free software and on-face a good thing, but it is contingent and needs an accompanying strong social commitment to not incorporate it in proprietary software. If free software's major long-term impact is enabling businesses to more efficiently make products that restrict us, then we have achieved nothing for computer user freedom."
|
||||
|
||||
### Rising to new challenges ###
|
||||
|
||||
30 years is an impressive time for any organization to be around, and particularly one with such important goals that span so many different industries, professions, governments, and cultures.
|
||||
|
||||
As I started to wrap up the interview I wanted to get a better sense of what the FSF's primary function is today, 30 years after the mission started.
|
||||
|
||||
"I think the FSF is in a very interesting position of both being a steady rock and actively pushing the envelope."
|
||||
|
||||
"We have core documents like the [Free Software Definition][13], the [GNU General Public License][14], and the [list we maintain of free and nonfree software licenses][15], which have been keystones in the construction of the world of free software we have today. People place a great deal of trust in us to stay true to the principles outlined in those documents, and to apply them correctly and wisely in our assessments of new products or practices in computing. In this role, we hold the ladder for others to climb. As a 501(c)(3) charity held legally accountable to the public interest, and about 85% funded by individuals, we have the right structure for this."
|
||||
|
||||
"But we also push the envelope. We take on challenges that others say are too hard. I guess that means we also build ladders? Or maybe I should stop with the metaphors."
|
||||
|
||||
While John may not be great with metaphors (like I am one to talk), the FSF is great at setting a mission and demonstrating a devout commitment to it. This mission starts with a belief that free software should be everywhere.
|
||||
|
||||
"We are not satisfied with the idea that you can get a laptop that works with free software except for a few components. We're not satisfied that you can have a tablet that runs a lot of free software, and just uses proprietary software to communicate with networks and to accelerate video and to take pictures and to check in on your flight and to call an Über and to.. Well, we are happy about some such developments for sure, but we are also unhappy about the suggestion that we should be fully content with them. Any proprietary software on a system is both an injustice to the user and inherently a threat to users' security. These almost-free things can be stepping stones on the way to a free world, but only if we keep our feet moving."
|
||||
|
||||
In the early years of the FSF, we actually had to get a free operating system written. This has now been done by GNU and Linux and many collaborators, although there is always more software to write and bugs to fix. So while the FSF does still sponsor free software development in specific areas, there are thankfully many other organizations also doing this."
|
||||
|
||||
A key part of the challenge John is referring to is getting the right hardware into the hands of the right people.
|
||||
|
||||
"What we have been focusing on now are the challenges I highlighted in the first question. We are in desperate need of hardware in several different areas that fully supports free software. We have been talking a lot at the FSF about what we can do to address this, and I expect us to be making some significant moves to both increase our support for some of the projects already out there—as we having been doing to some extent through our Respects Your Freedom certification program—and possibly to launch some projects of our own. The same goes for the network service problem. I think we need to tackle them together, because having full control over the mobile components has great potential for changing how we relate to services, and decentralizing more and more services will in turn shape the mobile components."
|
||||
|
||||
I hope folks will support the FSF as we work to grow and tackle these challenges. Hardware is expensive and difficult, as is making usable, decentralized, federated replacements for network services. We're going to need the resources and creativity of a lot of people. But, 30 years ago, a community rallied around RMS and the concept of copyleft to write an entire operating system. I've spent my last 12 years at the FSF because I believe we can rise to the new challenges in the same way."
|
||||
|
||||
### Final thoughts ###
|
||||
|
||||
In reading John's thoughtful responses to my questions, and in knowing various FSF members, the one sense that resonates for me is the sheer level of passion that is alive and kicking in the FSF. This is not an organization that has got bored or disillusioned with its mission. Its passion and commitment is as voracious as it has ever been.
|
||||
|
||||
While I don't always agree with the FSF and I sometimes think its approach is a little one-dimensional at times, I have been and will continue to be a huge fan and supporter of its work. The FSF represent the ethical heartbeat of much of the free software and open source work that happens across the world. It represents a world view that is pretty hard to the left, but I believe its passion and conviction helps to bring people further to the right a little closer to the left too.
|
||||
|
||||
Sure, RMS can be odd, somewhat hardline, and a little sensational, but he is precisely the kind of leader that is valuable in a movement that encapsulates a mixture of technology, ethics, and culture. We need an RMS in much the same way we need a Torvalds, a Shuttleworth, a Whitehurst, and a Zemlin. These different people bring together mixture of perspectives that ultimately maps to technology that can be adaptable to almost any set of use cases, ethics, and ambitions.
|
||||
|
||||
So, in closing, I want to thank the FSF for its tremendous efforts, and I wish the FSF and its fearless leaders, one Richard M. Stallman and one John Sullivan, another 30 years of fighting the good fight. Go get 'em!
|
||||
|
||||
> This article is part of Jono Bacon's Six Degrees column, where he shares his thoughts and perspectives on culture, communities, and trends in open source.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://opensource.com/business/15/9/free-software-foundation-30-years
|
||||
|
||||
作者:[Jono Bacon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://opensource.com/users/jonobacon
|
||||
[1]:Welcome back, folks, to a new Six Degrees column. As usual, please send your thoughts on this piece to the comment box and your suggestions for future columns to my inbox.
|
||||
[2]:http://www.fsf.org/
|
||||
[3]:http://twitter.com/johns_fsf/
|
||||
[4]:https://en.wikipedia.org/wiki/Amiga_1000
|
||||
[5]:https://en.wikipedia.org/wiki/Adobe_PageMaker
|
||||
[6]:https://www.youtube.com/watch?v=izGwDsrQ1eQ
|
||||
[7]:http://fsf.org/
|
||||
[8]:http://emailselfdefense.fsf.org/
|
||||
[9]:http://fsf.org/ryf
|
||||
[10]:http://directory.fsf.org/
|
||||
[11]:http://www.replicant.us/
|
||||
[12]:http://www.osthinktank.com/
|
||||
[13]:http://www.fsf.org/about/what-is-free-software
|
||||
[14]:http://www.gnu.org/licenses/gpl-3.0.en.html
|
||||
[15]:http://www.gnu.org/licenses/licenses.en.html
|
||||
@ -1,54 +0,0 @@
|
||||
ictlyh Translating
|
||||
Do Simple Math In Ubuntu And elementary OS With NaSC
|
||||
================================================================================
|
||||

|
||||
|
||||
[NaSC][1], abbreviation Not a Soulver Clone, is a third party app developed for elementary OS. Whatever the name suggests, NaSC is heavily inspired by [Soulver][2], an OS X app for doing maths like a normal person.
|
||||
|
||||
elementary OS itself draws from OS X and it is not a surprise that a number of the third party apps it has got, are also inspired by OS X apps.
|
||||
|
||||
Coming back to NaSC, what exactly it means by “maths like a normal person “? Well, it means to write like how you think in your mind. As per the description of the app:
|
||||
|
||||
> “Its an app where you do maths like a normal person. It lets you type whatever you want and smartly figures out what is math and spits out an answer on the right pane. Then you can plug those answers in to future equations and if that answer changes, so does the equations its used in.”
|
||||
|
||||
Still not convinced? Here, take a look at this screenshot.
|
||||
|
||||

|
||||
|
||||
Now, you see what is ‘math for normal person’? Honestly, I am not a fan of such apps but it might be useful for some of you perhaps. Let’s see how can you install NaSC in elementary OS, Ubuntu and Linux Mint.
|
||||
|
||||
### Install NaSC in Ubuntu, elementary OS and Mint ###
|
||||
|
||||
There is a PPA available for installing NaSC. The PPA says ‘daily’ which could mean daily build (i.e. unstable) but in my quick test, it worked just fine.
|
||||
|
||||
Open a terminal and use the following commands:
|
||||
|
||||
sudo apt-add-repository ppa:nasc-team/daily
|
||||
sudo apt-get update
|
||||
sudo apt-get install nasc
|
||||
|
||||
Here is a screenshot of NaSC in Ubuntu 15.04:
|
||||
|
||||

|
||||
|
||||
If you want to remove it, you can use the following commands:
|
||||
|
||||
sudo apt-get remove nasc
|
||||
sudo apt-add-repository --remove ppa:nasc-team/daily
|
||||
|
||||
If you try it, do share your experience with it. In addition to this, you can also try [Vocal podcast app for Linux][3] from third party elementary OS apps.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/math-ubuntu-nasc/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://parnold-x.github.io/nasc/
|
||||
[2]:http://www.acqualia.com/soulver/
|
||||
[3]:http://itsfoss.com/podcast-app-vocal-linux/
|
||||
@ -1,117 +0,0 @@
|
||||
ictlyh Translating
|
||||
How To Manage Log Files With Logrotate On Ubuntu 12.10
|
||||
================================================================================
|
||||
#### About Logrotate ####
|
||||
|
||||
Logrotate is a utility/tool that manages activities like automatic rotation, removal and compression of log files in a system. This is an excellent tool to manage your logs conserve precious disk space. By having a simple yet powerful configuration file, different parameters of logrotation can be controlled. This gives complete control over the way logs can be automatically managed and need not necessitate manual intervention.
|
||||
|
||||
### Prerequisites ###
|
||||
|
||||
As a prerequisite, we are assuming that you have gone through the article on how to set up your droplet or VPS. If not, you can find the article [here][1]. This tutorial requires you to have a VPS up and running and have you log into it.
|
||||
|
||||
#### Setup Logrotate ####
|
||||
|
||||
### Step 1—Update System and System Packages ###
|
||||
|
||||
Run the following command to update the package lists from apt-get and get the information on the newest versions of packages and their dependencies.
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
### Step 2—Install Logrotate ###
|
||||
|
||||
If logrotate is not already on your VPS, install it now through apt-get.
|
||||
|
||||
sudo apt-get install logrotate
|
||||
|
||||
### Step 3 — Confirmation ###
|
||||
|
||||
To verify that logrotate was successfully installed, run this in the command prompt.
|
||||
|
||||
logrotate
|
||||
|
||||
Since the logrotate utility is based on configuration files, the above command will not rotate any files and will show you a brief overview of the usage and the switch options available.
|
||||
|
||||
### Step 4—Configure Logrotate ###
|
||||
|
||||
Configurations and default options for the logrotate utility are present in:
|
||||
|
||||
/etc/logrotate.conf
|
||||
|
||||
Some of the important configuration settings are : rotation-interval, log-file-size, rotation-count and compression.
|
||||
|
||||
Application-specific log file information (to override the defaults) are kept at:
|
||||
|
||||
/etc/logrotate.d/
|
||||
|
||||
We will have a look at a few examples to understand the concept better.
|
||||
|
||||
### Step 5—Example ###
|
||||
|
||||
An example application configuration setting would be the dpkg (Debian package management system), that is stored in /etc/logrotate.d/dpkg. One of the entries in this file would be:
|
||||
|
||||
/var/log/dpkg.log {
|
||||
monthly
|
||||
rotate 12
|
||||
compress
|
||||
delaycompress
|
||||
missingok
|
||||
notifempty
|
||||
create 644 root root
|
||||
}
|
||||
|
||||
What this means is that:
|
||||
|
||||
- the logrotation for dpkg monitors the /var/log/dpkg.log file and does this on a monthly basis this is the rotation interval.
|
||||
- 'rotate 12' signifies that 12 days worth of logs would be kept.
|
||||
- logfiles can be compressed using the gzip format by specifying 'compress' and 'delaycompress' delays the compression process till the next log rotation. 'delaycompress' will work only if 'compress' option is specified.
|
||||
- 'missingok' avoids halting on any error and carries on with the next log file.
|
||||
- 'notifempty' avoid log rotation if the logfile is empty.
|
||||
- 'create <mode> <owner> <group>' creates a new empty file with the specified properties after log-rotation.
|
||||
|
||||
Though missing in the above example, 'size' is also an important setting if you want to control the sizing of the logs growing in the system.
|
||||
|
||||
A configuration setting of around 100MB would look like:
|
||||
|
||||
size 100M
|
||||
|
||||
Note that If both size and rotation interval are set, then size is taken as a higher priority. That is, if a configuration file has the following settings:
|
||||
|
||||
monthly
|
||||
size 100M
|
||||
|
||||
then the logs are rotated once the file size reaches 100M and this need not wait for the monthly cycle.
|
||||
|
||||
### Step 6—Cron Job ###
|
||||
|
||||
You can also set the logrotation as a cron so that the manual process can be avoided and this is taken care of automatically. By specifying an entry in /etc/cron.daily/logrotate , the rotation is triggered daily.
|
||||
|
||||
### Step 7—Status Check and Verification ###
|
||||
|
||||
To verify if a particular log is indeed rotating or not and to check the last date and time of its rotation, check the /var/lib/logrotate/status file. This is a neatly formatted file that contains the log file name and the date on which it was last rotated.
|
||||
|
||||
cat /var/lib/logrotate/status
|
||||
|
||||
A few entries from this file, for example:
|
||||
|
||||
"/var/log/lpr.log" 2013-4-11
|
||||
"/var/log/dpkg.log" 2013-4-11
|
||||
"/var/log/pm-suspend.log" 2013-4-11
|
||||
"/var/log/syslog" 2013-4-11
|
||||
"/var/log/mail.info" 2013-4-11
|
||||
"/var/log/daemon.log" 2013-4-11
|
||||
"/var/log/apport.log" 2013-4-11
|
||||
|
||||
Congratulations! You have logrotate installed in your system. Now, change the configuration settings as per your requirements.
|
||||
|
||||
Try 'man logrotate' or 'logrotate -?' for more details.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.digitalocean.com/community/tutorials/how-to-manage-log-files-with-logrotate-on-ubuntu-12-10
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://www.digitalocean.com/community/articles/initial-server-setup-with-ubuntu-12-04
|
||||
@ -1,63 +0,0 @@
|
||||
ictlyh Translating
|
||||
Make Math Simple in Ubuntu / Elementary OS via NaSC
|
||||
================================================================================
|
||||

|
||||
|
||||
NaSC (Not a Soulver Clone) is an open source software designed for Elementary OS to do arithmetics. It’s kinda similar to the Mac app [Soulver][1].
|
||||
|
||||
> Its an app where you do maths like a normal person. It lets you type whatever you want and smartly figures out what is math and spits out an answer on the right pane. Then you can plug those answers in to future equations and if that answer changes, so does the equations its used in.
|
||||
|
||||
With NaSC you can for example:
|
||||
|
||||
- Perform calculations with strangers you can define yourself
|
||||
- Change the units and values (in m cm, dollar euro …)
|
||||
- Knowing the surface area of a planet
|
||||
- Solve of second-degree polynomial
|
||||
- and more …
|
||||
|
||||
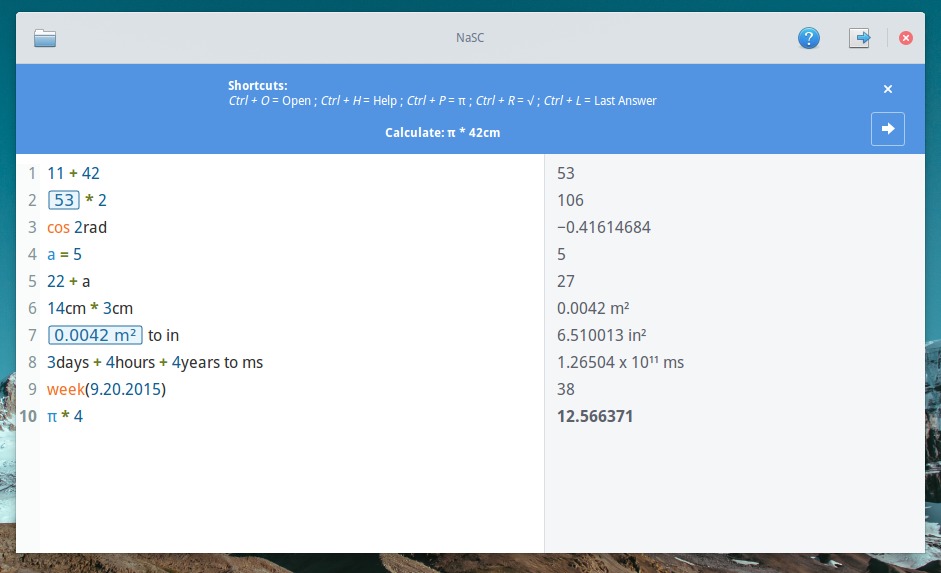
|
||||
|
||||
At the first launch, NaSC offers a tutorial that details possible features. You can later click the help icon on headerbar to get more.
|
||||
|
||||
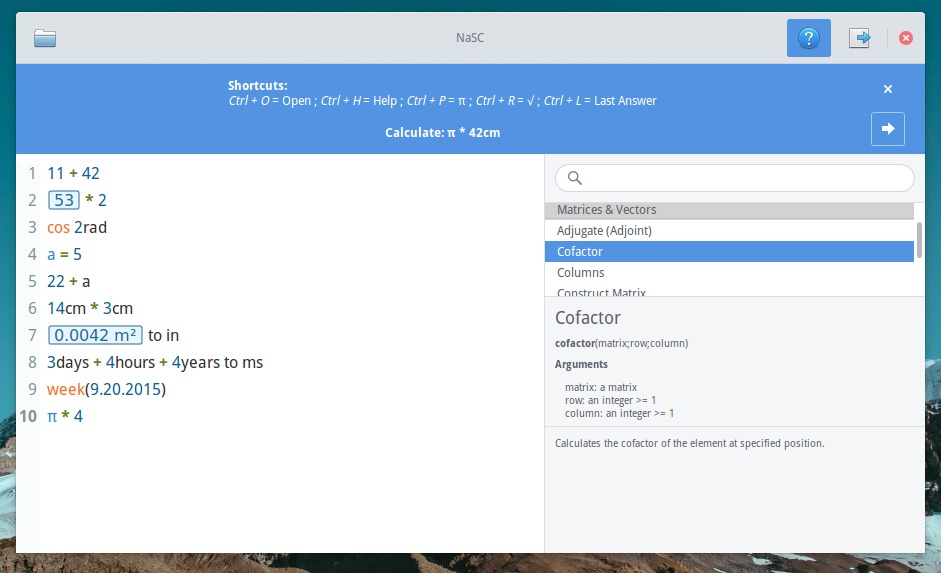
|
||||
|
||||
In addition, the software allows to save your file in order to continue the work. It can be also shared on Pastebin with a defined time.
|
||||
|
||||
### Install NaSC in Ubuntu / Elementary OS Freya: ###
|
||||
|
||||
For Ubuntu 15.04, Ubuntu 15.10, Elementary OS Freya, open terminal from the Dash, App Launcher and run below commands one by one:
|
||||
|
||||
1. Add the [NaSC PPA][2] via command:
|
||||
|
||||
sudo apt-add-repository ppa:nasc-team/daily
|
||||
|
||||
|
||||
|
||||
2. If you’ve installed Synaptic Package Manager, search for and install `nasc` via it after clicking Reload button.
|
||||
|
||||
Or run below commands to update system cache and install the software:
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
sudo apt-get install nasc
|
||||
|
||||
3. **(Optional)** To remove the software as well as NaSC, run:
|
||||
|
||||
sudo apt-get remove nasc && sudo add-apt-repository -r ppa:nasc-team/daily
|
||||
|
||||
For those who don’t want to add PPA, grab the .deb package directly from [this page][3].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ubuntuhandbook.org/index.php/2015/09/make-math-simple-in-ubuntu-elementary-os-via-nasc/
|
||||
|
||||
作者:[Ji m][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ubuntuhandbook.org/index.php/about/
|
||||
[1]:http://www.acqualia.com/soulver/
|
||||
[2]:https://launchpad.net/~nasc-team/+archive/ubuntu/daily/
|
||||
[3]:http://ppa.launchpad.net/nasc-team/daily/ubuntu/pool/main/n/nasc/
|
||||
@ -1,67 +0,0 @@
|
||||
translating wi-cuckoo
|
||||
How to Download, Install, and Configure Plank Dock in Ubuntu
|
||||
================================================================================
|
||||
It’s a well-known fact that Linux is extremely customizable with users having a lot of options to choose from – be it the operating systems’ various distributions or desktop environments available for a single distro. Like users of any other OS, Linux users also have different tastes and preferences, especially when it comes to desktop.
|
||||
|
||||
While some users aren’t particularly bothered about their desktop, others take special care to make sure that their desktop looks cool and attractive, something for which there are various applications available. One such application that brings life to your desktop – especially if you use a global menu on the top – is the dock. There are many dock applications available for Linux; if you’re looking for the simplest one, then look no further than [Plank][1], which we’ll be discussing in this article.
|
||||
|
||||
**Note**: the examples and commands mentioned here have been tested on Ubuntu (version 14.10) and Plank version 0.9.1.1383.
|
||||
|
||||
### Plank ###
|
||||
|
||||
The official documentation describes Plank as the “simplest dock on the planet.” The project’s goal is to provide just what a dock needs, although it’s essentially a library which can be extended to create other dock programs with more advanced features.
|
||||
|
||||
What’s worth mentioning here is that Plank, which comes pre-installed in elementary OS, is the underlying technology for Docky, a popular dock application which is very similar in functionality to Mac OS X’s Dock.
|
||||
|
||||
### Download and Install ###
|
||||
|
||||
You can download and install Plank by executing the following commands on your terminal:
|
||||
|
||||
sudo add-apt-repository ppa:docky-core/stable
|
||||
sudo apt-get update
|
||||
sudo apt-get install plank
|
||||
|
||||
Once installed successfully, you can open the application by typing the name Plank in Unity Dash (see image below), or open it from the App Menu if you aren’t using the Unity environment.
|
||||
|
||||

|
||||
|
||||
### Features ###
|
||||
|
||||
Once the Plank dock is enabled, you’ll see it sitting at the center-bottom of your desktop.
|
||||
|
||||

|
||||
|
||||
As you can see in the image above, the dock contains some application icons with an orange color indication below those which are currently running. Needless to say, you can click an icon to open that application. Also, a right-click on any application icon will produce some more options that you might be interested in. For example, see the screen-shot below:
|
||||
|
||||

|
||||
|
||||
To access the configuration options, you’ll have to do a right-click on Plank’s icon (which is the first one from the left), and then click the Preferences option. This will produce the following window.
|
||||
|
||||

|
||||
|
||||
As you can see, the preference window consists of two tabs: Appearance and Behavior, with the former being selected by default. The Appearance tab contains settings related to the Plank theme, the dock’s position, and alignment, as well as that related to icons, while the Behavior tab contains settings related to the dock itself.
|
||||
|
||||

|
||||
|
||||
For example, I changed the position of the dock to Right from within the Appearance tab and locked the icons (which means no “Keep in Dock” option on right-click) from the Behavior tab.
|
||||
|
||||

|
||||
|
||||
As you can see in the screen-shot above, the changes came into effect. Similarly, you can tweak any available setting as per your requirement.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Like I said in the beginning, having a dock isn’t mandatory. However, using one definitely makes things convenient, especially if you’ve been using Mac and have recently switched over to Linux for whatever reason. For its part, Plank not only offers simplicity, but dependability and stability as well – the project is well-maintained.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/download-install-configure-plank-dock-ubuntu/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/himanshu/
|
||||
[1]:https://launchpad.net/plank
|
||||
@ -0,0 +1,250 @@
|
||||
10 Useful Linux Command Line Tricks for Newbies – Part 2
|
||||
================================================================================
|
||||
I remember when I first started using Linux and I was used to the graphical interface of Windows, I truly hated the Linux terminal. Back then I was finding the commands hard to remember and proper use of each one of them. With time I realised the beauty, flexibility and usability of the Linux terminal and to be honest a day doesn’t pass without using. Today, I would like to share some useful tricks and tips for Linux new comers to ease their transition to Linux or simply help them learn something new (hopefully).
|
||||
|
||||

|
||||
|
||||
10 Linux Commandline Tricks – Part 2
|
||||
|
||||
- [5 Interesting Command Line Tips and Tricks in Linux – Part 1][1]
|
||||
- [5 Useful Commands to Manage Linux File Types – Part 3][2]
|
||||
|
||||
This article intends to show you some useful tricks how to use the Linux terminal like a pro with minimum amount of skills. All you need is a Linux terminal and some free time to test these commands.
|
||||
|
||||
### 1. Find the right command ###
|
||||
|
||||
Executing the right command can be vital for your system. However in Linux there are so many different command lines that they are often hard to remember. So how do you search for the right command you need? The answer is apropos. All you need to run is:
|
||||
|
||||
# apropos <description>
|
||||
|
||||
Where you should change the “description” with the actual description of the command you are looking for. Here is a good example:
|
||||
|
||||
# apropos "list directory"
|
||||
|
||||
dir (1) - list directory contents
|
||||
ls (1) - list directory contents
|
||||
ntfsls (8) - list directory contents on an NTFS filesystem
|
||||
vdir (1) - list directory contents
|
||||
|
||||
On the left you can see the commands and on the right their description.
|
||||
|
||||
### 2. Execute Previous Command ###
|
||||
|
||||
Many times you will need to execute the same command over and over again. While you can repeatedly press the Up key on your keyboard, you can use the history command instead. This command will list all commands you entered since you launched the terminal:
|
||||
|
||||
# history
|
||||
|
||||
1 fdisk -l
|
||||
2 apt-get install gnome-paint
|
||||
3 hostname tecmint.com
|
||||
4 hostnamectl tecmint.com
|
||||
5 man hostnamectl
|
||||
6 hostnamectl --set-hostname tecmint.com
|
||||
7 hostnamectl -set-hostname tecmint.com
|
||||
8 hostnamectl set-hostname tecmint.com
|
||||
9 mount -t "ntfs" -o
|
||||
10 fdisk -l
|
||||
11 mount -t ntfs-3g /dev/sda5 /mnt
|
||||
12 mount -t rw ntfs-3g /dev/sda5 /mnt
|
||||
13 mount -t -rw ntfs-3g /dev/sda5 /mnt
|
||||
14 mount -t ntfs-3g /dev/sda5 /mnt
|
||||
15 mount man
|
||||
16 man mount
|
||||
17 mount -t -o ntfs-3g /dev/sda5 /mnt
|
||||
18 mount -o ntfs-3g /dev/sda5 /mnt
|
||||
19 mount -ro ntfs-3g /dev/sda5 /mnt
|
||||
20 cd /mnt
|
||||
...
|
||||
|
||||
As you will see from the output above, you will receive a list of all commands that you have ran. On each line you have number indicating the row in which you have entered the command. You can recall that command by using:
|
||||
|
||||
!#
|
||||
|
||||
Where # should be changed with the actual number of the command. For better understanding, see the below example:
|
||||
|
||||
!501
|
||||
|
||||
Is equivalent to:
|
||||
|
||||
# history
|
||||
|
||||
### 3. Use midnight Commander ###
|
||||
|
||||
If you are not used to using commands such cd, cp, mv, rm than you can use the midnight command. It is an easy to use visual shell in which you can also use mouse:
|
||||
|
||||
|
||||
|
||||
Midnight Commander in Action
|
||||
|
||||
Thanks to the F1 – F12 keys, you can easy perform different tasks. Simply check the legend at the bottom. To select a file or folder click the “Insert” button.
|
||||
|
||||
In short the midnight command is called “mc“. To install mc on your system simply run:
|
||||
|
||||
$ sudo apt-get install mc [On Debian based systems]
|
||||
|
||||
----------
|
||||
|
||||
# yum install mc [On Fedora based systems]
|
||||
|
||||
Here is a simple example of using midnight commander. Open mc by simply typing:
|
||||
|
||||
# mc
|
||||
|
||||
Now use the TAB button to switch between windows – left and right. I have a LibreOffice file that I will move to “Software” folder:
|
||||
|
||||

|
||||
|
||||
Midnight Commander Move Files
|
||||
|
||||
To move the file in the new directory press F6 button on your keyboard. MC will now ask you for confirmation:
|
||||
|
||||

|
||||
|
||||
Move Files to New Directory
|
||||
|
||||
Once confirmed, the file will be moved in the new destination directory.
|
||||
|
||||
Read More: [How to Use Midnight Commander File Manager in Linux][4]
|
||||
|
||||
### 4. Shutdown Computer at Specific Time ###
|
||||
|
||||
Sometimes you will need to shutdown your computer some hours after your work hours have ended. You can configure your computer to shut down at specific time by using:
|
||||
|
||||
$ sudo shutdown 21:00
|
||||
|
||||
This will tell your computer to shut down at the specific time you have provided. You can also tell the system to shutdown after specific amount of minutes:
|
||||
|
||||
$ sudo shutdown +15
|
||||
|
||||
That way the system will shut down in 15 minutes.
|
||||
|
||||
### 5. Show Information about Known Users ###
|
||||
|
||||
You can use a simple command to list your Linux system users and some basic information about them. Simply use:
|
||||
|
||||
# lslogins
|
||||
|
||||
This should bring you the following output:
|
||||
|
||||
UID USER PWD-LOCK PWD-DENY LAST-LOGIN GECOS
|
||||
0 root 0 0 Apr29/11:35 root
|
||||
1 bin 0 1 bin
|
||||
2 daemon 0 1 daemon
|
||||
3 adm 0 1 adm
|
||||
4 lp 0 1 lp
|
||||
5 sync 0 1 sync
|
||||
6 shutdown 0 1 Jul19/10:04 shutdown
|
||||
7 halt 0 1 halt
|
||||
8 mail 0 1 mail
|
||||
10 uucp 0 1 uucp
|
||||
11 operator 0 1 operator
|
||||
12 games 0 1 games
|
||||
13 gopher 0 1 gopher
|
||||
14 ftp 0 1 FTP User
|
||||
23 squid 0 1
|
||||
25 named 0 1 Named
|
||||
27 mysql 0 1 MySQL Server
|
||||
47 mailnull 0 1
|
||||
48 apache 0 1 Apache
|
||||
...
|
||||
|
||||
### 6. Search for Files ###
|
||||
|
||||
Searching for files can sometimes be not as easy as you think. A good example for searching for files is:
|
||||
|
||||
# find /home/user -type f
|
||||
|
||||
This command will search for all files located in /home/user. The find command is extremely powerful one and you can pass more options to it to make your search even more detailed. If you want to search for files larger than given size, you can use:
|
||||
|
||||
# find . -type f -size 10M
|
||||
|
||||
The above command will search from current directory for all files that are larger than 10 MB. Make sure not to run the command from the root directory of your Linux system as this may cause high I/O on your machine.
|
||||
|
||||
One of the most frequently used combinations that I use find with is “exec” option, which basically allows you to run some actions on the results of the find command.
|
||||
|
||||
For example, lets say that we want to find all files in a directory and change their permissions. This can be easily done with:
|
||||
|
||||
# find /home/user/files/ -type f -exec chmod 644 {} \;
|
||||
|
||||
The above command will search for all files in the specified directory recursively and will executed chmod command on the found files. I am sure you will find many more uses on this command in future, for now read [35 Examples of Linux ‘find’ Command and Usage][5].
|
||||
|
||||
### 7. Build Directory Trees with one Command ###
|
||||
|
||||
You probably know that you can create new directories by using the mkdir command. So if you want to create a new folder you will run something like this:
|
||||
|
||||
# mkdir new_folder
|
||||
|
||||
But what, if you want to create 5 subfolders within that folder? Running mkdir 5 times in a row is not a good solution. Instead you can use -p option like that:
|
||||
|
||||
# mkdir -p new_folder/{folder_1,folder_2,folder_3,folder_4,folder_5}
|
||||
|
||||
In the end you should have 5 folders located in new_folder:
|
||||
|
||||
# ls new_folder/
|
||||
|
||||
folder_1 folder_2 folder_3 folder_4 folder_5
|
||||
|
||||
### 8. Copy File into Multiple Directories ###
|
||||
|
||||
File copying is usually performed with the cp command. Copying a file usually looks like this:
|
||||
|
||||
# cp /path-to-file/my_file.txt /path-to-new-directory/
|
||||
|
||||
Now imagine that you need to copy that file in multiple directories:
|
||||
|
||||
# cp /home/user/my_file.txt /home/user/1
|
||||
# cp /home/user/my_file.txt /home/user/2
|
||||
# cp /home/user/my_file.txt /home/user/3
|
||||
|
||||
This is a bit absurd. Instead you can solve the problem with a simple one line command:
|
||||
|
||||
# echo /home/user/1/ /home/user/2/ /home/user/3/ | xargs -n 1 cp /home/user/my_file.txt
|
||||
|
||||
### 9. Deleting Larger Files ###
|
||||
|
||||
Sometimes files can grow extremely large. I have seen cases where a single log file went over 250 GB large due to poor administrating skills. Removing the file with rm utility might not be sufficient in such cases due to the fact that there is extremely large amount of data that needs to be removed. The operation will be a “heavy” one and should be avoided. Instead, you can go with a really simple solution:
|
||||
|
||||
# > /path-to-file/huge_file.log
|
||||
|
||||
Where of course you will need to change the path and the file names with the exact ones to match your case. The above command will simply write an empty output to the file. In more simpler words it will empty the file without causing high I/O on your system.
|
||||
|
||||
### 10. Run Same Command on Multiple Linux Servers ###
|
||||
|
||||
Recently one of our readers asked in our [LinuxSay forum][6], how to execute single command to multiple Linux boxes at once using SSH. He had his machines IP addresses looking like this:
|
||||
|
||||
10.0.0.1
|
||||
10.0.0.2
|
||||
10.0.0.3
|
||||
10.0.0.4
|
||||
10.0.0.5
|
||||
|
||||
So here is a simple solution of this issue. Collect the IP addresses of the servers in a one file called list.txt one under other just as shown above. Then you can run:
|
||||
|
||||
# for in $i(cat list.txt); do ssh user@$i 'bash command'; done
|
||||
|
||||
In the above example you will need to change “user” with the actual user with which you will be logging and “bash command” with the actual bash command you wish to execute. The method is better working when you are [using passwordless authentication with SSH key][7] to your machines as that way you will not need to enter the password for your user over and over again.
|
||||
|
||||
Note that you may need to pass some additional parameters to the SSH command depending on your Linux boxes setup.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
The above examples are really simple ones and I hope they have helped you to find some of the beauty of Linux and how you can easily perform different operations that can take much more time on other operating systems.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/10-useful-linux-command-line-tricks-for-newbies/
|
||||
|
||||
作者:[Marin Todorov][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/marintodorov89/
|
||||
[1]:http://www.tecmint.com/5-linux-command-line-tricks/
|
||||
[2]:http://www.tecmint.com/manage-file-types-and-set-system-time-in-linux/
|
||||
[3]:http://www.tecmint.com/history-command-examples/
|
||||
[4]:http://www.tecmint.com/midnight-commander-a-console-based-file-manager-for-linux/
|
||||
[5]:http://www.tecmint.com/35-practical-examples-of-linux-find-command/
|
||||
[6]:http://www.linuxsay.com/
|
||||
[7]:http://www.tecmint.com/ssh-passwordless-login-using-ssh-keygen-in-5-easy-steps/
|
||||
@ -0,0 +1,279 @@
|
||||
5 Useful Commands to Manage File Types and System Time in Linux – Part 3
|
||||
================================================================================
|
||||
Adapting to using the command line or terminal can be very hard for beginners who want to learn Linux. Because the terminal gives more control over a Linux system than GUIs programs, one has to get a used to running commands on the terminal. Therefore to memorize different commands in Linux, you should use the terminal on a daily basis to understand how commands are used with different options and arguments.
|
||||
|
||||

|
||||
|
||||
Manage File Types and Set Time in Linux – Part 3
|
||||
|
||||
Please go through our previous parts of this [Linux Tricks][1] series.
|
||||
|
||||
- [5 Interesting Command Line Tips and Tricks in Linux – Part 1][2]
|
||||
- [ Useful Commandline Tricks for Newbies – Part 2][3]
|
||||
|
||||
In this article, we are going to look at some tips and tricks of using 10 commands to work with files and time on the terminal.
|
||||
|
||||
### File Types in Linux ###
|
||||
|
||||
In Linux, everything is considered as a file, your devices, directories and regular files are all considered as files.
|
||||
|
||||
There are different types of files in a Linux system:
|
||||
|
||||
- Regular files which may include commands, documents, music files, movies, images, archives and so on.
|
||||
- Device files: which are used by the system to access your hardware components.
|
||||
|
||||
There are two types of device files block files that represent storage devices such as harddisks, they read data in blocks and character files read data in a character by character manner.
|
||||
|
||||
- Hardlinks and softlinks: they are used to access files from any where on a Linux filesystem.
|
||||
- Named pipes and sockets: allow different processes to communicate with each other.
|
||||
|
||||
#### 1. Determining the type of a file using ‘file’ command ####
|
||||
|
||||
You can determine the type of a file by using the file command as follows. The screenshot below shows different examples of using the file command to determine the types of different files.
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ dir
|
||||
BACKUP master.zip
|
||||
crossroads-stable.tar.gz num.txt
|
||||
EDWARD-MAYA-2011-2012-NEW-REMIX.mp3 reggea.xspf
|
||||
Linux-Security-Optimization-Book.gif tmp-link
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ file BACKUP/
|
||||
BACKUP/: directory
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ file master.zip
|
||||
master.zip: Zip archive data, at least v1.0 to extract
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ file crossroads-stable.tar.gz
|
||||
crossroads-stable.tar.gz: gzip compressed data, from Unix, last modified: Tue Apr 5 15:15:20 2011
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ file Linux-Security-Optimization-Book.gif
|
||||
Linux-Security-Optimization-Book.gif: GIF image data, version 89a, 200 x 259
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ file EDWARD-MAYA-2011-2012-NEW-REMIX.mp3
|
||||
EDWARD-MAYA-2011-2012-NEW-REMIX.mp3: Audio file with ID3 version 2.3.0, contains: MPEG ADTS, layer III, v1, 192 kbps, 44.1 kHz, JntStereo
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ file /dev/sda1
|
||||
/dev/sda1: block special
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ file /dev/tty1
|
||||
/dev/tty1: character special
|
||||
|
||||
#### 2. Determining the file type using ‘ls’ and ‘dir’ commands ####
|
||||
|
||||
Another way of determining the type of a file is by performing a long listing using the ls and [dir][4] commands.
|
||||
|
||||
Using ls -l to determine the type of a file.
|
||||
|
||||
When you view the file permissions, the first character shows the file type and the other charcters show the file permissions.
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ ls -l
|
||||
total 6908
|
||||
drwxr-xr-x 2 tecmint tecmint 4096 Sep 9 11:46 BACKUP
|
||||
-rw-r--r-- 1 tecmint tecmint 1075620 Sep 9 11:47 crossroads-stable.tar.gz
|
||||
-rwxr----- 1 tecmint tecmint 5916085 Sep 9 11:49 EDWARD-MAYA-2011-2012-NEW-REMIX.mp3
|
||||
-rw-r--r-- 1 tecmint tecmint 42122 Sep 9 11:49 Linux-Security-Optimization-Book.gif
|
||||
-rw-r--r-- 1 tecmint tecmint 17627 Sep 9 11:46 master.zip
|
||||
-rw-r--r-- 1 tecmint tecmint 5 Sep 9 11:48 num.txt
|
||||
-rw-r--r-- 1 tecmint tecmint 0 Sep 9 11:46 reggea.xspf
|
||||
-rw-r--r-- 1 tecmint tecmint 5 Sep 9 11:47 tmp-link
|
||||
|
||||
Using ls -l to determine block and character files.
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ ls -l /dev/sda1
|
||||
brw-rw---- 1 root disk 8, 1 Sep 9 10:53 /dev/sda1
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ ls -l /dev/tty1
|
||||
crw-rw---- 1 root tty 4, 1 Sep 9 10:54 /dev/tty1
|
||||
|
||||
Using dir -l to determine the type of a file.
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ dir -l
|
||||
total 6908
|
||||
drwxr-xr-x 2 tecmint tecmint 4096 Sep 9 11:46 BACKUP
|
||||
-rw-r--r-- 1 tecmint tecmint 1075620 Sep 9 11:47 crossroads-stable.tar.gz
|
||||
-rwxr----- 1 tecmint tecmint 5916085 Sep 9 11:49 EDWARD-MAYA-2011-2012-NEW-REMIX.mp3
|
||||
-rw-r--r-- 1 tecmint tecmint 42122 Sep 9 11:49 Linux-Security-Optimization-Book.gif
|
||||
-rw-r--r-- 1 tecmint tecmint 17627 Sep 9 11:46 master.zip
|
||||
-rw-r--r-- 1 tecmint tecmint 5 Sep 9 11:48 num.txt
|
||||
-rw-r--r-- 1 tecmint tecmint 0 Sep 9 11:46 reggea.xspf
|
||||
-rw-r--r-- 1 tecmint tecmint 5 Sep 9 11:47 tmp-link
|
||||
|
||||
#### 3. Counting number of files of a specific type ####
|
||||
|
||||
Next we shall look at tips on counting number of files of a specific type in a given directory using the ls, [grep][5] and [wc][6] commands. Communication between the commands is achieved through named piping.
|
||||
|
||||
- grep – command to search according to a given pattern or regular expression.
|
||||
- wc – command to count lines, words and characters.
|
||||
|
||||
Counting number of regular files
|
||||
|
||||
In Linux, regular files are represented by the `–` symbol.
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ ls -l | grep ^- | wc -l
|
||||
7
|
||||
|
||||
**Counting number of directories**
|
||||
|
||||
In Linux, directories are represented by the `d` symbol.
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ ls -l | grep ^d | wc -l
|
||||
1
|
||||
|
||||
**Counting number of symbolic and hard links**
|
||||
|
||||
In Linux, symblic and hard links are represented by the l symbol.
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ ls -l | grep ^l | wc -l
|
||||
0
|
||||
|
||||
**Counting number of block and character files**
|
||||
|
||||
In Linux, block and character files are represented by the `b` and `c` symbols respectively.
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ ls -l /dev | grep ^b | wc -l
|
||||
37
|
||||
tecmint@tecmint ~/Linux-Tricks $ ls -l /dev | grep ^c | wc -l
|
||||
159
|
||||
|
||||
#### 4. Finding files on a Linux system ####
|
||||
|
||||
Next we shall look at some commands one can use to find files on a Linux system, these include the locate, find, whatis and which commands.
|
||||
|
||||
**Using the locate command to find files**
|
||||
|
||||
In the output below, I am trying to locate the [Samba server configuration][7] for my system.
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ locate samba.conf
|
||||
/usr/lib/tmpfiles.d/samba.conf
|
||||
/var/lib/dpkg/info/samba.conffiles
|
||||
|
||||
**Using the find command to find files**
|
||||
|
||||
To learn how to use the find command in Linux, you can read our following article that shows more than 30+ practical examples and usage of find command in Linux.
|
||||
|
||||
- [35 Examples of ‘find’ Command in Linux][8]
|
||||
|
||||
**Using the whatis command to locate commands**
|
||||
|
||||
The whatis command is mostly used to locate commands and it is special because it gives information about a command, it also finds configurations files and manual entries for a command.
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ whatis bash
|
||||
bash (1) - GNU Bourne-Again SHell
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ whatis find
|
||||
find (1) - search for files in a directory hierarchy
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ whatis ls
|
||||
ls (1) - list directory contents
|
||||
|
||||
**Using which command to locate commands**
|
||||
|
||||
The which command is used to locate commands on the filesystem.
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ which mkdir
|
||||
/bin/mkdir
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ which bash
|
||||
/bin/bash
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ which find
|
||||
/usr/bin/find
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ $ which ls
|
||||
/bin/ls
|
||||
|
||||
#### 5. Working with time on your Linux system ####
|
||||
|
||||
When working in a networked environment, it is a good practice to keep the correct time on your Linux system. There are certain services on Linux systems that require correct time to work efficiently on a network.
|
||||
|
||||
We shall look at commands you can use to manage time on your machine. In Linux, time is managed in two ways: system time and hardware time.
|
||||
|
||||
The system time is managed by a system clock and the hardware time is managed by a hardware clock.
|
||||
|
||||
To view your system time, date and timezone, use the date command as follows.
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ date
|
||||
Wed Sep 9 12:25:40 IST 2015
|
||||
|
||||
Set your system time using date -s or date –set=”STRING” as follows.
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ sudo date -s "12:27:00"
|
||||
Wed Sep 9 12:27:00 IST 2015
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ sudo date --set="12:27:00"
|
||||
Wed Sep 9 12:27:00 IST 2015
|
||||
|
||||
You can also set time and date as follows.
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ sudo date 090912302015
|
||||
Wed Sep 9 12:30:00 IST 2015
|
||||
|
||||
Viewing current date from a calendar using cal command.
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ cal
|
||||
September 2015
|
||||
Su Mo Tu We Th Fr Sa
|
||||
1 2 3 4 5
|
||||
6 7 8 9 10 11 12
|
||||
13 14 15 16 17 18 19
|
||||
20 21 22 23 24 25 26
|
||||
27 28 29 30
|
||||
|
||||
View hardware clock time using the hwclock command.
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ sudo hwclock
|
||||
Wednesday 09 September 2015 06:02:58 PM IST -0.200081 seconds
|
||||
|
||||
To set the hardware clock time, use hwclock –set –date=”STRING” as follows.
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ sudo hwclock --set --date="09/09/2015 12:33:00"
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ sudo hwclock
|
||||
Wednesday 09 September 2015 12:33:11 PM IST -0.891163 seconds
|
||||
|
||||
The system time is set by the hardware clock during booting and when the system is shutting down, the hardware time is reset to the system time.
|
||||
|
||||
Therefore when you view system time and hardware time, they are the same unless when you change the system time. Your hardware time may be incorrect when the CMOS battery is weak.
|
||||
|
||||
You can also set your system time using time from the hardware clock as follows.
|
||||
|
||||
$ sudo hwclock --hctosys
|
||||
|
||||
It is also possible to set hardware clock time using the system clock time as follows.
|
||||
|
||||
$ sudo hwclock --systohc
|
||||
|
||||
To view how long your Linux system has been running, use the uptime command.
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ uptime
|
||||
12:36:27 up 1:43, 2 users, load average: 1.39, 1.34, 1.45
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ uptime -p
|
||||
up 1 hour, 43 minutes
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ uptime -s
|
||||
2015-09-09 10:52:47
|
||||
|
||||
### Summary ###
|
||||
|
||||
Understanding file types is Linux is a good practice for begginers, and also managing time is critical especially on servers to manage services reliably and efficiently. Hope you find this guide helpful. If you have any additional information, do not forget to post a comment. Stay connected to Tecmint.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/manage-file-types-and-set-system-time-in-linux/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/tag/linux-tricks/
|
||||
[2]:http://www.tecmint.com/free-online-linux-learning-guide-for-beginners/
|
||||
[3]:http://www.tecmint.com/10-useful-linux-command-line-tricks-for-newbies/
|
||||
[4]:http://www.tecmint.com/linux-dir-command-usage-with-examples/
|
||||
[5]:http://www.tecmint.com/12-practical-examples-of-linux-grep-command/
|
||||
[6]:http://www.tecmint.com/wc-command-examples/
|
||||
[7]:http://www.tecmint.com/setup-samba-file-sharing-for-linux-windows-clients/
|
||||
[8]:http://www.tecmint.com/35-practical-examples-of-linux-find-command/
|
||||
@ -0,0 +1,111 @@
|
||||
mosh - 一个基于SSH用于连接远程Unix/Linux系统的工具
|
||||
================================================================================
|
||||
Mosh表示移动Shell(Mobile Shell)是一个用于从客户端连接远程服务器的命令行工具。它可以像ssh那样使用并包含了更多的功能。它是一个类似ssh的程序,但是提供更多的功能。程序最初由Keith Winstein编写用于类Unix的操作系统中,发布于GNU GPL v3协议下。
|
||||
|
||||

|
||||
|
||||
Mosh客户端
|
||||
|
||||
#### Mosh的功能 ####
|
||||
|
||||
- 它是一个支持漫游的远程终端程序。
|
||||
- 在所有主流类Unix版本中可用如Linux、FreeBSD、Solaris、Mac OS X和Android。
|
||||
- 中断连接支持
|
||||
- 支持智能本地echo
|
||||
- 用户按键行编辑支持
|
||||
- 响应式设计及在wifi、3G、长距离连接下的鲁棒性
|
||||
- 在IP改变后保持连接。它使用UDP代替TCP(在SSH中使用)当连接被重置或者获得新的IP后TCP会超时但是UDP仍然保持连接。
|
||||
- 在你很长之间之后恢复会话时仍然保持连接。
|
||||
- 没有网络延迟。立即显示用户输入和删除而没有延迟
|
||||
- 像SSH那样支持一些旧的方式登录。
|
||||
- 包丢失处理机制
|
||||
|
||||
### Linux中mosh的安装 ###
|
||||
|
||||
在Debian、Ubuntu和Mint类似的系统中,你可以很容易地用[apt-get包管理器][1]安装。
|
||||
|
||||
# apt-get update
|
||||
# apt-get install mosh
|
||||
|
||||
在基于RHEL/CentOS/Fedora的系统中,要使用[yum 包管理器][3]安装mosh,你需要打开第三方的[EPEL][2]。
|
||||
|
||||
# yum update
|
||||
# yum install mosh
|
||||
|
||||
在Fedora 22+的版本中,你需要使用[dnf包管理器][4]来安装mosh。
|
||||
|
||||
# dnf install mosh
|
||||
|
||||
### 我该如何使用mosh? ###
|
||||
|
||||
1. 让我们尝试使用mosh登录远程Linux服务器。
|
||||
|
||||
$ mosh root@192.168.0.150
|
||||
|
||||

|
||||
|
||||
mosh远程连接
|
||||
|
||||
**注意**:你有没有看到一个连接错误,因为我在CentOS 7中还有打开这个端口。一个快速但是我并不建议的解决方法是:
|
||||
|
||||
# systemctl stop firewalld [on Remote Server]
|
||||
|
||||
更好的方法是打开一个端口并更新防火墙规则。接着用mosh连接到预定义的端口中。至于更深入的细节,也许你会对下面的文章感兴趣。
|
||||
|
||||
- [如何配置Firewalld][5]
|
||||
|
||||
2. 让我们假设把默认的22端口改到70,这时使用-p选项来使用自定义端口。
|
||||
|
||||
$ mosh -p 70 root@192.168.0.150
|
||||
|
||||
3. 检查mosh的版本
|
||||
|
||||
$ mosh --version
|
||||
|
||||

|
||||
|
||||
检查mosh版本
|
||||
|
||||
4. 你可以输入‘exit’来退出mosh会话。
|
||||
|
||||
$ exit
|
||||
|
||||
5. mosh支持很多选项,你可以用下面的方法看到:
|
||||
|
||||
$ mosh --help
|
||||
|
||||

|
||||
|
||||
Mosh选项
|
||||
|
||||
#### mosh的利弊 ####
|
||||
|
||||
- mosh有额外的需求,比如需要允许UDP直接连接,这在SSH不需要。
|
||||
- 动态分配的端口范围是60000-61000。第一个打开的端口是分配的。每个连接都需要一个端口。
|
||||
- 默认端口分配是一个严重的安全问题,尤其是在生产环境中。
|
||||
- 支持IPv6连接,但是不支持IPv6漫游。
|
||||
- 不支持回溯
|
||||
- 不支持X11转发
|
||||
- 不支持ssh-agent转发
|
||||
|
||||
### 总结 ###
|
||||
|
||||
Mosh is a nice small utility which is available for download in the repository of most of the Linux Distributions. Though it has a few discrepancies specially security concern and additional requirement it’s features like remaining connected even while roaming is its plus point. My recommendation is Every Linux-er who deals with SSH should try this application and mind it, Mosh is worth a try.
|
||||
mosh是一款在大多数linux发行版的仓库中可以下载的一款小工具。虽然它有一些差异尤其是安全问题和额外的需求,它的功能像漫游后保持连接是一个加分点。我的建议是任何一个使用ssh的linux用户都应该试试这个程序,mosh值得一试
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-mosh-shell-ssh-client-in-linux/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/useful-basic-commands-of-apt-get-and-apt-cache-for-package-management/
|
||||
[2]:http://www.tecmint.com/how-to-enable-epel-repository-for-rhel-centos-6-5/
|
||||
[3]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
|
||||
[4]:http://www.tecmint.com/dnf-commands-for-fedora-rpm-package-management/
|
||||
[5]:http://www.tecmint.com/configure-firewalld-in-centos-7/
|
||||
@ -1,127 +0,0 @@
|
||||
Translating by H-mudcup
|
||||
|
||||
守卫自由的Linux世界
|
||||
================================================================================
|
||||

|
||||
|
||||
**"合作是开源的一部分。OIN的CEO Keith Bergelt解释说,开放创新网络(Open Invention Network)模式允许众多企业和公司决定它们该在哪较量,在哪合作。随着开源的演变,“我们需要为合作创造渠道。否则我们将会有几百个团体把数十亿美元花费到同样的技术上。”**
|
||||
|
||||
[开放创新网络(Open Invention Network)][1],既OIN,正在全球范围内开展让 Linux 远离专利诉讼的伤害的活动。它的努力得到了一千多个公司的热烈回应,它们的加入让这股力量成为了历史上最大的反专利管理组织。
|
||||
|
||||
开放创新网络以白帽子组织的身份创建于2005年,目的是保护 Linux 免受来自许可证方面的困扰。包括Google、 IBM、 NEC、 Novell、 Philips、 [Red Hat][2] 和 Sony这些成员的董事会给予了它可观的经济支持。世界范围内的多个组织通过签署自由 OIN 协议加入了这个社区。
|
||||
|
||||
创立开放创新网络的组织成员把它当作利用知识产权保护 Linux 的大胆尝试。它的商业模式非常的难以理解。它要求它的成员持无专利证并永远放弃由于 Linux 相关知识产权起诉其他成员的机会。
|
||||
|
||||
然而,从 Linux 收购风波——想想服务器和云平台——那时起,保护 Linux 知识产权的策略就变得越加的迫切。
|
||||
|
||||
在过去的几年里,Linux 的版图曾经历了一场变革。OIN 不必再向人们解释这个组织的定义,也不必再解释为什么 Linux 需要保护。据 OIN 的 CEO Keith Bergelt 说,现在 Linux 的重要性得到了全世界的关注。
|
||||
|
||||
“我们已经见到了一场人们了解到OIN如何让合作受益的文化变革,”他对 LinuxInsider 说。
|
||||
|
||||
### 如何运作 ###
|
||||
|
||||
开放创新网络使用专利权的方式创建了一个协作环境。这种方法有助于确保创新的延续。这已经使很多软件商贩、顾客、新型市场和投资者受益。
|
||||
|
||||
开放创新网络的专利证可以让任何公司、公共机构或个人免版权使用。这些权利的获得建立在签署者同意不会专为了维护专利而攻击 Linux 系统的基础上。
|
||||
|
||||
OIN 确保 Linux 的源代码保持开放的状态。这让编程人员、设备出售人员、独立软件开发者和公共机构在投资和使用 Linux 时不用过多的担心知识产权的问题。这让对 Linux 进行重新装配、嵌入和使用的公司省了不少钱。
|
||||
|
||||
“随着版权许可证越来越广泛的使用,对 OIN 许可证的需求也变得更加的迫切。现在,人们正在寻找更加简单或更功利的解决方法”,Bergelt 说。
|
||||
|
||||
OIN 法律防御援助对成员是免费的。成员必须承诺不对 OIN 名单带上的软件发起专利诉讼。为了保护该软件,他们也同意提供他们自己的专利。最终,这些保证将导致几十万的交叉许可通过网络连接,Bergelt 如此解释道。
|
||||
|
||||
### 填补法律漏洞 ###
|
||||
|
||||
“OIN 正在做的事情是非常必要的。它提供额另一层 IP 保护,”[休斯顿法律中心大学][3]的副教授 Greg R. Vetter 这样说道。
|
||||
|
||||
他回答 LinuxInsider 说,某些人设想的第二版 GPL 许可证会隐含的提供专利许可,但是律师们更喜欢明确的许可。
|
||||
|
||||
OIN 所提供的许可填补了这个空白。它还明确的覆盖了 Linux 核心。据 Vetter 说,明确的专利许可并不是 GPLv2 中的必要部分,但是这个部分曾在 GPLv3 中。
|
||||
|
||||
拿一个在 GPLv3 中写了10000行代码的代码编写者来说。随着时间推移,其他的代码编写者会贡献更多行的代码到 IP 中。GPLv3 中的软件专利许可条款将保护所有基于参与其中的贡献者的专利的全部代码的使用,Vetter 如此说道。
|
||||
|
||||
### 并不完全一样 ###
|
||||
|
||||
专利权和许可证在法律结构上层层叠叠互相覆盖。弄清两者对开源软件的作用就像是穿越雷区。
|
||||
|
||||
Vetter 说“许可证是授予通常是建立在专利和版权法律上的额外权利的法律结构。许可证被认为是给予了人们做一些的可能会侵犯到其他人的 IP 权利的事的许可。”
|
||||
|
||||
Vetter 指出,很多自由开源许可证(例如 Mozilla 公共许可、GNU、GPLv3 以及 Apache 软件许可)融合了某些互惠专利权的形式。Vetter 指出,像 BSD 和 MIT 这样旧的许可证不会提到专利。
|
||||
|
||||
一个软件的许可证让其他人可以在某种程度上使用这个编程人员创造的代码。版权对所属权的建立是自动的,只要某个人写或者画了某个原创的东西。然而,版权只覆盖了个别的表达方式和衍生的作品。他并没有涵盖代码的功能性或可用的想法。
|
||||
|
||||
专利涵盖了功能性。专利权还可以成为许可证。版权可能无法保护某人如何独立的对另一个人的代码的实现的开发,但是专利填补了这个小瑕疵,Vetter 解释道。
|
||||
|
||||
### 寻找安全通道 ###
|
||||
|
||||
许可证和专利混合的法律性质可能会对开源开发者产生威胁。据 [Chaotic Moon Studios][4] 的创办者之一、 [IEEE][5] 计算机协会成员 William Hurley 说,对于某些人来说即使是 GPL 也会成为威胁。
|
||||
|
||||
"在很久以前,开源是个完全不同的世界。被彼此间的尊重和把代码视为艺术而非资产的观点所驱动,那时的程序和代码比现在更加的开放。我相信很多为最好的意图所做的努力几乎最后总是背负着意外的结果,"Hurley 这样告诉 LinuxInsider。
|
||||
|
||||
他暗示说,成员人数超越了1000人可能带来了一个关于知识产权保护重要性的混乱信息。这可能会继续搅混开源生态系统这滩浑水。
|
||||
|
||||
“最终,这些显现出了围绕着知识产权的常见的一些错误概念。拥有几千个开发者并不会减少风险——而是增加。给专利许可的开发者越多,它们看起来就越值钱,”Hurley 说。“它们看起来越值钱,有着类似专利的或者其他知识产权的人就越可能试图利用并从中榨取他们自己的经济利益。”
|
||||
|
||||
### 共享与竞争共存 ###
|
||||
|
||||
竞合策略是开源的一部分。OIN 模型让各个公司能够决定他们将在哪竞争以及在哪合作,Bergelt 解释道。
|
||||
|
||||
“开源演化中的许多改变已经把我们移到了另一个方向上。我们必须为合作创造渠道。否则我们将会有几百个团体把数十亿美元花费到同样的技术上,”他说。
|
||||
|
||||
手机产业的革新就是个很好的例子。各个公司放出了不同的标准。没有共享,没有合作,Bergelt 解释道。
|
||||
|
||||
他说:“这让我们在美国接触技术的能力落后了七到五年。我们接触设备的经验远远落后于世界其他地方的人。在我们等待 CDMA (Code Division Multiple Access 码分多址访问通信技术)时自满于 GSM (Global System for Mobile Communications 全球移动通信系统)。”
|
||||
|
||||
### 改变格局 ###
|
||||
|
||||
OIN 在去年经历了增长了400个新许可的浪潮。这意味着着开源有了新趋势。
|
||||
|
||||
Bergelt 说:“市场到达了一个临界点,组织内的人们终于意识到直白地合作和竞争的需要。结果是两件事同时进行。这可能会变得复杂、费力。”
|
||||
|
||||
然而,这个由人们开始考虑合作和竞争的文化革新所驱动的转换过程是可以忍受的。他解释说,这也是人们在以把开源作为开源社区的最重要的工程的方式拥抱开源——尤其是 Linux——的转变。
|
||||
|
||||
还有一个迹象是,最具意义的新工程都没有在 GPLv3 许可下开发。
|
||||
|
||||
### 二个总比一个好 ###
|
||||
|
||||
“GPL 极为重要,但是事实是有一堆的许可模型正被使用着。在Eclipse、Apache 和 Berkeley 许可中,专利问题的相对可解决性通常远远低于在 GPLv3 中的。”Bergelt 说。
|
||||
|
||||
GPLv3 对于解决专利问题是个自然的补充——但是 GPL 自身不足以独自解决围绕专利使用的潜在冲突。所以 OIN 的设计是以能够补充版权许可为目的的,他补充道。
|
||||
|
||||
然而,层层叠叠的专利和许可也许并没有带来多少好处。到最后,专利在几乎所有的案例中都被用于攻击目的——而不是防御目的,Bergelt 暗示说。
|
||||
|
||||
“如果你不准备对其他人采取法律行动,那么对于你的知识财产来说专利可能并不是最佳的法律保护方式”,他说。“我们现在生活在一个对软件——开放和专有——误会重重的世界里。这些软件还被错误并过时的专利系统所捆绑。我们每天在工业化的被窒息的创新中挣扎”,他说。
|
||||
|
||||
### 法院是最后的手段###
|
||||
|
||||
想到 OIN 的出现抑制了诉讼的泛滥就感到十分欣慰,Bergelt 说,或者至少可以说 OIN 的出现扼制了特定的某些威胁。
|
||||
|
||||
“可以说我们让人们放下它们了的武器。同时我们正在创建一种新的文化规范。一旦你入股这个模型中的非侵略专利,所产生的相关影响就是对合作的鼓励”,他说。
|
||||
|
||||
如果你愿意承诺合作,你的第一反应就会趋向于不急着起诉。相反的,你会想如何让我们允许你使用我们所拥有的东西并让它为你赚钱,而同时我们也能使用你所拥有的东西,Bergelt 解释道。
|
||||
|
||||
“OIN 是个多面的解决方式。他鼓励签署者创造双赢协议”,他说。“这让起诉成为最逼不得已的行为。那才是它的位置。”
|
||||
|
||||
### 底线###
|
||||
|
||||
Bergelt 坚信,OIN 的运作是为了阻止 Linux 受到专利伤害。在 Linux 的世界里没有诉讼的地方。
|
||||
|
||||
唯一临近的是和微软的移动大战,这主要关系到堆栈中高的元素。那些来自法律的挑战可能是为了提高包括使用 Linux 产品的所属权的成本,Bergelt 说。
|
||||
|
||||
尽管如此“这些并不是有关 Linux 诉讼”,他说。“他们的重点并不在于 Linux 的核心。他们关注的是 Linux 系统里都有些什么。”
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxinsider.com/story/Defending-the-Free-Linux-World-81512.html
|
||||
|
||||
作者:Jack M. Germain
|
||||
译者:[H-mudcup](https://github.com/H-mudcup)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.openinventionnetwork.com/
|
||||
[2]:http://www.redhat.com/
|
||||
[3]:http://www.law.uh.edu/
|
||||
[4]:http://www.chaoticmoon.com/
|
||||
[5]:http://www.ieee.org/
|
||||
@ -0,0 +1,123 @@
|
||||
学习数据结构与算法分析如何帮助您成为更优秀的开发人员?
|
||||
================================================================================
|
||||
|
||||
> "相较于其它方式,我一直热衷于推崇围绕数据设计代码,我想这也是Git能够如此成功的一大原因[…]在我看来,区别程序员优劣的一大标准就在于他是否认为自己设计的代码或数据结构更为重要。"
|
||||
-- Linus Torvalds
|
||||
|
||||
---
|
||||
|
||||
> "优秀的数据结构与简陋的代码组合远比倒过来的组合方式更好。"
|
||||
-- Eric S. Raymond, The Cathedral and The Bazaar
|
||||
|
||||
学习数据结构与算法分析会让您成为一名出色的程序员。
|
||||
|
||||
**数据结构与算法分析是一种解决问题的思维模式** 在您的个人知识库中,数据结构与算法分析的相关知识储备越多,您将具备应对并解决越多各类繁杂问题的能力。掌握了这种思维模式,您还将有能力针对新问题提出更多以前想不到的漂亮的解决方案。
|
||||
|
||||
您将***更深入地***了解,计算机如何完成各项操作。无论您是否是直接使用给定的算法,它都影响着您作出的各种技术决定。从计算机操作系统的内存分配到RDBMS的内在工作机制,以及网络堆栈如何实现将数据从地球的一个角落发送至另一个角落这些大大小小的工作的完成,都离不开基础的数据结构与算法,理解并掌握它将会让您更了解计算机的运作机理。
|
||||
|
||||
对算法广泛深入的学习能让为您应对大体系的问题储备解决方案。之前建模困难时遇到的问题如今通常都能融合进经典的数据结构中得到很好地解决。即使是最基础的数据结构,只要对它进行足够深入的钻研,您将会发现在每天的编程任务中都能经常用到这些知识。
|
||||
|
||||
有了这种思维模式,在遇到磨棱两可的问题时,您会具备想出新的解决方案的能力。即使最初并没有打算用数据结构与算法解决相应问题的情况,当真正用它们解决这些问题时您会发现它们将非常有用。要意识到这一点,您至少要对数据结构与算法分析的基础知识有深入直观的认识。
|
||||
|
||||
理论认识就讲到这里,让我们一起看看下面几个例子。
|
||||
|
||||
###最短路径问题###
|
||||
|
||||
我们想要开发一个计算从一个国际机场出发到另一个国际机场的最短距离的软件。假设我们受限于以下路线:
|
||||
|
||||

|
||||
|
||||
从这张画出机场各自之间的距离以及目的地的图中,我们如何才能找到最短距离,比方说从赫尔辛基到伦敦?**Dijkstra算法**是能让我们在最短的时间得到正确答案的适用算法。
|
||||
|
||||
在所有可能的解法中,如果您曾经遇到过这类问题,知道可以用Dijkstra算法求解,您大可不必从零开始实现它,只需***知道***该算法能指向固定的代码库帮助您解决相关的实现问题。
|
||||
|
||||
实现了该算法,您将深入理解一项著名的重要图论算法。您会发现实际上该算法太集成化,因此名为A*的扩展包经常会代替该算法使用。这个算法应用广泛,从机器人指引的功能实现到TCP数据包路由,以及GPS寻径问题都能应用到这个算法。
|
||||
|
||||
###先后排序问题###
|
||||
|
||||
您想要在开放式在线课程平台上(如Udemy或Khan学院)学习某课程,有些课程之间彼此依赖。例如,用户学习牛顿力学机制课程前必须先修微积分课程,课程之间可以有多种依赖关系。用YAML表述举例如下:
|
||||
|
||||
# Mapping from course name to requirements
|
||||
#
|
||||
# If you're a physcist or a mathematicisn and you're reading this, sincere
|
||||
# apologies for the completely made-up dependency tree :)
|
||||
courses:
|
||||
arithmetic: []
|
||||
algebra: [arithmetic]
|
||||
trigonometry: [algebra]
|
||||
calculus: [algebra, trigonometry]
|
||||
geometry: [algebra]
|
||||
mechanics: [calculus, trigonometry]
|
||||
atomic_physics: [mechanics, calculus]
|
||||
electromagnetism: [calculus, atomic_physics]
|
||||
radioactivity: [algebra, atomic_physics]
|
||||
astrophysics: [radioactivity, calculus]
|
||||
quantumn_mechanics: [atomic_physics, radioactivity, calculus]
|
||||
|
||||
鉴于以上这些依赖关系,作为一名用户,我希望系统能帮我列出必修课列表,让我在之后可以选择任意一门课程学习。如果我选择了`微积分`课程,我希望系统能返回以下列表:
|
||||
|
||||
arithmetic -> algebra -> trigonometry -> calculus
|
||||
|
||||
这里有两个潜在的重要约束条件:
|
||||
|
||||
- 返回的必修课列表中,每门课都与下一门课存在依赖关系
|
||||
- 必修课列表中不能有重复项
|
||||
|
||||
这是解决数据间依赖关系的例子,解决该问题的排序算法称作拓扑排序算法(tsort)。它适用于解决上述我们用YAML列出的依赖关系图的情况,以下是在图中显示的相关结果(其中箭头代表`需要先修的课程`):
|
||||
|
||||

|
||||
|
||||
拓扑排序算法的实现就是从如上所示的图中找到满足各层次要求的依赖关系。因此如果我们只列出包含`radioactivity`和与它有依赖关系的子图,运行tsort排序,会得到如下的顺序表:
|
||||
|
||||
arithmetic
|
||||
algebra
|
||||
trigonometry
|
||||
calculus
|
||||
mechanics
|
||||
atomic_physics
|
||||
radioactivity
|
||||
|
||||
这符合我们上面描述的需求,用户只需选出`radioactivity`,就能得到在此之前所有必修课程的有序列表。
|
||||
|
||||
在运用该排序算法之前,我们甚至不需要深入了解算法的实现细节。一般来说,选择不同的编程语言在其标准库中都会有相应的算法实现。即使最坏的情况,Unix也会默认安装`tsort`程序,运行`tsort`程序,您就可以实现该算法。
|
||||
|
||||
###其它拓扑排序适用场合###
|
||||
|
||||
- **工具** 使用诸如`make`的工具您可以声明任务之间的依赖关系,这里拓扑排序算法将从底层实现具有依赖关系的任务顺序执行的功能。
|
||||
- **有`require`指令的编程语言**,适用于要运行当前文件需先运行另一个文件的情况。这里拓扑排序用于识别文件运行顺序以保证每个文件只加载一次,且满足所有文件间的依赖关系要求。
|
||||
- **包含甘特图的项目管理工具**.甘特图能直观列出给定任务的所有依赖关系,在这些依赖关系之上能提供给用户任务完成的预估时间。我不常用到甘特图,但这些绘制甘特图的工具很可能会用到拓扑排序算法。
|
||||
|
||||
###霍夫曼编码实现数据压缩###
|
||||
[霍夫曼编码](http://en.wikipedia.org/wiki/Huffman_coding)是一种用于无损数据压缩的编码算法。它的工作原理是先分析要压缩的数据,再为每个字符创建一个二进制编码。字符出现的越频繁,编码赋值越小。因此在一个数据集中`e`可能会编码为`111`,而`x`会编码为`10010`。创建了这种编码模式,就可以串联无定界符,也能正确地进行解码。
|
||||
|
||||
在gzip中使用的DEFLATE算法就结合了霍夫曼编码与LZ77一同用于实现数据压缩功能。gzip应用领域很广,特别适用于文件压缩(以`.gz`为扩展名的文件)以及用于数据传输中的http请求与应答。
|
||||
|
||||
学会实现并使用霍夫曼编码有如下益处:
|
||||
|
||||
- 您会理解为什么较大的压缩文件会获得较好的整体压缩效果(如压缩的越多,压缩率也越高)。这也是SPDY协议得以推崇的原因之一:在复杂的HTTP请求/响应过程数据有更好的压缩效果。
|
||||
- 您会了解数据传输过程中如果想要压缩JavaScript/CSS文件,运行压缩软件是完全没有意义的。PNG文件也是类似,因为它们已经使用DEFLATE算法完成了压缩。
|
||||
- 如果您试图强行破译加密的信息,您可能会发现重复数据压缩质量越好,给定的密文单位bit的数据压缩将帮助您确定相关的[分组密码模式](http://en.wikipedia.org/wiki/Block_cipher_mode_of_operation).
|
||||
|
||||
###下一步选择学习什么是困难的###
|
||||
作为一名程序员应当做好持续学习的准备。为成为一名web开发人员,您需要了解标记语言以及Ruby/Python,正则表达式,SQL,JavaScript等高级编程语言,还需要了解HTTP的工作原理,如何运行UNIX终端以及面向对象的编程艺术。您很难有效地预览到未来的职业全景,因此选择下一步要学习哪些知识是困难的。
|
||||
|
||||
我没有快速学习的能力,因此我不得不在时间花费上非常谨慎。我希望尽可能地学习到有持久生命力的技能,即不会在几年内就过时的技术。这意味着我也会犹豫这周是要学习JavaScript框架还是那些新的编程语言。
|
||||
|
||||
只要占主导地位的计算模型体系不变,我们如今使用的数据结构与算法在未来也必定会以另外的形式继续适用。您可以放心地将时间投入到深入掌握数据结构与算法知识中,它们将会成为您作为一名程序员的职业生涯中一笔长期巨大的财富。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.happybearsoftware.com/how-learning-data-structures-and-algorithms-makes-you-a-better-developer
|
||||
|
||||
作者:[Happy Bear][a]
|
||||
译者:[icybreaker](https://github.com/icybreaker)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.happybearsoftware.com/
|
||||
[1]:http://en.wikipedia.org/wiki/Huffman_coding
|
||||
[2]:http://en.wikipedia.org/wiki/Block_cipher_mode_of_operation
|
||||
|
||||
|
||||
|
||||
@ -1,348 +0,0 @@
|
||||
Shilpa Nair 分享了她面试 RedHat Linux 包管理方面的经验
|
||||
========================================================================
|
||||
**Shilpa Nair 刚于2015年毕业。她之后去了一家位于 Noida,Delhi 的国家新闻电视台,应聘实习生的岗位。在她去年毕业季的时候,常逛 Tecmint 寻求作业上的帮助。从那时开始,她就常去 Tecmint。**
|
||||
|
||||

|
||||
|
||||
有关 RPM 方面的 Linux 面试题
|
||||
|
||||
所有的问题和回答都是 Shilpa Nair 根据回忆重写的。
|
||||
|
||||
> “大家好!我是来自 Delhi 的Shilpa Nair。我不久前才顺利毕业,正寻找一个实习的机会。在大学早期的时候,我就对 UNIX 十分喜爱,所以我也希望这个机会能适合我,满足我的兴趣。我被提问了很多问题,大部分都是关于 RedHat 包管理的基础问题。”
|
||||
|
||||
下面就是我被问到的问题,和对应的回答。我仅贴出了与 RedHat GNU/Linux 包管理相关的,也是主要被提问的。
|
||||
|
||||
### 1,里如何查找一个包安装与否?假设你需要确认 ‘nano’ 有没有安装,你怎么做? ###
|
||||
|
||||
> **回答**:为了确认 nano 软件包有没有安装,我们可以使用 rpm 命令,配合 -q 和 -a 选项来查询所有已安装的包
|
||||
>
|
||||
> # rpm -qa nano
|
||||
> OR
|
||||
> # rpm -qa | grep -i nano
|
||||
>
|
||||
> nano-2.3.1-10.el7.x86_64
|
||||
>
|
||||
> 同时包的名字必须是完成的,不完整的包名返回提示,不打印任何东西,就是说这包(包名字不全)未安装。下面的例子会更好理解些:
|
||||
>
|
||||
> 我们通常使用 vim 替代 vi 命令。当时如果我们查找安装包 vi/vim 的时候,我们就会看到标准输出上没有任何结果。
|
||||
>
|
||||
> # vi
|
||||
> # vim
|
||||
>
|
||||
> 尽管如此,我们仍然可以通过使用 vi/vim 命令来清楚地知道包有没有安装。Here is ... name(这句不知道)。如果我们不确切知道完整的文件名,我们可以使用通配符:
|
||||
>
|
||||
> # rpm -qa vim*
|
||||
>
|
||||
> vim-minimal-7.4.160-1.el7.x86_64
|
||||
>
|
||||
> 通过这种方式,我们可以获得任何软件包的信息,安装与否。
|
||||
|
||||
### 2. 你如何使用 rpm 命令安装 XYZ 软件包? ###
|
||||
|
||||
> **回答**:我们可以使用 rpm 命令安装任何的软件包(*.rpm),像下面这样,选项 -i(install),-v(冗余或者显示额外的信息)和 -h(打印#号显示进度,在安装过程中)。
|
||||
>
|
||||
> # rpm -ivh peazip-1.11-1.el6.rf.x86_64.rpm
|
||||
>
|
||||
> Preparing... ################################# [100%]
|
||||
> Updating / installing...
|
||||
> 1:peazip-1.11-1.el6.rf ################################# [100%]
|
||||
>
|
||||
> 如果要升级一个早期版本的包,应加上 -U 选项,选项 -v 和 -h 可以确保我们得到用 # 号表示的冗余输出,这增加了可读性。
|
||||
|
||||
### 3. 你已经安装了一个软件包(假设是 httpd),现在你想看看软件包创建并安装的所有文件和目录,你会怎么做? ###
|
||||
|
||||
> **回答**:使用选项 -l(列出所有文件)和 -q(查询)列出 httpd 软件包安装的所有文件(Linux哲学:所有的都是文件,包括目录)。
|
||||
>
|
||||
> # rpm -ql httpd
|
||||
>
|
||||
> /etc/httpd
|
||||
> /etc/httpd/conf
|
||||
> /etc/httpd/conf.d
|
||||
> ...
|
||||
|
||||
### 4. 假如你要移除一个软件包,叫 postfix。你会怎么做? ###
|
||||
|
||||
> **回答**:首先我们需要知道什么包安装了 postfix。查找安装 postfix 的包名后,使用 -e(擦除/卸载软件包)和 -v(冗余输出)两个选项来实现。
|
||||
>
|
||||
> # rpm -qa postfix*
|
||||
>
|
||||
> postfix-2.10.1-6.el7.x86_64
|
||||
>
|
||||
> 然后移除 postfix,如下:
|
||||
>
|
||||
> # rpm -ev postfix-2.10.1-6.el7.x86_64
|
||||
>
|
||||
> Preparing packages...
|
||||
> postfix-2:3.0.1-2.fc22.x86_64
|
||||
|
||||
### 5. 获得一个已安装包的具体信息,如版本,发行号,安装日期,大小,总结和一个间短的描述。 ###
|
||||
|
||||
> **回答**:我们通过使用 rpm 的选项 -qi,后面接包名,可以获得关于一个已安装包的具体信息。
|
||||
>
|
||||
> 举个例子,为了获得 openssh 包的具体信息,我需要做的就是:
|
||||
>
|
||||
> # rpm -qi openssh
|
||||
>
|
||||
> [root@tecmint tecmint]# rpm -qi openssh
|
||||
> Name : openssh
|
||||
> Version : 6.8p1
|
||||
> Release : 5.fc22
|
||||
> Architecture: x86_64
|
||||
> Install Date: Thursday 28 May 2015 12:34:50 PM IST
|
||||
> Group : Applications/Internet
|
||||
> Size : 1542057
|
||||
> License : BSD
|
||||
> ....
|
||||
|
||||
### 6. 假如你不确定一个指定包的配置文件在哪,比如 httpd。你如何找到所有 httpd 提供的配置文件列表和位置。 ###
|
||||
|
||||
> **回答**: 我们需要用选项 -c 接包名,这会列出所有配置文件的名字和他们的位置。
|
||||
>
|
||||
> # rpm -qc httpd
|
||||
>
|
||||
> /etc/httpd/conf.d/autoindex.conf
|
||||
> /etc/httpd/conf.d/userdir.conf
|
||||
> /etc/httpd/conf.d/welcome.conf
|
||||
> /etc/httpd/conf.modules.d/00-base.conf
|
||||
> /etc/httpd/conf/httpd.conf
|
||||
> /etc/sysconfig/httpd
|
||||
>
|
||||
> 相似地,我们可以列出所有相关的文档文件,如下:
|
||||
>
|
||||
> # rpm -qd httpd
|
||||
>
|
||||
> /usr/share/doc/httpd/ABOUT_APACHE
|
||||
> /usr/share/doc/httpd/CHANGES
|
||||
> /usr/share/doc/httpd/LICENSE
|
||||
> ...
|
||||
>
|
||||
> 我们也可以列出所有相关的证书文件,如下:
|
||||
>
|
||||
> # rpm -qL openssh
|
||||
>
|
||||
> /usr/share/licenses/openssh/LICENCE
|
||||
>
|
||||
> 忘了说明上面的选项 -d 和 -L 分别表示 “文档” 和 “证书”,抱歉。
|
||||
|
||||
### 7. 你进入了一个配置文件,位于‘/usr/share/alsa/cards/AACI.conf’,现在你不确定该文件属于哪个包。你如何查找出包的名字? ###
|
||||
|
||||
> **回答**:当一个包被安装后,相关的信息就存储在了数据库里。所以使用选项 -qf(-f 查询包拥有的文件)很容易追踪谁提供了上述的包。
|
||||
>
|
||||
> # rpm -qf /usr/share/alsa/cards/AACI.conf
|
||||
> alsa-lib-1.0.28-2.el7.x86_64
|
||||
>
|
||||
> 类似地,我们可以查找(谁提供的)关于任何子包,文档和证书文件的信息。
|
||||
|
||||
### 8. 你如何使用 rpm 查找最近安装的软件列表? ###
|
||||
|
||||
> **回答**:如刚刚说的,每一样被安装的文件都记录在了数据库里。所以这并不难,通过查询 rpm 的数据库,找到最近安装软件的列表。
|
||||
>
|
||||
> 我们通过运行下面的命令,使用选项 -last(打印出最近安装的软件)达到目的。
|
||||
>
|
||||
> # rpm -qa --last
|
||||
>
|
||||
> 上面的命令会打印出所有安装的软件,最近一次安装的软件在列表的顶部。
|
||||
>
|
||||
> 如果我们关心的是找出特定的包,我们可以使用 grep 命令从列表中匹配包(假设是 sqlite ),简单如下:
|
||||
>
|
||||
> # rpm -qa --last | grep -i sqlite
|
||||
>
|
||||
> sqlite-3.8.10.2-1.fc22.x86_64 Thursday 18 June 2015 05:05:43 PM IST
|
||||
>
|
||||
> 我们也可以获得10个最近安装的软件列表,简单如下:
|
||||
>
|
||||
> # rpm -qa --last | head
|
||||
>
|
||||
> 我们可以重定义一下,输出想要的结果,简单如下:
|
||||
>
|
||||
> # rpm -qa --last | head -n 2
|
||||
>
|
||||
> 上面的命令中,-n 代表数目,后面接一个常数值。该命令是打印2个最近安装的软件的列表。
|
||||
|
||||
### 9. 安装一个包之前,你如果要检查其依赖。你会怎么做? ###
|
||||
|
||||
> **回答**:检查一个 rpm 包(XYZ.rpm)的依赖,我们可以使用选项 -q(查询包),-p(指定包名)和 -R(查询/列出该包依赖的包,嗯,就是依赖)。
|
||||
>
|
||||
> # rpm -qpR gedit-3.16.1-1.fc22.i686.rpm
|
||||
>
|
||||
> /bin/sh
|
||||
> /usr/bin/env
|
||||
> glib2(x86-32) >= 2.40.0
|
||||
> gsettings-desktop-schemas
|
||||
> gtk3(x86-32) >= 3.16
|
||||
> gtksourceview3(x86-32) >= 3.16
|
||||
> gvfs
|
||||
> libX11.so.6
|
||||
> ...
|
||||
|
||||
### 10. rpm 是不是一个前端的包管理工具呢? ###
|
||||
|
||||
> **回答**:不是!rpm 是一个后端管理工具,适用于基于 Linux 发行版的 RPM (此处指 Redhat Package Management)。
|
||||
>
|
||||
> [YUM][1],全称 Yellowdog Updater Modified,是一个 RPM 的前端工具。YUM 命令自动完成所有工作,包括解决依赖和其他一切事务。
|
||||
>
|
||||
> 最近,[DNF][2](YUM命令升级版)在Fedora 22发行版中取代了 YUM。尽管 YUM 仍然可以在 RHEL 和 CentOS 平台使用,我们也可以安装 dnf,与 YUM 命令共存使用。据说 DNF 较于 YUM 有很多提高。
|
||||
>
|
||||
> 知道更多总是好的,保持自我更新。现在我们移步到前端部分来谈谈。
|
||||
|
||||
### 11. 你如何列出一个系统上面所有可用的仓库列表。 ###
|
||||
|
||||
> **回答**:简单地使用下面的命令,我们就可以列出一个系统上所有可用的仓库列表。
|
||||
>
|
||||
> # yum repolist
|
||||
> 或
|
||||
> # dnf repolist
|
||||
>
|
||||
> Last metadata expiration check performed 0:30:03 ago on Mon Jun 22 16:50:00 2015.
|
||||
> repo id repo name status
|
||||
> *fedora Fedora 22 - x86_64 44,762
|
||||
> ozonos Repository for Ozon OS 61
|
||||
> *updates Fedora 22 - x86_64 - Updates
|
||||
>
|
||||
> 上面的命令仅会列出可用的仓库。如果你需要列出所有的仓库,不管可用与否,可以这样做。
|
||||
>
|
||||
> # yum repolist all
|
||||
> or
|
||||
> # dnf repolist all
|
||||
>
|
||||
> Last metadata expiration check performed 0:29:45 ago on Mon Jun 22 16:50:00 2015.
|
||||
> repo id repo name status
|
||||
> *fedora Fedora 22 - x86_64 enabled: 44,762
|
||||
> fedora-debuginfo Fedora 22 - x86_64 - Debug disabled
|
||||
> fedora-source Fedora 22 - Source disabled
|
||||
> ozonos Repository for Ozon OS enabled: 61
|
||||
> *updates Fedora 22 - x86_64 - Updates enabled: 5,018
|
||||
> updates-debuginfo Fedora 22 - x86_64 - Updates - Debug
|
||||
|
||||
### 12. 你如何列出一个系统上所有可用并且安装了的包? ###
|
||||
|
||||
> **回答**:列出一个系统上所有可用的包,我们可以这样做:
|
||||
>
|
||||
> # yum list available
|
||||
> 或
|
||||
> # dnf list available
|
||||
>
|
||||
> ast metadata expiration check performed 0:34:09 ago on Mon Jun 22 16:50:00 2015.
|
||||
> Available Packages
|
||||
> 0ad.x86_64 0.0.18-1.fc22 fedora
|
||||
> 0ad-data.noarch 0.0.18-1.fc22 fedora
|
||||
> 0install.x86_64 2.6.1-2.fc21 fedora
|
||||
> 0xFFFF.x86_64 0.3.9-11.fc22 fedora
|
||||
> 2048-cli.x86_64 0.9-4.git20141214.723738c.fc22 fedora
|
||||
> 2048-cli-nocurses.x86_64 0.9-4.git20141214.723738c.fc22 fedora
|
||||
> ....
|
||||
>
|
||||
> 而列出一个系统上所有已安装的包,我们可以这样做。
|
||||
>
|
||||
> # yum list installed
|
||||
> or
|
||||
> # dnf list installed
|
||||
>
|
||||
> Last metadata expiration check performed 0:34:30 ago on Mon Jun 22 16:50:00 2015.
|
||||
> Installed Packages
|
||||
> GeoIP.x86_64 1.6.5-1.fc22 @System
|
||||
> GeoIP-GeoLite-data.noarch 2015.05-1.fc22 @System
|
||||
> NetworkManager.x86_64 1:1.0.2-1.fc22 @System
|
||||
> NetworkManager-libnm.x86_64 1:1.0.2-1.fc22 @System
|
||||
> aajohan-comfortaa-fonts.noarch 2.004-4.fc22 @System
|
||||
> ....
|
||||
>
|
||||
> 而要同时满足两个要求的时候,我们可以这样做。
|
||||
>
|
||||
> # yum list
|
||||
> 或
|
||||
> # dnf list
|
||||
>
|
||||
> Last metadata expiration check performed 0:32:56 ago on Mon Jun 22 16:50:00 2015.
|
||||
> Installed Packages
|
||||
> GeoIP.x86_64 1.6.5-1.fc22 @System
|
||||
> GeoIP-GeoLite-data.noarch 2015.05-1.fc22 @System
|
||||
> NetworkManager.x86_64 1:1.0.2-1.fc22 @System
|
||||
> NetworkManager-libnm.x86_64 1:1.0.2-1.fc22 @System
|
||||
> aajohan-comfortaa-fonts.noarch 2.004-4.fc22 @System
|
||||
> acl.x86_64 2.2.52-7.fc22 @System
|
||||
> ....
|
||||
|
||||
### 13. 你会怎么分别安装和升级一个包与一组包,在一个系统上面使用 YUM/DNF? ###
|
||||
|
||||
> **回答**:安装一个包(假设是 nano),我们可以这样做,
|
||||
>
|
||||
> # yum install nano
|
||||
>
|
||||
> 而安装一组包(假设是 Haskell),我们可以这样做,
|
||||
>
|
||||
> # yum groupinstall 'haskell'
|
||||
>
|
||||
> 升级一个包(还是 nano),我们可以这样做,
|
||||
>
|
||||
> # yum update nano
|
||||
>
|
||||
> 而为了升级一组包(还是 haskell),我们可以这样做,
|
||||
>
|
||||
> # yum groupupdate 'haskell'
|
||||
|
||||
### 14. 你会如何同步一个系统上面的所有安装软件到稳定发行版? ###
|
||||
|
||||
> **回答**:我们可以一个系统上(假设是 CentOS 或者 Fedora)的所有包到稳定发行版,如下,
|
||||
>
|
||||
> # yum distro-sync [On CentOS/ RHEL]
|
||||
> 或
|
||||
> # dnf distro-sync [On Fedora 20之后版本]
|
||||
|
||||
似乎来面试之前你做了相当不多的功课,很好!在进一步交谈前,我还想问一两个问题。
|
||||
|
||||
### 15. 你对 YUM 本地仓库熟悉吗?你尝试过建立一个本地 YUM 仓库吗?让我们简单看看你会怎么建立一个本地 YUM 仓库。 ###
|
||||
|
||||
> **回答**:首先,感谢你的夸奖。回到问题,我必须承认我对本地 YUM 仓库十分熟悉,并且在我的本地主机上也部署过,作为测试用。
|
||||
>
|
||||
> 1. 为了建立本地 YUM 仓库,我们需要安装下面三个包:
|
||||
>
|
||||
> # yum install deltarpm python-deltarpm createrepo
|
||||
>
|
||||
> 2. 新建一个目录(假设 /home/$USER/rpm),然后复制 RedHat/CentOS DVD 上的 RPM 包到这个文件夹下
|
||||
>
|
||||
> # mkdir /home/$USER/rpm
|
||||
> # cp /path/to/rpm/on/DVD/*.rpm /home/$USER/rpm
|
||||
>
|
||||
> 3. 新建基本的库头文件如下。
|
||||
>
|
||||
> # createrepo -v /home/$USER/rpm
|
||||
>
|
||||
> 4. 在路径 /etc/yum.repo.d 下创建一个 .repo 文件(如 abc.repo):
|
||||
>
|
||||
> cd /etc/yum.repos.d && cat << EOF > abc.repo
|
||||
> [local-installation]name=yum-local
|
||||
> baseurl=file:///home/$USER/rpm
|
||||
> enabled=1
|
||||
> gpgcheck=0
|
||||
> EOF
|
||||
|
||||
**重要**:用你的用户名替换掉 $USER。
|
||||
|
||||
以上就是创建一个本地 YUM 仓库所要做的全部工作。我们现在可以从这里安装软件了,相对快一些,安全一些,并且最重要的是不需要 Internet 连接。
|
||||
|
||||
好了!面试过程很愉快。我已经问完了。我会将你推荐给 HR。你是一个年轻且十分聪明的候选者,我们很愿意你加入进来。如果你有任何问题,你可以问我。
|
||||
|
||||
**我**:谢谢,这确实是一次愉快的面试,我感到非常幸运今天,然后这次面试就毁了。。。
|
||||
|
||||
显然,不会在这里结束。我问了很多问题,比如他们正在做的项目。我会担任什么角色,负责什么,,,balabalabala
|
||||
|
||||
小伙伴们,3天以前 HR 轮的所有问题到时候也会被写成文档。希望我当时表现不错。感谢你们所有的祝福。
|
||||
|
||||
谢谢伙伴们和 Tecmint,花时间来编辑我的面试经历。我相信 Tecmint 好伙伴们做了很大的努力,必要要赞一个。当我们与他人分享我们的经历的时候,其他人从我们这里知道了更多,而我们自己则发现了自己的不足。
|
||||
|
||||
这增加了我们的信心。如果你最近也有任何类似的面试经历,别自己蔵着。分享出来!让我们所有人都知道。你可以使用如下的格式来与我们分享你的经历。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-rpm-package-management-interview-questions/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[wi-cuckoo](https://github.com/wi-cuckoo)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
|
||||
[2]:http://www.tecmint.com/dnf-commands-for-fedora-rpm-package-management/
|
||||
@ -1,674 +0,0 @@
|
||||
如何构建Linux 内核
|
||||
================================================================================
|
||||
介绍
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
我不会告诉你怎么在自己的电脑上去构建、安装一个定制化的Linux 内核,这样的[资料](https://encrypted.google.com/search?q=building+linux+kernel#q=building+linux+kernel+from+source+code) 太多了,它们会对你有帮助。本文会告诉你当你在内核源码路径里敲下`make` 时会发生什么。当我刚刚开始学习内核代码时,[Makefile](https://github.com/torvalds/linux/blob/master/Makefile) 是我打开的第一个文件,这个文件看起来真令人害怕 :)。那时候这个[Makefile](https://en.wikipedia.org/wiki/Make_%28software%29) 还只包含了`1591` 行代码,当我开始写本文是,这个[Makefile](https://github.com/torvalds/linux/commit/52721d9d3334c1cb1f76219a161084094ec634dc) 已经是第三个候选版本了。
|
||||
|
||||
这个makefile 是Linux 内核代码的根makefile ,内核构建就始于此处。是的,它的内容很多,但是如果你已经读过内核源代码,你就会发现每个包含代码的目录都有一个自己的makefile。当然了,我们不会去描述每个代码文件是怎么编译链接的。所以我们将只会挑选一些通用的例子来说明问题,而你不会在这里找到构建内核的文档、如何整洁内核代码、[tags](https://en.wikipedia.org/wiki/Ctags) 的生成和[交叉编译](https://en.wikipedia.org/wiki/Cross_compiler) 相关的说明,等等。我们将从`make` 开始,使用标准的内核配置文件,到生成了内核镜像[bzImage](https://en.wikipedia.org/wiki/Vmlinux#bzImage) 结束。
|
||||
|
||||
如果你已经很了解[make](https://en.wikipedia.org/wiki/Make_%28software%29) 工具那是最好,但是我也会描述本文出现的相关代码。
|
||||
|
||||
让我们开始吧
|
||||
|
||||
|
||||
编译内核前的准备
|
||||
---------------------------------------------------------------------------------
|
||||
|
||||
在开始编译前要进行很多准备工作。最主要的就是找到并配置好配置文件,`make` 命令要使用到的参数都需要从这些配置文件获取。现在就让我们深入内核的根`makefile` 吧
|
||||
|
||||
内核的根`Makefile` 负责构建两个主要的文件:[vmlinux](https://en.wikipedia.org/wiki/Vmlinux) (内核镜像可执行文件)和模块文件。内核的 [Makefile](https://github.com/torvalds/linux/blob/master/Makefile) 从此处开始:
|
||||
|
||||
```Makefile
|
||||
VERSION = 4
|
||||
PATCHLEVEL = 2
|
||||
SUBLEVEL = 0
|
||||
EXTRAVERSION = -rc3
|
||||
NAME = Hurr durr I'ma sheep
|
||||
```
|
||||
|
||||
这些变量决定了当前内核的版本,并且被使用在很多不同的地方,比如`KERNELVERSION` :
|
||||
|
||||
```Makefile
|
||||
KERNELVERSION = $(VERSION)$(if $(PATCHLEVEL),.$(PATCHLEVEL)$(if $(SUBLEVEL),.$(SUBLEVEL)))$(EXTRAVERSION)
|
||||
```
|
||||
|
||||
接下来我们会看到很多`ifeq` 条件判断语句,它们负责检查传给`make` 的参数。内核的`Makefile` 提供了一个特殊的编译选项`make help` ,这个选项可以生成所有的可用目标和一些能传给`make` 的有效的命令行参数。举个例子,`make V=1` 会在构建过程中输出详细的编译信息,第一个`ifeq` 就是检查传递给make的`V=n` 选项。
|
||||
|
||||
```Makefile
|
||||
ifeq ("$(origin V)", "command line")
|
||||
KBUILD_VERBOSE = $(V)
|
||||
endif
|
||||
ifndef KBUILD_VERBOSE
|
||||
KBUILD_VERBOSE = 0
|
||||
endif
|
||||
|
||||
ifeq ($(KBUILD_VERBOSE),1)
|
||||
quiet =
|
||||
Q =
|
||||
else
|
||||
quiet=quiet_
|
||||
Q = @
|
||||
endif
|
||||
|
||||
export quiet Q KBUILD_VERBOSE
|
||||
```
|
||||
|
||||
如果`V=n` 这个选项传给了`make` ,系统就会给变量`KBUILD_VERBOSE` 选项附上`V` 的值,否则的话`KBUILD_VERBOSE` 就会为`0`。然后系统会检查`KBUILD_VERBOSE` 的值,以此来决定`quiet` 和`Q` 的值。符号`@` 控制命令的输出,如果它被放在一个命令之前,这条命令的执行将会是`CC scripts/mod/empty.o`,而不是`Compiling .... scripts/mod/empty.o`(注:CC 在makefile 中一般都是编译命令)。最后系统仅仅导出所有的变量。下一个`ifeq` 语句检查的是传递给`make` 的选项`O=/dir`,这个选项允许在指定的目录`dir` 输出所有的结果文件:
|
||||
|
||||
```Makefile
|
||||
ifeq ($(KBUILD_SRC),)
|
||||
|
||||
ifeq ("$(origin O)", "command line")
|
||||
KBUILD_OUTPUT := $(O)
|
||||
endif
|
||||
|
||||
ifneq ($(KBUILD_OUTPUT),)
|
||||
saved-output := $(KBUILD_OUTPUT)
|
||||
KBUILD_OUTPUT := $(shell mkdir -p $(KBUILD_OUTPUT) && cd $(KBUILD_OUTPUT) \
|
||||
&& /bin/pwd)
|
||||
$(if $(KBUILD_OUTPUT),, \
|
||||
$(error failed to create output directory "$(saved-output)"))
|
||||
|
||||
sub-make: FORCE
|
||||
$(Q)$(MAKE) -C $(KBUILD_OUTPUT) KBUILD_SRC=$(CURDIR) \
|
||||
-f $(CURDIR)/Makefile $(filter-out _all sub-make,$(MAKECMDGOALS))
|
||||
|
||||
skip-makefile := 1
|
||||
endif # ifneq ($(KBUILD_OUTPUT),)
|
||||
endif # ifeq ($(KBUILD_SRC),)
|
||||
```
|
||||
|
||||
系统会检查变量`KBUILD_SRC`,如果他是空的(第一次执行makefile 时总是空的),并且变量`KBUILD_OUTPUT` 被设成了选项`O` 的值(如果这个选项被传进来了),那么这个值就会用来代表内核源码的顶层目录。下一步会检查变量`KBUILD_OUTPUT` ,如果之前设置过这个变量,那么接下来会做以下几件事:
|
||||
|
||||
* 将变量`KBUILD_OUTPUT` 的值保存到临时变量`saved-output`;
|
||||
* 尝试创建输出目录;
|
||||
* 检查创建的输出目录,如果失败了就打印错误;
|
||||
* 如果成功创建了输出目录,那么就在新目录重新执行`make` 命令(参见选项`-C`)。
|
||||
|
||||
下一个`ifeq` 语句会检查传递给make 的选项`C` 和`M`:
|
||||
|
||||
```Makefile
|
||||
ifeq ("$(origin C)", "command line")
|
||||
KBUILD_CHECKSRC = $(C)
|
||||
endif
|
||||
ifndef KBUILD_CHECKSRC
|
||||
KBUILD_CHECKSRC = 0
|
||||
endif
|
||||
|
||||
ifeq ("$(origin M)", "command line")
|
||||
KBUILD_EXTMOD := $(M)
|
||||
endif
|
||||
```
|
||||
|
||||
第一个选项`C` 会告诉`makefile` 需要使用环境变量`$CHECK` 提供的工具来检查全部`c` 代码,默认情况下会使用[sparse](https://en.wikipedia.org/wiki/Sparse)。第二个选项`M` 会用来编译外部模块(本文不做讨论)。因为设置了这两个变量,系统还会检查变量`KBUILD_SRC`,如果`KBUILD_SRC` 没有被设置,系统会设置变量`srctree` 为`.`:
|
||||
|
||||
```Makefile
|
||||
ifeq ($(KBUILD_SRC),)
|
||||
srctree := .
|
||||
endif
|
||||
|
||||
objtree := .
|
||||
src := $(srctree)
|
||||
obj := $(objtree)
|
||||
|
||||
export srctree objtree VPATH
|
||||
```
|
||||
|
||||
这将会告诉`Makefile` 内核的源码树就在执行make 命令的目录。然后要设置`objtree` 和其他变量为执行make 命令的目录,并且将这些变量导出。接着就是要获取`SUBARCH` 的值,这个变量代表了当前的系统架构(注:一般都指CPU 架构):
|
||||
|
||||
```Makefile
|
||||
SUBARCH := $(shell uname -m | sed -e s/i.86/x86/ -e s/x86_64/x86/ \
|
||||
-e s/sun4u/sparc64/ \
|
||||
-e s/arm.*/arm/ -e s/sa110/arm/ \
|
||||
-e s/s390x/s390/ -e s/parisc64/parisc/ \
|
||||
-e s/ppc.*/powerpc/ -e s/mips.*/mips/ \
|
||||
-e s/sh[234].*/sh/ -e s/aarch64.*/arm64/ )
|
||||
```
|
||||
|
||||
如你所见,系统执行[uname](https://en.wikipedia.org/wiki/Uname) 得到机器、操作系统和架构的信息。因为我们得到的是`uname` 的输出,所以我们需要做一些处理在赋给变量`SUBARCH` 。获得`SUBARCH` 之后就要设置`SRCARCH` 和`hfr-arch`,`SRCARCH`提供了硬件架构相关代码的目录,`hfr-arch` 提供了相关头文件的目录:
|
||||
|
||||
```Makefile
|
||||
ifeq ($(ARCH),i386)
|
||||
SRCARCH := x86
|
||||
endif
|
||||
ifeq ($(ARCH),x86_64)
|
||||
SRCARCH := x86
|
||||
endif
|
||||
|
||||
hdr-arch := $(SRCARCH)
|
||||
```
|
||||
|
||||
注意:`ARCH` 是`SUBARCH` 的别名。如果没有设置过代表内核配置文件路径的变量`KCONFIG_CONFIG`,下一步系统会设置它,默认情况下就是`.config` :
|
||||
|
||||
```Makefile
|
||||
KCONFIG_CONFIG ?= .config
|
||||
export KCONFIG_CONFIG
|
||||
```
|
||||
以及编译内核过程中要用到的[shell](https://en.wikipedia.org/wiki/Shell_%28computing%29)
|
||||
|
||||
```Makefile
|
||||
CONFIG_SHELL := $(shell if [ -x "$$BASH" ]; then echo $$BASH; \
|
||||
else if [ -x /bin/bash ]; then echo /bin/bash; \
|
||||
else echo sh; fi ; fi)
|
||||
```
|
||||
|
||||
接下来就要设置一组和编译内核的编译器相关的变量。我们会设置主机的`C` 和`C++` 的编译器及相关配置项:
|
||||
|
||||
```Makefile
|
||||
HOSTCC = gcc
|
||||
HOSTCXX = g++
|
||||
HOSTCFLAGS = -Wall -Wmissing-prototypes -Wstrict-prototypes -O2 -fomit-frame-pointer -std=gnu89
|
||||
HOSTCXXFLAGS = -O2
|
||||
```
|
||||
|
||||
下一步会去适配代表编译器的变量`CC`,那为什么还要`HOST*` 这些选项呢?这是因为`CC` 是编译内核过程中要使用的目标架构的编译器,但是`HOSTCC` 是要被用来编译一组`host` 程序的(下面我们就会看到)。然后我们就看看变量`KBUILD_MODULES` 和`KBUILD_BUILTIN` 的定义,这两个变量决定了我们要编译什么东西(内核、模块还是其他):
|
||||
|
||||
```Makefile
|
||||
KBUILD_MODULES :=
|
||||
KBUILD_BUILTIN := 1
|
||||
|
||||
ifeq ($(MAKECMDGOALS),modules)
|
||||
KBUILD_BUILTIN := $(if $(CONFIG_MODVERSIONS),1)
|
||||
endif
|
||||
```
|
||||
|
||||
在这我们可以看到这些变量的定义,并且,如果们仅仅传递了`modules` 给`make`,变量`KBUILD_BUILTIN` 会依赖于内核配置选项`CONFIG_MODVERSIONS`。下一步操作是引入下面的文件:
|
||||
|
||||
```Makefile
|
||||
include scripts/Kbuild.include
|
||||
```
|
||||
|
||||
文件`kbuild` ,[Kbuild](https://github.com/torvalds/linux/blob/master/Documentation/kbuild/kbuild.txt) 或者又叫做 `Kernel Build System`是一个用来管理构建内核和模块的特殊框架。`kbuild` 文件的语法与makefile 一样。文件[scripts/Kbuild.include](https://github.com/torvalds/linux/blob/master/scripts/Kbuild.include) 为`kbuild` 系统同提供了一些原生的定义。因为我们包含了这个`kbuild` 文件,我们可以看到和不同工具关联的这些变量的定义,这些工具会在内核和模块编译过程中被使用(比如链接器、编译器、二进制工具包[binutils](http://www.gnu.org/software/binutils/),等等):
|
||||
|
||||
```Makefile
|
||||
AS = $(CROSS_COMPILE)as
|
||||
LD = $(CROSS_COMPILE)ld
|
||||
CC = $(CROSS_COMPILE)gcc
|
||||
CPP = $(CC) -E
|
||||
AR = $(CROSS_COMPILE)ar
|
||||
NM = $(CROSS_COMPILE)nm
|
||||
STRIP = $(CROSS_COMPILE)strip
|
||||
OBJCOPY = $(CROSS_COMPILE)objcopy
|
||||
OBJDUMP = $(CROSS_COMPILE)objdump
|
||||
AWK = awk
|
||||
...
|
||||
...
|
||||
...
|
||||
```
|
||||
|
||||
在这些定义好的变量后面,我们又定义了两个变量:`USERINCLUDE` 和`LINUXINCLUDE`。他们包含了头文件的路径(第一个是给用户用的,第二个是给内核用的):
|
||||
|
||||
```Makefile
|
||||
USERINCLUDE := \
|
||||
-I$(srctree)/arch/$(hdr-arch)/include/uapi \
|
||||
-Iarch/$(hdr-arch)/include/generated/uapi \
|
||||
-I$(srctree)/include/uapi \
|
||||
-Iinclude/generated/uapi \
|
||||
-include $(srctree)/include/linux/kconfig.h
|
||||
|
||||
LINUXINCLUDE := \
|
||||
-I$(srctree)/arch/$(hdr-arch)/include \
|
||||
...
|
||||
```
|
||||
|
||||
以及标准的C 编译器标志:
|
||||
```Makefile
|
||||
KBUILD_CFLAGS := -Wall -Wundef -Wstrict-prototypes -Wno-trigraphs \
|
||||
-fno-strict-aliasing -fno-common \
|
||||
-Werror-implicit-function-declaration \
|
||||
-Wno-format-security \
|
||||
-std=gnu89
|
||||
```
|
||||
|
||||
这并不是最终确定的编译器标志,他们还可以在其他makefile 里面更新(比如`arch/` 里面的kbuild)。变量定义完之后,全部会被导出供其他makefile 使用。下面的两个变量`RCS_FIND_IGNORE` 和 `RCS_TAR_IGNORE` 包含了被版本控制系统忽略的文件:
|
||||
|
||||
```Makefile
|
||||
export RCS_FIND_IGNORE := \( -name SCCS -o -name BitKeeper -o -name .svn -o \
|
||||
-name CVS -o -name .pc -o -name .hg -o -name .git \) \
|
||||
-prune -o
|
||||
export RCS_TAR_IGNORE := --exclude SCCS --exclude BitKeeper --exclude .svn \
|
||||
--exclude CVS --exclude .pc --exclude .hg --exclude .git
|
||||
```
|
||||
|
||||
这就是全部了,我们已经完成了所有的准备工作,下一个点就是如果构建`vmlinux`.
|
||||
|
||||
直面构建内核
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
现在我们已经完成了所有的准备工作,根makefile(注:内核根目录下的makefile)的下一步工作就是和编译内核相关的了。在我们执行`make` 命令之前,我们不会在终端看到任何东西。但是现在编译的第一步开始了,这里我们需要从内核根makefile的的[598](https://github.com/torvalds/linux/blob/master/Makefile#L598) 行开始,这里可以看到目标`vmlinux`:
|
||||
|
||||
```Makefile
|
||||
all: vmlinux
|
||||
include arch/$(SRCARCH)/Makefile
|
||||
```
|
||||
|
||||
不要操心我们略过的从`export RCS_FIND_IGNORE.....` 到`all: vmlinux.....` 这一部分makefile 代码,他们只是负责根据各种配置文件生成不同目标内核的,因为之前我就说了这一部分我们只讨论构建内核的通用途径。
|
||||
|
||||
目标`all:` 是在命令行如果不指定具体目标时默认使用的目标。你可以看到这里包含了架构相关的makefile(在这里就指的是[arch/x86/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/Makefile))。从这一时刻起,我们会从这个makefile 继续进行下去。如我们所见,目标`all` 依赖于根makefile 后面声明的`vmlinux`:
|
||||
|
||||
```Makefile
|
||||
vmlinux: scripts/link-vmlinux.sh $(vmlinux-deps) FORCE
|
||||
```
|
||||
|
||||
`vmlinux` 是linux 内核的静态链接可执行文件格式。脚本[scripts/link-vmlinux.sh](https://github.com/torvalds/linux/blob/master/scripts/link-vmlinux.sh) 把不同的编译好的子模块链接到一起形成了vmlinux。第二个目标是`vmlinux-deps`,它的定义如下:
|
||||
|
||||
```Makefile
|
||||
vmlinux-deps := $(KBUILD_LDS) $(KBUILD_VMLINUX_INIT) $(KBUILD_VMLINUX_MAIN)
|
||||
```
|
||||
|
||||
它是由内核代码下的每个顶级目录的`built-in.o` 组成的。之后我们还会检查内核所有的目录,`kbuild` 会编译各个目录下所有的对应`$obj-y` 的源文件。接着调用`$(LD) -r` 把这些文件合并到一个`build-in.o` 文件里。此时我们还没有`vmloinux-deps`, 所以目标`vmlinux` 现在还不会被构建。对我而言`vmlinux-deps` 包含下面的文件
|
||||
|
||||
```
|
||||
arch/x86/kernel/vmlinux.lds arch/x86/kernel/head_64.o
|
||||
arch/x86/kernel/head64.o arch/x86/kernel/head.o
|
||||
init/built-in.o usr/built-in.o
|
||||
arch/x86/built-in.o kernel/built-in.o
|
||||
mm/built-in.o fs/built-in.o
|
||||
ipc/built-in.o security/built-in.o
|
||||
crypto/built-in.o block/built-in.o
|
||||
lib/lib.a arch/x86/lib/lib.a
|
||||
lib/built-in.o arch/x86/lib/built-in.o
|
||||
drivers/built-in.o sound/built-in.o
|
||||
firmware/built-in.o arch/x86/pci/built-in.o
|
||||
arch/x86/power/built-in.o arch/x86/video/built-in.o
|
||||
net/built-in.o
|
||||
```
|
||||
|
||||
下一个可以被执行的目标如下:
|
||||
|
||||
```Makefile
|
||||
$(sort $(vmlinux-deps)): $(vmlinux-dirs) ;
|
||||
$(vmlinux-dirs): prepare scripts
|
||||
$(Q)$(MAKE) $(build)=$@
|
||||
```
|
||||
|
||||
就像我们看到的,`vmlinux-dir` 依赖于两部分:`prepare` 和`scripts`。第一个`prepare` 定义在内核的根`makefile` ,准备工作分成三个阶段:
|
||||
|
||||
```Makefile
|
||||
prepare: prepare0
|
||||
prepare0: archprepare FORCE
|
||||
$(Q)$(MAKE) $(build)=.
|
||||
archprepare: archheaders archscripts prepare1 scripts_basic
|
||||
|
||||
prepare1: prepare2 $(version_h) include/generated/utsrelease.h \
|
||||
include/config/auto.conf
|
||||
$(cmd_crmodverdir)
|
||||
prepare2: prepare3 outputmakefile asm-generic
|
||||
```
|
||||
|
||||
第一个`prepare0` 展开到`archprepare` ,后者又展开到`archheader` 和`archscripts`,这两个变量定义在`x86_64` 相关的[Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/Makefile)。让我们看看这个文件。`x86_64` 特定的makefile从变量定义开始,这些变量都是和特定架构的配置文件 ([defconfig](https://github.com/torvalds/linux/tree/master/arch/x86/configs),等等)有关联。变量定义之后,这个makefile 定义了编译[16-bit](https://en.wikipedia.org/wiki/Real_mode)代码的编译选项,根据变量`BITS` 的值,如果是`32`, 汇编代码、链接器、以及其它很多东西(全部的定义都可以在[arch/x86/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/Makefile)找到)对应的参数就是`i386`,而`64`就对应的是`x86_84`。生成的系统调用列表(syscall table)的makefile 里第一个目标就是`archheaders` :
|
||||
|
||||
```Makefile
|
||||
archheaders:
|
||||
$(Q)$(MAKE) $(build)=arch/x86/entry/syscalls all
|
||||
```
|
||||
|
||||
这个makefile 里第二个目标就是`archscripts`:
|
||||
|
||||
```Makefile
|
||||
archscripts: scripts_basic
|
||||
$(Q)$(MAKE) $(build)=arch/x86/tools relocs
|
||||
```
|
||||
|
||||
我们可以看到`archscripts` 是依赖于根[Makefile](https://github.com/torvalds/linux/blob/master/Makefile)里的`scripts_basic` 。首先我们可以看出`scripts_basic` 是按照[scripts/basic](https://github.com/torvalds/linux/blob/master/scripts/basic/Makefile) 的mekefile 执行make 的:
|
||||
|
||||
```Maklefile
|
||||
scripts_basic:
|
||||
$(Q)$(MAKE) $(build)=scripts/basic
|
||||
```
|
||||
|
||||
`scripts/basic/Makefile`包含了编译两个主机程序`fixdep` 和`bin2` 的目标:
|
||||
|
||||
```Makefile
|
||||
hostprogs-y := fixdep
|
||||
hostprogs-$(CONFIG_BUILD_BIN2C) += bin2c
|
||||
always := $(hostprogs-y)
|
||||
|
||||
$(addprefix $(obj)/,$(filter-out fixdep,$(always))): $(obj)/fixdep
|
||||
```
|
||||
|
||||
第一个工具是`fixdep`:用来优化[gcc](https://gcc.gnu.org/) 生成的依赖列表,然后在重新编译源文件的时候告诉make。第二个工具是`bin2c`,他依赖于内核配置选项`CONFIG_BUILD_BIN2C`,并且它是一个用来将标准输入接口(注:即stdin)收到的二进制流通过标准输出接口(即:stdout)转换成C 头文件的非常小的C 程序。你可以注意到这里有些奇怪的标志,如`hostprogs-y`等。这些标志使用在所有的`kbuild` 文件,更多的信息你可以从[documentation](https://github.com/torvalds/linux/blob/master/Documentation/kbuild/makefiles.txt) 获得。在我们的用例`hostprogs-y` 中,他告诉`kbuild` 这里有个名为`fixed` 的程序,这个程序会通过和`Makefile` 相同目录的`fixdep.c` 编译而来。执行make 之后,终端的第一个输出就是`kbuild` 的结果:
|
||||
|
||||
```
|
||||
$ make
|
||||
HOSTCC scripts/basic/fixdep
|
||||
```
|
||||
|
||||
当目标`script_basic` 被执行,目标`archscripts` 就会make [arch/x86/tools](https://github.com/torvalds/linux/blob/master/arch/x86/tools/Makefile) 下的makefile 和目标`relocs`:
|
||||
|
||||
```Makefile
|
||||
$(Q)$(MAKE) $(build)=arch/x86/tools relocs
|
||||
```
|
||||
|
||||
代码`relocs_32.c` 和`relocs_64.c` 包含了[重定位](https://en.wikipedia.org/wiki/Relocation_%28computing%29) 的信息,将会被编译,者可以在`make` 的输出中看到:
|
||||
|
||||
```Makefile
|
||||
HOSTCC arch/x86/tools/relocs_32.o
|
||||
HOSTCC arch/x86/tools/relocs_64.o
|
||||
HOSTCC arch/x86/tools/relocs_common.o
|
||||
HOSTLD arch/x86/tools/relocs
|
||||
```
|
||||
|
||||
在编译完`relocs.c` 之后会检查`version.h`:
|
||||
|
||||
```Makefile
|
||||
$(version_h): $(srctree)/Makefile FORCE
|
||||
$(call filechk,version.h)
|
||||
$(Q)rm -f $(old_version_h)
|
||||
```
|
||||
|
||||
我们可以在输出看到它:
|
||||
|
||||
```
|
||||
CHK include/config/kernel.release
|
||||
```
|
||||
|
||||
以及在内核根Makefiel 使用`arch/x86/include/generated/asm`的目标`asm-generic` 来构建`generic` 汇编头文件。在目标`asm-generic` 之后,`archprepare` 就会被完成,所以目标`prepare0` 会接着被执行,如我上面所写:
|
||||
|
||||
```Makefile
|
||||
prepare0: archprepare FORCE
|
||||
$(Q)$(MAKE) $(build)=.
|
||||
```
|
||||
|
||||
注意`build`,它是定义在文件[scripts/Kbuild.include](https://github.com/torvalds/linux/blob/master/scripts/Kbuild.include),内容是这样的:
|
||||
|
||||
```Makefile
|
||||
build := -f $(srctree)/scripts/Makefile.build obj
|
||||
```
|
||||
|
||||
或者在我们的例子中,他就是当前源码目录路径——`.`:
|
||||
```Makefile
|
||||
$(Q)$(MAKE) -f $(srctree)/scripts/Makefile.build obj=.
|
||||
```
|
||||
|
||||
参数`obj` 会告诉脚本[scripts/Makefile.build](https://github.com/torvalds/linux/blob/master/scripts/Makefile.build) 那些目录包含`kbuild` 文件,脚本以此来寻找各个`kbuild` 文件:
|
||||
|
||||
```Makefile
|
||||
include $(kbuild-file)
|
||||
```
|
||||
|
||||
然后根据这个构建目标。我们这里`.` 包含了[Kbuild](https://github.com/torvalds/linux/blob/master/Kbuild),就用这个文件来生成`kernel/bounds.s` 和`arch/x86/kernel/asm-offsets.s`。这样目标`prepare` 就完成了它的工作。`vmlinux-dirs` 也依赖于第二个目标——`scripts` ,`scripts`会编译接下来的几个程序:`filealias`,`mk_elfconfig`,`modpost`等等。`scripts/host-programs` 编译完之后,我们的目标`vmlinux-dirs` 就可以开始编译了。第一步,我们先来理解一下`vmlinux-dirs` 都包含了那些东西。在我们的例子中它包含了接下来要使用的内核目录的路径:
|
||||
|
||||
```
|
||||
init usr arch/x86 kernel mm fs ipc security crypto block
|
||||
drivers sound firmware arch/x86/pci arch/x86/power
|
||||
arch/x86/video net lib arch/x86/lib
|
||||
```
|
||||
|
||||
我们可以在内核的根[Makefile](https://github.com/torvalds/linux/blob/master/Makefile) 里找到`vmlinux-dirs` 的定义:
|
||||
|
||||
```Makefile
|
||||
vmlinux-dirs := $(patsubst %/,%,$(filter %/, $(init-y) $(init-m) \
|
||||
$(core-y) $(core-m) $(drivers-y) $(drivers-m) \
|
||||
$(net-y) $(net-m) $(libs-y) $(libs-m)))
|
||||
|
||||
init-y := init/
|
||||
drivers-y := drivers/ sound/ firmware/
|
||||
net-y := net/
|
||||
libs-y := lib/
|
||||
...
|
||||
...
|
||||
...
|
||||
```
|
||||
|
||||
这里我们借助函数`patsubst` 和`filter`去掉了每个目录路径里的符号`/`,并且把结果放到`vmlinux-dirs` 里。所以我们就有了`vmlinux-dirs` 里的目录的列表,以及下面的代码:
|
||||
|
||||
```Makefile
|
||||
$(vmlinux-dirs): prepare scripts
|
||||
$(Q)$(MAKE) $(build)=$@
|
||||
```
|
||||
|
||||
符号`$@` 在这里代表了`vmlinux-dirs`,这就表明程序会递归遍历从`vmlinux-dirs` 以及它内部的全部目录(依赖于配置),并且在对应的目录下执行`make` 命令。我们可以在输出看到结果:
|
||||
|
||||
```
|
||||
CC init/main.o
|
||||
CHK include/generated/compile.h
|
||||
CC init/version.o
|
||||
CC init/do_mounts.o
|
||||
...
|
||||
CC arch/x86/crypto/glue_helper.o
|
||||
AS arch/x86/crypto/aes-x86_64-asm_64.o
|
||||
CC arch/x86/crypto/aes_glue.o
|
||||
...
|
||||
AS arch/x86/entry/entry_64.o
|
||||
AS arch/x86/entry/thunk_64.o
|
||||
CC arch/x86/entry/syscall_64.o
|
||||
```
|
||||
|
||||
每个目录下的源代码将会被编译并且链接到`built-io.o` 里:
|
||||
|
||||
```
|
||||
$ find . -name built-in.o
|
||||
./arch/x86/crypto/built-in.o
|
||||
./arch/x86/crypto/sha-mb/built-in.o
|
||||
./arch/x86/net/built-in.o
|
||||
./init/built-in.o
|
||||
./usr/built-in.o
|
||||
...
|
||||
...
|
||||
```
|
||||
|
||||
好了,所有的`built-in.o` 都构建完了,现在我们回到目标`vmlinux` 上。你应该还记得,目标`vmlinux` 是在内核的根makefile 里。在链接`vmlinux` 之前,系统会构建[samples](https://github.com/torvalds/linux/tree/master/samples), [Documentation](https://github.com/torvalds/linux/tree/master/Documentation)等等,但是如上文所述,我不会在本文描述这些。
|
||||
|
||||
```Makefile
|
||||
vmlinux: scripts/link-vmlinux.sh $(vmlinux-deps) FORCE
|
||||
...
|
||||
...
|
||||
+$(call if_changed,link-vmlinux)
|
||||
```
|
||||
|
||||
你可以看到,`vmlinux` 的调用脚本[scripts/link-vmlinux.sh](https://github.com/torvalds/linux/blob/master/scripts/link-vmlinux.sh) 的主要目的是把所有的`built-in.o` 链接成一个静态可执行文件、生成[System.map](https://en.wikipedia.org/wiki/System.map)。 最后我们来看看下面的输出:
|
||||
|
||||
```
|
||||
LINK vmlinux
|
||||
LD vmlinux.o
|
||||
MODPOST vmlinux.o
|
||||
GEN .version
|
||||
CHK include/generated/compile.h
|
||||
UPD include/generated/compile.h
|
||||
CC init/version.o
|
||||
LD init/built-in.o
|
||||
KSYM .tmp_kallsyms1.o
|
||||
KSYM .tmp_kallsyms2.o
|
||||
LD vmlinux
|
||||
SORTEX vmlinux
|
||||
SYSMAP System.map
|
||||
```
|
||||
|
||||
以及内核源码树根目录下的`vmlinux` 和`System.map`
|
||||
|
||||
```
|
||||
$ ls vmlinux System.map
|
||||
System.map vmlinux
|
||||
```
|
||||
|
||||
这就是全部了,`vmlinux` 构建好了,下一步就是创建[bzImage](https://en.wikipedia.org/wiki/Vmlinux#bzImage).
|
||||
|
||||
制作bzImage
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
`bzImage` 就是压缩了的linux 内核镜像。我们可以在构建了`vmlinux` 之后通过执行`make bzImage` 获得`bzImage`。同时我们可以仅仅执行`make` 而不带任何参数也可以生成`bzImage` ,因为它是在[arch/x86/kernel/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/Makefile) 里预定义的、默认生成的镜像:
|
||||
|
||||
```Makefile
|
||||
all: bzImage
|
||||
```
|
||||
|
||||
让我们看看这个目标,他能帮助我们理解这个镜像是怎么构建的。我已经说过了`bzImage` 师被定义在[arch/x86/kernel/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/Makefile),定义如下:
|
||||
|
||||
```Makefile
|
||||
bzImage: vmlinux
|
||||
$(Q)$(MAKE) $(build)=$(boot) $(KBUILD_IMAGE)
|
||||
$(Q)mkdir -p $(objtree)/arch/$(UTS_MACHINE)/boot
|
||||
$(Q)ln -fsn ../../x86/boot/bzImage $(objtree)/arch/$(UTS_MACHINE)/boot/$@
|
||||
```
|
||||
|
||||
在这里我们可以看到第一次为boot 目录执行`make`,在我们的例子里是这样的:
|
||||
|
||||
```Makefile
|
||||
boot := arch/x86/boot
|
||||
```
|
||||
|
||||
现在的主要目标是编译目录`arch/x86/boot` 和`arch/x86/boot/compressed` 的代码,构建`setup.bin` 和`vmlinux.bin`,然后用这两个文件生成`bzImage`。第一个目标是定义在[arch/x86/boot/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/boot/Makefile) 的`$(obj)/setup.elf`:
|
||||
|
||||
```Makefile
|
||||
$(obj)/setup.elf: $(src)/setup.ld $(SETUP_OBJS) FORCE
|
||||
$(call if_changed,ld)
|
||||
```
|
||||
|
||||
我们已经在目录`arch/x86/boot`有了链接脚本`setup.ld`,并且将变量`SETUP_OBJS` 扩展到`boot` 目录下的全部源代码。我们可以看看第一个输出:
|
||||
|
||||
```Makefile
|
||||
AS arch/x86/boot/bioscall.o
|
||||
CC arch/x86/boot/cmdline.o
|
||||
AS arch/x86/boot/copy.o
|
||||
HOSTCC arch/x86/boot/mkcpustr
|
||||
CPUSTR arch/x86/boot/cpustr.h
|
||||
CC arch/x86/boot/cpu.o
|
||||
CC arch/x86/boot/cpuflags.o
|
||||
CC arch/x86/boot/cpucheck.o
|
||||
CC arch/x86/boot/early_serial_console.o
|
||||
CC arch/x86/boot/edd.o
|
||||
```
|
||||
|
||||
下一个源码文件是[arch/x86/boot/header.S](https://github.com/torvalds/linux/blob/master/arch/x86/boot/header.S),但是我们不能现在就编译它,因为这个目标依赖于下面两个头文件:
|
||||
|
||||
```Makefile
|
||||
$(obj)/header.o: $(obj)/voffset.h $(obj)/zoffset.h
|
||||
```
|
||||
|
||||
第一个头文件`voffset.h` 是使用`sed` 脚本生成的,包含用`nm` 工具从`vmlinux` 获取的两个地址:
|
||||
|
||||
```C
|
||||
#define VO__end 0xffffffff82ab0000
|
||||
#define VO__text 0xffffffff81000000
|
||||
```
|
||||
|
||||
这两个地址是内核的起始和结束地址。第二个头文件`zoffset.h` 在[arch/x86/boot/compressed/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/boot/compressed/Makefile) 可以看出是依赖于目标`vmlinux`的:
|
||||
|
||||
```Makefile
|
||||
$(obj)/zoffset.h: $(obj)/compressed/vmlinux FORCE
|
||||
$(call if_changed,zoffset)
|
||||
```
|
||||
|
||||
目标`$(obj)/compressed/vmlinux` 依赖于变量`vmlinux-objs-y` —— 说明需要编译目录[arch/x86/boot/compressed](https://github.com/torvalds/linux/tree/master/arch/x86/boot/compressed) 下的源代码,然后生成`vmlinux.bin`, `vmlinux.bin.bz2`, 和编译工具 - `mkpiggy`。我们可以在下面的输出看出来:
|
||||
|
||||
```Makefile
|
||||
LDS arch/x86/boot/compressed/vmlinux.lds
|
||||
AS arch/x86/boot/compressed/head_64.o
|
||||
CC arch/x86/boot/compressed/misc.o
|
||||
CC arch/x86/boot/compressed/string.o
|
||||
CC arch/x86/boot/compressed/cmdline.o
|
||||
OBJCOPY arch/x86/boot/compressed/vmlinux.bin
|
||||
BZIP2 arch/x86/boot/compressed/vmlinux.bin.bz2
|
||||
HOSTCC arch/x86/boot/compressed/mkpiggy
|
||||
```
|
||||
|
||||
`vmlinux.bin` 是去掉了调试信息和注释的`vmlinux` 二进制文件,加上了占用了`u32` (注:即4-Byte)的长度信息的`vmlinux.bin.all` 压缩后就是`vmlinux.bin.bz2`。其中`vmlinux.bin.all` 包含了`vmlinux.bin` 和`vmlinux.relocs`(注:vmlinux 的重定位信息),其中`vmlinux.relocs` 是`vmlinux` 经过程序`relocs` 处理之后的`vmlinux` 镜像(见上文所述)。我们现在已经获取到了这些文件,汇编文件`piggy.S` 将会被`mkpiggy` 生成、然后编译:
|
||||
|
||||
```Makefile
|
||||
MKPIGGY arch/x86/boot/compressed/piggy.S
|
||||
AS arch/x86/boot/compressed/piggy.o
|
||||
```
|
||||
|
||||
这个汇编文件会包含经过计算得来的、压缩内核的偏移信息。处理完这个汇编文件,我们就可以看到`zoffset` 生成了:
|
||||
|
||||
```Makefile
|
||||
ZOFFSET arch/x86/boot/zoffset.h
|
||||
```
|
||||
|
||||
现在`zoffset.h` 和`voffset.h` 已经生成了,[arch/x86/boot](https://github.com/torvalds/linux/tree/master/arch/x86/boot/) 里的源文件可以继续编译:
|
||||
|
||||
```Makefile
|
||||
AS arch/x86/boot/header.o
|
||||
CC arch/x86/boot/main.o
|
||||
CC arch/x86/boot/mca.o
|
||||
CC arch/x86/boot/memory.o
|
||||
CC arch/x86/boot/pm.o
|
||||
AS arch/x86/boot/pmjump.o
|
||||
CC arch/x86/boot/printf.o
|
||||
CC arch/x86/boot/regs.o
|
||||
CC arch/x86/boot/string.o
|
||||
CC arch/x86/boot/tty.o
|
||||
CC arch/x86/boot/video.o
|
||||
CC arch/x86/boot/video-mode.o
|
||||
CC arch/x86/boot/video-vga.o
|
||||
CC arch/x86/boot/video-vesa.o
|
||||
CC arch/x86/boot/video-bios.o
|
||||
```
|
||||
|
||||
所有的源代码会被编译,他们最终会被链接到`setup.elf` :
|
||||
|
||||
```Makefile
|
||||
LD arch/x86/boot/setup.elf
|
||||
```
|
||||
|
||||
|
||||
或者:
|
||||
|
||||
```
|
||||
ld -m elf_x86_64 -T arch/x86/boot/setup.ld arch/x86/boot/a20.o arch/x86/boot/bioscall.o arch/x86/boot/cmdline.o arch/x86/boot/copy.o arch/x86/boot/cpu.o arch/x86/boot/cpuflags.o arch/x86/boot/cpucheck.o arch/x86/boot/early_serial_console.o arch/x86/boot/edd.o arch/x86/boot/header.o arch/x86/boot/main.o arch/x86/boot/mca.o arch/x86/boot/memory.o arch/x86/boot/pm.o arch/x86/boot/pmjump.o arch/x86/boot/printf.o arch/x86/boot/regs.o arch/x86/boot/string.o arch/x86/boot/tty.o arch/x86/boot/video.o arch/x86/boot/video-mode.o arch/x86/boot/version.o arch/x86/boot/video-vga.o arch/x86/boot/video-vesa.o arch/x86/boot/video-bios.o -o arch/x86/boot/setup.elf
|
||||
```
|
||||
|
||||
最后两件事是创建包含目录`arch/x86/boot/*` 下的编译过的代码的`setup.bin`:
|
||||
|
||||
```
|
||||
objcopy -O binary arch/x86/boot/setup.elf arch/x86/boot/setup.bin
|
||||
```
|
||||
|
||||
以及从`vmlinux` 生成`vmlinux.bin` :
|
||||
|
||||
```
|
||||
objcopy -O binary -R .note -R .comment -S arch/x86/boot/compressed/vmlinux arch/x86/boot/vmlinux.bin
|
||||
```
|
||||
|
||||
最后,我们编译主机程序[arch/x86/boot/tools/build.c](https://github.com/torvalds/linux/blob/master/arch/x86/boot/tools/build.c),它将会用来把`setup.bin` 和`vmlinux.bin` 打包成`bzImage`:
|
||||
|
||||
```
|
||||
arch/x86/boot/tools/build arch/x86/boot/setup.bin arch/x86/boot/vmlinux.bin arch/x86/boot/zoffset.h arch/x86/boot/bzImage
|
||||
```
|
||||
|
||||
实际上`bzImage` 就是把`setup.bin` 和`vmlinux.bin` 连接到一起。最终我们会看到输出结果,就和那些用源码编译过内核的同行的结果一样:
|
||||
|
||||
```
|
||||
Setup is 16268 bytes (padded to 16384 bytes).
|
||||
System is 4704 kB
|
||||
CRC 94a88f9a
|
||||
Kernel: arch/x86/boot/bzImage is ready (#5)
|
||||
```
|
||||
|
||||
|
||||
全部结束。
|
||||
|
||||
结论
|
||||
================================================================================
|
||||
|
||||
这就是本文的最后一节。本文我们了解了编译内核的全部步骤:从执行`make` 命令开始,到最后生成`bzImage`。我知道,linux 内核的makefiles 和构建linux 的过程第一眼看起来可能比较迷惑,但是这并不是很难。希望本文可以帮助你理解构建linux 内核的整个流程。
|
||||
|
||||
|
||||
链接
|
||||
================================================================================
|
||||
|
||||
* [GNU make util](https://en.wikipedia.org/wiki/Make_%28software%29)
|
||||
* [Linux kernel top Makefile](https://github.com/torvalds/linux/blob/master/Makefile)
|
||||
* [cross-compilation](https://en.wikipedia.org/wiki/Cross_compiler)
|
||||
* [Ctags](https://en.wikipedia.org/wiki/Ctags)
|
||||
* [sparse](https://en.wikipedia.org/wiki/Sparse)
|
||||
* [bzImage](https://en.wikipedia.org/wiki/Vmlinux#bzImage)
|
||||
* [uname](https://en.wikipedia.org/wiki/Uname)
|
||||
* [shell](https://en.wikipedia.org/wiki/Shell_%28computing%29)
|
||||
* [Kbuild](https://github.com/torvalds/linux/blob/master/Documentation/kbuild/kbuild.txt)
|
||||
* [binutils](http://www.gnu.org/software/binutils/)
|
||||
* [gcc](https://gcc.gnu.org/)
|
||||
* [Documentation](https://github.com/torvalds/linux/blob/master/Documentation/kbuild/makefiles.txt)
|
||||
* [System.map](https://en.wikipedia.org/wiki/System.map)
|
||||
* [Relocation](https://en.wikipedia.org/wiki/Relocation_%28computing%29)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://github.com/0xAX/linux-insides/blob/master/Misc/how_kernel_compiled.md
|
||||
|
||||
译者:[译者ID](https://github.com/oska874)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,53 @@
|
||||
在 Ubuntu 和 Elementary OS 上使用 NaSC 进行简单数学运算
|
||||
================================================================================
|
||||

|
||||
|
||||
[NaSC][1],Not a Soulver Clone 的缩写,是为 elementary 操作系统开发的第三方应用程序。正如名字暗示的那样,NaSC 的灵感来源于 [Soulver][2],后者是像普通人一样进行数学计算的 OS X 应用。
|
||||
|
||||
Elementary OS 它自己本身借鉴了 OS X,也就不奇怪它的很多第三方应用灵感都来自于 OS X 应用。
|
||||
|
||||
回到 NaSC,“像普通人一样进行数学计算”到底是什么意思呢?事实上,它意味着正如你想的那样去书写。按照该应用程序的介绍:
|
||||
|
||||
> “它能使你像平常那样进行计算。它允许你输入任何你想输入的,智能识别其中的数学部分并在右边面板打印出结果。然后你可以在后面的等式中使用这些结果,如果结果发生了改变,等式中使用的也会同样变化。”
|
||||
|
||||
还不相信?让我们来看一个截图。
|
||||
|
||||

|
||||
|
||||
现在,你明白什么是 “像普通人一样做数学” 了吗?坦白地说,我并不是这类应用程序的粉丝,但对你们中的某些人可能会有用。让我们来看看怎么在 Elementary OS、Ubuntu 和 Linux Mint 上安装 NaSC。
|
||||
|
||||
### 在 Ubuntu、Elementary OS 和 Mint 上安装 NaSC ###
|
||||
|
||||
安装 NaSC 有一个可用的 PPA。PPA 中说 ‘每日’,意味着所有构建(包括不稳定),但作为我的快速测试,并没什么影响。
|
||||
|
||||
打卡一个终端并运行下面的命令:
|
||||
|
||||
sudo apt-add-repository ppa:nasc-team/daily
|
||||
sudo apt-get update
|
||||
sudo apt-get install nasc
|
||||
|
||||
这是 Ubuntu 15.04 中使用 NaSC 的一个截图:
|
||||
|
||||

|
||||
|
||||
如果你想卸载它,可以使用下面的命令:
|
||||
|
||||
sudo apt-get remove nasc
|
||||
sudo apt-add-repository --remove ppa:nasc-team/daily
|
||||
|
||||
如果你试用了这个软件,要分享你的经验哦。除此之外,你也可以在第三方 Elementary OS 应用中体验[Vocal podcast app for Linux][3]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/math-ubuntu-nasc/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[ictlyh](http://www.mutouxiaogui.cn/blog/)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://parnold-x.github.io/nasc/
|
||||
[2]:http://www.acqualia.com/soulver/
|
||||
[3]:http://itsfoss.com/podcast-app-vocal-linux/
|
||||
@ -0,0 +1,62 @@
|
||||
在 Ubuntu 和 Elementary 上使用 NaSC 做简单数学运算
|
||||
================================================================================
|
||||

|
||||
|
||||
NaSC(Not a Soulver Clone,并非 Soulver 的克隆品)是为 Elementary 操作系统进行数学计算而设计的一款开源软件。类似于 Mac 上的 [Soulver][1]。
|
||||
|
||||
> 它能使你像平常那样进行计算。它允许你输入任何你想输入的,智能识别其中的数学部分并在右边面板打印出结果。然后你可以在后面的等式中使用这些结果,如果结果发生了改变,等式中使用的也会同样变化。
|
||||
|
||||
用 NaSC,你可以:
|
||||
|
||||
- 自己定义复杂的计算
|
||||
- 改变单位和值(英尺、米、厘米,美元、欧元等)
|
||||
- 了解行星的表面积
|
||||
- 解二次多项式
|
||||
- 以及其它
|
||||
|
||||

|
||||
|
||||
第一次启动时,NaSC 提供了一个关于现有功能的教程。以后你还可以通过点击标题栏上的帮助图标再次查看。
|
||||
|
||||

|
||||
|
||||
另外,这个软件还允许你保存文件以便以后继续工作。还可以在一定时间内通过粘贴板共用。
|
||||
|
||||
### 在 Ubuntu 或 Elementary OS Freya 上安装 NaSC: ###
|
||||
|
||||
对于 Ubuntu 15.04,Ubuntu 15.10,Elementary OS Freya,从 Dash 或应用启动器中打开终端,逐条运行下面的命令:
|
||||
|
||||
1. 通过命令添加 [NaSC PPA][2]:
|
||||
|
||||
sudo apt-add-repository ppa:nasc-team/daily
|
||||
|
||||

|
||||
|
||||
2. 如果安装了 Synaptic 软件包管理器,点击 ‘Reload’ 后搜索并安装 ‘nasc’。
|
||||
|
||||
或者运行下面的命令更新系统缓存并安装软件:
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
sudo apt-get install nasc
|
||||
|
||||
3. **(可选)** 要卸载软件以及 NaSC,运行:
|
||||
|
||||
sudo apt-get remove nasc && sudo add-apt-repository -r ppa:nasc-team/daily
|
||||
|
||||
对于不想添加 PPA 的人,可以直接从[该网页][3]获取 .deb 安装包。、
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ubuntuhandbook.org/index.php/2015/09/make-math-simple-in-ubuntu-elementary-os-via-nasc/
|
||||
|
||||
作者:[Ji m][a]
|
||||
译者:[ictlyh](http://www.mutouxiaogui.cn/blog/)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ubuntuhandbook.org/index.php/about/
|
||||
[1]:http://www.acqualia.com/soulver/
|
||||
[2]:https://launchpad.net/~nasc-team/+archive/ubuntu/daily/
|
||||
[3]:http://ppa.launchpad.net/nasc-team/daily/ubuntu/pool/main/n/nasc/
|
||||
@ -0,0 +1,66 @@
|
||||
在 Ubuntu 里,如何下载,安装和配置 Plank Dock
|
||||
=============================================================================
|
||||
一个众所周知的事实就是,Linux 是一个用户可以高度自定义的系统,有很多选项可以选择 —— 作为操作系统,有各种各样的发行版,而对于单个发行版来说,又有很多桌面环境可以选择。与其他操作系统的用户一样,Linux 用户也有不同的口味和喜好,特别是对于桌面来说。
|
||||
|
||||
一些用户并非很在意他们的桌面,而其他一些则非常关心,要确保他们的桌面看起来很酷,很有吸引力,对于这种情况,有很多不错的应用可以派上用场。有一个应用可以给你的桌面带来活力 —— 特别是当你常用一个全局菜单的时候 —— 这就是 dock 。Linux 上有很多 dock 应用可选用;如果你希望是一个最简洁的,那么就选择 [Plank][1] 吧,文章接下来就要讨论这个应用。
|
||||
|
||||
**注意**:接下提到的例子和命令都已在 Ubuntu(版本 14.10)和 Plank(版本 0.9.1.1383)上测试通过。
|
||||
|
||||
### Plank ###
|
||||
|
||||
官方的文档描述 Plank 是“这个星球上最简洁的 dock”。该项目的目的就是提供一个 dock 仅需要的功能,尽管这是很基础的一个库,却可以被扩展,创造其他的含更多高级功能的 dock 程序。
|
||||
|
||||
这里值得一提的就是,在 elementary OS 里,Plank 是预装的。并且 Plank 是 Docky 的基础,Docky 也是一个非常流行的 dock 应用,在功能上与 Mac OS X 的 Dock 非常相似。
|
||||
|
||||
### 下载和安装 ###
|
||||
|
||||
通过在终端里执行下面的命令,可以下载并安装 Plank:
|
||||
|
||||
sudo add-apt-repository ppa:docky-core/stable
|
||||
sudo apt-get update
|
||||
sudo apt-get install plank
|
||||
|
||||
安装成功后,你就可以在 Unity Dash(见下面图片)里通过输入 Plank 来打开该应用,或者从应用菜单里面打开,如果你没有使用 Unity 环境的话。
|
||||
|
||||

|
||||
|
||||
### 特性 ###
|
||||
|
||||
当 Plank 启用后,你会看见它停靠在你桌面的底部中间位置。
|
||||
|
||||

|
||||
|
||||
正如上面图片显示的那样,dock 包含许多带橙色的应用图标,这表明这些应用正处于运行状态。无需说,你可以点击一个图标来打开那个应用。同时,右击一个应用图标会给出更多的选项,你可能会感兴趣。举个例子,该下面的屏幕快照:
|
||||
|
||||

|
||||
|
||||
为了获得配置的选项,你不得不右击一下 Plank 的图标(左数第一个),然后点击 Preferences 选项。这就会产生接下来的窗口。
|
||||
|
||||

|
||||
|
||||
如你所见,Preferences 窗口包含两个标签:Apperance 和 Behavior,前者是默认选中的。Appearance 标签栏包含 Plank 主题相关的设置,dock 的位置,对齐,还有图标相关的,而 Behavior 标签栏包含 dock 本身相关的设定。
|
||||
|
||||

|
||||
|
||||
举个例子,我在 Appearance 里改变 dock 的位置为右侧,在 Behavior 里锁定图标(这表示右击选项中不再有 “Keep in Dock”)。
|
||||
|
||||

|
||||
|
||||
如你所见的上面屏幕快照一样,改变生效了。类似地,根据你个人需求,改变任何可用的设定。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
如我开始所说的那样,使用 dock 不是强制的。尽管如此,使用一个会让事情变得方便,特别是你习惯了 Mac,而最近由于一些原因切换到了 Linux 系统。就其本身而言,Plank 不仅提供简洁性,还有可信任和稳定性 —— 该项目一直被很好地维护着。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/download-install-configure-plank-dock-ubuntu/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[wi-cuckoo](https://github.com/wi-cuckoo)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/himanshu/
|
||||
[1]:https://launchpad.net/plank
|
||||
@ -1,11 +1,11 @@
|
||||
translating by tnuoccalanosrep
|
||||
List Of 10 Funny Linux Commands
|
||||
10条真心有趣的Linux命令
|
||||
================================================================================
|
||||
**Working from the Terminal is really fun. Today, we’ll list really funny Linux commands which will bring smile on your face.**
|
||||
|
||||
**在终端工作是一件很有趣的事情。今天,我们将会列举一些有趣得为你带来欢笑的Linux命令。**
|
||||
|
||||
### 1. rev ###
|
||||
|
||||
Create a file, type some words in this file, rev command will dump all words written by you in reverse.
|
||||
创建一个文件,在文件里面输入几个单词,rev命令会将你写的东西反转输出到控制台。
|
||||
|
||||
# rev <file name>
|
||||
|
||||
@ -15,13 +15,13 @@ Create a file, type some words in this file, rev command will dump all words wri
|
||||
|
||||
### 2. fortune ###
|
||||
|
||||
This command is not install by default, install with apt-get and fortune will display some random sentence.
|
||||
这个命令没有被默认安装,用apt-get命令安装它,fortune命令会随机显示一些句子
|
||||
|
||||
crank@crank-System:~$ sudo apt-get install fortune
|
||||
|
||||

|
||||
|
||||
Use **-s** option with fortune, it will limit the out to one sentence.
|
||||
利用fortune命令的**_s** 选项,他会限制一个句子的输出长度。
|
||||
|
||||
# fortune -s
|
||||
|
||||
@ -31,15 +31,14 @@ Use **-s** option with fortune, it will limit the out to one sentence.
|
||||
|
||||
#yes <string>
|
||||
|
||||
This command will keep displaying the string for infinite time until the process is killed by the user.
|
||||
这个命令会不停打印字符串,直到用户把这进程给结束掉。
|
||||
|
||||
# yes unixmen
|
||||
|
||||

|
||||
|
||||
### 4. figlet ###
|
||||
|
||||
This command can be installed with apt-get, comes with some ascii fonts which are located in **/usr/share/figlet**.
|
||||
这个命令可以用apt-get安装,安装之后,在**/usr/share/figlet**可以看到一些ascii字体文件。
|
||||
|
||||
cd /usr/share/figlet
|
||||
|
||||
@ -57,34 +56,33 @@ e.g.
|
||||
|
||||

|
||||
|
||||
You can try another options also.
|
||||
当然,你也可以尝试使用其他的选项。
|
||||
|
||||
### 5. asciiquarium ###
|
||||
|
||||
This command will transform your terminal in to a Sea Aquarium.
|
||||
Download term animator
|
||||
这个命令会将你的终端变成一个海洋馆。
|
||||
下载term animator
|
||||
|
||||
# wget http://search.cpan.org/CPAN/authors/id/K/KB/KBAUCOM/Term-Animation-2.4.tar.gz
|
||||
|
||||
Install and Configure above package.
|
||||
安装并且配置这个包
|
||||
|
||||
# tar -zxvf Term-Animation-2.4.tar.gz
|
||||
# cd Term-Animation-2.4/
|
||||
# perl Makefile.PL && make && make test
|
||||
# sudo make install
|
||||
|
||||
Install following package:
|
||||
接着安装下面这个包:
|
||||
|
||||
# apt-get install libcurses-perl
|
||||
|
||||
Download and install asciiquarium
|
||||
下载并且安装asciiquarium
|
||||
|
||||
# wget http://www.robobunny.com/projects/asciiquarium/asciiquarium.tar.gz
|
||||
# tar -zxvf asciiquarium.tar.gz
|
||||
# cd asciiquarium_1.0/
|
||||
# cp asciiquarium /usr/local/bin/
|
||||
|
||||
Run,
|
||||
执行如下命令
|
||||
|
||||
# /usr/local/bin/asciiquarium
|
||||
|
||||
@ -95,13 +93,13 @@ Run,
|
||||
# apt-get install bb
|
||||
# bb
|
||||
|
||||
See what comes out:
|
||||
看看会输出什么?
|
||||
|
||||

|
||||
|
||||
### 7. sl ###
|
||||
|
||||
Sometimes you type **sl** instead of **ls** by mistake,actually **sl** is a command and a locomotive engine will start moving if you type sl.
|
||||
有的时候你可能把 **ls** 误打成了 **sl**,其实 **sl** 也是一个命令,如果你打 sl的话,你会看到一个移动的火车头
|
||||
|
||||
# apt-get install sl
|
||||
|
||||
@ -113,7 +111,7 @@ Sometimes you type **sl** instead of **ls** by mistake,actually **sl** is a com
|
||||
|
||||
### 8. cowsay ###
|
||||
|
||||
Very common command, is will display in ascii form whatever you wants to say.
|
||||
一个很常见的命令,它会用ascii显示你想说的话。
|
||||
|
||||
apt-get install cowsay
|
||||
|
||||
@ -123,7 +121,7 @@ Very common command, is will display in ascii form whatever you wants to say.
|
||||
|
||||

|
||||
|
||||
Or, you can use another character instead of com, such characters are stored in **/usr/share/cowsay/cows**
|
||||
或者,你可以用其他的角色来取代默认角色来说这句话,这些角色都存储在**/usr/share/cowsay/cows**目录下
|
||||
|
||||
# cd /usr/share/cowsay/cows
|
||||
|
||||
@ -133,7 +131,7 @@ Or, you can use another character instead of com, such characters are stored in
|
||||
|
||||

|
||||
|
||||
or
|
||||
或者
|
||||
|
||||
# cowsay -f bud-frogs.cow Rajneesh
|
||||
|
||||
@ -141,7 +139,7 @@ or
|
||||
|
||||
### 9. toilet ###
|
||||
|
||||
Yes, this is a command, it dumps ascii strings in colored form to the terminal.
|
||||
你没看错,这是个命令来的,他会将字符串以彩色的ascii字符串形式输出到终端
|
||||
|
||||
# apt-get install toilet
|
||||
|
||||
@ -161,7 +159,7 @@ Yes, this is a command, it dumps ascii strings in colored form to the terminal.
|
||||
|
||||
### 10. aafire ###
|
||||
|
||||
Put you terminal on fire with aafire.
|
||||
aafire能让你的终端燃起来。
|
||||
|
||||
# apt-get install libaa-bin
|
||||
|
||||
@ -171,14 +169,14 @@ Put you terminal on fire with aafire.
|
||||
|
||||

|
||||
|
||||
That it, Have fun with Linux Terminal!!
|
||||
就这么多,祝你们在Linux终端玩得开心哈!!!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/list-10-funny-linux-commands/
|
||||
|
||||
作者:[Rajneesh Upadhyay][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[tnuoccalanosrep](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,211 @@
|
||||
安装 Samba 并配置 Firewalld 和 SELinux 使得能在 Linux 和 Windows 之间共享文件 - 第六部分
|
||||
================================================================================
|
||||
由于计算机很少作为一个独立的系统工作,作为一个系统管理员或工程师,就应该知道如何在有多种类型的服务器之间搭设和维护网络。
|
||||
|
||||
在本篇以及该系列后面的文章中,我们会介绍用 Windows/Linux 配置 Samba 和 NFS 服务器以及 Linux 客户端。
|
||||
|
||||

|
||||
|
||||
RHCE 系列第六部分 - 设置 Samba 文件共享
|
||||
|
||||
如果有人叫你设置文件服务器用于协作或者配置很可能有多种不同类型操作系统和设备的企业环境,这篇文章就能派上用场。
|
||||
|
||||
由于你可以在网上找到很多关于 Samba 和 NFS 背景和技术方面的介绍,在这篇文章以及后续文章中我们就省略了这些部分直接进入到我们的主题。
|
||||
|
||||
### 步骤一: 安装 Samba 服务器 ###
|
||||
|
||||
我们当前的测试环境包括两台 RHEL 7 和一台 Windows 8:
|
||||
|
||||
1. Samba / NFS 服务器 [box1 (RHEL 7): 192.168.0.18],
|
||||
2. Samba 客户端 #1 [box2 (RHEL 7): 192.168.0.20]
|
||||
3. Samba 客户端 #2 [Windows 8 machine: 192.168.0.106]
|
||||
|
||||

|
||||
|
||||
测试安装 Samba
|
||||
|
||||
在 box1 中安装以下软件包:
|
||||
|
||||
# yum update && yum install samba samba-client samba-common
|
||||
|
||||
在 box2:
|
||||
|
||||
# yum update && yum install samba samba-client samba-common cifs-utils
|
||||
|
||||
安装完成后,就可以配置我们的共享了。
|
||||
|
||||
### 步骤二: 设置通过 Samba 进行文件共享 ###
|
||||
|
||||
Samba 这么重要的原因之一是它为 SMB/CIFS 客户端(译者注:SMB 是微软和英特尔制定的一种通信协议,CIFS 是其中一个版本,更详细的介绍可以参考[Wiki][6])提供了文件和打印设备,这使得客户端看起来服务器就是一个 Windows 系统(我必须承认写这篇文章的时候我有一点激动,因为这是我多年前作为一个新手 Linux 系统管理员的第一次设置)。
|
||||
|
||||
**添加系统用户并设置权限和属性**
|
||||
|
||||
为了允许组协作,我们会在 box1 中用 [useradd 命令][1]创建一个有两个用户(user1 和 user2)的组 finance 和目录 /finance。
|
||||
|
||||
我们同时会把这个目录的组所有者更改为 finance 并把权限设置为 0777(所有者和组属主可读可写可执行):
|
||||
|
||||
# groupadd finance
|
||||
# useradd user1
|
||||
# useradd user2
|
||||
# usermod -a -G finance user1
|
||||
# usermod -a -G finance user2
|
||||
# mkdir /finance
|
||||
# chmod 0770 /finance
|
||||
# chgrp finance /finance
|
||||
|
||||
### 步骤三: 配置 SELinux 和 Firewalld ###
|
||||
|
||||
在配置 /finance 作为 Samba 共享目录之前,我们需要像下面那样停用 SELinux 或设置恰当的布尔值和安全选项(否则,SELinux 会阻止客户端访问共享目录):
|
||||
|
||||
# setsebool -P samba_export_all_ro=1 samba_export_all_rw=1
|
||||
# getsebool –a | grep samba_export
|
||||
# semanage fcontext –at samba_share_t "/finance(/.*)?"
|
||||
# restorecon /finance
|
||||
|
||||
另外我们必须确保 [firewalld][2] 允许 Samba 流量通过。
|
||||
|
||||
# firewall-cmd --permanent --add-service=samba
|
||||
# firewall-cmd --reload
|
||||
|
||||
### 步骤四: 配置 Samba 共享目录 ###
|
||||
|
||||
现在我们来看看配置文件 /etc/samba/smb.conf 并添加用于共享的章节(section):我们希望组 finance 的成员可以浏览 /finance 的内容,在里面保存/创建文件或者子目录(默认权限为 0777,组所有者为 finance):
|
||||
|
||||
**smb.conf**
|
||||
|
||||
----------
|
||||
|
||||
[finance]
|
||||
comment=Directory for collaboration of the company's finance team
|
||||
browsable=yes
|
||||
path=/finance
|
||||
public=no
|
||||
valid users=@finance
|
||||
write list=@finance
|
||||
writeable=yes
|
||||
create mask=0770
|
||||
Force create mode=0770
|
||||
force group=finance
|
||||
|
||||
保存文件然后用 testparm 工具进行测试。如果这里有任何错误,命令的输出或提示你需要如何修复。否则,会显示你 Samba 服务器配置的回顾:
|
||||
|
||||
|
||||
|
||||
测试 Samba 配置
|
||||
|
||||
如果你要添加另一个公开的共享目录(意味着没有任何验证),在 /etc/samba/smb.conf 中创建另一章节,在共享目录名称下面复制上面的章节,只需要把 public=no 更改为 public=yes 并去掉有效用户和写列表命令。
|
||||
|
||||
### 步骤五: 添加 Samba 用户 ###
|
||||
|
||||
下一步,你需要添加 user1 和 user2 作为 Samba 的用户。要做到这点,你需要用 smbpasswd 命令,它会和 Samba 的数据库进行交互。会提示你输入一个命令用于你之后和共享目录连接:
|
||||
|
||||
# smbpasswd -a user1
|
||||
# smbpasswd -a user2
|
||||
|
||||
最后,重启 Samda,启用系统启动时自动启动服务,并确保共享目录对网络客户端可用:
|
||||
|
||||
# systemctl start smb
|
||||
# systemctl enable smb
|
||||
# smbclient -L localhost –U user1
|
||||
# smbclient -L localhost –U user2
|
||||
|
||||
|
||||

|
||||
|
||||
验证 Samba 共享
|
||||
|
||||
到这里,已经正确安装和配置了 Samba 文件服务器。现在让我们在 RHEL 7 和 Windows 8 客户端中测试该配置。
|
||||
|
||||
### 步骤六: 在 Linux 中挂载 Samba 共享 ###
|
||||
|
||||
首先,确保客户端可以访问 Samba 共享:
|
||||
|
||||
# smbclient –L 192.168.0.18 -U user2
|
||||
|
||||
|
||||

|
||||
|
||||
在 Linux 上挂载 Samba 共享
|
||||
|
||||
(为 user1 重复上面的命令)
|
||||
|
||||
正如任何其它存储介质,当你需要的时候你可以挂载(之后卸载)该网络共享:
|
||||
|
||||
# mount //192.168.0.18/finance /media/samba -o username=user1
|
||||
|
||||

|
||||
|
||||
挂载 Samba 网络共享
|
||||
|
||||
(其中 /media/samba 是一个已有的目录)
|
||||
|
||||
或者在 /etc/fstab 文件中添加下面的条目自动挂载:
|
||||
|
||||
**fstab**
|
||||
|
||||
----------
|
||||
|
||||
//192.168.0.18/finance /media/samba cifs credentials=/media/samba/.smbcredentials,defaults 0 0
|
||||
|
||||
其中隐藏文件 /media/samba/.smbcredentials(它的权限被设置为 600 和 root:root)有两行,指示允许使用共享的账户的用户名和密码:
|
||||
|
||||
**.smbcredentials**
|
||||
|
||||
----------
|
||||
|
||||
username=user1
|
||||
password=PasswordForUser1
|
||||
|
||||
最后,让我们在 /finance 中创建一个文件并检查权限和属性:
|
||||
|
||||
# touch /media/samba/FileCreatedInRHELClient.txt
|
||||
|
||||

|
||||
|
||||
在 Samba 共享中创建文件
|
||||
|
||||
正如你看到的,用权限 0770 和属主 user1:finance 创建了文件。
|
||||
|
||||
### 步骤七: 在 Windows 上挂载 Samba 共享 ###
|
||||
|
||||
要在 Windows 上挂载 Samba 共享,进入 ‘我的计算机’ 并选择 ‘计算机’,‘网络驱动映射’。下一步,为要映射的驱动分配一个字母并用不同的认证检查连接(下面的截图使用我的母语西班牙语):
|
||||
|
||||

|
||||
|
||||
在 Windows 中挂载 Samba 共享
|
||||
|
||||
最后,让我们新建一个文件并检查权限和属性:
|
||||
|
||||

|
||||
|
||||
在 Windows Samba 共享中新建文件
|
||||
|
||||
# ls -l /finance
|
||||
|
||||
这次文件属于 user2,因为这是我们用于从 Windows 客户端中连接的账户。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
在这篇文章中我们不仅介绍了如何使用不同操作系统设置 Samba 服务器和两个客户端,也介绍了[如何配置 Firewalld][3] 和 [服务器中的 SELinux][4] 以获取所需的组协作功能。
|
||||
|
||||
最后,同样重要的是,我推荐阅读网上的 [smb.conf man 手册][5] 查看其它可能针对你的情况比本文中介绍的场景更加合适的配置命令。
|
||||
|
||||
正如往常,欢迎在下面的评论框中留下你的评论或建议。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/setup-samba-file-sharing-for-linux-windows-clients/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[ictlyh](http://www.mutouxiaogui.cn/blog/)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/add-users-in-linux/
|
||||
[2]:http://www.tecmint.com/firewalld-vs-iptables-and-control-network-traffic-in-firewall/
|
||||
[3]:http://www.tecmint.com/configure-firewalld-in-centos-7/
|
||||
[4]:http://www.tecmint.com/selinux-essentials-and-control-filesystem-access/
|
||||
[5]:https://www.samba.org/samba/docs/man/manpages-3/smb.conf.5.html
|
||||
[6]:https://en.wikipedia.org/wiki/Server_Message_Block
|
||||
@ -0,0 +1,190 @@
|
||||
第七部分 - 在 Linux 客户端配置基于 Kerberos 身份验证的 NFS 服务器
|
||||
================================================================================
|
||||
在本系列的前一篇文章,我们回顾了[如何在可能包括多种类型操作系统的网络上配置 Samba 共享][1]。现在,如果你需要为一组类-Unix 客户端配置文件共享,很自然的你会想到网络文件系统,或简称 NFS。
|
||||
|
||||
|
||||

|
||||
|
||||
RHCE 系列:第七部分 - 设置使用 Kerberos 进行身份验证的 NFS 服务器
|
||||
|
||||
在这篇文章中我们会介绍配置基于 Kerberos 身份验证的 NFS 共享的整个流程。假设你已经配置好了一个 NFS 服务器和一个客户端。如果还没有,可以参考 [安装和配置 NFS 服务器][2] - 它列出了需要安装的依赖软件包并解释了在进行下一步之前如何在服务器上进行初始化配置。
|
||||
|
||||
另外,你可能还需要配置 [SELinux][3] 和 [firewalld][4] 以允许通过 NFS 进行文件共享。
|
||||
|
||||
下面的例子假设你的 NFS 共享目录在 box2 的 /nfs:
|
||||
|
||||
# semanage fcontext -a -t public_content_rw_t "/nfs(/.*)?"
|
||||
# restorecon -R /nfs
|
||||
# setsebool -P nfs_export_all_rw on
|
||||
# setsebool -P nfs_export_all_ro on
|
||||
|
||||
(其中 -P 标记指示重启持久有效)。
|
||||
|
||||
最后,别忘了:
|
||||
|
||||
#### 创建 NFS 组并配置 NFS 共享目录 ####
|
||||
|
||||
1. 新建一个名为 nfs 的组并给它添加用户 nfsnobody,然后更改 /nfs 目录的权限为 0770,组属主为 nfs。于是,nfsnobody(对应请求用户)在共享目录有写的权限,你就不需要在 /etc/exports 文件中使用 no_root_squash(译者注:设为 root_squash 意味着在访问 NFS 服务器上的文件时,客户机上的 root 用户不会被当作 root 用户来对待)。
|
||||
|
||||
# groupadd nfs
|
||||
# usermod -a -G nfs nfsnobody
|
||||
# chmod 0770 /nfs
|
||||
# chgrp nfs /nfs
|
||||
|
||||
2. 像下面那样更改 export 文件(/etc/exports)只允许从 box1 使用 Kerberos 安全验证的访问(sec=krb5)。
|
||||
|
||||
**注意**:anongid 的值设置为之前新建的组 nfs 的 GID:
|
||||
|
||||
**exports – 添加 NFS 共享**
|
||||
|
||||
----------
|
||||
|
||||
/nfs box1(rw,sec=krb5,anongid=1004)
|
||||
|
||||
3. 再次 exprot(-r)所有(-a)NFS 共享。为输出添加详情(-v)是个好主意,因为它提供了发生错误时解决问题的有用信息:
|
||||
|
||||
# exportfs -arv
|
||||
|
||||
4. 重启并启用 NFS 服务器以及相关服务。注意你不需要启动 nfs-lock 和 nfs-idmapd,因为系统启动时其它服务会自动启动它们:
|
||||
|
||||
# systemctl restart rpcbind nfs-server nfs-lock nfs-idmap
|
||||
# systemctl enable rpcbind nfs-server
|
||||
|
||||
#### 测试环境和其它前提要求 ####
|
||||
|
||||
在这篇指南中我们使用下面的测试环境:
|
||||
|
||||
- 客户端机器 [box1: 192.168.0.18]
|
||||
- NFS / Kerberos 服务器 [box2: 192.168.0.20] (也称为密钥分发中心,简称 KDC)。
|
||||
|
||||
**注意**:Kerberos 服务是至关重要的认证方案。
|
||||
|
||||
正如你看到的,为了简便,NFS 服务器和 KDC 在同一台机器上,当然如果你有更多可用机器你也可以把它们安装在不同的机器上。两台机器都在 `mydomain.com` 域。
|
||||
|
||||
最后同样重要的是,Kerberos 要求客户端和服务器中至少有一个域名解析的基本模式和[网络时间协议][5]服务,因为 Kerberos 身份验证的安全一部分基于时间戳。
|
||||
|
||||
为了配置域名解析,我们在客户端和服务器中编辑 /etc/hosts 文件:
|
||||
|
||||
**host 文件 – 为域添加 DNS**
|
||||
|
||||
----------
|
||||
|
||||
192.168.0.18 box1.mydomain.com box1
|
||||
192.168.0.20 box2.mydomain.com box2
|
||||
|
||||
在 RHEL 7 中,chrony 是用于 NTP 同步的默认软件:
|
||||
|
||||
# yum install chrony
|
||||
# systemctl start chronyd
|
||||
# systemctl enable chronyd
|
||||
|
||||
为了确保 chrony 确实在和时间服务器同步你系统的时间,你可能要输入下面的命令两到三次,确保时间偏差尽可能接近 0:
|
||||
|
||||
# chronyc tracking
|
||||
|
||||
|
||||

|
||||
|
||||
用 Chrony 同步服务器时间
|
||||
|
||||
### 安装和配置 Kerberos ###
|
||||
|
||||
要设置 KDC,首先在客户端和服务器安装下面的软件包(客户端不需要 server 软件包):
|
||||
|
||||
# yum update && yum install krb5-server krb5-workstation pam_krb5
|
||||
|
||||
安装完成后,编辑配置文件(/etc/krb5.conf 和 /var/kerberos/krb5kdc/kadm5.acl),像下面那样用 `mydomain.com` 替换所有 example.com。
|
||||
|
||||
下一步,确保 Kerberos 能功过防火墙并启动/启用相关服务。
|
||||
|
||||
**重要**:客户端也必须启动和启用 nfs-secure:
|
||||
|
||||
# firewall-cmd --permanent --add-service=kerberos
|
||||
# systemctl start krb5kdc kadmin nfs-secure
|
||||
# systemctl enable krb5kdc kadmin nfs-secure
|
||||
|
||||
现在创建 Kerberos 数据库(请注意这可能会需要一点时间,因为它会和你的系统进行多次交互)。为了加速这个过程,我打开了另一个终端并运行了 ping -f localhost 30 到 45 秒):
|
||||
|
||||
# kdb5_util create -s
|
||||
|
||||

|
||||
|
||||
创建 Kerberos 数据库
|
||||
|
||||
下一步,使用 kadmin.local 工具为 root 创建管理权限:
|
||||
|
||||
# kadmin.local
|
||||
# addprinc root/admin
|
||||
|
||||
添加 Kerberos 服务器到数据库:
|
||||
|
||||
# addprinc -randkey host/box2.mydomain.com
|
||||
|
||||
在客户端(box1)和服务器(box2)上对 NFS 服务同样操作。请注意下面的截图中在退出前我忘了在 box1 上进行操作:
|
||||
|
||||
# addprinc -randkey nfs/box2.mydomain.com
|
||||
# addprinc -randkey nfs/box1.mydomain.com
|
||||
|
||||
输入 quit 和回车键退出:
|
||||
|
||||

|
||||
|
||||
添加 Kerberos 到 NFS 服务器
|
||||
|
||||
为 root/admin 获取和缓存票据授权票据(ticket-granting ticket):
|
||||
|
||||
# kinit root/admin
|
||||
# klist
|
||||
|
||||
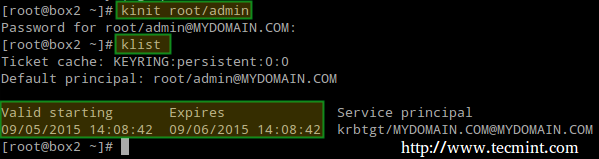
|
||||
|
||||
缓存 Kerberos
|
||||
|
||||
真正使用 Kerberos 之前的最后一步是保存被授权使用 Kerberos 身份验证的规则到一个密钥表文件(在服务器中):
|
||||
|
||||
# kdadmin.local
|
||||
# ktadd host/box2.mydomain.com
|
||||
# ktadd nfs/box2.mydomain.com
|
||||
# ktadd nfs/box1.mydomain.com
|
||||
|
||||
最后,挂载共享目录并进行一个写测试:
|
||||
|
||||
# mount -t nfs4 -o sec=krb5 box2:/nfs /mnt
|
||||
# echo "Hello from Tecmint.com" > /mnt/greeting.txt
|
||||
|
||||

|
||||
|
||||
挂载 NFS 共享
|
||||
|
||||
现在让我们卸载共享,在客户端中重命名密钥表文件(模拟它不存在)然后试着再次挂载共享目录:
|
||||
|
||||
# umount /mnt
|
||||
# mv /etc/krb5.keytab /etc/krb5.keytab.orig
|
||||
|
||||

|
||||
|
||||
挂载/卸载 Kerberos NFS 共享
|
||||
|
||||
现在你可以使用基于 Kerberos 身份验证的 NFS 共享了。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
在这篇文章中我们介绍了如何设置带 Kerberos 身份验证的 NFS。和我们在这篇指南中介绍的相比,该主题还有很多相关内容,可以在 [Kerberos 手册][6] 查看,另外至少可以说 Kerberos 有一点棘手,如果你在测试或实现中遇到了任何问题或需要帮助,别犹豫在下面的评论框中告诉我们吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/setting-up-nfs-server-with-kerberos-based-authentication/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[ictlyh](http://www.mutouxiaogui.cn/blog/)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/setup-samba-file-sharing-for-linux-windows-clients/
|
||||
[2]:http://www.tecmint.com/configure-nfs-server/
|
||||
[3]:http://www.tecmint.com/selinux-essentials-and-control-filesystem-access/
|
||||
[4]:http://www.tecmint.com/firewalld-rules-for-centos-7/
|
||||
[5]:http://www.tecmint.com/install-ntp-server-in-centos/
|
||||
[6]:http://web.mit.edu/kerberos/krb5-1.12/doc/admin/admin_commands/
|
||||
@ -1,224 +0,0 @@
|
||||
RHCSA 系列: 如何管理RHEL7的用户和组 – Part 3
|
||||
================================================================================
|
||||
和管理其他Linux服务器一样,管理一个 RHEL 7 服务器 要求你能够添加,修改,暂停或删除用户帐户,并且授予他们文件,目录,其他系统资源所必要的权限。
|
||||

|
||||
|
||||
RHCSA: 用户和组管理 – Part 3
|
||||
|
||||
### 管理用户帐户##
|
||||
|
||||
如果想要给RHEL 7 服务器添加账户,你需要以root用户执行如下两条命令
|
||||
|
||||
# adduser [new_account]
|
||||
# useradd [new_account]
|
||||
|
||||
当添加新的用户帐户时,默认会执行下列操作。
|
||||
|
||||
- 他/她 的主目录就会被创建(一般是"/home/用户名",除非你特别设置)
|
||||
- 一些隐藏文件 如`.bash_logout`, `.bash_profile` 以及 `.bashrc` 会被复制到用户的主目录,并且会为用户的回话提供环境变量.你可以进一步查看他们的相关细节。
|
||||
- 会为您的账号添加一个邮件池目录
|
||||
- 会创建一个和用户名同样的组
|
||||
|
||||
用户帐户的全部信息被保存在`/etc/passwd `文件。这个文件以如下格式保存了每一个系统帐户的所有信息(以:分割)
|
||||
[username]:[x]:[UID]:[GID]:[Comment]:[Home directory]:[Default shell]
|
||||
|
||||
- `[username]` 和`[Comment]` 是用于自我解释的
|
||||
- ‘x’表示帐户的密码保护(详细在`/etc/shadow`文件),就是我们用于登录的`[username]`.
|
||||
- `[UID]` 和`[GID]`是用于显示`[username]` 的 用户认证和主用户组。
|
||||
|
||||
最后,
|
||||
|
||||
- `[Home directory]`显示`[username]`的主目录的绝对路径
|
||||
- `[Default shell]` 是当用户登录系统后使用的默认shell
|
||||
|
||||
另外一个你必须要熟悉的重要的文件是存储组信息的`/etc/group`.因为和`/etc/passwd`类似,所以也是由:分割
|
||||
[Group name]:[Group password]:[GID]:[Group members]
|
||||
|
||||
|
||||
|
||||
- `[Group name]` 是组名
|
||||
- 这个组是否使用了密码 (如果是"X"意味着没有).
|
||||
- `[GID]`: 和`/etc/passwd`中一样
|
||||
- `[Group members]`:用户列表,使用,隔开。里面包含组内的所有用户
|
||||
|
||||
添加过帐户后,任何时候你都可以通过 usermod 命令来修改用户战壕沟,基础的语法如下:
|
||||
# usermod [options] [username]
|
||||
|
||||
相关阅读
|
||||
|
||||
- [15 ‘useradd’ Command Examples][1]
|
||||
- [15 ‘usermod’ Command Examples][2]
|
||||
|
||||
#### 示例1 : 设置帐户的过期时间 ####
|
||||
|
||||
如果你的公司有一些短期使用的帐户或者你相应帐户在有限时间内使用,你可以使用 `--expiredate` 参数 ,后加YYYY-MM-DD格式的日期。为了查看是否生效,你可以使用如下命令查看
|
||||
# chage -l [username]
|
||||
|
||||
帐户更新前后的变动如下图所示
|
||||

|
||||
|
||||
修改用户信息
|
||||
|
||||
#### 示例 2: 向组内追加用户 ####
|
||||
|
||||
除了创建用户时的主用户组,一个用户还能被添加到别的组。你需要使用 -aG或 -append -group 选项,后跟逗号分隔的组名
|
||||
#### 示例 3: 修改用户主目录或默认Shell ####
|
||||
|
||||
如果因为一些原因,你需要修改默认的用户主目录(一般为 /home/用户名),你需要使用 -d 或 -home 参数,后跟绝对路径来修改主目录
|
||||
如果有用户想要使用其他的shell来取代bash(比如sh ),一般默认是bash .使用 usermod ,并使用 -shell 的参数,后加新的shell的路径
|
||||
#### 示例 4: 展示组内的用户 ####
|
||||
|
||||
当把用户添加到组中后,你可以使用如下命令验证属于哪一个组
|
||||
|
||||
# groups [username]
|
||||
# id [username]
|
||||
|
||||
下面图片的演示了示例2到示例四
|
||||
|
||||

|
||||
|
||||
添加用户到额外的组
|
||||
|
||||
在上面的示例中:
|
||||
|
||||
# usermod --append --groups gacanepa,users --home /tmp --shell /bin/sh tecmint
|
||||
|
||||
如果想要从组内删除用户,省略 `--append` 切换,并且可以使用 `--groups` 来列举组内的用户
|
||||
|
||||
#### 示例 5: 通过锁定密码来停用帐户 ####
|
||||
|
||||
如果想要关闭帐户,你可以使用 -l(小写的L)或 -lock 选项来锁定用户的密码。这将会阻止用户登录。
|
||||
|
||||
#### 示例 6: 解锁密码 ####
|
||||
|
||||
当你想要重新启用帐户让他可以继续登录时,属于 -u 或 –unlock 选项来解锁用户的密码,就像示例5 介绍的那样
|
||||
|
||||
# usermod --unlock tecmint
|
||||
|
||||
下面的图片展示了示例5和示例6
|
||||
|
||||

|
||||
|
||||
锁定上锁用户
|
||||
|
||||
#### 示例 7:删除组和用户 ####
|
||||
|
||||
如果要删除一个组,你需要使用 groupdel ,如果需要删除用户 你需要使用 userdel (添加 -r 可以删除主目录和邮件池的内容)
|
||||
# groupdel [group_name] # 删除组
|
||||
# userdel -r [user_name] # 删除用户,并删除主目录和邮件池
|
||||
|
||||
如果一些文件属于组,他们将不会被删除。但是组拥有者将会被设置为删除掉的组的GID
|
||||
### 列举,设置,并且修改 ugo/rwx 权限 ###
|
||||
|
||||
著名的 [ls 命令][3] 是管理员最好的助手. 当我们使用 -l 参数, 这个工具允许您查看一个目录中的内容(或详细格式).
|
||||
|
||||
而且,该命令还可以应用于单个文件中。无论哪种方式,在“ls”输出中的前10个字符表示每个文件的属性。
|
||||
这10个字符序列的第一个字符用于表示文件类型:
|
||||
|
||||
- – (连字符): 一个标准文件
|
||||
- d: 一个目录
|
||||
- l: 一个符号链接
|
||||
- c: 字符设备(将数据作为字节流,即一个终端)
|
||||
- b: 块设备(处理数据块,即存储设备)
|
||||
|
||||
文件属性的下一个九个字符,分为三个组,被称为文件模式,并注明读(r),写(w),并执行(x)授予文件的所有者,文件的所有组,和其他的用户(通常被称为“世界”)。
|
||||
在文件的读取权限允许打开和读取相同的权限时,允许其内容被列出,如果还设置了执行权限,还允许它作为一个程序和运行。
|
||||
文件权限是通过chmod命令改变的,它的基本语法如下:
|
||||
|
||||
# chmod [new_mode] file
|
||||
|
||||
new_mode是一个八进制数或表达式,用于指定新的权限。适合每一个随意的案例。或者您已经有了一个更好的方式来设置文件的权限,所以你觉得可以自由地使用最适合你自己的方法。
|
||||
八进制数可以基于二进制等效计算,可以从所需的文件权限的文件的所有者,所有组,和世界。一定权限的存在等于2的幂(R = 22,W = 21,x = 20),没有时意为0。例如:
|
||||

|
||||
|
||||
文件权限
|
||||
|
||||
在八进制形式下设置文件的权限,如上图所示
|
||||
|
||||
# chmod 744 myfile
|
||||
|
||||
请用一分钟来对比一下我们以前的计算,在更改文件的权限后,我们的实际输出为:
|
||||
|
||||

|
||||
|
||||
长列表格式
|
||||
|
||||
#### 示例 8: 寻找777权限的文件 ####
|
||||
|
||||
出于安全考虑,你应该确保在正常情况下,尽可能避免777权限(读、写、执行的文件)。虽然我们会在以后的教程中教你如何更有效地找到所有的文件在您的系统的权限集的说明,你现在仍可以使用LS grep获取这种信息。
|
||||
在下面的例子,我们会寻找 /etc 目录下的777权限文件. 注意,我们要使用第二章讲到的管道的知识[第二章:文件和目录管理][4]:
|
||||
|
||||
# ls -l /etc | grep rwxrwxrwx
|
||||
|
||||

|
||||
|
||||
查找所有777权限的文件
|
||||
|
||||
#### 示例 9: 为所有用户指定特定权限 ####
|
||||
|
||||
shell脚本,以及一些二进制文件,所有用户都应该有权访问(不只是其相应的所有者和组),应该有相应的执行权限(我们会讨论特殊情况下的问题):
|
||||
# chmod a+x script.sh
|
||||
|
||||
**注意**: 我们可以设置文件模式使用表示用户权限的字母如“u”,组所有者权限的字母“g”,其余的为o 。所有权限为a.权限可以通过`+` 或 `-` 来管理。
|
||||
|
||||

|
||||
|
||||
为文件设置执行权限
|
||||
|
||||
长目录列表还显示了该文件的所有者和其在第一和第二列中的组主。此功能可作为系统中文件的第一级访问控制方法:
|
||||
|
||||

|
||||
|
||||
检查文件的属主和属组
|
||||
|
||||
改变文件的所有者,您将使用chown命令。请注意,您可以在同一时间或单独的更改文件的所有权:
|
||||
# chown user:group file
|
||||
|
||||
虽然可以在同一时间更改用户或组,或在同一时间的两个属性,但是不要忘记冒号区分,如果你想要更新其他属性,让另外的选项保持空白:
|
||||
# chown :group file # Change group ownership only
|
||||
# chown user: file # Change user ownership only
|
||||
|
||||
#### 示例 10:从一个文件复制权限到另一个文件####
|
||||
|
||||
If you would like to “clone” ownership from one file to another, you can do so using the –reference flag, as follows:
|
||||
如果你想“克隆”一个文件的所有权到另一个,你可以这样做,使用–reference参数,如下:
|
||||
# chown --reference=ref_file file
|
||||
|
||||
ref_file的所有信息会复制给 file
|
||||
|
||||

|
||||
|
||||
复制文件属主信息
|
||||
|
||||
### 设置 SETGID 协作目录 ###
|
||||
|
||||
你应该授予在一个特定的目录中拥有访问所有的文件的权限给一个特点的用户组,你将有可能使用目录设置setgid的方法。当setgid后设置,真实用户的有效GID成为团队的主人。
|
||||
因此,任何用户都可以访问该文件的组所有者授予的权限的文件。此外,当setgid设置在一个目录中,新创建的文件继承同一组目录,和新创建的子目录也将继承父目录的setgid。
|
||||
# chmod g+s [filename]
|
||||
|
||||
为了设置 setgid 在八进制形式,预先准备好数字2 来给基本的权限
|
||||
# chmod 2755 [directory]
|
||||
|
||||
### 总结 ###
|
||||
|
||||
扎实的用户和组管理知识,符合规则的,Linux权限管理,以及部分实践,可以帮你快速解决RHEL 7 服务器的文件权限。
|
||||
我向你保证,当你按照本文所概述的步骤和使用系统文档(和第一章解释的那样 [Part 1: Reviewing Essential Commands & System Documentation][5] of this series) 你将掌握基本的系统管理的能力。
|
||||
|
||||
请随时让我们知道你是否有任何问题或意见使用下面的表格。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/rhcsa-exam-manage-users-and-groups/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[xiqingongzi](https://github.com/xiqingongzi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/add-users-in-linux/
|
||||
[2]:http://www.tecmint.com/usermod-command-examples/
|
||||
[3]:http://www.tecmint.com/ls-interview-questions/
|
||||
[4]:http://www.tecmint.com/file-and-directory-management-in-linux/
|
||||
[5]:http://www.tecmint.com/rhcsa-exam-reviewing-essential-commands-system-documentation/
|
||||
Loading…
Reference in New Issue
Block a user