mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-21 02:10:11 +08:00
commit
294606899f
@ -0,0 +1,99 @@
|
||||
5 款适合程序员的开源字体
|
||||
======
|
||||
|
||||
> 编程字体有些在普通字体中没有的特点,这五种字体你可以看看。
|
||||
|
||||

|
||||
|
||||
什么是最好的编程字体呢?首先,你需要考虑到字体被设计出来的初衷可能并不相同。当选择一款用于休闲阅读的字体时,读者希望该字体的字母能够顺滑地衔接,提供一种轻松愉悦的体验。一款标准字体的每个字符,类似于拼图的一块,它需要被仔细的设计,从而与整个字体的其他部分融合在一起。
|
||||
|
||||
然而,在编写代码时,通常来说对字体的要求更具功能性。这也是为什么大多数程序员在选择时更偏爱使用固定宽度的等宽字体。选择一款带有容易分辨的数字和标点的字体在美学上令人愉悦;但它是否拥有满足你需求的版权许可也是非常重要的。
|
||||
|
||||
某些功能使得字体更适合编程。首先要清楚是什么使得等宽字体看上去井然有序。这里,让我们对比一下字母 `w` 和字母 `i`。当选择一款字体时,重要的是要考虑字母本身及周围的空白。在纸质的书籍和报纸中,有效地利用空间是极为重要的,为瘦小的 `i` 分配较小的空间,为宽大的字母 `w` 分配较大的空间是有意义的。
|
||||
|
||||
然而在终端中,你没有这些限制。每个字符享有相等的空间将非常有用。这么做的首要好处是你可以随意扫过一段代码来“估测”代码的长度。第二个好处是能够轻松地对齐字符和标点,高亮在视觉上更加明显。另外打印纸张上的等宽字体比均衡字体更加容易通过 OCR 识别。
|
||||
|
||||
在本篇文章中,我们将探索 5 款卓越的开源字体,使用它们来编程和写代码都非常理想。
|
||||
|
||||
### 1、Firacode:最佳整套编程字体
|
||||
|
||||
![FiraCode 示例][1]
|
||||
|
||||
*FiraCode, Andrew Lekashman*
|
||||
|
||||
在我们列表上的首款字体是 [FiraCode][3],一款真正符合甚至超越了其职责的编程字体。FiraCode 是 Fira 的扩展,而后者是由 Mozilla 委托设计的开源字体族。使得 FiraCode 与众不同的原因是它修改了在代码中常使用的一些符号的组合或连字,使得它看上去更具可读性。这款字体有几种不同的风格,特别是还包含 Retina 选项。你可以在它的 [GitHub][3] 主页中找到它被使用到多种编程语言中的例子。
|
||||
|
||||
![FiraCode compared to Fira Mono][2]
|
||||
|
||||
*FiraCode 与 Fira Mono 的对比,[Nikita Prokopov][3],源自 GitHub*
|
||||
|
||||
### 2、Inconsolata:优雅且由卓越设计者创造
|
||||
|
||||
![Inconsolata 示例][4]
|
||||
|
||||
*Inconsolata, Andrew Lekashman*
|
||||
|
||||
[Inconsolata][5] 是最为漂亮的等宽字体之一。从 2006 年开始它便一直是一款开源和可免费获取的字体。它的创造者 Raph Levien 在设计 Inconsolata 时秉承的一个基本原则是:等宽字体并不应该那么糟糕。使得 Inconsolata 如此优秀的两个原因是:对于 `0` 和 `o` 这两个字符它们有很大的不同,另外它还特别地设计了标点符号。
|
||||
|
||||
### 3、DejaVu Sans Mono:许多 Linux 发行版的标准配置,庞大的字形覆盖率
|
||||
|
||||
![DejaVu Sans Mono example][6]
|
||||
|
||||
*DejaVu Sans Mono, Andrew Lekashman*
|
||||
|
||||
受在 GNOME 中使用的带有版权和闭源的 Vera 字体的启发,[DejaVu Sans Mono][7] 是一个非常受欢迎的编程字体,几乎在每个现代的 Linux 发行版中都带有它。在 Book Variant 风格下 DejaVu 拥有惊人的 3310 个字形,相比于一般的字体,它们含有 100 个左右的字形。在工作中你将不会出现缺少某些字符的情况,它覆盖了 Unicode 的绝大部分,并且一直在活跃地增长着。
|
||||
|
||||
### 4、Source Code Pro:优雅、可读性强,由 Adobe 中一个小巧但天才的团队打造
|
||||
|
||||
![Source Code Pro example][8]
|
||||
|
||||
*Source Code Pro, Andrew Lekashman*
|
||||
|
||||
由 Paul Hunt 和 Teo Tuominen 设计,[Source Code Pro][9] 是[由 Adobe 创造的][10],成为了它的首款开源字体。Source Code Pro 值得注意的地方在于它极具可读性,且对于容易混淆的字符和标点,它有着非常好的区分度。Source Code Pro 也是一个字体族,有 7 中不同的风格:Extralight、Light、Regular、Medium、Semibold、Bold 和 Black,每种风格都还有斜体变体。
|
||||
|
||||
![Differentiating potentially confusable characters][11]
|
||||
|
||||
*潜在易混淆的字符之间的区别,[Paul D. Hunt][10] 源自 Adobe Typekit 博客。*
|
||||
|
||||
![Metacharacters with special meaning in computer languages][12]
|
||||
|
||||
*在计算机领域中有特别含义的特殊元字符, [Paul D. Hunt][10] 源自 Adobe Typekit 博客。*
|
||||
|
||||
### 5、Noto Mono:巨量的语言覆盖率,由 Google 中的一个大团队打造
|
||||
|
||||
![Noto Mono example][13]
|
||||
|
||||
*Noto Mono, Andrew Lekashman*
|
||||
|
||||
在我们列表上的最后一款字体是 [Noto Mono][14],这是 Google 打造的庞大 Note 字体族中的等宽版本。尽管它并不是专为编程所设计,但它在 209 种语言(包括 emoji 颜文字!)中都可以使用,并且一直在维护和更新。该项目非常庞大,是 Google 宣称 “组织全世界信息” 的使命的延续。假如你想更多地了解它,可以查看这个绝妙的[关于这些字体的视频][15]。
|
||||
|
||||
### 选择合适的字体
|
||||
|
||||
无论你选择那个字体,你都有可能在每天中花费数小时面对它,所以请确保它在审美和哲学层面上与你产生共鸣。选择正确的开源字体是确保你拥有最佳生产环境的一个重要部分。这些字体都是很棒的选择,每个都具有让它脱颖而出的功能强大的特性。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/11/how-select-open-source-programming-font
|
||||
|
||||
作者:[Andrew Lekashman][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com
|
||||
[1]:https://opensource.com/sites/default/files/u128651/firacode.png (FiraCode example)
|
||||
[2]:https://opensource.com/sites/default/files/u128651/firacode2.png (FiraCode compared to Fira Mono)
|
||||
[3]:https://github.com/tonsky/FiraCode
|
||||
[4]:https://opensource.com/sites/default/files/u128651/inconsolata.png (Inconsolata example)
|
||||
[5]:http://www.levien.com/type/myfonts/inconsolata.html
|
||||
[6]:https://opensource.com/sites/default/files/u128651/dejavu_sans_mono.png (DejaVu Sans Mono example)
|
||||
[7]:https://dejavu-fonts.github.io/
|
||||
[8]:https://opensource.com/sites/default/files/u128651/source_code_pro.png (Source Code Pro example)
|
||||
[9]:https://github.com/adobe-fonts/source-code-pro
|
||||
[10]:https://blog.typekit.com/2012/09/24/source-code-pro/
|
||||
[11]:https://opensource.com/sites/default/files/u128651/source_code_pro2.png (Differentiating potentially confusable characters)
|
||||
[12]:https://opensource.com/sites/default/files/u128651/source_code_pro3.png (Metacharacters with special meaning in computer languages)
|
||||
[13]:https://opensource.com/sites/default/files/u128651/noto.png (Noto Mono example)
|
||||
[14]:https://www.google.com/get/noto/#mono-mono
|
||||
[15]:https://www.youtube.com/watch?v=AAzvk9HSi84
|
||||
94
published/201904/20171226 The shell scripting trap.md
Normal file
94
published/201904/20171226 The shell scripting trap.md
Normal file
@ -0,0 +1,94 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (jdh8383)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10772-1.html)
|
||||
[#]: subject: (The shell scripting trap)
|
||||
[#]: via: (https://arp242.net/weblog/shell-scripting-trap.html)
|
||||
[#]: author: (Martin Tournoij https://arp242.net/)
|
||||
|
||||
Shell 脚本编程陷阱
|
||||
======
|
||||
|
||||
Shell 脚本很棒,你可以非常轻松地写出有用的东西来。甚至像是下面这个傻瓜式的命令:
|
||||
|
||||
```
|
||||
# 用含有 Go 的词汇起名字:
|
||||
$ grep -i ^go /usr/share/dict/* | cut -d: -f2 | sort -R | head -n1
|
||||
goldfish
|
||||
```
|
||||
|
||||
如果用其他编程语言,就需要花费更多的脑力,用多行代码实现,比如用 Ruby 的话:
|
||||
|
||||
```
|
||||
puts(Dir['/usr/share/dict/*-english'].map do |f|
|
||||
File.open(f)
|
||||
.readlines
|
||||
.select { |l| l[0..1].downcase == 'go' }
|
||||
end.flatten.sample.chomp)
|
||||
```
|
||||
|
||||
Ruby 版本的代码虽然不是那么长,也并不复杂。但是 shell 版是如此简单,我甚至不用实际测试就可以确保它是正确的。而 Ruby 版的我就没法确定它不会出错了,必须得测试一下。而且它要长一倍,看起来也更复杂。
|
||||
|
||||
这就是人们使用 Shell 脚本的原因,它简单却实用。下面是另一个例子:
|
||||
|
||||
```
|
||||
curl https://nl.wikipedia.org/wiki/Lijst_van_Nederlandse_gemeenten |
|
||||
grep '^<li><a href=' |
|
||||
sed -r 's|<li><a href="/wiki/.+" title=".+">(.+)</a>.*</li>|\1|' |
|
||||
grep -Ev '(^Tabel van|^Lijst van|Nederland)'
|
||||
```
|
||||
|
||||
这个脚本可以从维基百科上获取荷兰基层政权的列表。几年前我写了这个临时的脚本,用来快速生成一个数据库,到现在它仍然可以正常运行,当时写它并没有花费我多少精力。但要用 Ruby 完成同样的功能则会麻烦得多。
|
||||
|
||||
---
|
||||
|
||||
现在来说说 shell 的缺点吧。随着代码量的增加,你的脚本会变得越来越难以维护,但你也不会想用别的语言重写一遍,因为你已经在这个 shell 版上花费了很多时间。
|
||||
|
||||
我把这种情况称为“Shell 脚本编程陷阱”,这是[沉没成本谬论][1]的一种特例(LCTT 译注:“沉没成本谬论”是一个经济学概念,可以简单理解为,对已经投入的成本可能被浪费而念念不忘)。
|
||||
|
||||
实际上许多脚本会增长到超出预期的大小,你经常会花费过多的时间来“修复某个 bug”,或者“添加一个小功能”。如此循环往复,让人头大。
|
||||
|
||||
如果你从一开始就使用 Python、Ruby 或是其他类似的语言来写这个程序,你可能会在写第一版的时候多花些时间,但以后维护起来就容易很多,bug 也肯定会少很多。
|
||||
|
||||
以我的 [packman.vim][2] 脚本为例。它起初只包含一个简单的用来遍历所有目录的 `for` 循环,外加一个 `git pull`,但在这之后就刹不住车了,它现在有 200 行左右的代码,这肯定不能算是最复杂的脚本,但假如我一上来就按计划用 Go 来编写它的话,那么增加一些像“打印状态”或者“从配置文件里克隆新的 git 库”这样的功能就会轻松很多;添加“并行克隆”的支持也几乎不算个事儿了,而在 shell 脚本里却很难实现(尽管不是不可能)。事后看来,我本可以节省时间,并且获得更好的结果。
|
||||
|
||||
出于类似的原因,我很后悔写出了许多这样的 shell 脚本,而我在 2018 年的新年誓言就是不要再犯类似的错误了。
|
||||
|
||||
### 附录:问题汇总
|
||||
|
||||
需要指出的是,shell 编程的确存在一些实际的限制。下面是一些例子:
|
||||
|
||||
* 在处理一些包含“空格”或者其他“特殊”字符的文件名时,需要特别注意细节。绝大多数脚本都会犯错,即使是那些经验丰富的作者(比如我)编写的脚本,因为太容易写错了,[只添加引号是不够的][3]。
|
||||
* 有许多所谓“正确”和“错误”的做法。你应该用 `which` 还是 `command`?该用 `$@` 还是 `$*`,是不是得加引号?你是该用 `cmd $arg` 还是 `cmd "$arg"`?等等等等。
|
||||
* 你没法在变量里存储空字节(0x00);shell 脚本处理二进制数据很麻烦。
|
||||
* 虽然你可以非常快速地写出有用的东西,但实现更复杂的算法则要痛苦许多,即使用 ksh/zsh/bash 扩展也是如此。我上面那个解析 HTML 的脚本临时用用是可以的,但你真的不会想在生产环境中使用这种脚本。
|
||||
* 很难写出跨平台的通用型 shell 脚本。`/bin/sh` 可能是 `dash` 或者 `bash`,不同的 shell 有不同的运行方式。外部工具如 `grep`、`sed` 等,不一定能支持同样的参数。你能确定你的脚本可以适用于 Linux、macOS 和 Windows 的所有版本吗(无论是过去、现在还是将来)?
|
||||
* 调试 shell 脚本会很难,特别是你眼中的语法可能会很快变得记不清了,并不是所有人都熟悉 shell 编程的语境。
|
||||
* 处理错误会很棘手(检查 `$?` 或是 `set -e`),排查一些超过“出了个小错”级别的复杂错误几乎是不可能的。
|
||||
* 除非你使用了 `set -u`,变量未定义将不会报错,而这会导致一些“搞笑事件”,比如 `rm -r ~/$undefined` 会删除用户的整个家目录([瞅瞅 Github 上的这个悲剧][4])。
|
||||
* 所有东西都是字符串。一些 shell 引入了数组,能用,但是语法非常丑陋和费解。带分数的数字运算仍然难以应付,并且依赖像 `bc` 或 `dc` 这样的外部工具(`$(( .. ))` 这种方式只能对付一下整数)。
|
||||
|
||||
**反馈**
|
||||
|
||||
你可以发邮件到 [martin@arp242.net][5],或者[在 GitHub 上创建 issue][6] 来向我反馈,提问等。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://arp242.net/weblog/shell-scripting-trap.html
|
||||
|
||||
作者:[Martin Tournoij][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[jdh8383](https://github.com/jdh8383)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://arp242.net/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://youarenotsosmart.com/2011/03/25/the-sunk-cost-fallacy/
|
||||
[2]: https://github.com/Carpetsmoker/packman.vim
|
||||
[3]: https://dwheeler.com/essays/filenames-in-shell.html
|
||||
[4]: https://github.com/ValveSoftware/steam-for-linux/issues/3671
|
||||
[5]: mailto:martin@arp242.net
|
||||
[6]: https://github.com/Carpetsmoker/arp242.net/issues/new
|
||||
@ -0,0 +1,173 @@
|
||||
12 个最佳 GNOME(GTK)主题
|
||||
======
|
||||
|
||||
> 让我们来看一些漂亮的 GTK 主题,你不仅可以用在 Ubuntu 上,也可以用在其它使用 GNOME 的 Linux 发行版上。
|
||||
|
||||
对于我们这些使用 Ubuntu 的人来说,默认的桌面环境从 Unity 变成了 Gnome 使得主题和定制变得前所未有的简单。Gnome 有个相当大的定制用户社区,其中不乏可供用户选择的漂亮的 GTK 主题。最近几个月,我不断找到了一些喜欢的主题。我相信这些是你所能找到的最好的主题之一了。
|
||||
|
||||
### Ubuntu 和其它 Linux 发行版的最佳主题
|
||||
|
||||
这不是一个详细清单,可能不包括一些你已经使用和喜欢的主题,但希望你能至少找到一个能让你喜爱的没见过的主题。所有这里提及的主题都可以工作在 Gnome 3 上,不管是 Ubuntu 还是其它 Linux 发行版。有一些主题的屏幕截屏我没有,所以我从官方网站上找到了它们的图片。
|
||||
|
||||
在这里列出的主题没有特别的次序。
|
||||
|
||||
但是,在你看这些最好的 GNOME 主题前,你应该学习一下 [如何在 Ubuntu GNOME 中安装主题][1]。
|
||||
|
||||
#### 1、Arc-Ambiance
|
||||
|
||||
![][2]
|
||||
|
||||
Arc 和 Arc 变体主题已经出现了相当长的时间,普遍认为它们是最好的主题之一。在这个示例中,我选择了 Arc-Ambiance ,因为它是 Ubuntu 中的默认 Ambiance 主题。
|
||||
|
||||
我是 Arc 主题和默认 Ambiance 主题的粉丝,所以不用说,当我遇到一个融合了两者优点的主题,我不禁长吸了一口气。如果你是 Arc 主题的粉丝,但不是这个特定主题的粉丝,Gnome 的外观上当然还有适合你口味的大量的选择。
|
||||
|
||||
- [下载 Arc-Ambiance 主题][3]
|
||||
|
||||
#### 2、Adapta Colorpack
|
||||
|
||||
![][4]
|
||||
|
||||
Adapta 主题是我所见过的最喜欢的扁平主题之一。像 Arc 一样,Adapata 被很多 Linux 用户广泛采用。我选择这个配色包,是因为一次下载你就有数个可选择的配色方案。事实上,有 19 个配色方案可以选择,是的,你没看错,19 个呢!
|
||||
|
||||
所以,如果你是如今常见的扁平风格/<ruby>材料设计风格<rt>Material Design Language</rt></ruby>的粉丝,那么,在这个主题包中很可能至少有一个能满足你喜好的变体。
|
||||
|
||||
- [下载 Adapta Colorpack 主题][5]
|
||||
|
||||
#### 3、Numix Collection
|
||||
|
||||
![][6]
|
||||
|
||||
啊,Numix! 让我想起了我们一起度过的那些年!对于那些在过去几年装点过桌面环境的人来说,你肯定在某个时间点上遇到过 Numix 主题或图标包。Numix 可能是我爱上的第一个 Linux 现代主题,现在我仍然爱它。虽然经过这些年,但它仍然魅力不失。
|
||||
|
||||
灰色色调贯穿主题,尤其是默认的粉红色高亮,带来了真正干净而完整的体验。你可能很难找到一个像 Numix 一样精美的主题包。而且在这个主题包中,你还有很多可供选择的余地,简直不要太棒了!
|
||||
|
||||
- [下载 Numix Collection 主题][7]
|
||||
|
||||
#### 4、Hooli
|
||||
|
||||
![][8]
|
||||
|
||||
Hooli 是一个已经出现了一段时间的主题,但是我最近才偶然发现它。我是很多扁平主题的粉丝,但是通常不太喜欢材料设计风格的主题。Hooli 像 Adapta 一样吸取了那些设计风格,但是我认为它和其它的那些有所不同。绿色高亮是我对这个主题最喜欢的部分之一,并且,它在不冲击整个主题方面做的很好。
|
||||
|
||||
- [下载 Hooli 主题][9]
|
||||
|
||||
#### 5、Arrongin/Telinkrin
|
||||
|
||||
![][10]
|
||||
|
||||
福利:二合一主题!它们是在主题领域中的相对新的竞争者。它们都吸取了 Ubuntu 接近完成的 “[communitheme][11]” 的思路,并带它到了你的桌面。这两个主题我能找到的唯一真正的区别就是颜色。Arrongin 以 Ubuntu 家族的橙色颜色为中心,而 Telinkrin 则更偏向于 KDE Breeze 系的蓝色,我个人更喜欢蓝色,但是两者都是极好的选择!
|
||||
|
||||
- [下载 Arrongin/Telinkrin 主题][12]
|
||||
|
||||
#### 6、Gnome-osx
|
||||
|
||||
![][13]
|
||||
|
||||
我不得不承认,通常,当我看到一个主题有 “osx” 或者在标题中有类似的内容时我就不会不期望太多。大多数受 Apple 启发的主题看起来都比较雷同,我真不能找到使用它们的原因。但我想这两个主题能够打破这种思维定式:这就是 Arc-osc 主题和 Gnome-osx 主题。
|
||||
|
||||
我喜欢 Gnome-osx 主题的原因是它在 Gnome 桌面上看起来确实很像 OSX。它在融入桌面环境而不至于变的太扁平方面做得很好。所以,对于那些喜欢稍微扁平的主题的人来说,如果你喜欢红黄绿按钮样式(用于关闭、最小化和最大化),这个主题非常适合你。
|
||||
|
||||
- [下载 Gnome-osx 主题][14]
|
||||
|
||||
#### 7、Ultimate Maia
|
||||
|
||||
![][15]
|
||||
|
||||
曾经有一段时间我使用 Manjaro Gnome。尽管那以后我又回到了 Ubuntu,但是,我希望我能打包带走的一个东西是 Manjaro 主题。如果你对 Manjaro 主题和我一样感受相同,那么你是幸运的,因为你可以带它到你想运行 Gnome 的任何 Linux 发行版!
|
||||
|
||||
丰富的绿色颜色,Breeze 式的关闭、最小化、最大化按钮,以及全面雕琢过的主题使它成为一个不可抗拒的选择。如果你不喜欢绿色,它甚至为你提供一些其它颜色的变体。但是说实话……谁会不喜欢 Manjaro 的绿色呢?
|
||||
|
||||
- [下载 Ultimate Maia 主题][16]
|
||||
|
||||
#### 8、Vimix
|
||||
|
||||
![][17]
|
||||
|
||||
这是一个让我激动的主题。它是现代风格的,吸取了 macOS 的红黄绿按钮的风格,但并不是直接复制了它们,并且减少了多变的主题颜色,使之成为了大多数主题的独特替代品。它带来三个深色的变体和几个彩色配色,我们中大多数人都可以从中找到我们喜欢的。
|
||||
|
||||
- [下载 Vimix 主题][18]
|
||||
|
||||
#### 9、Ant
|
||||
|
||||
![][19]
|
||||
|
||||
像 Vimix 一样,Ant 从 macOS 的按钮颜色中吸取了灵感,但不是直接复制了样式。在 Vimix 减少了颜色花哨的地方,Ant 却增加了丰富的颜色,在我的 System 76 Galago Pro 屏幕看起来绚丽极了。三个主题变体的变化差异大相径庭,虽然它可能不见得符合每个人的口味,它无疑是最适合我的。
|
||||
|
||||
- [下载 Ant 主题][20]
|
||||
|
||||
#### 10、Flat Remix
|
||||
|
||||
![][21]
|
||||
|
||||
如果你还没有注意到这点,对于一些关注关闭、最小化、最大化按钮的人来说我就是一个傻瓜。Flat Remix 使用的颜色主题是我从未在其它地方看到过的,它采用红色、蓝色和橙色方式。把这些添加到一个几乎看起来像是一个混合了 Arc 和 Adapta 的主题的上面,就有了 Flat Remix。
|
||||
|
||||
我本人喜欢它的深色主题,但是换成亮色的也是非常好的。因此,如果你喜欢稍稍透明、风格一致的深色主题,以及偶尔的一点点颜色,那 Flat Remix 就适合你。
|
||||
|
||||
- [下载 Flat Remix 主题][22]
|
||||
|
||||
#### 11、Paper
|
||||
|
||||
![][23]
|
||||
|
||||
[Paper][24] 已经出现一段时间。我记得第一次使用它是在 2014 年。可以说,Paper 的图标包比其 GTK 主题更出名,但是这并不意味着它自身的主题不是一个极好的选择。即使我从一开始就倾心于 Paper 图标,我不能说当我第一次尝试它的时候我就是一个 Paper 主题忠实粉丝。
|
||||
|
||||
我觉得鲜亮的色彩和有趣的方式被放到一个主题里是一种“不成熟”的体验。现在,几年后,Paper 在我心目中已经长大,至少可以这样说,这个主题采取的轻快方式是我非常欣赏的一个。
|
||||
|
||||
- [下载 Paper 主题][25]
|
||||
|
||||
#### 12、Pop
|
||||
|
||||
![][26]
|
||||
|
||||
Pop 在这个列表上是一个较新的主题,是由 [System 76][27] 的人们创造的,Pop GTK 主题是前面列出的 Adapta 主题的一个分支,并带有一个匹配的图标包,图标包是先前提到的 Paper 图标包的一个分支。
|
||||
|
||||
该主题是在 System 76 发布了 [他们自己的发行版][28] Pop!_OS 之后不久发布的。你可以阅读我的 [Pop!_OS 点评][29] 来了解更多信息。不用说,我认为 Pop 是一个极好的主题,带有华丽的装饰,并为 Gnome 桌面带来了一股清新之风。
|
||||
|
||||
- [下载 Pop 主题][30]
|
||||
|
||||
#### 结束语
|
||||
|
||||
很明显,我们有比文中所描述的主题更多的选择,但是这些大多是我在最近几月所使用的最完整、最精良的主题。如果你认为我们错过一些你确实喜欢的主题,或你确实不喜欢我在上面描述的主题,那么在下面的评论区让我们知道,并分享你喜欢的主题更好的原因!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/best-gtk-themes/
|
||||
|
||||
作者:[Phillip Prado][a]
|
||||
译者:[robsean](https://github.com/robsean)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/phillip/
|
||||
[1]:https://itsfoss.com/install-themes-ubuntu/
|
||||
[2]:https://i2.wp.com/itsfoss.com/wp-content/uploads/2018/03/arcambaince.png
|
||||
[3]:https://www.gnome-look.org/p/1193861/
|
||||
[4]:https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/03/adapta.jpg
|
||||
[5]:https://www.gnome-look.org/p/1190851/
|
||||
[6]:https://i2.wp.com/itsfoss.com/wp-content/uploads/2018/03/numix.png
|
||||
[7]:https://www.gnome-look.org/p/1170667/
|
||||
[8]:https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/03/hooli2.jpg
|
||||
[9]:https://www.gnome-look.org/p/1102901/
|
||||
[10]:https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/03/AT.jpg
|
||||
[11]:https://itsfoss.com/ubuntu-community-theme/
|
||||
[12]:https://www.gnome-look.org/p/1215199/
|
||||
[13]:https://itsfoss.com/wp-content/uploads/2018/03/gosx-800x473.jpg
|
||||
[14]:https://www.opendesktop.org/s/Gnome/p/1171688/
|
||||
[15]:https://itsfoss.com/wp-content/uploads/2018/03/ultimatemaia-800x450.jpg
|
||||
[16]:https://www.opendesktop.org/s/Gnome/p/1193879/
|
||||
[17]:https://itsfoss.com/wp-content/uploads/2018/03/vimix-800x450.jpg
|
||||
[18]:https://www.gnome-look.org/p/1013698/
|
||||
[19]:https://itsfoss.com/wp-content/uploads/2018/03/ant-800x533.png
|
||||
[20]:https://www.opendesktop.org/p/1099856/
|
||||
[21]:https://itsfoss.com/wp-content/uploads/2018/03/flatremix-800x450.png
|
||||
[22]:https://www.opendesktop.org/p/1214931/
|
||||
[23]:https://itsfoss.com/wp-content/uploads/2018/04/paper-800x450.jpg
|
||||
[24]:https://itsfoss.com/install-paper-theme-linux/
|
||||
[25]:https://snwh.org/paper/download
|
||||
[26]:https://itsfoss.com/wp-content/uploads/2018/04/pop-800x449.jpg
|
||||
[27]:https://system76.com/
|
||||
[28]:https://itsfoss.com/system76-popos-linux/
|
||||
[29]:https://itsfoss.com/pop-os-linux-review/
|
||||
[30]:https://github.com/pop-os/gtk-theme/blob/master/README.md
|
||||
78
published/201904/20180718 3 Emacs modes for taking notes.md
Normal file
78
published/201904/20180718 3 Emacs modes for taking notes.md
Normal file
@ -0,0 +1,78 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lujun9972)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10792-1.html)
|
||||
[#]: subject: (3 Emacs modes for taking notes)
|
||||
[#]: via: (https://opensource.com/article/18/7/emacs-modes-note-taking)
|
||||
[#]: author: (Scott Nesbitt https://opensource.com/users/scottnesbitt)
|
||||
|
||||
用来记笔记的三个 Emacs 模式
|
||||
======
|
||||
|
||||
> 借助这些 Emacs 模式轻松记录信息。
|
||||
|
||||

|
||||
|
||||
|
||||
不管你从事哪种工作,你都无可避免地需要记笔记。而且可能还不是一点点。现在这年头,大家都开始以数字的形式来记笔记了。
|
||||
|
||||
开源软件爱好者有多种途径来以电子的方式记下他们的创意、想法和研究过程。你可以使用 [网页工具][1],可以使用 [桌面应用][2],或者你也可以 [使用命令行工具][3]。
|
||||
|
||||
如果你使用 [Emacs][4](伪装成文本编辑器的强力操作系统),有多个<ruby>模式<rt>mode</rt></ruby>可以帮你有效地记录笔记。我们这里列举三个例子。
|
||||
|
||||
### Deft
|
||||
|
||||
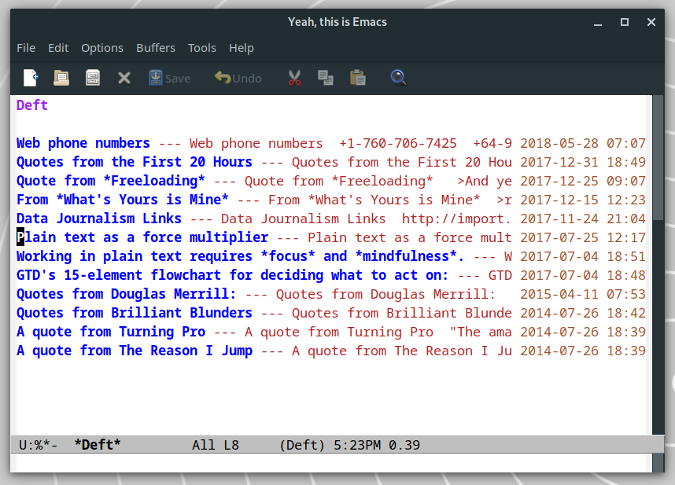
|
||||
|
||||
在少数情况下,我只能使用 Mac时,有一个工具是我不能缺少的:[nvALT][5] 笔记应用。[Deft 模式][6] 为 Emacs 带来了 nvALT 式的体验。
|
||||
|
||||
Deft 将你的笔记以文本文件的形式存储在电脑中的某个文件夹中。当你进入 Deft 模式,你会看到一系列的笔记及其摘要。这些摘要其实就是文本文件的第一行。若第一行是 Markdown、LaTeX,甚至 Emacs Org 模式的格式的话,Deft 会忽略掉这些格式而只显示文本内容。
|
||||
|
||||
要打开笔记,只需要向下滚动到该笔记的位置然后按下回车即可。然而 Deft 不仅仅只是这样。根据 Deft 开发者 Jason Blevins 的说法,它的*主要操作是搜索和过滤*。Deft 的实现方式简单而有效。输入关键字然后 Deft 会只显示标题中包含关键字的笔记。这在你要从大量笔记中找到某条笔记时非常有用。
|
||||
|
||||
### Org 模式
|
||||
|
||||
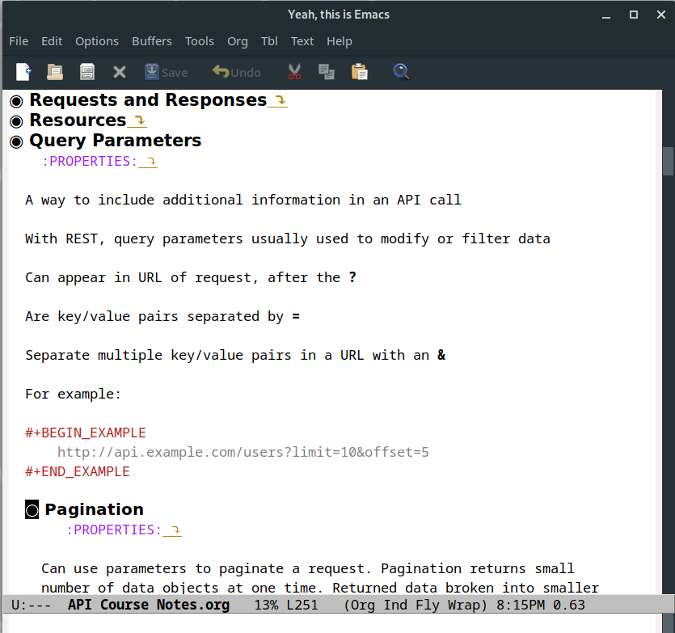
|
||||
|
||||
如果本文没有包含 [Org 模式][7] 的话,那么我可能会被人所诟病。为什么?它可以说是 Emacs 中最灵活、使用最广泛的记录笔记的方式了。以正确的方式使用它,Org 模式可以极大地增强记笔记的能力。
|
||||
|
||||
Org 模式的主要优势在于它组织笔记的方式。在 Org 模式中,一个笔记文件会被组织成一个巨大的大纲。每个章节就是大纲里的一个节点,你可以对它进行展开和折叠。这些章节又可以有子章节,这些子章节也可以展开和折叠。这不仅使你一次只关注于某个章节,而且可以让你浏览整个大纲。
|
||||
|
||||
你可以在多个章节之间 [进行互联][8],无需通过剪切和复制就能快速移动章节,以及 [附加文件][9] 到笔记中。Org 模式支持带格式的字符和表格。如果你需要转换笔记到其他格式,Org 模式也有大量的[导出选项][10]。
|
||||
|
||||
|
||||
### Howm
|
||||
|
||||
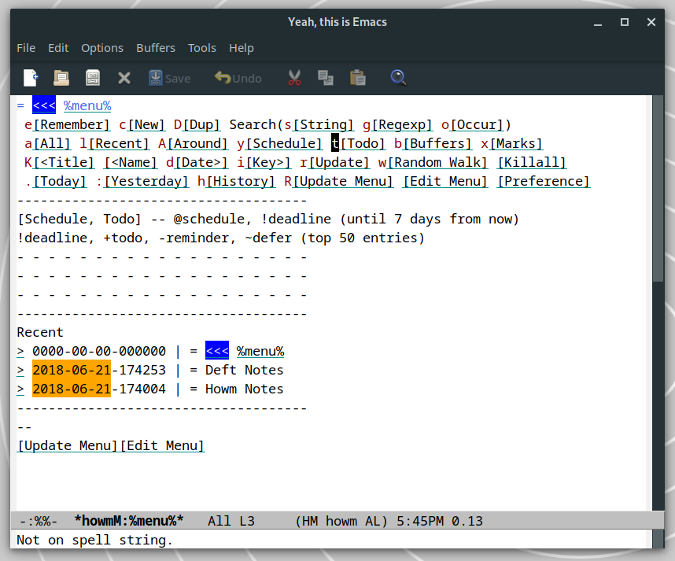
|
||||
|
||||
当我使用 Emacs 已经成为一种习惯时,[howm][11] 马上就成为我严重依赖的模式之一了。虽然我特别喜欢使用 Org 模式,但 howm 依然占有一席之地。
|
||||
|
||||
Howm 就好像是一个小型维基。你可以创建笔记和任务列表,还能在它们之间创建链接。通过输入或点击某个链接,你可以在笔记之间跳转。如果你需要,还可以使用关键字为笔记添加标签。不仅如此,你可以对笔记进行搜索、排序和合并。
|
||||
|
||||
Howm 不是最漂亮的 Emacs 模式,它的用户体验也不是最佳。它需要你花一点时间来适应它,而一旦你适应了它,记录和查找笔记就是轻而易举的事情了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/emacs-modes-note-taking
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/scottnesbitt
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/alternatives/evernote
|
||||
[2]: https://opensource.com/life/16/9/4-desktop-note-taking-applications
|
||||
[3]: https://opensource.com/article/18/3/command-line-note-taking-applications
|
||||
[4]: https://www.gnu.org/software/emacs/
|
||||
[5]: http://brettterpstra.com/projects/nvalt/
|
||||
[6]: https://jblevins.org/projects/deft/
|
||||
[7]: https://orgmode.org/
|
||||
[8]: https://orgmode.org/org.html#Hyperlinks
|
||||
[9]: https://orgmode.org/org.html#Attachments
|
||||
[10]: https://orgmode.org/org.html#Exporting
|
||||
[11]: https://howm.osdn.jp/
|
||||
@ -0,0 +1,301 @@
|
||||
Sensu 监控入门
|
||||
======
|
||||
> 这个开源解决方案可以简单而有效地监控你的云基础设施。
|
||||
|
||||

|
||||
|
||||
Sensu 是一个开源的基础设施和应用程序监控解决方案,它可以监控服务器、相关服务和应用程序健康状况,并通过第三方集成发送警报和通知。Sensu 用 Ruby 编写,可以使用 [RabbitMQ][1] 或 [Redis][2] 来处理消息,它使用 Redis 来存储数据。
|
||||
|
||||
如果你想以一种简单而有效的方式监控云基础设施,Sensu 是一个不错的选择。它可以与你的组织已经使用的许多现代 DevOps 组件集成,比如 [Slack][3]、[HipChat][4] 或 [IRC][5],它甚至可以用 [PagerDuty][6] 发送移动或寻呼机的警报。
|
||||
|
||||
Sensu 的[模块化架构][7]意味着每个组件都可以安装在同一台服务器上或者在完全独立的机器上。
|
||||
|
||||
### 结构
|
||||
|
||||
Sensu 的主要通信机制是 Transport。每个 Sensu 组件必须连接到 Transport 才能相互发送消息。Transport 可以使用 RabbitMQ(在生产环境中推荐使用)或 Redis。
|
||||
|
||||
Sensu 服务器处理事件数据并采取行动。它注册客户端并使用过滤器、增变器和处理程序检查结果和监视事件。服务器向客户端发布检查说明,Sensu API 提供 RESTful API,提供对监控数据和核心功能的访问。
|
||||
|
||||
[Sensu 客户端][8]执行 Sensu 服务器安排的检查或本地检查定义。Sensu 使用数据存储(Redis)来保存所有的持久数据。最后,[Uchiwa][9] 是与 Sensu API 进行通信的 Web 界面。
|
||||
|
||||
![][11]
|
||||
|
||||
### 安装 Sensu
|
||||
|
||||
#### 条件
|
||||
|
||||
* 一个 Linux 系统作为服务器节点(本文使用了 CentOS 7)
|
||||
* 要监控的一台或多台 Linux 机器(客户机)
|
||||
|
||||
#### 服务器侧
|
||||
|
||||
Sensu 需要安装 Redis。要安装 Redis,启用 EPEL 仓库:
|
||||
|
||||
```
|
||||
$ sudo yum install epel-release -y
|
||||
```
|
||||
|
||||
然后安装 Redis:
|
||||
|
||||
```
|
||||
$ sudo yum install redis -y
|
||||
```
|
||||
|
||||
修改 `/etc/redis.conf` 来禁用保护模式,监听每个地址并设置密码:
|
||||
|
||||
```
|
||||
$ sudo sed -i 's/^protected-mode yes/protected-mode no/g' /etc/redis.conf
|
||||
$ sudo sed -i 's/^bind 127.0.0.1/bind 0.0.0.0/g' /etc/redis.conf
|
||||
$ sudo sed -i 's/^# requirepass foobared/requirepass password123/g' /etc/redis.conf
|
||||
```
|
||||
|
||||
启用并启动 Redis 服务:
|
||||
|
||||
```
|
||||
$ sudo systemctl enable redis
|
||||
$ sudo systemctl start redis
|
||||
```
|
||||
|
||||
Redis 现在已经安装并准备好被 Sensu 使用。
|
||||
|
||||
现在让我们来安装 Sensu。
|
||||
|
||||
首先,配置 Sensu 仓库并安装软件包:
|
||||
|
||||
```
|
||||
$ sudo tee /etc/yum.repos.d/sensu.repo << EOF
|
||||
[sensu]
|
||||
name=sensu
|
||||
baseurl=https://sensu.global.ssl.fastly.net/yum/\$releasever/\$basearch/
|
||||
gpgcheck=0
|
||||
enabled=1
|
||||
EOF
|
||||
|
||||
$ sudo yum install sensu uchiwa -y
|
||||
```
|
||||
|
||||
让我们为 Sensu 创建最简单的配置文件:
|
||||
|
||||
```
|
||||
$ sudo tee /etc/sensu/conf.d/api.json << EOF
|
||||
{
|
||||
"api": {
|
||||
"host": "127.0.0.1",
|
||||
"port": 4567
|
||||
}
|
||||
}
|
||||
EOF
|
||||
```
|
||||
|
||||
然后,配置 `sensu-api` 在本地主机上使用端口 4567 监听:
|
||||
|
||||
```
|
||||
$ sudo tee /etc/sensu/conf.d/redis.json << EOF
|
||||
{
|
||||
"redis": {
|
||||
"host": "<IP of server>",
|
||||
"port": 6379,
|
||||
"password": "password123"
|
||||
}
|
||||
}
|
||||
EOF
|
||||
|
||||
|
||||
$ sudo tee /etc/sensu/conf.d/transport.json << EOF
|
||||
{
|
||||
"transport": {
|
||||
"name": "redis"
|
||||
}
|
||||
}
|
||||
EOF
|
||||
```
|
||||
|
||||
在这两个文件中,我们将 Sensu 配置为使用 Redis 作为传输机制,还有 Reids 监听的地址。客户端需要直接连接到传输机制。每台客户机都需要这两个文件。
|
||||
|
||||
```
|
||||
$ sudo tee /etc/sensu/uchiwa.json << EOF
|
||||
{
|
||||
"sensu": [
|
||||
{
|
||||
"name": "sensu",
|
||||
"host": "127.0.0.1",
|
||||
"port": 4567
|
||||
}
|
||||
],
|
||||
"uchiwa": {
|
||||
"host": "0.0.0.0",
|
||||
"port": 3000
|
||||
}
|
||||
}
|
||||
EOF
|
||||
```
|
||||
|
||||
在这个文件中,我们配置 Uchiwa 监听每个地址(0.0.0.0)的端口 3000。我们还配置 Uchiwa 使用 `sensu-api`(已配置好)。
|
||||
|
||||
出于安全原因,更改刚刚创建的配置文件的所有者:
|
||||
|
||||
```
|
||||
$ sudo chown -R sensu:sensu /etc/sensu
|
||||
```
|
||||
|
||||
启用并启动 Sensu 服务:
|
||||
|
||||
```
|
||||
$ sudo systemctl enable sensu-server sensu-api sensu-client
|
||||
$ sudo systemctl start sensu-server sensu-api sensu-client
|
||||
$ sudo systemctl enable uchiwa
|
||||
$ sudo systemctl start uchiwa
|
||||
```
|
||||
|
||||
尝试访问 Uchiwa 网站:`http://<服务器的 IP 地址>:3000`
|
||||
|
||||
对于生产环境,建议运行 RabbitMQ 集群作为 Transport 而不是 Redis(虽然 Redis 集群也可以用于生产环境),运行多个 Sensu 服务器实例和 API 实例,以实现负载均衡和高可用性。
|
||||
|
||||
Sensu 现在安装完成,让我们来配置客户端。
|
||||
|
||||
#### 客户端侧
|
||||
|
||||
要添加一个新客户端,你需要通过创建 `/etc/yum.repos.d/sensu.repo` 文件在客户机上启用 Sensu 仓库。
|
||||
|
||||
```
|
||||
$ sudo tee /etc/yum.repos.d/sensu.repo << EOF
|
||||
[sensu]
|
||||
name=sensu
|
||||
baseurl=https://sensu.global.ssl.fastly.net/yum/\$releasever/\$basearch/
|
||||
gpgcheck=0
|
||||
enabled=1
|
||||
EOF
|
||||
```
|
||||
|
||||
启用仓库后,安装 Sensu:
|
||||
|
||||
```
|
||||
$ sudo yum install sensu -y
|
||||
```
|
||||
|
||||
要配置 `sensu-client`,创建在服务器中相同的 `redis.json` 和 `transport.json`,还有 `client.json` 配置文件:
|
||||
|
||||
```
|
||||
$ sudo tee /etc/sensu/conf.d/client.json << EOF
|
||||
{
|
||||
"client": {
|
||||
"name": "rhel-client",
|
||||
"environment": "development",
|
||||
"subscriptions": [
|
||||
"frontend"
|
||||
]
|
||||
}
|
||||
}
|
||||
EOF
|
||||
```
|
||||
|
||||
在 `name` 字段中,指定一个名称来标识此客户机(通常是主机名)。`environment` 字段可以帮助你过滤,而 `subscriptions` 定义了客户机将执行哪些监视检查。
|
||||
|
||||
最后,启用并启动服务并签入 Uchiwa,因为客户机会自动注册:
|
||||
|
||||
```
|
||||
$ sudo systemctl enable sensu-client
|
||||
$ sudo systemctl start sensu-client
|
||||
```
|
||||
|
||||
### Sensu 检查
|
||||
|
||||
Sensu 检查有两个组件:一个插件和一个定义。
|
||||
|
||||
Sensu 与 [Nagios 检查插件规范][12]兼容,因此无需修改即可使用用于 Nagios 的任何检查。检查是可执行文件,由 Sensu 客户机运行。
|
||||
|
||||
检查定义可以让 Sensu 知道如何、在哪以及何时运行插件。
|
||||
|
||||
#### 客户端侧
|
||||
|
||||
让我们在客户机上安装一个检查插件。请记住,此插件将在客户机上执行。
|
||||
|
||||
启用 EPEL 并安装 `nagios-plugins-http`:
|
||||
|
||||
```
|
||||
$ sudo yum install -y epel-release
|
||||
$ sudo yum install -y nagios-plugins-http
|
||||
```
|
||||
|
||||
现在让我们通过手动执行它来了解这个插件。尝试检查客户机上运行的 Web 服务器的状态。它应该会失败,因为我们并没有运行 Web 服务器:
|
||||
|
||||
```
|
||||
$ /usr/lib64/nagios/plugins/check_http -I 127.0.0.1
|
||||
connect to address 127.0.0.1 and port 80: Connection refused
|
||||
HTTP CRITICAL - Unable to open TCP socket
|
||||
```
|
||||
|
||||
不出所料,它失败了。检查执行的返回值:
|
||||
|
||||
```
|
||||
$ echo $?
|
||||
2
|
||||
```
|
||||
|
||||
Nagios 检查插件规范定义了插件执行的四个返回值:
|
||||
|
||||
| 插件返回码 | 状态 |
|
||||
|----------|-----------|
|
||||
| 0 | OK |
|
||||
| 1 | WARNING |
|
||||
| 2 | CRITICAL |
|
||||
| 3 | UNKNOWN |
|
||||
|
||||
有了这些信息,我们现在可以在服务器上创建检查定义。
|
||||
|
||||
#### 服务器侧
|
||||
|
||||
在服务器机器上,创建 `/etc/sensu/conf.d/check_http.json` 文件:
|
||||
|
||||
```
|
||||
{
|
||||
"checks": {
|
||||
"check_http": {
|
||||
"command": "/usr/lib64/nagios/plugins/check_http -I 127.0.0.1",
|
||||
"interval": 10,
|
||||
"subscribers": [
|
||||
"frontend"
|
||||
]
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
在 `command` 字段中,使用我们之前测试过的命令。`interval` 会告诉 Sensu 这个检查的频率,以秒为单位。最后,`subscribers` 将定义执行检查的客户机。
|
||||
|
||||
重新启动 `sensu-api` 和 `sensu-server` 并确认新检查在 Uchiwa 中可用。
|
||||
|
||||
```
|
||||
$ sudo systemctl restart sensu-api sensu-server
|
||||
```
|
||||
|
||||
### 接下来
|
||||
|
||||
Sensu 是一个功能强大的工具,本文只简要介绍它可以干什么。参阅[文档][13]了解更多信息,访问 Sensu 网站了解有关 [Sensu 社区][14]的更多信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/getting-started-sensu-monitoring-solution
|
||||
|
||||
作者:[Michael Zamot][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/mzamot
|
||||
[1]:https://www.rabbitmq.com/
|
||||
[2]:https://redis.io/topics/config
|
||||
[3]:https://slack.com/
|
||||
[4]:https://en.wikipedia.org/wiki/HipChat
|
||||
[5]:http://www.irc.org/
|
||||
[6]:https://www.pagerduty.com/
|
||||
[7]:https://docs.sensu.io/sensu-core/1.4/overview/architecture/
|
||||
[8]:https://docs.sensu.io/sensu-core/1.4/installation/install-sensu-client/
|
||||
[9]:https://uchiwa.io/#/
|
||||
[10]:/file/406576
|
||||
[11]:https://opensource.com/sites/default/files/uploads/sensu_system.png (sensu_system.png)
|
||||
[12]:https://assets.nagios.com/downloads/nagioscore/docs/nagioscore/4/en/pluginapi.html
|
||||
[13]:https://docs.sensu.io/
|
||||
[14]:https://sensu.io/community
|
||||
@ -0,0 +1,201 @@
|
||||
Linux 初学者:移动文件
|
||||
=====================
|
||||
|
||||

|
||||
|
||||
在之前的该系列的部分中,[你学习了有关目录][1]和[访问目录][2][的权限][7]是如何工作的。你在这些文章中学习的大多数内容都可应用于文件,除了如何让一个文件变成可执行文件。
|
||||
|
||||
因此让我们在开始之前先解决这个问题。
|
||||
|
||||
### 不需要 .exe 扩展名
|
||||
|
||||
在其他操作系统中,一个文件的性质通常由它的后缀决定。如果一个文件有一个 .jpg 扩展,操作系统会认为它是一幅图像;如果它以 .wav 结尾,它是一个音频文件;如果它在文件名末尾以 .exe 结尾,它就是一个你可以执行的程序。
|
||||
|
||||
这导致了严重的问题,比如说木马可以伪装成文档文件。幸运的是,在 Linux 下事物不是这样运行的。可以确定的是,你可能会看到有些可执行文件是以 .sh 结尾暗示它们是可执行的脚本,但是这大部分是为了便于人眼找到文件,就像你使用 `ls --color` 将可执行文件的名字以亮绿色显示的方式相同。
|
||||
|
||||
事实上大多数应用根本没有扩展名。决定一个文件是否是一个真正程序的是 `x` (指*可执行的*)位。你可以通过运行以下命令使任何文件变得可执行,
|
||||
|
||||
```
|
||||
chmod a+x some_program
|
||||
```
|
||||
|
||||
而不管它的扩展名是什么或者是否存在。在上面命令中的 `x` 设置了 `x` 位,`a` 说明你为*所有*用户设置它。你同样可以为一组用户设置成拥有这个文件(`g+x`),或者只为一个用户——拥有者——设置 (`u+x`)。
|
||||
|
||||
尽管我们会在该系列之后的部分包含从命令行创建和运行脚本的内容,并学习通过输入它的路径并在结尾加上程序名的方式运行一个程序:
|
||||
|
||||
```
|
||||
path/to/directory/some_program
|
||||
```
|
||||
|
||||
或者,如果你当前在相同目录,你可以使用:
|
||||
|
||||
```
|
||||
./some_program
|
||||
```
|
||||
|
||||
还有其他方式可以使你的程序在目录树的任意位置运行 (提示:查询 `$PATH` 环境变量),但是当我们讨论 shell 脚本的时候你会读到这些。
|
||||
|
||||
### 复制、移动、链接
|
||||
|
||||
明显地,从命令行修改和处理文件有很多的方式,而不仅仅是处理它们的权限。当你试图打开一个不存在的文件是,大多数应用会创建一个新文件。如果 `test.txt` 当前并不存在,下列命令:
|
||||
|
||||
```
|
||||
nano test.txt
|
||||
```
|
||||
|
||||
```
|
||||
vim test.txt
|
||||
```
|
||||
|
||||
([nano][3] 和 [vim][4] 是流行的命令行文本编辑器)都将为你创建一个空的 `test.txt` 文件来编辑。
|
||||
|
||||
你可以通过 “触摸” (`touch`)来创建一个空的文件,
|
||||
|
||||
```
|
||||
touch test.txt
|
||||
```
|
||||
|
||||
会创建一个文件,但是不会在任何应用中打开它。
|
||||
|
||||
你可以使用 `cp` 来拷贝一个文件到另一个位置,或者使用一个不同的名字:
|
||||
|
||||
```
|
||||
cp test.txt copy_of_test.txt
|
||||
```
|
||||
|
||||
你也可以拷贝一堆文件:
|
||||
|
||||
```
|
||||
cp *.png /home/images
|
||||
```
|
||||
|
||||
上面的命令拷贝当前目录下的所有 PNG 文件到相对你的主目录下的 `images/` 目录。在你尝试之前 `images/` 目录必须存在, 不然 `cp` 将显示一个错误。同样的,警惕,当你复制一个文件到一个已经包含相同名字的文件的目录时,`cp` 会静默地用新文件覆盖老的文件。
|
||||
|
||||
你可以使用:
|
||||
|
||||
```
|
||||
cp -i *.png /home/images
|
||||
```
|
||||
|
||||
如果你想要 `cp` 命令在有任何危险时警告你 (`-i` 选项代表*交互式的*)。
|
||||
|
||||
你同样可以复制整个目录,但是为了做到这样,你需要 `-r` 选项:
|
||||
|
||||
```
|
||||
cp -rv directory_a/ directory_b
|
||||
```
|
||||
|
||||
`-r` 选项代表*递归*,意味着 `cp` 会向下探索目录 `directory_a`,复制所有的文件和子目录下内部包含的。我个人喜欢包含 `-v` 选项,因为它使 `cp` 冗长而啰嗦,意味着它会显示你当前它正在做什么而不是仅仅静默的复制然后存在。
|
||||
|
||||
`mv` 命令移动东西。也就是说,它移动文件从一个位置到另一个位置。最简单的形式,`mv` 表现的更像 `cp`:
|
||||
|
||||
```
|
||||
mv test.txt new_test.txt
|
||||
```
|
||||
|
||||
上面的命令使 `new_test.txt` 出现,`test.txt` 消失。
|
||||
|
||||
```
|
||||
mv *.png /home/images
|
||||
```
|
||||
|
||||
移动当前目录下所有的 PNG 文件到相对于你的主目录的 `images/` 目录。同样的你必须小心你没有意外的覆盖已存在的文件。使用
|
||||
|
||||
```
|
||||
mv -i *.png /home/images
|
||||
|
||||
```
|
||||
|
||||
如果你想站在安全的角度,你可以使用与 `cp` 相同的方式。
|
||||
|
||||
除了移动与拷贝的不同外,另一个 `mv` 和 `cp` 之间的不同是当你移动目录时:
|
||||
|
||||
```
|
||||
mv directory_a/ directory_b
|
||||
```
|
||||
|
||||
不需要添加递归的标志。这是因为你实际做的是重命名一个目录,与第一个例子相同,你做的是重命名文件。实际上,即使你从一个目录到另一个目录 “移动” 一个文件,只要两个目录在相同的存储设备和分区,你就是在重命名文件。
|
||||
|
||||
你可以做一个实验来证明。 `time` 是一个工具来让你测量一个命令花费多久来执行。找一个非常大的文件,可以是几百 MB 甚至 几 GB (例如一个长视频),像下方这样尝试拷贝到另一个目录:
|
||||
|
||||
```
|
||||
$ time cp hefty_file.mkv another_directory/
|
||||
real 0m3,868s
|
||||
user 0m0,016s
|
||||
sys 0m0,887s
|
||||
```
|
||||
|
||||
下面是 `time` 的输出。需要关注的是第一行, real 时间。它花费了几乎 4 秒来拷贝 355 MB 的 `hefty_file.mkv` 到 `another_directory/` 目录。
|
||||
|
||||
现在让我们尝试移动它:
|
||||
|
||||
```
|
||||
$ time mv hefty_file.mkv another_directory/
|
||||
real 0m0,004s
|
||||
user 0m0,000s
|
||||
sys 0m0,003s
|
||||
```
|
||||
|
||||
移动几乎是瞬时的!这是违反直觉的,因为看起来 `mv` 必须复制这个文件然后删除原来的。这是 `mv` 对比 `cp` 命令必须做的两件事。但是,实际上,`mv` 快了 1000 倍。
|
||||
|
||||
这是因为文件系统结构中,它的所有目录树,只为了让用户便利而存在。在每个分区的开始,有一个称作*分区表*的东西告诉操作系统在实际的物理磁盘上去哪找每个文件。在磁盘上,数据没有分为目录甚至是文件。[作为替代的是轨道、扇区和簇][5]。当你在相同分区 “移动” 一个文件时,操作系统实际做的仅仅是在分区表中改变了那个文件的入口,但它仍然指向磁盘上相同的簇信息。
|
||||
|
||||
是的!移动是一个谎言!至少在相同分区下是。如果你试图移动一个文件到一个不同的分区或者不同的设备, `mv` 仍然很快,但可以察觉到它比在相同分区下移动文件慢了。这是因为实际上发生了复制和清除数据。
|
||||
|
||||
### 重命名
|
||||
|
||||
有几个不同的命令行 `rename` 工具。没有一个像 `cp` 和 `mv` 那样固定,并且它们工作的方式都有一点不同,相同的一点是它们都被用来改变文件名的部分。
|
||||
|
||||
在 Debian 和 Ubuntu 中, 默认的 `rename` 工具使用 [正则表达式][6](字符组成的字符串模式)来大量的改变目录中的文件。命令:
|
||||
|
||||
```
|
||||
rename 's/\.JPEG$/.jpg/' *
|
||||
```
|
||||
|
||||
将改变所有扩展名为 `JPEG` 的文件为 `jpg`。文件 `IMG001.JPEG` 变成 `IMG001.jpg`、 `my_pic.JPEG` 变成 `my_pic.jpg`,等等。
|
||||
|
||||
另一个 `rename` 版本默认在 Manjaro 上可获得,这是一个 Arch 的衍生版,更简单,但是可能没有那么强大:
|
||||
|
||||
```
|
||||
rename .JPEG .jpg *
|
||||
```
|
||||
|
||||
这和你之前看到的上面做相同的重命名操作。在这个版本,`.JPEG` 是你想改变的字符组成的字符串,`.jpg` 是你想要改变成为的,`*` 表示当前目录下的所有文件。
|
||||
|
||||
基本原则是如果你所做的仅仅是重命名一个文件或者目录,你最好用 `mv`,这是因为 `mv` 在所有分发版上都是可靠一致的。
|
||||
|
||||
### 了解更多
|
||||
|
||||
查看 `mv` 和 `cp` 的 man 页面了解更多。运行
|
||||
|
||||
```
|
||||
man cp
|
||||
```
|
||||
|
||||
或者
|
||||
```
|
||||
man mv
|
||||
```
|
||||
|
||||
来阅读这些命令自带的所有选项,这些使他们使用起来更强大和安全。
|
||||
|
||||
----------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2018/8/linux-beginners-moving-things-around
|
||||
|
||||
作者:[Paul Brown][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[warmfrog](https://github.com/warmfrog)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/bro66
|
||||
[1]: https://linux.cn/article-10066-1.html
|
||||
[2]: https://linux.cn/article-10399-1.html
|
||||
[3]: https://www.nano-editor.org/
|
||||
[4]: https://www.vim.org/
|
||||
[5]: https://en.wikipedia.org/wiki/Disk_sector
|
||||
[6]: https://en.wikipedia.org/wiki/Regular_expression
|
||||
[7]: https://linux.cn/article-10370-1.html
|
||||
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (liujing97)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10727-1.html)
|
||||
[#]: subject: (7 Methods To Identify Disk Partition/FileSystem UUID On Linux)
|
||||
[#]: via: (https://www.2daygeek.com/check-partitions-uuid-filesystem-uuid-universally-unique-identifier-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
@ -10,27 +10,23 @@
|
||||
Linux 中获取硬盘分区或文件系统的 UUID 的七种方法
|
||||
======
|
||||
|
||||
作为一个 Linux 系统管理员,你应该知道如何去查看分区的 UUID 或文件系统的 UUID。
|
||||
|
||||
因为大多数的 Linux 系统使用 UUID 挂载分区。在 `/etc/fstab` 文件中可以验证此的内容。
|
||||
作为一个 Linux 系统管理员,你应该知道如何去查看分区的 UUID 或文件系统的 UUID。因为现在大多数的 Linux 系统都使用 UUID 挂载分区。你可以在 `/etc/fstab` 文件中可以验证。
|
||||
|
||||
有许多可用的实用程序可以查看 UUID。本文我们将会向你展示多种查看 UUID 的方法,并且你可以选择一种适合于你的方法。
|
||||
|
||||
### 何为 UUID?
|
||||
|
||||
UUID 代表着通用唯一识别码,它帮助 Linux 系统去识别一个磁盘驱动分区而不是块设备文件。
|
||||
UUID 意即<ruby>通用唯一识别码<rt>Universally Unique Identifier</rt></ruby>,它可以帮助 Linux 系统识别一个磁盘分区而不是块设备文件。
|
||||
|
||||
libuuid 是内核 2.15.1 中 util-linux-ng 包中的一部分,它被默认安装在 Linux 系统中。
|
||||
自内核 2.15.1 起,libuuid 就是 util-linux-ng 包中的一部分,它被默认安装在 Linux 系统中。UUID 由该库生成,可以合理地认为在一个系统中 UUID 是唯一的,并且在所有系统中也是唯一的。
|
||||
|
||||
UUID 由该库生成,可以合理地认为它在一个系统中是唯一的,并且在所有系统中也是唯一的。
|
||||
这是在计算机系统中用来标识信息的一个 128 位(比特)的数字。UUID 最初被用在<ruby>阿波罗网络计算机系统<rt>Apollo Network Computing System</rt></ruby>(NCS)中,之后 UUID 被<ruby>开放软件基金会<rt>Open Software Foundation</rt></ruby>(OSF)标准化,成为<ruby>分布式计算环境<rt>Distributed Computing Environment</rt></ruby>(DCE)的一部分。
|
||||
|
||||
在计算机系统中使用了 128 位数字去标识信息。UUID 最初被用在 Apollo 网络计算机系统(NCS)中,之后 UUID 被开放软件基金会(OSF)标准化,成为分布式计算环境(DCE)的一部分。
|
||||
UUID 以 32 个十六进制的数字表示,被连字符分割为 5 组显示,总共的 36 个字符的格式为 8-4-4-4-12(32 个字母或数字和 4 个连字符)。
|
||||
|
||||
UUID 以 32 个十六进制(基数为 16)的数字表示,被连字符分割为 5 组显示,总共的 36 个字符格式为 8-4-4-4-12(32 个字母或数字和 4 个连字符)。
|
||||
例如: `d92fa769-e00f-4fd7-b6ed-ecf7224af7fa`
|
||||
|
||||
例如:d92fa769-e00f-4fd7-b6ed-ecf7224af7fa
|
||||
|
||||
我的 /etc/fstab 文件示例。
|
||||
我的 `/etc/fstab` 文件示例:
|
||||
|
||||
```
|
||||
# cat /etc/fstab
|
||||
@ -48,19 +44,17 @@ UUID=a2092b92-af29-4760-8e68-7a201922573b swap swap defaults,noatime 0 2
|
||||
|
||||
我们可以使用下面的 7 个命令来查看。
|
||||
|
||||
* **`blkid 命令:`** 定位或打印块设备的属性。
|
||||
* **`lsblk 命令:`** lsblk 列出所有可用的或指定的块设备的信息。
|
||||
* **`hwinfo 命令:`** hwinfo 表示硬件信息工具,是另外一个很好的实用工具,用于查询系统中已存在硬件。
|
||||
* **`udevadm 命令:`** udev 管理工具
|
||||
* **`tune2fs 命令:`** 调整 ext2/ext3/ext4 文件系统上的可调文件系统参数。
|
||||
* **`dumpe2fs 命令:`** 查询 ext2/ ext3/ext4 文件系统的信息。
|
||||
* **`使用 by-uuid 路径:`** 该目录下包含有 UUID 和实际的块设备文件,UUID 与实际的块设备文件链接在一起。
|
||||
|
||||
|
||||
* `blkid` 命令:定位或打印块设备的属性。
|
||||
* `lsblk` 命令:列出所有可用的或指定的块设备的信息。
|
||||
* `hwinfo` 命令:硬件信息工具,是另外一个很好的实用工具,用于查询系统中已存在硬件。
|
||||
* `udevadm` 命令:udev 管理工具
|
||||
* `tune2fs` 命令:调整 ext2/ext3/ext4 文件系统上的可调文件系统参数。
|
||||
* `dumpe2fs` 命令:查询 ext2/ext3/ext4 文件系统的信息。
|
||||
* 使用 `by-uuid` 路径:该目录下包含有 UUID 和实际的块设备文件,UUID 与实际的块设备文件链接在一起。
|
||||
|
||||
### Linux 中如何使用 blkid 命令查看磁盘分区或文件系统的 UUID?
|
||||
|
||||
blkid 是定位或打印块设备属性的命令行实用工具。它利用 libblkid 库在 Linux 系统中获得到磁盘分区的 UUID。
|
||||
`blkid` 是定位或打印块设备属性的命令行实用工具。它利用 libblkid 库在 Linux 系统中获得到磁盘分区的 UUID。
|
||||
|
||||
```
|
||||
# blkid
|
||||
@ -72,24 +66,24 @@ blkid 是定位或打印块设备属性的命令行实用工具。它利用 libb
|
||||
|
||||
### Linux 中如何使用 lsblk 命令查看磁盘分区或文件系统的 UUID?
|
||||
|
||||
lsblk 列出所有有关可用或指定块设备的信息。lsblk 命令读取 sysfs 文件系统和 udev 数据库以收集信息。
|
||||
`lsblk` 列出所有有关可用或指定块设备的信息。`lsblk` 命令读取 sysfs 文件系统和 udev 数据库以收集信息。
|
||||
|
||||
如果 udev 数据库是不可用的或者编译的 lsblk 是不支持 udev 的,它会试图从块设备中读取 LABEL,UUID 和文件系统类型。这种情况下,必须为 root 身份。该命令默认会以类似于树的格式打印出所有的块设备(RAM 盘除外)。
|
||||
如果 udev 数据库不可用或者编译的 lsblk 不支持 udev,它会试图从块设备中读取卷标、UUID 和文件系统类型。这种情况下,必须以 root 身份运行。该命令默认会以类似于树的格式打印出所有的块设备(RAM 盘除外)。
|
||||
|
||||
```
|
||||
# lsblk -o name,mountpoint,size,uuid
|
||||
NAME MOUNTPOINT SIZE UUID
|
||||
sda 30G
|
||||
└─sda1 / 20G d92fa769-e00f-4fd7-b6ed-ecf7224af7fa
|
||||
sdb 10G
|
||||
sdc 10G
|
||||
├─sdc1 1G d17e3c31-e2c9-4f11-809c-94a549bc43b7
|
||||
├─sdc3 1G ca307aa4-0866-49b1-8184-004025789e63
|
||||
├─sdc4 1K
|
||||
└─sdc5 1G
|
||||
sdd 10G
|
||||
sde 10G
|
||||
sr0 1024M
|
||||
NAME MOUNTPOINT SIZE UUID
|
||||
sda 30G
|
||||
└─sda1 / 20G d92fa769-e00f-4fd7-b6ed-ecf7224af7fa
|
||||
sdb 10G
|
||||
sdc 10G
|
||||
├─sdc1 1G d17e3c31-e2c9-4f11-809c-94a549bc43b7
|
||||
├─sdc3 1G ca307aa4-0866-49b1-8184-004025789e63
|
||||
├─sdc4 1K
|
||||
└─sdc5 1G
|
||||
sdd 10G
|
||||
sde 10G
|
||||
sr0 1024M
|
||||
```
|
||||
|
||||
### Linux 中如何使用 by-uuid 路径查看磁盘分区或文件系统的 UUID?
|
||||
@ -106,7 +100,7 @@ lrwxrwxrwx 1 root root 10 Jan 29 08:34 d92fa769-e00f-4fd7-b6ed-ecf7224af7fa -> .
|
||||
|
||||
### Linux 中如何使用 hwinfo 命令查看磁盘分区或文件系统的 UUID?
|
||||
|
||||
**[hwinfo][1]** 表示硬件信息工具,是另外一种很好的实用工具。它被用来检测系统中已存在的硬件,并且以可读的格式显示各种硬件组件的细节信息。
|
||||
[hwinfo][1] 意即硬件信息工具,是另外一种很好的实用工具。它被用来检测系统中已存在的硬件,并且以可读的格式显示各种硬件组件的细节信息。
|
||||
|
||||
```
|
||||
# hwinfo --block | grep by-uuid | awk '{print $3,$7}'
|
||||
@ -117,16 +111,16 @@ lrwxrwxrwx 1 root root 10 Jan 29 08:34 d92fa769-e00f-4fd7-b6ed-ecf7224af7fa -> .
|
||||
|
||||
### Linux 中如何使用 udevadm 命令查看磁盘分区或文件系统的 UUID?
|
||||
|
||||
udevadm 需要命令和命令特定的操作。它控制 systemd-udevd 的运行时的行为,请求内核事件、管理事件队列并且提供简单的调试机制。
|
||||
`udevadm` 需要命令和命令特定的操作。它控制 systemd-udevd 的运行时行为,请求内核事件、管理事件队列并且提供简单的调试机制。
|
||||
|
||||
```
|
||||
udevadm info -q all -n /dev/sdc1 | grep -i by-uuid | head -1
|
||||
# udevadm info -q all -n /dev/sdc1 | grep -i by-uuid | head -1
|
||||
S: disk/by-uuid/d17e3c31-e2c9-4f11-809c-94a549bc43b7
|
||||
```
|
||||
|
||||
### Linux 中如何使用 tune2fs 命令查看磁盘分区或文件系统的 UUID?
|
||||
|
||||
tune2fs 允许系统管理员在 Linux 的 ext2, ext3, ext4 文件系统中调整各种可调的文件系统参数。这些选项的当前值可以使用选项 -l 显示。
|
||||
`tune2fs` 允许系统管理员在 Linux 的 ext2、ext3、ext4 文件系统中调整各种可调的文件系统参数。这些选项的当前值可以使用选项 `-l` 显示。
|
||||
|
||||
```
|
||||
# tune2fs -l /dev/sdc1 | grep UUID
|
||||
@ -135,7 +129,7 @@ Filesystem UUID: d17e3c31-e2c9-4f11-809c-94a549bc43b7
|
||||
|
||||
### Linux 中如何使用 dumpe2fs 命令查看磁盘分区或文件系统的 UUID?
|
||||
|
||||
dumpe2fs 打印出现在设备文件系统中的超级块和块组的信息。
|
||||
`dumpe2fs` 打印出现在设备文件系统中的超级块和块组的信息。
|
||||
|
||||
```
|
||||
# dumpe2fs /dev/sdc1 | grep UUID
|
||||
@ -150,7 +144,7 @@ via: https://www.2daygeek.com/check-partitions-uuid-filesystem-uuid-universally-
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[liujing97](https://github.com/liujing97)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,86 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10774-1.html)
|
||||
[#]: subject: (Enjoy Netflix? You Should Thank FreeBSD)
|
||||
[#]: via: (https://itsfoss.com/netflix-freebsd-cdn/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
喜欢 Netflix 么?你应该感谢 FreeBSD
|
||||
======
|
||||
|
||||
![][7]
|
||||
|
||||
Netflix 是世界上最受欢迎的流媒体服务之一。对,你已经知道了。但你可能不知道的是 Netflix 使用 [FreeBSD][1] 向你提供内容。
|
||||
|
||||
是的。Netflix 依靠 FreeBSD 来构建其内部内容交付网络(CDN)。
|
||||
|
||||
[CDN][2] 是一组位于世界各地的服务器。它主要用于向终端用户分发像图像和视频这样的“大文件”。
|
||||
|
||||
Netflix 没有选择商业 CDN 服务,而是建立了自己的内部 CDN,名为 [Open Connect][3]。
|
||||
|
||||
Open Connect 使用[自定义硬件][4]:Open Connect Appliance。你可以在下面的图片中看到它。它可以每秒处理 40Gb 的数据,存储容量为 248 TB。
|
||||
|
||||
![Netflix’s Open Connect Appliance runs FreeBSD][5]
|
||||
|
||||
Netflix 免费为合格的互联网服务提供商(ISP) 提供 Open Connect Appliance。通过这种方式,大量的 Netflix 流量得到了本地化,ISP 可以更高效地提供 Netflix 内容。
|
||||
|
||||
Open Connect Appliance 运行在 FreeBSD 操作系统上,并且[几乎完全运行开源软件][6]。
|
||||
|
||||
### Open Connect 使用最新版 FreeBSD
|
||||
|
||||
|
||||
你或许会觉得 Netflix 会在这样一个关键基础设施上使用 FreeBSD 的稳定版本,但 Netflix 会跟踪 [FreeBSD 最新/当前版本][8]。Netflix 表示,跟踪“最新版”可以让他们“保持前瞻性,专注于创新”。
|
||||
|
||||
以下是 Netflix 跟踪最新版 FreeBSD 的好处:
|
||||
|
||||
* 更快的功能迭代
|
||||
* 更快地使用 FreeBSD 的新功能
|
||||
* 更快的 bug 修复
|
||||
* 实现协作
|
||||
* 尽量减少合并冲突
|
||||
* 摊销合并“成本”
|
||||
|
||||
> 运行 FreeBSD “最新版” 可以让我们非常高效地向用户分发大量数据,同时保持高速的功能开发。
|
||||
>
|
||||
> Netflix
|
||||
|
||||
请记得,甚至[谷歌也使用 Debian][9] 测试版而不是 Debian 稳定版。也许这些企业更喜欢最先进的功能。
|
||||
|
||||
与谷歌一样,Netflix 也计划向上游提供代码。这应该有助于 FreeBSD 和其他基于 FreeBSD 的 BSD 发行版。
|
||||
|
||||
那么 Netflix 用 FreeBSD 实现了什么?以下是一些统计数据:
|
||||
|
||||
> 使用 FreeBSD 和商业硬件,我们在 16 核 2.6 GHz CPU 上使用约 55% 的 CPU,实现了 90 Gb/s 的 TLS 加密连接。
|
||||
>
|
||||
> Netflix
|
||||
|
||||
如果你想了解更多关于 Netflix 和 FreeBSD 的信息,可以参考 [FOSDEM 的这个演示文稿][10]。你还可以在[这里][11]观看演示文稿的视频。
|
||||
|
||||
目前,大型企业主要依靠 Linux 来实现其服务器基础架构,但 Netflix 已经信任了 BSD。这对 BSD 社区来说是一件好事,因为如果像 Netflix 这样的行业领导者重视 BSD,那么其他人也可以跟上。你怎么看?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/netflix-freebsd-cdn/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.freebsd.org/
|
||||
[2]: https://www.cloudflare.com/learning/cdn/what-is-a-cdn/
|
||||
[3]: https://openconnect.netflix.com/en/
|
||||
[4]: https://openconnect.netflix.com/en/hardware/
|
||||
[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/02/netflix-open-connect-appliance.jpeg?fit=800%2C533&ssl=1
|
||||
[6]: https://openconnect.netflix.com/en/software/
|
||||
[7]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/netflix-freebsd.png?resize=800%2C450&ssl=1
|
||||
[8]: https://www.bsdnow.tv/tutorials/stable-current
|
||||
[9]: https://itsfoss.com/goobuntu-glinux-google/
|
||||
[10]: https://fosdem.org/2019/schedule/event/netflix_freebsd/attachments/slides/3103/export/events/attachments/netflix_freebsd/slides/3103/FOSDEM_2019_Netflix_and_FreeBSD.pdf
|
||||
[11]: http://mirror.onet.pl/pub/mirrors/video.fosdem.org/2019/Janson/netflix_freebsd.webm
|
||||
@ -0,0 +1,48 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (MjSeven)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10769-1.html)
|
||||
[#]: subject: (Which programming languages should you learn?)
|
||||
[#]: via: (https://opensource.com/article/19/2/which-programming-languages-should-you-learn)
|
||||
[#]: author: (Marty Kalin https://opensource.com/users/mkalindepauledu)
|
||||
|
||||
你应该学习哪种编程语言?
|
||||
======
|
||||
|
||||
> 学习一门新的编程语言是在你的职业生涯中继续前进的好方法,但是应该学习哪一门呢?
|
||||
|
||||

|
||||
|
||||
如果你想要开始你的编程生涯或继续前进,那么学习一门新语言是一个聪明的主意。但是,大量活跃使用的语言引发了一个问题:哪种编程语言是最好的?要回答这个问题,让我们从一个简单的问题开始:你想做什么样的程序?
|
||||
|
||||
如果你想在客户端进行网络编程,那么特定语言 HTML、CSS 和 JavaScript(看似无穷无尽的方言之一)是必须要学习的。
|
||||
|
||||
如果你想在服务器端进行 Web 编程,那么选择包括常见的通用语言:C++、Golang、Java、C#、 Node.js、Perl、Python、Ruby 等等。当然,服务器程序与数据存储(例如关系数据库和其他数据库)打交道,这意味着 SQL 等查询语言可能会发挥作用。
|
||||
|
||||
如果你正在为移动设备编写原生应用程序,那么了解目标平台非常重要。对于 Apple 设备,Swift 已经取代 Objective C 成为首选语言。对于 Android 设备,Java(带有专用库和工具集)仍然是主要语言。有一些特殊语言,如与 C# 一起使用的 Xamarin,可以为 Apple、Android 和 Windows 设备生成特定于平台的代码。
|
||||
|
||||
那么通用语言呢?通常有各种各样的选择。在*动态*或*脚本*语言(如 Perl、Python 和 Ruby)中,有一些新东西,如 Node.js。而 Java 和 C# 的相似之处比它们的粉丝愿意承认的还要多,仍然是针对虚拟机(分别是 JVM 和 CLR)的主要*静态编译*语言。在可以编译为*原生可执行文件*的语言中,C++ 仍在使用,还有后来出现的 Golang 和 Rust 等。通用的*函数式*语言比比皆是(如 Clojure、Haskell、Erlang、F#、Lisp 和 Scala),它们通常都有热情投入的社区。值得注意的是,面向对象语言(如 Java 和 C#)已经添加了函数式构造(特别是 lambdas),而动态语言从一开始就有函数式构造。
|
||||
|
||||
让我以 C 语言结尾,它是一种小巧、优雅、可扩展的语言,不要与 C++ 混淆。现代操作系统主要用 C 语言编写,其余部分用汇编语言编写。任何平台上的标准库大多数都是用 C 语言编写的。例如,任何打印 `Hello, world!` 这种问候都是通过调用名为 `write` 的 C 库函数来实现的。
|
||||
|
||||
C 作为一种可移植的汇编语言,公开了其他高级语言有意隐藏的底层系统的详细信息。因此,理解 C 可以更好地掌握程序如何竞争执行所需的共享系统资源(如处理器、内存和 I/O 设备)。C 语言既高级又接近硬件,因此在性能方面无与伦比,当然,汇编语言除外。最后,C 是编程语言中的通用语言,几乎所有通用语言都支持某种形式的 C 调用。
|
||||
|
||||
有关现代 C 语言的介绍,参考我的书籍 《[C 语言编程:可移植的汇编器介绍][1]》。无论你怎么做,学习 C 语言,你会学到比另一种编程语言多得多的东西。
|
||||
|
||||
你认为学习哪些编程语言很重要?你是否同意这些建议?在评论告知我们!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/2/which-programming-languages-should-you-learn
|
||||
|
||||
作者:[Marty Kalin][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mkalindepauledu
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.amazon.com/dp/1977056954?ref_=pe_870760_150889320
|
||||
@ -1,20 +1,20 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10723-1.html)
|
||||
[#]: subject: (Ubuntu 14.04 is Reaching the End of Life. Here are Your Options)
|
||||
[#]: via: (https://itsfoss.com/ubuntu-14-04-end-of-life/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
Ubuntu 14.04 即将结束支持。下面是你的选择
|
||||
Ubuntu 14.04 即将结束支持,你该怎么办?
|
||||
======
|
||||
|
||||
Ubuntu 14.04 即将于 2019 年 4 月 30 日结束支持。这意味着在此日期之后 Ubuntu 14.04 用户将无法获得安全和维护更新。
|
||||
|
||||
你甚至不会获得已安装应用的更新,并且不手动修改 sources.list 则无法使用 apt 命令或软件中心安装新应用。
|
||||
你甚至不会获得已安装应用的更新,并且不手动修改 `sources.list` 则无法使用 `apt` 命令或软件中心安装新应用。
|
||||
|
||||
Ubuntu 14.04 大约在五年前发布。这是 Ubuntu 长期支持版本。
|
||||
Ubuntu 14.04 大约在五年前发布。这是 Ubuntu 长期支持版本(LTS)。
|
||||
|
||||
[检查 Ubuntu 版本][1]并查看你是否仍在使用 Ubuntu 14.04。如果是桌面或服务器版,你可能想知道在这种情况下你应该怎么做。
|
||||
|
||||
@ -36,7 +36,7 @@ Ubuntu 16.04 也是一个长期支持版本,它将支持到 2021 年 4 月。
|
||||
|
||||
我说的备份指的是将这些文件夹复制到外部 USB 盘。换句话说,你应该有办法将数据复制回计算机,因为你将格式化你的系统。
|
||||
|
||||
我建议桌面用户使用此选项。 Ubuntu 18.04 是目前的长期支持版本,它将至少在 2023 年 4 月之前得到支持。在你被迫进行下次升级之前,你将有四年的时间。
|
||||
我建议桌面用户使用此选项。Ubuntu 18.04 是目前的长期支持版本,它将至少在 2023 年 4 月之前得到支持。在你被迫进行下次升级之前,你将有四年的时间。
|
||||
|
||||
### 支付扩展安全维护费用并继续使用 Ubuntu 14.04
|
||||
|
||||
@ -48,7 +48,7 @@ Ubuntu Advantage 计划用户还有[扩展安全维护][4](ESM)功能。即
|
||||
|
||||
### 还在使用 Ubuntu 14.04 吗?
|
||||
|
||||
如果你还在使用 Ubuntu 14.04,那么你应该开始了解这些选择,因为你还有不到两个月的时间。
|
||||
如果你还在使用 Ubuntu 14.04,那么你应该开始了解这些选择,因为你还有不到一个月的时间。
|
||||
|
||||
在任何情况下,你都不能在 2019 年 4 月 30 日之后使用 Ubuntu 14.04,因为你的系统由于缺乏安全更新而容易受到攻击。无法安装新应用将是一个额外的痛苦。
|
||||
|
||||
@ -61,7 +61,7 @@ via: https://itsfoss.com/ubuntu-14-04-end-of-life/
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,53 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10731-1.html)
|
||||
[#]: subject: (How to contribute to the Raspberry Pi community)
|
||||
[#]: via: (https://opensource.com/article/19/3/contribute-raspberry-pi-community)
|
||||
[#]: author: (Anderson Silva (Red Hat) https://opensource.com/users/ansilva/users/kepler22b/users/ansilva)
|
||||
|
||||
树莓派使用入门:如何为树莓派社区做出贡献
|
||||
======
|
||||
|
||||
> 在我们的入门系列的第 13 篇文章中,发现参与树莓派社区的方法。
|
||||
|
||||
![][1]
|
||||
|
||||
这个系列已经逐渐接近尾声,我已经写了很多它的乐趣,我大多希望它能帮助人们使用树莓派进行教育或娱乐。也许这些文章能说服你买你的第一个树莓派,或者让你重新发现抽屉里的吃灰设备。如果这里有真的,那么我认为这个系列就是成功的。
|
||||
|
||||
如果你想买一台,并宣传这块绿色的小板子有多么多功能,这里有几个方法帮你与树莓派社区建立连接:
|
||||
|
||||
* 帮助改进[官方文档][2]
|
||||
* 贡献代码给依赖的[项目][3]
|
||||
* 用 Raspbian 报告 [bug][4]
|
||||
* 报告不同 ARM 架构分发版的的 bug
|
||||
* 看一眼英国国内的树莓派基金会的[代码俱乐部][5]或英国境外的[国际代码俱乐部][6],帮助孩子学习编码
|
||||
* 帮助[翻译][7]
|
||||
* 在 [Raspberry Jam][8] 当志愿者
|
||||
|
||||
这些只是你可以为树莓派社区做贡献的几种方式。最后但同样重要的是,你可以加入我并[投稿文章][9]到你最喜欢的开源网站 [Opensource.com][10]。 :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/contribute-raspberry-pi-community
|
||||
|
||||
作者:[Anderson Silva (Red Hat)][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ansilva/users/kepler22b/users/ansilva
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/raspberry_pi_community.jpg?itok=dcKwb5et
|
||||
[2]: https://www.raspberrypi.org/documentation/CONTRIBUTING.md
|
||||
[3]: https://www.raspberrypi.org/github/
|
||||
[4]: https://www.raspbian.org/RaspbianBugs
|
||||
[5]: https://www.codeclub.org.uk/
|
||||
[6]: https://www.codeclubworld.org/
|
||||
[7]: https://www.raspberrypi.org/translate/
|
||||
[8]: https://www.raspberrypi.org/jam/
|
||||
[9]: https://opensource.com/participate
|
||||
[10]: http://Opensource.com
|
||||
@ -0,0 +1,75 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10734-1.html)
|
||||
[#]: subject: (14 days of celebrating the Raspberry Pi)
|
||||
[#]: via: (https://opensource.com/article/19/3/happy-pi-day)
|
||||
[#]: author: (Anderson Silva (Red Hat) https://opensource.com/users/ansilva)
|
||||
|
||||
树莓派使用入门:庆祝树莓派的 14 天
|
||||
======
|
||||
|
||||
> 在我们关于树莓派入门系列的第 14 篇也是最后一篇文章中,回顾一下我们学到的所有东西。
|
||||
|
||||
![][1]
|
||||
|
||||
### 派节快乐!
|
||||
|
||||
每年的 3 月 14 日,我们这些极客都会庆祝派节。我们用这种方式缩写日期: `MMDD`,3 月 14 于是写成 03/14,它的数字上提醒我们 3.14,或者说 [π][2] 的前三位数字。许多美国人没有意识到的是,世界上几乎没有其他国家使用这种[日期格式][3],因此派节几乎只适用于美国,尽管它在全球范围内得到了庆祝。
|
||||
|
||||
无论你身在何处,让我们一起庆祝树莓派,并通过回顾过去两周我们所涉及的主题来结束本系列:
|
||||
|
||||
* 第 1 天:[你应该选择哪种树莓派?][4]
|
||||
* 第 2 天:[如何购买树莓派][5]
|
||||
* 第 3 天:[如何启动一个新的树莓派][6]
|
||||
* 第 4 天:[用树莓派学习 Linux][7]
|
||||
* 第 5 天:[教孩子们用树莓派学编程的 5 种方法][8]
|
||||
* 第 6 天:[可以使用树莓派学习的 3 种流行编程语言][9]
|
||||
* 第 7 天:[如何更新树莓派][10]
|
||||
* 第 8 天:[如何使用树莓派来娱乐][11]
|
||||
* 第 9 天:[树莓派上的模拟器和原生 Linux 游戏][12]
|
||||
* 第 10 天:[进入物理世界 —— 如何使用树莓派的 GPIO 针脚][13]
|
||||
* 第 11 天:[通过树莓派和 kali Linux 学习计算机安全][14]
|
||||
* 第 12 天:[在树莓派上使用 Mathematica 进行高级数学运算][15]
|
||||
* 第 13 天:[如何为树莓派社区做出贡献][16]
|
||||
|
||||
![Pi Day illustration][18]
|
||||
|
||||
我将结束本系列,感谢所有关注的人,尤其是那些在过去 14 天里从中学到了东西的人!我还想鼓励大家不断扩展他们对树莓派以及围绕它构建的所有开源(和闭源)技术的了解。
|
||||
|
||||
我还鼓励你了解其他文化、哲学、宗教和世界观。让我们成为人类的是这种惊人的 (有时是有趣的) 能力,我们不仅要适应外部环境,而且要适应智力环境。
|
||||
|
||||
不管你做什么,保持学习!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/happy-pi-day
|
||||
|
||||
作者:[Anderson Silva (Red Hat)][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ansilva
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/raspberry-pi-juggle.png?itok=oTgGGSRA
|
||||
[2]: https://www.piday.org/million/
|
||||
[3]: https://en.wikipedia.org/wiki/Date_format_by_country
|
||||
[4]: https://linux.cn/article-10611-1.html
|
||||
[5]: https://linux.cn/article-10615-1.html
|
||||
[6]: https://linux.cn/article-10644-1.html
|
||||
[7]: https://linux.cn/article-10645-1.html
|
||||
[8]: https://linux.cn/article-10653-1.html
|
||||
[9]: https://linux.cn/article-10661-1.html
|
||||
[10]: https://linux.cn/article-10665-1.html
|
||||
[11]: https://linux.cn/article-10669-1.html
|
||||
[12]: https://linux.cn/article-10682-1.html
|
||||
[13]: https://linux.cn/article-10687-1.html
|
||||
[14]: https://linux.cn/article-10690-1.html
|
||||
[15]: https://linux.cn/article-10711-1.html
|
||||
[16]: https://linux.cn/article-10731-1.html
|
||||
[17]: /file/426561
|
||||
[18]: https://opensource.com/sites/default/files/uploads/raspberrypi_14_piday.jpg (Pi Day illustration)
|
||||
@ -92,7 +92,7 @@ via: https://itsfoss.com/history-of-firefox
|
||||
[3]: https://en.wikipedia.org/wiki/Tim_Berners-Lee
|
||||
[4]: https://www.w3.org/DesignIssues/TimBook-old/History.html
|
||||
[5]: http://viola.org/
|
||||
[6]: https://en.wikipedia.org/wiki/Mosaic_(web_browser
|
||||
[6]: https://en.wikipedia.org/wiki/Mosaic_(web_browser)
|
||||
[7]: http://www.computinghistory.org.uk/det/1789/Marc-Andreessen/
|
||||
[8]: http://www.davetitus.com/mozilla/
|
||||
[9]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/03/Mozilla_boxing.jpg?ssl=1
|
||||
@ -110,7 +110,7 @@ via: https://itsfoss.com/history-of-firefox
|
||||
[21]: https://en.wikipedia.org/wiki/Usage_share_of_web_browsers
|
||||
[22]: http://gs.statcounter.com/browser-market-share/desktop/worldwide/#monthly-201901-201901-bar
|
||||
[23]: https://en.wikipedia.org/wiki/Red_panda
|
||||
[24]: https://en.wikipedia.org/wiki/Flock_(web_browser
|
||||
[24]: https://en.wikipedia.org/wiki/Flock_(web_browser)
|
||||
[25]: https://www.windowscentral.com/microsoft-building-chromium-powered-web-browser-windows-10
|
||||
[26]: https://itsfoss.com/why-firefox/
|
||||
[27]: https://itsfoss.com/firefox-quantum-ubuntu/
|
||||
@ -1,24 +1,24 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10732-1.html)
|
||||
[#]: subject: (Sweet Home 3D: An open source tool to help you decide on your dream home)
|
||||
[#]: via: (https://opensource.com/article/19/3/tool-find-home)
|
||||
[#]: author: (Jeff Macharyas (Community Moderator) )
|
||||
|
||||
Sweet Home 3D:一个帮助你决定梦想家庭的开源工具
|
||||
Sweet Home 3D:一个帮助你寻找梦想家庭的开源工具
|
||||
======
|
||||
|
||||
室内设计应用可以轻松渲染你喜欢的房子,不管是真实的或是想象的。
|
||||
> 室内设计应用可以轻松渲染你喜欢的房子,不管是真实的或是想象的。
|
||||
|
||||
![Houses in a row][1]
|
||||
|
||||
我最近接受了一份在弗吉尼亚州的新工作。由于我妻子一直在纽约工作,看着我们在纽约的房子直至出售,我有责任出去为我们和我们的猫找一所新房子。在我们搬进去之前她不会看到的房子!
|
||||
我最近接受了一份在弗吉尼亚州的新工作。由于我妻子一直在纽约工作,看着我们在纽约的房子直至出售,我有责任出去为我们和我们的猫找一所新房子。在我们搬进去之前她看不到新房子。
|
||||
|
||||
我和一个房地产经纪人签约,并看了几间房子,拍了许多照片,写下了潦草的笔记。晚上,我会将照片上传到 Google Drive 文件夹中,我和我老婆会通过手机同时查看这些照片,同时我还想记住房间是在右边还是左边,是否有风扇等。
|
||||
我和一个房地产经纪人签约,并看了几间房子,拍了许多照片,写下了潦草的笔记。晚上,我会将照片上传到 Google Drive 文件夹中,我和我老婆会通过手机同时查看这些照片,同时我还要记住房间是在右边还是左边,是否有风扇等。
|
||||
|
||||
由于这是一个相当繁琐且不太准确的方式来展示我的发现,我因此去寻找一个开源解决方案,以更好地展示我们未来的梦想之家将会是什么样的,而不会取决于我的模糊记忆和模糊的照片。
|
||||
由于这是一个相当繁琐且不太准确的展示我的发现的方式,我因此去寻找一个开源解决方案,以更好地展示我们未来的梦想之家将会是什么样的,而不会取决于我的模糊记忆和模糊的照片。
|
||||
|
||||
[Sweet Home 3D][2] 完全满足了我的要求。Sweet Home 3D 可在 Sourceforge 上获取,并在 GNU 通用公共许可证下发布。它的[网站][3]信息非常丰富,我能够立即启动并运行。Sweet Home 3D 由总部位于巴黎的 eTeks 的 Emmanuel Puybaret 开发。
|
||||
|
||||
@ -32,19 +32,19 @@ Sweet Home 3D:一个帮助你决定梦想家庭的开源工具
|
||||
|
||||
现在我画完了“内墙”,我从网站下载了各种“家具”,其中包括实际的家具以及门、窗、架子等。每个项目都以 ZIP 文件的形式下载,因此我创建了一个包含所有未压缩文件的文件夹。我可以自定义每件家具和重复的物品比如门,可以方便地复制粘贴到指定的地方。
|
||||
|
||||
在我将所有墙壁和门窗都布置完后,我就使用应用的 3D 视图浏览房屋。根据照片和记忆,我对所有物体进行了调整直到接近房屋的样子。我可以花更多时间添加纹理,附属家具和物品,但这已经达到了我需要的程度。
|
||||
在我将所有墙壁和门窗都布置完后,我就使用这个应用的 3D 视图浏览房屋。根据照片和记忆,我对所有物体进行了调整,直到接近房屋的样子。我可以花更多时间添加纹理,附属家具和物品,但这已经达到了我需要的程度。
|
||||
|
||||
![Sweet Home 3D floorplan][7]
|
||||
|
||||
完成之后,我将计划导出为 OBJ 文件,它可在各种程序中打开,例如 [Blender][8] 和 Mac 上的 Preview,方便旋转房屋并从各个角度查看。视频功能最有用,我可以创建一个起点,然后在房子中绘制一条路径,并记录“旅程”。我将视频导出为 MOV 文件,并使用 QuickTime 在 Mac 上打开和查看。
|
||||
完成之后,我将该项目导出为 OBJ 文件,它可在各种程序中打开,例如 [Blender][8] 和 Mac 上的“预览”中,方便旋转房屋并从各个角度查看。视频功能最有用,我可以创建一个起点,然后在房子中绘制一条路径,并记录“旅程”。我将视频导出为 MOV 文件,并使用 QuickTime 在 Mac 上打开和查看。
|
||||
|
||||
我的妻子能够(几乎)所有我看到的,我们甚至可以开始在搬家前布置家具。现在,我所要做的就是装上卡车搬到新家。
|
||||
我的妻子能够(几乎)能看到所有我看到的,我们甚至可以开始在搬家前布置家具。现在,我所要做的就是把行李装上卡车搬到新家。
|
||||
|
||||
Sweet Home 3D 在我的新工作中也是有用的。我正在寻找一种方法来改善学院建筑的地图,并计划在 [Inkscape][9] 或 Illustrator 或其他软件中重新绘制它。但是,由于我有平面地图,我可以使用 Sweet Home 3D 创建平面图的 3D 版本并将其上传到我们的网站以便更方便地找到地方。
|
||||
|
||||
### 开源犯罪现场?
|
||||
|
||||
一件有趣的事:根据 [Sweet Home 3D 的博客][10],“法国法医办公室(科学警察)最近选择 Sweet Home 3D 作为设计计划表示路线和犯罪现场的工具。这是法国政府建议优先考虑免费开源解决方案的具体应用。“
|
||||
一件有趣的事:根据 [Sweet Home 3D 的博客][10],“法国法医办公室(科学警察)最近选择 Sweet Home 3D 作为设计规划表示路线和犯罪现场的工具。这是法国政府建议优先考虑自由开源解决方案的具体应用。“
|
||||
|
||||
这是公民和政府如何利用开源解决方案创建个人项目、解决犯罪和建立世界的又一点证据。
|
||||
|
||||
@ -55,11 +55,11 @@ via: https://opensource.com/article/19/3/tool-find-home
|
||||
作者:[Jeff Macharyas (Community Moderator)][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[a]: https://opensource.com/users/jeffmacharyas
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/house_home_colors_live_building.jpg?itok=HLpsIfIL (Houses in a row)
|
||||
[2]: https://sourceforge.net/projects/sweethome3d/
|
||||
@ -1,18 +1,16 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (liujing97)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10746-1.html)
|
||||
[#]: subject: (How To Configure sudo Access In Linux?)
|
||||
[#]: via: (https://www.2daygeek.com/how-to-configure-sudo-access-in-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
Linux 中如何配置 sudo 访问权限?
|
||||
如何在 Linux 中配置 sudo 访问权限
|
||||
======
|
||||
|
||||
Linux 系统中 root 用户拥有所有的控制权力。
|
||||
|
||||
Linux 系统中 root 是拥有最高权力的用户,可以在系统中实施任意的行为。
|
||||
Linux 系统中 root 用户拥有 Linux 中全部控制权力。Linux 系统中 root 是拥有最高权力的用户,可以在系统中实施任意的行为。
|
||||
|
||||
如果其他用户想去实施一些行为,不能为所有人都提供 root 访问权限。因为如果他或她做了一些错误的操作,没有办法去纠正它。
|
||||
|
||||
@ -20,43 +18,40 @@ Linux 系统中 root 是拥有最高权力的用户,可以在系统中实施
|
||||
|
||||
我们可以把 sudo 权限发放给相应的用户来克服这种情况。
|
||||
|
||||
sudo 命令提供了一种机制,它可以在不用分享 root 用户的密码的前提下,为信任的用户提供系统的管理权限。
|
||||
`sudo` 命令提供了一种机制,它可以在不用分享 root 用户的密码的前提下,为信任的用户提供系统的管理权限。
|
||||
|
||||
他们可以执行大部分的管理操作,但又不像 root 一样有全部的权限。
|
||||
|
||||
### 什么是 sudo?
|
||||
|
||||
sudo 是一个程序,普通用户可以使用它以超级用户或其他用户的身份执行命令,是由安全策略指定的。
|
||||
`sudo` 是一个程序,普通用户可以使用它以超级用户或其他用户的身份执行命令,是由安全策略指定的。
|
||||
|
||||
sudo 用户的访问权限是由 `/etc/sudoers` 文件控制的。
|
||||
|
||||
### sudo 用户有什么优点?
|
||||
|
||||
在 Linux 系统中,如果你不熟悉一个命令,sudo 是运行它的一个安全方式。
|
||||
在 Linux 系统中,如果你不熟悉一个命令,`sudo` 是运行它的一个安全方式。
|
||||
|
||||
* Linux 系统在 `/var/log/secure` 和 `/var/log/auth.log` 文件中保留日志,并且你可以验证 sudo 用户实施了哪些行为操作。
|
||||
* 每一次它都为当前的操作提示输入密码。所以,你将会有时间去验证这个操作是不是你想要执行的。如果你发觉它是不正确的行为,你可以安全地退出而且没有执行此操作。
|
||||
* Linux 系统在 `/var/log/secure` 和 `/var/log/auth.log` 文件中保留日志,并且你可以验证 sudo 用户实施了哪些行为操作。
|
||||
* 每一次它都为当前的操作提示输入密码。所以,你将会有时间去验证这个操作是不是你想要执行的。如果你发觉它是不正确的行为,你可以安全地退出而且没有执行此操作。
|
||||
|
||||
基于 RHEL 的系统(如 Redhat (RHEL)、 CentOS 和 Oracle Enterprise Linux (OEL))和基于 Debian 的系统(如 Debian、Ubuntu 和 LinuxMint)在这点是不一样的。
|
||||
|
||||
基于 RHEL 的系统(如 Redhat (RHEL), CentOS 和 Oracle Enterprise Linux (OEL))和基于 Debian 的系统(如 Debian, Ubuntu 和 LinuxMint)在这点是不一样的。
|
||||
|
||||
我们将会教你如何在本文中的两种发行版中执行该操作。
|
||||
我们将会教你如何在本文中提及的两种发行版中执行该操作。
|
||||
|
||||
这里有三种方法可以应用于两个发行版本。
|
||||
|
||||
* 增加用户到相应的组。基于 RHEL 的系统,我们需要添加用户到 `wheel` 组。基于 Debain 的系统,我们添加用户到 `sudo` 或 `admin` 组。
|
||||
* 手动添加用户到 `/etc/group` 文件中。
|
||||
* 用 visudo 命令添加用户到 `/etc/sudoers` 文件中。
|
||||
|
||||
|
||||
* 增加用户到相应的组。基于 RHEL 的系统,我们需要添加用户到 `wheel` 组。基于 Debain 的系统,我们添加用户到 `sudo` 或 `admin` 组。
|
||||
* 手动添加用户到 `/etc/group` 文件中。
|
||||
* 用 `visudo` 命令添加用户到 `/etc/sudoers` 文件中。
|
||||
|
||||
### 如何在 RHEL/CentOS/OEL 系统中配置 sudo 访问权限?
|
||||
|
||||
在基于 RHEL 的系统中(如 Redhat (RHEL), CentOS 和 Oracle Enterprise Linux (OEL)),使用下面的三个方法就可以做到。
|
||||
在基于 RHEL 的系统中(如 Redhat (RHEL)、 CentOS 和 Oracle Enterprise Linux (OEL)),使用下面的三个方法就可以做到。
|
||||
|
||||
### 方法 1:在 Linux 中如何使用 wheel 组为普通用户授予超级用户访问权限?
|
||||
#### 方法 1:在 Linux 中如何使用 wheel 组为普通用户授予超级用户访问权限?
|
||||
|
||||
Wheel 是基于 RHEL 的系统中的一个特殊组,它提供额外的权限,可以授权用户像超级用户一样执行受到限制的命令。
|
||||
wheel 是基于 RHEL 的系统中的一个特殊组,它提供额外的权限,可以授权用户像超级用户一样执行受到限制的命令。
|
||||
|
||||
注意,应该在 `/etc/sudoers` 文件中激活 `wheel` 组来获得该访问权限。
|
||||
|
||||
@ -70,7 +65,7 @@ Wheel 是基于 RHEL 的系统中的一个特殊组,它提供额外的权限
|
||||
|
||||
假设我们已经创建了一个用户账号来执行这些操作。在此,我将会使用 `daygeek` 这个用户账号。
|
||||
|
||||
执行下面的命令,添加用户到 wheel 组。
|
||||
执行下面的命令,添加用户到 `wheel` 组。
|
||||
|
||||
```
|
||||
# usermod -aG wheel daygeek
|
||||
@ -87,10 +82,10 @@ wheel:x:10:daygeek
|
||||
|
||||
```
|
||||
$ tail -5 /var/log/secure
|
||||
tail: cannot open _/var/log/secure_ for reading: Permission denied
|
||||
tail: cannot open /var/log/secure for reading: Permission denied
|
||||
```
|
||||
|
||||
当我试图以普通用户身份访问 `/var/log/secure` 文件时出现错误。 我将使用 sudo 访问同一个文件,让我们看看这个魔术。
|
||||
当我试图以普通用户身份访问 `/var/log/secure` 文件时出现错误。 我将使用 `sudo` 访问同一个文件,让我们看看这个魔术。
|
||||
|
||||
```
|
||||
$ sudo tail -5 /var/log/secure
|
||||
@ -102,9 +97,9 @@ Mar 17 07:05:10 CentOS7 sudo: daygeek : TTY=pts/0 ; PWD=/home/daygeek ; USER=roo
|
||||
Mar 17 07:05:10 CentOS7 sudo: pam_unix(sudo:session): session opened for user root by daygeek(uid=0)
|
||||
```
|
||||
|
||||
### 方法 2:在 RHEL/CentOS/OEL 中如何使用 /etc/group 文件为普通用户授予超级用户访问权限?
|
||||
#### 方法 2:在 RHEL/CentOS/OEL 中如何使用 /etc/group 文件为普通用户授予超级用户访问权限?
|
||||
|
||||
我们可以通过编辑 `/etc/group` 文件来手动地添加用户到 wheel 组。
|
||||
我们可以通过编辑 `/etc/group` 文件来手动地添加用户到 `wheel` 组。
|
||||
|
||||
只需打开该文件,并在恰当的组后追加相应的用户就可完成这一点。
|
||||
|
||||
@ -115,7 +110,7 @@ wheel:x:10:daygeek,user1
|
||||
|
||||
在该例中,我将使用 `user1` 这个用户账号。
|
||||
|
||||
我将要通过在系统中重启 `Apache` 服务来检查用户 `user1` 是不是拥有 sudo 访问权限。让我们看看这个魔术。
|
||||
我将要通过在系统中重启 Apache httpd 服务来检查用户 `user1` 是不是拥有 sudo 访问权限。让我们看看这个魔术。
|
||||
|
||||
```
|
||||
$ sudo systemctl restart httpd
|
||||
@ -128,11 +123,11 @@ Mar 17 07:10:40 CentOS7 sudo: user1 : TTY=pts/0 ; PWD=/home/user1 ; USER=root ;
|
||||
Mar 17 07:12:35 CentOS7 sudo: user1 : TTY=pts/0 ; PWD=/home/user1 ; USER=root ; COMMAND=/bin/grep -i httpd /var/log/secure
|
||||
```
|
||||
|
||||
### 方法 3:在 Linux 中如何使用 /etc/sudoers 文件为普通用户授予超级用户访问权限?
|
||||
#### 方法 3:在 Linux 中如何使用 /etc/sudoers 文件为普通用户授予超级用户访问权限?
|
||||
|
||||
sudo 用户的访问权限是被 `/etc/sudoers` 文件控制的。因此,只需将用户添加到 wheel 组下的 sudoers 文件中即可。
|
||||
sudo 用户的访问权限是被 `/etc/sudoers` 文件控制的。因此,只需将用户添加到 `sudoers` 文件中 的 `wheel` 组下即可。
|
||||
|
||||
只需通过 visudo 命令将期望的用户追加到 /etc/sudoers 文件中。
|
||||
只需通过 `visudo` 命令将期望的用户追加到 `/etc/sudoers` 文件中。
|
||||
|
||||
```
|
||||
# grep -i user2 /etc/sudoers
|
||||
@ -141,7 +136,7 @@ user2 ALL=(ALL) ALL
|
||||
|
||||
在该例中,我将使用 `user2` 这个用户账号。
|
||||
|
||||
我将要通过在系统中重启 `MariaDB` 服务来检查用户 `user2` 是不是拥有 sudo 访问权限。让我们看看这个魔术。
|
||||
我将要通过在系统中重启 MariaDB 服务来检查用户 `user2` 是不是拥有 sudo 访问权限。让我们看看这个魔术。
|
||||
|
||||
```
|
||||
$ sudo systemctl restart mariadb
|
||||
@ -155,11 +150,11 @@ Mar 17 07:26:52 CentOS7 sudo: user2 : TTY=pts/0 ; PWD=/home/user2 ; USER=root ;
|
||||
|
||||
### 在 Debian/Ubuntu 系统中如何配置 sudo 访问权限?
|
||||
|
||||
在基于 Debian 的系统中(如 Debian, Ubuntu 和 LinuxMint),使用下面的三个方法就可以做到。
|
||||
在基于 Debian 的系统中(如 Debian、Ubuntu 和 LinuxMint),使用下面的三个方法就可以做到。
|
||||
|
||||
### 方法 1:在 Linux 中如何使用 sudo 或 admin 组为普通用户授予超级用户访问权限?
|
||||
#### 方法 1:在 Linux 中如何使用 sudo 或 admin 组为普通用户授予超级用户访问权限?
|
||||
|
||||
sudo 或 admin 是基于 Debian 的系统中的特殊组,它提供额外的权限,可以授权用户像超级用户一样执行受到限制的命令。
|
||||
`sudo` 或 `admin` 是基于 Debian 的系统中的特殊组,它提供额外的权限,可以授权用户像超级用户一样执行受到限制的命令。
|
||||
|
||||
注意,应该在 `/etc/sudoers` 文件中激活 `sudo` 或 `admin` 组来获得该访问权限。
|
||||
|
||||
@ -175,7 +170,7 @@ sudo 或 admin 是基于 Debian 的系统中的特殊组,它提供额外的权
|
||||
|
||||
假设我们已经创建了一个用户账号来执行这些操作。在此,我将会使用 `2gadmin` 这个用户账号。
|
||||
|
||||
执行下面的命令,添加用户到 sudo 组。
|
||||
执行下面的命令,添加用户到 `sudo` 组。
|
||||
|
||||
```
|
||||
# usermod -aG sudo 2gadmin
|
||||
@ -195,7 +190,7 @@ $ less /var/log/auth.log
|
||||
/var/log/auth.log: Permission denied
|
||||
```
|
||||
|
||||
当我试图以普通用户身份访问 `/var/log/auth.log` 文件时出现错误。 我将要使用 sudo 访问同一个文件,让我们看看这个魔术。
|
||||
当我试图以普通用户身份访问 `/var/log/auth.log` 文件时出现错误。 我将要使用 `sudo` 访问同一个文件,让我们看看这个魔术。
|
||||
|
||||
```
|
||||
$ sudo tail -5 /var/log/auth.log
|
||||
@ -209,7 +204,7 @@ Mar 17 20:40:48 Ubuntu18 sudo: pam_unix(sudo:session): session opened for user r
|
||||
|
||||
或者,我们可以通过添加用户到 `admin` 组来执行相同的操作。
|
||||
|
||||
运行下面的命令,添加用户到 admin 组。
|
||||
运行下面的命令,添加用户到 `admin` 组。
|
||||
|
||||
```
|
||||
# usermod -aG admin user1
|
||||
@ -231,9 +226,9 @@ Mar 17 20:53:36 Ubuntu18 sudo: user1 : TTY=pts/0 ; PWD=/home/user1 ; USER=root ;
|
||||
Mar 17 20:53:36 Ubuntu18 sudo: pam_unix(sudo:session): session opened for user root by user1(uid=0)
|
||||
```
|
||||
|
||||
### 方法 2:在 Debian/Ubuntu 中如何使用 /etc/group 文件为普通用户授予超级用户访问权限?
|
||||
#### 方法 2:在 Debian/Ubuntu 中如何使用 /etc/group 文件为普通用户授予超级用户访问权限?
|
||||
|
||||
我们可以通过编辑 `/etc/group` 文件来手动地添加用户到 sudo 组或 admin 组。
|
||||
我们可以通过编辑 `/etc/group` 文件来手动地添加用户到 `sudo` 组或 `admin` 组。
|
||||
|
||||
只需打开该文件,并在恰当的组后追加相应的用户就可完成这一点。
|
||||
|
||||
@ -244,7 +239,7 @@ sudo:x:27:2gadmin,user2
|
||||
|
||||
在该例中,我将使用 `user2` 这个用户账号。
|
||||
|
||||
我将要通过在系统中重启 `Apache` 服务来检查用户 `user2` 是不是拥有 sudo 访问权限。让我们看看这个魔术。
|
||||
我将要通过在系统中重启 Apache httpd 服务来检查用户 `user2` 是不是拥有 `sudo` 访问权限。让我们看看这个魔术。
|
||||
|
||||
```
|
||||
$ sudo systemctl restart apache2
|
||||
@ -257,11 +252,11 @@ Mar 17 21:01:04 Ubuntu18 systemd: pam_unix(systemd-user:session): session opened
|
||||
Mar 17 21:01:33 Ubuntu18 sudo: user2 : TTY=pts/0 ; PWD=/home/user2 ; USER=root ; COMMAND=/bin/systemctl restart apache2
|
||||
```
|
||||
|
||||
### 方法 3:在 Linux 中如何使用 /etc/sudoers 文件为普通用户授予超级用户访问权限?
|
||||
#### 方法 3:在 Linux 中如何使用 /etc/sudoers 文件为普通用户授予超级用户访问权限?
|
||||
|
||||
sudo 用户的访问权限是被 `/etc/sudoers` 文件控制的。因此,只需将用户添加到 sudo 或 admin 组下的 sudoers 文件中即可。
|
||||
sudo 用户的访问权限是被 `/etc/sudoers` 文件控制的。因此,只需将用户添加到 `sudoers` 文件中的 `sudo` 或 `admin` 组下即可。
|
||||
|
||||
只需通过 visudo 命令将期望的用户追加到 /etc/sudoers 文件中。
|
||||
只需通过 `visudo` 命令将期望的用户追加到 `/etc/sudoers` 文件中。
|
||||
|
||||
```
|
||||
# grep -i user3 /etc/sudoers
|
||||
@ -270,7 +265,7 @@ user3 ALL=(ALL:ALL) ALL
|
||||
|
||||
在该例中,我将使用 `user3` 这个用户账号。
|
||||
|
||||
我将要通过在系统中重启 `MariaDB` 服务来检查用户 `user3` 是不是拥有 sudo 访问权限。让我们看看这个魔术。
|
||||
我将要通过在系统中重启 MariaDB 服务来检查用户 `user3` 是不是拥有 `sudo` 访问权限。让我们看看这个魔术。
|
||||
|
||||
```
|
||||
$ sudo systemctl restart mariadb
|
||||
@ -285,6 +280,7 @@ Mar 17 21:12:53 Ubuntu18 sudo: pam_unix(sudo:session): session closed for user r
|
||||
Mar 17 21:13:08 Ubuntu18 sudo: user3 : TTY=pts/0 ; PWD=/home/user3 ; USER=root ; COMMAND=/usr/bin/tail -f /var/log/auth.log
|
||||
Mar 17 21:13:08 Ubuntu18 sudo: pam_unix(sudo:session): session opened for user root by user3(uid=0)
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-configure-sudo-access-in-linux/
|
||||
@ -292,7 +288,7 @@ via: https://www.2daygeek.com/how-to-configure-sudo-access-in-linux/
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[liujing97](https://github.com/liujing97)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,33 +1,27 @@
|
||||
[#]: collector: "lujun9972"
|
||||
[#]: translator: "zero-MK"
|
||||
[#]: reviewer: " "
|
||||
[#]: publisher: " "
|
||||
[#]: url: " "
|
||||
[#]: reviewer: "wxy"
|
||||
[#]: publisher: "wxy"
|
||||
[#]: url: "https://linux.cn/article-10766-1.html"
|
||||
[#]: subject: "How To Check If A Port Is Open On Multiple Remote Linux System Using Shell Script With nc Command?"
|
||||
[#]: via: "https://www.2daygeek.com/check-a-open-port-on-multiple-remote-linux-server-using-nc-command/"
|
||||
[#]: author: "Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/"
|
||||
|
||||
|
||||
如何检查多个远程 Linux 系统是否打开了指定端口?
|
||||
======
|
||||
|
||||
# 如何使用带有 nc 命令的 Shell 脚本来检查多个远程 Linux 系统是否打开了指定端口?
|
||||
我们最近写了一篇文章关于如何检查远程 Linux 服务器是否打开指定端口。它能帮助你检查单个服务器。
|
||||
|
||||
我们最近写了一篇文章关于如何检查远程 Linux 服务器是否打开指定端口。它能帮助您检查单个服务器。
|
||||
如果要检查五个服务器有没有问题,可以使用以下任何一个命令,如 `nc`(netcat)、`nmap` 和 `telnet`。但是如果想检查 50 多台服务器,那么你的解决方案是什么?
|
||||
|
||||
如果要检查五个服务器有没有问题,可以使用以下任何一个命令,如 nc(netcat),nmap 和 telnet。
|
||||
要检查所有服务器并不容易,如果你一个一个这样做,完全没有必要,因为这样你将会浪费大量的时间。为了解决这种情况,我使用 `nc` 命令编写了一个 shell 小脚本,它将允许我们扫描任意数量服务器给定的端口。
|
||||
|
||||
但是如果想检查 50 多台服务器,那么你的解决方案是什么?
|
||||
如果你要查找单个服务器扫描,你有多个选择,你只需阅读 [检查远程 Linux 系统上的端口是否打开?][1] 了解更多信息。
|
||||
|
||||
要检查所有服务器并不容易,如果你一个一个这样做,完全没有必要,因为这样你将会浪费大量的时间。
|
||||
本教程中提供了两个脚本,这两个脚本都很有用。这两个脚本都用于不同的目的,你可以通过阅读标题轻松理解其用途。
|
||||
|
||||
为了解决这种情况,我使用 nc 命令编写了一个 shell 小脚本,它将允许我们扫描任意数量服务器给定的端口。
|
||||
|
||||
如果您要查找单个服务器扫描,您有多个选择,你只需导航到到 **[检查远程 Linux 系统上的端口是否打开?][1]** 了解更多信息。
|
||||
|
||||
本教程中提供了两个脚本,这两个脚本都很有用。
|
||||
|
||||
这两个脚本都用于不同的目的,您可以通过阅读标题轻松理解其用途。
|
||||
|
||||
在你阅读这篇文章之前,我会问你几个问题,如果你知道答案或者你可以通过阅读这篇文章来获得答案。
|
||||
在你阅读这篇文章之前,我会问你几个问题,如果你不知道答案你可以通过阅读这篇文章来获得答案。
|
||||
|
||||
如何检查一个远程 Linux 服务器上指定的端口是否打开?
|
||||
|
||||
@ -35,17 +29,17 @@
|
||||
|
||||
如何检查多个远程 Linux 服务器上是否打开了多个指定的端口?
|
||||
|
||||
### 什么是nc(netcat)命令?
|
||||
### 什么是 nc(netcat)命令?
|
||||
|
||||
nc 即 netcat 。Netcat 是一个简单实用的 Unix 程序,它使用 TCP 或 UDP 协议进行跨网络连接进行数据读取和写入。
|
||||
`nc` 即 netcat。它是一个简单实用的 Unix 程序,它使用 TCP 或 UDP 协议进行跨网络连接进行数据读取和写入。
|
||||
|
||||
它被设计成一个可靠的 “后端” (back-end) 工具,我们可以直接使用或由其他程序和脚本轻松驱动它。
|
||||
它被设计成一个可靠的 “后端” 工具,我们可以直接使用或由其他程序和脚本轻松驱动它。
|
||||
|
||||
同时,它也是一个功能丰富的网络调试和探索工具,因为它可以创建您需要的几乎任何类型的连接,并具有几个有趣的内置功能。
|
||||
同时,它也是一个功能丰富的网络调试和探索工具,因为它可以创建你需要的几乎任何类型的连接,并具有几个有趣的内置功能。
|
||||
|
||||
Netcat 有三个主要的模式。分别是连接模式,监听模式和隧道模式。
|
||||
netcat 有三个主要的模式。分别是连接模式,监听模式和隧道模式。
|
||||
|
||||
**nc(netcat)的通用语法:**
|
||||
`nc`(netcat)的通用语法:
|
||||
|
||||
```
|
||||
$ nc [-options] [HostName or IP] [PortNumber]
|
||||
@ -55,9 +49,9 @@ $ nc [-options] [HostName or IP] [PortNumber]
|
||||
|
||||
如果要检查多个远程 Linux 服务器上给定端口是否打开,请使用以下 shell 脚本。
|
||||
|
||||
在我的例子中,我们将检查端口 22 是否在以下远程服务器中打开,确保您已经更新文件中的服务器列表而不是还是使用我的服务器列表。
|
||||
在我的例子中,我们将检查端口 22 是否在以下远程服务器中打开,确保你已经更新文件中的服务器列表而不是使用我的服务器列表。
|
||||
|
||||
您必须确保已经更新服务器列表 : `server-list.txt file` 。每个服务器(IP)应该在单独的行中。
|
||||
你必须确保已经更新服务器列表 :`server-list.txt` 。每个服务器(IP)应该在单独的行中。
|
||||
|
||||
```
|
||||
# cat server-list.txt
|
||||
@ -77,12 +71,12 @@ $ nc [-options] [HostName or IP] [PortNumber]
|
||||
#!/bin/sh
|
||||
for server in `more server-list.txt`
|
||||
do
|
||||
#echo $i
|
||||
nc -zvw3 $server 22
|
||||
#echo $i
|
||||
nc -zvw3 $server 22
|
||||
done
|
||||
```
|
||||
|
||||
设置 `port_scan.sh` 文件的可执行权限。
|
||||
设置 `port_scan.sh` 文件的可执行权限。
|
||||
|
||||
```
|
||||
$ chmod +x port_scan.sh
|
||||
@ -105,9 +99,9 @@ Connection to 192.168.1.7 22 port [tcp/ssh] succeeded!
|
||||
|
||||
如果要检查多个服务器中的多个端口,请使用下面的脚本。
|
||||
|
||||
在我的例子中,我们将检查给定服务器的 22 和 80 端口是否打开。确保您必须替换所需的端口和服务器名称而不使用是我的。
|
||||
在我的例子中,我们将检查给定服务器的 22 和 80 端口是否打开。确保你必须替换所需的端口和服务器名称而不使用是我的。
|
||||
|
||||
您必须确保已经将要检查的端口写入 `port-list.txt` 文件中。每个端口应该在一个单独的行中。
|
||||
你必须确保已经将要检查的端口写入 `port-list.txt` 文件中。每个端口应该在一个单独的行中。
|
||||
|
||||
```
|
||||
# cat port-list.txt
|
||||
@ -115,7 +109,7 @@ Connection to 192.168.1.7 22 port [tcp/ssh] succeeded!
|
||||
80
|
||||
```
|
||||
|
||||
您必须确保已经将要检查的服务器( IP 地址 )写入 `server-list.txt` 到文件中。每个服务器( IP ) 应该在单独的行中。
|
||||
你必须确保已经将要检查的服务器(IP 地址)写入 `server-list.txt` 到文件中。每个服务器(IP) 应该在单独的行中。
|
||||
|
||||
```
|
||||
# cat server-list.txt
|
||||
@ -135,12 +129,12 @@ Connection to 192.168.1.7 22 port [tcp/ssh] succeeded!
|
||||
#!/bin/sh
|
||||
for server in `more server-list.txt`
|
||||
do
|
||||
for port in `more port-list.txt`
|
||||
do
|
||||
#echo $server
|
||||
nc -zvw3 $server $port
|
||||
echo ""
|
||||
done
|
||||
for port in `more port-list.txt`
|
||||
do
|
||||
#echo $server
|
||||
nc -zvw3 $server $port
|
||||
echo ""
|
||||
done
|
||||
done
|
||||
```
|
||||
|
||||
@ -180,10 +174,10 @@ via: https://www.2daygeek.com/check-a-open-port-on-multiple-remote-linux-server-
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[zero-MK](https://github.com/zero-mk)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/how-to-check-whether-a-port-is-open-on-the-remote-linux-system-server/
|
||||
[1]: https://linux.cn/article-10675-1.html
|
||||
@ -0,0 +1,222 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (Modrisco)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10752-1.html)
|
||||
[#]: subject: (Getting started with Vim: The basics)
|
||||
[#]: via: (https://opensource.com/article/19/3/getting-started-vim)
|
||||
[#]: author: (Bryant Son https://opensource.com/users/brson)
|
||||
|
||||
Vim 入门:基础
|
||||
======
|
||||
|
||||
> 为工作或者新项目学习足够的 Vim 知识。
|
||||
|
||||
![Person standing in front of a giant computer screen with numbers, data][1]
|
||||
|
||||
我还清晰地记得我第一次接触 Vim 的时候。那时我还是一名大学生,计算机学院的机房里都装着 Ubuntu 系统。尽管我在上大学前也曾接触过不同的 Linux 发行版(比如 RHEL —— Red Hat 在百思买出售它的 CD),但这却是我第一次要在日常中频繁使用 Linux 系统,因为我的课程要求我这样做。当我开始使用 Linux 时,正如我的前辈和将来的后继者们一样,我感觉自己像是一名“真正的程序员”了。
|
||||
|
||||
![Real Programmers comic][2]
|
||||
|
||||
*真正的程序员,来自 [xkcd][3]*
|
||||
|
||||
学生们可以使用像 [Kate][4] 一样的图形文本编辑器,这也安装在学校的电脑上了。对于那些可以使用 shell 但不习惯使用控制台编辑器的学生,最流行的选择是 [Nano][5],它提供了很好的交互式菜单和类似于 Windows 图形文本编辑器的体验。
|
||||
|
||||
我有时会用 Nano,但当我听说 [Vi/Vim][6] 和 [Emacs][7] 能做一些很棒的事情时我决定试一试它们(主要是因为它们看起来很酷,而且我也很好奇它们有什么特别之处)。第一次使用 Vim 时吓到我了 —— 我不想搞砸任何事情!但是,一旦我掌握了它的诀窍,事情就变得容易得多,我就可以欣赏这个编辑器的强大功能了。至于 Emacs,呃,我有点放弃了,但我很高兴我坚持和 Vim 在一起。
|
||||
|
||||
在本文中,我将介绍一下 Vim(基于我的个人经验),这样你就可以在 Linux 系统上用它来作为编辑器使用了。这篇文章不会让你变成 Vim 的专家,甚至不会触及 Vim 许多强大功能的皮毛。但是起点总是很重要的,我想让开始的经历尽可能简单,剩下的则由你自己去探索。
|
||||
|
||||
### 第 0 步:打开一个控制台窗口
|
||||
|
||||
在使用 Vim 前,你需要做一些准备工作。在 Linux 操作系统打开控制台终端。(因为 Vim 也可以在 MacOS 上使用,Mac 用户也可以使用这些说明)。
|
||||
|
||||
打开终端窗口后,输入 `ls` 命令列出当前目录下的内容。然后,输入 `mkdir Tutorial` 命令创建一个名为 `Tutorial` 的新目录。通过输入 `cd Tutorial` 来进入该目录。
|
||||
|
||||
![Create a folder][8]
|
||||
|
||||
这就是全部的准备工作。现在是时候转到有趣的部分了——开始使用 Vim。
|
||||
|
||||
### 第 1 步:创建一个 Vim 文件和不保存退出
|
||||
|
||||
还记得我一开始说过我不敢使用 Vim 吗?我当时在害怕“如果我改变了一个现有的文件,把事情搞砸了怎么办?”毕竟,一些计算机科学作业要求我修改现有的文件。我想知道:_如何在不保存更改的情况下打开和关闭文件?_
|
||||
|
||||
好消息是你可以使用相同的命令在 Vim 中创建或打开文件:`vim <FILE_NAME>`,其中 `<FILE_NAME>` 表示要创建或修改的目标文件名。让我们通过输入 `vim HelloWorld.java` 来创建一个名为 `HelloWorld.java` 的文件。
|
||||
|
||||
你好,Vim!现在,讲一下 Vim 中一个非常重要的概念,可能也是最需要记住的:Vim 有多种模式,下面是 Vim 基础中需要知道的的三种:
|
||||
|
||||
模式 | 描述
|
||||
---|---
|
||||
正常模式 | 默认模式,用于导航和简单编辑
|
||||
插入模式 | 用于直接插入和修改文本
|
||||
命令行模式 | 用于执行如保存,退出等命令
|
||||
|
||||
Vim 也有其他模式,例如可视模式、选择模式和命令模式。不过上面的三种模式对我们来说已经足够用了。
|
||||
|
||||
你现在正处于正常模式,如果有文本,你可以用箭头键移动或使用其他导航键(将在稍后看到)。要确定你正处于正常模式,只需按下 `esc` (Escape)键即可。
|
||||
|
||||
> **提示:** `Esc` 切换到正常模式。即使你已经在正常模式下,点击 `Esc` 只是为了练习。
|
||||
|
||||
现在,有趣的事情发生了。输入 `:` (冒号键)并接着 `q!` (完整命令:`:q!`)。你的屏幕将显示如下:
|
||||
|
||||
![Editing Vim][9]
|
||||
|
||||
在正常模式下输入冒号会将 Vim 切换到命令行模式,执行 `:q!` 命令将退出 Vim 编辑器而不进行保存。换句话说,你放弃了所有的更改。你也可以使用 `ZQ` 命令;选择你认为更方便的选项。
|
||||
|
||||
一旦你按下 `Enter` (回车),你就不再在 Vim 中。重复练习几次来掌握这条命令。熟悉了这部分内容之后,请转到下一节,了解如何对文件进行更改。
|
||||
|
||||
### 第 2 步:在 Vim 中修改并保存
|
||||
|
||||
通过输入 `vim HelloWorld.java` 和回车键来再次打开这个文件。你可以在插入模式中修改文件。首先,通过 `Esc` 键来确定你正处于正常模式。接着输入 `i` 来进入插入模式(没错,就是字母 **i**)。
|
||||
|
||||
在左下角,你将看到 `-- INSERT --`,这标志着你这处于插入模式。
|
||||
|
||||
![Vim insert mode][10]
|
||||
|
||||
写一些 Java 代码。你可以写任何你想写的,不过这也有一份你可以参照的例子。你的屏幕将显示如下:
|
||||
|
||||
```
|
||||
public class HelloWorld {
|
||||
public static void main([String][11][] args) {
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
非常漂亮!注意文本是如何在 Java 语法中高亮显示的。因为这是个 Java 文件,所以 Vim 将自动检测语法并高亮颜色。
|
||||
|
||||
保存文件:按下 `Esc` 来退出插入模式并进入命令行模式。输入 `:` 并接着 `x!` (完整命令:`:x!`),按回车键来保存文件。你也可以输入 `wq` 来执行相同的操作。
|
||||
|
||||
现在,你知道了如何使用插入模式输入文本并使用以下命令保存文件:`:x!` 或者 `:wq`。
|
||||
|
||||
### 第 3 步:Vim 中的基本导航
|
||||
|
||||
虽然你总是可以使用上箭头、下箭头、左箭头和右箭头在文件中移动,但在一个几乎有数不清行数的大文件中,这将是非常困难的。能够在一行中跳跃光标将会是很有用的。虽然 Vim 提供了不少很棒的导航功能,不过在一开始,我想向你展示如何在 Vim 中到达某一特定的行。
|
||||
|
||||
单击 `Esc` 来确定你处于正常模式,接着输入 `:set number` 并键入回车。
|
||||
|
||||
瞧!你现在可以在每一行的左侧看到行号。
|
||||
|
||||
![Showing Line Numbers][12]
|
||||
|
||||
好,你也许会说,“这确实很酷,不过我该怎么跳到某一行呢?”再一次的,确认你正处于正常模式。接着输入 `:<LINE_NUMBER>`,在这里 `<LINE_NUMBER>` 是你想去的那一行的行数。按下回车键来试着移动到第二行。
|
||||
|
||||
```
|
||||
:2
|
||||
```
|
||||
|
||||
现在,跳到第三行。
|
||||
|
||||
![Jump to line 3][13]
|
||||
|
||||
但是,假如你正在处理一个一千多行的文件,而你正想到文件底部。这该怎么办呢?确认你正处于正常模式,接着输入 `:$` 并按下回车。
|
||||
|
||||
你将来到最后一行!
|
||||
|
||||
现在,你知道如何在行间跳跃了,作为补充,我们来学一下如何移动到一行的行尾。确认你正处于有文本内容的一行,如第三行,接着输入 `$`。
|
||||
|
||||
![Go to the last character][14]
|
||||
|
||||
你现在来到这行的最后一个字节了。在此示例中,高亮左大括号以显示光标移动到的位置,右大括号被高亮是因为它是高亮的左大括号的匹配字符。
|
||||
|
||||
这就是 Vim 中的基本导航功能。等等,别急着退出文件。让我们转到 Vim 中的基本编辑。不过,你可以暂时顺便喝杯咖啡或茶休息一下。
|
||||
|
||||
### 第 4 步:Vim 中的基本编辑
|
||||
|
||||
现在,你已经知道如何通过跳到想要的一行来在文件中导航,你可以使用这个技能在 Vim 中进行一些基本编辑。切换到插入模式。(还记得怎么做吗?是不是输入 `i` ?)当然,你可以使用键盘逐一删除或插入字符来进行编辑,但是 Vim 提供了更快捷的方法来编辑文件。
|
||||
|
||||
来到第三行,这里的代码是 `public static void main(String[] args) {`。双击 `d` 键,没错,就是 `dd`。如果你成功做到了,你将会看到,第三行消失了,剩下的所有行都向上移动了一行。(例如,第四行变成了第三行)。
|
||||
|
||||
![Deleting A Line][15]
|
||||
|
||||
这就是<ruby>删除<rt>delete</rt></ruby>命令。不要担心,键入 `u`,你会发现这一行又回来了。喔,这就是<ruby>撤销<rt>undo</rt></ruby>命令。
|
||||
|
||||
![Undoing a change in Vim][16]
|
||||
|
||||
下一课是学习如何复制和粘贴文本,但首先,你需要学习如何在 Vim 中突出显示文本。按下 `v` 并向左右移动光标来选择或反选文本。当你向其他人展示代码并希望标识你想让他们注意到的代码时,这个功能也非常有用。
|
||||
|
||||
![Highlighting text in Vim][17]
|
||||
|
||||
来到第四行,这里的代码是 `System.out.println("Hello, Opensource");`。高亮这一行的所有内容。好了吗?当第四行的内容处于高亮时,按下 `y`。这就叫做<ruby>复制<rt>yank</rt></ruby>模式,文本将会被复制到剪贴板上。接下来,输入 `o` 来创建新的一行。注意,这将让你进入插入模式。通过按 `Esc` 退出插入模式,然后按下 `p`,代表<ruby>粘贴<rt>paste</rt></ruby>。这将把复制的文本从第三行粘贴到第四行。
|
||||
|
||||
![Pasting in Vim][18]
|
||||
|
||||
作为练习,请重复这些步骤,但也要修改新创建的行中的文字。此外,请确保这些行对齐工整。
|
||||
|
||||
> **提示:** 您需要在插入模式和命令行模式之间来回切换才能完成此任务。
|
||||
|
||||
当你完成了,通过 `x!` 命令保存文件。以上就是 Vim 基本编辑的全部内容。
|
||||
|
||||
### 第 5 步:Vim 中的基本搜索
|
||||
|
||||
假设你的团队领导希望你更改项目中的文本字符串。你该如何快速完成任务?你可能希望使用某个关键字来搜索该行。
|
||||
|
||||
Vim 的搜索功能非常有用。通过 `Esc` 键来进入命令模式,然后输入冒号 `:`,我们可以通过输入 `/<SEARCH_KEYWORD>` 来搜索关键词, `<SEARCH_KEYWORD>` 指你希望搜索的字符串。在这里,我们搜索关键字符串 `Hello`。在下面的图示中没有显示冒号,但这是必须输入的。
|
||||
|
||||
![Searching in Vim][19]
|
||||
|
||||
但是,一个关键字可以出现不止一次,而这可能不是你想要的那一个。那么,如何找到下一个匹配项呢?只需按 `n` 键即可,这代表<ruby>下一个<rt>next</rt></ruby>。执行此操作时,请确保你没有处于插入模式!
|
||||
|
||||
### 附加步骤:Vim 中的分割模式
|
||||
|
||||
以上几乎涵盖了所有的 Vim 基础知识。但是,作为一个额外奖励,我想给你展示 Vim 一个很酷的特性,叫做<ruby>分割<rt>split</rt></ruby>模式。
|
||||
|
||||
退出 `HelloWorld.java` 并创建一个新文件。在控制台窗口中,输入 `vim GoodBye.java` 并按回车键来创建一个名为 `GoodBye.java` 的新文件。
|
||||
|
||||
输入任何你想输入的让内容,我选择输入 `Goodbye`。保存文件(记住你可以在命令模式中使用 `:x!` 或者 `:wq`)。
|
||||
|
||||
在命令模式中,输入 `:split HelloWorld.java`,来看看发生了什么。
|
||||
|
||||
![Split mode in Vim][20]
|
||||
|
||||
Wow!快看! `split` 命令将控制台窗口水平分割成了两个部分,上面是 `HelloWorld.java`,下面是 `GoodBye.java`。该怎么能在窗口之间切换呢? 按住 `Control` 键(在 Mac 上)或 `Ctrl` 键(在 PC 上),然后按下 `ww` (即双击 `w` 键)。
|
||||
|
||||
作为最后一个练习,尝试通过复制和粘贴 `HelloWorld.java` 来编辑 `GoodBye.java` 以匹配下面屏幕上的内容。
|
||||
|
||||
![Modify GoodBye.java file in Split Mode][21]
|
||||
|
||||
保存两份文件,成功!
|
||||
|
||||
> **提示 1:** 如果你想将两个文件窗口垂直分割,使用 `:vsplit <FILE_NAME>` 命令。(代替 `:split <FILE_NAME>` 命令,`<FILE_NAME>` 指你想要使用分割模式打开的文件名)。
|
||||
>
|
||||
> **提示 2:** 你可以通过调用任意数量的 `split` 或者 `vsplit` 命令来打开两个以上的文件。试一试,看看它效果如何。
|
||||
|
||||
### Vim 速查表
|
||||
|
||||
在本文中,您学会了如何使用 Vim 来完成工作或项目,但这只是你开启 Vim 强大功能之旅的开始,可以查看其他很棒的教程和技巧。
|
||||
|
||||
为了让一切变得简单些,我已经将你学到的一切总结到了 [一份方便的速查表][22] 中。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/getting-started-vim
|
||||
|
||||
作者:[Bryant Son][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[Modrisco](https://github.com/Modrisco)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/brson
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/data_metrics_analytics_desktop_laptop.png?itok=9QXd7AUr (Person standing in front of a giant computer screen with numbers, data)
|
||||
[2]: https://opensource.com/sites/default/files/uploads/1_xkcdcartoon.jpg (Real Programmers comic)
|
||||
[3]: https://xkcd.com/378/
|
||||
[4]: https://kate-editor.org
|
||||
[5]: https://www.nano-editor.org
|
||||
[6]: https://www.vim.org
|
||||
[7]: https://www.gnu.org/software/emacs
|
||||
[8]: https://opensource.com/sites/default/files/uploads/2_createtestfolder.jpg (Create a folder)
|
||||
[9]: https://opensource.com/sites/default/files/uploads/4_existingvim.jpg (Editing Vim)
|
||||
[10]: https://opensource.com/sites/default/files/uploads/6_insertionmode.jpg (Vim insert mode)
|
||||
[11]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+string
|
||||
[12]: https://opensource.com/sites/default/files/uploads/10_setnumberresult_0.jpg (Showing Line Numbers)
|
||||
[13]: https://opensource.com/sites/default/files/uploads/12_jumpintoline3.jpg (Jump to line 3)
|
||||
[14]: https://opensource.com/sites/default/files/uploads/14_gotolastcharacter.jpg (Go to the last character)
|
||||
[15]: https://opensource.com/sites/default/files/uploads/15_deletinglines.jpg (Deleting A Line)
|
||||
[16]: https://opensource.com/sites/default/files/uploads/16_undoingtheline.jpg (Undoing a change in Vim)
|
||||
[17]: https://opensource.com/sites/default/files/uploads/17_highlighting.jpg (Highlighting text in Vim)
|
||||
[18]: https://opensource.com/sites/default/files/uploads/19_pasting.jpg (Pasting in Vim)
|
||||
[19]: https://opensource.com/sites/default/files/uploads/22_searchmode.jpg (Searching in Vim)
|
||||
[20]: https://opensource.com/sites/default/files/uploads/26_copytonewfiles.jpg (Split mode in Vim)
|
||||
[21]: https://opensource.com/sites/default/files/uploads/27_exercise.jpg (Modify GoodBye.java file in Split Mode)
|
||||
[22]: https://opensource.com/downloads/cheat-sheet-vim
|
||||
104
published/201904/20190328 How to run PostgreSQL on Kubernetes.md
Normal file
104
published/201904/20190328 How to run PostgreSQL on Kubernetes.md
Normal file
@ -0,0 +1,104 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (arrowfeng)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10762-1.html)
|
||||
[#]: subject: (How to run PostgreSQL on Kubernetes)
|
||||
[#]: via: (https://opensource.com/article/19/3/how-run-postgresql-kubernetes)
|
||||
[#]: author: (Jonathan S. Katz https://opensource.com/users/jkatz05)
|
||||
|
||||
怎样在 Kubernetes 上运行 PostgreSQL
|
||||
======
|
||||
|
||||
> 创建统一管理的,具备灵活性的云原生生产部署来部署一个个性化的数据库即服务(DBaaS)。
|
||||
|
||||
![cubes coming together to create a larger cube][1]
|
||||
|
||||
通过在 [Kubernetes][2] 上运行 [PostgreSQL][3] 数据库,你能创建统一管理的,具备灵活性的云原生生产部署应用来部署一个个性化的数据库即服务为你的特定需求进行量身定制。
|
||||
|
||||
对于 Kubernetes,使用 Operator 允许你提供额外的上下文去[管理有状态应用][4]。当使用像PostgreSQL 这样开源的数据库去执行包括配置、扩展、高可用和用户管理时,Operator 也很有帮助。
|
||||
|
||||
让我们来探索如何在 Kubernetes 上启动并运行 PostgreSQL。
|
||||
|
||||
### 安装 PostgreSQL Operator
|
||||
|
||||
将 PostgreSQL 和 Kubernetes 结合使用的第一步是安装一个 Operator。在针对 Linux 系统的Crunchy 的[快速启动脚本][6]的帮助下,你可以在任意基于 Kubernetes 的环境下启动和运行开源的[Crunchy PostgreSQL Operator][5]。
|
||||
|
||||
快速启动脚本有一些必要前提:
|
||||
|
||||
* [Wget][7] 工具已安装。
|
||||
* [kubectl][8] 工具已安装。
|
||||
* 在你的 Kubernetes 中已经定义了一个 [StorageClass][9]。
|
||||
* 拥有集群权限的可访问 Kubernetes 的用户账号,以安装 Operator 的 [RBAC][10] 规则。
|
||||
* 一个 PostgreSQL Operator 的 [命名空间][11]。
|
||||
|
||||
执行这个脚本将提供给你一个默认的 PostgreSQL Operator 部署,其默认假设你采用 [动态存储][12]和一个名为 `standard` 的 StorageClass。这个脚本允许用户采用自定义的值去覆盖这些默认值。
|
||||
|
||||
通过下列命令,你能下载这个快速启动脚本并把它的权限设置为可执行:
|
||||
|
||||
```
|
||||
wget <https://raw.githubusercontent.com/CrunchyData/postgres-operator/master/examples/quickstart.sh>
|
||||
chmod +x ./quickstart.sh
|
||||
```
|
||||
|
||||
然后你运行快速启动脚本:
|
||||
|
||||
```
|
||||
./examples/quickstart.sh
|
||||
```
|
||||
|
||||
在脚本提示你相关的 Kubernetes 集群基本信息后,它将执行下列操作:
|
||||
|
||||
* 下载 Operator 配置文件
|
||||
* 将 `$HOME/.pgouser` 这个文件设置为默认设置
|
||||
* 以 Kubernetes [Deployment][13] 部署 Operator
|
||||
* 设置你的 `.bashrc` 文件包含 Operator 环境变量
|
||||
* 设置你的 `$HOME/.bash_completion` 文件为 `pgo bash_completion` 文件
|
||||
|
||||
在快速启动脚本的执行期间,你将会被提示在你的 Kubernetes 集群设置 RBAC 规则。在另一个终端,执行快速启动命令所提示你的命令。
|
||||
|
||||
一旦这个脚本执行完成,你将会得到提示设置一个端口以转发到 PostgreSQL Operator pod。在另一个终端,执行这个端口转发操作;这将允许你开始对 PostgreSQL Operator 执行命令!尝试输入下列命令创建集群:
|
||||
|
||||
```
|
||||
pgo create cluster mynewcluster
|
||||
```
|
||||
|
||||
你能输入下列命令测试你的集群运行状况:
|
||||
|
||||
```
|
||||
pgo test mynewcluster
|
||||
```
|
||||
|
||||
现在,你能在 Kubernetes 环境下管理你的 PostgreSQL 数据库了!你可以在[官方文档][14]找到非常全面的命令,包括扩容,高可用,备份等等。
|
||||
|
||||
这篇文章部分参考了该作者为 Crunchy 博客而写的[在 Kubernetes 上开始运行 PostgreSQL][15]。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/how-run-postgresql-kubernetes
|
||||
|
||||
作者:[Jonathan S. Katz][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[arrowfeng](https://github.com/arrowfeng)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jkatz05
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/cube_innovation_process_block_container.png?itok=vkPYmSRQ (cubes coming together to create a larger cube)
|
||||
[2]: https://www.postgresql.org/
|
||||
[3]: https://kubernetes.io/
|
||||
[4]: https://opensource.com/article/19/2/scaling-postgresql-kubernetes-operators
|
||||
[5]: https://github.com/CrunchyData/postgres-operator
|
||||
[6]: https://crunchydata.github.io/postgres-operator/stable/installation/#quickstart-script
|
||||
[7]: https://www.gnu.org/software/wget/
|
||||
[8]: https://kubernetes.io/docs/tasks/tools/install-kubectl/
|
||||
[9]: https://kubernetes.io/docs/concepts/storage/storage-classes/
|
||||
[10]: https://kubernetes.io/docs/reference/access-authn-authz/rbac/
|
||||
[11]: https://kubernetes.io/docs/concepts/overview/working-with-objects/namespaces/
|
||||
[12]: https://kubernetes.io/docs/concepts/storage/dynamic-provisioning/
|
||||
[13]: https://kubernetes.io/docs/concepts/workloads/controllers/deployment/
|
||||
[14]: https://crunchydata.github.io/postgres-operator/stable/#documentation
|
||||
[15]: https://info.crunchydata.com/blog/get-started-runnning-postgresql-on-kubernetes
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10722-1.html)
|
||||
[#]: subject: (3 cool text-based email clients)
|
||||
[#]: via: (https://fedoramagazine.org/3-cool-text-based-email-clients/)
|
||||
[#]: author: (Clément Verna https://fedoramagazine.org/author/cverna/)
|
||||
@ -12,13 +12,13 @@
|
||||
|
||||
![][1]
|
||||
|
||||
编写和接收电子邮件是每个人日常工作的重要组成部分,选择电子邮件客户端通常是一个重要决定。 Fedora 系统提供了大量的电子邮件客户端选择,其中包括基于文本的电子邮件应用。
|
||||
编写和接收电子邮件是每个人日常工作的重要组成部分,选择电子邮件客户端通常是一个重要决定。Fedora 系统提供了大量的电子邮件客户端可供选择,其中包括基于文本的电子邮件应用。
|
||||
|
||||
### Mutt
|
||||
|
||||
Mutt 可能是最受欢迎的基于文本的电子邮件客户端之一。它有人们期望的所有常见功能。Mutt 支持颜色代码、邮件会话、POP3 和 IMAP。但它最好的功能之一是它具有高度可配置性。实际上,用户可以轻松地更改键绑定,并创建宏以使工具适应特定的工作流程。
|
||||
Mutt 可能是最受欢迎的基于文本的电子邮件客户端之一。它有人们期望的所有常用功能。Mutt 支持颜色代码、邮件会话、POP3 和 IMAP。但它最好的功能之一是它具有高度可配置性。实际上,用户可以轻松地更改键绑定,并创建宏以使工具适应特定的工作流程。
|
||||
|
||||
要尝试 Mutt,请[使用 sudo][2] 和 dnf 安装它:
|
||||
要尝试 Mutt,请[使用 sudo][2] 和 `dnf` 安装它:
|
||||
|
||||
```
|
||||
$ sudo dnf install mutt
|
||||
@ -28,27 +28,27 @@ $ sudo dnf install mutt
|
||||
|
||||
### Alpine
|
||||
|
||||
Alpine 也是最受欢迎的基于文本的电子邮件客户端。它比 Mutt 更适合初学者,你可以通过应用本身配置大部分功能而无需编辑文件。Alpine 的一个强大功能是能够对电子邮件进行评分。这对那些订阅含有大量邮件的邮件列表如 Fedora 的[开发列表][4]的用户来说尤其有趣。通过使用分数,Alpine 可以根据用户的兴趣对电子邮件进行排序,首先显示高分的电子邮件。
|
||||
Alpine 也是最受欢迎的基于文本的电子邮件客户端。它比 Mutt 更适合初学者,你可以通过应用本身配置大部分功能而无需编辑配置文件。Alpine 的一个强大功能是能够对电子邮件进行评分。这对那些订阅含有大量邮件的邮件列表如 Fedora 的[开发列表][4]的用户来说尤其有趣。通过使用分数,Alpine 可以根据用户的兴趣对电子邮件进行排序,首先显示高分的电子邮件。
|
||||
|
||||
也可以使用 dnf 从 Fedora 的仓库安装 Alpine。
|
||||
也可以使用 `dnf` 从 Fedora 的仓库安装 Alpine。
|
||||
|
||||
```
|
||||
$ sudo dnf install alpine
|
||||
```
|
||||
|
||||
使用 Alpine 时,你可以按 _Ctrl+G_ 组合键轻松访问文档。
|
||||
使用 Alpine 时,你可以按 `Ctrl+G` 组合键轻松访问文档。
|
||||
|
||||
### nmh
|
||||
|
||||
nmh(new Mail Handling)遵循 UNIX 工具哲学。它提供了一组用于发送、接收、保存、检索和操作电子邮件的单一用途程序。这使你可以将 _nmh_ 命令与其他程序交换,或利用 _nmh_ 编写脚本来创建更多自定义工具。例如,你可以将 Mutt 与 nmh 一起使用。
|
||||
nmh(new Mail Handling)遵循 UNIX 工具哲学。它提供了一组用于发送、接收、保存、检索和操作电子邮件的单一用途程序。这使你可以将 `nmh` 命令与其他程序交换,或利用 `nmh` 编写脚本来创建更多自定义工具。例如,你可以将 Mutt 与 `nmh` 一起使用。
|
||||
|
||||
使用 dnf 可以轻松安装 nmh。
|
||||
使用 `dnf` 可以轻松安装 `nmh`。
|
||||
|
||||
```
|
||||
$ sudo dnf install nmh
|
||||
```
|
||||
|
||||
要了解有关 nmh 和邮件处理的更多信息,你可以阅读这本 GPL 许可证的[书][5]。
|
||||
要了解有关 `nmh` 和邮件处理的更多信息,你可以阅读这本 GPL 许可的[书][5]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -57,7 +57,7 @@ via: https://fedoramagazine.org/3-cool-text-based-email-clients/
|
||||
作者:[Clément Verna][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,74 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10742-1.html)
|
||||
[#]: subject: (Parallel computation in Python with Dask)
|
||||
[#]: via: (https://opensource.com/article/19/4/parallel-computation-python-dask)
|
||||
[#]: author: (Moshe Zadka (Community Moderator) https://opensource.com/users/moshez)
|
||||
|
||||
使用 Dask 在 Python 中进行并行计算
|
||||
======
|
||||
|
||||
> Dask 库可以将 Python 计算扩展到多个核心甚至是多台机器。
|
||||
|
||||
![Pair programming][1]
|
||||
|
||||
关于 Python 性能的一个常见抱怨是[全局解释器锁][2](GIL)。由于 GIL,同一时刻只能有一个线程执行 Python 字节码。因此,即使在现代的多核机器上,使用线程也不会加速计算。
|
||||
|
||||
但当你需要并行化到多核时,你不需要放弃使用 Python:[Dask][3] 库可以将计算扩展到多个内核甚至多个机器。某些设置可以在数千台机器上配置 Dask,每台机器都有多个内核。虽然存在扩展规模的限制,但一般达不到。
|
||||
|
||||
虽然 Dask 有许多内置的数组操作,但举一个非内置的例子,我们可以计算[偏度][4]:
|
||||
|
||||
```
|
||||
import numpy
|
||||
import dask
|
||||
from dask import array as darray
|
||||
|
||||
arr = dask.from_array(numpy.array(my_data), chunks=(1000,))
|
||||
mean = darray.mean()
|
||||
stddev = darray.std(arr)
|
||||
unnormalized_moment = darry.mean(arr * arr * arr)
|
||||
## See formula in wikipedia:
|
||||
skewness = ((unnormalized_moment - (3 * mean * stddev ** 2) - mean ** 3) /
|
||||
stddev ** 3)
|
||||
```
|
||||
|
||||
请注意,每个操作将根据需要使用尽可能多的内核。这将在所有核心上并行化执行,即使在计算数十亿个元素时也是如此。
|
||||
|
||||
当然,并不是我们所有的操作都可由这个库并行化,有时我们需要自己实现并行性。
|
||||
|
||||
为此,Dask 有一个“延迟”功能:
|
||||
|
||||
```
|
||||
import dask
|
||||
|
||||
def is_palindrome(s):
|
||||
return s == s[::-1]
|
||||
|
||||
palindromes = [dask.delayed(is_palindrome)(s) for s in string_list]
|
||||
total = dask.delayed(sum)(palindromes)
|
||||
result = total.compute()
|
||||
```
|
||||
|
||||
这将计算字符串是否是回文并返回回文的数量。
|
||||
|
||||
虽然 Dask 是为数据科学家创建的,但它绝不仅限于数据科学。每当我们需要在 Python 中并行化任务时,我们可以使用 Dask —— 无论有没有 GIL。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/parallel-computation-python-dask
|
||||
|
||||
作者:[Moshe Zadka (Community Moderator)][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/moshez
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/collab-team-pair-programming-code-keyboard.png?itok=kBeRTFL1 (Pair programming)
|
||||
[2]: https://wiki.python.org/moin/GlobalInterpreterLock
|
||||
[3]: https://github.com/dask/dask
|
||||
[4]: https://en.wikipedia.org/wiki/Skewness#Definition
|
||||
@ -0,0 +1,165 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (HankChow)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10761-1.html)
|
||||
[#]: subject: (Using Square Brackets in Bash: Part 2)
|
||||
[#]: via: (https://www.linux.com/blog/learn/2019/4/using-square-brackets-bash-part-2)
|
||||
[#]: author: (Paul Brown https://www.linux.com/users/bro66)
|
||||
|
||||
在 Bash 中使用[方括号](二)
|
||||
======
|
||||
|
||||
![square brackets][1]
|
||||
|
||||
> 我们继续来看方括号的用法,它们甚至还可以在 Bash 当中作为一个命令使用。
|
||||
|
||||
欢迎回到我们的方括号专题。在[前一篇文章][3]当中,我们介绍了方括号在命令行中可以用于通配操作,如果你已经读过前一篇文章,就可以从这里继续了。
|
||||
|
||||
方括号还可以以一个命令的形式使用,就像这样:
|
||||
|
||||
```
|
||||
[ "a" = "a" ]
|
||||
```
|
||||
|
||||
上面这种 `[ ... ]` 的形式就可以看成是一个可执行的命令。要注意,方括号内部的内容 `"a" = "a"` 和方括号 `[`、`]` 之间是有空格隔开的。因为这里的方括号被视作一个命令,因此要用空格将命令和它的参数隔开。
|
||||
|
||||
上面这个命令的含义是“判断字符串 `"a"` 和字符串 `"a"` 是否相同”,如果判断结果为真,那么 `[ ... ]` 就会以<ruby>状态码<rt>status code</rt></ruby> 0 退出,否则以状态码 1 退出。在[之前的文章][4]中,我们也有介绍过状态码的概念,可以通过 `$?` 变量获取到最近一个命令的状态码。
|
||||
|
||||
分别执行
|
||||
|
||||
```
|
||||
[ "a" = "a" ]
|
||||
echo $?
|
||||
```
|
||||
|
||||
以及
|
||||
|
||||
```
|
||||
[ "a" = "b" ]
|
||||
echo $?
|
||||
```
|
||||
|
||||
这两段命令中,前者会输出 0(判断结果为真),后者则会输出 1(判断结果为假)。在 Bash 当中,如果一个命令的状态码是 0,表示这个命令正常执行完成并退出,而且其中没有出现错误,对应布尔值 `true`;如果在命令执行过程中出现错误,就会返回一个非零的状态码,对应布尔值 `false`。而 `[ ... ]` 也同样遵循这样的规则。
|
||||
|
||||
因此,`[ ... ]` 很适合在 `if ... then`、`while` 或 `until` 这种在代码块结束前需要判断是否达到某个条件结构中使用。
|
||||
|
||||
对应使用的逻辑判断运算符也相当直观:
|
||||
|
||||
```
|
||||
[ STRING1 = STRING2 ] => 检查字符串是否相等
|
||||
[ STRING1 != STRING2 ] => 检查字符串是否不相等
|
||||
[ INTEGER1 -eq INTEGER2 ] => 检查整数 INTEGER1 是否等于 INTEGER2
|
||||
[ INTEGER1 -ge INTEGER2 ] => 检查整数 INTEGER1 是否大于等于 INTEGER2
|
||||
[ INTEGER1 -gt INTEGER2 ] => 检查整数 INTEGER1 是否大于 INTEGER2
|
||||
[ INTEGER1 -le INTEGER2 ] => 检查整数 INTEGER1 是否小于等于 INTEGER2
|
||||
[ INTEGER1 -lt INTEGER2 ] => 检查整数 INTEGER1 是否小于 INTEGER2
|
||||
[ INTEGER1 -ne INTEGER2 ] => 检查整数 INTEGER1 是否不等于 INTEGER2
|
||||
等等……
|
||||
```
|
||||
|
||||
方括号的这种用法也可以很有 shell 风格,例如通过带上 `-f` 参数可以判断某个文件是否存在:
|
||||
|
||||
```
|
||||
for i in {000..099}; \
|
||||
do \
|
||||
if [ -f file$i ]; \
|
||||
then \
|
||||
echo file$i exists; \
|
||||
else \
|
||||
touch file$i; \
|
||||
echo I made file$i; \
|
||||
fi; \
|
||||
done
|
||||
```
|
||||
|
||||
如果你在上一篇文章使用到的测试目录中运行以上这串命令,其中的第 3 行会判断那几十个文件当中的某个文件是否存在。如果文件存在,会输出一条提示信息;如果文件不存在,就会把对应的文件创建出来。最终,这个目录中会完整存在从 `file000` 到 `file099` 这一百个文件。
|
||||
|
||||
上面这段命令还可以写得更加简洁:
|
||||
|
||||
```
|
||||
for i in {000..099};\
|
||||
do\
|
||||
if [ ! -f file$i ];\
|
||||
then\
|
||||
touch file$i;\
|
||||
echo I made file$i;\
|
||||
fi;\
|
||||
done
|
||||
```
|
||||
|
||||
其中 `!` 运算符表示将判断结果取反,因此第 3 行的含义就是“如果文件 `file$i` 不存在”。
|
||||
|
||||
可以尝试一下将测试目录中那几十个文件随意删除几个,然后运行上面的命令,你就可以看到它是如何把被删除的文件重新创建出来的。
|
||||
|
||||
除了 `-f` 之外,还有很多有用的参数。`-d` 参数可以判断某个目录是否存在,`-h` 参数可以判断某个文件是不是一个符号链接。可以用 `-G` 参数判断某个文件是否属于某个用户组,用 `-ot` 参数判断某个文件的最后更新时间是否早于另一个文件,甚至还可以判断某个文件是否为空文件。
|
||||
|
||||
运行下面的几条命令,可以向几个文件中写入一些内容:
|
||||
|
||||
```
|
||||
echo "Hello World" >> file023
|
||||
echo "This is a message" >> file065
|
||||
echo "To humanity" >> file010
|
||||
```
|
||||
|
||||
然后运行:
|
||||
|
||||
```
|
||||
for i in {000..099};\
|
||||
do\
|
||||
if [ ! -s file$i ];\
|
||||
then\
|
||||
rm file$i;\
|
||||
echo I removed file$i;\
|
||||
fi;\
|
||||
done
|
||||
```
|
||||
|
||||
你就会发现所有空文件都被删除了,只剩下少数几个非空的文件。
|
||||
|
||||
如果你还想了解更多别的参数,可以执行 `man test` 来查看 `test` 命令的 man 手册(`test` 是 `[ ... ]` 的命令别名)。
|
||||
|
||||
有时候你还会看到 `[[ ... ]]` 这种双方括号的形式,使用起来和单方括号差别不大。但双方括号支持的比较运算符更加丰富:例如可以使用 `==` 来判断某个字符串是否符合某个<ruby>模式<rt>pattern</rt></ruby>,也可以使用 `<`、`>` 来判断两个字符串的出现顺序。
|
||||
|
||||
可以在 [Bash 表达式文档][5]中了解到双方括号支持的更多运算符。
|
||||
|
||||
### 下一集
|
||||
|
||||
在下一篇文章中,我们会开始介绍圆括号 `()` 在 Linux 命令行中的用法,敬请关注!
|
||||
|
||||
### 更多
|
||||
|
||||
- [Linux 工具:点的含义][6]
|
||||
- [理解 Bash 中的尖括号][7]
|
||||
- [Bash 中尖括号的更多用法][8]
|
||||
- [Linux 中的 &][9]
|
||||
- [Bash 中的 & 符号和文件描述符][10]
|
||||
- [Bash 中的逻辑和(&)][4]
|
||||
- [浅析 Bash 中的 {花括号}][11]
|
||||
- [在 Bash 中使用[方括号] (一)][3]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/2019/4/using-square-brackets-bash-part-2
|
||||
|
||||
作者:[Paul Brown][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/bro66
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/square-brackets-3734552_1920.jpg?itok=hv9D6TBy "square brackets"
|
||||
[2]: /LICENSES/CATEGORY/CREATIVE-COMMONS-ZERO
|
||||
[3]: https://linux.cn/article-10717-1.html
|
||||
[4]: https://linux.cn/article-10596-1.html
|
||||
[5]: https://www.gnu.org/software/bash/manual/bashref.html#Bash-Conditional-Expressions
|
||||
[6]: https://linux.cn/article-10465-1.html
|
||||
[7]: https://linux.cn/article-10502-1.html
|
||||
[8]: https://linux.cn/article-10529-1.html
|
||||
[9]: https://linux.cn/article-10587-1.html
|
||||
[10]: https://linux.cn/article-10591-1.html
|
||||
[11]: https://linux.cn/article-10624-1.html
|
||||
|
||||
@ -1,64 +1,64 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (MjSeven)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10757-1.html)
|
||||
[#]: subject: (5 useful open source log analysis tools)
|
||||
[#]: via: (https://opensource.com/article/19/4/log-analysis-tools)
|
||||
[#]: author: (Sam Bocetta https://opensource.com/users/sambocetta)
|
||||
|
||||
5 个有用的开源日志分析工具
|
||||
======
|
||||
监控网络活动既重要又繁琐,以下这些工具可以使它更容易。
|
||||
|
||||
> 监控网络活动既重要又繁琐,以下这些工具可以使它更容易。
|
||||
|
||||
![People work on a computer server][1]
|
||||
|
||||
监控网络活动是一项繁琐的工作,但有充分的理由这样做。例如,它允许你查找和调查工作站、连接到网络的设备和服务器上的可疑登录,同时确定管理员滥用了什么。你还可以跟踪软件安装和数据传输,以实时识别潜在问题,而不是在损坏发生后才进行跟踪。
|
||||
监控网络活动是一项繁琐的工作,但有充分的理由这样做。例如,它允许你查找和调查工作站和连接到网络的设备及服务器上的可疑登录,同时确定管理员滥用了什么。你还可以跟踪软件安装和数据传输,以实时识别潜在问题,而不是在损坏发生后才进行跟踪。
|
||||
|
||||
这些日志还有助于使你的公司遵守适用于在欧盟范围内运营的任何实体的[通用数据保护条例][2](GFPR)。如果你的网站在欧盟可以浏览,那么你就有资格。
|
||||
这些日志还有助于使你的公司遵守适用于在欧盟范围内运营的任何实体的[通用数据保护条例][2](GDPR)。如果你的网站在欧盟可以浏览,那么你就有遵守的该条例的资格。
|
||||
|
||||
日志记录,包括跟踪和分析,应该是任何监控基础设置中的一个基本过程。要从灾难中恢复 SQL Server 数据库,需要事务日志文件。此外,通过跟踪日志文件,DevOps 团队和数据库管理员(DBA)可以保持最佳的数据库性能,或者,在网络攻击的情况下找到未经授权活动的证据。因此,定期监视和分析系统日志非常重要。这是一种可靠的方式来重新创建导致出现任何问题的事件链。
|
||||
日志记录,包括跟踪和分析,应该是任何监控基础设置中的一个基本过程。要从灾难中恢复 SQL Server 数据库,需要事务日志文件。此外,通过跟踪日志文件,DevOps 团队和数据库管理员(DBA)可以保持最佳的数据库性能,又或者,在网络攻击的情况下找到未经授权活动的证据。因此,定期监视和分析系统日志非常重要。这是一种重新创建导致出现任何问题的事件链的可靠方式。
|
||||
|
||||
现在有很多开源日志跟踪器和分析工具可供使用,这使得为活动日志选择合适的资源比你想象的更容易。免费和开源软件社区提供的日志设计适用于各种站点和操作系统。以下是五个我用过的最好的,它们并没有特别的顺序。
|
||||
现在有很多开源日志跟踪器和分析工具可供使用,这使得为活动日志选择合适的资源比你想象的更容易。自由和开源软件社区提供的日志设计适用于各种站点和操作系统。以下是五个我用过的最好的工具,它们并没有特别的顺序。
|
||||
|
||||
### Graylog
|
||||
|
||||
[Graylog][3] 于 2011 年在德国启动,现在作为开源工具或商业解决方案提供。它被设计成一个集中式日志管理系统,接受来自不同服务器或端点的数据流,并允许你快速浏览或分析该信息。
|
||||
[Graylog][3] 于 2011 年在德国创立,现在作为开源工具或商业解决方案提供。它被设计成一个集中式日志管理系统,接受来自不同服务器或端点的数据流,并允许你快速浏览或分析该信息。
|
||||
|
||||
![Graylog screenshot][4]
|
||||
|
||||
Graylog 在系统管理员中建立了良好的声誉,因为它易于扩展。大多数 Web 项目都是从小规模开始的,‘但它们可能指数级增长。Graylog 可以平衡后端服务网络中的负载,每天可以处理几 TB 的日志数据。
|
||||
Graylog 在系统管理员中有着良好的声誉,因为它易于扩展。大多数 Web 项目都是从小规模开始的,但它们可能指数级增长。Graylog 可以均衡后端服务网络中的负载,每天可以处理几 TB 的日志数据。
|
||||
|
||||
IT 管理员会发现 Graylog 的前端界面易于使用,而且功能强大。Graylog 是围绕仪表板的概念构建的,它允许你选择你认为最有价值的指标或数据源,并快速查看一段时间内的趋势。
|
||||
|
||||
当发生安全或性能事件时,IT 管理员希望能够尽可能地将症状追根溯源。Graylog 的搜索功能使这变得容易。它有内置的容错功能,可运行多线程搜索,因此你可以同时分析多个潜在的威胁。
|
||||
当发生安全或性能事件时,IT 管理员希望能够尽可能地根据症状追根溯源。Graylog 的搜索功能使这变得容易。它有内置的容错功能,可运行多线程搜索,因此你可以同时分析多个潜在的威胁。
|
||||
|
||||
### Nagios
|
||||
|
||||
[Nagios][5] 于 1999 年开始由一个开发人员开发,现在已经发展成为管理日志数据最可靠的开源工具之一。当前版本的 Nagios 可以与运行 Microsoft Windows, Linux 或 Unix 的服务器集成。
|
||||
[Nagios][5] 始于 1999 年,最初是由一个开发人员开发的,现在已经发展成为管理日志数据最可靠的开源工具之一。当前版本的 Nagios 可以与运行 Microsoft Windows、Linux 或 Unix 的服务器集成。
|
||||
|
||||
![Nagios Core][6]
|
||||
|
||||
它的主要产品是日志服务器,旨在简化数据收集并使系统管理员更容易访问信息。Nagios 日志服务器引擎将实时捕获数据并将其提供给一个强大的搜索工具。通过内置的设置向导,可以轻松地与新端点或应用程序集成。
|
||||
它的主要产品是日志服务器,旨在简化数据收集并使系统管理员更容易访问信息。Nagios 日志服务器引擎将实时捕获数据,并将其提供给一个强大的搜索工具。通过内置的设置向导,可以轻松地与新端点或应用程序集成。
|
||||
|
||||
Nagios 最常用于需要监控其本地网络安全性的组织。它可以审核一系列与网络相关的事件,并帮助自动分发警报。如果满足特定条件,甚至可以将 Nagios 配置为运行预定义的脚本,从而允许你在人员介入之前解决问题。
|
||||
|
||||
作为网络审核的一部分,Nagios 将根据日志数据来源的地理位置过滤日志数据。这意味着你可以使用映射技术构建全面的仪表板,以了解 Web 流量是如何流动的。
|
||||
作为网络审计的一部分,Nagios 将根据日志数据来源的地理位置过滤日志数据。这意味着你可以使用地图技术构建全面的仪表板,以了解 Web 流量是如何流动的。
|
||||
|
||||
### Elastic Stack ("ELK Stack")
|
||||
### Elastic Stack (ELK Stack)
|
||||
|
||||
[Elastic Stack][7],通常称为 ELK Stack,是需要筛选大量数据并理解其日志系统的组织中最受欢迎的开源工具之一(这也是我个人的最爱)。
|
||||
|
||||
![ELK Stack][8]
|
||||
|
||||
它的主要产品由三个独立的产品组成:Elasticsearch, Kibana 和 Logstash:
|
||||
它的主要产品由三个独立的产品组成:Elasticsearch、Kibana 和 Logstash:
|
||||
|
||||
* 顾名思义, _**Elasticsearch**_ 旨在帮助用户使用多种查询语言和类型在数据集中找到匹配项。速度是它最大的优势。它可以扩展成由数百个服务器节点组成的集群,轻松处理 PB 级的数据。
|
||||
* 顾名思义, Elasticsearch 旨在帮助用户使用多种查询语言和类型在数据集之中找到匹配项。速度是它最大的优势。它可以扩展成由数百个服务器节点组成的集群,轻松处理 PB 级的数据。
|
||||
* Kibana 是一个可视化工具,与 Elasticsearch 一起工作,允许用户分析他们的数据并构建强大的报告。当你第一次在服务器集群上安装 Kibana 引擎时,你会看到一个显示着统计数据、图表甚至是动画的界面。
|
||||
* ELK Stack 的最后一部分是 Logstash,它作为一个纯粹的服务端管道进入 Elasticsearch 数据库。你可以将 Logstash 与各种编程语言和 API 集成,这样你的网站和移动应用程序中的信息就可以直接提供给强大的 Elastic Stalk 搜索引擎中。
|
||||
|
||||
* _**Kibana**_ 是一个可视化工具,与 Elasticsearch 一起工作,允许用户分析他们的数据并构建强大的报告。当你第一次在服务器集群上安装 Kibana 引擎时,你将访问一个显示统计数据、图表甚至是动画的界面。
|
||||
|
||||
* ELK Stack 的最后一部分是 _**Logstash**_ ,它作为一个纯粹的服务端管道进入 Elasticsearch 数据库。你可以将 Logstash 与各种编程语言和 API 集成,这样你的网站和移动应用程序中的信息就可以直接提供给强大的 Elastic Stalk 搜索引擎中。
|
||||
|
||||
ELK Stack 的一个独特功能是,它允许你监视构建在 WordPress 开源安装上的应用程序。与[跟踪管理员和 PHP 日志][9]的大多数开箱即用的安全审计日志工具相比,ELK Stack 可以筛选 Web 服务器和数据库日志。
|
||||
ELK Stack 的一个独特功能是,它允许你监视构建在 WordPress 开源网站上的应用程序。与[跟踪管理日志和 PHP 日志][9]的大多数开箱即用的安全审计日志工具相比,ELK Stack 可以筛选 Web 服务器和数据库日志。
|
||||
|
||||
糟糕的日志跟踪和数据库管理是导致网站性能不佳的最常见原因之一。没有定期检查、优化和清空数据库日志,不仅会降低站点的运行速度,还可能导致其完全崩溃。因此,ELK Stack 对于每个 WordPress 开发人员的工具包来说都是一个优秀的工具。
|
||||
|
||||
@ -97,7 +97,7 @@ via: https://opensource.com/article/19/4/log-analysis-tools
|
||||
作者:[Sam Bocetta][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,89 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (tomjlw)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10741-1.html)
|
||||
[#]: subject: (Streaming internet radio with RadioDroid)
|
||||
[#]: via: (https://opensource.com/article/19/4/radiodroid-internet-radio-player)
|
||||
[#]: author: (Chris Hermansen (Community Moderator) https://opensource.com/users/clhermansen)
|
||||
|
||||
使用 RadioDroid 流传输网络广播
|
||||
======
|
||||
|
||||
> 通过简单的设置使用你家中的音响收听你最爱的网络电台。
|
||||
|
||||
![][1]
|
||||
|
||||
最近网络媒体对 [Google 的 Chromecast 音频设备的下架][2]发出叹息。该设备在音频媒体界备受[好评][3],因此我已经在考虑入手一个。基于 Chromecast 退场的消息,我决定在它们全部被打包扔进垃圾堆之前以一个合理价位买一个。
|
||||
|
||||
我在 [MobileFun][4] 上找到一个放进我的订单中。这个设备最终到货了。它被包在一个普普通通、简简单单的 Google 包装袋中,外面打印着非常简短的使用指南。
|
||||
|
||||
![Google Chromecast 音频][5]
|
||||
|
||||
我通过我的数模转换器的光纤 S/PDIF 连接接入到家庭音响,希望以此能提供最佳的音质。
|
||||
|
||||
安装过程并无纰漏,在五分钟后我就可以播放一些音乐了。我知道一些安卓应用支持 Chromecast,因此我决定用 Google Play Music 测试它。意料之中,它工作得不错,音乐效果听上去也相当好。然而作为一个具有开源精神的人,我决定看看我能找到什么开源播放器能兼容 Chromecast。
|
||||
|
||||
### RadioDroid 的救赎
|
||||
|
||||
[RadioDroid 安卓应用][6] 满足条件。它是开源的,并且可从 [GitHub][7]、Google Play 以及 [F-Droid][8] 上获取。根据帮助文档,RadioDroid 从 [Community Radio Browser][9] 网页寻找播放流。因此我决定在我的手机上安装尝试一下。
|
||||
|
||||
![RadioDroid][10]
|
||||
|
||||
安装过程快速顺利,RadioDroid 打开展示当地电台十分迅速。你可以在这个屏幕截图的右上方附近看到 Chromecast 按钮(看上去像一个有着波阵面的长方形图标)。
|
||||
|
||||
我尝试了几个当地电台。这个应用可靠地在我手机喇叭上播放了音乐。但是我不得不摆弄 Chromecast 按钮来通过 Chromecast 把音乐传到流上。但是它确实可以做到流传输。
|
||||
|
||||
我决定找一下我喜爱的网络广播电台:法国马赛的 [格雷诺耶广播电台][11]。在 RadioDroid 上有许多找到电台的方法。其中一种是使用标签——“当地”、“最流行”等——就在电台列表上方。其中一个标签是国家,我找到法国,在其 1500 个电台中划来划去寻找格雷诺耶广播电台。另一种办法是使用屏幕上方的查询按钮;查询迅速找到了那家美妙的电台。我尝试了其它几次查询它们都返回了合理的信息。
|
||||
|
||||
回到“当地”标签,我在列表中翻来覆去,发现“当地”的定义似乎是“在同一个国家”。因此尽管西雅图、波特兰、旧金山、洛杉矶和朱诺比多伦多更靠近我的家,我并没有在“当地”标签中看到它们。然而通过使用查询功能,我可以发现所有名字中带有西雅图的电台。
|
||||
|
||||
“语言”标签使我找到所有用葡语(及葡语方言)播报的电台。我很快发现了另一个最爱的电台 [91 Rock Curitiba][12]。
|
||||
|
||||
接着灵感来了,虽然现在是春天了,但又如何呢?让我们听一些圣诞音乐。意料之中,搜寻圣诞把我引到了 [181.FM – Christmas Blender][13]。不错,一两分钟的欣赏对我就够了。
|
||||
|
||||
因此总的来说,我推荐把 RadioDroid 和 Chromecast 的组合作为一种用家庭音响以合理价位播放网络电台的良好方式。
|
||||
|
||||
### 对于音乐方面……
|
||||
|
||||
最近我从 [Blue Coast Music][16] 商店里选了一个 [Qua Continuum][15] 创作的叫作 [Continuum One][14] 的有趣的氛围(甚至无节拍)音乐专辑。
|
||||
|
||||
Blue Coast 有许多可提供给开源音乐爱好者的。音乐可以无需通过那些奇怪的平台专用下载管理器下载(有时以物理形式)。它通常提供几种形式,包括 WAV、FLAC 和 DSD;WAV 和 FLAC 还提供不同的字长和比特率,包括 16/44.1、24/96 和 24/192,针对 DSD 则有 2.8、5.6 和 11.2 MHz。音乐是用优秀的仪器精心录制的。不幸的是,我并没有找到许多符合我口味的音乐,尽管我喜欢 Blue Coast 上能获取的几个艺术家,包括 Qua Continuum,[Art Lande][17] 以及 [Alex De Grassi][18]。
|
||||
|
||||
在 [Bandcamp][19] 上,我挑选了 [Emancipator's Baralku][20] 和 [Framework's Tides][21],两个都是我喜欢的。两位艺术家创作的音乐符合我的口味——电音但又(总体来说)不是舞蹈,它们的音乐旋律优美,副歌也很好听。有许多可以让开源音乐发烧友爱上 Bandcamp 的东西,比如买前试听整首歌的服务;没有垃圾软件下载器;与大量音乐家的合作;以及对 [Creative Commons music][22] 的支持。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/radiodroid-internet-radio-player
|
||||
|
||||
作者:[Chris Hermansen (Community Moderator)][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[tomjlw](https://github.com/tomjlw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/clhermansen
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/programming-code-keyboard-laptop-music-headphones.png?itok=EQZ2WKzy (woman programming)
|
||||
[2]: https://www.theverge.com/2019/1/11/18178751/google-chromecast-audio-discontinued-sale
|
||||
[3]: https://www.whathifi.com/google/chromecast-audio/review
|
||||
[4]: https://www.mobilefun.com/google-chromecast-audio-black-70476
|
||||
[5]: https://opensource.com/sites/default/files/uploads/internet-radio_chromecast.png (Google Chromecast Audio)
|
||||
[6]: https://play.google.com/store/apps/details?id=net.programmierecke.radiodroid2
|
||||
[7]: https://github.com/segler-alex/RadioDroid
|
||||
[8]: https://f-droid.org/en/packages/net.programmierecke.radiodroid2/
|
||||
[9]: http://www.radio-browser.info/gui/#!/
|
||||
[10]: https://opensource.com/sites/default/files/uploads/internet-radio_radiodroid.png (RadioDroid)
|
||||
[11]: http://www.radiogrenouille.com/
|
||||
[12]: https://91rock.com.br/
|
||||
[13]: http://player.181fm.com/?station=181-xblender
|
||||
[14]: https://www.youtube.com/watch?v=PqLCQXPS8iQ
|
||||
[15]: https://bluecoastmusic.com/artists/qua-continuum
|
||||
[16]: https://bluecoastmusic.com/store
|
||||
[17]: https://bluecoastmusic.com/store?f%5B0%5D=search_api_multi_aggregation_1%3Aart%20lande
|
||||
[18]: https://bluecoastmusic.com/store?f%5B0%5D=search_api_multi_aggregation_1%3Aalex%20de%20grassi
|
||||
[19]: https://bandcamp.com/
|
||||
[20]: https://emancipator.bandcamp.com/album/baralku
|
||||
[21]: https://frameworksuk.bandcamp.com/album/tides
|
||||
[22]: https://bandcamp.com/tag/creative-commons
|
||||
186
published/201904/20190407 Fixing Ubuntu Freezing at Boot Time.md
Normal file
186
published/201904/20190407 Fixing Ubuntu Freezing at Boot Time.md
Normal file
@ -0,0 +1,186 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (Raverstern)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10756-1.html)
|
||||
[#]: subject: (Fixing Ubuntu Freezing at Boot Time)
|
||||
[#]: via: (https://itsfoss.com/fix-ubuntu-freezing/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
解决 Ubuntu 在启动时冻结的问题
|
||||
======
|
||||
|
||||
> 本文将向你一步步展示如何通过安装 NVIDIA 专有驱动来处理 Ubuntu 在启动过程中冻结的问题。本教程仅在一个新安装的 Ubuntu 系统上操作验证过,不过在其它情况下也理应可用。
|
||||
|
||||
不久前我买了台[宏碁掠夺者][1]笔记本电脑来测试各种 Linux 发行版。这台庞大且笨重的机器与我喜欢的,类似[戴尔 XPS][3]那般小巧轻便的笔记本电脑大相径庭。
|
||||
|
||||
我即便不打游戏也选择这台电竞笔记本电脑的原因,就是为了 [NVIDIA 的显卡][4]。宏碁掠夺者 Helios 300 上搭载了一块 [NVIDIA Geforce][5] GTX 1050Ti 显卡。
|
||||
|
||||
NVIDIA 那糟糕的 Linux 兼容性为人们所熟知。过去很多 It’s FOSS 的读者都向我求助过关于 NVIDIA 笔记本电脑的问题,而我当时无能为力,因为我手头上没有使用 NVIDIA 显卡的系统。
|
||||
|
||||
所以当我决定搞一台专门的设备来测试 Linux 发行版时,我选择了带有 NVIDIA 显卡的笔记本电脑。
|
||||
|
||||
这台笔记本原装的 Windows 10 系统安装在 120 GB 的固态硬盘上,并另外配有 1 TB 的机械硬盘来存储数据。在此之上我配置好了 [Windows 10 和 Ubuntu 18.04 双系统][6]。整个的安装过程舒适、方便、快捷。
|
||||
|
||||
随后我启动了 [Ubuntu][7]。那熟悉的紫色界面展现了出来,然后我就发现它卡在那儿了。鼠标一动不动,我也输入不了任何东西,然后除了长按电源键强制关机以外我啥事儿都做不了。
|
||||
|
||||
然后再次尝试启动,结果一模一样。整个系统就一直卡在那个紫色界面,随后的登录界面也出不来。
|
||||
|
||||
这听起来很耳熟吧?下面就让我来告诉你如何解决这个 Ubuntu 在启动过程中冻结的问题。
|
||||
|
||||
> 如果你用的不是 Ubuntu
|
||||
|
||||
> 请注意,尽管是在 Ubuntu 18.04 上操作的,本教程应该也能用于其他基于 Ubuntu 的发行版,例如 Linux Mint、elementary OS 等等。关于这点我已经在 Zorin OS 上确认过。
|
||||
|
||||
### 解决 Ubuntu 启动中由 NVIDIA 驱动引起的冻结问题
|
||||
|
||||
![][8]
|
||||
|
||||
我介绍的解决方案适用于配有 NVIDIA 显卡的系统,因为你所面临的系统冻结问题是由开源的 [NVIDIA Nouveau 驱动][9]所导致的。
|
||||
|
||||
事不宜迟,让我们马上来看看如何解决这个问题。
|
||||
|
||||
#### 步骤 1:编辑 Grub
|
||||
|
||||
在启动系统的过程中,请你在如下图所示的 Grub 界面上停下。如果你没看到这个界面,在启动电脑时请按住 `Shift` 键。
|
||||
|
||||
在这个界面上,按 `E` 键进入编辑模式。
|
||||
|
||||
![按“E”按键][10]
|
||||
|
||||
你应该看到一些如下图所示的代码。此刻你应关注于以 “linux” 开头的那一行。
|
||||
|
||||
![前往 Linux 开头的那一行][11]
|
||||
|
||||
#### 步骤 2:在 Grub 中临时修改 Linux 内核参数
|
||||
|
||||
回忆一下,我们的问题出在 NVIDIA 显卡驱动上,是开源版 NVIDIA 驱动的不适配导致了我们的问题。所以此处我们能做的就是禁用这些驱动。
|
||||
|
||||
此刻,你有多种方式可以禁用这些驱动。我最喜欢的方式是通过 `nomodeset` 来禁用所有显卡的驱动。
|
||||
|
||||
请把下列文本添加到以 “linux” 开头的那一行的末尾。此处你应该可以正常输入。请确保你把这段文本加到了行末。
|
||||
|
||||
```
|
||||
nomodeset
|
||||
```
|
||||
|
||||
现在你屏幕上的显示应如下图所示:
|
||||
|
||||
![通过向内核添加 nomodeset 来禁用显卡驱动][12]
|
||||
|
||||
按 `Ctrl+X` 或 `F10` 保存并退出。下次你就将以修改后的内核参数来启动。
|
||||
|
||||
> 对以上操作的解释
|
||||
|
||||
> 所以我们究竟做了些啥?那个 `nomodeset` 又是个什么玩意儿?让我来向你简单地解释一下。
|
||||
|
||||
> 通常来说,显卡是在 X 或者是其他显示服务器开始执行后才被启用的,也就是在你登录系统并看到图形界面以后。
|
||||
|
||||
> 但近来,视频模式的设置被移进了内核。这么做的众多优点之一就是能你看到一个漂亮且高清的启动画面。
|
||||
|
||||
> 若你往内核中加入 `nomodeset` 参数,它就会指示内核在显示服务启动后才加载显卡驱动。
|
||||
|
||||
> 换句话说,你在此时禁止视频驱动的加载,由此产生的冲突也会随之消失。你在登录进系统以后,还是能看到一切如旧,那是因为显卡驱动在随后的过程中被加载了。
|
||||
|
||||
#### 步骤 3:更新你的系统并安装 NVIDIA 专有驱动
|
||||
|
||||
别因为现在可以登录系统了就过早地高兴起来。你之前所做的只是临时措施,在下次启动的时候,你的系统依旧会尝试加载 Nouveau 驱动而因此冻结。
|
||||
|
||||
这是否意味着你将不得不在 Grub 界面上不断地编辑内核?可喜可贺,答案是否定的。
|
||||
|
||||
你可以在 Ubuntu 上为 NVIDIA 显卡[安装额外的驱动][13]。在使用专有驱动后,Ubuntu 将不会在启动过程中冻结。
|
||||
|
||||
我假设这是你第一次登录到一个新安装的系统。这意味着在做其他事情之前你必须先[更新 Ubuntu][14]。通过 Ubuntu 的 `Ctrl+Alt+T` [系统快捷键][15]打开一个终端,并输入以下命令:
|
||||
|
||||
```
|
||||
sudo apt update && sudo apt upgrade -y
|
||||
```
|
||||
|
||||
在上述命令执行完以后,你可以尝试安装额外的驱动。不过根据我的经验,在安装新驱动之前你需要先重启一下你的系统。在你重启时,你还是需要按我们之前做的那样修改内核参数。
|
||||
|
||||
当你的系统已经更新和重启完毕,按下 `Windows` 键打开一个菜单栏,并搜索“<ruby>软件与更新<rt>Software & Updates</rt></ruby>”。
|
||||
|
||||
![点击“软件与更新”(Software & Updates)][16]
|
||||
|
||||
然后切换到“<ruby>额外驱动<rt>Additional Drivers</rt></ruby>”标签页,并等待数秒。然后你就能看到可供系统使用的专有驱动了。在这个列表上你应该可以找到 NVIDIA。
|
||||
|
||||
选择专有驱动并点击“<ruby>应用更改<rt>Apply Changes</rt></ruby>”。
|
||||
|
||||
![NVIDIA 驱动安装中][17]
|
||||
|
||||
新驱动的安装会费点时间。若你的系统启用了 UEFI 安全启动,你将被要求设置一个密码。*你可以将其设置为任何容易记住的密码*。它的用处我将在步骤 4 中说明。
|
||||
|
||||
![你可能需要设置一个安全启动密码][18]
|
||||
|
||||
安装完成后,你会被要求重启系统以令之前的更改生效。
|
||||
|
||||
![在新驱动安装好后重启你的系统][19]
|
||||
|
||||
#### 步骤 4:处理 MOK(仅针对启用了 UEFI 安全启动的设备)
|
||||
|
||||
如果你之前被要求设置安全启动密码,此刻你会看到一个蓝色界面,上面写着 “MOK management”。这是个复杂的概念,我试着长话短说。
|
||||
|
||||
对 MOK([设备所有者密码][20])的要求是因为安全启动的功能要求所有内核模块都必须被签名。Ubuntu 中所有随 ISO 镜像发行的内核模块都已经签了名。由于你安装了一个新模块(也就是那个额外的驱动),或者你对内核模块做了修改,你的安全系统可能视之为一个未经验证的外部修改,从而拒绝启动。
|
||||
|
||||
因此,你可以自己对系统模块进行签名(以告诉 UEFI 系统莫要大惊小怪,这些修改是你做的),或者你也可以简单粗暴地[禁用安全启动][21]。
|
||||
|
||||
现在你对[安全启动和 MOK][22] 有了一定了解,那咱们就来看看在遇到这个蓝色界面后该做些什么。
|
||||
|
||||
如果你选择“继续启动”,你的系统将有很大概率如往常一样启动,并且你啥事儿也不用做。不过在这种情况下,新驱动的有些功能有可能工作不正常。
|
||||
|
||||
这就是为什么,你应该“选择注册 MOK”。
|
||||
|
||||
![][23]
|
||||
|
||||
它会在下一个页面让你点击“继续”,然后要你输入一串密码。请输入在上一步中,在安装额外驱动时设置的密码。
|
||||
|
||||
> 别担心!
|
||||
|
||||
> 如果你错过了这个关于 MOK 的蓝色界面,或不小心点了“继续启动”而不是“注册 MOK”,不必惊慌。你的主要目的是能够成功启动系统,而通过禁用 Nouveau 显卡驱动,你已经成功地实现了这一点。
|
||||
|
||||
> 最坏的情况也不过就是你的系统切换到 Intel 集成显卡而不再使用 NVIDIA 显卡。你可以之后的任何时间安装 NVIDIA 显卡驱动。你的首要任务是启动系统。
|
||||
|
||||
#### 步骤 5:享受安装了专有 NVIDIA 驱动的 Linux 系统
|
||||
|
||||
当新驱动被安装好后,你需要再次重启系统。别担心!目前的情况应该已经好起来了,并且你不必再去修改内核参数,而是能够直接启动 Ubuntu 系统了。
|
||||
|
||||
我希望本教程帮助你解决了 Ubuntu 系统在启动中冻结的问题,并让你能够成功启动 Ubuntu 系统。
|
||||
|
||||
如果你有任何问题或建议,请在下方评论区给我留言。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/fix-ubuntu-freezing/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[Raverstern](https://github.com/Raverstern)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://amzn.to/2YVV6rt
|
||||
[2]: https://itsfoss.com/affiliate-policy/
|
||||
[3]: https://itsfoss.com/dell-xps-13-ubuntu-review/
|
||||
[4]: https://www.nvidia.com/en-us/
|
||||
[5]: https://www.nvidia.com/en-us/geforce/
|
||||
[6]: https://itsfoss.com/install-ubuntu-1404-dual-boot-mode-windows-8-81-uefi/
|
||||
[7]: https://www.ubuntu.com/
|
||||
[8]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/04/fixing-frozen-ubuntu.png?resize=800%2C450&ssl=1
|
||||
[9]: https://nouveau.freedesktop.org/wiki/
|
||||
[10]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/04/edit-grub-menu.jpg?resize=800%2C393&ssl=1
|
||||
[11]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/04/editing-grub-to-fix-nvidia-issue.jpg?resize=800%2C343&ssl=1
|
||||
[12]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/04/editing-grub-to-fix-nvidia-issue-2.jpg?resize=800%2C320&ssl=1
|
||||
[13]: https://itsfoss.com/install-additional-drivers-ubuntu/
|
||||
[14]: https://itsfoss.com/update-ubuntu/
|
||||
[15]: https://itsfoss.com/ubuntu-shortcuts/
|
||||
[16]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/activities_software_updates_search-e1551416201782-800x228.png?resize=800%2C228&ssl=1
|
||||
[17]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/04/install-nvidia-driver-ubuntu.jpg?resize=800%2C520&ssl=1
|
||||
[18]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/04/secure-boot-nvidia.jpg?ssl=1
|
||||
[19]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/04/nvidia-drivers-installed-Ubuntu.jpg?resize=800%2C510&ssl=1
|
||||
[20]: https://firmware.intel.com/blog/using-mok-and-uefi-secure-boot-suse-linux
|
||||
[21]: https://itsfoss.com/disable-secure-boot-in-acer/
|
||||
[22]: https://wiki.ubuntu.com/UEFI/SecureBoot/DKMS
|
||||
[23]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/04/MOK-Secure-boot.jpg?resize=800%2C350&ssl=1
|
||||
@ -1,44 +1,45 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (MjSeven)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10725-1.html)
|
||||
[#]: subject: (Bash vs. Python: Which language should you use?)
|
||||
[#]: via: (https://opensource.com/article/19/4/bash-vs-python)
|
||||
[#]: author: (Archit Modi Red Hat https://opensource.com/users/architmodi/users/greg-p/users/oz123)
|
||||
|
||||
|
||||
Bash vs Python: 该使用哪种语言?
|
||||
Bash vs Python:你该使用哪个?
|
||||
======
|
||||
两种编程语言都各有优缺点,一些任务使得它们在某些方面互有胜负。
|
||||
|
||||
> 两种编程语言都各有优缺点,它们在某些任务方面互有胜负。
|
||||
|
||||
![][1]
|
||||
|
||||
[Bash][2] 和 [Python][3] 是大多数自动化工程师最喜欢的编程语言。它们都各有优缺点,有时很难选择应该使用哪一个。诚实的答案是:这取决于任务、范围、背景和任务的复杂性。
|
||||
[Bash][2] 和 [Python][3] 是大多数自动化工程师最喜欢的编程语言。它们都各有优缺点,有时很难选择应该使用哪一个。所以,最诚实的答案是:这取决于任务、范围、背景和任务的复杂性。
|
||||
|
||||
让我们来比较一下这两种语言,以便更好地理解它们各自的优点。
|
||||
|
||||
### Bash
|
||||
|
||||
* 是一种 Linux/Unix shell 命令语言
|
||||
* 非常适合编写使用命令行界面(CLI)实用程序的 shell 脚本,利用一个命令的输出传递给另一个命令(管道),以及执行简单的任务(最多 100 行代码)
|
||||
* 非常适合编写使用命令行界面(CLI)实用程序的 shell 脚本,利用一个命令的输出传递给另一个命令(管道),以及执行简单的任务(可以多达 100 行代码)
|
||||
* 可以按原样使用命令行命令和实用程序
|
||||
* 启动时间比 Python 快,但执行时间性能差
|
||||
* Windows 默认没有安装。你的脚本可能不会兼容多个操作系统,但是 Bash 是大多数 Linux/Unix 系统的默认 shell
|
||||
* 与其它 shell (如 csh、zsh、fish) _不_ 完全兼容。
|
||||
* 管道 ("|") CLI 实用程序如 sed、awk、grep 等可以降低其性能
|
||||
* 缺少很多函数、对象、数据结构和多线程,这限制了它在复杂脚本或编程中的使用
|
||||
* 启动时间比 Python 快,但执行时性能差
|
||||
* Windows 中默认没有安装。你的脚本可能不会兼容多个操作系统,但是 Bash 是大多数 Linux/Unix 系统的默认 shell
|
||||
* 与其它 shell (如 csh、zsh、fish) *不* 完全兼容。
|
||||
* 通过管道(`|`)传递 CLI 实用程序如 `sed`、`awk`、`grep` 等会降低其性能
|
||||
* 缺少很多函数、对象、数据结构和多线程支持,这限制了它在复杂脚本或编程中的使用
|
||||
* 缺少良好的调试工具和实用程序
|
||||
|
||||
### Python
|
||||
|
||||
* 是一种面对对象编程语言(OOP),因此它比 Bash 更加通用
|
||||
* 几乎可以用于任何任务
|
||||
* 适用于大多数操作系统,默认情况下它安装在大多数 Unix/Linux 系统中
|
||||
* 适用于大多数操作系统,默认情况下它在大多数 Unix/Linux 系统中都有安装
|
||||
* 与伪代码非常相似
|
||||
* 具有简单、清晰、易于学习和阅读的语法
|
||||
* 拥有大量的库、文档以及一个活跃的社区
|
||||
* 提供比 Bash 更友好的错误处理特性
|
||||
* 有比 Bash 更好的调试工具和实用程序,这使得它在开发涉及很多行代码的复杂软件应用程序中是一种很棒的语言
|
||||
* 有比 Bash 更好的调试工具和实用程序,这使得它在开发涉及到很多行代码的复杂软件应用程序时是一种很棒的语言
|
||||
* 应用程序(或脚本)可能包含许多第三方依赖项,这些依赖项必须在执行前安装
|
||||
* 对于简单任务,需要编写比 Bash 更多的代码
|
||||
|
||||
@ -53,7 +54,7 @@ via: https://opensource.com/article/19/4/bash-vs-python
|
||||
作者:[Archit Modi (Red Hat)][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,74 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (tomjlw)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10747-1.html)
|
||||
[#]: subject: (Cisco, Google reenergize multicloud/hybrid cloud joint development)
|
||||
[#]: via: (https://www.networkworld.com/article/3388218/cisco-google-reenergize-multicloudhybrid-cloud-joint-development.html#tk.rss_all)
|
||||
[#]: author: (Michael Cooney https://www.networkworld.com/author/Michael-Cooney/)
|
||||
|
||||
思科、谷歌重新赋能多/混合云共同开发
|
||||
======
|
||||
> 思科、VMware、HPE 等公司开始采用了新的 Google Cloud Athos 云技术。
|
||||
|
||||
![Thinkstock][1]
|
||||
|
||||
思科与谷歌已扩展它们的混合云开发活动,以帮助其客户可以在从本地数据中心到公共云上的任何地方更轻松地搭建安全的多云以及混合云应用。
|
||||
|
||||
这次扩张围绕着谷歌被称作 Anthos 的新的开源混合云包展开,它是在这周的 Google Next 活动上推出的。Anthos 基于并取代了谷歌现有的谷歌云服务测试版。Anthos 将让客户们无须修改应用就可以在现有的本地硬件或公共云上运行应用。据谷歌说,它可以在[谷歌云平台][5] (GCP) 与 [谷歌 Kubernetes 引擎][6] (GKE) 或者在数据中心中与 [GKE On-Prem][7] 一同使用。谷歌说,Anthos 首次让客户们可以无需管理员和开发者了解不同的坏境和 API 就能从谷歌平台上管理在第三方云上(如 AWS 和 Azure)的工作负荷。
|
||||
|
||||
关键在于,Athos 提供了一个单一的托管服务,它使得客户们无须担心不同的环境或 API 就能跨云管理、部署工作负荷。
|
||||
|
||||
作为首秀的一部分,谷歌也宣布一个叫做 [Anthos Migrate][8] 的测试计划,它能够从本地环境或者其它云自动迁移虚拟机到 GKE 上的容器中。谷歌说,“这种独特的迁移技术使你无须修改原来的虚拟机或者应用就能以一种行云流水般的方式迁移、更新你的基础设施”。谷歌称它给予了公司按客户节奏转移本地应用到云环境的灵活性。
|
||||
|
||||
### 思科和谷歌
|
||||
|
||||
就思科来说,它宣布对 Anthos 的支持并承诺将它紧密集成进思科的数据中心技术中,例如 HyperFlex 超融合包、应用中心基础设施(思科的旗舰 SDN 方案)、SD-WAN 和 StealthWatch 云。思科说,无论是本地的还是在云端的,这次集成将通过自动更新到最新版本和安全补丁,给予一种一致的、云般的感觉。
|
||||
|
||||
“谷歌云在容器(Kubernetes)和<ruby>服务网格<rt>service mesh</rt></ruby>(Istio)上的专业与它们在开发者社区的领导力,再加上思科的企业级网络、计算、存储和安全产品及服务,将为我们的顾客促成一次强强联合。”思科的云平台和解决方案集团资深副总裁 Kip Compton 这样[写道][9],“思科对于 Anthos 的集成将会帮助顾客跨本地数据中心和公共云搭建、管理多云/混合云应用,让他们专注于创新和灵活性,同时不会影响安全性或增加复杂性。”
|
||||
|
||||
### 谷歌云和思科
|
||||
|
||||
谷歌云工程副总裁 Eyal Manor [写道][10] 通过思科对 Anthos 的支持,客户将能够:
|
||||
|
||||
* 受益于全托管服务例如 GKE 以及思科的超融合基础设施、网络和安全技术;
|
||||
* 在企业数据中心和云中一致运行
|
||||
* 在企业数据中心使用云服务
|
||||
* 用最新的云技术更新本地基础设施
|
||||
|
||||
思科和谷歌从 2017 年 10 月就在紧密合作,当时他们表示正在开发一个能够连接本地基础设施和云环境的开放混合云平台。该套件,即[思科为谷歌云打造的混合云平台][11],大致在 2018 年 9 月上市。它使得客户们能通过谷歌云托管 Kubernetes 容器开发企业级功能,包含思科网络和安全技术以及来自 Istio 的服务网格监控。
|
||||
|
||||
谷歌说开源的 Istio 的容器和微服务优化技术给开发者提供了一种一致的方式,通过服务级的 mTLS (双向传输层安全)身份验证访问控制来跨云连接、保护、管理和监听微服务。因此,客户能够轻松实施新的可移植的服务,并集中配置和管理这些服务。
|
||||
|
||||
思科不是唯一宣布对 Anthos 支持的供应商。谷歌表示,至少 30 家大型合作商包括 [VMware][12]、[Dell EMC][13]、[HPE][14]、Intel 和联想致力于为他们的客户在它们自己的超融合基础设施上提供 Anthos 服务。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3388218/cisco-google-reenergize-multicloudhybrid-cloud-joint-development.html
|
||||
|
||||
作者:[Michael Cooney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[tomjlw](https://github.com/tomjlw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Michael-Cooney/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.techhive.com/images/article/2016/12/hybrid_cloud-100700390-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3233132/cloud-computing/what-is-hybrid-cloud-computing.html
|
||||
[3]: https://www.networkworld.com/article/3252775/hybrid-cloud/multicloud-mania-what-to-know.html
|
||||
[4]: https://www.networkworld.com/newsletters/signup.html
|
||||
[5]: https://cloud.google.com/
|
||||
[6]: https://cloud.google.com/kubernetes-engine/
|
||||
[7]: https://cloud.google.com/gke-on-prem/
|
||||
[8]: https://cloud.google.com/contact/
|
||||
[9]: https://blogs.cisco.com/news/next-phase-cisco-google-cloud
|
||||
[10]: https://cloud.google.com/blog/topics/partners/google-cloud-partners-with-cisco-on-hybrid-cloud-next19?utm_medium=unpaidsocial&utm_campaign=global-googlecloud-liveevent&utm_content=event-next
|
||||
[11]: https://cloud.google.com/cisco/
|
||||
[12]: https://blogs.vmware.com/networkvirtualization/2019/04/vmware-and-google-showcase-hybrid-cloud-deployment.html/
|
||||
[13]: https://www.dellemc.com/en-us/index.htm
|
||||
[14]: https://www.hpe.com/us/en/newsroom/blog-post/2019/04/hpe-and-google-cloud-join-forces-to-accelerate-innovation-with-hybrid-cloud-solutions-optimized-for-containerized-applications.html
|
||||
[15]: https://www.facebook.com/NetworkWorld/
|
||||
[16]: https://www.linkedin.com/company/network-world
|
||||
|
||||
67
published/201904/20190409 Enhanced security at the edge.md
Normal file
67
published/201904/20190409 Enhanced security at the edge.md
Normal file
@ -0,0 +1,67 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (hopefully2333)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10773-1.html)
|
||||
[#]: subject: (Enhanced security at the edge)
|
||||
[#]: via: (https://www.networkworld.com/article/3388130/enhanced-security-at-the-edge.html#tk.rss_all)
|
||||
[#]: author: (Anne Taylor https://www.networkworld.com/author/Anne-Taylor/)
|
||||
|
||||
增强边缘计算的安全性
|
||||
======
|
||||
|
||||
> 边缘计算环境带来的安全风险迫使公司必须特别关注它的安全措施。
|
||||
|
||||

|
||||
|
||||
说数据安全是高管们和董事会最关注的问题已经是陈词滥调了。但问题是:数据安全问题不会自己消失。
|
||||
|
||||
骇客和攻击者一直在寻找利用缺陷的新方法。就像公司开始使用人工智能和机器学习等新兴技术来自动化地保护他们的组织一样,那些不良分子们也在使用这些技术来达成他们的目的。
|
||||
|
||||
简而言之,安全问题是一定不能忽视的。现在,随着越来越多的公司开始使用边缘计算,如何保护这些边缘计算环境,需要有新的安全考量。
|
||||
|
||||
### 边缘计算的风险更高
|
||||
|
||||
正如 Network World 的一篇文章所说,边缘计算的安全架构应该将重点放在物理安全上。这并不是说要忽视保护传输过程中的数据。而是说,实际的物理环境和物理设备更加值得关注。
|
||||
|
||||
例如,边缘计算的硬件设备通常位于较大的公司或者广阔空间中,有时候是在很容易进入的共享办公室和公共区域里。从表面上看,这节省了成本,能更快地访问到相关的数据,而不必在后端的数据中心和前端的设备之间往返。
|
||||
|
||||
但是,如果没有任何级别的访问控制,这台设备就会暴露在恶意操作和简单人为错误的双重风险之下。想象一下办公室的清洁工意外地关掉了设备,以及随之而来的停机所造成的后果。
|
||||
|
||||
另一个风险是 “影子边缘 IT”。有时候非 IT 人员会部署一个边缘设备来快速启动项目,却没有及时通知 IT 部门这个设备正在连接到网络。例如,零售商店可能会主动安装他们自己的数字标牌,或者,销售团队会将物联网传感器应用到电视中,并在销售演示中实时地部署它们。
|
||||
|
||||
在这种情况下,IT 部门很少甚至完全看不到这些边缘设备,这就使得网络可能暴露在外。
|
||||
|
||||
### 保护边缘计算环境
|
||||
|
||||
部署微型数据中心(MDC)是规避上述风险的一个简单方法。
|
||||
|
||||
> “在历史上,大多数这些[边缘]环境都是不受控制的,”施耐德电气安全能源部门的首席技术官和创新高级副总裁 Kevin Brown 说。“它们可能是第 1 级,但很可能是第 0 级类型的设计 —— 它们就像开放的配线柜。它们现在需要像微型数据中心一样的对待。你管理它需要像管理关键任务数据中心一样”
|
||||
|
||||
单说听起来的感觉,这个解决方案是一个安全、独立的机箱,它包括在室内和室外运行程序所需的所有存储空间、处理性能和网络资源。它同样包含必要的电源、冷却、安全和管理工具。
|
||||
|
||||
而它最重要的是高级别的安全性。这个装置是封闭的,有上锁的门,可以防止非法入侵。通过合适的供应商,DMC 可以进行定制,包括用于远程数字化管理的监控摄像头、传感器和监控技术。
|
||||
|
||||
随着越来越多的公司开始利用边缘计算的优势,他们必须利用安全解决方案的优势来保护他们的数据和边缘环境。
|
||||
|
||||
在 APC.com 上了解保护你的边缘计算环境的最佳方案。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3388130/enhanced-security-at-the-edge.html
|
||||
|
||||
作者:[Anne Taylor][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[hopefully2333](https://github.com/hopefully2333)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Anne-Taylor/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/04/istock-1091707448-100793312-large.jpg
|
||||
[2]: https://www.csoonline.com/article/3250144/6-ways-hackers-will-use-machine-learning-to-launch-attacks.html
|
||||
[3]: https://www.marketwatch.com/press-release/edge-computing-market-2018-global-analysis-opportunities-and-forecast-to-2023-2018-08-20
|
||||
[4]: https://www.networkworld.com/article/3224893/what-is-edge-computing-and-how-it-s-changing-the-network.html
|
||||
[5]: https://www.youtube.com/watch?v=1NLk1cXEukQ
|
||||
[6]: https://www.apc.com/us/en/solutions/business-solutions/edge-computing.jsp
|
||||
@ -0,0 +1,340 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (NeverKnowsTomorrow)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10768-1.html)
|
||||
[#]: subject: (Four Methods To Add A User To Group In Linux)
|
||||
[#]: via: (https://www.2daygeek.com/linux-add-user-to-group-primary-secondary-group-usermod-gpasswd/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
在 Linux 中把用户添加到组的四个方法
|
||||
======
|
||||
|
||||
Linux 组是用于管理 Linux 中用户帐户的组织单位。对于 Linux 系统中的每一个用户和组,它都有惟一的数字标识号。它被称为 用户 ID(UID)和组 ID(GID)。组的主要目的是为组的成员定义一组特权。它们都可以执行特定的操作,但不能执行其他操作。
|
||||
|
||||
Linux 中有两种类型的默认组。每个用户应该只有一个 <ruby>主要组<rt>primary group</rt></ruby> 和任意数量的 <ruby>次要组<rt>secondary group</rt></ruby>。
|
||||
|
||||
* **主要组:** 创建用户帐户时,已将主要组添加到用户。它通常是用户的名称。在执行诸如创建新文件(或目录)、修改文件或执行命令等任何操作时,主要组将应用于用户。用户的主要组信息存储在 `/etc/passwd` 文件中。
|
||||
* **次要组:** 它被称为次要组。它允许用户组在同一组成员文件中执行特定操作。例如,如果你希望允许少数用户运行 Apache(httpd)服务命令,那么它将非常适合。
|
||||
|
||||
你可能对以下与用户管理相关的文章感兴趣。
|
||||
|
||||
* [在 Linux 中创建用户帐户的三种方法?][1]
|
||||
* [如何在 Linux 中创建批量用户?][2]
|
||||
* [如何在 Linux 中使用不同的方法更新/更改用户密码?][3]
|
||||
|
||||
可以使用以下四种方法实现。
|
||||
|
||||
* `usermod`:修改系统帐户文件,以反映在命令行中指定的更改。
|
||||
* `gpasswd`:用于管理 `/etc/group` 和 `/etc/gshadow`。每个组都可以有管理员、成员和密码。
|
||||
* Shell 脚本:可以让管理员自动执行所需的任务。
|
||||
* 手动方式:我们可以通过编辑 `/etc/group` 文件手动将用户添加到任何组中。
|
||||
|
||||
我假设你已经拥有此操作所需的组和用户。在本例中,我们将使用以下用户和组:`user1`、`user2`、`user3`,另外的组是 `mygroup` 和 `mygroup1`。
|
||||
|
||||
在进行更改之前,我希望检查一下用户和组信息。详见下文。
|
||||
|
||||
我可以看到下面的用户与他们自己的组关联,而不是与其他组关联。
|
||||
|
||||
```
|
||||
# id user1
|
||||
uid=1008(user1) gid=1008(user1) groups=1008(user1)
|
||||
|
||||
# id user2
|
||||
uid=1009(user2) gid=1009(user2) groups=1009(user2)
|
||||
|
||||
# id user3
|
||||
uid=1010(user3) gid=1010(user3) groups=1010(user3)
|
||||
```
|
||||
|
||||
我可以看到这个组中没有关联的用户。
|
||||
|
||||
```
|
||||
# getent group mygroup
|
||||
mygroup:x:1012:
|
||||
|
||||
# getent group mygroup1
|
||||
mygroup1:x:1013:
|
||||
```
|
||||
|
||||
### 方法 1:使用 usermod 命令
|
||||
|
||||
`usermod` 命令修改系统帐户文件,以反映命令行上指定的更改。
|
||||
|
||||
#### 如何使用 usermod 命令将现有的用户添加到次要组或附加组?
|
||||
|
||||
要将现有用户添加到辅助组,请使用带有 `-G` 选项和组名称的 `usermod` 命令。
|
||||
|
||||
语法:
|
||||
|
||||
```
|
||||
# usermod [-G] [GroupName] [UserName]
|
||||
```
|
||||
|
||||
如果系统中不存在给定的用户或组,你将收到一条错误消息。如果没有得到任何错误,那么用户已经被添加到相应的组中。
|
||||
|
||||
```
|
||||
# usermod -a -G mygroup user1
|
||||
```
|
||||
|
||||
让我使用 `id` 命令查看输出。是的,添加成功。
|
||||
|
||||
```
|
||||
# id user1
|
||||
uid=1008(user1) gid=1008(user1) groups=1008(user1),1012(mygroup)
|
||||
```
|
||||
|
||||
#### 如何使用 usermod 命令将现有的用户添加到多个次要组或附加组?
|
||||
|
||||
要将现有用户添加到多个次要组中,请使用带有 `-G` 选项的 `usermod` 命令和带有逗号分隔的组名称。
|
||||
|
||||
语法:
|
||||
|
||||
```
|
||||
# usermod [-G] [GroupName1,GroupName2] [UserName]
|
||||
```
|
||||
|
||||
在本例中,我们将把 `user2` 添加到 `mygroup` 和 `mygroup1` 中。
|
||||
|
||||
```
|
||||
# usermod -a -G mygroup,mygroup1 user2
|
||||
```
|
||||
|
||||
让我使用 `id` 命令查看输出。是的,`user2` 已成功添加到 `myGroup` 和 `myGroup1` 中。
|
||||
|
||||
```
|
||||
# id user2
|
||||
uid=1009(user2) gid=1009(user2) groups=1009(user2),1012(mygroup),1013(mygroup1)
|
||||
```
|
||||
|
||||
#### 如何改变用户的主要组?
|
||||
|
||||
要更改用户的主要组,请使用带有 `-g` 选项和组名称的 `usermod` 命令。
|
||||
|
||||
语法:
|
||||
|
||||
```
|
||||
# usermod [-g] [GroupName] [UserName]
|
||||
```
|
||||
|
||||
我们必须使用 `-g` 改变用户的主要组。
|
||||
|
||||
```
|
||||
# usermod -g mygroup user3
|
||||
```
|
||||
|
||||
让我们看看输出。是的,已成功更改。现在,显示`user3` 主要组是 `mygroup` 而不是 `user3`。
|
||||
|
||||
```
|
||||
# id user3
|
||||
uid=1010(user3) gid=1012(mygroup) groups=1012(mygroup)
|
||||
```
|
||||
|
||||
### 方法 2:使用 gpasswd 命令
|
||||
|
||||
`gpasswd` 命令用于管理 `/etc/group` 和 `/etc/gshadow`。每个组都可以有管理员、成员和密码。
|
||||
|
||||
#### 如何使用 gpasswd 命令将现有用户添加到次要组或者附加组?
|
||||
|
||||
要将现有用户添加到次要组,请使用带有 `-M` 选项和组名称的 `gpasswd` 命令。
|
||||
|
||||
语法:
|
||||
|
||||
```
|
||||
# gpasswd [-M] [UserName] [GroupName]
|
||||
```
|
||||
|
||||
在本例中,我们将把 `user1 ` 添加到 `mygroup` 中。
|
||||
|
||||
```
|
||||
# gpasswd -M user1 mygroup
|
||||
```
|
||||
|
||||
让我使用 `id` 命令查看输出。是的,`user1` 已成功添加到 `mygroup` 中。
|
||||
|
||||
```
|
||||
# id user1
|
||||
uid=1008(user1) gid=1008(user1) groups=1008(user1),1012(mygroup)
|
||||
```
|
||||
|
||||
#### 如何使用 gpasswd 命令添加多个用户到次要组或附加组中?
|
||||
|
||||
要将多个用户添加到辅助组中,请使用带有 `-M` 选项和组名称的 `gpasswd` 命令。
|
||||
|
||||
语法:
|
||||
|
||||
```
|
||||
# gpasswd [-M] [UserName1,UserName2] [GroupName]
|
||||
```
|
||||
|
||||
在本例中,我们将把 `user2` 和 `user3` 添加到 `mygroup1` 中。
|
||||
|
||||
```
|
||||
# gpasswd -M user2,user3 mygroup1
|
||||
```
|
||||
|
||||
让我使用 `getent` 命令查看输出。是的,`user2` 和 `user3` 已成功添加到 `myGroup1` 中。
|
||||
|
||||
```
|
||||
# getent group mygroup1
|
||||
mygroup1:x:1013:user2,user3
|
||||
```
|
||||
|
||||
#### 如何使用 gpasswd 命令从组中删除一个用户?
|
||||
|
||||
要从组中删除用户,请使用带有 `-d` 选项的 `gpasswd` 命令以及用户和组的名称。
|
||||
|
||||
语法:
|
||||
|
||||
```
|
||||
# gpasswd [-d] [UserName] [GroupName]
|
||||
```
|
||||
|
||||
在本例中,我们将从 `mygroup` 中删除 `user1` 。
|
||||
|
||||
```
|
||||
# gpasswd -d user1 mygroup
|
||||
Removing user user1 from group mygroup
|
||||
```
|
||||
|
||||
### 方法 3:使用 Shell 脚本
|
||||
|
||||
基于上面的例子,我知道 `usermod` 命令没有能力将多个用户添加到组中,可以通过 `gpasswd` 命令完成。但是,它将覆盖当前与组关联的现有用户。
|
||||
|
||||
例如,`user1` 已经与 `mygroup` 关联。如果要使用 `gpasswd` 命令将 `user2` 和 `user3` 添加到 `mygroup` 中,它将不会按预期生效,而是对组进行修改。
|
||||
|
||||
如果要将多个用户添加到多个组中,解决方案是什么?
|
||||
|
||||
两个命令中都没有默认选项来实现这一点。
|
||||
|
||||
因此,我们需要编写一个小的 shell 脚本来实现这一点。
|
||||
|
||||
#### 如何使用 gpasswd 命令将多个用户添加到次要组或附加组?
|
||||
|
||||
如果要使用 `gpasswd` 命令将多个用户添加到次要组或附加组,请创建以下 shell 脚本。
|
||||
|
||||
创建用户列表。每个用户应该在单独的行中。
|
||||
|
||||
```bash
|
||||
$ cat user-lists.txt
|
||||
user1
|
||||
user2
|
||||
user3
|
||||
```
|
||||
|
||||
使用以下 shell 脚本将多个用户添加到单个次要组。
|
||||
|
||||
```bash
|
||||
vi group-update.sh
|
||||
|
||||
#!/bin/bash
|
||||
for user in `cat user-lists.txt`
|
||||
do
|
||||
usermod -a -G mygroup $user
|
||||
done
|
||||
```
|
||||
|
||||
设置 `group-update.sh` 文件的可执行权限。
|
||||
|
||||
```
|
||||
# chmod + group-update.sh
|
||||
```
|
||||
|
||||
最后运行脚本来实现它。
|
||||
|
||||
```
|
||||
# sh group-update.sh
|
||||
```
|
||||
|
||||
让我看看使用 `getent` 命令的输出。 是的,`user1`、`user2` 和 `user3` 已成功添加到 `mygroup` 中。
|
||||
|
||||
```
|
||||
# getent group mygroup
|
||||
mygroup:x:1012:user1,user2,user3
|
||||
```
|
||||
|
||||
#### 如何使用 gpasswd 命令将多个用户添加到多个次要组或附加组?
|
||||
|
||||
如果要使用 `gpasswd` 命令将多个用户添加到多个次要组或附加组中,请创建以下 shell 脚本。
|
||||
|
||||
创建用户列表。每个用户应该在单独的行中。
|
||||
|
||||
```bash
|
||||
$ cat user-lists.txt
|
||||
user1
|
||||
user2
|
||||
user3
|
||||
```
|
||||
|
||||
创建组列表。每组应在单独的行中。
|
||||
|
||||
```bash
|
||||
$ cat group-lists.txt
|
||||
mygroup
|
||||
mygroup1
|
||||
```
|
||||
|
||||
使用以下 shell 脚本将多个用户添加到多个次要组。
|
||||
|
||||
```bash
|
||||
#!/bin/sh
|
||||
for user in `more user-lists.txt`
|
||||
do
|
||||
for group in `more group-lists.txt`
|
||||
do
|
||||
usermod -a -G $group $user
|
||||
done
|
||||
```
|
||||
|
||||
设置 `group-update-1.sh` 文件的可执行权限。
|
||||
|
||||
```
|
||||
# chmod +x group-update-1.sh
|
||||
```
|
||||
|
||||
最后运行脚本来实现它。
|
||||
|
||||
```
|
||||
# sh group-update-1.sh
|
||||
```
|
||||
|
||||
让我看看使用 `getent` 命令的输出。 是的,`user1`、`user2` 和 `user3` 已成功添加到 `mygroup` 中。
|
||||
|
||||
```
|
||||
# getent group mygroup
|
||||
mygroup:x:1012:user1,user2,user3
|
||||
```
|
||||
|
||||
此外,`user1`、`user2` 和 `user3` 已成功添加到 `mygroup1` 中。
|
||||
|
||||
```
|
||||
# getent group mygroup1
|
||||
mygroup1:x:1013:user1,user2,user3
|
||||
```
|
||||
|
||||
### 方法 4:在 Linux 中将用户添加到组中的手动方法
|
||||
|
||||
我们可以通过编辑 `/etc/group` 文件手动将用户添加到任何组中。
|
||||
|
||||
打开 `/etc/group` 文件并搜索要更新用户的组名。最后将用户更新到相应的组中。
|
||||
|
||||
```
|
||||
# vi /etc/group
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/linux-add-user-to-group-primary-secondary-group-usermod-gpasswd/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[NeverKnowsTomorrow](https://github.com/NeverKnowsTomorrow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux 中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/linux-user-account-creation-useradd-adduser-newusers/
|
||||
[2]: https://www.2daygeek.com/how-to-create-the-bulk-users-in-linux/
|
||||
[3]: https://www.2daygeek.com/linux-passwd-chpasswd-command-set-update-change-users-password-in-linux-using-shell-script/
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (MjSeven)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10751-1.html)
|
||||
[#]: subject: (How To Install And Enable Flatpak Support On Linux?)
|
||||
[#]: via: (https://www.2daygeek.com/how-to-install-and-enable-flatpak-support-on-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
@ -10,35 +10,30 @@
|
||||
如何在 Linux 上安装并启用 Flatpak 支持?
|
||||
======
|
||||
|
||||
<to 校正:之前似乎发表过跟这个类似的一篇 https://linux.cn/article-10459-1.html>
|
||||
|
||||
目前,我们都在使用 Linux 发行版的官方软件包管理器来安装所需的软件包。
|
||||
|
||||
在 Linux 中,它做得很好,没有任何问题。(它很好地完成了它应该做的工作,同时它没有任何妥协)
|
||||
在 Linux 中,它做得很好,没有任何问题。(它不打折扣地很好的完成了它应该做的工作)
|
||||
|
||||
在一些方面它也有一些限制,所以会让我们考虑其他替代解决方案来解决。
|
||||
但在一些方面它也有一些限制,所以会让我们考虑其他替代解决方案来解决。
|
||||
|
||||
是的,默认情况下,我们不会从发行版官方软件包管理器获取最新版本的软件包,因为这些软件包是在构建当前 OS 版本时构建的。它们只会提供安全更新,直到下一个主要版本发布。
|
||||
是的,默认情况下,我们不能从发行版官方软件包管理器获取到最新版本的软件包,因为这些软件包是在构建当前 OS 版本时构建的。它们只会提供安全更新,直到下一个主要版本发布。
|
||||
|
||||
那么,这种情况有什么解决办法吗?
|
||||
|
||||
是的,我们有多种解决方案,而且我们大多数人已经开始使用其中的一些了。
|
||||
那么,这种情况有什么解决办法吗?是的,我们有多种解决方案,而且我们大多数人已经开始使用其中的一些了。
|
||||
|
||||
有些什么呢,它们有什么好处?
|
||||
|
||||
* **对于基于 Ubuntu 的系统:** PPAs
|
||||
* **对于基于 RHEL 的系统:** [EPEL Repository][1]、[ELRepo Repository][2]、[nux-dextop Repository][3]、[IUS Community Repo][4]、[RPMfusion Repository][5] 和 [Remi Repository][6]
|
||||
* **对于基于 Ubuntu 的系统:** PPA
|
||||
* **对于基于 RHEL 的系统:** [EPEL 仓库][1]、[ELRepo 仓库][2]、[nux-dextop 仓库][3]、[IUS 社区仓库][4]、[RPMfusion 仓库][5] 和 [Remi 仓库][6]
|
||||
|
||||
|
||||
使用上面的仓库,我们将获得最新的软件包。这些软件包通常都得到了很好的维护,还有大多数社区的建议。但这对于操作系统来说应该是适当的,因为它们可能并不安全。
|
||||
使用上面的仓库,我们将获得最新的软件包。这些软件包通常都得到了很好的维护,还有大多数社区的推荐。但这些只是建议,可能并不总是安全的。
|
||||
|
||||
近年来,出现了一下通用软件包封装格式,并且得到了广泛的应用。
|
||||
|
||||
* **`Flatpak:`** 它是独立于发行版的包格式,主要贡献者是 Fedora 项目团队。大多数主要的 Linux 发行版都采用了 Flatpak 框架。
|
||||
* **`Snaps:`** Snappy 是一种通用的软件包封装格式,最初由 Canonical 为 Ubuntu 手机及其操作系统设计和构建的。后来,大多数发行版都进行了改编。
|
||||
* **`AppImage:`** AppImage 是一种可移植的包格式,可以在不安装或不需要 root 权限的情况下运行。
|
||||
* Flatpak:它是独立于发行版的包格式,主要贡献者是 Fedora 项目团队。大多数主要的 Linux 发行版都采用了 Flatpak 框架。
|
||||
* Snaps:Snappy 是一种通用的软件包封装格式,最初由 Canonical 为 Ubuntu 手机及其操作系统设计和构建的。后来,更多的发行版都接纳了它。
|
||||
* AppImage:AppImage 是一种可移植的包格式,可以在不安装和不需要 root 权限的情况下运行。
|
||||
|
||||
我们之前已经介绍过 **[Snap 包管理器和包封装格式][7]**。今天我们将讨论 Flatpak 包封装格式。
|
||||
我们之前已经介绍过 [Snap 包管理器和包封装格式][7]。今天我们将讨论 Flatpak 包封装格式。
|
||||
|
||||
### 什么是 Flatpak?
|
||||
|
||||
@ -56,13 +51,13 @@ Flatpak 的一个缺点是不像 Snap 和 AppImage 那样支持服务器操作
|
||||
|
||||
大多数 Linux 发行版官方仓库都提供 Flatpak 软件包。因此,可以使用它们来进行安装。
|
||||
|
||||
对于 **`Fedora`** 系统,使用 **[DNF 命令][8]** 来安装 flatpak。
|
||||
对于 Fedora 系统,使用 [DNF 命令][8] 来安装 flatpak。
|
||||
|
||||
```
|
||||
$ sudo dnf install flatpak
|
||||
```
|
||||
|
||||
对于 **`Debian/Ubuntu`** 系统,使用 **[APT-GET 命令][9]** 或 **[APT 命令][10]** 来安装 flatpak。
|
||||
对于 Debian/Ubuntu 系统,使用 [APT-GET 命令][9] 或 [APT 命令][10] 来安装 flatpak。
|
||||
|
||||
```
|
||||
$ sudo apt install flatpak
|
||||
@ -76,19 +71,19 @@ $ sudo apt update
|
||||
$ sudo apt install flatpak
|
||||
```
|
||||
|
||||
对于基于 **`Arch Linux`** 的系统,使用 **[Pacman 命令][11]** 来安装 flatpak。
|
||||
对于基于 Arch Linux 的系统,使用 [Pacman 命令][11] 来安装 flatpak。
|
||||
|
||||
```
|
||||
$ sudo pacman -S flatpak
|
||||
```
|
||||
|
||||
对于 **`RHEL/CentOS`** 系统,使用 **[YUM 命令][12]** 来安装 flatpak。
|
||||
对于 RHEL/CentOS 系统,使用 [YUM 命令][12] 来安装 flatpak。
|
||||
|
||||
```
|
||||
$ sudo yum install flatpak
|
||||
```
|
||||
|
||||
对于 **`openSUSE Leap`** 系统,使用 **[Zypper 命令][13]** 来安装 flatpak。
|
||||
对于 openSUSE Leap 系统,使用 [Zypper 命令][13] 来安装 flatpak。
|
||||
|
||||
```
|
||||
$ sudo zypper install flatpak
|
||||
@ -96,9 +91,7 @@ $ sudo zypper install flatpak
|
||||
|
||||
### 如何在 Linux 上启用 Flathub 支持?
|
||||
|
||||
Flathub 网站是一个应用程序商店,你可以在其中找到 flatpak。
|
||||
|
||||
它是一个中央仓库,所有的 flatpak 应用程序都可供用户使用。
|
||||
Flathub 网站是一个应用程序商店,你可以在其中找到 flatpak 软件包。它是一个中央仓库,所有的 flatpak 应用程序都可供用户使用。
|
||||
|
||||
运行以下命令在 Linux 上启用 Flathub 支持:
|
||||
|
||||
@ -226,7 +219,7 @@ org.gnome.Platform/x86_64/3.30 system,runtime
|
||||
|
||||
### 如何查看有关已安装应用程序的详细信息?
|
||||
|
||||
运行以下命令以查看有关已安装应用程序的详细信息。
|
||||
运行以下命令以查看有关已安装应用程序的详细信息:
|
||||
|
||||
```
|
||||
$ flatpak info com.github.muriloventuroso.easyssh
|
||||
@ -264,6 +257,7 @@ $ flatpak update com.github.muriloventuroso.easyssh
|
||||
### 如何移除已安装的应用程序?
|
||||
|
||||
运行以下命令来移除已安装的应用程序:
|
||||
|
||||
```
|
||||
$ sudo flatpak uninstall com.github.muriloventuroso.easyssh
|
||||
```
|
||||
@ -281,7 +275,7 @@ via: https://www.2daygeek.com/how-to-install-and-enable-flatpak-support-on-linux
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,45 +1,35 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (heguangzhi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10736-1.html)
|
||||
[#]: subject: (How To Check The List Of Open Ports In Linux?)
|
||||
[#]: via: (https://www.2daygeek.com/linux-scan-check-open-ports-using-netstat-ss-nmap/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
|
||||
如何检查Linux中的开放端口列表?
|
||||
如何检查 Linux 中的开放端口列表?
|
||||
======
|
||||
|
||||
最近,我们就同一主题写了两篇文章。
|
||||
最近,我们就同一主题写了两篇文章。这些文章内容帮助你如何检查远程服务器中给定的端口是否打开。
|
||||
|
||||
这些文章内容帮助您如何检查远程服务器中给定的端口是否打开。
|
||||
如果你想 [检查远程 Linux 系统上的端口是否打开][1] 请点击链接浏览。如果你想 [检查多个远程 Linux 系统上的端口是否打开][2] 请点击链接浏览。如果你想 [检查多个远程 Linux 系统上的多个端口状态][2] 请点击链接浏览。
|
||||
|
||||
如果您想 **[检查远程 Linux 系统上的端口是否打开][1]** 请点击链接浏览。
|
||||
但是本文帮助你检查本地系统上的开放端口列表。
|
||||
|
||||
如果您想 **[检查多个远程 Linux 系统上的端口是否打开][2]** 请点击链接浏览。
|
||||
在 Linux 中很少有用于此目的的实用程序。然而,我提供了四个最重要的 Linux 命令来检查这一点。
|
||||
|
||||
如果您想 **[检查多个远程Linux系统上的多个端口状态][2]** 请点击链接浏览。
|
||||
|
||||
但是本文帮助您检查本地系统上的开放端口列表。
|
||||
|
||||
在 Linux 中很少有用于此目的的实用程序。
|
||||
|
||||
然而,我提供了四个最重要的 Linux 命令来检查这一点。
|
||||
|
||||
您可以使用以下四个命令来完成这个工作。这些命令是非常出名的并被 Linux 管理员广泛使用。
|
||||
|
||||
* **`netstat:`** netstat (“network statistics”) 是一个显示网络连接(进和出)相关信息命令行工具,例如:路由表, 伪装连接,多点传送成员和网络端口。
|
||||
* **`nmap:`** Nmap (“Network Mapper”) 是一个网络探索与安全审计的开源工具。它旨在快速扫描大型网络。
|
||||
* **`ss:`** ss 被用于转储套接字统计信息。它也可以类似 netstat 使用。相比其他工具它可以展示更多的TCP状态信息。
|
||||
* **`lsof:`** lsof 是 List Open File 的缩写. 它用于输出被某个进程打开的所有文件。
|
||||
你可以使用以下四个命令来完成这个工作。这些命令是非常出名的并被 Linux 管理员广泛使用。
|
||||
|
||||
* `netstat`:netstat (“network statistics”) 是一个显示网络连接(进和出)相关信息命令行工具,例如:路由表, 伪装连接,多点传送成员和网络端口。
|
||||
* `nmap`:Nmap (“Network Mapper”) 是一个网络探索与安全审计的开源工具。它旨在快速扫描大型网络。
|
||||
* `ss`: ss 被用于转储套接字统计信息。它也可以类似 netstat 使用。相比其他工具它可以展示更多的TCP状态信息。
|
||||
* `lsof`: lsof 是 List Open File 的缩写. 它用于输出被某个进程打开的所有文件。
|
||||
|
||||
### 如何使用 Linux 命令 netstat 检查系统中的开放端口列表
|
||||
|
||||
netstat 是 Network Statistics 的缩写,是一个显示网络连接(进和出)相关信息命令行工具,例如:路由表, 伪装连接,多点传送成员和网络端口。
|
||||
`netstat` 是 Network Statistics 的缩写,是一个显示网络连接(进和出)相关信息命令行工具,例如:路由表、伪装连接、多播成员和网络端口。
|
||||
|
||||
它可以列出所有的 tcp, udp 连接 和所有的 unix 套接字连接。
|
||||
它可以列出所有的 tcp、udp 连接和所有的 unix 套接字连接。
|
||||
|
||||
它用于发现发现网络问题,确定网络连接数量。
|
||||
|
||||
@ -81,7 +71,7 @@ eth0 1 ff02::1
|
||||
eth0 1 ff01::1
|
||||
```
|
||||
|
||||
您也可以使用下面的命令检查特定的端口。
|
||||
你也可以使用下面的命令检查特定的端口。
|
||||
|
||||
```
|
||||
# # netstat -tplugn | grep :22
|
||||
@ -92,7 +82,7 @@ tcp6 0 0 :::22 :::* LISTEN
|
||||
|
||||
### 如何使用 Linux 命令 ss 检查系统中的开放端口列表?
|
||||
|
||||
ss 被用于转储套接字统计信息。它也可以类似 netstat 使用。相比其他工具它可以展示更多的TCP状态信息。
|
||||
`ss` 被用于转储套接字统计信息。它也可以显示类似 `netstat` 的信息。相比其他工具它可以展示更多的 TCP 状态信息。
|
||||
|
||||
```
|
||||
# ss -lntu
|
||||
@ -121,7 +111,7 @@ tcp LISTEN 0 100 :::25
|
||||
tcp LISTEN 0 128 :::22 :::*
|
||||
```
|
||||
|
||||
您也可以使用下面的命令检查特定的端口。
|
||||
你也可以使用下面的命令检查特定的端口。
|
||||
|
||||
```
|
||||
# # ss -lntu | grep ':25'
|
||||
@ -132,12 +122,11 @@ tcp LISTEN 0 100 :::25 :::*
|
||||
|
||||
### 如何使用 Linux 命令 nmap 检查系统中的开放端口列表?
|
||||
|
||||
|
||||
Nmap (“Network Mapper”) 是一个网络探索与安全审计的开源工具。它旨在快速扫描大型网络,当然它也可以工作在独立主机上。
|
||||
|
||||
Nmap使用裸 IP 数据包以一种新颖的方式来确定网络上有哪些主机可用,这些主机提供什么服务(应用程序名称和版本),它们运行什么操作系统(操作系统版本),使用什么类型的数据包过滤器/防火墙,以及许多其他特征。
|
||||
Nmap 使用裸 IP 数据包以一种新颖的方式来确定网络上有哪些主机可用,这些主机提供什么服务(应用程序名称和版本),它们运行什么操作系统(版本),使用什么类型的数据包过滤器/防火墙,以及许多其他特征。
|
||||
|
||||
虽然 Nmap 通常用于安全审计,但许多系统和网络管理员发现它对于日常工作也非常有用,例如网络清点、管理服务升级计划以及监控主机或服务正常运行时间。
|
||||
虽然 Nmap 通常用于安全审计,但许多系统和网络管理员发现它对于日常工作也非常有用,例如网络资产清点、管理服务升级计划以及监控主机或服务正常运行时间。
|
||||
|
||||
```
|
||||
# nmap -sTU -O localhost
|
||||
@ -166,9 +155,7 @@ OS detection performed. Please report any incorrect results at http://nmap.org/s
|
||||
Nmap done: 1 IP address (1 host up) scanned in 1.93 seconds
|
||||
```
|
||||
|
||||
|
||||
您也可以使用下面的命令检查特定的端口。
|
||||
|
||||
你也可以使用下面的命令检查特定的端口。
|
||||
|
||||
```
|
||||
# nmap -sTU -O localhost | grep 123
|
||||
@ -176,10 +163,9 @@ Nmap done: 1 IP address (1 host up) scanned in 1.93 seconds
|
||||
123/udp open ntp
|
||||
```
|
||||
|
||||
|
||||
### 如何使用 Linux 命令 lsof 检查系统中的开放端口列表?
|
||||
|
||||
它向您显示系统上打开的文件列表以及打开它们的进程。还会向您显示与文件相关的其他信息。
|
||||
它向你显示系统上打开的文件列表以及打开它们的进程。还会向你显示与文件相关的其他信息。
|
||||
|
||||
```
|
||||
# lsof -i
|
||||
@ -214,8 +200,7 @@ httpd 13374 apache 3u IPv4 20337 0t0 TCP *:http (LISTEN)
|
||||
httpd 13375 apache 3u IPv4 20337 0t0 TCP *:http (LISTEN)
|
||||
```
|
||||
|
||||
您也可以使用下面的命令检查特定的端口。
|
||||
|
||||
你也可以使用下面的命令检查特定的端口。
|
||||
|
||||
```
|
||||
# lsof -i:80
|
||||
@ -236,11 +221,11 @@ via: https://www.2daygeek.com/linux-scan-check-open-ports-using-netstat-ss-nmap/
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[heguangzhi](https://github.com/heguangzhi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/how-to-check-whether-a-port-is-open-on-the-remote-linux-system-server/
|
||||
[1]: https://linux.cn/article-10675-1.html
|
||||
[2]: https://www.2daygeek.com/check-a-open-port-on-multiple-remote-linux-server-using-nc-command/
|
||||
117
published/201904/20190410 Managing Partitions with sgdisk.md
Normal file
117
published/201904/20190410 Managing Partitions with sgdisk.md
Normal file
@ -0,0 +1,117 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10771-1.html)
|
||||
[#]: subject: (Managing Partitions with sgdisk)
|
||||
[#]: via: (https://fedoramagazine.org/managing-partitions-with-sgdisk/)
|
||||
[#]: author: (Gregory Bartholomew https://fedoramagazine.org/author/glb/)
|
||||
|
||||
使用 sgdisk 管理分区
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
[Roderick W. Smith][2] 的 `sgdisk` 命令可在命令行中管理硬盘的分区。下面将介绍使用它所需的基础知识。
|
||||
|
||||
使用 sgdisk 的大多数基本功能只需要了解以下六个参数:
|
||||
|
||||
1、`-p` *打印* 分区表:
|
||||
|
||||
```
|
||||
# sgdisk -p /dev/sda
|
||||
```
|
||||
|
||||
2、 `-d x` *删除* 分区 x:
|
||||
|
||||
```
|
||||
# sgdisk -d 1 /dev/sda
|
||||
```
|
||||
|
||||
3、 `-n x:y:z` 创建一个编号 x 的*新*分区,从 y 开始,从 z 结束:
|
||||
|
||||
```
|
||||
# sgdisk -n 1:1MiB:2MiB /dev/sda
|
||||
```
|
||||
|
||||
4、`-c x:y` *更改*分区 x 的名称为 y:
|
||||
|
||||
```
|
||||
# sgdisk -c 1:grub /dev/sda
|
||||
```
|
||||
|
||||
5、`-t x:y` 将分区 x 的*类型*更改为 y:
|
||||
|
||||
```
|
||||
# sgdisk -t 1:ef02 /dev/sda
|
||||
```
|
||||
|
||||
6、`–list-types` 列出分区类型代码:
|
||||
|
||||
```
|
||||
# sgdisk --list-types
|
||||
```
|
||||
|
||||
![The SGDisk Command][3]
|
||||
|
||||
如你在上面的例子中所见,大多数命令都要求将要操作的硬盘的[设备文件名][4]指定为最后一个参数。
|
||||
|
||||
可以组合上面的参数,这样你可以一次定义所有分区:
|
||||
|
||||
```
|
||||
# sgdisk -n 1:1MiB:2MiB -t 1:ef02 -c 1:grub /dev/sda
|
||||
```
|
||||
|
||||
在值的前面加上 `+` 或 `–` 符号,可以为某些字段指定相对值。如果你使用相对值,`sgdisk` 会为你做数学运算。例如,上面的例子可以写成:
|
||||
|
||||
```
|
||||
# sgdisk -n 1:1MiB:+1MiB -t 1:ef02 -c 1:grub /dev/sda
|
||||
```
|
||||
|
||||
`0` 值对于以下几个字段有特殊意义:
|
||||
|
||||
* 对于*分区号*字段,0 表示应使用下一个可用编号(编号从 1 开始)。
|
||||
* 对于*起始地址*字段,0 表示使用最大可用空闲块的头。硬盘开头的一些空间始终保留给分区表本身。
|
||||
* 对于*结束地址*字段,0 表示使用最大可用空闲块的末尾。
|
||||
|
||||
通过在适当的字段中使用 `0` 和相对值,你可以创建一系列分区,而无需预先计算任何绝对值。例如,如果在一块空白硬盘中,以下 `sgdisk` 命令序列将创建典型 Linux 安装所需的所有基本分区:
|
||||
|
||||
```
|
||||
# sgdisk -n 0:0:+1MiB -t 0:ef02 -c 0:grub /dev/sda
|
||||
# sgdisk -n 0:0:+1GiB -t 0:ea00 -c 0:boot /dev/sda
|
||||
# sgdisk -n 0:0:+4GiB -t 0:8200 -c 0:swap /dev/sda
|
||||
# sgdisk -n 0:0:0 -t 0:8300 -c 0:root /dev/sda
|
||||
```
|
||||
|
||||
上面的例子展示了如何为基于 BIOS 的计算机分区硬盘。基于 UEFI 的计算机上不需要 [grub 分区][5]。由于 `sgdisk` 在上面的示例中为你计算了所有绝对值,因此你可以在基于 UEFI 的计算机上跳过第一个命令,并且可以无需修改即可运行其余命令。同样,你可以跳过创建交换分区,并且不需要修改其余命令。
|
||||
|
||||
还有使用一个命令删除硬盘上所有分区的快捷方式:
|
||||
|
||||
```
|
||||
# sgdisk --zap-all /dev/sda
|
||||
```
|
||||
|
||||
关于最新和详细信息,请查看手册页:
|
||||
|
||||
```
|
||||
$ man sgdisk
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/managing-partitions-with-sgdisk/
|
||||
|
||||
作者:[Gregory Bartholomew][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/glb/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/04/managing-partitions-816x345.png
|
||||
[2]: https://www.rodsbooks.com/
|
||||
[3]: https://fedoramagazine.org/wp-content/uploads/2019/04/sgdisk.jpg
|
||||
[4]: https://en.wikipedia.org/wiki/Device_file
|
||||
[5]: https://en.wikipedia.org/wiki/BIOS_boot_partition
|
||||
@ -0,0 +1,106 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10778-1.html)
|
||||
[#]: subject: (How to Zip Files and Folders in Linux [Beginner Tip])
|
||||
[#]: via: (https://itsfoss.com/linux-zip-folder/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
初级:如何在 Linux 中 zip 压缩文件和文件夹
|
||||
======
|
||||
|
||||
> 本文向你展示了如何在 Ubuntu 和其他 Linux 发行版中创建一个 zip 文件夹。终端和 GUI 方法都有。
|
||||
|
||||
zip 是最流行的归档文件格式之一。使用 zip,你可以将多个文件压缩到一个文件中。这不仅节省了磁盘空间,还节省了网络带宽。这就是为什么你几乎一直会看到 zip 文件的原因。
|
||||
|
||||
作为普通用户,大多数情况下你会在 Linux 中解压缩文件夹。但是如何在 Linux 中压缩文件夹?本文可以帮助你回答这个问题。
|
||||
|
||||
**先决条件:验证是否安装了 zip**
|
||||
|
||||
通常 [zip][1] 已经安装,但验证下也没坏处。你可以运行以下命令来安装 `zip` 和 `unzip`。如果它尚未安装,它将立即安装。
|
||||
|
||||
```
|
||||
sudo apt install zip unzip
|
||||
```
|
||||
|
||||
现在你知道你的系统有 zip 支持,你可以继续了解如何在 Linux 中压缩一个目录。
|
||||
|
||||
![][2]
|
||||
|
||||
### 在 Linux 命令行中压缩文件夹
|
||||
|
||||
`zip` 命令的语法非常简单。
|
||||
|
||||
```
|
||||
zip [option] output_file_name input1 input2
|
||||
```
|
||||
|
||||
虽然有几个选项,但我不希望你将它们混淆。如果你只想要将一堆文件变成一个 zip 文件夹,请使用如下命令:
|
||||
|
||||
```
|
||||
zip -r output_file.zip file1 folder1
|
||||
```
|
||||
|
||||
`-r` 选项将递归目录并压缩其内容。输出文件中的 .zip 扩展名是可选的,因为默认情况下会添加 .zip。
|
||||
|
||||
你应该会在 zip 操作期间看到要添加到压缩文件夹中的文件。
|
||||
|
||||
```
|
||||
zip -r myzip abhi-1.txt abhi-2.txt sample_directory
|
||||
adding: abhi-1.txt (stored 0%)
|
||||
adding: abhi-2.txt (stored 0%)
|
||||
adding: sample_directory/ (stored 0%)
|
||||
adding: sample_directory/newfile.txt (stored 0%)
|
||||
adding: sample_directory/agatha.txt (deflated 41%)
|
||||
```
|
||||
|
||||
你可以使用 `-e` 选项[在 Linux 中创建密码保护的 zip 文件夹][3]。
|
||||
|
||||
你并不是只能通过终端创建 zip 归档文件。你也可以用图形方式做到这一点。下面是如何做的!
|
||||
|
||||
### 在 Ubuntu Linux 中使用 GUI 压缩文件夹
|
||||
|
||||
*虽然我在这里使用 Ubuntu,但在使用 GNOME 或其他桌面环境的其他发行版中,方法应该基本相同。*
|
||||
|
||||
如果要在 Linux 桌面中压缩文件或文件夹,只需点击几下即可。
|
||||
|
||||
进入到你想将文件(和文件夹)压缩到一个 zip 文件夹的所在文件夹。
|
||||
|
||||
在这里,选择文件和文件夹。现在,右键单击并选择“压缩”。你也可以对单个文件执行相同操作。
|
||||
|
||||
![Select the files, right click and click compress][4]
|
||||
|
||||
现在,你可以使用 zip、tar xz 或 7z 格式创建压缩归档文件。如果你好奇,这三个都是各种压缩算法,你可以使用它们来压缩文件。
|
||||
|
||||
输入一个你想要的名字,并点击“创建”。
|
||||
|
||||
![Create archive file][5]
|
||||
|
||||
这不会花很长时间,你会同一目录中看到一个归档文件。
|
||||
|
||||
![][6]
|
||||
|
||||
好了,就是这些。你已经成功地在 Linux 中创建了一个 zip 文件夹。
|
||||
|
||||
我希望这篇文章能帮助你了解 zip 文件。请随时分享你的建议。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/linux-zip-folder/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Zip_(file_format)
|
||||
[2]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/04/zip-folder-linux.png?resize=800%2C450&ssl=1
|
||||
[3]: https://itsfoss.com/password-protect-zip-file/
|
||||
[4]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/04/create-zip-file-ubuntu.jpg?resize=800%2C428&ssl=1
|
||||
[5]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/04/create-zip-folder-ubuntu-1.jpg?ssl=1
|
||||
[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/04/zip-file-created-in-ubuntu.png?resize=800%2C277&ssl=1
|
||||
443
published/201904/20190413 The Fargate Illusion.md
Normal file
443
published/201904/20190413 The Fargate Illusion.md
Normal file
@ -0,0 +1,443 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10740-1.html)
|
||||
[#]: subject: (The Fargate Illusion)
|
||||
[#]: via: (https://leebriggs.co.uk/blog/2019/04/13/the-fargate-illusion.html)
|
||||
[#]: author: (Lee Briggs https://leebriggs.co.uk/)
|
||||
|
||||
破除对 AWS Fargate 的幻觉
|
||||
======
|
||||
|
||||
我在 $work 建立了一个基于 Kubernetes 的平台已经快一年了,而且有点像 Kubernetes 的布道者了。真的,我认为这项技术太棒了。然而我并没有对它的运营和维护的困难程度抱过什么幻想。今年早些时候我读了[这样][1]的一篇文章,并对其中某些观点深以为然。如果我在一家规模较小的、有 10 到 15 个工程师的公司,假如有人建议管理和维护一批 Kubernetes 集群,那我会感到害怕的,因为它的运维开销太高了!
|
||||
|
||||
尽管我现在对 Kubernetes 的一切都很感兴趣,但我仍然对“<ruby>无服务器<rt>Serverless</rt></ruby>”计算会消灭运维工程师的说法抱有好奇。这种好奇心主要来源于我希望在未来仍然能有一份有报酬的工作 —— 如果我们前景光明的未来不需要运维工程师,那我得明白到底是怎么回事。我已经在 Lamdba 和Google Cloud Functions 上做了一些实验,结果让我印象十分深刻,但我仍然坚信无服务器解决方案只是解决了一部分问题。
|
||||
|
||||
我关注 [AWS Fargate][2] 已经有一段时间了,这就是 $work 的开发人员所推崇为“无服务器计算”的东西 —— 主要是因为 Fargate,用它你就可以无需管理底层节点而运行你的 Docker 容器。我想看看它到底意味着什么,所以我开始尝试从头开始在 Fargate 上运行一个应用,看看是否可以成功。这里我对成功的定义是一个与“生产级”应用程序相近的东西,我想应该包含以下内容:
|
||||
|
||||
* 一个在 Fargate 上运行的容器
|
||||
* 配置信息以环境变量的形式下推
|
||||
* “秘密信息” 不能是明文的
|
||||
* 位于负载均衡器之后
|
||||
* 有效的 SSL 证书的 TLS 通道
|
||||
|
||||
我以“基础设施即代码”的角度来开始整个任务,不遵循默认的 AWS 控制台向导,而是使用 terraform 来定义基础架构。这很可能让整个事情变得复杂,但我想确保任何部署都是可重现的,任何想要遵循此步骤的人都可发现我的结论。
|
||||
|
||||
上述所有标准通常都可以通过基于 Kubernetes 的平台使用一些外部的附加组件和插件来实现,所以我确实是以一种比较的心态来处理整个任务的,因为我要将它与我的常用工作流程进行比较。我的主要目标是看看Fargate 有多容易,特别是与 Kubernetes 相比时。结果让我感到非常惊讶。
|
||||
|
||||
### AWS 是有开销的
|
||||
|
||||
我有一个干净的 AWS 账户,并决定从零到部署一个 webapp。与 AWS 中的其它基础设施一样,我必须首先使基本的基础设施正常工作起来,因此我需要先定义一个 VPC。
|
||||
|
||||
遵循最佳实践,因此我将这个 VPC 划分为跨可用区(AZ)的子网,一个公共子网和私有子网。这时我想到,只要这种设置基础设施的需求存在,我就能找到一份这种工作。AWS 是"免"运维的这一概念一直让我感到愤怒。开发者社区中的许多人理所当然地认为在设置和定义一个设计良好的 AWS 账户和基础设施是不需要付出多少工作和努力的。而这种想当然甚至发生在开始谈论多帐户架构*之前*就有了——现在我仍然使用单一帐户,我已经必须定义好基础设施和传统的网络设备。
|
||||
|
||||
这里也值得记住,我已经做了很多次,所以我*很清楚*该做什么。我可以在我的帐户中使用默认的 VPC 以及预先提供的子网,我觉得很多刚开始的人也可以使用它。这大概花了我半个小时才运行起来,但我不禁想到,即使我想运行 lambda 函数,我仍然需要某种连接和网络。定义 NAT 网关和在 VPC 中路由根本不会让你觉得很“Serverless”,但要往下进行这就是必须要做的。
|
||||
|
||||
### 运行简单的容器
|
||||
|
||||
在我启动运行了基本的基础设施之后,现在我想让我的 Docker 容器运行起来。我开始翻阅 Fargate 文档并浏览 [入门][3] 文档,这些就马上就展现在了我面前:
|
||||
|
||||
![][4]
|
||||
|
||||
等等,只是让我的容器运行就至少要有**三个**步骤?这完全不像我所想的,不过还是让我们开始吧。
|
||||
|
||||
#### 任务定义
|
||||
|
||||
“<ruby>任务定义<rt>Task Definition<rt></ruby>”用来定义要运行的实际容器。我在这里遇到的问题是,任务定义这件事非常复杂。这里有很多选项都很简单,比如指定 Docker 镜像和内存限制,但我还必须定义一个网络模型以及我并不熟悉的其它各种选项。真需要这样吗?如果我完全没有 AWS 方面的知识就进入到这个过程里,那么在这个阶段我会感觉非常的不知所措。可以在 AWS 页面上找到这些 [参数][5] 的完整列表,这个列表很长。我知道我的容器需要一些环境变量,它需要暴露一个端口。所以我首先在一个神奇的 [terraform 模块][6] 的帮助下定义了这一点,这真的让这件事更容易了。如果没有这个模块,我就得手写 JSON 来定义我的容器定义。
|
||||
|
||||
首先我定义了一些环境变量:
|
||||
|
||||
```
|
||||
container_environment_variables = [
|
||||
{
|
||||
name = "USER"
|
||||
value = "${var.user}"
|
||||
},
|
||||
{
|
||||
name = "PASSWORD"
|
||||
value = "${var.password}"
|
||||
}
|
||||
]
|
||||
```
|
||||
|
||||
然后我使用上面提及的模块组成了任务定义:
|
||||
|
||||
```
|
||||
module "container_definition_app" {
|
||||
source = "cloudposse/ecs-container-definition/aws"
|
||||
version = "v0.7.0"
|
||||
|
||||
container_name = "${var.name}"
|
||||
container_image = "${var.image}"
|
||||
|
||||
container_cpu = "${var.ecs_task_cpu}"
|
||||
container_memory = "${var.ecs_task_memory}"
|
||||
container_memory_reservation = "${var.container_memory_reservation}"
|
||||
|
||||
port_mappings = [
|
||||
{
|
||||
containerPort = "${var.app_port}"
|
||||
hostPort = "${var.app_port}"
|
||||
protocol = "tcp"
|
||||
},
|
||||
]
|
||||
|
||||
environment = "${local.container_environment_variables}"
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
在这一点上我非常困惑,我需要在这里定义很多配置才能运行,而这时什么都没有开始呢,但这是必要的 —— 运行 Docker 容器肯定需要了解一些容器配置的知识。我 [之前写过][7] 关于 Kubernetes 和配置管理的问题的文章,在这里似乎遇到了同样的问题。
|
||||
|
||||
接下来,我在上面的模块中定义了任务定义(幸好从我这里抽象出了所需的 JSON —— 如果我不得不手写JSON,我可能已经放弃了)。
|
||||
|
||||
当我定义模块参数时,我突然意识到我漏掉了一些东西。我需要一个 IAM 角色!好吧,让我来定义:
|
||||
|
||||
```
|
||||
resource "aws_iam_role" "ecs_task_execution" {
|
||||
name = "${var.name}-ecs_task_execution"
|
||||
|
||||
assume_role_policy = <<EOF
|
||||
{
|
||||
"Version": "2008-10-17",
|
||||
"Statement": [
|
||||
{
|
||||
"Action": "sts:AssumeRole",
|
||||
"Principal": {
|
||||
"Service": "ecs-tasks.amazonaws.com"
|
||||
},
|
||||
"Effect": "Allow"
|
||||
}
|
||||
]
|
||||
}
|
||||
EOF
|
||||
}
|
||||
|
||||
resource "aws_iam_role_policy_attachment" "ecs_task_execution" {
|
||||
count = "${length(var.policies_arn)}"
|
||||
|
||||
role = "${aws_iam_role.ecs_task_execution.id}"
|
||||
policy_arn = "${element(var.policies_arn, count.index)}"
|
||||
}
|
||||
```
|
||||
|
||||
这样做是有意义的,我需要在 Kubernetes 中定义一个 RBAC 策略,所以在这里我还未完全错失或获得任何东西。这时我开始觉得从 Kubernetes 的角度来看,这种感觉非常熟悉。
|
||||
|
||||
```
|
||||
resource "aws_ecs_task_definition" "app" {
|
||||
family = "${var.name}"
|
||||
network_mode = "awsvpc"
|
||||
requires_compatibilities = ["FARGATE"]
|
||||
cpu = "${var.ecs_task_cpu}"
|
||||
memory = "${var.ecs_task_memory}"
|
||||
execution_role_arn = "${aws_iam_role.ecs_task_execution.arn}"
|
||||
task_role_arn = "${aws_iam_role.ecs_task_execution.arn}"
|
||||
|
||||
container_definitions = "${module.container_definition_app.json}"
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
现在,为了运行起来我已经写了很多行代码,我阅读了很多 ECS 文档,我所做的就是定义一个任务定义。我还没有让这个东西运行起来。在这一点上,我真的很困惑这个基于 Kubernetes 的平台到底增值了什么,但我继续前行。
|
||||
|
||||
#### 服务
|
||||
|
||||
服务,一定程度上是将容器如何暴露给外部,另外是如何定义它拥有的副本数量。我的第一个想法是“啊!这就像一个 Kubernetes 服务!”我开始着手映射端口等。这是我第一次在 terraform 上跑:
|
||||
|
||||
```
|
||||
resource "aws_ecs_service" "app" {
|
||||
name = "${var.name}"
|
||||
cluster = "${module.ecs.this_ecs_cluster_id}"
|
||||
task_definition = "${data.aws_ecs_task_definition.app.family}:${max(aws_ecs_task_definition.app.revision, data.aws_ecs_task_definition.app.revision)}"
|
||||
desired_count = "${var.ecs_service_desired_count}"
|
||||
launch_type = "FARGATE"
|
||||
deployment_maximum_percent = "${var.ecs_service_deployment_maximum_percent}"
|
||||
deployment_minimum_healthy_percent = "${var.ecs_service_deployment_minimum_healthy_percent}"
|
||||
|
||||
network_configuration {
|
||||
subnets = ["${values(local.private_subnets)}"]
|
||||
security_groups = ["${module.app.this_security_group_id}"]
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
当我必须定义允许访问所需端口的安全组时,我再次感到沮丧,当我这样做了并将其插入到网络配置中后,我就像被扇了一巴掌。
|
||||
|
||||
我还需要定义自己的负载均衡器?
|
||||
|
||||
什么?
|
||||
|
||||
当然不是吗?
|
||||
|
||||
##### 负载均衡器从未远离
|
||||
|
||||
老实说,我很满意,我甚至不确定为什么。我已经习惯了 Kubernetes 的服务和 Ingress 对象,我一心认为用 Kubernetes 将我的应用程序放到网上是多么容易。当然,我们在 $work 花了几个月的时间建立一个平台,以便更轻松。我是 [external-dns][8] 和 [cert-manager][9] 的重度用户,它们可以自动填充 Ingress 对象上的 DNS 条目并自动化 TLS 证书,我非常了解进行这些设置所需的工作,但老实说,我认为在 Fargate 上做这件事会更容易。我认识到 Fargate 并没有声称自己是“如何运行应用程序”这件事的全部和最终目的,它只是抽象出节点管理,但我一直被告知这比 Kubernetes *更加容易*。我真的很惊讶。定义负载均衡器(即使你不想使用 Ingress 和 Ingress Controller)也是向 Kubernetes 部署服务的重要组成部分,我不得不在这里再次做同样的事情。这一切都让人觉得如此熟悉。
|
||||
|
||||
我现在意识到我需要:
|
||||
|
||||
* 一个负载均衡器
|
||||
* 一个 TLS 证书
|
||||
* 一个 DNS 名字
|
||||
|
||||
所以我着手做了这些。我使用了一些流行的 terraform 模块,并做了这个:
|
||||
|
||||
```
|
||||
# Define a wildcard cert for my app
|
||||
module "acm" {
|
||||
source = "terraform-aws-modules/acm/aws"
|
||||
version = "v1.1.0"
|
||||
|
||||
create_certificate = true
|
||||
|
||||
domain_name = "${var.route53_zone_name}"
|
||||
zone_id = "${data.aws_route53_zone.this.id}"
|
||||
|
||||
subject_alternative_names = [
|
||||
"*.${var.route53_zone_name}",
|
||||
]
|
||||
|
||||
|
||||
tags = "${local.tags}"
|
||||
|
||||
}
|
||||
# Define my loadbalancer
|
||||
resource "aws_lb" "main" {
|
||||
name = "${var.name}"
|
||||
subnets = [ "${values(local.public_subnets)}" ]
|
||||
security_groups = ["${module.alb_https_sg.this_security_group_id}", "${module.alb_http_sg.this_security_group_id}"]
|
||||
}
|
||||
|
||||
resource "aws_lb_target_group" "main" {
|
||||
name = "${var.name}"
|
||||
port = "${var.app_port}"
|
||||
protocol = "HTTP"
|
||||
vpc_id = "${local.vpc_id}"
|
||||
target_type = "ip"
|
||||
depends_on = [ "aws_lb.main" ]
|
||||
}
|
||||
|
||||
# Redirect all traffic from the ALB to the target group
|
||||
resource "aws_lb_listener" "main" {
|
||||
load_balancer_arn = "${aws_lb.main.id}"
|
||||
port = "80"
|
||||
protocol = "HTTP"
|
||||
|
||||
default_action {
|
||||
target_group_arn = "${aws_lb_target_group.main.id}"
|
||||
type = "forward"
|
||||
}
|
||||
}
|
||||
|
||||
resource "aws_lb_listener" "main-tls" {
|
||||
load_balancer_arn = "${aws_lb.main.id}"
|
||||
port = "443"
|
||||
protocol = "HTTPS"
|
||||
certificate_arn = "${module.acm.this_acm_certificate_arn}"
|
||||
|
||||
default_action {
|
||||
target_group_arn = "${aws_lb_target_group.main.id}"
|
||||
type = "forward"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
我必须承认,我在这里搞砸了好几次。我不得不在 AWS 控制台中四处翻弄,以弄清楚我做错了什么。这当然不是一个“轻松”的过程,而且我之前已经做过很多次了。老实说,在这一点上,Kubernetes 看起来对我很有启发性,但我意识到这是因为我对它非常熟悉。幸运的是我能够使用托管的 Kubernetes 平台(预装了 external-dns 和 cert-manager),我真的很想知道我漏掉了 Fargate 什么增值的地方。它真的感觉不那么简单。
|
||||
|
||||
经过一番折腾,我现在有一个可以工作的 ECS 服务。包括服务在内的最终定义如下所示:
|
||||
|
||||
```
|
||||
data "aws_ecs_task_definition" "app" {
|
||||
task_definition = "${var.name}"
|
||||
depends_on = ["aws_ecs_task_definition.app"]
|
||||
}
|
||||
|
||||
resource "aws_ecs_service" "app" {
|
||||
name = "${var.name}"
|
||||
cluster = "${module.ecs.this_ecs_cluster_id}"
|
||||
task_definition = "${data.aws_ecs_task_definition.app.family}:${max(aws_ecs_task_definition.app.revision, data.aws_ecs_task_definition.app.revision)}"
|
||||
desired_count = "${var.ecs_service_desired_count}"
|
||||
launch_type = "FARGATE"
|
||||
deployment_maximum_percent = "${var.ecs_service_deployment_maximum_percent}"
|
||||
deployment_minimum_healthy_percent = "${var.ecs_service_deployment_minimum_healthy_percent}"
|
||||
|
||||
network_configuration {
|
||||
subnets = ["${values(local.private_subnets)}"]
|
||||
security_groups = ["${module.app_sg.this_security_group_id}"]
|
||||
}
|
||||
|
||||
load_balancer {
|
||||
target_group_arn = "${aws_lb_target_group.main.id}"
|
||||
container_name = "app"
|
||||
container_port = "${var.app_port}"
|
||||
}
|
||||
|
||||
depends_on = [
|
||||
"aws_lb_listener.main",
|
||||
]
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
我觉得我已经接近完成了,但后来我记起了我只完成了最初的“入门”文档中所需的 3 个步骤中的 2 个,我仍然需要定义 ECS 群集。
|
||||
|
||||
#### 集群
|
||||
|
||||
感谢 [定义模块][10],定义要所有这些运行的集群实际上非常简单。
|
||||
|
||||
```
|
||||
module "ecs" {
|
||||
source = "terraform-aws-modules/ecs/aws"
|
||||
version = "v1.1.0"
|
||||
|
||||
name = "${var.name}"
|
||||
}
|
||||
```
|
||||
|
||||
这里让我感到惊讶的是为什么我必须定义一个集群。作为一个相当熟悉 ECS 的人,你会觉得你需要一个集群,但我试图从一个必须经历这个过程的新人的角度来考虑这一点 —— 对我来说,Fargate 标榜自己“
|
||||
Serverless”而你仍需要定义集群,这似乎很令人惊讶。当然这是一个小细节,但它确实盘旋在我的脑海里。
|
||||
|
||||
### 告诉我你的 Secret
|
||||
|
||||
在这个阶段,我很高兴我成功地运行了一些东西。然而,我的原始的成功标准缺少一些东西。如果我们回到任务定义那里,你会记得我的应用程序有一个存放密码的环境变量:
|
||||
|
||||
```
|
||||
container_environment_variables = [
|
||||
{
|
||||
name = "USER"
|
||||
value = "${var.user}"
|
||||
},
|
||||
{
|
||||
name = "PASSWORD"
|
||||
value = "${var.password}"
|
||||
}
|
||||
]
|
||||
```
|
||||
|
||||
如果我在 AWS 控制台中查看我的任务定义,我的密码就在那里,明晃晃的明文。我希望不要这样,所以我开始尝试将其转化为其他东西,类似于 [Kubernetes 的Secrets管理][11]。
|
||||
|
||||
#### AWS SSM
|
||||
|
||||
Fargate / ECS 执行<ruby>secret 管理<rt>secret management</rt></ruby>部分的方式是使用 [AWS SSM][12](此服务的全名是 AWS 系统管理器参数存储库 Systems Manager Parameter Store,但我不想使用这个名称,因为坦率地说这个名字太愚蠢了)。
|
||||
|
||||
AWS 文档很好的[涵盖了这个内容][13],因此我开始将其转换为 terraform。
|
||||
|
||||
##### 指定秘密信息
|
||||
|
||||
首先,你必须定义一个参数并为其命名。在 terraform 中,它看起来像这样:
|
||||
|
||||
```
|
||||
resource "aws_ssm_parameter" "app_password" {
|
||||
name = "${var.app_password_param_name}" # The name of the value in AWS SSM
|
||||
type = "SecureString"
|
||||
value = "${var.app_password}" # The actual value of the password, like correct-horse-battery-stable
|
||||
}
|
||||
```
|
||||
|
||||
显然,这里的关键部分是 “SecureString” 类型。这会使用默认的 AWS KMS 密钥来加密数据,这对我来说并不是很直观。这比 Kubernetes 的 Secret 管理具有巨大优势,默认情况下,这些 Secret 在 etcd 中是不加密的。
|
||||
|
||||
然后我为 ECS 指定了另一个本地值映射,并将其作为 Secret 参数传递:
|
||||
|
||||
```
|
||||
container_secrets = [
|
||||
{
|
||||
name = "PASSWORD"
|
||||
valueFrom = "${var.app_password_param_name}"
|
||||
},
|
||||
]
|
||||
|
||||
module "container_definition_app" {
|
||||
source = "cloudposse/ecs-container-definition/aws"
|
||||
version = "v0.7.0"
|
||||
|
||||
container_name = "${var.name}"
|
||||
container_image = "${var.image}"
|
||||
|
||||
container_cpu = "${var.ecs_task_cpu}"
|
||||
container_memory = "${var.ecs_task_memory}"
|
||||
container_memory_reservation = "${var.container_memory_reservation}"
|
||||
|
||||
port_mappings = [
|
||||
{
|
||||
containerPort = "${var.app_port}"
|
||||
hostPort = "${var.app_port}"
|
||||
protocol = "tcp"
|
||||
},
|
||||
]
|
||||
|
||||
environment = "${local.container_environment_variables}"
|
||||
secrets = "${local.container_secrets}"
|
||||
```
|
||||
|
||||
##### 出了个问题
|
||||
|
||||
此刻,我重新部署了我的任务定义,并且非常困惑。为什么任务没有正确拉起?当新的任务定义(版本 8)可用时,我一直在控制台中看到正在运行的应用程序仍在使用先前的任务定义(版本 7)。解决这件事花费的时间比我预期的要长,但是在控制台的事件屏幕上,我注意到了 IAM 错误。我错过了一个步骤,容器无法从 AWS SSM 中读取 Secret 信息,因为它没有正确的 IAM 权限。这是我第一次真正对整个这件事情感到沮丧。从用户体验的角度来看,这里的反馈非常*糟糕*。如果我没有发觉的话,我会认为一切都很好,因为仍然有一个任务正在运行,我的应用程序仍然可以通过正确的 URL 访问 —— 只不过是旧的配置而已。
|
||||
|
||||
在 Kubernetes 里,我会清楚地看到 pod 定义中的错误。Fargate 可以确保我的应用不会停止,这绝对是太棒了,但作为一名运维,我需要一些关于发生了什么的实际反馈。这真的不够好。我真的希望 Fargate 团队的人能够读到这篇文章,改善这种体验。
|
||||
|
||||
### 就这样了
|
||||
|
||||
到这里就结束了,我的应用程序正在运行,也符合我的所有标准。我确实意识到我做了一些改进,其中包括:
|
||||
|
||||
* 定义一个 cloudwatch 日志组,这样我就可以正确地写日志了
|
||||
* 添加了一个 route53 托管区域,使整个事情从 DNS 角度更容易自动化
|
||||
* 修复并重新调整了 IAM 权限,这里太宽泛了
|
||||
|
||||
但老实说,现在我想反思一下这段经历。我写了一个关于我的经历的 [推特会话][14],然后花了其余时间思考我在这里的真实感受。
|
||||
|
||||
### 代价
|
||||
|
||||
经过一夜的反思,我意识到无论你是使用 Fargate 还是 Kubernetes,这个过程都大致相同。最让我感到惊讶的是,尽管我经常听说 Fargate “更容易”,但我真的没有看到任何超过 Kubernetes 平台的好处。现在,如果你正在构建 Kubernetes 集群,我绝对可以看到这里的价值 —— 管理节点和控制面板只是不必要的开销,问题是 —— 基于 Kubernetes 的平台的大多数消费者都*没有*这样做。如果你很幸运能够使用 GKE,你几乎不需要考虑集群的管理,你可以使用单个 `gcloud` 命令来运行集群。我经常使用 Digital Ocean 的 Kubernetes 托管服务,我可以肯定地说它就像操作 Fargate 集群一样简单,实际上在某种程度上它更容易。
|
||||
|
||||
必须定义一些基础设施来运行你的容器就是此时的代价。谷歌本周可能刚刚使用他们的 [Google Cloud Run][15] 产品改变了游戏规则,但他们在这一领域的领先优势远远领先于其他所有人。
|
||||
|
||||
从这整个经历中,我可以肯定的说:*大规模运行容器仍然很难。*它需要思考,需要领域知识,需要运维和开发人员之间的协作。它还需要一个基础来构建 —— 任何基于 AWS 的操作都需要事先定义和运行一些基础架构。我对一些公司似乎渴望的 “NoOps” 概念非常感兴趣。我想如果你正在运行一个无状态应用程序,你可以把它全部放在一个 lambda 函数和一个 API 网关中,这可能不错,但我们是否真的适合在任何一种企业环境中这样做?我真的不这么认为。
|
||||
|
||||
#### 公平比较
|
||||
|
||||
令我印象深刻的另一个现实是,技术 A 和技术 B 之间的比较通常不太公平,我经常在 AWS 上看到这一点。这种实际情况往往与 Jeff Barr 博客文章截然不同。如果你是一家足够小的公司,你可以使用 AWS 控制台在 AWS 中部署你的应用程序并接受所有默认值,这绝对更容易。但是,我不想使用默认值,因为默认值几乎是不适用于生产环境的。一旦你开始剥离掉云服务商服务的层面,你就会开始意识到最终你仍然是在运行软件 —— 它仍然需要设计良好、部署良好、运行良好。我相信 AWS 和 Kubernetes 以及所有其他云服务商的增值服务使得它更容易运行、设计和操作,但它绝对不是免费的。
|
||||
|
||||
#### Kubernetes 的争议
|
||||
|
||||
最后就是:如果你将 Kubernetes 纯粹视为一个容器编排工具,你可能会喜欢 Fargate。然而,随着我对 Kubernetes 越来越熟悉,我开始意识到它作为一种技术的重要性 —— 不仅因为它是一个伟大的容器编排工具,而且因为它的设计模式 —— 它是声明性的、API 驱动的平台。 在*整个* Fargate 过程期间发生的一个简单的事情是,如果我删除这里某个东西,Fargate 不一定会为我重新创建它。自动缩放很不错,不需要管理服务器和操作系统的补丁及更新也很棒,但我觉得因为无法使用 Kubernetes 自我修复和 API 驱动模型而失去了很多。当然,Kubernetes 有一个学习曲线,但从这里的体验来看,Fargate 也是如此。
|
||||
|
||||
### 总结
|
||||
|
||||
尽管我在这个过程中遭遇了困惑,但我确实很喜欢这种体验。我仍然相信 Fargate 是一项出色的技术,AWS 团队对 ECS/Fargate 所做的工作确实非常出色。然而,我的观点是,这绝对不比 Kubernetes “更容易”,只是……难点不同。
|
||||
|
||||
在生产环境中运行容器时出现的问题大致相同。如果你从这篇文章中有所收获,它应该是这样的:*不管你选择的哪种方式都有运维开销*。不要相信你选择一些东西你的世界就变得更轻松。我个人的意见是:如果你有一个运维团队,而你的公司要为多个应用程序团队部署容器 —— 选择一种技术并围绕它构建流程和工具以使其更容易。
|
||||
|
||||
人们说的一点肯定没错,用点技巧可以更容易地使用某种技术。在这个阶段,谈到 Fargate,下面的漫画这总结了我的感受:
|
||||
|
||||
![][16]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://leebriggs.co.uk/blog/2019/04/13/the-fargate-illusion.html
|
||||
|
||||
作者:[Lee Briggs][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[Bestony](https://github.com/Bestony)
|
||||
校对:[wxy](https://github.com/wxy), 临石(阿里云智能技术专家)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://leebriggs.co.uk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://matthias-endler.de/2019/maybe-you-dont-need-kubernetes/
|
||||
[2]: https://aws.amazon.com/fargate/
|
||||
[3]: https://docs.aws.amazon.com/AmazonECS/latest/developerguide/ECS_GetStarted.html
|
||||
[4]: https://i.imgur.com/YfMyXBdl.png
|
||||
[5]: https://docs.aws.amazon.com/AmazonECS/latest/developerguide/task_definition_parameters.html
|
||||
[6]: https://github.com/cloudposse/terraform-aws-ecs-container-definition
|
||||
[7]: https://leebriggs.co.uk/blog/2018/05/08/kubernetes-config-mgmt.html
|
||||
[8]: https://github.com/kubernetes-incubator/external-dns
|
||||
[9]: https://github.com/jetstack/cert-manager
|
||||
[10]: https://github.com/terraform-aws-modules/terraform-aws-ecs
|
||||
[11]: https://kubernetes.io/docs/concepts/configuration/secret/
|
||||
[12]: https://docs.aws.amazon.com/systems-manager/latest/userguide/systems-manager-paramstore.html
|
||||
[13]: https://docs.aws.amazon.com/AmazonECS/latest/developerguide/specifying-sensitive-data.html
|
||||
[14]: https://twitter.com/briggsl/status/1116870900719030272
|
||||
[15]: https://cloud.google.com/run/
|
||||
[16]: https://i.imgur.com/Bx7Q50Jl.jpg
|
||||
@ -0,0 +1,121 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10780-1.html)
|
||||
[#]: subject: (Getting started with Mercurial for version control)
|
||||
[#]: via: (https://opensource.com/article/19/4/getting-started-mercurial)
|
||||
[#]: author: (Moshe Zadka https://opensource.com/users/moshez)
|
||||
|
||||
Mercurial 版本控制入门
|
||||
======
|
||||
|
||||
> 了解 Mercurial 的基础知识,它是一个用 Python 写的分布式版本控制系统。
|
||||
|
||||
![][1]
|
||||
|
||||
[Mercurial][2] 是一个用 Python 编写的分布式版本控制系统。因为它是用高级语言编写的,所以你可以用 Python 函数编写一个 Mercurial 扩展。
|
||||
|
||||
在[官方文档中][3]说明了几种安装 Mercurial 的方法。我最喜欢的一种方法不在里面:使用 `pip`。这是开发本地扩展的最合适方式!
|
||||
|
||||
目前,Mercurial 仅支持 Python 2.7,因此你需要创建一个 Python 2.7 虚拟环境:
|
||||
|
||||
```
|
||||
python2 -m virtualenv mercurial-env
|
||||
./mercurial-env/bin/pip install mercurial
|
||||
```
|
||||
|
||||
为了让命令简短一些,以及满足人们对化学幽默的渴望,该命令称之为 `hg`。
|
||||
|
||||
```
|
||||
$ source mercurial-env/bin/activate
|
||||
(mercurial-env)$ mkdir test-dir
|
||||
(mercurial-env)$ cd test-dir
|
||||
(mercurial-env)$ hg init
|
||||
(mercurial-env)$ hg status
|
||||
(mercurial-env)$
|
||||
```
|
||||
|
||||
由于还没有任何文件,因此状态为空。添加几个文件:
|
||||
|
||||
```
|
||||
(mercurial-env)$ echo 1 > one
|
||||
(mercurial-env)$ echo 2 > two
|
||||
(mercurial-env)$ hg status
|
||||
? one
|
||||
? two
|
||||
(mercurial-env)$ hg addremove
|
||||
adding one
|
||||
adding two
|
||||
(mercurial-env)$ hg commit -m 'Adding stuff'
|
||||
(mercurial-env)$ hg log
|
||||
changeset: 0:1f1befb5d1e9
|
||||
tag: tip
|
||||
user: Moshe Zadka <[moshez@zadka.club][4]>
|
||||
date: Fri Mar 29 12:42:43 2019 -0700
|
||||
summary: Adding stuff
|
||||
```
|
||||
|
||||
`addremove` 命令很有用:它将任何未被忽略的新文件添加到托管文件列表中,并移除任何已删除的文件。
|
||||
|
||||
如我所说,Mercurial 扩展用 Python 写成,它们只是常规的 Python 模块。
|
||||
|
||||
这是一个简短的 Mercurial 扩展示例:
|
||||
|
||||
```
|
||||
from mercurial import registrar
|
||||
from mercurial.i18n import _
|
||||
|
||||
cmdtable = {}
|
||||
command = registrar.command(cmdtable)
|
||||
|
||||
@command('say-hello',
|
||||
[('w', 'whom', '', _('Whom to greet'))])
|
||||
def say_hello(ui, repo, `opts):
|
||||
ui.write("hello ", opts['whom'], "\n")
|
||||
```
|
||||
|
||||
简单的测试方法是将它手动加入虚拟环境中的文件中:
|
||||
|
||||
```
|
||||
`$ vi ../mercurial-env/lib/python2.7/site-packages/hello_ext.py`
|
||||
```
|
||||
|
||||
然后你需要*启用*扩展。你可以仅在当前仓库中启用它:
|
||||
|
||||
```
|
||||
$ cat >> .hg/hgrc
|
||||
[extensions]
|
||||
hello_ext =
|
||||
```
|
||||
|
||||
现在,问候有了:
|
||||
|
||||
```
|
||||
(mercurial-env)$ hg say-hello --whom world
|
||||
hello world
|
||||
```
|
||||
|
||||
大多数扩展会做更多有用的东西,甚至可能与 Mercurial 有关。 `repo` 对象是 `mercurial.hg.repository` 的对象。
|
||||
|
||||
有关 Mercurial API 的更多信息,请参阅[官方文档][5]。并访问[官方仓库][6]获取更多示例和灵感。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/getting-started-mercurial
|
||||
|
||||
作者:[Moshe Zadka][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/moshez
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/rh_003499_01_cloud21x_cc.png?itok=5UwC92dO
|
||||
[2]: https://www.mercurial-scm.org/
|
||||
[3]: https://www.mercurial-scm.org/wiki/UnixInstall
|
||||
[4]: mailto:moshez@zadka.club
|
||||
[5]: https://www.mercurial-scm.org/wiki/MercurialApi#Repositories
|
||||
[6]: https://www.mercurial-scm.org/repo/hg/file/tip/hgext
|
||||
@ -0,0 +1,127 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (MjSeven)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10777-1.html)
|
||||
[#]: subject: (How to identify duplicate files on Linux)
|
||||
[#]: via: (https://www.networkworld.com/article/3387961/how-to-identify-duplicate-files-on-linux.html#tk.rss_all)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
如何识别 Linux 上的文件分身
|
||||
======
|
||||
|
||||
> Linux 系统上的一些文件可能出现在多个位置。按照本文指示查找并识别这些“同卵双胞胎”,还可以了解为什么硬链接会如此有利。
|
||||
|
||||
![Archana Jarajapu \(CC BY 2.0\)][1]
|
||||
|
||||
识别使用同一个磁盘空间的文件依赖于利用文件使用相同的 inode 这一事实。这种数据结构存储除了文件名和内容之外的所有信息。如果两个或多个文件具有不同的名称和文件系统位置,但共享一个 inode,则它们还共享内容、所有权、权限等。
|
||||
|
||||
这些文件通常被称为“硬链接”,不像符号链接(即软链接)那样仅仅通过包含它们的名称指向其他文件,符号链接很容易在文件列表中通过第一个位置的 `l` 和引用文件的 `->` 符号识别出来。
|
||||
|
||||
```
|
||||
$ ls -l my*
|
||||
-rw-r--r-- 4 shs shs 228 Apr 12 19:37 myfile
|
||||
lrwxrwxrwx 1 shs shs 6 Apr 15 11:18 myref -> myfile
|
||||
-rw-r--r-- 4 shs shs 228 Apr 12 19:37 mytwin
|
||||
```
|
||||
|
||||
在单个目录中的硬链接并不是很明显,但它仍然非常容易找到。如果使用 `ls -i` 命令列出文件并按 inode 编号排序,则可以非常容易地挑选出硬链接。在这种类型的 `ls` 输出中,第一列显示 inode 编号。
|
||||
|
||||
```
|
||||
$ ls -i | sort -n | more
|
||||
...
|
||||
788000 myfile <==
|
||||
788000 mytwin <==
|
||||
801865 Name_Labels.pdf
|
||||
786692 never leave home angry
|
||||
920242 NFCU_Docs
|
||||
800247 nmap-notes
|
||||
```
|
||||
|
||||
扫描输出,查找相同的 inode 编号,任何匹配都会告诉你想知道的内容。
|
||||
|
||||
另一方面,如果你只是想知道某个特定文件是否是另一个文件的硬链接,那么有一种方法比浏览数百个文件的列表更简单,即 `find` 命令的 `-samefile` 选项将帮助你完成工作。
|
||||
|
||||
```
|
||||
$ find . -samefile myfile
|
||||
./myfile
|
||||
./save/mycopy
|
||||
./mytwin
|
||||
```
|
||||
|
||||
注意,提供给 `find` 命令的起始位置决定文件系统会扫描多少来进行匹配。在上面的示例中,我们正在查看当前目录和子目录。
|
||||
|
||||
使用 `find` 的 `-ls` 选项添加输出的详细信息可能更有说服力:
|
||||
|
||||
```
|
||||
$ find . -samefile myfile -ls
|
||||
788000 4 -rw-r--r-- 4 shs shs 228 Apr 12 19:37 ./myfile
|
||||
788000 4 -rw-r--r-- 4 shs shs 228 Apr 12 19:37 ./save/mycopy
|
||||
788000 4 -rw-r--r-- 4 shs shs 228 Apr 12 19:37 ./mytwin
|
||||
```
|
||||
|
||||
第一列显示 inode 编号,然后我们会看到文件权限、链接、所有者、文件大小、日期信息以及引用相同磁盘内容的文件的名称。注意,在这种情况下,链接字段是 “4” 而不是我们可能期望的 “3”。这告诉我们还有另一个指向同一个 inode 的链接(但不在我们的搜索范围内)。
|
||||
|
||||
如果你想在一个目录中查找所有硬链接的实例,可以尝试以下的脚本来创建列表并为你查找副本:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
# seaches for files sharing inodes
|
||||
|
||||
prev=""
|
||||
|
||||
# list files by inode
|
||||
ls -i | sort -n > /tmp/$0
|
||||
|
||||
# search through file for duplicate inode #s
|
||||
while read line
|
||||
do
|
||||
inode=`echo $line | awk '{print $1}'`
|
||||
if [ "$inode" == "$prev" ]; then
|
||||
grep $inode /tmp/$0
|
||||
fi
|
||||
prev=$inode
|
||||
done < /tmp/$0
|
||||
|
||||
# clean up
|
||||
rm /tmp/$0
|
||||
```
|
||||
|
||||
```
|
||||
$ ./findHardLinks
|
||||
788000 myfile
|
||||
788000 mytwin
|
||||
```
|
||||
|
||||
你还可以使用 `find` 命令按 inode 编号查找文件,如命令中所示。但是,此搜索可能涉及多个文件系统,因此可能会得到错误的结果。因为相同的 inode 编号可能会在另一个文件系统中使用,代表另一个文件。如果是这种情况,文件的其他详细信息将不相同。
|
||||
|
||||
```
|
||||
$ find / -inum 788000 -ls 2> /dev/null
|
||||
788000 4 -rw-r--r-- 4 shs shs 228 Apr 12 19:37 /tmp/mycopy
|
||||
788000 4 -rw-r--r-- 4 shs shs 228 Apr 12 19:37 /home/shs/myfile
|
||||
788000 4 -rw-r--r-- 4 shs shs 228 Apr 12 19:37 /home/shs/save/mycopy
|
||||
788000 4 -rw-r--r-- 4 shs shs 228 Apr 12 19:37 /home/shs/mytwin
|
||||
```
|
||||
|
||||
注意,错误输出被重定向到 `/dev/null`,这样我们就不必查看所有 “Permission denied” 错误,否则这些错误将显示在我们不允许查看的其他目录中。
|
||||
|
||||
此外,扫描包含相同内容但不共享 inode 的文件(即,简单的文本拷贝)将花费更多的时间和精力。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3387961/how-to-identify-duplicate-files-on-linux.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/04/reflections-candles-100793651-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3242170/linux/invaluable-tips-and-tricks-for-troubleshooting-linux.html
|
||||
[3]: https://www.facebook.com/NetworkWorld/
|
||||
[4]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,236 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (arrowfeng)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10789-1.html)
|
||||
[#]: subject: (How to Install MySQL in Ubuntu Linux)
|
||||
[#]: via: (https://itsfoss.com/install-mysql-ubuntu/)
|
||||
[#]: author: (Sergiu https://itsfoss.com/author/sergiu/)
|
||||
|
||||
怎样在 Ubuntu Linux 上安装 MySQL
|
||||
======
|
||||
|
||||
> 本教程教你如何在基于 Ubuntu 的 Linux 发行版上安装 MySQL。对于首次使用的用户,你将会学习到如何验证你的安装和第一次怎样去连接 MySQL。
|
||||
|
||||
[MySQL][1] 是一个典型的数据库管理系统。它被用于许多技术栈中,包括流行的 [LAMP][2] (Linux、Apache、MySQL、PHP)技术栈。它已经被证实了其稳定性。另一个让 MySQL 受欢迎的原因是它是开源的。
|
||||
|
||||
MySQL 是关系型数据库(基本上是表格数据)。以这种方式它很容易去存储、组织和访问数据。它使用SQL(结构化查询语言)来管理数据。
|
||||
|
||||
这这篇文章中,我将向你展示如何在 Ubuntu 18.04 安装和使用 MySQL 8.0。让我们一起来看看吧!
|
||||
|
||||
### 在 Ubuntu 上安装 MySQL
|
||||
|
||||
![][3]
|
||||
|
||||
我将会介绍两种在 Ubuntu 18.04 上安装 MySQL 的方法:
|
||||
|
||||
1. 从 Ubuntu 仓库上安装 MySQL。非常简单,但不是最新版(5.7)
|
||||
2. 从官方仓库安装 MySQL。你将额外增加一些步处理过程,但不用担心。你将会拥有最新版的MySQL(8.0)
|
||||
|
||||
有必要的时候,我将会提供屏幕截图去引导你。但这篇文章中的大部分步骤,我将直接在终端(默认热键: `CTRL+ALT+T`)输入命令。别害怕!
|
||||
|
||||
#### 方法 1、从 Ubuntu 仓库安装 MySQL
|
||||
|
||||
首先,输入下列命令确保你的仓库已经被更新:
|
||||
|
||||
```
|
||||
sudo apt update
|
||||
```
|
||||
|
||||
现在,安装 MySQL 5.7,简单输入下列命令:
|
||||
|
||||
```
|
||||
sudo apt install mysql-server -y
|
||||
```
|
||||
|
||||
就是这样!简单且高效。
|
||||
|
||||
#### 方法 2、使用官方仓库安装 MySQL
|
||||
|
||||
虽然这个方法多了一些步骤,但我将逐一介绍,并尝试写下清晰的笔记。
|
||||
|
||||
首先浏览 MySQL 官方网站的[下载页面][4]。
|
||||
|
||||
![][5]
|
||||
|
||||
在这里,选择 DEB 软件包,点击“Download”链接。
|
||||
|
||||
![][6]
|
||||
|
||||
滑到有关于 Oracle 网站信息的底部,右键 “No thanks, just start my download.”,然后选择 “Copy link location”。
|
||||
|
||||
现在回到终端,我们将使用 [Curl][7] 命令去下载这个软件包:
|
||||
|
||||
```
|
||||
curl -OL https://dev.mysql.com/get/mysql-apt-config_0.8.12-1_all.deb
|
||||
```
|
||||
|
||||
`https://dev.mysql.com/get/mysql-apt-config_0.8.12-1_all.deb` 是我刚刚从网页上复制的链接。根据当前的 MySQL 版本,它有可能不同。让我们使用 `dpkg` 去开始安装 MySQL:
|
||||
|
||||
```
|
||||
sudo dpkg -i mysql-apt-config*
|
||||
```
|
||||
|
||||
更新你的仓库:
|
||||
|
||||
```
|
||||
sudo apt update
|
||||
```
|
||||
|
||||
要实际安装 MySQL,我们将使用像第一个方法中同样的命令来安装:
|
||||
|
||||
```
|
||||
sudo apt install mysql-server -y
|
||||
```
|
||||
|
||||
这样做会在你的终端中打开包配置的提示。使用向下箭头选择“Ok”选项。
|
||||
|
||||
![][8]
|
||||
|
||||
点击回车。这应该会提示你输入密码:这是在为 MySQL 设置 root 密码。不要与 [Ubuntu 的 root 密码混淆][9]。
|
||||
|
||||
![][10]
|
||||
|
||||
输入密码然后点击 Tab 键去选择“Ok“。点击回车键,你将重新输入密码。操作完之后,再次键入 Tab 去选择 “Ok”。按下回车键。
|
||||
|
||||
![][11]
|
||||
|
||||
将会展示一些关于 MySQL Server 的配置信息。再次按下 Tab 去选择 “Ok” 和按下回车键:
|
||||
|
||||
![][12]
|
||||
|
||||
这里你需要去选择默认验证插件。确保选择了“Use Strong Password Encryption”。按下 Tab 键和回车键。
|
||||
|
||||
就是这样!你已经成功地安装了 MySQL。
|
||||
|
||||
#### 验证你的 MySQL 安装
|
||||
|
||||
要验证 MySQL 已经正确安装,使用下列命令:
|
||||
|
||||
```
|
||||
sudo systemctl status mysql.service
|
||||
```
|
||||
|
||||
这将展示一些关于 MySQL 服务的信息:
|
||||
|
||||
![][13]
|
||||
|
||||
你应该在那里看到 “Active: active (running)”。如果你没有看到,使用下列命令去开始这个服务:
|
||||
|
||||
```
|
||||
sudo systemctl start mysql.service
|
||||
```
|
||||
|
||||
#### 配置/保护 MySQL
|
||||
|
||||
对于刚安装的 MySQL,你应该运行它提供的安全相关的更新命令。就是:
|
||||
|
||||
```
|
||||
sudo mysql_secure_installation
|
||||
```
|
||||
|
||||
这样做首先会询问你是否想使用 “<ruby>密码有效强度<rt>validate password component</rt></ruby>”。如果你想使用它,你将必须选择一个最小密码强度(0 – 低,1 – 中,2 – 高)。你将无法输入任何不遵守所选规则的密码。如果你没有使用强密码的习惯(本应该使用),这可能会配上用场。如果你认为它可能有帮助,那你就键入 `y` 或者 `Y`,按下回车键,然后为你的密码选择一个强度等级和输入一个你想使用的密码。如果成功,你将继续强化过程;否则你将重新输入一个密码。
|
||||
|
||||
但是,如果你不想要此功能(我不会),只需按回车或任何其他键即可跳过使用它。
|
||||
|
||||
对于其他选项,我建议开启它们(对于每一步输入 `y` 或者 `Y` 和按下回车)。它们(依序)是:“<ruby>移除匿名用户<rt>remove anonymous user</rt></ruby>”,“<ruby>禁止 root 远程登录<rt>disallow root login remotely</rt></ruby>”,“<ruby>移除测试数据库及其访问<rt>remove test database and access to it</rt></ruby>”。“<ruby>重新载入权限表<rt>reload privilege tables now</rt></ruby>”。
|
||||
|
||||
#### 链接与断开 MySQL Server
|
||||
|
||||
为了运行 SQL 查询,你首先必须使用 MySQL 连到服务器并在 MySQL 提示符使用。
|
||||
|
||||
执行此操作的命令是:
|
||||
|
||||
```
|
||||
mysql -h host_name -u user -p
|
||||
```
|
||||
|
||||
* `-h` 用来指定一个主机名(如果这个服务被安装到其他机器上,那么会有用;如果没有,忽略它)
|
||||
* `-u` 指定登录的用户
|
||||
* `-p` 指定你想输入的密码.
|
||||
|
||||
虽然出于安全原因不建议,但是你可以在命令行最右边的 `-p` 后直接输入密码。例如,如果用户`test_user` 的密码是 `1234`,那么你可以在你使用的机器上尝试去连接,你可以这样使用:
|
||||
|
||||
```
|
||||
mysql -u test_user -p1234
|
||||
```
|
||||
|
||||
如果你成功输入了必要的参数,你将会收到由 MySQL shell 提示符提供的欢迎(`mysql >`):
|
||||
|
||||
![][14]
|
||||
|
||||
要从服务端断开连接和离开 MySQL 提示符,输入:
|
||||
|
||||
```
|
||||
QUIT
|
||||
```
|
||||
|
||||
输入 `quit` (MySQL 不区分大小写)或者 `\q` 也能工作。按下回车退出。
|
||||
|
||||
你使用简单的命令也能输出关于版本的信息:
|
||||
|
||||
```
|
||||
sudo mysqladmin -u root version -p
|
||||
```
|
||||
|
||||
如果你想看命令行选项列表,使用:
|
||||
|
||||
```
|
||||
mysql --help
|
||||
```
|
||||
|
||||
#### 卸载 MySQL
|
||||
|
||||
如果您决定要使用较新版本或只是想停止使用 MySQL。
|
||||
|
||||
首先,关闭服务:
|
||||
|
||||
```
|
||||
sudo systemctl stop mysql.service && sudo systemctl disable mysql.service
|
||||
```
|
||||
|
||||
确保你备份了你的数据库,以防你之后想使用它们。你可以通过运行下列命令卸载 MySQL:
|
||||
|
||||
```
|
||||
sudo apt purge mysql*
|
||||
```
|
||||
|
||||
清理依赖:
|
||||
|
||||
```
|
||||
sudo apt autoremove
|
||||
```
|
||||
|
||||
### 小结
|
||||
|
||||
在这篇文章中,我已经介绍如何在 Ubuntu Linux 上安装 Mysql。我很高兴如果这篇文章能帮助到那些正为此挣扎的用户或者刚刚开始的用户。
|
||||
|
||||
如果你发现这篇文章是一个很有用的资源,在评论里告诉我们。你为了什么使用 MySQL? 我们渴望收到你的任何反馈、印象和建议。感谢阅读,并毫不犹豫地尝试这个很棒的工具!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/install-mysql-ubuntu/
|
||||
|
||||
作者:[Sergiu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[arrowfeng](https://github.com/arrowfeng)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/sergiu/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.mysql.com/
|
||||
[2]: https://en.wikipedia.org/wiki/LAMP_(software_bundle)
|
||||
[3]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/04/install-mysql-ubuntu.png?resize=800%2C450&ssl=1
|
||||
[4]: https://dev.mysql.com/downloads/repo/apt/
|
||||
[5]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/04/mysql_apt_download_page.jpg?fit=800%2C280&ssl=1
|
||||
[6]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/04/mysql_deb_download_link.jpg?fit=800%2C507&ssl=1
|
||||
[7]: https://linuxhandbook.com/curl-command-examples/
|
||||
[8]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/04/mysql_package_configuration_ok.jpg?fit=800%2C587&ssl=1
|
||||
[9]: https://itsfoss.com/change-password-ubuntu/
|
||||
[10]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/04/mysql_enter_password.jpg?fit=800%2C583&ssl=1
|
||||
[11]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/04/mysql_information_on_configuring.jpg?fit=800%2C581&ssl=1
|
||||
[12]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/04/mysql_default_authentication_plugin.jpg?fit=800%2C586&ssl=1
|
||||
[13]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/04/mysql_service_information.jpg?fit=800%2C402&ssl=1
|
||||
[14]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/04/mysql_shell_prompt-2.jpg?fit=800%2C423&ssl=1
|
||||
@ -0,0 +1,311 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (zgj1024)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10765-1.html)
|
||||
[#]: subject: (HTTPie – A Modern Command Line HTTP Client For Curl And Wget Alternative)
|
||||
[#]: via: (https://www.2daygeek.com/httpie-curl-wget-alternative-http-client-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
HTTPie:替代 Curl 和 Wget 的现代 HTTP 命令行客户端
|
||||
======
|
||||
|
||||
大多数时间我们会使用 `curl` 命令或是 `wget` 命令下载文件或者做其他事。
|
||||
|
||||
我们以前曾写过 [最佳命令行下载管理器][1] 的文章。你可以点击相应的 URL 连接来浏览这些文章。
|
||||
|
||||
* [aria2 – Linux 下的多协议命令行下载工具][2]
|
||||
* [Axel – Linux 下的轻量级命令行下载加速器][3]
|
||||
* [Wget – Linux 下的标准命令行下载工具][4]
|
||||
* [curl – Linux 下的实用的命令行下载工具][5]
|
||||
|
||||
今天我们将讨论同样的话题。这个实用程序名为 HTTPie。
|
||||
|
||||
它是现代命令行 http 客户端,也是 `curl` 和 `wget` 命令的最佳替代品。
|
||||
|
||||
### 什么是 HTTPie?
|
||||
|
||||
HTTPie (发音是 aitch-tee-tee-pie) 是一个 HTTP 命令行客户端。
|
||||
|
||||
HTTPie 工具是现代的 HTTP 命令行客户端,它能通过命令行界面与 Web 服务进行交互。
|
||||
|
||||
它提供一个简单的 `http` 命令,允许使用简单而自然的语法发送任意的 HTTP 请求,并会显示彩色的输出。
|
||||
|
||||
HTTPie 能用于测试、调试及与 HTTP 服务器交互。
|
||||
|
||||
### 主要特点
|
||||
|
||||
* 具表达力的和直观语法
|
||||
* 格式化的及彩色化的终端输出
|
||||
* 内置 JSON 支持
|
||||
* 表单和文件上传
|
||||
* HTTPS、代理和认证
|
||||
* 任意请求数据
|
||||
* 自定义头部
|
||||
* 持久化会话
|
||||
* 类似 `wget` 的下载
|
||||
* 支持 Python 2.7 和 3.x
|
||||
|
||||
### 在 Linux 下如何安装 HTTPie
|
||||
|
||||
大部分 Linux 发行版都提供了系统包管理器,可以用它来安装。
|
||||
|
||||
Fedora 系统,使用 [DNF 命令][6] 来安装 httpie:
|
||||
|
||||
```
|
||||
$ sudo dnf install httpie
|
||||
```
|
||||
|
||||
Debian/Ubuntu 系统,使用 [APT-GET 命令][7] 或 [APT 命令][8] 来安装 HTTPie。
|
||||
|
||||
```
|
||||
$ sudo apt install httpie
|
||||
```
|
||||
|
||||
基于 Arch Linux 的系统,使用 [Pacman 命令][9] 来安装 HTTPie。
|
||||
|
||||
```
|
||||
$ sudo pacman -S httpie
|
||||
```
|
||||
|
||||
RHEL/CentOS 的系统,使用 [YUM 命令][10] 来安装 HTTPie。
|
||||
|
||||
```
|
||||
$ sudo yum install httpie
|
||||
```
|
||||
|
||||
openSUSE Leap 系统,使用 [Zypper 命令][11] 来安装 HTTPie。
|
||||
|
||||
```
|
||||
$ sudo zypper install httpie
|
||||
```
|
||||
|
||||
### 用法
|
||||
|
||||
#### 如何使用 HTTPie 请求 URL?
|
||||
|
||||
HTTPie 的基本用法是将网站的 URL 作为参数。
|
||||
|
||||
```
|
||||
# http 2daygeek.com
|
||||
HTTP/1.1 301 Moved Permanently
|
||||
CF-RAY: 4c4a618d0c02ce6d-LHR
|
||||
Cache-Control: max-age=3600
|
||||
Connection: keep-alive
|
||||
Date: Tue, 09 Apr 2019 06:21:28 GMT
|
||||
Expires: Tue, 09 Apr 2019 07:21:28 GMT
|
||||
Location: https://2daygeek.com/
|
||||
Server: cloudflare
|
||||
Transfer-Encoding: chunked
|
||||
Vary: Accept-Encoding
|
||||
```
|
||||
|
||||
#### 如何使用 HTTPie 下载文件
|
||||
|
||||
你可以使用带 `--download` 参数的 HTTPie 命令下载文件。类似于 `wget` 命令。
|
||||
|
||||
```
|
||||
# http --download https://www.2daygeek.com/wp-content/uploads/2019/04/Anbox-Easy-Way-To-Run-Android-Apps-On-Linux.png
|
||||
HTTP/1.1 200 OK
|
||||
Accept-Ranges: bytes
|
||||
CF-Cache-Status: HIT
|
||||
CF-RAY: 4c4a65d5ca360a66-LHR
|
||||
Cache-Control: public, max-age=7200
|
||||
Connection: keep-alive
|
||||
Content-Length: 32066
|
||||
Content-Type: image/png
|
||||
Date: Tue, 09 Apr 2019 06:24:23 GMT
|
||||
Expect-CT: max-age=604800, report-uri="https://report-uri.cloudflare.com/cdn-cgi/beacon/expect-ct"
|
||||
Expires: Tue, 09 Apr 2019 08:24:23 GMT
|
||||
Last-Modified: Mon, 08 Apr 2019 04:54:25 GMT
|
||||
Server: cloudflare
|
||||
Set-Cookie: __cfduid=dd2034b2f95ae42047e082f59f2b964f71554791063; expires=Wed, 08-Apr-20 06:24:23 GMT; path=/; domain=.2daygeek.com; HttpOnly; Secure
|
||||
Vary: Accept-Encoding
|
||||
|
||||
Downloading 31.31 kB to "Anbox-Easy-Way-To-Run-Android-Apps-On-Linux.png"
|
||||
Done. 31.31 kB in 0.01187s (2.58 MB/s)
|
||||
```
|
||||
|
||||
你还可以使用 `-o` 参数用不同的名称保存输出文件。
|
||||
|
||||
```
|
||||
# http --download https://www.2daygeek.com/wp-content/uploads/2019/04/Anbox-Easy-Way-To-Run-Android-Apps-On-Linux.png -o Anbox-1.png
|
||||
HTTP/1.1 200 OK
|
||||
Accept-Ranges: bytes
|
||||
CF-Cache-Status: HIT
|
||||
CF-RAY: 4c4a68194daa0a66-LHR
|
||||
Cache-Control: public, max-age=7200
|
||||
Connection: keep-alive
|
||||
Content-Length: 32066
|
||||
Content-Type: image/png
|
||||
Date: Tue, 09 Apr 2019 06:25:56 GMT
|
||||
Expect-CT: max-age=604800, report-uri="https://report-uri.cloudflare.com/cdn-cgi/beacon/expect-ct"
|
||||
Expires: Tue, 09 Apr 2019 08:25:56 GMT
|
||||
Last-Modified: Mon, 08 Apr 2019 04:54:25 GMT
|
||||
Server: cloudflare
|
||||
Set-Cookie: __cfduid=d3eea753081690f9a2d36495a74407dd71554791156; expires=Wed, 08-Apr-20 06:25:56 GMT; path=/; domain=.2daygeek.com; HttpOnly; Secure
|
||||
Vary: Accept-Encoding
|
||||
|
||||
Downloading 31.31 kB to "Anbox-1.png"
|
||||
Done. 31.31 kB in 0.01551s (1.97 MB/s)
|
||||
```
|
||||
|
||||
#### 如何使用 HTTPie 恢复部分下载?
|
||||
|
||||
你可以使用带 `-c` 参数的 HTTPie 继续下载。
|
||||
|
||||
```
|
||||
# http --download --continue https://speed.hetzner.de/100MB.bin -o 100MB.bin
|
||||
HTTP/1.1 206 Partial Content
|
||||
Connection: keep-alive
|
||||
Content-Length: 100442112
|
||||
Content-Range: bytes 4415488-104857599/104857600
|
||||
Content-Type: application/octet-stream
|
||||
Date: Tue, 09 Apr 2019 06:32:52 GMT
|
||||
ETag: "5253f0fd-6400000"
|
||||
Last-Modified: Tue, 08 Oct 2013 11:48:13 GMT
|
||||
Server: nginx
|
||||
Strict-Transport-Security: max-age=15768000; includeSubDomains
|
||||
|
||||
Downloading 100.00 MB to "100MB.bin"
|
||||
| 24.14 % 24.14 MB 1.12 MB/s 0:01:07 ETA^C
|
||||
```
|
||||
|
||||
你根据下面的输出验证是否同一个文件:
|
||||
|
||||
```
|
||||
[email protected]:/var/log# ls -lhtr 100MB.bin
|
||||
-rw-r--r-- 1 root root 25M Apr 9 01:33 100MB.bin
|
||||
```
|
||||
|
||||
#### 如何使用 HTTPie 上传文件?
|
||||
|
||||
你可以通过使用带有小于号 `<` 的 HTTPie 命令上传文件
|
||||
|
||||
```
|
||||
$ http https://transfer.sh < Anbox-1.png
|
||||
```
|
||||
|
||||
#### 如何使用带有重定向符号 > 下载文件?
|
||||
|
||||
你可以使用带有重定向 `>` 符号的 HTTPie 命令下载文件。
|
||||
|
||||
```
|
||||
# http https://www.2daygeek.com/wp-content/uploads/2019/03/How-To-Install-And-Enable-Flatpak-Support-On-Linux-1.png > Flatpak.png
|
||||
|
||||
# ls -ltrh Flatpak.png
|
||||
-rw-r--r-- 1 root root 47K Apr 9 01:44 Flatpak.png
|
||||
```
|
||||
|
||||
#### 发送一个 HTTP GET 请求?
|
||||
|
||||
您可以在请求中发送 HTTP GET 方法。GET 方法会使用给定的 URI,从给定服务器检索信息。
|
||||
|
||||
|
||||
```
|
||||
# http GET httpie.org
|
||||
HTTP/1.1 301 Moved Permanently
|
||||
CF-RAY: 4c4a83a3f90dcbe6-SIN
|
||||
Cache-Control: max-age=3600
|
||||
Connection: keep-alive
|
||||
Date: Tue, 09 Apr 2019 06:44:44 GMT
|
||||
Expires: Tue, 09 Apr 2019 07:44:44 GMT
|
||||
Location: https://httpie.org/
|
||||
Server: cloudflare
|
||||
Transfer-Encoding: chunked
|
||||
Vary: Accept-Encoding
|
||||
```
|
||||
|
||||
#### 提交表单?
|
||||
|
||||
使用以下格式提交表单。POST 请求用于向服务器发送数据,例如客户信息、文件上传等。要使用 HTML 表单。
|
||||
|
||||
```
|
||||
# http -f POST Ubuntu18.2daygeek.com hello='World'
|
||||
HTTP/1.1 200 OK
|
||||
Accept-Ranges: bytes
|
||||
Connection: Keep-Alive
|
||||
Content-Encoding: gzip
|
||||
Content-Length: 3138
|
||||
Content-Type: text/html
|
||||
Date: Tue, 09 Apr 2019 06:48:12 GMT
|
||||
ETag: "2aa6-5844bf1b047fc-gzip"
|
||||
Keep-Alive: timeout=5, max=100
|
||||
Last-Modified: Sun, 17 Mar 2019 15:29:55 GMT
|
||||
Server: Apache/2.4.29 (Ubuntu)
|
||||
Vary: Accept-Encoding
|
||||
```
|
||||
|
||||
运行下面的指令以查看正在发送的请求。
|
||||
|
||||
```
|
||||
# http -v Ubuntu18.2daygeek.com
|
||||
GET / HTTP/1.1
|
||||
Accept: */*
|
||||
Accept-Encoding: gzip, deflate
|
||||
Connection: keep-alive
|
||||
Host: ubuntu18.2daygeek.com
|
||||
User-Agent: HTTPie/0.9.8
|
||||
|
||||
hello=World
|
||||
|
||||
HTTP/1.1 200 OK
|
||||
Accept-Ranges: bytes
|
||||
Connection: Keep-Alive
|
||||
Content-Encoding: gzip
|
||||
Content-Length: 3138
|
||||
Content-Type: text/html
|
||||
Date: Tue, 09 Apr 2019 06:48:30 GMT
|
||||
ETag: "2aa6-5844bf1b047fc-gzip"
|
||||
Keep-Alive: timeout=5, max=100
|
||||
Last-Modified: Sun, 17 Mar 2019 15:29:55 GMT
|
||||
Server: Apache/2.4.29 (Ubuntu)
|
||||
Vary: Accept-Encoding
|
||||
```
|
||||
|
||||
#### HTTP 认证?
|
||||
|
||||
当前支持的身份验证认证方案是基本认证(Basic)和摘要验证(Digest)。
|
||||
|
||||
基本认证:
|
||||
|
||||
```
|
||||
$ http -a username:password example.org
|
||||
```
|
||||
|
||||
摘要验证:
|
||||
|
||||
```
|
||||
$ http -A digest -a username:password example.org
|
||||
```
|
||||
|
||||
提示输入密码:
|
||||
|
||||
```
|
||||
$ http -a username example.org
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/httpie-curl-wget-alternative-http-client-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[zgj1024](https://github.com/zgj1024)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/best-4-command-line-download-managers-accelerators-for-linux/
|
||||
[2]: https://www.2daygeek.com/aria2-linux-command-line-download-utility-tool/
|
||||
[3]: https://www.2daygeek.com/axel-linux-command-line-download-accelerator/
|
||||
[4]: https://www.2daygeek.com/wget-linux-command-line-download-utility-tool/
|
||||
[5]: https://www.2daygeek.com/curl-linux-command-line-download-manager/
|
||||
[6]: https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
[7]: https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[8]: https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[9]: https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
|
||||
[10]: https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||
[11]: https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
|
||||
97
published/201904/20190417 Managing RAID arrays with mdadm.md
Normal file
97
published/201904/20190417 Managing RAID arrays with mdadm.md
Normal file
@ -0,0 +1,97 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10785-1.html)
|
||||
[#]: subject: (Managing RAID arrays with mdadm)
|
||||
[#]: via: (https://fedoramagazine.org/managing-raid-arrays-with-mdadm/)
|
||||
[#]: author: (Gregory Bartholomew https://fedoramagazine.org/author/glb/)
|
||||
|
||||
使用 mdadm 管理 RAID 阵列
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
mdadm 是<ruby>多磁盘和设备管理<rt>Multiple Disk and Device Administration</rt></ruby> 的缩写。它是一个命令行工具,可用于管理 Linux 上的软件 [RAID][2] 阵列。本文概述了使用它的基础知识。
|
||||
|
||||
以下 5 个命令是你使用 mdadm 的基础功能:
|
||||
|
||||
1. **创建 RAID 阵列**:`mdadm --create /dev/md/test --homehost=any --metadata=1.0 --level=1 --raid-devices=2 /dev/sda1 /dev/sdb1`
|
||||
2. **组合(并启动)RAID 阵列**:`mdadm --assemble /dev/md/test /dev/sda1 /dev/sdb1`
|
||||
3. **停止 RAID 阵列**:`mdadm --stop /dev/md/test`
|
||||
4. **删除 RAID 阵列**:`mdadm --zero-superblock /dev/sda1 /dev/sdb1`
|
||||
5. **检查所有已组合的 RAID 阵列的状态**:`cat /proc/mdstat`
|
||||
|
||||
### 功能说明
|
||||
|
||||
#### mdadm --create
|
||||
|
||||
上面的创建命令除了 `-create` 参数自身和设备名之外,还包括了四个参数:
|
||||
|
||||
1、`–homehost`:
|
||||
|
||||
默认情况下,`mdadm` 将你的计算机名保存为 RAID 阵列的属性。如果你的计算机名与存储的名称不匹配,则阵列将不会自动组合。此功能在共享硬盘的服务器群集中很有用,因为如果多个服务器同时尝试访问同一驱动器,通常会发生文件系统损坏。名称 `any` 是保留字段,并禁用 `-homehost` 限制。
|
||||
|
||||
2、 `–metadata`:
|
||||
|
||||
`-mdadm` 保留每个 RAID 设备的一小部分空间,以存储有关 RAID 阵列本身的信息。 `-metadata` 参数指定信息的格式和位置。`1.0` 表示使用版本 1 格式,并将元数据存储在设备的末尾。
|
||||
|
||||
3、`–level`:
|
||||
|
||||
`-level` 参数指定数据应如何在底层设备之间分布。级别 `1` 表示每个设备应包含所有数据的完整副本。此级别也称为[磁盘镜像] [3]。
|
||||
|
||||
4、`–raid-devices`:
|
||||
|
||||
`-raid-devices` 参数指定将用于创建 RAID 阵列的设备数。
|
||||
|
||||
通过将 `-level=1`(镜像)与 `-metadata=1.0` (将元数据存储在设备末尾)结合使用,可以创建一个 RAID1 阵列,如果不通过 mdadm 驱动访问,那么它的底层设备会正常显示。这在灾难恢复的情况下很有用,因为即使新系统不支持 mdadm 阵列,你也可以访问该设备。如果程序需要在 mdadm 可用之前以*只读*访问底层设备时也很有用。例如,计算机中的 [UEFI][4] 固件可能需要在启动 mdadm 之前从 [ESP][5] 读取引导加载程序。
|
||||
|
||||
#### mdadm --assemble
|
||||
|
||||
如果成员设备丢失或损坏,上面的组合命令将会失败。要强制 RAID 阵列在其中一个成员丢失时进行组合并启动,请使用以下命令:
|
||||
|
||||
```
|
||||
# mdadm --assemble --run /dev/md/test /dev/sda1
|
||||
```
|
||||
|
||||
### 其他重要说明
|
||||
|
||||
避免直接写入底层是 RAID1 的设备。这导致设备不同步,并且 mdadm 不会知道它们不同步。如果你访问了在其他地方被修改了设备的某个 RAID1 阵列,则可能导致文件系统损坏。如果你在其他地方修改 RAID1 设备并需要强制阵列重新同步,请从要覆盖的设备中删除 mdadm 元数据,然后将其重新添加到阵列,如下所示:
|
||||
|
||||
```
|
||||
# mdadm --zero-superblock /dev/sdb1
|
||||
# mdadm --assemble --run /dev/md/test /dev/sda1
|
||||
# mdadm /dev/md/test --add /dev/sdb1
|
||||
```
|
||||
|
||||
以上用 sda1 的内容完全覆盖 sdb1 的内容。
|
||||
|
||||
要指定在计算机启动时自动激活的 RAID 阵列,请创建 `/etc/mdadm.conf` 配置。
|
||||
|
||||
有关最新和详细信息,请查看手册页:
|
||||
|
||||
```
|
||||
$ man mdadm
|
||||
$ man mdadm.conf
|
||||
```
|
||||
|
||||
本系列的下一篇文章将展示如何将现有的单磁盘 Linux 系统变为镜像磁盘安装,这意味着即使其中一个硬盘突然停止工作,系统仍将继续运行!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/managing-raid-arrays-with-mdadm/
|
||||
|
||||
作者:[Gregory Bartholomew][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/glb/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/04/mdadm-816x345.jpg
|
||||
[2]: https://en.wikipedia.org/wiki/RAID
|
||||
[3]: https://en.wikipedia.org/wiki/Disk_mirroring
|
||||
[4]: https://en.wikipedia.org/wiki/Unified_Extensible_Firmware_Interface
|
||||
[5]: https://en.wikipedia.org/wiki/EFI_system_partition
|
||||
@ -0,0 +1,69 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (arrowfeng)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10797-1.html)
|
||||
[#]: subject: (Most data center workers happy with their jobs -- despite the heavy demands)
|
||||
[#]: via: (https://www.networkworld.com/article/3389359/most-data-center-workers-happy-with-their-jobs-despite-the-heavy-demands.html#tk.rss_all)
|
||||
[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
|
||||
|
||||
许多数据中心的工作者很满意他们的工作,将鼓励他们的孩子继续从事这份工作
|
||||
======
|
||||
|
||||
> 一份 Informa Engage 和 Data Center Knowledge 的报告调查发现,在数据中心工作的人很满意他们的工作,因此他们将会鼓励他们的孩子从事这份工作。
|
||||
|
||||
![Thinkstock][1]
|
||||
|
||||
一份由 [Informa Engage 和 Data Center Knowledge][2] 主导的调查报告显示,数据中心的工作者总体上对他们的工作很满意。尽管对时间和大脑的要求很高,但是他们还是鼓励自己的孩子能从事这项工作。
|
||||
|
||||
总体满意度非常好,72% 的受访者普遍同意“我喜欢我目前的工作”这一说法,三分之一的受访者则表示非常同意。75% 的人同意声明,“如果我的孩子、侄女或侄子问,我将建议他们进入 IT 行业。”
|
||||
|
||||
在数据中心工作的员工之中,有一种很重要的感觉,88% 的人觉得他们自己对于雇主的成功非常重要。
|
||||
|
||||
尽管存在一些挑战,其中最主要的是技能和认证的缺乏。调查的受访者认为缺乏技能是最受关注的领域。只有 56% 的人认为他们需要完成工作所需的培训,74% 的人表示他们已经在 IT 行业工作了十多年。
|
||||
|
||||
这个行业提供认证计划,每个主要的 IT 硬件供应商都有,但是 61% 的人表示在过去的 12 个月里他们并没有完成或者重新续订证书。有几个原因:
|
||||
|
||||
三分之一(34%)说是由于他们工作的组织缺乏培训预算,而 24% 的人认为是缺乏时间,16% 的人表示管理者认为不需要培训,以及另外 16% 的人表示在他们的工作地点没有培训计划。
|
||||
|
||||
这并不让我感到惊讶,因为科技是世界上最开放的行业之一,在那里你可以找到培训和教育材料并自学。已经证实了[许多程序员是自学成才][4],包括行业巨头比尔·盖茨、史蒂夫·沃兹尼亚克、约翰·卡马克和杰克·多尔西。
|
||||
|
||||
### 数据中心工作者们的薪水
|
||||
|
||||
数据中心工作者不会抱怨酬劳。当然,大部分不会。50% 的人每年可以赚到 $100,000 甚至更多,然而 11% 的人赚的少于 $40,000。三分之二的受访者来自于美国,因此那些低端收入人士可能在国外。
|
||||
|
||||
有一个值得注意的差异。史蒂夫·布朗是伦敦数据中心人力资源的总经理,他说软件工程师获得的薪水比硬件工程师多。
|
||||
|
||||
布朗在这篇报道中说,“数据中心软件工程方面的工作可以与高收入的职业媲美,而在物理基础设施——机械/电气方面的工作——情况并非如此。它更像是中层管理。”
|
||||
|
||||
### 数据中心的专业人士仍然主要是男性
|
||||
|
||||
最不令人惊讶的发现?10 个受访者中有 9 个是男性。该行业正在调整解决性别歧视问题,但是现在没什么改变。
|
||||
|
||||
这篇报告的结论有一点不太好,但是我认为是错的:
|
||||
|
||||
> “随着数据中心基础设施完成云计算模式的过渡,软件进入到容器和微服务时代,数据中心剩下来的珍贵领导者——在 20 世纪获得技能的人——可能会发现没有任何他们了解的东西需要管理,也没有人需要他们领导。当危机最终来临时,我们可能会感到震惊,但是我们不能说我们没有受到警告。"
|
||||
|
||||
我说过了很多次,[数据中心不会消失][6]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3389359/most-data-center-workers-happy-with-their-jobs-despite-the-heavy-demands.html
|
||||
|
||||
作者:[Andy Patrizio][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[arrowfeng](https://github.com/arrowfeng)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Andy-Patrizio/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2018/02/data_center_thinkstock_879720438-100749725-large.jpg
|
||||
[2]: https://informa.tradepub.com/c/pubRD.mpl?sr=oc&_t=oc:&qf=w_dats04&ch=datacenterkids
|
||||
[3]: https://www.networkworld.com/article/3276025/20-hot-jobs-ambitious-it-pros-should-shoot-for.html
|
||||
[4]: https://www.networkworld.com/article/3046178/survey-finds-most-coders-are-self-taught.html
|
||||
[5]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fpaths%2Fupgrading-your-technology-career
|
||||
[6]: https://www.networkworld.com/article/3289509/two-studies-show-the-data-center-is-thriving-instead-of-dying.html
|
||||
[7]: https://www.facebook.com/NetworkWorld/
|
||||
[8]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,105 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10795-1.html)
|
||||
[#]: subject: (Ubuntu 19.04 ‘Disco Dingo’ Has Arrived: Downloads Available Now!)
|
||||
[#]: via: (https://itsfoss.com/ubuntu-19-04-release/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
下载安装 Ubuntu 19.04 “Disco Dingo”
|
||||
======
|
||||
|
||||
Ubuntu 19.04 “Disco Dingo” 已经发布,可以下载了。虽然我们已经知道 [Ubuntu 19.04 中的新功能][1] —— 我将在下面提到一些重要的地方,还会给出官方的下载链接。
|
||||
|
||||
### Ubuntu 19.04:你需要知道什么
|
||||
|
||||
以下是你应该了解的有关 Ubuntu 19.04 Disco Dingo 发布的一些内容。
|
||||
|
||||
#### Ubuntu 19.04 不是 LTS 版本
|
||||
|
||||
与 Ubuntu 18.04 LTS 不同,它不会[支持 10 年][2]。相反,非 LTS 的 19.04 将支持 **9 个月,直到 2020 年 1 月。**
|
||||
|
||||
因此,如果你有生产环境,我们可能不会立即建议你进行升级。例如,如果你有一台运行在 Ubuntu 18.04 LTS 上的服务器 —— 只是因为它是一个新的版本就将它升级到 19.04 可能不是一个好主意。
|
||||
|
||||
但是,对于希望在计算机上安装最新版本的用户,可以尝试一下。
|
||||
|
||||
![][3]
|
||||
|
||||
#### Ubuntu 19.04 对 NVIDIA GPU 用户是个不错的更新
|
||||
|
||||
Martin Wimpress(来自 Canonical)在 Ubuntu MATE 19.04(Ubuntu 版本之一)的 [GitHub][4] 的最终发布说明中提到 Ubuntu 19.04 对 NVIDIA GPU 用户来说特别重要。
|
||||
|
||||
换句话说,在安装专有图形驱动时 —— 它现在会选择与你特定 GPU 型号兼容最佳的驱动程序。
|
||||
|
||||
#### Ubuntu 19.04 功能
|
||||
|
||||
- https://youtu.be/sbbPYdpdMb8
|
||||
|
||||
尽管我们已经讨论过 [Ubuntu 19.04][1] Disco Dingo 的[最佳功能][1],但值得一提的是,我对本次发布的主要变化:桌面更新 (GNOME 3.32) 和 Linux 内核 (5.0)感到兴奋。
|
||||
|
||||
#### 从 Ubuntu 18.10 升级到 19.04
|
||||
|
||||
显而易见,如果你安装了 Ubuntu 18.10,你应该升级它。18.10 将于 2019 年 7 月停止支持 —— 所以我们建议你将其升级到 19.04。
|
||||
|
||||
要做到这一点,你可以直接进入“软件和更新”设置,然后选择“更新”选项卡。
|
||||
|
||||
现在将选项从“通知我新的 Ubuntu 版本” 变成 “任何新版本都通知我”。
|
||||
|
||||
现在再次运行更新管理器时,你应该会看到 Ubuntu 19.04。
|
||||
|
||||
![][5]
|
||||
|
||||
#### 从 Ubuntu 18.04 升级到 19.04
|
||||
|
||||
建议不要直接从 18.04 升级到 19.04,因为你需要先将操作系统更新到 18.10,然后再继续升级到 19.04。
|
||||
|
||||
相反,你只需下载 Ubuntu 19.04 的官方 ISO 映像,然后在你的系统上重新安装 Ubuntu。
|
||||
|
||||
### Ubuntu 19.04:所有版本都可下载
|
||||
|
||||
根据[发行说明][6],现在可以下载 Ubuntu 19.04。你可以在其官方发布下载页面上获取种子或 ISO 文件。
|
||||
|
||||
- [下载 Ubuntu 19.04][7]
|
||||
|
||||
如果你需要不同的桌面环境或需要特定的东西,你应该查看 Ubuntu 的官方版本:
|
||||
|
||||
* [Ubuntu MATE][8]
|
||||
* [Kubuntu][9]
|
||||
* [Lubuntu][10]
|
||||
* [Ubuntu Budgie][11]
|
||||
* [Ubuntu Studio][12]
|
||||
* [Xubuntu][13]
|
||||
|
||||
上面提到的一些 Ubuntu 版本还没有在页面提供 19.04。但你可以[仍然在 Ubuntu 的发行说明网页上找到 ISO][6]。就个人而言,我使用带 GNOME 桌面的 Ubuntu。你可以选择你喜欢的。
|
||||
|
||||
### 总结
|
||||
|
||||
你如何看待 Ubuntu 19.04 Disco Dingo?这些新功能是否足够令人兴奋?你试过了吗?请在下面的评论中告诉我们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/ubuntu-19-04-release/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/ubuntu-19-04-release-features/
|
||||
[2]: https://itsfoss.com/ubuntu-18-04-ten-year-support/
|
||||
[3]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2018/11/ubuntu-19-04-Disco-Dingo-default-wallpaper.jpg?resize=800%2C450&ssl=1
|
||||
[4]: https://github.com/ubuntu-mate/ubuntu-mate.org/blob/master/blog/20190418-ubuntu-mate-disco-final-release.md
|
||||
[5]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/04/ubuntu-19-04-upgrade-available.jpg?ssl=1
|
||||
[6]: https://wiki.ubuntu.com/DiscoDingo/ReleaseNotes
|
||||
[7]: https://www.ubuntu.com/download/desktop
|
||||
[8]: https://ubuntu-mate.org/download/
|
||||
[9]: https://kubuntu.org/getkubuntu/
|
||||
[10]: https://lubuntu.me/cosmic-released/
|
||||
[11]: https://ubuntubudgie.org/downloads
|
||||
[12]: https://ubuntustudio.org/2019/04/ubuntu-studio-19-04-released/
|
||||
[13]: https://xubuntu.org/download/
|
||||
@ -0,0 +1,105 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10787-1.html)
|
||||
[#]: subject: (4 cool new projects to try in COPR for April 2019)
|
||||
[#]: via: (https://fedoramagazine.org/4-cool-new-projects-to-try-in-copr-for-april-2019/)
|
||||
[#]: author: (Dominik Turecek https://fedoramagazine.org/author/dturecek/)
|
||||
|
||||
COPR 仓库中 4 个很酷的新软件(2019.4)
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
COPR 是个人软件仓库[集合][1],它不在 Fedora 中。这是因为某些软件不符合轻松打包的标准。或者它可能不符合其他 Fedora 标准,尽管它是自由而开源的。COPR 可以在 Fedora 套件之外提供这些项目。COPR 中的软件不受 Fedora 基础设施的支持,或者是由项目自己背书的。但是,这是一种尝试新的或实验性的软件的一种巧妙的方式。
|
||||
|
||||
这是 COPR 中一组新的有趣项目。
|
||||
|
||||
### Joplin
|
||||
|
||||
[Joplin][3] 是一个笔记和待办事项应用。笔记以 Markdown 格式编写,并通过使用标签和将它们分类到各种笔记本中进行组织。Joplin 可以从任何 Markdown 源导入笔记或从 Evernote 导出笔记。除了桌面应用之外,还有一个 Android 版本,通过使用 Nextcloud、Dropbox 或其他云服务同步笔记。最后,它还有 Chrome 和 Firefox 的浏览器扩展程序,用于保存网页和屏幕截图。
|
||||
|
||||
![][4]
|
||||
|
||||
#### 安装说明
|
||||
|
||||
[COPR 仓库][5]目前为 Fedora 29 和 30 以及 EPEL 7 提供 Joplin。要安装 Joplin,请[带上 sudo][6] 使用这些命令:
|
||||
|
||||
```
|
||||
sudo dnf copr enable taw/joplin
|
||||
sudo dnf install joplin
|
||||
```
|
||||
|
||||
### Fzy
|
||||
|
||||
[Fzy][7] 是用于模糊字符串搜索的命令行程序。它从标准输入读取并根据最有可能的搜索结果进行排序,然后打印所选行。除了命令行,`fzy` 也可以在 vim 中使用。你可以在这个在线 [demo][8] 中尝试 `fzy`。
|
||||
|
||||
#### 安装说明
|
||||
|
||||
[COPR 仓库][9]目前为 Fedora 29、30 和 Rawhide 以及其他发行版提供了 `fzy`。要安装 `fzy`,请使用以下命令:
|
||||
|
||||
```
|
||||
sudo dnf copr enable lehrenfried/fzy
|
||||
sudo dnf install fzy
|
||||
```
|
||||
|
||||
### Fondo
|
||||
|
||||
Fondo 是一个浏览 [unsplash.com][10] 网站照片的程序。它有一个简单的界面,允许你一次查找某个主题或所有主题的图片。然后,你可以通过单击将找到的图片设置为壁纸,或者共享它。
|
||||
|
||||
![][11]
|
||||
|
||||
#### 安装说明
|
||||
|
||||
[COPR 仓库][12]目前为 Fedora 29、30 和 Rawhide 提供 Fondo。要安装 Fondo,请使用以下命令:
|
||||
|
||||
```
|
||||
sudo dnf copr enable atim/fondo
|
||||
sudo dnf install fondo
|
||||
```
|
||||
|
||||
### YACReader
|
||||
|
||||
[YACReader][13] 是一款数字漫画阅读器,它支持许多漫画和图像格式,例如 cbz、cbr、pdf 等。YACReader 会跟踪阅读进度,并可以从 [Comic Vine][14] 下载漫画信息。它还有一个 YACReader 库,用于组织和浏览你的漫画集。
|
||||
|
||||
![][15]
|
||||
|
||||
#### 安装说明
|
||||
|
||||
[COPR 仓库][16]目前为 Fedora 29、30 和 Rawhide 提供 YACReader。要安装 YACReader,请使用以下命令:
|
||||
|
||||
```
|
||||
sudo dnf copr enable atim/yacreader
|
||||
sudo dnf install yacreader
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/4-cool-new-projects-to-try-in-copr-for-april-2019/
|
||||
|
||||
作者:[Dominik Turecek][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/dturecek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2017/08/4-copr-945x400.jpg
|
||||
[2]: https://copr.fedorainfracloud.org/
|
||||
[3]: https://joplin.cozic.net/
|
||||
[4]: https://fedoramagazine.org/wp-content/uploads/2019/04/joplin.png
|
||||
[5]: https://copr.fedorainfracloud.org/coprs/taw/joplin/
|
||||
[6]: https://fedoramagazine.org/howto-use-sudo/
|
||||
[7]: https://github.com/jhawthorn/fzy
|
||||
[8]: https://jhawthorn.github.io/fzy-demo/
|
||||
[9]: https://copr.fedorainfracloud.org/coprs/lehrenfried/fzy/
|
||||
[10]: https://unsplash.com/
|
||||
[11]: https://fedoramagazine.org/wp-content/uploads/2019/04/fondo.png
|
||||
[12]: https://copr.fedorainfracloud.org/coprs/atim/fondo/
|
||||
[13]: https://www.yacreader.com/
|
||||
[14]: https://comicvine.gamespot.com/
|
||||
[15]: https://fedoramagazine.org/wp-content/uploads/2019/04/yacreader.png
|
||||
[16]: https://copr.fedorainfracloud.org/coprs/atim/yacreader/
|
||||
@ -0,0 +1,147 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (warmfrog)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10790-1.html)
|
||||
[#]: subject: (New Features Coming to Debian 10 Buster Release)
|
||||
[#]: via: (https://itsfoss.com/new-features-coming-to-debian-10-buster-release/)
|
||||
[#]: author: (Shirish https://itsfoss.com/author/shirish/)
|
||||
|
||||
即将到来的 Debian 10 Buster 发布版的新特点
|
||||
=======================================
|
||||
|
||||
Debian 10 Buster 即将发布。第一个发布候选版已经发布,我们预期可以在几周内见到待最终版。
|
||||
|
||||
如果你期待对这个新的主要发布版本,让我告诉你里面有什么。
|
||||
|
||||
### Debian 10 Buster 发布计划
|
||||
|
||||
[Debian 10 Buster][1] 的发布日期并没有确定。为什么这样呢?不像其他分发版,[Debian][2] 并不基于时间发布。相反地它主要关注于修复<ruby>发布版重要 Bug<rt>release-critical bug</rt></ruby>。发布版重要 Bug 要么是严重的安全问题([CVE][3]),要么是一些其他阻止 Debian 发布的严重问题。
|
||||
|
||||
Debian 在它的软件归档中分为三个部分,叫做 Main、contrib 和 non-free。在这三者之中,Debian 开发者和发布管理者最关心的包组成了该分发版的基石。Main 是像石头一样稳定的。因此他们要确保那里没有主要的功能或者安全问题。他们同样给予了不同的优先级,例如 Essential、Required、Important、Standard、Optional 和 Extra。更多关于此方面的知识参考后续的 Debian 文章。
|
||||
|
||||
这是必要的,因为 Debian 在很多环境中被用作服务器,人们已经变得依赖 Debian。他们同样看重升级周期是否有破环,因此他们寻找人们来测试,来查看当升级的时候是否有破坏并通知 Debian 有这样的问题。
|
||||
|
||||
这种提交方式带来的稳定性[是我喜欢 Debian 的众多原因之一][4]。
|
||||
|
||||
### Debian 10 Buster 版本的新内容
|
||||
|
||||
这里是即将到来的 Debian 主要发布版的一些视觉上和内部的改变。
|
||||
|
||||
#### 新的主题和壁纸
|
||||
|
||||
Buster 的 Debian 主题被称为 [FuturePrototype][5] 并且看起来如下图:
|
||||
|
||||
![Debian Buster FuturePrototype Theme][6]
|
||||
|
||||
#### 1、GNOME 桌面 3.30
|
||||
|
||||
Debian Stretch 版中的 GNOME 桌面在 Buster 中从 1.3.22 升级到了 1.3.30。在 GNOME 桌面发布版中新包含的一些包是 gnome-todo、tracker 替代了 tracker-gui、gstreamer1.0-packagekit 的依赖,因此可以通过自动地安装编码解码器来做播放电影之类的事。对于所有包来说一个大的改变是从 libgtk2+ 到 libgtk3+。
|
||||
|
||||
#### 2、Linux 内核 4.19.0-4
|
||||
|
||||
Debian 使用 LTS 内核版本,因此你可以期待更好的硬件支持和长达 5 年的维护和支持周期。我们已经从内核 4.9.0.3 到 4.19.0-4。
|
||||
|
||||
```
|
||||
$ uname -r
|
||||
4.19.0-4-amd64
|
||||
```
|
||||
|
||||
#### 3、OpenJDK 11.0
|
||||
|
||||
Debian 在很长时间里都是 OpenJDK 8.0。现在在 Debian Buster 里我们已经升级为 OpenJDK 11.0,并且会有一个团队维护新的版本。
|
||||
|
||||
#### 4、默认启用 AppArmor
|
||||
|
||||
在 Debian Buster 中是默认启用 [AppArmor][7] 的。这是一个好事,谨慎是系统管理员必须采取的正确策略。这仅仅是第一步,并且可能需要修复很多对用户觉得有用的脚本。
|
||||
|
||||
#### 5、Nodejs 10.15.2
|
||||
|
||||
在很长一段时间里 Debian 在仓库中都只有 Nodejs 4.8。在这个周期里 Debian 已经移到 Nodejs 10.15.2。事实上,Debian Buster 有很多 javascript 库例如 yarnpkg (一个 nmp 的替代品)等等。
|
||||
|
||||
当然,你可以从该项目仓库[在 Debian 中安装最新的 Nodejs][8],但是从 Debian 仓库中看到更新的版本是很棒的。
|
||||
|
||||
#### 6、NFtables 替代了 iptables
|
||||
|
||||
Debian Buster 提供了 nftables 来完整地替代了 iptables,因为它有更好、更简单的语法,更好的支持双栈 ipv4/v6 防火墙等等。
|
||||
|
||||
#### 7、支持更多的 ARM 64 和 ARMHF 的单板机。
|
||||
|
||||
Debian 已经支持一些常见的新的单板机,其中最新的包括 pine64_plus、ARM64 的 pinebook、Firefly-RK3288、ARMHF 64 的 u-boot-rockchip 以及 Odroid HC1/HC2 板、SolidRun Cubox-i 双核/四核(1.5som)和 SolidRun Cubox-i 双核/四核(1.5som+emmc)板、Cubietruckplus 等。同样支持 Rock 64、Banana Pi M2 Berry、Pine A64 LTS Board、Olimex A64 Teres-1 与 Rapberry Pi 1、Zero 和 Pi 3。对于 RISC-V 系统同样支持开箱即用。
|
||||
|
||||
#### 8、Python 2 已死,Python 3 长存
|
||||
|
||||
在 2020 年 1 月 1 日,Python 2 将被 python.org 废弃。在 Debian 将所有的软件包从 Python 2.7 移到 Python 3 以后,Python 2.7 将从软件仓库中移除。这可能发生在 Buster 发布版或者将来的某个发布版,这是肯定要来临的。因此 Python 开发者被鼓励移植他们的代码库来兼容 Python 3。在写本文的时候,在 Debian Buster 中同时支持 python2 和 pythone3。
|
||||
|
||||
#### 9、Mailman 3
|
||||
|
||||
在 Debian 中终于可以使用 Mailman3 了。同时 [Mailman][10] 已经被细分成为组件。要安装整个软件栈,可以安装 mailman3-full 来获取所有组件。
|
||||
|
||||
#### 10、任意已有的 Postgresql 数据库将需要重新索引
|
||||
|
||||
由于 glibc 本地数据的更新,放入文本索引中的信息排序的方式将会改变,因为重新索引是有益的,这样在将来就不会有数据破坏发生。
|
||||
|
||||
#### 11、默认 Bash 5.0
|
||||
|
||||
你可能已经了解了 [Bash 5.0 的新特点][11],在 Debian 中已经是该版本了。
|
||||
|
||||
#### 12、Debian 实现 /usr/merge
|
||||
|
||||
我们已经分享过一个优秀的 freedesktop [读物][12],介绍了 `/usr/merge` 带来了什么。有一些事项需要注意。当 Debian 想要整个过渡时,可能由于未预见的情况,一些二进制文件可能并没有做这些改变。需要指出的一点是,`/var` 和 `/etc` 不会被触及,因此使用容器或者云技术的不需要考虑太多 :)。
|
||||
|
||||
#### 13、支持安全启动
|
||||
|
||||
在 Buster RC1 中,Debian 现在支持<ruby>安全启动<rt>secure-boot</rt></ruby>。这意味着打开了安全启动设置的机器应该能够轻松安装 Debian。不再需要禁止或者处理安全启动的事 :)
|
||||
|
||||
#### 14、Debian-Live 镜像的 Calameres Live-installer
|
||||
|
||||
对于 Debian Buster 的 Live 版,Debian 引入了 [Calameres 安装器][13]来替代老的 Debian-installer。Debian-installer 比 Calameres 功能更多,但对于初学者,Calameres 相对于 Debian-installer 提供了另外一种全新的安装方式。安装过程的截图:
|
||||
|
||||
![Calamares Partitioning Stage][14]
|
||||
|
||||
如图所见,在 Calamares 下安装 Debian 相当简单,只要经历 5 个步骤你就能在你的机器上安装 Debian。
|
||||
|
||||
### 下载 Debian 10 Live 镜像 (只用于测试)
|
||||
|
||||
现在还不要将它用于生产机器。可以在测试机上尝试或者一个虚拟机。
|
||||
|
||||
你可以从 Debian Live [目录][15]获取 Debian 64 位和 32 位的镜像。如果你想要 64 位的就进入 `64-bit` 目录,如果你想要 32 位的,就进入 `32-bit` 目录。
|
||||
|
||||
- [下载 Debian 10 Buster Live Images][15]
|
||||
|
||||
如果你从已存在的稳定版升级并且出现了一些问题,查看它是否在预安装的[升级报告][16]中提及了,使用 [reportbug][17] 报告你看到的问题。如果 bug 没有被报告,那么请尽可能地报告和分享更多地信息。
|
||||
|
||||
### 总结
|
||||
|
||||
当上千个包被升级时,看起来不可能一一列出。我已经列出了一些你在 Debian Buster 可以找到的一些主要的改变。你怎么看呢?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/new-features-coming-to-debian-10-buster-release/
|
||||
|
||||
作者:[Shirish][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[warmfrog](https://github.com/warmfrog)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/shirish/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://wiki.debian.org/DebianBuster
|
||||
[2]: https://www.debian.org/
|
||||
[3]: https://en.wikipedia.org/wiki/Common_Vulnerabilities_and_Exposures
|
||||
[4]: https://itsfoss.com/reasons-why-i-love-debian/
|
||||
[5]: https://wiki.debian.org/DebianArt/Themes/futurePrototype
|
||||
[6]: https://itsfoss.com/wp-content/uploads/2019/04/debian-buster-theme-800x450.png
|
||||
[7]: https://wiki.debian.org/AppArmor
|
||||
[8]: https://itsfoss.com/install-nodejs-ubuntu/
|
||||
[9]: https://www.python.org/dev/peps/pep-0373/
|
||||
[10]: https://www.list.org/
|
||||
[11]: https://itsfoss.com/bash-5-release/
|
||||
[12]: https://www.freedesktop.org/wiki/Software/systemd/TheCaseForTheUsrMerge/
|
||||
[13]: https://calamares.io/about/
|
||||
[14]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/04/calamares-partitioning-wizard.jpg?fit=800%2C538&ssl=1
|
||||
[15]: https://cdimage.debian.org/cdimage/weekly-live-builds/
|
||||
[16]: https://bugs.debian.org/cgi-bin/pkgreport.cgi?pkg=upgrade-reports;dist=unstable
|
||||
[17]: https://itsfoss.com/bug-report-debian/
|
||||
108
published/20190409 5 open source mobile apps.md
Normal file
108
published/20190409 5 open source mobile apps.md
Normal file
@ -0,0 +1,108 @@
|
||||
[#]: collector: "lujun9972"
|
||||
[#]: translator: "fuzheng1998"
|
||||
[#]: reviewer: "wxy"
|
||||
[#]: publisher: "wxy"
|
||||
[#]: url: "https://linux.cn/article-10931-1.html"
|
||||
[#]: subject: "5 open source mobile apps"
|
||||
[#]: via: "https://opensource.com/article/19/4/mobile-apps"
|
||||
[#]: author: "Chris Hermansen https://opensource.com/users/clhermansen/users/bcotton/users/clhermansen/users/bcotton/users/clhermansen"
|
||||
|
||||
5 个可以满足你的生产力、沟通和娱乐需求的开源手机应用
|
||||
======
|
||||
|
||||
> 你可以依靠这些应用来满足你的生产力、沟通和娱乐需求。
|
||||
|
||||

|
||||
|
||||
像世界上大多数人一样,我的手似乎就没有离开过手机。多亏了我从 Google Play 和 F-Droid 安装的开源移动应用程序,让我的 Android 设备好像提供了无限的沟通、生产力和娱乐服务一样。
|
||||
|
||||
在我的手机上的许多开源应用程序中,当想听音乐、与朋友/家人和同事联系、或者在旅途中完成工作时,以下五个是我一直使用的。
|
||||
|
||||
### MPDroid
|
||||
|
||||
一个音乐播放器进程 (MPD)的 Android 控制器。
|
||||
|
||||
![MPDroid][2]
|
||||
|
||||
MPD 是将音乐从小型音乐服务器电脑传输到大型的黑色立体声音箱的好方法。它直连 ALSA,因此可以通过 ALSA 硬件接口与数模转换器(DAC)对话,它可以通过我的网络进行控制——但是用什么东西控制呢?好吧,事实证明 MPDroid 是一个很棒的 MPD 控制器。它可以管理我的音乐数据库,显示专辑封面,处理播放列表,并支持互联网广播。而且它是开源的,所以如果某些东西不好用的话……
|
||||
|
||||
MPDroid 可在 [Google Play][4] 和 [F-Droid][5] 上找到。
|
||||
|
||||
### RadioDroid
|
||||
|
||||
一台能单独使用及与 Chromecast 搭配使用的 Android 网络收音机。
|
||||
|
||||
![RadioDroid][6]
|
||||
|
||||
RadioDroid 是一个网络收音机,而 MPDroid 则管理我音乐的数据库;从本质上讲,RadioDroid 是 [Internet-Radio.com][7] 的一个前端。此外,通过将耳机插入 Android 设备,通过耳机插孔或 USB 将 Android 设备直接连接到立体声系统,或通过兼容设备使用其 Chromecast 功能,可以享受 RadioDroid。这是一个查看芬兰天气情况,听取排名前 40 的西班牙语音乐,或收到到最新新闻消息的好方法。
|
||||
|
||||
RadioDroid 可在 [Google Play][8] 和 [F-Droid][9] 上找到。
|
||||
|
||||
### Signal
|
||||
|
||||
一个支持 Android、iOS,还有桌面系统的安全即时消息客户端。
|
||||
|
||||
![Signal][10]
|
||||
|
||||
如果你喜欢 WhatsApp,但是因为它与 Facebook [日益密切][11]的关系而感到困扰,那么 Signal 应该是你的下一个产品。Signal 的唯一问题是说服你的朋友们最好用 Signal 取代 WhatsApp。但除此之外,它有一个与 WhatsApp 类似的界面;很棒的语音和视频通话;很好的加密;恰到好处的匿名;并且它受到了一个不打算通过使用软件来获利的基金会的支持。为什么不喜欢它呢?
|
||||
|
||||
Signal 可用于 [Android][12]、[iOS][13] 和 [桌面][14]。
|
||||
|
||||
### ConnectBot
|
||||
|
||||
Android SSH 客户端。
|
||||
|
||||
![ConnectBot][15]
|
||||
|
||||
有时我离电脑很远,但我需要登录服务器才能办事。[ConnectBot][16] 是将 SSH 会话搬到手机上的绝佳解决方案。
|
||||
|
||||
ConnectBot 可在 [Google Play][17] 上找到。
|
||||
|
||||
### Termux
|
||||
|
||||
有多种熟悉的功能的安卓终端模拟器。
|
||||
|
||||
![Termux][18]
|
||||
|
||||
你是否需要在手机上运行 `awk` 脚本?[Termux][19] 是个解决方案。如果你需要做终端类的工作,而且你不想一直保持与远程计算机的 SSH 连接,请使用 ConnectBot 将文件放到手机上,然后退出会话,在 Termux 中执行你的操作,用 ConnectBot 发回结果。
|
||||
|
||||
Termux 可在 [Google Play][20] 和 [F-Droid][21] 上找到。
|
||||
|
||||
* * *
|
||||
|
||||
你最喜欢用于工作或娱乐的开源移动应用是什么呢?请在评论中分享它们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/mobile-apps
|
||||
|
||||
作者:[Chris Hermansen][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[fuzheng1998](https://github.com/fuzheng1998)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/clhermansen/users/bcotton/users/clhermansen/users/bcotton/users/clhermansen
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/rh_003588_01_rd3os.combacktoschoolserieshe_rh_041x_0.png?itok=tfg6_I78
|
||||
[2]: https://opensource.com/sites/default/files/uploads/mpdroid.jpg "MPDroid"
|
||||
[3]: https://opensource.com/article/17/4/fun-new-gadget
|
||||
[4]: https://play.google.com/store/apps/details?id=com.namelessdev.mpdroid&hl=en_US
|
||||
[5]: https://f-droid.org/en/packages/com.namelessdev.mpdroid/
|
||||
[6]: https://opensource.com/sites/default/files/uploads/radiodroid.png "RadioDroid"
|
||||
[7]: https://www.internet-radio.com/
|
||||
[8]: https://play.google.com/store/apps/details?id=net.programmierecke.radiodroid2
|
||||
[9]: https://f-droid.org/en/packages/net.programmierecke.radiodroid2/
|
||||
[10]: https://opensource.com/sites/default/files/uploads/signal.png "Signal"
|
||||
[11]: https://opensource.com/article/19/3/open-messenger-client
|
||||
[12]: https://play.google.com/store/apps/details?id=org.thoughtcrime.securesms
|
||||
[13]: https://itunes.apple.com/us/app/signal-private-messenger/id874139669?mt=8
|
||||
[14]: https://signal.org/download/
|
||||
[15]: https://opensource.com/sites/default/files/uploads/connectbot.png "ConnectBot"
|
||||
[16]: https://connectbot.org/
|
||||
[17]: https://play.google.com/store/apps/details?id=org.connectbot
|
||||
[18]: https://opensource.com/sites/default/files/uploads/termux.jpg "Termux"
|
||||
[19]: https://termux.com/
|
||||
[20]: https://play.google.com/store/apps/details?id=com.termux
|
||||
[21]: https://f-droid.org/packages/com.termux/
|
||||
135
published/20190411 Be your own certificate authority.md
Normal file
135
published/20190411 Be your own certificate authority.md
Normal file
@ -0,0 +1,135 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10921-1.html)
|
||||
[#]: subject: (Be your own certificate authority)
|
||||
[#]: via: (https://opensource.com/article/19/4/certificate-authority)
|
||||
[#]: author: (Moshe Zadka https://opensource.com/users/moshez/users/elenajon123)
|
||||
|
||||
|
||||
自己成为一个证书颁发机构(CA)
|
||||
======
|
||||
|
||||
> 为你的微服务架构或者集成测试创建一个简单的内部 CA。
|
||||
|
||||

|
||||
|
||||
传输层安全([TLS][2])模型(有时也称它的旧名称 SSL)基于<ruby>[证书颁发机构][3]<rt>certificate authoritie</rt></ruby>(CA)的概念。这些机构受到浏览器和操作系统的信任,从而*签名*服务器的的证书以用于验证其所有权。
|
||||
|
||||
但是,对于内部网络,微服务架构或集成测试,有时候*本地 CA*更有用:一个只在内部受信任的 CA,然后签名本地服务器的证书。
|
||||
|
||||
这对集成测试特别有意义。获取证书可能会带来负担,因为这会占用服务器几分钟。但是在代码中使用“忽略证书”可能会被引入到生产环境,从而导致安全灾难。
|
||||
|
||||
CA 证书与常规服务器证书没有太大区别。重要的是它被本地代码信任。例如,在 Python `requests` 库中,可以通过将 `REQUESTS_CA_BUNDLE` 变量设置为包含此证书的目录来完成。
|
||||
|
||||
在为集成测试创建证书的例子中,不需要*长期的*证书:如果你的集成测试需要超过一天,那么你应该已经测试失败了。
|
||||
|
||||
因此,计算**昨天**和**明天**作为有效期间隔:
|
||||
|
||||
```
|
||||
>>> import datetime
|
||||
>>> one_day = datetime.timedelta(days=1)
|
||||
>>> today = datetime.date.today()
|
||||
>>> yesterday = today - one_day
|
||||
>>> tomorrow = today - one_day
|
||||
```
|
||||
|
||||
现在你已准备好创建一个简单的 CA 证书。你需要生成私钥,创建公钥,设置 CA 的“参数”,然后自签名证书:CA 证书*总是*自签名的。最后,导出证书文件以及私钥文件。
|
||||
|
||||
```
|
||||
from cryptography.hazmat.primitives.asymmetric import rsa
|
||||
from cryptography.hazmat.primitives import hashes, serialization
|
||||
from cryptography import x509
|
||||
from cryptography.x509.oid import NameOID
|
||||
|
||||
|
||||
private_key = rsa.generate_private_key(
|
||||
public_exponent=65537,
|
||||
key_size=2048,
|
||||
backend=default_backend()
|
||||
)
|
||||
public_key = private_key.public_key()
|
||||
builder = x509.CertificateBuilder()
|
||||
builder = builder.subject_name(x509.Name([
|
||||
x509.NameAttribute(NameOID.COMMON_NAME, 'Simple Test CA'),
|
||||
]))
|
||||
builder = builder.issuer_name(x509.Name([
|
||||
x509.NameAttribute(NameOID.COMMON_NAME, 'Simple Test CA'),
|
||||
]))
|
||||
builder = builder.not_valid_before(yesterday)
|
||||
builder = builder.not_valid_after(tomorrow)
|
||||
builder = builder.serial_number(x509.random_serial_number())
|
||||
builder = builder.public_key(public_key)
|
||||
builder = builder.add_extension(
|
||||
x509.BasicConstraints(ca=True, path_length=None),
|
||||
critical=True)
|
||||
certificate = builder.sign(
|
||||
private_key=private_key, algorithm=hashes.SHA256(),
|
||||
backend=default_backend()
|
||||
)
|
||||
private_bytes = private_key.private_bytes(
|
||||
encoding=serialization.Encoding.PEM,
|
||||
format=serialization.PrivateFormat.TraditionalOpenSSL,
|
||||
encryption_algorithm=serialization.NoEncrption())
|
||||
public_bytes = certificate.public_bytes(
|
||||
encoding=serialization.Encoding.PEM)
|
||||
with open("ca.pem", "wb") as fout:
|
||||
fout.write(private_bytes + public_bytes)
|
||||
with open("ca.crt", "wb") as fout:
|
||||
fout.write(public_bytes)
|
||||
```
|
||||
|
||||
通常,真正的 CA 会需要[证书签名请求][4](CSR)来签名证书。但是,当你是自己的 CA 时,你可以制定自己的规则!可以径直签名你想要的内容。
|
||||
|
||||
继续集成测试的例子,你可以创建私钥并立即签名相应的公钥。注意 `COMMON_NAME` 需要是 `https` URL 中的“服务器名称”。如果你已配置名称查询,你需要服务器能响应对 `service.test.local` 的请求。
|
||||
|
||||
```
|
||||
service_private_key = rsa.generate_private_key(
|
||||
public_exponent=65537,
|
||||
key_size=2048,
|
||||
backend=default_backend()
|
||||
)
|
||||
service_public_key = service_private_key.public_key()
|
||||
builder = x509.CertificateBuilder()
|
||||
builder = builder.subject_name(x509.Name([
|
||||
x509.NameAttribute(NameOID.COMMON_NAME, 'service.test.local')
|
||||
]))
|
||||
builder = builder.not_valid_before(yesterday)
|
||||
builder = builder.not_valid_after(tomorrow)
|
||||
builder = builder.public_key(public_key)
|
||||
certificate = builder.sign(
|
||||
private_key=private_key, algorithm=hashes.SHA256(),
|
||||
backend=default_backend()
|
||||
)
|
||||
private_bytes = service_private_key.private_bytes(
|
||||
encoding=serialization.Encoding.PEM,
|
||||
format=serialization.PrivateFormat.TraditionalOpenSSL,
|
||||
encryption_algorithm=serialization.NoEncrption())
|
||||
public_bytes = certificate.public_bytes(
|
||||
encoding=serialization.Encoding.PEM)
|
||||
with open("service.pem", "wb") as fout:
|
||||
fout.write(private_bytes + public_bytes)
|
||||
```
|
||||
|
||||
现在 `service.pem` 文件有一个私钥和一个“有效”的证书:它已由本地的 CA 签名。该文件的格式可以给 Nginx、HAProxy 或大多数其他 HTTPS 服务器使用。
|
||||
|
||||
通过将此逻辑用在测试脚本中,只要客户端配置信任该 CA,那么就可以轻松创建看起来真实的 HTTPS 服务器。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/certificate-authority
|
||||
|
||||
作者:[Moshe Zadka][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/moshez/users/elenajon123
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/rh_commun_4604_02_mech_connections_rhcz0.5x.png?itok=YPPU4dMj
|
||||
[2]: https://en.wikipedia.org/wiki/Transport_Layer_Security
|
||||
[3]: https://en.wikipedia.org/wiki/Certificate_authority
|
||||
[4]: https://en.wikipedia.org/wiki/Certificate_signing_request
|
||||
@ -0,0 +1,374 @@
|
||||
[#]: collector: "lujun9972"
|
||||
[#]: translator: "FSSlc"
|
||||
[#]: reviewer: "wxy"
|
||||
[#]: publisher: "wxy"
|
||||
[#]: url: "https://linux.cn/article-10930-1.html"
|
||||
[#]: subject: "Inter-process communication in Linux: Sockets and signals"
|
||||
[#]: via: "https://opensource.com/article/19/4/interprocess-communication-linux-networking"
|
||||
[#]: author: "Marty Kalin https://opensource.com/users/mkalindepauledu"
|
||||
|
||||
Linux 下的进程间通信:套接字和信号
|
||||
======
|
||||
|
||||
> 学习在 Linux 中进程是如何与其他进程进行同步的。
|
||||
|
||||

|
||||
|
||||
本篇是 Linux 下[进程间通信][1](IPC)系列的第三篇同时也是最后一篇文章。[第一篇文章][2]聚焦在通过共享存储(文件和共享内存段)来进行 IPC,[第二篇文章][3]则通过管道(无名的或者命名的)及消息队列来达到相同的目的。这篇文章将目光从高处(套接字)然后到低处(信号)来关注 IPC。代码示例将用力地充实下面的解释细节。
|
||||
|
||||
### 套接字
|
||||
|
||||
正如管道有两种类型(命名和无名)一样,套接字也有两种类型。IPC 套接字(即 Unix 套接字)给予进程在相同设备(主机)上基于通道的通信能力;而网络套接字给予进程运行在不同主机的能力,因此也带来了网络通信的能力。网络套接字需要底层协议的支持,例如 TCP(传输控制协议)或 UDP(用户数据报协议)。
|
||||
|
||||
与之相反,IPC 套接字依赖于本地系统内核的支持来进行通信;特别的,IPC 通信使用一个本地的文件作为套接字地址。尽管这两种套接字的实现有所不同,但在本质上,IPC 套接字和网络套接字的 API 是一致的。接下来的例子将包含网络套接字的内容,但示例服务器和客户端程序可以在相同的机器上运行,因为服务器使用了 `localhost`(127.0.0.1)这个网络地址,该地址表示的是本地机器上的本地机器地址。
|
||||
|
||||
套接字以流的形式(下面将会讨论到)被配置为双向的,并且其控制遵循 C/S(客户端/服务器端)模式:客户端通过尝试连接一个服务器来初始化对话,而服务器端将尝试接受该连接。假如万事顺利,来自客户端的请求和来自服务器端的响应将通过管道进行传输,直到其中任意一方关闭该通道,从而断开这个连接。
|
||||
|
||||
一个迭代服务器(只适用于开发)将一直和连接它的客户端打交道:从最开始服务第一个客户端,然后到这个连接关闭,然后服务第二个客户端,循环往复。这种方式的一个缺点是处理一个特定的客户端可能会挂起,使得其他的客户端一直在后面等待。生产级别的服务器将是并发的,通常使用了多进程或者多线程的混合。例如,我台式机上的 Nginx 网络服务器有一个 4 个<ruby>工人<rt>worker</rt></ruby>的进程池,它们可以并发地处理客户端的请求。在下面的代码示例中,我们将使用迭代服务器,使得我们将要处理的问题保持在一个很小的规模,只关注基本的 API,而不去关心并发的问题。
|
||||
|
||||
最后,随着各种 POSIX 改进的出现,套接字 API 随着时间的推移而发生了显著的变化。当前针对服务器端和客户端的示例代码特意写的比较简单,但是它着重强调了基于流的套接字中连接的双方。下面是关于流控制的一个总结,其中服务器端在一个终端中开启,而客户端在另一个不同的终端中开启:
|
||||
|
||||
* 服务器端等待客户端的连接,对于给定的一个成功连接,它就读取来自客户端的数据。
|
||||
* 为了强调是双方的会话,服务器端会对接收自客户端的数据做回应。这些数据都是 ASCII 字符代码,它们组成了一些书的标题。
|
||||
* 客户端将书的标题写给服务器端的进程,并从服务器端的回应中读取到相同的标题。然后客户端和服务器端都在屏幕上打印出标题。下面是服务器端的输出,客户端的输出也和它完全一样:
|
||||
|
||||
```
|
||||
Listening on port 9876 for clients...
|
||||
War and Peace
|
||||
Pride and Prejudice
|
||||
The Sound and the Fury
|
||||
```
|
||||
|
||||
#### 示例 1. 使用套接字的客户端程序
|
||||
|
||||
```c
|
||||
#include <string.h>
|
||||
#include <stdio.h>
|
||||
#include <stdlib.h>
|
||||
#include <unistd.h>
|
||||
#include <sys/types.h>
|
||||
#include <sys/socket.h>
|
||||
#include <netinet/tcp.h>
|
||||
#include <arpa/inet.h>
|
||||
#include "sock.h"
|
||||
|
||||
void report(const char* msg, int terminate) {
|
||||
perror(msg);
|
||||
if (terminate) exit(-1); /* failure */
|
||||
}
|
||||
|
||||
int main() {
|
||||
int fd = socket(AF_INET, /* network versus AF_LOCAL */
|
||||
SOCK_STREAM, /* reliable, bidirectional: TCP */
|
||||
0); /* system picks underlying protocol */
|
||||
if (fd < 0) report("socket", 1); /* terminate */
|
||||
|
||||
/* bind the server's local address in memory */
|
||||
struct sockaddr_in saddr;
|
||||
memset(&saddr, 0, sizeof(saddr)); /* clear the bytes */
|
||||
saddr.sin_family = AF_INET; /* versus AF_LOCAL */
|
||||
saddr.sin_addr.s_addr = htonl(INADDR_ANY); /* host-to-network endian */
|
||||
saddr.sin_port = htons(PortNumber); /* for listening */
|
||||
|
||||
if (bind(fd, (struct sockaddr *) &saddr, sizeof(saddr)) < 0)
|
||||
report("bind", 1); /* terminate */
|
||||
|
||||
/* listen to the socket */
|
||||
if (listen(fd, MaxConnects) < 0) /* listen for clients, up to MaxConnects */
|
||||
report("listen", 1); /* terminate */
|
||||
|
||||
fprintf(stderr, "Listening on port %i for clients...\n", PortNumber);
|
||||
/* a server traditionally listens indefinitely */
|
||||
while (1) {
|
||||
struct sockaddr_in caddr; /* client address */
|
||||
int len = sizeof(caddr); /* address length could change */
|
||||
|
||||
int client_fd = accept(fd, (struct sockaddr*) &caddr, &len); /* accept blocks */
|
||||
if (client_fd < 0) {
|
||||
report("accept", 0); /* don't terminated, though there's a problem */
|
||||
continue;
|
||||
}
|
||||
|
||||
/* read from client */
|
||||
int i;
|
||||
for (i = 0; i < ConversationLen; i++) {
|
||||
char buffer[BuffSize + 1];
|
||||
memset(buffer, '\0', sizeof(buffer));
|
||||
int count = read(client_fd, buffer, sizeof(buffer));
|
||||
if (count > 0) {
|
||||
puts(buffer);
|
||||
write(client_fd, buffer, sizeof(buffer)); /* echo as confirmation */
|
||||
}
|
||||
}
|
||||
close(client_fd); /* break connection */
|
||||
} /* while(1) */
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
上面的服务器端程序执行典型的 4 个步骤来准备回应客户端的请求,然后接受其他的独立请求。这里每一个步骤都以服务器端程序调用的系统函数来命名。
|
||||
|
||||
1. `socket(…)`:为套接字连接获取一个文件描述符
|
||||
2. `bind(…)`:将套接字和服务器主机上的一个地址进行绑定
|
||||
3. `listen(…)`:监听客户端请求
|
||||
4. `accept(…)`:接受一个特定的客户端请求
|
||||
|
||||
上面的 `socket` 调用的完整形式为:
|
||||
|
||||
```
|
||||
int sockfd = socket(AF_INET, /* versus AF_LOCAL */
|
||||
SOCK_STREAM, /* reliable, bidirectional */
|
||||
0); /* system picks protocol (TCP) */
|
||||
```
|
||||
|
||||
第一个参数特别指定了使用的是一个网络套接字,而不是 IPC 套接字。对于第二个参数有多种选项,但 `SOCK_STREAM` 和 `SOCK_DGRAM`(数据报)是最为常用的。基于流的套接字支持可信通道,在这种通道中如果发生了信息的丢失或者更改,都将会被报告。这种通道是双向的,并且从一端到另外一端的有效载荷在大小上可以是任意的。相反的,基于数据报的套接字大多是不可信的,没有方向性,并且需要固定大小的载荷。`socket` 的第三个参数特别指定了协议。对于这里展示的基于流的套接字,只有一种协议选择:TCP,在这里表示的 `0`。因为对 `socket` 的一次成功调用将返回相似的文件描述符,套接字可以被读写,对应的语法和读写一个本地文件是类似的。
|
||||
|
||||
对 `bind` 的调用是最为复杂的,因为它反映出了在套接字 API 方面上的各种改进。我们感兴趣的点是这个调用将一个套接字和服务器端所在机器中的一个内存地址进行绑定。但对 `listen` 的调用就非常直接了:
|
||||
|
||||
```
|
||||
if (listen(fd, MaxConnects) < 0)
|
||||
```
|
||||
|
||||
第一个参数是套接字的文件描述符,第二个参数则指定了在服务器端处理一个拒绝连接错误之前,有多少个客户端连接被允许连接。(在头文件 `sock.h` 中 `MaxConnects` 的值被设置为 `8`。)
|
||||
|
||||
`accept` 调用默认将是一个阻塞等待:服务器端将不做任何事情直到一个客户端尝试连接它,然后进行处理。`accept` 函数返回的值如果是 `-1` 则暗示有错误发生。假如这个调用是成功的,则它将返回另一个文件描述符,这个文件描述符被用来指代另一个可读可写的套接字,它与 `accept` 调用中的第一个参数对应的接收套接字有所不同。服务器端使用这个可读可写的套接字来从客户端读取请求然后写回它的回应。接收套接字只被用于接受客户端的连接。
|
||||
|
||||
在设计上,服务器端可以一直运行下去。当然服务器端可以通过在命令行中使用 `Ctrl+C` 来终止它。
|
||||
|
||||
#### 示例 2. 使用套接字的客户端
|
||||
|
||||
```c
|
||||
#include <string.h>
|
||||
#include <stdio.h>
|
||||
#include <stdlib.h>
|
||||
#include <unistd.h>
|
||||
#include <sys/types.h>
|
||||
#include <sys/socket.h>
|
||||
#include <arpa/inet.h>
|
||||
#include <netinet/in.h>
|
||||
#include <netinet/tcp.h>
|
||||
#include <netdb.h>
|
||||
#include "sock.h"
|
||||
|
||||
const char* books[] = {"War and Peace",
|
||||
"Pride and Prejudice",
|
||||
"The Sound and the Fury"};
|
||||
|
||||
void report(const char* msg, int terminate) {
|
||||
perror(msg);
|
||||
if (terminate) exit(-1); /* failure */
|
||||
}
|
||||
|
||||
int main() {
|
||||
/* fd for the socket */
|
||||
int sockfd = socket(AF_INET, /* versus AF_LOCAL */
|
||||
SOCK_STREAM, /* reliable, bidirectional */
|
||||
0); /* system picks protocol (TCP) */
|
||||
if (sockfd < 0) report("socket", 1); /* terminate */
|
||||
|
||||
/* get the address of the host */
|
||||
struct hostent* hptr = gethostbyname(Host); /* localhost: 127.0.0.1 */
|
||||
if (!hptr) report("gethostbyname", 1); /* is hptr NULL? */
|
||||
if (hptr->h_addrtype != AF_INET) /* versus AF_LOCAL */
|
||||
report("bad address family", 1);
|
||||
|
||||
/* connect to the server: configure server's address 1st */
|
||||
struct sockaddr_in saddr;
|
||||
memset(&saddr, 0, sizeof(saddr));
|
||||
saddr.sin_family = AF_INET;
|
||||
saddr.sin_addr.s_addr =
|
||||
((struct in_addr*) hptr->h_addr_list[0])->s_addr;
|
||||
saddr.sin_port = htons(PortNumber); /* port number in big-endian */
|
||||
|
||||
if (connect(sockfd, (struct sockaddr*) &saddr, sizeof(saddr)) < 0)
|
||||
report("connect", 1);
|
||||
|
||||
/* Write some stuff and read the echoes. */
|
||||
puts("Connect to server, about to write some stuff...");
|
||||
int i;
|
||||
for (i = 0; i < ConversationLen; i++) {
|
||||
if (write(sockfd, books[i], strlen(books[i])) > 0) {
|
||||
/* get confirmation echoed from server and print */
|
||||
char buffer[BuffSize + 1];
|
||||
memset(buffer, '\0', sizeof(buffer));
|
||||
if (read(sockfd, buffer, sizeof(buffer)) > 0)
|
||||
puts(buffer);
|
||||
}
|
||||
}
|
||||
puts("Client done, about to exit...");
|
||||
close(sockfd); /* close the connection */
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
客户端程序的设置代码和服务器端类似。两者主要的区别既不是在于监听也不在于接收,而是连接:
|
||||
|
||||
```
|
||||
if (connect(sockfd, (struct sockaddr*) &saddr, sizeof(saddr)) < 0)
|
||||
```
|
||||
|
||||
对 `connect` 的调用可能因为多种原因而导致失败,例如客户端拥有错误的服务器端地址或者已经有太多的客户端连接上了服务器端。假如 `connect` 操作成功,客户端将在一个 `for` 循环中,写入它的请求然后读取返回的响应。在会话后,服务器端和客户端都将调用 `close` 去关闭这个可读可写套接字,尽管任何一边的关闭操作就足以关闭它们之间的连接。此后客户端可以退出了,但正如前面提到的那样,服务器端可以一直保持开放以处理其他事务。
|
||||
|
||||
从上面的套接字示例中,我们看到了请求信息被回显给客户端,这使得客户端和服务器端之间拥有进行丰富对话的可能性。也许这就是套接字的主要魅力。在现代系统中,客户端应用(例如一个数据库客户端)和服务器端通过套接字进行通信非常常见。正如先前提及的那样,本地 IPC 套接字和网络套接字只在某些实现细节上面有所不同,一般来说,IPC 套接字有着更低的消耗和更好的性能。它们的通信 API 基本是一样的。
|
||||
|
||||
### 信号
|
||||
|
||||
信号会中断一个正在执行的程序,在这种意义下,就是用信号与这个程序进行通信。大多数的信号要么可以被忽略(阻塞)或者被处理(通过特别设计的代码)。`SIGSTOP` (暂停)和 `SIGKILL`(立即停止)是最应该提及的两种信号。这种符号常量有整数类型的值,例如 `SIGKILL` 对应的值为 `9`。
|
||||
|
||||
信号可以在与用户交互的情况下发生。例如,一个用户从命令行中敲了 `Ctrl+C` 来终止一个从命令行中启动的程序;`Ctrl+C` 将产生一个 `SIGTERM` 信号。`SIGTERM` 意即终止,它可以被阻塞或者被处理,而不像 `SIGKILL` 信号那样。一个进程也可以通过信号和另一个进程通信,这样使得信号也可以作为一种 IPC 机制。
|
||||
|
||||
考虑一下一个多进程应用,例如 Nginx 网络服务器是如何被另一个进程优雅地关闭的。`kill` 函数:
|
||||
|
||||
```
|
||||
int kill(pid_t pid, int signum); /* declaration */
|
||||
```
|
||||
|
||||
可以被一个进程用来终止另一个进程或者一组进程。假如 `kill` 函数的第一个参数是大于 `0` 的,那么这个参数将会被认为是目标进程的 `pid`(进程 ID),假如这个参数是 `0`,则这个参数将会被视作信号发送者所属的那组进程。
|
||||
|
||||
`kill` 的第二个参数要么是一个标准的信号数字(例如 `SIGTERM` 或 `SIGKILL`),要么是 `0` ,这将会对信号做一次询问,确认第一个参数中的 `pid` 是否是有效的。这样优雅地关闭一个多进程应用就可以通过向组成该应用的一组进程发送一个终止信号来完成,具体来说就是调用一个 `kill` 函数,使得这个调用的第二个参数是 `SIGTERM` 。(Nginx 主进程可以通过调用 `kill` 函数来终止其他工人进程,然后再停止自己。)就像许多库函数一样,`kill` 函数通过一个简单的可变语法拥有更多的能力和灵活性。
|
||||
|
||||
#### 示例 3. 一个多进程系统的优雅停止
|
||||
|
||||
```c
|
||||
#include <stdio.h>
|
||||
#include <signal.h>
|
||||
#include <stdlib.h>
|
||||
#include <unistd.h>
|
||||
#include <sys/wait.h>
|
||||
|
||||
void graceful(int signum) {
|
||||
printf("\tChild confirming received signal: %i\n", signum);
|
||||
puts("\tChild about to terminate gracefully...");
|
||||
sleep(1);
|
||||
puts("\tChild terminating now...");
|
||||
_exit(0); /* fast-track notification of parent */
|
||||
}
|
||||
|
||||
void set_handler() {
|
||||
struct sigaction current;
|
||||
sigemptyset(¤t.sa_mask); /* clear the signal set */
|
||||
current.sa_flags = 0; /* enables setting sa_handler, not sa_action */
|
||||
current.sa_handler = graceful; /* specify a handler */
|
||||
sigaction(SIGTERM, ¤t, NULL); /* register the handler */
|
||||
}
|
||||
|
||||
void child_code() {
|
||||
set_handler();
|
||||
|
||||
while (1) { /` loop until interrupted `/
|
||||
sleep(1);
|
||||
puts("\tChild just woke up, but going back to sleep.");
|
||||
}
|
||||
}
|
||||
|
||||
void parent_code(pid_t cpid) {
|
||||
puts("Parent sleeping for a time...");
|
||||
sleep(5);
|
||||
|
||||
/* Try to terminate child. */
|
||||
if (-1 == kill(cpid, SIGTERM)) {
|
||||
perror("kill");
|
||||
exit(-1);
|
||||
}
|
||||
wait(NULL); /` wait for child to terminate `/
|
||||
puts("My child terminated, about to exit myself...");
|
||||
}
|
||||
|
||||
int main() {
|
||||
pid_t pid = fork();
|
||||
if (pid < 0) {
|
||||
perror("fork");
|
||||
return -1; /* error */
|
||||
}
|
||||
if (0 == pid)
|
||||
child_code();
|
||||
else
|
||||
parent_code(pid);
|
||||
return 0; /* normal */
|
||||
}
|
||||
```
|
||||
|
||||
上面的停止程序模拟了一个多进程系统的优雅退出,在这个例子中,这个系统由一个父进程和一个子进程组成。这次模拟的工作流程如下:
|
||||
|
||||
* 父进程尝试去 `fork` 一个子进程。假如这个 `fork` 操作成功了,每个进程就执行它自己的代码:子进程就执行函数 `child_code`,而父进程就执行函数 `parent_code`。
|
||||
* 子进程将会进入一个潜在的无限循环,在这个循环中子进程将睡眠一秒,然后打印一个信息,接着再次进入睡眠状态,以此循环往复。来自父进程的一个 `SIGTERM` 信号将引起子进程去执行一个信号处理回调函数 `graceful`。这样这个信号就使得子进程可以跳出循环,然后进行子进程和父进程之间的优雅终止。在终止之前,进程将打印一个信息。
|
||||
* 在 `fork` 一个子进程后,父进程将睡眠 5 秒,使得子进程可以执行一会儿;当然在这个模拟中,子进程大多数时间都在睡眠。然后父进程调用 `SIGTERM` 作为第二个参数的 `kill` 函数,等待子进程的终止,然后自己再终止。
|
||||
|
||||
下面是一次运行的输出:
|
||||
|
||||
```
|
||||
% ./shutdown
|
||||
Parent sleeping for a time...
|
||||
Child just woke up, but going back to sleep.
|
||||
Child just woke up, but going back to sleep.
|
||||
Child just woke up, but going back to sleep.
|
||||
Child just woke up, but going back to sleep.
|
||||
Child confirming received signal: 15 ## SIGTERM is 15
|
||||
Child about to terminate gracefully...
|
||||
Child terminating now...
|
||||
My child terminated, about to exit myself...
|
||||
```
|
||||
|
||||
对于信号的处理,上面的示例使用了 `sigaction` 库函数(POSIX 推荐的用法)而不是传统的 `signal` 函数,`signal` 函数有移植性问题。下面是我们主要关心的代码片段:
|
||||
|
||||
* 假如对 `fork` 的调用成功了,父进程将执行 `parent_code` 函数,而子进程将执行 `child_code` 函数。在给子进程发送信号之前,父进程将会等待 5 秒:
|
||||
|
||||
```
|
||||
puts("Parent sleeping for a time...");
|
||||
sleep(5);
|
||||
if (-1 == kill(cpid, SIGTERM)) {
|
||||
...sleepkillcpidSIGTERM...
|
||||
```
|
||||
|
||||
假如 `kill` 调用成功了,父进程将在子进程终止时做等待,使得子进程不会变成一个僵尸进程。在等待完成后,父进程再退出。
|
||||
|
||||
* `child_code` 函数首先调用 `set_handler` 然后进入它的可能永久睡眠的循环。下面是我们将要查看的 `set_handler` 函数:
|
||||
|
||||
```
|
||||
void set_handler() {
|
||||
struct sigaction current; /* current setup */
|
||||
sigemptyset(¤t.sa_mask); /* clear the signal set */
|
||||
current.sa_flags = 0; /* for setting sa_handler, not sa_action */
|
||||
current.sa_handler = graceful; /* specify a handler */
|
||||
sigaction(SIGTERM, ¤t, NULL); /* register the handler */
|
||||
}
|
||||
```
|
||||
|
||||
上面代码的前三行在做相关的准备。第四个语句将为 `graceful` 设定为句柄,它将在调用 `_exit` 来停止之前打印一些信息。第 5 行和最后一行的语句将通过调用 `sigaction` 来向系统注册上面的句柄。`sigaction` 的第一个参数是 `SIGTERM` ,用作终止;第二个参数是当前的 `sigaction` 设定,而最后的参数(在这个例子中是 `NULL` )可被用来保存前面的 `sigaction` 设定,以备后面的可能使用。
|
||||
|
||||
使用信号来作为 IPC 的确是一个很轻量的方法,但确实值得尝试。通过信号来做 IPC 显然可以被归入 IPC 工具箱中。
|
||||
|
||||
### 这个系列的总结
|
||||
|
||||
在这个系列中,我们通过三篇有关 IPC 的文章,用示例代码介绍了如下机制:
|
||||
|
||||
* 共享文件
|
||||
* 共享内存(通过信号量)
|
||||
* 管道(命名和无名)
|
||||
* 消息队列
|
||||
* 套接字
|
||||
* 信号
|
||||
|
||||
甚至在今天,在以线程为中心的语言,例如 Java、C# 和 Go 等变得越来越流行的情况下,IPC 仍然很受欢迎,因为相比于使用多线程,通过多进程来实现并发有着一个明显的优势:默认情况下,每个进程都有它自己的地址空间,除非使用了基于共享内存的 IPC 机制(为了达到安全的并发,竞争条件在多线程和多进程的时候必须被加上锁),在多进程中可以排除掉基于内存的竞争条件。对于任何一个写过即使是基本的通过共享变量来通信的多线程程序的人来说,他都会知道想要写一个清晰、高效、线程安全的代码是多么具有挑战性。使用单线程的多进程的确是很有吸引力的,这是一个切实可行的方式,使用它可以利用好今天多处理器的机器,而不需要面临基于内存的竞争条件的风险。
|
||||
|
||||
当然,没有一个简单的答案能够回答上述 IPC 机制中的哪一个更好。在编程中每一种 IPC 机制都会涉及到一个取舍问题:是追求简洁,还是追求功能强大。以信号来举例,它是一个相对简单的 IPC 机制,但并不支持多个进程之间的丰富对话。假如确实需要这样的对话,另外的选择可能会更合适一些。带有锁的共享文件则相对直接,但是当要处理大量共享的数据流时,共享文件并不能很高效地工作。管道,甚至是套接字,有着更复杂的 API,可能是更好的选择。让具体的问题去指导我们的选择吧。
|
||||
|
||||
尽管所有的示例代码(可以在[我的网站][4]上获取到)都是使用 C 写的,其他的编程语言也经常提供这些 IPC 机制的轻量包装。这些代码示例都足够短小简单,希望这样能够鼓励你去进行实验。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/interprocess-communication-linux-networking
|
||||
|
||||
作者:[Marty Kalin][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mkalindepauledu
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Inter-process_communication
|
||||
[2]: https://linux.cn/article-10826-1.html
|
||||
[3]: https://linux.cn/article-10845-1.html
|
||||
[4]: http://condor.depaul.edu/mkalin
|
||||
@ -0,0 +1,69 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10926-1.html)
|
||||
[#]: subject: (4 open source apps for plant-based diets)
|
||||
[#]: via: (https://opensource.com/article/19/4/apps-plant-based-diets)
|
||||
[#]: author: (Joshua Allen Holm https://opensource.com/users/holmja)
|
||||
|
||||
4 款“吃草”的开源应用
|
||||
======
|
||||
|
||||
> 这些应用使素食者、纯素食主义者和那些想吃得更健康的杂食者找到可以吃的食物。
|
||||
|
||||

|
||||
|
||||
减少对肉类、乳制品和加工食品的消费对地球来说更好,也对你的健康更有益。改变你的饮食习惯可能很困难,但是一些开源的 Android 应用可以让你吃的更清淡。无论你是参加[无肉星期一][2]、践行 Mark Bittman 的 [6:00 前的素食][3]指南,还是完全切换到<ruby>[植物全食饮食][4]<rt>whole-food, plant-based diet</rt></ruby>(WFPB),这些应用能帮助你找出要吃什么、发现素食和素食友好的餐馆,并轻松地将你的饮食偏好传达给他人,来助你更好地走这条路。所有这些应用都是开源的,可从 [F-Droid 仓库][5]下载。
|
||||
|
||||
### Daily Dozen
|
||||
|
||||
![Daily Dozen app][6]
|
||||
|
||||
[Daily Dozen][7] 提供了医学博士、美国法医学会院士(FACLM) Michael Greger 推荐的项目清单作为健康饮食和生活方式的一部分。Greger 博士建议食用由多种食物组成的基于植物的全食饮食,并坚持日常锻炼。该应用可以让你跟踪你吃的每种食物的份数,你喝了多少份水(或其他获准的饮料,如茶),以及你是否每天锻炼。每类食物都提供食物分量和属于该类别的食物清单。例如,十字花科蔬菜类包括白菜、花椰菜、抱子甘蓝等许多其他建议。
|
||||
|
||||
### Food Restrictions
|
||||
|
||||
![Food Restrictions app][8]
|
||||
|
||||
[Food Restrictions][9] 是一个简单的应用,它可以帮助你将你的饮食限制传达给他人,即使这些人不会说你的语言。用户可以输入七种不同类别的食物限制:鸡肉、牛肉、猪肉、鱼、奶酪、牛奶和辣椒。每种类别都有“我不吃”和“我过敏”选项。“不吃”选项会显示带有红色 X 的图标。“过敏” 选项显示 “X” 和小骷髅图标。可以使用文本而不是图标显示相同的信息,但文本仅提供英语和葡萄牙语。还有一个选项可以显示一条文字信息,说明用户是素食主义者或纯素食主义者,它比选择选项更简洁、更准确地总结了这些饮食限制。纯素食主义者的文本清楚地提到不吃鸡蛋和蜂蜜,这在选择选项中是没有的。但是,就像选择选项方式的文字版本一样,这些句子仅提供英语和葡萄牙语。
|
||||
|
||||
### OpenFoodFacts
|
||||
|
||||
![Open Food Facts app][10]
|
||||
|
||||
购买杂货时避免买入不必要的成分可能令人沮丧,但 [OpenFoodFacts][11] 可以帮助简化流程。该应用可让你扫描产品上的条形码,以获得有关产品成分和是否健康的报告。即使产品符合纯素产品的标准,产品仍然可能非常不健康。拥有成分列表和营养成分可让你在购物时做出明智的选择。此应用的唯一缺点是数据是用户贡献的,因此并非每个产品都可有数据,但如果你想回馈项目,你可以贡献新数据。
|
||||
|
||||
### OpenVegeMap
|
||||
|
||||
![OpenVegeMap app][12]
|
||||
|
||||
使用 [OpenVegeMap][13] 查找你附近的纯素食或素食主义餐厅。此应用可以通过手机的当前位置或者输入地址来搜索。餐厅分类为仅限纯素食者、适合纯素食者,仅限素食主义者,适合素食者,非素食和未知。该应用使用来自 [OpenStreetMap][14] 的数据和用户提供的有关餐馆的信息,因此请务必仔细检查以确保所提供的信息是最新且准确的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/apps-plant-based-diets
|
||||
|
||||
作者:[Joshua Allen Holm][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/holmja
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/rh_003588_01_rd3os.combacktoschoolserieshe_rh_041x_0.png?itok=tfg6_I78
|
||||
[2]: https://www.meatlessmonday.com/
|
||||
[3]: https://www.amazon.com/dp/0385344740/
|
||||
[4]: https://nutritionstudies.org/whole-food-plant-based-diet-guide/
|
||||
[5]: https://f-droid.org/
|
||||
[6]: https://opensource.com/sites/default/files/uploads/daily_dozen.png (Daily Dozen app)
|
||||
[7]: https://f-droid.org/en/packages/org.nutritionfacts.dailydozen/
|
||||
[8]: https://opensource.com/sites/default/files/uploads/food_restrictions.png (Food Restrictions app)
|
||||
[9]: https://f-droid.org/en/packages/br.com.frs.foodrestrictions/
|
||||
[10]: https://opensource.com/sites/default/files/uploads/openfoodfacts.png (Open Food Facts app)
|
||||
[11]: https://f-droid.org/en/packages/openfoodfacts.github.scrachx.openfood/
|
||||
[12]: https://opensource.com/sites/default/files/uploads/openvegmap.png (OpenVegeMap app)
|
||||
[13]: https://f-droid.org/en/packages/pro.rudloff.openvegemap/
|
||||
[14]: https://www.openstreetmap.org/
|
||||
@ -0,0 +1,146 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (cycoe)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10929-1.html)
|
||||
[#]: subject: (Monitoring CPU and GPU Temperatures on Linux)
|
||||
[#]: via: (https://itsfoss.com/monitor-cpu-gpu-temp-linux/)
|
||||
[#]: author: (It's FOSS Community https://itsfoss.com/author/itsfoss/)
|
||||
|
||||
在 Linux 上监控 CPU 和 GPU 温度
|
||||
======
|
||||
|
||||
> 本篇文章讨论了在 Linux 命令行中监控 CPU 和 GPU 温度的两种简单方式。
|
||||
|
||||
由于 [Steam][1](包括 [Steam Play][2],即 Proton)和一些其他的发展,GNU/Linux 正在成为越来越多计算机用户的日常游戏平台的选择。也有相当一部分用户在遇到像[视频编辑][3]或图形设计等(Kdenlive 和 [Blender][4] 是这类应用程序中很好的例子)资源消耗型计算任务时,也会使用 GNU/Linux。
|
||||
|
||||
不管你是否是这些用户中的一员或其他用户,你也一定想知道你的电脑 CPU 和 GPU 能有多热(如果你想要超频的话更会如此)。如果是这样,那么继续读下去。我们会介绍两个非常简单的命令来监控 CPU 和 GPU 温度。
|
||||
|
||||
我的装置包括一台 [Slimbook Kymera][5] 和两台显示器(一台 TV 和一台 PC 监视器),使得我可以用一台来玩游戏,另一台来留意监控温度。另外,因为我使用 [Zorin OS][6],我会将关注点放在 Ubuntu 和 Ubuntu 的衍生发行版上。
|
||||
|
||||
为了监控 CPU 和 GPU 的行为,我们将利用实用的 `watch` 命令在每几秒钟之后动态地得到读数。
|
||||
|
||||
![][7]
|
||||
|
||||
### 在 Linux 中监控 CPU 温度
|
||||
|
||||
对于 CPU 温度,我们将结合使用 `watch` 与 `sensors` 命令。一篇关于[此工具的图形用户界面版本][8]的有趣文章已经在 It's FOSS 中介绍过了。然而,我们将在此处使用命令行版本:
|
||||
|
||||
```
|
||||
watch -n 2 sensors
|
||||
```
|
||||
|
||||
`watch` 保证了读数会在每 2 秒钟更新一次(当然,这个周期值能够根据你的需要去更改):
|
||||
|
||||
```
|
||||
Every 2,0s: sensors
|
||||
|
||||
iwlwifi-virtual-0
|
||||
Adapter: Virtual device
|
||||
temp1: +39.0°C
|
||||
|
||||
acpitz-virtual-0
|
||||
Adapter: Virtual device
|
||||
temp1: +27.8°C (crit = +119.0°C)
|
||||
temp2: +29.8°C (crit = +119.0°C)
|
||||
|
||||
coretemp-isa-0000
|
||||
Adapter: ISA adapter
|
||||
Package id 0: +37.0°C (high = +82.0°C, crit = +100.0°C)
|
||||
Core 0: +35.0°C (high = +82.0°C, crit = +100.0°C)
|
||||
Core 1: +35.0°C (high = +82.0°C, crit = +100.0°C)
|
||||
Core 2: +33.0°C (high = +82.0°C, crit = +100.0°C)
|
||||
Core 3: +36.0°C (high = +82.0°C, crit = +100.0°C)
|
||||
Core 4: +37.0°C (high = +82.0°C, crit = +100.0°C)
|
||||
Core 5: +35.0°C (high = +82.0°C, crit = +100.0°C)
|
||||
```
|
||||
|
||||
除此之外,我们还能得到如下信息:
|
||||
|
||||
* 我们有 5 个核心正在被使用(并且当前的最高温度为 37.0℃)。
|
||||
* 温度超过 82.0℃ 会被认为是过热。
|
||||
* 超过 100.0℃ 的温度会被认为是超过临界值。
|
||||
|
||||
根据以上的温度值我们可以得出结论,我的电脑目前的工作负载非常小。
|
||||
|
||||
### 在 Linux 中监控 GPU 温度
|
||||
|
||||
现在让我们来看看显卡。我从来没使用过 AMD 的显卡,因此我会将重点放在 Nvidia 的显卡上。我们需要做的第一件事是从 [Ubuntu 的附加驱动][10] 中下载合适的最新驱动。
|
||||
|
||||
在 Ubuntu(Zorin 或 Linux Mint 也是相同的)中,进入“软件和更新 > 附加驱动”选项,选择最新的可用驱动。另外,你可以添加或启用显示卡的官方 ppa(通过命令行或通过“软件和更新 > 其他软件”来实现)。安装驱动程序后,你将可以使用 “Nvidia X Server” 的 GUI 程序以及命令行工具 `nvidia-smi`(Nvidia 系统管理界面)。因此我们将使用 `watch` 和 `nvidia-smi`:
|
||||
|
||||
```
|
||||
watch -n 2 nvidia-smi
|
||||
```
|
||||
|
||||
与 CPU 的情况一样,我们会在每两秒得到一次更新的读数:
|
||||
|
||||
```
|
||||
Every 2,0s: nvidia-smi
|
||||
|
||||
Fri Apr 19 20:45:30 2019
|
||||
+-----------------------------------------------------------------------------+
|
||||
| Nvidia-SMI 418.56 Driver Version: 418.56 CUDA Version: 10.1 |
|
||||
|-------------------------------+----------------------+----------------------+
|
||||
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
|
||||
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|
||||
|===============================+======================+======================|
|
||||
| 0 GeForce GTX 106... Off | 00000000:01:00.0 On | N/A |
|
||||
| 0% 54C P8 10W / 120W | 433MiB / 6077MiB | 4% Default |
|
||||
+-------------------------------+----------------------+----------------------+
|
||||
|
||||
+-----------------------------------------------------------------------------+
|
||||
| Processes: GPU Memory |
|
||||
| GPU PID Type Process name Usage |
|
||||
|=============================================================================|
|
||||
| 0 1557 G /usr/lib/xorg/Xorg 190MiB |
|
||||
| 0 1820 G /usr/bin/gnome-shell 174MiB |
|
||||
| 0 7820 G ...equest-channel-token=303407235874180773 65MiB |
|
||||
+-----------------------------------------------------------------------------+
|
||||
```
|
||||
|
||||
从这个表格中我们得到了关于显示卡的如下信息:
|
||||
|
||||
* 它正在使用版本号为 418.56 的开源驱动。
|
||||
* 显示卡的当前温度为 54.0℃,并且风扇的使用量为 0%。
|
||||
* 电量的消耗非常低:仅仅 10W。
|
||||
* 总量为 6GB 的 vram(视频随机存取存储器),只使用了 433MB。
|
||||
* vram 正在被 3 个进程使用,他们的 ID 分别为 1557、1820 和 7820。
|
||||
|
||||
大部分这些事实或数值都清晰地表明,我们没有在玩任何消耗系统资源的游戏或处理大负载的任务。当我们开始玩游戏、处理视频或其他类似任务时,这些值就会开始上升。
|
||||
|
||||
#### 结论
|
||||
|
||||
即便我们有 GUI 工具,但我还是发现这两个命令对于实时监控硬件非常的顺手。
|
||||
|
||||
你将如何去使用它们呢?你可以通过阅读他们的 man 手册来学习更多关于这些工具的使用技巧。
|
||||
|
||||
你有其他偏爱的工具吗?在评论里分享给我们吧 ;)。
|
||||
|
||||
玩得开心!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/monitor-cpu-gpu-temp-linux/
|
||||
|
||||
作者:[Alejandro Egea-Abellán][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[cycoe](https://github.com/cycoe)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/itsfoss/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/install-steam-ubuntu-linux/
|
||||
[2]: https://itsfoss.com/steam-play-proton/
|
||||
[3]: https://itsfoss.com/best-video-editing-software-linux/
|
||||
[4]: https://www.blender.org/
|
||||
[5]: https://slimbook.es/
|
||||
[6]: https://zorinos.com/
|
||||
[7]: https://itsfoss.com/wp-content/uploads/2019/04/monitor-cpu-gpu-temperature-linux-800x450.png
|
||||
[8]: https://itsfoss.com/check-laptop-cpu-temperature-ubuntu/
|
||||
[9]: https://itsfoss.com/best-command-line-games-linux/
|
||||
[10]: https://itsfoss.com/install-additional-drivers-ubuntu/
|
||||
[11]: https://itsfoss.com/review-googler-linux/
|
||||
[12]: https://itsfoss.com/wp-content/uploads/2019/04/EGEA-ABELLAN-Alejandro.jpg
|
||||
@ -0,0 +1,112 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10919-1.html)
|
||||
[#]: subject: (Installing Budgie Desktop on Ubuntu [Quick Guide])
|
||||
[#]: via: (https://itsfoss.com/install-budgie-ubuntu/)
|
||||
[#]: author: (Atharva Lele https://itsfoss.com/author/atharva/)
|
||||
|
||||
在 Ubuntu 上安装 Budgie 桌面
|
||||
======
|
||||
|
||||
> 在这个逐步的教程中学习如何在 Ubuntu 上安装 Budgie 桌面。
|
||||
|
||||
在所有[各种 Ubuntu 版本][1]中,[Ubuntu Budgie][2] 是最被低估的版本。它外观优雅,而且需要的资源也不多。
|
||||
|
||||
阅读这篇 《[Ubuntu Budgie 点评][3]》或观看下面的视频,了解 Ubuntu Budgie 18.04 的外观如何。
|
||||
|
||||
- [Ubuntu 18.04 Budgie Desktop Tour [It's Elegant]](https://youtu.be/KXgreWOK33k)
|
||||
|
||||
如果你喜欢 [Budgie 桌面][5]但你正在使用其他版本的 Ubuntu,例如默认 Ubuntu 带有 GNOME 桌面,我有个好消息。你可以在当前的 Ubuntu 系统上安装 Budgie 并切换桌面环境。
|
||||
|
||||
在这篇文章中,我将告诉你到底该怎么做。但首先,对那些不了解 Budgie 的人进行一点介绍。
|
||||
|
||||
Budgie 桌面环境主要由 [Solus Linux 团队开发][6]。它的设计注重优雅和现代使用。Budgie 适用于所有主流 Linux 发行版,可以让用户在其上尝试体验这种新的桌面环境。Budgie 现在非常成熟,并提供了出色的桌面体验。
|
||||
|
||||
> 警告
|
||||
>
|
||||
> 在同一系统上安装多个桌面可能会导致冲突,你可能会遇到一些问题,如面板中缺少图标或同一程序的多个图标。
|
||||
>
|
||||
> 你也许不会遇到任何问题。是否要尝试不同桌面由你决定。
|
||||
|
||||
### 在 Ubuntu 上安装 Budgie
|
||||
|
||||
此方法未在 Linux Mint 上进行测试,因此我建议你 Mint 上不要按照此指南进行操作。
|
||||
|
||||
对于正在使用 Ubuntu 的人,Budgie 现在默认是 Ubuntu 仓库的一部分。因此,我们不需要添加任何 PPA 来下载 Budgie。
|
||||
|
||||
要安装 Budgie,只需在终端中运行此命令即可。我们首先要确保系统已完全更新。
|
||||
|
||||
```
|
||||
sudo apt update && sudo apt upgrade
|
||||
sudo apt install ubuntu-budgie-desktop
|
||||
```
|
||||
|
||||
下载完成后,你将看到选择显示管理器的提示。选择 “lightdm” 以获得完整的 Budgie 体验。
|
||||
|
||||
![Select lightdm][7]
|
||||
|
||||
安装完成后,重启计算机。然后,你会看到 Budgie 的登录页面。输入你的密码进入主屏幕。
|
||||
|
||||
![Budgie Desktop Home][8]
|
||||
|
||||
### 切换到其他桌面环境
|
||||
|
||||
![Budgie login screen][9]
|
||||
|
||||
你可以单击登录名旁边的 Budgie 图标获取登录选项。在那里,你可以在已安装的桌面环境(DE)之间进行选择。就我而言,我看到了 Budgie 和默认的 Ubuntu(GNOME)桌面。
|
||||
|
||||
![Select your DE][10]
|
||||
|
||||
因此,无论何时你想登录 GNOME,都可以使用此菜单执行此操作。
|
||||
|
||||
### 如何删除 Budgie
|
||||
|
||||
如果你不喜欢 Budgie 或只是想回到常规的以前的 Ubuntu,你可以如上节所述切换回常规桌面。
|
||||
|
||||
但是,如果你真的想要删除 Budgie 及其组件,你可以按照以下命令回到之前的状态。
|
||||
|
||||
**在使用这些命令之前先切换到其他桌面环境:**
|
||||
|
||||
```
|
||||
sudo apt remove ubuntu-budgie-desktop ubuntu-budgie* lightdm
|
||||
sudo apt autoremove
|
||||
sudo apt install --reinstall gdm3
|
||||
```
|
||||
|
||||
成功运行所有命令后,重启计算机。
|
||||
|
||||
现在,你将回到 GNOME 或其他你有的桌面。
|
||||
|
||||
### 你对 Budgie 有什么看法?
|
||||
|
||||
Budgie 是[最佳 Linux 桌面环境][12]之一。希望这个简短的指南帮助你在 Ubuntu 上安装了很棒的 Budgie 桌面。
|
||||
|
||||
如果你安装了 Budgie,你最喜欢它的什么?请在下面的评论中告诉我们。像往常一样,欢迎任何问题或建议。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/install-budgie-ubuntu/
|
||||
|
||||
作者:[Atharva Lele][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/atharva/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/which-ubuntu-install/
|
||||
[2]: https://ubuntubudgie.org/
|
||||
[3]: https://itsfoss.com/ubuntu-budgie-18-review/
|
||||
[4]: https://www.youtube.com/c/itsfoss?sub_confirmation=1
|
||||
[5]: https://github.com/solus-project/budgie-desktop
|
||||
[6]: https://getsol.us/home/
|
||||
[7]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/04/budgie_install_select_dm.png?fit=800%2C559&ssl=1
|
||||
[8]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/04/budgie_homescreen.jpg?fit=800%2C500&ssl=1
|
||||
[9]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/04/budgie_install_lockscreen.png?fit=800%2C403&ssl=1
|
||||
[10]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/04/budgie_install_lockscreen_select_de.png?fit=800%2C403&ssl=1
|
||||
[11]: https://itsfoss.com/snapd-error-ubuntu/
|
||||
[12]: https://itsfoss.com/best-linux-desktop-environments/
|
||||
@ -7,37 +7,37 @@
|
||||
|
||||
**`/dev/urandom` 不安全。加密用途必须使用 `/dev/random`**
|
||||
|
||||
事实:`/dev/urandom` 才是类 Unix 操作系统下推荐的加密种子。
|
||||
*事实*:`/dev/urandom` 才是类 Unix 操作系统下推荐的加密种子。
|
||||
|
||||
**`/dev/urandom` 是<ruby>伪随机数生成器<rt>pseudo random number generator</rt></ruby>(PRND),而 `/dev/random` 是“真”随机数生成器。**
|
||||
|
||||
事实:它们两者本质上用的是同一种 CSPRNG (一种密码学伪随机数生成器)。它们之间细微的差别和“真”不“真”随机完全无关
|
||||
*事实*:它们两者本质上用的是同一种 CSPRNG (一种密码学伪随机数生成器)。它们之间细微的差别和“真”“不真”随机完全无关。(参见:“Linux 随机数生成器的构架”一节)
|
||||
|
||||
**`/dev/random` 在任何情况下都是密码学应用更好地选择。即便 `/dev/urandom` 也同样安全,我们还是不应该用它。**
|
||||
|
||||
事实:`/dev/random` 有个很恶心人的问题:它是阻塞的。(LCTT 译注:意味着请求都得逐个执行,等待前一个请求完成)
|
||||
*事实*:`/dev/random` 有个很恶心人的问题:它是阻塞的。(参见:“阻塞有什么问题?”一节)(LCTT 译注:意味着请求都得逐个执行,等待前一个请求完成)
|
||||
|
||||
**但阻塞不是好事吗!`/dev/random` 只会给出电脑收集的信息熵足以支持的随机量。`/dev/urandom` 在用完了所有熵的情况下还会不断吐不安全的随机数给你。**
|
||||
**但阻塞不是好事吗!`/dev/random` 只会给出电脑收集的信息熵足以支持的随机量。`/dev/urandom` 在用完了所有熵的情况下还会不断吐出不安全的随机数给你。**
|
||||
|
||||
事实:这是误解。就算我们不去考虑应用层面后续对随机种子的用法,“用完信息熵池”这个概念本身就不存在。仅仅 256 位的熵就足以生成计算上安全的随机数很长、很长的一段时间了。
|
||||
*事实*:这是误解。就算我们不去考虑应用层面后续对随机种子的用法,“用完信息熵池”这个概念本身就不存在。仅仅 256 位的熵就足以生成计算上安全的随机数很长、很长的一段时间了。(参见:“那熵池快空了的情况呢?”一节)
|
||||
|
||||
问题的关键还在后头:`/dev/random` 怎么知道有系统会*多少*可用的信息熵?接着看!
|
||||
|
||||
**但密码学家老是讨论重新选种子(re-seeding)。这难道不和上一条冲突吗?**
|
||||
|
||||
事实:你说的也没错!某种程度上吧。确实,随机数生成器一直在使用系统信息熵的状态重新选种。但这么做(一部分)是因为别的原因。
|
||||
*事实*:你说的也没错!某种程度上吧。确实,随机数生成器一直在使用系统信息熵的状态重新选种。但这么做(一部分)是因为别的原因。(参见:“重新选种”一节)
|
||||
|
||||
这样说吧,我没有说引入新的信息熵是坏的。更多的熵肯定更好。我只是说在熵池低的时候阻塞是没必要的。
|
||||
|
||||
**好,就算你说的都对,但是 `/dev/(u)random` 的 man 页面和你说的也不一样啊!到底有没有专家同意你说的这堆啊?**
|
||||
|
||||
事实:其实 man 页面和我说的不冲突。它看似好像在说 `/dev/urandom` 对密码学用途来说不安全,但如果你真的理解这堆密码学术语你就知道它说的并不是这个意思。
|
||||
*事实*:其实 man 页面和我说的不冲突。它看似好像在说 `/dev/urandom` 对密码学用途来说不安全,但如果你真的理解这堆密码学术语你就知道它说的并不是这个意思。(参见:“random 和 urandom 的 man 页面”一节)
|
||||
|
||||
man 页面确实说在一些情况下推荐使用 `/dev/random` (我觉得也没问题,但绝对不是说必要的),但它也推荐在大多数“一般”的密码学应用下使用 `/dev/urandom` 。
|
||||
|
||||
虽然诉诸权威一般来说不是好事,但在密码学这么严肃的事情上,和专家统一意见是很有必要的。
|
||||
|
||||
所以说呢,还确实有一些*专家*和我的一件事一致的:`/dev/urandom` 就应该是类 UNIX 操作系统下密码学应用的首选。显然的,是他们的观点说服了我而不是反过来的。
|
||||
所以说呢,还确实有一些*专家*和我的一件事一致的:`/dev/urandom` 就应该是类 UNIX 操作系统下密码学应用的首选。显然的,是他们的观点说服了我而不是反过来的。(参见:“正道”一节)
|
||||
|
||||
------
|
||||
|
||||
@ -45,9 +45,9 @@ man 页面确实说在一些情况下推荐使用 `/dev/random` (我觉得也
|
||||
|
||||
我尝试不讲太高深的东西,但是有两点内容必须先提一下才能让我们接着论证观点。
|
||||
|
||||
首当其冲的,*什么是随机性*,或者更准确地:我们在探讨什么样的随机性?
|
||||
首当其冲的,*什么是随机性*,或者更准确地:我们在探讨什么样的随机性?(参见:“真随机”一节)
|
||||
|
||||
另外一点很重要的是,我*没有尝试以说教的态度*对你们写这段话。我写这篇文章是为了日后可以在讨论起的时候指给别人看。比 140 字长(LCTT 译注:推特长度)。这样我就不用一遍遍重复我的观点了。能把论点磨炼成一篇文章本身就很有助于将来的讨论。
|
||||
另外一点很重要的是,我*没有尝试以说教的态度*对你们写这段话。我写这篇文章是为了日后可以在讨论起的时候指给别人看。比 140 字长(LCTT 译注:推特长度)。这样我就不用一遍遍重复我的观点了。能把论点磨炼成一篇文章本身就很有助于将来的讨论。(参见:“你是在说我笨?!”一节)
|
||||
|
||||
并且我非常乐意听到不一样的观点。但我只是认为单单地说 `/dev/urandom` 坏是不够的。你得能指出到底有什么问题,并且剖析它们。
|
||||
|
||||
@ -55,43 +55,43 @@ man 页面确实说在一些情况下推荐使用 `/dev/random` (我觉得也
|
||||
|
||||
绝对没有!
|
||||
|
||||
事实上我自己也相信了 “`/dev/urandom` 是不安全的” 好些年。这几乎不是我们的错,因为那么德高望重的人在 Usenet、论坛、推特上跟我们重复这个观点。甚至*连 man 手册*都似是而非地说着。我们当年怎么可能鄙视诸如“信息熵太低了”这种看上去就很让人信服的观点呢?
|
||||
事实上我自己也相信了 “`/dev/urandom` 是不安全的” 好些年。这几乎不是我们的错,因为那么德高望重的人在 Usenet、论坛、推特上跟我们重复这个观点。甚至*连 man 手册*都似是而非地说着。我们当年怎么可能鄙视诸如“信息熵太低了”这种看上去就很让人信服的观点呢?(参见:“random 和 urandom 的 man 页面”一节)
|
||||
|
||||
整个流言之所以如此广为流传不是因为人们太蠢,而是因为但凡有点关于信息熵和密码学概念的人都会觉得这个说法很有道理。直觉似乎都在告诉我们这流言讲的很有道理。很不幸直觉在密码学里通常不管用,这次也一样。
|
||||
|
||||
### 真随机
|
||||
|
||||
什么叫一个随机变量是“真随机的”?
|
||||
随机数是“真正随机”是什么意思?
|
||||
|
||||
我不想搞的太复杂以至于变成哲学范畴的东西。这种讨论很容易走偏因为随机模型大家见仁见智,讨论很快变得毫无意义。
|
||||
我不想搞的太复杂以至于变成哲学范畴的东西。这种讨论很容易走偏因为对于随机模型大家见仁见智,讨论很快变得毫无意义。
|
||||
|
||||
在我看来“真随机”的“试金石”是量子效应。一个光子穿过或不穿过一个半透镜。或者观察一个放射性粒子衰变。这类东西是现实世界最接近真随机的东西。当然,有些人也不相信这类过程是真随机的,或者这个世界根本不存在任何随机性。这个就百家争鸣了,我也不好多说什么了。
|
||||
|
||||
密码学家一般都会通过不去讨论什么是“真随机”来避免这种争论。它们更关心的是<ruby>不可预测性<rt> unpredictability</rt></ruby>。只要没有*任何*方法能猜出下一个随机数就可以了。所以当你以密码学应用为前提讨论一个随机数好不好的时候,在我看来这才是最重要的。
|
||||
密码学家一般都会通过不去讨论什么是“真随机”来避免这种哲学辩论。他们更关心的是<ruby>不可预测性<rt>unpredictability</rt></ruby>。只要没有*任何*方法能猜出下一个随机数就可以了。所以当你以密码学应用为前提讨论一个随机数好不好的时候,在我看来这才是最重要的。
|
||||
|
||||
无论如何,我不怎么关心“哲学上安全”的随机数,这也包括别人嘴里的“真”随机数。
|
||||
|
||||
## 两种安全,一种有用
|
||||
### 两种安全,一种有用
|
||||
|
||||
但就让我们退一步说,你有了一个“真”随机变量。你下一步做什么呢?
|
||||
|
||||
你把它们打印出来然后挂在墙上来展示量子宇宙的美与和谐?牛逼!我很理解你。
|
||||
你把它们打印出来然后挂在墙上来展示量子宇宙的美与和谐?牛逼!我支持你。
|
||||
|
||||
但是等等,你说你要*用*它们?做密码学用途?额,那这就废了,因为这事情就有点复杂了。
|
||||
|
||||
事情是这样的,你的真随机,量子力学加护的随机数即将被用进不理想的现实世界程序里。
|
||||
事情是这样的,你的真随机、量子力学加护的随机数即将被用进不理想的现实世界算法里去。
|
||||
|
||||
因为我们使用的大多数算法并不是<ruby>理论信息学<rt>information-theoretic</rt></ruby>上安全的。它们“只能”提供 **计算意义上的安全**。我能想到为数不多的例外就只有 Shamir 密钥分享 和 One-time pad 算法。并且就算前者是名副其实的(如果你实际打算用的话),后者则毫无可行性可言。
|
||||
因为我们使用的几乎所有的算法都并不是<ruby>信息论安全性<rt>information-theoretic security </rt></ruby>的。它们“只能”提供**计算意义上的安全**。我能想到为数不多的例外就只有 Shamir 密钥分享和<ruby>一次性密码本<rt>One-time pad</rt></ruby>(OTP)算法。并且就算前者是名副其实的(如果你实际打算用的话),后者则毫无可行性可言。
|
||||
|
||||
但所有那些大名鼎鼎的密码学算法,AES、RSA、Diffie-Hellman、椭圆曲线,还有所有那些加密软件包,OpenSSL、GnuTLS、Keyczar、你的操作系统的加密 API,都仅仅是计算意义上的安全的。
|
||||
但所有那些大名鼎鼎的密码学算法,AES、RSA、Diffie-Hellman、椭圆曲线,还有所有那些加密软件包,OpenSSL、GnuTLS、Keyczar、你的操作系统的加密 API,都仅仅是计算意义上安全的。
|
||||
|
||||
那区别是什么呢?理论信息学上的安全肯定是安全的,绝对是,其它那些的算法都可能在理论上被拥有无限计算力的穷举破解。我们依然愉快地使用它们因为全世界的计算机加起来都不可能在宇宙年龄的时间里破解,至少现在是这样。而这就是我们文章里说的“不安全”。
|
||||
那区别是什么呢?信息论安全的算法肯定是安全的,绝对是,其它那些的算法都可能在理论上被拥有无限计算力的穷举破解。我们依然愉快地使用它们是因为全世界的计算机加起来都不可能在宇宙年龄的时间里破解,至少现在是这样。而这就是我们文章里说的“不安全”。
|
||||
|
||||
除非哪个聪明的家伙破解了算法本身——在只需要极少量计算力的情况下。这也是每个密码学家梦寐以求的圣杯:破解 AES 本身、破解 RSA 本身等等。
|
||||
除非哪个聪明的家伙破解了算法本身 —— 在只需要更少量计算力、在今天可实现的计算力的情况下。这也是每个密码学家梦寐以求的圣杯:破解 AES 本身、破解 RSA 本身等等。
|
||||
|
||||
所以现在我们来到了更底层的东西:随机数生成器,你坚持要“真随机”而不是“伪随机”。但是没过一会儿你的真随机数就被喂进了你极为鄙视的伪随机算法里了!
|
||||
|
||||
真相是,如果我们最先进的 hash 算法被破解了,或者最先进的块加密被破解了,你得到这些那些“哲学上不安全的”甚至无所谓了,因为反正你也没有安全的应用方法了。
|
||||
真相是,如果我们最先进的哈希算法被破解了,或者最先进的分组加密算法被破解了,你得到的这些“哲学上不安全”的随机数甚至无所谓了,因为反正你也没有安全的应用方法了。
|
||||
|
||||
所以把计算性上安全的随机数喂给你的仅仅是计算性上安全的算法就可以了,换而言之,用 `/dev/urandom`。
|
||||
|
||||
@ -103,7 +103,7 @@ man 页面确实说在一些情况下推荐使用 `/dev/random` (我觉得也
|
||||
|
||||
![image: mythical structure of the kernel's random number generator][1]
|
||||
|
||||
“真随机数”,尽管可能有点瑕疵,进入操作系统然后它的熵立刻被加入内部熵计数器。然后经过“矫偏”和“漂白”之后它进入内核的熵池,然后 `/dev/random` 和 `/dev/urandom` 从里面生成随机数。
|
||||
“真正的随机性”,尽管可能有点瑕疵,进入操作系统然后它的熵立刻被加入内部熵计数器。然后经过“矫偏”和“漂白”之后它进入内核的熵池,然后 `/dev/random` 和 `/dev/urandom` 从里面生成随机数。
|
||||
|
||||
“真”随机数生成器,`/dev/random`,直接从池里选出随机数,如果熵计数器表示能满足需要的数字大小,那就吐出数字并且减少熵计数。如果不够的话,它会阻塞程序直至有足够的熵进入系统。
|
||||
|
||||
@ -123,25 +123,25 @@ man 页面确实说在一些情况下推荐使用 `/dev/random` (我觉得也
|
||||
|
||||
![image: actual structure of the kernel's random number generator before Linux 4.8][2]
|
||||
|
||||
> 这是个很粗糙的简化。实际上不仅有一个,而是三个熵池。一个主池,另一个给 `/dev/random`,还有一个给 `/dev/urandom`,后两者依靠从主池里获取熵。这三个池都有各自的熵计数器,但二级池(后两个)的计数器基本都在 0 附近,而“新鲜”的熵总在需要的时候从主池流过来。同时还有好多混合和回流进系统在同时进行。整个过程对于这篇文档来说都过于复杂了我们跳过。
|
||||
|
||||
你看到最大的区别了吗?CSPRNG 并不是和随机数生成器一起跑的,以 `/dev/urandom` 需要输出但熵不够的时候进行填充。CSPRNG 是整个随机数生成过程的内部组件之一。从来就没有什么 `/dev/random` 直接从池里输出纯纯的随机性。每个随机源的输入都在 CSPRNG 里充分混合和散列过了,这一切都发生在实际变成一个随机数,被 `/dev/urandom` 或者 `/dev/random` 吐出去之前。
|
||||
你看到最大的区别了吗?CSPRNG 并不是和随机数生成器一起跑的,它在 `/dev/urandom` 需要输出但熵不够的时候进行填充。CSPRNG 是整个随机数生成过程的内部组件之一。从来就没有什么 `/dev/random` 直接从池里输出纯纯的随机性。每个随机源的输入都在 CSPRNG 里充分混合和散列过了,这一切都发生在实际变成一个随机数,被 `/dev/urandom` 或者 `/dev/random` 吐出去之前。
|
||||
|
||||
另外一个重要的区别是这里没有熵计数器的任何事情,只有预估。一个源给你的熵的量并不是什么很明确能直接得到的数字。你得预估它。注意,如果你太乐观地预估了它,那 `/dev/random` 最重要的特性——只给出熵允许的随机量——就荡然无存了。很不幸的,预估熵的量是很困难的。
|
||||
|
||||
Linux 内核只使用事件的到达时间来预估熵的量。它通过多项式插值,某种模型,来预估实际的到达时间有多“出乎意料”。这种多项式插值的方法到底是不是好的预估熵量的方法本身就是个问题。同时硬件情况会不会以某种特定的方式影响到达时间也是个问题。而所有硬件的取样率也是个问题,因为这基本上就直接决定了随机数到达时间的颗粒度。
|
||||
> 这是个很粗糙的简化。实际上不仅有一个,而是三个熵池。一个主池,另一个给 `/dev/random`,还有一个给 `/dev/urandom`,后两者依靠从主池里获取熵。这三个池都有各自的熵计数器,但二级池(后两个)的计数器基本都在 0 附近,而“新鲜”的熵总在需要的时候从主池流过来。同时还有好多混合和回流进系统在同时进行。整个过程对于这篇文档来说都过于复杂了,我们跳过。
|
||||
|
||||
Linux 内核只使用事件的到达时间来预估熵的量。根据模型,它通过多项式插值来预估实际的到达时间有多“出乎意料”。这种多项式插值的方法到底是不是好的预估熵量的方法本身就是个问题。同时硬件情况会不会以某种特定的方式影响到达时间也是个问题。而所有硬件的取样率也是个问题,因为这基本上就直接决定了随机数到达时间的颗粒度。
|
||||
|
||||
说到最后,至少现在看来,内核的熵预估还是不错的。这也意味着它比较保守。有些人会具体地讨论它有多好,这都超出我的脑容量了。就算这样,如果你坚持不想在没有足够多的熵的情况下吐出随机数,那你看到这里可能还会有一丝紧张。我睡的就很香了,因为我不关心熵预估什么的。
|
||||
|
||||
最后强调一下终点:`/dev/random` 和 `/dev/urandom` 都是被同一个 CSPRNG 喂的输入。只有它们在用完各自熵池(根据某种预估标准)的时候,它们的行为会不同:`/dev/random` 阻塞,`/dev/urandom` 不阻塞。
|
||||
最后要明确一下:`/dev/random` 和 `/dev/urandom` 都是被同一个 CSPRNG 饲喂的。只有它们在用完各自熵池(根据某种预估标准)的时候,它们的行为会不同:`/dev/random` 阻塞,`/dev/urandom` 不阻塞。
|
||||
|
||||
##### Linux 4.8 以后
|
||||
|
||||
在 Linux 4.8 里,`/dev/random` 和 `/dev/urandom` 的等价性被放弃了。现在 `/dev/urandom` 的输出不来自于熵池,而是直接从 CSPRNG 来。
|
||||
|
||||
![image: actual structure of the kernel's random number generator from Linux 4.8 onward][3]
|
||||
|
||||
*我们很快会理解*为什么这不是一个安全问题。
|
||||
在 Linux 4.8 里,`/dev/random` 和 `/dev/urandom` 的等价性被放弃了。现在 `/dev/urandom` 的输出不来自于熵池,而是直接从 CSPRNG 来。
|
||||
|
||||
*我们很快会理解*为什么这不是一个安全问题。(参见:“CSPRNG 没问题”一节)
|
||||
|
||||
### 阻塞有什么问题?
|
||||
|
||||
@ -149,7 +149,7 @@ Linux 内核只使用事件的到达时间来预估熵的量。它通过多项
|
||||
|
||||
这些都是问题。阻塞本质上会降低可用性。换而言之你的系统不干你让它干的事情。不用我说,这是不好的。要是它不干活你干嘛搭建它呢?
|
||||
|
||||
> 我在工厂自动化里做过和安全相关的系统。猜猜看安全系统失效的主要原因是什么?被错误操作。就这么简单。很多安全措施的流程让工人恼火了。比如时间太长,或者太不方便。你要知道人很会找捷径来“解决”问题。
|
||||
> 我在工厂自动化里做过和安全相关的系统。猜猜看安全系统失效的主要原因是什么?操作问题。就这么简单。很多安全措施的流程让工人恼火了。比如时间太长,或者太不方便。你要知道人很会找捷径来“解决”问题。
|
||||
|
||||
但其实有个更深刻的问题:人们不喜欢被打断。它们会找一些绕过的方法,把一些诡异的东西接在一起仅仅因为这样能用。一般人根本不知道什么密码学什么乱七八糟的,至少正常的人是这样吧。
|
||||
|
||||
@ -157,23 +157,23 @@ Linux 内核只使用事件的到达时间来预估熵的量。它通过多项
|
||||
|
||||
到头来如果东西太难用的话,你的用户就会被迫开始做一些降低系统安全性的事情——你甚至不知道它们会做些什么。
|
||||
|
||||
我们很容易会忽视可用性之类的重要性。毕竟安全第一对吧?所以比起牺牲安全,不可用,难用,不方便都是次要的?
|
||||
我们很容易会忽视可用性之类的重要性。毕竟安全第一对吧?所以比起牺牲安全,不可用、难用、不方便都是次要的?
|
||||
|
||||
这种二元对立的想法是错的。阻塞不一定就安全了。正如我们看到的,`/dev/urandom` 直接从 CSPRNG 里给你一样好的随机数。用它不好吗!
|
||||
|
||||
### CSPRNG 没问题
|
||||
|
||||
现在情况听上去很沧桑。如果连高质量的 `/dev/random` 都是从一个 CSPRNG 里来的,我们怎么敢在高安全性的需求上使用它呢?
|
||||
现在情况听上去很惨淡。如果连高质量的 `/dev/random` 都是从一个 CSPRNG 里来的,我们怎么敢在高安全性的需求上使用它呢?
|
||||
|
||||
实际上,“看上去随机”是现存大多数密码学基础组件的基本要求。如果你观察一个密码学哈希的输出,它一定得和随机的字符串不可区分,密码学家才会认可这个算法。如果你生成一个块加密,它的输出(在你不知道密钥的情况下)也必须和随机数据不可区分才行。
|
||||
实际上,“看上去随机”是现存大多数密码学基础组件的基本要求。如果你观察一个密码学哈希的输出,它一定得和随机的字符串不可区分,密码学家才会认可这个算法。如果你生成一个分组加密,它的输出(在你不知道密钥的情况下)也必须和随机数据不可区分才行。
|
||||
|
||||
如果任何人能比暴力穷举要更有效地破解一个加密,比如它利用了某些 CSPRNG 伪随机的弱点,那这就又是老一套了:一切都废了,也别谈后面的了。块加密、哈希,一切都是基于某个数学算法,比如 CSPRNG。所以别害怕,到头来都一样。
|
||||
如果任何人能比暴力穷举要更有效地破解一个加密,比如它利用了某些 CSPRNG 伪随机的弱点,那这就又是老一套了:一切都废了,也别谈后面的了。分组加密、哈希,一切都是基于某个数学算法,比如 CSPRNG。所以别害怕,到头来都一样。
|
||||
|
||||
### 那熵池快空了的情况呢?
|
||||
|
||||
毫无影响。
|
||||
|
||||
加密算法的根基建立在攻击者不能预测输出上,只要最一开始有足够的随机性(熵)就行了。一般的下限是 256 位,不需要更多了。
|
||||
加密算法的根基建立在攻击者不能预测输出上,只要最一开始有足够的随机性(熵)就行了。“足够”的下限可以是 256 位,不需要更多了。
|
||||
|
||||
介于我们一直在很随意的使用“熵”这个概念,我用“位”来量化随机性希望读者不要太在意细节。像我们之前讨论的那样,内核的随机数生成器甚至没法精确地知道进入系统的熵的量。只有一个预估。而且这个预估的准确性到底怎么样也没人知道。
|
||||
|
||||
@ -211,7 +211,7 @@ Linux 内核只使用事件的到达时间来预估熵的量。它通过多项
|
||||
|
||||
我们在回到 man 页面说:“使用 `/dev/random`”。我们已经知道了,虽然 `/dev/urandom` 不阻塞,但是它的随机数和 `/dev/random` 都是从同一个 CSPRNG 里来的。
|
||||
|
||||
如果你真的需要信息论理论上安全的随机数(你不需要的,相信我),那才有可能成为唯一一个你需要等足够熵进入 CSPRNG 的理由。而且你也不能用 `/dev/random`。
|
||||
如果你真的需要信息论安全性的随机数(你不需要的,相信我),那才有可能成为唯一一个你需要等足够熵进入 CSPRNG 的理由。而且你也不能用 `/dev/random`。
|
||||
|
||||
man 页面有毒,就这样。但至少它还稍稍挽回了一下自己:
|
||||
|
||||
@ -227,7 +227,7 @@ man 页面有毒,就这样。但至少它还稍稍挽回了一下自己:
|
||||
|
||||
### 正道
|
||||
|
||||
本篇文章里的观点显然在互联网上是“小众”的。但如果问问一个真正的密码学家,你很难找到一个认同阻塞 `/dev/random` 的人。
|
||||
本篇文章里的观点显然在互联网上是“小众”的。但如果问一个真正的密码学家,你很难找到一个认同阻塞 `/dev/random` 的人。
|
||||
|
||||
比如我们看看 [Daniel Bernstein][5](即著名的 djb)的看法:
|
||||
|
||||
@ -238,8 +238,6 @@ man 页面有毒,就这样。但至少它还稍稍挽回了一下自己:
|
||||
>
|
||||
> 对密码学家来说这甚至都不好笑了
|
||||
|
||||
|
||||
|
||||
或者 [Thomas Pornin][6] 的看法,他也是我在 stackexchange 上见过最乐于助人的一位:
|
||||
|
||||
> 简单来说,是的。展开说,答案还是一样。`/dev/urandom` 生成的数据可以说和真随机完全无法区分,至少在现有科技水平下。使用比 `/dev/urandom` “更好的“随机性毫无意义,除非你在使用极为罕见的“信息论安全”的加密算法。这肯定不是你的情况,不然你早就说了。
|
||||
@ -260,13 +258,13 @@ Linux 的 `/dev/urandom` 会很乐意给你吐点不怎么随机的随机数,
|
||||
|
||||
FreeBSD 的行为更正确点:`/dev/random` 和 `/dev/urandom` 是一样的,在系统启动的时候 `/dev/random` 会阻塞到有足够的熵为止,然后它们都再也不阻塞了。
|
||||
|
||||
> 与此同时 Linux 实行了一个新的<ruby>系统调用<rt>syscall</rt></ruby>,最早由 OpenBSD 引入叫 `getentrypy(2)`,在 Linux 下这个叫 `getrandom(2)`。这个系统调用有着上述正确的行为:阻塞到有足够的熵为止,然后再也不阻塞了。当然,这是个系统调用,而不是一个字节设备(LCTT 译注:指不在 `/dev/` 下),所以它在 shell 或者别的脚本语言里没那么容易获取。这个系统调用 自 Linux 3.17 起存在。
|
||||
> 与此同时 Linux 实行了一个新的<ruby>系统调用<rt>syscall</rt></ruby>,最早由 OpenBSD 引入叫 `getentrypy(2)`,在 Linux 下这个叫 `getrandom(2)`。这个系统调用有着上述正确的行为:阻塞到有足够的熵为止,然后再也不阻塞了。当然,这是个系统调用,而不是一个字节设备(LCTT 译注:不在 `/dev/` 下),所以它在 shell 或者别的脚本语言里没那么容易获取。这个系统调用 自 Linux 3.17 起存在。
|
||||
|
||||
在 Linux 上其实这个问题不太大,因为 Linux 发行版会在启动的过程中储蓄一点随机数(这发生在已经有一些熵之后,因为启动程序不会在按下电源的一瞬间就开始运行)到一个种子文件中,以便系统下次启动的时候读取。所以每次启动的时候系统都会从上一次会话里带一点随机性过来。
|
||||
在 Linux 上其实这个问题不太大,因为 Linux 发行版会在启动的过程中保存一点随机数(这发生在已经有一些熵之后,因为启动程序不会在按下电源的一瞬间就开始运行)到一个种子文件中,以便系统下次启动的时候读取。所以每次启动的时候系统都会从上一次会话里带一点随机性过来。
|
||||
|
||||
显然这比不上在关机脚本里写入一些随机种子,因为这样的显然就有更多熵可以操作了。但这样做显而易见的好处就是它不用关心系统是不是正确关机了,比如可能你系统崩溃了。
|
||||
|
||||
而且这种做法在你真正第一次启动系统的时候也没法帮你随机,不过好在系统安装器一般会写一个种子文件,所以基本上问题不大。
|
||||
而且这种做法在你真正第一次启动系统的时候也没法帮你随机,不过好在 Linux 系统安装程序一般会保存一个种子文件,所以基本上问题不大。
|
||||
|
||||
虚拟机是另外一层问题。因为用户喜欢克隆它们,或者恢复到某个之前的状态。这种情况下那个种子文件就帮不到你了。
|
||||
|
||||
@ -0,0 +1,279 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (robsean)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10850-1.html)
|
||||
[#]: subject: (Build a game framework with Python using the module Pygame)
|
||||
[#]: via: (https://opensource.com/article/17/12/game-framework-python)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
使用 Python 和 Pygame 模块构建一个游戏框架
|
||||
======
|
||||
|
||||
> 这系列的第一篇通过创建一个简单的骰子游戏来探究 Python。现在是来从零制作你自己的游戏的时间。
|
||||
|
||||

|
||||
|
||||
在我的[这系列的第一篇文章][1] 中, 我已经讲解如何使用 Python 创建一个简单的、基于文本的骰子游戏。这次,我将展示如何使用 Python 模块 Pygame 来创建一个图形化游戏。它将需要几篇文章才能来得到一个确实做成一些东西的游戏,但是到这系列的结尾,你将更好地理解如何查找和学习新的 Python 模块和如何从其基础上构建一个应用程序。
|
||||
|
||||
在开始前,你必须安装 [Pygame][2]。
|
||||
|
||||
### 安装新的 Python 模块
|
||||
|
||||
有几种方法来安装 Python 模块,但是最通用的两个是:
|
||||
|
||||
* 从你的发行版的软件存储库
|
||||
* 使用 Python 的软件包管理器 `pip`
|
||||
|
||||
两个方法都工作的很好,并且每一个都有它自己的一套优势。如果你是在 Linux 或 BSD 上开发,可以利用你的发行版的软件存储库来自动和及时地更新。
|
||||
|
||||
然而,使用 Python 的内置软件包管理器可以给予你控制更新模块时间的能力。而且,它不是特定于操作系统的,这意味着,即使当你不是在你常用的开发机器上时,你也可以使用它。`pip` 的其它的优势是允许本地安装模块,如果你没有正在使用的计算机的管理权限,这是有用的。
|
||||
|
||||
### 使用 pip
|
||||
|
||||
如果 Python 和 Python3 都安装在你的系统上,你想使用的命令很可能是 `pip3`,它用来区分 Python 2.x 的 `pip` 的命令。如果你不确定,先尝试 `pip3`。
|
||||
|
||||
`pip` 命令有些像大多数 Linux 软件包管理器一样工作。你可以使用 `search` 搜索 Python 模块,然后使用 `install` 安装它们。如果你没有你正在使用的计算机的管理权限来安装软件,你可以使用 `--user` 选项来仅仅安装模块到你的家目录。
|
||||
|
||||
```
|
||||
$ pip3 search pygame
|
||||
[...]
|
||||
Pygame (1.9.3) - Python Game Development
|
||||
sge-pygame (1.5) - A 2-D game engine for Python
|
||||
pygame_camera (0.1.1) - A Camera lib for PyGame
|
||||
pygame_cffi (0.2.1) - A cffi-based SDL wrapper that copies the pygame API.
|
||||
[...]
|
||||
$ pip3 install Pygame --user
|
||||
```
|
||||
|
||||
Pygame 是一个 Python 模块,这意味着它仅仅是一套可以使用在你的 Python 程序中的库。换句话说,它不是一个像 [IDLE][3] 或 [Ninja-IDE][4] 一样可以让你启动的程序。
|
||||
|
||||
### Pygame 新手入门
|
||||
|
||||
一个电子游戏需要一个背景设定:故事发生的地点。在 Python 中,有两种不同的方法来创建你的故事背景:
|
||||
|
||||
* 设置一种背景颜色
|
||||
* 设置一张背景图片
|
||||
|
||||
你的背景仅是一张图片或一种颜色。你的电子游戏人物不能与在背景中的东西相互作用,因此,不要在后面放置一些太重要的东西。它仅仅是设置装饰。
|
||||
|
||||
### 设置你的 Pygame 脚本
|
||||
|
||||
要开始一个新的 Pygame 工程,先在计算机上创建一个文件夹。游戏的全部文件被放在这个目录中。在你的工程文件夹内部保持所需要的所有的文件来运行游戏是极其重要的。
|
||||
|
||||
|
||||
|
||||
一个 Python 脚本以文件类型、你的姓名,和你想使用的许可证开始。使用一个开放源码许可证,以便你的朋友可以改善你的游戏并与你一起分享他们的更改:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
# by Seth Kenlon
|
||||
|
||||
## GPLv3
|
||||
# This program is free software: you can redistribute it and/or
|
||||
# modify it under the terms of the GNU General Public License as
|
||||
# published by the Free Software Foundation, either version 3 of the
|
||||
# License, or (at your option) any later version.
|
||||
#
|
||||
# This program is distributed in the hope that it will be useful, but
|
||||
# WITHOUT ANY WARRANTY; without even the implied warranty of
|
||||
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
|
||||
# General Public License for more details.
|
||||
#
|
||||
# You should have received a copy of the GNU General Public License
|
||||
# along with this program. If not, see <http://www.gnu.org/licenses/>.
|
||||
```
|
||||
|
||||
然后,你告诉 Python 你想使用的模块。一些模块是常见的 Python 库,当然,你想包括一个你刚刚安装的 Pygame 模块。
|
||||
|
||||
```
|
||||
import pygame # 加载 pygame 关键字
|
||||
import sys # 让 python 使用你的文件系统
|
||||
import os # 帮助 python 识别你的操作系统
|
||||
```
|
||||
|
||||
由于你将用这个脚本文件做很多工作,在文件中分成段落是有帮助的,以便你知道在哪里放代码。你可以使用块注释来做这些,这些注释仅在看你的源文件代码时是可见的。在你的代码中创建三个块。
|
||||
|
||||
```
|
||||
'''
|
||||
Objects
|
||||
'''
|
||||
|
||||
# 在这里放置 Python 类和函数
|
||||
|
||||
'''
|
||||
Setup
|
||||
'''
|
||||
|
||||
# 在这里放置一次性的运行代码
|
||||
|
||||
'''
|
||||
Main Loop
|
||||
'''
|
||||
|
||||
# 在这里放置游戏的循环代码指令
|
||||
```
|
||||
|
||||
接下来,为你的游戏设置窗口大小。注意,不是每一个人都有大计算机屏幕,所以,最好使用一个适合大多数人的计算机的屏幕大小。
|
||||
|
||||
这里有一个方法来切换全屏模式,很多现代电子游戏都会这样做,但是,由于你刚刚开始,简单起见仅设置一个大小即可。
|
||||
|
||||
```
|
||||
'''
|
||||
Setup
|
||||
'''
|
||||
worldx = 960
|
||||
worldy = 720
|
||||
```
|
||||
|
||||
在脚本中使用 Pygame 引擎前,你需要一些基本的设置。你必须设置帧频,启动它的内部时钟,然后开始 (`init`)Pygame 。
|
||||
|
||||
```
|
||||
fps = 40 # 帧频
|
||||
ani = 4 # 动画循环
|
||||
clock = pygame.time.Clock()
|
||||
pygame.init()
|
||||
```
|
||||
|
||||
现在你可以设置你的背景。
|
||||
|
||||
### 设置背景
|
||||
|
||||
在你继续前,打开一个图形应用程序,为你的游戏世界创建一个背景。在你的工程目录中的 `images` 文件夹内部保存它为 `stage.png` 。
|
||||
|
||||
这里有一些你可以使用的自由图形应用程序。
|
||||
|
||||
* [Krita][5] 是一个专业级绘图素材模拟器,它可以被用于创建漂亮的图片。如果你对创建电子游戏艺术作品非常感兴趣,你甚至可以购买一系列的[游戏艺术作品教程][6]。
|
||||
* [Pinta][7] 是一个基本的,易于学习的绘图应用程序。
|
||||
* [Inkscape][8] 是一个矢量图形应用程序。使用它来绘制形状、线、样条曲线和贝塞尔曲线。
|
||||
|
||||
你的图像不必很复杂,你可以以后回去更改它。一旦有了它,在你文件的 Setup 部分添加这些代码:
|
||||
|
||||
```
|
||||
world = pygame.display.set_mode([worldx,worldy])
|
||||
backdrop = pygame.image.load(os.path.join('images','stage.png').convert())
|
||||
backdropbox = world.get_rect()
|
||||
```
|
||||
|
||||
如果你仅仅用一种颜色来填充你的游戏的背景,你需要做的就是:
|
||||
|
||||
```
|
||||
world = pygame.display.set_mode([worldx,worldy])
|
||||
```
|
||||
|
||||
你也必须定义颜色以使用。在你的 Setup 部分,使用红、绿、蓝 (RGB) 的值来创建一些颜色的定义。
|
||||
|
||||
```
|
||||
'''
|
||||
Setup
|
||||
'''
|
||||
|
||||
BLUE = (25,25,200)
|
||||
BLACK = (23,23,23 )
|
||||
WHITE = (254,254,254)
|
||||
```
|
||||
|
||||
至此,你理论上可以启动你的游戏了。问题是,它可能仅持续了一毫秒。
|
||||
|
||||
为证明这一点,保存你的文件为 `your-name_game.py`(用你真实的名称替换 `your-name`)。然后启动你的游戏。
|
||||
|
||||
如果你正在使用 IDLE,通过选择来自 “Run” 菜单的 “Run Module” 来运行你的游戏。
|
||||
|
||||
如果你正在使用 Ninja,在左侧按钮条中单击 “Run file” 按钮。
|
||||
|
||||
|
||||
|
||||
你也可以直接从一个 Unix 终端或一个 Windows 命令提示符中运行一个 Python 脚本。
|
||||
|
||||
```
|
||||
$ python3 ./your-name_game.py
|
||||
```
|
||||
|
||||
如果你正在使用 Windows,使用这命令:
|
||||
|
||||
```
|
||||
py.exe your-name_game.py
|
||||
```
|
||||
|
||||
启动它,不过不要期望很多,因为你的游戏现在仅仅持续几毫秒。你可以在下一部分中修复它。
|
||||
|
||||
### 循环
|
||||
|
||||
除非另有说明,一个 Python 脚本运行一次并仅一次。近来计算机的运行速度是非常快的,所以你的 Python 脚本运行时间会少于 1 秒钟。
|
||||
|
||||
为强制你的游戏来处于足够长的打开和活跃状态来让人看到它(更不要说玩它),使用一个 `while` 循环。为使你的游戏保存打开,你可以设置一个变量为一些值,然后告诉一个 `while` 循环只要变量保持未更改则一直保存循环。
|
||||
|
||||
这经常被称为一个“主循环”,你可以使用术语 `main` 作为你的变量。在你的 Setup 部分的任意位置添加代码:
|
||||
|
||||
```
|
||||
main = True
|
||||
```
|
||||
|
||||
在主循环期间,使用 Pygame 关键字来检查键盘上的按键是否已经被按下或释放。添加这些代码到你的主循环部分:
|
||||
|
||||
```
|
||||
'''
|
||||
Main loop
|
||||
'''
|
||||
while main == True:
|
||||
for event in pygame.event.get():
|
||||
if event.type == pygame.QUIT:
|
||||
pygame.quit(); sys.exit()
|
||||
main = False
|
||||
|
||||
if event.type == pygame.KEYDOWN:
|
||||
if event.key == ord('q'):
|
||||
pygame.quit()
|
||||
sys.exit()
|
||||
main = False
|
||||
```
|
||||
|
||||
也是在你的循环中,刷新你世界的背景。
|
||||
|
||||
如果你使用一个图片作为背景:
|
||||
|
||||
```
|
||||
world.blit(backdrop, backdropbox)
|
||||
```
|
||||
|
||||
如果你使用一种颜色作为背景:
|
||||
|
||||
```
|
||||
world.fill(BLUE)
|
||||
```
|
||||
|
||||
最后,告诉 Pygame 来重新刷新屏幕上的所有内容,并推进游戏的内部时钟。
|
||||
|
||||
```
|
||||
pygame.display.flip()
|
||||
clock.tick(fps)
|
||||
```
|
||||
|
||||
保存你的文件,再次运行它来查看你曾经创建的最无趣的游戏。
|
||||
|
||||
退出游戏,在你的键盘上按 `q` 键。
|
||||
|
||||
在这系列的 [下一篇文章][9] 中,我将向你演示,如何加强你当前空空如也的游戏世界,所以,继续学习并创建一些将要使用的图形!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/12/game-framework-python
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[robsean](https://github.com/robsean)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://linux.cn/article-9071-1.html
|
||||
[2]: http://www.pygame.org/wiki/about
|
||||
[3]: https://en.wikipedia.org/wiki/IDLE
|
||||
[4]: http://ninja-ide.org/
|
||||
[5]: http://krita.org
|
||||
[6]: https://gumroad.com/l/krita-game-art-tutorial-1
|
||||
[7]: https://pinta-project.com/pintaproject/pinta/releases
|
||||
[8]: http://inkscape.org
|
||||
[9]: https://opensource.com/article/17/12/program-game-python-part-3-spawning-player
|
||||
@ -0,0 +1,163 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (cycoe)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10858-1.html)
|
||||
[#]: subject: (How to add a player to your Python game)
|
||||
[#]: via: (https://opensource.com/article/17/12/game-python-add-a-player)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
如何在你的 Python 游戏中添加一个玩家
|
||||
======
|
||||
> 这是用 Python 从头开始构建游戏的系列文章的第三部分。
|
||||
|
||||

|
||||
|
||||
在 [这个系列的第一篇文章][1] 中,我解释了如何使用 Python 创建一个简单的基于文本的骰子游戏。在第二部分中,我向你们展示了如何从头开始构建游戏,即从 [创建游戏的环境][2] 开始。但是每个游戏都需要一名玩家,并且每个玩家都需要一个可操控的角色,这也就是我们接下来要在这个系列的第三部分中需要做的。
|
||||
|
||||
在 Pygame 中,玩家操控的图标或者化身被称作<ruby>妖精<rt>sprite</rt></ruby>。如果你现在还没有任何可用于玩家妖精的图像,你可以使用 [Krita][3] 或 [Inkscape][4] 来自己创建一些图像。如果你对自己的艺术细胞缺乏自信,你也可以在 [OpenClipArt.org][5] 或 [OpenGameArt.org][6] 搜索一些现成的图像。如果你还未按照上一篇文章所说的单独创建一个 `images` 文件夹,那么你需要在你的 Python 项目目录中创建它。将你想要在游戏中使用的图片都放 `images` 文件夹中。
|
||||
|
||||
为了使你的游戏真正的刺激,你应该为你的英雄使用一张动态的妖精图片。这意味着你需要绘制更多的素材,并且它们要大不相同。最常见的动画就是走路循环,通过一系列的图像让你的妖精看起来像是在走路。走路循环最快捷粗糙的版本需要四张图像。
|
||||
|
||||
|
||||
|
||||
注意:这篇文章中的代码示例同时兼容静止的和动态的玩家妖精。
|
||||
|
||||
将你的玩家妖精命名为 `hero.png`。如果你正在创建一个动态的妖精,则需要在名字后面加上一个数字,从 `hero1.png` 开始。
|
||||
|
||||
### 创建一个 Python 类
|
||||
|
||||
在 Python 中,当你在创建一个你想要显示在屏幕上的对象时,你需要创建一个类。
|
||||
|
||||
在你的 Python 脚本靠近顶端的位置,加入如下代码来创建一个玩家。在以下的代码示例中,前三行已经在你正在处理的 Python 脚本中:
|
||||
|
||||
```
|
||||
import pygame
|
||||
import sys
|
||||
import os # 以下是新代码
|
||||
|
||||
class Player(pygame.sprite.Sprite):
|
||||
'''
|
||||
生成一个玩家
|
||||
'''
|
||||
def __init__(self):
|
||||
pygame.sprite.Sprite.__init__(self)
|
||||
self.images = []
|
||||
img = pygame.image.load(os.path.join('images','hero.png')).convert()
|
||||
self.images.append(img)
|
||||
self.image = self.images[0]
|
||||
self.rect = self.image.get_rect()
|
||||
```
|
||||
|
||||
如果你的可操控角色拥有一个走路循环,在 `images` 文件夹中将对应图片保存为 `hero1.png` 到 `hero4.png` 的独立文件。
|
||||
|
||||
使用一个循环来告诉 Python 遍历每个文件。
|
||||
|
||||
```
|
||||
'''
|
||||
对象
|
||||
'''
|
||||
|
||||
class Player(pygame.sprite.Sprite):
|
||||
'''
|
||||
生成一个玩家
|
||||
'''
|
||||
def __init__(self):
|
||||
pygame.sprite.Sprite.__init__(self)
|
||||
self.images = []
|
||||
for i in range(1,5):
|
||||
img = pygame.image.load(os.path.join('images','hero' + str(i) + '.png')).convert()
|
||||
self.images.append(img)
|
||||
self.image = self.images[0]
|
||||
self.rect = self.image.get_rect()
|
||||
```
|
||||
|
||||
### 将玩家带入游戏世界
|
||||
|
||||
现在已经创建好了一个 Player 类,你需要使用它在你的游戏世界中生成一个玩家妖精。如果你不调用 Player 类,那它永远不会起作用,(游戏世界中)也就不会有玩家。你可以通过立马运行你的游戏来验证一下。游戏会像上一篇文章末尾看到的那样运行,并得到明确的结果:一个空荡荡的游戏世界。
|
||||
|
||||
为了将一个玩家妖精带到你的游戏世界,你必须通过调用 Player 类来生成一个妖精,并将它加入到 Pygame 的妖精组中。在如下的代码示例中,前三行是已经存在的代码,你需要在其后添加代码:
|
||||
|
||||
```
|
||||
world = pygame.display.set_mode([worldx,worldy])
|
||||
backdrop = pygame.image.load(os.path.join('images','stage.png')).convert()
|
||||
backdropbox = screen.get_rect()
|
||||
|
||||
# 以下是新代码
|
||||
|
||||
player = Player() # 生成玩家
|
||||
player.rect.x = 0 # 移动 x 坐标
|
||||
player.rect.y = 0 # 移动 y 坐标
|
||||
player_list = pygame.sprite.Group()
|
||||
player_list.add(player)
|
||||
```
|
||||
|
||||
尝试启动你的游戏来看看发生了什么。高能预警:它不会像你预期的那样工作,当你启动你的项目,玩家妖精没有出现。事实上它生成了,只不过只出现了一毫秒。你要如何修复一个只出现了一毫秒的东西呢?你可能回想起上一篇文章中,你需要在主循环中添加一些东西。为了使玩家的存在时间超过一毫秒,你需要告诉 Python 在每次循环中都绘制一次。
|
||||
|
||||
将你的循环底部的语句更改如下:
|
||||
|
||||
```
|
||||
world.blit(backdrop, backdropbox)
|
||||
player_list.draw(screen) # 绘制玩家
|
||||
pygame.display.flip()
|
||||
clock.tick(fps)
|
||||
```
|
||||
|
||||
现在启动你的游戏,你的玩家出现了!
|
||||
|
||||
### 设置 alpha 通道
|
||||
|
||||
根据你如何创建你的玩家妖精,在它周围可能会有一个色块。你所看到的是 alpha 通道应该占据的空间。它本来是不可见的“颜色”,但 Python 现在还不知道要使它不可见。那么你所看到的,是围绕在妖精周围的边界区(或现代游戏术语中的“<ruby>命中区<rt>hit box</rt></ruby>”)内的空间。
|
||||
|
||||

|
||||
|
||||
你可以通过设置一个 alpha 通道和 RGB 值来告诉 Python 使哪种颜色不可见。如果你不知道你使用 alpha 通道的图像的 RGB 值,你可以使用 Krita 或 Inkscape 打开它,并使用一种独特的颜色,比如 `#00ff00`(差不多是“绿屏绿”)来填充图像周围的空白区域。记下颜色对应的十六进制值(此处为 `#00ff00`,绿屏绿)并将其作为 alpha 通道用于你的 Python 脚本。
|
||||
|
||||
使用 alpha 通道需要在你的妖精生成相关代码中添加如下两行。类似第一行的代码已经存在于你的脚本中,你只需要添加另外两行:
|
||||
|
||||
```
|
||||
img = pygame.image.load(os.path.join('images','hero' + str(i) + '.png')).convert()
|
||||
img.convert_alpha() # 优化 alpha
|
||||
img.set_colorkey(ALPHA) # 设置 alpha
|
||||
```
|
||||
|
||||
除非你告诉它,否则 Python 不知道将哪种颜色作为 alpha 通道。在你代码的设置相关区域,添加一些颜色定义。将如下的变量定义添加于你的设置相关区域的任意位置:
|
||||
|
||||
```
|
||||
ALPHA = (0, 255, 0)
|
||||
```
|
||||
|
||||
在以上示例代码中,`0,255,0` 被我们使用,它在 RGB 中所代表的值与 `#00ff00` 在十六进制中所代表的值相同。你可以通过一个优秀的图像应用程序,如 [GIMP][7]、Krita 或 Inkscape,来获取所有这些颜色值。或者,你可以使用一个优秀的系统级颜色选择器,如 [KColorChooser][8],来检测颜色。
|
||||
|
||||
|
||||
|
||||
如果你的图像应用程序将你的妖精背景渲染成了其他的值,你可以按需调整 `ALPHA` 变量的值。不论你将 alpha 设为多少,最后它都将“不可见”。RGB 颜色值是非常严格的,因此如果你需要将 alpha 设为 000,但你又想将 000 用于你图像中的黑线,你只需要将图像中线的颜色设为 111。这样一来,(图像中的黑线)就足够接近黑色,但除了电脑以外没有人能看出区别。
|
||||
|
||||
运行你的游戏查看结果。
|
||||
|
||||

|
||||
|
||||
在 [这个系列的第四篇文章][9] 中,我会向你们展示如何使你的妖精动起来。多么的激动人心啊!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/12/game-python-add-a-player
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[cycoe](https://github.com/cycoe)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://linux.cn/article-9071-1.html
|
||||
[2]: https://linux.cn/article-10850-1.html
|
||||
[3]: http://krita.org
|
||||
[4]: http://inkscape.org
|
||||
[5]: http://openclipart.org
|
||||
[6]: https://opengameart.org/
|
||||
[7]: http://gimp.org
|
||||
[8]: https://github.com/KDE/kcolorchooser
|
||||
[9]: https://opensource.com/article/17/12/program-game-python-part-4-moving-your-sprite
|
||||
@ -0,0 +1,130 @@
|
||||
DomTerm:一款为 Linux 打造的终端模拟器
|
||||
======
|
||||
> 了解一下 DomTerm,这是一款终端模拟器和复用器,带有 HTML 图形和其它不多见的功能。
|
||||
|
||||

|
||||
|
||||
[DomTerm][1] 是一款现代化的终端模拟器,它使用浏览器引擎作为 “GUI 工具包”。这就支持了一些相关的特性,例如可嵌入图像和链接、HTML 富文本以及可折叠(显示/隐藏)命令。除此以外,它看起来感觉就像一个功能完整、独立的终端模拟器,有着出色 xterm 兼容性(包括鼠标处理和 24 位色)和恰当的 “装饰” (菜单)。另外它内置支持了会话管理和副窗口(如同 `tmux` 和 `GNU Screen` 中一样)、基本输入编辑(如在 `readline` 中)以及分页(如在 `less` 中)。
|
||||
|
||||
|
||||
|
||||
*图 1: DomTerminal 终端模拟器。*
|
||||
|
||||
在以下部分我们将看一看这些特性。我们将假设你已经安装好了 `domterm` (如果你需要获取并构建 Dormterm 请跳到本文最后)。开始之前先让我们概览一下这项技术。
|
||||
|
||||
### 前端 vs. 后端
|
||||
|
||||
DomTerm 大部分是用 JavaScript 写的,它运行在一个浏览器引擎中。它可以是像例如 Chrome 或者 Firefox 一样的桌面浏览器(见图 3),也可以是一个内嵌的浏览器。使用一个通用的网页浏览器没有问题,但是用户体验却不够好(因为菜单是为通用的网页浏览而不是为了终端模拟器所打造),并且其安全模型也会妨碍使用。因此使用内嵌的浏览器更好一些。
|
||||
|
||||
目前以下这些是支持的:
|
||||
|
||||
* qdomterm,使用了 Qt 工具包 和 QtWebEngine
|
||||
* 一个内嵌的 [Electron][2](见图 1)
|
||||
* atom-domterm 以 [Atom 文本编辑器][3](同样基于 Electron)包的形式运行 DomTerm,并和 Atom 面板系统集成在一起(见图 2)
|
||||
* 一个为 JavaFX 的 WebEngine 包装器,这对 Java 编程十分有用(见图 4)
|
||||
* 之前前端使用 [Firefox-XUL][4] 作为首选,但是 Mozilla 已经终止了 XUL
|
||||
|
||||
![在 Atom 编辑器中的 DomTerm 终端面板][6]
|
||||
|
||||
*图 2:在 Atom 编辑器中的 DomTerm 终端面板。*
|
||||
|
||||
目前,Electron 前端可能是最佳选择,紧随其后的是 Qt 前端。如果你使用 Atom,atom-domterm 也工作得相当不错。
|
||||
|
||||
后端服务器是用 C 写的。它管理着伪终端(PTY)和会话。它同样也是一个为前端提供 Javascript 和其它文件的 HTTP 服务器。`domterm` 命令启动终端任务和执行其它请求。如果没有服务器在运行,domterm 就会自己来服务。后端与服务器之间的通讯通常是用 WebSockets(在服务器端是[libwebsockets][8])完成的。然而,JavaFX 的嵌入既不用 Websockets 也不用 DomTerm 服务器。相反 Java 应用直接通过 Java-Javascript 桥接进行通讯。
|
||||
|
||||
### 一个稳健的可兼容 xterm 的终端模拟器
|
||||
|
||||
DomTerm 看上去感觉像一个现代的终端模拟器。它处理鼠标事件、24 位色、Unicode、倍宽字符(CJK)以及输入方式。DomTerm 在 [vttest 测试套件][9] 上工作地十分出色。
|
||||
|
||||
其不同寻常的特性包括:
|
||||
|
||||
**展示/隐藏按钮(“折叠”):** 小三角(如上图 2)是隐藏/展示相应输出的按钮。仅需在[提示符][11]中添加特定的[转义字符][10]就可以创建按钮。
|
||||
|
||||
**对于 readline 和类似输入编辑器的鼠标点击支持:** 如果你点击输入区域(黄色),DomTerm 会向应用发送正确的方向键按键序列。(可以通过提示符中的转义字符启用这一特性,你也可以通过 `Alt+点击` 强制使用。)
|
||||
|
||||
**用 CSS 样式化终端:** 这通常是在 `~/.domterm/settings.ini` 里完成的,保存时会自动重载。例如在图 2 中,设置了终端专用的背景色。
|
||||
|
||||
### 一个更好的 REPL 控制台
|
||||
|
||||
一个经典的终端模拟器基于长方形的字符单元格工作的。这在 REPL(命令行)上没问题,但是并不理想。这里有些通常在终端模拟器中不常见的 REPL 很有用的 DomTerm 特性:
|
||||
|
||||
**一个能“打印”图片、图形、数学公式或者一组可点击的链接的命令:** 应用可以发送包含几乎任何 HTML 的转义字符。(HTML 会被剔除部分,以移除 JavaScript 和其它危险特性。)
|
||||
|
||||
图 3 显示了来自 [gnuplot][12] 会话的一个片段。Gnuplot(2.1 或者跟高版本)支持 DormTerm 作为终端类型。图形输出被转换成 [SVG 图片][13],然后被打印到终端。我的博客帖子[在 DormTerm 上的 Gnuplot 展示][14]在这方面提供了更多信息。
|
||||
|
||||
|
||||
|
||||
*图 3:Gnuplot 截图。*
|
||||
|
||||
[Kawa][15] 语言有一个创建并转换[几何图像值][16]的库。如果你将这样的图片值打印到 DomTerm 终端,图片就会被转换成 SVG 形式并嵌入进输出中。
|
||||
|
||||
|
||||
|
||||
*图 4:Kawa 中可计算的几何形状。*
|
||||
|
||||
**富文本输出:** 有着 HTML 样式的帮助信息更加便于阅读,看上去也更漂亮。图片 1 的下面面板展示 `dormterm help` 的输出。(如果没在 DomTerm 下运行的话输出的是普通文本。)注意自带的分页器中的 `PAUSED` 消息。
|
||||
|
||||
**包括可点击链接的错误消息:** DomTerm 可以识别语法 `filename:line:column` 并将其转化成一个能在可定制文本编辑器中打开文件并定位到行的链接。(这适用于相对路径的文件名,如果你用 `PROMPT_COMMAND` 或类似的跟踪目录。)
|
||||
|
||||
编译器可以侦测到它在 DomTerm 下运行,并直接用转义字符发出文件链接。这比依赖 DomTerm 的样式匹配要稳健得多,因为它可以处理空格和其他字符并且无需依赖目录追踪。在图 4 中,你可以看到来自 [Kawa Compiler][15] 的错误消息。悬停在文件位置上会使其出现下划线,`file:` URL 出现在 `atom-domterm` 消息栏(窗口底部)中。(当不用 atom-domterm 时,这样的消息会在一个浮层的框中显示,如图 1 中所看到的 `PAUSED` 消息所示。)
|
||||
|
||||
点击链接时的动作是可以配置的。默认对于带有 `#position` 后缀的 `file:` 链接的动作是在文本编辑器中打开那个文件。
|
||||
|
||||
**结构化内部表示:**以下内容均以内部节点结构表示:命令、提示符、输入行、正常和错误输出、标签,如果“另存为 HTML”,则保留结构。HTML 文件与 XML 兼容,因此你可以使用 XML 工具搜索或转换输出。命令 `domterm view-saved` 会以一种启用命令折叠(显示/隐藏按钮处于活动状态)和重新调整窗口大小的方式打开保存的 HTML 文件。
|
||||
|
||||
**内建的 Lisp 样式优美打印:** 你可以在输出中包括优美打印指令(比如,grouping),这样断行会根据窗口大小调整而重新计算。查看我的文章 [DomTerm 中的动态优美打印][17]以更深入探讨。
|
||||
|
||||
**基本的内建行编辑**,带着历史记录(像 GNU readline 一样): 这使用浏览器自带的编辑器,因此它有着优秀的鼠标和选择处理机制。你可以在正常字符模式(大多数输入的字符被指接送向进程);或者行模式(通常的字符是直接插入的,而控制字符导致编辑操作,回车键会向进程发送被编辑行)之间转换。默认的是自动模式,根据 PTY 是在原始模式还是终端模式中,DomTerm 在字符模式与行模式间转换。
|
||||
|
||||
**自带的分页器**(类似简化版的 `less`):键盘快捷键控制滚动。在“页模式”中,输出在每个新的屏幕(或者单独的行,如果你想一行行地向前移)后暂停;页模式对于用户输入简单智能,因此(如果你想的话)你无需阻碍交互式程序就可以运行它。
|
||||
|
||||
### 多路复用和会话
|
||||
|
||||
**标签和平铺:** 你不仅可以创建多个终端标签,也可以平铺它们。你可以要么使用鼠标或键盘快捷键来创建或者切换面板和标签。它们可以用鼠标重新排列并调整大小。这是通过 [GoldenLayout][18] JavaScript 库实现的。图 1 展示了一个有着两个面板的窗口。上面的有两个标签,一个运行 [Midnight Commander][20];底下的面板以 HTML 形式展示了 `dormterm help` 输出。然而相反在 Atom 中我们使用其自带的可拖拽的面板和标签。你可以在图 2 中看到这个。
|
||||
|
||||
**分离或重接会话:** 与 `tmux` 和 GNU `screen` 类似,DomTerm 支持会话安排。你甚至可以给同样的会话接上多个窗口或面板。这支持多用户会话分享和远程链接。(为了安全,同一个服务器的所有会话都需要能够读取 Unix 域接口和一个包含随机密钥的本地文件。当我们有了良好、安全的远程链接,这个限制将会有所放松。)
|
||||
|
||||
**domterm 命令** 类似与 `tmux` 和 GNU `screen`,它有多个选项可以用于控制或者打开单个或多个会话的服务器。主要的差别在于,如果它没在 DomTerm 下运行,`dormterm` 命令会创建一个新的顶层窗口,而不是在现有的终端中运行。
|
||||
|
||||
与 `tmux` 和 `git` 类似,`dormterm` 命令有许多子命令。一些子命令创建窗口或者会话。另一些(例如“打印”一张图片)仅在现有的 DormTerm 会话下起作用。
|
||||
|
||||
命令 `domterm browse` 打开一个窗口或者面板以浏览一个指定的 URL,例如浏览文档的时候。
|
||||
|
||||
### 获取并安装 DomTerm
|
||||
|
||||
DomTerm 可以从其 [Github 仓库][21]获取。目前没有提前构建好的包,但是有[详细指导][22]。所有的前提条件在 Fedora 27 上都有,这使得其特别容易被搭建。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/introduction-domterm-terminal-emulator
|
||||
|
||||
作者:[Per Bothner][a]
|
||||
译者:[tomjlw](https://github.com/tomjlw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/perbothner
|
||||
[1]:http://domterm.org/
|
||||
[2]:https://electronjs.org/
|
||||
[3]:https://atom.io/
|
||||
[4]:https://en.wikipedia.org/wiki/XUL
|
||||
[5]:/file/385346
|
||||
[6]:https://opensource.com/sites/default/files/images/dt-atom1.png (DomTerm terminal panes in Atom editor)
|
||||
[7]:https://opensource.com/sites/default/files/images/dt-atom1.png
|
||||
[8]:https://libwebsockets.org/
|
||||
[9]:http://invisible-island.net/vttest/
|
||||
[10]:http://domterm.org/Wire-byte-protocol.html
|
||||
[11]:http://domterm.org/Shell-prompts.html
|
||||
[12]:http://www.gnuplot.info/
|
||||
[13]:https://developer.mozilla.org/en-US/docs/Web/SVG
|
||||
[14]:http://per.bothner.com/blog/2016/gnuplot-in-domterm/
|
||||
[15]:https://www.gnu.org/software/kawa/
|
||||
[16]:https://www.gnu.org/software/kawa/Composable-pictures.html
|
||||
[17]:http://per.bothner.com/blog/2017/dynamic-prettyprinting/
|
||||
[18]:https://golden-layout.com/
|
||||
[19]:https://opensource.com/sites/default/files/u128651/domterm1.png
|
||||
[20]:https://midnight-commander.org/
|
||||
[21]:https://github.com/PerBothner/DomTerm
|
||||
[22]:http://domterm.org/Downloading-and-building.html
|
||||
|
||||
@ -0,0 +1,229 @@
|
||||
ddgr:一个从终端搜索 DuckDuckGo 的命令行工具
|
||||
======
|
||||
|
||||
在 Linux 中,Bash 技巧非常棒,它使 Linux 中的一切成为可能。
|
||||
|
||||
对于开发人员或系统管理员来说,它真的很管用,因为他们大部分时间都在使用终端。你知道他们为什么喜欢这种技巧吗?
|
||||
|
||||
因为这些技巧可以提高他们的工作效率,也能使他们工作更快。
|
||||
|
||||
### 什么是 ddgr
|
||||
|
||||
[ddgr][1] 是一个命令行实用程序,用于从终端搜索 DuckDuckGo。如果设置了 `BROWSER` 环境变量,ddgr 可以在几个基于文本的浏览器中开箱即用。
|
||||
|
||||
确保你的系统安装了任何一个基于文本的浏览器。你可能知道 [googler][2],它允许用户从 Linux 命令行进行 Google 搜索。
|
||||
|
||||
它在命令行用户中非常受欢迎,他们期望对隐私敏感的 DuckDuckGo 也有类似的实用程序,这就是 `ddgr` 出现的原因。
|
||||
|
||||
与 Web 界面不同,你可以指定每页要查看的搜索结果数。
|
||||
|
||||
**建议阅读:**
|
||||
|
||||
- [Googler – 从 Linux 命令行搜索 Google][2]
|
||||
- [Buku – Linux 中一个强大的命令行书签管理器][3]
|
||||
- [SoCLI – 从终端搜索和浏览 StackOverflow 的简单方法][4]
|
||||
- [RTV(Reddit 终端查看器)- 一个简单的 Reddit 终端查看器][5]
|
||||
|
||||
### 什么是 DuckDuckGo
|
||||
|
||||
DDG 即 DuckDuckGo。DuckDuckGo(DDG)是一个真正保护用户搜索和隐私的互联网搜索引擎。它没有过滤用户的个性化搜索结果,对于给定的搜索词,它会向所有用户显示相同的搜索结果。
|
||||
|
||||
大多数用户更喜欢谷歌搜索引擎,但是如果你真的担心隐私,那么你可以放心地使用 DuckDuckGo。
|
||||
|
||||
### ddgr 特性
|
||||
|
||||
* 快速且干净(没有广告、多余的 URL 或杂物参数),自定义颜色
|
||||
* 旨在以最小的空间提供最高的可读性
|
||||
* 指定每页显示的搜索结果数
|
||||
* 可以在 omniprompt 中导航结果,在浏览器中打开 URL
|
||||
* 用于 Bash、Zsh 和 Fish 的搜索和选项补完脚本
|
||||
* 支持 DuckDuckGo Bang(带有自动补完)
|
||||
* 直接在浏览器中打开第一个结果(如同 “I’m Feeling Ducky”)
|
||||
* 不间断搜索:无需退出即可在 omniprompt 中触发新搜索
|
||||
* 关键字支持(例如:filetype:mime、site:somesite.com)
|
||||
* 按时间、指定区域搜索,禁用安全搜索
|
||||
* 支持 HTTPS 代理,支持 Do Not Track,可选择禁用用户代理字符串
|
||||
* 支持自定义 URL 处理程序脚本或命令行实用程序
|
||||
* 全面的文档,man 页面有方便的使用示例
|
||||
* 最小的依赖关系
|
||||
|
||||
### 需要条件
|
||||
|
||||
`ddgr` 需要 Python 3.4 或更高版本。因此,确保你的系统应具有 Python 3.4 或更高版本。
|
||||
|
||||
```
|
||||
$ python3 --version
|
||||
Python 3.6.3
|
||||
```
|
||||
|
||||
### 如何在 Linux 中安装 ddgr
|
||||
|
||||
我们可以根据发行版使用以下命令轻松安装 `ddgr`。
|
||||
|
||||
对于 Fedora ,使用 [DNF 命令][6]来安装 `ddgr`。
|
||||
|
||||
```
|
||||
# dnf install ddgr
|
||||
```
|
||||
|
||||
或者我们可以使用 [SNAP 命令][7]来安装 `ddgr`。
|
||||
|
||||
```
|
||||
# snap install ddgr
|
||||
```
|
||||
|
||||
对于 LinuxMint/Ubuntu,使用 [APT-GET 命令][8] 或 [APT 命令][9]来安装 `ddgr`。
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:twodopeshaggy/jarun
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install ddgr
|
||||
```
|
||||
|
||||
对于基于 Arch Linux 的系统,使用 [Yaourt 命令][10]或 [Packer 命令][11]从 AUR 仓库安装 `ddgr`。
|
||||
|
||||
```
|
||||
$ yaourt -S ddgr
|
||||
或
|
||||
$ packer -S ddgr
|
||||
```
|
||||
|
||||
对于 Debian,使用 [DPKG 命令][12] 安装 `ddgr`。
|
||||
|
||||
```
|
||||
# wget https://github.com/jarun/ddgr/releases/download/v1.2/ddgr_1.2-1_debian9.amd64.deb
|
||||
# dpkg -i ddgr_1.2-1_debian9.amd64.deb
|
||||
```
|
||||
|
||||
对于 CentOS 7,使用 [YUM 命令][13]来安装 `ddgr`。
|
||||
|
||||
```
|
||||
# yum install https://github.com/jarun/ddgr/releases/download/v1.2/ddgr-1.2-1.el7.3.centos.x86_64.rpm
|
||||
```
|
||||
|
||||
对于 opensuse,使用 [zypper 命令][14]来安装 `ddgr`。
|
||||
|
||||
```
|
||||
# zypper install https://github.com/jarun/ddgr/releases/download/v1.2/ddgr-1.2-1.opensuse42.3.x86_64.rpm
|
||||
```
|
||||
|
||||
### 如何启动 ddgr
|
||||
|
||||
在终端上输入 `ddgr` 命令,不带任何选项来进行 DuckDuckGo 搜索。你将获得类似于下面的输出。
|
||||
|
||||
```
|
||||
$ ddgr
|
||||
```
|
||||
|
||||
![][16]
|
||||
|
||||
### 如何使用 ddgr 进行搜索
|
||||
|
||||
我们可以通过两种方式启动搜索。从 omniprompt 或者直接从终端开始。你可以搜索任何你想要的短语。
|
||||
|
||||
直接从终端:
|
||||
|
||||
```
|
||||
$ ddgr 2daygeek
|
||||
```
|
||||
|
||||
![][17]
|
||||
|
||||
从 omniprompt:
|
||||
|
||||
![][18]
|
||||
|
||||
### Omniprompt 快捷方式
|
||||
|
||||
输入 `?` 以获得 omniprompt,它将显示关键字列表和进一步使用 `ddgr` 的快捷方式。
|
||||
|
||||
![][19]
|
||||
|
||||
### 如何移动下一页、上一页和第一页
|
||||
|
||||
它允许用户移动下一页、上一页或第一页。
|
||||
|
||||
* `n`: 移动到下一组搜索结果
|
||||
* `p`: 移动到上一组搜索结果
|
||||
* `f`: 跳转到第一页
|
||||
|
||||
![][20]
|
||||
|
||||
### 如何启动新搜索
|
||||
|
||||
`d` 选项允许用户从 omniprompt 发起新的搜索。例如,我搜索了 “2daygeek website”,现在我将搜索 “Magesh Maruthamuthu” 这个新短语。
|
||||
|
||||
从 omniprompt:
|
||||
|
||||
```
|
||||
ddgr (? for help) d magesh maruthmuthu
|
||||
```
|
||||
|
||||
![][21]
|
||||
|
||||
### 在搜索结果中显示完整的 URL
|
||||
|
||||
默认情况下,它仅显示文章标题,在搜索中添加 `x` 选项以在搜索结果中显示完整的文章网址。
|
||||
|
||||
```
|
||||
$ ddgr -n 5 -x 2daygeek
|
||||
```
|
||||
|
||||
![][22]
|
||||
|
||||
### 限制搜索结果
|
||||
|
||||
默认情况下,搜索结果每页显示 10 个结果。如果你想为方便起见限制页面结果,可以使用 `ddgr` 带有 `--num` 或 ` -n` 参数。
|
||||
|
||||
```
|
||||
$ ddgr -n 5 2daygeek
|
||||
```
|
||||
|
||||
![][23]
|
||||
|
||||
### 网站特定搜索
|
||||
|
||||
要搜索特定网站的特定页面,使用以下格式。这将从网站获取给定关键字的结果。例如,我们在 2daygeek 网站下搜索 “Package Manager”,查看结果。
|
||||
|
||||
```
|
||||
$ ddgr -n 5 --site 2daygeek "package manager"
|
||||
```
|
||||
|
||||
![][24]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/ddgr-duckduckgo-search-from-the-command-line-in-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/magesh/
|
||||
[1]:https://github.com/jarun/ddgr
|
||||
[2]:https://www.2daygeek.com/googler-google-search-from-the-command-line-on-linux/
|
||||
[3]:https://www.2daygeek.com/buku-command-line-bookmark-manager-linux/
|
||||
[4]:https://www.2daygeek.com/socli-search-and-browse-stack-overflow-from-linux-terminal/
|
||||
[5]:https://www.2daygeek.com/rtv-reddit-terminal-viewer-a-simple-terminal-viewer-for-reddit/
|
||||
[6]:https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
[7]:https://www.2daygeek.com/snap-command-examples/
|
||||
[8]:https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[9]:https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[10]:https://www.2daygeek.com/install-yaourt-aur-helper-on-arch-linux/
|
||||
[11]:https://www.2daygeek.com/install-packer-aur-helper-on-arch-linux/
|
||||
[12]:https://www.2daygeek.com/dpkg-command-to-manage-packages-on-debian-ubuntu-linux-mint-systems/
|
||||
[13]:https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||
[14]:https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
|
||||
[15]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[16]:https://www.2daygeek.com/wp-content/uploads/2018/03/ddgr-duckduckgo-command-line-search-for-linux1.png
|
||||
[17]:https://www.2daygeek.com/wp-content/uploads/2018/03/ddgr-duckduckgo-command-line-search-for-linux-3.png
|
||||
[18]:https://www.2daygeek.com/wp-content/uploads/2018/03/ddgr-duckduckgo-command-line-search-for-linux-2.png
|
||||
[19]:https://www.2daygeek.com/wp-content/uploads/2018/03/ddgr-duckduckgo-command-line-search-for-linux-4.png
|
||||
[20]:https://www.2daygeek.com/wp-content/uploads/2018/03/ddgr-duckduckgo-command-line-search-for-linux-5a.png
|
||||
[21]:https://www.2daygeek.com/wp-content/uploads/2018/03/ddgr-duckduckgo-command-line-search-for-linux-6a.png
|
||||
[22]:https://www.2daygeek.com/wp-content/uploads/2018/03/ddgr-duckduckgo-command-line-search-for-linux-7a.png
|
||||
[23]:https://www.2daygeek.com/wp-content/uploads/2018/03/ddgr-duckduckgo-command-line-search-for-linux-8.png
|
||||
[24]:https://www.2daygeek.com/wp-content/uploads/2018/03/ddgr-duckduckgo-command-line-search-for-linux-9a.png
|
||||
155
published/201905/20180429 The Easiest PDO Tutorial (Basics).md
Normal file
155
published/201905/20180429 The Easiest PDO Tutorial (Basics).md
Normal file
@ -0,0 +1,155 @@
|
||||
PHP PDO 简单教程
|
||||
======
|
||||
|
||||

|
||||
|
||||
大约 80% 的 Web 应用程序由 PHP 提供支持。类似地,SQL 也是如此。PHP 5.5 版本之前,我们有用于访问 MySQL 数据库的 mysql_ 命令,但由于安全性不足,它们最终被弃用。
|
||||
|
||||
弃用这件事是发生在 2013 年的 PHP 5.5 上,我写这篇文章的时间是 2018 年,PHP 版本为 7.2。mysql_ 的弃用带来了访问数据库的两种主要方法:mysqli 和 PDO 库。
|
||||
|
||||
虽然 mysqli 库是官方指定的,但由于 mysqli 只能支持 mysql 数据库,而 PDO 可以支持 12 种不同类型的数据库驱动程序,因此 PDO 获得了更多的赞誉。此外,PDO 还有其它一些特性,使其成为大多数开发人员的更好选择。你可以在下表中看到一些特性比较:
|
||||
|
||||
| | PDO | MySQLi
|
||||
---|---|---
|
||||
| 数据库支持 | 12 种驱动 | 只有 MySQL
|
||||
| 范例 | OOP | 过程 + OOP
|
||||
| 预处理语句(客户端侧) | Yes | No
|
||||
| 1命名参数 | Yes | No
|
||||
|
||||
现在我想对于大多数开发人员来说,PDO 是首选的原因已经很清楚了。所以让我们深入研究它,并希望在本文中尽量涵盖关于 PDO 你需要的了解的。
|
||||
|
||||
### 连接
|
||||
|
||||
第一步是连接到数据库,由于 PDO 是完全面向对象的,所以我们将使用 PDO 类的实例。
|
||||
|
||||
我们要做的第一件事是定义主机、数据库名称、用户名、密码和数据库字符集。
|
||||
|
||||
```
|
||||
$host = 'localhost';
|
||||
$db = 'theitstuff';
|
||||
$user = 'root';
|
||||
$pass = 'root';
|
||||
$charset = 'utf8mb4';
|
||||
$dsn = "mysql:host=$host;dbname=$db;charset=$charset";
|
||||
$conn = new PDO($dsn, $user, $pass);
|
||||
```
|
||||
|
||||
之后,正如你在上面的代码中看到的,我们创建了 DSN 变量,DSN 变量只是一个保存数据库信息的变量。对于一些在外部服务器上运行 MySQL 的人,你还可以通过提供一个 `port=$port_number` 来调整端口号。
|
||||
|
||||
最后,你可以创建一个 PDO 类的实例,我使用了 `$conn` 变量,并提供了 `$dsn`、`$user`、`$pass` 参数。如果你遵循这些步骤,你现在应该有一个名为 `$conn` 的对象,它是 PDO 连接类的一个实例。现在是时候进入数据库并运行一些查询。
|
||||
|
||||
### 一个简单的 SQL 查询
|
||||
|
||||
现在让我们运行一个简单的 SQL 查询。
|
||||
|
||||
```
|
||||
$tis = $conn->query('SELECT name, age FROM students');
|
||||
while ($row = $tis->fetch())
|
||||
{
|
||||
echo $row['name']."\t";
|
||||
echo $row['age'];
|
||||
echo "<br>";
|
||||
}
|
||||
```
|
||||
|
||||
这是使用 PDO 运行查询的最简单形式。我们首先创建了一个名为 `tis`(TheITStuff 的缩写 )的变量,然后你可以看到我们使用了创建的 `$conn` 对象中的查询函数。
|
||||
|
||||
然后我们运行一个 `while` 循环并创建了一个 `$row` 变量来从 `$tis` 对象中获取内容,最后通过调用列名来显示每一行。
|
||||
|
||||
很简单,不是吗?现在让我们来看看预处理语句。
|
||||
|
||||
### 预处理语句
|
||||
|
||||
预处理语句是人们开始使用 PDO 的主要原因之一,因为它提供了可以阻止 SQL 注入的语句。
|
||||
|
||||
有两种基本方法可供使用,你可以使用位置参数或命名参数。
|
||||
|
||||
#### 位置参数
|
||||
|
||||
让我们看一个使用位置参数的查询示例。
|
||||
|
||||
```
|
||||
$tis = $conn->prepare("INSERT INTO STUDENTS(name, age) values(?, ?)");
|
||||
$tis->bindValue(1,'mike');
|
||||
$tis->bindValue(2,22);
|
||||
$tis->execute();
|
||||
```
|
||||
|
||||
在上面的例子中,我们放置了两个问号,然后使用 `bindValue()` 函数将值映射到查询中。这些值绑定到语句问号中的位置。
|
||||
|
||||
我还可以使用变量而不是直接提供值,通过使用 `bindParam()` 函数相同例子如下:
|
||||
|
||||
```
|
||||
$name='Rishabh'; $age=20;
|
||||
$tis = $conn->prepare("INSERT INTO STUDENTS(name, age) values(?, ?)");
|
||||
$tis->bindParam(1,$name);
|
||||
$tis->bindParam(2,$age);
|
||||
$tis->execute();
|
||||
```
|
||||
|
||||
### 命名参数
|
||||
|
||||
命名参数也是预处理语句,它将值/变量映射到查询中的命名位置。由于没有位置绑定,因此在多次使用相同变量的查询中非常有效。
|
||||
|
||||
```
|
||||
$name='Rishabh'; $age=20;
|
||||
$tis = $conn->prepare("INSERT INTO STUDENTS(name, age) values(:name, :age)");
|
||||
$tis->bindParam(':name', $name);
|
||||
$tis->bindParam(':age', $age);
|
||||
$tis->execute();
|
||||
```
|
||||
|
||||
你可以注意到,唯一的变化是我使用 `:name` 和 `:age` 作为占位符,然后将变量映射到它们。冒号在参数之前使用,让 PDO 知道该位置是一个变量,这非常重要。
|
||||
|
||||
你也可以类似地使用 `bindValue()` 来使用命名参数直接映射值。
|
||||
|
||||
### 获取数据
|
||||
|
||||
PDO 在获取数据时非常丰富,它实际上提供了许多格式来从数据库中获取数据。
|
||||
|
||||
你可以使用 `PDO::FETCH_ASSOC` 来获取关联数组,`PDO::FETCH_NUM` 来获取数字数组,使用 `PDO::FETCH_OBJ` 来获取对象数组。
|
||||
|
||||
```
|
||||
$tis = $conn->prepare("SELECT * FROM STUDENTS");
|
||||
$tis->execute();
|
||||
$result = $tis->fetchAll(PDO::FETCH_ASSOC);
|
||||
```
|
||||
|
||||
你可以看到我使用了 `fetchAll`,因为我想要所有匹配的记录。如果只需要一行,你可以简单地使用 `fetch`。
|
||||
|
||||
现在我们已经获取了数据,现在是时候循环它了,这非常简单。
|
||||
|
||||
```
|
||||
foreach ($result as $lnu){
|
||||
echo $lnu['name'];
|
||||
echo $lnu['age']."<br>";
|
||||
}
|
||||
```
|
||||
|
||||
你可以看到,因为我请求了关联数组,所以我正在按名称访问各个成员。
|
||||
|
||||
虽然在定义希望如何传输递数据方面没有要求,但在定义 `$conn` 变量本身时,实际上可以将其设置为默认值。
|
||||
|
||||
你需要做的就是创建一个 `$options` 数组,你可以在其中放入所有默认配置,只需在 `$conn` 变量中传递数组即可。
|
||||
|
||||
```
|
||||
$options = [
|
||||
PDO::ATTR_DEFAULT_FETCH_MODE => PDO::FETCH_ASSOC,
|
||||
];
|
||||
$conn = new PDO($dsn, $user, $pass, $options);
|
||||
```
|
||||
|
||||
这是一个非常简短和快速的 PDO 介绍,我们很快就会制作一个高级教程。如果你在理解本教程的任何部分时遇到任何困难,请在评论部分告诉我,我会在那你为你解答。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.theitstuff.com/easiest-pdo-tutorial-basics
|
||||
|
||||
作者:[Rishabh Kandari][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.theitstuff.com/author/reevkandari
|
||||
@ -1,21 +1,22 @@
|
||||
没有恶棍,英雄又将如何?如何向你的 Python 游戏中添加一个敌人
|
||||
如何向你的 Python 游戏中添加一个敌人
|
||||
======
|
||||
|
||||
> 在本系列的第五部分,学习如何增加一个坏蛋与你的好人战斗。
|
||||
|
||||

|
||||
|
||||
在本系列的前几篇文章中(参见 [第一部分][1]、[第二部分][2]、[第三部分][3] 以及 [第四部分][4]),你已经学习了如何使用 Pygame 和 Python 在一个空白的视频游戏世界中生成一个可玩的角色。但没有恶棍,英雄又将如何?
|
||||
|
||||
如果你没有敌人,那将会是一个非常无聊的游戏。所以在此篇文章中,你将为你的游戏添加一个敌人并构建一个用于创建关卡的框架。
|
||||
|
||||
在对玩家妖精实现全部功能仍有许多事情可做之前,跳向敌人似乎就很奇怪。但你已经学到了很多东西,创造恶棍与与创造玩家妖精非常相似。所以放轻松,使用你已经掌握的知识,看看能挑起怎样一些麻烦。
|
||||
在对玩家妖精实现全部功能之前,就来实现一个敌人似乎就很奇怪。但你已经学到了很多东西,创造恶棍与与创造玩家妖精非常相似。所以放轻松,使用你已经掌握的知识,看看能挑起怎样一些麻烦。
|
||||
|
||||
针对本次训练,你能够从 [Open Game Art][5] 下载一些预创建的素材。此处是我使用的一些素材:
|
||||
|
||||
|
||||
+ 印加花砖(译注:游戏中使用的花砖贴图)
|
||||
+ 印加花砖(LCTT 译注:游戏中使用的花砖贴图)
|
||||
+ 一些侵略者
|
||||
+ 妖精、角色、物体以及特效
|
||||
|
||||
|
||||
### 创造敌方妖精
|
||||
|
||||
是的,不管你意识到与否,你其实已经知道如何去实现敌人。这个过程与创造一个玩家妖精非常相似:
|
||||
@ -24,40 +25,27 @@
|
||||
2. 创建 `update` 方法使得敌人能够检测碰撞
|
||||
3. 创建 `move` 方法使得敌人能够四处游荡
|
||||
|
||||
|
||||
|
||||
从类入手。从概念上看,它与你的 Player 类大体相同。你设置一张或者一组图片,然后设置妖精的初始位置。
|
||||
从类入手。从概念上看,它与你的 `Player` 类大体相同。你设置一张或者一组图片,然后设置妖精的初始位置。
|
||||
|
||||
在继续下一步之前,确保你有一张你的敌人的图像,即使只是一张临时图像。将图像放在你的游戏项目的 `images` 目录(你放置你的玩家图像的相同目录)。
|
||||
|
||||
如果所有的活物都拥有动画,那么游戏看起来会好得多。为敌方妖精设置动画与为玩家妖精设置动画具有相同的方式。但现在,为了保持简单,我们使用一个没有动画的妖精。
|
||||
|
||||
在你代码 `objects` 节的顶部,使用以下代码创建一个叫做 `Enemy` 的类:
|
||||
|
||||
```
|
||||
class Enemy(pygame.sprite.Sprite):
|
||||
|
||||
'''
|
||||
|
||||
生成一个敌人
|
||||
|
||||
'''
|
||||
|
||||
def __init__(self,x,y,img):
|
||||
|
||||
pygame.sprite.Sprite.__init__(self)
|
||||
|
||||
self.image = pygame.image.load(os.path.join('images',img))
|
||||
|
||||
self.image.convert_alpha()
|
||||
|
||||
self.image.set_colorkey(ALPHA)
|
||||
|
||||
self.rect = self.image.get_rect()
|
||||
|
||||
self.rect.x = x
|
||||
|
||||
self.rect.y = y
|
||||
|
||||
```
|
||||
|
||||
如果你想让你的敌人动起来,使用让你的玩家拥有动画的 [相同方式][4]。
|
||||
@ -67,25 +55,21 @@ class Enemy(pygame.sprite.Sprite):
|
||||
你能够通过告诉类,妖精应使用哪张图像,应出现在世界上的什么地方,来生成不只一个敌人。这意味着,你能够使用相同的敌人类,在游戏世界的任意地方生成任意数量的敌方妖精。你需要做的仅仅是调用这个类,并告诉它应使用哪张图像,以及你期望生成点的 X 和 Y 坐标。
|
||||
|
||||
再次,这从原则上与生成一个玩家精灵相似。在你脚本的 `setup` 节添加如下代码:
|
||||
|
||||
```
|
||||
enemy = Enemy(20,200,'yeti.png') # 生成敌人
|
||||
|
||||
enemy_list = pygame.sprite.Group() # 创建敌人组
|
||||
|
||||
enemy_list.add(enemy) # 将敌人加入敌人组
|
||||
|
||||
```
|
||||
|
||||
在示例代码中,X 坐标为 20,Y 坐标为 200。你可能需要根据你的敌方妖精的大小,来调整这些数字,但尽量生成在一个地方,使得你的玩家妖精能够到它。`Yeti.png` 是用于敌人的图像。
|
||||
在示例代码中,X 坐标为 20,Y 坐标为 200。你可能需要根据你的敌方妖精的大小,来调整这些数字,但尽量生成在一个范围内,使得你的玩家妖精能够碰到它。`Yeti.png` 是用于敌人的图像。
|
||||
|
||||
接下来,将敌人组的所有敌人绘制在屏幕上。现在,你只有一个敌人,如果你想要更多你可以稍后添加。一但你将一个敌人加入敌人组,它就会在主循环中被绘制在屏幕上。中间这一行是你需要添加的新行:
|
||||
|
||||
```
|
||||
player_list.draw(world)
|
||||
|
||||
enemy_list.draw(world) # 刷新敌人
|
||||
|
||||
pygame.display.flip()
|
||||
|
||||
```
|
||||
|
||||
启动你的游戏,你的敌人会出现在游戏世界中你选择的 X 和 Y 坐标处。
|
||||
@ -96,42 +80,31 @@ enemy_list.add(enemy) # 将敌人加入敌人组
|
||||
|
||||
思考一下“关卡”是什么。你如何知道你是在游戏中的一个特定关卡中呢?
|
||||
|
||||
你可以把关卡想成一系列项目的集合。就像你刚刚创建的这个平台中,一个关卡,包含了平台、敌人放置、赃物等的一个特定排列。你可以创建一个类,用来在你的玩家附近创建关卡。最终,当你创建了超过一个关卡,你就可以在你的玩家达到特定目标时,使用这个类生成下一个关卡。
|
||||
你可以把关卡想成一系列项目的集合。就像你刚刚创建的这个平台中,一个关卡,包含了平台、敌人放置、战利品等的一个特定排列。你可以创建一个类,用来在你的玩家附近创建关卡。最终,当你创建了一个以上的关卡,你就可以在你的玩家达到特定目标时,使用这个类生成下一个关卡。
|
||||
|
||||
将你写的用于生成敌人及其群组的代码,移动到一个每次生成新关卡时都会被调用的新函数中。你需要做一些修改,使得每次你创建新关卡时,你都能够创建一些敌人。
|
||||
|
||||
```
|
||||
class Level():
|
||||
|
||||
def bad(lvl,eloc):
|
||||
|
||||
if lvl == 1:
|
||||
|
||||
enemy = Enemy(eloc[0],eloc[1],'yeti.png') # 生成敌人
|
||||
|
||||
enemy_list = pygame.sprite.Group() # 生成敌人组
|
||||
|
||||
enemy_list.add(enemy) # 将敌人加入敌人组
|
||||
|
||||
if lvl == 2:
|
||||
|
||||
print("Level " + str(lvl) )
|
||||
|
||||
|
||||
|
||||
return enemy_list
|
||||
|
||||
```
|
||||
|
||||
`return` 语句确保了当你调用 `Level.bad` 方法时,你将会得到一个 `enemy_list` 变量包含了所有你定义的敌人。
|
||||
|
||||
因为你现在将创造敌人作为每个关卡的一部分,你的 `setup` 部分也需要做些更改。不同于创造一个敌人,取而代之的是你必须去定义敌人在那里生成,以及敌人属于哪个关卡。
|
||||
|
||||
```
|
||||
eloc = []
|
||||
|
||||
eloc = [200,20]
|
||||
|
||||
enemy_list = Level.bad( 1, eloc )
|
||||
|
||||
```
|
||||
|
||||
再次运行游戏来确认你的关卡生成正确。与往常一样,你应该会看到你的玩家,并且能看到你在本章节中添加的敌人。
|
||||
@ -140,31 +113,27 @@ enemy_list = Level.bad( 1, eloc )
|
||||
|
||||
一个敌人如果对玩家没有效果,那么它不太算得上是一个敌人。当玩家与敌人发生碰撞时,他们通常会对玩家造成伤害。
|
||||
|
||||
因为你可能想要去跟踪玩家的生命值,因此碰撞检测发生在 Player 类,而不是 Enemy 类中。当然如果你想,你也可以跟踪敌人的生命值。它们之间的逻辑与代码大体相似,现在,我们只需要跟踪玩家的生命值。
|
||||
因为你可能想要去跟踪玩家的生命值,因此碰撞检测发生在 `Player` 类,而不是 `Enemy` 类中。当然如果你想,你也可以跟踪敌人的生命值。它们之间的逻辑与代码大体相似,现在,我们只需要跟踪玩家的生命值。
|
||||
|
||||
为了跟踪玩家的生命值,你必须为它确定一个变量。代码示例中的第一行是上下文提示,那么将第二行代码添加到你的 Player 类中:
|
||||
|
||||
```
|
||||
self.frame = 0
|
||||
|
||||
self.health = 10
|
||||
|
||||
```
|
||||
|
||||
在你 Player 类的 `update` 方法中,添加如下代码块:
|
||||
在你 `Player` 类的 `update` 方法中,添加如下代码块:
|
||||
|
||||
```
|
||||
hit_list = pygame.sprite.spritecollide(self, enemy_list, False)
|
||||
|
||||
for enemy in hit_list:
|
||||
|
||||
self.health -= 1
|
||||
|
||||
print(self.health)
|
||||
|
||||
```
|
||||
|
||||
这段代码使用 Pygame 的 `sprite.spritecollide` 方法,建立了一个碰撞检测器,称作 `enemy_hit`。每当它的父类妖精(生成检测器的玩家妖精)的碰撞区触碰到 `enemy_list` 中的任一妖精的碰撞区时,碰撞检测器都会发出一个信号。当这个信号被接收,`for` 循环就会被触发,同时扣除一点玩家生命值。
|
||||
|
||||
一旦这段代码出现在你 Player 类的 `update` 方法,并且 `update` 方法在你的主循环中被调用,Pygame 会在每个时钟 tick 检测一次碰撞。
|
||||
一旦这段代码出现在你 `Player` 类的 `update` 方法,并且 `update` 方法在你的主循环中被调用,Pygame 会在每个时钟滴答中检测一次碰撞。
|
||||
|
||||
### 移动敌人
|
||||
|
||||
@ -176,60 +145,41 @@ enemy_list = Level.bad( 1, eloc )
|
||||
|
||||
举个例子,你告诉你的敌方妖精向右移动 10 步,向左移动 10 步。但敌方妖精不会计数,因此你需要创建一个变量来跟踪你的敌人已经移动了多少步,并根据计数变量的值来向左或向右移动你的敌人。
|
||||
|
||||
首先,在你的 Enemy 类中创建计数变量。添加以下代码示例中的最后一行代码:
|
||||
首先,在你的 `Enemy` 类中创建计数变量。添加以下代码示例中的最后一行代码:
|
||||
|
||||
```
|
||||
self.rect = self.image.get_rect()
|
||||
|
||||
self.rect.x = x
|
||||
|
||||
self.rect.y = y
|
||||
|
||||
self.counter = 0 # 计数变量
|
||||
|
||||
```
|
||||
|
||||
然后,在你的 Enemy 类中创建一个 `move` 方法。使用 if-else 循环来创建一个所谓的死循环:
|
||||
然后,在你的 `Enemy` 类中创建一个 `move` 方法。使用 if-else 循环来创建一个所谓的死循环:
|
||||
|
||||
* 如果计数在 0 到 100 之间,向右移动;
|
||||
* 如果计数在 100 到 200 之间,向左移动;
|
||||
* 如果计数大于 200,则将计数重置为 0。
|
||||
|
||||
|
||||
|
||||
死循环没有终点,因为循环判断条件永远为真,所以它将永远循环下去。在此情况下,计数器总是介于 0 到 100 或 100 到 200 之间,因此敌人会永远地从左向右再从右向左移动。
|
||||
|
||||
你用于敌人在每个方向上移动距离的具体值,取决于你的屏幕尺寸,更确切地说,取决于你的敌人移动的平台大小。从较小的值开始,依据习惯逐步提高数值。首先进行如下尝试:
|
||||
|
||||
```
|
||||
def move(self):
|
||||
|
||||
'''
|
||||
|
||||
敌人移动
|
||||
|
||||
'''
|
||||
|
||||
distance = 80
|
||||
|
||||
speed = 8
|
||||
|
||||
|
||||
|
||||
if self.counter >= 0 and self.counter <= distance:
|
||||
|
||||
self.rect.x += speed
|
||||
|
||||
elif self.counter >= distance and self.counter <= distance*2:
|
||||
|
||||
self.rect.x -= speed
|
||||
|
||||
else:
|
||||
|
||||
self.counter = 0
|
||||
|
||||
|
||||
|
||||
self.counter += 1
|
||||
|
||||
```
|
||||
|
||||
你可以根据需要调整距离和速度。
|
||||
@ -237,13 +187,11 @@ enemy_list = Level.bad( 1, eloc )
|
||||
当你现在启动游戏,这段代码有效果吗?
|
||||
|
||||
当然不,你应该也知道原因。你必须在主循环中调用 `move` 方法。如下示例代码中的第一行是上下文提示,那么添加最后两行代码:
|
||||
|
||||
```
|
||||
enemy_list.draw(world) #refresh enemy
|
||||
|
||||
for e in enemy_list:
|
||||
|
||||
e.move()
|
||||
|
||||
```
|
||||
|
||||
启动你的游戏看看当你打击敌人时发生了什么。你可能需要调整妖精的生成地点,使得你的玩家和敌人能够碰撞。当他们发生碰撞时,查看 [IDLE][6] 或 [Ninja-IDE][7] 的控制台,你可以看到生命值正在被扣除。
|
||||
@ -261,15 +209,15 @@ via: https://opensource.com/article/18/5/pygame-enemy
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[cycoe](https://github.com/cycoe)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[1]:https://opensource.com/article/17/10/python-101
|
||||
[2]:https://opensource.com/article/17/12/game-framework-python
|
||||
[3]:https://opensource.com/article/17/12/game-python-add-a-player
|
||||
[4]:https://opensource.com/article/17/12/game-python-moving-player
|
||||
[1]:https://linux.cn/article-9071-1.html
|
||||
[2]:https://linux.cn/article-10850-1.html
|
||||
[3]:https://linux.cn/article-10858-1.html
|
||||
[4]:https://linux.cn/article-10874-1.html
|
||||
[5]:https://opengameart.org
|
||||
[6]:https://docs.python.org/3/library/idle.html
|
||||
[7]:http://ninja-ide.org/
|
||||
@ -0,0 +1,130 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10830-1.html)
|
||||
[#]: subject: (How to use autofs to mount NFS shares)
|
||||
[#]: via: (https://opensource.com/article/18/6/using-autofs-mount-nfs-shares)
|
||||
[#]: author: (Alan Formy-Duval https://opensource.com/users/alanfdoss)
|
||||
|
||||
如何使用 autofs 挂载 NFS 共享
|
||||
======
|
||||
|
||||
> 给你的网络文件系统(NFS)配置一个基本的自动挂载功能。
|
||||
|
||||
|
||||
|
||||
大多数 Linux 文件系统在引导时挂载,并在系统运行时保持挂载状态。对于已在 `fstab` 中配置的任何远程文件系统也是如此。但是,有时你可能希望仅按需挂载远程文件系统。例如,通过减少网络带宽使用来提高性能,或出于安全原因隐藏或混淆某些目录。[autofs][1] 软件包提供此功能。在本文中,我将介绍如何配置基本的自动挂载。
|
||||
|
||||
首先做点假设:假设有台 NFS 服务器 `tree.mydatacenter.net` 已经启动并运行。另外假设一个名为 `ourfiles` 的数据目录还有供 Carl 和 Sarah 使用的用户目录,它们都由服务器共享。
|
||||
|
||||
一些最佳实践可以使工作更好:服务器上的用户和任何客户端工作站上的帐号有相同的用户 ID。此外,你的工作站和服务器应有相同的域名。检查相关配置文件应该确认。
|
||||
|
||||
```
|
||||
alan@workstation1:~$ sudo getent passwd carl sarah
|
||||
[sudo] password for alan:
|
||||
carl:x:1020:1020:Carl,,,:/home/carl:/bin/bash
|
||||
sarah:x:1021:1021:Sarah,,,:/home/sarah:/bin/bash
|
||||
|
||||
alan@workstation1:~$ sudo getent hosts
|
||||
127.0.0.1 localhost
|
||||
127.0.1.1 workstation1.mydatacenter.net workstation1
|
||||
10.10.1.5 tree.mydatacenter.net tree
|
||||
```
|
||||
|
||||
如你所见,客户端工作站和 NFS 服务器都在 `hosts` 文件中配置。我假设这是一个基本的家庭甚至小型办公室网络,可能缺乏适合的内部域名服务(即 DNS)。
|
||||
|
||||
### 安装软件包
|
||||
|
||||
你只需要安装两个软件包:用于 NFS 客户端的 `nfs-common` 和提供自动挂载的 `autofs`。
|
||||
|
||||
```
|
||||
alan@workstation1:~$ sudo apt-get install nfs-common autofs
|
||||
```
|
||||
|
||||
你可以验证 autofs 相关的文件是否已放在 `/etc` 目录中:
|
||||
|
||||
```
|
||||
alan@workstation1:~$ cd /etc; ll auto*
|
||||
-rw-r--r-- 1 root root 12596 Nov 19 2015 autofs.conf
|
||||
-rw-r--r-- 1 root root 857 Mar 10 2017 auto.master
|
||||
-rw-r--r-- 1 root root 708 Jul 6 2017 auto.misc
|
||||
-rwxr-xr-x 1 root root 1039 Nov 19 2015 auto.net*
|
||||
-rwxr-xr-x 1 root root 2191 Nov 19 2015 auto.smb*
|
||||
alan@workstation1:/etc$
|
||||
```
|
||||
|
||||
### 配置 autofs
|
||||
|
||||
现在你需要编辑其中几个文件并添加 `auto.home` 文件。首先,将以下两行添加到文件 `auto.master` 中:
|
||||
|
||||
```
|
||||
/mnt/tree /etc/auto.misc
|
||||
/home/tree /etc/auto.home
|
||||
```
|
||||
|
||||
每行以挂载 NFS 共享的目录开头。继续创建这些目录:
|
||||
|
||||
```
|
||||
alan@workstation1:/etc$ sudo mkdir /mnt/tree /home/tree
|
||||
```
|
||||
|
||||
接下来,将以下行添加到文件 `auto.misc`:
|
||||
|
||||
```
|
||||
ourfiles -fstype=nfs tree:/share/ourfiles
|
||||
```
|
||||
|
||||
该行表示 autofs 将挂载 `auto.master` 文件中匹配 `auto.misc` 的 `ourfiles` 共享。如上所示,这些文件将在 `/mnt/tree/ourfiles` 目录中。
|
||||
|
||||
第三步,使用以下行创建文件 `auto.home`:
|
||||
|
||||
```
|
||||
* -fstype=nfs tree:/home/&
|
||||
```
|
||||
|
||||
该行表示 autofs 将挂载 `auto.master` 文件中匹配 `auto.home` 的用户共享。在这种情况下,Carl 和 Sarah 的文件将分别在目录 `/home/tree/carl` 或 `/home/tree/sarah`中。星号 `*`(称为通配符)使每个用户的共享可以在登录时自动挂载。`&` 符号也可以作为表示服务器端用户目录的通配符。它们的主目录会相应地根据 `passwd` 文件映射。如果你更喜欢本地主目录,则无需执行此操作。相反,用户可以将其用作特定文件的简单远程存储。
|
||||
|
||||
最后,重启 `autofs` 守护进程,以便识别并加载这些配置的更改。
|
||||
|
||||
```
|
||||
alan@workstation1:/etc$ sudo service autofs restart
|
||||
```
|
||||
|
||||
### 测试 autofs
|
||||
|
||||
如果更改文件 `auto.master` 中的列出目录,并运行 `ls` 命令,那么不会立即看到任何内容。例如,切换到目录 `/mnt/tree`。首先,`ls` 的输出不会显示任何内容,但在运行 `cd ourfiles` 之后,将自动挂载 `ourfiles` 共享目录。 `cd` 命令也将被执行,你将进入新挂载的目录中。
|
||||
|
||||
```
|
||||
carl@workstation1:~$ cd /mnt/tree
|
||||
carl@workstation1:/mnt/tree$ ls
|
||||
carl@workstation1:/mnt/tree$ cd ourfiles
|
||||
carl@workstation1:/mnt/tree/ourfiles$
|
||||
```
|
||||
|
||||
为了进一步确认正常工作,`mount` 命令会显示已挂载共享的细节。
|
||||
|
||||
```
|
||||
carl@workstation1:~$ mount
|
||||
|
||||
tree:/mnt/share/ourfiles on /mnt/tree/ourfiles type nfs4 (rw,relatime,vers=4.0,rsize=131072,wsize=131072,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.10.1.22,local_lock=none,addr=10.10.1.5)
|
||||
|
||||
```
|
||||
|
||||
对于 Carl 和 Sarah,`/home/tree` 目录工作方式相同。
|
||||
|
||||
我发现在我的文件管理器中添加这些目录的书签很有用,可以用来快速访问。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/using-autofs-mount-nfs-shares
|
||||
|
||||
作者:[Alan Formy-Duval][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/alanfdoss
|
||||
[1]:https://wiki.archlinux.org/index.php/autofs
|
||||
@ -0,0 +1,86 @@
|
||||
Adobe Lightroom 的三个开源替代品
|
||||
=======
|
||||
|
||||
> 摄影师们:在没有 Lightroom 套件的情况下,可以看看这些 RAW 图像处理器。
|
||||
|
||||

|
||||
|
||||
如今智能手机的摄像功能已经完备到多数人认为可以代替传统摄影了。虽然这在傻瓜相机的市场中是个事实,但是对于许多摄影爱好者和专业摄影师看来,一个高端单反相机所能带来的照片景深、清晰度以及真实质感是口袋中的智能手机无法与之相比的。
|
||||
|
||||
所有的这些功能在便利性上要付出一些很小的代价;就像传统的胶片相机中的反色负片,单反照相得到的 RAW 格式文件必须预先处理才能印刷或编辑;因此对于单反相机,照片的后期处理是无可替代的,并且 首选应用就是 Adobe Lightroom。但是由于 Adobe Lightroom 的昂贵价格、基于订阅的定价模式以及专有许可证都使更多人开始关注其开源替代品。
|
||||
|
||||
Lightroom 有两大主要功能:处理 RAW 格式的图片文件,以及数字资产管理系统(DAM) —— 通过标签、评星以及其他元数据信息来简单清晰地整理照片。
|
||||
|
||||
在这篇文章中,我们将介绍三个开源的图片处理软件:Darktable、LightZone 以及 RawTherapee。所有的软件都有 DAM 系统,但没有任何一个具有 Lightroom 基于机器学习的图像分类和标签功能。如果你想要知道更多关于开源的 DAM 系统的软件,可以看 Terry Hacock 的文章:“[开源项目的 DAM 管理][2]”,他分享了他在自己的 [Lunatics!][3] 电影项目研究过的开源多媒体软件。
|
||||
|
||||
### Darktable
|
||||
|
||||
![Darktable][4]
|
||||
|
||||
类似其他两个软件,Darktable 可以处理 RAW 格式的图像并将它们转换成可用的文件格式 —— JPEG、PNG、TIFF、PPM、PFM 和 EXR,它同时支持 Google 和 Facebook 的在线相册,上传至 Flikr,通过邮件附件发送以及创建在线相册。
|
||||
|
||||
它有 61 个图像处理模块,可以调整图像的对比度、色调、明暗、色彩、噪点;添加水印;切割以及旋转;等等。如同另外两个软件一样,不论你做出多少次修改,这些修改都是“无损的” —— 你的初始 RAW 图像文件始终会被保存。
|
||||
|
||||
Darktable 可以从 400 多种相机型号中直接导入照片,以及有 JPEG、CR2、DNG、OpenEXR 和 PFM 等格式的支持。图像在一个数据库中显示,因此你可以轻易地过滤并查询这些元数据,包括了文字标签、评星以及颜色标签。软件同时支持 21 种语言,支持 Linux、MacOS、BSD、Solaris 11/GNOME 以及 Windows(Windows 版本是最新发布的,Darktable 声明它比起其他版本可能还有一些不完备之处,有一些未实现的功能)。
|
||||
|
||||
Darktable 在开源许可证 [GPLv3][7] 下发布,你可以了解更多它的 [特性][8],查阅它的 [用户手册][9],或者直接去 Github 上看[源代码][10] 。
|
||||
|
||||
### LightZone
|
||||
|
||||
![LightZone's tool stack][11]
|
||||
|
||||
[LightZone][12] 和其他两个软件类似同样是无损的 RAW 格式图像处理工具:它是跨平台的,有 Windows、MacOS 和 Linux 版本,除 RAW 格式之外,它还支持 JPG 和 TIFF 格式的图像处理。接下来说说 LightZone 其他独特特性。
|
||||
|
||||
这个软件最初在 2005 年时,是以专有许可证发布的图像处理软件,后来在 BSD 证书下开源。此外,在你下载这个软件之前,你必须注册一个免费账号,以便 LightZone的 开发团队可以跟踪软件的下载数量以及建立相关社区。(许可很快,而且是自动的,因此这不是一个很大的使用障碍。)
|
||||
|
||||
除此之外的一个特性是这个软件的图像处理通常是通过很多可组合的工具实现的,而不是叠加滤镜(就像大多数图像处理软件),这些工具组可以被重新编排以及移除,以及被保存并且复制用到另一些图像上。如果想要编辑图片的部分区域,你还可以通过矢量工具或者根据色彩和亮度来选择像素。
|
||||
|
||||
想要了解更多,见 LightZone 的[论坛][13] 或者查看 Github上的 [源代码][14]。
|
||||
|
||||
### RawTherapee
|
||||
|
||||
![RawTherapee][15]
|
||||
|
||||
[RawTherapee][16] 是另一个值得关注的开源([GPL][17])的 RAW 图像处理器。就像 Darktable 和 LightZone,它是跨平台的(支持 Windows、MacOS 和 Linux),一切修改都在无损条件下进行,因此不论你叠加多少滤镜做出多少改变,你都可以回到你最初的 RAW 文件。
|
||||
|
||||
RawTherapee 采用的是一个面板式的界面,包括一个历史记录面板来跟踪你做出的修改,以方便随时回到先前的图像;一个快照面板可以让你同时处理一张照片的不同版本;一个可滚动的工具面板可以方便准确地选择工具。这些工具包括了一系列的调整曝光、色彩、细节、图像变换以及去马赛克功能。
|
||||
|
||||
这个软件可以从多数相机直接导入 RAW 文件,并且支持超过 25 种语言,得到了广泛使用。批量处理以及 [SSE][18] 优化这类功能也进一步提高了图像处理的速度以及对 CPU 性能的利用。
|
||||
|
||||
RawTherapee 还提供了很多其他 [功能][19];可以查看它的 [官方文档][20] 以及 [源代码][21] 了解更多细节。
|
||||
|
||||
你是否在摄影中使用另外的开源 RAW 图像处理工具?有任何建议和推荐都可以在评论中分享。
|
||||
|
||||
------
|
||||
|
||||
via: https://opensource.com/alternatives/adobe-lightroom
|
||||
|
||||
作者:[Opensource.com][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[scoutydren](https://github.com/scoutydren)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com
|
||||
[1]: https://en.wikipedia.org/wiki/Raw_image_format
|
||||
[2]: https://opensource.com/article/18/3/movie-open-source-software
|
||||
[3]: http://lunatics.tv/
|
||||
[4]: https://opensource.com/sites/default/files/styles/panopoly_image_original/public/uploads/raw-image-processors_darkroom1.jpg?itok=0fjk37tC "Darktable"
|
||||
[5]: http://www.darktable.org/
|
||||
[6]: https://www.darktable.org/about/faq/#faq-windows
|
||||
[7]: https://github.com/darktable-org/darktable/blob/master/LICENSE
|
||||
[8]: https://www.darktable.org/about/features/
|
||||
[9]: https://www.darktable.org/resources/
|
||||
[10]: https://github.com/darktable-org/darktable
|
||||
[11]: https://opensource.com/sites/default/files/styles/panopoly_image_original/public/uploads/raw-image-processors_lightzone1tookstack.jpg?itok=1e3s85CZ
|
||||
[12]: http://www.lightzoneproject.org/
|
||||
[13]: http://www.lightzoneproject.org/Forum
|
||||
[14]: https://github.com/ktgw0316/LightZone
|
||||
[15]: https://opensource.com/sites/default/files/styles/panopoly_image_original/public/uploads/raw-image-processors_rawtherapee.jpg?itok=meiuLxPw "RawTherapee"
|
||||
[16]: http://rawtherapee.com/
|
||||
[17]: https://github.com/Beep6581/RawTherapee/blob/dev/LICENSE.txt
|
||||
[18]: https://en.wikipedia.org/wiki/Streaming_SIMD_Extensions
|
||||
[19]: http://rawpedia.rawtherapee.com/Features
|
||||
[20]: http://rawpedia.rawtherapee.com/Main_Page
|
||||
[21]: https://github.com/Beep6581/RawTherapee
|
||||
@ -0,0 +1,593 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (robsean)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10902-1.html)
|
||||
[#]: subject: (Put platforms in a Python game with Pygame)
|
||||
[#]: via: (https://opensource.com/article/18/7/put-platforms-python-game)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
在 Pygame 游戏中放置平台
|
||||
======
|
||||
|
||||
> 在这个从零构建一个 Python 游戏系列的第六部分中,为你的角色创建一些平台来旅行。
|
||||
|
||||

|
||||
|
||||
这是仍在进行中的关于使用 Pygame 模块来在 Python 3 中创建电脑游戏的系列文章的第六部分。先前的文章是:
|
||||
|
||||
+ [通过构建一个简单的掷骰子游戏去学习怎么用 Python 编程][24]
|
||||
+ [使用 Python 和 Pygame 模块构建一个游戏框架][25]
|
||||
+ [如何在你的 Python 游戏中添加一个玩家][26]
|
||||
+ [用 Pygame 使你的游戏角色移动起来][27]
|
||||
+ [如何向你的 Python 游戏中添加一个敌人][28]
|
||||
|
||||
一个平台类游戏需要平台。
|
||||
|
||||
在 [Pygame][1] 中,平台本身也是个妖精,正像你那个可玩的妖精。这一点是重要的,因为有个是对象的平台,可以使你的玩家妖精更容易与之互动。
|
||||
|
||||
创建平台有两个主要步骤。首先,你必须给该对象编写代码,然后,你必须映射出你希望该对象出现的位置。
|
||||
|
||||
### 编码平台对象
|
||||
|
||||
要构建一个平台对象,你要创建一个名为 `Platform` 的类。它是一个妖精,正像你的 `Player` [妖精][2] 一样,带有很多相同的属性。
|
||||
|
||||
你的 `Platform` 类需要知道很多平台类型的信息,它应该出现在游戏世界的哪里、它应该包含的什么图片等等。这其中很多信息可能还尚不存在,这要看你为你的游戏计划了多少,但是没有关系。正如直到[移动你的游戏角色][3]那篇文章结束时,你都没有告诉你的玩家妖精移动速度有多快,你不必事先告诉 `Platform` 每一件事。
|
||||
|
||||
在这系列中你所写的脚本的开头附近,创建一个新的类。在这个代码示例中前三行是用于说明上下文,因此在注释的下面添加代码:
|
||||
|
||||
```
|
||||
import pygame
|
||||
import sys
|
||||
import os
|
||||
## 新代码如下:
|
||||
|
||||
class Platform(pygame.sprite.Sprite):
|
||||
# x location, y location, img width, img height, img file
|
||||
def __init__(self,xloc,yloc,imgw,imgh,img):
|
||||
pygame.sprite.Sprite.__init__(self)
|
||||
self.image = pygame.image.load(os.path.join('images',img)).convert()
|
||||
self.image.convert_alpha()
|
||||
self.image.set_colorkey(ALPHA)
|
||||
self.rect = self.image.get_rect()
|
||||
self.rect.y = yloc
|
||||
self.rect.x = xloc
|
||||
```
|
||||
|
||||
当被调用时,这个类在某个 X 和 Y 位置上创建一个屏上对象,具有某种宽度和高度,并使用某种图像作为纹理。这与如何在屏上绘制出玩家或敌人非常类似。
|
||||
|
||||
### 平台的类型
|
||||
|
||||
下一步是绘制出你的平台需要出现的地方。
|
||||
|
||||
#### 瓷砖方式
|
||||
|
||||
实现平台类游戏世界有几种不同的方法。在最初的横向滚轴游戏中,例如,马里奥超级兄弟和刺猬索尼克,这个技巧是使用“瓷砖”方式,也就是说有几个代表地面和各种平台的块,并且这些块被重复使用来制作一个关卡。你只能有 8 或 12 种不同的块,你可以将它们排列在屏幕上来创建地面、浮动的平台,以及你游戏中需要的一切其它的事物。有人发现这是制作游戏最容易的方法了,因为你只需要制作(或下载)一小组关卡素材就能创建很多不同的关卡。然而,这里的代码需要一点数学知识。
|
||||
|
||||
![Supertux, a tile-based video game][5]
|
||||
|
||||
*[SuperTux][6] ,一个基于瓷砖的电脑游戏。*
|
||||
|
||||
#### 手工绘制方式
|
||||
|
||||
另一种方法是将每个素材作为一个整体图像。如果你喜欢为游戏世界创建素材,那你会在用图形应用程序构建游戏世界的每个部分上花费很多时间。这种方法不需要太多的数学知识,因为所有的平台都是整体的、完整的对象,你只需要告诉 [Python][7] 将它们放在屏幕上的什么位置。
|
||||
|
||||
每种方法都有优势和劣势,并且根据于你选择使用的方式,代码稍有不同。我将覆盖这两方面,所以你可以在你的工程中使用一种或另一种,甚至两者的混合。
|
||||
|
||||
### 关卡绘制
|
||||
|
||||
总的来说,绘制你的游戏世界是关卡设计和游戏编程中的一个重要的部分。这需要数学知识,但是没有什么太难的,而且 Python 擅长数学,它会有所帮助。
|
||||
|
||||
你也许发现先在纸张上设计是有用的。拿一张表格纸,并绘制一个方框来代表你的游戏窗体。在方框中绘制平台,并标记其每一个平台的 X 和 Y 坐标,以及它的宽度和高度。在方框中的实际位置没有必要是精确的,你只要保持数字合理即可。譬如,假设你的屏幕是 720 像素宽,那么你不能在一个屏幕上放 8 块 100 像素的平台。
|
||||
|
||||
当然,不是你游戏中的所有平台都必须容纳在一个屏幕大小的方框里,因为你的游戏将随着你的玩家行走而滚动。所以,可以继续绘制你的游戏世界到第一屏幕的右侧,直到关卡结束。
|
||||
|
||||
如果你更喜欢精确一点,你可以使用方格纸。当设计一个瓷砖类的游戏时,这是特别有用的,因为每个方格可以代表一个瓷砖。
|
||||
|
||||
![Example of a level map][9]
|
||||
|
||||
*一个关卡地图示例。*
|
||||
|
||||
#### 坐标系
|
||||
|
||||
你可能已经在学校中学习过[笛卡尔坐标系][10]。你学习的东西也适用于 Pygame,除了在 Pygame 中你的游戏世界的坐标系的原点 `0,0` 是放置在你的屏幕的左上角而不是在中间,是你在地理课上用过的坐标是在中间的。
|
||||
|
||||
![Example of coordinates in Pygame][12]
|
||||
|
||||
*在 Pygame 中的坐标示例。*
|
||||
|
||||
X 轴起始于最左边的 0,向右无限增加。Y 轴起始于屏幕顶部的 0,向下延伸。
|
||||
|
||||
#### 图片大小
|
||||
|
||||
如果你不知道你的玩家、敌人、平台是多大的,绘制出一个游戏世界是毫无意义的。你可以在图形程序中找到你的平台或瓷砖的尺寸。例如在 [Krita][13] 中,单击“图像”菜单,并选择“属性”。你可以在“属性”窗口的最顶部处找到它的尺寸。
|
||||
|
||||
另外,你也可以创建一个简单的 Python 脚本来告诉你的一个图像的尺寸。打开一个新的文本文件,并输入这些代码到其中:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
|
||||
from PIL import Image
|
||||
import os.path
|
||||
import sys
|
||||
|
||||
if len(sys.argv) > 1:
|
||||
print(sys.argv[1])
|
||||
else:
|
||||
sys.exit('Syntax: identify.py [filename]')
|
||||
|
||||
pic = sys.argv[1]
|
||||
dim = Image.open(pic)
|
||||
X = dim.size[0]
|
||||
Y = dim.size[1]
|
||||
|
||||
print(X,Y)
|
||||
```
|
||||
|
||||
保存该文本文件为 `identify.py`。
|
||||
|
||||
要使用这个脚本,你必须安装一些额外的 Python 模块,它们包含了这个脚本中新使用的关键字:
|
||||
|
||||
```
|
||||
$ pip3 install Pillow --user
|
||||
```
|
||||
|
||||
一旦安装好,在你游戏工程目录中运行这个脚本:
|
||||
|
||||
```
|
||||
$ python3 ./identify.py images/ground.png
|
||||
(1080, 97)
|
||||
```
|
||||
|
||||
在这个示例中,地面平台的图形的大小是 1080 像素宽和 97 像素高。
|
||||
|
||||
### 平台块
|
||||
|
||||
如果你选择单独地绘制每个素材,你必须创建想要插入到你的游戏世界中的几个平台和其它元素,每个素材都放在它自己的文件中。换句话说,你应该让每个素材都有一个文件,像这样:
|
||||
|
||||
![One image file per object][15]
|
||||
|
||||
*每个对象一个图形文件。*
|
||||
|
||||
你可以按照你希望的次数重复使用每个平台,只要确保每个文件仅包含一个平台。你不能使用一个文件包含全部素材,像这样:
|
||||
|
||||
![Your level cannot be one image file][17]
|
||||
|
||||
*你的关卡不能是一个图形文件。*
|
||||
|
||||
当你完成时,你可能希望你的游戏看起来像这样,但是如果你在一个大文件中创建你的关卡,你就没有方法从背景中区分出一个平台,因此,要么把对象绘制在它们自己的文件中,要么从一个更大的文件中裁剪出它们,并保存为单独的副本。
|
||||
|
||||
**注意:** 如同你的其它素材,你可以使用 [GIMP][18]、Krita、[MyPaint][19],或 [Inkscape][20] 来创建你的游戏素材。
|
||||
|
||||
平台出现在每个关卡开始的屏幕上,因此你必须在你的 `Level` 类中添加一个 `platform` 函数。在这里特例是地面平台,它重要到应该拥有它自己的一个组。通过把地面看作一组特殊类型的平台,你可以选择它是否滚动,或它上面是否可以站立,而其它平台可以漂浮在它上面。这取决于你。
|
||||
|
||||
添加这两个函数到你的 `Level` 类:
|
||||
|
||||
```
|
||||
def ground(lvl,x,y,w,h):
|
||||
ground_list = pygame.sprite.Group()
|
||||
if lvl == 1:
|
||||
ground = Platform(x,y,w,h,'block-ground.png')
|
||||
ground_list.add(ground)
|
||||
|
||||
if lvl == 2:
|
||||
print("Level " + str(lvl) )
|
||||
|
||||
return ground_list
|
||||
|
||||
def platform( lvl ):
|
||||
plat_list = pygame.sprite.Group()
|
||||
if lvl == 1:
|
||||
plat = Platform(200, worldy-97-128, 285,67,'block-big.png')
|
||||
plat_list.add(plat)
|
||||
plat = Platform(500, worldy-97-320, 197,54,'block-small.png')
|
||||
plat_list.add(plat)
|
||||
if lvl == 2:
|
||||
print("Level " + str(lvl) )
|
||||
|
||||
return plat_list
|
||||
```
|
||||
|
||||
`ground` 函数需要一个 X 和 Y 位置,以便 Pygame 知道在哪里放置地面平台。它也需要知道平台的宽度和高度,这样 Pygame 知道地面延伸到每个方向有多远。该函数使用你的 `Platform` 类来生成一个屏上对象,然后将这个对象添加到 `ground_list` 组。
|
||||
|
||||
`platform` 函数本质上是相同的,除了其有更多的平台。在这个示例中,仅有两个平台,但是你可以想有多少就有多少。在进入一个平台后,在列出另一个前你必须添加它到 `plat_list` 中。如果你不添加平台到组中,那么它将不出现在你的游戏中。
|
||||
|
||||
> **提示:** 很难想象你的游戏世界的 0 是在顶部,因为在真实世界中发生的情况是相反的;当估计你有多高时,你不会从上往下测量你自己,而是从脚到头顶来测量。
|
||||
>
|
||||
> 如果对你来说从“地面”上来构建你的游戏世界更容易,将 Y 轴值表示为负数可能有帮助。例如,你知道你的游戏世界的底部是 `worldy` 的值。因此 `worldy` 减去地面的高度(在这个示例中是 97)是你的玩家正常站立的位置。如果你的角色是 64 像素高,那么地面减去 128 正好是你的玩家的两倍高。事实上,一个放置在 128 像素处平台大约是相对于你的玩家的两层楼高度。一个平台在 -320 处比三层楼更高。等等。
|
||||
|
||||
正像你现在可能所知的,如果你不使用它们,你的类和函数是没有价值的。添加这些代码到你的设置部分(第一行只是上下文,所以添加最后两行):
|
||||
|
||||
```
|
||||
enemy_list = Level.bad( 1, eloc )
|
||||
ground_list = Level.ground( 1,0,worldy-97,1080,97 )
|
||||
plat_list = Level.platform( 1 )
|
||||
```
|
||||
|
||||
并把这些行加到你的主循环(再一次,第一行仅用于上下文):
|
||||
|
||||
```
|
||||
enemy_list.draw(world) # 刷新敌人
|
||||
ground_list.draw(world) # 刷新地面
|
||||
plat_list.draw(world) # 刷新平台
|
||||
```
|
||||
|
||||
### 瓷砖平台
|
||||
|
||||
瓷砖类游戏世界更容易制作,因为你只需要在前面绘制一些块,就能在游戏中一再使用它们创建每个平台。在像 [OpenGameArt.org][21] 这样的网站上甚至有一套瓷砖供你来使用。
|
||||
|
||||
`Platform` 类与在前面部分中的类是相同的。
|
||||
|
||||
`ground` 和 `platform` 在 `Level` 类中,然而,必须使用循环来计算使用多少块来创建每个平台。
|
||||
|
||||
如果你打算在你的游戏世界中有一个坚固的地面,这种地面是很简单的。你只需要从整个窗口的一边到另一边“克隆”你的地面瓷砖。例如,你可以创建一个 X 和 Y 值的列表来规定每个瓷砖应该放置的位置,然后使用一个循环来获取每个值并绘制每一个瓷砖。这仅是一个示例,所以不要添加这到你的代码:
|
||||
|
||||
```
|
||||
# Do not add this to your code
|
||||
gloc = [0,656,64,656,128,656,192,656,256,656,320,656,384,656]
|
||||
```
|
||||
|
||||
不过,如果你仔细看,你可以看到所有的 Y 值是相同的,X 值以 64 的增量不断地增加 —— 这就是瓷砖的大小。这种重复是精确地,是计算机擅长的,因此你可以使用一点数学逻辑来让计算机为你做所有的计算:
|
||||
|
||||
添加这些到你的脚本的设置部分:
|
||||
|
||||
```
|
||||
gloc = []
|
||||
tx = 64
|
||||
ty = 64
|
||||
|
||||
i=0
|
||||
while i <= (worldx/tx)+tx:
|
||||
gloc.append(i*tx)
|
||||
i=i+1
|
||||
|
||||
ground_list = Level.ground( 1,gloc,tx,ty )
|
||||
```
|
||||
|
||||
现在,不管你的窗口的大小,Python 会通过瓷砖的宽度分割游戏世界的宽度,并创建一个数组列表列出每个 X 值。这里不计算 Y 值,因为在平的地面上这个从不会变化。
|
||||
|
||||
为了在一个函数中使用数组,使用一个 `while` 循环,查看每个条目并在适当的位置添加一个地面瓷砖:
|
||||
|
||||
```
|
||||
def ground(lvl,gloc,tx,ty):
|
||||
ground_list = pygame.sprite.Group()
|
||||
i=0
|
||||
if lvl == 1:
|
||||
while i < len(gloc):
|
||||
ground = Platform(gloc[i],worldy-ty,tx,ty,'tile-ground.png')
|
||||
ground_list.add(ground)
|
||||
i=i+1
|
||||
|
||||
if lvl == 2:
|
||||
print("Level " + str(lvl) )
|
||||
|
||||
return ground_list
|
||||
```
|
||||
|
||||
除了 `while` 循环,这几乎与在上面一部分中提供的瓷砖类平台的 `ground` 函数的代码相同。
|
||||
|
||||
对于移动的平台,原理是相似的,但是这里有一些技巧可以使它简单。
|
||||
|
||||
你可以通过它的起始像素(它的 X 值)、距地面的高度(它的 Y 值)、绘制多少瓷砖来定义一个平台,而不是通过像素绘制每个平台。这样,你不必操心每个平台的宽度和高度。
|
||||
|
||||
这个技巧的逻辑有一点复杂,因此请仔细复制这些代码。有一个 `while` 循环嵌套在另一个 `while` 循环的内部,因为这个函数必须考虑每个数组项的三个值来成功地建造一个完整的平台。在这个示例中,这里仅有三个平台以 `ploc.append` 语句定义,但是你的游戏可能需要更多,因此你需要多少就定义多少。当然,有一些不会出现,因为它们远在屏幕外,但是一旦当你进行滚动时,它们将呈现在眼前。
|
||||
|
||||
```
|
||||
def platform(lvl,tx,ty):
|
||||
plat_list = pygame.sprite.Group()
|
||||
ploc = []
|
||||
i=0
|
||||
if lvl == 1:
|
||||
ploc.append((200,worldy-ty-128,3))
|
||||
ploc.append((300,worldy-ty-256,3))
|
||||
ploc.append((500,worldy-ty-128,4))
|
||||
while i < len(ploc):
|
||||
j=0
|
||||
while j <= ploc[i][2]:
|
||||
plat = Platform((ploc[i][0]+(j*tx)),ploc[i][1],tx,ty,'tile.png')
|
||||
plat_list.add(plat)
|
||||
j=j+1
|
||||
print('run' + str(i) + str(ploc[i]))
|
||||
i=i+1
|
||||
|
||||
if lvl == 2:
|
||||
print("Level " + str(lvl) )
|
||||
|
||||
return plat_list
|
||||
```
|
||||
|
||||
要让这些平台出现在你的游戏世界,它们必须出现在你的主循环中。如果你还没有这样做,添加这些行到你的主循环(再一次,第一行仅被用于上下文)中:
|
||||
|
||||
```
|
||||
enemy_list.draw(world) # 刷新敌人
|
||||
ground_list.draw(world) # 刷新地面
|
||||
plat_list.draw(world) # 刷新平台
|
||||
```
|
||||
|
||||
启动你的游戏,根据需要调整你的平台的放置位置。如果你看不见屏幕外产生的平台,不要担心;你不久后就可以修复它。
|
||||
|
||||
到目前为止,这是游戏的图片和代码:
|
||||
|
||||
![Pygame game][23]
|
||||
|
||||
*到目前为止,我们的 Pygame 平台。*
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
# draw a world
|
||||
# add a player and player control
|
||||
# add player movement
|
||||
# add enemy and basic collision
|
||||
# add platform
|
||||
|
||||
# GNU All-Permissive License
|
||||
# Copying and distribution of this file, with or without modification,
|
||||
# are permitted in any medium without royalty provided the copyright
|
||||
# notice and this notice are preserved. This file is offered as-is,
|
||||
# without any warranty.
|
||||
|
||||
import pygame
|
||||
import sys
|
||||
import os
|
||||
|
||||
'''
|
||||
Objects
|
||||
'''
|
||||
|
||||
class Platform(pygame.sprite.Sprite):
|
||||
# x location, y location, img width, img height, img file
|
||||
def __init__(self,xloc,yloc,imgw,imgh,img):
|
||||
pygame.sprite.Sprite.__init__(self)
|
||||
self.image = pygame.image.load(os.path.join('images',img)).convert()
|
||||
self.image.convert_alpha()
|
||||
self.rect = self.image.get_rect()
|
||||
self.rect.y = yloc
|
||||
self.rect.x = xloc
|
||||
|
||||
class Player(pygame.sprite.Sprite):
|
||||
'''
|
||||
Spawn a player
|
||||
'''
|
||||
def __init__(self):
|
||||
pygame.sprite.Sprite.__init__(self)
|
||||
self.movex = 0
|
||||
self.movey = 0
|
||||
self.frame = 0
|
||||
self.health = 10
|
||||
self.score = 1
|
||||
self.images = []
|
||||
for i in range(1,9):
|
||||
img = pygame.image.load(os.path.join('images','hero' + str(i) + '.png')).convert()
|
||||
img.convert_alpha()
|
||||
img.set_colorkey(ALPHA)
|
||||
self.images.append(img)
|
||||
self.image = self.images[0]
|
||||
self.rect = self.image.get_rect()
|
||||
|
||||
def control(self,x,y):
|
||||
'''
|
||||
control player movement
|
||||
'''
|
||||
self.movex += x
|
||||
self.movey += y
|
||||
|
||||
def update(self):
|
||||
'''
|
||||
Update sprite position
|
||||
'''
|
||||
|
||||
self.rect.x = self.rect.x + self.movex
|
||||
self.rect.y = self.rect.y + self.movey
|
||||
|
||||
# moving left
|
||||
if self.movex < 0:
|
||||
self.frame += 1
|
||||
if self.frame > ani*3:
|
||||
self.frame = 0
|
||||
self.image = self.images[self.frame//ani]
|
||||
|
||||
# moving right
|
||||
if self.movex > 0:
|
||||
self.frame += 1
|
||||
if self.frame > ani*3:
|
||||
self.frame = 0
|
||||
self.image = self.images[(self.frame//ani)+4]
|
||||
|
||||
# collisions
|
||||
enemy_hit_list = pygame.sprite.spritecollide(self, enemy_list, False)
|
||||
for enemy in enemy_hit_list:
|
||||
self.health -= 1
|
||||
print(self.health)
|
||||
|
||||
ground_hit_list = pygame.sprite.spritecollide(self, ground_list, False)
|
||||
for g in ground_hit_list:
|
||||
self.health -= 1
|
||||
print(self.health)
|
||||
|
||||
|
||||
class Enemy(pygame.sprite.Sprite):
|
||||
'''
|
||||
Spawn an enemy
|
||||
'''
|
||||
def __init__(self,x,y,img):
|
||||
pygame.sprite.Sprite.__init__(self)
|
||||
self.image = pygame.image.load(os.path.join('images',img))
|
||||
#self.image.convert_alpha()
|
||||
#self.image.set_colorkey(ALPHA)
|
||||
self.rect = self.image.get_rect()
|
||||
self.rect.x = x
|
||||
self.rect.y = y
|
||||
self.counter = 0
|
||||
|
||||
def move(self):
|
||||
'''
|
||||
enemy movement
|
||||
'''
|
||||
distance = 80
|
||||
speed = 8
|
||||
|
||||
if self.counter >= 0 and self.counter <= distance:
|
||||
self.rect.x += speed
|
||||
elif self.counter >= distance and self.counter <= distance*2:
|
||||
self.rect.x -= speed
|
||||
else:
|
||||
self.counter = 0
|
||||
|
||||
self.counter += 1
|
||||
|
||||
class Level():
|
||||
def bad(lvl,eloc):
|
||||
if lvl == 1:
|
||||
enemy = Enemy(eloc[0],eloc[1],'yeti.png') # spawn enemy
|
||||
enemy_list = pygame.sprite.Group() # create enemy group
|
||||
enemy_list.add(enemy) # add enemy to group
|
||||
|
||||
if lvl == 2:
|
||||
print("Level " + str(lvl) )
|
||||
|
||||
return enemy_list
|
||||
|
||||
def loot(lvl,lloc):
|
||||
print(lvl)
|
||||
|
||||
def ground(lvl,gloc,tx,ty):
|
||||
ground_list = pygame.sprite.Group()
|
||||
i=0
|
||||
if lvl == 1:
|
||||
while i < len(gloc):
|
||||
print("blockgen:" + str(i))
|
||||
ground = Platform(gloc[i],worldy-ty,tx,ty,'ground.png')
|
||||
ground_list.add(ground)
|
||||
i=i+1
|
||||
|
||||
if lvl == 2:
|
||||
print("Level " + str(lvl) )
|
||||
|
||||
return ground_list
|
||||
|
||||
'''
|
||||
Setup
|
||||
'''
|
||||
worldx = 960
|
||||
worldy = 720
|
||||
|
||||
fps = 40 # frame rate
|
||||
ani = 4 # animation cycles
|
||||
clock = pygame.time.Clock()
|
||||
pygame.init()
|
||||
main = True
|
||||
|
||||
BLUE = (25,25,200)
|
||||
BLACK = (23,23,23 )
|
||||
WHITE = (254,254,254)
|
||||
ALPHA = (0,255,0)
|
||||
|
||||
world = pygame.display.set_mode([worldx,worldy])
|
||||
backdrop = pygame.image.load(os.path.join('images','stage.png')).convert()
|
||||
backdropbox = world.get_rect()
|
||||
player = Player() # spawn player
|
||||
player.rect.x = 0
|
||||
player.rect.y = 0
|
||||
player_list = pygame.sprite.Group()
|
||||
player_list.add(player)
|
||||
steps = 10 # how fast to move
|
||||
|
||||
eloc = []
|
||||
eloc = [200,20]
|
||||
gloc = []
|
||||
#gloc = [0,630,64,630,128,630,192,630,256,630,320,630,384,630]
|
||||
tx = 64 #tile size
|
||||
ty = 64 #tile size
|
||||
|
||||
i=0
|
||||
while i <= (worldx/tx)+tx:
|
||||
gloc.append(i*tx)
|
||||
i=i+1
|
||||
print("block: " + str(i))
|
||||
|
||||
enemy_list = Level.bad( 1, eloc )
|
||||
ground_list = Level.ground( 1,gloc,tx,ty )
|
||||
|
||||
'''
|
||||
Main loop
|
||||
'''
|
||||
while main == True:
|
||||
for event in pygame.event.get():
|
||||
if event.type == pygame.QUIT:
|
||||
pygame.quit(); sys.exit()
|
||||
main = False
|
||||
|
||||
if event.type == pygame.KEYDOWN:
|
||||
if event.key == pygame.K_LEFT or event.key == ord('a'):
|
||||
player.control(-steps,0)
|
||||
if event.key == pygame.K_RIGHT or event.key == ord('d'):
|
||||
player.control(steps,0)
|
||||
if event.key == pygame.K_UP or event.key == ord('w'):
|
||||
print('jump')
|
||||
|
||||
if event.type == pygame.KEYUP:
|
||||
if event.key == pygame.K_LEFT or event.key == ord('a'):
|
||||
player.control(steps,0)
|
||||
if event.key == pygame.K_RIGHT or event.key == ord('d'):
|
||||
player.control(-steps,0)
|
||||
if event.key == ord('q'):
|
||||
pygame.quit()
|
||||
sys.exit()
|
||||
main = False
|
||||
|
||||
# world.fill(BLACK)
|
||||
world.blit(backdrop, backdropbox)
|
||||
player.update()
|
||||
player_list.draw(world) #refresh player position
|
||||
enemy_list.draw(world) # refresh enemies
|
||||
ground_list.draw(world) # refresh enemies
|
||||
for e in enemy_list:
|
||||
e.move()
|
||||
pygame.display.flip()
|
||||
clock.tick(fps)
|
||||
```
|
||||
|
||||
(LCTT 译注:到本文翻译完为止,该系列已经近一年没有继续更新了~)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/put-platforms-python-game
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[robsean](https://github.com/robsean)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.pygame.org/news
|
||||
[2]: https://opensource.com/article/17/12/game-python-add-a-player
|
||||
[3]: https://opensource.com/article/17/12/game-python-moving-player
|
||||
[4]: /file/403841
|
||||
[5]: https://opensource.com/sites/default/files/uploads/supertux.png (Supertux, a tile-based video game)
|
||||
[6]: https://www.supertux.org/
|
||||
[7]: https://www.python.org/
|
||||
[8]: /file/403861
|
||||
[9]: https://opensource.com/sites/default/files/uploads/layout.png (Example of a level map)
|
||||
[10]: https://en.wikipedia.org/wiki/Cartesian_coordinate_system
|
||||
[11]: /file/403871
|
||||
[12]: https://opensource.com/sites/default/files/uploads/pygame_coordinates.png (Example of coordinates in Pygame)
|
||||
[13]: https://krita.org/en/
|
||||
[14]: /file/403876
|
||||
[15]: https://opensource.com/sites/default/files/uploads/pygame_floating.png (One image file per object)
|
||||
[16]: /file/403881
|
||||
[17]: https://opensource.com/sites/default/files/uploads/pygame_flattened.png (Your level cannot be one image file)
|
||||
[18]: https://www.gimp.org/
|
||||
[19]: http://mypaint.org/about/
|
||||
[20]: https://inkscape.org/en/
|
||||
[21]: https://opengameart.org/content/simplified-platformer-pack
|
||||
[22]: /file/403886
|
||||
[23]: https://opensource.com/sites/default/files/uploads/pygame_platforms.jpg (Pygame game)
|
||||
[24]: https://linux.cn/article-9071-1.html
|
||||
[25]: https://linux.cn/article-10850-1.html
|
||||
[26]: https://linux.cn/article-10858-1.html
|
||||
[27]: https://linux.cn/article-10874-1.html
|
||||
[28]: https://linux.cn/article-10883-1.html
|
||||
|
||||
@ -0,0 +1,596 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10848-1.html)
|
||||
[#]: subject: (TLP – An Advanced Power Management Tool That Improve Battery Life On Linux Laptop)
|
||||
[#]: via: (https://www.2daygeek.com/tlp-increase-optimize-linux-laptop-battery-life/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
TLP:一个可以延长 Linux 笔记本电池寿命的高级电源管理工具
|
||||
======
|
||||
|
||||

|
||||
|
||||
笔记本电池是针对 Windows 操作系统进行了高度优化的,当我在笔记本电脑中使用 Windows 操作系统时,我已经意识到这一点,但对于 Linux 来说却不一样。
|
||||
|
||||
多年来,Linux 在电池优化方面取得了很大进步,但我们仍然需要做一些必要的事情来改善 Linux 中笔记本电脑的电池寿命。
|
||||
|
||||
当我考虑延长电池寿命时,我没有多少选择,但我觉得 TLP 对我来说是一个更好的解决方案,所以我会继续使用它。
|
||||
|
||||
在本教程中,我们将详细讨论 TLP 以延长电池寿命。
|
||||
|
||||
我们之前在我们的网站上写过三篇关于 Linux [笔记本电池节电工具][1] 的文章:[PowerTOP][2] 和 [电池充电状态][3]。
|
||||
|
||||
### TLP
|
||||
|
||||
[TLP][4] 是一款自由开源的高级电源管理工具,可在不进行任何配置更改的情况下延长电池寿命。
|
||||
|
||||
由于它的默认配置已针对电池寿命进行了优化,因此你可能只需要安装,然后就忘记它吧。
|
||||
|
||||
此外,它可以高度定制化,以满足你的特定要求。TLP 是一个具有自动后台任务的纯命令行工具。它不包含GUI。
|
||||
|
||||
TLP 适用于各种品牌的笔记本电脑。设置电池充电阈值仅适用于 IBM/Lenovo ThinkPad。
|
||||
|
||||
所有 TLP 设置都存储在 `/etc/default/tlp` 中。其默认配置提供了开箱即用的优化的节能设置。
|
||||
|
||||
以下 TLP 设置可用于自定义,如果需要,你可以相应地进行必要的更改。
|
||||
|
||||
### TLP 功能
|
||||
|
||||
* 内核笔记本电脑模式和脏缓冲区超时
|
||||
* 处理器频率调整,包括 “turbo boost”/“turbo core”
|
||||
* 限制最大/最小的 P 状态以控制 CPU 的功耗
|
||||
* HWP 能源性能提示
|
||||
* 用于多核/超线程的功率感知进程调度程序
|
||||
* 处理器性能与节能策略(`x86_energy_perf_policy`)
|
||||
* 硬盘高级电源管理级别(APM)和降速超时(按磁盘)
|
||||
* AHCI 链路电源管理(ALPM)与设备黑名单
|
||||
* PCIe 活动状态电源管理(PCIe ASPM)
|
||||
* PCI(e) 总线设备的运行时电源管理
|
||||
* Radeon 图形电源管理(KMS 和 DPM)
|
||||
* Wifi 省电模式
|
||||
* 关闭驱动器托架中的光盘驱动器
|
||||
* 音频省电模式
|
||||
* I/O 调度程序(按磁盘)
|
||||
* USB 自动暂停,支持设备黑名单/白名单(输入设备自动排除)
|
||||
* 在系统启动和关闭时启用或禁用集成的 wifi、蓝牙或 wwan 设备
|
||||
* 在系统启动时恢复无线电设备状态(从之前的关机时的状态)
|
||||
* 无线电设备向导:在网络连接/断开和停靠/取消停靠时切换无线电
|
||||
* 禁用 LAN 唤醒
|
||||
* 挂起/休眠后恢复集成的 WWAN 和蓝牙状态
|
||||
* 英特尔处理器的动态电源降低 —— 需要内核和 PHC-Patch 支持
|
||||
* 电池充电阈值 —— 仅限 ThinkPad
|
||||
* 重新校准电池 —— 仅限 ThinkPad
|
||||
|
||||
### 如何在 Linux 上安装 TLP
|
||||
|
||||
TLP 包在大多数发行版官方存储库中都可用,因此,使用发行版的 [包管理器][5] 来安装它。
|
||||
|
||||
对于 Fedora 系统,使用 [DNF 命令][6] 安装 TLP。
|
||||
|
||||
```
|
||||
$ sudo dnf install tlp tlp-rdw
|
||||
```
|
||||
|
||||
ThinkPad 需要一些附加软件包。
|
||||
|
||||
```
|
||||
$ sudo dnf install https://download1.rpmfusion.org/free/fedora/rpmfusion-free-release-$(rpm -E %fedora).noarch.rpm
|
||||
$ sudo dnf install http://repo.linrunner.de/fedora/tlp/repos/releases/tlp-release.fc$(rpm -E %fedora).noarch.rpm
|
||||
$ sudo dnf install akmod-tp_smapi akmod-acpi_call kernel-devel
|
||||
```
|
||||
|
||||
安装 smartmontool 以显示 tlp-stat 中 S.M.A.R.T. 数据。
|
||||
|
||||
```
|
||||
$ sudo dnf install smartmontools
|
||||
```
|
||||
|
||||
对于 Debian/Ubuntu 系统,使用 [APT-GET 命令][7] 或 [APT 命令][8] 安装 TLP。
|
||||
|
||||
```
|
||||
$ sudo apt install tlp tlp-rdw
|
||||
```
|
||||
|
||||
ThinkPad 需要一些附加软件包。
|
||||
|
||||
```
|
||||
$ sudo apt-get install tp-smapi-dkms acpi-call-dkms
|
||||
```
|
||||
|
||||
安装 smartmontool 以显示 tlp-stat 中 S.M.A.R.T. 数据。
|
||||
|
||||
```
|
||||
$ sudo apt-get install smartmontools
|
||||
```
|
||||
|
||||
当基于 Ubuntu 的系统的官方软件包过时时,请使用以下 PPA 存储库,该存储库提供最新版本。运行以下命令以使用 PPA 安装 TLP。
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:linrunner/tlp
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install tlp
|
||||
```
|
||||
|
||||
对于基于 Arch Linux 的系统,使用 [Pacman 命令][9] 安装 TLP。
|
||||
|
||||
```
|
||||
$ sudo pacman -S tlp tlp-rdw
|
||||
```
|
||||
|
||||
ThinkPad 需要一些附加软件包。
|
||||
|
||||
```
|
||||
$ pacman -S tp_smapi acpi_call
|
||||
```
|
||||
|
||||
安装 smartmontool 以显示 tlp-stat 中 S.M.A.R.T. 数据。
|
||||
|
||||
```
|
||||
$ sudo pacman -S smartmontools
|
||||
```
|
||||
|
||||
对于基于 Arch Linux 的系统,在启动时启用 TLP 和 TLP-Sleep 服务。
|
||||
|
||||
```
|
||||
$ sudo systemctl enable tlp.service
|
||||
$ sudo systemctl enable tlp-sleep.service
|
||||
```
|
||||
|
||||
对于基于 Arch Linux 的系统,你还应该屏蔽以下服务以避免冲突,并确保 TLP 的无线电设备切换选项的正确操作。
|
||||
|
||||
```
|
||||
$ sudo systemctl mask systemd-rfkill.service
|
||||
$ sudo systemctl mask systemd-rfkill.socket
|
||||
```
|
||||
|
||||
对于 RHEL/CentOS 系统,使用 [YUM 命令][10] 安装 TLP。
|
||||
|
||||
```
|
||||
$ sudo yum install tlp tlp-rdw
|
||||
```
|
||||
|
||||
安装 smartmontool 以显示 tlp-stat 中 S.M.A.R.T. 数据。
|
||||
|
||||
```
|
||||
$ sudo yum install smartmontools
|
||||
```
|
||||
|
||||
对于 openSUSE Leap 系统,使用 [Zypper 命令][11] 安装 TLP。
|
||||
|
||||
```
|
||||
$ sudo zypper install TLP
|
||||
```
|
||||
|
||||
安装 smartmontool 以显示 tlp-stat 中 S.M.A.R.T. 数据。
|
||||
|
||||
```
|
||||
$ sudo zypper install smartmontools
|
||||
```
|
||||
|
||||
成功安装 TLP 后,使用以下命令启动服务。
|
||||
|
||||
```
|
||||
$ systemctl start tlp.service
|
||||
```
|
||||
|
||||
### 使用方法
|
||||
|
||||
#### 显示电池信息
|
||||
|
||||
```
|
||||
$ sudo tlp-stat -b
|
||||
或
|
||||
$ sudo tlp-stat --battery
|
||||
```
|
||||
|
||||
```
|
||||
--- TLP 1.1 --------------------------------------------
|
||||
|
||||
+++ Battery Status
|
||||
/sys/class/power_supply/BAT0/manufacturer = SMP
|
||||
/sys/class/power_supply/BAT0/model_name = L14M4P23
|
||||
/sys/class/power_supply/BAT0/cycle_count = (not supported)
|
||||
/sys/class/power_supply/BAT0/energy_full_design = 60000 [mWh]
|
||||
/sys/class/power_supply/BAT0/energy_full = 48850 [mWh]
|
||||
/sys/class/power_supply/BAT0/energy_now = 48850 [mWh]
|
||||
/sys/class/power_supply/BAT0/power_now = 0 [mW]
|
||||
/sys/class/power_supply/BAT0/status = Full
|
||||
|
||||
Charge = 100.0 [%]
|
||||
Capacity = 81.4 [%]
|
||||
```
|
||||
|
||||
#### 显示磁盘信息
|
||||
|
||||
```
|
||||
$ sudo tlp-stat -d
|
||||
或
|
||||
$ sudo tlp-stat --disk
|
||||
```
|
||||
|
||||
```
|
||||
--- TLP 1.1 --------------------------------------------
|
||||
|
||||
+++ Storage Devices
|
||||
/dev/sda:
|
||||
Model = WDC WD10SPCX-24HWST1
|
||||
Firmware = 02.01A02
|
||||
APM Level = 128
|
||||
Status = active/idle
|
||||
Scheduler = mq-deadline
|
||||
|
||||
Runtime PM: control = on, autosuspend_delay = (not available)
|
||||
|
||||
SMART info:
|
||||
4 Start_Stop_Count = 18787
|
||||
5 Reallocated_Sector_Ct = 0
|
||||
9 Power_On_Hours = 606 [h]
|
||||
12 Power_Cycle_Count = 1792
|
||||
193 Load_Cycle_Count = 25775
|
||||
194 Temperature_Celsius = 31 [°C]
|
||||
|
||||
|
||||
+++ AHCI Link Power Management (ALPM)
|
||||
/sys/class/scsi_host/host0/link_power_management_policy = med_power_with_dipm
|
||||
/sys/class/scsi_host/host1/link_power_management_policy = med_power_with_dipm
|
||||
/sys/class/scsi_host/host2/link_power_management_policy = med_power_with_dipm
|
||||
/sys/class/scsi_host/host3/link_power_management_policy = med_power_with_dipm
|
||||
|
||||
+++ AHCI Host Controller Runtime Power Management
|
||||
/sys/bus/pci/devices/0000:00:17.0/ata1/power/control = on
|
||||
/sys/bus/pci/devices/0000:00:17.0/ata2/power/control = on
|
||||
/sys/bus/pci/devices/0000:00:17.0/ata3/power/control = on
|
||||
/sys/bus/pci/devices/0000:00:17.0/ata4/power/control = on
|
||||
```
|
||||
|
||||
#### 显示 PCI 设备信息
|
||||
|
||||
```
|
||||
$ sudo tlp-stat -e
|
||||
或
|
||||
$ sudo tlp-stat --pcie
|
||||
```
|
||||
|
||||
```
|
||||
$ sudo tlp-stat -e
|
||||
or
|
||||
$ sudo tlp-stat --pcie
|
||||
|
||||
--- TLP 1.1 --------------------------------------------
|
||||
|
||||
+++ Runtime Power Management
|
||||
Device blacklist = (not configured)
|
||||
Driver blacklist = amdgpu nouveau nvidia radeon pcieport
|
||||
|
||||
/sys/bus/pci/devices/0000:00:00.0/power/control = auto (0x060000, Host bridge, skl_uncore)
|
||||
/sys/bus/pci/devices/0000:00:01.0/power/control = auto (0x060400, PCI bridge, pcieport)
|
||||
/sys/bus/pci/devices/0000:00:02.0/power/control = auto (0x030000, VGA compatible controller, i915)
|
||||
/sys/bus/pci/devices/0000:00:14.0/power/control = auto (0x0c0330, USB controller, xhci_hcd)
|
||||
|
||||
......
|
||||
```
|
||||
|
||||
#### 显示图形卡信息
|
||||
|
||||
```
|
||||
$ sudo tlp-stat -g
|
||||
或
|
||||
$ sudo tlp-stat --graphics
|
||||
```
|
||||
|
||||
```
|
||||
--- TLP 1.1 --------------------------------------------
|
||||
|
||||
+++ Intel Graphics
|
||||
/sys/module/i915/parameters/enable_dc = -1 (use per-chip default)
|
||||
/sys/module/i915/parameters/enable_fbc = 1 (enabled)
|
||||
/sys/module/i915/parameters/enable_psr = 0 (disabled)
|
||||
/sys/module/i915/parameters/modeset = -1 (use per-chip default)
|
||||
```
|
||||
|
||||
#### 显示处理器信息
|
||||
|
||||
```
|
||||
$ sudo tlp-stat -p
|
||||
或
|
||||
$ sudo tlp-stat --processor
|
||||
```
|
||||
|
||||
```
|
||||
--- TLP 1.1 --------------------------------------------
|
||||
|
||||
+++ Processor
|
||||
CPU model = Intel(R) Core(TM) i7-6700HQ CPU @ 2.60GHz
|
||||
|
||||
/sys/devices/system/cpu/cpu0/cpufreq/scaling_driver = intel_pstate
|
||||
/sys/devices/system/cpu/cpu0/cpufreq/scaling_governor = powersave
|
||||
/sys/devices/system/cpu/cpu0/cpufreq/scaling_available_governors = performance powersave
|
||||
/sys/devices/system/cpu/cpu0/cpufreq/scaling_min_freq = 800000 [kHz]
|
||||
/sys/devices/system/cpu/cpu0/cpufreq/scaling_max_freq = 3500000 [kHz]
|
||||
/sys/devices/system/cpu/cpu0/cpufreq/energy_performance_preference = balance_power
|
||||
/sys/devices/system/cpu/cpu0/cpufreq/energy_performance_available_preferences = default performance balance_performance balance_power power
|
||||
|
||||
......
|
||||
|
||||
/sys/devices/system/cpu/intel_pstate/min_perf_pct = 22 [%]
|
||||
/sys/devices/system/cpu/intel_pstate/max_perf_pct = 100 [%]
|
||||
/sys/devices/system/cpu/intel_pstate/no_turbo = 0
|
||||
/sys/devices/system/cpu/intel_pstate/turbo_pct = 33 [%]
|
||||
/sys/devices/system/cpu/intel_pstate/num_pstates = 28
|
||||
|
||||
x86_energy_perf_policy: program not installed.
|
||||
|
||||
/sys/module/workqueue/parameters/power_efficient = Y
|
||||
/proc/sys/kernel/nmi_watchdog = 0
|
||||
|
||||
+++ Undervolting
|
||||
PHC kernel not available.
|
||||
```
|
||||
|
||||
#### 显示系统数据信息
|
||||
|
||||
```
|
||||
$ sudo tlp-stat -s
|
||||
或
|
||||
$ sudo tlp-stat --system
|
||||
```
|
||||
|
||||
```
|
||||
--- TLP 1.1 --------------------------------------------
|
||||
|
||||
+++ System Info
|
||||
System = LENOVO Lenovo ideapad Y700-15ISK 80NV
|
||||
BIOS = CDCN35WW
|
||||
Release = "Manjaro Linux"
|
||||
Kernel = 4.19.6-1-MANJARO #1 SMP PREEMPT Sat Dec 1 12:21:26 UTC 2018 x86_64
|
||||
/proc/cmdline = BOOT_IMAGE=/boot/vmlinuz-4.19-x86_64 root=UUID=69d9dd18-36be-4631-9ebb-78f05fe3217f rw quiet resume=UUID=a2092b92-af29-4760-8e68-7a201922573b
|
||||
Init system = systemd
|
||||
Boot mode = BIOS (CSM, Legacy)
|
||||
|
||||
+++ TLP Status
|
||||
State = enabled
|
||||
Last run = 11:04:00 IST, 596 sec(s) ago
|
||||
Mode = battery
|
||||
Power source = battery
|
||||
```
|
||||
|
||||
#### 显示温度和风扇速度信息
|
||||
|
||||
```
|
||||
$ sudo tlp-stat -t
|
||||
或
|
||||
$ sudo tlp-stat --temp
|
||||
```
|
||||
|
||||
```
|
||||
--- TLP 1.1 --------------------------------------------
|
||||
|
||||
+++ Temperatures
|
||||
CPU temp = 36 [°C]
|
||||
Fan speed = (not available)
|
||||
```
|
||||
|
||||
#### 显示 USB 设备数据信息
|
||||
|
||||
```
|
||||
$ sudo tlp-stat -u
|
||||
或
|
||||
$ sudo tlp-stat --usb
|
||||
```
|
||||
|
||||
```
|
||||
--- TLP 1.1 --------------------------------------------
|
||||
|
||||
+++ USB
|
||||
Autosuspend = disabled
|
||||
Device whitelist = (not configured)
|
||||
Device blacklist = (not configured)
|
||||
Bluetooth blacklist = disabled
|
||||
Phone blacklist = disabled
|
||||
WWAN blacklist = enabled
|
||||
|
||||
Bus 002 Device 001 ID 1d6b:0003 control = auto, autosuspend_delay_ms = 0 -- Linux Foundation 3.0 root hub (hub)
|
||||
Bus 001 Device 003 ID 174f:14e8 control = auto, autosuspend_delay_ms = 2000 -- Syntek (uvcvideo)
|
||||
|
||||
......
|
||||
```
|
||||
|
||||
#### 显示警告信息
|
||||
|
||||
```
|
||||
$ sudo tlp-stat -w
|
||||
或
|
||||
$ sudo tlp-stat --warn
|
||||
```
|
||||
|
||||
```
|
||||
--- TLP 1.1 --------------------------------------------
|
||||
|
||||
No warnings detected.
|
||||
```
|
||||
|
||||
#### 状态报告及配置和所有活动的设置
|
||||
|
||||
```
|
||||
$ sudo tlp-stat
|
||||
```
|
||||
|
||||
```
|
||||
--- TLP 1.1 --------------------------------------------
|
||||
|
||||
+++ Configured Settings: /etc/default/tlp
|
||||
TLP_ENABLE=1
|
||||
TLP_DEFAULT_MODE=AC
|
||||
TLP_PERSISTENT_DEFAULT=0
|
||||
DISK_IDLE_SECS_ON_AC=0
|
||||
DISK_IDLE_SECS_ON_BAT=2
|
||||
MAX_LOST_WORK_SECS_ON_AC=15
|
||||
MAX_LOST_WORK_SECS_ON_BAT=60
|
||||
|
||||
......
|
||||
|
||||
+++ System Info
|
||||
System = LENOVO Lenovo ideapad Y700-15ISK 80NV
|
||||
BIOS = CDCN35WW
|
||||
Release = "Manjaro Linux"
|
||||
Kernel = 4.19.6-1-MANJARO #1 SMP PREEMPT Sat Dec 1 12:21:26 UTC 2018 x86_64
|
||||
/proc/cmdline = BOOT_IMAGE=/boot/vmlinuz-4.19-x86_64 root=UUID=69d9dd18-36be-4631-9ebb-78f05fe3217f rw quiet resume=UUID=a2092b92-af29-4760-8e68-7a201922573b
|
||||
Init system = systemd
|
||||
Boot mode = BIOS (CSM, Legacy)
|
||||
|
||||
+++ TLP Status
|
||||
State = enabled
|
||||
Last run = 11:04:00 IST, 684 sec(s) ago
|
||||
Mode = battery
|
||||
Power source = battery
|
||||
|
||||
+++ Processor
|
||||
CPU model = Intel(R) Core(TM) i7-6700HQ CPU @ 2.60GHz
|
||||
|
||||
/sys/devices/system/cpu/cpu0/cpufreq/scaling_driver = intel_pstate
|
||||
/sys/devices/system/cpu/cpu0/cpufreq/scaling_governor = powersave
|
||||
/sys/devices/system/cpu/cpu0/cpufreq/scaling_available_governors = performance powersave
|
||||
|
||||
......
|
||||
|
||||
/sys/devices/system/cpu/intel_pstate/min_perf_pct = 22 [%]
|
||||
/sys/devices/system/cpu/intel_pstate/max_perf_pct = 100 [%]
|
||||
/sys/devices/system/cpu/intel_pstate/no_turbo = 0
|
||||
/sys/devices/system/cpu/intel_pstate/turbo_pct = 33 [%]
|
||||
/sys/devices/system/cpu/intel_pstate/num_pstates = 28
|
||||
|
||||
x86_energy_perf_policy: program not installed.
|
||||
|
||||
/sys/module/workqueue/parameters/power_efficient = Y
|
||||
/proc/sys/kernel/nmi_watchdog = 0
|
||||
|
||||
+++ Undervolting
|
||||
PHC kernel not available.
|
||||
|
||||
+++ Temperatures
|
||||
CPU temp = 42 [°C]
|
||||
Fan speed = (not available)
|
||||
|
||||
+++ File System
|
||||
/proc/sys/vm/laptop_mode = 2
|
||||
/proc/sys/vm/dirty_writeback_centisecs = 6000
|
||||
/proc/sys/vm/dirty_expire_centisecs = 6000
|
||||
/proc/sys/vm/dirty_ratio = 20
|
||||
/proc/sys/vm/dirty_background_ratio = 10
|
||||
|
||||
+++ Storage Devices
|
||||
/dev/sda:
|
||||
Model = WDC WD10SPCX-24HWST1
|
||||
Firmware = 02.01A02
|
||||
APM Level = 128
|
||||
Status = active/idle
|
||||
Scheduler = mq-deadline
|
||||
|
||||
Runtime PM: control = on, autosuspend_delay = (not available)
|
||||
|
||||
SMART info:
|
||||
4 Start_Stop_Count = 18787
|
||||
5 Reallocated_Sector_Ct = 0
|
||||
9 Power_On_Hours = 606 [h]
|
||||
12 Power_Cycle_Count = 1792
|
||||
193 Load_Cycle_Count = 25777
|
||||
194 Temperature_Celsius = 31 [°C]
|
||||
|
||||
|
||||
+++ AHCI Link Power Management (ALPM)
|
||||
/sys/class/scsi_host/host0/link_power_management_policy = med_power_with_dipm
|
||||
/sys/class/scsi_host/host1/link_power_management_policy = med_power_with_dipm
|
||||
/sys/class/scsi_host/host2/link_power_management_policy = med_power_with_dipm
|
||||
/sys/class/scsi_host/host3/link_power_management_policy = med_power_with_dipm
|
||||
|
||||
+++ AHCI Host Controller Runtime Power Management
|
||||
/sys/bus/pci/devices/0000:00:17.0/ata1/power/control = on
|
||||
/sys/bus/pci/devices/0000:00:17.0/ata2/power/control = on
|
||||
/sys/bus/pci/devices/0000:00:17.0/ata3/power/control = on
|
||||
/sys/bus/pci/devices/0000:00:17.0/ata4/power/control = on
|
||||
|
||||
+++ PCIe Active State Power Management
|
||||
/sys/module/pcie_aspm/parameters/policy = powersave
|
||||
|
||||
+++ Intel Graphics
|
||||
/sys/module/i915/parameters/enable_dc = -1 (use per-chip default)
|
||||
/sys/module/i915/parameters/enable_fbc = 1 (enabled)
|
||||
/sys/module/i915/parameters/enable_psr = 0 (disabled)
|
||||
/sys/module/i915/parameters/modeset = -1 (use per-chip default)
|
||||
|
||||
+++ Wireless
|
||||
bluetooth = on
|
||||
wifi = on
|
||||
wwan = none (no device)
|
||||
|
||||
hci0(btusb) : bluetooth, not connected
|
||||
wlp8s0(iwlwifi) : wifi, connected, power management = on
|
||||
|
||||
+++ Audio
|
||||
/sys/module/snd_hda_intel/parameters/power_save = 1
|
||||
/sys/module/snd_hda_intel/parameters/power_save_controller = Y
|
||||
|
||||
+++ Runtime Power Management
|
||||
Device blacklist = (not configured)
|
||||
Driver blacklist = amdgpu nouveau nvidia radeon pcieport
|
||||
|
||||
/sys/bus/pci/devices/0000:00:00.0/power/control = auto (0x060000, Host bridge, skl_uncore)
|
||||
/sys/bus/pci/devices/0000:00:01.0/power/control = auto (0x060400, PCI bridge, pcieport)
|
||||
/sys/bus/pci/devices/0000:00:02.0/power/control = auto (0x030000, VGA compatible controller, i915)
|
||||
|
||||
......
|
||||
|
||||
+++ USB
|
||||
Autosuspend = disabled
|
||||
Device whitelist = (not configured)
|
||||
Device blacklist = (not configured)
|
||||
Bluetooth blacklist = disabled
|
||||
Phone blacklist = disabled
|
||||
WWAN blacklist = enabled
|
||||
|
||||
Bus 002 Device 001 ID 1d6b:0003 control = auto, autosuspend_delay_ms = 0 -- Linux Foundation 3.0 root hub (hub)
|
||||
Bus 001 Device 003 ID 174f:14e8 control = auto, autosuspend_delay_ms = 2000 -- Syntek (uvcvideo)
|
||||
Bus 001 Device 002 ID 17ef:6053 control = on, autosuspend_delay_ms = 2000 -- Lenovo (usbhid)
|
||||
Bus 001 Device 004 ID 8087:0a2b control = auto, autosuspend_delay_ms = 2000 -- Intel Corp. (btusb)
|
||||
Bus 001 Device 001 ID 1d6b:0002 control = auto, autosuspend_delay_ms = 0 -- Linux Foundation 2.0 root hub (hub)
|
||||
|
||||
+++ Battery Status
|
||||
/sys/class/power_supply/BAT0/manufacturer = SMP
|
||||
/sys/class/power_supply/BAT0/model_name = L14M4P23
|
||||
/sys/class/power_supply/BAT0/cycle_count = (not supported)
|
||||
/sys/class/power_supply/BAT0/energy_full_design = 60000 [mWh]
|
||||
/sys/class/power_supply/BAT0/energy_full = 51690 [mWh]
|
||||
/sys/class/power_supply/BAT0/energy_now = 50140 [mWh]
|
||||
/sys/class/power_supply/BAT0/power_now = 12185 [mW]
|
||||
/sys/class/power_supply/BAT0/status = Discharging
|
||||
|
||||
Charge = 97.0 [%]
|
||||
Capacity = 86.2 [%]
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/tlp-increase-optimize-linux-laptop-battery-life/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/check-laptop-battery-status-and-charging-state-in-linux-terminal/
|
||||
[2]: https://www.2daygeek.com/powertop-monitors-laptop-battery-usage-linux/
|
||||
[3]: https://www.2daygeek.com/monitor-laptop-battery-charging-state-linux/
|
||||
[4]: https://linrunner.de/en/tlp/docs/tlp-linux-advanced-power-management.html
|
||||
[5]: https://www.2daygeek.com/category/package-management/
|
||||
[6]: https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
[7]: https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[8]: https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[9]: https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
|
||||
[10]: https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||
[11]: https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
|
||||
@ -0,0 +1,354 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (cycoe)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10874-1.html)
|
||||
[#]: subject: (Using Pygame to move your game character around)
|
||||
[#]: via: (https://opensource.com/article/17/12/game-python-moving-player)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
用 Pygame 使你的游戏角色移动起来
|
||||
======
|
||||
> 在本系列的第四部分,学习如何编写移动游戏角色的控制代码。
|
||||
|
||||

|
||||
|
||||
在这个系列的第一篇文章中,我解释了如何使用 Python 创建一个简单的[基于文本的骰子游戏][1]。在第二部分中,我向你们展示了如何从头开始构建游戏,即从 [创建游戏的环境][2] 开始。然后在第三部分,我们[创建了一个玩家妖精][3],并且使它在你的(而不是空的)游戏世界内生成。你可能已经注意到,如果你不能移动你的角色,那么游戏不是那么有趣。在本篇文章中,我们将使用 Pygame 来添加键盘控制,如此一来你就可以控制你的角色的移动。
|
||||
|
||||
在 Pygame 中有许多函数可以用来添加(除键盘外的)其他控制,但如果你正在敲击 Python 代码,那么你一定是有一个键盘的,这将成为我们接下来会使用的控制方式。一旦你理解了键盘控制,你可以自己去探索其他选项。
|
||||
|
||||
在本系列的第二篇文章中,你已经为退出游戏创建了一个按键,移动角色的(按键)原则也是相同的。但是,使你的角色移动起来要稍微复杂一点。
|
||||
|
||||
让我们从简单的部分入手:设置控制器按键。
|
||||
|
||||
### 为控制你的玩家妖精设置按键
|
||||
|
||||
在 IDLE、Ninja-IDE 或文本编辑器中打开你的 Python 游戏脚本。
|
||||
|
||||
因为游戏需要时刻“监听”键盘事件,所以你写的代码需要连续运行。你知道应该把需要在游戏周期中持续运行的代码放在哪里吗?
|
||||
|
||||
如果你回答“放在主循环中”,那么你是正确的!记住除非代码在循环中,否则(大多数情况下)它只会运行仅一次。如果它被写在一个从未被使用的类或函数中,它可能根本不会运行。
|
||||
|
||||
要使 Python 监听传入的按键,将如下代码添加到主循环。目前的代码还不能产生任何的效果,所以使用 `print` 语句来表示成功的信号。这是一种常见的调试技术。
|
||||
|
||||
```
|
||||
while main == True:
|
||||
for event in pygame.event.get():
|
||||
if event.type == pygame.QUIT:
|
||||
pygame.quit(); sys.exit()
|
||||
main = False
|
||||
|
||||
if event.type == pygame.KEYDOWN:
|
||||
if event.key == pygame.K_LEFT or event.key == ord('a'):
|
||||
print('left')
|
||||
if event.key == pygame.K_RIGHT or event.key == ord('d'):
|
||||
print('right')
|
||||
if event.key == pygame.K_UP or event.key == ord('w'):
|
||||
print('jump')
|
||||
|
||||
if event.type == pygame.KEYUP:
|
||||
if event.key == pygame.K_LEFT or event.key == ord('a'):
|
||||
print('left stop')
|
||||
if event.key == pygame.K_RIGHT or event.key == ord('d'):
|
||||
print('right stop')
|
||||
if event.key == ord('q'):
|
||||
pygame.quit()
|
||||
sys.exit()
|
||||
main = False
|
||||
```
|
||||
|
||||
一些人偏好使用键盘字母 `W`、`A`、`S` 和 `D` 来控制玩家角色,而另一些偏好使用方向键。因此确保你包含了两种选项。
|
||||
|
||||
注意:当你在编程时,同时考虑所有用户是非常重要的。如果你写代码只是为了自己运行,那么很可能你会成为你写的程序的唯一用户。更重要的是,如果你想找一个通过写代码赚钱的工作,你写的代码就应该让所有人都能运行。给你的用户选择权,比如提供使用方向键或 WASD 的选项,是一个优秀程序员的标志。
|
||||
|
||||
使用 Python 启动你的游戏,并在你按下“上下左右”方向键或 `A`、`D` 和 `W` 键的时候查看控制台窗口的输出。
|
||||
|
||||
```
|
||||
$ python ./your-name_game.py
|
||||
left
|
||||
left stop
|
||||
right
|
||||
right stop
|
||||
jump
|
||||
```
|
||||
|
||||
这验证了 Pygame 可以正确地检测按键。现在是时候来完成使妖精移动的艰巨任务了。
|
||||
|
||||
### 编写玩家移动函数
|
||||
|
||||
为了使你的妖精移动起来,你必须为你的妖精创建一个属性代表移动。当你的妖精没有在移动时,这个变量被设为 `0`。
|
||||
|
||||
如果你正在为你的妖精设置动画,或者你决定在将来为它设置动画,你还必须跟踪帧来使走路循环保持在轨迹上。
|
||||
|
||||
在 `Player` 类中创建如下变量。开头两行作为上下文对照(如果你一直跟着做,你的代码中就已经有这两行),因此只需要添加最后三行:
|
||||
|
||||
```
|
||||
def __init__(self):
|
||||
pygame.sprite.Sprite.__init__(self)
|
||||
self.movex = 0 # 沿 X 方向移动
|
||||
self.movey = 0 # 沿 Y 方向移动
|
||||
self.frame = 0 # 帧计数
|
||||
```
|
||||
|
||||
设置好了这些变量,是时候去为妖精移动编写代码了。
|
||||
|
||||
玩家妖精不需要时刻响应控制,有时它并没有在移动。控制妖精的代码,仅仅只是玩家妖精所有能做的事情中的一小部分。在 Python 中,当你想要使一个对象做某件事并独立于剩余其他代码时,你可以将你的新代码放入一个函数。Python 的函数以关键词 `def` 开头,(该关键词)代表了定义函数。
|
||||
|
||||
在你的 `Player` 类中创建如下函数,来为你的妖精在屏幕上的位置增加几个像素。现在先不要担心你增加几个像素,这将在后续的代码中确定。
|
||||
|
||||
```
|
||||
def control(self,x,y):
|
||||
'''
|
||||
控制玩家移动
|
||||
'''
|
||||
self.movex += x
|
||||
self.movey += y
|
||||
```
|
||||
|
||||
为了在 Pygame 中移动妖精,你需要告诉 Python 在新的位置重绘妖精,以及这个新位置在哪里。
|
||||
|
||||
因为玩家妖精并不总是在移动,所以更新只需要是 Player 类中的一个函数。将此函数添加前面创建的 `control` 函数之后。
|
||||
|
||||
要使妖精看起来像是在行走(或者飞行,或是你的妖精应该做的任何事),你需要在按下适当的键时改变它在屏幕上的位置。要让它在屏幕上移动,你需要将它的位置(由 `self.rect.x` 和 `self.rect.y` 属性指定)重新定义为当前位置加上已应用的任意 `movex` 或 `movey`。(移动的像素数量将在后续进行设置。)
|
||||
|
||||
```
|
||||
def update(self):
|
||||
'''
|
||||
更新妖精位置
|
||||
'''
|
||||
self.rect.x = self.rect.x + self.movex
|
||||
```
|
||||
|
||||
对 Y 方向做同样的处理:
|
||||
|
||||
```
|
||||
self.rect.y = self.rect.y + self.movey
|
||||
```
|
||||
|
||||
对于动画,在妖精移动时推进动画帧,并使用相应的动画帧作为玩家的图像:
|
||||
|
||||
```
|
||||
# 向左移动
|
||||
if self.movex < 0:
|
||||
self.frame += 1
|
||||
if self.frame > 3*ani:
|
||||
self.frame = 0
|
||||
self.image = self.images[self.frame//ani]
|
||||
|
||||
# 向右移动
|
||||
if self.movex > 0:
|
||||
self.frame += 1
|
||||
if self.frame > 3*ani:
|
||||
self.frame = 0
|
||||
self.image = self.images[(self.frame//ani)+4]
|
||||
```
|
||||
|
||||
通过设置一个变量来告诉代码为你的妖精位置增加多少像素,然后在触发你的玩家妖精的函数时使用这个变量。
|
||||
|
||||
首先,在你的设置部分创建这个变量。在如下代码中,开头两行是上下文对照,因此只需要在你的脚本中增加第三行代码:
|
||||
|
||||
```
|
||||
player_list = pygame.sprite.Group()
|
||||
player_list.add(player)
|
||||
steps = 10 # 移动多少个像素
|
||||
```
|
||||
|
||||
现在你已经有了适当的函数和变量,使用你的按键来触发函数并将变量传递给你的妖精。
|
||||
|
||||
为此,将主循环中的 `print` 语句替换为玩家妖精的名字(`player`)、函数(`.control`)以及你希望玩家妖精在每个循环中沿 X 轴和 Y 轴移动的步数。
|
||||
|
||||
```
|
||||
if event.type == pygame.KEYDOWN:
|
||||
if event.key == pygame.K_LEFT or event.key == ord('a'):
|
||||
player.control(-steps,0)
|
||||
if event.key == pygame.K_RIGHT or event.key == ord('d'):
|
||||
player.control(steps,0)
|
||||
if event.key == pygame.K_UP or event.key == ord('w'):
|
||||
print('jump')
|
||||
|
||||
if event.type == pygame.KEYUP:
|
||||
if event.key == pygame.K_LEFT or event.key == ord('a'):
|
||||
player.control(steps,0)
|
||||
if event.key == pygame.K_RIGHT or event.key == ord('d'):
|
||||
player.control(-steps,0)
|
||||
if event.key == ord('q'):
|
||||
pygame.quit()
|
||||
sys.exit()
|
||||
main = False
|
||||
```
|
||||
|
||||
记住,`steps` 变量代表了当一个按键被按下时,你的妖精会移动多少个像素。如果当你按下 `D` 或右方向键时,你的妖精的位置增加了 10 个像素。那么当你停止按下这个键时,你必须(将 `step`)减 10(`-steps`)来使你的妖精的动量回到 0。
|
||||
|
||||
现在尝试你的游戏。注意:它不会像你预想的那样运行。
|
||||
|
||||
为什么你的妖精仍无法移动?因为主循环还没有调用 `update` 函数。
|
||||
|
||||
将如下代码加入到你的主循环中来告诉 Python 更新你的玩家妖精的位置。增加带注释的那行:
|
||||
|
||||
```
|
||||
player.update() # 更新玩家位置
|
||||
player_list.draw(world)
|
||||
pygame.display.flip()
|
||||
clock.tick(fps)
|
||||
```
|
||||
|
||||
再次启动你的游戏来见证你的玩家妖精在你的命令下在屏幕上来回移动。现在还没有垂直方向的移动,因为这部分函数会被重力控制,不过这是另一篇文章中的课程了。
|
||||
|
||||
与此同时,如果你拥有一个摇杆,你可以尝试阅读 Pygame 中 [joystick][4] 模块相关的文档,看看你是否能通过这种方式让你的妖精移动起来。或者,看看你是否能通过[鼠标][5]与你的妖精互动。
|
||||
|
||||
最重要的是,玩的开心!
|
||||
|
||||
### 本教程中用到的所有代码
|
||||
|
||||
为了方便查阅,以下是目前本系列文章用到的所有代码。
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
# 绘制世界
|
||||
# 添加玩家和玩家控制
|
||||
# 添加玩家移动控制
|
||||
|
||||
# GNU All-Permissive License
|
||||
# Copying and distribution of this file, with or without modification,
|
||||
# are permitted in any medium without royalty provided the copyright
|
||||
# notice and this notice are preserved. This file is offered as-is,
|
||||
# without any warranty.
|
||||
|
||||
import pygame
|
||||
import sys
|
||||
import os
|
||||
|
||||
'''
|
||||
Objects
|
||||
'''
|
||||
|
||||
class Player(pygame.sprite.Sprite):
|
||||
'''
|
||||
生成玩家
|
||||
'''
|
||||
def __init__(self):
|
||||
pygame.sprite.Sprite.__init__(self)
|
||||
self.movex = 0
|
||||
self.movey = 0
|
||||
self.frame = 0
|
||||
self.images = []
|
||||
for i in range(1,5):
|
||||
img = pygame.image.load(os.path.join('images','hero' + str(i) + '.png')).convert()
|
||||
img.convert_alpha()
|
||||
img.set_colorkey(ALPHA)
|
||||
self.images.append(img)
|
||||
self.image = self.images[0]
|
||||
self.rect = self.image.get_rect()
|
||||
|
||||
def control(self,x,y):
|
||||
'''
|
||||
控制玩家移动
|
||||
'''
|
||||
self.movex += x
|
||||
self.movey += y
|
||||
|
||||
def update(self):
|
||||
'''
|
||||
更新妖精位置
|
||||
'''
|
||||
|
||||
self.rect.x = self.rect.x + self.movex
|
||||
self.rect.y = self.rect.y + self.movey
|
||||
|
||||
# 向左移动
|
||||
if self.movex < 0:
|
||||
self.frame += 1
|
||||
if self.frame > 3*ani:
|
||||
self.frame = 0
|
||||
self.image = self.images[self.frame//ani]
|
||||
|
||||
# 向右移动
|
||||
if self.movex > 0:
|
||||
self.frame += 1
|
||||
if self.frame > 3*ani:
|
||||
self.frame = 0
|
||||
self.image = self.images[(self.frame//ani)+4]
|
||||
|
||||
|
||||
'''
|
||||
设置
|
||||
'''
|
||||
worldx = 960
|
||||
worldy = 720
|
||||
|
||||
fps = 40 # 帧刷新率
|
||||
ani = 4 # 动画循环
|
||||
clock = pygame.time.Clock()
|
||||
pygame.init()
|
||||
main = True
|
||||
|
||||
BLUE = (25,25,200)
|
||||
BLACK = (23,23,23 )
|
||||
WHITE = (254,254,254)
|
||||
ALPHA = (0,255,0)
|
||||
|
||||
world = pygame.display.set_mode([worldx,worldy])
|
||||
backdrop = pygame.image.load(os.path.join('images','stage.png')).convert()
|
||||
backdropbox = world.get_rect()
|
||||
player = Player() # 生成玩家
|
||||
player.rect.x = 0
|
||||
player.rect.y = 0
|
||||
player_list = pygame.sprite.Group()
|
||||
player_list.add(player)
|
||||
steps = 10 # 移动速度
|
||||
|
||||
'''
|
||||
主循环
|
||||
'''
|
||||
while main == True:
|
||||
for event in pygame.event.get():
|
||||
if event.type == pygame.QUIT:
|
||||
pygame.quit(); sys.exit()
|
||||
main = False
|
||||
|
||||
if event.type == pygame.KEYDOWN:
|
||||
if event.key == pygame.K_LEFT or event.key == ord('a'):
|
||||
player.control(-steps,0)
|
||||
if event.key == pygame.K_RIGHT or event.key == ord('d'):
|
||||
player.control(steps,0)
|
||||
if event.key == pygame.K_UP or event.key == ord('w'):
|
||||
print('jump')
|
||||
|
||||
if event.type == pygame.KEYUP:
|
||||
if event.key == pygame.K_LEFT or event.key == ord('a'):
|
||||
player.control(steps,0)
|
||||
if event.key == pygame.K_RIGHT or event.key == ord('d'):
|
||||
player.control(-steps,0)
|
||||
if event.key == ord('q'):
|
||||
pygame.quit()
|
||||
sys.exit()
|
||||
main = False
|
||||
|
||||
# world.fill(BLACK)
|
||||
world.blit(backdrop, backdropbox)
|
||||
player.update()
|
||||
player_list.draw(world) # 更新玩家位置
|
||||
pygame.display.flip()
|
||||
clock.tick(fps)
|
||||
```
|
||||
|
||||
你已经学了很多,但还仍有许多可以做。在接下来的几篇文章中,你将实现添加敌方妖精、模拟重力等等。与此同时,练习 Python 吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/12/game-python-moving-player
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[cycoe](https://github.com/cycoe)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://linux.cn/article-9071-1.html
|
||||
[2]: https://linux.cn/article-10850-1.html
|
||||
[3]: https://linux.cn/article-10858-1.html
|
||||
[4]: http://pygame.org/docs/ref/joystick.html
|
||||
[5]: http://pygame.org/docs/ref/mouse.html#module-pygame.mouse
|
||||
172
published/201905/20190107 Aliases- To Protect and Serve.md
Normal file
172
published/201905/20190107 Aliases- To Protect and Serve.md
Normal file
@ -0,0 +1,172 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10918-1.html)
|
||||
[#]: subject: (Aliases: To Protect and Serve)
|
||||
[#]: via: (https://www.linux.com/blog/learn/2019/1/aliases-protect-and-serve)
|
||||
[#]: author: (Paul Brown https://www.linux.com/users/bro66)
|
||||
|
||||
命令别名:保护和服务
|
||||
======
|
||||
|
||||
> Linux shell 允许你将命令彼此链接在一起,一次触发执行复杂的操作,并且可以对此创建别名作为快捷方式。
|
||||
|
||||

|
||||
|
||||
让我们将继续我们的别名系列。到目前为止,你可能已经阅读了我们的[关于别名的第一篇文章][1],并且应该非常清楚它们是如何为你省去很多麻烦的最简单方法。例如,你已经看到它们帮助我们减少了输入,让我们看看别名派上用场的其他几个案例。
|
||||
|
||||
### 别名即快捷方式
|
||||
|
||||
Linux shell 最美妙的事情之一是可以使用数以万计的选项和把命令连接在一起执行真正复杂的操作。好吧,也许这种美丽是在旁观者的眼中的,但是我们觉得这个功能很实用。
|
||||
|
||||
不利的一面是,你经常需要记得难以记忆或难以打字出来的命令组合。比如说硬盘上的空间非常宝贵,而你想要做一些清洁工作。你的第一步可能是寻找隐藏在你的家目录里的东西。你可以用来判断的一个标准是查找不再使用的内容。`ls` 可以帮助你:
|
||||
|
||||
```
|
||||
ls -lct
|
||||
```
|
||||
|
||||
上面的命令显示了每个文件和目录的详细信息(`-l`),并显示了每一项上次访问的时间(`-c`),然后它按从最近访问到最少访问的顺序排序这个列表(`-t`)。
|
||||
|
||||
这难以记住吗?你可能不会每天都使用 `-c` 和 `-t` 选项,所以也许是吧。无论如何,定义一个别名,如:
|
||||
|
||||
```
|
||||
alias lt='ls -lct'
|
||||
```
|
||||
|
||||
会更容易一些。
|
||||
|
||||
然后,你也可能希望列表首先显示最旧的文件:
|
||||
|
||||
```
|
||||
alias lo='lt -F | tac'
|
||||
```
|
||||
|
||||
![aliases][3]
|
||||
|
||||
*图 1:使用 lt 和 lo 别名。*
|
||||
|
||||
这里有一些有趣的事情。首先,我们使用别名(`lt`)来创建另一个别名 —— 这是完全可以的。其次,我们将一个新参数传递给 `lt`(后者又通过 `lt` 别名的定义传递给了 `ls`)。
|
||||
|
||||
`-F` 选项会将特殊符号附加到项目的名称后,以便更好地区分常规文件(没有符号)和可执行文件(附加了 `*`)、目录文件(以 `/` 结尾),以及所有链接文件、符号链接文件(以 `@` 符号结尾)等等。`-F` 选项是当你回归到单色终端的日子里,没有其他方法可以轻松看到列表项之间的差异时用的。在这里使用它是因为当你将输出从 `lt` 传递到 `tac` 时,你会丢失 `ls` 的颜色。
|
||||
|
||||
第三件我们需要注意的事情是我们使用了管道。管道用于你将一个命令的输出传递给另外一个命令时。第二个命令可以使用这些输出作为它的输入。在包括 Bash 在内的许多 shell 里,你可以使用管道符(`|`) 来做传递。
|
||||
|
||||
在这里,你将来自 `lt -F` 的输出导给 `tac`。`tac` 这个命令有点玩笑的意思,你或许听说过 `cat` 命令,它名义上用于将文件彼此连接(con`cat`),而在实践中,它被用于将一个文件的内容打印到终端。`tac` 做的事情一样,但是它是以逆序将接收到的内容输出出来。明白了吗?`cat` 和 `tac`,技术人有时候也挺有趣的。
|
||||
|
||||
`cat` 和 `tac` 都能输出通过管道传递过来的内容,在这里,也就是一个按时间顺序排序的文件列表。
|
||||
|
||||
那么,在有些离题之后,最终我们得到的就是这个列表将当前目录中的文件和目录以新鲜度的逆序列出(即老的在前)。
|
||||
|
||||
最后你需要注意的是,当在当前目录或任何目录运行 `lt` 时:
|
||||
|
||||
```
|
||||
# 这可以工作:
|
||||
lt
|
||||
# 这也可以:
|
||||
lt /some/other/directory
|
||||
```
|
||||
|
||||
……而 `lo` 只能在当前目录奏效:
|
||||
|
||||
```
|
||||
# 这可工作:
|
||||
lo
|
||||
# 而这不行:
|
||||
lo /some/other/directory
|
||||
```
|
||||
|
||||
这是因为 Bash 会展开别名的组分。当你键入:
|
||||
|
||||
```
|
||||
lt /some/other/directory
|
||||
```
|
||||
|
||||
Bash 实际上运行的是:
|
||||
|
||||
```
|
||||
ls -lct /some/other/directory
|
||||
```
|
||||
|
||||
这是一个有效的 Bash 命令。
|
||||
|
||||
而当你键入:
|
||||
|
||||
```
|
||||
lo /some/other/directory
|
||||
```
|
||||
|
||||
Bash 试图运行:
|
||||
|
||||
```
|
||||
ls -lct -F | tac /some/other/directory
|
||||
```
|
||||
|
||||
这不是一个有效的命令,主要是因为 `/some/other/directory` 是个目录,而 `cat` 和 `tac` 不能用于目录。
|
||||
|
||||
### 更多的别名快捷方式
|
||||
|
||||
* `alias lll='ls -R'` 会打印出目录的内容,并深入到子目录里面打印子目录的内容,以及子目录的子目录,等等。这是一个查看一个目录下所有内容的方式。
|
||||
* `mkdir='mkdir -pv'` 可以让你一次性创建目录下的目录。按照 `mkdir` 的基本形式,要创建一个包含子目录的目录,你必须这样:
|
||||
|
||||
```
|
||||
mkdir newdir
|
||||
mkdir newdir/subdir
|
||||
```
|
||||
|
||||
或这样:
|
||||
|
||||
```
|
||||
mkdir -p newdir/subdir
|
||||
```
|
||||
|
||||
而用这个别名你将只需要这样就行:
|
||||
|
||||
```
|
||||
mkdir newdir/subdir
|
||||
```
|
||||
|
||||
你的新 `mkdir` 也会告诉你创建子目录时都做了什么。
|
||||
|
||||
### 别名也是一种保护
|
||||
|
||||
别名的另一个好处是它可以作为防止你意外地删除或覆写已有的文件的保护措施。你可能听说过这个 Linux 新用户的传言,当他们以 root 身份运行:
|
||||
|
||||
```
|
||||
rm -rf /
|
||||
```
|
||||
|
||||
整个系统就爆了。而决定输入如下命令的用户:
|
||||
|
||||
```
|
||||
rm -rf /some/directory/ *
|
||||
```
|
||||
|
||||
就很好地干掉了他们的家目录的全部内容。这里不小心键入的目录和 `*` 之间的那个空格有时候很容易就会被忽视掉。
|
||||
|
||||
这两种情况我们都可以通过 `alias rm='rm -i'` 别名来避免。`-i` 选项会使 `rm` 询问用户是否真的要做这个操作,在你对你的文件系统做出不可弥补的损失之前给你第二次机会。
|
||||
|
||||
对于 `cp` 也是一样,它能够覆盖一个文件而不会给你任何提示。创建一个类似 `alias cp='cp -i'` 来保持安全吧。
|
||||
|
||||
### 下一次
|
||||
|
||||
我们越来越深入到了脚本领域,下一次,我们将沿着这个方向,看看如何在命令行组合命令以给你真正的乐趣,并可靠地解决系统管理员每天面临的问题。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/2019/1/aliases-protect-and-serve
|
||||
|
||||
作者:[Paul Brown][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/bro66
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://linux.cn/article-10377-1.html
|
||||
[2]: https://www.linux.com/files/images/fig01png-0
|
||||
[3]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/fig01_0.png?itok=crqTm_va (aliases)
|
||||
[4]: https://www.linux.com/licenses/category/used-permission
|
||||
@ -0,0 +1,212 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (bodhix)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10804-1.html)
|
||||
[#]: subject: (How to Restart a Network in Ubuntu [Beginner’s Tip])
|
||||
[#]: via: (https://itsfoss.com/restart-network-ubuntu)
|
||||
[#]: author: (Sergiu https://itsfoss.com/author/sergiu/)
|
||||
|
||||
Linux 初学者:如何在 Ubuntu 中重启网络
|
||||
======
|
||||
|
||||
你[是否正在使用基于 Ubuntu 的系统,然后发现无法连接网络][1]?你一定会很惊讶,很多的问题都可以简单地通过重启服务解决。
|
||||
|
||||
在这篇文章中,我会介绍在 Ubuntu 或者其他 Linux 发行版中重启网络的几种方法,你可以根据自身需要选择对应的方法。这些方法基本分为两类:
|
||||
|
||||
![Ubuntu Restart Network][2]
|
||||
|
||||
### 通过命令行方式重启网络
|
||||
|
||||
如果你使用的 Ubuntu 服务器版,那么你已经在使用命令行终端了。如果你使用的是桌面版,那么你可以通过快捷键 `Ctrl+Alt+T` [Ubuntu 键盘快捷键][3] 打开命令行终端。
|
||||
|
||||
在 Ubuntu 中,有多个命令可以重启网络。这些命令,一部分或者说大部分,也适用于在 Debian 或者其他的 Linux 发行版中重启网络。
|
||||
|
||||
#### 1、network manager 服务
|
||||
|
||||
这是通过命令行方式重启网络最简单的方法。它相当于是通过图形化界面重启网络(重启 Network-Manager 服务)。
|
||||
|
||||
```
|
||||
sudo service network-manager restart
|
||||
```
|
||||
|
||||
此时,网络图标会消失一会儿然后重新显示。
|
||||
|
||||
#### 2、systemd
|
||||
|
||||
`service` 命令仅仅是这个方式的一个封装(同样的也是 init.d 系列脚本和 Upstart 相关命令的封装)。`systemctl` 命令的功能远多于 `service` 命令。通常我更喜欢使用这个命令。
|
||||
|
||||
```
|
||||
sudo systemctl restart NetworkManager.service
|
||||
```
|
||||
|
||||
这时,网络图标又会消失一会儿。 如果你想了解 `systemctl` 的其他选项, 可以参考 man 帮助文档。
|
||||
|
||||
#### 3、nmcli
|
||||
|
||||
这是 Linux 上可以管理网络的另一个工具。这是一个功能强大而且实用的工具。很多系统管理员都喜欢使用该工具,因为它非常容易使用。
|
||||
|
||||
这种方法有两个操作步骤:关闭网络,再开启网络。
|
||||
|
||||
```
|
||||
sudo nmcli networking off
|
||||
```
|
||||
|
||||
这样就会关闭网络,网络图标会消失。接下来,再开启网络:
|
||||
|
||||
```
|
||||
sudo nmcli networking on
|
||||
```
|
||||
|
||||
你可以通过 man 帮助文档了解 nmcli 的更多用法。
|
||||
|
||||
#### 4、ifup & ifdown
|
||||
|
||||
这两个命令直接操作网口,切换网口是否可以收发包的状态。这是 [Linux 中最应该了解的网络命令][4] 之一。
|
||||
|
||||
使用 `ifdown` 关闭所有网口,再使用 `ifup` 重新启用网口。
|
||||
|
||||
通常推荐的做法是将这两个命令一起使用。
|
||||
|
||||
```
|
||||
sudo ifdown -a && sudo ifup -a
|
||||
```
|
||||
|
||||
注意:这种方法不会让网络图标从系统托盘中消失,另外,各种网络连接也会断。
|
||||
|
||||
#### 补充工具: nmtui
|
||||
|
||||
这是系统管理员们常用的另外一种方法。它是在命令行终端中管理网络的文本菜单工具。
|
||||
|
||||
```
|
||||
nmtui
|
||||
```
|
||||
|
||||
打开如下菜单:
|
||||
|
||||
![nmtui Menu][5]
|
||||
|
||||
注意:在 nmtui 中,可以通过 `up` 和 `down` 方向键选择选项。
|
||||
|
||||
选择 “Activate a connection”:
|
||||
|
||||
![nmtui Menu Select "Activate a connection"][6]
|
||||
|
||||
按下回车键,打开 “connections” 菜单。
|
||||
|
||||
![nmtui Connections Menu][7]
|
||||
|
||||
接下来,选择前面带星号(*)的网络。在这个例子中,就是 MGEO72。
|
||||
|
||||
![Select your connection in the nmtui connections menu.][8]
|
||||
|
||||
按下回车键。 这就将“停用”你的网络连接。
|
||||
|
||||
![nmtui Connections Menu with no active connection][9]
|
||||
|
||||
选择你要连接的网络:
|
||||
|
||||
![Select the connection you want in the nmtui connections menu.][10]
|
||||
|
||||
按下回车键。这样就重新激活了所选择的网络连接。
|
||||
|
||||
![nmtui Connections Menu][11]
|
||||
|
||||
按下 `Tab` 键两次,选择 “Back”:
|
||||
|
||||
![Select "Back" in the nmtui connections menu.][12]
|
||||
|
||||
按下回车键,回到 nmtui 的主菜单。
|
||||
|
||||
![nmtui Main Menu][13]
|
||||
|
||||
选择 “Quit” :
|
||||
|
||||
![nmtui Quit Main Menu][14]
|
||||
|
||||
退出该界面,返回到命令行终端。
|
||||
|
||||
就这样,你已经成功重启网络了。
|
||||
|
||||
### 通过图形化界面重启网络
|
||||
|
||||
显然,这是 Ubuntu 桌面版用户重启网络最简单的方法。如果这个方法不生效,你可以尝试使用前文提到的命令行方式重启网络。
|
||||
|
||||
NM 小程序是 [NetworkManager][15] 的系统托盘程序标志。我们将使用它来重启网络。
|
||||
|
||||
首先,查看顶部状态栏。你会在系统托盘找到一个网络图标 (因为我使用 Wi-Fi,所以这里是一个 Wi-Fi 图标)。
|
||||
|
||||
接下来,点击该图标(也可以点击音量图标或电池图标)。打开菜单。选择 “Turn Off” 关闭网络。
|
||||
|
||||
![Restart network in Ubuntu][16]
|
||||
|
||||
网络图标会在状态栏中消失,这表示你已经成功关闭网络了。
|
||||
|
||||
再次点击系统托盘重新打开菜单,选择 “Turn On”,重新开启网络。
|
||||
|
||||
![Restarting network in Ubuntu][17]
|
||||
|
||||
恭喜!你现在已经重启你的网络了。
|
||||
|
||||
#### 其他提示:刷新可用网络列表
|
||||
|
||||
如果你已经连接上一个网络,但是你想连接到另外一个网络,你如何刷新 WiFi 列表,查找其他可用的网络呢?我来向你展示一下。
|
||||
|
||||
Ubuntu 没有可以直接 “刷新 WiFi 网络” 的选项,它有点隐蔽。
|
||||
|
||||
你需要再次打开配置菜单,然后点击 “Select Network” 。
|
||||
|
||||
![Refresh wifi network list in Ubuntu][18]
|
||||
|
||||
选择对应的网络修改你的 WiFi 连接。
|
||||
|
||||
你无法马上看到可用的无线网络列表。打开网络列表之后,大概需要 5 秒才会显示其它可用的无线网络。
|
||||
|
||||
![Select another wifi network in Ubuntu][19]
|
||||
|
||||
等待大概 5 秒钟,看到其他可用的网络。
|
||||
|
||||
现在,你就可以选择你想要连接的网络,点击连接。这样就完成了。
|
||||
|
||||
### 总结
|
||||
|
||||
重启网络连接是每个 Linux 用户在使用过程中必须经历的事情。
|
||||
|
||||
我们希望这些方法可以帮助你处理这样的问题!
|
||||
|
||||
你是如何重启或管理你的网络的?我们是否还有遗漏的?请在下方留言。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/restart-network-ubuntu
|
||||
|
||||
作者:[Sergiu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[bodhix](https://github.com/bodhix)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/sergiu/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/fix-no-wireless-network-ubuntu/
|
||||
[2]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/03/ubuntu-restart-network.png?resize=800%2C450&ssl=1
|
||||
[3]: https://itsfoss.com/ubuntu-shortcuts/
|
||||
[4]: https://itsfoss.com/basic-linux-networking-commands/
|
||||
[5]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/03/nmtui_menu.png?fit=800%2C602&ssl=1
|
||||
[6]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/03/nmtui_menu_select_option.png?fit=800%2C579&ssl=1
|
||||
[7]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/03/nmui_connection_menu_on.png?fit=800%2C585&ssl=1
|
||||
[8]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/03/nmui_select_connection_on.png?fit=800%2C576&ssl=1
|
||||
[9]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/03/nmui_connection_menu_off.png?fit=800%2C572&ssl=1
|
||||
[10]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/03/nmui_select_connection_off.png?fit=800%2C566&ssl=1
|
||||
[11]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/03/nmui_connection_menu_on-1.png?fit=800%2C585&ssl=1
|
||||
[12]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/03/nmui_connection_menu_back.png?fit=800%2C585&ssl=1
|
||||
[13]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/03/nmtui_menu_select_option-1.png?fit=800%2C579&ssl=1
|
||||
[14]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/03/nmui_menu_quit.png?fit=800%2C580&ssl=1
|
||||
[15]: https://wiki.gnome.org/Projects/NetworkManager
|
||||
[16]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/03/restart-network-ubuntu-1.jpg?resize=800%2C400&ssl=1
|
||||
[17]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/03/restart-network-ubuntu-2.jpg?resize=800%2C400&ssl=1
|
||||
[18]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/03/select-wifi-network-ubuntu.jpg?resize=800%2C400&ssl=1
|
||||
[19]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/03/select-wifi-network-ubuntu-1.jpg?resize=800%2C400&ssl=1
|
||||
[20]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/03/ubuntu-restart-network.png?fit=800%2C450&ssl=1
|
||||
@ -0,0 +1,210 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10884-1.html)
|
||||
[#]: subject: (Virtual filesystems in Linux: Why we need them and how they work)
|
||||
[#]: via: (https://opensource.com/article/19/3/virtual-filesystems-linux)
|
||||
[#]: author: (Alison Chariken )
|
||||
|
||||
详解 Linux 中的虚拟文件系统
|
||||
======
|
||||
|
||||
> 虚拟文件系统是一种神奇的抽象,它使得 “一切皆文件” 哲学在 Linux 中成为了可能。
|
||||
|
||||

|
||||
|
||||
什么是文件系统?根据早期的 Linux 贡献者和作家 [Robert Love][1] 所说,“文件系统是一个遵循特定结构的数据的分层存储。” 不过,这种描述也同样适用于 VFAT(<ruby>虚拟文件分配表<rt>Virtual File Allocation Table</rt></ruby>)、Git 和[Cassandra][2](一种 [NoSQL 数据库][3])。那么如何区别文件系统呢?
|
||||
|
||||
### 文件系统基础概念
|
||||
|
||||
Linux 内核要求文件系统必须是实体,它还必须在持久对象上实现 `open()`、`read()` 和 `write()` 方法,并且这些实体需要有与之关联的名字。从 [面向对象编程][4] 的角度来看,内核将通用文件系统视为一个抽象接口,这三大函数是“虚拟”的,没有默认定义。因此,内核的默认文件系统实现被称为虚拟文件系统(VFS)。
|
||||
|
||||
![][5]
|
||||
|
||||
*如果我们能够 `open()`、`read()` 和 `write()`,它就是一个文件,如这个主控台会话所示。*
|
||||
|
||||
VFS 是著名的类 Unix 系统中 “一切皆文件” 概念的基础。让我们看一下它有多奇怪,上面的小小演示体现了字符设备 `/dev/console` 实际的工作。该图显示了一个在虚拟电传打字控制台(tty)上的交互式 Bash 会话。将一个字符串发送到虚拟控制台设备会使其显示在虚拟屏幕上。而 VFS 甚至还有其它更奇怪的属性。例如,它[可以在其中寻址][6]。
|
||||
|
||||
我们熟悉的文件系统如 ext4、NFS 和 /proc 都在名为 [file_operations] [7] 的 C 语言数据结构中提供了三大函数的定义。此外,个别的文件系统会以熟悉的面向对象的方式扩展和覆盖了 VFS 功能。正如 Robert Love 指出的那样,VFS 的抽象使 Linux 用户可以轻松地将文件复制到(或复制自)外部操作系统或抽象实体(如管道),而无需担心其内部数据格式。在用户空间这一侧,通过系统调用,进程可以使用文件系统方法之一 `read()` 从文件复制到内核的数据结构中,然后使用另一种文件系统的方法 `write()` 输出数据。
|
||||
|
||||
属于 VFS 基本类型的函数定义本身可以在内核源代码的 [fs/*.c 文件][8] 中找到,而 `fs/` 的子目录中包含了特定的文件系统。内核还包含了类似文件系统的实体,例如 cgroup、`/dev` 和 tmpfs,在引导过程的早期需要它们,因此定义在内核的 `init/` 子目录中。请注意,cgroup、`/dev` 和 tmpfs 不会调用 `file_operations` 的三大函数,而是直接读取和写入内存。
|
||||
|
||||
下图大致说明了用户空间如何访问通常挂载在 Linux 系统上的各种类型文件系统。像管道、dmesg 和 POSIX 时钟这样的结构在此图中未显示,它们也实现了 `struct file_operations`,而且其访问也要通过 VFS 层。
|
||||
|
||||
![How userspace accesses various types of filesystems][9]
|
||||
|
||||
VFS 是个“垫片层”,位于系统调用和特定 `file_operations` 的实现(如 ext4 和 procfs)之间。然后,`file_operations` 函数可以与特定于设备的驱动程序或内存访问器进行通信。tmpfs、devtmpfs 和 cgroup 不使用 `file_operations` 而是直接访问内存。
|
||||
|
||||
VFS 的存在促进了代码重用,因为与文件系统相关的基本方法不需要由每种文件系统类型重新实现。代码重用是一种被广泛接受的软件工程最佳实践!唉,但是如果重用的代码[引入了严重的错误][10],那么继承常用方法的所有实现都会受到影响。
|
||||
|
||||
### /tmp:一个小提示
|
||||
|
||||
找出系统中存在的 VFS 的简单方法是键入 `mount | grep -v sd | grep -v :/`,在大多数计算机上,它将列出所有未驻留在磁盘上,同时也不是 NFS 的已挂载文件系统。其中一个列出的 VFS 挂载肯定是 `/tmp`,对吧?
|
||||
|
||||
![Man with shocked expression][11]
|
||||
|
||||
*谁都知道把 /tmp 放在物理存储设备上简直是疯了!图片:<https://tinyurl.com/ybomxyfo>*
|
||||
|
||||
为什么把 `/tmp` 留在存储设备上是不可取的?因为 `/tmp` 中的文件是临时的(!),并且存储设备比内存慢,所以创建了 tmpfs 这种文件系统。此外,比起内存,物理设备频繁写入更容易磨损。最后,`/tmp` 中的文件可能包含敏感信息,因此在每次重新启动时让它们消失是一项功能。
|
||||
|
||||
不幸的是,默认情况下,某些 Linux 发行版的安装脚本仍会在存储设备上创建 /tmp。如果你的系统出现这种情况,请不要绝望。按照一直优秀的 [Arch Wiki][12] 上的简单说明来解决问题就行,记住分配给 tmpfs 的内存就不能用于其他目的了。换句话说,包含了大文件的庞大的 tmpfs 可能会让系统耗尽内存并崩溃。
|
||||
|
||||
另一个提示:编辑 `/etc/fstab` 文件时,请务必以换行符结束,否则系统将无法启动。(猜猜我怎么知道。)
|
||||
|
||||
### /proc 和 /sys
|
||||
|
||||
除了 `/tmp` 之外,大多数 Linux 用户最熟悉的 VFS 是 `/proc` 和 `/sys`。(`/dev` 依赖于共享内存,而没有 `file_operations` 结构)。为什么有两种呢?让我们来看看更多细节。
|
||||
|
||||
procfs 为用户空间提供了内核及其控制的进程的瞬时状态的快照。在 `/proc` 中,内核发布有关其提供的设施的信息,如中断、虚拟内存和调度程序。此外,`/proc/sys` 是存放可以通过 [sysctl 命令][13]配置的设置的地方,可供用户空间访问。单个进程的状态和统计信息在 `/proc/<PID>` 目录中报告。
|
||||
|
||||
![Console][14]
|
||||
|
||||
*/proc/meminfo 是一个空文件,但仍包含有价值的信息。*
|
||||
|
||||
`/proc` 文件的行为说明了 VFS 可以与磁盘上的文件系统不同。一方面,`/proc/meminfo` 包含了可由命令 `free` 展现出来的信息。另一方面,它还是空的!怎么会这样?这种情况让人联想起康奈尔大学物理学家 N. David Mermin 在 1985 年写的一篇名为《[没有人看见月亮的情况吗?][15]现实和量子理论》。事实是当进程从 `/proc` 请求数据时内核再收集有关内存的统计信息,而且当没有人查看它时,`/proc` 中的文件实际上没有任何内容。正如 [Mermin 所说][16],“这是一个基本的量子学说,一般来说,测量不会揭示被测属性的预先存在的价值。”(关于月球的问题的答案留作练习。)
|
||||
|
||||
![Full moon][17]
|
||||
|
||||
*当没有进程访问它们时,/proc 中的文件为空。([来源][18])*
|
||||
|
||||
procfs 的空文件是有道理的,因为那里可用的信息是动态的。sysfs 的情况则不同。让我们比较一下 `/proc` 与 `/sys` 中不为空的文件数量。
|
||||
|
||||

|
||||
|
||||
procfs 只有一个不为空的文件,即导出的内核配置,这是一个例外,因为每次启动只需要生成一次。另一方面,`/sys` 有许多更大一些的文件,其中大多数由一页内存组成。通常,sysfs 文件只包含一个数字或字符串,与通过读取 `/proc/meminfo` 等文件生成的信息表格形成鲜明对比。
|
||||
|
||||
sysfs 的目的是将内核称为 “kobject” 的可读写属性公开给用户空间。kobject 的唯一目的是引用计数:当删除对 kobject 的最后一个引用时,系统将回收与之关联的资源。然而,`/sys` 构成了内核著名的“[到用户空间的稳定 ABI][19]”,它的大部分内容[在任何情况下都没有人能“破坏”][20]。但这并不意味着 sysfs 中的文件是静态,这与易失性对象的引用计数相反。
|
||||
|
||||
内核的稳定 ABI 限制了 `/sys` 中可能出现的内容,而不是任何给定时刻实际存在的内容。列出 sysfs 中文件的权限可以了解如何设置或读取设备、模块、文件系统等的可配置、可调参数。逻辑上强调 procfs 也是内核稳定 ABI 的一部分的结论,尽管内核的[文档][19]没有明确说明。
|
||||
|
||||
![Console][21]
|
||||
|
||||
*sysfs 中的文件确切地描述了实体的每个属性,并且可以是可读的、可写的,或两者兼而有之。文件中的“0”表示 SSD 不可移动的存储设备。*
|
||||
|
||||
### 用 eBPF 和 bcc 工具一窥 VFS 内部
|
||||
|
||||
了解内核如何管理 sysfs 文件的最简单方法是观察它的运行情况,在 ARM64 或 x86_64 上观看的最简单方法是使用 eBPF。eBPF(<ruby>扩展的伯克利数据包过滤器<rt>extended Berkeley Packet Filter</rt></ruby>)由[在内核中运行的虚拟机][22]组成,特权用户可以从命令行进行查询。内核源代码告诉读者内核可以做什么;而在一个启动的系统上运行 eBPF 工具会显示内核实际上做了什么。
|
||||
|
||||
令人高兴的是,通过 [bcc][23] 工具入门使用 eBPF 非常容易,这些工具在[主要 Linux 发行版的软件包][24] 中都有,并且已经由 Brendan Gregg [给出了充分的文档说明][25]。bcc 工具是带有小段嵌入式 C 语言片段的 Python 脚本,这意味着任何对这两种语言熟悉的人都可以轻松修改它们。据当前统计,[bcc/tools 中有 80 个 Python 脚本][26],使得系统管理员或开发人员很有可能能够找到与她/他的需求相关的已有脚本。
|
||||
|
||||
要了解 VFS 在正在运行中的系统上的工作情况,请尝试使用简单的 [vfscount][27] 或 [vfsstat][28] 脚本,这可以看到每秒都会发生数十次对 `vfs_open()` 及其相关的调用。
|
||||
|
||||
![Console - vfsstat.py][29]
|
||||
|
||||
*vfsstat.py 是一个带有嵌入式 C 片段的 Python 脚本,它只是计数 VFS 函数调用。*
|
||||
|
||||
作为一个不太重要的例子,让我们看一下在运行的系统上插入 USB 记忆棒时 sysfs 中会发生什么。
|
||||
|
||||
![Console when USB is inserted][30]
|
||||
|
||||
*用 eBPF 观察插入 USB 记忆棒时 /sys 中会发生什么,简单的和复杂的例子。*
|
||||
|
||||
在上面的第一个简单示例中,只要 `sysfs_create_files()` 命令运行,[trace.py][31] bcc 工具脚本就会打印出一条消息。我们看到 `sysfs_create_files()` 由一个 kworker 线程启动,以响应 USB 棒的插入事件,但是它创建了什么文件?第二个例子说明了 eBPF 的强大能力。这里,`trace.py` 正在打印内核回溯(`-K` 选项)以及 `sysfs_create_files()` 创建的文件的名称。单引号内的代码段是一些 C 源代码,包括一个易于识别的格式字符串,所提供的 Python 脚本[引入 LLVM 即时编译器(JIT)][32] 来在内核虚拟机内编译和执行它。必须在第二个命令中重现完整的 `sysfs_create_files()` 函数签名,以便格式字符串可以引用其中一个参数。在此 C 片段中出错会导致可识别的 C 编译器错误。例如,如果省略 `-I` 参数,则结果为“无法编译 BPF 文本”。熟悉 C 或 Python 的开发人员会发现 bcc 工具易于扩展和修改。
|
||||
|
||||
插入 USB 记忆棒后,内核回溯显示 PID 7711 是一个 kworker 线程,它在 sysfs 中创建了一个名为 `events` 的文件。使用 `sysfs_remove_files()` 进行相应的调用表明,删除 USB 记忆棒会导致删除该 `events` 文件,这与引用计数的想法保持一致。在 USB 棒插入期间(未显示)在 eBPF 中观察 `sysfs_create_link()` 表明创建了不少于 48 个符号链接。
|
||||
|
||||
无论如何,`events` 文件的目的是什么?使用 [cscope][33] 查找函数 [`__device_add_disk()`][34] 显示它调用 `disk_add_events()`,并且可以将 “media_change” 或 “eject_request” 写入到该文件。这里,内核的块层通知用户空间该 “磁盘” 的出现和消失。考虑一下这种检查 USB 棒的插入的工作原理的方法与试图仅从源头中找出该过程的速度有多快。
|
||||
|
||||
### 只读根文件系统使得嵌入式设备成为可能
|
||||
|
||||
确实,没有人通过拔出电源插头来关闭服务器或桌面系统。为什么?因为物理存储设备上挂载的文件系统可能有挂起的(未完成的)写入,并且记录其状态的数据结构可能与写入存储器的内容不同步。当发生这种情况时,系统所有者将不得不在下次启动时等待 [fsck 文件系统恢复工具][35] 运行完成,在最坏的情况下,实际上会丢失数据。
|
||||
|
||||
然而,狂热爱好者会听说许多物联网和嵌入式设备,如路由器、恒温器和汽车现在都运行着 Linux。许多这些设备几乎完全没有用户界面,并且没有办法干净地让它们“解除启动”。想一想启动电池耗尽的汽车,其中[运行 Linux 的主机设备][36] 的电源会不断加电断电。当引擎最终开始运行时,系统如何在没有长时间 fsck 的情况下启动呢?答案是嵌入式设备依赖于[只读根文件系统][37](简称 ro-rootfs)。
|
||||
|
||||
![Photograph of a console][38]
|
||||
|
||||
*ro-rootfs 是嵌入式系统不经常需要 fsck 的原因。 来源:<https://tinyurl.com/yxoauoub>*
|
||||
|
||||
ro-rootfs 提供了许多优点,虽然这些优点不如耐用性那么显然。一个是,如果 Linux 进程不可以写入,那么恶意软件也无法写入 `/usr` 或 `/lib`。另一个是,基本上不可变的文件系统对于远程设备的现场支持至关重要,因为支持人员拥有理论上与现场相同的本地系统。也许最重要(但也是最微妙)的优势是 ro-rootfs 迫使开发人员在项目的设计阶段就决定好哪些系统对象是不可变的。处理 ro-rootfs 可能经常是不方便甚至是痛苦的,[编程语言中的常量变量][39]经常就是这样,但带来的好处很容易偿还这种额外的开销。
|
||||
|
||||
对于嵌入式开发人员,创建只读根文件系统确实需要做一些额外的工作,而这正是 VFS 的用武之地。Linux 需要 `/var` 中的文件可写,此外,嵌入式系统运行的许多流行应用程序会尝试在 `$HOME` 中创建配置的点文件。放在家目录中的配置文件的一种解决方案通常是预生成它们并将它们构建到 rootfs 中。对于 `/var`,一种方法是将其挂载在单独的可写分区上,而 `/` 本身以只读方式挂载。使用绑定或叠加挂载是另一种流行的替代方案。
|
||||
|
||||
### 绑定和叠加挂载以及在容器中的使用
|
||||
|
||||
运行 [man mount][40] 是了解<ruby>绑定挂载<rt>bind mount</rt></ruby>和<ruby>叠加挂载<rt>overlay mount</rt></ruby>的最好办法,这种方法使得嵌入式开发人员和系统管理员能够在一个路径位置创建文件系统,然后以另外一个路径将其提供给应用程序。对于嵌入式系统,这代表着可以将文件存储在 `/var` 中的不可写闪存设备上,但是在启动时将 tmpfs 中的路径叠加挂载或绑定挂载到 `/var` 路径上,这样应用程序就可以在那里随意写它们的内容了。下次加电时,`/var` 中的变化将会消失。叠加挂载为 tmpfs 和底层文件系统提供了联合,允许对 ro-rootfs 中的现有文件进行直接修改,而绑定挂载可以使新的空 tmpfs 目录在 ro-rootfs 路径中显示为可写。虽然叠加文件系统是一种适当的文件系统类型,而绑定挂载由 [VFS 命名空间工具][41] 实现的。
|
||||
|
||||
根据叠加挂载和绑定挂载的描述,没有人会对 [Linux 容器][42] 中大量使用它们感到惊讶。让我们通过运行 bcc 的 `mountsnoop` 工具监视当使用 [systemd-nspawn][43] 启动容器时会发生什么:
|
||||
|
||||
![Console - system-nspawn invocation][44]
|
||||
|
||||
*在 mountsnoop.py 运行的同时,system-nspawn 调用启动容器。*
|
||||
|
||||
让我们看看发生了什么:
|
||||
|
||||
![Console - Running mountsnoop][45]
|
||||
|
||||
*在容器 “启动” 期间运行 `mountsnoop` 可以看到容器运行时很大程度上依赖于绑定挂载。(仅显示冗长输出的开头)*
|
||||
|
||||
这里,`systemd-nspawn` 将主机的 procfs 和 sysfs 中的选定文件按其 rootfs 中的路径提供给容器。除了设置绑定挂载时的 `MS_BIND` 标志之外,`mount` 系统调用的一些其它标志用于确定主机命名空间和容器中的更改之间的关系。例如,绑定挂载可以将 `/proc` 和 `/sys` 中的更改传播到容器,也可以隐藏它们,具体取决于调用。
|
||||
|
||||
### 总结
|
||||
|
||||
理解 Linux 内部结构看似是一项不可能完成的任务,因为除了 Linux 用户空间应用程序和 glibc 这样的 C 库中的系统调用接口,内核本身也包含大量代码。取得进展的一种方法是阅读一个内核子系统的源代码,重点是理解面向用户空间的系统调用和头文件以及主要的内核内部接口,这里以 `file_operations` 表为例。`file_operations` 使得“一切都是文件”得以可以实际工作,因此掌握它们收获特别大。顶级 `fs/` 目录中的内核 C 源文件构成了虚拟文件系统的实现,虚拟文件系统是支持流行的文件系统和存储设备的广泛且相对简单的互操作性的垫片层。通过 Linux 命名空间进行绑定挂载和覆盖挂载是 VFS 魔术,它使容器和只读根文件系统成为可能。结合对源代码的研究,eBPF 内核工具及其 bcc 接口使得探测内核比以往任何时候都更简单。
|
||||
|
||||
非常感谢 [Akkana Peck][46] 和 [Michael Eager][47] 的评论和指正。
|
||||
|
||||
Alison Chaiken 也于 3 月 7 日至 10 日在加利福尼亚州帕萨迪纳举行的第 17 届南加州 Linux 博览会([SCaLE 17x][49])上演讲了[本主题][48]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/virtual-filesystems-linux
|
||||
|
||||
作者:[Alison Chariken][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/chaiken
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.pearson.com/us/higher-education/program/Love-Linux-Kernel-Development-3rd-Edition/PGM202532.html
|
||||
[2]: http://cassandra.apache.org/
|
||||
[3]: https://en.wikipedia.org/wiki/NoSQL
|
||||
[4]: http://lwn.net/Articles/444910/
|
||||
[5]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_1-console.png (Console)
|
||||
[6]: https://lwn.net/Articles/22355/
|
||||
[7]: https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/include/linux/fs.h
|
||||
[8]: https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/fs
|
||||
[9]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_2-shim-layer.png (How userspace accesses various types of filesystems)
|
||||
[10]: https://lwn.net/Articles/774114/
|
||||
[11]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_3-crazy.jpg (Man with shocked expression)
|
||||
[12]: https://wiki.archlinux.org/index.php/Tmpfs
|
||||
[13]: http://man7.org/linux/man-pages/man8/sysctl.8.html
|
||||
[14]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_4-proc-meminfo.png (Console)
|
||||
[15]: http://www-f1.ijs.si/~ramsak/km1/mermin.moon.pdf
|
||||
[16]: https://en.wikiquote.org/wiki/David_Mermin
|
||||
[17]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_5-moon.jpg (Full moon)
|
||||
[18]: https://commons.wikimedia.org/wiki/Moon#/media/File:Full_Moon_Luc_Viatour.jpg
|
||||
[19]: https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/Documentation/ABI/stable
|
||||
[20]: https://lkml.org/lkml/2012/12/23/75
|
||||
[21]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_7-sysfs.png (Console)
|
||||
[22]: https://events.linuxfoundation.org/sites/events/files/slides/bpf_collabsummit_2015feb20.pdf
|
||||
[23]: https://github.com/iovisor/bcc
|
||||
[24]: https://github.com/iovisor/bcc/blob/master/INSTALL.md
|
||||
[25]: http://brendangregg.com/ebpf.html
|
||||
[26]: https://github.com/iovisor/bcc/tree/master/tools
|
||||
[27]: https://github.com/iovisor/bcc/blob/master/tools/vfscount_example.txt
|
||||
[28]: https://github.com/iovisor/bcc/blob/master/tools/vfsstat.py
|
||||
[29]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_8-vfsstat.png (Console - vfsstat.py)
|
||||
[30]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_9-ebpf.png (Console when USB is inserted)
|
||||
[31]: https://github.com/iovisor/bcc/blob/master/tools/trace_example.txt
|
||||
[32]: https://events.static.linuxfound.org/sites/events/files/slides/bpf_collabsummit_2015feb20.pdf
|
||||
[33]: http://northstar-www.dartmouth.edu/doc/solaris-forte/manuals/c/user_guide/cscope.html
|
||||
[34]: https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/block/genhd.c#n665
|
||||
[35]: http://www.man7.org/linux/man-pages/man8/fsck.8.html
|
||||
[36]: https://wiki.automotivelinux.org/_media/eg-rhsa/agl_referencehardwarespec_v0.1.0_20171018.pdf
|
||||
[37]: https://elinux.org/images/1/1f/Read-only_rootfs.pdf
|
||||
[38]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_10-code.jpg (Photograph of a console)
|
||||
[39]: https://www.meetup.com/ACCU-Bay-Area/events/drpmvfytlbqb/
|
||||
[40]: http://man7.org/linux/man-pages/man8/mount.8.html
|
||||
[41]: https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/Documentation/filesystems/sharedsubtree.txt
|
||||
[42]: https://coreos.com/os/docs/latest/kernel-modules.html
|
||||
[43]: https://www.freedesktop.org/software/systemd/man/systemd-nspawn.html
|
||||
[44]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_11-system-nspawn.png (Console - system-nspawn invocation)
|
||||
[45]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_12-mountsnoop.png (Console - Running mountsnoop)
|
||||
[46]: http://shallowsky.com/
|
||||
[47]: http://eagercon.com/
|
||||
[48]: https://www.socallinuxexpo.org/scale/17x/presentations/virtual-filesystems-why-we-need-them-and-how-they-work
|
||||
[49]: https://www.socallinuxexpo.org/
|
||||
@ -0,0 +1,56 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10914-1.html)
|
||||
[#]: subject: (Blockchain 2.0: Blockchain In Real Estate [Part 4])
|
||||
[#]: via: (https://www.ostechnix.com/blockchain-2-0-blockchain-in-real-estate/)
|
||||
[#]: author: (ostechnix https://www.ostechnix.com/author/editor/)
|
||||
|
||||
区块链 2.0:房地产区块链(四)
|
||||
======
|
||||
|
||||

|
||||
|
||||
### 区块链 2.0:“更”智能的房地产
|
||||
|
||||
在本系列的[上一篇文章][1]中我们探讨了区块链的特征,这些区块链将使机构能够将**传统银行**和**融资系统**转换和交织在一起。这部分将探讨**房地产区块链**。房地产业正在走向革命。它是人类已知的交易最活跃、最重要的资产类别之一。然而,由于充满了监管障碍和欺诈、欺骗的无数可能性,它也是最难参与交易的之一。利用适当的共识算法的区块链的分布式分类账本功能被吹捧为这个行业的前进方向,而这个行业传统上被认为其面对变革是保守的。
|
||||
|
||||
就其无数的业务而言,房地产一直是一个非常保守的行业。这似乎也是理所当然的。2008 年金融危机或 20 世纪上半叶的大萧条等重大经济危机成功摧毁了该行业及其参与者。然而,与大多数具有经济价值的产品一样,房地产行业具有弹性,而这种弹性则源于其保守性。
|
||||
|
||||
全球房地产市场由价值 228 万亿 [^1] 美元的资产类别组成,出入不大。其他投资资产,如股票、债券和股票合计价值仅为 170 万亿美元。显然,在这样一个行业中实施的交易在很大程度上都是精心策划和执行的。很多时候,房地产也因许多欺诈事件而臭名昭著,并且随之而来的是毁灭性的损失。由于其运营非常保守,该行业也难以驾驭。它受到了法律的严格监管,创造了一个交织在一起的细微差别网络,这对于普通人来说太难以完全理解,使得大多数人无法进入和参与。如果你曾参与过这样的交易,那么你就会知道纸质文件的重要性和长期性。
|
||||
|
||||
从一个微不足道的开始,虽然是一个重要的例子,以显示当前的记录管理实践在房地产行业有多糟糕,考虑一下[产权保险业务][2] [^3]。产权保险用于对冲土地所有权和所有权记录不可接受且从而无法执行的可能性。诸如此类的保险产品也称为赔偿保险。在许多情况下,法律要求财产拥有产权保险,特别是在处理多年来多次易手的财产时。抵押贷款公司在支持房地产交易时也可能坚持同样的要求。事实上,这种产品自 19 世纪 50 年代就已存在,并且仅在美国每年至少有 1.5 万亿美元的商业价值这一事实证明了一开始的说法。在这种情况下,这些记录的维护方式必须进行改革,区块链提供了一个可持续解决方案。根据[美国土地产权协会][4],平均每个案例的欺诈平均约为 10 万美元,并且涉及交易的所有产权中有 25% 的文件存在问题。区块链允许设置一个不可变的永久数据库,该数据库将跟踪资产本身,记录已经进入的每个交易或投资。这样的分类帐本系统将使包括一次性购房者在内的房地产行业的每个人的生活更加轻松,并使诸如产权保险等金融产品基本上无关紧要。将诸如房地产之类的实物资产转换为这样的数字资产是非常规的,并且目前仅在理论上存在。然而,这种变化迫在眉睫,而不是迟到 [^5]。
|
||||
|
||||
区块链在房地产中影响最大的领域如上所述,在维护透明和安全的产权管理系统方面。基于区块链的财产记录可以包含有关财产、其所在地、所有权历史以及相关的公共记录的[信息][6]。这将允许房地产交易快速完成,并且无需第三方监控和监督。房地产评估和税收计算等任务成为有形的、客观的参数问题,而不是主观测量和猜测,因为可靠的历史数据是可公开验证的。[UBITQUITY][7] 就是这样一个平台,为企业客户提供定制的基于区块链的解决方案。该平台允许客户跟踪所有房产细节、付款记录、抵押记录,甚至允许运行智能合约,自动处理税收和租赁。
|
||||
|
||||
这为我们带来了房地产区块链的第二大机遇和用例。由于该行业受到众多第三方的高度监管,除了参与交易的交易对手外,尽职调查和财务评估可能非常耗时。这些流程主要通过离线渠道进行,文书工作需要在最终评估报告出来之前进行数天。对于公司房地产交易尤其如此,这构成了顾问所收取的总计费时间的大部分。如果交易由抵押背书,则这些过程的重复是不可避免的。一旦与所涉及的人员和机构的数字身份相结合,就可以完全避免当前的低效率,并且可以在几秒钟内完成交易。租户、投资者、相关机构、顾问等可以单独验证数据并达成一致的共识,从而验证永久性的财产记录 [^8]。这提高了验证流程的准确性。房地产巨头 RE/MAX 最近宣布与服务提供商 XYO Network Partners 合作,[建立墨西哥房上市地产国家数据库][9]。他们希望有朝一日能够创建世界上最大的(截至目前)去中心化房地产登记中心之一。
|
||||
|
||||
然而,区块链可以带来的另一个重要且可以说是非常民主的变化是投资房地产。与其他投资资产类别不同,即使是小型家庭投资者也可能参与其中,房地产通常需要大量的手工付款才能参与。诸如 ATLANT 和 BitOfProperty 之类的公司将房产的账面价值代币化,并将其转换为加密货币的等价物。这些代币随后在交易所出售,类似于股票和股票的交易方式。[房地产后续产生的任何现金流都会根据其在财产中的“份额”记入贷方或借记给代币所有者][4]。
|
||||
|
||||
然而,尽管如此,区块链技术仍处于房地产领域的早期采用阶段,目前的法规还没有明确定义它。诸如分布式应用程序、分布式匿名组织(DAO)、智能合约等概念在许多国家的法律领域是闻所未闻的。一旦所有利益相关者充分接受了区块链复杂性的良好教育,就会彻底改革现有的法规和指导方针,这是最务实的前进方式。 同样,这将是一个缓慢而渐进的变化,但是它是一个急需的变化。本系列的下一篇文章将介绍 “智能合约”,例如由 UBITQUITY 和 XYO 等公司实施的那些是如何在区块链中创建和执行的。
|
||||
|
||||
[^1]: HSBC, “Global Real Estate,” no. April, 2008
|
||||
[^3]: D. B. Burke, Law of title insurance. Aspen Law & Business, 2000.
|
||||
[^5]: M. Swan, O’Reilly – Blockchain. Blueprint for a New Economy – 2015.
|
||||
[^8]: Deloite, “Blockchain in commercial real estate The future is here ! Table of contents.”
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/blockchain-2-0-blockchain-in-real-estate/
|
||||
|
||||
作者:[ostechnix][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/editor/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://linux.cn/article-10689-1.html
|
||||
[2]: https://www.forbes.com/sites/jordanlulich/2018/06/21/what-is-title-insurance-and-why-its-important/#1472022b12bb
|
||||
[4]: https://www.cbinsights.com/research/blockchain-real-estate-disruption/#financing
|
||||
[6]: https://www2.deloitte.com/us/en/pages/financial-services/articles/blockchain-in-commercial-real-estate.html
|
||||
[7]: https://www.ubitquity.io/
|
||||
[9]: https://www.businesswire.com/news/home/20181012005068/en/XYO-Network-Partners-REMAX-M%C3%A9xico-Bring-Blockchain
|
||||
@ -0,0 +1,123 @@
|
||||
[#]: collector: "lujun9972"
|
||||
[#]: translator: "zgj1024"
|
||||
[#]: reviewer: "wxy"
|
||||
[#]: publisher: "wxy"
|
||||
[#]: url: "https://linux.cn/article-10834-1.html"
|
||||
[#]: subject: "Why DevOps is the most important tech strategy today"
|
||||
[#]: via: "https://opensource.com/article/19/3/devops-most-important-tech-strategy"
|
||||
[#]: author: "Kelly Albrecht https://opensource.com/users/ksalbrecht"
|
||||
|
||||
为何 DevOps 是如今最重要的技术策略
|
||||
======
|
||||
|
||||
> 消除一些关于 DevOps 的疑惑。
|
||||
|
||||
![CICD with gears][1]
|
||||
|
||||
很多人初学 [DevOps][2] 时,看到它其中一个结果就问这个是如何得来的。其实理解这部分 Devops 的怎样实现并不重要,重要的是——理解(使用) DevOps 策略的原因——这是做一个行业的领导者还是追随者的差别。
|
||||
|
||||
你可能会听过些 Devops 的难以置信的成果,例如生产环境非常有弹性,就算是有个“<ruby>[癫狂的猴子][3]<rt>Chaos Monkey</rt></ruby>)跳来跳去将不知道哪个插头随便拔下,每天仍可以处理数千个发布。这是令人印象深刻的,但就其本身而言,这是一个 DevOps 的证据不足的案例,其本质上会被一个[反例][4]困扰:DevOps 环境有弹性是因为严重的故障还没有被观测到。
|
||||
|
||||
有很多关于 DevOps 的疑惑,并且许多人还在尝试弄清楚它的意义。下面是来自我 LinkedIn Feed 中的某个人的一个案例:
|
||||
|
||||
> 最近我参加一些 #DevOps 的交流会,那里一些演讲人好像在倡导 #敏捷开发是 DevOps 的子集。不知为何,我的理解恰恰相反。
|
||||
>
|
||||
> 能听一下你们的想法吗?你认为敏捷开发和 DevOps 之间是什么关系呢?
|
||||
>
|
||||
> 1. DevOps 是敏捷开发的子集
|
||||
> 2. 敏捷开发是 DevOps 的子集
|
||||
> 3. DevOps 是敏捷开发的扩展,从敏捷开发结束的地方开始
|
||||
> 4. DevOps 是敏捷开发的新版本
|
||||
|
||||
科技行业的专业人士在那篇 LinkedIn 的帖子上表达了各种各样的答案,你会怎样回复呢?
|
||||
|
||||
### DevOps 源于精益和敏捷
|
||||
|
||||
如果我们从亨利福特的战略和丰田生产系统对福特车型的改进(的历史)开始, DevOps 就更有意义了。精益制造就诞生在那段历史中,人们对精益制作进行了良好的研究。James P. Womack 和 Daniel T. Jones 将精益思维([Lean Thinking][5])提炼为五个原则:
|
||||
|
||||
1. 指明客户所需的价值
|
||||
2. 确定提供该价值的每个产品的价值流,并对当前提供该价值所需的所有浪费步骤提起挑战
|
||||
3. 使产品通过剩余的增值步骤持续流动
|
||||
4. 在可以连续流动的所有步骤之间引入拉力
|
||||
5. 管理要尽善尽美,以便为客户服务所需的步骤数量和时间以及信息量持续下降
|
||||
|
||||
精益致力于持续消除浪费并增加客户的价值流动。这很容易识别并明白精益的核心原则:单一流。我们可以做一些游戏去了解为何同一时间移动单个比批量移动要快得多。其中的两个游戏是[硬币游戏][6]和[飞机游戏][7]。在硬币游戏中,如果一批 20 个硬币到顾客手中要用 2 分钟,顾客等 2 分钟后能拿到整批硬币。如果一次只移动一个硬币,顾客会在 5 秒内得到第一枚硬币,并会持续获得硬币,直到在大约 25 秒后第 20 个硬币到达。(LCTT 译注:有相关的视频的)
|
||||
|
||||
这是巨大的不同,但是不是生活中的所有事都像硬币游戏那样简单并可预测的。这就是敏捷的出现的原因。我们当然看到了高效绩敏捷团队的精益原则,但这些团队需要的不仅仅是精益去做他们要做的事。
|
||||
|
||||
为了能够处理典型的软件开发任务的不可预见性和变化,敏捷开发的方法论会将重点放在意识、审议、决策和行动上,以便在不断变化的现实中调整。例如,敏捷框架(如 srcum)通过每日站立会议和冲刺评审会议等仪式提高意识。如果 scrum 团队意识到新的事实,框架允许并鼓励他们在必要时及时调整路线。
|
||||
|
||||
要使团队做出这些类型的决策,他们需要高度信任的环境中的自我组织能力。以这种方式工作的高效绩敏捷团队在不断调整的同时实现快速的价值流,消除错误方向上的浪费。
|
||||
|
||||
### 最佳批量大小
|
||||
|
||||
要了解 DevOps 在软件开发中的强大功能,这会帮助我们理解批处理大小的经济学。请考虑以下来自Donald Reinertsen 的[产品开发流程原则][8]的U曲线优化示例:
|
||||
|
||||
![U-curve optimization illustration of optimal batch size][9]
|
||||
|
||||
这可以类比杂货店购物来解释。假设你需要买一些鸡蛋,而你住的地方离商店只有 30 分钟的路程。买一个鸡蛋(图中最左边)意味着每次要花 30 分钟的路程,这就是你的*交易成本*。*持有成本*可能是鸡蛋变质和在你的冰箱中持续地占用空间。*总成本*是*交易成本*加上你的*持有成本*。这个 U 型曲线解释了为什么对大部分人来说,一次买一打鸡蛋是他们的*最佳批量大小*。如果你就住在商店的旁边,步行到那里不会花费你任何的时候,你可能每次只会买一小盒鸡蛋,以此来节省冰箱的空间并享受新鲜的鸡蛋。
|
||||
|
||||
这 U 型优化曲线可以说明为什么在成功的敏捷转换中生产力会显著提高。考虑敏捷转换对组织决策的影响。在传统的分级组织中,决策权是集中的。这会导致较少的人做更大的决策。敏捷方法论会有效地降低组织决策中的交易成本,方法是将决策分散到最被人熟知的认识和信息的位置:跨越高度信任,自组织的敏捷团队。
|
||||
|
||||
下面的动画演示了降低事务成本后,最佳批量大小是如何向左移动。在更频繁地做出更快的决策方面,你不能低估组织的价值。
|
||||
|
||||
![U-curve optimization illustration][10]
|
||||
|
||||
### DevOps 适合哪些地方
|
||||
|
||||
自动化是 DevOps 最知名的事情之一。前面的插图非常详细地展示了自动化的价值。通过自动化,我们将交易成本降低到接近于零,实质上是可以免费进行测试和部署。这使我们可以利用越来越小的批量工作。较小批量的工作更容易理解、提交、测试、审查和知道何时能完成。这些较小的批量大小也包含较少的差异和风险,使其更易于部署,如果出现问题,可以进行故障排除和恢复。通过自动化与扎实的敏捷实践相结合,我们可以使我们的功能开发非常接近单件流程,从而快速、持续地为客户提供价值。
|
||||
|
||||
更传统地说,DevOps 被理解为一种打破开发团队和运营团队之间混乱局面的方法。在这个模型中,开发团队开发新的功能,而运营团队则保持系统的稳定和平稳运行。摩擦的发生是因为开发过程中的新功能将更改引入到系统中,从而增加了停机的风险,运营团队并不认为要对此负责,但无论如何都必须处理这一问题。DevOps 不仅仅尝试让人们一起工作,更重要的是尝试在复杂的环境中安全地进行更频繁的更改。
|
||||
|
||||
我们可以看看 [Ron Westrum][11] 在有关复杂组织中实现安全性的研究。在研究为什么有些组织比其他组织更安全时,他发现组织的文化可以预测其安全性。他确定了三种文化:病态的、官僚主义的和生产式的。他发现病态的可以预测其安全性较低,而生产式文化被预测为更安全(例如,在他的主要研究领域中,飞机坠毁或意外住院死亡的数量要少得多)。
|
||||
|
||||
![Three types of culture identified by Ron Westrum][12]
|
||||
|
||||
高效的 DevOps 团队通过精益和敏捷的实践实现了一种生成性文化,这表明速度和安全性是互补的,或者说是同一个问题的两个方面。通过将决策和功能的最佳批量大小减少到非常小,DevOps 实现了更快的信息流和价值,同时消除了浪费并降低了风险。
|
||||
|
||||
与 Westrum 的研究一致,在提高安全性和可靠性的同时,变化也很容易发生。当一个敏捷的 DevOps 团队被信任做出自己的决定时,我们将获得 DevOps 目前最为人所知的工具和技术:自动化和持续交付。通过这种自动化,交易成本比以往任何时候都进一步降低,并且实现了近乎单一的精益流程,每天创造数千个决策和发布的潜力,正如我们在高效绩的 DevOps 组织中看到的那样
|
||||
|
||||
### 流动、反馈、学习
|
||||
|
||||
DevOps 并不止于此。我们主要讨论了 DevOps 实现了革命性的流程,但通过类似的努力可以进一步放大精益和敏捷实践,从而实现更快的反馈循环和更快的学习。在[DevOps手册][13] 中,作者除了详细解释快速流程外, DevOps 如何在整个价值流中实现遥测,从而获得快速且持续的反馈。此外,利用[精益求精的突破][14]和 scrum 的[回顾][15],高效的 DevOps 团队将不断推动学习和持续改进深入到他们的组织的基础,实现软件产品开发行业的精益制造革命。
|
||||
|
||||
### 从 DevOps 评估开始
|
||||
|
||||
利用 DevOps 的第一步是,经过大量研究或在 DevOps 顾问和教练的帮助下,对高效绩 DevOps 团队中始终存在的一系列维度进行评估。评估应确定需要改进的薄弱或不存在的团队规范。对评估的结果进行评估,以找到具有高成功机会的快速获胜焦点领域,从而产生高影响力的改进。快速获胜非常重要,能让团队获取解决更具挑战性领域所需的动力。团队应该产生可以快速尝试的想法,并开始关注 DevOps 转型。
|
||||
|
||||
一段时间后,团队应重新评估相同的维度,以衡量改进并确立新的高影响力重点领域,并再次采纳团队的新想法。一位好的教练将根据需要进行咨询、培训、指导和支持,直到团队拥有自己的持续改进方案,并通过不断地重新评估、试验和学习,在所有维度上实现近乎一致。
|
||||
|
||||
在本文的[第二部分][16]中,我们将查看 Drupal 社区中 DevOps 调查的结果,并了解最有可能找到快速获胜的位置。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/devops-most-important-tech-strategy
|
||||
|
||||
作者:[Kelly Albrecht][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[zgj1024](https://github.com/zgj1024)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ksalbrecht/users/brentaaronreed/users/wpschaub/users/wpschaub/users/ksalbrecht
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/cicd_continuous_delivery_deployment_gears.png?itok=kVlhiEkc "CICD with gears"
|
||||
[2]: https://opensource.com/resources/devops
|
||||
[3]: https://github.com/Netflix/chaosmonkey
|
||||
[4]: https://en.wikipedia.org/wiki/Burden_of_proof_(philosophy)#Proving_a_negative
|
||||
[5]: https://www.amazon.com/dp/B0048WQDIO/ref=dp-kindle-redirect?_encoding=UTF8&btkr=1
|
||||
[6]: https://youtu.be/5t6GhcvKB8o?t=54
|
||||
[7]: https://www.shmula.com/paper-airplane-game-pull-systems-push-systems/8280/
|
||||
[8]: https://www.amazon.com/dp/B00K7OWG7O/ref=dp-kindle-redirect?_encoding=UTF8&btkr=1
|
||||
[9]: https://opensource.com/sites/default/files/uploads/batch_size_optimal_650.gif "U-curve optimization illustration of optimal batch size"
|
||||
[10]: https://opensource.com/sites/default/files/uploads/batch_size_650.gif "U-curve optimization illustration"
|
||||
[11]: https://en.wikipedia.org/wiki/Ron_Westrum
|
||||
[12]: https://opensource.com/sites/default/files/uploads/information_flow.png "Three types of culture identified by Ron Westrum"
|
||||
[13]: https://www.amazon.com/DevOps-Handbook-World-Class-Reliability-Organizations/dp/1942788002/ref=sr_1_3?keywords=DevOps+handbook&qid=1553197361&s=books&sr=1-3
|
||||
[14]: https://en.wikipedia.org/wiki/Kaizen
|
||||
[15]: https://www.scrum.org/resources/what-is-a-sprint-retrospective
|
||||
[16]: https://opensource.com/article/19/3/where-drupal-community-stands-devops-adoption
|
||||
[17]: https://events.drupal.org/seattle2019/sessions/devops-why-how-and-what
|
||||
[18]: https://events.drupal.org/seattle2019/bofs/devops-getting-started
|
||||
[19]: https://events.drupal.org/seattle2019
|
||||
@ -0,0 +1,173 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (robsean)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10916-1.html)
|
||||
[#]: subject: (How to manage your Linux environment)
|
||||
[#]: via: (https://www.networkworld.com/article/3385516/how-to-manage-your-linux-environment.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
如何管理你的 Linux 环境变量
|
||||
======
|
||||
|
||||
> Linux 用户环境变量可以帮助你找到你需要的命令,无须了解系统如何配置的细节而完成大量工作。而这些设置来自哪里和如何被修改它们是另一个话题。
|
||||
|
||||
![IIP Photo Archive \(CC BY 2.0\)][1]
|
||||
|
||||
在 Linux 系统上的用户账户配置以多种方法简化了系统的使用。你可以运行命令,而不需要知道它们的位置。你可以重新使用先前运行的命令,而不用发愁系统是如何追踪到它们的。你可以查看你的电子邮件,查看手册页,并容易地回到你的家目录,而不用管你在文件系统中身在何方。并且,当需要的时候,你可以调整你的账户设置,以便其更符合你喜欢的方式。
|
||||
|
||||
Linux 环境设置来自一系列的文件:一些是系统范围(意味着它们影响所有用户账户),一些是处于你的家目录中的配置文件里。系统范围的设置在你登录时生效,而本地设置在其后生效,所以,你在你账户中作出的更改将覆盖系统范围设置。对于 bash 用户,这些文件包含这些系统文件:
|
||||
|
||||
```
|
||||
/etc/environment
|
||||
/etc/bash.bashrc
|
||||
/etc/profile
|
||||
```
|
||||
|
||||
以及一些本地文件:
|
||||
|
||||
```
|
||||
~/.bashrc
|
||||
~/.profile # 如果有 ~/.bash_profile 或 ~/.bash_login 就不会读此文件
|
||||
~/.bash_profile
|
||||
~/.bash_login
|
||||
```
|
||||
|
||||
你可以修改本地存在的四个文件的任何一个,因为它们处于你的家目录,并且它们是属于你的。
|
||||
|
||||
### 查看你的 Linux 环境设置
|
||||
|
||||
为查看你的环境设置,使用 `env` 命令。你的输出将可能与这相似:
|
||||
|
||||
```
|
||||
$ env
|
||||
LS_COLORS=rs=0:di=01;34:ln=01;36:mh=00:pi=40;33:so=01;35:do=01;35:bd=40;33;01:cd=40;33;
|
||||
01:or=40;31;01:mi=00:su=37;41:sg=30;43:ca=30;41:tw=30;42:ow=34;42:st=37;44:ex=01;32:
|
||||
*.tar=01;31:*.tgz=01;31:*.arc=01;31:*.arj=01;31:*.taz=01;31:*.lha=01;31:*.lz4=01;31:
|
||||
*.lzh=01;31:*.lzma=01;31:*.tlz=01;31:*.txz=01;31:*.tzo=01;31:*.t7z=01;31:*.zip=01;31:
|
||||
*.z=01;31:*.Z=01;31:*.dz=01;31:*.gz=01;31:*.lrz=01;31:*.lz=01;31:*.lzo=01;31:*.xz=01;
|
||||
31:*.zst=01;31:*.tzst=01;31:*.bz2=01;31:*.bz=01;31:*.tbz=01;31:*.tbz2=01;31:*.tz=01;31:
|
||||
*.deb=01;31:*.rpm=01;31:*.jar=01;31:*.war=01;31:*.ear=01;31:*.sar=01;31:*.rar=01;31:
|
||||
*.alz=01;31:*.ace=01;31:*.zoo=01;31:*.cpio=01;31:*.7z=01;31:*.rz=01;31:*.cab=01;31:
|
||||
*.wim=01;31:*.swm=01;31:*.dwm=01;31:*.esd=01;31:*.jpg=01;35:*.jpeg=01;35:*.mjpg=01;35:
|
||||
*.mjpeg=01;35:*.gif=01;35:*.bmp=01;35:*.pbm=01;35:*.pgm=01;35:*.ppm=01;35:*.tga=01;35:
|
||||
*.xbm=01;35:*.xpm=01;35:*.tif=01;35:*.tiff=01;35:*.png=01;35:*.svg=01;35:*.svgz=01;35:
|
||||
*.mng=01;35:*.pcx=01;35:*.mov=01;35:*.mpg=01;35:*.mpeg=01;35:*.m2v=01;35:*.mkv=01;35:
|
||||
*.webm=01;35:*.ogm=01;35:*.mp4=01;35:*.m4v=01;35:*.mp4v=01;35:*.vob=01;35:*.qt=01;35:
|
||||
*.nuv=01;35:*.wmv=01;35:*.asf=01;35:*.rm=01;35:*.rmvb=01;35:*.flc=01;35:*.avi=01;35:
|
||||
*.fli=01;35:*.flv=01;35:*.gl=01;35:*.dl=01;35:*.xcf=01;35:*.xwd=01;35:*.yuv=01;35:
|
||||
*.cgm=01;35:*.emf=01;35:*.ogv=01;35:*.ogx=01;35:*.aac=00;36:*.au=00;36:*.flac=00;36:
|
||||
*.m4a=00;36:*.mid=00;36:*.midi=00;36:*.mka=00;36:*.mp3=00;36:*.mpc=00;36:*.ogg=00;36:
|
||||
*.ra=00;36:*.wav=00;36:*.oga=00;36:*.opus=00;36:*.spx=00;36:*.spf=00;36:
|
||||
SSH_CONNECTION=192.168.0.21 34975 192.168.0.11 22
|
||||
LESSCLOSE=/usr/bin/lesspipe %s %s
|
||||
LANG=en_US.UTF-8
|
||||
OLDPWD=/home/shs
|
||||
XDG_SESSION_ID=2253
|
||||
USER=shs
|
||||
PWD=/home/shs
|
||||
HOME=/home/shs
|
||||
SSH_CLIENT=192.168.0.21 34975 22
|
||||
XDG_DATA_DIRS=/usr/local/share:/usr/share:/var/lib/snapd/desktop
|
||||
SSH_TTY=/dev/pts/0
|
||||
MAIL=/var/mail/shs
|
||||
TERM=xterm
|
||||
SHELL=/bin/bash
|
||||
SHLVL=1
|
||||
LOGNAME=shs
|
||||
DBUS_SESSION_BUS_ADDRESS=unix:path=/run/user/1000/bus
|
||||
XDG_RUNTIME_DIR=/run/user/1000
|
||||
PATH=/home/shs/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin
|
||||
LESSOPEN=| /usr/bin/lesspipe %s
|
||||
_=/usr/bin/env
|
||||
```
|
||||
|
||||
虽然你可能会看到大量的输出,上面显示的第一大部分用于在命令行上使用颜色标识各种文件类型。当你看到类似 `*.tar=01;31:` 这样的东西,这告诉你 `tar` 文件将以红色显示在文件列表中,然而 `*.jpg=01;35:` 告诉你 jpg 文件将以紫色显现出来。这些颜色旨在使它易于从一个文件列表中分辨出某些文件。你可以在《[在 Linux 命令行中自定义你的颜色][3]》处学习更多关于这些颜色的定义,和如何自定义它们。
|
||||
|
||||
当你更喜欢一种不加装饰的显示时,一种关闭颜色显示的简单方法是使用如下命令:
|
||||
|
||||
```
|
||||
$ ls -l --color=never
|
||||
```
|
||||
|
||||
这个命令可以简单地转换到一个别名:
|
||||
|
||||
```
|
||||
$ alias ll2='ls -l --color=never'
|
||||
```
|
||||
|
||||
你也可以使用 `echo` 命令来单独地显现某个设置。在这个命令中,我们显示在历史缓存区中将被记忆命令的数量:
|
||||
|
||||
```
|
||||
$ echo $HISTSIZE
|
||||
1000
|
||||
```
|
||||
|
||||
如果你已经移动到某个位置,你在文件系统中的最后位置会被记在这里:
|
||||
|
||||
```
|
||||
PWD=/home/shs
|
||||
OLDPWD=/tmp
|
||||
```
|
||||
|
||||
### 作出更改
|
||||
|
||||
你可以使用一个像这样的命令更改环境设置,但是,如果你希望保持这个设置,在你的 `~/.bashrc` 文件中添加一行代码,例如 `HISTSIZE=1234`。
|
||||
|
||||
```
|
||||
$ export HISTSIZE=1234
|
||||
```
|
||||
|
||||
### “export” 一个变量的本意是什么
|
||||
|
||||
导出一个环境变量可使设置用于你的 shell 和可能的子 shell。默认情况下,用户定义的变量是本地的,并不被导出到新的进程,例如,子 shell 和脚本。`export` 命令使得环境变量可用在子进程中发挥功用。
|
||||
|
||||
### 添加和移除变量
|
||||
|
||||
你可以很容易地在命令行和子 shell 上创建新的变量,并使它们可用。然而,当你登出并再次回来时这些变量将消失,除非你也将它们添加到 `~/.bashrc` 或一个类似的文件中。
|
||||
|
||||
```
|
||||
$ export MSG="Hello, World!"
|
||||
```
|
||||
|
||||
如果你需要,你可以使用 `unset` 命令来消除一个变量:
|
||||
|
||||
```
|
||||
$ unset MSG
|
||||
```
|
||||
|
||||
如果变量是局部定义的,你可以通过加载你的启动文件来简单地将其设置回来。例如:
|
||||
|
||||
```
|
||||
$ echo $MSG
|
||||
Hello, World!
|
||||
$ unset $MSG
|
||||
$ echo $MSG
|
||||
|
||||
$ . ~/.bashrc
|
||||
$ echo $MSG
|
||||
Hello, World!
|
||||
```
|
||||
|
||||
### 小结
|
||||
|
||||
用户账户是用一组恰当的启动文件设立的,创建了一个有用的用户环境,而个人用户和系统管理员都可以通过编辑他们的个人设置文件(对于用户)或很多来自设置起源的文件(对于系统管理员)来更改默认设置。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3385516/how-to-manage-your-linux-environment.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[robsean](https://github.com/robsean)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/03/environment-rocks-leaves-100792229-large.jpg
|
||||
[2]: https://www.youtube.com/playlist?list=PL7D2RMSmRO9J8OTpjFECi8DJiTQdd4hua
|
||||
[3]: https://www.networkworld.com/article/3269587/customizing-your-text-colors-on-the-linux-command-line.html
|
||||
[4]: https://www.facebook.com/NetworkWorld/
|
||||
[5]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,164 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (warmfrog)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10812-1.html)
|
||||
[#]: subject: (What is 5G? How is it better than 4G?)
|
||||
[#]: via: (https://www.networkworld.com/article/3203489/what-is-5g-how-is-it-better-than-4g.html#tk.rss_all)
|
||||
[#]: author: (Josh Fruhlinger https://www.networkworld.com/author/Josh-Fruhlinger/)
|
||||
|
||||
什么是 5G?它比 4G 好在哪里?
|
||||
==========================
|
||||
|
||||
> 5G 网络将使无线网络吞吐量提高 10 倍并且能够替代有线宽带。但是它们什么时候能够投入使用呢,为什么 5G 和物联网如此紧密地联系在一起呢?
|
||||
|
||||
![Thinkstock][1]
|
||||
|
||||
[5G 无线][2] 是一个概括的术语,用来描述一系列更快的无线互联网的标准和技术,理论上比 4G 快了 20 倍并且延迟降低了 120 倍,为物联网的发展和对新的高带宽应用的支持奠定了基础。
|
||||
|
||||
### 什么是 5G?科技还是流行词?
|
||||
|
||||
这个技术在世界范围内完全发挥它的潜能还需要数年时间,但同时当今一些 5G 网络服务已经投入使用。5G 不仅是一个技术术语,也是一个营销术语,并不是市场上的所有 5G 服务是标准的。
|
||||
|
||||
- [来自世界移动大会:[5G 时代即将来到][3]]
|
||||
|
||||
### 5G 与 4G 的速度对比
|
||||
|
||||
无线技术的每一代,最大的呼吁是增加速度。5G 网络潜在的峰值下载速度可以达到[20 Gbps,一般在 10 Gbps][4]。这不仅仅比当前 4G 网络更快,4G 目前峰值大约 1 Gbps,并且比更多家庭的有线网络连接更快。5G 提供的网络速度能够与光纤一较高下。
|
||||
|
||||
吞吐量不是 5G 仅有的速度提升;它还有的特点是极大降低了网络延迟。这是一个重要的区分:吞吐量用来测量花费多久来下载一个大文件,而延迟由网络瓶颈决定,延迟在往返的通讯中减慢了响应速度。
|
||||
|
||||
延迟很难量化,因为它因各种网络状态变化而变化,但是 5G 网络在理想情况下有能力使延迟率在 1 ms 内。总的来说,5G 延迟将比 4G 降低 60 到 120 倍。这会使很多应用变得可能,例如当前虚拟现实的延迟使它变得不实际。
|
||||
|
||||
### 5G 技术
|
||||
|
||||
5G 技术的基础有一系列标准定义,在过去的 10 年里一直在研究更好的部分。这些里面最重要的是 5G New Radio(5G NR),由 3GPP(一个为移动电话开发协议的标准化组织)组织标准化。5G NR 规定了很多 5G 设备操作的方式,[于 2018 年 7 月 完成终版][5]。
|
||||
|
||||
很多独特的技术同时出现来尽可能地提升 5G 的速度并降低延迟,下面是一些重要的。
|
||||
|
||||
### 毫米波
|
||||
|
||||
5G 网络大部分使用在 30 到 300 GHz 范围的频率。(正如名称一样,这些频率的波长在 1 到 10 毫米之间)这些高频范围能够[在每个时间单元比低频信号携带更多的信息][7],4G LTE 当前使用的就是通常频率在 1 GHz 以下的低频信号,或者 WiFi,最高 6 GHz。
|
||||
|
||||
毫米波技术传统上是昂贵并且难于部署的。科技进步已经克服了这些困难,这也是 5G 在如今成为了可能的原因。
|
||||
|
||||
### 小蜂窝
|
||||
|
||||
毫米波传输的一个缺点是当它们传输通过物理对象的时候比 4G 或 WiFi 信号更容易被干扰。
|
||||
|
||||
为了克服这些,5G 基础设施的模型将不同于 4G。替代了大的像景观一样移动天线桅杆,5G 网络将由[分布在城市中大概间距 250 米的更小的基站][8]提供支持,创建更小的服务区域。
|
||||
|
||||
这些 5G 基站的功率要求低于 4G,并且可以更容易地连接到建筑物和电线杆上。
|
||||
|
||||
### 大量的 MIMO
|
||||
|
||||
尽管 5G 基站比 4G 的对应部分小多了,但它们却带了更多的天线。这些天线是[多输入多输出的(MIMO)][9],意味着在相同的数据信道能够同时处理多个双向会话。5G 网络能够处理比 4G 网络超过 20 倍的会话。
|
||||
|
||||
大量的 MIMO 保证了[基站容量限制下的极大提升][10],允许单个基站承载更多的设备会话。这就是 5G 可能推动物联网更广泛应用的原因。理论上,更多的连接到互联网的无线设备能够部署在相同的空间而不会使网络被压垮。
|
||||
|
||||
### 波束成形
|
||||
|
||||
确保所有的会话来回地到达正确的地方是比较棘手的,尤其是前面提到的毫米波信号的干涉问题。为了克服这些问题,5G 基站部署了更高级的波束技术,使用建设性和破坏性的无线电干扰来使信号有向而不是广播。这在一个特定的方向上有效地加强了信号强度和范围。
|
||||
|
||||
### 5G 可获得性
|
||||
|
||||
第一个 5G 商用网络 [2018 年 5 月在卡塔尔推出][12]。自那以后,5G 网络已经扩展到全世界,从阿根廷到越南。[Lifewire 有一个不错的,经常更新的列表][13].
|
||||
|
||||
牢记一点的是,尽管这样,目前不是所有的 5G 网络都履行了所有的技术承诺。一些早期的 5G 产品依赖于现有的 4G 基础设施,减少了可以获得的潜在速度;其它服务为了市场目的而标榜 5G 但是并不符合标准。仔细观察美国无线运营商的产品都会发现一些陷阱。
|
||||
|
||||
### 无线运营商和 5G
|
||||
|
||||
技术上讲,5G 服务如今在美国已经可获得了。但声明中包含的注意事项因运营商而异,表明 5G 普及之前还有很长的路要走。
|
||||
|
||||
Verizon 可能是早期 5G 最大的推动者。它宣告到 2018 年 10 月 将有 4 个城市成为 [5G 家庭][14]的一部分,这是一项需要你的其他设备通过 WiFi 来连接特定的 5G 热点,由热点连接到网络的服务。
|
||||
|
||||
Verizon 计划四月在 [Minneapolis 和 Chicago 发布 5G 移动服务][15],该服务将在这一年内传播到其他城市。访问 5G 网络将需要消费者每月额外花费费用,加上购买能够实际访问 5G 的手机花费(稍后会详细介绍)。另外,Verizon 的部署被称作 [5G TF][16],实际上不符合 5G NR 的标准。
|
||||
|
||||
AT&T [声明在 2018 年 12 月将有美国的 12 个城市可以使用 5G][17],在 2019 年的末尾将增加 9 个城市,但最终在这些城市里,只有市中心商业区能够访问。为了访问 5G 网络,需要一个特定的 Netgear 热点来连接到 5G 服务,然后为手机和其他设备提供一个 Wi-Fi 信号。
|
||||
|
||||
与此同时,AT&T 也在推出 4G 网络的速度提升计划,被成为 5GE,即使这些提升和 5G 网络没有关系。([这会向后兼容][18])
|
||||
|
||||
Sprint 将在 2019 年 5 月之前在四个城市提供 5G 服务,在年末将有更多。但是 Sprint 的 5G 产品充分利用了 MIMO 单元,他们[没有使用毫米波信道][19],意味着 Sprint 的用户不会看到像其他运营商一样的速度提升。
|
||||
|
||||
T-Mobile 采用相似的模型,它[在 2019 年年底之前不会推出 5G 服务][20],因为他们没有手机能够连接到它。
|
||||
|
||||
一个可能阻止 5G 速度的迅速传播的障碍是需要铺开所有这些小蜂窝基站。它们小的尺寸和较低的功耗需求使它们技术上比 4G 技术更容易部署,但这不意味着它能够很简单的使政府和财产拥有者信服到处安装一堆基站。Verizon 实际上建立了[向本地民选官员请愿的网站][21]来加速 5G 基站的部署。
|
||||
|
||||
### 5G 手机:何时可获得?何时可以买?
|
||||
|
||||
第一部声称为 5G 手机的是 Samsung Galaxy S10 5G,将在 2019 年夏末首发。你也可以从 Verizon 订阅一个“[Moto Mod][22]”,用来[转换 Moto Z3 手机为 5G 兼容设备][23]。
|
||||
|
||||
但是除非你不能忍受作为一个早期使用者的诱惑,你会希望再等待一下;一些关于运营商的奇怪和突显的问题意味着可能你的手机[不兼容你的运营商的整个 5G 网络][24]。
|
||||
|
||||
一个可能令你吃惊的落后者是苹果:分析者确信最早直到 2020 年以前 iPhone 不会与 5G 兼容。但这符合该公司的特点;苹果在 2012 年末也落后于三星发布兼容 4G 的手机。
|
||||
|
||||
不可否认,5G 洪流已经到来。5G 兼容的设备[在 2019 年统治了巴塞罗那世界移动大会][3],因此期待视野里有更多的选择。
|
||||
|
||||
### 为什么人们已经在讨论 6G 了?
|
||||
|
||||
一些专家说缺点是[5G 不能够达到延迟和可靠性的目标][27]。这些完美主义者已经在探寻 6G,来试图解决这些缺点。
|
||||
|
||||
有一个[研究新的能够融入 6G 技术的小组][28],自称为“融合 TeraHertz 通信与传感中心”(ComSenTer)。根据说明,他们努力让每个设备的带宽达到 100Gbps。
|
||||
|
||||
除了增加可靠性,还突破了可靠性并增加速度,6G 同样试图允许上千的并发连接。如果成功的话,这个特点将帮助物联网设备联网,使在工业设置中部署上千个传感器。
|
||||
|
||||
即使仍在胚胎当中,6G 已经由于新发现的 [在基于 tera-hretz 的网络中潜在的中间人攻击][29]的紧迫性面临安全的考虑。好消息是有大量时间来解决这个问题。6G 网络直到 2030 之前才可能出现。
|
||||
|
||||
阅读更多关于 5G 网络:
|
||||
|
||||
* [企业如何为 5G 网络做准备][30]
|
||||
* [5G 与 4G:速度、延迟和应用支持的差异][31]
|
||||
* [私人 5G 网络即将到来][32]
|
||||
* [5G 和 6G 无线存在安全问题][33]
|
||||
* [毫米波无线技术如何支持 5G 和物联网][34]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3203489/what-is-5g-how-is-it-better-than-4g.html
|
||||
|
||||
作者:[Josh Fruhlinger][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[warmfrog](https://github.com/warmfrog)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Josh-Fruhlinger/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.techhive.com/images/article/2017/04/5g-100718139-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3203489/what-is-5g-wireless-networking-benefits-standards-availability-versus-lte.html
|
||||
[3]: https://www.networkworld.com/article/3354477/mobile-world-congress-the-time-of-5g-is-almost-here.html
|
||||
[4]: https://www.networkworld.com/article/3330603/5g-versus-4g-how-speed-latency-and-application-support-differ.html
|
||||
[5]: https://www.theverge.com/2018/6/15/17467734/5g-nr-standard-3gpp-standalone-finished
|
||||
[6]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fcourses%2Fmobile-device-management-big-picture
|
||||
[7]: https://www.networkworld.com/article/3291323/millimeter-wave-wireless-could-help-support-5g-and-iot.html
|
||||
[8]: https://spectrum.ieee.org/video/telecom/wireless/5g-bytes-small-cells-explained
|
||||
[9]: https://www.networkworld.com/article/3250268/what-is-mu-mimo-and-why-you-need-it-in-your-wireless-routers.html
|
||||
[10]: https://spectrum.ieee.org/tech-talk/telecom/wireless/5g-researchers-achieve-new-spectrum-efficiency-record
|
||||
[11]: https://www.networkworld.com/article/3262991/future-wireless-networks-will-have-no-capacity-limits.html
|
||||
[12]: https://venturebeat.com/2018/05/14/worlds-first-commercial-5g-network-launches-in-qatar/
|
||||
[13]: https://www.lifewire.com/5g-availability-world-4156244
|
||||
[14]: https://www.digitaltrends.com/computing/verizon-5g-home-promises-up-to-gigabit-internet-speeds-for-50/
|
||||
[15]: https://lifehacker.com/heres-your-cheat-sheet-for-verizons-new-5g-data-plans-1833278817
|
||||
[16]: https://www.theverge.com/2018/10/2/17927712/verizon-5g-home-internet-real-speed-meaning
|
||||
[17]: https://www.cnn.com/2018/12/18/tech/5g-mobile-att/index.html
|
||||
[18]: https://www.networkworld.com/article/3339720/like-4g-before-it-5g-is-being-hyped.html?nsdr=true
|
||||
[19]: https://www.digitaltrends.com/mobile/sprint-5g-rollout/
|
||||
[20]: https://www.cnet.com/news/t-mobile-delays-full-600-mhz-5g-launch-until-second-half/
|
||||
[21]: https://lets5g.com/
|
||||
[22]: https://www.verizonwireless.com/support/5g-moto-mod-faqs/?AID=11365093&SID=100098X1555750Xbc2e857934b22ebca1a0570d5ba93b7c&vendorid=CJM&PUBID=7105813&cjevent=2e2150cb478c11e98183013b0a1c0e0c
|
||||
[23]: https://www.digitaltrends.com/cell-phone-reviews/moto-z3-review/
|
||||
[24]: https://www.businessinsider.com/samsung-galaxy-s10-5g-which-us-cities-have-5g-networks-2019-2
|
||||
[25]: https://www.cnet.com/news/why-apples-in-no-rush-to-sell-you-a-5g-iphone/
|
||||
[26]: https://mashable.com/2012/09/09/iphone-5-4g-lte/#hYyQUelYo8qq
|
||||
[27]: https://www.networkworld.com/article/3305359/6g-will-achieve-terabits-per-second-speeds.html
|
||||
[28]: https://www.networkworld.com/article/3285112/get-ready-for-upcoming-6g-wireless-too.html
|
||||
[29]: https://www.networkworld.com/article/3315626/5g-and-6g-wireless-technologies-have-security-issues.html
|
||||
[30]: https://%20https//www.networkworld.com/article/3306720/mobile-wireless/how-enterprises-can-prep-for-5g.html
|
||||
[31]: https://%20https//www.networkworld.com/article/3330603/mobile-wireless/5g-versus-4g-how-speed-latency-and-application-support-differ.html
|
||||
[32]: https://%20https//www.networkworld.com/article/3319176/mobile-wireless/private-5g-networks-are-coming.html
|
||||
[33]: https://www.networkworld.com/article/3315626/network-security/5g-and-6g-wireless-technologies-have-security-issues.html
|
||||
[34]: https://www.networkworld.com/article/3291323/mobile-wireless/millimeter-wave-wireless-could-help-support-5g-and-iot.html
|
||||
[35]: https://www.facebook.com/NetworkWorld/
|
||||
[36]: https://www.linkedin.com/company/network-world
|
||||
|
||||
@ -0,0 +1,87 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (MjSeven)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10809-1.html)
|
||||
[#]: subject: (Command line quick tips: Cutting content out of files)
|
||||
[#]: via: (https://fedoramagazine.org/command-line-quick-tips-cutting-content-out-of-files/)
|
||||
[#]: author: (Stephen Snow https://fedoramagazine.org/author/jakfrost/)
|
||||
|
||||
命令行技巧:分割文件内容
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
Fedora 发行版是一个功能齐全的操作系统,有出色的图形化桌面环境。用户可以很容易地通过单击动作来完成任何典型任务。所有这些美妙的易用性掩盖了其底层强大的命令行细节。本文是向你展示一些常见命令行实用程序的系列文章的一部分。让我们进入 shell 来看看 `cut`。
|
||||
|
||||
通常,当你在命令行中工作时,你处理的是文本文件。有时这些文件可能很长,虽然可以完整地阅读它们,但是可能会耗费大量时间,并且容易出错。在本文中,你将学习如何从文本文件中提取内容,并从中获取你所需的信息。
|
||||
|
||||
重要的是要意识到,在 Fedora 中有许多方法可以完成类似的命令行任务。例如,Fedora 仓库含有用于解析和处理文本的完整语言系统。此外,还有多个命令行实用程序可用于 shell 中任何可能的用途。本文只关注使用其中几个实用程序选项,从文件中提取一些信息并以可读的格式呈现。
|
||||
|
||||
### cut 使用
|
||||
|
||||
为了演示这个例子,在系统上使用一个标准的大文件,如 `/etc/passwd`。正如本系列的前一篇文章所示,你可以执行 `cat` 命令来查看整个文件:
|
||||
|
||||
```
|
||||
$ cat /etc/passwd
|
||||
root:x:0:0:root:/root:/bin/bash
|
||||
bin:x:1:1:bin:/bin:/sbin/nologin
|
||||
daemon:x:2:2:daemon:/sbin:/sbin/nologin
|
||||
adm:x:3:4:adm:/var/adm:/sbin/nologin
|
||||
...
|
||||
```
|
||||
|
||||
此文件包含系统上所有所有账户的信息。它有一个特定的格式:
|
||||
|
||||
```
|
||||
name:password:user-id:group-id:comment:home-directory:shell
|
||||
```
|
||||
|
||||
假设你只想要系统上所有账户名的列表,如果你只能从每一行中删除 “name” 值。这就是 `cut` 命令派上用场的地方!它一次处理一行输入,并提取该行的特定部分。
|
||||
|
||||
`cut` 命令提供了以不同方式选择一行的部分的选项,在本示例中需要两个,`-d` 和 `-f`。`-d` 选项允许你声明用于分隔行中值的分隔符。在本例中,冒号(`:`)用于分隔值。`-f` 选项允许你选择要提取哪些字段值。因此,在本例中,输入的命令是:
|
||||
|
||||
```
|
||||
$ cut -d: -f1 /etc/passwd
|
||||
root
|
||||
bin
|
||||
daemon
|
||||
adm
|
||||
...
|
||||
```
|
||||
|
||||
太棒了,成功了!但是你将输出打印到标准输出,在终端会话中意味着它需要占据屏幕。如果你需要稍后完成另一项任务所需的信息,这该怎么办?如果有办法将 `cut` 命令的输出保存到文本文件中,那就太好了。对于这样的任务,shell 有一个简单的内置功能,重定向功能(`>`)。
|
||||
|
||||
```
|
||||
$ cut -d: -f1 /etc/passwd > names.txt
|
||||
```
|
||||
|
||||
这会将 `cut` 的输出放到一个名为 `names.txt` 的文件中,你可以使用 `cat` 来查看它的内容:
|
||||
|
||||
```
|
||||
$ cat names.txt
|
||||
root
|
||||
bin
|
||||
daemon
|
||||
adm
|
||||
...
|
||||
```
|
||||
|
||||
使用两个命令和一个 shell 功能,可以很容易地使用 `cat` 从一个文件进行识别、提取和重定向一些信息,并将其保存到另一个文件以供以后使用。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/command-line-quick-tips-cutting-content-out-of-files/
|
||||
|
||||
作者:[Stephen Snow][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/jakfrost/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/04/commandline-cutting-816x345.jpg
|
||||
[2]: https://unsplash.com/photos/tA5eSY_hay8?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[3]: https://unsplash.com/search/photos/command-line?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
@ -0,0 +1,108 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10833-1.html)
|
||||
[#]: subject: (Getting started with Python's cryptography library)
|
||||
[#]: via: (https://opensource.com/article/19/4/cryptography-python)
|
||||
[#]: author: (Moshe Zadka https://opensource.com/users/moshez)
|
||||
|
||||
Python 的加密库入门
|
||||
======
|
||||
|
||||
> 加密你的数据并使其免受攻击者的攻击。
|
||||
|
||||
![lock on world map][1]
|
||||
|
||||
密码学俱乐部的第一条规则是:永远不要自己*发明*密码系统。密码学俱乐部的第二条规则是:永远不要自己*实现*密码系统:在现实世界中,在*实现*以及设计密码系统阶段都找到过许多漏洞。
|
||||
|
||||
Python 中的一个有用的基本加密库就叫做 [cryptography][2]。它既是一个“安全”方面的基础库,也是一个“危险”层。“危险”层需要更加小心和相关的知识,并且使用它很容易出现安全漏洞。在这篇介绍性文章中,我们不会涵盖“危险”层中的任何内容!
|
||||
|
||||
cryptography 库中最有用的高级安全功能是一种 Fernet 实现。Fernet 是一种遵循最佳实践的加密缓冲区的标准。它不适用于非常大的文件,如千兆字节以上的文件,因为它要求你一次加载要加密或解密的内容到内存缓冲区中。
|
||||
|
||||
Fernet 支持<ruby>对称<rt>symmetric</rt></ruby>(即<ruby>密钥<rt>secret key</rt></ruby>)加密方式*:加密和解密使用相同的密钥,因此必须保持安全。
|
||||
|
||||
生成密钥很简单:
|
||||
|
||||
```
|
||||
>>> k = fernet.Fernet.generate_key()
|
||||
>>> type(k)
|
||||
<class 'bytes'>
|
||||
```
|
||||
|
||||
这些字节可以写入有适当权限的文件,最好是在安全的机器上。
|
||||
|
||||
有了密钥后,加密也很容易:
|
||||
|
||||
```
|
||||
>>> frn = fernet.Fernet(k)
|
||||
>>> encrypted = frn.encrypt(b"x marks the spot")
|
||||
>>> encrypted[:10]
|
||||
b'gAAAAABb1'
|
||||
```
|
||||
|
||||
如果在你的机器上加密,你会看到略微不同的值。不仅因为(我希望)你生成了和我不同的密钥,而且因为 Fernet 将要加密的值与一些随机生成的缓冲区连接起来。这是我之前提到的“最佳实践”之一:它将阻止对手分辨哪些加密值是相同的,这有时是攻击的重要部分。
|
||||
|
||||
解密同样简单:
|
||||
|
||||
```
|
||||
>>> frn = fernet.Fernet(k)
|
||||
>>> frn.decrypt(encrypted)
|
||||
b'x marks the spot'
|
||||
```
|
||||
|
||||
请注意,这仅加密和解密*字节串*。为了加密和解密*文本串*,通常需要对它们使用 [UTF-8][3] 进行编码和解码。
|
||||
|
||||
20 世纪中期密码学最有趣的进展之一是<ruby>公钥<rt>public key</rt></ruby>加密。它可以在发布加密密钥的同时而让*解密密钥*保持保密。例如,它可用于保存服务器使用的 API 密钥:服务器是唯一可以访问解密密钥的一方,但是任何人都可以保存公共加密密钥。
|
||||
|
||||
虽然 cryptography 没有任何支持公钥加密的*安全*功能,但 [PyNaCl][4] 库有。PyNaCl 封装并提供了一些很好的方法来使用 Daniel J. Bernstein 发明的 [NaCl][5] 加密系统。
|
||||
|
||||
NaCl 始终同时<ruby>加密<rt>encrypt</rt></ruby>和<ruby>签名<rt>sign</rt></ruby>或者同时<ruby>解密<rt>decrypt</rt></ruby>和<ruby>验证签名<rt>verify signature</rt></ruby>。这是一种防止<ruby>基于可伸缩性<rt>malleability-based</rt></ruby>的攻击的方法,其中攻击者会修改加密值。
|
||||
|
||||
加密是使用公钥完成的,而签名是使用密钥完成的:
|
||||
|
||||
```
|
||||
>>> from nacl.public import PrivateKey, PublicKey, Box
|
||||
>>> source = PrivateKey.generate()
|
||||
>>> with open("target.pubkey", "rb") as fpin:
|
||||
... target_public_key = PublicKey(fpin.read())
|
||||
>>> enc_box = Box(source, target_public_key)
|
||||
>>> result = enc_box.encrypt(b"x marks the spot")
|
||||
>>> result[:4]
|
||||
b'\xe2\x1c0\xa4'
|
||||
```
|
||||
|
||||
解密颠倒了角色:它需要私钥进行解密,需要公钥验证签名:
|
||||
|
||||
```
|
||||
>>> from nacl.public import PrivateKey, PublicKey, Box
|
||||
>>> with open("source.pubkey", "rb") as fpin:
|
||||
... source_public_key = PublicKey(fpin.read())
|
||||
>>> with open("target.private_key", "rb") as fpin:
|
||||
... target = PrivateKey(fpin.read())
|
||||
>>> dec_box = Box(target, source_public_key)
|
||||
>>> dec_box.decrypt(result)
|
||||
b'x marks the spot'
|
||||
```
|
||||
|
||||
最后,[PocketProtector][6] 库构建在 PyNaCl 之上,包含完整的密钥管理方案。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/cryptography-python
|
||||
|
||||
作者:[Moshe Zadka][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/moshez
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/security-lock-cloud-safe.png?itok=yj2TFPzq (lock on world map)
|
||||
[2]: https://cryptography.io/en/latest/
|
||||
[3]: https://en.wikipedia.org/wiki/UTF-8
|
||||
[4]: https://pynacl.readthedocs.io/en/stable/
|
||||
[5]: https://nacl.cr.yp.to/
|
||||
[6]: https://github.com/SimpleLegal/pocket_protector/blob/master/USER_GUIDE.md
|
||||
@ -0,0 +1,74 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10822-1.html)
|
||||
[#]: subject: (How to quickly deploy, run Linux applications as unikernels)
|
||||
[#]: via: (https://www.networkworld.com/article/3387299/how-to-quickly-deploy-run-linux-applications-as-unikernels.html#tk.rss_all)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
如何快速部署并作为 unikernel 运行 Linux 应用
|
||||
======
|
||||
|
||||
unikernel 是一种用于在云基础架构上部署应用程序的更小、更快、更安全的方式。使用 NanoVMs OPS,任何人都可以将 Linux 应用程序作为 unikernel 运行而无需额外编码。
|
||||
|
||||
![Marcho Verch \(CC BY 2.0\)][1]
|
||||
|
||||
随着 unikernel 的出现,构建和部署轻量级应用变得更容易、更可靠。虽然功能有限,但 unikernal 在速度和安全性方面有许多优势。
|
||||
|
||||
### 什么是 unikernel?
|
||||
|
||||
unikernel 是一种非常特殊的<ruby>单一地址空间<rt>single-address-space</rt></ruby>的机器镜像,类似于已经主导大批互联网的云应用,但它们相当小并且是单一用途的。它们很轻,只提供所需的资源。它们加载速度非常快,而且安全性更高 —— 攻击面非常有限。单个可执行文件中包含所需的所有驱动、I/O 例程和支持库。其最终生成的虚拟镜像可以无需其它部分就可以引导和运行。它们通常比容器快 10 到 20 倍。
|
||||
|
||||
潜在的攻击者无法进入 shell 并获得控制权,因为它没有 shell。他们无法获取系统的 `/etc/passwd`或 `/etc/shadow` 文件,因为这些文件不存在。创建一个 unikernel 就像应用将自己变成操作系统。使用 unikernel,应用和操作系统将成为一个单一的实体。你忽略了不需要的东西,从而消除了漏洞并大幅提高性能。
|
||||
|
||||
简而言之,unikernel:
|
||||
|
||||
* 提供更高的安全性(例如,shell 破解代码无用武之地)
|
||||
* 比标准云应用占用更小空间
|
||||
* 经过高度优化
|
||||
* 启动非常快
|
||||
|
||||
### unikernel 有什么缺点吗?
|
||||
|
||||
unikernel 的唯一严重缺点是你必须构建它们。对于许多开发人员来说,这是一个巨大的进步。由于应用的底层特性,将应用简化为所需的内容然后生成紧凑、平稳运行的应用可能很复杂。在过去,你几乎必须是系统开发人员或底层程序员才能生成它们。
|
||||
|
||||
### 这是怎么改变的?
|
||||
|
||||
最近(2019 年 3 月 24 日)[NanoVMs][3] 宣布了一个将任何 Linux 应用加载为 unikernel 的工具。使用 NanoVMs OPS,任何人都可以将 Linux 应用作为 unikernel 运行而无需额外编码。该应用还可以更快、更安全地运行,并且成本和开销更低。
|
||||
|
||||
### 什么是 NanoVMs OPS?
|
||||
|
||||
NanoVMs 是给开发人员的 unikernel 工具。它能让你运行各种企业级软件,但仍然可以非常严格地控制它的运行。
|
||||
|
||||
使用 OPS 的其他好处包括:
|
||||
|
||||
* 无需经验或知识,开发人员就可以构建 unikernel。
|
||||
* 该工具可在笔记本电脑上本地构建和运行 unikernel。
|
||||
* 无需创建帐户,只需下载并一个命令即可执行 OPS。
|
||||
|
||||
NanoVMs 的介绍可以在 [Youtube 上的 NanoVMs 视频][5] 上找到。你还可以查看该公司的 [LinkedIn 页面][6]并在[此处][7]阅读有关 NanoVMs 安全性的信息。
|
||||
|
||||
还有有关如何[入门][8]的一些信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3387299/how-to-quickly-deploy-run-linux-applications-as-unikernels.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/04/corn-kernels-100792925-large.jpg
|
||||
[3]: https://nanovms.com/
|
||||
[5]: https://www.youtube.com/watch?v=VHWDGhuxHPM
|
||||
[6]: https://www.linkedin.com/company/nanovms/
|
||||
[7]: https://nanovms.com/security
|
||||
[8]: https://nanovms.gitbook.io/ops/getting_started
|
||||
[9]: https://www.facebook.com/NetworkWorld/
|
||||
[10]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,177 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (robsean)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10843-1.html)
|
||||
[#]: subject: (Anbox – Easy Way To Run Android Apps On Linux)
|
||||
[#]: via: (https://www.2daygeek.com/anbox-best-android-emulator-for-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
Anbox:在 Linux 上运行 Android 应用程序的简单方式
|
||||
======
|
||||
|
||||
Android 模拟器允许我们直接从 Linux 系统上运行我们最喜欢的 Android 应用程序或游戏。对于 Linux 来说,有很多的这样的 Android 模拟器,在过去我们介绍过几个此类应用程序。
|
||||
|
||||
你可以通过导航到下面的网址回顾它们。
|
||||
|
||||
* [如何在 Linux 上安装官方 Android 模拟器 (SDK)][1]
|
||||
* [如何在 Linux 上安装 GenyMotion (Android 模拟器)][2]
|
||||
|
||||
今天我们将讨论 Anbox Android 模拟器。
|
||||
|
||||
### Anbox 是什么?
|
||||
|
||||
Anbox 是 “Android in a box” 的缩写。Anbox 是一个基于容器的方法,可以在普通的 GNU/Linux 系统上启动完整的 Android 系统。
|
||||
|
||||
它是现代化的新模拟器之一。
|
||||
|
||||
Anbox 可以让你在 Linux 系统上运行 Android,而没有虚拟化的迟钝,因为核心的 Android 操作系统已经使用 Linux 命名空间(LXE)放置到容器中了。
|
||||
|
||||
Android 容器不能直接访问到任何硬件,所有硬件的访问都是通过在主机上的守护进程进行的。
|
||||
|
||||
每个应用程序将在一个单独窗口打开,就像其它本地系统应用程序一样,并且它可以显示在启动器中。
|
||||
|
||||
### 如何在 Linux 中安装 Anbox ?
|
||||
|
||||
Anbox 也可作为 snap 软件包安装,请确保你已经在你的系统上启用了 snap 支持。
|
||||
|
||||
Anbox 软件包最近被添加到 Ubuntu 18.10 (Cosmic) 和 Debian 10 (Buster) 软件仓库。如果你正在运行这些版本,那么你可以轻松地在官方发行版的软件包管理器的帮助下安装。否则可以用 snap 软件包安装。
|
||||
|
||||
为使 Anbox 工作,确保需要的内核模块已经安装在你的系统中。对于基于 Ubuntu 的用户,使用下面的 PPA 来安装它。
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:morphis/anbox-support
|
||||
$ sudo apt update
|
||||
$ sudo apt install linux-headers-generic anbox-modules-dkms
|
||||
```
|
||||
|
||||
在你安装 `anbox-modules-dkms` 软件包后,你必须手动重新加载内核模块,或需要系统重新启动。
|
||||
|
||||
```
|
||||
$ sudo modprobe ashmem_linux
|
||||
$ sudo modprobe binder_linux
|
||||
```
|
||||
|
||||
对于 Debian/Ubuntu 系统,使用 [APT-GET 命令][3] 或 [APT 命令][4] 来安装 anbox。
|
||||
|
||||
```
|
||||
$ sudo apt install anbox
|
||||
```
|
||||
|
||||
对于基于 Arch Linux 的系统,我们总是习惯从 AUR 储存库中获取软件包。所以,使用任一个的 [AUR 助手][5] 来安装它。我喜欢使用 [Yay 工具][6]。
|
||||
|
||||
```
|
||||
$ yuk -S anbox-git
|
||||
```
|
||||
|
||||
否则,你可以通过导航到下面的文章来 [在 Linux 中安装和配置 snap][7]。如果你已经在你的系统上安装 snap,其它的步骤可以忽略。
|
||||
|
||||
```
|
||||
$ sudo snap install --devmode --beta anbox
|
||||
```
|
||||
|
||||
### Anbox 的必要条件
|
||||
|
||||
默认情况下,Anbox 并没有带有 Google Play Store。因此,我们需要手动下载每个应用程序(APK),并使用 Android 调试桥(ADB)安装它。
|
||||
|
||||
ADB 工具在大多数的发行版的软件仓库是轻易可获得的,我们可以容易地安装它。
|
||||
|
||||
对于 Debian/Ubuntu 系统,使用 [APT-GET 命令][3] 或 [APT 命令][4] 来安装 ADB。
|
||||
|
||||
```
|
||||
$ sudo apt install android-tools-adb
|
||||
```
|
||||
|
||||
对于 Fedora 系统,使用 [DNF 命令][8] 来安装 ADB。
|
||||
|
||||
```
|
||||
$ sudo dnf install android-tools
|
||||
```
|
||||
|
||||
对于基于 Arch Linux 的系统,使用 [Pacman 命令][9] 来安装 ADB。
|
||||
|
||||
```
|
||||
$ sudo pacman -S android-tools
|
||||
```
|
||||
|
||||
对于 openSUSE Leap 系统,使用 [Zypper 命令][10] 来安装 ADB。
|
||||
|
||||
```
|
||||
$ sudo zypper install android-tools
|
||||
```
|
||||
|
||||
### 在哪里下载 Android 应用程序?
|
||||
|
||||
既然我们不能使用 Play Store ,你就得从信得过的网站来下载 APK 软件包,像 [APKMirror][11] ,然后手动安装它。
|
||||
|
||||
### 如何启动 Anbox?
|
||||
|
||||
Anbox 可以从 Dash 启动。这是默认的 Anbox 外貌。
|
||||
|
||||
![][13]
|
||||
|
||||
### 如何把应用程序推到 Anbox ?
|
||||
|
||||
像我先前所说,我们需要手动安装它。为测试目的,我们将安装 YouTube 和 Firefox 应用程序。
|
||||
|
||||
首先,你需要启动 ADB 服务。为做到这样,运行下面的命令。
|
||||
|
||||
```
|
||||
$ adb devices
|
||||
```
|
||||
|
||||
我们已经下载 YouTube 和 Firefox 应用程序,现在我们将安装。
|
||||
|
||||
语法格式:
|
||||
|
||||
```
|
||||
$ adb install Name-Of-Your-Application.apk
|
||||
```
|
||||
|
||||
安装 YouTube 和 Firefox 应用程序:
|
||||
|
||||
```
|
||||
$ adb install 'com.google.android.youtube_14.13.54-1413542800_minAPI19(x86_64)(nodpi)_apkmirror.com.apk'
|
||||
Success
|
||||
|
||||
$ adb install 'org.mozilla.focus_9.0-330191219_minAPI21(x86)(nodpi)_apkmirror.com.apk'
|
||||
Success
|
||||
```
|
||||
|
||||
我已经在我的 Anbox 中安装 YouTube 和 Firefox。查看下面的截图。
|
||||
|
||||
![][14]
|
||||
|
||||
像我们在文章的开始所说,它将以新的标签页打开任何的应用程序。在这里,我们将打开 Firefox ,并访问 [2daygeek.com][15] 网站。
|
||||
|
||||
![][16]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/anbox-best-android-emulator-for-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[robsean](https://github.com/robsean)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/install-configure-sdk-android-emulator-on-linux/
|
||||
[2]: https://www.2daygeek.com/install-genymotion-android-emulator-on-ubuntu-debian-fedora-arch-linux/
|
||||
[3]: https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[4]: https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[5]: https://www.2daygeek.com/category/aur-helper/
|
||||
[6]: https://www.2daygeek.com/install-yay-yet-another-yogurt-aur-helper-on-arch-linux/
|
||||
[7]: https://www.2daygeek.com/linux-snap-package-manager-ubuntu/
|
||||
[8]: https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
[9]: https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
|
||||
[10]: https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
|
||||
[11]: https://www.apkmirror.com/
|
||||
[12]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[13]: https://www.2daygeek.com/wp-content/uploads/2019/04/anbox-best-android-emulator-for-linux-1.jpg
|
||||
[14]: https://www.2daygeek.com/wp-content/uploads/2019/04/anbox-best-android-emulator-for-linux-2.jpg
|
||||
[15]: https://www.2daygeek.com/
|
||||
[16]: https://www.2daygeek.com/wp-content/uploads/2019/04/anbox-best-android-emulator-for-linux-3.jpg
|
||||
@ -0,0 +1,211 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (arrowfeng)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10820-1.html)
|
||||
[#]: subject: (How To Install And Configure Chrony As NTP Client?)
|
||||
[#]: via: (https://www.2daygeek.com/configure-ntp-client-using-chrony-in-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
如何安装和配置 Chrony 作为 NTP 客户端?
|
||||
======
|
||||
|
||||
NTP 服务器和 NTP 客户端可以让我们通过网络来同步时钟。之前,我们已经撰写了一篇关于 [NTP 服务器和 NTP 客户端的安装与配置][1] 的文章。
|
||||
|
||||
如果你想看这些内容,点击上述的 URL 访问。
|
||||
|
||||
### Chrony 客户端
|
||||
|
||||
Chrony 是 NTP 客户端的替代品。它能以更精确的时间和更快的速度同步时钟,并且它对于那些不是全天候在线的系统非常有用。
|
||||
|
||||
chronyd 更小、更节能,它占用更少的内存且仅当需要时它才唤醒 CPU。即使网络拥塞较长时间,它也能很好地运行。它支持 Linux 上的硬件时间戳,允许在本地网络进行极其准确的同步。
|
||||
|
||||
它提供下列两个服务。
|
||||
|
||||
* `chronyc`:Chrony 的命令行接口。
|
||||
* `chronyd`:Chrony 守护进程服务。
|
||||
|
||||
### 如何在 Linux 上安装和配置 Chrony?
|
||||
|
||||
由于安装包在大多数发行版的官方仓库中可用,因此直接使用包管理器去安装它。
|
||||
|
||||
对于 Fedora 系统,使用 [DNF 命令][2] 去安装 chrony。
|
||||
|
||||
```
|
||||
$ sudo dnf install chrony
|
||||
```
|
||||
|
||||
对于 Debian/Ubuntu 系统,使用 [APT-GET 命令][3] 或者 [APT 命令][4] 去安装 chrony。
|
||||
|
||||
```
|
||||
$ sudo apt install chrony
|
||||
```
|
||||
|
||||
对基于 Arch Linux 的系统,使用 [Pacman 命令][5] 去安装 chrony。
|
||||
|
||||
```
|
||||
$ sudo pacman -S chrony
|
||||
```
|
||||
|
||||
对于 RHEL/CentOS 系统,使用 [YUM 命令][6] 去安装 chrony。
|
||||
|
||||
```
|
||||
$ sudo yum install chrony
|
||||
```
|
||||
|
||||
对于 openSUSE Leap 系统,使用 [Zypper 命令][7] 去安装 chrony。
|
||||
|
||||
```
|
||||
$ sudo zypper install chrony
|
||||
```
|
||||
|
||||
在这篇文章中,我们将使用下列设置去测试。
|
||||
|
||||
* NTP 服务器:主机名:CentOS7.2daygeek.com,IP:192.168.1.5,OS:CentOS 7
|
||||
* Chrony 客户端:主机名:Ubuntu18.2daygeek.com,IP:192.168.1.3,OS:Ubuntu 18.04
|
||||
|
||||
服务器的安装请访问 [在 Linux 上安装和配置 NTP 服务器][1] 的 URL。
|
||||
|
||||
我已经在 CentOS7.2daygeek.com 这台主机上安装和配置了 NTP 服务器,因此,将其附加到所有的客户端机器上。此外,还包括其他所需信息。
|
||||
|
||||
`chrony.conf` 文件的位置根据你的发行版不同而不同。
|
||||
|
||||
对基于 RHEL 的系统,它位于 `/etc/chrony.conf`。
|
||||
|
||||
对基于 Debian 的系统,它位于 `/etc/chrony/chrony.conf`。
|
||||
|
||||
```
|
||||
# vi /etc/chrony/chrony.conf
|
||||
|
||||
server CentOS7.2daygeek.com prefer iburst
|
||||
keyfile /etc/chrony/chrony.keys
|
||||
driftfile /var/lib/chrony/chrony.drift
|
||||
logdir /var/log/chrony
|
||||
maxupdateskew 100.0
|
||||
makestep 1 3
|
||||
cmdallow 192.168.1.0/24
|
||||
```
|
||||
|
||||
更新配置后需要重启 Chrony 服务。
|
||||
|
||||
对于 sysvinit 系统。基于 RHEL 的系统需要去运行 `chronyd` 而不是 `chrony`。
|
||||
|
||||
```
|
||||
# service chronyd restart
|
||||
# chkconfig chronyd on
|
||||
```
|
||||
|
||||
对于 systemctl 系统。 基于 RHEL 的系统需要去运行 `chronyd` 而不是 `chrony`。
|
||||
|
||||
```
|
||||
# systemctl restart chronyd
|
||||
# systemctl enable chronyd
|
||||
```
|
||||
|
||||
使用像 `tacking`、`sources` 和 `sourcestats` 这样的子命令去检查 chrony 的同步细节。
|
||||
|
||||
去检查 chrony 的追踪状态。
|
||||
|
||||
```
|
||||
# chronyc tracking
|
||||
Reference ID : C0A80105 (CentOS7.2daygeek.com)
|
||||
Stratum : 3
|
||||
Ref time (UTC) : Thu Mar 28 05:57:27 2019
|
||||
System time : 0.000002545 seconds slow of NTP time
|
||||
Last offset : +0.001194361 seconds
|
||||
RMS offset : 0.001194361 seconds
|
||||
Frequency : 1.650 ppm fast
|
||||
Residual freq : +184.101 ppm
|
||||
Skew : 2.962 ppm
|
||||
Root delay : 0.107966967 seconds
|
||||
Root dispersion : 1.060455322 seconds
|
||||
Update interval : 2.0 seconds
|
||||
Leap status : Normal
|
||||
```
|
||||
|
||||
运行 `sources` 命令去显示当前时间源的信息。
|
||||
|
||||
```
|
||||
# chronyc sources
|
||||
210 Number of sources = 1
|
||||
MS Name/IP address Stratum Poll Reach LastRx Last sample
|
||||
===============================================================================
|
||||
^* CentOS7.2daygeek.com 2 6 17 62 +36us[+1230us] +/- 1111ms
|
||||
```
|
||||
|
||||
`sourcestats` 命令显示有关 chronyd 当前正在检查的每个源的漂移率和偏移估计过程的信息。
|
||||
|
||||
```
|
||||
# chronyc sourcestats
|
||||
210 Number of sources = 1
|
||||
Name/IP Address NP NR Span Frequency Freq Skew Offset Std Dev
|
||||
==============================================================================
|
||||
CentOS7.2daygeek.com 5 3 71 -97.314 78.754 -469us 441us
|
||||
```
|
||||
|
||||
当 chronyd 配置为 NTP 客户端或对等端时,你就能通过 `chronyc ntpdata` 命令向每一个 NTP 源发送/接收时间戳模式和交错模式的报告。
|
||||
|
||||
```
|
||||
# chronyc ntpdata
|
||||
|
||||
Remote address : 192.168.1.5 (C0A80105)
|
||||
Remote port : 123
|
||||
Local address : 192.168.1.3 (C0A80103)
|
||||
Leap status : Normal
|
||||
Version : 4
|
||||
Mode : Server
|
||||
Stratum : 2
|
||||
Poll interval : 6 (64 seconds)
|
||||
Precision : -23 (0.000000119 seconds)
|
||||
Root delay : 0.108994 seconds
|
||||
Root dispersion : 0.076523 seconds
|
||||
Reference ID : 85F3EEF4 ()
|
||||
Reference time : Thu Mar 28 06:43:35 2019
|
||||
Offset : +0.000160221 seconds
|
||||
Peer delay : 0.000664478 seconds
|
||||
Peer dispersion : 0.000000178 seconds
|
||||
Response time : 0.000243252 seconds
|
||||
Jitter asymmetry: +0.00
|
||||
NTP tests : 111 111 1111
|
||||
Interleaved : No
|
||||
Authenticated : No
|
||||
TX timestamping : Kernel
|
||||
RX timestamping : Kernel
|
||||
Total TX : 46
|
||||
Total RX : 46
|
||||
Total valid RX : 46
|
||||
```
|
||||
|
||||
最后运行 `date` 命令。
|
||||
|
||||
```
|
||||
# date
|
||||
Thu Mar 28 03:08:11 CDT 2019
|
||||
```
|
||||
|
||||
为了立即跟进系统时钟,绕过任何正在进行的缓步调整,请以 root 身份运行以下命令(以手动调整系统时钟)。
|
||||
|
||||
```
|
||||
# chronyc makestep
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/configure-ntp-client-using-chrony-in-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[arrowfeng](https://github.com/arrowfeng)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://linux.cn/article-10811-1.html
|
||||
[2]: https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
[3]: https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[4]: https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[5]: https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
|
||||
[6]: https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||
[7]: https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
|
||||
@ -0,0 +1,252 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (arrowfeng)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10811-1.html)
|
||||
[#]: subject: (How To Install And Configure NTP Server And NTP Client In Linux?)
|
||||
[#]: via: (https://www.2daygeek.com/install-configure-ntp-server-ntp-client-in-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
如何在 Linux 上安装、配置 NTP 服务器和客户端?
|
||||
======
|
||||
|
||||
你也许听说过这个词很多次或者你可能已经在使用它了。在这篇文章中我将会清晰的告诉你 NTP 服务器和客户端的安装。
|
||||
|
||||
之后我们将会了解 **[Chrony NTP 客户端的安装][1]**。
|
||||
|
||||
### 什么是 NTP 服务?
|
||||
|
||||
NTP 意即<ruby>网络时间协议<rt>Network Time Protocol</rt></ruby>。它是通过网络在计算机系统之间进行时钟同步的网络协议。换言之,它可以让那些通过 NTP 或者 Chrony 客户端连接到 NTP 服务器的系统保持时间上的一致(它能保持一个精确的时间)。
|
||||
|
||||
NTP 在公共互联网上通常能够保持时间延迟在几十毫秒以内的精度,并在理想条件下,它能在局域网下达到低于一毫秒的延迟精度。
|
||||
|
||||
它使用用户数据报协议(UDP)在端口 123 上发送和接受时间戳。它是个 C/S 架构的应用程序。
|
||||
|
||||
### NTP 客户端
|
||||
|
||||
NTP 客户端将其时钟与网络时间服务器同步。
|
||||
|
||||
### Chrony 客户端
|
||||
|
||||
Chrony 是 NTP 客户端的替代品。它能以更精确的时间更快的同步系统时钟,并且它对于那些不总是在线的系统很有用。
|
||||
|
||||
### 为什么我们需要 NTP 服务?
|
||||
|
||||
为了使你组织中的所有服务器与基于时间的作业保持精确的时间同步。
|
||||
|
||||
为了说明这点,我将告诉你一个场景。比如说,我们有两个服务器(服务器 1 和服务器 2)。服务器 1 通常在 10:55 完成离线作业,然后服务器 2 在 11:00 需要基于服务器 1 完成的作业报告去运行其他作业。
|
||||
|
||||
如果两个服务器正在使用不同的时间(如果服务器 2 时间比服务器 1 提前,服务器 1 的时间就落后于服务器 2),然后我们就不能去执行这个作业。为了达到时间一致,我们应该安装 NTP。
|
||||
|
||||
希望上述能清除你对于 NTP 的疑惑。
|
||||
|
||||
在这篇文章中,我们将使用下列设置去测试。
|
||||
|
||||
* **NTP 服务器:** 主机名:CentOS7.2daygeek.com,IP:192.168.1.8,OS:CentOS 7
|
||||
* **NTP 客户端:** 主机名:Ubuntu18.2daygeek.com,IP:192.168.1.5,OS:Ubuntu 18.04
|
||||
|
||||
### NTP 服务器端:如何在 Linux 上安装 NTP?
|
||||
|
||||
因为它是 C/S 架构,所以 NTP 服务器端和客户端的安装包没有什么不同。在发行版的官方仓库中都有 NTP 安装包,因此可以使用发行版的包管理器安装它。
|
||||
|
||||
对于 Fedora 系统,使用 [DNF 命令][2] 去安装 ntp。
|
||||
|
||||
```
|
||||
$ sudo dnf install ntp
|
||||
```
|
||||
|
||||
对于 Debian/Ubuntu 系统,使用 [APT-GET 命令][3] 或者 [APT 命令][4] 去安装 ntp。
|
||||
|
||||
```
|
||||
$ sudo apt install ntp
|
||||
```
|
||||
|
||||
对基于 Arch Linux 的系统,使用 [Pacman 命令][5] 去安装 ntp。
|
||||
|
||||
```
|
||||
$ sudo pacman -S ntp
|
||||
```
|
||||
|
||||
对 RHEL/CentOS 系统,使用 [YUM 命令][6] 去安装 ntp。
|
||||
|
||||
```
|
||||
$ sudo yum install ntp
|
||||
```
|
||||
|
||||
对于 openSUSE Leap 系统,使用 [Zypper 命令][7] 去安装 ntp。
|
||||
|
||||
```
|
||||
$ sudo zypper install ntp
|
||||
```
|
||||
|
||||
### 如何在 Linux 上配置 NTP 服务器?
|
||||
|
||||
安装 NTP 软件包后,请确保在服务器端的 `/etc/ntp.conf` 文件中取消以下配置的注释。
|
||||
|
||||
默认情况下,NTP 服务器配置依赖于 `X.distribution_name.pool.ntp.org`。 如果有必要,可以使用默认配置,也可以访问<https://www.ntppool.org/zone/@>站点,根据你所在的位置(特定国家/地区)进行更改。
|
||||
|
||||
比如说如果你在印度,然后你的 NTP 服务器将是 `0.in.pool.ntp.org`,并且这个地址适用于大多数国家。
|
||||
|
||||
```
|
||||
# vi /etc/ntp.conf
|
||||
|
||||
restrict default kod nomodify notrap nopeer noquery
|
||||
restrict -6 default kod nomodify notrap nopeer noquery
|
||||
restrict 127.0.0.1
|
||||
restrict -6 ::1
|
||||
server 0.asia.pool.ntp.org
|
||||
server 1.asia.pool.ntp.org
|
||||
server 2.asia.pool.ntp.org
|
||||
server 3.asia.pool.ntp.org
|
||||
restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
|
||||
driftfile /var/lib/ntp/drift
|
||||
keys /etc/ntp/keys
|
||||
```
|
||||
|
||||
我们仅允许 `192.168.1.0/24` 子网的客户端访问这个 NTP 服务器。
|
||||
|
||||
由于默认情况下基于 RHEL7 的发行版的防火墙是打开的,因此要允许 ntp 服务通过。
|
||||
|
||||
```
|
||||
# firewall-cmd --add-service=ntp --permanent
|
||||
# firewall-cmd --reload
|
||||
```
|
||||
|
||||
更新配置后要重启服务:
|
||||
|
||||
对于 sysvinit 系统。基于 Debian 的系统需要去运行 `ntp` 而不是 `ntpd`。
|
||||
|
||||
```
|
||||
# service ntpd restart
|
||||
# chkconfig ntpd on
|
||||
```
|
||||
|
||||
对于 systemctl 系统。基于 Debian 的需要去运行 `ntp` 和 `ntpd`。
|
||||
|
||||
```
|
||||
# systemctl restart ntpd
|
||||
# systemctl enable ntpd
|
||||
```
|
||||
|
||||
### NTP 客户端:如何在 Linux 上安装 NTP 客户端?
|
||||
|
||||
正如我在这篇文章中前面所说的。NTP 服务器端和客户端的安装包没有什么不同。因此在客户端上也安装同样的软件包。
|
||||
|
||||
对于 Fedora 系统,使用 [DNF 命令][2] 去安装 ntp。
|
||||
|
||||
```
|
||||
$ sudo dnf install ntp
|
||||
```
|
||||
|
||||
对于 Debian/Ubuntu 系统,使用 [APT-GET 命令][3] 或者 [APT 命令][4] 去安装 ntp。
|
||||
|
||||
```
|
||||
$ sudo apt install ntp
|
||||
```
|
||||
|
||||
对基于 Arch Linux 的系统,使用 [Pacman 命令][5] 去安装 ntp。
|
||||
|
||||
```
|
||||
$ sudo pacman -S ntp
|
||||
```
|
||||
|
||||
对 RHEL/CentOS 系统,使用 [YUM 命令][6] 去安装 ntp。
|
||||
|
||||
```
|
||||
$ sudo yum install ntp
|
||||
```
|
||||
|
||||
对于 openSUSE Leap 系统,使用 [Zypper 命令][7] 去安装 ntp。
|
||||
|
||||
```
|
||||
$ sudo zypper install ntp
|
||||
```
|
||||
|
||||
我已经在 CentOS7.2daygeek.com` 这台主机上安装和配置了 NTP 服务器,因此将其附加到所有的客户端机器上。
|
||||
|
||||
```
|
||||
# vi /etc/ntp.conf
|
||||
```
|
||||
|
||||
```
|
||||
restrict default kod nomodify notrap nopeer noquery
|
||||
restrict -6 default kod nomodify notrap nopeer noquery
|
||||
restrict 127.0.0.1
|
||||
restrict -6 ::1
|
||||
server CentOS7.2daygeek.com prefer iburst
|
||||
driftfile /var/lib/ntp/drift
|
||||
keys /etc/ntp/keys
|
||||
```
|
||||
|
||||
更新配置后重启服务:
|
||||
|
||||
对于 sysvinit 系统。基于 Debian 的系统需要去运行 `ntp` 而不是 `ntpd`。
|
||||
|
||||
```
|
||||
# service ntpd restart
|
||||
# chkconfig ntpd on
|
||||
```
|
||||
|
||||
对于 systemctl 系统。基于 Debian 的需要去运行 `ntp` 和 `ntpd`。
|
||||
|
||||
```
|
||||
# systemctl restart ntpd
|
||||
# systemctl enable ntpd
|
||||
```
|
||||
|
||||
重新启动 NTP 服务后等待几分钟以便从 NTP 服务器获取同步的时间。
|
||||
|
||||
在 Linux 上运行下列命令去验证 NTP 服务的同步状态。
|
||||
|
||||
```
|
||||
# ntpq –p
|
||||
或
|
||||
# ntpq -pn
|
||||
|
||||
remote refid st t when poll reach delay offset jitter
|
||||
==============================================================================
|
||||
*CentOS7.2daygee 133.243.238.163 2 u 14 64 37 0.686 0.151 16.432
|
||||
```
|
||||
|
||||
运行下列命令去得到 ntpd 的当前状态。
|
||||
|
||||
```
|
||||
# ntpstat
|
||||
synchronised to NTP server (192.168.1.8) at stratum 3
|
||||
time correct to within 508 ms
|
||||
polling server every 64 s
|
||||
```
|
||||
|
||||
最后运行 `date` 命令。
|
||||
|
||||
```
|
||||
# date
|
||||
Tue Mar 26 23:17:05 CDT 2019
|
||||
```
|
||||
|
||||
如果你观察到 NTP 中输出的时间偏移很大。运行下列命令从 NTP 服务器手动同步时钟。当你执行下列命令的时候,确保你的 NTP 客户端应该为未活动状态。(LCTT 译注:当时间偏差很大时,客户端的自动校正需要花费很长时间才能逐步追上,因此应该手动运行以更新)
|
||||
|
||||
```
|
||||
# ntpdate –uv CentOS7.2daygeek.com
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/install-configure-ntp-server-ntp-client-in-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[arrowfeng](https://github.com/arrowfeng)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/configure-ntp-client-using-chrony-in-linux/
|
||||
[2]: https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
[3]: https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[4]: https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[5]: https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
|
||||
[6]: https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||
[7]: https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
|
||||
@ -0,0 +1,133 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (warmfrog)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10817-1.html)
|
||||
[#]: subject: (Installing Ubuntu MATE on a Raspberry Pi)
|
||||
[#]: via: (https://itsfoss.com/ubuntu-mate-raspberry-pi/)
|
||||
[#]: author: (Chinmay https://itsfoss.com/author/chinmay/)
|
||||
|
||||
在树莓派上安装 Ubuntu MATE
|
||||
=================================
|
||||
|
||||
> 简介: 这篇快速指南告诉你如何在树莓派设备上安装 Ubuntu MATE。
|
||||
|
||||
[树莓派][1] 是目前最流行的单板机并且是创客首选的板子。[Raspbian][2] 是基于 Debian 的树莓派官方操作系统。它是轻量级的,内置了教育工具和能在大部分场景下完成工作的工具。
|
||||
|
||||
[安装 Raspbian][3] 安装同样简单,但是与 [Debian][4] 随同带来的问题是慢的升级周期和旧的软件包。
|
||||
|
||||
在树莓派上运行 Ubuntu 可以给你带来一个更丰富的体验和最新的软件。当在你的树莓派上运行 Ubuntu 时我们有几个选择。
|
||||
|
||||
1. [Ubuntu MATE][5] :Ubuntu MATE 是仅有的原生支持树莓派且包含一个完整的桌面环境的发行版。
|
||||
2. [Ubuntu Server 18.04][6] + 手动安装一个桌面环境。
|
||||
3. 使用 [Ubuntu Pi Flavor Maker][7] 社区构建的镜像,这些镜像只支持树莓派 2B 和 3B 的变种,并且**不能**更新到最新的 LTS 发布版。
|
||||
|
||||
第一个选择安装是最简单和快速的,而第二个选择给了你自由选择安装桌面环境的机会。我推荐选择前两个中的任一个。
|
||||
|
||||
这里是一些磁盘镜像下载链接。在这篇文章里我只会提及 Ubuntu MATE 的安装。
|
||||
|
||||
### 在树莓派上安装 Ubuntu MATE
|
||||
|
||||
去 Ubuntu MATE 的下载页面获取推荐的镜像。
|
||||
|
||||
![][8]
|
||||
|
||||
试验性的 ARM64 版本只应在你需要在树莓派服务器上运行像 MongoDB 这样的 64 位应用时使用。
|
||||
|
||||
- [下载为树莓派准备的 Ubuntu MATE][9]
|
||||
|
||||
#### 第 1 步:设置 SD 卡
|
||||
|
||||
镜像文件一旦下载完成后需要解压。你可以简单的右击来提取它。
|
||||
|
||||
也可以使用下面命令做同样的事。
|
||||
|
||||
```
|
||||
xz -d ubuntu-mate***.img.xz
|
||||
```
|
||||
|
||||
如果你在 Windows 上你可以使用 [7-zip][10] 替代。
|
||||
|
||||
安装 [Balena Etcher][11],我们将使用这个工具将镜像写入 SD 卡。确保你的 SD 卡有至少 8 GB 的容量。
|
||||
|
||||
启动 Etcher,选择镜像文件和 SD 卡。
|
||||
|
||||
![][12]
|
||||
|
||||
一旦进度完成 SD 卡就准备好了。
|
||||
|
||||
#### 第 2 步:设置树莓派
|
||||
|
||||
你可能已经知道你需要一些外设才能使用树莓派,例如鼠标、键盘、HDMI 线等等。你同样可以[不用键盘和鼠标安装树莓派][13],但是这篇指南不是那样。
|
||||
|
||||
* 插入一个鼠标和一个键盘。
|
||||
* 连接 HDMI 线缆。
|
||||
* 插入 SD 卡 到 SD 卡槽。
|
||||
|
||||
插入电源线给它供电。确保你有一个好的电源供应(5V、3A 至少)。一个不好的电源供应可能降低性能。
|
||||
|
||||
#### Ubuntu MATE 安装
|
||||
|
||||
一旦你给树莓派供电,你将遇到非常熟悉的 Ubuntu 安装过程。在这里的安装过程相当直接。
|
||||
|
||||
![选择你的键盘布局][14]
|
||||
|
||||
![选择你的时区][15]
|
||||
|
||||
选择你的 WiFi 网络并且在网络连接中输入密码。
|
||||
|
||||
![添加用户名和密码][16]
|
||||
|
||||
在设置了键盘布局、时区和用户凭证后,在几分钟后你将被带到登录界面。瞧!你快要完成了。
|
||||
|
||||
![][17]
|
||||
|
||||
一旦登录,第一件事你应该做的是[更新 Ubuntu][18]。你应该使用下列命令。
|
||||
|
||||
```
|
||||
sudo apt update
|
||||
sudo apt upgrade
|
||||
```
|
||||
|
||||
你同样可以使用软件更新器。
|
||||
|
||||
![][19]
|
||||
|
||||
一旦更新完成安装你就可以开始了。你可以根据你的需要继续安装树莓派平台为 GPIO 和其他 I/O 准备的特定软件包。
|
||||
|
||||
是什么让你考虑在 Raspberry 上安装 Ubuntu,你对 Raspbian 的体验如何呢?请在下方评论来让我知道。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/ubuntu-mate-raspberry-pi/
|
||||
|
||||
作者:[Chinmay][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[warmfrog](https://github.com/warmfrog)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/chinmay/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.raspberrypi.org/
|
||||
[2]: https://www.raspberrypi.org/downloads/
|
||||
[3]: https://itsfoss.com/tutorial-how-to-install-raspberry-pi-os-raspbian-wheezy/
|
||||
[4]: https://www.debian.org/
|
||||
[5]: https://ubuntu-mate.org/
|
||||
[6]: https://wiki.ubuntu.com/ARM/RaspberryPi#Recovering_a_system_using_the_generic_kernel
|
||||
[7]: https://ubuntu-pi-flavour-maker.org/download/
|
||||
[8]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/04/ubuntu-mate-raspberry-pi-download.jpg?ssl=1
|
||||
[9]: https://ubuntu-mate.org/download/
|
||||
[10]: https://www.7-zip.org/download.html
|
||||
[11]: https://www.balena.io/etcher/
|
||||
[12]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/04/Screenshot-from-2019-04-08-01-36-16.png?ssl=1
|
||||
[13]: https://linuxhandbook.com/raspberry-pi-headless-setup/
|
||||
[14]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/04/Keyboard-layout-ubuntu.jpg?fit=800%2C467&ssl=1
|
||||
[15]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/04/select-time-zone-ubuntu.jpg?fit=800%2C468&ssl=1
|
||||
[16]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/04/Credentials-ubuntu.jpg?fit=800%2C469&ssl=1
|
||||
[17]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/04/Desktop-ubuntu.jpg?fit=800%2C600&ssl=1
|
||||
[18]: https://itsfoss.com/update-ubuntu/
|
||||
[19]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/04/update-software.png?ssl=1
|
||||
|
||||
|
||||
@ -0,0 +1,317 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (warmfrog)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10823-1.html)
|
||||
[#]: subject: (12 Single Board Computers: Alternative to Raspberry Pi)
|
||||
[#]: via: (https://itsfoss.com/raspberry-pi-alternatives/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
12 个可替代树莓派的单板机
|
||||
================================
|
||||
|
||||
> 正在寻找树莓派的替代品?这里有一些单板机可以满足你的 DIY 渴求。
|
||||
|
||||
树莓派是当前最流行的单板机。你可以在你的 DIY 项目中使用它,或者用它作为一个成本效益高的系统来学习编代码,或者为了你的便利,利用一个[流媒体软件][1]运行在上面作为流媒体设备。
|
||||
|
||||
你可以使用树莓派做很多事,但它不是各种极客的最终解决方案。一些人可能在寻找更便宜的开发板,一些可能在寻找更强大的。
|
||||
|
||||
无论是哪种情况,我们都有很多原因需要树莓派的替代品。因此,在这片文章里,我们将讨论最好的 12 个我们认为能够替代树莓派的单板机。
|
||||
|
||||
![][2]
|
||||
|
||||
### 满足你 DIY 渴望的树莓派替代品
|
||||
|
||||
这个列表没有特定的顺序排名。链接的一部分是赞助链接。请阅读我们的[赞助政策][3]。
|
||||
|
||||
#### 1、Onion Omega2+
|
||||
|
||||
![][4]
|
||||
|
||||
只要 $13,Omega2+ 是这里你可以找到的最便宜的 IoT 单板机设备。它运行 LEDE(Linux 嵌入式开发环境)Linux 系统 —— 这是一个基于 [OpenWRT][5] 的发行版。
|
||||
|
||||
由于运行一个自定义 Linux 系统,它的组成元件、花费和灵活性使它完美适合几乎所有类型的 IoT 应用。
|
||||
|
||||
你可以在[亚马逊商城的 Onion Omega 套件][6]或者从他们的网站下单,可能会收取额外的邮费。
|
||||
|
||||
**关键参数:**
|
||||
|
||||
* MT7688 SoC
|
||||
* 2.4 GHz IEEE 802.11 b/g/n WiFi
|
||||
* 128 MB DDR2 RAM
|
||||
* 32 MB on-board flash storage
|
||||
* MicroSD Slot
|
||||
* USB 2.0
|
||||
* 12 GPIO Pins
|
||||
|
||||
[查看官网][7]
|
||||
|
||||
#### 2、NVIDIA Jetson Nano Developer Kit
|
||||
|
||||
这是来自 NVIDIA 的只要 **$99** 的非常独特和有趣的树莓派替代品。是的,它不是每个人都能充分利用的设备 —— 只为特定的一组极客或者开发者而生。
|
||||
|
||||
NVIDIA 使用下面的用例解释它:
|
||||
|
||||
> NVIDIA® Jetson Nano™ Developer Kit 是一个小的、强大的计算机,可以让你并行运行多个神经网络的应用像图像分类、对象侦察、图像分段、语音处理。全部在一个易于使用的、运行功率只有 5 瓦特的平台上。
|
||||
>
|
||||
> nvidia
|
||||
|
||||
因此,基本上,如果你正在研究 AI 或者深度学习,你可以充分利用开发设备。如果你很好奇,该设备的产品计算模块将在 2019 年 7 月到来。
|
||||
|
||||
**关键参数:**
|
||||
|
||||
* CPU: Quad-core ARM A57 @ 1.43 GHz
|
||||
* GPU: 128-core Maxwell
|
||||
* RAM: 4 GB 64-bit LPDDR4 25.6 GB/s
|
||||
* Display: HDMI 2.0
|
||||
* 4 x USB 3.0 and eDP 1.4
|
||||
|
||||
[查看官网][9]
|
||||
|
||||
#### 3、ASUS Tinker Board S
|
||||
|
||||
![][10]
|
||||
|
||||
ASUS Tinker Board S 不是大多数人可负担得起的树莓派的替换设备 (**$82**,[亚马逊商城][11]),但是它是一个强大的替代品。它的特点是它有你通常可以发现与标准树莓派 3 一样的 40 针脚的连接器,但是提供了强大的处理器和 GPU。同样的,Tinker Board S 的大小恰巧和标准的树莓派3 一样大。
|
||||
|
||||
这个板子的主要亮点是 16 GB [eMMC][12] (用外行术语说,它的板上有一个类似 SSD 的存储单元使它工作时运行的更快。) 的存在。
|
||||
|
||||
**关键参数:**
|
||||
|
||||
* Rockchip Quad-Core RK3288 processor
|
||||
* 2 GB DDR3 RAM
|
||||
* Integrated Graphics Processor
|
||||
* ARM® Mali™-T764 GPU
|
||||
* 16 GB eMMC
|
||||
* MicroSD Card Slot
|
||||
* 802.11 b/g/n, Bluetooth V4.0 + EDR
|
||||
* USB 2.0
|
||||
* 28 GPIO pins
|
||||
* HDMI Interface
|
||||
|
||||
[查看网站][13]
|
||||
|
||||
#### 4、ClockworkPi
|
||||
|
||||
![][14]
|
||||
|
||||
如果你正在想方设法组装一个模块化的复古的游戏控制台,Clockwork Pi 可能就是你需要的,它通常是 [GameShell Kit][15] 的一部分。然而,你可以 使用 $49 单独购买板子。
|
||||
|
||||
它紧凑的大小、WiFi 连接性和 micro HDMI 端口的存在使它成为许多方面的选择。
|
||||
|
||||
**关键参数:**
|
||||
|
||||
* Allwinner R16-J Quad-core Cortex-A7 CPU @1.2GHz
|
||||
* Mali-400 MP2 GPU
|
||||
* RAM: 1GB DDR3
|
||||
* WiFi & Bluetooth v4.0
|
||||
* Micro HDMI output
|
||||
* MicroSD Card Slot
|
||||
|
||||
[查看官网][16]
|
||||
|
||||
#### 5、Arduino Mega 2560
|
||||
|
||||
![][17]
|
||||
|
||||
如果你正在研究机器人项目或者你想要一个 3D 打印机 —— Arduino Mega 2560 将是树莓派的便利的替代品。不像树莓派,它是基于微控制器而不是微处理器的。
|
||||
|
||||
在他们的[官网][18],你需要花费 $38.50,或者在[在亚马逊商城是 $33][19]。
|
||||
|
||||
**关键参数:**
|
||||
|
||||
* Microcontroller: ATmega2560
|
||||
* Clock Speed: 16 MHz
|
||||
* Digital I/O Pins: 54
|
||||
* Analog Input Pins: 16
|
||||
* Flash Memory: 256 KB of which 8 KB used by bootloader
|
||||
|
||||
[查看官网][18]
|
||||
|
||||
#### 6、Rock64 Media Board
|
||||
|
||||
![][20]
|
||||
|
||||
用与你可能想要的树莓派 3 B+ 相同的价格,你将在 Rock64 Media Board 上获得更快的处理器和双倍的内存。除此之外,如果你想要 1 GB RAM 版的,它提供了一个比树莓派更便宜的替代品,花费更少,只要 $10 。
|
||||
|
||||
不像树莓派,它没有无线连接支持,但是 USB 3.0 和 HDMI 2.0 的存在使它与众不同,如果它对你很重要的话。
|
||||
|
||||
**关键参数:**
|
||||
|
||||
* Rockchip RK3328 Quad-Core ARM Cortex A53 64-Bit Processor
|
||||
* Supports up to 4GB 1600MHz LPDDR3 RAM
|
||||
* eMMC module socket
|
||||
* MicroSD Card slot
|
||||
* USB 3.0
|
||||
* HDMI 2.0
|
||||
|
||||
[查看官网][21]
|
||||
|
||||
#### 7、Odroid-XU4
|
||||
|
||||
![][22]
|
||||
|
||||
Odroid-XU4 是一个完美的树莓派的替代品,如果你有能够稍微提高预算的空间($80-$100 甚至更低,取决于存储的容量)。
|
||||
|
||||
它确实是一个强大的替代品并且体积更小。支持 eMMC 和 USB 3.0 使它工作起来更快。
|
||||
|
||||
**关键参数:**
|
||||
|
||||
* Samsung Exynos 5422 Octa ARM Cortex™-A15 Quad 2Ghz and Cortex™-A7 Quad 1.3GHz CPUs
|
||||
* 2Gbyte LPDDR3 RAM
|
||||
* GPU: Mali-T628 MP6
|
||||
* USB 3.0
|
||||
* HDMI 1.4a
|
||||
* eMMC 5.0 module socket
|
||||
* MicroSD Card Slot
|
||||
|
||||
[查看官网][23]
|
||||
|
||||
#### 8、PocketBeagle
|
||||
|
||||
![][24]
|
||||
|
||||
它是一个难以置信的小的单板机 —— 几乎和树莓派Zero 相似。然而它的价格相当于完整大小的树莓派 3。主要的亮点是你可以用它作为一个 USB 便携式信息终端,并且进入 Linux 命令行工作。
|
||||
|
||||
**关键参数:**
|
||||
|
||||
* Processor: Octavo Systems OSD3358 1GHz ARM® Cortex-A8
|
||||
* RAM: 512 MB DDR3
|
||||
* 72 expansion pin headers
|
||||
* microUSB
|
||||
* USB 2.0
|
||||
|
||||
[查看官网][25]
|
||||
|
||||
#### 9、Le Potato
|
||||
|
||||
![][26]
|
||||
|
||||
由 [Libre Computer][27] 出品的 Le Potato,其型号是 AML-S905X-CC。它需要花费你 [$45][28]。
|
||||
|
||||
如果你花费的比树莓派更多的钱,你就能得到双倍内存和 HDMI 2.0 接口,这可能是一个完美的选择。尽管,你还是不能找到嵌入的无线连接。
|
||||
|
||||
**关键参数:**
|
||||
|
||||
* Amlogic S905X SoC
|
||||
* 2GB DDR3 SDRAM
|
||||
* USB 2.0
|
||||
* HDMI 2.0
|
||||
* microUSB
|
||||
* MicroSD Card Slot
|
||||
* eMMC Interface
|
||||
|
||||
[查看官网][29]
|
||||
|
||||
#### 10、Banana Pi M64
|
||||
|
||||
![][30]
|
||||
|
||||
它自带了 8G 的 eMMC —— 这是替代树莓派的主要亮点。因此,它需要花费 $60。
|
||||
|
||||
HDMI 接口的存在使它胜任 4K。除此之外,Banana Pi 提供了更多种类的开源单板机作为树莓派的替代。
|
||||
|
||||
**关键参数:**
|
||||
|
||||
* 1.2 Ghz Quad-Core ARM Cortex A53 64-Bit Processor-R18
|
||||
* 2GB DDR3 SDRAM
|
||||
* 8 GB eMMC
|
||||
* WiFi & Bluetooth
|
||||
* USB 2.0
|
||||
* HDMI
|
||||
|
||||
[查看官网][31]
|
||||
|
||||
#### 11、Orange Pi Zero
|
||||
|
||||
![][32]
|
||||
|
||||
Orange Pi Zero 相对于树莓派来说难以置信的便宜。你可以在 Aliexpress 或者亚马逊上以最多 $10 就能够获得。如果[稍微多花点,你能够获得 512 MB RAM][33]。
|
||||
|
||||
如果这还不够,你可以花费大概 $25 获得更好的配置,比如 Orange Pi 3。
|
||||
|
||||
**关键参数:**
|
||||
|
||||
* H2 Quad-core Cortex-A7
|
||||
* Mali400MP2 GPU
|
||||
* RAM: Up to 512 MB
|
||||
* TF Card support
|
||||
* WiFi
|
||||
* USB 2.0
|
||||
|
||||
[查看官网][34]
|
||||
|
||||
#### 12、VIM 2 SBC by Khadas
|
||||
|
||||
![][35]
|
||||
|
||||
由 Khadas 出品的 VIM 2 是最新的单板机,因此你能够在板上得到蓝牙 5.0 支持。它的价格范围[从 $99 的基础款到上限 $140][36]。
|
||||
|
||||
基础款包含 2 GB RAM、16 GB eMMC 和蓝牙 4.1。然而,Pro/Max 版包含蓝牙 5.0,更多的内存,更多的 eMMC 存储。
|
||||
|
||||
**关键参数:**
|
||||
|
||||
* Amlogic S912 1.5GHz 64-bit Octa-Core CPU
|
||||
* T820MP3 GPU
|
||||
* Up to 3 GB DDR4 RAM
|
||||
* Up to 64 GB eMMC
|
||||
* Bluetooth 5.0 (Pro/Max)
|
||||
* Bluetooth 4.1 (Basic)
|
||||
* HDMI 2.0a
|
||||
* WiFi
|
||||
|
||||
### 总结
|
||||
|
||||
我们知道有很多不同种类的单板机电脑。一些比树莓派更好 —— 它的一些小规格的版本有更便宜的价格。同样的,像 Jetson Nano 这样的单板机已经被裁剪用于特定用途。因此,取决于你需要什么 —— 你应该检查一下单板机的配置。
|
||||
|
||||
如果你知道比上述提到的更好的东西,请随意在下方评论来让我们知道。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/raspberry-pi-alternatives/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[warmfrog](https://github.com/warmfrog)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/best-linux-media-server/
|
||||
[2]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/04/raspberry-pi-alternatives.png?resize=800%2C450&ssl=1
|
||||
[3]: https://itsfoss.com/affiliate-policy/
|
||||
[4]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/04/omega-2-plus-e1555306748755-800x444.jpg?resize=800%2C444&ssl=1
|
||||
[5]: https://openwrt.org/
|
||||
[6]: https://amzn.to/2Xj8pkn
|
||||
[7]: https://onion.io/store/omega2p/
|
||||
[8]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/04/Jetson-Nano-e1555306350976-800x590.jpg?resize=800%2C590&ssl=1
|
||||
[9]: https://developer.nvidia.com/embedded/buy/jetson-nano-devkit
|
||||
[10]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/04/asus-tinker-board-s-e1555304945760-800x450.jpg?resize=800%2C450&ssl=1
|
||||
[11]: https://amzn.to/2XfkOFT
|
||||
[12]: https://en.wikipedia.org/wiki/MultiMediaCard
|
||||
[13]: https://www.asus.com/in/Single-Board-Computer/Tinker-Board-S/
|
||||
[14]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/04/clockwork-pi-e1555305016242-800x506.jpg?resize=800%2C506&ssl=1
|
||||
[15]: https://itsfoss.com/gameshell-console/
|
||||
[16]: https://www.clockworkpi.com/product-page/cpi-v3-1
|
||||
[17]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/04/arduino-mega-2560-e1555305257633.jpg?ssl=1
|
||||
[18]: https://store.arduino.cc/usa/mega-2560-r3
|
||||
[19]: https://amzn.to/2KCi041
|
||||
[20]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/04/ROCK64_board-e1555306092845-800x440.jpg?resize=800%2C440&ssl=1
|
||||
[21]: https://www.pine64.org/?product=rock64-media-board-computer
|
||||
[22]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/04/odroid-xu4.jpg?fit=800%2C354&ssl=1
|
||||
[23]: https://www.hardkernel.com/shop/odroid-xu4-special-price/
|
||||
[24]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/04/PocketBeagle.jpg?fit=800%2C450&ssl=1
|
||||
[25]: https://beagleboard.org/p/products/pocketbeagle
|
||||
[26]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/04/aml-libre.-e1555306237972-800x514.jpg?resize=800%2C514&ssl=1
|
||||
[27]: https://libre.computer/
|
||||
[28]: https://amzn.to/2DpG3xl
|
||||
[29]: https://libre.computer/products/boards/aml-s905x-cc/
|
||||
[30]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/04/banana-pi-m6.jpg?fit=800%2C389&ssl=1
|
||||
[31]: http://www.banana-pi.org/m64.html
|
||||
[32]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/04/orange-pi-zero.jpg?fit=800%2C693&ssl=1
|
||||
[33]: https://amzn.to/2IlI81g
|
||||
[34]: http://www.orangepi.org/orangepizero/index.html
|
||||
[35]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/04/khadas-vim-2-e1555306505640-800x563.jpg?resize=800%2C563&ssl=1
|
||||
[36]: https://amzn.to/2UDvrFE
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user