mirror of
https://github.com/LCTT/TranslateProject.git
synced 2024-12-26 21:30:55 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
29060bb4f9
@ -1,6 +1,7 @@
|
||||
如何在双系统引导下替换 Linux 发行版
|
||||
======
|
||||
在双系统引导的状态下,你可以将已安装的 Linux 发行版替换为另一个发行版,同时还可以保留原本的个人数据。
|
||||
|
||||
> 在双系统引导的状态下,你可以将已安装的 Linux 发行版替换为另一个发行版,同时还可以保留原本的个人数据。
|
||||
|
||||
![How to Replace One Linux Distribution With Another From Dual Boot][1]
|
||||
|
||||
@ -26,11 +27,9 @@
|
||||
* 需要安装的 Linux 发行版的 USB live 版
|
||||
* 在外部磁盘备份 Windows 和 Linux 中的重要文件(并非必要,但建议备份一下)
|
||||
|
||||
|
||||
|
||||
#### 在替换 Linux 发行版时要记住保留你的 home 目录
|
||||
|
||||
如果想让个人文件在安装新 Linux 系统的过程中不受影响,原有的 Linux 系统必须具有单独的 root 目录和 home 目录。你可能会发现我的[双系统引导教程][8]在安装过程中不选择“与 Windows 一起安装”选项,而选择“其它”选项,然后手动创建 root 和 home 分区。所以,手动创建单独的 home 分区也算是一个磨刀不误砍柴工的操作。因为如果要在不丢失文件的情况下,将现有的 Linux 发行版替换为另一个发行版,需要将 home 目录存放在一个单独的分区上。
|
||||
如果想让个人文件在安装新 Linux 系统的过程中不受影响,原有的 Linux 系统必须具有单独的 root 目录和 home 目录。你可能会发现我的[双系统引导教程][8]在安装过程中不选择“与 Windows 共存”选项,而选择“其它”选项,然后手动创建 root 和 home 分区。所以,手动创建单独的 home 分区也算是一个磨刀不误砍柴工的操作。因为如果要在不丢失文件的情况下,将现有的 Linux 发行版替换为另一个发行版,需要将 home 目录存放在一个单独的分区上。
|
||||
|
||||
不过,你必须记住现有 Linux 系统的用户名和密码才能使用与新系统中相同的 home 目录。
|
||||
|
||||
@ -51,69 +50,80 @@
|
||||
在安装过程中,进入“安装类型”界面时,选择“其它”选项。
|
||||
|
||||
![Replacing one Linux with another from dual boot][10]
|
||||
(在这里选择“其它”选项)
|
||||
|
||||
*在这里选择“其它”选项*
|
||||
|
||||
#### 步骤 3:准备分区操作
|
||||
|
||||
下图是分区界面。你会看到使用 Ext4 文件系统类型来安装 Linux。
|
||||
|
||||
![Identifying Linux partition in dual boot][11]
|
||||
(确定 Linux 的安装位置)
|
||||
|
||||
*确定 Linux 的安装位置*
|
||||
|
||||
在上图中,标记为 Linux Mint 19 的 Ext4 分区是 root 分区,大小为 82691 MB 的第二个 Ext4 分区是 home 分区。在这里我这里没有使用[交换空间][12]。
|
||||
|
||||
如果你只有一个 Ext4 分区,就意味着你的 home 目录与 root 目录位于同一分区。在这种情况下,你就无法保留 home 目录中的文件了,这个时候我建议将重要文件复制到外部磁盘,否则这些文件将不会保留。
|
||||
|
||||
然后是删除 root 分区。选择 root 分区,然后点击 - 号,这个操作释放了一些磁盘空间。
|
||||
然后是删除 root 分区。选择 root 分区,然后点击 `-` 号,这个操作释放了一些磁盘空间。
|
||||
|
||||
![Delete root partition of your existing Linux install][13]
|
||||
(删除 root 分区)
|
||||
|
||||
磁盘空间释放出来后,点击 + 号。
|
||||
*删除 root 分区*
|
||||
|
||||
磁盘空间释放出来后,点击 `+` 号。
|
||||
|
||||
![Create root partition for the new Linux][14]
|
||||
(创建新的 root 分区)
|
||||
|
||||
*创建新的 root 分区*
|
||||
|
||||
现在已经在可用空间中创建一个新分区。如果你之前的 Linux 系统中只有一个 root 分区,就应该在这里创建 root 分区和 home 分区。如果需要,还可以创建交换分区。
|
||||
|
||||
如果你之前已经有 root 分区和 home 分区,那么只需要从已删除的 root 分区创建 root 分区就可以了。
|
||||
|
||||
![Create root partition for the new Linux][15]
|
||||
(创建 root 分区)
|
||||
|
||||
你可能有疑问,为什么要经过“删除”和“添加”两个过程,而不使用“更改”选项。这是因为以前使用“更改”选项好像没有效果,所以我更喜欢用 - 和 +。这是迷信吗?也许是吧。
|
||||
*创建 root 分区*
|
||||
|
||||
你可能有疑问,为什么要经过“删除”和“添加”两个过程,而不使用“更改”选项。这是因为以前使用“更改”选项好像没有效果,所以我更喜欢用 `-` 和 `+`。这是迷信吗?也许是吧。
|
||||
|
||||
这里有一个重要的步骤,对新创建的 root 分区进行格式化。在没有更改分区大小的情况下,默认是不会对分区进行格式化的。如果分区没有被格式化,之后可能会出现问题。
|
||||
|
||||
![][16]
|
||||
(格式化 root 分区很重要)
|
||||
|
||||
*格式化 root 分区很重要*
|
||||
|
||||
如果你在新的 Linux 系统上已经划分了单独的 home 分区,选中它并点击更改。
|
||||
|
||||
![Recreate home partition][17]
|
||||
(修改已有的 home 分区)
|
||||
|
||||
*修改已有的 home 分区*
|
||||
|
||||
然后指定将其作为 home 分区挂载即可。
|
||||
|
||||
![Specify the home mount point][18]
|
||||
(指定 home 分区的挂载点)
|
||||
|
||||
*指定 home 分区的挂载点*
|
||||
|
||||
如果你还有交换分区,可以重复与 home 分区相同的步骤,唯一不同的是要指定将空间用作交换空间。
|
||||
|
||||
现在的状态应该是有一个 root 分区(将被格式化)和一个 home 分区(如果需要,还可以使用交换分区)。点击“立即安装”可以开始安装。
|
||||
|
||||
![Verify partitions while replacing one Linux with another][19]
|
||||
(检查分区情况)
|
||||
|
||||
*检查分区情况*
|
||||
|
||||
接下来的几个界面就很熟悉了,要重点注意的是创建用户和密码的步骤。如果你之前有一个单独的 home 分区,并且还想使用相同的 home 目录,那你必须使用和之前相同的用户名和密码,至于设备名称则可以任意指定。
|
||||
|
||||
![To keep the home partition intact, use the previous user and password][20]
|
||||
(要保持 home 分区不变,请使用之前的用户名和密码)
|
||||
|
||||
*要保持 home 分区不变,请使用之前的用户名和密码*
|
||||
|
||||
接下来只要静待安装完成,不需执行任何操作。
|
||||
|
||||
![Wait for installation to finish][21]
|
||||
(等待安装完成)
|
||||
|
||||
*等待安装完成*
|
||||
|
||||
安装完成后重新启动系统,你就能使用新的 Linux 发行版。
|
||||
|
||||
@ -126,7 +136,7 @@ via: https://itsfoss.com/replace-linux-from-dual-boot/
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,15 +1,15 @@
|
||||
系统管理员需知的 16 个 iptables 使用技巧
|
||||
=======
|
||||
|
||||
iptables 是一款控制系统进出流量的强大配置工具。
|
||||
> iptables 是一款控制系统进出流量的强大配置工具。
|
||||
|
||||

|
||||
|
||||
现代 Linux 内核带有一个叫 [Netfilter][1] 的数据包过滤框架。Netfilter 提供了允许、禁止以及修改等操作来控制进出系统的流量数据包。基于 Netfilter 框架的用户层命令行工具 **iptables** 提供了强大的防火墙配置功能,允许你添加规则来构建防火墙策略。[iptables][2] 丰富复杂的功能以及其巴洛克式命令语法可能让人难以驾驭。我们就来探讨一下其中的一些功能,提供一些系统管理员解决某些问题需要的使用技巧。
|
||||
现代 Linux 内核带有一个叫 [Netfilter][1] 的数据包过滤框架。Netfilter 提供了允许、丢弃以及修改等操作来控制进出系统的流量数据包。基于 Netfilter 框架的用户层命令行工具 `iptables` 提供了强大的防火墙配置功能,允许你添加规则来构建防火墙策略。[iptables][2] 丰富复杂的功能以及其巴洛克式命令语法可能让人难以驾驭。我们就来探讨一下其中的一些功能,提供一些系统管理员解决某些问题需要的使用技巧。
|
||||
|
||||
### 避免封锁自己
|
||||
|
||||
应用场景:假设你将对公司服务器上的防火墙规则进行修改,需要避免封锁你自己以及其他同事的情况(这将会带来一定时间和金钱的损失,也许一旦发生马上就有部门打电话找你了)
|
||||
应用场景:假设你将对公司服务器上的防火墙规则进行修改,你需要避免封锁你自己以及其他同事的情况(这将会带来一定时间和金钱的损失,也许一旦发生马上就有部门打电话找你了)
|
||||
|
||||
#### 技巧 #1: 开始之前先备份一下 iptables 配置文件。
|
||||
|
||||
@ -17,7 +17,6 @@ iptables 是一款控制系统进出流量的强大配置工具。
|
||||
|
||||
```
|
||||
/sbin/iptables-save > /root/iptables-works
|
||||
|
||||
```
|
||||
#### 技巧 #2: 更妥当的做法,给文件加上时间戳。
|
||||
|
||||
@ -25,28 +24,24 @@ iptables 是一款控制系统进出流量的强大配置工具。
|
||||
|
||||
```
|
||||
/sbin/iptables-save > /root/iptables-works-`date +%F`
|
||||
|
||||
```
|
||||
|
||||
然后你就可以生成如下名字的文件:
|
||||
|
||||
```
|
||||
/root/iptables-works-2018-09-11
|
||||
|
||||
```
|
||||
|
||||
这样万一使得系统不工作了,你也可以很快的利用备份文件恢复原状:
|
||||
|
||||
```
|
||||
/sbin/iptables-restore < /root/iptables-works-2018-09-11
|
||||
|
||||
```
|
||||
|
||||
#### 技巧 #3: 每次创建 iptables 配置文件副本时,都创建一个指向 `latest` 的文件的链接。
|
||||
#### 技巧 #3: 每次创建 iptables 配置文件副本时,都创建一个指向最新的文件的链接。
|
||||
|
||||
```
|
||||
ln –s /root/iptables-works-`date +%F` /root/iptables-works-latest
|
||||
|
||||
```
|
||||
|
||||
#### 技巧 #4: 将特定规则放在策略顶部,底部放置通用规则。
|
||||
@ -55,19 +50,17 @@ ln –s /root/iptables-works-`date +%F` /root/iptables-works-latest
|
||||
|
||||
```
|
||||
iptables -A INPUT -p tcp --dport 22 -j DROP
|
||||
|
||||
```
|
||||
|
||||
你在规则中指定的条件越多,封锁自己的可能性就越小。不要使用上面暗中通用规则,而是使用如下的规则:
|
||||
你在规则中指定的条件越多,封锁自己的可能性就越小。不要使用上面非常通用的规则,而是使用如下的规则:
|
||||
|
||||
```
|
||||
iptables -A INPUT -p tcp --dport 22 –s 10.0.0.0/8 –d 192.168.100.101 -j DROP
|
||||
|
||||
```
|
||||
|
||||
此规则表示在 **INPUT** 链尾追加一条新规则,将源地址为 **10.0.0.0/8**、 目的地址是 **192.168.100.101**、目的端口号是 **22** (**\--dport 22** ) 的 **tcp**(**-p tcp** )数据包通通丢弃掉。
|
||||
此规则表示在 `INPUT` 链尾追加一条新规则,将源地址为 `10.0.0.0/8`、 目的地址是 `192.168.100.101`、目的端口号是 `22` (`--dport 22` ) 的 TCP(`-p tcp` )数据包通通丢弃掉。
|
||||
|
||||
还有很多方法可以设置更具体的规则。例如,使用 **-i eth0** 将会限制这条规则作用于 **eth0** 网卡,对 **eth1** 网卡则不生效。
|
||||
还有很多方法可以设置更具体的规则。例如,使用 `-i eth0` 将会限制这条规则作用于 `eth0` 网卡,对 `eth1` 网卡则不生效。
|
||||
|
||||
#### 技巧 #5: 在策略规则顶部将你的 IP 列入白名单。
|
||||
|
||||
@ -75,10 +68,9 @@ iptables -A INPUT -p tcp --dport 22 –s 10.0.0.0/8 –d 192.168.100.101 -j DROP
|
||||
|
||||
```
|
||||
iptables -I INPUT -s <your IP> -j ACCEPT
|
||||
|
||||
```
|
||||
|
||||
你需要将该规则添加到策略首位置。**-I** 表示则策略首部插入规则,**-A** 表示在策略尾部追加规则。
|
||||
你需要将该规则添加到策略首位置。`-I` 表示则策略首部插入规则,`-A` 表示在策略尾部追加规则。
|
||||
|
||||
#### 技巧 #6: 理解现有策略中的所有规则。
|
||||
|
||||
@ -100,7 +92,7 @@ iptables -I INPUT -s <your IP> -j ACCEPT
|
||||
|
||||
#### 技巧 #2: 将用户完成工作所需的最少量服务设置为允许
|
||||
|
||||
该策略需要允许工作站能通过 DHCP (**-p udp --dport 67:68 -sport 67:68**)来获取 IP 地址、子网掩码以及其他一些信息。对于远程操作,需要允许 SSH 服务(**-dport 22**),邮件服务(**--dport 25**),DNS服务(**--dport 53**),ping 功能(**-p icmp**),NTP 服务(**--dport 123 --sport 123**)以及HTTP 服务(**-dport 80**)和 HTTPS 服务(**--dport 443**)。
|
||||
该策略需要允许工作站能通过 DHCP(`-p udp --dport 67:68 -sport 67:68`)来获取 IP 地址、子网掩码以及其他一些信息。对于远程操作,需要允许 SSH 服务(`-dport 22`),邮件服务(`--dport 25`),DNS 服务(`--dport 53`),ping 功能(`-p icmp`),NTP 服务(`--dport 123 --sport 123`)以及 HTTP 服务(`-dport 80`)和 HTTPS 服务(`--dport 443`)。
|
||||
|
||||
```
|
||||
# Set a default policy of DROP
|
||||
@ -144,7 +136,7 @@ COMMIT
|
||||
|
||||
### 限制 IP 地址范围
|
||||
|
||||
应用场景:贵公司的 CEO 认为员工在 Facebook 上花费过多的时间,需要采取一些限制措施。CEO 命令下达给 CIO,CIO 命令CISO,最终任务由你来执行。你决定阻止一切到 Facebook 的访问连接。首先你使用 `host` 或者 `whois` 命令来获取 Facebook 的 IP 地址。
|
||||
应用场景:贵公司的 CEO 认为员工在 Facebook 上花费过多的时间,需要采取一些限制措施。CEO 命令下达给 CIO,CIO 命令 CISO,最终任务由你来执行。你决定阻止一切到 Facebook 的访问连接。首先你使用 `host` 或者 `whois` 命令来获取 Facebook 的 IP 地址。
|
||||
|
||||
```
|
||||
host -t a www.facebook.com
|
||||
@ -153,33 +145,33 @@ star.c10r.facebook.com has address 31.13.65.17
|
||||
whois 31.13.65.17 | grep inetnum
|
||||
inetnum: 31.13.64.0 - 31.13.127.255
|
||||
```
|
||||
然后使用 [CIDR to IPv4转换][3] 页面来将其转换为 CIDR 表示法。然后你得到 **31.13.64.0/18** 的地址。输入以下命令来阻止对 Facebook 的访问:
|
||||
|
||||
然后使用 [CIDR 到 IPv4 转换][3] 页面来将其转换为 CIDR 表示法。然后你得到 `31.13.64.0/18` 的地址。输入以下命令来阻止对 Facebook 的访问:
|
||||
|
||||
```
|
||||
iptables -A OUTPUT -p tcp -i eth0 –o eth1 –d 31.13.64.0/18 -j DROP
|
||||
```
|
||||
|
||||
### 按时间规定做限制-场景1
|
||||
### 按时间规定做限制 - 场景1
|
||||
|
||||
应用场景:公司员工强烈反对限制一切对 Facebook 的访问,这导致了 CEO 放宽了要求(考虑到员工的反对以及他的助理提醒说她将 HIS Facebook 页面保持在最新状态)。然后 CEO 决定允许在午餐时间访问 Facebook(中午12点到下午1点之间)。假设默认规则是丢弃,使用 iptables 的时间功能便可以实现。
|
||||
应用场景:公司员工强烈反对限制一切对 Facebook 的访问,这导致了 CEO 放宽了要求(考虑到员工的反对以及他的助理提醒说她负责更新他的 Facebook 页面)。然后 CEO 决定允许在午餐时间访问 Facebook(中午 12 点到下午 1 点之间)。假设默认规则是丢弃,使用 iptables 的时间功能便可以实现。
|
||||
|
||||
```
|
||||
iptables –A OUTPUT -p tcp -m multiport --dport http,https -i eth0 -o eth1 -m time --timestart 12:00 –timestop 13:00 –d 31.13.64.0/18 -j ACCEPT
|
||||
```
|
||||
|
||||
该命令中指定在中午12点(**\--timestart 12:00**)到下午1点(**\--timestop 13:00**)之间允许(**-j ACCEPT**)到 Facebook.com (**-d [31.13.64.0/18][5]**)的 http 以及 https (**-m multiport --dport http,https**)的访问。
|
||||
该命令中指定在中午12点(`--timestart 12:00`)到下午 1 点(`--timestop 13:00`)之间允许(`-j ACCEPT`)到 Facebook.com (`-d [31.13.64.0/18][5]`)的 http 以及 https (`-m multiport --dport http,https`)的访问。
|
||||
|
||||
### 按时间规定做限制-场景2
|
||||
### 按时间规定做限制 - 场景2
|
||||
|
||||
应用场景
|
||||
Scenario: 在计划系统维护期间,你需要设置凌晨2点到3点之间拒绝所有的 TCP 和 UDP 访问,这样维护任务就不会受到干扰。使用两个 iptables 规则可实现:
|
||||
应用场景:在计划系统维护期间,你需要设置凌晨 2 点到 3 点之间拒绝所有的 TCP 和 UDP 访问,这样维护任务就不会受到干扰。使用两个 iptables 规则可实现:
|
||||
|
||||
```
|
||||
iptables -A INPUT -p tcp -m time --timestart 02:00 --timestop 03:00 -j DROP
|
||||
iptables -A INPUT -p udp -m time --timestart 02:00 --timestop 03:00 -j DROP
|
||||
```
|
||||
|
||||
该规则禁止(**-j DROP**)在凌晨2点(**\--timestart 02:00**)到凌晨3点(**\--timestop 03:00**)之间的 TCP 和 UDP (**-p tcp and -p udp**)的数据进入(**-A INPUT**)访问。
|
||||
该规则禁止(`-j DROP`)在凌晨2点(`--timestart 02:00`)到凌晨3点(`--timestop 03:00`)之间的 TCP 和 UDP (`-p tcp and -p udp`)的数据进入(`-A INPUT`)访问。
|
||||
|
||||
### 限制连接数量
|
||||
|
||||
@ -189,11 +181,11 @@ iptables -A INPUT -p udp -m time --timestart 02:00 --timestop 03:00 -j DROP
|
||||
iptables –A INPUT –p tcp –syn -m multiport -–dport http,https –m connlimit -–connlimit-above 20 –j REJECT -–reject-with-tcp-reset
|
||||
```
|
||||
|
||||
分析一下上面的命令。如果单个主机在一分钟之内新建立(**-p tcp -syn**)超过20个(**-connlimit-above 20**)到你的 web 服务器(**--dport http,https**)的连接,服务器将拒绝(**-j REJECT**)建立新的连接,然后通知该主机新建连接被拒绝(**--reject-with-tcp-reset**)。
|
||||
分析一下上面的命令。如果单个主机在一分钟之内新建立(`-p tcp -syn`)超过 20 个(`-connlimit-above 20`)到你的 web 服务器(`--dport http,https`)的连接,服务器将拒绝(`-j REJECT`)建立新的连接,然后通知对方新建连接被拒绝(`--reject-with-tcp-reset`)。
|
||||
|
||||
### 监控 iptables 规则
|
||||
|
||||
应用场景:由于数据包会遍历链中的规则,iptables遵循 ”首次匹配获胜“ 的原则,因此经常匹配的规则应该靠近策略的顶部,而不太频繁匹配的规则应该接近底部。 你怎么知道哪些规则使用最多或最少,可以在顶部或底部附近监控?
|
||||
应用场景:由于数据包会遍历链中的规则,iptables 遵循 “首次匹配获胜” 的原则,因此经常匹配的规则应该靠近策略的顶部,而不太频繁匹配的规则应该接近底部。 你怎么知道哪些规则使用最多或最少,可以在顶部或底部附近监控?
|
||||
|
||||
#### 技巧 #1: 查看规则被访问了多少次
|
||||
|
||||
@ -203,7 +195,7 @@ iptables –A INPUT –p tcp –syn -m multiport -–dport http,https –m connl
|
||||
iptables -L -v -n –line-numbers
|
||||
```
|
||||
|
||||
用 **-L** 选项列出链中的所有规则。因为没有指定具体哪条链,所有链规则都会被输出,使用 **-v** 选项显示详细信息,**-n** 选项则显示数字格式的数据包和字节计数器,每个规则开头的数值表示该规则在链中的位置。
|
||||
用 `-L` 选项列出链中的所有规则。因为没有指定具体哪条链,所有链规则都会被输出,使用 `-v` 选项显示详细信息,`-n` 选项则显示数字格式的数据包和字节计数器,每个规则开头的数值表示该规则在链中的位置。
|
||||
|
||||
根据数据包和字节计数的结果,你可以将访问频率最高的规则放到顶部,将访问频率最低的规则放到底部。
|
||||
|
||||
@ -215,17 +207,17 @@ iptables -L -v -n –line-numbers
|
||||
iptables -nvL | grep -v "0 0"
|
||||
```
|
||||
|
||||
注意:两个数字0之间不是 Tab 键,而是 5 个空格。
|
||||
注意:两个数字 0 之间不是 Tab 键,而是 **5** 个空格。
|
||||
|
||||
#### 技巧 #3: 监控正在发生什么
|
||||
|
||||
可能你也想像使用 **top** 命令一样来实时监控 iptables 的情况。使用如下命令来动态监视 iptables 中的活动,并仅显示正在遍历的规则:
|
||||
可能你也想像使用 `top` 命令一样来实时监控 iptables 的情况。使用如下命令来动态监视 iptables 中的活动,并仅显示正在遍历的规则:
|
||||
|
||||
```
|
||||
watch --interval=5 'iptables -nvL | grep -v "0 0"'
|
||||
```
|
||||
|
||||
**watch** 命令通过参数 **iptables -nvL | grep -v “0 0“** 每隔 5s 输出 iptables 的动态。这条命令允许你查看数据包和字节计数的变化。
|
||||
`watch` 命令通过参数 `iptables -nvL | grep -v “0 0“` 每隔 5 秒输出 iptables 的动态。这条命令允许你查看数据包和字节计数的变化。
|
||||
|
||||
### 输出日志
|
||||
|
||||
@ -239,7 +231,7 @@ watch --interval=5 'iptables -nvL | grep -v "0 0"'
|
||||
|
||||
### 不要满足于允许和丢弃规则
|
||||
|
||||
本文中已经涵盖了 iptables 的很多方面,从避免封锁自己、iptables 配置防火墙以及监控 iptables 中的活动等等方面介绍了 iptables。你可以从这里开始探索 iptables 甚至获取更多的使用技巧。
|
||||
本文中已经涵盖了 iptables 的很多方面,从避免封锁自己、配置 iptables 防火墙以及监控 iptables 中的活动等等方面介绍了 iptables。你可以从这里开始探索 iptables 甚至获取更多的使用技巧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -247,8 +239,8 @@ via: https://opensource.com/article/18/10/iptables-tips-and-tricks
|
||||
|
||||
作者:[Gary Smith][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[jrg](https://github.com/jrglinu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[jrg](https://github.com/jrglinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
在 Linux 命令行中使用 ls 列出文件的提示
|
||||
在 Linux 命令行中使用 ls 列出文件的技巧
|
||||
======
|
||||
|
||||
学习一些 Linux `ls` 命令最有用的变化。
|
||||
> 学习一些 Linux `ls` 命令最有用的变化。
|
||||
|
||||

|
||||
|
||||
@ -3,30 +3,30 @@
|
||||
|
||||

|
||||
|
||||
前段时间,我写了一篇在安装 Windows 后在 Arch Linux 上**[如何重新安装 Grub][1]的教程。**
|
||||
前段时间,我写了一篇在安装 Windows 后在 Arch Linux 上[如何重新安装 Grub][1]的教程。
|
||||
|
||||
几周前,我不得不在我的笔记本上从头开始重新安装 **Arch Linux**,同时我发现安装 **Grub** 并不像我想的那么简单。
|
||||
几周前,我不得不在我的笔记本上从头开始重新安装 Arch Linux,同时我发现安装 Grub 并不像我想的那么简单。
|
||||
|
||||
出于这个原因,由于在新安装 **Arch Linux** 时**在 UEFI bios 中安装 Grub** 并不容易,所以我要写这篇教程。
|
||||
出于这个原因,由于在新安装 Arch Linux 时在 UEFI bios 中安装 Grub 并不容易,所以我要写这篇教程。
|
||||
|
||||
### 定位 EFI 分区
|
||||
|
||||
在 **Arch Linux** 上安装 **Grub** 的第一件重要事情是定位 **EFI** 分区。让我们运行以下命令以找到此分区:
|
||||
在 Arch Linux 上安装 Grub 的第一件重要事情是定位 EFI 分区。让我们运行以下命令以找到此分区:
|
||||
|
||||
```
|
||||
# fdisk -l
|
||||
```
|
||||
|
||||
我们需要检查标记为 **EFI System** 的分区,我这里是 **/dev/sda2**。
|
||||
我们需要检查标记为 EFI System 的分区,我这里是 `/dev/sda2`。
|
||||
|
||||
之后,我们需要在例如 /boot/efi 上挂载这个分区:
|
||||
之后,我们需要在例如 `/boot/efi` 上挂载这个分区:
|
||||
|
||||
```
|
||||
# mkdir /boot/efi
|
||||
# mount /dev/sdb2 /boot/efi
|
||||
```
|
||||
|
||||
另一件重要的事情是将此分区添加到 **/etc/fstab** 中。
|
||||
另一件重要的事情是将此分区添加到 `/etc/fstab` 中。
|
||||
|
||||
#### 安装 Grub
|
||||
|
||||
@ -39,7 +39,7 @@
|
||||
|
||||
#### 自动将 Windows 添加到 Grub 菜单中
|
||||
|
||||
为了自动将**Windows 条目添加到 Grub 菜单**,我们需要安装 **os-prober**:
|
||||
为了自动将 Windows 条目添加到 Grub 菜单,我们需要安装 os-prober:
|
||||
|
||||
```
|
||||
# pacman -Sy os-prober
|
||||
@ -62,7 +62,7 @@ via: http://fasterland.net/how-to-install-grub-on-arch-linux-uefi.html
|
||||
作者:[Francesco Mondello][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,75 +0,0 @@
|
||||
(translating by runningwater)
|
||||
CPU Power Manager – Control And Manage CPU Frequency In Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
If you are a laptop user, you probably know that power management on Linux isn’t really as good as on other OSes. While there are tools like **TLP** , [**Laptop Mode Tools** and **powertop**][1] to help reduce power consumption, overall battery life on Linux isn’t as good as Windows or Mac OS. Another way to reduce power consumption is to limit the frequency of your CPU. While this is something that has always been doable, it generally requires complicated terminal commands, making it inconvenient. But fortunately, there’s a gnome extension that helps you easily set and manage your CPU’s frequency – **CPU Power Manager**. CPU Power Manager uses the **intel_pstate** frequency scaling driver (supported by almost every Intel CPU) to control and manage CPU frequency in your GNOME desktop.
|
||||
|
||||
Another reason to use this extension is to reduce heating in your system. There are many systems out there which can get uncomfortably hot in normal usage. Limiting your CPU’s frequency could reduce heating. It will also decrease the wear and tear on your CPU and other components.
|
||||
|
||||
### Installing CPU Power Manager
|
||||
|
||||
First, go to the [**extension’s page**][2], and install the extension.
|
||||
|
||||
Once the extension has installed, you’ll get a CPU icon at the right side of the Gnome top bar. Click the icon, and you get an option to install the extension:
|
||||
|
||||

|
||||
|
||||
If you click **“Attempt Installation”** , you’ll get a password prompt. The extension needs root privileges to add policykit rule for controlling CPU frequency. This is what the prompt looks like:
|
||||
|
||||

|
||||
|
||||
Type in your password and Click **“Authenticate”** , and that finishes installation. The last action adds a policykit file – **mko.cpupower.setcpufreq.policy** at **/usr/share/polkit-1/actions**.
|
||||
|
||||
After installation is complete, if you click the CPU icon at the top right, you’ll get something like this:
|
||||
|
||||

|
||||
|
||||
### Features
|
||||
|
||||
* **See the current CPU frequency:** Obviously, you can use this window to see the frequency that your CPU is running at.
|
||||
* **Set maximum and minimum frequency:** With this extension, you can set maximum and minimum frequency limits in terms of percentage of max frequency. Once these limits are set, the CPU will operate only in this range of frequencies.
|
||||
* **Turn Turbo Boost On and Off:** This is my favorite feature. Most Intel CPU’s have “Turbo Boost” feature, whereby the one of the cores of the CPU is boosted past the normal maximum frequency for extra performance. While this can make your system more performant, it also increases power consumption a lot. So if you aren’t doing anything intensive, it’s nice to be able to turn off Turbo Boost and save power. In fact, in my case, I have Turbo Boost turned off most of the time.
|
||||
* **Make Profiles:** You can make profiles with max and min frequency that you can turn on/off easily instead of fiddling with max and frequencies.
|
||||
|
||||
|
||||
|
||||
### Preferences
|
||||
|
||||
You can also customize the extension via the preferences window:
|
||||
|
||||

|
||||
|
||||
As you can see, you can set whether CPU frequency is to be displayed, and whether to display it in **Mhz** or **Ghz**.
|
||||
|
||||
You can also edit and create/delete profiles:
|
||||
|
||||

|
||||
|
||||
You can set maximum and minimum frequencies, and turbo boost for each profile.
|
||||
|
||||
### Conclusion
|
||||
|
||||
As I said in the beginning, power management on Linux is not the best, and many people are always looking to eek out a few minutes more out of their Linux laptop. If you are one of those, check out this extension. This is a unconventional method to save power, but it does work. I certainly love this extension, and have been using it for a few months now.
|
||||
|
||||
What do you think about this extension? Put your thoughts in the comments below!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/cpu-power-manager-control-and-manage-cpu-frequency-in-linux/
|
||||
|
||||
作者:[EDITOR][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/editor/
|
||||
[1]: https://www.ostechnix.com/improve-laptop-battery-performance-linux/
|
||||
[2]: https://extensions.gnome.org/extension/945/cpu-power-manager/
|
||||
@ -1,639 +0,0 @@
|
||||
BriFuture is translating this article
|
||||
|
||||
# Compiling Lisp to JavaScript From Scratch in 350
|
||||
|
||||
In this article we will look at a from-scratch implementation of a compiler from a simple LISP-like calculator language to JavaScript. The complete source code can be found [here][7].
|
||||
|
||||
We will:
|
||||
|
||||
1. Define our language and write a simple program in it
|
||||
|
||||
2. Implement a simple parser combinator library
|
||||
|
||||
3. Implement a parser for our language
|
||||
|
||||
4. Implement a pretty printer for our language
|
||||
|
||||
5. Define a subset of JavaScript for our usage
|
||||
|
||||
6. Implement a code translator to the JavaScript subset we defined
|
||||
|
||||
7. Glue it all together
|
||||
|
||||
Let's start!
|
||||
|
||||
### 1\. Defining the language
|
||||
|
||||
The main attraction of lisps is that their syntax already represent a tree, this is why they are so easy to parse. We'll see that soon. But first let's define our language. Here's a BNF description of our language's syntax:
|
||||
|
||||
```
|
||||
program ::= expr
|
||||
expr ::= <integer> | <name> | ([<expr>])
|
||||
```
|
||||
|
||||
Basically, our language let's us define one expression at the top level which it will evaluate. An expression is composed of either an integer, for example `5`, a variable, for example `x`, or a list of expressions, for example `(add x 1)`.
|
||||
|
||||
An integer evaluate to itself, a variable evaluates to what it's bound in the current environment, and a list evaluates to a function call where the first argument is the function and the rest are the arguments to the function.
|
||||
|
||||
We have some built-in special forms in our language so we can do more interesting stuff:
|
||||
|
||||
* let expression let's us introduce new variables in the environment of the body of the let. The syntax is:
|
||||
|
||||
```
|
||||
let ::= (let ([<letarg>]) <body>)
|
||||
letargs ::= (<name> <expr>)
|
||||
body ::= <expr>
|
||||
```
|
||||
|
||||
* lambda expression: evaluates to an anonymous function definition. The syntax is:
|
||||
|
||||
```
|
||||
lambda ::= (lambda ([<name>]) <body>)
|
||||
```
|
||||
|
||||
We also have a few built in functions: `add`, `mul`, `sub`, `div` and `print`.
|
||||
|
||||
Let's see a quick example of a program written in our language:
|
||||
|
||||
```
|
||||
(let
|
||||
((compose
|
||||
(lambda (f g)
|
||||
(lambda (x) (f (g x)))))
|
||||
(square
|
||||
(lambda (x) (mul x x)))
|
||||
(add1
|
||||
(lambda (x) (add x 1))))
|
||||
(print ((compose square add1) 5)))
|
||||
```
|
||||
|
||||
This program defines 3 functions: `compose`, `square` and `add1`. And then prints the result of the computation:`((compose square add1) 5)`
|
||||
|
||||
I hope this is enough information about the language. Let's start implementing it!
|
||||
|
||||
We can define the language in Haskell like this:
|
||||
|
||||
```
|
||||
type Name = String
|
||||
|
||||
data Expr
|
||||
= ATOM Atom
|
||||
| LIST [Expr]
|
||||
deriving (Eq, Read, Show)
|
||||
|
||||
data Atom
|
||||
= Int Int
|
||||
| Symbol Name
|
||||
deriving (Eq, Read, Show)
|
||||
```
|
||||
|
||||
We can parse programs in the language we defined to an `Expr`. Also, we are giving the new data types `Eq`, `Read`and `Show` instances to aid in testing and debugging. You'll be able to use those in the REPL for example to verify all this actually works.
|
||||
|
||||
The reason we did not define `lambda`, `let` and the other built-in functions as part of the syntax is because we can get away with it in this case. These functions are just a more specific case of a `LIST`. So I decided to leave this to a later phase.
|
||||
|
||||
Usually, you would like to define these special cases in the abstract syntax - to improve error messages, to unable static analysis and optimizations and such, but we won't do that here so this is enough for us.
|
||||
|
||||
Another thing you would like to do usually is add some annotation to the syntax. For example the location: Which file did this `Expr` come from and which row and col in the file. You can use this in later stages to print the location of errors, even if they are not in the parser stage.
|
||||
|
||||
* _Exercise 1_ : Add a `Program` data type to include multiple `Expr` sequentially
|
||||
|
||||
* _Exercise 2_ : Add location annotation to the syntax tree.
|
||||
|
||||
### 2\. Implement a simple parser combinator library
|
||||
|
||||
First thing we are going to do is define an Embedded Domain Specific Language (or EDSL) which we will use to define our languages' parser. This is often referred to as parser combinator library. The reason we are doing it is strictly for learning purposes, Haskell has great parsing libraries and you should definitely use them when building real software, or even when just experimenting. One such library is [megaparsec][8].
|
||||
|
||||
First let's talk about the idea behind our parser library implementation. In it's essence, our parser is a function that takes some input, might consume some or all of the input, and returns the value it managed to parse and the rest of the input it didn't parse yet, or throws an error if it failed. Let's write that down.
|
||||
|
||||
```
|
||||
newtype Parser a
|
||||
= Parser (ParseString -> Either ParseError (a, ParseString))
|
||||
|
||||
data ParseString
|
||||
= ParseString Name (Int, Int) String
|
||||
|
||||
data ParseError
|
||||
= ParseError ParseString Error
|
||||
|
||||
type Error = String
|
||||
|
||||
```
|
||||
|
||||
Here we defined three main new types.
|
||||
|
||||
First, `Parser a`, is the parsing function we described before.
|
||||
|
||||
Second, `ParseString` is our input or state we carry along. It has three significant parts:
|
||||
|
||||
* `Name`: This is the name of the source
|
||||
|
||||
* `(Int, Int)`: This is the current location in the source
|
||||
|
||||
* `String`: This is the remaining string left to parse
|
||||
|
||||
Third, `ParseError` contains the current state of the parser and an error message.
|
||||
|
||||
Now we want our parser to be flexible, so we will define a few instances for common type classes for it. These instances will allow us to combine small parsers to make bigger parsers (hence the name 'parser combinators').
|
||||
|
||||
The first one is a `Functor` instance. We want a `Functor` instance because we want to be able to define a parser using another parser simply by applying a function on the parsed value. We will see an example of this when we define the parser for our language.
|
||||
|
||||
```
|
||||
instance Functor Parser where
|
||||
fmap f (Parser parser) =
|
||||
Parser (\str -> first f <$> parser str)
|
||||
```
|
||||
|
||||
The second instance is an `Applicative` instance. One common use case for this instance instance is to lift a pure function on multiple parsers.
|
||||
|
||||
```
|
||||
instance Applicative Parser where
|
||||
pure x = Parser (\str -> Right (x, str))
|
||||
(Parser p1) <*> (Parser p2) =
|
||||
Parser $
|
||||
\str -> do
|
||||
(f, rest) <- p1 str
|
||||
(x, rest') <- p2 rest
|
||||
pure (f x, rest')
|
||||
|
||||
```
|
||||
|
||||
(Note: _We will also implement a Monad instance so we can use do notation here._ )
|
||||
|
||||
The third instance is an `Alternative` instance. We want to be able to supply an alternative parser in case one fails.
|
||||
|
||||
```
|
||||
instance Alternative Parser where
|
||||
empty = Parser (`throwErr` "Failed consuming input")
|
||||
(Parser p1) <|> (Parser p2) =
|
||||
Parser $
|
||||
\pstr -> case p1 pstr of
|
||||
Right result -> Right result
|
||||
Left _ -> p2 pstr
|
||||
```
|
||||
|
||||
The forth instance is a `Monad` instance. So we'll be able to chain parsers.
|
||||
|
||||
```
|
||||
instance Monad Parser where
|
||||
(Parser p1) >>= f =
|
||||
Parser $
|
||||
\str -> case p1 str of
|
||||
Left err -> Left err
|
||||
Right (rs, rest) ->
|
||||
case f rs of
|
||||
Parser parser -> parser rest
|
||||
|
||||
```
|
||||
|
||||
Next, let's define a way to run a parser and a utility function for failure:
|
||||
|
||||
```
|
||||
|
||||
runParser :: String -> String -> Parser a -> Either ParseError (a, ParseString)
|
||||
runParser name str (Parser parser) = parser $ ParseString name (0,0) str
|
||||
|
||||
throwErr :: ParseString -> String -> Either ParseError a
|
||||
throwErr ps@(ParseString name (row,col) _) errMsg =
|
||||
Left $ ParseError ps $ unlines
|
||||
[ "*** " ++ name ++ ": " ++ errMsg
|
||||
, "* On row " ++ show row ++ ", column " ++ show col ++ "."
|
||||
]
|
||||
|
||||
```
|
||||
|
||||
Now we'll start implementing the combinators which are the API and heart of the EDSL.
|
||||
|
||||
First, we'll define `oneOf`. `oneOf` will succeed if one of the characters in the list supplied to it is the next character of the input and will fail otherwise.
|
||||
|
||||
```
|
||||
oneOf :: [Char] -> Parser Char
|
||||
oneOf chars =
|
||||
Parser $ \case
|
||||
ps@(ParseString name (row, col) str) ->
|
||||
case str of
|
||||
[] -> throwErr ps "Cannot read character of empty string"
|
||||
(c:cs) ->
|
||||
if c `elem` chars
|
||||
then Right (c, ParseString name (row, col+1) cs)
|
||||
else throwErr ps $ unlines ["Unexpected character " ++ [c], "Expecting one of: " ++ show chars]
|
||||
```
|
||||
|
||||
`optional` will stop a parser from throwing an error. It will just return `Nothing` on failure.
|
||||
|
||||
```
|
||||
optional :: Parser a -> Parser (Maybe a)
|
||||
optional (Parser parser) =
|
||||
Parser $
|
||||
\pstr -> case parser pstr of
|
||||
Left _ -> Right (Nothing, pstr)
|
||||
Right (x, rest) -> Right (Just x, rest)
|
||||
```
|
||||
|
||||
`many` will try to run a parser repeatedly until it fails. When it does, it'll return a list of successful parses. `many1`will do the same, but will throw an error if it fails to parse at least once.
|
||||
|
||||
```
|
||||
many :: Parser a -> Parser [a]
|
||||
many parser = go []
|
||||
where go cs = (parser >>= \c -> go (c:cs)) <|> pure (reverse cs)
|
||||
|
||||
many1 :: Parser a -> Parser [a]
|
||||
many1 parser =
|
||||
(:) <$> parser <*> many parser
|
||||
|
||||
```
|
||||
|
||||
These next few parsers use the combinators we defined to make more specific parsers:
|
||||
|
||||
```
|
||||
char :: Char -> Parser Char
|
||||
char c = oneOf [c]
|
||||
|
||||
string :: String -> Parser String
|
||||
string = traverse char
|
||||
|
||||
space :: Parser Char
|
||||
space = oneOf " \n"
|
||||
|
||||
spaces :: Parser String
|
||||
spaces = many space
|
||||
|
||||
spaces1 :: Parser String
|
||||
spaces1 = many1 space
|
||||
|
||||
withSpaces :: Parser a -> Parser a
|
||||
withSpaces parser =
|
||||
spaces *> parser <* spaces
|
||||
|
||||
parens :: Parser a -> Parser a
|
||||
parens parser =
|
||||
(withSpaces $ char '(')
|
||||
*> withSpaces parser
|
||||
<* (spaces *> char ')')
|
||||
|
||||
sepBy :: Parser a -> Parser b -> Parser [b]
|
||||
sepBy sep parser = do
|
||||
frst <- optional parser
|
||||
rest <- many (sep *> parser)
|
||||
pure $ maybe rest (:rest) frst
|
||||
|
||||
```
|
||||
|
||||
Now we have everything we need to start defining a parser for our language.
|
||||
|
||||
* _Exercise_ : implement an EOF (end of file/input) parser combinator.
|
||||
|
||||
### 3\. Implementing a parser for our language
|
||||
|
||||
To define our parser, we'll use the top-bottom method.
|
||||
|
||||
```
|
||||
parseExpr :: Parser Expr
|
||||
parseExpr = fmap ATOM parseAtom <|> fmap LIST parseList
|
||||
|
||||
parseList :: Parser [Expr]
|
||||
parseList = parens $ sepBy spaces1 parseExpr
|
||||
|
||||
parseAtom :: Parser Atom
|
||||
parseAtom = parseSymbol <|> parseInt
|
||||
|
||||
parseSymbol :: Parser Atom
|
||||
parseSymbol = fmap Symbol parseName
|
||||
|
||||
```
|
||||
|
||||
Notice that these four function are a very high-level description of our language. This demonstrate why Haskell is so nice for parsing. Still, after defining the high-level parts, we still need to define the lower-level `parseName` and `parseInt`.
|
||||
|
||||
What characters can we use as names in our language? Let's decide to use lowercase letters, digits and underscores, where the first character must be a letter.
|
||||
|
||||
```
|
||||
parseName :: Parser Name
|
||||
parseName = do
|
||||
c <- oneOf ['a'..'z']
|
||||
cs <- many $ oneOf $ ['a'..'z'] ++ "0123456789" ++ "_"
|
||||
pure (c:cs)
|
||||
```
|
||||
|
||||
For integers, we want a sequence of digits optionally preceding by '-':
|
||||
|
||||
```
|
||||
parseInt :: Parser Atom
|
||||
parseInt = do
|
||||
sign <- optional $ char '-'
|
||||
num <- many1 $ oneOf "0123456789"
|
||||
let result = read $ maybe num (:num) sign of
|
||||
pure $ Int result
|
||||
```
|
||||
|
||||
Lastly, we'll define a function to run a parser and get back an `Expr` or an error message.
|
||||
|
||||
```
|
||||
runExprParser :: Name -> String -> Either String Expr
|
||||
runExprParser name str =
|
||||
case runParser name str (withSpaces parseExpr) of
|
||||
Left (ParseError _ errMsg) -> Left errMsg
|
||||
Right (result, _) -> Right result
|
||||
```
|
||||
|
||||
* _Exercise 1_ : Write a parser for the `Program` type you defined in the first section
|
||||
|
||||
* _Exercise 2_ : Rewrite `parseName` in Applicative style
|
||||
|
||||
* _Exercise 3_ : Find a way to handle the overflow case in `parseInt` instead of using `read`.
|
||||
|
||||
### 4\. Implement a pretty printer for our language
|
||||
|
||||
One more thing we'd like to do is be able to print our programs as source code. This is useful for better error messages.
|
||||
|
||||
```
|
||||
printExpr :: Expr -> String
|
||||
printExpr = printExpr' False 0
|
||||
|
||||
printAtom :: Atom -> String
|
||||
printAtom = \case
|
||||
Symbol s -> s
|
||||
Int i -> show i
|
||||
|
||||
printExpr' :: Bool -> Int -> Expr -> String
|
||||
printExpr' doindent level = \case
|
||||
ATOM a -> indent (bool 0 level doindent) (printAtom a)
|
||||
LIST (e:es) ->
|
||||
indent (bool 0 level doindent) $
|
||||
concat
|
||||
[ "("
|
||||
, printExpr' False (level + 1) e
|
||||
, bool "\n" "" (null es)
|
||||
, intercalate "\n" $ map (printExpr' True (level + 1)) es
|
||||
, ")"
|
||||
]
|
||||
|
||||
indent :: Int -> String -> String
|
||||
indent tabs e = concat (replicate tabs " ") ++ e
|
||||
```
|
||||
|
||||
* _Exercise_ : Write a pretty printer for the `Program` type you defined in the first section
|
||||
|
||||
Okay, we wrote around 200 lines so far of what's typically called the front-end of the compiler. We have around 150 more lines to go and three more tasks: We need to define a subset of JS for our usage, define the translator from our language to that subset, and glue the whole thing together. Let's go!
|
||||
|
||||
### 5\. Define a subset of JavaScript for our usage
|
||||
|
||||
First, we'll define the subset of JavaScript we are going to use:
|
||||
|
||||
```
|
||||
data JSExpr
|
||||
= JSInt Int
|
||||
| JSSymbol Name
|
||||
| JSBinOp JSBinOp JSExpr JSExpr
|
||||
| JSLambda [Name] JSExpr
|
||||
| JSFunCall JSExpr [JSExpr]
|
||||
| JSReturn JSExpr
|
||||
deriving (Eq, Show, Read)
|
||||
|
||||
type JSBinOp = String
|
||||
```
|
||||
|
||||
This data type represent a JavaScript expression. We have two atoms - `JSInt` and `JSSymbol` to which we'll translate our languages' `Atom`, We have `JSBinOp` to represent a binary operation such as `+` or `*`, we have `JSLambda`for anonymous functions same as our `lambda expression`, We have `JSFunCall` which we'll use both for calling functions and introducing new names as in `let`, and we have `JSReturn` to return values from functions as that's required in JavaScript.
|
||||
|
||||
This `JSExpr` type is an **abstract representation** of a JavaScript expression. We will translate our own `Expr`which is an abstract representation of our languages' expression to `JSExpr` and from there to JavaScript. But in order to do that we need to take this `JSExpr` and produce JavaScript code from it. We'll do that by pattern matching on `JSExpr` recursively and emit JS code as a `String`. This is basically the same thing we did in `printExpr`. We'll also track the scoping of elements so we can indent the generated code in a nice way.
|
||||
|
||||
```
|
||||
printJSOp :: JSBinOp -> String
|
||||
printJSOp op = op
|
||||
|
||||
printJSExpr :: Bool -> Int -> JSExpr -> String
|
||||
printJSExpr doindent tabs = \case
|
||||
JSInt i -> show i
|
||||
JSSymbol name -> name
|
||||
JSLambda vars expr -> (if doindent then indent tabs else id) $ unlines
|
||||
["function(" ++ intercalate ", " vars ++ ") {"
|
||||
,indent (tabs+1) $ printJSExpr False (tabs+1) expr
|
||||
] ++ indent tabs "}"
|
||||
JSBinOp op e1 e2 -> "(" ++ printJSExpr False tabs e1 ++ " " ++ printJSOp op ++ " " ++ printJSExpr False tabs e2 ++ ")"
|
||||
JSFunCall f exprs -> "(" ++ printJSExpr False tabs f ++ ")(" ++ intercalate ", " (fmap (printJSExpr False tabs) exprs) ++ ")"
|
||||
JSReturn expr -> (if doindent then indent tabs else id) $ "return " ++ printJSExpr False tabs expr ++ ";"
|
||||
```
|
||||
|
||||
* _Exercise 1_ : Add a `JSProgram` type that will hold multiple `JSExpr` and create a function `printJSExprProgram` to generate code for it.
|
||||
|
||||
* _Exercise 2_ : Add a new type of `JSExpr` - `JSIf`, and generate code for it.
|
||||
|
||||
### 6\. Implement a code translator to the JavaScript subset we defined
|
||||
|
||||
We are almost there. In this section we'll create a function to translate `Expr` to `JSExpr`.
|
||||
|
||||
The basic idea is simple, we'll translate `ATOM` to `JSSymbol` or `JSInt` and `LIST` to either a function call or a special case we'll translate later.
|
||||
|
||||
```
|
||||
type TransError = String
|
||||
|
||||
translateToJS :: Expr -> Either TransError JSExpr
|
||||
translateToJS = \case
|
||||
ATOM (Symbol s) -> pure $ JSSymbol s
|
||||
ATOM (Int i) -> pure $ JSInt i
|
||||
LIST xs -> translateList xs
|
||||
|
||||
translateList :: [Expr] -> Either TransError JSExpr
|
||||
translateList = \case
|
||||
[] -> Left "translating empty list"
|
||||
ATOM (Symbol s):xs
|
||||
| Just f <- lookup s builtins ->
|
||||
f xs
|
||||
f:xs ->
|
||||
JSFunCall <$> translateToJS f <*> traverse translateToJS xs
|
||||
|
||||
```
|
||||
|
||||
`builtins` is a list of special cases to translate, like `lambda` and `let`. Every case gets the list of arguments for it, verify that its syntactically valid and translates it to the equivalent `JSExpr`.
|
||||
|
||||
```
|
||||
type Builtin = [Expr] -> Either TransError JSExpr
|
||||
type Builtins = [(Name, Builtin)]
|
||||
|
||||
builtins :: Builtins
|
||||
builtins =
|
||||
[("lambda", transLambda)
|
||||
,("let", transLet)
|
||||
,("add", transBinOp "add" "+")
|
||||
,("mul", transBinOp "mul" "*")
|
||||
,("sub", transBinOp "sub" "-")
|
||||
,("div", transBinOp "div" "/")
|
||||
,("print", transPrint)
|
||||
]
|
||||
|
||||
```
|
||||
|
||||
In our case, we treat built-in special forms as special and not first class, so will not be able to use them as first class functions and such.
|
||||
|
||||
We'll translate a Lambda to an anonymous function:
|
||||
|
||||
```
|
||||
transLambda :: [Expr] -> Either TransError JSExpr
|
||||
transLambda = \case
|
||||
[LIST vars, body] -> do
|
||||
vars' <- traverse fromSymbol vars
|
||||
JSLambda vars' <$> (JSReturn <$> translateToJS body)
|
||||
|
||||
vars ->
|
||||
Left $ unlines
|
||||
["Syntax error: unexpected arguments for lambda."
|
||||
,"expecting 2 arguments, the first is the list of vars and the second is the body of the lambda."
|
||||
,"In expression: " ++ show (LIST $ ATOM (Symbol "lambda") : vars)
|
||||
]
|
||||
|
||||
fromSymbol :: Expr -> Either String Name
|
||||
fromSymbol (ATOM (Symbol s)) = Right s
|
||||
fromSymbol e = Left $ "cannot bind value to non symbol type: " ++ show e
|
||||
|
||||
```
|
||||
|
||||
We'll translate let to a definition of a function with the relevant named arguments and call it with the values, Thus introducing the variables in that scope:
|
||||
|
||||
```
|
||||
transLet :: [Expr] -> Either TransError JSExpr
|
||||
transLet = \case
|
||||
[LIST binds, body] -> do
|
||||
(vars, vals) <- letParams binds
|
||||
vars' <- traverse fromSymbol vars
|
||||
JSFunCall . JSLambda vars' <$> (JSReturn <$> translateToJS body) <*> traverse translateToJS vals
|
||||
where
|
||||
letParams :: [Expr] -> Either Error ([Expr],[Expr])
|
||||
letParams = \case
|
||||
[] -> pure ([],[])
|
||||
LIST [x,y] : rest -> ((x:) *** (y:)) <$> letParams rest
|
||||
x : _ -> Left ("Unexpected argument in let list in expression:\n" ++ printExpr x)
|
||||
|
||||
vars ->
|
||||
Left $ unlines
|
||||
["Syntax error: unexpected arguments for let."
|
||||
,"expecting 2 arguments, the first is the list of var/val pairs and the second is the let body."
|
||||
,"In expression:\n" ++ printExpr (LIST $ ATOM (Symbol "let") : vars)
|
||||
]
|
||||
```
|
||||
|
||||
We'll translate an operation that can work on multiple arguments to a chain of binary operations. For example: `(add 1 2 3)` will become `1 + (2 + 3)`
|
||||
|
||||
```
|
||||
transBinOp :: Name -> Name -> [Expr] -> Either TransError JSExpr
|
||||
transBinOp f _ [] = Left $ "Syntax error: '" ++ f ++ "' expected at least 1 argument, got: 0"
|
||||
transBinOp _ _ [x] = translateToJS x
|
||||
transBinOp _ f list = foldl1 (JSBinOp f) <$> traverse translateToJS list
|
||||
```
|
||||
|
||||
And we'll translate a `print` as a call to `console.log`
|
||||
|
||||
```
|
||||
transPrint :: [Expr] -> Either TransError JSExpr
|
||||
transPrint [expr] = JSFunCall (JSSymbol "console.log") . (:[]) <$> translateToJS expr
|
||||
transPrint xs = Left $ "Syntax error. print expected 1 arguments, got: " ++ show (length xs)
|
||||
|
||||
```
|
||||
|
||||
Notice that we could have skipped verifying the syntax if we'd parse those as special cases of `Expr`.
|
||||
|
||||
* _Exercise 1_ : Translate `Program` to `JSProgram`
|
||||
|
||||
* _Exercise 2_ : add a special case for `if Expr Expr Expr` and translate it to the `JSIf` case you implemented in the last exercise
|
||||
|
||||
### 7\. Glue it all together
|
||||
|
||||
Finally, we are going to glue this all together. We'll:
|
||||
|
||||
1. Read a file
|
||||
|
||||
2. Parse it to `Expr`
|
||||
|
||||
3. Translate it to `JSExpr`
|
||||
|
||||
4. Emit JavaScript code to the standard output
|
||||
|
||||
We'll also enable a few flags for testing:
|
||||
|
||||
* `--e` will parse and print the abstract representation of the expression (`Expr`)
|
||||
|
||||
* `--pp` will parse and pretty print
|
||||
|
||||
* `--jse` will parse, translate and print the abstract representation of the resulting JS (`JSExpr`)
|
||||
|
||||
* `--ppc` will parse, pretty print and compile
|
||||
|
||||
```
|
||||
main :: IO ()
|
||||
main = getArgs >>= \case
|
||||
[file] ->
|
||||
printCompile =<< readFile file
|
||||
["--e",file] ->
|
||||
either putStrLn print . runExprParser "--e" =<< readFile file
|
||||
["--pp",file] ->
|
||||
either putStrLn (putStrLn . printExpr) . runExprParser "--pp" =<< readFile file
|
||||
["--jse",file] ->
|
||||
either print (either putStrLn print . translateToJS) . runExprParser "--jse" =<< readFile file
|
||||
["--ppc",file] ->
|
||||
either putStrLn (either putStrLn putStrLn) . fmap (compile . printExpr) . runExprParser "--ppc" =<< readFile file
|
||||
_ ->
|
||||
putStrLn $ unlines
|
||||
["Usage: runghc Main.hs [ --e, --pp, --jse, --ppc ] <filename>"
|
||||
,"--e print the Expr"
|
||||
,"--pp pretty print Expr"
|
||||
,"--jse print the JSExpr"
|
||||
,"--ppc pretty print Expr and then compile"
|
||||
]
|
||||
|
||||
printCompile :: String -> IO ()
|
||||
printCompile = either putStrLn putStrLn . compile
|
||||
|
||||
compile :: String -> Either Error String
|
||||
compile str = printJSExpr False 0 <$> (translateToJS =<< runExprParser "compile" str)
|
||||
|
||||
```
|
||||
|
||||
That's it. We have a compiler from our language to JS. Again, you can view the full source file [here][9].
|
||||
|
||||
Running our compiler with the example from the first section yields this JavaScript code:
|
||||
|
||||
```
|
||||
$ runhaskell Lisp.hs example.lsp
|
||||
(function(compose, square, add1) {
|
||||
return (console.log)(((compose)(square, add1))(5));
|
||||
})(function(f, g) {
|
||||
return function(x) {
|
||||
return (f)((g)(x));
|
||||
};
|
||||
}, function(x) {
|
||||
return (x * x);
|
||||
}, function(x) {
|
||||
return (x + 1);
|
||||
})
|
||||
```
|
||||
|
||||
If you have node.js installed on your computer, you can run this code by running:
|
||||
|
||||
```
|
||||
$ runhaskell Lisp.hs example.lsp | node -p
|
||||
36
|
||||
undefined
|
||||
```
|
||||
|
||||
* _Final exercise_ : instead of compiling an expression, compile a program of multiple expressions.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://gilmi.me/blog/post/2016/10/14/lisp-to-js
|
||||
|
||||
作者:[ Gil Mizrahi ][a]
|
||||
选题:[oska874][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://gilmi.me/home
|
||||
[b]:https://github.com/oska874
|
||||
[1]:https://gilmi.me/blog/authors/Gil
|
||||
[2]:https://gilmi.me/blog/tags/compilers
|
||||
[3]:https://gilmi.me/blog/tags/fp
|
||||
[4]:https://gilmi.me/blog/tags/haskell
|
||||
[5]:https://gilmi.me/blog/tags/lisp
|
||||
[6]:https://gilmi.me/blog/tags/parsing
|
||||
[7]:https://gist.github.com/soupi/d4ff0727ccb739045fad6cdf533ca7dd
|
||||
[8]:https://mrkkrp.github.io/megaparsec/
|
||||
[9]:https://gist.github.com/soupi/d4ff0727ccb739045fad6cdf533ca7dd
|
||||
[10]:https://gilmi.me/blog/post/2016/10/14/lisp-to-js
|
||||
@ -1,100 +0,0 @@
|
||||
translating by dianbanjiu
|
||||
Download an OS with GNOME Boxes
|
||||
======
|
||||
|
||||

|
||||
|
||||
Boxes is the GNOME application for running virtual machines. Recently Boxes added a new feature that makes it easier to run different Linux distributions. You can now automatically install these distros in Boxes, as well as operating systems like FreeBSD and FreeDOS. The list even includes Red Hat Enterprise Linux. The Red Hat Developer Program includes a [no-cost subscription to Red Hat Enterprise Linux][1]. With a [Red Hat Developer][2] account, Boxes can automatically set up a RHEL virtual machine entitled to the Developer Suite subscription. Here’s how it works.
|
||||
|
||||
### Red Hat Enterprise Linux
|
||||
|
||||
To create a Red Hat Enterprise Linux virtual machine, launch Boxes and click New. Select Download an OS from the source selection list. At the top, pick Red Hat Enterprise Linux. This opens a web form at [developers.redhat.com][2]. Sign in with an existing Red Hat Developer Account, or create a new one.
|
||||
|
||||
![][3]
|
||||
|
||||
If this is a new account, Boxes requires some additional information before continuing. This step is required to enable the Developer Subscription on the account. Be sure to [accept the Terms & Conditions][4] now too. This saves a step later during registration.
|
||||
|
||||
![][5]
|
||||
|
||||
Click Submit and the installation disk image starts to download. The download can take a while, depending on your Internet connection. This is a great time to go fix a cup of tea or coffee!
|
||||
|
||||
![][6]
|
||||
|
||||
Once the media has downloaded (conveniently to ~/Downloads), Boxes offers to perform an Express Install. Fill in the account and password information and click Continue. Click Create after you verify the virtual machine details. The Express Install automatically performs the entire installation! (Now is a great time to enjoy a second cup of tea or coffee, if so inclined.)
|
||||
|
||||
![][7]
|
||||
|
||||
![][8]
|
||||
|
||||
![][9]
|
||||
|
||||
Once the installation is done, the virtual machine reboots and logs directly into the desktop. Inside the virtual machine, launch the Red Hat Subscription Manager via the Applications menu, under System Tools. Enter the root password to launch the utility.
|
||||
|
||||
![][10]
|
||||
|
||||
Click the Register button and follow the steps through the registration assistant. Log in with your Red Hat Developers account when prompted.
|
||||
|
||||
![][11]
|
||||
|
||||
![][12]
|
||||
|
||||
Now you can download and install updates through any normal update method, such as yum or GNOME Software.
|
||||
|
||||
![][13]
|
||||
|
||||
### FreeDOS anyone?
|
||||
|
||||
Boxes can install a lot more than just Red Hat Enterprise Linux, too. As a front end to KVM and qemu, Boxes supports a wide variety of operating systems. Using [libosinfo][14], Boxes can automatically download (and in some cases, install) quite a few different ones.
|
||||
|
||||
![][15]
|
||||
|
||||
To install an OS from the list, select it and finish creating the new virtual machine. Some OSes, like FreeDOS, do not support an Express Install. In those cases the virtual machine boots from the installation media. You can then manually install.
|
||||
|
||||
![][16]
|
||||
|
||||
![][17]
|
||||
|
||||
### Popular operating systems on Boxes
|
||||
|
||||
These are just a few of the popular choices available in Boxes today.
|
||||
|
||||
![][18]![][19]![][20]![][21]![][22]![][23]
|
||||
|
||||
Fedora updates its osinfo-db package regularly. Be sure to check back frequently for new OS options.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/download-os-gnome-boxes/
|
||||
|
||||
作者:[Link Dupont][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/linkdupont/
|
||||
[1]:https://developers.redhat.com/blog/2016/03/31/no-cost-rhel-developer-subscription-now-available/
|
||||
[2]:http://developers.redhat.com
|
||||
[3]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-14-33-13.png
|
||||
[4]:https://www.redhat.com/wapps/tnc/termsack?event%5B%5D=signIn
|
||||
[5]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-14-34-37.png
|
||||
[6]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-14-37-27.png
|
||||
[7]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-15-09-11.png
|
||||
[8]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-15-15-19-1024x815.png
|
||||
[9]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-15-21-53-1024x815.png
|
||||
[10]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-15-26-29-1024x815.png
|
||||
[11]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-15-30-48-1024x815.png
|
||||
[12]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-15-31-17-1024x815.png
|
||||
[13]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-15-32-29-1024x815.png
|
||||
[14]:https://libosinfo.org
|
||||
[15]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-20-02-56.png
|
||||
[16]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-15-40-25.png
|
||||
[17]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-15-43-02-1024x815.png
|
||||
[18]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-16-55-20-1024x815.png
|
||||
[19]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-16-28-28-1024x815.png
|
||||
[20]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-16-11-43-1024x815.png
|
||||
[21]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-16-58-09-1024x815.png
|
||||
[22]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-17-46-38-1024x815.png
|
||||
[23]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-18-34-11-1024x815.png
|
||||
@ -1,3 +1,4 @@
|
||||
Translateing By DavidChenLiang
|
||||
Top Linux developers' recommended programming books
|
||||
======
|
||||
Without question, Linux was created by brilliant programmers who employed good computer science knowledge. Let the Linux programmers whose names you know share the books that got them started and the technology references they recommend for today's developers. How many of them have you read?
|
||||
|
||||
@ -1,61 +0,0 @@
|
||||
translating by belitex
|
||||
|
||||
A sysadmin's guide to containers
|
||||
======
|
||||
|
||||

|
||||
|
||||
The term "containers" is heavily overused. Also, depending on the context, it can mean different things to different people.
|
||||
|
||||
Traditional Linux containers are really just ordinary processes on a Linux system. These groups of processes are isolated from other groups of processes using resource constraints (control groups [cgroups]), Linux security constraints (Unix permissions, capabilities, SELinux, AppArmor, seccomp, etc.), and namespaces (PID, network, mount, etc.).
|
||||
|
||||
If you boot a modern Linux system and took a look at any process with `cat /proc/PID/cgroup`, you see that the process is in a cgroup. If you look at `/proc/PID/status`, you see capabilities. If you look at `/proc/self/attr/current`, you see SELinux labels. If you look at `/proc/PID/ns`, you see the list of namespaces the process is in. So, if you define a container as a process with resource constraints, Linux security constraints, and namespaces, by definition every process on a Linux system is in a container. This is why we often say [Linux is containers, containers are Linux][1]. **Container runtimes** are tools that modify these resource constraints, security, and namespaces and launch the container.
|
||||
|
||||
Docker introduced the concept of a **container image** , which is a standard TAR file that combines:
|
||||
|
||||
* **Rootfs (container root filesystem):** A directory on the system that looks like the standard root (`/`) of the operating system. For example, a directory with `/usr`, `/var`, `/home`, etc.
|
||||
* **JSON file (container configuration):** Specifies how to run the rootfs; for example, what **command** or **entrypoint** to run in the rootfs when the container starts; **environment variables** to set for the container; the container's **working directory** ; and a few other settings.
|
||||
|
||||
|
||||
|
||||
Docker "`tar`'s up" the rootfs and the JSON file to create the **base image**. This enables you to install additional content on the rootfs, create a new JSON file, and `tar` the difference between the original image and the new image with the updated JSON file. This creates a **layered image**.
|
||||
|
||||
The definition of a container image was eventually standardized by the [Open Container Initiative (OCI)][2] standards body as the [OCI Image Specification][3].
|
||||
|
||||
Tools used to create container images are called **container image builders**. Sometimes container engines perform this task, but several standalone tools are available that can build container images.
|
||||
|
||||
Docker took these container images ( **tarballs** ) and moved them to a web service from which they could be pulled, developed a protocol to pull them, and called the web service a **container registry**.
|
||||
|
||||
**Container engines** are programs that can pull container images from container registries and reassemble them onto **container storage**. Container engines also launch **container runtimes** (see below).
|
||||
|
||||
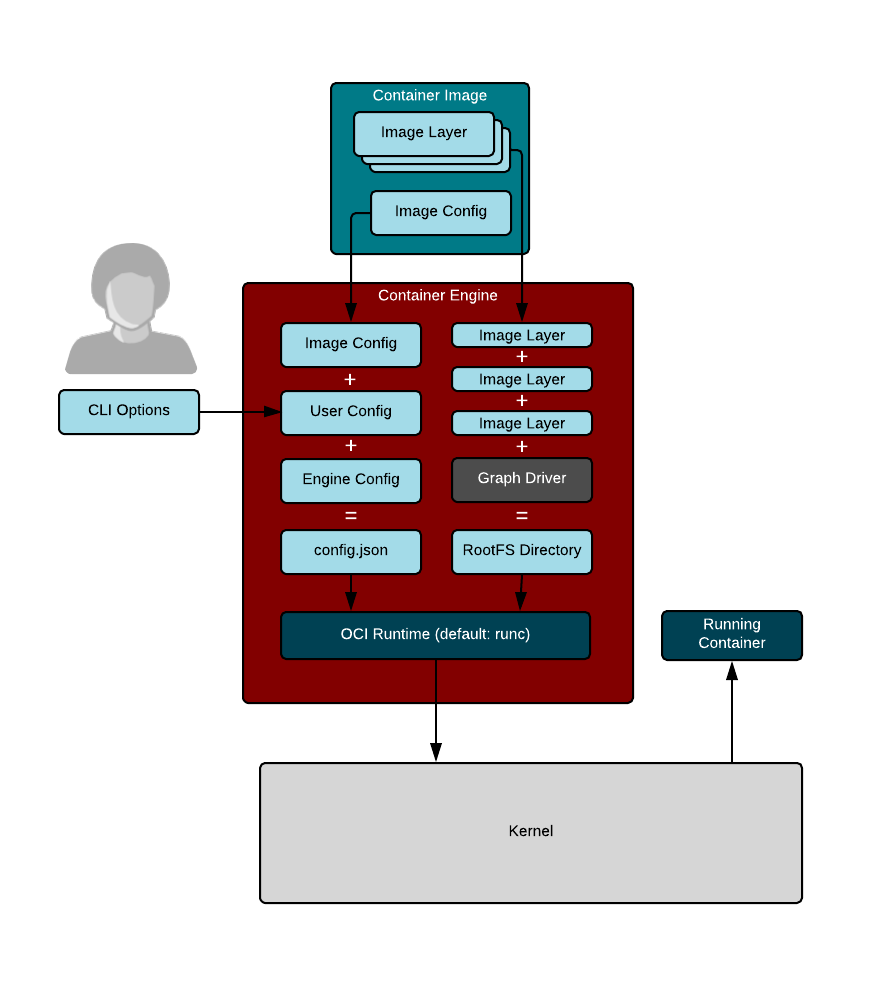
|
||||
|
||||
Container storage is usually a **copy-on-write** (COW) layered filesystem. When you pull down a container image from a container registry, you first need to untar the rootfs and place it on disk. If you have multiple layers that make up your image, each layer is downloaded and stored on a different layer on the COW filesystem. The COW filesystem allows each layer to be stored separately, which maximizes sharing for layered images. Container engines often support multiple types of container storage, including `overlay`, `devicemapper`, `btrfs`, `aufs`, and `zfs`.
|
||||
|
||||
|
||||
After the container engine downloads the container image to container storage, it needs to create aThe runtime configuration combines input from the caller/user along with the content of the container image specification. For example, the caller might want to specify modifications to a running container's security, add additional environment variables, or mount volumes to the container.
|
||||
|
||||
The layout of the container runtime configuration and the exploded rootfs have also been standardized by the OCI standards body as the [OCI Runtime Specification][4].
|
||||
|
||||
Finally, the container engine launches a **container runtime** that reads the container runtime specification; modifies the Linux cgroups, Linux security constraints, and namespaces; and launches the container command to create the container's **PID 1**. At this point, the container engine can relay `stdin`/`stdout` back to the caller and control the container (e.g., stop, start, attach).
|
||||
|
||||
Note that many new container runtimes are being introduced to use different parts of Linux to isolate containers. People can now run containers using KVM separation (think mini virtual machines) or they can use other hypervisor strategies (like intercepting all system calls from processes in containers). Since we have a standard runtime specification, these tools can all be launched by the same container engines. Even Windows can use the OCI Runtime Specification for launching Windows containers.
|
||||
|
||||
At a much higher level are **container orchestrators.** Container orchestrators are tools used to coordinate the execution of containers on multiple different nodes. Container orchestrators talk to container engines to manage containers. Orchestrators tell the container engines to start containers and wire their networks together. Orchestrators can monitor the containers and launch additional containers as the load increases.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/sysadmins-guide-containers
|
||||
|
||||
作者:[Daniel J Walsh][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/rhatdan
|
||||
[1]:https://www.redhat.com/en/blog/containers-are-linux
|
||||
[2]:https://www.opencontainers.org/
|
||||
[3]:https://github.com/opencontainers/image-spec/blob/master/spec.md
|
||||
[4]:https://github.com/opencontainers/runtime-spec
|
||||
@ -1,58 +0,0 @@
|
||||
translating by dianbanjiu
|
||||
6 places to host your git repository
|
||||
======
|
||||
|
||||

|
||||
|
||||
Perhaps you're one of the few people who didn't notice, but a few months back, [Microsoft bought GitHub][1]. Nothing against either company. Microsoft has become a vocal supporter of open source in recent years, and GitHub has been the de facto code repository for a heaping large number of open source projects almost since its inception.
|
||||
|
||||
However, the recent(-ish) purchase may have gotten you a little itchy. After all, there's nothing quite like a corporate buy-out to make you realize you've had your open source code sitting on a commercial platform. Maybe you're not quite ready to jump ship just yet, but it would at least be helpful to know your options. Let's have a look around the web and see what's available.
|
||||
|
||||
### Option 1: GitHub
|
||||
|
||||
Seriously, this is a valid option. [GitHub][2] doesn't have a history of acting in bad faith, and Microsoft certainly has been smiling on open source of late. There's nothing wrong with keeping your project on GitHub and taking a wait-and-see perspective. It's still the largest community website for software development, and it still has some of the best tools for issue tracking, code review, continuous integration, and general code management. And its underpinnings are still on Git, everyone's favorite open source distributed version control system. Your code is still your code. There's nothing wrong with leaving things where they are if nothing is broken.
|
||||
|
||||
### Option 2: GitLab
|
||||
|
||||
[GitLab][3] is probably the leading contender when it comes to alternative code platforms. It's fully open source. You can host your code right on GitLab's site much like you would on GitHub, but you can also choose to self-host a GitLab instance of your own on your own server and have full control over who has access to everything there and how things are managed. GitLab pretty much has feature parity with GitHub, and some folks might even say its continuous integration and testing tools are superior. Although the community of developers on GitLab is certainly smaller than the one on GitHub, it's still nothing to sneeze at. And it's possible that you'll find more like-minded developers among the population there.
|
||||
|
||||
### Option 3: Bitbucket
|
||||
|
||||
[Bitbucket][4] has been around for many years. In some ways, it could serve as a looking glass into the future of GitHub. Bitbucket was acquired by a larger corporation (Atlassian) eight years ago and has already been through some of that change-over process. It's still a commercial platform like GitHub, but it's far from being a startup, and it's on pretty stable footing, organizationally speaking. Bitbucket shares most of the features available on GitHub and GitLab, plus a few novel features of its own, like native support for [Mercurial][5] repositories.
|
||||
|
||||
### Option 4: SourceForge
|
||||
|
||||
The granddaddy of open source code repository sites is [SourceForge][6]. It used to be that if you had an open source project, SourceForge was the place to host your code and share your releases. It took a little while to migrate to Git for version control, and it had its own rash of commercial acquiring and re-acquiring events, coupled with a few unfortunate bundling decisions for a few open source projects. That said, SourceForge seems to have recovered since then, and the site is still a place where quite a few open source projects live. A lot of folks still feel a bit burned, though, and some people aren't huge fans of its various attempts to monetize the platform, so be sure you go in with open eyes.
|
||||
|
||||
### Option 5: Roll your own
|
||||
|
||||
If you want full control of your project's destiny (and no one to blame but yourself), then doing it all yourself may be the best option for you. It is a good alternative for both large and small projects. Git is open source, so it's easily self-hosted. If you want issue tracking and code review, you can run an instance of GitLab or [Phabricator][7]. For continuous integration, you can set up your own instance of the [Jenkins][8] automation server. Yes, you'll need to take responsibility for your own infrastructure overhead and the associated security requirements. However, it's not that hard to get yourself set up. And if you want a sure-fire way to avoid being beholden to the whims of anyone else's platform, this is the way to do it.
|
||||
|
||||
### Option 6: All of the above
|
||||
|
||||
Here's the beauty of all of this: Despite the proprietary drapery strewn over some of these platforms, they're still built on top of solid open source technology. And not just open source, but explicitly designed to be distributed across multiple nodes on a large network (like the internet). You're not required to use just one. You can use a couple… or all of them. Roll your own setup as a guaranteed home base using GitLab and have clone repositories on GitHub and Bitbucket for issue tracking and continuous integration. Keep your main codebase on GitHub but have "backup" clones sitting on GitLab for your own piece of mind.
|
||||
|
||||
The key thing is you have options. And we have those options thanks to open source licensing on very useful and powerful projects. The future is bright.
|
||||
|
||||
Of course, I'm bound to have missed some of the open source options available out there. Feel free to pipe up with your favorites. Are you using multiple platforms? What's your setup? Let everyone know in the comments!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/github-alternatives
|
||||
|
||||
作者:[Jason van Gumster][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mairin
|
||||
[1]: https://www.theverge.com/2018/6/4/17422788/microsoft-github-acquisition-official-deal
|
||||
[2]: https://github.com/
|
||||
[3]: https://gitlab.com
|
||||
[4]: https://bitbucket.org
|
||||
[5]: https://www.mercurial-scm.org/wiki/Repository
|
||||
[6]: https://sourceforge.net
|
||||
[7]: https://phacility.com/phabricator/
|
||||
[8]: https://jenkins.io
|
||||
@ -1,3 +1,4 @@
|
||||
FSSlc Translating
|
||||
Flameshot – A Simple, Yet Powerful Feature-rich Screenshot Tool
|
||||
======
|
||||
|
||||
|
||||
@ -0,0 +1,75 @@
|
||||
qhwdw is translating
|
||||
|
||||
|
||||
Greg Kroah-Hartman Explains How the Kernel Community Is Securing Linux
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
Kernel maintainer Greg Kroah-Hartman talks about how the kernel community is hardening Linux against vulnerabilities.[Creative Commons Zero][2]
|
||||
|
||||
As Linux adoption expands, it’s increasingly important for the kernel community to improve the security of the world’s most widely used technology. Security is vital not only for enterprise customers, it’s also important for consumers, as 80 percent of mobile devices are powered by Linux. In this article, Linux kernel maintainer Greg Kroah-Hartman provides a glimpse into how the kernel community deals with vulnerabilities.
|
||||
|
||||
### There will be bugs
|
||||
|
||||
|
||||

|
||||
|
||||
Greg Kroah-Hartman[The Linux Foundation][1]
|
||||
|
||||
As Linus Torvalds once said, most security holes are bugs, and bugs are part of the software development process. As long as the software is being written, there will be bugs.
|
||||
|
||||
“A bug is a bug. We don’t know if a bug is a security bug or not. There is a famous bug that I fixed and then three years later Red Hat realized it was a security hole,” said Kroah-Hartman.
|
||||
|
||||
There is not much the kernel community can do to eliminate bugs, but it can do more testing to find them. The kernel community now has its own security team that’s made up of kernel developers who know the core of the kernel.
|
||||
|
||||
“When we get a report, we involve the domain owner to fix the issue. In some cases it’s the same people, so we made them part of the security team to speed things up,” Kroah Hartman said. But he also stressed that all parts of the kernel have to be aware of these security issues because kernel is a trusted environment and they have to protect it.
|
||||
|
||||
“Once we fix things, we can put them in our stack analysis rules so that they are never reintroduced,” he said.
|
||||
|
||||
Besides fixing bugs, the community also continues to add hardening to the kernel. “We have realized that we need to have mitigations. We need hardening,” said Kroah-Hartman.
|
||||
|
||||
Huge efforts have been made by Kees Cook and others to take the hardening features that have been traditionally outside of the kernel and merge or adapt them for the kernel. With every kernel released, Cook provides a summary of all the new hardening features. But hardening the kernel is not enough, vendors have to enable the new features and take advantage of them. That’s not happening.
|
||||
|
||||
Kroah-Hartman [releases a stable kernel every week][5], and companies pick one to support for a longer period so that device manufacturers can take advantage of it. However, Kroah-Hartman has observed that, aside from the Google Pixel, most Android phones don’t include the additional hardening features, meaning all those phones are vulnerable. “People need to enable this stuff,” he said.
|
||||
|
||||
“I went out and bought all the top of the line phones based on kernel 4.4 to see which one actually updated. I found only one company that updated their kernel,” he said. “I'm working through the whole supply chain trying to solve that problem because it's a tough problem. There are many different groups involved -- the SoC manufacturers, the carriers, and so on. The point is that they have to push the kernel that we create out to people.”
|
||||
|
||||
The good news is that unlike with consumer electronics, the big vendors like Red Hat and SUSE keep the kernel updated even in the enterprise environment. Modern systems with containers, pods, and virtualization make this even easier. It’s effortless to update and reboot with no downtime. It is, in fact, easier to keep things secure than it used to be.
|
||||
|
||||
### Meltdown and Spectre
|
||||
|
||||
No security discussion is complete without the mention of Meltdown and Spectre. The kernel community is still working on fixes as new flaws are discovered. However, Intel has changed its approach in light of these events.
|
||||
|
||||
“They are reworking on how they approach security bugs and how they work with the community because they know they did it wrong,” Kroah-Hartman said. “The kernel has fixes for almost all of the big Spectre issues, but there is going to be a long tail of minor things.”
|
||||
|
||||
The good news is that these Intel vulnerabilities proved that things are getting better for the kernel community. “We are doing more testing. With the latest round of security patches, we worked on our own for four months before releasing them to the world because we were embargoed. But once they hit the real world, it made us realize how much we rely on the infrastructure we have built over the years to do this kind of testing, which ensures that we don’t have bugs before they hit other people,” he said. “So things are certainly getting better.”
|
||||
|
||||
The increasing focus on security is also creating more job opportunities for talented people. Since security is an area that gets eyeballs, those who want to build a career in kernel space, security is a good place to get started with.
|
||||
|
||||
“If there are people who want a job to do this type of work, we have plenty of companies who would love to hire them. I know some people who have started off fixing bugs and then got hired,” Kroah-Hartman said.
|
||||
|
||||
You can hear more in the video below:
|
||||
|
||||
[视频](https://youtu.be/jkGVabyMh1I)
|
||||
|
||||
_Check out the schedule of talks for Open Source Summit Europe and sign up to receive updates:_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2018/10/greg-kroah-hartman-explains-how-kernel-community-securing-linux-0
|
||||
|
||||
作者:[SWAPNIL BHARTIYA][a]
|
||||
选题:[oska874][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/arnieswap
|
||||
[b]:https://github.com/oska874
|
||||
[1]:https://www.linux.com/licenses/category/linux-foundation
|
||||
[2]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[3]:https://www.linux.com/files/images/greg-k-hpng
|
||||
[4]:https://www.linux.com/files/images/kernel-securityjpg-0
|
||||
[5]:https://www.kernel.org/category/releases.html
|
||||
@ -0,0 +1,126 @@
|
||||
qhwdw is translating
|
||||
|
||||
LinuxBoot for Servers: Enter Open Source, Goodbye Proprietary UEFI
|
||||
============================================================
|
||||
|
||||
[LinuxBoot][13] is an Open Source [alternative][14] to Proprietary [UEFI][15] firmware. It was released last year and is now being increasingly preferred by leading hardware manufacturers as default firmware. Last year, LinuxBoot was warmly [welcomed][16]into the Open Source family by The Linux Foundation.
|
||||
|
||||
This project was an initiative by Ron Minnich, author of LinuxBIOS and lead of [coreboot][17] at Google, in January 2017.
|
||||
|
||||
Google, Facebook, [Horizon Computing Solutions][18], and [Two Sigma][19] collaborated together to develop the [LinuxBoot project][20] (formerly called [NERF][21]) for server machines based on Linux.
|
||||
|
||||
Its openness allows Server users to easily customize their own boot scripts, fix issues, build their own [runtimes][22] and [reflash their firmware][23] with their own keys. They do not need to wait for vendor updates.
|
||||
|
||||
Following is a video of [Ubuntu Xenial][24] booting for the first time with NERF BIOS:
|
||||
|
||||
[视频](https://youtu.be/HBkZAN3xkJg)
|
||||
|
||||
Let’s talk about some other advantages by comparing it to UEFI in terms of Server hardware.
|
||||
|
||||
### Advantages of LinuxBoot over UEFI
|
||||
|
||||

|
||||
|
||||
Here are some of the major advantages of LinuxBoot over UEFI:
|
||||
|
||||
### Significantly faster startup
|
||||
|
||||
It can boot up Server boards in less than twenty seconds, versus multiple minutes on UEFI.
|
||||
|
||||
### Significantly more flexible
|
||||
|
||||
LinuxBoot can make use of any devices, filesystems and protocols that Linux supports.
|
||||
|
||||
### Potentially more secure
|
||||
|
||||
Linux device drivers and filesystems have significantly more scrutiny than through UEFI.
|
||||
|
||||
We can argue that UEFI is partly open with [EDK II][25] and LinuxBoot is partly closed. But it has been [addressed][26] that even such EDK II code does not have the proper level of inspection and correctness as the [Linux Kernel][27] goes through, while there is a huge amount of other Closed Source components within UEFI development.
|
||||
|
||||
On the other hand, LinuxBoot has a significantly smaller amount of binaries with only a few hundred KB, compared to the 32 MB of UEFI binaries.
|
||||
|
||||
To be precise, LinuxBoot fits a whole lot better into the [Trusted Computing Base][28], unlike UEFI.
|
||||
|
||||
[Suggested readBest Free and Open Source Alternatives to Adobe Products for Linux][29]
|
||||
|
||||
LinuxBoot has a [kexec][30] based bootloader which does not support startup on Windows/non-Linux kernels, but that is insignificant since most clouds are Linux-based Servers.
|
||||
|
||||
### LinuxBoot adoption
|
||||
|
||||
In 2011, the [Open Compute Project][31] was started by [Facebook][32] who [open-sourced][33] designs of some of their Servers, built to make its data centers more efficient. LinuxBoot has been tested on a few Open Compute Hardware listed as under:
|
||||
|
||||
* Winterfell
|
||||
|
||||
* Leopard
|
||||
|
||||
* Tioga Pass
|
||||
|
||||
More [OCP][34] hardware are described [here][35] in brief. The OCP Foundation runs a dedicated project on firmware through [Open System Firmware][36].
|
||||
|
||||
Some other devices that support LinuxBoot are:
|
||||
|
||||
* [QEMU][9] emulated [Q35][10] systems
|
||||
|
||||
* [Intel S2600wf][11]
|
||||
|
||||
* [Dell R630][12]
|
||||
|
||||
Last month end, [Equus Compute Solutions][37] [announced][38] the release of its [WHITEBOX OPEN™][39] M2660 and M2760 Servers, as a part of their custom, cost-optimized Open-Hardware Servers and storage platforms. Both of them support LinuxBoot to customize the Server BIOS for flexibility, improved security, and create a blazingly fast booting experience.
|
||||
|
||||
### What do you think of LinuxBoot?
|
||||
|
||||
LinuxBoot is quite well documented [on GitHub][40]. Do you like the features that set it apart from UEFI? Would you prefer using LinuxBoot rather than UEFI for starting up Servers, owing to the former’s open-ended development and future? Let us know in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/linuxboot-uefi/
|
||||
|
||||
作者:[ Avimanyu Bandyopadhyay][a]
|
||||
选题:[oska874][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/avimanyu/
|
||||
[b]:https://github.com/oska874
|
||||
[1]:https://itsfoss.com/linuxboot-uefi/#
|
||||
[2]:https://itsfoss.com/linuxboot-uefi/#
|
||||
[3]:https://itsfoss.com/linuxboot-uefi/#
|
||||
[4]:https://itsfoss.com/linuxboot-uefi/#
|
||||
[5]:https://itsfoss.com/linuxboot-uefi/#
|
||||
[6]:https://itsfoss.com/linuxboot-uefi/#
|
||||
[7]:https://itsfoss.com/author/avimanyu/
|
||||
[8]:https://itsfoss.com/linuxboot-uefi/#comments
|
||||
[9]:https://en.wikipedia.org/wiki/QEMU
|
||||
[10]:https://wiki.qemu.org/Features/Q35
|
||||
[11]:https://trmm.net/S2600
|
||||
[12]:https://trmm.net/NERF#Installing_on_a_Dell_R630
|
||||
[13]:https://www.linuxboot.org/
|
||||
[14]:https://www.phoronix.com/scan.php?page=news_item&px=LinuxBoot-OSFC-2018-State
|
||||
[15]:https://itsfoss.com/check-uefi-or-bios/
|
||||
[16]:https://www.linuxfoundation.org/blog/2018/01/system-startup-gets-a-boost-with-new-linuxboot-project/
|
||||
[17]:https://en.wikipedia.org/wiki/Coreboot
|
||||
[18]:http://www.horizon-computing.com/
|
||||
[19]:https://www.twosigma.com/
|
||||
[20]:https://trmm.net/LinuxBoot_34c3
|
||||
[21]:https://trmm.net/NERF
|
||||
[22]:https://trmm.net/LinuxBoot_34c3#Runtimes
|
||||
[23]:http://www.tech-faq.com/flashing-firmware.html
|
||||
[24]:https://itsfoss.com/features-ubuntu-1604/
|
||||
[25]:https://www.tianocore.org/
|
||||
[26]:https://media.ccc.de/v/34c3-9056-bringing_linux_back_to_server_boot_roms_with_nerf_and_heads
|
||||
[27]:https://medium.com/@bhumikagoyal/linux-kernel-development-cycle-52b4c55be06e
|
||||
[28]:https://en.wikipedia.org/wiki/Trusted_computing_base
|
||||
[29]:https://itsfoss.com/adobe-alternatives-linux/
|
||||
[30]:https://en.wikipedia.org/wiki/Kexec
|
||||
[31]:https://en.wikipedia.org/wiki/Open_Compute_Project
|
||||
[32]:https://github.com/facebook
|
||||
[33]:https://github.com/opencomputeproject
|
||||
[34]:https://www.networkworld.com/article/3266293/lan-wan/what-is-the-open-compute-project.html
|
||||
[35]:http://hyperscaleit.com/ocp-server-hardware/
|
||||
[36]:https://www.opencompute.org/projects/open-system-firmware
|
||||
[37]:https://www.equuscs.com/
|
||||
[38]:http://www.dcvelocity.com/products/Software_-_Systems/20180924-equus-compute-solutions-introduces-whitebox-open-m2660-and-m2760-servers/
|
||||
[39]:https://www.equuscs.com/servers/whitebox-open/
|
||||
[40]:https://github.com/linuxboot/linuxboot
|
||||
@ -1,60 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Happy birthday, KDE: 11 applications you never knew existed
|
||||
======
|
||||
Which fun or quirky app do you need today?
|
||||
|
||||
|
||||
The Linux desktop environment KDE celebrates its 22nd anniversary on October 14 this year. There are a gazillion* applications created by the KDE community of users, many of which provide fun and quirky services. We perused the list and picked out 11 applications you might like to know exist.
|
||||
|
||||
*Not really, but [there are a lot][1].
|
||||
|
||||
### 11 KDE applications you never knew existed
|
||||
|
||||
1\. [KTeaTime][2] is a timer for steeping tea. Set it by choosing the type of tea you are drinking—green, black, herbal, etc.—and the timer will ding when it's ready to remove the tea bag and drink.
|
||||
|
||||
2\. [KTux][3] is just a screensaver... or is it? Tux is flying in outer space in his green spaceship.
|
||||
|
||||
3\. [Blinken][4] is a memory game based on Simon Says, an electronic game released in 1978. Players are challenged to remember sequences of increasing length.
|
||||
|
||||
4\. [Tellico][5] is a collection manager for organizing your favorite hobby. Maybe you still collect baseball cards. Maybe you're part of a wine club. Maybe you're a serious bookworm. Maybe all three!
|
||||
|
||||
5\. [KRecipes][6] is **not** a simple recipe manager. It's got a lot going on! Shopping lists, nutrient analysis, advanced search, recipe ratings, import/export various formats, and more.
|
||||
|
||||
6\. [KHangMan][7] is based on the classic game Hangman where you guess the word letter by letter. This game is available in several languages, and it can be used to improve your learning of another language. It has four categories, one of which is "animals" which is great for kids.
|
||||
|
||||
7\. [KLettres][8] is another app that may help you learn a new language. It teaches the alphabet and challenges the user to read and pronounce syllables.
|
||||
|
||||
8\. [KDiamond][9] is similar to Bejeweled or other single player puzzle games where the goal of the game is to build lines of a certain number of the same type of jewel or object. In this case, diamonds.
|
||||
|
||||
9\. [KolourPaint][10] is a very simple editing tool for your images or app for creating simple vectors.
|
||||
|
||||
10\. [Kiriki][11] is a dice game for 2-6 players similar to Yahtzee.
|
||||
|
||||
11\. [RSIBreak][12] doesn't start with a K. What!? It starts with an "RSI" for "Repetitive Strain Injury," which can occur from working for long hours, day in and day out, with a mouse and keyboard. This app reminds you to take breaks and can be personalized to meet your needs.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/kde-applications
|
||||
|
||||
作者:[Opensource.com][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.kde.org/applications/
|
||||
[2]: https://www.kde.org/applications/games/kteatime/
|
||||
[3]: https://userbase.kde.org/KTux
|
||||
[4]: https://www.kde.org/applications/education/blinken
|
||||
[5]: http://tellico-project.org/
|
||||
[6]: https://www.kde.org/applications/utilities/krecipes/
|
||||
[7]: https://edu.kde.org/khangman/
|
||||
[8]: https://edu.kde.org/klettres/
|
||||
[9]: https://games.kde.org/game.php?game=kdiamond
|
||||
[10]: https://www.kde.org/applications/graphics/kolourpaint/
|
||||
[11]: https://www.kde.org/applications/games/kiriki/
|
||||
[12]: https://userbase.kde.org/RSIBreak
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
How To Lock Virtual Console Sessions On Linux
|
||||
======
|
||||
|
||||
|
||||
@ -0,0 +1,176 @@
|
||||
How To Determine Which System Manager Is Running On Linux System
|
||||
======
|
||||
We all are heard about this word many times but only few of us know what is this exactly. We will show you how to identify the system manager.
|
||||
|
||||
I will try my best to let you know about this. Most of us know about System V and systemd system manager. System V (Sysv) is an old and traditional init system and system manager for old systems.
|
||||
|
||||
Systemd is a new init system and system manager which was adapted by most of the major distribution.
|
||||
|
||||
There are three major init systems are available in Linux which are very famous and still in use. Most of the Linux distribution falls under in one of the below init system.
|
||||
|
||||
### What is init System Manager?
|
||||
|
||||
In Linux/Unix based operating systems, init (short for initialization) is the first process that started during the system boot up by the kernel.
|
||||
|
||||
It’s holding a process id (PID) of 1. It will be running in the background continuously until the system is shut down.
|
||||
|
||||
Init looks at the `/etc/inittab` file to decide the Linux run level then it starts all other processes & applications in the background as per the run level.
|
||||
|
||||
BIOS, MBR, GRUB and Kernel processes were kicked up before hitting init process as part of Linux booting process.
|
||||
|
||||
Below are the available run levels for Linux (There are seven runlevels exist, from zero to six).
|
||||
|
||||
* **`0:`** halt
|
||||
* **`1:`** Single user mode
|
||||
* **`2:`** Multiuser, without NFS
|
||||
* **`3:`** Full multiuser mode
|
||||
* **`4:`** Unused
|
||||
* **`5:`** X11 (GUI – Graphical User Interface)
|
||||
* **`:`** reboot
|
||||
|
||||
|
||||
|
||||
Below three init systems are widely used in Linux.
|
||||
|
||||
* **`System V (Sys V):`** System V (Sys V) is one of the first and traditional init system for Unix like operating system.
|
||||
* **`Upstart:`** Upstart is an event-based replacement for the /sbin/init daemon.
|
||||
* **`systemd:`** Systemd is a new init system and system manager which was implemented/adapted into all the major Linux distributions over the traditional SysV init systems.
|
||||
|
||||
|
||||
|
||||
### What is System V (Sys V)?
|
||||
|
||||
System V (Sys V) is one of the first and traditional init system for Unix like operating system. init is the first process that started during the system boot up by the kernel and it’s a parent process for everything.
|
||||
|
||||
Most of the Linux distributions started using traditional init system called System V (Sys V) first. Over the years, several replacement init systems were released to address design limitations in the standard versions such as launchd, the Service Management Facility, systemd and Upstart.
|
||||
|
||||
But systemd has been adopted by several major Linux distributions over the traditional SysV init systems.
|
||||
|
||||
### How to identify the System V (Sys V) system manager on Linux
|
||||
|
||||
Run the following commands to identify that your system is running with System V (Sys V) system manager.
|
||||
|
||||
### Method-1: Using ps command
|
||||
|
||||
ps – report a snapshot of the current processes. ps displays information about a selection of the active processes.
|
||||
This output doesn’t give the exact results either System V (SysV) or upstart so, i would suggest you to go with other method to confirm this.
|
||||
|
||||
```
|
||||
# ps -p1 | grep "init\|upstart\|systemd"
|
||||
1 ? 00:00:00 init
|
||||
```
|
||||
|
||||
### Method-2: Using rpm command
|
||||
|
||||
RPM stands for `Red Hat Package Manager` is a powerful, command line [Package Management][1] utility for Red Hat based system such as (RHEL, CentOS, Fedora, openSUSE & Mageia) distributions. The utility allow you to install, upgrade, remove, query & verify the software on your Linux system/server. RPM files comes with `.rpm` extension.
|
||||
RPM package built with required libraries and dependency which will not conflicts other packages were installed on your system.
|
||||
|
||||
```
|
||||
# rpm -qf /sbin/init
|
||||
SysVinit-2.86-17.el5
|
||||
```
|
||||
|
||||
### What is Upstart?
|
||||
|
||||
Upstart is an event-based replacement for the /sbin/init daemon which handles starting of tasks and services during boot, stopping them during shutdown and supervising them while the system is running.
|
||||
|
||||
It was originally developed for the Ubuntu distribution, but is intended to be suitable for deployment in all Linux distributions as a replacement for the venerable System-V init.
|
||||
|
||||
It was used in Ubuntu from 9.10 to Ubuntu 14.10 & RHEL 6 based systems after that they are replaced with systemd.
|
||||
|
||||
### How to identify the Upstart system manager on Linux
|
||||
|
||||
Run the following commands to identify that your system is running with Upstart system manager.
|
||||
|
||||
### Method-1: Using ps command
|
||||
|
||||
ps – report a snapshot of the current processes. ps displays information about a selection of the active processes.
|
||||
This output doesn’t give the exact results either System V (SysV) or upstart so, i would suggest you to go with other method to confirm this.
|
||||
|
||||
```
|
||||
# ps -p1 | grep "init\|upstart\|systemd"
|
||||
1 ? 00:00:00 init
|
||||
```
|
||||
|
||||
### Method-2: Using rpm command
|
||||
|
||||
RPM stands for `Red Hat Package Manager` is a powerful, command line Package Management utility for Red Hat based system such as (RHEL, CentOS, Fedora, openSUSE & Mageia) distributions. The [RPM Command][2] allow you to install, upgrade, remove, query & verify the software on your Linux system/server. RPM files comes with `.rpm` extension.
|
||||
RPM package built with required libraries and dependency which will not conflicts other packages were installed on your system.
|
||||
|
||||
```
|
||||
# rpm -qf /sbin/init
|
||||
upstart-0.6.5-16.el6.x86_64
|
||||
```
|
||||
|
||||
### Method-3: Using /sbin/init file
|
||||
|
||||
The `/sbin/init` program will load or switch the root file system from memory to the hard disk.
|
||||
This is the main part of the boot process. The runlevel at the start of this process is “N” (none). The /sbin/init program initializes the system following the description in the /etc/inittab configuration file.
|
||||
|
||||
```
|
||||
# /sbin/init --version
|
||||
init (upstart 0.6.5)
|
||||
Copyright (C) 2010 Canonical Ltd.
|
||||
|
||||
This is free software; see the source for copying conditions. There is NO warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
|
||||
```
|
||||
|
||||
### What is systemd?
|
||||
|
||||
Systemd is a new init system and system manager which was implemented/adapted into all the major Linux distributions over the traditional SysV init systems.
|
||||
|
||||
systemd is compatible with SysV and LSB init scripts. It can work as a drop-in replacement for sysvinit system. systemd is the first process get started by kernel and holding PID 1.
|
||||
|
||||
It’s a parant process for everything and Fedora 15 is the first distribution which was adapted systemd instead of upstart. [systemctl][3] is command line utility and primary tool to manage the systemd daemons/services such as (start, restart, stop, enable, disable, reload & status).
|
||||
|
||||
systemd uses .service files Instead of bash scripts (SysVinit uses). systemd sorts all daemons into their own Linux cgroups and you can see the system hierarchy by exploring `/cgroup/systemd` file.
|
||||
|
||||
### How to identify the systemd system manager on Linux
|
||||
|
||||
Run the following commands to identify that your system is running with systemd system manager.
|
||||
|
||||
### Method-1: Using ps command
|
||||
|
||||
ps – report a snapshot of the current processes. ps displays information about a selection of the active processes.
|
||||
|
||||
```
|
||||
# ps -p1 | grep "init\|upstart\|systemd"
|
||||
1 ? 00:18:09 systemd
|
||||
```
|
||||
|
||||
### Method-2: Using rpm command
|
||||
|
||||
RPM stands for `Red Hat Package Manager` is a powerful, command line Package Management utility for Red Hat based system such as (RHEL, CentOS, Fedora, openSUSE & Mageia) distributions. The utility allow you to install, upgrade, remove, query & verify the software on your Linux system/server. RPM files comes with `.rpm` extension.
|
||||
RPM package built with required libraries and dependency which will not conflicts other packages were installed on your system.
|
||||
|
||||
```
|
||||
# rpm -qf /sbin/init
|
||||
systemd-219-30.el7_3.9.x86_64
|
||||
```
|
||||
|
||||
### Method-3: Using /sbin/init file
|
||||
|
||||
The `/sbin/init` program will load or switch the root file system from memory to the hard disk.
|
||||
This is the main part of the boot process. The runlevel at the start of this process is “N” (none). The /sbin/init program initializes the system following the description in the /etc/inittab configuration file.
|
||||
|
||||
```
|
||||
# file /sbin/init
|
||||
/sbin/init: symbolic link to `../lib/systemd/systemd'
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-determine-which-init-system-manager-is-running-on-linux-system/
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/prakash/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/category/package-management/
|
||||
[2]: https://www.2daygeek.com/rpm-command-examples/
|
||||
[3]: https://www.2daygeek.com/how-to-check-all-running-services-in-linux/
|
||||
133
sources/tech/20181018 Understanding Linux Links- Part 1.md
Normal file
133
sources/tech/20181018 Understanding Linux Links- Part 1.md
Normal file
@ -0,0 +1,133 @@
|
||||
Understanding Linux Links: Part 1
|
||||
======
|
||||
|
||||

|
||||
|
||||
Along with `cp` and `mv`, both of which we talked about at length in [the previous installment of this series][1], links are another way of putting files and directories where you want them to be. The advantage is that links let you have one file or directory show up in several places at the same time.
|
||||
|
||||
As noted previously, at the physical disk level, things like files and directories don't really exist. A filesystem conjures them up for our human convenience. But at the disk level, there is something called a _partition table_ , which lives at the beginning of every partition, and then the data scattered over the rest of the disk.
|
||||
|
||||
Although there are different types of partition tables, the ones at the beginning of a partition containing your data will map where each directory and file starts and ends. The partition table acts like an index: When you load a file from your disk, your operating system looks up the entry on the table and the table says where the file starts on the disk and where it finishes. The disk header moves to the start point, reads the data until it reaches the end point and, hey presto: here's your file.
|
||||
|
||||
### Hard Links
|
||||
|
||||
A hard link is simply an entry in the partition table that points to an area on a disk that **has already been assigned to a file**. In other words, a hard link points to data that has already been indexed by another entry. Let's see how this works.
|
||||
|
||||
Open a terminal, create a directory for tests and move into it:
|
||||
|
||||
```
|
||||
mkdir test_dir
|
||||
cd test_dir
|
||||
```
|
||||
|
||||
Create a file by [touching][1] it:
|
||||
|
||||
```
|
||||
touch test.txt
|
||||
```
|
||||
|
||||
For extra excitement (?), open _test.txt_ in a text editor and add some a few words into it.
|
||||
|
||||
Now make a hard link by executing:
|
||||
|
||||
```
|
||||
ln test.txt hardlink_test.txt
|
||||
```
|
||||
|
||||
Run `ls`, and you'll see your directory now contains two files... Or so it would seem. As you read before, really what you are seeing is two names for the exact same file: _hardlink_test.txt_ contains the same content, has not filled any more space in the disk (try with a large file to test this), and shares the same inode as _test.txt_ :
|
||||
|
||||
```
|
||||
$ ls -li *test*
|
||||
16515846 -rw-r--r-- 2 paul paul 14 oct 12 09:50 hardlink_test.txt
|
||||
16515846 -rw-r--r-- 2 paul paul 14 oct 12 09:50 test.txt
|
||||
```
|
||||
|
||||
_ls_ 's `-i` option shows the _inode number_ of a file. The _inode_ is the chunk of information in the partition table that contains the location of the file or directory on the disk, the last time it was modified, and other data. If two files share the same inode, they are, to all practical effects, the same file, regardless of where they are located in the directory tree.
|
||||
|
||||
### Fluffy Links
|
||||
|
||||
Soft links, also known as _symlinks_ , are different: a soft link is really an independent file, it has its own inode and its own little slot on the disk. But it only contains a snippet of data that points the operating system to another file or directory.
|
||||
|
||||
You can create a soft link using `ln` with the `-s` option:
|
||||
|
||||
```
|
||||
ln -s test.txt softlink_test.txt
|
||||
```
|
||||
|
||||
This will create the soft link _softlink_test.txt_ to _test.txt_ in the current directory.
|
||||
|
||||
By running `ls -li` again, you can see the difference between the two different kinds of links:
|
||||
|
||||
```
|
||||
$ ls -li
|
||||
total 8
|
||||
16515846 -rw-r--r-- 2 paul paul 14 oct 12 09:50 hardlink_test.txt
|
||||
16515855 lrwxrwxrwx 1 paul paul 8 oct 12 09:50 softlink_test.txt -> test.txt
|
||||
16515846 -rw-r--r-- 2 paul paul 14 oct 12 09:50 test.txt
|
||||
```
|
||||
|
||||
_hardlink_test.txt_ and _test.txt_ contain some text and take up the same space *literally*. They also share the same inode number. Meanwhile, _softlink_test.txt_ occupies much less and has a different inode number, marking it as a different file altogether. Using the _ls_ 's `-l` option also shows the file or directory your soft link points to.
|
||||
|
||||
### Why Use Links?
|
||||
|
||||
They are good for **applications that come with their own environment**. It often happens that your Linux distro does not come with the latest version of an application you need. Take the case of the fabulous [Blender 3D][2] design software. Blender allows you to create 3D still images as well as animated films and who wouldn't to have that on their machine? The problem is that the current version of Blender is always at least one version ahead of that found in any distribution.
|
||||
|
||||
Fortunately, [Blender provides downloads][3] that run out of the box. These packages come, apart from with the program itself, a complex framework of libraries and dependencies that Blender needs to work. All these bits and piece come within their own hierarchy of directories.
|
||||
|
||||
Every time you want to run Blender, you could `cd` into the folder you downloaded it to and run:
|
||||
|
||||
```
|
||||
./blender
|
||||
```
|
||||
|
||||
But that is inconvenient. It would be better if you could run the `blender` command from anywhere in your file system, as well as from your desktop command launchers.
|
||||
|
||||
The way to do that is to link the _blender_ executable into a _bin/_ directory. On many systems, you can make the `blender` command available from anywhere in the file system by linking to it like this:
|
||||
|
||||
```
|
||||
ln -s /path/to/blender_directory/blender /home/<username>/bin
|
||||
```
|
||||
|
||||
Another case in which you will need links is for **software that needs outdated libraries**. If you list your _/usr/lib_ directory with `ls -l,` you will see a lot of soft-linked files fly by. Take a closer look, and you will see that the links usually have similar names to the original files they are linking to. You may see _libblah_ linking to _libblah.so.2_ , and then, you may even notice that _libblah.so.2_ links in turn to _libblah.so.2.1.0_ , the original file.
|
||||
|
||||
This is because applications often require older versions of alibrary than what is installed. The problem is that, even if the more modern versions are still compatible with the older versions (and usually they are), the program will bork if it doesn't find the version it is looking for. To solve this problem distributions often create links so that the picky application believes it has found the older version, when, in reality, it has only found a link and ends up using the more up to date version of the library.
|
||||
|
||||
Somewhat related is what happens with **programs you compile yourself from the source code**. Programs you compile yourself often end up installed under _/usr/local_ : the program itself ends up in _/usr/local/bin_ and it looks for the libraries it needs _/_ in the _/usr/local/lib_ directory. But say that your new program needs _libblah_ , but _libblah_ lives in _/usr/lib_ and that's where all your other programs look for it. You can link it to _/usr/local/lib_ by doing:
|
||||
|
||||
```
|
||||
ln -s /usr/lib/libblah /usr/local/lib
|
||||
```
|
||||
|
||||
Or, if you prefer, by `cd`ing into _/usr/local/lib_...
|
||||
|
||||
```
|
||||
cd /usr/local/lib
|
||||
```
|
||||
|
||||
... and then linking with:
|
||||
|
||||
```
|
||||
ln -s ../lib/libblah
|
||||
```
|
||||
|
||||
There are dozens more cases in which linking proves useful, and you will undoubtedly discover them as you become more proficient in using Linux, but these are the most common. Next time, we’ll look at some linking quirks you need to be aware of.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][4]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/intro-to-linux/2018/10/linux-links-part-1
|
||||
|
||||
作者:[Paul Brown][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/bro66
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.linux.com/blog/2018/8/linux-beginners-moving-things-around
|
||||
[2]: https://www.blender.org/
|
||||
[3]: https://www.blender.org/download/
|
||||
[4]: https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -0,0 +1,53 @@
|
||||
Edit your videos with Pitivi on Fedora
|
||||
======
|
||||
|
||||

|
||||
Looking to produce a video of your adventures this weekend? There are many different options for editing videos out there. However, if you are looking for a video editor that is simple to pick up, and also available in the official Fedora Repositories, give [Pitivi][1] a go.
|
||||
|
||||
Pitivi is an open source, non-linear video editor that uses the GStreamer framework. Out of the box on Fedora, Pitivi supports OGG Video, WebM, and a range of other formats. Additionally, more support for for video formats is available via gstreamer plugins. Pitivi is also tightly integrated with the GNOME Desktop, so the UI will feel at home among the other newer applications on Fedora Workstation.
|
||||
|
||||
### Installing Pitivi on Fedora
|
||||
|
||||
Pitivi is available in the Fedora Repositories. On Fedora Workstation, simply search and install Pitivi from the Software application.
|
||||
|
||||
![][2]
|
||||
|
||||
Alternatively, install Pitivi using the following command in the Terminal:
|
||||
|
||||
```
|
||||
sudo dnf install pitivi
|
||||
```
|
||||
|
||||
### Basic Editing
|
||||
|
||||
Pitivi has a wide range of tools built-in to allow quick and effective editing of your clips. Simply import videos, audio, and images into the Pitivi media library, then drag them onto the timeline. Additionally, pitivi allows you to easily split, trim, and group parts of clips together, in addition to simple fade transitions on the timeline.
|
||||
|
||||
![][3]
|
||||
|
||||
### Transitions and Effects
|
||||
|
||||
In addition to a basic fade between two clips, Pitivi also features a range of different transitions and wipes. Additionally, there are over a hundred effects that can be applied to either videos or audio to change how the media elements are played or displayed in your final presentation
|
||||
|
||||
![][4]
|
||||
|
||||
Pitivi also features a range of other great features, so be sure to check out the [tour][5] on their website for a full description of the features of the awesome Pitivi.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/edit-your-videos-with-pitivi-on-fedora/
|
||||
|
||||
作者:[Ryan Lerch][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/introducing-flatpak/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://www.pitivi.org/
|
||||
[2]: https://fedoramagazine.org/wp-content/uploads/2018/10/Screenshot-from-2018-10-19-14-46-12.png
|
||||
[3]: https://fedoramagazine.org/wp-content/uploads/2018/10/Screenshot-from-2018-10-19-15-37-29.png
|
||||
[4]: http://www.pitivi.org/i/screenshots/archive/0.94.jpg
|
||||
[5]: http://www.pitivi.org/?go=tour
|
||||
@ -0,0 +1,341 @@
|
||||
How to use Pandoc to produce a research paper
|
||||
======
|
||||
Learn how to manage section references, figures, tables, and more in Markdown.
|
||||
|
||||
|
||||
This article takes a deep dive into how to produce a research paper using (mostly) [Markdown][1] syntax. We'll cover how to create and reference sections, figures (in Markdown and [LaTeX][2]) and bibliographies. We'll also discuss troublesome cases and why writing them in LaTeX is the right approach.
|
||||
|
||||
### Research
|
||||
|
||||
Research papers usually contain references to sections, figures, tables, and a bibliography. [Pandoc][3] by itself cannot easily cross-reference these, but it can leverage the [pandoc-crossref][4] filter to do the automatic numbering and cross-referencing of sections, figures, and tables.
|
||||
|
||||
Let’s start by rewriting [an example of an educational research paper][5] originally written in LaTeX and rewrites it in Markdown (and some LaTeX) with Pandoc and pandoc-crossref.
|
||||
|
||||
#### Adding and referencing sections
|
||||
|
||||
Sections are automatically numbered and must be written using the Markdown heading H1. Subsections are written with subheadings H2-H4 (it is uncommon to need more than that). For example, to write a section titled “Implementation”, write `# Implementation {#sec:implementation}`, and Pandoc produces `3. Implementation` (or the corresponding numbered section). The title “Implementation” uses heading H1 and declares a label `{#sec:implementation}` that authors can use to refer to that section. To reference a section, type the `@` symbol followed by the label of the section and enclose it in square brackets: `[@sec:implementation]`.
|
||||
|
||||
[In this paper][5], we find the following example:
|
||||
|
||||
```
|
||||
we lack experience (consistency between TAs, [@sec:implementation]).
|
||||
```
|
||||
|
||||
Pandoc produces:
|
||||
|
||||
```
|
||||
we lack experience (consistency between TAs, Section 4).
|
||||
```
|
||||
|
||||
Sections are numbered automatically (this is covered in the `Makefile` at the end of the article). To create unnumbered sections, type the title of the section, followed by `{-}`. For example, `### Designing a game for maintainability {-}` creates an unnumbered subsection with the title “Designing a game for maintainability”.
|
||||
|
||||
#### Adding and referencing figures
|
||||
|
||||
Adding and referencing a figure is similar to referencing a section and adding a Markdown image:
|
||||
|
||||
```
|
||||
{#fig:scatter-matrix}
|
||||
```
|
||||
|
||||
The line above tells Pandoc that there is a figure with the caption Scatterplot matrix and the path to the image is `data/scatterplots/RScatterplotMatrix2.png`. `{#fig:scatter-matrix}` declares the name that should be used to reference the figure.
|
||||
|
||||
Here is an example of a figure reference from the example paper:
|
||||
|
||||
```
|
||||
The boxes "Enjoy", "Grade" and "Motivation" ([@fig:scatter-matrix]) ...
|
||||
```
|
||||
|
||||
Pandoc produces the following output:
|
||||
|
||||
```
|
||||
The boxes "Enjoy", "Grade" and "Motivation" (Fig. 1) ...
|
||||
```
|
||||
|
||||
#### Adding and referencing a bibliography
|
||||
|
||||
Most research papers keep references in a BibTeX database file. In this example, this file is named [biblio.bib][6] and it contains all the references of the paper. Here is what this file looks like:
|
||||
|
||||
```
|
||||
@inproceedings{wrigstad2017mastery,
|
||||
Author = {Wrigstad, Tobias and Castegren, Elias},
|
||||
Booktitle = {SPLASH-E},
|
||||
Title = {Mastery Learning-Like Teaching with Achievements},
|
||||
Year = 2017
|
||||
}
|
||||
|
||||
@inproceedings{review-gamification-framework,
|
||||
Author = {A. Mora and D. Riera and C. Gonzalez and J. Arnedo-Moreno},
|
||||
Publisher = {IEEE},
|
||||
Booktitle = {2015 7th International Conference on Games and Virtual Worlds
|
||||
for Serious Applications (VS-Games)},
|
||||
Doi = {10.1109/VS-GAMES.2015.7295760},
|
||||
Keywords = {formal specification;serious games (computing);design
|
||||
framework;formal design process;game components;game design
|
||||
elements;gamification design frameworks;gamification-based
|
||||
solutions;Bibliographies;Context;Design
|
||||
methodology;Ethics;Games;Proposals},
|
||||
Month = {Sept},
|
||||
Pages = {1-8},
|
||||
Title = {A Literature Review of Gamification Design Frameworks},
|
||||
Year = 2015,
|
||||
Bdsk-Url-1 = {http://dx.doi.org/10.1109/VS-GAMES.2015.7295760}
|
||||
}
|
||||
|
||||
...
|
||||
```
|
||||
|
||||
The first line, `@inproceedings{wrigstad2017mastery,`, declares the type of publication (`inproceedings`) and the label used to refer to that paper (`wrigstad2017mastery`).
|
||||
|
||||
To cite the paper with its title, Mastery Learning-Like Teaching with Achievements, type:
|
||||
|
||||
```
|
||||
the achievement-driven learning methodology [@wrigstad2017mastery]
|
||||
```
|
||||
|
||||
Pandoc will output:
|
||||
|
||||
```
|
||||
the achievement- driven learning methodology [30]
|
||||
```
|
||||
|
||||
The paper we will produce includes a bibliography section with numbered references like these:
|
||||
|
||||

|
||||
|
||||
Citing a collection of articles is easy: Simply cite each article, separating the labeled references using a semi-colon: `;`. If there are two labeled references—i.e., `SEABORN201514` and `gamification-leaderboard-benefits`—cite them together, like this:
|
||||
|
||||
```
|
||||
Thus, the most important benefit is its potential to increase students' motivation
|
||||
|
||||
and engagement [@SEABORN201514;@gamification-leaderboard-benefits].
|
||||
```
|
||||
|
||||
Pandoc will produce:
|
||||
|
||||
```
|
||||
Thus, the most important benefit is its potential to increase students’ motivation
|
||||
|
||||
and engagement [26, 28]
|
||||
```
|
||||
|
||||
### Problematic cases
|
||||
|
||||
A common problem involves objects that do not fit in the page. They then float to wherever they fit best, even if that position is not where the reader expects to see it. Since papers are easier to read when figures or tables appear close to where they are mentioned, we need to have some control over where these elements are placed. For this reason, I recommend the use of the `figure` LaTeX environment, which enables users to control the positioning of figures.
|
||||
|
||||
Let’s take the figure example shown above:
|
||||
|
||||
```
|
||||
{#fig:scatter-matrix}
|
||||
```
|
||||
|
||||
And rewrite it in LaTeX:
|
||||
|
||||
```
|
||||
\begin{figure}[t]
|
||||
\includegraphics{data/scatterplots/RScatterplotMatrix2.png}
|
||||
\caption{\label{fig:matrix}Scatterplot matrix}
|
||||
\end{figure}
|
||||
```
|
||||
|
||||
In LaTeX, the `[t]` option in the `figure` environment declares that the image should be placed at the top of the page. For more options, refer to the Wikibooks article [LaTex/Floats, Figures, and Captions][7].
|
||||
|
||||
### Producing the paper
|
||||
|
||||
So far, we've covered how to add and reference (sub-)sections and figures and cite the bibliography—now let's review how to produce the research paper in PDF format. To generate the PDF, we will use Pandoc to generate a LaTeX file that can be compiled to the final PDF. We will also discuss how to generate the research paper in LaTeX using a customized template and a meta-information file, and how to compile the LaTeX document into its final PDF form.
|
||||
|
||||
Most conferences provide a **.cls** file or a template that specifies how papers should look; for example, whether they should use a two-column format and other design treatments. In our example, the conference provided a file named **acmart.cls**.
|
||||
|
||||
Authors are generally expected to include the institution to which they belong in their papers. However, this option was not included in the default Pandoc’s LaTeX template (note that the Pandoc template can be inspected by typing `pandoc -D latex`). To include the affiliation, take the default Pandoc’s LaTeX template and add a new field. The Pandoc template was copied into a file named `mytemplate.tex` as follows:
|
||||
|
||||
```
|
||||
pandoc -D latex > mytemplate.tex
|
||||
```
|
||||
|
||||
The default template contains the following code:
|
||||
|
||||
```
|
||||
$if(author)$
|
||||
\author{$for(author)$$author$$sep$ \and $endfor$}
|
||||
$endif$
|
||||
$if(institute)$
|
||||
\providecommand{\institute}[1]{}
|
||||
\institute{$for(institute)$$institute$$sep$ \and $endfor$}
|
||||
$endif$
|
||||
```
|
||||
|
||||
Because the template should include the author’s affiliation and email address, among other things, we updated it to include these fields (we made other changes as well but did not include them here due to the file length):
|
||||
|
||||
```
|
||||
latex
|
||||
$for(author)$
|
||||
$if(author.name)$
|
||||
\author{$author.name$}
|
||||
$if(author.affiliation)$
|
||||
\affiliation{\institution{$author.affiliation$}}
|
||||
$endif$
|
||||
$if(author.email)$
|
||||
\email{$author.email$}
|
||||
$endif$
|
||||
$else$
|
||||
$author$
|
||||
$endif$
|
||||
$endfor$
|
||||
```
|
||||
|
||||
With these changes in place, we should have the following files:
|
||||
|
||||
* `main.md` contains the research paper
|
||||
* `biblio.bib` contains the bibliographic database
|
||||
* `acmart.cls` is the class of the document that we should use
|
||||
* `mytemplate.tex` is the template file to use (instead of the default)
|
||||
|
||||
|
||||
|
||||
Let’s add the meta-information of the paper in a `meta.yaml`file:
|
||||
|
||||
```
|
||||
---
|
||||
template: 'mytemplate.tex'
|
||||
documentclass: acmart
|
||||
classoption: sigconf
|
||||
title: The impact of opt-in gamification on `\\`{=latex} students' grades in a software design course
|
||||
author:
|
||||
- name: Kiko Fernandez-Reyes
|
||||
affiliation: Uppsala University
|
||||
email: kiko.fernandez@it.uu.se
|
||||
- name: Dave Clarke
|
||||
affiliation: Uppsala University
|
||||
email: dave.clarke@it.uu.se
|
||||
- name: Janina Hornbach
|
||||
affiliation: Uppsala University
|
||||
email: janina.hornbach@fek.uu.se
|
||||
bibliography: biblio.bib
|
||||
abstract: |
|
||||
An achievement-driven methodology strives to give students more control over their learning with enough flexibility to engage them in deeper learning. (more stuff continues)
|
||||
|
||||
include-before: |
|
||||
\```{=latex}
|
||||
\copyrightyear{2018}
|
||||
\acmYear{2018}
|
||||
\setcopyright{acmlicensed}
|
||||
\acmConference[MODELS '18 Companion]{ACM/IEEE 21th International Conference on Model Driven Engineering Languages and Systems}{October 14--19, 2018}{Copenhagen, Denmark}
|
||||
\acmBooktitle{ACM/IEEE 21th International Conference on Model Driven Engineering Languages and Systems (MODELS '18 Companion), October 14--19, 2018, Copenhagen, Denmark}
|
||||
\acmPrice{XX.XX}
|
||||
\acmDOI{10.1145/3270112.3270118}
|
||||
\acmISBN{978-1-4503-5965-8/18/10}
|
||||
|
||||
\begin{CCSXML}
|
||||
<ccs2012>
|
||||
<concept>
|
||||
<concept_id>10010405.10010489</concept_id>
|
||||
<concept_desc>Applied computing~Education</concept_desc>
|
||||
<concept_significance>500</concept_significance>
|
||||
</concept>
|
||||
</ccs2012>
|
||||
\end{CCSXML}
|
||||
|
||||
\ccsdesc[500]{Applied computing~Education}
|
||||
|
||||
\keywords{gamification, education, software design, UML}
|
||||
\```
|
||||
figPrefix:
|
||||
- "Fig."
|
||||
- "Figs."
|
||||
secPrefix:
|
||||
- "Section"
|
||||
- "Sections"
|
||||
...
|
||||
```
|
||||
|
||||
This meta-information file sets the following variables in LaTeX:
|
||||
|
||||
* `template` refers to the template to use (‘mytemplate.tex’)
|
||||
* `documentclass` refers to the LaTeX document class to use (`acmart`)
|
||||
* `classoption` refers to the options of the class, in this case `sigconf`
|
||||
* `title` specifies the title of the paper
|
||||
* `author` is an object that contains other fields, such as `name`, `affiliation`, and `email`.
|
||||
* `bibliography`refers to the file that contains the bibliography (biblio.bib)
|
||||
* `abstract` contains the abstract of the paper
|
||||
* `include-before`is information that should be included before the actual content of the paper; this is known as the [preamble][8] in LaTeX. I have included it here to show how to generate a computer science paper, but you may choose to skip it
|
||||
* `figPrefix` specifies how to refer to figures in the document, i.e., what should be displayed when one refers to the figure `[@fig:scatter-matrix]`. For example, the current `figPrefix` produces in the example `The boxes "Enjoy", "Grade" and "Motivation" ([@fig:scatter-matrix])` this output: `The boxes "Enjoy", "Grade" and "Motivation" (Fig. 3)`. If there are multiple figures, the current setup declares that it should instead display `Figs.` next to the figure numbers.
|
||||
* `secPrefix` specifies how to refer to sections mentioned elsewhere in the document (similar to figures, described above)
|
||||
|
||||
|
||||
|
||||
Now that the meta-information is set, let’s create a `Makefile` that produces the desired output. This `Makefile` uses Pandoc to produce the LaTeX file, `pandoc-crossref` to produce the cross-references, `pdflatex` to compile the LaTeX to PDF, and `bibtex `to process the references.
|
||||
|
||||
The `Makefile` is shown below:
|
||||
|
||||
```
|
||||
all: paper
|
||||
|
||||
paper:
|
||||
@pandoc -s -F pandoc-crossref --natbib meta.yaml --template=mytemplate.tex -N \
|
||||
-f markdown -t latex+raw_tex+tex_math_dollars+citations -o main.tex main.md
|
||||
@pdflatex main.tex &> /dev/null
|
||||
@bibtex main &> /dev/null
|
||||
@pdflatex main.tex &> /dev/null
|
||||
@pdflatex main.tex &> /dev/null
|
||||
|
||||
clean:
|
||||
rm main.aux main.tex main.log main.bbl main.blg main.out
|
||||
|
||||
.PHONY: all clean paper
|
||||
```
|
||||
|
||||
Pandoc uses the following flags:
|
||||
|
||||
* `-s` to create a standalone LaTeX document
|
||||
* `-F pandoc-crossref` to make use of the filter `pandoc-crossref`
|
||||
* `--natbib` to render the bibliography with `natbib` (you can also choose `--biblatex`)
|
||||
* `--template` sets the template file to use
|
||||
* `-N` to number the section headings
|
||||
* `-f` and `-t` specify the conversion from and to which format. `-t` usually contains the format and is followed by the Pandoc extensions used. In the example, we declared `raw_tex+tex_math_dollars+citations` to allow use of `raw_tex` LaTeX in the middle of the Markdown file. `tex_math_dollars` enables us to type math formulas as in LaTeX, and `citations` enables us to use [this extension][9].
|
||||
|
||||
|
||||
|
||||
To generate a PDF from LaTeX, follow the guidelines [from bibtex][10] to process the bibliography:
|
||||
|
||||
```
|
||||
@pdflatex main.tex &> /dev/null
|
||||
@bibtex main &> /dev/null
|
||||
@pdflatex main.tex &> /dev/null
|
||||
@pdflatex main.tex &> /dev/null
|
||||
```
|
||||
|
||||
The script contains `@` to ignore the output, and we redirect the file handle of the standard output and error to `/dev/null`so that we don’t see the output generated from the execution of these commands.
|
||||
|
||||
The final result is shown below. The repository for the article can be found [on GitHub][11]:
|
||||
|
||||

|
||||
|
||||
### Conclusion
|
||||
|
||||
In my opinion, research is all about collaboration, dissemination of ideas, and improving the state of the art in whatever field one happens to be in. Most computer scientists and engineers write papers using the LaTeX document system, which provides excellent support for math. Researchers from the social sciences seem to stick to DOCX documents.
|
||||
|
||||
When researchers from different communities write papers together, they should first discuss which format they will use. While DOCX may not be convenient for engineers if there is math involved, LaTeX may be troublesome for researchers who lack a programming background. As this article shows, Markdown is an easy-to-use language that can be used by both engineers and social scientists.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/pandoc-research-paper
|
||||
|
||||
作者:[Kiko Fernandez-Reyes][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/kikofernandez
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Markdown
|
||||
[2]: https://www.latex-project.org/
|
||||
[3]: https://pandoc.org/
|
||||
[4]: http://lierdakil.github.io/pandoc-crossref/
|
||||
[5]: https://dl.acm.org/citation.cfm?id=3270118
|
||||
[6]: https://github.com/kikofernandez/pandoc-examples/blob/master/research-paper/biblio.bib
|
||||
[7]: https://en.wikibooks.org/wiki/LaTeX/Floats,_Figures_and_Captions#Figures
|
||||
[8]: https://www.sharelatex.com/learn/latex/Creating_a_document_in_LaTeX#The_preamble_of_a_document
|
||||
[9]: http://pandoc.org/MANUAL.html#citations
|
||||
[10]: http://www.bibtex.org/Using/
|
||||
[11]: https://github.com/kikofernandez/pandoc-examples/tree/master/research-paper
|
||||
@ -0,0 +1,151 @@
|
||||
To BeOS or not to BeOS, that is the Haiku
|
||||
======
|
||||
|
||||

|
||||
|
||||
Back in 2001, a new operating system arrived that promised to change the way users worked with their computers. That platform was BeOS and I remember it well. What I remember most about it was the desktop, and how much it looked and felt like my favorite window manager (at the time) AfterStep. I also remember how awkward and overly complicated BeOS was to install and use. In fact, upon installation, it was never all too clear how to make the platform function well enough to use on a daily basis. That was fine, however, because BeOS seemed to live in a perpetual state of “alpha release.”
|
||||
|
||||
That was then. This is very much now.
|
||||
|
||||
Now we have haiku
|
||||
|
||||
Bringing BeOS to life
|
||||
|
||||
An AfterStep joy.
|
||||
|
||||
No, Haiku has nothing to do with AfterStep, but it fit perfectly with the haiku meter, so work with me.
|
||||
|
||||
The [Haiku][1] project released it’s R1 Alpha 4 six years ago. Back in September of 2018, it finally released it’s R1 Beta 1 and although it took them eons (in computer time), seeing Haiku installed (on a virtual machine) was worth the wait … even if only for the nostalgia aspect. The big difference between R1 Beta 1 and R1 Alpha 4 (and BeOS, for that matter), is that Haiku now works like a real operating system. It’s lighting fast (and I do mean fast), it finally enjoys a modicum of stability, and has a handful of useful apps. Before you get too excited, you’re not going to install Haiku and immediately become productive. In fact, the list of available apps is quite limiting (more on this later). Even so, Haiku is definitely worth installing, even if only to see how far the project has come.
|
||||
|
||||
Speaking of which, let’s do just that.
|
||||
|
||||
### Installing Haiku
|
||||
|
||||
The installation isn’t quite as point and click as the standard Linux distribution. That doesn’t mean it’s a challenge. It’s not; in fact, the installation is handled completely through a GUI, so you won’t have to even touch the command line.
|
||||
|
||||
To install Haiku, you must first [download an image][2]. Download this file into your ~/Downloads directory. This image will be in a compressed format, so once it’s downloaded you’ll need to decompress it. Open a terminal window and issue the command unzip ~/Downloads/haiku*.zip. A new directory will be created, called haiku-r1beta1XXX-anyboot (Where XXX is the architecture for your hardware). Inside that directory you’ll find the ISO image to be used for installation.
|
||||
|
||||
For my purposes, I installed Haiku as a VirtualBox virtual machine. I highly recommend going the same route, as you don’t want to have to worry about hardware detection. Creating Haiku as a virtual machine doesn’t require any special setup (beyond the standard). Once the live image has booted, you’ll be asked if you want to run the installer or boot directly to the desktop (Figure 1). Click Run Installer to begin the process.
|
||||
|
||||
|
||||
![Haiku installer][4]
|
||||
|
||||
Figure 1: Selecting to run the Haiku installer.
|
||||
|
||||
[Used with permission][5]
|
||||
|
||||
The next window is nothing more than a warning that Haiku is beta software and informing you that the installer will make the Haiku partition bootable, but doesn’t integrate with your existing boot menu (in other words, it will not set up dual booting). In this window, click the Continue button.
|
||||
|
||||
You will then be warned that no partitions have been found. Click the OK button, so you can create a partition table. In the remaining window (Figure 2), click the Set up partitions button.
|
||||
|
||||
![Haiku][7]
|
||||
|
||||
Figure 2: The Haiku Installer in action.
|
||||
|
||||
[Used with permission][5]
|
||||
|
||||
In the resulting window (Figure 3), select the partition to be used and then click Disk > Initialize > GUID Partition Map. You will be prompted to click Continue and then Write Changes.
|
||||
|
||||
![target partition][9]
|
||||
|
||||
Figure 3: Our target partition ready to be initialized.
|
||||
|
||||
[Used with permission][5]
|
||||
|
||||
Select the newly initialized partition and then click Partition > Format > Be File System. When prompted, click Continue. In the resulting window, leave everything default and click Initialize and then click Write changes.
|
||||
|
||||
Close the DriveSetup window (click the square in the titlebar) to return to the Haiku Installer. You should now be able to select the newly formatted partition in the Onto drop-down (Figure 4).
|
||||
|
||||
![partition][11]
|
||||
|
||||
Figure 4: Selecting our partition for installation.
|
||||
|
||||
[Used with permission][5]
|
||||
|
||||
After selecting the partition, click Begin and the installation will start. Don’t blink, as the entire installation takes less than 30 seconds. You read that correctly—the installation of Haiku takes less than 30 seconds. When it finishes, click Restart to boot your newly installed Haiku OS.
|
||||
|
||||
### Usage
|
||||
|
||||
When Haiku boots, it’ll go directly to the desktop. There is no login screen (or even the means to log in). You’ll be greeted with a very simple desktop that includes a few clickable icons and what is called the Tracker(Figure 5).
|
||||
|
||||

|
||||
|
||||
The Tracker includes any minimized application and a desktop menu that gives you access to all of the installed applications. Left click on the leaf icon in the Tracker to reveal the desktop menu (Figure 6).
|
||||
|
||||
![menu][13]
|
||||
|
||||
Figure 6: The Haiku desktop menu.
|
||||
|
||||
[Used with permission][5]
|
||||
|
||||
From within the menu, click Applications and you’ll see all the available tools. In that menu you’ll find the likes of:
|
||||
|
||||
* ActivityMonitor (Track system resources)
|
||||
|
||||
* BePDF (PDF reader)
|
||||
|
||||
* CodyCam (allows you to take pictures from a webcam)
|
||||
|
||||
* DeskCalc (calculator)
|
||||
|
||||
* Expander (unpack common archives)
|
||||
|
||||
* HaikuDepot (app store)
|
||||
|
||||
* Mail (email client)
|
||||
|
||||
* MediaPlay (play audio files)
|
||||
|
||||
* People (contact database)
|
||||
|
||||
* PoorMan (simple web server)
|
||||
|
||||
* SoftwareUpdater (update Haiku software)
|
||||
|
||||
* StyledEdit (text editor)
|
||||
|
||||
* Terminal (terminal emulator)
|
||||
|
||||
* WebPositive (web browser)
|
||||
|
||||
|
||||
|
||||
|
||||
You will find, in the HaikuDepot, a limited number of available applications. What you won’t find are many productivity tools. Missing are office suites, image editors, and more. What we have with this beta version of Haiku is not a replacement for your desktop, but a view into the work the developers have put into giving the now-defunct BoOS new life. Chances are you won’t spend too much time with Haiku, beyond kicking the tires. However, this blast from the past is certainly worth checking out.
|
||||
|
||||
### A positive step forward
|
||||
|
||||
Based on my experience with BeOS and the alpha of Haiku (all those years ago), the developers have taken a big, positive step forward. Hopefully, the next beta release won’t take as long and we might even see a final release in the coming years. Although Haiku won’t challenge the likes of Ubuntu, Mint, Arch, or Elementary OS, it could develop its own niche following. No matter its future, it’s good to see something new from the developers. Bravo to Haiku.
|
||||
|
||||
Your OS is prime
|
||||
|
||||
For a beta 2 release
|
||||
|
||||
Make it so, my friends.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/2018/10/beos-or-not-beos-haiku
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/jlwallen
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.haiku-os.org/
|
||||
[2]: https://www.haiku-os.org/get-haiku
|
||||
[3]: /files/images/haiku1jpg
|
||||
[4]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/haiku_1.jpg?itok=PTTBoLCf (Haiku installer)
|
||||
[5]: /licenses/category/used-permission
|
||||
[6]: /files/images/haiku2jpg
|
||||
[7]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/haiku_2.jpg?itok=NV1yavv_ (Haiku)
|
||||
[8]: /files/images/haiku3jpg
|
||||
[9]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/haiku_3.jpg?itok=XWBz6kVT (target partition)
|
||||
[10]: /files/images/haiku4jpg
|
||||
[11]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/haiku_4.jpg?itok=6RbuCbAx (partition)
|
||||
[12]: /files/images/haiku6jpg
|
||||
[13]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/haiku_6.jpg?itok=-mmzNBxa (menu)
|
||||
@ -1,4 +1,4 @@
|
||||
9 个方法,提升开发者与设计师之间的协作
|
||||
9 个提升开发者与设计师协作的方法
|
||||
======
|
||||
|
||||

|
||||
@ -9,45 +9,45 @@
|
||||
|
||||
两边都有自己的成见。工程师经常认为设计师们古怪不理性,而设计师也认为工程师们死板要求高。在一天的工作快要结束时,情况会变得更加微妙。设计师和开发者们的命运永远交织在一起。
|
||||
|
||||
做到以下九件事,便可以增强他们之间的合作
|
||||
做到以下九件事,便可以改进他们之间的合作。
|
||||
|
||||
### 1\. 首先,说实在的,打破壁垒。
|
||||
### 1. 首先,说实在的,打破壁垒
|
||||
|
||||
几乎每一个行业都有“<ruby>迷惑之墙<rt>wall of confusion</rt></ruby>”的模子。无论你干什么工作,拆除这堵墙的第一步就是要双方都认同它需要拆除。一旦所有的人都认为现有的流程效率低下,你就可以从其他想法中获得灵感,然后解决问题。
|
||||
几乎每一个行业都有“<ruby>迷墙<rt>wall of confusion</rt></ruby>”的因子。无论你干什么工作,拆除这堵墙的第一步就是要双方都认同它需要拆除。一旦所有的人都认为现有的流程效率低下,你就可以从其它想法中获得灵感,然后解决问题。
|
||||
|
||||
### 2\. 学会共情
|
||||
### 2. 学会共情
|
||||
|
||||
在撸起袖子开始干之前,休息一下。这是团队建设的重要的交汇点。一个时机去认识到:我们都是成人,我们都有自己的优点与缺点,更重要的是,我们是一个团队。围绕工作流程与工作效率的讨论会经常发生,因此在开始之前,建立一个信任与协作的基础至关重要。
|
||||
在撸起袖子开始干之前,先等一下。这是团队建设的重要的交汇点,也是建立共同认知的时机:我们都是成人,我们都有自己的优点与缺点,更重要的是,我们是一个团队。围绕工作流程与工作效率的讨论会经常发生,因此在开始之前,建立一个信任与协作的基础至关重要。
|
||||
|
||||
### 3\. 认识差异
|
||||
### 3. 认识差异
|
||||
|
||||
设计师和开发者从不同的角度攻克问题。对于相同的问题,设计师会追求更好的效果,而开发者会寻求更高的效率。这两种观点不必互相排斥。谈判和妥协的余地很大,并且在二者之间必然存在一个用户满意度最佳的中点。
|
||||
|
||||
### 4\. 拥抱共性
|
||||
### 4. 拥抱共性
|
||||
|
||||
这一切都是与工作流程相关的。<ruby>持续集成<rt>Continuous Integration</rt></ruby>/<ruby>持续交付<rt>Continuous Delivery</rt></ruby>,scrum,agille 等等,都基本上说了一件事:构思,迭代,考察,重复。迭代和重复是两种工作的相同点。因此,不再让开发周期紧跟设计周期,而是同时并行地运行它们,这样会更有意义。<ruby>同步周期<rt>Syncing cycles</rt></ruby>允许团队在每一步上交流、协作、互相影响。
|
||||
这一切都是与工作流程相关的。<ruby>持续集成<rt>Continuous Integration</rt></ruby>/<ruby>持续交付<rt>Continuous Delivery</rt></ruby>,scrum,agile 等等,都基本上说了一件事:构思,迭代,考察,重复。迭代和重复是两种工作的相同点。因此,不再让开发周期紧跟设计周期,而是同时并行地运行它们,这样会更有意义。<ruby>同步周期<rt>Syncing cycles</rt></ruby>允许团队在每个环节交流、协作、互相影响。
|
||||
|
||||
### 5\. 管理期望
|
||||
### 5. 管理期望
|
||||
|
||||
一切冲突的起因一言以蔽之:期望不符。因此,防止系统性分裂的简单办法就是通过确保团队成员在说之前先想、在做之前先说来管理期望。设定的期望往往会通过日常对话不断演变。强迫团队通过开会以达到其效果可能会适得其反。
|
||||
|
||||
### 6\. 按需开会
|
||||
### 6. 按需开会
|
||||
|
||||
只在工作开始和工作结束开一次会远远不够。但也不意味着每天或每周都要开会。定期开会也可能会适得其反。试着按需开会吧。即兴会议可能会发生很棒的事情,即使是在开水房。如果你的团队是分散式的或者甚至有一名远程员工,视频会议,文本聊天或者打电话都是开会的好方法。团队中的每人都有多种方式互相沟通,这一点非常重要。
|
||||
只在工作开始和工作结束开一次会远远不够。但也不意味着每天或每周都要开会。定期开会也可能会适得其反。试着按需开会吧。即兴会议,即使是员工闲聊,也可能会发生很棒的事情。如果你的团队是分散式的或者甚至有一名远程员工,视频会议,文本聊天或者打电话都是开会的好方法。团队中的每人都有多种方式互相沟通,这一点非常重要。
|
||||
|
||||
### 7\. 建立词库
|
||||
### 7. 建立词库
|
||||
|
||||
设计师和开发者有时候对相似的想法有着不同的术语,就像把猫叫了个咪。毕竟,所有人都用的惯比起术语的准确度和适应度更重要。
|
||||
设计师和开发者有时候对相似的想法有着不同的术语,就像把猫叫成喵。毕竟,比起术语的准确度和合适度来,大家统一说法才更重要。
|
||||
|
||||
### 8\. 学会沟通
|
||||
### 8. 学会沟通
|
||||
|
||||
无论什么时候,团队中的每个人都有责任去维持一个有效的沟通。每个人都应该努力做到一字一板。
|
||||
|
||||
### 9\. 不断改善
|
||||
### 9. 不断改善
|
||||
|
||||
仅一名团队成员就能破坏整个进度。全力以赴。如果每个人都不关心产品或目标,继续项目或者做出改变的动机就会出现问题。
|
||||
|
||||
本文参考 [Designers and developers: Finding common ground for effective collaboration][2],演讲的作者将会出席在旧金山五月 8-10 号举办的[Red Hat Summit 2018][3]。[五月 7 号][3]注册将节省 500 美元。支付时使用优惠码 **OPEN18** 以获得更多折扣。
|
||||
本文参考[开发者与设计师: 找出有效合作的共同点][2],演讲的作者将会出席 5 月 8-10 号在旧金山举办的[红帽峰会 2018][3]。[5 月 7 号][3]注册将节省 500 美元。支付时使用优惠码 **OPEN18** 以获得更多折扣。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -56,11 +56,11 @@ via: https://opensource.com/article/18/5/9-ways-improve-collaboration-developers
|
||||
作者:[Jason Brock][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[LuuMing](https://github.com/LuuMing)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[pityonline](https://github.com/pityonline)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jkbrock
|
||||
[1]:https://opensource.com/users/lightguardjp
|
||||
[2]:https://agenda.summit.redhat.com/SessionDetail.aspx?id=154267
|
||||
[3]:https://www.redhat.com/en/summit/2018
|
||||
[a]: https://opensource.com/users/jkbrock
|
||||
[1]: https://opensource.com/users/lightguardjp
|
||||
[2]: https://agenda.summit.redhat.com/SessionDetail.aspx?id=154267
|
||||
[3]: https://www.redhat.com/en/summit/2018
|
||||
|
||||
@ -0,0 +1,74 @@
|
||||
CPU 电源管理工具 - Linux 系统中 CPU 主频的控制和管理
|
||||
======
|
||||
|
||||

|
||||
|
||||
你使用笔记本的话,可能知道 Linux 系统的电源管理做的很不好。虽然有 **TLP**、[**Laptop Mode Tools** 和 **powertop**][1] 这些工具来辅助减少电量消耗,但跟 Windows 和 Mac OS 系统比较起来,电池的整个使用周期还是不尽如意。此外,还有一种降低功耗的办法就是限制 CPU 的频率。这是可行的,然而却需要编写很复杂的终端命令来设置,所以使用起来不太方便。幸好,有一款名为 **CPU Power Manager** 的 GNOME 扩展插件,可以很容易的就设置和管理你的 CPU 主频。GNOME 桌面系统中,CPU Power Manager 使用名为 **intel_pstate** 的功率驱动程序(几乎所有的 Intel CPU 都支持)来控制和管理 CPU 主频。
|
||||
|
||||
使用这个扩展插件的另一个原因是可以减少系统的发热量,因为很多系统在正常使用中的发热量总让人不舒服,限制 CPU 的主频就可以减低发热量。它还可以减少 CPU 和其他组件的磨损。
|
||||
|
||||
### 安装 CPU Power Manager
|
||||
|
||||
首先,进入[**扩展插件主页面**][2],安装此扩展插件。
|
||||
|
||||
安装好插件后,在 GNOME 顶部栏的右侧会出现一个 CPU 图标。点击图标,会出现安装此扩展一个选项提示,如下示:
|
||||
|
||||

|
||||
|
||||
点击**“尝试安装”**按纽,会弹出输入密码确认框。插件需要 root 权限来添加 policykit 规则,进而控制 CPU 主频。下面是弹出的提示框样子:
|
||||
|
||||

|
||||
|
||||
输入密码,点击**“认证”**按纽,完成安装。最后在 **/usr/share/polkit-1/actions** 目录下添加了一个名为 **mko.cpupower.setcpufreq.policy** 的 policykit 文件。
|
||||
|
||||
都安装完成后,如果点击右上脚的 CPU 图标,会出现如下所示:
|
||||
|
||||

|
||||
|
||||
### 功能特性
|
||||
|
||||
* **查看 CPU 主频:** 显然,你可以通过这个提示窗口看到 CPU 的当前运行频率。
|
||||
* **设置最大最小主频:** 使用此扩展,你可以根据列出的最大、最小频率百分比进度条来分别设置其频率限制。一旦设置,CPU 将会严格按照此设置范围运行。
|
||||
* **开/关 Turbo Boost:** 这是我最喜欢的功能特性。大多数 Intel CPU 都有 “Turbo Boost” 特性,为了提高额外性能,其中的一个内核为自动进行超频。此功能虽然可以使系统获得更高的性能,但也大大增加功耗。所以,如果不做 CPU 密集运行的话,为节约电能,最好关闭 Turbo Boost 功能。事实上,在我电脑上,我大部分时间是把 Turbo Boost 关闭的。
|
||||
* **生成配置文件:** 可以生成最大和最小频率的配置文件,就可以很轻松打开/关闭,而不是每次手工调整设置。
|
||||
|
||||
|
||||
|
||||
### 偏好设置
|
||||
|
||||
你也可以通过偏好设置窗口来自定义扩展插件显示形式:
|
||||
|
||||

|
||||
|
||||
如你所见,你可以设置是否显示 CPU 主频,也可以设置是否以 **Ghz** 来代替 **Mhz** 显示。
|
||||
|
||||
你也可以编辑和创建/删除配置:
|
||||
|
||||

|
||||
|
||||
可以为每个配置分别设置最大、最小主频及开/关 Turbo boost。
|
||||
|
||||
### 结论
|
||||
|
||||
正如我在开始时所说的,Linux 系统的电源管理并不是最好的,许多人总是希望他们的 Linux 笔记本电脑电池能多用几分钟。如果你也是其中一员,就试试此扩展插件吧。为了省电,虽然这是非常规的做法,但有效果。我确实喜欢这个插件,到现在已经使用了好几个月了。
|
||||
|
||||
What do you think about this extension? Put your thoughts in the comments below!你对此插件有何看法呢?请把你的观点留在下面的评论区吧。
|
||||
|
||||
祝贺!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/cpu-power-manager-control-and-manage-cpu-frequency-in-linux/
|
||||
|
||||
作者:[EDITOR][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/editor/
|
||||
[1]: https://www.ostechnix.com/improve-laptop-battery-performance-linux/
|
||||
[2]: https://extensions.gnome.org/extension/945/cpu-power-manager/
|
||||
@ -0,0 +1,637 @@
|
||||
# 用 350 行代码从零开始,将 Lisp 编译成 JavaScript
|
||||
|
||||
我们将会在本篇文章中看到从零开始实现的编译器,将简单的类 LISP 计算语言编译成 JavaScript。完整的源代码在 [这里][7].
|
||||
|
||||
我们将会:
|
||||
|
||||
1. 自定义语言,并用它编写一个简单的程序
|
||||
|
||||
2. 实现一个简单的解析器组合器
|
||||
|
||||
3. 为该语言实现一个解析器
|
||||
|
||||
4. 为该语言实现一个美观的打印器
|
||||
|
||||
5. 为我们的需求定义 JavaScript 的一个子集
|
||||
|
||||
6. 实现代码转译器,将代码转译成我们定义的 JavaScript 子集
|
||||
|
||||
7. 把所有东西整合在一起
|
||||
|
||||
开始吧!
|
||||
|
||||
### 1. 定义语言
|
||||
|
||||
lisps 最迷人的地方在于,它们的语法就是树状表示的,这就是这门语言很容易解析的原因。我们很快就能接触到它。但首先让我们把自己的语言定义好。关于我们语言的语法的范式(BNF)描述如下:
|
||||
|
||||
```
|
||||
program ::= expr
|
||||
expr ::= <integer> | <name> | ([<expr>])
|
||||
```
|
||||
|
||||
基本上,我们可以在该语言的最顶层定义表达式并对其进行运算。表达式由一个整数(比如 `5`)、一个变量(比如 `x`)或者一个表达式列表(比如 `(add x 1)`)组成。
|
||||
|
||||
整数对应它本身的值,变量对应它在当前环境中绑定的值,表达式列表对应一个函数调用,该列表的第一个参数是相应的函数,剩下的表达式是传递给这个函数的参数。
|
||||
|
||||
该语言中,我们保留一些内建的特殊形式,这样我们就能做一些更有意思的事情:
|
||||
|
||||
* let 表达式使我们可以在它的 body 环境中引入新的变量。语法如下:
|
||||
|
||||
```
|
||||
let ::= (let ([<letarg>]) <body>)
|
||||
letargs ::= (<name> <expr>)
|
||||
body ::= <expr>
|
||||
```
|
||||
|
||||
* lambda 表达式:也就是匿名函数定义。语法如下:
|
||||
|
||||
```
|
||||
lambda ::= (lambda ([<name>]) <body>)
|
||||
```
|
||||
|
||||
还有一些内建函数: `add`、`mul`、`sub`、`div` 和 `print`。
|
||||
|
||||
让我们看看用我们这门语言编写的入门示例程序:
|
||||
|
||||
```
|
||||
(let
|
||||
((compose
|
||||
(lambda (f g)
|
||||
(lambda (x) (f (g x)))))
|
||||
(square
|
||||
(lambda (x) (mul x x)))
|
||||
(add1
|
||||
(lambda (x) (add x 1))))
|
||||
(print ((compose square add1) 5)))
|
||||
```
|
||||
|
||||
这个程序定义了 3 个函数:`compose`、`square` 和 `add1`。然后将计算结果的值 `((compose square add1) 5)` 输出出来。
|
||||
|
||||
我相信了解这门语言,这些信息就足够了。开始实现它吧。
|
||||
|
||||
在 Haskell 中,我们可以这样定义语言:
|
||||
|
||||
```
|
||||
type Name = String
|
||||
|
||||
data Expr
|
||||
= ATOM Atom
|
||||
| LIST [Expr]
|
||||
deriving (Eq, Read, Show)
|
||||
|
||||
data Atom
|
||||
= Int Int
|
||||
| Symbol Name
|
||||
deriving (Eq, Read, Show)
|
||||
```
|
||||
|
||||
我们可以解析用该语言用 `Expr` 定义的程序。而且,这里我们添加了新数据类型 `Eq`、`Read` 和 `Show` 等实例用于测试和调试。你能够在 REPL 中使用这些数据类型,验证它们确实有用。
|
||||
|
||||
我们不在语法中定义 `lambda`、`let` 或其它的内建函数,原因在于,当前情况下我们没必要用到这些东西。这些函数仅仅是 `LIST` (表达式列表)的更加特殊的用例。所以我决定将它放到后面的部分。
|
||||
|
||||
一般来说你想要在抽象语法中定义这些特殊用例 —— 用于改进错误信息、禁用静态分析和优化等等,但在这里我们不会这样做,对我们来说这些已经足够了。
|
||||
|
||||
另一件你想做的事情可能是在语法中添加一些注释信息。比如定位:`Expr` 是来自哪个文件的,具体到这个文件的哪一行哪一列。你可以在后面的阶段中使用这一特性,打印出错误定位,即使它们不是处于解析阶段。
|
||||
|
||||
* _练习 1_:添加一个 `Program` 数据类型,可以按顺序包含多个 `Expr`
|
||||
|
||||
* _练习 2_:向语法树中添加一个定位注解。
|
||||
|
||||
### 2. 实现一个简单的解析器组合库
|
||||
|
||||
我们要做的第一件事情是定义一个嵌入式领域专用语言(Embedded Domain Specific Language 或者 EDSL),我们会用它来定义我们的语言解析器。这常常被称为解析器组合库。我们做这件事完全是出于学习的目的,Haskell 里有很好的解析库,在实际构建软件或者进行实验时,你应该使用它们。[megaparsec][8] 就是这样的一个库。
|
||||
|
||||
首先我们来谈谈解析库的实现的思路。本质上,我们的解析器就是一个函数,接受一些输入,可能会读取输入的一些或全部内容,然后返回解析出来的值和无法解析的输入部分,或者在解析失败时抛出异常。我们把它写出来。
|
||||
|
||||
```
|
||||
newtype Parser a
|
||||
= Parser (ParseString -> Either ParseError (a, ParseString))
|
||||
|
||||
data ParseString
|
||||
= ParseString Name (Int, Int) String
|
||||
|
||||
data ParseError
|
||||
= ParseError ParseString Error
|
||||
|
||||
type Error = String
|
||||
|
||||
```
|
||||
|
||||
这里我们定义了三个主要的新类型。
|
||||
|
||||
第一个,`Parser a` 是之前讨论的解析函数。
|
||||
|
||||
第二个,`ParseString` 是我们的输入或携带的状态。它有三个重要的部分:
|
||||
|
||||
* `Name`: 这是源的名字
|
||||
|
||||
* `(Int, Int)`: 这是源的当前位置
|
||||
|
||||
* `String`: 这是等待解析的字符串
|
||||
|
||||
第三个,`ParseError` 包含了解析器的当前状态和一个错误信息。
|
||||
|
||||
现在我们想让这个解析器更灵活,我们将会定义一些常用类型的实例。这些实例让我们能够将小巧的解析器和复杂的解析器结合在一起(因此它的名字叫做 “解析器组合器”)。
|
||||
|
||||
第一个是 `Functor` 实例。我们需要 `Functor` 实例,因为我们要能够对解析值应用函数从而使用不同的解析器。当我们定义自己语言的解析器时,我们将会看到关于它的示例。
|
||||
|
||||
```
|
||||
instance Functor Parser where
|
||||
fmap f (Parser parser) =
|
||||
Parser (\str -> first f <$> parser str)
|
||||
```
|
||||
|
||||
第二个是 `Applicative` 实例。该实例的常见用例是在多个解析器中实现一个纯函数。
|
||||
|
||||
```
|
||||
instance Applicative Parser where
|
||||
pure x = Parser (\str -> Right (x, str))
|
||||
(Parser p1) <*> (Parser p2) =
|
||||
Parser $
|
||||
\str -> do
|
||||
(f, rest) <- p1 str
|
||||
(x, rest') <- p2 rest
|
||||
pure (f x, rest')
|
||||
|
||||
```
|
||||
|
||||
(注意:_我们还会实现一个 Monad 实例,这样我们才能使用符号_)
|
||||
|
||||
第三个是 `Alternative` 实例。万一前面的解析器解析失败了,我们要能够提供一个备用的解析器。
|
||||
|
||||
```
|
||||
instance Alternative Parser where
|
||||
empty = Parser (`throwErr` "Failed consuming input")
|
||||
(Parser p1) <|> (Parser p2) =
|
||||
Parser $
|
||||
\pstr -> case p1 pstr of
|
||||
Right result -> Right result
|
||||
Left _ -> p2 pstr
|
||||
```
|
||||
|
||||
第四个是 `Monad` 实例。这样我们就能链接解析器。
|
||||
|
||||
```
|
||||
instance Monad Parser where
|
||||
(Parser p1) >>= f =
|
||||
Parser $
|
||||
\str -> case p1 str of
|
||||
Left err -> Left err
|
||||
Right (rs, rest) ->
|
||||
case f rs of
|
||||
Parser parser -> parser rest
|
||||
|
||||
```
|
||||
|
||||
接下来,让我们定义一种的方式,用于运行解析器和防止失败的助手函数:
|
||||
|
||||
```
|
||||
|
||||
runParser :: String -> String -> Parser a -> Either ParseError (a, ParseString)
|
||||
runParser name str (Parser parser) = parser $ ParseString name (0,0) str
|
||||
|
||||
throwErr :: ParseString -> String -> Either ParseError a
|
||||
throwErr ps@(ParseString name (row,col) _) errMsg =
|
||||
Left $ ParseError ps $ unlines
|
||||
[ "*** " ++ name ++ ": " ++ errMsg
|
||||
, "* On row " ++ show row ++ ", column " ++ show col ++ "."
|
||||
]
|
||||
|
||||
```
|
||||
|
||||
现在我们将会开始实现组合器,这是 EDSL 的 API,也是它的核心。
|
||||
|
||||
首先,我们会定义 `oneOf`。如果输入列表中的字符后面还有字符的话,`oneOf` 将会成功,否则就会失败。
|
||||
|
||||
```
|
||||
oneOf :: [Char] -> Parser Char
|
||||
oneOf chars =
|
||||
Parser $ \case
|
||||
ps@(ParseString name (row, col) str) ->
|
||||
case str of
|
||||
[] -> throwErr ps "Cannot read character of empty string"
|
||||
(c:cs) ->
|
||||
if c `elem` chars
|
||||
then Right (c, ParseString name (row, col+1) cs)
|
||||
else throwErr ps $ unlines ["Unexpected character " ++ [c], "Expecting one of: " ++ show chars]
|
||||
```
|
||||
|
||||
`optional` 将会抛出异常,停止解析器。失败时它仅仅会返回 `Nothing`。
|
||||
|
||||
```
|
||||
optional :: Parser a -> Parser (Maybe a)
|
||||
optional (Parser parser) =
|
||||
Parser $
|
||||
\pstr -> case parser pstr of
|
||||
Left _ -> Right (Nothing, pstr)
|
||||
Right (x, rest) -> Right (Just x, rest)
|
||||
```
|
||||
|
||||
`many` 将会试着重复运行解析器,直到失败。当它完成的时候,会返回成功运行的解析器列表。`many1` 做的事情是一样的,但解析失败时它至少会抛出一次异常。
|
||||
|
||||
```
|
||||
many :: Parser a -> Parser [a]
|
||||
many parser = go []
|
||||
where go cs = (parser >>= \c -> go (c:cs)) <|> pure (reverse cs)
|
||||
|
||||
many1 :: Parser a -> Parser [a]
|
||||
many1 parser =
|
||||
(:) <$> parser <*> many parser
|
||||
|
||||
```
|
||||
|
||||
下面的这些解析器通过我们定义的组合器来实现一些特殊的解析器:
|
||||
|
||||
```
|
||||
char :: Char -> Parser Char
|
||||
char c = oneOf [c]
|
||||
|
||||
string :: String -> Parser String
|
||||
string = traverse char
|
||||
|
||||
space :: Parser Char
|
||||
space = oneOf " \n"
|
||||
|
||||
spaces :: Parser String
|
||||
spaces = many space
|
||||
|
||||
spaces1 :: Parser String
|
||||
spaces1 = many1 space
|
||||
|
||||
withSpaces :: Parser a -> Parser a
|
||||
withSpaces parser =
|
||||
spaces *> parser <* spaces
|
||||
|
||||
parens :: Parser a -> Parser a
|
||||
parens parser =
|
||||
(withSpaces $ char '(')
|
||||
*> withSpaces parser
|
||||
<* (spaces *> char ')')
|
||||
|
||||
sepBy :: Parser a -> Parser b -> Parser [b]
|
||||
sepBy sep parser = do
|
||||
frst <- optional parser
|
||||
rest <- many (sep *> parser)
|
||||
pure $ maybe rest (:rest) frst
|
||||
|
||||
```
|
||||
|
||||
现在为该门语言定义解析器所需要的所有东西都有了。
|
||||
|
||||
* _练习_ :实现一个 EOF(end of file/input,即文件或输入终止符)解析器组合器。
|
||||
|
||||
### 3. 为我们的语言实现解析器
|
||||
|
||||
我们会用自顶而下的方法定义解析器。
|
||||
|
||||
```
|
||||
parseExpr :: Parser Expr
|
||||
parseExpr = fmap ATOM parseAtom <|> fmap LIST parseList
|
||||
|
||||
parseList :: Parser [Expr]
|
||||
parseList = parens $ sepBy spaces1 parseExpr
|
||||
|
||||
parseAtom :: Parser Atom
|
||||
parseAtom = parseSymbol <|> parseInt
|
||||
|
||||
parseSymbol :: Parser Atom
|
||||
parseSymbol = fmap Symbol parseName
|
||||
|
||||
```
|
||||
|
||||
注意到这四个函数是在我们这门语言中属于高阶描述。这解释了为什么 Haskell 执行解析工作这么棒。在定义完高级部分后,我们还需要定义低级别的 `parseName` 和 `parseInt`。
|
||||
|
||||
我们能在这门语言中用什么字符作为名字呢?用小写的字母、数字和下划线吧,而且名字的第一个字符必须是字母。
|
||||
|
||||
```
|
||||
parseName :: Parser Name
|
||||
parseName = do
|
||||
c <- oneOf ['a'..'z']
|
||||
cs <- many $ oneOf $ ['a'..'z'] ++ "0123456789" ++ "_"
|
||||
pure (c:cs)
|
||||
```
|
||||
|
||||
整数是一系列数字,数字前面可能有负号 ‘-’:
|
||||
|
||||
```
|
||||
parseInt :: Parser Atom
|
||||
parseInt = do
|
||||
sign <- optional $ char '-'
|
||||
num <- many1 $ oneOf "0123456789"
|
||||
let result = read $ maybe num (:num) sign of
|
||||
pure $ Int result
|
||||
```
|
||||
|
||||
最后,我们会定义用来运行解析器的函数,返回值可能是一个 `Expr` 或者是一条错误信息。
|
||||
|
||||
```
|
||||
runExprParser :: Name -> String -> Either String Expr
|
||||
runExprParser name str =
|
||||
case runParser name str (withSpaces parseExpr) of
|
||||
Left (ParseError _ errMsg) -> Left errMsg
|
||||
Right (result, _) -> Right result
|
||||
```
|
||||
|
||||
* _练习 1_ :为第一节中定义的 `Program` 类型编写一个解析器
|
||||
|
||||
* _练习 2_ :用 Applicative 的形式重写 `parseName`
|
||||
|
||||
* _练习 3_ :`parseInt` 可能出现溢出情况,找到处理它的方法,不要用 `read`。
|
||||
|
||||
### 4. 为这门语言实现一个更好看的输出器
|
||||
|
||||
我们还想做一件事,将我们的程序以源代码的形式打印出来。这对完善错误信息很有用。
|
||||
|
||||
```
|
||||
printExpr :: Expr -> String
|
||||
printExpr = printExpr' False 0
|
||||
|
||||
printAtom :: Atom -> String
|
||||
printAtom = \case
|
||||
Symbol s -> s
|
||||
Int i -> show i
|
||||
|
||||
printExpr' :: Bool -> Int -> Expr -> String
|
||||
printExpr' doindent level = \case
|
||||
ATOM a -> indent (bool 0 level doindent) (printAtom a)
|
||||
LIST (e:es) ->
|
||||
indent (bool 0 level doindent) $
|
||||
concat
|
||||
[ "("
|
||||
, printExpr' False (level + 1) e
|
||||
, bool "\n" "" (null es)
|
||||
, intercalate "\n" $ map (printExpr' True (level + 1)) es
|
||||
, ")"
|
||||
]
|
||||
|
||||
indent :: Int -> String -> String
|
||||
indent tabs e = concat (replicate tabs " ") ++ e
|
||||
```
|
||||
|
||||
* _练习_ :为第一节中定义的 `Program` 类型编写一个美观的输出器
|
||||
|
||||
好,目前为止我们写了近 200 行代码,这些代码一般叫做编译器的前端。我们还要写大概 150 行代码,用来执行三个额外的任务:我们需要根据需求定义一个 JS 的子集,定义一个将我们的语言转译成这个子集的转译器,最后把所有东西整合在一起。开始吧。
|
||||
|
||||
### 5. 根据需求定义 JavaScript 的子集
|
||||
|
||||
首先,我们要定义将要使用的 JavaScript 的子集:
|
||||
|
||||
```
|
||||
data JSExpr
|
||||
= JSInt Int
|
||||
| JSSymbol Name
|
||||
| JSBinOp JSBinOp JSExpr JSExpr
|
||||
| JSLambda [Name] JSExpr
|
||||
| JSFunCall JSExpr [JSExpr]
|
||||
| JSReturn JSExpr
|
||||
deriving (Eq, Show, Read)
|
||||
|
||||
type JSBinOp = String
|
||||
```
|
||||
|
||||
这个数据类型表示 JavaScript 表达式。我们有两个原子类型 `JSInt` 和 `JSSymbol`,它们是由我们这个语言中的 `Atom` 转译来的,我们用 `JSBinOp` 来表示二元操作,比如 `+` 或 `*`,用 `JSLambda` 来表示匿名函数,和我们语言中的 `lambda expression(lambda 表达式)` 一样,我们将会用 `JSFunCall` 来调用函数,用 `let` 来引入新名字,用 `JSReturn` 从函数中返回值,在 JavaScript 中是需要返回值的。
|
||||
|
||||
`JSExpr` 类型是对 JavaScript 表达式的 **抽象表示**。我们会把自己语言中表达式的抽象表示 `Expr` 转译成 JavaScript 表达式的抽象表示 `JSExpr`。但为了实现这个功能,我们需要实现 `JSExpr` ,并从这个抽象表示中生成 JavaScript 代码。我们将通过递归匹配 `JSExpr` 实现,将 JS 代码当作 `String` 来输出。这和我们在 `printExpr` 中做的基本上是一样的。我们还会追踪元素的作用域,这样我们才可以用合适的方式缩进生成的代码。
|
||||
|
||||
```
|
||||
printJSOp :: JSBinOp -> String
|
||||
printJSOp op = op
|
||||
|
||||
printJSExpr :: Bool -> Int -> JSExpr -> String
|
||||
printJSExpr doindent tabs = \case
|
||||
JSInt i -> show i
|
||||
JSSymbol name -> name
|
||||
JSLambda vars expr -> (if doindent then indent tabs else id) $ unlines
|
||||
["function(" ++ intercalate ", " vars ++ ") {"
|
||||
,indent (tabs+1) $ printJSExpr False (tabs+1) expr
|
||||
] ++ indent tabs "}"
|
||||
JSBinOp op e1 e2 -> "(" ++ printJSExpr False tabs e1 ++ " " ++ printJSOp op ++ " " ++ printJSExpr False tabs e2 ++ ")"
|
||||
JSFunCall f exprs -> "(" ++ printJSExpr False tabs f ++ ")(" ++ intercalate ", " (fmap (printJSExpr False tabs) exprs) ++ ")"
|
||||
JSReturn expr -> (if doindent then indent tabs else id) $ "return " ++ printJSExpr False tabs expr ++ ";"
|
||||
```
|
||||
|
||||
* _练习 1_ :添加 `JSProgram` 类型,它可以包含多个 `JSExpr` ,然后创建一个叫做 `printJSExprProgram` 的函数来生成代码。
|
||||
|
||||
* _练习 2_ :添加 `JSExpr` 的新类型:`JSIf`,并为其生成代码。
|
||||
|
||||
### 6. 实现到我们定义的 JavaScript 子集的代码转译器
|
||||
|
||||
我们快做完了。这一节将会创建函数,将 `Expr` 转译成 `JSExpr`。
|
||||
|
||||
基本思想很简单,我们会将 `ATOM` 转译成 `JSSymbol` 或者 `JSInt`,然后会将 `LIST` 转译成一个函数调用或者转译的特例。
|
||||
|
||||
```
|
||||
type TransError = String
|
||||
|
||||
translateToJS :: Expr -> Either TransError JSExpr
|
||||
translateToJS = \case
|
||||
ATOM (Symbol s) -> pure $ JSSymbol s
|
||||
ATOM (Int i) -> pure $ JSInt i
|
||||
LIST xs -> translateList xs
|
||||
|
||||
translateList :: [Expr] -> Either TransError JSExpr
|
||||
translateList = \case
|
||||
[] -> Left "translating empty list"
|
||||
ATOM (Symbol s):xs
|
||||
| Just f <- lookup s builtins ->
|
||||
f xs
|
||||
f:xs ->
|
||||
JSFunCall <$> translateToJS f <*> traverse translateToJS xs
|
||||
|
||||
```
|
||||
|
||||
`builtins` 是一系列要转译的特例,就像 `lambada` 和 `let`。每一种情况都可以获得一系列参数,验证它是否合乎语法规范,然后将其转译成等效的 `JSExpr`。
|
||||
|
||||
```
|
||||
type Builtin = [Expr] -> Either TransError JSExpr
|
||||
type Builtins = [(Name, Builtin)]
|
||||
|
||||
builtins :: Builtins
|
||||
builtins =
|
||||
[("lambda", transLambda)
|
||||
,("let", transLet)
|
||||
,("add", transBinOp "add" "+")
|
||||
,("mul", transBinOp "mul" "*")
|
||||
,("sub", transBinOp "sub" "-")
|
||||
,("div", transBinOp "div" "/")
|
||||
,("print", transPrint)
|
||||
]
|
||||
|
||||
```
|
||||
|
||||
我们这种情况,会将内建的特殊形式当作特殊的、非第一类的进行对待,因此不可能将它们当作第一类函数。
|
||||
|
||||
我们会把 Lambda 表达式转译成一个匿名函数:
|
||||
|
||||
```
|
||||
transLambda :: [Expr] -> Either TransError JSExpr
|
||||
transLambda = \case
|
||||
[LIST vars, body] -> do
|
||||
vars' <- traverse fromSymbol vars
|
||||
JSLambda vars' <$> (JSReturn <$> translateToJS body)
|
||||
|
||||
vars ->
|
||||
Left $ unlines
|
||||
["Syntax error: unexpected arguments for lambda."
|
||||
,"expecting 2 arguments, the first is the list of vars and the second is the body of the lambda."
|
||||
,"In expression: " ++ show (LIST $ ATOM (Symbol "lambda") : vars)
|
||||
]
|
||||
|
||||
fromSymbol :: Expr -> Either String Name
|
||||
fromSymbol (ATOM (Symbol s)) = Right s
|
||||
fromSymbol e = Left $ "cannot bind value to non symbol type: " ++ show e
|
||||
|
||||
```
|
||||
|
||||
我们会将 let 转译成带有相关名字参数的函数定义,然后带上参数调用函数,因此会在这一作用域中引入变量:
|
||||
|
||||
```
|
||||
transLet :: [Expr] -> Either TransError JSExpr
|
||||
transLet = \case
|
||||
[LIST binds, body] -> do
|
||||
(vars, vals) <- letParams binds
|
||||
vars' <- traverse fromSymbol vars
|
||||
JSFunCall . JSLambda vars' <$> (JSReturn <$> translateToJS body) <*> traverse translateToJS vals
|
||||
where
|
||||
letParams :: [Expr] -> Either Error ([Expr],[Expr])
|
||||
letParams = \case
|
||||
[] -> pure ([],[])
|
||||
LIST [x,y] : rest -> ((x:) *** (y:)) <$> letParams rest
|
||||
x : _ -> Left ("Unexpected argument in let list in expression:\n" ++ printExpr x)
|
||||
|
||||
vars ->
|
||||
Left $ unlines
|
||||
["Syntax error: unexpected arguments for let."
|
||||
,"expecting 2 arguments, the first is the list of var/val pairs and the second is the let body."
|
||||
,"In expression:\n" ++ printExpr (LIST $ ATOM (Symbol "let") : vars)
|
||||
]
|
||||
```
|
||||
|
||||
我们会将可以在多个参数之间执行的操作符转译成一系列二元操作符。比如:`(add 1 2 3)` 将会变成 `1 + (2 + 3)`。
|
||||
|
||||
```
|
||||
transBinOp :: Name -> Name -> [Expr] -> Either TransError JSExpr
|
||||
transBinOp f _ [] = Left $ "Syntax error: '" ++ f ++ "' expected at least 1 argument, got: 0"
|
||||
transBinOp _ _ [x] = translateToJS x
|
||||
transBinOp _ f list = foldl1 (JSBinOp f) <$> traverse translateToJS list
|
||||
```
|
||||
|
||||
然后我们会将 `print` 转换成对 `console.log` 的调用。
|
||||
|
||||
```
|
||||
transPrint :: [Expr] -> Either TransError JSExpr
|
||||
transPrint [expr] = JSFunCall (JSSymbol "console.log") . (:[]) <$> translateToJS expr
|
||||
transPrint xs = Left $ "Syntax error. print expected 1 arguments, got: " ++ show (length xs)
|
||||
|
||||
```
|
||||
|
||||
注意,如果我们将这些代码当作 `Expr` 的特例进行解析,那我们就可能会跳过语法验证。
|
||||
|
||||
* _练习 1_ :将 `Program` 转译成 `JSProgram`
|
||||
|
||||
* _练习 2_ :为 `if Expr Expr Expr` 添加一个特例,并将它转译成你在上一次练习中实现的 `JSIf` 条件语句。
|
||||
|
||||
### 7. 把所有东西整合到一起
|
||||
|
||||
最终,我们将会把所有东西整合到一起。我们会:
|
||||
|
||||
1. 读取文件
|
||||
|
||||
2. 将文件解析成 `Expr`
|
||||
|
||||
3. 将文件转译成 `JSExpr`
|
||||
|
||||
4. 将 JavaScript 代码发送到标准输出流
|
||||
|
||||
我们还会启用一些用于测试的标志位:
|
||||
|
||||
* `--e` 将进行解析并打印出表达式的抽象表示(`Expr`)
|
||||
|
||||
* `--pp` 将进行解析,美化输出
|
||||
|
||||
* `--jse` 将进行解析、转译、并打印出生成的 JS 表达式(`JSExpr`)的抽象表示
|
||||
|
||||
* `--ppc` 将进行解析,美化输出并进行编译
|
||||
|
||||
```
|
||||
main :: IO ()
|
||||
main = getArgs >>= \case
|
||||
[file] ->
|
||||
printCompile =<< readFile file
|
||||
["--e",file] ->
|
||||
either putStrLn print . runExprParser "--e" =<< readFile file
|
||||
["--pp",file] ->
|
||||
either putStrLn (putStrLn . printExpr) . runExprParser "--pp" =<< readFile file
|
||||
["--jse",file] ->
|
||||
either print (either putStrLn print . translateToJS) . runExprParser "--jse" =<< readFile file
|
||||
["--ppc",file] ->
|
||||
either putStrLn (either putStrLn putStrLn) . fmap (compile . printExpr) . runExprParser "--ppc" =<< readFile file
|
||||
_ ->
|
||||
putStrLn $ unlines
|
||||
["Usage: runghc Main.hs [ --e, --pp, --jse, --ppc ] <filename>"
|
||||
,"--e print the Expr"
|
||||
,"--pp pretty print Expr"
|
||||
,"--jse print the JSExpr"
|
||||
,"--ppc pretty print Expr and then compile"
|
||||
]
|
||||
|
||||
printCompile :: String -> IO ()
|
||||
printCompile = either putStrLn putStrLn . compile
|
||||
|
||||
compile :: String -> Either Error String
|
||||
compile str = printJSExpr False 0 <$> (translateToJS =<< runExprParser "compile" str)
|
||||
|
||||
```
|
||||
|
||||
大功告成。将自己的语言编译到 JS 子集的编译器已经完成了。再说一次,你可以在 [这里][9] 看到完整的源文件。
|
||||
|
||||
用我们的编译器运行第一节的示例,产生的 JavaScript 代码如下:
|
||||
|
||||
```
|
||||
$ runhaskell Lisp.hs example.lsp
|
||||
(function(compose, square, add1) {
|
||||
return (console.log)(((compose)(square, add1))(5));
|
||||
})(function(f, g) {
|
||||
return function(x) {
|
||||
return (f)((g)(x));
|
||||
};
|
||||
}, function(x) {
|
||||
return (x * x);
|
||||
}, function(x) {
|
||||
return (x + 1);
|
||||
})
|
||||
```
|
||||
|
||||
如果你在自己电脑上安装了 node.js,你可以用以下命令运行这段代码:
|
||||
|
||||
```
|
||||
$ runhaskell Lisp.hs example.lsp | node -p
|
||||
36
|
||||
undefined
|
||||
```
|
||||
|
||||
* _最终练习_ : 编译有多个表达式的程序而非仅编译一个表达式。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://gilmi.me/blog/post/2016/10/14/lisp-to-js
|
||||
|
||||
作者:[ Gil Mizrahi ][a]
|
||||
选题:[oska874][b]
|
||||
译者:[BriFuture](https://github.com/BriFuture)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://gilmi.me/home
|
||||
[b]:https://github.com/oska874
|
||||
[1]:https://gilmi.me/blog/authors/Gil
|
||||
[2]:https://gilmi.me/blog/tags/compilers
|
||||
[3]:https://gilmi.me/blog/tags/fp
|
||||
[4]:https://gilmi.me/blog/tags/haskell
|
||||
[5]:https://gilmi.me/blog/tags/lisp
|
||||
[6]:https://gilmi.me/blog/tags/parsing
|
||||
[7]:https://gist.github.com/soupi/d4ff0727ccb739045fad6cdf533ca7dd
|
||||
[8]:https://mrkkrp.github.io/megaparsec/
|
||||
[9]:https://gist.github.com/soupi/d4ff0727ccb739045fad6cdf533ca7dd
|
||||
[10]:https://gilmi.me/blog/post/2016/10/14/lisp-to-js
|
||||
99
translated/tech/20180601 Download an OS with GNOME Boxes.md
Normal file
99
translated/tech/20180601 Download an OS with GNOME Boxes.md
Normal file
@ -0,0 +1,99 @@
|
||||
用 GNOME Boxes 下载一个镜像
|
||||
======
|
||||
|
||||

|
||||
|
||||
Boxes 是 GNOME 上的虚拟机应用。最近 Boxes 添加了一个新的特性,使得它在运行不同的 Linux 发行版时更加容易。你现在可以在 Boxes 中自动安装列表中这些发行版。该列表甚至包括红帽企业 Linux。红帽开发人员计划包括[免费订阅红帽企业版 Linux][1]。 使用[红帽开发者][2]帐户,Boxes 可以自动设置一个名为 Developer Suite 订阅的 RHEL 虚拟机。 下面是它的工作原理。
|
||||
|
||||
### 红帽企业版 Linux
|
||||
|
||||
要创建一个红帽企业版 Linux 的虚拟机,启动 Boxes,点击新建。从源选择列表中选择下载一个镜像。在顶部,点击红帽企业版 Linux。这将会打开网址为 [developers.redhat.com][2] 的一个网络表单。使用已有的红帽开发者账号登录,或是新建一个。
|
||||
|
||||
![][3]
|
||||
|
||||
如果这是一个新帐号,Boxes 在继续之前需要一些额外的信息。这一步需要在账户中开启开发者订阅。还要确保 [接受条款和条件][4],这样可以在之后的注册中节省一步。
|
||||
|
||||
![][5]
|
||||
|
||||
点击提交,然后就会开始下载安装磁盘镜像。下载需要的时间取决于你的网络状况。在这期间你可以去喝杯茶或者咖啡歇息一下。
|
||||
|
||||
![][6]
|
||||
|
||||
等媒体下载完成(一般位于 ~/Downloads ),Boxes 会有一个快速安装的显示。填入账号和密码然后点击继续,当你确认了虚拟机的信息之后点击创建。快速安装会自动完成接下来的整个安装!(现在你可以去享受你的第二杯茶或者咖啡了)
|
||||
|
||||
![][7]
|
||||
|
||||
![][8]
|
||||
|
||||
![][9]
|
||||
|
||||
等到安装结束,虚拟机会直接重启并登录到桌面。在虚拟机里,在应用菜单的系统工具一栏启动红帽订阅管理。这一步需要输入管理员密码。
|
||||
|
||||
![][10]
|
||||
|
||||
单击“注册”按钮,然后按照注册助手中的步骤操作。 出现提示时,使用你的红帽开发者帐户登录。
|
||||
|
||||
![][11]
|
||||
|
||||
![][12]
|
||||
|
||||
现在你可以通过任何一种更新方法,像是 yum 或是 GNOME Software 进行下载和更新了。
|
||||
|
||||
![][13]
|
||||
|
||||
### FreeDOS 或是其他
|
||||
|
||||
Boxes 可以安装很多的 Linux 发行版,而不仅仅只是红帽企业版。 作为 KVM 和 qemu 的前端,Boxes 支持各种操作系统。 使用 [libosinfo][14],Boxes 可以自动下载(在某些情况下安装)相当多不同操作系统。
|
||||
|
||||
![][15]
|
||||
|
||||
要从列表中安装一个操作系统,只需选择并完成创建一个新的虚拟机。一些操作系统,比如 FreeDOS,并不支持快速安装。这些操作系统需要虚拟机从安装介质中引导。之后你可以手动安装。
|
||||
|
||||
![][16]
|
||||
|
||||
![][17]
|
||||
|
||||
### 在 Boxes 上受欢迎的操作系统
|
||||
|
||||
这里仅仅是一些目前在它上面比较受欢迎的选择。
|
||||
|
||||
![][18]![][19]![][20]![][21]![][22]![][23]
|
||||
|
||||
Fedora 会定期更新它的操作系统信息数据库。确保你会经常检查是否有新的操作系统选项。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/download-os-gnome-boxes/
|
||||
|
||||
作者:[Link Dupont][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[dianbanjiu](https://github.com/dianbanjiu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/linkdupont/
|
||||
[1]:https://developers.redhat.com/blog/2016/03/31/no-cost-rhel-developer-subscription-now-available/
|
||||
[2]:http://developers.redhat.com
|
||||
[3]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-14-33-13.png
|
||||
[4]:https://www.redhat.com/wapps/tnc/termsack?event%5B%5D=signIn
|
||||
[5]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-14-34-37.png
|
||||
[6]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-14-37-27.png
|
||||
[7]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-15-09-11.png
|
||||
[8]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-15-15-19-1024x815.png
|
||||
[9]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-15-21-53-1024x815.png
|
||||
[10]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-15-26-29-1024x815.png
|
||||
[11]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-15-30-48-1024x815.png
|
||||
[12]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-15-31-17-1024x815.png
|
||||
[13]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-15-32-29-1024x815.png
|
||||
[14]:https://libosinfo.org
|
||||
[15]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-20-02-56.png
|
||||
[16]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-15-40-25.png
|
||||
[17]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-15-43-02-1024x815.png
|
||||
[18]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-16-55-20-1024x815.png
|
||||
[19]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-16-28-28-1024x815.png
|
||||
[20]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-16-11-43-1024x815.png
|
||||
[21]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-16-58-09-1024x815.png
|
||||
[22]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-17-46-38-1024x815.png
|
||||
[23]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-18-34-11-1024x815.png
|
||||
56
translated/tech/20180827 A sysadmin-s guide to containers.md
Normal file
56
translated/tech/20180827 A sysadmin-s guide to containers.md
Normal file
@ -0,0 +1,56 @@
|
||||
写给系统管理员的容器手册
|
||||
======
|
||||
|
||||

|
||||
|
||||
现在人们严重地过度使用“容器”这个术语。另外,对不同的人来说,它可能会有不同的含义,这取决于上下文。
|
||||
|
||||
传统的 Linux 容器只是系统上普通的进程组成的进程组。进程组之间是相互隔离的,实现方法包括:资源限制(控制组 [cgoups])、Linux 安全限制(文件权限,基于 Capability 的安全模块,SELinux,AppArmor,seccomp 等)还有名字空间(进程 ID,网络,挂载等)。
|
||||
|
||||
如果你启动一台现代 Linux 操作系统,使用 `cat /proc/PID/cgroup` 命令就可以看到该进程是属于一个控制组的。还可以从 `/proc/PID/status` 文件中查看进程的 Capability 信息,从 `/proc/self/attr/current` 文件中查看进程的 SELinux 标签信息,从 `/proc/PID/ns` 目录下的文件查看进程所属的名字空间。因此,如果把容器定义为带有资源限制、Linux 安全限制和名字空间的进程,那么按照这个定义,Linux 操作系统上的每一个进程都在容器里。因此我们常说 [Linux 就是容器,容器就是 Linux][1]。而**容器运行时**是这样一种工具,它调整上述资源限制、安全限制和名字空间,并启动容器。
|
||||
|
||||
Docker 引入了**容器镜像**的概念,镜像是一个普通的 TAR 包文件,包含了:
|
||||
|
||||
* **Rootfs(容器的根文件系统):**一个目录,看起来像是操作系统的普通根目录(/),例如,一个包含 `/usr`, `/var`, `/home` 等的目录。
|
||||
* **JSON 文件(容器的配置):**定义了如何运行 rootfs;例如,当容器启动的时候要在 rootfs 里运行什么 **command** 或者 **entrypoint**,给容器定义什么样的**环境变量**,容器的**工作目录**是哪个,以及其他一些设置。
|
||||
|
||||
Docker 把 rootfs 和 JSON 配置文件打包成**基础镜像**。你可以在这个基础之上,给 rootfs 安装更多东西,创建新的 JSON 配置文件,然后把相对于原始镜像的不同内容打包到新的镜像。这种方法创建出来的是**分层的镜像**。
|
||||
|
||||
[Open Container Initiative(开放容器计划 OCI)][2] 标准组织最终把容器镜像的格式标准化了,也就是 [OCI Image Specification(OCI 镜像规范)][3]。
|
||||
|
||||
用来创建容器镜像的工具被称为**容器镜像构建器**。有时候容器引擎做这件事情,不过可以用一些独立的工具来构建容器镜像。
|
||||
|
||||
Docker 把这些容器镜像(**tar 包**)托管到 web 服务中,并开发了一种协议来支持从 web 拉取镜像,这个 web 服务就叫**容器仓库**。
|
||||
|
||||
**容器引擎**是能从镜像仓库拉取镜像并装载到**容器存储**上的程序。容器引擎还能启动**容器运行时**(见下图)。
|
||||
|
||||

|
||||
|
||||
容器存储一般是**写入时复制**(COW)的分层文件系统。从容器仓库拉取一个镜像时,其中的 rootfs 首先被解压到磁盘。如果这个镜像是多层的,那么每一层都会被下载到 COW 文件系统的不同分层。 COW 文件系统保证了镜像的每一层独立存储,这最大化了多个分层镜像之间的文件共享程度。容器引擎通常支持多种容器存储类型,包括 `overlay`、`devicemapper`、`btrfs`、`aufs` 和 `zfs`。
|
||||
|
||||
容器引擎将容器镜像下载到容器存储中之后,需要创建一份**容器运行时配置**,这份配置是用户/调用者的输入和镜像配置的合并。例如,容器的调用者可能会调整安全设置,添加额外的环境变量或者挂载一些卷到容器中。
|
||||
|
||||
容器运行时配置的格式,和解压出来的 rootfs 也都被开放容器计划 OCI 标准组织做了标准化,称为 [OCI 运行时规范][4]。
|
||||
|
||||
最终,容器引擎启动了一个**容器运行时**来读取运行时配置,修改 Linux 控制组、安全限制和名字空间,并执行容器命令来创建容器的 **PID 1**。至此,容器引擎已经可以把容器的标准输入/标准输出转给调用方,并控制容器了(例如,stop,start,attach)。
|
||||
|
||||
值得一提的是,现在出现了很多新的容器运行时,它们使用 Linux 的不同特性来隔离容器。可以使用 KVM 技术来隔离容器(想想迷你虚拟机),或者使用其他虚拟机监视器策略(例如拦截所有从容器内的进程发起的系统调用)。既然我们有了标准的运行时规范,这些工具都能被相同的容器引擎来启动。即使在 Windows 系统下,也可以使用 OCI 运行时规范来启动 Windows 容器。
|
||||
|
||||
容器编排器是一个更高层次的概念。它是在多个不同的节点上协调容器执行的工具。容器编排工具通过和容器引擎的通信来管理容器。编排器控制容器引擎做容器的启动和容器间的网络连接,它能够监控容器,在负载变高的时候进行容器扩容。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/sysadmins-guide-containers
|
||||
|
||||
作者:[Daniel J Walsh][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[belitex](https://github.com/belitex)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/rhatdan
|
||||
[1]:https://www.redhat.com/en/blog/containers-are-linux
|
||||
[2]:https://www.opencontainers.org/
|
||||
[3]:https://github.com/opencontainers/image-spec/blob/master/spec.md
|
||||
[4]:https://github.com/opencontainers/runtime-spec
|
||||
@ -0,0 +1,59 @@
|
||||
6 个托管你 git 仓库的地方
|
||||
======
|
||||
|
||||

|
||||
|
||||
也许你是少数一些没有注意到的人之一就在几周前,[微软收购了 GitHub][1]。两家公司达成了共识。微软在近些年已经变成了开源的有力支持者,GitHub 从成立起,就已经成为了许多开源项目的实际代码库。
|
||||
|
||||
然而,最近的购买可能会带给你一些烦躁。毕竟公司的收购让你意识到了你的开源代码放在了一个商业平台上。可能你现在还没准备好迁移到其他的平台上去,但是至少这可以给你提供一些可选项。让我们找找网上现在都有哪些可用的平台。
|
||||
|
||||
### 选择之一: GitHub
|
||||
|
||||
严格来说,这是一个合格的选项。[GitHub][2] 历史上没有什么糟糕的失败,而且微软最近也确实发展了不少开源项目。把你的项目继续放在 GitHub 上,继续保持观望没有什么不可以。它现在依然是最大的软件开发的网络社区,同时还有许多对于问题追踪、代码复查、持续集成、通用的代码管理很有用的工具。而且它还是基于 Git 的,Git 是每个人都喜欢的开源版本控制系统。你的代码还是你的代码。
|
||||
|
||||
### 选择之二: GitLab
|
||||
|
||||
[GitLab][3] 是代码库平台主要的竞争者。它是完全开源的。你可以像在 GitHhub 一样把你的代码托管在 GitLab,但你也可以选择在你自己的服务器上自行托管你自己的 GitLab 实例,并完全控制谁可以访问那里的所有内容以及如何访问、管理。 GitLab 与 GitHub 功能几乎相同,有些人甚至可能会说它的持续集成和测试工具更优越。尽管 GitLab 上的开发者社区肯定比 GitHub 上的开发者社区要小,但它仍然没有什么可以被指责的。你可能会在那里的人群中找到更多志同道合的开发者。
|
||||
|
||||
### 选择之三: Bitbucket
|
||||
|
||||
[Bitbucket][4] 已经存在很多年了。在某些方面,它可以作为 GitHub 未来的一面镜子。 Bitbucket 八年前被一家大公司(Atlassian)收购,并且已经经历了一些转换过程。 它仍然是一个像 GitHub 这样的商业平台,但它远不是一个创业公司,而且从组织上说它的基础相当稳定。 Bitbucket 分享了 GitHub 和 GitLab 上的大部分功能,以及它自己的一些新功能,如对 [Mercurial][5] 存储库的本机支持。
|
||||
|
||||
### 选择之四: SourceForge
|
||||
|
||||
[SourceForge][6] 是开源代码库的鼻祖。如果你曾经有一个开源项目,Sourceforge 是一个托管你的代码和向他人分享你的发行版的地方。迁移到 Git 进行版本控制需要一段时间,它有自己的商业收购和重新组构的事件,以及一些开源项目的一些不幸的捆绑决策。也就是说,SourceForge 从那时起似乎已经恢复,该网站仍然是一个有着不少开源项目的地方。 然而,很多人仍然感到有点受伤,而且有些人并不是各种尝试通过平台货币化的忠实粉丝,所以一定要睁大眼睛。
|
||||
|
||||
### 选择之五: 自己管理
|
||||
|
||||
如果你想自己掌握自己项目的命运(除了你自己没人可以责备你),然后一切都由自己来做对你来说可能是最佳的选择。无论对于大项目还是小项目。Git 是开源的,所以自己托管也很容易。如果你问题追踪和代码审查,你可以运行一个 GitLab 或者 [Phabricator][7] 的实例。对于持续集成,你可以设置自己的 [Jenkins][8] 自动化服务的实例。是的,你需要对自己的基础架构开销和相关的安全要求负责。但是,这个设置过程并不是很困难。所以如果你不想自己的代码被其他人的平台所吞没,这就是一种很好的方法。
|
||||
|
||||
### 选择之六:以上全部
|
||||
|
||||
以下是所有这些的美妙之处:尽管这些平台上有一些专有的选项,但它们仍然建立在坚实的开源技术之上。 而且不仅仅是开源,而是明确设计为分布在大型网络(如互联网)上的多个节点上。 你不需要只使用一个。 你可以使用一对......或者全部。 使用 GitLab 将你自己的设置作为保证的基础,并在 GitHub 和 Bitbucket 上安装克隆存储库,以进行问题跟踪和持续集成。 将你的主代码库保留在 GitHub 上,但是为了你自己的想法,可以在 GitLab 上安装“备份”克隆。
|
||||
|
||||
关键在于你的选择是什么。我们能有这么多选择,都是得益于那些非常有用的项目上的开源协议。未来一片光明。
|
||||
|
||||
当然,在这个列表中我肯定忽略了一些开源平台。你是否使用了很多的平台?哪个是你最喜欢的?你都可以在这里说出来!
|
||||
|
||||
:)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/github-alternatives
|
||||
|
||||
作者:[Jason van Gumster][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[dianbanjiu](https://github.com/dianbanjiu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mairin
|
||||
[1]: https://www.theverge.com/2018/6/4/17422788/microsoft-github-acquisition-official-deal
|
||||
[2]: https://github.com/
|
||||
[3]: https://gitlab.com
|
||||
[4]: https://bitbucket.org
|
||||
[5]: https://www.mercurial-scm.org/wiki/Repository
|
||||
[6]: https://sourceforge.net
|
||||
[7]: https://phacility.com/phabricator/
|
||||
[8]: https://jenkins.io
|
||||
@ -1,38 +1,39 @@
|
||||
PyTorch 1.0 预览版发布: Facebook 最新 AI 开源框架
|
||||
PyTorch 1.0 预览版发布:Facebook 最新 AI 开源框架
|
||||
======
|
||||
|
||||
Facebook 在人工智能项目中广泛使用自己的开源 AI 框架 PyTorch,最近,他们已经发布了 PyTorch 1.0 的预览版本。
|
||||
|
||||
对于那些不熟悉的人, [PyTorch][1] 是一个基于 Python 的科学计算库。
|
||||
如果你尚不了解,[PyTorch][1] 是一个基于 Python 的科学计算库。
|
||||
|
||||
PyTorch 利用 [GPUs 超强的运算能力 ][2] 来实现复杂的 [张量][3] 计算 和 [深度神经网络][4]。 因此, 它被世界各地的研究人员和开发人员广泛使用。
|
||||
PyTorch 利用 [GPU 超强的运算能力][2] 来实现复杂的 [张量][3] 计算 和 [深度神经网络][4]。 因此, 它被世界各地的研究人员和开发人员广泛使用。
|
||||
|
||||
这一新的能够使用的 [预览版][5] 已在2018年10月2日周二旧金山举办的 [PyTorch 开发人员大会][6] 的[中途][7]宣布。
|
||||
这一新的可以投入使用的 [预览版][5] 已于 2018 年 10 月 2 日周二在旧金山 [The Midway][7] 举办的 [PyTorch 开发人员大会][6] 宣布。
|
||||
|
||||
### PyTorch 1.0 候选版本的亮点
|
||||
|
||||
![PyTorhc is Python based open source AI framework from Facebook][8]
|
||||
|
||||
候选版本中的一些主要新功能包括:
|
||||
候选版本中的一些主要新功能包括:
|
||||
|
||||
#### 1\. JIT
|
||||
#### 1、 JIT
|
||||
|
||||
JIT 是一个编译工具集,使研究和生产更加接近。 它包含一个基于 Python 语言的叫做 Torch Script 的脚本语言,也有能使现有代码与它自己兼容的方法。
|
||||
|
||||
#### 2\. 全新的 torch.distributed 库: “C10D”
|
||||
#### 2、 全新的 torch.distributed 库: “C10D”
|
||||
|
||||
“C10D” 能够在不同的后端上启用异步操作, 并在较慢的网络上提高性能。
|
||||
|
||||
#### 3\. C++ 前端 (实验性功能)
|
||||
#### 3、 C++ 前端 (实验性功能)
|
||||
|
||||
虽然它被特别提到是一个不稳定的 API (预计在预发行版中), 这是一个 PyTorch 后端的纯 c++ 接口, 遵循 API 和建立的 Python 前端的体系结构,以实现高性能、 低延迟的研究和开发直接安装在硬件上的 c++ 应用程序。
|
||||
虽然它被特别提到是一个不稳定的 API (估计是在预发行版中), 这是一个 PyTorch 后端的纯 C++ 接口, 遵循 API 和建立的 Python 前端的体系结构,以实现高性能、低延迟的研究和开发直接安装在硬件上的 C++ 应用程序。
|
||||
|
||||
想要了解更多,可以在 GitHub 上查看完整的 [更新说明][9]。
|
||||
|
||||
第一个PyTorch 1.0 的稳定版本将在夏季发布。
|
||||
第一个 PyTorch 1.0 的稳定版本将在夏季发布。(LCTT 译注:此信息可能有误)
|
||||
|
||||
### 在 Linux 上安装 PyTorch
|
||||
|
||||
为了安装 PyTorch v1.0rc0, 开发人员建议使用 [conda][10], 同时也可以按照[本地安装][11]所示,使用其他方法可以安装,所有必要的细节详见文档。
|
||||
为了安装 PyTorch v1.0rc0, 开发人员建议使用 [conda][10], 同时也可以按照[本地安装页面][11]所示,使用其他方法可以安装,所有必要的细节详见文档。
|
||||
|
||||
#### 前提
|
||||
|
||||
@ -41,18 +42,16 @@ JIT 是一个编译工具集,使研究和生产更加接近。 它包含一个
|
||||
* Python
|
||||
* [CUDA][12] (对于使用 Nvidia GPU 的用户)
|
||||
|
||||
|
||||
|
||||
我们已经知道[如何安装和使用 Pip][13],那就让我们来了解如何使用 Pip 安装 PyTorch。
|
||||
|
||||
请注意,PyTorch 具有 GPU 和仅限 CPU 的不同安装包。你应该安装一个适合你硬件的安装包。
|
||||
|
||||
#### 安装 PyTorch 的旧版本和稳定版
|
||||
|
||||
如果你想在 GPU 机器上安装稳定版(0.4 版本),使用:
|
||||
|
||||
```
|
||||
pip install torch torchvision
|
||||
|
||||
```
|
||||
|
||||
使用以下两个命令,来安装仅用于 CPU 的稳定版:
|
||||
@ -60,7 +59,6 @@ pip install torch torchvision
|
||||
```
|
||||
pip install http://download.pytorch.org/whl/cpu/torch-0.4.1-cp27-cp27mu-linux_x86_64.whl
|
||||
pip install torchvision
|
||||
|
||||
```
|
||||
|
||||
#### 安装 PyTorch 1.0 候选版本
|
||||
@ -69,21 +67,19 @@ pip install torchvision
|
||||
|
||||
```
|
||||
pip install torch_nightly -f https://download.pytorch.org/whl/nightly/cu92/torch_nightly.html
|
||||
|
||||
```
|
||||
如果没有GPU,并且更喜欢使用 仅限CPU 版本,使用如下命令:
|
||||
如果没有GPU,并且更喜欢使用 仅限 CPU 版本,使用如下命令:
|
||||
|
||||
```
|
||||
pip install torch_nightly -f https://download.pytorch.org/whl/nightly/cpu/torch_nightly.html
|
||||
|
||||
```
|
||||
|
||||
#### 验证 PyTorch 安装
|
||||
|
||||
使用如下简单的命令,启动终端上的 python 控制台:
|
||||
|
||||
```
|
||||
python
|
||||
|
||||
```
|
||||
|
||||
现在,按行输入下面的示例代码以验证您的安装:
|
||||
@ -93,7 +89,6 @@ from __future__ import print_function
|
||||
import torch
|
||||
x = torch.rand(5, 3)
|
||||
print(x)
|
||||
|
||||
```
|
||||
|
||||
你应该得到如下输出:
|
||||
@ -104,7 +99,6 @@ tensor([[0.3380, 0.3845, 0.3217],
|
||||
[0.2979, 0.7141, 0.9069],
|
||||
[0.1449, 0.1132, 0.1375],
|
||||
[0.4675, 0.3947, 0.1426]])
|
||||
|
||||
```
|
||||
|
||||
若要检查是否可以使用 PyTorch 的 GPU 功能, 可以使用以下示例代码:
|
||||
@ -112,18 +106,18 @@ tensor([[0.3380, 0.3845, 0.3217],
|
||||
```
|
||||
import torch
|
||||
torch.cuda.is_available()
|
||||
|
||||
```
|
||||
|
||||
输出结果应该是:
|
||||
|
||||
```
|
||||
True
|
||||
|
||||
```
|
||||
|
||||
支持 PyTorch 的 AMD GPU 仍在开发中, 因此, 尚未按[报告][14]提供完整的测试覆盖,如果您有 AMD GPU ,请在[这里][15]提出建议。
|
||||
|
||||
现在让我们来看看一些广泛使用 PyTorch 的研究项目:
|
||||
|
||||
### 基于 PyTorch 的持续研究项目
|
||||
|
||||
* [Detectron][16]: Facebook AI 研究院的软件系统, 可以智能地进行对象检测和分类。它之前是基于 Caffe2 的。今年早些时候,Caffe2 和 PyTorch [合力][17]创建了一个研究 + 生产的 PyTorch 1.0
|
||||
@ -144,7 +138,7 @@ via: https://itsfoss.com/pytorch-open-source-ai-framework/
|
||||
作者:[Avimanyu Bandyopadhyay][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[distant1219](https://github.com/distant1219)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -1,63 +1,62 @@
|
||||
translating by dianbanjiu
|
||||
How To List The Enabled/Active Repositories In Linux
|
||||
列出在 Linux 上已开启/激活的仓库
|
||||
======
|
||||
There are many ways to list enabled repositories in Linux.
|
||||
这里有很多方法可以列出在 Linux 已开启的仓库。
|
||||
|
||||
Here we are going to show you the easy methods to list active repositories.
|
||||
我们将在下面展示给你列出已激活仓库的简便方法。
|
||||
|
||||
It will helps you to know what are the repositories enabled on your system.
|
||||
这有助于你知晓你的系统上都开启了哪些仓库。
|
||||
|
||||
Once you have this information in handy then you can add any repositories that you want if it’s not already enabled.
|
||||
一旦你掌握了这些信息,你就可以添加任何之前还没有准备开启的仓库了。
|
||||
|
||||
Say for example, if you would like to enable `epel repository` then you need to check whether the epel repository is enabled or not. In this case this tutorial would help you.
|
||||
举个例子,如果你想开启 `epel repository` ,你需要先检查 epel repository 是否已经开启了。这篇教程将会帮助你做这件事情。
|
||||
|
||||
### What Is Repository?
|
||||
### 什么是仓库?
|
||||
|
||||
A software repository is a central place which stores the software packages for the particular application.
|
||||
存储特定程序软件包的中枢位置就是一个软件仓库。
|
||||
|
||||
All the Linux distributions are maintaining their own repositories and they allow users to retrieve and install packages on their machine.
|
||||
所有的 Linux 发行版都开发了他们自己的仓库,而且允许用户下载并安装这些软件包到他们的机器上。
|
||||
|
||||
Each vendor offered a unique package management tool to manage their repositories such as search, install, update, upgrade, remove, etc.
|
||||
每个供应商都提供了一套包管理工具,用以管理他们的仓库,比如搜索、安装、更新、升级、移除等等。
|
||||
|
||||
Most of the Linux distributions comes as freeware except RHEL and SUSE. To access their repositories you need to buy a subscriptions.
|
||||
大多数 Linux 发行版都作为免费软件,除了 RHEL 和 SUSE。接收他们的仓库你需要先购买订阅。
|
||||
|
||||
**Suggested Read :**
|
||||
**(#)** [How To Add, Enable And Disable A Repository By Using The DNF/YUM Config Manager Command On Linux][1]
|
||||
**(#)** [How To List Installed Packages By Size (Largest) On Linux][2]
|
||||
**(#)** [How To View/List The Available Packages Updates In Linux][3]
|
||||
**(#)** [How To View A Particular Package Installed/Updated/Upgraded/Removed/Erased Date On Linux][4]
|
||||
**(#)** [How To View Detailed Information About A Package In Linux][5]
|
||||
**(#)** [How To Search If A Package Is Available On Your Linux Distribution Or Not][6]
|
||||
**(#)** [How To List An Available Package Groups In Linux][7]
|
||||
**(#)** [Newbies corner – A Graphical frontend tool for Linux Package Manager][8]
|
||||
**(#)** [Linux Expert should knows, list of Command line Package Manager & Usage][9]
|
||||
**建议阅读:**
|
||||
**(#)** [在 Linux 上,如何通过 DNF/YUM 设置管理命令添加、开启、关闭一个仓库][1]
|
||||
**(#)** [在 Linux 上如何以尺寸列出已安装的包][2]
|
||||
**(#)** [在 Linux 上如何列出升级的包][3]
|
||||
**(#)** [在 Linux 上如何查看一个特定包已安装/已升级/已更新/已移除/已清除的数据][4]
|
||||
**(#)** [在 Linux 上如何查看一个包的详细信息][5]
|
||||
**(#)** [在你的 Linux 发行版上如何查看一个包是否可用][6]
|
||||
**(#)** [在 Linux 如何列出可用的软件包组][7]
|
||||
**(#)** [Newbies corner - 一个图形化的 Linux 包管理的前端工具][8]
|
||||
**(#)** [Linux 专家须知,命令行包管理 & 使用列表][9]
|
||||
|
||||
### How To List The Enabled Repositories on RHEL/CentOS
|
||||
### 在 RHEL/CentOS上列出已开启的库
|
||||
|
||||
RHEL & CentOS systems are using RPM packages hence we can use the `Yum Package Manager` to get this information.
|
||||
RHEL 和 CentOS 系统使用的是 RPM 包管理,所以我们可以使用 `Yum 包管理` 查看这些信息。
|
||||
|
||||
YUM stands for Yellowdog Updater, Modified is an open-source command-line front-end package-management utility for RPM based systems such as Red Hat Enterprise Linux (RHEL) and CentOS.
|
||||
YUM 代表的是 `Yellowdog Updater,Modified`,它是一个包管理的开源前端,作用在基于 RPM 的系统上,例如 RHEL 和 CentOS。
|
||||
|
||||
Yum is the primary tool for getting, installing, deleting, querying, and managing RPM packages from distribution repositories, as well as other third-party repositories.
|
||||
YUM 是获取、安装、删除、查询和管理来自发行版仓库和其他第三方库的 RPM 包的主要工具。
|
||||
|
||||
**Suggested Read :** [YUM Command To Manage Packages on RHEL/CentOS Systems][10]
|
||||
**建议阅读:Suggested Read :** [在 RHEL/CentOS 系统上用 YUM 命令管理包][10]
|
||||
|
||||
RHEL based systems are mainly offering the below three major repositories. These repository will be enabled by default.
|
||||
基于 RHEL 的系统主要提供以下三个主要的仓库。这些仓库是默认开启的。
|
||||
|
||||
* **`base:`** It’s containing all the core packages and base packages.
|
||||
* **`extras:`** It provides additional functionality to CentOS without breaking upstream compatibility or updating base components. It is an upstream repository, as well as additional CentOS packages.
|
||||
* **`updates:`** It’s offering bug fixed packages, Security packages and Enhancement packages.
|
||||
* **`base:`** 它包含了所有的核心包和基础包。
|
||||
* **`extras:`** 它向 CentOS 提供不破坏上游兼容性或更新基本组件的额外功能。这是一个上游仓库,还有额外的 CentOS 包。
|
||||
* **`updates:`** 它提供了 bug 修复包、安全性包和增强包。
|
||||
|
||||
|
||||
|
||||
```
|
||||
# yum repolist
|
||||
or
|
||||
或者
|
||||
# yum repolist enabled
|
||||
|
||||
Loaded plugins: fastestmirror
|
||||
Determining fastest mirrors
|
||||
选题模板.txt 中文排版指北.md comic core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LCTT翻译规范.md LICENSE Makefile published README.md sign.md sources translated epel: ewr.edge.kernel.org
|
||||
epel: ewr.edge.kernel.org
|
||||
repo id repo name status
|
||||
!base/7/x86_64 CentOS-7 - Base 9,911
|
||||
!epel/x86_64 Extra Packages for Enterprise Linux 7 - x86_64 12,687
|
||||
@ -67,26 +66,26 @@ repolist: 24,349
|
||||
|
||||
```
|
||||
|
||||
### How To List The Enabled Repositories on Fedora
|
||||
### 如何列出 Fedora 上已开启的包
|
||||
|
||||
DNF stands for Dandified yum. We can tell DNF, the next generation of yum package manager (Fork of Yum) using hawkey/libsolv library for backend. Aleš Kozumplík started working on DNF since Fedora 18 and its implemented/launched in Fedora 22 finally.
|
||||
DNF 代表 Dandified yum。我们可以说 DNF 是下一代的 yum 包管理,使用了 hawkey/libsolv 作为后端。自从 Fedroa 18 开始,Aleš Kozumplík 就开始研究 DNF 最终在 Fedora 22 上实现。
|
||||
|
||||
Dnf command is used to install, update, search & remove packages on Fedora 22 and later system. It automatically resolve dependencies and make it smooth package installation without any trouble.
|
||||
Fedora 22 及之后的系统上都使用 Dnf 安装、升级、搜索和移除包。它可以自动解决依赖问题,并使包的安装过程平顺没有任何麻烦。
|
||||
|
||||
Yum replaced by DNF due to several long-term problems in Yum which was not solved. Asked why ? he did not patches the Yum issues. Aleš Kozumplík explains that patching was technically hard and YUM team wont accept the changes immediately and other major critical, YUM is 56K lines but DNF is 29K lies. So, there is no option for further development, except to fork.
|
||||
因为 Yum 许多未解决的问题,现在 Yum 已经被 DNF 所替代。你问为什么?他没有给 Yum 打补丁。Aleš Kozumplík 解释说修补在技术上太困难了,YUM 团队无法立即承受这些变更,还有其他的问题,YUM 是 56k 行,而 DNF 是 29k 行。因此,除了 fork 之外,别无选择。
|
||||
|
||||
**Suggested Read :** [DNF (Fork of YUM) Command To Manage Packages on Fedora System][11]
|
||||
**建议阅读:** [在 Fedora 上使用 DNF(Fork 自 YUM)管理软件][11]
|
||||
|
||||
Fedora system is mainly offering the below two major repositories. These repository will be enabled by default.
|
||||
Fedora 主要提供下面两个主仓库。这些库将被默认开启。
|
||||
|
||||
* **`fedora:`** It’s containing all the core packages and base packages.
|
||||
* **`updates:`** It’s offering bug fixed packages, Security packages and Enhancement packages from the stable release branch.
|
||||
* **`fedora:`** 它包括所有的核心包和基础包。
|
||||
* **`updates:`** 它提供了来自稳定发行版的 bug 修复包、安全性包和增强包
|
||||
|
||||
|
||||
|
||||
```
|
||||
# dnf repolist
|
||||
or
|
||||
或者
|
||||
# dnf repolist enabled
|
||||
|
||||
Last metadata expiration check: 0:02:56 ago on Wed 10 Oct 2018 06:12:22 PM IST.
|
||||
@ -106,13 +105,13 @@ rabiny-albert Copr repo for albert owned by rabiny 3
|
||||
|
||||
```
|
||||
|
||||
### How To List The Enabled Repositories on Debian/Ubuntu
|
||||
### 如何列出 Debian/Ubuntu 上已开启的仓库
|
||||
|
||||
Debian based systems are using APT/APT-GET package manager hence we can use the `APT/APT-GET Package Manager` to get this information.
|
||||
基于 Debian 的系统使用的是 APT/APT-GET 包管理,因此我们可以使用 `APT/APT-GET 包管理` 去获取更多的信息。
|
||||
|
||||
APT stands for Advanced Packaging Tool (APT) which is replacement for apt-get, like how DNF came to picture instead of YUM. It’s feature rich command-line tools with included all the futures in one command (APT) such as apt-cache, apt-search, dpkg, apt-cdrom, apt-config, apt-key, etc..,. and several other unique features. For example we can easily install .dpkg packages through APT but we can’t do through Apt-Get similar more features are included into APT command. APT-GET replaced by APT Due to lock of futures missing in apt-get which was not solved.
|
||||
APT 代表 Advanced Packaging Tool,它取代了 apt-get,就像 DNF 取代 Yum一样。 它具有丰富的命令行工具,在一个命令(APT)中包含了所有,如 apt-cache,apt-search,dpkg,apt-cdrom,apt-config,apt-key等。 还有其他几个独特的功能。 例如,我们可以通过 APT 轻松安装 .dpkg 软件包,而我们无法通过 Apt-Get 获得和包含在 APT 命令中类似的更多功能。 由于未能解决的 apt-get 问题,用 APT 取代了 APT-GET 的锁定。
|
||||
|
||||
Apt-Get stands for Advanced Packaging Tool (APT). apg-get is a powerful command-line tool which is used to automatically download and install new software packages, upgrade existing software packages, update the package list index, and to upgrade the entire Debian based systems.
|
||||
APT_GET 代表 Advanced Packaging Tool。apt-get 是一个强大的命令行工具,它用以自动下载和安装新的软件包、升级已存在的软件包、更新包索引列表、还有升级整个基于 Debian 的系统。
|
||||
|
||||
```
|
||||
# apt-cache policy
|
||||
@ -156,13 +155,13 @@ Pinned packages:
|
||||
|
||||
```
|
||||
|
||||
### How To List The Enabled Repositories on openSUSE
|
||||
### 如何在 openSUSE 上列出已开启的仓库
|
||||
|
||||
openSUSE system uses zypper package manager hence we can use the zypper Package Manager to get this information.
|
||||
openSUSE 使用 zypper 包管理,因此我们可以使用 zypper 包管理获得更多信息。
|
||||
|
||||
Zypper is a command line package manager for suse & openSUSE distributions. It’s used to install, update, search & remove packages & manage repositories, perform various queries, and more. Zypper command-line interface to ZYpp system management library (libzypp).
|
||||
Zypper 是 suse 和 openSUSE 发行版的命令行包管理。它用于安装、更新、搜索、移除包和管理仓库,执行各种查询等。Zypper 以 libzypp(ZYpp 系统管理库)作为后端。
|
||||
|
||||
**Suggested Read :** [Zypper Command To Manage Packages On openSUSE & suse Systems][12]
|
||||
**建议阅读:** [在 openSUSE 和 suse 系统上使用 Zypper 命令管理包][12]
|
||||
|
||||
```
|
||||
# zypper repos
|
||||
@ -179,7 +178,7 @@ Zypper is a command line package manager for suse & openSUSE distributions. It
|
||||
|
||||
```
|
||||
|
||||
List Repositories with URI.
|
||||
以 URI 列出仓库。
|
||||
|
||||
```
|
||||
# zypper lr -u
|
||||
@ -196,7 +195,7 @@ List Repositories with URI.
|
||||
|
||||
```
|
||||
|
||||
List Repositories by priority.
|
||||
通过优先级列出仓库。
|
||||
|
||||
```
|
||||
# zypper lr -p
|
||||
@ -213,13 +212,13 @@ List Repositories by priority.
|
||||
|
||||
```
|
||||
|
||||
### How To List The Enabled Repositories on ArchLinux
|
||||
### 如何列出 Arch Linux 上已开启的仓库
|
||||
|
||||
Arch Linux based systems are using pacman package manager hence we can use the pacman Package Manager to get this information.
|
||||
基于 Arch Linux 的系统使用 pacman 包管理,因此我们可以使用 pacman 包管理获取这些信息。
|
||||
|
||||
pacman stands for package manager utility (pacman). pacman is a command-line utility to install, build, remove and manage Arch Linux packages. pacman uses libalpm (Arch Linux Package Management (ALPM) library) as a back-end to perform all the actions.
|
||||
pacman 代表 package manager utility。pacman 是一个命令行实用程序,用以安装、构建、移除和管理 Arch Linux 包。pacman 使用 libalpm (Arch Linux包管理库)作为后端去进行这些操作。
|
||||
|
||||
**Suggested Read :** [Pacman Command To Manage Packages On Arch Linux Based Systems][13]
|
||||
**建议阅读:** [在基于 Arch Linux的系统上使用 Pacman命令管理包][13]
|
||||
|
||||
```
|
||||
# pacman -Syy
|
||||
@ -231,15 +230,15 @@ pacman stands for package manager utility (pacman). pacman is a command-line uti
|
||||
|
||||
```
|
||||
|
||||
### How To List The Enabled Repositories on Linux using INXI Utility
|
||||
### 如何使用 INXI Utility 列出 Linux 上已开启的仓库
|
||||
|
||||
inxi is a nifty tool to check hardware information on Linux and offers wide range of option to get all the hardware information on Linux system that i never found in any other utility which are available in Linux. It was forked from the ancient and mindbendingly perverse yet ingenius infobash, by locsmif.
|
||||
inix 是 Linux 上检查硬件信息非常有用的工具,还提供很多的选项去获取 Linux 上的所有硬件信息,我从未在 Linux 上发现其他有如此效用的程序。它由 locsmif fork 自 ingenius infobash。
|
||||
|
||||
inxi is a script that quickly shows system hardware, CPU, drivers, Xorg, Desktop, Kernel, GCC version(s), Processes, RAM usage, and a wide variety of other useful information, also used for forum technical support & debugging tool.
|
||||
inix 是一个可以快速显示硬件信息、CPU、硬盘、Xorg、桌面、内核、GCC 版本、进程、内存使用和很多其他有用信息的程序,还使用于论坛技术支持和调试工具上。
|
||||
|
||||
Additionally this utility will display all the distribution repository data information such as RHEL, CentOS, Fedora, Debain, Ubuntu, LinuxMint, ArchLinux, openSUSE, Manjaro, etc.,
|
||||
这个实用程序将会显示所有发行版仓库的数据信息,例如 RHEL、CentOS、Fedora、Debain、Ubuntu、LinuxMint、ArchLinux、openSUSE、Manjaro等。
|
||||
|
||||
**Suggested Read :** [inxi – A Great Tool to Check Hardware Information on Linux][14]
|
||||
**建议阅读:** [inxi – 一个在 Linux 上检查硬件信息的好工具][14]
|
||||
|
||||
```
|
||||
# inxi -r
|
||||
@ -267,7 +266,7 @@ via: https://www.2daygeek.com/how-to-list-the-enabled-active-repositories-in-lin
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[dianbanjiu](https://github.com/dianbanjiu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,58 @@
|
||||
生日快乐,KDE:你从不知道的 11 个应用
|
||||
======
|
||||
你今天需要哪种有趣或奇特的应用?
|
||||

|
||||
|
||||
Linux 桌面环境 KDE 将于今年 10 月 14 日庆祝诞生 22 周年。KDE 社区用户创建了大量应用,它们很多都提供有趣和奇特的服务。我们仔细看了该列表,并挑选出了你可能想了解的 11 个应用。
|
||||
|
||||
没有很多,但[也有不少][1]。
|
||||
|
||||
### 11 个你从没了解的 KDE 应用
|
||||
|
||||
1\. [KTeaTime][2] 是一个泡茶计时器。选择你正在饮用的茶的类型 - 绿茶、红茶、凉茶等 - 当可以取出茶包来饮用时,计时器将会响。
|
||||
|
||||
2\. [KTux][3] 就是一个屏保程序......是么?Tux 用他的绿色飞船在外太空飞行。
|
||||
|
||||
3\. [Blinken][4] 是一款基于 Simon Says 的记忆游戏,这是一个 1978 年发布的电子游戏。玩家们在记住长度增加的序列时会有挑战。
|
||||
|
||||
4\. [Tellico][5] 是一个收集管理器,用于组织你最喜欢的爱好。也许你还在收集棒球卡。也许你是红酒俱乐部的一员。也许你是一个严肃的书虫。也许三个都是!
|
||||
|
||||
5\. [KRecipes][6] **不是** 简单的食谱管理器。它还有很多其他功能!购物清单、营养素分析、高级搜索、菜谱评级、导入/导出各种格式等。
|
||||
|
||||
6\. [KHangMan][7] 基于经典游戏 Hangman,你可以按逐个字母猜测单词。这个游戏有多种语言版本,这可以用来改善你学习另一种语言。它有四个分类,其中一个是“动物”,非常适合孩子。
|
||||
|
||||
7\. [KLettres][8] 是另一款可以帮助你学习新语言的应用。它教授字母表并挑战用户阅读和发音音节。
|
||||
|
||||
8\. [KDiamond][9] 类似于宝石迷阵或其他单人益智游戏,其中游戏的目标是搭建一定数量的相同类型的宝石或物体的行。这里是钻石。
|
||||
|
||||
9\. [KolourPaint][10] 是一个非常简单的图像编辑工具,也可以用于创建简单的矢量图形。
|
||||
|
||||
10\. [Kiriki][11] 是一款类似于 Yahtzee 的 2-6 名玩家的骰子游戏。
|
||||
|
||||
11\. [RSIBreak][12] 没有以 K 开头。什么!?它以“RSI”开头代表“重复性劳损” (Repetitive Strain Injury),这会在日复一日长时间使用鼠标和键盘后发生。这个应用会提醒你休息,并可以个性化,以满足你的需求。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/kde-applications
|
||||
|
||||
作者:[Opensource.com][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.kde.org/applications/
|
||||
[2]: https://www.kde.org/applications/games/kteatime/
|
||||
[3]: https://userbase.kde.org/KTux
|
||||
[4]: https://www.kde.org/applications/education/blinken
|
||||
[5]: http://tellico-project.org/
|
||||
[6]: https://www.kde.org/applications/utilities/krecipes/
|
||||
[7]: https://edu.kde.org/khangman/
|
||||
[8]: https://edu.kde.org/klettres/
|
||||
[9]: https://games.kde.org/game.php?game=kdiamond
|
||||
[10]: https://www.kde.org/applications/graphics/kolourpaint/
|
||||
[11]: https://www.kde.org/applications/games/kiriki/
|
||||
[12]: https://userbase.kde.org/RSIBreak
|
||||
Loading…
Reference in New Issue
Block a user