mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-30 02:40:11 +08:00
commit
28b5dfd027
published
20150104 How to debug a C or C++ program with Nemiver debugger.md20150114 Install Gitblit On Ubuntu or Fedora or CentOS.md20150115 Get back your privacy and control.md20150121 How to Monitor Network Usage with nload in Linux.md20150122 How To Recover Windows 7 And Delete Ubuntu In 3 Easy Steps.md20150126 4 lvcreate Command Examples on Linux.md20150126 CD Audio Grabbers--Graphical Based.md20150126 Improve system performance by moving your log files to RAM Using Ramlog.md20150127 How to limit network bandwidth on Linux.md20150127 LinSSID--A Graphical Wi-Fi Scanner for Linux.md20150203 How To Install KDE Plasma 5.2 In Ubuntu 14.10.md20150205 How To Use Smartphones Like Weather Conky In Linux.md20150205 Linux Basics--Assign Multiple IP Addresses To Single Network Interface Card On CentOS 7.md20150211 Best Known Linux Archive or Compress Tools.md20150211 How To Protect Ubuntu Server Against the GHOST Vulnerability.md20150309 15 Basic 'ls' Command Examples in Linux.md
sources
share
20150323 Papyrus--An Open Source Note Manager.md20150323 Red Hat Developer Toolset 3.1 beta arrives.md20150323 Square 2.0 Icon Pack Is Twice More Beautiful.md20150324 How to Install Telegram Messenger Application on Linux.md20150326 Mydumper--Mysql Database Backup tool.md
talk
tech
20150227 How to Install Lightweight Budgie v8 Desktop in Ubuntu 14.04.md20150302 How to Manage KVM Virtual Environment using Commandline Tools in Linux.md20150320 Locate Stolen laptops and Smart phones Using Prey Tool in Ubuntu.md20150323 How to enable ssh login without entering password.md20150323 How to set up networking between Docker containers.md20150323 Linux FAQs with Answers--How to install and access CentOS remote desktop on VPS.md20150324 7 Quirky' ls' Command Tricks Every Linux User Should Know.md20150324 How to Host Open Source Code Repository in github.md20150324 How to Interactively Create a Docker Container.md20150326 A Peep into Process Management Commands in Linux.md20150326 How to set up server monitoring system with Monit.md
translated
share
talk
tech
20150104 How to debug a C or C++ program with Nemiver debugger.md20150121 How to Monitor Network Usage with nload in Linux.md20150126 Improve system performance by moving your log files to RAM Using Ramlog.md20150227 How to Install Lightweight Budgie v8 Desktop in Ubuntu 14.04.md20150302 How to Manage KVM Virtual Environment using Commandline Tools in Linux.md20150320 Locate Stolen laptops and Smart phones Using Prey Tool in Ubuntu.md20150323 Linux FAQs with Answers--How to compress JPEG images from the command line on Linux.md20150324 4 Tools to Securely Delete Files from Linux.md20150324 Prips--Print IP address on a given range.md
@ -0,0 +1,110 @@
|
||||
使用Nemiver调试器来调试 C/C++ 程序
|
||||
================================================================================
|
||||
|
||||
如果你读过我写的[使用GDB命令行调试器调试C/C++程序][1],你就会明白一个调试器对一段C/C++程序来说有多么的重要和有用。然而,如果一个像GDB这样的命令行对你而言听起来更像一个问题而不是一个解决方案的话,那么你也许会对Nemiver更感兴趣。[Nemiver][2] 是一款基于 GTK+ 的用于C/C++程序的图形化的独立调试器,它以GDB作为其后端。最令人赞赏的是其速度和稳定性,Nemiver是一个非常可靠,具备许多优点的调试工具。
|
||||
|
||||
### Nemiver的安装 ###
|
||||
|
||||
基于Debian发行版,它的安装时非常直接简单,如下:
|
||||
|
||||
$ sudo apt-get install nemiver
|
||||
|
||||
在Arch Linux中安装如下:
|
||||
|
||||
$ sudo pacman -S nemiver
|
||||
|
||||
在Fedora中安装如下:
|
||||
|
||||
$ sudo yum install nemiver
|
||||
|
||||
如果你选择自己编译,[GNOME 网站][3]上有最新源码包。
|
||||
|
||||
最令人欣慰的是,它能够很好地与GNOME环境像结合。
|
||||
|
||||
### Nemiver的基本用法 ###
|
||||
|
||||
启动Nemiver的命令:
|
||||
|
||||
$ nemiver
|
||||
|
||||
你也可以通过执行一下命令来启动:
|
||||
|
||||
$ nemiver [需要调试的可执行程序的路径]
|
||||
|
||||
注意,如果在调试模式下编译程序(在 GCC 中使用 -g 选项)将会对 nemiver 更有帮助。
|
||||
|
||||
还有一个优点是Nemiver的加载很快,所以你马上就可以看到主屏幕的默认布局。
|
||||
|
||||
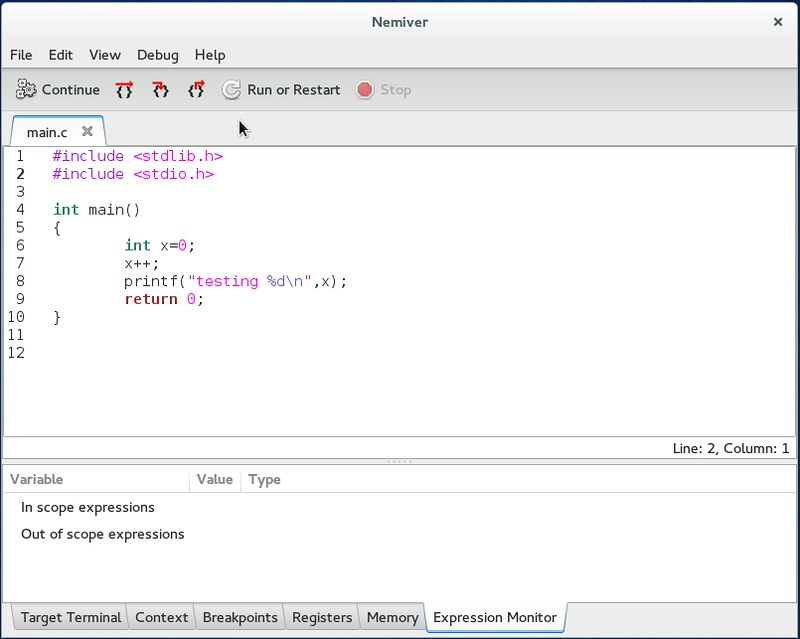
|
||||
|
||||
默认情况下,断点通常位于主函数的第一行。这样就可以空出时间让你去认识调试器的基本功能:
|
||||
|
||||

|
||||
|
||||
- 执行到下一行 (按键是F6)
|
||||
- 执行到函数内部即停止(F7)
|
||||
- 执行到函数外部即停止(Shift+F7)
|
||||
|
||||
不过我个人喜欢“Run to cursor(运行至光标所在行)”,该选项使你的程序准确的运行至你光标所在行,它的默认按键是F11。
|
||||
|
||||
断点是很容易使用的。最快捷的方式是在一行代码上按下F8来设置一个断点。但是Nemiver在“Debug”菜单下也有一个更复杂的菜单,它允许你在一个特定的函数,某一行,二进制文件中的位置,或者类似异常、分支或者exec的事件上设置断点。
|
||||
|
||||
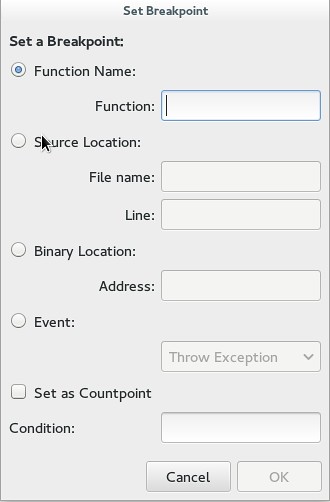
|
||||
|
||||
你也可以通过追踪来查看一个变量。在“Debug”中,你可以用一个表达式的名字来检查它的值,然后也可以通过将其添加到列表中以方便访问。这可能是最有用的一个功能,虽然我从未有兴趣将鼠标悬停在一个变量来获取它的值。值得注意的是,虽然鼠标悬停可以取到值,如果想要让它更好地工作,Nemiver是可以看到结构并给出所有成员的变量的赋值。
|
||||
|
||||
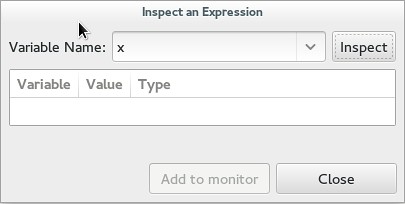
|
||||
|
||||
谈到方便地访问信息,我也非常欣赏这个程序的布局。默认情况下,代码在上半部分,功能区标签在下半部分。这可以让你访问终端的输出、上下文追踪器、断点列表、注册器地址、内存映射和变量控制。但是请注意在“Edit”-“Preferences”-“Layout”下你可以选择不同的布局,包括一个可以修改的动态布局。
|
||||
|
||||

|
||||
|
||||
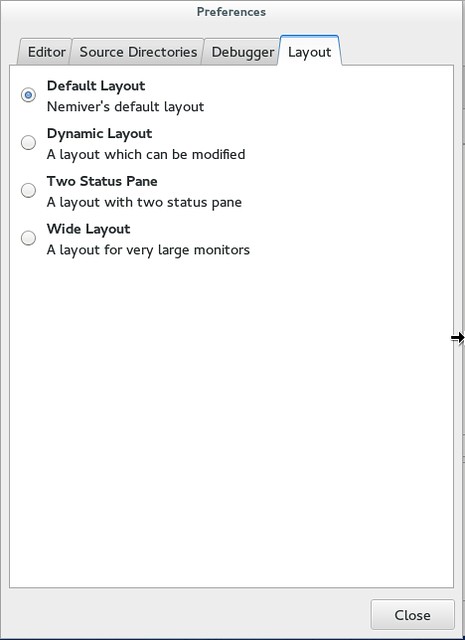
|
||||
|
||||
自然,当你设置了全部断点,观察点和布局,您可以在“File”菜单下很方便地保存该会话,以便你下次打开时恢复。
|
||||
|
||||
### Nemiver的高级用法 ###
|
||||
|
||||
到目前为止,我们讨论的都是Nemiver的基本特征,例如,你马上开始调试一个简单的程序需要了解什么。如果你有更高的需求,特别是对于一些更加复杂的程序,你应该会对接下来提到的这些特征更感兴趣。
|
||||
|
||||
#### 调试一个正在运行的进程 ####
|
||||
|
||||
Nemiver允许你驳接到一个正在运行的进程进行调试。在“File”菜单,你可以筛选出正在运行的进程,并驳接到某个进程。
|
||||
|
||||

|
||||
|
||||
#### 通过TCP连接远程调试一个程序 ####
|
||||
|
||||
Nemiver支持远程调试,你可以在一台远程机器上设置一个轻量级调试服务器,然后你在另外一台机器上启动 nemiver 去调试运行在调试服务器上的程序。如果出于某些原因,你不能在远程机器上很好地驾驭 Nemiver或者GDB,那么远程调试对于你来说将非常有用。在“File”菜单下,指定二进制文件、共享库位置、远程地址和端口。
|
||||
|
||||
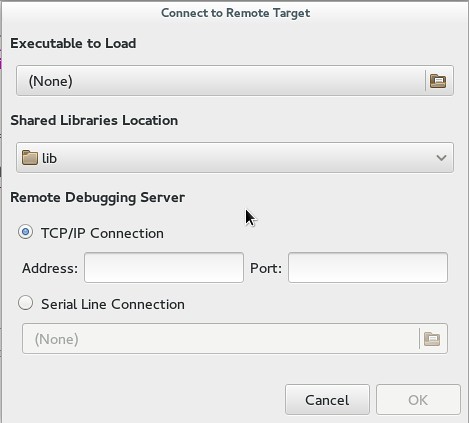
|
||||
|
||||
#### 使用你的GDB二进制程序进行调试 ####
|
||||
|
||||
如果你的Nemiver是自行编译的,你可以在“Edit(编辑)”-“Preferences(首选项)”-“Debug(调试)”下给GDB指定一个新的位置。如果你想在Nemiver下使用定制版本的GDB,那么这个选项对你来说是非常实用的。
|
||||
|
||||
#### 跟随一个子进程或者父进程 ####
|
||||
|
||||
当你的程序分支时,Nemiver是可以设置为跟随子进程或者父进程的。想激活这个功能,请到“Debugger”下面的“Preferences(首选项)”。
|
||||
|
||||
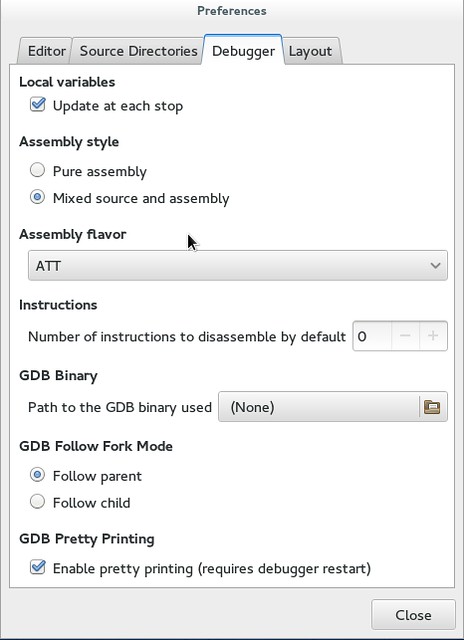
|
||||
|
||||
总而言之,Nemiver大概是我最喜欢的不在IDE里面的调试程序。在我看来,它甚至可以击败GDB,它和命令行程序一样深深吸引了我。所以,如果你从未使用过的话,我会强烈推荐你使用。我十分感谢它背后的开发团队给了我这么一个可靠、稳定的程序。
|
||||
|
||||
你对Nemiver有什么见解?你是否也考虑它作为独立的调试工具?或者仍然坚持使用IDE?让我们在评论中探讨吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/debug-program-nemiver-debugger.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[disylee](https://github.com/disylee)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/adrien
|
||||
[1]:http://linux.cn/article-4302-1.html
|
||||
[2]:https://wiki.gnome.org/Apps/Nemiver
|
||||
[3]:https://download.gnome.org/sources/nemiver/0.9/
|
||||
[4]:http://xmodulo.com/recommend/linuxclibook
|
||||
@ -2,13 +2,13 @@
|
||||
================================================================================
|
||||
**Git**是一款注重速度、数据完整性、分布式支持和非线性工作流的分布式版本控制工具。Git最初由Linus Torvalds在2005年为Linux内核开发而设计,如今已经成为被广泛接受的版本控制系统。
|
||||
|
||||
和其他大多数分布式版本控制系统比起来,不像大多数客户端-服务端的系统,每个Git工作目录是一个完整的仓库,带有完整的历史记录和完整的版本跟踪能力,不需要依赖网络或者中心服务器。像Linux内核一样,Git意识在GPLv2许可证下的免费软件。
|
||||
和其他大多数分布式版本控制系统比起来,不像大多数客户端-服务端的系统,每个Git工作目录是一个完整的仓库,带有完整的历史记录和完整的版本跟踪能力,不需要依赖网络或者中心服务器。像Linux内核一样,Git也是在GPLv2许可证下分发的自由软件。
|
||||
|
||||
本篇教程我会演示如何安装gitlit服务器。gitlit的最新稳定版是1.6.2。[Gitblit][1]是一款开源、纯Java开发的用于管理浏览和服务的[Git][2]仓库。它被设计成一款为希望托管中心仓库的小工作组服务的工具。
|
||||
本篇教程我会演示如何安装 gitlit 服务器。gitlit的最新稳定版是1.6.2。[Gitblit][1]是一款开源、纯Java开发的用于管理、浏览和提供[Git][2]仓库服务的软件。它被设计成一款为希望托管中心仓库的小型工作组服务的工具。
|
||||
|
||||
mkdir -p /opt/gitblit; cd /opt/gitblit; wget http://dl.bintray.com/gitblit/releases/gitblit-1.6.2.tar.gz
|
||||
|
||||
### 列出目录: ###
|
||||
### 列出解压后目录内容: ###
|
||||
|
||||
root@vps124229 [/opt/gitblit]# ls
|
||||
./ docs/ gitblit-stop.sh* LICENSE service-ubuntu.sh*
|
||||
@ -21,7 +21,7 @@
|
||||
|
||||
### 启动gitlit服务: ###
|
||||
|
||||
### 通过service命令: ###
|
||||
**通过service命令:**
|
||||
|
||||
root@vps124229 [/opt/gitblit]# cp service-centos.sh /etc/init.d/gitblit
|
||||
root@vps124229 [/opt/gitblit]# chkconfig --add gitblit
|
||||
@ -29,7 +29,7 @@
|
||||
Starting gitblit server
|
||||
.
|
||||
|
||||
### 手动启动: ###
|
||||
**手动启动:**
|
||||
|
||||
root@vps124229 [/opt/gitblit]# java -jar gitblit.jar --baseFolder data
|
||||
2015-01-10 09:16:53 [INFO ] *****************************************************************
|
||||
@ -108,15 +108,15 @@
|
||||
|
||||
打开浏览器,依据你的配置进入**http://localhost:8080** 或者 **https://localhost:8443**。 输入默认的管理员授权:**admin / admin** 并点击**Login** 按钮
|
||||
|
||||

|
||||

|
||||
|
||||
### 添加用户: ###
|
||||
|
||||

|
||||

|
||||
|
||||
添加仓库:
|
||||
###添加仓库:###
|
||||
|
||||

|
||||

|
||||
|
||||
### 用命令行创建新的仓库: ###
|
||||
|
||||
@ -140,7 +140,7 @@ via: http://www.unixmen.com/install-gitblit-ubuntu-fedora-centos/
|
||||
|
||||
作者:[M.el Khamlichi][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,42 +1,42 @@
|
||||
在短短几个小时里拿回自己数据的隐私和控制权:为自己和朋友们搭建私有云
|
||||
权威指南:构建个人私有云,拿回你的数据隐私的控制权!
|
||||
================================================================================
|
||||
8年里40'000多次搜索!这是我的Google搜索历史。你的呢?(可以在[这里][1]自己找一下)有经过这么长时间积累下来的这么多数据点,Google已经能非常精确的推测你对什么感兴趣,曾经的想法,担忧过的事情,以及从你第一次获得Google帐号后这些年里所有这些的变化。
|
||||
8年里40000多次搜索!这是我的Google搜索历史。你的呢?(可以在[这里][1]自己找一下)有经过这么长时间积累下来的这么多数据点,Google已经能非常精确的推测你对什么感兴趣、曾经的想法、担忧过的事情,以及从你第一次获得Google帐号后这些年里所有这些的变化!
|
||||
|
||||
### 很多非常私人的信息不受自己控制地存储在世界范围内的服务器上 ###
|
||||
## 很多非常私人的信息不受自己控制地存储在世界范围内的服务器上 ##
|
||||
|
||||
比如说你也像我一样从2006年到2013年都是Gmail用户,意味着你收到了30'000+的电子邮件以及在这7年里写了差不多5000封电子邮件。这些发送或收到的电子邮件里有很多是非常私人的,私人到你甚至不希望自己的家人或好友能系统地查看。也许你还写过一些草稿邮件,因为最后一分钟改变主意而从没发出去。但是尽管你从未发出去,这些邮件仍然保存在服务器上的某个地方。结论是,说Google服务器比你最亲密的朋友或家人都更了解你的个人生活一点也不过分。
|
||||
比如说你也像我一样从2006年到2013年都是Gmail用户,意味着你收到了30000封以上的电子邮件,以及在这7年里写了差不多5000封电子邮件。这些发送或收到的电子邮件里有很多是非常私人的,私人到你甚至不希望自己的家人或好友可以系统地查看。也许你还写过一些草稿邮件,因为最后一分钟改变主意而从没发出去。但是尽管你从未发出去,这些邮件仍然保存在服务器上的某个地方。结论是,说Google服务器比你最亲密的朋友或家人都更了解你的个人生活一点也不过分。
|
||||
|
||||
从统计数据来看,可以很安全地赌你拥有一部智能手机。如果不使用联系人应用的话手机将基本没法用,而它默认会将你的联系人信息保存到Google服务器上的Google联系人里。所以,现在Google不仅知道了你的电子邮件,还有了你的离线联系人:你喜欢打给谁,谁来过电话,你发过短信给谁,以及发了些什么。你也不需要听我的片面之词,可以自己检查一下,看看你开放给类似Google Play服务的一些应用的权限,用来读取来电信息以及收到的短信。你是否还会用到手机里自带的日历应用?除非你在设置日程的时候明确地去掉,那么Google将精确地知道你将要做什么,一天里的每个时段,每一天,每一年。用iPhone代替Android手机也是一样的,只是Apple会代替Google来掌握你的往来邮件,联系人和日程计划。
|
||||
从统计数据来看,我可以很保险地打赌你拥有一部智能手机。如果不使用联系人应用的话手机将基本没法用,而它默认会将你的联系人信息保存到Google服务器上的Google联系人里。所以,现在Google不仅知道了你的电子邮件,还有了你的离线联系人:你喜欢打给谁、谁来过电话、你发过短信给谁,以及发了些什么。你也不需要听我的片面之词,可以自己检查一下,看看你开放给类似Google Play服务的一些应用的权限,用来读取来电信息以及收到的短信。你是否还会用到手机里自带的日历应用?除非你在设置日程的时候明确地去掉同步,那么Google将精确地知道你将要做什么,一天里的每个时段、每一天、每一年。用iPhone代替Android手机也是一样的,只是Apple会代替Google来掌握你的往来邮件、联系人和日程计划。
|
||||
|
||||
你是否还会非常小心地同步自己的联系人信息,在你朋友,同事或家人换工作或换服务商的时候更新他们的电子邮件地址和手机号?这给Google提供了一副你社交网络的非常精确的,最新的图片。还有你非常喜欢手机的GPS功能,经常配合Google地图使用。这意味着Google不仅能从日程里知道你在干什么,还知道你在哪儿,住在哪儿,在哪儿工作。然后再关联用户之间的GPS位置信息,GOogle还能知道你现在可能正在和哪些人来往。
|
||||
你是否还会非常小心地同步自己的联系人信息,在你朋友,同事或家人换工作或换服务商的时候更新他们的电子邮件地址和手机号?这给Google提供了一副你的社交网络的非常精确的、最新的描绘。还有你非常喜欢手机的GPS功能,经常配合Google地图使用。这意味着Google不仅能从日程里知道你在干什么,还知道你在哪儿、住在哪儿、在哪儿工作。然后再关联用户之间的GPS位置信息,Google还能知道你现在可能正在和哪些人来往。
|
||||
|
||||
### 这种泄漏自己私人信息的日常爱好会以一种甚至没人能够预测的方式影响你的生活 ###
|
||||
## 这种泄漏自己私人信息的日常爱好会以一种甚至没人能够预测的方式影响你的生活 ##
|
||||
|
||||
总结一下,如果你是一个普通的因特网用户,Google拥有过去差不多10年里你最新的,深度的信息,关于你的兴趣,忧虑,热情,疑问。它还收集了一些你很私人的信息(电子邮件,短信),精确到小时的你的日常活动和位置,一副你社交网络的高品质图片。关于你的如此私密的数据,很可能已经超越了你最亲密的朋友,家人或爱人对你的了解。
|
||||
总结一下,如果你是一个普通的因特网用户,Google拥有过去差不多10年里你最新的、深度的信息,关于你的兴趣、忧虑、热情、疑问。它还收集了一些你很私人的信息(电子邮件、短信),精确到小时的你的日常活动和位置,一副你社交网络的高精度的描绘。关于你的如此私密的数据,很可能已经超越了你最亲密的朋友,家人或爱人对你的了解。
|
||||
|
||||
不敢想象把这些深度的个人信息交给完全陌生的人,就好像把这些信息拷到一个U盘里,然后随便放到某个咖啡厅的桌上,留张纸条说“Olivier Martin的个人数据,请随便”。谁知道什么人会拿到它以及用来干嘛?然而,我们毫不犹豫地把自己的主要信息交给那些对我们的数据很感兴趣的IT公司的陌生人(这是他们制造面包的材料)以及[世界级的数据分析专家][2]手里,也许只是因为我们在点击那个绿色的'接受'按钮时根本没有想这么多。
|
||||
|
||||
有这么多的高质量信息,这么多年里,Google可能会比你希望自我了解的更了解你自己:尼玛,回想我过去的数字生活,我已经不记得5年前发出的邮件里的一半了。我很高兴能重新发现早在2005年对马克思主义的兴趣以及第二年加入了[ATTAC][3](一个致力于通过征收金融交易税来限制投机和改善社会公平的组织)。天知道为什么我竟然在2007年这么喜欢跳舞。这些都是无关紧要的信息(你不要指望我能爆出什么猛料,不会吧?;-)。但是,连接起这些高质量数据点,关于你生活的方方面面(做什么,什么时候,和谁一起,在哪里,...),并跨越这么长时间间隔,应该能推测出你的未来状态。比如说,根据一个17岁女孩的购物习惯,超市甚至可以在他父亲听说之前断定这个女孩怀孕了([真实故事][4])。谁知道通过像Google所掌握的这些远远超出购物习惯的高质量数据能做些什么?连接起这些点,也许有人能预测你未来几年里口味或政治观点的变化。如今,[你从未听过的公司声称拥有你500项数据点][5],包括宗教信仰,性取向和政治观点。提到政治,如果说你决定今后10年内进入政坛会怎么样?你的生活会改变,你的观点也一样,甚至你有时候会有所遗忘,但是Google不会。那你会不会担心你的对手会接触一些可以从Google访问你数据的人并会从你过去这些年里积累的个人数据深渊里挖出一些猛料呢?[就像最近Sony被黑][6]一样,多久以后会轮到Google或Facebook,以致让你的个人信息最终永远暴露?
|
||||
有这么多的高质量信息,这么多年里,Google可能会比你希望自我了解的更了解你自己:尼玛,回想我过去的数字生活,5年前发出的邮件里有一半我已经不记得了。我很高兴能重新发现早在2005年对xxx主义的兴趣以及第二年加入了[ATTAC][3](一个致力于通过征收金融交易税来限制投机和改善社会公平的组织)。天知道为什么我竟然在2007年这么喜欢跳舞。这些都是无关紧要的信息(你不指望我能爆出什么猛料,是吧?;-)。但是,连接起这些高质量数据点,关于你生活的方方面面(做什么、什么时候、和谁一起、在哪里,...),并跨越这么长时间间隔,应该能推测出你的未来状态。比如说,根据一个17岁女孩的购物习惯,超市甚至可以在他父亲听说之前断定这个女孩怀孕了(这是一个[真实的故事][4])。谁知道通过像Google所掌握的这些远远超出购物习惯的高质量数据能做些什么?连接起这些点,也许有人能预测你未来几年里口味或观点的变化。如今,[你从未听过的公司声称拥有你500项数据点][5],包括宗教信仰、性取向和政治观点。提到政治,如果说你决定今后10年内进入政坛会怎么样?你的生活会改变,你的观点也一样,甚至你有时候会有所遗忘,但是Google不会。那你会不会担心你的对手会接触一些可以从Google访问你数据的人并会从你过去这些年里积累的个人数据深渊里挖出一些猛料呢?[就像最近Sony被黑][6]一样,多久以后会轮到Google或Facebook,以致让你的个人信息最终永远暴露?
|
||||
|
||||
我们大多数人把自己的个人数据托付给这些公司的一个原因就是它们提供免费服务。但是真的免费吗?一般的Google帐号的价值根据评估方式不同会有些差别:你花在写邮件上的时间占到[1000美元/年][7],你的帐号对于广告产业的价值差不多在[220美元/年][8]到[500美元/年][9]之间。所以这些服务并不是真的免费:会通过广告和我们的数据在未来的一些未知使用来间接付费。
|
||||
|
||||
我写的最多的是Google,这是因为这是我托付个人数字信息的,以及目前我所知道做的最好的公司。但是我也提到过Apple或Facebook。这些公司通过它们在设计,工程和我们(曾经)喜欢每天使用的服务方面的神奇进步实实在在地改变了世界。但是这并不是说我们应该把所有我们最私人的个人数据堆积到它们的服务器上并把我们的数字生活托付给它们:潜在的危害实在太大了。
|
||||
我写的最多的是Google,这是因为这是我托付个人数字信息的,以及目前我所知道做的最好的公司。但是我也提到过Apple或Facebook。这些公司通过它们在设计、工程和我们(曾经)喜欢每天使用的服务方面的神奇进步实实在在地改变了世界。但是这并不是说我们应该把所有我们最私人的个人数据堆积到它们的服务器上并把我们的数字生活托付给它们:潜在的危害实在太大了。
|
||||
|
||||
### 只要5小时,拿回自己以及关心的人的隐私权 ###
|
||||
## 只要5小时,拿回自己以及关心的人的隐私权 ##
|
||||
|
||||
并不是一定要这样做。你可以生活在21世纪,拿着智能手机,每天都用电子邮件和GPS,却仍然可以保留自己的隐私。你所需要的就是拿回自己个人数据的控制权:邮件、日程、联系人、文件,等等。[Prism-Break.org][10]网站上列出了一些能帮你掌握个人数据命运的软件。除此以外,控制自己个人数据的最安全和最有效的方式是架设自己的服务器并搭建自己的云。不过你也许只是没有时间或精力去研究具体该怎么做以及如何让它能流畅工作。
|
||||
但是事实并不是一定必须这样的。你可以生活在21世纪,拿着智能手机,每天都用电子邮件和GPS,却仍然可以保留自己的隐私。你所需要的就是拿回自己个人数据的控制权:邮件、日程、联系人、文件,等等。[Prism-Break.org][10]网站上列出了一些能帮你掌握个人数据命运的软件。除此以外,控制自己个人数据的最安全和最有效的方式是架设自己的服务器并搭建自己的云。不过你也许只是没有时间或精力去研究具体该怎么做以及如何让它能流畅工作。
|
||||
|
||||
这也是这篇文章的意义所在。仅仅5个小时内,我们将配置出一台服务器来支撑你的邮件、联系人、日程表和各种文件,为你、你的朋友和你的家人。这个服务器将设计成一个个人数据中心或云,所以你能时刻保留它的完整控制。数据将自动在你的台式机/笔记本、手机和平板之间同步。从根本上来说,**我们将建立一个系统来代替Gmail、Google文件/Dropbox、Google联系人、Google日历和Picasa**。
|
||||
|
||||
为自己做这件事情已经是迈出很大一步了。但是,你个人信息的很大一部分将仍然泄漏出去并保存到硅谷的一些主机上,只是因为和你日常来往的太多人在用Gmail和使用智能手机。所以最好是带上你一些比较亲近的人加入这次探险。
|
||||
为自己做这件事情已经是迈出很大一步了。但是,你个人信息的很大一部分将仍然泄漏出去并保存到硅谷的一些主机上,只是因为和你日常来往的太多人在用Gmail和使用智能手机,所以最好是带上你一些比较亲近的人加入这次探险。
|
||||
|
||||
我们将构建的系统能够
|
||||
我们将构建的系统能够:
|
||||
|
||||
- **支持任意数目的域名和用户**。这样就能轻易地和你的家人朋友共享这台服务器,所以他们也能掌控自己的个人数据,并且还能和你一起分摊服务费用。和你一起共享服务器的人可以使用他们自己的域名或者共享你的。
|
||||
- **允许你从任意网络发送和接收电子邮件**,需要成功登录服务器之后。这样,你可以通过任意的邮件地址,任意设备(台式机、手机、平板),任意网络(家里、公司、公共网络、...)来发送电子邮件。
|
||||
- **允许你从任意网络发送和接收电子邮件**,需要成功登录服务器之后。这样,你可以通过任意的邮件地址、任意设备(台式机、手机、平板)、任意网络(家里、公司、公共网络、...)来发送电子邮件。
|
||||
- **在发送和接收邮件的时候加密网络数据**,这样,你不信任的人不能钓出你的密码,也不能看到你的私人邮件。
|
||||
- **提供最先进的反垃圾邮件技术**,结合了已知垃圾邮件黑名单,自动灰名单,和自适应垃圾邮件过滤。如果邮件被误判了只需要简单地把它拖入或拖出垃圾目录就可以重新配置垃圾邮件过滤器。而且,服务器还会为基于社区的反垃圾邮件努力做出贡献。
|
||||
- **一段时间里只需要几分钟的维护**,基本上只是安装安全更新和简单地检查一下服务器日志。添加一个新的邮件地址只需要在数据库中插入一条记录。除此之外,你可以忘记它的存在过自己的生活。我在14个月之前搭建了本文描述的这个系统,从那以后就一直顺利运行。所以我完全把它给忘了,直到我最近觉得随便按下手机上的‘检查邮件’会导致电子一路跑到冰岛(我放置服务器的地方)再回来的想法有点好笑才想起来。
|
||||
- **提供最先进的反垃圾邮件技术**,结合了已知垃圾邮件黑名单、自动灰名单、和自适应垃圾邮件过滤。如果邮件被误判了只需要简单地把它拖入或拖出垃圾目录就可以重新调校垃圾邮件过滤器。而且,服务器还会为基于社区的反垃圾邮件努力做出贡献。
|
||||
- **一段时间里只需要几分钟的维护**,基本上只是安装安全更新和简单地检查一下服务器日志。添加一个新的邮件地址只需要在数据库中插入一条记录。除此之外,你可以忘记它的存在过自己的生活。我在14个月之前搭建了本文描述的这个系统,从那以后就一直顺利运行。所以我完全把它给忘了,直到我最近觉得随便按下手机上的‘检查邮件’会导致电子信号一路跑到冰岛(我放置服务器的地方)再回来的想法有点好笑才想起来。
|
||||
|
||||
要完成这篇文章里的工作,你需要一点基本的技术能力。如果你知道SMTP和IMAP的区别,什么是DNS,以及对TCP/IP有基本了解的话,就够了。你还将需要一点基本的Unix知识(在命令行下和文件一起工作,基本的系统管理)。然后你需要花总共5小时时间来搭建。
|
||||
|
||||
@ -49,7 +49,7 @@
|
||||
- [使用Owncloud提供日历,联系人,文件服务并配置webmail][15]
|
||||
- [在云上同步你的设备][16]
|
||||
|
||||
### 这篇文章是受之前工作的启发并以之为基础 ###
|
||||
## 这篇文章是受之前工作的启发并以之为基础 ##
|
||||
|
||||
本文很大程度参考了两篇文章,由[Xavier Claude][17]和[Drew Crawford][18]写的关于架设私有邮件服务器的介绍。
|
||||
|
||||
@ -62,13 +62,13 @@
|
||||
- 我增加了webmail。
|
||||
- 我增加了设定云服务器的部分,不仅能收发邮件还能管理文件,地址本/联系人(邮件地址,电话号码,生日,等等等),日程表和图片,供所有设备访问使用。
|
||||
|
||||
### 申请一个虚拟私人服务器,一个域名,并把它们配置好 ###
|
||||
## 申请一个虚拟私人服务器,一个域名,并把它们配置好 ##
|
||||
|
||||
让我们从设置基础设施开始:我们的虚拟私人主机和我们的域名。
|
||||
|
||||
我用过[1984.is][19]和[Linode][20]提供的虚拟私人主机(VPS),体验非常好。在本文中,我们将使用**Debian Wheezy**,这个在1984和Linode都提供了已经做好的映像文件可以直接布置到你的VPS上。我喜欢1984是因为它的服务器在冰岛,也是唯一使用可再生能源(地热和水力发电)的地方,目前还没有影响过气候变化,不像[大多数美国数据中心目前大多数依赖于烧煤的火力发电站][21]。而且,他们注重[民权,透明,自由][22]以及[免费软件][23]。
|
||||
|
||||
最好是在服务器上创建一个文件用来保存后面要用到的各种密码(用户账号,邮件账号,云帐号,数据库帐号)。当然最好是加密一下(可以用[GnuPG][24]),这样就算用来设定服务器的电脑被偷了或被入侵了,你的服务器就不会那么容易被攻击。
|
||||
最好是在服务器上创建一个文件用来保存后面要用到的各种密码(用户账号、邮件账号、云帐号、数据库帐号)。当然最好是加密一下(可以用[GnuPG][24]),这样就算用来设定服务器的电脑被偷了或被入侵了,你的服务器就不会那么容易被攻击。
|
||||
|
||||
关于注册域名,我已经使用[grandi][25]的服务超过10年了,也很满意。在本文中,我们将开辟一个叫**jhausse.net**的域名。然后在上面增加一个叫**cloud.jhausse.net**的二级域名,并绑定MX纪录。在完成之后,设置比较短的纪录生存时间(TTL)比如300秒,这样你在设置服务器的时候,可以修改你的域并很快测试到结果。
|
||||
|
||||
@ -78,7 +78,7 @@
|
||||
|
||||
adduser roudy
|
||||
|
||||
然后,在文件**/etc/ssh/sshd_config**中设置
|
||||
然后,在文件**/etc/ssh/sshd\_config**中设置
|
||||
|
||||
PermitRootLogin no
|
||||
|
||||
@ -90,7 +90,7 @@
|
||||
|
||||
cloud
|
||||
|
||||
然后,编辑ssh服务的公钥文件**/etc/ssh/ssh_host_rsa_key.pub, /etc/ssh/ssh_host_dsa_key.pub, /etc/ssh/ssh_host_ecdsa_key.pub**,这样文件末尾可以反映你的主机名,比如**root@cloud**。然后重启系统保证主机名在系统的每个需要它的角落都生效了。
|
||||
然后,编辑ssh服务的公钥文件**/etc/ssh/ssh\_host\_rsa\_key.pub, /etc/ssh/ssh\_host\_dsa\_key.pub, /etc/ssh/ssh\_host\_ecdsa\_key.pub**,这样文件末尾可以反映你的主机名,比如**root@cloud**。然后重启系统保证主机名在系统的每个需要它的角落都生效了。
|
||||
|
||||
reboot
|
||||
|
||||
@ -103,15 +103,15 @@
|
||||
apt-get autoremove
|
||||
apt-get install vim
|
||||
|
||||
我喜欢使用vim远程编辑配置文件。打开自动语法高亮会很有帮助。添加下面这一行到**~/.vimrc**文件中。
|
||||
我喜欢使用vim远程编辑配置文件。打开vim 的自动语法高亮会很有帮助。添加下面这一行到**~/.vimrc**文件中。
|
||||
|
||||
syn on
|
||||
|
||||
### 设置postfix和dovecot来收发电子邮件 ###
|
||||
## 设置postfix和dovecot来收发电子邮件 ##
|
||||
|
||||
apt-get install postfix postfix-mysql dovecot-core dovecot-imapd dovecot-mysql mysql-server dovecot-lmtpd postgrey
|
||||
|
||||
在[Postfix][27]的配置菜单里,选择**因特网站点**,把系统邮件名设为**jhausse.net**。
|
||||
在[Postfix][27]的配置菜单里,选择`Internet Site`,设置这个系统的邮件名称为**jhausse.net**。
|
||||
|
||||
现在开始添加一个数据库用于保存主机上管理的域名列表,和每个域名下的用户列表(同时也包括他们各自的密码),以及邮件别名列表(用于从一个地址往另一个地址转发邮件)。
|
||||
|
||||
@ -142,14 +142,14 @@
|
||||
FOREIGN KEY (domain_id) REFERENCES virtual_domains(id) ON DELETE CASCADE
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
|
||||
|
||||
我们将承载**jhausse.net**域名。如果还需要加入其他域名,也没问题。我们也会为每个域名设置一个邮件管理地址,转寄给**roudy@jhausse.net**。
|
||||
这里我们为**jhausse.net**域名提供邮件服务。如果还需要加入其他域名,也没问题。我们也会为每个域名设置一个邮件管理地址(postmaster),转寄给**roudy@jhausse.net**。
|
||||
|
||||
mysql> INSERT INTO virtual_domains (`name`) VALUES ('jhausse.net');
|
||||
mysql> INSERT INTO virtual_domains (`name`) VALUES ('otherdomain.net');
|
||||
mysql> INSERT INTO virtual_aliases (`domain_id`, `source`, `destination`) VALUES ('1', 'postmaster', 'roudy@jhausse.net');
|
||||
mysql> INSERT INTO virtual_aliases (`domain_id`, `source`, `destination`) VALUES ('2', 'postmaster', 'roudy@jhausse.net');
|
||||
|
||||
现在已经添加了一个本地邮件账号**roudy@jhausse.net**。首先,为它生成一个哈希密码:
|
||||
现在已经添加了一个本地邮件账号**roudy@jhausse.net**。首先,为它生成一个密码的哈希串:
|
||||
|
||||
doveadm pw -s SHA512-CRYPT
|
||||
|
||||
@ -157,7 +157,7 @@
|
||||
|
||||
mysql> INSERT INTO `mailserver`.`virtual_users` (`domain_id`, `password`, `email`) VALUES ('1', '$6$YOURPASSWORDHASH', 'roudy@jhausse.net');
|
||||
|
||||
现在我们的域名,别名和用户列表都设置好了,然后开始设置postfix(SMTP服务器,用来发送邮件)。把文件**/etc/postfix/main.cf**替换为下面的内容:
|
||||
现在我们的域名、别名和用户列表都设置好了,然后开始设置postfix(这是一个SMTP服务器,用来发送邮件)。把文件**/etc/postfix/main.cf**替换为下面的内容:
|
||||
|
||||
myhostname = cloud.jhausse.net
|
||||
myorigin = /etc/mailname
|
||||
@ -239,7 +239,7 @@
|
||||
|
||||
如果一切都正常配置了的话,头两个查询应该输出1,第3个查询应该输出**roudy@jhausse.net**,而最后一个应该什么都不输出。
|
||||
|
||||
现在,让我们设置一下dovecot(一个IMAP服务程序,用来在我们的设备上从服务器获取收件箱里的邮件)。编辑文件**/etc/dovecot/dovecot.conf**设置以下参数:
|
||||
现在,让我们设置一下dovecot(一个IMAP服务程序,用来在我们的设备上从服务器获取收到的邮件)。编辑文件**/etc/dovecot/dovecot.conf**设置以下参数:
|
||||
|
||||
# Enable installed protocol
|
||||
# !include_try /usr/share/dovecot/protocols.d/*.protocol
|
||||
@ -253,7 +253,7 @@
|
||||
[...]
|
||||
first_valid_uid = 0
|
||||
|
||||
这样邮件将被保存到目录/var/mail/domainname/username下。注意下这几个选项散布在配置文件的不同位置,有时已经在那里写好了:我们只需要取消注释。文件里的其他设定选项,可以维持原样。在本文后面还有很多文件需要用同样的方式更新设置。在文件**/etc/dovecot/conf.d/10-auth.conf**里,设置以下参数:
|
||||
这样邮件将被保存到目录 /var/mail/domainname/username 下。注意下这几个选项散布在配置文件的不同位置,有时已经在那里写好了:我们只需要取消注释即可。文件里的其他设定选项,可以维持原样。在本文后面还有很多文件需要用同样的方式更新设置。在文件**/etc/dovecot/conf.d/10-auth.conf**里,设置以下参数:
|
||||
|
||||
disable_plaintext_auth = yes
|
||||
auth_mechanisms = plain
|
||||
@ -366,9 +366,10 @@
|
||||
在服务器上,尝试发送邮件给本地用户:
|
||||
|
||||
telnet localhost 25
|
||||
|
||||
EHLO cloud.jhausse.net
|
||||
MAIL FROM:youremail@domain.com
|
||||
rcpt to:roudy@jhausse.net
|
||||
RCPT TO:roudy@jhausse.net
|
||||
data
|
||||
Subject: Hallo!
|
||||
|
||||
@ -397,18 +398,18 @@
|
||||
|
||||
554 5.7.1 <bob@gmail.com>: Relay access denied
|
||||
|
||||
这个没问题:如果服务器能接受这封邮件,那意味着我们架设的postfix是一个对全世界所有垃圾邮件都开放的中继,将完全没法使用。除了'Relay access denied'消息,你也可能会收到这样的响应:
|
||||
这个没问题:如果服务器能接受这封邮件而不是返回如上的拒绝消息,那意味着我们架设的postfix是一个对全世界所有垃圾邮件都开放的中继,这将完全没法使用。除了'Relay access denied'消息,你也可能会收到这样的响应:
|
||||
|
||||
554 5.7.1 Service unavailable; Client host [87.68.61.119] blocked using zen.spamhaus.org; http://www.spamhaus.org/query/bl?ip=87.68.61.119
|
||||
|
||||
意思是你正尝试从一个被标记成垃圾邮件发送者的IP地址连接服务器。我在通过普通的因特网服务提供商(ISP)连接服务器时曾收到过这样的消息。要解决这个问题,可以试着从另一个主机发起连接,比如另外一个你可以SSH登录的主机。另外一种方式是,你可以修改postfix的**main.cf**配置文件,不要使用Spamhous的RBL,重启postfix服务,然后再检查上面的测试是否正常。不管用哪种方式,最重要的是你要确定一个能工作的,因为我们后面马上要测试其他功能。如果你选择了重新配置postfix不使用RBL,别忘了在完成本文后重新开启RBL并重启postfix,以避免收到一些不必要的垃圾邮件。
|
||||
意思是你正尝试从一个被标记成垃圾邮件发送者的IP地址连接服务器。我在通过普通的因特网服务提供商(ISP)连接服务器时曾收到过这样的消息。要解决这个问题,可以试着从另一个主机发起连接,比如另外一个你可以SSH登录的主机。另外一种方式是,你可以修改postfix的**main.cf**配置文件,不要使用Spamhous的RBL,重启postfix服务,然后再检查上面的测试是否正常。不管用哪种方式,最重要的是你要确定一个能工作的,因为我们后面马上要测试其他功能。如果你选择了重新配置postfix不使用RBL,别忘了在完成本文后重新开启RBL并重启postfix,以避免收到一些不必要的垃圾邮件。(LCTT 译者注:在国内可以使用 CASA 的 RBL:cblplus.anti-spam.org.cn,参见:http://www.anti-spam.org.cn/ 。)
|
||||
|
||||
现在,我们试一下往SMTP端口25发送一封有效的邮件,这是一般正常的邮件服务器用来彼此对话的方式:
|
||||
|
||||
openssl s_client -connect cloud.jhausse.net:25 -starttls smtp
|
||||
EHLO cloud.jhausse.net
|
||||
MAIL FROM:youremail@domain.com
|
||||
rcpt to:roudy@jhausse.net
|
||||
RCPT TO:roudy@jhausse.net
|
||||
|
||||
服务器应该有这样的响应
|
||||
|
||||
@ -425,7 +426,7 @@
|
||||
4 UID fetch 1:1 (UID RFC822.SIZE FLAGS BODY.PEEK[])
|
||||
5 LOGOUT
|
||||
|
||||
这里,你应该把mypassword替换为你自己为这个邮件账号设定的密码。如果能正常工作,基本上我们已经拥有一个能接收邮件的邮件服务器了,通过它我们可以在各种设备(PC/笔记本,平板,手机,...)上收取邮件了。但是我们不能把邮件给它发送出去,除非我们自己从服务器发送。现在我们将让postfix为我们转发邮件,但是这个只有成功登录才可以,这是为了保证邮件是由服务器上的某个有效帐号发出来的。要做到这个,我们要打开一个特殊的,全程SSL连接的,SASL鉴权的邮件提交服务。在文件**/etc/postfix/master.cf**里设置下面的参数:
|
||||
这里,你应该把*mypassword*替换为你自己为这个邮件账号设定的密码。如果能正常工作,基本上我们已经拥有一个能接收邮件的邮件服务器了,通过它我们可以在各种设备(PC/笔记本、平板、手机...)上收取邮件了。但是我们不能把邮件给它发送出去,除非我们自己从服务器发送。现在我们将让postfix为我们转发邮件,但是这个只有成功登录才可以,这是为了保证邮件是由服务器上的某个有效帐号发出来的。要做到这个,我们要打开一个特殊的,全程SSL连接的,SASL鉴权的邮件提交服务。在文件**/etc/postfix/master.cf**里设置下面的参数:
|
||||
|
||||
submission inet n - - - - smtpd
|
||||
-o syslog_name=postfix/submission
|
||||
@ -437,7 +438,7 @@
|
||||
-o smtpd_sasl_security_options=noanonymous
|
||||
-o smtpd_recipient_restrictions=permit_sasl_authenticated,reject_non_fqdn_recipient,reject_unauth_destination
|
||||
|
||||
然后重启postfix服务
|
||||
然后重启postfix服务:
|
||||
|
||||
service postfix reload
|
||||
|
||||
@ -446,7 +447,7 @@
|
||||
openssl s_client -connect cloud.jhausse.net:587 -starttls smtp
|
||||
EHLO cloud.jhausse.net
|
||||
|
||||
注意一下服务器建议的'250-AUTH PLAIN'功能,在从端口25连接的时候不会生效。
|
||||
注意一下服务器建议的'250-AUTH PLAIN'功能,在从端口25连接的时候不会出现。
|
||||
|
||||
MAIL FROM:asdf@jkl.net
|
||||
rcpt to:bob@gmail.com
|
||||
@ -494,13 +495,13 @@
|
||||
|
||||
PS:不要忘记再次[试试通过端口25往自己架设的服务器上的帐号发送邮件][29],来验证你已经没有被postgrey阻挡了。
|
||||
|
||||
### 阻止垃圾邮件进入你的收件箱 ###
|
||||
## 阻止垃圾邮件进入你的收件箱 ##
|
||||
|
||||
为了过滤垃圾邮件,我们已经使用了实时黑名单(RBLs)和灰名单(postgrey)。现在我们将增加自适应垃圾邮件过滤来让我们的垃圾邮件过滤能力提高一个等级。这意味着我们将为我们的邮件服务器增加人工智能,这样它就能从经验中学习哪些有件是垃圾哪些不是。我们将使用[dspam][30]来实现这个功能。
|
||||
为了过滤垃圾邮件,我们已经使用了实时黑名单(RBL)和灰名单(postgrey)。现在我们将增加自适应垃圾邮件过滤来让我们的垃圾邮件过滤能力提高一个等级。这意味着我们将为我们的邮件服务器增加人工智能,这样它就能从经验中学习哪些邮件是垃圾哪些不是。我们将使用[dspam][30]来实现这个功能。
|
||||
|
||||
apt-get install dspam dovecot-antispam postfix-pcre dovecot-sieve
|
||||
|
||||
dovecot-antispam是一个安装包,可以在我们发现有邮件被dspan误分类了之后让dovecot重新更新垃圾邮件过滤器。基本上,我们所需要做的就只是把邮件放进或拿出垃圾箱。dovecot-antispam将负责调用dspam来更新过滤器。至于postfix-pcre和dovecot-sieve,我们将分别用它们来把接收的邮件递给垃圾邮件过滤器以及自动把垃圾邮件放入用户的垃圾箱。
|
||||
dovecot-antispam是一个安装包,可以在我们发现有邮件被dspam误分类了之后让dovecot重新更新垃圾邮件过滤器。基本上,我们所需要做的就只是把邮件放进或拿出垃圾箱。dovecot-antispam将负责调用dspam来更新过滤器。至于postfix-pcre和dovecot-sieve,我们将分别用它们来把接收的邮件传递给垃圾邮件过滤器以及自动把垃圾邮件放入用户的垃圾箱。
|
||||
|
||||
在配置文件**/etc/dspam/dspam.conf**里,为以下参数设置相应的值:
|
||||
|
||||
@ -535,7 +536,7 @@ dovecot-antispam是一个安装包,可以在我们发现有邮件被dspan误
|
||||
dovecot unix - n n - - pipe
|
||||
flags=DRhu user=mail:mail argv=/usr/lib/dovecot/deliver -f ${sender} -d ${recipient}
|
||||
|
||||
现在我们将告诉postfix通过dspam来过滤所有提交给服务器端口25(一般的SMTP通信)的新邮件,除非该邮件是从服务器本身发出(permit_mynetworks)。注意下我们通过SASL鉴权提交给postfix的邮件不会通过dspam过滤,因为我们在前面部分里为这种方式设定了独立的提交服务。编辑文件**/etc/postfix/main.cf**将选项**smtpd_client_restrictions**改为如下内容:
|
||||
现在我们将告诉postfix通过dspam来过滤所有提交给服务器端口25(一般的SMTP通信)的新邮件,除非该邮件是从服务器本身发出(permit\_mynetworks)。注意下我们通过SASL鉴权提交给postfix的邮件不会通过dspam过滤,因为我们在前面部分里为这种方式设定了独立的提交服务。编辑文件**/etc/postfix/main.cf**将选项**smtpd\_client\_restrictions**改为如下内容:
|
||||
|
||||
smtpd_client_restrictions = permit_mynetworks, reject_rbl_client zen.spamhaus.org, check_policy_service inet:127.0.0.1:10023, check_client_access pcre:/etc/postfix/dspam_filter_access
|
||||
|
||||
@ -544,11 +545,11 @@ dovecot-antispam是一个安装包,可以在我们发现有邮件被dspan误
|
||||
# For DSPAM, only scan one mail at a time
|
||||
dspam_destination_recipient_limit = 1
|
||||
|
||||
现在我们需要指定我们定义的过滤器。基本上,我们将告诉postfix把所有邮件(/./)通过unix套接字发给dspam。创建一个新文件**/etc/postfix/dspam_filter_access**并把下面一行写进去:
|
||||
现在我们需要指定我们定义的过滤器。基本上,我们将告诉postfix把所有邮件(如下用 /./ 代表)通过unix套接字发给dspam。创建一个新文件**/etc/postfix/dspam\_filter\_access**并把下面一行写进去:
|
||||
|
||||
/./ FILTER dspam:unix:/run/dspam/dspam.sock
|
||||
|
||||
这是postfix部分的配置。现在让我们为dovecot设置垃圾过滤。在文件**/etc/dovecot/conf.d/20-imap.conf**里,修改**imap mail_plugin**插件参数为下面的方式:
|
||||
这是postfix部分的配置。现在让我们为dovecot设置垃圾过滤。在文件**/etc/dovecot/conf.d/20-imap.conf**里,修改**imap mail\_plugin**插件参数为下面的方式:
|
||||
|
||||
mail_plugins = $mail_plugins antispam
|
||||
|
||||
@ -581,7 +582,7 @@ dovecot-antispam是一个安装包,可以在我们发现有邮件被dspan误
|
||||
|
||||
sieve_default = /etc/dovecot/default.sieve
|
||||
|
||||
什么是sieve以及为什么我们需要为所有用户设置一个默认脚本?sieve可以在IMAP服务器上为我们自动处理任务。在我们的例子里,我们想让所有被确定为垃圾的邮件会被移到垃圾箱而不是收件箱里。我们希望这是服务器上所有用户的默认行为;这是为什么我们把这个脚本设为默认脚本。现在让我们来创建这个脚本,建立一个新文件**/etc/dovecot/default.sieve**并写入以下内容:
|
||||
什么是sieve以及为什么我们需要为所有用户设置一个默认脚本?sieve可以在IMAP服务器上为我们自动处理任务。在我们的例子里,我们想让所有被确定为垃圾的邮件移到垃圾箱而不是收件箱里。我们希望这是服务器上所有用户的默认行为;这是为什么我们把这个脚本设为默认脚本。现在让我们来创建这个脚本,建立一个新文件**/etc/dovecot/default.sieve**并写入以下内容:
|
||||
|
||||
require ["regex", "fileinto", "imap4flags"];
|
||||
# Catch mail tagged as Spam, except Spam retrained and delivered to the mailbox
|
||||
@ -603,7 +604,7 @@ dovecot-antispam是一个安装包,可以在我们发现有邮件被dspan误
|
||||
chmod 0640 default.sieve
|
||||
chmod 0750 default.svbin
|
||||
|
||||
最后,我们需要修改dspam要读取的两个postfix配置文件的权限:
|
||||
最后,我们需要修改dspam需要读取的两个postfix配置文件的权限:
|
||||
|
||||
chmod 0644 /etc/postfix/dynamicmaps.cf /etc/postfix/main.cf
|
||||
|
||||
@ -669,21 +670,21 @@ dovecot-antispam是一个安装包,可以在我们发现有邮件被dspan误
|
||||
|
||||
很好!你现在已经为你服务器上的用户配置好自适应垃圾邮件过滤。当然,每个用户将需要在开始的几周里培训过滤器。要标记一则信息为垃圾,只需要在你的任意设备(电脑,平板,手机)上将它移动到叫“垃圾箱”或“废纸篓”的目录里。否则它将被标记为有用。
|
||||
|
||||
### 确保你发出的邮件能通过垃圾邮件过滤器 ###
|
||||
## 确保你发出的邮件能通过垃圾邮件过滤器 ##
|
||||
|
||||
这个部分我们的目标是让我们的邮件服务器能尽量干净地出现在世界上,并让垃圾邮件发送者们更难以我们的名义发邮件。作为附加效果,这也有助于让我们的邮件能通过其他邮件服务器的垃圾邮件过滤器。
|
||||
|
||||
#### 发送者策略框架 ####
|
||||
### 发送者策略框架(SPF) ###
|
||||
|
||||
发送者策略框架(SPF)是你添加到自己服务器区域里的一份记录,声明了整个因特网上哪些邮件服务器能以你的域名发邮件。设置非常简单,使用[microsoft.com][31]上的SPF向导来生成你的SPF记录,然后作为一个TXT记录添加到自己的服务器区域里。看上去像这样:
|
||||
|
||||
jhausse.net. 300 IN TXT v=spf1 mx mx:cloud.jhausse.net -all
|
||||
|
||||
#### 反向PTR ####
|
||||
### 反向PTR ###
|
||||
|
||||
我们[之前][32]在本文里讨论过这个问题,建议你为自己的服务器正确地设置反向DNS,这样对服务器IP地址的反向查询能返回你服务器的实际名字。
|
||||
|
||||
#### OpenDKIM ####
|
||||
### OpenDKIM ###
|
||||
|
||||
当我们激活[OpenDKIM][33]后,postfix会用密钥为每封发出去的邮件签名。然后我们将把这个密钥存储在DNS域中。这样的话,世界上任意一个邮件服务器都能够检验邮件是否真的是我们发出的,或是由垃圾邮件发送者伪造的。让我们先安装opendkim:
|
||||
|
||||
@ -710,7 +711,7 @@ dovecot-antispam是一个安装包,可以在我们发现有邮件被dspan误
|
||||
UMask 022
|
||||
UserID opendkim:opendkim
|
||||
|
||||
我们还需要几个额外的文件,将保存在目录**/etc/opendkim**里:
|
||||
我们还需要几个额外的文件,需保存在目录**/etc/opendkim**里:
|
||||
|
||||
mkdir -pv /etc/opendkim/
|
||||
cd /etc/opendkim/
|
||||
@ -740,7 +741,7 @@ dovecot-antispam是一个安装包,可以在我们发现有邮件被dspan误
|
||||
|
||||
cat mail.txt
|
||||
|
||||
然后把它作为一个TXT记录添加到区域文件里,应该是这样的
|
||||
然后把它作为一个TXT记录添加到区域文件里,应该是类似这样的
|
||||
|
||||
mail._domainkey.cloud1984.net. 300 IN TXT v=DKIM1; k=rsa; p=MIGfMA0GCSqG...
|
||||
|
||||
@ -751,30 +752,30 @@ dovecot-antispam是一个安装包,可以在我们发现有邮件被dspan误
|
||||
non_smtpd_milters = $smtpd_milters
|
||||
milter_default_action = accept
|
||||
|
||||
然后重启相关服务
|
||||
然后重启相关服务:
|
||||
|
||||
service postfix reload
|
||||
service opendkim restart
|
||||
|
||||
现在让我们测试一下能找到我们的OpenDKIM公钥并和私钥匹配:
|
||||
现在让我们测试一下是否能找到我们的OpenDKIM公钥并和私钥匹配:
|
||||
|
||||
opendkim-testkey -d jhausse.net -s mail -k mail.private -vvv
|
||||
|
||||
这个应该返回
|
||||
这个应该返回:
|
||||
|
||||
opendkim-testkey: key OK
|
||||
|
||||
这个你可能需要等一会直到域名服务器重新加载该区域(对于Linode,每15分钟会更新一次)。你可以用**dig**来检查区域是否已经重新加载。
|
||||
|
||||
如果这个没问题,让我们测试一下其他服务器能验证我们的OpenDKIM签名和SPF记录。要做这个,我们可以用[Brandon Checkett的邮件测试][34]。发送一封邮件到[Brandon的网页][34]上提供的测试地址,我们可以在服务器上运行下面的命令
|
||||
如果这个没问题,让我们测试一下其他服务器能验证我们的OpenDKIM签名和SPF记录。要做这个,我们可以用[Brandon Checkett的邮件测试系统][34]。发送一封邮件到[Brandon的网页][34]上提供的测试地址,我们可以在服务器上运行下面的命令
|
||||
|
||||
mail -s CloudCheck ihAdmTBmUH@www.brandonchecketts.com
|
||||
|
||||
在Brandon的网页上,我们应该可以在'DKIM Signature'部分里看到**result = pass**的文字,以及在'SPF Information'部分看到**Result: pass**的文字。如果我们的邮件通过这个测试,只要不加-t开关重新生成OpenDKIM密钥,上传新的密钥到区域文件里,然后重新测试检查是否仍然可以通过这些测试。如果可以的话,恭喜!你已经在你的服务器上成功配置好OpenDKIM和SPF了!
|
||||
|
||||
### 使用Owncloud提供日历,联系人,文件服务并通过Roundcube配置网页邮件 ###
|
||||
## 使用Owncloud提供日历,联系人,文件服务并通过Roundcube配置网页邮件 ##
|
||||
|
||||
既然我们已经拥有了一流的邮件服务器,让我们再为它增加在云上保存通讯录,日程表和文件的能力。这些是[Owncloud][35]所提供的非常赞的服务。在这个弄好后,我们还会设置一个网页邮件,这样就算你没带任何电子设备出去旅行时,或者说在你的手机或笔记本没电的情况下,也可以检查邮件。
|
||||
既然我们已经拥有了一流的邮件服务器,让我们再为它增加在云上保存通讯录,日程表和文件的能力。这些是[Owncloud][35]所提供的非常赞的服务。在这个弄好后,我们还会设置一个网页邮件,这样就算你没带任何电子设备出去旅行时,或者说在你的手机或笔记本没电的情况下,也可以通过网吧来检查邮件。
|
||||
|
||||
安装Owncloud非常直观,而且在[这里][36]有非常好的介绍。在Debian系统里,归根结底就是把owncloud的仓库添加到apt源里,下载Owncloud的发行密钥并安装到apt钥匙链中,然后通过apt-get安装Owncloud:
|
||||
|
||||
@ -784,20 +785,20 @@ dovecot-antispam是一个安装包,可以在我们发现有邮件被dspan误
|
||||
apt-get update
|
||||
apt-get install apache2 owncloud roundcube
|
||||
|
||||
在有提示的时候,选择**dbconfig**然后说你希望**roundcube**使用**mysql**。然后,提供一下mysql的root密码并为roundcube的mysql用户设置一个漂亮的密码。然后,按如下方式编辑roundcube的配置文件**/etc/roundcube/main.inc.php**,这样登录roundcube默认会使用你的IMAP服务器:
|
||||
在有提示的时候,选择**dbconfig**并设置**roundcube**使用**mysql**。然后,提供一下mysql的root密码并为roundcube的mysql用户设置一个漂亮的密码。然后,按如下方式编辑roundcube的配置文件**/etc/roundcube/main.inc.php**,这样登录roundcube默认会使用你的IMAP服务器:
|
||||
|
||||
$rcmail_config['default_host'] = 'ssl://localhost';
|
||||
$rcmail_config['default_port'] = 993;
|
||||
|
||||
现在我们来配置一下apache2网页服务器增加SSL支持,这样我们可以和Owncloud和Roundcube对话时使用加密的方式传输我们的密码和数据。让我们打开Apache的ssl模块:
|
||||
现在我们来配置一下apache2网页服务器增加SSL支持,这样我们可以和Owncloud和Roundcube对话时使用加密的方式传输我们的密码和数据。让我们打开Apache的SSL模块:
|
||||
|
||||
a2enmod ssl
|
||||
|
||||
然后编辑文件**/etc/apache2/ports.conf**并设定以下参数:
|
||||
|
||||
NameVirtualHost *:80
|
||||
Listen 80
|
||||
ServerName www.jhausse.net
|
||||
NameVirtualHost *:80
|
||||
Listen 80
|
||||
ServerName www.jhausse.net
|
||||
|
||||
<IfModule mod_ssl.c>
|
||||
# If you add NameVirtualHost *:443 here, you will also have to change
|
||||
@ -969,9 +970,9 @@ ServerName www.jhausse.net
|
||||
a2ensite default default-ssl roundcube
|
||||
service apache2 restart
|
||||
|
||||
关于网页邮件,可以通过网址**https://webmail.jhausse.net**来访问,基本上能工作。之后使用邮箱全名(例如roudy@jhausse.net)和在本文一开始在邮件服务器数据库里设定的密码登录。第一次连接成功,浏览器会警告说证书没有可靠机构的签名。这个没什么关系,只要添加一个例外。
|
||||
关于网页邮件,可以通过网址**https://webmail.jhausse.net**来访问,基本上能工作。之后使用邮箱全名(例如roudy@jhausse.net)和在本文一开始在邮件服务器数据库里设定的密码登录。第一次连接成功,浏览器会警告说证书没有可靠机构的签名。这个没什么关系,只要添加一个例外即可。
|
||||
|
||||
最后但很重要的是,我们将通过把以下内容你哦个写入**/etc/apache2/sites-available/owncloud**来为Owncloud创建一个虚拟主机。
|
||||
最后但很重要的是,我们将通过把以下内容写入到**/etc/apache2/sites-available/owncloud**来为Owncloud创建一个虚拟主机。
|
||||
|
||||
<IfModule mod_ssl.c>
|
||||
<VirtualHost *:443>
|
||||
@ -1040,33 +1041,33 @@ ServerName www.jhausse.net
|
||||
|
||||
就这些了!现在你已经拥有自己的Google Drive,日程表,联系人,Dropbox,以及Gmail!好好享受下新鲜恢复保护的隐私吧!:-)
|
||||
|
||||
### 在云上同步你的设备 ###
|
||||
## 在云上同步你的设备 ##
|
||||
|
||||
要同步你的邮件,你可以只是用你喜欢的邮件客户端:Android或iOS自带的默认邮件应用,[k9mail][37],或者电脑上的Thunderbird。或者你也可以使用我们设置好的网页邮件。
|
||||
要同步你的邮件,你只需用你喜欢的邮件客户端即可:Android或iOS自带的默认邮件应用,[k9mail][37],或者电脑上的Thunderbird。或者你也可以使用我们设置好的网页邮件。
|
||||
|
||||
在Owncloud的文档里描述了如何与云端同步你的日程表和联系人。在Android系统中,我用的是CalDAV-Sync,CardDAV-Sync应用桥接了手机上Android自带日历以及联系人应用和Owncloud服务器。
|
||||
|
||||
对于文件,有一个叫Owncloud的Android应用可以访问你手机上的文件,然后自动把你拍的图片和视频上传到云中。在你的Mac/PC上访问云端文件也很容易,在[Owncloud文档里有很好的描述][38]。
|
||||
|
||||
### 最后一点提示 ###
|
||||
## 最后一点提示 ##
|
||||
|
||||
在上线后的前几个星期里,最好每天检查一下日志**/var/log/syslog**和**/var/log/mail.log**以保证一切都在顺利运行。在你邀请其他人(朋友,家人,等等)加入你的服务器之前这很重要。他们信任你能很好地架设个人服务器维护他们的数据,但是如果服务器突然崩溃会让他们很失望。
|
||||
|
||||
要添加另一个邮件用户,只要在数据库**mailserver**的**virtual_users**表中增加一行。
|
||||
要添加另一个邮件用户,只要在数据库**mailserver**的**virtual\_users**表中增加一行。
|
||||
|
||||
要添加一个域名,只要在**virtual_domains**表中增加一行。然后更新**/etc/opendkim/SigningTable**为发出的邮件签名,上传OpenDKIM密钥到服务器区域,然后吃哦更年期OpenDKIM服务。
|
||||
要添加一个域名,只要在**virtual_domains**表中增加一行。然后更新**/etc/opendkim/SigningTable**为发出的邮件签名,上传OpenDKIM密钥到服务器区域,然后重启OpenDKIM服务。
|
||||
|
||||
Owncloud有自己的用户数据库,在用管理员帐号登录后可以修改。
|
||||
|
||||
最后,万一在服务器临时崩溃的时候想办法找解决方案很重要。比如说,在服务器恢复之前你的邮件应该送往哪儿?一种方式是找个能帮你做备份MX的朋友,同时你也可以当他的备份MX(看下postfix的配置文件**main.cf**里**relay_domains**和**relay_recipient_maps**里的设定)。与此类似,如果你的服务器被破解然后一个坏蛋把你所有文件删了怎么办?对于这个,考虑增加一个常规备份系统就很重要了。Linode提供了备份选项。在1984.is里,我用crontabs和scp做了一个基本但管用的自动备份系统。
|
||||
最后,万一在服务器临时崩溃的时候想办法找解决方案很重要。比如说,在服务器恢复之前你的邮件应该送往哪儿?一种方式是找个能帮你做备份MX的朋友,同时你也可以当他的备份MX(看下postfix的配置文件**main.cf**里**relay\_domains**和**relay\_recipient\_maps**里的设定)。与此类似,如果你的服务器被破解然后一个坏蛋把你所有文件删了怎么办?对于这个,考虑增加一个常规备份系统就很重要了。Linode提供了备份选项。在1984.is里,我用crontabs和scp做了一个基本但管用的自动备份系统。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/build-your-own-cloud-on-debian-wheezy/
|
||||
|
||||
作者:[Roudy Jhausse ][a]
|
||||
作者:[Roudy Jhausse][a]
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,202 @@
|
||||
在linux中如何通过nload来监控网络使用情况
|
||||
================================================================================
|
||||
nload 是一个 linux 自由软件工具,通过提供两个简单的图形来帮助linux用户和系统管理员来实时监控网络流量以及宽带使用情况:一个是进入流量,一个是流出流量。
|
||||
|
||||
我真的很喜欢用**nload**来在屏幕上显示当前的下载速度、总的流入量和平均下载速度等信息。nload工具的报告图非常容易理解,最重要的是这些信息真的非常有用。
|
||||
|
||||
在其使用手册上说到,在默认情况下它会监控所有网络设备。但是你可以轻松地指定你想要监控的设备,而且可以通过方向键在不同的网络设备之间进行转换。另外还有很多的选项可用,例如 ‘-t’选项以毫秒来设定刷新显示时间间隔(默认时间间隔值是500毫秒),‘-m’选项用来同时显示多个设备(在使用该选项时不会显示流量图),‘-u’选项用来设置显示流量数字的单位,另外还有许多其他的选项将会在本教程中探索和练习。
|
||||
|
||||
### 如何将 nload安装到你的linux机器上 ###
|
||||
|
||||
**Ubuntu** 和 **Fedora** 用户可以从默认的软件仓库中容易地安装。
|
||||
|
||||
在Ubuntu上使用以下命令进行安装。
|
||||
|
||||
sudo apt-get install nload
|
||||
|
||||
在Fedora上使用以下命令进行安装。
|
||||
|
||||
sudo yum install nload
|
||||
|
||||
**CentOS**用户该怎么办呢? 只需要在你的机器上输入以下命令就可以安装成功。
|
||||
|
||||
sudo yum install nload
|
||||
|
||||
以下的命令会帮助你在OpenBSD系统中安装nload。
|
||||
|
||||
sudo pkg_add -i nload
|
||||
|
||||
在 linux 机器上的另外一个非常有效的安装软件的方式就是编译源代码,下载并安装最新的版本意味着能够获得更好地性能、更酷的特性以及更少的bug。
|
||||
|
||||
### 如何通过源代码安装nload ###
|
||||
|
||||
在从源代码安装nload之前,你需要首先下载源代码。 我通常使用wget工具来进行下载--该工具在许多linux机器上默认可用。该免费工具帮助用户以非交互式的方式从网络上下载文件,并支持以下协议:
|
||||
|
||||
- HTTP
|
||||
- HTTPS
|
||||
- FTP
|
||||
|
||||
通过以下命令来进入到**/tmp**目录中。
|
||||
|
||||
cd /tmp
|
||||
|
||||
然后在你的终端中输入以下命令就可以将最新版本的nload下载到你的linux机器上了。
|
||||
|
||||
wget http://www.roland-riegel.de/nload/nload-0.7.4.tar.gz
|
||||
|
||||
如果你不喜欢使用wget工具,也可以通过简单的一个鼠标点击轻松地从[官网][1]上下载其源代码。
|
||||
|
||||
由于该软件非常轻巧,其下载过程几乎在瞬间就会完成。接下来的步骤就是通过**tar**工具来将下载的源代码包进行解压。
|
||||
|
||||
tar归档工具可以用来从磁带或硬盘文档中存储或解压文件,该工具有许多可用的选项,但是我们只需要下面的几个选项来执行我们的操作。
|
||||
|
||||
1. **-x** 从归档中解压文件
|
||||
1. **-v** 使用繁琐模式运行--用来显示详细信息
|
||||
1. **-f** 用来指定归档文件
|
||||
|
||||
例如(LCTT 译注:tar 命令的参数前的“-”可以省略):
|
||||
|
||||
tar xvf example.tar
|
||||
|
||||
现在你学会了如何使用tar工具,我可以非常肯定你知道了如何从命令行中解压这个.tar文档。
|
||||
|
||||
tar xvf nload-0.7.4.tar.gz
|
||||
|
||||
之后使用cd命令来进入到nload*目录中:
|
||||
|
||||
cd nload*
|
||||
|
||||
在我的系统上看起来是这样的:
|
||||
|
||||
oltjano@baby:/tmp/nload-0.7.4$
|
||||
|
||||
然后运行下面这个命令来为你的系统配置该软件包:
|
||||
|
||||
./configure
|
||||
|
||||
此时会有“一大波僵尸”会在你的屏幕上显示出来,下面的一个屏幕截图描述了它的样子。
|
||||
|
||||

|
||||
|
||||
在上述命令完成之后,通过下面的命令来编译nload。
|
||||
|
||||
make
|
||||
|
||||

|
||||
|
||||
好了,终于....,通过以下命令可以将nload安装在你的机器上了。
|
||||
|
||||
sudo make install
|
||||
|
||||

|
||||
|
||||
安装好nload之后就是让你学习如何使用它的时间了。
|
||||
|
||||
###如何使用nload###
|
||||
|
||||
我喜欢探索,所以在你的终端输入以下命令.
|
||||
|
||||
nload
|
||||
|
||||
看到了什么?
|
||||
|
||||
我得到了下面的结果。
|
||||
|
||||

|
||||
|
||||
如上述截图可以看到,我得到了以下信息:
|
||||
|
||||
#### 流入量####
|
||||
|
||||
**当前下载速度**
|
||||
|
||||

|
||||
|
||||
**平均下载速度**
|
||||
|
||||

|
||||
|
||||
**最小下载速度**
|
||||
|
||||

|
||||
|
||||
**最大下载速度**
|
||||
|
||||

|
||||
|
||||
**总的流入量按字节进行显示**
|
||||
|
||||

|
||||
|
||||
#### 流出量 ####
|
||||
|
||||
类似的同样适用于流出量
|
||||
|
||||
#### 一些nload有用的选项####
|
||||
|
||||
使用选项
|
||||
|
||||
-u
|
||||
|
||||
用来设置显示流量单位。
|
||||
|
||||
下面的命令会帮助你使用MBit/s显示单元
|
||||
|
||||
nload -u m
|
||||
|
||||
下面的屏幕截图显示了上述命令的结果。
|
||||
|
||||

|
||||
|
||||
尝试以下命令然后看看有什么结果。
|
||||
|
||||
nload -u g
|
||||
|
||||

|
||||
|
||||
同时还有一个**-U**选项。根据手册描述,该选项基本上与-u选项类似,只是用在合计数据。 我测试了这个命令,老实说,当你需要检查总的流入与流出量时非常有用。
|
||||
|
||||
nload -U G
|
||||
|
||||

|
||||
|
||||
从上面的截图中可以看到,**nload -U G** 使用Gbyte来显示数据总量。
|
||||
|
||||
另外一个我喜欢使用的有用选项是 **-t**。 该选项用来设置刷新显示事件间隔,单位为毫秒,默认值为500毫秒。
|
||||
|
||||
我会通过下面的命令做一些小的实验。
|
||||
|
||||
nload -t 130
|
||||
|
||||
那么上述命令做了什么呢?它将刷新显示时间间隔设置为130毫秒。 通常推荐不要将该时间间隔值设置为小于100毫秒,因为nload在生成报告时计算错误。
|
||||
|
||||
另外的一个选项为 **-a**, 在你想要设置计算平均值的时间窗口的秒数时使用,默认该值为300秒。
|
||||
|
||||
那么当你想要监控指定的网络设备该如何呢? 非常容易, 像下面这样简单地指定设备或者列出想要监控的设备列表即可。
|
||||
|
||||
nload wlan0
|
||||
|
||||

|
||||
|
||||
下面的语法可帮助你监控指定的多个设备。
|
||||
|
||||
nload [options] device1 device2 devicen
|
||||
|
||||
例如,使用下面的命令来监控eth0和eth1。
|
||||
|
||||
nload wlan0 eth0
|
||||
|
||||
如果不带选项来运行nload,那么它会监控所有自动检测到的设备,你可以通过左右方向键来显示其中的任何一个设备的信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/monitoring-2/monitor-network-usage-nload/
|
||||
|
||||
作者:[Oltjano Terpollari][a]
|
||||
译者:[theo-l](https://github.com/theo-l)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/oltjano/
|
||||
[1]:http://www.roland-riegel.de/nload/nload-0.7.4.tar.gz
|
||||
@ -1,4 +1,4 @@
|
||||
如何通过简单的3步恢复Windows7同时删除Ubuntu
|
||||
如何通过简单的3步恢复Windows 7同时删除Ubuntu
|
||||
================================================================================
|
||||
### 说明 ###
|
||||
|
||||
@ -8,11 +8,11 @@
|
||||
|
||||
那么为什么我现在要写这篇文章呢?
|
||||
|
||||
到目前为止我曾经在很多场合被问到如何从一个装有Windows7或Windows8的双系统中删除Unbuntu系统,因此写这篇文章就变得有意义了。
|
||||
到目前为止我曾经在很多场合被问到如何从一个装有Windows7或Windows8的双系统中删除Ubuntu系统,因此写这篇文章就变得有意义了。
|
||||
|
||||
我在圣诞节期间浏览了人们在我文章中的留言,感觉是时候把缺失的文章写完同时更新一下那些比较老的又需要关注的文章了。
|
||||
|
||||
我打算把一月份剩下的时间都用在这上面。这是第一步。如果你的电脑上安装了Windown7和Ubuntu双系统,同时你不想通过恢复出厂设置的方式恢复Windows7系统,那么请参考该教程。(注意:对于Windows8系统,有一个独立的教程)
|
||||
我打算把一月份剩下的时间都用在这上面。这是第一步。如果你的电脑上安装了Windows7和Ubuntu双系统,同时你不想通过恢复出厂设置的方式恢复Windows7系统,那么请参考该教程。(注意:对于Windows8系统,有一个独立的教程)
|
||||
|
||||
### 删除Ubuntu系统需要的步骤 ###
|
||||
|
||||
@ -24,11 +24,10 @@
|
||||
|
||||
在你开始之前,我建议为你的系统保留一个备份。
|
||||
|
||||
我也建议不要放弃这样的机会也不要使用微软自带的工具。
|
||||
我建议你不要放弃备份的机会,但也不要使用微软自带的工具。
|
||||
|
||||
[点击查看如何使用Macrinum Reflect备份你的驱动][1]
|
||||
|
||||
|
||||
如果Ubuntu中有你希望保存的数据,现在就登录进去然后将数据保存到外部硬盘驱动器,USB驱动器或者DVD中。
|
||||
|
||||
### 步骤1 - 删除Grub启动菜单 ###
|
||||
@ -57,7 +56,7 @@
|
||||
|
||||
点击“创建光盘”。
|
||||
|
||||
将光盘留在电脑中重启电脑,当出现从CD中启动的消息的时候按下键盘上的“回车”键。
|
||||
将光盘留在电脑中并重启电脑,当出现从CD中启动的消息的时候按下键盘上的“回车”键。
|
||||
|
||||
|
||||
|
||||
@ -111,13 +110,13 @@
|
||||
|
||||
对于Windows系统来说,我们真正需要的只有驱动器C,所以剩下的是可以删掉的。
|
||||
|
||||
**注意: 注意一下.你的磁盘上可能有恢复分区。 不要删除恢复分区.。它们应该会被标记,将文件系统设置为NTFS或FAT32**
|
||||
**注意: 注意一下.你的磁盘上可能有恢复分区。 不要删除恢复分区。它们应该有专门的卷标,文件系统也许是NTFS或FAT32**
|
||||
|
||||
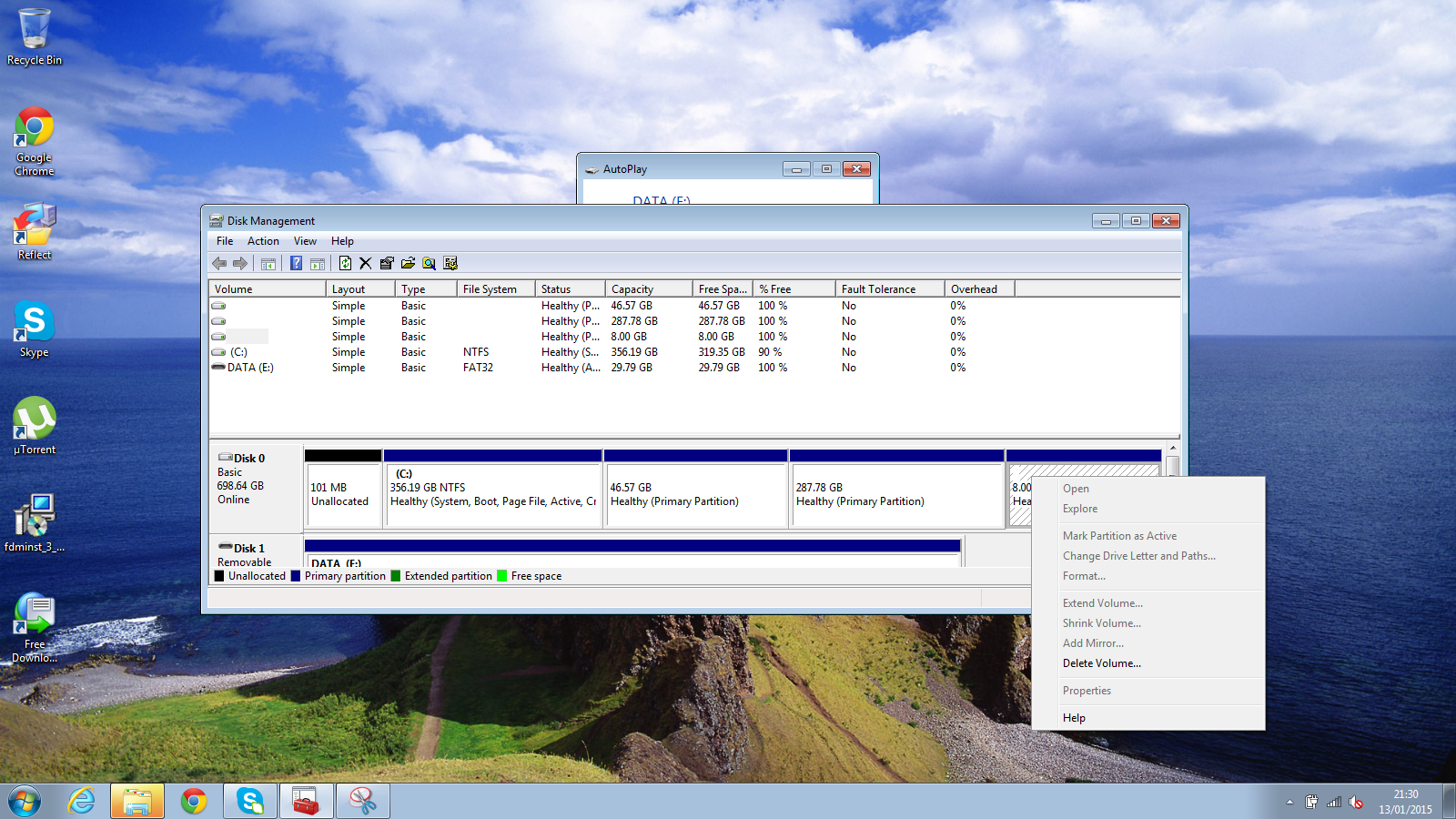
|
||||
|
||||
在你希望删除的分区上单击右键(例如:root,home和swap分区),然后从弹出的菜单中点击“删除卷”。
|
||||
|
||||
**(不要删除任何NTFS或者FAT32文件系统的分区)**
|
||||
**(不要删除任何NTFS或者FAT32文件系统的分区!)**
|
||||
|
||||
对于剩下的两个分区重复执行上面的操作。
|
||||
|
||||
@ -134,11 +133,12 @@
|
||||
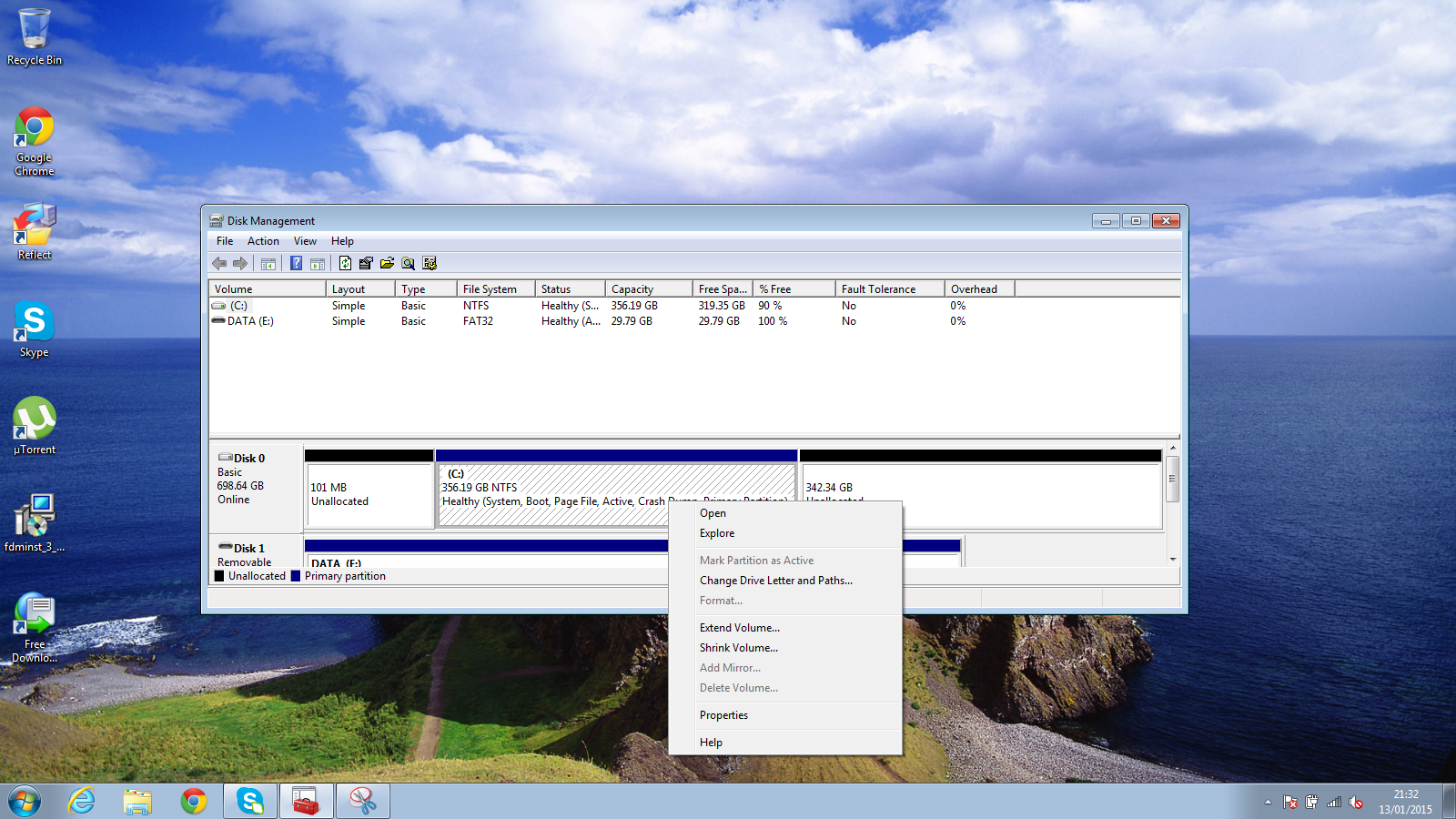
|
||||
|
||||
最后一步是扩展Windows以便于将它再变成一个大的分区。
|
||||
|
||||
右键点击Windows分区(C盘),然后选择“扩展卷”。
|
||||
|
||||
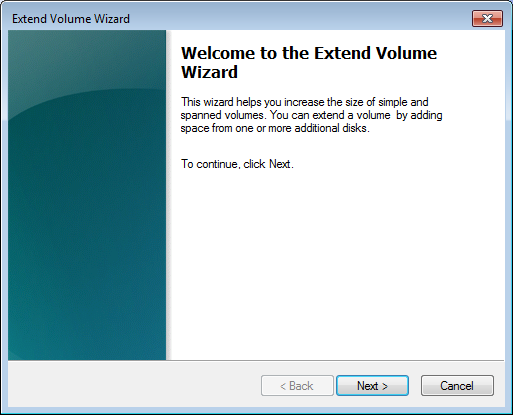
|
||||
|
||||
当出现左面的窗口的时候点击“下一步”,
|
||||
当出现左面的窗口的时候点击“下一步”。
|
||||
|
||||

|
||||
|
||||
@ -165,13 +165,14 @@
|
||||
这就是全部内容。一个致力于Linux的网站刚刚向你展示了如何移除Linux然后用Windows7取而代之。
|
||||
|
||||
有任何疑问可以在下面评论区留言。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.everydaylinuxuser.com/2015/01/how-to-recover-windows-7-and-delete.html
|
||||
|
||||
作者:Gary Newell
|
||||
译者:[Medusar](https://github.com/Medusar)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,39 +1,38 @@
|
||||
在linux中4个lvcreate命令例子
|
||||
4 个 lvcreate 常用命令举例
|
||||
================================================================================
|
||||
逻辑卷管理(LVM)是广泛使用的技术,并拥有极其灵活磁盘管理方案。主要包含3个基础命令:
|
||||
|
||||
a. 创建物理卷使用**pvcreate**
|
||||
b. 创建卷组并给卷组增加分区**vgcreate**
|
||||
c. 创建新的逻辑卷使用**lvcreate**
|
||||
1. 创建物理卷使用**pvcreate**
|
||||
2. 创建卷组并给卷组增加分区**vgcreate**
|
||||
3. 创建新的逻辑卷使用**lvcreate**
|
||||
|
||||

|
||||
|
||||
随后的例子着重在已经存在的卷组上使用**lvcreate**创建逻辑卷。**lvcreate**命令可以在来自自由物理扩展池的卷组分配逻辑扩展。通常,逻辑卷可以随意使用底层逻辑卷上的任意空间。修改逻辑卷将释放或重新分配在物理卷空间。这些例子已经在CentOS 5, CentOS 6, CentOS 7, RHEL 5, RHEl 6 和 RHEL 7 版本中测试通过。
|
||||
下列例子主要讲述在已经存在的卷组上使用**lvcreate**创建逻辑卷。**lvcreate**命令可以在卷组的可用物理扩展池中分配逻辑扩展。通常,逻辑卷可以随意使用底层逻辑卷上的任意空间。修改逻辑卷将释放或重新分配物理卷的空间。这些例子已经在CentOS 5, CentOS 6, CentOS 7, RHEL 5, RHEl 6 和 RHEL 7 版本中测试通过。
|
||||
|
||||
### 4个lvcreate命令例子 ###
|
||||
|
||||
1. 在名为vg_newlvm卷组中创建15G大小的逻辑卷:
|
||||
1. 在名为vg_newlvm的卷组中创建15G大小的逻辑卷:
|
||||
|
||||
[root@centos7 ~]# lvcreate -L 15G vg_newlvm
|
||||
[root@centos7 ~]# lvcreate -L 15G vg_newlvm
|
||||
|
||||
2. 在名为vg_newlvm中创建大小为2500MB的逻辑卷并命名centos7_newvol,创建块设备/dev/vg_newlvm/centos7_newvol:
|
||||
2. 在名为vg_newlvm的卷组中创建大小为2500MB的逻辑卷,并命名为centos7_newvol,这样就创建了块设备/dev/vg_newlvm/centos7_newvol:
|
||||
|
||||
[root@centos7 ~]# lvcreate -L 2500 -n centos7_newvol vg_newlvm
|
||||
[root@centos7 ~]# lvcreate -L 2500 -n centos7_newvol vg_newlvm
|
||||
|
||||
3.可以使用**lvcreate**命令的参数-l,能指定一些特别的逻辑卷扩展大小。也可以使用这个参数以卷组的大小百分比来扩展逻辑卷。这下列的命令创建了centos7_newvol卷组的50%大小的逻辑卷vg_newlvm:
|
||||
3. 可以使用**lvcreate**命令的参数-l来指定逻辑卷扩展的大小。也可以使用这个参数以卷组的大小百分比来扩展逻辑卷。这下列的命令创建了centos7_newvol卷组的50%大小的逻辑卷vg_newlvm:
|
||||
|
||||
[root@centos7 ~]# lvcreate -l 50%VG -n centos7_newvol vg_newlvm
|
||||
[root@centos7 ~]# lvcreate -l 50%VG -n centos7_newvol vg_newlvm
|
||||
|
||||
4. 使用卷组剩下的所有空间创建逻辑卷
|
||||
|
||||
[root@centos7 ~]# lvcreate --name centos7_newvol -l 100%FREE vg_newlvm
|
||||
[root@centos7 ~]# lvcreate --name centos7_newvol -l 100%FREE vg_newlvm
|
||||
|
||||
更多帮助,使用**lvcreate**命令--help选项来查看:
|
||||
|
||||
[root@centos7 ~]# lvcreate --help
|
||||
|
||||
----------
|
||||
以下空号中是帮助字面翻译
|
||||
|
||||
lvcreate: Create a logical volume(创建逻辑卷)
|
||||
|
||||
@ -46,8 +45,8 @@ c. 创建新的逻辑卷使用**lvcreate**
|
||||
[-C|--contiguous {y|n}]
|
||||
[-d|--debug]
|
||||
[-h|-?|--help]
|
||||
[--ignoremonitoring](忽略监听)
|
||||
[--monitor {y|n}](监听)
|
||||
[--ignoremonitoring](忽略监控)
|
||||
[--monitor {y|n}](监控)
|
||||
[-i|--stripes Stripes [-I|--stripesize StripeSize]]
|
||||
[-k|--setactivationskip {y|n}]
|
||||
[-K|--ignoreactivationskip]
|
||||
@ -66,7 +65,7 @@ c. 创建新的逻辑卷使用**lvcreate**
|
||||
[--discards {ignore|nopassdown|passdown}]
|
||||
[--poolmetadatasize MetadataSize[bBsSkKmMgG]]]
|
||||
[--poolmetadataspare {y|n}]
|
||||
[--thinpool ThinPoolLogicalVolume{Name|Path}]精简池逻辑卷
|
||||
[--thinpool ThinPoolLogicalVolume{Name|Path}] (精简池逻辑卷)
|
||||
[-t|--test]
|
||||
[--type VolumeType](卷类型)
|
||||
[-v|--verbose]
|
||||
@ -75,18 +74,14 @@ c. 创建新的逻辑卷使用**lvcreate**
|
||||
[--version]
|
||||
VolumeGroupName [PhysicalVolumePath...]
|
||||
|
||||
lvcreate
|
||||
{ {-s|--snapshot} OriginalLogicalVolume[Path] |
|
||||
[-s|--snapshot] VolumeGroupName[Path] -V|--virtualsize VirtualSize}
|
||||
{-T|--thin} VolumeGroupName[Path][/PoolLogicalVolume]
|
||||
-V|--virtualsize VirtualSize}(
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.ehowstuff.com/4-lvcreate-command-examples-on-linux/
|
||||
|
||||
作者:[skytech][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[Vic020](https://github.com/Vic020)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
121
published/20150126 CD Audio Grabbers--Graphical Based.md
Normal file
121
published/20150126 CD Audio Grabbers--Graphical Based.md
Normal file
@ -0,0 +1,121 @@
|
||||
4 个图形界面的 CD 音频抓取器
|
||||
================================================================================
|
||||
CD音频抓取器设计用来从光盘中提取(“RIP”)原始数字音频(通常被称为 CDDA 格式)并把它保存成文件或以其他形式输出。这类软件使用户能把数字音频编码成各种格式,并可以从在线光盘数据库 freedb 中下载或上传光盘信息。
|
||||
|
||||
复制CD合法吗?在美国版权法中,把一个原始CD转换成数字文件用于个人使用等同于‘合理使用’。然而,美国版权法并没有明确的允许或禁止拷贝私人音频CD,而且判例法还没有确立出在具体的哪种情况下可以视为合理使用。而在英国,其版权的定位则更清晰一些。从2014年开始,英国公民制造CD,MP3,DVD,蓝光和电子书的行为成为合法行为。当然,这仅适用于这个人拥有被采集的媒体的实体,并且复制品仅用于他们个人使用。对于欧盟的其他国家,成员国也允许私人复制这种特例。
|
||||
|
||||
如果你不确定在你生活的国家里这种版权是如何界定的,在你使用这篇文章中所列举的软件前请查询本地的版权法以确定你处在合法的一边。
|
||||
|
||||
在某种程度上,提取CD音轨看起来有点多余。如[Spotify][5]和Google Play Music这类流媒体服务提供了一个巨大的以通用格式的音乐的库,无需采集你的CD集。但是,如果你已将收藏了一个数量巨大的CD集。能把你的CD转换成可以在便携设备如智能手机、平板和便携式MP3播放器上播放的格式仍然是个诱人的选择。
|
||||
|
||||
这篇文章推荐了我最喜欢的音频CD抓取器。我挑了四个最好的图形界面的音频抓取器。所有这些应用程序都是在开源许可下发行的。
|
||||
|
||||
###fre:ac
|
||||
|
||||

|
||||
|
||||
fre:ac是个开源的音频转换器和CD提取器,支持很多种流行格式和编码器。目前这个应用可以在MA3、MP4/M4A、WMA、Ogg Vorbis、FLAC、AAC、WAV和Bonk格式间转换。这来源于几种不同形式的LAME编码器。
|
||||
|
||||
#### 功能包括: ####
|
||||
|
||||
- 易学易用
|
||||
- MP3、MP4/M4A、WMA、Ogg Vorbis、FLAC、AAC、WAV和Bonk格式转换器
|
||||
- 集成了CDDB/freedb标题数据库支持的CD提取器
|
||||
- 多核优化的编码器加速了现代PC上的转换速度
|
||||
- 对于标签和文件名称的全Unicode支持
|
||||
- 易学易用,而当你需要时还提供专家级选项
|
||||
- 任务列表
|
||||
- 可以使用Winamp 2输入插件
|
||||
- 多语言用户界面支持41种语言
|
||||
|
||||
- 网址: [freac.org][1]
|
||||
- 开发人员:Robert Kausch
|
||||
- 许可证: GNU GPL v2
|
||||
- 版本号: 20141005
|
||||
|
||||
###Audex
|
||||
|
||||

|
||||
|
||||
Audex是个简单易用的开源的音频CD提取应用。虽然它还处于早期开发阶段,但这个KDE桌面工具足够稳定、智能和简单易用。
|
||||
|
||||
它的助手可以为LAME、OGG Vorbis(oggenc)、FLAC、FAAC(AAC/MP4)和RIFF WAVE等格式创建配置文件。除了这个助手,你也可以定义你自己的配置文件,这意味着,Audex适用于大部分的命令行编码器。
|
||||
|
||||
#### 功能包括: ####
|
||||
|
||||
- 可提取CDDA Paranoia
|
||||
- 提取和编码同时进行
|
||||
- 文件名采用本地和远程的CDDB/FreeDB数据库
|
||||
- 可以提交到CDDB/FreeDB数据库
|
||||
- 类似capitalize的元数据纠正工具
|
||||
- 多配置文件提取(每个配置文件文件有一个命令行编码器)
|
||||
- 从互联网上抓取封面并将他们存在数据库中
|
||||
- 在目标目录中创建播放列表、封面和基于模板的信息文件
|
||||
- 创建提取和编码协议
|
||||
- 将文件传送到FTP服务器
|
||||
- 支持国际化
|
||||
|
||||
- 网址: [kde.maniatek.com/audex][2]
|
||||
- 开发人员: Marco Nelles
|
||||
- 许可证: GNU GPL v3
|
||||
- 版本号: 0.79
|
||||
|
||||
###Sound Juicer
|
||||
|
||||

|
||||
|
||||
Sound Juicer是个使用GTK+和GStreamer开发的轻量级CD提取器。它从CD中提取音频并把它转换成音频文件。Sound Juicer还可以直接播放CD中的音轨,在提取前提供预览。
|
||||
|
||||
它支持任何GStreamer插件所支持的音频编码,包括 MP3、Ogg Vorbis、FLAC和未压缩的PCM格式。
|
||||
|
||||
它是GNOME桌面环境内建的一部分。
|
||||
|
||||
#### 功能包括: ####
|
||||
|
||||
- 自动通过CDDB给音轨加标签
|
||||
- 可编码成ogg/vorbis、FLAC和原始WAV
|
||||
- 编码路径的设置很简单
|
||||
- 多种风格流派
|
||||
- 国际化支持
|
||||
|
||||
- 网址:[burtonini.com][3]
|
||||
- 开发人员: Ross Burton
|
||||
- 许可证:GNU GPL v2
|
||||
- 版本号:3.14
|
||||
|
||||
###ripperX
|
||||
|
||||

|
||||
|
||||
ripperX是个开源的图形界面的程序,用于提取CD音轨并把他们编码成Ogg、MP2、MP3或FLAC格式。它的目的是容易使用,只需要点几下鼠标就能转换整张专辑。它支持在CDDB寻找专辑和音轨信息。
|
||||
|
||||
他使用cdparanoia把CD音轨转换(也就是“提取”)成WAV文件,然后调用Vorbis/Ogg编码器oggenc把WAV文件转换成OGG文件。它还可以调用flac让WAV文件生成无损压缩的FLAC文件。
|
||||
|
||||
#### 功能包括: ####
|
||||
|
||||
- 非常简单易用
|
||||
- 可以把CD音轨提取成WAV、MP3、OGG或FLAC文件
|
||||
- 支持CDDB查找
|
||||
- 支持ID3v2标签
|
||||
- 可暂停提取进程
|
||||
|
||||
- 网址:[sourceforge.net/projects/ripperx][4]
|
||||
- 开发人员:Marc André Tanner
|
||||
- 许可证:MIT/X Consortium License
|
||||
- 版本号:2.8.0
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
转自:http://www.linuxlinks.com/article/20150125043738417/AudioGrabbersGraphical.html
|
||||
|
||||
作者:Frazer Kline
|
||||
译者:[H-mudcup](https://github.com/H-mudcup)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.freac.org/
|
||||
[2]:http://kde.maniatek.com/audex/
|
||||
[3]:http://burtonini.com/blog/computers/sound-juicer
|
||||
[4]:http://sourceforge.net/projects/ripperx/
|
||||
[5]:http://linux.cn/article-3130-1.html
|
||||
@ -0,0 +1,107 @@
|
||||
性能优化:使用ramlog将日志文件转移到内存中
|
||||
================================================================================
|
||||
Ramlog 以系统守护进程的形式运行。在系统启动时它创建虚拟磁盘(ramdisk),将 /var/log 下的文件复制到虚拟磁盘中,同时把虚拟磁盘挂载为/var/log。然后所有的日志就会更新到虚拟磁盘上。而当 ramlog 重启或停止时,需要记录到硬盘上的日志就会保留在目录/var/log.hdd中。而关机的时候,(ramdisk上的)日志文件会重新保存到硬盘上,以确保日志一致性。Ramlog 2.x默认使用tmpfs文件系统,同时也可以支持ramfs和内核ramdisk。使用rsync(译注:Linux数据镜像备份工具)这个工具来同步日志。
|
||||
|
||||
注意:如果突然断电或者内核崩溃(kernel panic)时,没有保存进硬盘的日志将会丢失。
|
||||
|
||||
如果你拥有够多的可用内存,而又想把日志放进虚拟磁盘,就安装ramlog吧。它是笔记本用户、带有UPS的系统或是直接在flash中运行的系统的优良选择,可以节省日志的写入时间。
|
||||
|
||||
Ramlog的运行机制以及步骤如下:
|
||||
|
||||
1. Ramlog 由第一个守护进程(这取决于你所安装过的其它守护进程)启动。
|
||||
|
||||
2. 然后创建目录/var/log.hdd并将其硬链至/var/log。
|
||||
|
||||
3. 如果使用的是tmpfs(默认)或者ramfs 文件系统,将其挂载到/var/log上。
|
||||
|
||||
4. 而如果使用的是内核ramdisk,ramdisk会在/dev/ram9中创建,并将其挂载至/var/log。默认情况下ramlog会占用所有ramdisk的内存,其大小由内核参数"ramdisk_size"指定。
|
||||
|
||||
5. 接着其它的守护进程被启动,并在ramdisk中更新日志。Logrotate(译注:Linux日志轮替工具)和 ramdisk 配合的也很好。
|
||||
|
||||
6. 重启(默认一天一次)ramlog时,目录/var/log.hdd将借助rsync与/var/log保持同步。日志自动保存的频率可以通过cron(译注:Linux例行性工作调度)来控制。默认情况下,ramlog 的调度任务放置在目录/etc/cron.daily下。
|
||||
|
||||
7. 系统关机时,ramlog在最后一个守护进程关闭之前关闭。
|
||||
|
||||
8. 在ramlog关闭期间,/var/log.hdd中的文件将被同步至/var/log,接着/var/log和/var/log.hdd都被卸载,然后删除空目录/var/log.hdd。
|
||||
|
||||
**注意:- 此文仅面向高级用户**
|
||||
|
||||
### 在Ubuntu中安装Ramlog ###
|
||||
|
||||
首先需要用以下命令,从[这里][1]下载.deb安装包:
|
||||
|
||||
wget http://www.tremende.com/ramlog/download/ramlog_2.0.0_all.deb
|
||||
|
||||
下载ramlog\_2.0.0\_all.deb安装包完毕,使用以下命令进行安装:
|
||||
|
||||
sudo dpkg -i ramlog_2.0.0_all.deb
|
||||
|
||||
这一步会完成整个安装,现在你需要运行以下命令:
|
||||
|
||||
sudo update-rc.d ramlog start 2 2 3 4 5 . stop 99 0 1 6 .
|
||||
|
||||
现在,在更新sysklogd的初始化顺序,使之能在ramlog停止运行前正确关闭:
|
||||
|
||||
sudo update-rc.d -f sysklogd remove
|
||||
|
||||
sudo update-rc.d sysklogd start 10 2 3 4 5 . stop 90 0 1 6 .
|
||||
|
||||
然后重启系统:
|
||||
|
||||
sudo reboot
|
||||
|
||||
系统重启完毕,运行'ramlog getlogsize'来获取你当前的/var/log的空间大小。在此基础之上多分配40%的空间,确保ramdisk有足够的空间(这整个都将作为ramdisk的空间大小)。
|
||||
|
||||
编辑引导配置文件,如/etc/grub.conf,、/boot/grub/menu.lst 或/etc/lilo.conf(译注:具体哪个配置文件视不同引导加载程序而定),给你的当前内核的新增选项 'ramdisk_size=xxx' ,其中xxx是ramdisk的空间大小。
|
||||
|
||||
### 配置Ramlog ###
|
||||
|
||||
基于deb的系统中,Ramlog的配置文件位于/etc/default/ramlog,你可以在该配置文件中设置以下变量:
|
||||
|
||||
RAMDISKTYPE=0
|
||||
# 取值:
|
||||
# 0 -- tmpfs (可被交换到交换分区) -- 默认
|
||||
# 1 -- ramfs (旧内核不能设置最大空间大小,
|
||||
# 不能被交换到交换分区,和 SELinux 不兼容)
|
||||
# 2 -- 老式的内核 ramdisk
|
||||
TMPFS_RAMFS_SIZE=
|
||||
# 可以用于 tmpfs 或 ramfs 的最大内存大小
|
||||
# 这个值可以是百分比或数值(单位是 Mb),例如:
|
||||
# TMPFS_RAMFS_SIZE=40%
|
||||
# TMPFS_RAMFS_SIZE=100m
|
||||
# 该值为空表示 tmpfs/ramfs 的大小是全部内存的 50%
|
||||
# 更多选项可以参考 ‘man mount' 中的‘Mount options for tmpfs' 一节
|
||||
# (补充,在较新的内核中,ramfs 支持大小限制,
|
||||
# 虽然 man 中说没有这个挂载选项)
|
||||
# 该选项仅用于 RAMDISKTYPE=0 或 1 时
|
||||
KERNEL_RAMDISK_SIZE=MAX
|
||||
#以 kb 为单位指定的内核 ramdisk 大小,或者使用 MAX 来使用整个 ramdisk。
|
||||
#该选项仅用于 RAMDISKTYPE=2 时
|
||||
LOGGING=1
|
||||
# 0=关闭, 1=打开 。记录自身的日志到 /var/log/ramdisk
|
||||
LOGNAME=ramlog
|
||||
# 自身的日志文件名 (用于 LOGGING=1时)
|
||||
VERBOSE=1
|
||||
# 0=关闭, 1=打开 (设置为 1时,启动或停止失败时会调用 teststartstop 将细节
|
||||
# 写到日志中)
|
||||
|
||||
### 在Ubuntu中卸载ramlog ###
|
||||
|
||||
打开终端运行以下命令:
|
||||
|
||||
sudo dpkg -P ramlog
|
||||
|
||||
注意:如果ramlog卸载之前仍在运行,需要重启系统完成整个卸载工作。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.ubuntugeek.com/improve-system-performance-by-moving-your-log-files-to-ram-using-ramlog.html
|
||||
|
||||
作者:[ruchi][a]
|
||||
译者:[soooogreen](https://github.com/soooogreen)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.ubuntugeek.com/author/ubuntufix
|
||||
[1]:http://www.tremende.com/ramlog/download/ramlog_2.0.0_all.deb
|
||||
@ -1,12 +1,12 @@
|
||||
怎样在 Linux 中限制网络带宽
|
||||
怎样在 Linux 中限制网络带宽使用
|
||||
================================================================================
|
||||
假如你经常在 Linux 桌面上运行多个网络应用,或在家中让多台电脑共享带宽;(这时,)你可能想更好地控制带宽的使用。否则,当你使用下载器下载一个大文件时,交互式 SSH 会话可能会变得缓慢以至不可用;或者当你通过 Dropbox 来同步一个大文件夹时,你的室友可能会抱怨在她的电脑上,视频流变得断断续续。
|
||||
假如你经常在 Linux 桌面上运行多个网络应用,或在家中让多台电脑共享带宽;那么你可能想更好地控制带宽的使用。否则,当你使用下载器下载一个大文件时,交互式 SSH 会话可能会变得缓慢以至不可用;或者当你通过 Dropbox 来同步一个大文件夹时,你的室友可能会抱怨在她的电脑上,视频流变得断断续续。
|
||||
|
||||
在本教程中,我将为你描述两种 在 Linux 中限制网络流量速率的不同方法。
|
||||
在本教程中,我将为你描述两种在 Linux 中限制网络流量速率的不同方法。
|
||||
|
||||
### 在 Linux 中限制一个应用的速率 ###
|
||||
|
||||
限制网络流量速率的一种方法是通过一个名为[trickle][1]的命令行工具。通过在程序运行时,预先加载一个 速率限制 socket 库 的方法,trickle 命令允许你改变任意一个特定程序的流量。 关于 trickle 命令的一个很好的特征是 它仅在用户空间中运行,这意味着,你不必需要 root 权限来达到限制一个程序的带宽使用的目的。为了与 trickle 程序兼容,这个特定程序必须使用没有静态链接库的套接字接口。当你想对一个不具有内置带宽控制功能的程序进行速率限制时,trickle 可以帮得上忙。
|
||||
限制网络流量速率的一种方法是通过一个名为[trickle][1]的命令行工具。通过在程序运行时,预先加载一个速率限制 socket 库 的方法,trickle 命令允许你改变任意一个特定程序的流量。 trickle 命令有一个很好的特性是它仅在用户空间中运行,这意味着,你不必需要 root 权限就可以限制一个程序的带宽使用。要能使用 trickle 程序控制程序的带宽,这个程序就必须使用非静态链接库的套接字接口。当你想对一个不具有内置带宽控制功能的程序进行速率限制时,trickle 可以帮得上忙。
|
||||
|
||||
在 Ubuntu,Debian 及其衍生发行版中安装 trickle :
|
||||
|
||||
@ -20,10 +20,10 @@ $ sudo apt-get install trickle
|
||||
$ sudo yum install trickle
|
||||
```
|
||||
|
||||
trickle 的基本使用方法如下。仅需简单地把 trickle 命令(带有速率参数)放在你想运行的命令之前。
|
||||
trickle 的基本使用方法如下。仅需简单地把 trickle 命令(及速率参数)放在你想运行的命令之前。
|
||||
|
||||
```
|
||||
$ trickle -d <download-rate> -u <upload-rate> <command>
|
||||
$ trickle -d <download-rate> -u <upload-rate> <command>
|
||||
```
|
||||
|
||||
这就可以将 `<command>` 的下载和上传速率限定为特定值(单位 KBytes/s)。
|
||||
@ -34,27 +34,27 @@ $ trickle -d <download-rate> -u <upload-rate> <command>
|
||||
$ trickle -u 100 scp backup.tgz alice@remote_host.com:
|
||||
```
|
||||
|
||||
如若你想,你可以使用下面的命令为你的 Firefox 浏览器设定最大下载速率(e.g. , 300 KB/s),通过产生一个[自定义启动器][3]的方式。
|
||||
如若你想,你可以通过创建一个[自定义启动器][3]的方式,使用下面的命令为你的 Firefox 浏览器设定最大下载速率(例如, 300 KB/s)。
|
||||
|
||||
```
|
||||
trickle -d 300 firefox %u
|
||||
```
|
||||
|
||||
最后, trickle 也可以 以守护进程模式运行,在该模式下,它将会限制所有通过 trickle 启动且正在运行的程序的总的带宽和。 启动 trickle 使其作为一个守护进程(i.e., trickled):
|
||||
最后, trickle 也可以以守护进程模式运行,在该模式下,它将会限制所有通过 trickle 启动且正在运行的程序的总带宽之和。 启动 trickle 使其作为一个守护进程(例如, trickled):
|
||||
|
||||
```
|
||||
$ sudo trickled -d 1000
|
||||
```
|
||||
|
||||
一旦 trickled 守护进程在后台运行,你便可以通过 trickle 命令来启动其他程序。假如你通过 trickle 启动一个程序,那么这个程序的最大下载速率将是 1000 KB/s, 假如你再通过 trickle 启动了另一个程序,则每个程序的(下载)速率极限将会被限制为 500 KB/s, 等等。
|
||||
一旦 trickled 守护进程在后台运行,你便可以通过 trickle 命令来启动其他程序。假如你通过 trickle 启动一个程序,那么这个程序的最大下载速率将是 1000 KB/s, 假如你再通过 trickle 启动了另一个程序,则每个程序的(下载)速率极限将会被限制为 500 KB/s,等等。
|
||||
|
||||
### 在 Linux 中限制一个网络接口的速率 ###
|
||||
|
||||
另一种控制你的带宽资源的方式是在每一个接口上限制带宽。这在你与其他人分享你的网络连接的上行带宽时尤为实用。同其他一样,Linux 有一个工具来为你做这件事。[wondershaper][4]恰好执行限制网络接口速率的任务。
|
||||
另一种控制你的带宽资源的方式是在每一个接口上限制带宽。这在你与其他人分享你的网络连接的上行带宽时尤为实用。同其他一样,Linux 有一个工具来为你做这件事。[wondershaper][4]就是干这个的。
|
||||
|
||||
wondershaper 实际上是一个 shell 脚本,它使用 [tc][5] 来定义流量调整命令,使用 QoS 来处理特定的网络接口。通过放置被赋予不同的优先级的传出流量在一个队列中,达到限制传出流量速率的目的, 而传入流量通过丢包的方式来达到速率限制的目的。
|
||||
wondershaper 实际上是一个 shell 脚本,它使用 [tc][5] 来定义流量调整命令,使用 QoS 来处理特定的网络接口。外发流量通过放在不同优先级的队列中,达到限制传出流量速率的目的;而传入流量通过丢包的方式来达到速率限制的目的。
|
||||
|
||||
事实上, wondershaper 的既定目标不仅仅是对一个接口增加其带宽上限;当批量下载或上传正在进行时,wondershaper 还试图去保持互动性会话如SSH 的低延迟。同样的,它还确保批量上传(e.g. , Dropbox 的同步)不会使得下载“窒息”,反之亦然。
|
||||
事实上, wondershaper 的既定目标不仅仅是对一个接口增加其带宽上限;当批量下载或上传正在进行时,wondershaper 还试图去保持互动性会话如 SSH 的低延迟。同样的,它还会控制批量上传(例如, Dropbox 的同步)不会使得下载“窒息”,反之亦然。
|
||||
|
||||
在 Ubuntu Debian 及其衍生发行版本 中安装 wondershaper:
|
||||
|
||||
@ -62,9 +62,9 @@ wondershaper 实际上是一个 shell 脚本,它使用 [tc][5] 来定义流量
|
||||
$ sudo apt-get install wondershaper
|
||||
```
|
||||
|
||||
在 Fdora 或 CentOS/RHEL (带有 [EPEL 软件仓库][2]) 中安装 wondershaper:(注:这里 链接 2 和 6 一样,可以删除其中之一)
|
||||
在 Fdora 或 CentOS/RHEL (带有 [EPEL 软件仓库][2]) 中安装 wondershaper:
|
||||
|
||||
``
|
||||
```
|
||||
$ sudo yum install wondershaper
|
||||
```
|
||||
|
||||
@ -90,7 +90,7 @@ $ sudo wondershaper clear eth0
|
||||
|
||||
### 总结 ###
|
||||
|
||||
在本教程中,我介绍了两种不同的方法,来达到如何在 Linux 桌面环境中,控制每个应用或每个接口的带宽使用的目的。 这些工具对用户都及其友好,都为用户提供了一个快速且容易的方式来调整或限制流量。 对于那些想更多地了解如何在 Linux 中进行速率控制的读者,请参考 [the Linux bible][7].
|
||||
在本教程中,我介绍了两种不同的方法,来达到如何在 Linux 桌面环境中,控制每个应用或每个接口的带宽使用的目的。 这些工具的使用都很简单,都为用户提供了一个快速且容易的方式来调整或限制流量。 对于那些想更多地了解如何在 Linux 中进行速率控制的读者,请参考 [the Linux bible][7].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -98,15 +98,15 @@ via: http://xmodulo.com/limit-network-bandwidth-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://monkey.org/~marius/trickle
|
||||
[2]:http://xmodulo.com/how-to-set-up-epel-repository-on-centos.html
|
||||
[2]:http://linux.cn/article-2324-1.html
|
||||
[3]:http://xmodulo.com/create-desktop-shortcut-launcher-linux.html
|
||||
[4]:http://lartc.org/wondershaper/
|
||||
[5]:http://lartc.org/manpages/tc.txt
|
||||
[6]:http://xmodulo.com/how-to-set-up-epel-repository-on-centos.html
|
||||
[6]:http://linux.cn/article-2324-1.html
|
||||
[7]:http://www.lartc.org/lartc.html
|
||||
@ -1,14 +1,14 @@
|
||||
LinSSID - 一款Linux下的图形化Wi-Fi扫描器
|
||||
LinSSID:一款Linux下的图形化Wi-Fi扫描器
|
||||
================================================================================
|
||||
### 介绍 ###
|
||||
|
||||
如你所知,**LinSSID** 是一款可以用于寻找可用无线网络的图形化软件。它完全开源,用C++写成,使用了Linux无线工具、Qt5、Qwt6.1,它在外观和功能上与**Inssider** (MS Windows)相近。
|
||||
你可能知道,**LinSSID** 是一款可以用于寻找可用无线网络的图形化软件。它完全开源,用C++写成,使用了Linux wireless tools、Qt5、Qwt6.1,它在外观和功能上与**Inssider** (MS Windows 下的)相近。
|
||||
|
||||
### 安装 ###
|
||||
|
||||
你可以使用源码安装,如果你使用的是基于DEB的系统比如Ubuntu和LinuxMint等等,你也可以使用PPA安装。
|
||||
|
||||
你可用从[this link][1]这个链接下载并安装LinSSID。
|
||||
你可用从[这个][1]下载并安装LinSSID。
|
||||
|
||||
这里我门将使用PPA来安装并测试这个软件。
|
||||
|
||||
@ -22,22 +22,21 @@ LinSSID - 一款Linux下的图形化Wi-Fi扫描器
|
||||
|
||||
安装完成之后,你可以从菜单或者unity中启动。
|
||||
|
||||
你将被要求输入管理员密码。
|
||||
你需要输入管理员密码。
|
||||
|
||||

|
||||

|
||||
|
||||
这就是LinSSID的界面。
|
||||
|
||||

|
||||

|
||||
|
||||
现在选择你想要连接无线网络的网卡,比如这里是wlan0.点击Play按钮来搜寻wi-fi网络列表。
|
||||
现在选择你想要连接无线网络的网卡,比如这里是wlan0,点击Play按钮来搜寻wi-fi网络列表。
|
||||
|
||||
几秒钟之后,LinSSID就会显示wi-fi网络了。
|
||||
|
||||

|
||||
|
||||
如你在上面的截屏中所见,LinSSID显示SSID名、MAC ID、通道、隐私、加密方式、信号和协议等等信息。当然,你可以让LinSSID显示更多的选项,比如安全、带宽等等。要显示这些,进入**View**菜单并选择需要的选项。同样,它显示了不同通道中的信号随着时间信号强度的变化。最后,它可以工作在2.4Ghz和5Ghz通道上。
|
||||

|
||||
|
||||
如你在上面的截屏中所见,LinSSID显示SSID名、MAC ID、通道、隐私、加密方式、信号和协议等等信息。当然,你可以让LinSSID显示更多的选项,比如安全设置、带宽等等。要显示这些,进入**View**菜单并选择需要的选项。同样,它显示了不同的通道中的信号随着时间信号强度的变化。最后,它可以工作在2.4Ghz和5Ghz通道上。
|
||||
|
||||
就是这样。希望这个工具对你有用。
|
||||
|
||||
@ -53,7 +52,7 @@ via: http://www.unixmen.com/linssid-graphical-wi-fi-scanner-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -2,11 +2,11 @@
|
||||
================================================================================
|
||||

|
||||
|
||||
[KDE][1] Plasma 5.2已经[发布][2],在本篇中我们将看到如何在Ubuntu 14.10 上安装KDE Plasma 5.2。
|
||||
[KDE][1] Plasma 5.2已经[发布][2]一段时间了,在本篇中我们将看到如何在Ubuntu 14.10 上安装KDE Plasma 5.2。
|
||||
|
||||
Ubuntu的默认桌面环境Unity很漂亮还有很多特性。但是如果你问任何有经验的Linux用户关于桌面自定义,他的回答将是KDE。KDE在定制上是王者并且它得到流行大概是由于Ubuntu有官方的KDE版本,也就是Kubuntu[3]。
|
||||
Ubuntu的默认桌面环境Unity很漂亮还有很多特性,但是如果你问任何有经验的Linux用户关于桌面定制能力,他的回答将是KDE。KDE在定制上是王者并且它得到流行大概是由于Ubuntu有官方的KDE版本,也就是Kubuntu[3]。
|
||||
|
||||
对于Ubuntu(或者任何其他的Linux系统而言)的一个好消息是它没有绑定任何特定的桌面环境。你可以安装额外的桌面环境并且可以在不同的桌面环境间切换。早先我们已经了解了桌面环境的安装。
|
||||
对于Ubuntu(或者任何其他的Linux系统)而言的一个好消息是它们没有绑定在任何特定的桌面环境上,你可以安装额外的桌面环境并在不同的桌面环境间切换。早先我们已经了解如下的桌面环境的安装。
|
||||
|
||||
- [如何在Ubuntu 14.04中安装Mate桌面][4]
|
||||
- [如何在Ubuntu 14.04中安装Cinnamon桌面][5]
|
||||
@ -17,25 +17,24 @@ Ubuntu的默认桌面环境Unity很漂亮还有很多特性。但是如果你问
|
||||
|
||||
### 如何在Ubuntu 14.10 上安装KDE Plasma 5.2 ###
|
||||
|
||||
在Ubuntu 14.10上安装Plasma之前,你要知道这会下载大概1GB的内容。因此在安装KDE之前要考虑速度和数据包。我们下载所使用的PPA是KDEs社区官方提供的。在终端中使用下面的命令:
|
||||
在Ubuntu 14.10上安装Plasma之前,你要知道这会下载大概1GB的内容。因此在安装KDE之前要考虑速度和数据存放空间。我们下载所使用的PPA是KDE社区官方提供的。在终端中使用下面的命令:
|
||||
|
||||
sudo apt-add-repository ppa:kubuntu-ppa/next-backports
|
||||
sudo apt-get update
|
||||
sudo apt-get dist-upgrade
|
||||
sudo apt-get install kubuntu-plasma5-desktop plasma-workspace-wallpapers
|
||||
|
||||
During the installation, it will as you to choose the default display manager. I chose the default LightDM. Once installed, restart the system. At the login, click on the Ubuntu symbol beside the login field. In here, select Plasma.
|
||||
在安装中,我们要选择默认的显示管理器。我选择的是默认的LightDM。安装完成后,重启系统。在登录时,点击登录区域旁边的Ubuntu图标。这里选择Plasma。
|
||||
|
||||

|
||||
|
||||
你现在就登录到KDE Plasma了。这里有一个KDE Plasma 5.2在Ubuntu 14.10下的截图
|
||||
你现在就登录到KDE Plasma了。这里有一个KDE Plasma 5.2在Ubuntu 14.10下的截图:
|
||||
|
||||

|
||||
|
||||
### 从Ubuntu卸载KDE Plasma ###
|
||||
### 从Ubuntu中卸载KDE Plasma ###
|
||||
|
||||
如果你想要还原更改,使用下面的命令从Ubuntu 14.10中卸载KDE Plasma。
|
||||
如果你想要卸载它,使用下面的命令从Ubuntu 14.10中卸载KDE Plasma。
|
||||
|
||||
sudo apt-get install ppa-purge
|
||||
sudo apt-get remove kubuntu-plasma5-desktop
|
||||
@ -47,7 +46,7 @@ via: http://itsfoss.com/install-kde-plasma-ubuntu-1410/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -2,7 +2,7 @@
|
||||
================================================================================
|
||||

|
||||
|
||||
智能手机都拥有一些平滑融入手机外观的天气小插件,幸亏有了 Flair Weather Conky,你便可以**在你的 Linux 桌面中拥有像智能手机一样的天气外观**。我们将使用一个 GUI 工具[Conky Manager 在 Linux 中轻松地管理 Conky][1]。那就先让我们看看如何在 Ubuntu 14.10,14.04、Linux Mint 17 及其他 Linux 发行版本中安装 Conky Manager 吧。
|
||||
智能手机都拥有一些平滑地融入手机外观的天气小插件,现在幸亏有了 Flair Weather Conky,你便可以**在你的 Linux 桌面中拥有像智能手机一样的天气外观**。我们将使用一个 GUI 工具[Conky Manager 在 Linux 中轻松地管理 Conky][1]。那就先让我们看看如何在 Ubuntu 14.10,14.04、Linux Mint 17 及其他 Linux 发行版本中安装 Conky Manager 吧。
|
||||
|
||||
### 安装 Conky Manager ###
|
||||
|
||||
@ -16,7 +16,7 @@
|
||||
|
||||
### 确保 `curl` 已被安装 ###
|
||||
|
||||
请确保 [curl][2] 已被安装。(如果没有安装它,)可以使用下面的命令来安装:
|
||||
请确保 [curl][2] 已被安装。如果没有安装它,可以使用下面的命令来安装:
|
||||
|
||||
sudo apt-get install curl
|
||||
|
||||
@ -30,15 +30,15 @@
|
||||
|
||||
#### 步骤 1: ####
|
||||
|
||||
同你在 Ubuntu 14.04 中安装主题一样,在你的家目录中应该有一个 `.conky` 目录。假如你使用命令行,则不需要让我来告诉你如何找到这个目录。对于新手,请用文件管理器切换到你的家目录下,并按 `Ctrl+H` 来 [在 Ubuntu 中显示隐藏文件][4]。在这里查找 `.conky` 文件夹,假如没有这个文件夹,则创建一个。
|
||||
同你在 Ubuntu 14.04 中安装主题一样,在你的家目录中应该有一个 `.conky` 目录。假如你使用命令行,我想我不需要告诉你如何找到这个目录。对于新手,请用文件管理器切换到你的家目录下,并按 `Ctrl+H` 来 [在 Ubuntu 中显示隐藏文件][4]。在这里查找 `.conky` 文件夹,假如没有这个文件夹,则创建一个。
|
||||
|
||||
#### 步骤 2: ####
|
||||
|
||||
在 `.conky` 目录中,解压下载到的 Flair Weather 文件。请注意在默认情况下它会自动解压到一个名为 `.conky` 目录。所以请进入这个目录,将 Flair Weather 文件夹从中取出,然后将它粘贴到真正的 `.conky` 目录下。
|
||||
在 `.conky` 目录中,解压下载到的 Flair Weather 文件。请注意在默认情况下它会自动解压到一个名为 `.conky` 目录下。所以请进入这个目录,将其中的 Flair Weather 文件夹从中取出,然后将它粘贴到真正的 `.conky` 目录下。
|
||||
|
||||
#### 步骤 3: ####
|
||||
|
||||
Flair Weather 使用 Yahoo 的天气服务,但它不能自动地识别你的位置。你需要手动地编辑它。到[Yahoo 天气][5] 网页,然后通过键入你的城市/Pin 码来得到你所在城市的 位置 ID号。你可以从网页地址栏中取得位置 ID 号。
|
||||
Flair Weather 使用 Yahoo 的天气服务,但它不能自动地识别你的位置。你需要手动地编辑它。到[Yahoo 天气][5] 网页,然后通过键入你的城市/Pin 码来得到你所在城市的位置 ID号。你可以从网页地址栏中取得位置 ID 号。
|
||||
|
||||

|
||||
|
||||
@ -46,7 +46,7 @@ Flair Weather 使用 Yahoo 的天气服务,但它不能自动地识别你的
|
||||
|
||||
打开 Conky Manager,它应该能够读取新安装的 Conky 脚本。这里有两款样式可用,黑色主题或亮丽主题。你可以选择你偏爱的那一款。当你选择后,你就可以在桌面上看到 conky 的显示了。
|
||||
|
||||
在 Flair Weather 中,默认位置被设定为 Melbourne。你必须手动编辑 conky 文件。
|
||||
在 Flair Weather 中,默认位置被设定为 Melbourne。你必须手动编辑 conky 文件来修改。
|
||||
|
||||

|
||||
|
||||
@ -56,44 +56,49 @@ Flair Weather 使用 Yahoo 的天气服务,但它不能自动地识别你的
|
||||
|
||||

|
||||
|
||||
在上面查找的相同位置,假如你将 C 替换为 F,则温度的单位将从摄氏温标改为华氏温标 。不要忘了重启 Conky 来查看已经做出的修改。
|
||||
在上面查找的相同位置,假如你将`u=c` 替换为`u=f`,则温度的单位将从摄氏温标改为华氏温标 。不要忘了重启 Conky 来查看已经做出的修改。
|
||||
|
||||
#### 可能的故障排除 ####
|
||||
(注:这一小节在 md 文件中没有,原文新添加的。)
|
||||
|
||||
在 Ubuntu 14.04 和 Ubuntu 14.10 中,假如你发现 Conky 展示的时间有重叠现象,则请编辑 conky 脚本。查找下面的这些行:
|
||||
|
||||
```
|
||||
## cairo-compmgr
|
||||
own_window_type override
|
||||
own_window_argb_visual no
|
||||
```
|
||||
|
||||
然后将内容更换为下面的这些行:
|
||||
|
||||
|
||||
```
|
||||
## cairo-compmgr
|
||||
own_window_type dock
|
||||
own_window_argb_visual no
|
||||
```
|
||||
|
||||
保存更改并重启 conky。这就应该解决了这个问题。感谢 Jesse(这个 Conky 脚本的开发者)给我们提供了这个解决方法和为其他相关问题给予的支持。
|
||||
|
||||
#### 尝试尝试 ####
|
||||
### 尝试一下 ###
|
||||
|
||||
在这篇文章中,我们实际上学到了不少东西。我们见证了如何轻松地使用任何 Conky 脚本,如何编辑脚本以及如何使用 Conky Manager 来达到不同的目的。我希望这些对你有用。
|
||||
|
||||
需要留心的是,Ubuntu 14.10 用户可能会看到重叠的时间数字。请在开发者 Jesse 绝妙的[Google + 主页][6] 中报告任何相关的问题。(注:这句在 md 文件中的内容与原文有差异,我按照原文翻译,并加上了 链接)
|
||||
需要留心的是,Ubuntu 14.10 用户可能会看到重叠的时间数字。请在开发者 Jesse 绝妙的[Google + 主页][6] 中报告任何相关的问题。
|
||||
|
||||
我已经向你展示了在我的系统上 Flair Weather conky 外观的截图。现在是该你尝试它并炫耀你的桌面的时间了。
|
||||
|
||||
我已经向你展示了在我的系统上 Flair Weather conky 外观的截图。现在该你尝试它并炫耀你的桌面的时间了。
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/weather-conky-linux/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/Abhishek/
|
||||
[1]:http://itsfoss.com/conky-gui-ubuntu-1304/
|
||||
[1]:http://www.linux.cn/article-3434-1.html
|
||||
[2]:http://www.computerhope.com/unix/curl.htm
|
||||
[3]:http://speedracker.deviantart.com/art/Flair-Weather-Conky-Made-for-Conky-Manager-510130311
|
||||
[4]:http://itsfoss.com/hide-folders-and-show-hidden-files-in-ubuntu-beginner-trick/
|
||||
@ -1,6 +1,6 @@
|
||||
Linux 基础:在CentOS 7上给一个网卡分配多个IP地址
|
||||
在CentOS 7上给一个网卡分配多个IP地址
|
||||
================================================================================
|
||||
有时你也许想要给一个网卡多个地址。你该怎么做呢?另外买一个网卡来分配地址?不用这么做(只要在小型网络中)。我们现在可以再CentOS/RHEL 7中给一个网卡分配多个ip地址。想知道怎么做么?好的,跟随我,这并不难。
|
||||
有时你也许想要给一个网卡多个地址。你该怎么做呢?另外买一个网卡来分配地址?在小型网络中其实不用这么做。我们现在可以在CentOS/RHEL 7中给一个网卡分配多个ip地址。想知道怎么做么?好的,跟随我,这并不难。
|
||||
|
||||
首先,让我们找到网卡的IP地址。在我的CentOS 7服务器中,我只使用了一个网卡。
|
||||
|
||||
@ -83,7 +83,6 @@ Linux 基础:在CentOS 7上给一个网卡分配多个IP地址
|
||||
|
||||
类似地,你可以加入更多的ip地址。
|
||||
|
||||
Finally, save and close the file. Restart network service to take effect the changes.
|
||||
最后,保存并退出文件。重启网络服务来使更改生效。
|
||||
|
||||
systemctl restart network
|
||||
@ -172,11 +171,9 @@ Finally, save and close the file. Restart network service to take effect the cha
|
||||
IPV6_PEERDNS="yes"
|
||||
IPV6_PEERROUTES="yes"
|
||||
|
||||
你可以看到我已经添加一个A类地址(10.0.0.1)并且前缀是16
|
||||
你可以看到我已经添加一个A类地址(10.0.0.1)并且前缀是16。
|
||||
|
||||
保存并退出文件。重启网络服务,
|
||||
|
||||
接着,ping新增的地址:
|
||||
保存并退出文件。重启网络服务,接着,ping新增的地址:
|
||||
|
||||
ping -c 4 10.0.0.1
|
||||
|
||||
@ -202,7 +199,7 @@ via: http://www.unixmen.com/linux-basics-assign-multiple-ip-addresses-single-net
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -2,16 +2,11 @@ Linux 下最为人熟知的归档/压缩工具
|
||||
================================================================================
|
||||
很多时候,通过互联网发送或接收大文件和图片是一件令人头疼的事。压缩及解压缩工具正好可以应对这个问题。下面让我们快速浏览一些可以使得我们的工作更加轻松的开源工具。
|
||||
|
||||
Tar
|
||||
gzip, gunzip
|
||||
bzip2, bunzip2
|
||||
7-Zip
|
||||
|
||||
### Tar ###
|
||||
|
||||
Tar 由 'Tape archiver' 衍生而来,最初被用来在磁带上归档和存储文件。Tar 是一个 GNU 软件,它可以压缩一组文件(归档),或提取它们以及对已经存在的压缩文件进行相关操作。在存储、备份以及转移文件方面,它是很有帮助的。在创建归档文件时,Tar 可以保持原有文件和目录结构不变。通过 Tar 归档的文件的后缀名为 ‘.tar’。
|
||||
Tar 由 'Tape archiver(磁带归档器)' 衍生而来,最初被用来在磁带上归档和存储文件。Tar 是一个 GNU 软件,它可以压缩一组文件(归档),或提取它们以及对已有的归档文件进行相关操作。在存储、备份以及传输文件方面,它是很有用的。在创建归档文件时,Tar 可以保持原有文件和目录结构不变。通过 Tar 归档的文件的后缀名为 ‘.tar’。
|
||||
|
||||
基本用法
|
||||
**基本用法如下:**
|
||||
|
||||
#### a) 创建归档 (c / --create) ####
|
||||
|
||||
@ -23,7 +18,7 @@ Tar 由 'Tape archiver' 衍生而来,最初被用来在磁带上归档和存
|
||||
|
||||

|
||||
|
||||
创建一个归档
|
||||
*创建一个归档*
|
||||
|
||||
#### b) 列出归档文件内容 ( t / --list) ####
|
||||
|
||||
@ -31,7 +26,7 @@ Tar 由 'Tape archiver' 衍生而来,最初被用来在磁带上归档和存
|
||||
|
||||

|
||||
|
||||
列出归档中包含的文件
|
||||
*列出归档中包含的文件*
|
||||
|
||||
#### c) 提取归档 (x / --extract) ####
|
||||
|
||||
@ -41,45 +36,45 @@ Tar 由 'Tape archiver' 衍生而来,最初被用来在磁带上归档和存
|
||||
|
||||

|
||||
|
||||
提取文件
|
||||
*提取文件*
|
||||
|
||||

|
||||
|
||||
只提取需要的文件
|
||||
*只提取需要的文件*
|
||||
|
||||
#### d) 对归档进行更新 ( u / --update) ####
|
||||
#### d) 对归档文件进行更新 ( u / --update) ####
|
||||
|
||||
tar uvf archive.tar newfile.c - 假如归档的版本比先前存在的版本新,通过添加文件 newfile.c 来更新归档.
|
||||
tar uvf archive.tar newfile.c - 假如归档的newfile.c 要比先前已经归档的新,则添加更新的 newfile.c 到归档里面.
|
||||
|
||||

|
||||
|
||||
更新一个归档
|
||||
*更新一个归档*
|
||||
|
||||
#### e) 从归档中删除文件 (--delete) ####
|
||||
|
||||
tar--delete -f archive.tar file1.c - 从压缩包'archive.tar' 中删除文件'file1.c'
|
||||
tar --delete -f archive.tar file1.c - 从压缩包'archive.tar' 中删除文件'file1.c'
|
||||
|
||||

|
||||
|
||||
删除文件
|
||||
*删除文件*
|
||||
|
||||
更加具体的使用方法请参考[tar 主页][1]。
|
||||
|
||||
### Gzip / Gunzip ###
|
||||
|
||||
Gzip 代表 GNU zip,它是一个被广泛用于 Linux 操作系统中的压缩应用,被其压缩的文件的后缀名为'*.gz' 。
|
||||
Gzip 即 GNU zip,它是一个被广泛用于 Linux 操作系统中的压缩应用,被其压缩的文件的后缀名为'*.gz' 。
|
||||
|
||||
** 基本用法 **
|
||||
**基本用法如下:**
|
||||
|
||||
#### a) 压缩文件 ####
|
||||
|
||||
gzip file(s)
|
||||
|
||||
每个文件将被单独压缩。
|
||||
每个文件将被**单独压缩**。
|
||||
|
||||

|
||||
|
||||
压缩文件
|
||||
*压缩文件*
|
||||
|
||||
通常在压缩完成后,它会将原来的文件删除。我们可以使用 `-c` 选项来保留原来的文件。
|
||||
|
||||
@ -87,7 +82,7 @@ Gzip 代表 GNU zip,它是一个被广泛用于 Linux 操作系统中的压缩
|
||||
|
||||

|
||||
|
||||
压缩后保留原有文件
|
||||
*压缩后保留原有文件*
|
||||
|
||||
我们也可以将一组文件压缩到一个单独的文件中
|
||||
|
||||
@ -95,7 +90,7 @@ Gzip 代表 GNU zip,它是一个被广泛用于 Linux 操作系统中的压缩
|
||||
|
||||

|
||||
|
||||
压缩一组文件
|
||||
*压缩一组文件*
|
||||
|
||||
#### b) 检查压缩比 ####
|
||||
|
||||
@ -105,17 +100,17 @@ Gzip 代表 GNU zip,它是一个被广泛用于 Linux 操作系统中的压缩
|
||||
|
||||

|
||||
|
||||
检查压缩率
|
||||
*检查压缩率*
|
||||
|
||||
#### c) 解压文件 ####
|
||||
|
||||
Gunzip 被用来解压文件,在这里,原有文件在被解压后同样会被删除。使用 `-c`选项来保留原始文件。
|
||||
Gunzip 用来解压文件,在这里,原有的(压缩)文件在被解压后同样会被删除。使用 `-c`选项来保留原始文件。
|
||||
|
||||
gunzip -c archieve.gz
|
||||
|
||||

|
||||
|
||||
解压文件
|
||||
*解压文件*
|
||||
|
||||
gzip 加上'-d'选项 和 gunzip 对压缩文件有同样的效果。
|
||||
|
||||
@ -125,47 +120,50 @@ gzip 加上'-d'选项 和 gunzip 对压缩文件有同样的效果。
|
||||
|
||||
同 gzip 一样,[Bzip2][3] 也是一个压缩工具,与其他传统的工具相比,它可以将文件压缩到更小,但其缺点为:运行速度比 gzip 慢。
|
||||
|
||||
** 基本用法 **
|
||||
**基本用法如下:**
|
||||
|
||||
#### a) 压缩文件 ####
|
||||
|
||||
一般情况下,针对压缩而言,Bzip2 没有选项可供选择,将被压缩的文件被传递为它的参数。每个文件被单独压缩,且压缩文件以 'bz2' 为后缀名。
|
||||
一般情况下,针对压缩而言,Bzip2 不用什么选项,将被压缩的文件被传递为它的参数。每个文件被单独压缩,且压缩文件以 'bz2' 为后缀名。
|
||||
|
||||
bzip2 file1 file2 file3
|
||||
|
||||

|
||||
|
||||
文件压缩
|
||||
*文件压缩*
|
||||
|
||||
使用 '-k' 选项可以使得 在压缩或解压缩之后保留原有的文件。
|
||||
使用 '-k' 选项可以使得在压缩或解压缩之后保留原有的文件。
|
||||
|
||||

|
||||
|
||||
在压缩后保留原有文件。
|
||||
*在压缩后保留原有文件*
|
||||
|
||||
'-d' 选项被用来强制解压缩。
|
||||
|
||||
#### b) 解压 ####
|
||||
|
||||
'-d' 选项被用来解压缩。
|
||||
|
||||

|
||||
|
||||
使用 -d 选项删除文件 (!! 注:我(FSSlc)认为 这里的图片说明有误,可以参考 manpage或bzip 的官网来校对一下。)
|
||||
*使用 -d 选项解压缩文件*
|
||||
|
||||
#### b) 解压 ####
|
||||
也可以使用 bunzip2 来解压缩。
|
||||
|
||||
bunzip2 filename
|
||||
|
||||

|
||||
|
||||
解压文件
|
||||
*解压文件*
|
||||
|
||||
bunzip2 可以解压后缀名为 bz2, bz, tbz2 和 tbz 的文件。带有 tbz2 和 tbz 的文件在压缩后,后缀名将变为'.tar' 。
|
||||
|
||||
bzip2 -dc 执行解压文件到标准输出的功能。
|
||||
bzip2 -dc - 执行解压文件到标准输出的功能。
|
||||
|
||||
### 7-zip ###
|
||||
|
||||
[7-zip][4] 是另一个开源压缩软件。它使用 7z 这种新的压缩格式,并支持高压缩比。因此,它被认为是比先前提及的压缩工具更好的软件。在 Linux 下,可以通过 p7zip 软件包得到,该软件包里包含 3 个二进制文件 – 7z, 7za 和 7zr,读者可以参考 [p7zip wiki][5] 来了解这三个二进制文件之间的不同。在本篇中,我们将使用 7zr 来解释 7-zip 的用法。归档文件以 '.7z' 为后缀名。
|
||||
[7-zip][4] 是另一个开源压缩软件。它使用 7z 这种新的压缩格式,并支持高压缩比。因此,它被认为是比先前提及的压缩工具更好的软件。在 Linux 下,可以通过 p7zip 软件包得到,该软件包里包含 3 个二进制文件: 7z, 7za 和 7zr,读者可以参考 [p7zip wiki][5] 来了解这三个二进制文件之间的不同。在本篇中,我们将使用 7zr 来解释 7-zip 的用法。归档文件以 '.7z' 为后缀名。
|
||||
|
||||
** 基本用法 **
|
||||
**基本用法如下:**
|
||||
|
||||
#### a) 创建归档 ####
|
||||
|
||||
@ -173,7 +171,7 @@ bunzip2 可以解压后缀名为 bz2, bz, tbz2 和 tbz 的文件。带有 tbz2
|
||||
|
||||

|
||||
|
||||
创建一个归档文件
|
||||
*创建一个归档文件*
|
||||
|
||||
#### b) 列出归档包含文件 ####
|
||||
|
||||
@ -181,7 +179,7 @@ bunzip2 可以解压后缀名为 bz2, bz, tbz2 和 tbz 的文件。带有 tbz2
|
||||
|
||||

|
||||
|
||||
列出归档中包含的文件
|
||||
*列出归档中包含的文件*
|
||||
|
||||
#### c) 提取归档文件 ####
|
||||
|
||||
@ -189,7 +187,7 @@ bunzip2 可以解压后缀名为 bz2, bz, tbz2 和 tbz 的文件。带有 tbz2
|
||||
|
||||

|
||||
|
||||
提取归档
|
||||
*提取归档*
|
||||
|
||||
#### d) 更新归档文件 ####
|
||||
|
||||
@ -197,7 +195,7 @@ bunzip2 可以解压后缀名为 bz2, bz, tbz2 和 tbz 的文件。带有 tbz2
|
||||
|
||||

|
||||
|
||||
更新一个归档文件
|
||||
*更新一个归档文件*
|
||||
|
||||
#### e) 从归档文件中删除文件 ####
|
||||
|
||||
@ -205,11 +203,11 @@ bunzip2 可以解压后缀名为 bz2, bz, tbz2 和 tbz 的文件。带有 tbz2
|
||||
|
||||

|
||||
|
||||
删除文件
|
||||
*删除文件*
|
||||
|
||||

|
||||
|
||||
确认文件删除
|
||||
*确认文件删除*
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -217,7 +215,7 @@ via: http://linoxide.com/tools/linux-compress-decompress-tools/
|
||||
|
||||
作者:[B N Poornima][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -36,7 +36,7 @@ via: http://www.ubuntugeek.com/how-to-protect-ubuntu-server-against-the-ghost-vu
|
||||
|
||||
作者:[ruchi][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,9 +1,10 @@
|
||||
Linux中的15个基本‘ls’命令示例
|
||||
================================================================================
|
||||
ls命令是Linux系统中最被频繁使用的命令之一,我相信ls命令一定是你进入一台Linux系统的电脑打开命令提示符后第一个使用的命令。我们每天都在频繁地使用ls命令即使我们可能没有意识也从来用不到所以可用的选项。本文中,我们将讨论下一些基本的ls命令并且覆盖尽可能多的有关参数来讲解。
|
||||
ls命令是Linux系统中最被频繁使用的命令之一,我相信ls命令一定是你进入一台Linux系统的电脑打开命令提示符后第一个使用的命令。我们每天都在频繁地使用ls命令,即使我们可能没有意识也从来用不到所有可用的选项。本文中,我们将讨论下一些基本的ls命令并且覆盖尽可能多的有关参数来讲解。
|
||||
|
||||

|
||||
Linux的ls命令
|
||||
|
||||
*Linux的ls命令*
|
||||
|
||||
### 1. 不带任何选项列出文件 ###
|
||||
|
||||
@ -14,7 +15,7 @@ Linux的ls命令
|
||||
0001.pcap Desktop Downloads index.html install.log.syslog Pictures Templates
|
||||
anaconda-ks.cfg Documents fbcmd_update.php install.log Music Public Videos
|
||||
|
||||
### 2 带–l选项列出文件列表 ###
|
||||
### 2 带 –l 选项列出文件列表 ###
|
||||
|
||||
你看,ls -l(-l是字母不是“1”)就能展示出是文件还是目录,它的大小、修改日期和时间、文件或目录的名字以及文件的属主和它的权限。
|
||||
|
||||
@ -50,9 +51,9 @@ Linux的ls命令
|
||||
.bash_logout Desktop fbcmd_update.php .ICEauthority .mozilla Public Videos
|
||||
.bash_profile .digrc .gconf index.html Music .pulse .wireshark
|
||||
|
||||
### 4. 用-lh选项来以人类可读方式列出文件 ###
|
||||
### 4. 用 -lh 选项来以易读方式列出文件 ###
|
||||
|
||||
用-lh组合选项,以人类可读方式来显示大小。
|
||||
用-lh组合选项,以易读方式来显示大小。
|
||||
|
||||
# ls -lh
|
||||
|
||||
@ -74,7 +75,7 @@ Linux的ls命令
|
||||
|
||||
### 5. 以尾部以‘/’字符结尾的方式列出文件和目录 ###
|
||||
|
||||
Using -F option with ls command, will add the ‘/’ Character at the end each directory.
|
||||
使用 ls 命令的 -F 选项,会在每个目录的末尾添加“/”字符显示。
|
||||
|
||||
# ls -F
|
||||
|
||||
@ -83,7 +84,7 @@ Using -F option with ls command, will add the ‘/’ Character at the end each
|
||||
|
||||
### 6. 倒序列出文件 ###
|
||||
|
||||
ls -r选项能以倒序方式显示文件和目录。
|
||||
ls -r 选项能以倒序方式显示文件和目录。
|
||||
|
||||
# ls -r
|
||||
|
||||
@ -92,7 +93,7 @@ ls -r选项能以倒序方式显示文件和目录。
|
||||
|
||||
### 7. 递归列出子目录 ###
|
||||
|
||||
ls -R选项能列出非常长的目录树,来看看示例输出:
|
||||
ls -R 选项能列出非常长的目录树,来看看示例输出:
|
||||
|
||||
# ls -R
|
||||
|
||||
@ -115,7 +116,7 @@ ls -R选项能列出非常长的目录树,来看看示例输出:
|
||||
-rw-r--r--. 1 root root 0 Aug 12 03:17 access.log
|
||||
-rw-r--r--. 1 root root 390 Aug 12 03:17 access.log-20120812.gz
|
||||
|
||||
### 8. 反向输出次序 ###
|
||||
### 8. 以修改时间倒序列出 ###
|
||||
|
||||
带-ltr组合选项能以文件或目录的最新修改时间的次序来显示它们。
|
||||
|
||||
@ -159,9 +160,9 @@ ls -R选项能列出非常长的目录树,来看看示例输出:
|
||||
-rw-------. 1 root root 1586 Jul 31 02:17 anaconda-ks.cfg
|
||||
-rw-r--r--. 1 root root 683 Aug 19 09:59 0001.pcap
|
||||
|
||||
### 10. 显示文件或目录的索引节点数 ###
|
||||
### 10. 显示文件或目录的索引节点号 ###
|
||||
|
||||
我们有时候可以看到一些数字打印在文件或目录名之前,带-i选项就能列出文件或目录的索引节点数。
|
||||
我们有时候可以看到一些数字打印在文件或目录名之前,带-i选项就能列出文件或目录的索引节点号。
|
||||
|
||||
# ls -i
|
||||
|
||||
@ -192,7 +193,7 @@ ls -R选项能列出非常长的目录树,来看看示例输出:
|
||||
|
||||
### 13. 列出目录信息 ###
|
||||
|
||||
用ls -l命令列出/tmp目录下的文件,其中-ld参数可以显示/tmp目录的信息。
|
||||
用ls -l命令列出/tmp目录下的文件,其中-ld参数可以只显示/tmp目录的信息。
|
||||
|
||||
# ls -l /tmp
|
||||
total 408
|
||||
@ -225,13 +226,13 @@ ls -R选项能列出非常长的目录树,来看看示例输出:
|
||||
-rw-rw-r--. 1 500 500 12 Aug 21 13:06 tmp.txt
|
||||
drwxr-xr-x. 2 500 500 4096 Aug 2 01:52 Videos
|
||||
|
||||
### 15. ls命令和它的别名功能 ###
|
||||
### 15. ls命令和它的别名 ###
|
||||
|
||||
我们给ls命令设置过别名之后,当我们执行ls命令的时候它会默认执行-l选项并且像上文提到的那样显示长列表。
|
||||
我们给ls命令设置如下别名之后,当我们执行ls命令的时候它会默认执行-l选项并且像上文提到的那样显示长列表。
|
||||
|
||||
# alias ls="ls -l"
|
||||
|
||||
注意:我们可以通过不加任何参数的alias命令来看到目前系统中可用的所有alias设置,当然它们同时也可以unalias。
|
||||
注意:我们可以通过不加任何参数的alias命令来看到目前系统中可用的所有alias设置,当然它们同时也可以unalias来取消。
|
||||
|
||||
# alias
|
||||
|
||||
@ -255,7 +256,7 @@ via: http://www.tecmint.com/15-basic-ls-command-examples-in-linux/
|
||||
|
||||
作者:[Ravi Saive][a]
|
||||
译者:[ZTinoZ](https://github.com/ZTinoZ)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,57 @@
|
||||
Papyrus: An Open Source Note Manager
|
||||
================================================================================
|
||||

|
||||
|
||||
In last post, we saw an [open source to-do app Go For It!][1]. In a similar article, today we’ll see an **open source note taking application Papyrus**.
|
||||
|
||||
[Papyrus][2] is a fork of [Kaqaz note manager][3] and is built on QT5. It brings a clean, polished user interface and is security focused (as it claims). Emphasizing on simplicity, I find Papyrus similar to OneNote. You organize your notes in ‘paper’ and add them a label for grouping those papers. Simple enough!
|
||||
|
||||
### Papyrus features: ###
|
||||
|
||||
Though Papyrus focuses on simplicity, it still has plenty of features up its sleeves. Some of the main features are:
|
||||
|
||||
- Note management with labels and categories
|
||||
- Advanced search options
|
||||
- Touch mode available
|
||||
- Full screen option
|
||||
- Back up to Dropbox/hard drive/external
|
||||
- Password protection for selective papers
|
||||
- Sharing papers with other applications
|
||||
- Encrypted synchronization via Dropbox
|
||||
- Available for Android, Windows and OS X apart from Linux
|
||||
|
||||
### Install Papyrus ###
|
||||
|
||||
Papyrus has APK available for Android users. There are installer files for Windows and OS X. Linux users can get source code of the application. Ubuntu and other Ubuntu based distributions can use the .deb packages. Based on your OS and preference, you can get the respective files from the Papyrus download page:
|
||||
|
||||
- [Download Papyrus][4]
|
||||
|
||||
### Screenshots ###
|
||||
|
||||
Here are some screenshots of the application:
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Give Papyrus a try and see if you like it. Do share your experience with it with the rest of us here.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/papyrus-open-source-note-manager/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://itsfoss.com/go-for-it-to-do-app-in-linux/
|
||||
[2]:http://aseman.co/en/products/papyrus/
|
||||
[3]:https://github.com/sialan-labs/kaqaz/
|
||||
[4]:http://aseman.co/en/products/papyrus/
|
||||
@ -0,0 +1,52 @@
|
||||
Red Hat Developer Toolset 3.1 beta arrives
|
||||
================================================================================
|
||||
> **Summary**:Want the newest developer tools for Red Hat Enterprise Linux 6 or 7? The beta's ready for you now.
|
||||
|
||||
It's one of those eternal problems between developers and operators that even [DevOps][1] can't entirely solve. System administrators want the most stable operating system possible, while programmers want the latest and greatest development tools. [Red Hat][2]'s solution for this dilemma has been to take those brand spanking-new tools, test them out on the latest stable [Red Hat Enterprise Linux (RHEL)][3], and then release them to developers.
|
||||
|
||||

|
||||
Red Hat Developer Toolset
|
||||
|
||||
So it is that Red Hat has just announced its latest toys for developers, [Red Hat Developer Toolset 3.1][4]. This packaging of the hottest new tools is now available in beta.
|
||||
|
||||
This update includes:
|
||||
|
||||
[GNUCompiler Collection (GCC) 4.9][5]: the latest stable upstream version of GCC, which provides numerous improvements and bug fixes
|
||||
|
||||
[Eclipse 4.4.1][6]: with support for Java 8 and updated versions of Eclipse CDT (8.5), Eclipse Linux Tools (3.1), Eclipse Mylyn (3.14), and Eclipse Egit/Jgit (3.6.1)
|
||||
|
||||
Numerous additional updated packages: These include GDB 7.8.2, elfutils 0.161, memstomp 0.1.5, SystemTap 2.6, Valgrind 3.10.1, Dyninst 8.2.1, and ltrace 0.7.91.
|
||||
|
||||
With these development programs, you'll be able to create applications for RHEL 6 and 7.x. These apps will then run on RHEL regardless of whether you're running it on a physical, virtual or cloud environments. They will also run on Red Hat's [OpenShift][7], its Platform-as-a-Service (PaaS) offering.
|
||||
|
||||
This new set of developer programs includes packages for both RHEL 7 and 7 running on [AMD64 and Intel 64 architectures][8]. Although the tools are 64-bit you can use them to create and modify 32-bit binaries.
|
||||
|
||||
Before you try running any of these programs, you should patch RHEL with all the latest updates. To install the beta Toolset, your systems need to be subscribed to the Optional channel to access all the required Red Hat Developer Toolset tool-chain packages.
|
||||
|
||||
In addition, if you've installed earlier Toolkits you may run into some [problems while installing Toolkit 3.1][9]. While these difficulties are easy enough to fix, you should go over these possible hiccups before trying to install the new Toolkit.
|
||||
|
||||
Finally, you may notice that some of the most exciting of the new tools, such as Docker, Kubernetes, and other container tools aren't here. That's because they're in the newly released [RHEL 7.1][10] and [Red Hat Enterprise Linux 7 Atomic Host (RHELAH)][11]. [Red Hat has partnered with Docker][12], but you'll need to move to a Docker-friendly version of RHEL to get at these container-friendly programs.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.zdnet.com/article/red-hat-developer-toolset-3-1-beta-arrives/
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.zdnet.com/meet-the-team/us/sjvn/
|
||||
[1]:http://blogs.csc.com/2015/02/03/devops-theory-for-beginners/
|
||||
[2]:http://www.redhat.com/en
|
||||
[3]:http://www.redhat.com/en/technologies/linux-platforms/enterprise-linux
|
||||
[4]:http://www.redhat.com/en/about/blog/red-hat-developer-toolset-31-beta-now-available
|
||||
[5]:https://gcc.gnu.org/gcc-4.9/
|
||||
[6]:https://projects.eclipse.org/projects/eclipse/releases/4.4.1
|
||||
[7]:https://www.openshift.com/
|
||||
[8]:https://access.redhat.com/documentation/en-US/Red_Hat_Developer_Toolset/3-Beta/html/3.1_Release_Notes/System_Requirements.html
|
||||
[9]:https://access.redhat.com/documentation/en-US/Red_Hat_Developer_Toolset/3-Beta/html/3.1_Release_Notes/DTS3.1_Release.html#Known_Issues
|
||||
[10]:http://www.zdnet.com/article/red-hat-7-1-is-here-centos-7-1-is-coming-soon/
|
||||
[11]:http://www.zdnet.com/article/red-hat-buys-into-docker-containers-with-atomic-host/
|
||||
[12]:http://www.zdnet.com/article/red-hat-partners-with-docker-to-create-linuxdocker-software-stack/
|
||||
@ -0,0 +1,56 @@
|
||||
Square 2.0 Icon Pack Is Twice More Beautiful
|
||||
================================================================================
|
||||

|
||||
|
||||
Elegant, modern looking [Square icon theme][1] has recently been upgraded to version 2.0, which makes it more beautiful than ever. Square icon packs are compatible with all major desktop environments such as **Unity, GNOME, KDE, MATE** etc. Which means that you can use them for all popular Linux distributions such as Ubuntu, Fedora, Linux Mint, elementary OS etc. The vastness of this icon pack can be estimated from the fact it contains over 15,000 icons.
|
||||
|
||||
### Install and use Square icon pack 2.0 in Linux ###
|
||||
|
||||
There are two variants of Square icons, dark and light. Based on your preference, you can choose either of the two. For experimentation sake, I would advise you to download both variants of the icon theme.
|
||||
|
||||
You can download the icon pack from the link below. The files are stored in Google Drive, so don’t be suspicious if you don’t see a standard website like [SourceForge][2].
|
||||
|
||||
- [Square Dark Icons][3]
|
||||
- [Square Light Icons][4]
|
||||
|
||||
To use the icon theme, extract the downloaded files in ~/.icons directory. If this doesn’t exist, create it. Once you have the files in the right place, based on your desktop environment, use a tool to change the icon theme. I have written some small tutorials in the past on this topic. Feel free to refer to them if you need further help:
|
||||
|
||||
- [How to change themes in Ubuntu Unity][5]
|
||||
- [How to change themes in GNOME Shell][6]
|
||||
- [How to change themes in Linux Mint][7]
|
||||
- [How to change theme in Elementary OS Freya][8]
|
||||
|
||||
### Give it a try ###
|
||||
|
||||
Here is what my Ubuntu 14.04 looks like with Square icons. I am using [Ubuntu 15.04 default wallpaper][9] in the background.
|
||||
|
||||

|
||||
|
||||
A quick look at several icons in the Square theme:
|
||||
|
||||

|
||||
|
||||
How do you find it? Do you think it can be considered as one of the [best icon themes for Ubuntu 14.04][10]? Do share your thoughts and stay tuned for more articles on customizing your Linux desktop.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/square-2-0-icon-pack-linux/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://gnome-look.org/content/show.php/Square?content=163513
|
||||
[2]:http://sourceforge.net/
|
||||
[3]:http://gnome-look.org/content/download.php?content=163513&id=1&tan=62806435
|
||||
[4]:http://gnome-look.org/content/download.php?content=163513&id=2&tan=19789941
|
||||
[5]:http://itsfoss.com/how-to-install-themes-in-ubuntu-13-10/
|
||||
[6]:http://itsfoss.com/install-switch-themes-gnome-shell/
|
||||
[7]:http://itsfoss.com/install-icon-linux-mint/
|
||||
[8]:http://itsfoss.com/install-themes-icons-elementary-os-freya/
|
||||
[9]:http://itsfoss.com/default-wallpapers-ubuntu-1504/
|
||||
[10]:http://itsfoss.com/best-icon-themes-ubuntu-1404/
|
||||
@ -0,0 +1,132 @@
|
||||
How to Install Telegram Messenger Application on Linux
|
||||
================================================================================
|
||||
Telegram is an Instant Messaging (IM) application similar to whatsapp. It has a very large user base. It has a lot of features that differentiate it from other messaging application.
|
||||
|
||||
|
||||
Telegram Messenger for Linux
|
||||
|
||||
This article aims at making you aware of telegram application followed by detailed installation instructions on Linux Box.
|
||||
|
||||
#### Features of Telegram ####
|
||||
|
||||
- Implementation for mobile devices
|
||||
- Available for Desktop.
|
||||
- Application Program Interface (API) of Telegram can be Accessed by third party developers.
|
||||
- Available for Android, iphone/ipad, Windows Phone, Web-Version, PC, Mac and Linux
|
||||
- The above application provides Heavily Encrypted and self destruct messages.
|
||||
- Lets you access your message from multiple devices and platform.
|
||||
- The overall processing and message delivery is lightening fast.
|
||||
- Distributed server across the globe for security and speed.
|
||||
- Open API and Free Protocol
|
||||
- NoAds, No Subscription charge. – Free forever.
|
||||
- Powerful – No limit to media and chats
|
||||
- Several security measures that make it safe from Hackers.
|
||||
- Reply to Specific message in group. Mention @username to notify multiple users in group.
|
||||
|
||||
#### Why Telegram? ####
|
||||
|
||||
When Applications like whatsapp and other IM are providing almost same things in bag, why should someone opt for Telegram?
|
||||
|
||||
Well Availability of API to third party developer is enough to say. Moreover availability for PC which means you won’t have to struggle typing message using your mobile, but you can use your PC and that is pretty more than sufficient.
|
||||
|
||||
Also The option to connect on remote locations, Co-ordinate – Group of upto 200 Members, Sync all your devices, Send – Documents of all kind, Encrypt message, Self destruction of message, Storage of Media in Cloud, Build own tool on freely available API and what not.
|
||||
|
||||
**Testing Environment**
|
||||
|
||||
We have used Debian GNU/Linux, x86_64 architecture to test it and the overall process went very smooth for us. Here what we did stepwise.
|
||||
|
||||
### Installation of Telegram Messenger in Linux ###
|
||||
|
||||
First go to the official Telegram site, and download Telegram source package ([tsetup.0.7.23.tar.xz][1]) for Linux system or you may use following wget command to download directly.
|
||||
|
||||
# wget https://updates.tdesktop.com/tlinux/tsetup.0.7.23.tar.xz
|
||||
|
||||
Once package has been downloaded, unpack the tarball and switch from current working directory to the extracted directory.
|
||||
|
||||
# tar -xf tsetup.0.7.23.tar.xz
|
||||
# cd Telegram/
|
||||
|
||||
Next, execute the binary file ‘Telegram’ from the command line as shown below.
|
||||
|
||||
# ./Telegram
|
||||
|
||||
1. The first Impression. Click “START MESSAGING”.
|
||||
|
||||

|
||||
Start Messaging
|
||||
|
||||
2. Enter Your phone Number. Click “NEXT”. If you have not registered for telegram before this, using the same number as entered above you will get a warning that you don’t have a telegram account yet. Click “Register Here”.
|
||||
|
||||

|
||||
Signup for Telegram
|
||||
|
||||
3. After submitting your phone number, telegram will send you a verification code, shortly. You need to Enter it.
|
||||
|
||||

|
||||
Telegram Verification Code
|
||||
|
||||
4. Enter your First_Name, Last_name and pics and click “SIGNUP”.
|
||||
|
||||

|
||||
Enter Account Details
|
||||
|
||||
5. After account creation, I got this interface. Everything seems at its place, even when I am new to telegram Application. The interface is really simple.
|
||||
|
||||

|
||||
Telegram Interface
|
||||
|
||||
6. Click Add a contact and Enter Their first_name, last_name and Phone number. Click create when done!.
|
||||
|
||||
|
||||
Add New Telegram Contact
|
||||
|
||||
7. If the contact you added is not on telegram already, You get a warning message and telegram will acknowledge you when your contact joins telegram.
|
||||
|
||||

|
||||
Telegram Contact Notification
|
||||
|
||||
8. As soon as the contact joins telegram you get a message (pop-out like) that reads [YOUR_CONTACT] joined telegram.
|
||||
|
||||
9. A formal chat window on Linux Machine. Nice experience…
|
||||
|
||||

|
||||
Telegram Contact Join Message
|
||||
|
||||
10. At the same time, I’ve tried messaging from my android mobile device, the interface looks similar on both.
|
||||
|
||||

|
||||
Telegram Mobile Interface
|
||||
|
||||
11. Telegram settings page. You have a lot of options to configure.
|
||||
|
||||

|
||||
Telegram Settings
|
||||
|
||||
12. About Telegram.
|
||||
|
||||

|
||||
About Telegram
|
||||
|
||||
#### Less Interesting Points ####
|
||||
|
||||
- Telegram usage protocol MTProto Mobile protocol.
|
||||
- Released Initially for iPhone in the year 2013 (August 14)..
|
||||
- People Behind this Amazing Project: Pavel and Nikolai Durov..
|
||||
|
||||
That’s all for now. I’ll be here again with another interesting article you will love to read. I take the pleasure on behalf of Tecmint to thank all our valuable readers and critics who made us stand where we are now through continuous self evolving process. Keep Connected! Keep Commenting. Share if you care for us.
|
||||
|
||||
- [https://telegram.org/][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-telegram-in-linux/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:https://tdesktop.com/linux
|
||||
[2]:https://telegram.org/
|
||||
110
sources/share/20150326 Mydumper--Mysql Database Backup tool.md
Normal file
110
sources/share/20150326 Mydumper--Mysql Database Backup tool.md
Normal file
@ -0,0 +1,110 @@
|
||||
Mydumper – Mysql Database Backup tool
|
||||
================================================================================
|
||||
Mydumper is a tool used for backing up MySQL database servers much faster than the mysqldump tool distributed with MySQL. It also has the capability to retrieve the binary logs from the remote server at the same time as the dump itself.
|
||||
|
||||
### Mydumper advantages ###
|
||||
|
||||
o Parallelism (hence, speed) and performance (avoids expensive character set conversion routines, efficient code overall)
|
||||
|
||||
o Easier to manage output (separate files for tables, dump metadata,etc, easy to view/parse data)
|
||||
|
||||
o Consistency -- maintains snapshot across all threads, provides accurate master and slave log positions, etc
|
||||
|
||||
o Manageability -- supports PCRE for specifying database and tables inclusions and exclusions
|
||||
|
||||
### Install mydumper on ubuntu ###
|
||||
|
||||
Open the terminal and run the following command
|
||||
|
||||
sudo apt-get install mydumper
|
||||
|
||||
### Using Mydumper ###
|
||||
|
||||
#### Syntax ####
|
||||
|
||||
mydumper [options]
|
||||
|
||||
Application Options:
|
||||
|
||||
- -B, --database Database to dump
|
||||
- -T, --tables-list Comma delimited table list to dump (does not exclude regex option)
|
||||
- -o, --outputdir Directory to output files to
|
||||
- -s, --statement-size Attempted size of INSERT statement in bytes, default 1000000
|
||||
- -r, --rows Try to split tables into chunks of this many rows
|
||||
- -c, --compress Compress output files
|
||||
- -e, --build-empty-files Build dump files even if no data available from table
|
||||
- -x, --regex Regular expression for ‘db.table' matching
|
||||
- -i, --ignore-engines Comma delimited list of storage engines to ignore
|
||||
- -m, --no-schemas Do not dump table schemas with the data
|
||||
- -k, --no-locks Do not execute the temporary shared read lock. WARNING: This will cause inconsistent backups
|
||||
- -l, --long-query-guard Set long query timer in seconds, default 60
|
||||
- --kill-long-queries Kill long running queries (instead of aborting)
|
||||
- -b, --binlogs Get a snapshot of the binary logs as well as dump data
|
||||
- -D, --daemon Enable daemon mode
|
||||
- -I, --snapshot-interval Interval between each dump snapshot (in minutes), requires --daemon, default 60
|
||||
- -L, --logfile Log file name to use, by default stdout is used
|
||||
- -h, --host The host to connect to
|
||||
- -u, --user Username with privileges to run the dump
|
||||
- -p, --password User password
|
||||
- -P, --port TCP/IP port to connect to
|
||||
- -S, --socket UNIX domain socket file to use for connection
|
||||
- -t, --threads Number of threads to use, default 4
|
||||
- -C, --compress-protocol Use compression on the MySQL connection
|
||||
- -V, --version Show the program version and exit
|
||||
- -v, --verbose Verbosity of output, 0 = silent, 1 = errors, 2 = warnings, 3 = info, default 2
|
||||
|
||||
#### Mydumper Example ####
|
||||
|
||||
mydumper \
|
||||
--database=$DB_NAME \
|
||||
--host=$DB_HOST \
|
||||
--user=$DB_USER \
|
||||
--password=$DB_PASS \
|
||||
--outputdir=$DB_DUMP \
|
||||
--rows=500000 \
|
||||
--compress \
|
||||
--build-empty-files \
|
||||
--threads=2 \
|
||||
--compress-protocol
|
||||
|
||||
Description of Mydumper's output data
|
||||
|
||||
Mydumper does not output to files, but rather to files in a directory. The --outputdir option specifies the name of the directory to use.
|
||||
|
||||
The output is two parts
|
||||
|
||||
Schema
|
||||
|
||||
For each table in the database, a file containing the CREATE TABLE statement will be created. It will be named:
|
||||
|
||||
dbname.tablename-schema.sql.gz
|
||||
|
||||
Data
|
||||
|
||||
For each table with number of rows above the --rows parameter, you will have a file called:
|
||||
|
||||
dbname.tablename.0000n.sql.gz
|
||||
|
||||
Where "n" starts with 0 up to the number of.
|
||||
|
||||
If you want to restore these backup you can use Myloader
|
||||
|
||||
myloader \
|
||||
--database=$DB_NAME \
|
||||
--directory=$DB_DUMP \
|
||||
--queries-per-transaction=50000 \
|
||||
--threads=10 \
|
||||
--compress-protocol \
|
||||
--verbose=3
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.ubuntugeek.com/mydumper-mysql-database-backup-tool.html
|
||||
|
||||
作者:[ruchi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.ubuntugeek.com/author/ubuntufix
|
||||
@ -1,3 +1,4 @@
|
||||
[raywang]
|
||||
Open source all over the world
|
||||
================================================================================
|
||||

|
||||
|
||||
@ -1,82 +0,0 @@
|
||||
[translating by KayGuoWhu]
|
||||
The future of Linux storage
|
||||
================================================================================
|
||||
> **Summary**:Linux software developers are working hard on expanding Linux's file and storage options.
|
||||
|
||||
BOSTON - At the [Linux Foundation's][1] new [Vault][2] show, it's all about file systems and storage. You might think that there's nothing new to say about either topic, but you'd be wrong.
|
||||
|
||||

|
||||
Linux file systems, such as Btrfs, and storage support options are constantly evolving. -- Facebook
|
||||
|
||||
Storage technology has come a long way from the days of, as Linus Torvalds put it, "[nasty platters of spinning rust][3]" and Linux has had to keep up. In recent years, for example, [flash memory has arrived as enterprise server primary storage][4] and [persistent memory][5] is bringing us storage that works at DRAM speeds. At the same time, Big Data, cloud computing, and containers are all bringing new use cases to Linux.
|
||||
|
||||
To deal with this, Linux developers are both expanding their existing file and storage programs and working on new ones.
|
||||
|
||||
### Btrfs ###
|
||||
|
||||
For instance, Chris Mason, a Facebook software engineer and one of the [Btrfs][6] (pronounced Butter FS) maintainers, explained how Facebook uses this file system. Btrfs has many advantages as a file system such as the ability to handle both numerous small files and single files as large as 16 exabytes; baked in RAID; built-in file-system compression; and integrated multi-storage device support.
|
||||
|
||||
Facebook, of course, runs on Linux. To be exact, Facebook runs the 3.10 and 3.18 Linux kernels on an internal distribution, which is based on [CentOS][7]. For Facebook, the real win is that Btrfs is stable and fast under the endless input/output operations per second (IOPS) pounding from Facebook's constantly updating users.
|
||||
|
||||
That's the good news. The bad news is that Btrfs is still much too slow for traditional DBMSs such as MySQL. For those, Facebook uses [XFS][8]. To co-ordinate the two file systems, Facebook uses [Gluster][9], the open-source distributed file system.
|
||||
|
||||
Facebook, which works hand-in-glove with the upstream Btrfs Linux kernel developers, is working on improving Btrfs's DBMS speed. Mason, and his companions, are doing this by using Btrfs with the [RocksDB][10] database. This is a persistent key-value store for fast storage, which can be used as the foundation for a client-server database.
|
||||
|
||||
Btrfs also still has some bugs. For example, if you're foolish enough to fill a disk almost to bursting, Btrfs will stop you from writing to storage before the disk is completely stuffed. For some projects, such as [CoreOS][12], the enterprise Linux that relies on containers, that's a showstopper. [CoreOS has since switched to using xt4 and overlayfs][11].
|
||||
|
||||
The Btrfs crew is also working on data deduplication. In this, when a file system has more than one identical file, you automatically delete the duplicate. As Mason said, "Not everyone needs this, but if you need it, you really need it!"
|
||||
|
||||
Btrfs isn't the only file system that's both very important and getting worked on. John Spray, a senior software engineer at [Red Hat][13], talked about the distributed [Ceph][14] file system.
|
||||
|
||||
### Ceph FS ###
|
||||
|
||||
Ceph provides a distributed object store and file system which, in turn, relies on a resilient and scalable storage model (RADOS) using clusters of commodity hardware. Along with the RADOS block device (RBD), and the RADOS object gateway (RGW), Ceph provides a [POSIX][15] file-system interface -- Ceph FS. While RBD and RGW have been in use for production workloads for some time, efforts to make Ceph FS ready for production are now underway.
|
||||
|
||||
[Red Hat, after acquiring Inktank][16], Ceph's parent company, in 2014 has been working hard on making CephFS production ready. For better or worse, Spray said, "Some people are already using it in production; we're terrified of this. It's really not ready yet." Still, Spray added, that this "is a mixed blessing because while it's a bit scary, we get really useful feedback and testing from those users."
|
||||
|
||||
That's because while Ceph object stores scale out well, Ceph FS, as a POSIX compliant file-system, are hard to scale out. For example, as a distributed file system, Ceph FS has to deal with multiple writes from multiple clients. This can lead to all or nothing situations where one client can write and others must wait. This can result in file-locking situations that are more complicated than those in ordinary file systems.
|
||||
|
||||
Still, Ceph FS is worth doing, Spray said, "since POSIX file-systems are an operating system lingua franca." That's not to say that Ceph FS doesn't work. "It's not horribly broken. It works. What's missing is the repair and monitoring tools."
|
||||
|
||||
Red Hat is currently hard at work on getting [fsck][17] and journal repair tools, snapshot hardening, better client access control, and cloud and container integration. For now, though, Ceph FS is a file system that only the very brave, or foolish, should use in production.
|
||||
|
||||
### File and storage odds and ends ###
|
||||
|
||||
As for larger issues of file-systems and storage, Jeff Layton, senior software engineer at [Primary Data][18], explained that there are efforts under way to to create "tests for catastrophic power failure, without actually pulling the plug." These tests will soon be integrated with [xfstests][19], the gold standard for Linux file-system testing.
|
||||
|
||||
Rik van Riel, a Red Hat principal software engineer, spoke about the problem of dealing with persistent memory products. You can treat them as storage or as memory. But, you can't currently take snapshots for backups if you use them as memory. The real problem: van Riel is certain that people will try to use persistent memory as both, which will lead to such as situations as "Without back up, how do you deal with a 200GB persistent memory database?" Adding insult to injury, logging systems don't currently work with persistent memory.
|
||||
|
||||
What's the right answer? Linux doesn't have one yet, but programmers are working on it.
|
||||
|
||||
So, while Linux has many file systems and can use any kind of storage out there that can hold a byte, there's still a lot of work to be done. Technology never stands still. Linux, which runs on everything from devices to desktops to servers to clouds to supercomputers, has to keep up with storage advances no matter where they appear.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.zdnet.com/article/linux-storage-futures/
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.zdnet.com/meet-the-team/us/sjvn/
|
||||
[1]:http://www.linuxfoundation.org/
|
||||
[2]:http://events.linuxfoundation.org/events/vault
|
||||
[3]:http://www.wired.com/2012/10/linus-torvalds-hard-disks/
|
||||
[4]:http://www.zdnet.com/article/sandisk-launches-infiniflash-aims-to-bring-flash-array-costs-down/
|
||||
[5]:http://events.linuxfoundation.org/sites/events/files/eeus13_wheeler.pdf
|
||||
[6]:https://btrfs.wiki.kernel.org/index.php/Main_Page
|
||||
[7]:http://www.centos.org/
|
||||
[8]:http://oss.sgi.com/projects/xfs/
|
||||
[9]:http://www.gluster.org/
|
||||
[10]:http://rocksdb.org/
|
||||
[11]:http://lwn.net/Articles/627232/
|
||||
[12]:https://coreos.com/
|
||||
[13]:http://www.redhat.com/
|
||||
[14]:http://ceph.com/
|
||||
[15]:http://pubs.opengroup.org/onlinepubs/9699919799/
|
||||
[16]:http://www.zdnet.com/article/red-hat-acquires-inktank-for-175m/
|
||||
[17]:http://linux.die.net/man/8/fsck
|
||||
[18]:http://primarydata.com/
|
||||
[19]:http://oss.sgi.com/cgi-bin/gitweb.cgi?p=xfs/cmds/xfstests.git;a=summary
|
||||
@ -1,99 +0,0 @@
|
||||
johnhoow translating...
|
||||
How to Install Lightweight Budgie ( v8) Desktop in Ubuntu 14.04
|
||||
================================================================================
|
||||
Budgie is the flagship desktop of the Evolve OS Linux Distribution, and is an Evolve OS project. Designed with the modern user in mind, it focuses on simplicity and elegance. A huge advantage for the Budgie desktop is that it is not a fork of another project, but rather one written from scratch with integration in mind.
|
||||
|
||||
The [Budgie Desktop][1] tightly integrates with the GNOME stack, employing underlying technologies to offer an alternative desktop experience. In the spirit of open source, the project is compatible with and available for other Linux distributions.
|
||||
|
||||
Also note that Budgie can now emulate the look and feel of the GNOME 2 desktop, optionally, via a setting in the panel preferences.
|
||||
|
||||
### Features in the 0.8 release ###
|
||||
|
||||
- IconTasklist: Add pinning support
|
||||
- IconTasklist: Use .desktop files for quicklists
|
||||
- IconTasklist: Use .desktop files for icon resolution
|
||||
- IconTasklist: Support “attention” hint (blue blink)
|
||||
- Panel: Support dark theme (used by default)
|
||||
- Add Menubar applet
|
||||
- Panel: Initial autohide support (manual, not automatic)
|
||||
- Panel: Support shadow onall screen edges
|
||||
- Panel: Dynamic support for gnome panel theming
|
||||
- RunDialog: Complete visual refresh (bootiful)
|
||||
- BudgieMenu: Add compact mode, use by default
|
||||
- BudgieMenu: Sort items by usage
|
||||
- BudgieMenu: Remove old power option
|
||||
- Editor: Add all menu options to UI
|
||||
- Support from GNOME 3.10 up to 3.16 (unreleased, git)
|
||||
- wm: Kill workspace animation (resolve after v8)
|
||||
- wm: Better animations for changing of wallpapers
|
||||
|
||||
### Important information ###
|
||||
|
||||
- Budgie [released version 0.8][2] so it is still in development and a beta.
|
||||
- No nnative network management; can be fixed by using Ubuntu's applet.
|
||||
- Budgie is intended for the Evolve OS so even with this PPA it might be buggy.
|
||||
- GNOME themes work better than the native Ubuntu themes.
|
||||
- Ubuntu’s overlay scrollbars are not working.
|
||||
- If you want to read more visit the Evolve OS website.
|
||||
|
||||
### Installation ###
|
||||
|
||||
Now, we'll install our Lightweight Budgie Desktop in our Ubuntu 14.04 LTS "Trusty" distribution of Linux Operating System. First of all, we'll need to add ppa repository to our Ubuntu PC. To do so, we'll need to execute the below command in a shell or terminal.
|
||||
|
||||
$ sudo add-apt-repository ppa:evolve-os/ppa
|
||||
|
||||

|
||||
|
||||
Now, after we finish adding PPA to our Ubuntu Computer, we'll need to update the local repository index in it. It can be done by running the following command in the same terminal or shell after above is done.
|
||||
|
||||
$ sudo apt-get update
|
||||
|
||||
Then, finally, we'll install the one and only Budgie Desktop Environment in our Ubuntu machine running the latest version 14.04 LTS.
|
||||
|
||||
$ sudo apt-get install budgie-desktop
|
||||
|
||||

|
||||
|
||||
**Notes**
|
||||
|
||||
It is in active development and features remain missing, including, but not limited to: no network management support, no volume control applet (keyboard keys will work fine), no notification system and no way to ‘pin’ apps to the task bar.
|
||||
|
||||
As a workaround you can disable overlay scrollbars, set a different default theme and quit a session from the terminal using the following command:
|
||||
|
||||
$ gnome-session-quit
|
||||
|
||||

|
||||
|
||||
### Log into the Budgie Session ###
|
||||
|
||||
After installation is completed, we’ll be able to select ‘Budgie’ from the session selector of the Unity Greeter. For that, we'll need to logout the current user and get back to the login screen. Then, we'll be able to switch to Budgie Desktop Environment.
|
||||
|
||||

|
||||
|
||||
### Budgie Desktop Environment ###
|
||||
|
||||

|
||||
|
||||
### Logging Out ###
|
||||
|
||||
You can simply execute **budgie-session --logout** in a shell or terminal to logout it.
|
||||
|
||||
$ budgie-sessioon --logout
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Hurray! We have successfully installed our Lightweight Budgie Desktop Environment in our Ubuntu 14.04 LTS "Trusty" box. As we know, Budgie Desktop is still underdevelopment which makes it a lot of stuffs missing. Though it’s based on Gnome’s GTK3, it’s not a fork. The desktop is written completely from scratch, and the design is elegant and well thought out. If you have any questions, comments, feedback please do write on the comment box below and let us know what stuffs needs to be added or improved. Thank You! Enjoy Budgie Desktop 0.8 :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/install-lightweight-budgie-v8-desktop-ubuntu/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:https://evolve-os.com/budgie/
|
||||
[2]:https://evolve-os.com/2014/11/16/courageous-budgie-v8-released/
|
||||
@ -1,153 +0,0 @@
|
||||
Translating by ZTinoZ
|
||||
How to Manage KVM Virtual Environment using Commandline Tools in Linux
|
||||
================================================================================
|
||||
In this 4th part of our [KVM series][1], we are discussing KVM environment management using CLI. We use ‘virt-install’ CL tool to create and configure virtual machines, virsh CL tool to create and configure storage pools and qemu-img CL tool to create and manage disk images.
|
||||
|
||||

|
||||
KVM Management in Linux
|
||||
|
||||
There is nothing new concepts in this article, we just do the previous tasks using command line tools. There is no new prerequisite, just the same procedure, we have discussed in previous parts.
|
||||
|
||||
### Step 1: Configure Storage Pool ###
|
||||
|
||||
Virsh CLI tool is a management user interface for managing virsh guest domains. The virsh program can be used either to run one command by giving the command and its arguments on the shell command line.
|
||||
|
||||
In this section, we will use it to create storage pool for our KVM environment. For more information about the tool, use the following command.
|
||||
|
||||
# man virsh
|
||||
|
||||
**1. Using the command pool-define-as with virsh to define new storage pool, you need also to specify name, type and type’s arguments.**
|
||||
|
||||
In our case, name will be Spool1, type will be dir. By default you could provide five arguments for the type:
|
||||
|
||||
- source-host
|
||||
- source-path
|
||||
- source-dev
|
||||
- source-name
|
||||
- target
|
||||
|
||||
For (Dir) type, we need the last argumet “target” to specify the path of storage pool, for the other arguments we could use “-” to unspecific them.
|
||||
|
||||
# virsh pool-define-as Spool1 dir - - - - "/mnt/personal-data/SPool1/"
|
||||
|
||||

|
||||
Create New Storage Pool
|
||||
|
||||
**2. To check the all storage pools you have in the environment, use the following command.**
|
||||
|
||||
# virsh pool-list --all
|
||||
|
||||

|
||||
List All Storage Pools
|
||||
|
||||
**3. Now it’s time to build the storage pool, which we have defined above with the following command.**
|
||||
|
||||
# virsh pool-build Spool1
|
||||
|
||||

|
||||
Build Storage Pool
|
||||
|
||||
**4. Using the virsh command pool-start to active/enable the storage pool we have just created/built above.**
|
||||
|
||||
# virsh pool-start Spool1
|
||||
|
||||

|
||||
Active Storage Pool
|
||||
|
||||
**5. Check the status of environment storage pools using the following command.**
|
||||
|
||||
# virsh pool-list --all
|
||||
|
||||

|
||||
Check Storage Pool Status
|
||||
|
||||
You will notice that the status of Spool1 converted to active.
|
||||
|
||||
**6. Configure Spool1 to start by libvirtd service every time automaticlly.**
|
||||
|
||||
# virsh pool-autostart Spool1
|
||||
|
||||

|
||||
Configure KVM Storage Pool
|
||||
|
||||
**7. Finally lets display information about our new storage pool.**
|
||||
|
||||
# virsh pool-info Spool1
|
||||
|
||||

|
||||
Check KVM Storage Pool Information
|
||||
|
||||
Congratulations, Spool1 is ready to be used lets try to create storage volumes using it.
|
||||
|
||||
### Step 2: Configure Storage Volumes/Disk Images ###
|
||||
|
||||
Now it is disk image’s turn, using qemu-img to create new disk image from Spool1. For more details about qemy-img, use the man page.
|
||||
|
||||
# man qemu-img
|
||||
|
||||
**8. We should specify the qemu-img command “create, check,….etc”, disk image format, the path of disk image you want to create and the size.**
|
||||
|
||||
# qemu-img create -f raw /mnt/personal-data/SPool1/SVol1.img 10G
|
||||
|
||||

|
||||
Create Storage Volume
|
||||
|
||||
**9. By using qemu-img command info, you could get information about your new disk image.**
|
||||
|
||||

|
||||
Check Storage Volume Information
|
||||
|
||||
**Warning**: Never use qemu-img to modify images in use by a running virtual machine or any other process; this may destroy the image.
|
||||
|
||||
Now its time to create virtual machines in the next step.
|
||||
|
||||
### Step 3: Create Virtual Machines ###
|
||||
|
||||
10. Now with the last and latest part, we will create virtual machines using virt-istall. The virt-install is a command line tool for creating new KVM virtual machines using the “libvirt” hypervisor management library. For more details about it, use:
|
||||
|
||||
# man virt-install
|
||||
|
||||
To create new KVM virtual machine, you need to use the following command with all the details like shown in the below.
|
||||
|
||||
- Name: Virtual Machine’s name.
|
||||
- Disk Location: Location of disk image.
|
||||
- Graphics : How to connect to VM “Usually be SPICE”.
|
||||
- vcpu : Number of virtual CPU’s.
|
||||
- ram : Amount of allocated memory in megabytes.
|
||||
- Location : Specify the installation source path.
|
||||
- Network : Specify the virtual network “Usually be vibr00 bridge”.
|
||||
|
||||
# virt-install --name=rhel7 --disk path=/mnt/personal-data/SPool1/SVol1.img --graphics spice --vcpu=1 --ram=1024 --location=/run/media/dos/9e6f605a-f502-4e98-826e-e6376caea288/rhel-server-7.0-x86_64-dvd.iso --network bridge=virbr0
|
||||
|
||||

|
||||
Create New Virtual Machine
|
||||
|
||||
**11. You will find also a pop-up virt-vierwer window appears to communicate with virtual machine through it.**
|
||||
|
||||

|
||||
Booting Virtual Machine
|
||||
|
||||

|
||||
Installation of Virtual Machine
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
This is the latest part of our KVM tutorial, we haven’t covered everything of course. It a shot to scratch the KVM environment so its your turn to search and keep hands dirty using this nice resources.
|
||||
|
||||
- [KVM Getting Started Guide][2]
|
||||
- [KVM Virtualization Deployment and Administration Guide][3]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/kvm-management-tools-to-manage-virtual-machines/
|
||||
|
||||
作者:[Mohammad Dosoukey][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/dos2009/
|
||||
[1]:http://www.tecmint.com/install-and-configure-kvm-in-linux/
|
||||
[2]:https://access.redhat.com/site/documentation/en-US/Red_Hat_Enterprise_Linux/7/html/Virtualization_Getting_Started_Guide/index.html
|
||||
[3]:https://access.redhat.com/site/documentation/en-US/Red_Hat_Enterprise_Linux/7/html/Virtualization_Deployment_and_Administration_Guide/index.html
|
||||
@ -1,70 +0,0 @@
|
||||
Locate Stolen laptops and Smart phones Using Prey Tool in Ubuntu
|
||||
================================================================================
|
||||
Prey is an open source, cross platform tool which helps recover your stolen laptops, desktops, tablet computers and smart phones. It has gained vast popularity and has claimed to help recover hundreds of missing laptops and smart phones. The working of this tool is pretty simple, install it on your Laptop or smart phone, and if your device goes missing, login the Prey website with your credentials and mark your device as “Missing” there. As soon as the thief connects your device with internet, it will immediately send you the Geo location of your device. If your laptop is having webcam, it will also capture the screenshot of the thief.
|
||||
|
||||
Prey consumes minimum system resources; it does not affect your device’s performance in any way. You can also use it alongside any other anti-theft application you had installed on your device. It uses secure and encrypted channels to communicate your device data with Prey servers.
|
||||
|
||||
### Installing and configuring Prey on Ubuntu ###
|
||||
|
||||
Let’s see how we can install and configure Prey on ubuntu, note that during configuration process, we will have to register an account at Prey official website. Once done, it will be able to monitor your devices. Its free account monitors up-to 3 devices, if you need to add more devices to its watch list, you need to purchase appropriate plan.
|
||||
|
||||
Considering the popularity and use of Prey, it has been added to the official ubuntu repository now. That means you don’t need to add any additional PPA to the package manager. Simply launch your terminal application and run the following command to install it:
|
||||
|
||||
sudo apt-get install prey
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
It is a very lightweight application, uses only few MB of space on the system, once installation is completed, launch it from Applications >> Prey and it will ask you for the configuration.
|
||||
|
||||
Choose “New user” if you are using this app for first time.
|
||||
|
||||

|
||||
|
||||
This second step is actually the process to sign you up on Prey official website. Please provide your username, email address and password for free account.
|
||||
|
||||

|
||||
|
||||
Hit “Apply” once done, that’s all, your computer is now protected by Prey.
|
||||
|
||||

|
||||
|
||||
Login your newly created [Prey account][1] and you should be able to see your device information there under “Devices” menu.
|
||||
|
||||

|
||||
|
||||
As soon as your laptop or any other device goes missing, simply login your Prey web account and change the device status to “missing” by clicking “Set Device to Missing” option.
|
||||
|
||||

|
||||
|
||||
Choose report frequency from here and hit “Yes, my device is missing”. Report Frequency option is the time interval after which this app will send you status updates for your device location. It will email you as soon as the device status is changed from web interface.
|
||||
|
||||

|
||||
|
||||
As soon as your stolen device is connected to the internet, it will immediately send you report, containing your device's Geo whereabouts and IP address.
|
||||
|
||||

|
||||
|
||||
Click the report link and you should be able to see your device’s Geo location and IP address.
|
||||
|
||||

|
||||
|
||||
There is one known drawback in Prey , It needs your device to be connected to internet for sending Geo location, if thief is smart enough to format your device hard disk before connecting it to the network, then you’ll never get report of its recovery. But there is still a work around to overcome this drawback, make sure to add a BIOS password and disable booting the system from removable devices.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
It is a small, very useful security application which lets you track all of your devices on a single place, although not perfect, but still provides good level of recovery chances for your stolen devices. It runs seamlessly on Linux, Windows and Mac operating system. Here are details about Prey Pro plans.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/anti-theft-application-prey-ubuntu/
|
||||
|
||||
作者:[Aun Raza][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunrz/
|
||||
[1]:https://preyproject.com/
|
||||
@ -0,0 +1,42 @@
|
||||
[translating by KayGuoWhu]
|
||||
How to enable ssh login without entering password
|
||||
================================================================================
|
||||
Assume that you are a user "aliceA" on hostA, and wish to ssh to hostB as user "aliceB", without entering her password on hostB. You can follow this guide to **enable ssh login without entering a password**.
|
||||
|
||||
First of all, you need to be logged in as user "aliceA" on hostA.
|
||||
|
||||
Generate a public/private rsa key pair by using ssh-keygen. The generated key pair will be stored in ~/.ssh directory.
|
||||
|
||||
$ ssh-keygen -t rsa
|
||||
|
||||
Then, create ~/.ssh directory on aliceB account at the destination hostB by running the following command. This step can be omitted if there is already .ssh directory at aliceB@hostB.
|
||||
|
||||
$ ssh aliceB@hostB mkdir -p .ssh
|
||||
|
||||
Finally, copy the public key of user "aliceA" on hostA to aliceB@hostB to enable password-less ssh.
|
||||
|
||||
$ cat .ssh/id_rsa.pub | ssh aliceB@hostB 'cat >> .ssh/authorized_keys'
|
||||
|
||||
From this point on, you no longer need to type in password to ssh to aliceB@hostB from aliceA@hostA.
|
||||
|
||||
### Troubleshooting ###
|
||||
|
||||
1. You are still asked for an SSH password even after enabling key authentication. In this case, check for system logs (e.g., /var/log/secure) to see if you see something like the following.
|
||||
|
||||
Authentication refused: bad ownership or modes for file /home/aliceB/.ssh/authorized_keys
|
||||
|
||||
In this case, failure of key authentication is due to the fact that the permission or ownership ~/.ssh/authorized_keys file is not correct. Typically this error can happen if ~/.ssh/authorized_keys is read accessible to anyone but yourself. To fix this problem, change the file permission as follows.
|
||||
|
||||
$ chmod 700 ~/.ssh/authorized_keys
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/how-to-enable-ssh-login-without.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
@ -0,0 +1,160 @@
|
||||
How to set up networking between Docker containers
|
||||
================================================================================
|
||||
As you may be aware, Docker container technology has emerged as a viable lightweight alternative to full-blown virtualization. There are a growing number of use cases of Docker that the industry adopted in different contexts, for example, enabling rapid build environment, simplifying configuration of your infrastructure, isolating applications in multi-tenant environment, and so on. While you can certainly deploy an application sandbox in a standalone Docker container, many real-world use cases of Docker in production environments may involve deploying a complex multi-tier application in an ensemble of multiple containers, where each container plays a specific role (e.g., load balancer, LAMP stack, database, UI).
|
||||
|
||||
There comes the problem of **Docker container networking**: How can we interconnect different Docker containers spawned potentially across different hosts when we do not know beforehand on which host each container will be created?
|
||||
|
||||
One pretty neat open-source solution for this is [weave][1]. This tool makes interconnecting multiple Docker containers pretty much hassle-free. When I say this, I really mean it.
|
||||
|
||||
In this tutorial, I am going to demonstrate **how to set up Docker networking across different hosts using weave**.
|
||||
|
||||
### How Weave Works ###
|
||||
|
||||
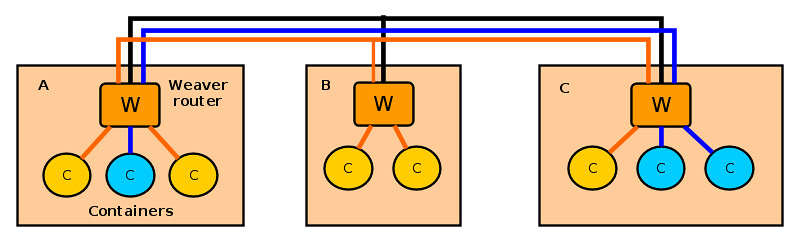
|
||||
|
||||
Let's first see how weave works. Weave creates a network of "peers", where each peer is a virtual router container called "weave router" residing on a distinct host. The weave routers on different hosts maintain TCP connections among themselves to exchange topology information. They also establish UDP connections among themselves to carry inter-container traffic. A weave router on each host is then connected via a bridge to all other Docker containers created on the host. When two containers on different hosts want to exchange traffic, a weave router on each host captures their traffic via a bridge, encapsulates the traffic with UDP, and forwards it to the other router over a UDP connection.
|
||||
|
||||
Each weave router maintains up-to-date weave router topology information, as well as container's MAC address information (similar to switch's MAC learning), so that it can make forwarding decision on container traffic. Weave is able to route traffic between containers created on hosts which are not directly reachable, as long as two hosts are interconnected via an intermediate weave router on weave topology. Optionally, weave routers can be set to encrypt both TCP control data and UDP data traffic based on public key cryptography.
|
||||
|
||||
### Prerequisite ###
|
||||
|
||||
Before using weave on Linux, of course you need to set up Docker environment on each host where you want to run [Docker][2] containers. Check out [these][3] [tutorials][4] on how to create Docker containers on Ubuntu or CentOS/Fedora.
|
||||
|
||||
Once Docker environment is set up, install weave on Linux as follows.
|
||||
|
||||
$ wget https://github.com/zettio/weave/releases/download/latest_release/weave
|
||||
$ chmod a+x weave
|
||||
$ sudo cp weave /usr/local/bin
|
||||
|
||||
Make sure that /usr/local/bin is include in your PATH variable by appending the following in /etc/profile.
|
||||
|
||||
export PATH="$PATH:/usr/local/bin"
|
||||
|
||||
Repeat weave installation on every host where Docker containers will be deployed.
|
||||
|
||||
Weave uses TCP/UDP 6783 port. If you are using firewall, make sure that these port numbers are not blocked by the firewall.
|
||||
|
||||
### Launch Weave Router on Each Host ###
|
||||
|
||||
When you want to interconnect Docker containers across multiple hosts, the first step is to launch a weave router on every host.
|
||||
|
||||
On the first host, run the following command, which will create and start a weave router container.
|
||||
|
||||
$ sudo weave launch
|
||||
|
||||
The first time you run this command, it will take a couple of minutes to download a weave image before launching a router container. On successful launch, it will print the ID of a launched weave router.
|
||||
|
||||
To check the status of the router, use this command:
|
||||
|
||||
$ sudo weave status
|
||||
|
||||
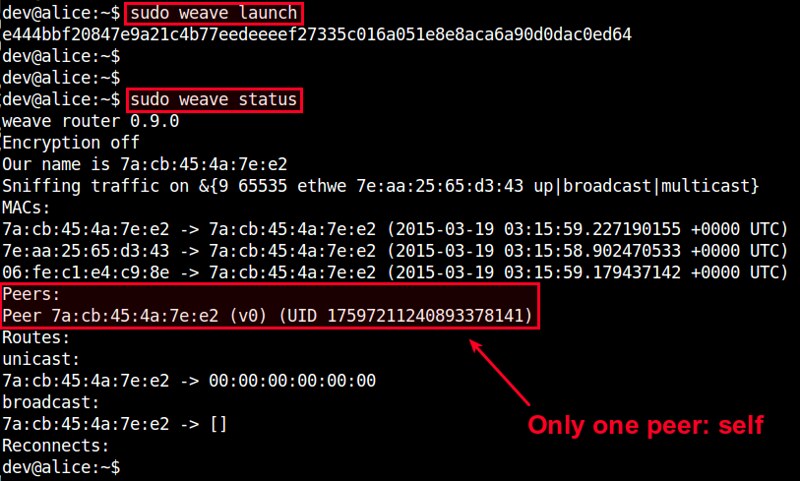
|
||||
|
||||
Since this is the first weave router launched, there will be only one peer in the peer list.
|
||||
|
||||
You can also verify the launch of a weave router by using docker command.
|
||||
|
||||
$ docker ps
|
||||
|
||||

|
||||
|
||||
On the second host, run the following command, where we specify the IP address of the first host as a peer to join.
|
||||
|
||||
$ sudo weave launch <first-host-IP-address>
|
||||
|
||||
When you check the status of the router, you will see two peers: the current host and the first host.
|
||||
|
||||
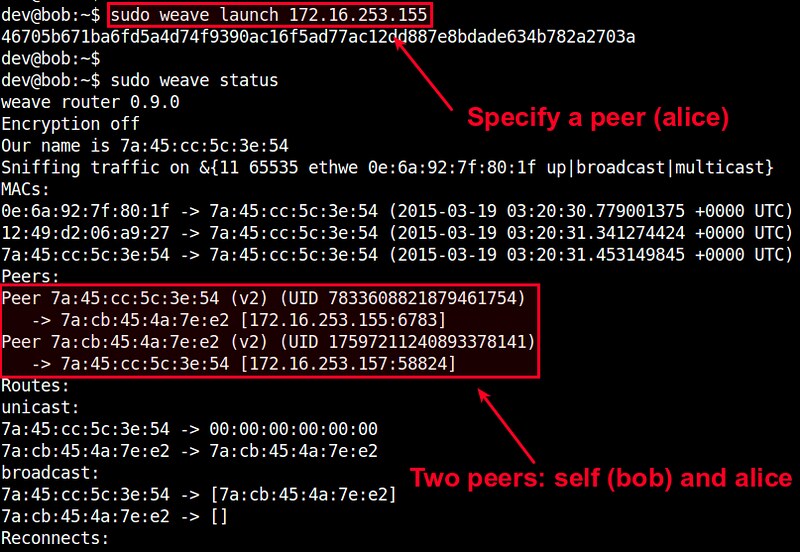
|
||||
|
||||
As you launch more routers on subsequent hosts, the peer list will grow accordingly. When launching a router, just make sure that you specify any previously launched peer's IP address.
|
||||
|
||||
At this point, you should have a weave network up and running, which consists of multiple weave routers across different hosts.
|
||||
|
||||
### Interconnect Docker Containers across Multiple Hosts ###
|
||||
|
||||
Now it is time to launch Docker containers on different hosts, and interconnect them on a virtual network.
|
||||
|
||||
Let's say we want to create a private network 10.0.0.0/24, to interconnect two Docker containers. We will assign random IP addressses from this subnet to the containers.
|
||||
|
||||
When you create a Docker container to deploy on a weave network, you need to use weave command, not docker command. Internally, the weave command uses docker command to create a container, and then sets up Docker networking on it.
|
||||
|
||||
Here is how to create a Ubuntu container on hostA, and attach the container to 10.0.0.0/24 subnet with an IP addresss 10.0.0.1.
|
||||
|
||||
hostA:~$ sudo weave run 10.0.0.1/24 -t -i ubuntu
|
||||
|
||||
On successful run, it will print the ID of a created container. You can use this ID to attach to the running container and access its console as follows.
|
||||
|
||||
hostA:~$ docker attach <container-id>
|
||||
|
||||
Move to hostB, and let's create another container. Attach it to the same subnet (10.0.0.0/24) with a different IP address 10.0.0.2.
|
||||
|
||||
hostB:~$ sudo weave run 10.0.0.2/24 -t -i ubuntu
|
||||
|
||||
Let's attach to the second container's console as well:
|
||||
|
||||
hostB:~$ docker attach <container-id>
|
||||
|
||||
At this point, those two containers should be able to ping each other via the other's IP address. Verify that from each container's console.
|
||||
|
||||
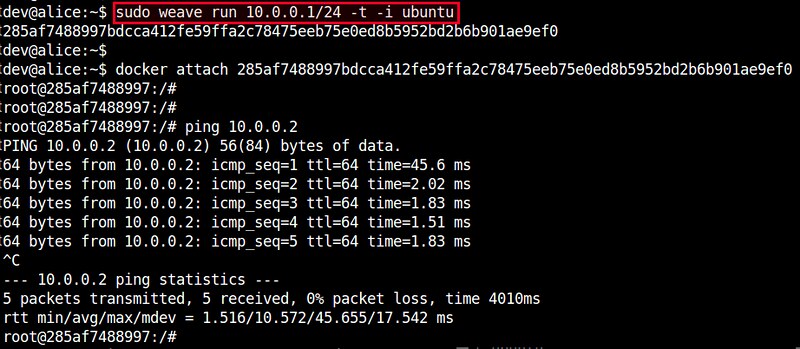
|
||||
|
||||
If you check the interfaces of each container, you will see an interface named "ethwe" which is assigned an IP address (e.g., 10.0.0.1 and 10.0.0.2) you specified.
|
||||
|
||||
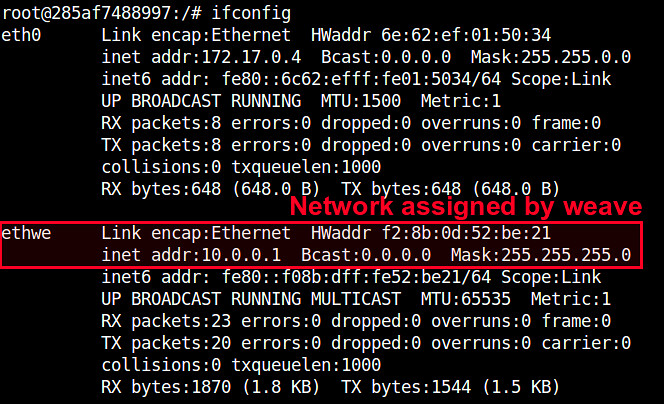
|
||||
|
||||
### Other Advanced Usages of Weave ###
|
||||
|
||||
Weave offers a number of pretty neat features. Let me briefly cover a few here.
|
||||
|
||||
#### Application Isolation ####
|
||||
|
||||
Using weave, you can create multiple virtual networks and dedicate each network to a distinct application. For example, create 10.0.0.0/24 for one group of containers, and 10.10.0.0/24 for another group of containers, and so on. Weave automatically takes care of provisioning these networks, and isolating container traffic on each network. Going further, you can flexibly detach a container from one network, and attach it to another network without restarting containers. For example:
|
||||
|
||||
First launch a container on 10.0.0.0/24:
|
||||
|
||||
$ sudo weave run 10.0.0.2/24 -t -i ubuntu
|
||||
|
||||
Detach the container from 10.0.0.0/24:
|
||||
|
||||
$ sudo weave detach 10.0.0.2/24 <container-id>
|
||||
|
||||
Re-attach the container to another network 10.10.0.0/24:
|
||||
|
||||
$ sudo weave attach 10.10.0.2/24 <container-id>
|
||||
|
||||

|
||||
|
||||
Now this container should be able to communicate with other containers on 10.10.0.0/24. This is a pretty useful feature when network information is not available at the time you create a container.
|
||||
|
||||
#### Integrate Weave Networks with Host Network ####
|
||||
|
||||
Sometimes you may need to allow containers on a virtual weave network to access physical host network. Conversely, hosts may want to access containers on a weave network. To support this requirement, weave allows weave networks to be integrated with host network.
|
||||
|
||||
For example, on hostA where a container is running on network 10.0.0.0/24, run the following command.
|
||||
|
||||
hostA:~$ sudo weave expose 10.0.0.100/24
|
||||
|
||||
This will assign IP address 10.0.0.100 to hostA, so that hostA itself is also connected to 10.0.0.0/24 network. Obviously, you need to choose an IP address which is not used by any other containers on the network.
|
||||
|
||||
At this point, hostA should be able to access any containers on 10.0.0.0/24, whether or not the containers are residing on hostA. Pretty neat!
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
As you can see, weave is a pretty useful Docker networking tool. This tutorial only covers a glimpse of [its powerful features][5]. If you are more ambitious, you can try its multi-hop routing, which can be pretty useful in multi-cloud environment, dynamic re-routing, which is a neat fault-tolerance feature, or even its distributed DNS service which allows you to name containers on weave networks. If you decide to use this gem in your environment, feel free to share your use case!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/networking-between-docker-containers.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:https://github.com/zettio/weave
|
||||
[2]:http://xmodulo.com/recommend/dockerbook
|
||||
[3]:http://xmodulo.com/manage-linux-containers-docker-ubuntu.html
|
||||
[4]:http://xmodulo.com/docker-containers-centos-fedora.html
|
||||
[5]:http://zettio.github.io/weave/features.html
|
||||
@ -0,0 +1,121 @@
|
||||
Linux FAQs with Answers--How to install and access CentOS remote desktop on VPS
|
||||
================================================================================
|
||||
> **Question**: I want to install CentOS desktop on VPS, and be able to access the desktop GUI remotely from home. What is a recommended way to set up and access CentOS-based remote desktop on VPS?
|
||||
|
||||
Nowadays teleworking or remote working with flexible hours is increasingly popular in tech industry. One of the enabling technologies behind this trend is remote desktop. Your desktop environment is in the cloud, and you can access the remote desktop anywhere you go, either from home or at your workplace.
|
||||
|
||||
This tutorial describes how you can set up CentOS based remote desktop on VPS. Here we are going to demonstrate CentOS 7 based environment.
|
||||
|
||||
We assume that you already created a CentOS 7 VPS instance somewhere (e.g., using [DigitalOcean][1] or Amazon EC2). Make sure that the VPS instance has at least 1GB memory. Otherwise, CentOS desktop will crash when you try to access remote desktop.
|
||||
|
||||
### Step One: Install CentOS Desktop ###
|
||||
|
||||
If an available CentOS image is a minimal version of CentOS without desktop, you will need to install desktop (e.g., GNOME) on your CentOS VPS before proceeding. For example, DigitalOcean's CentOS image is such a minimal version, which requires [desktop GUI installation][2] as follows.
|
||||
|
||||
# yum groupinstall "GNOME Desktop"
|
||||
|
||||
Reboot a VPS after finishing installation.
|
||||
|
||||
### Step Two: Install and Configure VNC Server ###
|
||||
|
||||
The next step is to install and configure VNC server. We are going to use TigerVNC, an open-source VNC server implementation.
|
||||
|
||||
# yum install tigervnc-server
|
||||
|
||||
Now create a user account (e.g., xmodulo) which will be used to access remote desktop.
|
||||
|
||||
# useradd xmodulo
|
||||
# passwd xmodulo
|
||||
|
||||
When a user tries to access remote desktop using VNC, a dedicated VNC server daemon will be launched to handle its requests. This means that you will need to create a separate VNC server configuration for each user.
|
||||
|
||||
CentOS 7 relies on systemd to manage and configure system services. So we are going to configure VNC server for xmodulo user using systemd.
|
||||
|
||||
Let's first check the status of VNC server by running either command below:
|
||||
|
||||
# systemctl status vncserver@:.service
|
||||
# systemctl is-enabled vncserver@.service
|
||||
|
||||
By default, freshly installed VNC service is not active (disabled).
|
||||
|
||||
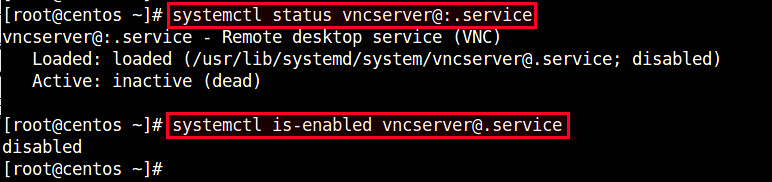
|
||||
|
||||
Now create a VNC service configuration for xmodulo user by copying a generic VNC service unit file as follows.
|
||||
|
||||
# cp /lib/systemd/system/vncserver@.service /etc/systemd/system/vncserver@:1.service
|
||||
|
||||
Open the configuration file with a text editor, and replace <USER> with an actual user name (e.g., xmodulo) under [Service] section. Also, append "-geometry <resolution>" parameter in ExecStart. In the end, the following two lines with bold font will be modified.
|
||||
|
||||
# vi /etc/systemd/system/vncserver@:1.service
|
||||
|
||||
----------
|
||||
|
||||
[Service]
|
||||
Type=forking
|
||||
# Clean any existing files in /tmp/.X11-unix environment
|
||||
ExecStartPre=/bin/sh -c '/usr/bin/vncserver -kill %i > /dev/null 2>&1 || :'
|
||||
ExecStart=/sbin/runuser -l xmodulo -c "/usr/bin/vncserver %i -geometry 1024x768"
|
||||
PIDFile=/home/xmodulo/.vnc/%H%i.pid
|
||||
ExecStop=/bin/sh -c '/usr/bin/vncserver -kill %i > /dev/null 2>&1 || :'
|
||||
|
||||
Now set up (optional) VNC password for xmodulo user for security. For this, switch to the user, and run vncserver command.
|
||||
|
||||
# su - xmodulo
|
||||
# vncserver
|
||||
|
||||
You will be prompted to enter a VNC password for the user. Once the password is set, you will need to use this password to gain access to remote desktop.
|
||||
|
||||
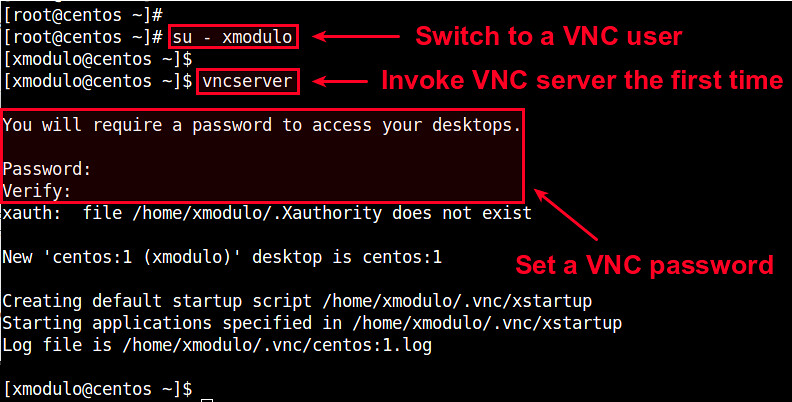
|
||||
|
||||
Finally, reload services to activate the new VNC configuration:
|
||||
|
||||
# systemctl daemon-reload
|
||||
|
||||
and enable VNC service to make it start automatically upon boot:
|
||||
|
||||
# systemctl enable vncserver@:1.service
|
||||
|
||||
Check the port number that a VNC server is listening on by running:
|
||||
|
||||
# netstat -tulpn | grep vnc
|
||||
|
||||
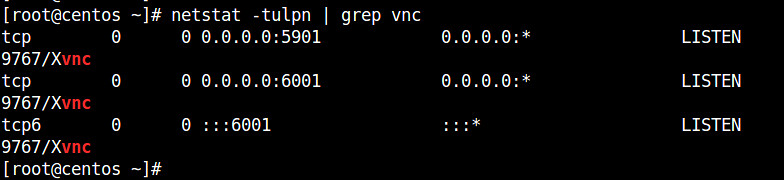
|
||||
|
||||
Port 5901 is the default port number for VNC client to connect to a VNC server.
|
||||
|
||||
### Step Three: Connect to Remote Desktop over SSH ###
|
||||
|
||||
By design, Remote Frame Buffer (RFB) protocol used by VNC is not a secure protocol. Thus it is not a good idea to directly connect to a remote VNC server running on VPS using a VNC client. Any sensitive information such as password could easily be leaked from VNC traffic. So instead, I strongly recommend that you [tunnel VNC traffic][3] over a secure SSH tunnel, as described here.
|
||||
|
||||
On a local host where you want to run VNC client, create an SSH tunnel to a remote VPS using the following command. When prompted for SSH password, type the password of the user.
|
||||
|
||||
$ ssh xmodulo@<VPS-IP-address> -L 5901:127.0.0.1:5901
|
||||
|
||||
Replace "xmodulo" with your own VNC user, and fill in the IP address of your VPS instance.
|
||||
|
||||
Once an SSH tunnel is established, remote VNC traffic will be routed over the SSH tunnel, and be sent to 127.0.0.1:5901.
|
||||
|
||||
Now go ahead and launch your favorite VNC client (e.g., vinagre), and connect to 127.0.0.1:5901.
|
||||
|
||||
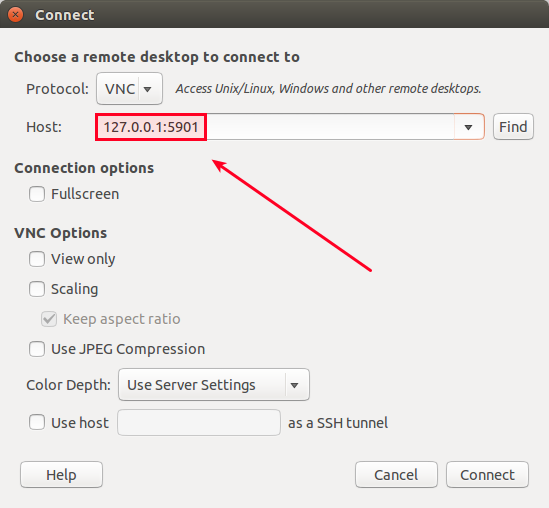
|
||||
|
||||
You will be asked to enter a VNC password. When you type a correct VNC password, you will finally be able to CentOS remote desktop on VPS securely.
|
||||
|
||||
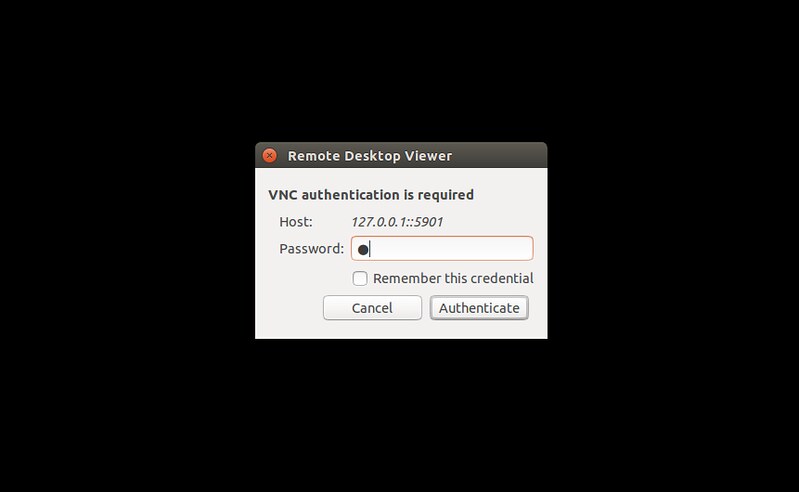
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/centos-remote-desktop-vps.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/go/digitalocean
|
||||
[2]:http://xmodulo.com/how-to-install-gnome-desktop-on-centos.html
|
||||
[3]:http://xmodulo.com/how-to-set-up-vnc-over-ssh.html
|
||||
@ -0,0 +1,163 @@
|
||||
7 Quirky ‘ls’ Command Tricks Every Linux User Should Know
|
||||
================================================================================
|
||||
We have covered most of the things on ‘ls‘ command in last two articles of our Interview series. This article is the last part of the ‘ls command‘ series. If you have not gone through last two articles of this series you may visit the links below.
|
||||
|
||||
注:以下三篇都做过源文,看看翻译了没有,如果发布了可适当改链接地址
|
||||
- [15 Basic ‘ls’ Command Examples in Linux][]
|
||||
- [15 Interview Questions on Linux “ls” Command – Part 1][]
|
||||
- [10 Useful ‘ls’ Command Interview Questions – Part 2][]
|
||||
|
||||

|
||||
7 Quirky ls Command Tricks
|
||||
|
||||
### 1. List the contents of a directory with time using various time styles. ###
|
||||
|
||||
To list the contents of a directory with times using style, we need to choose any of the below two methods.
|
||||
|
||||
# ls -l –time-style=[STYLE] (Method A)
|
||||
|
||||
**Note** – The above switch (`--time` style must be run with switch `-l`, else it won’t serve the purpose).
|
||||
|
||||
# ls –full-time (Method B)
|
||||
|
||||
Replace `[STYLE]` with any of the below option.
|
||||
|
||||
full-iso
|
||||
long-iso
|
||||
iso
|
||||
locale
|
||||
+%H:%M:%S:%D
|
||||
|
||||
**Note** – In the above line H(Hour), M(Minute), S(Second), D(Date) can be used in any order.
|
||||
|
||||
Moreover you just choose those relevant and not all options. E.g., `ls -l --time-style=+%H` will show only hour.
|
||||
|
||||
`ls -l --time-style=+%H:%M:%D` will show Hour, Minute and date.
|
||||
|
||||
# ls -l --time-style=full-iso
|
||||
|
||||

|
||||
ls Command Full Time Style
|
||||
|
||||
# ls -l --time-style=long-iso
|
||||
|
||||

|
||||
Long Time Style Listing
|
||||
|
||||
# ls -l --time-style=iso
|
||||
|
||||

|
||||
Time Style Listing
|
||||
|
||||
# ls -l --time-style=locale
|
||||
|
||||

|
||||
Locale Time Style Listing
|
||||
|
||||
# ls -l --time-style=+%H:%M:%S:%D
|
||||
|
||||

|
||||
Date and Time Style Listing
|
||||
|
||||
# ls --full-time
|
||||
|
||||

|
||||
|
||||
Full Style Time Listing
|
||||
|
||||
### 2. Output the contents of a directory in various formats such as separated by commas, horizontal, long, vertical, across, etc. ###
|
||||
|
||||
Contents of directory can be listed using ls command in various format as suggested below.
|
||||
|
||||
- across
|
||||
- comma
|
||||
- horizontal
|
||||
- long
|
||||
- single-column
|
||||
- verbose
|
||||
- vertical
|
||||
|
||||
# ls –-format=across
|
||||
# ls --format=comma
|
||||
# ls --format=horizontal
|
||||
# ls --format=long
|
||||
# ls --format=single-column
|
||||
# ls --format=verbose
|
||||
# ls --format=vertical
|
||||
|
||||

|
||||
Listing Formats of ls Command
|
||||
|
||||
### 3. Use ls command to append indicators like (/=@|) in output to the contents of the directory. ###
|
||||
|
||||
The option `-p` with ‘ls‘ command will server the purpose. It will append one of the above indicator, based upon the type of file.
|
||||
|
||||
# ls -p
|
||||
|
||||

|
||||
Append Indicators to Content
|
||||
|
||||
### 4. Sort the contents of directory on the basis of extension, size, time and version. ###
|
||||
|
||||
We can use options like `--extension` to sort the output by extension, size by extension `--size`, time by using extension `-t` and version using extension `-v`.
|
||||
|
||||
Also we can use option `--none` which will output in general way without any sorting in actual.
|
||||
|
||||
# ls --sort=extension
|
||||
# ls --sort=size
|
||||
# ls --sort=time
|
||||
# ls --sort=version
|
||||
# ls --sort=none
|
||||
|
||||

|
||||
Sort Listing of Content by Options
|
||||
|
||||
### 5. Print numeric UID and GID for every contents of a directory using ls command. ###
|
||||
|
||||
The above scenario can be achieved using flag -n (Numeric-uid-gid) along with ls command.
|
||||
|
||||
# ls -n
|
||||
|
||||

|
||||
Print Listing of Content by UID and GID
|
||||
|
||||
### 6. Print the contents of a directory on standard output in more columns than specified by default. ###
|
||||
|
||||
Well ls command output the contents of a directory according to the size of the screen automatically.
|
||||
|
||||
We can however manually assign the value of screen width and control number of columns appearing. It can be done using switch ‘`--width`‘.
|
||||
|
||||
# ls --width 80
|
||||
# ls --width 100
|
||||
# ls --width 150
|
||||
|
||||

|
||||
List Content Based on Window Sizes
|
||||
|
||||
**Note**: You can experiment what value you should pass with width flag.
|
||||
|
||||
### 7. Include manual tab size at the contents of directory listed by ls command instead of default 8. ###
|
||||
|
||||
# ls --tabsize=[value]
|
||||
|
||||

|
||||
List Content by Table Size
|
||||
|
||||
**Note**: Specify the `[Value]=` Numeric value.
|
||||
|
||||
That’s all for now. Stay tuned to Tecmint till we come up with next article. Do not forget to provide us with your valuable feedback in the comments below. Like and share us and help us get spread.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-ls-command-tricks/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/15-basic-ls-command-examples-in-linux/
|
||||
[2]:http://www.tecmint.com/ls-command-interview-questions/
|
||||
[3]:http://www.tecmint.com/ls-interview-questions/
|
||||
@ -0,0 +1,114 @@
|
||||
Translating by ZTinoZ
|
||||
How to Host Open Source Code Repository in github
|
||||
================================================================================
|
||||
Hi all, today we will be learning how to host Source Code of Open Source Software in the repository hosted by github.com . GitHub is a web-based Git repository hosting service, which offers all of the distributed revision control and source code management (SCM) functionality of Git as well as adding its own features. It provides a workplace to host powerful collaboration, code review, and code management for open source and private projects. Unlike Git, which is strictly a command-line tool, GitHub provides a web-based graphical interface and desktop as well as mobile integration. GitHub offers both paid plans for private repositories and free accounts, which are usually used to host open-source software projects.
|
||||
|
||||

|
||||
|
||||
It is fast and more flexible web based hosting service which is easy to use and to manage distributed revision control. Anyone can host their software's source code in github's repository for the use, contribution, sharing, issue tracking and many more by millions of people across the globe. Here are some easy and quick steps to easily host software's source code.
|
||||
|
||||
### 1. Creating a new Github Account ###
|
||||
|
||||
First of all, open your favorite browser and go to Github's homepage url ie [github][1]. Then, the homepage will be opened as shown below.
|
||||
|
||||

|
||||
|
||||
Now, after the homepage has been opened, please fill form shown to sign up for a new github account.
|
||||
|
||||
After the you entered the valid information required for sign up, you'll be redirected to the plan choosing step. We have 5 plans listed in this page. One can choose the plan according to their requirement. Here, we'll go for a free plan. So, click on Choose to the Free plan and click on Finish Sign up. If we are planning to create an organization then, we need to tick on Help me setup an organization next.
|
||||
|
||||

|
||||
|
||||
### 2. Creating a New Repository ###
|
||||
|
||||
After we have successfully signed up a new account or logged in to Github, we'll now need to create a new Repository to get started.
|
||||
|
||||
Click on **(+)** button which is located at the top right near the account id. Then Click on New Repository .
|
||||
|
||||

|
||||
|
||||
Now, after clicking on add a new repository, we'll now be directed to the page where we'll need to enter the required information.
|
||||
|
||||

|
||||
|
||||
Now, after entering the required information about the new repository, we'll need to click on green Create repository button.
|
||||
|
||||
After it is done, we'll get to see something similar like this image.
|
||||
|
||||

|
||||
|
||||
### 3. Uploading an existing Project ###
|
||||
|
||||
If we want to share our existing project on Github, we'll surely need to push the codes to the repository we created. To do so, we'll first need to install git in our Linux machine. As I am running Ubuntu 14.04 LTS in my machine, I'll need to run **apt** manger to install it.
|
||||
|
||||
$ sudo apt-get install git
|
||||
|
||||

|
||||
|
||||
Now, as git is ready, we are now ready to upload the codes.
|
||||
|
||||
**Note**: To avoid errors, do not initialize the new repository with **README**, license, or gitignore files. You can add these files after your project has been pushed to GitHub.
|
||||
|
||||
In Terminal, we'll need to change the current working directory to your local project then initialize the local directory as a Git repository/
|
||||
|
||||
$ git init
|
||||
|
||||
We'll then add the files in our new local repository. This stages them for the first commit.
|
||||
|
||||
$ git add .
|
||||
|
||||
Now, we'll need to commit the files that we've staged in our local repository.
|
||||
|
||||
$ git commit -m 'First commit'
|
||||
|
||||

|
||||
|
||||
In Terminal, we'll add the URL for the remote repository where our local repostory will be pushed.
|
||||
|
||||
$ git remote add origin remote Repository url
|
||||
$ git remote -v
|
||||
|
||||

|
||||
|
||||
Note: Please do replace remote Repository url to the url of the remote repo.
|
||||
|
||||
Now, to push the changes in our local repository to GitHub's repo we'll need to run as below and enter the required credential for the repository.
|
||||
|
||||
$ git push origin master
|
||||
|
||||

|
||||
|
||||
### Cloning a Repo ###
|
||||
|
||||
If we want to download a code repository from github straight to our local drives with a single command then, we can simply use git clone command which will clone the current directory to the remote repository.
|
||||
|
||||
$ git clone https://github.com/aruntechgeek/linspeed.git
|
||||
|
||||

|
||||
|
||||
Please change the above url to the repository you want to clone from.
|
||||
|
||||
### Updating a Change ###
|
||||
|
||||
If we made changes to our code and want to push them to our remote repository then after changing the changes, we should run the following commands inside that directory.
|
||||
|
||||
$ git add .
|
||||
$ git commit -m "Updating"
|
||||
$ git push
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Hurray! We have successfully hosted our Project Source Code in Github repository. Github is fast and more flexible web based hosting service which is easy to use and to manage distributed revision control. Millions of awesome Open Source projects are hosted in github. So, if you have any questions, suggestions, feedback please write them in the comment box below. Thank you ! Enjoy Github :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/usr-mgmt/host-open-source-code-repository-github/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://github.com/
|
||||
@ -0,0 +1,100 @@
|
||||
translating wi-cuckoo LLAP
|
||||
How to Interactively Create a Docker Container
|
||||
================================================================================
|
||||
Hi everyone, today we'll learn how we can interactively create a docker container using a docker image. Once we start a process in Docker from an Image, Docker fetches the image and its Parent Image, and repeats the process until it reaches the Base Image. Then the Union File System adds a read-write layer on top. That read-write layer, the information about its Parent Image and some other information like its unique id, networking configuration, and resource limits is called a **Container**. Containers has states as they can change from **running** to **exited** state. A container with state as **running** includes a tree of processes running on the CPU, isolated from the other processes running on the host where as **exited** is the state of the file system and its exit value is preserved. You can start, stop, and restart a container with it.
|
||||
|
||||
Docker Technology has brought a remarkable change in the field of IT enabling cloud service for sharing applications and automating workflows, enabling apps to be quickly assembled from components and eliminates the friction between development, QA, and production environments. In this article, we'll build CentOS Instance in which we'll host a website running under Apache Web Server.
|
||||
|
||||
Here is quick and easy tutorial on how we can create a container in an interactive method using an interactive shell.
|
||||
|
||||
### 1. Running a Docker Instance ###
|
||||
|
||||
Docker initially tries to fetch and run the required image locally and if its not found in local host the it pulls from the [Docker Public Registry Hub][1] . Here. we'll fetch and create a fedora instance in a Docker Container and attach a bash shell to the tty.
|
||||
|
||||
# docker run -i -t fedora bash
|
||||
|
||||

|
||||
|
||||
### 2. Installing Apache Web Server ###
|
||||
|
||||
Now, after our Fedora base image with instance is ready, we'll now gonna install Apache Web Server interactively without creating a Dockerfile for it. To do so, we'll need to run the following commands in a terminal or shell.
|
||||
|
||||
# yum update
|
||||
|
||||

|
||||
|
||||
# yum install httpd
|
||||
|
||||

|
||||
|
||||
# exit
|
||||
|
||||
### 3. Saving the Image ###
|
||||
|
||||
Now, we'll gonna save the changes we made into the Fedora Instance. To do that, we'll first gonna need to know the Container ID of the Instance. To get that we'll need to run the following command.
|
||||
|
||||
# docker ps -a
|
||||
|
||||

|
||||
|
||||
Then, we'll save the changes as a new image by running the below command.
|
||||
|
||||
# docker commit c16378f943fe fedora-httpd
|
||||
|
||||

|
||||
|
||||
Here, the changes are saved using the Container ID and image name fedora-httpd. To make sure that the new image is running or not, we'll run the following command.
|
||||
|
||||
# docker images
|
||||
|
||||

|
||||
|
||||
### 4. Adding the Contents to the new image ###
|
||||
|
||||
As we have our new Fedora Apache image running successfully, now we'll want to add the web contents which includes our website to Apache Web Server so that our website will run successfully out of the box. To do so, we'll need to create a new Dockerfile which will handle the operation from copying web contents to allowing port 80. To do so, we'll need to create a file Dockerfile using our favorite text editor as shown below.
|
||||
|
||||
# nano Dockerfile
|
||||
|
||||
Now, we'll need to add the following lines into that file.
|
||||
|
||||
FROM fedora-httpd
|
||||
ADD mysite.tar /tmp/
|
||||
RUN mv /tmp/mysite/* /var/www/html
|
||||
EXPOSE 80
|
||||
ENTRYPOINT [ "/usr/sbin/httpd" ]
|
||||
CMD [ "-D", "FOREGROUND" ]
|
||||
|
||||

|
||||
|
||||
Here, in above Dockerfile, the web content which we have in mysite.tar will get automatically extracted to /tmp/ folder. Then, the entire site will move to the Apache Web root ie /var/www/html/ and the expose 80 will open port 80 so that the website will be available normally. Then, the entrypoint is set to /usr/sbin/httpd so that the Apache Server will execute.
|
||||
|
||||
### 5. Building and running a Container ###
|
||||
|
||||
Now, we'll build our Container using the Dockerfile we just created in order to add our website on it. To do so, we'll need to run the following command.
|
||||
|
||||
# docker build -rm -t mysite .
|
||||
|
||||

|
||||
|
||||
After building our new container, we'll want to run the container using the command below.
|
||||
|
||||
# docker run -d -P mysite
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Finally, we've successfully built a Docker Container interactively. In this method, we build our containers and image directly via interactive shell commands. This method is quite easy and quick to build and deploy our images and containers. If you have any questions, suggestions, feedback please write them in the comment box below so that we can improve or update our contents. Thank you ! Enjoy :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/interactively-create-docker-container/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:https://registry.hub.docker.com/
|
||||
@ -0,0 +1,191 @@
|
||||
A Peep into Process Management Commands in Linux
|
||||
================================================================================
|
||||
A program in execution is called a process. While a program is an executable file present in storage and is passive, a process is a dynamic entity comprising of allocated system resources, memory, security attributes and has a state associated with it. There can be multiple processes associated with the same program and operating simultaneously without interfering with each other. The operating system efficiently manages and keeps track of all the processes running in the system.
|
||||
|
||||
In order to manage these processes, user should be able to
|
||||
|
||||
- See all the processes that are running
|
||||
- View the system resources consumed by the processes
|
||||
- Locate a particular process and take specific action on it
|
||||
- Change the priority levels associated with processes
|
||||
- Kill the required processes
|
||||
- Restrict the system resources available to processes etc.
|
||||
|
||||
Linux offers many commands to the user to effectively handle the above mentioned scenarios. Let's understand them one by one.
|
||||
|
||||
### 1. ps ###
|
||||
|
||||
'ps' is one of the basic commands in Linux to view the processes on the system. It lists the running processes in a system along with other details such as process id, command, cpu usage, memory usage etc. Some of the following options come handy to get more useful information
|
||||
|
||||
ps -a - List all the running / active processes
|
||||
|
||||

|
||||
|
||||
ps -ef |grep - List only the required process
|
||||
|
||||
ps -aux - Displays processes including those with no terminals(x) Output is user oriented (u) with fields like USER, PID, %CPU, %MEM etc
|
||||
|
||||
### 2. pstree ###
|
||||
|
||||
In Linux, every process gets spawned by its parent process. This command helps visualize the processes by displaying a tree diagram of the processes showing the relationship between them. If a pid is mentioned, the root of the tree will be the pid. Else it will be rooted at init.
|
||||
|
||||

|
||||
|
||||
### 3. top ###
|
||||
|
||||
'top' is a very useful command to monitor the system as it shows the system resources used by different processes. It gives a snapshot of the situation that the system is currently in. Its output includes data like process identification number(PID), user of the process, nice value, %CPU and %memory currently consumed by the process etc. One can use this output to figure out which process is hogging the CPU or memory.
|
||||
|
||||

|
||||
|
||||
### 4. htop ###
|
||||
|
||||
htop is similar to top, but is an interactive text mode process viewer. It displays the per CPU usage and memory, swap usage using a text graph. One can use the Up/Down arrow key to select processes, F7 and F8 to change the priority and F9 to kill a process. It is not present by default in the system and need to be installed explicitly.
|
||||
|
||||

|
||||
|
||||
### 5. nice ###
|
||||
|
||||
With the help of nice command, users can set or change the priorities of processes in Linux. Higher the priority of a process, more is the CPU time allocated by the kernel for it. By default, a process gets launched with priority 0. Process priority can be viewed using the top command output under the NI (nice value) column.
|
||||
|
||||
Values of process priority range from -20 to 19. Lower the nice value, higher the priority.
|
||||
|
||||
nice <priority value> <process name> - starts the process by setting its priority to the given value
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
In the above example, 'top' gets launched with a priority -3.
|
||||
|
||||
### 6. renice ###
|
||||
|
||||
It is similar to nice command. Use this command to change the priority of an already running process. Please note that users can change the priority of only the processes that they own.
|
||||
|
||||
renice -n -p - change the priority of the given process
|
||||
|
||||

|
||||
|
||||
Priority of process with id 3806 which had an initial priority of 0 is now changed to priority 4.
|
||||
|
||||
renice -u -g - change the priority of processes owned by the given user and group
|
||||

|
||||
|
||||
In the above example, priority of all processes owned by user 'mint' get changed to '-3'
|
||||
|
||||
### 7. kill ###
|
||||
|
||||
This is a command used to terminate processes by sending signals. If a process is not responding to kill command, then it can be forcefully killed using the kill -9 command. But this needs to be used carefully as it does not give a chance for the process to clean up and might end up in corrupted files. If we are not aware of the PID of the process to be killed or want to mention the process name to be killed, then killall comes to rescue.
|
||||
|
||||
kill <pid>
|
||||
|
||||
kill -9 <pid>
|
||||
|
||||
killall -9 - kill all instances having the same process name
|
||||
|
||||
If you use kill, you need to know the process id of the process to be killed. pkill is a similar command but can be used to kill processes using a pattern, i.e. process name, process owner etc.
|
||||
|
||||
pkill <process name>
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
### 8. ulimit ###
|
||||
|
||||
Command useful in controlling the system-wide resources available to the shells and processes. Mostly useful for system administrators to manage systems that are heavily used and have performance problems. Limiting the resources ensures that important processes continue to run while other processes do not consume more resources.
|
||||
|
||||
ulimit -a - Displays the current limits associated with the current user.
|
||||
|
||||

|
||||
|
||||
-f - maximum file size
|
||||
|
||||
-v - maximum virtual memory size (in KB)
|
||||
|
||||
-n - maximum file descriptor plus 1
|
||||
|
||||
-H : To change and report the hard limit
|
||||
|
||||
-S : To change and report the soft limit
|
||||
|
||||
Check out the ulimit man page for more options.
|
||||
|
||||
### 9. w ###
|
||||
|
||||
w gives us information about the users who have currently logged in and the processes that they are running. The header details displayed contain information like current time, how long the system has been running, total number of users logged in, load average of the system for the last 1, 5 and 15 minutes
|
||||
|
||||
Based on the user information, one can take care before terminating any processes that do not belong to them.
|
||||
|
||||

|
||||
|
||||
**who** is a related command and gives a list of currently logged in users, time of last system boot, current run levels etc.
|
||||
|
||||

|
||||
|
||||
**whoami** command prints the username of the current user ID
|
||||
|
||||

|
||||
|
||||
### 10. pgrep ###
|
||||
|
||||
pgrep stands for "Process-ID Global Regular Expression Print". It scans the currently running processes and lists the process IDs that match the selection criteria mentioned on command line to stdout. Useful for retrieving the process id of a process by using its name.
|
||||
|
||||
pgrep -u mint sh
|
||||
|
||||
This command will display the process ID for the process named 'sh' and owned by user 'mint'
|
||||
|
||||

|
||||
|
||||
### 11. fg , bg ###
|
||||
|
||||
Sometimes, the commands that we execute take a long time to complete. In such situations, we can push the jobs to be executed in the background using 'bg' command and can be brought to the foreground with the 'fg' command.
|
||||
|
||||
We can start a program in background by using the '&' :
|
||||
|
||||
find . -name *iso > /tmp/res.txt &
|
||||
|
||||
A program that is already running can also be sent to the background using 'CTRL+Z' and 'bg' command:
|
||||
|
||||
find . -name *iso > /tmp/res.txt & - start the job in the background
|
||||
|
||||
ctrl+z - suspend the currently executing foreground job
|
||||
|
||||
bg - push the command execution to background
|
||||
|
||||
We can list all the background processes using 'jobs' command
|
||||
|
||||
jobs
|
||||
|
||||
We can bring back a background process to foreground using the 'fg' command.
|
||||
|
||||
fg %
|
||||
|
||||

|
||||
|
||||
### 12. ipcs ###
|
||||
|
||||
ipcs command is used for listing the inter-process communication facilities (shared memory, semaphores and message queues).
|
||||
|
||||
This command with -p option can be combined with options -m, -s or-q to display the process id which recently accessed the corresponding ipc facility.
|
||||
|
||||
ipcs -p -m
|
||||
|
||||
The screen shot below is listing the creator id and process id which accessed the shared memory recently.
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Generally, it is considered the job of administrators to fix problems and tweak the system to improve the performance. But users also need to deal with processes in Linux quite often. Hence, it is essential to familiarise ourselves with the various commands available to manage them effectively.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-command/process-management-commands-linux/
|
||||
|
||||
作者:[B N Poornima][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/bnpoornima/
|
||||
@ -0,0 +1,252 @@
|
||||
How to set up server monitoring system with Monit
|
||||
================================================================================
|
||||
Many Linux admins rely on a centralized remote monitoring system (e.g., [Nagios][1] or [Cacti][2]) to check the health of their network infrastructure. While centralized monitoring makes an admin's life easy when dealing with many hosts and devices, a dedicated monitoring box obviously becomes a single point of failure; if the monitoring box goes down or becomes unreachable for whatever reason (e.g., bad hardware or network outage), you will lose visibility on your entire infrastructure.
|
||||
|
||||
One way to add redundancy to your monitoring system is to install standalone monitoring software (as a fallback) at least on any critical/core servers on your network. In case a centralized monitor is down, you will still be able to maintain visibility on your core servers from their backup monitor.
|
||||
|
||||
### What is Monit? ###
|
||||
|
||||
[Monit][3] is a cross-platform open-source tool for monitoring Unix/Linux systems (e.g., Linux, BSD, OSX, Solaris). Monit is extremely easy to install and reasonably lightweight (with only 500KB in size), and does not require any third-party programs, plugins or libraries. Yet, Monit lends itself to full-blown monitoring, capable of process status monitoring, filesystem change monitoring, email notification, customizable actions for core services, and so on. The combination of ease of setup, lightweight implementation and powerful features makes Monit an ideal candidate for a backup monitoring tool.
|
||||
|
||||
I have been using Monit for several years on multiple hosts, and I am very pleased how reliable it has been. Even as a full-blown monitoring system, Monit is very useful and powerful for any Linux admin. In this tutorial, let me demonstrate how to set up Monit on a local server (as a backup monitor) to monitor common services. With this setup, I will only scrach the surface of what Monit can do for us.
|
||||
|
||||
### Installation of Monit on Linux ###
|
||||
|
||||
Most Linux distributions already include Monit in their repositories.
|
||||
|
||||
Debian, Ubuntu or Linux Mint:
|
||||
|
||||
$ sudo aptitude install monit
|
||||
|
||||
Fedora or CentOS/RHEL:
|
||||
|
||||
On CentOS/RHEL, you must enable either [EPEL][4] or [Repoforge][5] repository first.
|
||||
|
||||
# yum install monit
|
||||
|
||||
Monit comes with a very well documented configuration file with a lots of examples. The main configuration file is located in /etc/monit.conf in Fedora/CentOS/RHEL, or /etc/monit/monitrc in Debian/Ubuntu/Mint. Monit configuration has two parts: "Global" and "Services" sections.
|
||||
|
||||
Gl### ###obal Configuration: Web Status Page
|
||||
|
||||
Monit can use several mail servers for notifications, and/or an HTTP/HTTPS status page. Let's start with the web status page with the following requirements.
|
||||
|
||||
- Monit listens on port 1966.
|
||||
- Access to the web status page is encrypted with SSL.
|
||||
- Login requires monituser/romania as user/password.
|
||||
- Login is permitted from localhost, myhost.mydomain.ro, and internal LAN (192.168.0.0/16) only.
|
||||
- Monit stores an SSL certificate in a pem format.
|
||||
|
||||
For subsequent steps, I will use a Red Hat based system. Similar steps will be applicable on a Debian based system.
|
||||
|
||||
First, generate and store a self-signed certificate (monit.pem) in /var/cert.
|
||||
|
||||
# mkdir /var/certs
|
||||
# cd /etc/pki/tls/certs
|
||||
# ./make-dummy-cert monit.pem
|
||||
# cp monit.pem /var/certs
|
||||
# chmod 0400 /var/certs/monit.pem
|
||||
|
||||
Now put the following snippet in the Monit's main configuration file. You can start with an empty configuration file or make a copy of the original file.
|
||||
|
||||
set httpd port 1966 and
|
||||
SSL ENABLE
|
||||
PEMFILE /var/certs/monit.pem
|
||||
allow monituser:romania
|
||||
allow localhost
|
||||
allow 192.168.0.0/16
|
||||
allow myhost.mydomain.ro
|
||||
|
||||
### Global Configuration: Email Notification ###
|
||||
|
||||
Next, let's set up email notification in Monit. We need at least one active [SMTP server][6] which can send mails from the Monit host. Something like the following will do (adjust it for your case):
|
||||
|
||||
- Mail server hostname: smtp.monit.ro
|
||||
- Sender email address used by monit (from): monit@monit.ro
|
||||
- Who will receive mail from monit daemon: guletz@monit.ro
|
||||
- SMTP port used by mail server: 587 (default is 25)
|
||||
|
||||
With the above information, email notification would be configured like this:
|
||||
|
||||
set mailserver smtp.monit.ro port 587
|
||||
set mail-format {
|
||||
from: monit@monit.ro
|
||||
subject: $SERVICE $EVENT at $DATE on $HOST
|
||||
message: Monit $ACTION $SERVICE $EVENT at $DATE on $HOST : $DESCRIPTION.
|
||||
|
||||
Yours sincerely,
|
||||
Monit
|
||||
|
||||
}
|
||||
|
||||
set alert guletz@monit.ro
|
||||
|
||||
As you can see, Monit offers several built-in variables ($DATE, $EVENT, $HOST, etc.), and you can customize your email message for your needs. If you want to send mails from the Monit host itself, you need a sendmail-compatible program (e.g., postfix or ssmtp) already installed.
|
||||
|
||||
### Global Configuration: Monit Daemon ###
|
||||
|
||||
The next part is setting up monit daemon. We will set it up as follows.
|
||||
|
||||
- Performs the first check after 120 seconds.
|
||||
- Checks services once every 3 minutes.
|
||||
- Use syslog for logging.
|
||||
|
||||
Place the following snippet to achieve the above setting.
|
||||
|
||||
set daemon 120
|
||||
with start delay 240
|
||||
set logfile syslog facility log_daemon
|
||||
|
||||
We must also define "idfile", a unique ID used by monit demon, and "eventqueue", a path where mails sent by monit but undelivered due to SMTP/network errors. Verifiy that path (/var/monit) already exists. The following configuration will do.
|
||||
|
||||
set idfile /var/monit/id
|
||||
set eventqueue
|
||||
basedir /var/monit
|
||||
|
||||
### Test Global Configuration ###
|
||||
|
||||
Now the "Global" section is finished. The Monit configuration file will look like this:
|
||||
|
||||
# Global Section
|
||||
|
||||
# status webpage and acl's
|
||||
set httpd port 1966 and
|
||||
SSL ENABLE
|
||||
PEMFILE /var/certs/monit.pem
|
||||
allow monituser:romania
|
||||
allow localhost
|
||||
allow 192.168.0.0/16
|
||||
allow myhost.mydomain.ro
|
||||
|
||||
# mail-server
|
||||
set mailserver smtp.monit.ro port 587
|
||||
# email-format
|
||||
set mail-format {
|
||||
from: monit@monit.ro
|
||||
subject: $SERVICE $EVENT at $DATE on $HOST
|
||||
message: Monit $ACTION $SERVICE $EVENT at $DATE on $HOST : $DESCRIPTION.
|
||||
|
||||
Yours sincerely,
|
||||
Monit
|
||||
|
||||
}
|
||||
|
||||
set alert guletz@monit.ro
|
||||
|
||||
# delay checks
|
||||
set daemon 120
|
||||
with start delay 240
|
||||
set logfile syslog facility log_daemon
|
||||
|
||||
# idfile and mail queue path
|
||||
set idfile /var/monit/id
|
||||
set eventqueue
|
||||
basedir /var/monit
|
||||
|
||||
Now it is time to check what we have done. You can test an existing configuration file (/etc/monit.conf) by running:
|
||||
|
||||
# monit -t
|
||||
|
||||
----------
|
||||
|
||||
Control file syntax OK
|
||||
|
||||
If Monit complains about any error, please review the configuration file again. Fortunately, error/warnings messages are informative. For example:
|
||||
|
||||
monit: Cannot stat the SSL server PEM file '/var/certs/monit.pem' -- No such file or directory
|
||||
/etc/monit/monitrc:10: Warning: hostname did not resolve 'smtp.monit.ro'
|
||||
|
||||
Once you verify the syntax of configuration, start monit daemon, and wait 2 to 3 minutes:
|
||||
|
||||
# service monit start
|
||||
|
||||
If you are using systemd, run:
|
||||
|
||||
# systemctl start monit
|
||||
|
||||
Now open a browser window, and go to https://<monit_host>:1966. Replace &<monit_host> with your Monit hostname or IP address.
|
||||
|
||||
Note that if you have a self-signed SSL certificate, you will see a warning message in your browser.
|
||||
|
||||

|
||||
|
||||
After you have completed login, you must see the following page.
|
||||
|
||||
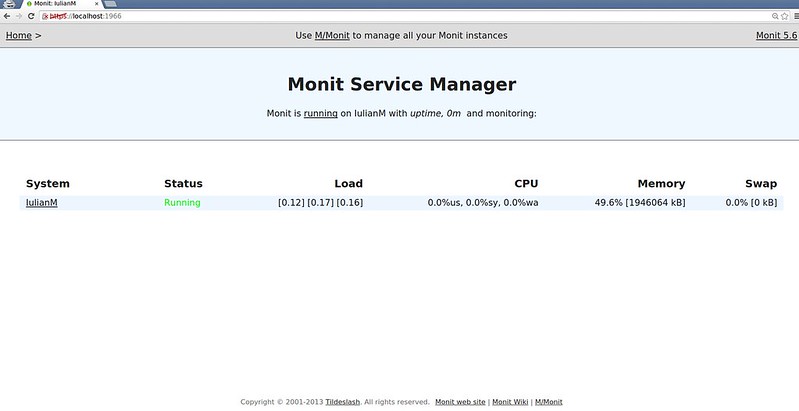
|
||||
|
||||
In the rest of the tutorial, let me show how we can monitor a local server and common services. You will see a lot of useful examples on the [official wiki page][7]. Most of them are copy-and-pastable!
|
||||
|
||||
### Service Configuration: CPU/Memory Monitoring ###
|
||||
|
||||
Let start with monitoring a local server's CPU/memory usage. Copy the following snippet in the configuration file.
|
||||
|
||||
check system localhost
|
||||
if loadavg (1min) > 10 then alert
|
||||
if loadavg (5min) > 6 then alert
|
||||
if memory usage > 75% then alert
|
||||
if cpu usage (user) > 70% then alert
|
||||
if cpu usage (system) > 60% then alert
|
||||
if cpu usage (wait) > 75% then alert
|
||||
|
||||
You can easily interpret the above configuration. The above checks are performed on local host for every monitoring cycle (which is set to 120 seconds in the Global section). If any condition is met, monit daemon will send an alert with an email.
|
||||
|
||||
If certain properties do not need to be monitored for every cycle, you can use the following format. For example, this will monitor average load every other cycle (i.e., every 240 seconds).
|
||||
|
||||
if loadavg (1min) > 10 for 2 cycles then alert
|
||||
|
||||
### Service Configuration: SSH Service Monitoring ###
|
||||
|
||||
Let's check if we have sshd binary installed in /usr/sbin/sshd:
|
||||
|
||||
check file sshd_bin with path /usr/sbin/sshd
|
||||
|
||||
We also want to check if the init script for sshd exist:
|
||||
|
||||
check file sshd_init with path /etc/init.d/sshd
|
||||
|
||||
Finally, we want to check if sshd daemon is up an running, and listens on port 22:
|
||||
|
||||
check process sshd with pidfile /var/run/sshd.pid
|
||||
start program "/etc/init.d/sshd start"
|
||||
stop program "/etc/init.d/sshd stop"
|
||||
if failed port 22 protocol ssh then restart
|
||||
if 5 restarts within 5 cycles then timeout
|
||||
|
||||
More specifically, we can interpret the above configuration as follows. We check if a process named sshd and a pidfile (/var/run/sshd.pid) exist. If either one does not exist, we restart sshd demon using init script. We check if a process listening on port 22 can speak SSH protocol. If not, we restart sshd daemon. If there are at least 5 restarts within the last 5 monitoring cycles (i.e., 5x120 seconds), sshd daemon is declared non-functional, and we do not try to check again.
|
||||
|
||||
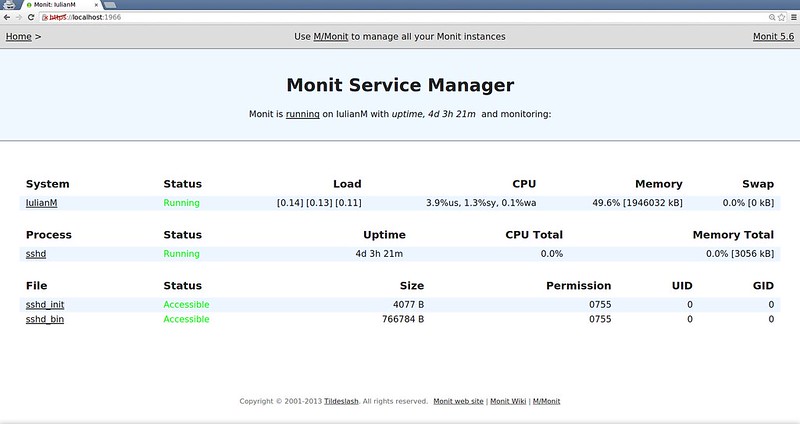
|
||||
|
||||
### Service Configuration: SMTP Service Monitoring ###
|
||||
|
||||
Now let's set up a check on a remote SMTP mail server (e.g., 192.168.111.102). Let's assume that the SMTP server is running SMTP, IMAP and SSH on its LAN interface.
|
||||
|
||||
check host MAIL with address 192.168.111.102
|
||||
if failed icmp type echo within 10 cycles then alert
|
||||
if failed port 25 protocol smtp then alert
|
||||
else if recovered then exec "/scripts/mail-script"
|
||||
if failed port 22 protocol ssh then alert
|
||||
if failed port 143 protocol imap then alert
|
||||
|
||||
We check if the remote host responds to ICMP. If we haven't received ICMP response within 10 cycles, we send out an alert. If testing for SMTP protocol on port 25 fails, we send out an alert. If testing succeeds again after a failed test, we run a script (/scripts/mail-script). If testing for SSH and IMAP protocols fail on port 22 and 143, respectively, we send out an alert.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
In this tutorial, I demonstrate how to set up Monit on a local server. What I showed here is just the tip of the iceberg, as far as Monit's capabilities are concerned. Take your time and read the man page about Monit (a very good one). Monit can do a lot for any Linux admin with a very nice and easy to understand syntax. If you put together a centralized remote monitor and Monit to work for you, you will have a more reliable monitoring system. What is your thought on Monit?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/server-monitoring-system-monit.html
|
||||
|
||||
作者:[Iulian Murgulet][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/iulian
|
||||
[1]:http://xmodulo.com/monitor-common-services-nagios.html
|
||||
[2]:http://xmodulo.com/monitor-linux-servers-snmp-cacti.html
|
||||
[3]:http://mmonit.com/monit/
|
||||
[4]:http://xmodulo.com/how-to-set-up-epel-repository-on-centos.html
|
||||
[5]:http://xmodulo.com/how-to-set-up-rpmforge-repoforge-repository-on-centos.html
|
||||
[6]:http://xmodulo.com/mail-server-ubuntu-debian.html
|
||||
[7]:http://mmonit.com/wiki/Monit/ConfigurationExamples
|
||||
@ -1,129 +0,0 @@
|
||||
|
||||
CD音频抓取器——基于图形界面
|
||||
================================================================================
|
||||
CD音频抓取器是为了从光盘中提取(“剖出”)原始数字音频(它在一个通常被称为CDDA的格式中)并把它保存成文件或以其他形式输出而设计的。这类软件使用户能把数字音频编码成各种格式,并能下载和上传在线CD目录服务——一个在线的光盘数据库——中的光盘信息。
|
||||
|
||||
复制CD合法吗?在美国版权法中,把一个原始CD转换成数字文件用于个人使用在被引用时等同于‘合理使用’。然而,美国版权法并没有明确的允许或禁止拷贝私人音频CD,而且判例法还没有确立出在具体的哪种情况下可以视为合理使用。在英国版权的位置更清晰一些。从2014年开始,英国公民制造CD,MP3,DVD,蓝光和电子书的行为成为合法行为。这仅适用于这个人拥有被采集的媒体的实体,并且复制品仅用于他们个人使用。对于欧盟的其他国家,成员国可以允许私人复制这种特例。
|
||||
|
||||
如果你不确定在你生活的国家里版权处于什么位置,在你使用这两页文章中所列举的软件前请查询本地的版权法以确定你处在合法的一边。
|
||||
|
||||
在某种程度上,提取CD音轨看起来有点多余。如Spotify和Google Play Music这类流服务提供了一个巨大的以通用格式存在的音乐的库,无需采集你的CD集。但是,如果你已将收藏了一个数量巨大的CD集。能把你的CD转换成可以在便携设备如智能手机、平板和便携式MP3播放器上播放的格式仍然是个诱人的选择。
|
||||
|
||||
这两页文章推荐了我最喜欢的音频CD抓取器。我挑了四个最好的图形界面的音频抓取器,四个最好的控制台音频抓取器。所有这些应用程序都是在开源许可下发行的。
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
fre:ac是个开源音频转换器和CD提取器,支持很多种流行格式和编码器。目前这个应用可以在MA3、MP4/M4A、WMA、Ogg Vorbis、FLAC、AAC、WAV和Bonk格式间转换。这来源于几种不同形式的LAME编码器。
|
||||
|
||||
#### 功能包括: ####
|
||||
|
||||
- 易学易用
|
||||
- MP3、MP4/M4A、WMA、Ogg Vorbis、FLAC、AAC、WAV和Bonk格式转换器
|
||||
- 集成了CDDB/freedb标题数据库支持的CD提取器
|
||||
- 多核优化的编码器加速了现代PC上的转换速度
|
||||
- 对于标签和文件名称的全Unicode支持
|
||||
- 易学易用,当你需要时还提供专家级选项
|
||||
- 任务列表
|
||||
- 可以使用Winamp 2加入附件
|
||||
- 多语言用户界面可以使用41种语言
|
||||
|
||||
- 网址: [freac.org][1]
|
||||
- 开发人员:Robert Kausch
|
||||
- 许可证: GNU GPL v2
|
||||
- 版本号: 20141005
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Audex是个简单易用的开源音频CD提取应用。虽然它还处于早期开发阶段,这个KDE桌面工具足够稳定、聪明和简单,可以使用。
|
||||
|
||||
助手可以给LAME、OGG Vorbis(oggenc)、FLAC、FAAC(AAC/MP4)和RIFF WAVE创建配置文件。除去这个助手,你可以定义你自己的配置文件,这意味着,Audex适用于大部分的命令行编码器。
|
||||
|
||||
#### 功能包括: ####
|
||||
|
||||
- 可提取CDDA Paranoia
|
||||
- 提取和编码同时进行
|
||||
- 文件名采用本地和远程CDDB/FreeDB数据库
|
||||
- 提供新的CDDB/FreeDB数据库入口
|
||||
- 类似capitalize的元数据纠正工具
|
||||
- 多配置文件提取(每个配置文件文件有一个命令行编码器)
|
||||
- 从互联网上抓取封面并将他们存在数据库中
|
||||
- 在目标目录中创建播放列表、封面和基于模板的信息文件
|
||||
- 创建提取和编码协议
|
||||
- 将文件传送到FTP服务器
|
||||
- 支持国际化
|
||||
|
||||
- 网址: [kde.maniatek.com/audex][2]
|
||||
- 开发人员: Marco Nelles
|
||||
- 许可证: GNU GPL v3
|
||||
- 版本号: 0.79
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Sound Juicer是个使用GTK+和GStreamer的轻量级CD提取器。它从CD中提取音频并把它转换成音频文件。Sound Juicer还可以直接播放CD中的音轨,在提取前提供预览。
|
||||
|
||||
由于GStreamer插件它支持任何音频编码,包括 MP3、Ogg Vorbis、FLAC和未压缩的PCM格式。
|
||||
|
||||
它是GNOME桌面环境已建成的一部分。
|
||||
|
||||
#### 功能包括: ####
|
||||
|
||||
- 自动通过CDDB给音轨加标签
|
||||
- 可编码成ogg/vorbis、FLAC和原始WAV
|
||||
- 编码路径的设置很简单
|
||||
- 多种流派
|
||||
- 国际化支持
|
||||
|
||||
- 网址:[burtonini.com][3]
|
||||
- 开发人员: Ross Burton
|
||||
- 许可证:GNU GPL v2
|
||||
- 版本号:3.14
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
ripperX是个开源的图形交互界面,用于提取CD音轨并把他们编码成Ogg、MP2、MP3或FLAC格式。它的目的是容易使用,只需要点几下鼠标就能转换整张专辑。它支持在CDDB寻找专辑和音轨信息。
|
||||
|
||||
他使用cdparanoia把CD音轨转换(也就是“提取”)成WAV文件,然后访问Vorbis/Ogg编码器oggenc把WAV文件转换成OGG文件。它还可以访问flac让WAV文件有无损压缩的表现,制成FLAC文件。
|
||||
|
||||
#### 功能包括: ####
|
||||
|
||||
- 非常简单易用
|
||||
- 可以把CD音轨提取成WAV、MP3、OGG或FLAC文件
|
||||
- 支持CDDB查找
|
||||
- 支持ID3v2标签
|
||||
- 可暂停提取进程
|
||||
|
||||
- 网址:[sourceforge.net/projects/ripperx][4]
|
||||
- 开发人员:Marc André Tanner
|
||||
- 许可证:MIT/X Consortium License
|
||||
- 版本号:2.8.0
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
转自:http://www.linuxlinks.com/article/20150125043738417/AudioGrabbersGraphical.html
|
||||
|
||||
作者:Frazer Kline
|
||||
译者:[H-mudcup](https://github.com/H-mudcup)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.freac.org/
|
||||
[2]:http://kde.maniatek.com/audex/
|
||||
[3]:http://burtonini.com/blog/computers/sound-juicer
|
||||
[4]:http://sourceforge.net/projects/ripperx/
|
||||
@ -1,24 +1,23 @@
|
||||
2015你可以买的一款基于Linux的迷你PC
|
||||
2015年你可以买的四款基于Linux的迷你PC
|
||||
================================================================================
|
||||

|
||||
|
||||
在我看来迷你PC将在不久的将来会替代传统桌面电脑。传统桌面的有一个像送风机那样占据大量空间的风扇。迷你PC,在另一方面说很小巧和紧凑。通常是4″或者5″大小,可以轻易地放在桌子上。
|
||||
在我看来迷你PC将在不久的将来会替代传统桌面电脑。传统桌面的有一个像吹风机那样占据大量空间的风扇。迷你PC,在另一方面说很小巧和紧凑。通常是4″或者5″大小,可以轻易地放在桌子上。
|
||||
|
||||
不仅如此,这些迷你PC的无风扇设计是一个好处。当然,你可以购买无风扇的常规电脑,但是空间占用仍然是一个问题。对我个人来说,我觉得迷你PC外观上看着很可爱。如果你不是一个游戏玩家也不想买新的桌面PC,我强烈建议你**购买一个基于Linux的迷你PC**。
|
||||
不仅如此,这些迷你PC的无风扇设计是一个优点。当然,你可以购买无风扇的常规电脑,但是空间占用仍然是一个问题。对我个人来说,我觉得迷你PC外观上看着很可爱。如果你不是一个游戏玩家也不想买新的桌面PC,我强烈建议你**购买一款基于Linux的迷你PC**。
|
||||
|
||||
如果你考虑我的建议买一个,那么你或许想知道该买哪款。不要担心,这篇文章我们会介绍**四款你可以在2015购买的基于Linux的迷你PC**。
|
||||
如果你考虑我的建议,那么你或许想知道该买哪款。不要担心,这篇文章我们会介绍**2015年你可以购买的四款基于Linux的迷你PC**。
|
||||
|
||||
### 基于Linux的迷你PC ###
|
||||
|
||||
请注意这些PC可能还不能下单。它们中有些还刚刚公布,在不久的将来才会面向公众出售。
|
||||
需要注意的是,这其中的一些PC可能还不能下单。它们中有些还刚刚公布,在不久的将来才会面向公众出售。
|
||||
|
||||
|
||||
#### 1. System76出品的Meerkat ####
|
||||
|
||||

|
||||
|
||||
[System76][1] is a computer manufacturer exclusively dealing with only Ubuntu based desktop, laptops and servers. [System76 announced an Ubuntu based mini PC Meerkat][2] last week. Let’s take a quick look at its specification:
|
||||
[System76][1] 是一家仅出品基于Ubuntu电脑、笔记本、服务器的电脑生产商。[System76在上周宣布了一款基于Ubuntu的迷你PC][2]。让我看一下它的规格:
|
||||
[System76][1] 是一家仅出品基于Ubuntu电脑、笔记本、服务器的电脑生产商。[System76在上周公布了一款基于Ubuntu的迷你PC][2]。让我看一下它的规格:
|
||||
|
||||
**规格**
|
||||
|
||||
@ -43,7 +42,7 @@
|
||||
|
||||

|
||||
|
||||
[Compulab][3]将它的旗舰产品基于Linux Mint的桌面设备成了[Mintbox Mini][4]。紧凑的版本在4″大小。更多的细节如下:
|
||||
[Compulab][3]将它基于Linux Mint的期间PC设备压缩,从Mintbox变为[Mintbox Mini][4]。这个紧凑的版本大小在4″左右。更多的细节如下:
|
||||
|
||||
**规格**
|
||||
|
||||
@ -59,19 +58,17 @@
|
||||
|
||||
**价格**
|
||||
|
||||
$300起售
|
||||
$300左右起售
|
||||
|
||||
**发售日期**
|
||||
|
||||
2015第二季度
|
||||
2015年第二季度
|
||||
|
||||
#### 3. Compulab出品的Utilite2 ####
|
||||
|
||||

|
||||
|
||||
It’s not that Compulab has stuck with Linux Mint only. It announced an ARM desktop PC running Ubuntu in last December. With a size of 3.4″x2.3″, [Utilite2][5] has modest feature and modest price.
|
||||
Compulab并不是坚持用Linux Mint的。它在去年12月宣布了一款运行Ubuntu的ARM桌面PC。大小是3.4″x2.3″,[Utilite2][5]有最现代的特性和价格
|
||||
|
||||
Compulab并不仅仅被Linux Mint所限制。它在去年12月公布了一款运行Ubuntu的ARM桌面PC。大小是3.4″x2.3″,[Utilite2][5]有最适合的性价比。
|
||||
|
||||
**规格**
|
||||
|
||||
@ -85,20 +82,19 @@ Compulab并不是坚持用Linux Mint的。它在去年12月宣布了一款运行
|
||||
|
||||
**价格**
|
||||
|
||||
常规版售价$192、带硬盘售价$229。邮费另付。
|
||||
常规版售价$192、带硬盘售价$229。运费另付。
|
||||
|
||||
**发售日期**
|
||||
|
||||
现在就可购买。运送将花费4周。
|
||||
|
||||
#### Think Penguin出品的Penguin Pocket Wee ####
|
||||
#### 4. Think Penguin出品的Penguin Pocket Wee ####
|
||||
|
||||

|
||||
|
||||
[Think Penguin][6]是一家开源硬件生产商。在迷你PC领域,它提供了[Penguin Pocket Wee][7]。大小是4.6″x 4.4″x 1.4″ ,, Penguin Pocket Wee提供了大量的配置。你可以选择处理器、存储、网卡等。你可以选择购买预装你喜欢的Linux发行版,默认系统是Ubuntu。
|
||||
[Think Penguin][6]是一家开源硬件生产商。在迷你PC领域,它提供了[Penguin Pocket Wee][7]。大小是4.6″x 4.4″x 1.4″ ,, Penguin Pocket Wee为你提供了大量的配置。你可以选择处理器、存储、网卡等。你可以选择购买预装你喜欢的Linux发行版,默认系统是Ubuntu。
|
||||
|
||||
The general configuration is as following:
|
||||
下面的默认的配置
|
||||
下面是默认的配置:
|
||||
|
||||
- Intel Core i3 或者 i5处理器,最高支持1080p视频
|
||||
- 最高扩展至 16GB 的 DDR3内存
|
||||
@ -110,18 +106,17 @@ The general configuration is as following:
|
||||
|
||||
**价格**
|
||||
|
||||
Basic model starts at $499 and it can go up to $1000 based on the configuration you select.
|
||||
基础版本$499起售,根据你的配置最大是$1000。
|
||||
基础版本$499起售,根据你选择的配置最高价格是$1000。
|
||||
|
||||
**发售日期**
|
||||
|
||||
现在就可下订单。该公司在美国和英国也有办公司,所以应也可以运送到南美和欧洲。
|
||||
现在就可下订单。该公司在美国和英国也有办公地点,所以应也可以运送到南美和欧洲。
|
||||
|
||||
### 你会选哪种? ###
|
||||
|
||||
我故意没有介绍[Raspberry Pi 2][8]或者其他Linux微电脑如[Intel的电脑棒][9]。原因是我不认为这些微电脑属于迷你PC的范畴。
|
||||
|
||||
你怎么看?你想用迷你PC代替你的桌面PC么?是不是还有我没有在**最好的基于Linux的迷你PC**列出的PC?分享你们的观点吧。
|
||||
你怎么看?你想用迷你PC代替你的桌面PC么?是不是还有我没有在**基于Linux的最好的迷你PC**列表里列出的PC?在评论区分享你们的观点吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -129,7 +124,7 @@ via: http://itsfoss.com/4-linux-based-mini-pc-buy-2015/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
86
translated/talk/20150318 The future of Linux storage.md
Normal file
86
translated/talk/20150318 The future of Linux storage.md
Normal file
@ -0,0 +1,86 @@
|
||||
Linux存储的未来
|
||||
================================================================================
|
||||
> **摘要**:Linux系统的软件开发者们正致力于使Linux支持更多种类的文件和存储方案。
|
||||
|
||||
波士顿 - 在[Linux基金会][1]最近的[Vault][2]展示会上,全都是关于文件系统和存储方案的讨论。你可以会想关于这两个主题并没有什么展值得讨论的最新进展,但事实并非如此。
|
||||
|
||||

|
||||
|
||||
对Linux文件系统,比如Btrfs,和存储方案的支持正在持续发展中。 -- Facebook
|
||||
|
||||
自从Linus提出“[讨厌的、生锈的机械磁盘]”的观点以来,存储技术已经走过一段长路,Linux也始终保持跟进。比如说,近几年来,[闪存已经逐渐成为企业服务器的主要存储器][4],[持久化内存][5]也正给我们带来拥有DRAM一般快速的存储。与此同时,大数据、云计算和容器化技术正给Linux引入新的应用场景。
|
||||
|
||||
为了应对挑战,Linux开发者们一边继续扩展已有的文件系统和存储程序,一边致力于开发新的方案。
|
||||
|
||||
### Btrfs ###
|
||||
|
||||
例如,Chris Mason,一位来自Facebook的软件工程师,也是[Btrfs][6](对外宣称Butter FS)的维护者之一,说明了Facebook是如何使用这种文件系统。Btrfs拥有文件系统固有的许多优点,比如既能处理大量的小文件,也能处理大小可达16EB的单个文件;支持RAID的baked(烦请校正补充);内置的文件系统压缩,以及集成了对多种存储设备的支持。
|
||||
|
||||
当然,Facebook的服务器也运行在Linux上。更准确地讲,是运行在一个基于[CentOS][7]的内部发行版上,它是基于3.10和3.18版的内核。对Facebook来说,真正的收获是Btrfs在由Facebook持续的更新用户操作带来的巨大的IOPS(每秒钟输入输出的操作数)的负载下依旧保持稳定和快速。
|
||||
|
||||
这就是好消息,但坏消息是对于像MySQL一样的传统DBMS(数据库管理系统)来说Btrfs还是太慢了。对此,Facebook采用了[XFS][8]。为了协同这两种文件系统,Facebook又用到了一种叫做[Gluster][9]的开源分布式文件系统。
|
||||
|
||||
Facebook,一直与上游的负责Btrfs的Linux内核开发者保持密切联系,致力于提高Btrfs在DBMS上的速度。Mason和他的同事在[RocksDB][10]数据库上使用Btrfs以达成目标,RocksDB是一种为提供快速存储开发的持久化键值存储系统,可以作为客户端服务器模式数据库的基础部分。
|
||||
|
||||
当然Btrfs也还存在一些问题,比如,如果有用户傻到用数据把硬盘几乎要撑爆时,Btrfs会在硬盘被完全装满前阻止用户继续写入。对某些工程来说,比如[CoreOS][12],一款依赖容器化的企业版Linux系统,这种问题是致命的。[因此,CoreOS已经切换到使用xt4和overlayfs了][11]。
|
||||
|
||||
Btrfs的开发人员正致力于数据去重。在这一点上,当文件系统中拥有超过一个的相同文件时,会自动删除多余文件。正如Mason所说,“并非每个人都需要这个功能,但如果有人需要,那就是真的需要!”
|
||||
|
||||
在正在开展的重要性工作中,Btrfs并非是唯一的文件系统。John Spary,[Red Hat][13]的一位高级软件工程师,提到了另一款名为[Ceph][14]的分布式文件系统。
|
||||
|
||||
### Ceph FS ###
|
||||
|
||||
Ceph提供了一种分布式对象存储方案和文件系统,反过来它依托于一种使用商用硬件集群的弹性的、可扩展的存储模型(RADOS)。配合RADOS块设备(RBD)和RADOS对象网关(RGW),Ceph提供了一种[POSIX][15]接口的文件系统 -- Ceph FS。尽管RBD和RGW已经在生产环境中使用了一段时间,但使Ceph FS适用于生产的工作还是进行中。
|
||||
|
||||
[Rad Hat,在收购Ceph的母公司Inktank后][16],在2014年一直致力于使CephFS适用于生产环境。不管怎样,Spray说,“有些人已经在生产中使用了它;我们对此表示担忧,毕竟它还没有准备好。”然而,Spray也补充说,“这具有两面性,因为一方面这是让人担心的,另一方面我们又从用户获得了真正有用的反馈和测试。”
|
||||
|
||||
这是因为尽管Ceph对象存储很好地支持扩展,但Ceph Fs,作为一种兼容POSIX的文件系统,却很难实现扩展。比如,作为一种分布式文件系统,Ceph FS必须解决来自多个客户端的多个写操作。这会导致全有或全无的情况,即一个客户端可以写入,但其它客户端必须等待,也会产生文件加锁的情形,即相比普通文件系统中更加复杂。
|
||||
|
||||
但是,Ceph FS仍值得去做,正如Spray所说,“因为兼容POSIX的文件系统是操作系统通用的。”这并不是说Ceph FS就一无是处。“它并不是支离破碎的,相反它奏效了。所缺的是修复和监控工具。”
|
||||
|
||||
Red Hat目前正致力于获得[fsck][17]和日志修复工具、快照强化、更好客户端访问控制,以及云与容器的集成。尽管Ceph FS到目前为止只是一种有潜力或者没前景的文件系统,但仍然值得用在生产环境中。
|
||||
|
||||
### 文件与存储的差别与目标 ###
|
||||
|
||||
至于文件系统和存储上的更大问题,Jeff Layton,[Primary Data][18]的一位高级软件工程师,解释说为了“在不断开电源的情况下给灾难性的电源故障提供测试”,大量的相关工作正在进行中。这些测试很快会被集成到[xftests][19]中,它是Linux文件系统测试的黄金标准。
|
||||
|
||||
Rik van Riel,一位Red Hat的主要软件工程师,谈到了解决持久化内存产品的问题。你可以把它们作为存储器或者内存。但是,如果你现在把它们作为内存来用,是不能为备份创建快照。真正的问题是:van Riel确信人们会尝试使用持久的内存作这两种用途,这会导致出现和“如果不备份,你会如何处理一个200GB大小的持久化内存数据库?”类似的情形发生。更糟的是,现在日志系统也无法和持久化的内存一起发挥作用。
|
||||
|
||||
正确的答案是什么呢?Linux至今还没有一个,但编程人员们正在努力寻找答案。
|
||||
|
||||
因此,尽管Linux支持很多文件系统,可以使用这里以外的任何一种存储器来存储数据,但是仍然有很多工作要做。技术从来不会止步不前。Linux,正运行在移动设备、桌面电脑、服务器、云端和超级计算机上等几乎所有的主流设备上,必须跟紧存储的发展步伐,不管它们以何种形式出现。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.zdnet.com/article/linux-storage-futures/
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols][a]
|
||||
译者:[KayGuoWhu](https://github.com/KayGuoWhu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.zdnet.com/meet-the-team/us/sjvn/
|
||||
[1]:http://www.linuxfoundation.org/
|
||||
[2]:http://events.linuxfoundation.org/events/vault
|
||||
[3]:http://www.wired.com/2012/10/linus-torvalds-hard-disks/
|
||||
[4]:http://www.zdnet.com/article/sandisk-launches-infiniflash-aims-to-bring-flash-array-costs-down/
|
||||
[5]:http://events.linuxfoundation.org/sites/events/files/eeus13_wheeler.pdf
|
||||
[6]:https://btrfs.wiki.kernel.org/index.php/Main_Page
|
||||
[7]:http://www.centos.org/
|
||||
[8]:http://oss.sgi.com/projects/xfs/
|
||||
[9]:http://www.gluster.org/
|
||||
[10]:http://rocksdb.org/
|
||||
[11]:http://lwn.net/Articles/627232/
|
||||
[12]:https://coreos.com/
|
||||
[13]:http://www.redhat.com/
|
||||
[14]:http://ceph.com/
|
||||
[15]:http://pubs.opengroup.org/onlinepubs/9699919799/
|
||||
[16]:http://www.zdnet.com/article/red-hat-acquires-inktank-for-175m/
|
||||
[17]:http://linux.die.net/man/8/fsck
|
||||
[18]:http://primarydata.com/
|
||||
[19]:http://oss.sgi.com/cgi-bin/gitweb.cgi?p=xfs/cmds/xfstests.git;a=summary
|
||||
|
||||
|
||||
|
||||
|
||||
@ -1,126 +0,0 @@
|
||||
使用Nemiver调试器找出C/C++程序中的bug
|
||||
================================================================================
|
||||
|
||||
如果你读过[my post on GDB][1],你就会明白我认为一个调试器对一段C/C++程序来说意味着多么的重要和有用。然而,如果一个像GDB的命令行对你而言听起来更像一个问题而不是一个解决方案,那么你也许会对Nemiver更感兴趣。[Nemiver][2] 是一款基于GTK+的独立图形化用于C/C++程序的调试器,同时它以GDB作为其后端。最令人佩服的是其速度和稳定性,Nemiver时一个非常可靠,具备许多优点的调试工具。
|
||||
|
||||
### Nemiver的安装 ###
|
||||
|
||||
基于Debian发行版,它的安装时非常直接简单如下:
|
||||
|
||||
$ sudo apt-get install nemiver
|
||||
|
||||
在Arch Linux中安装如下:
|
||||
|
||||
$ sudo pacman -S nemiver
|
||||
|
||||
在Fedora中安装如下:
|
||||
|
||||
$ sudo yum install nemiver
|
||||
|
||||
如果你选择自己变异,[GNOME website][3]中最新源码包可用。
|
||||
|
||||
最令人欣慰的是,它能够很好地与GNOME环境像结合。
|
||||
|
||||
### Nemiver的基本用法 ###
|
||||
|
||||
启动Nemiver的命令:
|
||||
|
||||
$ nemiver
|
||||
|
||||
你也可以通过执行一下命令来启动:
|
||||
|
||||
$ nemiver [path to executable to debug]
|
||||
|
||||
你会注意到如果在调试模式下执行编译(-g标志表示GCC)将会更有帮助。
|
||||
|
||||
还有一个优点是Nemiver的快速加载,所以你应该可以马上看到主屏幕的默认布局。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
默认情况下,断点通常位于主函数的第一行。这样就可以空出时间让你去认识调试器的基本功能:
|
||||
|
||||

|
||||
|
||||
- Next line (mapped to F6)
|
||||
- Step inside a function (F7)
|
||||
- Step out of a function (Shift+F7)
|
||||
- 下一行 (映射到F6)
|
||||
- 执行内部行数(F7)
|
||||
- 执行外部函数(Shift+F7) ## 我不确定这个保留哪个都翻译出来了 ##
|
||||
|
||||
但是由于我个人的喜好是“Run to cursor(运行至光标)”,该选项使你的程序运行精确至你光标下的行,并且默认映射到F11.
|
||||
|
||||
下一步,断点通常是容易使用的。最快捷的方式是使用F8设置一个断点在相应的行。但是Nemiver也有一个更富在的菜单在“Debug”项,这允许你在一个特定的函数,行数,二进制位置文件的位置,或者类似一个异常,分支或者exec的事件。
|
||||
|
||||

|
||||
|
||||
|
||||
你也可以通过追踪来查看一个变量。在“Debug”选项,你可以通过命名来匹配一个表达式来检查。然后也可以通过将其添加到列表中以方便访问。这可能是最有用的一个功能虽然我从未因为浓厚的兴趣将鼠标悬停在一个变量来获取它的值。值得注意的是,将鼠标放置在相应位置时不生效的。如果想要让它更好地工作,Nemiver是可以看到结构并给所有成员的变量赋值。
|
||||
|
||||

|
||||
|
||||
|
||||
谈到方便地访问信息,我也非常欣赏这个程序的平面布局。默认情况下,代码在上个部分,标签在下半部分。这授予你访问中断输出、文本追踪、断点列表、注册地址、内存映射和变量控制。但是注意到在“Edit”“Preferences”“Layout”下你可以选择不同的布局,包括动态修改。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
|
||||
自然而然,一旦你设置了所有短点,观察点和布局,您可以在“File”下很方便地保存以免你不小心关掉Nemiver。
|
||||
|
||||
|
||||
### Nemiver的高级用法 ###
|
||||
|
||||
|
||||
到目前为止,我们讨论的都是Nemiver的基本特征,例如,你马上开始喝调试一个简单的程序需要什么。如果你有更高的药求,特别是对于一些更佳复杂的程序,你应该会对接下来提到的这些特征更感兴趣。
|
||||
|
||||
|
||||
#### 调试一个正在运行的进程 ####
|
||||
|
||||
|
||||
Nemiver允许你连接到一个正在运行的进程进行调试。在“File”菜单,你可以过滤出正在运行的进程,并连接到这个进程。
|
||||
|
||||

|
||||
|
||||
|
||||
#### 通过TCP连接远程调试一个程序 ####
|
||||
|
||||
Nemiver支持远程调试,当你在一台远程机器设置一个轻量级调试服务器,你可以通过调试服务器启动Nemiver从另一台机器去调试承载远程服务器上的目标。如果出于某些原因,你不能在远程机器上吗很好地驾驭Nemiver或者GDB,那么远程调试对于你来说将非常有用。在“File”菜单下,指定二进制文件、共享库的地址和端口。
|
||||
|
||||

|
||||
|
||||
#### 使用你的GDB二进制进行调试 ####
|
||||
|
||||
如果你想自行通过Nemiver进行编译,你可以在“Edit(编辑)”“Preferences(首选项)”“Debug(调试)”下给GDB制定一个新的位置。如果你想在Nemiver使用GDB的定制版本,那么这个选项对你来说是非常实用的。
|
||||
|
||||
|
||||
#### 循序一个子进程或者父进程 ####
|
||||
|
||||
Nemiver是可以兼容一个子进程或者附近成的。想激活这个功能,请到“Debugger”下面的“Preferences(首选项)”。
|
||||
|
||||

|
||||
|
||||
总而言之,Nemiver大概是我最喜欢的没有IDE的调试程序。在我看来,它甚至可以击败GDB,并且[命令行][4]程序对我本身来说更接地气。所以,如果你从未使用过的话,我会强烈推荐你使用。我只能庆祝我们团队背后给了我这么一个可靠、稳定的程序。
|
||||
|
||||
你对Nemiver有什么见解?你是否也考虑它作为独立的调试工具?或者仍然坚持使用IDE?让我们在评论中探讨吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/debug-program-nemiver-debugger.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[disylee](https://github.com/disylee)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/adrien
|
||||
[1]:http://xmodulo.com/gdb-command-line-debugger.html
|
||||
[2]:https://wiki.gnome.org/Apps/Nemiver
|
||||
[3]:https://download.gnome.org/sources/nemiver/0.9/
|
||||
[4]:http://xmodulo.com/recommend/linuxclibook
|
||||
@ -1,196 +0,0 @@
|
||||
在linux中如何通过nload来监控网络使用情况
|
||||
================================================================================
|
||||
nload 是一个免费的linux工具,通过提供两个简单的图形化界面来帮助linux用户和系统管理员来实时监控网络流量以及宽带使用情况:一个作为进入流量,一个作为流出流量.
|
||||
|
||||
我是真的很喜欢用**nload**来在屏幕上显示当前的下载速度,总的流入量和平均下载速度等信息。nload工具的报告图非常容易理解,最重要的是这些信息真的非常有用。
|
||||
|
||||
|
||||
|
||||
在使用手册上说到,在默认情况下会监控所有网络设备。但是你可以轻松地指定你想要监控的设备,而且可以可以通过方向键头在不同的网络设备之间进行转换。另外还有很多的选项可用,例如 ‘-r’选项确定以毫秒来刷新显示时间间隔(默认时间间隔值是500毫秒),‘-m’选项用来实时显示多个设备(流量图在使用该选项时不会显示), ‘-u’选项用来设置显示流量数字的单元类型,另外还有许多其他的选项将会在该教程中探索和练习。
|
||||
|
||||
### 如何将 nload安装到你的linux机器上 ###
|
||||
|
||||
**Ubuntu** 和 **Fedora** 用户可以从默认的软件仓库中容易地安装。
|
||||
|
||||
在Ubuntu上使用以下命令进行安装。
|
||||
|
||||
sudo apt-get install nload
|
||||
|
||||
在Fedora上使用以下命令进行安装。
|
||||
|
||||
sudo yum install nload
|
||||
|
||||
**CentOS**用户该怎么办呢? 只需要在你的机器上输入以下命令,通用能够达到相同的结果--殊途同归。
|
||||
|
||||
sudo yum install nload
|
||||
|
||||
以下的命令会帮助你在OpenBSD系统中安装nload.
|
||||
|
||||
sudo pkg_add -i nload
|
||||
|
||||
linux机器上的另外一个非常有效的安装软件的方式就是编译源代码,通过下载并安装最新的版本意味着能够获得更好地性能,更酷的特性以及越少的bug数。
|
||||
|
||||
### 如何通过源代码安装nload ###
|
||||
|
||||
在从源代码安装nload之前,你需要首先下载源代码。 我通常使用wget工具来进行下载--该工具在许多linux机器上默认可用。该免费工具帮助用户以非交互式的方式从网络上下载文件,并支持以下协议:
|
||||
|
||||
- HTTP
|
||||
- HTTPS
|
||||
- FTP
|
||||
|
||||
通过以下命令来进入到**/tmp**目录中。
|
||||
|
||||
cd /tmp
|
||||
|
||||
然后在你的终端中输入以下命令就可以将最新版本的nload下载到你的linux机器上了。
|
||||
|
||||
wget http://www.roland-riegel.de/nload/nload-0.7.4.tar.gz
|
||||
|
||||
如果你不喜欢使用wget工具,也可以通过简单的一个鼠标点击轻松地从[官网][1]上下载源代码。
|
||||
|
||||
由于该软件非常轻巧,其下载过程几乎在瞬间就会完成。接下来的步骤就是通过**tar**工具来将下载的源代码包进行解压。
|
||||
|
||||
tar归档工具可以用来从磁带或硬盘文档中存储或解压文件,该工具具有许多可用的选项,但是我们只需要下面的几个选项来执行我们的操作。
|
||||
|
||||
1. **-x** to extract files from an archive
|
||||
1. **-x** 从文档中解压文件
|
||||
1. **-v** to run in verbose mode
|
||||
1. **-v** 使用繁琐模式运行--用来输入详细信息
|
||||
1. **-f** to specify the files
|
||||
1. **-f** 用来指定文件
|
||||
|
||||
例如:
|
||||
|
||||
tar xvf example.tar
|
||||
|
||||
现在你学会了如何使用tar工具,我可以非常肯定你会知道如何从命令行中解压.tar文档。
|
||||
|
||||
tar xvf nload-0.7.4.tar.gz
|
||||
|
||||
之后使用cd命令来进入到nload*目录中
|
||||
|
||||
cd nload*
|
||||
|
||||
在我的系统上看起来是这样的
|
||||
|
||||
oltjano@baby:/tmp/nload-0.7.4$
|
||||
|
||||
然后运行下面这个命令来为你的系统配置包
|
||||
|
||||
./configure
|
||||
|
||||
此时会有一大波僵尸会在你的屏幕上显示出来,下面的一个屏幕截图描述了它的样子。
|
||||
|
||||

|
||||
|
||||
在上述命令完成之后,通过下面的命令来编译nload。
|
||||
|
||||
make
|
||||
|
||||

|
||||
|
||||
好了,终于....,下载通过以下命令可以将nload安装在你的机器上了。
|
||||
|
||||
sudo make install
|
||||
|
||||

|
||||
|
||||
安装好nload之后就是时间来让你学习如何使用它了。
|
||||
|
||||
###如何使用nload###
|
||||
|
||||
我喜欢探索,所以在你的终端输入以下命令.
|
||||
|
||||
nload
|
||||
|
||||
看到了什么?
|
||||
|
||||
我得到了下面的结果。
|
||||
|
||||

|
||||
|
||||
如上述截图可以看到,我得到了以下信息:
|
||||
### 流入量###
|
||||
|
||||
#### 当前下载速度####
|
||||

|
||||
|
||||
#### 平均下载速度####
|
||||

|
||||
|
||||
#### 最小下载速度####
|
||||

|
||||
|
||||
#### 最大下载速度####
|
||||

|
||||
|
||||
#### 总的流入量按字节进行显示####
|
||||

|
||||
|
||||
### 流出量 ###
|
||||
|
||||
类似的同样适用于流出量
|
||||
#### 一些nload有用的选项####
|
||||
|
||||
使用选项
|
||||
-u
|
||||
|
||||
用来设置显示流量单元的类型.
|
||||
|
||||
下面的命令会帮助你使用MBit/s显示单元
|
||||
nload -u m
|
||||
|
||||
下面的屏幕截图显示了上述命令的结果.
|
||||

|
||||
|
||||
尝试以下命令然后看看有什么结果.
|
||||
|
||||
nload -u g
|
||||
|
||||

|
||||
|
||||
同时还有一个**-U**选项.根据手册描述,该选项基本上与-u选项类似,只是用在合计数据. 我测试了这个命令,老实说,当你需要检查总的流入与流出量时非常有用.
|
||||
|
||||
nload -U G
|
||||
|
||||

|
||||
|
||||
从上面的截图中可以看到,**nload -U G** 使用Gbyte来显示数据总量.
|
||||
|
||||
另外一个我喜欢使用的有用选项是 **-t**. 该选项用来设置刷新显示事件间隔为毫秒,默认值为500毫秒.
|
||||
|
||||
我会通过下面的命令做一些小的实验.
|
||||
nload -t 130
|
||||
|
||||
那么上述命令做了什么呢,它讲刷新显示时间间隔设置为130毫秒. 通常推荐不要讲该时间间隔值设置为小于100毫秒,因为nload在计算过程中可能会生成带错的报告.
|
||||
|
||||
另外的一个选项为 **-a**. 在你想要设置计算平均值的时间窗口秒数长度时使用,默认该值为300秒.
|
||||
|
||||
那么当你想要监控指定的网络设备该如何呢? 非常容易, 想下面这样简单地指定设备或者列出想要监控的设备列表.
|
||||
|
||||
nload wlan0
|
||||
|
||||

|
||||
|
||||
下面的语法可帮助你监控指定的多个设备.
|
||||
|
||||
nload [options] device1 device2 devicen
|
||||
|
||||
例如,使用下面的命令来监控eth0和eth1.
|
||||
|
||||
nload wlan0 eth0
|
||||
|
||||
如果不带选项来运行nload,那么它会监控监控所有自动检测到的设备,你可以通过左右方向键来显示其中的任何一个设备的信息.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/monitoring-2/monitor-network-usage-nload/
|
||||
|
||||
作者:[Oltjano Terpollari][a]
|
||||
译者:[theo-l](https://github.com/theo-l)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/oltjano/
|
||||
[1]:http://www.roland-riegel.de/nload/nload-0.7.4.tar.gz
|
||||
@ -1,111 +0,0 @@
|
||||
系统性能优化支招:使用Ramlog将日志文件转移到RAM
|
||||
================================================================================
|
||||
Ramlog以系统守护进程的形式存在。它系统启动的时候创建了虚拟磁盘(ramdisk),将文件从目录/var/log复制到虚拟磁盘中,同时把虚拟磁盘挂载为/var/log。接着更新虚拟磁盘上所有的日志。硬盘上的日志会保留在目录/var/log中,直到ramlog重启或停止时被更新。而关机的时候,(ramdisk上的)日志文件会重新保存到硬盘上,以确保日志一致性。Ramlog 2.x默认使用tmpfs文件系统,同时也可以支持ramfs和内核ramdisk。使用rsync(译注:Linux数据镜像备份工具)这个工具来同步日志。
|
||||
|
||||
注意:没有保存进硬盘的日志将在断电或者内核混乱(kernel panic)的情况下丢失。
|
||||
|
||||
如果你拥有空间足够的可用内存,而又想把日志放进虚拟磁盘,就安装ramlog吧。它是笔记本用户、UPS系统或是直接在flash中运行的系统节省写周期的优良选择。
|
||||
|
||||
Ramlog的运行机制以及步骤:
|
||||
|
||||
1.Ramlog在第一个守护进程(这取决于你所安装过的其它守护进程)的基础上启动。
|
||||
|
||||
2.然后创建目录/var/log.hdd并将其硬链至/var/log。
|
||||
|
||||
3.如果使用的是tmpfs(默认)或者ramfs之一的文件系统,将其挂载到/var/log上。
|
||||
|
||||
而如果使用的是内核ramdisk,ramdisk将在/dev/ram9中创建,并将挂载至/var/log。默认情况下ramlog会占用所有ramdisk的内存,其大小由内核参数"ramdisk_size"指定。
|
||||
|
||||
5.接着其它的守护进程被启动,并在ramdisk中更新日志。Logrotate(译注:Linux日志轮替工具)也是在ramdiks之上运行。
|
||||
|
||||
6.重启(默认一天一次)ramlog时,目录/var/log.hdd将借助rsync与/var/log保持同步。日志自动保存的频率可以通过cron(译注:Linux例行性工作调度)来控制。默认情况下,ramlog文件放置在目录/etc/cron.daily下。
|
||||
|
||||
7.系统关机时,ramlog在最后一个守护进程关闭之前关闭。
|
||||
|
||||
在ramlog关闭期间,/var/log.hdd中的文件将被同步至/var/log,接着/var/log和/var/log.hdd都被卸载,然后删除空目录/var/log.hdd。
|
||||
|
||||
**注意:- 此文仅面向高级用户**
|
||||
|
||||
### 在Ubuntu中安装Ramlog ###
|
||||
|
||||
首先需要用以下命令,从[这里][1]下载.deb安装包:
|
||||
|
||||
wget http://www.tremende.com/ramlog/download/ramlog_2.0.0_all.deb
|
||||
|
||||
下载ramlog_2.0.0_all.deb安装包完毕,使用以下命令进行安装:
|
||||
|
||||
sudo dpkg -i ramlog_2.0.0_all.deb
|
||||
|
||||
这一步会完成整个安装,现在你需要运行以下命令:
|
||||
|
||||
sudo update-rc.d ramlog start 2 2 3 4 5 . stop 99 0 1 6 .
|
||||
|
||||
#现在,在初始状态下升级sysklogd,使之能在ramlog停止运行前正确关闭:
|
||||
|
||||
sudo update-rc.d -f sysklogd remove
|
||||
|
||||
sudo update-rc.d sysklogd start 10 2 3 4 5 . stop 90 0 1 6 .
|
||||
|
||||
然后重启系统:
|
||||
|
||||
sudo reboot
|
||||
|
||||
系统重启完毕,运行'ramlog getlogsize'获取/var/log的空间大小。在此基础之上多分配40%的空间,确保ramdisk有足够的空间(这整个都将作为ramdisk的空间大小)。
|
||||
|
||||
编辑引导配置文件,如/etc/grub.conf,、/boot/grub/menu.lst 或/etc/lilo.conf(译注:具体哪个配置文件视不同引导加载程序而定),kernel参数新增项'ramdisk_size=xxx'以更新当前内核,其中xxx是ramdisk的空间大小。
|
||||
|
||||
### 配置Ramlog ###
|
||||
|
||||
基于deb的系统中,Ramlog的配置文件位于/etc/default/ramlog,你可以在该目录下设置以下变量:
|
||||
|
||||
Variable (with default value):
|
||||
|
||||
Description:
|
||||
|
||||
RAMDISKTYPE=0
|
||||
# Values:
|
||||
# 0 -- tmpfs (can be swapped) -- default
|
||||
# 1 -- ramfs (no max size in older kernels,
|
||||
# cannot be swapped, not SELinux friendly)
|
||||
# 2 -- old kernel ramdisk
|
||||
TMPFS_RAMFS_SIZE=
|
||||
#Maximum size of memory to be used by tmpfs or ramfs.
|
||||
# The value can be percentage of total RAM or size in megabytes -- for example:
|
||||
# TMPFS_RAMFS_SIZE=40%
|
||||
# TMPFS_RAMFS_SIZE=100m
|
||||
# Empty value means default tmpfs/ramfs size which is 50% of total RAM.
|
||||
# For more options please check ‘man mount', section ‘Mount options for tmpfs'
|
||||
# (btw -- ramfs supports size limit in newer kernels
|
||||
# as well despite man says there are no mount options)
|
||||
# It has only effect if RAMDISKTYPE=0 or 1
|
||||
KERNEL_RAMDISK_SIZE=MAX
|
||||
#Kernel ramdisk size in kilobytes or MAX to use entire ramdisk.
|
||||
#It has only effect if RAMDISKTYPE=2
|
||||
LOGGING=1
|
||||
# 0=off, 1=on Logs can be found in /var/log/ramdisk
|
||||
LOGNAME=ramlog
|
||||
# name of the ramlog log file (makes sense if LOGGING=1)
|
||||
VERBOSE=1
|
||||
# 0=off, 1=on (if 1, teststartstop puts detials
|
||||
# to the logs and it is called after start or stop fails)
|
||||
|
||||
### 在Ubuntu中卸载ramlog ###
|
||||
|
||||
打开终端运行以下命令:
|
||||
|
||||
sudo dpkg -P ramlog
|
||||
|
||||
注意:如果ramlog卸载之前仍在运行,需要重启系统完成整个卸载工作。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.ubuntugeek.com/improve-system-performance-by-moving-your-log-files-to-ram-using-ramlog.html
|
||||
|
||||
作者:[ruchi][a]
|
||||
译者:[soooogreen](https://github.com/soooogreen)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.ubuntugeek.com/author/ubuntufix
|
||||
[1]:http://www.tremende.com/ramlog/download/ramlog_2.0.0_all.deb
|
||||
@ -0,0 +1,97 @@
|
||||
如何在ubuntu14.04上安装轻量级的Budgie桌面(v8)
|
||||
================================================================================
|
||||
Budgie是为Linux发行版定制的旗舰桌面,也是一个定制工程。为思想前卫的用户设计,致力于简单和简洁。它的一个巨大优势是它不是别的项目的fork版本,是从都到尾都独立的。
|
||||
|
||||
[Budgie桌面][1]与GNOME栈紧密结合,使用先进的技术从而提供一个可选择的桌面体验。出于开源理念,这个桌面之后也能在别的Linux发行版中看到。
|
||||
|
||||
现在Budgie能够通过面板的设置达到和GNOME2桌面相似的使用体验。
|
||||
|
||||
### 0.8版的特点 ###
|
||||
|
||||
- 任务栏:支持应用锁定到任务栏
|
||||
- 任务栏:使用.desktop文件来配置quicklists菜单
|
||||
- 任务栏:使用.desktop文件来配置图标分辨率
|
||||
- 任务栏:支持有通知时蓝色闪烁
|
||||
- 面板:支持默认深色主体
|
||||
- 添加菜单条的小组件
|
||||
- 面板:自动隐藏菜单条和工具条(这配置为手动)
|
||||
- 面板:支持屏幕边缘处阴影
|
||||
- 面板:动态支持gnome面板主题
|
||||
- 运行对话框:虚拟刷新
|
||||
- Budgie菜单: 增加紧凑模式,并默认采用
|
||||
- Budgie菜单: 按照使用顺序排列菜单项
|
||||
- Budgie菜单: 移除旧的电源选项
|
||||
- 编辑器: 在UI中增加所有的菜单选项
|
||||
- 支持从GNOME 3.10 升级到3.16
|
||||
- wm: 关闭工作区的动画(v8之后)
|
||||
- wm: 改变壁纸时更好的动画
|
||||
|
||||
### 重要信息 ###
|
||||
|
||||
- Budgie [0.8版发行版][2]目前只是beta
|
||||
- 无本地网络管理;可以通过使用ubuntu的小组件解决
|
||||
- Budgie 是为Evolve OS设计的,因此这个PPA可能会有bug
|
||||
- GNOME 主题比Ubuntu本地的主题效果更好
|
||||
- Ubuntu的滚动栏将不在工作
|
||||
- 如果你想了解的更多可以访问Evolve OS网站
|
||||
|
||||
### 安装 ###
|
||||
|
||||
现在,我们将在Ubuntu14.04 LTS中安装我们自己的轻量级Budgie桌面。首先,我们要把PPA源添加到我们的Ubuntu中。执行以下命令:
|
||||
|
||||
$ sudo add-apt-repository ppa:evolve-os/ppa
|
||||
|
||||

|
||||
|
||||
添加完ppa之后,运行下面的命令更新本地软件仓库。
|
||||
|
||||
$ sudo apt-get update
|
||||
|
||||
然后只要执行下面的命令安装
|
||||
|
||||
$ sudo apt-get install budgie-desktop
|
||||
|
||||

|
||||
|
||||
**注意点**
|
||||
|
||||
这是一个活跃的开发版本,一些主要的特点可能还不是特别的完善,如:网络管理器,为数不多的控制组件,无通知系统斌并且无法将app锁定到任务栏。
|
||||
|
||||
作为工作区你能够禁用滚动栏,通过设置一个默认的主题并且通过下面的命令退出当前的会话
|
||||
|
||||
$ gnome-session-quit
|
||||
|
||||

|
||||
|
||||
### 登录Budgie会话 ###
|
||||
|
||||
安装完成之后,我们能在登录时选择机进入budgie桌面。
|
||||
|
||||

|
||||
|
||||
### Budgie 桌面环境 ###
|
||||
|
||||

|
||||
|
||||
### 注销当前用户 ###
|
||||
|
||||
$ budgie-sessioon --logout
|
||||
|
||||
### 结论 ###
|
||||
|
||||
Hurray! We have successfully installed our Lightweight Budgie Desktop Environment in our Ubuntu 14.04 LTS "Trusty" box. As we know, Budgie Desktop is still underdevelopment which makes it a lot of stuffs missing. Though it’s based on Gnome’s GTK3, it’s not a fork. The desktop is written completely from scratch, and the design is elegant and well thought out. If you have any questions, comments, feedback please do write on the comment box below and let us know what stuffs needs to be added or improved. Thank You! Enjoy Budgie Desktop 0.8 :-)
|
||||
Budgie桌面当前正在开发过程中,因此有目前有很多功能的缺失。虽然它是基于Gnome,但不是完全的复制。Budgie是完全从零开始实现,它的设计是优雅的并且正在不断的完善。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/install-lightweight-budgie-v8-desktop-ubuntu/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[johnhoow](https://github.com/johnhoow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:https://evolve-os.com/budgie/
|
||||
[2]:https://evolve-os.com/2014/11/16/courageous-budgie-v8-released/
|
||||
@ -0,0 +1,153 @@
|
||||
如何在Linux中用命令行工具管理KVM虚拟环境
|
||||
================================================================================
|
||||
在我们[KVM系列专题][1]的第四部分,我们将会一起讨论下在命令行界面下来管理KVM环境。我们分别用‘virt-install’和virsh命令行工具来创建并配置虚拟机和存储池,用qemu-img命令行工具来创建并管理磁盘映像。
|
||||
|
||||

|
||||
|
||||
Linux系统的KVM管理
|
||||
|
||||
在这篇文章里没有什么新的概念,我们只是用命令行工具重复之前所做过的事情,也没有什么前提条件,都是相同的过程,之前的文章我们都讨论过。
|
||||
|
||||
### 第一步: 配置存储池 ###
|
||||
|
||||
Virsh命令行工具是一款管理virsh客户域的用户界面。virsh程序能在命令行中运行所给的命令以及它的参数。
|
||||
|
||||
本节中,我们要用它给我们的KVM环境创建存储池。想知道关于这个工具的更多信息,用以下这条命令。
|
||||
|
||||
# man virsh
|
||||
|
||||
**1. 用virsh带pool-define-as的命令来定义新的存储池,你需要指定名字、类型和类型参数。**
|
||||
|
||||
本例中,我们将名字取为Spool1,类型为目录。默认情况下你可以提供五个参数给该类型:
|
||||
|
||||
- source-host
|
||||
- source-path
|
||||
- source-dev
|
||||
- source-name
|
||||
- target
|
||||
|
||||
对于目录类型,我们需要用最后一个参数“target”来指定存储池的路径,其它参数项我们可以用“-”来填充。
|
||||
|
||||
# virsh pool-define-as Spool1 dir - - - - "/mnt/personal-data/SPool1/"
|
||||
|
||||

|
||||
创建新存储池
|
||||
|
||||
**2. 查看环境中我们所有的存储池,用以下命令。**
|
||||
|
||||
# virsh pool-list --all
|
||||
|
||||

|
||||
列出所有存储池
|
||||
|
||||
**3. 现在我们来构造存储池了,用以下命令来构造我们刚才定义的存储池。**
|
||||
|
||||
# virsh pool-build Spool1
|
||||
|
||||

|
||||
构造存储池
|
||||
|
||||
**4. 用virsh带pool-start的命令来激活并启动我们刚才创建并构造完成的存储池。**
|
||||
|
||||
# virsh pool-start Spool1
|
||||
|
||||

|
||||
激活存储池
|
||||
|
||||
**5. 查看环境中存储池的状态,用以下命令。**
|
||||
|
||||
# virsh pool-list --all
|
||||
|
||||

|
||||
查看存储池状态
|
||||
|
||||
你会发现Spool1的状态变成了已激活。
|
||||
|
||||
**6. 对Spool1进行配置,让它每次都能被libvirtd服务自启动。**
|
||||
|
||||
# virsh pool-autostart Spool1
|
||||
|
||||

|
||||
配置KVM存储池
|
||||
|
||||
**7. 最后来看看我们新的存储池的信息吧。**
|
||||
|
||||
# virsh pool-info Spool1
|
||||
|
||||

|
||||
查看KVM存储池信息
|
||||
|
||||
恭喜你,Spool1已经准备好待命,接下来我们试着创建存储卷来使用它。
|
||||
|
||||
### 第二步: 配置存储卷/磁盘映像 ###
|
||||
|
||||
现在轮到磁盘映像了,用qemu-img命令在Spool1中创建一个新磁盘映像。获取更多细节信息,可以查看man手册。
|
||||
|
||||
# man qemu-img
|
||||
|
||||
**8. 我们应该在qemu-img命令之后指定“create, check,…”等等操作、磁盘映像格式、你想要创建的磁盘映像的路径和大小。**
|
||||
|
||||
# qemu-img create -f raw /mnt/personal-data/SPool1/SVol1.img 10G
|
||||
|
||||

|
||||
创建存储卷
|
||||
|
||||
**9. 通过使用带info的qemu-img命令,你可以获取到你的新磁盘映像的一些信息。**
|
||||
|
||||

|
||||
查看存储卷信息
|
||||
|
||||
**警告**: 不要用qemu-img命令来修改被运行中的虚拟机或任何其它进程所正在使用的映像,那样映像会被破坏。
|
||||
|
||||
现在是时候来创建虚拟机了。
|
||||
|
||||
### 第三步: 创建虚拟机 ###
|
||||
|
||||
**10. 现在到最后一个环节了,在最后一步中,我们将用virt-install命令来创建虚拟机。virt-install是一个用来创建新的KVM虚拟机命令行工具,它使用“libvirt”管理程序库。想获取更多细节,同样可以查看man手册。**
|
||||
|
||||
# man virt-install
|
||||
|
||||
要创建新的KVM虚拟机,你需要用到带以下所有信息的命令。
|
||||
|
||||
- Name: 虚拟机的名字。
|
||||
- Disk Location: 磁盘映像的位置。
|
||||
- Graphics : 怎样连接VM,通常是SPICE。
|
||||
- vcpu : 虚拟CPU的数量。
|
||||
- ram : 以兆字节计算的已分配内存大小。
|
||||
- Location : 指定安装源路径。
|
||||
- Network : 指定虚拟网络,通常是virbr0网桥。
|
||||
|
||||
# virt-install --name=rhel7 --disk path=/mnt/personal-data/SPool1/SVol1.img --graphics spice --vcpu=1 --ram=1024 --location=/run/media/dos/9e6f605a-f502-4e98-826e-e6376caea288/rhel-server-7.0-x86_64-dvd.iso --network bridge=virbr0
|
||||
|
||||

|
||||
创建新的虚拟机
|
||||
|
||||
**11. 你会看到弹出一个virt-vierwer窗口,像是在通过它在与虚拟机通信。**
|
||||
|
||||

|
||||
虚拟机启动程式
|
||||
|
||||

|
||||
虚拟机安装过程
|
||||
|
||||
### 结论 ###
|
||||
|
||||
以上就是我们KVM教程的最后一部分了,当然我们还没有完全覆盖到全部,我们只是打了个擦边球,所以现在该轮到你来好好地利用这些丰富的资源来做自己想做的事了。
|
||||
|
||||
- [KVM Getting Started Guide][2]
|
||||
- [KVM Virtualization Deployment and Administration Guide][3]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/kvm-management-tools-to-manage-virtual-machines/
|
||||
|
||||
作者:[Mohammad Dosoukey][a]
|
||||
译者:[ZTinoZ](https://github.com/ZTinoZ)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/dos2009/
|
||||
[1]:http://www.tecmint.com/install-and-configure-kvm-in-linux/
|
||||
[2]:https://access.redhat.com/site/documentation/en-US/Red_Hat_Enterprise_Linux/7/html/Virtualization_Getting_Started_Guide/index.html
|
||||
[3]:https://access.redhat.com/site/documentation/en-US/Red_Hat_Enterprise_Linux/7/html/Virtualization_Deployment_and_Administration_Guide/index.html
|
||||
@ -0,0 +1,70 @@
|
||||
Ubuntu中,使用Prey定位被盗的笔记本与手机
|
||||
===============================================================================
|
||||
Prey是一款跨平台的开源工具,可以帮助你找回被盗的笔记本,台式机,平板和智能手机。它已经获得了广泛的流行,声称帮助召回了成百上千台丢失的笔记本和智能手机。Prey的使用特别简单,首先安装在你的笔记本或者手机上,当你的设备不见了,用你的账号登入Prey网站,并且标记你的设备为“丢失”。只要小偷将设备接入网络,Prey就会马上发送设备的地理位置给你。如果你的笔记本有摄像头,它还会拍下小偷。
|
||||
|
||||
Prey占用很小的系统资源;你不会对你的设备运行有任何影响。你也可以配合其他你已经在设备上安装的防盗软件使用。Prey采用安全加密的通道,在你的设备与Prey服务器之间进行数据传输。
|
||||
|
||||
### 在Ubuntu上安装并配置Prey ###
|
||||
|
||||
让我们来看看如何在Ubuntu上安装和配置Prey,需要提醒的是,在配置过程中,我们必须到Prey官网进行账号注册。一旦完成上述工作,Prey将会开始监视的设备了。免费的账号最多可以监视三个设备,如果你需要添加更多的设备,你就需要购买合适的的套餐了。
|
||||
|
||||
想象一下Prey多么流行与被广泛使用,它现在已经被添加到了官方的软件库中了。这意味着你不要往软件包管理器添加任何PPA。很简单地,登录你的终端,运行以下的命令来安装它:
|
||||
|
||||
sudo apt-get install prey
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Prey是十分轻巧的软件,只使用了系统几兆的空间,安装完成后,从Application >> Prey启动,之后它会询问你进行相关配置。
|
||||
|
||||
选择“New User”,如果你是第一次使用的话。
|
||||
|
||||

|
||||
|
||||
第二步实际上就是官网注册的流程。请提供你的用户名,邮箱地址和密码,来申清一个免费的账号。
|
||||
|
||||

|
||||
|
||||
点击“Apply”完成,所有工作搞定,现在你的计算机被Prey保护了。
|
||||
|
||||

|
||||
|
||||
登录你最新建立的[Prey 账号][1],你就应该可以在“Devices”菜单下看见你的设备信息了。
|
||||
|
||||

|
||||
|
||||
只要你的笔记本或者任何其他设备丢失了,就登录你的Prey网站账号,然后点击“Set Device to Missing”选项修改设备状态为“missing”。
|
||||
|
||||

|
||||
|
||||
从这里选择定时报告,并点击“Yes,my device is missing”。定时报告选项是指一段时间间隔后,软件会更新并发送给你设备的地理位置。它还会从网页界面那发邮件给你,只要设备的状态改变了。
|
||||
|
||||

|
||||
|
||||
而一旦被盗的设备接入了互联网,Prey就会马上发送报告给你,包括设备的地理位置和IP地址。
|
||||
|
||||

|
||||
|
||||
点击报告链接,你应该会看到设备的地理位置和IP地址。
|
||||
|
||||

|
||||
|
||||
Prey有一个明显的不足。它需要你的设备接入互联网才会发送地理位置给你,如果小偷比较聪明,在接入网络前将你的设备磁盘格式化了,那么你就永远不会收到设备被发现的报告了。但是这里仍然是有一个方法克服这个不足,确保添加一个BIOS密码,并且禁用从可移除的设备里启动系统。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
这是一款小巧,非常有用的安全保护应用,可以让你在一个地方追踪你所有的设备,尽管不完美,但是仍然提供了找回被盗设备的机会。它在Linux,Windows和Mac平台上无缝运行。以上就是Prey完整使用的所有细节。
|
||||
|
||||
-------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/anti-theft-application-prey-ubuntu/
|
||||
|
||||
作者:[Aun Raza][a]
|
||||
译者:[wi-cuckoo](https://github.com/wi-cuckoo)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunrz/
|
||||
[1]:https://preyproject.com/
|
||||
@ -0,0 +1,100 @@
|
||||
Linux有问必答--如何使用命令行压缩JPEG图像
|
||||
================================================================================
|
||||
> **问题**: 我有许多数码照相机拍出来的照片。我想在上传到Dropbox之前,优化和压缩下JPEG图片。有没有什么简单的方法压缩JPEG图片并不损耗他们的质量?
|
||||
|
||||
如今拍照设备(如智能手机、数码相机)拍出来的图片分辨率越来越大。甚至3630万像素的Nikon D800已经冲入市场,并且这个趋势根本停不下来。如今的拍照设备不断地提高着照片分辨率,使得我们不得不压缩后,再上传到有储存限制、带宽限制的云。
|
||||
|
||||
事实上,这里有一个非常简单的方法压缩JPEG图像。一个叫“jpegoptim”命令行工具可以帮助你“无损”美化JPEG图像,所以你可以压缩JPEG图片而不至于牺牲他们的质量。万一你的存储空间和带宽预算真的很少,jpegoptim也支持“有损耗”压缩来调整图像大小。
|
||||
|
||||
如果要压缩PNG图像,参考[this guideline][1]例子。
|
||||
|
||||
### 安装jpegoptim ###
|
||||
|
||||
Ubuntu, Debian 或 Linux Mint:
|
||||
|
||||
$ sudo apt-get install jpegoptim
|
||||
|
||||
Fedora:
|
||||
|
||||
$ sudo yum install jpegoptim
|
||||
|
||||
CentOS/RHEL安装,先开启[EPEL库][2],然后运行下列命令:
|
||||
|
||||
$ sudo yum install jpegoptim
|
||||
|
||||
### 无损压缩jpeg图像 ###
|
||||
|
||||
为了无损地压缩一副JPG图片,使用:
|
||||
|
||||
$ jpegoptim photo.jpg
|
||||
|
||||
----------
|
||||
|
||||
photo.jpg 2048x1536 24bit N ICC JFIF [OK] 882178 --> 821064 bytes (6.93%), optimized.
|
||||
|
||||
注意,原始图像会被压缩后图像覆盖。
|
||||
|
||||
如果jpegoptim不能无损美化图像,将不会覆盖
|
||||
|
||||
$ jpegoptim -v photo.jpg
|
||||
|
||||
----------
|
||||
|
||||
photo.jpg 2048x1536 24bit N ICC JFIF [OK] 821064 --> 821064 bytes (0.00%), skipped.
|
||||
|
||||
如果你想保护原始图片,使用"-d"参数指明保存目录
|
||||
|
||||
$ jpegoptim -d ./compressed photo.jpg
|
||||
|
||||
这样,压缩的图片将会保存在./compressed目录(已同样的输入文件名)
|
||||
|
||||
如果你想要保护文件的创建修改时间,使用"-p"参数。这样压缩后的图片会得到与原始图片相同的日期时间。
|
||||
|
||||
$ jpegoptim -d ./compressed -p photo.jpg
|
||||
|
||||
如果你只是想获得无损压缩率,使用"-n"参数来模拟压缩,然后它会打印压缩率。
|
||||
|
||||
$ jpegoptim -n photo.jpg
|
||||
|
||||
### 有损压缩JPG图像 ###
|
||||
|
||||
万一你真的需要要保存在云空间上,你可以使用有损压缩JPG图片。
|
||||
|
||||
这种情况下,使用"-m<质量>"选项,质量数范围0到100。(0是最好质量,100是最坏质量)
|
||||
|
||||
例如,用50%质量压缩图片:
|
||||
|
||||
$ jpegoptim -m50 photo.jpg
|
||||
|
||||
----------
|
||||
|
||||
photo.jpg 2048x1536 24bit N ICC JFIF [OK] 882178 --> 301780 bytes (65.79%), optimized.
|
||||
|
||||
在牺牲质量的基础上,将会得到一个更小的图片。
|
||||
|
||||
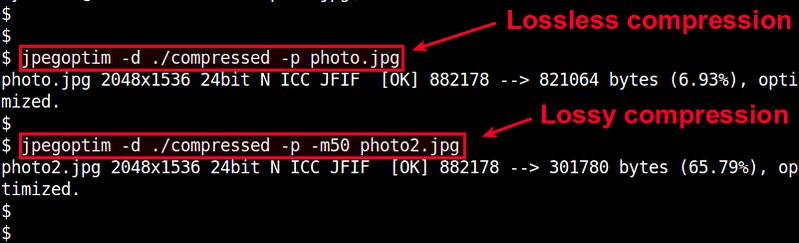
|
||||
|
||||
### 一次压缩多张JPEG图像 ###
|
||||
|
||||
最常见的情况是需要压缩一个目录下的多张JPEG图像文件。为了应付这种情况,你可以使用接下里的脚本。
|
||||
|
||||
#!/bin/sh
|
||||
|
||||
# 压缩当前目录下所有*.jpg文件
|
||||
# 保存在./compressed目录
|
||||
# 并拥有与原始文件同样的修改日期
|
||||
for i in *.jpg; do jpegoptim -d ./compressed -p "$i"; done
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/compress-jpeg-images-command-line-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[VicYu/Vic020](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/how-to-compress-png-files-on-linux.html
|
||||
[2]:http://xmodulo.com/how-to-set-up-epel-repository-on-centos.html
|
||||
@ -0,0 +1,130 @@
|
||||
# Linux 下四种安全删除文件的工具 #
|
||||
|
||||
任何一个普通水平的计算机用户都知道,从计算机系统中删除的任意数据都可以稍候通过一些努力恢复出来。当你不小心删除了你的重要数据,这是一个不错的方案。但是大多数情况,你不希望你的隐私数据被轻易地恢复。不论何时,我们删除任意的文件,操作系统删除的仅仅是特定数据的索引。这就意味着,数据仍然保存在磁盘的某块地方,这种方法是不安全的,任何一个聪明的计算机黑客可以使用任意不错的数据恢复工具来恢复你删除的数据。Linux 用户利用我们都知晓的 "rm" 命令来从他们的操作系统中删除数据,但是 "rm" 命令在约定俗成的场景下工作。从这个命令删除的数据也可以使用特殊的文件恢复工具恢复。
|
||||
|
||||
让我们看看怎样安全并且完整地从你地 Linux 系统中删除文件或者文件夹。以下提到的工具可以完全地删除数据,因此那些恢复工具很难找到真实数据的痕迹然后恢复它。
|
||||
|
||||
### Secure-Delete ###
|
||||
|
||||
Secure-Delete 是一组为 Linux 操作系统而生的工具集合,他们为永久删除文件提供高级的技术支持。一旦 Secure-Delete 安装在任意的 Linux 系统,它会提供如下的四个命令:
|
||||
|
||||
- srm
|
||||
- smem
|
||||
- sfill
|
||||
- sswap
|
||||
|
||||
在 ubuntu 的终端中运行如下命令安装此工具:
|
||||
|
||||
sudo apt-get install secure-delete
|
||||
|
||||

|
||||
|
||||
在 RHEL,Fedora 或者 Centos 中运行如下命令安装此工具:
|
||||
|
||||
sudo yum install secure-delete
|
||||
|
||||
“**srm**” 命令的工作方式和 "rm" 命令类似,但是它不仅仅是删除文件,它首先使用一些随机的数据重写数次文件,然后彻底地删除此文件。这个命令的语法是相当地简单,仅仅指定要删除的文件或者目录,然后它会负责此任务。
|
||||
|
||||
sudo srm /home/aun/Documents/xueo/1.png
|
||||
|
||||
"**sfill**" 检测在指定的分区或者目录被标记为空闲或者可用的空间,然后使用它自身的算法用一些随机数据填充。因此它保证了在此分区没有可以恢复的文件或者文件夹。
|
||||
|
||||
sudo sfill /home
|
||||
|
||||
"**sswap**" 命令用来安全地清除你的交换分区。交换分区用来存放运行程序的数据。首先我们需要运行如下命令来找到你的交换分区。
|
||||
|
||||
cat /proc/swaps
|
||||
|
||||
如下是上述命令的输出示例:
|
||||
|
||||
aun@eagle:~$ cat /proc/swaps
|
||||
Filename Type Size Used Priority
|
||||
/dev/sda5 partition 2084860 71216 -1
|
||||
|
||||
从现在起,你可以看到你的交换分区设置在哪个分区,然后使用如下命令安全地清除。替换 "/dev/sda5" 部分为你的交换分区名字。
|
||||
|
||||
sudo sswap /dev/sda5
|
||||
|
||||
“**smem**” 用来清理在内存中的内容,它保证当系统重启或者关机时随机存取存储器(RAM)中的内容被清理,但是残余的数据痕迹仍然保存在内存。这个命令提供安全的内存清理,简单地在终端中运行 smem 命令。
|
||||
|
||||
smem
|
||||
|
||||
### Shred ###
|
||||
|
||||
"shred" 命令销毁文件或者文件夹的内容,在某种程度上,不可能恢复。它使用随机生成的数据模式来持续重写文件,因此很难恢复任意的被销毁的数据,即使是那些黑客或者窃贼使用高水平的数据恢复工具或者设备。Shred 在 Linux 发行版中时默认安装的,如果你想,你可以运行如下命令来找到它的安装目录:
|
||||
|
||||
aun@eagle:~$ whereis shred
|
||||
|
||||
shred: /usr/bin/shred /usr/share/man/man1/shred.1.gz
|
||||
|
||||
使用 shred 工具运行如下命令来删除文件:
|
||||
|
||||
shred /home/aun/Documents/xueo/1.png
|
||||
|
||||
使用 shred 运行如下命令来删除任意的分区,用你期望的分区来替换分区名字。
|
||||
|
||||
shred /dev/sda5
|
||||
|
||||
Shred 默认情况下使用随机内容重写数据 25 次。如果你想它重写文件更多次数,可以使用 "shred -n" 选项来简单地指定你所期望的次数。
|
||||
|
||||
shred -n 100 filename
|
||||
|
||||
如果你想在重写后截断或者删除文件,使用 "shred -u" 选项:
|
||||
|
||||
shred -u filename
|
||||
|
||||
### dd ###
|
||||
|
||||
这个命令起初是用于磁盘克隆的。它用于一个分区或者一个磁盘复制到另一个分区或者磁盘。但是它还用于安全地清除硬盘或者分区的内容。运行如下命令使用随机数据来重写你的当前数据。你不需要安装 dd 命令,所有的 Linux 分发版都已经包含了此命令。
|
||||
|
||||
sudo dd if=/dev/random of=/dev/sda
|
||||
|
||||
你也可以重写磁盘或者分区中的内容,只需要简单地将所有替换为 “zero”。
|
||||
|
||||
sudo dd if=/dev/zero of=/dev/sda
|
||||
|
||||
### Wipe ###
|
||||
|
||||
Wipe 起初开发的目的是从磁媒体中安全地擦除文件。这个命令行工具使用特殊的模式来重复地写文件。它使用 fsync() 调用和或 O_SYNC 位来强制访问磁盘,并且使用 Gutmann 算法来重复地写。你可以使用此命令删除单个文件,文件夹或者整个磁盘的内容,但是使用 wipe 命令来删除整个磁盘的模式会耗费大量的时间。另外,安装和使用这个工具相当容易。
|
||||
|
||||
在 ubuntu 的终端中运行如下命令来安装 wipe。
|
||||
|
||||
sudo aptitude install wipe
|
||||
|
||||

|
||||
|
||||
使用如下命令在 Redhat Linux,Centos 或者 Fedora 中安装 Wipe:
|
||||
|
||||
sudo yum install wipe
|
||||
|
||||
一旦安装完成,在终端中运行如下命令来获得完整的可用选项列表:
|
||||
|
||||
man wipe
|
||||
|
||||
删除任意文件或者目录:
|
||||
|
||||
wipe filename
|
||||
|
||||
运行如下命令来安全地移除 tmp 分区:
|
||||
|
||||
wipe -r /tmp
|
||||
|
||||
使用如下的命令来删除完整分区的内容(替换分区名字为你所期望的分区)。
|
||||
|
||||
wipe /dev/sda1
|
||||
|
||||
### 小结 ###
|
||||
|
||||
我们期望这篇文章对你有帮助,你的数据隐私是有决定性意义的,在你的系统中安装这些安全的删除工具对你来说非常重要,因此你可以删除你的隐私数据而不用担心它们被轻易地恢复。上面提到的所有工具都是相当轻量的,它们只需要耗费最低的系统资源来运行,并且无论如何也不会影响你的系统性能。享受它们带来的便利吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/security/delete-files-permanatly-linux/
|
||||
|
||||
作者:[Aun Raza][a]
|
||||
译者:[dbarobin](https://github.com/dbarobin)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunrz/
|
||||
@ -0,0 +1,60 @@
|
||||
Prips - 打印指定范围内的IP地址
|
||||
================================================================================
|
||||
prips是一个可以打印出指定范围内所有ip地址的一个工具。它可以增强那些只能同时工作在一个主机上的工具的可用性。
|
||||
|
||||
### 在ubuntu上安装prips ###
|
||||
|
||||
打开终端并输入下面的命令
|
||||
|
||||
sudo apt-get install prips
|
||||
|
||||
### 使用prips ###
|
||||
|
||||
### prips语法 ###
|
||||
|
||||
prips [-c] [-d delim] [-e exclude] [-f format] [-i incr] start end
|
||||
prips [-c] [-d delim] [-e exclude] [-f format] [-i incr] CIDR-block
|
||||
|
||||
### 可用选项 ###
|
||||
|
||||
prips接受下面的命令行选项:
|
||||
|
||||
- -c -- 以CIDR形式打印范围。
|
||||
- -d delim -- 用ASCII码作为分隔符,0 <= delim <= 255。
|
||||
- -e -- 排除输出的范围。
|
||||
- -f format -- 设置地址格式 (16进制, 10进制, 或者dot).
|
||||
- -i incr -- 设置增长上限
|
||||
|
||||
### Prips示例 ###
|
||||
|
||||
显示保留的子网内的所有地址:
|
||||
|
||||
prips 192.168.32.0 192.168.32.255
|
||||
|
||||
同样使用CIDR标示:
|
||||
|
||||
prips 192.168.32/24
|
||||
|
||||
只显示A类保留子网内所有可用的地址,用空格而不是换行作为分隔符:
|
||||
|
||||
prips -d 32 10.0.0.1 10.255.255.255
|
||||
|
||||
每块显示4个ip地址:
|
||||
|
||||
prips -i 4 192.168.32.7 192.168.33.5
|
||||
|
||||
打印包含两个地址的最小CIDR块。
|
||||
|
||||
prips -c 192.168.32.5 192.168.32.11
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.ubuntugeek.com/prips-print-ip-address-on-a-given-range.html
|
||||
|
||||
作者:[ruchi][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.ubuntugeek.com/author/ubuntufix
|
||||
Loading…
Reference in New Issue
Block a user