mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-30 02:40:11 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject
This commit is contained in:
commit
283d14d9d9
README.md
published
20161020 Useful Vim editor plugins for software developers - part 3 a.vim.md20161104 Build Strong Real-Time Streaming Apps with Apache Calcite.md
201701
20161028 Inkscape Adding some colour.md20170109 CentOS vs Ubuntu Which one is better for a server.md
20170107 Min Browser Muffles the Web Noise.md20170118 Linux command line navigation tips- the basics of pushd and popd commands.md20170125 An executive's guide to containers.md201702
20170208 4 open source tools for conducting online surveys.md20170214 10 Best Linux Terminal Emulators For Ubuntu And Fedora.md201703
20131113 Your visual how-to guide for SELinux policy enforcement.md20150413 Why most High Level Languages are Slow.md20151127 5 ways to change GRUB background in Kali Linux.md20160104 How to Change Linux IO Scheduler.md20160917 A Web Crawler With asyncio Coroutines.md20161018 Suspend to Idle.md20161207 Manage Samba4 AD Domain Controller DNS and Group Policy from Windows – Part 4.md20170101 FTPS vs SFTP.md20170109 How to record a region of your desktop as animated GIF on Linux.md20170111 Explore climate data with open source tools.md20170111 Join an Additional Ubuntu DC to Samba4 AD DC for FailOver Replication – Part 5.md20170111 Linux command line navigation tips and tricks - part 1.md20170111 NMAP Common Scans – Part One.md20170113 How to Speed up Odoo copy.md20170116 Terrible Ideas in Git.md20170116 Use Docker remotely on Atomic Host.md20170117 How to Install WordPress with HHVM and Nginx on CentOS 7.md20170117 How to Keep Hackers out of Your Linux Machine Part 2 Three More Easy Security Tips.md20170118 Do I need to provide access to source code under the AGPLv3 license.md20170118 Why Linux Installers Need to Add Security Features.md20170119 Get to know Tuleap for project management.md20170119 Long-term Embedded Linux Maintenance Made Easier.md20170120 How to write web apps in R with Shiny.md20170124 Compile-time assertions in Go.md20170126 How to join a technical community.md20170128 Wkhtmltopdf – A Smart Tool to Convert Website HTML Page to PDF in Linux.md20170130 How to get up and running with sweet Orange Pi.md20170201 Protecting Your Privacy With Firefox on Linux.md20170202 How to Configure Custom SSH Connections to Simplify Remote Access.md20170204 How to Configure Network Between Guest VM and Host in Oracle VirtualBox.md20170207 How To Write and Use Custom Shell Functions and Libraries.md20170208 free – A Standard Command to Check Memory Usage Statistics in Linux.md20170210 5 Linux Music Players You Should Consider Switching To.md20170210 How to perform search operations in Vim.md20170213 A beginners guide to understanding sudo on Ubuntu.md20170213 How to Auto Execute CommandsScripts During Reboot or Startup.md20170213 Orange Pi as Time Machine Server.md20170213 Set Up and Configure a Firewall with FirewallD on CentOS 7.md20170213 The Best Operating System for Linux Gaming Which One Do You Use and Why.md20170214 CentOS-vs-Ubuntu.md20170214 How to Install Ubuntu with Separate Root and Home Hard Drives.md20170215 Best Windows Like Linux Distributions For New Linux Users.md20170215 Generate random data for your applications with Elizabeth.md20170215 How to change the Linux Boot Splash screen.md20170215 openSUSE on Raspberry Pi 3.md20170216 Getting Started with PowerShell 6.0 in Linux.md20170216 MASTER Cpp PROGRAMMING WITH OPEN-SOURCE BOOKS.md20170219 Windows wins the desktop, but Linux takes the world.md20170220 How to create your own Linux Distribution with Yocto on Ubuntu.md20170221 How to Install and Configure FTP Server in Ubuntu.md20170221 How to access shell or run external commands from within Vim.md20170222 Introduction to LaTeXila - a multi-language LaTeX editor for Linux.md20170223 How to install Arch Linux on VirtualBox.md20170224 Setting Up a Secure FTP Server using SSL-TLS on Ubuntu.md20170225 How to Upload or Download Files-Directories Using sFTP in Linux.md20170227 How to Install MariaDB 10 on Debian and Ubuntu.md20170227 How to setup a Linux server on Amazon AWS.md20170228 How to Install and Secure MariaDB 10 in CentOS 7.md20170301 How to Install or Upgrade to Latest Kernel Version in CentOS 7.md20170304 7 Ways to Determine the File System Type in Linux.md20170306 How to Upgrade Kernel to Latest Version in Ubuntu.md20170307 How to make release notes count.md20170308 How to Reset MySQL or MariaDB Root Password in Linux.md20170309 How to Change Root Password of MySQL or MariaDB in Linux.md20170310 Restrict SSH User Access to Certain Directory Using Chrooted Jail.md20170311 6 Best PDF Page Cropping Tools For Linux.md20170314 binary tree.md20170316 How to Install Latest Python 3.6 Version in Linux.md20170317 Kgif – A Simple Shell Script to Create a Gif File from Active Window.md20170317 The End of the Line for EPEL-5.md20170320 ELRepo – Community Repo for Enterprise Linux RHEL CentOS SL.md20170323 3 open source link shorteners.md20170324 This Xfce Bug Is Wrecking Users Monitors.md20170325 How to Install a DHCP Server in Ubuntu and Debian.md
20170302 How to use markers and perform text selection in Vim.md20170320 Why Go.md20170327 Using vi-mode in your shell.mdlinux-distro-explain
sources
comic
talk
20170213 The decline of GPL.md20170223 What a Linux Desktop Does Better.md20170309 The impact GitHub is having on your software career.md20170314 One Year Using Go.md20170315 Hire a DDoS service to take down your enemies.md20170317 Why AlphaGo Is Not AI.md20170317 Why do you use Linux and open source software.md20170320 Education of a Programmer.md
92
README.md
92
README.md
@ -56,7 +56,9 @@ LCTT 的组成
|
||||
* 2016/02/29 选题 DeadFire 病逝。
|
||||
* 2016/05/09 提升 PurlingNayuki 为校对。
|
||||
* 2016/09/10 LCTT 三周年。
|
||||
* 2016/12/24 拟定 LCTT [Core 规则](core.md),并增加新的 Core 成员: @ucasFL、@martin2011qi,及调整一些组。
|
||||
* 2016/12/24 拟定 LCTT [Core 规则](core.md),并增加新的 Core 成员: ucasFL、martin2011qi,及调整一些组。
|
||||
* 2017/03/13 制作了 LCTT 主页、成员列表和成员主页,LCTT 主页将移动至 https://linux.cn/lctt 。
|
||||
* 2017/03/16 提升 GHLandy、bestony、rusking 为新的 Core 成员。创建 Comic 小组。
|
||||
|
||||
活跃成员
|
||||
-------------------------------
|
||||
@ -69,7 +71,7 @@ LCTT 的组成
|
||||
- CORE @GOLinux,
|
||||
- CORE @ictlyh,
|
||||
- CORE @strugglingyouth,
|
||||
- CORE @FSSlc
|
||||
- CORE @FSSlc,
|
||||
- CORE @zpl1025,
|
||||
- CORE @runningwater,
|
||||
- CORE @bazz2,
|
||||
@ -77,8 +79,11 @@ LCTT 的组成
|
||||
- CORE @alim0x,
|
||||
- CORE @tinyeyeser,
|
||||
- CORE @Locez,
|
||||
- CORE @ucasFL
|
||||
- CORE @martin2011qi
|
||||
- CORE @ucasFL,
|
||||
- CORE @martin2011qi,
|
||||
- CORE @GHLandy,
|
||||
- CORE @bestony,
|
||||
- CORE @rusking,
|
||||
- Senior @DeadFire,
|
||||
- Senior @reinoir222,
|
||||
- Senior @vito-L,
|
||||
@ -87,85 +92,8 @@ LCTT 的组成
|
||||
- Senior @dongfengweixiao,
|
||||
- Senior @PurlingNayuki,
|
||||
- Senior @carolinewuyan,
|
||||
- cposture,
|
||||
- ZTinoZ,
|
||||
- theo-l,
|
||||
- Luoxcat,
|
||||
- GHLandy,
|
||||
- wi-cuckoo,
|
||||
- StdioA,
|
||||
- disylee,
|
||||
- wwy-hust,
|
||||
- felixonmars,
|
||||
- KayGuoWhu,
|
||||
- mr-ping,
|
||||
- wyangsun,
|
||||
- su-kaiyao,
|
||||
- ivo-wang,
|
||||
- cvsher,
|
||||
- OneNewLife
|
||||
- DongShuaike,
|
||||
- flsf,
|
||||
- SPccman,
|
||||
- Stevearzh,
|
||||
- bestony,
|
||||
- Linchenguang,
|
||||
- Linux-pdz,
|
||||
- 2q1w2007,
|
||||
- NearTan,
|
||||
- H-mudcup,
|
||||
- GitFuture,
|
||||
- MikeCoder,
|
||||
- xiqingongzi,
|
||||
- goreliu,
|
||||
- rusking,
|
||||
- jiajia9linuxer,
|
||||
- name1e5s,
|
||||
- TxmszLou,
|
||||
- ZhouJ-sh,
|
||||
- wangjiezhe,
|
||||
- icybreaker,
|
||||
- zky001,
|
||||
- vim-kakali,
|
||||
- shipsw,
|
||||
- LinuxBars,
|
||||
- Moelf,
|
||||
- Chao-zhi
|
||||
- johnhoow,
|
||||
- soooogreen,
|
||||
- kokialoves,
|
||||
- linuhap,
|
||||
- ChrisLeeGit,
|
||||
- blueabysm,
|
||||
- yangmingming,
|
||||
- boredivan,
|
||||
- yechunxiao19,
|
||||
- XLCYun,
|
||||
- KevinSJ,
|
||||
- l3b2w1,
|
||||
- tenght,
|
||||
- firstadream,
|
||||
- coloka,
|
||||
- luoyutiantang,
|
||||
- sonofelice,
|
||||
- scusjs,
|
||||
- woodboow,
|
||||
- 1w2b3l,
|
||||
- JonathanKang,
|
||||
- crowner,
|
||||
- dingdongnigetou,
|
||||
- mtunique,
|
||||
- hyaocuk,
|
||||
- szrlee,
|
||||
- nd0104,
|
||||
- chenzhijun,
|
||||
- frankatlingingdigital,
|
||||
- willcoderwang,
|
||||
- liuaiping,
|
||||
- rogetfan,
|
||||
- JeffDing,
|
||||
|
||||
(按增加行数排名前百,更新于2016/12/24)
|
||||
全部成员列表请参见: https://linux.cn/lctt-list/ 。
|
||||
|
||||
谢谢大家的支持!
|
||||
|
||||
|
||||
@ -0,0 +1,87 @@
|
||||
开发者的实用 Vim 插件(三)
|
||||
============================================================
|
||||
|
||||
目前为止,在一系列介绍 vim 插件文章中,我们介绍了使用 Pathogen 插件管理包安装基本的 vim 插件,也提及了另外三个插件:[Tagbar、delimitMate](https://linux.cn/article-7901-1.html) 和 [Syntastic](https://linux.cn/article-7909-1.html)。现在,在最后一部分,我们将介绍另一个十分有用的插件 a.vim。
|
||||
|
||||
请注意所有本篇教程所提及的例子、命令和指导,它们已经在 Ubuntu 16.04 测试完毕,vim 使用版本为 vim7.4 (LCTT 译注:Ubuntu 16.04 的默认版本)
|
||||
|
||||
### A.vim
|
||||
|
||||
如果你一直用像 C、C++ 这样的语言进行开发工作,你一定有这样的感触:我特么已经数不清我在头文件和源代码之间切换过多少次了。我想说的是,确实,这个操作十分基本,十分频繁。
|
||||
|
||||
尽管使用基于 GUI(图形界面)的 IDE(集成开发环境)非常容易通过鼠标的双击切换文件,但是如果你是资深 vim 粉,习惯用命令工作就有点尴尬了。但是不要害怕,我有秘籍--插件 a.vim。它可以让你解决尴尬,专治各种文件切换。
|
||||
|
||||
在我们介绍这个神器用法之前,我必须强调一点:这个插件的安装过程和我们其他篇介绍的不太一样,步骤如下:
|
||||
|
||||
* 首先,你需要下载两个文件(a.vim 和 alternate.txt),你可以在[这里][1]找到它们。
|
||||
* 接下来,创建如下目录:`~/.vim/bundle/avim`、`~/.vim/bundle/avim/doc`、 `~/.vim/bundle/avim/plugin` 和 `~/.vim/bundle/autoload`。
|
||||
* 创建好目录之后,将 `a.vim` 放到 `~/.vim/bundle/avim/plugin` 和 `~/.vim/bundle/autoload`,以及将 `alternate.txt` 放到 `~/.vim/bundle/avim/doc`。
|
||||
|
||||
就是这样,如果上述步骤被你成功完成,你的系统就会安装好这个插件。
|
||||
|
||||
使用这个插件十分简单,你仅仅需要运行这个命令 `:A` 如果目前的文件是源文件(比如 `test.c`),这个神器就会帮你打开 `test.c` 对应的头文件(`test.h`),反之亦然。
|
||||
|
||||
当然咯,不是每个文件对应的头文件都存在。这种情况下,如果那你运行 `:A` 命令,神器就会为你新建一个文件。比如,如果 `test.h` 不存在,那么运行此命令就会帮你创建一个 `test.h`,然后打开它。
|
||||
|
||||
如果你不想要神器开启此功能,你可以在你的家目录的隐藏文件 `.vimrc` 中写入 `g:alternateNonDefaultAlternate` 变量,并且赋给它一个非零值即可。
|
||||
|
||||
还有一种情况也很普遍,你需要打开的文件并非是当前源代码的头文件。比如你目前在 `test.c` 你想打开 `men.h` 这个头文件,那么你可以输入这个命令 `:IH <filename>` ,毋需赘言,你肯定要在后面输入你要打开的的文件名称 `<filename>`。
|
||||
|
||||
目前为止,我们讨论的功能都仅限于你当前文件和要操作的文件都在同一个目录去实现。但是,你也知道,我们还有特殊情况,我是说,许多项目中头文件与对应的源文件并不一定在同一目录下。
|
||||
|
||||
为了搞定这个问题,你要使用这个 `g:alternateSearchPath` 这个变量。官方文档是这么[解释](https://github.com/csliu/a.vim/blob/master/doc/alternate.txt)的:
|
||||
|
||||
> 这个插件可以让用户配置它的搜索源文件和头文件的搜索路径。这个搜索路径可以通过设置 `g:alternateSearchPath` 这个变量的值指定。默认的设定如下:
|
||||
|
||||
> ```
|
||||
> g:alternateSearchPath = 'sfr:../source,sfr:../src,sfr:../include,sfr:../inc'
|
||||
> ```
|
||||
|
||||
> 使用这个代码表示神器将搜索 `../source`、`../src`、`../include` 和 `../inc` 下所有与目标文件相关的文件。 `g:alternateSearchPath` 变量的值由前缀和路径组成,每个单元用逗号隔开。 `sfr` 前缀是指后面的路径是相对于目前文件的,`wdr` 前缀是指目录是相对于目前的工作目录, `abs` 是指路径是绝对路径。如果不指定前缀,那么默认为 `sfr`。
|
||||
|
||||
如果我们前文所提及的特性就能让你觉得很炫酷,那我不得不告诉你,这才哪跟哪。还有一个十分有用的功能是分割 Vim 屏幕,这样你就可以同时看到头文件和相应的源文件。
|
||||
|
||||
哦,还有,你还可以选择垂直或者水平分割。全凭你心意。使用 `:AS` 命令可以水平分割,使用 `:AV` 可以垂直分割。
|
||||
|
||||
[
|
||||
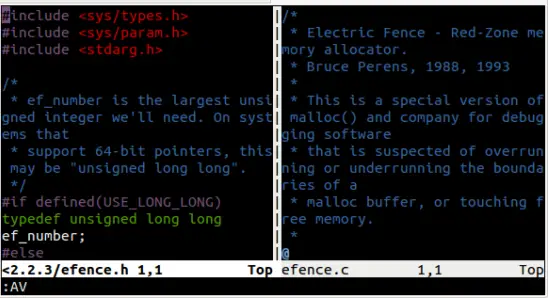
|
||||
][5]
|
||||
|
||||
[
|
||||
|
||||
][6]
|
||||
|
||||
使用 `:A` 命令在已经打开的文件中切换。
|
||||
|
||||
这个插件还可以让你在同一个 Vim 窗口中不同选项卡中打开多个相应的文件,你键入这个命令 `:AT`。
|
||||
|
||||
[
|
||||
|
||||
][7]
|
||||
|
||||
当然,你可以用这些命令 `:AV`、`:AS` 和 `:AT`,也可以使用这些命令 `:IHV`、`:IHS` 和 `:IHT`。
|
||||
|
||||
### 最后
|
||||
|
||||
还有许多和编程相关的 Vim 的插件,我们在这个三篇系列主要讨论的是,如果你为你的软件开发工作安装了合适的插件,你就会明白为什么 vim 被叫做编辑器之神。
|
||||
|
||||
当然,我们在这只关注编程方面,对于那些把 Vim 当做日常文档编辑器的人来说,你也应该了解一些 Vim 的插件,让你的编辑更好,更高效.我们就改日再谈这个问题吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/vim-editor-plugins-for-software-developers-3/
|
||||
|
||||
作者:[Ansh][a]
|
||||
译者:[Taylor1024](https://github.com/Taylor1024)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/vim-editor-plugins-for-software-developers-3/
|
||||
[1]:http://www.vim.org/scripts/script.php?script_id=31
|
||||
[2]:https://www.howtoforge.com/tutorial/vim-editor-plugins-for-software-developers/
|
||||
[3]:https://www.howtoforge.com/tutorial/vim-editor-plugins-for-software-developers-2-syntastic/
|
||||
[4]:https://github.com/csliu/a.vim/blob/master/doc/alternate.txt
|
||||
[5]:https://www.howtoforge.com/images/vim-editor-plugins-for-software-developers-3/big/vim-ver-split.png
|
||||
[6]:https://www.howtoforge.com/images/vim-editor-plugins-for-software-developers-3/big/vim-hor-split.png
|
||||
[7]:https://www.howtoforge.com/images/vim-editor-plugins-for-software-developers-3/big/vim-tab1.png
|
||||
@ -0,0 +1,55 @@
|
||||
用 Apache Calcite 构建强大的实时流式应用
|
||||
==============
|
||||
|
||||

|
||||
|
||||
Calcite 是一个数据框架,它允许你创建自定义数据库功能,微软开发者 Atri Sharma 在 Apache 2016 年 11 月 14-16 日在西班牙塞维利亚举行的 Big Data Europe 中对此进行了讲演。
|
||||
|
||||
[Creative Commons Zero][2] Wikimedia Commons: Parent Géry
|
||||
|
||||
[Apache Calcite][7] 数据管理框架包含了典型的数据库管理系统的许多部分,但省略了如数据的存储和处理数据的算法等其他部分。 Microsoft 的 Azure Data Lake 的软件工程师 Atri Sharma 在西班牙塞维利亚的 [Apache:Big Data][6] 会议上的演讲中讨论了使用 [Apache Calcite][5] 的高级查询规划能力。我们与 Sharma 讨论了解有关 Calcite 的更多信息,以及现有程序如何利用其功能。
|
||||
|
||||

|
||||
|
||||
*Atri Sharma,微软 Azure Data Lake 的软件工程师,已经[授权使用][1]*
|
||||
|
||||
**Linux.com:你能提供一些关于 Apache Calcite 的背景吗? 它有什么作用?
|
||||
|
||||
Atri Sharma:Calcite 是一个框架,它是许多数据库内核的基础。Calcite 允许你构建自定义的数据库功能来使用 Calcite 所需的资源。例如,Hive 使用 Calcite 进行基于成本的查询优化、Drill 和 Kylin 使用 Calcite 进行 SQL 解析和优化、Apex 使用 Calcite 进行流式 SQL。
|
||||
|
||||
**Linux.com:有哪些是使得 Apache Calcite 与其他框架不同的特性?
|
||||
|
||||
Atri:Calcite 是独一无二的,它允许你建立自己的数据平台。 Calcite 不直接管理你的数据,而是允许你使用 Calcite 的库来定义你自己的组件。 例如,它允许使用 Calcite 中可用的 Planner 定义你的自定义查询优化器,而不是提供通用查询优化器。
|
||||
|
||||
**Linux.com:Apache Calcite 本身不会存储或处理数据。 它如何影响程序开发?
|
||||
|
||||
Atri:Calcite 是数据库内核中的依赖项。它针对的是希望扩展其功能,而无需从头开始编写大量功能的的数据管理平台。
|
||||
|
||||
** Linux.com:谁应该使用它? 你能举几个例子吗?**
|
||||
|
||||
Atri:任何旨在扩展其功能的数据管理平台都应使用 Calcite。 我们是你下一个高性能数据库的基础!
|
||||
|
||||
具体来说,我认为最大的例子是 Hive 使用 Calcite 用于查询优化、Flink 解析和流 SQL 处理。 Hive 和 Flink 是成熟的数据管理引擎,并将 Calcite 用于相当专业的用途。这是对 Calcite 应用进一步加强数据管理平台核心的一个好的案例研究。
|
||||
|
||||
**Linux.com:你有哪些期待的新功能?
|
||||
|
||||
Atri:流式 SQL 增强是令我非常兴奋的事情。这些功能令人兴奋,因为它们将使 Calcite 的用户能够更快地开发实时流式应用程序,并且这些程序的强大和功能将是多方面的。流式应用程序是新的事实,并且在流式 SQL 中具有查询优化的优点对于大部分人将是非常有用的。此外,关于暂存表的讨论还在进行,所以请继续关注!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/build-strong-real-time-streaming-apps-apache-calcite
|
||||
|
||||
作者:[AMBER ANKERHOLZ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/aankerholz
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[3]:https://www.linux.com/files/images/atri-sharmajpg
|
||||
[4]:https://www.linux.com/files/images/calcitejpg
|
||||
[5]:https://calcite.apache.org/
|
||||
[6]:http://events.linuxfoundation.org/events/apache-big-data-europe
|
||||
[7]:https://calcite.apache.org/
|
||||
124
published/20170107 Min Browser Muffles the Web Noise.md
Normal file
124
published/20170107 Min Browser Muffles the Web Noise.md
Normal file
@ -0,0 +1,124 @@
|
||||
使用 Min 浏览器消除 web 噪音
|
||||
============================================================
|
||||

|
||||
|
||||
[Min][1] 是一款精简设计的 web 浏览器,功能简便,响应迅速。
|
||||
|
||||
在软件设计中,“简单”并不意味着功能低级、有待改进。你如果喜欢花哨工具比较少的文本编辑器和笔记程序,那么在 Min 浏览器中会有同样舒适的感觉。
|
||||
|
||||
我经常在台式机和笔记本电脑上使用 Google Chrome、Chromium 和 Firefox。我研究了它们的很多附加功能,所以我在长期的研究和工作中可以享用它们的特色服务。
|
||||
|
||||
然而,有时我希望有个快速、整洁的替代品来上网。随着多个项目的进行,我需要一个可以很快打开一大批选项卡甚至是独立窗口的强大浏览器。
|
||||
|
||||
我试过其他浏览器但很少能令我满意。替代品通常有一套独特的花哨的附件和功能,它们会让我开小差。
|
||||
|
||||
Min 浏览器就不这样。它是一个易于使用,并在 GitHub 开源的 web 浏览器,不会使我分心。
|
||||
|
||||
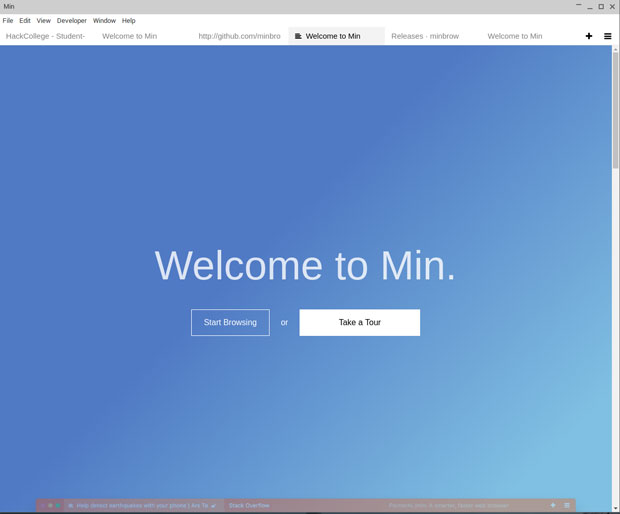
|
||||
|
||||
*Min 浏览器是精简的浏览器,提供了简单的功能以及快速的响应。只是不要指望马上能上手。*
|
||||
|
||||
### 它做些什么
|
||||
|
||||
Min 浏览器提供了 Debian Linux、Windows 和 Mac 机器的版本。它不能与功能众多的主流跨平台 web 浏览器竞争。
|
||||
|
||||
但它不必竞争,它很有名的原因应该是补充而不是取代那些主流浏览器。
|
||||
|
||||
其中一个主要原因是其内置的广告拦截功能。开箱即用的 Min 浏览器不需要配置或寻找兼容的第三方应用程序来拦截广告。
|
||||
|
||||
在 Edit/Preferences 菜单中,你可以通过三个选项来设置阻止的内容。它很容易修改屏蔽策略来满足你的喜好。阻止跟踪器和广告选项使用 EasyList 和 EasyPrivacy。 如果没有其他原因,请保持此选项选中。
|
||||
|
||||
你还可以阻止脚本和图像。这样做可以最大限度地提高网站加载速度,并能有效防御恶意代码。
|
||||
|
||||
### 按你的方式搜索
|
||||
|
||||
如果你在搜索上花费大量时间,你会喜欢 Min 处理搜索的方式。这是一个顶级的功能。
|
||||
|
||||
可以直接在浏览器的网址栏中使用搜索功能。Min 使用搜索引擎 DuckDuckGo 和维基百科的内容进行搜索。你可以直接在 web 地址栏中输入要搜索的东西。
|
||||
|
||||
这种方法很节省时间,因为你不必先进入搜索引擎窗口。 还有一个好处是可以搜索你的书签。
|
||||
|
||||
在 Edit/Preferences 菜单中,可以选择默认的搜索引擎。该列表包括 DuckDuckGo、Google、Bing、Yahoo、Baidu、Wikipedia 和 Yandex。
|
||||
|
||||
尝试将 DuckDuckGo 作为默认搜索引擎。 Min 默认使用这个引擎,但你也能更换。
|
||||
|
||||
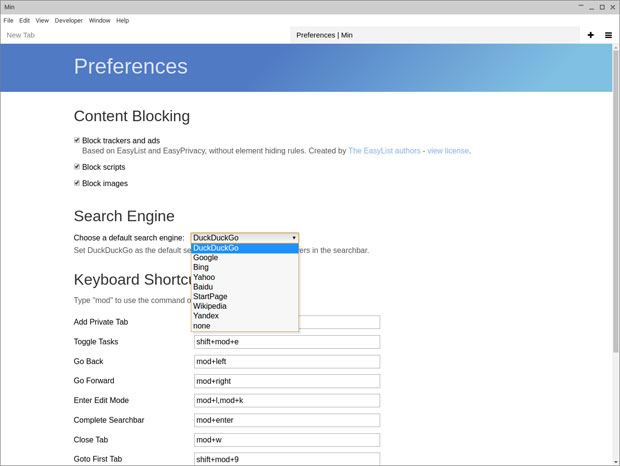
|
||||
|
||||
*Min 浏览器的搜索功能是 URL 栏的一部分。Min 会使用搜索引擎 DuckDuckGo 和维基百科的内容。你可以直接在 web 地址栏中输入要搜索的东西。*
|
||||
|
||||
搜索栏会非常快速地显示问题的答案。它会使用 DuckDuckGo 的信息,包括维基百科条目、计算器和其它的内容。
|
||||
|
||||
它能快速提供片段、答案和网络建议。它有点像不是基于 Goolge 环境的替代品。
|
||||
|
||||
### 导航辅助
|
||||
|
||||
Min 允许你使用模糊搜索快速跳转到任何网站。它能立即向你提出建议。
|
||||
|
||||
我喜欢在当前标签旁边打开标签的方式。你不必设置此选项。它在默认情况下没有其他选择,但这也有道理。
|
||||
|
||||
|
||||
|
||||
*Min 的一个很酷的功能是将标签整理到任务栏中,这样你随时都可以搜索。*
|
||||
|
||||
不点击标签,过一会儿它就会消失。这使你可以专注于当前的任务,而不会分心。
|
||||
|
||||
Min 不需要附加工具来控制多个标签。浏览器会显示标签列表,并允许你将它们分组。
|
||||
|
||||
### 保持专注
|
||||
|
||||
Min 在“视图”菜单中有一个可选的“聚焦模式”。启用后,除了你打开的选项卡外,它会隐藏其它所有选项卡。 你必须返回到菜单,关闭“聚焦模式”,才能打开新选项卡。
|
||||
|
||||
任务功能还可以帮助你保持专注。你可以在 File 菜单或使用 `Ctrl+Shift+N` 创建任务。如果要打开新选项卡,可以在 File 菜单中选择该选项,或使用 `Control+T`。
|
||||
|
||||
按照你的风格打开新任务。我喜欢按组来管理和显示标签,这组标签与工作项目或研究的某些部分相关。我可以在任何时间重新打开整个列表,从而轻松快速的方式找到我的浏览记录。
|
||||
|
||||
另一个好用的功能是可以在选项卡区域找到段落对齐按钮。单击它启用阅读模式。此模式会保存文章以供将来参考,并删除页面上的一切,以便你可以专注于阅读任务。
|
||||
|
||||
### 并不完美
|
||||
|
||||
Min 浏览器并不是强大的,功能丰富的完美替代品。它有一些明显的缺点,开发人员花了很多时间也没有修正。
|
||||
|
||||
例如,它缺乏一个支持论坛和详细用户指南的开发人员网站。可能部分原因是它的官网在 GitHub,而不是一个独立的开发人员网站。尽管如此,对新用户而言这是一个缺点。
|
||||
|
||||
没有网站支持,用户被迫在 GitHub 上寻找自述文件和各种目录列表。你也可以在 Min 浏览器的帮助菜单中访问它们 - 但这没有太多帮助。
|
||||
|
||||
一个例子是当你启动浏览器时,屏幕会显示欢迎界面。它会显示两个按钮,一个人是 “Start Browsing”,另一个是 “Take a Tour.”。但是没有一个按钮可以使用。
|
||||
|
||||
但是,你可以通过单击 Min 窗口顶部的菜单栏开始浏览。但是,还没有解决缺少概览办法。
|
||||
|
||||
### 底线
|
||||
|
||||
Min 并不是一个功能完善、丰富的 web 浏览器。你在功能完善的主流浏览器中所用的插件和其它许多功能都不是 Min 的设计目标。然而,Min 在快速响应和免打扰方面很有用。
|
||||
|
||||
我越使用 Min 浏览器,我越觉得它高效 - 但是当你第一次使用它时要小心。
|
||||
|
||||
Min 并不复杂,也不难操作 - 它只是有点古怪。你必须要体验一下才能明白它如何使用。
|
||||
|
||||
### 想要提建议么?
|
||||
|
||||
有没有你建议回顾的 Linux 程序或发行版?有没有你爱的或者想要了解的?
|
||||
|
||||
请[在电子邮件中给我发送你的想法][3],我会考虑将来在 “Linux Picks and Pans” 专栏上登出。
|
||||
|
||||
可以使用下方的读者评论功能说出你的想法!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Jack M. Germain 从苹果 II 和 PC 的早期起就一直在写关于计算机技术。他仍然有他原来的 IBM PC-Jr 和一些其他遗留的 DOS 和 Windows 机器。他为 Linux 桌面的开源世界留下过共享软件。他运行几个版本的 Windows 和 Linux 操作系统,还通常不能决定是否用他的平板电脑、上网本或 Android 智能手机,还是用他的台式机或笔记本电脑。你可以在 Google+ 上与他联系。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxinsider.com/story/84212.html
|
||||
|
||||
作者:[Jack M. Germain][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[GitFuture](https://github.com/GitFuture)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxinsider.com/story/84212.html?rss=1#searchbyline
|
||||
[1]:https://github.com/minbrowser/min/releases/
|
||||
[2]:http://www.linuxinsider.com/article_images/2017/84212_1200x750.jpg
|
||||
[3]:mailto:jack.germain@newsroom.ectnews.com
|
||||
@ -0,0 +1,166 @@
|
||||
Linux 命令行工具使用小贴士及技巧(二)
|
||||
============================================================
|
||||
|
||||
在本系列的[第一部分][4]中,我们通过讨论 `cd -` 命令的用法,重点介绍了 Linux 中的命令行导航。还讨论了一些其他相关要点/概念。现在进一步讨论,在本文中,我们将讨论如何使用 `pushd` 和 `popd` 命令在 Linux 命令行上获得更快的导航体验。
|
||||
|
||||
在我们开始之前,值得说明的一点是,此后提到的所有指导和命令已经在 Ubuntu 14.04 和 Bash shell(4.3.11)上测试过。
|
||||
|
||||
### pushd 和 popd 命令基础
|
||||
|
||||
为了更好地理解 `pushd` 和 `popd` 命令的作用,让我们先讨论堆栈的概念。想象你厨房案板上有一个空白区域,你想在上面放一套盘子。你会怎么做?很简单,一个接一个地放在上面。
|
||||
|
||||
所以在整个过程的最后,案板上的第一个盘子是盘子中的最后一个,你手中最后一个盘子是盘子堆中的第一个。现在当你需要一个盘子时,你选择在堆的顶部的那个盘子并使用它,然后需要时选择下一个。
|
||||
|
||||
`pushd` 和 `popd` 命令是类似的概念。在 Linux 系统上有一个目录堆栈,你可以堆叠目录路径以供将来使用。你可以使用 `dirs` 命令来在任何时间点快速查看堆栈的内容。
|
||||
|
||||
下面的例子显示了在命令行终端启动后立即在我的系统上使用 dirs 命令的输出:
|
||||
|
||||
```
|
||||
$ dirs
|
||||
~
|
||||
```
|
||||
|
||||
输出中的波浪号(`~`)表示目录堆栈当前仅包含用户的主目录。
|
||||
|
||||
继续下去,使用 `pushd` 和 `popd` 命令来执行存储目录路径并删除它的操作。使用 `pushd` 非常容易 - 只需将要存储在目录堆栈中的路径作为此命令的参数传递。这里有一个例子:
|
||||
|
||||
```
|
||||
pushd /home/himanshu/Downloads/
|
||||
```
|
||||
|
||||
上述命令的作用是,将当前工作目录更改为你作为参数传递的目录,并且还将路径添加到目录堆栈中。为了方便用户,`pushd` 命令在其输出中产生目录堆栈的内容。因此,当运行上面的命令时,产生了以下输出:
|
||||
|
||||
```
|
||||
~/Downloads ~
|
||||
```
|
||||
|
||||
输出显示现在堆栈中有两个目录路径:一个是用户的主目录,还有用户的下载目录。它们的保存顺序是:主目录位于底部,新添加的 `Downloads` 目录位于其上。
|
||||
|
||||
要验证 `pushd` 的输出是正确的,你还可以使用 `dirs` 命令:
|
||||
|
||||
```
|
||||
$ dirs
|
||||
~/Downloads ~
|
||||
```
|
||||
|
||||
因此你可以看到 `dirs` 命令同样产生相同的输出。
|
||||
|
||||
让我们再使用下 `pushd` 命令:
|
||||
|
||||
```
|
||||
$ pushd /usr/lib/; pushd /home/himanshu/Desktop/
|
||||
/usr/lib ~/Downloads ~
|
||||
~/Desktop /usr/lib ~/Downloads ~
|
||||
```
|
||||
|
||||
所以目录堆栈现在包含总共四个目录路径,其中主目录(`~`)在底部,并且用户的桌面目录在顶部。
|
||||
|
||||
一定要记住的是堆栈的头是你当前的目录。这意味着现在我们当前的工作目录是 `~/Desktop`。
|
||||
|
||||
现在,假设你想回到 `/usr/lib` 目录,所以你所要做的就是执行 `popd` 命令:
|
||||
|
||||
```
|
||||
$ popd
|
||||
/usr/lib ~/Downloads ~
|
||||
```
|
||||
|
||||
`popd` 命令不仅会将当前目录切换到 `/usr/lib`,它还会从目录堆栈中删除 `~/Desktop`,这一点可以从命令输出中看出。这样,popd 命令将允许你以相反的顺序浏览这些目录。
|
||||
|
||||
### 一些高级用法
|
||||
|
||||
现在我们已经讨论了 `pushd` 和 `popd` 命令的基础知识,让我们继续讨论与这些命令相关的一些其它细节。首先,这些命令还允许你操作目录堆栈。例如,假设你的目录堆栈看起来像这样:
|
||||
|
||||
```
|
||||
$ dirs
|
||||
~/Desktop /usr/lib ~ ~/Downloads
|
||||
```
|
||||
|
||||
现在,我们的要求是改变堆栈中目录路径的顺序,最上面的元素(`~/Desktop`)放到底部,剩下的每个都向上移动一个位置。这可以使用以下命令实现:
|
||||
|
||||
```
|
||||
pushd +1
|
||||
```
|
||||
|
||||
上面的命令对目录堆栈做的结果:
|
||||
|
||||
```
|
||||
$ dirs
|
||||
/usr/lib ~ ~/Downloads ~/Desktop
|
||||
```
|
||||
|
||||
因此,我们看到目录堆栈中的元素顺序已经改变,并且现在和我们想要的一样。当然,你可以让目录堆栈元素移动任何次数。例如,以下命令会将它们向上移动两次:
|
||||
|
||||
```
|
||||
$ pushd +2
|
||||
~/Downloads ~/Desktop /usr/lib ~
|
||||
```
|
||||
|
||||
你也可以使用负的索引值:
|
||||
|
||||
```
|
||||
$ pushd -1
|
||||
/usr/lib ~ ~/Downloads ~/Desktop
|
||||
```
|
||||
|
||||
相似地,你可以在 `popd` 命令中使用此技术来从目录堆栈删除任何条目,而不用离开当前工作目录。例如,如果要使用 `popd` 从顶部(目前是 `~/Downloads`)删除第三个条目,你可以运行以下命令:
|
||||
|
||||
```
|
||||
popd +2
|
||||
```
|
||||
|
||||
记住堆栈索引的初始值是 `0`,因此我们使用 `2` 来访问第三个条目。
|
||||
|
||||
因此目录堆栈现在包含:
|
||||
|
||||
```
|
||||
$ dirs
|
||||
/usr/lib ~ ~/Desktop
|
||||
```
|
||||
|
||||
确认条目已经被移除了。
|
||||
|
||||
如果由于某些原因,你发现你很难记住元素在目录堆栈中的位置以及它们的索引,你则可以对在 `dirs` 命令中使用 `-v` 选项。这里有一个例子:
|
||||
|
||||
```
|
||||
$ dirs -v
|
||||
0 /usr/lib
|
||||
1 ~
|
||||
2 ~/Desktop
|
||||
```
|
||||
|
||||
你可能已经猜到了,左边的数字是索引,接下来跟的是这个索引对应的目录路径。
|
||||
|
||||
**注意**: 在 `dir` 中使用 `-c` 选项清除目录堆栈。
|
||||
|
||||
现在让我们简要地讨论一下 `popd` 和 `pushd` 命令的实际用法。虽然它们第一眼看起来可能有点复杂,但是这些命令在编写 shell 脚本时会派上用场 - 你不需要记住你从哪里来;只要执行一下 `popd`,你就能回到你来的目录。
|
||||
|
||||
经验丰富的脚本编写者通常以以下方式使用这些命令:
|
||||
|
||||
```
|
||||
popd >/dev/null 2>&1
|
||||
```
|
||||
|
||||
上述命令确保 `popd` 保持静默(不产生任何输出)。同样,你也可以静默 `pushd`。
|
||||
|
||||
`pushd` 和 `popd` 命令也被 Linux 服务器管理员使用,他们通常在几个相同的目录之间移动。 在[这里][5]介绍了一些其他有用的使用场景。
|
||||
|
||||
### 总结
|
||||
|
||||
我同意 `pushd` 和 `popd` 的概念不是很直接。但是,它需要的只是一点练习 - 是的,你需要多实践。花一些时间在这些命令上,你就会开始喜欢它们,特别是当它们提供了方便时。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/linux-command-line-tips-tricks-part-2/
|
||||
|
||||
作者:[Ansh][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/linux-command-line-tips-tricks-part-2/
|
||||
[1]:https://www.howtoforge.com/tutorial/linux-command-line-tips-tricks-part-2/#the-basics-of-pushd-and-popd-commands
|
||||
[2]:https://www.howtoforge.com/tutorial/linux-command-line-tips-tricks-part-2/#some-advanced-points
|
||||
[3]:https://www.howtoforge.com/tutorial/linux-command-line-tips-tricks-part-2/#conclusion
|
||||
[4]:https://linux.cn/article-8335-1.html
|
||||
[5]:http://unix.stackexchange.com/questions/77077/how-do-i-use-pushd-and-popd-commands
|
||||
132
published/20170125 An executive's guide to containers.md
Normal file
132
published/20170125 An executive's guide to containers.md
Normal file
@ -0,0 +1,132 @@
|
||||
容器实践指南
|
||||
============================================================
|
||||
|
||||
 图片来源:[Maersk Line][1]. [CC SA-BY 4.0][2]
|
||||
|
||||
与互联网领域的领导们关于"容器"的讨论通常被总结如下:
|
||||
|
||||
_作为一名 CxO,我面临杠杆时间术的持续的压力。IT 预算不断减少,我只有有限的资源。然而,交付的工作量却比以往更多。我花费太多的时间致力于解决预算的约束。另外,互联网的格局正在经历一个快速的改变,而且新的技术一直在被引进。我从我最信任的顾问那听来的最新的话题是一个“容器策略”的实现。我想理解:_
|
||||
|
||||
1. _什么是容器?_
|
||||
2. _过渡到容器的企业价值是什么?_
|
||||
3. _为什么我现在应该转移到容器?如果我不采纳会有一些坏处吗?_
|
||||
4. _容器是否已经足够成熟用于企业消费?_
|
||||
5. _我如何让我的企业因使用容器而快速地发展?_
|
||||
|
||||
让我们从最开头开始。
|
||||
|
||||
### 容器
|
||||
|
||||
在过去的 10 年左右,企业已经从物理基础设施转向了虚拟机(VM)。转向 VM 的关键优势是可以减少数据中心的用量。通过在同一个物理机器上运行多个虚拟机,你可以在更少数量的物理机器上安装更多的应用程序。使用容器是另一种更轻量地打包应用程序的方式,而且其交付模式更快。它们是一种在单一的机器里运行多个应用程序进程的奇特方式,无论那个机器是一个虚拟机还是一个物理机。另外,容器在 DevOps 、微服务和云战略场景方面也扮演了重要角色。
|
||||
|
||||
### 容器 vs 虚拟机
|
||||
|
||||
容器和虚拟机在一些方面并不相同。一台虚拟机尽管不是物理机,但是它表现地就像是一台物理机。虚拟机是一个包含所有东西的独立的环境,是一个完整的(来宾)操作系统。在另一方面,容器是一个共享同一个物理机或虚拟机上资源的进程。容器显然更加有趣,因为:
|
||||
|
||||
* 相比较而言,虚拟机要重一些,而容器更轻。因为容器只包括了它们所运行的程序所需要的库。
|
||||
* 虚拟机需要花费几分钟来启动,而容器在几秒钟内就可以启动。
|
||||
* 通常,相当于虚拟机你的基础设施中可以容纳更多的容器。
|
||||
|
||||

|
||||
|
||||
技术已经发展到足以保持这些容器安全、彼此独立,而且正确的设计选择可以保证那些坏掉的容器不会影响运行在同一个机器里的其他容器的性能。实际上,操作系统天生就是被用来构建成优化和运行容器的。
|
||||
|
||||
然而,当你转向容器时,你需要做出正确的选择。你需要做足够的尽职调查,以便你选择合适的技术合作伙伴和能够制作容器的制造商。开源技术起着很关键的作用。开源的 [Docker 项目][5]使得分层格式的容器很容易构建和使用。[开放容器计划][6](OCI)已经成为被所有主要技术供应商所支持的开源容器标准。如 Red Hat 这样的开源技术提供商提供了为容器而准备的安全的操作系统。例如, Red Hat Enterprise Linux 7.x (包括 Red Hat Enterprise Linux 原子主机)进行了优化以原生地运行容器,同时也提供监控和管理容器的工具。其他的开源项目如来自 Tectonic 的 CoreOS 也正在进入市场。的确,容器正等着被企业所采用。
|
||||
|
||||
### 容器平台
|
||||
|
||||
容器平台让容器成为企业消耗品。在过去这些年中,你可能在你的企业里处理过虚拟机散乱的问题,容器散乱比那要糟糕好几倍。在你的数据中心横跨不同主机运行不同规模的容器,尽管容器故障仍然保证你的应用程序的高可用性,自动化健康检查和基于流入的工作载荷的自动化容器缩放等等,这些是你能期待容器平台应该有的一些关键特性。
|
||||
|
||||
当在一个被定位为容器即服务模型(CaaS)的平台上运行容器时,这些平台的一些其它特性如自动化生成和部署使这个平台成为平台即服务模型(PaaS)。虽然 CaaS 能让你规模化运行容器,但是,PaaS 可以让你利用你的源代码编译、创建容器,为你运行那些容器。另外,这些平台提供了完整操作管理特性,例如,集群的管理和监控、容器的安全缺陷检测,以及安全地运行容器、跟踪日志和度量等等。
|
||||
|
||||
尽管一些技术供应商正在使用他们的专有技术来构建容器平台,但总的来说,企业们正在围绕建立在 [Kubernetes][7](K8S)的基础上的开源技术而进行标准化。K8S 是一项由 Google 发起的开源项目,现在很多大平台的供应商也支持它。K8S 也是[云端原生计算基金会][8](CNCF)的一部分,CNCF 正在发展成以云为中心技术的标准体。当你在容器平台上做出选择时,围绕开源流程编排技术的标准化是非常重要的。它基本上允许你移植到不同的容器平台,如果你不喜欢你第一次做的选择的话。K8S 还允许你的容器工作载荷可跨越不同的公有云进行迁移。这些就是为什么我们会看到越来越多的技术公司正在使用 Kubernetes 的原因。
|
||||
|
||||
一些企业正在试图通过拼接几个包括 K8S 在内开源项目来打造他们自己 DIY 的容器平台。这确实是比继续跟随专有技术要更好的一种解决方案,但是要完成这项工作也仍然包含很多需要探讨的地方。然而,一个企业的维护和保持这样的 DIY 平台的能力应该被认真评估。许多企业并不是想做创建 IT 平台的工作,而是他们希望运行自己的主流业务。有很多可行的基于 K8S 的解决方案,比如[红帽 OpenShift 平台容器][9]、[Apprenda][10]、[Deis][11] 和 [Rancher][12],它们提供一个企业级平台,这些解决方案中的每种都有不同完整程度的功能。
|
||||
|
||||
这些解决方案是由供应商认证和支持。有些方案是完全的开源 PaaS 解决方案,而另外一些可能是 CaaS。根据你的企业的需求,这些解决方案可能是比 DIY 容器平台更好的替代品。
|
||||
|
||||
### 企业的担忧和它们与容器的关系
|
||||
|
||||
今天,几乎每个企业都正在与数字时代转型打交道,这些转型影响包括 DevOps 战略、微服务和云等多个领域。容器在这些领域中的每一个中都起着相当重要的作用。
|
||||
|
||||
### DevOps 策略
|
||||
|
||||
IT 组织被分成运维和应用开发,他们作为两个独立的团队运作,每一队都只有他们自己的一套目标。大多数企业为了将这两个团队联合起来正在朝 DevOps 的方向前进。
|
||||
|
||||
容器在 DevOps 倡议的成功中发挥着重要的作用。在 DevOps 中成功的关键标准之一是增加开发人员在运营中的份额。开发人员不仅应该把代码交给运维人员,而且他们还应该考虑他们的代码是如何在生产环境中运行的。普遍的技术是采用“架构即代码”,而不是提供几页容易出错的安装说明指示,开发团队应该提供像编程时的环境配置。
|
||||
|
||||
这恰恰就是容器可以解决的问题。可以作为容器的模版的容器镜像包括了从基本操作系统到应用程序代码的整个环境堆栈。利用容器,开发人员将不再只是从 Dev 到 QA 再到 Prod 这样生成应用程序;相反,他们将传递一个版本化的容器镜像,这个镜像包括生成的运行程序和它运行需要的环境。容器是包罗万象的,从操作系统库到中间件再到应用程序的所有东西都被整合进一个镜像里面。因此,容器在开发环境运行的方式和它在质量保证环境和生产环境下运行的方式完全一样。容器是 DevOps 成功的重要因素。
|
||||
|
||||

|
||||
|
||||
另外,容器平台正在进一步发展。典型的持续集成和交付(CICD)工具,如 [Jenkins](https://jenkins.io/),可以作为容器,这个容器能在容器平台本身运行整个 CICD 过程,而不需要额外的基础设施。现在你可以使用 PaaS 平台来生成和运行你的 CICD 管道。
|
||||
|
||||
### 微服务策略
|
||||
|
||||
微服务是今天 IT 领域的另一个热门话题。应用程序是这样被设计的:把应用程序分解为离散化的小的服务,每个服务完成一个小任务。这些服务中的每一个都可以根据合适的技术用不同的编程语言进行编写。它们可以由小团队(双比萨团队)创建和管理,并且可以迅速地改变它们。所有这些要求再次需要用到容器。容器足够小到成为微服务的基础。容器能够支持任何你选择的技术和语言,容器易于创建和运行,并且可以快速地改变。微服务和容器现在已经不分彼此,如果有人说不使用容器来实现微服务,他们将会受到别人奇怪的表情。
|
||||
|
||||
实际情况是,虽然微服务有望让情况变得简单,但是它们的扩张也增加了复杂性。有几个微服务的设计和开发模式将能使它们易于实现。这意味着开发人员现在急需这样一个开发平台,在这个平台下,开发人员可以轻松地部署和组织微服务,而且还能:
|
||||
|
||||
* 以一种语言不可知的方式实现这些微服务设计模式。
|
||||
* 不会因代码侵入而增加代码的复杂性,以便开发人员能将许多模式的代码包括进他们的业务逻辑中。
|
||||
* 足够灵活以便部署在你所选择的基础设施上,并且不会把你捆绑在特定的云上。
|
||||
|
||||
这就是选择一个正确的容器平台所起作用的地方。在具体的基础设施上按照某一特定供应商的方法来实现这些微服务将会把你的应用程序捆绑在那些供应商的平台上。使用类似兼容 OCI 的容器的容器化微服务将可以保证你的微服务能够被运行在任何兼容 OCI 的平台上。
|
||||
|
||||
选择正确的容器平台来运行你的微服务是需要做的另一个重要的决定。今天,有很少的选择和许多的 FUD。如果你作出选择时不足够慎重,其中一些选择会把你带到非标准的、特定供应商的路线上。
|
||||
|
||||
### 云策略
|
||||
|
||||
云战略是 IT 领域的又一个热门话题。无论你是否喜欢,服务化模型都是不可避免的变化。如果你不将其作为 IT 服务进行提供,你的开发团队将可能会找到创建“shadow IT”的方法来访问云。另外,尽管使用云技术将会让你从资本支出转移到运营支出,但是,管理云支出是一个不断的挑战。
|
||||
|
||||
云可以提供虚拟机,在你添加额外的虚拟机之前,你要确认这个云上的 CPU、内存和网络等资源都处于最佳使用状态。容器在这个地方扮演着很重要的角色。因为容器比虚拟机要小得多。并且,如果你的应用程序正运行在容器中,你可以在虚拟机中安装更多的容器,这比在每台虚拟机中运行一个应用程序组件要多很多。
|
||||
|
||||
公有云供应商有很多,其中 Amazon Web Services(AWS)、Microsoft Azure 和 Google Cloud 最受欢迎。另外,你可能想在你的基于 OpenStack 的数据中心里拥有你自己的私有云。这些云环境中的每一个都有它们自己的协议、API 和工具。当你想让你的应用程序在云上运行时,你不会想要让您的应用编排被云供应商所制约,也不会想要维护任何特定云的代码。在你的技术上与特定的云供应商锁定就像在未来几年内向供应商签署空白支票。
|
||||
|
||||
云的可移植性对您的云战略至关重要。你可以编写应用程序,而不用担心它们在哪里运行,容器平台可以将你和特定的云供应商协议隔离开来,从而避免你与一个云供应商锁定。
|
||||
|
||||
### 传统系统
|
||||
|
||||
微服务架构带给开发的优势很多,但并不是每个应用程序都可以重构它们自己,有些只能重构一部分。传统的应用程序被普遍接受,它们需要维护和管理。虽然容器可以实现微服务,但容器不仅仅只是微服务。可以想象,你可以将大型应用程序和微服务作为容器来运行,因此只要你选择正确的容器技术和正确的应用程序平台,就可以将许多(如果不是所有)的传统的应用程序作为容器运行。
|
||||
|
||||
### 总结
|
||||
|
||||
我希望这篇对各种策略和容器的深入剖析有助于你的公司对下一步进行评估。让我在评论里面了解您公司学习到的经验,或者说没能大步向前跨越,他们还需要我再提供一些什么信息。
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Veer Muchandi -- 开源爱好者,容器和PaaS倡导者,喜欢学习和分享。
|
||||
|
||||
-------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/1/container-strategy-for-executives
|
||||
|
||||
作者:[Veer Muchandi][a]
|
||||
译者:[zhousiyu325](https://github.com/zhousiyu)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
|
||||
|
||||
[a]:https://opensource.com/users/veermuchandi
|
||||
[1]:https://www.flickr.com/photos/maerskline/6955071566
|
||||
[2]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[3]:https://opensource.com/article/17/1/container-strategy-for-executives?rate=DuiecCOvGMj-GXcdlJsN8xdZJ82yPUX1M3M9ZNkT99A
|
||||
[4]:https://opensource.com/resources/what-are-linux-containers
|
||||
[5]:https://opensource.com/resources/what-docker
|
||||
[6]:https://opensource.com/business/16/8/inside-look-future-linux-containers
|
||||
[7]:https://opensource.com/resources/what-is-kubernetes
|
||||
[8]:https://www.cncf.io/
|
||||
[9]:https://www.openshift.com/container-platform/
|
||||
[10]:https://apprenda.com/
|
||||
[11]:http://deis.io/
|
||||
[12]:http://rancher.com/
|
||||
[13]:https://jenkins.io/
|
||||
[14]:https://opensource.com/resources/what-are-microservices
|
||||
[15]:https://opensource.com/user/92826/feed
|
||||
[16]:https://opensource.com/article/17/1/container-strategy-for-executives#comments
|
||||
[17]:https://opensource.com/users/veermuchandi
|
||||
@ -7,7 +7,7 @@
|
||||
|
||||
啊,一个好的调查,能够以快速、简单、便宜、有效的方式收集朋友、家人、同学、同事、客户、读者和其他人的意见。
|
||||
|
||||
许多人开始使用专有工具,如 SurveyGizmo、Polldaddy、SurveyMonkey 甚至 Google 表单来设置他们的调查。但是如果你想对应用还有收集到的数据有更多的控制,那么你会希望使用开源工具。
|
||||
许多人开始使用专有工具,如 SurveyGizmo、Polldaddy、SurveyMonkey 甚至 Google 表单来设置他们的调查。但是如果你不仅是对这些应用还有你自己收集到的数据有更多的控制,那么你会希望使用开源工具。
|
||||
|
||||
让我们来看看四个开源调查工具,无论需求简单还是复杂,它们都可以满足你的需求。
|
||||
|
||||
@ -23,7 +23,7 @@ LimeSurvey 还允许你使用自己的 JavaScript、照片和视频自定义调
|
||||
|
||||
如果 LimeSurvey 没有为你提供足够的功能,并且对 Java 驱动的 web 程序感兴趣,那么我推荐 [JD Esurvey][5]。它被称为“一个开源的企业调查 web 应用”。它绝对强大,并满足了那些寻找大容量、健壮的调查工具的组织的很多需求。
|
||||
|
||||
使用 JD Esurvey,你可以收集一系列信息,包括 “是/否” 问题的答案以及产品和服务的星级。你甚至可以处理多个部分的问题的答案。JD Esurvey 支持使用平板电脑和智能手机创建和管理调查,你发布的调查也是移动友好的。根据开发者的说法,该程序[残疾人也可使用][6]。
|
||||
使用 JD Esurvey,你可以收集一系列信息,包括 “是/否” 问题的答案以及产品和服务的星级。你甚至可以处理带有多个部分答案的问题。JD Esurvey 支持使用平板电脑和智能手机创建和管理调查,你发布的调查也是移动友好的。根据开发者的说法,该程序[残疾人也可使用][6]。
|
||||
|
||||
要使用它,你可以[在 GitHub 上 fork JD Esurvey][7] 或者[下载并安装][8]程序的预编译版本。
|
||||
|
||||
@ -37,11 +37,11 @@ Quick Survey 只允许你创建问答和多选调查列表。你可以添加问
|
||||
|
||||
### TellForm
|
||||
|
||||
在功能方面,[TellForm][13] 位于 LimeSurvey 和 Quick Survey 之间。它适合那些功能需求超出最小需求,但无需完全功能的人使用。
|
||||
在功能方面,[TellForm][13] 介于 LimeSurvey 和 Quick Survey 之间。它适合那些功能需求超出最小需求,但无需完整功能的人使用。
|
||||
|
||||
除了有 11 种不同类型的调查之外,TellForm 还有很好的分析功能。你可以轻松地自定义调查的外观和感觉,而且程序的界面简单干净。
|
||||
|
||||
如果你想自己托管 TellForm,你可以从[ GitHub 仓库][14]中获取代码。或者,你可以注册[免费托管帐户][15]。
|
||||
如果你想自己托管 TellForm,你可以从 [GitHub 仓库][14]中获取代码。或者,你可以注册[免费托管帐户][15]。
|
||||
|
||||
* * *
|
||||
|
||||
@ -58,7 +58,7 @@ Scott Nesbitt - 作家、编辑、雇佣兵(Soldier of fortune)、豹猫牧
|
||||
|
||||
via: https://opensource.com/article/17/2/tools-online-surveys-polls
|
||||
|
||||
作者:[Scott Nesbitt ][a]
|
||||
作者:[Scott Nesbitt][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
@ -0,0 +1,165 @@
|
||||
10 个常见的 Linux 终端仿真器
|
||||
==========
|
||||
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
对于 Linux 用户来说,最重要的应用程序之一就是终端仿真器。它允许每个用户获得对 shell 的访问。而 Bash 是 Linux 和 UNIX 发行版中最常用的 shell,它很强大,对于新手和高级用户来说,掌握 bash 都很有必要。因此,在这篇文章中,你可以了解 Linux 用户有哪些优秀的终端仿真器可以选择。
|
||||
|
||||
### 1、Terminator
|
||||
|
||||
这个项目的目标是创造一个能够很好排列终端的有用工具。它受到一些如 gnome-multi-term、quadkonsole 等程序的启发,重点是以网格的形式排列终端。
|
||||
|
||||
#### 特性浏览
|
||||
|
||||
* 以网格形式排列终端
|
||||
* Tab 设定
|
||||
* 通过拖放重新排布终端
|
||||
* 大量的快捷键
|
||||
* 通过 GUI 参数编辑器保存多个布局和配置文件
|
||||
* 同时对任意组合的终端进行输入
|
||||
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
你可以通过下面的命令安装 Terminator:
|
||||
|
||||
```
|
||||
sudo apt-get install terminator
|
||||
```
|
||||
|
||||
### 2、Tilda - 一个可以下拉的终端
|
||||
|
||||
**Tilda** 的独特之处在于它不像一个普通的窗口,相反,你可以使用一个特殊的热键从屏幕的顶部拉下和收回它。
|
||||
另外,Tilda 是高度可配置的,可以自定义绑定热键,改变外观,以及其他许多能够影响 Tilda 特性的选项。
|
||||
|
||||
在 Ubuntu 和 Fedora 上都可以使用包管理器安装 Tilda,当然,你也可以查看它的 [GitHub 仓库][14]。
|
||||
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
### 3、Guake
|
||||
|
||||
Guake 是一个和 Tilda 或 yakuake 类似的下拉式终端仿真器。如果你知道一些关于 Python、Git 和 GTK 的知识的话,你可以给 Guake 添加一些新的特性。
|
||||
|
||||
Guake 在许多发行版上均可用,所以如果你想安装它,你可以查看你的版本仓库。
|
||||
|
||||
#### 特性浏览
|
||||
|
||||
* 轻量
|
||||
* 简单易用且优雅
|
||||
* 将终端自然地集成到 GUI 之中
|
||||
* 当你使用的时候出现,一旦按下预定义热键便消失(默认情况下是 F12)
|
||||
* 支持Compiz 透明
|
||||
* 多重 Tab
|
||||
* 丰富的调色板
|
||||
* 还有更多……
|
||||
|
||||
主页: [http://guake-project.org/][15]
|
||||
|
||||
### 4、ROXTerm
|
||||
|
||||
如果你正在寻找一个轻量型、高度可定制的终端仿真器,那么 ROXTerm 就是专门为你准备的。这是一个旨在提供和 gnome-terminal 相似特性的终端仿真器,它们都基于相同的 VTE 库。它的最初设计是只占用很小的资源并且能够快速启动,它具有比 gnome-terminal 更强的可配置性,更加针对经常使用终端的 “Power” 用户。
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
[http://roxterm.sourceforge.net/index.php?page=index&lang=en][16]
|
||||
|
||||
### 5、XTerm
|
||||
|
||||
Xterm 是 Linux 和 UNIX 系统上最受欢迎的终端仿真器,因为它是 X 窗口系统的默认终端仿真器,并且很轻量、很简单。
|
||||
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
### 6、Eterm
|
||||
|
||||
如果你正在寻找一个漂亮、强大的终端仿真器,那么 Eterm 是你最好的选择。Eterm 是一个彩色 vt102 终端仿真器,被当作是 Xterm 的替代品。它按照自由选择的哲学思想进行设计,将尽可能多的权利、灵活性和自由交到用户手中。
|
||||
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
官网: [http://www.eterm.org/][17]
|
||||
|
||||
### 7、Gnome Terminal
|
||||
|
||||
Gnome Terminal 是最受欢迎的终端仿真器之一,它被许多 Linux 用户使用,因为它默认安装在 Gnome 桌面环境中,而 Gnome 桌面很常用。它有许多特性并且支持大量主题。
|
||||
|
||||
在许多 Linux 发行版中都默认安装有 Gnome Terminal,但你如果没有的话,也可以使用你的包管理器来安装它。
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
### 8、Sakura
|
||||
|
||||
Sakura 是一个基于 GTK 和 VTE 的终端仿真器。它是一个只有很少依赖的终端仿真器,所以你不需要先安装一个完整的 GNOME 桌面才能有一个像样的终端仿真器。
|
||||
|
||||
你可以使用你的包管理器来安装它,因为 Sakura 在绝大多数发行版中都是可用的。
|
||||
|
||||
### 9、LilyTerm
|
||||
|
||||
LilyTerm 是一个基于 libvte 的终端仿真器,旨在快速和轻量,是 GPLv3 授权许可的。
|
||||
|
||||
#### 特性浏览
|
||||
|
||||
* 低资源占用
|
||||
* 多重 Tab
|
||||
* 配色方案丰富
|
||||
* 支持超链接
|
||||
* 支持全屏
|
||||
* 还有更多的……
|
||||
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
### 10、Konsole
|
||||
|
||||
如果你是一名 KDE 或 Plasma 用户,那么你一定知道 Konsole,因为它是 KDE 桌面的默认终端仿真器,也是我最喜爱的终端仿真器之一,因为它很舒适易用。
|
||||
|
||||
它在 Ubuntu 和 fedora 上均可用,但如果你在使用 Ubuntu (Unity),那么你需要选择别的终端仿真器,或者你可以考虑使用 Kubuntu 。
|
||||
|
||||
[
|
||||

|
||||
][11]
|
||||
|
||||
### 结论
|
||||
|
||||
我们是 Linux 用户,根据自己的需求,可以有许多选择来挑选更好的应用。因此,你可以选择**最好的终端**来满足个人需求,虽然你也可以选择另一个 shell 来满足个人需求,比如你也可以使用 fish shell。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/10-best-linux-terminals-for-ubuntu-and-fedora
|
||||
|
||||
作者:[Mohd Sohail][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://disqus.com/by/MohdSohail1/
|
||||
[1]:http://www.linuxandubuntu.com/home/terminator-a-linux-terminal-emulator-with-multiple-terminals-in-one-window
|
||||
[2]:http://www.linuxandubuntu.com/home/another-linux-terminal-app-guake
|
||||
[3]:http://www.linuxandubuntu.com/home/10-best-linux-terminals-for-ubuntu-and-fedora
|
||||
[4]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/terminator-linux-terminals_orig.png
|
||||
[5]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/tilda-linux-terminal_orig.png
|
||||
[6]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/roxterm-linux-terminal_orig.png
|
||||
[7]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/xterm-linux-terminal_orig.png
|
||||
[8]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/etern-linux-terminal_orig.jpg
|
||||
[9]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/gnome-terminal_orig.jpg
|
||||
[10]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/lilyterm-linux-terminal_orig.jpg
|
||||
[11]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/konsole-linux-terminal_orig.png
|
||||
[12]:http://www.linuxandubuntu.com/home/10-best-linux-terminals-for-ubuntu-and-fedora
|
||||
[13]:http://www.linuxandubuntu.com/home/10-best-linux-terminals-for-ubuntu-and-fedora#comments
|
||||
[14]:https://github.com/lanoxx/tilda
|
||||
[15]:http://guake-project.org/
|
||||
[16]:http://roxterm.sourceforge.net/index.php?page=index&lang=en
|
||||
[17]:http://www.eterm.org/
|
||||
@ -0,0 +1,172 @@
|
||||
看漫画学 SELinux 强制策略
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
>图像来自: opensource.com
|
||||
|
||||
今年是我们一起庆祝 SELinux 纪念日的第十个年头了(LCTT 译者注:本文发表于 2013 年)。真是太难以置信了!SELinux 最初在 Fedora Core 3 中被引入,随后加入了红帽企业版 Linux 4。从来没有使用过 SELinux 的家伙,你可要好好儿找个理由了……
|
||||
|
||||
SElinux 是一个标签型系统。每一个进程都有一个标签。操作系统中的每一个文件/目录客体(object)也都有一个标签。甚至连网络端口、设备,乃至潜在的主机名都被分配了标签。我们把控制访问进程的标签的规则写入一个类似文件的客体标签中,这些规则我们称之为策略(policy)。内核强制实施了这些规则。有时候这种“强制”被称为强制访问控制体系(Mandatory Access Control)(MAC)。
|
||||
|
||||
一个客体的拥有者对客体的安全属性并没有自主权。标准 Linux 访问控制体系,拥有者/分组 + 权限标志如 rwx,常常被称作自主访问控制(Discretionary Access Control)(DAC)。SELinux 没有文件 UID 或拥有权的概念。一切都被标签控制,这意味着在没有至高无上的 root 权限进程时,也可以设置 SELinux 系统。
|
||||
|
||||
**注意:** _SELinux不允许你摒弃 DAC 控制。SELinux 是一个并行的强制模型。一个应用必须同时支持 SELinux 和 DAC 来完成特定的行为。这可能会导致管理员迷惑为什么进程被拒绝访问。管理员被拒绝访问是因为在 DAC 中有些问题,而不是在 SELinux 标签。
|
||||
|
||||
### 类型强制
|
||||
|
||||
让我们更深入的研究下标签。SELinux 最主要的“模型”或“强制”叫做类型强制(type enforcement)。基本上这意味着我们根据进程的类型来定义其标签,以及根据文件系统客体的类型来定义其标签。
|
||||
|
||||
_打个比方_
|
||||
|
||||
想象一下在一个系统里定义客体的类型为猫和狗。猫(CAT)和狗(DOG)都是进程类型(process type)。
|
||||
|
||||
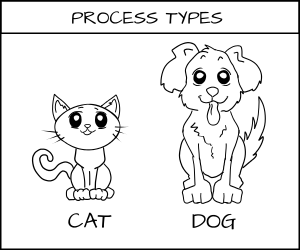
|
||||
|
||||
我们有一类希望能与之交互的客体,我们称之为食物。而我希望能够为食物增加类型:`cat_food` (猫的食物)和 `dog_food`(狗的食物)。
|
||||
|
||||
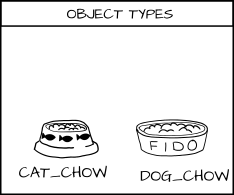
|
||||
|
||||
作为一个策略制定者,我可以说一只狗有权限去吃狗粮(`dog_chow`),而一只猫有权限去吃猫粮(`cat_chow`)。在 SELinux 中我可以将这条规则写入策略中。
|
||||
|
||||

|
||||
|
||||
`allow cat cat_chow:food eat;`
|
||||
|
||||
`允许 猫 猫粮:食物 吃;`
|
||||
|
||||
`allow dog dog_chow:food eat;`
|
||||
|
||||
`允许 狗 狗粮:食物 吃;`
|
||||
|
||||
有了这些规则,内核会允许猫进程去吃打上猫粮标签 `cat_chow` 的食物,允许狗去吃打上狗粮标签 `dog_chow` 的食物。
|
||||
|
||||
|
||||
|
||||
此外,在 SELinux 系统中,由于禁止是默认规则,这意味着,如果狗进程想要去吃猫粮 `cat_chow`,内核会阻止它。
|
||||
|
||||
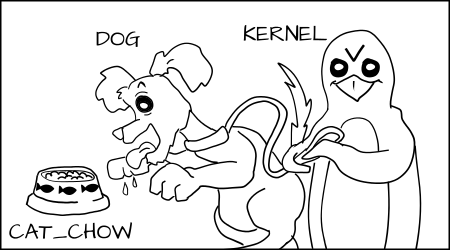
|
||||
|
||||
同理,猫也不允许去接触狗粮。
|
||||
|
||||

|
||||
|
||||
_现实例子_
|
||||
|
||||
我们将 Apache 进程标为 `httpd_t`,将 Apache 上下文标为 `httpd_sys_content_t` 和 `httpdsys_content_rw_t`。假设我们把信用卡数据存储在 MySQL 数据库中,其标签为 `msyqld_data_t`。如果一个 Apache 进程被劫持,黑客可以获得 `httpd_t` 进程的控制权,从而能够去读取 `httpd_sys_content_t` 文件并向 `httpd_sys_content_rw_t` 文件执行写操作。但是黑客却不允许去读信用卡数据(`mysqld_data_t`),即使 Apache 进程是在 root 下运行。在这种情况下 SELinux 减轻了这次闯入的后果。
|
||||
|
||||
### 多类别安全强制
|
||||
|
||||
_打个比方_
|
||||
|
||||
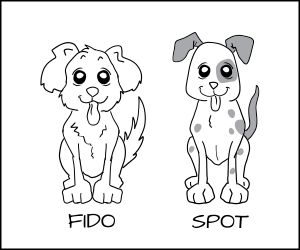
上面我们定义了狗进程和猫进程,但是如果你有多个狗进程:Fido 和 Spot,而你想要阻止 Fido 去吃 Spot 的狗粮 `dog_chow` 怎么办呢?
|
||||
|
||||

|
||||
|
||||
一个解决方式是创建大量的新类型,如 `Fido_dog` 和 `Fido_dog_chow`。但是这很快会变得难以驾驭因为所有的狗都有差不多相同的权限。
|
||||
|
||||
为了解决这个问题我们发明了一种新的强制形式,叫做多类别安全(Multi Category Security)(MCS)。在 MCS 中,我们在狗进程和狗粮的标签上增加了另外一部分标签。现在我们将狗进程标记为 `dog:random1(Fido)` 和 `dog:random2(Spot)`。
|
||||
|
||||
|
||||
|
||||
我们将狗粮标记为 `dog_chow:random1(Fido)` 和 `dog_chow:random2(Spot)`。
|
||||
|
||||

|
||||
|
||||
MCS 规则声明如果类型强制规则被遵守而且该 MCS 随机标签正确匹配,则访问是允许的,否则就会被拒绝。
|
||||
|
||||
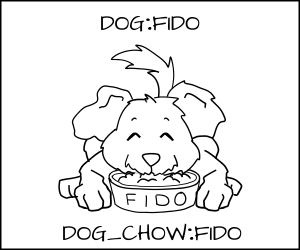
Fido (`dog:random1`) 尝试去吃 `cat_chow:food` 被类型强制拒绝了。
|
||||
|
||||

|
||||
|
||||
Fido (`dog:random1`) 允许去吃 `dog_chow:random1`。
|
||||
|
||||
|
||||
|
||||
Fido (`dog:random1`) 去吃 spot(`dog_chow:random2`)的食物被拒绝。
|
||||
|
||||

|
||||
|
||||
_现实例子_
|
||||
|
||||
在计算机系统中我们经常有很多具有同样访问权限的进程,但是我们又希望它们各自独立。有时我们称之为多租户环境(multi-tenant environment)。最好的例子就是虚拟机。如果我有一个运行很多虚拟机的服务器,而其中一个被劫持,我希望能够阻止它去攻击其它虚拟机和虚拟机镜像。但是在一个类型强制系统中 KVM 虚拟机被标记为 `svirt_t` 而镜像被标记为 `svirt_image_t`。 我们允许 `svirt_t` 可以读/写/删除标记为 `svirt_image_t` 的上下文。通过使用 libvirt 我们不仅实现了类型强制隔离,而且实现了 MCS 隔离。当 libvirt 将要启动一个虚拟机时,它会挑选出一个 MCS 随机标签如 `s0:c1,c2`,接着它会将 `svirt_image_t:s0:c1,c2` 标签分发给虚拟机需要去操作的所有上下文。最终,虚拟机以 `svirt_t:s0:c1,c2` 为标签启动。因此,SELinux 内核控制 `svirt_t:s0:c1,c2` 不允许写向 `svirt_image_t:s0:c3,c4`,即使虚拟机被一个黑客劫持并接管,即使它是运行在 root 下。
|
||||
|
||||
我们在 OpenShift 中使用[类似的隔离策略][8]。每一个 gear(user/app process)都有相同的 SELinux 类型(`openshift_t`)(LCTT 译注:gear 为 OpenShift 的计量单位)。策略定义的规则控制着 gear 类型的访问权限,而一个独一无二的 MCS 标签确保了一个 gear 不能影响其他 gear。
|
||||
|
||||
请观看[这个短视频][9]来看 OpenShift gear 切换到 root 会发生什么。
|
||||
|
||||
### 多级别安全强制
|
||||
|
||||
另外一种不经常使用的 SELinux 强制形式叫做多级别安全(Multi Level Security)(MLS);它开发于上世纪 60 年代,并且主要使用在受信操作系统上如 Trusted Solaris。
|
||||
|
||||
其核心观点就是通过进程使用的数据等级来控制进程。一个 _secret_ 进程不能读取 _top secret_ 数据。
|
||||
|
||||
MLS 很像 MCS,除了它在强制策略中增加了支配的概念。MCS 标签必须完全匹配,但一个 MLS 标签可以支配另一个 MLS 标签并且获得访问。
|
||||
|
||||
_打个比方_
|
||||
|
||||
不讨论不同名字的狗,我们现在来看不同种类。我们现在有一只格雷伊猎犬和一只吉娃娃。
|
||||
|
||||
|
||||
|
||||
我们可能想要允许格雷伊猎犬去吃任何狗粮,但是吉娃娃如果尝试去吃格雷伊猎犬的狗粮可能会被呛到。
|
||||
|
||||
我们把格雷伊猎犬标记为 `dog:Greyhound`,把它的狗粮标记为 `dog_chow:Greyhound`,把吉娃娃标记为 `dog:Chihuahua`,把它的狗粮标记为 `dog_chow:Chihuahua`。
|
||||
|
||||
|
||||
|
||||
使用 MLS 策略,我们可以使 MLS 格雷伊猎犬标签支配吉娃娃标签。这意味着 `dog:Greyhound` 允许去吃 `dog_chow:Greyhound` 和 `dog_chow:Chihuahua`。
|
||||
|
||||

|
||||
|
||||
但是 `dog:Chihuahua` 不允许去吃 `dog_chow:Greyhound`。
|
||||
|
||||

|
||||
|
||||
当然,由于类型强制, `dog:Greyhound` 和 `dog:Chihuahua` 仍然不允许去吃 `cat_chow:Siamese`,即使 MLS 类型 GreyHound 支配 Siamese。
|
||||
|
||||
|
||||
|
||||
_现实例子_
|
||||
|
||||
有两个 Apache 服务器:一个以 `httpd_t:TopSecret` 运行,一个以 `httpd_t:Secret` 运行。如果 Apache 进程 `httpd_t:Secret` 被劫持,黑客可以读取 `httpd_sys_content_t:Secret` 但会被禁止读取 `httpd_sys_content_t:TopSecret`。
|
||||
|
||||
但是如果运行 `httpd_t:TopSecret` 的 Apache 进程被劫持,它可以读取 `httpd_sys_content_t:Secret` 数据和 `httpd_sys_content_t:TopSecret` 数据。
|
||||
|
||||
我们在军事系统上使用 MLS,一个用户可能被允许读取 _secret_ 数据,但是另一个用户在同一个系统上可以读取 _top secret_ 数据。
|
||||
|
||||
### 结论
|
||||
|
||||
SELinux 是一个功能强大的标签系统,控制着内核授予每个进程的访问权限。最主要的特性是类型强制,策略规则定义的进程访问权限基于进程被标记的类型和客体被标记的类型。也引入了另外两个控制手段,分离有着同样类型进程的叫做 MCS,而 MLS,则允许进程间存在支配等级。
|
||||
|
||||
_*所有的漫画都来自 [Máirín Duffy][6]_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Daniel J Walsh - Daniel Walsh 已经在计算机安全领域工作了将近 30 年。Daniel 与 2001 年 8 月加入红帽。
|
||||
|
||||
-------------------------
|
||||
|
||||
via: https://opensource.com/business/13/11/selinux-policy-guide
|
||||
|
||||
作者:[Daniel J Walsh][a]
|
||||
译者:[xiaow6](https://github.com/xiaow6)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/rhatdan
|
||||
[1]:https://opensource.com/resources/what-is-linux?src=linux_resource_menu
|
||||
[2]:https://opensource.com/resources/what-are-linux-containers?src=linux_resource_menu
|
||||
[3]:https://opensource.com/article/16/11/managing-devices-linux?src=linux_resource_menu
|
||||
[4]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=7016000000127cYAAQ
|
||||
[5]:https://opensource.com/tags/linux?src=linux_resource_menu
|
||||
[6]:https://opensource.com/users/mairin
|
||||
[7]:https://opensource.com/business/13/11/selinux-policy-guide?rate=XNCbBUJpG2rjpCoRumnDzQw-VsLWBEh-9G2hdHyB31I
|
||||
[8]:http://people.fedoraproject.org/~dwalsh/SELinux/Presentations/openshift_selinux.ogv
|
||||
[9]:http://people.fedoraproject.org/~dwalsh/SELinux/Presentations/openshift_selinux.ogv
|
||||
[10]:https://opensource.com/user/16673/feed
|
||||
[11]:https://opensource.com/business/13/11/selinux-policy-guide#comments
|
||||
[12]:https://opensource.com/users/rhatdan
|
||||
@ -0,0 +1,107 @@
|
||||
为什么(大多数)高级语言运行效率较慢
|
||||
============================================================
|
||||
|
||||
在近一两个月中,我多次的和线上线下的朋友讨论了这个话题,所以我干脆直接把它写在博客中,以便以后查阅。
|
||||
|
||||
大部分高级语言运行效率较慢的原因通常有两点:
|
||||
|
||||
1. 没有很好的利用缓存;
|
||||
2. 垃圾回收机制性能消耗高。
|
||||
|
||||
但事实上,这两个原因可以归因于:高级语言强烈地鼓励编程人员分配很多的内存。
|
||||
|
||||
首先,下文内容主要讨论客户端应用。如果你的程序有 99.9% 的时间都在等待网络 I/O,那么这很可能不是拖慢语言运行效率的原因——优先考虑的问题当然是优化网络。在本文中,我们主要讨论程序在本地执行的速度。
|
||||
|
||||
我将选用 C# 语言作为本文的参考语言,其原因有二:首先它是我常用的高级语言;其次如果我使用 Java 语言,许多使用 C# 的朋友会告诉我 C# 不会有这些问题,因为它有值类型(但这是错误的)。
|
||||
|
||||
接下来我将会讨论,出于编程习惯编写的代码、使用普遍编程方法(with the grain)的代码或使用库或教程中提到的常用代码来编写程序时会发生什么。我对那些使用难搞的办法来解决语言自身毛病以“证明”语言没毛病这事没兴趣,当然你可以和语言抗争来避免它的毛病,但这并不能说明语言本身是没有问题的。
|
||||
|
||||
### 回顾缓存消耗问题
|
||||
|
||||
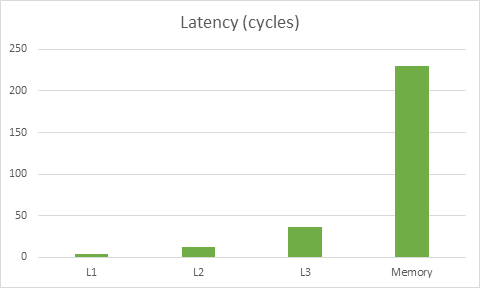
首先我们先来回顾一下合理使用缓存的重要性。下图是基于在 Haswell 架构下内存延迟对 CPU 影响的 [数据][10]:
|
||||
|
||||
|
||||
|
||||
针对这款 CPU 读取内存的延迟,CPU 需要消耗近 230 个运算周期从内存读取数据,同时需要消耗 4 个运算周期来读取 L1 缓冲区。因此错误的去使用缓存可导致运行速度拖慢近 50 倍。还好这并不是最糟糕的——在现代 CPU 中它们能同时地做多种操作,所以当你加载 L1 缓冲区内容的同时这个内容已经进入到了寄存器,因此数据从 L1 缓冲区加载这个过程的性能消耗就被部分或完整的掩盖了起来。
|
||||
|
||||
撇开选择合理的算法不谈,不夸张地讲,在性能优化中你要考虑的最主要因素其实是缓存未命中。当你能够有效的访问一个数据时候,你才需要考虑优化你的每个具体的操作。与缓存未命中的问题相比,那些次要的低效问题对运行速度并没有什么过多的影响。
|
||||
|
||||
这对于编程语言的设计者来说是一个好消息!你都_不必_去编写一个最高效的编译器,你可以完全摆脱一些额外的开销(比如:数组边界检查),你只需要专注怎么设计语言能高效地编写代码来访问数据,而不用担心与 C 语言代码比较运行速度。
|
||||
|
||||
### 为什么 C# 存在缓存未命中问题
|
||||
|
||||
坦率地讲 C# 在设计时就没打算在现代缓存中实现高效运行。我又一次提到程序语言设计的局限性以及其带给程序员无法编写高效的代码的“压力”。大部分的理论上的解决方法其实都非常的不便,这里我说的是那些编程语言“希望”你这样编写的惯用写法。
|
||||
|
||||
C# 最基本的问题是对基础值类型(value-base)低下的支持性。其大部分的数据结构都是“内置”在语言内定义的(例如:栈,或其他内置对象)。但这些具有帮助性的内置结构体有一些大问题,以至于更像是创可贴而不是解决方案。
|
||||
|
||||
* 你得把自己定义的结构体类型在最先声明——这意味着你如果需要用到这个类型作为堆分配,那么所有的结构体都会被堆分配。你也可以使用一些类包装器来打包你的结构体和其中的成员变量,但这十分的痛苦。如果类和结构体可以相同的方式声明,并且可根据具体情况来使用,这将是更好的。当数据可以作为值地存储在自定义的栈中,当这个数据需要被堆分配时你就可以将其定义为一个对象,比如 C++ 就是这样工作的。因为只有少数的内容需要被堆分配,所以我们不鼓励所有的内容都被定义为对象类型。
|
||||
|
||||
* _引用_ 值被苛刻的限制。你可以将一个引用值传给函数,但只能这样。你不能直接引用 `List<int>` 中的元素,你必须先把所有的引用和索引全部存储下来。你不能直接取得指向栈、对象中的变量(或其他变量)的指针。你只能把它们复制一份,除了将它们传给一个函数(使用引用的方式)。当然这也是可以理解的。如果类型安全是一个先驱条件,灵活的引用变量和保证类型安全这两项要同时支持太难了(虽然不是不可能)。这些限制背后的理念并不能改变限制存在的事实。
|
||||
|
||||
* [固定大小的缓冲区][6] 不支持自定义类型,而且还必须使用 `unsafe` 关键字。
|
||||
|
||||
* 有限的“数组切片”功能。虽然有提供 `ArraySegment` 类,但并没有人会使用它,这意味着如果只需要传递数组的一部分,你必须去创建一个 `IEnumerable` 对象,也就意味着要分配大小(包装)。就算接口接受 `ArraySegment` 对象作为参数,也是不够的——你只能用普通数组,而不能用 `List<T>`,也不能用 [栈数组][4] 等等。
|
||||
|
||||
最重要的是,除了非常简单的情况之外,C# 非常惯用堆分配。如果所有的数据都被堆分配,这意味着被访问时会造成缓存未命中(从你无法决定对象是如何在堆中存储开始)。所以当 C++ 程序面临着如何有效的组织数据在缓存中的存储这个挑战时,C# 则鼓励程序员去将数据分开地存放在一个个堆分配空间中。这就意味着程序员无法控制数据存储方式了,也开始产生不必要的缓存未命中问题,而导致性能急速的下降。[C# 已经支持原生编译][11] 也不会提升太多性能——毕竟在内存不足的情况下,提高代码质量本就杯水车薪。
|
||||
|
||||
再加上存储是有开销的。在 64 位的机器上每个地址值占 8 位内存,而每次分配都会有存储元数据而产生的开销。与存储着少量大数据(以固定偏移的方式存储在其中)的堆相比,存储着大量小数据的堆(并且其中的数据到处都被引用)会产生更多的内存开销。尽管你可能不怎么关心内存怎么用,但事实上就是那些头部内容和地址信息导致堆变得臃肿,也就是在浪费缓存了,所以也造成了更多的缓存未命中,降低了代码性能。
|
||||
|
||||
当然有些时候也是有办法的,比如你可以使用一个很大的 `List<T>` 来构造数据池以存储分配你需要的数据和自己的结构体。这样你就可以方便的遍历或者批量更新你的数据池中的数据了。但这也会很混乱,因为无论你在哪要引用什么对象都要先能引用这个池,然后每次引用都需要做数组索引。从上文可以得出,在 C# 中做类似这样的处理的痛感比在 C++ 中做来的更痛,因为 C# 在设计时就是这样。此外,通过这种方式来访问池中的单个对象比直接将这个对象分配到内存来访问更加的昂贵——前者你得先访问池(这是个类)的地址,这意味着可能产生 _2_ 次缓存未命中。你还可以通过复制 `List<T>` 的结构形式来避免更多的缓存未命中问题,但这就更难搞了。我就写过很多类似的代码,自然这样的代码只会水平很低而且容易出错。
|
||||
|
||||
最后,我想说我指出的问题不仅是那些“热门”的代码。惯用手段编写的 C# 代码倾向于几乎所有地方都用类和引用。意思就是在你的代码中会频率均匀地随机出现数百次的运算周期损耗,使得操作的损耗似乎降低了。这虽然也可以被找出来,但你优化了这问题后,这还是一个 [均匀变慢][12] 的程序。
|
||||
|
||||
### 垃圾回收
|
||||
|
||||
在读下文之前我会假设你已经知道为什么在许多用例中垃圾回收是影响性能问题的重要原因。播放动画时总是随机的暂停通常都是大家都不能接受的吧。我会继续解释为什么设计语言时还加剧了这个问题。
|
||||
|
||||
因为 C# 在处理变量上的一些局限性,它强烈不建议你去使用大内存块分配来存储很多里面是内置对象的变量(可能存在栈中),这就使得你必须使用很多分配在堆中的小型类对象。说白了就是内存分配越多会导致花在垃圾回收上的时间就越多。
|
||||
|
||||
有些测评说 C# 或者 Java 是怎么在一些特定的例子中打败 C++ 的,其实是因为内存分配器都基于一种吞吐还算不错的垃圾回收机制(廉价的分配,允许统一的释放分配)。然而,这些测试场景都太特殊了。想要使 C# 的程序的内存分配率变得和那些非常普通的 C++ 程序都能达到的一样就必须要耗费更大的精力来编写它,所以这种比较就像是拿一个高度优化的管理程序和一个最简单原生的程序相比较一样。当你花同样的精力来写一个 C++ 程序时,肯定比你用 C# 来写性能好的多。
|
||||
|
||||
我还是相信你可以写出一套适用于高性能低延迟的应用的垃圾回收机制的(比如维护一个增量的垃圾回收,每次消耗固定的时间来做回收),但这还是不够的,大部分的高级语言在设计时就没考虑程序启动时就会产生大量的垃圾,这将会是最大的问题。当你就像写 C 一样习惯的去少去在 C# 分配内存,垃圾回收在高性能应用中可能就不会暴露出很多的问题了。而就算你 _真的_ 去实现了一个增量垃圾回收机制,这意味着你还可能需要为其做一个写屏障——这就相当于又消耗了一些性能了。
|
||||
|
||||
看看 `.Net` 库里那些基本类,内存分配几乎无处不在!我数了下,在 [.Net 核心框架][13] 中公共类比结构体的数量多出 19 倍之多,为了使用它们,你就得把这些东西全都弄到内存中去。就算是 `.Net` 框架的创造者们也无法抵抗设计语言时的警告啊!我都不知道怎么去统计了,使用基础类库时,你会很快意识到这不仅仅是值或对象的选择问题了,就算如此也还是 _伴随_ 着超级多的内存分配。这一切都让你觉得分配内存好像很容易一样,其实怎么可能呢,没有内存分配你连一个整形值都没法输出!不说这个,就算你使用预分配的 `StringBuilder`,你要是不用标准库来分配内存,也还不是连个整型都存不住。你要这么问我那就挺蠢的了。
|
||||
|
||||
当然还不仅仅是标准库,其他的 C# 库也一样。就算是 `Unity`(一个 _游戏引擎_,可能能更多的关心平均性能问题)也会有一些全局返回已分配对象(或数组)的接口,或者强制调用时先将其分配内存再使用。举个例子,在一个 `GameObject` 中要使用 `GetComponents` 来调用一个数组,`Unity` 会强制地分配一个数组以便调用。就此而言,其实有许多的接口可以采用,但他们不选择,而去走常规路线来直接使用内存分配。写 `Unity` 的同胞们写的一手“好 C#”呀,但就是不那么高性能罢了。
|
||||
|
||||
### 结语
|
||||
|
||||
如果你在设计一门新的语言,拜托你可以考虑一下我提到的那些性能问题。在你创造出一款“足够聪明的编译器”之后这些都不是什么难题了。当然,没有垃圾回收器就要求类型安全很难。当然,没有一个规范的数据表示就创造一个垃圾回收器很难。当然,出现指向随机值的指针时难以去推出其作用域规则。当然,还有大把大把的问题摆在那里,然而解决了这些所有的问题,设计出来的语言就会是我们想的那样吗?那为什么这么多主要的语言都是在那些六十年代就已经被设计出的语言的基础上迭代的呢?
|
||||
|
||||
尽管你不能修复这些问题,但也许你可以尽可能的靠近?或者可以使用域类型(比如 `Rust` 语言)去保证其类型安全。或者也许可以考虑直接放弃“类型安全成本”去使用更多的运行时检查(如果这不会造成更多的缓存未命中的话,这其实没什么所谓。其实 C# 也有类似的东西,叫协变式数组,严格上讲是违背系统数据类型的,会导致一些运行时异常)。
|
||||
|
||||
如果你想在高性能场景中替代 C++,最基本的一点就是要考虑数据的存放布局和存储方式。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
我叫 Sebastian Sylvan。我来自瑞典,目前居住在西雅图。我在微软工作,研究全息透镜。诚然我的观点仅代表本人,与微软公司无关。
|
||||
|
||||
我的博客以图像、编程语言、性能等内容为主。联系我请点击我的 Twitter 或 E-mail。
|
||||
|
||||
------------
|
||||
|
||||
|
||||
via: https://www.sebastiansylvan.com/post/why-most-high-level-languages-are-slow
|
||||
|
||||
作者:[Sebastian Sylvan][a]
|
||||
译者:[kenxx](https://github.com/kenxx)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.sebastiansylvan.com/about/
|
||||
[1]:https://www.sebastiansylvan.com/post/why-most-high-level-languages-are-slow/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#cache-costs-review
|
||||
[2]:https://www.sebastiansylvan.com/post/why-most-high-level-languages-are-slow/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#why-c-introduces-cache-misses
|
||||
[3]:https://www.sebastiansylvan.com/post/why-most-high-level-languages-are-slow/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#garbage-collection
|
||||
[4]:https://msdn.microsoft.com/en-us/library/vstudio/cx9s2sy4(v=vs.100).aspx
|
||||
[5]:https://www.sebastiansylvan.com/post/why-most-high-level-languages-are-slow/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#closing-remarks
|
||||
[6]:https://msdn.microsoft.com/en-us/library/vstudio/zycewsya(v=vs.100).aspx
|
||||
[7]:https://www.sebastiansylvan.com/post/why-most-high-level-languages-are-slow/
|
||||
[8]:https://www.sebastiansylvan.com/categories/programming-languages
|
||||
[9]:https://www.sebastiansylvan.com/categories/software-engineering
|
||||
[10]:http://www.7-cpu.com/cpu/Haswell.html
|
||||
[11]:https://msdn.microsoft.com/en-us/vstudio/dotnetnative.aspx
|
||||
[12]:http://c2.com/cgi/wiki?UniformlySlowCode
|
||||
[13]:https://github.com/dotnet/corefx
|
||||
@ -0,0 +1,253 @@
|
||||
在 Kali Linux 中更改 GRUB 背景的 5 种方式
|
||||
============================================================
|
||||
|
||||
这是一个关于如何在 Kali Linux 中更改 GRUB 背景的简单指南(实际上它是 Kali Linux 的
|
||||
GRUB 启动图像)。 Kali 开发团队在这方面做的不多,他们好像太忙了,所以在这篇文章中,我会对 GRUB 解释一二,但是不会冗长到我失去写作的激情。 那么我们开始吧……
|
||||
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
### 查找 GRUB 设置
|
||||
|
||||
这通常是所有人首先会遇到的一个问题,在哪里设置?有很多方法来查找 GRUB 设置。每个人都可能有自己的方法,但我发现 `update-grub` 是最简单的。如果在 VMWare 或 VirtualBox 中执行 `update-grub`,你将看到如下所示的内容:
|
||||
|
||||
```
|
||||
root@kali:~# update-grub
|
||||
Generating grub configuration file ...
|
||||
Found background image: /usr/share/images/desktop-base/desktop-grub.png
|
||||
Found linux image: /boot/vmlinuz-4.0.0-kali1-amd64
|
||||
Found initrd image: /boot/initrd.img-4.0.0-kali1-amd64
|
||||
No volume groups found
|
||||
done
|
||||
root@kali:~#
|
||||
```
|
||||
|
||||
如果您是双系统,或者三系统,那么您将看到 GRUB 以及其他操作系统入口。然而,我们感兴趣的部分是背景图像,这是在我这里看到的(你会看到完全相同的内容):
|
||||
|
||||
```
|
||||
Found background image: /usr/share/images/desktop-base/desktop-grub.png
|
||||
```
|
||||
|
||||
### GRUB 启动图像搜索顺序
|
||||
|
||||
在 grub-2.02 中,对基于 Debian 的系统来说,它将按照以下顺序搜索启动背景:
|
||||
|
||||
1. `/etc/default/grub` 里的 `GRUB_BACKGROUND` 行
|
||||
2. 在 `/boot/grub/` 里找到的第一个图像(如果发现多张,将以字母顺序排序)
|
||||
3. 在 `/usr/share/desktop-base/grub_background.sh` 中指定的
|
||||
4. 在 `/etc/grub.d/05_debian_theme` 里 `WALLPAPER` 行列出的
|
||||
|
||||
现在将此信息留在这里,我们会尽快重新检查它。
|
||||
|
||||
### Kali Linux GRUB 启动图像
|
||||
|
||||
在我使用 Kali Linux 时(因为我喜欢用它做事),会发现 Kali 正在使用这里的背景图像:`/usr/share/images/desktop-base/desktop-grub.png`
|
||||
|
||||
为了确定,我们来检查一下这个 `.png` 文件的属性。
|
||||
|
||||
```
|
||||
root@kali:~#
|
||||
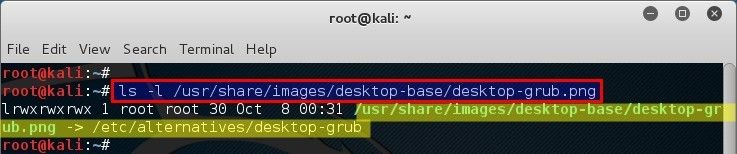
root@kali:~# ls -l /usr/share/images/desktop-base/desktop-grub.png
|
||||
lrwxrwxrwx 1 root root 30 Oct 8 00:31 /usr/share/images/desktop-base/desktop-grub.png -> /etc/alternatives/desktop-grub
|
||||
root@kali:~#
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][11]
|
||||
|
||||
什么?它只是 `/etc/alternatives/desktop-grub` 的一个符号链接? 但是 `/etc/alternatives/desktop-grub` 不是图片文件。看来我也要检查一下它的属性。
|
||||
|
||||
```
|
||||
root@kali:~#
|
||||
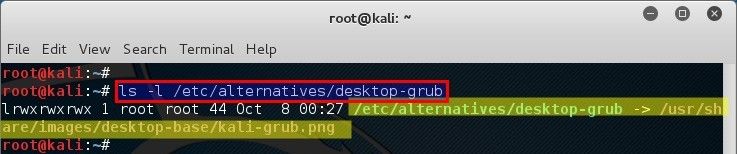
root@kali:~# ls -l /etc/alternatives/desktop-grub
|
||||
lrwxrwxrwx 1 root root 44 Oct 8 00:27 /etc/alternatives/desktop-grub -> /usr/share/images/desktop-base/kali-grub.png
|
||||
root@kali:~#
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][12]
|
||||
|
||||
好吧,真让人费解。 `/etc/alternatives/desktop-grub` 也是一个符号链接,它指向 `/usr/share/images/desktop-base/kali-grub.png`,来自最初同样的文件夹。呃! 无语。 但是现在我们至少可以替换该文件并将其解决。
|
||||
|
||||
在替换之前,我们需要检查 `/usr/share/images/desktop-base/kali-grub.png` 的属性,以确保下载相同类型和大小的文件。
|
||||
|
||||
```
|
||||
root@kali:~#
|
||||
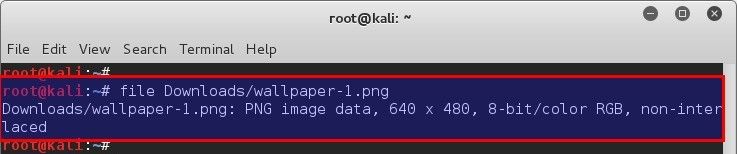
root@kali:~# file /usr/share/images/desktop-base/kali-grub.png
|
||||
/usr/share/images/desktop-base/kali-grub.png: PNG image data, 640 x 480, 8-bit/color RGB, non-interlaced
|
||||
root@kali:~#
|
||||
```
|
||||
|
||||
可以确定这是一个 PNG 图像文件,像素尺寸为 640 x 480。
|
||||
|
||||
### GRUB 背景图像属性
|
||||
|
||||
可以使用 `PNG`, `JPG`/`JPEG` 以及 `TGA` 类型的图像文件作为 GRUB 2 的背景。必须符合以下规范:
|
||||
|
||||
* `JPG`/`JPEG` 图像必须是 `8-bit` (256 色)
|
||||
* 图像应该是非索引的,`RGB`
|
||||
|
||||
默认情况下,如果安装了 `desktop-base` 软件包,符合上述规范的图像将放在 `/usr/share/images/desktop-base/` 目录中。在谷歌上很容易找到类似的文件。我也找了一个。
|
||||
|
||||
```
|
||||
root@kali:~#
|
||||
root@kali:~# file Downloads/wallpaper-1.png
|
||||
Downloads/wallpaper-1.png: PNG image data, 640 x 480, 8-bit/color RGB, non-interlaced
|
||||
root@kali:~#
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][13]
|
||||
|
||||
### 方式 1:替换图像
|
||||
|
||||
现在我们只需简单的用新文件将 `/usr/share/images/desktop-base/kali-grub.png` 替换掉。值得注意这是最简单的方法,不需要修改 `grub-config` 文件。 如果你对 GRUB 很熟,建议你简单的修改 GRUB 的默认配置文件,然后执行 `update-grub`。
|
||||
|
||||
像往常一样,我会将原文件重命名为 `kali-grub.png.bkp` 进行备份。
|
||||
|
||||
```
|
||||
root@kali:~#
|
||||
root@kali:~# mv /usr/share/images/desktop-base/kali-grub.png /usr/share/images/desktop-base/kali-grub.png.bkp
|
||||
root@kali:~#
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][14]
|
||||
|
||||
现在我们将下载的文件重命名为 `kali-grub.png`。
|
||||
|
||||
```
|
||||
root@kali:~#
|
||||
root@kali:~# cp Downloads/wallpaper-1.png /usr/share/images/desktop-base/kali-grub.png
|
||||
root@kali:~#
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][15]
|
||||
|
||||
最后执行命令 `update-grub`:
|
||||
|
||||
```
|
||||
root@kali:~# update-grub
|
||||
Generating grub configuration file ...
|
||||
Found background image: /usr/share/images/desktop-base/desktop-grub.png
|
||||
Found linux image: /boot/vmlinuz-4.0.0-kali1-amd64
|
||||
Found initrd image: /boot/initrd.img-4.0.0-kali1-amd64
|
||||
No volume groups found
|
||||
done
|
||||
root@kali:~#
|
||||
```
|
||||
|
||||
[
|
||||
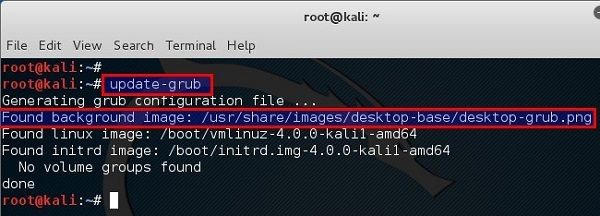
|
||||
][16]
|
||||
|
||||
下次重新启动你的 Kali Linux 时,你会看到 GRUB 背景变成了你自己的图像(GRUB 启动界面)。
|
||||
|
||||
下面是我现在正在使用的新 GRUB 启动背景。你呢?要不要试试这个办法?
|
||||
|
||||
[
|
||||

|
||||
][17]
|
||||
|
||||
这是最简单最安全的办法,最糟的情况也不过是在 GRUB 看到一个蓝色的背景,但你依然可以登录后修复它们。现在如果你有信心,让我们尝试一个改变 GRUB 设置的更好的方法(有点复杂)。后续步骤更加有趣,而且可以在任何使用 GRUB 引导的 Linux 上使用。
|
||||
|
||||
现在回忆一下 GRUB 在哪 4 个地方寻找启动背景图像?再看一遍:
|
||||
|
||||
1. `/etc/default/grub` 里的 `GRUB_BACKGROUND` 行
|
||||
2. 在 `/boot/grub/` 里找到的第一个图像(如果发现多张,将以字母顺序排序)
|
||||
3. 在 `/usr/share/desktop-base/grub_background.sh` 中指定的
|
||||
4. 在 `/etc/grub.d/05_debian_theme` 里 WALLPAPER 行列出的
|
||||
|
||||
那么我们再在 Kali Linux 上(或任意使用 GRUB2 的 Linux系统)试一下新的选择。
|
||||
|
||||
### 方式 2:在 GRUB_BACKGROUND 中定义图像路径
|
||||
|
||||
所以你可以根据上述的查找优先级使用上述任一项,将 GRUB 背景图像改为自己的。以下是我自己系统上 `/etc/default/grub` 的内容。
|
||||
|
||||
```
|
||||
root@kali:~# vi /etc/default/grub
|
||||
```
|
||||
|
||||
按照 `GRUB_BACKGROUND="/root/World-Map.jpg"` 的格式添加一行,其中 World-Map.jpg 是你要作为 GRUB 背景的图像文件。
|
||||
|
||||
```
|
||||
# If you change this file, run 'update-grub' afterwards to update
|
||||
# /boot/grub/grub.cfg.
|
||||
# For full documentation of the options in this file, see:
|
||||
# info -f grub -n 'Simple configuration'
|
||||
|
||||
GRUB_DEFAULT=0
|
||||
GRUB_TIMEOUT=15
|
||||
GRUB_DISTRIBUTOR=`lsb_release -i -s 2> /dev/null || echo Debian`
|
||||
GRUB_CMDLINE_LINUX_DEFAULT="quiet"
|
||||
GRUB_CMDLINE_LINUX="initrd=/install/gtk/initrd.gz"
|
||||
GRUB_BACKGROUND="/root/World-Map.jpg"
|
||||
```
|
||||
|
||||
一旦使用上述方式完成更改,务必执行 `update-grub` 命令,如下所示。
|
||||
|
||||
```
|
||||
root@kali:~# update-grub
|
||||
Generating grub configuration file ...
|
||||
Found background: /root/World-Map.jpg
|
||||
Found background image: /root/World-Map.jpg
|
||||
Found linux image: /boot/vmlinuz-4.0.0-kali1-amd64
|
||||
Found initrd image: /boot/initrd.img-4.0.0-kali1-amd64
|
||||
No volume groups found
|
||||
done
|
||||
root@kali:~#
|
||||
```
|
||||
|
||||
现在重启机器,你会在 GRUB 看到自定义的图像。
|
||||
|
||||
### 方式 3:把图像文件放到 /boot/grub/ 文件夹
|
||||
|
||||
如果没有在 `/etc/default/grub` 文件中指定 `GRUB_BACKGROUND` 项,理论上 GRUB 应当使用在 `/boot/grub/` 文件夹找到的第一个图像文件作为背景。如果 GRUB 在 `/boot/grub/` 找到多个图像文件,它会按字母排序并使用第一个图像文件。
|
||||
|
||||
### 方式 4:在 grub_background.sh 指定图像路径
|
||||
|
||||
如果没有在 `/etc/default/grub` 文件中指定 `GRUB_BACKGROUND` 项,而且 `/boot/grub/` 目录下没有图像文件,GRUB 将会开始在 `/usr/share/desktop-base/grub_background.sh` 文件中指定的图像路径中搜索。Kali Linux 是在这里指定的。每个 Linux 发行版都有自己的特色。
|
||||
|
||||
### 方式 5:在 /etc/grub.d/05\_debian\_theme 文件的 WALLPAPER 一行指定图像
|
||||
|
||||
这是 GRUB 搜寻背景图像的最后一个位置。如果在其他部分都没有找到,它将会在这里查找。
|
||||
|
||||
### 结论
|
||||
|
||||
这篇文章较长,但我想介绍一些基础但很重要的东西。如果你有仔细阅读,你会理解如何在 Kali Linux 上来回跟踪符号链接。当你需要在一些 Linux 系统上查找 GRUB 背景图像的位置时,你会感到得心应手。只要再多阅读一点来理解 GRUB 颜色的工作方式,你就是行家了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.blackmoreops.com/2015/11/27/change-grub-background-in-kali-linux/
|
||||
|
||||
作者:[https://www.blackmoreops.com/][a]
|
||||
译者:[fuowang](https://github.com/fuowang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.blackmoreops.com/2015/11/27/change-grub-background-in-kali-linux/
|
||||
[1]:http://www.facebook.com/sharer.php?u=https://www.blackmoreops.com/?p=5958
|
||||
[2]:https://twitter.com/intent/tweet?text=5+ways+to+change+GRUB+background+in+Kali+Linux%20via%20%40blackmoreops&url=https://www.blackmoreops.com/?p=5958
|
||||
[3]:https://plusone.google.com/_/+1/confirm?hl=en&url=https://www.blackmoreops.com/?p=5958&name=5+ways+to+change+GRUB+background+in+Kali+Linux
|
||||
[4]:https://www.blackmoreops.com/how-to/
|
||||
[5]:https://www.blackmoreops.com/kali-linux/
|
||||
[6]:https://www.blackmoreops.com/kali-linux-2-x-sana/
|
||||
[7]:https://www.blackmoreops.com/administration/
|
||||
[8]:https://www.blackmoreops.com/usability/
|
||||
[9]:https://www.blackmoreops.com/2015/11/27/change-grub-background-in-kali-linux/#comments
|
||||
[10]:http://www.blackmoreops.com/wp-content/uploads/2015/11/Change-GRUB-background-in-Kali-Linux-blackMORE-OPs-10.jpg
|
||||
[11]:http://www.blackmoreops.com/2015/11/27/change-grub-background-in-kali-linux/change-grub-background-in-kali-linux-blackmore-ops-1/
|
||||
[12]:http://www.blackmoreops.com/2015/11/27/change-grub-background-in-kali-linux/change-grub-background-in-kali-linux-blackmore-ops-3/
|
||||
[13]:http://www.blackmoreops.com/2015/11/27/change-grub-background-in-kali-linux/change-grub-background-in-kali-linux-blackmore-ops-6/
|
||||
[14]:http://www.blackmoreops.com/2015/11/27/change-grub-background-in-kali-linux/change-grub-background-in-kali-linux-blackmore-ops-4/
|
||||
[15]:http://www.blackmoreops.com/2015/11/27/change-grub-background-in-kali-linux/change-grub-background-in-kali-linux-blackmore-ops-5/
|
||||
[16]:http://www.blackmoreops.com/2015/11/27/change-grub-background-in-kali-linux/change-grub-background-in-kali-linux-blackmore-ops-7/
|
||||
[17]:http://www.blackmoreops.com/wp-content/uploads/2015/11/Change-GRUB-background-in-Kali-Linux-blackMORE-OPs-9.jpg
|
||||
@ -0,0 +1,66 @@
|
||||
如何更改 Linux 的 I/O 调度器
|
||||
==================================
|
||||
|
||||
Linux 的 I/O 调度器是一个从存储卷以块式 I/O 访问的进程,有时也叫磁盘调度器。Linux I/O 调度器的工作机制是控制块设备的请求队列:确定队列中哪些 I/O 的优先级更高以及何时下发 I/O 到块设备,以此来减少磁盘寻道时间,从而提高系统的吞吐量。
|
||||
|
||||
目前 Linux 上有如下几种 I/O 调度算法:
|
||||
|
||||
1. noop - 通常用于内存存储的设备。
|
||||
2. cfq - 绝对公平调度器。进程平均使用IO带宽。
|
||||
3. Deadline - 针对延迟的调度器,每一个 I/O,都有一个最晚执行时间。
|
||||
4. Anticipatory - 启发式调度,类似 Deadline 算法,但是引入预测机制提高性能。
|
||||
|
||||
查看设备当前的 I/O 调度器:
|
||||
|
||||
```
|
||||
# cat /sys/block/<Disk_Name>/queue/scheduler
|
||||
```
|
||||
|
||||
假设磁盘名称是 `/dev/sdc`:
|
||||
|
||||
```
|
||||
# cat /sys/block/sdc/queue/scheduler
|
||||
noop anticipatory deadline [cfq]
|
||||
```
|
||||
|
||||
### 如何改变硬盘设备 I/O 调度器
|
||||
|
||||
使用如下指令:
|
||||
|
||||
```
|
||||
# echo {SCHEDULER-NAME} > /sys/block/<Disk_Name>/queue/scheduler
|
||||
```
|
||||
|
||||
比如设置 noop 调度器:
|
||||
|
||||
```
|
||||
# echo noop > /sys/block/sdc/queue/scheduler
|
||||
```
|
||||
|
||||
以上设置重启后会失效,要想重启后配置仍生效,需要在内核启动参数中将 `elevator=noop` 写入 `/boot/grub/menu.lst`:
|
||||
|
||||
#### 1. 备份 menu.lst 文件
|
||||
|
||||
```
|
||||
cp -p /boot/grub/menu.lst /boot/grub/menu.lst-backup
|
||||
```
|
||||
|
||||
#### 2. 更新 /boot/grub/menu.lst
|
||||
|
||||
将 `elevator=noop` 添加到文件末尾,比如:
|
||||
|
||||
```
|
||||
kernel /vmlinuz-2.6.16.60-0.91.1-smp root=/dev/sysvg/root splash=silent splash=off showopts elevator=noop
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxroutes.com/change-io-scheduler-linux/
|
||||
|
||||
作者:[UX Techno][a]
|
||||
译者:[honpey](https://github.com/honpey)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxroutes.com/change-io-scheduler-linux/
|
||||
86
published/201703/20170101 FTPS vs SFTP.md
Normal file
86
published/201703/20170101 FTPS vs SFTP.md
Normal file
@ -0,0 +1,86 @@
|
||||
FTPS(基于 SSL 的FTP)与 SFTP(SSH 文件传输协议)对比
|
||||
==================================================
|
||||
|
||||

|
||||
|
||||
<ruby>SSH 文件传输协议<rt>SSH File transfer protocol</rt></ruby>(SFTP)也称为<ruby>通过安全套接层的文件传输协议<rt>File Transfer protocol via Secure Socket Layer</rt></ruby>, 以及 FTPS 都是最常见的安全 FTP 通信技术,用于通过 TCP 协议将计算机文件从一个主机传输到另一个主机。SFTP 和 FTPS 都提供高级别文件传输安全保护,通过强大的算法(如 AES 和 Triple DES)来加密传输的数据。
|
||||
|
||||
但是 SFTP 和 FTPS 之间最显着的区别是如何验证和管理连接。
|
||||
|
||||
### FTPS
|
||||
|
||||
FTPS 是使用安全套接层(SSL)证书的 FTP 安全技术。整个安全 FTP 连接使用用户 ID、密码和 SSL 证书进行身份验证。一旦建立 FTPS 连接,[FTP 客户端软件][6]将检查目标[ FTP 服务器][7]证书是否可信的。
|
||||
|
||||
如果证书由已知的证书颁发机构(CA)签发,或者证书由您的合作伙伴自己签发,并且您的信任密钥存储区中有其公开证书的副本,则 SSL 证书将被视为受信任的证书。FTPS 所有的用户名和密码信息将通过安全的 FTP 连接加密。
|
||||
|
||||
以下是 FTPS 的优点和缺点:
|
||||
|
||||
优点:
|
||||
|
||||
- 通信可以被人们读取和理解
|
||||
- 提供服务器到服务器文件传输的服务
|
||||
- SSL/TLS 具有良好的身份验证机制(X.509 证书功能)
|
||||
- FTP 和 SSL 支持内置于许多互联网通信框架中
|
||||
|
||||
缺点:
|
||||
|
||||
- 没有统一的目录列表格式
|
||||
- 需要辅助数据通道(DATA),这使得难以通过防火墙使用
|
||||
- 没有定义文件名字符集(编码)的标准
|
||||
- 并非所有 FTP 服务器都支持 SSL/TLS
|
||||
- 没有获取和更改文件或目录属性的标准方式
|
||||
|
||||
|
||||
### SFTP
|
||||
|
||||
SFTP 或 SSH 文件传输协议是另一种安全的安全文件传输协议,设计为 SSH 扩展以提供文件传输功能,因此它通常仅使用 SSH 端口用于数据传输和控制。当 [FTP 客户端][8]软件连接到 SFTP 服务器时,它会将公钥传输到服务器进行认证。如果密钥匹配,提供任何用户/密码,身份验证就会成功。
|
||||
|
||||
以下是 SFTP 优点和缺点:
|
||||
|
||||
优点:
|
||||
|
||||
- 只有一个连接(不需要 DATA 连接)。
|
||||
- FTP 连接始终保持安全
|
||||
- FTP 目录列表是一致的和机器可读的
|
||||
- FTP 协议包括操作权限和属性操作,文件锁定和更多的功能。
|
||||
|
||||
缺点:
|
||||
|
||||
- 通信是二进制的,不能“按原样”记录下来用于人类阅读,
|
||||
- SSH 密钥更难以管理和验证。
|
||||
- 这些标准定义了某些可选或推荐的选项,这会导致不同供应商的不同软件之间存在某些兼容性问题。
|
||||
- 没有服务器到服务器的复制和递归目录删除操作
|
||||
- 在 VCL 和 .NET 框架中没有内置的 SSH/SFTP 支持。
|
||||
|
||||
### 对比
|
||||
|
||||
大多数 FTP 服务器软件这两种安全 FTP 技术都支持,以及强大的身份验证选项。
|
||||
|
||||
但 SFTP 显然是赢家,因为它适合防火墙。SFTP 只需要通过防火墙打开一个端口(默认为 22)。此端口将用于所有 SFTP 通信,包括初始认证、发出的任何命令以及传输的任何数据。
|
||||
|
||||
FTPS 通过严格安全的防火墙相对难以实现,因为 FTPS 使用多个网络端口号。每次进行文件传输请求(get,put)或目录列表请求时,需要打开另一个端口号。因此,必须在您的防火墙中打开一系列端口以允许 FTPS 连接,这可能是您的网络的安全风险。
|
||||
|
||||
支持 FTPS 和 SFTP 的 FTP 服务器软件:
|
||||
|
||||
1. [Cerberus FTP 服务器][2]
|
||||
2. [FileZilla - 最著名的免费 FTP 和 FTPS 服务器软件][3]
|
||||
3. [Serv-U FTP 服务器][4]
|
||||
|
||||
-------------------------------------------------- ------------------------------
|
||||
|
||||
via: http://www.techmixer.com/ftps-sftp/
|
||||
|
||||
作者:[Techmixer.com][a]
|
||||
译者:[Yuan0302](https://github.com/Yuan0302)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.techmixer.com/
|
||||
[1]:http://www.techmixer.com/ftps-sftp/#respond
|
||||
[2]:http://www.cerberusftp.com/
|
||||
[3]:http://www.techmixer.com/free-ftp-server-best-windows-ftp-server-download/
|
||||
[4]:http://www.serv-u.com/
|
||||
[6]:http://www.techmixer.com/free-ftp-file-transfer-protocol-softwares/
|
||||
[7]:http://www.techmixer.com/free-ftp-server-best-windows-ftp-server-download/
|
||||
[8]:http://www.techmixer.com/best-free-mac-ftp-client-connect-ftp-server/
|
||||
@ -0,0 +1,140 @@
|
||||
如何在 Linux 桌面上使用 Gifine 录制 GIF 动画?
|
||||
============================================================
|
||||
|
||||
不用我说,你也知道 GIF 动画在过去几年发展迅速。人们经常在线上文字交流时使用动画增添趣味,同时这些动画在很多其他地方也显得非常有用。
|
||||
|
||||
在技术领域使用动画能够很快的描述出现的问题或者返回的错误。它也能很好的展现出一个软件应用产品的特性。你可以在进行线上座谈会或者在进行公司展示时使用 GIF 动画,当然,你可以在更多的地方用到它。
|
||||
|
||||
现在,假设你的电脑桌面上打开了多个应用程序,或者无论出于什么目的,你想制作一个 GIF 动画来记录桌面上一个应用程序窗口的操作过程。你应该怎么做呢?显然,你需要一个工具来完成这件事。
|
||||
|
||||
如果你正在寻找了这样一个可以记录桌面上部分区域的工具,并且它可以自动把录屏转化成 GIF 动画; 现在,本教程会介绍一个 Linux 命令行工具来实现你的需求。
|
||||
|
||||
开始之前,你必须知道在本教程中所有的例子都是在 Ubuntu 14.04 上测试过的,它的 Bash 版本是 4.3.11(1) 。
|
||||
|
||||
### Gifine
|
||||
|
||||
这个工具的主页是 [Gifine][5] 。它基于 GTK 工具包,是用 MoonScript 使用 lgi 库编写的。Gifine 不仅能够录屏、创建动画或视频,而且能够用它来把几个小型动画或视频拼接在一起。
|
||||
|
||||
引述这个工具的开发者的话:“你可以加载一个视频帧的目录或者选择一个桌面的区域进行录屏。你加载了一些视频帧后,可以连续查看它们,并裁剪掉不需要的部分。最终完成录屏后可以导出为 gif 或者 mp4 文件。”
|
||||
|
||||
### Gifine 下载/安装/配置
|
||||
|
||||
在指引你下载和安装 Gifine 之前,应该指出安装这个工具时需要安装的依赖包。
|
||||
|
||||
首先需要安装的依赖包是 FFmpeg , 这个软件包是一种记录、转化和流化音频以及视频的跨平台解决方案。使用下列命令安装这个工具;
|
||||
|
||||
```
|
||||
sudo apt-get install ffmpeg
|
||||
```
|
||||
|
||||
接下来是图像处理系统 GraphicsMagick。这个工具的官网说:“它提供了一个稳健且高效的工具和库的集合,支持读写并且可以操作超过 88 种主要的图像格式,比如:DPX、 GIF、 JPEG、 JPEG-2000、 PNG、 PDF、 PNM 以及 TIFF 等。”
|
||||
|
||||
通过下面的命令安装:
|
||||
|
||||
```
|
||||
sudo apt-get install graphicsmagick
|
||||
```
|
||||
|
||||
接下来的需要的工具是 XrectSel 。在你移动鼠标选择区域的时候,它会显示矩形区域的坐标位置。我们只能通过源码安装 XrectSel ,你可以从 [这里][6] 下载它。
|
||||
|
||||
如果你下载了源码,接下来就可以解压下载的文件,进入解压后的目录中。然后,运行下列命令:
|
||||
|
||||
```
|
||||
./bootstrap
|
||||
```
|
||||
|
||||
如果 `configure` 文件不存在,就需要使用上面的命令
|
||||
|
||||
```
|
||||
./configure --prefix /usr
|
||||
|
||||
make
|
||||
|
||||
make DESTDIR="$directory" install
|
||||
```
|
||||
|
||||
最后的依赖包是 Gifsicle 。这是一个命令行工具,可以创建、编辑、查看 GIF 图像和动画的属性信息。下载和安装 Gifsicle 相当容易,你只需要运行下列命令:
|
||||
|
||||
```
|
||||
sudo apt-get install gifsicle
|
||||
```
|
||||
|
||||
这些是所有的依赖包。现在,我们开始安装 Gifine 。使用下面的命令完成安装。
|
||||
|
||||
```
|
||||
sudo apt-get install luarocks
|
||||
|
||||
sudo luarocks install --server=http://luarocks.org/dev gifine
|
||||
```
|
||||
|
||||
请注意第二个命令可能会返回下列错误:
|
||||
|
||||
```
|
||||
No package 'gobject-introspection-1.0' found
|
||||
```
|
||||
|
||||
你可以用下列命令安装这个包:
|
||||
```
|
||||
sudo apt-get install libgirepository1.0-dev
|
||||
```
|
||||
然后,再一次运行 'luarocks install' 命令。
|
||||
|
||||
### Gifine 使用
|
||||
|
||||
完成安装之后可以使用下面的命令运行这个工具:
|
||||
|
||||
```
|
||||
gifine
|
||||
```
|
||||
|
||||
这个应用程序的 UI 是这样的:
|
||||
[
|
||||
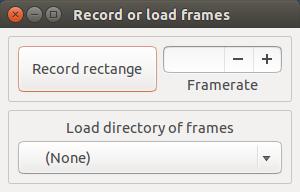
|
||||
][7]
|
||||
|
||||
这里你可以进行两种操作:录视频帧或者加载视频帧。如果你单击了录制矩形区域(Record rectange)按钮,你的鼠标指针处会变成一个 `+` ,这样便可以在你的屏幕上选择一个矩形区域。一旦你选择了一个区域,录屏就开始了,录制矩形区域(Record rectange)按钮就会变成停止录制(Stop recording)按钮。
|
||||
|
||||
[
|
||||
|
||||
][8]
|
||||
|
||||
单击停止录制(Stop recording)完成录屏,会在 Gifine 窗口出现一些按钮。
|
||||
|
||||
[
|
||||
|
||||
][9]
|
||||
|
||||
用户界面的上半部分显示已经录制的视频帧,你可以使用它下面的滑块进行逐帧浏览。如果你想要删除第 5 帧之前或第 50 帧之后的所有帧数,你可以使用裁剪左边(Trim left of) 和裁剪右边(Trim rigth of)按钮进行裁剪。也有可以删除特定帧数和减半删除帧数的按钮,当然,你可以重置所有的裁剪操作。
|
||||
|
||||
完成了所有的裁剪后,可以使用保存 GIF(Save GIF...) 或保存 MP4(Save MP4...) 按钮将录屏保存为动画或者视频;你会看到可以设置帧延迟、帧率以及循环次数的选项。
|
||||
|
||||
记住,“录屏帧不会自动清除。如果你想重新加载,可以在初始屏幕中使用加载目录(load directory)按钮在 '/tmp' 目录中找到它们。“
|
||||
|
||||
### 总结
|
||||
|
||||
Gifine 的学习曲线并不陡峭 —— 所有的功能都会以按钮、文本的形式体现出来。
|
||||
|
||||
对我来说,最大的问题是安装 —— 需要一个个安装它的依赖包,还要处理可能出现的错误,这会困扰很多人。否则,从整体上看,Gifine 绝对称得上是一个不错的工具,如果你正在寻找这样的工具,不妨一试。
|
||||
|
||||
已经是 Gifine 用户?到目前为止你得到了什么经验?在评论区告诉我们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/record-screen-to-animated-gif-on-linux/
|
||||
|
||||
作者:[Ansh][a]
|
||||
译者:[vim-kakali](https://github.com/vim-kakali)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/record-screen-to-animated-gif-on-linux/
|
||||
[1]:https://www.howtoforge.com/tutorial/record-screen-to-animated-gif-on-linux/#gifine
|
||||
[2]:https://www.howtoforge.com/tutorial/record-screen-to-animated-gif-on-linux/#gifine-downloadinstallationsetup
|
||||
[3]:https://www.howtoforge.com/tutorial/record-screen-to-animated-gif-on-linux/#gifine-usage
|
||||
[4]:https://www.howtoforge.com/tutorial/record-screen-to-animated-gif-on-linux/#conclusion
|
||||
[5]:https://github.com/leafo/gifine
|
||||
[6]:https://github.com/lolilolicon/xrectsel
|
||||
[7]:https://www.howtoforge.com/images/record-screen-to-animated-gif-on-linux/big/gifine-ui.png
|
||||
[8]:https://www.howtoforge.com/images/record-screen-to-animated-gif-on-linux/big/gifine-stop-rec.png
|
||||
[9]:https://www.howtoforge.com/images/record-screen-to-animated-gif-on-linux/big/gifine-post-rec.png
|
||||
@ -1,41 +1,42 @@
|
||||
使用开源工具探索气候数据的奥秘
|
||||
============================================================[up][1]
|
||||
============================================================
|
||||
|
||||

|
||||
图片源自:
|
||||
|
||||
[Flickr user: theaucitron][2] (CC BY-SA 2.0)
|
||||
图片源自: [Flickr user: theaucitron][2] (CC BY-SA 2.0)
|
||||
|
||||
如果这些天地球天气变化的不明显,你几乎无法察觉其中变化的格局。每个月,事实和数据都在向我们诠释一点——全球变暖。
|
||||
如今你看地球上的任何地方,都可以找到天气变化的证据,每个月,无论是事实还是数据都在向我们诠释一点 —— 全球变暖。
|
||||
|
||||
气候学家如是告诫我们——如今的不作为,对于我们的将来可能是致命的。五角大楼高层[最近警告][3]当选总统的川普。申明如果不对气候变化有所动作,可能会造成威胁国家安全的灾难。愈趋减少的的水供应和微薄的降雨量会导致作物歉收,这将迫使大量的移民逃往世界各地,到那些可以维持他们生计的地方去。
|
||||
气候学家如是告诫我们,如今的不作为,对于我们的将来可能是致命的。五角大楼的军事战略家[最近警告][3]当选总统的川普,向他申明如果不对气候变化有所动作,可能会造成威胁国家安全的灾难。愈趋减少的的水供应和微薄的降雨量会导致作物歉收,这将迫使大量的移民逃往世界各地,到那些可以维持他们生计的地方去。
|
||||
|
||||
遍览 NASA,美国国防部,以及其他机构针对气候的研究成果,我的心中有个疑惑。那就是是否有开源的工具,使对此感兴趣的人们能够自行去探索气候数据的奥秘,并总结出我们自己的结论。我在网上快速的检索了一下,然后找到了[Open Climate Workbench (开源气候工作台)][4],[Apache 软件基金会][5]旗下的一个工程。
|
||||
遍览 NASA、美国国防部,以及其他机构针对气候的研究成果,我的心中有个疑惑。那就是是否有开源的工具,使对此感兴趣的人们能够自行去探索气候数据的奥秘,并总结出我们自己的结论。我在网上快速的检索了一下,然后找到了 [Open Climate Workbench (开源气候工作台)][4],这是 [Apache 软件基金会][5]旗下的一个工程。
|
||||
|
||||
Open Climate Workbench (缩写 OCW) 开发用于对来自[Earth System Grid Federation (地球系统网格联盟,缩写 ESGF)][6],[Coordinated Regional Climate Downscaling Experiment (协调区域气候降尺度实验,缩写 CORDEX)][7],美国全球变化研究计划的 [National Climate Assessment (国家气候研究)][8],[North American Regional Climate Assessment Program (北美区域气候评估计划)][9],和 NASA,NOAA,以及其他组织或机构的数据进行气候模型评价。
|
||||
Open Climate Workbench (缩写 OCW) 开发该软件,对来自 [<ruby>地球系统网格联盟<rt>Earth System Grid Federation</rt></ruby>][6](缩写 ESGF)、[<ruby>协调区域气候降尺度实验<rt>Coordinated Regional Climate Downscaling Experiment</rt></ruby>][7](缩写 CORDEX)、美国全球变化研究项目的[<ruby>国家气候研究<rt> National Climate Assessment</rt></ruby>][8]、[<ruby>北美区域气候评估计划<rt>North American Regional Climate Assessment Program</rt></ruby>][9],以及 NASA、NOAA 和其他组织或机构的数据进行气候模型评价。
|
||||
|
||||
你可下载 OCW 的 [tar ball (压缩包)][10] 并将它安装到满足以下[条件][11]的 Linux 电脑上。也可以将它安装到 Vagrant 或者 VirtualBox 虚拟机中,详见 OCW 的[虚拟机指南][12]。
|
||||
你可下载 OCW 的 [tar 包][10] 并将它安装到满足其[条件][11]的 Linux 电脑上。也可以使用 Vagrant 或者 VirtualBox 将 OCW 安装到虚拟机中,详见 OCW 的[虚拟机指南][12]。
|
||||
|
||||
个人觉得想要了解 OCW 是如何工作的,最便捷的方式就是到 Regional Climate Model Evaluation System (区域气候模式评价系统,缩写 RCMES)下载一个[虚拟机镜像][13]。
|
||||
个人觉得想要了解 OCW 是如何工作的,最便捷的方式就是到 <ruby>区域气候模式评价系统<rt>Regional Climate Model Evaluation System </rt></ruby> (缩写 RCMES),下载一个[虚拟机镜像][13]。
|
||||
|
||||
从 RCMES 的网站上看,他们旨在通过为一系列广泛而全面的观测(例如,卫星观测,重新分析,现场观测)和建模资源(例如,[ESGF][16] 上的 [CMIP][14] 和 [CORDEX][15])提供标准化的访问,以及常规分析和可视化任务的工具(例如,OCW),来促进气候和地球系统模型的区域规模评估。
|
||||
|
||||
你需要在宿主机上安装 VirtualBox 和 Vagrant。通过它们,你就能看到一个超赞的 OCW 作业示例。RCMES 为下载,导入,运行虚拟机提供了[详细的说明][17]。当你的虚拟机开始工作时,你可以用以下身份登陆。
|
||||
你需要在宿主机上安装 VirtualBox 和 Vagrant。通过它们,你就能看到一个超赞的 OCW 作业示例。RCMES 为下载、导入、运行虚拟机提供了[详细的说明][17]。当你的虚拟机开始工作时,你可以用以下身份登陆。
|
||||
|
||||
** 用户名:vagrant,密码:vagrant。 **
|
||||
**用户名:vagrant,密码:vagrant。**
|
||||
|
||||

|
||||
|
||||
RCMES 数据样图
|
||||
*RCMES 数据样图*
|
||||
|
||||
RCMES 网页上的[教程][18]能帮助你迅速上手该软件。他们的[社区][19]十分活跃,而且看上去需要更多的[开发者][20]。 你也可以订阅他们[邮件列表][21]。
|
||||
RCMES 网页上的[教程][18]能帮助你迅速上手该软件。他们的[社区][19]十分活跃,而且在寻找更多的[开发者][20]。 你也可以订阅他们[邮件列表][21]。
|
||||
|
||||
工程的[源代码][22]部署在 GitHub 上,遵寻 Apache License, Version 2.0。
|
||||
该工程的[源代码][22]部署在 GitHub 上,遵寻 Apache License, Version 2.0。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Don Watkins(唐 沃特金斯) - 教育家,教育技术专家,企业家,开源支持者。心理学硕士,教育学硕士,Linux 系统管理员,CCNA,通过使用 Virtual Box 和 VMware 完成虚拟化。twitter 关注 @Don_Watkins。
|
||||
Don Watkins(唐 沃特金斯) - 教育家,教育技术专家,企业家,开源支持者。教育心理学硕士,Linux 系统管理员,CCNA,使用 Virtual Box 实现虚拟化。twitter 关注 @Don_Watkins。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -43,7 +44,7 @@ via: https://opensource.com/article/17/1/apache-open-climate-workbench
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
译者:[martin2011qi](https://github.com/martin2011qi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,16 +1,19 @@
|
||||
将另一台 Ubuntu DC 服务器加入到 Samba4 AD DC 实现双域控主机模式 ——(五)
|
||||
Samba 系列(五):将另一台 Ubuntu DC 服务器加入到 Samba4 AD DC 实现双域控主机模式
|
||||
============================================================
|
||||
|
||||
这篇文章将讲解如何使用 **Ubuntu 16.04** 服务器版系统来创建第二台 **Samba4** 域控制器,并将其加入到已创建好的 **Samba AD DC** 林环境中,以便为一些关键的 AD DC 服务提供负载均衡及故障切换功能,尤其是为那些重要的服务,比如 DNS 服务和使用 SAM 数据库的 AD DC LDAP 模式。
|
||||
|
||||
#### 需求
|
||||
|
||||
1、 这篇文章是 **Samba4 AD DC** 系列的第**五**篇,前边几篇如下:
|
||||
这篇文章是 **Samba4 AD DC** 系列的第**五**篇,前边几篇如下:
|
||||
|
||||
[在 Ubuntu16.04 系统上使用 Samba4 软件来创建活动目录架构(一)][1]
|
||||
[在 Linux 命令行下管理 Samba4 AD 架构(二)][2]
|
||||
[使用 Windows 10 系统的 RSAT 工具来管理 Samba4 活动目录架构 (三)][3]
|
||||
[在 Windows 系统下管理 Samba4 AD 域管制器 DNS 和组策略(四)][4]
|
||||
1、[在 Ubuntu16.04 系统上使用 Samba4 软件来创建活动目录架构(一)][1]
|
||||
|
||||
2、[在 Linux 命令行下管理 Samba4 AD 架构(二)][2]
|
||||
|
||||
3、[使用 Windows 10 系统的 RSAT 工具来管理 Samba4 活动目录架构 (三)][3]
|
||||
|
||||
4、[在 Windows 系统下管理 Samba4 AD 域管制器 DNS 和组策略(四)][4]
|
||||
|
||||
### 第一步:为设置 Samba4 进行初始化配置
|
||||
|
||||
@ -24,7 +27,7 @@
|
||||
# hostnamectl set-hostname adc2
|
||||
```
|
||||
|
||||
或者你也可以手动编辑 **/etc/hostname** 文件,在新的一行输入你想设置的主机名。
|
||||
或者你也可以手动编辑 `/etc/hostname` 文件,在新的一行输入你想设置的主机名。
|
||||
|
||||
```
|
||||
# nano /etc/hostname
|
||||
@ -55,11 +58,11 @@ IP_of_main_DC FQDN_of_main_DC short_name_of_main_DC
|
||||
|
||||
*为 Samba4 AD DC 服务器设置主机名*
|
||||
|
||||
3、下一步,打开 **/etc/network/interfaces** 配置文件并设置一个静态 IP 地址,如下图所示:
|
||||
3、下一步,打开 `/etc/network/interfaces` 配置文件并设置一个静态 IP 地址,如下图所示:
|
||||
|
||||
注意 **dns-nameservers** 和 **dns-search** 这两个参数的值。为了使 DNS 解析正常工作,需要把这两个值设置成主 Samba4 AD DC 服务器的 IP 地址和域名。
|
||||
注意 `dns-nameservers` 和 `dns-search` 这两个参数的值。为了使 DNS 解析正常工作,需要把这两个值设置成主 Samba4 AD DC 服务器的 IP 地址和域名。
|
||||
|
||||
重启网卡服务以让修改的配置生效。检查 **/etc/resolv.conf** 文件,确保该网卡上配置的这两个 DNS 的值已更新到这个文件。
|
||||
重启网卡服务以让修改的配置生效。检查 `/etc/resolv.conf` 文件,确保该网卡上配置的这两个 DNS 的值已更新到这个文件。
|
||||
|
||||
```
|
||||
# nano /etc/network/interfaces
|
||||
@ -90,7 +93,7 @@ dns-search tecmint.lan
|
||||
|
||||
*配置 Samba4 AD 服务器的 DNS*
|
||||
|
||||
当你通过简写名称(用于构建 FQDN 名)查询主机名时, **dns-search** 值将会自动把域名添加上。
|
||||
当你通过简写名称(用于构建 FQDN 名)查询主机名时, `dns-search` 值将会自动把域名添加上。
|
||||
|
||||
4、为了测试 DNS 解析是否正常,使用一系列 ping 命令测试,命令后分别为简写名, FQDN 名和域名,如下图所示:
|
||||
|
||||
@ -108,7 +111,7 @@ dns-search tecmint.lan
|
||||
# apt-get install ntpdate
|
||||
```
|
||||
|
||||
6、假设你想手动强制本地服务器与 **samba4 AD DC** 服务器时间同步,使用 **ntpdate** 命令加上主域控服务器的主机名,如下所示:
|
||||
6、假设你想手动强制本地服务器与 **samba4 AD DC** 服务器时间同步,使用 `ntpdate` 命令加上主域控服务器的主机名,如下所示:
|
||||
|
||||
```
|
||||
# ntpdate adc1
|
||||
@ -121,7 +124,7 @@ dns-search tecmint.lan
|
||||
|
||||
### 第 2 步:安装 Samba4 必须的依赖包
|
||||
|
||||
7、为了让 **Ubuntu 16.04** 系统加入到你的域中,你需要通过下面的命令从 Ubuntu 官方软件库中安装 **Samba4 套件, Kerberos** 客户端和其它一些重要的软件包以便将来使用:
|
||||
7、为了让 **Ubuntu 16.04** 系统加入到你的域中,你需要通过下面的命令从 Ubuntu 官方软件库中安装 **Samba4 套件、 Kerberos 客户端** 和其它一些重要的软件包以便将来使用:
|
||||
|
||||
```
|
||||
# apt-get install samba krb5-user krb5-config winbind libpam-winbind libnss-winbind
|
||||
@ -132,7 +135,7 @@ dns-search tecmint.lan
|
||||
|
||||
*在 Ubuntu 系统中安装 Samba4*
|
||||
|
||||
8、在安装的过程中,你需要提供 Kerberos 域名。输入大写的域名然后按 [Enter] 键完成安装过程。
|
||||
8、在安装的过程中,你需要提供 Kerberos 域名。输入大写的域名然后按回车键完成安装过程。
|
||||
|
||||
[
|
||||

|
||||
@ -140,7 +143,7 @@ dns-search tecmint.lan
|
||||
|
||||
*为 Samba4 配置 Kerberos 认证*
|
||||
|
||||
9、所有依赖包安装完成后,通过使用 kinit 命令为域管理员请求一个 Kerberos 票据以验证设置是否正确。使用 klist 命令来列出已授权的 kerberos 票据信息。
|
||||
9、所有依赖包安装完成后,通过使用 `kinit` 命令为域管理员请求一个 Kerberos 票据以验证设置是否正确。使用 `klist` 命令来列出已授权的 kerberos 票据信息。
|
||||
|
||||
```
|
||||
# kinit domain-admin-user@YOUR_DOMAIN.TLD
|
||||
@ -161,7 +164,7 @@ dns-search tecmint.lan
|
||||
# mv /etc/samba/smb.conf /etc/samba/smb.conf.initial
|
||||
```
|
||||
|
||||
11、在准备加入域前,先启动 **samba-ad-dc** 服务,之后使用域管理员账号运行 **samba-tool** 命令将服务器加入到域。
|
||||
11、在准备加入域前,先启动 **samba-ad-dc** 服务,之后使用域管理员账号运行 `samba-tool` 命令将服务器加入到域。
|
||||
|
||||
```
|
||||
# samba-tool domain join your_domain -U "your_domain_admin"
|
||||
@ -170,10 +173,10 @@ dns-search tecmint.lan
|
||||
加入域过程部分截图:
|
||||
|
||||
```
|
||||
# samba-tool domain join tecmint.lan DC -U"tecmint_user"
|
||||
# samba-tool domain join tecmint.lan DC -U "tecmint_user"
|
||||
```
|
||||
|
||||
##### 输出示例
|
||||
输出示例:
|
||||
|
||||
```
|
||||
Finding a writeable DC for domain 'tecmint.lan'
|
||||
@ -242,7 +245,7 @@ Joined domain TECMINT (SID S-1-5-21-715537322-3397311598-55032968) as a DC
|
||||
# nano /etc/samba/smb.conf
|
||||
```
|
||||
|
||||
添加以下内容到 smb.conf 配置文件中。
|
||||
添加以下内容到 `smb.conf` 配置文件中。
|
||||
|
||||
```
|
||||
dns forwarder = 192.168.1.1
|
||||
@ -255,7 +258,7 @@ winbind enum users = yes
|
||||
winbind enum groups = yes
|
||||
```
|
||||
|
||||
使用你自己的 **DNS forwarder IP** 地址替换掉上面地址。 Samba 将会把域权威区之外的所有 DNS 解析查询转发到这个 IP 地址。
|
||||
使用你自己的 **DNS 转发器 IP** 地址替换掉上面 `dns forwarder` 地址。 Samba 将会把域权威区之外的所有 DNS 解析查询转发到这个 IP 地址。
|
||||
|
||||
13、最后,重启 samba 服务以使修改的配置生效,然后执行如下命令来检查活动目录复制功能是否正常。
|
||||
|
||||
@ -270,9 +273,9 @@ winbind enum groups = yes
|
||||
|
||||
*配置 Samba4 DNS*
|
||||
|
||||
14、另外,还需要重命名原来的 /etc 下的 kerberos 配置文件,并使用在加入域的过程中 Samba 生成的新配置文件 krb5.conf 替换它。
|
||||
14、另外,还需要重命名原来的 `/etc `下的 kerberos 配置文件,并使用在加入域的过程中 Samba 生成的新配置文件 krb5.conf 替换它。
|
||||
|
||||
Samba 生成的新配置文件在 /var/lib/samba/private 目录下。使用 Linux 的符号链接将该文件链接到 /etc 目录。
|
||||
Samba 生成的新配置文件在 `/var/lib/samba/private` 目录下。使用 Linux 的符号链接将该文件链接到 `/etc` 目录。
|
||||
|
||||
```
|
||||
# mv /etc/krb6.conf /etc/krb5.conf.initial
|
||||
@ -285,7 +288,7 @@ Samba 生成的新配置文件在 /var/lib/samba/private 目录下。使用 Linu
|
||||
|
||||
*配置 Kerberos*
|
||||
|
||||
15、同样,使用 samba 的 **krb5.conf** 配置文件验证 Kerberos 认证是否正常。通过以下命令来请求一个管理员账号的票据并且列出已缓存的票据信息。
|
||||
15、同样,使用 samba 的 `krb5.conf` 配置文件验证 Kerberos 认证是否正常。通过以下命令来请求一个管理员账号的票据并且列出已缓存的票据信息。
|
||||
|
||||
```
|
||||
# kinit administrator
|
||||
@ -299,7 +302,7 @@ Samba 生成的新配置文件在 /var/lib/samba/private 目录下。使用 Linu
|
||||
|
||||
### 第 4 步:验证其它域服务
|
||||
|
||||
16、你首先要做的一个测试就是验证 **Samba4 DC DNS** 解析服务是否正常。要验证域 DNS 解析情况,使用 host 命令,加上一些重要的 AD DNS 记录,进行域名查询,如下图所示:
|
||||
16、你首先要做的一个测试就是验证 **Samba4 DC DNS** 解析服务是否正常。要验证域 DNS 解析情况,使用 `host` 命令,加上一些重要的 AD DNS 记录,进行域名查询,如下图所示:
|
||||
|
||||
每一次查询,DNS 服务器都应该返回两个 IP 地址。
|
||||
|
||||
@ -322,15 +325,15 @@ Samba 生成的新配置文件在 /var/lib/samba/private 目录下。使用 Linu
|
||||
|
||||
*通过 Windows RSAT 工具来验证 DNS 记录*
|
||||
|
||||
18、下一个验证是检查域 LDAP 复制同步是否正常。使用 **samba-tool** 工具,在第二个域控制器上创建一个账号,然后检查该账号是否自动同步到第一个 Samba4 AD DC 服务器上。
|
||||
18、下一个验证是检查域 LDAP 复制同步是否正常。使用 `samba-tool` 工具,在第二个域控制器上创建一个账号,然后检查该账号是否自动同步到第一个 Samba4 AD DC 服务器上。
|
||||
|
||||
##### On adc2:
|
||||
在 adc2 上:
|
||||
|
||||
```
|
||||
# samba-tool user add test_user
|
||||
```
|
||||
|
||||
##### On adc1:
|
||||
在 adc1 上:
|
||||
|
||||
```
|
||||
# samba-tool user list | grep test_user
|
||||
@ -349,7 +352,7 @@ Samba 生成的新配置文件在 /var/lib/samba/private 目录下。使用 Linu
|
||||
|
||||
19、你也可以从 **Microsoft AD DC** 控制台创建一个账号,然后验证该账号是否都出现在两个域控服务器上。
|
||||
|
||||
默认情况下,这个账号都应该在两个 samba 域控制器上自动创建完成。在 `adc1` 服务器上使用 **wbinfo** 命令查询该账号名。
|
||||
默认情况下,这个账号都应该在两个 samba 域控制器上自动创建完成。在 `adc1` 服务器上使用 `wbinfo` 命令查询该账号名。
|
||||
|
||||
[
|
||||

|
||||
@ -1,9 +1,9 @@
|
||||
Linux 命令行工具使用小贴士及技巧 ——(一)
|
||||
Linux 命令行工具使用小贴士及技巧(一)
|
||||
============================================================
|
||||
|
||||
### 相关内容
|
||||
|
||||
如果你刚开始在 Linux 系统中使用命令行工具,那么应该了解它是 Linux 操作系统中功能最强大和有用的工具之一。学习的难易程度跟你想研究的深度有关。但是,无论你的技术能力水平怎么样,这篇文章中的一些小贴士和技巧都会对你有所帮助。
|
||||
如果你刚开始在 Linux 系统中使用命令行工具,那么你应该知道它是 Linux 操作系统中功能最强大和有用的工具之一。学习的难易程度跟你想研究的深度有关。但是,无论你的技术能力水平怎么样,这篇文章中的一些小贴士和技巧都会对你有所帮助。
|
||||
|
||||
在本系列的文章中,我们将会讨论一些非常有用的命令行工具使用小技巧,希望你的命令行使用体验更加愉快。
|
||||
|
||||
@ -15,11 +15,11 @@ Linux 命令行工具使用小贴士及技巧 ——(一)
|
||||
|
||||
#### 轻松切换目录 —— 快捷方式
|
||||
|
||||
假设你正在命令行下做一些操作,并且你需要经常在两个目录间来回切换。而且这两个目录在完全不同的两个路径下,比如说,分别在 /home/ 和 /usr/ 下。你会怎么做呢?
|
||||
假设你正在命令行下做一些操作,并且你需要经常在两个目录间来回切换。而且这两个目录在完全不同的两个路径下,比如说,分别在 `/home/` 和 `/usr/` 下。你会怎么做呢?
|
||||
|
||||
其中,最简单直接的方式就是输入这些目录的全路径。虽然这种方式本身没什么问题,但是却很浪费时间。另外一种方式就是打开两个终端窗口分别进行操作。但是这两种方式使用起来既不方便,也显得没啥技术含量。
|
||||
|
||||
你应该感到庆幸的是,还有另外一种更为简捷的方法来解决这个问题。你需要做的就是先手动切换到这两个目录(通过 **cd** 命令分别加上各自的路径),之后你就可以使用 **cd -** 命令在两个目录之间来回快速切换了。
|
||||
你应该感到庆幸的是,还有另外一种更为简捷的方法来解决这个问题。你需要做的就是先手动切换到这两个目录(通过 `cd` 命令分别加上各自的路径),之后你就可以使用 `cd -` 命令在两个目录之间来回快速切换了。
|
||||
|
||||
例如:
|
||||
|
||||
@ -30,35 +30,35 @@ $ pwd
|
||||
/home/himanshu/Downloads
|
||||
```
|
||||
|
||||
然后,我切换到 /usr/ 路径下的其它目录:
|
||||
然后,我切换到 `/usr/` 路径下的其它目录:
|
||||
|
||||
```
|
||||
cd /usr/lib/
|
||||
```
|
||||
|
||||
现在,我可以很方便的使用下面的命令来向前向后快速地切换到两个目录:
|
||||
现在,我可以很方便的使用下面的命令来向前、向后快速地切换到两个目录:
|
||||
|
||||
```
|
||||
cd -
|
||||
```
|
||||
|
||||
下面是 **cd -** 命令的操作截图:
|
||||
下面是 `cd -` 命令的操作截图:
|
||||
|
||||
[
|
||||
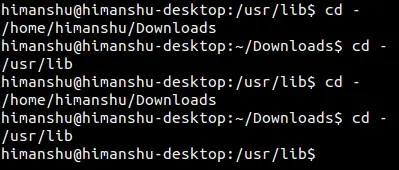
|
||||
][5]
|
||||
|
||||
有一点我得跟大家强调下,如果你在操作的过程中使用 cd 加路径的方式切换到第三个目录下,那么 **cd -** 命令将应用于当前目录及第三个目录之间进行切换。
|
||||
有一点我得跟大家强调下,如果你在操作的过程中使用 `cd` 加路径的方式切换到第三个目录下,那么 `cd -` 命令将应用于当前目录及第三个目录之间进行切换。
|
||||
|
||||
#### 轻松切换目录 —— 相关细节
|
||||
|
||||
对于那些有强烈好奇心的用户,他们想搞懂 **cd -** 的工作原理,解释如下:如大家所知道的那样, cd 命令需要加上一个路径作为它的参数。现在,当 - 符号作为参数传输给 cd 命令时,它将被 OLDPWD 环境变量的值所替代。
|
||||
对于那些有强烈好奇心的用户,他们想搞懂 `cd -` 的工作原理,解释如下:如大家所知道的那样, `cd` 命令需要加上一个路径作为它的参数。现在,当 `-` 符号作为参数传输给 `cd` 命令时,它将被 `OLDPWD` 环境变量的值所替代。
|
||||
|
||||
[
|
||||
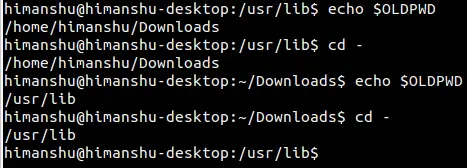
|
||||
][6]
|
||||
|
||||
现在应该明白了吧, OLDPWD 环境变量存储的是前一个操作目录的路径。这个解释在 cd 命令的 man 帮助文档中有说明,但是,很遗憾的是你的系统中可能没有预先安装 man 命令帮助工具(至少在 Ubuntu 系统下没有安装)。
|
||||
现在应该明白了吧, `OLDPWD` 环境变量存储的是前一个操作目录的路径。这个解释在 `cd` 命令的 man 帮助文档中有说明,但是,很遗憾的是你的系统中可能没有预先安装 `man` 命令帮助工具(至少在 Ubuntu 系统下没有安装)。
|
||||
|
||||
但是,安装这个 man 帮助工具也很简单,你只需要执行下的安装命令即可:
|
||||
|
||||
@ -80,43 +80,43 @@ man cd
|
||||
cd "$OLDPWD" && pwd
|
||||
```
|
||||
|
||||
毫无疑问, cd 命令设置了 OLDPWD 环境变量值。因此每一次你切换操作目录时,上一个目录的路径就会被保存到这个变量里。这还让我们看到很重要的一点就是:任何时候启动一个新的 shell 实例(包括手动执行或是使用 shell 脚本),都不存在 ‘上一个工作目录’。
|
||||
毫无疑问, `cd` 命令设置了 `OLDPWD` 环境变量值。因此每一次你切换操作目录时,上一个目录的路径就会被保存到这个变量里。这还让我们看到很重要的一点就是:任何时候启动一个新的 shell 实例(包括手动执行或是使用 shell 脚本),都不存在 ‘上一个工作目录’。
|
||||
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
这也很符合逻辑,因为 cd 命令设置了 OLDPWD 环境变量值。因此,除非你至少执行了一次 cd 命令,否则 OLDPWD 环境变量不会包含任何值。
|
||||
这也很符合逻辑,因为 `cd` 命令设置了 `OLDPWD` 环境变量值。因此,除非你至少执行了一次 `cd` 命令,否则 `OLDPWD` 环境变量不会包含任何值。
|
||||
|
||||
继续,尽管这有些难以理解, **cd -** 和 **cd $OLDWPD** 命令的执行结果并非在所有环境下都相同。比如说,你重新打开一个新的 shell 窗口时。
|
||||
继续,尽管这有些难以理解, `cd -` 和 `cd $OLDWPD` 命令的执行结果并非在所有环境下都相同。比如说,你重新打开一个新的 shell 窗口时。
|
||||
|
||||
[
|
||||
|
||||
][8]
|
||||
|
||||
从上面的截图可以清楚的看出,当执行 **cd -** 命令提示未设置 OLDPWD 值时, **cd $OLDPWD** 命令没有报任何错;实际上,它把当前的工作目录改变到用户的 home 目录里。
|
||||
从上面的截图可以清楚的看出,当执行 `cd -` 命令提示未设置 `OLDPWD` 值时, `cd $OLDPWD` 命令没有报任何错;实际上,它把当前的工作目录改变到用户的 home 目录里。
|
||||
|
||||
那是因为 OLDPWD 变量目前还没有被设置, $OLDPWD 仅仅是一个空字符串。因此, **cd $OLDPWD** 命令跟 **cd** 命令的执行结果是一致的,默认情况下,会把用户当前的工作目录切换到用户的 home 目录里。
|
||||
那是因为 `OLDPWD` 变量目前还没有被设置, `$OLDPWD` 仅仅是一个空字符串。因此, `cd $OLDPWD` 命令跟 `cd` 命令的执行结果是一致的,默认情况下,会把用户当前的工作目录切换到用户的 home 目录里。
|
||||
|
||||
最后,我还遇到过这样的要求,需要让 **cd -** 命令执行的结果不显示出来。我的意思是,有这样的情况(比如说,在写 shell 脚本的时候),你想让 **cd -** 命令的执行结果不要把目录信息显示出来。那种情况下,你就可以使用下面的命令方式了:
|
||||
最后,我还遇到过这样的要求,需要让 `cd -` 命令执行的结果不显示出来。我的意思是,有这样的情况(比如说,在写 shell 脚本的时候),你想让 `cd -` 命令的执行结果不要把目录信息显示出来。那种情况下,你就可以使用下面的命令方式了:
|
||||
|
||||
```
|
||||
cd - &>/dev/null
|
||||
```
|
||||
|
||||
上面的命令把文件描述符 2(标准输入)和 1(标准输出)的结果重定向到 [/dev/null][9] 目录。这意味着,这个命令产生的所有的错误不会显示出来。但是,你也可以使用通用的 [$? 方式][10]来检查这个命令的执行是否异常。如果这个命令执行报错, **echo $?** 将会返回 ‘1’,否则返回 ‘0’。
|
||||
上面的命令把文件描述符 2(标准输入)和 1(标准输出)的结果重定向到 [`/dev/null`][9] 目录。这意味着,这个命令产生的所有的错误不会显示出来。但是,你也可以使用通用的 [`$?` 方式][10]来检查这个命令的执行是否异常。如果这个命令执行报错, `echo $?` 将会返回 `1`,否则返回 `0`。
|
||||
|
||||
或者说,如果你觉得 **cd -** 命令出错时输出信息没有关系,你也可以使用下面的命令来代替:
|
||||
或者说,如果你觉得 `cd -` 命令出错时输出信息没有关系,你也可以使用下面的命令来代替:
|
||||
|
||||
```
|
||||
cd - > /dev/null
|
||||
```
|
||||
|
||||
这个命令仅用于将文件描述符 1 (标准输出)重定向到 '/dev/null' 。
|
||||
这个命令仅用于将文件描述符 1 (标准输出)重定向到 `/dev/null` 。
|
||||
|
||||
### 总结
|
||||
|
||||
遗憾的是,这篇文章仅包含了一个跟命令行相关的小技巧,但是,我们已经地对 **cd -** 命令的使用进行了深入地探讨。建议你在自己的 Linux 系统的命令行终端中测试本文中的实例。此外,也强烈建议你查看 man 帮助文档,然后对 cd 命令进行全面测试。
|
||||
遗憾的是,这篇文章仅包含了一个跟命令行相关的小技巧,但是,我们已经地对 `cd -` 命令的使用进行了深入地探讨。建议你在自己的 Linux 系统的命令行终端中测试本文中的实例。此外,也强烈建议你查看 man 帮助文档,然后对 cd 命令进行全面测试。
|
||||
|
||||
如果你对这篇文章有什么疑问,请在下面的评论区跟大家交流。同时,敬请关注下一篇文章,我们将以同样的方式探讨更多有用的命令行使用技巧。
|
||||
|
||||
94
published/201703/20170111 NMAP Common Scans – Part One.md
Normal file
94
published/201703/20170111 NMAP Common Scans – Part One.md
Normal file
@ -0,0 +1,94 @@
|
||||
NMAP 常用扫描简介(一)
|
||||
========================
|
||||
|
||||
我们之前在 [NMAP 的安装][1]一文中,列出了 10 种不同的 ZeNMAP 扫描模式。大多数的模式使用了各种参数。各种参数代表了执行不同的扫描模式。这篇文章将介绍其中的四种通用的扫描类型。
|
||||
|
||||
### 四种通用扫描类型
|
||||
|
||||
下面列出了最常使用的四种扫描类型:
|
||||
|
||||
1. PING 扫描 (`-sP`)
|
||||
2. TCP SYN 扫描 (`-sS`)
|
||||
3. TCP Connect() 扫描 (`-sT`)
|
||||
4. UDP 扫描 (`-sU`)
|
||||
|
||||
当我们利用 NMAP 来执行扫描的时候,这四种扫描类型是我们需要熟练掌握的。更重要的是需要知道这些命令做了什么并且需要知道这些命令是怎么做的。本文将介绍 PING 扫描和 UDP 扫描。在之后的文中会介绍 TCP 扫描。
|
||||
|
||||
### PING 扫描 (-sP)
|
||||
|
||||
某些扫描会造成网络拥塞,然而 Ping 扫描在网络中最多只会产生两个包。当然这两个包不包括可能需要的 DNS 搜索和 ARP 请求。每个被扫描的 IP 最少只需要一个包来完成 Ping 扫描。
|
||||
|
||||
通常 Ping 扫描是用来查看在指定的 IP 地址上是否有在线的主机存在。例如,当我拥有网络连接却连不上一台指定的网络服务器的时候,我就可以使用 PING 来判断这台服务器是否在线。PING 同样也可以用来验证我的当前设备与网络服务器之间的路由是否正常。
|
||||
|
||||
**注意:** 当我们讨论 TCP/IP 的时候,相关信息在使用 TCP/IP 协议的互联网与局域网(LAN)中都是相当有用的。这些程序都能工作。同样在广域网(WAN)也能工作得相当好。
|
||||
|
||||
当参数给出的是一个域名的时候,我们就需要域名解析服务来找到相对应的 IP 地址,这个时候将会生成一些额外的包。例如,当我们执行 `ping linuxforum.com` 的时候,需要首先请求域名(linuxforum.com)的 IP 地址(98.124.199.63)。当我们执行 `ping 98.124.199.63` 的时候 DNS 查询就不需要了。当 MAC 地址未知的时候,就需要发送 ARP 请求来获取指定 IP 地址的 MAC 地址了(LCTT 译注:这里的指定 IP 地址,未必是目的 IP)。
|
||||
|
||||
Ping 命令会向指定的 IP 地址发送一个英特网信息控制协议(ICMP)包。这个包是需要响应的 ICMP Echo 请求。当服务器系统在线的状态下我们会得到一个响应包。当两个系统之间存在防火墙的时候,PING 请求包可能会被防火墙丢弃。一些服务器也会被配置成不响应 PING 请求来避免可能发生的死亡之 PING。(LCTT 译注:现在的操作系统似乎不太可能)
|
||||
|
||||
**注意:** 死亡之 PING 是一种恶意构造的 PING 包当它被发送到系统的时候,会造成被打开的连接等待一个 rest 包。一旦有一堆这样的恶意请求被系统响应,由于所有的可用连接都已经被打开,所以系统将会拒绝所有其它的连接。技术上来说这种状态下的系统就是不可达的。
|
||||
|
||||
当系统收到 ICMP Echo 请求后它将会返回一个 ICMP Echo 响应。当源系统收到 ICMP Echo 响应后我们就能知道目的系统是在线可达的。
|
||||
|
||||
使用 NMAP 的时候你可以指定单个 IP 地址也可以指定某个 IP 地址段。当被指定为 PING 扫描(`-sP`)的时候,会对每一个 IP 地址执行 PING 命令。
|
||||
|
||||
在图 1 中你可以看到我执行 `nmap -sP 10.0.0.1-10` 命令后的结果。程序会试着联系 IP 地址 10.0.0.1 到 10.0.0.10 之间的每个系统。对每个 IP 地址都要发出三个 ARP 请求。在我们的例子中发出了三十个请求,这 10 个 IP 地址里面有两个有回应。(LCTT 译注:此处原文存疑。)
|
||||
|
||||

|
||||
|
||||
*图 1*
|
||||
|
||||
图 2 中展示了网络上另一台计算机利用 Wireshark 抓取的发出的请求——没错,是在 Windows 系统下完成这次抓取的。第一行展示了发出的第一条请求,广播请求的是 IP 地址 10.0.0.2 对应 MAC 地址。由于 NMAP 是在 10.0.0.1 这台机器上执行的,因此 10.0.0.1 被略过了。由于本机 IP 地址被略过,我们现在可以看到总共只发出了 27 个 ARP 请求。第二行展示了 10.0.0.2 这台机器的 ARP 响应。第三行到第十行是其它八个 IP 地址的 ARP 请求。第十一行是由于 10.0.0.2 没有收到请求系统(10.0.0.1)的反馈所以(重新)发送的另一个 ARP 响应。第十二行是源系统向 10.0.0.2 发起的 HTTP 连接的 ‘SYN’ 和 Sequence 0。第十三行和第十四行的两次 Restart(RST)和 Synchronize(SYN)响应是用来关闭(和重发)第十二行所打开的连接的。注意 Sequence ID 是 ‘1’ - 是源 Sequence ID + 1。第十五行开始就是类似相同的内容。(LCTT 译注:此处原文有误,根据情况已经修改。)
|
||||
|
||||

|
||||
|
||||
*图 2*
|
||||
|
||||
回到图 1 中我们可以看到有两台主机在线。其中一台是本机(10.0.0.1)另一台是(10.0.0.2)。整个扫描花费了 14.40 秒。
|
||||
|
||||
PING 扫描是一种用来发现在线主机的快速扫描方式。扫描结果中没有关于网络、系统的其它信息。这是一种较好的初步发现网络上在线主机的方式,接着你就可以针对在线系统执行更加复杂的扫描了。你可能还会发现一些不应该出现在网络上的系统。出现在网络上的流氓软件是很危险的,他们可以很轻易的收集内网信息和相关的系统信息。
|
||||
|
||||
一旦你获得了在线系统的列表,你就可以使用 UDP 扫描来查看哪些端口是可能开启了的。
|
||||
|
||||
### UDP 扫描 (-sU)
|
||||
|
||||
现在你已经知道了有那些系统是在线的,你的扫描就可以聚焦在这些 IP 地址之上。在整个网络上执行大量的没有针对性的扫描活动可不是一个好主意,系统管理员可以使用程序来监控网络流量当有大量异常活动发生的时候就会触发警报。
|
||||
|
||||
用户数据报协议(UDP)在发现在线系统的开放端口方面十分有用。由于 UDP 不是一个面向连接的协议,因此是不需要响应的。这种扫描方式可以向指定的端口发送一个 UDP 包。如果目标系统没有回应那么这个端口可能是关闭的也可能是被过滤了的。如果端口是开放状态的那么应该会有一个响应。在大多数的情况下目标系统会返回一个 ICMP 信息说端口不可达。ICMP 信息让 NMAP 知道端口是被关闭了。如果端口是开启的状态那么目标系统应该响应 ICMP 信息来告知 NMAP 端口可达。
|
||||
|
||||
**注意: **只有最前面的 1024 个常用端口会被扫描。(LCTT 译注:这里将 1000 改成了1024,因为手册中写的是默认扫描 1 到 1024 端口)在后面的文章中我们会介绍如何进行深度扫描。
|
||||
|
||||
由于我知道 10.0.0.2 这个主机是在线的,因此我只会针对这个 IP 地址来执行扫描。扫描过程中总共收发了 3278 个包。`sudo nmap -sU 10.0.0.2` 这个命令的输出结果在图 3 中展现。
|
||||
|
||||

|
||||
|
||||
*图 3*
|
||||
|
||||
在这副图中你可以看见端口 137(netbios-ns)被发现是开放的。在图 4 中展示了 Wireshark 抓包的结果。不能看到所有抓取的包,但是可以看到一长串的 UDP 包。
|
||||
|
||||

|
||||
|
||||
*图 4*
|
||||
|
||||
如果我把目标系统上的防火墙关闭之后会发生什么呢?我的结果有那么一点的不同。NMAP 命令的执行结果在图 5 中展示。
|
||||
|
||||

|
||||
|
||||
*图 5*
|
||||
|
||||
**注意:** 当你执行 UDP 扫描的时候是需要 root 权限的。
|
||||
|
||||
会产生大量的包是由于我们使用了 UDP。当 NMAP 发送 UDP 请求时它是不保证数据包会被收到的。因为数据包可能会在中途丢失因此它会多次发送请求。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxforum.com/threads/nmap-common-scans-part-one.3637/
|
||||
|
||||
作者:[Jarret][a]
|
||||
译者:[wcnnbdk1](https://github.com/wcnnbdk1)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxforum.com/members/jarret.268/
|
||||
[1]:https://www.linuxforum.com/threads/nmap-installation.3431/
|
||||
@ -1,30 +1,18 @@
|
||||
如何在 CentOS 7 中通过 HHVM 和 Nginx 安装 WordPress
|
||||
========================
|
||||
|
||||
### 导航
|
||||
HHVM (HipHop Virtual Machine) 是一个用于执行以 PHP 和 Hack 语言编写的代码的虚拟环境。它是由 Facebook 开发的,提供了当前 PHP 7 的大多数功能。要在你的服务器上运行 HHVM,你需要使用 FastCGI 来将 HHVM 和 Nginx 或 Apache 衔接起来,或者你也可以使用 HHVM 中的内置 Web 服务器 Proxygen。
|
||||
|
||||
1. [步骤 1 - 配置 SELinux 并添加v EPEL 仓库][1]
|
||||
2. [步骤 2 - 安装 Nginx][2]
|
||||
3. [步骤 3 - 安装并配置 MariaDB][3]
|
||||
4. [步骤 4 - 安装 HHVM][4]
|
||||
5. [步骤 5 - 配置 HHVM][5]
|
||||
6. [步骤 6 - 配置 HHVM 和 Nginx][6]
|
||||
7. [步骤 7 - 通过 HHVM 和 Nginx 创建虚拟主机][7]
|
||||
8. [步骤 8 - 安装 WordPress][8]
|
||||
9. [参考链接][9]
|
||||
|
||||
HHVM (HipHop Virtual Machine) is an open source virtual machine for executing programs written in PHP and Hack language. HHVM has been developed by Facebook, it provides most features of the current PHP 7 version. To run HHVM on your server, you can use a FastCGI to connect HHVM with a Nginx or Apache web server, or you can use the web server built into HHVM called "Proxygen".
|
||||
|
||||
In this tutorial, I will show you how to install WordPress with HHVM and Nginx as web server. I will use CentOS 7 as the operating system, so basic knowledge of CentOS is required.
|
||||
在这篇教程中,我将展示给你如何在 Nginx Web 服务器的 HHVM 上安装 WordPress。这里我使用 CentOS 7 作为操作系统,所以你需要懂一点 CentOS 操作的基础。
|
||||
|
||||
**先决条件**
|
||||
|
||||
* CentOS 7 - 64位
|
||||
* Root 特权
|
||||
* Root 权限
|
||||
|
||||
### 步骤 1 - 配置 SELinux 并添加v EPEL 仓库
|
||||
### 步骤 1 - 配置 SELinux 并添加 EPEL 仓库
|
||||
|
||||
在本教程中,我们将以强制模式来运行 SELinux,所以我们需要在系统上安装一个 SELinux 管理工具。这里我们使用 setools 和 setrobleshoot 来管理 SELinux 的各项配置。
|
||||
在本教程中,我们将使用 SELinux 的强制模式,所以我们需要在系统上安装一个 SELinux 管理工具。这里我们使用 `setools` 和 `setrobleshoot` 来管理 SELinux 的各项配置。
|
||||
|
||||
CentOS 7 已经默认启用 SELinux,我们可以通过以下命令来确认:
|
||||
|
||||
@ -37,13 +25,13 @@ CentOS 7 已经默认启用 SELinux,我们可以通过以下命令来确认:
|
||||
|
||||
如图,你能够看到,SELinux 已经开启了强制模式。
|
||||
|
||||
接下来就是使用 yum 来安装 setools 和 setroubleshoot 了。
|
||||
接下来就是使用 `yum` 来安装 `setools` 和 `setroubleshoot` 了。
|
||||
|
||||
```
|
||||
# yum -y install setroubleshoot setools net-tools
|
||||
```
|
||||
|
||||
安装好这两个后,在安装 EPEL 仓库。
|
||||
安装好这两个后,再安装 EPEL 仓库。
|
||||
|
||||
```
|
||||
# yum -y install epel-release
|
||||
@ -51,22 +39,22 @@ CentOS 7 已经默认启用 SELinux,我们可以通过以下命令来确认:
|
||||
|
||||
### 步骤 2 - 安装 Nginx
|
||||
|
||||
Nginx (发音:engine-x) 是一个高性能、低消耗的轻量级 Web 服务器软件。在 CentOS 中可以使用 yum 命令来安装 Nginx 包。记住用 root 用登录系统哦。
|
||||
Nginx (发音:engine-x) 是一个高性能、低内存消耗的轻量级 Web 服务器软件。在 CentOS 中可以使用 `yum` 命令来安装 Nginx 包。确保你以 root 用户登录系统。
|
||||
|
||||
使用 yum 命令从 CentOS 仓库中安装 nginx。
|
||||
使用 `yum` 命令从 CentOS 仓库中安装 nginx。
|
||||
|
||||
```
|
||||
# yum -y install nginx
|
||||
```
|
||||
|
||||
现在可以使用 systemctl 命令来启动 Nginx,同时将其设置为跟随系统启动。
|
||||
现在可以使用 `systemctl` 命令来启动 Nginx,同时将其设置为跟随系统启动。
|
||||
|
||||
```
|
||||
# systemctl start nginx
|
||||
# systemctl enable nginx
|
||||
```
|
||||
|
||||
为确保 Nginx 已经正确运行于服务器中,在浏览上输入服务器的 IP,或者如下使用 curl 命令检查显示结果。
|
||||
为确保 Nginx 已经正确运行于服务器中,在浏览器上输入服务器的 IP,或者如下使用 `curl` 命令检查显示结果。
|
||||
|
||||
```
|
||||
# curl 192.168.1.110
|
||||
@ -78,7 +66,7 @@ Nginx (发音:engine-x) 是一个高性能、低消耗的轻量级 Web 服务
|
||||
|
||||
### 步骤 3 - 安装并配置 MariaDB
|
||||
|
||||
MariaDB 是由原 MySQL 开发者 Monty Widenius 开发的一款开源数据库软件,它由 MySQL 分支而来,但与 MySQL 的主要用法保持一致。在这一步中,我们要安装 MariaDB 数据库并为之配置好 root 密码,然后在为 WordPress 安装的需要创建一个新的数据库和用户。
|
||||
MariaDB 是由原 MySQL 开发者 Monty Widenius 开发的一款开源数据库软件,它由 MySQL 分支而来,与 MySQL 的主要功能保持一致。在这一步中,我们要安装 MariaDB 数据库并为之配置好 root 密码,然后再为所要安装的 WordPress 创建一个新的数据库和用户。
|
||||
|
||||
安装 mariadb 和 mariadb-server:
|
||||
|
||||
@ -115,7 +103,7 @@ Reload privilege tables now? [Y/n] Y
|
||||
... Success!
|
||||
```
|
||||
|
||||
这样就设置好了 MariaDB 的 root 密码。现在登录到 MariaDB/MySQL shell 并为 WordPress 的安装创建一个新数据库 **"wordpressdb"** 和新用户 **"wpuser"**,密码设置为 **"wpuser@"**。在你的安装设置中要选用一个安全的密码。
|
||||
这样就设置好了 MariaDB 的 root 密码。现在登录到 MariaDB/MySQL shell 并为 WordPress 的安装创建一个新数据库 `wordpressdb` 和新用户 `wpuser`,密码设置为 `wpuser@`。为你的设置选用一个安全的密码。
|
||||
|
||||
登录到 MariaDB/MySQL shell:
|
||||
|
||||
@ -141,9 +129,9 @@ MariaDB [(none)]> \q
|
||||
|
||||
### 步骤 4 - 安装 HHVM
|
||||
|
||||
对于 HHVM,我们需要安装大量的依赖。作为选择,你可以从 GitHub 下载 HHVM 的源码来编译安装,也可以从网络上获取预编译的包进行安装。在本教程中,我使用的是预编译的安装包。
|
||||
对于 HHVM,我们需要安装大量的依赖项。作为选择,你可以从 GitHub 下载 HHVM 的源码来编译安装,也可以从网络上获取预编译的包进行安装。在本教程中,我使用的是预编译的安装包。
|
||||
|
||||
为 HHVM 安装依赖。
|
||||
为 HHVM 安装依赖项:
|
||||
|
||||
```
|
||||
# yum -y install cpp gcc-c++ cmake git psmisc {binutils,boost,jemalloc,numactl}-devel \
|
||||
@ -154,7 +142,7 @@ MariaDB [(none)]> \q
|
||||
> mariadb mariadb-server libc-client make
|
||||
```
|
||||
|
||||
然后是使用 rpm 安装从 [HHVM 预编译包镜像站点][13] 下载的 HHVM 预编译包。
|
||||
然后是使用 `rpm` 安装从 [HHVM 预编译包镜像站点][13] 下载的 HHVM 预编译包。
|
||||
|
||||
```
|
||||
# rpm -Uvh http://mirrors.linuxeye.com/hhvm-repo/7/x86_64/hhvm-3.15.2-1.el7.centos.x86_64.rpm
|
||||
@ -167,7 +155,7 @@ MariaDB [(none)]> \q
|
||||
# hhvm --version
|
||||
```
|
||||
|
||||
为了能使用 PHP 命令,可以把 hhvm 命令设置为 php。这样在 shell 中输入 'php' 命令的时候,你会看到和输入 hhvm 命令一样的结果。
|
||||
为了能使用 PHP 命令,可以把 `hhvm` 命令设置为 `php`。这样在 shell 中输入 `php` 命令的时候,你会看到和输入 `hhvm` 命令一样的结果。
|
||||
|
||||
```
|
||||
# sudo update-alternatives --install /usr/bin/php php /usr/bin/hhvm 60
|
||||
@ -178,9 +166,9 @@ MariaDB [(none)]> \q
|
||||
|
||||
### 步骤 5 - 配置 HHVM
|
||||
|
||||
这一步中,我们来配置 HHVM 以系统服务器来运行。我们不通过端口这种常规的方式来运行它,而是选择使用 unix socket 文件的方式,这样运行的更快速一点。
|
||||
这一步中,我们来配置 HHVM 以系统服务来运行。我们不通过端口这种常规的方式来运行它,而是选择使用 unix socket 文件的方式,这样运行的更快速一点。
|
||||
|
||||
进入 systemd 配置目录,并创建一个 hhvm.service 文件。
|
||||
进入 systemd 配置目录,并创建一个 `hhvm.service` 文件。
|
||||
|
||||
```
|
||||
# cd /etc/systemd/system/
|
||||
@ -203,14 +191,14 @@ WantedBy=multi-user.target
|
||||
|
||||
保存文件退出 vim。
|
||||
|
||||
接下来,进入 hhvm 目录并编辑 server.ini 文件。
|
||||
接下来,进入 `hhvm` 目录并编辑 `server.ini` 文件。
|
||||
|
||||
```
|
||||
# cd /etc/hhvm/
|
||||
# vim server.ini
|
||||
```
|
||||
|
||||
将第 7 行 hhvm.server.port 替换为 unix socket,如下:
|
||||
将第 7 行 `hhvm.server.port` 替换为 unix socket,如下:
|
||||
|
||||
```
|
||||
hhvm.server.file_socket = /var/run/hhvm/hhvm.sock
|
||||
@ -218,7 +206,7 @@ hhvm.server.file_socket = /var/run/hhvm/hhvm.sock
|
||||
|
||||
保存文件并退出编辑器。
|
||||
|
||||
我们已在 hhvm 服务文件中定义了 hhvm 以 'nginx' 用户身份运行,所以还需要把 socket 文件目录的属主变更为 'nginx'。然后我们还必须在 SELinux 中修改 hhvm 目录内容以便让它可以访问这个 socket 文件。
|
||||
我们已在 hhvm 服务文件中定义了 hhvm 以 `nginx` 用户身份运行,所以还需要把 socket 文件目录的属主变更为 `nginx`。然后我们还必须在 SELinux 中修改 hhvm 目录的权限上下文以便让它可以访问这个 socket 文件。
|
||||
|
||||
```
|
||||
# chown -R nginx:nginx /var/run/hhvm/
|
||||
@ -228,7 +216,7 @@ hhvm.server.file_socket = /var/run/hhvm/hhvm.sock
|
||||
|
||||
服务器重启之后,hhvm 将不能运行,因为没有存储 socket 文件的目录,所有还必须在启动的时候自动创建一个。
|
||||
|
||||
使用 vim 编辑 rc.local 文件。
|
||||
使用 vim 编辑 `rc.local` 文件。
|
||||
|
||||
```
|
||||
# vim /etc/rc.local
|
||||
@ -257,7 +245,7 @@ hhvm.server.file_socket = /var/run/hhvm/hhvm.sock
|
||||
# systemctl enable hhvm
|
||||
```
|
||||
|
||||
要确保无误,使用 netstat 命令验证 hhvm 运行于 socket 文件。
|
||||
要确保无误,使用 `netstat` 命令验证 hhvm 运行于 socket 文件。
|
||||
|
||||
```
|
||||
# netstat -pl | grep hhvm
|
||||
@ -267,16 +255,16 @@ hhvm.server.file_socket = /var/run/hhvm/hhvm.sock
|
||||
|
||||
### 步骤 6 - 配置 HHVM 和 Nginx
|
||||
|
||||
在这个步骤中,我们配置好 HHVM 已让它运行在 Nginx Web 服务中,这需要在 Nginx 目录创建一个 hhvm 的配置文件。
|
||||
在这个步骤中,我们将配置 HHVM 已让它运行在 Nginx Web 服务中,这需要在 Nginx 目录创建一个 hhvm 的配置文件。
|
||||
|
||||
进入 /etc/nginx 目录,创建 a hhvm.conf 文件。
|
||||
进入 `/etc/nginx` 目录,创建 `hhvm.conf` 文件。
|
||||
|
||||
```
|
||||
# cd /etc/nginx/
|
||||
# vim hhvm.conf
|
||||
```
|
||||
|
||||
粘贴一下内容到文件中。
|
||||
粘贴以下内容到文件中。
|
||||
|
||||
```
|
||||
location ~ \.(hh|php)$ {
|
||||
@ -291,13 +279,13 @@ location ~ \.(hh|php)$ {
|
||||
|
||||
然后,保存并退出。
|
||||
|
||||
接下来,编辑 nginx.conf 文件,添加 hhvm 配置文件到 include 行。
|
||||
接下来,编辑 `nginx.conf` 文件,添加 hhvm 配置文件到 `include` 行。
|
||||
|
||||
```
|
||||
# vim nginx.conf
|
||||
```
|
||||
|
||||
添加配置到第 57 行的 server 指令中。
|
||||
添加配置到第 57 行的 `server` 指令中。
|
||||
|
||||
```
|
||||
include /etc/nginx/hhvm.conf;
|
||||
@ -305,7 +293,7 @@ include /etc/nginx/hhvm.conf;
|
||||
|
||||
保存并退出。
|
||||
|
||||
然后修改 SELinux 中关于 hhvm 配置文件的内容。
|
||||
然后修改 SELinux 中关于 hhvm 配置文件的权限上下文。
|
||||
|
||||
```
|
||||
# semanage fcontext -a -t httpd_config_t /etc/nginx/hhvm.conf
|
||||
@ -319,19 +307,19 @@ include /etc/nginx/hhvm.conf;
|
||||
# systemctl restart nginx
|
||||
```
|
||||
|
||||
记住确保没有错误。
|
||||
记住确保测试配置没有错误。
|
||||
|
||||
### 步骤 7 - 通过 HHVM 和 Nginx 创建虚拟主机
|
||||
|
||||
在这一步中能,我们要为 Nginx 和 hhvm 创建一个新的虚拟主机配置文件。这里我使用域名 **"natsume.co"** 来作为例子.你可以使用你主机喜欢的域名,并在配置文件中相应位置以及 WordPress 安装过程中进行替换。
|
||||
在这一步中,我们要为 Nginx 和 hhvm 创建一个新的虚拟主机配置文件。这里我使用域名 `natsume.co` 来作为例子,你可以使用你主机喜欢的域名,并在配置文件中相应位置以及 WordPress 安装过程中进行替换。
|
||||
|
||||
进入 nginx conf.d 目录,我们将在该目录存储虚拟主机文件。
|
||||
进入 nginx 的 `conf.d` 目录,我们将在该目录存储虚拟主机文件。
|
||||
|
||||
```
|
||||
# cd /etc/nginx/conf.d/
|
||||
```
|
||||
|
||||
使用 vim 创建一个名为 "natsume.conf" 的配置文件。
|
||||
使用 vim 创建一个名为 `natsume.conf` 的配置文件。
|
||||
|
||||
```
|
||||
# vim natsume.conf
|
||||
@ -367,15 +355,14 @@ server {
|
||||
|
||||
保存并退出。
|
||||
|
||||
在这给虚拟主机配置文件中,我们定义该域名的 Web 根目录为 "/var/www/hakase"。目前该目录还不存在,所有我们要创建它,并变更属主为 nginx 用户和组。
|
||||
在这个虚拟主机配置文件中,我们定义该域名的 Web 根目录为 `/var/www/hakase`。目前该目录还不存在,所有我们要创建它,并变更属主为 nginx 用户和组。
|
||||
|
||||
```
|
||||
# mkdir -p /var/www/hakase
|
||||
# chown -R nginx:nginx /var/www/hakase
|
||||
```
|
||||
|
||||
|
||||
Next, configure the SELinux context for the file and directory.
|
||||
接下来,为该文件和目录配置 SELinux 上下文。
|
||||
|
||||
```
|
||||
# semanage fcontext -a -t httpd_config_t "/etc/nginx/conf.d(/.*)?"
|
||||
@ -393,28 +380,28 @@ Next, configure the SELinux context for the file and directory.
|
||||
|
||||
在步骤 5 的时候,我们已经为 WordPress 配置好了虚拟主机,现在只需要下载 WordPress 和使用我们在步骤 3 的时候创建的数据库和用户来编辑数据库配置就好了。
|
||||
|
||||
进入 Web 根目录 "/var/www/hakase" 并使用 Wget 命令下载 WordPress:
|
||||
进入 Web 根目录 `/var/www/hakase` 并使用 Wget 命令下载 WordPress:
|
||||
|
||||
```
|
||||
# cd /var/www/hakase
|
||||
# wget wordpress.org/latest.tar.gz
|
||||
```
|
||||
|
||||
解压 "latest.tar.gz" 并将 wordpress 文件夹中所有的文件和目录移动到当前目录:
|
||||
解压 `latest.tar.gz` 并将 `wordpress` 文件夹中所有的文件和目录移动到当前目录:
|
||||
|
||||
```
|
||||
# tar -xzvf latest.tar.gz
|
||||
# mv wordpress/* .
|
||||
```
|
||||
|
||||
下一步,复制一份 "wp-config-sample.php" 并更名为 "wp-config.php",然后使用 vim 进行编辑:
|
||||
下一步,复制一份 `wp-config-sample.php` 并更名为 `wp-config.php`,然后使用 vim 进行编辑:
|
||||
|
||||
```
|
||||
# cp wp-config-sample.php wp-config.php
|
||||
# vim wp-config.php
|
||||
```
|
||||
|
||||
将 DB_NAME 设置为 **"wordpressdb"**、DB_USER 设置为 **"wpuser"** 以及 DB_PASSWORD 设置为 **"wpuser@"**。
|
||||
将 `DB_NAME` 设置为 `wordpressdb`、`DB_USER` 设置为 `wpuser` 以及 `DB_PASSWORD` 设置为 `wpuser@`。
|
||||
|
||||
```
|
||||
define('DB_NAME', 'wordpressdb');
|
||||
@ -427,28 +414,28 @@ define('DB_HOST', 'localhost');
|
||||
|
||||
[][16]
|
||||
|
||||
修改关于 WordPress 目录的 SELinux 配置指令。
|
||||
修改关于 WordPress 目录的 SELinux 上下文。
|
||||
|
||||
```
|
||||
# semanage fcontext -a -t httpd_sys_content_t "/var/www/hakase(/.*)?"
|
||||
# restorecon -Rv /var/www/hakase
|
||||
```
|
||||
|
||||
现在打开 Web 浏览器,在地址栏输入你之前为 WordPress 设置的域名,我这里是 "natsume.co"。
|
||||
现在打开 Web 浏览器,在地址栏输入你之前为 WordPress 设置的域名,我这里是 `natsume.co`。
|
||||
|
||||
选择英语并点击 '继续 (Continue)'。
|
||||
选择语言并点击<ruby>继续<rt>Continue</rt></ruby>。
|
||||
|
||||
[][17]
|
||||
|
||||
根据自身要求填写站点标题和描述并点击 "安装 Wordpress (Install Wordpress)"。
|
||||
根据自身要求填写站点标题和描述并点击<ruby>安装 Wordpress<rt>Install Wordpress</rt></ruby>"。
|
||||
|
||||
[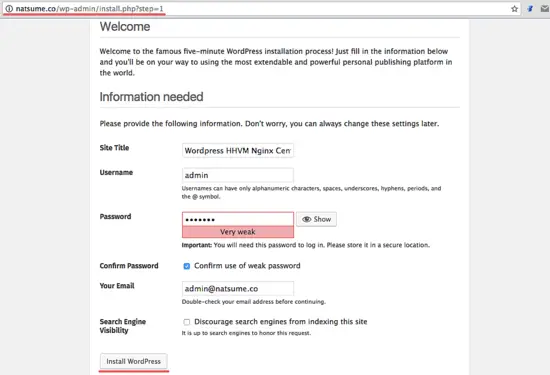][18]
|
||||
|
||||
耐心等待安装完成。你会见到如下页面,点击 "登录 (Log In)" 来登录到管理面板。
|
||||
耐心等待安装完成。你会见到如下页面,点击<ruby>登录<rt>Log In</rt></ruby>来登录到管理面板。
|
||||
|
||||
[][19]
|
||||
|
||||
输入你设置的管理员用户账号和密码,在此点击 "登录 (Log In)"。
|
||||
输入你设置的管理员用户账号和密码,在此点击<ruby>登录<rt>Log In</rt></ruby>。
|
||||
|
||||
[][20]
|
||||
|
||||
@ -456,7 +443,7 @@ define('DB_HOST', 'localhost');
|
||||
|
||||
[][21]
|
||||
|
||||
Wordpress 主页。
|
||||
Wordpress 的主页:
|
||||
|
||||
[][22]
|
||||
|
||||
@ -464,8 +451,7 @@ Wordpress 主页。
|
||||
|
||||
### 参考链接
|
||||
|
||||
- [https://www.howtoforge.com/tutorial/how-to-install-wordpress-with-hhvm-and-nginx-on-opensuse-leap-42-1/](https://www.howtoforge.com/tutorial/how-to-install-wordpress-with-hhvm-and-nginx-on-opensuse-leap-42-1/)
|
||||
- [https://www.nginx.com/blog/nginx-se-linux-changes-upgrading-rhel-6-6/https://www.nginx.com/blog/nginx-se-linux-changes-upgrading-rhel-6-6/](https://www.nginx.com/blog/nginx-se-linux-changes-upgrading-rhel-6-6/)
|
||||
- https://www.nginx.com/blog/nginx-se-linux-changes-upgrading-rhel-6-6/
|
||||
|
||||
------------------------------------
|
||||
|
||||
@ -477,9 +463,9 @@ Wordpress 主页。
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-install-wordpress-with-hhvm-and-nginx-on-centos-7/
|
||||
|
||||
作者:[ Muhammad Arul][a]
|
||||
作者:[Muhammad Arul][a]
|
||||
译者:[GHLandy](https://github.com/GHLandy)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,78 @@
|
||||
让你的 Linux 远离黑客(二):另外三个建议
|
||||
==========
|
||||
|
||||

|
||||
|
||||
在这个系列中, 我们会讨论一些阻止黑客入侵你的系统的重要信息。观看这个免费的网络点播研讨会获取更多的信息。
|
||||
|
||||
[Creative Commons Zero][1]Pixabay
|
||||
|
||||
在这个系列的[第一部分][3]中,我分享过两种简单的方法来阻止黑客黑掉你的 Linux 主机。这里是另外三条来自于我最近在 Linux 基金会的网络研讨会上的建议,在这次研讨会中,我分享了更多的黑客用来入侵你的主机的策略、工具和方法。完整的[网络点播研讨会][4]视频可以在网上免费观看。
|
||||
|
||||
### 简单的 Linux 安全提示 #3
|
||||
|
||||
**Sudo。**
|
||||
|
||||
Sudo 非常、非常的重要。我认为这只是很基本的东西,但就是这些基本的东西会让我的黑客生涯会变得更困难一些。如果你没有配置 sudo,还请配置好它。
|
||||
|
||||
还有,你主机上所有的用户必须使用他们自己的密码。不要都免密码使用 sudo 执行所有命令。当我有一个可以无需密码而可以 sudo 任何命令的用户,只会让我的黑客活动变得更容易。如果我可以无需验证就可以 sudo ,同时当我获得你的没有密码的 SSH 密钥后,我就能十分容易的开始任何黑客活动。这样,我就拥有了你机器的 root 权限。
|
||||
|
||||
保持较低的超时时间。我们喜欢劫持用户的会话,如果你的某个用户能够使用 sudo,并且设置的超时时间是 3 小时,当我劫持了你的会话,那么你就再次给了我一个自由的通道,哪怕你需要一个密码。
|
||||
|
||||
我推荐的超时时间大约为 10 分钟,甚至是 5 分钟。用户们将需要反复地输入他们的密码,但是,如果你设置了较低的超时时间,你将减少你的受攻击面。
|
||||
|
||||
还要限制可以访问的命令,并禁止通过 sudo 来访问 shell。大多数 Linux 发行版目前默认允许你使用 sudo bash 来获取一个 root 身份的 shell,当你需要做大量的系统管理的任务时,这种机制是非常好的。然而,应该对大多数用户实际需要运行的命令有一个限制。你对他们限制越多,你主机的受攻击面就越小。如果你允许我 shell 访问,我将能够做任何类型的事情。
|
||||
|
||||
### 简单的 Linux 安全提示 #4
|
||||
|
||||
**限制正在运行的服务。**
|
||||
|
||||
防火墙很好,你的边界防火墙非常的强大。当流量流经你的外部网络时,有几家防火墙产品可以帮你很好的保护好自己。但是防火墙内的人呢?
|
||||
|
||||
你正在使用基于主机的防火墙或者基于主机的入侵检测系统吗?如果是,请正确配置好它。怎样可以知道你的正在受到保护的东西是否出了问题呢?
|
||||
|
||||
答案是限制当前正在运行的服务。不要在不需要提供 MySQL 服务的机器上运行它。如果你有一个默认会安装完整的 LAMP 套件的 Linux 发行版,而你不会在它上面运行任何东西,那么卸载它。禁止那些服务,不要开启它们。
|
||||
|
||||
同时确保用户不要使用默认的身份凭证,确保那些内容已被安全地配置。如何你正在运行 Tomcat,你不应该可以上传你自己的小程序(applets)。确保它们不会以 root 的身份运行。如果我能够运行一个小程序,我不会想着以管理员的身份来运行它,我能访问就行。你对人们能够做的事情限制越多,你的机器就将越安全。
|
||||
|
||||
### 简单的 Linux 安全提示 #5
|
||||
|
||||
**小心你的日志记录。**
|
||||
|
||||
看看它们,认真地,小心你的日志记录。六个月前,我们遇到一个问题。我们的一个顾客从来不去看日志记录,尽管他们已经拥有了很久、很久的日志记录。假如他们曾经看过日志记录,他们就会发现他们的机器早就已经被入侵了,并且他们的整个网络都是对外开放的。我在家里处理的这个问题。每天早上起来,我都有一个习惯,我会检查我的 email,我会浏览我的日志记录。这仅会花费我 15 分钟,但是它却能告诉我很多关于什么正在发生的信息。
|
||||
|
||||
就在这个早上,机房里的三台电脑死机了,我不得不去重启它们。我不知道为什么会出现这样的情况,但是我可以从日志记录里面查出什么出了问题。它们是实验室的机器,我并不在意它们,但是有人会在意。
|
||||
|
||||
通过 Syslog、Splunk 或者任何其他日志整合工具将你的日志进行集中是极佳的选择。这比将日志保存在本地要好。我最喜欢做是事情就是修改你的日志记录让你不知道我曾经入侵过你的电脑。如果我能这么做,你将不会有任何线索。对我来说,修改集中的日志记录比修改本地的日志更难。
|
||||
|
||||
它们就像你的很重要的人,送给它们鲜花——磁盘空间。确保你有足够的磁盘空间用来记录日志。由于磁盘满而变成只读的文件系统并不是一件愉快的事情。
|
||||
|
||||
还需要知道什么是不正常的。这是一件非常困难的事情,但是从长远来看,这将使你日后受益匪浅。你应该知道什么正在进行和什么时候出现了一些异常。确保你知道那。
|
||||
|
||||
在[第三篇也是最后的一篇文章][5]里,我将就这次研讨会中问到的一些比较好的安全问题进行回答。[现在开始看这个完整的免费的网络点播研讨会][6]吧。
|
||||
|
||||
*** Mike Guthrie 就职于能源部,主要做红队交战和渗透测试。***
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
via: https://www.linux.com/news/webinar/2017/how-keep-hackers-out-your-linux-machine-part-2-three-more-easy-security-tips
|
||||
|
||||
作者:[MIKE GUTHRIE][a]
|
||||
译者:[zhousiyu325](https://github.com/zhousiyu325)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
[a]:https://www.linux.com/users/anch
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]:https://www.linux.com/files/images/security-tipsjpg
|
||||
[3]:https://linux.cn/article-8189-1.html
|
||||
[4]:http://portal.on24.com/view/channel/index.html?showId=1101876&showCode=linux&partnerref=linco
|
||||
[5]:https://www.linux.com/news/webinar/2017/how-keep-hackers-out-your-linux-machine-part-3-your-questions-answered
|
||||
[6]:http://bit.ly/2j89ISJ
|
||||
|
||||
|
||||
|
||||
|
||||
@ -2,11 +2,11 @@ Go 语言编译期断言
|
||||
============================================================
|
||||
|
||||
|
||||
这篇文章是关于一个鲜为人知的方法让 Go 在编译期断言。你可能不会使用它,但是了解一下也很有趣。
|
||||
这篇文章是关于一个鲜为人知的让 Go 在编译期断言的方法。你可能不会使用它,但是了解一下也很有趣。
|
||||
|
||||
作为一个热身,这里是一个在 Go 中相当知名的编译时断言:接口满意度检查。
|
||||
作为一个热身,来看一个在 Go 中熟知的编译期断言:接口满意度检查。
|
||||
|
||||
在这段代码([playground][1])中,`var _ =` 行确保类型 `W` 是一个 `stringWriter`,由 [`io.WriteString`][2] 检查。
|
||||
在这段代码([playground][1])中,`var _ =` 行确保类型 `W` 是一个 `stringWriter`,其由 [`io.WriteString`][2] 检查。
|
||||
|
||||
```
|
||||
package main
|
||||
@ -39,13 +39,13 @@ main.go:14: cannot use W literal (type W) as type stringWriter in assignment:
|
||||
|
||||
这是很有用的。对于大多数同时满足 `io.Writer` 和 `stringWriter` 的类型,如果你删除 `WriteString` 方法,一切都会像以前一样继续工作,但性能较差。
|
||||
|
||||
你可以使用编译时断言保护你的代码,而不是试图使用[`testing.T.AllocsPerRun'][3]为性能回归编写一个脆弱的测试。
|
||||
你可以使用编译期断言保护你的代码,而不是试图使用[`testing.T.AllocsPerRun'][3]为性能回归编写一个脆弱的测试。
|
||||
|
||||
这是[一个实际的 io 包中的技术例子][4]。
|
||||
|
||||
* * *
|
||||
|
||||
好的,让我们隐晦一点!
|
||||
好的,让我们低调一点!
|
||||
|
||||
接口满意检查是很棒的。但是如果你想检查一个简单的布尔表达式,如 `1 + 1 == 2` ?
|
||||
|
||||
@ -69,9 +69,9 @@ func main() {
|
||||
}
|
||||
```
|
||||
|
||||
`Hash` 可能是某种抽象的哈希结果。`init` 函数确保它将与[crypto/md5][6]一起工作。如果你改变 `Hash` 为(也就是)`[8]byte`,它会在进程启动时发生混乱。但是,这是一个运行时检查。如果我们想要早点发现怎么办?
|
||||
`Hash` 可能是某种抽象的哈希结果。`init` 函数确保它将与 [crypto/md5][6] 一起工作。如果你改变 `Hash` 为(比如说)`[8]byte`,它会在进程启动时发生崩溃。但是,这是一个运行时检查。如果我们想要早点发现怎么办?
|
||||
|
||||
就是这样。(没有 playground 链接,因为这在 playground 上不起作用。)
|
||||
如下。(没有 playground 链接,因为这在 playground 上不起作用。)
|
||||
|
||||
```
|
||||
package main
|
||||
@ -109,11 +109,11 @@ main.init.1: undefined: "main.hashIsTooSmall"
|
||||
|
||||
`hashIsTooSmall` 是[一个没有函数体的声明][7]。编译器假定别人将提供一个实现,也许是一个汇编程序。
|
||||
|
||||
当编译器可以证明 `len(Hash {})<md5.Size` 时,它消除了 if 语句中的代码。结果,没有人使用函数 `hashIsTooSmall`,所以链接器会消除它。没有其他损害。一旦断言失败,if 语句中的代码将被保留。不会消除 `hashIsTooSmall`。链接器然后注意到没有人提供了函数的实现然后链接失败,并出现错误,这是我们的目标。
|
||||
当编译器可以证明 `len(Hash {})< md5.Size` 时,它消除了 if 语句中的代码。结果,没有人使用函数 `hashIsTooSmall`,所以链接器会消除它。没有其他损害。一旦断言失败,if 语句中的代码将被保留。不会消除 `hashIsTooSmall`。链接器然后注意到没有人提供了函数的实现然后链接失败,并出现错误,这是我们的目标。
|
||||
|
||||
最后一个奇怪的点:为什么是 `import "C"`? go 工具知道在正常的 Go 代码中,所有函数都必须有主体,并指示编译器强制执行。通过切换到 cgo,我们删除该检查。(如果你在上面的代码中运行 `go build -x',而没有添加 `import "C"` 这行,你会看到编译器是用 `-complete` 标志调用的。)另一种方法是添加 `import "C"` 来[向包中添加一个名为 `foo.s` 的空文件][8]。
|
||||
最后一个奇怪的点:为什么是 `import "C"`? go 工具知道在正常的 Go 代码中,所有函数都必须有主体,并指示编译器强制执行。通过切换到 cgo,我们删除该检查。(如果你在上面的代码中运行 `go build -x`,而没有添加 `import "C"` 这行,你会看到编译器是用 `-complete` 标志调用的。)另一种方法是添加 `import "C"` 来[向包中添加一个名为 `foo.s` 的空文件][8]。
|
||||
|
||||
我在[编译器测试套件][9]中只知道这种使用。还有其他[可以发挥想象力的使用][10],但还没有人打扰。
|
||||
我仅见过一次这种技术的使用,是在[编译器测试套件][9]中。还有其他[可以发挥想象力的使用][10],但我还没见到过。
|
||||
|
||||
可能就是这样吧。 :)
|
||||
|
||||
@ -124,7 +124,7 @@ via: http://commaok.xyz/post/compile-time-assertions
|
||||
|
||||
作者:[Josh Bleecher Snyder][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,212 @@
|
||||
wkhtmltopdf:一个 Linux 中将网页转成 PDF 的智能工具
|
||||
============================================================
|
||||
|
||||
wkhtmltopdf 是一个开源、简单而有效的命令行 shell 程序,它可以将任何 HTML (网页)转换为 PDF 文档或图像(jpg、png 等)。
|
||||
|
||||
wkhtmltopdf 是用 C++ 编写的,并在 GNU/GPL (通用公共许可证)下发布。它使用 WebKit 渲染引擎将 HTML 页面转换为 PDF 文档且不会丢失页面的质量。这是一个用于实时创建和存储网页快照的非常有用且可信赖的解决方案。
|
||||
|
||||
### wkhtmltopdf 的功能
|
||||
|
||||
1. 开源并且跨平台。
|
||||
2. 使用 WebKit 引擎将任意 HTML 网页转换为 PDF 文件。
|
||||
3. 添加页眉和页脚的选项
|
||||
4. 目录生成 (TOC) 选项。
|
||||
5. 提供批量模式转换。
|
||||
6. 通过绑定 libwkhtmltox 来支持 PHP 或 Python。
|
||||
|
||||
在本文中,我们将介绍如何在 Linux 系统下使用 tar 包来安装 wkhtmltopdf。
|
||||
|
||||
### 安装 Evince (PDF 浏览器)
|
||||
|
||||
让我们在 Linux 系统中安装 evince (一个 PDF 阅读器)来浏览 PDF 文件。
|
||||
|
||||
```
|
||||
$ sudo yum install evince [RHEL/CentOS and Fedora]
|
||||
$ sudo dnf install evince [On Fedora 22+ versions]
|
||||
$ sudo apt-get install evince [On Debian/Ubuntu systems]
|
||||
```
|
||||
|
||||
### 下载 wkhtmltopdf 源码文件
|
||||
|
||||
使用 [wget 命令][1]根据你的 Linux 架构来下载 wkhtmltopdf 源码文件,或者你也可以在 [wkhtmltopdf 下载页][2]下载最新的版本(目前最新的稳定版是 0.12.4)
|
||||
|
||||
在 64 位 Linux 系统中:
|
||||
|
||||
```
|
||||
$ wget http://download.gna.org/wkhtmltopdf/0.12/0.12.4/wkhtmltox-0.12.4_linux-generic-amd64.tar.xz
|
||||
```
|
||||
|
||||
在 32 位 Linux 系统中:
|
||||
|
||||
```
|
||||
$ wget http://download.gna.org/wkhtmltopdf/0.12/0.12.4/wkhtmltox-0.12.4_linux-generic-i386.tar.xz
|
||||
```
|
||||
|
||||
### 在 Linux 中安装 wkhtmltopdf
|
||||
|
||||
使用 [tar 命令][3]解压文件到当前目录中。
|
||||
|
||||
```
|
||||
------ On 64-bit Linux OS ------
|
||||
$ sudo tar -xvf wkhtmltox-0.12.4_linux-generic-amd64.tar.xz
|
||||
------ On 32-bit Linux OS ------
|
||||
$ sudo tar -xvzf wkhtmltox-0.12.4_linux-generic-i386.tar.xz
|
||||
```
|
||||
|
||||
为了能从任意路径执行程序,将 wkhtmltopdf 安装到 `/usr/bin` 目录下。
|
||||
|
||||
```
|
||||
$ sudo cp wkhtmltox/bin/wkhtmltopdf /usr/bin/
|
||||
```
|
||||
|
||||
### 如何使用 wkhtmltopdf?
|
||||
|
||||
我们会看到如何将远程的 HTML 页面转换成 PDF 文件、验证信息、使用 evince 在 GNOME 桌面中浏览创建的文件。
|
||||
|
||||
#### 将 HTML 网页转成 PDF 文件
|
||||
|
||||
要将任意 HTML 页面转换成 PDF,运行下面的命令。它会在当前目录下将页面转换成 [10-Sudo-Configurations.pdf][4]。
|
||||
|
||||
```
|
||||
# wkhtmltopdf http://www.tecmint.com/sudoers-configurations-for-setting-sudo-in-linux/ 10-Sudo-Configurations.pdf
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
Loading pages (1/6)
|
||||
Counting pages (2/6)
|
||||
Resolving links (4/6)
|
||||
Loading headers and footers (5/6)
|
||||
Printing pages (6/6)
|
||||
Done
|
||||
```
|
||||
|
||||
#### 浏览生成的 PDF 文件
|
||||
|
||||
为了验证创建的文件,使用下面的命令。
|
||||
|
||||
```
|
||||
$ file 10-Sudo-Configurations.pdf
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
10-Sudo-Configurations.pdf: PDF document, version 1.4
|
||||
```
|
||||
|
||||
#### 浏览生成的 PDF 文件细节
|
||||
|
||||
要浏览生成的文件信息,运行下面的命令。
|
||||
|
||||
```
|
||||
$ pdfinfo 10-Sudo-Configurations.pdf
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
Title: 10 Useful Sudoers Configurations for Setting 'sudo' in Linux
|
||||
Creator: wkhtmltopdf 0.12.4
|
||||
Producer: Qt 4.8.7
|
||||
CreationDate: Sat Jan 28 13:02:58 2017
|
||||
Tagged: no
|
||||
UserProperties: no
|
||||
Suspects: no
|
||||
Form: none
|
||||
JavaScript: no
|
||||
Pages: 13
|
||||
Encrypted: no
|
||||
Page size: 595 x 842 pts (A4)
|
||||
Page rot: 0
|
||||
File size: 697827 bytes
|
||||
Optimized: no
|
||||
PDF version: 1.4
|
||||
```
|
||||
|
||||
#### 浏览创建的文件
|
||||
|
||||
在桌面中使用 evince 查看最新生成的 PDF 文件。
|
||||
|
||||
```
|
||||
$ evince 10-Sudo-Configurations.pdf
|
||||
```
|
||||
|
||||
示例截图:
|
||||
|
||||
在我的 Linux Mint 17 中看起来很棒。
|
||||
|
||||
[
|
||||
|
||||
][5]
|
||||
|
||||
*在 PDF 中浏览网页*
|
||||
|
||||
### 给 PDF 创建页面的 TOC (Table Of Content 即目录)
|
||||
|
||||
要创建一个 PDF 文件的目录,使用 toc 选项。
|
||||
|
||||
```
|
||||
$ wkhtmltopdf toc http://www.tecmint.com/sudoers-configurations-for-setting-sudo-in-linux/ 10-Sudo-Configurations.pdf
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
Loading pages (1/6)
|
||||
Counting pages (2/6)
|
||||
Loading TOC (3/6)
|
||||
Resolving links (4/6)
|
||||
Loading headers and footers (5/6)
|
||||
Printing pages (6/6)
|
||||
Done
|
||||
```
|
||||
|
||||
要查看已创建文件的 TOC,再次使用 evince。
|
||||
|
||||
```
|
||||
$ evince 10-Sudo-Configurations.pdf
|
||||
```
|
||||
|
||||
示例截图:
|
||||
|
||||
看一下下面的图。它上看去比上面的更好。
|
||||
|
||||
[
|
||||
|
||||
][6]
|
||||
|
||||
*在 PDF 中创建网页的目录*
|
||||
|
||||
#### wkhtmltopdf 选项及使用
|
||||
|
||||
更多关于 wkhtmltopdf 的使用及选项,使用下面的帮助命令。它会显示出所有可用的选项。
|
||||
|
||||
```
|
||||
$ wkhtmltopdf --help
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
我是 Ravi Saive,TecMint 的创建者。一个爱在网上分享的技巧和提示的电脑极客和 Linux 专家。我的大多数服务器运行在名为 Linux 的开源平台上。请在 Twitter、 Facebook 和 Google+ 等上关注我。
|
||||
|
||||
--------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/wkhtmltopdf-convert-website-html-page-to-pdf-linux/
|
||||
|
||||
作者:[Ravi Saive][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/admin/
|
||||
[1]:http://www.tecmint.com/10-wget-command-examples-in-linux/
|
||||
[2]:http://wkhtmltopdf.org/downloads.html
|
||||
[3]:http://www.tecmint.com/18-tar-command-examples-in-linux/
|
||||
[4]:http://www.tecmint.com/sudoers-configurations-for-setting-sudo-in-linux/
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2012/10/View-Website-Page-in-PDF.png
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2012/10/Create-Website-Page-Table-of-Contents-in-PDF.png
|
||||
@ -1,26 +1,25 @@
|
||||
|
||||
如何获取并运行 Orange Pi
|
||||
Orange Pi 新手起步指南
|
||||
===========================
|
||||
|
||||

|
||||

|
||||
|
||||
图片来源:Dave Egts, CC BY-SA 4.0
|
||||
|
||||
随着开源驱动的硬件越来越成为主流,比如 [Arduino][2] 和 [Raspberry Pi][3],这些开源硬件的成本不断下降,给那些全新且具有创新性的[物联网][4]和[STEM][5](LCTT译注:STEM 代表科学 Science,技术 Technology,工程 Engineering,数学 Mathematics)类软件打开了大门。我对两者都比较感兴趣,始终保持关注,以便能找到一些可以应用到教育产业的创新点,比如课堂教育和我女儿的[机器人小组][6]。当听说 [Orange Pi 比 Raspberry Pi 更优秀][7]时,我便开始关注Orange Pi了。
|
||||
随着开源驱动的硬件越来越成为主流,比如 [Arduino][2] 和 [Raspberry Pi][3],这些开源硬件的成本不断下降,给那些全新且具有创新性的[物联网][4]和[STEM][5](LCTT译注:STEM 代表科学 Science,技术 Technology,工程 Engineering,数学 Mathematics)类软件打开了大门。我对两者都比较感兴趣,始终保持关注,以便能找到一些可以应用到教育产业的创新点,比如课堂教育和我女儿的[机器人小组][6]。当听说 [Orange Pi 比 Raspberry Pi 更优秀][7]时,我便开始关注 Orange Pi了。
|
||||
|
||||
尽管 Orange Pi 是个略带酸味儿的名字,但是我仍然被 Orange Pi Zero 迷住了。我最近刚购买了一个 Orange Pi Zero 并将在本文中分享我的第一体验。真情提示:我是真的着迷了。
|
||||
|
||||
### 为什么是Orange Pi?
|
||||
### 为什么是 Orange Pi?
|
||||
|
||||
Orange Pi 是由 Linux 驱动的单板计算机家族的一员,由[深圳迅龙软件有限公司][8]生产并在 [AliExpress][9] 上售卖。在 AliExpress 上买东西需要有耐心,提前计划预留出 2 到 4 周的运输时间,因为这些产品都是从中国大陆直接发往全世界其它地方的。
|
||||
Orange Pi 是由 Linux 驱动的单板计算机家族的一员,由[深圳迅龙软件有限公司][8]生产并在 [全球速卖通(AliExpress)][9] 上售卖。在全球速卖通(AliExpress)上买东西需要有耐心,提前计划预留出 2 到 4 周的运输时间,因为这些产品都是从中国大陆直接发往全世界其它地方的。
|
||||
|
||||
与 Raspberry Pi 不同,Raspberry Pi 家族型号比较少,不过在逐步增加,为单板计算机家族添加了几个具有不同价位及功能特色的型号,但是相对而言 Orange Pi 的型号更丰富。好消息是可以在巨大的软件库中选择你需要的东西,但是坏消息就是选择数量实在太大了。以我的经验来看,使用 [Orange Pi Zero][10] 的 512 MB 版本足矣,因为该版本很好的平衡了功能与价格,适合中学及学术环境使用。
|
||||
与 Raspberry Pi 不同,Raspberry Pi 家族型号比较少,不过在逐步增加,为单板计算机家族添加了几个具有不同价位及功能特色的型号,但是相对而言 Orange Pi 的型号更丰富。好消息是可以在巨大的软件库中选择你需要的东西,但是坏消息就是选择范围实在太大了。以我的经验来看,使用 [Orange Pi Zero][10] 的 512 MB 版本足矣,因为该版本很好的平衡了功能与价格,适合中学及学术环境使用。
|
||||
|
||||
可以到 [Orange Pi Zero 网站][11] ,查看高清图及所有规格。
|
||||
|
||||
很明确的问题是,我希望这种设备的价格越便宜越好,但是要能做到开箱即用,并且能够直接联网以便 SSH 及物联网应用能正常使用。Orange Pi Zero 拥有板载的10/100 M 以太网及 802.11 b/g/n Wi-Fi 模块可以连接网络以满足需求。它还有 26 个与 Raspberry Pi 兼容的 [GPIO 端口][12],用于连接物联网应用传感器。我使用的是 512 MB 版本的 Orange Pi Zero 而不是 256MB 版本,因为内存大带来的好处很多,并且这两个版本只相差了 2 美元。除此之外,运费还需要 $12.30,这笔花费对于那些鼓励积极实验及创造魔法烟雾的课堂特别划算。(LCTT 译注:“创造魔法烟雾”是幽默的说法,意即因未知原因设备停止工作,原多用于电气工程师和技术员,最近常被程序员们采用)。
|
||||
|
||||
与 $5 的 [Raspberry Pi Zero][14] 相比,Orange Pi Zero 只贵了几元钱,但是这个开箱后更容易上手使用,因为它拥有板载的 Internet 连接模块及 4 核 CPU,而不是单核。这个板载网口使得 Orange Pi Zero 比 Raspberry Pi Zero 更容易使用,因为 Raspberry Pi Zero 还需要一个 Micro-USB-to-USB 转换器及一个 USB Wi-Fi 才能连上网。当赠送别人一个物联网设备作为礼物时,你当然希望对方能够尽快且容易的使用该产品,而不是送一个不完整的产品,那么这个礼物就只能躺在阁楼吃灰了。
|
||||
与 $5 的 [Raspberry Pi Zero][14] 相比,Orange Pi Zero 只贵了几元钱,但是这个开箱后更容易上手使用,因为它拥有板载的 Internet 连接模块及 4 核 CPU,而不是单核。这个板载网口使得 Orange Pi Zero 比 Raspberry Pi Zero 更容易使用,因为 Raspberry Pi Zero 还需要一个 Micro-USB 转 USB 的转换器及一个 USB Wi-Fi 才能连上网。当赠送别人一个物联网设备作为礼物时,你当然希望对方能够尽快且容易的使用该产品,而不是送一个不完整的产品,那么这个礼物就只能躺在阁楼吃灰了。
|
||||
|
||||
### 开箱经验
|
||||
|
||||
@ -32,7 +31,7 @@ Orange Pi 是由 Linux 驱动的单板计算机家族的一员,由[深圳迅
|
||||
|
||||
*SSH 登录进 Orange Pi Zero*
|
||||
|
||||
通过以太网 SSH 连上后,我可以使用 [nmtui-connect][18] 轻松连上我的无线接入点。然后执行 **apt-get update && apt-get upgrade** 命令,这个命令执行速度比 Raspberry Pi Zero 快,基本接近 [Raspberry Pi 3][19] 的表现了,其他人也[观察到类似的结果][20]。虽然 Orange Pi Zero 执行速度可能比不过Raspberry Pi 3,但是我也没有打算用它来计算基因排序或者挖比特币矿。Armbian 会自动调整 root 分区来使用整个 microSD 卡空间,而使用 Raspbian 的时候这是手动且很容易忘记的步骤。最后,和价值 $35 的 Raspberry Pi 3 相比,购买 $12 的 Orange Pi Zero 可以使得三倍多的学生有自己的学习工具,也可以将 Orange Pi Zero 作为礼物分享给三倍数量的朋友。
|
||||
通过以太网 SSH 连上后,我可以使用 [nmtui-connect][18] 轻松连上我的无线接入点。然后执行 `apt-get update && apt-get upgrade` 命令,这个命令执行速度比 Raspberry Pi Zero 快,基本接近 [Raspberry Pi 3][19] 的表现了,其他人也[观察到类似的结果][20]。虽然 Orange Pi Zero 执行速度可能比不过Raspberry Pi 3,但是我也没有打算用它来计算基因排序或者挖比特币矿。Armbian 会自动调整 root 分区来使用整个 microSD 卡空间,而使用 Raspbian 的时候这是手动且很容易忘记的步骤。最后,和价值 $35 的 Raspberry Pi 3 相比,购买 $12 的 Orange Pi Zero 可以使得三倍多的学生有自己的学习工具,也可以将 Orange Pi Zero 作为礼物分享给三倍数量的朋友。
|
||||
|
||||

|
||||
|
||||
@ -0,0 +1,156 @@
|
||||
在 Linux 上用火狐浏览器保护你的隐私
|
||||
=============================
|
||||
|
||||
### 介绍
|
||||
|
||||
隐私和安全正在逐渐成为一个重要的话题。虽然不可能做到 100% 安全,但是,还是能采取一些措施,特别是在 Linux 上,在你浏览网页的时候保护你的在线隐私安全。
|
||||
|
||||
基于这些目的选择浏览器的时候,火狐或许是你的最佳选择。谷歌 Chrome 不能信任。它是属于谷歌的,一个众所周知的数据收集公司,而且它是闭源的。 Chromium 或许还可以,但并不能保证。只有火狐保持了一定程度的用户权利承诺。
|
||||
|
||||
### 火狐设置
|
||||
|
||||
火狐里有几个你能设定的设置,能更好地保护你的隐私。这些设置唾手可得,能帮你控制那些在你浏览的时候分享的数据。
|
||||
|
||||
#### 健康报告
|
||||
|
||||
你首先可以设置的是对火狐健康报告发送的限制,以限制数据发送量。当然,这些数据只是被发送到 Mozilla,但这也是传输数据。
|
||||
|
||||
打开火狐的菜单,点击<ruby>“选项”<rt>Preferences</rt></ruby>。来到侧边栏里的<ruby>“高级”<rt>Advanced</rt></ruby>选项卡,点击<ruby>“数据选项”<rt>Data Choices</rt></ruby>。这里你能禁用任意数据的报告。
|
||||
|
||||
#### 搜索
|
||||
|
||||
新版的火狐浏览器默认使用雅虎搜索引擎。一些发行版会更改设置,替代使用的是谷歌。两个方法都不理想。火狐可以使用 DuckDuckGo 作为默认选项。
|
||||
|
||||

|
||||
|
||||
为了启用 DuckDuckGo,你得打开火狐菜单点击<ruby>“选项”<rt>Preferences</rt></ruby>。直接来到侧边栏的<ruby>“搜索”<rt>Search</rt></ruby>选项卡。然后,在<ruby>“默认搜索引擎”<rt>Default Search Engine</rt></ruby>的下拉菜单中选择 DuckDuckGo 。
|
||||
|
||||
#### <ruby>请勿跟踪<rt>Do Not Track</rt></ruby>
|
||||
|
||||
这个功能并不完美,但它确实向站点发送了一个信号,告诉它们不要使用分析工具来记录你的活动。这些网页或许会遵从,会许不会。但是,最好启用请勿跟踪,也许它们会遵从呢。
|
||||
|
||||

|
||||
|
||||
再次打开火狐的菜单,点击<ruby>“选项”<rt>Preferences</rt></ruby>,然后是<ruby>“隐私”<rt>Privacy</rt></ruby>。页面的最上面有一个<ruby>“跟踪”<rt>Tracking</rt></ruby>部分。点击那一行写着<ruby>“您还可以管理您的‘请勿跟踪’设置”<rt>You can also manage your Do Not Track settings</rt></ruby>的链接。会出现一个有复选框的弹出窗口,那里允许你启用“请勿跟踪”设置。
|
||||
|
||||
#### 禁用 Pocket
|
||||
|
||||
没有任何证据显示 Pocket 正在做一些不好的事情,但是禁用它或许更好,因为它确实连接了一个专有的应用。
|
||||
|
||||
禁用 Pocket 不是太难,但是你得注意只改变 Pocket 相关设置。要访问你所需的配置页面,在火狐的地址栏里输入`about:config`。
|
||||
|
||||
页面会加载一个设置表格,在表格的最上面是搜索栏,在那儿搜索 Pocket 。
|
||||
|
||||
你将会看到一个包含结果的新表格。找一下名为 `extensions.pocket.enabled` 的设置。当你找到它的时候,双击使其转变为“否”。你也能在这儿编辑 Pocket 的其他相关设置。不过没什么必要。注意不要编辑那些跟 Pocket 扩展不直接相关的任何东西。
|
||||
|
||||

|
||||
|
||||
### <ruby>附加组件<rt>Add-ons</rt></ruby>
|
||||
|
||||

|
||||
|
||||
火狐最有效地保护你隐私和安全的方式来自附加组件。火狐有大量的附加组件库,其中很多是免费、开源的。在这篇指导中着重提到的附加组件,在使浏览器更安全方面是名列前茅的。
|
||||
|
||||
#### HTTPS Everywhere
|
||||
|
||||
针对大量没有使用 SSL 证书的网页、许多不使用 `https` 协议的链接、指引用户前往不安全版本的网页等现状,<ruby>电子前线基金会<rt>Electronic Frontier Foundation</rt></ruby>开发了 HTTPS Everywhere。HTTPS Everywhere 确保了如果该链接存在有一个加密的版本,用户将会使用它。
|
||||
|
||||
给火狐设计的 [HTTPS Everywhere](https://addons.mozilla.org/en-us/firefox/addon/https-everywhere/) 已经可以使用,在火狐的附加组件搜索网页上。(LCTT 译注:对应的[中文页面](https://addons.mozilla.org/zh-CN/firefox/addon/https-everywhere/)。)
|
||||
|
||||
|
||||
#### Privacy Badger
|
||||
|
||||
电子前线基金会同样开发了 Privacy Badger。 [Privacy Badger](https://addons.mozilla.org/en-us/firefox/addon/privacy-badger17) 旨在通过阻止不想要的网页跟踪,弥补“请勿跟踪”功能的不足之处。它同样能通过火狐附加组件仓库安装。。(LCTT 译注:对应的[中文页面](https://addons.mozilla.org/zh-CN/firefox/addon/privacy-badger17/)。)
|
||||
|
||||
|
||||
#### uBlock Origin
|
||||
|
||||
现在有一类更通用的的隐私附加组件,屏蔽广告。这里的选择是 uBlock Origin,uBlock Origin 是个更轻量级的广告屏蔽插件,几乎不遗漏所有它会屏蔽的广告。 [uBlock Origin](https://addons.mozilla.org/en-us/firefox/addon/ublock-origin/) 将主要屏蔽各种广告,特别是侵入性的广告。你能在这儿找到它。。(LCTT 译注:对应的[中文页面](https://addons.mozilla.org/zh-CN/firefox/addon/ublock-origin/)。)
|
||||
|
||||
#### NoScript
|
||||
|
||||
阻止 JavaScript 是有点争议, JavaScript 虽说支撑了那么多的网站,但还是臭名昭著,因为 JavaScript 成为侵略隐私和攻击的媒介。NoScript 是应对 JavaScript 的绝佳方案。
|
||||
|
||||

|
||||
|
||||
NoScript 是一个 JavaScript 的白名单,它会屏蔽所有 JavaScript,除非该站点被添加进白名单中。可以通过插件的“选项”菜单,事先将一个站点加入白名单,或者通过在页面上点击 NoScript 图标的方式添加。
|
||||
|
||||

|
||||
|
||||
通过火狐附加组件仓库可以安装 [NoScript](https://addons.mozilla.org/en-US/firefox/addon/noscript/)
|
||||
如果网页提示不支持你使用的火狐版本,点<ruby>“无论如何下载”<rt>Download Anyway</rt></ruby>。这已经在 Firefox 51 上测试有效。
|
||||
|
||||
#### Disconnect
|
||||
|
||||
[Disconnect](https://addons.mozilla.org/en-US/firefox/addon/disconnect/) 做的事情很多跟 Privacy Badger 一样,它只是提供了另一个保护的方法。你能在附加组件仓库中找到它 (LCTT 译注:对应的[中文页面](https://addons.mozilla.org/zh-CN/firefox/addon/disconnect/))。如果网页提示不支持你使用的火狐版本,点<ruby>“无论如何下载”<rt>Download Anyway</rt></ruby>。这已经在 Firefox 51 上测试有效。
|
||||
|
||||
#### Random Agent Spoofer
|
||||
|
||||
Random Agent Spoofer 能改变火狐浏览器的签名,让浏览器看起来像是在其他任意平台上的其他任意浏览器。虽然有许多其他的用途,但是它也能用于预防浏览器指纹侦查。
|
||||
|
||||
<ruby>浏览器指纹侦查<rt>Browser Fingerprinting</rt></ruby>是网站基于所使用的浏览器和操作系统来跟踪用户的另一个方式。相比于 Windows 用户,浏览器指纹侦查更多影响到 Linux 和其他替代性操作系统用户,因为他们的浏览器特征更独特。
|
||||
|
||||
你能通过火狐附加插件仓库添加 [Random Agent Spoofer](https://addons.mozilla.org/en-us/firefox/addon/random-agent-spoofer/)。(LCTT 译注:对应的[中文页面](https://addons.mozilla.org/zh-CN/firefox/addon/random-agent-spoofer/))。像其他附加组件那样,页面或许会提示它不兼容最新版的火狐。再说一次,那并不是真的。
|
||||
|
||||

|
||||
|
||||
你可以通过点击火狐菜单栏上的图标来使用 Random Agent Spoofer。点开后将会出现一个下拉菜单,有不同模拟的浏览器选项。最好的选项之一是选择"Random Desktop" 和任意的切换时间。这样,就绝对没有办法来跟踪你了,也保证了你只能获得网页的桌面版本。
|
||||
|
||||
### 系统设置
|
||||
|
||||
#### 私人 DNS
|
||||
|
||||
请避免使用公共或者 ISP 的 DNS 服务器!即使你配置你的浏览器满足绝对的隐私标准,你向公共 DNS 服务器发出的 DNS 请求却暴露了所有你访问过的网页。诸如谷歌公共 DNS(IP:8.8.8.8 、8.8.4.4)这类的服务将会记录你的 IP 地址、你的 ISP 和地理位置信息。这些信息或许会被任何合法程序或者强制性的政府请求所分享。
|
||||
|
||||
> **当我在使用谷歌公共 DNS 服务时,谷歌会记录什么信息?**
|
||||
>
|
||||
> 谷歌公共 DNS 隐私页面有一个完整的收集信息列表。谷歌公共 DNS 遵循谷歌的主隐私政策,在<ruby>“隐私中心”<rt>Privacy Center</rt></ruby>可以看到。 用户的客户端 IP 地址是唯一会被临时记录的(一到两天后删除),但是为了让我们的服务更快、更好、更安全,关于 ISP 和城市/都市级别的信息将会被保存更长的时间。
|
||||
> 参考资料: `https://developers.google.com/speed/public-dns/faq#privacy`
|
||||
|
||||
由于以上原因,如果可能的话,配置并使用你私人的非转发 DNS 服务器。现在,这项任务或许跟在本地部署一些预先配置好的 DNS 服务器的 Docker 容器一样简单。例如,假设 Docker 服务已经在你的系统安装完成,下列命令将会部署你的私人本地 DNS 服务器:
|
||||
|
||||
```
|
||||
# docker run -d --name bind9 -p 53:53/udp -p 53:53 fike/bind9
|
||||
```
|
||||
|
||||
DNS 服务器现在已经启动并正在运行:
|
||||
|
||||
```
|
||||
# dig @localhost google.com
|
||||
; <<>> DiG 9.9.5-9+deb8u6-Debian <<>> @localhost google.com
|
||||
; (2 servers found)
|
||||
;; global options: +cmd
|
||||
;; Got answer:
|
||||
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 51110
|
||||
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 4, ADDITIONAL: 5
|
||||
|
||||
;; OPT PSEUDOSECTION:
|
||||
; EDNS: version: 0, flags:; udp: 4096
|
||||
;; QUESTION SECTION:
|
||||
;google.com. IN A
|
||||
|
||||
;; ANSWER SECTION:
|
||||
google.com. 242 IN A 216.58.199.46
|
||||
```
|
||||
|
||||
现在,在 `/etc/resolv.conf` 里设置你的域名服务器:
|
||||
|
||||
```
|
||||
nameserver 127.0.0.1
|
||||
```
|
||||
|
||||
### 结束语
|
||||
|
||||
没有完美的安全隐私解决方案。虽然本篇指导里的步骤可以明显改进它们。如果你真的很在乎隐私,[Tor 浏览器](https://www.torproject.org/projects/torbrowser.html.en) 是最佳选择。Tor 对于日常使用有点过犹不及,但是它的确使用了这篇指导里列出的一些措施。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxconfig.org/protecting-your-privacy-with-firefox-on-linux
|
||||
|
||||
作者:[Nick Congleton][a]
|
||||
译者:[ypingcn](https://ypingcn.github.io/wiki/lctt)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://linuxconfig.org/protecting-your-privacy-with-firefox-on-linux
|
||||
@ -0,0 +1,172 @@
|
||||
如何定制 SSH 来简化远程访问
|
||||
===================
|
||||
|
||||
SSH (指 SSH 客户端)是一个用于访问远程主机的程序,它使得用户能够 [在远程主机上执行命令][2]。这是在登录远程主机中的最受推崇的方法之一,因为其设计目的就是在非安全网络环境上为两台非受信主机的通信提供安全加密。
|
||||
|
||||
SSH 使用系统全局以及用户指定(用户自定义)的配置文件。在本文中,我们将介绍如何创建一个自定义的 ssh 配置文件,并且通过特定的选项来连接到远程主机。
|
||||
|
||||
### 先决条件:
|
||||
|
||||
1. 你必须 [在你的桌面 Linux 上安装好 OpenSSH 客户端][1]。
|
||||
2. 了解通过 ssh 进行远程连接的常用选项。
|
||||
|
||||
### SSH 客户端配置文件
|
||||
|
||||
以下为 ssh 客户端配置文件:
|
||||
|
||||
1. `/etc/ssh/ssh_config` 为默认的配置文件,属于系统全局配置文件,包含应用到所有用户的 ssh 客户端的设置。
|
||||
2. `~/.ssh/config` 或者 `$HOME/.ssh/config` 为用户指定/自定义配置文件,这个文件中的配置只对指定的用户有效,因此,它会覆盖掉默认的系统全局配置文件中的设置。这也是我们要创建和使用的文件。
|
||||
|
||||
默认情况下,用户是通过在 ssh 中输入密码来获取验证的,你可以以一个简单的步骤来 [使用 Keygen 来设置 ssh 无密码登录][3]。
|
||||
|
||||
注:如果你的系统上不存在 `~/.ssh` 目录,那就手动创建它,并设置如下权限:
|
||||
|
||||
```
|
||||
$ mkdir -p ~/.ssh
|
||||
$ chmod 0700 ~/.ssh
|
||||
```
|
||||
|
||||
以上的 `chmod` 命令表明,只有目录属主对该目录有读取、写入和执行权限,这也是 ssh 所要求的设置。
|
||||
|
||||
### 如何创建用户指定的 SSH 配置文件
|
||||
|
||||
该文件并不会被默认创建的,所以你需要使用具有读取/写入权限的用户来创建它。
|
||||
|
||||
```
|
||||
$ touch ~/.ssh/config
|
||||
$ chmod 0700 ~/.ssh/config
|
||||
```
|
||||
|
||||
上述文件包含由特定主机定义的各个部分,并且每个部分只应用到主机定义中相匹配的部分。
|
||||
|
||||
`~/.ssh/config` 文件的常见格式如下,其中所有的空行和以 `‘#’` 开头的行为注释:
|
||||
|
||||
```
|
||||
Host host1
|
||||
ssh_option1=value1
|
||||
ssh_option2=value1 value2
|
||||
ssh_option3=value1
|
||||
Host host2
|
||||
ssh_option1=value1
|
||||
ssh_option2=value1 value2
|
||||
Host *
|
||||
ssh_option1=value1
|
||||
ssh_option2=value1 value2
|
||||
```
|
||||
|
||||
如上格式详解:
|
||||
|
||||
1. `Host host1` 为关于 host1 的头部定义,主机相关的设置就从此处开始,直到下一个头部定义 `Host host2` 出现,这样形成一个完整的定义。
|
||||
2. host1 和 host2 是在命令行中使用的主机别名,并非实际的远程主机名。
|
||||
3. 其中,如 ssh_option1=value1、ssh_option2=value1 value2 等配置选项将应用到相匹配的主机,可以缩进以看起来更整齐些。
|
||||
4. 对于 ssh_option2=value1 value2 这样的选项,ssh 执行时会按照顺序优先使用 value1 的值。
|
||||
5. 头部定义 `Host *` (其中 `*` 为匹配模式/通配符,匹配零个或多个字符) 会匹配零个或者多个主机。
|
||||
|
||||
仍旧以上述的格式为例,ssh 也是也这样的形式类读取配置文件的。如果你执行 ssh 命令来访问远程主机 host1,如下:
|
||||
|
||||
```
|
||||
$ ssh host1
|
||||
```
|
||||
|
||||
以上 ssh 命令会进行一下动作:
|
||||
|
||||
1. 匹配配置文件中主机别名 host1,并使用头部定义中的各个设置项。
|
||||
2. 继续匹配下一个主机定义,然后发现命令行中提供的主机名没有匹配的了,所以接下来的各个设置项会被略过。
|
||||
3. 最后执行到最后一个主机定义 `Host *`, 这会匹配所有的主机。这里,会将接下来的所有设置选项应用到所有的主机连接中。但是它不会覆写之前已经有主机定义的那些选项。
|
||||
4. ssh host2 与此类似。
|
||||
|
||||
### 如何使用用户指定的 shh 配置文件
|
||||
|
||||
在你理解了 ssh 客户端配置文件的工作方式之后,你可以通过如下方式来创建它。记得使用你的服务器环境中对应的选项、值 (主机别名、端口号、用户名等)。
|
||||
|
||||
通过你最喜欢的编辑器来打开配置文件:
|
||||
|
||||
```
|
||||
$ vi ~/.ssh/config
|
||||
```
|
||||
|
||||
并定义必要的部分:
|
||||
|
||||
```
|
||||
Host fedora25
|
||||
HostName 192.168.56.15
|
||||
Port 22
|
||||
ForwardX11 no
|
||||
Host centos7
|
||||
HostName 192.168.56.10
|
||||
Port 22
|
||||
ForwardX11 no
|
||||
Host ubuntu
|
||||
HostName 192.168.56.5
|
||||
Port 2222
|
||||
ForwardX11 yes
|
||||
Host *
|
||||
User tecmint
|
||||
IdentityFile ~/.ssh/id_rsa
|
||||
Protocol 2
|
||||
Compression yes
|
||||
ServerAliveInterval 60
|
||||
ServerAliveCountMax 20
|
||||
LogLevel INFO
|
||||
```
|
||||
|
||||
以上 ssh 配置文件的详细解释:
|
||||
|
||||
1. `HostName` - 定义真正要登录的主机名,此外,你也可以使用数字 IP 地址,不管是在命令行或是 HostName 定义中都允许使用其中任一种。
|
||||
2. `User` – 指定以哪一个用户来登录。
|
||||
3. `Port` – 设置连接远程主机的端口,默认是 22 端口。但必须是远程主机的 sshd 配置文件中定义的端口号。
|
||||
4. `Protocol` – 这个选项定义了优先使用 ssh 支持的协议版本。常用的值为 ‘1’ 和 ‘2’,同时使用两个协议版本则必须使用英文逗号隔开。
|
||||
5. `IdentityFile` – 指定一个用于读取用户 DSA、Ed25519、ECDSA 等授权验证信息的文件。
|
||||
6. `ForwardX11` – 定义 X11 连接是否自动重定向到安全通道和 DISPLAY 设置。有两个可以设置的值,即 `yes` 或 `no`。
|
||||
7. `Compression` – 默认值为 `no`,如果设置为 `yes`,则在连接远程主机过程中使用压缩进行传输。
|
||||
8. `ServerAliveInterval` – 设置当没有收到服务器响应 (或者数据))时的超时时间,单位为秒,ssh 会通过加密信道发送信息,请求服务器响应。默认值为 `0`,这意味着 ssh 不会向服务器发送响应请求;如果定义了 BatchMode 选项,则默认是 300 秒。
|
||||
9. `ServerAliveCountMax` – 设置服务器在没有接收到服务器的任何响应时,由服务器发送的活动信息数量。
|
||||
10. `LogLevel` – 定义 ssh 登录信息的的日志冗余级别。允许的值为:`QUIET`、`FATAL`、`ERROR`、`INFO`、`VERBOSE`、`DEBUG`、`DEBUG1`、`DEBUG2` 和 `DEBUG3`,默认为 `INFO`。
|
||||
|
||||
连接任意远程主机的标准方法是在上述两个文件中定义第二个部分(我连接的是 CentOS 7)。一般情况下,我们这样输入命令:
|
||||
|
||||
```
|
||||
$ ssh -i ~/.ssh/id_rsa -p 22 tecmint@192.168.56.10
|
||||
```
|
||||
|
||||
然而,使用了 ssh 客户端配置文件之后,我们还可以这样:
|
||||
|
||||
```
|
||||
$ ssh centos7
|
||||
```
|
||||
|
||||
你也可以在 man 帮助页面寻找更多的设置选项和使用实例:
|
||||
|
||||
```
|
||||
$man ssh_config
|
||||
```
|
||||
|
||||
至此,文毕。我们在文中向你介绍了在 Linux 中如何使用用户指定 (自定义) 的 ssh 客户端配置文件。通过下方的反馈表单来写一些与本文的相关的想法吧。
|
||||
|
||||
------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili 是一名 Linux 和 F.O.S.S 忠实拥护者、高级 Linux 系统管理员、Web 开发者,目前在 TecMint 是一名活跃的博主,热衷于计算机并有着强烈的只是分享意愿。
|
||||
|
||||
-------------------------------------------------
|
||||
|
||||
译者简介:
|
||||
|
||||
[GHLandy](http://GHLandy.com) —— 生活中所有欢乐与苦闷都应藏在心中,有些事儿注定无人知晓,自己也无从说起。
|
||||
|
||||
-------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/configure-custom-ssh-connection-in-linux/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[GHLandy](https://github.com/GHLandy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
|
||||
[1]:http://www.tecmint.com/install-openssh-server-in-linux/
|
||||
[2]:http://www.tecmint.com/execute-commands-on-multiple-linux-servers-using-pssh/
|
||||
[3]:http://www.tecmint.com/ssh-passwordless-login-using-ssh-keygen-in-5-easy-steps/
|
||||
@ -1,13 +1,13 @@
|
||||
如何编写和使用自定义的 Shell 函数和函数库
|
||||
============================================================
|
||||
|
||||
在 Linux 系统下,Shell 脚本在各种不同的情形下给予我们帮助,例如展示信息,甚至 [自动执行特定的系统管理任务][1],创建简单的命令行工具等等。
|
||||
在 Linux 系统下,Shell 脚本可以在各种不同的情形下帮到我们,例如展示信息,甚至 [自动执行特定的系统管理任务][1],创建简单的命令行工具等等。
|
||||
|
||||
在本指南中,我们将向 Linux 新手展示如何可靠地存储自定义的 shell 脚本,解释如何编写 shell 函数和函数库,以及如何在其它的脚本中使用函数库中的函数。
|
||||
|
||||
### Shell 脚本要存储在何处
|
||||
|
||||
为了在执行你自己的脚本时不必输入脚本所在位置的完整或绝对路径,脚本必须被存储在 `$PATH`环境变量所定义的路径里的其中一个。
|
||||
为了在执行你自己的脚本时不必输入脚本所在位置的完整或绝对路径,脚本必须被存储在 `$PATH` 环境变量所定义的路径里的其中一个。
|
||||
|
||||
使用下面的命令可以查看你系统中的 `$PATH` 环境变量:
|
||||
|
||||
@ -16,7 +16,7 @@ $ echo $PATH
|
||||
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games
|
||||
```
|
||||
|
||||
通常来说,如果在用户的家目录下存在名为 `bin` 的目录,你就可以将 shell 脚本存储在那个目录下,因为那个目录会自动地被包含在用户的 `$PATH` 环境变量中(译者注:在 Centos6/7 下是这样的,在 Debian8 下不是这样的,在 Ubuntu16.04 下又是这样的)。
|
||||
通常来说,如果在用户的家目录下存在名为 `bin` 的目录,你就可以将 shell 脚本存储在那个目录下,因为那个目录会自动地被包含在用户的 `$PATH` 环境变量中(LCTT 译注:在 Centos 6/7 下是这样的,在 Debian 8 下不是这样的,在 Ubuntu 16.04 下又是这样的)。
|
||||
|
||||
因此,在你的主目录下创建 `bin` 目录吧(当然这里也可以用来存储 Perl、[Awk][2] 或 Python 的脚本,或者其它程序):
|
||||
|
||||
@ -32,14 +32,15 @@ $ mkdir -p ~/lib/sh
|
||||
|
||||
### 创建你自己的 Shell 函数和函数库
|
||||
|
||||
一个 `shell 函数` 就是在脚本中能够完成特定任务的一组命令。它们的工作原理与其他编程语言中的过程(译者注:可能指的是类似SQL中的存储过程之类的吧)、子例程、函数类似。
|
||||
一个 `shell 函数` 就是在脚本中能够完成特定任务的一组命令。它们的工作原理与其他编程语言中的过程(LCTT 译注:可能指的是类似 SQL 中的存储过程之类的吧)、子例程、函数类似。
|
||||
|
||||
编写一个函数的语法如下:
|
||||
|
||||
```
|
||||
函数名() { 一系列的命令 } (校对注:在函数名前可以加上 function 关键字,但也可省略不写)
|
||||
函数名() { 一系列的命令 }
|
||||
```
|
||||
|
||||
( LCTT 校注:在函数名前可以加上 `function` 关键字,但也可省略不写)
|
||||
|
||||
例如,你可以像下面那样在一个脚本中写一个用来显示日期的函数:
|
||||
|
||||
```
|
||||
@ -96,12 +97,13 @@ IFS="$oldifs" #store old internal field separator
|
||||
要使用某个 `lib` 目录下的函数,首先你需要按照下面的形式 将包含该函数的函数库导入到需要执行的 shell 脚本中:
|
||||
|
||||
```
|
||||
$ . /path/to/lib (译者注:这里的 . 和路径间应该是有空格的)
|
||||
$ . /path/to/lib
|
||||
或
|
||||
$ source /path/to/lib
|
||||
```
|
||||
(LCTT 译注:第一行的 `.` 和路径间**必须**是有空格的)
|
||||
|
||||
这样你就可以像下面演示的那样,在其它的脚本中使用来自 `~/lib/sh/libMYFUNCS.sh` 的 `printUSERDETS` 函数。
|
||||
这样你就可以像下面演示的那样,在其它的脚本中使用来自 `~/lib/sh/libMYFUNCS.sh` 的 `printUSERDETS` 函数了。
|
||||
|
||||
在下面的脚本中,如果要打印出某个特定用户的详细信息,你不必再一一编写代码,而只需要简单地调用已存在的函数即可。
|
||||
|
||||
@ -123,15 +125,16 @@ exit 0
|
||||
$ chmod 755 test.sh
|
||||
$ ./test.sh
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][3]
|
||||
|
||||
编写 shell 函数
|
||||
*编写 shell 函数*
|
||||
|
||||
在本文中,我们介绍了在哪里可靠地存储 shell 脚本,如何编写自己的 shell 函数和函数库,以及如何在一个普通的 shell 脚本中从函数库中调用库中的某些函数。
|
||||
|
||||
在之后,我们还会介绍一种相当简单直接的方式来将 Vim 配置为一个编写 Bash 脚本的 IDE(集成开发环境)。在那之前,记得要经常关注 TecMint ,如果能和我们分享你对这份指南的想法就更好了。
|
||||
在之后,我们还会介绍一种相当简单直接的方式来将 Vim 配置为一个编写 Bash 脚本的 IDE(集成开发环境)。在那之前,记得要经常关注我们 ,如果能和我们分享你对这份指南的想法就更好了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -0,0 +1,214 @@
|
||||
free:一个在 Linux 中检查内存使用情况的标准命令
|
||||
============================================================
|
||||
|
||||
我们都知道, IT 基础设施方面的大多数服务器(包括世界顶级的超级计算机)都运行在 Linux 平台上,因为和其他操作系统相比, Linux 更加灵活。有的操作系统对于一些微乎其微的改动和补丁更新都需要重启,但是 Linux 不需要,只有对于一些关键补丁的更新, Linux 才会需要重启。
|
||||
|
||||
Linux 系统管理员面临的一大挑战是如何在没有任何停机时间的情况下维护系统的良好运行。管理内存使用是 Linux 管理员又一个具有挑战性的任务。`free` 是 Linux 中一个标准的并且被广泛使用的命令,它被用来分析内存统计(空闲和已用)。今天,我们将要讨论 `free` 命令以及它的一些有用选项。
|
||||
|
||||
推荐文章:
|
||||
|
||||
* [smem - Linux 内存报告/统计工具][1]
|
||||
* [vmstat - 一个报告虚拟内存统计的标准而又漂亮的工具][2]
|
||||
|
||||
### Free 命令是什么
|
||||
|
||||
free 命令能够显示系统中物理上的空闲(free)和已用(used)内存,还有交换(swap)内存,同时,也能显示被内核使用的缓冲(buffers)和缓存(caches)。这些信息是通过解析文件 `/proc/meninfo` 而收集到的。
|
||||
|
||||
### 显示系统内存
|
||||
|
||||
不带任何选项运行 `free` 命令会显示系统内存,包括空闲(free)、已用(used)、交换(swap)、缓冲(buffers)、缓存(caches)和交换(swap)的内存总数。
|
||||
|
||||
```
|
||||
# free
|
||||
total used free shared buffers cached
|
||||
Mem: 32869744 25434276 7435468 0 412032 23361716
|
||||
-/+ buffers/cache: 1660528 31209216
|
||||
Swap: 4095992 0 4095992
|
||||
```
|
||||
|
||||
输出有三行:
|
||||
|
||||
* 第一行:表明全部内存、已用内存、空闲内存、共用内存(主要被 tmpfs(`/proc/meninfo` 中的 `Shmem` 项)使用)、用于缓冲的内存以及缓存内容大小。
|
||||
* 全部:全部已安装内存(`/proc/meminfo` 中的 `MemTotal` 项)
|
||||
* 已用:已用内存(全部计算 - 空间+缓冲+缓存)
|
||||
* 空闲:未使用内存(`/proc/meminfo` 中的 `MemFree` 项)
|
||||
* 共用:主要被 tmpfs 使用的内存(`/proc/meminfo` 中的 `Shmem` 项)
|
||||
* 缓冲:被内核缓冲使用的内存(`/proc/meminfo` 中的 `Buffers` 项)
|
||||
* 缓存:被页面缓存和 slab 使用的内存(`/proc/meminfo` 中的 `Cached` 和 `SSReclaimable` 项)
|
||||
* 第二行:表明已用和空闲的缓冲/缓存
|
||||
* 第三行:表明总交换内存(`/proc/meminfo` 中的 `SwapTotal` 项)、空闲内存(`/proc/meminfo` 中的 `SwapFree` 项)和已用交换内存。
|
||||
|
||||
### 以 MB 为单位显示系统内存
|
||||
|
||||
默认情况下, `free` 命令以 `KB - Kilobytes` 为单位输出系统内存,这对于绝大多数管理员来说会有一点迷糊(当系统内存很大的时候,我们中的许多人需要把输出转化为以 MB 为单位,从而才能够理解内存大小)。为了避免这个迷惑,我们在 ‘free’ 命令后面加上 `-m` 选项,就可以立即得到以 ‘MB - Megabytes’ 为单位的输出。
|
||||
|
||||
```
|
||||
# free -m
|
||||
total used free shared buffers cached
|
||||
Mem: 32099 24838 7261 0 402 22814
|
||||
-/+ buffers/cache: 1621 30477
|
||||
Swap: 3999 0 3999
|
||||
```
|
||||
|
||||
如何从上面的输出中检查剩余多少空闲内存?主要基于已用(used)和空闲(free)两列。你可能在想,你只有很低的空闲内存,因为它只有 `10%`, 为什么?
|
||||
|
||||
- 全部实际可用内存 = (全部内存 - 第 2 行的已用内存)
|
||||
- 全部内存 = 32099
|
||||
- 实际已用内存 = 1621 ( = 全部内存 - 缓冲 - 缓存)
|
||||
- 全部实际可用内存 = 30477
|
||||
|
||||
如果你的 Linux 版本是最新的,那么有一个查看实际空闲内存的选项,叫做可用(`available`) ,对于旧的版本,请看显示 `-/+ buffers/cache` 那一行对应的空闲(`free`)一列。
|
||||
|
||||
如何从上面的输出中检查有多少实际已用内存?基于已用(used)和空闲(free)一列。你可能想,你已经使用了超过 `95%` 的内存。
|
||||
|
||||
- 全部实际已用内存 = 第一列已用 - (第一列缓冲 + 第一列缓存)
|
||||
- 已用内存 = 24838
|
||||
- 已用缓冲 = 402
|
||||
- 已用缓存 = 22814
|
||||
- 全部实际已用内存 = 1621
|
||||
|
||||
### 以 GB 为单位显示内存
|
||||
|
||||
默认情况下, `free` 命令会以 `KB - kilobytes` 为单位显示输出,这对于大多数管理员来说会有一些迷惑,所以我们使用上面的选项来获得以 `MB - Megabytes` 为单位的输出。但是,当服务器的内存很大(超过 100 GB 或 200 GB)时,上面的选项也会让人很迷惑。所以,在这个时候,我们可以在 `free` 命令后面加上 `-g` 选项,从而立即得到以 `GB - Gigabytes` 为单位的输出。
|
||||
|
||||
```
|
||||
# free -g
|
||||
total used free shared buffers cached
|
||||
Mem: 31 24 7 0 0 22
|
||||
-/+ buffers/cache: 1 29
|
||||
Swap: 3 0 3
|
||||
```
|
||||
|
||||
### 显示全部内存行
|
||||
|
||||
默认情况下, `free` 命令的输出只有三行(内存、缓冲/缓存以及交换)。为了统一以单独一行显示(全部(内存+交换)、已用(内存+(已用-缓冲/缓存)+交换)以及空闲(内存+(已用-缓冲/缓存)+交换),在 ‘free’ 命令后面加上 `-t` 选项。
|
||||
|
||||
```
|
||||
# free -t
|
||||
total used free shared buffers cached
|
||||
Mem: 32869744 25434276 7435468 0 412032 23361716
|
||||
-/+ buffers/cache: 1660528 31209216
|
||||
Swap: 4095992 0 4095992
|
||||
Total: 36965736 27094804 42740676
|
||||
```
|
||||
|
||||
### 按延迟运行 free 命令以便更好的统计
|
||||
|
||||
默认情况下, free 命令只会显示一次统计输出,这是不足够进一步排除故障的,所以,可以通过添加延迟(延迟是指在几秒后再次更新)来定期统计内存活动。如果你想以两秒的延迟运行 free 命令,可以使用下面的命令(如果你想要更多的延迟,你可以按照你的意愿更改数值)。
|
||||
|
||||
下面的命令将会每 2 秒运行一次直到你退出:
|
||||
|
||||
```
|
||||
# free -s 2
|
||||
total used free shared buffers cached
|
||||
Mem: 32849392 25935844 6913548 188 182424 24632796
|
||||
-/+ buffers/cache: 1120624 31728768
|
||||
Swap: 20970492 0 20970492
|
||||
|
||||
total used free shared buffers cached
|
||||
Mem: 32849392 25935288 6914104 188 182424 24632796
|
||||
-/+ buffers/cache: 1120068 31729324
|
||||
Swap: 20970492 0 20970492
|
||||
|
||||
total used free shared buffers cached
|
||||
Mem: 32849392 25934968 6914424 188 182424 24632796
|
||||
-/+ buffers/cache: 1119748 31729644
|
||||
Swap: 20970492 0 20970492
|
||||
```
|
||||
|
||||
### 按延迟和具体次数运行 free 命令
|
||||
|
||||
另外,你可以按延迟和具体次数运行 free 命令,一旦达到某个次数,便自动退出。
|
||||
|
||||
下面的命令将会每 2 秒运行一次 free 命令,计数 5 次以后自动退出。
|
||||
|
||||
```
|
||||
# free -s 2 -c 5
|
||||
total used free shared buffers cached
|
||||
Mem: 32849392 25931052 6918340 188 182424 24632796
|
||||
-/+ buffers/cache: 1115832 31733560
|
||||
Swap: 20970492 0 20970492
|
||||
|
||||
total used free shared buffers cached
|
||||
Mem: 32849392 25931192 6918200 188 182424 24632796
|
||||
-/+ buffers/cache: 1115972 31733420
|
||||
Swap: 20970492 0 20970492
|
||||
|
||||
total used free shared buffers cached
|
||||
Mem: 32849392 25931348 6918044 188 182424 24632796
|
||||
-/+ buffers/cache: 1116128 31733264
|
||||
Swap: 20970492 0 20970492
|
||||
|
||||
total used free shared buffers cached
|
||||
Mem: 32849392 25931316 6918076 188 182424 24632796
|
||||
-/+ buffers/cache: 1116096 31733296
|
||||
Swap: 20970492 0 20970492
|
||||
|
||||
total used free shared buffers cached
|
||||
Mem: 32849392 25931308 6918084 188 182424 24632796
|
||||
-/+ buffers/cache: 1116088 31733304
|
||||
Swap: 20970492 0 20970492
|
||||
```
|
||||
|
||||
### 人类可读格式
|
||||
|
||||
为了以人类可读的格式输出,在 `free` 命令的后面加上 `-h` 选项,和其他选项比如 `-m` 和 `-g` 相比,这将会更人性化输出(自动使用 GB 和 MB 单位)。
|
||||
|
||||
```
|
||||
# free -h
|
||||
total used free shared buff/cache available
|
||||
Mem: 2.0G 1.6G 138M 20M 188M 161M
|
||||
Swap: 2.0G 1.8G 249M
|
||||
```
|
||||
|
||||
### 取消缓冲区和缓存内存输出
|
||||
|
||||
默认情况下, `缓冲/缓存` 内存输出是同时输出的。为了取消缓冲和缓存内存的输出,可以在 `free` 命令后面加上 `-w` 选项。(该选项在版本 3.3.12 上可用)
|
||||
|
||||
注意比较上面有`缓冲/缓存`的输出。
|
||||
|
||||
```
|
||||
# free -wh
|
||||
total used free shared buffers cache available
|
||||
Mem: 2.0G 1.6G 137M 20M 8.1M 183M 163M
|
||||
Swap: 2.0G 1.8G 249M
|
||||
```
|
||||
|
||||
### 显示最低和最高的内存统计
|
||||
|
||||
默认情况下, `free` 命令不会显示最低和最高的内存统计。为了显示最低和最高的内存统计,在 free 命令后面加上 `-l` 选项。
|
||||
|
||||
```
|
||||
# free -l
|
||||
total used free shared buffers cached
|
||||
Mem: 32849392 25931336 6918056 188 182424 24632808
|
||||
Low: 32849392 25931336 6918056
|
||||
High: 0 0 0
|
||||
-/+ buffers/cache: 1116104 31733288
|
||||
Swap: 20970492 0 20970492
|
||||
```
|
||||
|
||||
### 阅读关于 free 命令的更过信息
|
||||
|
||||
如果你想了解 free 命令的更多可用选项,只需查看其 man 手册。
|
||||
|
||||
```
|
||||
# free --help
|
||||
or
|
||||
# man free
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.2daygeek.com/free-command-to-check-memory-usage-statistics-in-linux/
|
||||
|
||||
作者:[MAGESH MARUTHAMUTHU][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.2daygeek.com/author/magesh/
|
||||
[1]:http://www.2daygeek.com/smem-linux-memory-usage-statistics-reporting-tool/
|
||||
[2]:http://www.2daygeek.com/linux-vmstat-command-examples-tool-report-virtual-memory-statistics/
|
||||
[3]:http://www.2daygeek.com/author/magesh/
|
||||
@ -0,0 +1,75 @@
|
||||
5 款值得尝试的 Linux 音乐播放器
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
目前 Linux 上有几十个音乐播放器,这使得找到一个最好用的变成很困难。之前我们已经回顾了其中的一些播放器,如 [Cantata][10],[Exaile][11],甚至不那么出名的 Clementine,Nightingale 和 Quod Libet。
|
||||
|
||||
在本篇文章中我将涵盖更多的 Linux 音乐播放器,在某些方面甚至比之前介绍过的那些播放器表现更好。
|
||||
|
||||
### 1、 Qmmp
|
||||
|
||||
[Qmmp][13] 并不是特性最丰富的(或最稳定的) Linux 音乐播放器,但却是我最喜欢的一款,这也是为什么我把它放在第一个。我知道有更好的播放器,但我就是喜欢这款并且最常使用它。它确实会崩溃,并且也有许多它不能播放的文件,但不管怎样我依然最爱它。上图!
|
||||
|
||||

|
||||
|
||||
Qmmp 是 Linux 上的 WinAMP。它(相对)轻量并且具有一个像样的特性集。因为 WinAMP 伴随着我的成长,并且我很喜欢它的键盘快捷键,当在 Linux 上有一个像 WinAMP 的播放器对我来说是个惊喜。对于音频格式,Qmmp 能够播放大部分流行的格式,如 MPEG1 layer 2/3、Ogg Vorbis 和 Opus、原生的 FLAC/Ogg FLAC、Musepack、WavePack、音轨模块(mod、s3m、it、xm 等等)、ADTS AAC、CD 音频、WMA、Monkey’s Audio(以及 FFmpeg 库提供的其他格式)、Midi、SID 和 Chiptune 格式(AY、GBS、GYM、HES、KSS、NSF、NSFE、SAP、SPC、VGM、VGZ 和 VTX)。
|
||||
|
||||
### 2、 Amarok
|
||||
|
||||
[Amarok][14] 是 KDE 的音乐播放器,当然你也可以把它用在其他的桌面环境。它是 Linux 上最古老的音乐播放器之一。这也许是它很流行的原因,虽然我个人并不是非常喜欢它。
|
||||
|
||||

|
||||
|
||||
Amarok 能播放大量的音频格式,但它的主要优势是丰富的插件。这个软件附带大量文档,不过它最近没有更新。Amarok 也由于与各种 Web 服务,如 Ampache、Jamendo Service、Last.fm、Librivox、MP3tunes、Magnatune 以及 OPML 播客目录的整合而闻名。
|
||||
|
||||
### 3、 Rhythmbox
|
||||
|
||||
既然我刚刚提到了 Amarok 和 KDE 音乐播放器,那接下来让我们转向 Gnome 的默认音乐播放器, [Rhythmbox][15] 。因为它与 Gnome 一起提供,所以你能猜到它是一款流行的软件。它不仅是一款音乐播放器,同时也是一款音乐管理软件。它支持 MP3 和 OGG,以及十几种其他的文件格式,也包括网络收音机、iPod 服务整合、音频文件播放、音频 CD 刻录和回放、音乐分享以及播客。总而言之,它是款不赖的播放器,但这不意味着你会最喜欢它。试用一下,看看自己是否喜欢。如果不喜欢,就往下看看吧。
|
||||
|
||||

|
||||
|
||||
### 4、 VLC
|
||||
|
||||
虽然 [VLC][16] 是以视频播放器而闻名,但单从它支持最多的解码器这一点来看,它也是一款非常棒的音乐播放器。它无法播放的文件,你也不太可能能用其他播放器打开。VLC 具有高度定制性,并且拥有很多扩展。它能够在 Windows,Linux,Mac OS X,Unix,iOS,Android 等等平台运行。
|
||||
|
||||

|
||||
|
||||
我个人不喜欢 VLC 的一点是它占用太多资源。并且我曾用它打开过一些文件,但回放质量离一流水准还差的很远。这个软件在播放一些其他播放器不难应付的文件时,经常会无故关闭。但很可能与播放器没多大关系,可能是文件本身的问题。尽管 VLC 不属于我常用的程序,我仍然由衷的推荐它。
|
||||
|
||||
### 5、 Cmus
|
||||
|
||||
如果你钟爱命令行程序,那么 [Cmus][17] 会是你的菜。你能用它来播放 Ogg Vorbis、MP3、FLAC、Opus、Musepack、WavPack、WAV、AAC、MP4、音频 CD 以及 ffmpeg 支持的所有格式(WMA、APE、MKA、TTA、SHN 等等)和 libmodplug。你也可以用它来播放 Shoutcast 或者 Icecast 的音频流。它不是特性最丰富的音乐播放器,但它拥有所有的基础及进阶功能。它的主要优势是非常轻量,并且它的内存需求真的很小。
|
||||
|
||||

|
||||
|
||||
所有的这些音乐播放器都很棒,都有擅长的方面。我没办法说出哪一款是最好的,这更多取决于个人喜好和需要。这些播放器大多要么做为发行版的默认选项安装,要么可以在包管理器中轻松找到。只要打开新立得、软件中心或你的发行版中使用的任意包管理器,搜索并安装它们。你也可以使用命令行,或只要双击从网站上下载的安装文件。使用何种方法取决于你。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/linux-music-players-to-check-out/
|
||||
|
||||
作者:[Ada Ivanova][a]
|
||||
译者:[cycoe](https://github.com/cycoe)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/adaivanoff/
|
||||
[1]:https://www.maketecheasier.com/author/adaivanoff/
|
||||
[2]:https://www.maketecheasier.com/linux-music-players-to-check-out/#comments
|
||||
[3]:https://www.maketecheasier.com/category/linux-tips/
|
||||
[4]:http://www.facebook.com/sharer.php?u=https%3A%2F%2Fwww.maketecheasier.com%2Flinux-music-players-to-check-out%2F
|
||||
[5]:http://twitter.com/share?url=https%3A%2F%2Fwww.maketecheasier.com%2Flinux-music-players-to-check-out%2F&text=5+Linux+Music+Players+You+Should+Consider+Switching+To
|
||||
[6]:mailto:?subject=5%20Linux%20Music%20Players%20You%20Should%20Consider%20Switching%20To&body=https%3A%2F%2Fwww.maketecheasier.com%2Flinux-music-players-to-check-out%2F
|
||||
[7]:https://www.maketecheasier.com/mastering-disk-utility-mac/
|
||||
[8]:https://www.maketecheasier.com/airy-youtube-video-downloader/
|
||||
[9]:https://support.google.com/adsense/troubleshooter/1631343
|
||||
[10]:https://www.maketecheasier.com/cantata-new-music-player-for-linux/
|
||||
[11]:https://www.maketecheasier.com/exaile-the-first-media-player-i-dont-hate/
|
||||
[12]:https://www.maketecheasier.com/the-lesser-known-music-players-for-linux/
|
||||
[13]:http://qmmp.ylsoftware.com/
|
||||
[14]:https://amarok.kde.org/
|
||||
[15]:https://wiki.gnome.org/Apps/Rhythmbox
|
||||
[16]:http://www.videolan.org/vlc/
|
||||
[17]:https://cmus.github.io/
|
||||
@ -1,92 +1,89 @@
|
||||
|
||||
在 CentOS 7 上利用 FirewallD 设置和配置防火墙
|
||||
CentOS 7 上的 FirewallD 简明指南
|
||||
============================================================
|
||||
|
||||

|
||||

|
||||
|
||||
FirewallD 是 CentOS 7 服务器上默认可用的防火墙管理工具。基本上,它是 iptables 的封装,有图形配置工具 firewall-config 和命令行工具 `firewall-cmd`。使用 iptables 服务,每次改动都要求刷新旧规则,并且从 `/etc/sysconfig/iptables` 读取新规则,然而 firewalld 只应用改动了的不同部分。
|
||||
|
||||
### FirewallD 的区域(zone)
|
||||
|
||||
FirewallD 是 CentOS 7 服务器上的一个默认可用的防火墙管理工具。基本上,它是 iptables 的封装,有图形配置工具 firewall-config 和命令行工具 firewall-cmd。使用 iptables 服务每次改动都要求刷新旧规则,并且从 `/etc/sysconfig/iptables` 读取新规则,然而 firewalld 仅仅会应用改动了的不同部分。
|
||||
FirewallD 使用服务(service) 和区域(zone)来代替 iptables 的规则(rule)和链(chain)。
|
||||
|
||||
### FirewallD zones
|
||||
默认情况下,有以下的区域(zone)可用:
|
||||
|
||||
* **drop** – 丢弃所有传入的网络数据包并且无回应,只有传出网络连接可用。
|
||||
* **block** — 拒绝所有传入网络数据包并回应一条主机禁止的 ICMP 消息,只有传出网络连接可用。
|
||||
* **public** — 只接受被选择的传入网络连接,用于公共区域。
|
||||
* **external** — 用于启用了地址伪装的外部网络,只接受选定的传入网络连接。
|
||||
* **dmz** — DMZ 隔离区,外部受限地访问内部网络,只接受选定的传入网络连接。
|
||||
* **work** — 对于处在你工作区域内的计算机,只接受被选择的传入网络连接。
|
||||
* **home** — 对于处在你家庭区域内的计算机,只接受被选择的传入网络连接。
|
||||
* **internal** — 对于处在你内部网络的计算机,只接受被选择的传入网络连接。
|
||||
* **trusted** — 所有网络连接都接受。
|
||||
|
||||
FirewallD 使用 services 和 zones 代替 iptables 的 rules 和 chains 。
|
||||
要列出所有可用的区域,运行:
|
||||
|
||||
默认情况下,有以下的 zones 可用:
|
||||
|
||||
|
||||
* drop – 丢弃所有传入的网络数据包并且无回应,只有传出网络连接可用。
|
||||
* block — 拒绝所有传入网络数据包并回应一条主机禁止 ICMP 的消息,只有传出网络连接可用。
|
||||
* public — 只接受被选择的传入网络连接,用于公共区域。
|
||||
* external — 用于启用伪装的外部网络,只接受被选择的传入网络连接。
|
||||
* dmz — DMZ 隔离区,外部受限地访问内部网络,只接受被选择的传入网络连接。
|
||||
* work — 对于处在你家庭区域内的计算机,只接受被选择的传入网络连接。
|
||||
* home — 对于处在你家庭区域内的计算机,只接受被选择的传入网络连接。
|
||||
* internal — 对于处在你内部网络的计算机,只接受被选择的传入网络连接。
|
||||
* trusted — 所有网络连接都接受。
|
||||
|
||||
列出所有可用的 zones :
|
||||
```
|
||||
# firewall-cmd --get-zones
|
||||
work drop internal external trusted home dmz public block
|
||||
```
|
||||
|
||||
列出默认的 zone :
|
||||
列出默认的区域 :
|
||||
|
||||
```
|
||||
# firewall-cmd --get-default-zone
|
||||
public
|
||||
```
|
||||
|
||||
改变默认的 zone :
|
||||
改变默认的区域 :
|
||||
|
||||
```
|
||||
# firewall-cmd --set-default-zone=dmz
|
||||
# firewall-cmd --get-default-zone
|
||||
dmz
|
||||
```
|
||||
|
||||
### FirewallD services
|
||||
### FirewallD 服务
|
||||
|
||||
FirewallD services 使用 XML 配置文件为 firewalld 录入服务信息。
|
||||
FirewallD 服务使用 XML 配置文件,记录了 firewalld 服务信息。
|
||||
|
||||
列出所有可用的服务:
|
||||
|
||||
列出所有可用的 services :
|
||||
```
|
||||
# firewall-cmd --get-services
|
||||
amanda-client amanda-k5-client bacula bacula-client ceph ceph-mon dhcp dhcpv6 dhcpv6-client dns docker-registry dropbox-lansync freeipa-ldap freeipa-ldaps freeipa-replication ftp high-availability http https imap imaps ipp ipp-client ipsec iscsi-target kadmin kerberos kpasswd ldap ldaps libvirt libvirt-tls mdns mosh mountd ms-wbt mysql nfs ntp openvpn pmcd pmproxy pmwebapi pmwebapis pop3 pop3s postgresql privoxy proxy-dhcp ptp pulseaudio puppetmaster radius rpc-bind rsyncd samba samba-client sane smtp smtps snmp snmptrap squid ssh synergy syslog syslog-tls telnet tftp tftp-client tinc tor-socks transmission-client vdsm vnc-server wbem-https xmpp-bosh xmpp-client xmpp-local xmpp-server
|
||||
```
|
||||
|
||||
|
||||
|
||||
XML 配置文件存储在 `/usr/lib/firewalld/services/` 和 `/etc/firewalld/services/` 目录。
|
||||
XML 配置文件存储在 `/usr/lib/firewalld/services/` 和 `/etc/firewalld/services/` 目录下。
|
||||
|
||||
### 用 FirewallD 配置你的防火墙
|
||||
|
||||
作为一个例子,假设你正在运行一个 web 服务器,SSH 服务端口为 7022 ,以及邮件服务,你可以利用 FirewallD 这样配置你的服务器:
|
||||
|
||||
作为一个例子,假设你正在运行一个 web 服务,端口为 7022 的 SSH 服务和邮件服务,你可以利用 FirewallD 这样配置你的 [RoseHosting VPS][6]:
|
||||
首先设置默认区为 dmz。
|
||||
|
||||
|
||||
首先设置默认 zone 为 dmz。
|
||||
```
|
||||
# firewall-cmd --set-default-zone=dmz
|
||||
# firewall-cmd --get-default-zone
|
||||
dmz
|
||||
```
|
||||
|
||||
添加持久性的 HTTP 和 HTTPS service 规则到 dmz zone :
|
||||
为 dmz 区添加持久性的 HTTP 和 HTTPS 规则:
|
||||
|
||||
```
|
||||
# firewall-cmd --zone=dmz --add-service=http --permanent
|
||||
# firewall-cmd --zone=dmz --add-service=https --permanent
|
||||
```
|
||||
|
||||
开启端口 25 (SMTP) 和端口 465 (SMTPS) :
|
||||
|
||||
开启端口 25 (SMTP) 和端口 465 (SMTPS) :
|
||||
```
|
||||
firewall-cmd --zone=dmz --add-service=smtp --permanent
|
||||
firewall-cmd --zone=dmz --add-service=smtps --permanent
|
||||
```
|
||||
|
||||
开启 IMAP、IMAPS、POP3 和 POP3S 端口:
|
||||
|
||||
开启 IMAP, IMAPS, POP3 和 POP3S 端口:
|
||||
```
|
||||
firewall-cmd --zone=dmz --add-service=imap --permanent
|
||||
firewall-cmd --zone=dmz --add-service=imaps --permanent
|
||||
@ -94,23 +91,23 @@ firewall-cmd --zone=dmz --add-service=pop3 --permanent
|
||||
firewall-cmd --zone=dmz --add-service=pop3s --permanent
|
||||
```
|
||||
|
||||
因为将 SSH 端口改到了 7022,所以要移除 ssh 服务(端口 22),开启端口 7022:
|
||||
|
||||
将 SSH 端口改到 7022 后,我们移除 ssh service (端口 22),并且开启端口 7022
|
||||
```
|
||||
firewall-cmd --remove-service=ssh --permanent
|
||||
firewall-cmd --add-port=7022/tcp --permanent
|
||||
```
|
||||
|
||||
要实现这些更改,我们需要重新加载防火墙:
|
||||
要应用这些更改,我们需要重新加载防火墙:
|
||||
|
||||
```
|
||||
firewall-cmd --reload
|
||||
```
|
||||
|
||||
|
||||
最后可以列出这些规则:
|
||||
### firewall-cmd –list-all
|
||||
|
||||
```
|
||||
# firewall-cmd –list-all
|
||||
dmz
|
||||
target: default
|
||||
icmp-block-inversion: no
|
||||
@ -129,11 +126,7 @@ rich rules:
|
||||
* * *
|
||||
|
||||
|
||||
|
||||
当然,如果你使用任何一个我们的 [CentOS VPS hosting][7] 服务,你完全不用做这些。在这种情况下,你可以直接叫我们的专家 Linux 管理员为你设置。他们提供 24x7 h 的帮助并且会马上回应你的请求。
|
||||
|
||||
|
||||
PS. 如果你喜欢这篇文章,请按分享按钮分享给你社交网络上的朋友或者直接在下面留下一个回复。谢谢。
|
||||
PS. 如果你喜欢这篇文章,请在下面留下一个回复。谢谢。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -145,7 +138,7 @@ via: https://www.rosehosting.com/blog/set-up-and-configure-a-firewall-with-firew
|
||||
|
||||
作者:[rosehosting.com][a]
|
||||
译者:[Locez](https://github.com/locez)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
83
published/201703/20170214 CentOS-vs-Ubuntu.md
Normal file
83
published/201703/20170214 CentOS-vs-Ubuntu.md
Normal file
@ -0,0 +1,83 @@
|
||||
CentOS 与 Ubuntu 有什么不同?
|
||||
============
|
||||
|
||||
[
|
||||
][4]
|
||||
|
||||
Linux 中的可选项似乎“无穷无尽”,因为每个人都可以通过修改一个已经发行的版本或者新的[白手起家的版本][7] (LFS) 来构建 Linux。
|
||||
|
||||
关于 Linux 发行版的选择,我们关注的因素包括用户界面、文件系统、软件包分发、新的特性以及更新周期和可维护性等。
|
||||
|
||||
在这篇文章中,我们会讲到两个较为熟知的 Linux 发行版,实际上,更多的是介绍两者之间的不同,以及在哪些方面一方比另一方更好。
|
||||
|
||||
### 什么是 CentOS?
|
||||
|
||||
CentOS(Community Enterprise Operating System)是脱胎于 Red Hat Enterprise Linux (RHEL) 并与之兼容的由社区支持的克隆版 Linux 发行版,所以我们可以认为 CentOS 是 RHEL 的一个免费版。CentOS 的每一套发行版都有 10 年的维护期,每个新版本的释出周期为 2 年。在 2014 年 1 月 8 日,[CentOS 声明正式加入红帽](https://linux.cn/article-2453-1.html),为新的 CentOS 董事会所管理,但仍然保持与 RHEL 的独立性。
|
||||
|
||||
扩展阅读:[如何安装 CentOS?][1]
|
||||
|
||||
#### CentOS 的历史和第一次释出
|
||||
|
||||
[CentOS][8] 第一次释出是在 2004 年,当时名叫 cAOs Linux;它是由社区维护和管理的一套基于 RPM 的发行版。
|
||||
|
||||
CentOS 结合了包括 Debian、Red Hat Linux/Fedora 和 FreeBSD 等在内的许多方面,使其能够令服务器和集群稳定工作 3 到 5 年的时间。它有一群开源软件开发者作为拥趸,是一个大型组织(CAOS 基金会)的一部分。
|
||||
|
||||
在 2006 年 6 月,David Parsley 宣布由他开发的 TAO Linux(另一个 RHEL 克隆版本)退出历史舞台并全力转入 CentOS 的开发工作。不过,他的领域转移并不会影响之前的 TAO 用户, 因为他们可以通过使用 `yum update` 来更新系统以迁移到 CentOS。
|
||||
|
||||
2014 年 1 月,红帽开始赞助 CentOS 项目,并移交了所有权和商标。
|
||||
|
||||
#### CentOS 设计
|
||||
|
||||
确切地说,CentOS 是付费 RHEL (Red Had Enterprise Edition) 版本的克隆。RHEL 提供源码以供之后 CentOS 修改和变更(移除商标和 logo)并完善为最终的成品。
|
||||
|
||||
### Ubuntu
|
||||
|
||||
Ubuntu 是一个基于 Debian 的 Linux 操作系统,应用于桌面、服务器、智能手机和平板电脑等多个领域。Ubuntu 是由一个英国的名为 Canonical Ltd. 的公司发行的,由南非的 Mark Shuttleworth 创立并赞助。
|
||||
|
||||
扩展阅读:[安装完 Ubuntu 16.10 必须做的 10 件事][2]
|
||||
|
||||
#### Ubuntu 的设计
|
||||
|
||||
Ubuntu 是一个在全世界的开发者共同努力下生成的开源发行版。在这些年的悉心经营下,Ubuntu 的界面变得越来越现代化和人性化,整个系统运行也更加流畅、安全,并且有成千上万的应用可供下载。
|
||||
|
||||
由于它是基于 [Debian][10] 的,因此它也支持 .deb 包、较新的包系统和更为安全的 [snap 包格式 (snappy)][11]。
|
||||
|
||||
这种新的打包系统允许分发的应用自带满足所需的依赖性。
|
||||
|
||||
扩展阅读:[点评 Ubuntu 16.10 中的 Unity 8][3]
|
||||
|
||||
### CentOS 与 Ubuntu 的区别
|
||||
|
||||
* Ubuntu 基于 Debian,CentOS 基于 RHEL;
|
||||
* Ubuntu 使用 .deb 和 .snap 的软件包,CentOS 使用 .rpm 和 flatpak 软件包;
|
||||
* Ubuntu 使用 apt 来更新,CentOS 使用 yum;
|
||||
* CentOS 看起来会更稳定,因为它不会像 Ubuntu 那样对包做常规性更新,但这并不意味着 Ubuntu 就不比 CentOS 安全;
|
||||
* Ubuntu 有更多的文档和免费的问题、信息支持;
|
||||
* Ubuntu 服务器版本在云服务和容器部署上的支持更多。
|
||||
|
||||
### 结论
|
||||
|
||||
不论你的选择如何,**是 Ubuntu 还是 CentOS**,两者都是非常优秀稳定的发行版。如果你想要一个发布周期更短的版本,那么就选 Ubuntu;如果你想要一个不经常变更包的版本,那么就选 CentOS。在下方留下的评论,说出你更钟爱哪一个吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/centos-vs-ubuntu
|
||||
|
||||
作者:[linuxandubuntu.com][a]
|
||||
译者:[Meditator-hkx](http://www.kaixinhuang.com)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com/home/centos-vs-ubuntu
|
||||
[1]:http://www.linuxandubuntu.com/home/how-to-install-centos
|
||||
[2]:http://www.linuxandubuntu.com/home/10-things-to-do-after-installing-ubuntu-16-04-xenial-xerus
|
||||
[3]:http://www.linuxandubuntu.com/home/linuxandubuntu-review-of-unity-8-preview-in-ubuntu-1610
|
||||
[4]:http://www.linuxandubuntu.com/home/centos-vs-ubuntu
|
||||
[5]:http://www.linuxandubuntu.com/home/centos-vs-ubuntu
|
||||
[6]:http://www.linuxandubuntu.com/home/centos-vs-ubuntu#comments
|
||||
[7]:http://www.linuxandubuntu.com/home/how-to-create-a-linux-distro
|
||||
[8]:http://www.linuxandubuntu.com/home/10-things-to-do-after-installing-centos
|
||||
[9]:https:]:http://www.linuxandubuntu.com/home/linuxandubuntu-review-of-unity-8-preview-in-ubuntu-1610
|
||||
[10]:https://www.debian.org/
|
||||
[11]:https://en.wikipedia.org/wiki/Snappy_(package_manager)
|
||||
@ -0,0 +1,86 @@
|
||||
在独立的 Root 和 Home 硬盘驱动器上安装 Ubuntu
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
安装 Linux 系统时,可以有两种不同的方式。第一种方式是在一个超快的固态硬盘上进行安装,这样可以保证迅速开机和高速访问数据。第二种方式是在一个较慢但很强大的普通硬盘驱动器上安装,这样的硬盘转速快并且存储容量大,从而可以存储大量的应用程序和数据。
|
||||
|
||||
然而,一些 Linux 用户都知道,固态硬盘很棒,但是又很贵,而普通硬盘容量很大但速度较慢。如果我告诉你,可以同时利用两种硬盘来安装 Linux 系统,会怎么样?一个超快、现代化的固态硬盘驱动 Linux 内核,一个容量很大的普通硬盘来存储其他数据。
|
||||
|
||||
在这篇文章中,我将阐述如何通过分离 Root 目录和 Home 目录安装 Ubuntu 系统 — Root 目录存于 SSD(固态硬盘)中,Home 目录存于普通硬盘中。
|
||||
|
||||
### 没有多余的硬盘驱动器?尝试一下 SD 卡(内存卡)!
|
||||
|
||||

|
||||
|
||||
在多个驱动器上安装 Linux 系统是很不错的,并且每一个高级用户都应该学会这样做。然而,还有一种情况使得用户应该这样安装 Linux 系统 - 在低存储容量的笔记本电脑上安装系统。可能你有一台很便宜、没有花费太多的笔记本电脑,上面安装了 Linux 系统,电脑上没有多余的硬盘驱动,但有一个 SD 卡插槽。
|
||||
|
||||
这篇教程也是针对这种类型的电脑的。跟随这篇教程,可以为笔记本电脑买一个高速的 SD 卡来存储 Home 目录,而不是使用另一个硬盘驱动。本教程也适用于这种使用情况。
|
||||
|
||||
### 制作 USB 启动盘
|
||||
|
||||
首先去[这个网站][11]下载最新的 Ubuntu Linux 版本。然后下载 [Etcher][12]- USB 镜像制作工具。这是一个使用起来很简单的工具,并且支持所有主流的操作系统。你还需要一个至少有 2GB 大小的 USB 驱动器。
|
||||
|
||||

|
||||
|
||||
安装好 Etcher 以后,直接打开。点击 <ruby>选择镜像<rt>Select Image</rt></ruby> 按钮来制作镜像。这将提示用户浏览、寻找 ISO 镜像,找到前面下载的 Ubuntu ISO 文件并选择。然后,插入 USB 驱动器,Etcher 应该会自动选择它。之后,点击 “Flash!” 按钮,Ubuntu 启动盘的制作过程就开始了。
|
||||
|
||||
为了能够启动 Ubuntu 系统,需要配置 BIOS。这是必需的,这样计算机才能启动新创建的 Ubuntu 启动盘。为了进入 BIOS,在插入 USB 的情况下重启电脑,然后按正确的键(Del、F2 或者任何和你的电脑相应的键)。找到从 USB 启动的选项,然后启用这个选项。
|
||||
|
||||
如果你的个人电脑不支持 USB 启动,那么把 Ubuntu 镜像刻入 DVD 中。
|
||||
|
||||
### 安装
|
||||
|
||||
当用启动盘第一次加载 Ubuntu 时,欢迎界面会出现两个选项。请选择 “安装 Ubuntu” 选项。在下一页中,Ubiquity 安装工具会请求用户选择一些选项。这些选项不是强制性的,可以忽略。然而,建议两个选项都勾选,因为这样可以节省安装系统以后的时间,特别是安装 MP3 解码器和更新系统。(LCTT 译注:当然如果你的网速不够快,还是不要勾选的好。)
|
||||
|
||||

|
||||
|
||||
勾选了<ruby>“准备安装 Ubuntu”<rt>Preparing to install Ubuntu</rt></ruby>页面中的两个选项以后,需要选择安装类型了。有许多种安装类型。然而,这个教程需要选择自定义安装类型。为了进入自定义安装页面,勾选<ruby>“其他”<rt>something else</rt></ruby>选项,然后点击“继续”。
|
||||
|
||||
现在将显示 Ubuntu 自定义安装分区工具。它将显示任何/所有能够安装 Ubuntu 系统的磁盘。如果两个硬盘均可用,那么它们都会显示。如果插有 SD 卡,那么它也会显示。
|
||||
|
||||
选择用于 Root 文件系统的硬盘驱动器。如果上面已经有分区表,编辑器会显示出来,请使用分区工具把它们全部删除。如果驱动没有格式化也没有分区,那么使用鼠标选择驱动器,然后点击<ruby>“新建分区表”<rt>new partition table</rt></ruby>。对所有驱动器执行这个操作,从而使它们都有分区表。(LCTT 译注:警告,如果驱动器上有你需要的数据,请先备份,否则重新分区后将永远丢失。)
|
||||
|
||||

|
||||
|
||||
现在所有分区都有了分区表(并已删除分区),可以开始进行配置了。在第一个驱动器下选择空闲空间,然后点击加号按钮来创建新分区。然后将会出现一个“创建分区窗口”。允许工具使用整个硬盘。然后转到<ruby>“挂载点”<rt>Mount Point</rt></ruby>下拉菜单。选择 `/` (Root)作为挂载点,之后点击 OK 按钮确认设置。
|
||||
|
||||
对第二个驱动器做相同的事,这次选择 `/home` 作为挂载点。两个驱动都设置好以后,选择要放入引导装载器的驱动器,然后点击 <ruby>“现在安装”<rt>install now</rt></ruby>,安装进程就开始了。
|
||||
|
||||

|
||||
|
||||
从这以后的安装进程是标准安装。创建用户名、选择时区等。
|
||||
|
||||
**注:** 你是以 UEFI 模式进行安装吗?如果是,那么需要给 boot 创建一个 512 MB 大小的 FAT32 分区。在创建其他任何分区前做这件事。确保选择 “/boot” 作为这个分区的挂载点。
|
||||
|
||||
如果你需要一个交换分区,那么,在创建用于 `/` 的分区前,在第一个驱动器上进行创建。可以通过点击 ‘+’ 按钮,然后输入所需大小,选择下拉菜单中的<ruby>“交换区域”<rt>swap area</rt></ruby>来创建交换分区。
|
||||
|
||||
### 结论
|
||||
|
||||
Linux 最好的地方就是可以自己按需配置。有多少其他操作系统可以让你把文件系统分割在不同的硬盘驱动上?并不多,这是肯定的。我希望有了这个指南,你将意识到 Ubuntu 能够提供的真正力量。
|
||||
|
||||
安装 Ubuntu 系统时你会用多个驱动器吗?请在下面的评论中让我们知道。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/install-ubuntu-with-different-root-home-hard-drives/
|
||||
|
||||
作者:[Derrik Diener][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/derrikdiener/
|
||||
[1]:https://www.maketecheasier.com/author/derrikdiener/
|
||||
[2]:https://www.maketecheasier.com/install-ubuntu-with-different-root-home-hard-drives/#respond
|
||||
[3]:https://www.maketecheasier.com/category/linux-tips/
|
||||
[4]:http://www.facebook.com/sharer.php?u=https%3A%2F%2Fwww.maketecheasier.com%2Finstall-ubuntu-with-different-root-home-hard-drives%2F
|
||||
[5]:http://twitter.com/share?url=https%3A%2F%2Fwww.maketecheasier.com%2Finstall-ubuntu-with-different-root-home-hard-drives%2F&text=How+to+Install+Ubuntu+with+Separate+Root+and+Home+Hard+Drives
|
||||
[6]:mailto:?subject=How%20to%20Install%20Ubuntu%20with%20Separate%20Root%20and%20Home%20Hard%20Drives&body=https%3A%2F%2Fwww.maketecheasier.com%2Finstall-ubuntu-with-different-root-home-hard-drives%2F
|
||||
[7]:https://www.maketecheasier.com/byb-dimmable-eye-care-desk-lamp/
|
||||
[8]:https://www.maketecheasier.com/download-appx-files-from-windows-store/
|
||||
[9]:https://support.google.com/adsense/troubleshooter/1631343
|
||||
[10]:http://www.maketecheasier.com/tag/ssd
|
||||
[11]:http://ubuntu.com/download
|
||||
[12]:https://etcher.io/
|
||||
@ -1,11 +1,11 @@
|
||||
# [Best Windows Like Linux Distributions For New Linux Users][12]
|
||||
[给新手的最佳类 Windows 界面的 Linux 发行版][12]
|
||||
给新手的最佳类 Windows 界面的 Linux 发行版
|
||||
=========
|
||||
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
Linux 世界的新同学们,大家好,当你看到这么多基于 Linux 内核的发行版后,是不是在选择的过程中无从下手呢。很多同学都是刚刚从熟悉的 Windows 系统来到陌生的 Linux 世界里,都希望使用一款即简单易用,又跟 Windows 长得很像的 Linux 发行版,因此我今天将给大家介绍几款这样的 Linux 发行版,它们的桌面环境跟 Windows 系统界面十分相似,咱们开始吧!
|
||||
Linux 世界的新同学们,大家好,当你看到这么多基于 Linux 内核的发行版后,是不是在选择的过程中无从下手呢。很多同学都是刚刚从熟悉的 Windows 系统来到陌生的 Linux 世界里,都希望使用一款既简单易用,又跟 Windows 长得很像的 Linux 发行版,因此我今天将给大家介绍几款这样的 Linux 发行版,它们的桌面环境跟 Windows 系统界面十分相似,咱们开始吧!
|
||||
|
||||
### Linux Mint
|
||||
|
||||
@ -13,7 +13,9 @@ Linux 世界的新同学们,大家好,当你看到这么多基于 Linux 内
|
||||

|
||||
][6]
|
||||
|
||||
我给大家介绍的第一款非常流行的 Linux 发行版就是 “[Linux Mint 操作系统”][14] 。当你决定使用 Linux 系统来代替 Windows 系统时,你应该在某些地方听说过 Linux Mint 这个发行版吧。 Linux Mint 和 Ubuntu 系统一样被公认为是最好用的 Linux 发行版之一, Linux Mint 系统因其简洁易用、功能强大的 Cinnamon 桌面环境而出名。 [Cinnamon][15] 使用起来非常简单,而且你还可以使用各种[桌面主题][16]、图标库、桌面小工具和应用组件来把 Linux Mint 系统配置得跟 Windows XP 、 Windows 7 、 Winows 8 或者 Windows 10 系统的界面一样。 [Cinnamon][17] 也是 Linux 系统中非常流行的桌面环境之一。你一定会对这个简单易用、功能强大的桌面环境爱不释手。同时,你也可以阅读这两篇文章 [Linux Mint 18.1 "Serena" —— 最幽雅的 Linux 发行版之一][1] 以及 [Cinnamon ——给新手的最佳 Linux 桌面环境][2] 来进一步了解 Linux Mint 操作系统和 Cinnamon 桌面环境。
|
||||
我给大家介绍的第一款非常流行的 Linux 发行版就是 “[Linux Mint 操作系统”][14] 。当你决定使用 Linux 系统来代替 Windows 系统时,你应该在某些地方听说过 Linux Mint 这个发行版吧。 Linux Mint 和 Ubuntu 系统一样被公认为是最好用的 Linux 发行版之一, Linux Mint 系统因其简洁易用、功能强大的 Cinnamon 桌面环境而出名。 [Cinnamon][15] 使用起来非常简单,而且你还可以使用各种[桌面主题][16]、图标库、桌面小工具和应用组件来把 Linux Mint 系统配置得跟 Windows XP 、 Windows 7 、 Winows 8 或者 Windows 10 系统的界面一样。 [Cinnamon][17] 也是 Linux 系统中非常流行的桌面环境之一。你一定会对这个简单易用、功能强大的桌面环境爱不释手。
|
||||
|
||||
同时,你也可以阅读这两篇文章 [Linux Mint 18.1 "Serena" —— 最幽雅的 Linux 发行版之一][1] 以及 [Cinnamon ——给新手的最佳 Linux 桌面环境][2] 来进一步了解 Linux Mint 操作系统和 Cinnamon 桌面环境。
|
||||
|
||||
### Zorin OS
|
||||
|
||||
@ -21,7 +23,9 @@ Linux 世界的新同学们,大家好,当你看到这么多基于 Linux 内
|
||||

|
||||
][7]
|
||||
|
||||
[Zorin OS 操作系统][18] 也是可以用来替代 Windows 7\ 系统的一款非常流行的 Linux 发行版。其开始菜单和任务栏非常漂亮,整体界面美观充满活力,而且在速度和稳定性方面也相当出色。如果你喜欢的是 Windows 7 而不是 Windows 10\ 系统,那么 Zorin OS 将会是你最好的选择。 Zorin OS 同样预安装了很多软件,因此你再也不用费尽周折的去找软件来安装了。其华丽的仿 Windows 7 系统的界面风格更是让人一见如故。大胆去尝试吧。你还可以阅读[Zorin OS 12 评测 | 本周 Linux 和 Ubuntu 发行版评测][3]这篇文章来进一步了解 Zorin OS 系统。
|
||||
[Zorin OS 操作系统][18] 也是可以用来替代 Windows 7 系统的一款非常流行的 Linux 发行版。其开始菜单和任务栏非常漂亮,整体界面美观充满活力,而且在速度和稳定性方面也相当出色。如果你喜欢的是 Windows 7 而不是 Windows 10 系统,那么 Zorin OS 将会是你最好的选择。 Zorin OS 同样预安装了很多软件,因此你再也不用费尽周折的去找软件来安装了。其华丽的仿 Windows 7 系统的界面风格更是让人一见如故。大胆去尝试吧。
|
||||
|
||||
你还可以阅读[Zorin OS 12 评测 | 本周 Linux 和 Ubuntu 发行版评测][3]这篇文章来进一步了解 Zorin OS 系统。
|
||||
|
||||
### Robolinux
|
||||
|
||||
@ -29,7 +33,7 @@ Linux 世界的新同学们,大家好,当你看到这么多基于 Linux 内
|
||||

|
||||
][8]
|
||||
|
||||
[Robolinux 操作系统][9] 是一个内嵌了 Windows 运行环境的 Linux 发行版。它支持用户在 Linux 系统中运行 Windows 应用程序,因此,你再也不用担心自己喜欢的 Windows 应用程序在 Linux 系统中无法使用的问题了。在 Robolinux 系统中,这个特性被称为“[隐形虚拟机][10]”。我对这个新颖独特的功能非常感兴趣。同时, Rololinux 系统还包括其它几个桌面环境,你可以根据自己的喜好选择某一个桌面环境。这个系统中还有一个用于完全备份 C 盘的工具,不会让你丢失任何文件。很独特吧,对不对?
|
||||
[Robolinux 操作系统][9] 是一个内嵌了 Windows 运行环境(Wine)的 Linux 发行版。它支持用户在 Linux 系统中运行 Windows 应用程序,因此,你再也不用担心自己喜欢的 Windows 应用程序在 Linux 系统中无法使用的问题了。在 Robolinux 系统中,这个特性被称为“[隐形虚拟机(Stealth VM)][10]”。我对这个新颖独特的功能非常感兴趣。同时, Rololinux 系统还包括其它几个桌面环境,你可以根据自己的喜好选择某一个桌面环境。这个系统中还有一个用于完全备份 C 盘的工具,不会让你丢失任何文件。很独特吧,对不对?
|
||||
|
||||
### ChaletOS
|
||||
|
||||
@ -37,13 +41,14 @@ Linux 世界的新同学们,大家好,当你看到这么多基于 Linux 内
|
||||

|
||||
][11]
|
||||
|
||||
大家有谁用过 [ChaletOS 操作系统][19] 吗?这是一款在界面外观和使用感觉上最接近于 Windows 的 [Linux 发行版][20] 之一。上面的截图是在我使用了 Windows 10 图标和主题包后的效果,使用这个主题包后,可以让 ChaletOS 的桌面变得和 Windows 10 界面一样。一些预安装的应用程序也可以帮助你更好的使用 ChaletOS 系统。在使用的过程中你仿佛又回到了熟悉的 Windows 世界里。上面的截图竟然让我的朋友们信以为真了。去试一试吧,你肯定会喜欢这个发行版。你还可以通过 [ChaletOS —— Linux 发行版中的新秀][4] 这篇文章来进一步了解 ChaletOS 系统。
|
||||
大家有谁用过 [ChaletOS 操作系统][19] 吗?这是一款在界面外观和使用感觉上最接近于 Windows 的 [Linux 发行版][20] 之一。上面的截图是在我使用了 Windows 10 图标和主题包后的效果,使用这个主题包后,可以让 ChaletOS 的桌面变得和 Windows 10 界面一样。一些预安装的应用程序也可以帮助你更好的使用 ChaletOS 系统。在使用的过程中你仿佛又回到了熟悉的 Windows 世界里。上面的截图竟然让我的朋友们信以为真了。去试一试吧,你肯定会喜欢这个发行版。
|
||||
|
||||
你还可以通过 [ChaletOS —— Linux 发行版中的新秀][4] 这篇文章来进一步了解 ChaletOS 系统。
|
||||
|
||||
### 总结
|
||||
|
||||
这篇文章中列出的发行版我尽量写得简短一些,否则会给新手们在选择的过程中造成太多的困惑,无从下手。还有一些大家正在使用的 Linux 发行版在本文中并未提及。希望你们在下面的评论中提出来,以帮助我们的新朋友们在选择 Linux 发行版的过程中作出正确的选择。
|
||||
|
||||
|
||||
好吧,到此为止吧,这 4 款操作系统都是从 Windows 转向 Linux 的新用户在学习过程中使用最广泛的 **Linux 发行版** ,当然 Kubuntu 和 Elementary OS 系统也不甘示弱。想安装哪个版本,完全由你自己决定。大多数情况下 [Linux Mint 操作系统][21] 一直独占鳌头。如果你刚踏入 Linux 的世界,我建议你从 Linux Mint 系统开始。行动起来吧,现在就安装一个自己喜欢的 Linux 系统,勇往直前,成为改变 Linux 开源世界的一员。|
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -52,7 +57,7 @@ via: http://www.linuxandubuntu.com/home/best-windows-like-linux-distributions-fo
|
||||
|
||||
作者:[linuxandubuntu.com][a]
|
||||
译者:[rusking](https://github.com/rusking)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,34 +1,34 @@
|
||||
Windows赢了桌面,而Linux赢得整个世界
|
||||
Windows 赢了桌面,而 Linux 赢得整个世界
|
||||
============================================================
|
||||
拥有最高级的 Linux 桌面系统项目的城市正转回 Windows 阵营,但 Linux 的命运已经不再与 PC 休戚相关。
|
||||
|
||||
> 最坚决推行 Linux 桌面系统项目的城市正在转回 Windows 阵营,但 Linux 的命运已经不再与 PC 休戚相关。
|
||||
|
||||

|
||||
|
||||
> 慕尼黑的 Linux 项目只是开源软件故事中的一小部分
|
||||
> 图片: Getty Images/iStockphoto
|
||||
|
||||
在实施从 Windows 系统迁移到 Linux 系统这一项目接近十年之久, 慕尼黑却突然走上了一条戏剧性的转弯。据说是到 2021 年,地方议会就会开始用 [Windows 10][4] 替换运行 LiMux (Ubuntu 的一种自定义版本)的 PC 机。
|
||||
在实施从 Windows 系统迁移到 Linux 系统这一项目接近十年之久后,慕尼黑却突然走上了一条戏剧性的转弯。据说是到 2021 年,该城市的地方议会就会开始用 [Windows 10][4] 替换运行 LiMux (Ubuntu 的一种自定义版本)的 PC 机。
|
||||
|
||||
若是回到 15 或者 20 年前,人们可能会争论什么时候 Linux 将会在桌面上取代 Windows。例如,当 Ubuntu 于 2004 年问世时,它是带着 [终结 Windows 的抱负][5] 而被设计为标准的桌面操作系统的。
|
||||
|
||||
剧透:这一切并没有发生。
|
||||
|
||||
桌面上的 Linux 在今天占有约为 2% 的市场,很多人都认为它复杂晦涩。与此同时,Windows 则稳航无虞,在 PC 市场笑傲群雄,天下十之有九。但商业中总还有些许 Linux 桌面的身影,它仍被需要——尤其是对开发者和数据科学家而言。
|
||||
桌面上的 Linux 在今天占有约为 2% 的市场,很多人都认为它复杂晦涩。与此同时,Windows 则航行无虞,在 PC 市场笑傲群雄,天下十有其九。但在商业领域中总还有些许 Linux 桌面的身影,它仍被需要——尤其是对开发者和数据科学家而言。
|
||||
|
||||
但遗憾的是,它永远也不会成为历史的主流。
|
||||
|
||||
慕尼黑的 Linux 项目因其规模之大,引起了许多人的兴趣。几乎没有哪家大型组织会做出从 Windows 到 Linux 的迁移,一些个别的案例像 [法国宪兵队和都灵市][6] 曾有类似之举。然而,[慕尼黑作为模范][7]:在这一事件上的失败将会大大打击那些仍在 [试图用 Linux 将 Windows 取而代之的信徒们][8]。
|
||||
|
||||
但现实就是如此,绝大多数公司乐于去使用主流的桌面操作系统,因为它具有完整一致、用户友好这种优势。
|
||||
|
||||
但现实就是如此,绝大多数公司乐于去使用主流的桌面操作系统,因为它具有完整性、用户友好这种天然的优势。
|
||||
|
||||
工作人员所抱怨的问题中,有多少是归咎于 Limux 软件以及多少是操作系统无端被责备的,已经不可计数。但重要的是,无论慕尼黑最后何去何从,Linux 的命运都已经脱离了桌面——是的,Linux 在多年前就已经输掉了桌面战争。
|
||||
工作人员所抱怨的问题中,有多少是归咎于 LiMux 软件以及多少是操作系统无端被责备的,已经不可计数。但重要的是,无论慕尼黑最后何去何从,Linux 的命运都已经脱离了桌面 —— 是的,Linux 在多年前就已经输掉了桌面战争。
|
||||
|
||||
但这对 Linux 来说无伤大雅,因为它赢得了智能手机之战,并且在云端和物联网之战上也是捷报连连。
|
||||
|
||||
你的口袋里,有七八成可能装的是一个 Linux 驱动的智能手机(Android 基于 Linux 内核)。你的身边,更是有成千上万 Linux 驱动的设备,虽然这些也许你甚至都没注意到。
|
||||
|
||||
你的口袋里,七八成装的是一个 Linux 驱动的智能手机(Android 基于 Linux 内核)。你的身边,更是有成千上万 Linux 驱动的设备,虽然这些也许你甚至都没注意到。
|
||||
|
||||
[像 Raspberry Pi][9] 这样运行大量不同类型 Linux 的设备,正在创建一个充满热情和活力的开发者社区,并且提供给初创公司一种低成本的驱动新设备的方法。
|
||||
[像树莓派][9]这样运行大量不同类型 Linux 的设备,正在创建一个充满热情和活力的开发者社区,并且提供给初创公司一种低成本的驱动新设备的方法。
|
||||
|
||||
大部分公有云也是以这样或那样的形式在 Linux 上运行的;即便是微软,也已经敞开大门,拥抱开源软件。无论你站在哪一个软件平台的立场,不可否认地,开发者和用户拥有更多丰富的可选项是一件好事,对决策来说,抑或是对创新来说,都是如此。
|
||||
|
||||
@ -36,15 +36,15 @@ Windows赢了桌面,而Linux赢得整个世界
|
||||
|
||||
虽然慕尼黑传奇的曲折变换与 Linux 在桌面上的冒险耐人寻味,但它们却并未给你呈现出一个完整的故事。
|
||||
|
||||
_同意? 还是不同意? 在下面添加你的评论来加入讨论吧!_
|
||||
_同意? 还是不同意? 在下面添加你的评论来加入讨论吧!_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.zdnet.com/article/windows-wins-the-desktop-but-linux-takes-the-world/
|
||||
|
||||
作者:[Steve Ranger ][a]
|
||||
作者:[Steve Ranger][a]
|
||||
译者:[Meditator-hkx](https://github.com/Meditator-hkx)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -3,13 +3,13 @@
|
||||
|
||||
FTP(文件传输协议)是一个较老且最常用的标准网络协议,用于在两台计算机之间通过网络上传/下载文件。然而, FTP 最初的时候并不安全,因为它仅通过用户凭证(用户名和密码)传输数据,没有进行加密。
|
||||
|
||||
警告:如果你打算使用 FTP, 考虑通过 SSL/TLS(将在下篇文章中讨论)配置 FTP 连接。否则,使用安全 FTP,比如 [SFTP][1] 会更好一些。
|
||||
警告:如果你打算使用 FTP, 需要考虑通过 SSL/TLS(将在下篇文章中讨论)配置 FTP 连接。否则,使用安全 FTP,比如 [SFTP][1] 会更好一些。
|
||||
|
||||
**推荐阅读:**[如何在 CentOS 7 中安装并保护 FTP 服务器][2]
|
||||
|
||||
在这个教程中,我将向你们展示如何在 Ubuntu 中安装、配置并保护 FTP 服务器(VSFTPD 的全称是 “Very Secure FTP Deamon”),从而拥有强大的安全性,能够防范 FTP 漏洞。
|
||||
|
||||
### 第一步:在 Ubuntu 中安装 VsFTP 服务器
|
||||
### 第一步:在 Ubuntu 中安装 VSFTPD 服务器
|
||||
|
||||
1、首先,我们需要更新系统安装包列表,然后像下面这样安装 VSFTPD 二进制包:
|
||||
|
||||
@ -29,7 +29,7 @@ $ sudo apt-get install vsftpd
|
||||
# chkconfig --level 35 vsftpd on
|
||||
```
|
||||
|
||||
3、接下来,如果你在服务器上启用了 [UFW 防火墙][3](默认情况下不启用),那么需要打开端口 20 和 21,FTP daemons 正在监听它们,从而才能允许从远程机器访问 FTP 服务,然后,像下面这样添加新的防火墙规则:
|
||||
3、接下来,如果你在服务器上启用了 [UFW 防火墙][3](默认情况下不启用),那么需要打开端口 20 和 21 —— FTP 守护进程正在监听它们——从而才能允许从远程机器访问 FTP 服务,然后,像下面这样添加新的防火墙规则:
|
||||
|
||||
```
|
||||
$ sudo ufw allow 20/tcp
|
||||
@ -37,7 +37,7 @@ $ sudo ufw allow 21/tcp
|
||||
$ sudo ufw status
|
||||
```
|
||||
|
||||
### 第二步:在 Ubuntu 中配置并保护 VsFTP 服务器
|
||||
### 第二步:在 Ubuntu 中配置并保护 VSFTPD 服务器
|
||||
|
||||
4、让我们进行一些配置来设置和保护 FTP 服务器。首先,我们像下面这样创建一个原始配置文件 `/etc/vsftpd/vsftpd.conf` 的备份文件:
|
||||
|
||||
@ -57,46 +57,46 @@ $ sudo nano /etc/vsftpd.conf
|
||||
|
||||
```
|
||||
anonymous_enable=NO # 关闭匿名登录
|
||||
local_enable=YES # 允许本地登录
|
||||
write_enable=YES # 启用改变文件系统的 FTP 命令
|
||||
local_enable=YES # 允许本地用户登录
|
||||
write_enable=YES # 启用可以修改文件的 FTP 命令
|
||||
local_umask=022 # 本地用户创建文件的 umask 值
|
||||
dirmessage_enable=YES # 启用从而当用户第一次进入新目录时显示消息
|
||||
dirmessage_enable=YES # 当用户第一次进入新目录时显示提示消息
|
||||
xferlog_enable=YES # 一个存有详细的上传和下载信息的日志文件
|
||||
connect_from_port_20=YES # 在服务器上针对端口类型连接使用端口 20(FTP 数据)
|
||||
connect_from_port_20=YES # 在服务器上针对 PORT 类型的连接使用端口 20(FTP 数据)
|
||||
xferlog_std_format=YES # 保持标准日志文件格式
|
||||
listen=NO # 阻止 vsftpd 在独立模式下运行
|
||||
listen_ipv6=YES # vsftpd 将监听 ipv6 而不是 IPv4
|
||||
pam_service_name=vsftpd # vsftpd 将使用的 PAM 设备的名字
|
||||
userlist_enable=YES # enable vsftpd to load a list of usernames启用 vsftpd 加载用户名字列表
|
||||
listen_ipv6=YES # vsftpd 将监听 ipv6 而不是 IPv4,你可以根据你的网络情况设置
|
||||
pam_service_name=vsftpd # vsftpd 将使用的 PAM 验证设备的名字
|
||||
userlist_enable=YES # 允许 vsftpd 加载用户名字列表
|
||||
tcp_wrappers=YES # 打开 tcp 包装器
|
||||
```
|
||||
|
||||
5、现在,配置 VSFTPD ,从而允许/拒绝 FTP 访问基于用户列表文件 `/etc/vsftpd.userlist` 的用户。
|
||||
5、现在,配置 VSFTPD ,基于用户列表文件 `/etc/vsftpd.userlist` 来允许或拒绝用户访问 FTP。
|
||||
|
||||
注意,在默认情况下,如果 `userlist_enable=YES` 而 `userlist_deny=YES` ,那么,用户列表文件 `/etc/vsftpd.userlist` 中的用户是不能登录访问的。
|
||||
注意,在默认情况下,如果通过 `userlist_enable=YES` 启用了用户列表,且设置 `userlist_deny=YES` 时,那么,用户列表文件 `/etc/vsftpd.userlist` 中的用户是不能登录访问的。
|
||||
|
||||
但是,选项 ` userlist_deny =NO` 则改变了默认设置,所以只有用户名被明确列出在用户列表文件 `/ etc / vsftpd` 中的用户才允许登录到FTP服务器。
|
||||
但是,选项 `userlist_deny=NO` 则反转了默认设置,这种情况下只有用户名被明确列出在 `/etc/vsftpd.userlist` 中的用户才允许登录到 FTP 服务器。
|
||||
|
||||
```
|
||||
userlist_enable=YES # vsftpd 将会从所给的用户列表文件中加载用户名字列表
|
||||
userlist_file=/etc/vsftpd.userlist # 存储用户名字
|
||||
userlist_deny=NO
|
||||
userlist_file=/etc/vsftpd.userlist # 存储用户名字的列表
|
||||
userlist_deny=NO
|
||||
```
|
||||
|
||||
重要的是,当用户登录 FTP 服务器以后,他们将进入 chrooted 环境,这是因为本地 root 目录将作为 FTP 会话唯一的 home 目录。
|
||||
重要的是,当用户登录 FTP 服务器以后,他们将进入 chrooted 环境,即当在 FTP 会话时,其 root 目录将是其 home 目录。
|
||||
|
||||
接下来,我们来看一看两种可能的途径来设置 chrooted(本地 root)目录,正如下面所展示的。
|
||||
|
||||
6、这时,让我们添加/修改/取消这两个选项来[阻止 FTP 用户进入 home 目录][4]
|
||||
6、这时,让我们添加/修改/取消这两个选项来[将 FTP 用户限制在其 home 目录][4]
|
||||
|
||||
```
|
||||
chroot_local_user=YES
|
||||
allow_writeable_chroot=YES
|
||||
```
|
||||
|
||||
选项 `chroot_local_user=YES` 意味着本地用户将进入 chroot 环境,当登录以后 root 目录成为默认的 home 目录。
|
||||
选项 `chroot_local_user=YES` 意味着本地用户将进入 chroot 环境,当登录以后默认情况下是其 home 目录。
|
||||
|
||||
并且我们要理解,默认情况下,出于安全原因,VSFTPD 不允许 chroot 目录具有可写权限。然而,我们可以通过选项 `allow_writeable_chroot=YES` 来改变这个设置
|
||||
并且我们要知道,默认情况下,出于安全原因,VSFTPD 不允许 chroot 目录具有可写权限。然而,我们可以通过选项 `allow_writeable_chroot=YES` 来改变这个设置
|
||||
|
||||
保存文件然后关闭。现在我们需要重启 VSFTPD 服务从而使上面的这些更改生效:
|
||||
|
||||
@ -109,15 +109,14 @@ allow_writeable_chroot=YES
|
||||
|
||||
### 第三步:在 Ubuntu 上测试 VsFTP 服务器
|
||||
|
||||
7、现在,我们通过使用下面展示的[ useradd 命令][5]创建一个 FTP 用户来测试 FTP 服务器:
|
||||
7、现在,我们通过使用下面展示的 [useradd 命令][5]创建一个 FTP 用户来测试 FTP 服务器:
|
||||
|
||||
```
|
||||
$ sudo useradd -m -c "Aaron Kili, Contributor" -s /bin/bash aaronkilik
|
||||
$ sudo passwd aaronkilik
|
||||
```
|
||||
|
||||
然后,我们需要像下面这样使用[ echo 命令][6]和 tee 命令来明确地列出文件 `/etc/vsftpd.userlist` 中的用户 aaronkilik:
|
||||
|
||||
然后,我们需要像下面这样使用 [echo 命令][6]和 tee 命令来明确地列出文件 `/etc/vsftpd.userlist` 中的用户 aaronkilik:
|
||||
|
||||
```
|
||||
$ echo "aaronkilik" | sudo tee -a /etc/vsftpd.userlist
|
||||
@ -131,10 +130,10 @@ $ cat /etc/vsftpd.userlist
|
||||
Connected to 192.168.56.102 (192.168.56.102).
|
||||
220 Welcome to TecMint.com FTP service.
|
||||
Name (192.168.56.102:aaronkilik) : anonymous
|
||||
530 权限拒绝.
|
||||
登录失败.
|
||||
530 Permission denied.
|
||||
Login failed.
|
||||
ftp> bye
|
||||
221 再见.
|
||||
221 Goodbye.
|
||||
```
|
||||
|
||||
9、接下来,我们将测试,如果用户的名字没有在文件 `/etc/vsftpd.userlist` 中,是否能够登录。从下面的输出中,我们看到,这是不可以的:
|
||||
@ -144,26 +143,27 @@ ftp> bye
|
||||
Connected to 192.168.56.102 (192.168.56.102).
|
||||
220 Welcome to TecMint.com FTP service.
|
||||
Name (192.168.56.10:root) : user1
|
||||
530 权限拒绝.
|
||||
登录失败.
|
||||
530 Permission denied.
|
||||
Login failed.
|
||||
ftp> bye
|
||||
221 再见.
|
||||
221 Goodbye.
|
||||
```
|
||||
|
||||
10、现在,我们将进行最后一项测试,来确定列在文件 `/etc/vsftpd.userlist` 文件中的用户登录以后,是否进入 home 目录。从下面的输出中可知,是这样的:
|
||||
10、现在,我们将进行最后一项测试,来确定列在文件 `/etc/vsftpd.userlist` 文件中的用户登录以后,是否实际处于 home 目录。从下面的输出中可知,是这样的:
|
||||
|
||||
```
|
||||
# ftp 192.168.56.102
|
||||
Connected to 192.168.56.102 (192.168.56.102).
|
||||
220 Welcome to TecMint.com FTP service.
|
||||
Name (192.168.56.102:aaronkilik) : aaronkilik
|
||||
331 请输入密码.
|
||||
331 Please specify the password.
|
||||
Password:
|
||||
230 登录成功.
|
||||
远程系统类型为 UNIX.
|
||||
使用二进制模式来传输文件.
|
||||
230 Login successful.
|
||||
Remote system type is UNIX.
|
||||
Using binary mode to transfer files.
|
||||
ftp> ls
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][7]
|
||||
@ -192,7 +192,7 @@ $ sudo nano /etc/vsftpd.conf
|
||||
#allow_writeable_chroot=YES
|
||||
```
|
||||
|
||||
接下来,创建一个可供用户选择的本地 root 目录(aaronkilik,你的可能和这不一样),然后,通过取消其他所有用户对此目录的写入权限来设置目录权限:
|
||||
接下来,为用户创建一个替代的本地 root 目录(aaronkilik,你的可能和这不一样),然后设置目录权限,取消其他所有用户对此目录的写入权限:
|
||||
|
||||
```
|
||||
$ sudo mkdir /home/aaronkilik/ftp
|
||||
@ -211,8 +211,8 @@ $ sudo chmod -R 0770 /home/aaronkilik/ftp/files/
|
||||
之后,将 VSFTPD 配置文件中的下面这些选项添加/修改为相应的值:
|
||||
|
||||
```
|
||||
user_sub_token=$USER # inserts the username in the local root directory
|
||||
local_root=/home/$USER/ftp # defines any users local root directory
|
||||
user_sub_token=$USER # 在本地 root 目录中插入用户名
|
||||
local_root=/home/$USER/ftp # 定义各个用户的本地 root 目录
|
||||
```
|
||||
|
||||
保存文件并关闭。然后重启 VSFTPD 服务来使上面的设置生效:
|
||||
@ -231,11 +231,11 @@ local_root=/home/$USER/ftp # defines any users local root directory
|
||||
Connected to 192.168.56.102 (192.168.56.102).
|
||||
220 Welcome to TecMint.com FTP service.
|
||||
Name (192.168.56.10:aaronkilik) : aaronkilik
|
||||
331 请输入密码.
|
||||
331 Please specify the password.
|
||||
Password:
|
||||
230 登录成功.
|
||||
远程系统类型为 UNIX.
|
||||
使用二进制模式来传输文件.
|
||||
230 Login successful.
|
||||
Remote system type is UNIX.
|
||||
Using binary mode to transfer files.
|
||||
ftp> ls
|
||||
```
|
||||
[
|
||||
@ -246,11 +246,10 @@ ftp> ls
|
||||
|
||||
就是这样的!记得通过下面的评论栏来分享你关于这篇指导的想法,或者你也可以提供关于这一话题的任何重要信息。
|
||||
|
||||
最后但不是不重要,请不要错过我的下一篇文章,在下一篇文章中,我将阐述如何[使用 SSL/TLS 来保护连接到 Ubuntu 16.04/16.10 的 FTP 服务器][9],在那之前,请始终关注 TecMint。
|
||||
最后但不是不重要,请不要错过我的下一篇文章,在下一篇文章中,我将阐述如何[使用 SSL/TLS 来保护连接到 Ubuntu 16.04/16.10 的 FTP 服务器][9],在那之前,请始终关注我们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili 是 Linux 和 F.O.S.S 爱好者,即将成为 Linux SysAdmin 和网络开发人员,目前是 TecMint 的内容创作者,他喜欢在电脑上工作,并坚信分享知识。
|
||||
@ -261,7 +260,7 @@ via: http://www.tecmint.com/install-ftp-server-in-ubuntu/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,120 @@
|
||||
如何从 Vim 中访问 shell 或者运行外部命令
|
||||
============================================================
|
||||
|
||||
Vim——正如你可能已经了解的那样——是一个包含很多特性的强大的编辑器。我们已经写了好多关于 Vim 的教程,覆盖了 [基本用法][4]、 [插件][5], 还有一些 [其他的][6] [有用的][7] 特性。鉴于 Vim 提供了多如海洋的特性,我们总能找到一些有用的东西来和我们的读者分享。
|
||||
|
||||
在这篇教程中,我们将会重点关注你如何在编辑窗口执行外部的命令,并且访问命令行 shell。
|
||||
|
||||
但是在我们开始之前,很有必要提醒一下,在这篇教程中提及到的所有例子、命令行和说明,我们已经在 Ubuntu 14.04 上测试过,我们使用的的 Vim 版本是 7.4 。
|
||||
|
||||
### 在 Vim 中执行外部命令
|
||||
|
||||
有的时候,你可能需要在 Vim 编辑窗口中执行外部的命令。例如,想象一下这种场景:你已经在 Vim 中打开了一个文件,并做了一些修改,然后等你尝试保存这些修改的时候,Vim 抛出一个错误说你没有足够的权限。
|
||||
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
现在,退出当前的 vim 会话,重新使用足够的权限打开文件将意味着你会丢失所做的所有修改,所以,你可能赞同,在大多数情况不是只有一个选择。像这样的情况,在编辑器内部运行外部命令的能力将会派上用场。
|
||||
|
||||
稍后我们再回来上面的用例,但是现在,让我们了解下如何在 vim 中运行基本的命令。
|
||||
|
||||
假设你在编辑一个文件,希望知道这个文件包含的行数、单词数和字符数。为了达到这个目的,在 vim 的命令行模式下,只需要输入冒号 `:`,接下来一个感叹号 `!`,最后是要执行的命令(这个例子中使用的是 `wc`)和紧接着的文件名(使用 `%` 表示当前文件)。
|
||||
|
||||
```
|
||||
:! wc %
|
||||
```
|
||||
|
||||
这是一个例子:
|
||||
|
||||
填入的上面提及的命令行准备执行:
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
下面是终端上的输出:
|
||||
|
||||
[
|
||||
|
||||
][10]
|
||||
|
||||
在你看到输出之后,输入回车键,你将会退回到你的 vim 会话中。
|
||||
|
||||
你正在编写代码或者脚本,并且希望尽快知道这段代码或者脚本是否包含编译时错误或者语法错误,这个时候,这种特性真的很方便。
|
||||
|
||||
继续,如果需求是添加输出到文件中,使用 `:read !` 命令。接下来是一个例子:
|
||||
|
||||
```
|
||||
:read ! wc %
|
||||
```
|
||||
|
||||
`read` 命令会把外部命令的输出作为新的一行插入到编辑的文件中的当前行的下面一行。如果你愿意,你也可以指定一个特定的行号——输出将会添加到特定行之后。
|
||||
|
||||
例如,下面的命令将会在文件的第二行之后添加 `wc` 的输出。
|
||||
|
||||
```
|
||||
:2read ! wc %
|
||||
```
|
||||
|
||||
**注意**: 使用 `$` 在最后一行插入, `0` 在第一行前面插入。
|
||||
|
||||
现在,回到最开始我们讨论的一个用例,下面的命令将会帮助你保存文件而不需要先关闭文件(这将意味着没有保存的内容不会丢失)然后使用 [sudo][11] 命令重新打开。
|
||||
|
||||
```
|
||||
:w ! sudo tee %
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
### 在 Vim 中访问 shell
|
||||
|
||||
除了可以执行单独的命令,你也可以在 vim 中放入自己新创建的 shell。为了达到这种目的,在编辑器中你必须要做的是运行以下的命令:
|
||||
|
||||
```
|
||||
:shell
|
||||
```
|
||||
|
||||
或者:
|
||||
|
||||
```
|
||||
:sh
|
||||
```
|
||||
|
||||
当你执行完了你的 shell 任务,输入 `exit` —— 这将带你回到原来离开的 Vim 会话中。
|
||||
|
||||
### 要谨记的漏洞
|
||||
|
||||
虽然在真实世界中,能够访问的 shell 绝对符合它们的用户权限,但是它也可以被用于提权技术。正如我们在早期的一篇文章(在 sudoedit 上)解释的那样,即使你提供给一个用户 `sudo` 的权限只是通过 Vim 编辑一个文件,他们仍可以使用这项技术从编辑器中运行一个新的 shell,而且他们可以做 `root` 用户或者管理员用户可以做的所有内容。
|
||||
|
||||
### 总结
|
||||
|
||||
能够在 Vim 中运行外部命令在好多场景中(有些场景我们已经在这篇文章中提及了)都是一个很有用的特性。这个功能的学习曲线并不麻烦,所以初学者和有经验的用户都可以好好使用它。
|
||||
|
||||
你现在使用这个特性有一段时间了吗?你是否有一些东西想分享呢?请在下面的评论中留下你的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-access-shell-or-run-external-commands-from-within-vim/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[yangmingming](https://github.com/yangmingming)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/how-to-access-shell-or-run-external-commands-from-within-vim/
|
||||
[1]:https://www.howtoforge.com/tutorial/how-to-access-shell-or-run-external-commands-from-within-vim/#execute-external-commands-in-vim
|
||||
[2]:https://www.howtoforge.com/tutorial/how-to-access-shell-or-run-external-commands-from-within-vim/#access-shell-in-vim
|
||||
[3]:https://www.howtoforge.com/tutorial/how-to-access-shell-or-run-external-commands-from-within-vim/#the-loophole-to-keep-in-mind
|
||||
[4]:https://www.howtoforge.com/vim-basics
|
||||
[5]:https://www.howtoforge.com/tutorial/vim-editor-plugins-for-software-developers-3/
|
||||
[6]:https://www.howtoforge.com/tutorial/vim-modeline-settings/
|
||||
[7]:https://www.howtoforge.com/tutorial/vim-editor-modes-explained/
|
||||
[8]:https://www.howtoforge.com/images/how-to-access-shell-or-run-external-commands-from-within-vim/big/vim-perm-error.png
|
||||
[9]:https://www.howtoforge.com/images/how-to-access-shell-or-run-external-commands-from-within-vim/big/vim-count-lines.png
|
||||
[10]:https://www.howtoforge.com/images/how-to-access-shell-or-run-external-commands-from-within-vim/big/vim-wc-output.png
|
||||
[11]:https://www.howtoforge.com/tutorial/sudo-beginners-guide/
|
||||
[12]:https://www.howtoforge.com/images/how-to-access-shell-or-run-external-commands-from-within-vim/big/vim-sudo-passwrd.png
|
||||
@ -1,98 +1,92 @@
|
||||
LaTeXila 简介 - Linux 下一个多语言 LaTeX 编辑器
|
||||
LaTeXila 简介:Linux 上的一个多语言 LaTeX 编辑器
|
||||
============================================================
|
||||
|
||||
### 在本文中你将看到
|
||||
|
||||
1. [为何选择使用 LaTeX?][1]
|
||||
2. [创建新文档并设定文档的基本结构][2]
|
||||
3. [LaTeXila 简单易用,公式齐全][3]
|
||||
4. [将 .tex 文件转换为 .rtf 文件][4]
|
||||
5. [结论][5]
|
||||
|
||||
LaTeXila 是一个多语言 LaTeX 编辑器,专为那些偏爱 GTK+ 外观的 Linux 用户设计。这个软件简单,但有足够强大,可定制性良好,所以如果你对 LaTeX 感兴趣,那么你就应该尝试一下这个工具。在下面的快速指南中,我将展示如何使用 LaTeXila 并介绍其主要功能。但在开始之前你可能要问:
|
||||
LaTeXila 是一个多语言 LaTeX 编辑器,专为那些偏爱 GTK+ 外观的 Linux 用户设计。这个软件简单,但又足够强大,可定制性良好,所以如果你对 LaTeX 感兴趣,那么你就应该尝试一下这个工具。在下面的快速指南中,我将展示如何使用 LaTeXila 并介绍其主要功能。但在开始之前你可能要问:
|
||||
|
||||
### 为何选择使用 LaTeX?
|
||||
|
||||
假如我想创建一个文本文档,为什么我不使用 LibreOffice 或者 Abiword 这些常规的工具呢?这个问题的答案是相比于常规的文本编辑器,LaTeX 编辑器一般来说都会提供更多功能强大的格式化工具,让你在写作期间专注于文档的内容。LaTeX 是一个文档准备系统,实际上这意味着它简化了大多数常见出版物的处理过程,这些出版物包括书籍或者科学报告,它们通常都包含很多数学公式,多语言排版元素,交叉引用及引文,参考文献等等需要处理的元素。尽管上面的那些元素也可以用 LibreOffice 来处理,但如果要保证最后处理过的文档是高质量的,相比于使用 LibreOffice,使用 LaTeXila 则要相对简单一些。
|
||||
假如我想创建一个文本文档,为什么我不使用 LibreOffice 或者 Abiword 这些常规的工具呢?原因是相比于常规的文本编辑器,LaTeX 编辑器一般来说都会提供更多功能强大的格式化工具,让你在写作期间专注于文档的内容。LaTeX 是一个文档准备系统,目的是简化大多数常见出版物的处理过程,例如书籍或者科学报告,它们通常都包含很多数学公式,多语言排版元素,交叉引用及引文,参考文献等等需要处理的元素。尽管上面的那些元素也可以用 LibreOffice 来处理,使用 LaTeXila 要相对简单一些,同时处理得当的话你最后得到的会是一份高质量的文档。
|
||||
|
||||
### 在一个新文档上开始工作并设定文章结构
|
||||
|
||||
首先,我们需要在 LaTeXila 中创建一个新文件,这个可以通过点击位于左上角的 “新建文件” 图标来实现,接着它将打开一个对话框,让我们选择一个模板从而快速地开始写作。
|
||||
|
||||
[
|
||||
|
||||
|
||||
][6]
|
||||
|
||||
在这里假设我将写一本书,所以我应该选择书籍模板,像下面的截图那样在相应的括号中添上标题和作者:
|
||||
在这里假设我将写一本书,所以我选择一个书籍模板,像下面的截图那样在相应的括号中添上标题和作者:
|
||||
|
||||
[
|
||||
|
||||
|
||||
][7]
|
||||
|
||||
现在就让我来解释一些关于文章结构的事情。我知道这看起来就像编代码,如若你是一位作家而非程序员,那么像下面那样工作或许很是奇怪,但请先容我讲完,下面我将对此进行解释。
|
||||
现在就让我来解释一些关于文章结构的事情。我知道这看起来就像编代码,如果你是一位作家而非程序员,那么像下面那样工作或许很是奇怪,但请先容我讲完,我将对此进行解释。
|
||||
|
||||
在第一行和第九行之间,我们已经写好了书写整个文档所需的所有基本要素。例如在第一行中,我们可以通过修改“[a4paper,11pt]”来定义纸张和字体的大小,在这个方括号中,我们可以添加更多的选项,选项之间以逗号来分隔。
|
||||
在第一行和第九行之间,我们已经写好了书写整个文档所需的所有基本要素。例如在第一行中,我们可以通过修改 `[a4paper,11pt]` 来定义纸张和字体的大小,在这个方括号中,我们可以添加更多的选项,选项之间以英文逗号来分隔。
|
||||
|
||||
在第二行和第四行之间,我们可以看到一些条目,它们都以“\userpackage”打头,紧接着的是用方括号包裹的选项和用括号包裹的命令。这些命令都是一些增强宏包,LaTeXila 默认已经安装它们到我们的系统上了,并且在大多数模板中都将使用它们。需要特别注意的是字体编码,字符编码和字体的类型。
|
||||
在第二行和第四行之间,我们可以看到一些条目,它们都以 `\userpackage` 打头,紧接着的是用方括号包裹的选项和用括号包裹的命令。这些命令都是一些增强宏包,LaTeXila 默认已经安装它们到我们的系统上了,并且在大多数模板中都将使用它们。需要特别注意的是字体编码,字符编码和字体的类型。
|
||||
|
||||
紧着让我们看看 "\maketitle" 这一行,这里我们可以添加一个单独的标题页,且默认情况下标题的内容将被放置在第一页的顶部。类似的,包含“\tableofcontents”的那行将会自动生成书籍的目录。
|
||||
紧接着让我们看看 `\maketitle` 这一行,这里我们可以添加一个单独的标题页,且默认情况下标题的内容将被放置在第一页的顶部。类似的,包含 `\tableofcontents` 的那行将会自动生成书籍的目录。
|
||||
|
||||
最后,我们可以自己命名章节的名称,这可以通过在“\chapter”后的括号中添加章节名称来实现。第一个章节将会被自动地标记为第一章。你可以在接下来的行中添加内容,一直到下一个以 "\chapter" 开头的新行为止,这些都将是这个章节的内容。新的章节将会被自动地标记为第二章,以此类推。
|
||||
最后,我们可以自己命名章节的名称,这可以通过在 `\chapter` 后的括号中添加章节名称来实现。第一个章节将会被自动地标记为第一章。你可以在接下来的行中添加内容,一直到下一个以 `\chapter` 开头的新行为止,这些都将是这个章节的内容。新的章节将会被自动地标记为第二章,以此类推。
|
||||
|
||||
[
|
||||
|
||||
|
||||
][8]
|
||||
|
||||
章节之间还可以用命令“\section”来划分为更小的块,甚至还可以使用“\subsection”来划分为更小的部分。各个小节和章都将被“\tableofcontents”自动检测到,并将使用它们的标题和页码来填充目录的内容。看看下面的截图就可以看到章和小节是如何在你的书中被排版的。
|
||||
章节之间还可以用命令 `\section` 来划分为更小的块,甚至还可以使用 `\subsection` 来划分为更小的部分。各个小节和章都将被 `\tableofcontents` 自动检测到,并将使用它们的标题和页码来填充目录的内容。看看下面的截图就可以看到章和小节是如何在你的书中被排版的。
|
||||
|
||||
[
|
||||
|
||||
|
||||
][9]
|
||||
|
||||
假如你想看看结构的大致布局,你可以将左边的工具栏更换到“结构”选项,并确保所有的内容用缩进隔开了。在工具栏中,你还可以可能控制位于各个小节中的任意数据表格和图片。
|
||||
假如你想浏览结构,你可以将左边的工具栏更换到<ruby>“结构”<rt>Structure</rt></ruby>选项,并确保所有的结构与预期相符。在这里,你还可以控制各小节中的任意数据表格和图片。
|
||||
|
||||
[
|
||||
|
||||
|
||||
][10]
|
||||
|
||||
讲到这里,有人或许想将表格和图片的位置也包含在目录中。要达到此目的,你需要将下面的两行添加到“\tableofcontents” 之后:
|
||||
讲到这里,有人或许想将表格和图片的位置也包含在目录中。要达到此目的,你需要将下面的两行添加到 `\tableofcontents` 之后:
|
||||
|
||||
```
|
||||
\listoffigures
|
||||
\listoftables
|
||||
```
|
||||
|
||||
最后标志着书籍结束的信号是“\end{document}”。所以你的布局应该总是以此为结尾。
|
||||
最后标志着书籍结束的信号是 `\end{document}`。你的布局应该总是以此为结尾。
|
||||
|
||||
### LaTeXila 简单易用,公式齐全
|
||||
|
||||
LaTeX 是一个基于命令的文档生成系统,它与使用的编辑器没有多少关联。这里需要强调的是 LaTeXila 提供了一系列强大的工具,使得在你书写报告或书籍时能够节省一些时间和精力。例如对于 LaTex 命令,它提供了自动补全功能,这个功能将在你每次开始输入命令时被激活。
|
||||
|
||||
[
|
||||
|
||||
|
||||
][11]
|
||||
|
||||
LaTeXila 还集成有基于 gspell 的拼写检测系统,你可以在最上面的“工具”菜单中设定合适的语言。最上面的工具栏里几乎包含了你要用到的所有按钮。从左到右,你可以完成添加章节,交叉引用,调整字符的大小,格式化被选取的部分,添加无序列表和数学函数等等。这些都可以手动地输入,但通过点击相应按钮来完成或许更加方便。
|
||||
|
||||
对于生成数学公式,结合侧边栏上的工具栏选项,你只需轻轻一点就可以添加相应的数学符号。点击位于左边的侧边栏中“符号”框,你就可以看到相关的符号分类,例如”关系运算符“,”希腊字母“,”算子“等等。下面的截图就是一些符号的示例:
|
||||
对于生成数学公式,结合侧边栏上的工具栏选项,你只需轻轻一点就可以添加相应的数学符号。点击位于左边的侧边栏中<ruby>“符号”<rt>Symbols</rt></ruby>框,你就可以看到相关的符号分类,例如“关系运算符”,“希腊字母”,“运算符”等等。下面的截图就是一些符号的示例:
|
||||
|
||||
[
|
||||
|
||||
|
||||
][12]
|
||||
|
||||
这些符号的图形化列表使得公式和数学表达式的生成犹如在公园中散步那样舒适。
|
||||
|
||||
### 将 .tex 文件转换为 .rtf 文件
|
||||
|
||||
默认情况下,LaTeXila 会将你的文档保存为标准的 `.tex` 文档,而我们可以使用 `.tex` 文档来生成一个”富文本“文档,这些富文本文档可以使用像 LibreOffice 那样的文本编辑器打开。要达到此目的,我们需要安装一个名为 `latex2rtf` 的工具,它在所有的 Linux 发行版本中都可以被获取到。像下面那样在文本所在的目录打开虚拟终端, 并输入 `latex2rtf 文件名称` :
|
||||
默认情况下,LaTeXila 会将你的文档保存为标准的 `.tex` 文档,而我们可以使用 `.tex` 文档来生成一个<ruby>“富文本”<rt>rich text format</rt></ruby>文档,这些富文本文档可以使用像 LibreOffice 那样的文本编辑器打开。要达到此目的,我们需要安装一个名为 `latex2rtf` 的工具,它在所有的 Linux 发行版本中都可以被获取到。在文本所在的目录打开虚拟终端, 并输入 `latex2rtf 文件名称`,如下所示 :
|
||||
|
||||
[
|
||||
|
||||
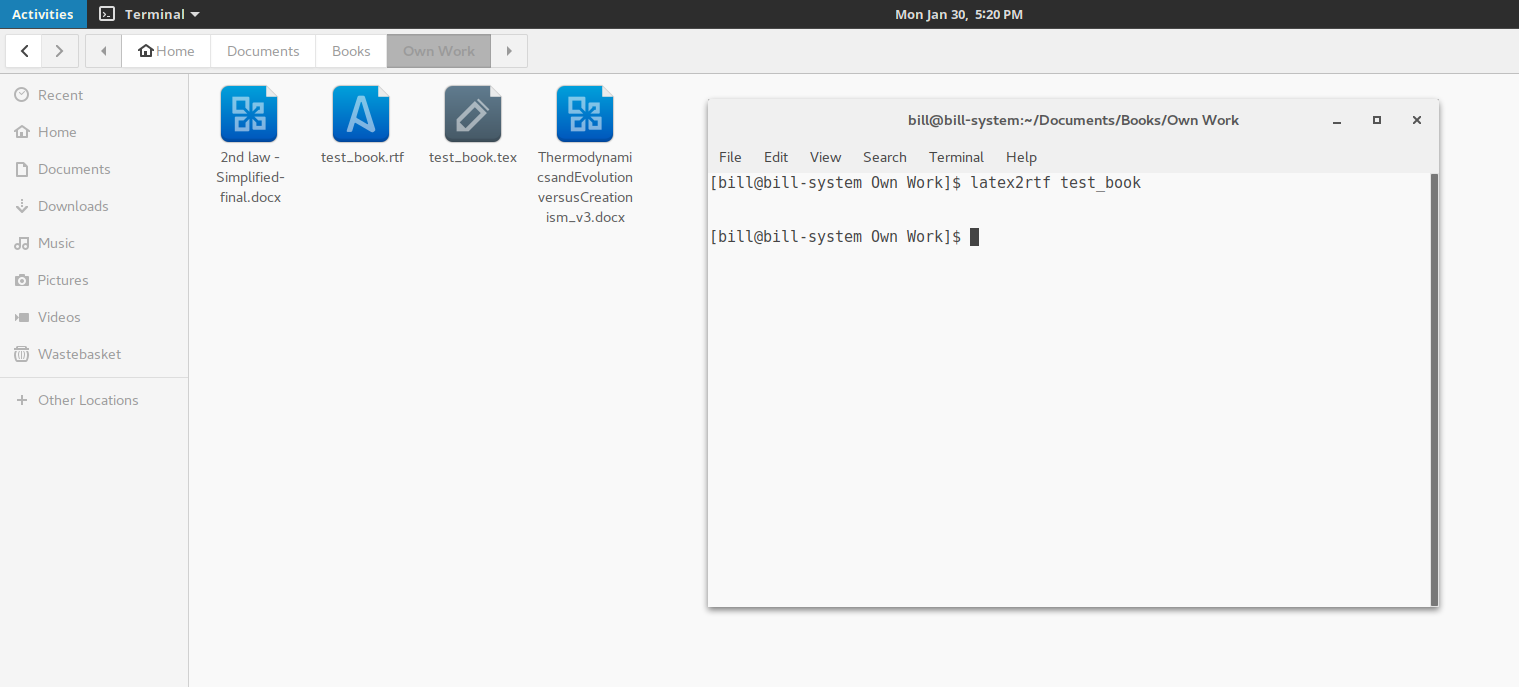
|
||||
][13]
|
||||
|
||||
当然 LLaTeXila 也提供了它自己的构建工具,这些工具可以在上面的工具栏或者最上面的面板(构建)中看到。但我向你推荐 latex2rtf 是以防在其他的操作系统上出现某些意想不到的问题。
|
||||
当然 LaTeXila 也提供了它自己的构建工具,这些工具可以在上面的工具栏或者最上面的面板(构建)中看到。但我向你推荐 latex2rtf 是以防它们在其他的操作系统上出现某些意想不到的问题,比如在我的系统上就不能正常工作。
|
||||
|
||||
### 结论
|
||||
|
||||
假如上面的介绍激发了你探索 LaTeX 的兴趣,那就再好不过了。我写这篇文章的目的是向新手介绍一款简单易用且适合他们写作的工具。要是 LaTeXila 还带有实时预览的双屏模式的话,它就更加完美了。。。
|
||||
假如上面的介绍激发了你探索 LaTeX 的兴趣,那就再好不过了。我写这篇文章的目的是向新手介绍一款简单易用且适合他们写作的工具。要是 LaTeXila 还带有实时预览的双屏模式的话,它就更加完美了...
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -100,7 +94,7 @@ via: https://www.howtoforge.com/tutorial/introduction-to-latexila-latex-editor/
|
||||
|
||||
作者:[Bill Toulas][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,139 @@
|
||||
如何在 Amazon AWS 上设置一台 Linux 服务器
|
||||
============================================================
|
||||
|
||||
AWS(Amazon Web Services)是全球领先的云服务器提供商之一。你可以使用 AWS 平台在一分钟内设置完服务器。在 AWS 上,你可以微调服务器的许多技术细节,如 CPU 数量,内存和磁盘空间,磁盘类型(更快的 SSD 或者经典的 IDE)等。关于 AWS 最好的一点是,你只需要为你使用到的服务付费。在开始之前,AWS 提供了一个名为 “Free Tier” 的特殊帐户,你可以免费使用一年的 AWS 技术服务,但会有一些小限制,例如,你每个月使用服务器时长不能超过 750 小时,超过这个他们就会向你收费。你可以在 [aws 官网][3]上查看所有相关的规则。
|
||||
|
||||
因为我的这篇文章是关于在 AWS 上创建 Linux 服务器,因此拥有 “Free Tier” 帐户是先决条件。要注册帐户,你可以使用此[链接][4]。请注意,你需要在创建帐户时输入信用卡详细信息。
|
||||
|
||||
让我们假设你已经创建了 “Free Tier” 帐户。
|
||||
|
||||
在继续之前,你必须了解 AWS 中的一些术语以了解设置:
|
||||
|
||||
1. EC2(弹性计算云):此术语用于虚拟机。
|
||||
2. AMI(Amazon 机器镜像):表示操作系统实例。
|
||||
3. EBS(弹性块存储):AWS 中的一种存储环境类型。
|
||||
|
||||
通过以下链接登录 AWS 控制台:[https://console.aws.amazon.com/][5] 。
|
||||
|
||||
AWS 控制台将如下所示:
|
||||
|
||||
[
|
||||
|
||||
][6]
|
||||
|
||||
### 在 AWS 中设置 Linux VM
|
||||
|
||||
1、 创建一个 EC2(虚拟机)实例:在开始安装系统之前,你必须在 AWS 中创建一台虚拟机。要创建虚拟机,在“<ruby>计算<rt>compute</rt></ruby>”菜单下点击 EC2:
|
||||
|
||||
[
|
||||
|
||||
][7]
|
||||
|
||||
2、 现在在<ruby>创建实例<rt>Create instance</rt></ruby>下点击<ruby>“启动实例”<rt>Launch Instance</rt></ruby>按钮。
|
||||
|
||||
[
|
||||
|
||||
][8]
|
||||
|
||||
3、 现在,当你使用的是一个 “Free Tier” 帐号,接着最好选择 “Free Tier” 单选按钮以便 AWS 可以过滤出可以免费使用的实例。这可以让你不用为使用 AWS 的资源而付费。
|
||||
|
||||
[
|
||||
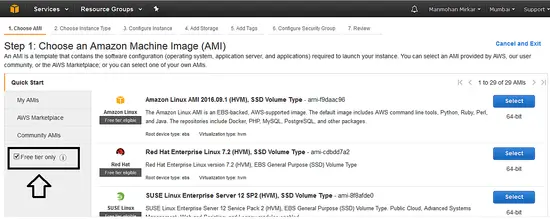
|
||||
][9]
|
||||
|
||||
4、 要继续操作,请选择以下选项:
|
||||
|
||||
a、 在经典实例向导中选择一个 AMI(Amazon Machine Image),然后选择使用 **Red Hat Enterprise Linux 7.2(HVM),SSD 存储**
|
||||
|
||||
b、 选择 “**t2.micro**” 作为实例详细信息。
|
||||
|
||||
c、 **配置实例详细信息**:不要更改任何内容,只需单击下一步。
|
||||
|
||||
d、 **添加存储**:不要更改任何内容,只需点击下一步,因为此时我们将使用默认的 10(GiB)硬盘。
|
||||
|
||||
e、 **添加标签**:不要更改任何内容只需点击下一步。
|
||||
|
||||
f、 **配置安全组**:现在选择用于 ssh 的 22 端口,以便你可以在任何地方访问此服务器。
|
||||
|
||||
[
|
||||
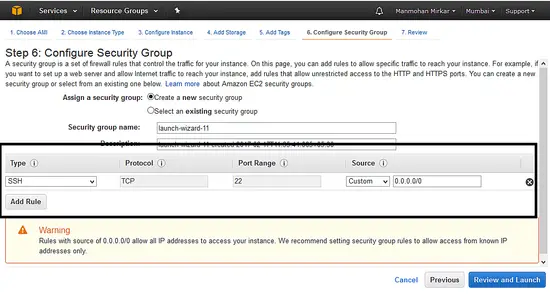
|
||||
][10]
|
||||
|
||||
g、 选择“<ruby>查看并启动<rt>Review and Launch</rt></ruby>”按钮。
|
||||
|
||||
h、 如果所有的详情都无误,点击 “<ruby>启动<rt>Launch</rt></ruby>”按钮。
|
||||
|
||||
i、 单击“<ruby>启动<rt>Launch</rt></ruby>”按钮后,系统会像下面那样弹出一个窗口以创建“密钥对”:选择选项“<ruby>创建密钥对<rt>create a new key pair</rt></ruby>”,并给密钥对起个名字,然后下载下来。在使用 ssh 连接到服务器时,需要此密钥对。最后,单击“<ruby>启动实例<rt>Launch Instance</rt></ruby>”按钮。
|
||||
|
||||
[
|
||||
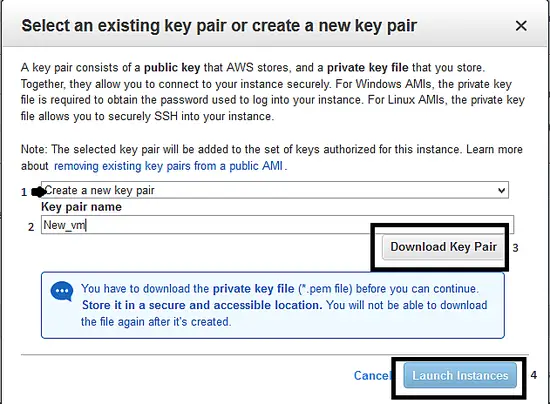
|
||||
][11]
|
||||
|
||||
j、 点击“<ruby>启动实例<rt>Launch Instance</rt></ruby>”按钮后,转到左上角的服务。选择“<ruby>计算<rt>compute</rt></ruby>”--> “EC2”。现在点击“<ruby>运行实例<rt>Running Instances</rt></ruby>”:
|
||||
|
||||
[
|
||||
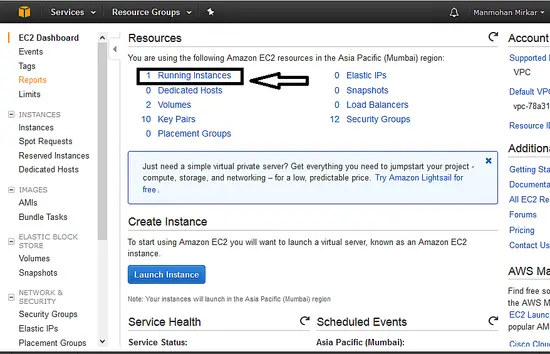
|
||||
][12]
|
||||
|
||||
k、 现在你可以看到,你的新 VM 的状态是 “<ruby>运行中<rt>running</rt></ruby>”。选择实例,请记下登录到服务器所需的 “<ruby>公开 DNS 名称<rt>Public DNS</rt></ruby>”。
|
||||
|
||||
[
|
||||
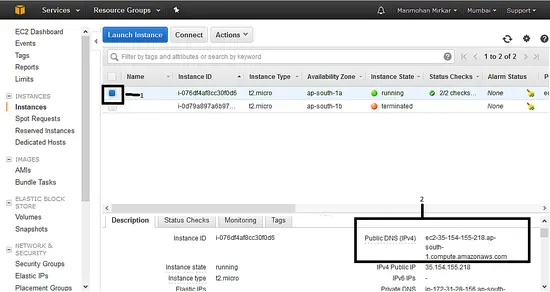
|
||||
][13]
|
||||
|
||||
现在你已完成创建一台运行 Linux 的 VM。要连接到服务器,请按照以下步骤操作。
|
||||
|
||||
### 从 Windows 中连接到 EC2 实例
|
||||
|
||||
1、 首先,你需要有 putty gen 和 Putty exe 用于从 Windows 连接到服务器(或 Linux 上的 SSH 命令)。你可以通过下面的[链接][14]下载 putty。
|
||||
|
||||
2、 现在打开 putty gen :`puttygen.exe`。
|
||||
|
||||
3、 你需要单击 “Load” 按钮,浏览并选择你从亚马逊上面下载的密钥对文件(pem 文件)。
|
||||
|
||||
4、 你需要选择 “ssh2-RSA” 选项,然后单击保存私钥按钮。请在下一个弹出窗口中选择 “yes”。
|
||||
|
||||
5、 将文件以扩展名 `.ppk` 保存。
|
||||
|
||||
6、 现在你需要打开 `putty.exe`。在左侧菜单中点击 “connect”,然后选择 “SSH”,然后选择 “Auth”。你需要单击浏览按钮来选择我们在步骤 4 中创建的 .ppk 文件。
|
||||
|
||||
7、 现在点击 “session” 菜单,并在“host name” 中粘贴在本教程中 “k” 步骤中的 DNS 值,然后点击 “open” 按钮。
|
||||
|
||||
8、 在要求用户名和密码时,输入 `ec2-user` 和空白密码,然后输入下面的命令。
|
||||
|
||||
```
|
||||
$ sudo su -
|
||||
```
|
||||
|
||||
哈哈,你现在是在 AWS 云上托管的 Linux 服务器上的主人啦。
|
||||
|
||||
[
|
||||
|
||||
][15]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-setup-linux-server-with-aws/
|
||||
|
||||
作者:[MANMOHAN MIRKAR][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/how-to-setup-linux-server-with-aws/
|
||||
[1]:https://www.howtoforge.com/tutorial/how-to-setup-linux-server-with-aws/#setup-a-linux-vm-in-aws
|
||||
[2]:https://www.howtoforge.com/tutorial/how-to-setup-linux-server-with-aws/#connect-to-an-ec-instance-from-windows
|
||||
[3]:http://aws.amazon.com/free/
|
||||
[4]:http://aws.amazon.com/ec2/
|
||||
[5]:https://console.aws.amazon.com/
|
||||
[6]:https://www.howtoforge.com/images/how_to_setup_linux_server_with_aws/big/aws_console.JPG
|
||||
[7]:https://www.howtoforge.com/images/how_to_setup_linux_server_with_aws/big/aws_console_ec21.png
|
||||
[8]:https://www.howtoforge.com/images/how_to_setup_linux_server_with_aws/big/aws_launch_ec2.png
|
||||
[9]:https://www.howtoforge.com/images/how_to_setup_linux_server_with_aws/big/aws_free_tier_radio1.png
|
||||
[10]:https://www.howtoforge.com/images/how_to_setup_linux_server_with_aws/big/aws_ssh_port1.png
|
||||
[11]:https://www.howtoforge.com/images/how_to_setup_linux_server_with_aws/big/aws_key_pair.png
|
||||
[12]:https://www.howtoforge.com/images/how_to_setup_linux_server_with_aws/big/aws_running_instance.png
|
||||
[13]:https://www.howtoforge.com/images/how_to_setup_linux_server_with_aws/big/aws_dns_value.png
|
||||
[14]:http://www.chiark.greenend.org.uk/~sgtatham/putty/latest.html
|
||||
[15]:https://www.howtoforge.com/images/how_to_setup_linux_server_with_aws/big/aws_putty1.JPG
|
||||
@ -0,0 +1,150 @@
|
||||
如何在 CentOS 7 上安装和安全配置 MariaDB 10
|
||||
===========================================
|
||||
|
||||
**MariaDB** 是 MySQL 数据库的自由开源分支,与 MySQL 在设计思想上同出一源,在未来仍将是自由且开源的。
|
||||
|
||||
在这篇博文中,我将会介绍如何在当前使用最广的 RHEL/CentOS 和 Fedora 发行版上安装 **MariaDB 10.1** 稳定版。
|
||||
|
||||
目前了解到的情况是:Red Hat Enterprise Linux/CentOS 7.0 发行版已将默认的数据库从 MySQL 切换到 MariaDB。
|
||||
|
||||
在本文中需要注意的是,我们假定您能够在服务器中使用 root 帐号工作,或者可以使用 [sudo][7] 命令运行任何命令。
|
||||
|
||||
### 第一步:添加 MariaDB yum 仓库
|
||||
|
||||
1、首先在 RHEL/CentOS 和 Fedora 操作系统中添加 MariaDB 的 YUM 配置文件 `MariaDB.repo` 文件。
|
||||
|
||||
```
|
||||
# vi /etc/yum.repos.d/MariaDB.repo
|
||||
```
|
||||
|
||||
根据您操作系统版本,选择下面的相应内容添加到文件的末尾。
|
||||
|
||||
#### 在 CentOS 7 中安装
|
||||
|
||||
```
|
||||
[mariadb]
|
||||
name = MariaDB
|
||||
baseurl = http://yum.mariadb.org/10.1/centos7-amd64
|
||||
gpgkey=https://yum.mariadb.org/RPM-GPG-KEY-MariaDB
|
||||
gpgcheck=1
|
||||
```
|
||||
|
||||
#### 在 RHEL 7 中安装
|
||||
|
||||
```
|
||||
[mariadb]
|
||||
name = MariaDB
|
||||
baseurl = http://yum.mariadb.org/10.1/rhel7-amd64
|
||||
gpgkey=https://yum.mariadb.org/RPM-GPG-KEY-MariaDB
|
||||
gpgcheck=1
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
*添加 MariaDB YUM 仓库*
|
||||
|
||||
### 第二步:在 CentOS 7 中安装 MariaDB
|
||||
|
||||
2、当 MariaDB 仓库地址添加好后,你可以通过下面的一行命令轻松安装 MariaDB。
|
||||
|
||||
```
|
||||
# yum install MariaDB-server MariaDB-client -y
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
*在 CentOS 7 中安装 MariaDB*
|
||||
|
||||
3、 MariaDB 包安装完毕后,立即启动数据库服务守护进程,并可以通过下面的操作设置,在操作系统重启后自动启动服务。
|
||||
|
||||
```
|
||||
# systemctl start mariadb
|
||||
# systemctl enable mariadb
|
||||
# systemctl status mariadb
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
*在 CentOS 7 中启动 MariaDB 服务*
|
||||
|
||||
### 第三步:在 CentOS 7 中对 MariaDB 进行安全配置
|
||||
|
||||
4、 现在可以通过以下操作进行安全配置:设置 MariaDB 的 root 账户密码,禁用 root 远程登录,删除测试数据库以及测试帐号,最后需要使用下面的命令重新加载权限。
|
||||
|
||||
```
|
||||
# mysql_secure_installation
|
||||
```
|
||||
[
|
||||

|
||||
][11]
|
||||
|
||||
*CentOS 7 中的 MySQL 安全配置*
|
||||
|
||||
5、 在配置完数据库的安全配置后,你可能想检查下 MariaDB 的特性,比如:版本号、默认参数列表、以及通过 MariaDB 命令行登录。如下所示:
|
||||
|
||||
```
|
||||
# mysql -V
|
||||
# mysqld --print-defaults
|
||||
# mysql -u root -p
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
*检查 MySQL 版本信息*
|
||||
|
||||
### 第四步:学习 MariaDB 管理
|
||||
|
||||
如果你刚开始学习使用 MySQL/MariaDB,可以通过以下指南学习:
|
||||
|
||||
1. [新手学习 MySQL / MariaDB(一)][1]
|
||||
2. [新手学习 MySQL / MariaDB(二)][2]
|
||||
3. [MySQL 数据库基础管理命令(三)][3]
|
||||
4. [20 MySQL 管理命令 Mysqladmin(四)][4]
|
||||
|
||||
同样查看下面的文档学习如何优化你的 MySQL/MariaDB 服务,并使用工具监控数据库的活动情况。
|
||||
|
||||
1. [15 个 MySQL/MariaDB 调优技巧][5]
|
||||
2. [4 监控 MySQL/MariaDB 数据库的工具][6]
|
||||
|
||||
文章到此就结束了,本文内容比较浅显,文中主要展示了如何在 RHEL/CentOS 和 Fefora 操作系统中安装 **MariaDB 10.1** 稳定版。您可以通过下面的联系方式将您遇到的任何问题或者想法发给我们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
Aaron Kill 是 Linux 和开源软件的狂热爱好者,即将成为一名 Linux 系统管理员和网站开发工程师,现在是 TecMint 的原创作者,喜欢使用电脑工作并且热衷分享知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-mariadb-in-centos-7/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[beyondworld](https://github.com/beyondworld)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
|
||||
[1]:http://www.tecmint.com/learn-mysql-mariadb-for-beginners/
|
||||
[2]:http://www.tecmint.com/learn-mysql-mariadb-advance-functions-sql-queries/
|
||||
[3]:http://www.tecmint.com/gliding-through-database-mysql-in-a-nutshell-part-i/
|
||||
[4]:http://www.tecmint.com/mysqladmin-commands-for-database-administration-in-linux/
|
||||
[5]:http://www.tecmint.com/mysql-mariadb-performance-tuning-and-optimization/
|
||||
[6]:http://www.tecmint.com/mysql-performance-monitoring/
|
||||
[7]:http://www.tecmint.com/sudoers-configurations-for-setting-sudo-in-linux/
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2017/02/Add-MariaDB-Repo.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2017/02/Install-MariaDB-in-CentOS-7.png
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2017/02/Start-MariaDB-Service-in-CentOS-7.png
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2017/02/Secure-MySQL-in-CentOS-7.png
|
||||
[12]:http://www.tecmint.com/wp-content/uploads/2017/02/Verify-MySQL-Version.png
|
||||
[13]:http://www.tecmint.com/author/aaronkili/
|
||||
[14]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[15]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -0,0 +1,173 @@
|
||||
如何在 CentOS 7 中安装或升级最新的内核
|
||||
============================================================
|
||||
|
||||
虽然有些人使用 Linux 来表示整个操作系统,但要注意的是,严格地来说,Linux 只是个内核。另一方面,发行版是一个完整功能的系统,它建立在内核之上,具有各种各样的应用程序工具和库。
|
||||
|
||||
在正常操作期间,内核负责执行两个重要任务:
|
||||
|
||||
1. 作为硬件和系统上运行的软件之间的接口。
|
||||
2. 尽可能高效地管理系统资源。
|
||||
|
||||
为此,内核通过内置的驱动程序或以后可作为模块安装的驱动程序与硬件通信。
|
||||
|
||||
例如,当你计算机上运行的程序想要连接到无线网络时,它会将该请求提交给内核,后者又会使用正确的驱动程序连接到网络。
|
||||
|
||||
- **建议阅读:** [如何在 Ubuntu 中升级内核][1]
|
||||
|
||||
随着新的设备和技术定期出来,如果我们想充分利用它们,保持最新的内核就很重要。此外,更新内核将帮助我们利用新的内核函数,并保护自己免受先前版本中发现的漏洞的攻击。
|
||||
|
||||
准备好了在 CentOS 7 或其衍生产品(如 RHEL 7和 Fedora)上更新内核了么?如果是这样,请继续阅读!
|
||||
|
||||
### 步骤 1:检查已安装的内核版本
|
||||
|
||||
让我们安装了一个发行版,它包含了一个特定版本的内核。为了展示当前系统中已安装的版本,我们可以:
|
||||
|
||||
```
|
||||
# uname -sr
|
||||
```
|
||||
|
||||
下面的图片展示了在一台 CentOS 7 服务器上的输出信息:
|
||||
|
||||
[
|
||||
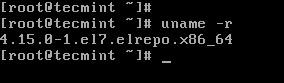
|
||||
][2]
|
||||
|
||||
*在 CentOS 7 上检查内核版本*
|
||||
|
||||
如果我们现在进入 [https://www.kernel.org/][3],在撰写本文时,我们看到最新的内核版本是4.10.1(其他版本可以从同一网站获得)。
|
||||
|
||||
还要考虑的一个重要的事情是内核版本的生命周期 - 如果你当前使用的版本接近它的生命周期结束,那么在该日期后将不会提供更多的 bug 修复。关于更多信息,请参阅[内核发布][4]页。
|
||||
|
||||
### 步骤 2:在 CentOS 7 中升级内核
|
||||
|
||||
大多数现代发行版提供了一种使用 [yum 等包管理系统][5]和官方支持的仓库升级内核的方法。
|
||||
|
||||
但是,这只会升级内核到仓库中可用的最新版本 - 而不是在 [https://www.kernel.org/][6] 中可用的最新版本。不幸的是,Red Hat 只允许使用前者升级内核。
|
||||
|
||||
与 Red Hat 不同,CentOS 允许使用 ELRepo,这是一个第三方仓库,可以将内核升级到最新版本。
|
||||
|
||||
要在 CentOS 7 上启用 ELRepo 仓库,请运行:
|
||||
|
||||
```
|
||||
# rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
|
||||
# rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-2.el7.elrepo.noarch.rpm
|
||||
```
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
*在 CentOS 7 启用 ELRepo*
|
||||
|
||||
仓库启用后,你可以使用下面的命令列出可用的内核相关包:
|
||||
|
||||
```
|
||||
# yum --disablerepo="*" --enablerepo="elrepo-kernel" list available
|
||||
```
|
||||
[
|
||||
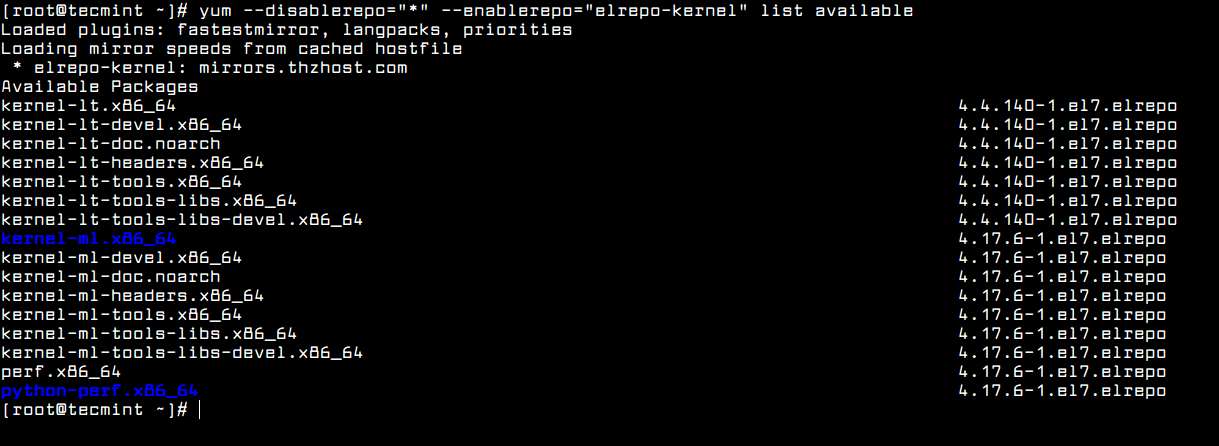
|
||||
][8]
|
||||
|
||||
*yum - 找出可用的内核版本*
|
||||
|
||||
接下来,安装最新的主线稳定内核:
|
||||
|
||||
```
|
||||
# yum --enablerepo=elrepo-kernel install kernel-ml
|
||||
```
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
*在 CentOS 7 中安装最新的内核版本*
|
||||
|
||||
最后,重启机器并应用最新内核,接着运行下面的命令检查最新内核版本:
|
||||
|
||||
```
|
||||
uname -sr
|
||||
```
|
||||
[
|
||||
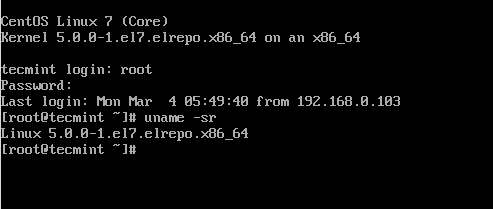
|
||||
][10]
|
||||
|
||||
*验证内核版本*
|
||||
|
||||
### 步骤 3:设置 GRUB 默认的内核版本
|
||||
|
||||
为了让新安装的内核成为默认启动选项,你需要如下修改 GRUB 配置:
|
||||
|
||||
打开并编辑 `/etc/default/grub` 并设置 `GRUB_DEFAULT=0`。意思是 GRUB 初始化页面的第一个内核将作为默认内核。
|
||||
|
||||
```
|
||||
GRUB_TIMEOUT=5
|
||||
GRUB_DEFAULT=0
|
||||
GRUB_DISABLE_SUBMENU=true
|
||||
GRUB_TERMINAL_OUTPUT="console"
|
||||
GRUB_CMDLINE_LINUX="rd.lvm.lv=centos/root rd.lvm.lv=centos/swap crashkernel=auto rhgb quiet"
|
||||
GRUB_DISABLE_RECOVERY="true"
|
||||
```
|
||||
|
||||
接下来运行下面的命令来重新创建内核配置。
|
||||
|
||||
```
|
||||
# grub2-mkconfig -o /boot/grub2/grub.cfg
|
||||
```
|
||||
[
|
||||
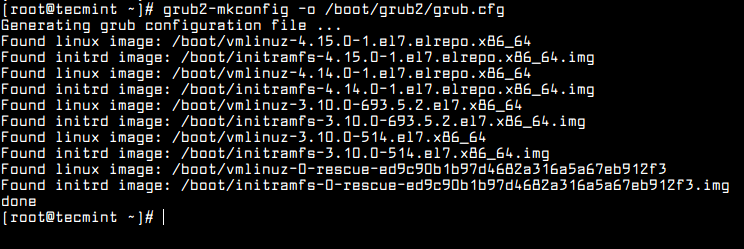
|
||||
][11]
|
||||
|
||||
*在 GRUB 中设置内核*
|
||||
|
||||
重启并验证最新的内核已作为默认内核。
|
||||
|
||||
[
|
||||
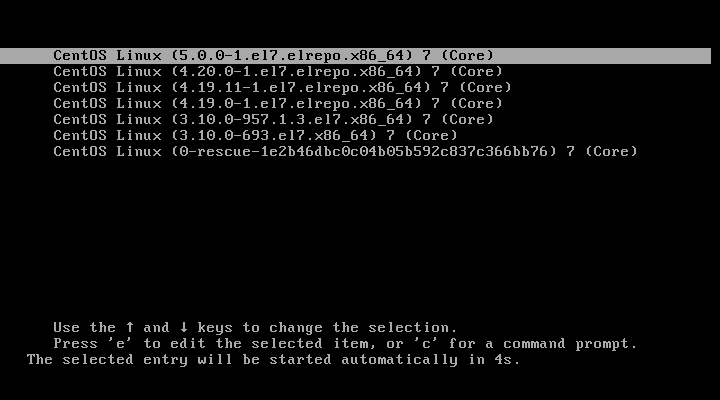
|
||||
][12]
|
||||
|
||||
在 CentOS 7 中启动默认内核版本
|
||||
|
||||
恭喜你!你已经在 CentOS 7 中升级内核了!
|
||||
|
||||
##### 总结
|
||||
|
||||
在本文中,我们解释了如何轻松升级系统上的 Linux 内核。我们还没讲到另外一个方法,因为它涉及从源代码编译内核,这可以写成一本书,并且不推荐在生产系统上这么做。
|
||||
|
||||
虽然它是最好的学习体验之一,并且允许细粒度配置内核,但是你可能会让你的系统不可用,并且可能必须从头重新安装它。
|
||||
|
||||
如果你仍然有兴趣构建内核作为学习经验,你可以在 [Kernel Newbies][13]页面中获得指导。
|
||||
|
||||
一如既往,如果你对本文有任何问题或意见,请随时使用下面的评论栏。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
我是一个计算机上瘾的家伙,并且是开源和 Linux 系统软件的粉丝,有大约 4 年的 Linux 发行版桌面、服务器和 bash 脚本的经验。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-upgrade-kernel-version-in-centos-7/
|
||||
|
||||
作者:[Matei Cezar][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/cezarmatei/
|
||||
|
||||
[1]:https://linux.cn/article-8284-1.html
|
||||
[2]:http://www.tecmint.com/wp-content/uploads/2017/03/Check-Kernel-Version-in-CentOS-7.png
|
||||
[3]:https://www.kernel.org/
|
||||
[4]:https://www.kernel.org/category/releases.html
|
||||
[5]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
|
||||
[6]:https://www.kernel.org/
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2017/03/Enable-ELRepo-in-CentOS-7.png
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2017/03/Yum-Find-Available-Kernel-Versions.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2017/03/Install-Latest-Kernel-Version-in-CentOS-7.png
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2017/03/Verify-Kernel-Version.png
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2017/03/Set-Kernel-in-GRUB.png
|
||||
[12]:http://www.tecmint.com/wp-content/uploads/2017/03/Booting-Default-Kernel-Version.png
|
||||
[13]:https://kernelnewbies.org/KernelBuild
|
||||
[14]:http://www.tecmint.com/author/gacanepa/
|
||||
[15]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[16]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -0,0 +1,99 @@
|
||||
在 Linux 中修改 MySQL 或 MariaDB 的 Root 密码
|
||||
============================================================
|
||||
|
||||
如果你是第一次[安装 MySQL 或 MariaDB][1],你可以执行 `mysql_secure_installation` 脚本来实现基本的安全设置。
|
||||
|
||||
其中的一个设置是数据库的 root 密码 —— 该密码必须保密,并且只在必要的时候使用。如果你需要修改它(例如,当数据库管理员换了人 —— 或者被解雇了!)。
|
||||
|
||||
**建议阅读:**[在 Linux 中恢复 MySQL 或 MariaDB 的 Root 密码][2]
|
||||
|
||||
这篇文章迟早会派上用场的。我们讲说明怎样来在 Linux 中修改 MySQL 或 MariaDB 数据库服务器的 root 密码。
|
||||
|
||||
尽管我们会在本文中使用 MariaDB 服务器,但本文中的用法说明对 MySQL 也有效。
|
||||
|
||||
### 修改 MySQL 或 MariaDB 的 root 密码
|
||||
|
||||
你知道 root 密码,但是想要重置它,对于这样的情况,让我们首先确定 MariaDB 正在运行:
|
||||
|
||||
```
|
||||
------------- CentOS/RHEL 7 and Fedora 22+ -------------
|
||||
# systemctl is-active mariadb
|
||||
------------- CentOS/RHEL 6 and Fedora -------------
|
||||
# /etc/init.d/mysqld status
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
*检查 MysQL 状态*
|
||||
|
||||
如果上面的命令返回中没有 `active` 这个关键词,那么该服务就是停止状态,你需要在进行下一步之前先启动数据库服务:
|
||||
|
||||
```
|
||||
------------- CentOS/RHEL 7 and Fedora 22+ -------------
|
||||
# systemctl start mariadb
|
||||
------------- CentOS/RHEL 6 and Fedora -------------
|
||||
# /etc/init.d/mysqld start
|
||||
```
|
||||
|
||||
接下来,我们将以 root 登录进数据库服务器:
|
||||
|
||||
```
|
||||
# mysql -u root -p
|
||||
```
|
||||
|
||||
为了兼容不同版本,我们将使用下面的声明来更新 mysql 数据库的用户表。注意,你需要将 `YourPasswordHere` 替换为你为 root 选择的新密码。
|
||||
|
||||
```
|
||||
MariaDB [(none)]> USE mysql;
|
||||
MariaDB [(none)]> UPDATE user SET password=PASSWORD('YourPasswordHere') WHERE User='root' AND Host = 'localhost';
|
||||
MariaDB [(none)]> FLUSH PRIVILEGES;
|
||||
```
|
||||
|
||||
要验证是否操作成功,请输入以下命令退出当前 MariaDB 会话。
|
||||
|
||||
```
|
||||
MariaDB [(none)]> exit;
|
||||
```
|
||||
|
||||
然后,敲回车。你现在应该可以使用新密码连接到服务器了。
|
||||
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
*修改 MysQL/MariaDB Root 密码*
|
||||
|
||||
|
||||
##### 小结
|
||||
|
||||
在本文中,我们说明了如何修改 MariaDB / MySQL 的 root 密码 —— 或许你知道当前所讲的这个方法,也可能不知道。
|
||||
|
||||
像往常一样,如果你有任何问题或者反馈,请尽管使用下面的评论框来留下你宝贵的意见或建议,我们期待着您的留言。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Gabriel Cánepa是一位来自阿根廷圣路易斯的 Villa Mercedes 的 GNU/Linux 系统管理员和 web 开发者。他为世界范围内的主要的消费产品公司工作,也很钟情于在他日常工作的方方面面中使用 FOSS 工具来提高生产效率。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/change-mysql-mariadb-root-password/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
|
||||
[1]:http://www.tecmint.com/install-mariadb-in-centos-7/
|
||||
[2]:http://www.tecmint.com/reset-mysql-or-mariadb-root-password/
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2017/03/Check-MySQL-Status.png
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2017/03/Change-MySQL-Root-Password.png
|
||||
[5]:http://www.tecmint.com/author/gacanepa/
|
||||
[6]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[7]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -1,23 +1,23 @@
|
||||
使用 chroot jail 限制 SSH 用户访问指定目录
|
||||
使用 chroot 监狱限制 SSH 用户访问指定目录
|
||||
============================================================
|
||||
|
||||
这有几个原因要[限制 SSH 用户会话][1]访问到特定的目录,特别是在 web 服务器上,但显而易见的是这是为了系统安全。为了锁定 SSH 用户在某个目录,我们可以使用 chroot 机制。
|
||||
将 [SSH 用户会话限制][1]访问到特定的目录内,特别是在 web 服务器上,这样做有多个原因,但最显而易见的是为了系统安全。为了锁定 SSH 用户在某个目录,我们可以使用 **chroot** 机制。
|
||||
|
||||
在诸如 Linux 之类的类 Unix 系统中更改 root(chroot)是将特定用户操作与其他 Linux 系统分离的一种手段; 使用一种称为 chroot jail 的方法更改当前运行的用户进程及其子进程的 root 目录。
|
||||
在诸如 Linux 之类的类 Unix 系统中更改 root(**chroot**)是将特定用户操作与其他 Linux 系统分离的一种手段;使用称为 **chrooted 监狱** 的新根目录更改当前运行的用户进程及其子进程的明显根目录。
|
||||
|
||||
在本教程中,我们将向你展示如何限制 SSH 用户访问 Linux 中指定的目录。注意,我们将以 root 用户身份运行所有命令,如果你以普通用户身份登录服务器,请使用[sudo 命令][2]。
|
||||
在本教程中,我们将向你展示如何限制 SSH 用户访问 Linux 中指定的目录。注意,我们将以 root 用户身份运行所有命令,如果你以普通用户身份登录服务器,请使用 [sudo 命令][2]。
|
||||
|
||||
### 步骤 1:创建 SSH chroot jail
|
||||
### 步骤 1:创建 SSH chroot 监狱
|
||||
|
||||
1. 使用 mkdir 命令开始创建 chroot jail:
|
||||
1、 使用 mkdir 命令开始创建 chroot 监狱:
|
||||
|
||||
```
|
||||
# mkdir -p /home/test
|
||||
```
|
||||
|
||||
2. 接下来,根据 sshd_config 手册识别所需的文件,`ChrootDirectory` 选项指定在验证后要被 chroot 的目录的路径名。该目录必须包含支持用户会话所必需的文件和目录。
|
||||
2、 接下来,根据 `sshd_config` 手册找到所需的文件,`ChrootDirectory` 选项指定在身份验证后要 chroot 到的目录的路径名。该目录必须包含支持用户会话所必需的文件和目录。
|
||||
|
||||
对于交互式会话,这需要至少一个 shell,通常为 `sh` 和基本的 `/dev` 节点,例如 null、zero、stdin、stdout、stderr和 tty 设备:
|
||||
对于交互式会话,这需要至少一个 shell,通常为 `sh` 和基本的 `/dev` 节点,例如 `null`、`zero`、`stdin`、`stdout`、`stderr` 和 `tty` 设备:
|
||||
|
||||
```
|
||||
# ls -l /dev/{null,zero,stdin,stdout,stderr,random,tty}
|
||||
@ -26,9 +26,9 @@
|
||||

|
||||
][3]
|
||||
|
||||
列出所需文件
|
||||
*列出所需文件*
|
||||
|
||||
3. 现在,使用 mknod 命令创建 `/dev` 文件。在下面的命令中,`-m` 标志用来指定文件权限位,`c` 意思是符号文件,两个数字分别是文件指向的主要和次要的数字。
|
||||
3、 现在,使用 `mknod` 命令创建 `/dev` 下的文件。在下面的命令中,`-m` 标志用来指定文件权限位,`c` 意思是字符文件,两个数字分别是文件指向的主要号和次要号。
|
||||
|
||||
```
|
||||
# mkdir -p /home/test/dev/
|
||||
@ -42,9 +42,9 @@
|
||||
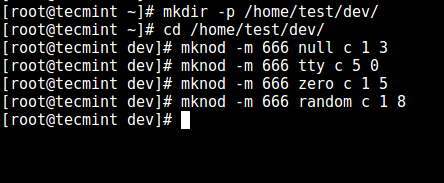
|
||||
][4]
|
||||
|
||||
创建 /dev 和所需文件
|
||||
*创建 /dev 和所需文件*
|
||||
|
||||
4. 在此之后,在 chroot jail 中设置合适的权限。注意 chroot jail 和它的子目录以及子文件必须被 root 用户所有,并且对普通用户或用户组不可写:
|
||||
4、 在此之后,在 chroot 监狱中设置合适的权限。注意 chroot 监狱和它的子目录以及子文件必须被 `root` 用户所有,并且对普通用户或用户组不可写:
|
||||
|
||||
```
|
||||
# chown root:root /home/test
|
||||
@ -55,11 +55,11 @@
|
||||

|
||||
][5]
|
||||
|
||||
设置目录权限
|
||||
*设置目录权限*
|
||||
|
||||
### 步骤 2:为 SSH chroot jail 设置交互式 shell
|
||||
### 步骤 2:为 SSH chroot 监狱设置交互式 shell
|
||||
|
||||
5. 首先,创建 `bin` 目录并复制 `/bin/bash` 到 `bin` 中:
|
||||
5、 首先,创建 `bin` 目录并复制 `/bin/bash` 到 `bin` 中:
|
||||
|
||||
```
|
||||
# mkdir -p /home/test/bin
|
||||
@ -69,9 +69,9 @@
|
||||

|
||||
][6]
|
||||
|
||||
复制文件到 bin 目录中
|
||||
*复制文件到 bin 目录中*
|
||||
|
||||
6. 现在,识别 bash 所需的共享`库`,如下所示复制它们到 `lib` 中:
|
||||
6、 现在,识别 bash 所需的共享库,如下所示复制它们到 `lib64` 中:
|
||||
|
||||
```
|
||||
# ldd /bin/bash
|
||||
@ -82,18 +82,18 @@
|
||||
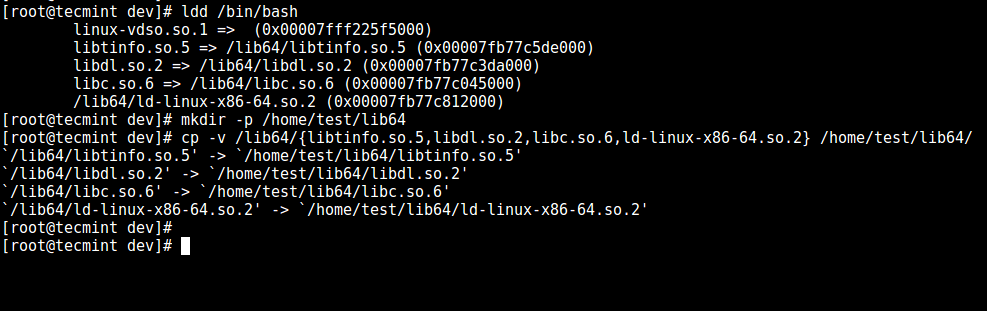
|
||||
][7]
|
||||
|
||||
复制共享库文件
|
||||
*复制共享库文件*
|
||||
|
||||
### 步骤 3:创建并配置 SSH 用户
|
||||
|
||||
7. 现在,使用[ useradd 命令][8]创建 SSH 用户,并设置安全密码:
|
||||
7、 现在,使用 [useradd 命令][8]创建 SSH 用户,并设置安全密码:
|
||||
|
||||
```
|
||||
# useradd tecmint
|
||||
# passwd tecmint
|
||||
```
|
||||
|
||||
8. 创建 chroot jail 通用配置目录 `/home/test/etc` 并复制已更新的账号文件(/etc/passwd and /etc/group)到这个目录中:
|
||||
8、 创建 chroot 监狱通用配置目录 `/home/test/etc` 并复制已更新的账号文件(`/etc/passwd` 和 `/etc/group`)到这个目录中:
|
||||
|
||||
```
|
||||
# mkdir /home/test/etc
|
||||
@ -103,31 +103,31 @@
|
||||

|
||||
][9]
|
||||
|
||||
复制密码文件
|
||||
*复制密码文件*
|
||||
|
||||
注意:你每次添加更多的 SSH 用户到系统中时,你将需要复制已更新的文件到 `/home/test/etc` 中。
|
||||
注意:每次向系统添加更多 SSH 用户时,都需要将更新的帐户文件复制到 `/home/test/etc` 目录中。
|
||||
|
||||
### 步骤 4:配置 SSH 来使用 chroot jail
|
||||
### 步骤 4:配置 SSH 来使用 chroot 监狱
|
||||
|
||||
9. 现在打开 `sshd_config` 文件。
|
||||
9、 现在打开 `sshd_config` 文件。
|
||||
|
||||
```
|
||||
# vi /etc/ssh/sshd_config
|
||||
```
|
||||
|
||||
在此文件中添加/修改下面这些行。
|
||||
在此文件中添加或修改下面这些行。
|
||||
|
||||
```
|
||||
#define username to apply chroot jail to
|
||||
# 定义要使用 chroot 监狱的用户
|
||||
Match User tecmint
|
||||
#specify chroot jail
|
||||
# 指定 chroot 监狱
|
||||
ChrootDirectory /home/test
|
||||
```
|
||||
[
|
||||
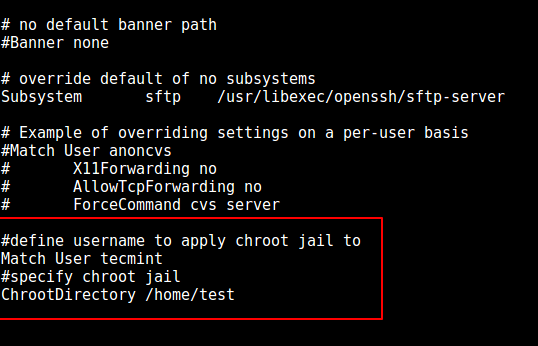
|
||||
][10]
|
||||
|
||||
配置 SSH chroot jail
|
||||
*配置 SSH chroot 监狱*
|
||||
|
||||
保存文件并退出,重启 sshd 服务:
|
||||
|
||||
@ -137,9 +137,9 @@ ChrootDirectory /home/test
|
||||
# service sshd restart
|
||||
```
|
||||
|
||||
### 步骤 5:用 chroot jail 测试 SSH
|
||||
### 步骤 5:测试 SSH 的 chroot 监狱
|
||||
|
||||
10. 这次,测试 chroot jail 的设置是否如希望的那样成功了:
|
||||
10、 这次,测试 chroot 监狱的设置是否如希望的那样成功了:
|
||||
|
||||
```
|
||||
# ssh tecmint@192.168.0.10
|
||||
@ -151,12 +151,11 @@ ChrootDirectory /home/test
|
||||
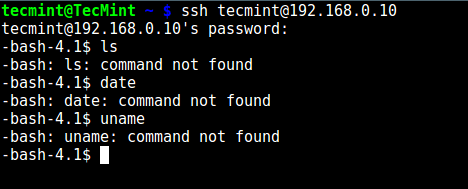
|
||||
][11]
|
||||
|
||||
Testing SSH User Chroot Jail
|
||||
测试 SSH 用户 chroot jail
|
||||
*测试 SSH 用户 chroot 监狱*
|
||||
|
||||
从上面的截图上来看,我们可以看到 SSH 用户被锁定在了 chroot jail 中,并且不能使用任何外部命令如(ls、date、uname 等等)。
|
||||
从上面的截图上来看,我们可以看到 SSH 用户被锁定在了 chroot 监狱中,并且不能使用任何外部命令如(`ls`、`date`、`uname` 等等)。
|
||||
|
||||
用户只可以执行 bash 以及它内置的命令(比如:pwd、history、echo 等等):
|
||||
用户只可以执行 `bash` 以及它内置的命令(比如:`pwd`、`history`、`echo` 等等):
|
||||
|
||||
```
|
||||
# ssh tecmint@192.168.0.10
|
||||
@ -168,11 +167,11 @@ Testing SSH User Chroot Jail
|
||||
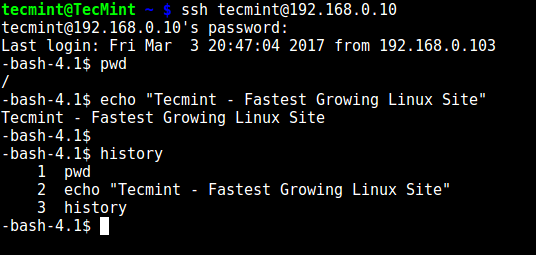
|
||||
][12]
|
||||
|
||||
SSH 内置命令
|
||||
*SSH 内置命令*
|
||||
|
||||
### 步骤6: 创建用户的家目录并添加 Linux 命令
|
||||
### 步骤6: 创建用户的主目录并添加 Linux 命令
|
||||
|
||||
11. 从前面的步骤中我们可以看到用户被锁定在了 root 目录,我们也可以为 SSH 也创建一个家目录(为所有将来的用户这么做):
|
||||
11、 从前面的步骤中,我们可以看到用户被锁定在了 root 目录,我们可以为 SSH 用户创建一个主目录(以及为所有将来的用户这么做):
|
||||
|
||||
```
|
||||
# mkdir -p /home/test/home/tecmint
|
||||
@ -183,9 +182,9 @@ SSH 内置命令
|
||||

|
||||
][13]
|
||||
|
||||
创建 SSH 用户家目录
|
||||
*创建 SSH 用户主目录*
|
||||
|
||||
12. 接下来,安装少量在 `bin` 目录中的用户命令如 ls、date、mkdir:
|
||||
12、 接下来,在 `bin` 目录中安装几个用户命令,如 `ls`、`date`、`mkdir`:
|
||||
|
||||
```
|
||||
# cp -v /bin/ls /home/test/bin/
|
||||
@ -196,9 +195,9 @@ SSH 内置命令
|
||||
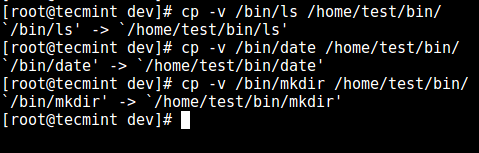
|
||||
][14]
|
||||
|
||||
给 SSH 用户添加命令
|
||||
*向 SSH 用户添加命令*
|
||||
|
||||
13. 接下来检查上面命令的共享库并将它们移到 chroot jail 的库目录中:
|
||||
13、 接下来,检查上面命令的共享库并将它们移到 chroot 监狱的库目录中:
|
||||
|
||||
```
|
||||
# ldd /bin/ls
|
||||
@ -208,16 +207,16 @@ SSH 内置命令
|
||||
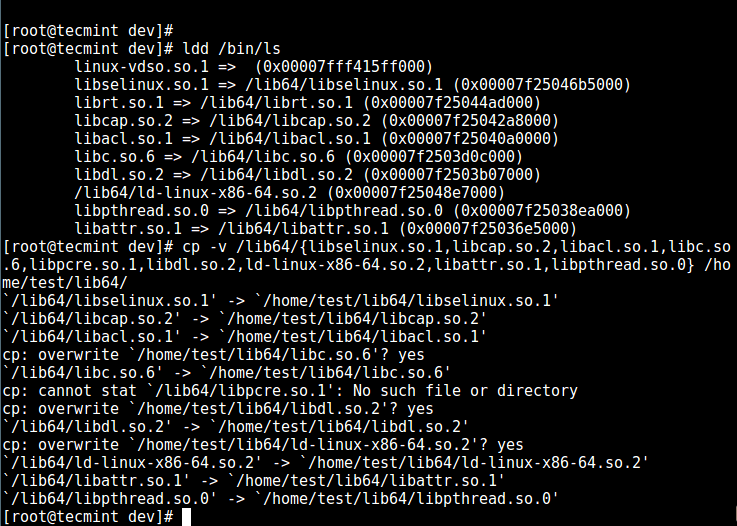
|
||||
][15]
|
||||
|
||||
复制共享库
|
||||
*复制共享库*
|
||||
|
||||
### 步骤 7:用 chroot jail 测试 sftp
|
||||
### 步骤 7:测试 sftp 的 用 chroot 监狱
|
||||
|
||||
14. 最后用 sftp 做一个测试;测试你先前安装的命令是否可用。
|
||||
14、 最后用 sftp 做一个测试;测试你先前安装的命令是否可用。
|
||||
|
||||
在 `/etc/ssh/sshd_config` 中添加下面的行:
|
||||
|
||||
```
|
||||
#Enable sftp to chrooted jail
|
||||
# 启用 sftp 的 chrooted 监狱
|
||||
ForceCommand internal-sftp
|
||||
```
|
||||
|
||||
@ -229,7 +228,7 @@ ForceCommand internal-sftp
|
||||
# service sshd restart
|
||||
```
|
||||
|
||||
15. 下载使用 ssh 测试,你会得到下面的错误:
|
||||
15、 现在使用 ssh 测试,你会得到下面的错误:
|
||||
|
||||
```
|
||||
# ssh tecmint@192.168.0.10
|
||||
@ -238,7 +237,7 @@ ForceCommand internal-sftp
|
||||

|
||||
][16]
|
||||
|
||||
测试 ssh root jail
|
||||
*测试 SSH Chroot 监狱*
|
||||
|
||||
试下使用 sftp:
|
||||
|
||||
@ -249,15 +248,14 @@ ForceCommand internal-sftp
|
||||
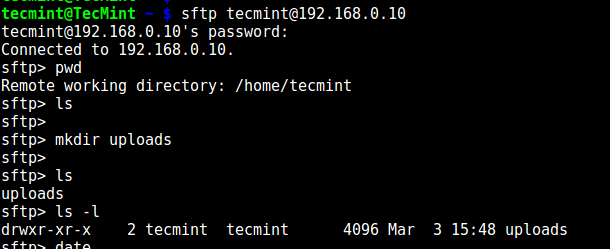
|
||||
][17]
|
||||
|
||||
测试 sFTP SSH 用户
|
||||
*测试 sFTP SSH 用户*
|
||||
|
||||
**建议阅读:** [使用 chroot jail 限制 sftp 用户到家目录中][18]
|
||||
**建议阅读:** [使用 chroot 监狱将 sftp 用户限制在主目录中][18]。
|
||||
|
||||
就是这样了!在文本中,我们向你展示如何在 Linux 中限制 ssh 用户到指定的目录中( chroot jail)。请在评论栏中给我们提供你的想法。
|
||||
就是这样了!在文本中,我们向你展示了如何在 Linux 中限制 ssh 用户到指定的目录中( chroot 监狱)。请在评论栏中给我们提供你的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili 是一个 Linux 及 F.O.S.S 热衷者,即将成为 Linux 系统管理员、web 开发者,目前是 TecMint 的内容创作者,他喜欢用电脑工作,并坚信分享知识。
|
||||
@ -268,7 +266,7 @@ via: http://www.tecmint.com/restrict-ssh-user-to-directory-using-chrooted-jail/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,111 @@
|
||||
如何在 Linux 中安装最新的 Python 3.6 版本
|
||||
============================================================
|
||||
|
||||
在这篇文章中,我将展示如何在 CentOS/RHEL 7、Debian 以及它的衍生版本比如 Ubuntu(最新的 Ubuntu 16.04 LTS 版本已经安装了最新的 Python 版本)或 Linux Mint 上安装和使用 Python 3.x 。我们的重点是安装可用于命令行的核心语言工具。
|
||||
|
||||
然后,我们也会阐述如何安装 Python IDLE - 一个基于 GUI 的工具,它允许我们运行 Python 代码和创建独立函数。
|
||||
|
||||
### 在 Linux 中安装 Python 3.6
|
||||
|
||||
在我写这篇文章的时候(2017 年三月中旬),在 CentOS 和 Debian 8 中可用的最新 Python 版本分别是 Python 3.4 和 Python 3.5 。
|
||||
|
||||
虽然我们可以使用 [yum][1] 和 [aptitude][2](或 [apt-get][3])安装核心安装包以及它们的依赖,但在这儿,我将阐述如何使用源代码进行安装。
|
||||
|
||||
为什么?理由很简单:这样我们能够获取语言的最新的稳定发行版(3.6),并且提供了一种和 Linux 版本无关的安装方法。
|
||||
|
||||
在 CentOS 7 中安装 Python 之前,请确保系统中已经有了所有必要的开发依赖:
|
||||
|
||||
```
|
||||
# yum -y groupinstall development
|
||||
# yum -y install zlib-devel
|
||||
```
|
||||
|
||||
在 Debian 中,我们需要安装 gcc、make 和 zlib 压缩/解压缩库:
|
||||
|
||||
```
|
||||
# aptitude -y install gcc make zlib1g-dev
|
||||
```
|
||||
|
||||
运行下面的命令来安装 Python 3.6:
|
||||
|
||||
```
|
||||
# wget https://www.python.org/ftp/python/3.6.0/Python-3.6.0.tar.xz
|
||||
# tar xJf Python-3.6.0.tar.xz
|
||||
# cd Python-3.6.0
|
||||
# ./configure
|
||||
# make && make install
|
||||
```
|
||||
|
||||
现在,放松一下,或者饿的话去吃个三明治,因为这可能需要花费一些时间。安装完成以后,使用 `which` 命令来查看主要二进制代码的位置:
|
||||
|
||||
```
|
||||
# which python3
|
||||
# python3 -V
|
||||
```
|
||||
|
||||
上面的命令的输出应该和这相似:
|
||||
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
*查看 Linux 系统中的 Python 版本*
|
||||
|
||||
要退出 Python 提示符,只需输入:
|
||||
|
||||
```
|
||||
quit()
|
||||
或
|
||||
exit()
|
||||
```
|
||||
|
||||
然后按回车键。
|
||||
|
||||
恭喜!Python 3.6 已经安装在你的系统上了。
|
||||
|
||||
### 在 Linux 中安装 Python IDLE
|
||||
|
||||
Python IDLE 是一个基于 GUI 的 Python 工具。如果你想安装 Python IDLE,请安装叫做 idle(Debian)或 python-tools(CentOS)的包:
|
||||
|
||||
```
|
||||
# apt-get install idle [On Debian]
|
||||
# yum install python-tools [On CentOS]
|
||||
```
|
||||
|
||||
输入下面的命令启动 Python IDLE:
|
||||
|
||||
```
|
||||
# idle
|
||||
```
|
||||
|
||||
### 总结
|
||||
|
||||
在这篇文章中,我们阐述了如何从源代码安装最新的 Python 稳定版本。
|
||||
|
||||
最后但不是不重要,如果你之前使用 Python 2,那么你可能需要看一下 [从 Python 2 迁移到 Python 3 的官方文档][5]。这是一个可以读入 Python 2 代码,然后转化为有效的 Python 3 代码的程序。
|
||||
|
||||
你有任何关于这篇文章的问题或想法吗?请使用下面的评论栏与我们联系
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Gabriel Cánepa - 一位来自阿根廷圣路易斯梅塞德斯镇 (Villa Mercedes, San Luis, Argentina) 的 GNU/Linux 系统管理员,Web 开发者。就职于一家世界领先级的消费品公司,乐于在每天的工作中能使用 FOSS 工具来提高生产力。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-python-in-linux/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
|
||||
[1]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
|
||||
[2]:http://www.tecmint.com/linux-package-management/
|
||||
[3]:http://www.tecmint.com/useful-basic-commands-of-apt-get-and-apt-cache-for-package-management/
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2017/03/Check-Python-Version-in-Linux.png
|
||||
[5]:https://docs.python.org/3.6/library/2to3.html
|
||||
@ -0,0 +1,154 @@
|
||||
Kgif:一个从活动窗口创建 GIF 的简单脚本
|
||||
============================================================
|
||||
|
||||
[Kgif][2] 是一个简单的 shell 脚本,它可以从活动窗口创建一个 GIF 文件。我觉得这个程序专门是为捕获终端活动设计的,我经常用于这个。
|
||||
|
||||
它将窗口的活动捕获为一系列的 PNG 图片,然后组合在一起创建一个GIF 动画。脚本以 0.5 秒的间隔截取活动窗口。如果你觉得这不符合你的要求,你可以根据你的需要修改脚本。
|
||||
|
||||
最初它是为了捕获 tty 输出以及创建 github 项目的预览图创建的。
|
||||
|
||||
确保你在运行 Kgif 之前已经安装了 scrot 和 ImageMagick 软件包。
|
||||
|
||||
推荐阅读:[Peek - 在 Linux 中创建一个 GIF 动画录像机][3]。
|
||||
|
||||
什么是 ImageMagick?ImageMagick 是一个命令行工具,用于图像转换和编辑。它支持所有类型的图片格式(超过 200 种),如 PNG、JPEG、JPEG-2000、GIF、TIFF、DPX、EXR、WebP、Postscript、PDF 和 SVG。
|
||||
|
||||
什么是 Scrot?Scrot 代表 SCReenshOT,它是一个开源的命令行工具,用于捕获桌面、终端或特定窗口的屏幕截图。
|
||||
|
||||
#### 安装依赖
|
||||
|
||||
Kgif 需要 scrot 以及 ImageMagick。
|
||||
|
||||
对于基于 Debian 的系统:
|
||||
|
||||
```
|
||||
$ sudo apt-get install scrot imagemagick
|
||||
```
|
||||
|
||||
对于基于 RHEL/CentOS 的系统:
|
||||
|
||||
```
|
||||
$ sudo yum install scrot ImageMagick
|
||||
```
|
||||
|
||||
对于 Fedora 系统:
|
||||
|
||||
```
|
||||
$ sudo dnf install scrot ImageMagick
|
||||
```
|
||||
|
||||
对于 openSUSE 系统:
|
||||
|
||||
```
|
||||
$ sudo zypper install scrot ImageMagick
|
||||
```
|
||||
|
||||
对于基于 Arch Linux 的系统:
|
||||
|
||||
```
|
||||
$ sudo pacman -S scrot ImageMagick
|
||||
```
|
||||
|
||||
#### 安装 Kgif 及使用
|
||||
|
||||
安装 Kgif 并不困难,因为不需要安装。只需从开发者的 github 页面克隆源文件,你就可以运行 `kgif.sh` 文件来捕获活动窗口了。默认情况下它的延迟为 1 秒,你可以用 `--delay` 选项来修改延迟。最后,按下 `Ctrl + c` 来停止捕获。
|
||||
|
||||
```
|
||||
$ git clone https://github.com/luminousmen/Kgif
|
||||
$ cd Kgif
|
||||
$ ./kgif.sh
|
||||
Setting delay to 1 sec
|
||||
|
||||
Capturing...
|
||||
^C
|
||||
Stop capturing
|
||||
Converting to gif...
|
||||
Cleaning...
|
||||
Done!
|
||||
```
|
||||
|
||||
检查系统中是否已存在依赖。
|
||||
|
||||
```
|
||||
$ ./kgif.sh --check
|
||||
OK: found scrot
|
||||
OK: found imagemagick
|
||||
```
|
||||
|
||||
设置在 N 秒延迟后开始捕获。
|
||||
|
||||
```
|
||||
$ ./kgif.sh --delay=5
|
||||
|
||||
Setting delay to 5 sec
|
||||
|
||||
Capturing...
|
||||
^C
|
||||
Stop capturing
|
||||
Converting to gif...
|
||||
Cleaning...
|
||||
Done!
|
||||
```
|
||||
|
||||
它会将文件保存为 `terminal.gif`,并且每次在生成新文件时都会覆盖。因此,我建议你添加 `--filename` 选项将文件保存为不同的文件名。
|
||||
|
||||
```
|
||||
$ ./kgif.sh --delay=5 --filename=2g-test.gif
|
||||
|
||||
Setting delay to 5 sec
|
||||
|
||||
Capturing...
|
||||
^C
|
||||
Stop capturing
|
||||
Converting to gif...
|
||||
Cleaning...
|
||||
Done!
|
||||
```
|
||||
|
||||
使用 `--noclean` 选项保留 png 截图。
|
||||
|
||||
```
|
||||
$ ./kgif.sh --delay=5 --noclean
|
||||
```
|
||||
|
||||
要了解更多的选项:
|
||||
|
||||
```
|
||||
$ ./kgif.sh --help
|
||||
|
||||
usage: ./kgif.sh [--delay] [--filename ] [--gifdelay] [--noclean] [--check] [-h]
|
||||
-h, --help Show this help, exit
|
||||
--check Check if all dependencies are installed, exit
|
||||
--delay= Set delay in seconds to specify how long script will wait until start capturing.
|
||||
--gifdelay= Set delay in seconds to specify how fast images appears in gif.
|
||||
--filename= Set file name for output gif.
|
||||
--noclean Set if you don't want to delete source *.png screenshots.
|
||||
```
|
||||
|
||||
默认捕获输出。
|
||||
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
我感觉默认的捕获非常快,接着我做了一些修改并得到了合适的输出。
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.2daygeek.com/kgif-create-animated-gif-file-active-window-screen-recorder-capture-arch-linux-mint-fedora-ubuntu-debian-opensuse-centos/
|
||||
|
||||
作者:[MAGESH MARUTHAMUTHU][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.2daygeek.com/author/magesh/
|
||||
[1]:http://www.2daygeek.com/author/magesh/
|
||||
[2]:https://github.com/luminousmen/Kgif
|
||||
[3]:http://www.2daygeek.com/kgif-create-animated-gif-file-active-window-screen-recorder-capture-arch-linux-mint-fedora-ubuntu-debian-opensuse-centos/www.2daygeek.com/peek-create-animated-gif-screen-recorder-capture-arch-linux-mint-fedora-ubuntu/
|
||||
[4]:http://www.2daygeek.com/wp-content/uploads/2017/03/kgif-test.gif
|
||||
[5]:http://www.2daygeek.com/wp-content/uploads/2017/03/kgif-test-delay-modified.gif
|
||||
46
published/201703/20170317 The End of the Line for EPEL-5.md
Normal file
46
published/201703/20170317 The End of the Line for EPEL-5.md
Normal file
@ -0,0 +1,46 @@
|
||||
EPEL-5 走向终点
|
||||
===========
|
||||
|
||||

|
||||
|
||||
在过去十年中,Fedora 项目一直都在为另外一个操作系统构建相同软件包。**然而,到 2017 年 3 月 31 日,它将会随着 Red Hat Enterprise Linux(RHEL)5 一起停止这项工作**。
|
||||
|
||||
### EPEL 的简短历史
|
||||
|
||||
RHEL 是 Fedora 发布版本的一个子集的下游重建版本,Red Hat 愿为之支持好多年。虽然那些软件包构成了完整的操作系统,但系统管理员一直都需要“更多”软件包。在 RHEL-5 之前,许多那些软件包会由不同的人打包并提供。随着 Fedora Extras 逐渐包含了更多软件包,并有几位打包者加入了 Fedora,随之出现了一个想法,结合力量并创建一个专门的子项目,重建特定于 RHEL 版本的 Fedora 软件包,然后从 Fedora 的中心化服务器上分发。
|
||||
|
||||
经过多次讨论,然而还是未能提出一个引人注目的名称之后,Fedora 创建了子项目 Extra Packages for Enterprise Linux(简称 EPEL)。在首次为 RHEL-4 重建软件包时,其主要目标是在 RHEL-5 发布时提供尽可能多的用于 RHEL-5 的软件包。打包者做了很多艰苦的工作,但大部分工作是在制定 EPEL 在未来十年的规则以及指导。[从所有人能够看到的邮件归档中][2]我们可以看到 Fedora 贡献者的激烈讨论,它们担心将 Fedora 的发布重心转移到外部贡献者会与已经存在的软件包产生冲突。
|
||||
|
||||
最后,EPEL-5 在 2007 年 4 月的某个时候上线了,在接下来的十年中,它已经成长为一个拥有 5000 多个源码包的仓库,并且每天会有 20 万个左右独立 IP 地址检查软件包,并在 2013 年初达到 24 万的高峰。虽然为 EPEL 构建的每个包都是使用 RHEL 软件包完成的,但所有这些软件包可以用于 RHEL 的各种社区重建版本(CentOS、Scientific Linux、Amazon Linux)。这意味着随着这些生态系统的增长,给 EPEL 带来了更多的用户,并在随后的 RHEL 版本发布时帮助打包。然而,随着新版本以及重建版本的使用量越来越多,EPEL-5 的用户数量逐渐下降为每天大约 16 万个独立 IP 地址。此外,在此期间,开发人员支持的软件包数量已经下降,仓库大小已缩小到 2000 个源代码包。
|
||||
|
||||
收缩的部分原因是由于 2007 年的原始规定。当时,Red Hat Enterprise Linux 被认为只有 6 年活跃的生命周期。有人认为,在这样一个“有限”的周期中,软件包可能就像在 RHEL 中那样在 EPEL 中被“冻结”。这意味着无论何时有可能的修复需要向后移植,也不允许有主要的修改。因为没有人来打包,软件包将不断从 EPEL-5 中移除,因为打包者不再想尝试并向后移植。尽管各种规则被放宽以允许更大的更改,Fedora 使用的打包规则从 2007 年开始不断地改变和改进。这使得在较旧的操作系统上尝试重新打包一个较新的版本变得越来越难。
|
||||
|
||||
### 2017 年 3 月 31 日会发生什么
|
||||
|
||||
如上所述,3 月 31 日,红帽将终止 RHEL-5 的支持并不再为普通客户提供更新。这意味着 Fedora 和各种重建版本将开始各种归档流程。对于 EPEL 项目,这意味着我们将跟随 Fedora 发行版每年发布的步骤。
|
||||
|
||||
1. 在 ** 3 月 27 日**,任何新版本将不会被允许推送到 EPEL-5,以便仓库本质上被冻结。这允许镜像拥有一个清晰的文件树。
|
||||
2. EPEL-5 中的所有包将从主镜像 `/pub/epel/5/` 以及 `/pub/epel/testing/5/` 移动到 `/pub/archives/epel/`。 **这将会在 27 号开始*,因此所有的归档镜像站点可以用它写入磁盘。
|
||||
3. 因为 3 月 31 日是星期五,系统管理员并不喜欢周五惊喜,所以它不会有变化。**4 月 3 日**,镜像管理器将更新指向归档。
|
||||
4. **4 月 6 日**,`/pub/epel/5/` 树将被删除,镜像也将相应更新。
|
||||
|
||||
对于使用 cron 执行 yum 更新的系统管理员而言,这应该只是一个小麻烦。系统能继续更新甚至安装归档中的任何软件包。那些直接使用脚本从镜像下载的系统管理员会有点麻烦,需要将脚本更改到 `/pub/archive/epel/5/` 这个新的位置。
|
||||
|
||||
虽然令人讨厌,但是对于仍使用旧版 Linux 的许多系统管理员也许算是好事吧。由于软件包不断地从 EPEL-5 中删除,各种支持邮件列表以及 irc 频道都有系统管理员惊奇他们需要的哪些软件包消失到哪里了。归档完成后,这将不会是一个问题,因为不会更多的包会被删除了 :)。
|
||||
|
||||
对于受此问题影响的系统管理员,较旧的 EPEL 软件包仍然可用,但速度较慢。所有 EPEL 软件包都是在 Fedora Koji 系统中构建的,所以你可以使用 [Koji 搜索][3]到较旧版本的软件包。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/the-end-of-the-line-for-epel-5/
|
||||
|
||||
作者:[smooge][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://smooge.id.fedoraproject.org/
|
||||
[1]:https://fedoramagazine.org/the-end-of-the-line-for-epel-5/
|
||||
[2]:https://www.redhat.com/archives/epel-devel-list/2007-March/thread.html
|
||||
[3]:https://koji.fedoraproject.org/koji/search
|
||||
@ -0,0 +1,100 @@
|
||||
ELRepo - Enterprise Linux (RHEL、CentOS 及 SL)的社区仓库
|
||||
============================================================
|
||||
|
||||
如果你正在使用 Enterprise Linux 发行版(Red Hat Enterprise Linux 或其衍生产品,如 CentOS 或 Scientific Linux),并且需要对特定硬件或新硬件支持,那么你找对地方了。
|
||||
|
||||
在本文中,我们将讨论如何启用 ELRepo 仓库,该软件源包含文件系统驱动以及网络摄像头驱动程序等等(支持显卡、网卡、声音设备甚至[新内核][1])
|
||||
|
||||
### 在 Enterprise Linux 中启用 ELRepo
|
||||
|
||||
虽然 ELRepo 是第三方仓库,但它有 Freenode(#elrepo)上的一个活跃社区以及用户邮件列表的良好支持。
|
||||
|
||||
如果你仍然对在软件源中添加一个独立的仓库表示担心,请注意 CentOS 已在它的 wiki([参见此处][2])将它列为是可靠的。如果你仍然有疑虑,请随时在评论中提问!
|
||||
|
||||
需要注意的是 ELRepo 不仅提供对 Enterprise Linux 7 提供支持,还支持以前的版本。考虑到 CentOS 5 在本月底(2017 年 3 月)结束支持(EOL),这可能看起来并不是一件很大的事,但请记住,CentOS 6 的 EOL 不会早于 2020 年 3 月之前。
|
||||
|
||||
不管你用的 EL 是何版本,在实际启用时需要先导入 GPG 密钥:
|
||||
|
||||
```
|
||||
# rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
|
||||
```
|
||||
|
||||
**在 EL5 中启用 ELRepo:**
|
||||
|
||||
```
|
||||
# rpm -Uvh http://www.elrepo.org/elrepo-release-5-5.el5.elrepo.noarch.rpm
|
||||
```
|
||||
|
||||
**在 EL6 中启用 ELRepo:**
|
||||
|
||||
```
|
||||
# rpm -Uvh http://www.elrepo.org/elrepo-release-6-6.el6.elrepo.noarch.rpm
|
||||
```
|
||||
|
||||
**在 EL7 中启用 ELRepo:**
|
||||
|
||||
```
|
||||
# rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-2.el7.elrepo.noarch.rpm
|
||||
```
|
||||
|
||||
这篇文章只会覆盖 EL7,在接下来的小节中分享几个例子。
|
||||
|
||||
### 理解 ELRepo 频道
|
||||
|
||||
为了更好地组织仓库中的软件,ELRepo 共分为 4 个独立频道:
|
||||
|
||||
* elrepo 是主频道,默认情况下启用。它不包含正式发行版中的包。
|
||||
* elrepo-extras 包含可以替代发行版提供的软件包。默认情况下不启用。为了避免混淆,当需要从该仓库中安装或更新软件包时,可以通过以下方式临时启用该频道(将软件包替换为实际软件包名称):`# yum --enablerepo=elrepo-extras install package`
|
||||
* elrepo-testing 提供将放入主频道中,但是仍在测试中的软件包。
|
||||
* elrepo-kernel 提供长期及稳定的主线内核,它们已经特别为 EL 配置过。
|
||||
|
||||
默认情况下,elrepo-testing 和 elrepo-kernel 都被禁用,如果我们[需要从中安装或更新软件包][3],可以像 elrepo-extras 那样启用它们。
|
||||
|
||||
要列出每个频道中的可用软件包,请运行以下命令之一:
|
||||
|
||||
```
|
||||
# yum --disablerepo="*" --enablerepo="elrepo" list available
|
||||
# yum --disablerepo="*" --enablerepo="elrepo-extras" list available
|
||||
# yum --disablerepo="*" --enablerepo="elrepo-testing" list available
|
||||
# yum --disablerepo="*" --enablerepo="elrepo-kernel" list available
|
||||
```
|
||||
|
||||
下面的图片说明了第一个例子:
|
||||
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
*列出 ELRepo 可用的软件包*
|
||||
|
||||
##### 总结
|
||||
|
||||
本篇文章中,我们已经解释 ELRepo 是什么,以及你从如何将它们添加到你的软件源。
|
||||
|
||||
如果你对本文有任何问题或意见,请随时在评论栏中联系我们。我们期待你的回音!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Gabriel Cánepa - 一位来自阿根廷圣路易斯梅塞德斯镇 (Villa Mercedes, San Luis, Argentina) 的 GNU/Linux 系统管理员,Web 开发者。就职于一家世界领先级的消费品公司,乐于在每天的工作中能使用 FOSS 工具来提高生产力。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/enable-elrepo-in-rhel-centos-scientific-linux/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
|
||||
[1]:http://www.tecmint.com/install-upgrade-kernel-version-in-centos-7/
|
||||
[2]:https://wiki.centos.org/AdditionalResources/Repositories
|
||||
[3]:http://www.tecmint.com/auto-install-security-patches-updates-on-centos-rhel/
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2017/03/List-ELRepo-Available-Packages.png
|
||||
[5]:http://www.tecmint.com/author/gacanepa/
|
||||
[6]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[7]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
85
published/201703/20170323 3 open source link shorteners.md
Normal file
85
published/201703/20170323 3 open source link shorteners.md
Normal file
@ -0,0 +1,85 @@
|
||||
3 个开源的链接缩短器
|
||||
============================================================
|
||||
|
||||
> 想要构建你自己的 URL 缩短器?这些开源项目使这个变得简单。
|
||||
|
||||

|
||||
|
||||
>图片提供: [Paul Lewin][2]。Opensource.com 修改。[CC BY-SA 2.0][3]
|
||||
|
||||
没有人喜欢一个非常长的 URL。
|
||||
|
||||
它们很难解析。但有时候,站点的深层目录结构还有最后加上的大量参数使得 URL 开始变得冗长。在 Twitter 添加自己的链接缩短服务之前的那些日子里,一个长的 URL 意味着不得不削减推文中珍贵的字符。
|
||||
|
||||
如今,因为很多原因,人们开始使用链接缩短器。这样人们可以更容易地输入或记住另一个冗长的网址。它们可以为社交媒体帐户带来一贯的品牌建设。它们使对一组网址进行分析变得更轻松。它们使得为频繁变化的网站 URL 提供统一的入口成为可能。
|
||||
|
||||
URL 缩短器确实有一些不足。在点击之前很难知道链接实际指向哪里,而且如果提供短网址服务消失,就会导致 [烂链(linkrot)][4]。但是尽管面临这些挑战,URL 缩短器不会消失。
|
||||
|
||||
但是,既然已经有这么多免费链接缩短服务,为什么还要自己构建?简而言之:方便控制。虽然有些服务可以让你选择自己的域名来使用,但得到的定制级别不同。使用自托管服务,你可以自己决定服务的运行时间、URL 的格式以及决定谁可以访问你的分析。这是你自己拥有并且可以操作的。
|
||||
|
||||
幸运的是,如果你想建立下一个 bit.ly、goo.gl 或 ow.ly,你可以有很多开源选项。你可以考虑下面几个。
|
||||
|
||||
### Lessn More
|
||||
|
||||
[Lessn More][5] 是一个个人 URL 缩短器,用 PHP 写成,并从一个名为 Buttered URL 的较旧项目 fork 而来,而 Buttered URL 又是从一个名为 Lessn 的项目的分支衍生而来。Lessn More 能提供你对 URL 缩短器所预期的大部分功能:API 和书签支持、自定义 URL 等。还有一些有用的功能,比如可以让 Lessn More 使用单词黑名单来避免不小心创建不适当的 URL、避免“看着相似”的字符来使 URL 更易读、能够选择是否使用混合大小写的字符,以及一些其它有用的功能。
|
||||
|
||||
[Lessn More][6] 在 GitHub 上以三句版 [BSD][8] 许可证公布了[源代码][7]。
|
||||
|
||||
### Polr
|
||||
|
||||
[Polr][9] 将自己描述为“现代、强大、可靠的 URL 缩短器”。它具有相当直接但现代化的界面,像我们这里详细介绍的其他选择那样,还提供了一个 API 来允许你从其他程序中使用它。在这三个可选品中,它在功能上是最轻量级的,但如果你正在寻找一个简单但功能完整的选择,那么这可能是你不错的选择。下载之前你可以查看[在线演示][10]。
|
||||
|
||||
Polr 的[源代码][11] 在 GitHub 中以 [GPLv2][12] 许可证公布。
|
||||
|
||||
### YOURLS
|
||||
|
||||
[YOURLS][13],是 “Your Own URL Shortener”(你自己的 URL 缩短器)的缩写,它是我最熟悉的选择。我在个人网站上已经运行了好几年,并且对其功能非常满意。
|
||||
|
||||
它是用 PHP 编写的,YOURLS 功能非常丰富并且可以很好地开箱即用。你可以将其配置为任何人可公开使用,或只允许某些用户使用它。它支持自定义 URL,拥有书签功能,使得共享很容易,它还具有非常强大的内置统计信息,并支持可插拔的架构,以允许其他人添加功能。它还有一个 API,可以轻松地用它创建其他程序。
|
||||
|
||||
你可以在 Github 中找到 [MIT 许可证][15]下的 YOURLS [源代码][14]。
|
||||
|
||||
* * *
|
||||
|
||||
这些选择都不喜欢么?看下互联网,你会发现还有其他几个选择:[shuri][16]、[Nimbus][17]、[Lstu][18] 等等。除了这些选择外,构建链接缩短器可以作为帮助了解新语言或 Web 框架的第一次编程项目。毕竟,它的核心功能非常简单:以 URL 作为输入,并重定向到另一个 URL。除此之外,它取决于你自己想要添加的功能。
|
||||
|
||||
你有喜欢但没有在这里列出的 URL 缩短器吗?请在评论栏中让我们知道你的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Jason Baker - Jason 热衷于使用技术使世界更加开放,从软件开发到阳光政府行动。Linux 桌面爱好者、地图/地理空间爱好者、树莓派工匠、数据分析和可视化极客、偶尔的码农、云本土主义者。在 Twitter 上关注他 @jehb。
|
||||
|
||||
------------
|
||||
|
||||
via: https://opensource.com/article/17/3/url-link-shortener
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jason-baker
|
||||
[1]:https://opensource.com/article/17/3/url-link-shortener?rate=5EGysFmjsUsxCc74bffDni4sFxxaIYiGRUG3UPznav8
|
||||
[2]:https://www.flickr.com/photos/digypho/7905320090
|
||||
[3]:https://creativecommons.org/licenses/by/2.0/
|
||||
[4]:https://en.wikipedia.org/wiki/Linkrot
|
||||
[5]:https://lessnmore.net/
|
||||
[6]:https://lessnmore.net/
|
||||
[7]:https://github.com/alanhogan/lessnmore
|
||||
[8]:https://github.com/alanhogan/lessnmore/blob/master/LICENSE.txt
|
||||
[9]:https://project.polr.me/
|
||||
[10]:http://demo.polr.me/
|
||||
[11]:https://github.com/cydrobolt/polr
|
||||
[12]:https://github.com/cydrobolt/polr/blob/master/LICENSE
|
||||
[13]:https://yourls.org/
|
||||
[14]:https://github.com/YOURLS/YOURLS
|
||||
[15]:https://github.com/YOURLS/YOURLS/blob/master/LICENSE.md
|
||||
[16]:https://github.com/pips-/shuri
|
||||
[17]:https://github.com/ethanal/nimbus
|
||||
[18]:https://github.com/ldidry/lstu
|
||||
[19]:https://opensource.com/user/19894/feed
|
||||
[20]:https://opensource.com/article/17/3/url-link-shortener#comments
|
||||
[21]:https://opensource.com/users/jason-baker
|
||||
@ -0,0 +1,53 @@
|
||||
一个可对显示器造成物理伤害的 Xfce Bug
|
||||
=======================================
|
||||
|
||||
Linux 上使用 Xfce 桌面环境或许是又快又灵活的 — 但是它目前在遭受着一个很严重的缺陷影响。
|
||||
|
||||
使用这个轻量级替代 GNOME 和 KDE 的 Xfce 桌面的用户报告说,其选用的默认壁纸会造成**笔记本电脑显示器和液晶显示器的损坏**!!!
|
||||
|
||||
有确凿的照片证据来支持此观点。
|
||||
|
||||
### Xfce Bug #12117
|
||||
|
||||
_“桌面默认开机画面造成显示器损坏!”_ 某用户在 Xfce 的 Bugzilla [Bug 提交区][1]尖叫道。
|
||||
|
||||
_“默认桌面壁纸导致我的动物去抓它,从我的液晶显示器掉落下来塑料!能让我们选择不同的壁纸吗?我不想再有划痕,谁想呢?让我们结束这老鼠游戏吧。”_ (LCTT 译注:原文是 whu not,可能想打 who not,也许因屏幕坏了太激动打错字了)
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
这缺陷(flaw) — 或者说是这爪爪(claw)? — 不是个别用户的桌面遇到问题。其他用户也重现了这个问题,尽管不太一样,在这第二个例子,是 <ruby>红迪网友<rt>Redditor</rt></ruby> 的不同图片证实的:
|
||||
|
||||

|
||||
|
||||
目前不知道这锅是 Xfce 的还是猫猫的。如果是后者就没希望修复了,就像便宜的 Android 手机商品(LCTT 译注:原文这里是用 cats 这个单词,是 catalogues 的缩写,一语双关“猫”。原文作者也是个猫奴,#TeamCat 成员)从来得不到他们的 OEM 厂商的升级。
|
||||
|
||||
值得庆幸的是 Xubuntu 用户们并没有受到这“爪爪”问题的影响。这是因为它这个基于 Xfce 的 Ubuntu 特色版带有自己的非老鼠的桌面壁纸。
|
||||
|
||||
对其他 Linux 发行版的 Xfce 用户来说,“爪爪们”显然对其桌面倒不是那么感兴趣。
|
||||
|
||||
已经有人已经提出了一个补丁修复这个问题,但是上游尚未接受。如果你们关注了 [bug #12117][1] ,就可以在你们自己的系统上手动应用这个补丁,去下载以下图片并设置成桌面壁纸。
|
||||
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2017/03/xfce-wallpaper-cat-bug
|
||||
|
||||
作者:[JOEY SNEDDON][a]
|
||||
译者:[ddvio](https://github.com/ddvio)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://bugzilla.xfce.org/show_bug.cgi?id=12117
|
||||
[2]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[3]:http://www.omgubuntu.co.uk/category/random-2
|
||||
[4]:http://www.omgubuntu.co.uk/wp-content/uploads/2017/02/xubuntu.jpg
|
||||
[5]:http://www.omgubuntu.co.uk/2017/03/xfce-wallpaper-cat-bug
|
||||
[6]:http://www.omgubuntu.co.uk/wp-content/uploads/2017/03/cat-xfce-bug-2.jpg
|
||||
[7]:http://www.omgubuntu.co.uk/wp-content/uploads/2017/03/xfce-dog-wallpaper.jpg
|
||||
@ -0,0 +1,177 @@
|
||||
如何在 Ubuntu 以及 Debian 中安装 DHCP 服务器
|
||||
============================================================
|
||||
|
||||
**动态主机配置协议(DHCP)** 是一种用于使主机能够从服务器自动分配 IP 地址和相关的网络配置的网络协议。
|
||||
|
||||
DHCP 服务器分配给 DHCP 客户端的 IP 地址处于“租用”状态,租用时间通常取决于客户端计算机要求连接的时间或 DHCP 服务器配置的时间。
|
||||
|
||||
#### DHCP 如何工作?
|
||||
|
||||
以下是 DHCP 实际工作原理的简要说明:
|
||||
|
||||
* 一旦客户端(配置为使用 DHCP 的机器)连接到网络后,它会向 DHCP 服务器发送 **DHCPDISCOVER** 数据包。
|
||||
* 当 DHCP 服务器收到 **DHCPDISCOVER** 请求报文后会使用 **DHCPOFFER** 包进行回复。
|
||||
* 然后客户端获取到 **DHCPOFFER** 数据包,并向服务器发送一个 **DHCPREQUEST** 包,表示它已准备好接收 **DHCPOFFER** 包中提供的网络配置信息。
|
||||
* 最后,DHCP 服务器从客户端收到 **DHCPREQUEST** 报文后,发送 **DHCPACK** 报文,表示现在允许客户端使用分配给它的 IP 地址。
|
||||
|
||||
在本文中,我们将介绍如何在 Ubuntu/Debian Linux 中设置 DHCP 服务器,我们将使用 [sudo 命令][1]来运行所有命令,以获得 root 用户权限。
|
||||
|
||||
### 测试环境设置
|
||||
|
||||
在这步中我们会使用如下的测试环境。
|
||||
|
||||
- DHCP Server - Ubuntu 16.04
|
||||
- DHCP Clients - CentOS 7 and Fedora 25
|
||||
|
||||
### 步骤 1:在 Ubuntu 中安装 DHCP 服务器
|
||||
|
||||
1、 运行下面的命令来安装 DHCP 服务器包,也就是 **dhcp3-server**。
|
||||
|
||||
```
|
||||
$ sudo apt install isc-dhcp-server
|
||||
```
|
||||
|
||||
2、 安装完成后,编辑 `/etc/default/isc-dhcp-server` 使用 `INTERFACES` 选项定义 DHCPD 响应 DHCP 请求所使用的接口。
|
||||
|
||||
比如,如果你想让 DHCPD 守护进程监听 `eth0`,按如下设置:
|
||||
|
||||
```
|
||||
INTERFACES="eth0"
|
||||
```
|
||||
|
||||
同样记得为上面的接口[配置静态地址][2]。
|
||||
|
||||
### 步骤 2:在 Ubuntu 中配置 DHCP 服务器
|
||||
|
||||
3、 DHCP 配置的主文件是 `/etc/dhcp/dhcpd.conf`, 你必须填写会发送到客户端的所有网络信息。
|
||||
|
||||
并且 DHCP 配置中定义了两种不同的声明,它们是:
|
||||
|
||||
* `parameters` - 指定如何执行任务、是否执行任务,还有指定要发送给 DHCP 客户端的网络配置选项。
|
||||
* `declarations` - 定义网络拓扑、指定客户端、为客户端提供地址,或将一组参数应用于一组声明。
|
||||
|
||||
4、 现在打开并修改主文件,定义 DHCP 服务器选项:
|
||||
|
||||
```
|
||||
$ sudo vi /etc/dhcp/dhcpd.conf
|
||||
```
|
||||
|
||||
在文件顶部设置以下全局参数,它们将应用于下面的所有声明(请指定适用于你情况的值):
|
||||
|
||||
```
|
||||
option domain-name "tecmint.lan";
|
||||
option domain-name-servers ns1.tecmint.lan, ns2.tecmint.lan;
|
||||
default-lease-time 3600;
|
||||
max-lease-time 7200;
|
||||
authoritative;
|
||||
```
|
||||
|
||||
5、 现在定义一个子网,这里我们为 `192.168.10.0/24` 局域网设置 DHCP (请使用适用你情况的参数):
|
||||
|
||||
```
|
||||
subnet 192.168.10.0 netmask 255.255.255.0 {
|
||||
option routers 192.168.10.1;
|
||||
option subnet-mask 255.255.255.0;
|
||||
option domain-search "tecmint.lan";
|
||||
option domain-name-servers 192.168.10.1;
|
||||
range 192.168.10.10 192.168.10.100;
|
||||
range 192.168.10.110 192.168.10.200;
|
||||
}
|
||||
```
|
||||
|
||||
### 步骤 3:在 DHCP 客户端上配置静态地址
|
||||
|
||||
6、 要给特定的客户机分配一个固定的(静态)的 IP,你需要显式将这台机器的 MAC 地址以及静态分配的地址添加到下面这部分。
|
||||
|
||||
```
|
||||
host centos-node {
|
||||
hardware ethernet 00:f0:m4:6y:89:0g;
|
||||
fixed-address 192.168.10.105;
|
||||
}
|
||||
host fedora-node {
|
||||
hardware ethernet 00:4g:8h:13:8h:3a;
|
||||
fixed-address 192.168.10.106;
|
||||
}
|
||||
```
|
||||
|
||||
保存并关闭文件。
|
||||
|
||||
7、 接下来,启动 DHCP 服务,并让它下次开机自启动,如下所示:
|
||||
|
||||
```
|
||||
------------ SystemD ------------
|
||||
$ sudo systemctl start isc-dhcp-server.service
|
||||
$ sudo systemctl enable isc-dhcp-server.service
|
||||
------------ SysVinit ------------
|
||||
$ sudo service isc-dhcp-server.service start
|
||||
$ sudo service isc-dhcp-server.service enable
|
||||
```
|
||||
|
||||
8、 接下来不要忘记允许 DHCP 服务(DHCP 守护进程监听 67 UDP 端口)的防火墙权限:
|
||||
|
||||
```
|
||||
$ sudo ufw allow 67/udp
|
||||
$ sudo ufw reload
|
||||
$ sudo ufw show
|
||||
```
|
||||
|
||||
### 步骤 4:配置 DHCP 客户端
|
||||
|
||||
9、 此时,你可以将客户端计算机配置为自动从 DHCP 服务器接收 IP 地址。
|
||||
|
||||
登录到客户端并编辑以太网接口的配置文件(注意接口名称/号码):
|
||||
|
||||
```
|
||||
$ sudo vi /etc/network/interfaces
|
||||
```
|
||||
|
||||
定义如下选项:
|
||||
|
||||
```
|
||||
auto eth0
|
||||
iface eth0 inet dhcp
|
||||
```
|
||||
|
||||
保存文件并退出。重启网络服务(或重启系统):
|
||||
|
||||
```
|
||||
------------ SystemD ------------
|
||||
$ sudo systemctl restart networking
|
||||
------------ SysVinit ------------
|
||||
$ sudo service networking restart
|
||||
```
|
||||
|
||||
另外你也可以使用 GUI 来在进行设置,如截图所示(在 Fedora 25 桌面中)设置将方式设为自动(DHCP)。
|
||||
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
*在 Fedora 中设置 DHCP 网络*
|
||||
|
||||
此时,如果所有设置完成了,你的客户端应该可以自动从 DHCP 服务器接收 IP 地址了。
|
||||
|
||||
就是这样了!在本篇教程中,我们向你展示了如何在 Ubuntu/Debian 设置 DHCP 服务器。在反馈栏中分享你的想法。如果你正在使用基于 Fedora 的发行版,请阅读如何在 CentOS/RHEL 中设置 DHCP 服务器。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
作者简介:
|
||||
|
||||
Aaron Kili 是 Linux 和 F.O.S.S 爱好者,将来的 Linux SysAdmin 和 web 开发人员,目前是 TecMint 的内容创建者,他喜欢用电脑工作,并坚信分享知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-dhcp-server-in-ubuntu-debian/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:https://linux.cn/tag-sudo.html
|
||||
[2]:http://www.tecmint.com/set-add-static-ip-address-in-linux/
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2017/03/Set-DHCP-Network-in-Fedora.png
|
||||
[4]:http://www.tecmint.com/author/aaronkili/
|
||||
[5]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[6]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -0,0 +1,107 @@
|
||||
如何在 Vim 中进行文本选择操作和使用标志
|
||||
============================================================
|
||||
|
||||
基于图形界面的文本或源代码编辑器,提供了一些诸如文本选择的功能。我是想说,可能大多数人不觉得这是一个功能。不过像 Vim 这种基于命令行的编辑器就不是这样。当你仅使用键盘操作 Vim 的时候,就需要学习特定的命令来选择你想要的文本。在这个教程中,我们将详细讨论文本选择这一功能以及 Vim 中的标志功能。
|
||||
|
||||
在此之前需要说明的是,本教程中所提到的例子、命令和指令都是在 Ubuntu 16.04 的环境下测试的。Vim 的版本是 7.4。
|
||||
|
||||
### Vim 的文本选择功能
|
||||
|
||||
我们假设你已经具备了 Vim 编辑器的基本知识(如果没有,可以先阅读[这篇文章][2])。你应该知道,`d` 命令能够剪切/删除一行内容。如果你想要剪切 3 行的话,可以重复命令 3 次。不过,如果需要剪切 15 行呢?重复 `d` 命令 15 次是个实用的解决方法吗?
|
||||
|
||||
显然不是。这种情况下的最佳方法是,选中你想要剪切/删除的行,再运行 `d` 命令。举个例子:
|
||||
|
||||
假如我想要剪切/删除下面截图中 INTRODUCTION 小节的第一段:
|
||||
|
||||
[][3]
|
||||
|
||||
那么我的做法是:将光标放在第一行的开始,(确保退出了 Insert 模式)按下 `V`(即 `Shift+v`)命令。这时 Vim 会开启视图模式,并选中第一行。
|
||||
|
||||
[][4]
|
||||
|
||||
现在,我可以使用方向键“下”,来选中整个段落。
|
||||
|
||||
[][5]
|
||||
|
||||
这就是我们想要的,对吧!现在只需按 `d` 键,就可以剪切/删除选中的段落了。当然,除了剪切/删除,你可以对选中的文本做任何操作。
|
||||
|
||||
这给我们带来了另一个重要的问题:当我们不需要删除整行的时候,该怎么做呢?也就是说,我们刚才讨论的解决方法,仅适用于想要对整行做操作的情况。那么如果我们只想删除段落的前三句话呢?
|
||||
|
||||
其实也有相应的命令 - 只需用小写 `v` 来代替大写 `V` 即可。在下面的例子中,我使用 `v` 来选中段落的前三句话:
|
||||
|
||||
[][6]
|
||||
|
||||
有时候,你需要处理的数据由单独的列组成,你的需求可能是选择特定的一列。考虑下面的截图:
|
||||
|
||||
[][7]
|
||||
|
||||
假设我们只需选择文本的第二列,即国家的名字。这种情况下,你可以将光标放在这一列的第一个字母上,按 `Ctrl+v` 一次。然后,按方向键“下”,选中每个国家名字的第一个字母:
|
||||
|
||||
[][8]
|
||||
|
||||
然后按方向键“右”,选中这一列。
|
||||
|
||||
[][9]
|
||||
|
||||
**小窍门**:如果你之前选中了某个文本块,现在想重新选中那个文本块,只需在命令模式下按 `gv` 即可。
|
||||
|
||||
### 使用标志
|
||||
|
||||
有时候,你在处理一个很大的文件(例如源代码文件或者一个 shell 脚本),可能想要切换到一个特定的位置,然后再回到刚才所在的行。如果这两行的位置不远,或者你并不常做这类操作,那么这不是什么问题。
|
||||
|
||||
但是,如果你需要频繁地在当前位置和一些较远的行之间切换,那么最好的方法就是使用标志。你只需标记当前的位置,然后就能够通过标志名,从文件的任意位置回到当前的位置。
|
||||
|
||||
在 Vim 中,我们使用 `m` 命令紧跟一个字母来标记一行(字母表示标志名,可用小写的 `a` - `z`)。例如 `ma`。然后你可以使用命令 `'a` (包括左侧的单引号)回到标志为 `a` 的行。
|
||||
|
||||
**小窍门**:你可以使用“单引号” `'` 来跳转到标志行的第一个字符,或使用“反引号” ` 来跳转到标志行的特定列。
|
||||
|
||||
Vim 的标志功能还有很多其他的用法。例如,你可以先标记一行,然后将光标移到其他行,运行下面的命令:
|
||||
|
||||
```
|
||||
d'[标志名]
|
||||
```
|
||||
|
||||
来删除当前位置和标志行之间的所有内容。
|
||||
|
||||
在 Vim 官方文档中,有一个重要的内容:
|
||||
|
||||
> 每个文件有一些由小写字母(`a`-`z`)定义的标志。此外,还存在一些由大写字母(`A`-`Z`)定义的全局标志,它们定义了一个特定文件的某个位置。例如,你可能在同时编辑十个文件,每个文件都可以有标志 `a`,但是只有一个文件能够有标志 `A`。
|
||||
|
||||
我们已经讨论了使用小写字母作为 Vim 标志的基本用法,以及它们的便捷之处。下面的这段摘录讲解的足够清晰:
|
||||
|
||||
> 由于种种局限性,大写字母标志可能乍一看不如小写字母标志好用,但它可以用作一种快速的文件书签。例如,打开 `.vimrc` 文件,按下 `mV`,然后退出。下次再想要编辑 `.vimrc` 文件的时候,按下 `'V` 就能够打开它。
|
||||
|
||||
最后,我们使用 `delmarks` 命令来删除标志。例如:
|
||||
|
||||
```
|
||||
:delmarks a
|
||||
```
|
||||
|
||||
这一命令将从文件中删除一个标志。当然,你也可以删除标志所在的行,这样标志将被自动删除。你可以在 [Vim 文档][11] 中找到关于标志的更多信息。
|
||||
|
||||
### 总结
|
||||
|
||||
当你开始使用 Vim 作为首选编辑器的时候,类似于这篇教程中提到的功能将会是非常有用的工具,能够节省大量的时间。你得承认,这里介绍的文本选择和标志功能几乎不怎么需要学习,所需要的只是一点练习。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-use-markers-and-perform-text-selection-in-vim/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[Cathon](https://github.com/Cathon)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/how-to-use-markers-and-perform-text-selection-in-vim/
|
||||
[1]:https://www.howtoforge.com/tutorials/shell/
|
||||
[2]:https://linux.cn/article-8143-1.html
|
||||
[3]:https://www.howtoforge.com/images/how-to-use-markers-and-perform-text-selection-in-vim/big/vim-select-example.png
|
||||
[4]:https://www.howtoforge.com/images/how-to-use-markers-and-perform-text-selection-in-vim/big/vim-select-initiated.png
|
||||
[5]:https://www.howtoforge.com/images/how-to-use-markers-and-perform-text-selection-in-vim/big/vim-select-working.png
|
||||
[6]:https://www.howtoforge.com/images/how-to-use-markers-and-perform-text-selection-in-vim/big/vim-select-partial-lines.png
|
||||
[7]:https://www.howtoforge.com/images/how-to-use-markers-and-perform-text-selection-in-vim/big/vim-select-columns.png
|
||||
[8]:https://www.howtoforge.com/images/how-to-use-markers-and-perform-text-selection-in-vim/big/vim-select-column-1.png
|
||||
[9]:https://www.howtoforge.com/images/how-to-use-markers-and-perform-text-selection-in-vim/big/vim-select-column-2.png
|
||||
[10]:http://vim.wikia.com/wiki/Vimrc
|
||||
[11]:http://vim.wikia.com/wiki/Using_marks
|
||||
62
published/20170320 Why Go.md
Normal file
62
published/20170320 Why Go.md
Normal file
@ -0,0 +1,62 @@
|
||||
为什么使用 Go 语言?
|
||||
============================================================
|
||||
|
||||
几个星期前,我一个朋友问我:“为什么要关心 Go 语言”? 因为他们知道我热衷于 Go 语言,但他们想知道为什么我认为_其他人_也应该关心。本文包含三个我认为 Go 是重要的编程语言的原因。
|
||||
|
||||
### 安全
|
||||
|
||||
个人而言,你和我或许完全有能力在 C 中编写程序,既不会泄漏内存,也不会不安全地重复使用内存。然而,整体上,即使有超过 [40 年][5]的经验,用 C 的程序员也无法可靠地这样做。
|
||||
|
||||
尽管静态代码分析、valgrind、tsan 以及 “-Werror” 已经存在了几十年,却很少有证据表明这些工具被广泛认可,更不用说广泛采用。总而言之,事实表明,程序员根本无法安全地管理自己的内存。现在是离开 C 的时候了。
|
||||
|
||||
Go 不需要程序员直接管理内存,所有内存分配都由语言运行时自行管理,使用前初始化,必要时检查边界。它肯定不是提供这些安全保障的第一个主流语言,Java(1995)可能是该冠军的竞争者。关键是,世界对不安全的编程语言没有胃口,所以人们默认认为,Go 是内存安全的。
|
||||
|
||||
### 开发人员生产力
|
||||
|
||||
从 20 世纪 70 年代末,开发人员的时间变得比硬件所耗费的时间更昂贵了。开发人员的生产力是一个不断扩展的话题,但它归结为这一点:你花了多少时间做有用的工作,又有多少时间等待编译器或者失望地迷失在外部代码库中。
|
||||
|
||||
有个笑话说 Go 是在等待 [C ++ 程序编译][6]时开发的。快速编译是 Go 的一个重要功能,也是吸引新开发人员的关键工具。虽然编译速度仍然是一个[永久的战场][7],但公平地说,在其他语言中需要几分钟的编译,在 Go 中只需要几秒钟。
|
||||
|
||||
Go 程序员意识到生产力的更根本的问题是代码是**为了读而写的**,所以将[代码的阅读行为放在编写之上][8]。Go 通过工具和自定义来强制所有代码格式化成特定的样式。这消除了学习项目特定语言的方言时的困难,并有助于发现错误,因为它们**看上去**就是不正确。
|
||||
|
||||
由于专注于分析和机器辅助,Go 开发人员开始采用越来越多的工具来发现常见的编码错误,这种工具从来没有在 C 语言开发者中产生共鸣 - Go 开发人员**希望**工具帮助他们保持代码清洁。
|
||||
|
||||
### 并发性
|
||||
|
||||
十多年来,芯片设计师一直在警告[免费午餐将会结束][9]。从最低端的手机到最耗电的服务器,硬件的并行性以[更多、更慢、堆砌 cpu 内核][10]的形式出现,但只有**当**你的语言可以利用它们才有意义。因此,并发特性需要内置到我们编写的要在今天的硬件上运行的软件中。
|
||||
|
||||
通过提供一种基于协程的[轻量级并发模型][11],或者是 Go 中已知的 goroutines,Go 超越了那些暴露操作系统的多进程或多线程并行模型的语言。goroutines 允许程序员避开复杂的回调,而语言运行时确保有足够的线程来保持你的内核的活跃。
|
||||
|
||||
### 总结
|
||||
|
||||
我给朋友推荐 Go 有三个原因:安全性、生产力和并发性。有些语言可以涵盖一个也有可能是两个方面,但是这三个方面的结合使得 Go 成为主流程序员的绝佳选择。
|
||||
|
||||
### 相关文章:
|
||||
|
||||
1. [为什么 Go 和 Rust 不是竞争对手][1]
|
||||
2. [听听我在 OSCON 上谈 Go 语言性能][2]
|
||||
3. [我在 GopherChina 和 GopherCon Singapore 中的演讲][3]
|
||||
4. [压力测试你 Go 包][4]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://dave.cheney.net/2017/03/20/why-go
|
||||
|
||||
作者:[Dave Cheney][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://dave.cheney.net/
|
||||
[1]:https://dave.cheney.net/2015/07/02/why-go-and-rust-are-not-competitors
|
||||
[2]:https://dave.cheney.net/2015/05/31/hear-me-speak-about-go-performance-at-oscon
|
||||
[3]:https://dave.cheney.net/2017/02/09/im-speaking-at-gopherchina-and-gophercon-singapore
|
||||
[4]:https://dave.cheney.net/2013/06/19/stress-test-your-go-packages
|
||||
[5]:https://en.wikipedia.org/wiki/C_(programming_language)
|
||||
[6]:https://commandcenter.blogspot.com.au/2012/06/less-is-exponentially-more.html
|
||||
[7]:https://dave.cheney.net/2016/11/19/go-1-8-toolchain-improvements
|
||||
[8]:https://twitter.com/rob_pike/status/791326139012620288
|
||||
[9]:http://www.gotw.ca/publications/concurrency-ddj.htm
|
||||
[10]:https://www.technologyreview.com/s/601441/moores-law-is-dead-now-what/
|
||||
[11]:https://blog.golang.org/concurrency-is-not-parallelism
|
||||
94
published/20170327 Using vi-mode in your shell.md
Normal file
94
published/20170327 Using vi-mode in your shell.md
Normal file
@ -0,0 +1,94 @@
|
||||
在 shell 中使用 vi 模式
|
||||
============================================================
|
||||
|
||||
> 介绍在命令行编辑中使用 vi 模式。
|
||||
|
||||

|
||||
|
||||
>图片提供: opensource.com
|
||||
|
||||
作为一名大型开源社区的参与者,更确切地说,作为 [Fedora 项目][2]的成员,我有机会与许多人会面并讨论各种有趣的技术主题。我最喜欢的主题是“命令行”或者说 [shell][3],因为了解人们如何熟练使用 shell 可以让你深入地了解他们的想法,他们喜欢什么样的工作流程,以及某种程度上是什么激发了他们的灵感。许多开发和运维人员在互联网上公开分享他们的“ dot 文件”(他们的 shell 配置文件的常见俚语),这将是一个有趣的协作机会,让每个人都能从对命令行有丰富经验的人中学习提示和技巧并分享快捷方式以及有效率的技巧。
|
||||
|
||||
今天我在这里会为你介绍 shell 中的 vi 模式。
|
||||
|
||||
在计算和操作系统的庞大生态系统中有[很多 shell][4]。然而,在 Linux 世界中,[bash][5] 已经成为事实上的标准,并在在撰写本文时,它是所有主要 Linux 发行版上的默认 shell。因此,它就是我所说的 shell。需要注意的是,bash 在其他类 UNIX 操作系统上也是一个相当受欢迎的选项,所以它可能跟你用的差别不大(对于 Windows 用户,可以用 [cygwin][6])。
|
||||
|
||||
在探索 shell 时,首先要做的是在其中输入命令并得到输出,如下所示:
|
||||
|
||||
```
|
||||
$ echo "Hello World!"
|
||||
Hello World!
|
||||
```
|
||||
|
||||
这是常见的练习,可能每个人都做过。没接触过的人和新手可能没有意识到 [bash][7] shell 的默认输入模式是 [Emacs][8] 模式,也就是说命令行中所用的行编辑功能都将使用 [Emacs 风格的“键盘快捷键”][9]。(行编辑功能实际上是由 [GNU Readline][10] 进行的。)
|
||||
|
||||
例如,如果你输入了 `echo "Hello Wrld!"`,并意识到你想要快速跳回一个单词(空格分隔)来修改打字错误,而无需按住左箭头键,那么你可以同时按下 `Alt+b`,光标会将向后跳到 `W`。
|
||||
|
||||
```
|
||||
$ echo "Hello Wrld!"
|
||||
^
|
||||
Cursor is here.
|
||||
```
|
||||
|
||||
这只是使用提供给 shell 用户的诸多 Emacs 快捷键组合之一完成的。还有其他更多东西,如复制文本、粘贴文本、删除文本以及使用快捷方式来编辑文本。使用复杂的快捷键组合并记住可能看起来很愚蠢,但是在使用较长的命令或从 shell 历史记录中调用一个命令并想再次编辑执行时,它们可能会非常强大。
|
||||
|
||||
尽管 Emacs 的键盘绑定都不错,如果你对 Emacs 编辑器熟悉或者发现它们很容易使用也不错,但是仍有一些人觉得 “vi 风格”的键盘绑定更舒服,因为他们经常使用 vi 编辑器(通常是 [vim][11] 或 [nvim][12])。bash shell(再说一次,通过 GNU Readline)可以为我们提供这个功能。要启用它,需要执行命令 `$ set -o vi`。
|
||||
|
||||
就像魔术一样,你现在处于 vi 模式了,现在可以使用 vi 风格的键绑定来轻松地进行编辑,以便复制文本、删除文本、并跳转到文本行中的不同位置。这与 Emacs 模式在功能方面没有太大的不同,但是它在你_如何_与 shell 进行交互执行操作上有一些差别,根据你的喜好这是一个强大的选择。
|
||||
|
||||
我们来看看先前的例子,但是在这种情况下一旦你在 shell 中进入 vi 模式,你就处于 INSERT 模式中,这意味着你可以和以前一样输入命令,现在点击 **Esc** 键,你将处于 NORMAL 模式,你可以自由浏览并进行文字修改。
|
||||
|
||||
看看先前的例子,如果你输入了 `echo "Hello Wrld!"`,并意识到你想跳回一个单词(再说一次,用空格分隔的单词)来修复那个打字错误,那么你可以点击 `Esc` 从 INSERT 模式变为 NORMAL 模式。然后,您可以输入 `B`(即 `Shift+b`),光标就能像以前那样回到前面了。(有关 vi 模式的更多信息,请参阅[这里][13]。):
|
||||
|
||||
```
|
||||
$ echo "Hello Wrld!"
|
||||
^
|
||||
Cursor is here.
|
||||
```
|
||||
|
||||
现在,对于 vi/vim/nvim 用户来说,你会惊喜地发现你可以一直使用相同的快捷键,而不仅仅是在编辑器中编写代码或文档的时候。如果你从未了解过这些,并且想要了解更多,那么我可能会建议你看看这个[交互式 vim 教程][14],看看 vi 风格的编辑是否有你所不知道的。
|
||||
|
||||
如果你喜欢在此风格下与 shell 交互,那么你可以在主目录中的 `~/.bashrc` 文件底部添加下面的行来持久设置它。
|
||||
|
||||
```
|
||||
set -o vi
|
||||
```
|
||||
|
||||
对于 emacs 模式的用户,希望这可以让你快速并愉快地看到 shell 的“另一面”。在结束之前,我认为每个人都应该使用任意一个让他们更有效率的编辑器和 shell 行编辑模式,如果你使用 vi 模式并且这篇文章给你展开了新的一页,那么恭喜你!现在就变得更有效率吧。
|
||||
|
||||
玩得愉快!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Adam Miller 是 Fedora 工程团队成员,专注于 Fedora 发布工程。他的工作包括下一代构建系统、自动化、RPM 包维护和基础架构部署。Adam 在山姆休斯顿州立大学完成了计算机科学学士学位与信息保障与安全科学硕士学位。他是一名红帽认证工程师(Cert#110-008-810),也是开源社区的活跃成员,并对 Fedora 项目(FAS 帐户名称:maxamillion)贡献有着悠久的历史。
|
||||
|
||||
|
||||
------------------------
|
||||
via: https://opensource.com/article/17/3/fun-vi-mode-your-shell
|
||||
|
||||
作者:[Adam Miller][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/maxamillion
|
||||
[1]:https://opensource.com/article/17/3/fun-vi-mode-your-shell?rate=5_eAB9UtByHOiZMysPcewU4Zz6hOrLwdcgIpu2Ub4vo
|
||||
[2]:https://getfedora.org/
|
||||
[3]:https://opensource.com/business/16/3/top-linux-shells
|
||||
[4]:https://opensource.com/business/16/3/top-linux-shells
|
||||
[5]:https://tiswww.case.edu/php/chet/bash/bashtop.html
|
||||
[6]:http://cygwin.org/
|
||||
[7]:https://tiswww.case.edu/php/chet/bash/bashtop.html
|
||||
[8]:https://www.gnu.org/software/emacs/
|
||||
[9]:https://en.wikipedia.org/wiki/GNU_Readline#Emacs_keyboard_shortcuts
|
||||
[10]:http://cnswww.cns.cwru.edu/php/chet/readline/rltop.html
|
||||
[11]:http://www.vim.org/
|
||||
[12]:https://neovim.io/
|
||||
[13]:https://en.wikibooks.org/wiki/Learning_the_vi_Editor/Vim/Modes
|
||||
[14]:http://www.openvim.com/tutorial.html
|
||||
[15]:https://opensource.com/user/10726/feed
|
||||
[16]:https://opensource.com/article/17/3/fun-vi-mode-your-shell#comments
|
||||
[17]:https://opensource.com/users/maxamillion
|
||||
@ -1,13 +1,14 @@
|
||||
### Linux Deepin - 一个拥有独特风格的发行版
|
||||
Linux Deepin :一个拥有独特风格的发行版
|
||||
===============
|
||||
|
||||
|
||||
这是本系列的第六篇 **Linux Deepin。**这个发行版真的是非常有意思,它有着许多吸引眼球的地方。许许多多的发行版,它们仅仅将已有的应用放入它的应用市场中,使得它们的应用市场十分冷清。但是 Deepin 却将一切变得不同,虽然这个发行版是基于 Debian 的,但是它提供了属于它自己的桌面环境。只有很少的发行版能够将他自己创造的软件做得很好。上次我们曾经提到了 **Elementary OS ** 有着自己的 Pantheon 桌面环境。让我们来看看 Deepin 做得怎么样。
|
||||
这是本系列的第六篇 **Linux Deepin。**这个发行版真的是非常有意思,它有着许多吸引眼球的地方。许许多多的发行版,它们仅仅将已有的应用放入它的应用市场中,使得它们的应用市场十分冷清。但是 Deepin 却将一切变得不同,虽然这个发行版是基于 Debian 的,但是它提供了属它自己的桌面环境。只有很少的发行版能够将它自己创造的软件做得很好。上次我们曾经提到了 **Elementary OS ** 有着自己的 Pantheon 桌面环境。让我们来看看 Deepin 做得怎么样。
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
首先,在你登录你的账户后,你会在你设计良好的桌面上看到一个欢迎界面和一个精美的 Dock。这个 Dock 是可定制的,当你将软件放到上面后,它可以有着各种特效。
|
||||
首先,在你登录你的账户后,你会在你设计良好的桌面上看到一个欢迎界面和一个精美的 Dock。这个 Dock 是可定制的,根据你放到上面的软件,它可以有着各种特效。
|
||||
|
||||
[
|
||||

|
||||
@ -21,13 +22,11 @@
|
||||
|
||||
你可以做上面的截图中看到,启动器中的应用被分类得井井有条。还有一个好的地方是当你用鼠标点击到左下角,所有桌面上的应用将会最小化。再次点击则会回复原样。
|
||||
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
如果你点击右下角,他将会滑出控制中心。这里可以更改所有电脑上的设置。
|
||||
|
||||
如果你点击右下角,它将会滑出控制中心。这里可以更改所有电脑上的设置。
|
||||
|
||||
[
|
||||

|
||||
@ -35,19 +34,17 @@
|
||||
|
||||
你可以看到截屏中的控制中心,设计得非常棒而且也是分类得井井有条,你可以在这里设置所有电脑上的项目。甚至可以自定义你的启动界面的壁纸。
|
||||
|
||||
|
||||
[
|
||||

|
||||
][11]
|
||||
|
||||
Deepin 有一个自己的应用市场。你可以在这里找到绝大多数软件,并且他们很容易安装。应用市场也被设计得很好,分类齐全易于导航。
|
||||
|
||||
Deepin 有一个自己的应用市场。你可以在这里找到绝大多数软件,并且它们很容易安装。应用市场也被设计得很好,分类齐全易于导航。
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
另一个亮点是 Deepin 的游戏。他提供许多免费的可联网玩耍的游戏,他们非常的有意思可以很好的用于消磨时光。
|
||||
另一个亮点是 Deepin 的游戏。它提供许多免费的可联网玩耍的游戏,它们非常的有意思可以很好的用于消磨时光。
|
||||
|
||||
[
|
||||

|
||||
@ -55,17 +52,17 @@ Deepin 有一个自己的应用市场。你可以在这里找到绝大多数软
|
||||
|
||||
Deepin 也提供一个好用的音乐播放软件,它有着网络电台点播功能。如果你本地没有音乐你也不用害怕,你可以调到网络电台模式来享受音乐。
|
||||
|
||||
总的来说,Deepin 知道如何让用户享受它的产品。就像他们的座右铭那样:“要做,就做出风格”。他们提供的支持服务也非常棒。尽管是个中国的发行版,但是英语支持得也很好,不用担心语言问题。他的安装镜像大约 1.5 GB。你的访问他们的**[官网][14]**来获得更多信息或者下载。我们非常的推荐你试试这个发行版。
|
||||
总的来说,Deepin 知道如何让用户享受它的产品。就像它们的座右铭那样:“要做,就做出风格”。它们提供的支持服务也非常棒。尽管是个中国的发行版,但是英语支持得也很好,不用担心语言问题。它的安装镜像大约 1.5 GB。你的访问它们的**[官网][14]**来获得更多信息或者下载。我们非常的推荐你试试这个发行版。
|
||||
|
||||
这就是本篇**Linux 发行版介绍** 的全部内容了,我们将会继续介绍其他的发行版。下次再见!
|
||||
这就是本篇 **Linux 发行版介绍**的全部内容了,我们将会继续介绍其它的发行版。下次再见!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.techphylum.com/2014/08/linux-deepin-distro-with-unique-style.html
|
||||
|
||||
作者:[sumit rohankar https://plus.google.com/112160169713374382262][a]
|
||||
作者:[sumit rohankar][a]
|
||||
译者:[Chao-zhi](https://github.com/Chao-zhi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,66 @@
|
||||
一个值得推荐的发行版:Manjaro Linux
|
||||
=========
|
||||
|
||||
这个系列的第七篇,我们来说一说什么是 Manjaro。[Manjaro](https://manjaro.org/) 是基于 Arch Linux 并且拥有一个漂亮的用户界面的操作系统。 Manjaro 并不像 Debian 或者 Arch 这些 Linux 发行版一样历史悠久,但是它依然十分的稳定而可靠,从而在各色发行版中显得鹤立鸡群。2011 年 Manjaro 才推出了第一个版本。从那以后它一直在不断的进步,今天最新的版本为 16.06.1,代号为 “Daniella”。(LCTT 译注:本文写作于 2016 年,当下最新版本是:17.0 )
|
||||
|
||||
**为什么我认为 Manjaro 超越了其他的发行版?** 我并没有强求你使用 Manjaro 来替代其他发行版,但是我会尝试说服你来使用 Manjaro。那么让我开始吧!
|
||||
|
||||
### 基于 Arch
|
||||
|
||||
就像许多人已经知道的那样,不开玩笑的说 Arch 绝对是一个优秀的发行版。但是它对于新手来说十分难以使用。许多新手根本就无法在非图形界面下完成 Arch 的安装。与之相反,Manjaro 有着一个好用的图形安装界面。所以那些想要尝试 Arch 但是又被它的高难度操作所困扰的人们可以去试试 Manjaro。Manjaro 很容易安装并且有着一个友好的用户界面。
|
||||
|
||||
### 桌面环境
|
||||
|
||||
Manjaro 在桌面环境上有着许多选择,比如 Xfce、KDE、Deepin、BspWM、Budgie、i3、LXDE、Cinnamon、Enlightenment、Netbook、Fluxbox、Gnome、JWM、LXQT、MATE、Openbox 和 PekWM。所有这些桌面环境在 Manjaro 中都十分漂亮。Manjaro 官方的桌面环境是 Xfce 和 KDE,而其他桌面环境则是社区支持的,我现在就是在 Manjaro 16.06.1 中使用 KDE Plasma 桌面环境。
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
*运行着 KDE plasma 5.6.5 的 Manjaro 16.06.1*
|
||||
|
||||
如果你不喜欢 Manjaro 中的 KDE 或者 Xfce,不用担心,你可以从软件包管理器中随时安装其他桌面环境。
|
||||
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
*从软件包管理器中下载 Budgie 桌面环境。*
|
||||
|
||||
### 稳定并且独特的包管理机制
|
||||
|
||||
虽然 Manjaro 很新,但是它也很稳定。Manjaro 的最后一个版本装载的是Linux 内核 4.6.2。Manjaro 不仅仅稳定,更新也比较快。软件更新不久后,就会被它编译到它的库中。Manjaro 用 pacman 来管理它的软件包。Arch Linux 因 Pacman 而名震天下 (当然也饱受争议)。Manjaro 则使用 Octopi 来使其变得更加用户友好,Octopi 是一个用 Qt 编写的 pacman 的图形前端。Manjaro 很好的维护了他自己的库,这也是它的一个优势。
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
*Octopi 软件包管理器*
|
||||
|
||||
### 社区支持
|
||||
|
||||
和其他发行版一样,Manjaro 也是一个基于社区的 linux 发行版。当你需要的时候,社区里总是会有人来帮助你。除了 Xfce 和 KDE 是官方支持的以外,其他所有桌面的编译和维护都是由社区完成的。任何用户有了疑问都可以到社区来寻求帮助,这里总是会有真实的 Manjaro 用户来帮助你。
|
||||
|
||||
在这里,我仅仅只列出了这么几点原因,但是如果你开始使用它了,你会发现更多惊喜的。
|
||||
|
||||
**还在考虑是否安装它?** 如果你还在彷徨与是否使用 Manjaro 你可以先在 Virtualbox 中试试它,然后再考虑在实体机中安装它。如果你喜欢它,请在这个话题下评论吧,欢迎点赞,关注,丢香蕉给我们,么么哒。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
原文: http://www.techphylum.com/2016/07/manjaro-linux-explained.html
|
||||
|
||||
作者:[sumit rohankar][a]
|
||||
译者:[Chao-zhi](https://github.com/Chao-zhi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/112160169713374382262
|
||||
[1]:http://www.techphylum.com/2014/08/linux-deepin-distro-with-unique-style.html
|
||||
[2]:http://www.techphylum.com/2014/06/linux-mint-introduction.html
|
||||
[3]:http://www.techphylum.com/2014/05/elementary-os-brief-introduction.html
|
||||
[4]:http://www.techphylum.com/2014/05/Introduction-to-fedora.html
|
||||
[5]:http://www.techphylum.com/2014/05/what-is-opensuse-introduction.html
|
||||
[6]:http://www.techphylum.com/2014/05/what-is-debian-brief-introduction.html
|
||||
[7]:https://4.bp.blogspot.com/-PvT_KN4_avM/V3_eMdhSAvI/AAAAAAAABLY/jjQDrV6dXOw9_vcS5XD3-kZy-chWsR1PQCLcB/s1600/Desktop%2B1_001.png
|
||||
[8]:https://1.bp.blogspot.com/-vxZ3bI1TTA4/V3_ePOiQG5I/AAAAAAAABLg/ANw2qSmRTVcxl0JZEsUxNGciBdkwuvt9wCKgB/s1600/Screenshot_20160708_223023.png
|
||||
[9]:https://1.bp.blogspot.com/-vxZ3bI1TTA4/V3_ePOiQG5I/AAAAAAAABLg/ANw2qSmRTVcxl0JZEsUxNGciBdkwuvt9wCKgB/s1600/Screenshot_20160708_223023.png
|
||||
@ -1,14 +0,0 @@
|
||||
Programmer Levels
|
||||
=======
|
||||

|
||||
|
||||
via: http://turnoff.us/geek/programmer-leves/
|
||||
|
||||
|
||||
作者:[Daniel Stori][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://turnoff.us/about/
|
||||
@ -1,277 +0,0 @@
|
||||
Index of turnoff.us
|
||||
====================
|
||||
|
||||
* ### [Ode To My Family][1]
|
||||
|
||||
* ### [The Depressed Developer 11][2]
|
||||
|
||||
* ### [The Jealous Process][3]
|
||||
|
||||
* ### [#!S][4]
|
||||
|
||||
* ### [The Depressed Developer 10][5]
|
||||
|
||||
* ### [User Space Election][6]
|
||||
|
||||
* ### [The Depressed Developer 7][7]
|
||||
|
||||
* ### [The War for Port 80][8]
|
||||
|
||||
* ### [The Depressed Developer 6][9]
|
||||
|
||||
* ### [Adopt a good cause, DON'T SIGKILL][10]
|
||||
|
||||
* ### [Happy 0b11111100001][11]
|
||||
|
||||
* ### [Bash History][12]
|
||||
|
||||
* ### [My (Dev) Morning Routine][13]
|
||||
|
||||
* ### [The Depressed Developer 5][14]
|
||||
|
||||
* ### [The Real Reason Not To Share a Mutable State][15]
|
||||
|
||||
* ### [Any Given Day][16]
|
||||
|
||||
* ### [One Last Question][17]
|
||||
|
||||
* ### [The Depressed Developer 3][18]
|
||||
|
||||
* ### [The Depressed Developer 4][19]
|
||||
|
||||
* ### [The Depressed Developer 2][20]
|
||||
|
||||
* ### [The Depressed Developer][21]
|
||||
|
||||
* ### [Protocols][22]
|
||||
|
||||
* ### [The Lord of The Matrix][23]
|
||||
|
||||
* ### [Inheritance versus Composition][24]
|
||||
|
||||
* ### [Coding From Anthill][25]
|
||||
|
||||
* ### [Life of Embedded Processes][26]
|
||||
|
||||
* ### [Deadline][27]
|
||||
|
||||
* ### [Ubuntu Core][28]
|
||||
|
||||
* ### [The Truth About Google][29]
|
||||
|
||||
* ### [Inside the Linux Kernel][30]
|
||||
|
||||
* ### [Programmer Levels][31]
|
||||
|
||||
* ### [Microservices][32]
|
||||
|
||||
* ### [Binary Tree][33]
|
||||
|
||||
* ### [Annoying Software 4 - Checkbox vs Radio Button][34]
|
||||
|
||||
* ### [Zombie Processes][35]
|
||||
|
||||
* ### [Poprocks and Coke][36]
|
||||
|
||||
* ### [jhamlet][37]
|
||||
|
||||
* ### [Java Thread Life][38]
|
||||
|
||||
* ### [Stranger Things - In The SysAdmin's World][39]
|
||||
|
||||
* ### [Who Killed MySQL? - Epilogue][40]
|
||||
|
||||
* ### [Sometimes They Are][41]
|
||||
|
||||
* ### [Dotnet on Linux][42]
|
||||
|
||||
* ### [Who Killed MySQL?][43]
|
||||
|
||||
* ### [To VI Or Not To VI][44]
|
||||
|
||||
* ### [Brothers Conflict (at linux kernel)][45]
|
||||
|
||||
* ### [Big Numbers][46]
|
||||
|
||||
* ### [The Codeless Developer][47]
|
||||
|
||||
* ### [Introducing the OOM Killer][48]
|
||||
|
||||
* ### [Reactive and Boring][49]
|
||||
|
||||
* ### [Hype Detected][50]
|
||||
|
||||
* ### [3rd World Daily News][51]
|
||||
|
||||
* ### [Java Evolution Parade][52]
|
||||
|
||||
* ### [The Opposite of RIP][53]
|
||||
|
||||
* ### [How I Met Your Mother][54]
|
||||
|
||||
* ### [Schrödinger's Cat Last Declarations][55]
|
||||
|
||||
* ### [Bash on Windows][56]
|
||||
|
||||
* ### [Ubuntu Updates][57]
|
||||
|
||||
* ### [SQL Server on Linux Part 2][58]
|
||||
|
||||
* ### [About JavaScript Developers][59]
|
||||
|
||||
* ### [The Real Reason to Not Use SIGKILL][60]
|
||||
|
||||
* ### [Java 20 - Predictions][61]
|
||||
|
||||
* ### [Do the Evolution, Baby!][62]
|
||||
|
||||
* ### [SQL Server on Linux][63]
|
||||
|
||||
* ### [When Just-In-Time Is Justin Time][64]
|
||||
|
||||
* ### [The Agile Restaurant][65]
|
||||
|
||||
* ### [I Love Windows PowerShell][66]
|
||||
|
||||
* ### [Linux Master Hero][67]
|
||||
|
||||
* ### [Doing a Great Job Together][68]
|
||||
|
||||
* ### [Geek Rivalries][69]
|
||||
|
||||
* ### [A Java Nightmare][70]
|
||||
|
||||
* ### [Java Family Crisis][71]
|
||||
|
||||
* ### [Annoying Software 3 - The Date Situation][72]
|
||||
|
||||
* ### [The (Sometimes Hard) Cloud Journey][73]
|
||||
|
||||
* ### [Thread.Sleep Room][74]
|
||||
|
||||
* ### [Web Server Upgrade Training][75]
|
||||
|
||||
* ### [Life in a Web Server][76]
|
||||
|
||||
* ### [Mastering RegExp][77]
|
||||
|
||||
* ### [Java Collections in Duck Life][78]
|
||||
|
||||
* ### [Java Garbage Collection Explained][79]
|
||||
|
||||
* ### [Waze vs Battery][80]
|
||||
|
||||
* ### [Masks][81]
|
||||
|
||||
* ### [Big Data Marriage][82]
|
||||
|
||||
* ### [Annoying Software 2][83]
|
||||
|
||||
* ### [Annoying Software][84]
|
||||
|
||||
* ### [Advanced Species][85]
|
||||
|
||||
* ### [The Modern Evil][86]
|
||||
|
||||
* ### [Software Testing][87]
|
||||
|
||||
* ### [Arduino Project][88]
|
||||
|
||||
* ### [Tales of DOS][89]
|
||||
|
||||
* ### [Developers][90]
|
||||
|
||||
* ### [TCP Buddies][91]
|
||||
|
||||
|
||||
[1]:https://turnoff.us/geek/ode-to-my-family
|
||||
[2]:https://turnoff.us/geek/the-depressed-developer-11
|
||||
[3]:https://turnoff.us/geek/the-jealous-process
|
||||
[4]:https://turnoff.us/geek/shebang
|
||||
[5]:https://turnoff.us/geek/the-depressed-developer-10
|
||||
[6]:https://turnoff.us/geek/user-space-election
|
||||
[7]:https://turnoff.us/geek/the-depressed-developer-7
|
||||
[8]:https://turnoff.us/geek/apache-vs-nginx
|
||||
[9]:https://turnoff.us/geek/the-depressed-developer-6
|
||||
[10]:https://turnoff.us/geek/dont-sigkill-2
|
||||
[11]:https://turnoff.us/geek/2016-2017
|
||||
[12]:https://turnoff.us/geek/bash-history
|
||||
[13]:https://turnoff.us/geek/my-morning-routine
|
||||
[14]:https://turnoff.us/geek/the-depressed-developer-5
|
||||
[15]:https://turnoff.us/geek/dont-share-mutable-state
|
||||
[16]:https://turnoff.us/geek/sql-injection
|
||||
[17]:https://turnoff.us/geek/one-last-question
|
||||
[18]:https://turnoff.us/geek/the-depressed-developer-3
|
||||
[19]:https://turnoff.us/geek/the-depressed-developer-4
|
||||
[20]:https://turnoff.us/geek/the-depressed-developer-2
|
||||
[21]:https://turnoff.us/geek/the-depressed-developer
|
||||
[22]:https://turnoff.us/geek/protocols
|
||||
[23]:https://turnoff.us/geek/the-lord-of-the-matrix
|
||||
[24]:https://turnoff.us/geek/inheritance-versus-composition
|
||||
[25]:https://turnoff.us/geek/ant
|
||||
[26]:https://turnoff.us/geek/ubuntu-core-2
|
||||
[27]:https://turnoff.us/geek/deadline
|
||||
[28]:https://turnoff.us/geek/ubuntu-core
|
||||
[29]:https://turnoff.us/geek/the-truth-about-google
|
||||
[30]:https://turnoff.us/geek/inside-the-linux-kernel
|
||||
[31]:https://turnoff.us/geek/programmer-leves
|
||||
[32]:https://turnoff.us/geek/microservices
|
||||
[33]:https://turnoff.us/geek/binary-tree
|
||||
[34]:https://turnoff.us/geek/annoying-software-4
|
||||
[35]:https://turnoff.us/geek/zombie-processes
|
||||
[36]:https://turnoff.us/geek/poprocks-and-coke
|
||||
[37]:https://turnoff.us/geek/jhamlet
|
||||
[38]:https://turnoff.us/geek/java-thread-life
|
||||
[39]:https://turnoff.us/geek/stranger-things-sysadmin-world
|
||||
[40]:https://turnoff.us/geek/who-killed-mysql-epilogue
|
||||
[41]:https://turnoff.us/geek/sad-robot
|
||||
[42]:https://turnoff.us/geek/dotnet-on-linux
|
||||
[43]:https://turnoff.us/geek/who-killed-mysql
|
||||
[44]:https://turnoff.us/geek/to-vi-or-not-to-vi
|
||||
[45]:https://turnoff.us/geek/brothers-conflict
|
||||
[46]:https://turnoff.us/geek/big-numbers
|
||||
[47]:https://turnoff.us/geek/codeless
|
||||
[48]:https://turnoff.us/geek/oom-killer
|
||||
[49]:https://turnoff.us/geek/reactive-and-boring
|
||||
[50]:https://turnoff.us/geek/tech-adoption
|
||||
[51]:https://turnoff.us/geek/3rd-world-news
|
||||
[52]:https://turnoff.us/geek/java-evolution-parade
|
||||
[53]:https://turnoff.us/geek/opposite-of-rip
|
||||
[54]:https://turnoff.us/geek/how-i-met-your-mother
|
||||
[55]:https://turnoff.us/geek/schrodinger-cat
|
||||
[56]:https://turnoff.us/geek/bash-on-windows
|
||||
[57]:https://turnoff.us/geek/ubuntu-updates
|
||||
[58]:https://turnoff.us/geek/sql-server-on-linux-2
|
||||
[59]:https://turnoff.us/geek/love-ecma6
|
||||
[60]:https://turnoff.us/geek/dont-sigkill
|
||||
[61]:https://turnoff.us/geek/java20-predictions
|
||||
[62]:https://turnoff.us/geek/its-evolution-baby
|
||||
[63]:https://turnoff.us/geek/sql-server-on-linux
|
||||
[64]:https://turnoff.us/geek/lazy-justin-is-late-again
|
||||
[65]:https://turnoff.us/geek/agile-restaurant
|
||||
[66]:https://turnoff.us/geek/love-powershell
|
||||
[67]:https://turnoff.us/geek/linux-master-hero
|
||||
[68]:https://turnoff.us/geek/duke-tux
|
||||
[69]:https://turnoff.us/geek/geek-rivalries
|
||||
[70]:https://turnoff.us/geek/a-java-nightmare
|
||||
[71]:https://turnoff.us/geek/java-family-crisis
|
||||
[72]:https://turnoff.us/geek/annoying-software-3
|
||||
[73]:https://turnoff.us/geek/cloud-sometimes-hard-journey
|
||||
[74]:https://turnoff.us/geek/thread-sleep-room
|
||||
[75]:https://turnoff.us/geek/webserver-upgrade-training
|
||||
[76]:https://turnoff.us/geek/life-in-a-web-server
|
||||
[77]:https://turnoff.us/geek/mastering-regexp
|
||||
[78]:https://turnoff.us/geek/java-collections
|
||||
[79]:https://turnoff.us/geek/java-gc-explained
|
||||
[80]:https://turnoff.us/geek/waze-vs-battery
|
||||
[81]:https://turnoff.us/geek/masks
|
||||
[82]:https://turnoff.us/geek/bigdata-marriage
|
||||
[83]:https://turnoff.us/geek/annoying-software-2
|
||||
[84]:https://turnoff.us/geek/annoying-software
|
||||
[85]:https://turnoff.us/geek/advanced-species
|
||||
[86]:https://turnoff.us/geek/modern-evil
|
||||
[87]:https://turnoff.us/geek/software-test
|
||||
[88]:https://turnoff.us/geek/arduino-project
|
||||
[89]:https://turnoff.us/geek/tales-of-dos
|
||||
[90]:https://turnoff.us/geek/developers
|
||||
[91]:https://turnoff.us/geek/tcp-buddies
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by SysTick
|
||||
|
||||
The decline of GPL?
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
# rusking translating
|
||||
What a Linux Desktop Does Better
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,75 +0,0 @@
|
||||
The impact GitHub is having on your software career
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
>Image credits : From GitHub
|
||||
|
||||
Over the next 12 to 24 months (in other words, between 2018 and 2019), how people hire software developers will change radically.
|
||||
|
||||
I spent from 2004 to 2014 working at Red Hat, the world's largest open source software engineering company. On my very first day there, in July 2004, my boss Marty Messer said to me, "All the work you do here will be in the open. In the future, you won't have a CV—people will just Google you."
|
||||
|
||||
This was one of the unique characteristics of working at Red Hat at the time. We had the opportunity to create our own personal brands and reputation in the open. Communication with other software engineers through mailing lists and bug trackers, and source code commits to mercurial, subversion, and CVS (Concurrent Versions System) repositories were all open and indexed by Google.
|
||||
|
||||
Fast-forward to 2017, and here we are living in a world that is being eaten by open source software.
|
||||
|
||||
There are two factors that give you a real sense of the times:
|
||||
|
||||
1. Microsoft, long the poster child for closed-source proprietary software and a crusader against open source, has embraced open source software whole-heartedly. The company formed the .NET Foundation (which has Red Hat as a member) and joined the Linux Foundation. .NET is now developed in the open as an open source project.
|
||||
2. GitHub has become a singular social network that ties together issue tracking and distributed source control.
|
||||
|
||||
For software developers coming from a primarily closed source background, it's not really clear yet what just happened. To them, open source equals "working for free in your spare time."
|
||||
|
||||
For those of us who spent the past decade making a billion-dollar open source software company, however, there is nothing free or spare time about working in the open. Also, the benefits and consequences of working in the open are clear, your reputation is yours and is portable between companies. GitHub is a social network where your social capital, created by your commits and contribution to the global conversation in whatever technology you are working, is yours—not tied to the company you happen to be working at temporarily.
|
||||
|
||||
Smart people will take advantage of this environment. They'll contribute patches, issues, and comments upstream to the languages and frameworks that they use daily in their job, including TypeScript, .NET, and Redux. They'll also advocate for and creatively arrange for as much of their work as possible to be done in the open, even if it is just their contribution graph to private repositories.
|
||||
|
||||
GitHub is a great equalizer. You may not be able to get a job in Australia from India, but there is nothing stopping you from working with Australians on GitHub from India.
|
||||
|
||||
The way to get a job at Red Hat during the last decade was obvious. You just started collaborating with Red Hat engineers on a piece of technology that they were working on in the open, then when it was clear that you were making a valuable contribution and were a great person to work with, you would apply for a job. (Or they would hit you up.)
|
||||
|
||||
Now that same pathway is open for everyone, into just about any technology. As the world is eaten by open source, the same dynamic is now prevalent everywhere.
|
||||
|
||||
In [a recent interview][3], Linus Torvalds (49K followers, following 0 on GitHub), the inventor of Linux and git, put it like this, "You shoot off a lot of small patches until the point where the maintainers trust you, and at that point you become more than just a guy who sends patches, you become part of the network of trust."
|
||||
|
||||
Your reputation is your location in a network of trust. When you change companies, this is weakened and some of it is lost. If you live in a small town and have been there for a long time, then people all over town know you. However, if you move countries, then that goes. You end up somewhere where no one knows you—and worse, no one knows anyone who knows you.
|
||||
|
||||
You've lost your first- and second-, and probably even third-degree connections. Unless you've built a brand by speaking at conferences or some other big ticket event, the trust you built up by working with others and committing code to a corporate internal repository is gone. However, if that work has been on GitHub, it's not gone. It's visible. It's connected to a network of trust that is visible.
|
||||
|
||||
One of the first things that will happen is that the disadvantaged will start to take advantage of this. Students, new grads, immigrants—they'll use this to move to Australia.
|
||||
|
||||
This will change the landscape. Previously privileged developers will suddenly find their network disrupted. One of the principles of open source is meritocracy—the best idea wins, the most commits wins, the most passing tests wins, the best implementation wins, etc.
|
||||
|
||||
It's not perfect, nothing is, and it doesn't do away with or discount being a good person to work with. Companies fire some rockstar engineers who just don't play well with others, and that stuff does show up in GitHub, mostly in the interactions with other contributors.
|
||||
|
||||
GitHub is not simply a code repository and a list of raw commit numbers, as some people paint it in strawman arguments. It is a social network. I put it like this: It's not your code on GitHub that counts; it's what other people say on GitHub about your code that counts.
|
||||
|
||||
GitHub is your portable reputation, and over the next 12 to 24 months, as some developers develop that and others don't, it's going to be a stark differentiator. It's like having email versus not having email (and now everyone has email), or having a cell phone versus not having a cell phone (and now everyone has a cell phone). Eventually, a vast majority will be working in the open, and it will again be a level playing field differentiated on other factors.
|
||||
|
||||
But right now, the developer career space is being disrupted by GitHub.
|
||||
|
||||
_[This article][1] originally appeared on Medium.com. Reprinted with permission._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Josh Wulf - About me: I'm a Legendary Recruiter at Just Digital People; a Red Hat alumnus; a CoderDojo mentor; a founder of Magikcraft.io; the producer of The JDP Internship — The World's #1 Software Development Reality Show;
|
||||
|
||||
-----------------------
|
||||
|
||||
via: https://opensource.com/article/17/3/impact-github-software-career
|
||||
|
||||
作者:[Josh Wulf ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/sitapati
|
||||
[1]:https://medium.com/@sitapati/the-impact-github-is-having-on-your-software-career-right-now-6ce536ec0b50#.dl79wpyww
|
||||
[2]:https://opensource.com/article/17/3/impact-github-software-career?rate=2gi7BrUHIADt4TWXO2noerSjzw18mLVZx56jwnExHqk
|
||||
[3]:http://www.theregister.co.uk/2017/02/15/think_different_shut_up_and_work_harder_says_linus_torvalds/
|
||||
[4]:https://opensource.com/user/118851/feed
|
||||
[5]:https://opensource.com/article/17/3/impact-github-software-career#comments
|
||||
[6]:https://opensource.com/users/sitapati
|
||||
111
sources/talk/20170314 One Year Using Go.md
Normal file
111
sources/talk/20170314 One Year Using Go.md
Normal file
@ -0,0 +1,111 @@
|
||||
[One Year Using Go][18]
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
Our ventures into [Go][5] all started as an internal experiment at [Mobile Jazz][6]. As the company name hints, we develop mobile apps.
|
||||
|
||||
After releasing an app into the wild, we soon realised we were missing a tool to check what was actually happening to users and how they were interacting with the app – something that would have been very handy in the case of any issues or bugs being reported.
|
||||
|
||||
There were a couple of tools around which claimed to help developers in this area, but none of them quite hit the mark, so we decided to build our own. We started by creating a basic set of scripts that quickly evolved into a fully-fledged tool known today as [Bugfender][7]!
|
||||
|
||||
As this was initially an experiment, we decided to try out a new trending technology. A love of learning and continual education is a key aspect of Mobile Jazz’s core values, so we decided to build it using Go; a relatively new programming language developed by Google. It’s a new player in the game and there have been many respected developers saying great things about it.
|
||||
|
||||
One year later and the experiment has turned into a startup, we’ve got an incredible tool that’s already helping thousands of developers all over the world. Our servers are processing over 200GB of data everyday incoming from more than 7 million devices.
|
||||
|
||||
After using Go for a year, we’d like to share some of our thoughts and experiences from taking our small experiment to a production server handling millions and millions of logs.
|
||||
|
||||
### Go Ecosystem
|
||||
|
||||
No one in the company had any previous experience using Go. Bugfender was our first dive into the language.
|
||||
|
||||
Learning the basics was pretty straight forward. Our previous experiences with C/C++/Java/Objective-C/PHP enabled us to learn Go quickly and get developing in days. There were, of course, a few new and unusual things to learn, including GOPATH and how to deal with packages, but that was expected.
|
||||
|
||||
Within a few days, we realized that even being a simplified language by design, Go was extremely powerful. It was able to do everything a modern programming language should: being able to work with JSON, communicate between servers and even access databases with no problems (and with just a few lines of code at that).
|
||||
|
||||
When building a server, you should first decide if you’re going to use any third party libraries or frameworks. For Bugfender, we decided to use:
|
||||
|
||||
### Martini
|
||||
|
||||
[Martini][8] is a powerful web framework for Go. At the time we started the experiment, it was a great solution and to this day, we haven’t experienced any problems with it. However if we were to start this experiment again today, we would choose a different framework as Martini is no longer maintained.
|
||||
|
||||
We’ve further experimented with [Iris][9] (our current favorite) and [Gin][10]. Gin is the successor to Martini and migrating to this will enable us to reuse our existing code.
|
||||
|
||||
In the past year, we’ve realized that Go’s standard libraries are really powerful and that you don’t really need to rely on a heavy web framework to build a server. It is better to use high-performance libraries that specialize in specific tasks.
|
||||
|
||||
~~Iris is our current ~~favourite~~ and in the future, we’ll re-write our servers to use it instead of Martini/Gin, but it’s not a priority right now.~~
|
||||
|
||||
**Edit:** After some discussions about Iris in differents places, we realized that Iris might not be the best option. If we ever decide to re-write our web components, we might look into other options, we are open to suggestions.
|
||||
|
||||
### Gorm
|
||||
|
||||
Some people are fans of ORM and others are not. We decided to use ORM and more specifically, [GORM][11]. Our implementation was for the web frontend only, keeping it optimized with hand-written SQL for the log ingestion API. In the beginning, we were really happy, but as time progresses, we’ve started to find problems and we are soon going to remove it completely from our code and use a lower level approach using a standard SQL library with [sqlx][12].
|
||||
|
||||
One of the main problems with GORM is Go’s ecosystem. As a new language, there have been many new versions since we started developing the product. Some changes in these new releases are not backwards compatible and so, to use the newest library versions we are frequently rewriting existing code and checking hacks we may have created to solve version issues.
|
||||
|
||||
These two libraries are the main building blocks of almost any web server, so it’s important to make a good choice because it can be difficult to change later and will affect your server performance.
|
||||
|
||||
### Third-Party Services
|
||||
|
||||
Another important area to consider when creating a real world product is the availability of libraries, third-party services and tools. Here, Go is still lacking maturity, most companies don’t yet provide a Go library, so you may need to rely on libraries written by other people where quality isn’t always guaranteed.
|
||||
|
||||
For example, there are great libraries for using [Redis][13] and [ElasticSearch][14], but libraries for other services such as Mixpanel or Stripe are not so good.
|
||||
|
||||
Our recommendation before using Go is to check beforehand if there’s a good library available for any specific products you may need.
|
||||
|
||||
We’ve also experienced a lot of problems with Go’s package management system. The way it handles versions is far from optimal and over the past year, we have run into various problems getting different versions of the same library between different team members. Recently, however, this problem has been almost solved thanks to the new Go feature that supports vendor packages, alongside the [gopkg.in][15] service.
|
||||
|
||||
### Developer Tools
|
||||
|
||||
|
||||
|
||||
As Go is a relatively new language, you might find the developer tools available are not so great when compared to other established languages like Java. When we started Bugfender it was really hard to use any IDE, none seemed to support Go. But in this last year, this has improved a lot with the introduction of [IntelliJ][16] and [Visual Studio Code Go][17] plugins.
|
||||
|
||||
Finally looking at other Go tools, the debugger is not-so-great and the profiler is even worse, so debugging your code or trying to optimize it can be hard at times.
|
||||
|
||||
### Heading for Production
|
||||
|
||||
This is definitely one of the best things about Go, if you want to deploy something to production you just need to build your binary and send it to the server, no dependencies, no need to install extra software, you only need to be able to run a binary file in your server.
|
||||
|
||||
If you’re used to dealing with other languages where you require a package manager or need to be careful with a language interpreter you may use, Go is a pleasure to work with.
|
||||
|
||||
We are also really happy with Go’s stability as the servers never seem to crash. We faced a problem some time ago sending big amounts of data to Go Routines but since then we’ve rarely seen any crashes. Note: if you need to send a lot of data to a Go Routine, you’ll need to be careful as you can have a heap overflow.
|
||||
|
||||
If you’re interested in performance, we cannot compare to other languages as we have started with Go from scratch, but given the amount of data we process, we feel it’s performance is very good, we definitely wouldn’t be able to process the same number of requests using PHP so easily.
|
||||
|
||||
### Conclusions
|
||||
|
||||
Over the year we’ve had our ups and downs regarding Go. At the beginning we were excited, but after the experiment converted to a real product we started unveiling problems. We’ve thought several times about a complete rewrite in Java, but here we are, still working with Go, and in this past year the ecosystem has had some great improvements that simplified our work.
|
||||
|
||||
If you want to build your product using Go, you can be sure it will work, but you need to be really careful with one thing: the availability of developers to hire. There are only a few senior Go developers in Silicon Valley, and finding one elsewhere can be a very difficult task.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://bugfender.com/one-year-using-go
|
||||
|
||||
作者:[ALEIX VENTAYOL][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://bugfender.com/author/aleixventayol
|
||||
[1]:https://bugfender.com/#facebook
|
||||
[2]:https://bugfender.com/#twitter
|
||||
[3]:https://bugfender.com/#google_plus
|
||||
[4]:https://www.addtoany.com/share#url=https%3A%2F%2Fbugfender.com%2Fone-year-using-go&title=One%20Year%20Using%20Go
|
||||
[5]:https://golang.org/
|
||||
[6]:http://mobilejazz.com/
|
||||
[7]:https://www.bugfender.com/
|
||||
[8]:https://github.com/go-martini/martini
|
||||
[9]:https://github.com/kataras/iris
|
||||
[10]:https://github.com/gin-gonic/gin
|
||||
[11]:https://github.com/jinzhu/gorm
|
||||
[12]:https://github.com/jmoiron/sqlx
|
||||
[13]:https://github.com/go-redis/redis
|
||||
[14]:https://github.com/olivere/elastic
|
||||
[15]:http://labix.org/gopkg.in
|
||||
[16]:https://plugins.jetbrains.com/plugin/5047-go
|
||||
[17]:https://github.com/Microsoft/vscode-go
|
||||
[18]:https://bugfender.com/one-year-using-go
|
||||
@ -0,0 +1,78 @@
|
||||
translating by [kenxx](https://github.com/kenxx)
|
||||
|
||||
Hire a DDoS service to take down your enemies
|
||||
========================
|
||||
|
||||
>With the rampant availability of IoT devices, cybercriminals offer denial of service attacks to take advantage of password problems.
|
||||
|
||||

|
||||
|
||||
With the onrush of connected internet of things (IoT) devices, distributed denial-of-service attacks are becoming a dangerous trend. Similar to what happened to [DNS service provider Dyn last fall][3], anyone and everyone is in the crosshairs. The idea of using unprotected IoT devices as a way to bombard networks is gaining momentum.
|
||||
|
||||
The advent of DDoS-for-hire services means that even the least tech-savvy individual can exact revenge on some website. Step on up to the counter and purchase a stresser that can systemically take down a company.
|
||||
|
||||
According to [Neustar][4], almost three quarters of all global brands, organizations and companies have been victims of a DDoS attack. And more than 3,700 [DDoS attacks occur each day][5].
|
||||
|
||||
|
||||
#### [■ RELATED: How can you detect a fake ransom letter?][1]
|
||||
|
||||
|
||||
Chase Cunningham, director of cyber operations at A10 Networks, said to find IoT-enabled devices, all you have to do is go on an underground site and ask around for the Mirai scanner code. Once you have that you can scan for anything talking to the internet that can be used for that type of attack.
|
||||
|
||||
“Or you can go to a site like Shodan and craft a couple of simple queries to look for device specific requests. Once you get that information you just go to your DDoS for hire tool and change the configuration to point at the right target and use the right type of traffic emulator and bingo, nuke whatever you like,” he said.
|
||||
|
||||
“Basically everything is for sale," he added. "You can buy a 'stresser', which is just a simple botnet type offering that will allow anyone who knows how to click the start button access to a functional DDoS botnet.”
|
||||
|
||||
>Once you get that information you just go to your DDoS for hire tool and change the configuration to point at the right target and use the right type of traffic emulator and bingo, nuke whatever you like.
|
||||
|
||||
>Chase Cunningham, A10 director of cyber operations
|
||||
|
||||
Cybersecurity vendor Imperva says for just a few dozen dollars, users can quickly get an attack up and running. The company writes on its website that these kits contain the bot payload and the CnC (command and control) files. Using these, aspiring bot masters (a.k.a. herders) can start distributing malware, infecting devices through a use of spam email, vulnerability scanners, brute force attacks and more.
|
||||
|
||||
|
||||
Most [stressers and booters][6] have embraced a commonplace SaaS (software as a service) business model, based on subscriptions. As the Incapsula [Q2 2015 DDoS report][7] has shown, the average one hour/month DDoS package will cost $38 (with $19.99 at the lower end of the scale).
|
||||
|
||||

|
||||
|
||||
“Stresser and booter services are just a byproduct of a new reality, where services that can bring down businesses and organizations are allowed to operate in a dubious grey area,” Imperva wrote.
|
||||
|
||||
While cost varies, [attacks can run businesses anywhere from $14,000 to $2.35 million per incident][8]. And once a business is attacked, there’s an [82 percent chance they’ll be attacked again][9].
|
||||
|
||||
DDoS of Things (DoT) use IoT devices to build botnets that create large DDoS attacks. The DoT attacks have leveraged hundreds of thousands of IoT devices to attack anything from large service providers to enterprises.
|
||||
|
||||
“Most of the reputable DDoS sellers have changeable configurations for their tool sets so you can easily set the type of attack you want to take place. I haven’t seen many yet that specifically include the option to ‘purchase’ an IoT-specific traffic emulator but I’m sure it’s coming. If it were me running the service I would definitely have that as an option,” Cunningham said.
|
||||
|
||||
According to an IDG News Service story, building a DDoS-for-service can also be easy. Often the hackers will rent six to 12 servers, and use them to push out internet traffic to whatever target. In late October, HackForums.net [shut down][10] its "Server Stress Testing" section, amid concerns that hackers were peddling DDoS-for-hire services through the site for as little as $10 a month.
|
||||
|
||||
Also in December, law enforcement agencies in the U.S. and Europe [arrested][11] 34 suspects involved in DDoS-for-hire services.
|
||||
|
||||
If it is so easy to do so, why don’t these attacks happen more often?
|
||||
|
||||
Cunningham said that these attacks do happen all the time, in fact they happen every second of the day. “You just don’t hear about it because a lot of these are more nuisance attacks than big time bring down the house DDoS type events,” he said.
|
||||
|
||||
Also a lot of the attack platforms being sold only take systems down for an hour or a bit longer. Usually an hour-long attack on a site will cost anywhere from $15 to $50\. It depends, though, sometimes for better attack platforms it can hundreds of dollars an hour, he said.
|
||||
|
||||
The solution to cutting down on these attacks involves users resetting factory preset passwords on anything connected to the internet. Change the default password settings and disable things that you really don’t need.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.csoonline.com/article/3180246/data-protection/hire-a-ddos-service-to-take-down-your-enemies.html
|
||||
|
||||
作者:[Ryan Francis][a]
|
||||
译者:[kenxx](https://github.com/kenxx)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.csoonline.com/author/Ryan-Francis/
|
||||
[1]:http://csoonline.com/article/3103122/security/how-can-you-detect-a-fake-ransom-letter.html#tk.cso-infsb
|
||||
[2]:https://www.incapsula.com/ddos/ddos-attacks/denial-of-service.html
|
||||
[3]:http://csoonline.com/article/3135986/security/ddos-attack-against-overwhelmed-despite-mitigation-efforts.html
|
||||
[4]:https://ns-cdn.neustar.biz/creative_services/biz/neustar/www/resources/whitepapers/it-security/ddos/2016-apr-ddos-report.pdf
|
||||
[5]:https://www.a10networks.com/resources/ddos-trends-report
|
||||
[6]:https://www.incapsula.com/ddos/booters-stressers-ddosers.html
|
||||
[7]:https://www.incapsula.com/blog/ddos-global-threat-landscape-report-q2-2015.html
|
||||
[8]:http://www.datacenterknowledge.com/archives/2016/05/13/number-of-costly-dos-related-data-center-outages-rising/
|
||||
[9]:http://www.networkworld.com/article/3064677/security/hit-by-ddos-you-will-likely-be-struck-again.html
|
||||
[10]:http://www.pcworld.com/article/3136730/hacking/hacking-forum-cuts-section-allegedly-linked-to-ddos-attacks.html
|
||||
[11]:http://www.pcworld.com/article/3149543/security/dozens-arrested-in-international-ddos-for-hire-crackdown.html
|
||||
80
sources/talk/20170317 Why AlphaGo Is Not AI.md
Normal file
80
sources/talk/20170317 Why AlphaGo Is Not AI.md
Normal file
@ -0,0 +1,80 @@
|
||||
Why AlphaGo Is Not AI
|
||||
============================================================
|
||||
|
||||

|
||||
>Photo: RobotCub
|
||||
>“There is no AI without robotics,” the author argues.
|
||||
|
||||
_This is a guest post. The views expressed here are solely those of the author and do not represent positions of _ IEEE Spectrum _ or the IEEE._
|
||||
|
||||
What is AI and what is not AI is, to some extent, a matter of definition. There is no denying that AlphaGo, the Go-playing artificial intelligence designed by Google DeepMind that [recently beat world champion Lee Sedol][1], and similar [deep learning approaches][2] have managed to solve quite hard computational problems in recent years. But is it going to get us to _full AI_ , in the sense of an artificial general intelligence, or [AGI][3], machine? Not quite, and here is why.
|
||||
|
||||
One of the key issues when building an AGI is that it will have to make sense of the world for itself, to develop its own, internal meaning for everything it will encounter, hear, say, and do. Failing to do this, you end up with today’s AI programs where all the meaning is actually provided by the designer of the application: the AI basically doesn’t understand what is going on and has a narrow domain of expertise.
|
||||
|
||||
The problem of meaning is perhaps the most fundamental problem of AI and has still not been solved today. One of the first to express it was cognitive scientist Stevan Harnad, in his 1990 paper about “The Symbol Grounding Problem.” Even if you don’t believe we are explicitly manipulating symbols, which is indeed questionable, the problem remains: _the grounding of whatever representation exists inside the system into the real world outside_ .
|
||||
|
||||
To be more specific, the problem of meaning leads us to four sub-problems:
|
||||
|
||||
1. How do you structure the information the agent (human or AI) is receiving from the world?
|
||||
2. How do you link this structured information to the world, or, taking the above definition, how do you build “meaning” for the agent?
|
||||
3. How do you synchronize this meaning with other agents? (Otherwise, there is no communication possible and you get an incomprehensible, isolated form of intelligence.)
|
||||
4. Why does the agent do something at all rather than nothing? How to set all this into motion?
|
||||
|
||||
The first problem, about structuring information, is very well addressed by deep learning and similar unsupervised learning algorithms, used for example in the [AlphaGo program][4]. We have made tremendous progress in this area, in part because of the recent gain in computing power and the use of GPUs that are especially good at parallelizing information processing. What these algorithms do is take a signal that is extremely redundant and expressed in a high dimensional space, and reduce it to a low dimensionality signal, minimizing the loss of information in the process. In other words, it “captures” what is important in the signal, from an information processing point of view.
|
||||
|
||||
“There is no AI without robotics . . . This realization is often called the ‘embodiment problem’ and most researchers in AI now agree that intelligence and embodiment are tightly coupled issues. Every different body has a different form of intelligence, and you see that pretty clearly in the animal kingdom.”</aside>
|
||||
|
||||
The second problem, about linking information to the real world, or creating “meaning,” is fundamentally tied to robotics. Because you need a body to interact with the world, and you need to interact with the world to build this link. That’s why I often say that there is no AI without robotics (although there can be pretty good robotics without AI, but that’s another story). This realization is often called the “embodiment problem” and most researchers in AI now agree that intelligence and embodiment are tightly coupled issues. Every different body has a different form of intelligence, and you see that pretty clearly in the animal kingdom.
|
||||
|
||||
It starts with simple things like making sense of your own body parts, and how you can control them to produce desired effects in the observed world around you, how you build your own notion of space, distance, color, etc. This has been studied extensively by researchers like [J. Kevin O’Regan][5] and his “sensorimotor theory.” It is just a first step however, because then you have to build up more and more abstract concepts, on top of those grounded sensorimotor structures. We are not quite there yet, but that’s the current state of research on that matter.
|
||||
|
||||
The third problem is fundamentally the question of the origin of culture. Some animals show some simple form of culture, even transgenerational acquired competencies, but it is very limited and only humans have reached the threshold of exponentially growing acquisition of knowledge that we call culture. Culture is the essential catalyst of intelligence and an AI without the capability to interact culturally would be nothing more than an academic curiosity.
|
||||
|
||||
However, culture can not be hand coded into a machine; it must be the result of a learning process. The best way to start looking to try to understand this process is in developmental psychology, with the work of Jean Piaget and Michael Tomasello, studying how children acquire cultural competencies. This approach gave birth to a new discipline in robotics called “developmental robotics,” which is taking the child as a model (as illustrated by the [iCub robot][6], pictured above).
|
||||
|
||||
“Culture is the essential catalyst of intelligence and an AI without the capability to interact culturally would be nothing more than an academic curiosity. However, culture can not be hand coded into a machine; it must be the result of a learning process.”</aside>
|
||||
|
||||
It is also closely linked to the study of language learning, which is one of the topics that I mostly focused on as a researcher myself. The work of people like [Luc Steels][7] and many others have shown that we can see language acquisition as an evolutionary process: the agent creates new meanings by interacting with the world, use them to communicate with other agents, and select the most successful structures that help to communicate (that is, to achieve joint intentions, mostly). After hundreds of trial and error steps, just like with biological evolution, the system evolves the best meaning and their syntactic/grammatical translation.
|
||||
|
||||
This process has been tested experimentally and shows striking resemblance with how natural languages evolve and grow. Interestingly, it accounts for instantaneous learning, when a concept is acquired in one shot, something that heavily statistical models like deep learning are _not_ capable to explain. Several research labs are now trying to go further into acquiring grammar, gestures, and more complex cultural conventions using this approach, in particular the [AI Lab][8] that I founded at [Aldebaran][9], the French robotics company—now part of the SoftBank Group—that created the robots [Nao][10], [Romeo][11], and [Pepper][12] (pictured below).
|
||||
|
||||

|
||||
>Aldebaran’s humanoid robots: Nao, Romeo, and Pepper.</figcaption>
|
||||
|
||||
Finally, the fourth problem deals with what is called “intrinsic motivation.” Why does the agent do anything at all, rather than nothing. Survival requirements are not enough to explain human behavior. Even perfectly fed and secure, humans don’t just sit idle until hunger comes back. There is more: they explore, they try, and all of that seems to be driven by some kind of intrinsic curiosity. Researchers like [Pierre-Yves Oudeyer][13] have shown that simple mathematical formulations of curiosity, as an expression of the tendency of the agent to maximize its rate of learning, are enough to account for incredibly complex and surprising behaviors (see, for example, [the Playground experiment][14] done at Sony CSL).
|
||||
|
||||
It seems that something similar is needed inside the system to drive its desire to go through the previous three steps: structure the information of the world, connect it to its body and create meaning, and then select the most “communicationally efficient” one to create a joint culture that enables cooperation. This is, in my view, the program of AGI.
|
||||
|
||||
Again, the rapid advances of deep learning and the recent success of this kind of AI at games like Go are very good news because they could lead to lots of really useful applications in medical research, industry, environmental preservation, and many other areas. But this is only one part of the problem, as I’ve tried to show here. I don’t believe deep learning is the silver bullet that will get us to true AI, in the sense of a machine that is able to learn to live in the world, interact naturally with us, understand deeply the complexity of our emotions and cultural biases, and ultimately help us to make a better world.
|
||||
|
||||
**[Jean-Christophe Baillie][15] is founder and president of [Novaquark][16], a Paris-based virtual reality startup developing [Dual Universe][17], a next-generation online world where participants will be able to create entire civilizations through fully emergent gameplay. A graduate from the École Polytechnique in Paris, Baillie received a PhD in AI from Paris IV University and founded the Cognitive Robotics Lab at ENSTA ParisTech and, later, Gostai, a robotics company acquired by the Aldebaran/SoftBank Group in 2012\. This article originally [appeared][18] in LinkedIn.**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://spectrum.ieee.org/automaton/robotics/artificial-intelligence/why-alphago-is-not-ai
|
||||
|
||||
作者:[Jean-Christophe Baillie][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linkedin.com/in/jcbaillie
|
||||
[1]:http://spectrum.ieee.org/tech-talk/computing/networks/alphago-wins-match-against-top-go-player
|
||||
[2]:http://spectrum.ieee.org/automaton/robotics/artificial-intelligence/facebook-ai-director-yann-lecun-on-deep-learning
|
||||
[3]:https://en.wikipedia.org/wiki/Artificial_general_intelligence
|
||||
[4]:http://spectrum.ieee.org/tech-talk/computing/software/monster-machine-defeats-prominent-pro-player
|
||||
[5]:http://nivea.psycho.univ-paris5.fr/
|
||||
[6]:http://www.icub.org/
|
||||
[7]:https://ai.vub.ac.be/members/steels
|
||||
[8]:http://a-labs.aldebaran.com/labs/ai-lab
|
||||
[9]:https://www.aldebaran.com/en
|
||||
[10]:http://spectrum.ieee.org/automaton/robotics/humanoids/aldebaran-new-nao-robot-demo
|
||||
[11]:http://spectrum.ieee.org/automaton/robotics/humanoids/france-developing-advanced-humanoid-robot-romeo
|
||||
[12]:http://spectrum.ieee.org/robotics/home-robots/how-aldebaran-robotics-built-its-friendly-humanoid-robot-pepper
|
||||
[13]:http://www.pyoudeyer.com/
|
||||
[14]:http://www.pyoudeyer.com/SS305OudeyerP-Y.pdf
|
||||
[15]:https://www.linkedin.com/in/jcbaillie
|
||||
[16]:http://www.dualthegame.com/novaquark
|
||||
[17]:http://www.dualthegame.com/
|
||||
[18]:https://www.linkedin.com/pulse/why-alphago-ai-jean-christophe-baillie
|
||||
@ -0,0 +1,98 @@
|
||||
#rusking translating
|
||||
Why do you use Linux and open source software?
|
||||
============================================================
|
||||
|
||||
>LinuxQuestions.org readers share reasons they use Linux and open source technologies. How will Opensource.com readers respond?
|
||||
|
||||

|
||||
>Image by : opensource.com
|
||||
|
||||
As I mentioned when [The Queue][4] launched, although typically I will answer questions from readers, sometimes I'll switch that around and ask readers a question. I haven't done so since that initial column, so it's overdue. I recently asked two related questions at LinuxQuestions.org and the response was overwhelming. Let's see how the Opensource.com community answers both questions, and how those responses compare and contrast to those on LQ.
|
||||
|
||||
### Why do you use Linux?
|
||||
|
||||
The first question I asked the LinuxQuestions.org community is: **[What are the reasons you use Linux?][1]**
|
||||
|
||||
### Answer highlights
|
||||
|
||||
_oldwierdal_ : I use Linux because it is fast, safe, and reliable. With contributors from all over the world, it has become, perhaps, the most advanced and innovative software available. And, here is the icing on the red-velvet cake; It is free!
|
||||
|
||||
_Timothy Miller_ : I started using it because it was free as in beer and I was poor so couldn't afford to keep buying new Windows licenses.
|
||||
|
||||
_ondoho_ : Because it's a global community effort, self-governed grassroot operating system. Because it's free in every sense. Because there's good reason to trust in it.
|
||||
|
||||
_joham34_ : Stable, free, safe, runs in low specs PCs, nice support community, little to no danger for viruses.
|
||||
|
||||
_Ook_ : I use Linux because it just works, something Windows never did well for me. I don't have to waste time and money getting it going and keeping it going.
|
||||
|
||||
_rhamel_ : I am very concerned about the loss of privacy as a whole on the internet. I recognize that compromises have to be made between privacy and convenience. I may be fooling myself but I think Linux gives me at least the possibility of some measure of privacy.
|
||||
|
||||
_educateme_ : I use Linux because of the open-minded, learning-hungry, passionately helpful community. And, it's free.
|
||||
|
||||
_colinetsegers_ : Why I use Linux? There's not only one reason. In short I would say:
|
||||
|
||||
1. The philosophy of free shared knowledge.
|
||||
2. Feeling safe while surfing the web.
|
||||
3. Lots of free and useful software.
|
||||
|
||||
_bamunds_ : Because I love freedom.
|
||||
|
||||
_cecilskinner1989_ : I use linux for two reasons: stability and privacy.
|
||||
|
||||
### Why do you use open source software?
|
||||
|
||||
The second questions is, more broadly: **[What are the reasons you use open source software?][2]** You'll notice that, although there is a fair amount of overlap here, the general tone is different, with some sentiments receiving more emphasis, and others less.
|
||||
|
||||
### Answer highlights
|
||||
|
||||
_robert leleu_ : Warm and cooperative atmosphere is the main reason of my addiction to open source.
|
||||
|
||||
_cjturner_ : Open Source is an answer to the Pareto Principle as applied to Applications; OOTB, a software package ends up meeting 80% of your requirements, and you have to get the other 20% done. Open Source gives you a mechanism and a community to share this burden, putting your own effort (if you have the skills) or money into your high-priority requirements.
|
||||
|
||||
_Timothy Miller_ : I like the knowledge that I _can_ examine the source code to verify that the software is secure if I so choose.
|
||||
|
||||
_teckk_ : There are no burdensome licensing requirements or DRM and it's available to everyone.
|
||||
|
||||
_rokytnji_ : Beer money. Motorcycle parts. Grandkids birthday presents.
|
||||
|
||||
_timl_ : Privacy is impossible without free software
|
||||
|
||||
_hazel_ : I like the philosophy of free software, but I wouldn't use it just for philosophical reasons if Linux was a bad OS. I use Linux because I love Linux, and because you can get it for free as in free beer. The fact that it's also free as in free speech is a bonus, because it makes me feel good about using it. But if I find that a piece of hardware on my machine needs proprietary firmware, I'll use proprietary firmware.
|
||||
|
||||
_lm8_ : I use open source software because I don't have to worry about it going obsolete when a company goes out of business or decides to stop supporting it. I can continue to update and maintain the software myself. I can also customize it if the software does almost everything I want, but it would be nice to have a few more features. I also like open source because I can share my favorite programs with friend and coworkers.
|
||||
|
||||
_donguitar_ : Because it empowers me and enables me to empower others.
|
||||
|
||||
### Your turn
|
||||
|
||||
So, what are the reasons _**you**_ use Linux? What are the reasons _**you**_ use open source software? Let us know in the comments.
|
||||
|
||||
### Fill The Queue
|
||||
|
||||
Lastly, what questions would you like to see answered in a future article? From questions on building and maintaining communities, to what you'd like to know about contributing to an open source project, to questions more technical in nature—[submit your Linux and open source questions][5].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Jeremy Garcia - Jeremy Garcia is the founder of LinuxQuestions.org and an ardent but realistic open source advocate. Follow Jeremy on Twitter: @linuxquestions
|
||||
|
||||
------------------
|
||||
|
||||
via: https://opensource.com/article/17/3/why-do-you-use-linux-and-open-source-software
|
||||
|
||||
作者:[Jeremy Garcia ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jeremy-garcia
|
||||
[1]:http://www.linuxquestions.org/questions/linux-general-1/what-are-the-reasons-you-use-linux-4175600842/
|
||||
[2]:http://www.linuxquestions.org/questions/linux-general-1/what-are-the-reasons-you-use-open-source-software-4175600843/
|
||||
[3]:https://opensource.com/article/17/3/why-do-you-use-linux-and-open-source-software?rate=lVazcbF6Oern5CpV86PgNrRNZltZ8aJZwrUp7SrZIAw
|
||||
[4]:https://opensource.com/tags/queue-column
|
||||
[5]:https://opensource.com/thequeue-submit-question
|
||||
[6]:https://opensource.com/user/86816/feed
|
||||
[7]:https://opensource.com/article/17/3/why-do-you-use-linux-and-open-source-software#comments
|
||||
[8]:https://opensource.com/users/jeremy-garcia
|
||||
155
sources/talk/20170320 Education of a Programmer.md
Normal file
155
sources/talk/20170320 Education of a Programmer.md
Normal file
@ -0,0 +1,155 @@
|
||||
Education of a Programmer
|
||||
============================================================
|
||||
|
||||
_When I left Microsoft in October 2016 after almost 21 years there and almost 35 years in the industry, I took some time to reflect on what I had learned over all those years. This is a lightly edited version of that post. Pardon the length!_
|
||||
|
||||
There are an amazing number of things you need to know to be a proficient programmer — details of languages, APIs, algorithms, data structures, systems and tools. These things change all the time — new languages and programming environments spring up and there always seems to be some hot new tool or language that “everyone” is using. It is important to stay current and proficient. A carpenter needs to know how to pick the right hammer and nail for the job and needs to be competent at driving the nail straight and true.
|
||||
|
||||
At the same time, I’ve found that there are some concepts and strategies that are applicable over a wide range of scenarios and across decades. We have seen multiple orders of magnitude change in the performance and capability of our underlying devices and yet certain ways of thinking about the design of systems still say relevant. These are more fundamental than any specific implementation. Understanding these recurring themes is hugely helpful in both the analysis and design of the complex systems we build.
|
||||
|
||||
Humility and Ego
|
||||
|
||||
This is not limited to programming, but in an area like computing which exhibits so much constant change, one needs a healthy balance of humility and ego. There is always more to learn and there is always someone who can help you learn it — if you are willing and open to that learning. One needs both the humility to recognize and acknowledge what you don’t know and the ego that gives you confidence to master a new area and apply what you already know. The biggest challenges I have seen are when someone works in a single deep area for a long time and “forgets” how good they are at learning new things. The best learning comes from actually getting hands dirty and building something, even if it is just a prototype or hack. The best programmers I know have had both a broad understanding of technology while at the same time have taken the time to go deep into some technology and become the expert. The deepest learning happens when you struggle with truly hard problems.
|
||||
|
||||
End to End Argument
|
||||
|
||||
Back in 1981, Jerry Saltzer, Dave Reed and Dave Clark were doing early work on the Internet and distributed systems and wrote up their [classic description][4] of the end to end argument. There is much misinformation out there on the Internet so it can be useful to go back and read the original paper. They were humble in not claiming invention — from their perspective this was a common engineering strategy that applies in many areas, not just in communications. They were simply writing it down and gathering examples. A minor paraphrasing is:
|
||||
|
||||
When implementing some function in a system, it can be implemented correctly and completely only with the knowledge and participation of the endpoints of the system. In some cases, a partial implementation in some internal component of the system may be important for performance reasons.
|
||||
|
||||
The SRC paper calls this an “argument”, although it has been elevated to a “principle” on Wikipedia and in other places. In fact, it is better to think of it as an argument — as they detail, one of the hardest problem for a system designer is to determine how to divide responsibilities between components of a system. This ends up being a discussion that involves weighing the pros and cons as you divide up functionality, isolate complexity and try to design a reliable, performant system that will be flexible to evolving requirements. There is no simple set of rules to follow.
|
||||
|
||||
Much of the discussion on the Internet focuses on communications systems, but the end-to-end argument applies in a much wider set of circumstances. One example in distributed systems is the idea of “eventual consistency”. An eventually consistent system can optimize and simplify by letting elements of the system get into a temporarily inconsistent state, knowing that there is a larger end-to-end process that can resolve these inconsistencies. I like the example of a scaled-out ordering system (e.g. as used by Amazon) that doesn’t require every request go through a central inventory control choke point. This lack of a central control point might allow two endpoints to sell the same last book copy, but the overall system needs some type of resolution system in any case, e.g. by notifying the customer that the book has been backordered. That last book might end up getting run over by a forklift in the warehouse before the order is fulfilled anyway. Once you realize an end-to-end resolution system is required and is in place, the internal design of the system can be optimized to take advantage of it.
|
||||
|
||||
In fact, it is this design flexibility in the service of either ongoing performance optimization or delivering other system features that makes this end-to-end approach so powerful. End-to-end thinking often allows internal performance flexibility which makes the overall system more robust and adaptable to changes in the characteristics of each of the components. This makes an end-to-end approach “anti-fragile” and resilient to change over time.
|
||||
|
||||
An implication of the end-to-end approach is that you want to be extremely careful about adding layers and functionality that eliminates overall performance flexibility. (Or other flexibility, but performance, especially latency, tends to be special.) If you expose the raw performance of the layers you are built on, end-to-end approaches can take advantage of that performance to optimize for their specific requirements. If you chew up that performance, even in the service of providing significant value-add functionality, you eliminate design flexibility.
|
||||
|
||||
The end-to-end argument intersects with organizational design when you have a system that is large and complex enough to assign whole teams to internal components. The natural tendency of those teams is to extend the functionality of those components, often in ways that start to eliminate design flexibility for applications trying to deliver end-to-end functionality built on top of them.
|
||||
|
||||
One of the challenges in applying the end-to-end approach is determining where the end is. “Little fleas have lesser fleas… and so on ad infinitum.”
|
||||
|
||||
Concentrating Complexity
|
||||
|
||||
Coding is an incredibly precise art, with each line of execution required for correct operation of the program. But this is misleading. Programs are not uniform in the overall complexity of their components or the complexity of how those components interact. The most robust programs isolate complexity in a way that lets significant parts of the system appear simple and straightforward and interact in simple ways with other components in the system. Complexity hiding can be isomorphic with other design approaches like information hiding and data abstraction but I find there is a different design sensibility if you really focus on identifying where the complexity lies and how you are isolating it.
|
||||
|
||||
The example I’ve returned to over and over again in my [writing][5] is the screen repaint algorithm that was used by early character video terminal editors like VI and EMACS. The early video terminals implemented control sequences for the core action of painting characters as well as additional display functions to optimize redisplay like scrolling the current lines up or down or inserting new lines or moving characters within a line. Each of those commands had different costs and those costs varied across different manufacturer’s devices. (See [TERMCAP][6] for links to code and a fuller history.) A full-screen application like a text editor wanted to update the screen as quickly as possible and therefore needed to optimize its use of these control sequences to transition the screen from one state to another.
|
||||
|
||||
These applications were designed so this underlying complexity was hidden. The parts of the system that modify the text buffer (where most innovation in functionality happens) completely ignore how these changes are converted into screen update commands. This is possible because the performance cost of computing the optimal set of updates for _any_ change in the content is swamped by the performance cost of actually executing the update commands on the terminal itself. It is a common pattern in systems design that performance analysis plays a key part in determining how and where to hide complexity. The screen update process can be asynchronous to the changes in the underlying text buffer and can be independent of the actual historical sequence of changes to the buffer. It is not important _how_ the buffer changed, but only _what_ changed. This combination of asynchronous coupling, elimination of the combinatorics of historical path dependence in the interaction between components and having a natural way for interactions to efficiently batch together are common characteristics used to hide coupling complexity.
|
||||
|
||||
Success in hiding complexity is determined not by the component doing the hiding but by the consumers of that component. This is one reason why it is often so critical for a component provider to actually be responsible for at least some piece of the end-to-end use of that component. They need to have clear optics into how the rest of the system interacts with their component and how (and whether) complexity leaks out. This often shows up as feedback like “this component is hard to use” — which typically means that it is not effectively hiding the internal complexity or did not pick a functional boundary that was amenable to hiding that complexity.
|
||||
|
||||
Layering and Componentization
|
||||
|
||||
It is the fundamental role of a system designer to determine how to break down a system into components and layers; to make decisions about what to build and what to pick up from elsewhere. Open Source may keep money from changing hands in this “build vs. buy” decision but the dynamics are the same. An important element in large scale engineering is understanding how these decisions will play out over time. Change fundamentally underlies everything we do as programmers, so these design choices are not only evaluated in the moment, but are evaluated in the years to come as the product continues to evolve.
|
||||
|
||||
Here are a few things about system decomposition that end up having a large element of time in them and therefore tend to take longer to learn and appreciate.
|
||||
|
||||
* Layers are leaky. Layers (or abstractions) are [fundamentally leaky][1]. These leaks have consequences immediately but also have consequences over time, in two ways. One consequence is that the characteristics of the layer leak through and permeate more of the system than you realize. These might be assumptions about specific performance characteristics or behavior ordering that is not an explicit part of the layer contract. This means that you generally are more _vulnerable_ to changes in the internal behavior of the component that you understood. A second consequence is it also means you are more _dependent_ on that internal behavior than is obvious, so if you consider changing that layer the consequences and challenges are probably larger than you thought.
|
||||
* Layers are too functional. It is almost a truism that a component you adopt will have more functionality than you actually require. In some cases, the decision to use it is based on leveraging that functionality for future uses. You adopt specifically because you want to “get on the train” and leverage the ongoing work that will go into that component. There are a few consequences of building on this highly functional layer. 1) The component will often make trade-offs that are biased by functionality that you do not actually require. 2) The component will embed complexity and constraints because of functionality you do not require and those constraints will impede future evolution of that component. 3) There will be more surface area to leak into your application. Some of that leakage will be due to true “leaky abstractions” and some will be explicit (but generally poorly controlled) increased dependence on the full capabilities of the component. Office is big enough that we found that for any layer we built on, we eventually fully explored its functionality in some part of the system. While that might appear to be positive (we are more completely leveraging the component), all uses are not equally valuable. So we end up having a massive cost to move from one layer to another based on this long-tail of often lower value and poorly recognized use cases. 4) The additional functionality creates complexity and opportunities for misuse. An XML validation API we used would optionally dynamically download the schema definition if it was specified as part of the XML tree. This was mistakenly turned on in our basic file parsing code which resulted in both a massive performance degradation as well as an (unintentional) distributed denial of service attack on a w3c.org web server. (These are colloquially known as “land mine” APIs.)
|
||||
* Layers get replaced. Requirements evolve, systems evolve, components are abandoned. You eventually need to replace that layer or component. This is true for external component dependencies as well as internal ones. This means that the issues above will end up becoming important.
|
||||
* Your build vs. buy decision will change. This is partly a corollary of above. This does not mean the decision to build or buy was wrong at the time. Often there was no appropriate component when you started and it only becomes available later. Or alternatively, you use a component but eventually find that it does not match your evolving requirements and your requirements are narrow enough, well-understood or so core to your value proposition that it makes sense to own it yourself. It does mean that you need to be just as concerned about leaky layers permeating more of the system for layers you build as well as for layers you adopt.
|
||||
* Layers get thick. As soon as you have defined a layer, it starts to accrete functionality. The layer is the natural throttle point to optimize for your usage patterns. The difficulty with a thick layer is that it tends to reduce your ability to leverage ongoing innovation in underlying layers. In some sense this is why OS companies hate thick layers built on top of their core evolving functionality — the pace at which innovation can be adopted is inherently slowed. One disciplined approach to avoid this is to disallow any additional state storage in an adaptor layer. Microsoft Foundation Classes took this general approach in building on top of Win32\. It is inevitably cheaper in the short term to just accrete functionality on to an existing layer (leading to all the eventual problems above) rather than refactoring and recomponentizing. A system designer who understands this looks for opportunities to break apart and simplify components rather than accrete more and more functionality within them.
|
||||
|
||||
Einsteinian Universe
|
||||
|
||||
I had been designing asynchronous distributed systems for decades but was struck by this quote from Pat Helland, a SQL architect, at an internal Microsoft talk. “We live in an Einsteinian universe — there is no such thing as simultaneity. “ When building distributed systems — and virtually everything we build is a distributed system — you cannot hide the distributed nature of the system. It’s just physics. This is one of the reasons I’ve always felt Remote Procedure Call, and especially “transparent” RPC that explicitly tries to hide the distributed nature of the interaction, is fundamentally wrong-headed. You need to embrace the distributed nature of the system since the implications almost always need to be plumbed completely through the system design and into the user experience.
|
||||
|
||||
Embracing the distributed nature of the system leads to a number of things:
|
||||
|
||||
* You think through the implications to the user experience from the start rather than trying to patch on error handling, cancellation and status reporting as an afterthought.
|
||||
* You use asynchronous techniques to couple components. Synchronous coupling is _impossible._ If something appears synchronous, it’s because some internal layer has tried to hide the asynchrony and in doing so has obscured (but definitely not hidden) a fundamental characteristic of the runtime behavior of the system.
|
||||
* You recognize and explicitly design for interacting state machines and that these states represent robust long-lived internal system states (rather than ad-hoc, ephemeral and undiscoverable state encoded by the value of variables in a deep call stack).
|
||||
* You recognize that failure is expected. The only guaranteed way to detect failure in a distributed system is to simply decide you have waited “too long”. This naturally means that [cancellation is first-class][2]. Some layer of the system (perhaps plumbed through to the user) will need to decide it has waited too long and cancel the interaction. Cancelling is only about reestablishing local state and reclaiming local resources — there is no way to reliably propagate that cancellation through the system. It can sometimes be useful to have a low-cost, unreliable way to attempt to propagate cancellation as a performance optimization.
|
||||
* You recognize that cancellation is not rollback since it is just reclaiming local resources and state. If rollback is necessary, it needs to be an end-to-end feature.
|
||||
* You accept that you can never really know the state of a distributed component. As soon as you discover the state, it may have changed. When you send an operation, it may be lost in transit, it might be processed but the response is lost, or it may take some significant amount of time to process so the remote state ultimately transitions at some arbitrary time in the future. This leads to approaches like idempotent operations and the ability to robustly and efficiently rediscover remote state rather than expecting that distributed components can reliably track state in parallel. The concept of “[eventual consistency][3]” succinctly captures many of these ideas.
|
||||
|
||||
I like to say you should “revel in the asynchrony”. Rather than trying to hide it, you accept it and design for it. When you see a technique like idempotency or immutability, you recognize them as ways of embracing the fundamental nature of the universe, not just one more design tool in your toolbox.
|
||||
|
||||
Performance
|
||||
|
||||
I am sure Don Knuth is horrified by how misunderstood his partial quote “Premature optimization is the root of all evil” has been. In fact, performance, and the incredible exponential improvements in performance that have continued for over 6 decades (or more than 10 decades depending on how willing you are to project these trends through discrete transistors, vacuum tubes and electromechanical relays), underlie all of the amazing innovation we have seen in our industry and all the change rippling through the economy as “software eats the world”.
|
||||
|
||||
A key thing to recognize about this exponential change is that while all components of the system are experiencing exponential change, these exponentials are divergent. So the rate of increase in capacity of a hard disk changes at a different rate from the capacity of memory or the speed of the CPU or the latency between memory and CPU. Even when trends are driven by the same underlying technology, exponentials diverge. [Latency improvements fundamentally trail bandwidth improvements][7]. Exponential change tends to look linear when you are close to it or over short periods but the effects over time can be overwhelming. This overwhelming change in the relationship between the performance of components of the system forces reevaluation of design decisions on a regular basis.
|
||||
|
||||
A consequence of this is that design decisions that made sense at one point no longer make sense after a few years. Or in some cases an approach that made sense two decades ago starts to look like a good trade-off again. Modern memory mapping has characteristics that look more like process swapping of the early time-sharing days than it does like demand paging. (This does sometimes result in old codgers like myself claiming that “that’s just the same approach we used back in ‘75” — ignoring the fact that it didn’t make sense for 40 years and now does again because some balance between two components — maybe flash and NAND rather than disk and core memory — has come to resemble a previous relationship).
|
||||
|
||||
Important transitions happen when these exponentials cross human constraints. So you move from a limit of two to the sixteenth characters (which a single user can type in a few hours) to two to the thirty-second (which is beyond what a single person can type). So you can capture a digital image with higher resolution than the human eye can perceive. Or you can store an entire music collection on a hard disk small enough to fit in your pocket. Or you can store a digitized video recording on a hard disk. And then later the ability to stream that recording in real time makes it possible to “record” it by storing it once centrally rather than repeatedly on thousands of local hard disks.
|
||||
|
||||
The things that stay as a fundamental constraint are three dimensions and the speed of light. We’re back to that Einsteinian universe. We will always have memory hierarchies — they are fundamental to the laws of physics. You will always have stable storage and IO, memory, computation and communications. The relative capacity, latency and bandwidth of these elements will change, but the system is always about how these elements fit together and the balance and tradeoffs between them. Jim Gray was the master of this analysis.
|
||||
|
||||
Another consequence of the fundamentals of 3D and the speed of light is that much of performance analysis is about three things: locality, locality, locality. Whether it is packing data on disk, managing processor cache hierarchies, or coalescing data into a communications packet, how data is packed together, the patterns for how you touch that data with locality over time and the patterns of how you transfer that data between components is fundamental to performance. Focusing on less code operating on less data with more locality over space and time is a good way to cut through the noise.
|
||||
|
||||
Jon Devaan used to say “design the data, not the code”. This also generally means when looking at the structure of a system, I’m less interested in seeing how the code interacts — I want to see how the data interacts and flows. If someone tries to explain a system by describing the code structure and does not understand the rate and volume of data flow, they do not understand the system.
|
||||
|
||||
A memory hierarchy also implies we will always have caches — even if some system layer is trying to hide it. Caches are fundamental but also dangerous. Caches are trying to leverage the runtime behavior of the code to change the pattern of interaction between different components in the system. They inherently need to model that behavior, even if that model is implicit in how they fill and invalidate the cache and test for a cache hit. If the model is poor _or becomes_ poor as the behavior changes, the cache will not operate as expected. A simple guideline is that caches _must_ be instrumented — their behavior will degrade over time because of changing behavior of the application and the changing nature and balance of the performance characteristics of the components you are modeling. Every long-time programmer has cache horror stories.
|
||||
|
||||
I was lucky that my early career was spent at BBN, one of the birthplaces of the Internet. It was very natural to think about communications between asynchronous components as the natural way systems connect. Flow control and queueing theory are fundamental to communications systems and more generally the way that any asynchronous system operates. Flow control is inherently resource management (managing the capacity of a channel) but resource management is the more fundamental concern. Flow control also is inherently an end-to-end responsibility, so thinking about asynchronous systems in an end-to-end way comes very naturally. The story of [buffer bloat][8]is well worth understanding in this context because it demonstrates how lack of understanding the dynamics of end-to-end behavior coupled with technology “improvements” (larger buffers in routers) resulted in very long-running problems in the overall network infrastructure.
|
||||
|
||||
The concept of “light speed” is one that I’ve found useful in analyzing any system. A light speed analysis doesn’t start with the current performance, it asks “what is the best theoretical performance I could achieve with this design?” What is the real information content being transferred and at what rate of change? What is the underlying latency and bandwidth between components? A light speed analysis forces a designer to have a deeper appreciation for whether their approach could ever achieve the performance goals or whether they need to rethink their basic approach. It also forces a deeper understanding of where performance is being consumed and whether this is inherent or potentially due to some misbehavior. From a constructive point of view, it forces a system designer to understand what are the true performance characteristics of their building blocks rather than focusing on the other functional characteristics.
|
||||
|
||||
I spent much of my career building graphical applications. A user sitting at one end of the system defines a key constant and constraint in any such system. The human visual and nervous system is not experiencing exponential change. The system is inherently constrained, which means a system designer can leverage ( _must_ leverage) those constraints, e.g. by virtualization (limiting how much of the underlying data model needs to be mapped into view data structures) or by limiting the rate of screen update to the perception limits of the human visual system.
|
||||
|
||||
The Nature of Complexity
|
||||
|
||||
I have struggled with complexity my entire career. Why do systems and apps get complex? Why doesn’t development within an application domain get easier over time as the infrastructure gets more powerful rather than getting harder and more constrained? In fact, one of our key approaches for managing complexity is to “walk away” and start fresh. Often new tools or languages force us to start from scratch which means that developers end up conflating the benefits of the tool with the benefits of the clean start. The clean start is what is fundamental. This is not to say that some new tool, platform or language might not be a great thing, but I can guarantee it will not solve the problem of complexity growth. The simplest way of controlling complexity growth is to build a smaller system with fewer developers.
|
||||
|
||||
Of course, in many cases “walking away” is not an alternative — the Office business is built on hugely valuable and complex assets. With OneNote, Office “walked away” from the complexity of Word in order to innovate along a different dimension. Sway is another example where Office decided that we needed to free ourselves from constraints in order to really leverage key environmental changes and the opportunity to take fundamentally different design approaches. With the Word, Excel and PowerPoint web apps, we decided that the linkage with our immensely valuable data formats was too fundamental to walk away from and that has served as a significant and ongoing constraint on development.
|
||||
|
||||
I was influenced by Fred Brook’s “[No Silver Bullet][9]” essay about accident and essence in software development. There is much irreducible complexity embedded in the essence of what the software is trying to model. I just recently re-read that essay and found it surprising on re-reading that two of the trends he imbued with the most power to impact future developer productivity were increasing emphasis on “buy” in the “build vs. buy” decision — foreshadowing the change that open-source and cloud infrastructure has had. The other trend was the move to more “organic” or “biological” incremental approaches over more purely constructivist approaches. A modern reader sees that as the shift to agile and continuous development processes. This in 1986!
|
||||
|
||||
I have been much taken with the work of Stuart Kauffman on the fundamental nature of complexity. Kauffman builds up from a simple model of Boolean networks (“[NK models][10]”) and then explores the application of this fundamentally mathematical construct to things like systems of interacting molecules, genetic networks, ecosystems, economic systems and (in a limited way) computer systems to understand the mathematical underpinning to emergent ordered behavior and its relationship to chaotic behavior. In a highly connected system, you inherently have a system of conflicting constraints that makes it (mathematically) hard to evolve that system forward (viewed as an optimization problem over a rugged landscape). A fundamental way of controlling this complexity is to batch the system into independent elements and limit the interconnections between elements (essentially reducing both “N” and “K” in the NK model). Of course this feels natural to a system designer applying techniques of complexity hiding, information hiding and data abstraction and using loose asynchronous coupling to limit interactions between components.
|
||||
|
||||
A challenge we always face is that many of the ways we want to evolve our systems cut across all dimensions. Real-time co-authoring has been a very concrete (and complex) recent example for the Office apps.
|
||||
|
||||
Complexity in our data models often equates with “power”. An inherent challenge in designing user experiences is that we need to map a limited set of gestures into a transition in the underlying data model state space. Increasing the dimensions of the state space inevitably creates ambiguity in the user gesture. This is “[just math][11]” which means that often times the most fundamental way to ensure that a system stays “easy to use” is to constrain the underlying data model.
|
||||
|
||||
Management
|
||||
|
||||
I started taking leadership roles in high school (student council president!) and always found it natural to take on larger responsibilities. At the same time, I was always proud that I continued to be a full-time programmer through every management stage. VP of development for Office finally pushed me over the edge and away from day-to-day programming. I’ve enjoyed returning to programming as I stepped away from that job over the last year — it is an incredibly creative and fulfilling activity (and maybe a little frustrating at times as you chase down that “last” bug).
|
||||
|
||||
Despite having been a “manager” for over a decade by the time I arrived at Microsoft, I really learned about management after my arrival in 1996\. Microsoft reinforced that “engineering leadership is technical leadership”. This aligned with my perspective and helped me both accept and grow into larger management responsibilities.
|
||||
|
||||
The thing that most resonated with me on my arrival was the fundamental culture of transparency in Office. The manager’s job was to design and use transparent processes to drive the project. Transparency is not simple, automatic, or a matter of good intentions — it needs to be designed into the system. The best transparency comes by being able to track progress as the granular output of individual engineers in their day-to-day activity (work items completed, bugs opened and fixed, scenarios complete). Beware subjective red/green/yellow, thumbs-up/thumbs-down dashboards!
|
||||
|
||||
I used to say my job was to design feedback loops. Transparent processes provide a way for every participant in the process — from individual engineer to manager to exec to use the data being tracked to drive the process and result and understand the role they are playing in the overall project goals. Ultimately transparency ends up being a great tool for empowerment — the manager can invest more and more local control in those closest to the problem because of confidence they have visibility to the progress being made. Coordination emerges naturally.
|
||||
|
||||
Key to this is that the goal has actually been properly framed (including key resource constraints like ship schedule). Decision-making that needs to constantly flow up and down the management chain usually reflects poor framing of goals and constraints by management.
|
||||
|
||||
I was at Beyond Software when I really internalized the importance of having a singular leader over a project. The engineering manager departed (later to hire me away for FrontPage) and all four of the leads were hesitant to step into the role — not least because we did not know how long we were going to stick around. We were all very technically sharp and got along well so we decided to work as peers to lead the project. It was a mess. The one obvious problem is that we had no strategy for allocating resources between the pre-existing groups — one of the top responsibilities of management! The deep accountability one feels when you know you are personally in charge was missing. We had no leader really accountable for unifying goals and defining constraints.
|
||||
|
||||
I have a visceral memory of the first time I fully appreciated the importance of _listening_ for a leader. I had just taken on the role of Group Development Manager for Word, OneNote, Publisher and Text Services. There was a significant controversy about how we were organizing the text services team and I went around to each of the key participants, heard what they had to say and then integrated and wrote up all I had heard. When I showed the write-up to one of the key participants, his reaction was “wow, you really heard what I had to say”! All of the largest issues I drove as a manager (e.g. cross-platform and the shift to continuous engineering) involved carefully listening to all the players. Listening is an active process that involves trying to understand the perspectives and then writing up what I learned and testing it to validate my understanding. When a key hard decision needed to happen, by the time the call was made everyone knew they had been heard and understood (whether they agreed with the decision or not).
|
||||
|
||||
It was the previous job, as FrontPage development manager, where I internalized the “operational dilemma” inherent in decision making with partial information. The longer you wait, the more information you will have to make a decision. But the longer you wait, the less flexibility you will have to actually implement it. At some point you just need to make a call.
|
||||
|
||||
Designing an organization involves a similar tension. You want to increase the resource domain so that a consistent prioritization framework can be applied across a larger set of resources. But the larger the resource domain, the harder it is to actually have all the information you need to make good decisions. An organizational design is about balancing these two factors. Software complicates this because characteristics of the software can cut across the design in an arbitrary dimensionality. Office has used [shared teams][12] to address both these issues (prioritization and resources) by having cross-cutting teams that can share work (add resources) with the teams they are building for.
|
||||
|
||||
One dirty little secret you learn as you move up the management ladder is that you and your new peers aren’t suddenly smarter because you now have more responsibility. This reinforces that the organization as a whole better be smarter than the leader at the top. Empowering every level to own their decisions within a consistent framing is the key approach to making this true. Listening and making yourself accountable to the organization for articulating and explaining the reasoning behind your decisions is another key strategy. Surprisingly, fear of making a dumb decision can be a useful motivator for ensuring you articulate your reasoning clearly and make sure you listen to all inputs.
|
||||
|
||||
Conclusion
|
||||
|
||||
At the end of my interview round for my first job out of college, the recruiter asked if I was more interested in working on “systems” or “apps”. I didn’t really understand the question. Hard, interesting problems arise at every level of the software stack and I’ve had fun plumbing all of them. Keep learning.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://hackernoon.com/education-of-a-programmer-aaecf2d35312
|
||||
|
||||
作者:[ Terry Crowley][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://hackernoon.com/@terrycrowley
|
||||
[1]:https://medium.com/@terrycrowley/leaky-by-design-7b423142ece0#.x67udeg0a
|
||||
[2]:https://medium.com/@terrycrowley/how-to-think-about-cancellation-3516fc342ae#.3pfjc5b54
|
||||
[3]:http://queue.acm.org/detail.cfm?id=2462076
|
||||
[4]:http://web.mit.edu/Saltzer/www/publications/endtoend/endtoend.pdf
|
||||
[5]:https://medium.com/@terrycrowley/model-view-controller-and-loose-coupling-6370f76e9cde#.o4gnupqzq
|
||||
[6]:https://en.wikipedia.org/wiki/Termcap
|
||||
[7]:http://www.ll.mit.edu/HPEC/agendas/proc04/invited/patterson_keynote.pdf
|
||||
[8]:https://en.wikipedia.org/wiki/Bufferbloat
|
||||
[9]:http://worrydream.com/refs/Brooks-NoSilverBullet.pdf
|
||||
[10]:https://en.wikipedia.org/wiki/NK_model
|
||||
[11]:https://medium.com/@terrycrowley/the-math-of-easy-to-use-14645f819201#.untmk9eq7
|
||||
[12]:https://medium.com/@terrycrowley/breaking-conways-law-a0fdf8500413#.gqaqf1c5k
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user