diff --git a/published/20090518 How to use yum-cron to automatically update RHEL-CentOS Linux.md b/published/20090518 How to use yum-cron to automatically update RHEL-CentOS Linux.md
new file mode 100644
index 0000000000..e2d88ce4ec
--- /dev/null
+++ b/published/20090518 How to use yum-cron to automatically update RHEL-CentOS Linux.md
@@ -0,0 +1,146 @@
+如何使用 yum-cron 自动更新 RHEL/CentOS Linux
+======
+
+`yum` 命令是 RHEL / CentOS Linux 系统中用来安装和更新软件包的一个工具。我知道如何使用 [yum 命令行][1] 更新系统,但是我想用 cron 任务自动更新软件包。该如何配置才能使得 `yum` 使用 [cron 自动更新][2]系统补丁或更新呢?
+
+首先需要安装 yum-cron 软件包。该软件包提供以 cron 命令运行 `yum` 更新所需的文件。如果你想要每晚通过 cron 自动更新可以安装这个软件包。
+
+### CentOS/RHEL 6.x/7.x 上安装 yum cron
+
+输入以下 [yum 命令][3]:
+
+```
+$ sudo yum install yum-cron
+```
+
+
+
+使用 CentOS/RHEL 7.x 上的 `systemctl` 启动服务:
+
+```
+$ sudo systemctl enable yum-cron.service
+$ sudo systemctl start yum-cron.service
+$ sudo systemctl status yum-cron.service
+```
+
+在 CentOS/RHEL 6.x 系统中,运行:
+
+```
+$ sudo chkconfig yum-cron on
+$ sudo service yum-cron start
+```
+
+
+
+`yum-cron` 是 `yum` 的一个替代方式。使得 cron 调用 `yum` 变得非常方便。该软件提供了元数据更新、更新检查、下载和安装等功能。`yum-cron` 的各种功能可以使用配置文件配置,而不是输入一堆复杂的命令行参数。
+
+### 配置 yum-cron 自动更新 RHEL/CentOS Linux
+
+使用 vi 等编辑器编辑文件 `/etc/yum/yum-cron.conf` 和 `/etc/yum/yum-cron-hourly.conf`:
+
+```
+$ sudo vi /etc/yum/yum-cron.conf
+```
+
+确保更新可用时自动更新:
+
+```
+apply_updates = yes
+```
+
+可以设置通知 email 的发件地址。注意: localhost` 将会被 `system_name` 的值代替。
+
+```
+email_from = root@localhost
+```
+
+列出发送到的 email 地址。
+
+```
+email_to = your-it-support@some-domain-name
+```
+
+发送 email 信息的主机名。
+
+```
+email_host = localhost
+```
+
+[CentOS/RHEL 7.x][4] 上不想更新内核的话,添加以下内容:
+
+```
+exclude=kernel*
+```
+
+RHEL/CentOS 6.x 下[添加以下内容来禁用内核更新][5]:
+
+```
+YUM_PARAMETER=kernel*
+```
+
+[保存并关闭文件][6]。如果想每小时更新系统的话修改文件 `/etc/yum/yum-cron-hourly.conf`,否则文件 `/etc/yum/yum-cron.conf` 将使用以下命令每天运行一次(使用 [cat 命令][7] 查看):
+
+```
+$ cat /etc/cron.daily/0yum-daily.cron
+```
+
+示例输出:
+
+```
+#!/bin/bash
+
+# Only run if this flag is set. The flag is created by the yum-cron init
+# script when the service is started -- this allows one to use chkconfig and
+# the standard "service stop|start" commands to enable or disable yum-cron.
+if [[ ! -f /var/lock/subsys/yum-cron ]]; then
+ exit 0
+fi
+
+# Action!
+exec /usr/sbin/yum-cron /etc/yum/yum-cron-hourly.conf
+[root@centos7-box yum]# cat /etc/cron.daily/0yum-daily.cron
+#!/bin/bash
+
+# Only run if this flag is set. The flag is created by the yum-cron init
+# script when the service is started -- this allows one to use chkconfig and
+# the standard "service stop|start" commands to enable or disable yum-cron.
+if [[ ! -f /var/lock/subsys/yum-cron ]]; then
+ exit 0
+fi
+
+# Action!
+exec /usr/sbin/yum-cron
+```
+
+完成配置。现在你的系统将每天自动更新一次。更多细节请参照 yum-cron 的说明手册。
+
+```
+$ man yum-cron
+```
+
+### 关于作者
+
+作者是 nixCraft 的创始人,一个经验丰富的系统管理员和 Linux/Unix 脚本培训师。他曾与全球客户合作,领域涉及IT,教育,国防和空间研究以及非营利部门等多个行业。请在 [Twitter][9]、[Facebook][10]、[Google+][11] 上关注他。获取更多有关系统管理、Linux/Unix 和开源话题请关注[我的 RSS/XML 地址][12]。
+
+--------------------------------------------------------------------------------
+
+via: https://www.cyberciti.biz/faq/fedora-automatic-update-retrieval-installation-with-cron/
+
+作者:[Vivek Gite][a]
+译者:[shipsw](https://github.com/shipsw)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.cyberciti.biz/
+[1]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/
+[2]:https://www.cyberciti.biz/faq/how-do-i-add-jobs-to-cron-under-linux-or-unix-oses
+[3]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/ [4]:https://www.cyberciti.biz/faq/yum-update-except-kernel-package-command/
+[5]:https://www.cyberciti.biz/faq/redhat-centos-linux-yum-update-exclude-packages/
+[6]:https://www.cyberciti.biz/faq/linux-unix-vim-save-and-quit-command/
+[7]:https://www.cyberciti.biz/faq/linux-unix-appleosx-bsd-cat-command-examples/
+[8]:https://www.cyberciti.biz/faq/how-do-i-add-jobs-to-cron-under-linux-or-unix-oses
+[9]:https://twitter.com/nixcraft
+[10]:https://facebook.com/nixcraft
+[11]:https://plus.google.com/+CybercitiBiz
+[12]:https://www.cyberciti.biz/atom/atom.xml
diff --git a/published/20171007 How to use GNU Stow to manage programs installed from source and dotfiles.md b/published/20171007 How to use GNU Stow to manage programs installed from source and dotfiles.md
new file mode 100644
index 0000000000..306684f885
--- /dev/null
+++ b/published/20171007 How to use GNU Stow to manage programs installed from source and dotfiles.md
@@ -0,0 +1,137 @@
+如何使用 GNU Stow 来管理从源代码安装的程序和点文件
+=====
+
+### 目的
+
+使用 GNU Stow 轻松管理从源代码安装的程序和点文件(LCTT 译注:点文件,即以 `.` 开头的文件,在 *nix 下默认为隐藏文件,常用于存储程序的配置信息。)
+
+### 要求
+
+* root 权限
+
+### 难度
+
+简单
+
+### 约定
+
+* `#` - 给定的命令要求直接以 root 用户身份或使用 `sudo` 命令以 root 权限执行
+* `$` - 给定的命令将作为普通的非特权用户来执行
+
+### 介绍
+
+有时候我们必须从源代码安装程序,因为它们也许不能通过标准渠道获得,或者我们可能需要特定版本的软件。 GNU Stow 是一个非常不错的符号链接工厂程序,它可以帮助我们保持文件的整洁,易于维护。
+
+### 获得 stow
+
+你的 Linux 发行版本很可能包含 `stow`,例如在 Fedora,你安装它只需要:
+
+```
+# dnf install stow
+```
+
+在 Ubuntu/Debian 中,安装 `stow` 需要执行:
+
+```
+# apt install stow
+```
+
+在某些 Linux 发行版中,`stow` 在标准库中是不可用的,但是可以通过一些额外的软件源(例如 RHEL 和 CentOS7 中的EPEL )轻松获得,或者,作为最后的手段,你可以从源代码编译它。只需要很少的依赖关系。
+
+### 从源代码编译
+
+最新的可用 stow 版本是 `2.2.2`。源码包可以在这里下载:`https://ftp.gnu.org/gnu/stow/`。
+
+一旦你下载了源码包,你就必须解压它。切换到你下载软件包的目录,然后运行:
+
+```
+$ tar -xvpzf stow-2.2.2.tar.gz
+```
+
+解压源文件后,切换到 `stow-2.2.2` 目录中,然后编译该程序,只需运行:
+
+```
+$ ./configure
+$ make
+```
+
+最后,安装软件包:
+
+```
+# make install
+```
+
+默认情况下,软件包将安装在 `/usr/local/` 目录中,但是我们可以改变它,通过配置脚本的 `--prefix` 选项指定目录,或者在运行 `make install` 时添加 `prefix="/your/dir"`。
+
+此时,如果所有工作都按预期工作,我们应该已经在系统上安装了 `stow`。
+
+### stow 是如何工作的?
+
+`stow` 背后主要的概念在程序手册中有很好的解释:
+
+> Stow 使用的方法是将每个软件包安装到自己的目录树中,然后使用符号链接使它看起来像文件一样安装在公共的目录树中
+
+为了更好地理解这个软件的运作,我们来分析一下它的关键概念:
+
+#### stow 文件目录
+
+stow 目录是包含所有 stow 软件包的根目录,每个包都有自己的子目录。典型的 stow 目录是 `/usr/local/stow`:在其中,每个子目录代表一个软件包。
+
+#### stow 软件包
+
+如上所述,stow 目录包含多个“软件包”,每个软件包都位于自己单独的子目录中,通常以程序本身命名。包就是与特定软件相关的文件和目录列表,作为一个实体进行管理。
+
+#### stow 目标目录
+
+stow 目标目录解释起来是一个非常简单的概念。它是包文件应该安装到的目录。默认情况下,stow 目标目录被视作是调用 stow 的目录。这种行为可以通过使用 `-t` 选项( `--target` 的简写)轻松改变,这使我们可以指定一个替代目录。
+
+### 一个实际的例子
+
+我相信一个好的例子胜过 1000 句话,所以让我来展示 `stow` 如何工作。假设我们想编译并安装 `libx264`,首先我们克隆包含其源代码的仓库:
+
+```
+$ git clone git://git.videolan.org/x264.git
+```
+
+运行该命令几秒钟后,将创建 `x264` 目录,它将包含准备编译的源代码。我们切换到 `x264` 目录中并运行 `configure` 脚本,将 `--prefix` 指定为 `/usr/local/stow/libx264` 目录。
+
+```
+$ cd x264 && ./configure --prefix=/usr/local/stow/libx264
+```
+
+然后我们构建该程序并安装它:
+
+```
+$ make
+# make install
+```
+
+`x264` 目录应该创建在 `stow` 目录内:它包含了所有通常直接安装在系统中的东西。 现在,我们所要做的就是调用 `stow`。 我们必须从 `stow` 目录内运行这个命令,通过使用 `-d` 选项来手动指定 `stow` 目录的路径(默认为当前目录),或者通过如前所述用 `-t` 指定目标。我们还应该提供要作为参数存储的软件包的名称。 在这里,我们从 `stow` 目录运行程序,所以我们需要输入的内容是:
+
+```
+# stow libx264
+```
+
+libx264 软件包中包含的所有文件和目录现在已经在调用 stow 的父目录 (/usr/local) 中进行了符号链接,因此,例如在 `/usr/local/ stow/x264/bin` 中包含的 libx264 二进制文件现在符号链接在 `/usr/local/bin` 之中,`/usr/local/stow/x264/etc` 中的文件现在符号链接在 `/usr/local/etc` 之中等等。通过这种方式,系统将显示文件已正常安装,并且我们可以容易地跟踪我们编译和安装的每个程序。要反转该操作,我们只需使用 `-D` 选项:
+
+```
+# stow -d libx264
+```
+
+完成了!符号链接不再存在:我们只是“卸载”了一个 stow 包,使我们的系统保持在一个干净且一致的状态。 在这一点上,我们应该清楚为什么 stow 还可以用于管理点文件。 通常的做法是在 git 仓库中包含用户特定的所有配置文件,以便轻松管理它们并使它们在任何地方都可用,然后使用 stow 将它们放在适当位置,如放在用户主目录中。
+
+stow 还会阻止你错误地覆盖文件:如果目标文件已经存在,并且没有指向 stow 目录中的包时,它将拒绝创建符号链接。 这种情况在 stow 术语中称为冲突。
+
+就是这样!有关选项的完整列表,请参阅 stow 帮助页,并且不要忘记在评论中告诉我们你对此的看法。
+
+--------------------------------------------------------------------------------
+
+via: https://linuxconfig.org/how-to-use-gnu-stow-to-manage-programs-installed-from-source-and-dotfiles
+
+作者:[Egidio Docile][a]
+译者:[MjSeven](https://github.com/MjSeven)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://linuxconfig.org
diff --git a/translated/tech/20171218 What Are Containers and Why Should You Care-.md b/published/20171218 What Are Containers and Why Should You Care-.md
similarity index 65%
rename from translated/tech/20171218 What Are Containers and Why Should You Care-.md
rename to published/20171218 What Are Containers and Why Should You Care-.md
index 8d612dbed0..32e8af76b0 100644
--- a/translated/tech/20171218 What Are Containers and Why Should You Care-.md
+++ b/published/20171218 What Are Containers and Why Should You Care-.md
@@ -1,44 +1,47 @@
什么是容器?为什么我们关注它?
======
+
+
+
什么是容器?你需要它们吗?为什么?在这篇文章中,我们会回答这些基本问题。
但是,为了回答这些问题,我们要提出更多的问题。当你开始考虑怎么用容器适配你的工作时,你需要弄清楚:你在哪开发应用?你在哪测试它?你在哪使用它?
-你可能在你的笔记本电脑上开发应用,你的电脑上已经装好了所需要的库文件,扩展包,开发工具,和开发框架。它在一个模拟生产环境的机器上进行测试,然后被用于生产。问题是这三种环境不一定都是一样的;他们没有同样的工具,框架,和库。你在你机器上开发的应用不一定可以在生产环境中正常工作。
+你可能在你的笔记本电脑上开发应用,你的电脑上已经装好了所需要的库文件、扩展包、开发工具和开发框架。它在一个模拟生产环境的机器上进行测试,然后被用于生产环境。问题是这三种环境不一定都是一样的;它们没有同样的工具、框架和库。你在你机器上开发的应用不一定可以在生产环境中正常工作。
-容器解决了这个问题。正如 Docker 解释的,“容器镜像是软件的一个轻量的,独立的,可执行的包,包括了执行它所需要的所有东西:代码,运行环境,系统工具,系统库,设置。”
+容器解决了这个问题。正如 Docker 解释的,“容器镜像是软件的一个轻量的、独立的、可执行的包,包括了执行它所需要的所有东西:代码、运行环境、系统工具、系统库、设置。”
-这代表着,一旦一个应用被封装成容器,那么它所依赖的下层环境就不再重要了。它可以在任何地方运行,甚至在混合云环境下也可以。这是容器在开发者,执行团队,甚至 CIO (信息主管)中变得如此流行的原因之一。
+这代表着,一旦一个应用被封装成容器,那么它所依赖的下层环境就不再重要了。它可以在任何地方运行,甚至在混合云环境下也可以。这是容器在开发人员,执行团队,甚至 CIO (信息主管)中变得如此流行的原因之一。
-### 容器对开发者的好处
+### 容器对开发人员的好处
-现在开发者或执行者不再需要关注他们要使用什么平台来运行应用。开发者不会再说:“这在我的系统上运行得好好的。”
+现在开发人员或运维人员不再需要关注他们要使用什么平台来运行应用。开发人员不会再说:“这在我的系统上运行得好好的。”
-容器的另一个重大优势时它的隔离性和安全性。因为容器将应用和运行平台隔离开了,应用以及它周边的东西都会变得安全。同时,不同的团队可以在一台设备上同时运行不同的应用——对于传统应用来说这是不可以的。
+容器的另一个重大优势是它的隔离性和安全性。因为容器将应用和运行平台隔离开了,应用以及它周边的东西都会变得安全。同时,不同的团队可以在一台设备上同时运行不同的应用——对于传统应用来说这是不可以的。
-这不是虚拟机( VM )所提供的吗?是的,也不是。虚拟机可以隔离应用,但它负载太高了。[在一份文献中][1],Canonical 比较了容器和虚拟机,结果是:“容器提供了一种新的虚拟化方法,它有着和传统虚拟机几乎相同的资源隔离水平。但容器的负载更小,它占用更少的内存,更为高效。这意味着可以实现高密度的虚拟化:一旦安装,你可以在相同的硬件上运行更多应用。”另外,虚拟机启动前需要更多的准备,而容器只需几秒就能运行,可以瞬间启动。
+这不是虚拟机( VM )所提供的吗?既是,也不是。虚拟机可以隔离应用,但它负载太高了。[在一份文献中][1],Canonical 比较了容器和虚拟机,结果是:“容器提供了一种新的虚拟化方法,它有着和传统虚拟机几乎相同的资源隔离水平。但容器的负载更小,它占用更少的内存,更为高效。这意味着可以实现高密度的虚拟化:一旦安装,你可以在相同的硬件上运行更多应用。”另外,虚拟机启动前需要更多的准备,而容器只需几秒就能运行,可以瞬间启动。
### 容器对应用生态的好处
-现在,一个庞大的,由供应商和解决方案组成的生态系统已经允许公司大规模地运用容器,不管是用于编排,监控,记录,或者生命周期管理。
+现在,一个庞大的,由供应商和解决方案组成的生态系统已经可以让公司大规模地运用容器,不管是用于编排、监控、记录或者生命周期管理。
-为了保证容器可以运行在任何地方,容器生态系统一起成立了[开源容器倡议][2](OCI)。这是一个 Linux 基金会的项目,目标在于创建关于容器运行环境和容器镜像格式这两个容器核心部分的规范。这两个规范确保容器空间中不会有任何碎片。
+为了保证容器可以运行在任何地方,容器生态系统一起成立了[开源容器倡议][2](OCI)。这是一个 Linux 基金会的项目,目标在于创建关于容器运行环境和容器镜像格式这两个容器核心部分的规范。这两个规范确保容器领域中不会有任何不一致。
-在很长的一段时间里,容器是专门用于 Linux 内核的,但微软和 Docker 的密切合作将容器带到了微软平台上。现在你可以在 Linux,Windows,Azure,AWS,Google 计算引擎,Rackspace,以及大型计算机上使用容器。甚至 VMware 也正在发展容器,它的 [vSphere Integrated Container][3](VIC)允许 IT 专业人员在他们平台的传统工作负载上运行容器。
+在很长的一段时间里,容器是专门用于 Linux 内核的,但微软和 Docker 的密切合作将容器带到了微软平台上。现在你可以在 Linux、Windows、Azure、AWS、Google 计算引擎、Rackspace,以及大型计算机上使用容器。甚至 VMware 也正在发展容器,它的 [vSphere Integrated Container][3](VIC)允许 IT 专业人员在他们平台的传统工作负载上运行容器。
### 容器对 CIO 的好处
-容器在开发者中因为以上的原因而变得十分流行,同时他们也给CIO提供了很大的便利。将工作负载迁移到容器中的优势正在改变着公司运行的模式。
+容器在开发人员中因为以上的原因而变得十分流行,同时他们也给 CIO 提供了很大的便利。将工作负载迁移到容器中的优势正在改变着公司运行的模式。
-传统的应用有大约十年的生命周期。新版本的发布需要多年的努力,因为应用是独立于平台的,有时需要经过几年的努力才能看到生产效果。由于这个生命周期,开发者会尽可能在应用里塞满各种功能,这会使应用变得庞大笨拙,漏洞百出。
+传统的应用有大约十年的生命周期。新版本的发布需要多年的努力,因为应用是依赖于平台的,有时几年也不能到达产品阶段。由于这个生命周期,开发人员会尽可能在应用里塞满各种功能,这会使应用变得庞大笨拙,漏洞百出。
这个过程影响了公司内部的创新文化。当人们几个月甚至几年都不能看到他们的创意被实现时,他们就不再有动力了。
-容器解决了这个问题。因为你可以将应用切分成更小的微服务。你可以在几周或几天内开发,测试和部署。新特性可以添加成为新的容器。他们可以在测试结束后以最快的速度被投入生产。公司可以更快转型,超过他们的竞争者。因为想法可以被很快转化为容器并部署,这个方式使得创意爆炸式增长。
+容器解决了这个问题。因为你可以将应用切分成更小的微服务。你可以在几周或几天内开发、测试和部署。新特性可以添加成为新的容器。他们可以在测试结束后以最快的速度被投入生产。公司可以更快转型,超过他们的竞争者。因为想法可以被很快转化为容器并部署,这个方式使得创意爆炸式增长。
### 结论
-容器解决了许多传统工作负载所面对的问题。但是,它并不能解决所有 IT 专业人员面对的问题。它只是众多解决方案中的一个。在下一篇文章中,我们将会覆盖一些容器的基本属于,然后我们会解释如何开始构建容器。
+容器解决了许多传统工作负载所面对的问题。但是,它并不能解决所有 IT 专业人员面对的问题。它只是众多解决方案中的一个。在下一篇文章中,我们将会覆盖一些容器的基本术语,然后我们会解释如何开始构建容器。
通过 Linux 基金会和 edX 提供的免费的 ["Introduction to Linux" ][4] 课程学习更多 Linux 知识。
@@ -46,9 +49,9 @@
via: https://www.linux.com/blog/intro-to-Linux/2017/12/what-are-containers-and-why-should-you-care
-作者:[wapnil Bhartiya][a]
+作者:[SWAPNIL BHARTIYA][a]
译者:[lonaparte](https://github.com/lonaparte)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/published/20180105 Ansible- the Automation Framework That Thinks Like a Sysadmin.md b/published/20180105 Ansible- the Automation Framework That Thinks Like a Sysadmin.md
new file mode 100644
index 0000000000..4c85c4f811
--- /dev/null
+++ b/published/20180105 Ansible- the Automation Framework That Thinks Like a Sysadmin.md
@@ -0,0 +1,180 @@
+Ansible:像系统管理员一样思考的自动化框架
+======
+
+这些年来,我已经写了许多关于 DevOps 工具的文章,也培训了这方面的人员。尽管这些工具很棒,但很明显,大多数都是按照开发人员的思路设计出来的。这也没有什么问题,因为以编程的方式接近配置管理是重点。不过,直到我开始接触 Ansible,我才觉得这才是系统管理员喜欢的东西。
+
+喜欢的一部分原因是 Ansible 与客户端计算机通信的方式,是通过 SSH 的。作为系统管理员,你们都非常熟悉通过 SSH 连接到计算机,所以从单词“去”的角度来看,相对于其它选择,你更容易理解 Ansible。
+
+考虑到这一点,我打算写一些文章,探讨如何使用 Ansible。这是一个很好的系统,但是当我第一次接触到这个系统的时候,不知道如何开始。这并不是学习曲线陡峭。事实上,问题是在开始使用 Ansible 之前,我并没有太多的东西要学,这才是让人感到困惑的。例如,如果您不必安装客户端程序(Ansible 没有在客户端计算机上安装任何软件),那么您将如何启动?
+
+### 踏出第一步
+
+起初 Ansible 对我来说非常困难的原因在于配置服务器/客户端的关系是非常灵活的,我不知道我该从何入手。事实是,Ansible 并不关心你如何设置 SSH 系统。它会利用你现有的任何配置。需要考虑以下几件事情:
+
+1. Ansible 需要通过 SSH 连接到客户端计算机。
+2. 连接后,Ansible 需要提升权限才能配置系统,安装软件包等等。
+
+不幸的是,这两个考虑真的带来了一堆蠕虫。连接到远程计算机并提升权限是一件可怕的事情。当您在远程计算机上安装代理并使用 Chef 或 Puppet 处理特权升级问题时,似乎感觉就没那么可怕了。 Ansible 并非不安全,而是安全的决定权在你手中。
+
+接下来,我将列出一系列潜在的配置,以及每个配置的优缺点。这不是一个详尽的清单,但是你会受到正确的启发,去思考在你自己的环境中什么是理想的配置。也需要注意,我不会提到像 Vagrant 这样的系统,因为尽管 Vagrant 在构建测试和开发的敏捷架构时非常棒,但是和一堆服务器是非常不同的,因此考虑因素是极不相似的。
+
+### 一些 SSH 场景
+
+#### 1)在 Ansible 配置中,root 用户以密码进入远程计算机。
+
+拥有这个想法是一个非常可怕的开始。这个设置的“优点”是它消除了对特权提升的需要,并且远程服务器上不需要其他用户帐户。 但是,这种便利的成本是不值得的。 首先,大多数系统不会让你在不改变默认配置的情况下以 root 身份进行 SSH 登录。默认的配置之所以如此,坦率地说,是因为允许 root 用户远程连接是一个不好的主意。 其次,将 root 密码放在 Ansible 机器上的纯文本配置文件中是不合适的。 真的,我提到了这种可能性,因为这是可以的,但这是应该避免的。 请记住,Ansible 允许你自己配置连接,它可以让你做真正愚蠢的事情。 但是请不要这么做。
+
+#### 2)使用存储在 Ansible 配置中的密码,以普通用户的身份进入远程计算机。
+
+这种情况的一个优点是它不需要太多的客户端配置。 大多数用户默认情况下都可以使用 SSH,因此 Ansible 应该能够使用用户凭据并且能够正常登录。 我个人不喜欢在配置文件中以纯文本形式存储密码,但至少它不是 root 密码。 如果您使用此方法,请务必考虑远程服务器上的权限提升方式。 我知道我还没有谈到权限提升,但是如果你在配置文件中配置了一个密码,这个密码可能会被用来获得 sudo 访问权限。 因此,一旦发生泄露,您不仅已经泄露了远程用户的帐户,还可能泄露整个系统。
+
+#### 3)使用具有空密码的密钥对进行身份验证,以普通用户身份进入远程计算机。
+
+这消除了将密码存储在配置文件中的弊端,至少在登录的过程中消除了。 没有密码的密钥对并不理想,但这是我经常做的事情。 在我的个人内部网络中,我通常使用没有密码的密钥对来自动执行许多事情,如需要身份验证的定时任务。 这不是最安全的选择,因为私钥泄露意味着可以无限制地访问远程用户的帐户,但是相对于在配置文件中存储密码我更喜欢这种方式。
+
+#### 4)使用通过密码保护的密钥对进行身份验证,以普通用户的身份通过 SSH 连接到远程计算机。
+
+这是处理远程访问的一种非常安全的方式,因为它需要两种不同的身份验证因素来解密:私钥和密码。 如果你只是以交互方式运行 Ansible,这可能是理想的设置。 当你运行命令时,Ansible 会提示你输入私钥的密码,然后使用密钥对登录到远程系统。 是的,只需使用标准密码登录并且不用在配置文件中指定密码即可完成,但是如果不管怎样都要在命令行上输入密码,那为什么不在保护层添加密钥对呢?
+
+#### 5)使用密码保护密钥对进行 SSH 连接,但是使用 ssh-agent “解锁”私钥。
+
+这并不能完美地解决无人值守、自动化的 Ansible 命令的问题,但是它确实也使安全设置变得相当方便。 ssh-agent 程序一次验证密码,然后使用该验证进行后续连接。当我使用 Ansible 时,这是我想要做的事情。如果我是完全值得信任的,我通常仍然使用没有密码的密钥对,但是这通常是因为我在我的家庭服务器上工作,是不是容易受到攻击的。
+
+在配置 SSH 环境时还要记住一些其他注意事项。 也许你可以限制 Ansible 用户(通常是你的本地用户),以便它只能从一个特定的 IP 地址登录。 也许您的 Ansible 服务器可以位于不同的子网中,位于强大的防火墙之后,因此其私钥更难以远程访问。 也许 Ansible 服务器本身没有安装 SSH 服务器,所以根本没法访问。 同样,Ansible 的优势之一是它使用 SSH 协议进行通信,而且这是一个你用了多年的协议,你已经把你的系统调整到最适合你的环境了。 我不是宣传“最佳实践”的忠实粉丝,因为实际上最好的做法是考虑你的环境,并选择最适合你情况的设置。
+
+### 权限提升
+
+一旦您的 Ansible 服务器通过 SSH 连接到它的客户端,就需要能够提升特权。 如果你选择了上面的选项 1,那么你已经是 root 了,这是一个有争议的问题。 但是由于没有人选择选项 1(对吧?),您需要考虑客户端计算机上的普通用户如何获得访问权限。 Ansible 支持各种权限提升的系统,但在 Linux 中,最常用的选项是 `sudo` 和 `su`。 和 SSH 一样,有几种情况需要考虑,虽然肯定还有其他选择。
+
+#### 1)使用 su 提升权限。
+
+对于 RedHat/CentOS 用户来说,可能默认是使用 `su` 来获得系统访问权限。 默认情况下,这些系统在安装过程中配置了 root 密码,要想获得特殊访问权限,您需要输入该密码。使用 `su` 的问题在于,虽说它可以给了您完全访问远程系统,而您确实也可以完全访问远程系统。 (是的,这是讽刺。)另外,`su` 程序没有使用密钥对进行身份验证的能力,所以密码必须以交互方式输入或存储在配置文件中。 由于它实际上是 root 密码,因此将其存储在配置文件中听起来像、也确实是一个可怕的想法。
+
+#### 2)使用 sudo 提升权限。
+
+这就是 Debian/Ubuntu 系统的配置方式。 正常用户组中的用户可以使用 `sudo` 命令并使用 root 权限执行该命令。 随之而来的是,这仍然存在密码存储或交互式输入的问题。 由于在配置文件中存储用户的密码看起来不太可怕,我猜这是使用 `su` 的一个进步,但是如果密码被泄露,仍然可以完全访问系统。 (毕竟,输入 `sudo` 和 `su -` 都将允许用户成为 root 用户,就像拥有 root 密码一样。)
+
+#### 3) 使用 sudo 提升权限,并在 sudoers 文件中配置 NOPASSWD。
+
+再次,在我的本地环境中,我就是这么做的。 这并不完美,因为它给予用户帐户无限制的 root 权限,并且不需要任何密码。 但是,当我这样做并且使用没有密码短语的 SSH 密钥对时,我可以让 Ansible 命令更轻松的自动化。 再次提示,虽然这很方便,但这不是一个非常安全的想法。
+
+#### 4)使用 sudo 提升权限,并在特定的可执行文件上配置 NOPASSWD。
+
+这个想法可能是安全性和便利性的最佳折衷。 基本上,如果你知道你打算用 Ansible 做什么,那么你可以为远程用户使用的那些应用程序提供 NOPASSWD 权限。 这可能会让人有些困惑,因为 Ansible 使用 Python 来处理很多事情,但是经过足够的尝试和错误,你应该能够弄清原理。 这是额外的工作,但确实消除了一些明显的安全漏洞。
+
+### 计划实施
+
+一旦你决定如何处理 Ansible 认证和权限提升,就需要设置它。 在熟悉 Ansible 之后,您可能会使用该工具来帮助“引导”新客户端,但首先手动配置客户端非常重要,以便您知道发生了什么事情。 将你熟悉的事情变得自动化比从头开始自动化要好。
+
+我已经写过关于 SSH 密钥对的文章,网上有无数的设置类的文章。 来自 Ansible 服务器的简短版本看起来像这样:
+
+```
+# ssh-keygen
+# ssh-copy-id -i .ssh/id_dsa.pub remoteuser@remote.computer.ip
+# ssh remoteuser@remote.computer.ip
+```
+
+如果您在创建密钥对时选择不使用密码,最后一步您应该可以直接进入远程计算机,而不用输入密码或密钥串。
+
+为了在 `sudo` 中设置权限提升,您需要编辑 `sudoers` 文件。 你不应该直接编辑文件,而是使用:
+
+```
+# sudo visudo
+```
+
+这将打开 `sudoers` 文件并允许您安全地进行更改(保存时会进行错误检查,所以您不会意外地因为输入错误将自己锁住)。 这个文件中有一些例子,所以你应该能够弄清楚如何分配你想要的确切的权限。
+
+一旦配置完成,您应该在使用 Ansible 之前进行手动测试。 尝试 SSH 到远程客户端,然后尝试使用您选择的任何方法提升权限。 一旦你确认配置的方式可以连接,就可以安装 Ansible 了。
+
+### 安装 Ansible
+
+由于 Ansible 程序仅安装在一台计算机上,因此开始并不是一件繁重的工作。 Red Hat/Ubuntu 系统的软件包安装有点不同,但都不是很困难。
+
+在 Red Hat/CentOS 中,首先启用 EPEL 库:
+
+```
+sudo yum install epel-release
+```
+
+然后安装 Ansible:
+
+```
+sudo yum install ansible
+```
+
+在 Ubuntu 中,首先启用 Ansible PPA:
+
+```
+sudo apt-add-repository spa:ansible/ansible
+(press ENTER to access the key and add the repo)
+```
+
+然后安装 Ansible:
+
+```
+sudo apt-get update
+sudo apt-get install ansible
+```
+
+### Ansible 主机文件配置
+
+Ansible 系统无法知道您希望它控制哪个客户端,除非您给它一个计算机列表。 该列表非常简单,看起来像这样:
+
+```
+# file /etc/ansible/hosts
+
+[webservers]
+blogserver ansible_host=192.168.1.5
+wikiserver ansible_host=192.168.1.10
+
+[dbservers]
+mysql_1 ansible_host=192.168.1.22
+pgsql_1 ansible_host=192.168.1.23
+```
+
+方括号内的部分是指定的组。 单个主机可以列在多个组中,而 Ansible 可以指向单个主机或组。 这也是配置文件,比如纯文本密码的东西将被存储,如果这是你计划的那种设置。 配置文件中的每一行配置一个主机地址,并且可以在 `ansible_host` 语句之后添加多个声明。 一些有用的选项是:
+
+```
+ansible_ssh_pass
+ansible_become
+ansible_become_method
+ansible_become_user
+ansible_become_pass
+```
+
+### Ansible 保险库
+
+(LCTT 译注:Vault 作为 ansible 的一项新功能可将例如密码、密钥等敏感数据文件进行加密,而非明文存放)
+
+我也应该注意到,尽管安装程序比较复杂,而且这不是在您首次进入 Ansible 世界时可能会做的事情,但该程序确实提供了一种加密保险库中的密码的方法。 一旦您熟悉 Ansible,并且希望将其投入生产,将这些密码存储在加密的 Ansible 保险库中是非常理想的。 但是本着先学会爬再学会走的精神,我建议首先在非生产环境下使用无密码方法。
+
+### 系统测试
+
+最后,你应该测试你的系统,以确保客户端可以正常连接。 `ping` 测试将确保 Ansible 计算机可以 `ping` 每个主机:
+
+```
+ansible -m ping all
+```
+
+运行后,如果 `ping` 成功,您应该看到每个定义的主机显示 `ping` 的消息:`pong`。 这实际上并没有测试认证,只是测试网络连接。 试试这个来测试你的认证:
+
+```
+ansible -m shell -a 'uptime' webservers
+```
+
+您应该可以看到 webservers 组中每个主机的运行时间命令的结果。
+
+在后续文章中,我计划开始深入 Ansible 管理远程计算机的功能。 我将介绍各种模块,以及如何使用 ad-hoc 模式来完成一些按键操作,这些操作在命令行上单独处理都需要很长时间。 如果您没有从上面的示例 Ansible 命令中获得预期的结果,请花些时间确保身份验证可以工作。 如果遇到困难,请查阅 [Ansible 文档][1]获取更多帮助。
+
+--------------------------------------------------------------------------------
+
+via: http://www.linuxjournal.com/content/ansible-automation-framework-thinks-sysadmin
+
+作者:[Shawn Powers][a]
+译者:[Flowsnow](https://github.com/Flowsnow)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.linuxjournal.com/users/shawn-powers
+[1]:http://docs.ansible.com
diff --git a/translated/tech/20180123 Never miss a Magazine-s article, build your own RSS notification system.md b/published/20180123 Never miss a Magazine-s article, build your own RSS notification system.md
similarity index 70%
rename from translated/tech/20180123 Never miss a Magazine-s article, build your own RSS notification system.md
rename to published/20180123 Never miss a Magazine-s article, build your own RSS notification system.md
index acd94006d8..feb3acbe71 100644
--- a/translated/tech/20180123 Never miss a Magazine-s article, build your own RSS notification system.md
+++ b/published/20180123 Never miss a Magazine-s article, build your own RSS notification system.md
@@ -1,4 +1,4 @@
-构建你自己的 RSS 提示系统——让杂志文章一篇也不会错过
+用 Python 构建你自己的 RSS 提示系统
======

@@ -7,9 +7,9 @@
### Fedora 和 Python —— 入门知识
-Python 3.6 在 Fedora 中是默认安装的,它包含了 Python 的很多标准库。标准库提供了一些可以让我们的任务更加简单完成的模块的集合。例如,在我们的案例中,我们将使用 [**sqlite3**][1] 模块在数据库中去创建表、添加和读取数据。在这个案例中,我们试图去解决的是在标准库中没有的特定的问题,也有可能已经有人为我们开发了这样一个模块。最好是使用像大家熟知的 [PyPI][2] Python 包索引去搜索一下。在我们的示例中,我们将使用 [**feedparser**][3] 去解析 RSS 源。
+Python 3.6 在 Fedora 中是默认安装的,它包含了 Python 的很多标准库。标准库提供了一些可以让我们的任务更加简单完成的模块的集合。例如,在我们的案例中,我们将使用 [sqlite3][1] 模块在数据库中去创建表、添加和读取数据。在这个案例中,我们试图去解决的是这样的一个特定问题,在标准库中没有包含,而有可能已经有人为我们开发了这样一个模块。最好是使用像大家熟知的 [PyPI][2] Python 包索引去搜索一下。在我们的示例中,我们将使用 [feedparser][3] 去解析 RSS 源。
-因为 **feedparser** 并不是标准库,我们需要将它安装到我们的系统上。幸运的是,在 Fedora 中有这个 RPM 包,因此,我们可以运行如下的命令去安装 **feedparser**:
+因为 feedparser 并不是标准库,我们需要将它安装到我们的系统上。幸运的是,在 Fedora 中有这个 RPM 包,因此,我们可以运行如下的命令去安装 feedparser:
```
$ sudo dnf install python3-feedparser
```
@@ -18,11 +18,12 @@ $ sudo dnf install python3-feedparser
### 存储源数据
-我们需要存储已经发布的文章的数据,这样我们的系统就可以只提示新发布的文章。我们要保存的数据将是用来辨别一篇文章的唯一方法。因此,我们将存储文章的**标题**和**发布日期**。
+我们需要存储已经发布的文章的数据,这样我们的系统就可以只提示新发布的文章。我们要保存的数据将是用来辨别一篇文章的唯一方法。因此,我们将存储文章的标题和发布日期。
-因此,我们来使用 Python **sqlite3** 模块和一个简单的 SQL 语句来创建我们的数据库。同时也添加一些后面将要用到的模块(**feedparse**,**smtplib**,和 **email**)。
+因此,我们来使用 Python sqlite3 模块和一个简单的 SQL 语句来创建我们的数据库。同时也添加一些后面将要用到的模块(feedparse,smtplib,和 email)。
#### 创建数据库
+
```
#!/usr/bin/python3
import sqlite3
@@ -34,14 +35,14 @@ import feedparser
db_connection = sqlite3.connect('/var/tmp/magazine_rss.sqlite')
db = db_connection.cursor()
db.execute(' CREATE TABLE IF NOT EXISTS magazine (title TEXT, date TEXT)')
-
```
-这几行代码创建一个新的保存在一个名为 'magazine_rss.sqlite' 文件中的 sqlite 数据库,然后在数据库创建一个名为 'magazine' 的新表。这个表有两个列 —— 'title' 和 'date' —— 它们能存诸 TEXT 类型的数据,也就是说每个列的值都是文本字符。
+这几行代码创建一个名为 `magazine_rss.sqlite` 文件的新 sqlite 数据库,然后在数据库创建一个名为 `magazine` 的新表。这个表有两个列 —— `title` 和 `date` —— 它们能存诸 TEXT 类型的数据,也就是说每个列的值都是文本字符。
#### 检查数据库中的旧文章
由于我们仅希望增加新的文章到我们的数据库中,因此我们需要一个功能去检查 RSS 源中的文章在数据库中是否存在。我们将根据它来判断是否发送(有新文章的)邮件提示。Ok,现在我们来写这个功能的代码。
+
```
def article_is_not_db(article_title, article_date):
""" Check if a given pair of article title and date
@@ -60,13 +61,14 @@ def article_is_not_db(article_title, article_date):
return False
```
-这个功能的主要部分是一个 SQL 查询,我们运行它去搜索数据库。我们使用一个 SELECT 命令去定义我们将要在哪个列上运行这个查询。我们使用 `*` 符号去选取所有列(title 和 date)。然后,我们使用查询的 WHERE 条件 `article_title` and `article_date` 去匹配标题和日期列中的值,以检索出我们需要的内容。
+这个功能的主要部分是一个 SQL 查询,我们运行它去搜索数据库。我们使用一个 `SELECT` 命令去定义我们将要在哪个列上运行这个查询。我们使用 `*` 符号去选取所有列(`title` 和 `date`)。然后,我们使用查询的 `WHERE` 条件 `article_title` 和 `article_date` 去匹配标题和日期列中的值,以检索出我们需要的内容。
最后,我们使用一个简单的返回 `True` 或者 `False` 的逻辑来表示是否在数据库中找到匹配的文章。
#### 在数据库中添加新文章
现在我们可以写一些代码去添加新文章到数据库中。
+
```
def add_article_to_db(article_title, article_date):
""" Add a new article title and date to the database
@@ -78,13 +80,14 @@ def add_article_to_db(article_title, article_date):
db_connection.commit()
```
-这个功能很简单,我们使用了一个 SQL 查询去插入一个新行到 'magazine' 表的 article_title 和 article_date 列中。然后提交它到数据库中永久保存。
+这个功能很简单,我们使用了一个 SQL 查询去插入一个新行到 `magazine` 表的 `article_title` 和 `article_date` 列中。然后提交它到数据库中永久保存。
这些就是在数据库中所需要的东西,接下来我们看一下,如何使用 Python 实现提示系统和发送电子邮件。
### 发送电子邮件提示
-我们来使用 Python 标准库模块 **smtplib** 来创建一个发送电子邮件的功能。我们也可以使用标准库中的 **email** 模块去格式化我们的电子邮件信息。
+我们使用 Python 标准库模块 smtplib 来创建一个发送电子邮件的功能。我们也可以使用标准库中的 email 模块去格式化我们的电子邮件信息。
+
```
def send_notification(article_title, article_url):
""" Add a new article title and date to the database
@@ -113,6 +116,7 @@ def send_notification(article_title, article_url):
### 读取 Fedora Magazine 的 RSS 源
我们已经有了在数据库中存储文章和发送提示电子邮件的功能,现在来创建一个解析 Fedora Magazine RSS 源并提取文章数据的功能。
+
```
def read_article_feed():
""" Get articles from RSS feed """
@@ -127,25 +131,26 @@ if __name__ == '__main__':
db_connection.close()
```
-在这里我们将使用 **feedparser.parse** 功能。这个功能返回一个用字典表示的 RSS 源,对于 **feedparser** 的完整描述可以参考它的 [文档][5]。
+在这里我们将使用 `feedparser.parse` 功能。这个功能返回一个用字典表示的 RSS 源,对于 feedparser 的完整描述可以参考它的 [文档][5]。
RSS 源解析将返回最后的 10 篇文章作为 `entries`,然后我们提取以下信息:标题、链接、文章发布日期。因此,我们现在可以使用前面定义的检查文章是否在数据库中存在的功能,然后,发送提示电子邮件并将这个文章添加到数据库中。
-当运行我们的脚本时,最后的 if 语句运行我们的 `read_article_feed` 功能,然后关闭数据库连接。
+当运行我们的脚本时,最后的 `if` 语句运行我们的 `read_article_feed` 功能,然后关闭数据库连接。
### 运行我们的脚本
-给脚本文件赋于正确运行权限。接下来,我们使用 **cron** 实用程序去每小时自动运行一次我们的脚本。**cron** 是一个作业计划程序,我们可以使用它在一个固定的时间去运行一个任务。
+给脚本文件赋于正确运行权限。接下来,我们使用 cron 实用程序去每小时自动运行一次我们的脚本。cron 是一个作业计划程序,我们可以使用它在一个固定的时间去运行一个任务。
+
```
$ chmod a+x my_rss_notifier.py
$ sudo cp my_rss_notifier.py /etc/cron.hourly
```
-**为了使该教程保持简单**,我们使用了 cron.hourly 目录每小时运行一次我们的脚本,如果你想学习关于 **cron** 的更多知识以及如何配置 **crontab**,请阅读 **cron** 的 wikipedia [页面][6]。
+为了使该教程保持简单,我们使用了 `cron.hourly` 目录每小时运行一次我们的脚本,如果你想学习关于 cron 的更多知识以及如何配置 crontab,请阅读 cron 的 wikipedia [页面][6]。
### 总结
-在本教程中,我们学习了如何使用 Python 去创建一个简单的 sqlite 数据库、解析一个 RSS 源、以及发送电子邮件。我希望通过这篇文章能够向你展示,**使用 Python 和 Fedora 构建你自己的应用程序是件多么容易的事**。
+在本教程中,我们学习了如何使用 Python 去创建一个简单的 sqlite 数据库、解析一个 RSS 源、以及发送电子邮件。我希望通过这篇文章能够向你展示,使用 Python 和 Fedora 构建你自己的应用程序是件多么容易的事。
这个脚本在 [GitHub][7] 上可以找到。
@@ -155,7 +160,7 @@ via: https://fedoramagazine.org/never-miss-magazines-article-build-rss-notificat
作者:[Clément Verna][a]
译者:[qhwdw](https://github.com/qhwdw)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/published/20180125 Keep Accurate Time on Linux with NTP.md b/published/20180125 Keep Accurate Time on Linux with NTP.md
new file mode 100644
index 0000000000..d501c32d25
--- /dev/null
+++ b/published/20180125 Keep Accurate Time on Linux with NTP.md
@@ -0,0 +1,147 @@
+在 Linux 上使用 NTP 保持精确的时间
+======
+
+
+
+如何保持正确的时间,如何使用 NTP 和 systemd 让你的计算机在不滥用时间服务器的前提下保持同步。
+
+### 它的时间是多少?
+
+让 Linux 来告诉你时间的时候,它是很奇怪的。你可能认为是使用 `time` 命令来告诉你时间,其实并不是,因为 `time` 只是一个测量一个进程运行了多少时间的计时器。为得到时间,你需要运行的是 `date` 命令,你想查看更多的日期,你可以运行 `cal` 命令。文件上的时间戳也是一个容易混淆的地方,因为根据你的发行版默认情况不同,它一般有两种不同的显示方法。下面是来自 Ubuntu 16.04 LTS 的示例:
+
+```
+$ ls -l
+drwxrwxr-x 5 carla carla 4096 Mar 27 2017 stuff
+drwxrwxr-x 2 carla carla 4096 Dec 8 11:32 things
+-rw-rw-r-- 1 carla carla 626052 Nov 21 12:07 fatpdf.pdf
+-rw-rw-r-- 1 carla carla 2781 Apr 18 2017 oddlots.txt
+```
+
+有些显示年,有些显示时间,这样的方式让你的文件更混乱。GNU 默认的情况是,如果你的文件在六个月以内,则显示时间而不是年。我想这样做可能是有原因的。如果你的 Linux 是这样的,尝试用 `ls -l --time-style=long-iso` 命令,让时间戳用同一种方式去显示,按字母顺序排序。请查阅 [如何更改 Linux 的日期和时间:简单的命令][1] 去学习 Linux 上管理时间的各种方法。
+
+### 检查当前设置
+
+NTP —— 网络时间协议,它是保持计算机正确时间的老式方法。`ntpd` 是 NTP 守护程序,它通过周期性地查询公共时间服务器来按需调整你的计算机时间。它是一个简单的、轻量级的协议,使用它的基本功能时设置非常容易。systemd 通过使用 `systemd-timesyncd.service` 已经越俎代庖地 “干了 NTP 的活”,它可以用作 `ntpd` 的客户端。
+
+在我们开始与 NTP “打交道” 之前,先花一些时间来了检查一下当前的时间设置是否正确。
+
+你的系统上(至少)有两个时钟:系统时间 —— 它由 Linux 内核管理,第二个是你的主板上的硬件时钟,它也称为实时时钟(RTC)。当你进入系统的 BIOS 时,你可以看到你的硬件时钟的时间,你也可以去改变它的设置。当你安装一个新的 Linux 时,在一些图形化的时间管理器中,你会被询问是否设置你的 RTC 为 UTC(世界标准时间)时区,因为所有的时区和夏令时都是基于 UTC 的。你可以使用 `hwclock` 命令去检查:
+
+```
+$ sudo hwclock --debug
+hwclock from util-linux 2.27.1
+Using the /dev interface to the clock.
+Hardware clock is on UTC time
+Assuming hardware clock is kept in UTC time.
+Waiting for clock tick...
+...got clock tick
+Time read from Hardware Clock: 2018/01/22 22:14:31
+Hw clock time : 2018/01/22 22:14:31 = 1516659271 seconds since 1969
+Time since last adjustment is 1516659271 seconds
+Calculated Hardware Clock drift is 0.000000 seconds
+Mon 22 Jan 2018 02:14:30 PM PST .202760 seconds
+```
+
+`Hardware clock is on UTC time` 表明了你的计算机的 RTC 是使用 UTC 时间的,虽然它把该时间转换为你的本地时间。如果它被设置为本地时间,它将显示 `Hardware clock is on local time`。
+
+你应该有一个 `/etc/adjtime` 文件。如果没有的话,使用如下命令同步你的 RTC 为系统时间,
+
+```
+$ sudo hwclock -w
+```
+
+这个命令将生成该文件,内容看起来类似如下:
+
+```
+$ cat /etc/adjtime
+0.000000 1516661953 0.000000
+1516661953
+UTC
+```
+
+新发明的 systemd 方式是去运行 `timedatectl` 命令,运行它不需要 root 权限:
+
+```
+$ timedatectl
+ Local time: Mon 2018-01-22 14:17:51 PST
+ Universal time: Mon 2018-01-22 22:17:51 UTC
+ RTC time: Mon 2018-01-22 22:17:51
+ Time zone: America/Los_Angeles (PST, -0800)
+ Network time on: yes
+NTP synchronized: yes
+ RTC in local TZ: no
+```
+
+`RTC in local TZ: no` 表明它使用 UTC 时间。那么怎么改成使用本地时间?这里有许多种方法可以做到。最简单的方法是使用一个图形配置工具,比如像 openSUSE 中的 YaST。你也可使用 `timedatectl`:
+
+```
+$ timedatectl set-local-rtc 0
+```
+
+或者编辑 `/etc/adjtime`,将 `UTC` 替换为 `LOCAL`。
+
+### systemd-timesyncd 客户端
+
+现在,我已经累了,但是我们刚到非常精彩的部分。谁能想到计时如此复杂?我们甚至还没有了解到它的皮毛;阅读 `man 8 hwclock` 去了解你的计算机如何保持时间的详细内容。
+
+systemd 提供了 `systemd-timesyncd.service` 客户端,它可以查询远程时间服务器并调整你的本地系统时间。在 `/etc/systemd/timesyncd.conf` 中配置你的(时间)服务器。大多数 Linux 发行版都提供了一个默认配置,它指向他们维护的时间服务器上,比如,以下是 Fedora 的:
+
+```
+[Time]
+#NTP=
+#FallbackNTP=0.fedora.pool.ntp.org 1.fedora.pool.ntp.org
+```
+
+你可以输入你希望使用的其它时间服务器,比如你自己的本地 NTP 服务器,在 `NTP=` 行上输入一个以空格分隔的服务器列表。(别忘了取消这一行的注释)`NTP=` 行上的任何内容都将覆盖掉 `FallbackNTP` 行上的配置项。
+
+如果你不想使用 systemd 呢?那么,你将需要 NTP 就行。
+
+### 配置 NTP 服务器和客户端
+
+配置你自己的局域网 NTP 服务器是一个非常好的实践,这样你的网内计算机就不需要不停查询公共 NTP 服务器。在大多数 Linux 上的 NTP 都来自 `ntp` 包,它们大多都提供 `/etc/ntp.conf` 文件去配置时间服务器。查阅 [NTP 时间服务器池][2] 去找到你所在的区域的合适的 NTP 服务器池。然后在你的 `/etc/ntp.conf` 中输入 4 - 5 个服务器,每个服务器用单独的一行:
+
+```
+driftfile /var/ntp.drift
+logfile /var/log/ntp.log
+server 0.europe.pool.ntp.org
+server 1.europe.pool.ntp.org
+server 2.europe.pool.ntp.org
+server 3.europe.pool.ntp.org
+```
+
+`driftfile` 告诉 `ntpd` 它需要保存用于启动时使用时间服务器快速同步你的系统时钟的信息。而日志也将保存在他们自己指定的目录中,而不是转储到 syslog 中。如果你的 Linux 发行版默认提供了这些文件,请使用它们。
+
+现在去启动守护程序;在大多数主流的 Linux 中它的命令是 `sudo systemctl start ntpd`。让它运行几分钟之后,我们再次去检查它的状态:
+
+```
+$ ntpq -p
+ remote refid st t when poll reach delay offset jitter
+==============================================================
++dev.smatwebdesi 192.168.194.89 3 u 25 64 37 92.456 -6.395 18.530
+*chl.la 127.67.113.92 2 u 23 64 37 75.175 8.820 8.230
++four0.fairy.mat 35.73.197.144 2 u 22 64 37 116.272 -10.033 40.151
+-195.21.152.161 195.66.241.2 2 u 27 64 37 107.559 1.822 27.346
+```
+
+我不知道这些内容是什么意思,但重要的是,你的守护程序已经与时间服务器开始对话了,而这正是我们所需要的。你可以去运行 `sudo systemctl enable ntpd` 命令,永久启用它。如果你的 Linux 没有使用 systemd,那么,给你留下的家庭作业就是找出如何去运行 `ntpd`。
+
+现在,你可以在你的局域网中的其它计算机上设置 `systemd-timesyncd`,这样它们就可以使用你的本地 NTP 服务器了,或者,在它们上面安装 NTP,然后在它们的 `/etc/ntp.conf` 上输入你的本地 NTP 服务器。
+
+NTP 服务器会受到攻击,而且需求在不断增加。你可以通过运行你自己的公共 NTP 服务器来提供帮助。下周我们将学习如何运行你自己的公共服务器。
+
+通过来自 Linux 基金会和 edX 的免费课程 [“Linux 入门”][3] 来学习更多 Linux 的知识。
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/learn/intro-to-linux/2018/1/keep-accurate-time-linux-ntp
+
+作者:[CARLA SCHRODER][a]
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.linux.com/users/cschroder
+[1]:https://www.linux.com/learn/how-change-linux-date-and-time-simple-commands
+[2]:http://support.ntp.org/bin/view/Servers/NTPPoolServers
+[3]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/translated/tech/20180127 How to install KVM on CentOS 7 - RHEL 7 Headless Server.md b/published/20180127 How to install KVM on CentOS 7 - RHEL 7 Headless Server.md
similarity index 66%
rename from translated/tech/20180127 How to install KVM on CentOS 7 - RHEL 7 Headless Server.md
rename to published/20180127 How to install KVM on CentOS 7 - RHEL 7 Headless Server.md
index 233daa72b2..fd9e9cdcba 100644
--- a/translated/tech/20180127 How to install KVM on CentOS 7 - RHEL 7 Headless Server.md
+++ b/published/20180127 How to install KVM on CentOS 7 - RHEL 7 Headless Server.md
@@ -1,56 +1,79 @@
如何在 CentOS 7 / RHEL 7 终端服务器上安装 KVM
======
-如何在 CnetOS 7 或 RHEL 7( Red Hat 企业版 Linux) 服务器上安装和配置 KVM(基于内核的虚拟机)?如何在 CnetOS 7 上设置 KMV 并使用云镜像/ cloud-init 来安装客户虚拟机?
+如何在 CnetOS 7 或 RHEL 7(Red Hat 企业版 Linux)服务器上安装和配置 KVM(基于内核的虚拟机)?如何在 CentOS 7 上设置 KVM 并使用云镜像 / cloud-init 来安装客户虚拟机?
+
+基于内核的虚拟机(KVM)是 CentOS 或 RHEL 7 的虚拟化软件。KVM 可以将你的服务器变成虚拟机管理器。本文介绍如何在 CentOS 7 或 RHEL 7 中使用 KVM 设置和管理虚拟化环境。还介绍了如何使用命令行在物理服务器上安装和管理虚拟机(VM)。请确保在服务器的 BIOS 中启用了**虚拟化技术(VT)**。你也可以运行以下命令[测试 CPU 是否支持 Intel VT 和 AMD_V 虚拟化技术][1]。
-基于内核的虚拟机(KVM)是 CentOS 或 RHEL 7 的虚拟化软件。KVM 将你的服务器变成虚拟机管理程序。本文介绍如何在 CentOS 7 或 RHEL 7 中使用 KVM 设置和管理虚拟化环境。还介绍了如何使用 CLI 在物理服务器上安装和管理虚拟机(VM)。确保在服务器的 BIOS 中启用了**虚拟化技术(vt)**。你也可以运行以下命令[测试 CPU 是否支持 Intel VT 和 AMD_V 虚拟化技术][1]。
```
$ lscpu | grep Virtualization
Virtualization: VT-x
```
-### 按照 CentOS 7/RHEL 7 终端服务器上的 KVM 安装步骤进行操作
+按照 CentOS 7/RHEL 7 终端服务器上的 KVM 安装步骤进行操作。
-#### 步骤 1: 安装 kvm
+### 步骤 1: 安装 kvm
输入以下 [yum 命令][2]:
-`# yum install qemu-kvm libvirt libvirt-python libguestfs-tools virt-install`
+
+```
+# yum install qemu-kvm libvirt libvirt-python libguestfs-tools virt-install
+```
[![How to install KVM on CentOS 7 RHEL 7 Headless Server][3]][3]
启动 libvirtd 服务:
+
```
# systemctl enable libvirtd
# systemctl start libvirtd
```
-#### 步骤 2: 确认 kvm 安装
+### 步骤 2: 确认 kvm 安装
-确保使用 lsmod 命令和 [grep命令][4] 加载 KVM 模块:
-`# lsmod | grep -i kvm`
+使用 `lsmod` 命令和 [grep命令][4] 确认加载了 KVM 模块:
-#### 步骤 3: 配置桥接网络
+```
+# lsmod | grep -i kvm
+```
+
+### 步骤 3: 配置桥接网络
+
+默认情况下,由 libvirtd 配置基于 dhcpd 的网桥。你可以使用以下命令验证:
-默认情况下,由 libvirtd 配置的基于 dhcpd 的网桥。你可以使用以下命令验证:
```
# brctl show
# virsh net-list
```
+
[![KVM default networking][5]][5]
-所有虚拟机(客户机器)只能在同一台服务器上对其他虚拟机进行网络访问。为你创建的私有网络是 192.168.122.0/24。验证:
-`# virsh net-dumpxml default`
+所有虚拟机(客户机)只能对同一台服务器上的其它虚拟机进行网络访问。为你创建的私有网络是 192.168.122.0/24。验证:
+
+```
+# virsh net-dumpxml default
+```
+
+如果你希望你的虚拟机可用于 LAN 上的其他服务器,请在连接到你的 LAN 的服务器上设置一个网桥。更新你的网卡配置文件,如 ifcfg-enp3s0 或 em1:
+
+```
+# vi /etc/sysconfig/network-scripts/ifcfg-enp3s0
+```
-如果你希望你的虚拟机可用于 LAN 上的其他服务器,请在连接到你的 LAN 的服务器上设置一个网桥。更新你的网卡配置文件,如 ifcfg-enp3s0 或 em1:
-`# vi /etc/sysconfig/network-scripts/enp3s0 `
添加一行:
+
```
BRIDGE=br0
```
-[使用 vi 保存并关闭文件][6]。编辑 /etc/sysconfig/network-scripts/ifcfg-br0 :
-`# vi /etc/sysconfig/network-scripts/ifcfg-br0`
-添加以下东西:
+[使用 vi 保存并关闭文件][6]。编辑 `/etc/sysconfig/network-scripts/ifcfg-br0`:
+
+```
+# vi /etc/sysconfig/network-scripts/ifcfg-br0
+```
+
+添加以下内容:
+
```
DEVICE="br0"
# I am getting ip from DHCP server #
@@ -62,29 +85,38 @@ TYPE="Bridge"
DELAY="0"
```
-重新启动网络服务(警告:ssh命令将断开连接,最好重新启动该设备):
-`# systemctl restart NetworkManager`
+重新启动网络服务(警告:ssh 命令将断开连接,最好重新启动该设备):
-用 brctl 命令验证它:
-`# brctl show`
+```
+# systemctl restart NetworkManager
+```
-#### 步骤 4: 创建你的第一个虚拟机
+用 `brctl` 命令验证它:
+
+```
+# brctl show
+```
+
+### 步骤 4: 创建你的第一个虚拟机
+
+我将会创建一个 CentOS 7.x 虚拟机。首先,使用 `wget` 命令获取 CentOS 7.x 最新的 ISO 镜像:
-我将会创建一个 CentOS 7.x 虚拟机。首先,使用 wget 命令获取 CentOS 7.x 最新的 ISO 镜像:
```
# cd /var/lib/libvirt/boot/
# wget https://mirrors.kernel.org/centos/7.4.1708/isos/x86_64/CentOS-7-x86_64-Minimal-1708.iso
```
验证 ISO 镜像:
+
```
# wget https://mirrors.kernel.org/centos/7.4.1708/isos/x86_64/sha256sum.txt
# sha256sum -c sha256sum.txt
```
-##### 创建 CentOS 7.x 虚拟机
+#### 创建 CentOS 7.x 虚拟机
在这个例子中,我创建了 2GB RAM,2 个 CPU 核心,1 个网卡和 40 GB 磁盘空间的 CentOS 7.x 虚拟机,输入:
+
```
# virt-install \
--virt-type=kvm \
@@ -98,35 +130,41 @@ DELAY="0"
--disk path=/var/lib/libvirt/images/centos7.qcow2,size=40,bus=virtio,format=qcow2
```
-从另一个终端通过 ssh 和 type 配置 vnc 登录:
+从另一个终端通过 `ssh` 配置 vnc 登录,输入:
+
```
# virsh dumpxml centos7 | grep v nc
```
-请记录下端口值(即 5901)。你需要使用 SSH 客户端来建立隧道和 VNC 客户端才能访问远程 vnc 服务区。在客户端/桌面/ macbook pro 系统中输入以下 SSH 端口转化命令:
-`$ ssh vivek@server1.cyberciti.biz -L 5901:127.0.0.1:5901`
+请记录下端口值(即 5901)。你需要使用 SSH 客户端来建立隧道和 VNC 客户端才能访问远程 vnc 服务器。在客户端/桌面/ macbook pro 系统中输入以下 SSH 端口转发命令:
+
+```
+$ ssh vivek@server1.cyberciti.biz -L 5901:127.0.0.1:5901
+```
一旦你建立了 ssh 隧道,你可以将你的 VNC 客户端指向你自己的 127.0.0.1 (localhost) 地址和端口 5901,如下所示:
+
[![][7]][7]
你应该看到 CentOS Linux 7 客户虚拟机安装屏幕如下:
+
[![][8]][8]
现在只需按照屏幕说明进行操作并安装CentOS 7。一旦安装完成后,请继续并单击重启按钮。 远程服务器关闭了我们的 VNC 客户端的连接。 你可以通过 KVM 客户端重新连接,以配置服务器的其余部分,包括基于 SSH 的会话或防火墙。
-#### 步骤 5: 使用云镜像
+### 使用云镜像
-以上安装方法对于学习目的或单个虚拟机而言是可行的。你需要部署大量的虚拟机吗? 尝试云镜像。你可以根据需要修改预先构建的云图像。例如,使用 [Cloud-init][9] 添加用户,ssh 密钥,设置时区等等,这是处理云实例的早期初始化的事实上的多分发包。让我们看看如何创建带有 1024MB RAM,20GB 磁盘空间和 1 个 vCPU 的 CentOS 7 虚拟机。(译注: vCPU 即电脑中的虚拟处理器)
+以上安装方法对于学习目的或单个虚拟机而言是可行的。你需要部署大量的虚拟机吗? 可以试试云镜像。你可以根据需要修改预先构建的云镜像。例如,使用 [Cloud-init][9] 添加用户、ssh 密钥、设置时区等等,这是处理云实例的早期初始化的事实上的多分发包。让我们看看如何创建带有 1024MB RAM,20GB 磁盘空间和 1 个 vCPU 的 CentOS 7 虚拟机。(LCTT 译注: vCPU 即电脑中的虚拟处理器)
-##### 获取 CentOS 7 云镜像
+#### 获取 CentOS 7 云镜像
```
# cd /var/lib/libvirt/boot
# wget http://cloud.centos.org/centos/7/images/CentOS-7-x86_64-GenericCloud.qcow2
```
-##### 创建所需的目录
+#### 创建所需的目录
```
# D=/var/lib/libvirt/images
@@ -135,31 +173,39 @@ DELAY="0"
mkdir: created directory '/var/lib/libvirt/images/centos7-vm1'
```
-##### 创建元数据文件
+#### 创建元数据文件
```
# cd $D/$VM
# vi meta-data
```
-添加以下东西:
+添加以下内容:
+
```
instance-id: centos7-vm1
local-hostname: centos7-vm1
```
-##### 创建用户数据文件
+#### 创建用户数据文件
+
+我将使用 ssh 密钥登录到虚拟机。所以确保你有 ssh 密钥:
+
+```
+# ssh-keygen -t ed25519 -C "VM Login ssh key"
+```
-我将使用 ssh 密钥登录到虚拟机。所以确保你有 ssh-keys:
-`# ssh-keygen -t ed25519 -C "VM Login ssh key"`
[![ssh-keygen command][10]][11]
-请参阅 "[如何在 Linux/Unix 系统上设置 SSH 密钥][12]" 来获取更多信息。编辑用户数据如下:
+请参阅 “[如何在 Linux/Unix 系统上设置 SSH 密钥][12]” 来获取更多信息。编辑用户数据如下:
+
```
# cd $D/$VM
# vi user-data
```
-添加如下(根据你的设置替换主机名,用户,ssh-authorized-keys):
+
+添加如下(根据你的设置替换 `hostname`、`users`、`ssh-authorized-keys`):
+
```
#cloud-config
@@ -199,14 +245,14 @@ runcmd:
- yum -y remove cloud-init
```
-##### 复制云镜像
+#### 复制云镜像
```
# cd $D/$VM
# cp /var/lib/libvirt/boot/CentOS-7-x86_64-GenericCloud.qcow2 $VM.qcow2
```
-##### 创建 20GB 磁盘映像
+#### 创建 20GB 磁盘映像
```
# cd $D/$VM
@@ -215,25 +261,30 @@ runcmd:
# virt-resize --quiet --expand /dev/sda1 $VM.qcow2 $VM.new.image
```
[![Set VM image disk size][13]][13]
-覆盖它的缩放图片:
+
+用压缩后的镜像覆盖它:
+
```
# cd $D/$VM
# mv $VM.new.image $VM.qcow2
```
-##### 创建一个 cloud-init ISO
+#### 创建一个 cloud-init ISO
+
+```
+# mkisofs -o $VM-cidata.iso -V cidata -J -r user-data meta-data
+```
-`# mkisofs -o $VM-cidata.iso -V cidata -J -r user-data meta-data`
[![Creating a cloud-init ISO][14]][14]
-##### 创建一个 pool
+#### 创建一个池
```
# virsh pool-create-as --name $VM --type dir --target $D/$VM
Pool centos7-vm1 created
```
-##### 安装 CentOS 7 虚拟机
+#### 安装 CentOS 7 虚拟机
```
# cd $D/$VM
@@ -247,23 +298,31 @@ Pool centos7-vm1 created
--graphics spice \
--noautoconsole
```
+
删除不需要的文件:
+
```
# cd $D/$VM
# virsh change-media $VM hda --eject --config
# rm meta-data user-data centos7-vm1-cidata.iso
```
-##### 查找虚拟机的 IP 地址
+#### 查找虚拟机的 IP 地址
-`# virsh net-dhcp-leases default`
+```
+# virsh net-dhcp-leases default
+```
[![CentOS7-VM1- Created][15]][15]
-##### 登录到你的虚拟机
+#### 登录到你的虚拟机
+
+使用 ssh 命令:
+
+```
+# ssh vivek@192.168.122.85
+```
-使用 ssh 命令:
-`# ssh vivek@192.168.122.85`
[![Sample VM session][16]][16]
### 有用的命令
@@ -272,7 +331,9 @@ Pool centos7-vm1 created
#### 列出所有虚拟机
-`# virsh list --all`
+```
+# virsh list --all
+```
#### 获取虚拟机信息
@@ -283,21 +344,33 @@ Pool centos7-vm1 created
#### 停止/关闭虚拟机
-`# virsh shutdown centos7-vm1`
+```
+# virsh shutdown centos7-vm1
+```
#### 开启虚拟机
-`# virsh start centos7-vm1`
+```
+# virsh start centos7-vm1
+```
#### 将虚拟机标记为在引导时自动启动
-`# virsh autostart centos7-vm1`
+```
+# virsh autostart centos7-vm1
+```
#### 重新启动(软安全重启)虚拟机
-`# virsh reboot centos7-vm1`
+```
+# virsh reboot centos7-vm1
+```
+
重置(硬重置/不安全)虚拟机
-`# virsh reset centos7-vm1`
+
+```
+# virsh reset centos7-vm1
+```
#### 删除虚拟机
@@ -309,7 +382,9 @@ Pool centos7-vm1 created
# VM=centos7-vm1
# rm -ri $D/$VM
```
-查看 virsh 命令类型的完整列表
+
+查看 virsh 命令类型的完整列表:
+
```
# virsh help | less
# virsh help | grep reboot
@@ -321,11 +396,11 @@ Pool centos7-vm1 created
--------------------------------------------------------------------------------
-via: [https://www.cyberciti.biz/faq/how-to-install-kvm-on-centos-7-rhel-7-headless-server/](https://www.cyberciti.biz/faq/how-to-install-kvm-on-centos-7-rhel-7-headless-server/)
+via: https://www.cyberciti.biz/faq/how-to-install-kvm-on-centos-7-rhel-7-headless-server/
作者:[Vivek Gite][a]
译者:[MjSeven](https://github.com/MjSeven)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/translated/tech/20180130 Use of du - df commands (with examples).md b/published/20180130 Use of du - df commands (with examples).md
similarity index 59%
rename from translated/tech/20180130 Use of du - df commands (with examples).md
rename to published/20180130 Use of du - df commands (with examples).md
index 40327aad3a..5f0f6e9c42 100644
--- a/translated/tech/20180130 Use of du - df commands (with examples).md
+++ b/published/20180130 Use of du - df commands (with examples).md
@@ -1,85 +1,85 @@
du 及 df 命令的使用(附带示例)
======
-在本文中,我将讨论 du 和 df 命令。du 和 df 命令都是 Linux 系统的重要工具,来显示 Linux 文件系统的磁盘使用情况。这里我们将通过一些例子来分享这两个命令的用法。
-**(推荐阅读:[使用 scp 和 rsync 命令传输文件][1])**
+在本文中,我将讨论 `du` 和 `df` 命令。`du` 和 `df` 命令都是 Linux 系统的重要工具,来显示 Linux 文件系统的磁盘使用情况。这里我们将通过一些例子来分享这两个命令的用法。
-**(另请阅读:[使用 dd 和 cat 命令为 Linux 系统克隆磁盘][2])**
+- **(推荐阅读:[使用 scp 和 rsync 命令传输文件][1])**
+- **(另请阅读:[使用 dd 和 cat 命令为 Linux 系统克隆磁盘][2])**
### du 命令
-du(disk usage 的简称)是用于查找文件和目录的磁盘使用情况的命令。du 命令在与各种选项一起使用时能以多种格式提供结果。
+`du`(disk usage 的简称)是用于查找文件和目录的磁盘使用情况的命令。`du` 命令在与各种选项一起使用时能以多种格式提供结果。
下面是一些例子:
- **1- 得到一个目录下所有子目录的磁盘使用概况**
+#### 1、 得到一个目录下所有子目录的磁盘使用概况
```
- $ du /home
+$ du /home
```
![du command][4]
-该命令的输出将显示 /home 中的所有文件和目录以及显示块大小。
+该命令的输出将显示 `/home` 中的所有文件和目录以及显示块大小。
-**2- 以人类可读格式也就是 kb、mb 等显示文件/目录大小**
+#### 2、 以人类可读格式也就是 kb、mb 等显示文件/目录大小
```
- $ du -h /home
+$ du -h /home
```
![du command][6]
-**3- 目录的总磁盘大小**
+#### 3、 目录的总磁盘大小
```
- $ du -s /home
+$ du -s /home
```
![du command][8]
-它是 /home 目录的总大小
+它是 `/home` 目录的总大小
### df 命令
-df(disk filesystem 的简称)用于显示 Linux 系统的磁盘利用率。
+df(disk filesystem 的简称)用于显示 Linux 系统的磁盘利用率。(LCTT 译注:`df` 可能应该是 disk free 的简称。)
下面是一些例子。
-**1- 显示设备名称、总块数、总磁盘空间、已用磁盘空间、可用磁盘空间和文件系统上的挂载点。**
+#### 1、 显示设备名称、总块数、总磁盘空间、已用磁盘空间、可用磁盘空间和文件系统上的挂载点。
```
- $ df
+$ df
```
![df command][10]
-**2- 人类可读格式的信息**
+#### 2、 人类可读格式的信息
```
- $ df -h
+$ df -h
```
![df command][12]
上面的命令以人类可读格式显示信息。
-**3- 显示特定分区的信息**
+#### 3、 显示特定分区的信息
```
- $ df -hT /etc
+$ df -hT /etc
```
![df command][14]
--hT 加上目标目录将以可读格式显示 /etc 的信息。
+`-hT` 加上目标目录将以可读格式显示 `/etc` 的信息。
-虽然 du 和 df 命令有更多选项,但是这些例子可以让你初步了解。如果在这里找不到你要找的东西,那么你可以参考有关命令的 man 页面。
+虽然 `du` 和 `df` 命令有更多选项,但是这些例子可以让你初步了解。如果在这里找不到你要找的东西,那么你可以参考有关命令的 man 页面。
另外,[**在这**][15]阅读我的其他帖子,在那里我分享了一些其他重要和经常使用的 Linux 命令。
-如往常一样,你的评论和疑问是受欢迎的,因此在下面留下你的评论和疑问,我会回复你。
+如往常一样,欢迎你留下评论和疑问,因此在下面留下你的评论和疑问,我会回复你。
--------------------------------------------------------------------------------
@@ -87,7 +87,7 @@ via: http://linuxtechlab.com/du-df-commands-examples/
作者:[SHUSAIN][a]
译者:[geekpi](https://github.com/geekpi)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/published/20180131 10 things I love about Vue.md b/published/20180131 10 things I love about Vue.md
new file mode 100644
index 0000000000..d36da57312
--- /dev/null
+++ b/published/20180131 10 things I love about Vue.md
@@ -0,0 +1,136 @@
+我喜欢 Vue 的 10 个方面
+============================================================
+
+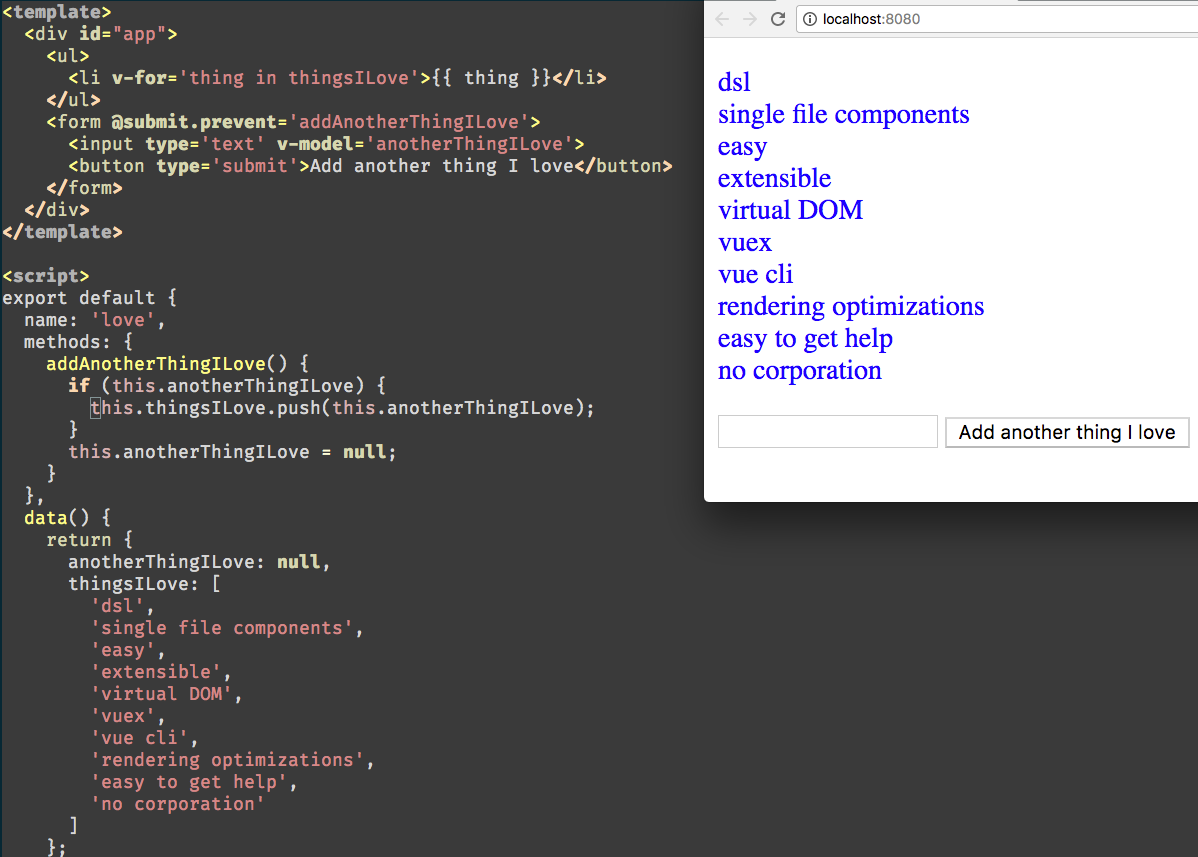
+
+我喜欢 Vue。当我在 2016 年第一次接触它时,也许那时我已经对 JavaScript 框架感到疲劳了,因为我已经具有Backbone、Angular、React 等框架的经验,没有太多的热情去尝试一个新的框架。直到我在 Hacker News 上读到一份评论,其描述 Vue 是类似于“新 jQuery” 的 JavaScript 框架,从而激发了我的好奇心。在那之前,我已经相当满意 React 这个框架,它是一个很好的框架,建立于可靠的设计原则之上,围绕着视图模板、虚拟 DOM 和状态响应等技术。而 Vue 也提供了这些重要的内容。
+
+在这篇文章中,我旨在解释为什么 Vue 适合我,为什么在上文中那些我尝试过的框架中选择它。也许你将同意我的一些观点,但至少我希望能够给大家使用 Vue 开发现代 JavaScript 应用一些灵感。
+
+### 1、 极少的模板语法
+
+Vue 默认提供的视图模板语法是极小的、简洁的和可扩展的。像其他 Vue 部分一样,可以很简单的使用类似 JSX 一样语法,而不使用标准的模板语法(甚至有官方文档说明了如何做),但是我觉得没必要这么做。JSX 有好的方面,也有一些有依据的批评,如混淆了 JavaScript 和 HTML,使得很容易导致在模板中出现复杂的代码,而本来应该分开写在不同的地方的。
+
+Vue 没有使用标准的 HTML 来编写视图模板,而是使用极少的模板语法来处理简单的事情,如基于视图数据迭代创建元素。
+
+```
+
+
+
+
+
+
+
+```
+
+
+我也喜欢 Vue 提供的简短绑定语法,`:` 用于在模板中绑定数据变量,`@` 用于绑定事件。这是一个细节,但写起来很爽而且能够让你的组件代码简洁。
+
+### 2、 单文件组件
+
+大多数人使用 Vue,都使用“单文件组件”。本质上就是一个 .vue 文件对应一个组件,其中包含三部分(CSS、HTML和JavaScript)。
+
+这种技术结合是对的。它让人很容易在一个单独的地方了解每个组件,同时也非常好的鼓励了大家保持每个组件代码的简短。如果你的组件中 JavaScript、CSS 和 HTML 代码占了很多行,那么就到了进一步模块化的时刻了。
+
+在使用 Vue 组件中的 `
-```
-
-
-我也喜欢Vue提供的简短绑定语法,“:”用于在模板中绑定数据变量,“@”用于绑定事件。这是一个细节,但写起来很爽而且能够让你的组件代码简洁。
-
-##2\. 单文件组件
-
-大多数人使用Vue,都使用“单文件组件”。本质上就是一个.vue文件对应一个组件,其中包含三部分(CSS,HTML和JavaScript)
-
-这种技术结合是对的。它让人很容易理解每个组件在一个单独的地方,同时也非常好的鼓励了大家保持每个组件代码的简短。如果你的组件中JavaScript,CSS和HTML代码占了很多行,那么就到了进一步模块化的时刻了。
-
-在使用Vue组件中的