mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-09 01:30:10 +08:00
commit
28361da3de
@ -0,0 +1,146 @@
|
||||
如何使用 yum-cron 自动更新 RHEL/CentOS Linux
|
||||
======
|
||||
|
||||
`yum` 命令是 RHEL / CentOS Linux 系统中用来安装和更新软件包的一个工具。我知道如何使用 [yum 命令行][1] 更新系统,但是我想用 cron 任务自动更新软件包。该如何配置才能使得 `yum` 使用 [cron 自动更新][2]系统补丁或更新呢?
|
||||
|
||||
首先需要安装 yum-cron 软件包。该软件包提供以 cron 命令运行 `yum` 更新所需的文件。如果你想要每晚通过 cron 自动更新可以安装这个软件包。
|
||||
|
||||
### CentOS/RHEL 6.x/7.x 上安装 yum cron
|
||||
|
||||
输入以下 [yum 命令][3]:
|
||||
|
||||
```
|
||||
$ sudo yum install yum-cron
|
||||
```
|
||||
|
||||

|
||||
|
||||
使用 CentOS/RHEL 7.x 上的 `systemctl` 启动服务:
|
||||
|
||||
```
|
||||
$ sudo systemctl enable yum-cron.service
|
||||
$ sudo systemctl start yum-cron.service
|
||||
$ sudo systemctl status yum-cron.service
|
||||
```
|
||||
|
||||
在 CentOS/RHEL 6.x 系统中,运行:
|
||||
|
||||
```
|
||||
$ sudo chkconfig yum-cron on
|
||||
$ sudo service yum-cron start
|
||||
```
|
||||
|
||||

|
||||
|
||||
`yum-cron` 是 `yum` 的一个替代方式。使得 cron 调用 `yum` 变得非常方便。该软件提供了元数据更新、更新检查、下载和安装等功能。`yum-cron` 的各种功能可以使用配置文件配置,而不是输入一堆复杂的命令行参数。
|
||||
|
||||
### 配置 yum-cron 自动更新 RHEL/CentOS Linux
|
||||
|
||||
使用 vi 等编辑器编辑文件 `/etc/yum/yum-cron.conf` 和 `/etc/yum/yum-cron-hourly.conf`:
|
||||
|
||||
```
|
||||
$ sudo vi /etc/yum/yum-cron.conf
|
||||
```
|
||||
|
||||
确保更新可用时自动更新:
|
||||
|
||||
```
|
||||
apply_updates = yes
|
||||
```
|
||||
|
||||
可以设置通知 email 的发件地址。注意: localhost` 将会被 `system_name` 的值代替。
|
||||
|
||||
```
|
||||
email_from = root@localhost
|
||||
```
|
||||
|
||||
列出发送到的 email 地址。
|
||||
|
||||
```
|
||||
email_to = your-it-support@some-domain-name
|
||||
```
|
||||
|
||||
发送 email 信息的主机名。
|
||||
|
||||
```
|
||||
email_host = localhost
|
||||
```
|
||||
|
||||
[CentOS/RHEL 7.x][4] 上不想更新内核的话,添加以下内容:
|
||||
|
||||
```
|
||||
exclude=kernel*
|
||||
```
|
||||
|
||||
RHEL/CentOS 6.x 下[添加以下内容来禁用内核更新][5]:
|
||||
|
||||
```
|
||||
YUM_PARAMETER=kernel*
|
||||
```
|
||||
|
||||
[保存并关闭文件][6]。如果想每小时更新系统的话修改文件 `/etc/yum/yum-cron-hourly.conf`,否则文件 `/etc/yum/yum-cron.conf` 将使用以下命令每天运行一次(使用 [cat 命令][7] 查看):
|
||||
|
||||
```
|
||||
$ cat /etc/cron.daily/0yum-daily.cron
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
# Only run if this flag is set. The flag is created by the yum-cron init
|
||||
# script when the service is started -- this allows one to use chkconfig and
|
||||
# the standard "service stop|start" commands to enable or disable yum-cron.
|
||||
if [[ ! -f /var/lock/subsys/yum-cron ]]; then
|
||||
exit 0
|
||||
fi
|
||||
|
||||
# Action!
|
||||
exec /usr/sbin/yum-cron /etc/yum/yum-cron-hourly.conf
|
||||
[root@centos7-box yum]# cat /etc/cron.daily/0yum-daily.cron
|
||||
#!/bin/bash
|
||||
|
||||
# Only run if this flag is set. The flag is created by the yum-cron init
|
||||
# script when the service is started -- this allows one to use chkconfig and
|
||||
# the standard "service stop|start" commands to enable or disable yum-cron.
|
||||
if [[ ! -f /var/lock/subsys/yum-cron ]]; then
|
||||
exit 0
|
||||
fi
|
||||
|
||||
# Action!
|
||||
exec /usr/sbin/yum-cron
|
||||
```
|
||||
|
||||
完成配置。现在你的系统将每天自动更新一次。更多细节请参照 yum-cron 的说明手册。
|
||||
|
||||
```
|
||||
$ man yum-cron
|
||||
```
|
||||
|
||||
### 关于作者
|
||||
|
||||
作者是 nixCraft 的创始人,一个经验丰富的系统管理员和 Linux/Unix 脚本培训师。他曾与全球客户合作,领域涉及IT,教育,国防和空间研究以及非营利部门等多个行业。请在 [Twitter][9]、[Facebook][10]、[Google+][11] 上关注他。获取更多有关系统管理、Linux/Unix 和开源话题请关注[我的 RSS/XML 地址][12]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/fedora-automatic-update-retrieval-installation-with-cron/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[shipsw](https://github.com/shipsw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz/
|
||||
[1]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/
|
||||
[2]:https://www.cyberciti.biz/faq/how-do-i-add-jobs-to-cron-under-linux-or-unix-oses
|
||||
[3]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/ [4]:https://www.cyberciti.biz/faq/yum-update-except-kernel-package-command/
|
||||
[5]:https://www.cyberciti.biz/faq/redhat-centos-linux-yum-update-exclude-packages/
|
||||
[6]:https://www.cyberciti.biz/faq/linux-unix-vim-save-and-quit-command/
|
||||
[7]:https://www.cyberciti.biz/faq/linux-unix-appleosx-bsd-cat-command-examples/
|
||||
[8]:https://www.cyberciti.biz/faq/how-do-i-add-jobs-to-cron-under-linux-or-unix-oses
|
||||
[9]:https://twitter.com/nixcraft
|
||||
[10]:https://facebook.com/nixcraft
|
||||
[11]:https://plus.google.com/+CybercitiBiz
|
||||
[12]:https://www.cyberciti.biz/atom/atom.xml
|
||||
@ -0,0 +1,137 @@
|
||||
如何使用 GNU Stow 来管理从源代码安装的程序和点文件
|
||||
=====
|
||||
|
||||
### 目的
|
||||
|
||||
使用 GNU Stow 轻松管理从源代码安装的程序和点文件(LCTT 译注:<ruby>点文件<rt>dotfile</rt></ruby>,即以 `.` 开头的文件,在 *nix 下默认为隐藏文件,常用于存储程序的配置信息。)
|
||||
|
||||
### 要求
|
||||
|
||||
* root 权限
|
||||
|
||||
### 难度
|
||||
|
||||
简单
|
||||
|
||||
### 约定
|
||||
|
||||
* `#` - 给定的命令要求直接以 root 用户身份或使用 `sudo` 命令以 root 权限执行
|
||||
* `$` - 给定的命令将作为普通的非特权用户来执行
|
||||
|
||||
### 介绍
|
||||
|
||||
有时候我们必须从源代码安装程序,因为它们也许不能通过标准渠道获得,或者我们可能需要特定版本的软件。 GNU Stow 是一个非常不错的<ruby>符号链接工厂<rt>symlinks factory</rt></ruby>程序,它可以帮助我们保持文件的整洁,易于维护。
|
||||
|
||||
### 获得 stow
|
||||
|
||||
你的 Linux 发行版本很可能包含 `stow`,例如在 Fedora,你安装它只需要:
|
||||
|
||||
```
|
||||
# dnf install stow
|
||||
```
|
||||
|
||||
在 Ubuntu/Debian 中,安装 `stow` 需要执行:
|
||||
|
||||
```
|
||||
# apt install stow
|
||||
```
|
||||
|
||||
在某些 Linux 发行版中,`stow` 在标准库中是不可用的,但是可以通过一些额外的软件源(例如 RHEL 和 CentOS7 中的EPEL )轻松获得,或者,作为最后的手段,你可以从源代码编译它。只需要很少的依赖关系。
|
||||
|
||||
### 从源代码编译
|
||||
|
||||
最新的可用 stow 版本是 `2.2.2`。源码包可以在这里下载:`https://ftp.gnu.org/gnu/stow/`。
|
||||
|
||||
一旦你下载了源码包,你就必须解压它。切换到你下载软件包的目录,然后运行:
|
||||
|
||||
```
|
||||
$ tar -xvpzf stow-2.2.2.tar.gz
|
||||
```
|
||||
|
||||
解压源文件后,切换到 `stow-2.2.2` 目录中,然后编译该程序,只需运行:
|
||||
|
||||
```
|
||||
$ ./configure
|
||||
$ make
|
||||
```
|
||||
|
||||
最后,安装软件包:
|
||||
|
||||
```
|
||||
# make install
|
||||
```
|
||||
|
||||
默认情况下,软件包将安装在 `/usr/local/` 目录中,但是我们可以改变它,通过配置脚本的 `--prefix` 选项指定目录,或者在运行 `make install` 时添加 `prefix="/your/dir"`。
|
||||
|
||||
此时,如果所有工作都按预期工作,我们应该已经在系统上安装了 `stow`。
|
||||
|
||||
### stow 是如何工作的?
|
||||
|
||||
`stow` 背后主要的概念在程序手册中有很好的解释:
|
||||
|
||||
> Stow 使用的方法是将每个软件包安装到自己的目录树中,然后使用符号链接使它看起来像文件一样安装在公共的目录树中
|
||||
|
||||
为了更好地理解这个软件的运作,我们来分析一下它的关键概念:
|
||||
|
||||
#### stow 文件目录
|
||||
|
||||
stow 目录是包含所有 stow 软件包的根目录,每个包都有自己的子目录。典型的 stow 目录是 `/usr/local/stow`:在其中,每个子目录代表一个软件包。
|
||||
|
||||
#### stow 软件包
|
||||
|
||||
如上所述,stow 目录包含多个“软件包”,每个软件包都位于自己单独的子目录中,通常以程序本身命名。包就是与特定软件相关的文件和目录列表,作为一个实体进行管理。
|
||||
|
||||
#### stow 目标目录
|
||||
|
||||
stow 目标目录解释起来是一个非常简单的概念。它是包文件应该安装到的目录。默认情况下,stow 目标目录被视作是调用 stow 的目录。这种行为可以通过使用 `-t` 选项( `--target` 的简写)轻松改变,这使我们可以指定一个替代目录。
|
||||
|
||||
### 一个实际的例子
|
||||
|
||||
我相信一个好的例子胜过 1000 句话,所以让我来展示 `stow` 如何工作。假设我们想编译并安装 `libx264`,首先我们克隆包含其源代码的仓库:
|
||||
|
||||
```
|
||||
$ git clone git://git.videolan.org/x264.git
|
||||
```
|
||||
|
||||
运行该命令几秒钟后,将创建 `x264` 目录,它将包含准备编译的源代码。我们切换到 `x264` 目录中并运行 `configure` 脚本,将 `--prefix` 指定为 `/usr/local/stow/libx264` 目录。
|
||||
|
||||
```
|
||||
$ cd x264 && ./configure --prefix=/usr/local/stow/libx264
|
||||
```
|
||||
|
||||
然后我们构建该程序并安装它:
|
||||
|
||||
```
|
||||
$ make
|
||||
# make install
|
||||
```
|
||||
|
||||
`x264` 目录应该创建在 `stow` 目录内:它包含了所有通常直接安装在系统中的东西。 现在,我们所要做的就是调用 `stow`。 我们必须从 `stow` 目录内运行这个命令,通过使用 `-d` 选项来手动指定 `stow` 目录的路径(默认为当前目录),或者通过如前所述用 `-t` 指定目标。我们还应该提供要作为参数存储的软件包的名称。 在这里,我们从 `stow` 目录运行程序,所以我们需要输入的内容是:
|
||||
|
||||
```
|
||||
# stow libx264
|
||||
```
|
||||
|
||||
libx264 软件包中包含的所有文件和目录现在已经在调用 stow 的父目录 (/usr/local) 中进行了符号链接,因此,例如在 `/usr/local/ stow/x264/bin` 中包含的 libx264 二进制文件现在符号链接在 `/usr/local/bin` 之中,`/usr/local/stow/x264/etc` 中的文件现在符号链接在 `/usr/local/etc` 之中等等。通过这种方式,系统将显示文件已正常安装,并且我们可以容易地跟踪我们编译和安装的每个程序。要反转该操作,我们只需使用 `-D` 选项:
|
||||
|
||||
```
|
||||
# stow -d libx264
|
||||
```
|
||||
|
||||
完成了!符号链接不再存在:我们只是“卸载”了一个 stow 包,使我们的系统保持在一个干净且一致的状态。 在这一点上,我们应该清楚为什么 stow 还可以用于管理点文件。 通常的做法是在 git 仓库中包含用户特定的所有配置文件,以便轻松管理它们并使它们在任何地方都可用,然后使用 stow 将它们放在适当位置,如放在用户主目录中。
|
||||
|
||||
stow 还会阻止你错误地覆盖文件:如果目标文件已经存在,并且没有指向 stow 目录中的包时,它将拒绝创建符号链接。 这种情况在 stow 术语中称为冲突。
|
||||
|
||||
就是这样!有关选项的完整列表,请参阅 stow 帮助页,并且不要忘记在评论中告诉我们你对此的看法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxconfig.org/how-to-use-gnu-stow-to-manage-programs-installed-from-source-and-dotfiles
|
||||
|
||||
作者:[Egidio Docile][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linuxconfig.org
|
||||
@ -1,44 +1,47 @@
|
||||
什么是容器?为什么我们关注它?
|
||||
======
|
||||
|
||||

|
||||
|
||||
什么是容器?你需要它们吗?为什么?在这篇文章中,我们会回答这些基本问题。
|
||||
|
||||
但是,为了回答这些问题,我们要提出更多的问题。当你开始考虑怎么用容器适配你的工作时,你需要弄清楚:你在哪开发应用?你在哪测试它?你在哪使用它?
|
||||
|
||||
你可能在你的笔记本电脑上开发应用,你的电脑上已经装好了所需要的库文件,扩展包,开发工具,和开发框架。它在一个模拟生产环境的机器上进行测试,然后被用于生产。问题是这三种环境不一定都是一样的;他们没有同样的工具,框架,和库。你在你机器上开发的应用不一定可以在生产环境中正常工作。
|
||||
你可能在你的笔记本电脑上开发应用,你的电脑上已经装好了所需要的库文件、扩展包、开发工具和开发框架。它在一个模拟生产环境的机器上进行测试,然后被用于生产环境。问题是这三种环境不一定都是一样的;它们没有同样的工具、框架和库。你在你机器上开发的应用不一定可以在生产环境中正常工作。
|
||||
|
||||
容器解决了这个问题。正如 Docker 解释的,“容器镜像是软件的一个轻量的,独立的,可执行的包,包括了执行它所需要的所有东西:代码,运行环境,系统工具,系统库,设置。”
|
||||
容器解决了这个问题。正如 Docker 解释的,“容器镜像是软件的一个轻量的、独立的、可执行的包,包括了执行它所需要的所有东西:代码、运行环境、系统工具、系统库、设置。”
|
||||
|
||||
这代表着,一旦一个应用被封装成容器,那么它所依赖的下层环境就不再重要了。它可以在任何地方运行,甚至在混合云环境下也可以。这是容器在开发者,执行团队,甚至 CIO (信息主管)中变得如此流行的原因之一。
|
||||
这代表着,一旦一个应用被封装成容器,那么它所依赖的下层环境就不再重要了。它可以在任何地方运行,甚至在混合云环境下也可以。这是容器在开发人员,执行团队,甚至 CIO (信息主管)中变得如此流行的原因之一。
|
||||
|
||||
### 容器对开发者的好处
|
||||
### 容器对开发人员的好处
|
||||
|
||||
现在开发者或执行者不再需要关注他们要使用什么平台来运行应用。开发者不会再说:“这在我的系统上运行得好好的。”
|
||||
现在开发人员或运维人员不再需要关注他们要使用什么平台来运行应用。开发人员不会再说:“这在我的系统上运行得好好的。”
|
||||
|
||||
容器的另一个重大优势时它的隔离性和安全性。因为容器将应用和运行平台隔离开了,应用以及它周边的东西都会变得安全。同时,不同的团队可以在一台设备上同时运行不同的应用——对于传统应用来说这是不可以的。
|
||||
容器的另一个重大优势是它的隔离性和安全性。因为容器将应用和运行平台隔离开了,应用以及它周边的东西都会变得安全。同时,不同的团队可以在一台设备上同时运行不同的应用——对于传统应用来说这是不可以的。
|
||||
|
||||
这不是虚拟机( VM )所提供的吗?是的,也不是。虚拟机可以隔离应用,但它负载太高了。[在一份文献中][1],Canonical 比较了容器和虚拟机,结果是:“容器提供了一种新的虚拟化方法,它有着和传统虚拟机几乎相同的资源隔离水平。但容器的负载更小,它占用更少的内存,更为高效。这意味着可以实现高密度的虚拟化:一旦安装,你可以在相同的硬件上运行更多应用。”另外,虚拟机启动前需要更多的准备,而容器只需几秒就能运行,可以瞬间启动。
|
||||
这不是虚拟机( VM )所提供的吗?既是,也不是。虚拟机可以隔离应用,但它负载太高了。[在一份文献中][1],Canonical 比较了容器和虚拟机,结果是:“容器提供了一种新的虚拟化方法,它有着和传统虚拟机几乎相同的资源隔离水平。但容器的负载更小,它占用更少的内存,更为高效。这意味着可以实现高密度的虚拟化:一旦安装,你可以在相同的硬件上运行更多应用。”另外,虚拟机启动前需要更多的准备,而容器只需几秒就能运行,可以瞬间启动。
|
||||
|
||||
### 容器对应用生态的好处
|
||||
|
||||
现在,一个庞大的,由供应商和解决方案组成的生态系统已经允许公司大规模地运用容器,不管是用于编排,监控,记录,或者生命周期管理。
|
||||
现在,一个庞大的,由供应商和解决方案组成的生态系统已经可以让公司大规模地运用容器,不管是用于编排、监控、记录或者生命周期管理。
|
||||
|
||||
为了保证容器可以运行在任何地方,容器生态系统一起成立了[开源容器倡议][2](OCI)。这是一个 Linux 基金会的项目,目标在于创建关于容器运行环境和容器镜像格式这两个容器核心部分的规范。这两个规范确保容器空间中不会有任何碎片。
|
||||
为了保证容器可以运行在任何地方,容器生态系统一起成立了[开源容器倡议][2](OCI)。这是一个 Linux 基金会的项目,目标在于创建关于容器运行环境和容器镜像格式这两个容器核心部分的规范。这两个规范确保容器领域中不会有任何不一致。
|
||||
|
||||
在很长的一段时间里,容器是专门用于 Linux 内核的,但微软和 Docker 的密切合作将容器带到了微软平台上。现在你可以在 Linux,Windows,Azure,AWS,Google 计算引擎,Rackspace,以及大型计算机上使用容器。甚至 VMware 也正在发展容器,它的 [vSphere Integrated Container][3](VIC)允许 IT 专业人员在他们平台的传统工作负载上运行容器。
|
||||
在很长的一段时间里,容器是专门用于 Linux 内核的,但微软和 Docker 的密切合作将容器带到了微软平台上。现在你可以在 Linux、Windows、Azure、AWS、Google 计算引擎、Rackspace,以及大型计算机上使用容器。甚至 VMware 也正在发展容器,它的 [vSphere Integrated Container][3](VIC)允许 IT 专业人员在他们平台的传统工作负载上运行容器。
|
||||
|
||||
### 容器对 CIO 的好处
|
||||
|
||||
容器在开发者中因为以上的原因而变得十分流行,同时他们也给CIO提供了很大的便利。将工作负载迁移到容器中的优势正在改变着公司运行的模式。
|
||||
容器在开发人员中因为以上的原因而变得十分流行,同时他们也给 CIO 提供了很大的便利。将工作负载迁移到容器中的优势正在改变着公司运行的模式。
|
||||
|
||||
传统的应用有大约十年的生命周期。新版本的发布需要多年的努力,因为应用是独立于平台的,有时需要经过几年的努力才能看到生产效果。由于这个生命周期,开发者会尽可能在应用里塞满各种功能,这会使应用变得庞大笨拙,漏洞百出。
|
||||
传统的应用有大约十年的生命周期。新版本的发布需要多年的努力,因为应用是依赖于平台的,有时几年也不能到达产品阶段。由于这个生命周期,开发人员会尽可能在应用里塞满各种功能,这会使应用变得庞大笨拙,漏洞百出。
|
||||
|
||||
这个过程影响了公司内部的创新文化。当人们几个月甚至几年都不能看到他们的创意被实现时,他们就不再有动力了。
|
||||
|
||||
容器解决了这个问题。因为你可以将应用切分成更小的微服务。你可以在几周或几天内开发,测试和部署。新特性可以添加成为新的容器。他们可以在测试结束后以最快的速度被投入生产。公司可以更快转型,超过他们的竞争者。因为想法可以被很快转化为容器并部署,这个方式使得创意爆炸式增长。
|
||||
容器解决了这个问题。因为你可以将应用切分成更小的微服务。你可以在几周或几天内开发、测试和部署。新特性可以添加成为新的容器。他们可以在测试结束后以最快的速度被投入生产。公司可以更快转型,超过他们的竞争者。因为想法可以被很快转化为容器并部署,这个方式使得创意爆炸式增长。
|
||||
|
||||
### 结论
|
||||
|
||||
容器解决了许多传统工作负载所面对的问题。但是,它并不能解决所有 IT 专业人员面对的问题。它只是众多解决方案中的一个。在下一篇文章中,我们将会覆盖一些容器的基本属于,然后我们会解释如何开始构建容器。
|
||||
容器解决了许多传统工作负载所面对的问题。但是,它并不能解决所有 IT 专业人员面对的问题。它只是众多解决方案中的一个。在下一篇文章中,我们将会覆盖一些容器的基本术语,然后我们会解释如何开始构建容器。
|
||||
|
||||
通过 Linux 基金会和 edX 提供的免费的 ["Introduction to Linux" ][4] 课程学习更多 Linux 知识。
|
||||
|
||||
@ -46,9 +49,9 @@
|
||||
|
||||
via: https://www.linux.com/blog/intro-to-Linux/2017/12/what-are-containers-and-why-should-you-care
|
||||
|
||||
作者:[wapnil Bhartiya][a]
|
||||
作者:[SWAPNIL BHARTIYA][a]
|
||||
译者:[lonaparte](https://github.com/lonaparte)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,180 @@
|
||||
Ansible:像系统管理员一样思考的自动化框架
|
||||
======
|
||||
|
||||
这些年来,我已经写了许多关于 DevOps 工具的文章,也培训了这方面的人员。尽管这些工具很棒,但很明显,大多数都是按照开发人员的思路设计出来的。这也没有什么问题,因为以编程的方式接近配置管理是重点。不过,直到我开始接触 Ansible,我才觉得这才是系统管理员喜欢的东西。
|
||||
|
||||
喜欢的一部分原因是 Ansible 与客户端计算机通信的方式,是通过 SSH 的。作为系统管理员,你们都非常熟悉通过 SSH 连接到计算机,所以从单词“去”的角度来看,相对于其它选择,你更容易理解 Ansible。
|
||||
|
||||
考虑到这一点,我打算写一些文章,探讨如何使用 Ansible。这是一个很好的系统,但是当我第一次接触到这个系统的时候,不知道如何开始。这并不是学习曲线陡峭。事实上,问题是在开始使用 Ansible 之前,我并没有太多的东西要学,这才是让人感到困惑的。例如,如果您不必安装客户端程序(Ansible 没有在客户端计算机上安装任何软件),那么您将如何启动?
|
||||
|
||||
### 踏出第一步
|
||||
|
||||
起初 Ansible 对我来说非常困难的原因在于配置服务器/客户端的关系是非常灵活的,我不知道我该从何入手。事实是,Ansible 并不关心你如何设置 SSH 系统。它会利用你现有的任何配置。需要考虑以下几件事情:
|
||||
|
||||
1. Ansible 需要通过 SSH 连接到客户端计算机。
|
||||
2. 连接后,Ansible 需要提升权限才能配置系统,安装软件包等等。
|
||||
|
||||
不幸的是,这两个考虑真的带来了一堆蠕虫。连接到远程计算机并提升权限是一件可怕的事情。当您在远程计算机上安装代理并使用 Chef 或 Puppet 处理特权升级问题时,似乎感觉就没那么可怕了。 Ansible 并非不安全,而是安全的决定权在你手中。
|
||||
|
||||
接下来,我将列出一系列潜在的配置,以及每个配置的优缺点。这不是一个详尽的清单,但是你会受到正确的启发,去思考在你自己的环境中什么是理想的配置。也需要注意,我不会提到像 Vagrant 这样的系统,因为尽管 Vagrant 在构建测试和开发的敏捷架构时非常棒,但是和一堆服务器是非常不同的,因此考虑因素是极不相似的。
|
||||
|
||||
### 一些 SSH 场景
|
||||
|
||||
#### 1)在 Ansible 配置中,root 用户以密码进入远程计算机。
|
||||
|
||||
拥有这个想法是一个非常可怕的开始。这个设置的“优点”是它消除了对特权提升的需要,并且远程服务器上不需要其他用户帐户。 但是,这种便利的成本是不值得的。 首先,大多数系统不会让你在不改变默认配置的情况下以 root 身份进行 SSH 登录。默认的配置之所以如此,坦率地说,是因为允许 root 用户远程连接是一个不好的主意。 其次,将 root 密码放在 Ansible 机器上的纯文本配置文件中是不合适的。 真的,我提到了这种可能性,因为这是可以的,但这是应该避免的。 请记住,Ansible 允许你自己配置连接,它可以让你做真正愚蠢的事情。 但是请不要这么做。
|
||||
|
||||
#### 2)使用存储在 Ansible 配置中的密码,以普通用户的身份进入远程计算机。
|
||||
|
||||
这种情况的一个优点是它不需要太多的客户端配置。 大多数用户默认情况下都可以使用 SSH,因此 Ansible 应该能够使用用户凭据并且能够正常登录。 我个人不喜欢在配置文件中以纯文本形式存储密码,但至少它不是 root 密码。 如果您使用此方法,请务必考虑远程服务器上的权限提升方式。 我知道我还没有谈到权限提升,但是如果你在配置文件中配置了一个密码,这个密码可能会被用来获得 sudo 访问权限。 因此,一旦发生泄露,您不仅已经泄露了远程用户的帐户,还可能泄露整个系统。
|
||||
|
||||
#### 3)使用具有空密码的密钥对进行身份验证,以普通用户身份进入远程计算机。
|
||||
|
||||
这消除了将密码存储在配置文件中的弊端,至少在登录的过程中消除了。 没有密码的密钥对并不理想,但这是我经常做的事情。 在我的个人内部网络中,我通常使用没有密码的密钥对来自动执行许多事情,如需要身份验证的定时任务。 这不是最安全的选择,因为私钥泄露意味着可以无限制地访问远程用户的帐户,但是相对于在配置文件中存储密码我更喜欢这种方式。
|
||||
|
||||
#### 4)使用通过密码保护的密钥对进行身份验证,以普通用户的身份通过 SSH 连接到远程计算机。
|
||||
|
||||
这是处理远程访问的一种非常安全的方式,因为它需要两种不同的身份验证因素来解密:私钥和密码。 如果你只是以交互方式运行 Ansible,这可能是理想的设置。 当你运行命令时,Ansible 会提示你输入私钥的密码,然后使用密钥对登录到远程系统。 是的,只需使用标准密码登录并且不用在配置文件中指定密码即可完成,但是如果不管怎样都要在命令行上输入密码,那为什么不在保护层添加密钥对呢?
|
||||
|
||||
#### 5)使用密码保护密钥对进行 SSH 连接,但是使用 ssh-agent “解锁”私钥。
|
||||
|
||||
这并不能完美地解决无人值守、自动化的 Ansible 命令的问题,但是它确实也使安全设置变得相当方便。 ssh-agent 程序一次验证密码,然后使用该验证进行后续连接。当我使用 Ansible 时,这是我想要做的事情。如果我是完全值得信任的,我通常仍然使用没有密码的密钥对,但是这通常是因为我在我的家庭服务器上工作,是不是容易受到攻击的。
|
||||
|
||||
在配置 SSH 环境时还要记住一些其他注意事项。 也许你可以限制 Ansible 用户(通常是你的本地用户),以便它只能从一个特定的 IP 地址登录。 也许您的 Ansible 服务器可以位于不同的子网中,位于强大的防火墙之后,因此其私钥更难以远程访问。 也许 Ansible 服务器本身没有安装 SSH 服务器,所以根本没法访问。 同样,Ansible 的优势之一是它使用 SSH 协议进行通信,而且这是一个你用了多年的协议,你已经把你的系统调整到最适合你的环境了。 我不是宣传“最佳实践”的忠实粉丝,因为实际上最好的做法是考虑你的环境,并选择最适合你情况的设置。
|
||||
|
||||
### 权限提升
|
||||
|
||||
一旦您的 Ansible 服务器通过 SSH 连接到它的客户端,就需要能够提升特权。 如果你选择了上面的选项 1,那么你已经是 root 了,这是一个有争议的问题。 但是由于没有人选择选项 1(对吧?),您需要考虑客户端计算机上的普通用户如何获得访问权限。 Ansible 支持各种权限提升的系统,但在 Linux 中,最常用的选项是 `sudo` 和 `su`。 和 SSH 一样,有几种情况需要考虑,虽然肯定还有其他选择。
|
||||
|
||||
#### 1)使用 su 提升权限。
|
||||
|
||||
对于 RedHat/CentOS 用户来说,可能默认是使用 `su` 来获得系统访问权限。 默认情况下,这些系统在安装过程中配置了 root 密码,要想获得特殊访问权限,您需要输入该密码。使用 `su` 的问题在于,虽说它可以给了您完全访问远程系统,而您确实也可以完全访问远程系统。 (是的,这是讽刺。)另外,`su` 程序没有使用密钥对进行身份验证的能力,所以密码必须以交互方式输入或存储在配置文件中。 由于它实际上是 root 密码,因此将其存储在配置文件中听起来像、也确实是一个可怕的想法。
|
||||
|
||||
#### 2)使用 sudo 提升权限。
|
||||
|
||||
这就是 Debian/Ubuntu 系统的配置方式。 正常用户组中的用户可以使用 `sudo` 命令并使用 root 权限执行该命令。 随之而来的是,这仍然存在密码存储或交互式输入的问题。 由于在配置文件中存储用户的密码看起来不太可怕,我猜这是使用 `su` 的一个进步,但是如果密码被泄露,仍然可以完全访问系统。 (毕竟,输入 `sudo` 和 `su -` 都将允许用户成为 root 用户,就像拥有 root 密码一样。)
|
||||
|
||||
#### 3) 使用 sudo 提升权限,并在 sudoers 文件中配置 NOPASSWD。
|
||||
|
||||
再次,在我的本地环境中,我就是这么做的。 这并不完美,因为它给予用户帐户无限制的 root 权限,并且不需要任何密码。 但是,当我这样做并且使用没有密码短语的 SSH 密钥对时,我可以让 Ansible 命令更轻松的自动化。 再次提示,虽然这很方便,但这不是一个非常安全的想法。
|
||||
|
||||
#### 4)使用 sudo 提升权限,并在特定的可执行文件上配置 NOPASSWD。
|
||||
|
||||
这个想法可能是安全性和便利性的最佳折衷。 基本上,如果你知道你打算用 Ansible 做什么,那么你可以为远程用户使用的那些应用程序提供 NOPASSWD 权限。 这可能会让人有些困惑,因为 Ansible 使用 Python 来处理很多事情,但是经过足够的尝试和错误,你应该能够弄清原理。 这是额外的工作,但确实消除了一些明显的安全漏洞。
|
||||
|
||||
### 计划实施
|
||||
|
||||
一旦你决定如何处理 Ansible 认证和权限提升,就需要设置它。 在熟悉 Ansible 之后,您可能会使用该工具来帮助“引导”新客户端,但首先手动配置客户端非常重要,以便您知道发生了什么事情。 将你熟悉的事情变得自动化比从头开始自动化要好。
|
||||
|
||||
我已经写过关于 SSH 密钥对的文章,网上有无数的设置类的文章。 来自 Ansible 服务器的简短版本看起来像这样:
|
||||
|
||||
```
|
||||
# ssh-keygen
|
||||
# ssh-copy-id -i .ssh/id_dsa.pub remoteuser@remote.computer.ip
|
||||
# ssh remoteuser@remote.computer.ip
|
||||
```
|
||||
|
||||
如果您在创建密钥对时选择不使用密码,最后一步您应该可以直接进入远程计算机,而不用输入密码或密钥串。
|
||||
|
||||
为了在 `sudo` 中设置权限提升,您需要编辑 `sudoers` 文件。 你不应该直接编辑文件,而是使用:
|
||||
|
||||
```
|
||||
# sudo visudo
|
||||
```
|
||||
|
||||
这将打开 `sudoers` 文件并允许您安全地进行更改(保存时会进行错误检查,所以您不会意外地因为输入错误将自己锁住)。 这个文件中有一些例子,所以你应该能够弄清楚如何分配你想要的确切的权限。
|
||||
|
||||
一旦配置完成,您应该在使用 Ansible 之前进行手动测试。 尝试 SSH 到远程客户端,然后尝试使用您选择的任何方法提升权限。 一旦你确认配置的方式可以连接,就可以安装 Ansible 了。
|
||||
|
||||
### 安装 Ansible
|
||||
|
||||
由于 Ansible 程序仅安装在一台计算机上,因此开始并不是一件繁重的工作。 Red Hat/Ubuntu 系统的软件包安装有点不同,但都不是很困难。
|
||||
|
||||
在 Red Hat/CentOS 中,首先启用 EPEL 库:
|
||||
|
||||
```
|
||||
sudo yum install epel-release
|
||||
```
|
||||
|
||||
然后安装 Ansible:
|
||||
|
||||
```
|
||||
sudo yum install ansible
|
||||
```
|
||||
|
||||
在 Ubuntu 中,首先启用 Ansible PPA:
|
||||
|
||||
```
|
||||
sudo apt-add-repository spa:ansible/ansible
|
||||
(press ENTER to access the key and add the repo)
|
||||
```
|
||||
|
||||
然后安装 Ansible:
|
||||
|
||||
```
|
||||
sudo apt-get update
|
||||
sudo apt-get install ansible
|
||||
```
|
||||
|
||||
### Ansible 主机文件配置
|
||||
|
||||
Ansible 系统无法知道您希望它控制哪个客户端,除非您给它一个计算机列表。 该列表非常简单,看起来像这样:
|
||||
|
||||
```
|
||||
# file /etc/ansible/hosts
|
||||
|
||||
[webservers]
|
||||
blogserver ansible_host=192.168.1.5
|
||||
wikiserver ansible_host=192.168.1.10
|
||||
|
||||
[dbservers]
|
||||
mysql_1 ansible_host=192.168.1.22
|
||||
pgsql_1 ansible_host=192.168.1.23
|
||||
```
|
||||
|
||||
方括号内的部分是指定的组。 单个主机可以列在多个组中,而 Ansible 可以指向单个主机或组。 这也是配置文件,比如纯文本密码的东西将被存储,如果这是你计划的那种设置。 配置文件中的每一行配置一个主机地址,并且可以在 `ansible_host` 语句之后添加多个声明。 一些有用的选项是:
|
||||
|
||||
```
|
||||
ansible_ssh_pass
|
||||
ansible_become
|
||||
ansible_become_method
|
||||
ansible_become_user
|
||||
ansible_become_pass
|
||||
```
|
||||
|
||||
### Ansible <ruby>保险库<rt>Vault</rt></ruby>
|
||||
|
||||
(LCTT 译注:Vault 作为 ansible 的一项新功能可将例如密码、密钥等敏感数据文件进行加密,而非明文存放)
|
||||
|
||||
我也应该注意到,尽管安装程序比较复杂,而且这不是在您首次进入 Ansible 世界时可能会做的事情,但该程序确实提供了一种加密保险库中的密码的方法。 一旦您熟悉 Ansible,并且希望将其投入生产,将这些密码存储在加密的 Ansible 保险库中是非常理想的。 但是本着先学会爬再学会走的精神,我建议首先在非生产环境下使用无密码方法。
|
||||
|
||||
### 系统测试
|
||||
|
||||
最后,你应该测试你的系统,以确保客户端可以正常连接。 `ping` 测试将确保 Ansible 计算机可以 `ping` 每个主机:
|
||||
|
||||
```
|
||||
ansible -m ping all
|
||||
```
|
||||
|
||||
运行后,如果 `ping` 成功,您应该看到每个定义的主机显示 `ping` 的消息:`pong`。 这实际上并没有测试认证,只是测试网络连接。 试试这个来测试你的认证:
|
||||
|
||||
```
|
||||
ansible -m shell -a 'uptime' webservers
|
||||
```
|
||||
|
||||
您应该可以看到 webservers 组中每个主机的运行时间命令的结果。
|
||||
|
||||
在后续文章中,我计划开始深入 Ansible 管理远程计算机的功能。 我将介绍各种模块,以及如何使用 ad-hoc 模式来完成一些按键操作,这些操作在命令行上单独处理都需要很长时间。 如果您没有从上面的示例 Ansible 命令中获得预期的结果,请花些时间确保身份验证可以工作。 如果遇到困难,请查阅 [Ansible 文档][1]获取更多帮助。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxjournal.com/content/ansible-automation-framework-thinks-sysadmin
|
||||
|
||||
作者:[Shawn Powers][a]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxjournal.com/users/shawn-powers
|
||||
[1]:http://docs.ansible.com
|
||||
@ -1,4 +1,4 @@
|
||||
构建你自己的 RSS 提示系统——让杂志文章一篇也不会错过
|
||||
用 Python 构建你自己的 RSS 提示系统
|
||||
======
|
||||
|
||||

|
||||
@ -7,9 +7,9 @@
|
||||
|
||||
### Fedora 和 Python —— 入门知识
|
||||
|
||||
Python 3.6 在 Fedora 中是默认安装的,它包含了 Python 的很多标准库。标准库提供了一些可以让我们的任务更加简单完成的模块的集合。例如,在我们的案例中,我们将使用 [**sqlite3**][1] 模块在数据库中去创建表、添加和读取数据。在这个案例中,我们试图去解决的是在标准库中没有的特定的问题,也有可能已经有人为我们开发了这样一个模块。最好是使用像大家熟知的 [PyPI][2] Python 包索引去搜索一下。在我们的示例中,我们将使用 [**feedparser**][3] 去解析 RSS 源。
|
||||
Python 3.6 在 Fedora 中是默认安装的,它包含了 Python 的很多标准库。标准库提供了一些可以让我们的任务更加简单完成的模块的集合。例如,在我们的案例中,我们将使用 [sqlite3][1] 模块在数据库中去创建表、添加和读取数据。在这个案例中,我们试图去解决的是这样的一个特定问题,在标准库中没有包含,而有可能已经有人为我们开发了这样一个模块。最好是使用像大家熟知的 [PyPI][2] Python 包索引去搜索一下。在我们的示例中,我们将使用 [feedparser][3] 去解析 RSS 源。
|
||||
|
||||
因为 **feedparser** 并不是标准库,我们需要将它安装到我们的系统上。幸运的是,在 Fedora 中有这个 RPM 包,因此,我们可以运行如下的命令去安装 **feedparser**:
|
||||
因为 feedparser 并不是标准库,我们需要将它安装到我们的系统上。幸运的是,在 Fedora 中有这个 RPM 包,因此,我们可以运行如下的命令去安装 feedparser:
|
||||
```
|
||||
$ sudo dnf install python3-feedparser
|
||||
```
|
||||
@ -18,11 +18,12 @@ $ sudo dnf install python3-feedparser
|
||||
|
||||
### 存储源数据
|
||||
|
||||
我们需要存储已经发布的文章的数据,这样我们的系统就可以只提示新发布的文章。我们要保存的数据将是用来辨别一篇文章的唯一方法。因此,我们将存储文章的**标题**和**发布日期**。
|
||||
我们需要存储已经发布的文章的数据,这样我们的系统就可以只提示新发布的文章。我们要保存的数据将是用来辨别一篇文章的唯一方法。因此,我们将存储文章的标题和发布日期。
|
||||
|
||||
因此,我们来使用 Python **sqlite3** 模块和一个简单的 SQL 语句来创建我们的数据库。同时也添加一些后面将要用到的模块(**feedparse**,**smtplib**,和 **email**)。
|
||||
因此,我们来使用 Python sqlite3 模块和一个简单的 SQL 语句来创建我们的数据库。同时也添加一些后面将要用到的模块(feedparse,smtplib,和 email)。
|
||||
|
||||
#### 创建数据库
|
||||
|
||||
```
|
||||
#!/usr/bin/python3
|
||||
import sqlite3
|
||||
@ -34,14 +35,14 @@ import feedparser
|
||||
db_connection = sqlite3.connect('/var/tmp/magazine_rss.sqlite')
|
||||
db = db_connection.cursor()
|
||||
db.execute(' CREATE TABLE IF NOT EXISTS magazine (title TEXT, date TEXT)')
|
||||
|
||||
```
|
||||
|
||||
这几行代码创建一个新的保存在一个名为 'magazine_rss.sqlite' 文件中的 sqlite 数据库,然后在数据库创建一个名为 'magazine' 的新表。这个表有两个列 —— 'title' 和 'date' —— 它们能存诸 TEXT 类型的数据,也就是说每个列的值都是文本字符。
|
||||
这几行代码创建一个名为 `magazine_rss.sqlite` 文件的新 sqlite 数据库,然后在数据库创建一个名为 `magazine` 的新表。这个表有两个列 —— `title` 和 `date` —— 它们能存诸 TEXT 类型的数据,也就是说每个列的值都是文本字符。
|
||||
|
||||
#### 检查数据库中的旧文章
|
||||
|
||||
由于我们仅希望增加新的文章到我们的数据库中,因此我们需要一个功能去检查 RSS 源中的文章在数据库中是否存在。我们将根据它来判断是否发送(有新文章的)邮件提示。Ok,现在我们来写这个功能的代码。
|
||||
|
||||
```
|
||||
def article_is_not_db(article_title, article_date):
|
||||
""" Check if a given pair of article title and date
|
||||
@ -60,13 +61,14 @@ def article_is_not_db(article_title, article_date):
|
||||
return False
|
||||
```
|
||||
|
||||
这个功能的主要部分是一个 SQL 查询,我们运行它去搜索数据库。我们使用一个 SELECT 命令去定义我们将要在哪个列上运行这个查询。我们使用 `*` 符号去选取所有列(title 和 date)。然后,我们使用查询的 WHERE 条件 `article_title` and `article_date` 去匹配标题和日期列中的值,以检索出我们需要的内容。
|
||||
这个功能的主要部分是一个 SQL 查询,我们运行它去搜索数据库。我们使用一个 `SELECT` 命令去定义我们将要在哪个列上运行这个查询。我们使用 `*` 符号去选取所有列(`title` 和 `date`)。然后,我们使用查询的 `WHERE` 条件 `article_title` 和 `article_date` 去匹配标题和日期列中的值,以检索出我们需要的内容。
|
||||
|
||||
最后,我们使用一个简单的返回 `True` 或者 `False` 的逻辑来表示是否在数据库中找到匹配的文章。
|
||||
|
||||
#### 在数据库中添加新文章
|
||||
|
||||
现在我们可以写一些代码去添加新文章到数据库中。
|
||||
|
||||
```
|
||||
def add_article_to_db(article_title, article_date):
|
||||
""" Add a new article title and date to the database
|
||||
@ -78,13 +80,14 @@ def add_article_to_db(article_title, article_date):
|
||||
db_connection.commit()
|
||||
```
|
||||
|
||||
这个功能很简单,我们使用了一个 SQL 查询去插入一个新行到 'magazine' 表的 article_title 和 article_date 列中。然后提交它到数据库中永久保存。
|
||||
这个功能很简单,我们使用了一个 SQL 查询去插入一个新行到 `magazine` 表的 `article_title` 和 `article_date` 列中。然后提交它到数据库中永久保存。
|
||||
|
||||
这些就是在数据库中所需要的东西,接下来我们看一下,如何使用 Python 实现提示系统和发送电子邮件。
|
||||
|
||||
### 发送电子邮件提示
|
||||
|
||||
我们来使用 Python 标准库模块 **smtplib** 来创建一个发送电子邮件的功能。我们也可以使用标准库中的 **email** 模块去格式化我们的电子邮件信息。
|
||||
我们使用 Python 标准库模块 smtplib 来创建一个发送电子邮件的功能。我们也可以使用标准库中的 email 模块去格式化我们的电子邮件信息。
|
||||
|
||||
```
|
||||
def send_notification(article_title, article_url):
|
||||
""" Add a new article title and date to the database
|
||||
@ -113,6 +116,7 @@ def send_notification(article_title, article_url):
|
||||
### 读取 Fedora Magazine 的 RSS 源
|
||||
|
||||
我们已经有了在数据库中存储文章和发送提示电子邮件的功能,现在来创建一个解析 Fedora Magazine RSS 源并提取文章数据的功能。
|
||||
|
||||
```
|
||||
def read_article_feed():
|
||||
""" Get articles from RSS feed """
|
||||
@ -127,25 +131,26 @@ if __name__ == '__main__':
|
||||
db_connection.close()
|
||||
```
|
||||
|
||||
在这里我们将使用 **feedparser.parse** 功能。这个功能返回一个用字典表示的 RSS 源,对于 **feedparser** 的完整描述可以参考它的 [文档][5]。
|
||||
在这里我们将使用 `feedparser.parse` 功能。这个功能返回一个用字典表示的 RSS 源,对于 feedparser 的完整描述可以参考它的 [文档][5]。
|
||||
|
||||
RSS 源解析将返回最后的 10 篇文章作为 `entries`,然后我们提取以下信息:标题、链接、文章发布日期。因此,我们现在可以使用前面定义的检查文章是否在数据库中存在的功能,然后,发送提示电子邮件并将这个文章添加到数据库中。
|
||||
|
||||
当运行我们的脚本时,最后的 if 语句运行我们的 `read_article_feed` 功能,然后关闭数据库连接。
|
||||
当运行我们的脚本时,最后的 `if` 语句运行我们的 `read_article_feed` 功能,然后关闭数据库连接。
|
||||
|
||||
### 运行我们的脚本
|
||||
|
||||
给脚本文件赋于正确运行权限。接下来,我们使用 **cron** 实用程序去每小时自动运行一次我们的脚本。**cron** 是一个作业计划程序,我们可以使用它在一个固定的时间去运行一个任务。
|
||||
给脚本文件赋于正确运行权限。接下来,我们使用 cron 实用程序去每小时自动运行一次我们的脚本。cron 是一个作业计划程序,我们可以使用它在一个固定的时间去运行一个任务。
|
||||
|
||||
```
|
||||
$ chmod a+x my_rss_notifier.py
|
||||
$ sudo cp my_rss_notifier.py /etc/cron.hourly
|
||||
```
|
||||
|
||||
**为了使该教程保持简单**,我们使用了 cron.hourly 目录每小时运行一次我们的脚本,如果你想学习关于 **cron** 的更多知识以及如何配置 **crontab**,请阅读 **cron** 的 wikipedia [页面][6]。
|
||||
为了使该教程保持简单,我们使用了 `cron.hourly` 目录每小时运行一次我们的脚本,如果你想学习关于 cron 的更多知识以及如何配置 crontab,请阅读 cron 的 wikipedia [页面][6]。
|
||||
|
||||
### 总结
|
||||
|
||||
在本教程中,我们学习了如何使用 Python 去创建一个简单的 sqlite 数据库、解析一个 RSS 源、以及发送电子邮件。我希望通过这篇文章能够向你展示,**使用 Python 和 Fedora 构建你自己的应用程序是件多么容易的事**。
|
||||
在本教程中,我们学习了如何使用 Python 去创建一个简单的 sqlite 数据库、解析一个 RSS 源、以及发送电子邮件。我希望通过这篇文章能够向你展示,使用 Python 和 Fedora 构建你自己的应用程序是件多么容易的事。
|
||||
|
||||
这个脚本在 [GitHub][7] 上可以找到。
|
||||
|
||||
@ -155,7 +160,7 @@ via: https://fedoramagazine.org/never-miss-magazines-article-build-rss-notificat
|
||||
|
||||
作者:[Clément Verna][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
147
published/20180125 Keep Accurate Time on Linux with NTP.md
Normal file
147
published/20180125 Keep Accurate Time on Linux with NTP.md
Normal file
@ -0,0 +1,147 @@
|
||||
在 Linux 上使用 NTP 保持精确的时间
|
||||
======
|
||||
|
||||

|
||||
|
||||
如何保持正确的时间,如何使用 NTP 和 systemd 让你的计算机在不滥用时间服务器的前提下保持同步。
|
||||
|
||||
### 它的时间是多少?
|
||||
|
||||
让 Linux 来告诉你时间的时候,它是很奇怪的。你可能认为是使用 `time` 命令来告诉你时间,其实并不是,因为 `time` 只是一个测量一个进程运行了多少时间的计时器。为得到时间,你需要运行的是 `date` 命令,你想查看更多的日期,你可以运行 `cal` 命令。文件上的时间戳也是一个容易混淆的地方,因为根据你的发行版默认情况不同,它一般有两种不同的显示方法。下面是来自 Ubuntu 16.04 LTS 的示例:
|
||||
|
||||
```
|
||||
$ ls -l
|
||||
drwxrwxr-x 5 carla carla 4096 Mar 27 2017 stuff
|
||||
drwxrwxr-x 2 carla carla 4096 Dec 8 11:32 things
|
||||
-rw-rw-r-- 1 carla carla 626052 Nov 21 12:07 fatpdf.pdf
|
||||
-rw-rw-r-- 1 carla carla 2781 Apr 18 2017 oddlots.txt
|
||||
```
|
||||
|
||||
有些显示年,有些显示时间,这样的方式让你的文件更混乱。GNU 默认的情况是,如果你的文件在六个月以内,则显示时间而不是年。我想这样做可能是有原因的。如果你的 Linux 是这样的,尝试用 `ls -l --time-style=long-iso` 命令,让时间戳用同一种方式去显示,按字母顺序排序。请查阅 [如何更改 Linux 的日期和时间:简单的命令][1] 去学习 Linux 上管理时间的各种方法。
|
||||
|
||||
### 检查当前设置
|
||||
|
||||
NTP —— 网络时间协议,它是保持计算机正确时间的老式方法。`ntpd` 是 NTP 守护程序,它通过周期性地查询公共时间服务器来按需调整你的计算机时间。它是一个简单的、轻量级的协议,使用它的基本功能时设置非常容易。systemd 通过使用 `systemd-timesyncd.service` 已经越俎代庖地 “干了 NTP 的活”,它可以用作 `ntpd` 的客户端。
|
||||
|
||||
在我们开始与 NTP “打交道” 之前,先花一些时间来了检查一下当前的时间设置是否正确。
|
||||
|
||||
你的系统上(至少)有两个时钟:系统时间 —— 它由 Linux 内核管理,第二个是你的主板上的硬件时钟,它也称为实时时钟(RTC)。当你进入系统的 BIOS 时,你可以看到你的硬件时钟的时间,你也可以去改变它的设置。当你安装一个新的 Linux 时,在一些图形化的时间管理器中,你会被询问是否设置你的 RTC 为 UTC(<ruby>世界标准时间<rt>Coordinated Universal Time</rt></ruby>)时区,因为所有的时区和夏令时都是基于 UTC 的。你可以使用 `hwclock` 命令去检查:
|
||||
|
||||
```
|
||||
$ sudo hwclock --debug
|
||||
hwclock from util-linux 2.27.1
|
||||
Using the /dev interface to the clock.
|
||||
Hardware clock is on UTC time
|
||||
Assuming hardware clock is kept in UTC time.
|
||||
Waiting for clock tick...
|
||||
...got clock tick
|
||||
Time read from Hardware Clock: 2018/01/22 22:14:31
|
||||
Hw clock time : 2018/01/22 22:14:31 = 1516659271 seconds since 1969
|
||||
Time since last adjustment is 1516659271 seconds
|
||||
Calculated Hardware Clock drift is 0.000000 seconds
|
||||
Mon 22 Jan 2018 02:14:30 PM PST .202760 seconds
|
||||
```
|
||||
|
||||
`Hardware clock is on UTC time` 表明了你的计算机的 RTC 是使用 UTC 时间的,虽然它把该时间转换为你的本地时间。如果它被设置为本地时间,它将显示 `Hardware clock is on local time`。
|
||||
|
||||
你应该有一个 `/etc/adjtime` 文件。如果没有的话,使用如下命令同步你的 RTC 为系统时间,
|
||||
|
||||
```
|
||||
$ sudo hwclock -w
|
||||
```
|
||||
|
||||
这个命令将生成该文件,内容看起来类似如下:
|
||||
|
||||
```
|
||||
$ cat /etc/adjtime
|
||||
0.000000 1516661953 0.000000
|
||||
1516661953
|
||||
UTC
|
||||
```
|
||||
|
||||
新发明的 systemd 方式是去运行 `timedatectl` 命令,运行它不需要 root 权限:
|
||||
|
||||
```
|
||||
$ timedatectl
|
||||
Local time: Mon 2018-01-22 14:17:51 PST
|
||||
Universal time: Mon 2018-01-22 22:17:51 UTC
|
||||
RTC time: Mon 2018-01-22 22:17:51
|
||||
Time zone: America/Los_Angeles (PST, -0800)
|
||||
Network time on: yes
|
||||
NTP synchronized: yes
|
||||
RTC in local TZ: no
|
||||
```
|
||||
|
||||
`RTC in local TZ: no` 表明它使用 UTC 时间。那么怎么改成使用本地时间?这里有许多种方法可以做到。最简单的方法是使用一个图形配置工具,比如像 openSUSE 中的 YaST。你也可使用 `timedatectl`:
|
||||
|
||||
```
|
||||
$ timedatectl set-local-rtc 0
|
||||
```
|
||||
|
||||
或者编辑 `/etc/adjtime`,将 `UTC` 替换为 `LOCAL`。
|
||||
|
||||
### systemd-timesyncd 客户端
|
||||
|
||||
现在,我已经累了,但是我们刚到非常精彩的部分。谁能想到计时如此复杂?我们甚至还没有了解到它的皮毛;阅读 `man 8 hwclock` 去了解你的计算机如何保持时间的详细内容。
|
||||
|
||||
systemd 提供了 `systemd-timesyncd.service` 客户端,它可以查询远程时间服务器并调整你的本地系统时间。在 `/etc/systemd/timesyncd.conf` 中配置你的(时间)服务器。大多数 Linux 发行版都提供了一个默认配置,它指向他们维护的时间服务器上,比如,以下是 Fedora 的:
|
||||
|
||||
```
|
||||
[Time]
|
||||
#NTP=
|
||||
#FallbackNTP=0.fedora.pool.ntp.org 1.fedora.pool.ntp.org
|
||||
```
|
||||
|
||||
你可以输入你希望使用的其它时间服务器,比如你自己的本地 NTP 服务器,在 `NTP=` 行上输入一个以空格分隔的服务器列表。(别忘了取消这一行的注释)`NTP=` 行上的任何内容都将覆盖掉 `FallbackNTP` 行上的配置项。
|
||||
|
||||
如果你不想使用 systemd 呢?那么,你将需要 NTP 就行。
|
||||
|
||||
### 配置 NTP 服务器和客户端
|
||||
|
||||
配置你自己的局域网 NTP 服务器是一个非常好的实践,这样你的网内计算机就不需要不停查询公共 NTP 服务器。在大多数 Linux 上的 NTP 都来自 `ntp` 包,它们大多都提供 `/etc/ntp.conf` 文件去配置时间服务器。查阅 [NTP 时间服务器池][2] 去找到你所在的区域的合适的 NTP 服务器池。然后在你的 `/etc/ntp.conf` 中输入 4 - 5 个服务器,每个服务器用单独的一行:
|
||||
|
||||
```
|
||||
driftfile /var/ntp.drift
|
||||
logfile /var/log/ntp.log
|
||||
server 0.europe.pool.ntp.org
|
||||
server 1.europe.pool.ntp.org
|
||||
server 2.europe.pool.ntp.org
|
||||
server 3.europe.pool.ntp.org
|
||||
```
|
||||
|
||||
`driftfile` 告诉 `ntpd` 它需要保存用于启动时使用时间服务器快速同步你的系统时钟的信息。而日志也将保存在他们自己指定的目录中,而不是转储到 syslog 中。如果你的 Linux 发行版默认提供了这些文件,请使用它们。
|
||||
|
||||
现在去启动守护程序;在大多数主流的 Linux 中它的命令是 `sudo systemctl start ntpd`。让它运行几分钟之后,我们再次去检查它的状态:
|
||||
|
||||
```
|
||||
$ ntpq -p
|
||||
remote refid st t when poll reach delay offset jitter
|
||||
==============================================================
|
||||
+dev.smatwebdesi 192.168.194.89 3 u 25 64 37 92.456 -6.395 18.530
|
||||
*chl.la 127.67.113.92 2 u 23 64 37 75.175 8.820 8.230
|
||||
+four0.fairy.mat 35.73.197.144 2 u 22 64 37 116.272 -10.033 40.151
|
||||
-195.21.152.161 195.66.241.2 2 u 27 64 37 107.559 1.822 27.346
|
||||
```
|
||||
|
||||
我不知道这些内容是什么意思,但重要的是,你的守护程序已经与时间服务器开始对话了,而这正是我们所需要的。你可以去运行 `sudo systemctl enable ntpd` 命令,永久启用它。如果你的 Linux 没有使用 systemd,那么,给你留下的家庭作业就是找出如何去运行 `ntpd`。
|
||||
|
||||
现在,你可以在你的局域网中的其它计算机上设置 `systemd-timesyncd`,这样它们就可以使用你的本地 NTP 服务器了,或者,在它们上面安装 NTP,然后在它们的 `/etc/ntp.conf` 上输入你的本地 NTP 服务器。
|
||||
|
||||
NTP 服务器会受到攻击,而且需求在不断增加。你可以通过运行你自己的公共 NTP 服务器来提供帮助。下周我们将学习如何运行你自己的公共服务器。
|
||||
|
||||
通过来自 Linux 基金会和 edX 的免费课程 [“Linux 入门”][3] 来学习更多 Linux 的知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/1/keep-accurate-time-linux-ntp
|
||||
|
||||
作者:[CARLA SCHRODER][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/learn/how-change-linux-date-and-time-simple-commands
|
||||
[2]:http://support.ntp.org/bin/view/Servers/NTPPoolServers
|
||||
[3]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,56 +1,79 @@
|
||||
如何在 CentOS 7 / RHEL 7 终端服务器上安装 KVM
|
||||
======
|
||||
|
||||
如何在 CnetOS 7 或 RHEL 7( Red Hat 企业版 Linux) 服务器上安装和配置 KVM(基于内核的虚拟机)?如何在 CnetOS 7 上设置 KMV 并使用云镜像/ cloud-init 来安装客户虚拟机?
|
||||
如何在 CnetOS 7 或 RHEL 7(Red Hat 企业版 Linux)服务器上安装和配置 KVM(基于内核的虚拟机)?如何在 CentOS 7 上设置 KVM 并使用云镜像 / cloud-init 来安装客户虚拟机?
|
||||
|
||||
基于内核的虚拟机(KVM)是 CentOS 或 RHEL 7 的虚拟化软件。KVM 可以将你的服务器变成虚拟机管理器。本文介绍如何在 CentOS 7 或 RHEL 7 中使用 KVM 设置和管理虚拟化环境。还介绍了如何使用命令行在物理服务器上安装和管理虚拟机(VM)。请确保在服务器的 BIOS 中启用了**虚拟化技术(VT)**。你也可以运行以下命令[测试 CPU 是否支持 Intel VT 和 AMD_V 虚拟化技术][1]。
|
||||
|
||||
基于内核的虚拟机(KVM)是 CentOS 或 RHEL 7 的虚拟化软件。KVM 将你的服务器变成虚拟机管理程序。本文介绍如何在 CentOS 7 或 RHEL 7 中使用 KVM 设置和管理虚拟化环境。还介绍了如何使用 CLI 在物理服务器上安装和管理虚拟机(VM)。确保在服务器的 BIOS 中启用了**虚拟化技术(vt)**。你也可以运行以下命令[测试 CPU 是否支持 Intel VT 和 AMD_V 虚拟化技术][1]。
|
||||
```
|
||||
$ lscpu | grep Virtualization
|
||||
Virtualization: VT-x
|
||||
```
|
||||
|
||||
### 按照 CentOS 7/RHEL 7 终端服务器上的 KVM 安装步骤进行操作
|
||||
按照 CentOS 7/RHEL 7 终端服务器上的 KVM 安装步骤进行操作。
|
||||
|
||||
#### 步骤 1: 安装 kvm
|
||||
### 步骤 1: 安装 kvm
|
||||
|
||||
输入以下 [yum 命令][2]:
|
||||
`# yum install qemu-kvm libvirt libvirt-python libguestfs-tools virt-install`
|
||||
|
||||
```
|
||||
# yum install qemu-kvm libvirt libvirt-python libguestfs-tools virt-install
|
||||
```
|
||||
|
||||
[![How to install KVM on CentOS 7 RHEL 7 Headless Server][3]][3]
|
||||
|
||||
启动 libvirtd 服务:
|
||||
|
||||
```
|
||||
# systemctl enable libvirtd
|
||||
# systemctl start libvirtd
|
||||
```
|
||||
|
||||
#### 步骤 2: 确认 kvm 安装
|
||||
### 步骤 2: 确认 kvm 安装
|
||||
|
||||
确保使用 lsmod 命令和 [grep命令][4] 加载 KVM 模块:
|
||||
`# lsmod | grep -i kvm`
|
||||
使用 `lsmod` 命令和 [grep命令][4] 确认加载了 KVM 模块:
|
||||
|
||||
#### 步骤 3: 配置桥接网络
|
||||
```
|
||||
# lsmod | grep -i kvm
|
||||
```
|
||||
|
||||
### 步骤 3: 配置桥接网络
|
||||
|
||||
默认情况下,由 libvirtd 配置基于 dhcpd 的网桥。你可以使用以下命令验证:
|
||||
|
||||
默认情况下,由 libvirtd 配置的基于 dhcpd 的网桥。你可以使用以下命令验证:
|
||||
```
|
||||
# brctl show
|
||||
# virsh net-list
|
||||
```
|
||||
|
||||
[![KVM default networking][5]][5]
|
||||
|
||||
所有虚拟机(客户机器)只能在同一台服务器上对其他虚拟机进行网络访问。为你创建的私有网络是 192.168.122.0/24。验证:
|
||||
`# virsh net-dumpxml default`
|
||||
所有虚拟机(客户机)只能对同一台服务器上的其它虚拟机进行网络访问。为你创建的私有网络是 192.168.122.0/24。验证:
|
||||
|
||||
```
|
||||
# virsh net-dumpxml default
|
||||
```
|
||||
|
||||
如果你希望你的虚拟机可用于 LAN 上的其他服务器,请在连接到你的 LAN 的服务器上设置一个网桥。更新你的网卡配置文件,如 ifcfg-enp3s0 或 em1:
|
||||
|
||||
```
|
||||
# vi /etc/sysconfig/network-scripts/ifcfg-enp3s0
|
||||
```
|
||||
|
||||
如果你希望你的虚拟机可用于 LAN 上的其他服务器,请在连接到你的 LAN 的服务器上设置一个网桥。更新你的网卡配置文件,如 ifcfg-enp3s0 或 em1:
|
||||
`# vi /etc/sysconfig/network-scripts/enp3s0 `
|
||||
添加一行:
|
||||
|
||||
```
|
||||
BRIDGE=br0
|
||||
```
|
||||
|
||||
[使用 vi 保存并关闭文件][6]。编辑 /etc/sysconfig/network-scripts/ifcfg-br0 :
|
||||
`# vi /etc/sysconfig/network-scripts/ifcfg-br0`
|
||||
添加以下东西:
|
||||
[使用 vi 保存并关闭文件][6]。编辑 `/etc/sysconfig/network-scripts/ifcfg-br0`:
|
||||
|
||||
```
|
||||
# vi /etc/sysconfig/network-scripts/ifcfg-br0
|
||||
```
|
||||
|
||||
添加以下内容:
|
||||
|
||||
```
|
||||
DEVICE="br0"
|
||||
# I am getting ip from DHCP server #
|
||||
@ -62,29 +85,38 @@ TYPE="Bridge"
|
||||
DELAY="0"
|
||||
```
|
||||
|
||||
重新启动网络服务(警告:ssh命令将断开连接,最好重新启动该设备):
|
||||
`# systemctl restart NetworkManager`
|
||||
重新启动网络服务(警告:ssh 命令将断开连接,最好重新启动该设备):
|
||||
|
||||
用 brctl 命令验证它:
|
||||
`# brctl show`
|
||||
```
|
||||
# systemctl restart NetworkManager
|
||||
```
|
||||
|
||||
#### 步骤 4: 创建你的第一个虚拟机
|
||||
用 `brctl` 命令验证它:
|
||||
|
||||
```
|
||||
# brctl show
|
||||
```
|
||||
|
||||
### 步骤 4: 创建你的第一个虚拟机
|
||||
|
||||
我将会创建一个 CentOS 7.x 虚拟机。首先,使用 `wget` 命令获取 CentOS 7.x 最新的 ISO 镜像:
|
||||
|
||||
我将会创建一个 CentOS 7.x 虚拟机。首先,使用 wget 命令获取 CentOS 7.x 最新的 ISO 镜像:
|
||||
```
|
||||
# cd /var/lib/libvirt/boot/
|
||||
# wget https://mirrors.kernel.org/centos/7.4.1708/isos/x86_64/CentOS-7-x86_64-Minimal-1708.iso
|
||||
```
|
||||
|
||||
验证 ISO 镜像:
|
||||
|
||||
```
|
||||
# wget https://mirrors.kernel.org/centos/7.4.1708/isos/x86_64/sha256sum.txt
|
||||
# sha256sum -c sha256sum.txt
|
||||
```
|
||||
|
||||
##### 创建 CentOS 7.x 虚拟机
|
||||
#### 创建 CentOS 7.x 虚拟机
|
||||
|
||||
在这个例子中,我创建了 2GB RAM,2 个 CPU 核心,1 个网卡和 40 GB 磁盘空间的 CentOS 7.x 虚拟机,输入:
|
||||
|
||||
```
|
||||
# virt-install \
|
||||
--virt-type=kvm \
|
||||
@ -98,35 +130,41 @@ DELAY="0"
|
||||
--disk path=/var/lib/libvirt/images/centos7.qcow2,size=40,bus=virtio,format=qcow2
|
||||
```
|
||||
|
||||
从另一个终端通过 ssh 和 type 配置 vnc 登录:
|
||||
从另一个终端通过 `ssh` 配置 vnc 登录,输入:
|
||||
|
||||
```
|
||||
# virsh dumpxml centos7 | grep v nc
|
||||
<graphics type='vnc' port='5901' autoport='yes' listen='127.0.0.1'>
|
||||
```
|
||||
|
||||
请记录下端口值(即 5901)。你需要使用 SSH 客户端来建立隧道和 VNC 客户端才能访问远程 vnc 服务区。在客户端/桌面/ macbook pro 系统中输入以下 SSH 端口转化命令:
|
||||
`$ ssh vivek@server1.cyberciti.biz -L 5901:127.0.0.1:5901`
|
||||
请记录下端口值(即 5901)。你需要使用 SSH 客户端来建立隧道和 VNC 客户端才能访问远程 vnc 服务器。在客户端/桌面/ macbook pro 系统中输入以下 SSH 端口转发命令:
|
||||
|
||||
```
|
||||
$ ssh vivek@server1.cyberciti.biz -L 5901:127.0.0.1:5901
|
||||
```
|
||||
|
||||
一旦你建立了 ssh 隧道,你可以将你的 VNC 客户端指向你自己的 127.0.0.1 (localhost) 地址和端口 5901,如下所示:
|
||||
|
||||
[![][7]][7]
|
||||
|
||||
你应该看到 CentOS Linux 7 客户虚拟机安装屏幕如下:
|
||||
|
||||
[![][8]][8]
|
||||
|
||||
现在只需按照屏幕说明进行操作并安装CentOS 7。一旦安装完成后,请继续并单击重启按钮。 远程服务器关闭了我们的 VNC 客户端的连接。 你可以通过 KVM 客户端重新连接,以配置服务器的其余部分,包括基于 SSH 的会话或防火墙。
|
||||
|
||||
#### 步骤 5: 使用云镜像
|
||||
### 使用云镜像
|
||||
|
||||
以上安装方法对于学习目的或单个虚拟机而言是可行的。你需要部署大量的虚拟机吗? 尝试云镜像。你可以根据需要修改预先构建的云图像。例如,使用 [Cloud-init][9] 添加用户,ssh 密钥,设置时区等等,这是处理云实例的早期初始化的事实上的多分发包。让我们看看如何创建带有 1024MB RAM,20GB 磁盘空间和 1 个 vCPU 的 CentOS 7 虚拟机。(译注: vCPU 即电脑中的虚拟处理器)
|
||||
以上安装方法对于学习目的或单个虚拟机而言是可行的。你需要部署大量的虚拟机吗? 可以试试云镜像。你可以根据需要修改预先构建的云镜像。例如,使用 [Cloud-init][9] 添加用户、ssh 密钥、设置时区等等,这是处理云实例的早期初始化的事实上的多分发包。让我们看看如何创建带有 1024MB RAM,20GB 磁盘空间和 1 个 vCPU 的 CentOS 7 虚拟机。(LCTT 译注: vCPU 即电脑中的虚拟处理器)
|
||||
|
||||
##### 获取 CentOS 7 云镜像
|
||||
#### 获取 CentOS 7 云镜像
|
||||
|
||||
```
|
||||
# cd /var/lib/libvirt/boot
|
||||
# wget http://cloud.centos.org/centos/7/images/CentOS-7-x86_64-GenericCloud.qcow2
|
||||
```
|
||||
|
||||
##### 创建所需的目录
|
||||
#### 创建所需的目录
|
||||
|
||||
```
|
||||
# D=/var/lib/libvirt/images
|
||||
@ -135,31 +173,39 @@ DELAY="0"
|
||||
mkdir: created directory '/var/lib/libvirt/images/centos7-vm1'
|
||||
```
|
||||
|
||||
##### 创建元数据文件
|
||||
#### 创建元数据文件
|
||||
|
||||
```
|
||||
# cd $D/$VM
|
||||
# vi meta-data
|
||||
```
|
||||
|
||||
添加以下东西:
|
||||
添加以下内容:
|
||||
|
||||
```
|
||||
instance-id: centos7-vm1
|
||||
local-hostname: centos7-vm1
|
||||
```
|
||||
|
||||
##### 创建用户数据文件
|
||||
#### 创建用户数据文件
|
||||
|
||||
我将使用 ssh 密钥登录到虚拟机。所以确保你有 ssh 密钥:
|
||||
|
||||
```
|
||||
# ssh-keygen -t ed25519 -C "VM Login ssh key"
|
||||
```
|
||||
|
||||
我将使用 ssh 密钥登录到虚拟机。所以确保你有 ssh-keys:
|
||||
`# ssh-keygen -t ed25519 -C "VM Login ssh key"`
|
||||
[![ssh-keygen command][10]][11]
|
||||
|
||||
请参阅 "[如何在 Linux/Unix 系统上设置 SSH 密钥][12]" 来获取更多信息。编辑用户数据如下:
|
||||
请参阅 “[如何在 Linux/Unix 系统上设置 SSH 密钥][12]” 来获取更多信息。编辑用户数据如下:
|
||||
|
||||
```
|
||||
# cd $D/$VM
|
||||
# vi user-data
|
||||
```
|
||||
添加如下(根据你的设置替换主机名,用户,ssh-authorized-keys):
|
||||
|
||||
添加如下(根据你的设置替换 `hostname`、`users`、`ssh-authorized-keys`):
|
||||
|
||||
```
|
||||
#cloud-config
|
||||
|
||||
@ -199,14 +245,14 @@ runcmd:
|
||||
- yum -y remove cloud-init
|
||||
```
|
||||
|
||||
##### 复制云镜像
|
||||
#### 复制云镜像
|
||||
|
||||
```
|
||||
# cd $D/$VM
|
||||
# cp /var/lib/libvirt/boot/CentOS-7-x86_64-GenericCloud.qcow2 $VM.qcow2
|
||||
```
|
||||
|
||||
##### 创建 20GB 磁盘映像
|
||||
#### 创建 20GB 磁盘映像
|
||||
|
||||
```
|
||||
# cd $D/$VM
|
||||
@ -215,25 +261,30 @@ runcmd:
|
||||
# virt-resize --quiet --expand /dev/sda1 $VM.qcow2 $VM.new.image
|
||||
```
|
||||
[![Set VM image disk size][13]][13]
|
||||
覆盖它的缩放图片:
|
||||
|
||||
用压缩后的镜像覆盖它:
|
||||
|
||||
```
|
||||
# cd $D/$VM
|
||||
# mv $VM.new.image $VM.qcow2
|
||||
```
|
||||
|
||||
##### 创建一个 cloud-init ISO
|
||||
#### 创建一个 cloud-init ISO
|
||||
|
||||
```
|
||||
# mkisofs -o $VM-cidata.iso -V cidata -J -r user-data meta-data
|
||||
```
|
||||
|
||||
`# mkisofs -o $VM-cidata.iso -V cidata -J -r user-data meta-data`
|
||||
[![Creating a cloud-init ISO][14]][14]
|
||||
|
||||
##### 创建一个 pool
|
||||
#### 创建一个池
|
||||
|
||||
```
|
||||
# virsh pool-create-as --name $VM --type dir --target $D/$VM
|
||||
Pool centos7-vm1 created
|
||||
```
|
||||
|
||||
##### 安装 CentOS 7 虚拟机
|
||||
#### 安装 CentOS 7 虚拟机
|
||||
|
||||
```
|
||||
# cd $D/$VM
|
||||
@ -247,23 +298,31 @@ Pool centos7-vm1 created
|
||||
--graphics spice \
|
||||
--noautoconsole
|
||||
```
|
||||
|
||||
删除不需要的文件:
|
||||
|
||||
```
|
||||
# cd $D/$VM
|
||||
# virsh change-media $VM hda --eject --config
|
||||
# rm meta-data user-data centos7-vm1-cidata.iso
|
||||
```
|
||||
|
||||
##### 查找虚拟机的 IP 地址
|
||||
#### 查找虚拟机的 IP 地址
|
||||
|
||||
`# virsh net-dhcp-leases default`
|
||||
```
|
||||
# virsh net-dhcp-leases default
|
||||
```
|
||||
|
||||
[![CentOS7-VM1- Created][15]][15]
|
||||
|
||||
##### 登录到你的虚拟机
|
||||
#### 登录到你的虚拟机
|
||||
|
||||
使用 ssh 命令:
|
||||
|
||||
```
|
||||
# ssh vivek@192.168.122.85
|
||||
```
|
||||
|
||||
使用 ssh 命令:
|
||||
`# ssh vivek@192.168.122.85`
|
||||
[![Sample VM session][16]][16]
|
||||
|
||||
### 有用的命令
|
||||
@ -272,7 +331,9 @@ Pool centos7-vm1 created
|
||||
|
||||
#### 列出所有虚拟机
|
||||
|
||||
`# virsh list --all`
|
||||
```
|
||||
# virsh list --all
|
||||
```
|
||||
|
||||
#### 获取虚拟机信息
|
||||
|
||||
@ -283,21 +344,33 @@ Pool centos7-vm1 created
|
||||
|
||||
#### 停止/关闭虚拟机
|
||||
|
||||
`# virsh shutdown centos7-vm1`
|
||||
```
|
||||
# virsh shutdown centos7-vm1
|
||||
```
|
||||
|
||||
#### 开启虚拟机
|
||||
|
||||
`# virsh start centos7-vm1`
|
||||
```
|
||||
# virsh start centos7-vm1
|
||||
```
|
||||
|
||||
#### 将虚拟机标记为在引导时自动启动
|
||||
|
||||
`# virsh autostart centos7-vm1`
|
||||
```
|
||||
# virsh autostart centos7-vm1
|
||||
```
|
||||
|
||||
#### 重新启动(软安全重启)虚拟机
|
||||
|
||||
`# virsh reboot centos7-vm1`
|
||||
```
|
||||
# virsh reboot centos7-vm1
|
||||
```
|
||||
|
||||
重置(硬重置/不安全)虚拟机
|
||||
`# virsh reset centos7-vm1`
|
||||
|
||||
```
|
||||
# virsh reset centos7-vm1
|
||||
```
|
||||
|
||||
#### 删除虚拟机
|
||||
|
||||
@ -309,7 +382,9 @@ Pool centos7-vm1 created
|
||||
# VM=centos7-vm1
|
||||
# rm -ri $D/$VM
|
||||
```
|
||||
查看 virsh 命令类型的完整列表
|
||||
|
||||
查看 virsh 命令类型的完整列表:
|
||||
|
||||
```
|
||||
# virsh help | less
|
||||
# virsh help | grep reboot
|
||||
@ -321,11 +396,11 @@ Pool centos7-vm1 created
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: [https://www.cyberciti.biz/faq/how-to-install-kvm-on-centos-7-rhel-7-headless-server/](https://www.cyberciti.biz/faq/how-to-install-kvm-on-centos-7-rhel-7-headless-server/)
|
||||
via: https://www.cyberciti.biz/faq/how-to-install-kvm-on-centos-7-rhel-7-headless-server/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,85 +1,85 @@
|
||||
du 及 df 命令的使用(附带示例)
|
||||
======
|
||||
在本文中,我将讨论 du 和 df 命令。du 和 df 命令都是 Linux 系统的重要工具,来显示 Linux 文件系统的磁盘使用情况。这里我们将通过一些例子来分享这两个命令的用法。
|
||||
|
||||
**(推荐阅读:[使用 scp 和 rsync 命令传输文件][1])**
|
||||
在本文中,我将讨论 `du` 和 `df` 命令。`du` 和 `df` 命令都是 Linux 系统的重要工具,来显示 Linux 文件系统的磁盘使用情况。这里我们将通过一些例子来分享这两个命令的用法。
|
||||
|
||||
**(另请阅读:[使用 dd 和 cat 命令为 Linux 系统克隆磁盘][2])**
|
||||
- **(推荐阅读:[使用 scp 和 rsync 命令传输文件][1])**
|
||||
- **(另请阅读:[使用 dd 和 cat 命令为 Linux 系统克隆磁盘][2])**
|
||||
|
||||
### du 命令
|
||||
|
||||
du(disk usage 的简称)是用于查找文件和目录的磁盘使用情况的命令。du 命令在与各种选项一起使用时能以多种格式提供结果。
|
||||
`du`(disk usage 的简称)是用于查找文件和目录的磁盘使用情况的命令。`du` 命令在与各种选项一起使用时能以多种格式提供结果。
|
||||
|
||||
下面是一些例子:
|
||||
|
||||
**1- 得到一个目录下所有子目录的磁盘使用概况**
|
||||
#### 1、 得到一个目录下所有子目录的磁盘使用概况
|
||||
|
||||
```
|
||||
$ du /home
|
||||
$ du /home
|
||||
```
|
||||
|
||||
![du command][4]
|
||||
|
||||
该命令的输出将显示 /home 中的所有文件和目录以及显示块大小。
|
||||
该命令的输出将显示 `/home` 中的所有文件和目录以及显示块大小。
|
||||
|
||||
**2- 以人类可读格式也就是 kb、mb 等显示文件/目录大小**
|
||||
#### 2、 以人类可读格式也就是 kb、mb 等显示文件/目录大小
|
||||
|
||||
```
|
||||
$ du -h /home
|
||||
$ du -h /home
|
||||
```
|
||||
|
||||
![du command][6]
|
||||
|
||||
**3- 目录的总磁盘大小**
|
||||
#### 3、 目录的总磁盘大小
|
||||
|
||||
```
|
||||
$ du -s /home
|
||||
$ du -s /home
|
||||
```
|
||||
|
||||
![du command][8]
|
||||
|
||||
它是 /home 目录的总大小
|
||||
它是 `/home` 目录的总大小
|
||||
|
||||
### df 命令
|
||||
|
||||
df(disk filesystem 的简称)用于显示 Linux 系统的磁盘利用率。
|
||||
df(disk filesystem 的简称)用于显示 Linux 系统的磁盘利用率。(LCTT 译注:`df` 可能应该是 disk free 的简称。)
|
||||
|
||||
下面是一些例子。
|
||||
|
||||
**1- 显示设备名称、总块数、总磁盘空间、已用磁盘空间、可用磁盘空间和文件系统上的挂载点。**
|
||||
#### 1、 显示设备名称、总块数、总磁盘空间、已用磁盘空间、可用磁盘空间和文件系统上的挂载点。
|
||||
|
||||
```
|
||||
$ df
|
||||
$ df
|
||||
```
|
||||
|
||||
|
||||
![df command][10]
|
||||
|
||||
**2- 人类可读格式的信息**
|
||||
#### 2、 人类可读格式的信息
|
||||
|
||||
```
|
||||
$ df -h
|
||||
$ df -h
|
||||
```
|
||||
|
||||
![df command][12]
|
||||
|
||||
上面的命令以人类可读格式显示信息。
|
||||
|
||||
**3- 显示特定分区的信息**
|
||||
#### 3、 显示特定分区的信息
|
||||
|
||||
```
|
||||
$ df -hT /etc
|
||||
$ df -hT /etc
|
||||
```
|
||||
|
||||
![df command][14]
|
||||
|
||||
-hT 加上目标目录将以可读格式显示 /etc 的信息。
|
||||
`-hT` 加上目标目录将以可读格式显示 `/etc` 的信息。
|
||||
|
||||
虽然 du 和 df 命令有更多选项,但是这些例子可以让你初步了解。如果在这里找不到你要找的东西,那么你可以参考有关命令的 man 页面。
|
||||
虽然 `du` 和 `df` 命令有更多选项,但是这些例子可以让你初步了解。如果在这里找不到你要找的东西,那么你可以参考有关命令的 man 页面。
|
||||
|
||||
另外,[**在这**][15]阅读我的其他帖子,在那里我分享了一些其他重要和经常使用的 Linux 命令。
|
||||
|
||||
如往常一样,你的评论和疑问是受欢迎的,因此在下面留下你的评论和疑问,我会回复你。
|
||||
如往常一样,欢迎你留下评论和疑问,因此在下面留下你的评论和疑问,我会回复你。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -87,7 +87,7 @@ via: http://linuxtechlab.com/du-df-commands-examples/
|
||||
|
||||
作者:[SHUSAIN][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
136
published/20180131 10 things I love about Vue.md
Normal file
136
published/20180131 10 things I love about Vue.md
Normal file
@ -0,0 +1,136 @@
|
||||
我喜欢 Vue 的 10 个方面
|
||||
============================================================
|
||||
|
||||
|
||||
|
||||
我喜欢 Vue。当我在 2016 年第一次接触它时,也许那时我已经对 JavaScript 框架感到疲劳了,因为我已经具有Backbone、Angular、React 等框架的经验,没有太多的热情去尝试一个新的框架。直到我在 Hacker News 上读到一份评论,其描述 Vue 是类似于“新 jQuery” 的 JavaScript 框架,从而激发了我的好奇心。在那之前,我已经相当满意 React 这个框架,它是一个很好的框架,建立于可靠的设计原则之上,围绕着视图模板、虚拟 DOM 和状态响应等技术。而 Vue 也提供了这些重要的内容。
|
||||
|
||||
在这篇文章中,我旨在解释为什么 Vue 适合我,为什么在上文中那些我尝试过的框架中选择它。也许你将同意我的一些观点,但至少我希望能够给大家使用 Vue 开发现代 JavaScript 应用一些灵感。
|
||||
|
||||
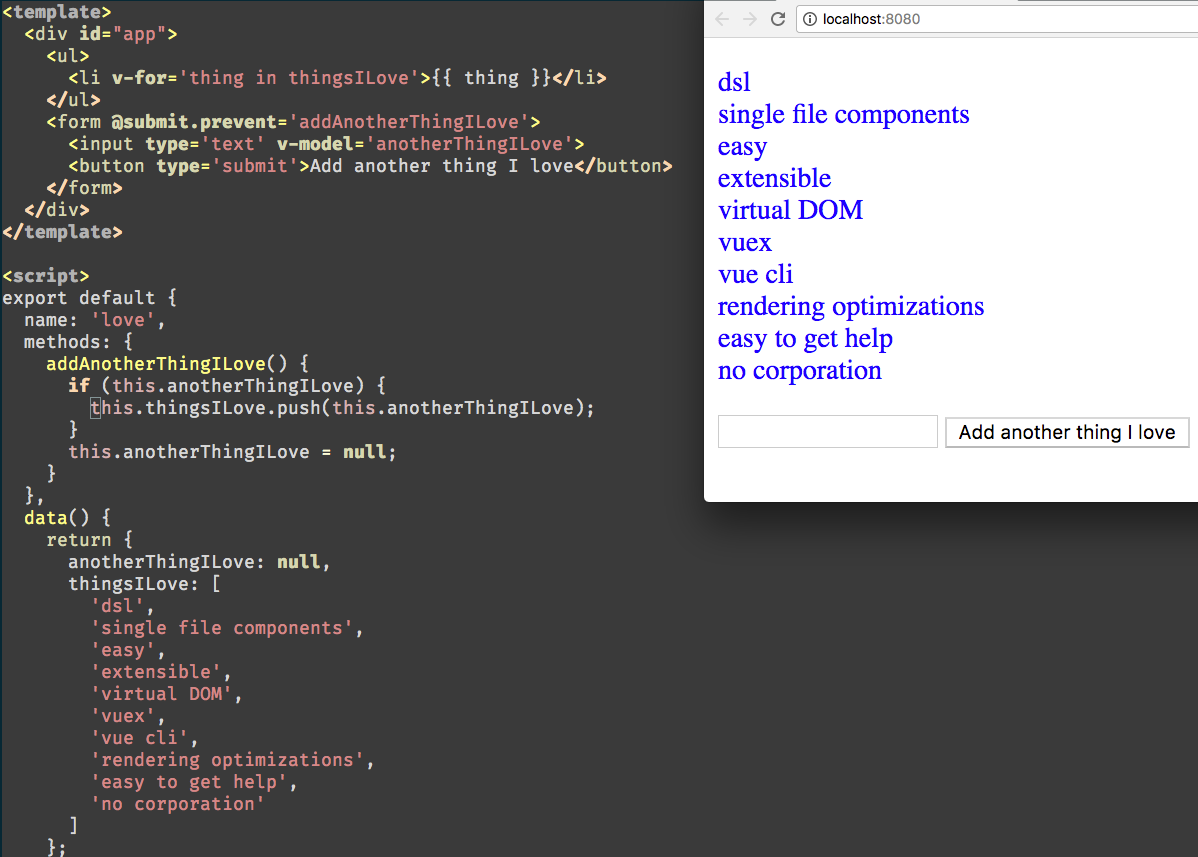
### 1、 极少的模板语法
|
||||
|
||||
Vue 默认提供的视图模板语法是极小的、简洁的和可扩展的。像其他 Vue 部分一样,可以很简单的使用类似 JSX 一样语法,而不使用标准的模板语法(甚至有官方文档说明了如何做),但是我觉得没必要这么做。JSX 有好的方面,也有一些有依据的批评,如混淆了 JavaScript 和 HTML,使得很容易导致在模板中出现复杂的代码,而本来应该分开写在不同的地方的。
|
||||
|
||||
Vue 没有使用标准的 HTML 来编写视图模板,而是使用极少的模板语法来处理简单的事情,如基于视图数据迭代创建元素。
|
||||
|
||||
```
|
||||
<template>
|
||||
<div id="app">
|
||||
<ul>
|
||||
<li v-for='number in numbers' :key='number'>{{ number }}</li>
|
||||
</ul>
|
||||
<form @submit.prevent='addNumber'>
|
||||
<input type='text' v-model='newNumber'>
|
||||
<button type='submit'>Add another number</button>
|
||||
</form>
|
||||
</div>
|
||||
</template>
|
||||
|
||||
<script>
|
||||
export default {
|
||||
name: 'app',
|
||||
methods: {
|
||||
addNumber() {
|
||||
const num = +this.newNumber;
|
||||
if (typeof num === 'number' && !isNaN(num)) {
|
||||
this.numbers.push(num);
|
||||
}
|
||||
}
|
||||
},
|
||||
data() {
|
||||
return {
|
||||
newNumber: null,
|
||||
numbers: [1, 23, 52, 46]
|
||||
};
|
||||
}
|
||||
}
|
||||
</script>
|
||||
|
||||
<style lang="scss">
|
||||
ul {
|
||||
padding: 0;
|
||||
li {
|
||||
list-style-type: none;
|
||||
color: blue;
|
||||
}
|
||||
}
|
||||
</style>
|
||||
```
|
||||
|
||||
|
||||
我也喜欢 Vue 提供的简短绑定语法,`:` 用于在模板中绑定数据变量,`@` 用于绑定事件。这是一个细节,但写起来很爽而且能够让你的组件代码简洁。
|
||||
|
||||
### 2、 单文件组件
|
||||
|
||||
大多数人使用 Vue,都使用“单文件组件”。本质上就是一个 .vue 文件对应一个组件,其中包含三部分(CSS、HTML和JavaScript)。
|
||||
|
||||
这种技术结合是对的。它让人很容易在一个单独的地方了解每个组件,同时也非常好的鼓励了大家保持每个组件代码的简短。如果你的组件中 JavaScript、CSS 和 HTML 代码占了很多行,那么就到了进一步模块化的时刻了。
|
||||
|
||||
在使用 Vue 组件中的 `<style>` 标签时,我们可以添加 `scoped` 属性。这会让整个样式完全的封装到当前组件,意思是在组件中如果我们写了 `.name` 的 css 选择器,它不会把样式应用到其他组件中。我非常喜欢这种方式来应用样式而不是像其他主要框架流行在 JS 中编写 CSS 的方式。
|
||||
|
||||
关于单文件组件另一个好处是 .vue 文件实际上是一个有效的 HTML 5 文件。`<template>`、 `<script>`、 `<style>` 都是 w3c 官方规范的标签。这就表示很多如 linters (LCTT 译注:一种代码检查工具插件)这样我们用于开发过程中的工具能够开箱即用或者添加一些适配后使用。
|
||||
|
||||
### 3、 Vue “新的 jQuery”
|
||||
|
||||
事实上,这两个库不相似而且用于做不同的事。让我提供给你一个很精辟的类比(我实际上非常喜欢描述 Vue 和 jQuery 之间的关系):披头士乐队和齐柏林飞船乐队(LCTT 译注:两个都是英国著名的乐队)。披头士乐队不需要介绍,他们是 20 世纪 60 年代最大的和最有影响力的乐队。但很难说披头士乐队是 20 世纪 70 年代最大的乐队,因为有时这个荣耀属于是齐柏林飞船乐队。你可以说两个乐队之间有着微妙的音乐联系或者说他们的音乐是明显不同的,但两者一些先前的艺术和影响力是不可否认的。也许 21 世纪初 JavaScript 的世界就像 20 世纪 70 年代的音乐世界一样,随着 Vue 获得更多关注使用,只会吸引更多粉丝。
|
||||
|
||||
一些使 jQuery 牛逼的哲学理念在 Vue 中也有呈现:非常容易的学习曲线但却具有基于现代 web 标准构建牛逼 web 应用所有你需要的功能。Vue 的核心本质上就是在 JavaScript 对象上包装了一层。
|
||||
|
||||
### 4、 极易扩展
|
||||
|
||||
正如前述,Vue 默认使用标准的 HTML、JS 和 CSS 构建组件,但可以很容易插入其他技术。如果我们想使用pug(LCTT译注:一款功能丰富的模板引擎,专门为 Node.js 平台开发)替换 HTML 或者使用 Typescript(LCTT译注:一种由微软开发的编程语言,是 JavaScript 的一个超集)替换 js 或者 Sass (LCTT 译注:一种 CSS 扩展语言)替换 CSS,只需要安装相关的 node 模块和在我们的单文件组件中添加一个属性到相关的标签即可。你甚至可以在一个项目中混合搭配使用 —— 如一些组件使用 HTML 其他使用 pug ——然而我不太确定这么做是最好的做法。
|
||||
|
||||
### 5、 虚拟 DOM
|
||||
|
||||
虚拟 DOM 是很好的技术,被用于现如今很多框架。其意味着这些框架能够做到根据我们状态的改变来高效的完成 DOM 更新,减少重新渲染,从而优化我们应用的性能。现如今每个框架都有虚拟 DOM 技术,所以虽然它不是什么独特的东西,但它仍然很出色。
|
||||
|
||||
### 6、 Vuex 很棒
|
||||
|
||||
对于大多数应用,管理状态成为一个棘手的问题,单独使用一个视图库不能解决这个问题。Vue 使用 Vuex 库来解决这个问题。Vuex 很容易构建而且和 Vue 集成的很好。熟悉 redux(另一个管理状态的库)的人学习 Vuex 会觉得轻车熟路,但是我发现 Vue 和 Vuex 集成起来更加简洁。最新 JavaScript 草案中(LCTT 译注:应该是指 ES7)提供了对象展开运算符(LCTT 译注:符号为 `...`),允许我们在状态或函数中进行合并,以操纵从 Vuex 到需要它的 Vue 组件中的状态。
|
||||
|
||||
### 7、 Vue 的命令行界面(CLI)
|
||||
|
||||
Vue 提供的命令行界面非常不错,很容易用 Vue 搭建一个基于 Webpack(LCTT 译注:一个前端资源加载/打包工具)的项目。单文件组件支持、babel(LCTT 译注:js 语法转换器)、linting(LCTT译注:代码检查工具)、测试工具支持,以及合理的项目结构,都可以在终端中一行命令创建。
|
||||
|
||||
然而有一个命令,我在 CLI 中没有找到,那就是 `vue build`。
|
||||
|
||||
> 如:
|
||||
> ```
|
||||
echo '<template><h1>Hello World!</h1></template>' > Hello.vue && vue build Hello.vue -o
|
||||
```
|
||||
|
||||
`vue build` 命令构建和运行组件并在浏览器中测试看起来非常简单。很不幸这个命令后来在 Vue 中删除了,现在推荐使用 Poi。Poi 本质上是在 Webpack 工具上封装了一层,但我不认我它像推特上说的那样简单。
|
||||
|
||||
### 8、 重新渲染优化
|
||||
|
||||
使用 Vue,你不必手动声明 DOM 的哪部分应该被重新渲染。我从来都不喜欢操纵 React 组件的渲染,像在`shouldComponentUpdate` 方法中停止整个 DOM 树重新渲染这种。Vue 在这方面非常巧妙。
|
||||
|
||||
### 9、 容易获得帮助
|
||||
|
||||
Vue 已经达到了使用这个框架来构建各种各样的应用的一种群聚效应。开发文档非常完善。如果你需要进一步的帮助,有多种渠道可用,每个渠道都有很多活跃开发者:stackoverflow、discord、twitter 等。相对于其他用户量少的框架,这就应该给你更多的信心来使用Vue构建应用。
|
||||
|
||||
### 10、 多机构维护
|
||||
|
||||
我认为,一个开源库,在发展方向方面的投票权利没有被单一机构操纵过多,是一个好事。就如同 React 的许可证问题(现已解决),Vue 就不可能涉及到。
|
||||
|
||||
总之,作为你接下来要开发的任何 JavaScript 项目,我认为 Vue 都是一个极好的选择。Vue 可用的生态圈比我博客中涉及到的其他库都要大。如果想要更全面的产品,你可以关注 Nuxt.js。如果你需要一些可重复使用的样式组件你可以关注类似 Vuetify 的库。
|
||||
|
||||
Vue 是 2017 年增长最快的库之一,我预测在 2018 年增长速度不会放缓。
|
||||
|
||||
如果你有空闲的 30 分钟,为什么不尝试下 Vue,看它可以给你提供什么呢?
|
||||
|
||||
P.S. — 这篇文档很好的展示了 Vue 和其他框架的比较:[https://vuejs.org/v2/guide/comparison.html][1]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.com/@dalaidunc/10-things-i-love-about-vue-505886ddaff2
|
||||
|
||||
作者:[Duncan Grant][a]
|
||||
译者:[yizhuoyan](https://github.com/yizhuoyan)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.com/@dalaidunc
|
||||
[1]:https://vuejs.org/v2/guide/comparison.html
|
||||
@ -1,18 +1,18 @@
|
||||
如何检查你的 Linux PC 是否存在 Meltdown 或者 Spectre 漏洞
|
||||
如何检查你的 Linux 系统是否存在 Meltdown 或者 Spectre 漏洞
|
||||
======
|
||||
|
||||

|
||||
|
||||
Meltdown 和 Specter 漏洞的最恐怖的现实之一是它们涉及非常广泛。几乎每台现代计算机都会受到一些影响。真正的问题是_你_是否受到了影响?每个系统都处于不同的脆弱状态,具体取决于已经或者还没有打补丁的软件。
|
||||
|
||||
由于 Meltdown 和 Spectre 都是相当新的,并且事情正在迅速发展,所以告诉你需要注意什么或在系统上修复了什么并非易事。有一些工具可以提供帮助。它们并不完美,但它们可以帮助你找出你需要知道的东西。
|
||||
由于 Meltdown 和 Spectre 都是相当新的漏洞,并且事情正在迅速发展,所以告诉你需要注意什么或在系统上修复了什么并非易事。有一些工具可以提供帮助。它们并不完美,但它们可以帮助你找出你需要知道的东西。
|
||||
|
||||
### 简单测试
|
||||
|
||||
顶级的 Linux 内核开发人员之一提供了一种简单的方式来检查系统在 Meltdown 和 Specter 漏洞方面的状态。它是简单的,也是最简洁的,但它不适用于每个系统。有些发行版不支持它。即使如此,也值得一试。
|
||||
|
||||
```
|
||||
grep . /sys/devices/system/cpu/vulnerabilities/*
|
||||
|
||||
```
|
||||
|
||||
![Kernel Vulnerability Check][1]
|
||||
@ -24,24 +24,24 @@ grep . /sys/devices/system/cpu/vulnerabilities/*
|
||||
如果上面的方法不适合你,或者你希望看到更详细的系统报告,一位开发人员已创建了一个 shell 脚本,它将检查你的系统来查看系统收到什么漏洞影响,还有做了什么来减轻 Meltdown 和 Spectre 的影响。
|
||||
|
||||
要得到脚本,请确保你的系统上安装了 Git,然后将脚本仓库克隆到一个你不介意运行它的目录中。
|
||||
|
||||
```
|
||||
cd ~/Downloads
|
||||
git clone https://github.com/speed47/spectre-meltdown-checker.git
|
||||
|
||||
```
|
||||
|
||||
这不是一个大型仓库,所以它应该只需要几秒钟就克隆完成。完成后,输入新创建的目录并运行提供的脚本。
|
||||
|
||||
```
|
||||
cd spectre-meltdown-checker
|
||||
./spectre-meltdown-checker.sh
|
||||
|
||||
```
|
||||
|
||||
你会在中断看到很多输出。别担心,它不是太难查看。首先,脚本检查你的硬件,然后运行三个漏洞:Specter v1、Spectre v2 和 Meltdown。每个漏洞都有自己的部分。在这之间,脚本明确地告诉你是否受到这三个漏洞的影响。
|
||||
你会在终端看到很多输出。别担心,它不是太难理解。首先,脚本检查你的硬件,然后运行三个漏洞检查:Specter v1、Spectre v2 和 Meltdown。每个漏洞都有自己的部分。在这之间,脚本明确地告诉你是否受到这三个漏洞的影响。
|
||||
|
||||
![Meltdown Spectre Check Script Ubuntu][2]
|
||||
|
||||
每个部分为你提供潜在的可用的缓解方案,以及它们是否已被应用。这里需要你的一点常识。它给出的决定可能看起来有冲突。研究一下,看看它所说的修复是否实际上完全缓解了这个问题。
|
||||
每个部分为你提供了潜在的可用的缓解方案,以及它们是否已被应用。这里需要你的一点常识。它给出的决定可能看起来有冲突。研究一下,看看它所说的修复是否实际上完全缓解了这个问题。
|
||||
|
||||
### 这意味着什么
|
||||
|
||||
@ -53,7 +53,7 @@ via: https://www.maketecheasier.com/check-linux-meltdown-spectre-vulnerability/
|
||||
|
||||
作者:[Nick Congleton][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,61 @@
|
||||
LKRG:用于运行时完整性检查的可加载内核模块
|
||||
======
|
||||
![LKRG logo][1]
|
||||
|
||||
开源社区的人们正在致力于一个 Linux 内核的新项目,它可以让内核更安全。命名为 Linux 内核运行时防护(Linux Kernel Runtime Guard,简称:LKRG),它是一个在 Linux 内核执行运行时完整性检查的可加载内核模块(LKM)。
|
||||
|
||||
它的用途是检测对 Linux 内核的已知的或未知的安全漏洞利用企图,以及去阻止这种攻击企图。
|
||||
|
||||
LKRG 也可以检测正在运行的进程的提权行为,在漏洞利用代码运行之前杀掉这个运行进程。
|
||||
|
||||
### 这个项目开发始于 2011 年,首个版本已经发布
|
||||
|
||||
因为这个项目开发的较早,LKRG 的当前版本仅仅是通过内核消息去报告违反内核完整性的行为,但是随着这个项目的成熟,将会部署一个完整的漏洞利用缓减系统。
|
||||
|
||||
LKRG 的成员 Alexander Peslyak 解释说,这个项目从 2011 年启动,并且 LKRG 已经经历了一个“重新开发"阶段。
|
||||
|
||||
LKRG 的首个公开版本是 LKRG v0.0,它现在可以从 [这个页面][2] 下载使用。[这里][3] 是这个项目的维基,为支持这个项目,它也有一个 [Patreon 页面][4]。
|
||||
|
||||
虽然 LKRG 仍然是一个开源项目,LKRG 的维护者也计划做一个 LKRG Pro 版本,这个版本将包含一个专用的 LKRG 发行版,它将支持对特定漏洞利用的检测,比如,容器泄漏。开发团队计划从 LKRG Pro 基金中提取部分资金用于保证项目的剩余工作。
|
||||
|
||||
### LKRG 是一个内核模块而不是一个补丁。
|
||||
|
||||
一个类似的项目是<ruby>附加内核监视器<rt>Additional Kernel Observer</rt></ruby>(AKO),但是 LKRG 与 AKO 是不一样的,因为 LKRG 是一个内核加载模块而不是一个补丁。LKRG 开发团队决定将它设计为一个内核模块是因为,在内核上打补丁对安全性、系统稳定性以及性能都有很直接的影响。
|
||||
|
||||
而以内核模块的方式提供,可以在每个系统上更容易部署 LKRG,而不必去修改核心的内核代码,修改核心的内核代码非常复杂并且很容易出错。
|
||||
|
||||
LKRG 内核模块在目前主流的 Linux 发行版上都可以使用,比如,RHEL7、OpenVZ 7、Virtuozzo 7、以及 Ubuntu 16.04 到最新的主线版本。
|
||||
|
||||
### 它并非是一个完美的解决方案
|
||||
|
||||
LKRG 的创建者警告用户,他们并不认为 LKRG 是一个完美的解决方案,它**提供不了**坚不可摧和 100% 的安全。他们说,LKRG 是 “设计为**可旁通**的”,并且仅仅提供了“多元化安全” 的**一个**方面。
|
||||
|
||||
> 虽然 LKRG 可以防御许多已有的 Linux 内核漏洞利用,而且也有可能会防御将来许多的(包括未知的)未特意设计去绕过 LKRG 的安全漏洞利用。它是设计为可旁通的(尽管有时候是以更复杂和/或低可利用为代价的)。因此,他们说 LKRG 通过多元化提供安全,就像运行一个不常见的操作系统内核一样,也就不会有真实运行一个不常见的操作系统的可用性弊端。
|
||||
|
||||
LKRG 有点像基于 Windows 的防病毒软件,它也是工作于内核级别去检测漏洞利用和恶意软件。但是,LKRG 团队说,他们的产品比防病毒软件以及其它终端安全软件更加安全,因为它的基础代码量比较小,所以在内核级别引入新 bug 和漏洞的可能性就更小。
|
||||
|
||||
### 运行当前版本的 LKRG 大约会带来 6.5% 的性能损失
|
||||
|
||||
Peslyak 说 LKRG 是非常适用于 Linux 机器的,它在修补内核的安全漏洞后不需要重启动机器。LKRG 允许用户持续运行带有安全措施的机器,直到在一个计划的维护窗口中测试和部署关键的安全补丁为止。
|
||||
|
||||
经测试显示,安装 LKRG v0.0 后大约会产生 6.5% 性能影响,但是,Peslyak 说将在后续的开发中持续降低这种影响。
|
||||
|
||||
测试也显示,LKRG 检测到了 CVE-2014-9322 (BadIRET)、CVE-2017-5123 (waitid(2) missing access_ok)、以及 CVE-2017-6074 (use-after-free in DCCP protocol) 的漏洞利用企图,但是没有检测到 CVE-2016-5195 (Dirty COW) 的漏洞利用企图。开发团队说,由于前面提到的“可旁通”的设计策略,LKRG 没有检测到 Dirty COW 提权攻击。
|
||||
|
||||
> 在 Dirty COW 的测试案例中,由于 bug 机制的原因,使得 LKRG 发生了 “旁通”,并且这也是一种利用方法,它也是将来类似的以用户空间为目标的绕过 LKRG 的一种方法。这样的漏洞利用是否会是普通情况(不太可能!除非 LKRG 或者类似机制的软件流行起来),以及对它的可用性的(负面的)影响是什么?(对于那些直接目标是用户空间的内核漏洞来说,这不太重要,也并不简单)。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.bleepingcomputer.com/news/linux/lkrg-linux-to-get-a-loadable-kernel-module-for-runtime-integrity-checking/
|
||||
|
||||
作者:[Catalin Cimpanu][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.bleepingcomputer.com/author/catalin-cimpanu/
|
||||
[1]:https://www.bleepstatic.com/content/posts/2018/02/04/LKRG-logo.png
|
||||
[2]:http://www.openwall.com/lkrg/
|
||||
[3]:http://openwall.info/wiki/p_lkrg/Main
|
||||
[4]:https://www.patreon.com/p_lkrg
|
||||
@ -1,113 +1,113 @@
|
||||
Python 中的 Hello World 和字符串操作
|
||||
初识 Python:Hello World 和字符串操作
|
||||
======
|
||||
|
||||
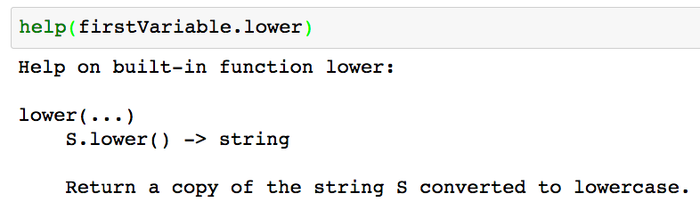
|
||||
|
||||
开始之前,说一下本文中的[代码][1]和[视频][2]可以在我的 github 上找到。
|
||||
开始之前,说一下本文中的[代码][1]和[视频][2]可以在我的 GitHub 上找到。
|
||||
|
||||
那么,让我们开始吧!如果你糊涂了,我建议你在单独的选项卡中打开下面的[视频][3]。
|
||||
那么,让我们开始吧!如果你糊涂了,我建议你在单独的选项卡中打开下面的视频。
|
||||
|
||||
[Python 的 Hello World 和字符串操作视频][2]
|
||||
- [Python 的 Hello World 和字符串操作视频][2]
|
||||
|
||||
#### ** 开始 (先决条件)
|
||||
### 开始 (先决条件)
|
||||
|
||||
在你的操作系统上安装 Anaconda(Python)。你可以从[官方网站][4]下载 anaconda 并自行安装,或者你可以按照以下这些 anaconda 安装教程进行安装。
|
||||
首先在你的操作系统上安装 Anaconda (Python)。你可以从[官方网站][4]下载 anaconda 并自行安装,或者你可以按照以下这些 anaconda 安装教程进行安装。
|
||||
|
||||
在 Windows 上安装 Anaconda: [链接[5]
|
||||
- 在 Windows 上安装 Anaconda: [链接[5]
|
||||
- 在 Mac 上安装 Anaconda: [链接][6]
|
||||
- 在 Ubuntu (Linux) 上安装 Anaconda:[链接][7]
|
||||
|
||||
在 Mac 上安装 Anaconda: [链接][6]
|
||||
|
||||
在 Ubuntu (Linux) 上安装 Anaconda:[链接][7]
|
||||
|
||||
#### 打开一个 Jupyter Notebook
|
||||
### 打开一个 Jupyter Notebook
|
||||
|
||||
打开你的终端(Mac)或命令行,并输入以下内容([请参考视频中的 1:16 处][8])来打开 Jupyter Notebook:
|
||||
|
||||
```
|
||||
jupyter notebook
|
||||
|
||||
```
|
||||
|
||||
#### 打印语句/Hello World
|
||||
### 打印语句/Hello World
|
||||
|
||||
在 Jupyter 的单元格中输入以下内容并按下 `shift + 回车`来执行代码。
|
||||
|
||||
在 Jupyter 的单元格中输入以下内容并按下 **shift + 回车**来执行代码。
|
||||
```
|
||||
# This is a one line comment
|
||||
print('Hello World!')
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
打印输出 “Hello World!”
|
||||

|
||||
|
||||
#### 字符串和字符串操作
|
||||
*打印输出 “Hello World!”*
|
||||
|
||||
### 字符串和字符串操作
|
||||
|
||||
字符串是 Python 类的一种特殊类型。作为对象,在类中,你可以使用 `.methodName()` 来调用字符串对象的方法。字符串类在 Python 中默认是可用的,所以你不需要 `import` 语句来使用字符串对象接口。
|
||||
|
||||
字符串是 python 类的一种特殊类型。作为对象,在类中,你可以使用 .methodName() 来调用字符串对象的方法。字符串类在 python 中默认是可用的,所以你不需要 import 语句来使用字符串对象接口。
|
||||
```
|
||||
# Create a variable
|
||||
# Variables are used to store information to be referenced
|
||||
# and manipulated in a computer program.
|
||||
firstVariable = 'Hello World'
|
||||
print(firstVariable)
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
输出打印变量 firstVariable
|
||||
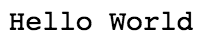
|
||||
|
||||
*输出打印变量 firstVariable*
|
||||
|
||||
```
|
||||
# Explore what various string methods
|
||||
print(firstVariable.lower())
|
||||
print(firstVariable.upper())
|
||||
print(firstVariable.title())
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
使用 .lower()、.upper() 和 title() 方法输出
|
||||

|
||||
|
||||
*使用 .lower()、.upper() 和 title() 方法输出*
|
||||
|
||||
```
|
||||
# Use the split method to convert your string into a list
|
||||
print(firstVariable.split(' '))
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
使用 split 方法输出(此例中以空格分隔)
|
||||
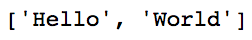
|
||||
|
||||
*使用 split 方法输出(此例中以空格分隔)*
|
||||
|
||||
```
|
||||
# You can add strings together.
|
||||
a = "Fizz" + "Buzz"
|
||||
print(a)
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
字符串连接
|
||||
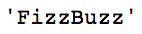
|
||||
|
||||
#### 查询方法的功能
|
||||
*字符串连接*
|
||||
|
||||
### 查询方法的功能
|
||||
|
||||
对于新程序员,他们经常问你如何知道每种方法的功能。Python 提供了两种方法来实现。
|
||||
|
||||
1.(在不在 Jupyter Notebook 中都可用)使用 **help** 查询每个方法的功能。
|
||||
1、(在不在 Jupyter Notebook 中都可用)使用 `help` 查询每个方法的功能。
|
||||
|
||||
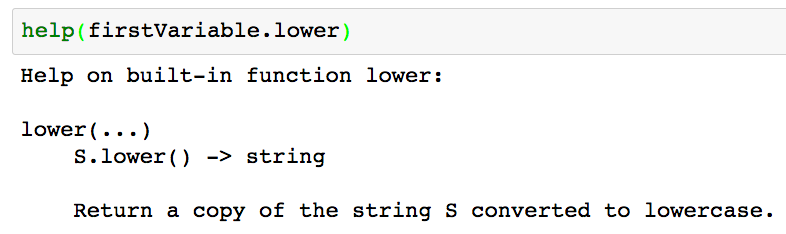
|
||||
|
||||
*查询每个方法的功能*
|
||||
|
||||
![][9]
|
||||
查询每个方法的功能
|
||||
|
||||
2. (Jupyter Notebook exclusive) You can also look up what a method does by having a question mark after a method.
|
||||
2.(Jupyter Notebook 专用)你也可以通过在方法之后添加问号来查找方法的功能。
|
||||
|
||||
2.(Jupyter Notebook 专用)你也可以通过在方法之后添加问号来查找方法的功能。
|
||||
|
||||
```
|
||||
# To look up what each method does in jupyter (doesnt work outside of jupyter)
|
||||
firstVariable.lower?
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
在 Jupyter 中查找每个方法的功能
|
||||
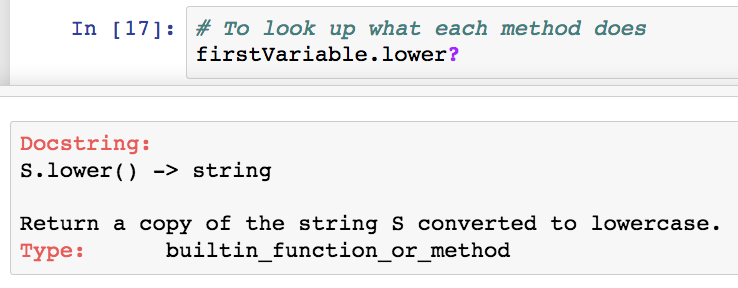
|
||||
|
||||
#### 结束语
|
||||
*在 Jupyter 中查找每个方法的功能*
|
||||
|
||||
如果你对本文或在[ YouTube 视频][2]的评论部分有任何疑问,请告诉我们。文章中的代码也可以在我的 [github][1] 上找到。本系列教程的第 2 部分是[简单的数学操作][10]。
|
||||
### 结束语
|
||||
|
||||
如果你对本文或在 [YouTube 视频][2]的评论部分有任何疑问,请告诉我们。文章中的代码也可以在我的 [GitHub][1] 上找到。本系列教程的第 2 部分是[简单的数学操作][10]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -115,7 +115,7 @@ via: https://www.codementor.io/mgalarny/python-hello-world-and-string-manipulati
|
||||
|
||||
作者:[Michael][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -7,13 +7,13 @@ Linux 新用户?来试试这 8 款重要的软件
|
||||
|
||||
下面这些应用程序大多不是 Linux 独有的。如果有过使用 Windows/Mac 的经验,您很可能会熟悉其中一些软件。根据兴趣和需求,下面的程序可能不全符合您的要求,但是在我看来,清单里大多数甚至全部的软件,对于新用户开启 Linux 之旅都是有帮助的。
|
||||
|
||||
**相关链接** : [每一个 Linux 用户都应该使用的 11 个便携软件][1]
|
||||
**相关链接** : [每一个 Linux 用户都应该使用的 11 个可移植软件][1]
|
||||
|
||||
### 1. Chromium 网页浏览器
|
||||
|
||||
![linux-apps-01-chromium][2]
|
||||
|
||||
很难有一个不需要使用网页浏览器的用户。您可以看到陈旧的 Linux 发行版几乎都会附带 Firefox(火狐浏览器)或者其他 [Linux 浏览器][3],关于浏览器,强烈建议您尝试 [Chromium][4]。它是谷歌浏览器的开源版。Chromium 的主要优点是速度和安全性。它同样拥有大量的附加组件。
|
||||
几乎不会不需要使用网页浏览器的用户。您可以看到陈旧的 Linux 发行版几乎都会附带 Firefox(火狐浏览器)或者其他 [Linux 浏览器][3],关于浏览器,强烈建议您尝试 [Chromium][4]。它是谷歌浏览器的开源版。Chromium 的主要优点是速度和安全性。它同样拥有大量的附加组件。
|
||||
|
||||
### 2. LibreOffice
|
||||
|
||||
@ -21,13 +21,13 @@ Linux 新用户?来试试这 8 款重要的软件
|
||||
|
||||
[LibreOffice][6] 是一个开源办公套件,其包括文字处理(Writer)、电子表格(Calc)、演示(Impress)、数据库(Base)、公式编辑器(Math)、矢量图和流程图(Draw)应用程序。它与 Microsoft Office 文档兼容,如果其基本功能不能满足需求,您可以使用 [LibreOffice 拓展][7]。
|
||||
|
||||
LibreOffice 当然是 Linux 应用中至关重要的一员,如果您使用 Linux 的计算机,安装它是有必要的。
|
||||
LibreOffice 显然是 Linux 应用中至关重要的一员,如果您使用 Linux 的计算机,安装它是有必要的。
|
||||
|
||||
### 3. GIMP(GNU Image Manipulation Program、GUN 图像处理程序)
|
||||
### 3. GIMP(<ruby>GUN 图像处理程序<rt>GNU Image Manipulation Program</rt></ruby>)
|
||||
|
||||
![linux-apps-03-gimp][8]
|
||||
|
||||
[GIMP][9] 是一款非常强大的开源图片处理程序,它类似于 Photoshop。通过 GIMP,您可以编辑或是创建用于 web 或是打印的光栅图(位图)。如果您对专业的图片处理没有概念,Linux 自然提供有更简单的图像编辑器,GIMP 看上去可能会复杂一点。GIMP 并不单纯提供图片裁剪和大小调整,它更覆盖了图层、滤镜、遮罩、路径和其他一些高级功能。
|
||||
[GIMP][9] 是一款非常强大的开源图片处理程序,它类似于 Photoshop。通过 GIMP,您可以编辑或是创建用于 Web 或是打印的光栅图(位图)。如果您对专业的图片处理没有概念,Linux 自然提供有更简单的图像编辑器,GIMP 看上去可能会复杂一点。GIMP 并不单纯提供图片裁剪和大小调整,它更覆盖了图层、滤镜、遮罩、路径和其他一些高级功能。
|
||||
|
||||
### 4. VLC 媒体播放器
|
||||
|
||||
@ -39,15 +39,15 @@ LibreOffice 当然是 Linux 应用中至关重要的一员,如果您使用 Lin
|
||||
|
||||
![linux-apps-05-jitsi][12]
|
||||
|
||||
[Jitsy][13] 完全是关于通讯的。您可以借助它使用 Google talk、Facebook chat、Yahoo、ICQ 和 XMPP。它是用于音视频通话(包括电话会议),桌面流和群组聊天的多用户工具。会话会被加密。Jistsy 同样能帮助您传输文件或记录电话。
|
||||
[Jitsy][13] 完全是关于通讯的。您可以借助它使用 Google talk、Facebook chat、Yahoo、ICQ 和 XMPP。它是用于音视频通话(包括电话会议),<ruby>桌面流<rt>desktop streaming</rt></ruby>和群组聊天的多用户工具。会话会被加密。Jistsy 同样能帮助您传输文件或记录电话。
|
||||
|
||||
### 6. Synaptic
|
||||
|
||||
![linux-apps-06-synaptic][14]
|
||||
|
||||
[Synaptic][15] 是一款基于 Debian 的系统发行版的另一款应用程序安装程序。并不是所有基于 Debian 的 Linux 都安装有它,如果您使用基于 Debian 的 Linux 操作系统没有预装,也许您可以试一试。Synaptic 是一款用于添加或移除系统应用的 GUI 工具,甚至相对于许多发行版默认安装的 [软件中心包管理器][16] ,经验丰富的 Linux 用户更亲睐于 Sunaptic。
|
||||
[Synaptic][15] 是一款基于 Debian 系统发行版的另一款应用程序安装程序。并不是所有基于 Debian 的 Linux 都安装有它,如果您使用基于 Debian 的 Linux 操作系统没有预装,也许您可以试一试。Synaptic 是一款用于添加或移除系统应用的 GUI 工具,甚至相对于许多发行版默认安装的 [软件中心包管理器][16] ,经验丰富的 Linux 用户更亲睐于 Sunaptic。
|
||||
|
||||
**相关链接** : [10 款您没听说过的充当生产力的 Linux 应用程序][17]
|
||||
**相关链接** : [10 款您没听说过的 Linux 生产力应用程序][17]
|
||||
|
||||
### 7. VirtualBox
|
||||
|
||||
@ -59,9 +59,9 @@ LibreOffice 当然是 Linux 应用中至关重要的一员,如果您使用 Lin
|
||||
|
||||
![linux-apps-08-aisleriot][20]
|
||||
|
||||
对于 Linux 的新用户来说,一款纸牌游戏并不是刚需,但是它真的太有趣了。当您进入这款纸牌游戏,您会发现,这是一款极好的纸牌包。[AisleRiot][21] 是 Linux 标志性的应用程序,原因是 - 它涵盖超过八十中纸牌游戏,包括流行的 Klondike、Bakers Dozen、Camelot 等等,这些只是预告片 - 它是会上瘾的,您可能会花很长时间沉迷于此!
|
||||
对于 Linux 的新用户来说,一款纸牌游戏并不是刚需,但是它真的太有趣了。当您进入这款纸牌游戏,您会发现,这是一款极好的纸牌游戏包。[AisleRiot][21] 是 Linux 标志性的应用程序,原因是 - 它涵盖超过八十种纸牌游戏,包括流行的 Klondike、Bakers Dozen、Camelot 等等,作为预警 - 它是会上瘾的,您可能会花很长时间沉迷于此!
|
||||
|
||||
根据您所使用的发行版,这些软件会有不同的安装方法。但是大多数都可以通过您使用的发行版中的包管理器安装使用,甚至它们可能会预装在您的发行版上。安装并且尝试它们想必是最好的,如果不和您的胃口,您可以轻松地删除它们。
|
||||
根据您所使用的发行版,这些软件会有不同的安装方法。但是大多数都可以通过您使用的发行版中的包管理器安装使用,甚至它们可能会预装在您的发行版上。安装并且尝试它们想必是最好的,如果不合您的胃口,您可以轻松地删除它们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -69,7 +69,7 @@ via: https://www.maketecheasier.com/essential-linux-apps/
|
||||
|
||||
作者:[Ada Ivanova][a]
|
||||
译者:[CYLeft](https://github.com/CYLeft)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,49 +1,48 @@
|
||||
开始使用 RStudio IDE
|
||||
RStudio IDE 入门
|
||||
======
|
||||
|
||||
> 用于统计技术的 R 项目是分析数据的有力方式,而 RStudio IDE 则可使这一切更加容易。
|
||||
|
||||

|
||||
|
||||
从我记事起,我就一直在与数字玩耍。作为 20 世纪 70 年代后期的本科生,我开始上统计学的课程,学习如何检查和分析数据以揭示某些意义。
|
||||
从我记事起,我就一直喜欢摆弄数字。作为 20 世纪 70 年代后期的大学生,我上过统计学的课程,学习了如何检查和分析数据以揭示其意义。
|
||||
|
||||
那时候,我有一部科学计算器,它让统计计算变得比以前容易很多。在 90 年代早期,作为一名从事 t 检验,相关性以及 [ANOVA][1] 研究的教育心理学研究生,我开始通过精心编写输入 IBM 主机的文本文件来进行计算。这个主机是对我的手持计算器的一个改进,但是一个小的间距错误会使得整个过程无效,而且这个过程仍然有点乏味。
|
||||
那时候,我有一部科学计算器,它让统计计算变得比以往更容易。在 90 年代早期,作为一名从事 <ruby>t 检验<rt>t-test</rt></ruby>、相关性以及 [ANOVA][1] 研究的教育心理学研究生,我开始通过精心编写输入到 IBM 主机的文本文件来进行计算。这个主机远超我的手持计算器,但是一个小的空格错误就会导致整个过程无效,而且这个过程仍然有点乏味。
|
||||
|
||||
撰写论文时,尤其是我的毕业论文,我需要一种方法能够根据我的数据来创建图表并将它们嵌入到文字处理文档中。我着迷于 Microsoft Excel 及其数字运算能力以及可以用计算结果创建出的大量图表。但每一步都有成本。在 20 世纪 90 年代,除了 Excel,还有其他专有软件包,比如 SAS 和 SPSS+,但对于我那已经满满的研究生时间表来说,学习曲线是一项艰巨的任务。
|
||||
撰写论文时,尤其是我的毕业论文,我需要一种方法能够根据我的数据来创建图表,并将它们嵌入到文字处理文档中。我着迷于 Microsoft Excel 及其数字运算能力以及可以用计算结果创建出的大量图表。但这条路每一步都有成本。在 20 世纪 90 年代,除了 Excel,还有其他专有软件包,比如 SAS 和 SPSS+,但对于我那已经满满的研究生时间表来说,学习曲线是一项艰巨的任务。
|
||||
|
||||
### 快速回到现在
|
||||
|
||||
最近,由于我对数据科学的兴趣浓厚,加上对 Linux 和开源软件的浓厚兴趣,我阅读了大量的数据科学文章,并在 Linux 会议上听了许多数据科学演讲者谈论他们的工作。因此,我开始对编程语言 R(一种开源的统计计算软件)非常感兴趣。
|
||||
最近,由于我对数据科学的兴趣浓厚,加上对 Linux 和开源软件感兴趣,我阅读了大量的数据科学文章,并在 Linux 会议上听了许多数据科学演讲者谈论他们的工作。因此,我开始对编程语言 R(一种开源的统计计算软件)非常感兴趣。
|
||||
|
||||
起初,这只是一个火花。当我和我的朋友 Michael J. Gallagher 博士谈论他如何在他的 [博士论文][2] 研究中使用 R 时,这个火花便增大了。最后,我访问了 [R project][3] 的网站,并了解到我可以轻松地安装 [R for Linux][4]。游戏开始!
|
||||
起初,这只是一个偶发的一个想法。当我和我的朋友 Michael J. Gallagher 博士谈论他如何在他的 [博士论文][2] 研究中使用 R 时,这个火花便增大了。最后,我访问了 [R 项目][3] 的网站,并了解到我可以轻松地安装 [R for Linux][4]。游戏开始!
|
||||
|
||||
### 安装 R
|
||||
|
||||
根据你的操作系统和分布情况,安装 R 会稍有不同。请参阅 [Comprehensive R Archive Network][5] (CRAN) 网站上的安装指南。CRAN 提供了在 [各种 Linux 发行版][6],[Fedora,RHEL,及其衍生版][7],[MacOS][8] 和 [Windows][9] 上的安装指示。
|
||||
根据你的操作系统和发行版情况,安装 R 会稍有不同。请参阅 [Comprehensive R Archive Network][5] (CRAN)网站上的安装指南。CRAN 提供了在 [各种 Linux 发行版][6],[Fedora,RHEL,及其衍生版][7],[MacOS][8] 和 [Windows][9] 上的安装指示。
|
||||
|
||||
我在使用 Ubuntu,则按照 CRAN 的指示,将以下行加入到我的 `/etc/apt/sources.list` 文件中:
|
||||
我在使用 Ubuntu,按照 CRAN 的指示,将以下行加入到我的 `/etc/apt/sources.list` 文件中:
|
||||
|
||||
```
|
||||
deb https://<my.favorite.cran.mirror>/bin/linux/ubuntu artful/
|
||||
|
||||
```
|
||||
|
||||
接着我在终端运行下面命令:
|
||||
|
||||
```
|
||||
$ sudo apt-get update
|
||||
|
||||
$ sudo apt-get install r-base
|
||||
|
||||
```
|
||||
|
||||
根据 CRAN,“需要从源码编译 R 的用户【如包的维护者,或者任何通过 `install.packages()` 安装包的用户】也应该安装 `r-base-dev` 的包。”
|
||||
根据 CRAN 说明,“需要从源码编译 R 的用户[如包的维护者,或者任何通过 `install.packages()` 安装包的用户]也应该安装 `r-base-dev` 的包。”
|
||||
|
||||
### 使用 R 和 Rstudio
|
||||
### 使用 R 和 RStudio
|
||||
|
||||
安装好了 R,我就准备了解更多关于使用这个强大的工具的信息。Gallagher 博士推荐了 [DataCamp][10] 上的 “Start learning R”,并且我也找到了适用于 R 新手的免费课程。两门课程都帮助我学习 R 的命令和语法。我还参加了 [Udemy][12] 上的 R 在线编程课程,并从 [No Starch Press][14] 上购买了 [Book of R][13]。
|
||||
安装好了 R,我就准备了解更多关于使用这个强大的工具的信息。Gallagher 博士推荐了 [DataCamp][10] 上的 “R 语言入门”,并且我也在 [Code School][11] 找到了适用于 R 新手的免费课程。两门课程都帮助我学习了 R 的命令和语法。我还参加了 [Udemy][12] 上的 R 在线编程课程,并从 [No Starch 出版社][14] 上购买了 [R 之书][13]。
|
||||
|
||||
在阅读更多内容并观看 YouTube 视频后,我意识到我还应该安装 [RStudio][15]。Rstudio 是 R 的开源 IDE,易于在 [Debian, Ubuntu, Fedora, 和 RHEL][16] 上安装。它也可以安装在 MacOS 和 Windows 上。
|
||||
在阅读更多内容并观看 YouTube 视频后,我意识到我还应该安装 [RStudio][15]。Rstudio 是 R 语言的开源 IDE,易于在 [Debian、Ubuntu、 Fedora 和 RHEL][16] 上安装。它也可以安装在 MacOS 和 Windows 上。
|
||||
|
||||
根据 Rstudio 网站的说明,可以根据你的偏好对 IDE 进行自定义,具体方法是选择工具菜单,然后从中选择全局选项。
|
||||
根据 RStudio 网站的说明,可以根据你的偏好对 IDE 进行自定义,具体方法是选择工具菜单,然后从中选择全局选项。
|
||||
|
||||

|
||||
|
||||
@ -51,11 +50,11 @@ R 提供了一些很棒的演示例子,可以通过在提示符处输入 `demo
|
||||
|
||||

|
||||
|
||||
你可能想要开始学习如何将 R 和一些样本数据结合起来使用,然后将这些知识应用到自己的数据上得到描述性统计。我自己没有丰富的数据来分析,但我搜索了可以使用的数据集 [datasets][18];这样一个数据集(我并没有用这个例子)是由圣路易斯联邦储备银行提供的 [经济研究数据][19]。我对一个题为“美国商业航空公司的乘客里程(1937-1960)”很感兴趣,因此我将它导入 RStudio 以测试 IDE 的功能。Rstudio 可以接受各种格式的数据,包括 CSV,Excel,SPSS 和 SAS。
|
||||
你可能想要开始学习如何将 R 和一些样本数据结合起来使用,然后将这些知识应用到自己的数据上得到描述性统计。我自己没有丰富的数据来分析,但我搜索了可以使用的数据集 [datasets][18];有一个这样的数据集(我并没有用这个例子)是由圣路易斯联邦储备银行提供的 [经济研究数据][19]。我对一个题为“美国商业航空公司的乘客里程(1937-1960)”很感兴趣,因此我将它导入 RStudio 以测试 IDE 的功能。RStudio 可以接受各种格式的数据,包括 CSV、Excel、SPSS 和 SAS。
|
||||
|
||||
|
||||
|
||||
数据导入后,我使用 `summary(AirPassengers)` 命令获取数据的一些初始描述性统计信息。按回车键后,我得到了 1949-1960 年的每月航空公司旅客的摘要以及其他数据,包括飞机乘客数量的最小值,最大值,第一四分位数,第三四分位数。中位数以及平均数。
|
||||
数据导入后,我使用 `summary(AirPassengers)` 命令获取数据的一些初始描述性统计信息。按回车键后,我得到了 1949-1960 年的每月航空公司旅客的摘要以及其他数据,包括飞机乘客数量的最小值、最大值、四分之一位数、四分之三位数、中位数以及平均数。
|
||||
|
||||

|
||||
|
||||
@ -63,7 +62,7 @@ R 提供了一些很棒的演示例子,可以通过在提示符处输入 `demo
|
||||
|
||||

|
||||
|
||||
接下来,我生成了一个数据直方图,通过输入 `hist(AirPassengers);` 得到,这以图形的方式显示此数据集;Rstudio 可以将数据导出为 PNG,PDF,JPEG,TIFF,SVG,EPS 或 BMP。
|
||||
接下来,我生成了一个数据直方图,通过输入 `hist(AirPassengers);` 得到,这会以图形的方式显示此数据集;RStudio 可以将数据导出为 PNG、PDF、JPEG、TIFF、SVG、EPS 或 BMP。
|
||||
|
||||
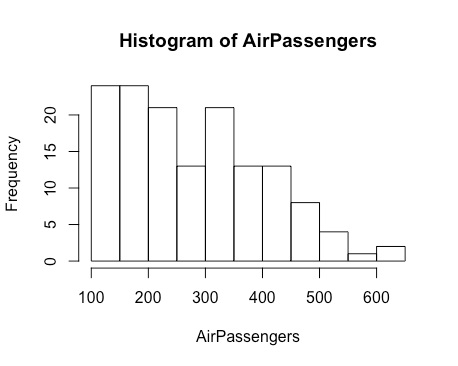
|
||||
|
||||
@ -79,9 +78,9 @@ R 提供了一些很棒的演示例子,可以通过在提示符处输入 `demo
|
||||
|
||||
在 R 提示符下输入 `help()` 可以很容易找到帮助信息。输入你正在寻找的信息的特定主题可以找到具体的帮助信息,例如 `help(sd)` 可以获得有关标准差的帮助。通过在提示符处输入 `contributors()` 可以获得有关 R 项目贡献者的信息。您可以通过在提示符处输入 `citation()` 来了解如何引用 R。通过在提示符出输入 `license()` 可以很容易地获得 R 的许可证信息。
|
||||
|
||||
R 是在 GNU General Public License(1991 年 6 月的版本 2,或者 2007 年 6 月的版本 3)的条款下发布的。有关 R 许可证的更多信息,请参考 [R Project website][20]。
|
||||
R 是在 GNU General Public License(1991 年 6 月的版本 2,或者 2007 年 6 月的版本 3)的条款下发布的。有关 R 许可证的更多信息,请参考 [R 项目官网][20]。
|
||||
|
||||
另外,RStudio 在 GUI 中提供了完美的帮助菜单。该区域包括 RStudio 备忘单(可作为 PDF 下载),[RStudio][21]的在线学习,RStudio 文档,支持和 [许可证信息][22]。
|
||||
另外,RStudio 在 GUI 中提供了完美的帮助菜单。该区域包括 RStudio 快捷表(可作为 PDF 下载),[RStudio][21]的在线学习、RStudio 文档、支持和 [许可证信息][22]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -89,7 +88,7 @@ via: https://opensource.com/article/18/2/getting-started-RStudio-IDE
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
译者:[szcf-weiya](https://github.com/szcf-weiya)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,113 @@
|
||||
使用 Zim 在你的 Linux 桌面上创建一个维基
|
||||
======
|
||||
|
||||
> 用强大而小巧的 Zim 在桌面上像维基一样管理信息。
|
||||
|
||||
|
||||
|
||||
不可否认<ruby>维基<rt>wiki</rt></ruby>的用处,即使对于一个极客来说也是如此。你可以用它做很多事——写笔记和手稿,协作项目,建立完整的网站。还有更多的事。
|
||||
|
||||
这些年来,我已经使用了几个维基,要么是为了我自己的工作,要么就是为了我接到的各种合同和全职工作。虽然传统的维基很好,但我真的喜欢[桌面版维基][1] 这个想法。它们体积小,易于安装和维护,甚至更容易使用。而且,正如你可能猜到的那样,有许多可以用在 Linux 中的桌面版维基。
|
||||
|
||||
让我们来看看更好的桌面版的 维基 之一: [Zim][2]。
|
||||
|
||||
### 开始吧
|
||||
|
||||
你可以从 Zim 的官网[下载][3]并安装 Zim,或者通过发行版的软件包管理器轻松地安装。
|
||||
|
||||
安装好了 Zim,就启动它。
|
||||
|
||||
在 Zim 中的一个关键概念是<ruby>笔记本<rt>notebook</rt></ruby>,它们就像某个单一主题的维基页面的集合。当你第一次启动 Zim 时,它要求你为你的笔记本指定一个文件夹和笔记本的名称。Zim 建议用 `Notes` 来表示文件夹的名称和指定文件夹为 `~/Notebooks/`。如果你愿意,你可以改变它。我是这么做的。
|
||||
|
||||
|
||||
|
||||
在为笔记本设置好名称和指定好文件夹后,单击 “OK” 。你得到的本质上是你的维基页面的容器。
|
||||
|
||||
|
||||
|
||||
### 将页面添加到笔记本
|
||||
|
||||
所以你有了一个容器。那现在怎么办?你应该开始往里面添加页面。当然,为此,选择 “File > New Page”。
|
||||
|
||||
|
||||
|
||||
输入该页面的名称,然后单击 “OK”。从那里开始,你可以开始输入信息以向该页面添加信息。
|
||||
|
||||
|
||||
|
||||
这一页可以是你想要的任何内容:你正在选修的课程的笔记、一本书或者一片文章或论文的大纲,或者是你的书的清单。这取决于你。
|
||||
|
||||
Zim 有一些格式化的选项,其中包括:
|
||||
|
||||
* 标题
|
||||
* 字符格式
|
||||
* 圆点和编号清单
|
||||
* 核对清单
|
||||
|
||||
你可以添加图片和附加文件到你的维基页面,甚至可以从文本文件中提取文本。
|
||||
|
||||
### Zim 的维基语法
|
||||
|
||||
你可以使用工具栏向一个页面添加格式。但这不是唯一的方法。如果你像我一样是个老派人士,你可以使用维基标记来进行格式化。
|
||||
|
||||
[Zim 的标记][4] 是基于在 [DokuWiki][5] 中使用的标记。它本质上是有一些小变化的 [WikiText][6] 。例如,要创建一个子弹列表,输入一个星号(`*`)。用两个星号包围一个单词或短语来使它加黑。
|
||||
|
||||
### 添加链接
|
||||
|
||||
如果你在笔记本上有一些页面,很容易将它们联系起来。有两种方法可以做到这一点。
|
||||
|
||||
第一种方法是使用 [驼峰命名法][7] 来命名这些页面。假设我有个叫做 “Course Notes” 的笔记本。我可以通过输入 “AnalysisCourse” 来重命名为我正在学习的数据分析课程。 当我想从笔记本的另一个页面链接到它时,我只需要输入 “AnalysisCourse” 然后按下空格键。即时超链接。
|
||||
|
||||
第二种方法是点击工具栏上的 “Insert link” 按钮。 在 “Link to” 中输入你想要链接到的页面的名称,从显示的列表中选择它,然后点击 “Link”。
|
||||
|
||||
|
||||
|
||||
我只能在同一个笔记本中的页面之间进行链接。每当我试图连接到另一个笔记本中的一个页面时,这个文件(有 .txt 的后缀名)总是在文本编辑器中被打开。
|
||||
|
||||
### 输出你的维基页面
|
||||
|
||||
也许有一天你会想在别的地方使用笔记本上的信息 —— 比如,在一份文件或网页上。你可以将笔记本页面导出到以下格式中的任何一种。而不是复制和粘贴(和丢失格式):
|
||||
|
||||
* HTML
|
||||
* LaTeX
|
||||
* Markdown
|
||||
* ReStructuredText
|
||||
|
||||
为此,点击你想要导出的维基页面。然后,选择 “File > Export”。决定是要导出整个笔记本还是一个页面,然后点击 “Forward”。
|
||||
|
||||
|
||||
|
||||
选择要用来保存页面或笔记本的文件格式。使用 HTML 和 LaTeX,你可以选择一个模板。 随便看看什么最适合你。 例如,如果你想把你的维基页面变成 HTML 演示幻灯片,你可以在 “Template” 中选择 “SlideShow s5”。 如果你想知道,这会产生由 [S5 幻灯片框架][8]驱动的幻灯片。
|
||||
|
||||
|
||||
|
||||
点击 “Forward”,如果你在导出一个笔记本,你可以选择将页面作为单个文件或一个文件导出。 你还可以指向要保存导出文件的文件夹。
|
||||
|
||||
|
||||
|
||||
### Zim 能做的就这些吗?
|
||||
|
||||
远远不止这些,还有一些 [插件][9] 可以扩展它的功能。它甚至包含一个内置的 Web 服务器,可以让你将你的笔记本作为静态的 HTML 文件。这对于在内部网络上分享你的页面和笔记本是非常有用的。
|
||||
|
||||
总的来说,Zim 是一个用来管理你的信息的强大而又紧凑的工具。这是我使用过的最好的桌面版维基,而且我一直在使用它。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/create-wiki-your-linux-desktop-zim
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
译者:[Auk7F7](https://github.com/Auk7F7)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:https://opensource.com/article/17/2/3-desktop-wikis
|
||||
[2]:http://zim-wiki.org/
|
||||
[3]:http://zim-wiki.org/downloads.html
|
||||
[4]:http://zim-wiki.org/manual/Help/Wiki_Syntax.html
|
||||
[5]:https://www.dokuwiki.org/wiki:syntax
|
||||
[6]:http://en.wikipedia.org/wiki/Wikilink
|
||||
[7]:https://en.wikipedia.org/wiki/Camel_case
|
||||
[8]:https://meyerweb.com/eric/tools/s5/
|
||||
[9]:http://zim-wiki.org/manual/Plugins.html
|
||||
@ -1,114 +0,0 @@
|
||||
lontow Translating
|
||||
|
||||
Evolutional Steps of Computer Systems
|
||||
======
|
||||
Throughout the history of the modern computer, there were several evolutional steps related to the way we interact with the system. I tend to categorize those steps as following:
|
||||
|
||||
1. Numeric Systems
|
||||
2. Application-Specific Systems
|
||||
3. Application-Centric Systems
|
||||
4. Information-Centric Systems
|
||||
5. Application-Less Systems
|
||||
|
||||
|
||||
|
||||
Following sections describe how I see those categories.
|
||||
|
||||
### Numeric Systems
|
||||
|
||||
[Early computers][1] were designed with numbers in mind. They could add, subtract, multiply, divide. Some of them were able to perform more complex mathematical operations such as differentiate or integrate.
|
||||
|
||||
If you map characters to numbers, they were able to «compute» [strings][2] as well but this is somewhat «creative use of numbers» instead of meaningful processing arbitrary information.
|
||||
|
||||
### Application-Specific Systems
|
||||
|
||||
For higher-level problems, pure numeric systems are not sufficient. Application-specific systems were developed to do one single task. They were very similar to numeric systems. However, with sufficiently complex number calculations, systems were able to accomplish very well-defined higher level tasks such as calculations related to scheduling problems or other optimization problems.
|
||||
|
||||
Systems of this category were built for one single purpose, one distinct problem they solved.
|
||||
|
||||
### Application-Centric Systems
|
||||
|
||||
Systems that are application-centric are the first real general purpose systems. Their main usage style is still mostly application-specific but with multiple applications working either time-sliced (one app after another) or in multi-tasking mode (multiple apps at the same time).
|
||||
|
||||
Early personal computers [from the 70s][3] of the previous century were the first application-centric systems that became popular for a wide group of people.
|
||||
|
||||
Yet modern operating systems - Windows, macOS, most GNU/Linux desktop environments - still follow the same principles.
|
||||
|
||||
Of course, there are sub-categories as well:
|
||||
|
||||
1. Strict Application-Centric Systems
|
||||
2. Loose Application-Centric Systems
|
||||
|
||||
|
||||
|
||||
Strict application-centric systems such as [Windows 3.1][4] (Program Manager and File Manager) or even the initial version of [Windows 95][5] had no pre-defined folder hierarchy. The user did start text processing software like [WinWord][6] and saved the files in the program folder of WinWord. When working with a spreadsheet program, its files were saved in the application folder of the spreadsheet tool. And so on. Users did not create their own hierarchy of folders mostly because of convenience, laziness, or because they did not saw any necessity. The number of files per user were sill within dozens up to a few hundreds.
|
||||
|
||||
For accessing information, the user typically opened an application and within the application, the files containing the generated data were retrieved using file/open.
|
||||
|
||||
It was [Windows 95][5] SP2 that introduced «[My Documents][7]» for the Windows platform. With this file hierarchy template, application designers began switching to «My Documents» as a default file save/open location instead of using the software product installation path. This made the users embrace this pattern and start to maintain folder hierarchies on their own.
|
||||
|
||||
This resulted in loose application-centric systems: typical file retrieval is done via a file manager. When a file is opened, the associated application is started by the operating system. It is a small or subtle but very important usage shift. Application-centric systems are still the dominant usage pattern for personal computers.
|
||||
|
||||
Nevertheless, this pattern comes with many disadvantages. For example in order to prevent data retrieval problems, there is the need to maintain a strict hierarchy of folders that contain all related files of a given project. Unfortunately, nature does not fit well in strict hierarchy of folders. Further more, [this does not scale well][8]. Desktop search engines and advanced data organizing tools like [tagstore][9] are able to smooth the edged a bit. As studies show, only a minority of users are using such advanced retrieval tools. Most users still navigate through the file system without using any alternative or supplemental retrieval techniques.
|
||||
|
||||
### Information-Centric Systems
|
||||
|
||||
One possible way of dealing with the issue that a certain topic needs to have a folder that holds all related files is to switch from an application-centric system to an information-centric systems.
|
||||
|
||||
Instead of opening a spreadsheet application to work with the project budget, opening a word processor application to write the project report, and opening another tool to work with image files, an information-centric system combines all the information on the project in one place, in one application.
|
||||
|
||||
The calculations for the previous month is right beneath notes from a client meeting which is right beneath a photography of the whiteboard notes which is right beneath some todo tasks. Without any application or file border in between.
|
||||
|
||||
Early attempts to create such an environment were IBM [OS/2][10], Microsoft [OLE][11] or [NeXT][12]. None of them were a major success for a variety of reasons. A very interesting information-centric environment is [Acme][13] from [Plan 9][14]. It combines [a wide variety of applications][15] within one application but it never reached a notable distribution even with its ports to Windows or GNU/Linux.
|
||||
|
||||
Modern approaches for an information-centric system are advanced [personal wikis][16] like [TheBrain][17] or [Microsoft OneNote][18].
|
||||
|
||||
My personal tool of choice is the [GNU/Emacs][19] platform with its [Org-mode][19] extension. I hardly leave Org-mode when I work with my computer. For accessing external data sources, I created [Memacs][20] which brings me a broad variety of data into Org-mode. I love to do spreadsheet calculations right beneath scheduled tasks, in-line images, internal and external links, and so forth. It is truly an information-centric system where the user doesn't have to deal with application borders or strictly hierarchical file-system folders. Multi-classifications is possible using simple or advanced tagging. All kinds of views can be derived with a single command. One of those views is my calendar, the agenda. Another derived view is the list of borrowed things. And so on. There are no limits for Org-mode users. If you can think of it, it is most likely possible within Org-mode.
|
||||
|
||||
Is this the end of the evolution? Certainly not.
|
||||
|
||||
### Application-Less Systems
|
||||
|
||||
I can think of a class of systems which I refer to as application-less systems. As the next logical step, there is no need to have single-domain applications even when they are as capable as Org-mode. The computer offers a nice to use interface to information and features, not files and applications. Even a classical operating system is not accessible.
|
||||
|
||||
Application-less systems might as well be combined with [artificial intelligence][21]. Think of it as some kind of [HAL 9000][22] from [A Space Odyssey][23]. Or [LCARS][24] from Star Trek.
|
||||
|
||||
It is hard to believe that there is a transition between our application-based, vendor-based software culture and application-less systems. Maybe the open source movement with its slow but constant development will be able to form a truly application-less environment where all kinds of organizations and people are contributing to.
|
||||
|
||||
Information and features to retrieve and manipulate information, this is all it takes. This is all we need. Everything else is just limiting distraction.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://karl-voit.at/2017/02/10/evolution-of-systems/
|
||||
|
||||
作者:[Karl Voit][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://karl-voit.at
|
||||
[1]:https://en.wikipedia.org/wiki/History_of_computing_hardware
|
||||
[2]:https://en.wikipedia.org/wiki/String_%2528computer_science%2529
|
||||
[3]:https://en.wikipedia.org/wiki/Xerox_Alto
|
||||
[4]:https://en.wikipedia.org/wiki/Windows_3.1x
|
||||
[5]:https://en.wikipedia.org/wiki/Windows_95
|
||||
[6]:https://en.wikipedia.org/wiki/Microsoft_Word
|
||||
[7]:https://en.wikipedia.org/wiki/My_Documents
|
||||
[8]:http://karl-voit.at/tagstore/downloads/Voit2012b.pdf
|
||||
[9]:http://karl-voit.at/tagstore/
|
||||
[10]:https://en.wikipedia.org/wiki/OS/2
|
||||
[11]:https://en.wikipedia.org/wiki/Object_Linking_and_Embedding
|
||||
[12]:https://en.wikipedia.org/wiki/NeXT
|
||||
[13]:https://en.wikipedia.org/wiki/Acme_%2528text_editor%2529
|
||||
[14]:https://en.wikipedia.org/wiki/Plan_9_from_Bell_Labs
|
||||
[15]:https://en.wikipedia.org/wiki/List_of_Plan_9_applications
|
||||
[16]:https://en.wikipedia.org/wiki/Personal_wiki
|
||||
[17]:https://en.wikipedia.org/wiki/TheBrain
|
||||
[18]:https://en.wikipedia.org/wiki/Microsoft_OneNote
|
||||
[19]:../../../../tags/emacs
|
||||
[20]:https://github.com/novoid/Memacs
|
||||
[21]:https://en.wikipedia.org/wiki/Artificial_intelligence
|
||||
[22]:https://en.wikipedia.org/wiki/HAL_9000
|
||||
[23]:https://en.wikipedia.org/wiki/2001:_A_Space_Odyssey
|
||||
[24]:https://en.wikipedia.org/wiki/LCARS
|
||||
@ -1,104 +0,0 @@
|
||||
[fuzheng1998 tranlating]
|
||||
我是如何创造“开源”这个词的
|
||||
============================================================
|
||||
|
||||
### Christine Peterson 最终发布了对于二十年前那决定命运一天的陈述。
|
||||
|
||||

|
||||
图片来自: opensource.com
|
||||
|
||||
In a few days, on February 3, the 20th anniversary of the introduction of the term "[开源软件][6]" is upon us. As open source software grows in popularity and powers some of the most robust and important innovations of our time, we reflect on its rise to prominence.
|
||||
|
||||
I am the originator of the term "open source software" and came up with it while executive director at Foresight Institute. Not a software developer like the rest, I thank Linux programmer Todd Anderson for supporting the term and proposing it to the group.
|
||||
|
||||
This is my account of how I came up with it, how it was proposed, and the subsequent reactions. Of course, there are a number of accounts of the coining of the term, for example by Eric Raymond and Richard Stallman, yet this is mine, written on January 2, 2006.
|
||||
|
||||
直到今天,它才公诸于世。
|
||||
|
||||
* * *
|
||||
|
||||
The introduction of the term "open source software" was a deliberate effort to make this field of endeavor more understandable to newcomers and to business, which was viewed as necessary to its spread to a broader community of users. The problem with the main earlier label, "free software," was not its political connotations, but that—to newcomers—its seeming focus on price is distracting. A term was needed that focuses on the key issue of source code and that does not immediately confuse those new to the concept. The first term that came along at the right time and fulfilled these requirements was rapidly adopted: open source.
|
||||
|
||||
This term had long been used in an "intelligence" (i.e., spying) context, but to my knowledge, use of the term with respect to software prior to 1998 has not been confirmed. The account below describes how the term [open source software][7] caught on and became the name of both an industry and a movement.
|
||||
|
||||
### 计算机安全会议
|
||||
|
||||
In late 1997, weekly meetings were being held at Foresight Institute to discuss computer security. Foresight is a nonprofit think tank focused on nanotechnology and artificial intelligence, and software security is regarded as central to the reliability and security of both. We had identified free software as a promising approach to improving software security and reliability and were looking for ways to promote it. Interest in free software was starting to grow outside the programming community, and it was increasingly clear that an opportunity was coming to change the world. However, just how to do this was unclear, and we were groping for strategies.
|
||||
|
||||
At these meetings, we discussed the need for a new term due to the confusion factor. The argument was as follows: those new to the term "free software" assume it is referring to the price. Oldtimers must then launch into an explanation, usually given as follows: "We mean free as in freedom, not free as in beer." At this point, a discussion on software has turned into one about the price of an alcoholic beverage. The problem was not that explaining the meaning is impossible—the problem was that the name for an important idea should not be so confusing to newcomers. A clearer term was needed. No political issues were raised regarding the free software term; the issue was its lack of clarity to those new to the concept.
|
||||
|
||||
### 网景发布
|
||||
|
||||
On February 2, 1998, Eric Raymond arrived on a visit to work with Netscape on the plan to release the browser code under a free-software-style license. We held a meeting that night at Foresight's office in Los Altos to strategize and refine our message. In addition to Eric and me, active participants included Brian Behlendorf, Michael Tiemann, Todd Anderson, Mark S. Miller, and Ka-Ping Yee. But at that meeting, the field was still described as free software or, by Brian, "source code available" software.
|
||||
|
||||
While in town, Eric used Foresight as a base of operations. At one point during his visit, he was called to the phone to talk with a couple of Netscape legal and/or marketing staff. When he was finished, I asked to be put on the phone with them—one man and one woman, perhaps Mitchell Baker—so I could bring up the need for a new term. They agreed in principle immediately, but no specific term was agreed upon.
|
||||
|
||||
Between meetings that week, I was still focused on the need for a better name and came up with the term "open source software." While not ideal, it struck me as good enough. I ran it by at least four others: Eric Drexler, Mark Miller, and Todd Anderson liked it, while a friend in marketing and public relations felt the term "open" had been overused and abused and believed we could do better. He was right in theory; however, I didn't have a better idea, so I thought I would try to go ahead and introduce it. In hindsight, I should have simply proposed it to Eric Raymond, but I didn't know him well at the time, so I took an indirect strategy instead.
|
||||
|
||||
Todd had agreed strongly about the need for a new term and offered to assist in getting the term introduced. This was helpful because, as a non-programmer, my influence within the free software community was weak. My work in nanotechnology education at Foresight was a plus, but not enough for me to be taken very seriously on free software questions. As a Linux programmer, Todd would be listened to more closely.
|
||||
|
||||
### 关键的会议
|
||||
|
||||
Later that week, on February 5, 1998, a group was assembled at VA Research to brainstorm on strategy. Attending—in addition to Eric Raymond, Todd, and me—were Larry Augustin, Sam Ockman, and attending by phone, Jon "maddog" Hall.
|
||||
|
||||
The primary topic was promotion strategy, especially which companies to approach. I said little, but was looking for an opportunity to introduce the proposed term. I felt that it wouldn't work for me to just blurt out, "All you technical people should start using my new term." Most of those attending didn't know me, and for all I knew, they might not even agree that a new term was greatly needed, or even somewhat desirable.
|
||||
|
||||
Fortunately, Todd was on the ball. Instead of making an assertion that the community should use this specific new term, he did something less directive—a smart thing to do with this community of strong-willed individuals. He simply used the term in a sentence on another topic—just dropped it into the conversation to see what happened. I went on alert, hoping for a response, but there was none at first. The discussion continued on the original topic. It seemed only he and I had noticed the usage.
|
||||
|
||||
Not so—memetic evolution was in action. A few minutes later, one of the others used the term, evidently without noticing, still discussing a topic other than terminology. Todd and I looked at each other out of the corners of our eyes to check: yes, we had both noticed what happened. I was excited—it might work! But I kept quiet: I still had low status in this group. Probably some were wondering why Eric had invited me at all.
|
||||
|
||||
Toward the end of the meeting, the [question of terminology][8] was brought up explicitly, probably by Todd or Eric. Maddog mentioned "freely distributable" as an earlier term, and "cooperatively developed" as a newer term. Eric listed "free software," "open source," and "sourceware" as the main options. Todd advocated the "open source" model, and Eric endorsed this. I didn't say much, letting Todd and Eric pull the (loose, informal) consensus together around the open source name. It was clear that to most of those at the meeting, the name change was not the most important thing discussed there; a relatively minor issue. Only about 10% of my notes from this meeting are on the terminology question.
|
||||
|
||||
But I was elated. These were some key leaders in the community, and they liked the new name, or at least didn't object. This was a very good sign. There was probably not much more I could do to help; Eric Raymond was far better positioned to spread the new meme, and he did. Bruce Perens signed on to the effort immediately, helping set up [Opensource.org][9] and playing a key role in spreading the new term.
|
||||
|
||||
For the name to succeed, it was necessary, or at least highly desirable, that Tim O'Reilly agree and actively use it in his many projects on behalf of the community. Also helpful would be use of the term in the upcoming official release of the Netscape Navigator code. By late February, both O'Reilly & Associates and Netscape had started to use the term.
|
||||
|
||||
### 名字的诞生
|
||||
|
||||
After this, there was a period during which the term was promoted by Eric Raymond to the media, by Tim O'Reilly to business, and by both to the programming community. It seemed to spread very quickly.
|
||||
|
||||
On April 7, 1998, Tim O'Reilly held a meeting of key leaders in the field. Announced in advance as the first "[Freeware Summit][10]," by April 14 it was referred to as the first "[Open Source Summit][11]."
|
||||
|
||||
These months were extremely exciting for open source. Every week, it seemed, a new company announced plans to participate. Reading Slashdot became a necessity, even for those like me who were only peripherally involved. I strongly believe that the new term was helpful in enabling this rapid spread into business, which then enabled wider use by the public.
|
||||
|
||||
A quick Google search indicates that "open source" appears more often than "free software," but there still is substantial use of the free software term, which remains useful and should be included when communicating with audiences who prefer it.
|
||||
|
||||
### A happy twinge
|
||||
|
||||
When an [early account][12] of the terminology change written by Eric Raymond was posted on the Open Source Initiative website, I was listed as being at the VA brainstorming meeting, but not as the originator of the term. This was my own fault; I had neglected to tell Eric the details. My impulse was to let it pass and stay in the background, but Todd felt otherwise. He suggested to me that one day I would be glad to be known as the person who coined the name "open source software." He explained the situation to Eric, who promptly updated his site.
|
||||
|
||||
Coming up with a phrase is a small contribution, but I admit to being grateful to those who remember to credit me with it. Every time I hear it, which is very often now, it gives me a little happy twinge.
|
||||
|
||||
The big credit for persuading the community goes to Eric Raymond and Tim O'Reilly, who made it happen. Thanks to them for crediting me, and to Todd Anderson for his role throughout. The above is not a complete account of open source history; apologies to the many key players whose names do not appear. Those seeking a more complete account should refer to the links in this article and elsewhere on the net.
|
||||
|
||||
### 关于作者
|
||||
|
||||
[][13] Christine Peterson - Christine Peterson writes, lectures, and briefs the media on coming powerful technologies, especially nanotechnology, artificial intelligence, and longevity. She is Cofounder and Past President of Foresight Institute, the leading nanotech public interest group. Foresight educates the public, technical community, and policymakers on coming powerful technologies and how to guide their long-term impact. She serves on the Advisory Board of the [Machine Intelligence... ][2][more about Christine Peterson][3][More about me][4]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/coining-term-open-source-software
|
||||
|
||||
作者:[ Christine Peterson][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/christine-peterson
|
||||
[1]:https://opensource.com/article/18/2/coining-term-open-source-software?rate=HFz31Mwyy6f09l9uhm5T_OFJEmUuAwpI61FY-fSo3Gc
|
||||
[2]:http://intelligence.org/
|
||||
[3]:https://opensource.com/users/christine-peterson
|
||||
[4]:https://opensource.com/users/christine-peterson
|
||||
[5]:https://opensource.com/user/206091/feed
|
||||
[6]:https://opensource.com/resources/what-open-source
|
||||
[7]:https://opensource.org/osd
|
||||
[8]:https://wiki2.org/en/Alternative_terms_for_free_software
|
||||
[9]:https://opensource.org/
|
||||
[10]:http://www.oreilly.com/pub/pr/636
|
||||
[11]:http://www.oreilly.com/pub/pr/796
|
||||
[12]:https://ipfs.io/ipfs/QmXoypizjW3WknFiJnKLwHCnL72vedxjQkDDP1mXWo6uco/wiki/Alternative_terms_for_free_software.html
|
||||
[13]:https://opensource.com/users/christine-peterson
|
||||
[14]:https://opensource.com/users/christine-peterson
|
||||
[15]:https://opensource.com/users/christine-peterson
|
||||
[16]:https://opensource.com/article/18/2/coining-term-open-source-software#comments
|
||||
@ -1,3 +1,5 @@
|
||||
fuzheng1998 translating
|
||||
|
||||
Why Linux is better than Windows or macOS for security
|
||||
======
|
||||
|
||||
|
||||
@ -0,0 +1,89 @@
|
||||
How to apply systems thinking in DevOps
|
||||
======
|
||||
|
||||

|
||||
For most organizations, adopting DevOps requires a mindset shift. Unless you understand the core of [DevOps][1], you might think it's hype or just another buzzword—or worse, you might believe you have already adopted DevOps because you are using the right tools.
|
||||
|
||||
Let’s dig deeper into what DevOps means, and explore how to apply systems thinking in your organization.
|
||||
|
||||
### What is systems thinking?
|
||||
|
||||
Systems thinking is a holistic approach to problem-solving. It's the opposite of analytical thinking, which separates a problem from the "bigger picture" to better understand it. Instead, systems thinking studies all the elements of a problem, along with the interactions between these elements.
|
||||
|
||||
Most people are not used to thinking this way. Since childhood, most of us were taught math, science, and every other subject separately, by different teachers. This approach to learning follows us throughout our lives, from school to university to the workplace. When we first join an organization, we typically work in only one department.
|
||||
|
||||
Unfortunately, the world is not that simple. Complexity, unpredictability, and sometimes chaos are unavoidable and require a broader way of thinking. Systems thinking helps us understand the systems we are part of, which in turn enables us to manage them rather than be controlled by them.
|
||||
|
||||
According to systems thinking, everything is a system: your body, your family, your neighborhood, your city, your company, and even the communities you belong to. These systems evolve organically; they are alive and fluid. The better you understand a system's behavior, the better you can manage and leverage it. You become their change agent and are accountable for them.
|
||||
|
||||
### Systems thinking and DevOps
|
||||
|
||||
All systems include properties that DevOps addresses through its practices and tools. Awareness of these properties helps us properly adapt to DevOps. Let's look at the properties of a system and how DevOps relates to each one.
|
||||
|
||||
### How systems work
|
||||
|
||||
The figure below represents a system. To reach a goal, the system requires input, which is processed and generates output. Feedback is essential for moving the system toward the goal. Without a purpose, the system dies.
|
||||
|
||||

|
||||
|
||||
If an organization is a system, its departments are subsystems. The flow of work moves through each department, starting with identifying a market need (the first input on the left) and moving toward releasing a solution that meets that need (the last output on the right). The output that each department generates serves as required input for the next department in the chain.
|
||||
|
||||
The more specialized teams an organization has, the more handoffs happen between departments. The process of generating value to clients is more likely to create bottlenecks and thus it takes longer to deliver value. Also, when work is passed between teams, the gap between the goal and what has been done widens.
|
||||
|
||||
DevOps aims to optimize the flow of work throughout the organization to deliver value to clients faster—in other words, DevOps reduces time to market. This is done in part by maximizing automation, but mainly by targeting the organization's goals. This empowers prioritization and reduces duplicated work and other inefficiencies that happen during the delivery process.
|
||||
|
||||
### System deterioration
|
||||
|
||||
All systems are affected by entropy. Nothing can prevent system degradation; that's irreversible. The tendency to decline shows the failure nature of systems. Moreover, systems are subject to threats of all types, and failure is a matter of time.
|
||||
|
||||
To mitigate entropy, systems require constant maintenance and improvements. The effects of entropy can be delayed only when new actions are taken or input is changed.
|
||||
|
||||
This pattern of deterioration and its opposite force, survival, can be observed in living organisms, social relationships, and other systems as well as in organizations. In fact, if an organization is not evolving, entropy is guaranteed to be increasing.
|
||||
|
||||
DevOps attempts to break the entropy process within an organization by fostering continuous learning and improvement. With DevOps, the organization becomes fault-tolerant because it recognizes the inevitability of failure. DevOps enables a blameless culture that offers the opportunity to learn from failure. The [postmortem][2] is an example of a DevOps practice used by organizations that embrace inherent failure.
|
||||
|
||||
The idea of intentionally embracing failure may sound counterintuitive, but that's exactly what happens in techniques like [Chaos Monkey][3]: Failure is intentionally introduced to improve availability and reliability in the system. DevOps suggests that putting some pressure into the system in a controlled way is not a bad thing. Like a muscle that gets stronger with exercise, the system benefits from the challenge.
|
||||
|
||||
### System complexity
|
||||
|
||||
The figure below shows how complex the systems can be. In most cases, one effect can have multiple causes, and one cause can generate multiple effects. The more elements and interactions a system has, the more complex the system.
|
||||
|
||||

|
||||
|
||||
In this scenario, we can't immediately identify the reason for a particular event. Likewise, we can't predict with 100% certainty what will happen if a specific action is taken. We are constantly making assumptions and dealing with hypotheses.
|
||||
|
||||
System complexity can be explained using the scientific method. In a recent study, for example, mice that were fed excess salt showed suppressed cerebral blood flow. This same experiment would have had different results if, say, the mice were fed sugar and salt. One variable can radically change results in complex systems.
|
||||
|
||||
DevOps handles complexity by encouraging experimentation—for example, using the scientific method—and reducing feedback cycles. Smaller changes inserted into the system can be tested and validated more quickly. With a "[fail-fast][4]" approach, organizations can pivot quickly and achieve resiliency. Reacting rapidly to changes makes organizations more adaptable.
|
||||
|
||||
DevOps also aims to minimize guesswork and maximize understanding by making the process of delivering value more tangible. By measuring processes, revealing flaws and advantages, and monitoring as much as possible, DevOps helps organizations discover the changes they need to make.
|
||||
|
||||
### System limitations
|
||||
|
||||
All systems have constraints that limit their performance; a system's overall capacity is delimited by its restrictions. Most of us have learned from experience that systems operating too long at full capacity can crash, and most systems work better when they function with some slack. Ignoring limitations puts systems at risk. For example, when we are under too much stress for a long time, we get sick. Similarly, overused vehicle engines can be damaged.
|
||||
|
||||
This principle also applies to organizations. Unfortunately, organizations can't put everything into a system at once. Although this limitation may sometimes lead to frustration, the quality of work usually improves when input is reduced.
|
||||
|
||||
Consider what happened when the speed limit on the main roads in São Paulo, Brazil was reduced from 90 km/h to 70 km/h. Studies showed that the number of accidents decreased by 38.5% and the average speed increased by 8.7%. In other words, the entire road system improved and more vehicles arrived safely at their destinations.
|
||||
|
||||
For organizations, DevOps suggests global rather than local improvements. It doesn't matter if some improvement is put after a constraint because there's no effect on the system at all. One constraint that DevOps addresses, for instance, is dependency on specialized teams. DevOps brings to organizations a more collaborative culture, knowledge sharing, and cross-functional teams.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Before adopting DevOps, understand what is involved and how you want to apply it to your organization. Systems thinking will help you accomplish that while also opening your mind to new possibilities. DevOps may be seen as a popular trend today, but in 10 or 20 years, it will be status quo.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/how-apply-systems-thinking-devops
|
||||
|
||||
作者:[Gustavo Muniz do Carmo][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/gustavomcarmo
|
||||
[1]:https://opensource.com/tags/devops
|
||||
[2]:https://landing.google.com/sre/book/chapters/postmortem-culture.html
|
||||
[3]:https://medium.com/netflix-techblog/the-netflix-simian-army-16e57fbab116
|
||||
[4]:https://en.wikipedia.org/wiki/Fail-fast
|
||||
@ -0,0 +1,63 @@
|
||||
Pi Day: 12 fun facts and ways to celebrate
|
||||
======
|
||||
|
||||

|
||||
Today, tech teams around the world will celebrate a number. March 14 (written 3/14 in the United States) is known as Pi Day, a holiday that people ring in with pie eating contests, pizza parties, and math puns. If the most important number in mathematics wasn’t enough of a reason to reach for a slice of pie, March 14 also happens to be Albert Einstein’s birthday, the release anniversary of Linux kernel 1.0.0, and the day Eli Whitney patented the cotton gin.
|
||||
|
||||
In honor of this special day, we’ve rounded up a dozen fun facts and interesting pi-related projects. Master you team’s Pi Day trivia, or borrow an idea or two for a team-building exercise. Do a project with a budding technologist. And let us know in the comments if you are doing anything unique to celebrate everyone’s favorite never-ending number.
|
||||
|
||||
### Pi Day celebrations:
|
||||
|
||||
* Today is the 30th anniversary of Pi Day. The first was held in 1988 in San Francisco at the Exploratorium by physicist Larry Shaw. “On [the first Pi Day][1], staff brought in fruit pies and a tea urn for the celebration. At 1:59 – the pi numbers that follow 3.14 – Shaw led a circular parade around the museum with his boombox blaring the digits of pi to the music of ‘Pomp and Circumstance.’” It wasn’t until 21 years later, March 2009, that Pi Day became an official national holiday in the U.S.
|
||||
* Although it started in San Francisco, one of the biggest Pi Day celebrations can be found in Princeton. The town holds a [number of events][2] over the course of five days, including an Einstein look-alike contest, a pie-throwing event, and a pi recitation competition. Some of the activities even offer a cash prize of $314.15 for the winner.
|
||||
* MIT Sloan School of Management (on Twitter as [@MITSloan][3]) is celebrating Pi Day with fun facts about pi – and pie. Follow along with the Twitter hashtag #PiVersusPie
|
||||
|
||||
|
||||
|
||||
### Pi-related projects and activities:
|
||||
|
||||
* If you want to keep your math skills sharpened, NASA Jet Propulsion Lab has posted a [new set of math problems][4] that illustrate how pi can be used to unlock the mysteries of space. This marks the fifth year of NASA’s Pi Day Challenge, geared toward students.
|
||||
* There's no better way to get into the spirit of Pi Day than to take on a [Raspberry Pi][5] project. Whether you are looking for a project to do with your kids or with your team, there’s no shortage of ideas out there. Since its launch in 2012, millions of the basic computer boards have been sold. In fact, it’s the [third best-selling general purpose computer][6] of all time. Here are a few Raspberry Pi projects and activities that caught our eye:
|
||||
* Grab an AIY (AI-Yourself) kit from Google. You can create a [voice-controlled digital assistant][7] or an [image-recognition device][8].
|
||||
* [Run Kubernetes][9] on a Raspberry Pi.
|
||||
* Save Princess Peach by building a [retro gaming system][10].
|
||||
* Host a [Raspberry Jam][11] with your team. The Raspberry Pi Foundation has released a [Guidebook][12] to make hosting easy. According to the website, Raspberry Jams provide, “a support network for people of all ages in digital making. All around the world, like-minded people meet up to discuss and share their latest projects, give workshops, and chat about all things Pi.”
|
||||
|
||||
|
||||
|
||||
### Other fun Pi facts:
|
||||
|
||||
* The current [world record holder][13] for reciting pi is Suresh Kumar Sharma, who in October 2015 recited 70,030 digits. It took him 17 hours and 14 minutes to do so. However, the [unofficial record][14] goes to Akira Haraguchi, who claims he can recite up to 111,700 digits.
|
||||
* And, there’s more to remember than ever before. In November 2016, R&D scientist Peter Trueb calculated 22,459,157,718,361 digits of pi – [9 trillion more digits][15] than the previous world record set in 2013. According to New Scientist, “The final file containing the 22 trillion digits of pi is nearly 9 terabytes in size. If printed out, it would fill a library of several million books containing a thousand pages each."
|
||||
|
||||
|
||||
|
||||
Happy Pi Day!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2018/3/pi-day-12-fun-facts-and-ways-celebrate
|
||||
|
||||
作者:[Carla Rudder][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://enterprisersproject.com/user/crudder
|
||||
[1]:https://www.exploratorium.edu/pi/pi-day-history
|
||||
[2]:https://princetontourcompany.com/activities/pi-day/
|
||||
[3]:https://twitter.com/MITSloan
|
||||
[4]:https://www.jpl.nasa.gov/news/news.php?feature=7074
|
||||
[5]:https://opensource.com/resources/raspberry-pi
|
||||
[6]:https://www.theverge.com/circuitbreaker/2017/3/17/14962170/raspberry-pi-sales-12-5-million-five-years-beats-commodore-64
|
||||
[7]:http://www.zdnet.com/article/raspberry-pi-this-google-kit-will-turn-your-pi-into-a-voice-controlled-digital-assistant/
|
||||
[8]:http://www.zdnet.com/article/google-offers-raspberry-pi-owners-this-new-ai-vision-kit-to-spot-cats-people-emotions/
|
||||
[9]:https://opensource.com/article/17/3/kubernetes-raspberry-pi
|
||||
[10]:https://opensource.com/article/18/1/retro-gaming
|
||||
[11]:https://opensource.com/article/17/5/how-run-raspberry-pi-meetup
|
||||
[12]:https://www.raspberrypi.org/blog/support-raspberry-jam-community/
|
||||
[13]:http://www.pi-world-ranking-list.com/index.php?page=lists&category=pi
|
||||
[14]:https://www.theguardian.com/science/alexs-adventures-in-numberland/2015/mar/13/pi-day-2015-memory-memorisation-world-record-japanese-akira-haraguchi
|
||||
[15]:https://www.newscientist.com/article/2124418-celebrate-pi-day-with-9-trillion-more-digits-than-ever-before/?utm_medium=Social&utm_campaign=Echobox&utm_source=Facebook&utm_term=Autofeed&cmpid=SOC%7CNSNS%7C2017-Echobox#link_time=1489480071
|
||||
@ -0,0 +1,111 @@
|
||||
6 ways a thriving community will help your project succeed
|
||||
======
|
||||
|
||||

|
||||
NethServer is an open source product that my company, [Nethesis][1], launched just a few years ago. [The product][2] wouldn't be [what it is today][3] without the vibrant community that surrounds and supports it.
|
||||
|
||||
In my previous article, I [discussed what organizations should expect to give][4] if they want to experience the benefits of thriving communities. In this article, I'll describe what organizations should expect to receive in return for their investments in the passionate people that make up their communities.
|
||||
|
||||
Let's review six benefits.
|
||||
|
||||
### 1\. Innovation
|
||||
|
||||
"Open innovation" occurs when a company sharing information also listens to the feedback and suggestions from outside the company. As a company, we don't just look at the crowd for ideas. We innovate in, with, and through communities.
|
||||
|
||||
You may know that "[the best way to have a good idea is to have a lot of ideas][5]." You can't always expect to have the right idea on your own, so having different point of views on your product is essential. How many truly disruptive ideas can a small company (like Nethesis) create? We're all young, caucasian, and European—while in our community, we can pick up a set of inspirations from a variety of people, with different genders, backgrounds, skills, and ethnicities.
|
||||
|
||||
So the ability to invite the entire world to continuously improve the product is now no longer a dream; it's happening before our eyes. Your community could be the idea factory for innovation. With the community, you can really leverage the power of the collective.
|
||||
|
||||
No matter who you are, most of the smartest people work for someone else. And community is the way to reach those smart people and work with them.
|
||||
|
||||
### 2\. Research
|
||||
|
||||
A community can be your strongest source of valuable product research.
|
||||
|
||||
First, it can help you avoid "ivory tower development." [As Stack Exchange co-founder Jeff Atwood has said][6], creating an environment where developers have no idea who the users are is dangerous. Isolated developers, who have worked for years in their high towers, often encounter bad results because they don't have any clue about how users actually use their software. Developing in an Ivory tower keeps you away from your users and can only lead to bad decisions. A community brings developers back to reality and helps them stay grounded. Gone are the days of developers working in isolation with limited resources. In this day and age, thanks to the advent of open source communities research department is opening up to the entire world.
|
||||
|
||||
No matter who you are, most of the smartest people work for someone else. And community is the way to reach those smart people and work with them.
|
||||
|
||||
Second, a community can be an obvious source of product feedback—always necessary as you're researching potential paths forward. If someone gives you feedback, it means that person cares about you. It's a big gift. The community is a good place to acquire such invaluable feedback. Receiving early feedback is super important, because it reduces the cost of developing something that doesn't work in your target market. You can safely fail early, fail fast, and fail often.
|
||||
|
||||
And third, communities help you generate comparisons with other projects. You can't know all the features, pros, and cons of your competitors' offerings. [The community, however, can.][7] Ask your community.
|
||||
|
||||
### 3\. Perspective
|
||||
|
||||
Communities enable companies to look at themselves and their products [from the outside][8], letting them catch strengths and weaknesses, and mostly realize who their products' audiences really are.
|
||||
|
||||
Let me offer an example. When we launched the NethServer, we chose a catchy tagline for it. We were all convinced the following sentence was perfect:
|
||||
|
||||
> [NethServer][9] is an operating system for Linux enthusiasts, designed for small offices and medium enterprises.
|
||||
|
||||
Two years have passed since then. And we've learned that sentence was an epic fail.
|
||||
|
||||
We failed to realize who our audience was. Now we know: NethServer is not just for Linux enthusiasts; actually, Windows users are the majority. It's not just for small offices and medium enterprises; actually, several home users install NethServer for personal use. Our community helps us to fully understand our product and look at it from our users' eyes.
|
||||
|
||||
### 4\. Development
|
||||
|
||||
In open source communities especially, communities can be a welcome source of product development.
|
||||
|
||||
They can, first of all, provide testing and bug reporting. In fact, if I ask my developers about the most important community benefit, they'd answer "testing and bug reporting." Definitely. But because your code is freely available to the whole world, practically anyone with a good working knowledge of it (even hobbyists and other companies) has the opportunity to play with it, tweak it, and constantly improve it (even develop additional modules, as in our case). People can do more than just report bugs; they can fix those bugs, too, if they have the time and knowledge.
|
||||
|
||||
But the community doesn't just create code. It can also generate resources like [how-to guides,][10] FAQs, support documents, and case studies. How much would it cost to fully translate your product in seven different languages? At NethServer, we got that for free—thanks to our community members.
|
||||
|
||||
### 5\. Marketing
|
||||
|
||||
Communities can help your company go global. Our small Italian company, for example, wasn't prepared for a global market. The community got us prepared. For example, we needed to study and improve our English so we could read and write correctly or speak in public without looking foolish for an audience. The community gently forced us to organize [our first NethServer Conference][11], too—only in English.
|
||||
|
||||
A strong community can also help your organization attain the holy grail of marketers everywhere: word of mouth marketing (or what Seth Godin calls "[tribal marketing][12]").
|
||||
|
||||
Communities ensure that your company's messaging travels not only from company to tribe but also "sideways," from tribe member to potential tribe member. The community will become your street team, spreading word of your organization and its projects to anyone who will listen.
|
||||
|
||||
In addition, communities help organizations satisfy one of the most fundamental members needs: the desire to belong, to be involved in something bigger than themselves, and to change the world together.
|
||||
|
||||
Never forget that working with communities is always a matter of giving and taking—striking a delicate balance between the company and the community.
|
||||
|
||||
### 6\. Loyalty
|
||||
|
||||
Attracting new users costs a business five times as much as keeping an existing one. So loyalty can have a huge impact on your bottom line. Quite simply, community helps us build brand loyalty. It's much more difficult to leave a group of people you're connected to than a faceless product or company. In a community, you're building connections with people, which is way more powerful than features or money (trust me!).
|
||||
|
||||
### Conclusion
|
||||
|
||||
Never forget that working with communities is always a matter of giving and taking—striking a delicate balance between the company and the community.
|
||||
|
||||
And I wouldn't be honest with you if I didn't admit that the approach has some drawbacks. Doing everything in the open means moderating, evaluating, and processing of all the data you're receiving. Supporting your members and leading the discussions definitely takes time and resources. But, if you look at what a community enables, you'll see that all this is totally worth the effort.
|
||||
|
||||
As my friend and mentor [David Spinks keeps saying over and over again][13], "Companies fail their communities when when they treat community as a tactic instead of making it a core part of their business philosophy." And [as I've said][4]: Communities aren't simply extensions of your marketing teams; "community" isn't an efficient short-term strategy. When community is a core part of your business philosophy, it can do so much more than give you short-term returns.
|
||||
|
||||
At Nethesis we experience that every single day. As a small company, we could never have achieved the results we have without our community. Never.
|
||||
|
||||
Community can completely set your business apart from every other company in the field. It can redefine markets. It can inspire millions of people, give them a sense of belonging, and make them feel an incredible bond with your company.
|
||||
|
||||
And it can make you a whole lot of money.
|
||||
|
||||
Community-driven companies will always win. Remember that.
|
||||
|
||||
[Subscribe to our weekly newsletter][14] to learn more about open organizations.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/18/3/why-build-community-3
|
||||
|
||||
作者:[Alessio Fattorini][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/alefattorini
|
||||
[1]:http://www.nethesis.it/
|
||||
[2]:https://www.nethserver.org/
|
||||
[3]:https://distrowatch.com/table.php?distribution=nethserver
|
||||
[4]:https://opensource.com/open-organization/18/2/why-build-community-2
|
||||
[5]:https://www.goodreads.com/author/quotes/52938.Linus_Pauling
|
||||
[6]:https://blog.codinghorror.com/ivory-tower-development/
|
||||
[7]:https://community.nethserver.org/tags/comparison
|
||||
[8]:https://community.nethserver.org/t/improve-our-communication/2569
|
||||
[9]:http://www.nethserver.org/
|
||||
[10]:https://community.nethserver.org/c/howto
|
||||
[11]:https://community.nethserver.org/t/nethserver-conference-in-italy-sept-29-30-2017/6404
|
||||
[12]:https://www.ted.com/talks/seth_godin_on_the_tribes_we_lead
|
||||
[13]:http://cmxhub.com/article/community-business-philosophy-tactic/
|
||||
[14]:https://opensource.com/open-organization/resources/newsletter
|
||||
@ -0,0 +1,40 @@
|
||||
Lessons Learned from Growing an Open Source Project Too Fast
|
||||
======
|
||||
![open source project][1]
|
||||
|
||||
Are you managing an open source project or considering launching one? If so, it may come as a surprise that one of the challenges you can face is rapid growth. Matt Butcher, Principal Software Development Engineer at Microsoft, addressed this issue in a presentation at Open Source Summit North America. His talk covered everything from teamwork to the importance of knowing your goals and sticking to them.
|
||||
|
||||
Butcher is no stranger to managing open source projects. As [Microsoft invests more deeply into open source][2], Butcher has been involved with many projects, including toolkits for Kubernetes and QueryPath, the jQuery-like library for PHP.
|
||||
|
||||
Butcher described a case study involving Kubernetes Helm, a package system for Kubernetes. Helm arose from a company team-building hackathon, with an original team of three people giving birth to it. Within 18 months, the project had hundreds of contributors and thousands of active users.
|
||||
|
||||
### Teamwork
|
||||
|
||||
“We were stretched to our limits as we learned to grow,” Butcher said. “When you’re trying to set up your team of core maintainers and they’re all trying to work together, you want to spend some actual time trying to optimize for a process that lets you be cooperative. You have to adjust some expectations regarding how you treat each other. When you’re working as a group of open source collaborators, the relationship is not employer/employee necessarily. It’s a collaborative effort.”
|
||||
|
||||
In addition to focusing on the right kinds of teamwork, Butcher and his collaborators learned that managing governance and standards is an ongoing challenge. “You want people to understand who makes decisions, how they make decisions and why they make the decisions that they make,” he said. “When we were a small project, there might have been two paragraphs in one of our documents on standards, but as a project grows and you get growing pains, these documented things gain a life of their own. They get their very own repositories, and they just keep getting bigger along with the project.”
|
||||
|
||||
Should all discussion surrounding a open source project go on in public, bathed in the hot lights of community scrutiny? Not necessarily, Butcher noted. “A minor thing can get blown into catastrophic proportions in a short time because of misunderstandings and because something that should have been done in private ended up being public,” he said. “Sometimes we actually make architectural recommendations as a closed group. The reason we do this is that we don’t want to miscue the community. The people who are your core maintainers are core maintainers because they’re experts, right? These are the people that have been selected from the community because they understand the project. They understand what people are trying to do with it. They understand the frustrations and concerns of users.”
|
||||
|
||||
### Acknowledge Contributions
|
||||
|
||||
Butcher added that it is essential to acknowledge people’s contributions to keep the environment surrounding a fast-growing project from becoming toxic. “We actually have an internal rule in our core maintainers guide that says, ‘Make sure that at least one comment that you leave on a code review, if you’re asking for changes, is a positive one,” he said. “It sounds really juvenile, right? But it serves a specific purpose. It lets somebody know, ‘I acknowledge that you just made a gift of your time and your resources.”
|
||||
|
||||
Want more tips on successfully launching and managing open source projects? Stay tuned for more insight from Matt Butcher’s talk, in which he provides specific project management issues faced by Kubernetes Helm.
|
||||
|
||||
For more information, be sure to check out [The Linux Foundation’s growing list of Open Source Guides for the Enterprise][3], covering topics such as starting an open source project, improving your open source impact, and participating in open source communities.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxfoundation.org/blog/lessons-learned-from-growing-an-open-source-project-too-fast/
|
||||
|
||||
作者:[Sam Dean][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxfoundation.org/author/sdean/
|
||||
[1]:https://www.linuxfoundation.org/wp-content/uploads/2018/03/huskies-2279627_1920.jpg
|
||||
[2]:https://thenewstack.io/microsoft-shifting-emphasis-open-source/
|
||||
[3]:https://www.linuxfoundation.org/resources/open-source-guides/
|
||||
@ -0,0 +1,119 @@
|
||||
How to avoid humiliating newcomers: A guide for advanced developers
|
||||
======
|
||||
|
||||

|
||||
Every year in New York City, a few thousand young men come to town, dress up like Santa Claus, and do a pub crawl. One year during this SantaCon event, I was walking on the sidewalk and minding my own business, when I saw an extraordinary scene. There was a man dressed up in a red hat and red jacket, and he was talking to a homeless man who was sitting in a wheelchair. The homeless man asked Santa Claus, "Can you spare some change?" Santa dug into his pocket and brought out a $5 bill. He hesitated, then gave it to the homeless man. The homeless man put the bill in his pocket.
|
||||
|
||||
In an instant, something went wrong. Santa yelled at the homeless man, "I gave you $5. I wanted to give you one dollar, but five is the smallest I had, so you oughtta be grateful. This is your lucky day, man. You should at least say thank you!"
|
||||
|
||||
This was a terrible scene to witness. First, the power difference was terrible: Santa was an able-bodied white man with money and a home, and the other man was black, homeless, and using a wheelchair. It was also terrible because Santa Claus was dressed like the very symbol of generosity! And he was behaving like Santa until, in an instant, something went wrong and he became cruel.
|
||||
|
||||
This is not merely a story about Drunk Santa, however; this is a story about technology communities. We, too, try to be generous when we answer new programmers' questions, and every day our generosity turns to rage. Why?
|
||||
|
||||
### My cruelty
|
||||
|
||||
I'm reminded of my own bad behavior in the past. I was hanging out on my company's Slack when a new colleague asked a question.
|
||||
|
||||
> **New Colleague:** Hey, does anyone know how to do such-and-such with MongoDB?
|
||||
> **Jesse:** That's going to be implemented in the next release.
|
||||
> **New Colleague:** What's the ticket number for that feature?
|
||||
> **Jesse:** I memorize all ticket numbers. It's #12345.
|
||||
> **New Colleague:** Are you sure? I can't find ticket 12345.
|
||||
|
||||
He had missed my sarcasm, and his mistake embarrassed him in front of his peers. I laughed to myself, and then I felt terrible. As one of the most senior programmers at MongoDB, I should not have been setting this example. And yet, such behavior is commonplace among programmers everywhere: We get sarcastic with newcomers, and we humiliate them.
|
||||
|
||||
### Why does it matter?
|
||||
|
||||
Perhaps you are not here to make friends; you are here to write code. If the code works, does it matter if we are nice to each other or not?
|
||||
|
||||
A few months ago on the Stack Overflow blog, David Robinson showed that [Python has been growing dramatically][1], and it is now the top language that people view questions about on Stack Overflow. Even in the most pessimistic forecast, it will far outgrow the other languages this year.
|
||||
|
||||
![Projections for programming language popularity][2]
|
||||
|
||||
If you are a Python expert, then the line surging up and to the right is good news for you. It does not represent competition, but confirmation. As more new programmers learn Python, our expertise becomes ever more valuable, and we will see that reflected in our salaries, our job opportunities, and our job security.
|
||||
|
||||
But there is a danger. There are soon to be more new Python programmers than ever before. To sustain this growth, we must welcome them, and we are not always a welcoming bunch.
|
||||
|
||||
### The trouble with Stack Overflow
|
||||
|
||||
I searched Stack Overflow for rude answers to beginners' questions, and they were not hard to find.
|
||||
|
||||
![An abusive answer on StackOverflow][3]
|
||||
|
||||
The message is plain: If you are asking a question this stupid, you are doomed. Get out.
|
||||
|
||||
I immediately found another example of bad behavior:
|
||||
|
||||
![Another abusive answer on Stack Overflow][4]
|
||||
|
||||
Who has never been confused by Unicode in Python? Yet the message is clear: You do not belong here. Get out.
|
||||
|
||||
Do you remember how it felt when you needed help and someone insulted you? It feels terrible. And it decimates the community. Some of our best experts leave every day because they see us treating each other this way. Maybe they still program Python, but they are no longer participating in conversations online. This cruelty drives away newcomers, too, particularly members of groups underrepresented in tech who might not be confident they belong. People who could have become the great Python programmers of the next generation, but if they ask a question and somebody is cruel to them, they leave.
|
||||
|
||||
This is not in our interest. It hurts our community, and it makes our skills less valuable because we drive people out. So, why do we act against our own interests?
|
||||
|
||||
### Why generosity turns to rage
|
||||
|
||||
There are a few scenarios that really push my buttons. One is when I act generously but don't get the acknowledgment I expect. (I am not the only person with this resentment: This is probably why Drunk Santa snapped when he gave a $5 bill to a homeless man and did not receive any thanks.)
|
||||
|
||||
Another is when answering requires more effort than I expect. An example is when my colleague asked a question on Slack and followed-up with, "What's the ticket number?" I had judged how long it would take to help him, and when he asked for more help, I lost my temper.
|
||||
|
||||
These scenarios boil down to one problem: I have expectations for how things are going to go, and when those expectations are violated, I get angry.
|
||||
|
||||
I've been studying Buddhism for years, so my understanding of this topic is based in Buddhism. I like to think that the Buddha discussed the problem of expectations in his first tech talk when, in his mid-30s, he experienced a breakthrough after years of meditation and convened a small conference to discuss his findings. He had not rented a venue, so he sat under a tree. The attendees were a handful of meditators the Buddha had met during his wanderings in northern India. The Buddha explained that he had discovered four truths:
|
||||
|
||||
* First, that to be alive is to be dissatisfied—to want things to be better than they are now.
|
||||
* Second, this dissatisfaction is caused by wants; specifically, by our expectation that if we acquire what we want and eliminate what we do not want, it will make us happy for a long time. This expectation is unrealistic: If I get a promotion or if I delete 10 emails, it is temporarily satisfying, but it does not make me happy over the long-term. We are dissatisfied because every material thing quickly disappoints us.
|
||||
* The third truth is that we can be liberated from this dissatisfaction by accepting our lives as they are.
|
||||
* The fourth truth is that the way to transform ourselves is to understand our minds and to live a generous and ethical life.
|
||||
|
||||
|
||||
|
||||
I still get angry at people on the internet. It happened to me recently, when someone posted a comment on [a video I published about Python co-routines][5]. It had taken me months of research and preparation to create this video, and then a newcomer commented, "I want to master python what should I do."
|
||||
|
||||
![Comment on YouTube][6]
|
||||
|
||||
This infuriated me. My first impulse was to be sarcastic, "For starters, maybe you could spell Python with a capital P and end a question with a question mark." Fortunately, I recognized my anger before I acted on it, and closed the tab instead. Sometimes liberation is just a Command+W away.
|
||||
|
||||
### What to do about it
|
||||
|
||||
If you joined a community with the intent to be helpful but on occasion find yourself flying into a rage, I have a method to prevent this. For me, it is the step when I ask myself, "Am I angry?" Knowing is most of the battle. Online, however, we can lose track of our emotions. It is well-established that one reason we are cruel on the internet is because, without seeing or hearing the other person, our natural empathy is not activated. But the other problem with the internet is that, when we use computers, we lose awareness of our bodies. I can be angry and type a sarcastic message without even knowing I am angry. I do not feel my heart pound and my neck grow tense. So, the most important step is to ask myself, "How do I feel?"
|
||||
|
||||
If I am too angry to answer, I can usually walk away. As [Thumper learned in Bambi][7], "If you can't say something nice, don't say nothing at all."
|
||||
|
||||
### The reward
|
||||
|
||||
Helping a newcomer is its own reward, whether you receive thanks or not. But it does not hurt to treat yourself to a glass of whiskey or a chocolate, or just a sigh of satisfaction after your good deed.
|
||||
|
||||
But besides our personal rewards, the payoff for the Python community is immense. We keep the line surging up and to the right. Python continues growing, and that makes our own skills more valuable. We welcome new members, people who might not be sure they belong with us, by reassuring them that there is no such thing as a stupid question. We use Python to create an inclusive and diverse community around writing code. And besides, it simply feels good to be part of a community where people treat each other with respect. It is the kind of community that I want to be a member of.
|
||||
|
||||
### The three-breath vow
|
||||
|
||||
There is one idea I hope you remember from this article: To control our behavior online, we must occasionally pause and notice our feelings. I invite you, if you so choose, to repeat the following vow out loud:
|
||||
|
||||
> I vow
|
||||
> to take three breaths
|
||||
> before I answer a question online.
|
||||
|
||||
This article is based on a talk, [Why Generosity Turns To Rage, and What To Do About It][8], that Jesse gave at PyTennessee in February. For more insight for Python developers, attend [PyCon 2018][9], May 9-17 in Cleveland, Ohio.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/avoid-humiliating-newcomers
|
||||
|
||||
作者:[A. Jesse][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/emptysquare
|
||||
[1]:https://stackoverflow.blog/2017/09/06/incredible-growth-python/
|
||||
[2]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/projections.png?itok=5QTeJ4oe (Projections for programming language popularity)
|
||||
[3]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/abusive-answer-1.jpg?itok=BIWW10Rl (An abusive answer on StackOverflow)
|
||||
[4]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/abusive-answer-2.jpg?itok=0L-n7T-k (Another abusive answer on Stack Overflow)
|
||||
[5]:https://www.youtube.com/watch?v=7sCu4gEjH5I
|
||||
[6]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/i-want-to-master-python.png?itok=Y-2u1XwA (Comment on YouTube)
|
||||
[7]:https://www.youtube.com/watch?v=nGt9jAkWie4
|
||||
[8]:https://www.pytennessee.org/schedule/presentation/175/
|
||||
[9]:https://us.pycon.org/2018/
|
||||
@ -0,0 +1,59 @@
|
||||
6 common questions about agile development practices for teams
|
||||
======
|
||||
|
||||

|
||||
"Any questions?"
|
||||
|
||||
You’ve probably heard a speaker ask this question at the end of their presentation. This is the most important part of the presentation—after all, you didn't attend just to hear a lecture but to participate in a conversation and a community.
|
||||
|
||||
Recently I had the opportunity to hear my fellow Red Hatters present a session called "[Agile in Practice][1]" to a group of technical students at a local university. During the session, software engineer Tomas Tomecek and agile practitioners Fernando Colleone and Pavel Najman collaborated to explain the foundations of agile methodology and showcase best practices for day-to-day activities.
|
||||
|
||||
### 1\. What is the perfect team size?
|
||||
|
||||
Knowing that students attended this session to learn what agile practice is and how to apply it to projects, I wondered how the students' questions would compare to those I hear every day as an agile practitioner at Red Hat. It turns out that the students asked the same questions as my colleagues. These questions drive straight into the core of agile in practice.
|
||||
|
||||
Students wanted to know the size of a small team versus a large team. This issue is relevant to anyone who has ever teamed up to work on a project. Based on Tomas's experience as a tech leader, 12 people working on a project would be considered a large team. In the real world, team size is not often directly correlated to productivity. In some cases, a smaller team located in a single location or time zone might be more productive than a larger team that's spread around the world. Ultimately, the presenters suggested that the ideal team size is probably five people (which aligns with scrum 7, +-2).
|
||||
|
||||
### 2\. What operational challenges do teams face?
|
||||
|
||||
The presenters compared projects supported by local teams (teams with all members in one office or within close proximity to each other) with distributed teams (teams located in different time zones). Engineers prefer local teams when the project requires close cooperation among team members because delays caused by time differences can destroy the "flow" of writing software. At the same time, distributed teams can bring together skill sets that may not be available locally and are great for certain development use cases. Also, there are various best practices to improve cooperation in distributed teams.
|
||||
|
||||
### 3\. How much time is needed to groom the backlog?
|
||||
|
||||
Because this was an introductory talk targeting students who were new to agile, the speakers focused on [Scrum][2] and [Kanban][3] as ways to make agile specific for them. They used the Scrum framework to illustrate a method of writing software and Kanban for a communication and work planning system. On the question of time needed to groom a project's backlog, the speakers explained that there is no fixed rule. Rather, practice makes perfect: During the early stages of development, when a project is new—and especially if some members of the team are new to agile—grooming can consume several hours per week. Over time and with practice, it becomes more efficient.
|
||||
|
||||
### 4\. Is a product owner necessary? What is their role?
|
||||
|
||||
Product owners help facilitate scaling; however, what matters is not the job title, but that you have someone on your team who represents the customer's voice and goals. In many teams, especially those that are part of a larger group of engineering teams working on a single output, a lead engineer can serve as the product owner.
|
||||
|
||||
### 5\. What agile tools do you suggest using? Is specific software necessary to implement Scrum or Kanban in practice?
|
||||
|
||||
Although using proprietary software such as Jira or Trello can be helpful, especially when working with large numbers of contributors working on big enterprise projects, they are not required. Scrum and Kanban can be done with tools as simple as paper cards. The key is to have a clear source of information and strong communication across the entire team. That said, two excellent open source kanban tools are [Taiga][4] and [Wekan][5]. For more information, see [5 open source alternatives to Trello][6] and [Top 7 open source project management tools for agile teams][7].
|
||||
|
||||
### 6\. How can students use agile techniques for school projects?
|
||||
|
||||
The presenters encouraged students to use kanban to visualize and outline tasks to be completed before the end of the project. The key is to create a common board so the entire team can see the status of the project. By using kanban or a similar high-visibility strategy, students won’t get to the end of the project and discover that any particular team member has not been keeping up.
|
||||
|
||||
Scrum practices such as sprints and daily standups are also excellent ways to ensure that everyone is making progress and that the various parts of the project will work together at the end. Regular check-ins and information-sharing are also essential. To learn more about Scrum, see [What is scrum?][8].
|
||||
|
||||
Remember that Kanban and Scrum are just two of many tools and frameworks that make up agile. They may not be the best approach for every situation.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/agile-mindset
|
||||
|
||||
作者:[Dominika Bula][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dominika
|
||||
[1]:http://zijemeit.cz/sessions/agile-in-practice/
|
||||
[2]:https://www.scrum.org/resources/what-is-scrum
|
||||
[3]:https://en.wikipedia.org/wiki/Kanban
|
||||
[4]:https://taiga.io/
|
||||
[5]:https://wekan.github.io/
|
||||
[6]:https://opensource.com/alternatives/trello
|
||||
[7]:https://opensource.com/article/18/2/agile-project-management-tools
|
||||
[8]:https://opensource.com/resources/scrum
|
||||
@ -0,0 +1,70 @@
|
||||
Can we build a social network that serves users rather than advertisers?
|
||||
======
|
||||
|
||||

|
||||
|
||||
Today, open source software is far-reaching and has played a key role driving innovation in our digital economy. The world is undergoing radical change at a rapid pace. People in all parts of the world need a purpose-built, neutral, and transparent online platform to meet the challenges of our time.
|
||||
|
||||
And open principles might just be the way to get us there. What would happen if we married digital innovation with social innovation using open-focused thinking?
|
||||
|
||||
This question is at the heart of our work at [Human Connection][1], a forward-thinking, Germany-based knowledge and action network with a mission to create a truly social network that serves the world. We're guided by the notion that human beings are inherently generous and sympathetic, and that they thrive on benevolent actions. But we haven't seen a social network that has fully supported our natural tendency towards helpfulness and cooperation to promote the common good. Human Connection aspires to be the platform that allows everyone to become an active changemaker.
|
||||
|
||||
In order to achieve the dream of a solution-oriented platform that enables people to take action around social causes by engaging with charities, community groups, and social change activists, Human Connection embraces open values as a vehicle for social innovation.
|
||||
|
||||
Here's how.
|
||||
|
||||
### Transparency first
|
||||
|
||||
Transparency is one of Human Connection's guiding principles. Human Connection invites programmers around the world to jointly work on the platform's source code (JavaScript, Vue, nuxt) by [making their source code available on Github][2] and support the idea of a truly social network by contributing to the code or programming additional functions.
|
||||
|
||||
But our commitment to transparency extends beyond our development practices. In fact—when it comes to building a new kind of social network that promotes true connection and interaction between people who are passionate about changing the world for the better—making the source code available is just one step towards being transparent.
|
||||
|
||||
To facilitate open dialogue, the Human Connection team holds [regular public meetings online][3]. Here we answer questions, encourage suggestions, and respond to potential concerns. Our Meet The Team events are also recorded and made available to the public afterwards. By being fully transparent with our process, our source code, and our finances, we can protect ourselves against critics or other potential backlashes.
|
||||
|
||||
The commitment to transparency also means that all user contributions that shared publicly on Human Connection will be released under a Creative Commons license and can eventually be downloaded as a data pack. By making crowd knowledge available, especially in a decentralized way, we create the opportunity for social pluralism.
|
||||
|
||||
Guiding all of our organizational decisions is one question: "Does it serve the people and the greater good?" And we use the [UN Charter][4] and the Universal Declaration of Human Rights as a foundation for our value system. As we'll grow bigger, especially with our upcoming open beta launch, it's important for us to stay accountable to that mission. I'm even open to the idea of inviting the Chaos Computer Club or other hacker clubs to verify the integrity of our code and our actions by randomly checking into our platform.
|
||||
|
||||
When it comes to building a new kind of social network that promotes true connection and interaction between people who are passionate about changing the world for the better, making the source code available is just one step towards being transparent.
|
||||
|
||||
### A collaborative community
|
||||
|
||||
A [collaborative, community-centered approach][5] to programming the Human Connection platform is the foundation for an idea that extends beyond the practical applications of a social network. Our team is driven by finding an answer to the question: "What makes a social network truly social?"
|
||||
|
||||
A network that abandons the idea of a profit-driven algorithm serving advertisers instead of end-users can only thrive by turning to the process of peer production and collaboration. Organizations like [Code Alliance][6] and [Code for America][7], for example, have demonstrated how technology can be created in an open source environment to benefit humanity and disrupt the status quo. Community-driven projects like the map-based reporting platform [FixMyStreet][8] or the [Tasking Manager][9] built for the Humanitarian OpenStreetMap initiative have embraced crowdsourcing as a way to move their mission forward.
|
||||
|
||||
Our approach to building Human Connection has been collaborative from the start. To gather initial data on the necessary functions and the purpose of a truly social network, we collaborated with the National Institute for Oriental Languages and Civilizations (INALCO) at the University Sorbonne in Paris and the Stuttgart Media University in Germany. Research findings from both projects were incorporated into the early development of Human Connection. Thanks to that research, [users will have a whole new set of functions available][10] that put them in control of what content they see and how they engage with others. As early supporters are [invited to the network's alpha version][10], they can experience the first available noteworthy functions. Here are just a few:
|
||||
|
||||
* Linking information to action was one key theme emerging from our research sessions. Current social networks leave users in the information stage. Student groups at both universities saw a need for an action-oriented component that serves our human instinct of working together to solve problems. So we built a ["Can Do" function][11] into our platform. It's one of the ways individuals can take action after reading about a certain topic. "Can Do's" are user-suggested activities in the "Take Action" area that everyone can implement.
|
||||
* The "Versus" function is another defining result. Where traditional social networks are limited to a comment function, our student groups saw the need for a more structured and useful way to engage in discussions and arguments. A "Versus" is a counter-argument to a public post that is displayed separately and provides an opportunity to highlight different opinions around an issue.
|
||||
* Today's social networks don't provide a lot of options to filter content. Research has shown that a filtering option by emotions can help us navigate the social space in accordance with our daily mood and potentially protect our emotional wellbeing by not displaying sad or upsetting posts on a day where we want to see uplifting content only.
|
||||
|
||||
|
||||
|
||||
Human Connection invites changemakers to collaborate on the development of a network with the potential to mobilize individuals and groups around the world to turn negative news into "Can Do's"—and participate in social innovation projects in conjunction with charities and non-profit organizations.
|
||||
|
||||
[Subscribe to our weekly newsletter][12] to learn more about open organizations.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/18/3/open-social-human-connection
|
||||
|
||||
作者:[Dennis Hack][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dhack
|
||||
[1]:https://human-connection.org/en/
|
||||
[2]:https://github.com/human-connection/
|
||||
[3]:https://youtu.be/tPcYRQcepYE
|
||||
[4]:http://www.un.org/en/charter-united-nations/index.html
|
||||
[5]:https://youtu.be/BQHBno-efRI
|
||||
[6]:http://codealliance.org/
|
||||
[7]:https://www.codeforamerica.org/
|
||||
[8]:http://fixmystreet.org/
|
||||
[9]:https://tasks.hotosm.org/
|
||||
[10]:https://youtu.be/AwSx06DK2oU
|
||||
[11]:https://youtu.be/g2gYLNx686I
|
||||
[12]:https://opensource.com/open-organization/resources/newsletter
|
||||
@ -0,0 +1,66 @@
|
||||
8 tips for better agile retrospective meetings
|
||||
======
|
||||
|
||||

|
||||
I’ve often thought that retrospectives should be called prospectives, as that term concerns the future rather than focusing on the past. The retro itself is truly future-looking: It’s the space where we can ask the question, “With what we know now, what’s the next experiment we need to try for improving our lives, and the lives of our customers?”
|
||||
|
||||
### What’s a retro supposed to look like?
|
||||
|
||||
There are two significant loops in product development: One produces the desired potentially shippable nugget. The other is where we examine how we’re working—not only to avoid doing what didn’t work so well, but also to determine how we can amplify the stuff we do well—and devise an experiment to pull into the next production loop to improve how our team is delighting our customers. This is the loop on the right side of this diagram:
|
||||
|
||||
|
||||
![Retrospective 1][2]
|
||||
|
||||
### When retros implode
|
||||
|
||||
While attending various teams' iteration retrospective meetings, I saw a common thread of malcontent associated with a relentless focus on continuous improvement.
|
||||
|
||||
One of the engineers put it bluntly: “[Our] continuous improvement feels like we are constantly failing.”
|
||||
|
||||
The teams talked about what worked, restated the stuff that didn’t work (perhaps already feeling like they were constantly failing), nodded to one another, and gave long sighs. Then one of the engineers (already late for another meeting) finally summed up the meeting: “Ok, let’s try not to submit all of the code on the last day of the sprint.” There was no opportunity to amplify the good, as the good was not discussed.
|
||||
|
||||
In effect, here’s what the retrospective felt like:
|
||||
|
||||

|
||||
|
||||
The anti-pattern is where retrospectives become dreaded sessions where we look back at the last iteration, make two columns—what worked and what didn’t work—and quickly come to some solution for the next iteration. There is no [scientific method][3] involved. There is no data gathering and research, no hypothesis, and very little deep thought. The result? You don’t get an experiment or a potential improvement to pull into the next iteration.
|
||||
|
||||
### 8 tips for better retrospectives
|
||||
|
||||
1. Amplify the good! Instead of focusing on what didn’t work well, why not begin the retro by having everyone mention one positive item first?
|
||||
2. Don’t jump to a solution. Thinking about a problem deeply instead of trying to solve it right away might be a better option.
|
||||
3. If the retrospective doesn’t make you feel excited about an experiment, maybe you shouldn’t try it in the next iteration.
|
||||
4. If you’re not analyzing how to improve, ([5 Whys][4], [force-field analysis][5], [impact mapping][6], or [fish-boning][7]), you might be jumping to solutions too quickly.
|
||||
5. Vary your methods. If every time you do a retrospective you ask, “What worked, what didn’t work?” and then vote on the top item from either column, your team will quickly get bored. [Retromat][8] is a great free retrospective tool to help vary your methods.
|
||||
6. End each retrospective by asking for feedback on the retro itself. This might seem a bit meta, but it works: Continually improving the retrospective is recursively improving as a team.
|
||||
7. Remove the impediments. Ask how you are enabling the team's search for improvement, and be prepared to act on any feedback.
|
||||
8. There are no "iteration police." Take breaks as needed. Deriving hypotheses from analysis and coming up with experiments involves creativity, and it can be taxing. Every once in a while, go out as a team and enjoy a nice retrospective lunch.
|
||||
|
||||
|
||||
|
||||
This article was inspired by [Retrospective anti-pattern: continuous improvement should not feel like constantly failing][9], posted at [Podojo.com][10].
|
||||
|
||||
**[See our related story,[How to build a business case for DevOps transformation][11].]**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/tips-better-agile-retrospective-meetings
|
||||
|
||||
作者:[Catherine Louis][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/catherinelouis
|
||||
[1]:/file/389021
|
||||
[2]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/images/life-uploads/retro_1.jpg?itok=bggmHN1Q (Retrospective 1)
|
||||
[3]:https://en.wikipedia.org/wiki/Scientific_method
|
||||
[4]:https://en.wikipedia.org/wiki/5_Whys
|
||||
[5]:https://en.wikipedia.org/wiki/Force-field_analysis
|
||||
[6]:https://opensource.com/open-organization/17/6/experiment-impact-mapping
|
||||
[7]:https://en.wikipedia.org/wiki/Ishikawa_diagram
|
||||
[8]:https://plans-for-retrospectives.com/en/?id=28
|
||||
[9]:http://www.podojo.com/retrospective-anti-pattern-continuous-improvement-should-not-feel-like-constantly-failing/
|
||||
[10]:http://www.podojo.com/
|
||||
[11]:https://opensource.com/article/18/2/how-build-business-case-devops-transformation
|
||||
104
sources/tech/20140107 Caffeinated 6.828- Exercise- Shell.md
Normal file
104
sources/tech/20140107 Caffeinated 6.828- Exercise- Shell.md
Normal file
@ -0,0 +1,104 @@
|
||||
Caffeinated 6.828: Exercise: Shell
|
||||
======
|
||||
|
||||
This assignment will make you more familiar with the Unix system call interface and the shell by implementing several features in a small shell. You can do this assignment on any operating system that supports the Unix API (a Linux Athena machine, your laptop with Linux or Mac OS, etc.). Please submit your shell to the the [submission web site][1] at any time before the first lecture.
|
||||
|
||||
While you shouldn't be shy about emailing the [staff mailing list][2] if you get stuck or don't understand something in this exercise, we do expect you to be able to handle this level of C programming on your own for the rest of the class. If you're not very familiar with C, consider this a quick check to see how familiar you are. Again, do feel encouraged to ask us for help if you have any questions.
|
||||
|
||||
Download the [skeleton][3] of the xv6 shell, and look it over. The skeleton shell contains two main parts: parsing shell commands and implementing them. The parser recognizes only simple shell commands such as the following:
|
||||
```
|
||||
ls > y
|
||||
cat < y | sort | uniq | wc > y1
|
||||
cat y1
|
||||
rm y1
|
||||
ls | sort | uniq | wc
|
||||
rm y
|
||||
|
||||
```
|
||||
|
||||
Cut and paste these commands into a file `t.sh`
|
||||
|
||||
You can compile the skeleton shell as follows:
|
||||
```
|
||||
$ gcc sh.c
|
||||
|
||||
```
|
||||
|
||||
which produces a file named `a.out`, which you can run:
|
||||
```
|
||||
$ ./a.out < t.sh
|
||||
|
||||
```
|
||||
|
||||
This execution will panic because you have not implemented several features. In the rest of this assignment you will implement those features.
|
||||
|
||||
### Executing simple commands
|
||||
|
||||
Implement simple commands, such as:
|
||||
```
|
||||
$ ls
|
||||
|
||||
```
|
||||
|
||||
The parser already builds an `execcmd` for you, so the only code you have to write is for the ' ' case in `runcmd`. To test that you can run "ls". You might find it useful to look at the manual page for `exec`; type `man 3 exec`.
|
||||
|
||||
You do not have to implement quoting (i.e., treating the text between double-quotes as a single argument).
|
||||
|
||||
### I/O redirection
|
||||
|
||||
Implement I/O redirection commands so that you can run:
|
||||
```
|
||||
echo "6.828 is cool" > x.txt
|
||||
cat < x.txt
|
||||
|
||||
```
|
||||
|
||||
The parser already recognizes '>' and '<', and builds a `redircmd` for you, so your job is just filling out the missing code in `runcmd` for those symbols. Make sure your implementation runs correctly with the above test input. You might find the man pages for `open` (`man 2 open`) and `close` useful.
|
||||
|
||||
Note that this shell will not process quotes in the same way that `bash`, `tcsh`, `zsh` or other UNIX shells will, and your sample file `x.txt` is expected to contain the quotes.
|
||||
|
||||
### Implement pipes
|
||||
|
||||
Implement pipes so that you can run command pipelines such as:
|
||||
```
|
||||
$ ls | sort | uniq | wc
|
||||
|
||||
```
|
||||
|
||||
The parser already recognizes "|", and builds a `pipecmd` for you, so the only code you must write is for the '|' case in `runcmd`. Test that you can run the above pipeline. You might find the man pages for `pipe`, `fork`, `close`, and `dup` useful.
|
||||
|
||||
Now you should be able the following command correctly:
|
||||
```
|
||||
$ ./a.out < t.sh
|
||||
|
||||
```
|
||||
|
||||
Don't forget to submit your solution to the [submission web site][1], with or without challenge solutions.
|
||||
|
||||
### Challenge exercises
|
||||
|
||||
If you'd like to experiment more, you can add any feature of your choice to your shell. You might try one of the following suggestions:
|
||||
|
||||
* Implement lists of commands, separated by `;`
|
||||
* Implement subshells by implementing `(` and `)`
|
||||
* Implement running commands in the background by supporting `&` and `wait`
|
||||
* Implement quoting of arguments
|
||||
|
||||
|
||||
|
||||
All of these require making changing to the parser and the `runcmd` function.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://sipb.mit.edu/iap/6.828/lab/shell/
|
||||
|
||||
作者:[mit][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://sipb.mit.edu
|
||||
[1]:https://exokernel.scripts.mit.edu/submit/
|
||||
[2]:mailto:sipb-iap-6.828@mit.edu
|
||||
[3]:https://sipb.mit.edu/iap/6.828/files/sh.c
|
||||
624
sources/tech/20140110 Caffeinated 6.828- Lab 1- Booting a PC.md
Normal file
624
sources/tech/20140110 Caffeinated 6.828- Lab 1- Booting a PC.md
Normal file
@ -0,0 +1,624 @@
|
||||
Caffeinated 6.828: Lab 1: Booting a PC
|
||||
======
|
||||
|
||||
### Introduction
|
||||
|
||||
This lab is split into three parts. The first part concentrates on getting familiarized with x86 assembly language, the QEMU x86 emulator, and the PC's power-on bootstrap procedure. The second part examines the boot loader for our 6.828 kernel, which resides in the `boot` directory of the `lab` tree. Finally, the third part delves into the initial template for our 6.828 kernel itself, named JOS, which resides in the `kernel` directory.
|
||||
|
||||
#### Software Setup
|
||||
|
||||
The files you will need for this and subsequent lab assignments in this course are distributed using the [Git][1] version control system. To learn more about Git, take a look at the [Git user's manual][2], or, if you are already familiar with other version control systems, you may find this [CS-oriented overview of Git][3] useful.
|
||||
|
||||
The URL for the course Git repository is `https://exokernel.scripts.mit.edu/joslab.git`. To install the files in your Athena account, you need to clone the course repository, by running the commands below. You can log into a public Athena host with `ssh -X athena.dialup.mit.edu`.
|
||||
```
|
||||
athena% mkdir ~/6.828
|
||||
athena% cd ~/6.828
|
||||
athena% add git
|
||||
athena% git clone https://exokernel.scripts.mit.edu/joslab.git lab
|
||||
Cloning into lab...
|
||||
athena% cd lab
|
||||
athena%
|
||||
|
||||
```
|
||||
|
||||
Git allows you to keep track of the changes you make to the code. For example, if you are finished with one of the exercises, and want to checkpoint your progress, you can commit your changes by running:
|
||||
```
|
||||
athena% git commit -am 'my solution for lab1 exercise 9'
|
||||
Created commit 60d2135: my solution for lab1 exercise 9
|
||||
1 files changed, 1 insertions(+), 0 deletions(-)
|
||||
athena%
|
||||
|
||||
```
|
||||
|
||||
You can keep track of your changes by using the `git diff` command. Running `git diff` will display the changes to your code since your last commit, and `git diff origin/lab1` will display the changes relative to the initial code supplied for this lab. Here, `origin/lab1` is the name of the git branch with the initial code you downloaded from our server for this assignment.
|
||||
|
||||
We have set up the appropriate compilers and simulators for you on Athena. To use them, run `add exokernel`. You must run this command every time you log in (or add it to your `~/.environment` file). If you get obscure errors while compiling or running `qemu`, double check that you added the course locker.
|
||||
|
||||
If you are working on a non-Athena machine, you'll need to install `qemu` and possibly `gcc` following the directions on the [tools page][4]. We've made several useful debugging changes to `qemu` and some of the later labs depend on these patches, so you must build your own. If your machine uses a native ELF toolchain (such as Linux and most BSD's, but notably not OS X), you can simply install `gcc` from your package manager. Otherwise, follow the directions on the tools page.
|
||||
|
||||
#### Hand-In Procedure
|
||||
|
||||
We use different Git repositories for you to hand in your lab. The hand-in repositories reside behind an SSH server. You will get your own hand-in repository, which is inaccessible by any other students. To authenticate yourself with the SSH server, you should have an RSA key pair, and let the server know your public key.
|
||||
|
||||
The lab code comes with a script that helps you to set up access to your hand-in repository. Before running the script, you must have an account at our [submission web interface][5]. On the login page, type in your Athena user name and click on "Mail me my password". You will receive your `6.828` password in your mailbox shortly. Note that every time you click the button, the system will assign you a new random password.
|
||||
|
||||
Now that you have your `6.828` password, in the `lab` directory, set up the hand-in repository by running:
|
||||
```
|
||||
athena% make handin-prep
|
||||
Using public key from ~/.ssh/id_rsa:
|
||||
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQD0lnnkoHSi4JDFA ...
|
||||
Continue? [Y/n] Y
|
||||
|
||||
Login to 6.828 submission website.
|
||||
If you do not have an account yet, sign up at https://exokernel.scripts.mit.edu/submit/
|
||||
before continuing.
|
||||
Username: <your Athena username>
|
||||
Password: <your 6.828 password>
|
||||
Your public key has been successfully updated.
|
||||
Setting up hand-in Git repository...
|
||||
Adding remote repository ssh://josgit@exokernel.mit.edu/joslab.git as 'handin'.
|
||||
Done! Use 'make handin' to submit your lab code.
|
||||
athena%
|
||||
|
||||
```
|
||||
|
||||
The script may also ask you to generate a new key pair if you did not have one:
|
||||
```
|
||||
athena% make handin-prep
|
||||
SSH key file ~/.ssh/id_rsa does not exists, generate one? [Y/n] Y
|
||||
Generating public/private rsa key pair.
|
||||
Your identification has been saved in ~/.ssh/id_rsa.
|
||||
Your public key has been saved in ~/.ssh/id_rsa.pub.
|
||||
The key fingerprint is:
|
||||
xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx
|
||||
The keyʼs randomart image is:
|
||||
+--[ RSA 2048]----+
|
||||
| ........ |
|
||||
| ........ |
|
||||
+-----------------+
|
||||
Using public key from ~/.ssh/id_rsa:
|
||||
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQD0lnnkoHSi4JDFA ...
|
||||
Continue? [Y/n] Y
|
||||
.....
|
||||
athena%
|
||||
|
||||
```
|
||||
|
||||
When you are ready to hand in your lab, first commit your changes with git commit, and then type make handin in the `lab` directory. The latter will run git push handin HEAD, which pushes the current branch to the same name on the remote `handin` repository.
|
||||
```
|
||||
athena% git commit -am "ready to submit my lab"
|
||||
[lab1 c2e3c8b] ready to submit my lab
|
||||
2 files changed, 18 insertions(+), 2 deletions(-)
|
||||
|
||||
athena% make handin
|
||||
Handin to remote repository using 'git push handin HEAD' ...
|
||||
Counting objects: 59, done.
|
||||
Delta compression using up to 4 threads.
|
||||
Compressing objects: 100% (55/55), done.
|
||||
Writing objects: 100% (59/59), 49.75 KiB, done.
|
||||
Total 59 (delta 3), reused 0 (delta 0)
|
||||
To ssh://josgit@am.csail.mit.edu/joslab.git
|
||||
* [new branch] HEAD -> lab1
|
||||
athena%
|
||||
|
||||
```
|
||||
|
||||
If you have made changes to your hand-in repository, an email receipt will be sent to you to confirm the submission. You can run make handin (or git push handin) as many times as you want. The late hours of your submission for a specific lab is based on the latest hand-in (push) time of the corresponding branch.
|
||||
|
||||
In the case that make handin does not work properly, try fixing the problem with Git commands. Or you can run make tarball. This will make a tar file for you, which you can then upload via our [web interface][5]. `make handin` provides more specific directions.
|
||||
|
||||
For Lab 1, you do not need to turn in answers to any of the questions below. (Do answer them for yourself though! They will help with the rest of the lab.)
|
||||
|
||||
We will be grading your solutions with a grading program. You can run make grade to test your solutions with the grading program.
|
||||
|
||||
### Part 1: PC Bootstrap
|
||||
|
||||
The purpose of the first exercise is to introduce you to x86 assembly language and the PC bootstrap process, and to get you started with QEMU and QEMU/GDB debugging. You will not have to write any code for this part of the lab, but you should go through it anyway for your own understanding and be prepared to answer the questions posed below.
|
||||
|
||||
#### Getting Started with x86 assembly
|
||||
|
||||
If you are not already familiar with x86 assembly language, you will quickly become familiar with it during this course! The [PC Assembly Language Book][6] is an excellent place to start. Hopefully, the book contains mixture of new and old material for you.
|
||||
|
||||
Warning: Unfortunately the examples in the book are written for the NASM assembler, whereas we will be using the GNU assembler. NASM uses the so-called Intel syntax while GNU uses the AT&T syntax. While semantically equivalent, an assembly file will differ quite a lot, at least superficially, depending on which syntax is used. Luckily the conversion between the two is pretty simple, and is covered in [Brennan's Guide to Inline Assembly][7].
|
||||
|
||||
> **Exercise 1**
|
||||
>
|
||||
> Familiarize yourself with the assembly language materials available on [the 6.828 reference page][8]. You don't have to read them now, but you'll almost certainly want to refer to some of this material when reading and writing x86 assembly.
|
||||
|
||||
We do recommend reading the section "The Syntax" in [Brennan's Guide to Inline Assembly][7]. It gives a good (and quite brief) description of the AT&T assembly syntax we'll be using with the GNU assembler in JOS.
|
||||
|
||||
Certainly the definitive reference for x86 assembly language programming is Intel's instruction set architecture reference, which you can find on [the 6.828 reference page][8] in two flavors: an HTML edition of the old [80386 Programmer's Reference Manual][9], which is much shorter and easier to navigate than more recent manuals but describes all of the x86 processor features that we will make use of in 6.828; and the full, latest and greatest [IA-32 Intel Architecture Software Developer's Manuals][10] from Intel, covering all the features of the most recent processors that we won't need in class but you may be interested in learning about. An equivalent (and often friendlier) set of manuals is [available from AMD][11]. Save the Intel/AMD architecture manuals for later or use them for reference when you want to look up the definitive explanation of a particular processor feature or instruction.
|
||||
|
||||
#### Simulating the x86
|
||||
|
||||
Instead of developing the operating system on a real, physical personal computer (PC), we use a program that faithfully emulates a complete PC: the code you write for the emulator will boot on a real PC too. Using an emulator simplifies debugging; you can, for example, set break points inside of the emulated x86, which is difficult to do with the silicon version of an x86.
|
||||
|
||||
In 6.828 we will use the [QEMU Emulator][12], a modern and relatively fast emulator. While QEMU's built-in monitor provides only limited debugging support, QEMU can act as a remote debugging target for the [GNU debugger][13] (GDB), which we'll use in this lab to step through the early boot process.
|
||||
|
||||
To get started, extract the Lab 1 files into your own directory on Athena as described above in "Software Setup", then type make (or gmake on BSD systems) in the `lab` directory to build the minimal 6.828 boot loader and kernel you will start with. (It's a little generous to call the code we're running here a "kernel," but we'll flesh it out throughout the semester.)
|
||||
```
|
||||
athena% cd lab
|
||||
athena% make
|
||||
+ as kern/entry.S
|
||||
+ cc kern/init.c
|
||||
+ cc kern/console.c
|
||||
+ cc kern/monitor.c
|
||||
+ cc kern/printf.c
|
||||
+ cc lib/printfmt.c
|
||||
+ cc lib/readline.c
|
||||
+ cc lib/string.c
|
||||
+ ld obj/kern/kernel
|
||||
+ as boot/boot.S
|
||||
+ cc -Os boot/main.c
|
||||
+ ld boot/boot
|
||||
boot block is 414 bytes (max 510)
|
||||
+ mk obj/kern/kernel.img
|
||||
|
||||
```
|
||||
|
||||
(If you get errors like "undefined reference to `__udivdi3'", you probably don't have the 32-bit gcc multilib. If you're running Debian or Ubuntu, try installing the gcc-multilib package.)
|
||||
|
||||
Now you're ready to run QEMU, supplying the file `obj/kern/kernel.img`, created above, as the contents of the emulated PC's "virtual hard disk." This hard disk image contains both our boot loader (`obj/boot/boot`) and our kernel (`obj/kernel`).
|
||||
```
|
||||
athena% make qemu
|
||||
|
||||
```
|
||||
|
||||
This executes QEMU with the options required to set the hard disk and direct serial port output to the terminal. Some text should appear in the QEMU window:
|
||||
```
|
||||
Booting from Hard Disk...
|
||||
6828 decimal is XXX octal!
|
||||
entering test_backtrace 5
|
||||
entering test_backtrace 4
|
||||
entering test_backtrace 3
|
||||
entering test_backtrace 2
|
||||
entering test_backtrace 1
|
||||
entering test_backtrace 0
|
||||
leaving test_backtrace 0
|
||||
leaving test_backtrace 1
|
||||
leaving test_backtrace 2
|
||||
leaving test_backtrace 3
|
||||
leaving test_backtrace 4
|
||||
leaving test_backtrace 5
|
||||
Welcome to the JOS kernel monitor!
|
||||
Type 'help' for a list of commands.
|
||||
K>
|
||||
|
||||
```
|
||||
|
||||
Everything after '`Booting from Hard Disk...`' was printed by our skeletal JOS kernel; the `K>` is the prompt printed by the small monitor, or interactive control program, that we've included in the kernel. These lines printed by the kernel will also appear in the regular shell window from which you ran QEMU. This is because for testing and lab grading purposes we have set up the JOS kernel to write its console output not only to the virtual VGA display (as seen in the QEMU window), but also to the simulated PC's virtual serial port, which QEMU in turn outputs to its own standard output. Likewise, the JOS kernel will take input from both the keyboard and the serial port, so you can give it commands in either the VGA display window or the terminal running QEMU. Alternatively, you can use the serial console without the virtual VGA by running make qemu-nox. This may be convenient if you are SSH'd into an Athena dialup.
|
||||
|
||||
There are only two commands you can give to the kernel monitor, `help` and `kerninfo`.
|
||||
```
|
||||
K> help
|
||||
help - display this list of commands
|
||||
kerninfo - display information about the kernel
|
||||
K> kerninfo
|
||||
Special kernel symbols:
|
||||
entry f010000c (virt) 0010000c (phys)
|
||||
etext f0101a75 (virt) 00101a75 (phys)
|
||||
edata f0112300 (virt) 00112300 (phys)
|
||||
end f0112960 (virt) 00112960 (phys)
|
||||
Kernel executable memory footprint: 75KB
|
||||
K>
|
||||
|
||||
```
|
||||
|
||||
The `help` command is obvious, and we will shortly discuss the meaning of what the `kerninfo` command prints. Although simple, it's important to note that this kernel monitor is running "directly" on the "raw (virtual) hardware" of the simulated PC. This means that you should be able to copy the contents of `obj/kern/kernel.img` onto the first few sectors of a real hard disk, insert that hard disk into a real PC, turn it on, and see exactly the same thing on the PC's real screen as you did above in the QEMU window. (We don't recommend you do this on a real machine with useful information on its hard disk, though, because copying `kernel.img` onto the beginning of its hard disk will trash the master boot record and the beginning of the first partition, effectively causing everything previously on the hard disk to be lost!)
|
||||
|
||||
#### The PC's Physical Address Space
|
||||
|
||||
We will now dive into a bit more detail about how a PC starts up. A PC's physical address space is hard-wired to have the following general layout:
|
||||
```
|
||||
+------------------+ <- 0xFFFFFFFF (4GB)
|
||||
| 32-bit |
|
||||
| memory mapped |
|
||||
| devices |
|
||||
| |
|
||||
/\/\/\/\/\/\/\/\/\/\
|
||||
|
||||
/\/\/\/\/\/\/\/\/\/\
|
||||
| |
|
||||
| Unused |
|
||||
| |
|
||||
+------------------+ <- depends on amount of RAM
|
||||
| |
|
||||
| |
|
||||
| Extended Memory |
|
||||
| |
|
||||
| |
|
||||
+------------------+ <- 0x00100000 (1MB)
|
||||
| BIOS ROM |
|
||||
+------------------+ <- 0x000F0000 (960KB)
|
||||
| 16-bit devices, |
|
||||
| expansion ROMs |
|
||||
+------------------+ <- 0x000C0000 (768KB)
|
||||
| VGA Display |
|
||||
+------------------+ <- 0x000A0000 (640KB)
|
||||
| |
|
||||
| Low Memory |
|
||||
| |
|
||||
+------------------+ <- 0x00000000
|
||||
|
||||
```
|
||||
|
||||
The first PCs, which were based on the 16-bit Intel 8088 processor, were only capable of addressing 1MB of physical memory. The physical address space of an early PC would therefore start at `0x00000000` but end at `0x000FFFFF` instead of `0xFFFFFFFF`. The 640KB area marked "Low Memory" was the only random-access memory (RAM) that an early PC could use; in fact the very earliest PCs only could be configured with 16KB, 32KB, or 64KB of RAM!
|
||||
|
||||
The 384KB area from `0x000A0000` through `0x000FFFFF` was reserved by the hardware for special uses such as video display buffers and firmware held in non-volatile memory. The most important part of this reserved area is the Basic Input/Output System (BIOS), which occupies the 64KB region from `0x000F0000` through `0x000FFFFF`. In early PCs the BIOS was held in true read-only memory (ROM), but current PCs store the BIOS in updateable flash memory. The BIOS is responsible for performing basic system initialization such as activating the video card and checking the amount of memory installed. After performing this initialization, the BIOS loads the operating system from some appropriate location such as floppy disk, hard disk, CD-ROM, or the network, and passes control of the machine to the operating system.
|
||||
|
||||
When Intel finally "broke the one megabyte barrier" with the 80286 and 80386 processors, which supported 16MB and 4GB physical address spaces respectively, the PC architects nevertheless preserved the original layout for the low 1MB of physical address space in order to ensure backward compatibility with existing software. Modern PCs therefore have a "hole" in physical memory from `0x000A0000` to `0x00100000`, dividing RAM into "low" or "conventional memory" (the first 640KB) and "extended memory" (everything else). In addition, some space at the very top of the PC's 32-bit physical address space, above all physical RAM, is now commonly reserved by the BIOS for use by 32-bit PCI devices.
|
||||
|
||||
Recent x86 processors can support more than 4GB of physical RAM, so RAM can extend further above `0xFFFFFFFF`. In this case the BIOS must arrange to leave a second hole in the system's RAM at the top of the 32-bit addressable region, to leave room for these 32-bit devices to be mapped. Because of design limitations JOS will use only the first 256MB of a PC's physical memory anyway, so for now we will pretend that all PCs have "only" a 32-bit physical address space. But dealing with complicated physical address spaces and other aspects of hardware organization that evolved over many years is one of the important practical challenges of OS development.
|
||||
|
||||
#### The ROM BIOS
|
||||
|
||||
In this portion of the lab, you'll use QEMU's debugging facilities to investigate how an IA-32 compatible computer boots.
|
||||
|
||||
Open two terminal windows. In one, enter `make qemu-gdb` (or `make qemu-nox-gdb`). This starts up QEMU, but QEMU stops just before the processor executes the first instruction and waits for a debugging connection from GDB. In the second terminal, from the same directory you ran `make`, run `make gdb`. You should see something like this,
|
||||
```
|
||||
athena% make gdb
|
||||
GNU gdb (GDB) 6.8-debian
|
||||
Copyright (C) 2008 Free Software Foundation, Inc.
|
||||
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
|
||||
This is free software: you are free to change and redistribute it.
|
||||
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
|
||||
and "show warranty" for details.
|
||||
This GDB was configured as "i486-linux-gnu".
|
||||
+ target remote localhost:1234
|
||||
The target architecture is assumed to be i8086
|
||||
[f000:fff0] 0xffff0: ljmp $0xf000,$0xe05b
|
||||
0x0000fff0 in ?? ()
|
||||
+ symbol-file obj/kern/kernel
|
||||
(gdb)
|
||||
|
||||
```
|
||||
|
||||
The `make gdb` target runs a script called `.gdbrc`, which sets up GDB to debug the 16-bit code used during early boot and directs it to attach to the listening QEMU.
|
||||
|
||||
The following line:
|
||||
```
|
||||
[f000:fff0] 0xffff0: ljmp $0xf000,$0xe05b
|
||||
|
||||
```
|
||||
|
||||
is GDB's disassembly of the first instruction to be executed. From this output you can conclude a few things:
|
||||
|
||||
* The IBM PC starts executing at physical address `0x000ffff0`, which is at the very top of the 64KB area reserved for the ROM BIOS.
|
||||
* The PC starts executing with `CS = 0xf000` and `IP = 0xfff0`.
|
||||
* The first instruction to be executed is a `jmp` instruction, which jumps to the segmented address `CS = 0xf000` and `IP = 0xe05b`.
|
||||
|
||||
|
||||
|
||||
Why does QEMU start like this? This is how Intel designed the 8088 processor, which IBM used in their original PC. Because the BIOS in a PC is "hard-wired" to the physical address range `0x000f0000-0x000fffff`, this design ensures that the BIOS always gets control of the machine first after power-up or any system restart - which is crucial because on power-up there is no other software anywhere in the machine's RAM that the processor could execute. The QEMU emulator comes with its own BIOS, which it places at this location in the processor's simulated physical address space. On processor reset, the (simulated) processor enters real mode and sets CS to `0xf000` and the IP to `0xfff0`, so that execution begins at that (CS:IP) segment address. How does the segmented address 0xf000:fff0 turn into a physical address?
|
||||
|
||||
To answer that we need to know a bit about real mode addressing. In real mode (the mode that PC starts off in), address translation works according to the formula: physical address = 16 * segment + offset. So, when the PC sets CS to `0xf000` and IP to `0xfff0`, the physical address referenced is:
|
||||
```
|
||||
16 * 0xf000 + 0xfff0 # in hex multiplication by 16 is
|
||||
= 0xf0000 + 0xfff0 # easy--just append a 0.
|
||||
= 0xffff0
|
||||
|
||||
```
|
||||
|
||||
`0xffff0` is 16 bytes before the end of the BIOS (`0x100000`). Therefore we shouldn't be surprised that the first thing that the BIOS does is `jmp` backwards to an earlier location in the BIOS; after all how much could it accomplish in just 16 bytes?
|
||||
|
||||
> **Exercise 2**
|
||||
>
|
||||
> Use GDB's `si` (Step Instruction) command to trace into the ROM BIOS for a few more instructions, and try to guess what it might be doing. You might want to look at [Phil Storrs I/O Ports Description][14], as well as other materials on the [6.828 reference materials page][8]. No need to figure out all the details - just the general idea of what the BIOS is doing first.
|
||||
|
||||
When the BIOS runs, it sets up an interrupt descriptor table and initializes various devices such as the VGA display. This is where the "`Starting SeaBIOS`" message you see in the QEMU window comes from.
|
||||
|
||||
After initializing the PCI bus and all the important devices the BIOS knows about, it searches for a bootable device such as a floppy, hard drive, or CD-ROM. Eventually, when it finds a bootable disk, the BIOS reads the boot loader from the disk and transfers control to it.
|
||||
|
||||
### Part 2: The Boot Loader
|
||||
|
||||
Floppy and hard disks for PCs are divided into 512 byte regions called sectors. A sector is the disk's minimum transfer granularity: each read or write operation must be one or more sectors in size and aligned on a sector boundary. If the disk is bootable, the first sector is called the boot sector, since this is where the boot loader code resides. When the BIOS finds a bootable floppy or hard disk, it loads the 512-byte boot sector into memory at physical addresses 0x7c00 through `0x7dff`, and then uses a `jmp` instruction to set the CS:IP to `0000:7c00`, passing control to the boot loader. Like the BIOS load address, these addresses are fairly arbitrary - but they are fixed and standardized for PCs.
|
||||
|
||||
The ability to boot from a CD-ROM came much later during the evolution of the PC, and as a result the PC architects took the opportunity to rethink the boot process slightly. As a result, the way a modern BIOS boots from a CD-ROM is a bit more complicated (and more powerful). CD-ROMs use a sector size of 2048 bytes instead of 512, and the BIOS can load a much larger boot image from the disk into memory (not just one sector) before transferring control to it. For more information, see the ["El Torito" Bootable CD-ROM Format Specification][15].
|
||||
|
||||
For 6.828, however, we will use the conventional hard drive boot mechanism, which means that our boot loader must fit into a measly 512 bytes. The boot loader consists of one assembly language source file, `boot/boot.S`, and one C source file, `boot/main.c` Look through these source files carefully and make sure you understand what's going on. The boot loader must perform two main functions:
|
||||
|
||||
1. First, the boot loader switches the processor from real mode to 32-bit protected mode, because it is only in this mode that software can access all the memory above 1MB in the processor's physical address space. Protected mode is described briefly in sections 1.2.7 and 1.2.8 of [PC Assembly Language][6], and in great detail in the Intel architecture manuals. At this point you only have to understand that translation of segmented addresses (segment:offset pairs) into physical addresses happens differently in protected mode, and that after the transition offsets are 32 bits instead of 16.
|
||||
2. Second, the boot loader reads the kernel from the hard disk by directly accessing the IDE disk device registers via the x86's special I/O instructions. If you would like to understand better what the particular I/O instructions here mean, check out the "IDE hard drive controller" section on [the 6.828 reference page][8]. You will not need to learn much about programming specific devices in this class: writing device drivers is in practice a very important part of OS development, but from a conceptual or architectural viewpoint it is also one of the least interesting.
|
||||
|
||||
|
||||
|
||||
After you understand the boot loader source code, look at the file `obj/boot/boot.asm`. This file is a disassembly of the boot loader that our GNUmakefile creates after compiling the boot loader. This disassembly file makes it easy to see exactly where in physical memory all of the boot loader's code resides, and makes it easier to track what's happening while stepping through the boot loader in GDB. Likewise, `obj/kern/kernel.asm` contains a disassembly of the JOS kernel, which can often be useful for debugging.
|
||||
|
||||
You can set address breakpoints in GDB with the `b` command. For example, `b *0x7c00` sets a breakpoint at address `0x7C00`. Once at a breakpoint, you can continue execution using the `c` and `si` commands: `c` causes QEMU to continue execution until the next breakpoint (or until you press Ctrl-C in GDB), and `si N` steps through the instructions `N` at a time.
|
||||
|
||||
To examine instructions in memory (besides the immediate next one to be executed, which GDB prints automatically), you use the `x/i` command. This command has the syntax `x/Ni ADDR`, where `N` is the number of consecutive instructions to disassemble and `ADDR` is the memory address at which to start disassembling.
|
||||
|
||||
> **Exercise 3**
|
||||
>
|
||||
> Take a look at the [lab tools guide][16], especially the section on GDB commands. Even if you're familiar with GDB, this includes some esoteric GDB commands that are useful for OS work.
|
||||
|
||||
Set a breakpoint at address 0x7c00, which is where the boot sector will be loaded. Continue execution until that breakpoint. Trace through the code in `boot/boot.S`, using the source code and the disassembly file `obj/boot/boot.asm` to keep track of where you are. Also use the `x/i` command in GDB to disassemble sequences of instructions in the boot loader, and compare the original boot loader source code with both the disassembly in `obj/boot/boot.asm` and GDB.
|
||||
|
||||
Trace into `bootmain()` in `boot/main.c`, and then into `readsect()`. Identify the exact assembly instructions that correspond to each of the statements in `readsect()`. Trace through the rest of `readsect()` and back out into `bootmain()`, and identify the begin and end of the `for` loop that reads the remaining sectors of the kernel from the disk. Find out what code will run when the loop is finished, set a breakpoint there, and continue to that breakpoint. Then step through the remainder of the boot loader.
|
||||
|
||||
Be able to answer the following questions:
|
||||
|
||||
* At what point does the processor start executing 32-bit code? What exactly causes the switch from 16- to 32-bit mode?
|
||||
* What is the last instruction of the boot loader executed, and what is the first instruction of the kernel it just loaded?
|
||||
* Where is the first instruction of the kernel?
|
||||
* How does the boot loader decide how many sectors it must read in order to fetch the entire kernel from disk? Where does it find this information?
|
||||
|
||||
|
||||
|
||||
#### Loading the Kernel
|
||||
|
||||
We will now look in further detail at the C language portion of the boot loader, in `boot/main.c`. But before doing so, this is a good time to stop and review some of the basics of C programming.
|
||||
|
||||
> **Exercise 4**
|
||||
>
|
||||
> Download the code for [pointers.c][17], run it, and make sure you understand where all of the printed values come from. In particular, make sure you understand where the pointer addresses in lines 1 and 6 come from, how all the values in lines 2 through 4 get there, and why the values printed in line 5 are seemingly corrupted.
|
||||
>
|
||||
> If you're not familiar with pointers, The C Programming Language by Brian Kernighan and Dennis Ritchie (known as 'K&R') is a good reference. Students can purchase this book (here is an [Amazon Link][18]) or find one of [MIT's 7 copies][19]. 3 copies are also available for perusal in the [SIPB Office][20].
|
||||
>
|
||||
> [A tutorial by Ted Jensen][21] that cites K&R heavily is available in the course readings.
|
||||
>
|
||||
> Warning: Unless you are already thoroughly versed in C, do not skip or even skim this reading exercise. If you do not really understand pointers in C, you will suffer untold pain and misery in subsequent labs, and then eventually come to understand them the hard way. Trust us; you don't want to find out what "the hard way" is.
|
||||
|
||||
To make sense out of `boot/main.c` you'll need to know what an ELF binary is. When you compile and link a C program such as the JOS kernel, the compiler transforms each C source ('`.c`') file into an object ('`.o`') file containing assembly language instructions encoded in the binary format expected by the hardware. The linker then combines all of the compiled object files into a single binary image such as `obj/kern/kernel`, which in this case is a binary in the ELF format, which stands for "Executable and Linkable Format".
|
||||
|
||||
Full information about this format is available in [the ELF specification][22] on [our reference page][8], but you will not need to delve very deeply into the details of this format in this class. Although as a whole the format is quite powerful and complex, most of the complex parts are for supporting dynamic loading of shared libraries, which we will not do in this class.
|
||||
|
||||
For purposes of 6.828, you can consider an ELF executable to be a header with loading information, followed by several program sections, each of which is a contiguous chunk of code or data intended to be loaded into memory at a specified address. The boot loader does not modify the code or data; it loads it into memory and starts executing it.
|
||||
|
||||
An ELF binary starts with a fixed-length ELF header, followed by a variable-length program header listing each of the program sections to be loaded. The C definitions for these ELF headers are in `inc/elf.h`. The program sections we're interested in are:
|
||||
|
||||
* `.text`: The program's executable instructions.
|
||||
* `.rodata`: Read-only data, such as ASCII string constants produced by the C compiler. (We will not bother setting up the hardware to prohibit writing, however.)
|
||||
* `.data`: The data section holds the program's initialized data, such as global variables declared with initializers like `int x = 5;`.
|
||||
|
||||
|
||||
|
||||
When the linker computes the memory layout of a program, it reserves space for uninitialized global variables, such as `int x;`, in a section called `.bss` that immediately follows `.data` in memory. C requires that "uninitialized" global variables start with a value of zero. Thus there is no need to store contents for `.bss` in the ELF binary; instead, the linker records just the address and size of the `.bss` section. The loader or the program itself must arrange to zero the `.bss` section.
|
||||
|
||||
Examine the full list of the names, sizes, and link addresses of all the sections in the kernel executable by typing:
|
||||
```
|
||||
athena% i386-jos-elf-objdump -h obj/kern/kernel
|
||||
|
||||
```
|
||||
|
||||
You can substitute `objdump` for `i386-jos-elf-objdump` if your computer uses an ELF toolchain by default like most modern Linuxen and BSDs.
|
||||
|
||||
You will see many more sections than the ones we listed above, but the others are not important for our purposes. Most of the others are to hold debugging information, which is typically included in the program's executable file but not loaded into memory by the program loader.
|
||||
|
||||
Take particular note of the "VMA" (or link address) and the "LMA" (or load address) of the `.text` section. The load address of a section is the memory address at which that section should be loaded into memory. In the ELF object, this is stored in the `ph->p_pa` field (in this case, it really is a physical address, though the ELF specification is vague on the actual meaning of this field).
|
||||
|
||||
The link address of a section is the memory address from which the section expects to execute. The linker encodes the link address in the binary in various ways, such as when the code needs the address of a global variable, with the result that a binary usually won't work if it is executing from an address that it is not linked for. (It is possible to generate position-independent code that does not contain any such absolute addresses. This is used extensively by modern shared libraries, but it has performance and complexity costs, so we won't be using it in 6.828.)
|
||||
|
||||
Typically, the link and load addresses are the same. For example, look at the `.text` section of the boot loader:
|
||||
```
|
||||
athena% i386-jos-elf-objdump -h obj/boot/boot.out
|
||||
|
||||
```
|
||||
|
||||
The BIOS loads the boot sector into memory starting at address 0x7c00, so this is the boot sector's load address. This is also where the boot sector executes from, so this is also its link address. We set the link address by passing `-Ttext 0x7C00` to the linker in `boot/Makefrag`, so the linker will produce the correct memory addresses in the generated code.
|
||||
|
||||
> **Exercise 5**
|
||||
>
|
||||
> Trace through the first few instructions of the boot loader again and identify the first instruction that would "break" or otherwise do the wrong thing if you were to get the boot loader's link address wrong. Then change the link address in `boot/Makefrag` to something wrong, run make clean, recompile the lab with make, and trace into the boot loader again to see what happens. Don't forget to change the link address back and make clean again afterward!
|
||||
|
||||
Look back at the load and link addresses for the kernel. Unlike the boot loader, these two addresses aren't the same: the kernel is telling the boot loader to load it into memory at a low address (1 megabyte), but it expects to execute from a high address. We'll dig in to how we make this work in the next section.
|
||||
|
||||
Besides the section information, there is one more field in the ELF header that is important to us, named `e_entry`. This field holds the link address of the entry point in the program: the memory address in the program's text section at which the program should begin executing. You can see the entry point:
|
||||
```
|
||||
athena% i386-jos-elf-objdump -f obj/kern/kernel
|
||||
|
||||
```
|
||||
|
||||
You should now be able to understand the minimal ELF loader in `boot/main.c`. It reads each section of the kernel from disk into memory at the section's load address and then jumps to the kernel's entry point.
|
||||
|
||||
> **Exercise 6**
|
||||
>
|
||||
> We can examine memory using GDB's x command. The [GDB manual][23] has full details, but for now, it is enough to know that the command `x/Nx ADDR` prints `N` words of memory at `ADDR`. (Note that both `x`s in the command are lowercase.) Warning: The size of a word is not a universal standard. In GNU assembly, a word is two bytes (the 'w' in xorw, which stands for word, means 2 bytes).
|
||||
|
||||
Reset the machine (exit QEMU/GDB and start them again). Examine the 8 words of memory at `0x00100000` at the point the BIOS enters the boot loader, and then again at the point the boot loader enters the kernel. Why are they different? What is there at the second breakpoint? (You do not really need to use QEMU to answer this question. Just think.)
|
||||
|
||||
### Part 3: The Kernel
|
||||
|
||||
We will now start to examine the minimal JOS kernel in a bit more detail. (And you will finally get to write some code!). Like the boot loader, the kernel begins with some assembly language code that sets things up so that C language code can execute properly.
|
||||
|
||||
#### Using virtual memory to work around position dependence
|
||||
|
||||
When you inspected the boot loader's link and load addresses above, they matched perfectly, but there was a (rather large) disparity between the kernel's link address (as printed by objdump) and its load address. Go back and check both and make sure you can see what we're talking about. (Linking the kernel is more complicated than the boot loader, so the link and load addresses are at the top of `kern/kernel.ld`.)
|
||||
|
||||
Operating system kernels often like to be linked and run at very high virtual address, such as `0xf0100000`, in order to leave the lower part of the processor's virtual address space for user programs to use. The reason for this arrangement will become clearer in the next lab.
|
||||
|
||||
Many machines don't have any physical memory at address `0xf0100000`, so we can't count on being able to store the kernel there. Instead, we will use the processor's memory management hardware to map virtual address `0xf0100000` (the link address at which the kernel code expects to run) to physical address `0x00100000` (where the boot loader loaded the kernel into physical memory). This way, although the kernel's virtual address is high enough to leave plenty of address space for user processes, it will be loaded in physical memory at the 1MB point in the PC's RAM, just above the BIOS ROM. This approach requires that the PC have at least a few megabytes of physical memory (so that physical address `0x00100000` works), but this is likely to be true of any PC built after about 1990.
|
||||
|
||||
In fact, in the next lab, we will map the entire bottom 256MB of the PC's physical address space, from physical addresses `0x00000000` through `0x0fffffff`, to virtual addresses `0xf0000000` through `0xffffffff` respectively. You should now see why JOS can only use the first 256MB of physical memory.
|
||||
|
||||
For now, we'll just map the first 4MB of physical memory, which will be enough to get us up and running. We do this using the hand-written, statically-initialized page directory and page table in `kern/entrypgdir.c`. For now, you don't have to understand the details of how this works, just the effect that it accomplishes. Up until `kern/entry.S` sets the `CR0_PG` flag, memory references are treated as physical addresses (strictly speaking, they're linear addresses, but boot/boot.S set up an identity mapping from linear addresses to physical addresses and we're never going to change that). Once `CR0_PG` is set, memory references are virtual addresses that get translated by the virtual memory hardware to physical addresses. `entry_pgdir` translates virtual addresses in the range `0xf0000000` through `0xf0400000` to physical addresses `0x00000000` through `0x00400000`, as well as virtual addresses `0x00000000` through `0x00400000` to physical addresses `0x00000000` through `0x00400000`. Any virtual address that is not in one of these two ranges will cause a hardware exception which, since we haven't set up interrupt handling yet, will cause QEMU to dump the machine state and exit (or endlessly reboot if you aren't using the 6.828-patched version of QEMU).
|
||||
|
||||
> **Exercise 7**
|
||||
>
|
||||
> Use QEMU and GDB to trace into the JOS kernel and stop at the `movl %eax, %cr0`. Examine memory at `0x00100000` and at `0xf0100000`. Now, single step over that instruction using the `stepi` GDB command. Again, examine memory at `0x00100000` and at `0xf0100000`. Make sure you understand what just happened.
|
||||
|
||||
What is the first instruction after the new mapping is established that would fail to work properly if the mapping weren't in place? Comment out the `movl %eax, %cr0` in `kern/entry.S`, trace into it, and see if you were right.
|
||||
|
||||
#### Formatted Printing to the Console
|
||||
|
||||
Most people take functions like `printf()` for granted, sometimes even thinking of them as "primitives" of the C language. But in an OS kernel, we have to implement all I/O ourselves.
|
||||
|
||||
Read through `kern/printf.c`, `lib/printfmt.c`, and `kern/console.c`, and make sure you understand their relationship. It will become clear in later labs why `printfmt.c` is located in the separate `lib` directory.
|
||||
|
||||
> **Exercise 8**
|
||||
>
|
||||
> We have omitted a small fragment of code - the code necessary to print octal numbers using patterns of the form "%o". Find and fill in this code fragment.
|
||||
>
|
||||
> Be able to answer the following questions:
|
||||
>
|
||||
> 1. Explain the interface between `printf.c` and `console.c`. Specifically, what function does `console.c` export? How is this function used by `printf.c`?
|
||||
>
|
||||
> 2. Explain the following from `console.c`:
|
||||
[code] > if (crt_pos >= CRT_SIZE) {
|
||||
> int i;
|
||||
> memcpy(crt_buf, crt_buf + CRT_COLS, (CRT_SIZE - CRT_COLS) * sizeof(uint16_t));
|
||||
> for (i = CRT_SIZE - CRT_COLS; i < CRT_SIZE; i++)
|
||||
> crt_buf[i] = 0x0700 | ' ';
|
||||
> crt_pos -= CRT_COLS;
|
||||
> }
|
||||
>
|
||||
```
|
||||
>
|
||||
> 3. For the following questions you might wish to consult the notes for Lecture 1. These notes cover GCC's calling convention on the x86.
|
||||
>
|
||||
> Trace the execution of the following code step-by-step:
|
||||
[code] > int x = 1, y = 3, z = 4;
|
||||
> cprintf("x %d, y %x, z %d\n", x, y, z);
|
||||
>
|
||||
```
|
||||
>
|
||||
> 1. In the call to `cprintf()`, to what does `fmt` point? To what does `ap` point?
|
||||
> 2. List (in order of execution) each call to `cons_putc`, `va_arg`, and `vcprintf`. For `cons_putc`, list its argument as well. For `va_arg`, list what `ap` points to before and after the call. For `vcprintf` list the values of its two arguments.
|
||||
> 4. Run the following code.
|
||||
[code] > unsigned int i = 0x00646c72;
|
||||
> cprintf("H%x Wo%s", 57616, &i);
|
||||
>
|
||||
```
|
||||
>
|
||||
> What is the output? Explain how this output is arrived at in the step-by-step manner of the previous exercise. [Here's an ASCII table][24] that maps bytes to characters.
|
||||
>
|
||||
> The output depends on that fact that the x86 is little-endian. If the x86 were instead big-endian what would you set `i` to in order to yield the same output? Would you need to change `57616` to a different value?
|
||||
>
|
||||
> [Here's a description of little- and big-endian][25] and [a more whimsical description][26].
|
||||
>
|
||||
> 5. In the following code, what is going to be printed after `y=`? (note: the answer is not a specific value.) Why does this happen?
|
||||
[code] > cprintf("x=%d y=%d", 3);
|
||||
>
|
||||
```
|
||||
>
|
||||
> 6. Let's say that GCC changed its calling convention so that it pushed arguments on the stack in declaration order, so that the last argument is pushed last. How would you have to change `cprintf` or its interface so that it would still be possible to pass it a variable number of arguments?
|
||||
>
|
||||
>
|
||||
|
||||
|
||||
#### The Stack
|
||||
|
||||
In the final exercise of this lab, we will explore in more detail the way the C language uses the stack on the x86, and in the process write a useful new kernel monitor function that prints a backtrace of the stack: a list of the saved Instruction Pointer (IP) values from the nested `call` instructions that led to the current point of execution.
|
||||
|
||||
> **Exercise 9**
|
||||
>
|
||||
> Determine where the kernel initializes its stack, and exactly where in memory its stack is located. How does the kernel reserve space for its stack? And at which "end" of this reserved area is the stack pointer initialized to point to?
|
||||
|
||||
The x86 stack pointer (`esp` register) points to the lowest location on the stack that is currently in use. Everything below that location in the region reserved for the stack is free. Pushing a value onto the stack involves decreasing the stack pointer and then writing the value to the place the stack pointer points to. Popping a value from the stack involves reading the value the stack pointer points to and then increasing the stack pointer. In 32-bit mode, the stack can only hold 32-bit values, and esp is always divisible by four. Various x86 instructions, such as `call`, are "hard-wired" to use the stack pointer register.
|
||||
|
||||
The `ebp` (base pointer) register, in contrast, is associated with the stack primarily by software convention. On entry to a C function, the function's prologue code normally saves the previous function's base pointer by pushing it onto the stack, and then copies the current `esp` value into `ebp` for the duration of the function. If all the functions in a program obey this convention, then at any given point during the program's execution, it is possible to trace back through the stack by following the chain of saved `ebp` pointers and determining exactly what nested sequence of function calls caused this particular point in the program to be reached. This capability can be particularly useful, for example, when a particular function causes an `assert` failure or `panic` because bad arguments were passed to it, but you aren't sure who passed the bad arguments. A stack backtrace lets you find the offending function.
|
||||
|
||||
> **Exercise 10**
|
||||
>
|
||||
> To become familiar with the C calling conventions on the x86, find the address of the `test_backtrace` function in `obj/kern/kernel.asm`, set a breakpoint there, and examine what happens each time it gets called after the kernel starts. How many 32-bit words does each recursive nesting level of `test_backtrace` push on the stack, and what are those words?
|
||||
|
||||
The above exercise should give you the information you need to implement a stack backtrace function, which you should call `mon_backtrace()`. A prototype for this function is already waiting for you in `kern/monitor.c`. You can do it entirely in C, but you may find the `read_ebp()` function in `inc/x86.h` useful. You'll also have to hook this new function into the kernel monitor's command list so that it can be invoked interactively by the user.
|
||||
|
||||
The backtrace function should display a listing of function call frames in the following format:
|
||||
```
|
||||
Stack backtrace:
|
||||
ebp f0109e58 eip f0100a62 args 00000001 f0109e80 f0109e98 f0100ed2 00000031
|
||||
ebp f0109ed8 eip f01000d6 args 00000000 00000000 f0100058 f0109f28 00000061
|
||||
...
|
||||
|
||||
```
|
||||
|
||||
The first line printed reflects the currently executing function, namely `mon_backtrace` itself, the second line reflects the function that called `mon_backtrace`, the third line reflects the function that called that one, and so on. You should print all the outstanding stack frames. By studying `kern/entry.S` you'll find that there is an easy way to tell when to stop.
|
||||
|
||||
Within each line, the `ebp` value indicates the base pointer into the stack used by that function: i.e., the position of the stack pointer just after the function was entered and the function prologue code set up the base pointer. The listed `eip` value is the function's return instruction pointer: the instruction address to which control will return when the function returns. The return instruction pointer typically points to the instruction after the `call` instruction (why?). Finally, the five hex values listed after `args` are the first five arguments to the function in question, which would have been pushed on the stack just before the function was called. If the function was called with fewer than five arguments, of course, then not all five of these values will be useful. (Why can't the backtrace code detect how many arguments there actually are? How could this limitation be fixed?)
|
||||
|
||||
Here are a few specific points you read about in K&R Chapter 5 that are worth remembering for the following exercise and for future labs.
|
||||
|
||||
* If `int *p = (int*)100`, then `(int)p + 1` and `(int)(p + 1)` are different numbers: the first is `101` but the second is `104`. When adding an integer to a pointer, as in the second case, the integer is implicitly multiplied by the size of the object the pointer points to.
|
||||
* `p[i]` is defined to be the same as `*(p+i)`, referring to the i'th object in the memory pointed to by p. The above rule for addition helps this definition work when the objects are larger than one byte.
|
||||
* `&p[i]` is the same as `(p+i)`, yielding the address of the i'th object in the memory pointed to by p.
|
||||
|
||||
|
||||
|
||||
Although most C programs never need to cast between pointers and integers, operating systems frequently do. Whenever you see an addition involving a memory address, ask yourself whether it is an integer addition or pointer addition and make sure the value being added is appropriately multiplied or not.
|
||||
|
||||
> **Exercise 11**
|
||||
>
|
||||
> Implement the backtrace function as specified above. Use the same format as in the example, since otherwise the grading script will be confused. When you think you have it working right, run make grade to see if its output conforms to what our grading script expects, and fix it if it doesn't. After you have handed in your Lab 1 code, you are welcome to change the output format of the backtrace function any way you like.
|
||||
|
||||
At this point, your backtrace function should give you the addresses of the function callers on the stack that lead to `mon_backtrace()` being executed. However, in practice you often want to know the function names corresponding to those addresses. For instance, you may want to know which functions could contain a bug that's causing your kernel to crash.
|
||||
|
||||
To help you implement this functionality, we have provided the function `debuginfo_eip()`, which looks up `eip` in the symbol table and returns the debugging information for that address. This function is defined in `kern/kdebug.c`.
|
||||
|
||||
> **Exercise 12**
|
||||
>
|
||||
> Modify your stack backtrace function to display, for each `eip`, the function name, source file name, and line number corresponding to that `eip`.
|
||||
|
||||
In `debuginfo_eip`, where do `__STAB_*` come from? This question has a long answer; to help you to discover the answer, here are some things you might want to do:
|
||||
|
||||
* look in the file `kern/kernel.ld` for `__STAB_*`
|
||||
* run i386-jos-elf-objdump -h obj/kern/kernel
|
||||
* run i386-jos-elf-objdump -G obj/kern/kernel
|
||||
* run i386-jos-elf-gcc -pipe -nostdinc -O2 -fno-builtin -I. -MD -Wall -Wno-format -DJOS_KERNEL -gstabs -c -S kern/init.c, and look at init.s.
|
||||
* see if the bootloader loads the symbol table in memory as part of loading the kernel binary
|
||||
|
||||
|
||||
|
||||
Complete the implementation of `debuginfo_eip` by inserting the call to `stab_binsearch` to find the line number for an address.
|
||||
|
||||
Add a `backtrace` command to the kernel monitor, and extend your implementation of `mon_backtrace` to call `debuginfo_eip` and print a line for each stack frame of the form:
|
||||
```
|
||||
K> backtrace
|
||||
Stack backtrace:
|
||||
ebp f010ff78 eip f01008ae args 00000001 f010ff8c 00000000 f0110580 00000000
|
||||
kern/monitor.c:143: monitor+106
|
||||
ebp f010ffd8 eip f0100193 args 00000000 00001aac 00000660 00000000 00000000
|
||||
kern/init.c:49: i386_init+59
|
||||
ebp f010fff8 eip f010003d args 00000000 00000000 0000ffff 10cf9a00 0000ffff
|
||||
kern/entry.S:70: <unknown>+0
|
||||
K>
|
||||
|
||||
```
|
||||
|
||||
Each line gives the file name and line within that file of the stack frame's `eip`, followed by the name of the function and the offset of the `eip` from the first instruction of the function (e.g., `monitor+106` means the return `eip` is 106 bytes past the beginning of `monitor`).
|
||||
|
||||
Be sure to print the file and function names on a separate line, to avoid confusing the grading script.
|
||||
|
||||
Tip: printf format strings provide an easy, albeit obscure, way to print non-null-terminated strings like those in STABS tables. `printf("%.*s", length, string)` prints at most `length` characters of `string`. Take a look at the printf man page to find out why this works.
|
||||
|
||||
You may find that some functions are missing from the backtrace. For example, you will probably see a call to `monitor()` but not to `runcmd()`. This is because the compiler in-lines some function calls. Other optimizations may cause you to see unexpected line numbers. If you get rid of the `-O2` from `GNUMakefile`, the backtraces may make more sense (but your kernel will run more slowly).
|
||||
|
||||
**This completes the lab.** In the `lab` directory, commit your changes with `git commit` and type `make handin` to submit your code.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://sipb.mit.edu/iap/6.828/lab/lab1/
|
||||
|
||||
作者:[mit][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://sipb.mit.edu
|
||||
[1]:http://www.git-scm.com/
|
||||
[2]:http://www.kernel.org/pub/software/scm/git/docs/user-manual.html
|
||||
[3]:http://eagain.net/articles/git-for-computer-scientists/
|
||||
[4]:https://sipb.mit.edu/iap/6.828/tools
|
||||
[5]:https://exokernel.scripts.mit.edu/submit/
|
||||
[6]:https://sipb.mit.edu/iap/6.828/readings/pcasm-book.pdf
|
||||
[7]:http://www.delorie.com/djgpp/doc/brennan/brennan_att_inline_djgpp.html
|
||||
[8]:https://sipb.mit.edu/iap/6.828/reference
|
||||
[9]:https://sipb.mit.edu/iap/6.828/readings/i386/toc.htm
|
||||
[10]:http://www.intel.com/content/www/us/en/processors/architectures-software-developer-manuals.html
|
||||
[11]:http://developer.amd.com/documentation/guides/Pages/default.aspx#manuals
|
||||
[12]:http://www.qemu.org/
|
||||
[13]:http://www.gnu.org/software/gdb/
|
||||
[14]:http://web.archive.org/web/20040404164813/members.iweb.net.au/%7Epstorr/pcbook/book2/book2.htm
|
||||
[15]:https://sipb.mit.edu/iap/6.828/readings/boot-cdrom.pdf
|
||||
[16]:https://sipb.mit.edu/iap/6.828/labguide
|
||||
[17]:https://sipb.mit.edu/iap/6.828/files/pointers.c
|
||||
[18]:http://www.amazon.com/C-Programming-Language-2nd/dp/0131103628/sr=8-1/qid=1157812738/ref=pd_bbs_1/104-1502762-1803102?ie=UTF8&s=books
|
||||
[19]:http://library.mit.edu/F/AI9Y4SJ2L5ELEE2TAQUAAR44XV5RTTQHE47P9MKP5GQDLR9A8X-10422?func=item-global&doc_library=MIT01&doc_number=000355242&year=&volume=&sub_library=
|
||||
[20]:http://sipb.mit.edu/
|
||||
[21]:https://sipb.mit.edu/iap/6.828/readings/pointers.pdf
|
||||
[22]:https://sipb.mit.edu/iap/6.828/readings/elf.pdf
|
||||
[23]:http://sourceware.org/gdb/current/onlinedocs/gdb_9.html#SEC63
|
||||
[24]:http://web.cs.mun.ca/%7Emichael/c/ascii-table.html
|
||||
[25]:http://www.webopedia.com/TERM/b/big_endian.html
|
||||
[26]:http://www.networksorcery.com/enp/ien/ien137.txt
|
||||
@ -1,95 +0,0 @@
|
||||
translating by kimii
|
||||
How To Safely Generate A Random Number — Quarrelsome
|
||||
======
|
||||
### Use urandom
|
||||
|
||||
Use [urandom][1]. Use [urandom][2]. Use [urandom][3]. Use [urandom][4]. Use [urandom][5]. Use [urandom][6].
|
||||
|
||||
### But what about for crypto keys?
|
||||
|
||||
Still [urandom][6].
|
||||
|
||||
### Why not {SecureRandom, OpenSSL, havaged, &c}?
|
||||
|
||||
These are userspace CSPRNGs. You want to use the kernel’s CSPRNG, because:
|
||||
|
||||
* The kernel has access to raw device entropy.
|
||||
|
||||
* It can promise not to share the same state between applications.
|
||||
|
||||
* A good kernel CSPRNG, like FreeBSD’s, can also promise not to feed you random data before it’s seeded.
|
||||
|
||||
|
||||
|
||||
|
||||
Study the last ten years of randomness failures and you’ll read a litany of userspace randomness failures. [Debian’s OpenSSH debacle][7]? Userspace random. Android Bitcoin wallets [repeating ECDSA k’s][8]? Userspace random. Gambling sites with predictable shuffles? Userspace random.
|
||||
|
||||
Userspace OpenSSL also seeds itself from “from uninitialized memory, magical fairy dust and unicorn horns” generators almost always depend on the kernel’s generator anyways. Even if they don’t, the security of your whole system sure does. **A userspace CSPRNG doesn’t add defense-in-depth; instead, it creates two single points of failure.**
|
||||
|
||||
### Doesn’t the man page say to use /dev/random?
|
||||
|
||||
You But, more on this later. Stay your pitchforks. should ignore the man page. Don’t use /dev/random. The distinction between /dev/random and /dev/urandom is a Unix design wart. The man page doesn’t want to admit that, so it invents a security concern that doesn’t really exist. Consider the cryptographic advice in random(4) an urban legend and get on with your life.
|
||||
|
||||
### But what if I need real random values, not psuedorandom values?
|
||||
|
||||
Both urandom and /dev/random provide the same kind of randomness. Contrary to popular belief, /dev/random doesn’t provide “true random” data. For cryptography, you don’t usually want “true random”.
|
||||
|
||||
Both urandom and /dev/random are based on a simple idea. Their design is closely related to that of a stream cipher: a small secret is stretched into an indefinite stream of unpredictable values. Here the secrets are “entropy”, and the stream is “output”.
|
||||
|
||||
Only on Linux are /dev/random and urandom still meaningfully different. The Linux kernel CSPRNG rekeys itself regularly (by collecting more entropy). But /dev/random also tries to keep track of how much entropy remains in its kernel pool, and will occasionally go on strike if it decides not enough remains. This design is as silly as I’ve made it sound; it’s akin to AES-CTR blocking based on how much “key” is left in the “keystream”.
|
||||
|
||||
If you use /dev/random instead of urandom, your program will unpredictably (or, if you’re an attacker, very predictably) hang when Linux gets confused about how its own RNG works. Using /dev/random will make your programs less stable, but it won’t make them any more cryptographically safe.
|
||||
|
||||
### There’s a catch here, isn’t there?
|
||||
|
||||
No, but there’s a Linux kernel bug you might want to know about, even though it doesn’t change which RNG you should use.
|
||||
|
||||
On Linux, if your software runs immediately at boot, and/or the OS has just been installed, your code might be in a race with the RNG. That’s bad, because if you win the race, there could be a window of time where you get predictable outputs from urandom. This is a bug in Linux, and you need to know about it if you’re building platform-level code for a Linux embedded device.
|
||||
|
||||
This is indeed a problem with urandom (and not /dev/random) on Linux. It’s also a [bug in the Linux kernel][9]. But it’s also easily fixed in userland: at boot, seed urandom explicitly. Most Linux distributions have done this for a long time. But don’t switch to a different CSPRNG.
|
||||
|
||||
### What about on other operating systems?
|
||||
|
||||
FreeBSD and OS X do away with the distinction between urandom and /dev/random; the two devices behave identically. Unfortunately, the man page does a poor job of explaining why this is, and perpetuates the myth that Linux urandom is scary.
|
||||
|
||||
FreeBSD’s kernel crypto RNG doesn’t block regardless of whether you use /dev/random or urandom. Unless it hasn’t been seeded, in which case both block. This behavior, unlike Linux’s, makes sense. Linux should adopt it. But if you’re an app developer, this makes little difference to you: Linux, FreeBSD, iOS, whatever: use urandom.
|
||||
|
||||
### tl;dr
|
||||
|
||||
Use urandom.
|
||||
|
||||
### Epilog
|
||||
|
||||
[ruby-trunk Feature #9569][10]
|
||||
|
||||
> Right now, SecureRandom.random_bytes tries to detect an OpenSSL to use before it tries to detect /dev/urandom. I think it should be the other way around. In both cases, you just need random bytes to unpack, so SecureRandom could skip the middleman (and second point of failure) and just talk to /dev/urandom directly if it’s available.
|
||||
|
||||
Resolution:
|
||||
|
||||
> /dev/urandom is not suitable to be used to generate directly session keys and other application level random data which is generated frequently.
|
||||
>
|
||||
> [the] random(4) [man page] on GNU/Linux [says]…
|
||||
|
||||
Thanks to Matthew Green, Nate Lawson, Sean Devlin, Coda Hale, and Alex Balducci for reading drafts of this. Fair warning: Matthew only mostly agrees with me.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://sockpuppet.org/blog/2014/02/25/safely-generate-random-numbers/
|
||||
|
||||
作者:[Thomas;Erin;Matasano][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://sockpuppet.org/blog
|
||||
[1]:http://blog.cr.yp.to/20140205-entropy.html
|
||||
[2]:http://cr.yp.to/talks/2011.09.28/slides.pdf
|
||||
[3]:http://golang.org/src/pkg/crypto/rand/rand_unix.go
|
||||
[4]:http://security.stackexchange.com/questions/3936/is-a-rand-from-dev-urandom-secure-for-a-login-key
|
||||
[5]:http://stackoverflow.com/a/5639631
|
||||
[6]:https://twitter.com/bramcohen/status/206146075487240194
|
||||
[7]:http://research.swtch.com/openssl
|
||||
[8]:http://arstechnica.com/security/2013/08/google-confirms-critical-android-crypto-flaw-used-in-5700-bitcoin-heist/
|
||||
[9]:https://factorable.net/weakkeys12.extended.pdf
|
||||
[10]:https://bugs.ruby-lang.org/issues/9569
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
How to resolve mount.nfs: Stale file handle error
|
||||
======
|
||||
Learn how to resolve mount.nfs: Stale file handle error on Linux platform. This is Network File System error can be resolved from client or server end.
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
[translating for laujinseoi]
|
||||
|
||||
7 Best eBook Readers for Linux
|
||||
======
|
||||
**Brief:** In this article, we are covering some of the best ebook readers for Linux. These apps give a better reading experience and some will even help in managing your ebooks.
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by rockouc
|
||||
|
||||
Why pair writing helps improve documentation
|
||||
======
|
||||

|
||||
|
||||
@ -1,60 +0,0 @@
|
||||
Translating by qhwdw
|
||||
What DevOps teams really need from a CIO
|
||||
======
|
||||
IT leaders can learn from plenty of material exploring [DevOps][1] and the challenging cultural shift required for [making the DevOps transition][2]. But are you in tune with the short and long term challenges that a DevOps team faces - and what they really need from a CIO?
|
||||
|
||||
In my conversations with DevOps team members, some of what I heard might surprise you. DevOps pros (whether part of an internal or external team) want to put the following things at the top of your CIO radar screen.
|
||||
|
||||
### 1. Communication
|
||||
|
||||
First and foremost, DevOps pros need peer-level communication. An experienced DevOps team is extremely knowledgeable on current DevOps trends, successes, and failures in the industry and is interested in sharing this information. DevOps concepts are difficult to convey, so be open to a new working relationship in which there are regular (don't worry, not weekly) conversations about the current state of your IT, how the pieces in the environment communicate, and your overall IT estate.
|
||||
|
||||
**[ Want even more wisdom from CIOs on leading DevOps? See our comprehensive resource,[DevOps: The IT Leader's Guide][3]. ]**
|
||||
|
||||
Conversely, be prepared to share current business needs and goals with the DevOps team. Business objectives no longer exist in isolation from IT: They are now an integral component of what drives your IT advancements, and your IT determines how effectively you can execute on your business needs and goals.
|
||||
|
||||
Focus on participating rather than leading. You are still the ultimate arbiter when it comes to decisions, but understand that these decisions are best made collaboratively in order to empower and motivate your DevOps team.
|
||||
|
||||
### 2. Reduction of technical debt
|
||||
|
||||
Second, strive to better understand technical debt and how DevOps efforts are going to reduce it. Your DevOps team is working hard on this front. In this case, technical debt refers to the manpower and infrastructure resources that are usurped daily by maintaining and adding new features on top of a monolithic, non-sustainable environment (read Rube Goldberg).
|
||||
|
||||
Common CIO questions include:
|
||||
|
||||
* Why do we need to do things in a new way?
|
||||
* Why are we spending time and money on this?
|
||||
* If there's no new functionality, just existing pieces being broken out with automation, then where is the gain?
|
||||
|
||||
|
||||
|
||||
The "if it ain't broke don't fix it" thinking is understandable. But if the car is driving fine while everyone on the road accelerates past you, your environment IS broken. Precious resources continue to be sucked into propping up or augmenting an environmental kluge.
|
||||
|
||||
Addressing every issue in isolation results in a compromised choice from the start that is worsened with each successive patch - layer upon layer added to a foundation that wasn't built to support it. In actuality, this approach is similar to plugging a continuously failing dike. Sooner or later you run out of fingers and the whole thing buckles under the added pressures, drowning your resources.
|
||||
|
||||
The solution: automation. The result of automation is scalability - less effort per person to maintain and grow your IT environment. If adding manpower is the only way to grow your business, then scalability is a pipe dream.
|
||||
|
||||
Automation reduces your manpower requirements and provides the flexibility required for continued IT evolution. Simple, right? Yes, but you must be prepared for delayed gratification. An upfront investment of time and effort for architectural and structural changes is required in order to reap the back-end financial benefits of automation with improved productivity and efficiency. Embracing these challenges as an IT leader is crucial in order for your DevOps team to successfully execute.
|
||||
|
||||
### 3. Trust
|
||||
|
||||
Lastly, trust your DevOps team and make sure they know it. DevOps experts understand that this is a tough request, but they must have your unquestionable support and your willingness to actively participate. It will often be a "learn as you go" experience for you as the DevOps team successively refines your IT environment, while they themselves adapt to ever-changing technology.
|
||||
|
||||
Listen, listen, listen to them and trust them. DevOps changes are valuable and well worth the time and money through increased efficiency, productivity, and business responsiveness. Trusting your DevOps team gives them the freedom to make the most effective IT improvements.
|
||||
|
||||
The new CIO bottom line: To maximize your DevOps team's potential, leave your leadership comfort zone and embrace a "CIOps" transition. Continuously work on finding common ground with the DevOps team throughout the DevOps transition, to help your organization achieve long-term IT success.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2017/12/what-devops-teams-really-need-cio
|
||||
|
||||
作者:[John Allessio][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://enterprisersproject.com/user/john-allessio
|
||||
[1]:https://enterprisersproject.com/tags/devops
|
||||
[2]:https://www.redhat.com/en/insights/devops?intcmp=701f2000000tjyaAAA
|
||||
[3]:https://enterprisersproject.com/devops?sc_cid=70160000000h0aXAAQ
|
||||
@ -1,59 +0,0 @@
|
||||
Translating by qhwdw
|
||||
Will DevOps steal my job?
|
||||
======
|
||||
|
||||
>Are you worried automation will replace people in the workplace? You may be right, but here's why that's not a bad thing.
|
||||
|
||||

|
||||
>Image by : opensource.com
|
||||
|
||||
It's a common fear: Will DevOps be the end of my job? After all, DevOps means developers doing operations, right? DevOps is automation. What if I automate myself out of a job? Do continuous delivery and containers mean operations staff are obsolete? DevOps is all about coding: infrastructure-as-code and testing-as-code and this-or-that-as-code. What if I don't have the skill set to be a part of this?
|
||||
|
||||
[DevOps][1] is a looming change, disruptive in the field, with seemingly fanatical followers talking about changing the world with the [Three Ways][2]--the three underpinnings of DevOps--and the tearing down of walls. It can all be overwhelming. So what's it going to be--is DevOps going to steal my job?
|
||||
|
||||
### The first fear: I'm not needed
|
||||
|
||||
As developers managing the entire lifecycle of an application, it's all too easy to get caught up in the idea of DevOps. Containers are probably a big contributing factor to this line of thought. When containers exploded onto the scene, they were touted as a way for developers to build, test, and deploy their code all-in-one. What role does DevOps leave for the operations team, or testing, or QA?
|
||||
|
||||
This stems from a misunderstanding of the principles of DevOps. The first principle of DevOps, or the First Way, is _Systems Thinking_ , or placing emphasis on a holistic approach to managing and understanding the whole lifecycle of an application or service. This does not mean that the developers of the application learn and manage the whole process. Rather, it is the collaboration of talented and skilled individuals to ensure success as a whole. To make developers solely responsible for the process is practically the extreme opposite of this tenant--essentially the enshrining of a single silo with the importance of the entire lifecycle.
|
||||
|
||||
There is a place for specialization in DevOps. Just as the classically educated software engineer with knowledge of linear regression and binary search is wasted writing Ansible playbooks and Docker files, the highly skilled sysadmin with the knowledge of how to secure a system and optimize database performance is wasted writing CSS and designing user flows. The most effective group to write, test, and maintain an application is a cross-discipline, functional team of people with diverse skill sets and backgrounds.
|
||||
|
||||
### The second fear: My job will be automated
|
||||
|
||||
Accurate or not, DevOps can sometimes be seen as a synonym for automation. What work is left for operations staff and testing teams when automated builds, testing, deployment, monitoring, and notifications are a huge part of the application lifecycle? This focus on automation can be partially related to the Second Way: _Amplify Feedback Loops_. This second tenant of DevOps deals with prioritizing quick feedback between teams in the opposite direction an application takes to deployment --from monitoring and maintaining to deployment, testing, development, etc., and the emphasis to make the feedback important and actionable. While the Second Way is not specifically related to automation, many of the automation tools teams use within their deployment pipelines facilitate quick notification and quick action, or course-correction based on feedback in support of this tenant. Traditionally done by humans, it is easy to understand why a focus on automation might lead to anxiety about the future of one's job.
|
||||
|
||||
Automation is just a tool, not a replacement for people. Smart people trapped doing the same things over and over, pushing the big red George Jetson button are a wasted, untapped wealth of intelligence and creativity. Automation of the drudgery of daily work means more time to spend solving real problems and coming up with creative solutions. Humans are needed to figure out the "how and why;" computers can handle the "copy and paste."
|
||||
|
||||
There will be no end of repetitive, predictable things to automate, and automation frees teams to focus on higher-order tasks in their field. Monitoring teams, no longer spending all their time configuring alerts or managing trending configuration, can start to focus on predicting alarms, correlating statistics, and creating proactive solutions. Systems administrators, freed of scheduled patching or server configuration, can spend time focusing on fleet management, performance, and scaling. Unlike the striking images of factory floors and assembly lines totally devoid of humans, automated tasks in the DevOps world mean humans can focus on creative, rewarding tasks instead of mind-numbing drudgery.
|
||||
|
||||
### The third fear: I do not have the skillset for this
|
||||
|
||||
"How am I going to keep up with this? I don't know how to automate. Everything is code now--do I have to be a developer and write code for a living to work in DevOps?" The third fear is ultimately a fear of self-confidence. As the culture changes, yes, teams will be asked to change along with it, and some may fear they lack the skills to perform what their jobs will become.
|
||||
|
||||
Most folks, however, are probably already closer than they think. What is the Dockerfile, or configuration management like Puppet or Ansible, but environment as code? System administrators already write shell scripts and Python programs to handle repetitive tasks for them. It's hardly a stretch to learn a little more and begin using some of the tools already at their disposal to solve more problems--orchestration, deployment, maintenance-as-code--especially when freed from the drudgery of manual tasks to focus on growth.
|
||||
|
||||
The answer to this fear lies in the third tenant of DevOps, the Third Way: _A Culture of Continual Experimentation and Learning_. The ability to try and fail and learn from mistakes without blame is a major factor in creating ever-more creative solutions. The Third Way is empowered by the first two ways --allowing for for quick detection of and repair of problems, and just as the developer is free to try and learn, other teams are as well. Operations teams that have never used configuration management or written programs to automate infrastructure provisioning are free to try and learn. Testing and QA teams are free to implement new testing pipelines and automate approval and release processes. In a culture that embraces learning and growing, everyone has the freedom to acquire the skills they need to succeed at and enjoy their job.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Any disruptive practice or change in an industry can create fear or uncertainty, and DevOps is no exception. A concern for one's job is a reasonable response to the hundreds of articles and presentations enumerating the countless practices and technologies seemingly dedicated to empowering developers to take responsibility for every aspect of the industry.
|
||||
|
||||
In truth, however, DevOps is "[a cross-disciplinary community of practice dedicated to the study of building, evolving, and operating rapidly changing resilient systems at scale][3]." DevOps means the end of silos, but not specialization. It is the delegation of drudgery to automated systems, freeing you to do what people do best: think and imagine. And if you're motivated to learn and grow, there will be no end of opportunities to solve new and challenging problems.
|
||||
|
||||
Will DevOps take away your job? Yes, but it will give you a better one.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/12/will-devops-steal-my-job
|
||||
|
||||
作者:[Chris Collins][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/clcollins
|
||||
[1]:https://opensource.com/resources/devops
|
||||
[2]:http://itrevolution.com/the-three-ways-principles-underpinning-devops/
|
||||
[3]:https://theagileadmin.com/what-is-devops/
|
||||
@ -1,191 +0,0 @@
|
||||
Translating by jessie-pang
|
||||
|
||||
How To Find (Top-10) Largest Files In Linux
|
||||
======
|
||||
When you are running out of disk space in system, you may prefer to check with df command or du command or ncdu command but all these will tell you only current directory files and doesn't shows the system wide files.
|
||||
|
||||
You have to spend huge amount of time to get the largest files in the system using the above commands, that to you have to navigate to each and every directory to achieve this.
|
||||
|
||||
It's making you to face trouble and this is not the right way to do it.
|
||||
|
||||
If so, what would be the suggested way to get top 10 largest files in Linux?
|
||||
|
||||
I have spend a lot of time with google but i didn't found this. Everywhere i could see an article which list the top 10 files in the current directory. So, i want to make this article useful for people whoever looking to get the top 10 largest files in the system.
|
||||
|
||||
In this tutorial, we are going to teach you how to find top 10 largest files in Linux system using below four methods.
|
||||
|
||||
### Method-1 :
|
||||
|
||||
There is no specific command available in Linux to do this, hence we are using more than one command (all together) to get this done.
|
||||
```
|
||||
# find / -type f -print0 | xargs -0 du -h | sort -rh | head -n 10
|
||||
|
||||
1.4G /swapfile
|
||||
1.1G /home/magi/ubuntu-17.04-desktop-amd64.iso
|
||||
564M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqTFU0XzkzUlJUZzA
|
||||
378M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqeldzUmhPeC03Zm8
|
||||
377M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqRGd4V0VrOXM4YVU
|
||||
100M /usr/lib/x86_64-linux-gnu/libOxideQtCore.so.0
|
||||
93M /usr/lib/firefox/libxul.so
|
||||
84M /var/lib/snapd/snaps/core_3604.snap
|
||||
84M /var/lib/snapd/snaps/core_3440.snap
|
||||
84M /var/lib/snapd/snaps/core_3247.snap
|
||||
|
||||
```
|
||||
|
||||
**Details :**
|
||||
**`find`** : It 's a command, Search for files in a directory hierarchy.
|
||||
**`/`** : Check in the whole system (starting from / directory)
|
||||
**`-type`** : File is of type
|
||||
|
||||
**`f`** : Regular file
|
||||
**`-print0`** : Print the full file name on the standard output, followed by a null character
|
||||
**`|`** : Control operator that send the output of one program to another program for further processing.
|
||||
|
||||
**`xargs`** : It 's a command, which build and execute command lines from standard input.
|
||||
**`-0`** : Input items are terminated by a null character instead of by whitespace
|
||||
**`du -h`** : It 's a command to calculate disk usage with human readable format
|
||||
|
||||
**`sort`** : It 's a command, Sort lines of text files
|
||||
**`-r`** : Reverse the result of comparisons
|
||||
**`-h`** : Print the output with human readable format
|
||||
|
||||
**`head`** : It 's a command, Output the first part of files
|
||||
**`n -10`** : Print the first 10 files.
|
||||
|
||||
### Method-2 :
|
||||
|
||||
This is an another way to find or check top 10 largest files in Linux system. Here also, we are putting few commands together to achieve this.
|
||||
```
|
||||
# find / -type f -exec du -Sh {} + | sort -rh | head -n 10
|
||||
|
||||
1.4G /swapfile
|
||||
1.1G /home/magi/ubuntu-17.04-desktop-amd64.iso
|
||||
564M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqTFU0XzkzUlJUZzA
|
||||
378M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqeldzUmhPeC03Zm8
|
||||
377M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqRGd4V0VrOXM4YVU
|
||||
100M /usr/lib/x86_64-linux-gnu/libOxideQtCore.so.0
|
||||
93M /usr/lib/firefox/libxul.so
|
||||
84M /var/lib/snapd/snaps/core_3604.snap
|
||||
84M /var/lib/snapd/snaps/core_3440.snap
|
||||
84M /var/lib/snapd/snaps/core_3247.snap
|
||||
|
||||
```
|
||||
|
||||
**Details :**
|
||||
**`find`** : It 's a command, Search for files in a directory hierarchy.
|
||||
**`/`** : Check in the whole system (starting from / directory)
|
||||
**`-type`** : File is of type
|
||||
|
||||
**`f`** : Regular file
|
||||
**`-exec`** : This variant of the -exec action runs the specified command on the selected files
|
||||
**`du`** : It 's a command to estimate file space usage.
|
||||
|
||||
**`-S`** : Do not include size of subdirectories
|
||||
**`-h`** : Print sizes in human readable format
|
||||
**`{}`** : Summarize disk usage of each FILE, recursively for directories.
|
||||
|
||||
**`|`** : Control operator that send the output of one program to another program for further processing.
|
||||
**`sort`** : It 's a command, Sort lines of text files
|
||||
**`-r`** : Reverse the result of comparisons
|
||||
|
||||
**`-h`** : Compare human readable numbers
|
||||
**`head`** : It 's a command, Output the first part of files
|
||||
**`n -10`** : Print the first 10 files.
|
||||
|
||||
### Method-3 :
|
||||
|
||||
It 's an another method to find or search top 10 largest files in Linux system.
|
||||
```
|
||||
# find / -type f -print0 | xargs -0 du | sort -n | tail -10 | cut -f2 | xargs -I{} du -sh {}
|
||||
|
||||
84M /var/lib/snapd/snaps/core_3247.snap
|
||||
84M /var/lib/snapd/snaps/core_3440.snap
|
||||
84M /var/lib/snapd/snaps/core_3604.snap
|
||||
93M /usr/lib/firefox/libxul.so
|
||||
100M /usr/lib/x86_64-linux-gnu/libOxideQtCore.so.0
|
||||
377M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqRGd4V0VrOXM4YVU
|
||||
378M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqeldzUmhPeC03Zm8
|
||||
564M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqTFU0XzkzUlJUZzA
|
||||
1.1G /home/magi/ubuntu-17.04-desktop-amd64.iso
|
||||
1.4G /swapfile
|
||||
|
||||
```
|
||||
|
||||
**Details :**
|
||||
**`find`** : It 's a command, Search for files in a directory hierarchy.
|
||||
**`/`** : Check in the whole system (starting from / directory)
|
||||
**`-type`** : File is of type
|
||||
|
||||
**`f`** : Regular file
|
||||
**`-print0`** : Print the full file name on the standard output, followed by a null character
|
||||
**`|`** : Control operator that send the output of one program to another program for further processing.
|
||||
|
||||
**`xargs`** : It 's a command, which build and execute command lines from standard input.
|
||||
**`-0`** : Input items are terminated by a null character instead of by whitespace
|
||||
**`du`** : It 's a command to estimate file space usage.
|
||||
|
||||
**`sort`** : It 's a command, Sort lines of text files
|
||||
**`-n`** : Compare according to string numerical value
|
||||
**`tail -10`** : It 's a command, output the last part of files (last 10 files)
|
||||
|
||||
**`cut`** : It 's a command, remove sections from each line of files
|
||||
**`-f2`** : Select only these fields value.
|
||||
**`-I{}`** : Replace occurrences of replace-str in the initial-arguments with names read from standard input.
|
||||
|
||||
**`-s`** : Display only a total for each argument
|
||||
**`-h`** : Print sizes in human readable format
|
||||
**`{}`** : Summarize disk usage of each FILE, recursively for directories.
|
||||
|
||||
### Method-4 :
|
||||
|
||||
It 's an another method to find or search top 10 largest files in Linux system.
|
||||
```
|
||||
# find / -type f -ls | sort -k 7 -r -n | head -10 | column -t | awk '{print $7,$11}'
|
||||
|
||||
1494845440 /swapfile
|
||||
1085984380 /home/magi/ubuntu-17.04-desktop-amd64.iso
|
||||
591003648 /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqTFU0XzkzUlJUZzA
|
||||
395770383 /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqeldzUmhPeC03Zm8
|
||||
394891761 /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqRGd4V0VrOXM4YVU
|
||||
103999072 /usr/lib/x86_64-linux-gnu/libOxideQtCore.so.0
|
||||
97356256 /usr/lib/firefox/libxul.so
|
||||
87896064 /var/lib/snapd/snaps/core_3604.snap
|
||||
87793664 /var/lib/snapd/snaps/core_3440.snap
|
||||
87089152 /var/lib/snapd/snaps/core_3247.snap
|
||||
|
||||
```
|
||||
|
||||
**Details :**
|
||||
**`find`** : It 's a command, Search for files in a directory hierarchy.
|
||||
**`/`** : Check in the whole system (starting from / directory)
|
||||
**`-type`** : File is of type
|
||||
|
||||
**`f`** : Regular file
|
||||
**`-ls`** : List current file in ls -dils format on standard output.
|
||||
**`|`** : Control operator that send the output of one program to another program for further processing.
|
||||
|
||||
**`sort`** : It 's a command, Sort lines of text files
|
||||
**`-k`** : start a key at POS1
|
||||
**`-r`** : Reverse the result of comparisons
|
||||
|
||||
**`-n`** : Compare according to string numerical value
|
||||
**`head`** : It 's a command, Output the first part of files
|
||||
**`-10`** : Print the first 10 files.
|
||||
|
||||
**`column`** : It 's a command, formats its input into multiple columns.
|
||||
**`-t`** : Determine the number of columns the input contains and create a table.
|
||||
**`awk`** : It 's a command, Pattern scanning and processing language
|
||||
**`'{print $7,$11}'`** : Print only mentioned column.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-find-search-check-print-top-10-largest-biggest-files-in-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/magesh/
|
||||
@ -1,3 +1,4 @@
|
||||
transalting by wyxplus
|
||||
4 Tools for Network Snooping on Linux
|
||||
======
|
||||
Computer networking data has to be exposed, because packets can't travel blindfolded, so join us as we use `whois`, `dig`, `nmcli`, and `nmap` to snoop networks.
|
||||
|
||||
@ -1,94 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Tlog - A Tool to Record / Play Terminal IO and Sessions
|
||||
======
|
||||
Tlog is a terminal I/O recording and playback package for Linux Distros. It's suitable for implementing centralized user session recording. It logs everything that passes through as JSON messages. The primary purpose of logging in JSON format is to eventually deliver the recorded data to a storage service such as Elasticsearch, where it can be searched and queried, and from where it can be played back. At the same time, they retain all the passed data and timing.
|
||||
|
||||
Tlog contains three tools namely tlog-rec, tlog-rec-session and tlog-play.
|
||||
|
||||
* `Tlog-rec tool` is used for recording terminal input or output of programs or shells in general.
|
||||
* `Tlog-rec-session tool` is used for recording I/O of whole terminal sessions, with protection from recorded users.
|
||||
* `Tlog-play tool` for playing back the recordings.
|
||||
|
||||
|
||||
|
||||
In this article, I'll explain how to install Tlog on a CentOS 7.4 server.
|
||||
|
||||
### Installation
|
||||
|
||||
Before proceeding with the install, we need to ensure that our system meets all the software requirements for compiling and installing the application. On the first step, update your system repositories and software packages by using the below command.
|
||||
```
|
||||
#yum update
|
||||
```
|
||||
|
||||
We need to install the required dependencies for this software installation. I've installed all dependency packages with these commands prior to the installation.
|
||||
```
|
||||
#yum install wget gcc
|
||||
#yum install systemd-devel json-c-devel libcurl-devel m4
|
||||
```
|
||||
|
||||
After completing these installations, we can download the [source package][1] for this tool and extract it on your server as required:
|
||||
```
|
||||
#wget https://github.com/Scribery/tlog/releases/download/v3/tlog-3.tar.gz
|
||||
#tar -xvf tlog-3.tar.gz
|
||||
# cd tlog-3
|
||||
```
|
||||
|
||||
Now you can start building this tool using our usual configure and make approach.
|
||||
```
|
||||
#./configure --prefix=/usr --sysconfdir=/etc && make
|
||||
#make install
|
||||
#ldconfig
|
||||
```
|
||||
|
||||
Finally, you need to run `ldconfig`. It creates the necessary links and cache to the most recent shared libraries found in the directories specified on the command line, in the file /etc/ld.so.conf, and in the trusted directories (/lib and /usr/lib).
|
||||
|
||||
### Tlog workflow chart
|
||||
|
||||
![Tlog working process][2]
|
||||
|
||||
Firstly, a user authenticates to login via PAM. The Name Service Switch (NSS) provides the information as `tlog` is a shell to the user. This initiates the tlog section and it collects the information from the Env/config files about the actual shell and starts the actual shell in a PTY. Then it starts logging everything passing between the terminal and the PTY via syslog or sd-journal.
|
||||
|
||||
### Usage
|
||||
|
||||
You can test if session recording and playback work in general with a freshly installed tlog, by recording a session into a file with `tlog-rec` and then playing it back with `tlog-play`.
|
||||
|
||||
#### Recording to a file
|
||||
|
||||
To record a session into a file, execute `tlog-rec` on the command line as such:
|
||||
```
|
||||
tlog-rec --writer=file --file-path=tlog.log
|
||||
```
|
||||
|
||||
This command will record our terminal session to a file named tlog.log and save it in the path specified in the command.
|
||||
|
||||
#### Playing back from a file
|
||||
|
||||
You can playback the recorded session during or after recording using `tlog-play` command.
|
||||
```
|
||||
tlog-play --reader=file --file-path=tlog.log
|
||||
```
|
||||
|
||||
This command reads the previously recorded file tlog.log from the file path mentioned in the command line.
|
||||
|
||||
### Wrapping up
|
||||
|
||||
Tlog is an open-source package which can be used for implementing centralized user session recording. This is mainly intended to be used as part of a larger user session recording solution but is designed to be independent and reusable.This tool can be a great help for recording everything users do and store it somewhere on the server side safe for the future reference. You can get more details about this package usage in this [documentation][3]. I hope this article is useful to you. Please post your valuable suggestions and comments on this.
|
||||
|
||||
### About Saheetha Shameer(the author)
|
||||
I'm working as a Senior System Administrator. I'm a quick learner and have a slight inclination towards following the current and emerging trends in the industry. My hobbies include hearing music, playing strategy computer games, reading and gardening. I also have a high passion for experimenting with various culinary delights :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linoxide.com/linux-how-to/tlog-tool-record-play-terminal-io-sessions/
|
||||
|
||||
作者:[Saheetha Shameer][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linoxide.com/author/saheethas/
|
||||
[1]:https://github.com/Scribery/tlog/releases/download/v3/tlog-3.tar.gz
|
||||
[2]:https://linoxide.com/wp-content/uploads/2018/01/Tlog-working-process.png
|
||||
[3]:https://github.com/Scribery/tlog/blob/master/README.md
|
||||
@ -1,195 +0,0 @@
|
||||
How to Create a Docker Image
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
Learn the basic steps for creating Docker images in this tutorial.[Creative Commons Zero][1]Pixabay
|
||||
|
||||
In the previous [article][4], we learned about how to get started with Docker on Linux, macOS, and Windows. In this article, we will get a basic understanding of creating Docker images. There are prebuilt images available on DockerHub that you can use for your own project, and you can publish your own image there.
|
||||
|
||||
We are going to use prebuilt images to get the base Linux subsystem, as it’s a lot of work to build one from scratch. You can get Alpine (the official distro used by Docker Editions), Ubuntu, BusyBox, or scratch. In this example, I will use Ubuntu.
|
||||
|
||||
Before we start building our images, let’s “containerize” them! By this I just mean creating directories for all of your Docker images so that you can maintain different projects and stages isolated from each other.
|
||||
|
||||
```
|
||||
$ mkdir dockerprojects
|
||||
|
||||
cd dockerprojects
|
||||
```
|
||||
|
||||
Now create a _Dockerfile_ inside the _dockerprojects_ directory using your favorite text editor; I prefer nano, which is also easy for new users.
|
||||
|
||||
```
|
||||
$ nano Dockerfile
|
||||
```
|
||||
|
||||
And add this line:
|
||||
|
||||
```
|
||||
FROM Ubuntu
|
||||
```
|
||||
|
||||

|
||||
|
||||
Save it with Ctrl+Exit then Y.
|
||||
|
||||
Now create your new image and provide it with a name (run these commands within the same directory):
|
||||
|
||||
```
|
||||
$ docker build -t dockp .
|
||||
```
|
||||
|
||||
(Note the dot at the end of the command.) This should build successfully, so you'll see:
|
||||
|
||||
```
|
||||
Sending build context to Docker daemon 2.048kB
|
||||
|
||||
Step 1/1 : FROM ubuntu
|
||||
|
||||
---> 2a4cca5ac898
|
||||
|
||||
Successfully built 2a4cca5ac898
|
||||
|
||||
Successfully tagged dockp:latest
|
||||
```
|
||||
|
||||
It’s time to run and test your image:
|
||||
|
||||
```
|
||||
$ docker run -it Ubuntu
|
||||
```
|
||||
|
||||
You should see root prompt:
|
||||
|
||||
```
|
||||
root@c06fcd6af0e8:/#
|
||||
```
|
||||
|
||||
This means you are literally running bare minimal Ubuntu inside Linux, Windows, or macOS. You can run all native Ubuntu commands and CLI utilities.
|
||||
|
||||

|
||||
|
||||
Let’s check all the Docker images you have in your directory:
|
||||
|
||||
```
|
||||
$docker images
|
||||
|
||||
REPOSITORY TAG IMAGE ID CREATED SIZE
|
||||
|
||||
dockp latest 2a4cca5ac898 1 hour ago 111MB
|
||||
|
||||
ubuntu latest 2a4cca5ac898 1 hour ago 111MB
|
||||
|
||||
hello-world latest f2a91732366c 8 weeks ago 1.85kB
|
||||
```
|
||||
|
||||
You can see all three images: _dockp, Ubuntu_ _,_ and _hello-world_ , which I created a few weeks ago when working on the previous articles of this series. Building a whole LAMP stack can be challenging, so we are going create a simple Apache server image with Dockerfile.
|
||||
|
||||
Dockerfile is basically a set of instructions to install all the needed packages, configure, and copy files. In this case, it’s Apache and Nginx.
|
||||
|
||||
You may also want to create an account on DockerHub and log into your account before building images, in case you are pulling something from DockerHub. To log into DockerHub from the command line, just run:
|
||||
|
||||
```
|
||||
$ docker login
|
||||
```
|
||||
|
||||
Enter your username and password and you are logged in.
|
||||
|
||||
Next, create a directory for Apache inside the dockerproject:
|
||||
|
||||
```
|
||||
$ mkdir apache
|
||||
```
|
||||
|
||||
Create a Dockerfile inside Apache folder:
|
||||
|
||||
```
|
||||
$ nano Dockerfile
|
||||
```
|
||||
|
||||
And paste these lines:
|
||||
|
||||
```
|
||||
FROM ubuntu
|
||||
|
||||
MAINTAINER Kimbro Staken version: 0.1
|
||||
|
||||
RUN apt-get update && apt-get install -y apache2 && apt-get clean && rm -rf /var/lib/apt/lists/*
|
||||
|
||||
ENV APACHE_RUN_USER www-data
|
||||
|
||||
ENV APACHE_RUN_GROUP www-data
|
||||
|
||||
ENV APACHE_LOG_DIR /var/log/apache2
|
||||
|
||||
EXPOSE 80
|
||||
|
||||
CMD ["/usr/sbin/apache2", "-D", "FOREGROUND"]
|
||||
```
|
||||
|
||||
Then, build the image:
|
||||
|
||||
```
|
||||
docker build -t apache .
|
||||
```
|
||||
|
||||
(Note the dot after a space at the end.)
|
||||
|
||||
It will take some time, then you should see successful build like this:
|
||||
|
||||
```
|
||||
Successfully built e7083fd898c7
|
||||
|
||||
Successfully tagged ng:latest
|
||||
|
||||
Swapnil:apache swapnil$
|
||||
```
|
||||
|
||||
Now let’s run the server:
|
||||
|
||||
```
|
||||
$ docker run –d apache
|
||||
|
||||
a189a4db0f7c245dd6c934ef7164f3ddde09e1f3018b5b90350df8be85c8dc98
|
||||
```
|
||||
|
||||
Eureka. Your container image is running. Check all the running containers:
|
||||
|
||||
```
|
||||
$ docker ps
|
||||
|
||||
CONTAINER ID IMAGE COMMAND CREATED
|
||||
|
||||
a189a4db0f7 apache "/usr/sbin/apache2ctl" 10 seconds ago
|
||||
```
|
||||
|
||||
You can kill the container with the _docker kill_ command:
|
||||
|
||||
```
|
||||
$docker kill a189a4db0f7
|
||||
```
|
||||
|
||||
So, you see the “image” itself is persistent that stays in your directory, but the container runs and goes away. Now you can create as many images as you want and spin and nuke as many containers as you need from those images.
|
||||
|
||||
That’s how to create an image and run containers.
|
||||
|
||||
To learn more, you can open your web browser and check out the documentation about how to build more complicated Docker images like the whole LAMP stack. Here is a[ Dockerfile][5] file for you to play with. In the next article, I’ll show how to push images to DockerHub.
|
||||
|
||||
_Learn more about Linux through the free ["Introduction to Linux" ][3]course from The Linux Foundation and edX._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/intro-to-linux/2018/1/how-create-docker-image
|
||||
|
||||
作者:[SWAPNIL BHARTIYA][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/arnieswap
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]:https://www.linux.com/files/images/container-imagejpg-0
|
||||
[3]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
[4]:https://www.linux.com/blog/learn/intro-to-linux/how-install-docker-ce-your-desktop
|
||||
[5]:https://github.com/fauria/docker-lamp/blob/master/Dockerfile
|
||||
@ -1,147 +0,0 @@
|
||||
Translating by qhwdw
|
||||
Keep Accurate Time on Linux with NTP
|
||||
======
|
||||
|
||||

|
||||
|
||||
How to keep the correct time and keep your computers synchronized without abusing time servers, using NTP and systemd.
|
||||
|
||||
### What Time is It?
|
||||
|
||||
Linux is funky when it comes to telling the time. You might think that the `time` tells the time, but it doesn't because it is a timer that measures how long a process runs. To get the time, you run the `date` command, and to view more than one date, you use `cal`. Timestamps on files are also a source of confusion as they are typically displayed in two different ways, depending on your distro defaults. This example is from Ubuntu 16.04 LTS:
|
||||
```
|
||||
$ ls -l
|
||||
drwxrwxr-x 5 carla carla 4096 Mar 27 2017 stuff
|
||||
drwxrwxr-x 2 carla carla 4096 Dec 8 11:32 things
|
||||
-rw-rw-r-- 1 carla carla 626052 Nov 21 12:07 fatpdf.pdf
|
||||
-rw-rw-r-- 1 carla carla 2781 Apr 18 2017 oddlots.txt
|
||||
|
||||
```
|
||||
|
||||
Some display the year, some display the time, which makes ordering your files rather a mess. The GNU default is files dated within the last six months display the time instead of the year. I suppose there is a reason for this. If your Linux does this, try `ls -l --time-style=long-iso` to display the timestamps all the same way, sorted alphabetically. See [How to Change the Linux Date and Time: Simple Commands][1] to learn all manner of fascinating ways to manage the time on Linux.
|
||||
|
||||
### Check Current Settings
|
||||
|
||||
NTP, the network time protocol, is the old-fashioned way of keeping correct time on computers. `ntpd`, the NTP daemon, periodically queries a public time server and adjusts your system time as needed. It's a simple lightweight protocol that is easy to set up for basic use. Systemd has barged into NTP territory with the `systemd-timesyncd.service`, which acts as a client to `ntpd`.
|
||||
|
||||
Before messing with NTP, let's take a minute to check that current time settings are correct.
|
||||
|
||||
There are (at least) two timekeepers on your system: system time, which is managed by the Linux kernel, and the hardware clock on your motherboard, which is also called the real-time clock (RTC). When you enter your system BIOS, you see the hardware clock time and you can change its settings. When you install a new Linux, and in some graphical time managers, you are asked if you want your RTC set to the UTC (Coordinated Universal Time) zone. It should be set to UTC, because all time zone and daylight savings time calculations are based on UTC. Use the `hwclock` command to check:
|
||||
```
|
||||
$ sudo hwclock --debug
|
||||
hwclock from util-linux 2.27.1
|
||||
Using the /dev interface to the clock.
|
||||
Hardware clock is on UTC time
|
||||
Assuming hardware clock is kept in UTC time.
|
||||
Waiting for clock tick...
|
||||
...got clock tick
|
||||
Time read from Hardware Clock: 2018/01/22 22:14:31
|
||||
Hw clock time : 2018/01/22 22:14:31 = 1516659271 seconds since 1969
|
||||
Time since last adjustment is 1516659271 seconds
|
||||
Calculated Hardware Clock drift is 0.000000 seconds
|
||||
Mon 22 Jan 2018 02:14:30 PM PST .202760 seconds
|
||||
|
||||
```
|
||||
|
||||
"Hardware clock is kept in UTC time" confirms that your RTC is on UTC, even though it translates the time to your local time. If it were set to local time it would report "Hardware clock is kept in local time."
|
||||
|
||||
You should have a `/etc/adjtime` file. If you don't, sync your RTC to system time:
|
||||
```
|
||||
$ sudo hwclock -w
|
||||
|
||||
```
|
||||
|
||||
This should generate the file, and the contents should look like this example:
|
||||
```
|
||||
$ cat /etc/adjtime
|
||||
0.000000 1516661953 0.000000
|
||||
1516661953
|
||||
UTC
|
||||
|
||||
```
|
||||
|
||||
The new-fangled systemd way is to run `timedatectl`, which does not need root permissions:
|
||||
```
|
||||
$ timedatectl
|
||||
Local time: Mon 2018-01-22 14:17:51 PST
|
||||
Universal time: Mon 2018-01-22 22:17:51 UTC
|
||||
RTC time: Mon 2018-01-22 22:17:51
|
||||
Time zone: America/Los_Angeles (PST, -0800)
|
||||
Network time on: yes
|
||||
NTP synchronized: yes
|
||||
RTC in local TZ: no
|
||||
|
||||
```
|
||||
|
||||
"RTC in local TZ: no" confirms that it is on UTC time. What if it is on local time? There are, as always, multiple ways to change it. The easy way is with a nice graphical configuration tool, like YaST in openSUSE. You can use `timedatectl`:
|
||||
```
|
||||
$ timedatectl set-local-rtc 0
|
||||
```
|
||||
|
||||
Or edit `/etc/adjtime`, replacing UTC with LOCAL.
|
||||
|
||||
### systemd-timesyncd Client
|
||||
|
||||
Now I'm tired, and we've just gotten to the good part. Who knew timekeeping was so complex? We haven't even scratched the surface; read `man 8 hwclock` to get an idea of how time is kept on computers.
|
||||
|
||||
Systemd provides the `systemd-timesyncd.service` client, which queries remote time servers and adjusts your system time. Configure your servers in `/etc/systemd/timesyncd.conf`. Most Linux distributions provide a default configuration that points to time servers that they maintain, like Fedora:
|
||||
```
|
||||
[Time]
|
||||
#NTP=
|
||||
#FallbackNTP=0.fedora.pool.ntp.org 1.fedora.pool.ntp.org
|
||||
|
||||
```
|
||||
|
||||
You may enter any other servers you desire, such as your own local NTP server, on the `NTP=` line in a space-delimited list. (Remember to uncomment this line.) Anything you put on the `NTP=` line overrides the fallback.
|
||||
|
||||
What if you are not using systemd? Then you need only NTP.
|
||||
|
||||
### Setting up NTP Server and Client
|
||||
|
||||
It is a good practice to set up your own LAN NTP server, so that you are not pummeling public NTP servers from all of your computers. On most Linuxes NTP comes in the `ntp` package, and most of them provide `/etc/ntp.conf` to configure the service. Consult [NTP Pool Time Servers][2] to find the NTP server pool that is appropriate for your region. Then enter 4-5 servers in your `/etc/ntp.conf` file, with each server on its own line:
|
||||
```
|
||||
driftfile /var/ntp.drift
|
||||
logfile /var/log/ntp.log
|
||||
server 0.europe.pool.ntp.org
|
||||
server 1.europe.pool.ntp.org
|
||||
server 2.europe.pool.ntp.org
|
||||
server 3.europe.pool.ntp.org
|
||||
|
||||
```
|
||||
|
||||
The `driftfile` tells `ntpd` where to store the information it needs to quickly synchronize your system clock with the time servers at startup, and your logs should have their own home instead of getting dumped into the syslog. Use your Linux distribution defaults for these files if it provides them.
|
||||
|
||||
Now start the daemon; on most Linuxes this is `sudo systemctl start ntpd`. Let it run for a few minutes, then check its status:
|
||||
```
|
||||
$ ntpq -p
|
||||
remote refid st t when poll reach delay offset jitter
|
||||
==============================================================
|
||||
+dev.smatwebdesi 192.168.194.89 3 u 25 64 37 92.456 -6.395 18.530
|
||||
*chl.la 127.67.113.92 2 u 23 64 37 75.175 8.820 8.230
|
||||
+four0.fairy.mat 35.73.197.144 2 u 22 64 37 116.272 -10.033 40.151
|
||||
-195.21.152.161 195.66.241.2 2 u 27 64 37 107.559 1.822 27.346
|
||||
|
||||
```
|
||||
|
||||
I have no idea what any of that means, other than your daemon is talking to the remote time servers, and that is what you want. To permanently enable it, run `sudo systemctl enable ntpd`. If your Linux doesn't use systemd then it is your homework to figure out how to run `ntpd`.
|
||||
|
||||
Now you can set up `systemd-timesyncd` on your other LAN hosts to use your local NTP server, or install NTP on them and enter your local server in their `/etc/ntp.conf` files.
|
||||
|
||||
NTP servers take a beating, and demand continually increases. You can help by running your own public NTP server. Come back next week to learn how.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][3]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/1/keep-accurate-time-linux-ntp
|
||||
|
||||
作者:[CARLA SCHRODER][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/learn/how-change-linux-date-and-time-simple-commands
|
||||
[2]:http://support.ntp.org/bin/view/Servers/NTPPoolServers
|
||||
[3]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,172 +0,0 @@
|
||||
Translating by qhwdw
|
||||
Your instant Kubernetes cluster
|
||||
============================================================
|
||||
|
||||
|
||||
This is a condensed and updated version of my previous tutorial [Kubernetes in 10 minutes][10]. I've removed just about everything I can so this guide still makes sense. Use it when you want to create a cluster on the cloud or on-premises as fast as possible.
|
||||
|
||||
### 1.0 Pick a host
|
||||
|
||||
We will be using Ubuntu 16.04 for this guide so that you can copy/paste all the instructions. Here are several environments where I've tested this guide. Just pick where you want to run your hosts.
|
||||
|
||||
* [DigitalOcean][1] - developer cloud
|
||||
|
||||
* [Civo][2] - UK developer cloud
|
||||
|
||||
* [Packet][3] - bare metal cloud
|
||||
|
||||
* 2x Dell Intel i7 boxes - at home
|
||||
|
||||
> Civo is a relatively new developer cloud and one thing that I really liked was how quickly they can bring up hosts - in about 25 seconds. I'm based in the UK so I also get very low latency.
|
||||
|
||||
### 1.1 Provision the machines
|
||||
|
||||
You can get away with a single host for testing but I'd recommend at least three so we have a single master and two worker nodes.
|
||||
|
||||
Here are some other guidelines:
|
||||
|
||||
* Pick dual-core hosts with ideally at least 2GB RAM
|
||||
|
||||
* If you can pick a custom username when provisioning the host then do that rather than root. For example Civo offers an option of `ubuntu`, `civo` or `root`.
|
||||
|
||||
Now run through the following steps on each machine. It should take you less than 5-10 minutes. If that's too slow for you then you can use my utility script [kept in a Gist][11]:
|
||||
|
||||
```
|
||||
$ curl -sL https://gist.githubusercontent.com/alexellis/e8bbec45c75ea38da5547746c0ca4b0c/raw/23fc4cd13910eac646b13c4f8812bab3eeebab4c/configure.sh | sh
|
||||
|
||||
```
|
||||
|
||||
### 1.2 Login and install Docker
|
||||
|
||||
Install Docker from the Ubuntu apt repository. This will be an older version of Docker but as Kubernetes is tested with old versions of Docker it will work in our favour.
|
||||
|
||||
```
|
||||
$ sudo apt-get update \
|
||||
&& sudo apt-get install -qy docker.io
|
||||
|
||||
```
|
||||
|
||||
### 1.3 Disable the swap file
|
||||
|
||||
This is now a mandatory step for Kubernetes. The easiest way to do this is to edit `/etc/fstab` and to comment out the line referring to swap.
|
||||
|
||||
To save a reboot then type in `sudo swapoff -a`.
|
||||
|
||||
> Disabling swap memory may appear like a strange requirement at first. If you are curious about this step then [read more here][4].
|
||||
|
||||
### 1.4 Install Kubernetes packages
|
||||
|
||||
```
|
||||
$ sudo apt-get update \
|
||||
&& sudo apt-get install -y apt-transport-https \
|
||||
&& curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -
|
||||
|
||||
$ echo "deb http://apt.kubernetes.io/ kubernetes-xenial main" \
|
||||
| sudo tee -a /etc/apt/sources.list.d/kubernetes.list \
|
||||
&& sudo apt-get update
|
||||
|
||||
$ sudo apt-get update \
|
||||
&& sudo apt-get install -y \
|
||||
kubelet \
|
||||
kubeadm \
|
||||
kubernetes-cni
|
||||
|
||||
```
|
||||
|
||||
### 1.5 Create the cluster
|
||||
|
||||
At this point we create the cluster by initiating the master with `kubeadm`. Only do this on the master node.
|
||||
|
||||
> Despite any warnings I have been assured by [Weaveworks][5] and Lucas (the maintainer) that `kubeadm` is suitable for production use.
|
||||
|
||||
```
|
||||
$ sudo kubeadm init
|
||||
|
||||
```
|
||||
|
||||
If you missed a step or there's a problem then `kubeadm` will let you know at this point.
|
||||
|
||||
Take a copy of the Kube config:
|
||||
|
||||
```
|
||||
mkdir -p $HOME/.kube
|
||||
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
|
||||
sudo chown $(id -u):$(id -g) $HOME/.kube/config
|
||||
|
||||
```
|
||||
|
||||
Make sure you note down the join token command i.e.
|
||||
|
||||
```
|
||||
$ sudo kubeadm join --token c30633.d178035db2b4bb9a 10.0.0.5:6443 --discovery-token-ca-cert-hash sha256:<hash>
|
||||
|
||||
```
|
||||
|
||||
### 2.0 Install networking
|
||||
|
||||
Many networking providers are available for Kubernetes, but none are included by default, so let's use Weave Net from [Weaveworks][12] which is one of the most popular options in the Kubernetes community. It tends to work out of the box without additional configuration.
|
||||
|
||||
```
|
||||
$ kubectl apply -f "https://cloud.weave.works/k8s/net?k8s-version=$(kubectl version | base64 | tr -d '\n')"
|
||||
|
||||
```
|
||||
|
||||
If you have private networking enabled on your host then you may need to alter the private subnet that Weavenet uses for allocating IP addresses to Pods (containers). Here's an example of how to do that:
|
||||
|
||||
```
|
||||
$ curl -SL "https://cloud.weave.works/k8s/net?k8s-version=$(kubectl version | base64 | tr -d '\n')&env.IPALLOC_RANGE=172.16.6.64/27" \
|
||||
| kubectl apply -f -
|
||||
|
||||
```
|
||||
|
||||
> Weave also have a very cool visualisation tool called Weave Cloud. It's free and will show you the path traffic is taking between your Pods. [See here for an example with the OpenFaaS project][6].
|
||||
|
||||
### 2.2 Join the worker nodes to the cluster
|
||||
|
||||
Now you can switch to each of your workers and use the `kubeadm join` command from 1.5\. Once you run that log out of the workers.
|
||||
|
||||
### 3.0 Profit
|
||||
|
||||
That's it - we're done. You have a cluster up and running and can deploy your applications. If you need to setup a dashboard UI then consult the [Kubernetes documentation][13].
|
||||
|
||||
```
|
||||
$ kubectl get nodes
|
||||
NAME STATUS ROLES AGE VERSION
|
||||
openfaas1 Ready master 20m v1.9.2
|
||||
openfaas2 Ready <none> 19m v1.9.2
|
||||
openfaas3 Ready <none> 19m v1.9.2
|
||||
|
||||
```
|
||||
|
||||
If you want to see my running through creating a cluster step-by-step and showing you how `kubectl` works then checkout my video below and make sure you subscribe
|
||||
|
||||
|
||||
You can also get an "instant" Kubernetes cluster on your Mac for development using Minikube or Docker for Mac Edge edition. [Read my review and first impressions here][14].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.alexellis.io/your-instant-kubernetes-cluster/
|
||||
|
||||
作者:[Alex Ellis ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.alexellis.io/author/alex/
|
||||
[1]:https://www.digitalocean.com/
|
||||
[2]:https://www.civo.com/
|
||||
[3]:https://packet.net/
|
||||
[4]:https://github.com/kubernetes/kubernetes/issues/53533
|
||||
[5]:https://weave.works/
|
||||
[6]:https://www.weave.works/blog/openfaas-gke
|
||||
[7]:https://blog.alexellis.io/tag/kubernetes/
|
||||
[8]:https://blog.alexellis.io/tag/k8s/
|
||||
[9]:https://blog.alexellis.io/tag/cloud-native/
|
||||
[10]:https://www.youtube.com/watch?v=6xJwQgDnMFE
|
||||
[11]:https://gist.github.com/alexellis/e8bbec45c75ea38da5547746c0ca4b0c
|
||||
[12]:https://weave.works/
|
||||
[13]:https://kubernetes.io/docs/tasks/access-application-cluster/web-ui-dashboard/
|
||||
[14]:https://blog.alexellis.io/docker-for-mac-with-kubernetes/
|
||||
[15]:https://blog.alexellis.io/your-instant-kubernetes-cluster/#
|
||||
@ -1,68 +0,0 @@
|
||||
A look inside Facebook's open source program
|
||||
============================================================
|
||||
|
||||
### Facebook developer Christine Abernathy discusses how open source helps the company share insights and boost innovation.
|
||||
|
||||

|
||||
Image by : opensource.com
|
||||
|
||||
|
||||
Open source becomes more ubiquitous every year, appearing everywhere from [government municipalities][11] to [universities][12]. Companies of all sizes are also increasingly turning to open source software. In fact, some companies are taking open source a step further by supporting projects financially or working with developers.
|
||||
|
||||
Facebook's open source program, for example, encourages others to release their code as open source, while working and engaging with the community to support open source projects. [Christine Abernathy][13], a Facebook developer, open source advocate, and member of the company's open source team, visited the Rochester Institute of Technology last November, presenting at the [November edition][14] of the FOSS Talks speaker series. In her talk, Abernathy explained how Facebook approaches open source and why it's an important part of the work the company does.
|
||||
|
||||
### Facebook and open source
|
||||
|
||||
Abernathy said that open source plays a fundamental role in Facebook's mission to create community and bring the world closer together. This ideological match is one motivating factor for Facebook's participation in open source. Additionally, Facebook faces unique infrastructure and development challenges, and open source provides a platform for the company to share solutions that could help others. Open source also provides a way to accelerate innovation and create better software, helping engineering teams produce better software and work more transparently. Today, Facebook's 443 projects on GitHub comprise 122,000 forks, 292,000 commits, and 732,000 followers.
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
Some of the Facebook projects released as open source include React, GraphQL, Caffe2, and others. (Image by Christine Abernathy, used with permission)
|
||||
|
||||
### Lessons learned
|
||||
|
||||
Abernathy emphasized that Facebook has learned many lessons from the open source community, and it looks forward to learning many more. She identified the three most important ones:
|
||||
|
||||
* Share what's useful
|
||||
|
||||
* Highlight your heroes
|
||||
|
||||
* Fix common pain points
|
||||
|
||||
_Christine Abernathy visited RIT as part of the FOSS Talks speaker series. Every month, a guest speaker from the open source world shares wisdom, insight, and advice about the open source world with students interested in free and open source software. The [FOSS @ MAGIC][3] community is thankful to have Abernathy attend as a speaker._
|
||||
|
||||
### About the author
|
||||
|
||||
[][15] Justin W. Flory - Justin is a student at the [Rochester Institute of Technology][4]majoring in Networking and Systems Administration. He is currently a contributor to the [Fedora Project][5]. In Fedora, Justin is the editor-in-chief of the [Fedora Magazine][6], the lead of the [Community... ][7][more about Justin W. Flory][8][More about me][9]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/inside-facebooks-open-source-program
|
||||
|
||||
作者:[Justin W. Flory ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jflory
|
||||
[1]:https://opensource.com/file/383786
|
||||
[2]:https://opensource.com/article/18/1/inside-facebooks-open-source-program?rate=H9_bfSwXiJfi2tvOLiDxC_tbC2xkEOYtCl-CiTq49SA
|
||||
[3]:http://foss.rit.edu/
|
||||
[4]:https://www.rit.edu/
|
||||
[5]:https://fedoraproject.org/wiki/Overview
|
||||
[6]:https://fedoramagazine.org/
|
||||
[7]:https://fedoraproject.org/wiki/CommOps
|
||||
[8]:https://opensource.com/users/jflory
|
||||
[9]:https://opensource.com/users/jflory
|
||||
[10]:https://opensource.com/user/74361/feed
|
||||
[11]:https://opensource.com/article/17/8/tirana-government-chooses-open-source
|
||||
[12]:https://opensource.com/article/16/12/2016-election-night-hackathon
|
||||
[13]:https://twitter.com/abernathyca
|
||||
[14]:https://www.eventbrite.com/e/fossmagic-talks-open-source-facebook-with-christine-abernathy-tickets-38955037566#
|
||||
[15]:https://opensource.com/users/jflory
|
||||
[16]:https://opensource.com/users/jflory
|
||||
[17]:https://opensource.com/users/jflory
|
||||
[18]:https://opensource.com/article/18/1/inside-facebooks-open-source-program#comments
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
Quick Look at the Arch Based Indie Linux Distribution: MagpieOS
|
||||
======
|
||||
Most of the Linux distros that are in use today are either created and developed in the US or Europe. A young developer from Bangladesh wants to change all that.
|
||||
|
||||
@ -1,177 +0,0 @@
|
||||
Translating by qhwdw
|
||||
Microservices vs. monolith: How to choose
|
||||
============================================================
|
||||
|
||||
### Both architectures have pros and cons, and the right decision depends on your organization's unique needs.
|
||||
|
||||
|
||||

|
||||
Image by :
|
||||
|
||||
Onasill ~ Bill Badzo on [Flickr][11]. [CC BY-NC-SA 2.0][12]. Modified by Opensource.com.
|
||||
|
||||
For many startups, conventional wisdom says to start with a monolith architecture over microservices. But are there exceptions to this?
|
||||
|
||||
The upcoming book, [_Microservices for Startups_][13] , explores the benefits and drawbacks of microservices, offering insights from dozens of CTOs.
|
||||
|
||||
While different CTOs take different approaches when starting new ventures, they agree that context and capability are key. If you're pondering whether your business would be best served by a monolith or microservices, consider the factors discussed below.
|
||||
|
||||
### Understanding the spectrum
|
||||
|
||||
More on Microservices
|
||||
|
||||
* [How to explain microservices to your CEO][1]
|
||||
|
||||
* [Free eBook: Microservices vs. service-oriented architecture][2]
|
||||
|
||||
* [Secured DevOps for microservices][3]
|
||||
|
||||
Let's first clarify what exactly we mean by “monolith” and “microservice.”
|
||||
|
||||
Microservices are an approach to developing a single application as a suite of small services, each running in its own process and communicating with lightweight mechanisms, often an HTTP resource API. These services are built around business capabilities and independently deployable by fully automated deployment machinery.
|
||||
|
||||
A monolithic application is built as a single, unified unit, and usually one massive code base. Often a monolith consists of three parts: a database, a client-side user interface (consisting of HTML pages and/or JavaScript running in a browser), and a server-side application.
|
||||
|
||||
“System architectures lie on a spectrum,” Zachary Crockett, CTO of [Particle][14], said in an interview. “When discussing microservices, people tend to focus on one end of that spectrum: many tiny applications passing too many messages to each other. At the other end of the spectrum, you have a giant monolith doing too many things. For any real system, there are many possible service-oriented architectures between those two extremes.”
|
||||
|
||||
Depending on your situation, there are good reasons to tend toward either a monolith or microservices.
|
||||
|
||||
"We want to use the best tool for each service." Julien Lemoine, CTO at Algolia
|
||||
|
||||
Contrary to what many people think, a monolith isn’t a dated architecture that's best left in the past. In certain circumstances, a monolith is ideal. I spoke to Steven Czerwinski, head of engineering at [Scaylr][15] and a former Google employee, to better understand this.
|
||||
|
||||
“Even though we had had positive experiences of using microservices at Google, we [at Scalyr] went [for a monolith] route because having one monolithic server means less work for us as two engineers,” he explained. (This was back in the early days of Scalyr.)
|
||||
|
||||
But if your team is experienced with microservices and you have a clear idea of the direction you’re going, microservices can be a great alternative.
|
||||
|
||||
Julien Lemoine, CTO at [Algolia][16], chimed in on this point: “We have always started with a microservices approach. The main goal was to be able to use different technology to build our service, for two big reasons:
|
||||
|
||||
* We want to use the best tool for each service. Our search API is highly optimized at the lowest level, and C++ is the perfect language for that. That said, using C++ for everything is a waste of productivity, especially to build a dashboard.
|
||||
|
||||
* We want the best talent, and using only one technology would limit our options. This is why we have different languages in the company.”
|
||||
|
||||
If your team is prepared, starting with microservices allows your organization to get used to the rhythm of developing in a microservice environment right from the start.
|
||||
|
||||
### Weighing the pros and cons
|
||||
|
||||
Before you decide which approach is best for your organization, it's important to consider the strengths and weaknesses of each.
|
||||
|
||||
### Monoliths
|
||||
|
||||
### Pros:
|
||||
|
||||
* **Fewer cross-cutting concerns:** Most apps have cross-cutting concerns, such as logging, rate limiting, and security features like audit trails and DOS protection. When everything is running through the same app, it’s easy to address those concerns by hooking up components.
|
||||
|
||||
* **Less operational overhead:** There’s only one application to set up for logging, monitoring, and testing. Also, it's generally less complex to deploy.
|
||||
|
||||
* **Performance:** A monolith architecture can offer performance advantages since shared-memory access is faster than inter-process communication (IPC).
|
||||
|
||||
### Cons:
|
||||
|
||||
* **Tightly coupled:** Monolithic app services tend to get tightly coupled and entangled as the application evolves, making it difficult to isolate services for purposes such as independent scaling or code maintainability.
|
||||
|
||||
* **Harder to understand:** Monolithic architectures are more difficult to understand because of dependencies, side effects, and other factors that are not obvious when you’re looking at a specific service or controller.
|
||||
|
||||
### Microservices
|
||||
|
||||
### Pros:
|
||||
|
||||
* **Better organization:** Microservice architectures are typically better organized, since each microservice has a specific job and is not concerned with the jobs of other components.
|
||||
|
||||
* **Decoupled:** Decoupled services are easier to recompose and reconfigure to serve different apps (for example, serving both web clients and the public API). They also allow fast, independent delivery of individual parts within a larger integrated system.
|
||||
|
||||
* **Performance:** Depending on how they're organized, microservices can offer performance advantages because you can isolate hot services and scale them independently of the rest of the app.
|
||||
|
||||
* **Fewer mistakes:** Microservices enable parallel development by establishing a strong boundary between different parts of your system. Doing this makes it more difficult to connect parts that shouldn’t be connected, for example, or couple too tightly those that need to be connected.
|
||||
|
||||
### Cons:
|
||||
|
||||
* **Cross-cutting concerns across each service:** As you build a new microservice architecture, you’re likely to discover cross-cutting concerns you may not have anticipated at design time. You’ll either need to incur the overhead of separate modules for each cross-cutting concern (i.e., testing), or encapsulate cross-cutting concerns in another service layer through which all traffic is routed. Eventually, even monolithic architectures tend to route traffic through an outer service layer for cross-cutting concerns, but with a monolithic architecture, it’s possible to delay the cost of that work until the project is more mature.
|
||||
|
||||
* **Higher operational overhead:** Microservices are frequently deployed on their own virtual machines or containers, causing a proliferation of VM wrangling. These tasks are frequently automated with container fleet management tools.
|
||||
|
||||
### Decision time
|
||||
|
||||
Once you understand the pros and cons of both approaches, how do you apply this information to your startup? Based on interviews with CTOs, here are three questions to guide your decision process:
|
||||
|
||||
**Are you in familiar territory?**
|
||||
|
||||
Diving directly into microservices is less risky if your team has previous domain experience (for example, in e-commerce) and knowledge concerning the needs of your customers. If you’re traveling down an unknown path, on the other hand, a monolith may be a safer option.
|
||||
|
||||
**Is your team prepared?**
|
||||
|
||||
Does your team have experience with microservices? If you quadruple the size of your team within the next year, will microservices offer the best environment? Evaluating the dimensions of your team is crucial to the success of your project.
|
||||
|
||||
**How’s your infrastructure?**
|
||||
|
||||
To make microservices work, you’ll need a cloud-based infrastructure.
|
||||
|
||||
David Strauss, CTO of [Pantheon][17], explained: “[Previously], you would want to start with a monolith because you wanted to deploy one database server. The idea of having to set up a database server for every single microservice and then scale out was a mammoth task. Only a huge, tech-savvy organization could do that. Today, with services like Google Cloud and Amazon AWS, you have many options for deploying tiny things without needing to own the persistence layer for each one.”
|
||||
|
||||
### Evaluate the business risk
|
||||
|
||||
As a tech-savvy startup with high ambitions, you might think microservices is the “right” way to go. But microservices can pose a business risk. Strauss explained, “A lot of teams overbuild their project initially. Everyone wants to think their startup will be the next unicorn, and they should therefore build everything with microservices or some other hyper-scalable infrastructure. But that's usually wrong.” In these cases, Strauss continued, the areas that they thought they needed to scale are often not the ones that actually should scale first, resulting in wasted time and effort.
|
||||
|
||||
### Situational awareness
|
||||
|
||||
Ultimately, context is key. Here are some tips from CTOs:
|
||||
|
||||
#### When to start with a monolith
|
||||
|
||||
* **Your team is at founding stage:** Your team is small—say, 2 to 5 members—and is unable to tackle a broader, high-overhead microservices architecture.
|
||||
|
||||
* **You’re building an unproven product or proof of concept:** If you're bringing a brand-new product to market, it will likely evolve over time, and a monolith is better-suited to allow for rapid product iteration. The same notion applies to a proof of concept, where your goal is to learn as much as possible as quickly as possible, even if you end up throwing it away.
|
||||
|
||||
* **You have no microservices experience:** Unless you can justify the risk of learning on the fly at an early stage, a monolith may be a safer approach for an inexperienced team.
|
||||
|
||||
#### When to start with microservices
|
||||
|
||||
* **You need quick, independent service delivery:** Microservices allow for fast, independent delivery of individual parts within a larger integrated system. Note that it can take some time to see service delivery gains with microservices compared to a monolith, depending on your team's size.
|
||||
|
||||
* **A piece of your platform needs to be extremely efficient:** If your business does intensive processing of petabytes of log volume, you’ll likely want to build that service out in an efficient language like C++, while your user dashboard may be built in [Ruby on Rails][5].
|
||||
|
||||
* **You plan to grow your team:** Starting with microservices gets your team used to developing in separate small services from the beginning, and teams that are separated by service boundaries are easier to scale as needed.
|
||||
|
||||
To decide whether a monolith or microservices is right for your organization, be honest and self-aware about your context and capabilities. This will help you find the best path to grow your business.
|
||||
|
||||
### Topics
|
||||
|
||||
[Microservices][21][DevOps][22]
|
||||
|
||||
### About the author
|
||||
|
||||
[][18] jakelumetta - Jake is the CEO of [ButterCMS, an API-first CMS][6]. He loves whipping up Butter puns and building tools that makes developers lives better. For more content like this, follow [@ButterCMS][7] on Twitter and [subscribe to our blog][8].[More about me][9]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/how-choose-between-monolith-microservices
|
||||
|
||||
作者:[jakelumetta ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jakelumetta
|
||||
[1]:https://blog.openshift.com/microservices-how-to-explain-them-to-your-ceo/?intcmp=7016000000127cYAAQ&src=microservices_resource_menu1
|
||||
[2]:https://www.openshift.com/promotions/microservices.html?intcmp=7016000000127cYAAQ&src=microservices_resource_menu2
|
||||
[3]:https://opensource.com/business/16/11/secured-devops-microservices?src=microservices_resource_menu3
|
||||
[4]:https://opensource.com/article/18/1/how-choose-between-monolith-microservices?rate=tSotlNvwc-Itch5fhYiIn5h0L8PcUGm_qGvqSVzu9w8
|
||||
[5]:http://rubyonrails.org/
|
||||
[6]:https://buttercms.com/
|
||||
[7]:https://twitter.com/ButterCMS
|
||||
[8]:https://buttercms.com/blog/
|
||||
[9]:https://opensource.com/users/jakelumetta
|
||||
[10]:https://opensource.com/user/205531/feed
|
||||
[11]:https://www.flickr.com/photos/onasill/16452059791/in/photolist-r4P7ci-r3xUqZ-JkWzgN-dUr8Mo-biVsvF-kA2Vot-qSLczk-nLvGTX-biVxwe-nJJmzt-omA1vW-gFtM5-8rsk8r-dk9uPv-5kja88-cv8YTq-eQqNJu-7NJiqd-pBUkk-pBUmQ-6z4dAw-pBULZ-vyM3V3-JruMsr-pBUiJ-eDrP5-7KCWsm-nsetSn-81M3EC-pBURh-HsVXuv-qjgBy-biVtvx-5KJ5zK-81F8xo-nGFQo3-nJr89v-8Mmi8L-81C9A6-qjgAW-564xeQ-ihmDuk-biVBNz-7C5VBr-eChMAV-JruMBe-8o4iKu-qjgwW-JhhFXn-pBUjw
|
||||
[12]:https://creativecommons.org/licenses/by-nc-sa/2.0/
|
||||
[13]:https://buttercms.com/books/microservices-for-startups/
|
||||
[14]:https://www.particle.io/Particle
|
||||
[15]:https://www.scalyr.com/
|
||||
[16]:https://www.algolia.com/
|
||||
[17]:https://pantheon.io/
|
||||
[18]:https://opensource.com/users/jakelumetta
|
||||
[19]:https://opensource.com/users/jakelumetta
|
||||
[20]:https://opensource.com/users/jakelumetta
|
||||
[21]:https://opensource.com/tags/microservices
|
||||
[22]:https://opensource.com/tags/devops
|
||||
@ -1,102 +0,0 @@
|
||||
Translating by qhwdw
|
||||
How to Run Your Own Public Time Server on Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
One of the most important public services is timekeeping, but it doesn't get a lot of attention. Most public time servers are run by volunteers to help meet always-increasing demands. Learn how to run your own public time server and contribute to an essential public good. (See [Keep Accurate Time on Linux with NTP][1] to learn how to set up a LAN time server.)
|
||||
|
||||
### Famous Time Server Abusers
|
||||
|
||||
Like everything in life, even something as beneficial as time servers are subject to abuse fueled by either incompetence or malice.
|
||||
|
||||
Vendors of consumer network appliances are notorious for creating big messes. The first one I recall happened in 2003, when Netgear hard-coded the address of the University of Wisconsin-Madison's NTP server into their routers. All of a sudden the server was getting hammered with requests, and as Netgear sold more routers, the worse it got. Adding to the fun, the routers were programmed to send requests every second, which is way too many. Netgear issued a firmware upgrade, but few users ever upgrade their devices, and a number of them are pummeling the University of Wisconsin-Madison's NTP server to this day. Netgear gave them a pile of money, which hopefully will cover their costs until the last defective router dies. Similar ineptitudes were perpetrated by D-Link, Snapchat, TP-Link, and others.
|
||||
|
||||
The NTP protocol has become a choice vector for distributed denial-of-service attacks, using both reflection and amplification. It is called reflection when an attacker uses a forged source address to target a victim; the attacker sends requests to multiple servers, which then reply and bombard the forged address. Amplification is a large reply to a small request. For example, on Linux the `ntpq` command is a useful tool to query your NTP servers to verify that they are operating correctly. Some replies, such as lists of peers, are large. Combine reflection with amplification, and an attacker can get a return of 10x or more on the bandwidth they spend on the attack.
|
||||
|
||||
How do you protect your nice beneficial public NTP server? Start by using NTP 4.2.7p26 or newer, which hopefully is not an issue with your Linux distribution because that version was released in 2010. That release shipped with the most significant abuse vectors disabled as the default. The [current release is 4.2.8p10][2], released in 2017.
|
||||
|
||||
Another step you can take, which you should be doing anyway, is use ingress and egress filtering on your network. Block packets from entering your network that claim to be from your network, and block outgoing packets with forged return addresses. Ingress filtering helps you, and egress filtering helps you and everyone else. Read [BCP38.info][3] for much more information.
|
||||
|
||||
### Stratum 0, 1, 2 Time Servers
|
||||
|
||||
NTP is more than 30 years old, one of the oldest Internet protocols that is still widely used. Its purpose is keep computers synchronized to Coordinated Universal Time (UTC). The NTP network is both hierarchical, organized into strata, and peer. Stratum 0 contains master timekeeping devices such as atomic clocks. Stratum 1 time servers synchronize with Stratum 0 devices. Stratum 2 time servers synchronize with Stratum 1 time servers, and Stratum 3 with Stratum 2. The NTP protocol supports 16 strata, though in real life there not that many. Servers in each stratum also peer with each other.
|
||||
|
||||
In the olden days, we selected individual NTP servers for our client configurations. Those days are long gone, and now the better way is to use the [NTP pool addresses][4], which use round-robin DNS to share the load. Pool addresses are only for clients, such as individual PCs and your local LAN NTP server. When you run your own public server you won't use the pool addresses.
|
||||
|
||||
### Public NTP Server Configuration
|
||||
|
||||
There are two steps to running a public NTP server: set up your server, and then apply to join the NTP server pool. Running a public NTP server is a noble deed, but make sure you know what you're getting into. Joining the NTP pool is a long-term commitment, because even if you run it for a short time and then quit, you'll be receiving requests for years.
|
||||
|
||||
You need a static public IP address, a permanent reliable Internet connection with at least 512Kb/s bandwidth, and know how to configure your firewall correctly. NTP uses UDP port 123. The machine itself doesn't have to be any great thing, and a lot of admins piggyback NTP on other public-facing servers such as Web servers.
|
||||
|
||||
Configuring a public NTP server is just like configuring a LAN NTP server, with a few more configurations. Start by reading the [Rules of Engagement][5]. Follow the rules and mind your manners; almost everyone maintaining a time server is a volunteer just like you. Then select 4-7 Stratum 2 upstream time servers from [StratumTwoTimeServers][6]. Select some that are geographically close to your upstream Internet service provider (mine is 300 miles away), read their access policies, and then use `ping` and `mtr` to find the servers with the lowest latency and least number of hops.
|
||||
|
||||
This example `/etc/ntp.conf` includes both IPv4 and IPv6 and basic safeguards:
|
||||
```
|
||||
# stratum 2 server list
|
||||
server servername_1 iburst
|
||||
server servername_2 iburst
|
||||
server servername_3 iburst
|
||||
server servername_4 iburst
|
||||
server servername_5 iburst
|
||||
|
||||
# access restrictions
|
||||
restrict -4 default kod noquery nomodify notrap nopeer limited
|
||||
restrict -6 default kod noquery nomodify notrap nopeer limited
|
||||
|
||||
# Allow ntpq and ntpdc queries only from localhost
|
||||
restrict 127.0.0.1
|
||||
restrict ::1
|
||||
|
||||
```
|
||||
|
||||
Start your NTP server, let it run for a few minutes, and then test that it is querying the remote servers:
|
||||
```
|
||||
$ ntpq -p
|
||||
remote refid st t when poll reach delay offset jitter
|
||||
=================================================================
|
||||
+tock.no-such-ag 200.98.196.212 2 u 36 64 7 98.654 88.439 65.123
|
||||
+PBX.cytranet.ne 45.33.84.208 3 u 37 64 7 72.419 113.535 129.313
|
||||
*eterna.binary.n 199.102.46.70 2 u 39 64 7 92.933 98.475 56.778
|
||||
+time.mclarkdev. 132.236.56.250 3 u 37 64 5 111.059 88.029 74.919
|
||||
|
||||
```
|
||||
|
||||
Good so far. Now test from another PC, using your NTP server name. The following example shows correct output. If something is not correct you'll see an error message.
|
||||
```
|
||||
$ ntpdate -q _yourservername_
|
||||
server 66.96.99.10, stratum 2, offset 0.017690, delay 0.12794
|
||||
server 98.191.213.2, stratum 1, offset 0.014798, delay 0.22887
|
||||
server 173.49.198.27, stratum 2, offset 0.020665, delay 0.15012
|
||||
server 129.6.15.28, stratum 1, offset -0.018846, delay 0.20966
|
||||
26 Jan 11:13:54 ntpdate[17293]: adjust time server 98.191.213.2 offset 0.014798 sec
|
||||
|
||||
```
|
||||
|
||||
Once your server is running satisfactorily apply at [manage.ntppool.org][7] to join the pool.
|
||||
|
||||
See the official handbook, [The Network Time Protocol (NTP) Distribution][8] to learn about all the command and configuration options, and advanced features such as management, querying, and authentication. Visit the following sites to learn pretty much everything you need about running a time server.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][9]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/2/how-run-your-own-public-time-server-linux
|
||||
|
||||
作者:[CARLA SCHRODER][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/learn/intro-to-linux/2018/1/keep-accurate-time-linux-ntp
|
||||
[2]:http://www.ntp.org/downloads.html
|
||||
[3]:http://www.bcp38.info/index.php/Main_Page
|
||||
[4]:http://www.pool.ntp.org/en/use.html
|
||||
[5]:http://support.ntp.org/bin/view/Servers/RulesOfEngagement
|
||||
[6]:http://support.ntp.org/bin/view/Servers/StratumTwoTimeServers?redirectedfrom=Servers.StratumTwo
|
||||
[7]:https://manage.ntppool.org/manage
|
||||
[8]:https://www.eecis.udel.edu/~mills/ntp/html/index.html
|
||||
[9]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,3 +1,6 @@
|
||||
translating by szcf-weiya
|
||||
|
||||
|
||||
API Star: Python 3 API Framework – Polyglot.Ninja()
|
||||
======
|
||||
For building quick APIs in Python, I have mostly depended on [Flask][1]. Recently I came across a new API framework for Python 3 named “API Star” which seemed really interesting to me for several reasons. Firstly the framework embraces modern Python features like type hints and asyncio. And then it goes ahead and uses these features to provide awesome development experience for us, the developers. We will get into those features soon but before we begin, I would like to thank Tom Christie for all the work he has put into Django REST Framework and now API Star.
|
||||
|
||||
@ -1,77 +0,0 @@
|
||||
translating by wyxplus
|
||||
Become a Hollywood movie hacker with these three command line tools
|
||||
======
|
||||
|
||||

|
||||
|
||||
If you ever spent time growing up watching spy thrillers, action flicks, or crime movies, you developed a clear picture in your mind of what a hacker's computer screen looked like. Rows upon rows of rapidly moving code, streams of grouped hexadecimal numbers flying past like [raining code][1] in The Matrix.
|
||||
|
||||
Perhaps there's a world map with flashing points of light and a few rapidly updating charts thrown in there for good measure. And probably a 3D rotating geometric shape, because why not? If possible, this is all shown on a ridiculous number of monitors in an ergonomically uncomfortable configuration. I think Swordfish sported seven.
|
||||
|
||||
Of course, those of us who pursued technical careers quickly realized that this was all utter nonsense. While many of us have dual monitors (or more), a dashboard of blinky, flashing data is usually pretty antithetical to focusing on work. Writing code, managing projects, and administering systems is not the same thing as day trading. Most of the situations we encounter require a great deal of thinking about the problem we're trying to solve, a good bit of communicating with stakeholders, some researching and organizing information, and very, very little [rapid-fire typing][7].
|
||||
|
||||
That doesn't mean that we sometimes don't feel like we want to be inside of one of those movies. Or maybe, we're just trying to look like we're "being productive."
|
||||
|
||||
**Side note: Of course I mean this article in jest.** If you're actually being evaluated on how busy you look, whether that's at your desk or in meetings, you've got a huge cultural problem at your workplace that needs to be addressed. A culture of manufactured busyness is a toxic culture and one that's almost certainly helping neither the company nor its employees.
|
||||
|
||||
That said, let's have some fun and fill our screens with some panels of good old-fashioned meaningless data and code snippets. (Well, the data might have some meaning, but not without context.) While there are plenty of fancy GUIs for this (consider checking out [Hacker Typer][8] or [GEEKtyper.com][9] for a web-based version), why not just use your standard Linux terminal? For a more old-school look, consider using [Cool Retro Term][10], which is indeed what it sounds like: A cool retro terminal. I'll use Cool Retro Term for the screenshots below because it does indeed look 100% cooler.
|
||||
|
||||
### Genact
|
||||
|
||||
The first tool we'll look at is Genact. Genact simply plays back a sequence of your choosing, slowly and indefinitely, letting your code “compile” while you go out for a coffee break. The sequence it plays is up to you, but included by default are a cryptocurrency mining simulator, Composer PHP dependency manager, kernel compiler, downloader, memory dump, and more. My favorite, though, is the setting which displays SimCity loading messages. So as long as no one checks too closely, you can spend all afternoon waiting on your computer to finish reticulating splines.
|
||||
|
||||
Genact has [releases][11] available for Linux, OS X, and Windows, and the Rust [source code][12] is available on GitHub under an [MIT license][13].
|
||||
|
||||
|
||||
|
||||
### Hollywood
|
||||
|
||||
Hollywood takes a more straightforward approach. It essentially creates a random number and configuration of split screens in your terminal and launches busy looking applications like htop, directory trees, source code files, and others, and switch them out every few seconds. It's put together as a shell script, so it's fairly straightforward to modify as you wish.
|
||||
|
||||
The [source code][14] for Hollywood can be found on GitHub under an [Apache 2.0][15] license.
|
||||
|
||||
|
||||
|
||||
### Blessed-contrib
|
||||
|
||||
My personal favorite isn't actually an application designed for this purpose. Instead, it's the demo file for a Node.js-based terminal dashboard building library called Blessed-contrib. Unlike the other two, I actually have used Blessed-contrib's library for doing something that resembles actual work, as opposed to pretend-work, as it is a quite helpful library and set of widgets for displaying information at the command line. But it's also easy to fill with dummy data to fulfill your dream of simulating the computer from WarGames.
|
||||
|
||||
The [source code][16] for Blessed-contrib can be found on GitHub under an [MIT license][17].
|
||||
|
||||
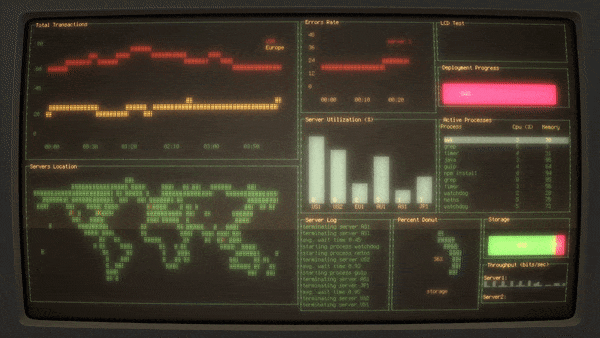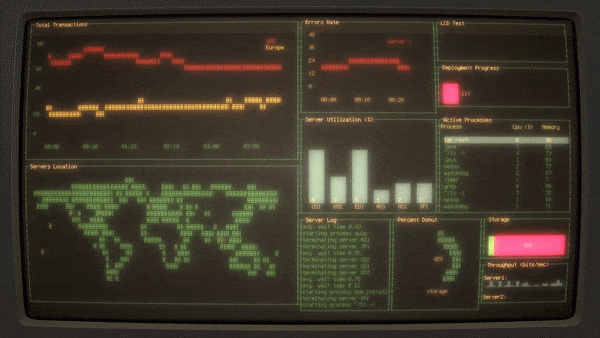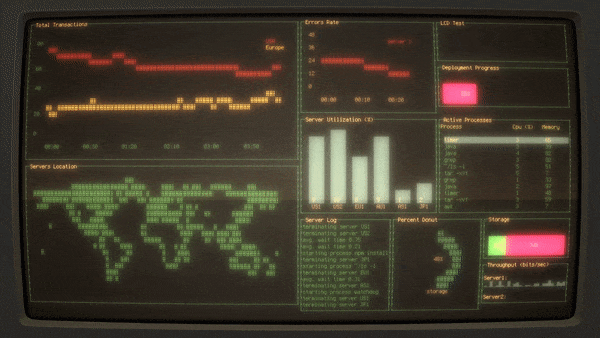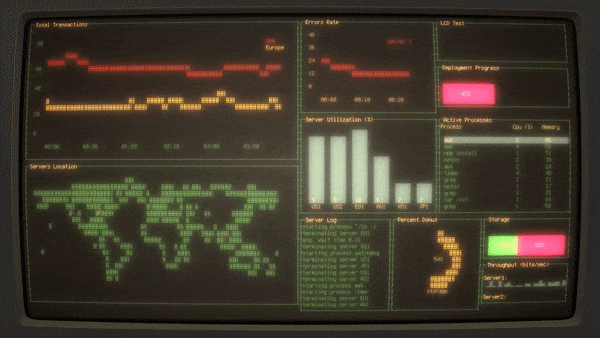
|
||||
|
||||
Of course, while these tools make it easy, there are plenty of ways to fill up your screen with nonsense. One of the most common tools you'll see in movies is Nmap, an open source security scanner. In fact, it is so overused as the tool to demonstrate on-screen hacking in Hollywood that the makers have created a page listing some of the movies it has [appeared in][18], from The Matrix Reloaded to The Bourne Ultimatum, The Girl with the Dragon Tattoo, and even Die Hard 4.
|
||||
|
||||
You can create your own combination, of course, using a terminal multiplexer like screen or tmux to fire up whatever selection of data-spitting applications you wish.
|
||||
|
||||
What's your go-to screen for looking busy?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/command-line-tools-productivity
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jason-baker
|
||||
[1]:http://tvtropes.org/pmwiki/pmwiki.php/Main/MatrixRainingCode
|
||||
[2]:https://opensource.com/resources/what-is-linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[3]:https://opensource.com/resources/what-are-linux-containers?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[4]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[5]:https://developers.redhat.com/cheat-sheet/advanced-linux-commands-cheatsheet?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[6]:https://opensource.com/tags/linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[7]:http://tvtropes.org/pmwiki/pmwiki.php/Main/RapidFireTyping
|
||||
[8]:https://hackertyper.net/
|
||||
[9]:http://geektyper.com
|
||||
[10]:https://github.com/Swordfish90/cool-retro-term
|
||||
[11]:https://github.com/svenstaro/genact/releases
|
||||
[12]:https://github.com/svenstaro/genact
|
||||
[13]:https://github.com/svenstaro/genact/blob/master/LICENSE
|
||||
[14]:https://github.com/dustinkirkland/hollywood
|
||||
[15]:http://www.apache.org/licenses/LICENSE-2.0
|
||||
[16]:https://github.com/yaronn/blessed-contrib
|
||||
[17]:http://opensource.org/licenses/MIT
|
||||
[18]:https://nmap.org/movies/
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by MjSeven
|
||||
|
||||
How to setup and configure network bridge on Debian Linux
|
||||
======
|
||||
|
||||
|
||||
@ -1,203 +0,0 @@
|
||||
How to clone, modify, add, and delete files in Git
|
||||
======
|
||||

|
||||
|
||||
In the [first article in this series][1] on getting started with Git, we created a simple Git repo and added a file to it by connecting it with our computer. In this article, we will learn a handful of other things about Git, namely how to clone (download), modify, add, and delete files in a Git repo.
|
||||
|
||||
### Let's make some clones
|
||||
|
||||
Say you already have a Git repo on GitHub and you want to get your files from it—maybe you lost the local copy on your computer or you're working on a different computer and want access to the files in your repository. What should you do? Download your files from GitHub? Exactly! We call this "cloning" in Git terminology. (You could also download the repo as a ZIP file, but we'll explore the clone method in this article.)
|
||||
|
||||
Let's clone the repo, called Demo, we created in the last article. (If you have not yet created a Demo repo, jump back to that article and do those steps before you proceed here.) To clone your file, just open your browser and navigate to `https://github.com/<your_username>/Demo` (where `<your_username>` is the name of your own repo. For example, my repo is `https://github.com/kedark3/Demo`). Once you navigate to that URL, click the "Clone or download" button, and your browser should look something like this:
|
||||
|
||||
|
||||
|
||||
As you can see above, the "Clone with HTTPS" option is open. Copy your repo's URL from that dropdown box (`https://github.com/<your_username>/Demo.git`). Open the terminal and type the following command to clone your GitHub repo to your computer:
|
||||
```
|
||||
git clone https://github.com/<your_username>/Demo.git
|
||||
|
||||
```
|
||||
|
||||
Then, to see the list of files in the `Demo` directory, enter the command:
|
||||
```
|
||||
ls Demo/
|
||||
|
||||
```
|
||||
|
||||
Your terminal should look like this:
|
||||
|
||||

|
||||
|
||||
### Modify files
|
||||
|
||||
Now that we have cloned the repo, let's modify the files and update them on GitHub. To begin, enter the commands below, one by one, to change the directory to `Demo/`, check the contents of `README.md`, echo new (additional) content to `README.md`, and check the status with `git status`:
|
||||
```
|
||||
cd Demo/
|
||||
|
||||
ls
|
||||
|
||||
cat README.md
|
||||
|
||||
echo "Added another line to REAMD.md" >> README.md
|
||||
|
||||
cat README.md
|
||||
|
||||
git status
|
||||
|
||||
```
|
||||
|
||||
This is how it will look in the terminal if you run these commands one by one:
|
||||
|
||||

|
||||
|
||||
Let's look at the output of `git status` and walk through what it means. Don't worry about the part that says:
|
||||
```
|
||||
On branch master
|
||||
|
||||
Your branch is up-to-date with 'origin/master'.".
|
||||
|
||||
```
|
||||
|
||||
because we haven't learned it yet. The next line says: `Changes not staged for commit`; this is telling you that the files listed below it aren't marked ready ("staged") to be committed. If you run `git add`, Git takes those files and marks them as `Ready for commit`; in other (Git) words, `Changes staged for commit`. Before we do that, let's check what we are adding to Git with the `git diff` command, then run `git add`.
|
||||
|
||||
Here is your terminal output:
|
||||
|
||||

|
||||
|
||||
Let's break this down:
|
||||
|
||||
* `diff --git a/README.md b/README.md` is what Git is comparing (i.e., `README.md` in this example).
|
||||
* `--- a/README.md` would show anything removed from the file.
|
||||
* `+++ b/README.md` would show anything added to your file.
|
||||
* Anything added to the file is printed in green text with a + at the beginning of the line.
|
||||
* If we had removed anything, it would be printed in red text with a - sign at the beginning.
|
||||
* Git status now says `Changes to be committed:` and lists the filename (i.e., `README.md`) and what happened to that file (i.e., it has been `modified` and is ready to be committed).
|
||||
|
||||
|
||||
|
||||
Tip: If you have already run `git add`, and now you want to see what's different, the usual `git diff` won't yield anything because you already added the file. Instead, you must use `git diff --cached`. It will show you the difference between the current version and previous version of files that Git was told to add. Your terminal output would look like this:
|
||||
|
||||
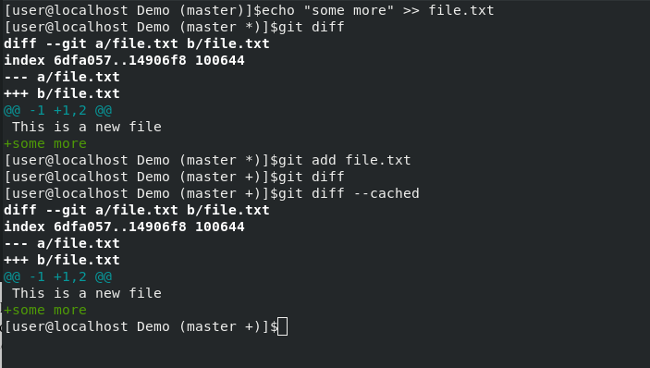
|
||||
|
||||
### Upload a file to your repo
|
||||
|
||||
We have modified the `README.md` file with some new content and it's time to upload it to GitHub.
|
||||
|
||||
Let's commit the changes and push those to GitHub. Run:
|
||||
```
|
||||
git commit -m "Updated Readme file"
|
||||
|
||||
```
|
||||
|
||||
This tells Git that you are "committing" to changes that you have "added" to it. You may recall from the first part of this series that it's important to add a message to explain what you did in your commit so you know its purpose when you look back at your Git log later. (We will look more at this topic in the next article.) `Updated Readme file` is the message for this commit—if you don't think this is the most logical way to explain what you did, feel free to write your commit message differently.
|
||||
|
||||
Run `git push -u origin master`. This will prompt you for your username and password, then upload the file to your GitHub repo. Refresh your GitHub page, and you should see the changes you just made to `README.md`.
|
||||
|
||||
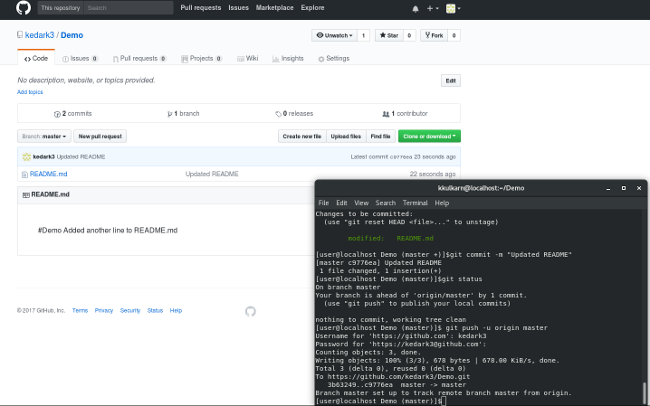
|
||||
|
||||
The bottom-right corner of the terminal shows that I committed the changes, checked the Git status, and pushed the changes to GitHub. Git status says:
|
||||
```
|
||||
Your branch is ahead of 'origin/master' by 1 commit
|
||||
|
||||
(use "git push" to publish your local commits)
|
||||
|
||||
```
|
||||
|
||||
The first line indicates there is one commit in the local repo but not present in origin/master (i.e., on GitHub). The next line directs us to push those changes to origin/master, and that is what we did. (To refresh your memory on what "origin" means in this case, refer to the first article in this series. I will explain what "master" means in the next article, when we discuss branching.)
|
||||
|
||||
### Add a new file to Git
|
||||
|
||||
Now that we have modified a file and updated it on GitHub, let's create a new file, add it to Git, and upload it to GitHub. Run:
|
||||
```
|
||||
echo "This is a new file" >> file.txt
|
||||
|
||||
```
|
||||
|
||||
This will create a new file named `file.txt`.
|
||||
|
||||
If you `cat` it out:
|
||||
```
|
||||
cat file.txt
|
||||
|
||||
```
|
||||
|
||||
You should see the contents of the file. Now run:
|
||||
```
|
||||
git status
|
||||
|
||||
```
|
||||
|
||||
Git reports that you have an untracked file (named `file.txt`) in your repository. This is Git's way of telling you that there is a new file in the repo directory on your computer that you haven't told Git about, and Git is not tracking that file for any changes you make.
|
||||
|
||||
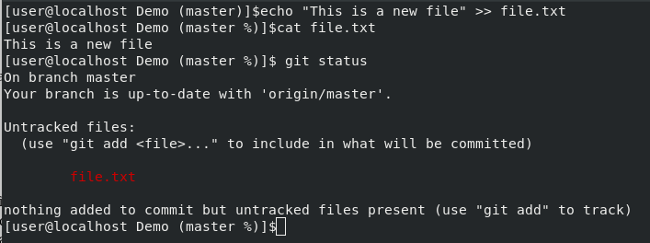
|
||||
|
||||
We need to tell Git to track this file so we can commit it and upload it to our repo. Here's the command to do that:
|
||||
```
|
||||
git add file.txt
|
||||
|
||||
git status
|
||||
|
||||
```
|
||||
|
||||
Your terminal output is:
|
||||
|
||||

|
||||
|
||||
Git status is telling you there are changes to `file.txt` to be committed, and that it is a `new file` to Git, which it was not aware of before this. Now that we have added `file.txt` to Git, we can commit the changes and push it to origin/master.
|
||||
|
||||

|
||||
|
||||
Git has now uploaded this new file to GitHub; if you refresh your GitHub page, you should see the new file, `file.txt`, in your Git repo on GitHub.
|
||||
|
||||
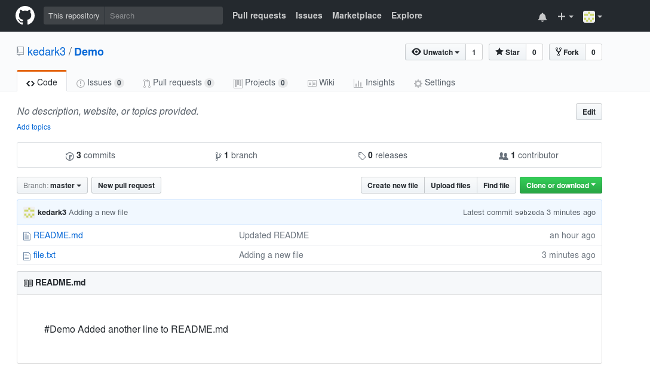
|
||||
|
||||
With these steps, you can create as many files as you like, add them to Git, and commit and push them up to GitHub.
|
||||
|
||||
### Delete a file from Git
|
||||
|
||||
What if we discovered we made an error and need to delete `file.txt` from our repo. One way is to remove the file from our local copy of the repo with this command:
|
||||
```
|
||||
rm file.txt
|
||||
|
||||
```
|
||||
|
||||
If you do `git status` now, Git says there is a file that is `not staged for commit` and it has been `deleted` from the local copy of the repo. If we now run:
|
||||
```
|
||||
git add file.txt
|
||||
|
||||
git status
|
||||
|
||||
```
|
||||
|
||||
I know we are deleting the file, but we still run `git add` ** because we need to tell Git about the **change** we are making. `git add` ** can be used when we are adding a new file to Git, modifying contents of an existing file and adding it to Git, or deleting a file from a Git repo. Effectively, `git add` takes all the changes into account and stages those changes for commit. If in doubt, carefully look at output of each command in the terminal screenshot below.
|
||||
|
||||
Git will tell us the deleted file is staged for commit. As soon as you commit this change and push it to GitHub, the file will be removed from the repo on GitHub as well. Do this by running:
|
||||
```
|
||||
git commit -m "Delete file.txt"
|
||||
|
||||
git push -u origin master
|
||||
|
||||
```
|
||||
|
||||
Now your terminal looks like this:
|
||||
|
||||
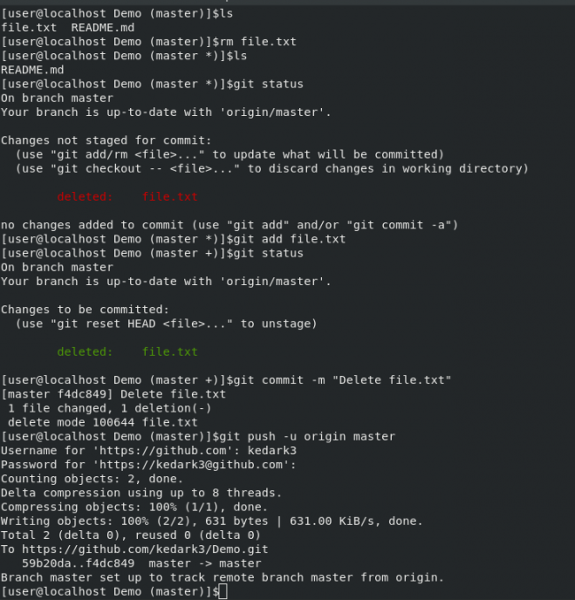
|
||||
|
||||
And your GitHub looks like this:
|
||||
|
||||
|
||||
|
||||
Now you know how to clone, add, modify, and delete Git files from your repo. The next article in this series will examine Git branching.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/how-clone-modify-add-delete-git-files
|
||||
|
||||
作者:[Kedar Vijay Kulkarni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/kkulkarn
|
||||
[1]:https://opensource.com/article/18/1/step-step-guide-git
|
||||
@ -1,70 +0,0 @@
|
||||
translating----geekpi
|
||||
|
||||
What is a Linux 'oops'?
|
||||
======
|
||||
If you check the processes running on your Linux systems, you might be curious about one called "kerneloops." And that’s “kernel oops,” not “kerne loops” just in case you didn’t parse that correctly.
|
||||
|
||||
Put very bluntly, an “oops” is a deviation from correct behavior on the part of the Linux kernel. Did you do something wrong? Probably not. But something did. And the process that did something wrong has probably at least just been summarily knocked off the CPU. At worst, the kernel may have panicked and abruptly shut the system down.
|
||||
|
||||
For the record, “oops” is NOT an acronym. It doesn’t stand for something like “object-oriented programming and systems” or “out of procedural specs”; it actually means “oops” like you just dropped your glass of wine or stepped on your cat. Oops! The plural of "oops" is "oopses."
|
||||
|
||||
An oops means that something running on the system has violated the kernel’s rules about proper behavior. Maybe the code tried to take a code path that was not allowed or use an invalid pointer. Whatever it was, the kernel — always on the lookout for process misbehavior — most likely will have stopped the particular process in its tracks and written some messages about what it did to the console, to /var/log/dmesg or the /var/log/kern.log file.
|
||||
|
||||
An oops can be caused by the kernel itself or by some process that tries to get the kernel to violate its rules about how things are allowed to run on the system and what they're allowed to do.
|
||||
|
||||
An oops will generate a crash signature that can help kernel developers figure out what went wrong and improve the quality of their code.
|
||||
|
||||
The kerneloops process running on your system will probably look like this:
|
||||
```
|
||||
kernoops 881 1 0 Feb11 ? 00:00:01 /usr/sbin/kerneloops
|
||||
|
||||
```
|
||||
|
||||
You might notice that the process isn't run by root, but by a user named "kernoops" and that it's accumulated extremely little run time. In fact, the only task assigned to this particular user is running kerneloops.
|
||||
```
|
||||
$ sudo grep kernoops /etc/passwd
|
||||
kernoops:x:113:65534:Kernel Oops Tracking Daemon,,,:/:/bin/false
|
||||
|
||||
```
|
||||
|
||||
If your Linux system isn't one that ships with kerneloops (like Debian), you might consider adding it. Check out this [Debian page][1] for more information.
|
||||
|
||||
### When should you be concerned about an oops?
|
||||
|
||||
An oops is not a big deal, except when it is. It depends in part on the role that the particular process was playing. It also depends on the class of oops.
|
||||
|
||||
Some oopses are so severe that they result in system panics. Technically speaking, a panic is a subset of the oops (i.e., the more serious of the oopses). A panic occurs when a problem detected by the kernel is bad enough that the kernel decides that it (the kernel) must stop running immediately to prevent data loss or other damage to the system. So, the system then needs to be halted and rebooted to keep any inconsistencies from making it unusable or unreliable. So a system that panics is actually trying to protect itself from irrevocable damage.
|
||||
|
||||
In short, all panics are oops, but not all oops are panics.
|
||||
|
||||
The /var/log/kern.log and related rotated logs (/var/log/kern.log.1, /var/log/kern.log.2 etc.) contain the logs produced by the kernel and handled by syslog.
|
||||
|
||||
The kerneloops program collects and by default submits information on the problems it runs into <http://oops.kernel.org/> where it can be analyzed and presented to kernel developers. Configuration details for this process are specified in the /etc/kerneloops.conf file. You can look at the settings easily with the command shown below:
|
||||
```
|
||||
$ sudo cat /etc/kerneloops.conf | grep -v ^# | grep -v ^$
|
||||
[sudo] password for shs:
|
||||
allow-submit = ask
|
||||
allow-pass-on = yes
|
||||
submit-url = http://oops.kernel.org/submitoops.php
|
||||
log-file = /var/log/kern.log
|
||||
submit-pipe = /usr/share/apport/kernel_oops
|
||||
|
||||
```
|
||||
|
||||
In the above (default) settings, information on kernel problems can be submitted, but the user is asked for permission. If set to allow-submit = always, the user will not be asked.
|
||||
|
||||
Debugging kernel problems is one of the finer arts of working with Linux systems. Fortunately, most Linux users seldom or never experience oops or panics. Still, it's nice to know what processes like kerneloops are doing on your system and to understand what might be reported and where when your system runs into a serious kernel violation.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3254778/linux/what-is-a-linux-oops.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[1]:https://packages.debian.org/stretch/kerneloops
|
||||
@ -1,215 +0,0 @@
|
||||
10 Quick Tips About sudo command for Linux systems
|
||||
======
|
||||
|
||||
![Linux-sudo-command-tips][1]
|
||||
|
||||
### Overview
|
||||
|
||||
**sudo** stands for **superuser do**. It allows authorized users to execute command as an another user. Another user can be regular user or superuser. However, most of the time we use it to execute command with elevated privileges.
|
||||
|
||||
sudo command works in conjunction with security policies, default security policy is sudoers and it is configurable via **/etc/sudoers** file. Its security policies are highly extendable. One can develop and distribute their own policies as plugins.
|
||||
|
||||
#### How it’s different than su
|
||||
|
||||
In GNU/Linux there are two ways to run command with elevated privileges:
|
||||
|
||||
* Using **su** command
|
||||
* Using **sudo** command
|
||||
|
||||
|
||||
|
||||
**su** stands for **switch user**. Using su, we can switch to root user and execute command. But there are few drawbacks with this approach.
|
||||
|
||||
* We need to share root password with another user.
|
||||
* We cannot give controlled access as root user is superuser
|
||||
* We cannot audit what user is doing.
|
||||
|
||||
|
||||
|
||||
sudo addresses these problems in unique way.
|
||||
|
||||
1. First of all, we don’t need to compromise root user password. Regular user uses its own password to execute command with elevated privileges.
|
||||
2. We can control access of sudo user meaning we can restrict user to execute only certain commands.
|
||||
3. In addition to this all activities of sudo user are logged hence we can always audit what actions were done. On Debian based GNU/Linux all activities are logged in **/var/log/auth.log** file.
|
||||
|
||||
|
||||
|
||||
Later sections of this tutorial sheds light on these points.
|
||||
|
||||
#### Hands on with sudo
|
||||
|
||||
Now, we have fair understanding about sudo. Let us get our hands dirty with practical. For demonstration, I am using Ubuntu. However, behavior with another distribution should be identical.
|
||||
|
||||
#### Allow sudo access
|
||||
|
||||
Let us add regular user as a sudo user. In my case user’s name is linuxtechi
|
||||
|
||||
1) Edit /etc/sudoers file as follows:
|
||||
```
|
||||
$ sudo visudo
|
||||
|
||||
```
|
||||
|
||||
2) Add below line to allow sudo access to user linuxtechi:
|
||||
```
|
||||
linuxtechi ALL=(ALL) ALL
|
||||
|
||||
```
|
||||
|
||||
In above command:
|
||||
|
||||
* linuxtechi indicates user name
|
||||
* First ALL instructs to permit sudo access from any terminal/machine
|
||||
* Second (ALL) instructs sudo command to be allowed to execute as any user
|
||||
* Third ALL indicates all command can be executed as root
|
||||
|
||||
|
||||
|
||||
#### Execute command with elevated privileges
|
||||
|
||||
To execute command with elevated privileges, just prepend sudo word to command as follows:
|
||||
```
|
||||
$ sudo cat /etc/passwd
|
||||
|
||||
```
|
||||
|
||||
When you execute this command, it will ask linuxtechi’s password and not root user password.
|
||||
|
||||
#### Execute command as an another user
|
||||
|
||||
In addition to this we can use sudo to execute command as another user. For instance, in below command, user linuxtechi executes command as a devesh user:
|
||||
```
|
||||
$ sudo -u devesh whoami
|
||||
[sudo] password for linuxtechi:
|
||||
devesh
|
||||
|
||||
```
|
||||
|
||||
#### Built in command behavior
|
||||
|
||||
One of the limitation of sudo is – Shell’s built in command doesn’t work with it. For instance, history is built in command, if you try to execute this command with sudo then command not found error will be reported as follows:
|
||||
```
|
||||
$ sudo history
|
||||
[sudo] password for linuxtechi:
|
||||
sudo: history: command not found
|
||||
|
||||
```
|
||||
|
||||
**Access root shell**
|
||||
|
||||
To overcome above problem, we can get access to root shell and execute any command from there including Shell’s built in.
|
||||
|
||||
To access root shell, execute below command:
|
||||
```
|
||||
$ sudo bash
|
||||
|
||||
```
|
||||
|
||||
After executing this command – you will observe that prompt sign changes to pound (#) character.
|
||||
|
||||
### Recipes
|
||||
|
||||
In this section we’ll discuss some useful recipes which will help you to improve productivity. Most of the commands can be used to complete day-to-day task.
|
||||
|
||||
#### Execute previous command as a sudo user
|
||||
|
||||
Let us suppose you want to execute previous command with elevated privileges, then below trick will be useful:
|
||||
```
|
||||
$ sudo !4
|
||||
|
||||
```
|
||||
|
||||
Above command will execute 4th command from history with elevated privileges.
|
||||
|
||||
#### sudo command with Vim
|
||||
|
||||
Many times we edit system’s configuration files and while saving we realize that we need root access to do this. Because this we may lose our changes. There is no need to get panic, we can use below command in Vim to rescue from this situation:
|
||||
```
|
||||
:w !sudo tee %
|
||||
|
||||
```
|
||||
|
||||
In above command:
|
||||
|
||||
* Colon (:) indicates we are in Vim’s ex mode
|
||||
* Exclamation (!) mark indicates that we are running shell command
|
||||
* sudo and tee are the shell commands
|
||||
* Percentage (%) sign indicates all lines from current line
|
||||
|
||||
|
||||
|
||||
#### Execute multiple commands using sudo
|
||||
|
||||
So far we have executed only single command with sudo but we can execute multiple commands with it. Just separate commands using semicolon (;) as follows:
|
||||
```
|
||||
$ sudo -- bash -c 'pwd; hostname; whoami'
|
||||
|
||||
```
|
||||
|
||||
In above command:
|
||||
|
||||
* Double hyphen (–) stops processing of command line switches
|
||||
* bash indicates shell name to be used for execution
|
||||
* Commands to be executed are followed by –c option
|
||||
|
||||
|
||||
|
||||
#### Run sudo command without password
|
||||
|
||||
When sudo command is executed first time then it will prompt for password and by default password will be cached for next 15 minutes. However, we can override this behavior and disable password authentication using NOPASSWD keyword as follows:
|
||||
```
|
||||
linuxtechi ALL=(ALL) NOPASSWD: ALL
|
||||
|
||||
```
|
||||
|
||||
#### Restrict user to execute certain commands
|
||||
|
||||
To provide controlled access we can restrict sudo user to execute only certain commands. For instance, below line allows execution of echo and ls commands only
|
||||
```
|
||||
linuxtechi ALL=(ALL) NOPASSWD: /bin/echo /bin/ls
|
||||
|
||||
```
|
||||
|
||||
#### Insights about sudo
|
||||
|
||||
Let us dig more about sudo command to get insights about it.
|
||||
```
|
||||
$ ls -l /usr/bin/sudo
|
||||
-rwsr-xr-x 1 root root 145040 Jun 13 2017 /usr/bin/sudo
|
||||
|
||||
```
|
||||
|
||||
If you observe file permissions carefully, **setuid** bit is enabled on sudo. When any user runs this binary it will run with the privileges of the user that owns the file. In this case it is root user.
|
||||
|
||||
To demonstrate this, we can use id command with it as follows:
|
||||
```
|
||||
$ id
|
||||
uid=1002(linuxtechi) gid=1002(linuxtechi) groups=1002(linuxtechi)
|
||||
|
||||
```
|
||||
|
||||
When we execute id command without sudo then id of user linuxtechi will be displayed.
|
||||
```
|
||||
$ sudo id
|
||||
uid=0(root) gid=0(root) groups=0(root)
|
||||
|
||||
```
|
||||
|
||||
But if we execute id command with sudo then id of root user will be displayed.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Takeaway from this article is – sudo provides more controlled access to regular users. Using these techniques multiple users can interact with GNU/Linux in secure manner.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxtechi.com/quick-tips-sudo-command-linux-systems/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxtechi.com/author/pradeep/
|
||||
[1]:https://www.linuxtechi.com/wp-content/uploads/2018/03/Linux-sudo-command-tips.jpg
|
||||
@ -1,92 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
An Open Source Desktop YouTube Player For Privacy-minded People
|
||||
======
|
||||
|
||||

|
||||
|
||||
You already know that we need a Google account to subscribe channels and download videos from YouTube. If you don’t want Google track what you’re doing on YouTube, well, there is an open source YouTube player named **“FreeTube”**. It allows you to watch, search and download Youtube videos and subscribe your favorite channels without an account, which prevents Google from having your information. It gives you complete ad-free experience. Another notable advantage is it has a built-in basic HTML5 player to watch videos. Since we’re not using the built-in YouTube player, Google can’t track the “views” and the video analytics either. FreeTube only sends your IP details, but this also can be overcome by using a VPN. It is completely free, open source and available for GNU/Linux, Mac OS X, and Windows.
|
||||
|
||||
### Features
|
||||
|
||||
* Watch videos without ads.
|
||||
* Prevent Google from tracking what you watch using cookies or JavaScript.
|
||||
* Subscribe to channels without an account.
|
||||
* Store subscriptions, history, and saved videos locally.
|
||||
* Import / Backup subscriptions.
|
||||
* Mini Player.
|
||||
* Light / Dark Theme.
|
||||
* Free, Open Source.
|
||||
* Cross-platform.
|
||||
|
||||
|
||||
|
||||
### Installing FreeTube
|
||||
|
||||
Go to the [**releases page**][1] and grab the version depending upon the OS you use. For the purpose of this guide, I will be using **.tar.gz** file.
|
||||
```
|
||||
$ wget https://github.com/FreeTubeApp/FreeTube/releases/download/v0.1.3-beta/FreeTube-linux-x64.tar.xz
|
||||
|
||||
```
|
||||
|
||||
Extract the downloaded archive:
|
||||
```
|
||||
$ tar xf FreeTube-linux-x64.tar.xz
|
||||
|
||||
```
|
||||
|
||||
Go to the Freetube folder:
|
||||
```
|
||||
$ cd FreeTube-linux-x64/
|
||||
|
||||
```
|
||||
|
||||
Launch Freeube using command:
|
||||
```
|
||||
$ ./FreeTub
|
||||
|
||||
```
|
||||
|
||||
This is how FreeTube default interface looks like.
|
||||
|
||||
![][3]
|
||||
|
||||
### Usage
|
||||
|
||||
FreeTube currently uses **YouTube API** to search for videos. And then, It uses **Youtube-dl HTTP API** to grab the raw video files and play them in a basic HTML5 video player. Since subscriptions, history, and saved videos are stored locally on your system, your details will not be sent to Google or anyone else.
|
||||
|
||||
Enter the video name in the search box and hit ENTER key. FreeTube will list out the results based on your search query.
|
||||
|
||||
![][4]
|
||||
|
||||
You can click on any video to play it.
|
||||
|
||||
![][5]
|
||||
|
||||
If you want to change the theme or default API, import/export subscriptions, go to the **Settings** section.
|
||||
|
||||
![][6]
|
||||
|
||||
Please note that FreeTube is still in **beta** stage, so there will be bugs. If there are any bugs, please report them in the GitHub page given at the end of this guide.
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/freetube-an-open-source-desktop-youtube-player-for-privacy-minded-people/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://github.com/FreeTubeApp/FreeTube/releases
|
||||
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/03/FreeTube-1.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2018/03/FreeTube-3.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/03/FreeTube-5-1.png
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2018/03/FreeTube-2.png
|
||||
@ -1,124 +0,0 @@
|
||||
Test Your BASH Skills By Playing Command Line Games
|
||||
======
|
||||
|
||||

|
||||
We tend to learn and remember Linux commands more effectively if we use them regularly in a live scenario. You may forget the Linux commands over a period of time, unless you use them often. Whether you’re newbie, intermediate user, there are always some exciting methods to test your BASH skills. In this tutorial, I am going to explain how to test your BASH skills by playing command line games. Well, technically these are not actual games like Super TuxKart, NFS, or Counterstrike etc. These are just gamified versions of Linux command training lessons. You will be given a task to complete by follow certain instructions in the game itself.
|
||||
|
||||
Now, we will see few games that will help you to learn and practice Linux commands in real-time. These are not a time-passing or mind-boggling games. These games will help you to get a hands-on experience of terminal commands. Read on.
|
||||
|
||||
### Test BASH Skills with “Wargames”
|
||||
|
||||
It is an online game, so you must have an active Internet connection. These games helps you to learn and practice Linux commands in the form of fun-filled games. Wargames are collection of shell games and each game has many levels. You can access the next levels only by solving previous levels. Not to be worried! Each game provides clear and concise instructions about how to access the next levels.
|
||||
|
||||
To play the Wargames, go the following link:
|
||||
|
||||
![][2]
|
||||
|
||||
As you can see, there many shell games listed on the left side. Each shell game has its own SSH port. So, you will have to connect to the game via SSH from your local system. You can find the information about how to connect to each game using SSH in the top left corner of the Wargames website.
|
||||
|
||||
For instance, let us play the **Bandit** game. To do so, click on the Bandit link on the Wargames homepage. On the top left corner, you will see SSH information of the Bandit game.
|
||||
|
||||
![][3]
|
||||
|
||||
As you see in the above screenshot, there are many levels. To go to each level, click on the respective link on the left column. Also, there are instructions for the beginners on the right side. Read them if you have any questions about how to play this game.
|
||||
|
||||
Now, let us go to the level 0 by clicking on it. In the next screen, you will SSH information of this level.
|
||||
|
||||
![][4]
|
||||
|
||||
As you can see on the above screenshot, you need to connect is **bandit.labs.overthewire.org** , on port 2220 via SSH. The username is **bandit0** and the password is **bandit0**.
|
||||
|
||||
Let us connect to Bandit game level 0.
|
||||
|
||||
Enter the password i.e **bandit0**
|
||||
|
||||
Sample output will be:
|
||||
|
||||
![][5]
|
||||
|
||||
Once logged in, type **ls** command to see what’s in their or go to the **Level 1 page** to find out how to beat Level 1 and so on. The list of suggested command have been provided in every level. So, you can pick and use any suitable command to solve the each level.
|
||||
|
||||
I must admit that Wargames are addictive and really fun to solve each level. However some levels are really challenging, so you may need to google to know how to solve it. Give it a try, you will really like it.
|
||||
|
||||
### Test BASH Skills with “Terminus” game
|
||||
|
||||
This is a yet another browser-based online CLI game which can be used to improve or test your Linux command skills. To play this game, open up your web browser and navigate to the following URL.
|
||||
|
||||
Once you entered in the game, you see the instructions to learn how to play it. Unlike Wargames, you don’t need to connect to their game server to play the games. Terminus has a built-in CLI where you can find the instructions about how to play it.
|
||||
|
||||
You can look at your surroundings with the command **“ls”** , move to a new location with the command **“cd LOCATION”** , go back with the command **“cd ..”** , interact with things in the world with the command **“less ITEM”** and so on. To know your current location, just type **“pwd”**.
|
||||
|
||||
![][6]
|
||||
|
||||
### Test BASH Skills with “clmystery” game
|
||||
|
||||
Unlike the above games, you can play this game locally. You don’t need to be connected with any remote system. This is completely offline game.
|
||||
|
||||
Trust me, this is an interesting game folks. You are going to play a detective role to solve a mystery case by following the given instructions.
|
||||
|
||||
First, clone the repository:
|
||||
```
|
||||
$ git clone https://github.com/veltman/clmystery.git
|
||||
|
||||
```
|
||||
|
||||
Or, download it as a zip file from [**here**][7]. Extract it and go to the location where you have the files. Finally, solve the mystery case by reading the “instructions” file.
|
||||
```
|
||||
[sk@sk]: clmystery-master>$ ls
|
||||
cheatsheet.md cheatsheet.pdf encoded hint1 hint2 hint3 hint4 hint5 hint6 hint7 hint8 instructions LICENSE.md mystery README.md solution
|
||||
|
||||
```
|
||||
|
||||
Here is the instructions to play this game:
|
||||
|
||||
There’s been a murder in Terminal City, and TCPD needs your help. You need to help them to figure out who did the crime.
|
||||
|
||||
To find out who did it, you need to go to the **‘mystery’** subdirectory and start working from there. You might need to look into all clues at the crime scene (the **‘crimescene’** file). The officers on the scene are pretty meticulous, so they’ve written down EVERYTHING in their officer reports. Fortunately the sergeant went through and marked the real clues with the word “CLUE” in all caps.
|
||||
|
||||
If you get stuck at anywhere, open one of the hint files such as hint1, hint2 etc. You can open the hint files using cat command like below.
|
||||
```
|
||||
$ cat hint1
|
||||
|
||||
$ cat hint2
|
||||
|
||||
```
|
||||
|
||||
To check your answer or find out the solution, open the file ‘solution’ in the clmystery directory.
|
||||
```
|
||||
$ cat solution
|
||||
|
||||
```
|
||||
|
||||
To get started on how to use the command line, refer **cheatsheet.md** or **cheatsheet.pdf** (from the command line, you can type ‘nano cheatsheet.md’). Don’t use a text editor to view any files except these instructions, the cheatsheet, and hints.
|
||||
|
||||
For more details, refer the [**clmystery GitHub**][8] page.
|
||||
|
||||
**Recommended read:**
|
||||
|
||||
And, that’s all I can remember now. I will keep adding more games if I came across anything in future. Bookmark this link and do visit from time to time. If you know any other similar games, please let me know in the comment section below. I will test and update this guide.
|
||||
|
||||
More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/test-your-bash-skills-by-playing-command-line-games/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/03/Wargames-1.png
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/03/Bandit-game.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2018/03/Bandit-level-0.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/03/Bandit-level-0-ssh-1.png
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2018/03/Terminus.png
|
||||
[7]:https://github.com/veltman/clmystery/archive/master.zip
|
||||
[8]:https://github.com/veltman/clmystery
|
||||
60
sources/tech/20180312 Continuous integration in Fedora.md
Normal file
60
sources/tech/20180312 Continuous integration in Fedora.md
Normal file
@ -0,0 +1,60 @@
|
||||
translating---geekpi
|
||||
|
||||
Continuous integration in Fedora
|
||||
======
|
||||
|
||||

|
||||
Continuous Integration (CI) is the process of running tests for every change made to a project, integrated as if this were the new deliverable. If done consistently, it means that software is always ready to be released. CI is a very well established process across the entire IT industry as well as free and open source projects. Fedora has been a little behind on this, but we’re catching up. Read below to find out how.
|
||||
|
||||
### Why do we need this?
|
||||
|
||||
CI will improve Fedora all around. It provides a more stable and consistent operating system by revealing bugs as early as possible. It lets you add tests when you encounter an issue so it doesn’t happen again (avoid regressions). CI can run tests from the upstream project as well as Fedora-specific ones that test the integration of the application in the distribution.
|
||||
|
||||
Above all, consistent CI allows automation and reduced manual labor. It frees up our valuable volunteers and contributors to spend more time on new things for Fedora.
|
||||
|
||||
### How will it look?
|
||||
|
||||
For starters, we’ll run tests for every commit to git repositories of Fedora’s packages (dist-git). These tests are independent of the tests each of these packages run when built. However, they test the functionality of the package in an environment as close as possible to what Fedora’s users run. In addition to package-specific tests, Fedora also runs some distribution-wide tests, such as upgrade testing from F27 to F28 or rawhide.
|
||||
|
||||
Packages are “gated” based on test results: test failures prevent an update being pushed to users. However, sometimes tests fail for various reasons. Perhaps the tests themselves are wrong, or not up to date with the software. Or perhaps an infrastructure issue occurred and prevented the tests from running correctly. Maintainers will be able to re-trigger the tests or waive their results until the tests are updated.
|
||||
|
||||
Eventually, Fedora’s CI will run tests when a new pull-request is opened or updated on <https://src.fedoraproject.org>. This will give maintainers information about the impact of the proposed change on the stability of the package, and help them decide how to proceed.
|
||||
|
||||
### What do we have today?
|
||||
|
||||
Currently, a CI pipeline runs tests on packages that are part of Fedora Atomic Host. Other packages can have tests in dist-git, but they won’t be run automatically yet. Distribution specific tests already run on all of our packages. These test results are used to gate packages with failures.
|
||||
|
||||
### How do I get involved?
|
||||
|
||||
The best way to get started is to read the documentation about [Continuous Integration in Fedora][1]. You should get familiar with the [Standard Test Interface][2], which describes a lot of the terminology as well as how to write tests and use existing ones.
|
||||
|
||||
With this knowledge, if you’re a package maintainer you can start adding tests to your packages. You can run them on your local machine or in a virtual machine. (This latter is advisable for destructive tests!)
|
||||
|
||||
The Standard Test Interface makes testing consistent. As a result, you can easily add any tests to a package you like, and submit them to the maintainers in a pull-request on its [repository][3].
|
||||
|
||||
Reach out on #fedora-ci on irc.freenode.net with feedback, questions or for a general discussion on CI.
|
||||
|
||||
Photo by [Samuel Zeller][4] on [Unsplash][5]
|
||||
|
||||
#### Like this:
|
||||
|
||||
Like
|
||||
|
||||
Loading...
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/continuous-integration-fedora/
|
||||
|
||||
作者:[Pierre-Yves Chibon;Dominik Perpeet][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org
|
||||
[1]:http://fedoraproject.org/wiki/CI
|
||||
[2]:http://fedoraproject.org/wiki/CI/Standard_Test_Interface
|
||||
[3]:https://src.fedoraproject.org
|
||||
[4]:https://unsplash.com/photos/77oXlGwwOw0?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[5]:https://unsplash.com/search/photos/factory-line?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
@ -0,0 +1,80 @@
|
||||
The Type Command Tutorial With Examples For Beginners
|
||||
======
|
||||
|
||||

|
||||
|
||||
The **Type** command is used to find out the information about a Linux command. As the name implies, you can easily find whether the given command is an alias, shell built-in, file, function, or keyword using “type” command. Additionally, you can find the actual path of the command too. Why would anyone need to find the command type? For instance, if you happen to work on a shared computer often, some guys may intentionally or accidentally create an alias to a particular Linux command to perform an unwanted operation, for example **“alias ls = rm -rf /”**. So, it is always good idea to inspect them before something worse happen. This is where the type command comes in help.
|
||||
|
||||
Let me show you some examples.
|
||||
|
||||
Run the Type command without any flags.
|
||||
```
|
||||
$ type ls
|
||||
ls is aliased to `ls --color=auto'
|
||||
|
||||
```
|
||||
|
||||
As you can see in the above output, the “ls” command has been aliased to “ls –color-auto”. It is, however, harmless. But just think of if the **ls** command is aliased to something dangerous. You don’t want that, do you?
|
||||
|
||||
You can use **-t** flag to find only the type of a Linux command. For example:
|
||||
```
|
||||
$ type -t ls
|
||||
alias
|
||||
|
||||
$ type -t mkdir
|
||||
file
|
||||
|
||||
$ type -t pwd
|
||||
builtin
|
||||
|
||||
$ type -t if
|
||||
keyword
|
||||
|
||||
$ type -t rvm
|
||||
function
|
||||
|
||||
```
|
||||
|
||||
This command just displays the type of the command, i.e alias. It doesn’t display what is aliased to the given command. If a command is not found, you will see nothing in the terminal.
|
||||
|
||||
The another useful advantage of type command is we can easily find out the absolute path of a given Linux command. To do so, use **-p** flag as shown below.
|
||||
```
|
||||
$ type -p cal
|
||||
/usr/bin/cal
|
||||
|
||||
```
|
||||
|
||||
This is similar to ‘which ls’ command. If the given command is aliased, nothing will be printed.
|
||||
|
||||
To display all information of a command, use **-a** flag.
|
||||
```
|
||||
$ type -a ls
|
||||
ls is aliased to `ls --color=auto'
|
||||
ls is /usr/bin/ls
|
||||
ls is /bin/ls
|
||||
|
||||
```
|
||||
|
||||
As you see, -a flag displays the type of the given command and its absolute path. For more details, refer man pages.
|
||||
```
|
||||
$ man type
|
||||
|
||||
```
|
||||
|
||||
Hope this helps. More good stuffs to come. Keep visiting!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/the-type-command-tutorial-with-examples-for-beginners/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
@ -0,0 +1,103 @@
|
||||
5 open source card and board games for Linux
|
||||
======
|
||||

|
||||
|
||||
Gaming has traditionally been one of Linux's weak points. That has changed somewhat in recent years thanks to Steam, GOG, and other efforts to bring commercial games to multiple operating systems, but many of those games are not open source. Sure, the games can be played on an open source operating system, but that is not good enough for an open source purist.
|
||||
|
||||
So, can someone who uses only free and open source software find games that are polished enough to offer a solid gaming experience without compromising their open source ideals? Absolutely. While open source games are unlikely ever to rival some of the AAA commercial games developed with massive budgets, there are plenty of open source games in many genres that are fun to play and can be installed from the repositories of most major Linux distributions. Even if a particular game is not packaged for a particular distribution, it is usually easy to download, install, and play by downloading it from the project's website.
|
||||
|
||||
This article looks at computer versions of popular board and card games. I have already written about [arcade-style games][1]. In future articles, I plan to cover puzzle, racing, role-playing, and strategy & simulation games.
|
||||
|
||||
### Kajongg
|
||||
|
||||
|
||||
There are many applications that are called [Mahjong][2], but almost all are versions of the tile-matching solitaire game that uses Mahjong tiles. [Kajongg][3] is a rare exception because it is an implementation of the classic rummy-style game for four players. This traditional multi-player version of Mahjong is most popular throughout East and Southeast Asia, but there are players throughout the world. This means there are many variations of [Mahjong rules][4]. Unfortunately, Kajongg does not support them all, but it does allow players to play a fairly standard game of Mahjong with two different rules variants. Kajongg can be played locally against computer players or online versus human opponents.
|
||||
|
||||
To install Kajongg, run the following command:
|
||||
|
||||
On Fedora: `dnf install kajongg`
|
||||
|
||||
On Debian/Ubuntu: `apt install kajongg`
|
||||
|
||||
### Pioneers
|
||||
|
||||
|
||||
|
||||
Klaus Teuber's [The Settlers of Catan][5] board game and its various expansions introduced many players to a world of board games that were more complex and more interesting than some of the most familiar board games like [Monopoly][6], [Sorry!][7], and [Risk][8].
|
||||
|
||||
Catan, for those not familiar with the game, is played on a board made of hexagonal tiles, each of which has a different terrain type and provides a resource like lumber or wool. During the initial setup phase, players take turns placing their initial settlements as well as segments of road. Settlements are placed at the point where the hexagonal tiles meet. Each tile has a number, and when that number is rolled during a player's turn, every player whose settlements are next to that tile get the associated resource. These resources are then used to build more and better structures. The first person to earn a certain number of victory points by building structures or by other methods wins the game. (There are more rules, but that is the basic premise.)
|
||||
|
||||
[Pioneers][9] brings an unofficial adaptation of that iconic board game to computers, complete with AI opponents and online play. There are several map layouts available in Pioneers, from the basic map to maps of North America and Europe for more complex games. While Pioneers does have a few minor rough edges, it is a solid implementation of Catan and a great way to experience or re-experience a classic board game.
|
||||
|
||||
To install Pioneers, run the following command:
|
||||
|
||||
On Fedora: `dnf install pioneers`
|
||||
|
||||
On Debian/Ubuntu: `apt install pioneers`
|
||||
|
||||
### PokerTH
|
||||
|
||||
|
||||
|
||||
[PokerTH][10] is a computer version of [Texas hold 'em poker][11], complete with online multiplayer (but no real gambling). Play against the computer locally, or go online to compete against other people. PokerTH is available for multiple platforms, so there are plenty of people playing it online. PokerTH's implementation of Texas hold 'em is polished and the game is feature-complete, with solid online play. Any fan of Texas hold 'em should check out PokerTH.
|
||||
|
||||
To install PokerTH, run the following command:
|
||||
|
||||
On Fedora: `dnf install pokerth`
|
||||
|
||||
On Debian/Ubuntu: `apt install pokerth`
|
||||
|
||||
### TripleA
|
||||
|
||||

|
||||
|
||||
[TripleA][12] is a turn-based strategy game styled after the [Axis & Allies][13] board game and other similar board games. TripleA's gameplay is very much like Axis & Allies, but there are many different maps available for TripleA that can alter the experience. The standard game board is based on World War II, but there are other maps that feature other settings—some historical, some fantastical, like J.R.R. Tolkien's Middle Earth. There are also maps that make the game behave like the board game [Diplomacy][14]. TripleA can be played locally against the computer or against other people in hot seat mode. Online play is also available using either the network option or the play by email/forum post option.
|
||||
|
||||
To install TripleA, run the following command:
|
||||
|
||||
On Debian/Ubuntu: `apt install triplea`
|
||||
|
||||
Unfortunately, TripleA is not packaged for Fedora, but a [Linux installer][15] is available from the project's website.
|
||||
|
||||
### XBoard
|
||||
|
||||

|
||||
|
||||
There are so many [chess computer programs][16], it is hard to pick just one, even from just the open source offerings. However, [XBoard][17] is a good choice for most users. XBoard supports multiple chess engines, can handle non-Western and non-traditional chess variants and has online and play-by-email capabilities. Some of the other open source chess applications might look a little nicer, but XBoard provides many features that make up for the lack of graphical polish. If you are looking for a lighter chess application with fancy 3D chessmen, you might want to look elsewhere, but if you want a powerful program that can help you analyze and improve your chess skills, XBoard is the superior open source option.
|
||||
|
||||
To install XBoard, run the following command:
|
||||
|
||||
On Fedora: `dnf install xboard`
|
||||
|
||||
On Debian/Ubuntu: `apt install xboard`
|
||||
|
||||
Did I miss one of your favorite open source board or card games? Share it in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/card-board-games-linux
|
||||
|
||||
作者:[Joshua Allen Holm][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/holmja
|
||||
[1]:https://opensource.com/article/18/1/arcade-games-linux
|
||||
[2]:https://boardgamegeek.com/boardgame/2093/mahjong
|
||||
[3]:https://www.kde.org/applications/games/kajongg/
|
||||
[4]:https://en.wikipedia.org/wiki/Mahjong#Variations
|
||||
[5]:https://boardgamegeek.com/boardgame/13/catan
|
||||
[6]:https://boardgamegeek.com/boardgame/1406/monopoly
|
||||
[7]:https://boardgamegeek.com/boardgame/2407/sorry
|
||||
[8]:https://boardgamegeek.com/boardgame/181/risk
|
||||
[9]:http://pio.sourceforge.net/
|
||||
[10]:https://pokerth.net
|
||||
[11]:https://en.wikipedia.org/wiki/Texas_hold_%27em
|
||||
[12]:http://www.triplea-game.org
|
||||
[13]:https://boardgamegeek.com/boardgame/98/axis-allies
|
||||
[14]:https://boardgamegeek.com/boardgame/483/diplomacy
|
||||
[15]:http://triplea-game.org/download/
|
||||
[16]:https://boardgamegeek.com/boardgame/171/chess
|
||||
[17]:https://www.gnu.org/software/xboard
|
||||
@ -0,0 +1,195 @@
|
||||
hankchow translating
|
||||
|
||||
How to measure particulate matter with a Raspberry Pi
|
||||
======
|
||||
|
||||

|
||||
We regularly measure particulate matter in the air at our school in Southeast Asia. The values here are very high, particularly between February and May, when weather conditions are very dry and hot, and many fields burn. These factors negatively affect the quality of the air. In this article, I will show you how to measure particulate matter using a Raspberry Pi.
|
||||
|
||||
### What is particulate matter?
|
||||
|
||||
Particulate matter is fine dust or very small particles in the air. A distinction is made between PM10 and PM2.5: PM10 refers to particles that are smaller than 10µm; PM2.5 refers to particles that are smaller than 2.5µm. The smaller the particles—i.e., anything smaller than 2.5µm—the more dangerous they are to one's health, as they can penetrate into the alveoli and impact the respiratory system.
|
||||
|
||||
The World Health Organization recommends [limiting particulate matter][1] to the following values:
|
||||
|
||||
* Annual average PM10 20 µg/m³
|
||||
* Annual average PM2,5 10 µg/m³ per year
|
||||
* Daily average PM10 50 µg/m³ without permitted days on which exceeding is possible.
|
||||
* Daily average PM2,5 25 µg/m³ without permitted days on which exceeding is possible.
|
||||
|
||||
|
||||
|
||||
These values are below the limits set in most countries. In the European Union, an annual average of 40 µg/m³ for PM10 is allowed.
|
||||
|
||||
### What is the Air Quality Index (AQI)?
|
||||
|
||||
The Air Quality Index indicates how “good” or “bad” air is based on its particulate measurement. Unfortunately, there is no uniform standard for AQI because not all countries calculate it the same way. The Wikipedia article on the [Air Quality Index][2] offers a helpful overview. At our school, we are guided by the classification established by the United States' [Environmental Protection Agency][3].
|
||||
|
||||
|
||||
![Air quality index][5]
|
||||
|
||||
Air quality index
|
||||
|
||||
### What do we need to measure particulate matter?
|
||||
|
||||
Measuring particulate matter requires only two things:
|
||||
|
||||
* A Raspberry Pi (every model works; a model with WiFi is best)
|
||||
* A particulates sensor SDS011
|
||||
|
||||
|
||||
|
||||
![Particulate sensor][7]
|
||||
|
||||
Particulate sensor
|
||||
|
||||
If you are using a Raspberry Pi Zero W, you will also need an adapter cable to a standard USB port because the Zero has only a Micro USB. These are available for about $20. The sensor comes with a USB adapter for the serial interface.
|
||||
|
||||
### Installation
|
||||
|
||||
For our Raspberry Pi we download the corresponding Raspbian Lite Image and [write it on the Micro SD card][8]. (I will not go into the details of setting up the WLAN connection; many tutorials are available online).
|
||||
|
||||
If you want to have SSH enabled after booting, you need to create an empty file named `ssh` in the boot partition. The IP of the Raspberry Pi can best be obtained via your own router/DHCP server. You can then log in via SSH (the default password is raspberry):
|
||||
```
|
||||
$ ssh pi@192.168.1.5
|
||||
|
||||
```
|
||||
|
||||
First we need to install some packages on the Pi:
|
||||
```
|
||||
$ sudo apt install git-core python-serial python-enum lighttpd
|
||||
|
||||
```
|
||||
|
||||
Before we can start, we need to know which serial port the USB adapter is connected to. `dmesg` helps us:
|
||||
```
|
||||
$ dmesg
|
||||
|
||||
[ 5.559802] usbcore: registered new interface driver usbserial
|
||||
|
||||
[ 5.559930] usbcore: registered new interface driver usbserial_generic
|
||||
|
||||
[ 5.560049] usbserial: USB Serial support registered for generic
|
||||
|
||||
[ 5.569938] usbcore: registered new interface driver ch341
|
||||
|
||||
[ 5.570079] usbserial: USB Serial support registered for ch341-uart
|
||||
|
||||
[ 5.570217] ch341 1–1.4:1.0: ch341-uart converter detected
|
||||
|
||||
[ 5.575686] usb 1–1.4: ch341-uart converter now attached to ttyUSB0
|
||||
|
||||
```
|
||||
|
||||
In the last line, you can see our interface: `ttyUSB0`. We now need a small Python script that reads the data and saves it in a JSON file, and then we will create a small HTML page that reads and displays the data.
|
||||
|
||||
### Reading data on the Raspberry Pi
|
||||
|
||||
We first create an instance of the sensor and then read the sensor every 5 minutes, for 30 seconds. These values can, of course, be adjusted. Between the measuring intervals, we put the sensor into a sleep mode to increase its lifespan (according to the manufacturer, the lifespan totals approximately 8000 hours).
|
||||
|
||||
We can download the script with this command:
|
||||
```
|
||||
$ wget -O /home/pi/aqi.py https://raw.githubusercontent.com/zefanja/aqi/master/python/aqi.py
|
||||
|
||||
```
|
||||
|
||||
For the script to run without errors, two small things are still needed:
|
||||
```
|
||||
$ sudo chown pi:pi /var/wwww/html/
|
||||
|
||||
$ echo[] > /var/wwww/html/aqi.json
|
||||
|
||||
```
|
||||
|
||||
Now you can start the script:
|
||||
```
|
||||
$ chmod +x aqi.py
|
||||
|
||||
$ ./aqi.py
|
||||
|
||||
PM2.5:55.3, PM10:47.5
|
||||
|
||||
PM2.5:55.5, PM10:47.7
|
||||
|
||||
PM2.5:55.7, PM10:47.8
|
||||
|
||||
PM2.5:53.9, PM10:47.6
|
||||
|
||||
PM2.5:53.6, PM10:47.4
|
||||
|
||||
PM2.5:54.2, PM10:47.3
|
||||
|
||||
…
|
||||
|
||||
```
|
||||
|
||||
### Run the script automatically
|
||||
|
||||
So that we don’t have to start the script manually every time, we can let it start with a cronjob, e.g., with every restart of the Raspberry Pi. To do this, open the crontab file:
|
||||
```
|
||||
$ crontab -e
|
||||
|
||||
```
|
||||
|
||||
and add the following line at the end:
|
||||
```
|
||||
@reboot cd /home/pi/ && ./aqi.py
|
||||
|
||||
```
|
||||
|
||||
Now our script starts automatically with every restart.
|
||||
|
||||
### HTML page for displaying measured values and AQI
|
||||
|
||||
We have already installed a lightweight webserver, `lighttpd`. So we need to save our HTML, JavaScript, and CSS files in the directory `/var/www/html/` so that we can access the data from another computer or smartphone. With the next three commands, we simply download the corresponding files:
|
||||
```
|
||||
$ wget -O /var/wwww/html/index.html https://raw.githubusercontent.com/zefanja/aqi/master/html/index.html
|
||||
|
||||
$ wget -O /var/wwww/html/aqi.js https://raw.githubusercontent.com/zefanja/aqi/master/html/aqi.js
|
||||
|
||||
$ wget -O /var/wwww/html/style.css https://raw.githubusercontent.com/zefanja/aqi/master/html/style.css
|
||||
|
||||
```
|
||||
|
||||
The main work is done in the JavaScript file, which opens our JSON file, takes the last value, and calculates the AQI based on this value. Then the background colors are adjusted according to the scale of the EPA.
|
||||
|
||||
Now you simply open the address of the Raspberry Pi in your browser and look at the current particulates values, e.g., [http://192.168.1.5:][9]
|
||||
|
||||
The page is very simple and can be extended, for example, with a chart showing the history of the last hours, etc. Pull requests are welcome.
|
||||
|
||||
The complete [source code is available on Github][10].
|
||||
|
||||
**[Enter our[Raspberry Pi week giveaway][11] for a chance at this arcade gaming kit.]**
|
||||
|
||||
### Wrapping up
|
||||
|
||||
For relatively little money, we can measure particulate matter with a Raspberry Pi. There are many possible applications, from a permanent outdoor installation to a mobile measuring device. At our school, we use both: There is a sensor that measures outdoor values day and night, and a mobile sensor that checks the effectiveness of the air conditioning filters in our classrooms.
|
||||
|
||||
[Luftdaten.info][12] offers guidance to build a similar sensor. The software is delivered ready to use, and the measuring device is even more compact because it does not use a Raspberry Pi. Great project!
|
||||
|
||||
Creating a particulates sensor is an excellent project to do with students in computer science classes or a workshop.
|
||||
|
||||
What do you use a [Raspberry Pi][13] for?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/how-measure-particulate-matter-raspberry-pi
|
||||
|
||||
作者:[Stephan Tetzel][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/stephan
|
||||
[1]:https://en.wikipedia.org/wiki/Particulates
|
||||
[2]:https://en.wikipedia.org/wiki/Air_quality_index
|
||||
[3]:https://en.wikipedia.org/wiki/United_States_Environmental_Protection_Agency
|
||||
[5]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/images/life-uploads/air_quality_index.png?itok=FwmGf1ZS (Air quality index)
|
||||
[7]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/images/life-uploads/particulate_sensor.jpg?itok=ddH3bBwO (Particulate sensor)
|
||||
[8]:https://www.raspberrypi.org/documentation/installation/installing-images/README.md
|
||||
[9]:http://192.168.1.5/
|
||||
[10]:https://github.com/zefanja/aqi
|
||||
[11]:https://opensource.com/article/18/3/raspberry-pi-week-giveaway
|
||||
[12]:http://luftdaten.info/
|
||||
[13]:https://openschoolsolutions.org/shutdown-servers-case-power-failure%e2%80%8a-%e2%80%8aups-nut-co/
|
||||
42
sources/tech/20180314 Playing with water.md
Normal file
42
sources/tech/20180314 Playing with water.md
Normal file
@ -0,0 +1,42 @@
|
||||
translating---geekpi
|
||||
|
||||
Playing with water
|
||||
======
|
||||
![H2o Flow gradient boosting job][1]
|
||||
|
||||
I'm currently taking a machine learning class and although it is an insane amount of work, I like it a lot. I initially had planned to use [R][2] to play around with the database I have, but the teacher recommended I use [H2o][3], a FOSS machine learning framework.
|
||||
|
||||
I was a bit sceptical at first since I'm already pretty good with R, but then I found out you could simply import H2o as an R library. H2o replaces most R functions by its own parallelized ones to cut down on processing time (no more `doParallel` calls) and uses an "external" server you have to run on the side instead of running R calls directly.
|
||||
|
||||
![H2o Flow gradient boosting model][4]
|
||||
|
||||
I was pretty happy with this situation, that is until I actually started using H2o in R. With the huge database I'm playing with, the library felt clunky and I had a hard time doing anything useful. Most of the time, I just ended up with long Java traceback calls. Much love.
|
||||
|
||||
I'm sure in the right hands using H2o as a library could have been incredibly powerful, but sadly it seems I haven't earned my black belt in R-fu yet.
|
||||
|
||||
![H2o Flow variable importance weights][5]
|
||||
|
||||
I was pissed for at least a whole day - not being able to achieve what I wanted to do - until I realised H2o comes with a WebUI called Flow. I'm normally not very fond of using web thingies to do important work like writing code, but Flow is simply incredible.
|
||||
|
||||
Automated graphing functions, integrated ETA when running resource intensive models, descriptions for each and every model parameters (the parameters are even divided in sections based on your familiarly with the statistical models in question), Flow seemingly has it all. In no time I was able to run 3 basic machine learning models and get actual interpretable results.
|
||||
|
||||
So yeah, if you've been itching to analyse very large databases using state of the art machine learning models, I would recommend using H2o. Try Flow at first instead of the Python or R hooks to see what it's capable of doing.
|
||||
|
||||
The only downside to all of this is that H2o is written in Java and depends on Java 1.7 to run... That, and be warned: it requires a metric fuckton of processing power and RAM. My poor server struggled quite a bit even with 10 available cores and 10Gb of RAM...
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://veronneau.org/playing-with-water.html
|
||||
|
||||
作者:[Louis-Philippe Véronneau][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://veronneau.org/
|
||||
[1]:https://veronneau.org/media/blog/2018-03-14/h2o_job.png (H2o Flow gradient boosting job)
|
||||
[2]:https://en.wikipedia.org/wiki/R_(programming_language)
|
||||
[3]:https://www.h2o.ai
|
||||
[4]:https://veronneau.org/media/blog/2018-03-14/h2o_model.png (H2o Flow gradient boosting model)
|
||||
[5]:https://veronneau.org/media/blog/2018-03-14/h2o_var_importance.png (H2o Flow variable importance weights)
|
||||
@ -0,0 +1,303 @@
|
||||
Protecting Code Integrity with PGP — Part 5: Moving Subkeys to a Hardware Device
|
||||
======
|
||||
|
||||

|
||||
|
||||
In this tutorial series, we're providing practical guidelines for using PGP. If you missed the previous article, you can catch up with the links below. But, in this article, we'll continue our discussion about securing your keys and look at some tips for moving your subkeys to a specialized hardware device.
|
||||
|
||||
[Part 1: Basic Concepts and Tools][1]
|
||||
|
||||
[Part 2: Generating Your Master Key][2]
|
||||
|
||||
[Part 3: Generating PGP Subkeys][3]
|
||||
|
||||
[Part 4: Moving Your Master Key to Offline Storage][4]
|
||||
|
||||
### Checklist
|
||||
|
||||
* Get a GnuPG-compatible hardware device (NICE)
|
||||
|
||||
* Configure the device to work with GnuPG (NICE)
|
||||
|
||||
* Set the user and admin PINs (NICE)
|
||||
|
||||
* Move your subkeys to the device (NICE)
|
||||
|
||||
|
||||
|
||||
|
||||
### Considerations
|
||||
|
||||
Even though the master key is now safe from being leaked or stolen, the subkeys are still in your home directory. Anyone who manages to get their hands on those will be able to decrypt your communication or fake your signatures (if they know the passphrase). Furthermore, each time a GnuPG operation is performed, the keys are loaded into system memory and can be stolen from there by sufficiently advanced malware (think Meltdown and Spectre).
|
||||
|
||||
The best way to completely protect your keys is to move them to a specialized hardware device that is capable of smartcard operations.
|
||||
|
||||
#### The benefits of smartcards
|
||||
|
||||
A smartcard contains a cryptographic chip that is capable of storing private keys and performing crypto operations directly on the card itself. Because the key contents never leave the smartcard, the operating system of the computer into which you plug in the hardware device is not able to retrieve the private keys themselves. This is very different from the encrypted USB storage device we used earlier for backup purposes -- while that USB device is plugged in and decrypted, the operating system is still able to access the private key contents. Using external encrypted USB media is not a substitute to having a smartcard-capable device.
|
||||
|
||||
Some other benefits of smartcards:
|
||||
|
||||
* They are relatively cheap and easy to obtain
|
||||
|
||||
* They are small and easy to carry with you
|
||||
|
||||
* They can be used with multiple devices
|
||||
|
||||
* Many of them are tamper-resistant (depends on manufacturer)
|
||||
|
||||
|
||||
|
||||
|
||||
#### Available smartcard devices
|
||||
|
||||
Smartcards started out embedded into actual wallet-sized cards, which earned them their name. You can still buy and use GnuPG-capable smartcards, and they remain one of the cheapest available devices you can get. However, actual smartcards have one important downside: they require a smartcard reader, and very few laptops come with one.
|
||||
|
||||
For this reason, manufacturers have started providing small USB devices, the size of a USB thumb drive or smaller, that either have the microsim-sized smartcard pre-inserted, or that simply implement the smartcard protocol features on the internal chip. Here are a few recommendations:
|
||||
|
||||
* [Nitrokey Start][5]: Open hardware and Free Software: one of the cheapest options for GnuPG use, but with fewest extra security features
|
||||
|
||||
* [Nitrokey Pro][6]: Similar to the Nitrokey Start, but is tamper-resistant and offers more security features (but not U2F, see the Fido U2F section of the guide)
|
||||
|
||||
* [Yubikey 4][7]: Proprietary hardware and software, but cheaper than Nitrokey Pro and comes available in the USB-C form that is more useful with newer laptops; also offers additional security features such as U2F
|
||||
|
||||
|
||||
|
||||
|
||||
Our recommendation is to pick a device that is capable of both smartcard functionality and U2F, which, at the time of writing, means a Yubikey 4.
|
||||
|
||||
#### Configuring your smartcard device
|
||||
|
||||
Your smartcard device should Just Work (TM) the moment you plug it into any modern Linux or Mac workstation. You can verify it by running:
|
||||
```
|
||||
$ gpg --card-status
|
||||
|
||||
```
|
||||
|
||||
If you didn't get an error, but a full listing of the card details, then you are good to go. Unfortunately, troubleshooting all possible reasons why things may not be working for you is way beyond the scope of this guide. If you are having trouble getting the card to work with GnuPG, please seek support via your operating system's usual support channels.
|
||||
|
||||
##### PINs don't have to be numbers
|
||||
|
||||
Note, that despite having the name "PIN" (and implying that it must be a "number"), neither the user PIN nor the admin PIN on the card need to be numbers.
|
||||
|
||||
Your device will probably have default user and admin PINs set up when it arrives. For Yubikeys, these are 123456 and 12345678, respectively. If those don't work for you, please check any accompanying documentation that came with your device.
|
||||
|
||||
##### Quick setup
|
||||
|
||||
To configure your smartcard, you will need to use the GnuPG menu system, as there are no convenient command-line switches:
|
||||
```
|
||||
$ gpg --card-edit
|
||||
[...omitted...]
|
||||
gpg/card> admin
|
||||
Admin commands are allowed
|
||||
gpg/card> passwd
|
||||
|
||||
```
|
||||
|
||||
You should set the user PIN (1), Admin PIN (3), and the Reset Code (4). Please make sure to record and store these in a safe place -- especially the Admin PIN and the Reset Code (which allows you to completely wipe the smartcard). You so rarely need to use the Admin PIN, that you will inevitably forget what it is if you do not record it.
|
||||
|
||||
Getting back to the main card menu, you can also set other values (such as name, sex, login data, etc), but it's not necessary and will additionally leak information about your smartcard should you lose it.
|
||||
|
||||
#### Moving the subkeys to your smartcard
|
||||
|
||||
Exit the card menu (using "q") and save all changes. Next, let's move your subkeys onto the smartcard. You will need both your PGP key passphrase and the admin PIN of the card for most operations. Remember, that [fpr] stands for the full 40-character fingerprint of your key.
|
||||
```
|
||||
$ gpg --edit-key [fpr]
|
||||
|
||||
Secret subkeys are available.
|
||||
|
||||
pub rsa4096/AAAABBBBCCCCDDDD
|
||||
created: 2017-12-07 expires: 2019-12-07 usage: C
|
||||
trust: ultimate validity: ultimate
|
||||
ssb rsa2048/1111222233334444
|
||||
created: 2017-12-07 expires: never usage: E
|
||||
ssb rsa2048/5555666677778888
|
||||
created: 2017-12-07 expires: never usage: S
|
||||
[ultimate] (1). Alice Engineer <alice@example.org>
|
||||
[ultimate] (2) Alice Engineer <allie@example.net>
|
||||
|
||||
gpg>
|
||||
|
||||
```
|
||||
|
||||
Using --edit-key puts us into the menu mode again, and you will notice that the key listing is a little different. From here on, all commands are done from inside this menu mode, as indicated by gpg>.
|
||||
|
||||
First, let's select the key we'll be putting onto the card -- you do this by typing key 1 (it's the first one in the listing, our [E] subkey):
|
||||
```
|
||||
gpg> key 1
|
||||
|
||||
```
|
||||
|
||||
The output should be subtly different:
|
||||
```
|
||||
pub rsa4096/AAAABBBBCCCCDDDD
|
||||
created: 2017-12-07 expires: 2019-12-07 usage: C
|
||||
trust: ultimate validity: ultimate
|
||||
ssb* rsa2048/1111222233334444
|
||||
created: 2017-12-07 expires: never usage: E
|
||||
ssb rsa2048/5555666677778888
|
||||
created: 2017-12-07 expires: never usage: S
|
||||
[ultimate] (1). Alice Engineer <alice@example.org>
|
||||
[ultimate] (2) Alice Engineer <allie@example.net>
|
||||
|
||||
```
|
||||
|
||||
Notice the * that is next to the ssb line corresponding to the key -- it indicates that the key is currently "selected." It works as a toggle, meaning that if you type key 1 again, the * will disappear and the key will not be selected any more.
|
||||
|
||||
Now, let's move that key onto the smartcard:
|
||||
```
|
||||
gpg> keytocard
|
||||
Please select where to store the key:
|
||||
(2) Encryption key
|
||||
Your selection? 2
|
||||
|
||||
```
|
||||
|
||||
Since it's our [E] key, it makes sense to put it into the Encryption slot. When you submit your selection, you will be prompted first for your PGP key passphrase, and then for the admin PIN. If the command returns without an error, your key has been moved.
|
||||
|
||||
**Important:** Now type key 1 again to unselect the first key, and key 2 to select the [S] key:
|
||||
```
|
||||
gpg> key 1
|
||||
gpg> key 2
|
||||
gpg> keytocard
|
||||
Please select where to store the key:
|
||||
(1) Signature key
|
||||
(3) Authentication key
|
||||
Your selection? 1
|
||||
|
||||
```
|
||||
|
||||
You can use the [S] key both for Signature and Authentication, but we want to make sure it's in the Signature slot, so choose (1). Once again, if your command returns without an error, then the operation was successful.
|
||||
|
||||
Finally, if you created an [A] key, you can move it to the card as well, making sure first to unselect key 2. Once you're done, choose "q":
|
||||
```
|
||||
gpg> q
|
||||
Save changes? (y/N) y
|
||||
|
||||
```
|
||||
|
||||
Saving the changes will delete the keys you moved to the card from your home directory (but it's okay, because we have them in our backups should we need to do this again for a replacement smartcard).
|
||||
|
||||
##### Verifying that the keys were moved
|
||||
|
||||
If you perform --list-secret-keys now, you will see a subtle difference in the output:
|
||||
```
|
||||
$ gpg --list-secret-keys
|
||||
sec# rsa4096 2017-12-06 [C] [expires: 2019-12-06]
|
||||
111122223333444455556666AAAABBBBCCCCDDDD
|
||||
uid [ultimate] Alice Engineer <alice@example.org>
|
||||
uid [ultimate] Alice Engineer <allie@example.net>
|
||||
ssb> rsa2048 2017-12-06 [E]
|
||||
ssb> rsa2048 2017-12-06 [S]
|
||||
|
||||
```
|
||||
|
||||
The > in the ssb> output indicates that the subkey is only available on the smartcard. If you go back into your secret keys directory and look at the contents there, you will notice that the .key files there have been replaced with stubs:
|
||||
```
|
||||
$ cd ~/.gnupg/private-keys-v1.d
|
||||
$ strings *.key
|
||||
|
||||
```
|
||||
|
||||
The output should contain shadowed-private-key to indicate that these files are only stubs and the actual content is on the smartcard.
|
||||
|
||||
#### Verifying that the smartcard is functioning
|
||||
|
||||
To verify that the smartcard is working as intended, you can create a signature:
|
||||
```
|
||||
$ echo "Hello world" | gpg --clearsign > /tmp/test.asc
|
||||
$ gpg --verify /tmp/test.asc
|
||||
|
||||
```
|
||||
|
||||
This should ask for your smartcard PIN on your first command, and then show "Good signature" after you run gpg --verify.
|
||||
|
||||
Congratulations, you have successfully made it extremely difficult to steal your digital developer identity!
|
||||
|
||||
### Other common GnuPG operations
|
||||
|
||||
Here is a quick reference for some common operations you'll need to do with your PGP key.
|
||||
|
||||
In all of the below commands, the [fpr] is your key fingerprint.
|
||||
|
||||
#### Mounting your master key offline storage
|
||||
|
||||
You will need your master key for any of the operations below, so you will first need to mount your backup offline storage and tell GnuPG to use it. First, find out where the media got mounted, for example, by looking at the output of the mount command. Then, locate the directory with the backup of your GnuPG directory and tell GnuPG to use that as its home:
|
||||
```
|
||||
$ export GNUPGHOME=/media/disk/name/gnupg-backup
|
||||
$ gpg --list-secret-keys
|
||||
|
||||
```
|
||||
|
||||
You want to make sure that you see sec and not sec# in the output (the # means the key is not available and you're still using your regular home directory location).
|
||||
|
||||
##### Updating your regular GnuPG working directory
|
||||
|
||||
After you make any changes to your key using the offline storage, you will want to import these changes back into your regular working directory:
|
||||
```
|
||||
$ gpg --export | gpg --homedir ~/.gnupg --import
|
||||
$ unset GNUPGHOME
|
||||
|
||||
```
|
||||
|
||||
#### Extending key expiration date
|
||||
|
||||
The master key we created has the default expiration date of 2 years from the date of creation. This is done both for security reasons and to make obsolete keys eventually disappear from keyservers.
|
||||
|
||||
To extend the expiration on your key by a year from current date, just run:
|
||||
```
|
||||
$ gpg --quick-set-expire [fpr] 1y
|
||||
|
||||
```
|
||||
|
||||
You can also use a specific date if that is easier to remember (e.g. your birthday, January 1st, or Canada Day):
|
||||
```
|
||||
$ gpg --quick-set-expire [fpr] 2020-07-01
|
||||
|
||||
```
|
||||
|
||||
Remember to send the updated key back to keyservers:
|
||||
```
|
||||
$ gpg --send-key [fpr]
|
||||
|
||||
```
|
||||
|
||||
#### Revoking identities
|
||||
|
||||
If you need to revoke an identity (e.g., you changed employers and your old email address is no longer valid), you can use a one-liner:
|
||||
```
|
||||
$ gpg --quick-revoke-uid [fpr] 'Alice Engineer <aengineer@example.net>'
|
||||
|
||||
```
|
||||
|
||||
You can also do the same with the menu mode using gpg --edit-key [fpr].
|
||||
|
||||
Once you are done, remember to send the updated key back to keyservers:
|
||||
```
|
||||
$ gpg --send-key [fpr]
|
||||
|
||||
```
|
||||
|
||||
Next time, we'll look at how Git supports multiple levels of integration with PGP.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][8]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/pgp/2018/3/protecting-code-integrity-pgp-part-5-moving-subkeys-hardware-device
|
||||
|
||||
作者:[KONSTANTIN RYABITSEV][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/mricon
|
||||
[1]:https://www.linux.com/blog/learn/2018/2/protecting-code-integrity-pgp-part-1-basic-pgp-concepts-and-tools
|
||||
[2]:https://www.linux.com/blog/learn/pgp/2018/2/protecting-code-integrity-pgp-part-2-generating-and-protecting-your-master-pgp-key
|
||||
[3]:https://www.linux.com/blog/learn/pgp/2018/2/protecting-code-integrity-pgp-part-3-generating-pgp-subkeys
|
||||
[4]:https://www.linux.com/blog/learn/pgp/2018/3/protecting-code-integrity-pgp-part-4-moving-your-master-key-offline-storage
|
||||
[5]:https://shop.nitrokey.com/shop/product/nitrokey-start-6
|
||||
[6]:https://shop.nitrokey.com/shop/product/nitrokey-pro-3
|
||||
[7]:https://www.yubico.com/product/yubikey-4-series/
|
||||
[8]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -0,0 +1,179 @@
|
||||
How to Encrypt Files From Within a File Manager
|
||||
======
|
||||
|
||||

|
||||
The Linux desktop and server enjoys a remarkable level of security. That doesn’t mean, however, you should simply rest easy. You should always consider that your data is always a quick hack away from being compromised. That being said, you might want to employ various tools for encryption, such as GnuPG, which lets you encrypt and decrypt files and much more. One problem with GnuPG is that some users don’t want to mess with the command line. If that’s the case, you can turn to a desktop file manager. Many Linux desktops include the ability to easily encrypt or decrypt files, and if that capability is not built in, it’s easy to add.
|
||||
|
||||
I will walk you through the process of encrypting and decrypting a file from within three popular Linux file managers:
|
||||
|
||||
* Nautilus (aka GNOME Files)
|
||||
|
||||
* Dolphin
|
||||
|
||||
* Thunar
|
||||
|
||||
|
||||
|
||||
|
||||
### Installing GnuPG
|
||||
|
||||
Before we get into the how to of this, we have to ensure your system includes the necessary base component… [GnuPG][1]. Most distributions ship with GnuPG included. On the off chance you use a distribution that doesn’t ship with GnuPG, here’s how to install it:
|
||||
|
||||
* Ubuntu-based distribution: sudo apt install gnupg
|
||||
|
||||
* Fedora-based distribution: sudo yum install gnupg
|
||||
|
||||
* openSUSE: sudo zypper in gnupg
|
||||
|
||||
* Arch-based distribution: sudo pacman -S gnupg
|
||||
|
||||
|
||||
|
||||
|
||||
Whether you’ve just now installed GnuPG or it was installed by default, you will have to create a GPG key for this to work. Each desktop uses a different GUI tool for this (or may not even include a GUI tool for the task), so let’s create that key from the command line. Open up your terminal window and issue the following command:
|
||||
```
|
||||
gpg --gen-key
|
||||
|
||||
```
|
||||
|
||||
You will then be asked to answer the following questions. Unless you have good reason, you can accept the defaults:
|
||||
|
||||
* What kind of key do you want?
|
||||
|
||||
* What key size do you want?
|
||||
|
||||
* Key is valid for?
|
||||
|
||||
|
||||
|
||||
|
||||
Once you’ve answered these questions, type y to indicate the answers are correct. Next you’ll need to supply the following information:
|
||||
|
||||
* Real name.
|
||||
|
||||
* Email address.
|
||||
|
||||
* Comment.
|
||||
|
||||
|
||||
|
||||
|
||||
Complete the above and then, when prompted, type O (for Okay). You will then be required to type a passphrase for the new key. Once the system has collected enough entropy (you’ll need to do some work on the desktop so this can happen), your key will have been created and you’re ready to go.
|
||||
|
||||
Let’s see how to encrypt/decrypt files from within the file managers.
|
||||
|
||||
### Nautilus
|
||||
|
||||
We start with the default GNOME file manager because it is the easiest. Nautilus requires no extra installation or extra work to encrypt/decrypt files from within it’s well-designed interface. Once you have your gpg key created, you can open up the file manager, navigate to the directory housing the file to be encrypted, right-click the file in question, and select Encrypt from the menu (Figure 1).
|
||||
|
||||
|
||||
![nautilus][3]
|
||||
|
||||
Figure 1: Encrypting a file from within Nautilus.
|
||||
|
||||
[Used with permission][4]
|
||||
|
||||
You will be asked to select a recipient (or list of recipients — Figure 2). NOTE: Recipients will be those users whose public keys you have imported. Select the necessary keys and then select your key (email address) from the Sign message as drop-down.
|
||||
|
||||
![nautilus][6]
|
||||
|
||||
Figure 2: Selecting recipients and a signer.
|
||||
|
||||
[Used with permission][4]
|
||||
|
||||
Notice you can also opt to encrypt the file with only a passphrase. This is important if the file will remain on your local machine (more on this later). Once you’ve set up the encryption, click OK and (when prompted) type the passphrase for your key. The file will be encrypted (now ending in .gpg) and saved in the working directory. You can now send that encrypted file to the recipients you selected during the encryption process.
|
||||
|
||||
Say someone (who has your public key) has sent you an encrypted file. Save that file, open the file manager, navigate to the directory housing that file, right-click the encrypted file, select Open With Decrypt File, give the file a new name (without the .gpg extension), and click Save. When prompted, type your gpg key passphrase and the file will be decrypted and ready to use.
|
||||
|
||||
### Dolphin
|
||||
|
||||
On the KDE front, there’s a package that must be installed in order to encrypt/decrypt from with the Dolphin file manager. Log into your KDE desktop, open the terminal window, and issue the following command (I’m demonstrating with Neon. If your distribution isn’t Ubuntu-based, you’ll have to alter the command accordingly):
|
||||
```
|
||||
sudo apt install kgpg
|
||||
|
||||
```
|
||||
|
||||
Once that installs, logout and log back into the KDE desktop. You can open up Dolphin and right-click a file to be encrypted. Since this is the first time you’ve used kgpg, you’ll have to walk through a quick setup wizard (which self-explanatory). When you’ve completed the wizard, you can go back to that file, right-click it (Figure 3), and select Encrypt File.
|
||||
|
||||
|
||||
![Dolphin][8]
|
||||
|
||||
Figure 3: Encrypting a file within Dolphin.
|
||||
|
||||
[Used with permission][4]
|
||||
|
||||
You’ll be prompted to select the key to use for encryption (Figure 4). Make your selection and click OK. The file will encrypt and you’re ready to send it to the recipient.
|
||||
|
||||
Note: With KDE’s Dolphin file manager, you cannot encrypt with a passphrase only.
|
||||
|
||||
|
||||
![Dolphin][10]
|
||||
|
||||
Figure 4: Selecting your recipients for encryption.
|
||||
|
||||
[Used with permission][4]
|
||||
|
||||
If you receive an encrypted file from a user who has your public key (or you have a file you’ve encrypted yourself), open up Dolphin, navigate to the file in question, double-click the file, give the file a new name, type the encryption passphrase, and click OK. You can now read your newly decrypted file. If you’ve encrypted the file with your own key, you won’t be prompted to type the passphrase (as it has already been stored).
|
||||
|
||||
### Thunar
|
||||
|
||||
The Thunar file manager is a bit trickier. There aren’t any extra packages to install; instead, you need to create new custom action for Encrypt. Once you’ve done this, you’ll have the ability to do this from within the file manager.
|
||||
|
||||
To create the custom actions, open up the Thunar file manager and click Edit > Configure Custom Actions. In the resulting window, click the + button (Figure 5) and enter the following for an Encrypt action:
|
||||
|
||||
Name: Encrypt
|
||||
|
||||
Description: File Encryption
|
||||
|
||||
Command: gnome-terminal -x gpg --encrypt --recipient %f
|
||||
|
||||
Click OK to save this action.
|
||||
|
||||
|
||||
![Thunar][12]
|
||||
|
||||
Figure 5: Creating an custom action within Thunar.
|
||||
|
||||
[Used with permission][4]
|
||||
|
||||
NOTE: If gnome-terminal isn’t your default terminal, substitute the command to open your default terminal in.
|
||||
|
||||
You can also create an action that encrypts with a passphrase only (not a key). To do this, the details for the action would be:
|
||||
|
||||
Name: Encrypt Passphrase
|
||||
|
||||
Description: Encrypt with Passphrase only
|
||||
|
||||
Command: gnome-terminal -x gpg -c %f
|
||||
|
||||
You don’t need to create a custom action for the decryption process, as Thunar already knows what to do with an encrypted file. To decrypt a file, simply right-click it (within Thunar), select Open With Decrypt File, give the decrypted file a name, and (when/if prompted) type the encryption passphrase. Viola, your encrypted file has been decrypted and is ready to use.
|
||||
|
||||
### One caveat
|
||||
|
||||
Do note: If you encrypt your own files, using your own keys, you won’t need to enter an encryption passphrase to decrypt them (because your public keys are stored). If, however, you receive files from others (who have your public key) you will be required to enter your passphrase. If you’re wanting to store your own encrypted files, instead of encrypting them with a key, encrypt them with a passphrase only. This is possible with Nautilus and Thunar (but not KDE). By opting for passphrase encryption (over key encryption), when you go to decrypt the file, it will always prompt you for the passphrase.
|
||||
|
||||
### Other file managers
|
||||
|
||||
There are plenty of other file managers out there, some of them can work with encryption, some cannot. Chances are, you’re using one of these three tools, so the ability to add encryption/decryption to the contextual menu is not only possible, it’s pretty easy. Give this a try and see if it doesn’t make the process of encryption and decryption much easier.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][13] course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/3/how-encrypt-files-within-file-manager
|
||||
|
||||
作者:[JACK WALLEN][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://www.gnupg.org/
|
||||
[3]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/nautilus.jpg?itok=ae7Gtj60 (nautilus)
|
||||
[4]:https://www.linux.com/licenses/category/used-permission
|
||||
[6]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/nautilus_2.jpg?itok=3ht7j63n (nautilus)
|
||||
[8]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/kde_0.jpg?itok=KSTctVw0 (Dolphin)
|
||||
[10]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/kde_2.jpg?itok=CeqWikNl (Dolphin)
|
||||
[12]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/thunar.jpg?itok=fXcHk08B (Thunar)
|
||||
[13]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -0,0 +1,347 @@
|
||||
How To Edit Multiple Files Using Vim Editor
|
||||
======
|
||||
|
||||

|
||||
Sometimes, you will find yourself in a situation where you want to make changes in multiple files or you might want to copy the contents of one file to another. If you’re on GUI mode, you could simply open the files in any graphical text editor, like gedit, and use CTRL+C and CTRL+V to copy/paste the contents. In CLI mode, you can’t use such editors. No worries! Where there is vim editor, there is a way! In this tutorial, we are going to learn to edit multiple files at the same time using Vim editor. Trust me, this is very interesting read.
|
||||
|
||||
### Installing Vim
|
||||
|
||||
Vim editor is available in the official repositories of most Linux distributions. So you can install it using the default package manager. For example, on Arch Linux and its variants you can install it using command:
|
||||
```
|
||||
$ sudo pacman -S vim
|
||||
|
||||
```
|
||||
|
||||
On Debian, Ubuntu:
|
||||
```
|
||||
$ sudo apt-get install vim
|
||||
|
||||
```
|
||||
|
||||
On RHEL, CentOS:
|
||||
```
|
||||
$ sudo yum install vim
|
||||
|
||||
```
|
||||
|
||||
On Fedora:
|
||||
```
|
||||
$ sudo dnf install vim
|
||||
|
||||
```
|
||||
|
||||
On openSUSE:
|
||||
```
|
||||
$ sudo zypper install vim
|
||||
|
||||
```
|
||||
|
||||
### Edit multiple files at a time using Vim editor in Linux
|
||||
|
||||
Let us now get down to the business. We can do this in two methods.
|
||||
|
||||
#### Method 1
|
||||
|
||||
I have two files namely **file1.txt** and **file2.txt** , with a bunch of random words. Let us have a look at them.
|
||||
```
|
||||
$ cat file1.txt
|
||||
ostechnix
|
||||
open source
|
||||
technology
|
||||
linux
|
||||
unix
|
||||
|
||||
$ cat file2.txt
|
||||
line1
|
||||
line2
|
||||
line3
|
||||
line4
|
||||
line5
|
||||
|
||||
```
|
||||
|
||||
Now, let us edit these two files at a time. To do so, run:
|
||||
```
|
||||
$ vim file1.txt file2.txt
|
||||
|
||||
```
|
||||
|
||||
Vim will display the contents of the files in an order. The first file’s contents will be shown first and then second file and so on.
|
||||
|
||||
![][2]
|
||||
|
||||
**Switch between files**
|
||||
|
||||
To move to the next file, type:
|
||||
```
|
||||
:n
|
||||
|
||||
```
|
||||
|
||||
![][3]
|
||||
|
||||
To go back to previous file, type:
|
||||
```
|
||||
:N
|
||||
|
||||
```
|
||||
|
||||
Vim won’t allow you to move to the next file if there are any unsaved changes. To save the changes in the current file, type:
|
||||
```
|
||||
ZZ
|
||||
|
||||
```
|
||||
|
||||
Please note that it is double capital letters ZZ (SHIFT+zz).
|
||||
|
||||
To abandon the changes and move to the previous file, type:
|
||||
```
|
||||
:N!
|
||||
|
||||
```
|
||||
|
||||
To view the files which are being currently edited, type:
|
||||
```
|
||||
:buffers
|
||||
|
||||
```
|
||||
|
||||
![][4]
|
||||
|
||||
You will see the list of loaded files at the bottom.
|
||||
|
||||
![][5]
|
||||
|
||||
To switch to the next file, type **:buffer** followed by the buffer number. For example, to switch to the first file, type:
|
||||
```
|
||||
:buffer 1
|
||||
|
||||
```
|
||||
|
||||
![][6]
|
||||
|
||||
**Opening additional files for editing**
|
||||
|
||||
We are currently editing two files namely file1.txt, file2.txt. I want to open another file named **file3.txt** for editing.
|
||||
What will you do? It’s easy! Just type **:e** followed by the file name like below.
|
||||
```
|
||||
:e file3.txt
|
||||
|
||||
```
|
||||
|
||||
![][7]
|
||||
|
||||
Now you can edit file3.txt.
|
||||
|
||||
To view how many files are being edited currently, type:
|
||||
```
|
||||
:buffers
|
||||
|
||||
```
|
||||
|
||||
![][8]
|
||||
|
||||
Please note that you can not switch between opened files with **:e** using either **:n** or **:N**. To switch to another file, type **:buffer** followed by the file buffer number.
|
||||
|
||||
**Copying contents of one file into another**
|
||||
|
||||
You know how to open and edit multiple files at the same time. Sometimes, you might want to copy the contents of one file into another. It is possible too. Switch to a file of your choice. For example, let us say you want to copy the contents of file1.txt into file2.txt.
|
||||
|
||||
To do so, first switch to file1.txt:
|
||||
```
|
||||
:buffer 1
|
||||
|
||||
```
|
||||
|
||||
Place the move cursor in-front of a line that wants to copy and type **yy** to yank(copy) the line. Then. move to file2.txt:
|
||||
```
|
||||
:buffer 2
|
||||
|
||||
```
|
||||
|
||||
Place the mouse cursor where you want to paste the copied lines from file1.txt and type **p**. For example, you want to paste the copied line between line2 and line3. To do so, put the mouse cursor before line and type **p**.
|
||||
|
||||
Sample output:
|
||||
```
|
||||
line1
|
||||
line2
|
||||
ostechnix
|
||||
line3
|
||||
line4
|
||||
line5
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
|
||||
To save the changes made in the current file, type:
|
||||
```
|
||||
ZZ
|
||||
|
||||
```
|
||||
|
||||
Again, please note that this is double capital ZZ (SHIFT+z).
|
||||
|
||||
To save the changes in all files and exit vim editor. type:
|
||||
```
|
||||
:wq
|
||||
|
||||
```
|
||||
|
||||
Similarly, you can copy any line from any file to other files.
|
||||
|
||||
**Copying entire file contents into another**
|
||||
|
||||
We know how to copy a single line. What about the entire file contents? That’s also possible. Let us say, you want to copy the entire contents of file1.txt into file2.txt.
|
||||
|
||||
To do so, open the file2.txt first:
|
||||
```
|
||||
$ vim file2.txt
|
||||
|
||||
```
|
||||
|
||||
If the files are already loaded, you can switch to file2.txt by typing:
|
||||
```
|
||||
:buffer 2
|
||||
|
||||
```
|
||||
|
||||
Move the cursor to the place where you wanted to copy the contents of file1.txt. I want to copy the contents of file1.txt after line5 in file2.txt, so I moved the cursor to line 5. Then, type the following command and hit ENTER key:
|
||||
```
|
||||
:r file1.txt
|
||||
|
||||
```
|
||||
|
||||
![][10]
|
||||
|
||||
Here, **r** means **read**.
|
||||
|
||||
Now you will see the contents of file1.txt is pasted after line5 in file2.txt.
|
||||
```
|
||||
line1
|
||||
line2
|
||||
line3
|
||||
line4
|
||||
line5
|
||||
ostechnix
|
||||
open source
|
||||
technology
|
||||
linux
|
||||
unix
|
||||
|
||||
```
|
||||
|
||||
![][11]
|
||||
|
||||
To save the changes in the current file, type:
|
||||
```
|
||||
ZZ
|
||||
|
||||
```
|
||||
|
||||
To save all changes in all loaded files and exit vim editor, type:
|
||||
```
|
||||
:wq
|
||||
|
||||
```
|
||||
|
||||
#### Method 2
|
||||
|
||||
The another method to open multiple files at once is by using either **-o** or **-O** flags.
|
||||
|
||||
To open multiple files in horizontal windows, run:
|
||||
```
|
||||
$ vim -o file1.txt file2.txt
|
||||
|
||||
```
|
||||
|
||||
![][12]
|
||||
|
||||
To switch between windows, press **CTRL-w w** (i.e Press **CTRL+w** and again press **w** ). Or, you the following shortcuts to move between windows.
|
||||
|
||||
* **CTRL-w k** – top window
|
||||
* **CTRL-w j** – bottom window
|
||||
|
||||
|
||||
|
||||
To open multiple files in vertical windows, run:
|
||||
```
|
||||
$ vim -O file1.txt file2.txt file3.txt
|
||||
|
||||
```
|
||||
|
||||
![][13]
|
||||
|
||||
To switch between windows, press **CTRL-w w** (i.e Press **CTRL+w** and again press **w** ). Or, use the following shortcuts to move between windows.
|
||||
|
||||
* **CTRL-w l** – left window
|
||||
* **CTRL-w h** – right window
|
||||
|
||||
|
||||
|
||||
Everything else is same as described in method 1.
|
||||
|
||||
For example, to list currently loaded files, run:
|
||||
```
|
||||
:buffers
|
||||
|
||||
```
|
||||
|
||||
To switch between files:
|
||||
```
|
||||
:buffer 1
|
||||
|
||||
```
|
||||
|
||||
To open an additional file, type:
|
||||
```
|
||||
:e file3.txt
|
||||
|
||||
```
|
||||
|
||||
To copy entire contents of a file into another:
|
||||
```
|
||||
:r file1.txt
|
||||
|
||||
```
|
||||
|
||||
The only difference in method 2 is once you saved the changes in the current file using **ZZ** , the file will automatically close itself. Also, you need to close the files one by one by typing **:wq**. But, had you followed the method 1, when typing **:wq** all changes will be saved in all files and all files will be closed at once.
|
||||
|
||||
For more details, refer man pages.
|
||||
```
|
||||
$ man vim
|
||||
|
||||
```
|
||||
|
||||
**Suggested read:**
|
||||
|
||||
You know now how to edit multiples files using vim editor in Linux. As you can see, editing multiple files is not that difficult. Vim editor has more powerful features. We will write more about Vim editor in the days to come.
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-edit-multiple-files-using-vim-editor/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/03/edit-multiple-files-1-1.png
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/03/edit-multiple-files-2.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2018/03/edit-multiple-files-5.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/03/edit-multiple-files-6.png
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2018/03/edit-multiple-files-7.png
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2018/03/edit-multiple-files-8.png
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2018/03/edit-multiple-files-10-1.png
|
||||
[9]:http://www.ostechnix.com/wp-content/uploads/2018/03/edit-multiple-files-11.png
|
||||
[10]:http://www.ostechnix.com/wp-content/uploads/2018/03/edit-multiple-files-12.png
|
||||
[11]:http://www.ostechnix.com/wp-content/uploads/2018/03/edit-multiple-files-13.png
|
||||
[12]:http://www.ostechnix.com/wp-content/uploads/2018/03/Edit-multiple-files-16.png
|
||||
[13]:http://www.ostechnix.com/wp-content/uploads/2018/03/Edit-multiple-files-17.png
|
||||
@ -0,0 +1,435 @@
|
||||
How To Manage Disk Partitions Using Parted Command
|
||||
======
|
||||
We all knows disk partitions is one of the important task for Linux administrator. They can not survive without knowing this.
|
||||
|
||||
In worst cases, at least once in a week they would get this request from dependent team but in big environment admins used to get this request very often.
|
||||
|
||||
You may ask why we need to use parted instead of fdisk? What is the difference? It’s a good question, i will give you more details about this.
|
||||
|
||||
* Parted allow users to create a partition when the disk size is larger than 2TB but fdisk doesn’t allow.
|
||||
* Parted is a higher-level tool than fdisk.
|
||||
* It supports multiple partition table which includes GPT.
|
||||
* It allows users to resize the partition but while shrinking the partition it does not worked as expected and i got error most of the time so, i would advise users to do not shrink the partition.
|
||||
|
||||
|
||||
|
||||
### What Is Parted
|
||||
|
||||
Parted is a program to manipulate disk partitions. It supports multiple partition table formats, including MS-DOS and GPT.
|
||||
|
||||
It allows user to create, delete, resize, shrink, move and copy partitions, reorganizing disk usage, and copying data to new hard disks. GParted is a GUI frontend of parted.
|
||||
|
||||
### How To Install Parted
|
||||
|
||||
Parted package is pre-installed on most of the Linux distribution. If not, use the following commands to install parted package.
|
||||
|
||||
For **`Debian/Ubuntu`** , use [APT-GET Command][1] or [APT Command][2] to install parted.
|
||||
```
|
||||
$ sudo apt install parted
|
||||
|
||||
```
|
||||
|
||||
For **`RHEL/CentOS`** , use [YUM Command][3] to install parted.
|
||||
```
|
||||
$ sudo yum install parted
|
||||
|
||||
```
|
||||
|
||||
For **`Fedora`** , use [DNF Command][4] to install parted.
|
||||
```
|
||||
$ sudo dnf install parted
|
||||
|
||||
```
|
||||
|
||||
For **`Arch Linux`** , use [Pacman Command][5] to install parted.
|
||||
```
|
||||
$ sudo pacman -S parted
|
||||
|
||||
```
|
||||
|
||||
For **`openSUSE`** , use [Zypper Command][6] to install parted.
|
||||
```
|
||||
$ sudo zypper in parted
|
||||
|
||||
```
|
||||
|
||||
### How To Launch Parted
|
||||
|
||||
The below parted command picks the `/dev/sda` disk automatically, because this is the first hard drive in this system.
|
||||
```
|
||||
$ sudo parted
|
||||
GNU Parted 3.2
|
||||
Using /dev/sda
|
||||
Welcome to GNU Parted! Type 'help' to view a list of commands.
|
||||
(parted)
|
||||
|
||||
```
|
||||
|
||||
Also we can go to the corresponding disk by selecting the appropriate disk using below command.
|
||||
```
|
||||
(parted) select /dev/sdb
|
||||
Using /dev/sdb
|
||||
(parted)
|
||||
|
||||
```
|
||||
|
||||
If you wants to go to particular disk, use the following format. In our case we are going to use `/dev/sdb`.
|
||||
```
|
||||
$ sudo parted [Device Name]
|
||||
|
||||
$ sudo parted /dev/sdb
|
||||
GNU Parted 3.2
|
||||
Using /dev/sdb
|
||||
Welcome to GNU Parted! Type 'help' to view a list of commands.
|
||||
(parted)
|
||||
|
||||
```
|
||||
|
||||
### How To List Available Disks Using Parted Command
|
||||
|
||||
If you don’t know what are the disks are added in your system. Just run the following command, which will display all the available disks name, and other useful information such as Disk Size, Model, Sector Size, Partition Table, Disk Flags, and partition information.
|
||||
```
|
||||
$ sudo parted -l
|
||||
Model: ATA VBOX HARDDISK (scsi)
|
||||
Disk /dev/sda: 32.2GB
|
||||
Sector size (logical/physical): 512B/512B
|
||||
Partition Table: msdos
|
||||
Disk Flags:
|
||||
|
||||
Number Start End Size Type File system Flags
|
||||
1 1049kB 32.2GB 32.2GB primary ext4 boot
|
||||
|
||||
|
||||
Error: /dev/sdb: unrecognised disk label
|
||||
Model: ATA VBOX HARDDISK (scsi)
|
||||
Disk /dev/sdb: 53.7GB
|
||||
Sector size (logical/physical): 512B/512B
|
||||
Partition Table: unknown
|
||||
Disk Flags:
|
||||
|
||||
```
|
||||
|
||||
The above error message clearly shows there is no valid disk label for the disk `/dev/sdb`. Hence, we have to set `disk label` first as it doesn’t take any label automatically.
|
||||
|
||||
### How To Create Disk Partition Using Parted Command
|
||||
|
||||
Parted allows us to create primary or extended partition. Procedure is same for both but make sure you have to pass an appropriate partition type like `primary` or `extended` while creating the partition.
|
||||
|
||||
To perform this activity, we have added a new `50GB` hard disk in the system, which falls under `/dev/sdb`.
|
||||
|
||||
In two ways we can create a partition, one is detailed way and other one is single command. In the below example we are going to add one primary partition in detailed way. Make a note, we should set `disk label` first as it doesn’t take any label automatically.
|
||||
|
||||
We are going to create a new partition with `10GB` of disk in the below example.
|
||||
```
|
||||
$ sudo parted /dev/sdb
|
||||
GNU Parted 3.2
|
||||
Using /dev/sdb
|
||||
Welcome to GNU Parted! Type 'help' to view a list of commands.
|
||||
(parted) mklabel msdos
|
||||
(parted) unit GB
|
||||
(parted) mkpart
|
||||
Partition type? primary/extended? primary
|
||||
File system type? [ext2]? ext4
|
||||
Start? 0.00GB
|
||||
End? 10.00GB
|
||||
(parted) print
|
||||
Model: ATA VBOX HARDDISK (scsi)
|
||||
Disk /dev/sdb: 53.7GB
|
||||
Sector size (logical/physical): 512B/512B
|
||||
Partition Table: msdos
|
||||
Disk Flags:
|
||||
|
||||
Number Start End Size Type File system Flags
|
||||
1 0.00GB 10.0GB 10.0GB primary ext4 lba
|
||||
|
||||
(parted) quit
|
||||
Information: You may need to update /etc/fstab.
|
||||
|
||||
```
|
||||
|
||||
Alternatively we can create a new partition using single parted command.
|
||||
|
||||
We are going to create second partition with `10GB` of disk in the below example.
|
||||
```
|
||||
$ sudo parted [Disk Name] [mkpart] [Partition Type] [Filesystem Type] [Partition Start Size] [Partition End Size]
|
||||
|
||||
$ sudo parted /dev/sdb mkpart primary ext4 10.0GB 20.0GB
|
||||
Information: You may need to update /etc/fstab.
|
||||
|
||||
```
|
||||
|
||||
### How To Create A Partition With All Remaining Space
|
||||
|
||||
You have created all required partitions except `/home` and you wants to use all the remaining space to `/home` partition, how to do that? use the following command to create a partition.
|
||||
|
||||
The below command create a new partition with 33.7GB, which starts from `20GB` and ends with `53GB`. `100%` end size will allow users to create a new partition with remaining all available space in the disk.
|
||||
```
|
||||
$ sudo parted [Disk Name] [mkpart] [Partition Type] [Filesystem Type] [Partition Start Size] [Partition End Size]
|
||||
|
||||
$ sudo parted /dev/sdb mkpart primary ext4 20.0GB 100%
|
||||
Information: You may need to update /etc/fstab.
|
||||
|
||||
```
|
||||
|
||||
### How To List All Partitions using Parted
|
||||
|
||||
As you aware of, we have created three partitions in the above step and if you want to list all available partitions on the disk use the print command.
|
||||
```
|
||||
$ sudo parted /dev/sdb print
|
||||
Model: ATA VBOX HARDDISK (scsi)
|
||||
Disk /dev/sdb: 53.7GB
|
||||
Sector size (logical/physical): 512B/512B
|
||||
Partition Table: msdos
|
||||
Disk Flags:
|
||||
|
||||
Number Start End Size Type File system Flags
|
||||
1 1049kB 10.0GB 9999MB primary ext4
|
||||
2 10.0GB 20.0GB 9999MB primary ext4
|
||||
3 20.0GB 53.7GB 33.7GB primary ext4
|
||||
|
||||
```
|
||||
|
||||
### How To Create A File System On Partition Using mkfs
|
||||
|
||||
Users can create a file system on the partition using mkfs. Follow the below procedure to create a filesystem using mkfs.
|
||||
```
|
||||
$ sudo mkfs.ext4 /dev/sdb1
|
||||
mke2fs 1.43.4 (31-Jan-2017)
|
||||
Creating filesystem with 2621440 4k blocks and 656640 inodes
|
||||
Filesystem UUID: 415cf467-634c-4403-8c9f-47526bbaa381
|
||||
Superblock backups stored on blocks:
|
||||
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632
|
||||
|
||||
Allocating group tables: done
|
||||
Writing inode tables: done
|
||||
Creating journal (16384 blocks): done
|
||||
Writing superblocks and filesystem accounting information: done
|
||||
|
||||
```
|
||||
|
||||
Do the same for other partitions as well.
|
||||
```
|
||||
$ sudo mkfs.ext4 /dev/sdb2
|
||||
$ sudo mkfs.ext4 /dev/sdb3
|
||||
|
||||
```
|
||||
|
||||
Create necessary folders and mount the partitions on that.
|
||||
```
|
||||
$ sudo mkdir /par1 /par2 /par3
|
||||
|
||||
$ sudo mount /dev/sdb1 /par1
|
||||
$ sudo mount /dev/sdb2 /par2
|
||||
$ sudo mount /dev/sdb3 /par3
|
||||
|
||||
```
|
||||
|
||||
Run the following command to check newly mounted partitions.
|
||||
```
|
||||
$ df -h /dev/sdb[1-3]
|
||||
Filesystem Size Used Avail Use% Mounted on
|
||||
/dev/sdb1 9.2G 37M 8.6G 1% /par1
|
||||
/dev/sdb2 9.2G 37M 8.6G 1% /par2
|
||||
/dev/sdb3 31G 49M 30G 1% /par3
|
||||
|
||||
```
|
||||
|
||||
### How To Check Free Space On The Disk
|
||||
|
||||
Run the following command to check available free space on the disk. This disk has `25.7GB` of free disk space.
|
||||
```
|
||||
$ sudo parted /dev/sdb print free
|
||||
Model: ATA VBOX HARDDISK (scsi)
|
||||
Disk /dev/sdb: 53.7GB
|
||||
Sector size (logical/physical): 512B/512B
|
||||
Partition Table: msdos
|
||||
Disk Flags:
|
||||
|
||||
Number Start End Size Type File system Flags
|
||||
32.3kB 1049kB 1016kB Free Space
|
||||
1 1049kB 10.0GB 9999MB primary ext4
|
||||
2 10.0GB 20.0GB 9999MB primary ext4
|
||||
3 20.0GB 28.0GB 8001MB primary ext4
|
||||
28.0GB 53.7GB 25.7GB Free Space
|
||||
|
||||
```
|
||||
|
||||
### How To Resize Partition Using Parted Command
|
||||
|
||||
Parted allow users to resize the partitions to big and smaller size. As i told in the beginning of the article, do not shrink partitions because this leads to face disk error issue.
|
||||
|
||||
Run the following command to check disk partitions and available free space. I could see `25.7GB` of free space on this disk.
|
||||
```
|
||||
$ sudo parted /dev/sdb print free
|
||||
Model: ATA VBOX HARDDISK (scsi)
|
||||
Disk /dev/sdb: 53.7GB
|
||||
Sector size (logical/physical): 512B/512B
|
||||
Partition Table: msdos
|
||||
Disk Flags:
|
||||
|
||||
Number Start End Size Type File system Flags
|
||||
32.3kB 1049kB 1016kB Free Space
|
||||
1 1049kB 10.0GB 9999MB primary ext4
|
||||
2 10.0GB 20.0GB 9999MB primary ext4
|
||||
3 20.0GB 28.0GB 8001MB primary ext4
|
||||
28.0GB 53.7GB 25.7GB Free Space
|
||||
|
||||
```
|
||||
|
||||
Run the following command to resize the partition. We are going to resize (increase) the partition 3 end size from `28GB to 33GB`.
|
||||
```
|
||||
$ sudo parted [Disk Name] [resizepart] [Partition Number] [Partition New End Size]
|
||||
|
||||
$ sudo parted /dev/sdb resizepart 3 33.0GB
|
||||
Information: You may need to update /etc/fstab.
|
||||
|
||||
```
|
||||
|
||||
Run the following command to verify whether this partition is increased or not. Yes, i could see the partition 3 got increased from `8GB to 13GB`.
|
||||
```
|
||||
$ sudo parted /dev/sdb print
|
||||
Model: ATA VBOX HARDDISK (scsi)
|
||||
Disk /dev/sdb: 53.7GB
|
||||
Sector size (logical/physical): 512B/512B
|
||||
Partition Table: msdos
|
||||
Disk Flags:
|
||||
|
||||
Number Start End Size Type File system Flags
|
||||
1 1049kB 10.0GB 9999MB primary ext4
|
||||
2 10.0GB 20.0GB 9999MB primary ext4
|
||||
3 20.0GB 33.0GB 13.0GB primary ext4
|
||||
|
||||
```
|
||||
|
||||
Resize the file system to grow the resized partition.
|
||||
```
|
||||
$ sudo resize2fs /dev/sdb3
|
||||
resize2fs 1.43.4 (31-Jan-2017)
|
||||
Resizing the filesystem on /dev/sdb3 to 3173952 (4k) blocks.
|
||||
The filesystem on /dev/sdb3 is now 3173952 (4k) blocks long.
|
||||
|
||||
```
|
||||
|
||||
Finally, check whether the mount point has been successfully increased or not.
|
||||
```
|
||||
$ df -h /dev/sdb[1-3]
|
||||
Filesystem Size Used Avail Use% Mounted on
|
||||
/dev/sdb1 9.2G 5.1G 3.6G 59% /par1
|
||||
/dev/sdb2 9.2G 2.1G 6.6G 24% /par2
|
||||
/dev/sdb3 12G 1.1G 11G 10% /par3
|
||||
|
||||
```
|
||||
|
||||
### How To Remove Partition Using Parted Command
|
||||
|
||||
We can simple remove the unused partition (if the partition is no longer use) using rm command. See the procedure below. We are going to remove partition 3 `/dev/sdb3` in this example.
|
||||
```
|
||||
$ sudo parted [Disk Name] [rm] [Partition Number]
|
||||
|
||||
$ sudo parted /dev/sdb rm 3
|
||||
Warning: Partition /dev/sdb3 is being used. Are you sure you want to continue?
|
||||
Yes/No? Yes
|
||||
Error: Partition(s) 3 on /dev/sdb have been written, but we have been unable to inform the kernel of the change, probably because it/they are in use. As a result, the old partition(s) will remain in use.
|
||||
You should reboot now before making further changes.
|
||||
Ignore/Cancel? Ignore
|
||||
Information: You may need to update /etc/fstab.
|
||||
|
||||
```
|
||||
|
||||
We can check the same using below command. Yes, i could see that partition 3 has been removed successfully.
|
||||
```
|
||||
$ sudo parted /dev/sdb print
|
||||
Model: ATA VBOX HARDDISK (scsi)
|
||||
Disk /dev/sdb: 53.7GB
|
||||
Sector size (logical/physical): 512B/512B
|
||||
Partition Table: msdos
|
||||
Disk Flags:
|
||||
|
||||
Number Start End Size Type File system Flags
|
||||
1 1049kB 10.0GB 9999MB primary ext4
|
||||
2 10.0GB 20.0GB 9999MB primary ext4
|
||||
|
||||
```
|
||||
|
||||
### How To Set/Change Partition Flag Using Parted Command
|
||||
|
||||
We can easily change the partition flag using below command. We are going to set `lvm` flag to partition 2 `/dev/sdb2`.
|
||||
```
|
||||
$ sudo parted [Disk Name] [set] [Partition Number] [Flags Name] [Flag On/Off]
|
||||
|
||||
$ sudo parted /dev/sdb set 2 lvm on
|
||||
Information: You may need to update /etc/fstab.
|
||||
|
||||
```
|
||||
|
||||
We can verify this modification by listing disk partitions.
|
||||
```
|
||||
$ sudo parted /dev/sdb print
|
||||
Model: ATA VBOX HARDDISK (scsi)
|
||||
Disk /dev/sdb: 53.7GB
|
||||
Sector size (logical/physical): 512B/512B
|
||||
Partition Table: msdos
|
||||
Disk Flags:
|
||||
|
||||
Number Start End Size Type File system Flags
|
||||
1 1049kB 10.0GB 9999MB primary ext4
|
||||
2 10.0GB 20.0GB 9999MB primary ext4 lvm
|
||||
|
||||
```
|
||||
|
||||
To know list of available flags, use the following command.
|
||||
```
|
||||
$ (parted) help set
|
||||
set NUMBER FLAG STATE change the FLAG on partition NUMBER
|
||||
|
||||
NUMBER is the partition number used by Linux. On MS-DOS disk labels, the primary partitions number from 1 to 4, logical partitions from 5 onwards.
|
||||
FLAG is one of: boot, root, swap, hidden, raid, lvm, lba, hp-service, palo, prep, msftres, bios_grub, atvrecv, diag, legacy_boot, msftdata, irst, esp
|
||||
STATE is one of: on, off
|
||||
|
||||
```
|
||||
|
||||
If you want to know the available options in parted, just navigate to `help` page.
|
||||
```
|
||||
$ sudo parted
|
||||
GNU Parted 3.2
|
||||
Using /dev/sda
|
||||
Welcome to GNU Parted! Type 'help' to view a list of commands.
|
||||
(parted) help
|
||||
align-check TYPE N check partition N for TYPE(min|opt) alignment
|
||||
help [COMMAND] print general help, or help on COMMAND
|
||||
mklabel,mktable LABEL-TYPE create a new disklabel (partition table)
|
||||
mkpart PART-TYPE [FS-TYPE] START END make a partition
|
||||
name NUMBER NAME name partition NUMBER as NAME
|
||||
print [devices|free|list,all|NUMBER] display the partition table, available devices, free space, all found partitions, or a particular partition
|
||||
quit exit program
|
||||
rescue START END rescue a lost partition near START and END
|
||||
resizepart NUMBER END resize partition NUMBER
|
||||
rm NUMBER delete partition NUMBER
|
||||
select DEVICE choose the device to edit
|
||||
disk_set FLAG STATE change the FLAG on selected device
|
||||
disk_toggle [FLAG] toggle the state of FLAG on selected device
|
||||
set NUMBER FLAG STATE change the FLAG on partition NUMBER
|
||||
toggle [NUMBER [FLAG]] toggle the state of FLAG on partition NUMBER
|
||||
unit UNIT set the default unit to UNIT
|
||||
version display the version number and copyright information of GNU Parted
|
||||
(parted) quit
|
||||
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-manage-disk-partitions-using-parted-command/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/magesh/
|
||||
[1]:https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[2]:https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[3]:https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||
[4]:https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
[5]:https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
|
||||
[6]:https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
|
||||
@ -0,0 +1,81 @@
|
||||
Migrating to Linux: Installing Software
|
||||
======
|
||||
|
||||

|
||||
With all the attention you are seeing on Linux and its use on the Internet and in devices like Arduino, Beagle, and Raspberry Pi boards and more, perhaps you are thinking it's time to try it out. This series will help you successfully make the transition to Linux. If you missed the earlier articles in the series, you can find them here:
|
||||
|
||||
[Part 1 - An Introduction][1]
|
||||
|
||||
[Part 2 - Disks, Files, and Filesystems][2]
|
||||
|
||||
[Part 3 - Graphical Environments][3]
|
||||
|
||||
[Part 4 - The Command Line][4]
|
||||
|
||||
[Part 5 - Using sudo][5]
|
||||
|
||||
### Installing software
|
||||
|
||||
To get new software on your computer, the typical approach used to be to get a software product from a vendor and then run an install program. The software product, in the past, would come on physical media like a CD-ROM or DVD. Now we often download the software product from the Internet instead.
|
||||
|
||||
With Linux, software is installed more like it is on your smartphone. Just like going to your phone's app store, on Linux there is a central repository of open source software tools and programs. Just about any program you might want will be in a list of available packages that you can install.
|
||||
|
||||
There isn't a separate install program that you run for each program. Instead you use the package management tools that come with your distribution of Linux. (Remember a Linux distribution is the Linux you install such as Ubuntu, Fedora, Debian, etc.) Each distribution has its own centralized place on the Internet (called a repository) where they store thousands of pre-built applications for you to install.
|
||||
|
||||
You may note that there are a few exceptions to how software is installed on Linux. Sometimes, you will still need to go to a vendor to get their software as the program doesn't exist in your distribution's central repository. This typically is the case when the software isn't open source and/or not free.
|
||||
|
||||
Also keep in mind that if you end up wanting to install a program that is not in your distribution's repositories, things aren't so simple, even if you are installing free and open source programs. This post doesn't get into these more complicated scenarios, and it's best to follow online directions.
|
||||
|
||||
With all the Linux packaging systems and tools out there, it may be confusing to know what's going on. This article should help clear up a few things.
|
||||
|
||||
### Package Managers
|
||||
|
||||
Several packaging systems to manage, install, and remove software compete for use in Linux distributions. The folks behind each distribution choose a package management system to use. Red Hat, Fedora, CentOS, Scientific Linux, SUSE, and others use the Red Hat Package Manager (RPM). Debian, Ubuntu, Linux Mint, and more use the Debian package system, or DPKG for short. Other package systems exist as well, while RPM and DPKG are the most common.
|
||||
|
||||

|
||||
|
||||
Regardless of the package manager you are using, they typically come with a set of tools that are layered on top of one another (Figure 1). At the lowest level is a command-line tool that lets you do anything and everything related to installed software. You can list installed programs, remove programs, install package files, and more.
|
||||
|
||||
This low-level tool isn't always the most convenient to use, so typically there is a command line tool that will find the package in the distribution's central repositories and download and install it along with any dependencies using a single command. Finally, there is usually a graphical application that lets you select what you want with a mouse and click an 'install'' button.
|
||||

|
||||
|
||||
For Red Hat based distributions, which includes Fedora, CentOS, Scientific Linux, and more, the low-level tool is rpm. The high-level tool is called dnf (or yum on older systems). And the graphical installer is called PackageKit (Figure 2) and may appear as "Add/Remove Software" under System Administration.
|
||||

|
||||
|
||||
For Debian based distributions, which includes Debian, Ubuntu, Linux Mint, Elementary OS, and more, the low-level, command-line tool is dpkg. The high-level tool is called apt. The graphical tool to manage installed software on Ubuntu is Ubuntu Software (Figure 3). For Debian and Linux Mint, the graphical tool is called Synaptic, which can also be installed on Ubuntu.
|
||||
|
||||
You can also install a text-based graphical tool on Debian related distributions called aptitude. It is more powerful than Synaptic, and works even if you only have access to the command line. You can try that one if you want access to all the bells and whistles, though with more options, it is more complicated to use than Synaptic. Other distributions may have their own unique tools.
|
||||
|
||||
### Command Line
|
||||
|
||||
Online instructions for installing software on Linux usually describe commands to type in the command line. The instructions are usually easier to understand and can be followed without making a mistake by copying and pasting the command into your command line window. This is opposed to following instructions like, "open this menu, select this program, enter in this search pattern, click this tab, select this program, and click this button," which often get lost in translation.
|
||||
|
||||
Sometimes the Linux installation you are using doesn't have a graphical environment, so it's good to be familiar with installing software packages from the command line. Tables 1 and 2 a few common operations and their associated commands for both RPM and DPKG based systems.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Note that SUSE, which uses RPM like Redhat and Fedora, doesn't have dnf or yum. Instead, it uses a program called zypper for the high-level, command-line tool. Other distributions may have different tools as well, such as, pacman on Arch Linux or emerge on Gentoo. There are many package tools out there, so you may need to look up what works on your distribution.
|
||||
|
||||
These tips should give you a much better idea on how to install programs on your new Linux installation and a better idea how the various package methods on your Linux installation relate to one another.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux"][6]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/2018/3/migrating-linux-installing-software
|
||||
|
||||
作者:[JOHN BONESIO][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/johnbonesio
|
||||
[1]:https://www.linux.com/blog/learn/intro-to-linux/2017/10/migrating-linux-introduction
|
||||
[2]:https://www.linux.com/blog/learn/intro-to-linux/2017/11/migrating-linux-disks-files-and-filesystems
|
||||
[3]:https://www.linux.com/blog/learn/2017/12/migrating-linux-graphical-environments
|
||||
[4]:https://www.linux.com/blog/learn/2018/1/migrating-linux-command-line
|
||||
[5]:https://www.linux.com/blog/learn/2018/3/migrating-linux-using-sudo
|
||||
[6]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -0,0 +1,207 @@
|
||||
hankchow translating
|
||||
|
||||
How to use Ansible to patch systems and install applications
|
||||
======
|
||||
|
||||

|
||||
Have you ever wondered how to patch your systems, reboot, and continue working?
|
||||
|
||||
If so, you'll be interested in [Ansible][1] , a simple configuration management tool that can make some of the hardest work easy. For example, system administration tasks that can be complicated, take hours to complete, or have complex requirements for security.
|
||||
|
||||
In my experience, one of the hardest parts of being a sysadmin is patching systems. Every time you get a Common Vulnerabilities and Exposure (CVE) notification or Information Assurance Vulnerability Alert (IAVA) mandated by security, you have to kick into high gear to close the security gaps. (And, believe me, your security officer will hunt you down unless the vulnerabilities are patched.)
|
||||
|
||||
Ansible can reduce the time it takes to patch systems by running [packaging modules][2]. To demonstrate, let's use the [yum module][3] to update the system. Ansible can install, update, remove, or install from another location (e.g., `rpmbuild` from continuous integration/continuous development). Here is the task for updating the system:
|
||||
```
|
||||
- name: update the system
|
||||
|
||||
yum:
|
||||
|
||||
name: "*"
|
||||
|
||||
state: latest
|
||||
|
||||
```
|
||||
|
||||
In the first line, we give the task a meaningful `name` so we know what Ansible is doing. In the next line, the `yum module` updates the CentOS virtual machine (VM), then `name: "*"` tells yum to update everything, and, finally, `state: latest` updates to the latest RPM.
|
||||
|
||||
After updating the system, we need to restart and reconnect:
|
||||
```
|
||||
- name: restart system to reboot to newest kernel
|
||||
|
||||
shell: "sleep 5 && reboot"
|
||||
|
||||
async: 1
|
||||
|
||||
poll: 0
|
||||
|
||||
|
||||
|
||||
- name: wait for 10 seconds
|
||||
|
||||
pause:
|
||||
|
||||
seconds: 10
|
||||
|
||||
|
||||
|
||||
- name: wait for the system to reboot
|
||||
|
||||
wait_for_connection:
|
||||
|
||||
connect_timeout: 20
|
||||
|
||||
sleep: 5
|
||||
|
||||
delay: 5
|
||||
|
||||
timeout: 60
|
||||
|
||||
|
||||
|
||||
- name: install epel-release
|
||||
|
||||
yum:
|
||||
|
||||
name: epel-release
|
||||
|
||||
state: latest
|
||||
|
||||
```
|
||||
|
||||
The `shell module` puts the system to sleep for 5 seconds then reboots. We use `sleep` to prevent the connection from breaking, `async` to avoid timeout, and `poll` to fire & forget. We pause for 10 seconds to wait for the VM to come back and use `wait_for_connection` to connect back to the VM as soon as it can make a connection. Then we `install epel-release` to test the RPM installation. You can run this playbook multiple times to show the `idempotent`, and the only task that will show as changed is the reboot since we are using the `shell` module. You can use `changed_when: False` to ignore the change when using the `shell` module if you expect no actual changes.
|
||||
|
||||
So far we've learned how to update a system, restart the VM, reconnect, and install a RPM. Next we will install NGINX using the role in [Ansible Lightbulb][4].
|
||||
```
|
||||
- name: Ensure nginx packages are present
|
||||
|
||||
yum:
|
||||
|
||||
name: nginx, python-pip, python-devel, devel
|
||||
|
||||
state: present
|
||||
|
||||
notify: restart-nginx-service
|
||||
|
||||
|
||||
|
||||
- name: Ensure uwsgi package is present
|
||||
|
||||
pip:
|
||||
|
||||
name: uwsgi
|
||||
|
||||
state: present
|
||||
|
||||
notify: restart-nginx-service
|
||||
|
||||
|
||||
|
||||
- name: Ensure latest default.conf is present
|
||||
|
||||
template:
|
||||
|
||||
src: templates/nginx.conf.j2
|
||||
|
||||
dest: /etc/nginx/nginx.conf
|
||||
|
||||
backup: yes
|
||||
|
||||
notify: restart-nginx-service
|
||||
|
||||
|
||||
|
||||
- name: Ensure latest index.html is present
|
||||
|
||||
template:
|
||||
|
||||
src: templates/index.html.j2
|
||||
|
||||
dest: /usr/share/nginx/html/index.html
|
||||
|
||||
|
||||
|
||||
- name: Ensure nginx service is started and enabled
|
||||
|
||||
service:
|
||||
|
||||
name: nginx
|
||||
|
||||
state: started
|
||||
|
||||
enabled: yes
|
||||
|
||||
|
||||
|
||||
- name: Ensure proper response from localhost can be received
|
||||
|
||||
uri:
|
||||
|
||||
url: "http://localhost:80/"
|
||||
|
||||
return_content: yes
|
||||
|
||||
register: response
|
||||
|
||||
until: 'nginx_test_message in response.content'
|
||||
|
||||
retries: 10
|
||||
|
||||
delay: 1
|
||||
|
||||
```
|
||||
|
||||
And the handler that restarts the nginx service:
|
||||
```
|
||||
# handlers file for nginx-example
|
||||
|
||||
- name: restart-nginx-service
|
||||
|
||||
service:
|
||||
|
||||
name: nginx
|
||||
|
||||
state: restarted
|
||||
|
||||
```
|
||||
|
||||
In this role, we install the RPMs `nginx`, `python-pip`, `python-devel`, and `devel` and install `uwsgi` with PIP. Next, we use the `template` module to copy over the `nginx.conf` and `index.html` for the page to display. After that, we make sure the service is enabled on boot and started. Then we use the `uri` module to check the connection to the page.
|
||||
|
||||
Here is a playbook showing an example of updating, restarting, and installing an RPM. Then continue installing nginx. This can be done with any other roles/applications you want.
|
||||
```
|
||||
- hosts: all
|
||||
|
||||
roles:
|
||||
|
||||
- centos-update
|
||||
|
||||
- nginx-simple
|
||||
|
||||
```
|
||||
|
||||
Watch this demo video for more insight on the process.
|
||||
|
||||
[demo](https://asciinema.org/a/166437/embed?)
|
||||
|
||||
This was just a simple example of how to update, reboot, and continue. For simplicity, I added the packages without [variables][5]. Once you start working with a large number of hosts, you will need to change a few settings:
|
||||
|
||||
This is because on your production environment you might want to update one system at a time (not fire & forget) and actually wait a longer time for your system to reboot and continue.
|
||||
|
||||
For more ways to automate your work with this tool, take a look at the other [Ansible articles on Opensource.com][6].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/ansible-patch-systems
|
||||
|
||||
作者:[Jonathan Lozada De La Matta][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jlozadad
|
||||
[1]:https://www.ansible.com/overview/how-ansible-works
|
||||
[2]:https://docs.ansible.com/ansible/latest/list_of_packaging_modules.html
|
||||
[3]:https://docs.ansible.com/ansible/latest/yum_module.html
|
||||
[4]:https://github.com/ansible/lightbulb/tree/master/examples/nginx-role
|
||||
[5]:https://docs.ansible.com/ansible/latest/playbooks_variables.html
|
||||
[6]:https://opensource.com/tags/ansible
|
||||
@ -0,0 +1,318 @@
|
||||
Protecting Code Integrity with PGP — Part 6: Using PGP with Git
|
||||
======
|
||||
|
||||

|
||||
In this tutorial series, we're providing practical guidelines for using PGP, including basic concepts and generating and protecting your keys. If you missed the previous articles, you can catch up below. In this article, we look at Git's integration with PGP, starting with signed tags, then introducing signed commits, and finally adding support for signed pushes.
|
||||
|
||||
[Part 1: Basic Concepts and Tools][1]
|
||||
|
||||
[Part 2: Generating Your Master Key][2]
|
||||
|
||||
[Part 3: Generating PGP Subkeys][3]
|
||||
|
||||
[Part 4: Moving Your Master Key to Offline Storage][4]
|
||||
|
||||
[Part 5: Moving Subkeys to a Hardware Device][5]
|
||||
|
||||
One of the core features of Git is its decentralized nature -- once a repository is cloned to your system, you have full history of the project, including all of its tags, commits and branches. However, with hundreds of cloned repositories floating around, how does anyone verify that the repository you downloaded has not been tampered with by a malicious third party? You may have cloned it from GitHub or some other official-looking location, but what if someone had managed to trick you?
|
||||
|
||||
Or what happens if a backdoor is discovered in one of the projects you've worked on, and the "Author" line in the commit says it was done by you, while you're pretty sure you had [nothing to do with it][6]?
|
||||
|
||||
To address both of these issues, Git introduced PGP integration. Signed tags prove the repository integrity by assuring that its contents are exactly the same as on the workstation of the developer who created the tag, while signed commits make it nearly impossible for someone to impersonate you without having access to your PGP keys.
|
||||
|
||||
### Checklist
|
||||
|
||||
* Understand signed tags, commits, and pushes (ESSENTIAL)
|
||||
|
||||
* Configure git to use your key (ESSENTIAL)
|
||||
|
||||
* Learn how tag signing and verification works (ESSENTIAL)
|
||||
|
||||
* Configure git to always sign annotated tags (NICE)
|
||||
|
||||
* Learn how commit signing and verification works (ESSENTIAL)
|
||||
|
||||
* Configure git to always sign commits (NICE)
|
||||
|
||||
* Configure gpg-agent options (ESSENTIAL)
|
||||
|
||||
|
||||
|
||||
|
||||
### Considerations
|
||||
|
||||
Git implements multiple levels of integration with PGP, first starting with signed tags, then introducing signed commits, and finally adding support for signed pushes.
|
||||
|
||||
#### Understanding Git Hashes
|
||||
|
||||
Git is a complicated beast, but you need to know what a "hash" is in order to have a good grasp on how PGP integrates with it. We'll narrow it down to two kinds of hashes: tree hashes and commit hashes.
|
||||
|
||||
##### Tree hashes
|
||||
|
||||
Every time you commit a change to a repository, git records checksum hashes of all objects in it -- contents (blobs), directories (trees), file names and permissions, etc, for each subdirectory in the repository. It only does this for trees and blobs that have changed with each commit, so as not to re-checksum the entire tree unnecessarily if only a small part of it was touched.
|
||||
|
||||
Then it calculates and stores the checksum of the toplevel tree, which will inevitably be different if any part of the repository has changed.
|
||||
|
||||
##### Commit hashes
|
||||
|
||||
Once the tree hash has been created, git will calculate the commit hash, which will include the following information about the repository and the change being made:
|
||||
|
||||
* The checksum hash of the tree
|
||||
|
||||
* The checksum hash of the tree before the change (parent)
|
||||
|
||||
* Information about the author (name, email, time of authorship)
|
||||
|
||||
* Information about the committer (name, email, time of commit)
|
||||
|
||||
* The commit message
|
||||
|
||||
|
||||
|
||||
|
||||
##### Hashing function
|
||||
|
||||
At the time of writing, git still uses the SHA1 hashing mechanism to calculate checksums, though work is under way to transition to a stronger algorithm that is more resistant to collisions. Note, that git already includes collision avoidance routines, so it is believed that a successful collision attack against git remains impractical.
|
||||
|
||||
#### Annotated tags and tag signatures
|
||||
|
||||
Git tags allow developers to mark specific commits in the history of each git repository. Tags can be "lightweight" \-- more or less just a pointer at a specific commit, or they can be "annotated," which becomes its own object in the git tree. An annotated tag object contains all of the following information:
|
||||
|
||||
* The checksum hash of the commit being tagged
|
||||
|
||||
* The tag name
|
||||
|
||||
* Information about the tagger (name, email, time of tagging)
|
||||
|
||||
* The tag message
|
||||
|
||||
|
||||
|
||||
|
||||
A PGP-signed tag is simply an annotated tag with all these entries wrapped around in a PGP signature. When a developer signs their git tag, they effectively assure you of the following:
|
||||
|
||||
* Who they are (and why you should trust them)
|
||||
|
||||
* What the state of their repository was at the time of signing:
|
||||
|
||||
* The tag includes the hash of the commit
|
||||
|
||||
* The commit hash includes the hash of the toplevel tree
|
||||
|
||||
* Which includes hashes of all files, contents, and subtrees
|
||||
* It also includes all information about authorship
|
||||
|
||||
* Including exact times when changes were made
|
||||
|
||||
|
||||
|
||||
|
||||
When you clone a git repository and verify a signed tag, that gives you cryptographic assurance that all contents in the repository, including all of its history, are exactly the same as the contents of the repository on the developer's computer at the time of signing.
|
||||
|
||||
#### Signed commits
|
||||
|
||||
Signed commits are very similar to signed tags -- the contents of the commit object are PGP-signed instead of the contents of the tag object. A commit signature also gives you full verifiable information about the state of the developer's tree at the time the signature was made. Tag signatures and commit PGP signatures provide exact same security assurances about the repository and its entire history.
|
||||
|
||||
#### Signed pushes
|
||||
|
||||
This is included here for completeness' sake, since this functionality needs to be enabled on the server receiving the push before it does anything useful. As we saw above, PGP-signing a git object gives verifiable information about the developer's git tree, but not about their intent for that tree.
|
||||
|
||||
For example, you can be working on an experimental branch in your own git fork trying out a promising cool feature, but after you submit your work for review, someone finds a nasty bug in your code. Since your commits are properly signed, someone can take the branch containing your nasty bug and push it into master, introducing a vulnerability that was never intended to go into production. Since the commit is properly signed with your key, everything looks legitimate and your reputation is questioned when the bug is discovered.
|
||||
|
||||
Ability to require PGP-signatures during git push was added in order to certify the intent of the commit, and not merely verify its contents.
|
||||
|
||||
#### Configure git to use your PGP key
|
||||
|
||||
If you only have one secret key in your keyring, then you don't really need to do anything extra, as it becomes your default key.
|
||||
|
||||
However, if you happen to have multiple secret keys, you can tell git which key should be used ([fpr] is the fingerprint of your key):
|
||||
```
|
||||
$ git config --global user.signingKey [fpr]
|
||||
|
||||
```
|
||||
|
||||
NOTE: If you have a distinct gpg2 command, then you should tell git to always use it instead of the legacy gpg from version 1:
|
||||
```
|
||||
$ git config --global gpg.program gpg2
|
||||
|
||||
```
|
||||
|
||||
#### How to work with signed tags
|
||||
|
||||
To create a signed tag, simply pass the -s switch to the tag command:
|
||||
```
|
||||
$ git tag -s [tagname]
|
||||
|
||||
```
|
||||
|
||||
Our recommendation is to always sign git tags, as this allows other developers to ensure that the git repository they are working with has not been maliciously altered (e.g. in order to introduce backdoors).
|
||||
|
||||
##### How to verify signed tags
|
||||
|
||||
To verify a signed tag, simply use the verify-tag command:
|
||||
```
|
||||
$ git verify-tag [tagname]
|
||||
|
||||
```
|
||||
|
||||
If you are verifying someone else's git tag, then you will need to import their PGP key. Please refer to the "Trusted Team communication" document in the same repository for guidance on this topic.
|
||||
|
||||
##### Verifying at pull time
|
||||
|
||||
If you are pulling a tag from another fork of the project repository, git should automatically verify the signature at the tip you're pulling and show you the results during the merge operation:
|
||||
```
|
||||
$ git pull [url] tags/sometag
|
||||
|
||||
```
|
||||
|
||||
The merge message will contain something like this:
|
||||
```
|
||||
Merge tag 'sometag' of [url]
|
||||
|
||||
[Tag message]
|
||||
|
||||
# gpg: Signature made [...]
|
||||
# gpg: Good signature from [...]
|
||||
|
||||
```
|
||||
|
||||
#### Configure git to always sign annotated tags
|
||||
|
||||
Chances are, if you're creating an annotated tag, you'll want to sign it. To force git to always sign annotated tags, you can set a global configuration option:
|
||||
```
|
||||
$ git config --global tag.forceSignAnnotated true
|
||||
|
||||
```
|
||||
|
||||
Alternatively, you can just train your muscle memory to always pass the -s switch:
|
||||
```
|
||||
$ git tag -asm "Tag message" tagname
|
||||
|
||||
```
|
||||
|
||||
#### How to work with signed commits
|
||||
|
||||
It is easy to create signed commits, but it is much more difficult to incorporate them into your workflow. Many projects use signed commits as a sort of "Committed-by:" line equivalent that records code provenance -- the signatures are rarely verified by others except when tracking down project history. In a sense, signed commits are used for "tamper evidence," and not to "tamper-proof" the git workflow.
|
||||
|
||||
To create a signed commit, you just need to pass the -S flag to the git commit command (it's capital -S due to collision with another flag):
|
||||
```
|
||||
$ git commit -S
|
||||
|
||||
```
|
||||
|
||||
Our recommendation is to always sign commits and to require them of all project members, regardless of whether anyone is verifying them (that can always come at a later time).
|
||||
|
||||
##### How to verify signed commits
|
||||
|
||||
To verify a single commit you can use verify-commit:
|
||||
```
|
||||
$ git verify-commit [hash]
|
||||
|
||||
```
|
||||
|
||||
You can also look at repository logs and request that all commit signatures are verified and shown:
|
||||
```
|
||||
$ git log --pretty=short --show-signature
|
||||
|
||||
```
|
||||
|
||||
##### Verifying commits during git merge
|
||||
|
||||
If all members of your project sign their commits, you can enforce signature checking at merge time (and then sign the resulting merge commit itself using the -S flag):
|
||||
```
|
||||
$ git merge --verify-signatures -S merged-branch
|
||||
|
||||
```
|
||||
|
||||
Note, that the merge will fail if there is even one commit that is not signed or does not pass verification. As it is often the case, technology is the easy part -- the human side of the equation is what makes adopting strict commit signing for your project difficult.
|
||||
|
||||
##### If your project uses mailing lists for patch management
|
||||
|
||||
If your project uses a mailing list for submitting and processing patches, then there is little use in signing commits, because all signature information will be lost when sent through that medium. It is still useful to sign your commits, just so others can refer to your publicly hosted git trees for reference, but the upstream project receiving your patches will not be able to verify them directly with git.
|
||||
|
||||
You can still sign the emails containing the patches, though.
|
||||
|
||||
#### Configure git to always sign commits
|
||||
|
||||
You can tell git to always sign commits:
|
||||
```
|
||||
git config --global commit.gpgSign true
|
||||
|
||||
```
|
||||
|
||||
Or you can train your muscle memory to always pass the -S flag to all git commit operations (this includes --amend).
|
||||
|
||||
#### Configure gpg-agent options
|
||||
|
||||
The GnuPG agent is a helper tool that will start automatically whenever you use the gpg command and run in the background with the purpose of caching the private key passphrase. This way you only have to unlock your key once to use it repeatedly (very handy if you need to sign a bunch of git operations in an automated script without having to continuously retype your passphrase).
|
||||
|
||||
There are two options you should know in order to tweak when the passphrase should be expired from cache:
|
||||
|
||||
* default-cache-ttl (seconds): If you use the same key again before the time-to-live expires, the countdown will reset for another period. The default is 600 (10 minutes).
|
||||
|
||||
* max-cache-ttl (seconds): Regardless of how recently you've used the key since initial passphrase entry, if the maximum time-to-live countdown expires, you'll have to enter the passphrase again. The default is 30 minutes.
|
||||
|
||||
|
||||
|
||||
|
||||
If you find either of these defaults too short (or too long), you can edit your ~/.gnupg/gpg-agent.conf file to set your own values:
|
||||
```
|
||||
# set to 30 minutes for regular ttl, and 2 hours for max ttl
|
||||
default-cache-ttl 1800
|
||||
max-cache-ttl 7200
|
||||
|
||||
```
|
||||
|
||||
##### Bonus: Using gpg-agent with ssh
|
||||
|
||||
If you've created an [A] (Authentication) key and moved it to the smartcard, you can use it with ssh for adding 2-factor authentication for your ssh sessions. You just need to tell your environment to use the correct socket file for talking to the agent.
|
||||
|
||||
First, add the following to your ~/.gnupg/gpg-agent.conf:
|
||||
```
|
||||
enable-ssh-support
|
||||
|
||||
```
|
||||
|
||||
Then, add this to your .bashrc:
|
||||
```
|
||||
export SSH_AUTH_SOCK=$(gpgconf --list-dirs agent-ssh-socket)
|
||||
|
||||
```
|
||||
|
||||
You will need to kill the existing gpg-agent process and start a new login session for the changes to take effect:
|
||||
```
|
||||
$ killall gpg-agent
|
||||
$ bash
|
||||
$ ssh-add -L
|
||||
|
||||
```
|
||||
|
||||
The last command should list the SSH representation of your PGP Auth key (the comment should say cardno:XXXXXXXX at the end to indicate it's coming from the smartcard).
|
||||
|
||||
To enable key-based logins with ssh, just add the ssh-add -L output to ~/.ssh/authorized_keys on remote systems you log in to. Congratulations, you've just made your ssh credentials extremely difficult to steal.
|
||||
|
||||
As a bonus, you can get other people's PGP-based ssh keys from public keyservers, should you need to grant them ssh access to anything:
|
||||
```
|
||||
$ gpg --export-ssh-key [keyid]
|
||||
|
||||
```
|
||||
|
||||
This can come in super handy if you need to allow developers access to git repositories over ssh. Next time, we'll provide tips for protecting your email accounts as well as your PGP keys.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/pgp/2018/3/protecting-code-integrity-pgp-part-6-using-pgp-git
|
||||
|
||||
作者:[KONSTANTIN RYABITSEV][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/mricon
|
||||
[1]:https://www.linux.com/blog/learn/2018/2/protecting-code-integrity-pgp-part-1-basic-pgp-concepts-and-tools
|
||||
[2]:https://www.linux.com/blog/learn/pgp/2018/2/protecting-code-integrity-pgp-part-2-generating-and-protecting-your-master-pgp-key
|
||||
[3]:https://www.linux.com/blog/learn/pgp/2018/2/protecting-code-integrity-pgp-part-3-generating-pgp-subkeys
|
||||
[4]:https://www.linux.com/blog/learn/pgp/2018/3/protecting-code-integrity-pgp-part-4-moving-your-master-key-offline-storage
|
||||
[5]:https://www.linux.com/blog/learn/pgp/2018/3/protecting-code-integrity-pgp-part-5-moving-subkeys-hardware-device
|
||||
[6]:https://github.com/jayphelps/git-blame-someone-else
|
||||
@ -0,0 +1,411 @@
|
||||
The Command line Personal Assistant For Your Linux System
|
||||
======
|
||||
|
||||

|
||||
A while ago, we wrote about a command line virtual assistant named [**“Betty”**][1]. Today, I stumbled upon a similar utility called **“Yoda”**. Yoda is a command line personal assistant who can help you to do some trivial tasks in Linux. It is a free, open source application written in Python. In this guide, we will see how to install and use Yoda in GNU/Linux.
|
||||
|
||||
### Installing Yoda, the command line personal assistant
|
||||
|
||||
Yoda requires **Python 2** and PIP. If PIP is not installed in your Linux box, refer the following guide to install it. Just make sure you have installed **python2-pip.** Yoda may not support Python 3.
|
||||
|
||||
**Note:** I recommend you to try Yoda under a virtual environment. Not just Yoda, always try any Python applications in a virtual environment, so they won’t interfere with globally installed packages. You can setup a virtual environment as described in the above link under the section titled “Creating Virtual Environments”.
|
||||
|
||||
Once you have installed pip on your system, git clone Yoda repository.
|
||||
```
|
||||
$ git clone https://github.com/yoda-pa/yoda
|
||||
|
||||
```
|
||||
|
||||
The above command will create a directory named “yoda” in your current working directory and clone all contents in it. Go to the Yoda directory:
|
||||
```
|
||||
$ cd yoda/
|
||||
|
||||
```
|
||||
|
||||
Run the following command to install Yoda application.
|
||||
```
|
||||
$ pip install .
|
||||
|
||||
```
|
||||
|
||||
Please note the dot (.) at the end. Now, all required packages will be downloaded and installed.
|
||||
|
||||
### Configure Yoda
|
||||
|
||||
First, setup configuration to save your information on your local system.
|
||||
|
||||
To do so, run:
|
||||
```
|
||||
$ yoda setup new
|
||||
|
||||
```
|
||||
|
||||
Answer the following questions:
|
||||
```
|
||||
Enter your name:
|
||||
Senthil Kumar
|
||||
What's your email id?
|
||||
[email protected]
|
||||
What's your github username?
|
||||
sk
|
||||
Enter your github password:
|
||||
Password:
|
||||
Where shall your config be stored? (Default: ~/.yoda/)
|
||||
|
||||
A configuration file already exists. Are you sure you want to overwrite it? (y/n)
|
||||
y
|
||||
|
||||
```
|
||||
|
||||
Your password is saved in the config file after encrypting, so don’t worry about it.
|
||||
|
||||
To check the current configuration, run:
|
||||
```
|
||||
$ yoda setup check
|
||||
|
||||
```
|
||||
|
||||
You will see an output something like below.
|
||||
```
|
||||
Name: Senthil Kumar
|
||||
Email: [email protected]
|
||||
Github username: sk
|
||||
|
||||
```
|
||||
|
||||
By default, your information is stored in **~/.yoda** directory.
|
||||
|
||||
To delete the existing configuration, do:
|
||||
```
|
||||
$ yoda setup delete
|
||||
|
||||
```
|
||||
|
||||
### Usage
|
||||
|
||||
Yoda contains a simple chat bot. You can interact with it using **chat** command like below.
|
||||
```
|
||||
$ yoda chat who are you
|
||||
|
||||
```
|
||||
|
||||
Sample output:
|
||||
```
|
||||
Yoda speaks:
|
||||
I'm a virtual agent
|
||||
|
||||
$ yoda chat how are you
|
||||
Yoda speaks:
|
||||
I'm doing very well. Thanks!
|
||||
|
||||
```
|
||||
|
||||
Here is the list of things we can do with Yoda:
|
||||
|
||||
**Test Internet speed**
|
||||
|
||||
Let us ask Yoda about the Internet speed. To do so, run:
|
||||
```
|
||||
$ yoda speedtest
|
||||
Speed test results:
|
||||
Ping: 108.45 ms
|
||||
Download: 0.75 Mb/s
|
||||
Upload: 1.95 Mb/s
|
||||
|
||||
```
|
||||
|
||||
**Shorten and expand URLs**
|
||||
|
||||
Yoda also helps to shorten any URL.
|
||||
```
|
||||
$ yoda url shorten https://www.ostechnix.com/
|
||||
Here's your shortened URL:
|
||||
https://goo.gl/hVW6U0
|
||||
|
||||
```
|
||||
|
||||
To expand the shortened URL:
|
||||
```
|
||||
$ yoda url expand https://goo.gl/hVW6U0
|
||||
Here's your original URL:
|
||||
https://www.ostechnix.com/
|
||||
|
||||
```
|
||||
|
||||
**Read Hacker News**
|
||||
|
||||
I am regular visitor of Hacker News website. If you’re anything like me, you can read the news from Hacker News website using Yoda like below.
|
||||
```
|
||||
$ yoda hackernews
|
||||
News-- 1/513
|
||||
|
||||
Title-- Show HN: a Yelp for iOS developers
|
||||
Description-- I came up with this idea "a Yelp for developers" when talking with my colleagues. My hypothesis is that, it would be very helpful if we know more about a library before choosing to use it. It's similar to that we want to know more about a restaurant by checki…
|
||||
url-- https://news.ycombinator.com/item?id=16636071
|
||||
|
||||
Continue? [press-"y"]
|
||||
|
||||
```
|
||||
|
||||
Yoda will display one item at a time. To read the next news, simply type “y” and hit ENTER.
|
||||
|
||||
**Manage personal diaries**
|
||||
|
||||
We can also maintain a personal diary to note important events.
|
||||
|
||||
Create a new diary using command:
|
||||
```
|
||||
$ yoda diary nn
|
||||
Input your entry for note:
|
||||
Today I learned about Yoda
|
||||
|
||||
```
|
||||
|
||||
To create a new note, run the above command again.
|
||||
|
||||
To view all notes:
|
||||
```
|
||||
$ yoda diary notes
|
||||
Today's notes:
|
||||
----------------
|
||||
Time | Note
|
||||
--------|-----
|
||||
16:41:41| Today I learned about Yoda
|
||||
|
||||
```
|
||||
|
||||
Not just notes, Yoda can also help you to create tasks.
|
||||
|
||||
To create a new task, run:
|
||||
```
|
||||
$ yoda diary nt
|
||||
Input your entry for task:
|
||||
Write an article about Yoda and publish it on OSTechNix
|
||||
|
||||
```
|
||||
|
||||
To view the list of tasks, run:
|
||||
```
|
||||
$ yoda diary tasks
|
||||
Today's agenda:
|
||||
----------------
|
||||
Status | Time | Text
|
||||
-------|---------|-----
|
||||
O | 16:44:03: Write an article about Yoda and publish it on OSTechNix
|
||||
----------------
|
||||
|
||||
Summary:
|
||||
----------------
|
||||
Incomplete tasks: 1
|
||||
Completed tasks: 0
|
||||
|
||||
```
|
||||
|
||||
As you see above, I have one incomplete task. To mark it as completed, run the following command and type the completed task serial number and hit ENTER:
|
||||
```
|
||||
$ yoda diary ct
|
||||
Today's agenda:
|
||||
----------------
|
||||
Number | Time | Task
|
||||
-------|---------|-----
|
||||
1 | 16:44:03: Write an article about Yoda and publish it on OSTechNix
|
||||
Enter the task number that you would like to set as completed
|
||||
1
|
||||
|
||||
```
|
||||
|
||||
You can analyze the current month’s tasks at any time using command:
|
||||
```
|
||||
$ yoda diary analyze
|
||||
Percentage of incomplete task : 0
|
||||
Percentage of complete task : 100
|
||||
Frequency of adding task (Task/Day) : 3
|
||||
|
||||
```
|
||||
|
||||
Sometimes, you may want to maintain a profile about a person you love, admire.
|
||||
|
||||
**Take notes about loved ones**
|
||||
|
||||
First, you need to setup configuration to store your friend’s details. To do so, run:
|
||||
```
|
||||
$ yoda love setup
|
||||
|
||||
```
|
||||
|
||||
Enter the details of your friend:
|
||||
```
|
||||
Enter their name:
|
||||
Abdul Kalam
|
||||
Enter sex(M/F):
|
||||
M
|
||||
Where do they live?
|
||||
Rameswaram
|
||||
|
||||
```
|
||||
|
||||
To view the details of the person, run:
|
||||
```
|
||||
$ yoda love status
|
||||
{'place': 'Rameswaram', 'name': 'Abdul Kalam', 'sex': 'M'}
|
||||
|
||||
```
|
||||
|
||||
To add the birthday of your love one:
|
||||
```
|
||||
$ yoda love addbirth
|
||||
Enter birthday
|
||||
15-10-1931
|
||||
|
||||
```
|
||||
|
||||
To view the birth date:
|
||||
```
|
||||
$ yoda love showbirth
|
||||
Birthday is 15-10-1931
|
||||
|
||||
```
|
||||
|
||||
You could even add notes about that person:
|
||||
```
|
||||
$ yoda love note
|
||||
Avul Pakir Jainulabdeen Abdul Kalam better known as A. P. J. Abdul Kalam, was the 11th President of India from 2002 to 2007.
|
||||
|
||||
```
|
||||
|
||||
You can view the notes using command:
|
||||
```
|
||||
$ yoda love notes
|
||||
Notes:
|
||||
1: Avul Pakir Jainulabdeen Abdul Kalam better known as A. P. J. Abdul Kalam, was the 11th President of India from 2002 to 2007.
|
||||
|
||||
```
|
||||
|
||||
You can also write the things that person like:
|
||||
```
|
||||
$ yoda love like
|
||||
Add things they like
|
||||
Physics, Aerospace
|
||||
Want to add more things they like? [y/n]
|
||||
n
|
||||
|
||||
```
|
||||
|
||||
To view the things they like, run:
|
||||
```
|
||||
$ yoda love likes
|
||||
Likes:
|
||||
1: Physics, Aerospace
|
||||
|
||||
```
|
||||
|
||||
**Tracking money expenses**
|
||||
|
||||
You don’t need a separate tool to maintain your financial expenditure. Yoda got your back.
|
||||
|
||||
First, setup configuration for your money expenses using command:
|
||||
```
|
||||
$ yoda money setup
|
||||
|
||||
```
|
||||
|
||||
Enter your currency code and the initial amount:
|
||||
```
|
||||
Enter default currency code:
|
||||
INR
|
||||
{u'USD': 0.015338, u'IDR': 211.06, u'BGN': 0.024436, u'ISK': 1.5305, u'ILS': 0.053402, u'GBP': 0.010959, u'DKK': 0.093063, u'CAD': 0.020041, u'MXN': 0.28748, u'HUF': 3.8873, u'RON': 0.058302, u'MYR': 0.060086, u'SEK': 0.12564, u'SGD': 0.020208, u'HKD': 0.12031, u'AUD': 0.019908, u'CHF': 0.014644, u'KRW': 16.429, u'CNY': 0.097135, u'TRY': 0.06027, u'HRK': 0.092986, u'NZD': 0.021289, u'THB': 0.47854, u'EUR': 0.012494, u'NOK': 0.11852, u'RUB': 0.88518, u'JPY': 1.6332, u'CZK': 0.31764, u'BRL': 0.050489, u'PLN': 0.052822, u'PHP': 0.79871, u'ZAR': 0.1834}
|
||||
₹
|
||||
Indian rupee
|
||||
Enter initial amount:
|
||||
10000
|
||||
|
||||
```
|
||||
|
||||
To view the money configuration, just run:``
|
||||
```
|
||||
$ yoda money status
|
||||
{'initial_money': 10000, 'currency_code': 'INR'}
|
||||
|
||||
```
|
||||
|
||||
Let us say you bought a book that costs 250 INR. To add this expense, run:
|
||||
```
|
||||
$ yoda money exp
|
||||
Spend 250 INR on books
|
||||
output:
|
||||
|
||||
```
|
||||
|
||||
To view the expenses, run:
|
||||
```
|
||||
$ yoda money exps
|
||||
2018-03-21 17:12:31 INR 250 books
|
||||
|
||||
```
|
||||
|
||||
**Creating Idea lists**
|
||||
|
||||
To create a new idea:
|
||||
```
|
||||
$ yoda ideas add --task <task_name> --inside <project_name>
|
||||
|
||||
```
|
||||
|
||||
List the ideas:
|
||||
```
|
||||
$ yoda ideas show
|
||||
|
||||
```
|
||||
|
||||
To remove a idea from the project:
|
||||
```
|
||||
$ yoda ideas remove --task <task_name> --inside <project_name>
|
||||
|
||||
```
|
||||
|
||||
To remove the idea completely, run:
|
||||
```
|
||||
$ yoda ideas remove --project <project_name>
|
||||
|
||||
```
|
||||
|
||||
**Learning English Vocabulary**
|
||||
|
||||
Yoda helps you to learn random English words and track your learning progress.
|
||||
|
||||
To learn a new word, type:
|
||||
```
|
||||
$ yoda vocabulary word
|
||||
|
||||
```
|
||||
|
||||
It will display a random word. Press ENTER to display the meaning of the word. Again, Yoda asks you if you already know the meaning of the word. If you know it already, type “yes”. If you don’t know, type “no”. This can help you to track your progress. Use the following command to know your progress.
|
||||
```
|
||||
$ yoda vocabulary accuracy
|
||||
|
||||
```
|
||||
|
||||
Also, Yoda can help you to do few other things like finding the definition of a word and creating flashcards to easily learn anything. For more details and list of available options, refer the help section.
|
||||
```
|
||||
$ yoda --help
|
||||
|
||||
```
|
||||
|
||||
More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/yoda-the-command-line-personal-assistant-for-your-linux-system/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/betty-siri-like-commandline-virtual-assistant-linux/
|
||||
@ -0,0 +1,113 @@
|
||||
计算机系统的进化论
|
||||
======
|
||||
纵观现代计算机的历史,从与系统的交互方式方面,可以划分为数个进化阶段。而我更倾向于将之归类为以下几个阶段:
|
||||
|
||||
1. 数字系统
|
||||
2. 专用应用系统
|
||||
3. 应用中心系统
|
||||
4. 信息中心系统
|
||||
5. 无应用系统
|
||||
|
||||
|
||||
|
||||
下面我们详细聊聊这几种分类。
|
||||
|
||||
### 数字系统
|
||||
|
||||
在我看来,[ 早期计算机 ][1],只被设计用来处理数字。它们能够加,减,乘,除。在它们中有一些能够运行像是微分和积分之类的更复杂的数学操作。
|
||||
|
||||
当然,如果你把字符映射成数字,它们也可以计算字符串。但这多少有点“数字的创造性使用”的意思,而不是直接处理各种信息。
|
||||
|
||||
### 专用应用系统
|
||||
|
||||
对于更高层级的问题,纯粹的数字系统是不够的。专用应用系统被开发用来处理单一任务。它们和数字系统十分相似,但是,它们拥有足够的复杂数字计算能力。这些系统能够完成十分明确的高层级任务,像调度问题的相关计算或者其他优化问题。
|
||||
|
||||
这类系统为单一目的而搭建,它们解决的是单一明确的问题。
|
||||
|
||||
### 应用中心系统
|
||||
|
||||
应用中心系统是第一个真正的通用系统。它们的主要使用风格很像专用应用系统,但是它们拥有以时间片模式(一个接一个)或以多任务模式(多应用同时)运行的多个应用程序。
|
||||
|
||||
上世纪 70 年代的[ 早期的个人电脑 ][3]是第一种受大量人们欢迎的应用中心系统。
|
||||
|
||||
如今的现在操作系统 —— Windows , macOS , 大多数 GNU/Linux 桌面环境 —— 一直遵循相同的法则。
|
||||
|
||||
当然,应用中心系统还可以再细分为两种子类:
|
||||
|
||||
1. 紧密型应用中心系统
|
||||
2. 松散型应用中心系统
|
||||
|
||||
|
||||
|
||||
精密型应用中心系统像是 [Windows 3.1][4] (拥有程序管理器和文件管理器)或者甚至 [ Windows 95 ][5] 的最初版本都没有预定义文件夹层次。用户启动文本处理程序(像 [ WinWord ][6])并且把文件保存在 WinWord 的程序文件夹中。在使用表格处理程序的时候,又把文件保存在表格处理工具的程序文件夹中。诸如此类。用户几乎不创建自己的文件层次结构,可能由于此举的不方便,用户单方面的懒惰,或者他们认为根本没有必要。那时,每个用户拥有几十个至多几百个文件。
|
||||
|
||||
为了访问文件中的信息,用户常常先打开一个应用程序,然后通过程序中的“文件/打开”功能来获取处理过的数据文件。
|
||||
|
||||
在 Windows 平台的[ Windows 95][5] SP2 中,«[ 我的文档 ][7]»首次被使用。有了这样一个文件层次结构的样板,应用设计者开始把 «[我的文档][7]» 作为程序的默认 保存 / 打开 目录,抛弃了原来将软件产品安装目录作为默认目录的做法。这样一来,用户渐渐适应了这种模式,并且开始自己维护文件夹层次。
|
||||
|
||||
松散型应用中心系统(通过文件管理器来提取文件)应用而生。在这种系统下,当打开一个文件的时候,操作系统会自动启动与之相关的应用程序。这是一次小而精妙的用法转变。这种应用中心系统的用法模式一直是个人电脑的主要用法模式。
|
||||
|
||||
然而,这种模式有很多的缺点。例如,对于一个给定的项目,为了防止数据提取出现问题,需要维护一个包含所有相关文件的严格文件夹层次结构。不幸的是,人们并不总能这样做。更进一步说,[ 这种模式不能很好的扩展 ][8]。 桌面搜索引擎和高级数据组织工具(像[ tagstore ][9])可以起到一点改善作用。正如研究显示的那样,只有一少部分人正在使用那些高级文件提取工具。大多数的用户不使用替代提取工具或者辅助提取技术在文件系统中寻找文件。
|
||||
|
||||
### 信息中心系统
|
||||
|
||||
解决上述问题的可行办法之一就是从应用中心系统转换到信息中心系统。
|
||||
|
||||
信息中心系统将项目的所有信息联合起来,放在一个地方,放在同一个应用程序里。
|
||||
因此,我们再也不需要计算项目预算时,打开表格处理程序;写工程报告时,打开文本处理程序;处理图片文件时,又打开另一个工具。
|
||||
|
||||
上个月的预算情况在客户会议笔记的右下方,客户会议笔记又在画板的右下方,而画板又在另一些要去完成的任务的右下方。在各个层之间没有文件或者应用程序来回切换的麻烦。
|
||||
|
||||
早期,IBM [ OS/2 ][10], Microsoft [ OLE ][11] 和 [NeXT][12] 都做过类似的尝试。但都由于各种原因没有取得重大成功。从 [ Plan 9][14] 发展而来的 [ACme][13] 是一个令人兴奋的信息中心环境。它在一个应用程序中包含了多种应用程序。但是相比 Windows 和 GNU/Linux 而言,它从不是一个值得注意的系统发行版(即使在系统接口级别)。
|
||||
|
||||
信息中心系统的现代形式是高级 [ 个人 wikis ][16](像 [ TheBrain ][17]和[ Microsoft OneNote ][18])。
|
||||
|
||||
我选择的个人工具是带 [Org-mode][19] 扩展的 [GNU/Emacs][20]。在用电脑的时候,我几乎不能没有 Org-mode 。为了访问外部数据资源,我创建了一个可以将多种数据导入 Org-mode 的插件 —— [Memacs][20] 。我喜欢将表格数据计算放到日程任务的右下方,然后是行内图片,内部和外部链接,等等。它是一个真正的用户不用必须切换程序或者切换严格层次文件系统文件夹的信息中心系统。同时,用简单的或高级的标签也可以进行多分类。一个命令可以派生多种视图。比如,一个视图有日历,待办事项。另一个视图是租借事宜。等等。它对 Org-mode 用户没有限制。只有你想不到,没有它做不到。
|
||||
|
||||
进化结束了吗? 当然没有。
|
||||
|
||||
### 无应用系统
|
||||
|
||||
我能想到这样一类操作系统,我称之为无应用系统。在下一步的发展中,系统将不需要单域应用程序,即使它们能和 Org-mode 一样出色。计算机直接提供一个处理信息和使用功能的友好用户接口,而不通过文件和程序。甚至连传统的操作系统也不需要。
|
||||
|
||||
无应用系统也可能和 [人工智能][21] 联系起来。把它想象成 [2001太空漫游][23] 中的 [HAL 9000][22] 和星际迷航中的 [LCARS][24]一类的东西就可以了。
|
||||
|
||||
从基于应用的,基于供应商的软件文化到无应用系统的转化让人很难相信。 或许,缓慢但却不断发展的开源环境,可以使一个由各种各样组织和人们贡献的真正无应用环境成型。
|
||||
|
||||
信息和提取、操作信息的功能,这是系统应该有的,同时也是我们所需要的。其他的东西仅仅是为了使我们不至于分散注意力。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://karl-voit.at/2017/02/10/evolution-of-systems/
|
||||
|
||||
作者:[Karl Voit][a]
|
||||
译者:[lontow](https://github.com/lontow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://karl-voit.at
|
||||
[1]:https://en.wikipedia.org/wiki/History_of_computing_hardware
|
||||
[2]:https://en.wikipedia.org/wiki/String_%2528computer_science%2529
|
||||
[3]:https://en.wikipedia.org/wiki/Xerox_Alto
|
||||
[4]:https://en.wikipedia.org/wiki/Windows_3.1x
|
||||
[5]:https://en.wikipedia.org/wiki/Windows_95
|
||||
[6]:https://en.wikipedia.org/wiki/Microsoft_Word
|
||||
[7]:https://en.wikipedia.org/wiki/My_Documents
|
||||
[8]:http://karl-voit.at/tagstore/downloads/Voit2012b.pdf
|
||||
[9]:http://karl-voit.at/tagstore/
|
||||
[10]:https://en.wikipedia.org/wiki/OS/2
|
||||
[11]:https://en.wikipedia.org/wiki/Object_Linking_and_Embedding
|
||||
[12]:https://en.wikipedia.org/wiki/NeXT
|
||||
[13]:https://en.wikipedia.org/wiki/Acme_%2528text_editor%2529
|
||||
[14]:https://en.wikipedia.org/wiki/Plan_9_from_Bell_Labs
|
||||
[15]:https://en.wikipedia.org/wiki/List_of_Plan_9_applications
|
||||
[16]:https://en.wikipedia.org/wiki/Personal_wiki
|
||||
[17]:https://en.wikipedia.org/wiki/TheBrain
|
||||
[18]:https://en.wikipedia.org/wiki/Microsoft_OneNote
|
||||
[19]:../../../../tags/emacs
|
||||
[20]:https://github.com/novoid/Memacs
|
||||
[21]:https://en.wikipedia.org/wiki/Artificial_intelligence
|
||||
[22]:https://en.wikipedia.org/wiki/HAL_9000
|
||||
[23]:https://en.wikipedia.org/wiki/2001:_A_Space_Odyssey
|
||||
[24]:https://en.wikipedia.org/wiki/LCARS
|
||||
104
translated/talk/20180201 How I coined the term open source.md
Normal file
104
translated/talk/20180201 How I coined the term open source.md
Normal file
@ -0,0 +1,104 @@
|
||||
[fuzheng1998 translating]
|
||||
我是如何创造“开源”这个词的
|
||||
============================================================
|
||||
|
||||
### Christine Peterson 最终公开讲述了二十年前那决定命运的一天。
|
||||
|
||||

|
||||
图片来自: opensource.com
|
||||
|
||||
几天后, 2 月 3 日, 术语“[开源软件][6]”创立 20 周年的纪念日即将到来。由于开源软件渐受欢迎并且为这个时代强有力的重要变革提供动力,我们仔细反思了它的初生到崛起。
|
||||
|
||||
我是 “开源软件” 这个词的始作俑者,它是我在前瞻技术协会(Foresight Institute)担任执行董事时想出的。并非向上面的一个程序开发者一样,我感谢 Linux 程序员 Todd Anderson 对这个术语的支持并将它提交小组讨论。
|
||||
|
||||
这是我对于它如何想到的,如何提出的,以及后续影响的记叙。当然,还有一些有关该术语的记叙,例如 Eric Raymond 和 Richard Stallman 写的,而我的,则写于 2006 年 1 月 2 日。
|
||||
|
||||
直到今天,它终于公诸于世。
|
||||
|
||||
* * *
|
||||
|
||||
推行术语“开源软件”是特地为了这个领域让新手和商业人士更加易懂,它的推广被认为对于更大的用户社区很有必要。早期称号的问题是,“自由软件” 并非有政治含义,但是那对于新手来说貌似对于价格的关注令人感到心烦意乱。一个术语需要聚焦于关键的源代码而且不会被立即把概念跟那些新东西混淆。一个恰好想出并且满足这些要求的第一个术语被快速接受:开源(open source)。
|
||||
|
||||
这个术语很长一段时间被用在“情报”(即间谍活动)的背景下,但据我所知,1998 年以前软件领域使用该术语尚未得到证实。下面这个就是讲述了术语“开源软件”如何流行起来并且变成了一项产业和一场运动名称的故事。
|
||||
|
||||
### 计算机安全会议
|
||||
|
||||
在 1997 年的晚些时候,为期一周的会议将被在前瞻技术协会(Foresight Insttitue) 举行来讨论计算机安全问题。这个协会是一个非盈利性智库,它专注于纳米技术和人工智能,并且认为软件安全是二者的安全性以及可靠性的核心。我们在那确定了自由软件是一个改进软件安全可靠性且具有发展前景的方法并将寻找推动它的方式。 对自由软件的兴趣开始在编程社区外开始增长,而且越来越清晰,一个改变世界的机会正在来临。然而,该怎么做我们并不清楚,因为我们当时正在摸索中。
|
||||
|
||||
在这些会议中,我们讨论了一些由于使人迷惑不解的因素而采用一个新术语的必要性。观点主要有以下:对于那些新接触“自由软件”的人把 "free" 当成了价格上的 “免费” 。老资格的成员们开始解释,通常像下面所说的:“我们的意思是自由的,而不是免费啤酒上的。"在这个点子上,一个软件方面的讨论变成了一个关于酒精价格的讨论。问题不在于解释不了含义——问题是重要概念的名称不应该使新手们感到困惑。所以需要一个更清晰的术语了。关于自由软件术语并没有政治上的问题;问题是缺乏对新概念的认识。
|
||||
|
||||
### 网景发布
|
||||
|
||||
1998 年 2 月 2 日,Eric Raymond 抵达访问网景并与它一起计划采用免费软件样式的许可证发布浏览器代码。我们那晚在前瞻位于罗斯阿尔托斯(Los Altos)的办公室制定了策略并改进了我们的要旨。除了 Eric 和我,活跃的参与者还有 Brian Behlendorf,Michael Tiemann,Todd Anderson,Mark S. Miller and Ka-Ping Yee。但在那次会议上,这个领域仍然被描述成“自由软件”,或者用 Brian 的话说, 叫“可获得源代码的” 软件。
|
||||
|
||||
在这个镇上,Eric 把前瞻协会(Foresight) 作为行动的大本营。他一开始访问行程,他就被几个网景法律和市场部门的员工通电话。当他挂电话后,我被要求带着电话跟他们——一男一女,可能是 Mitchell Baker——这样我才能谈论对于新术语的需求。他们原则上是立即同意了,但详细条款并未达成协议。
|
||||
|
||||
在那周的会议中,我仍然专注于起一个更好的名字并提出术语 “开源软件”。 虽然那不是完美的,但我觉得足够好了。我依靠至少另外四个人运营这个项目:Eric Drexler、Mark Miller,以及 Todd Anderson 和他这样的人,然而一个从事市场公关的朋友觉得术语 “open” 被滥用了并且相信我们能做更好再说。理论上它是对的,可我想不出更好的了,所以我想尝试并推广它。 事后一想我应该直接向 Eric Raymond 提案,但在那时我并不是很了解他,所以我采取了间接的策略。
|
||||
|
||||
Todd 强烈同意需要新的术语并提供协助推广它。这很有帮助,因为作为一个非编程人员,我在自由软件社区的影响力很弱。我从事的纳米技术是一个加分项,但不足以让我认真地接受自由软件问题的工作。作为一个Linux程序员,Todd 将会更仔细地聆听它。
|
||||
|
||||
### 关键的会议
|
||||
|
||||
那周之后,1998 年的 2 月 5 日,一伙人在 VA research 进行头脑风暴商量对策。与会者——除了 Eric Raymond,Todd和我之外,还有 Larry Augustin,Sam Ockman,还有 Jon“maddog”Hall 的电话。
|
||||
|
||||
会议的主要议题是推广策略,特别是要接洽的公司。 我几乎没说什么,而是在寻找机会推广已经提交讨论的术语。我觉得突然脱口而出那句话没什么用,“你们技术人员应当开始讨论我的新术语了。”他们大多数与会者不认识我,而且据我所知,他们可能甚至不同意对新术语的急切需求,或者是某种渴望。
|
||||
|
||||
幸运的是,Todd 是明智的。他没有主张社区应该用哪个特定的术语,而是间接地做了一些事——一件和社区里有强烈意愿的人做的明智之举。他简单地在其他话题中使用那个术语——把他放进对话里看看会发生什么。我警觉起来,希望得到一个答复,但是起初什么也没有。讨论继续进行原来的话题。似乎只有他和我注意了术语的使用。
|
||||
|
||||
不仅如此——模因演化(人类学术语)在起作用。几分钟后,另一个人明显地,没有提醒地,在仍然进行话题讨论而没说术语的情况下,用了这个术语。Todd 和我面面相觑对视:是的我们都注意到了发生的事。我很激动——它起作用了!但我保持了安静:我在小组中仍然地位不高。可能有些人都奇怪为什么 Eric 会最终邀请我。
|
||||
|
||||
临近会议尾声,可能是 Todd or Eric,[术语问题][8] 被明确提出。Maddog 提及了一个早期的术语“可自由分发的,和一个新的术语“合作开发的”。Eric 列出了“自由软件”、“开源软件”,并把 "自由软件源" 作为一个主要选项。Todd宣传 “开源” 模型,然后Eric 支持了他。我什么也没说,让 Todd 和 Eric 共同促进开源名字达成共识。对于大多数与会者,他们很清楚改名不是在这讨论的最重要议题;那只是一个次要的相关议题。 我在会议中只有大约10%的说明放在了术语问答中。
|
||||
|
||||
但是我很高兴。在那有许多社区的关键领导人,并且他们喜欢这新名字,或者至少没反对。这是一个好的信号信号。可能我帮不上什么忙; Eric Raymond 被相当好地放在了一个宣传模因的好位子上,而且他的确做到了。立即签约参加行动,帮助建立 [Opensource.org][9] 并在新术语的宣传中发挥重要作用。
|
||||
|
||||
对于这个成功的名字,那很必要,甚至是相当渴望, 因此 Tim O'Reilly 同意以社区的名义在公司积极使用它。在官方即将发布的 the Netscape Navigator(网景浏览器)代码中的术语使用也为此帮了忙。 到二月底, O'Reilly & Associates 还有网景公司(Netscape) 已经开始使用新术语。
|
||||
|
||||
### 名字的诞生
|
||||
|
||||
在那之后的一段时间,这条术语由 Eric Raymond 向媒体推广,由 Tim O'Reilly 向商业推广,并由二人向编程社区推广,那似乎传播的相当快。
|
||||
|
||||
1998 年 4 月 17 日, Tim O'Reilly 提前宣布首届 “[自由软件峰会][10]” ,在 4 月14 日之前,它以首届 “[开源峰会][11]” 被提及。
|
||||
|
||||
这几个月对于开源来说是相当激动人心的。似乎每周都有一个新公司宣布加入计划。读 Slashdot(科技资讯网站)已经成了一个必需操作, 甚至对于那些像我一样只能外围地参与者亦是如此。我坚信新术语能对快速传播到商业很有帮助,能被公众广泛使用。
|
||||
|
||||
尽管快捷的谷歌搜索表明“开源”比“自由软件”出现的更多,但后者仍然有大量的使用,特别是和偏爱它的人们沟通的时候。
|
||||
|
||||
### 一丝快感
|
||||
|
||||
当一个被 Eric Raymond 写的有关修改术语的早期的陈述被发布在了开放源代码促进会的网站上时,我上了 VA 头脑风暴会议的名单,但并不是作为一个术语的创始人。这是我自己的错,我没告诉 Eric 细节。我当时一时冲动只想让它表决通过然后我只是呆在后台,但是 Todd 不这样认为。他认为我总有一天将作为“开源软件”这个名词的创造者而感到高兴。他向 Eric 解释了这个情况,Eric 及时更新了它的网站。
|
||||
|
||||
想出这个短语只是一个小贡献,但是我得承认我十分感激那些把它归功于我的人。每次我听到它,它都给我些许激动的喜悦,到现在也时常感受到。
|
||||
|
||||
说服团队的大功劳归功于 Eric Raymond 和 Tim O'Reilly,这是他们搞定的。感谢他们对我的评价,并感谢 Todd Anderson 在整个过程中的角色。以上内容并非完整的开源历史记录,对很多没有无名人士表示歉意。那些寻求更完整讲述的人应该参考本文和网上其他地方的链接。
|
||||
|
||||
### 关于作者
|
||||
|
||||
[][13] Christine Peterson - Christine Peterson 撰写,举办讲座,并向媒体介绍未来强大的技术,特别是纳米技术,人工智能和长寿。她是著名的纳米科技公共利益集团的创始人和过去的前瞻技术协会主席。前瞻向公众、技术团体和政策制定者提供未来强大的技术的教育以及告诉它是如何引导他们的长期影响。她服务于 [机器智能 ][2]咨询委员会……[更多关于 Christine Peterson][3][关于我][4]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/coining-term-open-source-software
|
||||
|
||||
作者:[ Christine Peterson][a]
|
||||
译者:[fuzheng1998](https://github.com/fuzheng1998)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/christine-peterson
|
||||
[1]:https://opensource.com/article/18/2/coining-term-open-source-software?rate=HFz31Mwyy6f09l9uhm5T_OFJEmUuAwpI61FY-fSo3Gc
|
||||
[2]:http://intelligence.org/
|
||||
[3]:https://opensource.com/users/christine-peterson
|
||||
[4]:https://opensource.com/users/christine-peterson
|
||||
[5]:https://opensource.com/user/206091/feed
|
||||
[6]:https://opensource.com/resources/what-open-source
|
||||
[7]:https://opensource.org/osd
|
||||
[8]:https://wiki2.org/en/Alternative_terms_for_free_software
|
||||
[9]:https://opensource.org/
|
||||
[10]:http://www.oreilly.com/pub/pr/636
|
||||
[11]:http://www.oreilly.com/pub/pr/796
|
||||
[12]:https://ipfs.io/ipfs/QmXoypizjW3WknFiJnKLwHCnL72vedxjQkDDP1mXWo6uco/wiki/Alternative_terms_for_free_software.html
|
||||
[13]:https://opensource.com/users/christine-peterson
|
||||
[14]:https://opensource.com/users/christine-peterson
|
||||
[15]:https://opensource.com/users/christine-peterson
|
||||
[16]:https://opensource.com/article/18/2/coining-term-open-source-software#comments
|
||||
@ -1,141 +0,0 @@
|
||||
translating by shipsw
|
||||
|
||||
如何使用 yum-cron 自动更新 RHEL/CentOS Linux
|
||||
======
|
||||
yum 命令是 RHEL / CentOS Linux 系统中用来安装和更新软件包的一个工具。知道如何使用 [yum 命令行] 更新系统,但是我想用 cron 手工更新软件包。该如何配置才能使得 yum 使用 [cron 自动更新][2]系统补丁或更新呢?
|
||||
|
||||
首先需要安装 yum-cron 软件包。该软件包提供以 cron 命令运行 yum 更新所需的文件。安装这个软件可以使得 yum 以 cron 命令每晚更新。
|
||||
|
||||
### CentOS/RHEL 6.x/7.x 上安装 yum cron
|
||||
|
||||
输入以下 [yum 命令][3]:
|
||||
`$ sudo yum install yum-cron`
|
||||

|
||||
|
||||
使用 **CentOS/RHEL 7.x** 上的 systemctl 启动服务:
|
||||
```
|
||||
$ sudo systemctl enable yum-cron.service
|
||||
$ sudo systemctl start yum-cron.service
|
||||
$ sudo systemctl status yum-cron.service
|
||||
```
|
||||
在 **CentOS/RHEL 6.x** 系统中,运行:
|
||||
```
|
||||
$ sudo chkconfig yum-cron on
|
||||
$ sudo service yum-cron start
|
||||
```
|
||||

|
||||
|
||||
yum-cron 是 yum 的一个调用接口。使得 cron 调用 yum 变得非常方便。该软件提供元数据更新,更新检查、下载和安装等功能。yum-cron 的不同功能可以使用高配置文件配置,而不是输入一堆复杂的命令行参数。
|
||||
|
||||
### 配置 yum-cron 自动更新 RHEL/CentOS Linux
|
||||
|
||||
使用 vi 等编辑器编辑文件 /etc/yum/yum-cron.conf 和 /etc/yum/yum-cron-hourly.conf:
|
||||
`$ sudo vi /etc/yum/yum-cron.conf`
|
||||
确保更新可用时自动更新
|
||||
`apply_updates = yes`
|
||||
可以设置通知 email 地址。注意: localhost 将会被系统名称代替。
|
||||
`email_from = root@localhost`
|
||||
email 通知地址列表。
|
||||
`email_to = your-it-support@some-domain-name`
|
||||
发送 email 信息的主机名。
|
||||
`email_host = localhost`
|
||||
[CentOS/RHEL 7.x][4] 上不想更新内核的话,添加以下内容:
|
||||
`exclude=kernel*`
|
||||
RHEL/CentOS 6.x 下[添加以下内容来禁用内核更新][5]:
|
||||
`YUM_PARAMETER=kernel*`
|
||||
[保存并关闭文件][6]。如果想每小时更新系统的话修改文件 /etc/yum/yum-cron-hourly.conf,否则文件 /etc/yum/yum-cron.conf 将使用以下命令每天运行一次[cat 命令][7]:
|
||||
`$ cat /etc/cron.daily/0yum-daily.cron`
|
||||
示例输出:
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
# Only run if this flag is set. The flag is created by the yum-cron init
|
||||
# script when the service is started -- this allows one to use chkconfig and
|
||||
# the standard "service stop|start" commands to enable or disable yum-cron.
|
||||
if [[ ! -f /var/lock/subsys/yum-cron ]]; then
|
||||
exit 0
|
||||
fi
|
||||
|
||||
# Action!
|
||||
exec /usr/sbin/yum-cron /etc/yum/yum-cron-hourly.conf
|
||||
[root@centos7-box yum]# cat /etc/cron.daily/0yum-daily.cron
|
||||
#!/bin/bash
|
||||
|
||||
# Only run if this flag is set. The flag is created by the yum-cron init
|
||||
# script when the service is started -- this allows one to use chkconfig and
|
||||
# the standard "service stop|start" commands to enable or disable yum-cron.
|
||||
if [[ ! -f /var/lock/subsys/yum-cron ]]; then
|
||||
exit 0
|
||||
fi
|
||||
|
||||
# Action!
|
||||
exec /usr/sbin/yum-cron
|
||||
```
|
||||
|
||||
完成配置。现在你的系统将每天自动更新一次。更多细节请参照 yum-cron 的说明手册。
|
||||
`$ man yum-cron`
|
||||
|
||||
### 方法二 – 使用 shell 脚本
|
||||
|
||||
**警告** : 以下命令已经过时了. 不要在 RHEL/CentOS 6.x/7.x 系统中使用。 我写在这里仅仅是因为历史原因,该命令适合 CentOS/RHEL version 4.x/5.x 上运行。
|
||||
|
||||
让我们看看如何在 CentOS/RHEL 上配置 yum 安全更新包的检索和安装。你可以使用 CentOS / RHEL 提供的 yum-updatesd 服务。然而,系统提供的服务开销有点大。你可以使用以下的 shell 脚本配置每天后每周的系统更新。
|
||||
|
||||
* **/etc/cron.daily/yumupdate.sh** 每天更新
|
||||
* **/etc/cron.weekly/yumupdate.sh** 每周更新
|
||||
|
||||
|
||||
|
||||
#### 系统更新的示例脚本
|
||||
|
||||
以下脚本功能是使用 [cron][8] 定时安装更新更新:
|
||||
```
|
||||
#!/bin/bash
|
||||
YUM=/usr/bin/yum
|
||||
$YUM -y -R 120 -d 0 -e 0 update yum
|
||||
$YUM -y -R 10 -e 0 -d 0 update
|
||||
```
|
||||
|
||||
(Code listing -01: /etc/cron.daily/yumupdate.sh)
|
||||
|
||||
其中:
|
||||
|
||||
1. 第一条命令更新 yum 自己。
|
||||
2. **-R 120** : 设置允许一条命令前的等待最长时间
|
||||
3. **-e 0** : 设置错误级别为 0 (范围 0-10)。0 意味着只有关键性错误才会显示。
|
||||
4. -d 0 : 设置 debug 级别为 0 。增加或减少打印日志的量。(范围 0-10)
|
||||
5. **-y** : 默认同意;任何提示问题默认回答为 yes。
|
||||
|
||||
|
||||
|
||||
设置脚本的执行权限:
|
||||
`# chmod +x /etc/cron.daily/yumupdate.sh`
|
||||
|
||||
|
||||
### 关于作者
|
||||
|
||||
作者是 nixCraft 的创始人,一个经验丰富的系统管理员和 Linux/Unix 脚本培训师。他曾与全球客户合作,领域涉及IT,教育,国防和空间研究以及非营利部门等多个行业。请在 [Twitter][9]、[Facebook][10]、[Google+][11] 上关注他。**获取更多有关系统管理、Linux/Unix 和开源话题请关注[我的 RSS/XML 地址][12]**。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/fedora-automatic-update-retrieval-installation-with-cron/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[shipsw](https://github.com/shipsw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz/
|
||||
[1]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/
|
||||
[2]:https://www.cyberciti.biz/faq/how-do-i-add-jobs-to-cron-under-linux-or-unix-oses
|
||||
[3]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/ (See Linux/Unix yum command examples for more info)
|
||||
[4]:https://www.cyberciti.biz/faq/yum-update-except-kernel-package-command/
|
||||
[5]:https://www.cyberciti.biz/faq/redhat-centos-linux-yum-update-exclude-packages/
|
||||
[6]:https://www.cyberciti.biz/faq/linux-unix-vim-save-and-quit-command/
|
||||
[7]:https://www.cyberciti.biz/faq/linux-unix-appleosx-bsd-cat-command-examples/ (See Linux/Unix cat command examples for more info)
|
||||
[8]:https://www.cyberciti.biz/faq/how-do-i-add-jobs-to-cron-under-linux-or-unix-oses
|
||||
[9]:https://twitter.com/nixcraft
|
||||
[10]:https://facebook.com/nixcraft
|
||||
[11]:https://plus.google.com/+CybercitiBiz
|
||||
[12]:https://www.cyberciti.biz/atom/atom.xml
|
||||
@ -0,0 +1,94 @@
|
||||
如何安全地生成随机数 - 争论
|
||||
======
|
||||
### 使用 urandom
|
||||
|
||||
使用 urandom。使用 urandom。使用 urandom。使用 urandom。使用 urandom。使用 urandom。
|
||||
|
||||
### 但对于密码学密钥呢?
|
||||
|
||||
仍然使用 urandom[6]。
|
||||
|
||||
### 为什么不是 SecureRandom, OpenSSL, havaged 或者 c 语言实现呢?
|
||||
|
||||
这些是用户空间的 CSPRNG(伪随机数生成器)。你应该想用内核的 CSPRNG,因为:
|
||||
|
||||
* 内核可以访问原始设备熵。
|
||||
|
||||
* 它保证不在应用程序之间共享相同的状态。
|
||||
|
||||
* 一个好的内核 CSPRNG,像 FreeBSD 中的,也可以保证在提供种子之前不给你随机数据。
|
||||
|
||||
|
||||
|
||||
|
||||
研究过去十年中的随机失败案例,你会看到一连串的用户空间随机失败。[Debian 的 OpenSSH 崩溃][7]?用户空间随机。安卓的比特币钱包[重复 ECDSA k's][8]?用户空间随机。可预测洗牌的赌博网站?用户空间随机。
|
||||
|
||||
用户空间生成器几乎总是依赖于内核的生成器。即使它们不这样做,整个系统的安全性也会确保如此。**用户空间的 CSPRNG 不会增加防御深度;相反,它会产生两个单点故障。**
|
||||
|
||||
### 手册页不是说使用/dev/random嘛?
|
||||
|
||||
这个稍后详述,保留你的想法。你应该忽略掉手册页。不要使用 /dev/random。/dev/random 和 /dev/urandom 之间的区别是 Unix 设计缺陷。手册页不想承认这一点,因此它产生了一个并不存在的安全问题。把 random(4) 上的密码学上的建议当作传奇,继续你的生活。
|
||||
|
||||
### 但是如果我需要的是真随机值,而非伪随机值呢?
|
||||
|
||||
Urandom 和 /dev/random 提供的是同一类型的随机。与流行的观念相反,/dev/random 不提供“真正的随机”。从密码学上来说,你通常不需要“真正的随机”。
|
||||
|
||||
Urandom 和 /dev/random 都基于一个简单的想法。它们的设计与流密码的设计密切相关:一个小秘密被延伸到不可预测值的不确定流中。 这里的秘密是“熵”,而流是“输出”。
|
||||
|
||||
只在 Linux 上 /dev/random 和 urandom 仍然有意义上的不同。Linux 内核的 CSPRNG 定期进行密钥更新(通过收集更多的熵)。但是 /dev/random 也试图跟踪内核池中剩余的熵,并且如果它没有足够的剩余熵时,偶尔也会罢工。这种设计和我所说的一样蠢;这与基于“密钥流”中剩下多少“密钥”的 AES-CTR 设计类似。
|
||||
|
||||
如果你使用 /dev/random 而非 urandom,那么当 Linux 对自己的 RNG(随机数生成器)如何工作感到困惑时,你的程序将不可预测地(或者如果你是攻击者,非常可预测地)挂起。使用 /dev/random 会使你的程序不太稳定,但在密码学角度上它也不会让程序更加安全。
|
||||
|
||||
### 这里有个缺陷,不是吗?
|
||||
|
||||
不是,但存在一个你可能想要了解的 Linux 内核 bug,即使这并不能改变你应该使用哪一个 RNG。
|
||||
|
||||
在 Linux 上,如果你的软件在引导时立即运行,并且/或者刚刚安装了操作系统,那么你的代码可能会与 RNG 发生竞争。这很糟糕,因为如果你赢了比赛,那么你可能会在一段时间内从 urandom 获得可预测的输出。这是 Linux 中的一个 bug,如果你正在为 Linux 嵌入式设备构建平台级代码,那你需要了解它。
|
||||
|
||||
在 Linux 上,这确实是 urandom(而不是 /dev/random)的问题。这也是[Linux 内核中的错误][9]。 但它也容易在用户空间中修复:在引导时,明确地为 urandom 提供种子。长期以来,大多数 Linux 发行版都是这么做的。但不要切换到不同的 CSPRNG。
|
||||
|
||||
### 在其它操作系统上呢?
|
||||
|
||||
FreeBSD 和 OS X 消除了 urandom 和 /dev/random 之间的区别; 这两个设备的行为是相同的。不幸的是,手册页在解释为什么这样做上干的很糟糕,并延续了 Linux 上 urandom 可怕的神话。
|
||||
|
||||
无论你使用 /dev/random 还是 urandom,FreeBSD 的内核加密 RNG 都不会阻塞。 除非它没有被提供种子,在这种情况下,这两者都会阻塞。与 Linux 不同,这种行为是有道理的。Linux 应该采用它。但是,如果你是一名应用程序开发人员,这对你几乎没有什么影响:Linux,FreeBSD,iOS,无论什么:使用 urandom 吧。
|
||||
|
||||
### 太长了,懒得看
|
||||
|
||||
直接使用 urandom 吧。
|
||||
|
||||
### 结语
|
||||
|
||||
[ruby-trunk Feature #9569][10]
|
||||
|
||||
> 现在,在尝试检测 /dev/urandom 之前,SecureRandom.random_bytes 会尝试检测要使用的 OpenSSL。 我认为这应该反过来。在这两种情况下,你只需要将随机字节进行解压,所以 SecureRandom 可以跳过中间人(和第二个故障点),如果可用的话可以直接与 /dev/urandom 进行交互。
|
||||
|
||||
总结:
|
||||
|
||||
> /dev/urandom 不适合用来直接生成会话密钥和频繁生成其他应用程序级随机数据
|
||||
>
|
||||
> GNU/Linux 上的 random(4) 手册所述......
|
||||
|
||||
感谢 Matthew Green, Nate Lawson, Sean Devlin, Coda Hale, and Alex Balducci 阅读了本文草稿。公正警告:Matthew 只是大多同意我的观点。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://sockpuppet.org/blog/2014/02/25/safely-generate-random-numbers/
|
||||
|
||||
作者:[Thomas;Erin;Matasano][a]
|
||||
译者:[kimii](https://github.com/kimii)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://sockpuppet.org/blog
|
||||
[1]:http://blog.cr.yp.to/20140205-entropy.html
|
||||
[2]:http://cr.yp.to/talks/2011.09.28/slides.pdf
|
||||
[3]:http://golang.org/src/pkg/crypto/rand/rand_unix.go
|
||||
[4]:http://security.stackexchange.com/questions/3936/is-a-rand-from-dev-urandom-secure-for-a-login-key
|
||||
[5]:http://stackoverflow.com/a/5639631
|
||||
[6]:https://twitter.com/bramcohen/status/206146075487240194
|
||||
[7]:http://research.swtch.com/openssl
|
||||
[8]:http://arstechnica.com/security/2013/08/google-confirms-critical-android-crypto-flaw-used-in-5700-bitcoin-heist/
|
||||
[9]:https://factorable.net/weakkeys12.extended.pdf
|
||||
[10]:https://bugs.ruby-lang.org/issues/9569
|
||||
@ -1,131 +0,0 @@
|
||||
如何使用 GNU Stow 来管理从源代码和 dotfiles 安装的程序
|
||||
=====
|
||||
dotfiles(**.**开头的文件在 *nix 下默认为隐藏文件)
|
||||
### 目的
|
||||
|
||||
使用 GNU Stow 轻松管理从源代码和 dotfiles 安装的程序
|
||||
|
||||
### 要求
|
||||
|
||||
* root 权限
|
||||
|
||||
|
||||
### 难度
|
||||
|
||||
简单
|
||||
|
||||
### 约定
|
||||
|
||||
* **#** \- 要求直接以 root 用户身份或使用 `sudo` 命令以 root 权限执行给定的命令
|
||||
* **$** \- 给定的命令将作为普通的非特权用户来执行
|
||||
|
||||
### 介绍
|
||||
|
||||
有时候我们必须从源代码安装程序,因为它们也许不能通过标准渠道获得,或者我们可能需要特定版本的软件。 GNU Stow 是一个非常不错的 `symlinks factory` 程序,它可以帮助我们保持文件的整洁,易于维护。
|
||||
|
||||
### 获得 stow
|
||||
|
||||
你的 Linux 发行版本很可能包含 `stow`,例如在 Fedora,你安装它只需要:
|
||||
```
|
||||
# dnf install stow
|
||||
```
|
||||
|
||||
在 Ubuntu/Debian 中,安装 stow 需要执行:
|
||||
```
|
||||
# apt install stow
|
||||
```
|
||||
|
||||
在某些 Linux 发行版中,stow 在标准库中是不可用的,但是可以通过一些额外的软件源(例如 Rhel 和 CentOS7 中的epel )轻松获得,或者,作为最后的手段,你可以从源代码编译它。只需要很少的依赖关系。
|
||||
|
||||
### 从源代码编译
|
||||
|
||||
最新的可用 stow 版本是 `2.2.2`。源码包可以在这里下载:`https://ftp.gnu.org/gnu/stow/`。
|
||||
|
||||
一旦你下载了源码包,你就必须解压它。切换到你下载软件包的目录,然后运行:
|
||||
```
|
||||
$ tar -xvpzf stow-2.2.2.tar.gz
|
||||
```
|
||||
|
||||
解压源文件后,切换到 stow-2.2.2 目录中,然后编译该程序,只需运行:
|
||||
```
|
||||
$ ./configure
|
||||
$ make
|
||||
|
||||
```
|
||||
|
||||
最后,安装软件包:
|
||||
```
|
||||
# make install
|
||||
```
|
||||
|
||||
默认情况下,软件包将安装在 `/usr/local/` 目录中,但是我们可以改变它,通过配置脚本的 `--prefix` 选项指定目录,或者在运行 `make install` 时添加 `prefix="/your/dir"`。
|
||||
|
||||
此时,如果所有工作都按预期工作,我们应该已经在系统上安装了 `stow`。
|
||||
|
||||
### stow 是如何工作的?
|
||||
|
||||
stow 背后主要的概念在程序手册中有很好的解释:
|
||||
```
|
||||
Stow 使用的方法是将每个软件包安装到自己的树中,然后使用符号链接使它看起来像文件一样安装在普通树中
|
||||
|
||||
```
|
||||
|
||||
为了更好地理解这个软件的运作,我们来分析一下它的关键概念:
|
||||
|
||||
#### stow 文件目录
|
||||
|
||||
stow 目录是包含所有 `stow 包` 的根目录,每个包都有自己的子目录。典型的 stow 目录是 `/usr/local/stow`:在其中,每个子目录代表一个 `package`。
|
||||
|
||||
#### stow 包
|
||||
|
||||
如上所述,stow 目录包含多个 "包",每个包都位于自己单独的子目录中,通常以程序本身命名。包不过是与特定软件相关的文件和目录列表,作为实体进行管理。
|
||||
|
||||
#### stow 目标目录
|
||||
|
||||
stow 目标目录解释起来是一个非常简单的概念。它是包文件必须安装的目录。默认情况下,stow 目标目录被认为是从目录调用 stow 的目录。这种行为可以通过使用 `-t` 选项( --target 的简写)轻松改变,这使我们可以指定一个替代目录。
|
||||
|
||||
### 一个实际的例子
|
||||
|
||||
我相信一个好的例子胜过 1000 句话,所以让我来展示 stow 如何工作。假设我们想编译并安装 `libx264`,首先我们克隆包含其源代码的仓库:
|
||||
```
|
||||
$ git clone git://git.videolan.org/x264.git
|
||||
```
|
||||
|
||||
运行该命令几秒钟后,将创建 "x264" 目录,并且它将包含准备编译的源代码。我们切换到 "x264" 目录中并运行 `configure` 脚本,将 `--prefix` 指定为 /usr/local/stow/libx264 目录。
|
||||
```
|
||||
$ cd x264 && ./configure --prefix=/usr/local/stow/libx264
|
||||
```
|
||||
|
||||
然后我们构建该程序并安装它:
|
||||
```
|
||||
$ make
|
||||
# make install
|
||||
```
|
||||
|
||||
x264 目录应该在 stow 目录内创建:它包含所有通常直接安装在系统中的东西。 现在,我们所要做的就是调用 stow。 我们必须从 stow 目录内运行这个命令,通过使用 `-d` 选项来手动指定 stow 目录的路径(默认为当前目录),或者通过如前所述用 `-t` 指定目标。我们还应该提供要作为参数存储的包的名称。 在这种情况下,我们从 stow 目录运行程序,所以我们需要输入的内容是:
|
||||
```
|
||||
# stow libx264
|
||||
```
|
||||
|
||||
libx264 软件包中包含的所有文件和目录现在已经在调用 stow 的父目录 (/usr/local) 中进行了符号链接,因此,例如在 `/usr/local/ stow/x264/bin` 中包含的 libx264 二进制文件现在在 `/usr/local/bin` 中符号链接,`/usr/local/stow/x264/etc` 中的文件现在符号链接在 `/usr/local/etc` 中等等。通过这种方式,系统将显示文件已正常安装,并且我们可以容易地跟踪我们编译和安装的每个程序。要恢复该操作,我们只需使用 `-D` 选项:
|
||||
```
|
||||
# stow -d libx264
|
||||
```
|
||||
|
||||
完成了!符号链接不再存在:我们只是“卸载”了一个 stow 包,使我们的系统保持在一个干净且一致的状态。 在这一点上,我们应该清楚为什么 stow 还用于管理 dotfiles。 通常的做法是在 git 仓库中包含用户特定的所有配置文件,以便轻松管理它们并使它们在任何地方都可用,然后使用 stow 将它们放在适当位置,如放在用户主目录中。
|
||||
|
||||
Stow 还会阻止你错误地覆盖文件:如果目标文件已经存在并且没有指向 Stow 目录中的包时,它将拒绝创建符号链接。 这种情况在 Stow 术语中称为冲突。
|
||||
|
||||
就是这样!有关选项的完整列表,请参阅 stow 帮助页,并且不要忘记在评论中告诉我们你对此的看法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxconfig.org/how-to-use-gnu-stow-to-manage-programs-installed-from-source-and-dotfiles
|
||||
|
||||
作者:[Egidio Docile][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/ 校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linuxconfig.org
|
||||
@ -0,0 +1,58 @@
|
||||
CIO 真正需要 DevOps 团队做什么?
|
||||
======
|
||||
IT 领导者可以从大量的 [DevOps][1] 材料和 [向 DevOps 转变][2] 所要求的文化挑战中学习。但是,你在一个 DevOps 团队面对长期或短期挑战的调整中 —— 一个 CIO 真正需要他们做的是什么呢?
|
||||
|
||||
在我与 DevOps 团队成员的谈话中,我听到的其中一些内容让你感到非常的意外。DevOps 专家(无论是内部团队的还是外部团队的)都希望将下列的事情放在你的 CIO 优先关注的级别。
|
||||
|
||||
### 1. 沟通
|
||||
|
||||
第一个也是最重要的一个,DevOps 专家需要面对面的沟通。一个经验丰富的 DevOps 团队是非常了解当前 DevOps 的趋势,以及成功、和失败的经验,并且他们非常乐意去分享这些信息。表达 DevOps 的概念是很困难的,因此,要在这种新的工作关系中保持开放,定期(不用担心,不用每周)讨论有关你的 IT 的当前状态,如何评价你的沟通环境,以及你的整体的 IT 产业。
|
||||
|
||||
**[想从领导 DevOps 的 CIO 们处学习更多的知识吗?查看我们的综合资源,[DevOps: IT 领导者指南][3]。 ]**
|
||||
|
||||
相反,你应该准备好与 DevOps 团队去共享当前的业务需求和目标。业务不再是独立于 IT 的东西:它们现在是驱动 IT 发展的重要因素,并且 IT 决定了你的业务需求和目标运行的效果如何。
|
||||
|
||||
注重参与而不是领导。在需要做决策的时候,你仍然是最终的决策者,但是,理解这些决策的最好方式是协作,这样,你的 DevOps 团队将有更多的自主权,并因此受到更多激励。
|
||||
|
||||
### 2. 降低技术债务
|
||||
|
||||
第二,力争更好地理解技术债务,并在 DevOps 中努力降低它。你的 DevOps 团队面对的工作都非常难。在这种情况下,技术债务是指在一个庞大的、不可持续的环境(查看 Rube Goldberg)之中,通过维护和增加新功能而占用的人力资源和基础设备资源。
|
||||
|
||||
常见的 CIO 问题包括:
|
||||
|
||||
* 为什么我们要用一种新方法去做这件事情?
|
||||
* 为什么我们要在它上面花费时间和金钱?
|
||||
* 如果这里没有新功能,只是现有组件实现了自动化,那么我们的收益是什么?
|
||||
|
||||
|
||||
|
||||
"如果没有坏,就不要去修理它“ ,这样的事情是可以理解的。但是,如果你正在路上好好的开车,而每个人都加速超过你,这时候,你的环境就被破坏了。持续投入宝贵的资源去支撑或扩张拼凑起来的环境。
|
||||
|
||||
选择妥协,并且一个接一个的打补丁,以这种方式去处理每个独立的问题,结果将从一开始就变得很糟糕 —— 在一个不能支撑建筑物的地基上,一层摞一层地往上堆。事实上,这种方法就像不断地在电脑中插入坏磁盘一样。迟早有一天,面对出现的问题,你将会毫无办法。在外面持续增加的压力下,整个事情将变得一团糟,完全吞噬掉你的资源。
|
||||
|
||||
这种情况下,解决方案就是:自动化。使用自动化的结果是良好的可伸缩性 —— 每个维护人员在 IT 环境的维护和增长方面花费更少的努力。如果增加人力资源是实现业务增长的唯一办法,那么,可伸缩性就是白日做梦。
|
||||
|
||||
自动化降低了你的人力资源需求,并且对持续进行的 IT 提供了更灵活的需求。很简单,对吗?是的,但是你必须为迟到的满意做好心理准备。为了在提高生产力和效率的基础上获得后端经济效益,需要预先投入时间和精力对架构和结构进行变更。为了你的 DevOps 团队能够成功,接受这些挑战,对 IT 领导者来说是非常重要的。
|
||||
|
||||
### 3. 信任
|
||||
|
||||
最后,相信你的 DevOps 团队并且一定要理解他们。DevOps 专家也知道这个要求很难,但是他们必须有你的强大支持和你参与实践的意愿。因为 DevOps 团队持续改进你的 IT 环境,他们自身也在不断地适应这些变化的技术,而这些变化通常正是 “你要去学习的经验”。
|
||||
|
||||
倾听,倾听,倾听他们,并且相信他们。DevOps 的改变是非常有价值的,而且也是值的去投入时间和金钱的。它可以提高效率、生产力、和业务响应能力。信任你的 DevOps 团队,并且给予他们更多的自由,实现更高效率的 IT 改进。
|
||||
|
||||
新 CIO 的底线是:将你的 DevOps 团队的潜力最大化,离开你的领导 “舒适区”,拥抱一个 “CIOps" 的转变。通过 DevOps 转变,持续地与你的 DevOps 团队共同成长,以帮助你的组织获得长期的 IT 成功。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2017/12/what-devops-teams-really-need-cio
|
||||
|
||||
作者:[John Allessio][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://enterprisersproject.com/user/john-allessio
|
||||
[1]:https://enterprisersproject.com/tags/devops
|
||||
[2]:https://www.redhat.com/en/insights/devops?intcmp=701f2000000tjyaAAA
|
||||
[3]:https://enterprisersproject.com/devops?sc_cid=70160000000h0aXAAQ
|
||||
58
translated/tech/20171213 Will DevOps steal my job-.md
Normal file
58
translated/tech/20171213 Will DevOps steal my job-.md
Normal file
@ -0,0 +1,58 @@
|
||||
DevOps 将让你失业?
|
||||
======
|
||||
|
||||
>你是否担心工作中自动化将代替人?可能是对的,但是这并不是件坏事。
|
||||
|
||||

|
||||
>Image by : opensource.com
|
||||
|
||||
这是一个很正常的担心:DevOps 最终会让你失业?毕竟,DevOps 意味着开发人员做运营,对吗?DevOps 是自动化的。如果我的工作都自动化了,我去做什么?实行持续分发和容器化意味着运营已经过时了吗?对于 DevOps 来说,所有的东西都是代码:基础设施是代码、测试是代码、这个和那个都是代码。如果我没有这些技能怎么办?
|
||||
|
||||
[DevOps][1] 是一个即将到来的变化,将颠覆这一领域,狂热的拥挤者们正在谈论,如何使用 [三种方法][2] 去改变世界 —— 即 DevOps 的三大基础 —— 去推翻一个旧的世界。它是势不可档的。那么,问题来了 —— DevOps 将会让我失业吗?
|
||||
|
||||
### 第一个担心:再也不需要我了
|
||||
|
||||
由于开发者来管理应用程序的整个生命周期,接受 DevOps 的理念很容易。容器化可能是影响这一想法的重要因素。当容器化在各种场景下铺开之后,它们被吹嘘成开发者构建、测试、和部署他们代码的一站式解决方案。DevOps 对于运营、测试、以及 QA 团队来说,有什么作用呢?
|
||||
|
||||
这源于对 DevOps 原则的误解。DevOps 的第一原则,或者第一方法是,_系统思考_ ,或者强调整体管理方法和了解应用程序或服务的整个生命周期。这并不意味着应用程序的开发者将学习和管理整个过程。相反,是拥有各个专业和技能的人共同合作,以确保成功。让开发者对这一过程完全负责的作法,几乎是将开发者置于使用者的对立面—— 本质上就是 “将鸡蛋放在了一个篮子里”。
|
||||
|
||||
在 DevOps 中有一个为你保留的专门职位。就像将一个受过传统教育的、拥有线性回归和二分查找知识的软件工程师,被用去写一些 Ansible playbooks 和 Docker 文件,这是一种浪费。而对于那些拥有高级技能,知道如何保护一个系统和优化数据库执行的系统管理员,被浪费在写一些 CSS 和设计用户流这样的工作上。写代码、做测试、和维护应用程序的高效团队一般是跨学科、跨职能的、拥有不同专业技术和背景的人组成的混编团队。
|
||||
|
||||
### 第二个担心:我的工作将被自动化
|
||||
|
||||
或许是,或许不是,DevOps 可能在有时候是自动化的同义词。当自动化构建、测试、部署、监视、以及提醒等事项,已经占据了整个应用程序生命周期管理的时候,还会给我们剩下什么工作呢?这种对自动化的关注可能与第二个方法有关:_放大反馈循环_。DevOps 的第二个方法是在团队和部署的应用程序之间,采用相反的方向优先处理快速反馈 —— 从监视和维护部署、测试、开发、等等,通过强调,使反馈更加重要并且可操作。虽然这第二种方式与自动化并不是特别相关,许多自动化工具团队在它们的部署流水线中使用,以促进快速提醒和快速行动,或者基于对使用者的支持业务中产生的反馈来改进。传统的做法是靠人来完成的,这就可以理解为什么自动化可能会导致未来一些人失业的焦虑了。
|
||||
|
||||
自动化只是一个工具,它并不能代替人。聪明的人使用它来做一些重复的工作,不去开发智力和创造性的财富,而是去按红色的 “George Jetson” 按钮是一种极大的浪费。让每天工作中的苦活自动化,意味着有更多的时间去解决真正的问题和即将到来的创新的解决方案。人类需要解决更多的 “怎么做和为什么” 问题,而计算机只能处理 “复制和粘贴”。
|
||||
|
||||
并不会仅限于在可重复的、可预见的事情上进行自动化,自动化让团队有更多的时间和精力去专注于本领域中更高级别的任务上。监视团队不再花费他们的时间去配置报警或者管理传统的配置,它们可能专注于预测可能的报警、相关性统计、以及设计可能的预案。系统管理员从计划补丁或服务器配置中解放出来,可以花费更多的时间专注于整体管理、性能、和可伸缩性。与工厂车间和装配线上完全没有人的景像不同,DevOps 中的自动化任务,意味着人更多关注于创造性的、有更高价值的任务,而不是一些重复的、让人麻木的苦差事。
|
||||
|
||||
### 第三个担心:我没有这些技能怎么办
|
||||
|
||||
"我怎么去继续做这些事情?我不懂如何自动化。现在所有的工作都是代码 —— 我不是开发人员,我不会做 DevOps 中写代码的工作“,第三个担心是一种不自信的担心。由于文化的改变,是的,团队将也会要求随之改变,一些人可能担心,他们缺乏继续做他们工作的技能。
|
||||
|
||||
然而,大多数人或许已经比他们所想的更接近。Dockerfile 是什么,或者像 Puppet 或 Ansible 配置管理是什么,但是环境即代码,系统管理员已经写了 shell 脚本和 Python 程序去处理他们重复的任务。学习更多的知识并使用已有的工具处理他们的更多问题 —— 编排、部署、维护即代码 —— 尤其是当从繁重的手动任务中解放出来,专注于成长时。
|
||||
|
||||
在 DevOps 的使用者中去回答这第三个担心,第三个方法是:_一种不断实验和学习的文化_。尝试、失败、并从错误中吸取教训而不是责怪它们的能力,是设计出更有创意的解决方案的重要因素。第三个方法是为前两个方法授权—— 允许快速检测和修复问题,并且开发人员可以自由地尝试和学习,其它的团队也是如此。从未使用过配置管理或者写过自动供给基础设施程序的运营团队也要自由尝试并学习。测试和 QA 团队也要自由实现新测试流水线,并且自动批准和发布新流程。在一个拥抱学习和成长的文化中,每个人都可以自由地获取他们需要的技术,去享受工作带来的成功和喜悦。
|
||||
|
||||
### 结束语
|
||||
|
||||
在一个行业中,任何可能引起混乱的实践或变化都会产生担心和不确定,DevOps 也不例外。对自己工作的担心是对成百上千的文章和演讲的合理回应,其中列举了无数的实践和技术,而这些实践和技术正致力于授权开发者对行业的各个方面承担职责。
|
||||
|
||||
然而,事实上,DevOps 是 "[一个跨学科的沟通实践,致力于研究构建、进化、和运营快速变化的弹性系统][3]"。 DevOps 意味着终结 ”筒仓“,但并不专业化。它是受委托去做苦差事的自动化系统,解放你,让你去做人类更擅长做的事:思考和想像。并且,如果你愿意去学习和成长,它将不会终结你解决新的、挑战性的问题的机会。
|
||||
|
||||
DevOps 会让你失业吗?会的,但它同时给你提供了更好的工作。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/12/will-devops-steal-my-job
|
||||
|
||||
作者:[Chris Collins][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/clcollins
|
||||
[1]:https://opensource.com/resources/devops
|
||||
[2]:http://itrevolution.com/the-three-ways-principles-underpinning-devops/
|
||||
[3]:https://theagileadmin.com/what-is-devops/
|
||||
@ -0,0 +1,241 @@
|
||||
如何查找 Linux 中最大的 10 个文件
|
||||
======
|
||||
|
||||
|
||||
当系统的磁盘空间不足时,您可能更愿意使用 `df`、`du` 或 `ncdu` 命令进行检查,但这些命令只会显示当前目录的文件,并不会显示整个系统范围的文件。
|
||||
|
||||
您得花费大量的时间才能用上述命令获取系统中最大的文件,因为要进入到每个目录重复运行上述命令。
|
||||
|
||||
这个方法比较麻烦,也并不恰当。
|
||||
|
||||
如果是这样,那么该如何在 Linux 中找到最大的 10 个文件呢?
|
||||
|
||||
我在谷歌上搜索了很久,却没发现类似的文章,我反而看到了很多关于列出当前目录中最大的 10 个文件的文章。所以,我希望这篇文章对那些有类似需求的人有所帮助。
|
||||
|
||||
本教程中,我们将教您如何使用以下四种方法在 Linux 系统中查找最大的前 10 个文件。
|
||||
|
||||
### 方法 1:
|
||||
|
||||
在 Linux 中没有特定的命令可以直接执行此操作,因此我们需要将多个命令结合使用。
|
||||
|
||||
```
|
||||
# find / -type f -print0 | xargs -0 du -h | sort -rh | head -n 10
|
||||
|
||||
1.4G /swapfile
|
||||
1.1G /home/magi/ubuntu-17.04-desktop-amd64.iso
|
||||
564M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqTFU0XzkzUlJUZzA
|
||||
378M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqeldzUmhPeC03Zm8
|
||||
377M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqRGd4V0VrOXM4YVU
|
||||
100M /usr/lib/x86_64-linux-gnu/libOxideQtCore.so.0
|
||||
93M /usr/lib/firefox/libxul.so
|
||||
84M /var/lib/snapd/snaps/core_3604.snap
|
||||
84M /var/lib/snapd/snaps/core_3440.snap
|
||||
84M /var/lib/snapd/snaps/core_3247.snap
|
||||
|
||||
```
|
||||
|
||||
**详解:**
|
||||
|
||||
**`find`**:在目录结构中搜索文件的命令
|
||||
|
||||
**`/`**:在整个系统(从根目录开始)中查找
|
||||
|
||||
**`-type`**:指定文件类型
|
||||
|
||||
**`f`**:普通文件
|
||||
|
||||
**`-print0`**:输出完整的文件名,其后跟一个空字符
|
||||
|
||||
**`|`**:控制操作符,将一条命令的输出传递给下一个命令以供进一步处理
|
||||
|
||||
**`xargs`**:将标准输入转换成命令行参数的命令
|
||||
|
||||
**`-0`**:以空字符(null)而不是空白字符(whitespace)(LCTT 译者注:即空格、制表符和换行)来分割记录
|
||||
|
||||
**`du -h`**:以可读格式计算磁盘空间使用情况的命令
|
||||
|
||||
**`sort`**:对文本文件进行排序的命令
|
||||
|
||||
**`-r`**:反转结果
|
||||
|
||||
**`-h`**:用可读格式打印输出
|
||||
|
||||
**`head`**:输出文件开头部分的命令
|
||||
|
||||
**`n -10`**:打印前 10 个文件
|
||||
|
||||
### 方法 2:
|
||||
|
||||
这是查找 Linux 系统中最大的前 10 个文件的另一种方法。我们依然使用多个命令共同完成这个任务。
|
||||
|
||||
```
|
||||
# find / -type f -exec du -Sh {} + | sort -rh | head -n 10
|
||||
|
||||
1.4G /swapfile
|
||||
1.1G /home/magi/ubuntu-17.04-desktop-amd64.iso
|
||||
564M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqTFU0XzkzUlJUZzA
|
||||
378M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqeldzUmhPeC03Zm8
|
||||
377M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqRGd4V0VrOXM4YVU
|
||||
100M /usr/lib/x86_64-linux-gnu/libOxideQtCore.so.0
|
||||
93M /usr/lib/firefox/libxul.so
|
||||
84M /var/lib/snapd/snaps/core_3604.snap
|
||||
84M /var/lib/snapd/snaps/core_3440.snap
|
||||
84M /var/lib/snapd/snaps/core_3247.snap
|
||||
|
||||
```
|
||||
|
||||
**详解:**
|
||||
|
||||
**`find`**:在目录结构中搜索文件的命令
|
||||
|
||||
**`/`**:在整个系统(从根目录开始)中查找
|
||||
|
||||
**`-type`**:指定文件类型
|
||||
|
||||
**`f`**:普通文件
|
||||
|
||||
**`-exec`**:在所选文件上运行指定命令
|
||||
|
||||
**`du`**:计算文件占用的磁盘空间的命令
|
||||
|
||||
**`-S`**:不包含子目录的大小
|
||||
|
||||
**`-h`**:以可读格式打印
|
||||
|
||||
**`{}`**:递归地查找目录,统计每个文件占用的磁盘空间
|
||||
|
||||
**`|`**:控制操作符,将一条命令的输出传递给下一个命令以供进一步处理
|
||||
|
||||
**`sort`**:对文本文件进行按行排序的命令
|
||||
|
||||
**`-r`**:反转结果
|
||||
|
||||
**`-h`**:用可读格式打印输出
|
||||
|
||||
**`head`**:输出文件开头部分的命令
|
||||
|
||||
**`n -10`**:打印前 10 个文件
|
||||
|
||||
### 方法 3:
|
||||
|
||||
这里介绍另一种方法,在 Linux 系统中搜索最大的前 10 个文件。
|
||||
|
||||
```
|
||||
# find / -type f -print0 | xargs -0 du | sort -n | tail -10 | cut -f2 | xargs -I{} du -sh {}
|
||||
|
||||
84M /var/lib/snapd/snaps/core_3247.snap
|
||||
84M /var/lib/snapd/snaps/core_3440.snap
|
||||
84M /var/lib/snapd/snaps/core_3604.snap
|
||||
93M /usr/lib/firefox/libxul.so
|
||||
100M /usr/lib/x86_64-linux-gnu/libOxideQtCore.so.0
|
||||
377M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqRGd4V0VrOXM4YVU
|
||||
378M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqeldzUmhPeC03Zm8
|
||||
564M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqTFU0XzkzUlJUZzA
|
||||
1.1G /home/magi/ubuntu-17.04-desktop-amd64.iso
|
||||
1.4G /swapfile
|
||||
|
||||
```
|
||||
|
||||
**详解:**
|
||||
|
||||
**`find`**:在目录结构中搜索文件的命令
|
||||
|
||||
**`/`**:在整个系统(从根目录开始)中查找
|
||||
|
||||
**`-type`**:指定文件类型
|
||||
|
||||
**`f`**:普通文件
|
||||
|
||||
**`-print0`**:输出完整的文件名,其后跟一个空字符
|
||||
|
||||
**`|`**:控制操作符,将一条命令的输出传递给下一个命令以供进一步处理
|
||||
|
||||
**`xargs`**:将标准输入转换成命令行参数的命令
|
||||
|
||||
**`-0`**:以空字符(null)而不是空白字符(whitespace)来分割记录
|
||||
|
||||
**`du`**:计算文件占用的磁盘空间的命令
|
||||
|
||||
**`sort`**:对文本文件进行按行排序的命令
|
||||
|
||||
**`-n`**:根据数字大小进行比较
|
||||
|
||||
**`tail -10`**:输出文件结尾部分的命令(最后 10 个文件)
|
||||
|
||||
**`cut`**:从每行删除特定部分的命令
|
||||
|
||||
**`-f2`**:只选择特定字段值
|
||||
|
||||
**`-I{}`**:将初始参数中出现的每个替换字符串都替换为从标准输入读取的名称
|
||||
|
||||
**`-s`**:仅显示每个参数的总和
|
||||
|
||||
**`-h`**:用可读格式打印输出
|
||||
|
||||
**`{}`**:递归地查找目录,统计每个文件占用的磁盘空间
|
||||
|
||||
### 方法 4:
|
||||
|
||||
还有一种在 Linux 系统中查找最大的前 10 个文件的方法。
|
||||
|
||||
```
|
||||
# find / -type f -ls | sort -k 7 -r -n | head -10 | column -t | awk '{print $7,$11}'
|
||||
|
||||
1494845440 /swapfile
|
||||
1085984380 /home/magi/ubuntu-17.04-desktop-amd64.iso
|
||||
591003648 /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqTFU0XzkzUlJUZzA
|
||||
395770383 /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqeldzUmhPeC03Zm8
|
||||
394891761 /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqRGd4V0VrOXM4YVU
|
||||
103999072 /usr/lib/x86_64-linux-gnu/libOxideQtCore.so.0
|
||||
97356256 /usr/lib/firefox/libxul.so
|
||||
87896064 /var/lib/snapd/snaps/core_3604.snap
|
||||
87793664 /var/lib/snapd/snaps/core_3440.snap
|
||||
87089152 /var/lib/snapd/snaps/core_3247.snap
|
||||
|
||||
```
|
||||
|
||||
**详解:**
|
||||
|
||||
**`find`**:在目录结构中搜索文件的命令
|
||||
|
||||
**`/`**:在整个系统(从根目录开始)中查找
|
||||
|
||||
**`-type`**:指定文件类型
|
||||
|
||||
**`f`**:普通文件
|
||||
|
||||
**`-ls`**:在标准输出中以 `ls -dils` 的格式列出当前文件
|
||||
|
||||
**`|`**:控制操作符,将一条命令的输出传递给下一个命令以供进一步处理
|
||||
|
||||
**`sort`**:对文本文件进行按行排序的命令
|
||||
|
||||
**`-k`**:按指定列进行排序
|
||||
|
||||
**`-r`**:反转结果
|
||||
|
||||
**`-n`**:根据数字大小进行比较
|
||||
|
||||
**`head`**:输出文件开头部分的命令
|
||||
|
||||
**`-10`**:打印前 10 个文件
|
||||
|
||||
**`column`**:将其输入格式化为多列的命令
|
||||
|
||||
**`-t`**:确定输入包含的列数并创建一个表
|
||||
|
||||
**`awk`**:样式扫描和处理语言
|
||||
|
||||
**`'{print $7,$11}'`**:只打印指定的列
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-find-search-check-print-top-10-largest-biggest-files-in-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
译者:[jessie-pang](https://github.com/jessie-pang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/magesh/
|
||||
@ -0,0 +1,92 @@
|
||||
Tlog - 录制/播放终端 IO 和会话的工具
|
||||
======
|
||||
Tlog 是 Linux 中终端 I/O 录制和回放软件包。它用于实现集中式用户会话录制。它将所有经过的消息录制为 JSON 消息。录制为 JSON 格式的主要目的是将数据传送到 Elasticsearch 之类的存储服务,可以从中搜索和查询,以及回放。同时,他们保留所有通过的数据和时序。
|
||||
|
||||
Tlog 包含三个工具,分别是 tlog-rec、tlog-rec-session 和 tlog-play。
|
||||
|
||||
* `Tlog-rec tool` 一般用于录制终端、程序或 shell 的输入或输出。
|
||||
* `Tlog-rec-session tool` 用于录制整个终端会话的 I/O,并保护录制的用户。
|
||||
* `Tlog-rec-session tool` 用于回放录制。
|
||||
|
||||
|
||||
|
||||
在本文中,我将解释如何在 CentOS 7.4 服务器上安装 Tlog。
|
||||
|
||||
### 安装
|
||||
|
||||
在安装之前,我们需要确保我们的系统满足编译和安装程序的所有软件要求。在第一步中,使用以下命令更新系统仓库和软件包。
|
||||
```
|
||||
#yum update
|
||||
```
|
||||
|
||||
我们需要安装此软件安装所需的依赖项。在安装之前,我已经使用这些命令安装了所有依赖包。
|
||||
```
|
||||
#yum install wget gcc
|
||||
#yum install systemd-devel json-c-devel libcurl-devel m4
|
||||
```
|
||||
|
||||
完成这些安装后,我们可以下载该工具的[源码包][1]并根据需要将其解压到服务器上:
|
||||
```
|
||||
#wget https://github.com/Scribery/tlog/releases/download/v3/tlog-3.tar.gz
|
||||
#tar -xvf tlog-3.tar.gz
|
||||
# cd tlog-3
|
||||
```
|
||||
|
||||
现在,你可以使用我们通常的配置和制作方法开始构建此工具。
|
||||
```
|
||||
#./configure --prefix=/usr --sysconfdir=/etc && make
|
||||
#make install
|
||||
#ldconfig
|
||||
```
|
||||
|
||||
最后,你需要运行 `ldconfig`。它会创建必要的链接,并缓存命令行中指定目录中最近的共享库。( /etc/ld.so.conf 中的文件,以及信任的目录 (/lib and /usr/lib))
|
||||
|
||||
### Tlog 工作流程图
|
||||
|
||||
![Tlog working process][2]
|
||||
|
||||
首先,用户通过 PAM 进行身份验证登录。名称服务交换机(NSS)提供的 `tlog` 信息是用户的 shell。这初始化了 tlog 部分,并从环境变量/配置文件收集关于实际 shell 的信息,并以 PTY 的形式启动实际的 shell。然后通过 syslog 或 sd-journal 开始录制在终端和 PTY 之间传递的所有内容。
|
||||
|
||||
### 用法
|
||||
|
||||
你可以使用 `tlog-rec` 录制一个会话并使用 `tlog-play` 回放它来测试新安装的 tlog 是否能够正常录制和回放会话。
|
||||
|
||||
#### 录制到文件中
|
||||
|
||||
要将会话录制到文件中,请在命令行中执行 `tlog-rec`,如下所示:
|
||||
```
|
||||
tlog-rec --writer=file --file-path=tlog.log
|
||||
```
|
||||
|
||||
该命令会将我们的终端会话录制到名为 tlog.log 的文件中,并将其保存在命令中指定的路径中。
|
||||
|
||||
#### 从文件中回放
|
||||
|
||||
你可以在录制过程中或录制后使用 `tlog-play` 命令回放录制的会话。
|
||||
```
|
||||
tlog-play --reader=file --file-path=tlog.log
|
||||
```
|
||||
|
||||
该命令从指定的路径读取先前录制的文件 tlog.log。
|
||||
|
||||
### 总结
|
||||
|
||||
Tlog 是一个开源软件包,可用于实现集中式用户会话录制。它主要是作为一个更大的用户会话录制解决方案的一部分使用,但它被设计为独立且可重用的。该工具可以帮助录制用户所做的一切并将其存储在服务器的某个位置,以备将来参考。你可以从这个[文档][3]中获得关于这个软件包使用的更多细节。我希望这篇文章对你有用。请发表你的宝贵建议和意见。
|
||||
|
||||
### 关于 Saheetha Shameer (作者)
|
||||
我正在担任高级系统管理员。我是一名快速学习者,有轻微的倾向跟随行业中目前和正在出现的趋势。我的爱好包括听音乐、玩策略游戏、阅读和园艺。我对尝试各种美食也有很高的热情 :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linoxide.com/linux-how-to/tlog-tool-record-play-terminal-io-sessions/
|
||||
|
||||
作者:[Saheetha Shameer][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linoxide.com/author/saheethas/
|
||||
[1]:https://github.com/Scribery/tlog/releases/download/v3/tlog-3.tar.gz
|
||||
[2]:https://linoxide.com/wp-content/uploads/2018/01/Tlog-working-process.png
|
||||
[3]:https://github.com/Scribery/tlog/blob/master/README.md
|
||||
@ -1,180 +0,0 @@
|
||||
Ansible:像系统管理员一样思考的自动化框架
|
||||
======
|
||||
|
||||
这些年来,我已经写了许多关于DevOps工具的文章,也培训了这方面的人员,尽管这些工具很棒,但很明显,大多数都是按照开发人员的思路设计出来的。这也没有什么问题,因为以编程的方式接近配置管理是重点。不过,直到我开始接触Ansible,我才觉得这才是系统管理员喜欢的东西。
|
||||
|
||||
喜欢的一部分原因是Ansible与客户端计算机通信的方式,是通过SSH的。作为系统管理员,你们都非常熟悉通过SSH连接到计算机,所以从单词“去”的角度来看,你对Ansible的了解要比其他选择更好。
|
||||
|
||||
考虑到这一点,我打算写一些文章,探讨如何使用Ansible。这是一个很好的系统,但是当我第一次接触到这个系统的时候,不知道如何开始。也不是学习曲线陡峭。事实上,问题是在开始使用Ansible之前,我并没有太多的东西要学,这才是让人感到困惑的。例如,如果您不必安装客户端程序(Ansible没有在客户端计算机上安装任何软件),那么您将如何启动?
|
||||
|
||||
### 踏出第一步
|
||||
|
||||
起初Ansible对我来说非常困难的原因在于配置服务器/客户端的关系是非常灵活的,我不知道我该从何入手。事实是,Ansible并不关心你如何设置SSH系统。它会利用你现有的任何配置。需要考虑以下几件事情:
|
||||
|
||||
1. Ansible需要通过SSH连接到客户端计算机。
|
||||
2. 连接后,Ansible需要提升权限才能配置系统,安装软件包等等。
|
||||
|
||||
不幸的是,这两个考虑真的带来了一堆蠕虫。连接到远程计算机并提升权限是一件可怕的事情。出于某种原因,当您只需在远程计算机上安装代理并使用Chef或Puppet处理特权升级问题时,感觉就不那么差了。 Ansible并非不安全,而是安全的决定权在你手中。
|
||||
|
||||
接下来,我将列出一系列潜在的配置,以及每个配置的优缺点。这不是一个详尽的清单,但是你会受到正确的启发,去思考在你自己的环境中什么是理想的配置。也需要注意,我不会提到像Vagrant这样的系统,因为尽管Vagrant在构建测试和开发的敏捷架构时非常棒,但是和一堆服务器是非常不同的,因此考虑因素是极不相似的。
|
||||
|
||||
### 一些SSH场景
|
||||
|
||||
1)在Ansible配置中,以root用户密码进入远程计算机。
|
||||
|
||||
拥有这个想法是一个非常可怕的开始。这个设置的“优点”是它消除了对特权提升的需要,并且远程服务器上不需要其他用户帐户。 但是,这种便利的成本是不值得的。 首先,大多数系统不会让你在不改变默认配置的情况下以root身份进行SSH登录。 由于默认的配置都在固定的位置,坦率地说,允许root用户远程连接是一个不好的主意。 其次,将root密码放在Ansible机器上的纯文本配置文件中是不合适的。 真的,我提到了这种可能性,因为这是可能的,但这是应该避免的。 请记住,Ansible允许你自己配置连接,它可以让你做真正愚蠢的事情。 但是请不要这么做。
|
||||
|
||||
2)使用存储在Ansible配置中的密码,以普通用户的身份进入远程计算机。
|
||||
|
||||
这种情况的一个优点是它不需要太多的客户端配置。 大多数用户默认情况下都可以使用SSH,因此Ansible应该能够使用凭据并且能够正常登录。 我个人不喜欢在配置文件中以纯文本形式存储密码,但至少不是root密码。 如果您使用此方法,请务必考虑远程服务器上的权限提升方式。 我知道我还没有谈到权限提升,但是如果你在配置文件中配置了一个密码,这个密码可能会被用来获得sudo访问权限。 因此,一旦发生泄露,您不仅已经泄露了远程用户的帐户,还可能泄露整个系统。
|
||||
|
||||
3)以普通用户身份进入远程计算机,使用具有空密码的密钥对进行身份验证。
|
||||
|
||||
这消除了将密码存储在配置文件中的弊端,至少在登录的过程中消除了。 没有密码的密钥对并不理想,但这是我经常做的事情。 在我的个人内部网络中,我通常使用没有密码的密钥对来自动执行许多事情,如需要身份验证的定时任务。 这不是最安全的选择,因为私钥泄露意味着可以无限制地访问远程用户的帐户,但是相对于在配置文件中存储密码我更喜欢这种方式。
|
||||
|
||||
4)以普通用户的身份通过SSH连接到远程计算机,使用通过密码保护的密钥对进行身份验证。
|
||||
|
||||
这是处理远程访问的一种非常安全的方式,因为它需要两种不同的身份验证因素来解密:私钥和密码。 如果你只是以交互方式运行Ansible,这可能是理想的设置。 当你运行命令时,Ansible会提示你输入私钥,然后使用密钥对登录到远程系统。 是的,只需使用标准密码登录并且不用在配置文件中指定密码即可完成,但是如果不管怎样都要在命令行上输入密码,那为什么不在保护层添加密钥对呢?
|
||||
|
||||
5)使用密码保护密钥对进行SSH连接,但是使用ssh-agent“解锁”私钥。
|
||||
|
||||
这并不能完美地解决无人值守,自动化的Ansible命令的问题,但是它确实也使安全设置变得相当方便。 ssh-agent程序一次验证密码,然后使用该验证进行后续连接。当我使用Ansible时,这是我想要做的事情。如果我是完全值得信任的,我通常仍然使用没有密码的密钥对,但是这通常是因为我在我的家庭服务器上工作,是不是容易受到攻击的。
|
||||
|
||||
在配置SSH环境时还要记住一些其他注意事项。 也许你可以限制Ansible用户(通常是你的本地用户名),以便它只能从一个特定的IP地址登录。 也许您的Ansible服务器可以位于不同的子网中,位于强大的防火墙之后,因此其私钥更难以远程访问。 也许Ansible服务器本身没有安装SSH服务器,所以根本没法访问。 同样,Ansible的优势之一是它使用SSH协议进行通信,而且这是一个协议,你有多年的时间把你的系统调整到最适合你的环境的效果。 我不是宣传“最佳实践”的忠实粉丝,因为实际上最好的做法是考虑你的环境,并选择最适合你情况的设置。
|
||||
|
||||
### 权限提升
|
||||
|
||||
一旦您的Ansible服务器通过SSH连接到它的客户端,就需要能够提升特权。 如果你选择了上面的选项1,那么你已经是root了,这是一个有争议的问题。 但是由于没有人选择选项1(对吧?),您需要考虑客户端计算机上的普通用户如何获得访问权限。 Ansible支持各种权限提升的系统,但在Linux中,最常用的选项是sudo和su。 和SSH一样,有几种情况需要考虑,虽然肯定还有其他选择。
|
||||
|
||||
1)使用su提升权限。
|
||||
|
||||
对于RedHat/CentOS用户来说,可能默认是使用su来获得系统访问权限。 默认情况下,这些系统在安装过程中配置了root密码,要想获得特殊访问权限,您需要输入该密码。使用su的问题在于,虽说它可以让您完全访问远程系统,不过您确实可以完全访问远程系统。 (是的,这是讽刺。)另外,su程序没有使用密钥对进行身份验证的能力,所以密码必须以交互方式输入或存储在配置文件中。 由于它实际上是root密码,因此将其存储在配置文件中听起来像一个可怕的想法,因为它就是。
|
||||
|
||||
2)使用sudo提升权限。
|
||||
|
||||
这就是Debian/Ubuntu系统的配置方式。 正常用户组中的用户可以使用sudo命令并使用root权限执行该命令。 随之而来的是,这仍然存在密码存储或交互式输入的问题。 由于在配置文件中存储用户的密码看起来不太可怕,我猜这是使用su的一个步骤,但是如果密码被泄露,仍然可以完全访问系统。 (毕竟,输入`sudo`和`su -`都将允许用户成为root用户,就像拥有root密码一样。)
|
||||
|
||||
3) 使用sudo提升权限,并在sudoers文件中配置NOPASSWD。
|
||||
|
||||
再者,在我的本地环境中,我就是这么做的。 这并不完美,因为它给予用户帐户无限制的root权限,并且不需要任何密码。 但是,当我这样做并且使用没有密码短语的SSH密钥对时,我可以让Ansible命令更轻松的自动化。 我会再次注意到,虽然这很方便,但这不是一个非常安全的想法。
|
||||
|
||||
4)使用sudo提升权限,并在特定的可执行文件上配置NOPASSWD。
|
||||
|
||||
这个想法可能是安全性和便利性的最佳折衷。 基本上,如果你知道你打算用Ansible做什么,那么你可以为远程用户使用的那些应用程序提供NOPASSWD权限。 这可能会让人有些困惑,因为Ansible使用Python来处理很多事情,但是有足够的尝试和错误,你应该能够弄清原理。 这是额外的工作,但确实消除了一些明显的安全漏洞。
|
||||
|
||||
### 计划实施
|
||||
|
||||
一旦你决定如何处理Ansible认证和权限提升,就需要设置它。 在熟悉Ansible之后,您可能会使用该工具来帮助“引导”新客户端,但首先手动配置客户端非常重要,以便您知道发生了什么事情。 将你熟悉的事情变得自动化比从自动化开始要好。
|
||||
|
||||
我已经写过关于SSH密钥对的文章,网上有无数的设置类的文章。 来自Ansible服务器的简短版本看起来像这样:
|
||||
|
||||
```
|
||||
# ssh-keygen
|
||||
# ssh-copy-id -i .ssh/id_dsa.pub remoteuser@remote.computer.ip
|
||||
# ssh remoteuser@remote.computer.ip
|
||||
```
|
||||
|
||||
如果您在创建密钥对时选择不使用密码,最后一步您应该可以直接进入远程计算机,而不用输入密码或密钥串。
|
||||
|
||||
为了在sudo中设置权限提升,您需要编辑sudoers文件。 你不应该直接编辑文件,而是使用:
|
||||
|
||||
```
|
||||
# sudo visudo
|
||||
```
|
||||
|
||||
这将打开sudoers文件并允许您安全地进行更改(保存时会进行错误检查,所以您不会意外地因为输入错误将自己锁住)。 这个文件中有一些例子,所以你应该能够弄清楚如何分配你想要的确切的权限。
|
||||
|
||||
一旦配置完成,您应该在使用Ansible之前进行手动测试。 尝试SSH到远程客户端,然后尝试使用您选择的任何方法提升权限。 一旦你确认配置的这种方式可以连接,就可以安装Ansible了。
|
||||
|
||||
### Ansible安装
|
||||
|
||||
由于Ansible程序仅安装在一台计算机上,因此开始并不是一件繁重的工作。 Red Hat/Ubuntu系统的软件包安装有点不同,但都不是很困难。
|
||||
|
||||
在Red Hat/CentOS中,首先启用EPEL库:
|
||||
|
||||
```
|
||||
sudo yum install epel-release
|
||||
```
|
||||
|
||||
然后安装Ansible:
|
||||
|
||||
```
|
||||
sudo yum install ansible
|
||||
```
|
||||
|
||||
在Ubuntu中,首先启用Ansible PPA:
|
||||
|
||||
```
|
||||
sudo apt-add-repository spa:ansible/ansible
|
||||
(press ENTER to access the key and add the repo)
|
||||
```
|
||||
|
||||
然后安装Ansible:
|
||||
|
||||
```
|
||||
sudo apt-get update
|
||||
sudo apt-get install ansible
|
||||
```
|
||||
|
||||
### Ansible主机文件配置
|
||||
|
||||
Ansible系统无法知道您希望它控制哪个客户端,除非您给它一个计算机列表。 该列表非常简单,看起来像这样:
|
||||
|
||||
```
|
||||
# file /etc/ansible/hosts
|
||||
|
||||
[webservers]
|
||||
blogserver ansible_host=192.168.1.5
|
||||
wikiserver ansible_host=192.168.1.10
|
||||
|
||||
[dbservers]
|
||||
mysql_1 ansible_host=192.168.1.22
|
||||
pgsql_1 ansible_host=192.168.1.23
|
||||
```
|
||||
|
||||
括号内的部分是指定组。 单个主机可以列在多个组中,而Ansible可以指向单个主机或组。 这也是配置文件,比如纯文本密码的东西将被存储,如果这是你计划的那种设置。 配置文件中的每一行配置一个主机地址,并且可以在ansible_host语句之后添加多个声明。 一些有用的选项是:
|
||||
|
||||
```
|
||||
ansible_ssh_pass
|
||||
ansible_become
|
||||
ansible_become_method
|
||||
ansible_become_user
|
||||
ansible_become_pass
|
||||
```
|
||||
|
||||
### Ansible Vault保险库
|
||||
|
||||
(译者注:Vault作为 ansible 的一项新功能可将例如passwords,keys等敏感数据文件进行加密,而非明文存放)
|
||||
|
||||
我也应该注意到,尽管安装程序比较复杂,而且不是在您首次进入Ansible世界时可能会做的事情,但该程序确实提供了一种方法来加密保险库中的密码。 一旦您熟悉Ansible,并且希望将其投入生产,将这些密码存储在加密的Ansible库中是非常理想的。 但是本着先学会爬再学会走的精神,我建议首先在非生产环境下使用无密码方法。
|
||||
|
||||
### 系统测试
|
||||
|
||||
最后,你应该测试你的系统,以确保客户端可以正常连接。 ping测试将确保Ansible计算机可以ping每个主机:
|
||||
|
||||
```
|
||||
ansible -m ping all
|
||||
```
|
||||
|
||||
运行后,如果ping成功,您应该看到每个定义的主机显示ping的消息:pong。 这实际上并没有测试认证,只是测试网络连接。 试试这个来测试你的认证:
|
||||
|
||||
```
|
||||
ansible -m shell -a 'uptime' webservers
|
||||
```
|
||||
|
||||
您应该可以看到webservers组中每个主机的运行时间命令的结果。
|
||||
|
||||
在后续文章中,我计划开始深入Ansible管理远程计算机的功能。 我将介绍各种模块,以及如何使用ad-hoc模式来完成一些按键操作,这些操作在命令行上单独处理都需要很长时间。 如果您没有从上面的示例Ansible命令中获得预期的结果,请花些时间确保身份验证正在运行。 如果遇到困难,请查阅[Ansible文档][1]获取更多帮助。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxjournal.com/content/ansible-automation-framework-thinks-sysadmin
|
||||
|
||||
作者:[Shawn Powers][a]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxjournal.com/users/shawn-powers
|
||||
[1]:http://docs.ansible.com
|
||||
170
translated/tech/20180127 Your instant Kubernetes cluster.md
Normal file
170
translated/tech/20180127 Your instant Kubernetes cluster.md
Normal file
@ -0,0 +1,170 @@
|
||||
“开箱即用” 的 Kubernetes 集群
|
||||
============================================================
|
||||
|
||||
|
||||
这是我以前的 [10 分钟内配置 Kubernetes][10] 教程的精简版和更新版。我删除了一些我认为可以去掉的内容,所以,这个指南仍然是可理解的。当你想在云上创建一个集群或者尽可能快地构建基础设施时,你可能会用到它。
|
||||
|
||||
### 1.0 挑选一个主机
|
||||
|
||||
我们在本指南中将使用 Ubuntu 16.04,这样你就可以直接拷贝/粘贴所有的指令。下面是我用本指南测试过的几种环境。根据你运行的主机,你可以从中挑选一个。
|
||||
|
||||
* [DigitalOcean][1] - 开发者云
|
||||
|
||||
* [Civo][2] - UK 开发者云
|
||||
|
||||
* [Packet][3] - 裸机云
|
||||
|
||||
* 2x Dell Intel i7 服务器 —— 它在我家中
|
||||
|
||||
> Civo 是一个相对较新的开发者云,我比较喜欢的一点是,它开机时间只有 25 秒,我就在英国,因此,它的延迟很低。
|
||||
|
||||
### 1.1 准备机器
|
||||
|
||||
你可以使用一个单台主机进行测试,但是,我建议你至少使用三台机器,这样你就有一个主节点和两个工作节点。
|
||||
|
||||
下面是一些其他的指导原则:
|
||||
|
||||
* 最好选至少有 2 GB 内存的双核主机
|
||||
|
||||
* 在准备主机的时候,如果你可以自定义用户名,那么就不要使用 root。例如,Civo 通常让你在 `ubuntu`、`civo` 或者 `root` 中选一个。
|
||||
|
||||
现在,在每台机器上都运行以下的步骤。它将需要 5-10 钟时间。如果你觉得太慢了,你可以使用我的脚本 [kept in a Gist][11]:
|
||||
|
||||
```
|
||||
$ curl -sL https://gist.githubusercontent.com/alexellis/e8bbec45c75ea38da5547746c0ca4b0c/raw/23fc4cd13910eac646b13c4f8812bab3eeebab4c/configure.sh | sh
|
||||
|
||||
```
|
||||
|
||||
### 1.2 登入和安装 Docker
|
||||
|
||||
从 Ubuntu 的 apt 仓库中安装 Docker。它的版本可能有点老,但是,Kubernetes 在老版本的 Docker 中是测试过的,工作的很好。
|
||||
|
||||
```
|
||||
$ sudo apt-get update \
|
||||
&& sudo apt-get install -qy docker.io
|
||||
|
||||
```
|
||||
|
||||
### 1.3 禁用 swap 文件
|
||||
|
||||
这是 Kubernetes 的强制步骤。实现它很简单,编辑 `/etc/fstab` 文件,然后注释掉引用 swap 的行即可。
|
||||
|
||||
保存它,重启后输入 `sudo swapoff -a`。
|
||||
|
||||
> 一开始就禁用 swap 内存,你可能觉得这个要求很奇怪,如果你对这个做法感到好奇,你可以去 [这里阅读它的相关内容][4]。
|
||||
|
||||
### 1.4 安装 Kubernetes 包
|
||||
|
||||
```
|
||||
$ sudo apt-get update \
|
||||
&& sudo apt-get install -y apt-transport-https \
|
||||
&& curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -
|
||||
|
||||
$ echo "deb http://apt.kubernetes.io/ kubernetes-xenial main" \
|
||||
| sudo tee -a /etc/apt/sources.list.d/kubernetes.list \
|
||||
&& sudo apt-get update
|
||||
|
||||
$ sudo apt-get update \
|
||||
&& sudo apt-get install -y \
|
||||
kubelet \
|
||||
kubeadm \
|
||||
kubernetes-cni
|
||||
|
||||
```
|
||||
|
||||
### 1.5 创建集群
|
||||
|
||||
这时候,我们使用 `kubeadm` 初始化主节点并创建集群。这一步仅在主节点上操作。
|
||||
|
||||
> 虽然有警告,但是 [Weaveworks][5] 和 Lucas(他们是维护者)向我保证,`kubeadm` 是可用于生产系统的。
|
||||
|
||||
```
|
||||
$ sudo kubeadm init
|
||||
|
||||
```
|
||||
|
||||
如果你错过一个步骤或者有问题,`kubeadm` 将会及时告诉你。
|
||||
|
||||
我们复制一份 Kube 配置:
|
||||
|
||||
```
|
||||
mkdir -p $HOME/.kube
|
||||
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
|
||||
sudo chown $(id -u):$(id -g) $HOME/.kube/config
|
||||
|
||||
```
|
||||
|
||||
确保你一定要记下如下的加入 token 命令。
|
||||
|
||||
```
|
||||
$ sudo kubeadm join --token c30633.d178035db2b4bb9a 10.0.0.5:6443 --discovery-token-ca-cert-hash sha256:<hash>
|
||||
|
||||
```
|
||||
|
||||
### 2.0 安装网络
|
||||
|
||||
Kubernetes 可用于任何网络供应商的产品或服务,但是,默认情况下什么也没有,因此,我们使用来自 [Weaveworks][12] 的 Weave Net,它是 Kebernetes 社区中非常流行的选择之一。它倾向于不需要额外配置的 “开箱即用”。
|
||||
|
||||
```
|
||||
$ kubectl apply -f "https://cloud.weave.works/k8s/net?k8s-version=$(kubectl version | base64 | tr -d '\n')"
|
||||
|
||||
```
|
||||
|
||||
如果在你的主机上启用了私有网络,那么,你可能需要去修改 Weavenet 使用的私有子网络,以便于为 Pods(容器)分配 IP 地址。下面是命令示例:
|
||||
|
||||
```
|
||||
$ curl -SL "https://cloud.weave.works/k8s/net?k8s-version=$(kubectl version | base64 | tr -d '\n')&env.IPALLOC_RANGE=172.16.6.64/27" \
|
||||
| kubectl apply -f -
|
||||
|
||||
```
|
||||
|
||||
> Weave 也有很酷的称为 Weave Cloud 的可视化工具。它是免费的,你可以在它上面看到你的 Pods 之间的路径流量。[这里有一个使用 OpenFaaS 项目的示例][6]。
|
||||
|
||||
### 2.2 在集群中加入工作节点
|
||||
|
||||
现在,你可以切换到你的每一台工作节点,然后使用 1.5 节中的 `kubeadm join` 命令。运行完成后,登出那个工作节点。
|
||||
|
||||
### 3.0 收益
|
||||
|
||||
到此为止 —— 我们全部配置完成了。你现在有一个正在运行着的集群,你可以在它上面部署应用程序。如果你需要设置仪表板 UI,你可以去参考 [Kubernetes 文档][13]。
|
||||
|
||||
```
|
||||
$ kubectl get nodes
|
||||
NAME STATUS ROLES AGE VERSION
|
||||
openfaas1 Ready master 20m v1.9.2
|
||||
openfaas2 Ready <none> 19m v1.9.2
|
||||
openfaas3 Ready <none> 19m v1.9.2
|
||||
|
||||
```
|
||||
|
||||
如果你想看到我一步一步创建集群并且展示 `kubectl` 如何工作的视频,你可以看下面我的视频,你可以订阅它。
|
||||
|
||||
|
||||
想在你的 Mac 电脑上,使用 Minikube 或者 Docker 的 Mac Edge 版本,安装一个 “开箱即用” 的 Kubernetes 集群,[阅读在这里的我的评估和第一印象][14]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.alexellis.io/your-instant-kubernetes-cluster/
|
||||
|
||||
作者:[Alex Ellis ][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.alexellis.io/author/alex/
|
||||
[1]:https://www.digitalocean.com/
|
||||
[2]:https://www.civo.com/
|
||||
[3]:https://packet.net/
|
||||
[4]:https://github.com/kubernetes/kubernetes/issues/53533
|
||||
[5]:https://weave.works/
|
||||
[6]:https://www.weave.works/blog/openfaas-gke
|
||||
[7]:https://blog.alexellis.io/tag/kubernetes/
|
||||
[8]:https://blog.alexellis.io/tag/k8s/
|
||||
[9]:https://blog.alexellis.io/tag/cloud-native/
|
||||
[10]:https://www.youtube.com/watch?v=6xJwQgDnMFE
|
||||
[11]:https://gist.github.com/alexellis/e8bbec45c75ea38da5547746c0ca4b0c
|
||||
[12]:https://weave.works/
|
||||
[13]:https://kubernetes.io/docs/tasks/access-application-cluster/web-ui-dashboard/
|
||||
[14]:https://blog.alexellis.io/docker-for-mac-with-kubernetes/
|
||||
[15]:https://blog.alexellis.io/your-instant-kubernetes-cluster/#
|
||||
@ -0,0 +1,70 @@
|
||||
深入看看 Facebook 的开源计划
|
||||
============================================================
|
||||
|
||||
### Facebook 开发人员 Christine Abernathy 讨论了开源如何帮助公司分享见解并推动创新。
|
||||
|
||||

|
||||
图像来源:opensource.com
|
||||
|
||||
|
||||
开源每年在变得无处不在,从[政府直辖市][11]到[大学] [12]都有。各种规模的公司也越来越多地转向开源软件。事实上,一些公司正在通过财务支持项目或与开发人员合作进一步推进开源。
|
||||
|
||||
例如,Facebook 的开源计划鼓励其他人开源发布他们的代码,同时与社区合作支持开源项目。 [Christine Abernathy][13],一名 Facebook 开发者,开源支持者,公司开源团队成员,去年 11 月访问了罗切斯特理工学院,在[ 11 月][14] 的 FOSS 系列演讲中发表了演讲。在她的演讲中,Abernathy 解释了 Facebook 如何开源以及为什么它是公司所做工作的重要组成部分。
|
||||
|
||||
### Facebook 和开源
|
||||
|
||||
Abernathy 说,开源在 Facebook 创建社区和使世界更加紧密的使命中扮演着重要的角色。这种意识形态的匹配是 Facebook 参与开源的一个激励因素。此外,Facebook 面临着独特的基础设施和开发挑战,而开源则为公司提供了一个平台,以共享可帮助他人的解决方案。开源还提供了一种加速创新和创建更好软件的方法,帮助工程团队生产更好的软件并更透明地工作。今天,Facebook 在 GitHub 上有 443个 项目包括 122,000 个分支,292,000 个提交和 732,000 个关注。
|
||||
|
||||
|
||||

|
||||
|
||||
一些以开源方式发布的 Facebook 项目包括 React、GraphQL、Caffe2 等等。(图片提供:Christine Abernathy 图片,经许可使用)
|
||||
|
||||
### 得到的教训
|
||||
|
||||
Abernathy 强调说 Facebook 已经从开源社区吸取了很多教训,并期待学到更多。她明确了三个最重要的:
|
||||
|
||||
* 分享有用的东西
|
||||
|
||||
* 突出你的英雄
|
||||
|
||||
* 修复常见的痛点
|
||||
|
||||
_Christine Abernathy 作为 FOSS 演讲系列的嘉宾一员参观了 RIT。每个月,来自开源世界的演讲嘉宾都会与对免费和开源软件感兴趣的学生分享关于开源世界智慧、见解、建议。 [FOSS @MAGIC][3]社区感谢 Abernathy 作为演讲嘉宾出席。_
|
||||
|
||||
### 关于作者
|
||||
|
||||
[][15]
|
||||
Justin 是[罗切斯特理工学院][4]主修网络与系统管理的学生。他目前是 [Fedora Project][5] 的贡献者。在 Fedora 中,Justin 是 [Fedora Magazine][6] 的主编,[社区的领导][7]。。。[更多关于 Justin W. Flory][8]
|
||||
|
||||
[关于我更多][9]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/inside-facebooks-open-source-program
|
||||
|
||||
作者:[Justin W. Flory ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jflory
|
||||
[1]:https://opensource.com/file/383786
|
||||
[2]:https://opensource.com/article/18/1/inside-facebooks-open-source-program?rate=H9_bfSwXiJfi2tvOLiDxC_tbC2xkEOYtCl-CiTq49SA
|
||||
[3]:http://foss.rit.edu/
|
||||
[4]:https://www.rit.edu/
|
||||
[5]:https://fedoraproject.org/wiki/Overview
|
||||
[6]:https://fedoramagazine.org/
|
||||
[7]:https://fedoraproject.org/wiki/CommOps
|
||||
[8]:https://opensource.com/users/jflory
|
||||
[9]:https://opensource.com/users/jflory
|
||||
[10]:https://opensource.com/user/74361/feed
|
||||
[11]:https://opensource.com/article/17/8/tirana-government-chooses-open-source
|
||||
[12]:https://opensource.com/article/16/12/2016-election-night-hackathon
|
||||
[13]:https://twitter.com/abernathyca
|
||||
[14]:https://www.eventbrite.com/e/fossmagic-talks-open-source-facebook-with-christine-abernathy-tickets-38955037566#
|
||||
[15]:https://opensource.com/users/jflory
|
||||
[16]:https://opensource.com/users/jflory
|
||||
[17]:https://opensource.com/users/jflory
|
||||
[18]:https://opensource.com/article/18/1/inside-facebooks-open-source-program#comments
|
||||
@ -1,138 +0,0 @@
|
||||
#我喜欢Vue的10个方面
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
我喜欢Vue。当我在2016年第一次接触它时,也许那时我已有了JavaScript框架疲劳的观点,因为我已经具有Backbone, Angular, React等框架的经验
|
||||
而且我也没有过度的热情去尝试一个新的框架。直到我在hacker news上读到一份评论,其描述Vue是类似于“新jquery”的JavaScript框架,从而激发了我的好奇心。在那之前,我已经相当满意React这个框架,它是一个很好的框架,基于可靠的设计原则,围绕着视图模板,虚拟DOM和状态响应等技术。而Vue也提供了这些重要的内容。在这篇文章中,我旨在解释为什么Vue适合我,为什么在上文中那些我尝试过的框架中选择它。也许你将同意我的一些观点,但至少我希望能够给大家关于使用Vue开发现代JavaScript应用的一些灵感。
|
||||
|
||||
##1\. 极少的模板语法
|
||||
|
||||
Vue默认提供的视图模板语法是极小的,简洁的和可扩展的。像其他Vue部分一样,可以很简单的使用类似JSX一样语法而不使用标准的模板语法(甚至有官方文档说明如何这样做),但是我觉得没必要这么做。关于JSX有好的方面,也有一些有依据的批评,如混淆了JavaScript和HTML,使得很容易在模板中编写出复杂的代码,而本来应该分开写在不同的地方的。
|
||||
|
||||
Vue没有使用标准的HTML来编写视图模板,而是使用极少的模板语法来处理简单的事情,如基于视图数据迭代创建元素。
|
||||
```
|
||||
<template>
|
||||
<div id="app">
|
||||
<ul>
|
||||
<li v-for='number in numbers' :key='number'>{{ number }}</li>
|
||||
</ul>
|
||||
<form @submit.prevent='addNumber'>
|
||||
<input type='text' v-model='newNumber'>
|
||||
<button type='submit'>Add another number</button>
|
||||
</form>
|
||||
</div>
|
||||
</template>
|
||||
|
||||
<script>
|
||||
export default {
|
||||
name: 'app',
|
||||
methods: {
|
||||
addNumber() {
|
||||
const num = +this.newNumber;
|
||||
if (typeof num === 'number' && !isNaN(num)) {
|
||||
this.numbers.push(num);
|
||||
}
|
||||
}
|
||||
},
|
||||
data() {
|
||||
return {
|
||||
newNumber: null,
|
||||
numbers: [1, 23, 52, 46]
|
||||
};
|
||||
}
|
||||
}
|
||||
</script>
|
||||
|
||||
<style lang="scss">
|
||||
ul {
|
||||
padding: 0;
|
||||
li {
|
||||
list-style-type: none;
|
||||
color: blue;
|
||||
}
|
||||
}
|
||||
</style>
|
||||
```
|
||||
|
||||
|
||||
我也喜欢Vue提供的简短绑定语法,“:”用于在模板中绑定数据变量,“@”用于绑定事件。这是一个细节,但写起来很爽而且能够让你的组件代码简洁。
|
||||
|
||||
##2\. 单文件组件
|
||||
|
||||
大多数人使用Vue,都使用“单文件组件”。本质上就是一个.vue文件对应一个组件,其中包含三部分(CSS,HTML和JavaScript)
|
||||
|
||||
这种技术结合是对的。它让人很容易理解每个组件在一个单独的地方,同时也非常好的鼓励了大家保持每个组件代码的简短。如果你的组件中JavaScript,CSS和HTML代码占了很多行,那么就到了进一步模块化的时刻了。
|
||||
|
||||
在使用Vue组件中的<style>标签时,我们可以添加“scoped”属性。这会让整个样式完全的封装到当前组件,意思是在组件中如果我们写了.name的css选择器,它不会把样式应用到其他组件中。我非常喜欢这种方式来应用样式而不是像其他主要框架流行在JS中编写CSS的方式。
|
||||
|
||||
关于单文件组件另一个好处是.vue文件是一个有效的HTML5文件。
|
||||
<template>, <script>, <style> 都是w3c官方规范的标签。这就表示很多我们用于开发过程中的工具(如linters,LCTT 译注:一种代码检查工具插件)能够开箱即用或者添加一些适配后使用。
|
||||
|
||||
##3\. Vue “新的 jQuery”
|
||||
|
||||
事实上,这两个库不相似而且用于做不同的事。让我提供给你一个很精辟的类比(我实际上非常喜欢描述Vue和Jquery之间的关系):披头士乐队和齐柏林飞船乐队(LCTT译注:两个都是英国著名的乐队)。披头士乐队不需要介绍,他们是20世纪60年代最大的和最有影响力的乐队。但很难说披头士乐队是20世纪70年代最大的乐队,因为有时这个荣耀属于是齐柏林飞船乐队。你可以说两个乐队之间有着微妙的音乐联系或者说他们的音乐是明显不同的,但两者一些先前的艺术和影响力是不可否认的。也许21世纪初JavaScript的世界就像20世纪70年代的音乐世界一样,随着Vue获得更多关注使用,只会吸引更多粉丝。
|
||||
|
||||
一些使jQuery牛逼的哲学理念在Vue中也有呈现:非常容易的学习曲线但却具有基于现代web标准构建牛逼web应用所有你需要的功能。Vue的核心本质上就是在JavaScript对象上包装了一层。
|
||||
|
||||
##4\. 极易扩展
|
||||
|
||||
正如前述,Vue默认使用标准的HTML,JS和CSS构建组件,但可以很容易插入其他技术。如果我们想使用pug(LCTT译注:一款功能丰富的模板引擎,专门为 Node.js平台开发)替换HTML或者使用Typescript(LCTT译注:一种由微软开发的编程语言,是JavaScript的一个超集)替换js或者Sass(LCTT译注:一种CSS扩展语言)替换CSS,只需要安装相关的node模块和在我们的单文件组件中添加一个属性到相关的标签即可。你甚至可以在一个项目中混合搭配使用-如一些组件使用HTML其他使用pug-然而我不太确定这么做是最好的做法。
|
||||
|
||||
##5\. 虚拟DOM
|
||||
|
||||
虚拟DOM是很好的技术,被用于现如今很多框架。这就表示这些框架
|
||||
能够做到根据我们状态的改变来高效的完成DOM更新,减少重新渲染和优化我们应用的性能。现如今每个框架都有虚拟DOM技术,所以虽然它不是什么独特的东西,但它仍然很出色。
|
||||
|
||||
##6\. Vuex
|
||||
|
||||
对于大多数应用,管理状态成为一个棘手的问题,单独使用一个视图库不能解决这个问题。Vue使用Vuex库来解决这个问题。Vuex很容易构建而且和Vue集成的很好。熟悉redux(另一个管理状态的库)的学习Vuex会觉得轻车熟路,但是我发现Vue和Vuex集成起来更加简洁。最新JavaScript草案中(LCTT译注:应该是指ES7)提供了对象展开运算符(LCTT译注:符号为...),允许我们在状态或函数中进行合并,以操纵从Vuex到需要它的Vue组件中的状态。
|
||||
|
||||
##7\. Vue的命令行界面(CLI)
|
||||
|
||||
Vue提供的命令行界面非常不错,很容易开始搭建一个基于Webpack(LCTT译注:一个前端资源加载/打包工具)的Vue项目。在终端中一行命令即可创建包含单文件组件支持,babel(LCTT译注:js语法转换器),linting(LCTT译注:代码检查工具),测试工具支持,以及合理的项目结构。
|
||||
然而有一个命令,我从CLI中错过了,那就是“vue构建”。
|
||||
```
|
||||
如: `echo '<template><h1>Hello World!</h1></template>' > Hello.vue && vue build Hello.vue -o`
|
||||
```
|
||||
|
||||
“vue build”命令构建和运行组件并在浏览器中测试看起来非常简单。很不幸这个命令后来在Vue中删除了,现在推荐使用Poi. Poi本质上是在Webpack工具上封装了一层,但我不认我它像tweet上说的一样简单。
|
||||
|
||||
##8\. 重新渲染优化
|
||||
|
||||
|
||||
使用Vue,你不必声明DOM的哪部分应该被重新渲染。我从来都不喜欢操纵React组件的渲染,像在shouldComponentUpdate方法中停止整个DOM树重新渲染这种。Vue在这方面非常巧妙。
|
||||
|
||||
##9\. 容易获得帮助
|
||||
|
||||
|
||||
Vue已经达到了使用这个框架来构建各种各样的应用的一种群聚效应。开发文档非常完善。如果你需要进一步的帮助,有多种渠道可用,每个渠道都有很多活跃开发者:stackoverflow, discord,twitter等。相对于其他用户量少的框架,这就应该给你更多的信心来使用Vue构建应用。
|
||||
|
||||
##10\. 多机构维护
|
||||
|
||||
我认为,一个开源库,在发展方向方面的投票权利没有被单一机构操纵过多,是一个好事。就如同React的许可证问题(现已解决),Vue就不可能涉及到。
|
||||
|
||||
|
||||
总之,作为你接下来要开发的任何JavaScript项目,我认为Vue都是一个极好的选择。Vue可用的生态圈比我博客中涉及到的其他库都要大。如果想要更全面的产品,你可以关注Nuxt.js。如果你需要一些可重复使用的样式组件你可以关注类似Vuetify的库。
|
||||
Vue是2017年增长最快的库之一,我预测在2018年增长速度不会放缓。
|
||||
|
||||
如果你有空闲的30分钟,为什么不尝试下Vue,看它可以给你提供什么呢?
|
||||
|
||||
P.S. — 这篇文档很好的展示了Vue和其他框架的比较:[https://vuejs.org/v2/guide/comparison.html][1]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.com/@dalaidunc/10-things-i-love-about-vue-505886ddaff2
|
||||
|
||||
作者:[Duncan Grant ][a]
|
||||
译者:[yizhuoyan](https://github.com/yizhuoyan)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.com/@dalaidunc
|
||||
[1]:https://vuejs.org/v2/guide/comparison.html
|
||||
@ -0,0 +1,176 @@
|
||||
微服务 vs. 整体服务:如何选择
|
||||
============================================================
|
||||
|
||||
### 任何一种架构都是有利有弊的,而能满足你组织的独特需要的决策才是正确的选择。
|
||||
|
||||
|
||||

|
||||
Image by :
|
||||
|
||||
Onasill ~ Bill Badzo on [Flickr][11]. [CC BY-NC-SA 2.0][12]. Modified by Opensource.com.
|
||||
|
||||
对于许多初创公司来说,传统的知识认为,从单一整体架构开始,而不是使用微服务。但是,我们还有别的选择吗?
|
||||
|
||||
这本新书 —— [初创公司的微服务][13],从许多 CIO 们理解的微服务的角度,解释了微服务的优点与缺点。
|
||||
|
||||
对于初创公司,虽然不同的 CTO 对此给出的建议是不同的,但是他们都一致认为环境和性能很重要。如果你正考虑你的业务到底是采用微服务还是单一整体架构更好,下面讨论的这些因素正好可以为你提供一些参考。
|
||||
|
||||
### 理解范围
|
||||
|
||||
更多有关微服务的内容
|
||||
|
||||
* [如何向你的 CEO 解释微服务][1]
|
||||
|
||||
* [免费电子书:微服务 vs. 面向服务的架构][2]
|
||||
|
||||
* [DevOps 确保微服务安全][3]
|
||||
|
||||
首先,我们先来准确定义我们所谓的 “整体服务” 和 “微服务” 是什么。
|
||||
|
||||
微服务是一种方法,它开发一个单一的应用程序来作为构成整体服务的小服务,每个小服务都运行在它自己的进程中,并且使用一个轻量级的机制进行通讯,通常是一个 HTTP 资源 API。这些服务都围绕业务能力来构建,并且可依赖全自动部署机制来独立部署。
|
||||
|
||||
一个整体应用程序是按单个的、统一的单元来构建,并且,通常情况下它是基于一个大量的代码来实现的。一般来说,一个整体服务是由三部分组成的:一个数据库、一个客户端用户界面(由 HTML 页面和/或运行在浏览器中的 JavaScript 组成)、以及一个服务器端应用程序。
|
||||
|
||||
“系统架构处于一个范围之中”,Zachary Crockett,[Particle][14] 的 CTO,在一次访谈中,他说,”在讨论微服务时,人们倾向于关注这个范围的一端:许多极小的应用程序给其它应用程序传递了过多的信息。在另一端,有一个巨大的整体服务做了太多的事情。在任何现实中的系统上,在这两个极端之间有很多合适的面向服务的架构“。
|
||||
|
||||
根据你的情况不同,不论是使用整体服务还是微服务都有很多很好的理由。
|
||||
|
||||
"我们希望为每个服务使用最好的工具”,Julien Lemoine 说,他是 Algolia 的 CTO。
|
||||
|
||||
与很多人的想法正好相反,整体服务并不是过去遗留下来的过时的架构。在某些情况下,整体服务是非常理想的。我采访了 Steven Czerwinski 之后,更好地理解了这一点,他是 [Scaylr][15] 的工程主管,前谷歌员工。
|
||||
|
||||
“尽管我们在谷歌时有使用微服务的一些好的经验,我们现在 [在 Scalyr] 却使用的是整体服务的架构,因为一个整体服务架构意味着我们的工作量更少,我们只有两位工程师。“ 他解释说。(采访他时,Scaylr 正处于早期阶段)
|
||||
|
||||
但是,如果你的团队使用微服务的经验很丰富,并且你对你们的发展方向有明确的想法,微服务可能是一个很好的 替代者。
|
||||
|
||||
Julien Lemoine,[Algolia][16] 的 CTO,在这个问题上,他认为:”我们通常从使用微服务开始,主要目的是我们可以使用不同的技术来构建我们的服务,因为如下的两个主要原因:
|
||||
|
||||
* 我们想为每个服务使用最好的工具。我们的搜索 API 是在底层做过高度优化的,而 C++ 是非常适合这项工作的。他说,在任何地方都使用 C++ 是一种生产力的浪费,尤其是在构建仪表板方面。
|
||||
|
||||
* 我们希望使用最好的人才,而只使用一种技术将极大地限制我们的选择。这就是为什么在公司中有不同语言的原因。“
|
||||
|
||||
如果你的团队已经准备好从一开始就使用微服务,这样你的组织从一开始就可以适应微服务环境的开发节奏。
|
||||
|
||||
### 权衡利弊
|
||||
|
||||
在你决定那种方法更适合你的组织之前,考虑清楚每种方法的优缺点是非常重要的。
|
||||
|
||||
### 整体服务
|
||||
|
||||
### 优点:
|
||||
|
||||
* **很少担心横向联系:** 大多数应用程序开发者都担心横向联系,比如,日志、速度限制、以及像审计跟踪和 DoS 防护这样的安全特性。当所有的东西都运行在同一个应用程序中时,通过组件钩子来处理这些关注点就非常容易了。
|
||||
|
||||
* **运营开销很少:** 只需要为一个应用程序设置日志、监视、以及测试。一般情况下,部署也相对要简单。
|
||||
|
||||
* **性能:** 一个整体的架构可能会有更好的性能,因为共享内存的访问速度要比进程间通讯(IPC)更快。
|
||||
|
||||
### 缺点:
|
||||
|
||||
* **紧耦合:** 整体服务的应用程序倾向于紧耦合,并且应用程序是整体进化,分离特定用途的服务是非常困难的,比如,独立扩展或者代码维护。
|
||||
|
||||
* **理解起来很困难:** 当你想查看一个特定的服务或者控制器时,因为依赖、副作用、和其它的不可预见因素,整体架构理解起来更困难。
|
||||
|
||||
### 微服务
|
||||
|
||||
### 优点:
|
||||
|
||||
* **非常好组织:** 微服务架构一般很好组织它们,因为每个微服务都有一个特定的工作,并且还不用考虑其它组件的工作。
|
||||
|
||||
* **解耦合:** 解耦合的服务是能够非常容易地进行重组织和重配置,以服务于不同的应用程序(比如,同时向 Web 客户端和公共 API 提供服务)。它们在一个大的集成系统中,也允许快速、独立分发单个部分。
|
||||
|
||||
* **性能:** 根据组织的情况,微服务可以提供更好的性能,因为你可以分离热点服务,并根据其余应用程序的情况来扩展它们。
|
||||
|
||||
* **更少的错误:** 微服务允许系统中的不同部分,在维护良好边界的前提下进行并行开发。这样将使连接不该被连接的部分变得更困难,比如,需要连接的那些紧耦合部分。
|
||||
|
||||
### 缺点:
|
||||
|
||||
* **跨每个服务的横向联系点:** 由于你构建了一个新的微服务架构,你可能会发现在设计时没有预料到的很多横向联系的问题。这也将导致需要每个横向联系点的独立模块(比如,测试)的开销增加,或者在其它服务层面因封装横向联系点,所导致的所有流量都需要路由。最终,即便是整体服务架构也倾向于通过横向联系点的外部服务层来路由流量,但是,如果使用整体架构,在项目更加成熟之前,也不过只是推迟了工作成本。
|
||||
|
||||
* **更高的运营开销:** 微服务在它所属的虚拟机或容器上部署非常频繁,导致虚拟机争用激增。这些任务都是使用容器管理工具进行频繁的自动化部署的。
|
||||
|
||||
### 决策时刻
|
||||
|
||||
当你了解了每种方法的利弊之后,如何在你的初创公司使用这些信息?通过与这些 CTO 们的访谈,这里有三个问题可以指导你的决策过程:
|
||||
|
||||
**你是在熟悉的领域吗?**
|
||||
|
||||
如果你的团队有以前的一些领域的经验(比如,电子商务)和了解你的客户需求,那么分割成微服务是低风险的。如果你从未做过这些,从另一个角度说,整体服务或许是一个更安全的选择。
|
||||
|
||||
**你的团队做好准备了吗?**
|
||||
|
||||
你的团队有使用微服务的经验吗?如果明年,你的团队扩充到现在的四倍,将为微服务提供更好的环境?评估团队大小对项目的成功是非常重要的。
|
||||
|
||||
**你的基础设施怎么样?**
|
||||
|
||||
实施微服务,你需要基于云的基础设施。
|
||||
|
||||
David Strauss,[Pantheon][17] 的 CTO,他解释说:"[以前],你使用整体服务是因为,你希望部署在一个数据库上。每个单个的微服务都需要配置数据库服务器,然后,扩展它将是一个很重大的任务。只有大的、技术力量雄厚的组织才能做到。现在,使用像谷歌云和亚马逊 AWS 这样的云服务,为部署一个小的东西而不需要为它们中的每个都提供持久存储,对于这种需求你有很多的选择。“
|
||||
|
||||
### 评估业务风险
|
||||
|
||||
技术力量雄厚的初创公司为追求较高的目标,可以考虑使用微服务。但是微服务可能会带来业务风险。Strauss 解释说,”许多团队一开始就过度构建他们的项目。每个人都认为,他们的公司会成为下一个 “独角兽”,因此,他们使用微服务构建任何一个东西,或者一些其它的高扩展性的基础设施。但是这通常是一种错误的做法“。Strauss 说,在那种情况下,他们认为需要扩大规模的领域往往并不是一开始真正需要扩展的领域,最后的结果是浪费了时间和努力。
|
||||
|
||||
### 态势感知
|
||||
|
||||
最终,环境是关键。以下是一些来自 CTO 们的提示:
|
||||
|
||||
#### 什么时候使用整体服务
|
||||
|
||||
* **你的团队还在创建阶段:** 你的团队很小 —— 也就是说,有 2 到 5 位成员 —— 还无法应对大范围、高成本的微服务架构。
|
||||
|
||||
* **你正在构建的是一个未经证实的产品或者概念验证:** 如果你将一个全新的产品推向市场,随着时间的推移,它有可能会成功,而对于一个快速迭代的产品,整体架构是最合适的。这个提示也同样适用于概念验证,你的目标是尽可能快地学习,即便最终你可能会放弃它。
|
||||
|
||||
* **你没有使用微服务的经验:** 除非你有合理的理由证明早期学习阶段的风险可控,否则,一个整体的架构更适用于一个没有经验的团队。
|
||||
|
||||
#### 什么时候开始使用微服务
|
||||
|
||||
* **你需要快速、独立的分发服务:** 微服务允许在一个大的集成系统中快速、独立分发单个部分。请注意,根据你的团队规模,获取与整体服务的比较优势,可能需要一些时间。
|
||||
|
||||
* **你的平台中的某些部分需要更高效:** 如果你的业务要求集中处理 PB 级别的日志卷,你可能需要使用一个像 C++ 这样的更高效的语言来构建这个服务,尽管你的用户仪表板或许还是用 [Ruby on Rails][5] 构建的。
|
||||
|
||||
* **计划扩展你的团队:** 使用微服务,将让你的团队从一开始就开发独立的小服务,而服务边界独立的团队更易于按需扩展。
|
||||
|
||||
要决定整体服务还是微服务更适合你的组织,要坦诚并正确认识自己的环境和能力。这将有助于你找到业务成长的最佳路径。
|
||||
|
||||
### 主题
|
||||
|
||||
[微服务][21]、 [DevOps][22]
|
||||
|
||||
### 关于作者
|
||||
|
||||
[][18] jakelumetta - Jake 是 ButterCMS 的 CEO,它是一个 [API-first CMS][6]。他喜欢搅动出黄油双峰,以及构建让开发者工作更舒适的工具,喜欢他的更多内容,请在 Twitter 上关注 [@ButterCMS][7],订阅 [他的博客][8]。[关于他的更多信息][9]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/how-choose-between-monolith-microservices
|
||||
|
||||
作者:[jakelumetta ][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jakelumetta
|
||||
[1]:https://blog.openshift.com/microservices-how-to-explain-them-to-your-ceo/?intcmp=7016000000127cYAAQ&src=microservices_resource_menu1
|
||||
[2]:https://www.openshift.com/promotions/microservices.html?intcmp=7016000000127cYAAQ&src=microservices_resource_menu2
|
||||
[3]:https://opensource.com/business/16/11/secured-devops-microservices?src=microservices_resource_menu3
|
||||
[4]:https://opensource.com/article/18/1/how-choose-between-monolith-microservices?rate=tSotlNvwc-Itch5fhYiIn5h0L8PcUGm_qGvqSVzu9w8
|
||||
[5]:http://rubyonrails.org/
|
||||
[6]:https://buttercms.com/
|
||||
[7]:https://twitter.com/ButterCMS
|
||||
[8]:https://buttercms.com/blog/
|
||||
[9]:https://opensource.com/users/jakelumetta
|
||||
[10]:https://opensource.com/user/205531/feed
|
||||
[11]:https://www.flickr.com/photos/onasill/16452059791/in/photolist-r4P7ci-r3xUqZ-JkWzgN-dUr8Mo-biVsvF-kA2Vot-qSLczk-nLvGTX-biVxwe-nJJmzt-omA1vW-gFtM5-8rsk8r-dk9uPv-5kja88-cv8YTq-eQqNJu-7NJiqd-pBUkk-pBUmQ-6z4dAw-pBULZ-vyM3V3-JruMsr-pBUiJ-eDrP5-7KCWsm-nsetSn-81M3EC-pBURh-HsVXuv-qjgBy-biVtvx-5KJ5zK-81F8xo-nGFQo3-nJr89v-8Mmi8L-81C9A6-qjgAW-564xeQ-ihmDuk-biVBNz-7C5VBr-eChMAV-JruMBe-8o4iKu-qjgwW-JhhFXn-pBUjw
|
||||
[12]:https://creativecommons.org/licenses/by-nc-sa/2.0/
|
||||
[13]:https://buttercms.com/books/microservices-for-startups/
|
||||
[14]:https://www.particle.io/Particle
|
||||
[15]:https://www.scalyr.com/
|
||||
[16]:https://www.algolia.com/
|
||||
[17]:https://pantheon.io/
|
||||
[18]:https://opensource.com/users/jakelumetta
|
||||
[19]:https://opensource.com/users/jakelumetta
|
||||
[20]:https://opensource.com/users/jakelumetta
|
||||
[21]:https://opensource.com/tags/microservices
|
||||
[22]:https://opensource.com/tags/devops
|
||||
@ -0,0 +1,101 @@
|
||||
如何在 Linux 上运行你自己的公共时间服务器
|
||||
======
|
||||
|
||||

|
||||
|
||||
公共服务最重要的一点就是守时,但是很多人并没有意识到这一点。大多数公共时间服务器都是由志愿者管理,以满足不断增长的需求。学习如何运行你自己的时间服务器,为基本的公共利益做贡献。(查看 [在 Linux 上使用 NTP 保持精确时间][1] 去学习如何设置一台局域网时间服务器)
|
||||
|
||||
### 著名的时间服务器滥用事件
|
||||
|
||||
就像现实生活中任何一件事情一样,即便是像时间服务器这样的公益项目,也会遭受不称职的或者恶意的滥用。
|
||||
|
||||
消费类网络设备的供应商因制造了大混乱而臭名昭著。我回想起的第一件事发生在 2003 年,那时,Netgear 在它们的路由器中硬编码了 University of Wisconsin-Madison 的 NTP 时间服务器地址。使得时间服务器的查询请求突然增加,随着 NetGear 卖出越来越多的路由器,这种情况越发严重。更有意思的是,路由器的程序设置是每秒钟发送一次请求,这将使服务器难堪重负。后来 Netgear 发布了升级固件,但是,升级他们的设备的用户很少,并且他们的其中一些用户的设备,到今天为止,还在不停地每秒钟查询一次 University of Wisconsin-Madison 的 NTP 服务器。Netgear 给 University of Wisconsin-Madison 捐献了一些钱,以帮助弥补他们带来的成本增加,直到这些路由器全部淘汰。类似的事件还有 D-Link、Snapchat、TP-Link 等等。
|
||||
|
||||
对 NTP 协议进行反射和放大,已经成为发起 DDoS 攻击的一个选择。当攻击者使用一个伪造的源地址向目标受害者发送请求,称为反射;攻击者发送请求到多个服务器,这些服务器将回复请求,这样就使伪造的地址受到轰炸。放大是指一个很小的请求收到大量的回复信息。例如,在 Linux 上,`ntpq` 命令是一个查询你的 NTP 服务器并验证它们的系统时间是否正确的很有用的工具。一些回复,比如,对端列表,是非常大的。组合使用反射和放大,攻击者可以将 10 倍甚至更多带宽的数据量发送到被攻击者。
|
||||
|
||||
那么,如何保护提供公益服务的公共 NTP 服务器呢?从使用 NTP 4.2.7p26 或者更新的版本开始,它们可以帮助你的 Linux 发行版不会发生前面所说的这种问题,因为它们都是在 2010 年以后发布的。这个发行版都默认禁用了最常见的滥用攻击。目前,[最新版本是 4.2.8p10][2],它发布于 2017 年。
|
||||
|
||||
你可以采用的另一个措施是,在你的网络上启用入站和出站过滤器。阻塞进入你的网络的数据包,以及拦截发送到伪造地址的出站数据包。入站过滤器帮助你,而出站过滤器则帮助你和其他人。阅读 [BCP38.info][3] 了解更多信息。
|
||||
|
||||
### 层级为 0、1、2 的时间服务器
|
||||
|
||||
NTP 有超过 30 年的历史了,它是至今还在使用的最老的因特网协议之一。它的用途是保持计算机与协调世界时间(UTC)的同步。NTP 网络是分层组织的,并且同层的设备是对等的。层次 0 包含主守时设备,比如,原子钟。层级 1 的时间服务器与层级 0 的设备同步。层级 2 的设备与层级 1 的设备同步,层级 3 的设备与层级 2 的设备同步。NTP 协议支持 16 个层级,现实中并没有使用那么多的层级。同一个层级的服务器是相互对等的。
|
||||
|
||||
过去很长一段时间内,我们都为客户端选择配置单一的 NTP 服务器,而现在更好的做法是使用 [NTP 服务器地址池][4],它使用往返的 DNS 信息去共享负载。池地址只是为客户端服务的,比如单一的 PC 和你的本地局域网 NTP 服务器。当你运行一台自己的公共服务器时,你不能使用这些池中的地址。
|
||||
|
||||
### 公共 NTP 服务器配置
|
||||
|
||||
运行一台公共 NTP 服务器只有两步:设置你的服务器,然后加入到 NTP 服务器池。运行一台公共的 NTP 服务器是一种很高尚的行为,但是你得先知道如何加入到 NTP 服务器池中。加入 NTP 服务器池是一种长期责任,因为即使你加入服务器池后,运行了很短的时间马上退出,然后接下来的很多年你仍然会接收到请求。
|
||||
|
||||
你需要一个静态的公共 IP 地址,一个至少 512Kb/s 带宽的、可靠的、持久的因特网连接。NTP 使用的是 UDP 的 123 端口。它对机器本身要求并不高,很多管理员在其它的面向公共的服务器(比如,Web 服务器)上顺带架设了 NTP 服务。
|
||||
|
||||
配置一台公共的 NTP 服务器与配置一台用于局域网的 NTP 服务器是一样的,只需要几个配置。我们从阅读 [协议规则][5] 开始。遵守规则并注意你的行为;几乎每个时间服务器的维护者都是像你这样的志愿者。然后,从 [StratumTwoTimeServers][6] 中选择 2 台层级为 4-7 的上游服务器。选择的时候,选取地理位置上靠近(小于 300 英里的)你的因特网服务提供商的上游服务器,阅读他们的访问规则,然后,使用 `ping` 和 `mtr` 去找到延迟和跳数最小的服务器。
|
||||
|
||||
以下的 `/etc/ntp.conf` 配置示例文件,包括了 IPv4 和 IPv6,以及基本的安全防护:
|
||||
```
|
||||
# stratum 2 server list
|
||||
server servername_1 iburst
|
||||
server servername_2 iburst
|
||||
server servername_3 iburst
|
||||
server servername_4 iburst
|
||||
server servername_5 iburst
|
||||
|
||||
# access restrictions
|
||||
restrict -4 default kod noquery nomodify notrap nopeer limited
|
||||
restrict -6 default kod noquery nomodify notrap nopeer limited
|
||||
|
||||
# Allow ntpq and ntpdc queries only from localhost
|
||||
restrict 127.0.0.1
|
||||
restrict ::1
|
||||
|
||||
```
|
||||
|
||||
启动你的 NTP 服务器,让它运行几分钟,然后测试它对远程服务器的查询:
|
||||
```
|
||||
$ ntpq -p
|
||||
remote refid st t when poll reach delay offset jitter
|
||||
=================================================================
|
||||
+tock.no-such-ag 200.98.196.212 2 u 36 64 7 98.654 88.439 65.123
|
||||
+PBX.cytranet.ne 45.33.84.208 3 u 37 64 7 72.419 113.535 129.313
|
||||
*eterna.binary.n 199.102.46.70 2 u 39 64 7 92.933 98.475 56.778
|
||||
+time.mclarkdev. 132.236.56.250 3 u 37 64 5 111.059 88.029 74.919
|
||||
|
||||
```
|
||||
|
||||
目前表现很好。现在从另一台 PC 上使用你的 NTP 服务器名字进行测试。以下的示例是一个正确的输出。如果有不正确的地方,你将看到一些错误信息。
|
||||
```
|
||||
$ ntpdate -q _yourservername_
|
||||
server 66.96.99.10, stratum 2, offset 0.017690, delay 0.12794
|
||||
server 98.191.213.2, stratum 1, offset 0.014798, delay 0.22887
|
||||
server 173.49.198.27, stratum 2, offset 0.020665, delay 0.15012
|
||||
server 129.6.15.28, stratum 1, offset -0.018846, delay 0.20966
|
||||
26 Jan 11:13:54 ntpdate[17293]: adjust time server 98.191.213.2 offset 0.014798 sec
|
||||
|
||||
```
|
||||
|
||||
一旦你的服务器运行的很好,你就可以向 [manage.ntppool.org][7] 申请加入池中。
|
||||
|
||||
查看官方的手册 [分布式网络时间服务器(NTP)][8] 学习所有的命令、配置选项、以及高级特性,比如,管理、查询、和验证。访问以下的站点学习关于运行一台时间服务器所需要的一切东西。
|
||||
|
||||
通过来自 Linux 基金会和 edX 的免费课程 ["Linux 入门" ][9] 学习更多 Linux 的知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/2/how-run-your-own-public-time-server-linux
|
||||
|
||||
作者:[CARLA SCHRODER][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/learn/intro-to-linux/2018/1/keep-accurate-time-linux-ntp
|
||||
[2]:http://www.ntp.org/downloads.html
|
||||
[3]:http://www.bcp38.info/index.php/Main_Page
|
||||
[4]:http://www.pool.ntp.org/en/use.html
|
||||
[5]:http://support.ntp.org/bin/view/Servers/RulesOfEngagement
|
||||
[6]:http://support.ntp.org/bin/view/Servers/StratumTwoTimeServers?redirectedfrom=Servers.StratumTwo
|
||||
[7]:https://manage.ntppool.org/manage
|
||||
[8]:https://www.eecis.udel.edu/~mills/ntp/html/index.html
|
||||
[9]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,65 +0,0 @@
|
||||
LKRG:Linux 的适用于运行时完整性检查的可加载内核模块
|
||||
======
|
||||
![LKRG logo][1]
|
||||
|
||||
开源社区的成员正在致力于一个 Linux 内核的新项目,它可以让内核更安全。命名为 Linux 内核运行时防护(Linux Kernel Runtime Guard,简称:LKRG),它是一个在 Linux 内核执行运行时完整性检查时的可加载内核模块。
|
||||
|
||||
它的用途是检测对 Linux 内核的已知的或未知的安全漏洞利用企图,以及去阻止这种攻击企图。
|
||||
|
||||
LKRG 也可以检测正在运行的进程的提权行为,在漏洞利用代码运行之前杀掉这个运行进程。
|
||||
|
||||
### 这个项目从 2011 年开始开发以来,首个版本已经发布。
|
||||
|
||||
因为这个项目开发的较早,LKRG 的当前版本仅仅是通过内核消息去报告违反内核完整性的行为,但是随着这个项目的成熟,一个完整的漏洞利用缓减系统将会部署。
|
||||
|
||||
LKRG 的成员 Alexander Peslyak 解释说,这个项目从 2011 年启动,并且 LKRG 已经经历了“预开发"阶段。
|
||||
|
||||
LKRG 的首个公开版本是 — LKRG v0.0 — 它现在可以从 [这个页面][2] 下载使用。[这里][3] 是这个项目的维基,为支持这个项目,它也有一个 [Patreon 页面][4]。
|
||||
|
||||
虽然 LKRG 还是一个开源项目,LKRG 的维护者也计划做一个 LKRG Pro 版本,这个版本将包含一个专用的 LKRG 发行版,它将支持对特定漏洞利用的检测,比如,容器泄漏。开发团队计划从 LKRG Pro 基金中提取部分资金用于保证项目的剩余工作。
|
||||
|
||||
### LKRG 是一个内核模块而不是一个补丁。
|
||||
|
||||
一个类似的项目是去增加一个内核监视功能(AKO),但是 LKRG 与 AKO 是不一样的,因为 LKRG 是一个内核加载模式而不是一个补丁。LKRG 开发团队决定将它设计为一个内核模块是因为,在内核上打补丁对安全性、系统稳定性以及性能都有很直接的影响。
|
||||
|
||||
而作为内核模块的方式,可以在每个系统上更容易部署去 LKRG,而不必去修改核心的内核代码,修改核心的内核代码非常复杂并且很容易出错。
|
||||
|
||||
LKRG 内核模块在目前主流的 Linux 发行版上都可以使用,比如,RHEL7、OpenVZ 7、Virtuozzo 7、以及 Ubuntu 16.04 到最新的主线版本。
|
||||
|
||||
### 它并非是一个完美的解决方案
|
||||
|
||||
LKRG 的创建者警告用户,他们并不认为 LKRG 是一个完美的解决方案,它**提供不了**坚不可摧和 100% 的安全。他们说,LKRG 是 "设计为**可旁通**的",并且仅仅提供了"多元化安全" 的**一个**方面。
|
||||
|
||||
```
|
||||
虽然 LKRG 可以防御许多对 Linux 内核的已存在的漏洞利用,而且也有可能会防御将来许多的(包括未知的)未特意设计去绕过 LKRG 的安全漏洞利用。它是设计为可旁通的(尽管有时候是以更复杂和/或低可利用为代价的)。因此,他们说 LKRG 通过多元化提供安全,就像运行一个不常见的操作系统内核一样,也就不会有真实运行一个不常见的操作系统的可用性弊端。
|
||||
```
|
||||
|
||||
LKRG 有点像基于 Windows 的防病毒软件,它也是工作于内核级别去检测漏洞利用和恶意软件。但是,LKRG 团队说,他们的产品比防病毒软件以及其它终端安全软件更加安全,因为它的基础代码量比较小,所以在内核级别引入新 bug 和漏洞的可能性就更小。
|
||||
|
||||
### 运行当前版本的 LKRG 大约会带来 6.5% 的性能损失
|
||||
|
||||
Peslyak 说 LKRG 是非常适用于 Linux 机器的,它在修补内核的安全漏洞后不需要重启动机器。LKRG 允许用户去持续运行带有安全措施的机器,直到在一个计划的维护窗口中测试和部署关键的安全补丁为止。
|
||||
|
||||
经测试显示,安装 LKRG v0.0 后大约会产生 6.5% 性能影响,但是,Peslyak 说将在后续的开发中持续降低这种影响。
|
||||
|
||||
测试也显示,LKRG 检测到了 CVE-2014-9322 (BadIRET)、CVE-2017-5123 (waitid(2) missing access_ok)、以及 CVE-2017-6074 (use-after-free in DCCP protocol) 的漏洞利用企图,但是没有检测到 CVE-2016-5195 (Dirty COW) 的漏洞利用企图。开发团队说,由于前面提到的”可旁通“的设计策略,LKRG 没有检测到 Dirty COW 提权攻击。
|
||||
|
||||
```
|
||||
在 Dirty COW 的测试案例中,由于 bug 机制的原因,使得 LKRG 发生了 "旁通",并且这也是一种利用方法,它也是将来类似的以用户空间为目标的绕过 LKRG 的一种方法。这样的漏洞利用是否会是普通情况(不太可能!除非 LKRG 或者类似机制的软件流行起来),以及对它的可用性的(负面的)影响是什么?(对于那些直接目标是用户空间的内核漏洞来说,这不太重要,也并不简单)。
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.bleepingcomputer.com/news/linux/lkrg-linux-to-get-a-loadable-kernel-module-for-runtime-integrity-checking/
|
||||
|
||||
作者:[Catalin Cimpanu][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.bleepingcomputer.com/author/catalin-cimpanu/
|
||||
[1]:https://www.bleepstatic.com/content/posts/2018/02/04/LKRG-logo.png
|
||||
[2]:http://www.openwall.com/lkrg/
|
||||
[3]:http://openwall.info/wiki/p_lkrg/Main
|
||||
[4]:https://www.patreon.com/p_lkrg
|
||||
@ -0,0 +1,82 @@
|
||||
用这三个命令行工具成为好莱坞电影中的黑客
|
||||
======
|
||||
|
||||

|
||||
|
||||
如果在你成长过程中有看过谍战片、动作片或犯罪片,那么你就会清楚地了解黑客的电脑屏幕是什么样子。就像是在《黑客帝国》电影中,[代码雨][1] 一样的十六进制数字流,又或是一排排快速移动的代码 。
|
||||
|
||||
也许电影中出现一幅世界地图,其中布满了闪烁的光点除和一些快速更新的字符。 而且是3D旋转的几何图像,为什么不可能出现在现实中呢? 如果可能的话,那么就会出现数量多得不可思议的显示屏,以及不符合人体工学的电脑椅或其他配件。 在《剑鱼行动》电影中黑客就使用了七个显示屏。
|
||||
|
||||
当然,我们这些从事计算机行业的人一下子就明白这完全是胡说八道。虽然在我们中,许多人都有双显示器(或更多),但一个闪烁的数据仪表盘通常和专注工作是相互矛盾的。编写代码、项目管理和系统管理与日常工作不同。我们遇到的大多数情况,为了解决问题,都需要大量的思考,与客户沟通所得到一些研究和组织的资料,然后才是少许的 [敲代码][7]。
|
||||
|
||||
然而,这与我们想追求电影中的效果并不矛盾,也许,我们只是想要看起来“忙于工作”而已。
|
||||
|
||||
**注:当然,我仅仅是在此胡诌。**如果实际上您公司是根据您繁忙程度来评估您的工作时,无论您是蓝领还是白领,都需要亟待解决这样的工作文化。假装工作很忙是一种有毒的文化,对公司和员工都有害无益。
|
||||
|
||||
这就是说,让我们找些乐子,用一些老式的、毫无意义的数据和代码片段填充我们的屏幕。(当然,数据或许有意义,而不是没有上下文。)当然有许多有趣的图形界面,如 [hackertyper.net][8] 或是 [GEEKtyper.com][9] 网站(译者注:是在线模拟黑客网站),为什么不使用Linux终端程序呢?对于更老派的外观,可以考虑使用 [酷炫复古终端][10],这听起来确实如此:一个酷炫的复古终端程序。我将在下面的屏幕截图中使用酷炫复古终端,因为它看起来的确很酷。
|
||||
|
||||
|
||||
### Genact
|
||||
|
||||
我们来看下第一个工具——Genact。Genact的原理很简单,就是慢慢地循环播放您选择的一个序列,让您的代码在您外出休息时“编译”。由您来决定播放顺序,但是其中默认包含数字货币挖矿模拟器、PHP管理依赖关系工具、内核编译器、下载器、内存转储等工具。其中我最喜欢的是其中类似《模拟城市》加载显示。所以只要没有人仔细检查,你可以花一整个下午等待您的电脑完成进度条。
|
||||
|
||||
Genact[发行版][11]支持Linux、OS X和Windows。并且用Rust编写。[源代码][12] 在GitHub上开源(遵循[MIT许可证][13])
|
||||
|
||||

|
||||
|
||||
### Hollywood
|
||||
|
||||
|
||||
Hollywood采取更直接的方法。它本质上是在终端中创建一个随机数字和配置分屏,并启动跑个不停的应用程序,如htop,目录树,源代码文件等,并每隔几秒将其切换。它被放在一起作为一个shell脚本,所以可以非常容易地根据需求进行修改。
|
||||
|
||||
|
||||
Hollywood的 [源代码][14] 在GitHub上开源(遵循[Apache 2.0许可证][15])。
|
||||
|
||||

|
||||
|
||||
### Blessed-contrib
|
||||
|
||||
Blessed-contrib是我个人最喜欢的应用,实际上并不是为了表演而专门设计的应用。相反地,它是一个基于Node.js的后台终端构建库的演示文件。与其他两个不同,实际上我已经在工作中使用Blessed-contrib的库,而不是用于假装忙于工作。因为它是一个相当有用的库,并且可以使用一组在命令行显示信息的小部件。与此同时填充虚拟数据也很容易,所以可以很容易实现模拟《战争游戏》的想法。
|
||||
|
||||
|
||||
Blessed-contrib的[源代码][16]在GitHub上(遵循[MIT许可证][17])。
|
||||
|
||||
|
||||

|
||||
|
||||
当然,尽管这些工具很容易使用,但也有很多其他的方式使你的屏幕丰富。在你看到电影中最常用的工具之一就是Nmap,一个开源的网络安全扫描工具。实际上,它被广泛用作展示好莱坞电影中,黑客电脑屏幕上的工具。因此Nmap的开发者创建了一个 [页面][18],列出了它出现在其中的一些电影,从《黑客帝国2:重装上阵》到《谍影重重3》、《龙纹身的女孩》,甚至《虎胆龙威4》。
|
||||
|
||||
当然,您可以创建自己的组合,使用终端多路复用器(如屏幕或tmux)启动您希望的任何数据分散应用程序。
|
||||
|
||||
|
||||
那么,您是如何使用您的屏幕的呢?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/command-line-tools-productivity
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
译者:[wyxplus](https://github.com/wyxplus)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jason-baker
|
||||
[1]:http://tvtropes.org/pmwiki/pmwiki.php/Main/MatrixRainingCode
|
||||
[2]:https://opensource.com/resources/what-is-linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[3]:https://opensource.com/resources/what-are-linux-containers?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[4]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[5]:https://developers.redhat.com/cheat-sheet/advanced-linux-commands-cheatsheet?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[6]:https://opensource.com/tags/linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[7]:http://tvtropes.org/pmwiki/pmwiki.php/Main/RapidFireTyping
|
||||
[8]:https://hackertyper.net/
|
||||
[9]:http://geektyper.com
|
||||
[10]:https://github.com/Swordfish90/cool-retro-term
|
||||
[11]:https://github.com/svenstaro/genact/releases
|
||||
[12]:https://github.com/svenstaro/genact
|
||||
[13]:https://github.com/svenstaro/genact/blob/master/LICENSE
|
||||
[14]:https://github.com/dustinkirkland/hollywood
|
||||
[15]:http://www.apache.org/licenses/LICENSE-2.0
|
||||
[16]:https://github.com/yaronn/blessed-contrib
|
||||
[17]:http://opensource.org/licenses/MIT
|
||||
[18]:https://nmap.org/movies/
|
||||
@ -0,0 +1,202 @@
|
||||
在 Git 中怎样克隆,修改,添加和删除文件?
|
||||
=====
|
||||
|
||||

|
||||
|
||||
在 [本系列的第一篇文章][1] 开始使用 Git 时,我们创建了一个简单的 Git 仓库,并通过它连接到我们的计算机向其中添加一个文件。在本文中,我们将学习一些关于 Git 的其他内容,即如何克隆(下载),修改,添加和删除 Git 仓库中的文件。
|
||||
|
||||
|
||||
### 让我们来克隆一下
|
||||
|
||||
假设你在 GitHub 上已经有一个 Git 仓库,并且想从它那里获取你的文件-也许你在你的计算机上丢失了本地副本,或者你正在另一台计算机上工作,但是想访问仓库中的文件,你该怎么办?从 GitHub 下载你的文件?没错!我们称之为 Git 术语中的“克隆”。(你也可以将仓库作为 ZIP 文件下载,但我们将在本文中探讨克隆方法。)
|
||||
|
||||
让我们克隆在上一篇文章中创建的称为 Demo 的仓库。(如果你还没有创建 Demo 仓库,请跳回到那篇文章并在继续之前执行那些步骤。)要克隆文件,只需打开浏览器并导航到 `https://github.com/<your_username>/Demo` (其中 `<your_username>` 是你仓库的名称。例如,我的仓库是 `https://github.com/kedark3/Demo`)。一旦你导航到该 URL,点击“克隆或下载”按钮,你的浏览器看起来应该是这样的:
|
||||
|
||||

|
||||
|
||||
正如你在上面看到的,“使用 HTTPS 克隆”选项已打开。从该下拉框中复制你的仓库地址(`https://github.com/<your_username>/Demo.git`),打开终端并输入以下命令将 GitHub 仓库克隆到你的计算机:
|
||||
```
|
||||
git clone https://github.com/<your_username>/Demo.git
|
||||
|
||||
```
|
||||
|
||||
然后,要查看 `Demo` 目录中的文件列表,请输入以下命令:
|
||||
```
|
||||
ls Demo/
|
||||
|
||||
```
|
||||
|
||||
终端看起来应该是这样的:
|
||||
|
||||

|
||||
|
||||
### 修改文件
|
||||
|
||||
现在我们已经克隆了仓库,让我们修改文件并在 GitHub 上更新它们。首先,逐个输入下面的命令,将目录更改为 `Demo/`,检查 `README.md` 中的内容,添加新的(附加的)内容到 `README.md`,然后使用 `git status` 检查状态:
|
||||
```
|
||||
cd Demo/
|
||||
|
||||
ls
|
||||
|
||||
cat README.md
|
||||
|
||||
echo "Added another line to REAMD.md" >> README.md
|
||||
|
||||
cat README.md
|
||||
|
||||
git status
|
||||
|
||||
```
|
||||
|
||||
如果你逐一运行这些命令,终端看起开将会是这样:
|
||||
|
||||

|
||||
|
||||
让我们看一下 `git status` 的输出,并了解它的意思。不要担心这样的语句:
|
||||
```
|
||||
On branch master
|
||||
|
||||
Your branch is up-to-date with 'origin/master'.".
|
||||
|
||||
```
|
||||
因为我们还没有学习这些。(译注:学了你就知道了)下一行说:`Changes not staged for commit`;这是告诉你,它下面列出的文件没有标记就绪(“分阶段”)提交。如果你运行 `git add`,Git 会把这些文件标记为 `Ready for commit`;换句话说就是 `Changes staged for commit`。在我们这样做之前,让我们用 `git diff` 命令来检查我们添加了什么到 Git 中,然后运行 `git add`。
|
||||
|
||||
这里是终端输出:
|
||||
|
||||

|
||||
|
||||
我们来分析一下:
|
||||
|
||||
* `diff --git a/README.md b/README.md` 是 Git 比较的内容(在这个例子中是 `README.md`)。
|
||||
* `--- a/README.md` 会显示从文件中删除的任何东西。
|
||||
* `+++ b/README.md` 会显示从文件中添加的任何东西。
|
||||
* 任何添加到文件中的内容都以绿色文本打印,并在该行的开头加上 + 号。
|
||||
* 如果我们删除了任何内容,它将以红色文本打印,并在该行的开头加上 - 号。
|
||||
* 现在 git status 显示“Changes to be committed:”,并列出文件名(即 `README.md`)以及该文件发生了什么(即它已经被 `modified` 并准备提交)。
|
||||
|
||||
|
||||
提示:如果你已经运行了 `git add`,现在你想看看文件有什么不同,通常 `git diff` 不会产生任何东西,因为你已经添加了文件。相反,你必须使用 `git diff --cached`。它会告诉你 Git 添加的当前版本和以前版本文件之间的差别。你的终端输出看起来会是这样:
|
||||
|
||||

|
||||
|
||||
### 上传文件到你的仓库
|
||||
|
||||
我们用一些新内容修改了 `README.md` 文件,现在是时候将它上传到 GitHub。
|
||||
|
||||
让我们提交更改并将其推送到 GitHub。运行:
|
||||
```
|
||||
git commit -m "更新文件的名字"
|
||||
|
||||
```
|
||||
|
||||
这告诉 Git 你正在“提交”已经“添加”的更改,你可能还记得,从本系列的第一部分中,添加一条消息来解释你在提交中所做的操作是非常重要的,以便你在稍后回顾 Git 日志时了解当时的目的。(我们将在下一篇文章中更多地关注这个话题。)`Updated Readme file` 是这个提交的消息--如果你认为这不是解释你所做的事情的最合理的方式,那么请随便写下你的提交消息。
|
||||
|
||||
运行 `git push -u origin master`,这会提示你输入用户名和密码,然后将文件上传到你的 GitHub 仓库。刷新你的 GitHub 页面,你应该会看到刚刚对 `README.md` 所做的更改。
|
||||
|
||||

|
||||
|
||||
终端的右下角显示我提交了更改,检查了 Git 状态,并将更改推送到了 GitHub。git status 显示:
|
||||
```
|
||||
Your branch is ahead of 'origin/master' by 1 commit
|
||||
|
||||
(use "git push" to publish your local commits)
|
||||
|
||||
```
|
||||
|
||||
第一行表示在本地仓库中有一个提交,但不在原始/主文件中(即在 GitHub 上)。下一行指示我们将这些更改推送到原始/主文件中,这就是我们所做的。(在本例中,请参阅本系列的第一篇文章,以唤醒你对“原始”含义的记忆。我将在下一篇文章中讨论分支的时候,解释“主文件”的含义。)
|
||||
|
||||
### 添加新文件到 Git
|
||||
|
||||
现在我们修改了一个文件并在 GitHub 上更新了它,让我们创建一个新文件,将它添加到 Git,然后将其上传到 GitHub。
|
||||
运行:
|
||||
```
|
||||
echo "This is a new file" >> file.txt
|
||||
|
||||
```
|
||||
|
||||
这将会创建一个名为 `file.txt` 的新文件。
|
||||
|
||||
如果使用 `cat` 查看它:
|
||||
```
|
||||
cat file.txt
|
||||
|
||||
```
|
||||
你将看到文件的内容。现在继续运行:
|
||||
```
|
||||
git status
|
||||
|
||||
```
|
||||
|
||||
Git 报告说你的仓库中有一个未跟踪的文件(名为 `file.txt`)。这是 Git 告诉你说在你的计算机中的仓库目录下有一个新文件,然而你并没有告诉 Git,Git 也没有跟踪你所做的任何修改。
|
||||
|
||||

|
||||
|
||||
我们需要告诉 Git 跟踪这个文件,以便我们可以提交并上传文件到我们的仓库。以下是执行该操作的命令:
|
||||
```
|
||||
git add file.txt
|
||||
|
||||
git status
|
||||
|
||||
```
|
||||
|
||||
终端输出如下:
|
||||

|
||||
|
||||
git status 告诉你有 `file.txt` 被修改,对于 Git 来说它是一个 `new file`,Git 在此之前并不知道。现在我们已经为 Git 添加了 `file.txt`,我们可以提交更改并将其推送到 原始/主文件。
|
||||
|
||||

|
||||
|
||||
Git 现在已经将这个新文件上传到 GitHub;如果刷新 GitHub 页面,则应该在 GitHub 上的仓库中看到新文件 `file.txt`。
|
||||
|
||||

|
||||
|
||||
通过这些步骤,你可以创建尽可能多的文件,将它们添加到 Git 中,然后提交并将它们推送到 GitHub。
|
||||
|
||||
### 从 Git 中删除文件
|
||||
|
||||
如果我们发现我们犯了一个错误,并且需要从我们的仓库中删除 `file.txt`,该怎么办?一种方法是使用以下命令从本地副本中删除文件:
|
||||
```
|
||||
rm file.txt
|
||||
|
||||
```
|
||||
|
||||
如果你现在做 `git status`,Git 就会说有一个文件 `not staged for commit`,并且它已经从仓库的本地拷贝中删除了。如果我们现在运行:
|
||||
```
|
||||
git add file.txt
|
||||
|
||||
git status
|
||||
|
||||
```
|
||||
我知道我们正在删除这个文件,但是我们仍然运行 `git add`,因为我们需要告诉 Git 我们正在做的**更改**,`git add` 可以用在我们添加新文件,修改一个已存在文件的内容,或者从仓库中删除文件。实际上,`git add` 将所有更改考虑在内,并将这些更改分阶段进行提交。如果有疑问,请仔细查看下面终端屏幕截图中每个命令的输出。
|
||||
|
||||
Git 会告诉我们已删除的文件正在进行提交。只要你提交此更改并将其推送到 GitHub,该文件也将从 GitHub 的仓库中删除。运行以下命令:
|
||||
```
|
||||
git commit -m "Delete file.txt"
|
||||
|
||||
git push -u origin master
|
||||
|
||||
```
|
||||
|
||||
现在你的终端看起来像这样:
|
||||
|
||||

|
||||
|
||||
你的 GitHub 看起来像这样:
|
||||
|
||||

|
||||
|
||||
现在你知道如何从你的仓库克隆,添加,修改和删除 Git 文件。本系列的下一篇文章将检查 Git 分支。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/how-clone-modify-add-delete-git-files
|
||||
|
||||
作者:[Kedar Vijay Kulkarni][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/kkulkarn
|
||||
[1]:https://opensource.com/article/18/1/step-step-guide-git
|
||||
67
translated/tech/20180215 What is a Linux -oops.md
Normal file
67
translated/tech/20180215 What is a Linux -oops.md
Normal file
@ -0,0 +1,67 @@
|
||||
什么是 Linux “oops”?
|
||||
======
|
||||
如果你检查你的 Linux 系统上运行的进程,你可能会对一个叫做 “kerneloops” 的进程感到好奇。以防万一你没有正确认识,它是 “kernel oops”,而不是 “kerne loops”。
|
||||
|
||||
坦率地说,“oops” 是 Linux 内核的一部分出现了偏差。你有做错了什么么?可能没有。但发生了一些事情。而那个错误的进程可能已经被 CPU 结束。最糟糕的是,内核可能会报错并突然关闭系统。
|
||||
|
||||
对于记录,“oops” 不是首字母缩略词。它不代表像“面向对象的编程和系统” (object-oriented programming and systems) 或“超出程序规范” (out of procedural specs) 之类的东西。它实际上就是“哎呀” (oops),就像你刚掉下一杯酒或踩在你的猫上。哎呀! “oops” 的复数是 “oopses”。
|
||||
|
||||
oops 意味着系统上运行的某些东西违反了内核有关正确行为的规则。也许代码尝试采取不允许的代码路径或使用无效指针。不管它是什么,内核 - 总是在寻找进程的错误行为 - 很可能会阻止特定进程,并将它做了什么的消息写入控制台、 /var/log/dmesg 或 /var/log/kern.log 中。
|
||||
|
||||
oops 可能是由内核本身引起的,也可能是某些进程试图让内核违反在系统上能做的事以及它们被允许做的事。
|
||||
|
||||
oops 将生成一个崩溃签名,这可以帮助内核开发人员找出错误并提高代码质量。
|
||||
|
||||
系统上运行的 kerneloops 进程可能如下所示:
|
||||
```
|
||||
kernoops 881 1 0 Feb11 ? 00:00:01 /usr/sbin/kerneloops
|
||||
|
||||
```
|
||||
|
||||
你可能会注意到该进程不是由 root 运行的,而是由名为 “kernoops” 的用户运行的,并且它的运行时间极少。实际上,分配给这个特定用户的唯一任务是运行 kerneloops。
|
||||
```
|
||||
$ sudo grep kernoops /etc/passwd
|
||||
kernoops:x:113:65534:Kernel Oops Tracking Daemon,,,:/:/bin/false
|
||||
|
||||
```
|
||||
|
||||
如果你的 Linux 系统不带有 kerneloops(比如 Debian),你可以考虑添加它。查看这个[ Debian 页面][1]了解更多信息。
|
||||
|
||||
### 什么时候应该关注 oops?
|
||||
|
||||
除非是预期的,oops 没什么大不了的。它在一定程度上取决于特定进程所扮演的角色。它也取决于 oops 的类别。
|
||||
|
||||
有些 oops 很严重,会导致系统恐慌。从技术上讲,系统恐慌是 oops 的一个子集(即更严重的 oops)。当内核检测到的问题足够严重以至于内核认为它(内核)必须立即停止运行以防止数据丢失或对系统造成其他损害时会出现。因此,系统需要暂停并重新启动,以防止不一致导致不可用或不可靠。所以系统恐慌实际上是为了保护自己免受不可挽回的损害。
|
||||
|
||||
总之,所有的内核恐慌都是 oops,但并不是所有的 oops 都是内核恐慌。
|
||||
|
||||
/var/log/kern.log 和相关的轮转日志(/var/log/kern.log.1、/var/log/kern.log.2 等)包含由内核生成并由 syslog 处理的日志。
|
||||
|
||||
kerneloops 程序收集并默认将错误信息提交到<http://oops.kernel.org/>,在那里它会被分析并呈现给内核开发者。此进程的配置详细信息在 /etc/kerneloops.conf 文件中指定。你可以使用下面的命令轻松查看设置:
|
||||
```
|
||||
$ sudo cat /etc/kerneloops.conf | grep -v ^# | grep -v ^$
|
||||
[sudo] password for shs:
|
||||
allow-submit = ask
|
||||
allow-pass-on = yes
|
||||
submit-url = http://oops.kernel.org/submitoops.php
|
||||
log-file = /var/log/kern.log
|
||||
submit-pipe = /usr/share/apport/kernel_oops
|
||||
|
||||
```
|
||||
|
||||
在上面的(默认)设置中,内核问题可以被提交,但要求用户获得许可。如果设置为 allow-submit = always,则不会询问用户。
|
||||
|
||||
调试内核问题是使用 Linux 系统的更高级技巧之一。幸运的是,大多数 Linux 用户很少或从没有经历过 oops 或内核恐慌。不过,知道 kerneloops 这样的进程在系统中执行什么操作,了解可能会报告什么以及系统何时遇到严重的内核冲突也是很好的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3254778/linux/what-is-a-linux-oops.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[1]:https://packages.debian.org/stretch/kerneloops
|
||||
@ -1,116 +0,0 @@
|
||||
|
||||
使用 Zim 在你的 Linux 桌面上创建一个 wiki
|
||||
======
|
||||
|
||||

|
||||
|
||||
不可否认 wiki 的用处,即使对于一个极客来说也是如此。你可以用它做很多事——写笔记和手稿,协作项目,建立完整的网站。还有更多的事。
|
||||
|
||||
这些年来,我已经使用了超过几条维基百科,要么是为了我自己的工作,要么就是为了我所持有的各种合约和全职工作。虽然传统的维基很好,但我真的喜欢[桌面版 wiki][1] 这个想法。它们体积小,易于安装和维护,甚至更容易使用。而且,正如你可能猜到的那样,Linux 中有许多可用的桌面版 wiki。
|
||||
|
||||
让我们来看看更好的桌面版的 wiki 之一: [Zim][2]。
|
||||
|
||||
### 开始吧
|
||||
|
||||
你可以从 Zim 的官网[下载][3]并安装 Zim,或者通过发行版的软件包管理器轻松地安装。
|
||||
|
||||
一旦安装了 Zim,就启动它。
|
||||
|
||||
在 Zim 中的一个关键概念是笔记本,它们就像一个主题上的 wiki 页面的集合。当你第一次启动 Zim 时,它要求你为你的笔记本指定一个文件夹和笔记本的名称。Zim 建议用 "Notes" 来表示文件夹的名称和指定文件夹为`~/Notebooks/`。如果你愿意,你可以改变它。我是这么做的。
|
||||
|
||||

|
||||
|
||||
在为笔记本设置好名称和指定好文件夹后,单击 **OK** 。你得到的本质上是你的 wiki 页面的容器。
|
||||
|
||||

|
||||
|
||||
### 将页面添加到笔记本
|
||||
|
||||
所以你有了一个容器。那现在怎么办?你应该开始往里面添加页面。当然,为此,选择 **File > New Page**。
|
||||
|
||||

|
||||
|
||||
输入该页面的名称,然后单击 **OK**。从那里开始,你可以开始输入信息以向该页面添加信息。
|
||||
|
||||

|
||||
|
||||
这一页可以是你想要的任何内容:你正在选修的课程的笔记,一本书或者一片文章或论文的大纲,或者是你的书的清单。这取决于你。
|
||||
|
||||
Zim 有一些格式化的选项,其中包括:
|
||||
|
||||
* 标题
|
||||
* 字符格式
|
||||
* 子弹和编号清单
|
||||
* 核对清单
|
||||
|
||||
|
||||
|
||||
你可以添加图片和附加文件到你的 wiki 页面,甚至可以从文本文件中提取文本。
|
||||
|
||||
### Zim 的 wiki 语法
|
||||
|
||||
你可以使用工具栏向一个页面添加格式。但这不是唯一的方法。如果你像我一样是个老派人士,你可以使用 wiki 标记来进行格式化。
|
||||
|
||||
[Zim 的标记][4] 是基于在 [DokuWiki][5] 中使用的标记。它本质上是有一些小变化的 [WikiText][6] 。例如,要创建一个子弹列表,输入一个星号(*)。用两个星号包围一个单词或短语来使它加黑。
|
||||
|
||||
### 添加链接
|
||||
|
||||
如果你在笔记本上有一些页面,很容易将它们联系起来。有两种方法可以做到这一点。
|
||||
|
||||
第一种方法是使用 [CamelCase][7] 来命名这些页面。假设我有个叫做 "Course Notes." 的笔记本。我可以通过输入 "AnalysisCourse." 来重命名我正在学习的数据分析课程。 当我想从笔记本的另一个页面链接到它时,我只需要输入 "AnalysisCourse" 然后按下空格键。即时超链接。
|
||||
|
||||
第二种方法是点击工具栏上的 **Insert link** 按钮。 在 **Link to** 中输入你想要链接到的页面的名称,从显示的列表中选择它,然后点击 **Link**。
|
||||
|
||||

|
||||
|
||||
我只能在同一个笔记本中的页面之间进行链接。每当我试图连接到另一个笔记本中的一个页面时,这个文件(有 .txt 的后缀名)总是在文本编辑器中被打开。
|
||||
|
||||
### 输出你的 wiki 页面
|
||||
|
||||
也许有一天你会想在别的地方使用笔记本上的信息ーー比如, 在一份文件或网页上。你可以将笔记本页面导出到以下格式中的任何一种, 而不是复制和粘贴(和丢失格式) :
|
||||
|
||||
* HTML
|
||||
* LaTeX
|
||||
* Markdown
|
||||
* ReStructuredText
|
||||
|
||||
|
||||
|
||||
为此,点击你想要导出的 wiki 页面。然后,选择 **File > Export**。决定是要导出整个笔记本还是一个页面,然后点击 **Forward**。
|
||||
|
||||

|
||||
|
||||
选择要用来保存页面或笔记本的文件格式。 使用 HTML 和 LaTeX,你可以选择一个模板。 随便看看什么最适合你。 例如, 如果你想把你的 wiki 页面变成 HTML 演示幻灯片, 你可以在 **Template** 中选择 "SlideShow s5"。 如果你想知道, 这会产生由 [S5 幻灯片框架][8]驱动的幻灯片。
|
||||
|
||||

|
||||
|
||||
点击 **Forward**,如果你在导出一个笔记本, 你可以选择将页面作为单个文件或一个文件导出。 你还可以指向要保存导出文件的文件夹。
|
||||
|
||||

|
||||
|
||||
### Zim 能做的就这些吗?
|
||||
|
||||
远远不止这些,还有一些 [插件][9] 可以扩展它的功能。它甚至包含一个内置的 Web 服务器,可以让你将你的笔记本作为静态的 HTML 文件。这对于在内部网络上分享你的页面和笔记本是非常有用的。
|
||||
|
||||
总的来说,Zim 是一个用来管理你的信息的强大而又紧凑的工具。这是我使用过的最好的桌面版 wik ,而且我一直在使用它。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/create-wiki-your-linux-desktop-zim
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
译者:[Auk7F7](https://github.com/Auk7F7)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:https://opensource.com/article/17/2/3-desktop-wikis
|
||||
[2]:http://zim-wiki.org/
|
||||
[3]:http://zim-wiki.org/downloads.html
|
||||
[4]:http://zim-wiki.org/manual/Help/Wiki_Syntax.html
|
||||
[5]:https://www.dokuwiki.org/wiki:syntax
|
||||
[6]:http://en.wikipedia.org/wiki/Wikilink
|
||||
[7]:https://en.wikipedia.org/wiki/Camel_case
|
||||
[8]:https://meyerweb.com/eric/tools/s5/
|
||||
[9]:http://zim-wiki.org/manual/Plugins.html
|
||||
@ -0,0 +1,209 @@
|
||||
Linux 系统中 sudo 命令的 10 个技巧
|
||||
======
|
||||
|
||||
![Linux-sudo-command-tips][1]
|
||||
|
||||
### 概览
|
||||
|
||||
**sudo** 表示 **superuser do**。 它允许已验证的用户以其他用户的身份来运行命令。其他用户可以是普通用户或者超级用户。然而,大部分时候我们用它来以提升的权限来运行命令。
|
||||
|
||||
sudo 命令与安全策略配合使用,默认安全策略是 sudoers,可以通过文件 **/etc/sudoers** 来配置。其安全策略具有高度可拓展性。人们可以开发和分发他们自己的安全策略作为插件。
|
||||
|
||||
#### 与 su 的区别
|
||||
|
||||
在 GNU/Linux 中,有两种方式可以用提升的权限来运行命令:
|
||||
|
||||
* 使用 **su** 命令
|
||||
* 使用 **sudo** 命令
|
||||
|
||||
**su** 表示 **switch user**。使用 su,我们可以切换到 root 用户并且执行命令。但是这种方式存在一些缺点
|
||||
|
||||
* 我们需要与他人共享 root 的密码。
|
||||
* 因为 root 用户为超级用户,我们不能授予受控的访问权限。
|
||||
* 我们无法审查用户在做什么。
|
||||
|
||||
sudo 以独特的方式解决了这些问题。
|
||||
|
||||
1. 首先,我们不需要妥协来分享 root 用户的密码。普通用户使用他们自己的密码就可以用提升的权限来执行命令。
|
||||
2. 我们可以控制 sudo 用户的访问,这意味着我们可以限制用户只执行某些命令。
|
||||
3. 除此之外,sudo 用户的所有活动都会被记录下来,因此我们可以随时审查进行了哪些操作。在基于 Debian 的 GNU/Linux 中,所有活动都记录在 **/var/log/auth.log** 文件中。
|
||||
|
||||
本教程后面的部分阐述了这些要点。
|
||||
|
||||
#### 实际动手操作 sudo
|
||||
|
||||
现在,我们对 sudo 有了大致的了解。让我们实际动手操作吧。为了演示,我使用 Ubuntu。但是,其它发行版本的操作应该是相同的。
|
||||
|
||||
#### 允许 sudo 权限
|
||||
|
||||
让我们添加普通用户为超级用户吧。在我的情形中,用户名为 linuxtechi
|
||||
|
||||
1) 按如下所示编辑 /etc/sudoers 文件:
|
||||
```
|
||||
$ sudo visudo
|
||||
|
||||
```
|
||||
|
||||
2) 添加以下行来允许用户 linuxtechi 有 sudo 权限:
|
||||
```
|
||||
linuxtechi ALL=(ALL) ALL
|
||||
|
||||
```
|
||||
|
||||
上述命令中:
|
||||
|
||||
* linuxtechi 表示用户名
|
||||
* 第一个 ALL 指示允许从任何终端、机器访问 sudo
|
||||
* 第二个 (ALL) 指示 sudo 命令被允许以任何用户身份执行
|
||||
* 第三个 ALL 表示所有命令都可以作为 root 执行
|
||||
|
||||
|
||||
#### 以提升的权限执行命令
|
||||
|
||||
要用提升的权限执行命令,只需要在命令前加上 sudo,如下所示
|
||||
```
|
||||
$ sudo cat /etc/passwd
|
||||
|
||||
```
|
||||
|
||||
当你执行这个命令时,它会询问 linuxtechi 的密码,而不是 root 用户的密码。
|
||||
|
||||
#### 以其他用户执行命令
|
||||
|
||||
|
||||
除此之外,我们可以使用 sudo 以另一个用户身份执行命令。例如,在下面的命令中,用户 linuxtechi 以用户 devesh 的身份执行命令:
|
||||
```
|
||||
$ sudo -u devesh whoami
|
||||
[sudo] password for linuxtechi:
|
||||
devesh
|
||||
|
||||
```
|
||||
|
||||
#### 内置命令行为
|
||||
|
||||
sudo 的一个限制是——它无法使用 Shell 的内置命令。例如,历史记录是内置命令,如果你试图用 sudo 执行这个命令,那么会提示如下的未找到命令的错误:
|
||||
```
|
||||
$ sudo history
|
||||
[sudo] password for linuxtechi:
|
||||
sudo: history: command not found
|
||||
|
||||
```
|
||||
|
||||
**访问 root shell**
|
||||
|
||||
为了克服上述问题,我们可以访问 root shell,并在那里执行任何命令,包括 Shell 的内置命令。
|
||||
|
||||
要访问 root shell, 执行下面的命令:
|
||||
```
|
||||
$ sudo bash
|
||||
|
||||
```
|
||||
|
||||
执行完这个命令后——您将观察到提示符变为 磅(#)字符。
|
||||
|
||||
### 技巧
|
||||
|
||||
这节我们将讨论一些有用的技巧,这将有助于提高生产力。大多数命令可用于完成日常任务。
|
||||
|
||||
#### 以 sudo 用户执行之前的命令
|
||||
|
||||
让我们假设你想用提升的权限执行之前的命令,那么下面的技巧将会很有用:
|
||||
```
|
||||
$ sudo !4
|
||||
|
||||
```
|
||||
|
||||
上面的命令将使用提升的权限执行历史记录中的第 4 条命令。
|
||||
|
||||
#### sudo command with Vim
|
||||
|
||||
很多时候,我们编辑系统的配置文件时,在保存时意识到我们需要 root 访问权限来执行此操作。因为这个可能让我们失去我们对文件的改动。没有必要惊慌,我们可以在 Vim 中使用下面的命令来解决这种情况:
|
||||
```
|
||||
:w !sudo tee %
|
||||
|
||||
```
|
||||
|
||||
上述命令中:
|
||||
|
||||
* 冒号 (:) 表明我们处于 Vim 的退出模式
|
||||
* 感叹号 (!) 表明我们正在运行 shell 命令
|
||||
* sudo 和 tee 都是 shell 命令
|
||||
* 百分号 (%) 表明从当前行开始的所有行
|
||||
|
||||
|
||||
|
||||
#### 使用 sudo 执行多个命令
|
||||
|
||||
至今我们用 sudo 只执行了单个命令,但我们可以用它执行多个命令。只需要用分号 (;) 隔开命令,如下所示:
|
||||
```
|
||||
$ sudo -- bash -c 'pwd; hostname; whoami'
|
||||
|
||||
```
|
||||
|
||||
上述命令中
|
||||
|
||||
* 双连字符 (–) 停止命令行切换
|
||||
* bash 表示要用于执行命令的 shell 名称
|
||||
* -c 选项后面跟着要执行的命令
|
||||
|
||||
|
||||
|
||||
#### 无密码运行 sudo 命令
|
||||
|
||||
当第一次执行 sudo 命令时,它会提示输入密码,默认情形下密码被缓存 15 分钟。但是,我们可以避免这个操作,并使用 NOPASSWD 关键字禁用密码认证,如下所示:
|
||||
```
|
||||
linuxtechi ALL=(ALL) NOPASSWD: ALL
|
||||
|
||||
```
|
||||
|
||||
#### 限制用户执行某些命令
|
||||
|
||||
为了提供受控访问,我们可以限制 sudo 用户只执行某些命令。例如,下面的行只允许执行 echo 和 ls 命令
|
||||
```
|
||||
linuxtechi ALL=(ALL) NOPASSWD: /bin/echo /bin/ls
|
||||
|
||||
```
|
||||
|
||||
#### 深入了解 sudo
|
||||
|
||||
让我们进一步深入了解 sudo 命令。
|
||||
```
|
||||
$ ls -l /usr/bin/sudo
|
||||
-rwsr-xr-x 1 root root 145040 Jun 13 2017 /usr/bin/sudo
|
||||
|
||||
```
|
||||
|
||||
如果仔细观测文件权限,则发现 sudo 上启用了 **setuid** 位。当任何用户运行这个二进制文件时,它将以拥有该文件的用户权限运行。在所示情形下,它是 root 用户。
|
||||
|
||||
为了演示这一点,我们可以使用 id 命令,如下所示:
|
||||
```
|
||||
$ id
|
||||
uid=1002(linuxtechi) gid=1002(linuxtechi) groups=1002(linuxtechi)
|
||||
|
||||
```
|
||||
|
||||
当我们不使用 sudo 执行 id 命令时,将显示用户 linuxtechi 的 id。
|
||||
```
|
||||
$ sudo id
|
||||
uid=0(root) gid=0(root) groups=0(root)
|
||||
|
||||
```
|
||||
|
||||
但是,如果我们使用 sudo 执行 id 命令时,则会显示 root 用户的 id。
|
||||
|
||||
### 结论
|
||||
|
||||
从这篇文章可以看出——sudo 为普通用户提供了更多受控访问。使用这些技术,多用户可以用安全的方式与 GNU/Linux 进行交互。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxtechi.com/quick-tips-sudo-command-linux-systems/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[szcf-weiya](https://github.com/szcf-weiya)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxtechi.com/author/pradeep/
|
||||
[1]:https://www.linuxtechi.com/wp-content/uploads/2018/03/Linux-sudo-command-tips.jpg
|
||||
@ -0,0 +1,90 @@
|
||||
注重隐私的开源桌面 YouTube 播放器
|
||||
======
|
||||
|
||||

|
||||
|
||||
你已经知道我们需要 Google 帐户才能订阅频道并从 YouTube 下载视频。如果你不希望 Google 追踪你在 YouTube 上的行为,那么有一个名为 **“FreeTube”** 的开源 Youtube 播放器。它能让你无需使用帐户观看、搜索和下载 Youtube 视频并订阅你喜爱的频道,这可以防止 Google 获取你的信息。它为你提供完整的无广告体验。另一个值得注意的优势是它有一个内置的基础的 HTML5 播放器来观看视频。由于我们没有使用内置的 YouTube 播放器,因此 Google 无法跟踪“观看次数”,也无法视频分析。FreeTube 只会发送你的 IP 详细信息,但这也可以通过使用 VPN 来解决。它是完全免费、开源的,可用于 GNU/Linux、Mac OS X 和 Windows。
|
||||
|
||||
### 功能
|
||||
|
||||
* 观看没有广告的视频。
|
||||
* 防止 Google 使用 Cookie 或 JavaScript 跟踪你观看的内容。
|
||||
* 无须帐户订阅频道。
|
||||
* 本地存储订阅、历史记录和已保存的视频。
|
||||
* 导入/备份订阅。
|
||||
* 迷你播放器。
|
||||
* 轻/黑暗的主题。
|
||||
* 免费、开源。
|
||||
* 跨平台。
|
||||
|
||||
|
||||
|
||||
### 安装 FreeTube
|
||||
|
||||
进入[**发布页面**][1]并根据你使用的操作系统获取版本。在本指南中,我将使用 **.tar.gz** 文件。
|
||||
```
|
||||
$ wget https://github.com/FreeTubeApp/FreeTube/releases/download/v0.1.3-beta/FreeTube-linux-x64.tar.xz
|
||||
|
||||
```
|
||||
|
||||
解压下载的归档:
|
||||
```
|
||||
$ tar xf FreeTube-linux-x64.tar.xz
|
||||
|
||||
```
|
||||
|
||||
进入 Freetube 文件夹:
|
||||
```
|
||||
$ cd FreeTube-linux-x64/
|
||||
|
||||
```
|
||||
|
||||
使用命令启动 Freeube:
|
||||
```
|
||||
$ ./FreeTub
|
||||
|
||||
```
|
||||
|
||||
这就是 FreeTube 默认界面的样子。
|
||||
|
||||
![][3]
|
||||
|
||||
### 用法
|
||||
|
||||
FreeTube 目前使用 **YouTube API ** 搜索视频。然后,它使用 **Youtube-dl HTTP API** 获取原始视频文件并在基础的 HTML5 视频播放器中播放它们。由于订阅、历史记录和已保存的视频都存储在本地系统中,因此你的详细信息将不会发送给 Google 或其他任何人。
|
||||
|
||||
在搜索框中输入视频名称,然后按下回车键。FreeTube 会根据你的搜索查询列出结果。
|
||||
|
||||
![][4]
|
||||
|
||||
你可以点击任何视频来播放它。
|
||||
|
||||
![][5]
|
||||
|
||||
如果你想更改主题或默认 API、导入/导出订阅,请进入**设置**部分。
|
||||
|
||||
![][6]
|
||||
|
||||
请注意,FreeTube 仍处于 **beta** 阶段,所以仍然有 bug。如果有任何 bug,请在本指南最后给出的 GitHub 页面上报告。
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/freetube-an-open-source-desktop-youtube-player-for-privacy-minded-people/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://github.com/FreeTubeApp/FreeTube/releases
|
||||
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/03/FreeTube-1.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2018/03/FreeTube-3.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/03/FreeTube-5-1.png
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2018/03/FreeTube-2.png
|
||||
@ -0,0 +1,124 @@
|
||||
通过玩命令行游戏来测试你的 BASH 技能
|
||||
=====
|
||||
|
||||
|
||||

|
||||
|
||||
如果我们经常在实际场景中使用 Linux 命令,我们倾向于更有效的学习和记忆它们。除非你经常使用 Linux 命令,否则你可能会在一段时间内忘记它们。无论你是新手还是中级用户,总会有一些令人兴奋的方法来测试你的 BASH 技能。在本教程中,我将解释如何通过玩命令行游戏来测试你的 BASH 技能。其实从技术上讲,这些并不是真正的游戏,如 Super TuxKart,NFS 或 Counterstrike 等等。这些只是 Linux 命令培训课程的游戏化版本。你将根据游戏本身的某些指示来完成一个任务。
|
||||
|
||||
现在,我们将看到几款能帮助你实时学习和练习 Linux 命令的游戏。这些游戏不是消磨时间或者令人惊诧的,这些游戏将帮助你获得终端命令的真实体验。请继续阅读:
|
||||
|
||||
### 使用 “Wargames” 来测试 BASH 技能
|
||||
|
||||
这是一个在线游戏,所以你必须和互联网保持连接。这些游戏可以帮助你以充满乐趣的游戏形式学习和练习 Linux 命令。Wargames 是 shell 游戏的集合,每款游戏有很多关卡。只有通过解决先前的关卡才能访问下一个关卡。不要担心!每个游戏都提供了有关如何进入下一关的清晰简洁说明。
|
||||
|
||||
要玩 Wargames,请点击以下链接:
|
||||
|
||||
![][2]
|
||||
|
||||
如你所见,左边列出了许多 shell 游戏。每个 shell 游戏都有自己的 SSH 端口。所以,你必须通过本地系统配置 SSH 连接到游戏,你可以在 Wargames 网站的左上角找到关于如何使用 SSH 连接到每个游戏的信息。
|
||||
|
||||
例如,让我们来玩 **Bandit** 游戏吧。为此,单击 Wargames 主页上的 Bandit 链接。在左上角,你会看到 Bandit 游戏的 SSH 信息。
|
||||
|
||||
![][3]
|
||||
|
||||
正如你在上面的屏幕截图中看到的,有很多关卡。要进入每个关卡,请单机左侧列中的相应链接。此外,右侧还有适合初学者的说明。如果你对如何玩此游戏有任何疑问,请阅读它们。
|
||||
|
||||
现在,让我们点击它进入关卡 0。在下一个屏幕中,你将获得该关卡的 SSH 信息。
|
||||
|
||||
![][4]
|
||||
|
||||
正如你在上面的屏幕截图中看到的,你需要配置 SSH 端口 2220 连接 **bandit.labs.overthewire.org**,用户名是 **bandit0**,密码是 **bandit0**。
|
||||
|
||||
让我们连接到 Bandit 游戏关卡 0。
|
||||
|
||||
输入密码 **bandit0**
|
||||
|
||||
示例输出将是:
|
||||
|
||||
![][5]
|
||||
|
||||
登录后,输入 **ls** 命令查看内容或者进入 **关卡 1 页面**,了解如何通过关卡 1 等等。建议的命令列表已在每个关卡提供。所以,你可以选择和使用任何合适的命令来解决每个关卡。
|
||||
|
||||
我必须承认,Wargames 是令人上瘾的,并且解决每个关卡是非常有趣的。 尽管有些关卡确实很具挑战性,你可能需要谷歌才能知道如何解决问题。 试一试,你会很喜欢它。
|
||||
|
||||
### 使用 “Terminus” 来测试 BASH 技能
|
||||
|
||||
这是另一个基于浏览器的在线 CLI 游戏(译注:CLI 命令行界面),可用于改进或测试你的 Linux 命令技能。要玩这个游戏,请打开你的 web 浏览器并导航到以下 URL。
|
||||
|
||||
一旦你进入游戏,你会看到有关如何玩游戏的说明。与 Wargames 不同,你不需要连接到它们的游戏服务器来玩游戏。Terminus 有一个内置的 CLI,你可以在其中找到有关如何使用它的说明。
|
||||
|
||||
你可以使用命令 **“ls”** 查看周围的环境,使用命令 **“cd LOCATION”** 移动到新的位置,返回使用命令 **“cd ..”**,与这个世界进行交互使用命令 **“less ITEM”** 等等。要知道你当前的位置,只需输入 **“pwd”**。
|
||||
|
||||
![][6]
|
||||
|
||||
### 使用 “clmystery” 来测试 BASH 技能
|
||||
|
||||
与上述游戏不同,你可以在本地玩这款游戏。你不需要连接任何远程系统,这是完全离线的游戏。
|
||||
|
||||
相信我,这是一个有趣的游戏人。按照给定的说明,你将扮演一个侦探角色来解决一个神秘案件。
|
||||
|
||||
首先,克隆仓库:
|
||||
```
|
||||
$ git clone https://github.com/veltman/clmystery.git
|
||||
|
||||
```
|
||||
|
||||
或者,从 [这里][7] 将其作为 zip 文件下载。解压缩并切换到下载文件的地方。左后,通过阅读 “instructions” 文件来解决神秘案例。
|
||||
```
|
||||
[sk@sk]: clmystery-master>$ ls
|
||||
cheatsheet.md cheatsheet.pdf encoded hint1 hint2 hint3 hint4 hint5 hint6 hint7 hint8 instructions LICENSE.md mystery README.md solution
|
||||
|
||||
```
|
||||
|
||||
这里是玩这个游戏的说明:
|
||||
|
||||
终端城发生了一起谋杀案,TCPD 需要你的帮助。你需要帮助它们弄清楚是谁犯罪了。
|
||||
|
||||
为了查明是谁干的,你需要到 **‘mystery’** 子目录并从那里开始工作。你可能需要查看犯罪现场的所有线索( **‘crimescene’** 文件)。现场的警官相当谨慎,所以他们在警官报告中写下了一切。幸运的是,警官在所有的帽子里都用了 “CLUE” 一词,并把真正的线索标记了出来。
|
||||
|
||||
如果里遇到任何问题,请打开其中一个提示文件,例如 hint1,hint2 等。你可以使用下面的 cat 命令打开提示文件。
|
||||
```
|
||||
$ cat hint1
|
||||
|
||||
$ cat hint2
|
||||
|
||||
```
|
||||
|
||||
要检查你的答案或找出解决方案,请在 clmystery 目录中打开文件 “solution”。
|
||||
```
|
||||
$ cat solution
|
||||
|
||||
```
|
||||
|
||||
要开始如何使用命令行,请参阅 **cheatsheet.md** 或 **cheatsheet.pdf** (在命令行中,你可以输入 ‘nano cheatsheet.md’)。请勿使用文本编辑器查看除说明,备忘录和提示以外的任何文件。
|
||||
|
||||
有关更多详细信息,请参阅 [**clmystery GitHub**][8] 页面。
|
||||
|
||||
**推荐阅读:**
|
||||
|
||||
而这就是我现在所能记得的。如果将来遇到任何问题,我会继续添加更多游戏。将此链接加入书签并不时访问。如果你知道其他类似的游戏,请在下面的评论部分告诉我,我将测试和更新本指南。
|
||||
|
||||
还有更多好东西,敬请关注!
|
||||
|
||||
干杯!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/test-your-bash-skills-by-playing-command-line-games/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/03/Wargames-1.png
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/03/Bandit-game.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2018/03/Bandit-level-0.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/03/Bandit-level-0-ssh-1.png
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2018/03/Terminus.png
|
||||
[7]:https://github.com/veltman/clmystery/archive/master.zip
|
||||
[8]:https://github.com/veltman/clmystery
|
||||
84
translated/tech/20180313 Running DOS on the Raspberry Pi.md
Normal file
84
translated/tech/20180313 Running DOS on the Raspberry Pi.md
Normal file
@ -0,0 +1,84 @@
|
||||
在树莓派上运行 DOS 系统
|
||||
======
|
||||
|
||||
|
||||
[FreeDOS][1] 对大家来说也许并不陌生。它是一个完整、免费并且对 DOS 兼容良好的操作系统,它可以运行一些比较老旧的 DOS 游戏或者商用软件,也可以开发嵌入式的应用。只要在 MS-DOS 上能够运行的程序,在 FreeDOS 上都可以运行。
|
||||
|
||||
作为 FreeDOS 的发起者和项目协调人员,很多用户会把我作为内行人士进行发问。而我最常被问到的问题是:“FreeDOS 可以在树莓派上运行吗?”
|
||||
|
||||
这个问题并不令人意外。毕竟 Linux 在树莓派上能够很好地运行,而 FreeDOS 和 Linux 相比是一个更古老、占用资源更少的操作系统,那 FreeDOS 为啥不能树莓派上运行呢?
|
||||
|
||||
简单来说。由于 CPU 架构的原因,FreeDOS 并不能在树莓派中独立运行。和其它 DOS 类的系统一样,FreeDOS 需要英特尔 x86 架构 CPU 以及 BIOS 来提供基础的运行时服务。而树莓派运行在 ARM 架构的 CPU 上,与英特尔 CPU 二进制不兼容,也没有 BIOS。因此树莓派在硬件层面就不支持 FreeDOS。
|
||||
|
||||
不过通过 PC 模拟器还是能在树莓派上运行 FreeDOS 的,虽然这样也许稍有不足,但也不失为一个能在树莓派上运行 FreeDOS 的方法。
|
||||
|
||||
### DOSBox怎么样?
|
||||
|
||||
有人可能会问:“为什么不用 DOSBox 呢?” DOSBox 是一个开源的跨平台 x86 模拟器,在 Linux 上也能使用,它能够为应用软件尤其是游戏软件提供了一个类 DOS 的运行环境,所以如果你只是想玩 DOS 游戏的话,DOSBox是一个不错的选择。但在大众眼中,DOSBox 是专为 DOS 游戏而设的,而在运行一些别的 DOS 应用软件方面,DOSBox 只是表现平平。
|
||||
|
||||
对多数人来说,这只是个人偏好的问题,我喜欢用 FreeDOS 来运行 DOS 游戏和其它程序,完整的 DOS 系统和 DOSBox 相比能让我体验到更好的灵活性和操控性。我只用 DOSBox 来玩游戏,在其它方面还是选择完整的 FreeDOS。
|
||||
|
||||
### 在树莓派上安装 FreeDOS
|
||||
|
||||
[QEMU][3](Quick EMUlator)是一款能在 Linux 系统上运行 DOS 系统的开源的虚拟机软件。很多流行的 Linux 系统都自带 QEMU。QEMU 在我树莓派上的 Raspbian 系统中也同样能够运行,下文就有一些我在树莓派 [Raspbian GNU/Linux 9 (Stretch)][4] 系统中使用 QEMU 的截图。
|
||||
|
||||
去年我在写了一篇关于[如何在 Linux 系统中运行 DOS 程序][5]的文章的时候就用到了 QEMU,在树莓派上使用 QEMU 来安装运行 FreeDOS 的步骤基本上和在别的基于 GNOME 的系统上没有什么太大的区别。
|
||||
|
||||
在 QEMU 中你需要通过添加各种组件来搭建虚拟机。先指定一个用来安装运行 DOS 的虚拟磁盘镜像,通过`qemu-img` 命令来创建一个虚拟磁盘镜像,对于 FreeDOS 来说不需要太大的空间,所以我只创建了一个 200MB 的虚拟磁盘:
|
||||
```
|
||||
qemu-img create freedos.img 200M
|
||||
|
||||
```
|
||||
|
||||
和 VMware 或者 VirtualBox 这些 PC 模拟器不同,使用 QEMU 需要通过添加各种组件来搭建虚拟机,尽管有点麻烦,但是并不困难。我使用了以下这些参数来在树莓派上使用 QEMU 安装 FreeDOS 系统:
|
||||
```
|
||||
qemu-system-i386 -m 16 -k en-us -rtc base=localtime -soundhw sb16,adlib -device cirrus-vga -hda freedos.img -cdrom FD12CD.iso -boot order=d
|
||||
|
||||
```
|
||||
|
||||
你可以在我其它的[文章][5]中找到这些命令的完整介绍。简单来说,上面这条命令指定了一个英特尔 i386 兼容虚拟机,并且分配了 16MB 内存、一个英文输入键盘、一个基于系统时间的实时时钟、一个声卡、一个音乐卡以及一个 VGA 卡。文件 `freedos.img` 指定为第一个硬盘(`C:`),`FD12CD.iso` 镜像作为 CD-ROM (`D:`)驱动。QEMU 设定为从`D:`的 CD-ROM 启动。
|
||||
|
||||
你只需要按照提示就可以轻松安装好 FreeDOS 1.2 了。但是由于 microSD 卡在面对大量的 I/O 时速度比较慢,所以安装操作系统需要花费很长时间。
|
||||
|
||||
|
||||
### 在树莓派上运行 FreeDOS
|
||||
|
||||
你的运行情况取决于使用哪一种 microSD 卡。我用的是 SanDisk Ultra 64GB microSDXC UHS-I U1A1 ,其中 U1 这种型号专用于支持 1080p 的视频录制(例如 GoPro),它的最低串行写速度能够达到 10MB/s。相比之下,V60 型号专用于 4K 视频录制,最低连续写入速度能达到 60MB/s。如果你的树莓派使用的是 V60 的 microSD 卡甚至是 V30(也能达到 30MB/s),你就能明显看到它的 I/O 性能会比我的好。
|
||||
|
||||
FreeDOS 安装好之后,你可以直接从`C:`进行启动。只需要按照下面的命令用`-boot order=c`来指定 QEMU 的启动顺序即可:
|
||||
```
|
||||
qemu-system-i386 -m 16 -k en-us -rtc base=localtime -soundhw sb16,adlib -device cirrus-vga -hda freedos.img -cdrom FD12CD.iso -boot order=c
|
||||
|
||||
```
|
||||
|
||||
只要树莓派的 QEMU 上安装了 FreeDOS,就不会出现明显的性能问题。例如游戏通常在每一关开始的时候会加载地图、怪物、声音等一系列的数据,尽管这些内容需要加载一段时间,但在正常玩的时候并没有出现性能不足的现象。
|
||||
|
||||
FreeDOS 1.2 自带了很多游戏以及其它应用软件,可以使用`FDIMPLES`包管理程序来安装它们。FreeDOS 1.2 里面我最喜欢的是一款叫 WING 的太空射击游戏,让人想起经典的街机游戏 Galaga(WING 就是 Wing Is Not Galaga 的递归缩写词)。
|
||||
|
||||
As-Easy-As 是我最喜欢的一个 DOS 应用程序,作为20世纪8、90年代流行的电子表格程序,它和当时的 Lotus 1-2-3 以及现在的 Microsoft Excel、LibreOffice Calc 一样具有强大的威力。As-Easy-As 和 Lotus 1-2-3 都将数据保存为 WKS 文件,现在新版本的 Microsoft Excel 已经无法读取这种文件了,而 LibreOffice Calc 是兼容性而定有可能支持。鉴于 As-Easy-As 的初始版本是一个共享软件,TRIUS 仍然为 As-Easy-As 5.7 免费提供[激活码][6]。
|
||||
|
||||
我也非常喜欢 GNU Emacs 编辑器,FreeDOS 也自带了一个叫 Freemacs 的类 Emacs 的文本编辑器。它比 FreeDOS 默认的 FreeDOS Edit 编辑器更强大,也能带来 GNU Emacs 的体验。如果你也需要,可以在 FreeDOS 1.2 中通过`FDIMPLES`包管理程序来安装。
|
||||
|
||||
### 是的,你或许真的可以在树莓派上运行 DOS
|
||||
|
||||
While you can't run DOS on "bare hardware" on the Raspberry Pi, it's nice to know that you can still run DOS on the Raspberry Pi via an emulator. Thanks to the QEMU PC emulator and FreeDOS, it's possible to play classic DOS games and run other DOS programs on the Raspberry Pi. Expect a slight performance hit when doing any disk I/O, especially if you're doing something intensive on the disk, like writing large amounts of data, but things will run fine after that. Once you've set up QEMU as the virtual machine emulator and installed FreeDOS, you are all set to enjoy your favorite classic DOS programs on the Raspberry Pi.
|
||||
|
||||
即使树莓派在硬件上不支持 DOS,但是在模拟器的帮助下,DOS 还是能够在树莓派上运行。得益于 QEMU PC 模拟器,一些经典的 DOS 游戏和 DOS 应用程序能够运行在树莓派上。在执行磁盘 I/O ,尤其是大量密集操作(例如写入大量数据)的时候,性能可能会受到轻微的影响。当你使用 QEMU 并且在虚拟机里安装好 FreeDOS 之后,你就可以尽情享受经典的 DOS 程序了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/can-you-run-dos-raspberry-pi
|
||||
|
||||
作者:[Jim Hall][a]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jim-hall
|
||||
[1]:http://www.freedos.org/
|
||||
[2]:https://opensource.com/article/18/3/raspberry-pi-week-giveaway
|
||||
[3]:https://www.qemu.org/
|
||||
[4]:https://www.raspberrypi.org/downloads/
|
||||
[5]:https://opensource.com/article/17/10/run-dos-applications-linux
|
||||
[6]:http://www.triusinc.com/forums/viewtopic.php?t=10
|
||||
Loading…
Reference in New Issue
Block a user