mirror of
https://github.com/LCTT/TranslateProject.git
synced 2024-12-29 21:41:00 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject into new
This commit is contained in:
commit
275f1afef9
@ -1,57 +1,64 @@
|
|||||||
理解 Linux 链接:第一部分
|
理解 Linux 链接(一)
|
||||||
======
|
======
|
||||||
|
> 链接是可以将文件和目录放在你希望它们放在的位置的另一种方式。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
除了 `cp` 和 `mv` 这两个我们在[本系列的前一部分][1]中详细讨论过的,链接是另一种方式可以将文件和目录放在你希它们放在的位置。它的优点是可以让你同时在多个位置显示一个文件或目录。
|
除了 `cp` 和 `mv` 这两个我们在[本系列的前一部分][1]中详细讨论过的,链接是可以将文件和目录放在你希望它们放在的位置的另一种方式。它的优点是可以让你同时在多个位置显示一个文件或目录。
|
||||||
|
|
||||||
如前所述,在物理磁盘这个级别上,文件和目录之类的东西并不真正存在。文件系统为了方便人类使用,将它们虚构出来。但在磁盘级别上,有一个名为 _partition table_(分区表)的东西,它位于每个分区的开头,然后数据分散在磁盘的其余部分。
|
如前所述,在物理磁盘这个级别上,文件和目录之类的东西并不真正存在。文件系统是为了方便人类使用,将它们虚构出来。但在磁盘级别上,有一个名为<ruby>分区表<rt>partition table</rt></ruby>的东西,它位于每个分区的开头,然后数据分散在磁盘的其余部分。
|
||||||
|
|
||||||
虽然有不同类型的分区表,但是在分区开头的表包含的数据将映射每个目录和文件的开始和结束位置。分区表的就像一个索引:当从磁盘加载文件时,操作系统会查找表中的条目,分区表会告诉文件在磁盘上的起始位置和结束位置。然后磁盘头移动到起点,读取数据,直到它到达终点,最后告诉 presto:这就是你的文件。
|
虽然有不同类型的分区表,但是在分区开头的那个表包含的数据将映射每个目录和文件的开始和结束位置。分区表的就像一个索引:当从磁盘加载文件时,操作系统会查找表中的条目,分区表会告诉文件在磁盘上的起始位置和结束位置。然后磁盘头移动到起点,读取数据,直到它到达终点,您看:这就是你的文件。
|
||||||
|
|
||||||
### 硬链接
|
### 硬链接
|
||||||
|
|
||||||
硬链接只是分区表中的一个条目,它指向磁盘上的某个区域,表示该区域**已经被分配给文件**。换句话说,硬链接指向已经被另一个条目索引的数据。让我们看看它是如何工作的。
|
硬链接只是分区表中的一个条目,它指向磁盘上的某个区域,表示该区域**已经被分配给文件**。换句话说,硬链接指向已经被另一个条目索引的数据。让我们看看它是如何工作的。
|
||||||
|
|
||||||
打开终端,创建一个实验目录并进入:
|
打开终端,创建一个实验目录并进入:
|
||||||
|
|
||||||
```
|
```
|
||||||
mkdir test_dir
|
mkdir test_dir
|
||||||
cd test_dir
|
cd test_dir
|
||||||
```
|
```
|
||||||
|
|
||||||
使用 [touch][1] 创建一个文件:
|
使用 [touch][1] 创建一个文件:
|
||||||
|
|
||||||
```
|
```
|
||||||
touch test.txt
|
touch test.txt
|
||||||
```
|
```
|
||||||
|
|
||||||
为了获得更多的体验(?),在文本编辑器中打开 _test.txt_ 并添加一些单词。
|
为了获得更多的体验(?),在文本编辑器中打开 `test.txt` 并添加一些单词。
|
||||||
|
|
||||||
现在通过执行以下命令来建立硬链接:
|
现在通过执行以下命令来建立硬链接:
|
||||||
|
|
||||||
```
|
```
|
||||||
ln test.txt hardlink_test.txt
|
ln test.txt hardlink_test.txt
|
||||||
```
|
```
|
||||||
|
|
||||||
运行 `ls`,你会看到你的目录现在包含两个文件,或者看起来如此。正如你之前读到的那样,你真正看到的是完全相同的文件的两个名称: _hardlink\_test.txt_ 包含相同的内容,没有填充磁盘中的任何更多空间(尝试使用大文件来测试),并与 _test.txt_ 使用相同的 inode:
|
运行 `ls`,你会看到你的目录现在包含两个文件,或者看起来如此。正如你之前读到的那样,你真正看到的是完全相同的文件的两个名称: `hardlink_test.txt` 包含相同的内容,没有填充磁盘中的任何更多空间(可以尝试使用大文件来测试),并与 `test.txt` 使用相同的 inode:
|
||||||
|
|
||||||
```
|
```
|
||||||
$ ls -li *test*
|
$ ls -li *test*
|
||||||
16515846 -rw-r--r-- 2 paul paul 14 oct 12 09:50 hardlink_test.txt
|
16515846 -rw-r--r-- 2 paul paul 14 oct 12 09:50 hardlink_test.txt
|
||||||
16515846 -rw-r--r-- 2 paul paul 14 oct 12 09:50 test.txt
|
16515846 -rw-r--r-- 2 paul paul 14 oct 12 09:50 test.txt
|
||||||
```
|
```
|
||||||
|
|
||||||
_ls_ 的 `-i` 选项显示一个文件的 _inode 数值_。_inode_ 是分区表中的信息块,它包含磁盘上文件或目录的位置,上次修改的时间以及其它数据。如果两个文件使用相同的 inode,那么无论它们在目录树中的位置如何,它们在实际效果上都是相同的文件。
|
`ls` 的 `-i` 选项显示一个文件的 “inode 数值”。“inode” 是分区表中的信息块,它包含磁盘上文件或目录的位置、上次修改的时间以及其它数据。如果两个文件使用相同的 inode,那么无论它们在目录树中的位置如何,它们在实际上都是相同的文件。
|
||||||
|
|
||||||
### 软链接
|
### 软链接
|
||||||
|
|
||||||
软链接,也称为 _symlinks_(系统链接),它是不同的:软链接实际上是一个独立的文件,它有自己的 inode 和它自己在磁盘上的小插槽。但它只包含一小段数据,将操作系统指向另一个文件或目录。
|
软链接,也称为<ruby>符号链接<rt>symlink</rt></ruby>,它与硬链接是不同的:软链接实际上是一个独立的文件,它有自己的 inode 和它自己在磁盘上的小块地方。但它只包含一小段数据,将操作系统指向另一个文件或目录。
|
||||||
|
|
||||||
你可以使用 `ln` 的 `-s` 选项来创建一个软链接:
|
你可以使用 `ln` 的 `-s` 选项来创建一个软链接:
|
||||||
|
|
||||||
```
|
```
|
||||||
ln -s test.txt softlink_test.txt
|
ln -s test.txt softlink_test.txt
|
||||||
```
|
```
|
||||||
|
|
||||||
这将在当前目录中创建软链接 _softlink\_test.txt_,它指向 _test.txt_。
|
这将在当前目录中创建软链接 `softlink_test.txt`,它指向 `test.txt`。
|
||||||
|
|
||||||
再次执行 `ls -li`,你可以看到两种链接的不同之处:
|
再次执行 `ls -li`,你可以看到两种链接的不同之处:
|
||||||
|
|
||||||
```
|
```
|
||||||
$ ls -li
|
$ ls -li
|
||||||
total 8
|
total 8
|
||||||
@ -60,48 +67,53 @@ total 8
|
|||||||
16515846 -rw-r--r-- 2 paul paul 14 oct 12 09:50 test.txt
|
16515846 -rw-r--r-- 2 paul paul 14 oct 12 09:50 test.txt
|
||||||
```
|
```
|
||||||
|
|
||||||
_hardlink\_test.txt_ 和 _test.txt_ 包含一些文本并占据相同的空格*字面*。它们使用相同的 inode 数值。与此同时,_softlink\_test.txt_ 占用少得多,并且具有不同的 inode 数值,将其标记为完全不同的文件。使用 _ls_ 的 `-l` 选项还会显示软链接指向的文件或目录。
|
`hardlink_test.txt` 和 `test.txt` 包含一些文本并且*字面上*占据相同的空间。它们使用相同的 inode 数值。与此同时,`softlink_test.txt` 占用少得多,并且具有不同的 inode 数值,将其标记为完全不同的文件。使用 `ls` 的 `-l` 选项还会显示软链接指向的文件或目录。
|
||||||
|
|
||||||
### 为什么要用链接?
|
### 为什么要用链接?
|
||||||
|
|
||||||
它们适用于**带有自己环境的应用程序**。你的 Linux 发行版通常不会附带你需要应用程序的最新版本。以优秀的 [Blender 3D][2] 设计软件为例,Blender 允许你创建 3D 静态图像以及动画电影,人人都想在自己的机器上拥有它。问题是,当前版本的 Blender 至少比任何发行版中的自带的高一个版本。
|
它们适用于**带有自己环境的应用程序**。你的 Linux 发行版通常不会附带你需要应用程序的最新版本。以优秀的 [Blender 3D][2] 设计软件为例,Blender 允许你创建 3D 静态图像以及动画电影,人人都想在自己的机器上拥有它。问题是,当前版本的 Blender 至少比任何发行版中的自带的高一个版本。
|
||||||
|
|
||||||
幸运的是,[Blender 提供下载][3]开箱即用。除了程序本身之外,这些软件包还包含了 Blender 需要运行的复杂的库和依赖框架。所有这些数据和块都在它们自己的目录层次中。
|
幸运的是,[Blender 提供可以开箱即用的下载][3]。除了程序本身之外,这些软件包还包含了 Blender 需要运行的复杂的库和依赖框架。所有这些数据和块都在它们自己的目录层次中。
|
||||||
|
|
||||||
每次你想运行 Blender,你都可以 `cd` 到你下载它的文件夹并运行:
|
每次你想运行 Blender,你都可以 `cd` 到你下载它的文件夹并运行:
|
||||||
|
|
||||||
```
|
```
|
||||||
./blender
|
./blender
|
||||||
```
|
```
|
||||||
|
|
||||||
但这很不方便。如果你可以从文件系统的任何地方,比如桌面命令启动器中运行 `blender` 命令会更好。
|
但这很不方便。如果你可以从文件系统的任何地方,比如桌面命令启动器中运行 `blender` 命令会更好。
|
||||||
|
|
||||||
这样做的方法是将 _blender_ 可执行文件链接到 _bin/_ 目录。在许多系统上,你可以通过将其链接到文件系统中的任何位置来使 `blender` 命令可用,就像这样。
|
这样做的方法是将 `blender` 可执行文件链接到 `bin/` 目录。在许多系统上,你可以通过将其链接到文件系统中的任何位置来使 `blender` 命令可用,就像这样。
|
||||||
|
|
||||||
```
|
```
|
||||||
ln -s /path/to/blender_directory/blender /home/<username>/bin
|
ln -s /path/to/blender_directory/blender /home/<username>/bin
|
||||||
```
|
```
|
||||||
|
|
||||||
你需要链接的另一个情况是**软件需要过时的库**。如果你用 `ls -l` 列出你的 _/usr/lib_ 目录,你会看到许多软链接文件飞过。仔细看看,你会看到软链接通常与它们链接到的原始文件具有相似的名称。你可能会看到 _libblah_ 链接到 _libblah.so.2_,你甚至可能会注意到 _libblah.so.2_ 依次链接到原始文件 _libblah.so.2.1.0_。
|
你需要链接的另一个情况是**软件需要过时的库**。如果你用 `ls -l` 列出你的 `/usr/lib` 目录,你会看到许多软链接文件一闪而过。仔细看看,你会看到软链接通常与它们链接到的原始文件具有相似的名称。你可能会看到 `libblah` 链接到 `libblah.so.2`,你甚至可能会注意到 `libblah.so.2` 相应链接到原始文件 `libblah.so.2.1.0`。
|
||||||
|
|
||||||
这是因为应用程序通常需要安装比已安装版本更老的库。问题是,即使新版本仍然与旧版本(通常是)兼容,如果程序找不到它正在寻找的版本,程序将会出现问题。为了解决这个问题,发行版通常会创建链接,以便挑剔的应用程序相信它找到了旧版本,实际上它只找到了一个链接并最终使用了更新的库版本。
|
这是因为应用程序通常需要安装比已安装版本更老的库。问题是,即使新版本仍然与旧版本(通常是)兼容,如果程序找不到它正在寻找的版本,程序将会出现问题。为了解决这个问题,发行版通常会创建链接,以便挑剔的应用程序**相信**它找到了旧版本,实际上它只找到了一个链接并最终使用了更新的库版本。
|
||||||
|
|
||||||
|
有些是和**你自己从源代码编译的程序**相关。你自己编译的程序通常最终安装在 `/usr/local` 下,程序本身最终在 `/usr/local/bin` 中,它在 `/usr/local/bin` 目录中查找它需要的库。但假设你的新程序需要 `libblah`,但 `libblah` 在 `/usr/lib` 中,这就是所有其它程序都会寻找到它的地方。你可以通过执行以下操作将其链接到 `/usr/local/lib`:
|
||||||
|
|
||||||
有些是和**你自己从源代码编译的程序**相关。你自己编译的程序通常最终安装在 _/usr/local_ 下,程序本身最终在 _/usr/local/bin_ 中,它在 _/usr/local/bin_ 目录中查找它需要的库。但假设你的新程序需要 _libblah_,但 _libblah_ 在 _/usr/lib_ 中,这就是所有其它程序都会寻找到它的地方。你可以通过执行以下操作将其链接到 _/usr/local/lib_:
|
|
||||||
```
|
```
|
||||||
ln -s /usr/lib/libblah /usr/local/lib
|
ln -s /usr/lib/libblah /usr/local/lib
|
||||||
```
|
```
|
||||||
|
|
||||||
或者如果你愿意,可以 `cd` 到 _/usr/local/lib_:
|
或者如果你愿意,可以 `cd` 到 `/usr/local/lib`:
|
||||||
|
|
||||||
```
|
```
|
||||||
cd /usr/local/lib
|
cd /usr/local/lib
|
||||||
```
|
```
|
||||||
|
|
||||||
然后使用链接:
|
然后使用链接:
|
||||||
|
|
||||||
```
|
```
|
||||||
ln -s ../lib/libblah
|
ln -s ../lib/libblah
|
||||||
```
|
```
|
||||||
|
|
||||||
还有几十个案例证明软链接是有用的,当你使用 Linux 更熟练时,你肯定会发现它们,但这些是最常见的。下一次,我们将看一些你需要注意的链接怪异。
|
还有几十个案例证明软链接是有用的,当你使用 Linux 更熟练时,你肯定会发现它们,但这些是最常见的。下一次,我们将看一些你需要注意的链接怪异。
|
||||||
|
|
||||||
通过 Linux 基金会和 edX 的免费 ["Linux 简介"][4]课程了解有关 Linux 的更多信息。
|
通过 Linux 基金会和 edX 的免费 [“Linux 简介”][4]课程了解有关 Linux 的更多信息。
|
||||||
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
--------------------------------------------------------------------------------
|
||||||
@ -111,7 +123,7 @@ via: https://www.linux.com/blog/intro-to-linux/2018/10/linux-links-part-1
|
|||||||
作者:[Paul Brown][a]
|
作者:[Paul Brown][a]
|
||||||
选题:[lujun9972][b]
|
选题:[lujun9972][b]
|
||||||
译者:[MjSeven](https://github.com/MjSeven)
|
译者:[MjSeven](https://github.com/MjSeven)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
@ -1,71 +0,0 @@
|
|||||||
translating by belitex
|
|
||||||
|
|
||||||
What is an SRE and how does it relate to DevOps?
|
|
||||||
======
|
|
||||||
The SRE role is common in large enterprises, but smaller businesses need it, too.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
Even though the site reliability engineer (SRE) role has become prevalent in recent years, many people—even in the software industry—don't know what it is or does. This article aims to clear that up by explaining what an SRE is, how it relates to DevOps, and how an SRE works when your entire engineering organization can fit in a coffee shop.
|
|
||||||
|
|
||||||
### What is site reliability engineering?
|
|
||||||
|
|
||||||
[Site Reliability Engineering: How Google Runs Production Systems][1], written by a group of Google engineers, is considered the definitive book on site reliability engineering. Google vice president of engineering Ben Treynor Sloss [coined the term][2] back in the early 2000s. He defined it as: "It's what happens when you ask a software engineer to design an operations function."
|
|
||||||
|
|
||||||
Sysadmins have been writing code for a long time, but for many of those years, a team of sysadmins managed many machines manually. Back then, "many" may have been dozens or hundreds, but when you scale to thousands or hundreds of thousands of hosts, you simply can't continue to throw people at the problem. When the number of machines gets that large, the obvious solution is to use code to manage hosts (and the software that runs on them).
|
|
||||||
|
|
||||||
Also, until fairly recently, the operations team was completely separate from the developers. The skillsets for each job were considered completely different. The SRE role tries to bring both jobs together.
|
|
||||||
|
|
||||||
Before we dig deeper into what makes an SRE and how SREs work with the development team, we need to understand how site reliability engineering works within the DevOps paradigm.
|
|
||||||
|
|
||||||
### Site reliability engineering and DevOps
|
|
||||||
|
|
||||||
At its core, site reliability engineering is an implementation of the DevOps paradigm. There seems to be a wide array of ways to [define DevOps][3]. The traditional model, where the development ("devs") and operations ("ops") teams were separated, led to the team that writes the code not being responsible for how it works when customers start using it. The development team would "throw the code over the wall" to the operations team to install and support.
|
|
||||||
|
|
||||||
This situation can lead to a significant amount of dysfunction. The goals of the dev and ops teams are constantly at odds—a developer wants customers to use the "latest and greatest" piece of code, but the operations team wants a steady system with as little change as possible. Their premise is that any change can introduce instability, while a system with no changes should continue to behave in the same manner. (Noting that minimizing change on the software side is not the only factor in preventing instability is important. For example, if your web application stays exactly the same, but the number of customers grows by 10x, your application may break in many different ways.)
|
|
||||||
|
|
||||||
The premise of DevOps is that by merging these two distinct jobs into one, you eliminate contention. If the "dev" wants to deploy new code all the time, they have to deal with any fallout the new code creates. As Amazon's [Werner Vogels said][4], "you build it, you run it" (in production). But developers already have a lot to worry about. They are continually pushed to develop new features for their employer's products. Asking them to understand the infrastructure, including how to deploy, configure, and monitor their service, may be asking a little too much from them. This is where an SRE steps in.
|
|
||||||
|
|
||||||
When a web application is developed, there are often many people that contribute. There are user interface designers, graphic designers, frontend engineers, backend engineers, and a whole host of other specialties (depending on the technologies used). Requirements include how the code gets managed (e.g., deployed, configured, monitored)—which are the SRE's areas of specialty. But, just as an engineer developing a nice look and feel for an application benefits from knowledge of the backend-engineer's job (e.g., how data is fetched from a database), the SRE understands how the deployment system works and how to adapt it to the specific needs of that particular codebase or project.
|
|
||||||
|
|
||||||
So, an SRE is not just "an ops person who codes." Rather, the SRE is another member of the development team with a different set of skills particularly around deployment, configuration management, monitoring, metrics, etc. But, just as an engineer developing a nice look and feel for an application must know how data is fetched from a data store, an SRE is not singly responsible for these areas. The entire team works together to deliver a product that can be easily updated, managed, and monitored.
|
|
||||||
|
|
||||||
The need for an SRE naturally comes about when a team is implementing DevOps but realizes they are asking too much of the developers and need a specialist for what the ops team used to handle.
|
|
||||||
|
|
||||||
### How the SRE works at a startup
|
|
||||||
|
|
||||||
This is great when there are hundreds of employees (let alone when you are the size of Google or Facebook). Large companies have SRE teams that are split up and embedded into each development team. But a startup doesn't have those economies of scale, and engineers often wear many hats. So, where does the "SRE hat" sit in a small company? One approach is to fully adopt DevOps and have the developers be responsible for the typical tasks an SRE would perform at a larger company. On the other side of the spectrum, you hire specialists — a.k.a., SREs.
|
|
||||||
|
|
||||||
The most obvious advantage of trying to put the SRE hat on a developer's head is it scales well as your team grows. Also, the developer will understand all the quirks of the application. But many startups use a wide variety of SaaS products to power their infrastructure. The most obvious is the infrastructure platform itself. Then you add in metrics systems, site monitoring, log analysis, containers, and more. While these technologies solve some problems, they create an additional complexity cost. The developer would need to understand all those technologies and services in addition to the core technologies (e.g., languages) the application uses. In the end, keeping on top of all of that technology can be overwhelming.
|
|
||||||
|
|
||||||
The other option is to hire a specialist to handle the SRE job. Their responsibility would be to focus on deployment, configuration, monitoring, and metrics, freeing up the developer's time to write the application. The disadvantage is that the SRE would have to split their time between multiple, different applications (i.e., the SRE needs to support the breadth of applications throughout engineering). This likely means they may not have the time to gain any depth of knowledge of any of the applications; however, they would be in a position to see how all the different pieces fit together. This "30,000-foot view" can help prioritize the weak spots to fix in the system as a whole.
|
|
||||||
|
|
||||||
There is one key piece of information I am ignoring: your other engineers. They may have a deep desire to understand how deployment works and how to use the metrics system to the best of their ability. Also, hiring an SRE is not an easy task. You are looking for a mix of sysadmin skills and software engineering skills. (I am specific about software engineers, vs. just "being able to code," because software engineering involves more than just writing code [e.g., writing good tests or documentation].)
|
|
||||||
|
|
||||||
Therefore, in some cases, it may make more sense for the "SRE hat" to live on a developer's head. If so, keep an eye on the amount of complexity in both the code and the infrastructure (SaaS or internal). At some point, the complexity on either end will likely push toward more specialization.
|
|
||||||
|
|
||||||
### Conclusion
|
|
||||||
|
|
||||||
An SRE team is one of the most efficient ways to implement the DevOps paradigm in a startup. I have seen a couple of different approaches, but I believe that hiring a dedicated SRE (pretty early) at your startup will free up time for the developers to focus on their specific challenges. The SRE can focus on improving the tools (and processes) that make the developers more productive. Also, an SRE will focus on making sure your customers have a product that is reliable and secure.
|
|
||||||
|
|
||||||
Craig Sebenik will present [SRE (and DevOps) at a Startup][5] at [LISA18][6], October 29-31 in Nashville, Tennessee.
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: https://opensource.com/article/18/10/sre-startup
|
|
||||||
|
|
||||||
作者:[Craig Sebenik][a]
|
|
||||||
选题:[lujun9972][b]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]: https://opensource.com/users/craig5
|
|
||||||
[b]: https://github.com/lujun9972
|
|
||||||
[1]: http://shop.oreilly.com/product/0636920041528.do
|
|
||||||
[2]: https://landing.google.com/sre/interview/ben-treynor.html
|
|
||||||
[3]: https://opensource.com/resources/devops
|
|
||||||
[4]: https://queue.acm.org/detail.cfm?id=1142065
|
|
||||||
[5]: https://www.usenix.org/conference/lisa18/presentation/sebenik
|
|
||||||
[6]: https://www.usenix.org/conference/lisa18
|
|
||||||
@ -0,0 +1,108 @@
|
|||||||
|
Directing traffic: Demystifying internet-scale load balancing
|
||||||
|
======
|
||||||
|
Common techniques used to balance network traffic come with advantages and trade-offs.
|
||||||
|

|
||||||
|
Large, multi-site, internet-facing systems, including content-delivery networks (CDNs) and cloud providers, have several options for balancing traffic coming onto their networks. In this article, we'll describe common traffic-balancing designs, including techniques and trade-offs.
|
||||||
|
|
||||||
|
If you were an early cloud computing provider, you could take a single customer web server, assign it an IP address, configure a domain name system (DNS) record to associate it with a human-readable name, and advertise the IP address via the border gateway protocol (BGP), the standard way of exchanging routing information between networks.
|
||||||
|
|
||||||
|
It wasn't load balancing per se, but there probably was load distribution across redundant network paths and networking technologies to increase availability by routing around unavailable infrastructure (giving rise to phenomena like [asymmetric routing][1]).
|
||||||
|
|
||||||
|
### Doing simple DNS load balancing
|
||||||
|
|
||||||
|
As traffic to your customer's service grows, the business' owners want higher availability. You add a second web server with its own publicly accessible IP address and update the DNS record to direct users to both web servers (hopefully somewhat evenly). This is OK for a while until one web server unexpectedly goes offline. Assuming you detect the failure quickly, you can update the DNS configuration (either manually or with software) to stop referencing the broken server.
|
||||||
|
|
||||||
|
Unfortunately, because DNS records are cached, around 50% of requests to the service will likely fail until the record expires from the client caches and those of other nameservers in the DNS hierarchy. DNS records generally have a time to live (TTL) of several minutes or more, so this can create a significant impact on your system's availability.
|
||||||
|
|
||||||
|
Worse, some proportion of clients ignore TTL entirely, so some requests will be directed to your offline web server for some time. Setting very short DNS TTLs is not a great idea either; it means higher load on DNS services plus increased latency because clients will have to perform DNS lookups more often. If your DNS service is unavailable for any reason, access to your service will degrade more quickly with a shorter TTL because fewer clients will have your service's IP address cached.
|
||||||
|
|
||||||
|
### Adding network load balancing
|
||||||
|
|
||||||
|
To work around this problem, you can add a redundant pair of [Layer 4][2] (L4) network load balancers that serve the same virtual IP (VIP) address. They could be hardware appliances or software balancers like [HAProxy][3]. This means the DNS record points only at the VIP and no longer does load balancing.
|
||||||
|
|
||||||
|
![Layer 4 load balancers balance connections across webservers.][5]
|
||||||
|
|
||||||
|
Layer 4 load balancers balance connections from users across two webservers.
|
||||||
|
|
||||||
|
The L4 balancers load-balance traffic from the internet to the backend servers. This is generally done based on a hash (a mathematical function) of each IP packet's 5-tuple: the source and destination IP address and port plus the protocol (such as TCP or UDP). This is fast and efficient (and still maintains essential properties of TCP) and doesn't require the balancers to maintain state per connection. (For more information, [Google's paper on Maglev][6] discusses implementation of a software L4 balancer in significant detail.)
|
||||||
|
|
||||||
|
The L4 balancers can do health-checking and send traffic only to web servers that pass checks. Unlike in DNS balancing, there is minimal delay in redirecting traffic to another web server if one crashes, although existing connections will be reset.
|
||||||
|
|
||||||
|
L4 balancers can do weighted balancing, dealing with backends with varying capacity. L4 balancing gives significant power and flexibility to operators while being relatively inexpensive in terms of computing power.
|
||||||
|
|
||||||
|
### Going multi-site
|
||||||
|
|
||||||
|
The system continues to grow. Your customers want to stay up even if your data center goes down. You build a new data center with its own set of service backends and another cluster of L4 balancers, which serve the same VIP as before. The DNS setup doesn't change.
|
||||||
|
|
||||||
|
The edge routers in both sites advertise address space, including the service VIP. Requests sent to that VIP can reach either site, depending on how each network between the end user and the system is connected and how their routing policies are configured. This is known as anycast. Most of the time, this works fine. If one site isn't operating, you can stop advertising the VIP for the service via BGP, and traffic will quickly move to the alternative site.
|
||||||
|
|
||||||
|
![Serving from multiple sites using anycast][8]
|
||||||
|
|
||||||
|
Serving from multiple sites using anycast.
|
||||||
|
|
||||||
|
This setup has several problems. Its worst failing is that you can't control where traffic flows or limit how much traffic is sent to a given site. You also don't have an explicit way to route users to the nearest site (in terms of network latency), but the network protocols and configurations that determine the routes should, in most cases, route requests to the nearest site.
|
||||||
|
|
||||||
|
### Controlling inbound requests in a multi-site system
|
||||||
|
|
||||||
|
To maintain stability, you need to be able to control how much traffic is served to each site. You can get that control by assigning a different VIP to each site and use DNS to balance them using simple or weighted [round-robin][9].
|
||||||
|
|
||||||
|
![Serving from multiple sites using a primary VIP][11]
|
||||||
|
|
||||||
|
Serving from multiple sites using a primary VIP per site, backed up by secondary sites, with geo-aware DNS.
|
||||||
|
|
||||||
|
You now have two new problems.
|
||||||
|
|
||||||
|
First, using DNS balancing means you have cached records, which is not good if you need to redirect traffic quickly.
|
||||||
|
|
||||||
|
Second, whenever users do a fresh DNS lookup, a VIP connects them to the service at an arbitrary site, which may not be the closest site to them. If your service runs on widely separated sites, individual users will experience wide variations in your system's responsiveness, depending upon the network latency between them and the instance of your service they are using.
|
||||||
|
|
||||||
|
You can solve the first problem by having each site constantly advertise and serve the VIPs for all the other sites (and consequently the VIP for any faulty site). Networking tricks (such as advertising less-specific routes from the backups) can ensure that VIP's primary site is preferred, as long as it is available. This is done via BGP, so we should see traffic move within a minute or two of updating BGP.
|
||||||
|
|
||||||
|
There isn't an elegant solution to the problem of serving users from sites other than the nearest healthy site with capacity. Many large internet-facing services use DNS services that attempt to return different results to users in different locations, with some degree of success. This approach is always somewhat [complex and error-prone][12], given that internet-addressing schemes are not organized geographically, blocks of addresses can change locations (e.g., when a company reorganizes its network), and many end users can be served from a single caching nameserver.
|
||||||
|
|
||||||
|
### Adding Layer 7 load balancing
|
||||||
|
|
||||||
|
Over time, your customers begin to ask for more advanced features.
|
||||||
|
|
||||||
|
While L4 load balancers can efficiently distribute load among multiple web servers, they operate only on source and destination IP addresses, protocol, and ports. They don't know anything about the content of a request, so you can't implement many advanced features in an L4 balancer. Layer 7 (L7) load balancers are aware of the structure and contents of requests and can do far more.
|
||||||
|
|
||||||
|
Some things that can be implemented in L7 load balancers are caching, rate limiting, fault injection, and cost-aware load balancing (some requests require much more server time to process).
|
||||||
|
|
||||||
|
They can also balance based on a request's attributes (e.g., HTTP cookies), terminate SSL connections, and help defend against application layer denial-of-service (DoS) attacks. The downside of L7 balancers at scale is cost—they do more computation to process requests, and each active request consumes some system resources. Running L4 balancers in front of one or more pools of L7 balancers can help with scaling.
|
||||||
|
|
||||||
|
### Conclusion
|
||||||
|
|
||||||
|
Load balancing is a difficult and complex problem. In addition to the strategies described in this article, there are different [load-balancing algorithms][13], high-availability techniques used to implement load balancers, client load-balancing techniques, and the recent rise of service meshes.
|
||||||
|
|
||||||
|
Core load-balancing patterns have evolved alongside the growth of cloud computing, and they will continue to improve as large web services work to improve the control and flexibility that load-balancing techniques offer./p>
|
||||||
|
|
||||||
|
Laura Nolan and Murali Suriar will present [Keeping the Balance: Load Balancing Demystified][14] at [LISA18][15], October 29-31 in Nashville, Tennessee, USA.
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/18/10/internet-scale-load-balancing
|
||||||
|
|
||||||
|
作者:[Laura Nolan][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/lauranolan
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://www.noction.com/blog/bgp-and-asymmetric-routing
|
||||||
|
[2]: https://en.wikipedia.org/wiki/Transport_layer
|
||||||
|
[3]: https://www.haproxy.com/blog/failover-and-worst-case-management-with-haproxy/
|
||||||
|
[4]: /file/412596
|
||||||
|
[5]: https://opensource.com/sites/default/files/uploads/loadbalancing1_l4-network-loadbalancing.png (Layer 4 load balancers balance connections across webservers.)
|
||||||
|
[6]: https://ai.google/research/pubs/pub44824
|
||||||
|
[7]: /file/412601
|
||||||
|
[8]: https://opensource.com/sites/default/files/uploads/loadbalancing2_going-multisite.png (Serving from multiple sites using anycast)
|
||||||
|
[9]: https://en.wikipedia.org/wiki/Round-robin_scheduling
|
||||||
|
[10]: /file/412606
|
||||||
|
[11]: https://opensource.com/sites/default/files/uploads/loadbalancing3_controlling-inbound-requests.png (Serving from multiple sites using a primary VIP)
|
||||||
|
[12]: https://landing.google.com/sre/book/chapters/load-balancing-frontend.html
|
||||||
|
[13]: https://medium.com/netflix-techblog/netflix-edge-load-balancing-695308b5548c
|
||||||
|
[14]: https://www.usenix.org/conference/lisa18/presentation/suriar
|
||||||
|
[15]: https://www.usenix.org/conference/lisa18
|
||||||
@ -1,3 +1,4 @@
|
|||||||
|
Translating by DavidChenLiang
|
||||||
Python
|
Python
|
||||||
============================================================
|
============================================================
|
||||||
|
|
||||||
|
|||||||
@ -1,3 +1,5 @@
|
|||||||
|
translating---geekpi
|
||||||
|
|
||||||
How To Quickly Serve Files And Folders Over HTTP In Linux
|
How To Quickly Serve Files And Folders Over HTTP In Linux
|
||||||
======
|
======
|
||||||
|
|
||||||
|
|||||||
@ -1,3 +1,6 @@
|
|||||||
|
Translating by MjSeven
|
||||||
|
|
||||||
|
|
||||||
How To Disable Ads In Terminal Welcome Message In Ubuntu Server
|
How To Disable Ads In Terminal Welcome Message In Ubuntu Server
|
||||||
======
|
======
|
||||||
|
|
||||||
|
|||||||
@ -1,4 +1,4 @@
|
|||||||
Test containers with Python and Conu
|
translating by GraveAccent Test containers with Python and Conu
|
||||||
======
|
======
|
||||||
|
|
||||||

|

|
||||||
|
|||||||
@ -1,3 +1,5 @@
|
|||||||
|
Translating by way-ww
|
||||||
|
|
||||||
How To Run MS-DOS Games And Programs In Linux
|
How To Run MS-DOS Games And Programs In Linux
|
||||||
======
|
======
|
||||||
|
|
||||||
|
|||||||
@ -1,3 +1,5 @@
|
|||||||
|
translating by cyleft
|
||||||
|
|
||||||
Taking notes with Laverna, a web-based information organizer
|
Taking notes with Laverna, a web-based information organizer
|
||||||
======
|
======
|
||||||
|
|
||||||
|
|||||||
@ -1,248 +0,0 @@
|
|||||||
Translating by way-ww
|
|
||||||
|
|
||||||
How to Enable or Disable Services on Boot in Linux Using chkconfig and systemctl Command
|
|
||||||
======
|
|
||||||
It’s a important topic for Linux admin (such a wonderful topic) so, everyone must be aware of this and practice how to use this in the efficient way.
|
|
||||||
|
|
||||||
In Linux, whenever we install any packages which has services or daemons. By default all the services “init & systemd” scripts will be added into it but it wont enabled.
|
|
||||||
|
|
||||||
Hence, we need to enable or disable the service manually if it’s required. There are three major init systems are available in Linux which are very famous and still in use.
|
|
||||||
|
|
||||||
### What is init System?
|
|
||||||
|
|
||||||
In Linux/Unix based operating systems, init (short for initialization) is the first process that started during the system boot up by the kernel.
|
|
||||||
|
|
||||||
It’s holding a process id (PID) of 1. It will be running in the background continuously until the system is shut down.
|
|
||||||
|
|
||||||
Init looks at the `/etc/inittab` file to decide the Linux run level then it starts all other processes & applications in the background as per the run level.
|
|
||||||
|
|
||||||
BIOS, MBR, GRUB and Kernel processes were kicked up before hitting init process as part of Linux booting process.
|
|
||||||
|
|
||||||
Below are the available run levels for Linux (There are seven runlevels exist, from zero to six).
|
|
||||||
|
|
||||||
* **`0:`** halt
|
|
||||||
* **`1:`** Single user mode
|
|
||||||
* **`2:`** Multiuser, without NFS
|
|
||||||
* **`3:`** Full multiuser mode
|
|
||||||
* **`4:`** Unused
|
|
||||||
* **`5:`** X11 (GUI – Graphical User Interface)
|
|
||||||
* **`:`** reboot
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
Below three init systems are widely used in Linux.
|
|
||||||
|
|
||||||
* System V (Sys V)
|
|
||||||
* Upstart
|
|
||||||
* systemd
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### What is System V (Sys V)?
|
|
||||||
|
|
||||||
System V (Sys V) is one of the first and traditional init system for Unix like operating system. init is the first process that started during the system boot up by the kernel and it’s a parent process for everything.
|
|
||||||
|
|
||||||
Most of the Linux distributions started using traditional init system called System V (Sys V) first. Over the years, several replacement init systems were released to address design limitations in the standard versions such as launchd, the Service Management Facility, systemd and Upstart.
|
|
||||||
|
|
||||||
But systemd has been adopted by several major Linux distributions over the traditional SysV init systems.
|
|
||||||
|
|
||||||
### What is Upstart?
|
|
||||||
|
|
||||||
Upstart is an event-based replacement for the /sbin/init daemon which handles starting of tasks and services during boot, stopping them during shutdown and supervising them while the system is running.
|
|
||||||
|
|
||||||
It was originally developed for the Ubuntu distribution, but is intended to be suitable for deployment in all Linux distributions as a replacement for the venerable System-V init.
|
|
||||||
|
|
||||||
It was used in Ubuntu from 9.10 to Ubuntu 14.10 & RHEL 6 based systems after that they are replaced with systemd.
|
|
||||||
|
|
||||||
### What is systemd?
|
|
||||||
|
|
||||||
Systemd is a new init system and system manager which was implemented/adapted into all the major Linux distributions over the traditional SysV init systems.
|
|
||||||
|
|
||||||
systemd is compatible with SysV and LSB init scripts. It can work as a drop-in replacement for sysvinit system. systemd is the first process get started by kernel and holding PID 1.
|
|
||||||
|
|
||||||
It’s a parant process for everything and Fedora 15 is the first distribution which was adapted systemd instead of upstart. systemctl is command line utility and primary tool to manage the systemd daemons/services such as (start, restart, stop, enable, disable, reload & status).
|
|
||||||
|
|
||||||
systemd uses .service files Instead of bash scripts (SysVinit uses). systemd sorts all daemons into their own Linux cgroups and you can see the system hierarchy by exploring `/cgroup/systemd` file.
|
|
||||||
|
|
||||||
### How to Enable or Disable Services on Boot Using chkconfig Commmand?
|
|
||||||
|
|
||||||
The chkconfig utility is a command-line tool that allows you to specify in which
|
|
||||||
runlevel to start a selected service, as well as to list all available services along with their current setting.
|
|
||||||
|
|
||||||
Also, it will allows us to enable or disable a services from the boot. Make sure you must have superuser privileges (either root or sudo) to use this command.
|
|
||||||
|
|
||||||
All the services script are located on `/etc/rd.d/init.d`.
|
|
||||||
|
|
||||||
### How to list All Services in run-level
|
|
||||||
|
|
||||||
The `-–list` parameter displays all the services along with their current status (What run-level the services are enabled or disabled).
|
|
||||||
|
|
||||||
```
|
|
||||||
# chkconfig --list
|
|
||||||
NetworkManager 0:off 1:off 2:on 3:on 4:on 5:on 6:off
|
|
||||||
abrt-ccpp 0:off 1:off 2:off 3:on 4:off 5:on 6:off
|
|
||||||
abrtd 0:off 1:off 2:off 3:on 4:off 5:on 6:off
|
|
||||||
acpid 0:off 1:off 2:on 3:on 4:on 5:on 6:off
|
|
||||||
atd 0:off 1:off 2:off 3:on 4:on 5:on 6:off
|
|
||||||
auditd 0:off 1:off 2:on 3:on 4:on 5:on 6:off
|
|
||||||
.
|
|
||||||
.
|
|
||||||
```
|
|
||||||
|
|
||||||
### How to check the Status of Specific Service
|
|
||||||
|
|
||||||
If you would like to see a particular service status in run-level then use the following format and grep the required service.
|
|
||||||
|
|
||||||
In this case, we are going to check the `auditd` service status in run-level.
|
|
||||||
|
|
||||||
```
|
|
||||||
# chkconfig --list| grep auditd
|
|
||||||
auditd 0:off 1:off 2:on 3:on 4:on 5:on 6:off
|
|
||||||
```
|
|
||||||
|
|
||||||
### How to Enable a Particular Service on Run Levels
|
|
||||||
|
|
||||||
Use `--level` parameter to enable a service in the required run-level. In this case, we are going to enable `httpd` service on run-level 3 and 5.
|
|
||||||
|
|
||||||
```
|
|
||||||
# chkconfig --level 35 httpd on
|
|
||||||
```
|
|
||||||
|
|
||||||
### How to Disable a Particular Service on Run Levels
|
|
||||||
|
|
||||||
Use `--level` parameter to disable a service in the required run-level. In this case, we are going to enable `httpd` service on run-level 3 and 5.
|
|
||||||
|
|
||||||
```
|
|
||||||
# chkconfig --level 35 httpd off
|
|
||||||
```
|
|
||||||
|
|
||||||
### How to Add a new Service to the Startup List
|
|
||||||
|
|
||||||
The `-–add` parameter allows us to add any new service to the startup. By default, it will turn on level 2, 3, 4 and 5 automatically for that service.
|
|
||||||
|
|
||||||
```
|
|
||||||
# chkconfig --add nagios
|
|
||||||
```
|
|
||||||
|
|
||||||
### How to Remove a Service from Startup List
|
|
||||||
|
|
||||||
Use `--del` parameter to remove the service from the startup list. Here, we are going to remove the Nagios service from the startup list.
|
|
||||||
|
|
||||||
```
|
|
||||||
# chkconfig --del nagios
|
|
||||||
```
|
|
||||||
|
|
||||||
### How to Enable or Disable Services on Boot Using systemctl Command?
|
|
||||||
|
|
||||||
systemctl is command line utility and primary tool to manage the systemd daemons/services such as (start, restart, stop, enable, disable, reload & status).
|
|
||||||
|
|
||||||
All the created systemd unit files are located on `/etc/systemd/system/`.
|
|
||||||
|
|
||||||
### How to list All Services
|
|
||||||
|
|
||||||
Use the following command to list all the services which included enabled and disabled.
|
|
||||||
|
|
||||||
```
|
|
||||||
# systemctl list-unit-files --type=service
|
|
||||||
UNIT FILE STATE
|
|
||||||
arp-ethers.service disabled
|
|
||||||
auditd.service enabled
|
|
||||||
[email protected] enabled
|
|
||||||
blk-availability.service disabled
|
|
||||||
brandbot.service static
|
|
||||||
[email protected] static
|
|
||||||
chrony-wait.service disabled
|
|
||||||
chronyd.service enabled
|
|
||||||
cloud-config.service enabled
|
|
||||||
cloud-final.service enabled
|
|
||||||
cloud-init-local.service enabled
|
|
||||||
cloud-init.service enabled
|
|
||||||
console-getty.service disabled
|
|
||||||
console-shell.service disabled
|
|
||||||
[email protected] static
|
|
||||||
cpupower.service disabled
|
|
||||||
crond.service enabled
|
|
||||||
.
|
|
||||||
.
|
|
||||||
150 unit files listed.
|
|
||||||
```
|
|
||||||
|
|
||||||
If you would like to see a particular service status then use the following format and grep the required service. In this case, we are going to check the `httpd` service status.
|
|
||||||
|
|
||||||
```
|
|
||||||
# systemctl list-unit-files --type=service | grep httpd
|
|
||||||
httpd.service disabled
|
|
||||||
```
|
|
||||||
|
|
||||||
### How to Enable a Particular Service on boot
|
|
||||||
|
|
||||||
Use the following systemctl command format to enable a particular service. To enable a service, it will create a symlink. The same can be found below.
|
|
||||||
|
|
||||||
```
|
|
||||||
# systemctl enable httpd
|
|
||||||
Created symlink from /etc/systemd/system/multi-user.target.wants/httpd.service to /usr/lib/systemd/system/httpd.service.
|
|
||||||
```
|
|
||||||
|
|
||||||
Run the following command to double check whether the services is enabled or not on boot.
|
|
||||||
|
|
||||||
```
|
|
||||||
# systemctl is-enabled httpd
|
|
||||||
enabled
|
|
||||||
```
|
|
||||||
|
|
||||||
### How to Disable a Particular Service on boot
|
|
||||||
|
|
||||||
Use the following systemctl command format to disable a particular service. When you run the command, it will remove a symlink which was created by you while enabling the service. The same can be found below.
|
|
||||||
|
|
||||||
```
|
|
||||||
# systemctl disable httpd
|
|
||||||
Removed symlink /etc/systemd/system/multi-user.target.wants/httpd.service.
|
|
||||||
```
|
|
||||||
|
|
||||||
Run the following command to double check whether the services is disabled or not on boot.
|
|
||||||
|
|
||||||
```
|
|
||||||
# systemctl is-enabled httpd
|
|
||||||
disabled
|
|
||||||
```
|
|
||||||
|
|
||||||
### How to Check the current run level
|
|
||||||
|
|
||||||
Use the following systemctl command to verify which run-level you are in. Still “runlevel” command works with systemd, however runlevels is a legacy concept in systemd so, i would advise you to use systemctl command for all activity.
|
|
||||||
|
|
||||||
We are in `run-level 3`, the same is showing below as `multi-user.target`.
|
|
||||||
|
|
||||||
```
|
|
||||||
# systemctl list-units --type=target
|
|
||||||
UNIT LOAD ACTIVE SUB DESCRIPTION
|
|
||||||
basic.target loaded active active Basic System
|
|
||||||
cloud-config.target loaded active active Cloud-config availability
|
|
||||||
cryptsetup.target loaded active active Local Encrypted Volumes
|
|
||||||
getty.target loaded active active Login Prompts
|
|
||||||
local-fs-pre.target loaded active active Local File Systems (Pre)
|
|
||||||
local-fs.target loaded active active Local File Systems
|
|
||||||
multi-user.target loaded active active Multi-User System
|
|
||||||
network-online.target loaded active active Network is Online
|
|
||||||
network-pre.target loaded active active Network (Pre)
|
|
||||||
network.target loaded active active Network
|
|
||||||
paths.target loaded active active Paths
|
|
||||||
remote-fs.target loaded active active Remote File Systems
|
|
||||||
slices.target loaded active active Slices
|
|
||||||
sockets.target loaded active active Sockets
|
|
||||||
swap.target loaded active active Swap
|
|
||||||
sysinit.target loaded active active System Initialization
|
|
||||||
timers.target loaded active active Timers
|
|
||||||
```
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: https://www.2daygeek.com/how-to-enable-or-disable-services-on-boot-in-linux-using-chkconfig-and-systemctl-command/
|
|
||||||
|
|
||||||
作者:[Prakash Subramanian][a]
|
|
||||||
选题:[lujun9972][b]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]: https://www.2daygeek.com/author/prakash/
|
|
||||||
[b]: https://github.com/lujun9972
|
|
||||||
@ -0,0 +1,153 @@
|
|||||||
|
How to write your favorite R functions in Python
|
||||||
|
======
|
||||||
|
R or Python? This Python script mimics convenient R-style functions for doing statistics nice and easy.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
One of the great modern battles of data science and machine learning is "Python vs. R." There is no doubt that both have gained enormous ground in recent years to become top programming languages for data science, predictive analytics, and machine learning. In fact, according to a recent IEEE article, Python overtook C++ as the [top programming language][1] and R firmly secured its spot in the top 10.
|
||||||
|
|
||||||
|
However, there are some fundamental differences between these two. [R was developed primarily][2] as a tool for statistical analysis and quick prototyping of a data analysis problem. Python, on the other hand, was developed as a general purpose, modern object-oriented language in the same vein as C++ or Java but with a simpler learning curve and more flexible demeanor. Consequently, R continues to be extremely popular among statisticians, quantitative biologists, physicists, and economists, whereas Python has slowly emerged as the top language for day-to-day scripting, automation, backend web development, analytics, and general machine learning frameworks and has an extensive support base and open source development community work.
|
||||||
|
|
||||||
|
### Mimicking functional programming in a Python environment
|
||||||
|
|
||||||
|
[R's nature as a functional programming language][3] provides users with an extremely simple and compact interface for quick calculations of probabilities and essential descriptive/inferential statistics for a data analysis problem. For example, wouldn't it be great to be able to solve the following problems with just a single, compact function call?
|
||||||
|
|
||||||
|
* How to calculate the mean/median/mode of a data vector.
|
||||||
|
* How to calculate the cumulative probability of some event following a normal distribution. What if the distribution is Poisson?
|
||||||
|
* How to calculate the inter-quartile range of a series of data points.
|
||||||
|
* How to generate a few random numbers following a Student's t-distribution.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
The R programming environment can do all of these.
|
||||||
|
|
||||||
|
On the other hand, Python's scripting ability allows analysts to use those statistics in a wide variety of analytics pipelines with limitless sophistication and creativity.
|
||||||
|
|
||||||
|
To combine the advantages of both worlds, you just need a simple Python-based wrapper library that contains the most commonly used functions pertaining to probability distributions and descriptive statistics defined in R-style. This enables you to call those functions really fast without having to go to the proper Python statistical libraries and figure out the whole list of methods and arguments.
|
||||||
|
|
||||||
|
### Python wrapper script for most convenient R-functions
|
||||||
|
|
||||||
|
[I wrote a Python script][4] to define the most convenient and widely used R-functions in simple, statistical analysis—in Python. After importing this script, you will be able to use those R-functions naturally, just like in an R programming environment.
|
||||||
|
|
||||||
|
The goal of this script is to provide simple Python subroutines mimicking R-style statistical functions for quickly calculating density/point estimates, cumulative distributions, and quantiles and generating random variates for important probability distributions.
|
||||||
|
|
||||||
|
To maintain the spirit of R styling, the script uses no class hierarchy and only raw functions are defined in the file. Therefore, a user can import this one Python script and use all the functions whenever they're needed with a single name call.
|
||||||
|
|
||||||
|
Note that I use the word mimic. Under no circumstance am I claiming to emulate R's true functional programming paradigm, which consists of a deep environmental setup and complex relationships between those environments and objects. This script allows me (and I hope countless other Python users) to quickly fire up a Python program or Jupyter notebook, import the script, and start doing simple descriptive statistics in no time. That's the goal, nothing more, nothing less.
|
||||||
|
|
||||||
|
If you've coded in R (maybe in grad school) and are just starting to learn and use Python for data analysis, you will be happy to see and use some of the same well-known functions in your Jupyter notebook in a manner similar to how you use them in your R environment.
|
||||||
|
|
||||||
|
Whatever your reason, using this script is fun.
|
||||||
|
|
||||||
|
### Simple examples
|
||||||
|
|
||||||
|
To start, just import the script and start working with lists of numbers as if they were data vectors in R.
|
||||||
|
|
||||||
|
```
|
||||||
|
from R_functions import *
|
||||||
|
lst=[20,12,16,32,27,65,44,45,22,18]
|
||||||
|
<more code, more statistics...>
|
||||||
|
```
|
||||||
|
|
||||||
|
Say you want to calculate the [Tuckey five-number][5] summary from a vector of data points. You just call one simple function, **fivenum** , and pass on the vector. It will return the five-number summary in a NumPy array.
|
||||||
|
|
||||||
|
```
|
||||||
|
lst=[20,12,16,32,27,65,44,45,22,18]
|
||||||
|
fivenum(lst)
|
||||||
|
> array([12. , 18.5, 24.5, 41. , 65. ])
|
||||||
|
```
|
||||||
|
|
||||||
|
Maybe you want to know the answer to the following question:
|
||||||
|
|
||||||
|
Suppose a machine outputs 10 finished goods per hour on average with a standard deviation of 2. The output pattern follows a near normal distribution. What is the probability that the machine will output at least 7 but no more than 12 units in the next hour?
|
||||||
|
|
||||||
|
The answer is essentially this:
|
||||||
|
|
||||||
|
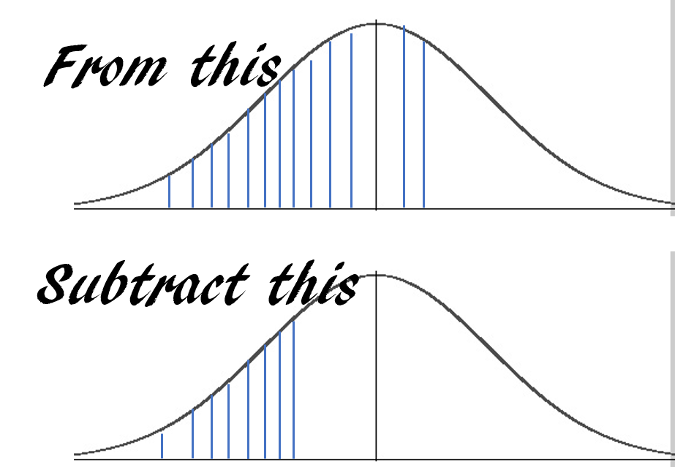
|
||||||
|
|
||||||
|
You can obtain the answer with just one line of code using **pnorm** :
|
||||||
|
|
||||||
|
```
|
||||||
|
pnorm(12,10,2)-pnorm(7,10,2)
|
||||||
|
> 0.7745375447996848
|
||||||
|
```
|
||||||
|
|
||||||
|
Or maybe you need to answer the following:
|
||||||
|
|
||||||
|
Suppose you have a loaded coin with the probability of turning heads up 60% every time you toss it. You are playing a game of 10 tosses. How do you plot and map out the chances of all the possible number of wins (from 0 to 10) with this coin?
|
||||||
|
|
||||||
|
You can obtain a nice bar chart with just a few lines of code using just one function, **dbinom** :
|
||||||
|
|
||||||
|
```
|
||||||
|
probs=[]
|
||||||
|
import matplotlib.pyplot as plt
|
||||||
|
for i in range(11):
|
||||||
|
probs.append(dbinom(i,10,0.6))
|
||||||
|
plt.bar(range(11),height=probs)
|
||||||
|
plt.grid(True)
|
||||||
|
plt.show()
|
||||||
|
```
|
||||||
|
|
||||||
|
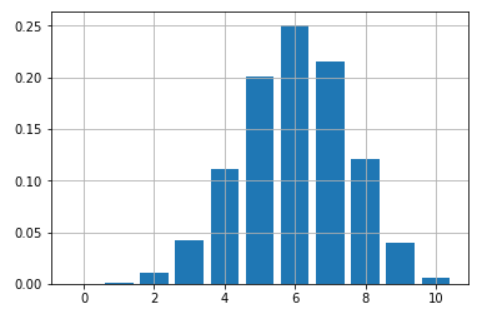
|
||||||
|
|
||||||
|
### Simple interface for probability calculations
|
||||||
|
|
||||||
|
R offers an extremely simple and intuitive interface for quick calculations from essential probability distributions. The interface goes like this:
|
||||||
|
|
||||||
|
* **d** {distribution} gives the density function value at a point **x**
|
||||||
|
* **p** {distribution} gives the cumulative value at a point **x**
|
||||||
|
* **q** {distribution} gives the quantile function value at a probability **p**
|
||||||
|
* **r** {distribution} generates one or multiple random variates
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
In our implementation, we stick to this interface and its associated argument list so you can execute these functions exactly like you would in an R environment.
|
||||||
|
|
||||||
|
### Currently implemented functions
|
||||||
|
|
||||||
|
The following R-style functions are implemented in the script for fast calling.
|
||||||
|
|
||||||
|
* Mean, median, variance, standard deviation
|
||||||
|
* Tuckey five-number summary, IQR
|
||||||
|
* Covariance of a matrix or between two vectors
|
||||||
|
* Density, cumulative probability, quantile function, and random variate generation for the following distributions: normal, uniform, binomial, Poisson, F, Student's t, Chi-square, beta, and gamma.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### Work in progress
|
||||||
|
|
||||||
|
Obviously, this is a work in progress, and I plan to add some other convenient R-functions to this script. For example, in R, a single line of command **lm** can get you an ordinary least-square fitted model to a numerical dataset with all the necessary inferential statistics (P-values, standard error, etc.). This is powerfully brief and compact! On the other hand, standard linear regression problems in Python are often tackled using [Scikit-learn][6], which needs a bit more scripting for this use, so I plan to incorporate this single function linear model fitting feature using Python's [statsmodels][7] backend.
|
||||||
|
|
||||||
|
If you like and use this script in your work, please help others find it by starring or forking its [GitHub repository][8]. Also, you can check my other [GitHub repos][9] for fun code snippets in Python, R, or MATLAB and some machine learning resources.
|
||||||
|
|
||||||
|
If you have any questions or ideas to share, please contact me at [tirthajyoti[AT]gmail.com][10]. If you are, like me, passionate about machine learning and data science, please [add me on LinkedIn][11] or [follow me on Twitter. ][12]
|
||||||
|
|
||||||
|
Originally published on [Towards Data Science][13]. Reposted under [CC BY-SA 4.0][14].
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/18/10/write-favorite-r-functions-python
|
||||||
|
|
||||||
|
作者:[Tirthajyoti Sarkar][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/tirthajyoti
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://spectrum.ieee.org/at-work/innovation/the-2018-top-programming-languages
|
||||||
|
[2]: https://www.coursera.org/lecture/r-programming/overview-and-history-of-r-pAbaE
|
||||||
|
[3]: http://adv-r.had.co.nz/Functional-programming.html
|
||||||
|
[4]: https://github.com/tirthajyoti/StatsUsingPython/blob/master/R_Functions.py
|
||||||
|
[5]: https://en.wikipedia.org/wiki/Five-number_summary
|
||||||
|
[6]: http://scikit-learn.org/stable/
|
||||||
|
[7]: https://www.statsmodels.org/stable/index.html
|
||||||
|
[8]: https://github.com/tirthajyoti/StatsUsingPython
|
||||||
|
[9]: https://github.com/tirthajyoti?tab=repositories
|
||||||
|
[10]: mailto:tirthajyoti@gmail.com
|
||||||
|
[11]: https://www.linkedin.com/in/tirthajyoti-sarkar-2127aa7/
|
||||||
|
[12]: https://twitter.com/tirthajyotiS
|
||||||
|
[13]: https://towardsdatascience.com/how-to-write-your-favorite-r-functions-in-python-11e1e9c29089
|
||||||
|
[14]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||||
98
sources/tech/20181025 Understanding Linux Links- Part 2.md
Normal file
98
sources/tech/20181025 Understanding Linux Links- Part 2.md
Normal file
@ -0,0 +1,98 @@
|
|||||||
|
Understanding Linux Links: Part 2
|
||||||
|
======
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
In the [first part of this series][1], we looked at hard links and soft links and discussed some of the various ways that linking can be useful. Linking may seem straightforward, but there are some non-obvious quirks you have to be aware of. That’s what we’ll be looking at here. Consider, for example, at the way we created the link to _libblah_ in the previous article. Notice how we linked from within the destination folder:
|
||||||
|
|
||||||
|
```
|
||||||
|
cd /usr/local/lib
|
||||||
|
|
||||||
|
ln -s /usr/lib/libblah
|
||||||
|
```
|
||||||
|
|
||||||
|
That will work. But this:
|
||||||
|
|
||||||
|
```
|
||||||
|
cd /usr/lib
|
||||||
|
|
||||||
|
ln -s libblah /usr/local/lib
|
||||||
|
```
|
||||||
|
|
||||||
|
That is, linking from within the original folder to the destination folder, will not work.
|
||||||
|
|
||||||
|
The reason for that is that _ln_ will think you are linking from inside _/usr/local/lib_ to _/usr/local/lib_ and will create a linked file from _libblah_ in _/usr/local/lib_ to _libblah_ also in _/usr/local/lib_. This is because all the link file gets is the name of the file ( _libblah_ ) but not the path to the file. The end result is a very broken link.
|
||||||
|
|
||||||
|
However, this:
|
||||||
|
|
||||||
|
```
|
||||||
|
cd /usr/lib
|
||||||
|
|
||||||
|
ln -s /usr/lib/libblah /usr/local/lib
|
||||||
|
```
|
||||||
|
|
||||||
|
will work. Then again, it would work regardless of from where you executed the instruction within the filesystem. Using absolute paths, that is, spelling out the whole the path, from root (/) drilling down to to the file or directory itself, is just best practice.
|
||||||
|
|
||||||
|
Another thing to note is that, as long as both _/usr/lib_ and _/usr/local/lib_ are on the same partition, making a hard link like this:
|
||||||
|
|
||||||
|
```
|
||||||
|
cd /usr/lib
|
||||||
|
|
||||||
|
ln -s libblah /usr/local/lib
|
||||||
|
```
|
||||||
|
|
||||||
|
will also work because hard links don't rely on pointing to a file within the filesystem to work.
|
||||||
|
|
||||||
|
Where hard links will not work is if you want to link across partitions. Say you have _fileA_ on partition A and the partition is mounted at _/path/to/partitionA/directory_. If you want to link _fileA_ to _/path/to/partitionB/directory_ that is on partition B, this will not work:
|
||||||
|
|
||||||
|
```
|
||||||
|
ln /path/to/partitionA/directory/file /path/to/partitionB/directory
|
||||||
|
```
|
||||||
|
|
||||||
|
As we saw previously, hard links are entries in a partition table that point to data on the *same partition*. You can't have an entry in the table of one partition pointing to data on another partition. Your only choice here would be to us a soft link:
|
||||||
|
|
||||||
|
```
|
||||||
|
ln -s /path/to/partitionA/directory/file /path/to/partitionB/directory
|
||||||
|
```
|
||||||
|
|
||||||
|
Another thing that soft links can do and hard links cannot is link to whole directories:
|
||||||
|
|
||||||
|
```
|
||||||
|
ln -s /path/to/some/directory /path/to/some/other/directory
|
||||||
|
```
|
||||||
|
|
||||||
|
will create a link to _/path/to/some/directory_ within _/path/to/some/other/directory_ without a hitch.
|
||||||
|
|
||||||
|
Trying to do the same by hard linking will show you an error saying that you are not allowed to do that. And the reason for that is unending recursiveness: if you have directory B inside directory A, and then you link A inside B, you have situation, because then A contains B within A inside B that incorporates A that encloses B, and so on ad-infinitum.
|
||||||
|
|
||||||
|
You can have recursive using soft links, but why would you do that to yourself?
|
||||||
|
|
||||||
|
### Should I use a hard or a soft link?
|
||||||
|
|
||||||
|
In general you can use soft links everywhere and for everything. In fact, there are situations in which you can only use soft links. That said, hard links are slightly more efficient: they take up less space on disk and are faster to access. On most machines you will not notice the difference, though: the difference in space and speed will be negligible given today's massive and speedy hard disks. However, if you are using Linux on an embedded system with a small storage and a low-powered processor, you may want to give hard links some consideration.
|
||||||
|
|
||||||
|
Another reason to use hard links is that a hard link is much more difficult to break. If you have a soft link and you accidentally move or delete the file it is pointing to, your soft link will be broken and point to... nothing. There is no danger of this happening with a hard link, since the hard link points directly to the data on the disk. Indeed, the space on the disk will not be flagged as free until the last hard link pointing to it is erased from the file system.
|
||||||
|
|
||||||
|
Soft links, on the other hand can do more than hard links and point to anything, be it file or directory. They can also point to items that are on different partitions. These two things alone often make them the only choice.
|
||||||
|
|
||||||
|
### Next Time
|
||||||
|
|
||||||
|
Now we have covered files and directories and the basic tools to manipulate them, you are ready to move onto the tools that let you explore the directory hierarchy, find data within files, and examine the contents. That's what we'll be dealing with in the next installment. See you then!
|
||||||
|
|
||||||
|
Learn more about Linux through the free ["Introduction to Linux" ][2]course from The Linux Foundation and edX.
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.linux.com/blog/2018/10/understanding-linux-links-part-2
|
||||||
|
|
||||||
|
作者:[Paul Brown][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://www.linux.com/users/bro66
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://www.linux.com/blog/intro-to-linux/2018/10/linux-links-part-1
|
||||||
|
[2]: https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||||
@ -0,0 +1,84 @@
|
|||||||
|
Ultimate Plumber – Writing Linux Pipes With Instant Live Preview
|
||||||
|
======
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
As you may already know, **Pipe** command is used to send the output of one command/program/process to another command/program/process for further processing in Unix-like operating systems. Using the Pipe command, we can combine two or more commands and redirect the standard input or output of one command to another easily and quickly. A pipe is represented by a vertical bar character ( **|** ) between two or more Linux commands. The general syntax of a pipe command is given below.
|
||||||
|
|
||||||
|
```
|
||||||
|
Command-1 | Command-2 | Command-3 | …| Command-N
|
||||||
|
```
|
||||||
|
|
||||||
|
If you use Pipe command often, I have a good news for you. Now, you can preview the Linux pipes results instantly while writing them. Say hello to **“Ultimate Plumber”** , shortly **UP** , a command line tool for writing Linux pipes with instant live preview. It is used to build complex Pipelines quickly, easily with instant, scrollable preview of the command results. The UP tool is quite handy if you often need to repeat piped commands to get the desired result.
|
||||||
|
|
||||||
|
In this brief guide, I will show you how to install UP and build complex Linux pipelines easily.
|
||||||
|
|
||||||
|
**Important warning:**
|
||||||
|
|
||||||
|
Please be careful when using this tool in production! It could be dangerous and you might inadvertently delete any important data. You must particularly be careful when using “rm” or “dd” commands with UP tool. You have been warned!
|
||||||
|
|
||||||
|
### Writing Linux Pipes With Instant Live Preview Using Ultimate Plumber
|
||||||
|
|
||||||
|
Here is a simple example to understand the underlying concept of UP. For example, let us pipe the output of **lshw** command into UP. To do so, type the following command in your Terminal and press ENTER:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ lshw |& up
|
||||||
|
```
|
||||||
|
|
||||||
|
You will see an input box at the top of the screen as shown in the below screenshot.
|
||||||
|

|
||||||
|
In the input box, start typing any pipelines and press ENTER key to execute the command you just typed. Now, the Ultimate Plumber utility will immediately show you the output of the pipeline in the **scrollable window** below. You can browse through the results using **PgUp/PgDn** or **Ctrl+ <left arrow)/Ctrl+<right arrow>** keys.
|
||||||
|
|
||||||
|
Once you’re satisfied with the result, press **Ctrl-X** to exit the UP. The Linux pipe command you just built will be saved in a file named **up1.sh** in the current working directory. If this file is already exists, an additional file named **up2.sh** will be created to save the result. This will go on until 1000 files. If you don’t want to save the output, just press **Ctrl-C**.
|
||||||
|
|
||||||
|
You can view the contents of the upX.sh file with cat command. Here is the output of my **up2.sh** file:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ cat up2.sh
|
||||||
|
#!/bin/bash
|
||||||
|
grep network -A5 | grep : | cut -d: -f2- | paste - -
|
||||||
|
```
|
||||||
|
|
||||||
|
If the command you piped into UP is long running, you will see a **~** (tilde) character in the top-left corner of the window. It means that UP is still waiting for the inputs. In such cases, you may need to freeze the Up’s input buffer size temporarily by pressing **Ctrl-S**. To unfreeze UP back, simply press **Ctrl-Q**. The current input buffer size of Ultimate Plumber is **40 MB**. Once you reached this limit, you will see a **+** (plus) sign on the top-left corner of the screen.
|
||||||
|
|
||||||
|
Here is the short demo of UP tool in action:
|
||||||
|

|
||||||
|
|
||||||
|
### Installing Ultimate Plumber
|
||||||
|
|
||||||
|
Liked it? Great! Go ahead and install it on your Linux system and start using it. Installing UP is quite easy! All you have to do is open your Terminal and run the following two commands to install UP.
|
||||||
|
|
||||||
|
Download the latest Ultimate Plumber binary file from the [**releases page**][1] and put it in your path, for example **/usr/local/bin/**.
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo wget -O /usr/local/bin/up wget https://github.com/akavel/up/releases/download/v0.2.1/up
|
||||||
|
```
|
||||||
|
|
||||||
|
Then, make the UP binary as executable using command:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo chmod a+x /usr/local/bin/up
|
||||||
|
```
|
||||||
|
|
||||||
|
Done! Start building Linux pipelines as described above!!
|
||||||
|
|
||||||
|
And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
|
||||||
|
|
||||||
|
Cheers!
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.ostechnix.com/ultimate-plumber-writing-linux-pipes-with-instant-live-preview/
|
||||||
|
|
||||||
|
作者:[SK][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://www.ostechnix.com/author/sk/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://github.com/akavel/up/releases
|
||||||
@ -0,0 +1,162 @@
|
|||||||
|
DF-SHOW – A Terminal File Manager Based On An Old DOS Application
|
||||||
|
======
|
||||||
|

|
||||||
|
|
||||||
|
If you have worked on good-old MS-DOS, you might have used or heard about **DF-EDIT**. The DF-EDIT, stands for **D** irectory **F** ile **Edit** or, is an obscure DOS file manager, originally written by **Larry Kroeker** for MS-DOS and PC-DOS systems. It is used to display the contents of a given directory or file in MS-DOS and PC-DOS systems. Today, I stumbled upon a similar utility named **DF-SHOW** ( **D** irectory **F** ile **S** how), a terminal file manager for Unix-like operating systems. It is an Unix rewrite of obscure DF-EDIT file manager and is based on DF-EDIT 2.3d release from 1986. DF-SHOW is completely free, open source and released under GPLv3.
|
||||||
|
|
||||||
|
DF-SHOW can be able to,
|
||||||
|
|
||||||
|
* List contents of a directory,
|
||||||
|
* View files,
|
||||||
|
* Edit files using your default file editor,
|
||||||
|
* Copy files to/from different locations,
|
||||||
|
* Rename files,
|
||||||
|
* Delete files,
|
||||||
|
* Create new directories from within the DF-SHOW interface,
|
||||||
|
* Update file permissions, owners and groups,
|
||||||
|
* Search files matching a search term,
|
||||||
|
* Launch executable files.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### DF-SHOW Usage
|
||||||
|
|
||||||
|
DF-SHOW consists of two programs, namely **“show”** and **“sf”**.
|
||||||
|
|
||||||
|
**Show command**
|
||||||
|
|
||||||
|
The “show” program (similar to the `ls` command) is used to display the contents of a directory, create new directories, rename, delete files/folders, update permissions, search files and so on.
|
||||||
|
|
||||||
|
To view the list of contents in a directory, use the following command:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ show <directory path>
|
||||||
|
```
|
||||||
|
|
||||||
|
Example:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ show dfshow
|
||||||
|
```
|
||||||
|
|
||||||
|
Here, dfshow is a directory. If you invoke the “show” command without specifying a directory path, it will display the contents of current directory.
|
||||||
|
|
||||||
|
Here is how DF-SHOW default interface looks like.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
As you can see, DF-SHOW interface is self-explanatory.
|
||||||
|
|
||||||
|
On the top bar, you see the list of available options such as Copy, Delete, Edit, Modify etc.
|
||||||
|
|
||||||
|
Complete list of available options are given below:
|
||||||
|
|
||||||
|
* **C** opy,
|
||||||
|
* **D** elete,
|
||||||
|
* **E** dit,
|
||||||
|
* **H** idden,
|
||||||
|
* **M** odify,
|
||||||
|
* **Q** uit,
|
||||||
|
* **R** ename,
|
||||||
|
* **S** how,
|
||||||
|
* h **U** nt,
|
||||||
|
* e **X** ec,
|
||||||
|
* **R** un command,
|
||||||
|
* **E** dit file,
|
||||||
|
* **H** elp,
|
||||||
|
* **M** ake dir,
|
||||||
|
* **Q** uit,
|
||||||
|
* **S** how dir
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
In each option, one letter has been capitalized and marked as bold. Just press the capitalized letter to perform the respective operation. For example, to rename a file, just press **R** and type the new name and hit ENTER to rename the selected item.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
To display all options or cancel an operation, just press **ESC** key.
|
||||||
|
|
||||||
|
Also, you will see a bunch of function keys at the bottom of DF-SHOW interface to navigate through the contents of a directory.
|
||||||
|
|
||||||
|
* **UP/DOWN** arrows or **F1/F2** – Move up and down (one line at time),
|
||||||
|
* **PgUp/Pg/Dn** – Move one page at a time,
|
||||||
|
* **F3/F4** – Instantly go to Top and bottom of the list,
|
||||||
|
* **F5** – Refresh,
|
||||||
|
* **F6** – Mark/Unmark files (Files marked will be indicated with an ***** in front of them),
|
||||||
|
* **F7/F8** – Mark/Unmark all files at once,
|
||||||
|
* **F9** – Sort the list by – Date & time, Name, Size.,
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Press **h** to learn more details about **show** command and its options.
|
||||||
|
|
||||||
|
To exit DF-SHOW, simply press **q**.
|
||||||
|
|
||||||
|
**SF Command**
|
||||||
|
|
||||||
|
The “sf” (show files) is used to display the contents of a file.
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sf <file>
|
||||||
|
```
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Press **h** to learn more “sf” command and its options. To quit, press **q**.
|
||||||
|
|
||||||
|
Want to give it a try? Great! Go ahead and install DF-SHOW on your Linux system as described below.
|
||||||
|
|
||||||
|
### Installing DF-SHOW
|
||||||
|
|
||||||
|
DF-SHOW is available in [**AUR**][1], so you can install it on any Arch-based system using AUR programs such as [**Yay**][2].
|
||||||
|
|
||||||
|
```
|
||||||
|
$ yay -S dfshow
|
||||||
|
```
|
||||||
|
|
||||||
|
On Ubuntu and its derivatives:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo add-apt-repository ppa:ian-hawdon/dfshow
|
||||||
|
|
||||||
|
$ sudo apt-get update
|
||||||
|
|
||||||
|
$ sudo apt-get install dfshow
|
||||||
|
```
|
||||||
|
|
||||||
|
On other Linux distributions, you can compile and build it from the source as shown below.
|
||||||
|
|
||||||
|
```
|
||||||
|
$ git clone https://github.com/roberthawdon/dfshow
|
||||||
|
$ cd dfshow
|
||||||
|
$ ./bootstrap
|
||||||
|
$ ./configure
|
||||||
|
$ make
|
||||||
|
$ sudo make install
|
||||||
|
```
|
||||||
|
|
||||||
|
The author of DF-SHOW project has only rewritten some of the applications of DF-EDIT utility. Since the source code is freely available on GitHub, you can add more features, improve the code and submit or fix the bugs (if there are any). It is still in alpha stage, but fully functional.
|
||||||
|
|
||||||
|
Have you tried it already? If so, how’d go? Tell us your experience in the comments section below.
|
||||||
|
|
||||||
|
And, that’s all for now. Hope this was useful.More good stuffs to come.
|
||||||
|
|
||||||
|
Stay tuned!
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.ostechnix.com/df-show-a-terminal-file-manager-based-on-an-old-dos-application/
|
||||||
|
|
||||||
|
作者:[SK][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://www.ostechnix.com/author/sk/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://aur.archlinux.org/packages/dfshow/
|
||||||
|
[2]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||||
@ -0,0 +1,112 @@
|
|||||||
|
Machine learning with Python: Essential hacks and tricks
|
||||||
|
======
|
||||||
|
Master machine learning, AI, and deep learning with Python.
|
||||||
|

|
||||||
|
|
||||||
|
It's never been easier to get started with machine learning. In addition to structured massive open online courses (MOOCs), there are a huge number of incredible, free resources available around the web. Here are a few that have helped me.
|
||||||
|
|
||||||
|
2. Learn to clearly differentiate between the buzzwords—for example, machine learning, artificial intelligence, deep learning, data science, computer vision, and robotics. Read or listen to talks by experts on each of them. Watch this [amazing video by Brandon Rohrer][1], an influential data scientist. Or this video about the [clear differences between various roles][2] associated with data science.
|
||||||
|
|
||||||
|
|
||||||
|
3. Clearly set a goal for what you want to learn. Then go and take [that Coursera course][3]. Or take the one [from the University of Washington][4], which is pretty good too.
|
||||||
|
|
||||||
|
|
||||||
|
5. If you are enthusiastic about taking online courses, check out this article for guidance on [choosing the right MOOC][5].
|
||||||
|
|
||||||
|
|
||||||
|
6. Most of all, develop a feel for it. Join some good social forums, but resist the temptation to latch onto sensationalized headlines and news. Do your own reading to understand what it is and what it is not, where it might go, and what possibilities it can open up. Then sit back and think about how you can apply machine learning or imbue data science principles into your daily work. Build a simple regression model to predict the cost of your next lunch or download your electricity usage data from your energy provider and do a simple time-series plot in Excel to discover some pattern of usage. And after you are thoroughly enamored with machine learning, you can watch this video.
|
||||||
|
|
||||||
|
<https://www.youtube.com/embed/IpGxLWOIZy4>
|
||||||
|
|
||||||
|
### Is Python a good language for machine learning/AI?
|
||||||
|
|
||||||
|
Familiarity and moderate expertise in at least one high-level programming language is useful for beginners in machine learning. Unless you are a Ph.D. researcher working on a purely theoretical proof of some complex algorithm, you are expected to mostly use the existing machine learning algorithms and apply them in solving novel problems. This requires you to put on a programming hat.
|
||||||
|
|
||||||
|
There's a lot of talk about the best language for data science. While the debate rages, grab a coffee and read this insightful FreeCodeCamp article to learn about [data science languages][6] . Or, check out this post on KDnuggets to dive directly into the [Python vs. R debate][7]
|
||||||
|
|
||||||
|
For now, it's widely believed that Python helps developers be more productive from development to deployment and maintenance. Python's syntax is simpler and at a higher level when compared to Java, C, and C++. It has a vibrant community, open source culture, hundreds of high-quality libraries focused on machine learning, and a huge support base from big names in the industry (e.g., Google, Dropbox, Airbnb, etc.).
|
||||||
|
|
||||||
|
### Fundamental Python libraries
|
||||||
|
|
||||||
|
Assuming you go with the widespread opinion that Python is the best language for machine learning, there are a few core Python packages and libraries you need to master.
|
||||||
|
|
||||||
|
#### NumPy
|
||||||
|
|
||||||
|
Short for [Numerical Python][8], NumPy is the fundamental package required for high-performance scientific computing and data analysis in the Python ecosystem. It's the foundation on which nearly all of the higher-level tools, such as [Pandas][9] and [scikit-learn][10], are built. [TensorFlow][11] uses NumPy arrays as the fundamental building blocks underpinning Tensor objects and graphflow for deep learning tasks. Many NumPy operations are implemented in C, making them super fast. For data science and modern machine learning tasks, this is an invaluable advantage.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
#### Pandas
|
||||||
|
|
||||||
|
Pandas is the most popular library in the scientific Python ecosystem for doing general-purpose data analysis. Pandas is built upon a NumPy array, thereby preserving fast execution speed and offering many data engineering features, including:
|
||||||
|
|
||||||
|
* Reading/writing many different data formats
|
||||||
|
* Selecting subsets of data
|
||||||
|
* Calculating across rows and down columns
|
||||||
|
* Finding and filling missing data
|
||||||
|
* Applying operations to independent groups within the data
|
||||||
|
* Reshaping data into different forms
|
||||||
|
* Combing multiple datasets together
|
||||||
|
* Advanced time-series functionality
|
||||||
|
* Visualization through Matplotlib and Seaborn
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
#### Matplotlib and Seaborn
|
||||||
|
|
||||||
|
Data visualization and storytelling with data are essential skills for every data scientist because it's crtitical to be able to communicate insights from analyses to any audience effectively. This is an equally critical part of your machine learning pipeline, as you often have to perform an exploratory analysis of a dataset before deciding to apply a particular machine learning algorithm.
|
||||||
|
|
||||||
|
[Matplotlib][12] is the most widely used 2D Python visualization library. It's equipped with a dazzling array of commands and interfaces for producing publication-quality graphics from your data. This amazingly detailed and rich article will help you [get started with Matplotlib][13].
|
||||||
|
|
||||||
|
|
||||||
|
[Seaborn][14] is another great visualization library focused on statistical plotting. It provides an API (with flexible choices for plot style and color defaults) on top of Matplotlib, defines simple high-level functions for common statistical plot types, and integrates with functionality provided by Pandas. You can start with this great tutorial on [Seaborn for beginners][15].
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
#### Scikit-learn
|
||||||
|
|
||||||
|
Scikit-learn is the most important general machine learning Python package to master. It features various [classification][16], [regression][17], and [clustering][18] algorithms, including [support vector machines][19], [random forests][20], [gradient boosting][21], [k-means][22], and [DBSCAN][23], and is designed to interoperate with the Python numerical and scientific libraries NumPy and [SciPy][24]. It provides a range of supervised and unsupervised learning algorithms via a consistent interface. The library has a level of robustness and support required for use in production systems. This means it has a deep focus on concerns such as ease of use, code quality, collaboration, documentation, and performance. Look at this [gentle introduction to machine learning vocabulary][25] used in the Scikit-learn universe or this article demonstrating [a simple machine learning pipeline][26] method using Scikit-learn.
|
||||||
|
|
||||||
|
This article was originally published on [Heartbeat][27] under [CC BY-SA 4.0][28].
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/18/10/machine-learning-python-essential-hacks-and-tricks
|
||||||
|
|
||||||
|
作者:[Tirthajyoti Sarkar][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/tirthajyoti
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://www.youtube.com/watch?v=tKa0zDDDaQk
|
||||||
|
[2]: https://www.youtube.com/watch?v=Ura_ioOcpQI
|
||||||
|
[3]: https://www.coursera.org/learn/machine-learning
|
||||||
|
[4]: https://www.coursera.org/specializations/machine-learning
|
||||||
|
[5]: https://towardsdatascience.com/how-to-choose-effective-moocs-for-machine-learning-and-data-science-8681700ed83f
|
||||||
|
[6]: https://medium.freecodecamp.org/which-languages-should-you-learn-for-data-science-e806ba55a81f
|
||||||
|
[7]: https://www.kdnuggets.com/2017/09/python-vs-r-data-science-machine-learning.html
|
||||||
|
[8]: http://numpy.org/
|
||||||
|
[9]: https://pandas.pydata.org/
|
||||||
|
[10]: http://scikit-learn.org/
|
||||||
|
[11]: https://www.tensorflow.org/
|
||||||
|
[12]: https://matplotlib.org/
|
||||||
|
[13]: https://realpython.com/python-matplotlib-guide/
|
||||||
|
[14]: https://seaborn.pydata.org/
|
||||||
|
[15]: https://www.datacamp.com/community/tutorials/seaborn-python-tutorial
|
||||||
|
[16]: https://en.wikipedia.org/wiki/Statistical_classification
|
||||||
|
[17]: https://en.wikipedia.org/wiki/Regression_analysis
|
||||||
|
[18]: https://en.wikipedia.org/wiki/Cluster_analysis
|
||||||
|
[19]: https://en.wikipedia.org/wiki/Support_vector_machine
|
||||||
|
[20]: https://en.wikipedia.org/wiki/Random_forests
|
||||||
|
[21]: https://en.wikipedia.org/wiki/Gradient_boosting
|
||||||
|
[22]: https://en.wikipedia.org/wiki/K-means_clustering
|
||||||
|
[23]: https://en.wikipedia.org/wiki/DBSCAN
|
||||||
|
[24]: https://en.wikipedia.org/wiki/SciPy
|
||||||
|
[25]: http://scikit-learn.org/stable/tutorial/basic/tutorial.html
|
||||||
|
[26]: https://towardsdatascience.com/machine-learning-with-python-easy-and-robust-method-to-fit-nonlinear-data-19e8a1ddbd49
|
||||||
|
[27]: https://heartbeat.fritz.ai/some-essential-hacks-and-tricks-for-machine-learning-with-python-5478bc6593f2
|
||||||
|
[28]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||||
@ -0,0 +1,68 @@
|
|||||||
|
什么是 SRE?它和 DevOps 是怎么关联的?
|
||||||
|
=====
|
||||||
|
|
||||||
|
大型企业里 SRE 角色比较常见,不过小公司也需要 SRE。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
虽然站点可靠性工程师(SRE)角色在近几年变得流行起来,但是很多人 —— 甚至是软件行业里的 —— 还不知道 SRE 是什么或者 SRE 都干些什么。为了搞清楚这些问题,这篇文章解释了 SRE 的含义,还有 SRE 怎样关联 DevOps,以及在工程师团队规模不大的组织里 SRE 该如何工作。
|
||||||
|
|
||||||
|
### 什么是站点可靠性工程?
|
||||||
|
|
||||||
|
谷歌的几个工程师写的《 [SRE:谷歌运维解密][1]》被认为是站点可靠性工程的权威书籍。谷歌的工程副总裁 Ben Treynor Sloss 在二十一世纪初[创造了这个术语][2]。他是这样定义的:“当你让软件工程师设计运维功能时,SRE 就产生了。”
|
||||||
|
|
||||||
|
虽然系统管理员从很久之前就在写代码,但是过去的很多时候系统管理团队是手动管理机器的。当时他们管理的机器可能有几十台或者上百台,不过当这个数字涨到了几千甚至几十万的时候,就不能简单的靠人去解决问题了。规模如此大的情况下,很明显应该用代码去管理机器(以及机器上运行的软件)。
|
||||||
|
|
||||||
|
另外,一直到近几年,运维团队和开发团队都还是完全独立的。两个岗位的技能要求也被认为是完全不同的。SRE 的角色想尝试把这两份工作结合起来。
|
||||||
|
|
||||||
|
在深入探讨什么是 SRE 以及 SRE 如何和开发团队协作之前,我们需要先了解一下 SRE 在 DevOps 范例中是怎么工作的。
|
||||||
|
|
||||||
|
### SRE 和 DevOps
|
||||||
|
|
||||||
|
站点可靠性工程的核心,就是对 DevOps 范例的实践。[DevOps 的定义][3]有很多种方式。开发团队(“devs”)和运维(“ops”)团队相互分离的传统模式下,写代码的团队在服务交付给用户使用之后就不再对服务状态负责了。开发团队“把代码扔到墙那边”让运维团队去部署和支持。
|
||||||
|
|
||||||
|
这种情况会导致大量失衡。开发和运维的目标总是不一致 —— 开发希望用户体验到“最新最棒”的代码,但是运维想要的是变更尽量少的稳定系统。运维是这样假定的,任何变更都可能引发不稳定,而不做任何变更的系统可以一直保持稳定。(减少软件的变更次数并不是避免故障的唯一因素,认识到这一点很重要。例如,虽然你的 web 应用保持不变,但是当用户数量涨到十倍时,服务可能就会以各种方式出问题。)
|
||||||
|
|
||||||
|
DevOps 理念认为通过合并这两个岗位就能够消灭争论。如果开发团队时刻都想把新代码部署上线,那么他们也必须对新代码引起的故障负责。就像亚马逊的 [Werner Vogels 说的][4]那样,“谁开发,谁运维”(生产环境)。但是开发人员已经有一大堆问题了。他们不断的被推动着去开发老板要的产品功能。再让他们去了解基础设施,包括如何部署、配置还有监控服务,这对他们的要求有点太多了。所以就需要 SRE 了。
|
||||||
|
|
||||||
|
开发一个 web 应用的时候经常是很多人一起参与。有用户界面设计师,图形设计师,前端工程师,后端工程师,还有许多其他工种(视技术选型的具体情况而定)。如何管理写好的代码也是需求之一(例如部署,配置,监控)—— 这是 SRE 的专业领域。但是,就像前端工程师受益于后端领域的知识一样(例如从数据库获取数据的方法),SRE 理解部署系统的工作原理,知道如何满足特定的代码或者项目的具体需求。
|
||||||
|
|
||||||
|
所以 SRE 不仅仅是“写代码的运维工程师”。相反,SRE 是开发团队的成员,他们有着不同的技能,特别是在发布部署、配置管理、监控、指标等方面。但是,就像前端工程师必须知道如何从数据库中获取数据一样,SRE 也不是只负责这些领域。为了提供更容易升级、管理和监控的产品,整个团队共同努力。
|
||||||
|
|
||||||
|
当一个团队在做 DevOps 实践,但是他们意识到对开发的要求太多了,过去由运维团队做的事情,现在需要一个专家来专门处理。这个时候,对 SRE 的需求很自然地就出现了。
|
||||||
|
|
||||||
|
### SRE 在初创公司怎么工作
|
||||||
|
|
||||||
|
如果你们公司有好几百位员工,那是非常好的(如果到了 Google 和 Facebook 的规模就更不用说了)。大公司的 SRE 团队分散在各个开发团队里。但是一个初创公司没有这种规模经济,工程师经常身兼数职。那么小公司该让谁做 SRE 呢?其中一种方案是完全践行 DevOps,那些大公司里属于 SRE 的典型任务,在小公司就让开发者去负责。另一种方案,则是聘请专家 —— 也就是 SRE。
|
||||||
|
|
||||||
|
让开发人员做 SRE 最显著的优点是,团队规模变大的时候也能很好的扩展。而且,开发人员将会全面地了解应用的特性。但是,许多初创公司的基础设施包含了各种各样的 SaaS 产品,这种多样性在基础设施上体现的最明显,因为连基础设施本身也是多种多样。然后你们在某个基础设施上引入指标系统、站点监控、日志分析、容器等等。这些技术解决了一部分问题,也增加了复杂度。开发人员除了要了解应用程序的核心技术(比如开发语言),还要了解上述所有技术和服务。最终,掌握所有的这些技术让人无法承受。
|
||||||
|
|
||||||
|
另一种方案是聘请专家专职做 SRE。他们专注于发布部署、配置管理、监控和指标,可以节省开发人员的时间。这种方案的缺点是,SRE 的时间必须分配给多个不同的应用(就是说 SRE 需要贯穿整个工程部门)。 这可能意味着 SRE 没时间对任何应用深入学习,然而他们可以站在一个能看到服务全貌的高度,知道各个部分是怎么组合在一起的。 这个“ 三万英尺高的视角”可以帮助 SRE 从系统整体上考虑,哪些薄弱环节需要优先修复。
|
||||||
|
|
||||||
|
有一个关键信息我还没提到:其他的工程师。他们可能很渴望了解发布部署的原理,也很想尽全力学会使用指标系统。而且,雇一个 SRE 可不是一件简单的事儿。因为你要找的是一个既懂系统管理又懂软件工程的人。(我之所以明确地说软件工程而不是说“能写代码”,是因为除了写代码之外软件工程还包括很多东西,比如编写良好的测试或文档。)
|
||||||
|
|
||||||
|
因此,在某些情况下让开发人员做 SRE 可能更合理一些。如果这样做了,得同时关注代码和基础设施(购买 SaaS 或内部自建)的复杂程度。这两边的复杂性,有时候能促进专业化。
|
||||||
|
|
||||||
|
### 总结
|
||||||
|
|
||||||
|
在初创公司做 DevOps 实践最有效的方式是组建 SRE 小组。我见过一些不同的方案,但是我相信初创公司(尽早)招聘专职 SRE 可以解放开发人员,让开发人员专注于特定的挑战。SRE 可以把精力放在改善工具(流程)上,以提高开发人员的生产力。不仅如此,SRE 还专注于确保交付给客户的产品是可靠且安全的。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/18/10/sre-startup
|
||||||
|
|
||||||
|
作者:[Craig Sebenik][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[BeliteX](https://github.com/belitex)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/craig5
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: http://shop.oreilly.com/product/0636920041528.do
|
||||||
|
[2]: https://landing.google.com/sre/interview/ben-treynor.html
|
||||||
|
[3]: https://opensource.com/resources/devops
|
||||||
|
[4]: https://queue.acm.org/detail.cfm?id=1142065
|
||||||
|
[5]: https://www.usenix.org/conference/lisa18/presentation/sebenik
|
||||||
|
[6]: https://www.usenix.org/conference/lisa18
|
||||||
@ -0,0 +1,485 @@
|
|||||||
|
如何使用chkconfig和systemctl命令启用或禁用linux服务
|
||||||
|
======
|
||||||
|
|
||||||
|
对于Linux管理员来说这是一个重要(美妙)的话题,所以每个人都必须知道并练习怎样才能更高效的使用它们。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
在Linux中,无论何时当你安装任何带有服务和守护进程的包,系统默认会把这些进程添加到 “init & systemd” 脚本中,不过此时它们并没有被启动 。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
我们需要手动的开启或者关闭那些服务。Linux中有三个著名的且一直在被使用的init系统。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### 什么是init系统?
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
在以Linux/Unix 为基础的操作系统上,init (初始化的简称) 是内核引导系统启动过程中第一个启动的进程。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
init的进程id(pid)是1,除非系统关机否则它将会一直在后台运行。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Init 首先根据 `/etc/inittab` 文件决定Linux运行的级别,然后根据运行级别在后台启动所有其他进程和应用程序。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
BIOS, MBR, GRUB 和内核程序在启动init之前就作为linux的引导程序的一部分开始工作了。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
下面是Linux中可以使用的运行级别(从0~6总共七个运行级别)
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
* **`0:`** 关机
|
||||||
|
|
||||||
|
* **`1:`** 单用户模式
|
||||||
|
|
||||||
|
* **`2:`** 多用户模式(没有NFS)
|
||||||
|
|
||||||
|
* **`3:`** 完全的多用户模式
|
||||||
|
|
||||||
|
* **`4:`** 系统未使用
|
||||||
|
|
||||||
|
* **`5:`** 图形界面模式
|
||||||
|
|
||||||
|
* **`:`** 重启
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
下面是Linux系统中最常用的三个init系统
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
* System V (Sys V)
|
||||||
|
|
||||||
|
* Upstart
|
||||||
|
|
||||||
|
* systemd
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### 什么是 System V (Sys V)?
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
System V (Sys V)是类Unix系统第一个传统的init系统之一。init是内核引导系统启动过程中第一支启动的程序 ,它是所有程序的父进程。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
大部分Linux发行版最开始使用的是叫作System V(Sys V)的传统的init系统。在过去的几年中,已经有好几个init系统被发布用来解决标准版本中的设计限制,例如:launchd, the Service Management Facility, systemd 和 Upstart。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
与传统的 SysV init系统相比,systemd已经被几个主要的Linux发行版所采用。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### 什么是 Upstart?
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Upstart 是一个基于事件的/sbin/init守护进程的替代品,它在系统启动过程中处理任务和服务的启动,在系统运行期间监视它们,在系统关机的时候关闭它们。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
它最初是为Ubuntu而设计,但是它也能够完美的部署在其他所有Linux系统中,用来代替古老的System-V。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Upstart被用于Ubuntu 从 9.10 到 Ubuntu 14.10和基于RHEL 6的系统,之后它被systemd取代。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### 什么是 systemd?
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Systemd是一个新的init系统和系统管理器, 和传统的SysV相比,它可以用于所有主要的Linux发行版。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
systemd 兼容 SysV 和 LSB init脚本。 它可以直接替代Sys V init系统。systemd是被内核启动的第一支程序,它的PID 是1。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
systemd是所有程序的父进程,Fedora 15 是第一个用systemd取代upstart的发行版。systemctl用于命令行,它是管理systemd的守护进程/服务的主要工具,例如:(开启,重启,关闭,启用,禁用,重载和状态)
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
systemd 使用.service 文件而不是bash脚本 (SysVinit 使用的). systemd将所有守护进程添加到cgroups中排序,你可以通过浏览`/cgroup/systemd` 文件查看系统等级。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### 如何使用chkconfig命令启用或禁用引导服务?
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
chkconfig实用程序是一个命令行工具,允许你在指定运行级别下启动所选服务,以及列出所有可用服务及其当前设置。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
此外,它还允许我们从启动中启用或禁用服务。前提是你有超级管理员权限(root或者sudo)运行这个命令。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
所有的服务脚本位于 `/etc/rd.d/init.d`文件中
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### 如何列出运行级别中所有的服务
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
`--list` 参数会展示所有的服务及其当前状态 (启用或禁用服务的运行级别)
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
# chkconfig --list
|
||||||
|
|
||||||
|
NetworkManager 0:off 1:off 2:on 3:on 4:on 5:on 6:off
|
||||||
|
|
||||||
|
abrt-ccpp 0:off 1:off 2:off 3:on 4:off 5:on 6:off
|
||||||
|
|
||||||
|
abrtd 0:off 1:off 2:off 3:on 4:off 5:on 6:off
|
||||||
|
|
||||||
|
acpid 0:off 1:off 2:on 3:on 4:on 5:on 6:off
|
||||||
|
|
||||||
|
atd 0:off 1:off 2:off 3:on 4:on 5:on 6:off
|
||||||
|
|
||||||
|
auditd 0:off 1:off 2:on 3:on 4:on 5:on 6:off
|
||||||
|
|
||||||
|
.
|
||||||
|
|
||||||
|
.
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### 如何查看指定服务的状态
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
如果你想查看运行级别下某个服务的状态,你可以使用下面的格式匹配出需要的服务。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
比如说我想查看运行级别中`auditd`服务的状态
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
# chkconfig --list| grep auditd
|
||||||
|
|
||||||
|
auditd 0:off 1:off 2:on 3:on 4:on 5:on 6:off
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### 如何在指定运行级别中启用服务
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
使用`--level`参数启用指定运行级别下的某个服务,下面展示如何在运行级别3和运行级别5下启用 `httpd` 服务。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
# chkconfig --level 35 httpd on
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### 如何在指定运行级别下禁用服务
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
同样使用 `--level`参数禁用指定运行级别下的服务,下面展示的是在运行级别3和运行级别5中禁用`httpd`服务。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
# chkconfig --level 35 httpd off
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### 如何将一个新服务添加到启动列表中
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
`-–add`参数允许我们添加任何信服务到启动列表中, 默认情况下,新添加的服务会在运行级别2,3,4,5下自动开启。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
# chkconfig --add nagios
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### 如何从启动列表中删除服务
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
可以使用 `--del` 参数从启动列表中删除服务,下面展示的事如何从启动列表中删除Nagios服务。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
# chkconfig --del nagios
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### 如何使用systemctl命令启用或禁用开机自启服务?
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
systemctl用于命令行,它是一个基础工具用来管理systemd的守护进程/服务,例如:(开启,重启,关闭,启用,禁用,重载和状态)
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
所有服务创建的unit文件位与`/etc/systemd/system/`.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### 如何列出全部的服务
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
使用下面的命令列出全部的服务(包括启用的和禁用的)
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
# systemctl list-unit-files --type=service
|
||||||
|
|
||||||
|
UNIT FILE STATE
|
||||||
|
|
||||||
|
arp-ethers.service disabled
|
||||||
|
|
||||||
|
auditd.service enabled
|
||||||
|
|
||||||
|
[email protected] enabled
|
||||||
|
|
||||||
|
blk-availability.service disabled
|
||||||
|
|
||||||
|
brandbot.service static
|
||||||
|
|
||||||
|
[email protected] static
|
||||||
|
|
||||||
|
chrony-wait.service disabled
|
||||||
|
|
||||||
|
chronyd.service enabled
|
||||||
|
|
||||||
|
cloud-config.service enabled
|
||||||
|
|
||||||
|
cloud-final.service enabled
|
||||||
|
|
||||||
|
cloud-init-local.service enabled
|
||||||
|
|
||||||
|
cloud-init.service enabled
|
||||||
|
|
||||||
|
console-getty.service disabled
|
||||||
|
|
||||||
|
console-shell.service disabled
|
||||||
|
|
||||||
|
[email protected] static
|
||||||
|
|
||||||
|
cpupower.service disabled
|
||||||
|
|
||||||
|
crond.service enabled
|
||||||
|
|
||||||
|
.
|
||||||
|
|
||||||
|
.
|
||||||
|
|
||||||
|
150 unit files listed.
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
使用下面的格式通过正则表达式匹配出你想要查看的服务的当前状态。下面是使用systemctl命令查看`httpd` 服务的状态。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
# systemctl list-unit-files --type=service | grep httpd
|
||||||
|
|
||||||
|
httpd.service disabled
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### 如何让指定的服务开机自启
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
使用下面格式的systemctl命令启用一个指定的服务。启用服务将会创建一个符号链接,如下可见
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
# systemctl enable httpd
|
||||||
|
|
||||||
|
Created symlink from /etc/systemd/system/multi-user.target.wants/httpd.service to /usr/lib/systemd/system/httpd.service.
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
运行下列命令再次确认服务是否被启用。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
# systemctl is-enabled httpd
|
||||||
|
|
||||||
|
enabled
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### 如何禁用指定的服务
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
运行下面的命令禁用服务将会移除你启用服务时所创建的
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
# systemctl disable httpd
|
||||||
|
|
||||||
|
Removed symlink /etc/systemd/system/multi-user.target.wants/httpd.service.
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
运行下面的命令再次确认服务是否被禁用
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
# systemctl is-enabled httpd
|
||||||
|
|
||||||
|
disabled
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### 如何查看系统当前的运行级别
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
使用systemctl命令确认你系统当前的运行级别,'运行级'别仍然由systemd管理,不过,运行级别对于systemd来说是一个历史遗留的概念。所以我建议你全部使用systemctl命令。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
我们当前处于`运行级别3`, 下面显示的是`multi-user.target`。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
# systemctl list-units --type=target
|
||||||
|
|
||||||
|
UNIT LOAD ACTIVE SUB DESCRIPTION
|
||||||
|
|
||||||
|
basic.target loaded active active Basic System
|
||||||
|
|
||||||
|
cloud-config.target loaded active active Cloud-config availability
|
||||||
|
|
||||||
|
cryptsetup.target loaded active active Local Encrypted Volumes
|
||||||
|
|
||||||
|
getty.target loaded active active Login Prompts
|
||||||
|
|
||||||
|
local-fs-pre.target loaded active active Local File Systems (Pre)
|
||||||
|
|
||||||
|
local-fs.target loaded active active Local File Systems
|
||||||
|
|
||||||
|
multi-user.target loaded active active Multi-User System
|
||||||
|
|
||||||
|
network-online.target loaded active active Network is Online
|
||||||
|
|
||||||
|
network-pre.target loaded active active Network (Pre)
|
||||||
|
|
||||||
|
network.target loaded active active Network
|
||||||
|
|
||||||
|
paths.target loaded active active Paths
|
||||||
|
|
||||||
|
remote-fs.target loaded active active Remote File Systems
|
||||||
|
|
||||||
|
slices.target loaded active active Slices
|
||||||
|
|
||||||
|
sockets.target loaded active active Sockets
|
||||||
|
|
||||||
|
swap.target loaded active active Swap
|
||||||
|
|
||||||
|
sysinit.target loaded active active System Initialization
|
||||||
|
|
||||||
|
timers.target loaded active active Timers
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
via: https://www.2daygeek.com/how-to-enable-or-disable-services-on-boot-in-linux-using-chkconfig-and-systemctl-command/
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
作者:[Prakash Subramanian][a]
|
||||||
|
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
|
||||||
|
译者:[way-ww](https://github.com/way-ww)
|
||||||
|
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
[a]: https://www.2daygeek.com/author/prakash/
|
||||||
|
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
|
||||||
Loading…
Reference in New Issue
Block a user