mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-27 02:30:10 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject.git
* 'master' of https://github.com/LCTT/TranslateProject.git: (60 commits) PRF&PUB:20171211 What Are Zombie Processes And How To Find & Kill Zombie Processes-.md Delete 20170607 Why Car Companies Are Hiring Computer Security Experts.md Create 20170607 Why Car Companies Are Hiring Computer Security Experts.md Update 20170607 Why Car Companies Are Hiring Computer Security Experts.md Update 20170607 Why Car Companies Are Hiring Computer Security Experts.md Update 20170607 Why Car Companies Are Hiring Computer Security Experts.md 选题: Protecting Your Website From Application Layer DOS Attacks With mod 选题: The Best Linux Laptop (2017-2018): A Buyer’s Guide with Picks from an RHCE 选题: How to Install Arch Linux [Step by Step Guide] 选题: Complete “Beginners to PRO” guide for GIT commands 选题: How To Find Files Based On their Permissions 选题: How to squeeze the most out of Linux file compression 选题: How to configure wireless wake-on-lan for Linux WiFi card 选题: How to Search PDF Files from the Terminal with pdfgrep update at 2017年 12月 14日 星期四 15:50:24 CST Translated by qhwdw translating translating translated 选题: Complete guide for creating Vagrant boxes with VirtualBox ...
This commit is contained in:
commit
271f4c8cc2
published
20170719 Containing System Services in Red Hat Enterprise Linux – Part 1.md20171031 How to use SVG as a Placeholder and Other Image Loading Techniques.md20171113 Glitch write fun small web projects instantly.md20171121 LibreOffice Is Now Available on Flathub the Flatpak App Store.md20171129 Suplemon - Modern CLI Text Editor with Multi Cursor Support.md20171207 7 tools for analyzing performance in Linux with bccBPF.md20171211 What Are Zombie Processes And How To Find & Kill Zombie Processes-.md
sources
talk
tech
20130402 Dynamic linker tricks Using LD_PRELOAD to cheat inject features and investigate programs.md20160330 How to turn any syscall into an event Introducing eBPF Kernel probes.md20170607 Why Car Companies Are Hiring Computer Security Experts.md20170730 Complete “Beginners to PRO” guide for GIT commands.md20170910 Useful Linux Commands that you should know.md20171019 3 Simple Excellent Linux Network Monitors.md20171102 Dive into BPF a list of reading material.md20171115 Security Jobs Are Hot Get Trained and Get Noticed.md20171119 10 Best LaTeX Editors For Linux.md20171120 Useful GNOME Shell Keyboard Shortcuts You Might Not Know About.md20171127 Protecting Your Website From Application Layer DOS Attacks With mod.md20171127 Long-term Linux support future clarified.md20171129 Someone Tries to Bring Back Ubuntus Unity from the Dead as an Official Spin.md20171129 Suplemon - Modern CLI Text Editor with Multi Cursor Support.md20171204 GNOME Boxes Makes It Easier to Test Drive Linux Distros.md20171206 10 useful ncat (nc) Command Examples for Linux Systems.md20171207 Cheat – A Collection Of Practical Linux Command Examples.md20171207 How To Find Files Based On their Permissions.md20171208 OnionShare - Share Files Anonymously.md20171208 The Biggest Problems With UC Browser.md20171210 The Best Linux Laptop (2017-2018)- A Buyer’s Guide with Picks from an RHCE.md20171211 How to Install Arch Linux [Step by Step Guide].md20171211 What Are Zombie Processes And How To Find & Kill Zombie Processes-.md20171212 How to Search PDF Files from the Terminal with pdfgrep.md20171212 Toplip – A Very Strong File Encryption And Decryption CLI Utility.md20171213 Creating a blog with pelican and Github pages.md20171213 How to configure wireless wake-on-lan for Linux WiFi card.md20171214 How to squeeze the most out of Linux file compression.md
translated
talk
tech
20160330 How to turn any syscall into an event Introducing eBPF Kernel probes.md20170607 Why Car Companies Are Hiring Computer Security Experts.md20170719 Containing System Services in Red Hat Enterprise Linux – Part 1.md20171010 Complete guide for creating Vagrant boxes with VirtualBox.md20171031 How to use SVG as a Placeholder and Other Image Loading Techniques.md20171102 Dive into BPF a list of reading material.md20171127 Long-term Linux support future clarified.md20171129 Someone Tries to Bring Back Ubuntus Unity from the Dead as an Official Spin.md20171204 GNOME Boxes Makes It Easier to Test Drive Linux Distros.md20171205 7 rules for avoiding documentation pitfalls.md20171206 10 useful ncat (nc) Command Examples for Linux Systems.md20171212 Internet protocols are changing.md
@ -0,0 +1,219 @@
|
||||
在红帽企业版 Linux 中将系统服务容器化(一)
|
||||
====================
|
||||
|
||||
在 2017 年红帽峰会上,有几个人问我“我们通常用完整的虚拟机来隔离如 DNS 和 DHCP 等网络服务,那我们可以用容器来取而代之吗?”答案是可以的,下面是在当前红帽企业版 Linux 7 系统上创建一个系统容器的例子。
|
||||
|
||||
### 我们的目的
|
||||
|
||||
**创建一个可以独立于任何其它系统服务而更新的网络服务,并且可以从主机端容易地管理和更新。**
|
||||
|
||||
让我们来探究一下在容器中建立一个运行在 systemd 之下的 BIND 服务器。在这一部分,我们将了解到如何建立自己的容器以及管理 BIND 配置和数据文件。
|
||||
|
||||
在本系列的第二部分,我们将看到如何整合主机中的 systemd 和容器中的 systemd。我们将探究如何管理容器中的服务,并且使它作为一种主机中的服务。
|
||||
|
||||
### 创建 BIND 容器
|
||||
|
||||
为了使 systemd 在一个容器中轻松运行,我们首先需要在主机中增加两个包:`oci-register-machine` 和 `oci-systemd-hook`。`oci-systemd-hook` 这个钩子允许我们在一个容器中运行 systemd,而不需要使用特权容器或者手工配置 tmpfs 和 cgroups。`oci-register-machine` 这个钩子允许我们使用 systemd 工具如 `systemctl` 和 `machinectl` 来跟踪容器。
|
||||
|
||||
```
|
||||
[root@rhel7-host ~]# yum install oci-register-machine oci-systemd-hook
|
||||
```
|
||||
|
||||
回到创建我们的 BIND 容器上。[红帽企业版 Linux 7 基础镜像][6]包含了 systemd 作为其初始化系统。我们可以如我们在典型的系统中做的那样安装并激活 BIND。你可以从 [git 仓库中下载这份 Dockerfile][8]。
|
||||
|
||||
```
|
||||
[root@rhel7-host bind]# vi Dockerfile
|
||||
|
||||
# Dockerfile for BIND
|
||||
FROM registry.access.redhat.com/rhel7/rhel
|
||||
ENV container docker
|
||||
RUN yum -y install bind && \
|
||||
yum clean all && \
|
||||
systemctl enable named
|
||||
STOPSIGNAL SIGRTMIN+3
|
||||
EXPOSE 53
|
||||
EXPOSE 53/udp
|
||||
CMD [ "/sbin/init" ]
|
||||
```
|
||||
|
||||
因为我们以 PID 1 来启动一个初始化系统,当我们告诉容器停止时,需要改变 docker CLI 发送的信号。从 `kill` 系统调用手册中 (`man 2 kill`):
|
||||
|
||||
> 唯一可以发送给 PID 1 进程(即 init 进程)的信号,是那些初始化系统明确安装了<ruby>信号处理器<rt>signal handler</rt></ruby>的信号。这是为了避免系统被意外破坏。
|
||||
|
||||
对于 systemd 信号处理器,`SIGRTMIN+3` 是对应于 `systemd start halt.target` 的信号。我们也需要为 BIND 暴露 TCP 和 UDP 端口号,因为这两种协议可能都要使用。
|
||||
|
||||
### 管理数据
|
||||
|
||||
有了一个可以工作的 BIND 服务,我们还需要一种管理配置文件和区域文件的方法。目前这些都放在容器里面,所以我们任何时候都可以进入容器去更新配置或者改变一个区域文件。从管理的角度来说,这并不是很理想。当要更新 BIND 时,我们将需要重建这个容器,所以镜像中的改变将会丢失。任何时候我们需要更新一个文件或者重启服务时,都需要进入这个容器,而这增加了步骤和时间。
|
||||
|
||||
相反的,我们将从这个容器中提取出配置文件和数据文件,把它们拷贝到主机上,然后在运行的时候挂载它们。用这种方式我们可以很容易地重启或者重建容器,而不会丢失所做出的更改。我们也可以使用容器外的编辑器来更改配置和区域文件。因为这个容器的数据看起来像“该系统所提供服务的特定站点数据”,让我们遵循 Linux <ruby>文件系统层次标准<rt>File System Hierarchy</rt></ruby>,并在当前主机上创建 `/srv/named` 目录来保持管理权分离。
|
||||
|
||||
```
|
||||
[root@rhel7-host ~]# mkdir -p /srv/named/etc
|
||||
|
||||
[root@rhel7-host ~]# mkdir -p /srv/named/var/named
|
||||
```
|
||||
|
||||
*提示:如果你正在迁移一个已有的配置文件,你可以跳过下面的步骤并且将它直接拷贝到 `/srv/named` 目录下。你也许仍然要用一个临时容器来检查一下分配给这个容器的 GID。*
|
||||
|
||||
让我们建立并运行一个临时容器来检查 BIND。在将 init 进程以 PID 1 运行时,我们不能交互地运行这个容器来获取一个 shell。我们会在容器启动后执行 shell,并且使用 `rpm` 命令来检查重要文件。
|
||||
|
||||
```
|
||||
[root@rhel7-host ~]# docker build -t named .
|
||||
|
||||
[root@rhel7-host ~]# docker exec -it $( docker run -d named ) /bin/bash
|
||||
|
||||
[root@0e77ce00405e /]# rpm -ql bind
|
||||
```
|
||||
|
||||
对于这个例子来说,我们将需要 `/etc/named.conf` 和 `/var/named/` 目录下的任何文件。我们可以使用 `machinectl` 命令来提取它们。如果注册了一个以上的容器,我们可以在任一机器上使用 `machinectl status` 命令来查看运行的是什么。一旦有了这些配置,我们就可以终止这个临时容器了。
|
||||
|
||||
*如果你喜欢,资源库中也有一个[样例 `named.conf` 和针对 `example.com` 的区域文件][8]。*
|
||||
|
||||
```
|
||||
[root@rhel7-host bind]# machinectl list
|
||||
|
||||
MACHINE CLASS SERVICE
|
||||
8824c90294d5a36d396c8ab35167937f container docker
|
||||
|
||||
[root@rhel7-host ~]# machinectl copy-from 8824c90294d5a36d396c8ab35167937f /etc/named.conf /srv/named/etc/named.conf
|
||||
|
||||
[root@rhel7-host ~]# machinectl copy-from 8824c90294d5a36d396c8ab35167937f /var/named /srv/named/var/named
|
||||
|
||||
[root@rhel7-host ~]# docker stop infallible_wescoff
|
||||
```
|
||||
|
||||
### 最终的创建
|
||||
|
||||
为了创建和运行最终的容器,添加卷选项以挂载:
|
||||
|
||||
- 将文件 `/srv/named/etc/named.conf` 映射为 `/etc/named.conf`
|
||||
- 将目录 `/srv/named/var/named` 映射为 `/var/named`
|
||||
|
||||
因为这是我们最终的容器,我们将提供一个有意义的名字,以供我们以后引用。
|
||||
|
||||
```
|
||||
[root@rhel7-host ~]# docker run -d -p 53:53 -p 53:53/udp -v /srv/named/etc/named.conf:/etc/named.conf:Z -v /srv/named/var/named:/var/named:Z --name named-container named
|
||||
```
|
||||
|
||||
在最终容器运行时,我们可以更改本机配置来改变这个容器中 BIND 的行为。这个 BIND 服务器将需要在这个容器分配的任何 IP 上监听。请确保任何新文件的 GID 与来自这个容器中的其余的 BIND 文件相匹配。
|
||||
|
||||
```
|
||||
[root@rhel7-host bind]# cp named.conf /srv/named/etc/named.conf
|
||||
|
||||
[root@rhel7-host ~]# cp example.com.zone /srv/named/var/named/example.com.zone
|
||||
|
||||
[root@rhel7-host ~]# cp example.com.rr.zone /srv/named/var/named/example.com.rr.zone
|
||||
```
|
||||
|
||||
> 很好奇为什么我不需要在主机目录中改变 SELinux 上下文?^注1
|
||||
|
||||
我们将运行这个容器提供的 `rndc` 二进制文件重新加载配置。我们可以使用 `journald` 以同样的方式检查 BIND 日志。如果运行出现错误,你可以在主机中编辑该文件,并且重新加载配置。在主机中使用 `host` 或 `dig`,我们可以检查来自该容器化服务的 example.com 的响应。
|
||||
|
||||
```
|
||||
[root@rhel7-host ~]# docker exec -it named-container rndc reload
|
||||
server reload successful
|
||||
|
||||
[root@rhel7-host ~]# docker exec -it named-container journalctl -u named -n
|
||||
-- Logs begin at Fri 2017-05-12 19:15:18 UTC, end at Fri 2017-05-12 19:29:17 UTC. --
|
||||
May 12 19:29:17 ac1752c314a7 named[27]: automatic empty zone: 9.E.F.IP6.ARPA
|
||||
May 12 19:29:17 ac1752c314a7 named[27]: automatic empty zone: A.E.F.IP6.ARPA
|
||||
May 12 19:29:17 ac1752c314a7 named[27]: automatic empty zone: B.E.F.IP6.ARPA
|
||||
May 12 19:29:17 ac1752c314a7 named[27]: automatic empty zone: 8.B.D.0.1.0.0.2.IP6.ARPA
|
||||
May 12 19:29:17 ac1752c314a7 named[27]: reloading configuration succeeded
|
||||
May 12 19:29:17 ac1752c314a7 named[27]: reloading zones succeeded
|
||||
May 12 19:29:17 ac1752c314a7 named[27]: zone 1.0.10.in-addr.arpa/IN: loaded serial 2001062601
|
||||
May 12 19:29:17 ac1752c314a7 named[27]: zone 1.0.10.in-addr.arpa/IN: sending notifies (serial 2001062601)
|
||||
May 12 19:29:17 ac1752c314a7 named[27]: all zones loaded
|
||||
May 12 19:29:17 ac1752c314a7 named[27]: running
|
||||
|
||||
[root@rhel7-host bind]# host www.example.com localhost
|
||||
Using domain server:
|
||||
Name: localhost
|
||||
Address: ::1#53
|
||||
Aliases:
|
||||
www.example.com is an alias for server1.example.com.
|
||||
server1.example.com is an alias for mail
|
||||
```
|
||||
|
||||
> 你的区域文件没有更新吗?可能是因为你的编辑器,而不是序列号。^注2
|
||||
|
||||
### 终点线
|
||||
|
||||
我们已经达成了我们打算完成的目标,从容器中为 DNS 请求和区域文件提供服务。我们已经得到一个持久化的位置来管理更新和配置,并且更新后该配置不变。
|
||||
|
||||
在这个系列的第二部分,我们将看到怎样将一个容器看作为主机中的一个普通服务来运行。
|
||||
|
||||
---
|
||||
|
||||
[关注 RHEL 博客](http://redhatstackblog.wordpress.com/feed/),通过电子邮件来获得本系列第二部分和其它新文章的更新。
|
||||
|
||||
---
|
||||
|
||||
### 附加资源
|
||||
|
||||
- **所附带文件的 Github 仓库:** [https://github.com/nzwulfin/named-container](https://github.com/nzwulfin/named-container)
|
||||
- **注1:** **通过容器访问本地文件的 SELinux 上下文**
|
||||
|
||||
你可能已经注意到当我从容器向本地主机拷贝文件时,我没有运行 `chcon` 将主机中的文件类型改变为 `svirt_sandbox_file_t`。为什么它没有出错?将一个文件拷贝到 `/srv` 会将这个文件标记为类型 `var_t`。我 `setenforce 0` (关闭 SELinux)了吗?
|
||||
|
||||
当然没有,这将让 [Dan Walsh 大哭](https://stopdisablingselinux.com/)(LCTT 译注:RedHat 的 SELinux 团队负责人,倡议不要禁用 SELinux)。是的,`machinectl` 确实将文件标记类型设置为期望的那样,可以看一下:
|
||||
|
||||
启动一个容器之前:
|
||||
|
||||
```
|
||||
[root@rhel7-host ~]# ls -Z /srv/named/etc/named.conf
|
||||
-rw-r-----. unconfined_u:object_r:var_t:s0 /srv/named/etc/named.conf
|
||||
```
|
||||
|
||||
不过,运行中我使用了一个卷选项可以使 Dan Walsh 先生高兴起来,`:Z`。`-v /srv/named/etc/named.conf:/etc/named.conf:Z` 命令的这部分做了两件事情:首先它表示这需要使用一个私有卷的 SELiunx 标记来重新标记;其次它表明以读写挂载。
|
||||
|
||||
启动容器之后:
|
||||
|
||||
```
|
||||
[root@rhel7-host ~]# ls -Z /srv/named/etc/named.conf
|
||||
-rw-r-----. root 25 system_u:object_r:svirt_sandbox_file_t:s0:c821,c956 /srv/named/etc/named.conf
|
||||
```
|
||||
|
||||
- **注2:** **VIM 备份行为能改变 inode**
|
||||
|
||||
如果你在本地主机中使用 `vim` 来编辑配置文件,而你没有看到容器中的改变,你可能不经意的创建了容器感知不到的新文件。在编辑时,有三种 `vim` 设定影响备份副本:`backup`、`writebackup` 和 `backupcopy`。
|
||||
|
||||
我摘录了 RHEL 7 中的来自官方 VIM [backup_table][9] 中的默认配置。
|
||||
|
||||
```
|
||||
backup writebackup
|
||||
off on backup current file, deleted afterwards (default)
|
||||
```
|
||||
所以我们不创建残留下的 `~` 副本,而是创建备份。另外的设定是 `backupcopy`,`auto` 是默认的设置:
|
||||
|
||||
```
|
||||
"yes" make a copy of the file and overwrite the original one
|
||||
"no" rename the file and write a new one
|
||||
"auto" one of the previous, what works best
|
||||
```
|
||||
|
||||
这种组合设定意味着当你编辑一个文件时,除非 `vim` 有理由(请查看文档了解其逻辑),你将会得到一个包含你编辑内容的新文件,当你保存时它会重命名为原先的文件。这意味着这个文件获得了新的 inode。对于大多数情况,这不是问题,但是这里容器的<ruby>绑定挂载<rt>bind mount</rt></ruby>对 inode 的改变很敏感。为了解决这个问题,你需要改变 `backupcopy` 的行为。
|
||||
|
||||
不管是在 `vim` 会话中还是在你的 `.vimrc`中,请添加 `set backupcopy=yes`。这将确保原先的文件被清空并覆写,维持了 inode 不变并且将该改变传递到了容器中。
|
||||
|
||||
------------
|
||||
|
||||
via: http://rhelblog.redhat.com/2017/07/19/containing-system-services-in-red-hat-enterprise-linux-part-1/
|
||||
|
||||
作者:[Matt Micene][a]
|
||||
译者:[liuxinyu123](https://github.com/liuxinyu123)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://rhelblog.redhat.com/2017/07/19/containing-system-services-in-red-hat-enterprise-linux-part-1/
|
||||
[1]:http://rhelblog.redhat.com/author/mmicenerht/
|
||||
[2]:http://rhelblog.redhat.com/2017/07/19/containing-system-services-in-red-hat-enterprise-linux-part-1/#repo
|
||||
[3]:http://rhelblog.redhat.com/2017/07/19/containing-system-services-in-red-hat-enterprise-linux-part-1/#sidebar_1
|
||||
[4]:http://rhelblog.redhat.com/2017/07/19/containing-system-services-in-red-hat-enterprise-linux-part-1/#sidebar_2
|
||||
[5]:http://redhatstackblog.wordpress.com/feed/
|
||||
[6]:https://access.redhat.com/containers
|
||||
[7]:http://rhelblog.redhat.com/2017/07/19/containing-system-services-in-red-hat-enterprise-linux-part-1/#repo
|
||||
[8]:https://github.com/nzwulfin/named-container
|
||||
[9]:http://vimdoc.sourceforge.net/htmldoc/editing.html#backup-table
|
||||
@ -0,0 +1,217 @@
|
||||
怎么使用 SVG 作为一个图像占位符
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
*从图像中生成的 SVG 可以用作占位符。请继续阅读!*
|
||||
|
||||
我对怎么去让 web 性能更优化和图像加载的更快充满了热情。在这些感兴趣的领域中的其中一项研究就是占位符:当图像还没有被加载的时候应该去展示些什么?
|
||||
|
||||
在前些天,我偶然发现了使用 SVG 的一些加载技术,我将在这篇文章中谈论它。
|
||||
|
||||
在这篇文章中我们将涉及如下的主题:
|
||||
|
||||
* 不同的占位符类型的概述
|
||||
* 基于 SVG 的占位符(边缘、形状和轮廓)
|
||||
* 自动化处理
|
||||
|
||||
### 不同的占位符类型的概述
|
||||
|
||||
之前 [我写过一篇关于图像占位符和<ruby>延迟加载<rt>lazy-loading</rt></ruby>][28] 的文章以及 [关于它的讨论][29]。当进行一个图像的延迟加载时,一个很好的办法是提供一个东西作为占位符,因为它可能会很大程度上影响用户的感知体验。之前我提供了几个选择:
|
||||
|
||||

|
||||
|
||||
在图像被加载之前,有几种办法去填充图像区域:
|
||||
|
||||
* 在图像区域保持空白:在一个响应式设计的环境中,这种方式防止了内容的跳跃。从用户体验的角度来看,那些布局的改变是非常差的作法。但是,它是为了性能的考虑,否则,每次为了获取图像尺寸,浏览器就要被迫进行布局重新计算,以便为它留下空间。
|
||||
* 占位符:在图像那里显示一个用户配置的图像。我们可以在背景上显示一个轮廓。它一直显示直到实际的图像被加载完成,它也被用于当请求失败或者当用户根本没有设置头像图像的情况下。这些图像一般都是矢量图,并且由于尺寸非常小,可以作为内联图片。
|
||||
* 单一颜色:从图像中获取颜色,并将其作为占位符的背景颜色。这可能是图像的主要颜色、最具活力的颜色 … 这个想法是基于你正在加载的图像,并且它将有助于在没有图像和图像加载完成之间进行平滑过渡。
|
||||
* 模糊的图像:也被称为模糊技术。你提供一个极小版本的图像,然后再去过渡到完整的图像。最初显示的图像的像素和尺寸是极小的。为去除<ruby>细节<rt>artifacts</rt></ruby>,该图像会被放大并模糊化。我在前面写的 [Medium 是怎么做的渐进加载图像][1]、[使用 WebP 去创建极小的预览图像][2]、和[渐进加载图像的更多示例][3] 中讨论过这方面的内容。
|
||||
|
||||
此外还有其它的更多的变种,许多聪明的人也开发了其它的创建占位符的技术。
|
||||
|
||||
其中一个就是用梯度图代替单一的颜色。梯度图可以创建一个更精确的最终图像的预览,它整体上非常小(提升了有效载荷)。
|
||||
|
||||

|
||||
|
||||
*使用梯度图作为背景。这是来自 Gradify 的截屏,它现在已经不在线了,代码 [在 GitHub][4]。*
|
||||
|
||||
另外一种技术是使用基于 SVG 的技术,它在最近的实验和研究中取得到了一些进展。
|
||||
|
||||
### 基于 SVG 的占位符
|
||||
|
||||
我们知道 SVG 是完美的矢量图像。而在大多数情况下我们是希望加载一个位图,所以,问题是怎么去矢量化一个图像。其中一些方法是使用边缘、形状和轮廓。
|
||||
|
||||
#### 边缘
|
||||
|
||||
在 [前面的文章中][30],我解释了怎么去找出一个图像的边缘并创建一个动画。我最初的目标是去尝试绘制区域,矢量化该图像,但是我并不知道该怎么去做到。我意识到使用边缘也可能是一种创新,我决定去让它们动起来,创建一个 “绘制” 的效果。
|
||||
|
||||
- [范例](https://codepen.io/jmperez/embed/oogqdp?default-tabs=html%2Cresult&embed-version=2&height=600&host=https%3A%2F%2Fcodepen.io&referrer=https%3A%2F%2Fmedium.freecodecamp.org%2Fmedia%2F8c5c44a4adf82b09692a34eb4daa3e2e%3FpostId%3Dbed1b810ab2c&slug-hash=oogqdp#result-box)
|
||||
|
||||
> [使用边缘检测绘制图像和 SVG 动画][31]
|
||||
|
||||
> 在以前,很少使用和支持 SVG。一段时间以后,我们开始用它去作为一个某些图标的传统位图的替代品……
|
||||
|
||||
#### 形状
|
||||
|
||||
SVG 也可以用于根据图像绘制区域而不是边缘/边界。用这种方法,我们可以矢量化一个位图来创建一个占位符。
|
||||
|
||||
在以前,我尝试去用三角形做类似的事情。你可以在 [CSSConf][33] 和 [Render Conf][34] 上我的演讲中看到它。
|
||||
|
||||
- [范例](https://codepen.io/jmperez/embed/BmaWmQ?default-tabs=html%2Cresult&embed-version=2&height=600&host=https%3A%2F%2Fcodepen.io&referrer=https%3A%2F%2Fmedium.freecodecamp.org%2Fmedia%2F05d1ee44f0537f8257258124d7b94613%3FpostId%3Dbed1b810ab2c&slug-hash=BmaWmQ#result-box)
|
||||
|
||||
上面的 codepen 是一个由 245 个三角形组成的基于 SVG 占位符的概念验证。生成的三角形是基于 [Delaunay triangulation][35] 的,使用了 [Possan’s polyserver][36]。正如预期的那样,使用更多的三角形,文件尺寸就更大。
|
||||
|
||||
#### Primitive 和 SQIP,一个基于 SVG 的 LQIP 技术
|
||||
|
||||
Tobias Baldauf 正在致力于另一个使用 SVG 的低质量图像占位符技术,它被称为 [SQIP][37]。在深入研究 SQIP 之前,我先简单介绍一下 [Primitive][38],它是基于 SQIP 的一个库。
|
||||
|
||||
Primitive 是非常吸引人的,我强烈建议你去了解一下。它讲解了一个位图怎么变成由重叠形状组成的 SVG。它尺寸比较小,适合于直接内联放置到页面中。当步骤较少时,在初始的 HTML 载荷中作为占位符是非常有意义的。
|
||||
|
||||
Primitive 基于三角形、长方形、和圆形等形状生成一个图像。在每一步中它增加一个新形状。很多步之后,图像的结果看起来非常接近原始图像。如果你输出的是 SVG,它意味着输出代码的尺寸将很大。
|
||||
|
||||
为了理解 Primitive 是怎么工作的,我通过几个图像来跑一下它。我用 10 个形状和 100 个形状来为这个插画生成 SVG:
|
||||
|
||||

|
||||

|
||||

|
||||
|
||||
使用 Primitive 处理 ,使用 [10 个形状][6] 、 [100 形状][7]、 [原图][5]。
|
||||
|
||||

|
||||

|
||||

|
||||
|
||||
使用 Primitive 处理,使用 [10 形状][9] 、 [100 形状][10]、 [原图][8] 。
|
||||
|
||||
当在图像中使用 10 个形状时,我们基本构画出了原始图像。在图像占位符这种使用场景里,我们可以使用这种 SVG 作为潜在的占位符。实际上,使用 10 个形状的 SVG 代码已经很小了,大约是 1030 字节,当通过 SVGO 传输时,它将下降到约 640 字节。
|
||||
|
||||
```
|
||||
<svg xmlns=”http://www.w3.org/2000/svg" width=”1024" height=”1024"><path fill=”#817c70" d=”M0 0h1024v1024H0z”/><g fill-opacity=”.502"><path fill=”#03020f” d=”M178 994l580 92L402–62"/><path fill=”#f2e2ba” d=”M638 894L614 6l472 440"/><path fill=”#fff8be” d=”M-62 854h300L138–62"/><path fill=”#76c2d9" d=”M410–62L154 530–62 38"/><path fill=”#62b4cf” d=”M1086–2L498–30l484 508"/><path fill=”#010412" d=”M430–2l196 52–76 356"/><path fill=”#eb7d3f” d=”M598 594l488–32–308 520"/><path fill=”#080a18" d=”M198 418l32 304 116–448"/><path fill=”#3f201d” d=”M1086 1062l-344–52 248–148"/><path fill=”#ebd29f” d=”M630 658l-60–372 516 320"/></g></svg>
|
||||
```
|
||||
|
||||
正如我们预计的那样,使用 100 个形状生成的图像更大,在 SVGO(之前是 8kB)之后,大小约为 5kB。它们在细节上已经很好了,但是仍然是个很小的载荷。使用多少三角形主要取决于图像类型和细腻程度(如,对比度、颜色数量、复杂度)。
|
||||
|
||||
还可以创建一个类似于 [cpeg-dssim][39] 的脚本,去调整所使用的形状的数量,以满足 [结构相似][40] 的阈值(或者最差情况中的最大数量)。
|
||||
|
||||
这些生成的 SVG 也可以用作背景图像。因为尺寸约束和矢量化,它们在展示<ruby>超大题图<rt>hero image</rt></ruby>和大型背景图像时是很好的选择。
|
||||
|
||||
#### SQIP
|
||||
|
||||
用 [Tobias 自己的话说][41]:
|
||||
|
||||
> SQIP 尝试在这两个极端之间找到一种平衡:它使用 [Primitive][42] 去生成一个 SVG,由几种简单的形状构成,近似于图像中可见的主要特征,使用 [SVGO][43] 优化 SVG,并且为它增加高斯模糊滤镜。产生的最终的 SVG 占位符后大小仅为约 800~1000 字节,在屏幕上看起来更为平滑,并提供一个图像内容的视觉提示。
|
||||
|
||||
这个结果和使用一个用了模糊技术的极小占位符图像类似。(看看 [Medium][44] 和 [其它站点][45] 是怎么做的)。区别在于它们使用了一个位图图像,如 JPG 或者 WebP,而这里是使用的占位符是 SVG。
|
||||
|
||||
如果我们使用 SQIP 而不是原始图像,我们将得到这样的效果:
|
||||
|
||||

|
||||

|
||||
|
||||
*[第一张图像][11] 和 [第二张图像][12] 使用了 SQIP 后的输出图像。*
|
||||
|
||||
输出的 SVG 约 900 字节,并且通过检查代码,我们可以发现 `feGaussianBlur` 过滤被应用到该组形状上:
|
||||
|
||||
```
|
||||
<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 2000 2000"><filter id="b"><feGaussianBlur stdDeviation="12" /></filter><path fill="#817c70" d="M0 0h2000v2000H0z"/><g filter="url(#b)" transform="translate(4 4) scale(7.8125)" fill-opacity=".5"><ellipse fill="#000210" rx="1" ry="1" transform="matrix(50.41098 -3.7951 11.14787 148.07886 107 194.6)"/><ellipse fill="#eee3bb" rx="1" ry="1" transform="matrix(-56.38179 17.684 -24.48514 -78.06584 205 110.1)"/><ellipse fill="#fff4bd" rx="1" ry="1" transform="matrix(35.40604 -5.49219 14.85017 95.73337 16.4 123.6)"/><ellipse fill="#79c7db" cx="21" cy="39" rx="65" ry="65"/><ellipse fill="#0c1320" cx="117" cy="38" rx="34" ry="47"/><ellipse fill="#5cb0cd" rx="1" ry="1" transform="matrix(-39.46201 77.24476 -54.56092 -27.87353 219.2 7.9)"/><path fill="#e57339" d="M271 159l-123–16 43 128z"/><ellipse fill="#47332f" cx="214" cy="237" rx="242" ry="19"/></g></svg>
|
||||
```
|
||||
|
||||
SQIP 也可以输出一个带有 Base64 编码的 SVG 内容的图像标签:
|
||||
|
||||
```
|
||||
<img width="640" height="640" src="example.jpg” alt="Add descriptive alt text" style="background-size: cover; background-image: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAw…<stripped base 64>…PjwvZz48L3N2Zz4=);">
|
||||
```
|
||||
|
||||
#### 轮廓
|
||||
|
||||
我们刚才看了使用了边缘和原始形状的 SVG。另外一种矢量化图像的方式是 “描绘” 它们。在几天前 [Mikael Ainalem][47] 分享了一个 [codepen][48] 代码,展示了怎么去使用两色轮廓作为一个占位符。结果非常漂亮:
|
||||
|
||||

|
||||
|
||||
SVG 在这种情况下是手工绘制的,但是,这种技术可以用工具快速生成并自动化处理。
|
||||
|
||||
* [Gatsby][13],一个用 React 支持的描绘 SVG 的静态网站生成器。它使用 [一个 potrace 算法的 JS 移植][14] 去矢量化图像。
|
||||
* [Craft 3 CMS][15],它也增加了对轮廓的支持。它使用了 [一个 potrace 算法的 PHP 移植][16]。
|
||||
* [image-trace-loader][17],一个使用了 potrace 算法去处理图像的 Webpack 加载器。
|
||||
|
||||
如果感兴趣,可以去看一下 Emil 的 webpack 加载器 (基于 potrace) 和 Mikael 的手工绘制 SVG 之间的比较。
|
||||
|
||||
这里我假设该输出是使用默认选项的 potrace 生成的。但是可以对它们进行优化。查看 [图像描绘加载器的选项][49],[传递给 potrace 的选项][50]非常丰富。
|
||||
|
||||
### 总结
|
||||
|
||||
我们看到了从图像中生成 SVG 并使用它们作为占位符的各种不同的工具和技术。与 [WebP 是一个用于缩略图的奇妙格式][51] 一样,SVG 也是一个用于占位符的有趣格式。我们可以控制细节的级别(和它们的大小),它是高可压缩的,并且很容易用 CSS 和 JS 进行处理。
|
||||
|
||||
#### 额外的资源
|
||||
|
||||
这篇文章上到了 [Hacker News 热文][52]。对此以及在该页面的评论中分享的其它资源的链接,我表示非常感谢。下面是其中一部分。
|
||||
|
||||
* [Geometrize][18] 是用 Haxe 写的 Primitive 的一个移植。也有[一个 JS 实现][19],你可以直接 [在你的浏览器上][20]尝试它。
|
||||
* [Primitive.js][21],它也是 Primitive 在 JS 中的一个移植,[primitive.nextgen][22],它是使用 Primitive.js 和 Electron 的 Primitive 的桌面版应用的一个移植。
|
||||
* 这里有两个 Twitter 帐户,里面你可以看到一些用 Primitive 和 Geometrize 生成的图像示例。访问 [@PrimitivePic][23] 和 [@Geometrizer][24]。
|
||||
* [imagetracerjs][25],它是在 JavaScript 中的光栅图像描绘器和矢量化程序。这里也有为 [Java][26] 和 [Android][27] 提供的移植。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.freecodecamp.org/using-svg-as-placeholders-more-image-loading-techniques-bed1b810ab2c
|
||||
|
||||
作者:[José M. Pérez][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.freecodecamp.org/@jmperezperez?source=post_header_lockup
|
||||
[1]:https://medium.com/@jmperezperez/how-medium-does-progressive-image-loading-fd1e4dc1ee3d
|
||||
[2]:https://medium.com/@jmperezperez/using-webp-to-create-tiny-preview-images-3e9b924f28d6
|
||||
[3]:https://medium.com/@jmperezperez/more-examples-of-progressive-image-loading-f258be9f440b
|
||||
[4]:https://github.com/fraser-hemp/gradify
|
||||
[5]:https://jmperezperez.com/assets/images/posts/svg-placeholders/pexels-photo-281184-square.jpg
|
||||
[6]:https://jmperezperez.com/assets/images/posts/svg-placeholders/pexels-photo-281184-square-10.svg
|
||||
[7]:https://jmperezperez.com/assets/images/posts/svg-placeholders/pexels-photo-281184-square-100.svg
|
||||
[8]:https://jmperezperez.com/assets/images/posts/svg-placeholders/pexels-photo-618463-square.jpg
|
||||
[9]:https://jmperezperez.com/assets/images/posts/svg-placeholders/pexels-photo-618463-square-10.svg
|
||||
[10]:https://jmperezperez.com/assets/images/posts/svg-placeholders/pexels-photo-618463-square-100.svg
|
||||
[11]:https://jmperezperez.com/assets/images/posts/svg-placeholders/pexels-photo-281184-square-sqip.svg
|
||||
[12]:https://jmperezperez.com/svg-placeholders/%28/assets/images/posts/svg-placeholders/pexels-photo-618463-square-sqip.svg
|
||||
[13]:https://www.gatsbyjs.org/
|
||||
[14]:https://www.npmjs.com/package/potrace
|
||||
[15]:https://craftcms.com/
|
||||
[16]:https://github.com/nystudio107/craft3-imageoptimize/blob/master/src/lib/Potracio.php
|
||||
[17]:https://github.com/EmilTholin/image-trace-loader
|
||||
[18]:https://github.com/Tw1ddle/geometrize-haxe
|
||||
[19]:https://github.com/Tw1ddle/geometrize-haxe-web
|
||||
[20]:http://www.samcodes.co.uk/project/geometrize-haxe-web/
|
||||
[21]:https://github.com/ondras/primitive.js
|
||||
[22]:https://github.com/cielito-lindo-productions/primitive.nextgen
|
||||
[23]:https://twitter.com/PrimitivePic
|
||||
[24]:https://twitter.com/Geometrizer
|
||||
[25]:https://github.com/jankovicsandras/imagetracerjs
|
||||
[26]:https://github.com/jankovicsandras/imagetracerjava
|
||||
[27]:https://github.com/jankovicsandras/imagetracerandroid
|
||||
[28]:https://medium.com/@jmperezperez/lazy-loading-images-on-the-web-to-improve-loading-time-and-saving-bandwidth-ec988b710290
|
||||
[29]:https://www.youtube.com/watch?v=szmVNOnkwoU
|
||||
[30]:https://medium.com/@jmperezperez/drawing-images-using-edge-detection-and-svg-animation-16a1a3676d3
|
||||
[31]:https://medium.com/@jmperezperez/drawing-images-using-edge-detection-and-svg-animation-16a1a3676d3
|
||||
[32]:https://medium.com/@jmperezperez/drawing-images-using-edge-detection-and-svg-animation-16a1a3676d3
|
||||
[33]:https://jmperezperez.com/cssconfau16/#/45
|
||||
[34]:https://jmperezperez.com/renderconf17/#/46
|
||||
[35]:https://en.wikipedia.org/wiki/Delaunay_triangulation
|
||||
[36]:https://github.com/possan/polyserver
|
||||
[37]:https://github.com/technopagan/sqip
|
||||
[38]:https://github.com/fogleman/primitive
|
||||
[39]:https://github.com/technopagan/cjpeg-dssim
|
||||
[40]:https://en.wikipedia.org/wiki/Structural_similarity
|
||||
[41]:https://github.com/technopagan/sqip
|
||||
[42]:https://github.com/fogleman/primitive
|
||||
[43]:https://github.com/svg/svgo
|
||||
[44]:https://medium.com/@jmperezperez/how-medium-does-progressive-image-loading-fd1e4dc1ee3d
|
||||
[45]:https://medium.com/@jmperezperez/more-examples-of-progressive-image-loading-f258be9f440b
|
||||
[46]:http://www.w3.org/2000/svg
|
||||
[47]:https://twitter.com/mikaelainalem
|
||||
[48]:https://codepen.io/ainalem/full/aLKxjm/
|
||||
[49]:https://github.com/EmilTholin/image-trace-loader#options
|
||||
[50]:https://www.npmjs.com/package/potrace#parameters
|
||||
[51]:https://medium.com/@jmperezperez/using-webp-to-create-tiny-preview-images-3e9b924f28d6
|
||||
[52]:https://news.ycombinator.com/item?id=15696596
|
||||
@ -1,19 +1,18 @@
|
||||
Glitch:立即写出有趣的小型网站项目
|
||||
Glitch:可以让你立即写出有趣的小型网站
|
||||
============================================================
|
||||
|
||||
我刚写了一篇关于 Jupyter Notebooks 是一个有趣的交互式写 Python 代码的方式。这让我想起我最近学习了 Glitch,这个我同样喜爱!我构建了一个小的程序来用于[关闭转发 twitter][2]。因此有了这篇文章!
|
||||
我刚写了一篇关于 Jupyter Notebooks 的文章,它是一个有趣的交互式写 Python 代码的方式。这让我想起我最近学习了 Glitch,这个我同样喜爱!我构建了一个小的程序来用于[关闭转发 twitter][2]。因此有了这篇文章!
|
||||
|
||||
[Glitch][3] 是一个简单的构建 Javascript web 程序的方式(javascript 后端、javascript 前端)
|
||||
[Glitch][3] 是一个简单的构建 Javascript web 程序的方式(javascript 后端、javascript 前端)。
|
||||
|
||||
关于 glitch 有趣的事有:
|
||||
关于 glitch 有趣的地方有:
|
||||
|
||||
1. 你在他们的网站输入 Javascript 代码
|
||||
|
||||
2. 只要输入了任何代码,它会自动用你的新代码重载你的网站。你甚至不必保存!它会自动保存。
|
||||
|
||||
所以这就像 Heroku,但更神奇!像这样的编码(你输入代码,代码立即在公共网络上运行)对我而言感觉很**有趣**。
|
||||
|
||||
这有点像 ssh 登录服务器,编辑服务器上的 PHP/HTML 代码,并让它立即可用,这也是我所喜爱的。现在我们有了“更好的部署实践”,而不是“编辑代码,它立即出现在互联网上”,但我们并不是在谈论严肃的开发实践,而是在讨论编写微型程序的乐趣。
|
||||
这有点像用 ssh 登录服务器,编辑服务器上的 PHP/HTML 代码,它立即就可用了,而这也是我所喜爱的方式。虽然现在我们有了“更好的部署实践”,而不是“编辑代码,让它立即出现在互联网上”,但我们并不是在谈论严肃的开发实践,而是在讨论编写微型程序的乐趣。
|
||||
|
||||
### Glitch 有很棒的示例应用程序
|
||||
|
||||
@ -22,18 +21,16 @@ Glitch 似乎是学习编程的好方式!
|
||||
比如,这有一个太空侵略者游戏(由 [Mary Rose Cook][4] 编写):[https://space-invaders.glitch.me/][5]。我喜欢的是我只需要点击几下。
|
||||
|
||||
1. 点击 “remix this”
|
||||
|
||||
2. 开始编辑代码使箱子变成橘色而不是黑色
|
||||
|
||||
3. 制作我自己太空侵略者游戏!我的在这:[http://julias-space-invaders.glitch.me/][1]。(我只做了很小的更改使其变成橘色,没什么神奇的)
|
||||
|
||||
他们有大量的示例程序,你可以从中启动 - 例如[机器人][6]、[游戏][7]等等。
|
||||
|
||||
### 实际有用的非常好的程序:tweetstorms
|
||||
|
||||
我学习 Glitch 的方式是从这个程序:[https://tweetstorms.glitch.me/][8],它会向你展示给定用户的 tweetstorm。
|
||||
我学习 Glitch 的方式是从这个程序开始的:[https://tweetstorms.glitch.me/][8],它会向你展示给定用户的推特云。
|
||||
|
||||
比如,你可以在 [https://tweetstorms.glitch.me/sarahmei][10] 看到 [@sarahmei][9] 的 tweetstorm(她发布了很多好的 tweetstorm!)。
|
||||
比如,你可以在 [https://tweetstorms.glitch.me/sarahmei][10] 看到 [@sarahmei][9] 的推特云(她发布了很多好的 tweetstorm!)。
|
||||
|
||||
### 我的 Glitch 程序: 关闭转推
|
||||
|
||||
@ -41,11 +38,11 @@ Glitch 似乎是学习编程的好方式!
|
||||
|
||||
我喜欢我不必设置一个本地开发环境,我可以直接开始输入然后开始!
|
||||
|
||||
Glitch 只支持 Javascript,我不非常了解 Javascript(我之前从没写过一个 Node 程序),所以代码不是很好。但是编写它很愉快 - 能够输入并立即看到我的代码运行是令人愉快的。这是我的项目:[https://turn-off-retweets.glitch.me/][11]。
|
||||
Glitch 只支持 Javascript,我不是非常了解 Javascript(我之前从没写过一个 Node 程序),所以代码不是很好。但是编写它很愉快 - 能够输入并立即看到我的代码运行是令人愉快的。这是我的项目:[https://turn-off-retweets.glitch.me/][11]。
|
||||
|
||||
### 就是这些!
|
||||
|
||||
使用 Glitch 感觉真的很有趣和民主。通常情况下,如果我想 fork 某人的 Web 项目,并做出更改,我不会这样做 - 我必须 fork,找一个托管,设置本地开发环境或者 Heroku 或其他,安装依赖项等。我认为像安装 node.js 依赖关系这样的任务过去很有趣,就像“我正在学习新东西很酷”,现在我觉得它们很乏味。
|
||||
使用 Glitch 感觉真的很有趣和民主。通常情况下,如果我想 fork 某人的 Web 项目,并做出更改,我不会这样做 - 我必须 fork,找一个托管,设置本地开发环境或者 Heroku 或其他,安装依赖项等。我认为像安装 node.js 依赖关系这样的任务在过去很有趣,就像“我正在学习新东西很酷”,但现在我觉得它们很乏味。
|
||||
|
||||
所以我喜欢只需点击 “remix this!” 并立即在互联网上能有我的版本。
|
||||
|
||||
@ -53,9 +50,9 @@ Glitch 只支持 Javascript,我不非常了解 Javascript(我之前从没写
|
||||
|
||||
via: https://jvns.ca/blog/2017/11/13/glitch--write-small-web-projects-easily/
|
||||
|
||||
作者:[Julia Evans ][a]
|
||||
作者:[Julia Evans][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,27 +1,22 @@
|
||||
# LibreOffice 现在在 Flatpak 的 Flathub 应用商店提供
|
||||
LibreOffice 上架 Flathub 应用商店
|
||||
===============
|
||||
|
||||

|
||||
|
||||
LibreOffice 现在可以从集中化的 Flatpak 应用商店 [Flathub][3] 进行安装。
|
||||
> LibreOffice 现在可以从集中化的 Flatpak 应用商店 [Flathub][3] 进行安装。
|
||||
|
||||
它的到来使任何运行现代 Linux 发行版的人都能只点击一两次安装 LibreOffice 的最新稳定版本,而无需搜索 PPA,纠缠 tar 包或等待发行商将其打包。
|
||||
它的到来使任何运行现代 Linux 发行版的人都能只点击一两次即可安装 LibreOffice 的最新稳定版本,而无需搜索 PPA,纠缠于 tar 包或等待发行版将其打包。
|
||||
|
||||
自去年 8 月份以来,[LibreOffice Flatpak][5] 已经可供用户下载和安装 [LibreOffice 5.2][6]。
|
||||
自去年 8 月份 [LibreOffice 5.2][6] 发布以来,[LibreOffice Flatpak][5] 已经可供用户下载和安装。
|
||||
|
||||
这里“新”的是发行方法。文档基金会选择使用 Flathub 而不是专门的服务器来发布更新。
|
||||
这里“新”的是指发行方法。<ruby>文档基金会<rt>Document Foundation</rt></ruby>选择使用 Flathub 而不是专门的服务器来发布更新。
|
||||
|
||||
这对于终端用户来说是一个_很好_的消息,因为这意味着不需要在新安装时担心仓库,但对于 Flatpak 的倡议者来说也是一个好消息:LibreOffice 是开源软件最流行的生产力套件。它对格式和应用商店的支持肯定会受到热烈的欢迎。
|
||||
这对于终端用户来说是一个_很好_的消息,因为这意味着不需要在新安装时担心仓库,但对于 Flatpak 的倡议者来说也是一个好消息:LibreOffice 是开源软件里最流行的生产力套件。它对该格式和应用商店的支持肯定会受到热烈的欢迎。
|
||||
|
||||
在撰写本文时,你可以从 Flathub 安装 LibreOffice 5.4.2。新的稳定版本将在发布时添加。
|
||||
|
||||
### 在 Ubuntu 上启用 Flathub
|
||||
|
||||

|
||||
|
||||
Fedora、Arch 和 Linux Mint 18.3 用户已经安装了 Flatpak,随时可以开箱即用。Mint 甚至预启用了 Flathub remote。
|
||||
|
||||
[从 Flathub 安装 LibreOffice][7]
|
||||
|
||||
要在 Ubuntu 上启动并运行 Flatpak,首先必须安装它:
|
||||
|
||||
```
|
||||
@ -34,17 +29,25 @@ sudo apt install flatpak gnome-software-plugin-flatpak
|
||||
flatpak remote-add --if-not-exists flathub https://flathub.org/repo/flathub.flatpakrepo
|
||||
```
|
||||
|
||||
这就行了。只需注销并返回(以便 Ubuntu Software 刷新其缓存),之后你应该能够通过 Ubuntu Software 看到 Flathub 上的任何 Flatpak 程序了。
|
||||
这就行了。只需注销并重新登录(以便 Ubuntu Software 刷新其缓存),之后你应该能够通过 Ubuntu Software 看到 Flathub 上的任何 Flatpak 程序了。
|
||||
|
||||

|
||||
|
||||
*Fedora、Arch 和 Linux Mint 18.3 用户已经安装了 Flatpak,随时可以开箱即用。Mint 甚至预启用了 Flathub remote。*
|
||||
|
||||
在本例中,搜索 “LibreOffice” 并在结果中找到下面有 Flathub 提示的结果。(请记住,Ubuntu 已经调整了客户端,来将 Snap 程序显示在最上面,所以你可能需要向下滚动列表来查看它)。
|
||||
|
||||
### 从 Flathub 安装 LibreOffice
|
||||
|
||||
- [从 Flathub 安装 LibreOffice][7]
|
||||
|
||||
从 flatpakref 中[安装 Flatpak 程序有一个 bug][8],所以如果上面的方法不起作用,你也可以使用命令行从 Flathub 中安装 Flathub 程序。
|
||||
|
||||
Flathub 网站列出了安装每个程序所需的命令。切换到“命令行”选项卡来查看它们。
|
||||
|
||||
#### Flathub 上更多的应用
|
||||
### Flathub 上更多的应用
|
||||
|
||||
如果你经常看这个网站,你就会知道我喜欢 Flathub。这是我最喜欢的一些应用(Corebird、Parlatype、GNOME MPV、Peek、Audacity、GIMP 等)的家园。我无需折衷就能获得这些应用程序的最新,稳定版本(加上它们需要的所有依赖)。
|
||||
如果你经常看这个网站,你就会知道我喜欢 Flathub。这是我最喜欢的一些应用(Corebird、Parlatype、GNOME MPV、Peek、Audacity、GIMP 等)的家园。我无需等待就能获得这些应用程序的最新、稳定版本(加上它们需要的所有依赖)。
|
||||
|
||||
而且,在我 twiiter 上发布一周左右后,大多数 Flatpak 应用现在看起来有很棒 GTK 主题 - 不再需要[临时方案][9]了!
|
||||
|
||||
@ -52,9 +55,9 @@ Flathub 网站列出了安装每个程序所需的命令。切换到“命令行
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2017/11/libreoffice-now-available-flathub-flatpak-app-store
|
||||
|
||||
作者:[ JOEY SNEDDON ][a]
|
||||
作者:[JOEY SNEDDON][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,127 @@
|
||||
Suplemon:带有多光标支持的现代 CLI 文本编辑器
|
||||
======
|
||||
|
||||
Suplemon 是一个 CLI 中的现代文本编辑器,它模拟 [Sublime Text][1] 的多光标行为和其它特性。它是轻量级的,非常易于使用,就像 Nano 一样。
|
||||
|
||||
使用 CLI 编辑器的好处之一是,无论你使用的 Linux 发行版是否有 GUI,你都可以使用它。这种文本编辑器也很简单、快速和强大。
|
||||
|
||||
你可以在其[官方仓库][2]中找到有用的信息和源代码。
|
||||
|
||||
### 功能
|
||||
|
||||
这些是一些它有趣的功能:
|
||||
|
||||
* 多光标支持
|
||||
* 撤销/重做
|
||||
* 复制和粘贴,带有多行支持
|
||||
* 鼠标支持
|
||||
* 扩展
|
||||
* 查找、查找所有、查找下一个
|
||||
* 语法高亮
|
||||
* 自动完成
|
||||
* 自定义键盘快捷键
|
||||
|
||||
### 安装
|
||||
|
||||
首先,确保安装了最新版本的 python3 和 pip3。
|
||||
|
||||
然后在终端输入:
|
||||
|
||||
```
|
||||
$ sudo pip3 install suplemon
|
||||
```
|
||||
|
||||
### 使用
|
||||
|
||||
#### 在当前目录中创建一个新文件
|
||||
|
||||
打开一个终端并输入:
|
||||
|
||||
```
|
||||
$ suplemon
|
||||
```
|
||||
|
||||
你将看到如下:
|
||||
|
||||

|
||||
|
||||
#### 打开一个或多个文件
|
||||
|
||||
打开一个终端并输入:
|
||||
|
||||
```
|
||||
$ suplemon <filename1> <filename2> ... <filenameN>
|
||||
```
|
||||
|
||||
例如:
|
||||
|
||||
```
|
||||
$ suplemon example1.c example2.c
|
||||
```
|
||||
|
||||
### 主要配置
|
||||
|
||||
你可以在 `~/.config/suplemon/suplemon-config.json` 找到配置文件。
|
||||
|
||||
编辑这个文件很简单,你只需要进入命令模式(进入 suplemon 后)并运行 `config` 命令。你可以通过运行 `config defaults` 来查看默认配置。
|
||||
|
||||
#### 键盘映射配置
|
||||
|
||||
我会展示 suplemon 的默认键映射。如果你想编辑它们,只需运行 `keymap` 命令。运行 `keymap default` 来查看默认的键盘映射文件。
|
||||
|
||||
| 操作 | 快捷键 |
|
||||
| ---- | ---- |
|
||||
| 退出| `Ctrl + Q`|
|
||||
| 复制行到缓冲区|`Ctrl + C`|
|
||||
| 剪切行缓冲区| `Ctrl + X`|
|
||||
| 插入缓冲区| `Ctrl + V`|
|
||||
| 复制行| `Ctrl + K`|
|
||||
| 跳转| `Ctrl + G`。 你可以跳转到一行或一个文件(只需键入一个文件名的开头)。另外,可以输入类似于 `exam:50` 跳转到 `example.c` 第 `50` 行。|
|
||||
| 用字符串或正则表达式搜索| `Ctrl + F`|
|
||||
| 搜索下一个| `Ctrl + D`|
|
||||
| 去除空格| `Ctrl + T`|
|
||||
| 在箭头方向添加新的光标| `Alt + 方向键`|
|
||||
| 跳转到上一个或下一个单词或行| `Ctrl + 左/右`|
|
||||
| 恢复到单光标/取消输入提示| `Esc`|
|
||||
| 向上/向下移动行| `Page Up` / `Page Down`|
|
||||
| 保存文件|`Ctrl + S`|
|
||||
| 用新名称保存文件|`F1`|
|
||||
| 重新载入当前文件|`F2`|
|
||||
| 打开文件|`Ctrl + O`|
|
||||
| 关闭文件|`Ctrl + W`|
|
||||
| 切换到下一个/上一个文件|`Ctrl + Page Up` / `Ctrl + Page Down`|
|
||||
| 运行一个命令|`Ctrl + E`|
|
||||
| 撤消|`Ctrl + Z`|
|
||||
| 重做|`Ctrl + Y`|
|
||||
| 触发可见的空格|`F7`|
|
||||
| 切换鼠标模式|`F8`|
|
||||
| 显示行号|`F9`|
|
||||
| 显示全屏|`F11`|
|
||||
|
||||
|
||||
|
||||
#### 鼠标快捷键
|
||||
|
||||
* 将光标置于指针位置:左键单击
|
||||
* 在指针位置添加一个光标:右键单击
|
||||
* 垂直滚动:向上/向下滚动滚轮
|
||||
|
||||
### 总结
|
||||
|
||||
在尝试 Suplemon 一段时间后,我改变了对 CLI 文本编辑器的看法。我以前曾经尝试过 Nano,是的,我喜欢它的简单性,但是它的现代特征的缺乏使它在日常使用中变得不实用。
|
||||
|
||||
这个工具有 CLI 和 GUI 世界最好的东西……简单性和功能丰富!所以我建议你试试看,并在评论中写下你的想法 :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linoxide.com/tools/suplemon-cli-text-editor-multi-cursor/
|
||||
|
||||
作者:[Ivo Ursino][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linoxide.com/author/ursinov/
|
||||
[1]:https://linoxide.com/tools/install-sublime-text-editor-linux/
|
||||
[2]:https://github.com/richrd/suplemon/
|
||||
@ -1,50 +1,31 @@
|
||||
translating by yongshouzhang
|
||||
|
||||
|
||||
7个 Linux 下使用 bcc/BPF 的性能分析工具
|
||||
7 个使用 bcc/BPF 的性能分析神器
|
||||
============================================================
|
||||
|
||||
###使用伯克利的包过滤(BPF)编译器集合(BCC)工具深度探查你的 linux 代码。
|
||||
> 使用<ruby>伯克利包过滤器<rt>Berkeley Packet Filter</rt></ruby>(BPF)<ruby>编译器集合<rt>Compiler Collection</rt></ruby>(BCC)工具深度探查你的 linux 代码。
|
||||
|
||||
[][7] 21 Nov 2017 [Brendan Gregg][8] [Feed][9]
|
||||
|
||||
43[up][10]
|
||||
|
||||
[4 comments][11]
|
||||

|
||||
|
||||
图片来源 :
|
||||
在 Linux 中出现的一种新技术能够为系统管理员和开发者提供大量用于性能分析和故障排除的新工具和仪表盘。它被称为<ruby>增强的伯克利数据包过滤器<rt>enhanced Berkeley Packet Filter</rt></ruby>(eBPF,或 BPF),虽然这些改进并不是由伯克利开发的,而且它们不仅仅是处理数据包,更多的是过滤。我将讨论在 Fedora 和 Red Hat Linux 发行版中使用 BPF 的一种方法,并在 Fedora 26 上演示。
|
||||
|
||||
opensource.com
|
||||
BPF 可以在内核中运行由用户定义的沙盒程序,可以立即添加新的自定义功能。这就像按需给 Linux 系统添加超能力一般。 你可以使用它的例子包括如下:
|
||||
|
||||
在 linux 中出现的一种新技术能够为系统管理员和开发者提供大量用于性能分析和故障排除的新工具和仪表盘。 它被称为增强的伯克利数据包过滤器(eBPF,或BPF),虽然这些改进并不由伯克利开发,它们不仅仅是处理数据包,更多的是过滤。我将讨论在 Fedora 和 Red Hat Linux 发行版中使用 BPF 的一种方法,并在 Fedora 26 上演示。
|
||||
* **高级性能跟踪工具**:对文件系统操作、TCP 事件、用户级事件等的可编程的低开销检测。
|
||||
* **网络性能**: 尽早丢弃数据包以提高对 DDoS 的恢复能力,或者在内核中重定向数据包以提高性能。
|
||||
* **安全监控**: 7x24 小时的自定义检测和记录内核空间与用户空间内的可疑事件。
|
||||
|
||||
BPF 可以在内核中运行用户定义的沙盒程序,以立即添加新的自定义功能。这就像可按需给 Linux 系统添加超能力一般。 你可以使用它的例子包括如下:
|
||||
|
||||
* 高级性能跟踪工具:文件系统操作、TCP事件、用户级事件等的编程低开销检测。
|
||||
|
||||
* 网络性能 : 尽早丢弃数据包以提高DDoS的恢复能力,或者在内核中重定向数据包以提高性能。
|
||||
|
||||
* 安全监控 : 24x7 小时全天候自定义检测和记录内核空间与用户空间内的可疑事件。
|
||||
|
||||
在可能的情况下,BPF 程序必须通过一个内核验证机制来保证它们的安全运行,这比写自定义的内核模块更安全。我在此假设大多数人并不编写自己的 BPF 程序,而是使用别人写好的。在 GitHub 上的 [BPF Compiler Collection (bcc)][12] 项目中,我已发布许多开源代码。bcc 提供不同的 BPF 开发前端支持,包括Python和Lua,并且是目前最活跃的 BPF 模具项目。
|
||||
在可能的情况下,BPF 程序必须通过一个内核验证机制来保证它们的安全运行,这比写自定义的内核模块更安全。我在此假设大多数人并不编写自己的 BPF 程序,而是使用别人写好的。在 GitHub 上的 [BPF Compiler Collection (bcc)][12] 项目中,我已发布许多开源代码。bcc 为 BPF 开发提供了不同的前端支持,包括 Python 和 Lua,并且是目前最活跃的 BPF 工具项目。
|
||||
|
||||
### 7 个有用的 bcc/BPF 新工具
|
||||
|
||||
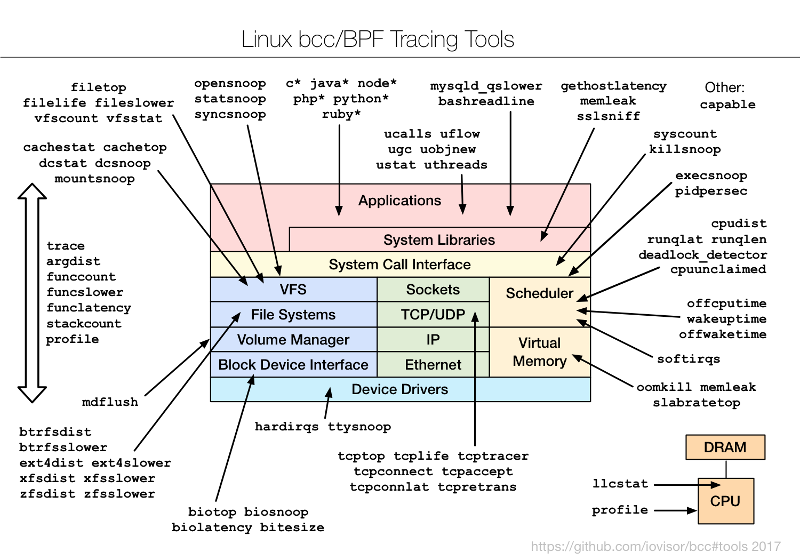
为了了解BCC / BPF工具和他们的乐器,我创建了下面的图表并添加到项目中
|
||||
To understand the bcc/BPF tools and what they instrument, I created the following diagram and added it to the bcc project:
|
||||
|
||||
### [bcc_跟踪工具.png][13]
|
||||
为了了解 bcc/BPF 工具和它们的检测内容,我创建了下面的图表并添加到 bcc 项目中。
|
||||
|
||||
|
||||
|
||||
Brendan Gregg, [CC BY-SA 4.0][14]
|
||||
这些是命令行界面工具,你可以通过 SSH 使用它们。目前大多数分析,包括我的老板,都是用 GUI 和仪表盘进行的。SSH 是最后的手段。但这些命令行工具仍然是预览 BPF 能力的好方法,即使你最终打算通过一个可用的 GUI 使用它。我已着手向一个开源 GUI 添加 BPF 功能,但那是另一篇文章的主题。现在我想向你分享今天就可以使用的 CLI 工具。
|
||||
|
||||
这些是命令行界面工具,你可以通过 SSH (安全外壳)使用它们。目前大多数分析,包括我的老板,是用 GUIs 和仪表盘进行的。SSH是最后的手段。但这些命令行工具仍然是预览BPF能力的好方法,即使你最终打算通过一个可用的 GUI 使用它。我已着手向一个开源 GUI 添加BPF功能,但那是另一篇文章的主题。现在我想分享你今天可以使用的 CLI 工具。
|
||||
#### 1、 execsnoop
|
||||
|
||||
### 1\. execsnoop
|
||||
|
||||
从哪儿开始? 如何查看新的进程。这些可以消耗系统资源,但很短暂,它们不会出现在 top(1)命令或其他工具中。 这些新进程可以使用[execsnoop] [15]进行检测(或使用行业术语,可以追踪)。 在追踪时,我将在另一个窗口中通过 SSH 登录:
|
||||
从哪儿开始呢?如何查看新的进程。那些会消耗系统资源,但很短暂的进程,它们甚至不会出现在 `top(1)` 命令或其它工具中的显示之中。这些新进程可以使用 [execsnoop][15] 进行检测(或使用行业术语说,可以<ruby>被追踪<rt>traced</rt></ruby>)。 在追踪时,我将在另一个窗口中通过 SSH 登录:
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/execsnoop
|
||||
@ -67,13 +48,14 @@ grep 12255 12254 0 /usr/bin/grep -qsi ^COLOR.*none /etc/GREP_COL
|
||||
grepconf.sh 12256 12239 0 /usr/libexec/grepconf.sh -c
|
||||
grep 12257 12256 0 /usr/bin/grep -qsi ^COLOR.*none /etc/GREP_COLORS
|
||||
```
|
||||
哇。 那是什么? 什么是grepconf.sh? 什么是 /etc/GREP_COLORS? 而且 grep通过运行自身阅读它自己的配置文件? 这甚至是如何工作的?
|
||||
|
||||
欢迎来到有趣的系统追踪世界。 你可以学到很多关于系统是如何工作的(或者一些情况下根本不工作),并且发现一些简单的优化。 execsnoop 通过跟踪 exec()系统调用来工作,exec() 通常用于在新进程中加载不同的程序代码。
|
||||
哇哦。 那是什么? 什么是 `grepconf.sh`? 什么是 `/etc/GREP_COLORS`? 是 `grep` 在读取它自己的配置文件……由 `grep` 运行的? 这究竟是怎么工作的?
|
||||
|
||||
### 2\. opensnoop
|
||||
欢迎来到有趣的系统追踪世界。 你可以学到很多关于系统是如何工作的(或者根本不工作,在有些情况下),并且发现一些简单的优化方法。 `execsnoop` 通过跟踪 `exec()` 系统调用来工作,`exec()` 通常用于在新进程中加载不同的程序代码。
|
||||
|
||||
从上面继续,所以,grepconf.sh可能是一个shell脚本,对吧? 我将运行file(1)来检查,并使用[opensnoop][16] bcc 工具来查看打开的文件:
|
||||
#### 2、 opensnoop
|
||||
|
||||
接着上面继续,所以,`grepconf.sh` 可能是一个 shell 脚本,对吧? 我将运行 `file(1)` 来检查它,并使用[opensnoop][16] bcc 工具来查看打开的文件:
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/opensnoop
|
||||
@ -91,18 +73,20 @@ PID COMM FD ERR PATH
|
||||
1 systemd 16 0 /proc/565/cgroup
|
||||
1 systemd 16 0 /proc/536/cgroup
|
||||
```
|
||||
像execsnoop和opensnoop这样的工具每个事件打印一行。上图显示 file(1)命令当前打开(或尝试打开)的文件:返回的文件描述符(“FD”列)对于 /etc/magic.mgc 是-1,而“ERR”列指示它是“文件未找到”。我不知道该文件,也不知道 file(1)正在读取的 /usr/share/misc/magic.mgc 文件。我不应该感到惊讶,但是 file(1)在识别文件类型时没有问题:
|
||||
|
||||
像 `execsnoop` 和 `opensnoop` 这样的工具会将每个事件打印一行。上图显示 `file(1)` 命令当前打开(或尝试打开)的文件:返回的文件描述符(“FD” 列)对于 `/etc/magic.mgc` 是 -1,而 “ERR” 列指示它是“文件未找到”。我不知道该文件,也不知道 `file(1)` 正在读取的 `/usr/share/misc/magic.mgc` 文件是什么。我不应该感到惊讶,但是 `file(1)` 在识别文件类型时没有问题:
|
||||
|
||||
```
|
||||
# file /usr/share/misc/magic.mgc /etc/magic
|
||||
/usr/share/misc/magic.mgc: magic binary file for file(1) cmd (version 14) (little endian)
|
||||
/etc/magic: magic text file for file(1) cmd, ASCII text
|
||||
```
|
||||
opensnoop通过跟踪 open()系统调用来工作。为什么不使用 strace -feopen file 命令呢? 这将在这种情况下起作用。然而,opensnoop 的一些优点在于它能在系统范围内工作,并且跟踪所有进程的 open()系统调用。注意上例的输出中包括了从systemd打开的文件。Opensnoop 也应该有更低的开销:BPF 跟踪已经被优化,并且当前版本的 strace(1)仍然使用较老和较慢的 ptrace(2)接口。
|
||||
|
||||
### 3\. xfsslower
|
||||
`opensnoop` 通过跟踪 `open()` 系统调用来工作。为什么不使用 `strace -feopen file` 命令呢? 在这种情况下是可以的。然而,`opensnoop` 的一些优点在于它能在系统范围内工作,并且跟踪所有进程的 `open()` 系统调用。注意上例的输出中包括了从 systemd 打开的文件。`opensnoop` 应该系统开销更低:BPF 跟踪已经被优化过,而当前版本的 `strace(1)` 仍然使用较老和较慢的 `ptrace(2)` 接口。
|
||||
|
||||
bcc/BPF 不仅仅可以分析系统调用。[xfsslower][17] 工具跟踪具有大于1毫秒(参数)延迟的常见XFS文件系统操作。
|
||||
#### 3、 xfsslower
|
||||
|
||||
bcc/BPF 不仅仅可以分析系统调用。[xfsslower][17] 工具可以跟踪大于 1 毫秒(参数)延迟的常见 XFS 文件系统操作。
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/xfsslower 1
|
||||
@ -119,15 +103,16 @@ TIME COMM PID T BYTES OFF_KB LAT(ms) FILENAME
|
||||
14:17:46 cksum 4168 R 65536 128 1.01 grub2-fstest
|
||||
[...]
|
||||
```
|
||||
在上图输出中,我捕获了多个延迟超过 1 毫秒 的 cksum(1)读数(字段“T”等于“R”)。这个工作是在 xfsslower 工具运行的时候,通过在 XFS 中动态地设置内核函数实现,当它结束的时候解除检测。其他文件系统也有这个 bcc 工具的版本:ext4slower,btrfsslower,zfsslower 和 nfsslower。
|
||||
|
||||
这是个有用的工具,也是 BPF 追踪的重要例子。对文件系统性能的传统分析主要集中在块 I/O 统计信息 - 通常你看到的是由 iostat(1)工具打印并由许多性能监视 GUI 绘制的图表。这些统计数据显示了磁盘如何执行,但不是真正的文件系统。通常比起磁盘你更关心文件系统的性能,因为应用程序是在文件系统中发起请求和等待。并且文件系统的性能可能与磁盘的性能大为不同!文件系统可以完全从内存缓存中读取数据,也可以通过预读算法和回写缓存填充缓存。xfsslower 显示了文件系统的性能 - 应用程序直接体验到什么。这对于免除整个存储子系统通常是有用的; 如果确实没有文件系统延迟,那么性能问题很可能在别处。
|
||||
在上图输出中,我捕获到了多个延迟超过 1 毫秒 的 `cksum(1)` 读取操作(字段 “T” 等于 “R”)。这是在 `xfsslower` 工具运行的时候,通过在 XFS 中动态地检测内核函数实现的,并当它结束的时候解除该检测。这个 bcc 工具也有其它文件系统的版本:`ext4slower`、`btrfsslower`、`zfsslower` 和 `nfsslower`。
|
||||
|
||||
### 4\. biolatency
|
||||
这是个有用的工具,也是 BPF 追踪的重要例子。对文件系统性能的传统分析主要集中在块 I/O 统计信息 —— 通常你看到的是由 `iostat(1)` 工具输出,并由许多性能监视 GUI 绘制的图表。这些统计数据显示的是磁盘如何执行,而不是真正的文件系统如何执行。通常比起磁盘来说,你更关心的是文件系统的性能,因为应用程序是在文件系统中发起请求和等待。并且,文件系统的性能可能与磁盘的性能大为不同!文件系统可以完全从内存缓存中读取数据,也可以通过预读算法和回写缓存来填充缓存。`xfsslower` 显示了文件系统的性能 —— 这是应用程序直接体验到的性能。通常这对于排除整个存储子系统的问题是有用的;如果确实没有文件系统延迟,那么性能问题很可能是在别处。
|
||||
|
||||
虽然文件系统性能对于理解应用程序性能非常重要,但研究磁盘性能也是有好处的。当各种缓存技巧不能再隐藏其延迟时,磁盘的低性能终会影响应用程序。 磁盘性能也是容量规划研究的目标。
|
||||
#### 4、 biolatency
|
||||
|
||||
iostat(1)工具显示平均磁盘 I/O 延迟,但平均值可能会引起误解。 以直方图的形式研究 I/O 延迟的分布是有用的,这可以通过使用 [biolatency] 来实现[18]:
|
||||
虽然文件系统性能对于理解应用程序性能非常重要,但研究磁盘性能也是有好处的。当各种缓存技巧都无法挽救其延迟时,磁盘的低性能终会影响应用程序。 磁盘性能也是容量规划研究的目标。
|
||||
|
||||
`iostat(1)` 工具显示了平均磁盘 I/O 延迟,但平均值可能会引起误解。 以直方图的形式研究 I/O 延迟的分布是有用的,这可以通过使用 [biolatency] 来实现[18]:
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/biolatency
|
||||
@ -147,9 +132,10 @@ Tracing block device I/O... Hit Ctrl-C to end.
|
||||
1024 -> 2047 : 117 |******** |
|
||||
2048 -> 4095 : 8 | |
|
||||
```
|
||||
这是另一个有用的工具和例子; 它使用一个名为maps的BPF特性,它可以用来实现高效的内核内摘要统计。从内核级别到用户级别的数据传输仅仅是“计数”列。 用户级程序生成其余的。
|
||||
|
||||
值得注意的是,其中许多工具支持CLI选项和参数,如其使用信息所示:
|
||||
这是另一个有用的工具和例子;它使用一个名为 maps 的 BPF 特性,它可以用来实现高效的内核摘要统计。从内核层到用户层的数据传输仅仅是“计数”列。 用户级程序生成其余的。
|
||||
|
||||
值得注意的是,这种工具大多支持 CLI 选项和参数,如其使用信息所示:
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/biolatency -h
|
||||
@ -175,11 +161,12 @@ examples:
|
||||
./biolatency -Q # include OS queued time in I/O time
|
||||
./biolatency -D # show each disk device separately
|
||||
```
|
||||
它们的行为像其他Unix工具是通过设计,以协助采用。
|
||||
|
||||
### 5\. tcplife
|
||||
它们的行为就像其它 Unix 工具一样,以利于采用而设计。
|
||||
|
||||
另一个有用的工具是[tcplife][19] ,该例显示TCP会话的生命周期和吞吐量统计
|
||||
#### 5、 tcplife
|
||||
|
||||
另一个有用的工具是 [tcplife][19] ,该例显示 TCP 会话的生命周期和吞吐量统计。
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/tcplife
|
||||
@ -189,11 +176,12 @@ PID COMM LADDR LPORT RADDR RPORT TX_KB RX_KB MS
|
||||
12844 wget 10.0.2.15 34250 54.204.39.132 443 11 1870 5712.26
|
||||
12851 curl 10.0.2.15 34252 54.204.39.132 443 0 74 505.90
|
||||
```
|
||||
在你说:“我不能只是刮 tcpdump(8)输出这个?”之前请注意,运行 tcpdump(8)或任何数据包嗅探器,在高数据包速率系统上花费的开销会很大,即使tcpdump(8)的用户级和内核级机制已经过多年优化(可能更差)。tcplife不会测试每个数据包; 它只会监视TCP会话状态的变化,从而影响会话的持续时间。它还使用已经跟踪吞吐量的内核计数器,以及处理和命令信息(“PID”和“COMM”列),这些对 tcpdump(8)等线上嗅探工具是做不到的。
|
||||
|
||||
### 6\. gethostlatency
|
||||
在你说 “我不是可以只通过 `tcpdump(8)` 就能输出这个?” 之前请注意,运行 `tcpdump(8)` 或任何数据包嗅探器,在高数据包速率的系统上的开销会很大,即使 `tcpdump(8)` 的用户层和内核层机制已经过多年优化(要不可能更差)。`tcplife` 不会测试每个数据包;它只会有效地监视 TCP 会话状态的变化,并由此得到该会话的持续时间。它还使用已经跟踪了吞吐量的内核计数器,以及进程和命令信息(“PID” 和 “COMM” 列),这些对于 `tcpdump(8)` 等线上嗅探工具是做不到的。
|
||||
|
||||
之前的每个例子都涉及到内核跟踪,所以我至少需要一个用户级跟踪的例子。 这是[gethostlatency] [20],其中gethostbyname(3)和相关的库调用名称解析:
|
||||
#### 6、 gethostlatency
|
||||
|
||||
之前的每个例子都涉及到内核跟踪,所以我至少需要一个用户级跟踪的例子。 这就是 [gethostlatency][20],它检测用于名称解析的 `gethostbyname(3)` 和相关的库调用:
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/gethostlatency
|
||||
@ -207,24 +195,26 @@ TIME PID COMM LATms HOST
|
||||
06:45:07 12952 curl 13.64 opensource.cats
|
||||
06:45:19 13139 curl 13.10 opensource.cats
|
||||
```
|
||||
是的,它始终是DNS,所以有一个工具来监视系统范围内的DNS请求可以很方便(这只有在应用程序使用标准系统库时才有效)看看我如何跟踪多个查找“opensource.com”? 第一个是188.98毫秒,然后是更快,不到10毫秒,毫无疑问,缓存的作用。它还追踪多个查找“opensource.cats”,一个可悲的不存在的主机,但我们仍然可以检查第一个和后续查找的延迟。 (第二次查找后是否有一点负面缓存?)
|
||||
|
||||
### 7\. trace
|
||||
是的,总是有 DNS 请求,所以有一个工具来监视系统范围内的 DNS 请求会很方便(这只有在应用程序使用标准系统库时才有效)。看看我如何跟踪多个对 “opensource.com” 的查找? 第一个是 188.98 毫秒,然后更快,不到 10 毫秒,毫无疑问,这是缓存的作用。它还追踪多个对 “opensource.cats” 的查找,一个不存在的可怜主机名,但我们仍然可以检查第一个和后续查找的延迟。(第二次查找后是否有一些否定缓存的影响?)
|
||||
|
||||
好的,再举一个例子。 [trace] [21]工具由Sasha Goldshtein提供,并提供了一些基本的printf(1)功能和自定义探针。 例如:
|
||||
#### 7、 trace
|
||||
|
||||
好的,再举一个例子。 [trace][21] 工具由 Sasha Goldshtein 提供,并提供了一些基本的 `printf(1)` 功能和自定义探针。 例如:
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/trace 'pam:pam_start "%s: %s", arg1, arg2'
|
||||
PID TID COMM FUNC -
|
||||
13266 13266 sshd pam_start sshd: root
|
||||
```
|
||||
在这里,我正在跟踪 libpam 及其 pam_start(3)函数并将其两个参数都打印为字符串。 Libpam 用于可插入的身份验证模块系统,输出显示 sshd 为“root”用户(我登录)调用了 pam_start()。 USAGE消息中有更多的例子(“trace -h”),而且所有这些工具在bcc版本库中都有手册页和示例文件。 例如trace_example.txt和trace.8。
|
||||
|
||||
在这里,我正在跟踪 `libpam` 及其 `pam_start(3)` 函数,并将其两个参数都打印为字符串。 `libpam` 用于插入式身份验证模块系统,该输出显示 sshd 为 “root” 用户调用了 `pam_start()`(我登录了)。 其使用信息中有更多的例子(`trace -h`),而且所有这些工具在 bcc 版本库中都有手册页和示例文件。 例如 `trace_example.txt` 和 `trace.8`。
|
||||
|
||||
### 通过包安装 bcc
|
||||
|
||||
安装 bcc 最佳的方法是从 iovisor 仓储库中安装,按照 bcc [INSTALL.md][22]。[IO Visor] [23]是包含 bcc 的Linux基金会项目。4.x系列Linux内核中增加了这些工具使用的BPF增强功能,上至4.9 \。这意味着拥有4.8内核的 Fedora 25可以运行大部分这些工具。 Fedora 26及其4.11内核可以运行它们(至少目前)。
|
||||
安装 bcc 最佳的方法是从 iovisor 仓储库中安装,按照 bcc 的 [INSTALL.md][22] 进行即可。[IO Visor][23] 是包括了 bcc 的 Linux 基金会项目。4.x 系列 Linux 内核中增加了这些工具所使用的 BPF 增强功能,直到 4.9 添加了全部支持。这意味着拥有 4.8 内核的 Fedora 25 可以运行这些工具中的大部分。 使用 4.11 内核的 Fedora 26 可以全部运行它们(至少在目前是这样)。
|
||||
|
||||
如果你使用的是Fedora 25(或者Fedora 26,而且这个帖子已经在很多个月前发布了 - 你好,来自遥远的过去!),那么这个包的方法应该是正常的。 如果您使用的是Fedora 26,那么请跳至“通过源代码安装”部分,该部分避免了已知的固定错误。 这个错误修复目前还没有进入Fedora 26软件包的依赖关系。 我使用的系统是:
|
||||
如果你使用的是 Fedora 25(或者 Fedora 26,而且这个帖子已经在很多个月前发布了 —— 你好,来自遥远的过去!),那么这个通过包安装的方式是可以工作的。 如果您使用的是 Fedora 26,那么请跳至“通过源代码安装”部分,它避免了一个[已修复的][26]的[已知][25]错误。 这个错误修复目前还没有进入 Fedora 26 软件包的依赖关系。 我使用的系统是:
|
||||
|
||||
```
|
||||
# uname -a
|
||||
@ -232,7 +222,8 @@ Linux localhost.localdomain 4.11.8-300.fc26.x86_64 #1 SMP Thu Jun 29 20:09:48 UT
|
||||
# cat /etc/fedora-release
|
||||
Fedora release 26 (Twenty Six)
|
||||
```
|
||||
以下是我所遵循的安装步骤,但请参阅INSTALL.md获取更新的版本:
|
||||
|
||||
以下是我所遵循的安装步骤,但请参阅 INSTALL.md 获取更新的版本:
|
||||
|
||||
```
|
||||
# echo -e '[iovisor]\nbaseurl=https://repo.iovisor.org/yum/nightly/f25/$basearch\nenabled=1\ngpgcheck=0' | sudo tee /etc/yum.repos.d/iovisor.repo
|
||||
@ -242,7 +233,8 @@ Total download size: 37 M
|
||||
Installed size: 143 M
|
||||
Is this ok [y/N]: y
|
||||
```
|
||||
安装完成后,您可以在/ usr / share中看到新的工具:
|
||||
|
||||
安装完成后,您可以在 `/usr/share` 中看到新的工具:
|
||||
|
||||
```
|
||||
# ls /usr/share/bcc/tools/
|
||||
@ -250,6 +242,7 @@ argdist dcsnoop killsnoop softirqs trace
|
||||
bashreadline dcstat llcstat solisten ttysnoop
|
||||
[...]
|
||||
```
|
||||
|
||||
试着运行其中一个:
|
||||
|
||||
```
|
||||
@ -262,7 +255,8 @@ Traceback (most recent call last):
|
||||
raise Exception("Failed to compile BPF module %s" % src_file)
|
||||
Exception: Failed to compile BPF module
|
||||
```
|
||||
运行失败,提示/lib/modules/4.11.8-300.fc26.x86_64/build丢失。 如果你也这样做,那只是因为系统缺少内核头文件。 如果你看看这个文件指向什么(这是一个符号链接),然后使用“dnf whatprovides”来搜索它,它会告诉你接下来需要安装的包。 对于这个系统,它是:
|
||||
|
||||
运行失败,提示 `/lib/modules/4.11.8-300.fc26.x86_64/build` 丢失。 如果你也遇到这个问题,那只是因为系统缺少内核头文件。 如果你看看这个文件指向什么(这是一个符号链接),然后使用 `dnf whatprovides` 来搜索它,它会告诉你接下来需要安装的包。 对于这个系统,它是:
|
||||
|
||||
```
|
||||
# dnf install kernel-devel-4.11.8-300.fc26.x86_64
|
||||
@ -272,7 +266,8 @@ Installed size: 63 M
|
||||
Is this ok [y/N]: y
|
||||
[...]
|
||||
```
|
||||
现在
|
||||
|
||||
现在:
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/opensnoop
|
||||
@ -283,11 +278,12 @@ PID COMM FD ERR PATH
|
||||
11792 ls 3 0 /lib64/libc.so.6
|
||||
[...]
|
||||
```
|
||||
运行起来了。 这是从另一个窗口中的ls命令捕捉活动。 请参阅前面的部分以获取其他有用的命令
|
||||
|
||||
运行起来了。 这是捕获自另一个窗口中的 ls 命令活动。 请参阅前面的部分以使用其它有用的命令。
|
||||
|
||||
### 通过源码安装
|
||||
|
||||
如果您需要从源代码安装,您还可以在[INSTALL.md] [27]中找到文档和更新说明。 我在Fedora 26上做了如下的事情:
|
||||
如果您需要从源代码安装,您还可以在 [INSTALL.md][27] 中找到文档和更新说明。 我在 Fedora 26 上做了如下的事情:
|
||||
|
||||
```
|
||||
sudo dnf install -y bison cmake ethtool flex git iperf libstdc++-static \
|
||||
@ -299,16 +295,16 @@ sudo dnf install -y \
|
||||
sudo pip install pyroute2
|
||||
sudo dnf install -y clang clang-devel llvm llvm-devel llvm-static ncurses-devel
|
||||
```
|
||||
除 netperf 外一切妥当,其中有以下错误:
|
||||
|
||||
除 `netperf` 外一切妥当,其中有以下错误:
|
||||
|
||||
```
|
||||
Curl error (28): Timeout was reached for http://pkgs.repoforge.org/netperf/netperf-2.6.0-1.el6.rf.x86_64.rpm [Connection timed out after 120002 milliseconds]
|
||||
```
|
||||
|
||||
不必理会,netperf是可选的 - 它只是用于测试 - 而 bcc 没有它也会编译成功。
|
||||
|
||||
以下是 bcc 编译和安装余下的步骤:
|
||||
不必理会,`netperf` 是可选的,它只是用于测试,而 bcc 没有它也会编译成功。
|
||||
|
||||
以下是余下的 bcc 编译和安装步骤:
|
||||
|
||||
```
|
||||
git clone https://github.com/iovisor/bcc.git
|
||||
@ -317,7 +313,8 @@ cmake .. -DCMAKE_INSTALL_PREFIX=/usr
|
||||
make
|
||||
sudo make install
|
||||
```
|
||||
在这一点上,命令应该起作用:
|
||||
|
||||
现在,命令应该可以工作了:
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/opensnoop
|
||||
@ -329,53 +326,35 @@ PID COMM FD ERR PATH
|
||||
[...]
|
||||
```
|
||||
|
||||
More Linux resources
|
||||
### 写在最后和其他的前端
|
||||
|
||||
* [What is Linux?][1]
|
||||
这是一个可以在 Fedora 和 Red Hat 系列操作系统上使用的新 BPF 性能分析强大功能的快速浏览。我演示了 BPF 的流行前端 [bcc][28] ,并包括了其在 Fedora 上的安装说明。bcc 附带了 60 多个用于性能分析的新工具,这将帮助您充分利用 Linux 系统。也许你会直接通过 SSH 使用这些工具,或者一旦 GUI 监控程序支持 BPF 的话,你也可以通过它们来使用相同的功能。
|
||||
|
||||
* [What are Linux containers?][2]
|
||||
此外,bcc 并不是正在开发的唯一前端。[ply][29] 和 [bpftrace][30],旨在为快速编写自定义工具提供更高级的语言支持。此外,[SystemTap][31] 刚刚发布[版本3.2][32],包括一个早期的实验性 eBPF 后端。 如果这个继续开发,它将为运行多年来开发的许多 SystemTap 脚本和 tapset(库)提供一个安全和高效的生产级引擎。(随同 eBPF 使用 SystemTap 将是另一篇文章的主题。)
|
||||
|
||||
* [Download Now: Linux commands cheat sheet][3]
|
||||
|
||||
* [Advanced Linux commands cheat sheet][4]
|
||||
|
||||
* [Our latest Linux articles][5]
|
||||
|
||||
### 写在最后和其他前端
|
||||
|
||||
这是一个可以在 Fedora 和 Red Hat 系列操作系统上使用的新 BPF 性能分析强大功能的快速浏览。我演示了BPF的流行前端 [bcc][28] ,并包含了其在 Fedora 上的安装说明。bcc 附带了60多个用于性能分析的新工具,这将帮助您充分利用Linux系统。也许你会直接通过SSH使用这些工具,或者一旦它们支持BPF,你也可以通过监视GUI来使用相同的功能。
|
||||
|
||||
此外,bcc并不是开发中唯一的前端。[ply][29]和[bpftrace][30],旨在为快速编写自定义工具提供更高级的语言。此外,[SystemTap] [31]刚刚发布[版本3.2] [32],包括一个早期的实验性eBPF后端。 如果这一点继续得到发展,它将为运行多年来开发的许多SystemTap脚本和攻击集(库)提供一个生产安全和高效的引擎。 (使用SystemTap和eBPF将成为另一篇文章的主题。)
|
||||
|
||||
如果您需要开发自定义工具,那么也可以使用 bcc 来实现,尽管语言比 SystemTap,ply 或 bpftrace 要冗长得多。 我的 bcc 工具可以作为代码示例,另外我还贡献了[教程] [33]来开发 Python 中的 bcc 工具。 我建议先学习bcc多工具,因为在需要编写新工具之前,你可能会从里面获得很多里程。 您可以从他们 bcc 存储库[funccount] [34],[funclatency] [35],[funcslower] [36],[stackcount] [37],[trace] [38] ,[argdist] [39] 的示例文件中研究 bcc。
|
||||
如果您需要开发自定义工具,那么也可以使用 bcc 来实现,尽管语言比 SystemTap、ply 或 bpftrace 要冗长得多。我的 bcc 工具可以作为代码示例,另外我还贡献了用 Python 开发 bcc 工具的[教程][33]。 我建议先学习 bcc 的 multi-tools,因为在需要编写新工具之前,你可能会从里面获得很多经验。 您可以从它们的 bcc 存储库[funccount] [34],[funclatency] [35],[funcslower] [36],[stackcount] [37],[trace] [38] ,[argdist] [39] 的示例文件中研究 bcc。
|
||||
|
||||
感谢[Opensource.com] [40]进行编辑。
|
||||
|
||||
### 专题
|
||||
### 关于作者
|
||||
|
||||
[Linux][41][系统管理员][42]
|
||||
[][43]
|
||||
|
||||
### About the author
|
||||
Brendan Gregg 是 Netflix 的一名高级性能架构师,在那里他进行大规模的计算机性能设计、分析和调优。
|
||||
|
||||
[][43] Brendan Gregg
|
||||
|
||||
-
|
||||
Brendan Gregg是Netflix的一名高级性能架构师,在那里他进行大规模的计算机性能设计,分析和调优。[关于更多] [44]
|
||||
|
||||
|
||||
* [Learn how you can contribute][6]
|
||||
(题图:opensource.com)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:https://opensource.com/article/17/11/bccbpf-performance
|
||||
|
||||
作者:[Brendan Gregg ][a]
|
||||
作者:[Brendan Gregg][a]
|
||||
译者:[yongshouzhang](https://github.com/yongshouzhang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[a]:https://opensource.com/users/brendang
|
||||
[1]:https://opensource.com/resources/what-is-linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[2]:https://opensource.com/resources/what-are-linux-containers?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[3]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
@ -0,0 +1,78 @@
|
||||
什么是僵尸进程,如何找到并杀掉僵尸进程?
|
||||
======
|
||||
|
||||
[][1]
|
||||
|
||||
如果你经常使用 Linux,你应该遇到这个术语“<ruby>僵尸进程<rt>Zombie Processes</rt></ruby>”。 那么什么是僵尸进程? 它们是怎么产生的? 它们是否对系统有害? 我要怎样杀掉这些进程? 下面将会回答这些问题。
|
||||
|
||||
### 什么是僵尸进程?
|
||||
|
||||
我们都知道进程的工作原理。我们启动一个程序,开始我们的任务,然后等任务结束了,我们就停止这个进程。 进程停止后, 该进程就会从进程表中移除。
|
||||
|
||||
你可以通过 `System-Monitor` 查看当前进程。
|
||||
|
||||
[][2]
|
||||
|
||||
但是,有时候有些程序即使执行完了也依然留在进程表中。
|
||||
|
||||
那么,这些完成了生命周期但却依然留在进程表中的进程,我们称之为 “僵尸进程”。
|
||||
|
||||
### 它们是如何产生的?
|
||||
|
||||
当你运行一个程序时,它会产生一个父进程以及很多子进程。 所有这些子进程都会消耗内核分配给它们的内存和 CPU 资源。
|
||||
|
||||
这些子进程完成执行后会发送一个 Exit 信号然后死掉。这个 Exit 信号需要被父进程所读取。父进程需要随后调用 `wait` 命令来读取子进程的退出状态,并将子进程从进程表中移除。
|
||||
|
||||
若父进程正确第读取了子进程的 Exit 信号,则子进程会从进程表中删掉。
|
||||
|
||||
但若父进程未能读取到子进程的 Exit 信号,则这个子进程虽然完成执行处于死亡的状态,但也不会从进程表中删掉。
|
||||
|
||||
### 僵尸进程对系统有害吗?
|
||||
|
||||
**不会**。由于僵尸进程并不做任何事情, 不会使用任何资源也不会影响其它进程, 因此存在僵尸进程也没什么坏处。 不过由于进程表中的退出状态以及其它一些进程信息也是存储在内存中的,因此存在太多僵尸进程有时也会是一些问题。
|
||||
|
||||
**你可以想象成这样:**
|
||||
|
||||
“你是一家建筑公司的老板。你每天根据工人们的工作量来支付工资。 有一个工人每天来到施工现场,就坐在那里, 你不用付钱, 他也不做任何工作。 他只是每天都来然后呆坐在那,仅此而已!”
|
||||
|
||||
这个工人就是僵尸进程的一个活生生的例子。**但是**, 如果你有很多僵尸工人, 你的建设工地就会很拥堵从而让那些正常的工人难以工作。
|
||||
|
||||
### 那么如何找出僵尸进程呢?
|
||||
|
||||
打开终端并输入下面命令:
|
||||
|
||||
```
|
||||
ps aux | grep Z
|
||||
```
|
||||
|
||||
会列出进程表中所有僵尸进程的详细内容。
|
||||
|
||||
### 如何杀掉僵尸进程?
|
||||
|
||||
正常情况下我们可以用 `SIGKILL` 信号来杀死进程,但是僵尸进程已经死了, 你不能杀死已经死掉的东西。 因此你需要输入的命令应该是
|
||||
|
||||
```
|
||||
kill -s SIGCHLD pid
|
||||
```
|
||||
|
||||
将这里的 pid 替换成父进程的进程 id,这样父进程就会删除所有以及完成并死掉的子进程了。
|
||||
|
||||
**你可以把它想象成:**
|
||||
|
||||
"你在道路中间发现一具尸体,于是你联系了死者的家属,随后他们就会将尸体带离道路了。"
|
||||
|
||||
不过许多程序写的不是那么好,无法删掉这些子僵尸(否则你一开始也见不到这些僵尸了)。 因此确保删除子僵尸的唯一方法就是杀掉它们的父进程。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/what-are-zombie-processes-and-how-to-find-kill-zombie-processes
|
||||
|
||||
作者:[linuxandubuntu][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com
|
||||
[1]:http://www.linuxandubuntu.com/home/what-are-zombie-processes-and-how-to-find-kill-zombie-processes
|
||||
[2]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/linux-check-zombie-processes_orig.jpg
|
||||
@ -1,65 +0,0 @@
|
||||
darsh8 Translating
|
||||
|
||||
Book review: Ours to Hack and to Own
|
||||
============================================================
|
||||
|
||||

|
||||
Image by : opensource.com
|
||||
|
||||
It seems like the age of ownership is over, and I'm not just talking about the devices and software that many of us bring into our homes and our lives. I'm also talking about the platforms and services on which those devices and apps rely.
|
||||
|
||||
While many of the services that we use are free, we don't have any control over them. The firms that do, in essence, control what we see, what we hear, and what we read. Not only that, but many of them are also changing the nature of work. They're using closed platforms to power a shift away from full-time work to the [gig economy][2], one that offers little in the way of security or certainty.
|
||||
|
||||
This move has wide-ranging implications for the Internet and for everyone who uses and relies on it. The vision of the open Internet from just 20-odd-years ago is fading and is rapidly being replaced by an impenetrable curtain.
|
||||
|
||||
One remedy that's becoming popular is building [platform cooperatives][3], which are digital platforms that their users own. The idea behind platform cooperatives has many of the same roots as open source, as the book "[Ours to Hack and to Own][4]" explains.
|
||||
|
||||
Scholar Trebor Scholz and writer Nathan Schneider have collected 40 essays discussing the rise of, and the need for, platform cooperatives as tools ordinary people can use to promote openness, and to counter the opaqueness and the restrictions of closed systems.
|
||||
|
||||
### Where open source fits in
|
||||
|
||||
At or near the core of any platform cooperative lies open source; not necessarily open source technologies, but the principles and the ethos that underlie open source—openness, transparency, cooperation, collaboration, and sharing.
|
||||
|
||||
In his introduction to the book, Trebor Scholz points out that:
|
||||
|
||||
> In opposition to the black-box systems of the Snowden-era Internet, these platforms need to distinguish themselves by making their data flows transparent. They need to show where the data about customers and workers are stored, to whom they are sold, and for what purpose.
|
||||
|
||||
It's that transparency, so essential to open source, which helps make platform cooperatives so appealing and a refreshing change from much of what exists now.
|
||||
|
||||
Open source software can definitely play a part in the vision of platform cooperatives that "Ours to Hack and to Own" shares. Open source software can provide a fast, inexpensive way for groups to build the technical infrastructure that can power their cooperatives.
|
||||
|
||||
Mickey Metts illustrates this in the essay, "Meet Your Friendly Neighborhood Tech Co-Op." Metts works for a firm called Agaric, which uses Drupal to build for groups and small business what they otherwise couldn't do for themselves. On top of that, Metts encourages anyone wanting to build and run their own business or co-op to embrace free and open source software. Why? It's high quality, it's inexpensive, you can customize it, and you can connect with large communities of helpful, passionate people.
|
||||
|
||||
### Not always about open source, but open source is always there
|
||||
|
||||
Not all of the essays in this book focus or touch on open source; however, the key elements of the open source way—cooperation, community, open governance, and digital freedom—are always on or just below the surface.
|
||||
|
||||
In fact, as many of the essays in "Ours to Hack and to Own" argue, platform cooperatives can be important building blocks of a more open, commons-based economy and society. That can be, in Douglas Rushkoff's words, organizations like Creative Commons compensating "for the privatization of shared intellectual resources." It can also be what Francesca Bria, Barcelona's CTO, describes as cities running their own "distributed common data infrastructures with systems that ensure the security and privacy and sovereignty of citizens' data."
|
||||
|
||||
### Final thought
|
||||
|
||||
If you're looking for a blueprint for changing the Internet and the way we work, "Ours to Hack and to Own" isn't it. The book is more a manifesto than user guide. Having said that, "Ours to Hack and to Own" offers a glimpse at what we can do if we apply the principles of the open source way to society and to the wider world.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Scott Nesbitt - Writer. Editor. Soldier of fortune. Ocelot wrangler. Husband and father. Blogger. Collector of pottery. Scott is a few of these things. He's also a long-time user of free/open source software who extensively writes and blogs about it. You can find Scott on Twitter, GitHub
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/1/review-book-ours-to-hack-and-own
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:https://opensource.com/article/17/1/review-book-ours-to-hack-and-own?rate=dgkFEuCLLeutLMH2N_4TmUupAJDjgNvFpqWqYCbQb-8
|
||||
[2]:https://en.wikipedia.org/wiki/Access_economy
|
||||
[3]:https://en.wikipedia.org/wiki/Platform_cooperative
|
||||
[4]:http://www.orbooks.com/catalog/ours-to-hack-and-to-own/
|
||||
[5]:https://opensource.com/user/14925/feed
|
||||
[6]:https://opensource.com/users/scottnesbitt
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by qhwdw
|
||||
# Dynamic linker tricks: Using LD_PRELOAD to cheat, inject features and investigate programs
|
||||
|
||||
**This post assumes some basic C skills.**
|
||||
@ -209,3 +210,5 @@ via: https://rafalcieslak.wordpress.com/2013/04/02/dynamic-linker-tricks-using-l
|
||||
|
||||
[a]:https://rafalcieslak.wordpress.com/
|
||||
[1]:http://www.zlibc.linux.lu/index.html
|
||||
|
||||
|
||||
|
||||
@ -1,361 +0,0 @@
|
||||
How to turn any syscall into an event: Introducing eBPF Kernel probes
|
||||
============================================================
|
||||
|
||||
|
||||
TL;DR: Using eBPF in recent (>=4.4) Linux kernel, you can turn any kernel function call into a user land event with arbitrary data. This is made easy by bcc. The probe is written in C while the data is handled by python.
|
||||
|
||||
If you are not familiar with eBPF or linux tracing, you really should read the full post. It tries to progressively go through the pitfalls I stumbled unpon while playing around with bcc / eBPF while saving you a lot of the time I spent searching and digging.
|
||||
|
||||
### A note on push vs pull in a Linux world
|
||||
|
||||
When I started to work on containers, I was wondering how we could update a load balancer configuration dynamically based on actual system state. A common strategy, which works, it to let the container orchestrator trigger a load balancer configuration update whenever it starts a container and then let the load balancer poll the container until some health check passes. It may be a simple “SYN” test.
|
||||
|
||||
While this configuration works, it has the downside of making your load balancer waiting for some system to be available while it should be… load balancing.
|
||||
|
||||
Can we do better?
|
||||
|
||||
When you want a program to react to some change in a system there are 2 possible strategies. The program may _poll_ the system to detect changes or, if the system supports it, the system may _push_ events and let the program react to them. Wether you want to use push or poll depends on the context. A good rule of the thumb is to use push events when the event rate is low with respect to the processing time and switch to polling when the events are coming fast or the system may become unusable. For example, typical network driver will wait for events from the network card while frameworks like dpdk will actively poll the card for events to achieve the highest throughput and lowest latency.
|
||||
|
||||
In an ideal world, we’d have some kernel interface telling us:
|
||||
|
||||
> * “Hey Mr. ContainerManager, I’ve just created a socket for the Nginx-ware of container _servestaticfiles_ , maybe you want to update your state?”
|
||||
>
|
||||
> * “Sure Mr. OS, Thanks for letting me know”
|
||||
|
||||
While Linux has a wide range of interfaces to deal with events, up to 3 for file events, there is no dedicated interface to get socket event notifications. You can get routing table events, neighbor table events, conntrack events, interface change events. Just, not socket events. Or maybe there is, deep hidden in a Netlink interface.
|
||||
|
||||
Ideally, we’d need a generic way to do it. How?
|
||||
|
||||
### Kernel tracing and eBPF, a bit of history
|
||||
|
||||
Until recently the only way was to patch the kernel or resort on SystemTap. [SytemTap][5] is a tracing Linux system. In a nutshell, it provides a DSL which is then compiled into a kernel module which is then live-loaded into the running kernel. Except that some production system disable dynamic module loading for security reasons. Including the one I was working on at that time. The other way would be to patch the kernel to trigger some events, probably based on netlink. This is not really convenient. Kernel hacking come with downsides including “interesting” new “features” and increased maintenance burden.
|
||||
|
||||
Hopefully, starting with Linux 3.15 the ground was laid to safely transform any traceable kernel function into userland events. “Safely” is common computer science expression referring to “some virtual machine”. This case is no exception. Linux has had one for years. Since Linux 2.1.75 released in 1997 actually. It’s called Berkeley Packet Filter of BPF for short. As its name suggests, it was originally developed for the BSD firewalls. It had only 2 registers and only allowed forward jumps meaning that you could not write loops with it (Well, you can, if you know the maximum iterations and you manually unroll them). The point was to guarantee the program would always terminate and hence never hang the system. Still not sure if it has any use while you have iptables? It serves as the [foundation of CloudFlare’s AntiDDos protection][6].
|
||||
|
||||
OK, so, with Linux the 3.15, [BPF was extended][7] turning it into eBPF. For “extended” BPF. It upgrades from 2 32 bits registers to 10 64 bits 64 registers and adds backward jumping among others. It has then been [further extended in Linux 3.18][8] moving it out of the networking subsystem, and adding tools like maps. To preserve the safety guarantees, it [introduces a checker][9] which validates all memory accesses and possible code path. If the checker can’t guarantee the code will terminate within fixed boundaries, it will deny the initial insertion of the program.
|
||||
|
||||
For more history, there is [an excellent Oracle presentation on eBPF][10].
|
||||
|
||||
Let’s get started.
|
||||
|
||||
### Hello from from `inet_listen`
|
||||
|
||||
As writing assembly is not the most convenient task, even for the best of us, we’ll use [bcc][11]. bcc is a collection of tools based on LLVM and Python abstracting the underlying machinery. Probes are written in C and the results can be exploited from python allowing to easily write non trivial applications.
|
||||
|
||||
Start by install bcc. For some of these examples, you may require a recent (read >= 4.4) version of the kernel. If you are willing to actually try these examples, I highly recommend that you setup a VM. _NOT_ a docker container. You can’t change the kernel in a container. As this is a young and dynamic projects, install instructions are highly platform/version dependant. You can find up to date instructions on [https://github.com/iovisor/bcc/blob/master/INSTALL.md][12]
|
||||
|
||||
So, we want to get an event whenever a program starts to listen on TCP socket. When calling the `listen()` syscall on a `AF_INET` + `SOCK_STREAM` socket, the underlying kernel function is [`inet_listen`][13]. We’ll start by hooking a “Hello World” `kprobe` on it’s entrypoint.
|
||||
|
||||
```
|
||||
from bcc import BPF
|
||||
|
||||
# Hello BPF Program
|
||||
bpf_text = """
|
||||
#include <net/inet_sock.h>
|
||||
#include <bcc/proto.h>
|
||||
|
||||
// 1\. Attach kprobe to "inet_listen"
|
||||
int kprobe__inet_listen(struct pt_regs *ctx, struct socket *sock, int backlog)
|
||||
{
|
||||
bpf_trace_printk("Hello World!\\n");
|
||||
return 0;
|
||||
};
|
||||
"""
|
||||
|
||||
# 2\. Build and Inject program
|
||||
b = BPF(text=bpf_text)
|
||||
|
||||
# 3\. Print debug output
|
||||
while True:
|
||||
print b.trace_readline()
|
||||
|
||||
```
|
||||
|
||||
This program does 3 things: 1\. It attaches a kernel probe to “inet_listen” using a naming convention. If the function was called, say, “my_probe”, it could be explicitly attached with `b.attach_kprobe("inet_listen", "my_probe"`. 2\. It builds the program using LLVM new BPF backend, inject the resulting bytecode using the (new) `bpf()` syscall and automatically attaches the probes matching the naming convention. 3\. It reads the raw output from the kernel pipe.
|
||||
|
||||
Note: eBPF backend of LLVM is still young. If you think you’ve hit a bug, you may want to upgrade.
|
||||
|
||||
Noticed the `bpf_trace_printk` call? This is a stripped down version of the kernel’s `printk()`debug function. When used, it produces tracing informations to a special kernel pipe in `/sys/kernel/debug/tracing/trace_pipe`. As the name implies, this is a pipe. If multiple readers are consuming it, only 1 will get a given line. This makes it unsuitable for production.
|
||||
|
||||
Fortunately, Linux 3.19 introduced maps for message passing and Linux 4.4 brings arbitrary perf events support. I’ll demo the perf event based approach later in this post.
|
||||
|
||||
```
|
||||
# From a first console
|
||||
ubuntu@bcc:~/dev/listen-evts$ sudo /python tcv4listen.py
|
||||
nc-4940 [000] d... 22666.991714: : Hello World!
|
||||
|
||||
# From a second console
|
||||
ubuntu@bcc:~$ nc -l 0 4242
|
||||
^C
|
||||
|
||||
```
|
||||
|
||||
Yay!
|
||||
|
||||
### Grab the backlog
|
||||
|
||||
Now, let’s print some easily accessible data. Say the “backlog”. The backlog is the number of pending established TCP connections, pending to be `accept()`ed.
|
||||
|
||||
Just tweak a bit the `bpf_trace_printk`:
|
||||
|
||||
```
|
||||
bpf_trace_printk("Listening with with up to %d pending connections!\\n", backlog);
|
||||
|
||||
```
|
||||
|
||||
If you re-run the example with this world-changing improvement, you should see something like:
|
||||
|
||||
```
|
||||
(bcc)ubuntu@bcc:~/dev/listen-evts$ sudo python tcv4listen.py
|
||||
nc-5020 [000] d... 25497.154070: : Listening with with up to 1 pending connections!
|
||||
|
||||
```
|
||||
|
||||
`nc` is a single connection program, hence the backlog of 1\. Nginx or Redis would output 128 here. But that’s another story.
|
||||
|
||||
Easy hue? Now let’s get the port.
|
||||
|
||||
### Grab the port and IP
|
||||
|
||||
Studying `inet_listen` source from the kernel, we know that we need to get the `inet_sock` from the `socket` object. Just copy from the sources, and insert at the beginning of the tracer:
|
||||
|
||||
```
|
||||
// cast types. Intermediate cast not needed, kept for readability
|
||||
struct sock *sk = sock->sk;
|
||||
struct inet_sock *inet = inet_sk(sk);
|
||||
|
||||
```
|
||||
|
||||
The port can now be accessed from `inet->inet_sport` in network byte order (aka: Big Endian). Easy! So, we could just replace the `bpf_trace_printk` with:
|
||||
|
||||
```
|
||||
bpf_trace_printk("Listening on port %d!\\n", inet->inet_sport);
|
||||
|
||||
```
|
||||
|
||||
Then run:
|
||||
|
||||
```
|
||||
ubuntu@bcc:~/dev/listen-evts$ sudo /python tcv4listen.py
|
||||
...
|
||||
R1 invalid mem access 'inv'
|
||||
...
|
||||
Exception: Failed to load BPF program kprobe__inet_listen
|
||||
|
||||
```
|
||||
|
||||
Except that it’s not (yet) so simple. Bcc is improving a _lot_ currently. While writing this post, a couple of pitfalls had already been addressed. But not yet all. This Error means the in-kernel checker could prove the memory accesses in program are correct. See the explicit cast. We need to help is a little by making the accesses more explicit. We’ll use `bpf_probe_read` trusted function to read an arbitrary memory location while guaranteeing all necessary checks are done with something like:
|
||||
|
||||
```
|
||||
// Explicit initialization. The "=0" part is needed to "give life" to the variable on the stack
|
||||
u16 lport = 0;
|
||||
|
||||
// Explicit arbitrary memory access. Read it:
|
||||
// Read into 'lport', 'sizeof(lport)' bytes from 'inet->inet_sport' memory location
|
||||
bpf_probe_read(&lport, sizeof(lport), &(inet->inet_sport));
|
||||
|
||||
```
|
||||
|
||||
Reading the bound address for IPv4 is basically the same, using `inet->inet_rcv_saddr`. If we put is all together, we should get the backlog, the port and the bound IP:
|
||||
|
||||
```
|
||||
from bcc import BPF
|
||||
|
||||
# BPF Program
|
||||
bpf_text = """
|
||||
#include <net/sock.h>
|
||||
#include <net/inet_sock.h>
|
||||
#include <bcc/proto.h>
|
||||
|
||||
// Send an event for each IPv4 listen with PID, bound address and port
|
||||
int kprobe__inet_listen(struct pt_regs *ctx, struct socket *sock, int backlog)
|
||||
{
|
||||
// Cast types. Intermediate cast not needed, kept for readability
|
||||
struct sock *sk = sock->sk;
|
||||
struct inet_sock *inet = inet_sk(sk);
|
||||
|
||||
// Working values. You *need* to initialize them to give them "life" on the stack and use them afterward
|
||||
u32 laddr = 0;
|
||||
u16 lport = 0;
|
||||
|
||||
// Pull in details. As 'inet_sk' is internally a type cast, we need to use 'bpf_probe_read'
|
||||
// read: load into 'laddr' 'sizeof(laddr)' bytes from address 'inet->inet_rcv_saddr'
|
||||
bpf_probe_read(&laddr, sizeof(laddr), &(inet->inet_rcv_saddr));
|
||||
bpf_probe_read(&lport, sizeof(lport), &(inet->inet_sport));
|
||||
|
||||
// Push event
|
||||
bpf_trace_printk("Listening on %x %d with %d pending connections\\n", ntohl(laddr), ntohs(lport), backlog);
|
||||
return 0;
|
||||
};
|
||||
"""
|
||||
|
||||
# Build and Inject BPF
|
||||
b = BPF(text=bpf_text)
|
||||
|
||||
# Print debug output
|
||||
while True:
|
||||
print b.trace_readline()
|
||||
|
||||
```
|
||||
|
||||
A test run should output something like:
|
||||
|
||||
```
|
||||
(bcc)ubuntu@bcc:~/dev/listen-evts$ sudo python tcv4listen.py
|
||||
nc-5024 [000] d... 25821.166286: : Listening on 7f000001 4242 with 1 pending connections
|
||||
|
||||
```
|
||||
|
||||
Provided that you listen on localhost. The address is displayed as hex here to avoid dealing with the IP pretty printing but that’s all wired. And that’s cool.
|
||||
|
||||
Note: you may wonder why `ntohs` and `ntohl` can be called from BPF while they are not trusted. This is because they are macros and inline functions from “.h” files and a small bug was [fixed][14]while writing this post.
|
||||
|
||||
All done, one more piece: We want to get the related container. In the context of networking, that’s means we want the network namespace. The network namespace being the building block of containers allowing them to have isolated networks.
|
||||
|
||||
### Grab the network namespace: a forced introduction to perf events
|
||||
|
||||
On the userland, the network namespace can be determined by checking the target of `/proc/PID/ns/net`. It should look like `net:[4026531957]`. The number between brackets is the inode number of the network namespace. This said, we could grab it by scrapping ‘/proc’ but this is racy, we may be dealing with short-lived processes. And races are never good. We’ll grab the inode number directly from the kernel. Fortunately, that’s an easy one:
|
||||
|
||||
```
|
||||
// Create an populate the variable
|
||||
u32 netns = 0;
|
||||
|
||||
// Read the netns inode number, like /proc does
|
||||
netns = sk->__sk_common.skc_net.net->ns.inum;
|
||||
|
||||
```
|
||||
|
||||
Easy. And it works.
|
||||
|
||||
But if you’ve read so far, you may guess there is something wrong somewhere. And there is:
|
||||
|
||||
```
|
||||
bpf_trace_printk("Listening on %x %d with %d pending connections in container %d\\n", ntohl(laddr), ntohs(lport), backlog, netns);
|
||||
|
||||
```
|
||||
|
||||
If you try to run it, you’ll get some cryptic error message:
|
||||
|
||||
```
|
||||
(bcc)ubuntu@bcc:~/dev/listen-evts$ sudo python tcv4listen.py
|
||||
error: in function kprobe__inet_listen i32 (%struct.pt_regs*, %struct.socket*, i32)
|
||||
too many args to 0x1ba9108: i64 = Constant<6>
|
||||
|
||||
```
|
||||
|
||||
What clang is trying to tell you is “Hey pal, `bpf_trace_printk` can only take 4 arguments, you’ve just used 5.“. I won’t dive into the details here, but that’s a BPF limitation. If you want to dig it, [here is a good starting point][15].
|
||||
|
||||
The only way to fix it is to… stop debugging and make it production ready. So let’s get started (and make sure run at least Linux 4.4). We’ll use perf events which supports passing arbitrary sized structures to userland. Additionally, only our reader will get it so that multiple unrelated eBPF programs can produce data concurrently without issues.
|
||||
|
||||
To use it, we need to:
|
||||
|
||||
1. define a structure
|
||||
|
||||
2. declare the event
|
||||
|
||||
3. push the event
|
||||
|
||||
4. re-declare the event on Python’s side (This step should go away in the future)
|
||||
|
||||
5. consume and format the event
|
||||
|
||||
This may seem like a lot, but it ain’t. See:
|
||||
|
||||
```
|
||||
// At the begining of the C program, declare our event
|
||||
struct listen_evt_t {
|
||||
u64 laddr;
|
||||
u64 lport;
|
||||
u64 netns;
|
||||
u64 backlog;
|
||||
};
|
||||
BPF_PERF_OUTPUT(listen_evt);
|
||||
|
||||
// In kprobe__inet_listen, replace the printk with
|
||||
struct listen_evt_t evt = {
|
||||
.laddr = ntohl(laddr),
|
||||
.lport = ntohs(lport),
|
||||
.netns = netns,
|
||||
.backlog = backlog,
|
||||
};
|
||||
listen_evt.perf_submit(ctx, &evt, sizeof(evt));
|
||||
|
||||
```
|
||||
|
||||
Python side will require a little more work, though:
|
||||
|
||||
```
|
||||
# We need ctypes to parse the event structure
|
||||
import ctypes
|
||||
|
||||
# Declare data format
|
||||
class ListenEvt(ctypes.Structure):
|
||||
_fields_ = [
|
||||
("laddr", ctypes.c_ulonglong),
|
||||
("lport", ctypes.c_ulonglong),
|
||||
("netns", ctypes.c_ulonglong),
|
||||
("backlog", ctypes.c_ulonglong),
|
||||
]
|
||||
|
||||
# Declare event printer
|
||||
def print_event(cpu, data, size):
|
||||
event = ctypes.cast(data, ctypes.POINTER(ListenEvt)).contents
|
||||
print("Listening on %x %d with %d pending connections in container %d" % (
|
||||
event.laddr,
|
||||
event.lport,
|
||||
event.backlog,
|
||||
event.netns,
|
||||
))
|
||||
|
||||
# Replace the event loop
|
||||
b["listen_evt"].open_perf_buffer(print_event)
|
||||
while True:
|
||||
b.kprobe_poll()
|
||||
|
||||
```
|
||||
|
||||
Give it a try. In this example, I have a redis running in a docker container and nc on the host:
|
||||
|
||||
```
|
||||
(bcc)ubuntu@bcc:~/dev/listen-evts$ sudo python tcv4listen.py
|
||||
Listening on 0 6379 with 128 pending connections in container 4026532165
|
||||
Listening on 0 6379 with 128 pending connections in container 4026532165
|
||||
Listening on 7f000001 6588 with 1 pending connections in container 4026531957
|
||||
|
||||
```
|
||||
|
||||
### Last word
|
||||
|
||||
Absolutely everything is now setup to use trigger events from arbitrary function calls in the kernel using eBPF, and you should have seen most of the common pitfalls I hit while learning eBPF. If you want to see the full version of this tool, along with some more tricks like IPv6 support, have a look at [https://github.com/iovisor/bcc/blob/master/tools/solisten.py][16]. It’s now an official tool, thanks to the support of the bcc team.
|
||||
|
||||
To go further, you may want to checkout Brendan Gregg’s blog, in particular [the post about eBPF maps and statistics][17]. He his one of the project’s main contributor.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.yadutaf.fr/2016/03/30/turn-any-syscall-into-event-introducing-ebpf-kernel-probes/
|
||||
|
||||
作者:[Jean-Tiare Le Bigot ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.yadutaf.fr/about
|
||||
[1]:https://blog.yadutaf.fr/tags/linux
|
||||
[2]:https://blog.yadutaf.fr/tags/tracing
|
||||
[3]:https://blog.yadutaf.fr/tags/ebpf
|
||||
[4]:https://blog.yadutaf.fr/tags/bcc
|
||||
[5]:https://en.wikipedia.org/wiki/SystemTap
|
||||
[6]:https://blog.cloudflare.com/bpf-the-forgotten-bytecode/
|
||||
[7]:https://blog.yadutaf.fr/2016/03/30/turn-any-syscall-into-event-introducing-ebpf-kernel-probes/TODO
|
||||
[8]:https://lwn.net/Articles/604043/
|
||||
[9]:http://lxr.free-electrons.com/source/kernel/bpf/verifier.c#L21
|
||||
[10]:http://events.linuxfoundation.org/sites/events/files/slides/tracing-linux-ezannoni-linuxcon-ja-2015_0.pdf
|
||||
[11]:https://github.com/iovisor/bcc
|
||||
[12]:https://github.com/iovisor/bcc/blob/master/INSTALL.md
|
||||
[13]:http://lxr.free-electrons.com/source/net/ipv4/af_inet.c#L194
|
||||
[14]:https://github.com/iovisor/bcc/pull/453
|
||||
[15]:http://lxr.free-electrons.com/source/kernel/trace/bpf_trace.c#L86
|
||||
[16]:https://github.com/iovisor/bcc/blob/master/tools/solisten.py
|
||||
[17]:http://www.brendangregg.com/blog/2015-05-15/ebpf-one-small-step.html
|
||||
@ -1,93 +0,0 @@
|
||||
Translating by XiatianSummer
|
||||
|
||||
Why Car Companies Are Hiring Computer Security Experts
|
||||
============================================================
|
||||
|
||||
Photo
|
||||

|
||||
The cybersecurity experts Marc Rogers, left, of CloudFlare and Kevin Mahaffey of Lookout were able to control various Tesla functions from their physically connected laptop. They pose in CloudFlare’s lobby in front of Lava Lamps used to generate numbers for encryption.CreditChristie Hemm Klok for The New York Times
|
||||
|
||||
It started about seven years ago. Iran’s top nuclear scientists were being assassinated in a string of similar attacks: Assailants on motorcycles were pulling up to their moving cars, attaching magnetic bombs and detonating them after the motorcyclists had fled the scene.
|
||||
|
||||
In another seven years, security experts warn, assassins won’t need motorcycles or magnetic bombs. All they’ll need is a laptop and code to send driverless cars careering off a bridge, colliding with a driverless truck or coming to an unexpected stop in the middle of fast-moving traffic.
|
||||
|
||||
Automakers may call them self-driving cars. But hackers call them computers that travel over 100 miles an hour.
|
||||
|
||||
“These are no longer cars,” said Marc Rogers, the principal security researcher at the cybersecurity firm CloudFlare. “These are data centers on wheels. Any part of the car that talks to the outside world is a potential inroad for attackers.”
|
||||
|
||||
Those fears came into focus two years ago when two “white hat” hackers — researchers who look for computer vulnerabilities to spot problems and fix them, rather than to commit a crime or cause problems — successfully gained access to a Jeep Cherokee from their computer miles away. They rendered their crash-test dummy (in this case a nervous reporter) powerless over his vehicle and disabling his transmission in the middle of a highway.
|
||||
|
||||
The hackers, Chris Valasek and Charlie Miller (now security researchers respectively at Uber and Didi, an Uber competitor in China), discovered an [electronic route from the Jeep’s entertainment system to its dashboard][10]. From there, they had control of the vehicle’s steering, brakes and transmission — everything they needed to paralyze their crash test dummy in the middle of a highway.
|
||||
|
||||
“Car hacking makes great headlines, but remember: No one has ever had their car hacked by a bad guy,” Mr. Miller wrote on Twitter last Sunday. “It’s only ever been performed by researchers.”
|
||||
|
||||
Still, the research by Mr. Miller and Mr. Valasek came at a steep price for Jeep’s manufacturer, Fiat Chrysler, which was forced to recall 1.4 million of its vehicles as a result of the hacking experiment.
|
||||
|
||||
It is no wonder that Mary Barra, the chief executive of General Motors, called cybersecurity her company’s top priority last year. Now the skills of researchers and so-called white hat hackers are in high demand among automakers and tech companies pushing ahead with driverless car projects.
|
||||
|
||||
Uber, [Tesla][11], Apple and Didi in China have been actively recruiting white hat hackers like Mr. Miller and Mr. Valasek from one another as well as from traditional cybersecurity firms and academia.
|
||||
|
||||
Last year, Tesla poached Aaron Sigel, Apple’s manager of security for its iOS operating system. Uber poached Chris Gates, formerly a white hat hacker at Facebook. Didi poached Mr. Miller from Uber, where he had gone to work after the Jeep hack. And security firms have seen dozens of engineers leave their ranks for autonomous-car projects.
|
||||
|
||||
Mr. Miller said he left Uber for Didi, in part, because his new Chinese employer has given him more freedom to discuss his work.
|
||||
|
||||
“Carmakers seem to be taking the threat of cyberattack more seriously, but I’d still like to see more transparency from them,” Mr. Miller wrote on Twitter on Saturday.
|
||||
|
||||
Like a number of big tech companies, Tesla and Fiat Chrysler started paying out rewards to hackers who turn over flaws the hackers discover in their systems. GM has done something similar, though critics say GM’s program is limited when compared with the ones offered by tech companies, and so far no rewards have been paid out.
|
||||
|
||||
One year after the Jeep hack by Mr. Miller and Mr. Valasek, they demonstrated all the other ways they could mess with a Jeep driver, including hijacking the vehicle’s cruise control, swerving the steering wheel 180 degrees or slamming on the parking brake in high-speed traffic — all from a computer in the back of the car. (Those exploits ended with their test Jeep in a ditch and calls to a local tow company.)
|
||||
|
||||
Granted, they had to be in the Jeep to make all that happen. But it was evidence of what is possible.
|
||||
|
||||
The Jeep penetration was preceded by a [2011 hack by security researchers at the University of Washington][12] and the University of California, San Diego, who were the first to remotely hack a sedan and ultimately control its brakes via Bluetooth. The researchers warned car companies that the more connected cars become, the more likely they are to get hacked.
|
||||
|
||||
Security researchers have also had their way with Tesla’s software-heavy Model S car. In 2015, Mr. Rogers, together with Kevin Mahaffey, the chief technology officer of the cybersecurity company Lookout, found a way to control various Tesla functions from their physically connected laptop.
|
||||
|
||||
One year later, a team of Chinese researchers at Tencent took their research a step further, hacking a moving Tesla Model S and controlling its brakes from 12 miles away. Unlike Chrysler, Tesla was able to dispatch a remote patch to fix the security holes that made the hacks possible.
|
||||
|
||||
In all the cases, the car hacks were the work of well meaning, white hat security researchers. But the lesson for all automakers was clear.
|
||||
|
||||
The motivations to hack vehicles are limitless. When it learned of Mr. Rogers’s and Mr. Mahaffey’s investigation into Tesla’s Model S, a Chinese app-maker asked Mr. Rogers if he would be interested in sharing, or possibly selling, his discovery, he said. (The app maker was looking for a backdoor to secretly install its app on Tesla’s dashboard.)
|
||||
|
||||
Criminals have not yet shown they have found back doors into connected vehicles, though for years, they have been actively developing, trading and deploying tools that can intercept car key communications.
|
||||
|
||||
But as more driverless and semiautonomous cars hit the open roads, they will become a more worthy target. Security experts warn that driverless cars present a far more complex, intriguing and vulnerable “attack surface” for hackers. Each new “connected” car feature introduces greater complexity, and with complexity inevitably comes vulnerability.
|
||||
|
||||
Twenty years ago, cars had, on average, one million lines of code. The General Motors 2010 [Chevrolet Volt][13] had about 10 million lines of code — more than an [F-35 fighter jet][14].
|
||||
|
||||
Today, an average car has more than 100 million lines of code. Automakers predict it won’t be long before they have 200 million. When you stop to consider that, on average, there are 15 to 50 defects per 1,000 lines of software code, the potentially exploitable weaknesses add up quickly.
|
||||
|
||||
The only difference between computer code and driverless car code is that, “Unlike data center enterprise security — where the biggest threat is loss of data — in automotive security, it’s loss of life,” said David Barzilai, a co-founder of Karamba Security, an Israeli start-up that is working on addressing automotive security.
|
||||
|
||||
To truly secure autonomous vehicles, security experts say, automakers will have to address the inevitable vulnerabilities that pop up in new sensors and car computers, address inherent vulnerabilities in the base car itself and, perhaps most challenging of all, bridge the cultural divide between automakers and software companies.
|
||||
|
||||
“The genie is out of the bottle, and to solve this problem will require a major cultural shift,” said Mr. Mahaffey of the cybersecurity company Lookout. “And an automaker that truly values cybersecurity will treat security vulnerabilities the same they would an airbag recall. We have not seen that industrywide shift yet.”
|
||||
|
||||
There will be winners and losers, Mr. Mahaffey added: “Automakers that transform themselves into software companies will win. Others will get left behind.”
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.nytimes.com/2017/06/07/technology/why-car-companies-are-hiring-computer-security-experts.html
|
||||
|
||||
作者:[NICOLE PERLROTH ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.nytimes.com/by/nicole-perlroth
|
||||
[1]:https://www.nytimes.com/2016/06/09/technology/software-as-weaponry-in-a-computer-connected-world.html
|
||||
[2]:https://www.nytimes.com/2015/08/29/technology/uber-hires-two-engineers-who-showed-cars-could-be-hacked.html
|
||||
[3]:https://www.nytimes.com/2015/08/11/opinion/zeynep-tufekci-why-smart-objects-may-be-a-dumb-idea.html
|
||||
[4]:https://www.nytimes.com/by/nicole-perlroth
|
||||
[5]:https://www.nytimes.com/column/bits
|
||||
[6]:https://www.nytimes.com/2017/06/07/technology/why-car-companies-are-hiring-computer-security-experts.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#story-continues-1
|
||||
[7]:http://www.nytimes.com/newsletters/sample/bits?pgtype=subscriptionspage&version=business&contentId=TU&eventName=sample&module=newsletter-sign-up
|
||||
[8]:https://www.nytimes.com/privacy
|
||||
[9]:https://www.nytimes.com/help/index.html
|
||||
[10]:https://bits.blogs.nytimes.com/2015/07/21/security-researchers-find-a-way-to-hack-cars/
|
||||
[11]:http://www.nytimes.com/topic/company/tesla-motors-inc?inline=nyt-org
|
||||
[12]:http://www.autosec.org/pubs/cars-usenixsec2011.pdf
|
||||
[13]:http://autos.nytimes.com/2011/Chevrolet/Volt/238/4117/329463/researchOverview.aspx?inline=nyt-classifier
|
||||
[14]:http://topics.nytimes.com/top/reference/timestopics/subjects/m/military_aircraft/f35_airplane/index.html?inline=nyt-classifier
|
||||
[15]:https://www.nytimes.com/2017/06/07/technology/why-car-companies-are-hiring-computer-security-experts.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#story-continues-3
|
||||
@ -0,0 +1,215 @@
|
||||
Complete “Beginners to PRO” guide for GIT commands
|
||||
======
|
||||
In our [**earlier tutorial,**][1] we have learned to install git on our machines. In this tutorial, we will discuss how we can use git i.e. various commands that are used with git. So let's start,In our earlier tutorial, we have learned to install git on our machines. In this tutorial, we will discuss how we can use git i.e. various commands that are used with git. So let's start,
|
||||
|
||||
( **Recommended Read** : [**How to install GIT on Linux (Ubuntu & CentOS)**][1] )
|
||||
|
||||
### Setting user information
|
||||
|
||||
This should the first step after installing git. We will add user information (user name & email), so that the when we commit the code, commit messages will be generated with the user information which makes it easier to keep track of the commit progress. To add user information about user, command is 'git config'
|
||||
|
||||
**$ git config - - global user.name "Daniel"**
|
||||
|
||||
**$ git config - - global user.email "dan.mike@xyz.com"**
|
||||
|
||||
After adding the information, we will now check if the information has been updated successfully by running,
|
||||
|
||||
**$ git config - - list**
|
||||
|
||||
& we should see our user information as the output.
|
||||
|
||||
( **Also Read** : [**Scheduling important jobs with CRONTAB**][3] )
|
||||
|
||||
### GIT Commands
|
||||
|
||||
#### Create a new repository
|
||||
|
||||
To create a new repository, run
|
||||
|
||||
**$ git init**
|
||||
|
||||
|
||||
#### Search a repository
|
||||
|
||||
To search a repository, command is
|
||||
|
||||
**$ git grep "repository"**
|
||||
|
||||
|
||||
#### Connect to a remote repository
|
||||
|
||||
To connect to a remote repository, run
|
||||
|
||||
**$ git remote add origin remote_server**
|
||||
|
||||
Then to check all the configured remote server,
|
||||
|
||||
**$ git remote -v**
|
||||
|
||||
|
||||
#### Clone a repository
|
||||
|
||||
To clone a repository from a local server, run the following commands
|
||||
|
||||
**$ git clone repository_path**
|
||||
|
||||
If we want to clone a repository locate at remote server, then the command to clone the repository is,
|
||||
|
||||
**$ git clone[[email protected]][2] :/repository_path**
|
||||
|
||||
|
||||
#### List Branches in repository
|
||||
|
||||
To check list all the available & the current working branch, execute
|
||||
|
||||
**$ git branch**
|
||||
|
||||
|
||||
#### Create new branch
|
||||
|
||||
To create & use a new branch, command is
|
||||
|
||||
**$ git checkout -b 'branchname'**
|
||||
|
||||
|
||||
#### Deleting a branch
|
||||
|
||||
To delete a branch, execute
|
||||
|
||||
**$ git branch -d 'branchname'**
|
||||
|
||||
To delete a branch on remote repository, execute
|
||||
|
||||
**$ git push origin : 'branchname'**
|
||||
|
||||
|
||||
#### Switch to another branch
|
||||
|
||||
To switch to another branch from current branch, use
|
||||
|
||||
**$ git checkout 'branchname'**
|
||||
|
||||
|
||||
#### Adding files
|
||||
|
||||
To add a file to the repo, run
|
||||
|
||||
**$ git add filename**
|
||||
|
||||
|
||||
#### Status of files
|
||||
|
||||
To check status of files (files that are to be commited or are to added), run
|
||||
|
||||
**$ git status**
|
||||
|
||||
|
||||
#### Commit the changes
|
||||
|
||||
After we have added a file or made changes to one, we will commit the code by running,
|
||||
|
||||
**$ git commit -a**
|
||||
|
||||
To commit changes to head and not to remote repository, command is
|
||||
|
||||
**$ git commit -m "message"**
|
||||
|
||||
|
||||
#### Push changes
|
||||
|
||||
To push changes made to the master branch of the repository, run
|
||||
|
||||
**$ git push origin master**
|
||||
|
||||
|
||||
#### Push branch to repository
|
||||
|
||||
To push the changes made on a single branch to remote repository, run
|
||||
|
||||
**$ git push origin 'branchname'**
|
||||
|
||||
To push all branches to remote repository, run
|
||||
|
||||
**$ git push -all origin**
|
||||
|
||||
|
||||
#### Merge two branches
|
||||
|
||||
To merge another branch into the current active branch, use
|
||||
|
||||
**$ git merge 'branchname'**
|
||||
|
||||
|
||||
#### Merge from remote to local server
|
||||
|
||||
To download/pull changes to working directory on local server from remote server, run
|
||||
|
||||
**$ git pull**
|
||||
|
||||
|
||||
#### Checking merge conflicts
|
||||
|
||||
To view merge conflicts against base file, run
|
||||
|
||||
**$ git diff -base 'filename'**
|
||||
|
||||
To see all the conflicts, run
|
||||
|
||||
**$ git diff**
|
||||
|
||||
If we want to preview all the changes before merging, execute
|
||||
|
||||
**$ git diff 'source-branch' 'target-branch'**
|
||||
|
||||
|
||||
#### Creating tags
|
||||
|
||||
To create tags to mark any significant changes, run
|
||||
|
||||
**$ git tag 'tag number' 'commit id'**
|
||||
|
||||
We can find commit id by running,
|
||||
|
||||
**$ git log**
|
||||
|
||||
|
||||
#### Push tags
|
||||
|
||||
To push all the created tags to remote server, run
|
||||
|
||||
**$ git push -tags origin**
|
||||
|
||||
|
||||
#### Revert changes made
|
||||
|
||||
If we want to replace changes made on current working tree with the last changes in head, run
|
||||
|
||||
**$ git checkout -'filename'**
|
||||
|
||||
We can also fetch the latest history from remote server & point it local repository's master branch, rather than dropping all local changes made. To do this, run
|
||||
|
||||
**$ git fetch origin**
|
||||
|
||||
**$ git reset -hard master**
|
||||
|
||||
That's it guys, these are the commands that we can use with git server. We will be back soon with more interesting tutorials. If you wish that we write a tutorial on a specific topic, please let us know via comment box below. As usual, your comments & suggestions are always welcome.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/beginners-to-pro-guide-for-git-commands/
|
||||
|
||||
作者:[Shusain][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1] http://linuxtechlab.com/install-git-linux-ubuntu-centos/
|
||||
[2] /cdn-cgi/l/email-protection
|
||||
[3] http://linuxtechlab.com/scheduling-important-jobs-crontab/
|
||||
[4] https://www.facebook.com/linuxtechlab/
|
||||
[5] https://twitter.com/LinuxTechLab
|
||||
[6] https://plus.google.com/+linuxtechlab
|
||||
[7] http://linuxtechlab.com/contact-us-2/
|
||||
@ -0,0 +1,263 @@
|
||||
Useful Linux Commands that you should know
|
||||
======
|
||||
If you are Linux system administrator or just a Linux enthusiast/lover, than
|
||||
you love & use command line aks CLI. Until some years ago majority of Linux
|
||||
work was accomplished using CLI only & even there are some limitations to GUI
|
||||
. Though there are plenty of Linux distributions that can complete tasks with
|
||||
GUI but still learning CLI is major part of mastering Linux.
|
||||
|
||||
To this effect, we present you list of useful Linux commands that you should
|
||||
know.
|
||||
|
||||
**Note:-** There is no definite order to all these commands & all of these
|
||||
commands are equally important to learn & master in order to excel in Linux
|
||||
administration. One more thing, we have only used some of the options for each
|
||||
command for an example, you can refer to 'man pages' for complete list of
|
||||
options for each command.
|
||||
|
||||
### 1- top command
|
||||
|
||||
'top' command displays the real time summary/information of our system. It
|
||||
also displays the processes and all the threads that are running & are being
|
||||
managed by the system kernel.
|
||||
|
||||
Information provided by top command includes uptime, number of users, Load
|
||||
average, running/sleeping/zombie processes, CPU usage in percentage based on
|
||||
users/system etc, system memory free & used, swap memory etc.
|
||||
|
||||
To use top command, open terminal & execute the comamnd,
|
||||
|
||||
**$ top**
|
||||
|
||||
To exit out the command, either press 'q' or 'ctrl+c'.
|
||||
|
||||
### 2- free command
|
||||
|
||||
'free' command is used to specifically used to get the information about
|
||||
system memory or RAM. With this command we can get information regarding
|
||||
physical memory, swap memory as well as system buffers. It provided amount of
|
||||
total, free & used memory available on the system.
|
||||
|
||||
To use this utility, execute following command in terminal
|
||||
|
||||
**$ free**
|
||||
|
||||
It will present all the data in kb or kilobytes, for megabytes use options
|
||||
'-m' & '-g ' for gb.
|
||||
|
||||
#### 3- cp command
|
||||
|
||||
'cp' or copy command is used to copy files among the folders. Syntax for using
|
||||
'cp' command is,
|
||||
|
||||
**$ cp source destination**
|
||||
|
||||
### 4- cd command
|
||||
|
||||
'cd' command is used for changing directory . We can switch among directories
|
||||
using cd command.
|
||||
|
||||
To use it, execute
|
||||
|
||||
**$ cd directory_location**
|
||||
|
||||
### 5- ifconfig
|
||||
|
||||
'Ifconfig' is very important utility for viewing & configuring network
|
||||
information on Linux machine.
|
||||
|
||||
To use it, execute
|
||||
|
||||
**$ ifconfig**
|
||||
|
||||
This will present the network information of all the networking devices on the
|
||||
system. There are number of options that can be used with 'ifconfig' for
|
||||
configuration, in fact they are some many options that we have created a
|
||||
separate article for it ( **Read it here ||[IFCONFIG command : Learn with some
|
||||
examples][1]** ).
|
||||
|
||||
### 6- crontab command
|
||||
|
||||
'Crontab' is another important utility that is used schedule a job on Linux
|
||||
system. With crontab, we can make sure that a command or a script is executed
|
||||
at the pre-defined time. To create a cron job, run
|
||||
|
||||
**$ crontab -e**
|
||||
|
||||
To display all the created jobs, run
|
||||
|
||||
**$ crontab -l**
|
||||
|
||||
You can read our detailed article regarding crontab ( **Read it here ||[
|
||||
Scheduling Important Jobs with Crontab][2]** )
|
||||
|
||||
### 7- cat command
|
||||
|
||||
'cat' command has many uses, most common use is that it's used to display
|
||||
content of a file,
|
||||
|
||||
**$ cat file.txt**
|
||||
|
||||
But it can also be used to merge two or more file using the syntax below,
|
||||
|
||||
**$ cat file1 file2 file3 file4 > file_new**
|
||||
|
||||
We can also use 'cat' command to clone a whole disk ( **Read it here ||
|
||||
[Cloning Disks using dd & cat commands for Linux systems][3]** )
|
||||
|
||||
### 8- df command
|
||||
|
||||
'df' command is used to show the disk utilization of our whole Linux file
|
||||
system. Simply run.
|
||||
|
||||
**$ df**
|
||||
|
||||
& we will be presented with disk complete utilization of all the partitions on
|
||||
our Linux machine.
|
||||
|
||||
### 9- du command
|
||||
|
||||
'du' command shows the amount of disk that is being utilized by the files &
|
||||
directories on our Linux machine. To run it, type
|
||||
|
||||
**$ du /directory**
|
||||
|
||||
( **Recommended Read :[Use of du & df commands with examples][4]** )
|
||||
|
||||
### 10- mv command
|
||||
|
||||
'mv' command is used to move the files or folders from one location to
|
||||
another. Command syntax for moving the files/folders is,
|
||||
|
||||
**$ mv /source/filename /destination**
|
||||
|
||||
We can also use 'mv' command to rename a file/folder. Syntax for changing name
|
||||
is,
|
||||
|
||||
**$ mv file_oldname file_newname**
|
||||
|
||||
### 11- rm command
|
||||
|
||||
'rm' command is used to remove files\folders from Linux system. To use it, run
|
||||
|
||||
**$ rm filename**
|
||||
|
||||
We can also use '-rf' option with 'rm' command to completely remove a
|
||||
file\folder from the system but we must use this with caution.
|
||||
|
||||
### 12- vi/vim command
|
||||
|
||||
VI or VIM is very famous & one of the widely used CLI-based text editor for
|
||||
Linux. It takes some time to master it but it has a great number of utilities,
|
||||
which makes it a favorite for Linux users.
|
||||
|
||||
For detailed knowledge of VIM, kindly refer to the articles [**Beginner 's
|
||||
Guide to LVM (Logical Volume Management)** & **Working with Vi/Vim Editor :
|
||||
Advanced concepts.**][5]
|
||||
|
||||
### 13- ssh command
|
||||
|
||||
SSH utility is to remotely access another machine from the current Linux
|
||||
machine. To access a machine, execute
|
||||
|
||||
**$ ssh[[email protected]][6] OR machine_name**
|
||||
|
||||
Once we have remote access to machine, we can work on CLI of that machine as
|
||||
if we are working on local machine.
|
||||
|
||||
### 14- tar command
|
||||
|
||||
'tar' command is used to compress & extract the files\folders. To compress the
|
||||
files\folders using tar, execute
|
||||
|
||||
**$ tar -cvf file.tar file_name**
|
||||
|
||||
where file.tar will be the name of compressed folder & 'file_name' is the name
|
||||
of source file or folders. To extract a compressed folder,
|
||||
|
||||
**$ tar -xvf file.tar**
|
||||
|
||||
For more details on 'tar' command, read [**Tar command : Compress & Decompress
|
||||
the files\directories**][7]
|
||||
|
||||
### 15- locate command
|
||||
|
||||
'locate' command is used to locate files & folders on your Linux machines. To
|
||||
use it, run
|
||||
|
||||
**$ locate file_name**
|
||||
|
||||
### 16- grep command
|
||||
|
||||
'grep' command another very important command that a Linux administrator
|
||||
should know. It comes especially handy when we want to grab a keyword or
|
||||
multiple keywords from a file. Syntax for using it is,
|
||||
|
||||
**$ grep 'pattern' file.txt**
|
||||
|
||||
It will search for 'pattern' in the file 'file.txt' and produce the output on
|
||||
the screen. We can also redirect the output to another file,
|
||||
|
||||
**$ grep 'pattern' file.txt > newfile.txt**
|
||||
|
||||
### 17- ps command
|
||||
|
||||
'ps' command is especially used to get the process id of a running process. To
|
||||
get information of all the processes, run
|
||||
|
||||
**$ ps -ef**
|
||||
|
||||
To get information regarding a single process, executed
|
||||
|
||||
**$ ps -ef | grep java**
|
||||
|
||||
### 18- kill command
|
||||
|
||||
'kill' command is used to kill a running process. To kill a process we will
|
||||
need its process id, which we can get using above 'ps' command. To kill a
|
||||
process, run
|
||||
|
||||
**$ kill -9 process_id**
|
||||
|
||||
### 19- ls command
|
||||
|
||||
'ls' command is used list all the files in a directory. To use it, execute
|
||||
|
||||
**$ ls**
|
||||
|
||||
### 20- mkdir command
|
||||
|
||||
To create a directory in Linux machine, we use command 'mkdir'. Syntax for
|
||||
using 'mkdir' is
|
||||
|
||||
**$ mkdir new_dir**
|
||||
|
||||
These were some of the useful linux commands that every System Admin should
|
||||
know, we will soon be sharing another list of some more important commands
|
||||
that you should know being a Linux lover. You can also leave your suggestions
|
||||
and queries in the comment box below.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/useful-linux-commands-you-should-know/
|
||||
|
||||
作者:[][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com
|
||||
[1]:http://linuxtechlab.com/ifconfig-command-learn-examples/
|
||||
[2]:http://linuxtechlab.com/scheduling-important-jobs-crontab/
|
||||
[3]:http://linuxtechlab.com/linux-disk-cloning-using-dd-cat-commands/
|
||||
[4]:http://linuxtechlab.com/du-df-commands-examples/
|
||||
[5]:http://linuxtechlab.com/working-vivim-editor-advanced-concepts/
|
||||
[6]:/cdn-cgi/l/email-protection#bbcec8dec9d5dad6defbf2ebdadfdfc9dec8c8
|
||||
[7]:http://linuxtechlab.com/tar-command-compress-decompress-files
|
||||
[8]:https://www.facebook.com/linuxtechlab/
|
||||
[9]:https://twitter.com/LinuxTechLab
|
||||
[10]:https://plus.google.com/+linuxtechlab
|
||||
[11]:http://linuxtechlab.com/contact-us-2/
|
||||
|
||||
@ -1,5 +1,6 @@
|
||||
3 Simple, Excellent Linux Network Monitors
|
||||
============================================================
|
||||
KeyLD translating
|
||||
|
||||

|
||||
Learn more about your network connections with the iftop, Nethogs, and vnstat tools.[Used with permission][3]
|
||||
|
||||
@ -1,713 +0,0 @@
|
||||
Translating by qhwdw Dive into BPF: a list of reading material
|
||||
============================================================
|
||||
|
||||
* [What is BPF?][143]
|
||||
|
||||
* [Dive into the bytecode][144]
|
||||
|
||||
* [Resources][145]
|
||||
* [Generic presentations][23]
|
||||
* [About BPF][1]
|
||||
|
||||
* [About XDP][2]
|
||||
|
||||
* [About other components related or based on eBPF][3]
|
||||
|
||||
* [Documentation][24]
|
||||
* [About BPF][4]
|
||||
|
||||
* [About tc][5]
|
||||
|
||||
* [About XDP][6]
|
||||
|
||||
* [About P4 and BPF][7]
|
||||
|
||||
* [Tutorials][25]
|
||||
|
||||
* [Examples][26]
|
||||
* [From the kernel][8]
|
||||
|
||||
* [From package iproute2][9]
|
||||
|
||||
* [From bcc set of tools][10]
|
||||
|
||||
* [Manual pages][11]
|
||||
|
||||
* [The code][27]
|
||||
* [BPF code in the kernel][12]
|
||||
|
||||
* [XDP hooks code][13]
|
||||
|
||||
* [BPF logic in bcc][14]
|
||||
|
||||
* [Code to manage BPF with tc][15]
|
||||
|
||||
* [BPF utilities][16]
|
||||
|
||||
* [Other interesting chunks][17]
|
||||
|
||||
* [LLVM backend][18]
|
||||
|
||||
* [Running in userspace][19]
|
||||
|
||||
* [Commit logs][20]
|
||||
|
||||
* [Troubleshooting][28]
|
||||
* [Errors at compilation time][21]
|
||||
|
||||
* [Errors at load and run time][22]
|
||||
|
||||
* [And still more!][29]
|
||||
|
||||
_~ [Updated][146] 2017-11-02 ~_
|
||||
|
||||
# What is BPF?
|
||||
|
||||
BPF, as in **B**erkeley **P**acket **F**ilter, was initially conceived in 1992 so as to provide a way to filter packets and to avoid useless packet copies from kernel to userspace. It initially consisted in a simple bytecode that is injected from userspace into the kernel, where it is checked by a verifier—to prevent kernel crashes or security issues—and attached to a socket, then run on each received packet. It was ported to Linux a couple of years later, and used for a small number of applications (tcpdump for example). The simplicity of the language as well as the existence of an in-kernel Just-In-Time (JIT) compiling machine for BPF were factors for the excellent performances of this tool.
|
||||
|
||||
Then in 2013, Alexei Starovoitov completely reshaped it, started to add new functionalities and to improve the performances of BPF. This new version is designated as eBPF (for “extended BPF”), while the former becomes cBPF (“classic” BPF). New features such as maps and tail calls appeared. The JIT machines were rewritten. The new language is even closer to native machine language than cBPF was. And also, new attach points in the kernel have been created.
|
||||
|
||||
Thanks to those new hooks, eBPF programs can be designed for a variety of use cases, that divide into two fields of applications. One of them is the domain of kernel tracing and event monitoring. BPF programs can be attached to kprobes and they compare with other tracing methods, with many advantages (and sometimes some drawbacks).
|
||||
|
||||
The other application domain remains network programming. In addition to socket filter, eBPF programs can be attached to tc (Linux traffic control tool) ingress or egress interfaces and perform a variety of packet processing tasks, in an efficient way. This opens new perspectives in the domain.
|
||||
|
||||
And eBPF performances are further leveraged through the technologies developed for the IO Visor project: new hooks have also been added for XDP (“eXpress Data Path”), a new fast path recently added to the kernel. XDP works in conjunction with the Linux stack, and relies on BPF to perform very fast packet processing.
|
||||
|
||||
Even some projects such as P4, Open vSwitch, [consider][155] or started to approach BPF. Some others, such as CETH, Cilium, are entirely based on it. BPF is buzzing, so we can expect a lot of tools and projects to orbit around it soon…
|
||||
|
||||
# Dive into the bytecode
|
||||
|
||||
As for me: some of my work (including for [BEBA][156]) is closely related to eBPF, and several future articles on this site will focus on this topic. Logically, I wanted to somehow introduce BPF on this blog before going down to the details—I mean, a real introduction, more developed on BPF functionalities that the brief abstract provided in first section: What are BPF maps? Tail calls? What do the internals look like? And so on. But there are a lot of presentations on this topic available on the web already, and I do not wish to create “yet another BPF introduction” that would come as a duplicate of existing documents.
|
||||
|
||||
So instead, here is what we will do. After all, I spent some time reading and learning about BPF, and while doing so, I gathered a fair amount of material about BPF: introductions, documentation, but also tutorials or examples. There is a lot to read, but in order to read it, one has to _find_ it first. Therefore, as an attempt to help people who wish to learn and use BPF, the present article introduces a list of resources. These are various kinds of readings, that hopefully will help you dive into the mechanics of this kernel bytecode.
|
||||
|
||||
# Resources
|
||||
|
||||

|
||||
|
||||
### Generic presentations
|
||||
|
||||
The documents linked below provide a generic overview of BPF, or of some closely related topics. If you are very new to BPF, you can try picking a couple of presentation among the first ones and reading the ones you like most. If you know eBPF already, you probably want to target specific topics instead, lower down in the list.
|
||||
|
||||
### About BPF
|
||||
|
||||
Generic presentations about eBPF:
|
||||
|
||||
* [_Making the Kernel’s Networking Data Path Programmable with BPF and XDP_][53] (Daniel Borkmann, OSSNA17, Los Angeles, September 2017):
|
||||
One of the best set of slides available to understand quickly all the basics about eBPF and XDP (mostly for network processing).
|
||||
|
||||
* [The BSD Packet Filter][54] (Suchakra Sharma, June 2017):
|
||||
A very nice introduction, mostly about the tracing aspects.
|
||||
|
||||
* [_BPF: tracing and more_][55] (Brendan Gregg, January 2017):
|
||||
Mostly about the tracing use cases.
|
||||
|
||||
* [_Linux BPF Superpowers_][56] (Brendan Gregg, March 2016):
|
||||
With a first part on the use of **flame graphs**.
|
||||
|
||||
* [_IO Visor_][57] (Brenden Blanco, SCaLE 14x, January 2016):
|
||||
Also introduces **IO Visor project**.
|
||||
|
||||
* [_eBPF on the Mainframe_][58] (Michael Holzheu, LinuxCon, Dubin, October 2015)
|
||||
|
||||
* [_New (and Exciting!) Developments in Linux Tracing_][59] (Elena Zannoni, LinuxCon, Japan, 2015)
|
||||
|
||||
* [_BPF — in-kernel virtual machine_][60] (Alexei Starovoitov, February 2015):
|
||||
Presentation by the author of eBPF.
|
||||
|
||||
* [_Extending extended BPF_][61] (Jonathan Corbet, July 2014)
|
||||
|
||||
**BPF internals**:
|
||||
|
||||
* Daniel Borkmann has been doing an amazing work to present **the internals** of eBPF, in particular about **its use with tc**, through several talks and papers.
|
||||
* [_Advanced programmability and recent updates with tc’s cls_bpf_][30] (netdev 1.2, Tokyo, October 2016):
|
||||
Daniel provides details on eBPF, its use for tunneling and encapsulation, direct packet access, and other features.
|
||||
|
||||
* [_cls_bpf/eBPF updates since netdev 1.1_][31] (netdev 1.2, Tokyo, October 2016, part of [this tc workshop][32])
|
||||
|
||||
* [_On getting tc classifier fully programmable with cls_bpf_][33] (netdev 1.1, Sevilla, February 2016):
|
||||
After introducing eBPF, this presentation provides insights on many internal BPF mechanisms (map management, tail calls, verifier). A must-read! For the most ambitious, [the full paper is available here][34].
|
||||
|
||||
* [_Linux tc and eBPF_][35] (fosdem16, Brussels, Belgium, January 2016)
|
||||
|
||||
* [_eBPF and XDP walkthrough and recent updates_][36] (fosdem17, Brussels, Belgium, February 2017)
|
||||
|
||||
These presentations are probably one of the best sources of documentation to understand the design and implementation of internal mechanisms of eBPF.
|
||||
|
||||
The [**IO Visor blog**][157] has some interesting technical articles about BPF. Some of them contain a bit of marketing talks.
|
||||
|
||||
**Kernel tracing**: summing up all existing methods, including BPF:
|
||||
|
||||
* [_Meet-cute between eBPF and Kerne Tracing_][62] (Viller Hsiao, July 2016):
|
||||
Kprobes, uprobes, ftrace
|
||||
|
||||
* [_Linux Kernel Tracing_][63] (Viller Hsiao, July 2016):
|
||||
Systemtap, Kernelshark, trace-cmd, LTTng, perf-tool, ftrace, hist-trigger, perf, function tracer, tracepoint, kprobe/uprobe…
|
||||
|
||||
Regarding **event tracing and monitoring**, Brendan Gregg uses eBPF a lot and does an excellent job at documenting some of his use cases. If you are in kernel tracing, you should see his blog articles related to eBPF or to flame graphs. Most of it are accessible [from this article][158] or by browsing his blog.
|
||||
|
||||
Introducing BPF, but also presenting **generic concepts of Linux networking**:
|
||||
|
||||
* [_Linux Networking Explained_][64] (Thomas Graf, LinuxCon, Toronto, August 2016)
|
||||
|
||||
* [_Kernel Networking Walkthrough_][65] (Thomas Graf, LinuxCon, Seattle, August 2015)
|
||||
|
||||
**Hardware offload**:
|
||||
|
||||
* eBPF with tc or XDP supports hardware offload, starting with Linux kernel version 4.9 and introduced by Netronome. Here is a presentation about this feature:
|
||||
[eBPF/XDP hardware offload to SmartNICs][147] (Jakub Kicinski and Nic Viljoen, netdev 1.2, Tokyo, October 2016)
|
||||
|
||||
About **cBPF**:
|
||||
|
||||
* [_The BSD Packet Filter: A New Architecture for User-level Packet Capture_][66] (Steven McCanne and Van Jacobson, 1992):
|
||||
The original paper about (classic) BPF.
|
||||
|
||||
* [The FreeBSD manual page about BPF][67] is a useful resource to understand cBPF programs.
|
||||
|
||||
* Daniel Borkmann realized at least two presentations on cBPF, [one in 2013 on mmap, BPF and Netsniff-NG][68], and [a very complete one in 2014 on tc and cls_bpf][69].
|
||||
|
||||
* On Cloudflare’s blog, Marek Majkowski presented his [use of BPF bytecode with the `xt_bpf`module for **iptables**][70]. It is worth mentioning that eBPF is also supported by this module, starting with Linux kernel 4.10 (I do not know of any talk or article about this, though).
|
||||
|
||||
* [Libpcap filters syntax][71]
|
||||
|
||||
### About XDP
|
||||
|
||||
* [XDP overview][72] on the IO Visor website.
|
||||
|
||||
* [_eXpress Data Path (XDP)_][73] (Tom Herbert, Alexei Starovoitov, March 2016):
|
||||
The first presentation about XDP.
|
||||
|
||||
* [_BoF - What Can BPF Do For You?_][74] (Brenden Blanco, LinuxCon, Toronto, August 2016).
|
||||
|
||||
* [_eXpress Data Path_][148] (Brenden Blanco, Linux Meetup at Santa Clara, July 2016):
|
||||
Contains some (somewhat marketing?) **benchmark results**! With a single core:
|
||||
* ip routing drop: ~3.6 million packets per second (Mpps)
|
||||
|
||||
* tc (with clsact qdisc) drop using BPF: ~4.2 Mpps
|
||||
|
||||
* XDP drop using BPF: 20 Mpps (<10 % CPU utilization)
|
||||
|
||||
* XDP forward (on port on which the packet was received) with rewrite: 10 Mpps
|
||||
|
||||
(Tests performed with the mlx4 driver).
|
||||
|
||||
* Jesper Dangaard Brouer has several excellent sets of slides, that are essential to fully understand the internals of XDP.
|
||||
* [_XDP − eXpress Data Path, Intro and future use-cases_][37] (September 2016):
|
||||
_“Linux Kernel’s fight against DPDK”_ . **Future plans** (as of this writing) for XDP and comparison with DPDK.
|
||||
|
||||
* [_Network Performance Workshop_][38] (netdev 1.2, Tokyo, October 2016):
|
||||
Additional hints about XDP internals and expected evolution.
|
||||
|
||||
* [_XDP – eXpress Data Path, Used for DDoS protection_][39] (OpenSourceDays, March 2017):
|
||||
Contains details and use cases about XDP, with **benchmark results**, and **code snippets** for **benchmarking** as well as for **basic DDoS protection** with eBPF/XDP (based on an IP blacklisting scheme).
|
||||
|
||||
* [_Memory vs. Networking, Provoking and fixing memory bottlenecks_][40] (LSF Memory Management Summit, March 2017):
|
||||
Provides a lot of details about current **memory issues** faced by XDP developers. Do not start with this one, but if you already know XDP and want to see how it really works on the page allocation side, this is a very helpful resource.
|
||||
|
||||
* [_XDP for the Rest of Us_][41] (netdev 2.1, Montreal, April 2017), with Andy Gospodarek:
|
||||
How to get started with eBPF and XDP for normal humans. This presentation was also summarized by Julia Evans on [her blog][42].
|
||||
|
||||
(Jesper also created and tries to extend some documentation about eBPF and XDP, see [related section][75].)
|
||||
|
||||
* [_XDP workshop — Introduction, experience, and future development_][76] (Tom Herbert, netdev 1.2, Tokyo, October 2016) — as of this writing, only the video is available, I don’t know if the slides will be added.
|
||||
|
||||
* [_High Speed Packet Filtering on Linux_][149] (Gilberto Bertin, DEF CON 25, Las Vegas, July 2017) — an excellent introduction to state-of-the-art packet filtering on Linux, oriented towards DDoS protection, talking about packet processing in the kernel, kernel bypass, XDP and eBPF.
|
||||
|
||||
### About other components related or based on eBPF
|
||||
|
||||
* [_P4 on the Edge_][77] (John Fastabend, May 2016):
|
||||
Presents the use of **P4**, a description language for packet processing, with BPF to create high-performance programmable switches.
|
||||
|
||||
* If you like audio presentations, there is an associated [OvS Orbit episode (#11), called _**P4** on the Edge_][78] , dating from August 2016\. OvS Orbit are interviews realized by Ben Pfaff, who is one of the core maintainers of Open vSwitch. In this case, John Fastabend is interviewed.
|
||||
|
||||
* [_P4, EBPF and Linux TC Offload_][79] (Dinan Gunawardena and Jakub Kicinski, August 2016):
|
||||
Another presentation on **P4**, with some elements related to eBPF hardware offload on Netronome’s **NFP** (Network Flow Processor) architecture.
|
||||
|
||||
* **Cilium** is a technology initiated by Cisco and relying on BPF and XDP to provide “fast in-kernel networking and security policy enforcement for containers based on eBPF programs generated on the fly”. [The code of this project][150] is available on GitHub. Thomas Graf has been performing a number of presentations of this topic:
|
||||
* [_Cilium: Networking & Security for Containers with BPF & XDP_][43] , also featuring a load balancer use case (Linux Plumbers conference, Santa Fe, November 2016)
|
||||
|
||||
* [_Cilium: Networking & Security for Containers with BPF & XDP_][44] (Docker Distributed Systems Summit, October 2016 — [video][45])
|
||||
|
||||
* [_Cilium: Fast IPv6 container Networking with BPF and XDP_][46] (LinuxCon, Toronto, August 2016)
|
||||
|
||||
* [_Cilium: BPF & XDP for containers_][47] (fosdem17, Brussels, Belgium, February 2017)
|
||||
|
||||
A good deal of contents is repeated between the different presentations; if in doubt, just pick the most recent one. Daniel Borkmann has also written [a generic introduction to Cilium][80] as a guest author on Google Open Source blog.
|
||||
|
||||
* There are also podcasts about **Cilium**: an [OvS Orbit episode (#4)][81], in which Ben Pfaff interviews Thomas Graf (May 2016), and [another podcast by Ivan Pepelnjak][82], still with Thomas Graf about eBPF, P4, XDP and Cilium (October 2016).
|
||||
|
||||
* **Open vSwitch** (OvS), and its related project **Open Virtual Network** (OVN, an open source network virtualization solution) are considering to use eBPF at various level, with several proof-of-concept prototypes already implemented:
|
||||
|
||||
* [Offloading OVS Flow Processing using eBPF][48] (William (Cheng-Chun) Tu, OvS conference, San Jose, November 2016)
|
||||
|
||||
* [Coupling the Flexibility of OVN with the Efficiency of IOVisor][49] (Fulvio Risso, Matteo Bertrone and Mauricio Vasquez Bernal, OvS conference, San Jose, November 2016)
|
||||
|
||||
These use cases for eBPF seem to be only at the stage of proposals (nothing merge to OvS main branch) as far as I know, but it will be very interesting to see what comes out of it.
|
||||
|
||||
* XDP is envisioned to be of great help for protection against Distributed Denial-of-Service (DDoS) attacks. More and more presentations focus on this. For example, the talks from people from Cloudflare ( [_XDP in practice: integrating XDP in our DDoS mitigation pipeline_][83] ) or from Facebook ( [_Droplet: DDoS countermeasures powered by BPF + XDP_][84] ) at the netdev 2.1 conference in Montreal, Canada, in April 2017, present such use cases.
|
||||
|
||||
* [_CETH for XDP_][85] (Yan Chan and Yunsong Lu, Linux Meetup, Santa Clara, July 2016):
|
||||
**CETH** stands for Common Ethernet Driver Framework for faster network I/O, a technology initiated by Mellanox.
|
||||
|
||||
* [**The VALE switch**][86], another virtual switch that can be used in conjunction with the netmap framework, has [a BPF extension module][87].
|
||||
|
||||
* **Suricata**, an open source intrusion detection system, [seems to rely on eBPF components][88] for its “capture bypass” features:
|
||||
[_The adventures of a Suricate in eBPF land_][89] (Éric Leblond, netdev 1.2, Tokyo, October 2016)
|
||||
[_eBPF and XDP seen from the eyes of a meerkat_][90] (Éric Leblond, Kernel Recipes, Paris, September 2017)
|
||||
|
||||
* [InKeV: In-Kernel Distributed Network Virtualization for DCN][91] (Z. Ahmed, M. H. Alizai and A. A. Syed, SIGCOMM, August 2016):
|
||||
**InKeV** is an eBPF-based datapath architecture for virtual networks, targeting data center networks. It was initiated by PLUMgrid, and claims to achieve better performances than OvS-based OpenStack solutions.
|
||||
|
||||
* [_**gobpf** - utilizing eBPF from Go_][92] (Michael Schubert, fosdem17, Brussels, Belgium, February 2017):
|
||||
A “library to create, load and use eBPF programs from Go”
|
||||
|
||||
* [**ply**][93] is a small but flexible open source dynamic **tracer** for Linux, with some features similar to the bcc tools, but with a simpler language inspired by awk and dtrace, written by Tobias Waldekranz.
|
||||
|
||||
* If you read my previous article, you might be interested in this talk I gave about [implementing the OpenState interface with eBPF][151], for stateful packet processing, at fosdem17.
|
||||
|
||||

|
||||
|
||||
### Documentation
|
||||
|
||||
Once you managed to get a broad idea of what BPF is, you can put aside generic presentations and start diving into the documentation. Below are the most complete documents about BPF specifications and functioning. Pick the one you need and read them carefully!
|
||||
|
||||
### About BPF
|
||||
|
||||
* The **specification of BPF** (both classic and extended versions) can be found within the documentation of the Linux kernel, and in particular in file[linux/Documentation/networking/filter.txt][94]. The use of BPF as well as its internals are documented there. Also, this is where you can find **information about errors thrown by the verifier** when loading BPF code fails. Can be helpful to troubleshoot obscure error messages.
|
||||
|
||||
* Also in the kernel tree, there is a document about **frequent Questions & Answers** on eBPF design in file [linux/Documentation/bpf/bpf_design_QA.txt][95].
|
||||
|
||||
* … But the kernel documentation is dense and not especially easy to read. If you look for a simple description of eBPF language, head for [its **summarized description**][96] on the IO Visor GitHub repository instead.
|
||||
|
||||
* By the way, the IO Visor project gathered a lot of **resources about BPF**. Mostly, it is split between[the documentation directory][97] of its bcc repository, and the whole content of [the bpf-docs repository][98], both on GitHub. Note the existence of this excellent [BPF **reference guide**][99] containing a detailed description of BPF C and bcc Python helpers.
|
||||
|
||||
* To hack with BPF, there are some essential **Linux manual pages**. The first one is [the `bpf(2)` man page][100] about the `bpf()` **system call**, which is used to manage BPF programs and maps from userspace. It also contains a description of BPF advanced features (program types, maps and so on). The second one is mostly addressed to people wanting to attach BPF programs to tc interface: it is [the `tc-bpf(8)` man page][101], which is a reference for **using BPF with tc**, and includes some example commands and samples of code.
|
||||
|
||||
* Jesper Dangaard Brouer initiated an attempt to **update eBPF Linux documentation**, including **the different kinds of maps**. [He has a draft][102] to which contributions are welcome. Once ready, this document should be merged into the man pages and into kernel documentation.
|
||||
|
||||
* The Cilium project also has an excellent [**BPF and XDP Reference Guide**][103], written by core eBPF developers, that should prove immensely useful to any eBPF developer.
|
||||
|
||||
* David Miller has sent several enlightening emails about eBPF/XDP internals on the [xdp-newbies][152]mailing list. I could not find a link that gathers them at a single place, so here is a list:
|
||||
* [bpf.h and you…][50]
|
||||
|
||||
* [Contextually speaking…][51]
|
||||
|
||||
* [BPF Verifier Overview][52]
|
||||
|
||||
The last one is possibly the best existing summary about the verifier at this date.
|
||||
|
||||
* Ferris Ellis started [a **blog post series about eBPF**][104]. As I write this paragraph, the first article is out, with some historical background and future expectations for eBPF. Next posts should be more technical, and look promising.
|
||||
|
||||
* [A **list of BPF features per kernel version**][153] is available in bcc repository. Useful is you want to know the minimal kernel version that is required to run a given feature. I contributed and added the links to the commits that introduced each feature, so you can also easily access the commit logs from there.
|
||||
|
||||
### About tc
|
||||
|
||||
When using BPF for networking purposes in conjunction with tc, the Linux tool for **t**raffic **c**ontrol, one may wish to gather information about tc’s generic functioning. Here are a couple of resources about it.
|
||||
|
||||
* It is difficult to find simple tutorials about **QoS on Linux**. The two links I have are long and quite dense, but if you can find the time to read it you will learn nearly everything there is to know about tc (nothing about BPF, though). There they are: [_Traffic Control HOWTO_ (Martin A. Brown, 2006)][105], and the [_Linux Advanced Routing & Traffic Control HOWTO_ (“LARTC”) (Bert Hubert & al., 2002)][106].
|
||||
|
||||
* **tc manual pages** may not be up-to-date on your system, since several of them have been added lately. If you cannot find the documentation for a particular queuing discipline (qdisc), class or filter, it may be worth checking the latest [manual pages for tc components][107].
|
||||
|
||||
* Some additional material can be found within the files of iproute2 package itself: the package contains [some documentation][108], including some files that helped me understand better [the functioning of **tc’s actions**][109].
|
||||
**Edit:** While still available from the Git history, these files have been deleted from iproute2 in October 2017.
|
||||
|
||||
* Not exactly documentation: there was [a workshop about several tc features][110] (including filtering, BPF, tc offload, …) organized by Jamal Hadi Salim during the netdev 1.2 conference (October 2016).
|
||||
|
||||
* Bonus information—If you use `tc` a lot, here are some good news: I [wrote a bash completion function][111] for this tool, and it should be shipped with package iproute2 coming with kernel version 4.6 and higher!
|
||||
|
||||
### About XDP
|
||||
|
||||
* Some [work-in-progress documentation (including specifications)][112] for XDP started by Jesper Dangaard Brouer, but meant to be a collaborative work. Under progress (September 2016): you should expect it to change, and maybe to be moved at some point (Jesper [called for contribution][113], if you feel like improving it).
|
||||
|
||||
* The [BPF and XDP Reference Guide][114] from Cilium project… Well, the name says it all.
|
||||
|
||||
### About P4 and BPF
|
||||
|
||||
[P4][159] is a language used to specify the behavior of a switch. It can be compiled for a number of hardware or software targets. As you may have guessed, one of these targets is BPF… The support is only partial: some P4 features cannot be translated towards BPF, and in a similar way there are things that BPF can do but that would not be possible to express with P4\. Anyway, the documentation related to **P4 use with BPF** [used to be hidden in bcc repository][160]. This changed with P4_16 version, the p4c reference compiler including [a backend for eBPF][161].
|
||||
|
||||

|
||||
|
||||
### Tutorials
|
||||
|
||||
Brendan Gregg has produced excellent **tutorials** intended for people who want to **use bcc tools** for tracing and monitoring events in the kernel. [The first tutorial about using bcc itself][162] comes with eleven steps (as of today) to understand how to use the existing tools, while [the one **intended for Python developers**][163] focuses on developing new tools, across seventeen “lessons”.
|
||||
|
||||
Sasha Goldshtein also has some [_**Linux Tracing Workshops Materials**_][164] involving the use of several BPF tools for tracing.
|
||||
|
||||
Another post by Jean-Tiare Le Bigot provides a detailed (and instructive!) example of [using perf and eBPF to setup a low-level tracer][165] for ping requests and replies
|
||||
|
||||
Few tutorials exist for network-related eBPF use cases. There are some interesting documents, including an _eBPF Offload Starting Guide_ , on the [Open NFP][166] platform operated by Netronome. Other than these, the talk from Jesper, [_XDP for the Rest of Us_][167] , is probably one of the best ways to get started with XDP.
|
||||
|
||||

|
||||
|
||||
### Examples
|
||||
|
||||
It is always nice to have examples. To see how things really work. But BPF program samples are scattered across several projects, so I listed all the ones I know of. The examples do not always use the same helpers (for instance, tc and bcc both have their own set of helpers to make it easier to write BPF programs in C language).
|
||||
|
||||
### From the kernel
|
||||
|
||||
The kernel contains examples for most types of program: filters to bind to sockets or to tc interfaces, event tracing/monitoring, and even XDP. You can find these examples under the [linux/samples/bpf/][168]directory.
|
||||
|
||||
Also do not forget to have a look to the logs related to the (git) commits that introduced a particular feature, they may contain some detailed example of the feature.
|
||||
|
||||
### From package iproute2
|
||||
|
||||
The iproute2 package provide several examples as well. They are obviously oriented towards network programming, since the programs are to be attached to tc ingress or egress interfaces. The examples dwell under the [iproute2/examples/bpf/][169] directory.
|
||||
|
||||
### From bcc set of tools
|
||||
|
||||
Many examples are [provided with bcc][170]:
|
||||
|
||||
* Some are networking example programs, under the associated directory. They include socket filters, tc filters, and a XDP program.
|
||||
|
||||
* The `tracing` directory include a lot of example **tracing programs**. The tutorials mentioned earlier are based on these. These programs cover a wide range of event monitoring functions, and some of them are production-oriented. Note that on certain Linux distributions (at least for Debian, Ubuntu, Fedora, Arch Linux), these programs have been [packaged][115] and can be “easily” installed by typing e.g. `# apt install bcc-tools`, but as of this writing (and except for Arch Linux), this first requires to set up IO Visor’s own package repository.
|
||||
|
||||
* There are also some examples **using Lua** as a different BPF back-end (that is, BPF programs are written with Lua instead of a subset of C, allowing to use the same language for front-end and back-end), in the third directory.
|
||||
|
||||
### Manual pages
|
||||
|
||||
While bcc is generally the easiest way to inject and run a BPF program in the kernel, attaching programs to tc interfaces can also be performed by the `tc` tool itself. So if you intend to **use BPF with tc**, you can find some example invocations in the [`tc-bpf(8)` manual page][171].
|
||||
|
||||

|
||||
|
||||
### The code
|
||||
|
||||
Sometimes, BPF documentation or examples are not enough, and you may have no other solution that to display the code in your favorite text editor (which should be Vim of course) and to read it. Or you may want to hack into the code so as to patch or add features to the machine. So here are a few pointers to the relevant files, finding the functions you want is up to you!
|
||||
|
||||
### BPF code in the kernel
|
||||
|
||||
* The file [linux/include/linux/bpf.h][116] and its counterpart [linux/include/uapi/bpf.h][117] contain **definitions** related to eBPF, to be used respectively in the kernel and to interface with userspace programs.
|
||||
|
||||
* On the same pattern, files [linux/include/linux/filter.h][118] and [linux/include/uapi/filter.h][119] contain information used to **run the BPF programs**.
|
||||
|
||||
* The **main pieces of code** related to BPF are under [linux/kernel/bpf/][120] directory. **The different operations permitted by the system call**, such as program loading or map management, are implemented in file `syscall.c`, while `core.c` contains the **interpreter**. The other files have self-explanatory names: `verifier.c` contains the **verifier** (no kidding), `arraymap.c` the code used to interact with **maps** of type array, and so on.
|
||||
|
||||
* The **helpers**, as well as several functions related to networking (with tc, XDP…) and available to the user, are implemented in [linux/net/core/filter.c][121]. It also contains the code to migrate cBPF bytecode to eBPF (since all cBPF programs are now translated to eBPF in the kernel before being run).
|
||||
|
||||
* The **JIT compilers** are under the directory of their respective architectures, such as file[linux/arch/x86/net/bpf_jit_comp.c][122] for x86.
|
||||
|
||||
* You will find the code related to **the BPF components of tc** in the [linux/net/sched/][123] directory, and in particular in files `act_bpf.c` (action) and `cls_bpf.c` (filter).
|
||||
|
||||
* I have not hacked with **event tracing** in BPF, so I do not really know about the hooks for such programs. There is some stuff in [linux/kernel/trace/bpf_trace.c][124]. If you are interested in this and want to know more, you may dig on the side of Brendan Gregg’s presentations or blog posts.
|
||||
|
||||
* Nor have I used **seccomp-BPF**. But the code is in [linux/kernel/seccomp.c][125], and some example use cases can be found in [linux/tools/testing/selftests/seccomp/seccomp_bpf.c][126].
|
||||
|
||||
### XDP hooks code
|
||||
|
||||
Once loaded into the in-kernel BPF virtual machine, **XDP** programs are hooked from userspace into the kernel network path thanks to a Netlink command. On reception, the function `dev_change_xdp_fd()` in file [linux/net/core/dev.c][172] is called and sets a XDP hook. Such hooks are located in the drivers of supported NICs. For example, the mlx4 driver used for some Mellanox hardware has hooks implemented in files under the [drivers/net/ethernet/mellanox/mlx4/][173] directory. File en_netdev.c receives Netlink commands and calls `mlx4_xdp_set()`, which in turns calls for instance `mlx4_en_process_rx_cq()` (for the RX side) implemented in file en_rx.c.
|
||||
|
||||
### BPF logic in bcc
|
||||
|
||||
One can find the code for the **bcc** set of tools [on the bcc GitHub repository][174]. The **Python code**, including the `BPF` class, is initiated in file [bcc/src/python/bcc/__init__.py][175]. But most of the interesting stuff—to my opinion—such as loading the BPF program into the kernel, happens [in the libbcc **C library**][176].
|
||||
|
||||
### Code to manage BPF with tc
|
||||
|
||||
The code related to BPF **in tc** comes with the iproute2 package, of course. Some of it is under the[iproute2/tc/][177] directory. The files f_bpf.c and m_bpf.c (and e_bpf.c) are used respectively to handle BPF filters and actions (and tc `exec` command, whatever this may be). File q_clsact.c defines the `clsact` qdisc especially created for BPF. But **most of the BPF userspace logic** is implemented in[iproute2/lib/bpf.c][178] library, so this is probably where you should head to if you want to mess up with BPF and tc (it was moved from file iproute2/tc/tc_bpf.c, where you may find the same code in older versions of the package).
|
||||
|
||||
### BPF utilities
|
||||
|
||||
The kernel also ships the sources of three tools (`bpf_asm.c`, `bpf_dbg.c`, `bpf_jit_disasm.c`) related to BPF, under the [linux/tools/net/][179] or [linux/tools/bpf/][180] directory depending on your version:
|
||||
|
||||
* `bpf_asm` is a minimal cBPF assembler.
|
||||
|
||||
* `bpf_dbg` is a small debugger for cBPF programs.
|
||||
|
||||
* `bpf_jit_disasm` is generic for both BPF flavors and could be highly useful for JIT debugging.
|
||||
|
||||
* `bpftool` is a generic utility written by Jakub Kicinski, and that can be used to interact with eBPF programs and maps from userspace, for example to show, dump, pin programs, or to show, create, pin, update, delete maps.
|
||||
|
||||
Read the comments at the top of the source files to get an overview of their usage.
|
||||
|
||||
### Other interesting chunks
|
||||
|
||||
If you are interested the use of less common languages with BPF, bcc contains [a **P4 compiler** for BPF targets][181] as well as [a **Lua front-end**][182] that can be used as alternatives to the C subset and (in the case of Lua) to the Python tools.
|
||||
|
||||
### LLVM backend
|
||||
|
||||
The BPF backend used by clang / LLVM for compiling C into eBPF was added to the LLVM sources in[this commit][183] (and can also be accessed on [the GitHub mirror][184]).
|
||||
|
||||
### Running in userspace
|
||||
|
||||
As far as I know there are at least two eBPF userspace implementations. The first one, [uBPF][185], is written in C. It contains an interpreter, a JIT compiler for x86_64 architecture, an assembler and a disassembler.
|
||||
|
||||
The code of uBPF seems to have been reused to produce a [generic implementation][186], that claims to support FreeBSD kernel, FreeBSD userspace, Linux kernel, Linux userspace and MacOSX userspace. It is used for the [BPF extension module for VALE switch][187].
|
||||
|
||||
The other userspace implementation is my own work: [rbpf][188], based on uBPF, but written in Rust. The interpreter and JIT-compiler work (both under Linux, only the interpreter for MacOSX and Windows), there may be more in the future.
|
||||
|
||||
### Commit logs
|
||||
|
||||
As stated earlier, do not hesitate to have a look at the commit log that introduced a particular BPF feature if you want to have more information about it. You can search the logs in many places, such as on [git.kernel.org][189], [on GitHub][190], or on your local repository if you have cloned it. If you are not familiar with git, try things like `git blame <file>` to see what commit introduced a particular line of code, then `git show <commit>` to have details (or search by keyword in `git log` results, but this may be tedious). See also [the list of eBPF features per kernel version][191] on bcc repository, that links to relevant commits.
|
||||
|
||||

|
||||
|
||||
### Troubleshooting
|
||||
|
||||
The enthusiasm about eBPF is quite recent, and so far I have not found a lot of resources intending to help with troubleshooting. So here are the few I have, augmented with my own recollection of pitfalls encountered while working with BPF.
|
||||
|
||||
### Errors at compilation time
|
||||
|
||||
* Make sure you have a recent enough version of the Linux kernel (see also [this document][127]).
|
||||
|
||||
* If you compiled the kernel yourself: make sure you installed correctly all components, including kernel image, headers and libc.
|
||||
|
||||
* When using the `bcc` shell function provided by `tc-bpf` man page (to compile C code into BPF): I once had to add includes to the header for the clang call:
|
||||
|
||||
```
|
||||
__bcc() {
|
||||
clang -O2 -I "/usr/src/linux-headers-$(uname -r)/include/" \
|
||||
-I "/usr/src/linux-headers-$(uname -r)/arch/x86/include/" \
|
||||
-emit-llvm -c $1 -o - | \
|
||||
llc -march=bpf -filetype=obj -o "`basename $1 .c`.o"
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
(seems fixed as of today).
|
||||
|
||||
* For other problems with `bcc`, do not forget to have a look at [the FAQ][128] of the tool set.
|
||||
|
||||
* If you downloaded the examples from the iproute2 package in a version that does not exactly match your kernel, some errors can be triggered by the headers included in the files. The example snippets indeed assume that the same version of iproute2 package and kernel headers are installed on the system. If this is not the case, download the correct version of iproute2, or edit the path of included files in the examples to point to the headers included in iproute2 (some problems may or may not occur at runtime, depending on the features in use).
|
||||
|
||||
### Errors at load and run time
|
||||
|
||||
* To load a program with tc, make sure you use a tc binary coming from an iproute2 version equivalent to the kernel in use.
|
||||
|
||||
* To load a program with bcc, make sure you have bcc installed on the system (just downloading the sources to run the Python script is not enough).
|
||||
|
||||
* With tc, if the BPF program does not return the expected values, check that you called it in the correct fashion: filter, or action, or filter with “direct-action” mode.
|
||||
|
||||
* With tc still, note that actions cannot be attached directly to qdiscs or interfaces without the use of a filter.
|
||||
|
||||
* The errors thrown by the in-kernel verifier may be hard to interpret. [The kernel documentation][129]may help, so may [the reference guide][130] or, as a last resort, the source code (see above) (good luck!). For this kind of errors it is also important to keep in mind that the verifier _does not run_ the program. If you get an error about an invalid memory access or about uninitialized data, it does not mean that these problems actually occurred (or sometimes, that they can possibly occur at all). It means that your program is written in such a way that the verifier estimates that such errors could happen, and therefore it rejects the program.
|
||||
|
||||
* Note that `tc` tool has a verbose mode, and that it works well with BPF: try appending `verbose`at the end of your command line.
|
||||
|
||||
* bcc also has verbose options: the `BPF` class has a `debug` argument that can take any combination of the three flags `DEBUG_LLVM_IR`, `DEBUG_BPF` and `DEBUG_PREPROCESSOR` (see details in [the source file][131]). It even embeds [some facilities to print output messages][132] for debugging the code.
|
||||
|
||||
* LLVM v4.0+ [embeds a disassembler][133] for eBPF programs. So if you compile your program with clang, adding the `-g` flag for compiling enables you to later dump your program in the rather human-friendly format used by the kernel verifier. To proceed to the dump, use:
|
||||
|
||||
```
|
||||
$ llvm-objdump -S -no-show-raw-insn bpf_program.o
|
||||
|
||||
```
|
||||
|
||||
* Working with maps? You want to have a look at [bpf-map][134], a very userful tool in Go created for the Cilium project, that can be used to dump the contents of kernel eBPF maps. There also exists [a clone][135] in Rust.
|
||||
|
||||
* There is an old [`bpf` tag on **StackOverflow**][136], but as of this writing it has been hardly used—ever (and there is nearly nothing related to the new eBPF version). If you are a reader from the Future though, you may want to check whether there has been more activity on this side.
|
||||
|
||||

|
||||
|
||||
### And still more!
|
||||
|
||||
* In case you would like to easily **test XDP**, there is [a Vagrant setup][137] available. You can also **test bcc**[in a Docker container][138].
|
||||
|
||||
* Wondering where the **development and activities** around BPF occur? Well, the kernel patches always end up [on the netdev mailing list][139] (related to the Linux kernel networking stack development): search for “BPF” or “XDP” keywords. Since April 2017, there is also [a mailing list specially dedicated to XDP programming][140] (both for architecture or for asking for help). Many discussions and debates also occur [on the IO Visor mailing list][141], since BPF is at the heart of the project. If you only want to keep informed from time to time, there is also an [@IOVisor Twitter account][142].
|
||||
|
||||
And come back on this blog from time to time to see if they are new articles [about BPF][192]!
|
||||
|
||||
_Special thanks to Daniel Borkmann for the numerous [additional documents][154] he pointed to me so that I could complete this collection._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/
|
||||
|
||||
作者:[Quentin Monnet ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://qmonnet.github.io/whirl-offload/about/
|
||||
[1]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#about-bpf
|
||||
[2]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#about-xdp
|
||||
[3]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#about-other-components-related-or-based-on-ebpf
|
||||
[4]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#about-bpf-1
|
||||
[5]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#about-tc
|
||||
[6]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#about-xdp-1
|
||||
[7]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#about-p4-and-bpf
|
||||
[8]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#from-the-kernel
|
||||
[9]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#from-package-iproute2
|
||||
[10]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#from-bcc-set-of-tools
|
||||
[11]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#manual-pages
|
||||
[12]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#bpf-code-in-the-kernel
|
||||
[13]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#xdp-hooks-code
|
||||
[14]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#bpf-logic-in-bcc
|
||||
[15]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#code-to-manage-bpf-with-tc
|
||||
[16]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#bpf-utilities
|
||||
[17]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#other-interesting-chunks
|
||||
[18]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#llvm-backend
|
||||
[19]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#running-in-userspace
|
||||
[20]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#commit-logs
|
||||
[21]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#errors-at-compilation-time
|
||||
[22]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#errors-at-load-and-run-time
|
||||
[23]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#generic-presentations
|
||||
[24]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#documentation
|
||||
[25]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#tutorials
|
||||
[26]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#examples
|
||||
[27]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#the-code
|
||||
[28]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#troubleshooting
|
||||
[29]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#and-still-more
|
||||
[30]:http://netdevconf.org/1.2/session.html?daniel-borkmann
|
||||
[31]:http://netdevconf.org/1.2/slides/oct5/07_tcws_daniel_borkmann_2016_tcws.pdf
|
||||
[32]:http://netdevconf.org/1.2/session.html?jamal-tc-workshop
|
||||
[33]:http://www.netdevconf.org/1.1/proceedings/slides/borkmann-tc-classifier-cls-bpf.pdf
|
||||
[34]:http://www.netdevconf.org/1.1/proceedings/papers/On-getting-tc-classifier-fully-programmable-with-cls-bpf.pdf
|
||||
[35]:https://archive.fosdem.org/2016/schedule/event/ebpf/attachments/slides/1159/export/events/attachments/ebpf/slides/1159/ebpf.pdf
|
||||
[36]:https://fosdem.org/2017/schedule/event/ebpf_xdp/
|
||||
[37]:http://people.netfilter.org/hawk/presentations/xdp2016/xdp_intro_and_use_cases_sep2016.pdf
|
||||
[38]:http://netdevconf.org/1.2/session.html?jesper-performance-workshop
|
||||
[39]:http://people.netfilter.org/hawk/presentations/OpenSourceDays2017/XDP_DDoS_protecting_osd2017.pdf
|
||||
[40]:http://people.netfilter.org/hawk/presentations/MM-summit2017/MM-summit2017-JesperBrouer.pdf
|
||||
[41]:http://netdevconf.org/2.1/session.html?gospodarek
|
||||
[42]:http://jvns.ca/blog/2017/04/07/xdp-bpf-tutorial/
|
||||
[43]:http://www.slideshare.net/ThomasGraf5/clium-container-networking-with-bpf-xdp
|
||||
[44]:http://www.slideshare.net/Docker/cilium-bpf-xdp-for-containers-66969823
|
||||
[45]:https://www.youtube.com/watch?v=TnJF7ht3ZYc&list=PLkA60AVN3hh8oPas3cq2VA9xB7WazcIgs
|
||||
[46]:http://www.slideshare.net/ThomasGraf5/cilium-fast-ipv6-container-networking-with-bpf-and-xdp
|
||||
[47]:https://fosdem.org/2017/schedule/event/cilium/
|
||||
[48]:http://openvswitch.org/support/ovscon2016/7/1120-tu.pdf
|
||||
[49]:http://openvswitch.org/support/ovscon2016/7/1245-bertrone.pdf
|
||||
[50]:https://www.spinics.net/lists/xdp-newbies/msg00179.html
|
||||
[51]:https://www.spinics.net/lists/xdp-newbies/msg00181.html
|
||||
[52]:https://www.spinics.net/lists/xdp-newbies/msg00185.html
|
||||
[53]:http://schd.ws/hosted_files/ossna2017/da/BPFandXDP.pdf
|
||||
[54]:https://speakerdeck.com/tuxology/the-bsd-packet-filter
|
||||
[55]:http://www.slideshare.net/brendangregg/bpf-tracing-and-more
|
||||
[56]:http://fr.slideshare.net/brendangregg/linux-bpf-superpowers
|
||||
[57]:https://www.socallinuxexpo.org/sites/default/files/presentations/Room%20211%20-%20IOVisor%20-%20SCaLE%2014x.pdf
|
||||
[58]:https://events.linuxfoundation.org/sites/events/files/slides/ebpf_on_the_mainframe_lcon_2015.pdf
|
||||
[59]:https://events.linuxfoundation.org/sites/events/files/slides/tracing-linux-ezannoni-linuxcon-ja-2015_0.pdf
|
||||
[60]:https://events.linuxfoundation.org/sites/events/files/slides/bpf_collabsummit_2015feb20.pdf
|
||||
[61]:https://lwn.net/Articles/603983/
|
||||
[62]:http://www.slideshare.net/vh21/meet-cutebetweenebpfandtracing
|
||||
[63]:http://www.slideshare.net/vh21/linux-kernel-tracing
|
||||
[64]:http://www.slideshare.net/ThomasGraf5/linux-networking-explained
|
||||
[65]:http://www.slideshare.net/ThomasGraf5/linuxcon-2015-linux-kernel-networking-walkthrough
|
||||
[66]:http://www.tcpdump.org/papers/bpf-usenix93.pdf
|
||||
[67]:http://www.gsp.com/cgi-bin/man.cgi?topic=bpf
|
||||
[68]:http://borkmann.ch/talks/2013_devconf.pdf
|
||||
[69]:http://borkmann.ch/talks/2014_devconf.pdf
|
||||
[70]:https://blog.cloudflare.com/introducing-the-bpf-tools/
|
||||
[71]:http://biot.com/capstats/bpf.html
|
||||
[72]:https://www.iovisor.org/technology/xdp
|
||||
[73]:https://github.com/iovisor/bpf-docs/raw/master/Express_Data_Path.pdf
|
||||
[74]:https://events.linuxfoundation.org/sites/events/files/slides/iovisor-lc-bof-2016.pdf
|
||||
[75]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#about-xdp-1
|
||||
[76]:http://netdevconf.org/1.2/session.html?herbert-xdp-workshop
|
||||
[77]:https://schd.ws/hosted_files/2016p4workshop/1d/Intel%20Fastabend-P4%20on%20the%20Edge.pdf
|
||||
[78]:https://ovsorbit.benpfaff.org/#e11
|
||||
[79]:http://open-nfp.org/media/pdfs/Open_NFP_P4_EBPF_Linux_TC_Offload_FINAL.pdf
|
||||
[80]:https://opensource.googleblog.com/2016/11/cilium-networking-and-security.html
|
||||
[81]:https://ovsorbit.benpfaff.org/
|
||||
[82]:http://blog.ipspace.net/2016/10/fast-linux-packet-forwarding-with.html
|
||||
[83]:http://netdevconf.org/2.1/session.html?bertin
|
||||
[84]:http://netdevconf.org/2.1/session.html?zhou
|
||||
[85]:http://www.slideshare.net/IOVisor/ceth-for-xdp-linux-meetup-santa-clara-july-2016
|
||||
[86]:http://info.iet.unipi.it/~luigi/vale/
|
||||
[87]:https://github.com/YutaroHayakawa/vale-bpf
|
||||
[88]:https://www.stamus-networks.com/2016/09/28/suricata-bypass-feature/
|
||||
[89]:http://netdevconf.org/1.2/slides/oct6/10_suricata_ebpf.pdf
|
||||
[90]:https://www.slideshare.net/ennael/kernel-recipes-2017-ebpf-and-xdp-eric-leblond
|
||||
[91]:https://github.com/iovisor/bpf-docs/blob/master/university/sigcomm-ccr-InKev-2016.pdf
|
||||
[92]:https://fosdem.org/2017/schedule/event/go_bpf/
|
||||
[93]:https://wkz.github.io/ply/
|
||||
[94]:https://www.kernel.org/doc/Documentation/networking/filter.txt
|
||||
[95]:https://git.kernel.org/pub/scm/linux/kernel/git/davem/net-next.git/tree/Documentation/bpf/bpf_design_QA.txt?id=2e39748a4231a893f057567e9b880ab34ea47aef
|
||||
[96]:https://github.com/iovisor/bpf-docs/blob/master/eBPF.md
|
||||
[97]:https://github.com/iovisor/bcc/tree/master/docs
|
||||
[98]:https://github.com/iovisor/bpf-docs/
|
||||
[99]:https://github.com/iovisor/bcc/blob/master/docs/reference_guide.md
|
||||
[100]:http://man7.org/linux/man-pages/man2/bpf.2.html
|
||||
[101]:http://man7.org/linux/man-pages/man8/tc-bpf.8.html
|
||||
[102]:https://prototype-kernel.readthedocs.io/en/latest/bpf/index.html
|
||||
[103]:http://docs.cilium.io/en/latest/bpf/
|
||||
[104]:https://ferrisellis.com/tags/ebpf/
|
||||
[105]:http://linux-ip.net/articles/Traffic-Control-HOWTO/
|
||||
[106]:http://lartc.org/lartc.html
|
||||
[107]:https://git.kernel.org/cgit/linux/kernel/git/shemminger/iproute2.git/tree/man/man8
|
||||
[108]:https://git.kernel.org/pub/scm/linux/kernel/git/shemminger/iproute2.git/tree/doc?h=v4.13.0
|
||||
[109]:https://git.kernel.org/pub/scm/linux/kernel/git/shemminger/iproute2.git/tree/doc/actions?h=v4.13.0
|
||||
[110]:http://netdevconf.org/1.2/session.html?jamal-tc-workshop
|
||||
[111]:https://git.kernel.org/cgit/linux/kernel/git/shemminger/iproute2.git/commit/bash-completion/tc?id=27d44f3a8a4708bcc99995a4d9b6fe6f81e3e15b
|
||||
[112]:https://prototype-kernel.readthedocs.io/en/latest/networking/XDP/index.html
|
||||
[113]:https://marc.info/?l=linux-netdev&m=147436253625672
|
||||
[114]:http://docs.cilium.io/en/latest/bpf/
|
||||
[115]:https://github.com/iovisor/bcc/blob/master/INSTALL.md
|
||||
[116]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/include/linux/bpf.h
|
||||
[117]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/include/uapi/linux/bpf.h
|
||||
[118]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/include/linux/filter.h
|
||||
[119]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/include/uapi/linux/filter.h
|
||||
[120]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/kernel/bpf
|
||||
[121]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/net/core/filter.c
|
||||
[122]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/arch/x86/net/bpf_jit_comp.c
|
||||
[123]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/net/sched
|
||||
[124]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/kernel/trace/bpf_trace.c
|
||||
[125]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/kernel/seccomp.c
|
||||
[126]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/tools/testing/selftests/seccomp/seccomp_bpf.c
|
||||
[127]:https://github.com/iovisor/bcc/blob/master/docs/kernel-versions.md
|
||||
[128]:https://github.com/iovisor/bcc/blob/master/FAQ.txt
|
||||
[129]:https://www.kernel.org/doc/Documentation/networking/filter.txt
|
||||
[130]:https://github.com/iovisor/bcc/blob/master/docs/reference_guide.md
|
||||
[131]:https://github.com/iovisor/bcc/blob/master/src/python/bcc/__init__.py
|
||||
[132]:https://github.com/iovisor/bcc/blob/master/docs/reference_guide.md#output
|
||||
[133]:https://www.spinics.net/lists/netdev/msg406926.html
|
||||
[134]:https://github.com/cilium/bpf-map
|
||||
[135]:https://github.com/badboy/bpf-map
|
||||
[136]:https://stackoverflow.com/questions/tagged/bpf
|
||||
[137]:https://github.com/iovisor/xdp-vagrant
|
||||
[138]:https://github.com/zlim/bcc-docker
|
||||
[139]:http://lists.openwall.net/netdev/
|
||||
[140]:http://vger.kernel.org/vger-lists.html#xdp-newbies
|
||||
[141]:http://lists.iovisor.org/pipermail/iovisor-dev/
|
||||
[142]:https://twitter.com/IOVisor
|
||||
[143]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#what-is-bpf
|
||||
[144]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#dive-into-the-bytecode
|
||||
[145]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#resources
|
||||
[146]:https://github.com/qmonnet/whirl-offload/commits/gh-pages/_posts/2016-09-01-dive-into-bpf.md
|
||||
[147]:http://netdevconf.org/1.2/session.html?jakub-kicinski
|
||||
[148]:http://www.slideshare.net/IOVisor/express-data-path-linux-meetup-santa-clara-july-2016
|
||||
[149]:https://cdn.shopify.com/s/files/1/0177/9886/files/phv2017-gbertin.pdf
|
||||
[150]:https://github.com/cilium/cilium
|
||||
[151]:https://fosdem.org/2017/schedule/event/stateful_ebpf/
|
||||
[152]:http://vger.kernel.org/vger-lists.html#xdp-newbies
|
||||
[153]:https://github.com/iovisor/bcc/blob/master/docs/kernel-versions.md
|
||||
[154]:https://github.com/qmonnet/whirl-offload/commit/d694f8081ba00e686e34f86d5ee76abeb4d0e429
|
||||
[155]:http://openvswitch.org/pipermail/dev/2014-October/047421.html
|
||||
[156]:https://qmonnet.github.io/whirl-offload/2016/07/15/beba-research-project/
|
||||
[157]:https://www.iovisor.org/resources/blog
|
||||
[158]:http://www.brendangregg.com/blog/2016-03-05/linux-bpf-superpowers.html
|
||||
[159]:http://p4.org/
|
||||
[160]:https://github.com/iovisor/bcc/tree/master/src/cc/frontends/p4
|
||||
[161]:https://github.com/p4lang/p4c/blob/master/backends/ebpf/README.md
|
||||
[162]:https://github.com/iovisor/bcc/blob/master/docs/reference_guide.md
|
||||
[163]:https://github.com/iovisor/bcc/blob/master/docs/tutorial_bcc_python_developer.md
|
||||
[164]:https://github.com/goldshtn/linux-tracing-workshop
|
||||
[165]:https://blog.yadutaf.fr/2017/07/28/tracing-a-packet-journey-using-linux-tracepoints-perf-ebpf/
|
||||
[166]:https://open-nfp.org/dataplanes-ebpf/technical-papers/
|
||||
[167]:http://netdevconf.org/2.1/session.html?gospodarek
|
||||
[168]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/samples/bpf
|
||||
[169]:https://git.kernel.org/cgit/linux/kernel/git/shemminger/iproute2.git/tree/examples/bpf
|
||||
[170]:https://github.com/iovisor/bcc/tree/master/examples
|
||||
[171]:http://man7.org/linux/man-pages/man8/tc-bpf.8.html
|
||||
[172]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/net/core/dev.c
|
||||
[173]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/drivers/net/ethernet/mellanox/mlx4/
|
||||
[174]:https://github.com/iovisor/bcc/
|
||||
[175]:https://github.com/iovisor/bcc/blob/master/src/python/bcc/__init__.py
|
||||
[176]:https://github.com/iovisor/bcc/blob/master/src/cc/libbpf.c
|
||||
[177]:https://git.kernel.org/cgit/linux/kernel/git/shemminger/iproute2.git/tree/tc
|
||||
[178]:https://git.kernel.org/cgit/linux/kernel/git/shemminger/iproute2.git/tree/lib/bpf.c
|
||||
[179]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/tools/net
|
||||
[180]:https://git.kernel.org/pub/scm/linux/kernel/git/davem/net-next.git/tree/tools/bpf
|
||||
[181]:https://github.com/iovisor/bcc/tree/master/src/cc/frontends/p4/compiler
|
||||
[182]:https://github.com/iovisor/bcc/tree/master/src/lua
|
||||
[183]:https://reviews.llvm.org/D6494
|
||||
[184]:https://github.com/llvm-mirror/llvm/commit/4fe85c75482f9d11c5a1f92a1863ce30afad8d0d
|
||||
[185]:https://github.com/iovisor/ubpf/
|
||||
[186]:https://github.com/YutaroHayakawa/generic-ebpf
|
||||
[187]:https://github.com/YutaroHayakawa/vale-bpf
|
||||
[188]:https://github.com/qmonnet/rbpf
|
||||
[189]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git
|
||||
[190]:https://github.com/torvalds/linux
|
||||
[191]:https://github.com/iovisor/bcc/blob/master/docs/kernel-versions.md
|
||||
[192]:https://qmonnet.github.io/whirl-offload/categories/#BPF
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
Security Jobs Are Hot: Get Trained and Get Noticed
|
||||
============================================================
|
||||
|
||||
|
||||
264
sources/tech/20171119 10 Best LaTeX Editors For Linux.md
Normal file
264
sources/tech/20171119 10 Best LaTeX Editors For Linux.md
Normal file
@ -0,0 +1,264 @@
|
||||
10 Best LaTeX Editors For Linux
|
||||
======
|
||||
**Brief: Once you get over the learning curve, there is nothing like LaTex.
|
||||
Here are the best LaTex editors for Linux and other systems.**
|
||||
|
||||
## What is LaTeX?
|
||||
|
||||
[LaTeX][1] is a document preparation system. Unlike plain text editor, you
|
||||
can't just write a plain text using LaTeX editors. Here, you will have to
|
||||
utilize LaTeX commands in order to manage the content of the document.
|
||||
|
||||
![LaTex Sample][2]![LaTex Sample][3]
|
||||
|
||||
LaTex Editors are generally used to publish scientific research documents or
|
||||
books for academic purposes. Most importantly, LaText editors come handy while
|
||||
dealing with a document containing complex Mathematical notations. Surely,
|
||||
LaTeX editors are fun to use. But, not that useful unless you have specific
|
||||
needs for a document.
|
||||
|
||||
## Why should you use LaTex?
|
||||
|
||||
Well, just like I previously mentioned, LaTeX editors are meant for specific
|
||||
purposes. You do not need to be a geek head in order to figure out the way to
|
||||
use LaTeX editors but it is not a productive solution for users who deal with
|
||||
basic text editors.
|
||||
|
||||
If you are looking to craft a document but you are not interested in spending
|
||||
time formatting the text, then LaTeX editors should be the one you should go
|
||||
for. With LaTeX editors, you just have to specify the type of document, and
|
||||
the text font and sizes will be taken care of accordingly. No wonder it is
|
||||
considered one of the [best open source tools for writers][4].
|
||||
|
||||
Do note that it isn't something automated, you will have to first learn LaTeX
|
||||
commands to let the editor handle the text formatting with precision.
|
||||
|
||||
## 10 Of The Best LaTeX Editors For Linux
|
||||
|
||||
Just for information, the list is not in any specific order. Editor at number
|
||||
three is not better than the editor at number seven.
|
||||
|
||||
### 1\. Lyx
|
||||
|
||||
![][2]
|
||||
|
||||
![][5]
|
||||
|
||||
Lyx is an open source LaTeX Editor. In other words, it is one of the best
|
||||
document processors available on the web.LyX helps you focus on the structure
|
||||
of the write-up, just as every LaTeX editor should and lets you forget about
|
||||
the word formatting. LyX would manage whatsoever depending on the type of
|
||||
document specified. You get to control a lot of stuff while you have it
|
||||
installed. The margins, headers/footers, spacing/indents, tables, and so on.
|
||||
|
||||
If you are into crafting scientific documents, research thesis, or similar,
|
||||
you will be delighted to experience Lyx's formula editor which should be a
|
||||
charm to use. LyX also includes a set of tutorials to get started without much
|
||||
of a hassle.
|
||||
|
||||
[Lyx][6]
|
||||
|
||||
### 2\. Texmaker
|
||||
|
||||
![][2]
|
||||
|
||||
![][7]
|
||||
|
||||
Texmaker is considered to be one of the best LaTeX editors for GNOME desktop
|
||||
environment. It presents a great user interface which results in a good user
|
||||
experience. It is also crowned to be one among the most useful LaTeX editor
|
||||
there is.If you perform PDF conversions often, you will find TeXmaker to be
|
||||
relatively faster than other LaTeX editors. You can take a look at a preview
|
||||
of what the final document would look like while you write. Also, one could
|
||||
observe the symbols being easy to reach when needed.
|
||||
|
||||
Texmaker also offers an extensive support for hotkeys configuration. Why not
|
||||
give it a try?
|
||||
|
||||
[Texmaker][8]
|
||||
|
||||
### 3\. TeXstudio
|
||||
|
||||
![][2]
|
||||
|
||||
![][9]
|
||||
|
||||
If you want a LaTeX editor which offers you a decent level of customizability
|
||||
along with an easy-to-use interface, then TeXstudio would be the perfect one
|
||||
to have installed. The UI is surely very simple but not clumsy. TeXstudio lets
|
||||
you highlight syntax, comes with an integrated viewer, lets you check the
|
||||
references and also bundles some other assistant tools.
|
||||
|
||||
It also supports some cool features like auto-completion, link overlay,
|
||||
bookmarks, multi-cursors, and so on - which makes writing a LaTeX document
|
||||
easier than ever before.
|
||||
|
||||
TeXstudio is actively maintained, which makes it a compelling choice for both
|
||||
novice users and advanced writers.
|
||||
|
||||
[TeXstudio][10]
|
||||
|
||||
### 4\. Gummi
|
||||
|
||||
![][2]
|
||||
|
||||
![][11]
|
||||
|
||||
Gummi is a very simple LaTeX editor based on the GTK+ toolkit. Well, you may
|
||||
not find a lot of fancy options here but if you are just starting out - Gummi
|
||||
will be our recommendation.It supports exporting the documents to PDF format,
|
||||
lets you highlight syntax, and helps you with some basic error checking
|
||||
functionalities. Though Gummi isn't actively maintained via GitHub it works
|
||||
just fine.
|
||||
|
||||
[Gummi][12]
|
||||
|
||||
### 5\. TeXpen
|
||||
|
||||
![][2]
|
||||
|
||||
![][13]
|
||||
|
||||
TeXpen is yet another simplified tool to go with. You get the auto-completion
|
||||
functionality with this LaTeX editor. However, you may not find the user
|
||||
interface impressive. If you do not mind the UI, but want a super easy LaTeX
|
||||
editor, TeXpen could fulfill that wish for you.Also, TeXpen lets you
|
||||
correct/improve the English grammar and expressions used in the document.
|
||||
|
||||
[TeXpen][14]
|
||||
|
||||
### 6\. ShareLaTeX
|
||||
|
||||
![][2]
|
||||
|
||||
![][15]
|
||||
|
||||
ShareLaTeX is an online LaTeX editor. If you want someone (or a group of
|
||||
people) to collaborate on documents you are working on, this is what you need.
|
||||
|
||||
It offers a free plan along with several paid packages. Even the students of
|
||||
Harvard University & Oxford University utilize this for their projects. With
|
||||
the free plan, you get the ability to add one collaborator.
|
||||
|
||||
The paid packages let you sync the documents on GitHub and Dropbox along with
|
||||
the ability to record the full document history. You can choose to have
|
||||
multiple collaborators as per your plan. For students, there's a separate
|
||||
pricing plan available.
|
||||
|
||||
[ShareLaTeX][16]
|
||||
|
||||
### 7\. Overleaf
|
||||
|
||||
![][2]
|
||||
|
||||
![][17]
|
||||
|
||||
Overleaf is yet another online LaTeX editor. Similar to ShareLaTeX, it offers
|
||||
separate pricing plans for professionals and students. It also includes a free
|
||||
plan where you can sync with GitHub, check your revision history, and add
|
||||
multiple collaborators.
|
||||
|
||||
There's a limit on the number of files you can create per project - so it
|
||||
could bother if you are a professional working with LaTeX documents most of
|
||||
the time.
|
||||
|
||||
[Overleaf][18]
|
||||
|
||||
### 8\. Authorea
|
||||
|
||||
![][2]
|
||||
|
||||
![][19]
|
||||
|
||||
Authorea is a wonderful online LaTeX editor. However, it is not the best out
|
||||
there - when considering the pricing plans. For free, it offers just 100 MB of
|
||||
data upload limit and 1 private document at a time. The paid plans offer you
|
||||
more perks but it may not be the cheapest from the lot.The only reason you
|
||||
should choose Authorea is the user interface. If you love to work with a tool
|
||||
offering an impressive user interface, there's no looking back.
|
||||
|
||||
[Authorea][20]
|
||||
|
||||
### 9\. Papeeria
|
||||
|
||||
![][2]
|
||||
|
||||
![][21]
|
||||
|
||||
Papeeria is the cheapest LaTeX editor you can find on the Internet -
|
||||
considering it is as reliable as the others. You do not get private projects
|
||||
if you want to utilize it for free. But, if you prefer public projects it lets
|
||||
you work on an unlimited number of projects with numerous collaborators. It
|
||||
features a pretty simple plot builder and includes Git sync for no additional
|
||||
cost.If you opt for the paid plan, it will empower you with the ability to
|
||||
work on 10 private projects.
|
||||
|
||||
[Papeeria][22]
|
||||
|
||||
### 10\. Kile
|
||||
|
||||
![Kile LaTeX editor][2]
|
||||
|
||||
![Kile LaTeX editor][23]
|
||||
|
||||
Last entry in our list of best LaTeX editor is Kile. Some people swear by
|
||||
Kile. Primarily because of the features it provides.
|
||||
|
||||
Kile is more than just an editor. It is an IDE tool like Eclipse that provides
|
||||
a complete environment to work on documents and projects. Apart from quick
|
||||
compilation and preview, you get features like auto-completion of commands,
|
||||
insert citations, organize document in chapters etc. You really have to use
|
||||
Kile to realize its true potential.
|
||||
|
||||
Kile is available for Linux and Windows.
|
||||
|
||||
[Kile][24]
|
||||
|
||||
### Wrapping Up
|
||||
|
||||
So, there go our recommendations for the LaTeX editors you should utilize on
|
||||
Ubuntu/Linux.
|
||||
|
||||
There are chances that we might have missed some interesting LaTeX editors
|
||||
available for Linux. If you happen to know about any, let us know down in the
|
||||
comments below.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/latex-editors-linux/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
译者:[翻译者ID](https://github.com/翻译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/ankush/
|
||||
[1]:https://www.latex-project.org/
|
||||
[2]:data:image/gif;base64,R0lGODdhAQABAPAAAP///wAAACwAAAAAAQABAEACAkQBADs=
|
||||
[3]:https://itsfoss.com/wp-content/uploads/2017/11/latex-sample-example.jpeg
|
||||
[4]:https://itsfoss.com/open-source-tools-writers/
|
||||
[5]:https://itsfoss.com/wp-content/uploads/2017/10/lyx_latex_editor.jpg
|
||||
[6]:https://www.lyx.org/
|
||||
[7]:https://itsfoss.com/wp-content/uploads/2017/10/texmaker_latex_editor.jpg
|
||||
[8]:http://www.xm1math.net/texmaker/
|
||||
[9]:https://itsfoss.com/wp-content/uploads/2017/10/tex_studio_latex_editor.jpg
|
||||
[10]:https://www.texstudio.org/
|
||||
[11]:https://itsfoss.com/wp-content/uploads/2017/10/gummi_latex_editor.jpg
|
||||
[12]:https://github.com/alexandervdm/gummi
|
||||
[13]:https://itsfoss.com/wp-content/uploads/2017/10/texpen_latex_editor.jpg
|
||||
[14]:https://sourceforge.net/projects/texpen/
|
||||
[15]:https://itsfoss.com/wp-content/uploads/2017/10/sharelatex.jpg
|
||||
[16]:https://www.sharelatex.com/
|
||||
[17]:https://itsfoss.com/wp-content/uploads/2017/10/overleaf.jpg
|
||||
[18]:https://www.overleaf.com/
|
||||
[19]:https://itsfoss.com/wp-content/uploads/2017/10/authorea.jpg
|
||||
[20]:https://www.authorea.com/
|
||||
[21]:https://itsfoss.com/wp-content/uploads/2017/10/papeeria_latex_editor.jpg
|
||||
[22]:https://www.papeeria.com/
|
||||
[23]:https://itsfoss.com/wp-content/uploads/2017/11/kile-latex-800x621.png
|
||||
[24]:https://kile.sourceforge.io/
|
||||
@ -0,0 +1,77 @@
|
||||
Useful GNOME Shell Keyboard Shortcuts You Might Not Know About
|
||||
======
|
||||
As Ubuntu has moved to Gnome Shell in its 17.10 release, many users may be interested to discover some of the most useful shortcuts in Gnome as well as how to create your own shortcuts. This article will explain both.
|
||||
|
||||
If you expect GNOME to ship with hundreds or thousands of shell shortcuts, you will be disappointed to learn this isn't the case. The list of shortcuts isn't miles long, and not all of them will be useful to you, but there are still many keyboard shortcuts you can take advantage of.
|
||||
|
||||
![gnome-shortcuts-01-settings][1]
|
||||
|
||||
![gnome-shortcuts-01-settings][1]
|
||||
|
||||
To access the list of shortcuts, go to "Settings -> Devices -> Keyboard." Here are some less popular, yet useful shortcuts.
|
||||
|
||||
* Ctrl + Alt + T - this combination launches the terminal; you can use this from anywhere within GNOME
|
||||
|
||||
|
||||
|
||||
Two shortcuts I personally use quite frequently are:
|
||||
|
||||
* Alt + F4 - close the window on focus
|
||||
* Alt + F8 - resize the window
|
||||
|
||||
|
||||
Most of you know how to switch between open applications (Alt + Tab), but you may not know you can use Alt + Shift + Tab to cycle through applications in reverse direction.
|
||||
|
||||
Another useful combination for switching within the windows of an application is Alt + (key above Tab) (example: Alt + ` on a US keyboard).
|
||||
|
||||
If you want to show the Activities overview, use Alt + F1.
|
||||
|
||||
There are quite a lot of shortcuts related to workspaces. If you are like me and don't use multiple workspaces frequently, these shortcuts are useless to you. Still, some of the ones worth noting are the following:
|
||||
|
||||
* Super + PageUp (or PageDown) moves to the workspace above or below
|
||||
* Ctrl + Alt + Left (or Right) moves to the workspace on the left/right
|
||||
|
||||
If you add Shift to these commands, e.g. Shift + Ctrl + Alt + Left, you move the window one worskpace above, below, to the left, or to the right.
|
||||
|
||||
Another favorite keyboard shortcut of mine is in the Accessibility section - Increase/Decrease Text Size. You can use Ctrl + + (and Ctrl + -) to zoom text size quickly. In some cases, this may be disabled by default, so do check it out before you try it.
|
||||
|
||||
The above-mentioned shortcuts are lesser known, yet useful keyboard shortcuts. If you are curious to see what else is available, you can check [the official GNOME shell cheat sheet][2].
|
||||
|
||||
If the default shortcuts are not to your liking, you can change them or create new ones. You do this from the same "Settings -> Devices -> Keyboard" dialog. Just select the entry you want to change, and the following dialog will popup.
|
||||
|
||||
![gnome-shortcuts-02-change-shortcut][3]
|
||||
|
||||
![gnome-shortcuts-02-change-shortcut][3]
|
||||
|
||||
Enter the keyboard combination you want.
|
||||
|
||||
![gnome-shortcuts-03-set-shortcut][4]
|
||||
|
||||
![gnome-shortcuts-03-set-shortcut][4]
|
||||
|
||||
If it is already in use you will get a message. If not, just click Set, and you are done.
|
||||
|
||||
If you want to add new shortcuts rather than change existing ones, scroll down until you see the "Plus" sign, click it, and in the dialog that appears, enter the name and keys of your new keyboard shortcut.
|
||||
|
||||
![gnome-shortcuts-04-add-custom-shortcut][5]
|
||||
|
||||
![gnome-shortcuts-04-add-custom-shortcut][5]
|
||||
|
||||
GNOME doesn't come with tons of shell shortcuts by default, and the above listed ones are some of the more useful ones. If these shortcuts are not enough for you, you can always create your own. Let us know if this is helpful to you.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/gnome-shell-keyboard-shortcuts/
|
||||
|
||||
作者:[Ada Ivanova][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/adaivanoff/
|
||||
[1]https://www.maketecheasier.com/assets/uploads/2017/10/gnome-shortcuts-01-settings.jpg (gnome-shortcuts-01-settings)
|
||||
[2]https://wiki.gnome.org/Projects/GnomeShell/CheatSheet
|
||||
[3]https://www.maketecheasier.com/assets/uploads/2017/10/gnome-shortcuts-02-change-shortcut.png (gnome-shortcuts-02-change-shortcut)
|
||||
[4]https://www.maketecheasier.com/assets/uploads/2017/10/gnome-shortcuts-03-set-shortcut.png (gnome-shortcuts-03-set-shortcut)
|
||||
[5]https://www.maketecheasier.com/assets/uploads/2017/10/gnome-shortcuts-04-add-custom-shortcut.png (gnome-shortcuts-04-add-custom-shortcut)
|
||||
@ -0,0 +1,221 @@
|
||||
Protecting Your Website From Application Layer DOS Attacks With mod
|
||||
======
|
||||
There exist many ways of maliciously taking a website offline. The more complicated methods involve technical knowledge of databases and programming. A far simpler method is known as a "Denial Of Service", or "DOS" attack. This attack derives its name from its goal which is to deny your regular clients or site visitors normal website service.
|
||||
|
||||
There are, generally speaking, two forms of DOS attack;
|
||||
|
||||
1. Layer 3,4 or Network-Layer attacks.
|
||||
2. Layer 7 or Application-Layer attacks.
|
||||
|
||||
|
||||
|
||||
The first type of DOS attack, network-layer, is when a huge quantity of junk traffic is directed at the web server. When the quantity of junk traffic exceeds the capacity of the network infrastructure the website is taken offline.
|
||||
|
||||
The second type of DOS attack, application-layer, is where instead of junk traffic legitimate looking page requests are made. When the number of page requests exceeds the capacity of the web server to serve pages legitimate visitors will not be able to use the site.
|
||||
|
||||
This guide will look at mitigating application-layer attacks. This is because mitigating networking-layer attacks requires huge quantities of available bandwidth and the co-operation of upstream providers. This is usually not something that can be protected against through configuration of the web server.
|
||||
|
||||
An application-layer attack, at least a modest one, can be protected against through the configuration of a normal web server. Protecting against this form of attack is important because [Cloudflare][1] have [recently reported][2] that the number of network-layer attacks is diminishing while the number of application-layer attacks is increasing.
|
||||
|
||||
This guide will explain using the Apache2 module [mod_evasive][3] by [zdziarski][4].
|
||||
|
||||
In addition, mod_evasive will stop an attacker trying to guess a username/password combination by attempting hundreds of combinations i.e. a brute force attack.
|
||||
|
||||
Mod_evasive works by keeping a record of the number of requests arriving from each IP address. When this number exceeds one of the several thresholds that IP is served an error page. Error pages require far fewer resources than a site page keeping the site online for legitimate visitors.
|
||||
|
||||
### Installing mod_evasive on Ubuntu 16.04
|
||||
|
||||
Mod_evasive is contained in the default Ubuntu 16.04 repositories with the package name "libapache2-mod-evasive". A simple `apt-get` will get it installed:
|
||||
```
|
||||
apt-get update
|
||||
apt-get upgrade
|
||||
apt-get install libapache2-mod-evasive
|
||||
|
||||
```
|
||||
|
||||
We now need to configure mod_evasive.
|
||||
|
||||
It's configuration file is located at `/etc/apache2/mods-available/evasive.conf`. By default, all the modules settings are commented after installation. Therefore, the module won't interfere with site traffic until the configuration file has been edited.
|
||||
```
|
||||
<IfModule mod_evasive20.c>
|
||||
#DOSHashTableSize 3097
|
||||
#DOSPageCount 2
|
||||
#DOSSiteCount 50
|
||||
#DOSPageInterval 1
|
||||
#DOSSiteInterval 1
|
||||
#DOSBlockingPeriod 10
|
||||
|
||||
#DOSEmailNotify you@yourdomain.com
|
||||
#DOSSystemCommand "su - someuser -c '/sbin/... %s ...'"
|
||||
#DOSLogDir "/var/log/mod_evasive"
|
||||
</IfModule>
|
||||
|
||||
```
|
||||
|
||||
The first block of directives mean as follows:
|
||||
|
||||
* **DOSHashTableSize** - The current list of accessing IP's and their request count.
|
||||
* **DOSPageCount** - The threshold number of page requests per DOSPageInterval.
|
||||
* **DOSPageInterval** - The amount of time in which mod_evasive counts up the page requests.
|
||||
* **DOSSiteCount** - The same as the DOSPageCount but counts requests from the same IP for any page on the site.
|
||||
* **DOSSiteInterval** - The amount of time that mod_evasive counts up the site requests.
|
||||
* **DOSBlockingPeriod** - The amount of time in seconds that an IP is blocked for.
|
||||
|
||||
|
||||
|
||||
If the default configuration shown above is used then an IP will be blocked if it:
|
||||
|
||||
* Requests a single page more than twice a second.
|
||||
* Requests more than 50 pages different pages per second.
|
||||
|
||||
|
||||
|
||||
If an IP exceeds these thresholds it is blocked for 10 seconds.
|
||||
|
||||
This may not seem like a lot, however, mod_evasive will continue monitoring the page requests even for blocked IP's and reset their block period. As long as an IP is attempting to DOS the site it will remain blocked.
|
||||
|
||||
The remaining directives are:
|
||||
|
||||
* **DOSEmailNotify** - An email address to receive notification of DOS attacks and IP's being blocked.
|
||||
* **DOSSystemCommand** - A command to run in the event of a DOS.
|
||||
* **DOSLogDir** - The directory where mod_evasive keeps some temporary files.
|
||||
|
||||
|
||||
|
||||
### Configuring mod_evasive
|
||||
|
||||
The default configuration is a good place to start as it should not block any legitimate users. The configuration file with all directives (apart from DOSSystemCommand) uncommented looks like the following:
|
||||
```
|
||||
<IfModule mod_evasive20.c>
|
||||
DOSHashTableSize 3097
|
||||
DOSPageCount 2
|
||||
DOSSiteCount 50
|
||||
DOSPageInterval 1
|
||||
DOSSiteInterval 1
|
||||
DOSBlockingPeriod 10
|
||||
|
||||
DOSEmailNotify JohnW@example.com
|
||||
#DOSSystemCommand "su - someuser -c '/sbin/... %s ...'"
|
||||
DOSLogDir "/var/log/mod_evasive"
|
||||
</IfModule>
|
||||
|
||||
```
|
||||
|
||||
The log directory must be created and given the same owner as the apache process. Here it is created at `/var/log/mod_evasive` and given the owner and group of the Apache web server on Ubuntu `www-data`:
|
||||
```
|
||||
mkdir /var/log/mod_evasive
|
||||
chown www-data:www-data /var/log/mod_evasive
|
||||
|
||||
```
|
||||
|
||||
After editing Apache's configuration, especially on a live website, it is always a good idea to check the syntax of the edits before restarting or reloading. This is because a syntax error will stop Apache from re-starting and taking your site offline.
|
||||
|
||||
Apache comes packaged with a helper command that has a configuration syntax checker. Simply run the following command to check your edits:
|
||||
```
|
||||
apachectl configtest
|
||||
|
||||
```
|
||||
|
||||
If your configuration is correct you will get the response:
|
||||
```
|
||||
Syntax OK
|
||||
|
||||
```
|
||||
|
||||
However, if there is a problem you will be told where it occurred and what it was, e.g.:
|
||||
```
|
||||
AH00526: Syntax error on line 6 of /etc/apache2/mods-enabled/evasive.conf:
|
||||
DOSSiteInterval takes one argument, Set site interval
|
||||
Action 'configtest' failed.
|
||||
The Apache error log may have more information.
|
||||
|
||||
```
|
||||
|
||||
If your configuration passes the configtest then the module can be safely enabled and Apache reloaded:
|
||||
```
|
||||
a2enmod evasive
|
||||
systemctl reload apache2.service
|
||||
|
||||
```
|
||||
|
||||
Mod_evasive is now configured and running.
|
||||
|
||||
### Testing
|
||||
|
||||
In order to test mod_evasive, we simply need to make enough web requests to the server that we exceed the threshold and record the response codes from Apache.
|
||||
|
||||
A normal, successful page request will receive the response:
|
||||
```
|
||||
HTTP/1.1 200 OK
|
||||
|
||||
```
|
||||
|
||||
However, one that has been denied by mod_evasive will return the following:
|
||||
```
|
||||
HTTP/1.1 403 Forbidden
|
||||
|
||||
```
|
||||
|
||||
The following script will make HTTP requests to `127.0.0.1:80`, that is localhost on port 80, as rapidly as possible and print out the response code of every request.
|
||||
|
||||
All you need to do is to copy the following bash script into a file e.g. `mod_evasive_test.sh`:
|
||||
```
|
||||
#!/bin/bash
|
||||
set -e
|
||||
|
||||
for i in {1..50}; do
|
||||
curl -s -I 127.0.0.1 | head -n 1
|
||||
done
|
||||
|
||||
```
|
||||
|
||||
The parts of this script mean as follows:
|
||||
|
||||
* curl - This is a command to make web requests.
|
||||
* -s - Hide the progress meter.
|
||||
* -I - Only display the response header information.
|
||||
* head - Print the first part of a file.
|
||||
* -n 1 - Only display the first line.
|
||||
|
||||
|
||||
|
||||
Then make it executable:
|
||||
```
|
||||
chmod 755 mod_evasive_test.sh
|
||||
|
||||
```
|
||||
|
||||
When the script is run **before** mod_evasive is enabled you will see 50 lines of `HTTP/1.1 200 OK` returned.
|
||||
|
||||
However, after mod_evasive is enabled you will see the following:
|
||||
```
|
||||
HTTP/1.1 200 OK
|
||||
HTTP/1.1 200 OK
|
||||
HTTP/1.1 403 Forbidden
|
||||
HTTP/1.1 403 Forbidden
|
||||
HTTP/1.1 403 Forbidden
|
||||
HTTP/1.1 403 Forbidden
|
||||
HTTP/1.1 403 Forbidden
|
||||
...
|
||||
|
||||
```
|
||||
|
||||
The first two requests were allowed, but then once a third in the same second was made mod_evasive denied any further requests. You will also receive an email letting you know that a DOS attempt was detected to the address you set with the `DOSEmailNotify` option.
|
||||
|
||||
Mod_evasive is now protecting your site!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://bash-prompt.net/guides/mod_proxy/
|
||||
|
||||
作者:[Elliot Cooper][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://bash-prompt.net/about/
|
||||
[1]:https://www.cloudflare.com
|
||||
[2]:https://blog.cloudflare.com/the-new-ddos-landscape/
|
||||
[3]:https://github.com/jzdziarski/mod_evasive
|
||||
[4]:https://www.zdziarski.com/blog/
|
||||
@ -1,54 +0,0 @@
|
||||
translating by liuxinyu123
|
||||
|
||||
Long-term Linux support future clarified
|
||||
============================================================
|
||||
|
||||
Long-term support Linux version 4.4 will get six years of life, but that doesn't mean other LTS editions will last so long.
|
||||
|
||||
[video](http://www.zdnet.com/video/video-torvalds-surprised-by-resilience-of-2-6-kernel-1/)
|
||||
|
||||
_Video: Torvalds surprised by resilience of 2.6 kernel_
|
||||
|
||||
In October 2017, the [Linux kernel team agreed to extend the next version of Linux's Long Term Support (LTS) from two years to six years][5], [Linux 4.14][6]. This helps [Android][7], embedded Linux, and Linux Internet of Things (IoT) developers. But this move did not mean all future Linux LTS versions will have a six-year lifespan.
|
||||
|
||||
As Konstantin Ryabitsev, [The Linux Foundation][8]'s director of IT infrastructure security, explained in a Google+ post, "Despite what various news sites out there may have told you, [kernel 4.14 LTS is not planned to be supported for 6 years][9]. Just because Greg Kroah-Hartman is doing it for 4.4 does not mean that all LTS kernels from now on are going to be maintained for that long."
|
||||
|
||||
So, in short, 4.14 will be supported until January 2020, while the 4.4 Linux kernel, which arrived on Jan. 20, 2016, will be supported until 2022\. Therefore, if you're working on a Linux distribution that's meant for the longest possible run, you want to base it on [Linux 4.4][10].
|
||||
|
||||
[Linux LTS versions][11] incorporate back-ported bug fixes for older kernel trees. Not all bug fixes are imported; only important bug fixes are applied to such kernels. They, especially for older trees, don't usually see very frequent releases.
|
||||
|
||||
The other Linux versions are Prepatch or release candidates (RC), Mainline, Stable, and LTS.
|
||||
|
||||
RC must be compiled from source and usually contains bug fixes and new features. These are maintained and released by Linus Torvalds. He also maintains the Mainline tree (this is where all new features are introduced). New mainline kernels are released every few months. When the mainline kernel is released for general use, it is considered "stable." Bug fixes for a stable kernel are back-ported from the mainline tree and applied by a designated stable kernel maintainer. There are usually only a few bug-fix kernel releases until the next mainline kernel becomes available.
|
||||
|
||||
As for the latest LTS, Linux 4.14, Ryabitsev said, "It is possible that someone may pick up maintainership of 4.14 after Greg is done with it (it's happened in the past on multiple occasions), but you should emphatically not plan on that."
|
||||
|
||||
Kroah-Hartman simply added to Ryabitsev's post: ["What he said."][12]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.zdnet.com/article/long-term-linux-support-future-clarified/
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/
|
||||
[1]:http://www.zdnet.com/article/long-term-linux-support-future-clarified/#comments-eb4f0633-955f-4fec-9e56-734c34ee2bf2
|
||||
[2]:http://www.zdnet.com/article/the-tension-between-iot-and-erp/
|
||||
[3]:http://www.zdnet.com/article/the-tension-between-iot-and-erp/
|
||||
[4]:http://www.zdnet.com/article/the-tension-between-iot-and-erp/
|
||||
[5]:http://www.zdnet.com/article/long-term-support-linux-gets-a-longer-lease-on-life/
|
||||
[6]:http://www.zdnet.com/article/the-new-long-term-linux-kernel-linux-4-14-has-arrived/
|
||||
[7]:https://www.android.com/
|
||||
[8]:https://www.linuxfoundation.org/
|
||||
[9]:https://plus.google.com/u/0/+KonstantinRyabitsev/posts/Lq97ZtL8Xw9
|
||||
[10]:http://www.zdnet.com/article/whats-new-and-nifty-in-linux-4-4/
|
||||
[11]:https://www.kernel.org/releases.html
|
||||
[12]:https://plus.google.com/u/0/+gregkroahhartman/posts/ZUcSz3Sn1Hc
|
||||
[13]:http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/
|
||||
[14]:http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/
|
||||
[15]:http://www.zdnet.com/blog/open-source/
|
||||
[16]:http://www.zdnet.com/topic/enterprise-software/
|
||||
@ -1,43 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Someone Tries to Bring Back Ubuntu's Unity from the Dead as an Official Spin
|
||||
============================================================
|
||||
|
||||
|
||||
|
||||
> The Ubuntu Unity remix would be supported for nine months
|
||||
|
||||
Canonical's sudden decision of killing its Unity user interface after seven years affected many Ubuntu users, and it looks like someone now tries to bring it back from the dead as an unofficial spin.
|
||||
|
||||
Long-time [Ubuntu][1] member Dale Beaudoin [ran a poll][2] last week on the official Ubuntu forums to take the pulse of the community and see if they are interested in an Ubuntu Unity Remix that would be released alongside Ubuntu 18.04 LTS (Bionic Beaver) next year and be supported for nine months or five years.
|
||||
|
||||
Thirty people voted in the poll, with 67 percent of them opting for an LTS (Long Term Support) release of the so-called Ubuntu Unity Remix, while 33 percent voted for the 9-month supported release. It also looks like this upcoming Ubuntu Unity Spin [looks to become an official flavor][3], yet this means commitment from those developing it.
|
||||
|
||||
"A recent poll voted 2/3rds in favor of Ubuntu Unity to become an LTS distribution. We should try to work this cycle assuming that it will be LTS and an official flavor," said Dale Beaudoin. "We will try and release an updated ISO once every week or 10 days using the current 18.04 daily builds of default Ubuntu Bionic Beaver as a platform."
|
||||
|
||||
### Is Ubuntu Unity making a comeback?
|
||||
|
||||
The last Ubuntu version to ship with Unity by default was Ubuntu 17.04 (Zesty Zapus), which will reach end of life on January 2018\. Ubuntu 17.10 (Artful Artful), the current stable release of the popular operating system, is the first to use the GNOME desktop environment by default for the main Desktop edition as Canonical CEO [announced][4] earlier this year that Unity would no longer be developed.
|
||||
|
||||
However, Canonical is still offering the Unity desktop environment from the official software repositories, so if someone wants to install it, it's one click away. But the bad news is that they'll be supported up until the release of Ubuntu 18.04 LTS (Bionic Beaver) in April 2018, so the developers of the Ubuntu Unity Remix would have to continue to keep in on life support on their a separate repository.
|
||||
|
||||
On the other hand, we don't believe Canonical will change their mind and accept this Ubuntu Unity Spin to become an official flavor, which would mean they failed to continue development of Unity, and now a handful of people can do it. Most probably, if interest in this Ubuntu Unity Remix won't fade away soon, it will be an unofficial spin supported by the nostalgic community.
|
||||
|
||||
Question is, would you be interested in an Ubuntu Unity spin, official or not?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/someone-tries-to-bring-back-ubuntu-s-unity-from-the-dead-as-an-unofficial-spin-518778.shtml
|
||||
|
||||
作者:[Marius Nestor ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/marius-nestor
|
||||
[1]:http://linux.softpedia.com/downloadTag/Ubuntu
|
||||
[2]:https://community.ubuntu.com/t/poll-unity-7-distro-9-month-spin-or-lts-for-18-04/2066
|
||||
[3]:https://community.ubuntu.com/t/unity-maintenance-roadmap/2223
|
||||
[4]:http://news.softpedia.com/news/canonical-to-stop-developing-unity-8-ubuntu-18-04-lts-ships-with-gnome-desktop-514604.shtml
|
||||
[5]:http://news.softpedia.com/editors/browse/marius-nestor
|
||||
@ -1,153 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Suplemon - Modern CLI Text Editor with Multi Cursor Support
|
||||
======
|
||||
Suplemon is a modern text editor for CLI that emulates the multi cursor behavior and other features of [Sublime Text][1]. It's lightweight and really easy to use, just as Nano is.
|
||||
|
||||
One of the benefits of using a CLI editor is that you can use it whether the Linux distribution that you're using has a GUI or not. This type of text editors also stands out as being simple, fast and powerful.
|
||||
|
||||
You can find useful information and the source code in the [official repository][2].
|
||||
|
||||
### Features
|
||||
|
||||
These are some of its interesting features:
|
||||
|
||||
* Multi cursor support
|
||||
|
||||
* Undo / Redo
|
||||
|
||||
* Copy and Paste, with multi line support
|
||||
|
||||
* Mouse support
|
||||
|
||||
* Extensions
|
||||
|
||||
* Find, find all, find next
|
||||
|
||||
* Syntax highlighting
|
||||
|
||||
* Autocomplete
|
||||
|
||||
* Custom keyboard shortcuts
|
||||
|
||||
### Installation
|
||||
|
||||
First, make sure you have the latest version of python3 and pip3 installed.
|
||||
|
||||
Then type in a terminal:
|
||||
|
||||
```
|
||||
$ sudo pip3 install suplemon
|
||||
```
|
||||
|
||||
Create a new file in the current directory
|
||||
|
||||
Open a terminal and type:
|
||||
|
||||
```
|
||||
$ suplemon
|
||||
```
|
||||
|
||||

|
||||
|
||||
Open one or multiple files
|
||||
|
||||
Open a terminal and type:
|
||||
|
||||
```
|
||||
$ suplemon ...
|
||||
```
|
||||
|
||||
```
|
||||
$ suplemon example1.c example2.c
|
||||
```
|
||||
|
||||
Main configuration
|
||||
|
||||
You can find the configuration file at ~/.config/suplemon/suplemon-config.json.
|
||||
|
||||
Editing this file is easy, you just have to enter command mode (once you are inside suplemon) and run the config command. You can view the default configuration by running config defaults.
|
||||
|
||||
Keymap configuration
|
||||
|
||||
I'll show you the default key mappings for suplemon. If you want to edit them, just run keymap command. Run keymap default to view the default keymap file.
|
||||
|
||||
* Exit: Ctrl + Q
|
||||
|
||||
* Copy line(s) to buffer: Ctrl + C
|
||||
|
||||
* Cut line(s) to buffer: Ctrl + X
|
||||
|
||||
* Insert buffer: Ctrl + V
|
||||
|
||||
* Duplicate line: Ctrl + K
|
||||
|
||||
* Goto: Ctrl + G. You can go to a line or to a file (just type the beginning of a file name). Also, it is possible to type something like 'exam:50' to go to the line 50 of the file example.c at line 50.
|
||||
|
||||
* Search for string or regular expression: Ctrl + F
|
||||
|
||||
* Search next: Ctrl + D
|
||||
|
||||
* Trim whitespace: Ctrl + T
|
||||
|
||||
* Add new cursor in arrow direction: Alt + Arrow key
|
||||
|
||||
* Jump to previous or next word or line: Ctrl + Left / Right
|
||||
|
||||
* Revert to single cursor / Cancel input prompt: Esc
|
||||
|
||||
* Move line(s) up / down: Page Up / Page Down
|
||||
|
||||
* Save file: Ctrl + S
|
||||
|
||||
* Save file with new name: F1
|
||||
|
||||
* Reload current file: F2
|
||||
|
||||
* Open file: Ctrl + O
|
||||
|
||||
* Close file: Ctrl + W
|
||||
|
||||
* Switch to next/previous file: Ctrl + Page Up / Ctrl + Page Down
|
||||
|
||||
* Run a command: Ctrl + E
|
||||
|
||||
* Undo: Ctrl + Z
|
||||
|
||||
* Redo: Ctrl + Y
|
||||
|
||||
* Toggle visible whitespace: F7
|
||||
|
||||
* Toggle mouse mode: F8
|
||||
|
||||
* Toggle line numbers: F9
|
||||
|
||||
* Toggle Full screen: F11
|
||||
|
||||
Mouse shortcuts
|
||||
|
||||
* Set cursor at pointer position: Left Click
|
||||
|
||||
* Add a cursor at pointer position: Right Click
|
||||
|
||||
* Scroll vertically: Scroll Wheel Up / Down
|
||||
|
||||
### Wrapping up
|
||||
|
||||
After trying Suplemon for some time, I have changed my opinion about CLI text editors. I had tried Nano before, and yes, I liked its simplicity, but its modern-feature lack made it non-practical for my everyday use.
|
||||
|
||||
This tool has the best of both CLI and GUI worlds... Simplicity and feature-richness! So I suggest you give it a try, and write your thoughts in the comments :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linoxide.com/tools/suplemon-cli-text-editor-multi-cursor/
|
||||
|
||||
作者:[Ivo Ursino][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linoxide.com/author/ursinov/
|
||||
[1]:https://linoxide.com/tools/install-sublime-text-editor-linux/
|
||||
[2]:https://github.com/richrd/suplemon/
|
||||
@ -1,47 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
# GNOME Boxes Makes It Easier to Test Drive Linux Distros
|
||||
|
||||

|
||||
|
||||
Creating Linux virtual machines on the GNOME desktop is about to get a whole lot easier.
|
||||
|
||||
The next major release of [_GNOME Boxes_][5] is able to download popular Linux (and BSD-based) operating systems directly inside the app itself.
|
||||
|
||||
Boxes is free, open-source software. It can be used to access both remote and virtual systems as it is built around [QEMU][6], KVM, and libvirt virtualisation technologies.
|
||||
|
||||
For its new ISO-toting integration _Boxes_ makes use of [libosinfo][7], a database of operating systems that also provides details on any virtualized environment requirements.
|
||||
|
||||
In [this (mis-titled) video][8] from GNOME developer Felipe Borges you can see just how easy the improved ‘Source Selection’ screen makes things, including the ability to download a specific ISO architecture for a given distro:
|
||||
|
||||
[video](https://youtu.be/CGahI05Gbac)
|
||||
|
||||
Despite it being a core GNOME app I have to confess that I have never used Boxes. It’s not that I don’t hear good things about it (I do) it’s just that I’m more familiar with setting up and configuring virtual machines in VirtualBox.
|
||||
|
||||
> ‘The lazy geek inside me is going to appreciate this integration’
|
||||
|
||||
Admitted it’s not exactly _difficult_ to head out and download an ISO using the browser, then point a virtual machine app to it (heck, it’s what most of us have been doing for a decade or so).
|
||||
|
||||
But the lazy geek inside me is really going to appreciate this integration.
|
||||
|
||||
So, thanks to this feature I’ll be unpacking Boxes on my system when GNOME 3.28 is released next March. I will be able to launch _Boxes_ , close my eyes,pick a distro from the list at random, and instantly broaden my Tux-shaped horizons.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2017/12/gnome-boxes-install-linux-distros-directly
|
||||
|
||||
作者:[ JOEY SNEDDON ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[2]:http://www.omgubuntu.co.uk/category/dev
|
||||
[3]:http://www.omgubuntu.co.uk/category/video
|
||||
[4]:http://www.omgubuntu.co.uk/2017/12/gnome-boxes-install-linux-distros-directly
|
||||
[5]:https://en.wikipedia.org/wiki/GNOME_Boxes
|
||||
[6]:https://en.wikipedia.org/wiki/QEMU
|
||||
[7]:https://libosinfo.org/
|
||||
[8]:https://blogs.gnome.org/felipeborges/boxes-downloadable-oses/
|
||||
@ -1,200 +0,0 @@
|
||||
translating by lujun9972
|
||||
10 useful ncat (nc) Command Examples for Linux Systems
|
||||
======
|
||||
[][1]
|
||||
|
||||
ncat or nc is networking utility with functionality similar to cat command but for network. It is a general purpose CLI tool for reading, writing, redirecting data across a network. It is designed to be a reliable back-end tool that can be used with scripts or other programs. It’s also a great tool for network debugging, as it can create any kind of connect one can need.
|
||||
|
||||
ncat/nc can be a port scanning tool, or a security tool, or monitoring tool and is also a simple TCP proxy. Since it has so many features, it is known as a network swiss army knife. It’s one of those tools that every System Admin should know & master.
|
||||
|
||||
In most of Debian distributions ‘nc’ is available and its package is automatically installed during installation. But in minimal CentOS 7 / RHEL 7 installation you will not find nc as a default package. You need to install using the following command.
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# yum install nmap-ncat -y
|
||||
```
|
||||
|
||||
System admins can use it audit their system security, they can use it find the ports that are opened & than secure them. Admins can also use it as a client for auditing web servers, telnet servers, mail servers etc, with ‘nc’ we can control every character sent & can also view the responses to sent queries.
|
||||
|
||||
We can also cause it to capture data being sent by client to understand what they are upto.
|
||||
|
||||
In this tutorial, we are going to learn about how to use ‘nc’ command with 10 examples,
|
||||
|
||||
#### Example: 1) Listen to inbound connections
|
||||
|
||||
Ncat can work in listen mode & we can listen for inbound connections on port number with option ‘l’. Complete command is,
|
||||
|
||||
$ ncat -l port_number
|
||||
|
||||
For example,
|
||||
|
||||
```
|
||||
$ ncat -l 8080
|
||||
```
|
||||
|
||||
Server will now start listening to port 8080 for inbound connections.
|
||||
|
||||
#### Example: 2) Connect to a remote system
|
||||
|
||||
To connect to a remote system with nc, we can use the following command,
|
||||
|
||||
$ ncat IP_address port_number
|
||||
|
||||
Let’s take an example,
|
||||
|
||||
```
|
||||
$ ncat 192.168.1.100 80
|
||||
```
|
||||
|
||||
Now a connection to server with IP address 192.168.1.100 will be made at port 80 & we can now send instructions to server. Like we can get the complete page content with
|
||||
|
||||
GET / HTTP/1.1
|
||||
|
||||
or get the page name,
|
||||
|
||||
GET / HTTP/1.1
|
||||
|
||||
or we can get banner for OS fingerprinting with the following,
|
||||
|
||||
HEAD / HTTP/1.1
|
||||
|
||||
This will tell what software is being used to run the web Server.
|
||||
|
||||
#### Example: 3) Connecting to UDP ports
|
||||
|
||||
By default , the nc utility makes connections only to TCP ports. But we can also make connections to UDP ports, for that we can use option ‘u’,
|
||||
|
||||
```
|
||||
$ ncat -l -u 1234
|
||||
```
|
||||
|
||||
Now our system will start listening a udp port ‘1234’, we can verify this using below netstat command,
|
||||
|
||||
```
|
||||
$ netstat -tunlp | grep 1234
|
||||
udp 0 0 0.0.0.0:1234 0.0.0.0:* 17341/nc
|
||||
udp6 0 0 :::1234 :::* 17341/nc
|
||||
```
|
||||
|
||||
Let’s assume we want to send or test UDP port connectivity to a specific remote host, then use the following command,
|
||||
|
||||
$ ncat -v -u {host-ip} {udp-port}
|
||||
|
||||
example:
|
||||
|
||||
```
|
||||
[root@localhost ~]# ncat -v -u 192.168.105.150 53
|
||||
Ncat: Version 6.40 ( http://nmap.org/ncat )
|
||||
Ncat: Connected to 192.168.105.150:53.
|
||||
```
|
||||
|
||||
#### Example: 4) NC as chat tool
|
||||
|
||||
NC can also be used as chat tool, we can configure server to listen to a port & than can make connection to server from a remote machine on same port & start sending message. On server side, run
|
||||
|
||||
```
|
||||
$ ncat -l 8080
|
||||
```
|
||||
|
||||
On remote client machine, run
|
||||
|
||||
```
|
||||
$ ncat 192.168.1.100 8080
|
||||
```
|
||||
|
||||
Than start sending messages & they will be displayed on server terminal.
|
||||
|
||||
#### Example: 5) NC as a proxy
|
||||
|
||||
NC can also be used as a proxy with a simple command. Let’s take an example,
|
||||
|
||||
```
|
||||
$ ncat -l 8080 | ncat 192.168.1.200 80
|
||||
```
|
||||
|
||||
Now all the connections coming to our server on port 8080 will be automatically redirected to 192.168.1.200 server on port 80\. But since we are using a pipe, data can only be transferred & to be able to receive the data back, we need to create a two way pipe. Use the following commands to do so,
|
||||
|
||||
```
|
||||
$ mkfifo 2way
|
||||
$ ncat -l 8080 0<2way | ncat 192.168.1.200 80 1>2way
|
||||
```
|
||||
|
||||
Now you will be able to send & receive data over nc proxy.
|
||||
|
||||
#### Example: 6) Copying Files using nc/ncat
|
||||
|
||||
NC can also be used to copy the files from one system to another, though it is not recommended & mostly all systems have ssh/scp installed by default. But none the less if you have come across a system with no ssh/scp, you can also use nc as last ditch effort.
|
||||
|
||||
Start with machine on which data is to be received & start nc is listener mode,
|
||||
|
||||
```
|
||||
$ ncat -l 8080 > file.txt
|
||||
```
|
||||
|
||||
Now on the machine from where data is to be copied, run the following command,
|
||||
|
||||
```
|
||||
$ ncat 192.168.1.100 8080 --send-only < data.txt
|
||||
```
|
||||
|
||||
Here, data.txt is the file that has to be sent. –send-only option will close the connection once the file has been copied. If not using this option, than we will have press ctrl+c to close the connection manually.
|
||||
|
||||
We can also copy entire disk partitions using this method, but it should be done with caution.
|
||||
|
||||
#### Example: 7) Create a backdoor via nc/nact
|
||||
|
||||
NC command can also be used to create backdoor to your systems & this technique is actually used by hackers a lot. We should know how it works in order to secure our system. To create a backdoor, the command is,
|
||||
|
||||
```
|
||||
$ ncat -l 10000 -e /bin/bash
|
||||
```
|
||||
|
||||
‘e‘ flag attaches a bash to port 10000\. Now a client can connect to port 10000 on server & will have complete access to our system via bash,
|
||||
|
||||
```
|
||||
$ ncat 192.168.1.100 1000
|
||||
```
|
||||
|
||||
#### Example: 8) Port forwarding via nc/ncat
|
||||
|
||||
We can also use NC for port forwarding with the help of option ‘c’ , syntax for accomplishing port forwarding is,
|
||||
|
||||
```
|
||||
$ ncat -u -l 80 -c 'ncat -u -l 8080'
|
||||
```
|
||||
|
||||
Now all the connections for port 80 will be forwarded to port 8080.
|
||||
|
||||
#### Example: 9) Set Connection timeouts
|
||||
|
||||
Listener mode in ncat will continue to run & would have to be terminated manually. But we can configure timeouts with option ‘w’,
|
||||
|
||||
```
|
||||
$ ncat -w 10 192.168.1.100 8080
|
||||
```
|
||||
|
||||
This will cause connection to be terminated in 10 seconds, but it can only be used on client side & not on server side.
|
||||
|
||||
#### Example: 10) Force server to stay up using -k option in ncat
|
||||
|
||||
When client disconnects from server, after sometime server also stops listening. But we can force server to stay connected & continuing port listening with option ‘k’. Run the following command,
|
||||
|
||||
```
|
||||
$ ncat -l -k 8080
|
||||
```
|
||||
|
||||
Now server will stay up, even if a connection from client is broken.
|
||||
|
||||
With this we end our tutorial, please feel free to ask any question regarding this article using the comment box below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxtechi.com/nc-ncat-command-examples-linux-systems/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxtechi.com/author/pradeep/
|
||||
[1]:https://www.linuxtechi.com/wp-content/uploads/2017/12/nc-ncat-command-examples-Linux-Systems.jpg
|
||||
@ -0,0 +1,197 @@
|
||||
translating---geekpi
|
||||
|
||||
Cheat – A Collection Of Practical Linux Command Examples
|
||||
======
|
||||
Many of us very often checks **[Man Pages][1]** to know about command switches
|
||||
(options), it shows you the details about command syntax, description,
|
||||
details, and available switches but it doesn 't has any practical examples.
|
||||
Hence, we are face some trouble to form a exact command format which we need.
|
||||
|
||||
Are you really facing the trouble on this and want a better solution? i would
|
||||
advise you to check about cheat utility.
|
||||
|
||||
#### What Is Cheat
|
||||
|
||||
[Cheat][2] allows you to create and view interactive cheatsheets on the
|
||||
command-line. It was designed to help remind *nix system administrators of
|
||||
options for commands that they use frequently, but not frequently enough to
|
||||
remember.
|
||||
|
||||
#### How to Install Cheat
|
||||
|
||||
Cheat package was developed using python, so install pip package to install
|
||||
cheat on your system.
|
||||
|
||||
For **`Debian/Ubuntu`** , use [apt-get command][3] or [apt command][4] to
|
||||
install pip.
|
||||
|
||||
```
|
||||
|
||||
[For Python2]
|
||||
|
||||
|
||||
$ sudo apt install python-pip python-setuptools
|
||||
|
||||
|
||||
|
||||
[For Python3]
|
||||
|
||||
|
||||
$ sudo apt install python3-pip
|
||||
|
||||
```
|
||||
|
||||
pip doesn't shipped with **`RHEL/CentOS`** system official repository so,
|
||||
enable [EPEL Repository][5] and use [YUM command][6] to install pip.
|
||||
|
||||
```
|
||||
|
||||
$ sudo yum install python-pip python-devel python-setuptools
|
||||
|
||||
```
|
||||
|
||||
For **`Fedora`** system, use [dnf Command][7] to install pip.
|
||||
|
||||
```
|
||||
|
||||
[For Python2]
|
||||
|
||||
|
||||
$ sudo dnf install python-pip
|
||||
|
||||
|
||||
|
||||
[For Python3]
|
||||
|
||||
|
||||
$ sudo dnf install python3
|
||||
|
||||
```
|
||||
|
||||
For **`Arch Linux`** based systems, use [Pacman Command][8] to install pip.
|
||||
|
||||
```
|
||||
|
||||
[For Python2]
|
||||
|
||||
|
||||
$ sudo pacman -S python2-pip python-setuptools
|
||||
|
||||
|
||||
|
||||
[For Python3]
|
||||
|
||||
|
||||
$ sudo pacman -S python-pip python3-setuptools
|
||||
|
||||
```
|
||||
|
||||
For **`openSUSE`** system, use [Zypper Command][9] to install pip.
|
||||
|
||||
```
|
||||
|
||||
[For Python2]
|
||||
|
||||
|
||||
$ sudo pacman -S python-pip
|
||||
|
||||
|
||||
|
||||
[For Python3]
|
||||
|
||||
|
||||
$ sudo pacman -S python3-pip
|
||||
|
||||
```
|
||||
|
||||
pip is a python module bundled with setuptools, it's one of the recommended
|
||||
tool for installing Python packages in Linux.
|
||||
|
||||
```
|
||||
|
||||
$ sudo pip install cheat
|
||||
|
||||
```
|
||||
|
||||
#### How to Use Cheat
|
||||
|
||||
Run `cheat` followed by corresponding `command` to view the cheatsheet, For
|
||||
demonstration purpose, we are going to check about `tar` command examples.
|
||||
|
||||
```
|
||||
|
||||
$ cheat tar
|
||||
# To extract an uncompressed archive:
|
||||
tar -xvf /path/to/foo.tar
|
||||
|
||||
# To create an uncompressed archive:
|
||||
tar -cvf /path/to/foo.tar /path/to/foo/
|
||||
|
||||
# To extract a .gz archive:
|
||||
tar -xzvf /path/to/foo.tgz
|
||||
|
||||
# To create a .gz archive:
|
||||
tar -czvf /path/to/foo.tgz /path/to/foo/
|
||||
|
||||
# To list the content of an .gz archive:
|
||||
tar -ztvf /path/to/foo.tgz
|
||||
|
||||
# To extract a .bz2 archive:
|
||||
tar -xjvf /path/to/foo.tgz
|
||||
|
||||
# To create a .bz2 archive:
|
||||
tar -cjvf /path/to/foo.tgz /path/to/foo/
|
||||
|
||||
# To extract a .tar in specified Directory:
|
||||
tar -xvf /path/to/foo.tar -C /path/to/destination/
|
||||
|
||||
# To list the content of an .bz2 archive:
|
||||
tar -jtvf /path/to/foo.tgz
|
||||
|
||||
# To create a .gz archive and exclude all jpg,gif,... from the tgz
|
||||
tar czvf /path/to/foo.tgz --exclude=\*.{jpg,gif,png,wmv,flv,tar.gz,zip} /path/to/foo/
|
||||
|
||||
# To use parallel (multi-threaded) implementation of compression algorithms:
|
||||
tar -z ... -> tar -Ipigz ...
|
||||
tar -j ... -> tar -Ipbzip2 ...
|
||||
tar -J ... -> tar -Ipixz ...
|
||||
|
||||
```
|
||||
|
||||
Run the following command to see what cheatsheets are available.
|
||||
|
||||
```
|
||||
|
||||
$ cheat -l
|
||||
|
||||
```
|
||||
|
||||
Navigate to help page for more details.
|
||||
|
||||
```
|
||||
|
||||
$ cheat -h
|
||||
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/cheat-a-collection-of-practical-linux-command-examples/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com
|
||||
[1]:https://www.2daygeek.com/linux-color-man-pages-configuration-less-most-command/
|
||||
[2]:https://github.com/chrisallenlane/cheat
|
||||
[3]:https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[4]:https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[5]:https://www.2daygeek.com/install-enable-epel-repository-on-rhel-centos-scientific-linux-oracle-linux/
|
||||
[6]:https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||
[7]:https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
[8]:https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
|
||||
[9]:https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
|
||||
@ -0,0 +1,171 @@
|
||||
How To Find Files Based On their Permissions
|
||||
======
|
||||
Finding files in Linux is not a big deal. There are plenty of free and open source graphical utilities available on the market. In my opinion, finding files from command line is much easier and faster. We already knew how to [**find and sort files based on access and modification date and time**][1]. Today, we will see how to find files based on their permissions in Unix-like operating systems.
|
||||
|
||||
For the purpose of this guide, I am going to create three files namely **file1** , **file2** and **file3** with permissions **777** , **766** , **655** respectively in a folder named **ostechnix**.
|
||||
```
|
||||
mkdir ostechnix && cd ostechnix/
|
||||
```
|
||||
```
|
||||
install -b -m 777 /dev/null file1
|
||||
```
|
||||
```
|
||||
install -b -m 766 /dev/null file2
|
||||
```
|
||||
```
|
||||
install -b -m 655 /dev/null file3
|
||||
```
|
||||
|
||||
[![][2]][3]
|
||||
|
||||
Now let us find the files based on their permissions.
|
||||
|
||||
### Find files Based On their Permissions
|
||||
|
||||
The typical syntax to find files based on their permissions is:
|
||||
```
|
||||
find -perm mode
|
||||
```
|
||||
|
||||
The MODE can be either with numeric or octal permission (like 777, 666.. etc) or symbolic permission (like u=x, a=r+x).
|
||||
|
||||
Before going further, we can specify the MODE in three different ways.
|
||||
|
||||
1. If we specify the mode without any prefixes, it will find files of **exact** permissions.
|
||||
2. If we use **" -"** prefix with mode, at least the files should have the given permission, not the exact permission.
|
||||
3. If we use **" /"** prefix, either the owner, the group, or other should have permission to the file.
|
||||
|
||||
|
||||
|
||||
Allow me to explain with some examples, so you can understand better.
|
||||
|
||||
First, we will see finding files based on numeric permissions.
|
||||
|
||||
### Find Files Based On their Numeric (octal) Permissions
|
||||
|
||||
Now let me run the following command:
|
||||
```
|
||||
find -perm 777
|
||||
```
|
||||
|
||||
This command will find the files with permission of **exactly 777** in the current directory.
|
||||
|
||||
[![][2]][4]
|
||||
|
||||
As you see in the above output, file1 is the only one that has **exact 777 permission**.
|
||||
|
||||
Now, let us use "-" prefix and see what happens.
|
||||
```
|
||||
find -perm -766
|
||||
```
|
||||
|
||||
[![][2]][5]
|
||||
|
||||
As you see, the above command displays two files. We have set 766 permission to file2, but this command displays two files, why? Because, here we have used "-" prefix". It means that this command will find all files where the file owner has read/write/execute permissions, file group members have read/write permissions and everything else has also read/write permission. In our case, file1 and file2 have met this criteria. In other words, the files need not to have exact 766 permission. It will display any files that falls under this 766 permission.
|
||||
|
||||
Next, we will use "/" prefix and see what happens.
|
||||
```
|
||||
find -perm /222
|
||||
```
|
||||
|
||||
[![][2]][6]
|
||||
|
||||
The above command will find files which are writable by somebody (either their owner, or their group, or anybody else). Here is another example.
|
||||
```
|
||||
find -perm /220
|
||||
```
|
||||
|
||||
This command will find files which are writable by either their owner or their group. That means the files **don 't have to be writable** by **both the owner and group** to be matched; **either** will do.
|
||||
|
||||
But if you run the same command with "-" prefix, you will only see the files only which are writable by both owner and group.
|
||||
```
|
||||
find -perm -220
|
||||
```
|
||||
|
||||
The following screenshot will show you the difference between these two prefixes.
|
||||
|
||||
[![][2]][7]
|
||||
|
||||
Like I already said, we can also use symbolic notation to represent the file permissions.
|
||||
|
||||
Also read:
|
||||
|
||||
### Find Files Based On their Permissions using symbolic notation
|
||||
|
||||
In the following examples, we use symbolic notations such as **u** ( for user), **g** (group), **o** (others). We can also use the letter **a** to represent all three of these categories. The permissions can be specified using letters **r** (read), **w** (write), **x** (executable).
|
||||
|
||||
For instance, to find any file with group **write** permission, run:
|
||||
```
|
||||
find -perm -g=w
|
||||
```
|
||||
|
||||
[![][2]][8]
|
||||
|
||||
As you see in the above example, file1 and file2 have group **write** permission. Please note that you can use either "=" or "+" for symbolic notation. It doesn't matter. For example, the following two commands do the same thing.
|
||||
```
|
||||
find -perm -g=w
|
||||
find -perm -g+w
|
||||
```
|
||||
|
||||
To find any file which are writable by the file owner, run:
|
||||
```
|
||||
find -perm -u=w
|
||||
```
|
||||
|
||||
To find any file which are writable by all (the file owner, group and everyone else), run:
|
||||
```
|
||||
find -perm -a=w
|
||||
```
|
||||
|
||||
To find files which are writable by **both** their **owner** and their **group** , use this command:
|
||||
```
|
||||
find -perm -g+w,u+w
|
||||
```
|
||||
|
||||
The above command is equivalent of "find -perm -220" command.
|
||||
|
||||
To find files which are writable by **either** their **owner** or their **group** , run:
|
||||
```
|
||||
find -perm /u+w,g+w
|
||||
```
|
||||
|
||||
Or,
|
||||
```
|
||||
find -perm /u=w,g=w
|
||||
```
|
||||
|
||||
These two commands does the same job as "find -perm /220" command.
|
||||
|
||||
For more details, refer the man pages.
|
||||
```
|
||||
man find
|
||||
```
|
||||
|
||||
Also, check the [**man pages alternatives**][9] to learn more simplified examples of any Linux command.
|
||||
|
||||
And, that's all for now folks. I hope this guide was useful. More good stuffs to come. Stay tuned.
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/find-files-based-permissions/
|
||||
|
||||
作者:[][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com
|
||||
[1] https://www.ostechnix.com/find-sort-files-based-access-modification-date-time-linux/
|
||||
[2] data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3] http://www.ostechnix.com/wp-content/uploads/2017/12/find-files-1-1.png ()
|
||||
[4] http://www.ostechnix.com/wp-content/uploads/2017/12/find-files-2.png ()
|
||||
[5] http://www.ostechnix.com/wp-content/uploads/2017/12/find-files-3.png ()
|
||||
[6] http://www.ostechnix.com/wp-content/uploads/2017/12/find-files-6.png ()
|
||||
[7] http://www.ostechnix.com/wp-content/uploads/2017/12/find-files-7.png ()
|
||||
[8] http://www.ostechnix.com/wp-content/uploads/2017/12/find-files-8.png ()
|
||||
[9] https://www.ostechnix.com/3-good-alternatives-man-pages-every-linux-user-know/
|
||||
@ -0,0 +1,79 @@
|
||||
translating---geekpi
|
||||
|
||||
OnionShare - Share Files Anonymously
|
||||
======
|
||||
In this Digital World, we share our media, documents, important files via the Internet using different cloud storage like Dropbox, Mega, Google Drive and many more. But every cloud storage comes with two major problems, one is the Size and the other Security. After getting used to Bit Torrent the size is not a matter anymore, but the security is.
|
||||
|
||||
Even though you send your files through the secure cloud services they will be noted by the company, if the files are confidential, even the government can have them. So to overcome these problems we use OnionShare, as per the name it uses the Onion internet i.e Tor to share files Anonymously to anyone.
|
||||
|
||||
### How to Use **OnionShare**?
|
||||
|
||||
* First Download the [OnionShare][1] and [Tor Browser][2]. After downloading install both of them.
|
||||
|
||||
|
||||
|
||||
[![install onionshare and tor browser][3]][3]
|
||||
|
||||
* Now open OnionShare from the start menu
|
||||
|
||||
|
||||
|
||||
[![onionshare share files anonymously][4]][4]
|
||||
|
||||
* Click on Add and add a File/Folder to share.
|
||||
* Click start sharing. It produces a .onion URL, you could share the URL with your recipient.
|
||||
|
||||
|
||||
|
||||
[![share file with onionshare anonymously][5]][5]
|
||||
|
||||
* To Download file from the URL, copy the URL and open Tor Browser and paste it. Open the URL and download the Files/Folder.
|
||||
|
||||
|
||||
|
||||
[![receive file with onionshare anonymously][6]][6]
|
||||
|
||||
### Start of **OnionShare**
|
||||
|
||||
A few years back when Glenn Greenwald found that some of the NSA documents which he received from Edward Snowden had been corrupted. But he needed the documents and decided to get the files by using a USB. It was not successful.
|
||||
|
||||
After reading the book written by Greenwald, Micah Lee crypto expert at The Intercept, released the OnionShare - simple, free software to share files anonymously and securely. He created the program to share big data dumps via a direct channel encrypted and protected by the anonymity software Tor, making it hard to get the files for the eavesdroppers.
|
||||
|
||||
### How Does **OnionShare** Work?
|
||||
|
||||
OnionShare starts a web server at 127.0.0.1 for sharing the file on a random port. It chooses any of two words from the wordlist of 6800-wordlist called slug. It makes the server available as Tor onion service to send the file. The final URL looks like:
|
||||
|
||||
`http://qx2d7lctsnqwfdxh.onion/subside-durable`
|
||||
|
||||
The OnionShare shuts down after downloading. There is an option to allow the files to be downloaded multiple times. This makes the file not available on the internet anymore.
|
||||
|
||||
### Advantages of using **OnionShare**
|
||||
|
||||
Other Websites or Applications have access to your files: The file the sender shares using OnionShare is not stored on any server. It is directly hosted on the sender's system.
|
||||
|
||||
No one can spy on the shared files: As the connection between the users is encrypted by the Onion service and Tor Browser. This makes the connection secure and hard to eavesdroppers to get the files.
|
||||
|
||||
Both users are Anonymous: OnionShare and Tor Browser make both sender and recipient anonymous.
|
||||
|
||||
### Conclusion
|
||||
|
||||
In this article, I have explained how to **share your documents, files anonymously**. I also explained how it works. Hope you have understood how OnionShare works, and if you still have a doubt regarding anything, just drop in a comment.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.theitstuff.com/onionshare-share-files-anonymously-2
|
||||
|
||||
作者:[Anirudh Rayapeddi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.theitstuff.com
|
||||
[1]https://onionshare.org/
|
||||
[2]https://www.torproject.org/projects/torbrowser.html.en
|
||||
[3]http://www.theitstuff.com/wp-content/uploads/2017/12/Icons.png
|
||||
[4]http://www.theitstuff.com/wp-content/uploads/2017/12/Onion-Share.png
|
||||
[5]http://www.theitstuff.com/wp-content/uploads/2017/12/With-Link.png
|
||||
[6]http://www.theitstuff.com/wp-content/uploads/2017/12/Tor.png
|
||||
@ -0,0 +1,95 @@
|
||||
translating---geekpi
|
||||
|
||||
The Biggest Problems With UC Browser
|
||||
======
|
||||
Before we even begin talking about the cons, I want to establish the fact that
|
||||
I have been a devoted UC Browser user for the past 3 years. I really love the
|
||||
download speeds I get, the ultra-sleek user interface and eye-catching icons
|
||||
used for tools. I was a Chrome for Android user in the beginning but I
|
||||
migrated to UC on a friend's recommendation. But in the past 1 year or so, I
|
||||
have seen some changes that have made me rethink about my choice and now I
|
||||
feel like migrating back to chrome again.
|
||||
|
||||
### The Unwanted **Notifications**
|
||||
|
||||
I am sure I am not the only one who gets these unwanted notifications every
|
||||
few hours. These clickbait articles are a real pain and the worst part is that
|
||||
you get them every few hours.
|
||||
|
||||
[![uc browser's annoying ads notifications][1]][1]
|
||||
|
||||
I tried closing them down from the notification settings but they still kept
|
||||
appearing with a less frequency.
|
||||
|
||||
### The **News Homepage**
|
||||
|
||||
Another unwanted section that is completely useless. We completely understand
|
||||
that UC browser is free to download and it may require funding but this is not
|
||||
the way to do it. The homepage features news articles that are extremely
|
||||
distracting and unwanted. Sometimes when you are in a professional or family
|
||||
environment some of these click baits might even cause awkwardness.
|
||||
|
||||
[![uc browser's embarrassing news homepage][2]][2]
|
||||
|
||||
And they even have a setting for that. To Turn the **UC** **News Display ON /
|
||||
OFF.** And guess what, I tried that too **.** In the image below, You can see
|
||||
my efforts on the left-hand side and the output on the right-hand side.[![uc
|
||||
browser homepage settings][3]][3]
|
||||
|
||||
And click bait news isn't enough, they have started adding some unnecessary
|
||||
features. So let's include them as well.
|
||||
|
||||
### UC **Music**
|
||||
|
||||
UC browser integrated a **music player** in their browser to play music. It 's
|
||||
just something that works, nothing too fancy. So why even have it? What's the
|
||||
point? Who needs a music player in their browsers?
|
||||
|
||||
[![uc browser adds uc music player][4]][4]
|
||||
|
||||
It's not even like it will play audio from the web directly via that player in
|
||||
the background. Instead, it is a music player that plays offline music. So why
|
||||
have it? I mean it is not even good enough to be used as a primary music
|
||||
player. Even if it was, it doesn't run independently of UC Browser. So why
|
||||
would someone have his/her browser running just to use your Music Player?
|
||||
|
||||
### The **Quick** Access Bar
|
||||
|
||||
I have seen 9 out of 10 average users have this bar hanging around in their
|
||||
notification area because it comes default with the installation and they
|
||||
don't know how to get rid of it. The settings on the right get the job done.
|
||||
|
||||
[![uc browser annoying quick access bar][5]][5]
|
||||
|
||||
But I still wanna ask, "Why does it come by default ?". It's a headache for
|
||||
most users. If we want it we will enable it. Why forcing the users though.
|
||||
|
||||
### Conclusion
|
||||
|
||||
UC browser is still one of the top players in the game. It provides one of the
|
||||
best experiences, however, I am not sure what UC is trying to prove by packing
|
||||
more and more unwanted features in their browser and forcing the user to use
|
||||
them.
|
||||
|
||||
I have loved UC for its speed and design. But recent experiences have led to
|
||||
me having a second thought about my primary browser.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.theitstuff.com/biggest-problems-uc-browser
|
||||
|
||||
作者:[Rishabh Kandari][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.theitstuff.com/author/reevkandari
|
||||
[1]:http://www.theitstuff.com/wp-content/uploads/2017/10/Untitled-design-6.png
|
||||
[2]:http://www.theitstuff.com/wp-content/uploads/2017/10/Untitled-design-1-1.png
|
||||
[3]:http://www.theitstuff.com/wp-content/uploads/2017/12/uceffort.png
|
||||
[4]:http://www.theitstuff.com/wp-content/uploads/2017/10/Untitled-design-3-1.png
|
||||
[5]:http://www.theitstuff.com/wp-content/uploads/2017/10/Untitled-design-4-1.png
|
||||
|
||||
@ -0,0 +1,224 @@
|
||||
The Best Linux Laptop (2017-2018): A Buyer’s Guide with Picks from an RHCE
|
||||
======
|
||||
![][1]
|
||||
|
||||
If you don't posses the right knowledge & the experience, then finding the best Linux laptop can be a daunting task. And thus you can easily end-up with something that looks great, features great performance, but struggles to cope with 'Linux', shame! So, as a **RedHat Certified Engineer** , the author & the webmaster of this blog, and as a **' Linux' user with 14+ years of experience**, I used all my knowledge to recommend to you a couple of laptops that I personally guarantee will let you run 'Linux' with ease. After 20+ hours of research (carefully looking through the hardware details & reading user feedback) I chose [Dell XP S9360-3591-SLV][2], at the top of the line. If you want a laptop that's equipped with modern features & excellent performance **that 'just works' with Linux**, then this is your best pick.
|
||||
|
||||
It's well built (aluminium chassis), lightweight (2.7 lb), features powerful hardware, long battery life, includes an excellent 13.3 inch Gorilla Glass touchscreen with 3200×1800 QHD resolution which should give you excellently sharp images without making anything too small & difficult to read, a good & roomy track-pad (earlier versions had a few issues with it, but now they seem to be gone) with rubber-like palm rest area and a good keyboard (the key travel is not deep, but it's a very think laptop so…) with Backlit, two USB 3.0 ports. Most importantly, two of the most common elements of a laptop that can give 'Linux' user a headache, the wireless adapter & the GPU (yes the Intel HD Graphics 620 **can play 4K videos at 60fps** ), they are both **super compatible with 'Linux'** on this Dell.
|
||||
|
||||
![][3]
|
||||
|
||||
![][4]
|
||||
|
||||
One drawback is that it doesn't have an HDMI port. In its place, Dell has added a Thunderbolt 3 port. So your only option is to use a Thunderbolt to HDMI converter (they're pretty cheap). Secondly, you can't upgrade the 8GB of RAM after purchasing (you can change the hardware configuration -- CPU, RAM & SSD, before purchasing), but in my opinion, 8GB is more than enough to run any 'Linux' distribution for doing everyday tasks with ease. I for one have an Asus laptop (received it as a gift) with a 5th generation of Core i7, 4GB of RAM, I use it as my main computer. With Chrome having opened 15-20 tabs, VLC running in the background, file manager & a code editor opened, it handles it with ease. If I cut back some of the browser tabs (say reduce them to to 4-5), then with the rest of the apps opened, I can even work with a virtual machine on Virtualbox. That's with having 4GB of RAM, so with 8GB of RAM and other more powerful hardware, you should be absolutely fine.
|
||||
|
||||
> **Note:** I 've chosen a solid set of [hardware for you][2], but if you want, you can further customize it. However, don't choose the '8GB RAM/128GB SSD' option. Because that version gives you the 1920×1080 FHD screen, and that resolution on a 13.3″ screen can make things like menus to appear a bit smaller, slightly difficult to read.
|
||||
|
||||
### **Best Cheap Linux Laptop**
|
||||
|
||||
![][5]
|
||||
|
||||
If the Dell is a bit pricey and you want something that is affordable, but still gives you surprisingly similar performance & really good compatibility on 'Linux, then your 2nd best option is to go for the [Acer Aspire E 15 E5-575G-57D4][6]. Its 15.6″ display is certainly not as good as the one Dell gives you, but the 1920×1080 Full HD resolution should still fits nicely with the 15.6″ screen making things sharp & clear. The rest of the hardware is actually very similar to the ones the more pricier Dell gives you, but **at 5.2 lb it 's a little heavy.**
|
||||
|
||||
You can actually customize it a lot. The basic setup includes a 7th generation Core i5 CPU, 15.6 inch FullHD (1920 x 1080) screen, 8GB of DDR4 RAM, 256GB SSD drive, Intel HD Graphics 620 GPU and also a separate (discreet) Nvidia 940 MX GPU, for ports: HDMI 2 USB 3.0, 1 x USB 2.0 & 1 USB 3.1. For $549, it also **includes a DVD burner** … [**it 's a bargain**][6].
|
||||
|
||||
As far as the 'Linux' compatibility goes, it's really good. It may not be top notched as the Dell XPS, yet, as far as I can see, if there is one thing that can give you troubles it's that Nvidia GPU. Except for one user, all the others who have given feedback on its 'Linux' compatibility say it runs very smoothly. Only one user has complained that he came up with a minor issue after installing the proprietary Nvidia driver in Linux Mint, but he says it's certainly not a deal breaker. This feedback is also in accordance with my experience with a mobile Nvidia GPU as well.
|
||||
|
||||
For instance, nowadays I use an Asus laptop and apart from the integrated Intel GPU, it also comes with a discreet Nvidia 920M GPU. I've been using it for about an year and a half. [I've run couple of 'Linux' distributions on it][7], and the only major issue I've had so far was that after installing the proprietary driver [on Ubuntu 17.10][8] and activating Nvidia as the default GPU the auto-user-login function stopped working. And every time I had to enter my login details at the login screen for entering into the desktop. It's nowhere near being a major issue, and I'm sure it could've been fixed by editing some configuration settings of the login-manager, but I didn't even care because I rarely use the Nvidia GPU. Therefore, I simply changed the GPU back to Intel and all was back to normal. Also, a while ago I [enabled 'Motion Interpolation' on the same Nvidia GPU][9] on [Ubuntu 16.04 LTS][10] and everything worked like a charm!
|
||||
|
||||
What I'm trying to say is that GPU drivers such as those from Nvidia & AMD/ATI used give users a real hard time in the past in 'Linux', but nowadays things have progressed a lot, or so it seems. Unless you have at your disposal a very recently released high-end GPU, chances are 'Linux' is going to work without lots of major issues.
|
||||
|
||||
### **Linux Gaming Laptop**
|
||||
|
||||
![][11]
|
||||
|
||||
Most of the time, with gaming laptops, you'll have to manually tweak things a bit. And those 'things' are mostly associated with the GPU. It can be as simple as installing the proprietary driver, to dealing with a system that refuses even to boot into the live CD/USB. But with enough patience, most of the time, they can be fixed. If your gaming laptop comes with a very recently released Nvidia/AMD GPU and if the issue is related to the driver, then fixing it simply means waiting for an updated driver. Sometimes that can take time. But if you buy a laptop with a GPU that's released a couple of months ago, then that alone should increase your chances of fixing any existing issues to a great degree.
|
||||
|
||||
So with that in mind, I've chosen the [Dell Inspiron i5577-7342BLK-PUS][12] as the gaming laptop choice. It's a powerful gaming laptop that has a power tag below 1000 bucks. The reason being is the 15.6″ FullHD (1920 x 1080) display mostly. Because when you look at the rest of the configuration (yes you can further customize it), it includes a 7th generation Core i7 CPU (quad-core), 16GB DDR4 RAM (up to 32GB), 512GB SSD drive and an Nvidia GTX 1050 GPU which has received lots of positive reviews. You won't be able to play high-end games in QHD or 4K resolutions with it say on an external display, but it can handle lots of games in FullHD resolution on its 15.6″ display nonetheless.
|
||||
|
||||
And the other reason I've chosen a Dell over the other is, for some reason, most Dell laptops (or computers in general) are quite compatible with 'Linux'. It's pretty much the same with this one as well. I've manually checked the hardware details on Dell, while I cannot vouch for any issues you might come up with that Nvidia GPU, the rest of the hardware should work very well on major 'Linux' distributions (such as with Ubuntu for instance).
|
||||
|
||||
### **Is that it?**
|
||||
|
||||
Actually yes, because I believe less is better.
|
||||
|
||||
Look, I could've added bunch of laptops here and thrust them at you by 'recommending' them. But I take very seriously what I do on this blog. So I can't just 'recommend' 10-12 laptops unless I'm confident that they're suited to run 'Linux' as smoothly as possible. While the list is at the moment, confined to 3 laptops, I've made sure that they will run 'Linux' comfortably (again, even with the gaming laptop, apart from the Nvidia GPU, the rest of the hardware SHOULD work), plus, the three models should cover requirements of a large audience in my opinion. That said, as time goes on, if I find laptops from other manufactures I can predict with confidence that will run 'Linux' quite well, then I'll add them. But for now, these are my recommendations. However, if you're not happy with these recommendations, then below are couple of simple things to look for. Once you get the basic idea, you can pretty easily predict with good accuracy whether a laptop is going to give you a difficult time running 'Linux' or not. I've already mentioned most of them above, but here they are anyway.
|
||||
|
||||
* **Find more information about the hardware:**
|
||||
|
||||
|
||||
|
||||
When you come up with a laptop take a note of its model. Now, on most websites, details such as the manufacturer of the Wireless adapter or the audio chip etc aren't given. But on most occasions such information can be easily extracted using a simple trick. And this is what I usually do.
|
||||
|
||||
If you know the model number and the manufacturer of the laptop, just search for its drivers in Google. Let's take the Dell gaming laptop I just mentioned as an example. If you take its name and search for its drivers in Google ('`Dell Inspiron i5577-7342BLK-PUS drivers`'), Google doesn't display an official Dell drivers page. This is not surprising because Dell (and other manufactures) sell laptops under the same generic model name with few (2 or three) hardware variations. So, to further narrow things down, starting from the left side, let's use the first three fields of the name and search for its drivers in Google ('`Dell Inspiron i5577 drivers`'), then as shown below, Google lists us, among other websites, an official Dell's drivers page for the Inspiron 5577 (without the 'i').
|
||||
|
||||
![][13]
|
||||
|
||||
If you enter into this page and look around the various drivers & hardware listed there and compare them with the model we're interested in, then you'll see that the hardware listed in the '`Dell Inspiron i5577-7342BLK-PUS`' are also listed there. I'm usually more keen to look for what's listed under 'audio' & 'network', because the exact model names of these chips are the most difficult to obtain from a buyer's website and others such as the GPU, CPU etc are listed. So if you look what's displayed under 'network' then you'll see that Dell gives us couple of drivers. One is for Realtek Ethernet adapter (Ethernet adapter are usually well supported in 'Linux'), Qualcomm QCA61x4A-QCA9377 Wireless adapter (if you further research the 'QCA61x4A' & 'QCA9377' separately, because they're separated by '-', then you'll find that these are actually two different yet very similar Wireless chips from Qualcomm. In other words, Dell has included two drivers in a single package), and couple of Intel wireless adapters (Intel hardware too is well supported in 'Linux').
|
||||
|
||||
But Qualcomm devices can sometimes give issues. I've come up with one or two, but none of it were ever major ones. That said, when in doubt, it's always best to seek. So take that 'Qualcomm QCA61x4A-QCA9377' (it doesn't really matter if you use one adapter or use the two names combined) and add to it a keyword like 'linux' or 'ubuntu' and Google it. If I search for something like 'Qualcomm QCA61x4A-QCA9377 ubuntu' then Google lists few results. The first one I get is from [AskUbuntu][14] (a community driven website dedicated to answer end-user's Q & A, excellent resource for fixing issues related to Ubuntu).
|
||||
|
||||
![][15]
|
||||
|
||||
If you go over to that page then you can see that the user complains that Qualcomm QCA9377 wireless adapter is giving him hard time on Ubuntu 15.10. Fortunately, that question has been answered. Plus, this seems to be an issue with Ubuntu 15.10 which was released back in October 2015, so this is two years ago. So there is a high probability that this particular issue is already fixed in the latter Ubuntu releases. Also remember that, this issue seem to related to the Qualcomm QCA9377 wireless chip not the QCA61x4A. So if our 'Linux' gaming Dell laptop has the latter chip, then most probably you wouldn't come up with this at all.
|
||||
|
||||
I hope I didn't over complicate things. I just wanted to give you a pointer on how to find subtle details about the hardware of the laptop that you're hoping to run 'Linux', so that you can better evaluate the situation. Use this technique with some common sense, and with experience, you'll become very efficient at it.
|
||||
|
||||
* **Don 't stop at the GPU & the Network Adapter:**
|
||||
|
||||
|
||||
|
||||
![][16]
|
||||
|
||||
While its true that the GPU and the Network adapter are among the two most common hardware devices that give you big issues in 'Linux' since you're buying a laptop, it's always good practice to research the compatibility of the audio, the touch-pad and the keyboard & its associated features (for instance, my old Dell's Backlit keyboard had a minor issue under 'Linux'. Backlit keyboards can give minor issues in 'Linux', again, it's from experience) as well.
|
||||
|
||||
* **If it 's too 'hot', wait 2-3 months:**
|
||||
|
||||
|
||||
|
||||
As far as the computer end-users are concerned, the market share of 'Linux' is quite small. Therefore, hardware manufacturers don't take 'Linux' seriously, yet. Thus, it take them a bit longer to fix any existing major issues with the drivers of their recently released hardware devices. This is even true to open-source drivers also, but they tend to come up with 'fixes' fast compared to proprietary ones in my experience. So, if you're buying a laptop that features hardware devices (mainly CPU & the GPU) that have been very recently released, then it's better to wait 2 or 3 months before buying the laptop to see if there are any major issues in 'Linux'. And hopefully by that time, you'll be able to find a fix or at least to predict when the fix is mostly likely to arrive.
|
||||
|
||||
* **What about the Screen & HiDPI support in 'Linux'?**
|
||||
|
||||
|
||||
|
||||
![][17]
|
||||
|
||||
'Pixel density' or 'High Pixel Density' displays are quite popular terms these days. And most people assume that having lots of pixels means better quality. While that maybe true with the common intuition, technically speaking, it's not accurate. This subject can be bit too complicated to understand, so I'll just go ever the basics so that you'll know enough to avoid unnecessary confusion.
|
||||
|
||||
Things that are displayed on your screen such as texts and icons are designed with certain fixed sizes. And these sizes are defined by what is called 'Dots per inch' or 'DPI' for short. This basically defines how many dots (pixels) there should be per inch for these items to appear correctly. And 72 dots per inch is the standard set by Apple and that's what matters. I'm sure you've heard that Windows use a different standard, 96 dots per inch, but that is not entirely correct. I'm not going to go into the details, but if you want to know more, [read Wikipedia][18]. In any case, all that you want to know to make sure that the display screen of your 'Linux' laptop is going to look sharp and readable simultaneously, is to do the following. First take a note of its size (13.3″, 15.6″, 17″…) and the resolution. Then go to [PXCALC.com][19] website which gives you a nice dots per inch calculator. Then enter the values in the correct fields. Once done, take a note of the DPI value the calculator gives you (it's on the top right corner, as shown below). Then take that value and simply divide it by 72, and here's the crucial part.
|
||||
|
||||
![][20]
|
||||
|
||||
If the answer you get resembles an integer increase such as 2, 3, 4 (+0.2 -- 0.2 variation is fine. The best ones may give you +0.1 -- 0.1 variation only. The finest will give you near 0.0 ones, such as the iMac 27 5K) then you have nothing to worry about. The higher the integer increase is (provided that the variation stays within the margins), the more sharper the screen is going to be. To give you a better idea, let's take an example.
|
||||
|
||||
Take the first laptop I gave you (Dell XPS 13.3″ with the QHD resolution) as an example. Once you're done with the calculation it'll give you answer '3.83' which roughly equals to '3.8' which is not an integer but as pointed out, it's safely within the margin (-0.2 to be precise). If you do the same calculation with the Acer laptop I recommend to you as the best cheapest option, then it'll give you a value of '1.95' which is roughly '2.0'. So other features (brightness, viewing angle etc) aside, the display on Dell is almost twice as sharp compared to Acer (trust me, this display still looks great and sharp. It'll look far better compared to a resolution of 1366 x 768 on either a 13.3″ or a 15.6″ screen).
|
||||
|
||||
* **RAM Size?**
|
||||
|
||||
|
||||
|
||||
![][21]
|
||||
|
||||
KDE and GNOME are the two most popular desktop environments in 'Linux'. While there are many others, I advice you to stick with one of them. These days my preference lies with KDE. KDE plasma is actually more lightweight & efficient compared to GNOME, as far as I can tell. If you want some numbers, then in [my Ubuntu 16.10 flavors review][22] (which is about an year old now), KDE plasma consumed about 369 MiB while GNOME edition of Ubuntu consumed 781 MiB! That's **112% increase!**
|
||||
|
||||
These days I use Kubuntu 17.10, although I haven't reviewed it, but I can tell that its memory consumption too is somewhere around 380-400 MiB. Coming back to the point, I would like to advice you **not to go below 8GB** when it comes to choosing RAM size for your 'Linux' laptop. That way, I can guarantee with great probability that you'll be able to use it for at least 4 years into the future without having to worry about laptop becoming slow and not being able to cope with the requirements set by distribution vendors and by most end-users.
|
||||
|
||||
If you're looking for **a laptop for gaming in 'Linux'**, then of course you should **go 12GB or more**. Other than that, 8GB is more than enough for most end-user needs.
|
||||
|
||||
* **What about an SSD?**
|
||||
|
||||
|
||||
|
||||
![][23]
|
||||
|
||||
Despite what operating system you use, adding an SSD will improve the overall performance & responsiveness of your laptop immediately because they are much faster than the rotational disks, as simple as that. That being said, in my experience, even though efficient and lightweight, KDE distributions take more time to boot compared to GNOME counterparts. Some 'Linux' distributions such as Ubuntu and Kubuntu come with a especially designed utility called 'ureadahead' that improves boot-up times (sometimes by **30%** or even more), unfortunately not all distributions come with such tools. And on such occasions, **KDE can take 50 seconds+ to boot on a 5400 rpm SATA drive**. [Manjaro 17.0.2 KDE][24] is one such example (shown in the graph above).
|
||||
|
||||
Thus, by simply making sure to buy a laptop that features an SSD can immensely help you out. **My Kubuntu 17.10 is on a smaller SSD drive (20GB) and it boots within 13-15 seconds**.
|
||||
|
||||
* **The GPU?**
|
||||
|
||||
|
||||
|
||||
As mentioned many time, if possible, always go with an Intel GPU. Just like Dell who's known to produce 'Linux friendly' hardware, Intel has also thoroughly invested in open-source projects, and some of its hardware too is such like. You won't regret it.
|
||||
|
||||
* **What about automatic GPU switching (e.g: Nvidia Optimus), will it work?**
|
||||
|
||||
|
||||
|
||||
If you're bought a laptop with a discreet graphics card, then in Windows, Nvidia has a feature called 'Optimus' which automatically switch between the integrated (weak) GPU and the discreet (more capable) GPU. ATI also has this capability. There is no official support of such features in 'Linux', but there are experimental work such as the [Bumblebee project][25]. But it does not always work as expected. I simply prefer to have installed the proprietary GPU driver and switch between each whenever I want, manually. To their credit, Fedora team has also been working on a solution of their own, I don't honestly know how far they've gone. Better [ask Christian][26] I guess.
|
||||
|
||||
* **Can 'Linux' give you good battery life?**
|
||||
|
||||
|
||||
|
||||
Of course it can! Once your hardware devices are properly configured, I recommend that you install a power usage optimizer. There are a few applications, but I recommend '[TLP][27]'. It's easy to install, cuts down the power usage impressively in my experience, and usually it requires no manual tweaks to work.
|
||||
|
||||
Below are two screenshots from my latest Ubuntu 17.10 review. First screenshot shows the power usage before installing 'tlp' and the second one shows the readings after installing it (the pictures say it all):
|
||||
|
||||
![][28]
|
||||
|
||||
![][29]
|
||||
|
||||
'tlp' should be available in major 'Linux' distributions. On Ubuntu based ones, you should be able to install it by issuing the following commands:
|
||||
|
||||
`sudo apt update`
|
||||
|
||||
`sudo apt install tlp`
|
||||
|
||||
Now reboot the computer, and you're done!
|
||||
|
||||
* **How did you measure the power usage in 'Linux'?**
|
||||
|
||||
|
||||
|
||||
Glad you asked! It's called '[powerstat][30]'. It's this amazing little utility (designed by Colin King, an Ubuntu developer) that gathers useful data that's related to power consumption (and debugging) and puts them all into a single screen. On Ubuntu based systems, enter the below commands to install it:
|
||||
|
||||
`sudo apt update`
|
||||
|
||||
`sudo apt install powerstat`
|
||||
|
||||
Most major 'Linux' distributions make it available through their software repositories these days.
|
||||
|
||||
* **Are there any 'Linux' operating systems you recommend?**
|
||||
|
||||
|
||||
|
||||
Well, my main operating system these days is Kubuntu 17.10. Now I have not reviewed it, but to make a long story short, I love it! It's very easy to install, beginner friendly, stable, beautiful, power efficient and easy to use. These days I literally laugh at GNOME! So if you're new to 'Linux', then I advice you to [try Kubuntu ][31] or [Linux Mint][32], first ('Mint' gives you couple of desktop choices. Go with either the KDE version or with 'Cinnamon').
|
||||
|
||||
Then once you get the hang of things, then you can move on to others, that's the best approach for a beginner.
|
||||
|
||||
### **Final Words**
|
||||
|
||||
Recall what I said at the beginning. If you're looking for a laptop that runs 'Linux' almost effortlessly, then by all means go with the [Dell XP S9360-3591-SLV][2]. It's a well build, powerful, very popular, ultra-portable laptop that not only can let you run 'Linux' easily, but also feature a great display screen that has been praised by many reviewers. If however, you want something cheap, then go with the [Acer Aspire E 15 E5-575G-57D4][6]. As far as 'Linux' compatibility goes, it's almost as good as the Dell, plus it's a great value for the money.
|
||||
|
||||
Thirdly, if you're looking for a laptop to do some gaming on 'Linux', then [Dell Inspiron i5577-7342BLK-PUS][12] looks pretty solid to me. Again, there are many other gaming laptops out there, true, but I specifically chose this one because, it features hardware that are already compatible with 'Linux', although I cannot vouch for the Nvidia GTX 1050 with the same confidence. That said, you shouldn't buy a 'Linux' gaming laptop without wanting to get your hands dirty a bit. In that case, if you're not happy with its hardware capabilities (it's quite capable) and would like to do the research and choose a different one, then by all means do so.
|
||||
|
||||
I wish you good luck with your purchase and thank you for reading!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.hecticgeek.com/2017/12/best-linux-laptop/
|
||||
|
||||
作者:[Gayan][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.hecticgeek.com/author/gayan/
|
||||
[1]:https://www.hecticgeek.com/wp-content/uploads/2017/12/Dell-XPS-9360-Linux.png
|
||||
[2]:https://www.amazon.com/gp/product/B01LQTXED8?ie=UTF8&tag=flooclea01-20&camp=1789&linkCode=xm2&creativeASIN=B01LQTXED8
|
||||
[3]:https://www.hecticgeek.com/wp-content/uploads/2017/12/Dell-XPS-9360-keyboard-the-track-pad.png
|
||||
[4]:https://www.hecticgeek.com/wp-content/uploads/2017/12/XPS-13.3-ports.png
|
||||
[5]:https://www.hecticgeek.com/wp-content/uploads/2017/12/Acer-Aspire-E-15-E5-575G-57D4-affordable-linux-laptop.png
|
||||
[6]:https://www.amazon.com/gp/product/B01LD4MGY4?ie=UTF8&tag=flooclea01-20&camp=1789&linkCode=xm2&creativeASIN=B01LD4MGY4
|
||||
[7]:https://www.hecticgeek.com/gnu-linux/
|
||||
[8]:https://www.hecticgeek.com/2017/11/ubuntu-17-10-review/
|
||||
[9]:https://www.hecticgeek.com/2016/06/motion-interpolation-linux-svp/
|
||||
[10]:https://www.hecticgeek.com/2016/04/ubuntu-16-04-lts-review/
|
||||
[11]:https://www.hecticgeek.com/wp-content/uploads/2017/12/DELL-Inspiron-15-i5577-5328BLK-linux-gaming-laptop.png
|
||||
[12]:https://www.amazon.com/gp/product/B06XFC44CL?ie=UTF8&tag=flooclea01-20&camp=1789&linkCode=xm2&creativeASIN=B06XFC44CL
|
||||
[13]:https://www.hecticgeek.com/wp-content/uploads/2017/12/Trying-to-gather-more-data-about-the-hardware-of-a-Dell-laptop-for-linux.png
|
||||
[14]:https://askubuntu.com/
|
||||
[15]:https://www.hecticgeek.com/wp-content/uploads/2017/12/Trying-to-find-if-the-network-adapter-from-Qualcomm-is-compatible-with-Linux.png
|
||||
[16]:https://www.hecticgeek.com/wp-content/uploads/2017/12/computer-hardware-illustration.jpg
|
||||
[17]:https://www.hecticgeek.com/wp-content/uploads/2017/12/Display-Scalling-Settings-on-KDE-Plasma-5.10.5.png
|
||||
[18]:https://en.wikipedia.org/wiki/Dots_per_inch#Computer_monitor_DPI_standards
|
||||
[19]:http://pxcalc.com/
|
||||
[20]:https://www.hecticgeek.com/wp-content/uploads/2017/12/Using-PXCALC-dpi-calculator.png
|
||||
[21]:https://www.hecticgeek.com/wp-content/uploads/2016/11/Ubuntu-16.10-vs-Ubuntu-GNOME-16.10-vs-Kubuntu-16.10-vs-Xubuntu-16.10-Memory-Usage-Graph.png
|
||||
[22]:https://www.hecticgeek.com/2016/11/ubuntu-16-10-flavors-comparison/
|
||||
[23]:https://www.hecticgeek.com/wp-content/uploads/2017/07/Kubuntu-16.10-vs-Ubuntu-17.04-vs-Manjaro-17.0.2-KDE-Boot_up-Times-Graph.png
|
||||
[24]:https://www.hecticgeek.com/2017/07/manjaro-17-0-2-kde-review/
|
||||
[25]:https://bumblebee-project.org/
|
||||
[26]:https://blogs.gnome.org/uraeus/2016/11/01/discrete-graphics-and-fedora-workstation-25/
|
||||
[27]:http://linrunner.de/en/tlp/docs/tlp-linux-advanced-power-management.html
|
||||
[28]:https://www.hecticgeek.com/wp-content/uploads/2017/11/Ubuntu-17.10-Power-Usage-idle.png
|
||||
[29]:https://www.hecticgeek.com/wp-content/uploads/2017/11/Ubuntu-17.10-Power-Usage-idle-after-installing-TLP.png
|
||||
[30]:https://www.hecticgeek.com/2012/02/powerstat-power-calculator-ubuntu-linux/
|
||||
[31]:https://kubuntu.org/
|
||||
[32]:https://linuxmint.com/
|
||||
[33]:https://twitter.com/share
|
||||
[34]:https://www.hecticgeek.com/2017/12/best-linux-laptop/?share=email (Click to email this to a friend)
|
||||
@ -0,0 +1,283 @@
|
||||
How to Install Arch Linux [Step by Step Guide]
|
||||
======
|
||||
**Brief: This tutorial shows you how to install Arch Linux in easy to follow steps.**
|
||||
|
||||
[Arch Linux][1] is a x86-64 general-purpose Linux distribution which has been popular among the [DIY][2] enthusiasts and hardcore Linux users. The default installation covers only a minimal base system and expects the end user to configure and use it. Based on the KISS - Keep It Simple, Stupid! principle, Arch Linux focus on elegance, code correctness, minimalist system and simplicity.
|
||||
|
||||
Arch Linux supports the Rolling release model and has its own package manager - [pacman][3]. With the aim to provide a cutting-edge operating system, Arch never misses out to have an up-to-date repository. The fact that it provides a minimal base system gives you a choice to install it even on low-end hardware and then install only the required packages over it.
|
||||
|
||||
Also, its one of the most popular OS for learning Linux from scratch. If you like to experiment with a DIY attitude, you should give Arch Linux a try. It's what many Linux users consider a core Linux experience.
|
||||
|
||||
In this article, we will see how to install and set up Arch Linux and then a desktop environment over it.
|
||||
|
||||
## How to install Arch Linux
|
||||
|
||||
![How to install Arch Linux][4]
|
||||
|
||||
![How to install Arch Linux][5]
|
||||
|
||||
The method we are going to discuss here **wipes out existing operating system** (s) from your computer and install Arch Linux on it. So if you are going to follow this tutorial, make sure that you have backed up your files or else you'll lose all of it. You have been warned.
|
||||
|
||||
But before we see how to install Arch Linux from a USB, please make sure that you have the following requirements:
|
||||
|
||||
### Requirements for installing Arch Linux:
|
||||
|
||||
* A x86_64 (i.e. 64 bit) compatible machine
|
||||
* Minimum 512 MB of RAM (recommended 2 GB)
|
||||
* At least 1 GB of free disk space (recommended 20 GB for basic usage)
|
||||
* An active internet connection
|
||||
* A USB drive with minimum 2 GB of storage capacity
|
||||
* Familiarity with Linux command line
|
||||
|
||||
|
||||
|
||||
Once you have made sure that you have all the requirements, let's proceed to install Arch Linux.
|
||||
|
||||
### Step 1: Download the ISO
|
||||
|
||||
You can download the ISO from the [official website][6]. Arch Linux requires a x86_64 (i.e. 64 bit) compatible machine with a minimum of 512 MB RAM and 800 MB disk space for a minimal installation. However, it is recommended to have 2 GB of RAM and at least 20 GB of storage for a GUI to work without hassle.
|
||||
|
||||
### Step 2: Create a live USB of Arch Linux
|
||||
|
||||
We will have to create a live USB of Arch Linux from the ISO you just downloaded.
|
||||
|
||||
If you are on Linux, you can use **dd command** to create a live USB. Replace /path/to/archlinux.iso with the path where you have downloaded ISO file, and /dev/sdx with your drive in the example below. You can get your drive information using [lsblk][7] command.
|
||||
```
|
||||
dd bs=4M if=/path/to/archlinux.iso of=/dev/sdx status=progress && sync
|
||||
```
|
||||
|
||||
On Windows, there are several tools to create a live USB. The recommended tool is Rufus. We have already covered a tutorial on [how to create a live USB of Antergos Linux using Rufus][8] in the past. Since Antergos is based on Arch, you can follow the same tutorial.
|
||||
|
||||
### Step 3: Boot from the live USB
|
||||
|
||||
Once you have created a live USB for Arch Linux, shut down your PC. Plugin your USB and boot your system. While booting keep pressing F2, F10 or F1dependinging upon your system) to go into boot settings. In here, select to boot from USB or removable disk.
|
||||
|
||||
Once you select that, you should see an option like this:
|
||||
|
||||
![Arch Linux][4]
|
||||
|
||||
![Arch Linux][9]
|
||||
Select Boot Arch Linux (x86_64). After various checks, Arch Linux will boot to login prompt with root user.
|
||||
|
||||
Select Boot Arch Linux (x86_64). After various checks, Arch Linux will boot to login prompt with root user.
|
||||
|
||||
Next steps include partitioning disk, creating the filesystem and mounting it.
|
||||
|
||||
### Step 4: Partitioning the disks
|
||||
|
||||
The first step includes partitioning your hard disk. A single root partition is the simplest one where we will create a root partition (/), a swapfile and home partition.
|
||||
|
||||
I have a 19 GB disk where I want to install Arch Linux. To create a disk, type
|
||||
```
|
||||
fdisk /dev/sda
|
||||
```
|
||||
|
||||
Type "n" for a new partition. Type in "p" for a primary partition and select the partition number.
|
||||
|
||||
The First sector is automatically selected and you just need to press Enter. For Last sector, type the size you want to allocate for this partition.
|
||||
|
||||
Create two more partitions similarly for home and swap, and press 'w' to save the changes and exit.
|
||||
|
||||
![root partition][4]
|
||||
|
||||
![root partition][10]
|
||||
|
||||
### Step 4: Creating filesystem
|
||||
|
||||
Since we have created 3 different partitions, the next step is to format the partition and create a filesystem.
|
||||
|
||||
We will use mkfs for root and home partition and mkswap for creating swap space. We are formatting our disk with ext4 filesystem.
|
||||
```
|
||||
mkfs.ext4 /dev/sda1
|
||||
mkfs.ext4 /dev/sda3
|
||||
|
||||
mkswap /dev/sda2
|
||||
swapon /dev/sda2
|
||||
```
|
||||
|
||||
Lets mount these filesystems to root and home
|
||||
```
|
||||
mount /dev/sda1 /mnt
|
||||
mkdir /mnt/home
|
||||
mount /dev/sda3 /mnt/home
|
||||
```
|
||||
|
||||
### Step 5: Installation
|
||||
|
||||
Since we have created partitioning and mounted it, let's install the base package. A base package contains all the necessary package to run a system, some of which are the GNU BASH shell, data compression tool, file system utilities, C library, compression tools, Linux kernels and modules, library packages, system utilities, USB devices utilities, vi text editor etc.
|
||||
```
|
||||
pacstrap /mnt base base-devel
|
||||
```
|
||||
|
||||
### **Step 6: Configuring the system**
|
||||
|
||||
Generate a fstab file to define how disk partitions, block devices or remote file systems are mounted into the filesystem.
|
||||
```
|
||||
genfstab -U /mnt >> /mnt/etc/fstab
|
||||
```
|
||||
|
||||
Change root into the new system, this allows changing the root directory for the current running process and the child process.
|
||||
```
|
||||
arch-chroot /mnt
|
||||
```
|
||||
|
||||
Some systemd tools which require an active dbus connection can not be used inside a chroot, hence it would be better if we exit from it. To exit chroot, simpy use the below command:
|
||||
```
|
||||
exit
|
||||
```
|
||||
|
||||
### Step 7. Setting Timezone
|
||||
|
||||
Use below command to set the time zone.
|
||||
```
|
||||
ln -sf /usr/share/<zoneinfo>/<Region>/<City> /etc/localtime
|
||||
```
|
||||
|
||||
To get a list of zone, type
|
||||
```
|
||||
ls /usr/share/zoneinfo
|
||||
```
|
||||
|
||||
Run hwclock to set the hardware clock.
|
||||
```
|
||||
hwclock --systohc --utc
|
||||
```
|
||||
|
||||
### Step 8. Setting up Locale.
|
||||
|
||||
File /etc/locale.gen contains all the local settings and system language in a commented format. Open the file using vi editor and un-comment the language you prefer. I had done it for **en_GB.UTF-8**.
|
||||
|
||||
Now generate the locale config in /etc directory file using the commands below:
|
||||
```
|
||||
locale-gen
|
||||
echo LANG=en_GB.UTF-8 > /etc/locale.conf
|
||||
export LANG=en_GB.UTF-8
|
||||
```
|
||||
|
||||
### Step 9. Installing bootloader, setting up hostname and root password
|
||||
|
||||
Create a /etc/hostname file and add a matching entry to host.
|
||||
|
||||
127.0.1.1 myhostname.localdomain myhostname
|
||||
|
||||
I am adding ItsFossArch as a hostname:
|
||||
```
|
||||
echo ItsFossArch > /etc/hostname
|
||||
```
|
||||
|
||||
and then to the /etc/hosts file.
|
||||
|
||||
To install a bootloader use below commands :
|
||||
```
|
||||
pacman -S grub
|
||||
grub-install /dev/sda
|
||||
grub-mkconfig -o /boot/grub/grub.cfg
|
||||
```
|
||||
|
||||
To create root password, type
|
||||
```
|
||||
passwd
|
||||
```
|
||||
|
||||
and enter your desired password.
|
||||
|
||||
Once done, update your system. Chances are that you already have an updated system since you have downloaded the latest ISO file.
|
||||
```
|
||||
pacman -Syu
|
||||
```
|
||||
|
||||
Congratulations! You have successfully installed a minimal command line Arch Linux.
|
||||
|
||||
In the next step, we will see how to set up a desktop environment or Graphical User Interface for the Arch Linux. I am a big fan of GNOME desktop environment, and we will be working on installing the same.
|
||||
|
||||
### Step 10: Install a desktop environment (GNOME in this case)
|
||||
|
||||
Before you can install a desktop environment, you will need to configure the network first.
|
||||
|
||||
You can see the interface name with below command:
|
||||
```
|
||||
ip link
|
||||
```
|
||||
|
||||
![][4]
|
||||
|
||||
![][11]
|
||||
|
||||
For me, it's **enp0s3.**
|
||||
|
||||
Add the following entries in the file
|
||||
```
|
||||
vi /etc/systemd/network/enp0s3.network
|
||||
|
||||
[Match]
|
||||
name=en*
|
||||
[Network]
|
||||
DHCP=yes
|
||||
```
|
||||
|
||||
Save and exit. Restart your systemd network for the changes to reflect.
|
||||
```
|
||||
systemctl restart systemd-networkd
|
||||
systemctl enable systemd-networkd
|
||||
```
|
||||
|
||||
And then add the below two entries in /etc/resolv.conf file.
|
||||
```
|
||||
nameserver 8.8.8.8
|
||||
nameserver 8.8.4.4
|
||||
```
|
||||
|
||||
Next step is to install X environment.
|
||||
|
||||
Type the below command to install the Xorg as display server.
|
||||
```
|
||||
pacman -S xorg xorg-server
|
||||
```
|
||||
|
||||
gnome contains the base GNOME desktop. gnome-extra contains GNOME applications, archive manager, disk manager, text editors and more.
|
||||
```
|
||||
pacman -S gnome gnome-extra
|
||||
```
|
||||
|
||||
The last step includes enabling the display manager GDM for Arch.
|
||||
```
|
||||
systemctl start gdm.service
|
||||
systemctl enable gdm.service
|
||||
```
|
||||
|
||||
Restart your system and you can see the GNOME login screen.
|
||||
|
||||
## Final Words on Arch Linux installation
|
||||
|
||||
A similar approach has been demonstrated in this video (watch in full screen to see the commands) by It's FOSS reader Gonzalo Tormo:
|
||||
|
||||
You might have realized by now that installing Arch Linux is not as easy as [installing Ubuntu][12]. However, with a little patience, you can surely accomplish it and then tell the world that you use Arch Linux.
|
||||
|
||||
Arch Linux installation itself provides a great deal of learning. And once you have installed it, I recommend referring to its comprehensive [wiki][13] where you can find steps to install various other desktop environments and learn more about the OS. You can keep playing with it and see how powerful Arch is.
|
||||
|
||||
Let us know in the comments if you face any difficulty while installing Arch Linux.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/install-arch-linux/
|
||||
|
||||
作者:[Ambarish Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/ambarish/
|
||||
[1] https://www.archlinux.org/
|
||||
[2] https://en.wikipedia.org/wiki/Do_it_yourself
|
||||
[3] https://wiki.archlinux.org/index.php/pacman
|
||||
[4] data:image/gif;base64,R0lGODdhAQABAPAAAP///wAAACwAAAAAAQABAEACAkQBADs=
|
||||
[5] https://itsfoss.com/wp-content/uploads/2017/12/install-arch-linux-featured-800x450.png
|
||||
[6] https://www.archlinux.org/download/
|
||||
[7] https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/6/html/deployment_guide/s1-sysinfo-filesystems
|
||||
[8] https://itsfoss.com/live-usb-antergos/
|
||||
[9] https://itsfoss.com/wp-content/uploads/2017/11/1-2.jpg
|
||||
[10] https://itsfoss.com/wp-content/uploads/2017/11/4-root-partition.png
|
||||
[11] https://itsfoss.com/wp-content/uploads/2017/12/11.png
|
||||
[12] https://itsfoss.com/install-ubuntu-1404-dual-boot-mode-windows-8-81-uefi/
|
||||
[13] https://wiki.archlinux.org/
|
||||
@ -1,90 +0,0 @@
|
||||
translating by lujun9972
|
||||
What Are Zombie Processes And How To Find & Kill Zombie Processes?
|
||||
======
|
||||
[][1]
|
||||
|
||||
If you are a regular Linux user, you must have encountered the term `Zombie Processes`. So what are the Zombie Processes? How do they get created? Are they harmful to the system? How do I kill these processes? Keep reading for the answers to all these questions.
|
||||
|
||||
### What are Zombie Processes?
|
||||
|
||||
So we all know how processes work. We launch a program, start our task & once our task is over, we end that process. Once the process has ended, it has to be removed from the processes table.
|
||||
|
||||
|
||||
|
||||
You can see the current processes in the ‘System-Monitor’.
|
||||
|
||||
[][2]
|
||||
|
||||
But, sometimes some of these processes stay in the processes table even after they have completed execution.
|
||||
|
||||
|
||||
|
||||
So these processes that have completed their life of execution but still exist in the processes table are called ‘Zombie Processes’.
|
||||
|
||||
### And How Exactly do they get Created?
|
||||
|
||||
Whenever we run a program it creates a parent process and a lot of child processes. All of these child processes use resources such as memory and CPU allocated to them by the kernel.
|
||||
|
||||
|
||||
|
||||
Once these child processes have finished executing they send an Exit call and die. This Exit call has to be read by the parent process which later calls the wait command to read the exit_status of the child process so that the child process can be removed from the processes table.
|
||||
|
||||
If the Parent reads the Exit call correctly sent by the Child Process, the process is removed from the processes table.
|
||||
|
||||
But, if the parent fails to read the exit call from the child process, the child process which has already finished its execution and is now dead will not be removed from the processes table.
|
||||
|
||||
### Are Zombie processes harmful to the System?
|
||||
|
||||
**No. **
|
||||
|
||||
Since zombie process is not doing any work, not using any resources or affecting any other process, there is no harm in having a zombie process. But since the exit_status and other process information from the process table are stored in the RAM, having too many Zombie processes can sometimes be an issue.
|
||||
|
||||
**_Imagine it Like this :_**
|
||||
|
||||
“
|
||||
|
||||
_You are the owner of a construction company. You pay daily wages to all your workers depending upon how they work. _ _A worker comes to the construction site every day, just sits there, you don’t have to pay him, he doesn’t do any work. _ _He just comes every day and sits, that’s it !”_
|
||||
|
||||
Such a worker is the living example of a zombie process.
|
||||
|
||||
**But,**
|
||||
|
||||
if you have a lot of zombie workers, your construction site will get crowded and it might get difficult for the people that are actually working.
|
||||
|
||||
### So how to find Zombie Processes?
|
||||
|
||||
Fire up a terminal and type the following command -
|
||||
|
||||
ps aux | grep Z
|
||||
|
||||
You will now get details of all zombie processes in the processes table.
|
||||
|
||||
### How to kill Zombie processes?
|
||||
|
||||
Normally we kill processes with the SIGKILL command but zombie processes are already dead. You Cannot kill something that is already dead. So what you do is you type this command -
|
||||
|
||||
kill -s SIGCHLD pid
|
||||
|
||||
Replace the pid with the id of the parent process so that the parent process will remove all the child processes that are dead and completed.
|
||||
|
||||
**_Imagine it Like this :_**
|
||||
|
||||
“
|
||||
|
||||
_You find a dead body in the middle of the road, you call the dead body’s family and they take that body away from the road.”_
|
||||
|
||||
But a lot of programs are not programmed well enough to remove these child zombies because if they were, you wouldn’t have those zombies in the first place. So the only thing guaranteed to remove Child Zombies is killing the parent.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/what-are-zombie-processes-and-how-to-find-kill-zombie-processes
|
||||
|
||||
作者:[linuxandubuntu][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com
|
||||
[1]:http://www.linuxandubuntu.com/home/what-are-zombie-processes-and-how-to-find-kill-zombie-processes
|
||||
[2]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/linux-check-zombie-processes_orig.jpg
|
||||
@ -0,0 +1,63 @@
|
||||
How to Search PDF Files from the Terminal with pdfgrep
|
||||
======
|
||||
Command line utilities such as [grep][1] and [ack-grep][2] are great for searching plain-text files for patterns matching a specified [regular expression][3]. But have you ever tried using these utilities to search for patterns in a PDF file? Well, don't! You will not get any result as these tools cannot read PDF files; they only read plain-text files.
|
||||
|
||||
[pdfgrep][4], as the name suggests, is a small command line utility that makes it possible to search for text in a PDF file without opening the file. It is insanely fast - faster than the search provided by virtually all PDF document viewers. A great distinction between grep and pdfgrep is that pdfgrep operates on pages, whereas grep operates on lines. It also prints a single line multiple times if more than one match is found on that line. Let's look at how exactly to use the tool.
|
||||
|
||||
For Ubuntu and other Linux distros based on Ubuntu, it is pretty simple:
|
||||
```
|
||||
sudo apt install pdfgrep
|
||||
```
|
||||
|
||||
For other distros, just provide `pdfgrep` as input for the [package manager][5], and that should get it installed. You can also check out the project's [GitLab page][6], in case you want to play around with the code.
|
||||
|
||||
Now that you have the tool installed, let's go for a test run. pdfgrep command takes this format:
|
||||
```
|
||||
pdfgrep [OPTION...] PATTERN [FILE...]
|
||||
```
|
||||
|
||||
**OPTION** is a list of extra attributes to give the command such as `-i` or `--ignore-case`, which both ignore the case distinction between the regular pattern specified and the once matching it from the file.
|
||||
|
||||
**PATTERN** is just an extended regular expression.
|
||||
|
||||
**FILE** is just the name of the file, if it is in the same working directory, or the path to the file.
|
||||
|
||||
I ran the command on Python 3.6 official documentation. The following image is the result.
|
||||
|
||||
![pdfgrep search][7]
|
||||
|
||||
![pdfgrep search][7]
|
||||
|
||||
The red highlights indicate all the places the word "queue" was encountered. Passing `-i` as option to the command included matches of the word "Queue." Remember, the case does not matter when `-i` is passed as an option.
|
||||
|
||||
pdfgrep has quite a number of interesting options to use. However, I'll cover only a few here.
|
||||
|
||||
* `-c` or `--count`: this suppresses the normal output of matches. Instead of displaying the long output of the matches, it only displays a value representing the number of times the word was encountered in the file
|
||||
* `-p` or `--page-count`: this option prints out the page numbers of matches and the number of occurrences of the pattern on the page
|
||||
* `-m` or `--max-count` [number]: specifies the maximum number of matches. That means when the number of matches is reached, the command stops reading the file.
|
||||
|
||||
|
||||
|
||||
The full list of supported options can be found in the man pages or in the pdfgrep online [documenation][8]. Don't forget pdfgrep can search multiple files at the same time, in case you're working with some bulk files. The default match highlight color can be changed by altering the GREP_COLORS environment variable.
|
||||
|
||||
The next time you think of opening up a PDF file to search for anything. think of using pdfgrep. The tool comes in handy and will save you time.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/search-pdf-files-pdfgrep/
|
||||
|
||||
作者:[Bruno Edoh][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com
|
||||
[1] https://www.maketecheasier.com/what-is-grep-and-uses/
|
||||
[2] https://www.maketecheasier.com/ack-a-better-grep/
|
||||
[3] https://www.maketecheasier.com/the-beginner-guide-to-regular-expressions/
|
||||
[4] https://pdfgrep.org/
|
||||
[5] https://www.maketecheasier.com/install-software-in-various-linux-distros/
|
||||
[6] https://gitlab.com/pdfgrep/pdfgrep
|
||||
[7] https://www.maketecheasier.com/assets/uploads/2017/11/pdfgrep-screenshot.png (pdfgrep search)
|
||||
[8] https://pdfgrep.org/doc.html
|
||||
@ -0,0 +1,282 @@
|
||||
Toplip – A Very Strong File Encryption And Decryption CLI Utility
|
||||
======
|
||||
There are numerous file encryption tools available on the market to protect
|
||||
your files. We have already reviewed some encryption tools such as
|
||||
[**Cryptomater**][1], [**Cryptkeeper**][2], [**CryptGo**][3], [**Cryptr**][4],
|
||||
[**Tomb**][5], and [**GnuPG**][6] etc. Today, we will be discussing yet
|
||||
another file encryption and decryption command line utility named **"
|
||||
Toplip"**. It is a free and open source encryption utility that uses a very
|
||||
strong encryption method called **[AES256][7]** , along with an **XTS-AES**
|
||||
design to safeguard your confidential data. Also, it uses [**Scrypt**][8], a
|
||||
password-based key derivation function, to protect your passphrases against
|
||||
brute-force attacks.
|
||||
|
||||
### Prominent features
|
||||
|
||||
Compared to other file encryption tools, toplip ships with the following
|
||||
unique and prominent features.
|
||||
|
||||
* Very strong XTS-AES256 based encryption method.
|
||||
* Plausible deniability.
|
||||
* Encrypt files inside images (PNG/JPG).
|
||||
* Multiple passphrase protection.
|
||||
* Simplified brute force recovery protection.
|
||||
* No identifiable output markers.
|
||||
* Open source/GPLv3.
|
||||
|
||||
### Installing Toplip
|
||||
|
||||
There is no installation required. Toplip is a standalone executable binary
|
||||
file. All you have to do is download the latest toplip from the [**official
|
||||
products page**][9] and make it as executable. To do so, just run:
|
||||
|
||||
```
|
||||
chmod +x toplip
|
||||
```
|
||||
|
||||
### Usage
|
||||
|
||||
If you run toplip without any arguments, you will see the help section.
|
||||
|
||||
```
|
||||
./toplip
|
||||
```
|
||||
|
||||
[![][10]][11]
|
||||
|
||||
Allow me to show you some examples.
|
||||
|
||||
For the purpose of this guide, I have created two files namely **file1** and
|
||||
**file2**. Also, I have an image file which we need it to hide the files
|
||||
inside it. And finally, I have **toplip** executable binary file. I have kept
|
||||
them all in a directory called **test**.
|
||||
|
||||
[![][12]][13]
|
||||
|
||||
**Encrypt/decrypt a single file**
|
||||
|
||||
Now, let us encrypt **file1**. To do so, run:
|
||||
|
||||
```
|
||||
./toplip file1 > file1.encrypted
|
||||
```
|
||||
|
||||
This command will prompt you to enter a passphrase. Once you have given the
|
||||
passphrase, it will encrypt the contents of **file1** and save them in a file
|
||||
called **file1.encrypted** in your current working directory.
|
||||
|
||||
Sample output of the above command would be:
|
||||
|
||||
```
|
||||
This is toplip v1.20 (C) 2015, 2016 2 Ton Digital. Author: Jeff Marrison A showcase piece for the HeavyThing library. Commercial support available Proudly made in Cooroy, Australia. More info: https://2ton.com.au/toplip file1 Passphrase #1: generating keys...Done
|
||||
Encrypting...Done
|
||||
```
|
||||
|
||||
To verify if the file is really encrypted., try to open it and you will see
|
||||
some random characters.
|
||||
|
||||
To decrypt the encrypted file, use **-d** flag like below:
|
||||
|
||||
```
|
||||
./toplip -d file1.encrypted
|
||||
```
|
||||
|
||||
This command will decrypt the given file and display the contents in the
|
||||
Terminal window.
|
||||
|
||||
To restore the file instead of writing to stdout, do:
|
||||
|
||||
```
|
||||
./toplip -d file1.encrypted > file1.decrypted
|
||||
```
|
||||
|
||||
Enter the correct passphrase to decrypt the file. All contents of **file1.encrypted** will be restored in a file called **file1.decrypted**.
|
||||
|
||||
Please don't follow this naming method. I used it for the sake of easy understanding. Use any other name(s) which is very hard to predict.
|
||||
|
||||
**Encrypt/decrypt multiple files
|
||||
**
|
||||
|
||||
Now we will encrypt two files with two separate passphrases for each one.
|
||||
|
||||
```
|
||||
./toplip -alt file1 file2 > file3.encrypted
|
||||
```
|
||||
|
||||
You will be asked to enter passphrase for each file. Use different
|
||||
passphrases.
|
||||
|
||||
Sample output of the above command will be:
|
||||
|
||||
```
|
||||
This is toplip v1.20 (C) 2015, 2016 2 Ton Digital. Author: Jeff Marrison A showcase piece for the HeavyThing library. Commercial support available Proudly made in Cooroy, Australia. More info: https://2ton.com.au/toplip
|
||||
**file2 Passphrase #1** : generating keys...Done
|
||||
**file1 Passphrase #1** : generating keys...Done
|
||||
Encrypting...Done
|
||||
```
|
||||
|
||||
What the above command will do is encrypt the contents of two files and save
|
||||
them in a single file called **file3.encrypted**. While restoring, just give
|
||||
the respective password. For example, if you give the passphrase of the file1,
|
||||
toplip will restore file1. If you enter the passphrase of file2, toplip will
|
||||
restore file2.
|
||||
|
||||
Each **toplip** encrypted output may contain up to four wholly independent
|
||||
files, and each created with their own separate and unique passphrase. Due to
|
||||
the way the encrypted output is put together, there is no way to easily
|
||||
determine whether or not multiple files actually exist in the first place. By
|
||||
default, even if only one file is encrypted using toplip, random data is added
|
||||
automatically. If more than one file is specified, each with their own
|
||||
passphrase, then you can selectively extract each file independently and thus
|
||||
deny the existence of the other files altogether. This effectively allows a
|
||||
user to open an encrypted bundle with controlled exposure risk, and no
|
||||
computationally inexpensive way for an adversary to conclusively identify that
|
||||
additional confidential data exists. This is called **Plausible deniability**
|
||||
, one of the notable feature of toplip.
|
||||
|
||||
To decrypt **file1** from **file3.encrypted** , just enter:
|
||||
|
||||
```
|
||||
./toplip -d file3.encrypted > file1.encrypted
|
||||
```
|
||||
|
||||
You will be prompted to enter the correct passphrase of file1.
|
||||
|
||||
To decrypt **file2** from **file3.encrypted** , enter:
|
||||
|
||||
```
|
||||
./toplip -d file3.encrypted > file2.encrypted
|
||||
```
|
||||
|
||||
Do not forget to enter the correct passphrase of file2.
|
||||
|
||||
**Use multiple passphrase protection**
|
||||
|
||||
This is another cool feature that I admire. We can provide multiple
|
||||
passphrases for a single file when encrypting it. It will protect the
|
||||
passphrases against brute force attempts.
|
||||
|
||||
```
|
||||
./toplip -c 2 file1 > file1.encrypted
|
||||
```
|
||||
|
||||
Here, **-c 2** represents two different passphrases. Sample output of above
|
||||
command would be:
|
||||
|
||||
```
|
||||
This is toplip v1.20 (C) 2015, 2016 2 Ton Digital. Author: Jeff Marrison A showcase piece for the HeavyThing library. Commercial support available Proudly made in Cooroy, Australia. More info: https://2ton.com.au/toplip
|
||||
**file1 Passphrase #1:** generating keys...Done
|
||||
**file1 Passphrase #2:** generating keys...Done
|
||||
Encrypting...Done
|
||||
```
|
||||
|
||||
As you see in the above example, toplip prompted me to enter two passphrases.
|
||||
Please note that you must **provide two different passphrases** , not a single
|
||||
passphrase twice.
|
||||
|
||||
To decrypt this file, do:
|
||||
|
||||
```
|
||||
$ ./toplip -c 2 -d file1.encrypted > file1.decrypted
|
||||
This is toplip v1.20 (C) 2015, 2016 2 Ton Digital. Author: Jeff Marrison A showcase piece for the HeavyThing library. Commercial support available Proudly made in Cooroy, Australia. More info: https://2ton.com.au/toplip
|
||||
**file1.encrypted Passphrase #1:** generating keys...Done
|
||||
**file1.encrypted Passphrase #2:** generating keys...Done
|
||||
Decrypting...Done
|
||||
```
|
||||
|
||||
**Hide files inside image**
|
||||
|
||||
The practice of concealing a file, message, image, or video within another
|
||||
file is called **steganography**. Fortunately, this feature exists in toplip
|
||||
by default.
|
||||
|
||||
To hide a file(s) inside images, use **-m** flag as shown below.
|
||||
|
||||
```
|
||||
$ ./toplip -m image.png file1 > image1.png
|
||||
This is toplip v1.20 (C) 2015, 2016 2 Ton Digital. Author: Jeff Marrison A showcase piece for the HeavyThing library. Commercial support available Proudly made in Cooroy, Australia. More info: https://2ton.com.au/toplip
|
||||
file1 Passphrase #1: generating keys...Done
|
||||
Encrypting...Done
|
||||
```
|
||||
|
||||
This command conceals the contents of file1 inside an image named image1.png.
|
||||
To decrypt it, run:
|
||||
|
||||
```
|
||||
$ ./toplip -d image1.png > file1.decrypted This is toplip v1.20 (C) 2015, 2016 2 Ton Digital. Author: Jeff Marrison A showcase piece for the HeavyThing library. Commercial support available Proudly made in Cooroy, Australia. More info: https://2ton.com.au/toplip
|
||||
image1.png Passphrase #1: generating keys...Done
|
||||
Decrypting...Done
|
||||
```
|
||||
|
||||
**Increase password complexity**
|
||||
|
||||
To make things even harder to break, we can increase the password complexity
|
||||
like below.
|
||||
|
||||
```
|
||||
./toplip -c 5 -i 0x8000 -alt file1 -c 10 -i 10 file2 > file3.encrypted
|
||||
```
|
||||
|
||||
The above command will prompt to you enter 10 passphrases for the file1, 5
|
||||
passphrases for the file2 and encrypt both of them in a single file called
|
||||
"file3.encrypted". As you may noticed, we have used one more additional flag
|
||||
**-i** in this example. This is used to specify key derivation iterations.
|
||||
This option overrides the default iteration count of 1 for scrypt's initial
|
||||
and final PBKDF2 stages. Hexadecimal or decimal values permitted, e.g.
|
||||
**0x8000** , **10** , etc. Please note that this can dramatically increase the
|
||||
calculation times.
|
||||
|
||||
To decrypt file1, use:
|
||||
|
||||
```
|
||||
./toplip -c 5 -i 0x8000 -d file3.encrypted > file1.decrypted
|
||||
```
|
||||
|
||||
To decrypt file2, use:
|
||||
|
||||
```
|
||||
./toplip -c 10 -i 10 -d file3.encrypted > file2.decrypted
|
||||
```
|
||||
|
||||
To know more about the underlying technical information and crypto methods
|
||||
used in toplip, refer its official website given at the end.
|
||||
|
||||
My personal recommendation to all those who wants to protect their data. Don't
|
||||
rely on single method. Always use more than one tools/methods to encrypt
|
||||
files. Do not write passphrases/passwords in a paper and/or do not save them
|
||||
in your local or cloud storage. Just memorize them and destroy the notes. If
|
||||
you're poor at remembering passwords, consider to use any trustworthy password
|
||||
managers.
|
||||
|
||||
And, that's all. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/toplip-strong-file-encryption-decryption-cli-utility/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/cryptomator-open-source-client-side-encryption-tool-cloud/
|
||||
[2]:https://www.ostechnix.com/how-to-encrypt-your-personal-foldersdirectories-in-linux-mint-ubuntu-distros/
|
||||
[3]:https://www.ostechnix.com/cryptogo-easy-way-encrypt-password-protect-files/
|
||||
[4]:https://www.ostechnix.com/cryptr-simple-cli-utility-encrypt-decrypt-files/
|
||||
[5]:https://www.ostechnix.com/tomb-file-encryption-tool-protect-secret-files-linux/
|
||||
[6]:https://www.ostechnix.com/an-easy-way-to-encrypt-and-decrypt-files-from-commandline-in-linux/
|
||||
[7]:http://en.wikipedia.org/wiki/Advanced_Encryption_Standard
|
||||
[8]:http://en.wikipedia.org/wiki/Scrypt
|
||||
[9]:https://2ton.com.au/Products/
|
||||
[10]:https://www.ostechnix.com/wp-content/uploads/2017/12/toplip-2.png%201366w,%20https://www.ostechnix.com/wp-content/uploads/2017/12/toplip-2-300x157.png%20300w,%20https://www.ostechnix.com/wp-content/uploads/2017/12/toplip-2-768x403.png%20768w,%20https://www.ostechnix.com/wp-content/uploads/2017/12/toplip-2-1024x537.png%201024w
|
||||
[11]:http://www.ostechnix.com/wp-content/uploads/2017/12/toplip-2.png
|
||||
[12]:https://www.ostechnix.com/wp-content/uploads/2017/12/toplip-1.png%20779w,%20https://www.ostechnix.com/wp-content/uploads/2017/12/toplip-1-300x101.png%20300w,%20https://www.ostechnix.com/wp-content/uploads/2017/12/toplip-1-768x257.png%20768w
|
||||
[13]:http://www.ostechnix.com/wp-content/uploads/2017/12/toplip-1.png
|
||||
|
||||
@ -0,0 +1,188 @@
|
||||
translating by liuxinyu123
|
||||
|
||||
Creating a blog with pelican and Github pages
|
||||
======
|
||||
|
||||
Today I'm going to talk about how this blog was created. Before we begin, I expect you to be familiarized with using Github and creating a Python virtual enviroment to develop. If you aren't, I recommend you to learn with the [Django Girls tutorial][2], which covers that and more.
|
||||
|
||||
This is a tutorial to help you publish a personal blog hosted by Github. For that, you will need a regular Github user account (instead of a project account).
|
||||
|
||||
The first thing you will do is to create the Github repository where your code will live. If you want your blog to point to only your username (like rsip22.github.io) instead of a subfolder (like rsip22.github.io/blog), you have to create the repository with that full name.
|
||||
|
||||
![Screenshot of Github, the menu to create a new repository is open and a new repo is being created with the name 'rsip22.github.io'][3]
|
||||
|
||||
I recommend that you initialize your repository with a README, with a .gitignore for Python and with a [free software license][4]. If you use a free software license, you still own the code, but you make sure that others will benefit from it, by allowing them to study it, reuse it and, most importantly, keep sharing it.
|
||||
|
||||
Now that the repository is ready, let's clone it to the folder you will be using to store the code in your machine:
|
||||
```
|
||||
$ git clone https://github.com/YOUR_USERNAME/YOUR_USERNAME.github.io.git
|
||||
|
||||
```
|
||||
|
||||
And change to the new directory:
|
||||
```
|
||||
$ cd YOUR_USERNAME.github.io
|
||||
|
||||
```
|
||||
|
||||
Because of how Github Pages prefers to work, serving the files from the master branch, you have to put your source code in a new branch, preserving the "master" for the output of the static files generated by Pelican. To do that, you must create a new branch called "source":
|
||||
```
|
||||
$ git checkout -b source
|
||||
|
||||
```
|
||||
|
||||
Create the virtualenv with the Python3 version installed on your system.
|
||||
|
||||
On GNU/Linux systems, the command might go as:
|
||||
```
|
||||
$ python3 -m venv venv
|
||||
|
||||
```
|
||||
|
||||
or as
|
||||
```
|
||||
$ virtualenv --python=python3.5 venv
|
||||
|
||||
```
|
||||
|
||||
And activate it:
|
||||
```
|
||||
$ source venv/bin/activate
|
||||
|
||||
```
|
||||
|
||||
Inside the virtualenv, you have to install pelican and it's dependencies. You should also install ghp-import (to help us with publishing to github) and Markdown (for writing your posts using markdown). It goes like this:
|
||||
```
|
||||
(venv)$ pip install pelican markdown ghp-import
|
||||
|
||||
```
|
||||
|
||||
Once that is done, you can start creating your blog using pelican-quickstart:
|
||||
```
|
||||
(venv)$ pelican-quickstart
|
||||
|
||||
```
|
||||
|
||||
Which will prompt us a series of questions. Before answering them, take a look at my answers below:
|
||||
```
|
||||
> Where do you want to create your new web site? [.] ./
|
||||
> What will be the title of this web site? Renata's blog
|
||||
> Who will be the author of this web site? Renata
|
||||
> What will be the default language of this web site? [pt] en
|
||||
> Do you want to specify a URL prefix? e.g., http://example.com (Y/n) n
|
||||
> Do you want to enable article pagination? (Y/n) y
|
||||
> How many articles per page do you want? [10] 10
|
||||
> What is your time zone? [Europe/Paris] America/Sao_Paulo
|
||||
> Do you want to generate a Fabfile/Makefile to automate generation and publishing? (Y/n) Y **# PAY ATTENTION TO THIS!**
|
||||
> Do you want an auto-reload & simpleHTTP script to assist with theme and site development? (Y/n) n
|
||||
> Do you want to upload your website using FTP? (y/N) n
|
||||
> Do you want to upload your website using SSH? (y/N) n
|
||||
> Do you want to upload your website using Dropbox? (y/N) n
|
||||
> Do you want to upload your website using S3? (y/N) n
|
||||
> Do you want to upload your website using Rackspace Cloud Files? (y/N) n
|
||||
> Do you want to upload your website using GitHub Pages? (y/N) y
|
||||
> Is this your personal page (username.github.io)? (y/N) y
|
||||
Done. Your new project is available at /home/username/YOUR_USERNAME.github.io
|
||||
|
||||
```
|
||||
|
||||
About the time zone, it should be specified as TZ Time zone (full list here: [List of tz database time zones][5]).
|
||||
|
||||
Now, go ahead and create your first blog post! You might want to open the project folder on your favorite code editor and find the "content" folder inside it. Then, create a new file, which can be called my-first-post.md (don't worry, this is just for testing, you can change it later). The contents should begin with the metadata which identifies the Title, Date, Category and more from the post before you start with the content, like this:
|
||||
```
|
||||
.lang="markdown" # DON'T COPY this line, it exists just for highlighting purposes
|
||||
Title: My first post
|
||||
Date: 2017-11-26 10:01
|
||||
Modified: 2017-11-27 12:30
|
||||
Category: misc
|
||||
Tags: first , misc
|
||||
Slug: My-first-post
|
||||
Authors: Your name
|
||||
Summary: What does your post talk about ? Write here.
|
||||
|
||||
This is the *first post* from my Pelican blog. ** YAY !**
|
||||
```
|
||||
|
||||
Let's see how it looks?
|
||||
|
||||
Go to the terminal, generate the static files and start the server. To do that, use the following command:
|
||||
```
|
||||
(venv)$ make html && make serve
|
||||
```
|
||||
|
||||
While this command is running, you should be able to visit it on your favorite web browser by typing localhost:8000 on the address bar.
|
||||
|
||||
![Screenshot of the blog home. It has a header with the title Renata\\'s blog, the first post on the left, info about the post on the right, links and social on the bottom.][6]
|
||||
|
||||
Pretty neat, right?
|
||||
|
||||
Now, what if you want to put an image in a post, how do you do that? Well, first you create a directory inside your content directory, where your posts are. Let's call this directory 'images' for easy reference. Now, you have to tell Pelican to use it. Find the pelicanconf.py, the file where you configure the system, and add a variable that contains the directory with your images:
|
||||
```
|
||||
.lang="python" # DON'T COPY this line, it exists just for highlighting purposes
|
||||
STATIC_PATHS = ['images']
|
||||
|
||||
```
|
||||
|
||||
Save it. Go to your post and add the image this way:
|
||||
```
|
||||
.lang="markdown" # DON'T COPY this line, it exists just for highlighting purposes
|
||||

|
||||
|
||||
```
|
||||
|
||||
You can interrupt the server at anytime pressing CTRL+C on the terminal. But you should start it again and check if the image is correct. Can you remember how?
|
||||
```
|
||||
(venv)$ make html && make serve
|
||||
```
|
||||
|
||||
One last step before your coding is "done": you should make sure anyone can read your posts using ATOM or RSS feeds. Find the pelicanconf.py, the file where you configure the system, and edit the part about feed generation:
|
||||
```
|
||||
.lang="python" # DON'T COPY this line, it exists just for highlighting purposes
|
||||
FEED_ALL_ATOM = 'feeds/all.atom.xml'
|
||||
FEED_ALL_RSS = 'feeds/all.rss.xml'
|
||||
AUTHOR_FEED_RSS = 'feeds/%s.rss.xml'
|
||||
RSS_FEED_SUMMARY_ONLY = False
|
||||
```
|
||||
|
||||
Save everything so you can send the code to Github. You can do that by adding all files, committing it with a message ('first commit') and using git push. You will be asked for your Github login and password.
|
||||
```
|
||||
$ git add -A && git commit -a -m 'first commit' && git push --all
|
||||
|
||||
```
|
||||
|
||||
And... remember how at the very beginning I said you would be preserving the master branch for the output of the static files generated by Pelican? Now it's time for you to generate them:
|
||||
```
|
||||
$ make github
|
||||
|
||||
```
|
||||
|
||||
You will be asked for your Github login and password again. And... voila! Your new blog should be live on https://YOUR_USERNAME.github.io.
|
||||
|
||||
If you had an error in any step of the way, please reread this tutorial, try and see if you can detect in which part the problem happened, because that is the first step to debbugging. Sometimes, even something simple like a typo or, with Python, a wrong indentation, can give us trouble. Shout out and ask for help online or on your community.
|
||||
|
||||
For tips on how to write your posts using Markdown, you should read the [Daring Fireball Markdown guide][7].
|
||||
|
||||
To get other themes, I recommend you visit [Pelican Themes][8].
|
||||
|
||||
This post was adapted from [Adrien Leger's Create a github hosted Pelican blog with a Bootstrap3 theme][9]. I hope it was somewhat useful for you.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://rsip22.github.io/blog/create-a-blog-with-pelican-and-github-pages.html
|
||||
|
||||
作者:[][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://rsip22.github.io
|
||||
[1]https://rsip22.github.io/blog/category/blog.html
|
||||
[2]https://tutorial.djangogirls.org
|
||||
[3]https://rsip22.github.io/blog/img/create_github_repository.png
|
||||
[4]https://www.gnu.org/licenses/license-list.html
|
||||
[5]https://en.wikipedia.org/wiki/List_of_tz_database_time_zones
|
||||
[6]https://rsip22.github.io/blog/img/blog_screenshot.png
|
||||
[7]https://daringfireball.net/projects/markdown/syntax
|
||||
[8]http://www.pelicanthemes.com/
|
||||
[9]https://a-slide.github.io/blog/github-pelican
|
||||
@ -0,0 +1,107 @@
|
||||
translating by lujun9972
|
||||
How to configure wireless wake-on-lan for Linux WiFi card
|
||||
======
|
||||
[![linux-configire-wake-on-wireless-lan-wowlan][1]][1]
|
||||
Wake on Wireless (WoWLAN or WoW) is a feature to allow the Linux system to go into a low-power state while the wireless NIC remains active and stay connected to an AP. This quick tutorial shows how to enable WoWLAN or WoW (wireless wake-on-lan) mode with a wifi card installed in a Linux based laptop or desktop computer.
|
||||
|
||||
Please note that not all WiFi cards or Linux drivers support the WoWLAN feature.
|
||||
|
||||
## Syntax
|
||||
|
||||
You need to use the iw command to see or manipulate wireless devices and their configuration on a Linux based system. The syntax is:
|
||||
```
|
||||
iw command
|
||||
iw [options] command
|
||||
```
|
||||
|
||||
## List all wireless devices and their capabilities
|
||||
|
||||
Type the following command:
|
||||
```
|
||||
$ iw list
|
||||
$ iw list | more
|
||||
$ iw dev`
|
||||
```
|
||||
Sample outputs:
|
||||
```
|
||||
phy#0
|
||||
Interface wlp3s0
|
||||
ifindex 3
|
||||
wdev 0x1
|
||||
addr 6c:88:14:ff:36:d0
|
||||
type managed
|
||||
channel 149 (5745 MHz), width: 40 MHz, center1: 5755 MHz
|
||||
txpower 15.00 dBm
|
||||
|
||||
```
|
||||
|
||||
Please note down phy0.
|
||||
|
||||
## Find out the current status of your wowlan
|
||||
|
||||
Open the terminal app and type the following command to tind out wowlan status:
|
||||
`$ iw phy0 wowlan show`
|
||||
Sample outputs:
|
||||
`WoWLAN is disabled`
|
||||
|
||||
## How to enable wowlan
|
||||
|
||||
The syntax is:
|
||||
`sudo iw phy {phyname} wowlan enable {option}`
|
||||
Where,
|
||||
|
||||
1. {phyname} - Use iw dev to get phy name.
|
||||
2. {option} - Can be any, disconnect, magic-packet and so on.
|
||||
|
||||
|
||||
|
||||
For example, I am going to enable wowlan for phy0:
|
||||
`$ sudo iw phy0 wowlan enable any`
|
||||
OR
|
||||
`$ sudo iw phy0 wowlan enable magic-packet disconnect`
|
||||
Verify it:
|
||||
`$ iw phy0 wowlan show`
|
||||
Sample outputs:
|
||||
```
|
||||
WoWLAN is enabled:
|
||||
* wake up on disconnect
|
||||
* wake up on magic packet
|
||||
|
||||
```
|
||||
|
||||
## Test it
|
||||
|
||||
Put your laptop in suspend or sleep mode and send ping request or magic packet from your nas server:
|
||||
`$ sudo sh -c 'echo mem > /sys/power/state'`
|
||||
Send ping request from your nas server using the [ping command][3]
|
||||
`$ ping your-laptop-ip`
|
||||
OR [send magic packet using wakeonlan command][4] :
|
||||
`$ wakeonlan laptop-mac-address-here
|
||||
$ etherwake MAC-Address-Here`
|
||||
|
||||
## How do I disable WoWLAN?
|
||||
|
||||
The syntax is:
|
||||
`$ sudo phy {phyname} wowlan disable
|
||||
$ sudo phy0 wowlan disable`
|
||||
|
||||
For more info read the iw command man page:
|
||||
`$ man iw
|
||||
$ iw --help`
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/configure-wireless-wake-on-lan-for-linux-wifi-wowlan-card/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://twitter.com/nixcraft
|
||||
[1] https://www.cyberciti.biz/media/new/faq/2017/12/linux-configire-wake-on-wireless-lan-wowlan.jpg
|
||||
[2] https://www.cyberciti.biz/tips/linux-send-wake-on-lan-wol-magic-packets.html
|
||||
[3] //www.cyberciti.biz/faq/unix-ping-command-examples/ (See Linux/Unix ping command examples for more info)
|
||||
[4] https://www.cyberciti.biz/faq/apple-os-x-wake-on-lancommand-line-utility/
|
||||
@ -0,0 +1,144 @@
|
||||
How to squeeze the most out of Linux file compression
|
||||
======
|
||||
If you have any doubt about the many commands and options available on Linux systems for file compression, you might want to take a look at the output of the **apropos compress** command. Chances are you'll be surprised by the many commands that you can use for compressing and decompressing files, as well as for comparing compressed files, examining and searching through the content of compressed files, and even changing a compressed file from one format to another (i.e., .z format to .gz format).
|
||||
|
||||
You're likely to see all of these entries just for the suite of bzip2 compression commands. Add in zip, gzip, and xz, and you've got a lot of interesting options.
|
||||
```
|
||||
$ apropos compress | grep ^bz
|
||||
bzcat (1) - decompresses files to stdout
|
||||
bzcmp (1) - compare bzip2 compressed files
|
||||
bzdiff (1) - compare bzip2 compressed files
|
||||
bzegrep (1) - search possibly bzip2 compressed
|
||||
files for a regular expression
|
||||
bzexe (1) - compress executable files in place
|
||||
bzfgrep (1) - search possibly bzip2 compressed
|
||||
files for a regular expression
|
||||
bzgrep (1) - search possibly bzip2 compressed
|
||||
files for a regular expression
|
||||
bzip2 (1) - a block-sorting file compressor,
|
||||
v1.0.6
|
||||
bzless (1) - file perusal filter for crt viewing
|
||||
of bzip2 compressed text
|
||||
bzmore (1) - file perusal filter for crt viewing
|
||||
of bzip2 compressed text
|
||||
|
||||
```
|
||||
|
||||
On my Ubuntu system, over 60 commands were listed in response to the apropos compress command.
|
||||
|
||||
### Compression algorithms
|
||||
|
||||
Compression is not a one-size-fits-all issue. Some compression tools are "lossy," such as those used to reduce the size of mp3 files while allowing listeners to have what is nearly the same musical experience as listening to the originals. But algorithms used on the Linux command line to compress or archive user files have to be able to reproduce the original content exactly. In other words, they have to be lossless.
|
||||
|
||||
How is that done? It's easy to imagine how 300 of the same character in a row could be compressed to something like "300X," but this type of algorithm wouldn't be of much benefit for most files because they wouldn't contain long sequences of the same character any more than they would completely random data. Compression algorithms are far more complex and have only been getting more so since compression was first introduced in the toddler years of Unix.
|
||||
|
||||
### Compression commands on Linux systems
|
||||
|
||||
The commands most commonly used for file compression on Linux systems include zip, gzip, bzip2 and xz. All of those commands work in similar ways, but there are some tradeoffs in terms of how much the file content is squeezed (how much space you save), how long the compression takes, and how compatible the compressed files are with other systems you might need to use them on.
|
||||
|
||||
Sometimes the time and effort of compressing a file doesn't pay off very well. In the example below, the "compressed" file is actually larger than the original. While this isn't generally the case, it can happen -- especially when the file content approaches some degree of randomness.
|
||||
```
|
||||
$ time zip bigfile.zip bigfile
|
||||
adding: bigfile (deflated 0%)
|
||||
|
||||
real 1m6.310s
|
||||
user 0m52.424s
|
||||
sys 0m2.288s
|
||||
$
|
||||
$ ls -l bigfile*
|
||||
-rw-rw-r-- 1 shs shs 1073741824 Dec 8 10:06 bigfile
|
||||
-rw-rw-r-- 1 shs shs 1073916184 Dec 8 11:39 bigfile.zip
|
||||
|
||||
```
|
||||
|
||||
Note that the compressed version of the file (bigfile.zip) is actually a little larger than the original file. If compression increases the size of a file or reduces its size by some very small percentage, the only benefit may be that you may have a convenient online backup. If you see a message like this after compressing a file, you're not gaining much.
|
||||
```
|
||||
(deflated 1%)
|
||||
|
||||
```
|
||||
|
||||
The content of a file plays a large role in how well it will compress. The file that grew in size in the example above was fairly random. Compress a file containing only zeroes, and you'll see an amazing compression ratio. In this admittedly extremely unlikely scenario, all three of the commonly used compression tools do an excellent job.
|
||||
```
|
||||
-rw-rw-r-- 1 shs shs 10485760 Dec 8 12:31 zeroes.txt
|
||||
-rw-rw-r-- 1 shs shs 49 Dec 8 17:28 zeroes.txt.bz2
|
||||
-rw-rw-r-- 1 shs shs 10219 Dec 8 17:28 zeroes.txt.gz
|
||||
-rw-rw-r-- 1 shs shs 1660 Dec 8 12:31 zeroes.txt.xz
|
||||
-rw-rw-r-- 1 shs shs 10360 Dec 8 12:24 zeroes.zip
|
||||
|
||||
```
|
||||
|
||||
While impressive, you're not likely to see files with over 10 million bytes compressing down to fewer than 50, since files like these are extremely unlikely.
|
||||
|
||||
In this more realistic example, the size differences are altogether different -- and not very significant -- for a fairly small jpg file.
|
||||
```
|
||||
-rw-r--r-- 1 shs shs 13522 Dec 11 18:58 image.jpg
|
||||
-rw-r--r-- 1 shs shs 13875 Dec 11 18:58 image.jpg.bz2
|
||||
-rw-r--r-- 1 shs shs 13441 Dec 11 18:58 image.jpg.gz
|
||||
-rw-r--r-- 1 shs shs 13508 Dec 11 18:58 image.jpg.xz
|
||||
-rw-r--r-- 1 shs shs 13581 Dec 11 18:58 image.jpg.zip
|
||||
|
||||
```
|
||||
|
||||
Do the same thing with a large text file, and you're likely to see some significant differences.
|
||||
```
|
||||
$ ls -l textfile*
|
||||
-rw-rw-r-- 1 shs shs 8740836 Dec 11 18:41 textfile
|
||||
-rw-rw-r-- 1 shs shs 1519807 Dec 11 18:41 textfile.bz2
|
||||
-rw-rw-r-- 1 shs shs 1977669 Dec 11 18:41 textfile.gz
|
||||
-rw-rw-r-- 1 shs shs 1024700 Dec 11 18:41 textfile.xz
|
||||
-rw-rw-r-- 1 shs shs 1977808 Dec 11 18:41 textfile.zip
|
||||
|
||||
```
|
||||
|
||||
In this case, xz reduced the size considerably more than the other commands with bzip2 coming in second.
|
||||
|
||||
### Looking at compressed files
|
||||
|
||||
The *more commands (bzmore and others) allow you to view the contents of compressed files without having to uncompress them first.
|
||||
```
|
||||
bzmore (1) - file perusal filter for crt viewing of bzip2 compressed text
|
||||
lzmore (1) - view xz or lzma compressed (text) files
|
||||
xzmore (1) - view xz or lzma compressed (text) files
|
||||
zmore (1) - file perusal filter for crt viewing of compressed text
|
||||
|
||||
```
|
||||
|
||||
These commands are all doing a good amount of work, since they have to decompress a file's content just to display it to you. They do not, on the other hand, leave uncompressed file content on the system. They simply decompress on the fly.
|
||||
```
|
||||
$ xzmore textfile.xz | head -1
|
||||
Here is the agenda for tomorrow's staff meeting:
|
||||
|
||||
```
|
||||
|
||||
### Comparing compressed files
|
||||
|
||||
While several of the compression toolsets include a diff command (e.g., xzdiff), these tools pass the work off to cmp and diff and are not doing any algorithm-specific comparisons. For example, the xzdiff command will compare bz2 files as easily as it will compare xz files.
|
||||
|
||||
### How to choose the best Linux compression tool
|
||||
|
||||
The best tool for the job depends on the job. In some cases, the choice may depend on the content of the data being compressed, but it's more likely that your organization's conventions are just as important unless you're in a real pinch for disk space. The best general suggestions seem to be these:
|
||||
|
||||
**zip** is best when files need to be shared with or used on Windows systems.
|
||||
|
||||
**gzip** may be best when you want the files to be usable on any Unix/Linux system. Though bzip2 is becoming nearly as ubiquitous, it is likely to take longer to run.
|
||||
|
||||
**bzip2** uses a different algorithm than gzip and is likely to yield a smaller file, but they take a little longer to get the job done.
|
||||
|
||||
**xz** generally offers the best compression rates, but also takes considerably longer to run. It's also newer than the other tools and may not yet exist on all the systems you need to work with.
|
||||
|
||||
### Wrap-up
|
||||
|
||||
There are a number of choices when it comes to how to compress files and only a few situations in which they don't yield valuable disk space savings.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3240938/linux/how-to-squeeze-the-most-out-of-linux-file-compression.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.networkworld.com
|
||||
@ -0,0 +1,63 @@
|
||||
书评:《Ours to Hack and to Own》
|
||||
============================================================
|
||||
|
||||

|
||||
Image by : opensource.com
|
||||
|
||||
私有制的时代看起来似乎结束了,我将不仅仅讨论那些由我们中的许多人引入到我们的家庭与生活的设备和软件。我也将讨论这些设备与应用依赖的平台与服务。
|
||||
|
||||
尽管我们使用的许多服务是免费的,我们对它们并没有任何控制。本质上讲,这些企业确实控制着我们所看到的,听到的以及阅读到的内容。不仅如此,许多企业还在改变工作的性质。他们正使用封闭的平台来助长由全职工作到[零工经济][2]的转变方式,这种方式提供极少的安全性与确定性。
|
||||
|
||||
这项行动对于网络以及每一个使用与依赖网络的人产生了广泛的影响。仅仅二十多年前的开放网络的想象正在逐渐消逝并迅速地被一块难以穿透的幕帘所取代。
|
||||
|
||||
一种变得流行的补救办法就是建立[平台合作][3], 由他们的用户所拥有的电子化平台。正如这本书所阐述的,平台合作社背后的观点与开源有许多相同的根源。
|
||||
|
||||
学者Trebor Scholz和作家Nathan Schneider已经收集了40篇探讨平台合作社作为普通人可使用以提升开放性并对闭源系统的不透明性及各种限制予以还击的工具的增长及需求的论文。
|
||||
|
||||
### 哪里适合开源
|
||||
|
||||
任何平台合作社核心及接近核心的部分依赖与开源;不仅开源技术是必要的,构成开源开放性,透明性,协同合作以及共享的准则与理念同样不可或缺。
|
||||
|
||||
在这本书的介绍中, Trebor Scholz指出:
|
||||
|
||||
> 与网络的黑盒子系统相反,这些平台需要使它们的数据流透明来辨别自身。他们需要展示客户与员工的数据在哪里存储,数据出售给了谁以及数据为了何种目的。
|
||||
|
||||
正是对开源如此重要的透明性,促使平台合作社如此吸引人并在目前大量已存平台之中成为令人耳目一新的变化。
|
||||
|
||||
开源软件在《Ours to Hack and to Own》所分享的平台合作社的构想中必然充当着重要角色。开源软件能够为群体建立助推合作社的技术型公共建设提供快速,不算昂贵的途径。
|
||||
|
||||
Mickey Metts在论文中这样形容, "与你的友好的社区型技术合作社相遇。(原文:Meet Your Friendly Neighborhood Tech Co-Op.)" Metts为一家名为Agaric的企业工作,这家企业使用Drupal为团体及小型企业建立他们不能独自完成的产品。除此以外, Metts还鼓励任何想要建立并运营自己的企业的公司或合作社的人接受免费且开源的软件。为什么呢?因为它是高质量的,不算昂贵的,可定制的,并且你能够与由乐于助人而又热情的人们组成的大型社区产生联系。
|
||||
|
||||
### 不总是开源的,但开源总在
|
||||
|
||||
这本书里不是所有的论文都聚焦或提及开源的;但是,开源方式的关键元素-合作,社区,开放管理以及电子自由化-总是在其表面若隐若现。
|
||||
|
||||
事实上正如《Ours to Hack and to Own》中许多论文所讨论的,建立一个更加开放,基于平常人的经济与社会区块,平台合作社会变得非常重要。用Douglas Rushkoff的话讲,那会是类似Creative Commons的组织“对共享知识资源的私有化”的补偿。它们也如Barcelona的CTO(首席执行官)Francesca Bria所描述的那样,是“通过确保市民数据安全性,隐私性和权利的系统”来运营他们自己的“分布式通用数据基础架构”的城市。
|
||||
|
||||
### 最后的思考
|
||||
|
||||
如果你在寻找改变互联网的蓝图以及我们工作的方式,《Ours to Hack and to Own》并不是你要寻找的。这本书与其说是用户指南,不如说是一种宣言。如书中所说,《Ours to Hack and to Own》让我们略微了解如果我们将开源方式准则应用于社会及更加广泛的世界我们能够做的事。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Scott Nesbitt -作家,编辑,雇佣兵,虎猫牛仔(原文:Ocelot wrangle),丈夫与父亲,博客写手,陶器收藏家。Scott正是做这样的一些事情。他还是大量写关于开源软件文章与博客的长期开源用户。你可以在Twitter,Github上找到他。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/1/review-book-ours-to-hack-and-own
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
译者:[darsh8](https://github.com/darsh8)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:https://opensource.com/article/17/1/review-book-ours-to-hack-and-own?rate=dgkFEuCLLeutLMH2N_4TmUupAJDjgNvFpqWqYCbQb-8
|
||||
[2]:https://en.wikipedia.org/wiki/Access_economy
|
||||
[3]:https://en.wikipedia.org/wiki/Platform_cooperative
|
||||
[4]:http://www.orbooks.com/catalog/ours-to-hack-and-to-own/
|
||||
[5]:https://opensource.com/user/14925/feed
|
||||
[6]:https://opensource.com/users/scottnesbitt
|
||||
@ -0,0 +1,363 @@
|
||||
怎么去转换任何系统调用为一个事件:介绍 eBPF 内核探针
|
||||
============================================================
|
||||
|
||||
|
||||
长文预警:在最新的 Linux 内核(>=4.4)中使用 eBPF,你可以使用任意数据将任何内核函数调用转换为一个用户空间事件。这通过 bcc 来做很容易。这个探针是用 C 语言写的,而数据是由 Python 来处理的。
|
||||
|
||||
如果你对 eBPF 或者 Linux 跟踪不熟悉,那你应该好好阅读一下本文。它尝试逐步去克服我在使用 bcc/eBPF 时遇到的困难,同时也节省了我在搜索和挖掘上花费的时间。
|
||||
|
||||
### 在 Linux 的世界中关于 push vs pull 的一个提示
|
||||
|
||||
当我开始在容器上工作的时候,我想知道我们怎么基于一个真实的系统状态去动态更新一个负载均衡器的配置。一个通用的策略是这样做的,无论什么时候只要一个容器启动,容器编排器触发一个负载均衡配置更新动作,负载均衡器去轮询每个容器,直到它的健康状态检查结束。它只是简单进行 “SYN” 测试。
|
||||
|
||||
虽然这种配置方式可以有效工作,但是它的缺点是你的负载均衡器为了让一些系统变得可用需要等待,而不是 … 让负载去均衡。
|
||||
|
||||
可以做的更好吗?
|
||||
|
||||
当你希望在一个系统中让一个程序对一些变化做出反应,这里有两种可能的策略。程序可以去 _轮询_ 系统去检测变化,或者,如果系统支持,系统可以 _推送_ 事件并且让程序对它作出反应。你希望去使用推送还是轮询取决于上下文环境。一个好的经验法则是,基于处理时间的考虑,如果事件发生的频率较低时使用推送,而当事件发生的较快或者让系统变得不可用时切换为轮询。例如,一般情况下,网络驱动将等待来自网卡的事件,但是,像 dpdk 这样的框架对事件将激活对网卡的轮询,以达到高吞吐低延迟的目的。
|
||||
|
||||
理想状态下,我们将有一些内核接口告诉我们:
|
||||
|
||||
> * “容器管理器,你好,我刚才为容器 _servestaticfiles_ 的 Nginx-ware 创建了一个套接字,或许你应该去更新你的状态?
|
||||
>
|
||||
> * “好的,操作系统,感谢你告诉我这个事件“
|
||||
|
||||
虽然 Linux 有大量的接口去处理事件,对于文件事件高达 3 个,但是没有专门的接口去得到套接字事件提示。你可以得到路由表事件、邻接表事件、连接跟踪事件、接口变化事件。唯独没有套接字事件。或者,也许它深深地隐藏在一个 Netlink 接口中。
|
||||
|
||||
理想情况下,我们需要一个做这件事的通用方法,怎么办呢?
|
||||
|
||||
### 内核跟踪和 eBPF,一些它们的历史
|
||||
|
||||
直到最近,仅有的方式是去在内核上打一个补丁程序或者借助于 SystemTap。[SytemTap][5] 是一个 Linux 系统跟踪器。简单地说,它提供了一个 DSL,然后编译进内核模块,然后被内核加载运行。除了一些因安全原因禁用动态模块加载的生产系统之外,包括在那个时候我工作的那一个。另外的方式是为内核打一个补丁程序去触发一些事件,可能是基于 netlink。但是这很不方便。深入内核带来的缺点包括 “有趣的” 新 “特性” 和增加了维护负担。
|
||||
|
||||
从 Linux 3.15 开始给我们带来了希望,它支持任何可跟踪内核函数可安全转换为用户空间事件。在一般的计算机科学中,“安全” 是指 ”一些虚拟机”。这里说的情况不是这种意思。Linux 已经有多好年了。自从 Linux 2.1.75 在 1997 年正式发行以来。但是,对被称为伯克利包过滤器的 BPF 来说它的历史是很短的。正如它的名字所表达的那样,它最初是为 BSD 防火墙开发的。它仅有两个寄存器,并且它仅允许跳转,意味着你不能使用它写一个循环(好吧,如果你知道最大迭代次数并且去手工实现它,你也可以实现循环)。这一点保证了程序总会终止并且从来不会使系统处于 hang 的状态。还不确定它的作用吗?即便你用的是 iptables。它的作用正如 [CloudFlare 的 DDos 防护基础][6]。
|
||||
|
||||
好的,因此,随着 Linux 3.15,[BPF 被扩展了][7] 转变为 eBPF。对于 “扩展的” BPF。它从两个 32 位寄存器升级到 10 个 64 位寄存器,并且增加了它们之间向后跳转的特性。它因此将被 [在 Linux 3.18 中进一步扩展][8],并将被移到网络子系统中,并且增加了像映射(maps)这样的工具。为保证安全,它 [引进了一个检查器][9],它验证所有的内存访问和可能的代码路径。如果检查器不能保证代码在固定的边界内,代码将被终止,它拒绝程序的初始插入。
|
||||
|
||||
关于它的更多历史,可以看 [Oracle 的关于 eBPF 的一个很捧的演讲][10]。
|
||||
|
||||
让我们开始吧!
|
||||
|
||||
### 来自 `inet_listen` 的问候
|
||||
|
||||
因为写一个汇编程序并不是件容易的任务,甚至对于很优秀的我们来说,我将使用 [bcc][11]。bcc 是一个基于 LLVM 的采集工具,并且用 Python 抽象了底层机制。探针是用 C 写的,并且返回的结果可以被 Python 利用,来写一些非常简单的应用程序。
|
||||
|
||||
首先安装 bcc。对于一些示例,你可能会被要求使用一个最新的内核版本(>= 4.4)。如果你想亲自去尝试一下这些示例,我强烈推荐你安装一台虚拟机。 _而不是_ 一个 Docker 容器。你不能在一个容器中改变内核。作为一个非常新的很活跃的项目,安装教程高度依赖平台/版本的。你可以在 [https://github.com/iovisor/bcc/blob/master/INSTALL.md][12] 上找到最新的教程。
|
||||
|
||||
现在,我希望在 TCP 套接字上进行监听,不管什么时候,只要有任何程序启动我将得到一个事件。当我在一个 `AF_INET` + `SOCK_STREAM` 套接字上调用一个 `listen()` 系统调用时,底层的内核函数是 [`inet_listen`][13]。我将钩在 `kprobe` 的输入点上,它启动时输出一个 “Hello World”。
|
||||
|
||||
```
|
||||
from bcc import BPF
|
||||
|
||||
# Hello BPF Program
|
||||
bpf_text = """
|
||||
#include <net/inet_sock.h>
|
||||
#include <bcc/proto.h>
|
||||
|
||||
// 1\. Attach kprobe to "inet_listen"
|
||||
int kprobe__inet_listen(struct pt_regs *ctx, struct socket *sock, int backlog)
|
||||
{
|
||||
bpf_trace_printk("Hello World!\\n");
|
||||
return 0;
|
||||
};
|
||||
"""
|
||||
|
||||
# 2\. Build and Inject program
|
||||
b = BPF(text=bpf_text)
|
||||
|
||||
# 3\. Print debug output
|
||||
while True:
|
||||
print b.trace_readline()
|
||||
|
||||
```
|
||||
|
||||
这个程序做了三件事件:1. 它使用一个命名惯例附加到一个内核探针上。如果函数被调用,输出 “my_probe”,它使用 `b.attach_kprobe("inet_listen", "my_probe")` 被显式地附加。2.它使用 LLVM 去 new 一个 BPF 后端来构建程序。使用 (new) `bpf()` 系统调用去注入结果字节码,并且按匹配的命名惯例自动附加探针。3. 从内核管道读取原生输出。
|
||||
|
||||
注意:eBPF 的后端 LLVM 还很新。如果你认为你发了一个 bug,你可以去升级它。
|
||||
|
||||
注意到 `bpf_trace_printk` 调用了吗?这是一个内核的 `printk()` 精简版的 debug 函数。使用时,它产生一个跟踪信息到 `/sys/kernel/debug/tracing/trace_pipe` 中的专门的内核管道。就像名字所暗示的那样,这是一个管道。如果多个读取者消费它,仅有一个将得到一个给定的行。对生产系统来说,这样是不合适的。
|
||||
|
||||
幸运的是,Linux 3.19 引入了对消息传递的映射以及 Linux 4.4 带来了任意 perf 事件支持。在这篇文章的后面部分,我将演示 perf 事件。
|
||||
|
||||
```
|
||||
# From a first console
|
||||
ubuntu@bcc:~/dev/listen-evts$ sudo /python tcv4listen.py
|
||||
nc-4940 [000] d... 22666.991714: : Hello World!
|
||||
|
||||
# From a second console
|
||||
ubuntu@bcc:~$ nc -l 0 4242
|
||||
^C
|
||||
|
||||
```
|
||||
|
||||
Yay!
|
||||
|
||||
### 抓取 backlog
|
||||
|
||||
现在,让我们输出一些很容易访问到的数据,叫做 “backlog”。backlog 是正在建立 TCP 连接的、即将成为 `accept()` 的数量。
|
||||
|
||||
只要稍微调整一下 `bpf_trace_printk`:
|
||||
|
||||
```
|
||||
bpf_trace_printk("Listening with with up to %d pending connections!\\n", backlog);
|
||||
|
||||
```
|
||||
|
||||
如果你用这个 “革命性” 的改善重新运行这个示例,你将看到如下的内容:
|
||||
|
||||
```
|
||||
(bcc)ubuntu@bcc:~/dev/listen-evts$ sudo python tcv4listen.py
|
||||
nc-5020 [000] d... 25497.154070: : Listening with with up to 1 pending connections!
|
||||
|
||||
```
|
||||
|
||||
`nc` 是一个单个的连接程序,因此,在 1\. Nginx 或者 Redis 上的 backlog 在这里将输出 128 。但是,那是另外一件事。
|
||||
|
||||
简单吧?现在让我们获取它的端口。
|
||||
|
||||
### 抓取端口和 IP
|
||||
|
||||
正在研究的 `inet_listen` 的信息来源于内核,我们知道它需要从 `socket` 对象中取得 `inet_sock`。就像从源头拷贝,然后插入到跟踪器的开始处:
|
||||
|
||||
```
|
||||
// cast types. Intermediate cast not needed, kept for readability
|
||||
struct sock *sk = sock->sk;
|
||||
struct inet_sock *inet = inet_sk(sk);
|
||||
|
||||
```
|
||||
|
||||
端口现在可以在按网络字节顺序(就是“从小到大”的顺序)的 `inet->inet_sport` 访问到。很容易吧!因此,我们将替换为 `bpf_trace_printk`:
|
||||
|
||||
```
|
||||
bpf_trace_printk("Listening on port %d!\\n", inet->inet_sport);
|
||||
|
||||
```
|
||||
|
||||
然后运行:
|
||||
|
||||
```
|
||||
ubuntu@bcc:~/dev/listen-evts$ sudo /python tcv4listen.py
|
||||
...
|
||||
R1 invalid mem access 'inv'
|
||||
...
|
||||
Exception: Failed to load BPF program kprobe__inet_listen
|
||||
|
||||
```
|
||||
|
||||
除了它不再简单之外,Bcc 现在提升了 _许多_。直到写这篇文章的时候,几个问题已经被处理了,但是并没有全部处理完。这个错误意味着内核检查器可以证实程序中的内存访问是正确的。看显式的类型转换。我们需要一点帮助,以使访问更加明确。我们将使用 `bpf_probe_read` 可信任的函数去读取一个任意内存位置,虽然为了确保,要像如下的那样做一些必需的检查:
|
||||
|
||||
```
|
||||
// Explicit initialization. The "=0" part is needed to "give life" to the variable on the stack
|
||||
u16 lport = 0;
|
||||
|
||||
// Explicit arbitrary memory access. Read it:
|
||||
// Read into 'lport', 'sizeof(lport)' bytes from 'inet->inet_sport' memory location
|
||||
bpf_probe_read(&lport, sizeof(lport), &(inet->inet_sport));
|
||||
|
||||
```
|
||||
|
||||
使用 `inet->inet_rcv_saddr` 读取 IPv4 边界地址,和它基本上是相同的。如果我把这些一起放上去,我们将得到 backlog,端口和边界 IP:
|
||||
|
||||
```
|
||||
from bcc import BPF
|
||||
|
||||
# BPF Program
|
||||
bpf_text = """
|
||||
#include <net/sock.h>
|
||||
#include <net/inet_sock.h>
|
||||
#include <bcc/proto.h>
|
||||
|
||||
// Send an event for each IPv4 listen with PID, bound address and port
|
||||
int kprobe__inet_listen(struct pt_regs *ctx, struct socket *sock, int backlog)
|
||||
{
|
||||
// Cast types. Intermediate cast not needed, kept for readability
|
||||
struct sock *sk = sock->sk;
|
||||
struct inet_sock *inet = inet_sk(sk);
|
||||
|
||||
// Working values. You *need* to initialize them to give them "life" on the stack and use them afterward
|
||||
u32 laddr = 0;
|
||||
u16 lport = 0;
|
||||
|
||||
// Pull in details. As 'inet_sk' is internally a type cast, we need to use 'bpf_probe_read'
|
||||
// read: load into 'laddr' 'sizeof(laddr)' bytes from address 'inet->inet_rcv_saddr'
|
||||
bpf_probe_read(&laddr, sizeof(laddr), &(inet->inet_rcv_saddr));
|
||||
bpf_probe_read(&lport, sizeof(lport), &(inet->inet_sport));
|
||||
|
||||
// Push event
|
||||
bpf_trace_printk("Listening on %x %d with %d pending connections\\n", ntohl(laddr), ntohs(lport), backlog);
|
||||
return 0;
|
||||
};
|
||||
"""
|
||||
|
||||
# Build and Inject BPF
|
||||
b = BPF(text=bpf_text)
|
||||
|
||||
# Print debug output
|
||||
while True:
|
||||
print b.trace_readline()
|
||||
|
||||
```
|
||||
|
||||
运行一个测试,输出的内容像下面这样:
|
||||
|
||||
```
|
||||
(bcc)ubuntu@bcc:~/dev/listen-evts$ sudo python tcv4listen.py
|
||||
nc-5024 [000] d... 25821.166286: : Listening on 7f000001 4242 with 1 pending connections
|
||||
|
||||
```
|
||||
|
||||
你的监听是在本地主机上提供的。因为没有处理为友好的输出,这里的地址以 16 进制的方式显示,并且那是有线的。并且它很酷。
|
||||
|
||||
注意:你可能想知道为什么 `ntohs` 和 `ntohl` 可以从 BPF 中被调用,即便它们并不可信。这是因为它们是宏,并且是从 “.h” 文件中来的内联函数,并且,在写这篇文章的时候一个小的 bug 已经 [修复了][14]。
|
||||
|
||||
全部完成之后,再来一个代码片断:我们希望获取相关的容器。在一个网络环境中,那意味着我们希望取得网络的命名空间。网络命名空间是一个容器的构建块,它允许它们拥有独立的网络。
|
||||
|
||||
### 抓取网络命名空间:被迫引入的 perf 事件
|
||||
|
||||
在用户空间中,网络命名空间可以通过检查 `/proc/PID/ns/net` 的目标来确定,它将看起来像 `net:[4026531957]` 这样。方括号中的数字是节点的网络空间编号。这就是说,我们可以通过 `/proc` 来取得,但是这并不是好的方式,我们或许可以临时处理时用一下。我们可以从内核中直接抓取节点编号。幸运的是,那样做很容易:
|
||||
|
||||
```
|
||||
// Create an populate the variable
|
||||
u32 netns = 0;
|
||||
|
||||
// Read the netns inode number, like /proc does
|
||||
netns = sk->__sk_common.skc_net.net->ns.inum;
|
||||
|
||||
```
|
||||
|
||||
很容易!而且它做到了。
|
||||
|
||||
但是,如果你看到这里,你可能猜到那里有一些错误。它在:
|
||||
|
||||
```
|
||||
bpf_trace_printk("Listening on %x %d with %d pending connections in container %d\\n", ntohl(laddr), ntohs(lport), backlog, netns);
|
||||
|
||||
```
|
||||
|
||||
如果你尝试去运行它,你将看到一些令人难解的错误信息:
|
||||
|
||||
```
|
||||
(bcc)ubuntu@bcc:~/dev/listen-evts$ sudo python tcv4listen.py
|
||||
error: in function kprobe__inet_listen i32 (%struct.pt_regs*, %struct.socket*, i32)
|
||||
too many args to 0x1ba9108: i64 = Constant<6>
|
||||
|
||||
```
|
||||
|
||||
clang 想尝试去告诉你的是 “Hey pal,`bpf_trace_printk` 只能带四个参数,你刚才给它传递了 5 个“。在这里我不打算继续追究细节了,但是,那是 BPF 的一个限制。如果你想继续去深入研究,[这里是一个很好的起点][15]。
|
||||
|
||||
去修复它的唯一方式是去 … 停止调试并且准备投入使用。因此,让我们开始吧(确保运行在内核版本为 4.4 的 Linux 系统上)我将使用 perf 事件,它支持传递任意大小的结构体到用户空间。另外,只有我们的读者可以获得它,因此,多个没有关系的 eBPF 程序可以并发产生数据而不会出现问题。
|
||||
|
||||
去使用它吧,我们需要:
|
||||
|
||||
1. 定义一个结构体
|
||||
|
||||
2. 声明事件
|
||||
|
||||
3. 推送事件
|
||||
|
||||
4. 在 Python 端重新声明事件(这一步以后将不再需要)
|
||||
|
||||
5. 消费和格式化事件
|
||||
|
||||
这看起来似乎很多,其它并不多,看下面示例:
|
||||
|
||||
```
|
||||
// At the begining of the C program, declare our event
|
||||
struct listen_evt_t {
|
||||
u64 laddr;
|
||||
u64 lport;
|
||||
u64 netns;
|
||||
u64 backlog;
|
||||
};
|
||||
BPF_PERF_OUTPUT(listen_evt);
|
||||
|
||||
// In kprobe__inet_listen, replace the printk with
|
||||
struct listen_evt_t evt = {
|
||||
.laddr = ntohl(laddr),
|
||||
.lport = ntohs(lport),
|
||||
.netns = netns,
|
||||
.backlog = backlog,
|
||||
};
|
||||
listen_evt.perf_submit(ctx, &evt, sizeof(evt));
|
||||
|
||||
```
|
||||
|
||||
Python 端将需要一点更多的工作:
|
||||
|
||||
```
|
||||
# We need ctypes to parse the event structure
|
||||
import ctypes
|
||||
|
||||
# Declare data format
|
||||
class ListenEvt(ctypes.Structure):
|
||||
_fields_ = [
|
||||
("laddr", ctypes.c_ulonglong),
|
||||
("lport", ctypes.c_ulonglong),
|
||||
("netns", ctypes.c_ulonglong),
|
||||
("backlog", ctypes.c_ulonglong),
|
||||
]
|
||||
|
||||
# Declare event printer
|
||||
def print_event(cpu, data, size):
|
||||
event = ctypes.cast(data, ctypes.POINTER(ListenEvt)).contents
|
||||
print("Listening on %x %d with %d pending connections in container %d" % (
|
||||
event.laddr,
|
||||
event.lport,
|
||||
event.backlog,
|
||||
event.netns,
|
||||
))
|
||||
|
||||
# Replace the event loop
|
||||
b["listen_evt"].open_perf_buffer(print_event)
|
||||
while True:
|
||||
b.kprobe_poll()
|
||||
|
||||
```
|
||||
|
||||
来试一下吧。在这个示例中,我有一个 redis 运行在一个 Docker 容器中,并且 nc 在主机上:
|
||||
|
||||
```
|
||||
(bcc)ubuntu@bcc:~/dev/listen-evts$ sudo python tcv4listen.py
|
||||
Listening on 0 6379 with 128 pending connections in container 4026532165
|
||||
Listening on 0 6379 with 128 pending connections in container 4026532165
|
||||
Listening on 7f000001 6588 with 1 pending connections in container 4026531957
|
||||
|
||||
```
|
||||
|
||||
### 结束语
|
||||
|
||||
现在,所有事情都可以在内核中使用 eBPF 将任何函数的调用设置为触发事件,并且在学习 eBPF 时,你将看到了我所遇到的大多数的问题。如果你希望去看这个工具的所有版本,像 IPv6 支持这样的一些技巧,看一看 [https://github.com/iovisor/bcc/blob/master/tools/solisten.py][16]。它现在是一个官方的工具,感谢 bcc 团队的支持。
|
||||
|
||||
更进一步地去学习,你可能需要去关注 Brendan Gregg 的博客,尤其是 [关于 eBPF 映射和统计的文章][17]。他是这个项目的主要贡献人之一。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.yadutaf.fr/2016/03/30/turn-any-syscall-into-event-introducing-ebpf-kernel-probes/
|
||||
|
||||
作者:[Jean-Tiare Le Bigot][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.yadutaf.fr/about
|
||||
[1]:https://blog.yadutaf.fr/tags/linux
|
||||
[2]:https://blog.yadutaf.fr/tags/tracing
|
||||
[3]:https://blog.yadutaf.fr/tags/ebpf
|
||||
[4]:https://blog.yadutaf.fr/tags/bcc
|
||||
[5]:https://en.wikipedia.org/wiki/SystemTap
|
||||
[6]:https://blog.cloudflare.com/bpf-the-forgotten-bytecode/
|
||||
[7]:https://blog.yadutaf.fr/2016/03/30/turn-any-syscall-into-event-introducing-ebpf-kernel-probes/TODO
|
||||
[8]:https://lwn.net/Articles/604043/
|
||||
[9]:http://lxr.free-electrons.com/source/kernel/bpf/verifier.c#L21
|
||||
[10]:http://events.linuxfoundation.org/sites/events/files/slides/tracing-linux-ezannoni-linuxcon-ja-2015_0.pdf
|
||||
[11]:https://github.com/iovisor/bcc
|
||||
[12]:https://github.com/iovisor/bcc/blob/master/INSTALL.md
|
||||
[13]:http://lxr.free-electrons.com/source/net/ipv4/af_inet.c#L194
|
||||
[14]:https://github.com/iovisor/bcc/pull/453
|
||||
[15]:http://lxr.free-electrons.com/source/kernel/trace/bpf_trace.c#L86
|
||||
[16]:https://github.com/iovisor/bcc/blob/master/tools/solisten.py
|
||||
[17]:http://www.brendangregg.com/blog/2015-05-15/ebpf-one-small-step.html
|
||||
|
||||
|
||||
@ -0,0 +1,91 @@
|
||||
为什么车企纷纷招聘计算机安全专家
|
||||
============================================================
|
||||
|
||||
Photo
|
||||

|
||||
来自 CloudFlare 公司的网络安全专家 Marc Rogers(左)和来自 Lookout 的 Kevin Mahaffey 能够通过直接连接在汽车上的笔记本电脑控制特斯拉的进行许多操作。图为他们在 CloudFlare 的大厅里的的熔岩灯前的合影,这些熔岩灯被用来生成密匙。纽约时报 CreditChristie Hemm Klok 拍摄
|
||||
|
||||
大约在七年前,伊朗的数位顶级核科学家经历过一系列形式类似的暗杀:凶手的摩托车接近他们乘坐的汽车,把磁性炸弹吸附在汽车上,然后逃离并引爆炸弹。
|
||||
|
||||
安全专家们警告人们,再过 7 年,凶手们不再需要摩托车或磁性炸弹。他们所需要的只是一台笔记本电脑和发送给无人驾驶汽车的一段代码——让汽车坠桥、被货车撞扁或者在高速公路上突然抛锚。
|
||||
|
||||
汽车制造商眼中的无人驾驶汽车。在黑客眼中只是一台可以达到时速 100 公里的计算机。
|
||||
|
||||
网络安全公司CloudFlare的首席安全研究员马克·罗杰斯(Marc Rogers)说:“它们已经不再是汽车了。它们是装在车轮上的数据中心。从外界接收的每一条数据都可以作为黑客的攻击载体。“
|
||||
|
||||
两年前,两名“白帽”黑客——寻找系统漏洞并修复它们的研究员,而不是利用漏洞来犯罪的破坏者(Cracker)——成功地在数里之外用电脑获得了一辆 Jeep Cherokee 的控制权。他们控制汽车撞击一个放置在高速公路中央的假人(在场景设定中是一位紧张的记者),直接终止了假人的一生。
|
||||
|
||||
黑客 Chris Valasek 和 Charlie Miller(现在是 Uber 和滴滴的安全研究人员)发现了一条 [由 Jeep 娱乐系统通向仪表板的电路][10]。他们利用这条线路控制了车辆转向、刹车和变速——他们在高速公路上撞击假人所需的一切。
|
||||
|
||||
Miller 先生上周日在 Twitter 上写道:“汽车被黑客入侵成为头条新闻,但是人们要清楚,没有人的汽车被坏人入侵过。 这些只是研究人员的测试。”
|
||||
|
||||
尽管如此,Miller 和 Valasek 的研究使 Jeep 汽车的制造商菲亚特克莱斯勒(Fiat Chrysler)付出了巨大的代价,因为这个安全漏洞,菲亚特克莱斯勒被迫召回了 140 万辆汽车。
|
||||
|
||||
毫无疑问,后来通用汽车首席执行官玛丽·巴拉(Mary Barra)把网络安全作为公司的首要任务。现在,计算机网络安全领域的人才在汽车制造商和高科技公司推进的无人驾驶汽车项目中的需求量很大。
|
||||
|
||||
优步 、[特斯拉][11]、苹果和中国的滴滴一直在积极招聘像 Miller 先生和 Valasek 先生这样的白帽黑客,传统的网络安全公司和学术界也有这样的趋势。
|
||||
|
||||
去年,特斯拉挖走了苹果 iOS 操作系统的安全经理 Aaron Sigel。优步挖走了 Facebook 的白帽黑客 Chris Gates。Miller 先生在发现 Jeep 的漏洞后就职于优步,然后被滴滴挖走。计算机安全领域已经有数十名优秀的工程师加入无人驾驶汽车项目研究的行列。
|
||||
|
||||
Miller 先生说,他离开了优步的一部分原因是滴滴给了他更自由的工作空间。
|
||||
|
||||
Miller 星期六在 Twitter 上写道:“汽车制造商对待网络攻击的威胁似乎更加严肃,但我仍然希望有更大的透明度。”
|
||||
|
||||
像许多大型科技公司一样,特斯拉和菲亚特克莱斯勒也开始给那些发现并提交漏洞的黑客们提供奖励。通用汽车公司也做了类似的事情,但批评人士认为通用汽车公司的计划与科技公司提供的计划相比诚意不足,迄今为止还收效甚微。
|
||||
|
||||
在 Miller 和 Valasek 发现 Jeep 漏洞的一年后,他们又向人们演示了所有其他可能危害乘客安全的方式,包括劫持车辆的速度控制系统,猛打方向盘或在高速行驶下拉动手刹——这一切都是由汽车外的电脑操作的。(在测试中使用的汽车最后掉进路边的沟渠,他们只能寻求当地拖车公司的帮助)
|
||||
|
||||
虽然他们必须在 Jeep 车上才能做到这一切,但这也证明了入侵的可能性。
|
||||
|
||||
在 Jeep 被入侵之前,华盛顿大学和加利福尼亚大学圣地亚哥分校的安全研究人员第一个通过蓝牙远程控制轿车并控制其刹车。研究人员警告汽车公司:汽车联网程度越高,被入侵的可能性就越大。
|
||||
|
||||
2015年,安全研究人员们发现了入侵高度软件化的特斯拉 Model S 的途径。Rogers 先生和网络安全公司 Lookout 的首席技术官凯文·马哈菲(Kevin Mahaffey)找到了一种通过直接连接在汽车上的笔记本电脑控制特斯拉汽车的方法。
|
||||
|
||||
一年后,来自中国腾讯的一支团队做了更进一步的尝试。他们入侵了一辆行驶中的特斯拉 Model S 并控制了其刹车器。和 Jeep 不同,特斯拉可以通过远程安装补丁来修复安全漏洞,这使得黑客的远程入侵也变的可能。
|
||||
|
||||
以上所有的例子中,入侵者都是无恶意的白帽黑客或者安全研究人员。但是给无人驾驶汽车制造商的教训是惨重的。
|
||||
|
||||
黑客入侵汽车的动机是无穷的。在得知 Rogers 先生和 Mahaffey 先生对特斯拉 Model S 的研究之后,一位中国 app 开发者和他们联系、询问他们是否愿意分享或者出售他们发现的漏洞。(这位 app 开发者正在寻找后门,试图在特斯拉的仪表盘上偷偷安装 app)
|
||||
|
||||
尽管犯罪分子们一直在积极开发、购买、使用能够破解汽车的关键通信数据的工具,但目前还没有证据能够表明犯罪分子们已经找到连接汽车的后门。
|
||||
|
||||
但随着越来越多的无人驾驶和半自动驾驶的汽车驶入公路,它们将成为更有价值的目标。安全专家警告道:无人驾驶汽车面临着更复杂、更多面的入侵风险,每一辆新无人驾驶汽车的加入,都使这个系统变得更复杂,而复杂性不可避免地带来脆弱性。
|
||||
|
||||
20年前,平均每辆汽车有100万行代码,通用汽车公司的2010雪佛兰Volt有大约1000万行代码——比一架F-35战斗机的代码还要多。
|
||||
|
||||
如今, 平均每辆汽车至少有1亿行代码。无人驾驶汽车公司预计不久以后它们将有2亿行代码。当你停下来考虑:平均每1000行代码有15到50个缺陷,那么潜在的可利用缺陷就会以很快的速度增加。
|
||||
|
||||
“计算机最大的安全威胁仅仅是数据被删除,但无人驾驶汽车一旦出现安全事故,失去的却是乘客的生命。”一家致力于解决汽车安全问题的以色列初创公司 Karamba Security 的联合创始人 David Barzilai 说。
|
||||
|
||||
安全专家说道:要想真正保障无人驾驶汽车的安全,汽车制造商必须想办法避免所有可能产生的漏洞——即使漏洞不可避免。其中最大的挑战,是汽车制造商和软件开发商们之间的缺乏合作经验。
|
||||
|
||||
网络安全公司 Lookout 的 Mahaffey 先生说:“新的革命已经出现,我们不能固步自封,应该寻求新的思维。我们需要像发明出安全气囊那样的人来解决安全漏洞,但我们现在还没有看到行业内有人做出改变。“
|
||||
|
||||
Mahaffey 先生说:”在这场无人驾驶汽车的竞争中,那些最注重软件的公司将会成为最后的赢家“
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.nytimes.com/2017/06/07/technology/why-car-companies-are-hiring-computer-security-experts.html
|
||||
|
||||
作者:[NICOLE PERLROTH ][a]
|
||||
译者:[XiatianSummer](https://github.com/XiatianSummer)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.nytimes.com/by/nicole-perlroth
|
||||
[1]:https://www.nytimes.com/2016/06/09/technology/software-as-weaponry-in-a-computer-connected-world.html
|
||||
[2]:https://www.nytimes.com/2015/08/29/technology/uber-hires-two-engineers-who-showed-cars-could-be-hacked.html
|
||||
[3]:https://www.nytimes.com/2015/08/11/opinion/zeynep-tufekci-why-smart-objects-may-be-a-dumb-idea.html
|
||||
[4]:https://www.nytimes.com/by/nicole-perlroth
|
||||
[5]:https://www.nytimes.com/column/bits
|
||||
[6]:https://www.nytimes.com/2017/06/07/technology/why-car-companies-are-hiring-computer-security-experts.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#story-continues-1
|
||||
[7]:http://www.nytimes.com/newsletters/sample/bits?pgtype=subscriptionspage&version=business&contentId=TU&eventName=sample&module=newsletter-sign-up
|
||||
[8]:https://www.nytimes.com/privacy
|
||||
[9]:https://www.nytimes.com/help/index.html
|
||||
[10]:https://bits.blogs.nytimes.com/2015/07/21/security-researchers-find-a-way-to-hack-cars/
|
||||
[11]:http://www.nytimes.com/topic/company/tesla-motors-inc?inline=nyt-org
|
||||
[12]:http://www.autosec.org/pubs/cars-usenixsec2011.pdf
|
||||
[13]:http://autos.nytimes.com/2011/Chevrolet/Volt/238/4117/329463/researchOverview.aspx?inline=nyt-classifier
|
||||
[14]:http://topics.nytimes.com/top/reference/timestopics/subjects/m/military_aircraft/f35_airplane/index.html?inline=nyt-classifier
|
||||
[15]:https://www.nytimes.com/2017/06/07/technology/why-car-companies-are-hiring-computer-security-experts.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#story-continues-3
|
||||
@ -1,202 +0,0 @@
|
||||
# 红帽企业版 Linux 包含的系统服务 - 第一部分
|
||||
|
||||
在 2017 年红帽峰会上,有几个人问我“我们通常用完整的虚拟机来隔离如 DSN 和 DHCP 等网络服务,那我们可以用容器来取而代之吗?”。答案是可以的,下面是在当前红帽企业版 Linux 7 系统上创建一个系统容器的例子。
|
||||
## **我们的目的**
|
||||
### *创建一个可以独立于任何其他系统服务来进行更新的网络服务,并且可以从主机端容易管理和更新。*
|
||||
让我们来探究在一个容器中建立一个运行在 systemd 之下的 BIND 服务器。在这一部分,我们将看到建立自己的容器以及管理 BIND 配置和数据文件。
|
||||
在第二部分,我们将看到主机中的 systemd 怎样和容器中的 systmed 整合。我们将探究管理容器中的服务,并且使它作为一种主机中的服务。
|
||||
## **创建 BIND 容器**
|
||||
为了使 systemd 在一个容器中容易运行,我们首先需要在主机中增加两个包:`oci-register-machine` 和 `oci-systemd-hook`。`oci-systemd-hook` 这个钩子允许我们在一个容器中运行 systemd,而不需要使用特权容器或者手工配置 tmpfs 和 cgroups。`oci-register-machine` 这个钩子允许我们使用 systemd 工具如 `systemctl` 和 `machinectl` 来跟踪容器。
|
||||
|
||||
```
|
||||
[root@rhel7-host ~]# yum install oci-register-machine oci-systemd-hook
|
||||
```
|
||||
|
||||
回到创建我们的 BIND 容器上。[红帽企业版 Linux 7 基础映像](https://access.redhat.com/containers)包含 systemd 作为一个 init 系统。我们安装并激活 BIND 正如我们在典型系统中做的那样。你可以从资源库中的 [git 仓库中下载这份 Dockerfile](http://rhelblog.redhat.com/2017/07/19/containing-system-services-in-red-hat-enterprise-linux-part-1/#repo)。
|
||||
|
||||
```
|
||||
[root@rhel7-host bind]# vi Dockerfile
|
||||
|
||||
# Dockerfile for BIND
|
||||
FROM registry.access.redhat.com/rhel7/rhel
|
||||
ENV container docker
|
||||
RUN yum -y install bind && \
|
||||
yum clean all && \
|
||||
systemctl enable named
|
||||
STOPSIGNAL SIGRTMIN+3
|
||||
EXPOSE 53
|
||||
EXPOSE 53/udp
|
||||
CMD [ "/sbin/init" ]
|
||||
```
|
||||
|
||||
因为我们以 PID 1 来启动一个 init 系统,当我们告诉容器停止时,需要改变 docker CLI 发送的信号。从 `kill` 系统调用手册中(man 2 kill):
|
||||
|
||||
```
|
||||
The only signals that can be sent to process ID 1, the init
|
||||
process, are those for which init has explicitly installed
|
||||
signal handlers. This is done to assure the system is not
|
||||
brought down accidentally.
|
||||
```
|
||||
|
||||
对于 systemd 信号句柄,`SIGRTMIN+3`是对应于 `systemd start halt.target` 的信号。我们也应该暴露 TCP 和 UDP 端口号用来 BIND ,因为这两种协议可能都在使用中。
|
||||
## **管理数据**
|
||||
有了一个实用的 BIND 服务,我们需要一种管理配置和区域文件的方法。目前这些都在容器里面,所以我们任何时候都可以进入容器去更新配置或者改变一个区域文件。从管理者角度来说,这并不是很理想。当要更新 BIND 时,我们将需要重建这个容器,所以映像中的改变将会丢失。任何时候我们需要更新一个文件或者重启服务时,都需要进入这个容器,而这增加了步骤和时间。
|
||||
相反的,我们将从这个容器中提取配置和数据文件,把它们拷贝到主机,然后在运行的时候挂载它们。这种方式我们可以很容易地重启或者重建容器,而不会丢失做出的更改。我们也可以使用容器外的编辑器来更改配置和区域文件。因为这个容器的数据看起来像“该系统服务的特定站点数据”,让我们遵循文件系统层次并在当前主机上创建 `/srv/named` 目录来保持管理权分离。
|
||||
|
||||
```
|
||||
[root@rhel7-host ~]# mkdir -p /srv/named/etc
|
||||
|
||||
[root@rhel7-host ~]# mkdir -p /srv/named/var/named
|
||||
```
|
||||
|
||||
***提示:如果你正在迁移一个存在的配置文件,你可以跳过下面的步骤并且将它直接拷贝到 `/srv/named` 目录下。你可能仍然想检查以一个临时容器分配给这个容器的 GID。***
|
||||
让我们建立并运行一个临时容器来检查 BIND。在将 init 进程作为 PID 1 运行时,我们不能交互地运行这个容器来获取一个 shell。我们会在容器 启动后执行 shell,并且使用 `rpm` 命令来检查重要文件。
|
||||
|
||||
```
|
||||
[root@rhel7-host ~]# docker build -t named .
|
||||
|
||||
[root@rhel7-host ~]# docker exec -it $( docker run -d named ) /bin/bash
|
||||
|
||||
[root@0e77ce00405e /]# rpm -ql bind
|
||||
```
|
||||
|
||||
对于这个例子来说,我们将需要 `/etc/named.conf` 和 `/var/named/` 目录下的任何文件。我们可以使用 `machinectl` 命令来提取它们。如果有一个以上的容器注册了,我们可以使用 `machinectl status` 命令来查看任一机器上运行的是什么。一旦有了这个配置我们就可以终止这个临时容器了。
|
||||
*如果你喜欢,资源库中也有一个[样例 `named.conf` 和针对 `example.com` 的区域文件](http://rhelblog.redhat.com/2017/07/19/containing-system-services-in-red-hat-enterprise-linux-part-1/#repo)*
|
||||
|
||||
```
|
||||
[root@rhel7-host bind]# machinectl list
|
||||
|
||||
MACHINE CLASS SERVICE
|
||||
8824c90294d5a36d396c8ab35167937f container docker
|
||||
|
||||
[root@rhel7-host ~]# machinectl copy-from 8824c90294d5a36d396c8ab35167937f /etc/named.conf /srv/named/etc/named.conf
|
||||
|
||||
[root@rhel7-host ~]# machinectl copy-from 8824c90294d5a36d396c8ab35167937f /var/named /srv/named/var/named
|
||||
|
||||
[root@rhel7-host ~]# docker stop infallible_wescoff
|
||||
```
|
||||
|
||||
## **最终的创建**
|
||||
为了创建和运行最终的容器,添加卷选项到挂载:
|
||||
- 将文件 `/srv/named/etc/named.conf` 映射为 `/etc/named.conf`
|
||||
- 将目录 `/srv/named/var/named` 映射为 `/var/named`
|
||||
|
||||
因为这是我们最终的容器,我们将提供一个有意义的名字,以供我们以后引用。
|
||||
```
|
||||
[root@rhel7-host ~]# docker run -d -p 53:53 -p 53:53/udp -v /srv/named/etc/named.conf:/etc/named.conf:Z -v /srv/named/var/named:/var/named:Z --name named-container named
|
||||
```
|
||||
|
||||
在最终容器运行时,我们可以更改本机配置来改变这个容器中 BIND 的行为。这个 BIND 服务器将需要在这个容器分配的任何 IP 上监听。确保任何新文件的 GID 与来自这个容器中的剩余 BIND 文件相匹配。
|
||||
|
||||
```
|
||||
[root@rhel7-host bind]# cp named.conf /srv/named/etc/named.conf
|
||||
|
||||
[root@rhel7-host ~]# cp example.com.zone /srv/named/var/named/example.com.zone
|
||||
|
||||
[root@rhel7-host ~]# cp example.com.rr.zone /srv/named/var/named/example.com.rr.zone
|
||||
```
|
||||
> [很好奇为什么我不需要在主机目录中改变 SELinux 上下文?](http://rhelblog.redhat.com/2017/07/19/containing-system-services-in-red-hat-enterprise-linux-part-1/#sidebar_1)
|
||||
|
||||
我们将运行这个容器提供的 `rndc` 二进制文件重新加载配置。我们可以使用 `journald` 以同样的方式检查 BIND 日志。如果运行出现错误,你可以在主机中编辑这个文件,并且重新加载配置。在主机中使用 `host` 或 `dig`, 我们可以检查来自针对 example.com 而包含的服务的响应。
|
||||
```
|
||||
[root@rhel7-host ~]# docker exec -it named-container rndc reload
|
||||
server reload successful
|
||||
|
||||
[root@rhel7-host ~]# docker exec -it named-container journalctl -u named -n
|
||||
-- Logs begin at Fri 2017-05-12 19:15:18 UTC, end at Fri 2017-05-12 19:29:17 UTC. --
|
||||
May 12 19:29:17 ac1752c314a7 named[27]: automatic empty zone: 9.E.F.IP6.ARPA
|
||||
May 12 19:29:17 ac1752c314a7 named[27]: automatic empty zone: A.E.F.IP6.ARPA
|
||||
May 12 19:29:17 ac1752c314a7 named[27]: automatic empty zone: B.E.F.IP6.ARPA
|
||||
May 12 19:29:17 ac1752c314a7 named[27]: automatic empty zone: 8.B.D.0.1.0.0.2.IP6.ARPA
|
||||
May 12 19:29:17 ac1752c314a7 named[27]: reloading configuration succeeded
|
||||
May 12 19:29:17 ac1752c314a7 named[27]: reloading zones succeeded
|
||||
May 12 19:29:17 ac1752c314a7 named[27]: zone 1.0.10.in-addr.arpa/IN: loaded serial 2001062601
|
||||
May 12 19:29:17 ac1752c314a7 named[27]: zone 1.0.10.in-addr.arpa/IN: sending notifies (serial 2001062601)
|
||||
May 12 19:29:17 ac1752c314a7 named[27]: all zones loaded
|
||||
May 12 19:29:17 ac1752c314a7 named[27]: running
|
||||
|
||||
[root@rhel7-host bind]# host www.example.com localhost
|
||||
Using domain server:
|
||||
Name: localhost
|
||||
Address: ::1#53
|
||||
Aliases:
|
||||
www.example.com is an alias for server1.example.com.
|
||||
server1.example.com is an alias for mail
|
||||
```
|
||||
> [你的区域文件没有更新吗?可能是因为你的编辑器,而不是序列号。](http://rhelblog.redhat.com/2017/07/19/containing-system-services-in-red-hat-enterprise-linux-part-1/#sidebar_2)
|
||||
|
||||
## **终点线**
|
||||
|
||||
我们已经知道我们打算完成什么。从容器中为 DNS 请求和区域文件提供服务。更新之后,我们已经得到一个持久化的位置来管理更新和配置。
|
||||
在这个系列的第二部分,我们将看到怎样将一个容器看作为主机中的一个普通服务。
|
||||
|
||||
---
|
||||
|
||||
[跟随 RHEL 博客](http://redhatstackblog.wordpress.com/feed/)通过电子邮件来获得本系列第二部分和其它新文章的更新。
|
||||
|
||||
---
|
||||
|
||||
## **额外的资源**
|
||||
**附带文件的 Github 仓库:**[**https://github.com/nzwulfin/named-container**](https://github.com/nzwulfin/named-container)
|
||||
**侧边栏 1:** **通过容器访问本地文件的 SELinux 上下文**
|
||||
你可能已经注意到当我从容器向本地主机拷贝文件时,我没有运行 `chcon` 将主机中的文件类型改变为 `svirt_sandbox_file_t`。为什么它没有终止?将一个文件拷贝到 `/srv` 本应该将这个文件标记为类型 `var_t`。我 `setenforce 0` 了吗?
|
||||
当然没有,这将让 Dan Walsh 大哭(译注:未知人名)。是的,`machinectl` 确实将文件标记类型设置为期望的那样,可以看一下:
|
||||
启动一个容器之前:
|
||||
```
|
||||
[root@rhel7-host ~]# ls -Z /srv/named/etc/named.conf
|
||||
|
||||
-rw-r-----. unconfined_u:object_r:var_t:s0 /srv/named/etc/named.conf
|
||||
```
|
||||
|
||||
After starting the container:
|
||||
不,运行中我使用了一个卷选项使 Dan Walsh 高兴,`:Z`。`-v /srv/named/etc/named.conf:/etc/named.conf:Z`命令的这部分做了两件事情:首先它表示这需要使用一个私有的卷 SELiunx 标记来重新标记,其次它表明以读写挂载。
|
||||
启动容器之后:
|
||||
```
|
||||
[root@rhel7-host ~]# ls -Z /srv/named/etc/named.conf
|
||||
|
||||
-rw-r-----. root 25 system_u:object_r:svirt_sandbox_file_t:s0:c821,c956 /srv/named/etc/named.conf
|
||||
```
|
||||
|
||||
**侧边栏 2:** **VIM 备份行为改变 inode**
|
||||
如果你在本地主机中使用 `vim` 来编辑配置文件,并且你没有看到容器中的改变,你可能不经意的创建了容器感知不到的新文件。在编辑中时,有三种 `vim` 设定影响背负副本:backup, writebackup 和 backupcopy。
|
||||
我从官方 VIM backup_table 中剪下了应用到 RHEL 7 中的默认配置
|
||||
[[http://vimdoc.sourceforge.net/htmldoc/editing.html#backup-table](http://vimdoc.sourceforge.net/htmldoc/editing.html#backup-table)]
|
||||
```
|
||||
backup writebackup
|
||||
|
||||
off on backup current file, deleted afterwards (default)
|
||||
```
|
||||
So we don’t create tilde copies that stick around, but we are creating backups. The other setting is backupcopy, where auto is the shipped default:
|
||||
所以我们不创建停留的副本,但我们将创建备份。另外的设定是 backupcopy,`auto` 是默认的设置:
|
||||
```
|
||||
"yes" make a copy of the file and overwrite the original one
|
||||
"no" rename the file and write a new one
|
||||
"auto" one of the previous, what works best
|
||||
```
|
||||
|
||||
这种组合设定意味着当你编辑一个文件时,除非 `vim` 有理由不去(检查文件逻辑),你将会得到包含你编辑之后的新文件,当你保存时它会重命名原先的文件。这意味着这个文件获得了新的 inode。对于大多数情况,这不是问题,但是这里绑定挂载到一个容器对 inode 的改变很敏感。为了解决这个问题,你需要改变 backupcopy 的行为。
|
||||
Either in the vim session or in your .vimrc, add set backupcopy=yes. This will make sure the original file gets truncated and overwritten, preserving the inode and propagating the changes into the container.
|
||||
不管是在 `vim` 会话还是在你的 `.vimrc`中,添加 `set backupcopy=yes`。这将确保原先的文件被截断并且被覆写,维持了 inode 并且在容器中产生了改变。
|
||||
|
||||
------------
|
||||
|
||||
via: http://rhelblog.redhat.com/2017/07/19/containing-system-services-in-red-hat-enterprise-linux-part-1/
|
||||
|
||||
作者:[Matt Micene ][a]
|
||||
译者:[liuxinyu123](https://github.com/liuxinyu123)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,122 @@
|
||||
使用 VirtualBox 创建 Vagrant boxes 的完全指南
|
||||
======
|
||||
Vagrant 是一个用来创建和管理虚拟机环境的工具,常用于建设开发环境。 它在 Docker, VirtualBox, Hyper-V, Vmware , AWS 等技术的基础上构建了一个易于使用且易于复制和重建的环境。
|
||||
|
||||
Vagrant Boxes 简化了软件配置部分的工作并且完全解决了软件开发项目中经常遇到的'它能在我机器上工作'的问题,从而提高开发效率。
|
||||
|
||||
在本文中,我们会在 Linux 机器上学习使用 VirtualBox 来配置 Vagrant Boxes。
|
||||
|
||||
### 前置条件
|
||||
|
||||
Vagrant 是基于虚拟化环境运行的,这里我们使用 VirtualBox 来提供虚拟化环境。 关于如何安装 VirutalBox 我们在 "[ **Installing VirtualBox on Linux**][1]" 中有详细描述, 阅读这篇文章并安装 VirtualBox。
|
||||
|
||||
安装好 VirtualBox 后,下一步就是配置 Vagrant 了。
|
||||
|
||||
**(推荐阅读 :[Create your first Docker Container ][2])**
|
||||
|
||||
### 安装
|
||||
|
||||
VirtualBox 准备好后,我们来安装最新的 vagrant 包。 在写本文的时刻, Vagrant 的最新版本为 2.0.0。 使用下面命令下载最新的 rpm 文件:
|
||||
|
||||
**$ wget https://releases.hashicorp.com/vagrant/2.0.0/vagrant_2.0.0_x86_64.rpm**
|
||||
|
||||
然后安装这个包:
|
||||
|
||||
**$ sudo yum install vagrant_2.0.0_x86_64.rpm**
|
||||
|
||||
如果是 Ubuntu,用下面这个命令来下载最新的 vagrant 包:
|
||||
|
||||
**$ wget https://releases.hashicorp.com/vagrant/2.0.0/vagrant_2.0.0_x86_64.deb**
|
||||
|
||||
然后安装它,
|
||||
|
||||
**$ sudo dpkg -i vagrant_2.0.0_x86_64.deb**
|
||||
|
||||
安装结束后,就该进入配置环节了。
|
||||
|
||||
### 配置
|
||||
|
||||
首先,我们需要创建一个目录给 vagrant 来安装我们需要的操作系统,
|
||||
|
||||
**$ mkdir /home/dan**
|
||||
|
||||
**$ cd /home/dan/vagrant**
|
||||
|
||||
**注意:-** 推荐在你的用户主目录下创建 vagrant,否则你可能会遇到本地用户相关的权限问题。
|
||||
|
||||
现在执行下面命令来安装操作系统,比如 CentOS:
|
||||
|
||||
**$ sudo vagrant init centos/7**
|
||||
|
||||
如果要安装 Ubuntu 则运行
|
||||
|
||||
**$ sudo vagrant init ubuntu/trusty64**
|
||||
|
||||
![vagrant boxes][3]
|
||||
|
||||
![vagrant boxes][4]
|
||||
|
||||
这还会在存放 vagrant OS 的目录中创建一个叫做 'Vagrantfile' 的配置文件。它包含了一些关于操作系统,私有 IP 网络,转发端口,主机名等信息。 若我们需要创建一个新的操作系统, 也可以编辑这个问题。
|
||||
|
||||
一旦我们用 vagrant 创建/修改了操作系统,我们可以用下面命令启动它:
|
||||
|
||||
**$ sudo vagrant up**
|
||||
|
||||
这可能要花一些时间,因为这条命令要构建操作系统,它需要从网络上下载所需的文件。 因此根据互联网的速度, 这个过程可能会比较耗时。
|
||||
|
||||
![vagrant boxes][5]
|
||||
|
||||
![vagrant boxes][6]
|
||||
|
||||
这个过程完成后,你就可以使用下面这些命令来管理 vagrant 实例了
|
||||
|
||||
启动 vagrant 服务器
|
||||
|
||||
**$ sudo vagrant up**
|
||||
|
||||
关闭服务器
|
||||
|
||||
**$ sudo vagrant halt**
|
||||
|
||||
完全删除服务器
|
||||
|
||||
**$ sudo vagrant destroy**
|
||||
|
||||
使用 ssh 访问服务器
|
||||
|
||||
**$ sudo vagrant ssh**
|
||||
|
||||
我们可以从 Vagrant Box 的启动过程中得到 ssh 的详细信息(参见上面的截屏)。
|
||||
|
||||
如果想看创建的 vagrant OS,可以打开 virtualbox 然后你就能看在 VirtualBox 创建的虚拟机中找到它了。 如果在 VirtualBox 中没有找到, 使用 sudo 权限打开 virtualbox, 然后应该就能看到了。
|
||||
|
||||
![vagrant boxes][7]
|
||||
|
||||
![vagrant boxes][8]
|
||||
|
||||
**注意:-** 在 Vagrant 官方网站(<https://app.vagrantup.com/boxes/search>)上可以下载预先配置好的 Vagrant OS。
|
||||
|
||||
这就是本文的内容了。如有疑问请在下方留言,我们会尽快回复。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/creating-vagrant-virtual-boxes-virtualbox/
|
||||
|
||||
作者:[Shusain][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:http://linuxtechlab.com/installing-virtualbox-on-linux-centos-ubuntu/
|
||||
[2]:http://linuxtechlab.com/create-first-docker-container-beginners-guide/
|
||||
[3]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=721%2C87
|
||||
[4]:https://i2.wp.com/linuxtechlab.com/wp-content/uploads/2017/10/vagrant-1.png?resize=721%2C87
|
||||
[5]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=980%2C414
|
||||
[6]:https://i2.wp.com/linuxtechlab.com/wp-content/uploads/2017/10/vagrant-2-e1510557565780.png?resize=980%2C414
|
||||
[7]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=769%2C582
|
||||
[8]:https://i1.wp.com/linuxtechlab.com/wp-content/uploads/2017/10/vagrant-3.png?resize=769%2C582
|
||||
[9]:https://www.facebook.com/linuxtechlab/
|
||||
[10]:https://twitter.com/LinuxTechLab
|
||||
[11]:https://plus.google.com/+linuxtechlab
|
||||
@ -1,238 +0,0 @@
|
||||
怎么去使用 SVG 作为一个占位符,以及其它图像加载技术
|
||||
============================================================
|
||||
|
||||

|
||||
从被用作占位符的图像中生成 SVGs。继续阅读!
|
||||
|
||||
我对怎么去让 web 性能更优化和图像加载的更快充满了热情。对这些感兴趣的领域中的其中一项研究就是占位符:当图像还没有被加载的时候应该去展示些什么?
|
||||
|
||||
在前此天,我偶然发现了使用 SVG 的一些加载技术,随后,我将在这篇文章中去描述它。
|
||||
|
||||
在这篇文章中我们将涉及如下的主题:
|
||||
|
||||
* 不同的占位符类型的概述
|
||||
|
||||
* 基于 SVG 的占位符(边缘、形状、和轮廓)
|
||||
|
||||
* 自动化处理
|
||||
|
||||
### 不同的占位符类型的概述
|
||||
|
||||
以前 [我写的关于占位符和图像延迟加载(lazy-loading)][28] 的文章和 [关于它的讨论][29] 中。当进行一个图像的延迟加载时,一个很好的主意是去考虑提供一个东西作为占位符,因为,它可能会很大程序上影响用户的感知体验。以前我提供了几个选项:
|
||||
|
||||
|
||||

|
||||
|
||||
在图像被加载之前,有几种办法去填充图像区域。
|
||||
|
||||
* 在图像区保持空白:在一个响应式设计的环境中,这种方式防止了内容的跳跃。这种布局从用户体验的角度来看是非常差的作法。但是,它是为了性能的考虑,否则,每次为了获取图像尺寸,浏览器被迫进行布局重计算,以为它留下空间。
|
||||
|
||||
* 占位符:在那里显示一个用户配置的图像。我们可以在背景上显示一个轮廓。它一直显示直到实际的图像被加载,它也被用于当请求失败或者当用户根本没有设置图像的情况下。这些图像一般都是矢量图,并且都选择尺寸非常小的内联图片。
|
||||
|
||||
* 固定的颜色:从图像中获取颜色,并将其作为占位符的背景颜色。这可能是主导的颜色,最具活力的 … 这个主意是基于你正在加载的图像,并且它将有助于在没有图像和图像加载完成之间进行平滑过渡。
|
||||
|
||||
* 模糊的图像:也被称为模糊技术。你提供一个极小版本的图像,然后再去过渡到完整的图像。最初的图像的像素和尺寸是极小的。为去除伪影图像(artifacts the image)被放大和模糊化。我在前面写的 [怎么去做中间的渐进加载的图像][1]、[使用 WebP 去创建极小的预览图像][2]、和 [渐进加载图像的更多示例][3] 中讨论过这方面的内容。
|
||||
|
||||
结果是,还有其它的更多的变化,并且许多聪明的人开发了其它的创建占位符的技术。
|
||||
|
||||
其中一个就是用梯度图代替固定的颜色。梯度图可以创建一个更精确的最终图像的预览,它整体上非常小(提升了有效载荷)。
|
||||
|
||||
|
||||

|
||||
使用梯度图作为背景。来自 Gradify 的截屏,它现在并不在线,代码 [在 GitHub][4]。
|
||||
|
||||
其它的技术是使用基于 SVGs 的技术,它在最近的实验和黑客中得到了一些支持。
|
||||
|
||||
### 基于 SVG 的占位符
|
||||
|
||||
我们知道 SVGs 是完美的矢量图像。在大多数情况下我们是希望去加载一个位图,所以,问题是怎么去矢量化一个图像。一些选择是使用边缘、形状和轮廓。
|
||||
|
||||
#### 边缘
|
||||
|
||||
在 [前面的文章中][30],我解释了怎么去找出一个图像的边缘和创建一个动画。我最初的目标是去尝试绘制区域,矢量化这个图像,但是,我并不知道该怎么去做到。我意识到使用边缘也可能被创新,并且,我决定去让它们动起来,创建一个 “绘制” 的效果。
|
||||
|
||||
[在以前,使用边缘检测绘制图像和 SVG 动画,在 SVG 中基本上不被使用和支持的。一段时间以后,我们开始用它去作为一个有趣的替代 … medium.com][31][][32]
|
||||
|
||||
#### 形状
|
||||
|
||||
SVG 也可以用于去从图像中绘制区域而不是边缘/边界。用这种方法,我们可以矢量化一个位图去创建一个占位符。
|
||||
|
||||
在以前,我尝试去用三角形做类似的事情。你可以在我的 [at CSSConf][33] 和 [Render Conf][34] 的演讲中看到它。
|
||||
|
||||
|
||||
上面的 codepen 是一个由 245 个三角形组成的基于 SVG 占位符的观点的证明。生成的三角形是使用 [Possan’s polyserver][36] 基于 [Delaunay triangulation][35]。正如预期的那样,使用更多的三角形,文件尺寸就更大。
|
||||
|
||||
#### Primitive 和 SQIP,一个基于 SVG 的 LQIP 技术
|
||||
|
||||
Tobias Baldauf 正在致力于另一个使用 SVGs 的被称为 [SQIP][37] 的低质量图像占位符技术。在深入研究 SQIP 之前,我先简单了解一下 [Primitive][38],它是基于 SQIP 的一个库。
|
||||
|
||||
Primitive 是非常吸引人的,我强烈建议你去了解一下。它讲解了一个位图怎么变成由重叠形状组成的 SVG。它尺寸比较小,一个更小的往返,更适合直接放置到页面中,在一个初始的 HTML 载荷中,它是非常有意义的。
|
||||
|
||||
Primitive 基于像三角形、长方形、和圆形等形状去生成一个图像。在每一步中它增加一个新形状。很多步之后,图像的结果看起来非常接近原始图像。如果你输出的是 SVG,它意味着输出代码的尺寸将很大。
|
||||
|
||||
为了理解 Primitive 是怎么工作的,我通过几个图像来跑一下它。我用 10 个形状和 100 个形状来为这个插画生成 SVGs:
|
||||
|
||||
** 此处有Canvas,请手动处理 **
|
||||
|
||||

|
||||
|
||||
|
||||

|
||||
|
||||

|
||||
Processing [this picture][5] 使用 Primitive,使用 [10 个形状][6] 和 [100 形状][7]。
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||

|
||||
Processing [this picture][8] 使用 Primitive,使用 [10 形状][9] 和 [100 形状][10]。
|
||||
|
||||
当在图像中使用 10 个形状时,我们基本构画出了原始图像。在图像环境占位符这里我们使用了 SVG 作为潜在的占位符。实际上,使用 10 个形状的 SVG 代码已经很小了,大约是 1030 字节,当通过 SVGO 传输时,它将下降到 ~640 字节。
|
||||
|
||||
```
|
||||
<svg xmlns=”http://www.w3.org/2000/svg" width=”1024" height=”1024"><path fill=”#817c70" d=”M0 0h1024v1024H0z”/><g fill-opacity=”.502"><path fill=”#03020f” d=”M178 994l580 92L402–62"/><path fill=”#f2e2ba” d=”M638 894L614 6l472 440"/><path fill=”#fff8be” d=”M-62 854h300L138–62"/><path fill=”#76c2d9" d=”M410–62L154 530–62 38"/><path fill=”#62b4cf” d=”M1086–2L498–30l484 508"/><path fill=”#010412" d=”M430–2l196 52–76 356"/><path fill=”#eb7d3f” d=”M598 594l488–32–308 520"/><path fill=”#080a18" d=”M198 418l32 304 116–448"/><path fill=”#3f201d” d=”M1086 1062l-344–52 248–148"/><path fill=”#ebd29f” d=”M630 658l-60–372 516 320"/></g></svg>
|
||||
```
|
||||
|
||||
使用 100 个形状生成的图像是很大的,正如我们预期的那样,在 SVGO(之前是 8kB)之后,加权大小为 ~5kB。它们在细节上已经很好了,但是仍然是个很小的载荷。使用多少三角形主要取决于图像类型和细腻程序(如,对比度、颜色数量、复杂度)。
|
||||
|
||||
它还可能去创建一个类似于 [cpeg-dssim][39] 的脚本,去调整所使用的形状的数量,以满足 [结构相似][40] 的阈值(或者最差情况中的最大数量)。
|
||||
|
||||
这些 SVG 的结果也可以用作背景图像。因为尺寸约束和矢量化,它们在图像和大规模的背景图像中是很好的选择。
|
||||
|
||||
#### SQIP
|
||||
|
||||
用 [Tobias 自己的话说][41]:
|
||||
|
||||
> SQIP 是尝试在这两个极端之间找到一种平衡:它使用 [Primitive][42] 去生成一个由几种简单图像构成的近似图像的可见特征的 SVG,使用 [SVGO][43] 去优化 SVG,并且为它增加高斯模糊滤镜。产生的最终的 SVG 占位符加权后大小为 ~800–1000 字节,在屏幕上看起来更为平滑,并提供一个可视的图像内容提示。
|
||||
|
||||
这个结果和使用一个极小的使用了模糊技术的占位符图像类似。(what [Medium][44] and [other sites][45] do)。区别在于它们使用了一个位图图像,如 JPG 或者 WebP,而这里是使用的占位符是 SVG。
|
||||
|
||||
如果我们使用 SQIP 而不是原始图像,我们将得到这样的效果:
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||

|
||||
[第一张图片][11] 和 [第二张][12] 的输出图像使用了 SQIP。
|
||||
|
||||
输出的 SVG 是 ~900 字节,并且检查代码,我们可以发现 `feGaussianBlur` 过滤应用到形状组上:
|
||||
|
||||
```
|
||||
<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 2000 2000"><filter id="b"><feGaussianBlur stdDeviation="12" /></filter><path fill="#817c70" d="M0 0h2000v2000H0z"/><g filter="url(#b)" transform="translate(4 4) scale(7.8125)" fill-opacity=".5"><ellipse fill="#000210" rx="1" ry="1" transform="matrix(50.41098 -3.7951 11.14787 148.07886 107 194.6)"/><ellipse fill="#eee3bb" rx="1" ry="1" transform="matrix(-56.38179 17.684 -24.48514 -78.06584 205 110.1)"/><ellipse fill="#fff4bd" rx="1" ry="1" transform="matrix(35.40604 -5.49219 14.85017 95.73337 16.4 123.6)"/><ellipse fill="#79c7db" cx="21" cy="39" rx="65" ry="65"/><ellipse fill="#0c1320" cx="117" cy="38" rx="34" ry="47"/><ellipse fill="#5cb0cd" rx="1" ry="1" transform="matrix(-39.46201 77.24476 -54.56092 -27.87353 219.2 7.9)"/><path fill="#e57339" d="M271 159l-123–16 43 128z"/><ellipse fill="#47332f" cx="214" cy="237" rx="242" ry="19"/></g></svg>
|
||||
```
|
||||
|
||||
SQIP 也可以输出一个 Base 64 编码的 SVG 内容的图像标签:
|
||||
|
||||
```
|
||||
<img width="640" height="640" src="example.jpg” alt="Add descriptive alt text" style="background-size: cover; background-image: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAw…<stripped base 64>…PjwvZz48L3N2Zz4=);">
|
||||
```
|
||||
|
||||
#### 轮廓
|
||||
|
||||
我们刚才看了使用了边缘和 primitive 形状的 SVG。另外一种可能是去矢量化图像以 “tracing” 它们。[Mikael 动画][47] 分享的 [a codepen][48],在几天前展示了怎么去使用两色轮廓作为一个占位符。结果非常漂亮:
|
||||
|
||||
|
||||

|
||||
|
||||
SVGs 在这种情况下是手工绘制的,但是,这种技术可以用工具快速生成并自动化处理。
|
||||
|
||||
* [Gatsby][13],一个 React 支持的描绘 SVGs 的静态网站生成器。它使用 [一个 potrace 算法的 JS 端口][14] 去矢量化图像。
|
||||
|
||||
* [Craft 3 CMS][15],它也增加了对轮廓的支持。它使用 [一个 potrace 算法的 PHP 端口][16]。
|
||||
|
||||
|
||||
* [image-trace-loader][17],一个使用了 Potrace 算法去处理图像的 Webpack 加载器。
|
||||
|
||||
|
||||
如果感兴趣,可以去看一下 Emil 的 webpack 加载器 (基于 potrace) 和 Mikael 的手工绘制 SVGs 之间的比较。
|
||||
|
||||
|
||||
假设我使用一个默认选项的 potrace 生成输出。但是,有可能对它们进行调整。查看 [the options for image-trace-loader][49],它非常漂亮 [the ones passed down to potrace][50]。
|
||||
|
||||
### 总结
|
||||
|
||||
我们看到有不同的工具和技术去从图像中生成 SVGs,并且使用它们作为占位符。与 [WebP 是一个奇妙格式的缩略图][51] 方式相同,SVG 也是一个用于占位符的有趣的格式。我们可以控制细节的级别(和它们的大小),它是高可压缩的,并且很容易用 CSS 和 JS 进行处理。
|
||||
|
||||
#### 额外的资源
|
||||
|
||||
这篇文章发表于 [the top of Hacker News][52]。我非常感谢它,并且,在页面上的注释中的其它资源的全部有链接。下面是其中一部分。
|
||||
|
||||
* [Geometrize][18] 是用 Haxe 写的 Primitive 的一个端口。这个也是,[一个 JS 实现][19],你可以直接 [在你的浏览器上][20]尝试。
|
||||
|
||||
* [Primitive.js][21],它也是在 JS 中的一个 Primitive 端口,[primitive.nextgen][22],它是使用 Primitive.js 和 Electron 的 Primitive 的桌面版应用的一个端口。
|
||||
|
||||
* 这里有两个 Twitter 帐户,里面你可以看到一些用 Primitive 和 Geometrize 生成的图像示例。访问 [@PrimitivePic][23] 和 [@Geometrizer][24]。
|
||||
|
||||
* [imagetracerjs][25],它是在 JavaScript 中的光栅图像跟踪和矢量化程序。这里也有为 [Java][26] 和 [Android][27] 提供的端口。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.freecodecamp.org/using-svg-as-placeholders-more-image-loading-techniques-bed1b810ab2c
|
||||
|
||||
作者:[ José M. Pérez][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.freecodecamp.org/@jmperezperez?source=post_header_lockup
|
||||
[1]:https://medium.com/@jmperezperez/how-medium-does-progressive-image-loading-fd1e4dc1ee3d
|
||||
[2]:https://medium.com/@jmperezperez/using-webp-to-create-tiny-preview-images-3e9b924f28d6
|
||||
[3]:https://medium.com/@jmperezperez/more-examples-of-progressive-image-loading-f258be9f440b
|
||||
[4]:https://github.com/fraser-hemp/gradify
|
||||
[5]:https://jmperezperez.com/assets/images/posts/svg-placeholders/pexels-photo-281184-square.jpg
|
||||
[6]:https://jmperezperez.com/assets/images/posts/svg-placeholders/pexels-photo-281184-square-10.svg
|
||||
[7]:https://jmperezperez.com/assets/images/posts/svg-placeholders/pexels-photo-281184-square-100.svg
|
||||
[8]:https://jmperezperez.com/assets/images/posts/svg-placeholders/pexels-photo-618463-square.jpg
|
||||
[9]:https://jmperezperez.com/assets/images/posts/svg-placeholders/pexels-photo-618463-square-10.svg
|
||||
[10]:https://jmperezperez.com/assets/images/posts/svg-placeholders/pexels-photo-618463-square-100.svg
|
||||
[11]:https://jmperezperez.com/assets/images/posts/svg-placeholders/pexels-photo-281184-square-sqip.svg
|
||||
[12]:https://jmperezperez.com/svg-placeholders/%28/assets/images/posts/svg-placeholders/pexels-photo-618463-square-sqip.svg
|
||||
[13]:https://www.gatsbyjs.org/
|
||||
[14]:https://www.npmjs.com/package/potrace
|
||||
[15]:https://craftcms.com/
|
||||
[16]:https://github.com/nystudio107/craft3-imageoptimize/blob/master/src/lib/Potracio.php
|
||||
[17]:https://github.com/EmilTholin/image-trace-loader
|
||||
[18]:https://github.com/Tw1ddle/geometrize-haxe
|
||||
[19]:https://github.com/Tw1ddle/geometrize-haxe-web
|
||||
[20]:http://www.samcodes.co.uk/project/geometrize-haxe-web/
|
||||
[21]:https://github.com/ondras/primitive.js
|
||||
[22]:https://github.com/cielito-lindo-productions/primitive.nextgen
|
||||
[23]:https://twitter.com/PrimitivePic
|
||||
[24]:https://twitter.com/Geometrizer
|
||||
[25]:https://github.com/jankovicsandras/imagetracerjs
|
||||
[26]:https://github.com/jankovicsandras/imagetracerjava
|
||||
[27]:https://github.com/jankovicsandras/imagetracerandroid
|
||||
[28]:https://medium.com/@jmperezperez/lazy-loading-images-on-the-web-to-improve-loading-time-and-saving-bandwidth-ec988b710290
|
||||
[29]:https://www.youtube.com/watch?v=szmVNOnkwoU
|
||||
[30]:https://medium.com/@jmperezperez/drawing-images-using-edge-detection-and-svg-animation-16a1a3676d3
|
||||
[31]:https://medium.com/@jmperezperez/drawing-images-using-edge-detection-and-svg-animation-16a1a3676d3
|
||||
[32]:https://medium.com/@jmperezperez/drawing-images-using-edge-detection-and-svg-animation-16a1a3676d3
|
||||
[33]:https://jmperezperez.com/cssconfau16/#/45
|
||||
[34]:https://jmperezperez.com/renderconf17/#/46
|
||||
[35]:https://en.wikipedia.org/wiki/Delaunay_triangulation
|
||||
[36]:https://github.com/possan/polyserver
|
||||
[37]:https://github.com/technopagan/sqip
|
||||
[38]:https://github.com/fogleman/primitive
|
||||
[39]:https://github.com/technopagan/cjpeg-dssim
|
||||
[40]:https://en.wikipedia.org/wiki/Structural_similarity
|
||||
[41]:https://github.com/technopagan/sqip
|
||||
[42]:https://github.com/fogleman/primitive
|
||||
[43]:https://github.com/svg/svgo
|
||||
[44]:https://medium.com/@jmperezperez/how-medium-does-progressive-image-loading-fd1e4dc1ee3d
|
||||
[45]:https://medium.com/@jmperezperez/more-examples-of-progressive-image-loading-f258be9f440b
|
||||
[46]:http://www.w3.org/2000/svg
|
||||
[47]:https://twitter.com/mikaelainalem
|
||||
[48]:https://codepen.io/ainalem/full/aLKxjm/
|
||||
[49]:https://github.com/EmilTholin/image-trace-loader#options
|
||||
[50]:https://www.npmjs.com/package/potrace#parameters
|
||||
[51]:https://medium.com/@jmperezperez/using-webp-to-create-tiny-preview-images-3e9b924f28d6
|
||||
[52]:https://news.ycombinator.com/item?id=15696596
|
||||
@ -0,0 +1,713 @@
|
||||
深入理解 BPF:一个阅读清单
|
||||
============================================================
|
||||
|
||||
* [什么是 BPF?][143]
|
||||
|
||||
* [深入理解字节码( bytecode)][144]
|
||||
|
||||
* [资源][145]
|
||||
* [简介][23]
|
||||
* [关于 BPF][1]
|
||||
|
||||
* [关于 XDP][2]
|
||||
|
||||
* [关于 基于 eBPF 或者 eBPF 相关的其它组件][3]
|
||||
|
||||
* [文档][24]
|
||||
* [关于 BPF][4]
|
||||
|
||||
* [关于 tc][5]
|
||||
|
||||
* [关于 XDP][6]
|
||||
|
||||
* [关于 P4 和 BPF][7]
|
||||
|
||||
* [教程][25]
|
||||
|
||||
* [示例][26]
|
||||
* [来自内核的示例][8]
|
||||
|
||||
* [来自包 iproute2 的示例][9]
|
||||
|
||||
* [来自 bcc 工具集的示例][10]
|
||||
|
||||
* [手册页面][11]
|
||||
|
||||
* [代码][27]
|
||||
* [内核中的 BPF 代码][12]
|
||||
|
||||
* [XDP 钩子(hook)代码][13]
|
||||
|
||||
* [bcc 中的 BPF 逻辑][14]
|
||||
|
||||
* [通过 tc 使用代码去管理 BPF][15]
|
||||
|
||||
* [BPF 实用工具][16]
|
||||
|
||||
* [其它感兴趣的 chunks][17]
|
||||
|
||||
* [LLVM 后端][18]
|
||||
|
||||
* [在用户空间中运行][19]
|
||||
|
||||
* [提交日志][20]
|
||||
|
||||
* [排错][28]
|
||||
* [编译时的错误][21]
|
||||
|
||||
* [加载和运行时的错误][22]
|
||||
|
||||
* [更多][29]
|
||||
|
||||
_~ [更新于][146] 2017-11-02 ~_
|
||||
|
||||
# 什么是 BPF?
|
||||
|
||||
BPF,是伯克利包过滤器(**B**erkeley **P**acket **F**ilter)的第一个字母的组合,最初构想于 1992 年,是为了提供一种过滤包的方法,以避免从内核到用户空间的无用的数据包副本。它最初是由从用户空间注入到内核的一个简单的字节码构成,它在哪里通过一个校验器进行检查 — 以避免内核崩溃或者安全问题 — 并附加到一个套接字上,然后运行在每个接收到的包上。几年后它被移植到 Linux 上,并且应用于一小部分应用程序上(例如,tcpdump)。简化的语言以及存在于内核中的即时编译器(JIT),使 BPF 成为一个性能卓越的工具。
|
||||
|
||||
然后,在 2013 年,Alexei Starovoitov 对 BPF 进行彻底地改造,并增加了新的功能,改善了它的性能。这个新版本被命名为 eBPF (意思是 “extended BPF”),同时将以前的变成 cBPF(意思是 “classic” BPF)。出现了如映射(maps)和 tail 调用(calls)。JIT 编译器被重写了。新的语言比 cBPF 更接近于原生机器语言。并且,在内核中创建了新的附加点。
|
||||
|
||||
感谢那些新的钩子,eBPF 程序才可以被设计用于各种各样的使用案例,它分为两个应用领域。其中一个应用领域是内核跟踪和事件监控。BPF 程序可以被附加到 kprobes,并且它与其它跟踪模式相比,有很多的优点(有时也有一些缺点)。
|
||||
|
||||
其它的应用领域是网络程序。除了套接字过滤器,eBPF 程序可以附加到 tc(Linux 流量控制工具) ingress 或者 egress 接口,并且用一种高效的方式去执行各种包处理任务。它在这个领域打开了一个新的思路。
|
||||
|
||||
并且 eBPF 的性能通过为 IO Visor 项目开发的技术进一步得到提升:也为 XDP(“eXpress Data Path”)增加了新的钩子,它是不久前增加到内核中的一种新的快速路径。XDP 与 Linux 栈一起工作,并且依赖 BPF 去执行更快的包处理。
|
||||
|
||||
甚至一些项目,如 P4、Open vSwitch、[考虑][155] 或者开始去接近(approach)BPF。其它的一些,如 CETH、Cilium,则是完全基于它的。BPF 是如此流行,因此,我们可以预计到不久后,将围绕它有很多工具和项目出现 …
|
||||
|
||||
# 深入理解字节码
|
||||
|
||||
就像我一样:我的一些工作(包括 [BEBA][156])是非常依赖 eBPF 的,并且在这个网站上以后的几篇文章将关注于这个主题。从逻辑上说,在这篇文章中我在深入到细节之前,希望以某种方式去介绍 BPF — 我的意思是,一个真正的介绍,更多的在 BPF 上开发的功能,它在开始节已经提供了一些简短的摘要:什么是 BPF 映射? Tail 调用?内部结构是什么样子?等等。但是,在这个网站上已经有很多这个主题的介绍了,并且,我也不希望去创建 “另一个 BPF 介绍” 的重复的文章。
|
||||
|
||||
毕竟,我花费了很多的时间去阅读和学习关于 BPF 的知识,并且,也是这么做的,因此,在这里我们将要做的是,我收集了非常多的关于 BPF 的阅读材料:介绍、文档、也有教程或者示例。这里有很多的材料可以去阅读,但是,为了去阅读它,首先要去 _找到_ 它。因此,为了能够帮助更多想去学习和使用 BPF 的人,现在的这篇文章是介绍了一个资源列表。这里有各种阅读材料,它可以帮你深入理解内核字节码的机制。
|
||||
|
||||
# 资源
|
||||
|
||||

|
||||
|
||||
### 简介
|
||||
|
||||
这篇文章中下面的链接提供了一个 BPF 的基本的概述,或者,一些与它密切相关的一些主题。如果你对 BPF 非常陌生,你可以在这些介绍文章中挑选出一篇你喜欢的文章去阅读。如果你已经理解了 BPF,你可以针对特定的主题去阅读,下面是阅读清单。
|
||||
|
||||
### 关于 BPF
|
||||
|
||||
关于 eBPF 的简介:
|
||||
|
||||
* [_利用 BPF 和 XDP 实现可编程的内核网络数据路径_][53] (Daniel Borkmann, OSSNA17, Los Angeles, September 2017):
|
||||
快速理解所有的关于 eBPF 和 XDP 的基础概念的许多文章中的一篇(大多数是关于网络处理的)
|
||||
|
||||
* [BSD 包过滤器][54] (Suchakra Sharma, June 2017):
|
||||
一篇非常好的介绍文章,大多数是关于跟踪方面的。
|
||||
|
||||
* [_BPF:跟踪及更多_][55] (Brendan Gregg, January 2017):
|
||||
大多数内容是跟踪使用案例相关的。
|
||||
|
||||
* [_Linux BPF 的超强功能_][56] (Brendan Gregg, March 2016):
|
||||
第一部分是关于 **火焰图(flame graphs)** 的使用。
|
||||
|
||||
* [_IO Visor_][57] (Brenden Blanco, SCaLE 14x, January 2016):
|
||||
介绍了 **IO Visor 项目**。
|
||||
|
||||
* [_大型机上的 eBPF_][58] (Michael Holzheu, LinuxCon, Dubin, October 2015)
|
||||
|
||||
* [_在 Linux 上新的(令人激动的)跟踪新产品_][59] (Elena Zannoni, LinuxCon, Japan, 2015)
|
||||
|
||||
* [_BPF — 内核中的虚拟机_][60] (Alexei Starovoitov, February 2015):
|
||||
eBPF 的作者写的一篇介绍文章。
|
||||
|
||||
* [_扩展 extended BPF_][61] (Jonathan Corbet, July 2014)
|
||||
|
||||
**BPF 内部结构**:
|
||||
|
||||
* Daniel Borkmann 正在做的一项令人称奇的工作,它用于去展现 eBPF 的 **内部结构**,特别是通过几次关于 **eBPF 用于 tc ** 的演讲和论文。
|
||||
* [_使用 tc 的 cls_bpf 的高级可编程和它的最新更新_][30] (netdev 1.2, Tokyo, October 2016):
|
||||
Daniel 介绍了 eBPF 的细节,它使用了隧道和封装、直接包访问、和其它特性。
|
||||
|
||||
* [_自 netdev 1.1 以来的 cls_bpf/eBPF 更新_][31] (netdev 1.2, Tokyo, October 2016, part of [this tc workshop][32])
|
||||
|
||||
* [_使用 cls_bpf 实现完全可编程的 tc 分类器_][33] (netdev 1.1, Sevilla, February 2016):
|
||||
介绍 eBPF 之后,它提供了许多 BPF 内部机制(映射管理、tail 调用、校验器)的见解。对于大多数有志于 BPF 的人来说,这是必读的![全文在这里][34]。
|
||||
|
||||
* [_Linux tc 和 eBPF_][35] (fosdem16, Brussels, Belgium, January 2016)
|
||||
|
||||
* [_eBPF 和 XDP 攻略和最新更新_][36] (fosdem17, Brussels, Belgium, February 2017)
|
||||
|
||||
这些介绍可能是理解 eBPF 内部机制设计与实现的最佳文档资源之一。
|
||||
|
||||
[**IO Visor 博客**][157] 有一些关于 BPF 感兴趣的技术文章。它们中的一些包含了许多营销讨论。
|
||||
|
||||
**内核跟踪**:总结了所有的已有的方法,包括 BPF:
|
||||
|
||||
* [_邂逅 eBPF 和内核跟踪_][62] (Viller Hsiao, July 2016):
|
||||
Kprobes、uprobes、ftrace
|
||||
|
||||
* [_Linux 内核跟踪_][63] (Viller Hsiao, July 2016):
|
||||
Systemtap、Kernelshark、trace-cmd、LTTng、perf-tool、ftrace、hist-trigger、perf、function tracer、tracepoint、kprobe/uprobe …
|
||||
|
||||
关于 **事件跟踪和监视**,Brendan Gregg 使用 eBPF 的一些心得,它使用 eBPFR 的一些案例,他做的非常出色。如果你正在做一些内核跟踪方面的工作,你应该去看一下他的关于 eBPF 和火焰图相关的博客文章。其中的大多数都可以 [从这篇文章中][158] 访问,或者浏览他的博客。
|
||||
|
||||
介绍 BPF,也介绍 **Linux 网络的一般概念**:
|
||||
|
||||
* [_Linux 网络详解_][64] (Thomas Graf, LinuxCon, Toronto, August 2016)
|
||||
|
||||
* [_内核网络攻略_][65] (Thomas Graf, LinuxCon, Seattle, August 2015)
|
||||
|
||||
**硬件 offload**(译者注:offload 是指原本由软件来处理的一些操作交由硬件来完成,以提升吞吐量,降低 CPU 负荷。):
|
||||
|
||||
* eBPF 与 tc 或者 XDP 一起支持硬件 offload,开始于 Linux 内核版本 4.9,并且由 Netronome 提出的。这里是关于这个特性的介绍:[eBPF/XDP hardware offload to SmartNICs][147] (Jakub Kicinski 和 Nic Viljoen, netdev 1.2, Tokyo, October 2016)
|
||||
|
||||
关于 **cBPF**:
|
||||
|
||||
* [_BSD 包过滤器:一个用户级包捕获的新架构_][66] (Steven McCanne 和 Van Jacobson, 1992):
|
||||
它是关于(classic)BPF 的最早的论文。
|
||||
|
||||
* [关于 BPF 的 FreeBSD 手册][67] 是理解 cBPF 程序的可用资源。
|
||||
|
||||
* 关于 cBPF,Daniel Borkmann 实现的至少两个演示,[一是,在 2013 年 mmap 中,BPF 和 Netsniff-NG][68],以及 [在 2014 中关于 tc 和 cls_bpf 的的一个非常完整的演示][69]。
|
||||
|
||||
* 在 Cloudflare 的博客上,Marek Majkowski 提出的它的 [BPF 字节码与 **iptables** 的 `xt_bpf` 模块一起的应用][70]。值得一提的是,从 Linux 内核 4.10 开始,eBPF 也是通过这个模块支持的。(虽然,我并不知道关于这件事的任何讨论或者文章)
|
||||
|
||||
* [Libpcap 过滤器语法][71]
|
||||
|
||||
### 关于 XDP
|
||||
|
||||
* 在 IO Visor 网站上的 [XDP 概述][72]。
|
||||
|
||||
* [_eXpress Data Path (XDP)_][73] (Tom Herbert, Alexei Starovoitov, March 2016):
|
||||
这是第一个关于 XDP 的演示。
|
||||
|
||||
* [_BoF - BPF 能为你做什么?_][74] (Brenden Blanco, LinuxCon, Toronto, August 2016)。
|
||||
|
||||
* [_eXpress Data Path_][148] (Brenden Blanco, Linux Meetup at Santa Clara, July 2016):
|
||||
包含一些(有点营销的意思?)**benchmark 结果**!使用一个单核心:
|
||||
* ip 路由丢弃: ~3.6 百万包每秒(Mpps)
|
||||
|
||||
* 使用 BPF,tc(使用 clsact qdisc)丢弃: ~4.2 Mpps
|
||||
|
||||
* 使用 BPF,XDP 丢弃:20 Mpps (CPU 利用率 < 10%)
|
||||
|
||||
* XDP 重写转发(在端口上它接收到的包):10 Mpps
|
||||
|
||||
(测试是用 mlx4 驱动执行的)。
|
||||
|
||||
* Jesper Dangaard Brouer 有几个非常好的幻灯片,它可以从本质上去理解 XDP 的内部结构。
|
||||
* [_XDP − eXpress Data Path, Intro and future use-cases_][37] (September 2016):
|
||||
_“Linux 内核与 DPDK 的斗争”_ 。**未来的计划**(在写这篇文章时)它用 XDP 和 DPDK 进行比较。
|
||||
|
||||
* [_网络性能研讨_][38] (netdev 1.2, Tokyo, October 2016):
|
||||
关于 XDP 内部结构和预期演化的附加提示。
|
||||
|
||||
* [_XDP – eXpress Data Path, 可用于 DDoS 防护_][39] (OpenSourceDays, March 2017):
|
||||
包含了关于 XDP 的详细情况和使用案例、用于 **benchmarking** 的 **benchmark 结果**、和 **代码片断**,以及使用 eBPF/XDP(基于一个 IP 黑名单模式)的用于 **基本的 DDoS 防护**。
|
||||
|
||||
* [_内存 vs. 网络,激发和修复内存瓶颈_][40] (LSF Memory Management Summit, March 2017):
|
||||
面对 XDP 开发者提出关于当前 **内存问题** 的许多细节。不要从这一个开始,如果你已经理解了 XDP,并且想去了解它在页面分配方面的真实工作方式,这是一个非常有用的资源。
|
||||
|
||||
* [_XDP 能为其它人做什么_][41](netdev 2.1, Montreal, April 2017),with Andy Gospodarek:
|
||||
对于普通人使用 eBPF 和 XDP 怎么去开始。这个演示也由 Julia Evans 在 [他的博客][42] 上做了总结。
|
||||
|
||||
( Jesper 也创建了并且尝试去扩展了有关 eBPF 和 XDP 的一些文档,查看 [相关节][75]。)
|
||||
|
||||
* [_XDP 研讨 — 介绍、体验、和未来发展_][76](Tom Herbert, netdev 1.2, Tokyo, October 2016) — 在这篇文章中,只有视频可用,我不知道是否有幻灯片。
|
||||
|
||||
* [_在 Linux 上进行高速包过滤_][149] (Gilberto Bertin, DEF CON 25, Las Vegas, July 2017) — 在 Linux 上的最先进的包过滤的介绍,面向 DDoS 的保护、讨论了关于在内核中进行包处理、内核旁通、XDP 和 eBPF。
|
||||
|
||||
### 关于 基于 eBPF 或者 eBPF 相关的其它组件
|
||||
|
||||
* [_在边缘上的 P4_][77] (John Fastabend, May 2016):
|
||||
提出了使用 **P4**,一个包处理的描述语言,使用 BPF 去创建一个高性能的可编程交换机。
|
||||
|
||||
* 如果你喜欢音频的介绍,这里有一个相关的 [OvS Orbit 片断(#11),叫做 _在边缘上的 **P4**_][78],日期是 2016 年 8 月。OvS Orbit 是对 Ben Pfaff 的访谈,它是 Open vSwitch 的其中一个核心维护者。在这个场景中,John Fastabend 是被访谈者。
|
||||
|
||||
* [_P4, EBPF 和 Linux TC Offload_][79] (Dinan Gunawardena and Jakub Kicinski, August 2016):
|
||||
另一个演示 **P4** 的,使用一些相关的元素在 Netronome 的 **NFP**(网络流处理器)架构上去实现 eBPF 硬件 offload。
|
||||
|
||||
* **Cilium** 是一个由 Cisco 最先发起的技术,它依赖 BPF 和 XDP 去提供 “在容器中基于 eBPF 程序,在运行中生成的强制实施的快速的内核中的网络和安全策略”。[这个项目的代码][150] 在 GitHub 上可以访问到。Thomas Graf 对这个主题做了很多的演示:
|
||||
* [_Cilium: 对容器利用 BPF & XDP 实现网络 & 安全_][43],也特别展示了一个负载均衡的使用案例(Linux Plumbers conference, Santa Fe, November 2016)
|
||||
|
||||
* [_Cilium: 对容器利用 BPF & XDP 实现网络 & 安全_][44] (Docker Distributed Systems Summit, October 2016 — [video][45])
|
||||
|
||||
* [_Cilium: 使用 BPF 和 XDP 的快速 IPv6 容器网络_][46] (LinuxCon, Toronto, August 2016)
|
||||
|
||||
* [_Cilium: 为窗口使用 BPF & XDP_][47] (fosdem17, Brussels, Belgium, February 2017)
|
||||
|
||||
在不同的演示中重复了大量的内容;如果有疑问,就选最近的一个。Daniel Borkmann 作为 Google 开源博客的特邀作者,也写了 [Cilium 简介][80]。
|
||||
|
||||
* 这里也有一个关于 **Cilium** 的播客节目:一个 [OvS Orbit episode (#4)][81],它是 Ben Pfaff 访谈 Thomas Graf (2016 年 5 月),和 [另外一个 Ivan Pepelnjak 的播客][82],仍然是 Thomas Graf 的与 eBPF、P4、XDP 和 Cilium (2016 年 10 月)。
|
||||
|
||||
* **Open vSwitch** (OvS),它是 **Open Virtual Network**(OVN,一个开源的网络虚拟化解决方案)相关的项目,正在考虑在不同的层次上使用 eBPF,它已经实现了几个概念验证原型:
|
||||
|
||||
* [使用 eBPF 的 Offloading OVS 流处理器][48] (William (Cheng-Chun) Tu, OvS conference, San Jose, November 2016)
|
||||
|
||||
* [将 OVN 的灵活性与 IOVisor 的高效率相结合][49] (Fulvio Risso, Matteo Bertrone and Mauricio Vasquez Bernal, OvS conference, San Jose, November 2016)
|
||||
|
||||
据我所知,这些 eBPF 的使用案例看上去仅处于提议阶段(并没有合并到 OvS 的主分支中),但是,看它带来了什么将是非常有趣的事情。
|
||||
|
||||
* XDP 的设计对分布式拒绝访问(DDoS)攻击是非常有用的。越来越多的演示都关注于它。例如,从 Cloudflare 中的人们的讨论([_XDP in practice: integrating XDP in our DDoS mitigation pipeline_][83])或者从 Facebook 上([_Droplet: DDoS countermeasures powered by BPF + XDP_][84])在 netdev 2.1 会议上,在 Montreal、Canada、在 2017 年 4 月,都存在这样的很多使用案例。
|
||||
|
||||
* [_CETH for XDP_][85] (Yan Chan 和 Yunsong Lu、Linux Meetup、Santa Clara、July 2016):
|
||||
**CETH**,是由 Mellanox 发起的,为实现更快的网络 I/O 而主张的通用以太网驱动程序架构。
|
||||
|
||||
* [**VALE 交换机**][86],另一个虚拟交换机,它可以与 netmap 框架结合,有 [一个 BPF 扩展模块][87]。
|
||||
|
||||
* **Suricata**,一个开源的入侵检测系统,它的捕获旁通特性 [似乎是依赖于 eBPF 组件][88]:
|
||||
[_The adventures of a Suricate in eBPF land_][89] (Éric Leblond, netdev 1.2, Tokyo, October 2016)
|
||||
[_eBPF and XDP seen from the eyes of a meerkat_][90] (Éric Leblond, Kernel Recipes, Paris, September 2017)
|
||||
|
||||
* [InKeV: 对于 DCN 的内核中分布式网络虚拟化][91] (Z. Ahmed, M. H. Alizai and A. A. Syed, SIGCOMM, August 2016):
|
||||
**InKeV** 是一个基于 eBPF 的虚拟网络、目标数据中心网络的数据路径架构。它最初由 PLUMgrid 提出,并且声称相比基于 OvS 的 OpenStack 解决方案可以获得更好的性能。
|
||||
|
||||
* [_**gobpf** - 从 Go 中利用 eBPF_][92] (Michael Schubert, fosdem17, Brussels, Belgium, February 2017):
|
||||
“一个从 Go 中的库,可以去创建、加载和使用 eBPF 程序”
|
||||
|
||||
* [**ply**][93] 是为 Linux 实现的一个小的但是非常灵活的开源动态 **跟踪器**,它的一些特性非常类似于 bcc 工具,是受 awk 和 dtrace 启发,但使用一个更简单的语言。它是由 Tobias Waldekranz 写的。
|
||||
|
||||
* 如果你读过我以前的文章,你可能对我在这篇文章中的讨论感兴趣,[使用 eBPF 实现 OpenState 接口][151],关于包状态处理,在 fosdem17 中。
|
||||
|
||||

|
||||
|
||||
### 文档
|
||||
|
||||
一旦你对 BPF 是做什么的有一个大体的理解。你可以抛开一般的演示而深入到文档中了。下面是 BPF 的规范和功能的最全面的文档,按你的需要挑一个开始阅读吧!
|
||||
|
||||
### 关于 BPF
|
||||
|
||||
* **BPF 的规范**(包含 classic 和 extended 版本)可以在 Linux 内核的文档中,和特定的文件 [linux/Documentation/networking/filter.txt][94] 中找到。BPF 使用以及它的内部结构也被记录在那里。此外,当加载 BPF 代码失败时,在这里可以找到 **被校验器抛出的错误信息**,这有助于你排除不明确的错误信息。
|
||||
|
||||
* 此外,在内核树中,在 eBPF 那里有一个关于 **常见的问 & 答** 的文档,它在文件 [linux/Documentation/bpf/bpf_design_QA.txt][95] 中。
|
||||
|
||||
* … 但是,内核文档是非常难懂的,并且非常不容易阅读。如果你只是去查找一个简单的 eBPF 语言的描述,可以去 IO Visor 的 GitHub 仓库,那儿有 [它的 **概括性描述**][96]。
|
||||
|
||||
* 顺便说一下,IO Visor 项目收集了许多 **关于 BPF 的资源**。大部分,分别在 bcc 仓库的 [文档目录][97] 中,和 [bpf-docs 仓库][98] 的整个内容中,它们都在 GitHub 上。注意,这个非常好的 [BPF **参考指南**][99] 包含一个详细的 BPF C 和 bcc Python 的 helper 的描述。
|
||||
|
||||
* 想深入到 BPF,那里有一些必要的 **Linux 手册页**。第一个是 [`bpf(2)` man page][100] 关于 `bpf()` **系统调用**,它用于从用户空间去管理 BPF 程序和映射。它也包含一个 BPF 高级特性的描述(程序类型、映射、等等)。第二个是主要去处理希望去附加到 tc 接口的 BPF 程序:它是 [`tc-bpf(8)` man page][101],它是 **使用 BPF 和 tc** 的一个参考,并且包含一些示例命令和参考代码。
|
||||
|
||||
* Jesper Dangaard Brouer 发起了一个 **更新 eBPF Linux 文档** 的尝试,包含 **不同的映射**。[他有一个草案][102],欢迎去贡献。一旦完成,这个文档将被合并进 man 页面并且进入到内核文档。
|
||||
|
||||
* Cilium 项目也有一个非常好的 [**BPF 和 XDP 参考指南**][103],它是由核心的 eBPF 开发者写的,它被证明对于 eBPF 开发者是极其有用的。
|
||||
|
||||
* David Miller 在 [xdp-newbies][152] 邮件列表中发了几封关于 eBPF/XDP 内部结构的富有启发性的电子邮件。我找不到一个单独的地方收集它们的链接,因此,这里是一个列表:
|
||||
|
||||
* [bpf.h 和你 …][50]
|
||||
|
||||
* [Contextually speaking…][51]
|
||||
|
||||
* [BPF 校验器概述][52]
|
||||
|
||||
最后一个可能是目前来说关于校验器的最佳的总结。
|
||||
|
||||
* Ferris Ellis 发布的 [一个关于 **eBPF 的系列博客文章**][104]。作为我写的这个短文,第一篇文章是关于 eBPF 的历史背景和未来期望。接下来的文章将更多的是技术方面,和前景展望。
|
||||
|
||||
* [一个 **每个内核版本的 BPF 特性列表**][153] 在 bcc 仓库中可以找到。如果你想去知道运行一个给定的特性所要求的最小的内核版本,它是非常有用的。我贡献和添加了链接到提交中,它介绍了每个特性,因此,你也可以从那里很容易地去访问提交历史。
|
||||
|
||||
### 关于 tc
|
||||
|
||||
当为了网络目的使用 BPF 与 tc 进行结合时,Linux 流量控制(**t**raffic **c**ontrol)工具,它可用于去采集关于 tc 的可用功能的信息。这里有几个关于它的资源。
|
||||
|
||||
* 找到关于 **Linux 上 QoS** 的简单教程是很困难的。这里有两个链接,它们很长而且很难懂,但是,如果你可以抽时间去阅读它,你将学习到几乎关于 tc 的任何东西(虽然,关于 BPF 它什么也没有)。它们在这里:[_怎么去实现流量控制_ (Martin A. Brown, 2006)][105],和 [_怎么去实现 Linux 的高级路由 & 流量控制_ (“LARTC”) (Bert Hubert & al., 2002)][106]。
|
||||
|
||||
* 在你的系统上的 **tc 手册页面** 并不是最新日期的,因为它们中的几个最近已经增加了。如果你没有找到关于特定的队列规则、分类或者过滤器的文档,它可能在最新的 [tc 组件的手册页面][107] 中。
|
||||
|
||||
* 一些额外的材料可以在 iproute2 包自已的文件中找到:这个包中有 [一些文档][108],包括一些文件,它可以帮你去理解 [**tc 的 action** 的功能][109]。
|
||||
**注意:** 这些文件在 2017 年 10 月 已经从 iproute2 中删除,然而,从 Git 历史中却一直可用。
|
||||
|
||||
* 非精确资料:这里是 [一个关于 tc 的几个特性的研讨会][110](包含过滤、BPF、tc offload、…) 由 Jamal Hadi Salim 在 netdev 1.2 会议上组织的(October 2016)。
|
||||
|
||||
* 额外信息 — 如果你使用 `tc` 较多,这里有一些好消息:我用这个工具 [写了一个 bash 完整的功能][111],并且它被包 iproute2 带到内核版本 4.6 和更高版中!
|
||||
|
||||
### 关于 XDP
|
||||
|
||||
* 对于 XDP 的一些 [进展中的文档(包括规范)][112] 已经由 Jesper Dangaard Brouer 启动,并且意味着将成为一个合作的工作。正在推进(2016 年 9 月):你期望它去改变,并且或许在一些节点上移动(Jesper [称为贡献][113],如果你想去改善它)。
|
||||
|
||||
* 自来 Cilium 项目的 [BPF 和 XDP 参考指南][114] … 好吧,这个名字已经说明了一切。
|
||||
|
||||
### 关于 P4 和 BPF
|
||||
|
||||
[P4][159] 是一个用于指定交换机行为的语言。它可以被编译为许多种目标硬件或软件。因此,你可能猜到了,这些目标中的一个就是 BPF … 仅部分支持的:一些 P4 特性并不能被转化到 BPF 中,并且,用类似的方法,BPF 可以做的事情,而使用 P4 却不能表达出现。不过,**P4 与 BPF 使用** 的相关文档,[用于去隐藏在 bcc 仓库中][160]。这个改变在 P4_16 版本中,p4c 引用的编辑器包含 [一个 eBPF 后端][161]。
|
||||
|
||||

|
||||
|
||||
### 教程
|
||||
|
||||
Brendan Gregg 为想去 **使用 bcc 工具** 跟踪和监视内核中的事件的人制作了一个非常好的 **教程**。[第一个教程是关于如何使用 bcc 工具][162],它总共有十一步,教你去理解怎么去使用已有的工具,而 [**针对 Python 开发者** 的一个目标][163] 是专注于开发新工具,它总共有十七节 “课程”。
|
||||
|
||||
Sasha Goldshtein 也有一些 [_**Linux 跟踪研究材料**_][164] 涉及到使用几个 BPF 去进行跟踪。
|
||||
|
||||
作者为 Jean-Tiare Le Bigot 的文章为 ping 请求和回复,提供了一个详细的(和有指导意义的)[使用 perf 和 eBPF 去设置一个低级的跟踪器][165] 的示例。
|
||||
|
||||
对于网络相关的 eBPF 使用案例也有几个教程。那里有一些有趣的文档,包含一个 _eBPF Offload 入门指南_,由 Netronome 在 [Open NFP][166] 平台上操作的。其它的那些,来自 Jesper 的演讲,[_XDP 能为其它人做什么_][167],可能是 XDP 入门的最好的方法之一。
|
||||
|
||||

|
||||
|
||||
### 示例
|
||||
|
||||
有示例是非常好的。看看它们是如何工作的。但是 BPF 程序示例是分散在几个项目中的,因此,我列出了我所知道的所有的示例。示例并不是使用相同的 helper(例如,tc 和 bcc 都有一套它们自己的 helper,使它可以很容易地去用 C 语言写 BPF 程序)
|
||||
|
||||
### 来自内核的示例
|
||||
|
||||
主要的程序类型都包含在内核的示例中:过滤器绑定到套接字或者到 tc 接口、事件跟踪/监视、甚至是 XDP。你可以在 [linux/samples/bpf/][168] 目录中找到这些示例。
|
||||
|
||||
也不要忘记去看一下 git 相关的提交历史,它们有一些指定的特性的介绍,它们也包含一些特性的详细的示例。
|
||||
|
||||
### 来自包 iproute2 的示例
|
||||
|
||||
iproute2 包也提供了几个示例。它们都很明显地偏向网络编程,因此,这个程序是附加到 tc ingress 或者 egress 接口上。这些示例在 [iproute2/examples/bpf/][169] 目录中。
|
||||
|
||||
### 来自 bcc 工具集的示例
|
||||
|
||||
许多示例都 [与 bcc 一起提供][170]:
|
||||
|
||||
* 一些网络编程的示例在关联的目录下面。它们包括套接字过滤器、tc 过滤器、和一个 XDP 程序。
|
||||
|
||||
* `tracing` 目录包含许多 **跟踪编程** 的示例。前面的教程中提到的都在那里。那些程序涉及了事件跟踪的很大的一个范围,并且,它们中的一些是面向生产系统的。注意,某些 Linux 分发版(至少是 Debian、Ubuntu、Fedora、Arch Linux)、这些程序已经被 [打包了][115] 并且可以很 “容易地” 通过比如 `# apt install bcc-tools` 进行安装。但是在写这篇文章的时候(除了 Arch Linux),第一个要求是去安装 IO Visor 的包仓库。
|
||||
|
||||
* 那里也有 **使用 Lua** 作为一个不同的 BPF 后端(那是因为 BPF 程序是用 Lua 写的,它是 C 语言的一个子集,它允许为前端和后端使用相同的语言)的一些示例,它在第三个目录中。
|
||||
|
||||
### 手册页面
|
||||
|
||||
虽然 bcc 一般可以用很容易的方式在内核中去注入和运行一个 BPF 程序,通过 `tc` 工具去将程序附加到 tc 接口也可以被执行。因此,如果你打算将 **BPF 与 tc 一起使用**,你可以在 [`tc-bpf(8)` 手册页面][171] 中找到一些调用示例。
|
||||
|
||||

|
||||
|
||||
### 代码
|
||||
|
||||
有时候,BPF 文档或者示例并不足够多,而且你可能没有其它的方式在你喜欢的文本编辑器(它当然应该是 Vim)中去显示代码并去阅读它。或者,你可能深入到代码中想去做一个补丁程序或者为机器增加一些新特性。因此,这里对有关的文件的几个建议,找到你想要的功能取决于你自己!
|
||||
|
||||
### 在内核中的 BPF 代码
|
||||
|
||||
* 文件 [linux/include/linux/bpf.h][116] 和它的副本 [linux/include/uapi/bpf.h][117] 包含有关 eBPF 的 **定义**,它分别被内核中和用户空间程序的接口使用。
|
||||
|
||||
* 相同的方式,文件 [linux/include/linux/filter.h][118] 和 [linux/include/uapi/filter.h][119] 包含的信息被 **运行的 BPF 程序** 使用。
|
||||
|
||||
* BPF 相关的 **主要的代码片断** 在 [linux/kernel/bpf/][120] 目录下面。**被系统以不同的操作许可调用** 比如,程序加载或者映射管理是在文件 `syscall.c` 中实现,虽然 `core.c` 包含在 **解析器** 中。其它的文件有明显的命名:`verifier.c` 包含在 **校验器** 中(不是开玩笑的),`arraymap.c` 的代码用于与阵列类型的 **映射** 去互动,等等。
|
||||
|
||||
* **helpers**,以及几个网络(与 tc、XDP 一起)和用户可用的相关功能是实现在 [linux/net/core/filter.c][121] 中。它也包含代码去移植 cBPF 字节码到 eBPF 中(因为在运行之前,内核中的所有的 cBPF 程序被转换成 eBPF)
|
||||
|
||||
* **JIT 编译器** 在它们各自的架构目录下面,比如,x86 架构的在 [linux/arch/x86/net/bpf_jit_comp.c][122] 中。
|
||||
|
||||
* 在 [linux/net/sched/][123] 目录下,你可以找到 **tc 的 BPF 组件** 相关的代码,尤其是在文件 `act_bpf.c` (action)和 `cls_bpf.c`(filter)中。
|
||||
|
||||
* 我并没有在 BPF 上深入到 **事件跟踪** 中,因此,我并不真正了解这些程序的钩子。在 [linux/kernel/trace/bpf_trace.c][124] 那里有一些东西。如果你对它感 兴趣,并且想去了解更多,你可以在 Brendan Gregg 的演示或者博客文章上去深入挖掘。
|
||||
|
||||
* 我也没有使用过 **seccomp-BPF**。但它的代码在 [linux/kernel/seccomp.c][125],并且可以在 [linux/tools/testing/selftests/seccomp/seccomp_bpf.c][126] 中找到一些它的使用示例。
|
||||
|
||||
### XDP 钩子代码
|
||||
|
||||
一旦将 BPF 虚拟机加载进内核,由一个 Netlink 命令将 **XDP** 程序从用户空间钩入到内核网络路径中。接收它的是在 [linux/net/core/dev.c][172] 文件中的被调用的 `dev_change_xdp_fd()` 函数,并且由它设置一个 XDP 钩子。比如,钩子位于在 NICs 支持的驱动中。例如,为一些 Mellanox 硬件使用的 mlx4 驱动的钩子实现在 [drivers/net/ethernet/mellanox/mlx4/][173] 目录下的文件中。文件 en_netdev.c 接收 Netlink 命令并调用 `mlx4_xdp_set()`,它再被在文件 en_rx.c 实现的实例 `mlx4_en_process_rx_cq()` 调用(对于 RX 侧)。
|
||||
|
||||
### 在 bcc 中的 BPF 逻辑
|
||||
|
||||
[在 bcc 的 GitHub 仓库][174] 上找到的 **bcc** 工具集的其中一个代码。**Python 代码**,包含在 `BPF` 类中,最初它在文件 [bcc/src/python/bcc/__init__.py][175] 中。但是许多感兴趣的东西 — 我的意见是 — 比如,加载 BPF 程序到内核中,碰巧在 [libbcc 的 **C 库**][176]中。
|
||||
|
||||
### 使用 tc 去管理 BPF 的代码
|
||||
|
||||
**在 tc** 中与 iproute2 包中一起带来的与 BPF 相关的代码。其中的一些在 [iproute2/tc/][177] 目录中。文件 f_bpf.c 和 m_bpf.c(和 e_bpf.c)是各自用于处理 BPF 的过滤器和动作的(和tc `exec` 命令,或许什么命令都可以)。文件 q_clsact.c 定义了 `clsact`,qdisc 是为 BPF 特别创建的。但是,**大多数的 BPF 用户空间逻辑** 是在 [iproute2/lib/bpf.c][178] 库中实现的,因此,如果你想去使用 BPF 和 tc,这里可能是会将你搞混乱的地方(它是从文件 iproute2/tc/tc_bpf.c 中来的,你也可以在旧版本的包中找到代码相同的地方)。
|
||||
|
||||
### BPF 实用工具
|
||||
|
||||
内核中也带有 BPF 相关的三个工具的源代码(`bpf_asm.c`, `bpf_dbg.c`, `bpf_jit_disasm.c`)、根据你的版本不同,在 [linux/tools/net/][179] 或者 [linux/tools/bpf/][180] 目录下面:
|
||||
|
||||
* `bpf_asm` 是一个极小的汇编程序。
|
||||
|
||||
* `bpf_dbg` 是一个很小的 cBPF 程序调试器。
|
||||
|
||||
* `bpf_jit_disasm` 对于两种 BPF 都是通用的,并且对于 JIT 调试来说非常有用。
|
||||
|
||||
* `bpftool` 是由 Jakub Kicinski 写的通用工具,并且它可以与 eBPF 程序和来自用户空间的映射进行交互,例如,去展示、转储、pin 程序、或者去展示、创建、pin、更新、删除映射。
|
||||
|
||||
阅读在源文件顶部的注释可以得到一个它们使用方法的概述。
|
||||
|
||||
### 其它感兴趣的 chunks
|
||||
|
||||
如果你对关于 BPF 的不常见的语言的使用感兴趣,bcc 包含 [一个为 BPF 目标的 **P4 编译器**][181]以及 [一个 **Lua 前端**][182],它可以被使用,它以代替 C 的一个子集,并且(在 Lua 的案例中)可以用于 Python 工具。
|
||||
|
||||
### LLVM 后端
|
||||
|
||||
在 [这个提交][183] 中,clang / LLVM 用于将 C 编译成 BPF 后端,将它添加到 LLVM 源(也可以在 [the GitHub mirror][184] 上访问)。
|
||||
|
||||
### 在用户空间中运行
|
||||
|
||||
到目前为止,我知道那里有至少两种 eBPF 用户空间实现。第一个是 [uBPF][185],它是用 C 写的。它包含一个解析器、一个 x86_64 架构的 JIT 编译器、一个汇编器和一个反汇编器。
|
||||
|
||||
uBPF 的代码似乎被重用了,去产生了一个 [通用实现][186],claims 支持 FreeBSD 内核、FreeBSD 用户空间、Linux 内核、Linux 用户空间和 Mac OSX 用户空间。它被 [VALE 交换机的 BPF 扩展模块][187]使用。
|
||||
|
||||
其它用户空间的实现是我做的:[rbpf][188],基于 uBPF,但是用 Rust 写的。写了解析器和 JIT 编译器 (Linux 下两个都有,Mac OSX 和 Windows 下仅有解析器),以后可能会有更多。
|
||||
|
||||
### 提交日志
|
||||
|
||||
正如前面所说的,如果你希望得到更多的关于它的信息,不要犹豫,去看一些提交日志,它介绍了一些特定的 BPF 特性。你可以在许多地方搜索日志,比如,在 [git.kernel.org][189]、[在 GitHub 上][190]、或者如果你克隆过它还有你的本地仓库中。如果你不熟悉 git,你可以尝试像这些去做 `git blame <file>` 去看看介绍特定代码行的提交内容,然后,`git show <commit>` 去看详细情况(或者在 `git log` 的结果中按关键字搜索,但是这样做通常比较单调乏味)也可以看在 bcc 仓库中的 [按内核版本区分的 eBPF 特性列表][191],它链接到相关的提交上。
|
||||
|
||||

|
||||
|
||||
### 排错
|
||||
|
||||
对 eBPF 的狂热是最近的事情,因此,到目前为止我还找不到许多关于怎么去排错的资源。所以这里只有几个,在使用 BPF 进行工作的时候,我对自己遇到的问题进行了记录。
|
||||
|
||||
### 编译时的错误
|
||||
|
||||
* 确保你有一个最新的 Linux 内核版本(也可以看 [这个文档][127])。
|
||||
|
||||
* 如果你自己编译内核:确保你安装了所有正确的组件,包括内核镜像、头文件和 libc。
|
||||
|
||||
* 当使用 `tc-bpf`(用于去编译 C 代码到 BPF 中)的 man 页面提供的 `bcc` shell 函数时:我只是添加包含 clang 调用的头部:
|
||||
|
||||
```
|
||||
__bcc() {
|
||||
clang -O2 -I "/usr/src/linux-headers-$(uname -r)/include/" \
|
||||
-I "/usr/src/linux-headers-$(uname -r)/arch/x86/include/" \
|
||||
-emit-llvm -c $1 -o - | \
|
||||
llc -march=bpf -filetype=obj -o "`basename $1 .c`.o"
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
(seems fixed as of today).
|
||||
|
||||
* 对于使用 `bcc` 的其它问题,不要忘了去看一看这个工具集的 [答疑][128]。
|
||||
|
||||
* 如果你从一个并不精确匹配你的内核版本的 iproute2 包中下载了示例,可能会通过在文件中包含的头文件触发一些错误。这些示例片断都假设安装在你的系统中内核的头文件与 iproute2 包是相同版本的。如果不是这种情况,下载正确的 iproute2 版本,或者编辑示例中包含的文件的路径,指向到 iproute2 中包含的头文件上(在运行时一些问题可能或者不可能发生,取决于你使用的特性)。
|
||||
|
||||
### 在加载和运行时的错误
|
||||
|
||||
* 使用 tc 去加载一个程序,确保你使用了一个与使用中的内核版本等价的 iproute2 中的 tc 二进制文件。
|
||||
|
||||
* 使用 bcc 去加载一个程序,确保在你的系统上安装了 bcc(仅下载源代码去运行 Python 脚本是不够的)。
|
||||
|
||||
* 使用 tc,如果 BPF 程序不能返回一个预期值,检查调用它的方式:过滤器、或者动作、或者使用 “直接传动” 模式的过滤器。
|
||||
|
||||
* 静态使用 tc,注意不使用过滤器,动作不会直接附加到 qdiscs 或者接口。
|
||||
|
||||
* 通过内核校验器抛出错误到解析器可能很难。[内核文档][129]或许可以提供帮助,因此,可以 [参考指南][130] 或者,万不得一的情况下,可以去看源代码(祝你好运!)。记住,校验器 _不运行_ 程序,对于这种类型的错误,它也是非常重要的。如果你得到一个关于无效内存访问或者关于未初始化的数据的错误,它并不意味着那些问题真实发生了(或者有时候,它们完全有可能发生)。它意味着你的程序是以校验器预计可能发生错误的方式写的,并且因此而拒绝这个程序。
|
||||
|
||||
* 注意 `tc` 工具有一个 `verbose` 模式,它与 BPF 一起工作的很好:在你的命令行尾部尝试追加一个 `verbose`。
|
||||
|
||||
* bcc 也有一个 verbose 选项:`BPF` 类有一个 `debug` 参数,它可以带 `DEBUG_LLVM_IR`、`DEBUG_BPF` 和 `DEBUG_PREPROCESSOR` 三个标志中任何组合(详细情况在 [源文件][131]中)。 为调试代码,它甚至嵌入了 [一些条件去打印输出代码][132]。
|
||||
|
||||
* LLVM v4.0+ 为 eBPF 程序 [嵌入一个反汇编器][133]。因此,如果你用 clang 编译你的程序,在编译时添加 `-g` 标志允许你通过内核校验器去以人类可读的格式去转储你的程序。处理转储文件,使用:
|
||||
|
||||
```
|
||||
$ llvm-objdump -S -no-show-raw-insn bpf_program.o
|
||||
|
||||
```
|
||||
|
||||
* 使用映射工作?你想去看 [bpf-map][134],一个为 Cilium 项目而用 Go 创建的非常有用的工具,它可以用于去转储内核中 eBPF 映射的内容。那里也有在 Rust 中的 [一个克隆][135]。
|
||||
|
||||
* 那里有一个旧的 [在 **StackOverflow** 上的 `bpf` 标签][136],但是,在这篇文章中它一直没有被使用过(并且那里几乎没有与新的 eBPF 相关的东西)。如果你是一位来自未来的阅读者,你可能想去看看在这方面是否有更多的活动。
|
||||
|
||||

|
||||
|
||||
### 更多!
|
||||
|
||||
* 如果你想很容易地去 **测试 XDP**,那是 [一个 Vagrant 设置][137] 可以使用。你也可以 **测试 bcc**[在一个 Docker 容器中][138]。
|
||||
|
||||
* 想知道围绕 BPF 的 **开发和活动** 在哪里吗?好吧,内核补丁总是结束于 [netdev 上的邮件列表][139](相关 Linux 内核的网络栈开发):以关键字 “BPF” 或者 “XDP” 来搜索。自 2017 年 4 月开始,那里也有 [一个专门用于 XDP 编程的邮件列表][140](是为了架构或者寻求帮助)。[在 IO Visor 的邮件列表上][141]也有许多的讨论和辨论,因为 BPF 是一个重要的项目。如果你只是想随时了解情况,那里也有一个 [@IOVisor Twitter 帐户][142]。
|
||||
|
||||
我经常会回到这篇博客中,来看一看 [关于 BPF][192] 有没有新的文章!
|
||||
|
||||
_特别感谢 Daniel Borkmann 指引我找到了许多的 [附加的文档][154],因此我才完成了这个合集。_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/
|
||||
|
||||
作者:[Quentin Monnet ][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://qmonnet.github.io/whirl-offload/about/
|
||||
[1]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#about-bpf
|
||||
[2]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#about-xdp
|
||||
[3]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#about-other-components-related-or-based-on-ebpf
|
||||
[4]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#about-bpf-1
|
||||
[5]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#about-tc
|
||||
[6]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#about-xdp-1
|
||||
[7]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#about-p4-and-bpf
|
||||
[8]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#from-the-kernel
|
||||
[9]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#from-package-iproute2
|
||||
[10]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#from-bcc-set-of-tools
|
||||
[11]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#manual-pages
|
||||
[12]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#bpf-code-in-the-kernel
|
||||
[13]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#xdp-·s-code
|
||||
[14]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#bpf-logic-in-bcc
|
||||
[15]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#code-to-manage-bpf-with-tc
|
||||
[16]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#bpf-utilities
|
||||
[17]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#other-interesting-chunks
|
||||
[18]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#llvm-backend
|
||||
[19]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#running-in-userspace
|
||||
[20]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#commit-logs
|
||||
[21]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#errors-at-compilation-time
|
||||
[22]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#errors-at-load-and-run-time
|
||||
[23]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#generic-presentations
|
||||
[24]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#documentation
|
||||
[25]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#tutorials
|
||||
[26]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#examples
|
||||
[27]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#the-code
|
||||
[28]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#troubleshooting
|
||||
[29]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#and-still-more
|
||||
[30]:http://netdevconf.org/1.2/session.html?daniel-borkmann
|
||||
[31]:http://netdevconf.org/1.2/slides/oct5/07_tcws_daniel_borkmann_2016_tcws.pdf
|
||||
[32]:http://netdevconf.org/1.2/session.html?jamal-tc-workshop
|
||||
[33]:http://www.netdevconf.org/1.1/proceedings/slides/borkmann-tc-classifier-cls-bpf.pdf
|
||||
[34]:http://www.netdevconf.org/1.1/proceedings/papers/On-getting-tc-classifier-fully-programmable-with-cls-bpf.pdf
|
||||
[35]:https://archive.fosdem.org/2016/schedule/event/ebpf/attachments/slides/1159/export/events/attachments/ebpf/slides/1159/ebpf.pdf
|
||||
[36]:https://fosdem.org/2017/schedule/event/ebpf_xdp/
|
||||
[37]:http://people.netfilter.org/hawk/presentations/xdp2016/xdp_intro_and_use_cases_sep2016.pdf
|
||||
[38]:http://netdevconf.org/1.2/session.html?jesper-performance-workshop
|
||||
[39]:http://people.netfilter.org/hawk/presentations/OpenSourceDays2017/XDP_DDoS_protecting_osd2017.pdf
|
||||
[40]:http://people.netfilter.org/hawk/presentations/MM-summit2017/MM-summit2017-JesperBrouer.pdf
|
||||
[41]:http://netdevconf.org/2.1/session.html?gospodarek
|
||||
[42]:http://jvns.ca/blog/2017/04/07/xdp-bpf-tutorial/
|
||||
[43]:http://www.slideshare.net/ThomasGraf5/clium-container-networking-with-bpf-xdp
|
||||
[44]:http://www.slideshare.net/Docker/cilium-bpf-xdp-for-containers-66969823
|
||||
[45]:https://www.youtube.com/watch?v=TnJF7ht3ZYc&list=PLkA60AVN3hh8oPas3cq2VA9xB7WazcIgs
|
||||
[46]:http://www.slideshare.net/ThomasGraf5/cilium-fast-ipv6-container-networking-with-bpf-and-xdp
|
||||
[47]:https://fosdem.org/2017/schedule/event/cilium/
|
||||
[48]:http://openvswitch.org/support/ovscon2016/7/1120-tu.pdf
|
||||
[49]:http://openvswitch.org/support/ovscon2016/7/1245-bertrone.pdf
|
||||
[50]:https://www.spinics.net/lists/xdp-newbies/msg00179.html
|
||||
[51]:https://www.spinics.net/lists/xdp-newbies/msg00181.html
|
||||
[52]:https://www.spinics.net/lists/xdp-newbies/msg00185.html
|
||||
[53]:http://schd.ws/hosted_files/ossna2017/da/BPFandXDP.pdf
|
||||
[54]:https://speakerdeck.com/tuxology/the-bsd-packet-filter
|
||||
[55]:http://www.slideshare.net/brendangregg/bpf-tracing-and-more
|
||||
[56]:http://fr.slideshare.net/brendangregg/linux-bpf-superpowers
|
||||
[57]:https://www.socallinuxexpo.org/sites/default/files/presentations/Room%20211%20-%20IOVisor%20-%20SCaLE%2014x.pdf
|
||||
[58]:https://events.linuxfoundation.org/sites/events/files/slides/ebpf_on_the_mainframe_lcon_2015.pdf
|
||||
[59]:https://events.linuxfoundation.org/sites/events/files/slides/tracing-linux-ezannoni-linuxcon-ja-2015_0.pdf
|
||||
[60]:https://events.linuxfoundation.org/sites/events/files/slides/bpf_collabsummit_2015feb20.pdf
|
||||
[61]:https://lwn.net/Articles/603983/
|
||||
[62]:http://www.slideshare.net/vh21/meet-cutebetweenebpfandtracing
|
||||
[63]:http://www.slideshare.net/vh21/linux-kernel-tracing
|
||||
[64]:http://www.slideshare.net/ThomasGraf5/linux-networking-explained
|
||||
[65]:http://www.slideshare.net/ThomasGraf5/linuxcon-2015-linux-kernel-networking-walkthrough
|
||||
[66]:http://www.tcpdump.org/papers/bpf-usenix93.pdf
|
||||
[67]:http://www.gsp.com/cgi-bin/man.cgi?topic=bpf
|
||||
[68]:http://borkmann.ch/talks/2013_devconf.pdf
|
||||
[69]:http://borkmann.ch/talks/2014_devconf.pdf
|
||||
[70]:https://blog.cloudflare.com/introducing-the-bpf-tools/
|
||||
[71]:http://biot.com/capstats/bpf.html
|
||||
[72]:https://www.iovisor.org/technology/xdp
|
||||
[73]:https://github.com/iovisor/bpf-docs/raw/master/Express_Data_Path.pdf
|
||||
[74]:https://events.linuxfoundation.org/sites/events/files/slides/iovisor-lc-bof-2016.pdf
|
||||
[75]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#about-xdp-1
|
||||
[76]:http://netdevconf.org/1.2/session.html?herbert-xdp-workshop
|
||||
[77]:https://schd.ws/hosted_files/2016p4workshop/1d/Intel%20Fastabend-P4%20on%20the%20Edge.pdf
|
||||
[78]:https://ovsorbit.benpfaff.org/#e11
|
||||
[79]:http://open-nfp.org/media/pdfs/Open_NFP_P4_EBPF_Linux_TC_Offload_FINAL.pdf
|
||||
[80]:https://opensource.googleblog.com/2016/11/cilium-networking-and-security.html
|
||||
[81]:https://ovsorbit.benpfaff.org/
|
||||
[82]:http://blog.ipspace.net/2016/10/fast-linux-packet-forwarding-with.html
|
||||
[83]:http://netdevconf.org/2.1/session.html?bertin
|
||||
[84]:http://netdevconf.org/2.1/session.html?zhou
|
||||
[85]:http://www.slideshare.net/IOVisor/ceth-for-xdp-linux-meetup-santa-clara-july-2016
|
||||
[86]:http://info.iet.unipi.it/~luigi/vale/
|
||||
[87]:https://github.com/YutaroHayakawa/vale-bpf
|
||||
[88]:https://www.stamus-networks.com/2016/09/28/suricata-bypass-feature/
|
||||
[89]:http://netdevconf.org/1.2/slides/oct6/10_suricata_ebpf.pdf
|
||||
[90]:https://www.slideshare.net/ennael/kernel-recipes-2017-ebpf-and-xdp-eric-leblond
|
||||
[91]:https://github.com/iovisor/bpf-docs/blob/master/university/sigcomm-ccr-InKev-2016.pdf
|
||||
[92]:https://fosdem.org/2017/schedule/event/go_bpf/
|
||||
[93]:https://wkz.github.io/ply/
|
||||
[94]:https://www.kernel.org/doc/Documentation/networking/filter.txt
|
||||
[95]:https://git.kernel.org/pub/scm/linux/kernel/git/davem/net-next.git/tree/Documentation/bpf/bpf_design_QA.txt?id=2e39748a4231a893f057567e9b880ab34ea47aef
|
||||
[96]:https://github.com/iovisor/bpf-docs/blob/master/eBPF.md
|
||||
[97]:https://github.com/iovisor/bcc/tree/master/docs
|
||||
[98]:https://github.com/iovisor/bpf-docs/
|
||||
[99]:https://github.com/iovisor/bcc/blob/master/docs/reference_guide.md
|
||||
[100]:http://man7.org/linux/man-pages/man2/bpf.2.html
|
||||
[101]:http://man7.org/linux/man-pages/man8/tc-bpf.8.html
|
||||
[102]:https://prototype-kernel.readthedocs.io/en/latest/bpf/index.html
|
||||
[103]:http://docs.cilium.io/en/latest/bpf/
|
||||
[104]:https://ferrisellis.com/tags/ebpf/
|
||||
[105]:http://linux-ip.net/articles/Traffic-Control-HOWTO/
|
||||
[106]:http://lartc.org/lartc.html
|
||||
[107]:https://git.kernel.org/cgit/linux/kernel/git/shemminger/iproute2.git/tree/man/man8
|
||||
[108]:https://git.kernel.org/pub/scm/linux/kernel/git/shemminger/iproute2.git/tree/doc?h=v4.13.0
|
||||
[109]:https://git.kernel.org/pub/scm/linux/kernel/git/shemminger/iproute2.git/tree/doc/actions?h=v4.13.0
|
||||
[110]:http://netdevconf.org/1.2/session.html?jamal-tc-workshop
|
||||
[111]:https://git.kernel.org/cgit/linux/kernel/git/shemminger/iproute2.git/commit/bash-completion/tc?id=27d44f3a8a4708bcc99995a4d9b6fe6f81e3e15b
|
||||
[112]:https://prototype-kernel.readthedocs.io/en/latest/networking/XDP/index.html
|
||||
[113]:https://marc.info/?l=linux-netdev&m=147436253625672
|
||||
[114]:http://docs.cilium.io/en/latest/bpf/
|
||||
[115]:https://github.com/iovisor/bcc/blob/master/INSTALL.md
|
||||
[116]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/include/linux/bpf.h
|
||||
[117]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/include/uapi/linux/bpf.h
|
||||
[118]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/include/linux/filter.h
|
||||
[119]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/include/uapi/linux/filter.h
|
||||
[120]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/kernel/bpf
|
||||
[121]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/net/core/filter.c
|
||||
[122]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/arch/x86/net/bpf_jit_comp.c
|
||||
[123]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/net/sched
|
||||
[124]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/kernel/trace/bpf_trace.c
|
||||
[125]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/kernel/seccomp.c
|
||||
[126]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/tools/testing/selftests/seccomp/seccomp_bpf.c
|
||||
[127]:https://github.com/iovisor/bcc/blob/master/docs/kernel-versions.md
|
||||
[128]:https://github.com/iovisor/bcc/blob/master/FAQ.txt
|
||||
[129]:https://www.kernel.org/doc/Documentation/networking/filter.txt
|
||||
[130]:https://github.com/iovisor/bcc/blob/master/docs/reference_guide.md
|
||||
[131]:https://github.com/iovisor/bcc/blob/master/src/python/bcc/__init__.py
|
||||
[132]:https://github.com/iovisor/bcc/blob/master/docs/reference_guide.md#output
|
||||
[133]:https://www.spinics.net/lists/netdev/msg406926.html
|
||||
[134]:https://github.com/cilium/bpf-map
|
||||
[135]:https://github.com/badboy/bpf-map
|
||||
[136]:https://stackoverflow.com/questions/tagged/bpf
|
||||
[137]:https://github.com/iovisor/xdp-vagrant
|
||||
[138]:https://github.com/zlim/bcc-docker
|
||||
[139]:http://lists.openwall.net/netdev/
|
||||
[140]:http://vger.kernel.org/vger-lists.html#xdp-newbies
|
||||
[141]:http://lists.iovisor.org/pipermail/iovisor-dev/
|
||||
[142]:https://twitter.com/IOVisor
|
||||
[143]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#what-is-bpf
|
||||
[144]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#dive-into-the-bytecode
|
||||
[145]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#resources
|
||||
[146]:https://github.com/qmonnet/whirl-offload/commits/gh-pages/_posts/2016-09-01-dive-into-bpf.md
|
||||
[147]:http://netdevconf.org/1.2/session.html?jakub-kicinski
|
||||
[148]:http://www.slideshare.net/IOVisor/express-data-path-linux-meetup-santa-clara-july-2016
|
||||
[149]:https://cdn.shopify.com/s/files/1/0177/9886/files/phv2017-gbertin.pdf
|
||||
[150]:https://github.com/cilium/cilium
|
||||
[151]:https://fosdem.org/2017/schedule/event/stateful_ebpf/
|
||||
[152]:http://vger.kernel.org/vger-lists.html#xdp-newbies
|
||||
[153]:https://github.com/iovisor/bcc/blob/master/docs/kernel-versions.md
|
||||
[154]:https://github.com/qmonnet/whirl-offload/commit/d694f8081ba00e686e34f86d5ee76abeb4d0e429
|
||||
[155]:http://openvswitch.org/pipermail/dev/2014-October/047421.html
|
||||
[156]:https://qmonnet.github.io/whirl-offload/2016/07/15/beba-research-project/
|
||||
[157]:https://www.iovisor.org/resources/blog
|
||||
[158]:http://www.brendangregg.com/blog/2016-03-05/linux-bpf-superpowers.html
|
||||
[159]:http://p4.org/
|
||||
[160]:https://github.com/iovisor/bcc/tree/master/src/cc/frontends/p4
|
||||
[161]:https://github.com/p4lang/p4c/blob/master/backends/ebpf/README.md
|
||||
[162]:https://github.com/iovisor/bcc/blob/master/docs/reference_guide.md
|
||||
[163]:https://github.com/iovisor/bcc/blob/master/docs/tutorial_bcc_python_developer.md
|
||||
[164]:https://github.com/goldshtn/linux-tracing-workshop
|
||||
[165]:https://blog.yadutaf.fr/2017/07/28/tracing-a-packet-journey-using-linux-tracepoints-perf-ebpf/
|
||||
[166]:https://open-nfp.org/dataplanes-ebpf/technical-papers/
|
||||
[167]:http://netdevconf.org/2.1/session.html?gospodarek
|
||||
[168]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/samples/bpf
|
||||
[169]:https://git.kernel.org/cgit/linux/kernel/git/shemminger/iproute2.git/tree/examples/bpf
|
||||
[170]:https://github.com/iovisor/bcc/tree/master/examples
|
||||
[171]:http://man7.org/linux/man-pages/man8/tc-bpf.8.html
|
||||
[172]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/net/core/dev.c
|
||||
[173]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/drivers/net/ethernet/mellanox/mlx4/
|
||||
[174]:https://github.com/iovisor/bcc/
|
||||
[175]:https://github.com/iovisor/bcc/blob/master/src/python/bcc/__init__.py
|
||||
[176]:https://github.com/iovisor/bcc/blob/master/src/cc/libbpf.c
|
||||
[177]:https://git.kernel.org/cgit/linux/kernel/git/shemminger/iproute2.git/tree/tc
|
||||
[178]:https://git.kernel.org/cgit/linux/kernel/git/shemminger/iproute2.git/tree/lib/bpf.c
|
||||
[179]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/tools/net
|
||||
[180]:https://git.kernel.org/pub/scm/linux/kernel/git/davem/net-next.git/tree/tools/bpf
|
||||
[181]:https://github.com/iovisor/bcc/tree/master/src/cc/frontends/p4/compiler
|
||||
[182]:https://github.com/iovisor/bcc/tree/master/src/lua
|
||||
[183]:https://reviews.llvm.org/D6494
|
||||
[184]:https://github.com/llvm-mirror/llvm/commit/4fe85c75482f9d11c5a1f92a1863ce30afad8d0d
|
||||
[185]:https://github.com/iovisor/ubpf/
|
||||
[186]:https://github.com/YutaroHayakawa/generic-ebpf
|
||||
[187]:https://github.com/YutaroHayakawa/vale-bpf
|
||||
[188]:https://github.com/qmonnet/rbpf
|
||||
[189]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git
|
||||
[190]:https://github.com/torvalds/linux
|
||||
[191]:https://github.com/iovisor/bcc/blob/master/docs/kernel-versions.md
|
||||
[192]:https://qmonnet.github.io/whirl-offload/categories/#BPF
|
||||
|
||||
|
||||
@ -0,0 +1,45 @@
|
||||
Linux 长期支持版关于未来的声明
|
||||
===============================
|
||||
Linux 4.4 长期支持版将得到 6年的使用期,但是这并不意味着其它长期支持版的使用期将持续这么久。
|
||||
[视频](http://www.zdnet.com/video/video-torvalds-surprised-by-resilience-of-2-6-kernel-1/)
|
||||
_视频: Torvalds 对内核版本 2.6 的弹性感到惊讶_
|
||||
|
||||
在 2017 年 10 月,[Linux 内核小组同意将 Linux 长期支持版(LTS)的下一个版本的生命期从两年延长至六年][5],而 LTS 的下一个版本正是 [Linux 4.14][6]。这对于 [Android][7],嵌入式 Linux 和 Linux 物联网(IoT)的开发者们是一个利好。但是这个变动并不意味着将来所有的 Linux LTS 版本将有 6 年的使用期。
|
||||
正如 [Linux 基金会][8]的 IT 技术设施安全主管 Konstantin Ryabitsev 在 google+ 上发文解释说,"尽管外面的各种各样的新闻网站可能已经告知你们,但是[内核版本 4.14 的 LTS 并不计划支持 6 年][9]。仅仅因为 Greg Kroah-Hartman 正在为 LTS 4.4 版本做这项工作并不表示从现在开始所有的 LTS 内核会维持那么久。"
|
||||
所以,简而言之,Linux 4.14 将支持到 2020年 1月份,而 2016 年 1 月 20 号问世的 Linux 4.4 内核将支持到 2022 年。因此,如果你正在编写一个打算能够长期运行的 Linux 发行版,那你需要基于 [Linux 4.4 版本][10]。
|
||||
[Linux LTS 版本][11]包含对旧内核树的后向移植漏洞的修复。不是所有漏洞的修复都被导入进来,只有重要漏洞的修复才用于这些内核中。它们不会非常频繁的发布,特别是对那些旧版本的内核树来说。
|
||||
Linux 其它的版本有尝鲜版或发布候选版(RC),主线版,稳定版和 LTS 版。
|
||||
RC 版必须从源代码编译并且通常包含漏洞的修复和新特性。这些都是由 Linux Torvalds 维护和发布的。他也维护主线版本树(这是所有新特性被引入的地方)。新的主线内核每几个月发布一次。当主线版本树为了通用才发布时,它被称为"稳定版"。一个稳定版内核漏洞的修复是从主线版本树后向移植的,并且这些修复是由一个指定的稳定版内核维护者来申请。在下一个主线内核变得可用之前,通常也有一些修复漏洞的内核发布。
|
||||
对于最新的 LTS 版本,Linux 4.14,Ryabitsev 说,"Greg 已经担负起了 4.14 版本的维护者责任(过去发生过多次),其他人想成为该版本的维护者也是有可能的,但是你应该断然不要去计划这件事。"
|
||||
Kroah-Hartman 在 Ryabitsev 的文章中仅仅添加了:"[他的言论][12]"
|
||||
|
||||
-------------------
|
||||
via: http://www.zdnet.com/article/long-term-linux-support-future-clarified/
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols ][a]
|
||||
译者:[liuxinyu123](https://github.com/liuxinyu123)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/
|
||||
[1]:http://www.zdnet.com/article/long-term-linux-support-future-clarified/#comments-eb4f0633-955f-4fec-9e56-734c34ee2bf2
|
||||
[2]:http://www.zdnet.com/article/the-tension-between-iot-and-erp/
|
||||
[3]:http://www.zdnet.com/article/the-tension-between-iot-and-erp/
|
||||
[4]:http://www.zdnet.com/article/the-tension-between-iot-and-erp/
|
||||
[5]:http://www.zdnet.com/article/long-term-support-linux-gets-a-longer-lease-on-life/
|
||||
[6]:http://www.zdnet.com/article/the-new-long-term-linux-kernel-linux-4-14-has-arrived/
|
||||
[7]:https://www.android.com/
|
||||
[8]:https://www.linuxfoundation.org/
|
||||
[9]:https://plus.google.com/u/0/+KonstantinRyabitsev/posts/Lq97ZtL8Xw9
|
||||
[10]:http://www.zdnet.com/article/whats-new-and-nifty-in-linux-4-4/
|
||||
[11]:https://www.kernel.org/releases.html
|
||||
[12]:https://plus.google.com/u/0/+gregkroahhartman/posts/ZUcSz3Sn1Hc
|
||||
[13]:http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/
|
||||
[14]:http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/
|
||||
[15]:http://www.zdnet.com/blog/open-source/
|
||||
[16]:http://www.zdnet.com/topic/enterprise-software/
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,41 @@
|
||||
有人试图将 Ubuntu Unity 非正式地从死亡带回来
|
||||
============================================================
|
||||
|
||||
|
||||
|
||||
> Ubuntu Unity Remix 将支持九个月
|
||||
|
||||
Canonical 在七年之后突然决定抛弃它的 Unity 用户界面影响了许多 Ubuntu 用户,看起来有人现在试图非正式地把它从死亡中带回来。
|
||||
|
||||
长期 [Ubuntu][1] 成员 Dale Beaudoin 上周在官方的 Ubuntu 论坛上[进行了一项调查][2]来了解社区,看看他们是否对明年发布的 Ubuntu 18.04 LTS(Bionic Beaver)的 Ubuntu Unity Remix 感兴趣,它将支持 9 个月或 5 年。
|
||||
|
||||
有 30 人进行了投票,其中 67% 的人选择了所谓的 Ubuntu Unity Remix 的 LTS(长期支持)版本,33% 的人投票支持 9 个月的支持版本。它也看起来像即将到来的 Ubuntu Unity Spin [看起来会成为官方版本][3],但这不意味着开发它的承诺。
|
||||
|
||||
Dale Beaudoin 表示:“最近的一项民意调查显示,2/3 的人支持 Ubuntu Unity 成为 LTS 发行版,我们应该尝试这个循环,假设它将是 LTS 和官方的风格。“我们将尝试使用当前默认的 Ubuntu Bionic Beaver 18.04 的每日版本作为平台每周或每 10 天发布一次更新的 ISO。”
|
||||
|
||||
### Ubuntu Unity 是否会卷土重来?
|
||||
|
||||
默认情况下,最后一个带有 Unity 的 Ubuntu 版本是 Ubuntu 17.04(Zesty Zapus),它将在 2018 年 1 月终止支持。当前流行操作系统的稳定版本 Ubuntu 17.10(Artful Artful),是今年早些时候 Canonical CEO [宣布][4]之后第一个默认使用 GNOME 桌面环境的版本,Unity 将不再开发。
|
||||
|
||||
然而,Canonical 仍然从官方软件仓库提供 Unity 桌面环境,所以如果有人想要安装它,只需点击一下即可。但坏消息是,它们支持到 2018 年 4 月发布 Ubuntu 18.04 LTS(Bionic Beaver)之前,所以 Ubuntu Unity Remix 的开发者们将不得不在独立的仓库中继续支持。
|
||||
|
||||
另一方面,我们不相信 Canonical 会改变主意,接受这个 Ubuntu Unity Spin 成为官方的风格,这意味着他们无法继续开发 Unity,现在只有一小部分人可以做到这一点。最有可能的是,如果对 Ubuntu Unity Remix 的兴趣没有很快消失,那么,这可能会是一个由怀旧社区支持的非官方版本。
|
||||
|
||||
问题是,你会对 你会对Ubuntu Unity Spin 感兴趣么,官方或者非官方?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/someone-tries-to-bring-back-ubuntu-s-unity-from-the-dead-as-an-unofficial-spin-518778.shtml
|
||||
|
||||
作者:[Marius Nestor ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/marius-nestor
|
||||
[1]:http://linux.softpedia.com/downloadTag/Ubuntu
|
||||
[2]:https://community.ubuntu.com/t/poll-unity-7-distro-9-month-spin-or-lts-for-18-04/2066
|
||||
[3]:https://community.ubuntu.com/t/unity-maintenance-roadmap/2223
|
||||
[4]:http://news.softpedia.com/news/canonical-to-stop-developing-unity-8-ubuntu-18-04-lts-ships-with-gnome-desktop-514604.shtml
|
||||
[5]:http://news.softpedia.com/editors/browse/marius-nestor
|
||||
@ -0,0 +1,45 @@
|
||||
# GNOME Boxes 使得测试 Linux 发行版更加简单
|
||||
|
||||

|
||||
|
||||
在 GNOME 桌面上创建 Linux 虚拟机即将变得更加简单。
|
||||
|
||||
[_GNOME Boxes_][5] 的下一个主要版本能够直接在应用程序内下载流行的 Linux(和基于 BSD 的)操作系统。
|
||||
|
||||
Boxes 是免费的开源软件。它可以用来访问远程和虚拟系统,因为它是用 [QEMU][6]、KVM 和 libvirt 虚拟化技术构建的。
|
||||
|
||||
对于新的 ISO-toting 的集成,_Boxes_ 利用 [libosinfo][7] 这一操作系统的数据库,该数据库还提供了有关任何虚拟化环境要求的详细信息。
|
||||
|
||||
在 GNOME 开发者 Felipe Borges 的[这个(起错标题)视频] [8]中,你可以看到改进的“源选择”页面,包括为给定的发行版下载特定 ISO 架构的能力:
|
||||
|
||||
[video](https://youtu.be/CGahI05Gbac)
|
||||
|
||||
尽管它是一个核心 GNOME 程序,我不得不承认,我从来没有使用过 Boxes。(我这么做)并不是说我没有听到有关它的好处,只是我更熟悉在 VirtualBox 中设置和配置虚拟机。
|
||||
|
||||
> “我内心的偷懒精神会欣赏这个集成”
|
||||
|
||||
我承认在浏览器中下载一个 ISO 然后将虚拟机指向它(见鬼,这是我们大多数在过去十年来一直做的事)并不是一件很_困难_的事。
|
||||
|
||||
但是我内心的偷懒精神会欣赏这个集成。
|
||||
|
||||
所以,感谢这个功能,我将在明年 3 月份发布 GNOME 3.28 时,在我的系统上解压 Boxes。我会启动 _Boxes_,闭上眼睛,随意从列表中挑选一个发行版,并立即拓宽我的视野。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2017/12/gnome-boxes-install-linux-distros-directly
|
||||
|
||||
作者:[ JOEY SNEDDON ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[2]:http://www.omgubuntu.co.uk/category/dev
|
||||
[3]:http://www.omgubuntu.co.uk/category/video
|
||||
[4]:http://www.omgubuntu.co.uk/2017/12/gnome-boxes-install-linux-distros-directly
|
||||
[5]:https://en.wikipedia.org/wiki/GNOME_Boxes
|
||||
[6]:https://en.wikipedia.org/wiki/QEMU
|
||||
[7]:https://libosinfo.org/
|
||||
[8]:https://blogs.gnome.org/felipeborges/boxes-downloadable-oses/
|
||||
@ -0,0 +1,69 @@
|
||||
防止文档陷阱的 7 条准则
|
||||
======
|
||||
英语是开源社区的通用语言。为了减少翻译成本,很多团队都改成用英语来写他们的文档。 但奇怪的是,为国际读者写英语并不一定就意味着英语为母语的人就占据更多的优势。 相反, 他们往往忘记了写文档用的语言可能并不是读者的母语。
|
||||
|
||||
我们以下面这个简单的句子为例: "Encrypt the password using the `foo bar` command。" 语法上来说,这个句子是正确的。 鉴于动名词的 '-ing' 形式在英语中很常见,大多数的母语人士都认为这是一种优雅的表达方式, 他们通常会很自然的写出这样的句子。 但是仔细观察, 这个句子存在歧义因为 "using" 可能指的宾语 ("the password") 也可能指的动词 ("encrypt")。 因此这个句子有两种解读方式:
|
||||
|
||||
* "加密使用了 `foo bar` 命令的密码。"
|
||||
* "使用命令 `foo bar` 来加密密码。"
|
||||
|
||||
如果你有相关的先验知识 (密码加密或这 `foo bar` 命令),你可以消除这种不确定性并且明白第二种方式才是真正的意思。 但是若你没有足够深入的知识怎么办呢? 如果你并不是这方面的专家,而只是一个拥有泛泛相关知识的翻译者而已怎么办呢? 再或者,如果你只是个非母语人士且对像动名词这种高级语法不熟悉怎么办呢?
|
||||
|
||||
即使是英语为母语的人也需要经过训练才能写出清晰直接的技术文档。训练的第一步就是提高对文本可用性以及潜在问题的警觉性, 下面让我们来看一下可以帮助避免常见陷阱的 7 条规则。
|
||||
|
||||
### 1。了解你的目标读者并代入其中。
|
||||
|
||||
如果你是一名开发者,而写作的对象是终端用户, 那么你需要站在他们的角度来看这个产品。 文档的结构是否反映了用户的目标? [人格面具 (persona) 技术][1] 能帮你专注于目标受众并为你的读者提供合适层次的细节。
|
||||
|
||||
### 2。准训 KISS 原则--保持文档简短而简单
|
||||
|
||||
这个原则适用于多个层次,从语法,句子到单词。 比如:
|
||||
|
||||
* 使用合适的最简单时态。比如, 当提到一个动作的结果时使用现在时:
|
||||
* " ~~Click 'OK。' The 'Printer Options' dialog will appear。~~" -> "Click 'OK。' The 'Printer Options' dialog appears。"
|
||||
* 按经验来说,一个句子表达一个主题; 然而, 短句子并不一定就容易理解(尤其当这些句子都是由名词组成时)。 有时, 将句子裁剪过度可能会引起歧义,而反过来太多单词则又难以理解。
|
||||
* 不常用的以及很长的单词会降低阅读速度,而且可能成为非母语人士的障碍。 使用更简单的替代词语:
|
||||
* " ~~utilize~~ " -> "use"
|
||||
* " ~~indicate~~ " -> "show," "tell," or "say"
|
||||
* " ~~prerequisite~~ " -> "requirement"
|
||||
|
||||
### 3。不要干扰阅读流
|
||||
|
||||
将虚词和较长的插入语移到句子的首部或者尾部:
|
||||
|
||||
* " ~~They are not,however, marked as installed。~~ " -> "However, they are not marked as installed。"
|
||||
|
||||
将长命令放在句子的末尾可以让自动/半自动的翻译拥有更好的断句。
|
||||
|
||||
### 4。区别对待两种基本的信息类型
|
||||
|
||||
描述型信息以及任务导向型信息有必要区分开来。描述型信息的一个典型例子就是命令行参考, 而 how-to 则是属于基于任务的信息; 然而, 技术写作中都会涉及这两种类型的信息。 仔细观察, 就会发现许多文本都同时包含了两种类型的信息。 然而如果能够清晰地划分这两种类型的信息那必是极好的。 为了跟好地区分他们,可以对他们进行分别标记(For better orientation, label them accordingly)。 标题应该能够反应章节的内容以及信息的类型。 对描述性章节使用基于名词的标题(比如"Types of Frobnicators"),而对基于任务的章节使用口头表达式的标题(例如"Installing Frobnicators")。 这可以让读者快速定位感兴趣的章节而跳过他无用的章节。
|
||||
|
||||
### 5。考虑不同的阅读场景和阅读模式
|
||||
|
||||
有些读者在转向阅读产品文档时会由于自己搞不定而感到十分的沮丧。他们也在一个嘈杂的环境中工作,很难专注于阅读。 同时,不要期望你的读者会一页一页的进行阅读,很多人都是快速浏览文本搜索关键字或者通过表格,索引以及全文搜索的方式来查找主题。 请牢记这一点, 从不同的角度来看待你的文字。 通常需要妥协才能找到一种适合多种情况的文本结构。
|
||||
|
||||
### 6。将复杂的信息分成小块。
|
||||
|
||||
这会让读者更容易记住和吸收信息。例如, 过程不应该超过 7 到 10 个步骤(根据认知心理学中的 [Miller's Law][2])。 如果需要更多的步骤, 那么就将任务分拆成不同的过程。
|
||||
|
||||
### 7。形式遵循功能
|
||||
|
||||
根据以下问题检查你的文字: 某句话/段落/章节的 _目的_ (功能)是什么?比如, 它是一个指令呢?还是一个结果呢?还是一个警告呢?如果是指令, 使用主动语气: "Configure the system。" 被动语气可能适合于进行描述: "The system is configured automatically。" 将警告放在危险操作的 _前面_ 。 专注于目的还有助于发现冗余的内容,可以清除类似 "basically" 或者 "easily" 这一类的填充词,类似 " ~~already~~ existing " or " ~~completely~~ new" 这一类的不必要的修改, 以及任何与你的目标大众无关的内容。
|
||||
|
||||
你现在可能已经猜到了,写作就是一个不断重写的过程。 好的写作需要付出努力和练习。 即使你只是偶尔写点东西, 你也可以通过关注目标大众并遵循上述规则来显著地改善你的文字。 文字的可读性越好, 理解就越容易, 这一点对不同语言能力的读者来说都是适合的。 尤其是当进行本地化时, 高质量的原始文本至关重要: "垃圾进, 垃圾出"。 如果原始文本就有缺陷, 翻译所需要的时间就会变长, 从而导致更高的成本。 最坏的情况下, 翻译会导致缺陷成倍增加,需要在不同的语言版本中修正这个缺陷。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/12/7-rules
|
||||
|
||||
作者:[Tanja Roth][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com
|
||||
[1]:https://en.wikipedia.org/wiki/Persona_(user_experience)
|
||||
[2]:https://en.wikipedia.org/wiki/The_Magical_Number_Seven,_Plus_or_Minus_Two
|
||||
@ -0,0 +1,199 @@
|
||||
10 个例子教你学会 ncat (nc) 命令
|
||||
======
|
||||
[][1]
|
||||
|
||||
ncat 或者说 nc 是一款功能类似 cat 的网络工具。它是一款拥有多种功能的 CLI 工具,可以用来在网络上读,写以及重定向数据。 它被设计成可以被脚本或其他程序调用的可靠后端工具。 同时由于它能创建任意所需的连接,因此也是一个很好的网络调试工具。
|
||||
|
||||
ncat/nc 既是一个端口扫描工具,也是一款安全工具, 还能是一款检测工具,甚至可以做一个简单的 TCP 代理。 由于有这么多的功能,它被誉为是网络界的瑞士军刀。 这是每个系统管理员都应该知道并且掌握它。
|
||||
|
||||
在大多数 Debian 发行版中,`nc` 是默认可用的,它会在安装系统的过程中自动被安装。 但是在 CentOS 7 / RHEL 7 的最小化安装中,`nc` 并不会默认被安装。 你需要用下列命令手工安装。
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# yum install nmap-ncat -y
|
||||
```
|
||||
|
||||
系统管理员可以用它来审计系统安全,用它来找出开放的端口然后保护这些端口。 管理员还能用它作为客户端来审计 Web 服务器, 远程登陆服务器, 邮件服务器等, 通过 `nc` 我们可以控制发送的每个字符,也可以查看对方的回应。
|
||||
|
||||
我们还可以 o 用它捕获客户端发送的数据一次来了解这些客户端是做什么的。
|
||||
|
||||
在本文中,我们会通过 10 个例子来学习如何使用 `nc` 命令。
|
||||
|
||||
### 例子: 1) 监听入站连接
|
||||
|
||||
通过 `l` 选项,ncat 可以进入监听模式,使我们可以在指定端口监听入站连接。 完整的命令是这样的
|
||||
|
||||
$ ncat -l port_number
|
||||
|
||||
比如,
|
||||
|
||||
```
|
||||
$ ncat -l 8080
|
||||
```
|
||||
|
||||
服务器就会开始在 8080 端口监听入站连接。
|
||||
|
||||
### 例子: 2) 连接远程系统
|
||||
|
||||
使用下面命令可以用 nc 来连接远程系统,
|
||||
|
||||
$ ncat IP_address port_number
|
||||
|
||||
让我们来看个例子,
|
||||
|
||||
```
|
||||
$ ncat 192。168。1。100 80
|
||||
```
|
||||
|
||||
这会创建一个连接,连接到 IP 为 192。168。1。100 的服务器上的 80 端口,然后我们就可以向服务器发送指令了。 比如我们可以输入下面内容来获取完整的网页内容
|
||||
|
||||
GET / HTTP/1.1
|
||||
|
||||
或者获取页面名称,
|
||||
|
||||
GET / HTTP/1.1
|
||||
|
||||
或者我们可以通过以下方式获得操作系统指纹标识,
|
||||
|
||||
HEAD / HTTP/1.1
|
||||
|
||||
这会告诉我们使用的是什么软件来运行这个 web 服务器的。
|
||||
|
||||
### 例子: 3) 连接 UDP 端口
|
||||
|
||||
默认情况下,nc 创建连接时只会连接 TCP 端口。 不过我们可以使用 `u` 选项来连接到 UDP 端口,
|
||||
|
||||
```
|
||||
$ ncat -l -u 1234
|
||||
```
|
||||
|
||||
现在我们的系统会开始监听 udp 的'1234'端口,我们可以使用下面的 netstat 命令来验证这一点,
|
||||
|
||||
```
|
||||
$ netstat -tunlp | grep 1234
|
||||
udp 0 0 0。0。0。0:1234 0。0。0。0:* 17341/nc
|
||||
udp6 0 0 :::1234 :::* 17341/nc
|
||||
```
|
||||
|
||||
假设我们想发送或者说测试某个远程主机 UDP 端口的连通性,我们可以使用下面命令,
|
||||
|
||||
$ ncat -v -u {host-ip} {udp-port}
|
||||
|
||||
比如:
|
||||
|
||||
```
|
||||
[root@localhost ~]# ncat -v -u 192。168。105。150 53
|
||||
Ncat: Version 6。40 ( http://nmap.org/ncat )
|
||||
Ncat: Connected to 192。168。105。150:53。
|
||||
```
|
||||
|
||||
#### 例子: 4) 将 NC 作为聊天工具
|
||||
|
||||
NC 也可以作为聊天工具来用,我们可以配置服务器监听某个端口,然后从远程主机上连接到服务器的这个端口,就可以开始发送消息了。 在服务器这端运行:
|
||||
|
||||
```
|
||||
$ ncat -l 8080
|
||||
```
|
||||
|
||||
在远程客户端主机上运行:
|
||||
|
||||
```
|
||||
$ ncat 192。168。1。100 8080
|
||||
```
|
||||
|
||||
之后开始发送消息,这些消息会在服务器终端上显示出来。
|
||||
|
||||
#### 例子: 5) 将 NC 作为代理
|
||||
|
||||
NC 也可以用来做代理。比如下面这个例子,
|
||||
|
||||
```
|
||||
$ ncat -l 8080 | ncat 192。168。1。200 80
|
||||
```
|
||||
|
||||
所有发往我们服务器 8080 端口的连接都会自动转发到 192。168。1。200 上的 80 端口。 不过由于我们使用了管道,数据只能被单向传输。 要同时能够接受返回的数据,我们需要创建一个双向管道。 使用下面命令可以做到这点:
|
||||
|
||||
```
|
||||
$ mkfifo 2way
|
||||
$ ncat -l 8080 0<2way | ncat 192。168。1。200 80 1>2way
|
||||
```
|
||||
|
||||
现在你可以通过 nc 代理来收发数据了。
|
||||
|
||||
#### 例子: 6) 使用 nc/ncat 拷贝文件
|
||||
|
||||
NC 还能用来在系统间拷贝文件,虽然这么做并不推荐,因为绝大多数系统默认都安装了 ssh/scp。 不过如果你恰好遇见个没有 ssh/scp 的系统的话, 你可以用 nc 来作最后的努力。
|
||||
|
||||
在要接受数据的机器上启动 nc 并让它进入监听模式:
|
||||
|
||||
```
|
||||
$ ncat -l 8080 > file.txt
|
||||
```
|
||||
|
||||
现在去要被拷贝数据的机器上运行下面命令:
|
||||
|
||||
```
|
||||
$ ncat 192。168。1。100 8080 --send-only < data.txt
|
||||
```
|
||||
|
||||
这里,data.txt 是要发送的文件。 –send-only 选项会在文件拷贝完后立即关闭连接。 如果不加该选项, 我们需要手工按下 ctrl+c to 来关闭连接。
|
||||
|
||||
我们也可以用这种方法拷贝整个磁盘分区,不过请一定要小心。
|
||||
|
||||
#### 例子: 7) 通过 nc/ncat 创建后门
|
||||
|
||||
NC 命令还可以用来在系统中创建后门,并且这种技术也确实被黑客大量使用。 为了保护我们的系统,我们需要知道它是怎么做的。 创建后门的命令为:
|
||||
|
||||
```
|
||||
$ ncat -l 10000 -e /bin/bash
|
||||
```
|
||||
|
||||
‘e‘ 标志将一个 bash 与端口 10000 相连。现在客户端只要连接到服务器上的 10000 端口就能通过 bash 获取我们系统的完整访问权限:
|
||||
|
||||
```
|
||||
$ ncat 192。168。1。100 10000
|
||||
```
|
||||
|
||||
#### 例子: 8) 通过 nc/ncat 进行端口转发
|
||||
|
||||
我们通过选项 `c` 来用 NC 进行端口转发,实现端口转发的语法为:
|
||||
|
||||
```
|
||||
$ ncat -u -l 80 -c 'ncat -u -l 8080'
|
||||
```
|
||||
|
||||
这样,所有连接到 80 端口的连接都会转发到 8080 端口。
|
||||
|
||||
#### 例子: 9) 设置连接超时
|
||||
|
||||
ncat 的监听模式会一直运行,直到手工终止。 不过我们可以通过选项 `w` 设置超时时间:
|
||||
|
||||
```
|
||||
$ ncat -w 10 192。168。1。100 8080
|
||||
```
|
||||
|
||||
这回导致连接 10 秒后终止,不过这个选项只能用于客户端而不是服务端。
|
||||
|
||||
#### 例子: 10) 使用 -k 选项强制 ncat 待命
|
||||
|
||||
当客户端从服务端断开连接后,过一段时间服务端也会停止监听。 但通过选项 `k` 我们可以强制服务器保持连接并继续监听端口。 命令如下:
|
||||
|
||||
```
|
||||
$ ncat -l -k 8080
|
||||
```
|
||||
|
||||
现在即使来自客户端的连接断了也依然会处于待命状态。
|
||||
|
||||
自此我们的教程就完了,如有疑问,请在下方留言。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxtechi.com/nc-ncat-command-examples-linux-systems/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxtechi.com/author/pradeep/
|
||||
[1]:https://www.linuxtechi.com/wp-content/uploads/2017/12/nc-ncat-command-examples-Linux-Systems.jpg
|
||||
178
translated/tech/20171212 Internet protocols are changing.md
Normal file
178
translated/tech/20171212 Internet protocols are changing.md
Normal file
@ -0,0 +1,178 @@
|
||||
因特网协议正在发生变化
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
|
||||
在上世纪九十年代,当因特网开始被广泛使用的时候,大部分的通讯只使用几个协议:IPv4 路由包,TCP 转发这些包到连接上,SSL(后来的 TLS)加密连接,DNS 命名连接上的主机,HTTP 是最常用的应用程序协议。
|
||||
|
||||
多年以来,这些核心的因特网协议的变化几乎是可以忽略的;HTTP 增加了几个新的报文头和方法,TLS 缓慢地进行了一点小修改,TCP 调整了拥塞控制,而 DNS 引入了像 DNSSEC 这样的特性。这些协议本身在很长一段时间以来都面向相同的 “线上(on the wire)” 环境(除了 IPv6,它已经引起网络运营商们的大量关注)。
|
||||
|
||||
因此,网络运营商、供应商、和政策制定者们,他们想去了解(并且有时是想去管理),因特网基于上面的这些协议的“影响(footpring)”已经采纳了的大量的实践 — 是否打算去调试问题、改善服务质量、或者强制实施策略。
|
||||
|
||||
现在,核心因特网协议的重要改变已经开始了。虽然它们的目的是与因特网兼容(因为,如果不兼容的话,它们不会被采纳),但是它们可以破坏那些在协议方面进行非法使用的人的自由,或者假设那些事件不会改变。
|
||||
|
||||
#### 为什么我们需要去改变因特网
|
||||
|
||||
那里有大量的因素推动这些变化。
|
||||
|
||||
首先,核心因特网协议的限制越来越明显,尤其是考虑到性能的时候。由于在应用程序和传输协议方面的结构上的问题,网络不能被高效地使用,导致终端用户感受到性能问题(特别是,延迟)。
|
||||
|
||||
这就转化成进化或者替换这些协议的强烈的动机,因为有 [大量的经验表明,即便是很小的性能改善也会产生影响][14]。
|
||||
|
||||
第二,有能力去进化因特网协议 — 在任何层面上 — 随着时间的推移会变得更加困难,很大程度上要感谢上面所讨论的网络带来的意想不到的使用。例如,尝试去压缩响应的 HTTP 代理,使的部署一个新的压缩技术更困难;中间设备中的 TCP 优化使得部署一个对 TCP 的改善越来越困难。
|
||||
|
||||
最后,[我们正处在一个更多地使用加密技术的因特网变化中][15],首次激起这种改变的事件是,2015 的 Edward Snowden 披露的信息(译者注:指的是美国中情局雇员斯诺登的事件)。那是一个单独讨论的话题,但是它的意义是,我们为确保协议可以进化,加密是其中一个很好的工具。
|
||||
|
||||
让我们来看一下都发生了什么,接下来会出现什么,它对网络有哪些影响,和它对网络协议的设计有哪些影响。
|
||||
|
||||
#### HTTP/2
|
||||
|
||||
[HTTP/2][16](基于 Google 的 SPDY) 是第一个发生重大变化的 — 在 2015 年被标准化,它多路传输多个请求到一个 TCP 连接中,因此可以在客户端上不阻塞任何一个其它请求的情况下避免了请求队列。它现在已经被广泛部署,并且被所有的主流浏览器和 web 服务器支持。
|
||||
|
||||
从一个网络的角度来看,HTTP/2 的一些显著变化。首先,适合一个二进制协议,因此,任何假定它是 HTTP/1.1 的设备都会被中断。
|
||||
|
||||
中断是在 HTTP/2 中另一个大的变化的主要原因;它有效地请求加密。这种改变的好处是避免了来自伪装的 HTTP/1.1 的中间人攻击,或者一些更狡滑的比如 “脱衣攻击” 或者阻止新的协议扩展 — 协议上的这两种情况都在工程师的工作中出现过,给他们带来了很明显的支持问题。
|
||||
|
||||
[当它被加密时,HTTP/2 也请求使用 TLS/1.2][17],并且 [黑名单][18] 密码组合已经被证明不安全 — 它只对暂时的密钥有效果。关于潜在的影响可以去看 TLS 1.3 的相关章节。
|
||||
|
||||
最终,HTTP/2 允许多于一个主机的请求去被 [合并到一个连接上][19],通过减少页面加载所使用的连接(和拥塞管理上下文)数量去提升性能。
|
||||
|
||||
例如,你可以为 <tt style="box-sizing: inherit;">www.example.com</tt> 有一个连接,也可以用这个连接去为 <tt style="box-sizing: inherit;">images.example.com</tt> 的请求所使用。[未来协议的扩展也可以允许另外的主机去被添加到连接][20],即便它们没有在最初的 TLS 证书中被列为可以使用。因此,假设连接上的通讯被限制了用途,那么在这种情况下它就不能被使用了。
|
||||
|
||||
值得注意的是,尽管存在这些变化,HTTP/2 并没有出现明显的互操作性问题或者来自网络的冲突。
|
||||
|
||||
#### TLS 1.3
|
||||
|
||||
[TLS 1.3][21] 仅通过了标准化的最后过程,并且已经被一些实现所支持。
|
||||
|
||||
不要被它只增加了版本号的名字所欺骗;它实际上是一个新的 TLS 版本,修改了很多 “握手”,它允许应用程序数据去从开始流出(经常被称为 ‘0RTT’)。新的设计依赖短暂的密钥交换,因此,排除了静态密钥。
|
||||
|
||||
这引起了一些网络运营商和供应商的担心 — 尤其是那些需要清晰地知道那些连接中发生了什么的人。
|
||||
|
||||
例如,假设一个对可视性有监管要求的银行数据中心,通过在网络中嗅探通讯包并且使用他们的服务器上的静态密钥解密它,它们可以记录合法通讯和识别有害通讯,是否是一个来自外部的攻击,或者员工从内部去泄露数据。
|
||||
|
||||
TLS 1.3 并不支持那些窃听通讯的特定技术,因此,它也可以 [以短暂的密钥来防范一种形式的攻击][22]。然而,因为他们有监管要求去使用更现代化的加密协议并且去监视他们的网络,这些使网络运营商处境很尴尬。
|
||||
|
||||
关于是否规定要求静态密钥、替代方式是否有效、并且为了相对较少的网络环境而减弱整个因特网的安全是否是一个正确的解决方案有很多的争论。确实,仍然有可能对使用 TLS 1.3 的通讯进行解密,但是,你需要去访问一个短暂的密钥才能做到,并且,按照设计,它们不可能长时间存在。
|
||||
|
||||
在这一点上,TLS 1.3 似乎不会去改变来适应这些网络,但是,关于去创建另外的协议去允许第三方去偷窥通讯内容 — 或者做更多的事情 — 对于这种使用情况,网络上到处充斥着不满的声音。
|
||||
|
||||
#### QUIC
|
||||
|
||||
在 HTTP/2 工作期间,可以很明显地看到 TCP 是很低效率的。因为 TCP 是一个按顺序发送的协议,丢失的包阻止了在缓存中的后面等待的包被发送到应用程序。对于一个多路协议来说,这对性能有很大的影响。
|
||||
|
||||
[QUIC][23] 是尝试去解决这种影响而在 UDP 之上重构的 TCP 语义(属于 HTTP/2 的流模型的一部分)像 HTTP/2 一样,它作为 Google 的一项成果被发起,并且现在已经进入了 IETF,它最初是作为一个 HTTP-over-UDP 的使用案例,并且它的目标是在 2018 年成为一个标准。但是,因为 Google 在 Chrome 浏览器和它的网站上中已经部署了 QUIC,它已经占有了因特网通讯超过 7% 的份额。
|
||||
|
||||
阅读 [关于 QUIC 的答疑][24]
|
||||
|
||||
除了大量的通讯(以及隐含的可能的网络调整)从 TCP 到 UDP 的转变之外,Google QUIC(gQUIC)和 IETF QUIC(iQUIC)都要求完全加密;这里没有非加密的 QUIC。
|
||||
|
||||
iQUIC 使用 TLS 1.3 去为一个会话创建一个密码,然后使用它去加密每个包。然而,因为,它是基于 UDP 的,在 QUIC 中许多会话信息和元数据在加密后的 TCP 包中被公开。
|
||||
|
||||
事实上,iQUIC 当前的 [‘短报文头’][25] — 被用于除了握手外的所有包 — 仅公开一个包编号、一个可选的连接标识符、和一个状态字节,像加密密钥转换计划和包字节(它最终也可能被加密)。
|
||||
|
||||
其它的所有东西都被加密 — 包括 ACKs,以提高 [通讯分析][26] 攻击的门槛。
|
||||
|
||||
然而,这意味着被动估算 RTT 和通过观察连接的丢失包将不再变得可能;因为这里没有足够多的信息了。在一些运营商中,由于缺乏可观测性,导致了大量的担忧,它们认为像这样的被动测量对于他们调试和了解它们的网络是至关重要的。
|
||||
|
||||
为满足这一需求,它们有一个提议是 ‘[Spin Bit][27]‘ — 在报文头中的一个 bit,它是一个往返的开关,因此,可能通过观察它来估算 RTT。因为,它从应用程序的状态中解耦的,它的出现并不会泄露关于终端的任何信息,也无法实现对网络位置的粗略估计。
|
||||
|
||||
#### DOH
|
||||
|
||||
可以肯定的即将发生的变化是 DOH — [DNS over HTTP][28]。[大量的研究表明,对网络实施策略的一个常用手段是通过 DNS 实现的][29](是否代表网络运营商或者一个更大的权威)。
|
||||
|
||||
使用加密去规避这种控制已经 [讨论了一段时间了][30],但是,它有一个不利条件(至少从某些立场来看)— 它可能从其它的通讯中被区别对待;例如,通过利用它的端口号被阻止访问。
|
||||
|
||||
DOH 将 DNS 通讯稍带在已经建立的 HTTP 连接上,因此,消除了任何的鉴别器。一个网络希望去阻止访问,仅需要去阻止 DNS 解析就可以做到阻止对特定网站的访问。
|
||||
|
||||
例如,如果 Google 在 <tt style="box-sizing: inherit;">www.google.com</tt> 上部署了它的 [基于 DOH 的公共 DNS 服务][31] 并且一个用户配置了它的浏览器去使用它,一个希望(或被要求的)被停止的网络,它将被 Google 有效的全部阻止(向他们提供的服务致敬!)。
|
||||
|
||||
DOH 才刚刚开始,但它已经引起很多人的兴趣和一些部署的声音。通过使用 DNS 来实施策略的网络(和政府机构)如何反应还有待观察。
|
||||
|
||||
阅读 [IETF 100, Singapore: DNS over HTTP (DOH!)][1]
|
||||
|
||||
#### 骨化和润滑
|
||||
|
||||
让我们返回到协议变化的动机,其中一个主题是吞吐量,协议设计者们遇到的越来越多的问题是怎么去假设关于通讯的问题。
|
||||
|
||||
例如,TLS 1.3 有一个使用旧版本协议的中间设备的最后结束时间的问题。gQUIC 黑名单控制网络的 UDP 通讯,因为,它们认为那是有害的或者是低优先级的通讯。
|
||||
|
||||
当一个协议因为已部署而 “冻结” 它的可扩展点导致不能被进化,我们称它为 _已骨化_ 。TCP 协议自身就是一个严重骨化的例子,因此,很中间设备在 TCP 上做了很多的事情 — 是否阻止有无法识别的 TCP 选项的数据包,或者,优化拥塞控制。
|
||||
|
||||
有必要去阻止骨化,去确保协议可以被进化,以满足未来因特网的需要;否则,它将成为一个 ”公共的悲剧“,它只能是满足一些个别的网络行为的地方 — 虽然很好 — 但是将影响整个因特网的健康发展。
|
||||
|
||||
这里有很多的方式去阻止骨化;如果被讨论的数据是加密的,它并不能被任何一方所访问,但是持有密钥的人,阻止了干扰。如果扩展点是未加密的,但是在一种可以打破应用程序可见性(例如,HTTP 报头)的方法被常规使用后,它不太可能会受到干扰。
|
||||
|
||||
协议设计者不能使用加密的地方和一个不经常使用的扩展点、人为发挥的可利用的扩展点;我们称之为 _润滑_ 它。
|
||||
|
||||
例如,QUIC 鼓励终端在 [版本协商][32] 中使用一系列的诱饵值,去避免它永远不变化的假定实现(就像在 TLS 实现中经常遇到的导致重大问题的情况)。
|
||||
|
||||
#### 网络和用户
|
||||
|
||||
除了避免骨化的愿望外,这些变化也反映出了网络和它们的用户之间的进化。很长时间以来,人们总是假设网络总是很仁慈好善的 — 或者至少是公正的 — 这种情况是不存在的,不仅是 [无孔不入的监视][33],也有像 [Firesheep][34] 的攻击。
|
||||
|
||||
因此,因特网用户的整体需求和那些想去访问流经它们的网络的用户数据的网络之间的关系日益紧张。尤其受影响的是那些希望去对它们的用户实施策略的网络;例如,企业网络。
|
||||
|
||||
在一些情况中,他们可以通过在它们的用户机器上安装软件(或一个 CA 证书,或者一个浏览器扩展)来达到他们的目的。然而,在网络不是所有者或者能够访问计算机的情况下,这并不容易;例如,BYOD 已经很常用,并且物联网设备几乎没有合适的控制接口。
|
||||
|
||||
因此,在 IETF 中围绕协议开发的许多讨论,是去接触企业和其它的 ”叶子“ 网络之间偶尔的需求竞争,并且这对因特网的整体是有好处的。
|
||||
|
||||
#### 参与
|
||||
|
||||
为了让因特网在以后工作的更好,它需要为终端用户提供价值、避免骨化、并且允许网络去控制。现在发生的变化需要去满足所有的三个目标,但是,我们需要网络运营商更多的投入。
|
||||
|
||||
如果这些变化影响你的网络 — 或者没有影响 — 请在下面留下评论,或者更好用了,通过参加会议、加入邮件列表、或者对草案提供反馈来参与 [IETF][35] 的工作。
|
||||
|
||||
感谢 Martin Thomson 和 Brian Trammell 的评论。
|
||||
|
||||
_Mark Nottingham 是因特网架构委员会的成员和 IETF 的 HTTP 和 QUIC 工作组的共同主持人。_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.apnic.net/2017/12/12/internet-protocols-changing/
|
||||
|
||||
作者:[Mark Nottingham][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.apnic.net/author/mark-nottingham/
|
||||
[1]:https://blog.apnic.net/2017/11/17/ietf-100-singapore-dns-http-doh/
|
||||
[2]:https://blog.apnic.net/author/mark-nottingham/
|
||||
[3]:https://blog.apnic.net/category/tech-matters/
|
||||
[4]:https://blog.apnic.net/tag/dns/
|
||||
[5]:https://blog.apnic.net/tag/doh/
|
||||
[6]:https://blog.apnic.net/tag/guest-post/
|
||||
[7]:https://blog.apnic.net/tag/http/
|
||||
[8]:https://blog.apnic.net/tag/ietf/
|
||||
[9]:https://blog.apnic.net/tag/quic/
|
||||
[10]:https://blog.apnic.net/tag/tls/
|
||||
[11]:https://blog.apnic.net/tag/protocol/
|
||||
[12]:https://blog.apnic.net/2017/12/12/internet-protocols-changing/#comments
|
||||
[13]:https://blog.apnic.net/
|
||||
[14]:https://www.smashingmagazine.com/2015/09/why-performance-matters-the-perception-of-time/
|
||||
[15]:https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/46197.pdf
|
||||
[16]:https://http2.github.io/
|
||||
[17]:http://httpwg.org/specs/rfc7540.html#TLSUsage
|
||||
[18]:http://httpwg.org/specs/rfc7540.html#BadCipherSuites
|
||||
[19]:http://httpwg.org/specs/rfc7540.html#reuse
|
||||
[20]:https://tools.ietf.org/html/draft-bishop-httpbis-http2-additional-certs
|
||||
[21]:https://datatracker.ietf.org/doc/draft-ietf-tls-tls13/
|
||||
[22]:https://en.wikipedia.org/wiki/Forward_secrecy
|
||||
[23]:https://quicwg.github.io/
|
||||
[24]:https://blog.apnic.net/2016/08/30/questions-answered-quic/
|
||||
[25]:https://quicwg.github.io/base-drafts/draft-ietf-quic-transport.html#short-header
|
||||
[26]:https://www.mjkranch.com/docs/CODASPY17_Kranch_Reed_IdentifyingHTTPSNetflix.pdf
|
||||
[27]:https://tools.ietf.org/html/draft-trammell-quic-spin
|
||||
[28]:https://datatracker.ietf.org/wg/doh/about/
|
||||
[29]:https://datatracker.ietf.org/meeting/99/materials/slides-99-maprg-fingerprint-based-detection-of-dns-hijacks-using-ripe-atlas/
|
||||
[30]:https://datatracker.ietf.org/wg/dprive/about/
|
||||
[31]:https://developers.google.com/speed/public-dns/
|
||||
[32]:https://quicwg.github.io/base-drafts/draft-ietf-quic-transport.html#rfc.section.3.7
|
||||
[33]:https://tools.ietf.org/html/rfc7258
|
||||
[34]:http://codebutler.com/firesheep
|
||||
[35]:https://www.ietf.org/
|
||||
|
||||
|
||||
Loading…
Reference in New Issue
Block a user