mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-19 22:51:41 +08:00
commit
271122873b
@ -1,36 +1,40 @@
|
||||
Python 版的 Nmon 分析器:让你远离 excel 宏
|
||||
======
|
||||
[Nigel's monitor][1],也叫做 "Nmon",是一个很好的监控,记录和分析 Linux/*nix 系统性能随时间变化的工具。Nmon 最初由 IBM 开发并于 2009 年夏天开源。时至今日 Nmon 已经在所有 linux 平台和架构上都可用了。它提供了大量的实时工具来可视化当前系统统计信息,这些统计信息包括 CPU,RAM,网络和磁盘 I/O。然而,Nmon 最棒的特性是可以随着时间的推移记录系统性能快照。
|
||||
比如:`nmon -f -s 1`。
|
||||
![nmon CPU and Disk utilization][2]
|
||||
会创建一个日志文件,该日志文件最开头是一些系统的元数据 T( 章节 AAA - BBBV),后面是定时抓取的监控系统属性的快照,比如 CPU 和内存的使用情况。这个文件很难直接由电子表格应用来处理,因此诞生了 [Nmon_Analyzer][3] excel 宏。如果你用的是 Windows/Mac 并安装了 Microsoft Office,那么这个工具非常不错。如果没有这个环境那也可以使用 Nmon2rrd 工具,这个工具能将日志文件转换 RRD 输入文件,进而生成图形。这个过程很死板而且有点麻烦。现在出现了一个更灵活的工具,像你们介绍一下 pyNmonAnalyzer,它一个可定制化的解决方案来生成结构化的 CSV 文件和基于 [matplotlib][4] 生成图片的简单 HTML 报告。
|
||||
|
||||
### 入门介绍:
|
||||
[Nigel's monitor][1],也叫做 “Nmon”,是一个很好的监控、记录和分析 Linux/*nix 系统性能随时间变化的工具。Nmon 最初由 IBM 开发并于 2009 年夏天开源。时至今日 Nmon 已经在所有 Linux 平台和架构上都可用了。它提供了很棒的当前系统统计信息的基于命令行的实时可视化报告,这些统计信息包括 CPU、RAM、网络和磁盘 I/O。然而,Nmon 最棒的特性是可以随着时间的推移记录系统性能快照。
|
||||
|
||||
比如:`nmon -f -s 1`。
|
||||
|
||||
![nmon CPU and Disk utilization][2]
|
||||
|
||||
会创建一个日志文件,该日志文件最开头是一些系统的元数据(AAA - BBBV 部分),后面是所监控的系统属性的定时快照,比如 CPU 和内存的使用情况。这个输出的文件很难直接由电子表格应用来处理,因此诞生了 [Nmon_Analyzer][3] excel 宏。如果你用的是 Windows/Mac 并安装了 Microsoft Office,那么这个工具非常不错。如果没有这个环境那也可以使用 Nmon2rrd 工具,这个工具能将日志文件转换 RRD 输入文件,进而生成图形。这个过程很死板而且有点麻烦。现在出现了一个更灵活的工具,我向你们介绍一下 pyNmonAnalyzer,它提供了一个可定制化的解决方案来生成结构化的 CSV 文件和带有用 [matplotlib][4] 生成的图片的简单 HTML 报告。
|
||||
|
||||
### 入门介绍
|
||||
|
||||
系统需求:
|
||||
|
||||
从名字中就能看出我们需要有 python。此外 pyNmonAnalyzer 还依赖于 matplotlib 和 numpy。若你使用的是 debian 衍生的系统,则你需要先安装这些包:
|
||||
```
|
||||
$> sudo apt-get install python-numpy python-matplotlib
|
||||
|
||||
```
|
||||
|
||||
##### 获取 pyNmonAnalyzer:
|
||||
|
||||
你可页克隆 git 仓库:
|
||||
```
|
||||
$> git clone git@github.com:madmaze/pyNmonAnalyzer.git
|
||||
|
||||
$ sudo apt-get install python-numpy python-matplotlib
|
||||
```
|
||||
|
||||
或者
|
||||
#### 获取 pyNmonAnalyzer:
|
||||
|
||||
直接从这里下载:[pyNmonAnalyzer-0.1.zip][5]
|
||||
你可以克隆 git 仓库:
|
||||
|
||||
接下来我们需要一个 Nmon 文件,如果没有的话,可以使用发行版中提供的实例或者自己录制一个样本:`nmon -F test.nmon -s 1 -c 120`,会录制每个 1 秒录制一次,供录制 120 个快照道 test.nmon 文件中 .nmon。
|
||||
```
|
||||
$ git clone git@github.com:madmaze/pyNmonAnalyzer.git
|
||||
```
|
||||
|
||||
或者,直接从这里下载:[pyNmonAnalyzer-0.1.zip][5] 。
|
||||
|
||||
接下来我们需要一个 Nmon 文件,如果没有的话,可以使用发行版中提供的实例或者自己录制一个样本:`nmon -F test.nmon -s 1 -c 120`,会录制 120 个快照,每秒一个,存储到 test.nmon 文件中。
|
||||
|
||||
让我们来看看基本的帮助信息:
|
||||
|
||||
```
|
||||
$> ./pyNmonAnalyzer.py -h
|
||||
$ ./pyNmonAnalyzer.py -h
|
||||
usage: pyNmonAnalyzer.py [-h] [-x] [-d] [-o OUTDIR] [-c] [-b] [-r CONFFNAME]
|
||||
input_file
|
||||
|
||||
@ -53,30 +57,29 @@ optional arguments:
|
||||
-r CONFFNAME, --reportConfig CONFFNAME
|
||||
Report config file, if none exists: we will write the
|
||||
default config file out (Default: ./report.config)
|
||||
|
||||
```
|
||||
|
||||
该工具有两个主要的选项
|
||||
|
||||
1。将 nmon 文件传唤成一系列独立的 CSV 文件
|
||||
2。使用 matplotlib 生成带图形的 HTML 报告
|
||||
|
||||
1. 将 nmon 文件传唤成一系列独立的 CSV 文件
|
||||
2. 使用 matplotlib 生成带图形的 HTML 报告
|
||||
|
||||
|
||||
下面命令既会生成 CSV 文件,也会生成 HTML 报告:
|
||||
```
|
||||
$> ./pyNmonAnalyzer.py -c -b test.nmon
|
||||
|
||||
```
|
||||
$ ./pyNmonAnalyzer.py -c -b test.nmon
|
||||
```
|
||||
|
||||
这会常见一个 `。/data` 目录,其中有一个存放 CSV 文件的目录 ("。/data/csv/"),一个存放 PNG 图片的目录 ("。/data/img/") 以及一个 HTML 报告 ("。/data/report.html")。
|
||||
这会创建一个 `./data` 目录,其中有一个存放 CSV 文件的目录 (`./data/csv/`),一个存放 PNG 图片的目录 (`./data/img/`) 以及一个 HTML 报告 (`./data/report.html`)。
|
||||
|
||||
默认情况下,HTML 报告中会用图片展示 CPU,磁盘繁忙度,内存使用情况和网络传输情况。所有这些都定义在一个自解释的配置文件中 ("report.config")。目前这个工具 h 那不是特别的灵活,因为 CPU 和 MEM 除了 on 和 off 外,无法做其他的配置。不过下一步将会改进作图的方法并允许用户灵活地指定针对哪些数据使用哪种作图方法。
|
||||
默认情况下,HTML 报告中会用图片展示 CPU、磁盘繁忙程度、内存使用情况和网络传输情况。所有这些都定义在一个不言自明的配置文件中 (`report.config`)。目前这个工具还不是特别的灵活,因为 CPU 和 MEM 除了 `on` 和 `off` 外,无法做其他的配置。不过下一步将会改进作图的方法并允许用户灵活地指定针对哪些数据使用哪种作图方法。
|
||||
|
||||
### 报告的例子:
|
||||
### 报告的例子
|
||||
|
||||
[![pyNmonAnalyzer Graph output][6]
|
||||
**Click to see the full Report**][7]
|
||||
![pyNmonAnalyzer Graph output][6]
|
||||
|
||||
[点击查看完整报告][7]
|
||||
|
||||
目前这些报告还十分的枯燥而且只能打印出基本的几种标记图表,不过它的功能还在不断的完善中。目前在开发的是一个向导来让配置调整变得更容易。如果有任何建议,找到任何 bug 或者有任何功能需求,欢迎与我交流。
|
||||
|
||||
@ -86,7 +89,7 @@ via: https://matthiaslee.com/python-nmon-analyzer-moving-away-from-excel-macros/
|
||||
|
||||
作者:[Matthias Lee][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
54
sources/talk/20180127 Write Dumb Code.md
Normal file
54
sources/talk/20180127 Write Dumb Code.md
Normal file
@ -0,0 +1,54 @@
|
||||
Write Dumb Code
|
||||
======
|
||||
The best way you can contribute to an open source project is to remove lines of code from it. We should endeavor to write code that a novice programmer can easily understand without explanation or that a maintainer can understand without significant time investment.
|
||||
|
||||
As students we attempt increasingly challenging problems with increasingly sophisticated technologies. We first learn loops, then functions, then classes, etc.. We are praised as we ascend this hierarchy, writing longer programs with more advanced technology. We learn that experienced programmers use monads while new programmers use for loops.
|
||||
|
||||
Then we graduate and find a job or open source project to work on with others. We search for something that we can add, and implement a solution pridefully, using the all the tricks that we learned in school.
|
||||
|
||||
Ah ha! I can extend this project to do X! And I can use inheritance here! Excellent!
|
||||
|
||||
We implement this feature and feel accomplished, and with good reason. Programming in real systems is no small accomplishment. This was certainly my experience. I was excited to write code and proud that I could show off all of the things that I knew how to do to the world. As evidence of my historical love of programming technology, here is a [linear algebra language][1] built with a another meta-programming language. Notice that no one has touched this code in several years.
|
||||
|
||||
However after maintaining code a bit more I now think somewhat differently.
|
||||
|
||||
1. We should not seek to build software. Software is the currency that we pay to solve problems, which is our actual goal. We should endeavor to build as little software as possible to solve our problems.
|
||||
2. We should use technologies that are as simple as possible, so that as many people as possible can use and extend them without needing to understand our advanced techniques. We should use advanced techniques only when we are not smart enough to figure out how to use more common techniques.
|
||||
|
||||
|
||||
|
||||
Neither of these points are novel. Most people I meet agree with them to some extent, but somehow we forget them when we go to contribute to a new project. The instinct to contribute by building and to demonstrate sophistication often take over.
|
||||
|
||||
### Software is a cost
|
||||
|
||||
Every line that you write costs people time. It costs you time to write it of course, but you are willing to make this personal sacrifice. However this code also costs the reviewers their time to understand it. It costs future maintainers and developers their time as they fix and modify your code. They could be spending this time outside in the sunshine or with their family.
|
||||
|
||||
So when you add code to a project you should feel meek. It should feel as though you are eating with your family and there isn't enough food on the table. You should take only what you need and no more. The people with you will respect you for your efforts to restrict yourself. Solving problems with less code is a hard, but it is a burden that you take on yourself to lighten the burdens of others.
|
||||
|
||||
### Complex technologies are harder to maintain
|
||||
|
||||
As students, we demonstrate merit by using increasingly advanced technologies. Our measure of worth depends on our ability to use functions, then classes, then higher order functions, then monads, etc. in public projects. We show off our solutions to our peers and feel pride or shame according to our sophistication.
|
||||
|
||||
However when working with a team to solve problems in the world the situation is reversed. Now we strive to solve problems with code that is as simple as possible. When we solve a problem simply we enable junior programmers to extend our solution to solve other problems. Simple code enables others and boosts our impact. We demonstrate our value by solving hard problems with only basic techniques.
|
||||
|
||||
Look! I replaced this recursive function with a for loop and it still does everything that we need it to. I know it's not as clever, but I noticed that the interns were having trouble with it and I thought that this change might help.
|
||||
|
||||
If you are a good programmer then you don't need to demonstrate that you know cool tricks. Instead, you can demonstrate your value by solving a problem in a simple way that enables everyone on your team to contribute in the future.
|
||||
|
||||
### But moderation, of course
|
||||
|
||||
That being said, over-adherence to the "build things with simple tools" dogma can be counter productive. Often a recursive solution can be much simpler than a for-loop solution and often times using a Class or a Monad is the right approach. But we should be mindful when using these technologies that we are building for ourselves our own system; a system with which others have had no experience.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://matthewrocklin.com/blog/work/2018/01/27/write-dumb-code
|
||||
|
||||
作者:[Matthew Rocklin][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://matthewrocklin.com
|
||||
[1]:https://github.com/mrocklin/matrix-algebra
|
||||
107
sources/talk/20180128 Being open about data privacy.md
Normal file
107
sources/talk/20180128 Being open about data privacy.md
Normal file
@ -0,0 +1,107 @@
|
||||
Being open about data privacy
|
||||
======
|
||||

|
||||
|
||||
|
||||
Image by : opensource.com
|
||||
|
||||
Today is [Data Privacy Day][1], ("Data Protection Day" in Europe), and you might think that those of us in the open source world should think that all data should be free, [as information supposedly wants to be][2], but life's not that simple. That's for two main reasons:
|
||||
|
||||
1. Most of us (and not just in open source) believe there's at least some data about us that we might not feel happy sharing (I compiled an example list in [a post][3] I published a while ago).
|
||||
2. Many of us working in open source actually work for commercial companies or other organisations subject to legal requirements around what they can share.
|
||||
|
||||
|
||||
|
||||
So actually, data privacy is something that's important for pretty much everybody.
|
||||
|
||||
It turns out that the starting point for what data people and governments believe should be available for organisations to use is somewhat different between the U.S. and Europe, with the former generally providing more latitude for entities--particularly, the more cynical might suggest, large commercial entities--to use data they've collected about us as they will. Europe, on the other hand, has historically taken a more restrictive view, and on the 25th of May, Europe's view arguably will have triumphed.
|
||||
|
||||
### The impact of GDPR
|
||||
|
||||
That's a rather sweeping statement, but the fact remains that this is the date on which a piece of legislation called the General Data Protection Regulation (GDPR), enacted by the European Union in 2016, becomes enforceable. The GDPR basically provides a stringent set of rules about how personal data can be stored, what it can be used for, who can see it, and how long it can be kept. It also describes what personal data is--and it's a pretty broad set of items, from your name and home address to your medical records and on through to your computer's IP address.
|
||||
|
||||
What is important about the GDPR, though, is that it doesn't apply just to European companies, but to any organisation processing data about EU citizens. If you're an Argentinian, Japanese, U.S., or Russian company and you're collecting data about an EU citizen, you're subject to it.
|
||||
|
||||
"Pah!" you may say,1 "I'm not based in the EU: what can they do to me?" The answer is simple: If you want to continue doing any business in the EU, you'd better comply, because if you breach GDPR rules, you could be liable for up to four percent of your global revenues. Yes, that's global revenues: not just revenues in a particular country in Europe or across the EU, not just profits, but global revenues. Those are the sorts of numbers that should lead you to talk to your legal team, who will direct you to your exec team, who will almost immediately direct you to your IT group to make sure you're compliant in pretty short order.
|
||||
|
||||
This may seem like it's not particularly relevant to non-EU citizens, but it is. For most companies, it's going to be simpler and more efficient to implement the same protection measures for data associated with all customers, partners, and employees they deal with, rather than just targeting specific measures at EU citizens. This has got to be a good thing.2
|
||||
|
||||
However, just because GDPR will soon be applied to organisations across the globe doesn't mean that everything's fine and dandy3: it's not. We give away information about ourselves all the time--and permission for companies to use it.
|
||||
|
||||
There's a telling (though disputed) saying: "If you're not paying, you're the product." What this suggests is that if you're not paying for a service, then somebody else is paying to use your data. Do you pay to use Facebook? Twitter? Gmail? How do you think they make their money? Well, partly through advertising, and some might argue that's a service they provide to you, but actually that's them using your data to get money from the advertisers. You're not really a customer of advertising--it's only once you buy something from the advertiser that you become their customer, but until you do, the relationship is between the the owner of the advertising platform and the advertiser.
|
||||
|
||||
Some of these services allow you to pay to reduce or remove advertising (Spotify is a good example), but on the other hand, advertising may be enabled even for services that you think you do pay for (Amazon is apparently working to allow adverts via Alexa, for instance). Unless we want to start paying to use all of these "free" services, we need to be aware of what we're giving up, and making some choices about what we expose and what we don't.
|
||||
|
||||
### Who's the customer?
|
||||
|
||||
There's another issue around data that should be exercising us, and it's a direct consequence of the amounts of data that are being generated. There are many organisations out there--including "public" ones like universities, hospitals, or government departments4--who generate enormous quantities of data all the time, and who just don't have the capacity to store it. It would be a different matter if this data didn't have long-term value, but it does, as the tools for handling Big Data are developing, and organisations are realising they can be mining this now and in the future.
|
||||
|
||||
The problem they face, though, as the amount of data increases and their capacity to store it fails to keep up, is what to do with it. Luckily--and I use this word with a very heavy dose of irony,5 big corporations are stepping in to help them. "Give us your data," they say, "and we'll host it for free. We'll even let you use the data you collected when you want to!" Sounds like a great deal, yes? A fantastic example of big corporations6 taking a philanthropic stance and helping out public organisations that have collected all of that lovely data about us.
|
||||
|
||||
Sadly, philanthropy isn't the only reason. These hosting deals come with a price: in exchange for agreeing to host the data, these corporations get to sell access to it to third parties. And do you think the public organisations, or those whose data is collected, will get a say in who these third parties are or how they will use it? I'll leave this as an exercise for the reader.7
|
||||
|
||||
### Open and positive
|
||||
|
||||
It's not all bad news, however. There's a growing "open data" movement among governments to encourage departments to make much of their data available to the public and other bodies for free. In some cases, this is being specifically legislated. Many voluntary organisations--particularly those receiving public funding--are starting to do the same. There are glimmerings of interest even from commercial organisations. What's more, there are techniques becoming available, such as those around differential privacy and multi-party computation, that are beginning to allow us to mine data across data sets without revealing too much about individuals--a computing problem that has historically been much less tractable than you might otherwise expect.
|
||||
|
||||
What does this all mean to us? Well, I've written before on Opensource.com about the [commonwealth of open source][4], and I'm increasingly convinced that we need to look beyond just software to other areas: hardware, organisations, and, relevant to this discussion, data. Let's imagine that you're a company (A) that provides a service to another company, a customer (B).8 There are four different types of data in play:
|
||||
|
||||
1. Data that's fully open: visible to A, B, and the rest of the world
|
||||
2. Data that's known, shared, and confidential: visible to A and B, but nobody else
|
||||
3. Data that's company-confidential: visible to A, but not B
|
||||
4. Data that's customer-confidential: visible to B, but not A
|
||||
|
||||
|
||||
|
||||
First of all, maybe we should be a bit more open about data and default to putting it into bucket 1. That data--on self-driving cars, voice recognition, mineral deposits, demographic statistics--could be enormously useful if it were available to everyone.9 Also, wouldn't it be great if we could find ways to make the data in buckets 2, 3, and 4--or at least some of it--available in bucket 1, whilst still keeping the details confidential? That's the hope for some of these new techniques being researched. They're a way off, though, so don't get too excited, and in the meantime, start thinking about making more of your data open by default.
|
||||
|
||||
### Some concrete steps
|
||||
|
||||
So, what can we do around data privacy and being open? Here are a few concrete steps that occurred to me: please use the comments to contribute more.
|
||||
|
||||
* Check to see whether your organisation is taking GDPR seriously. If it isn't, push for it.
|
||||
* Default to encrypting sensitive data (or hashing where appropriate), and deleting when it's no longer required--there's really no excuse for data to be in the clear to these days except for when it's actually being processed.
|
||||
* Consider what information you disclose when you sign up to services, particularly social media.
|
||||
* Discuss this with your non-technical friends.
|
||||
* Educate your children, your friends' children, and their friends. Better yet, go and talk to their teachers about it and present something in their schools.
|
||||
* Encourage the organisations you work for, volunteer for, or interact with to make data open by default. Rather than thinking, "why should I make this public?" start with "why shouldn't I make this public?"
|
||||
* Try accessing some of the open data sources out there. Mine it, create apps that use it, perform statistical analyses, draw pretty graphs,10 make interesting music, but consider doing something with it. Tell the organisations that sourced it, thank them, and encourage them to do more.
|
||||
|
||||
|
||||
|
||||
1. Though you probably won't, I admit.
|
||||
|
||||
2. Assuming that you believe that your personal data should be protected.
|
||||
|
||||
3. If you're wondering what "dandy" means, you're not alone at this point.
|
||||
|
||||
4. Exactly how public these institutions seem to you will probably depend on where you live: [YMMV][5].
|
||||
|
||||
5. And given that I'm British, that's a really very, very heavy dose.
|
||||
|
||||
6. And they're likely to be big corporations: nobody else can afford all of that storage and the infrastructure to keep it available.
|
||||
|
||||
7. No. The answer's "no."
|
||||
|
||||
8. Although the example works for people, too. Oh, look: A could be Alice, B could be Bob…
|
||||
|
||||
9. Not that we should be exposing personal data or data that actually needs to be confidential, of course--not that type of data.
|
||||
|
||||
10. A friend of mine decided that it always seemed to rain when she picked her children up from school, so to avoid confirmation bias, she accessed rainfall information across the school year and created graphs that she shared on social media.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/being-open-about-data-privacy
|
||||
|
||||
作者:[Mike Bursell][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/mikecamel
|
||||
[1]:https://en.wikipedia.org/wiki/Data_Privacy_Day
|
||||
[2]:https://en.wikipedia.org/wiki/Information_wants_to_be_free
|
||||
[3]:https://aliceevebob.wordpress.com/2017/06/06/helping-our-governments-differently/
|
||||
[4]:https://opensource.com/article/17/11/commonwealth-open-source
|
||||
[5]:http://www.outpost9.com/reference/jargon/jargon_40.html#TAG2036
|
||||
@ -0,0 +1,87 @@
|
||||
How To Turn On/Off Colors For ls Command In Bash On a Linux/Unix
|
||||
======
|
||||
|
||||
How do I turn on or off file name colors (ls command colors) in bash shell on a Linux or Unix like operating systems?
|
||||
|
||||
Most modern Linux distributions and Unix systems comes with alias that defines colors for your file. However, ls command is responsible for displaying color on screen for files, directories and other file system objects.
|
||||
|
||||
By default, color is not used to distinguish types of files. You need to pass --color option to the ls command on Linux. If you are using OS X or BSD based system pass -G option to the ls command. The syntax is as follows to turn on or off colors.
|
||||
|
||||
#### How to turn off colors for ls command
|
||||
|
||||
Type the following command
|
||||
`$ ls --color=none`
|
||||
Or just remove alias with the unalias command:
|
||||
`$ unalias ls`
|
||||
Please note that the following bash shell aliases are defined to display color with the ls command. Use combination of [alias command][1] and [grep command][2] as follows:
|
||||
`$ alias | grep ls`
|
||||
Sample outputs
|
||||
```
|
||||
alias l='ls -CF'
|
||||
alias la='ls -A'
|
||||
alias ll='ls -alF'
|
||||
alias ls='ls --color=auto'
|
||||
```
|
||||
|
||||
#### How to turn on colors for ls command
|
||||
|
||||
Use any one of the following command:
|
||||
```
|
||||
$ ls --color=auto
|
||||
$ ls --color=tty
|
||||
```
|
||||
[Define bash shell aliases ][3]if you want:
|
||||
`alias ls='ls --color=auto'`
|
||||
You can add or remove ls command alias to the ~/.bash_profile or [~/.bashrc file][4]. Edit file using a text editor such as vi command:
|
||||
`$ vi ~/.bashrc`
|
||||
Append the following code:
|
||||
```
|
||||
# my ls command aliases #
|
||||
alias ls = 'ls --color=auto'
|
||||
```
|
||||
|
||||
[Save and close the file in Vi/Vim text editor][5].
|
||||
|
||||
#### A note about *BSD/macOS/Apple OS X ls command
|
||||
|
||||
Pass the -G option to ls command to enable colorized output on a {Free,Net,Open}BSD or macOS and Apple OS X Unix family of operating systems:
|
||||
`$ ls -G`
|
||||
Sample outputs:
|
||||
[![How to enable colorized output for the ls command in Mac OS X Terminal][6]][7]
|
||||
How to enable colorized output for the ls command in Mac OS X Terminal
|
||||
|
||||
#### How do I skip colorful ls command output temporarily?
|
||||
|
||||
You can always [disable bash shell aliases temporarily][8] using any one of the following syntax:
|
||||
`\ls
|
||||
/bin/ls
|
||||
command ls
|
||||
'ls'`
|
||||
|
||||
|
||||
#### About the author
|
||||
|
||||
The author is the creator of nixCraft and a seasoned sysadmin and a trainer for the Linux operating system/Unix shell scripting. He has worked with global clients and in various industries, including IT, education, defense and space research, and the nonprofit sector. Follow him on [Twitter][9], [Facebook][10], [Google+][11].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/how-to-turn-on-or-off-colors-in-bash/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz/
|
||||
[1]:https://www.cyberciti.biz/tips/bash-aliases-mac-centos-linux-unix.html (See Linux/Unix alias command examples for more info)
|
||||
[2]:https://www.cyberciti.biz/faq/howto-use-grep-command-in-linux-unix/ (See Linux/Unix grep command examples for more info)
|
||||
[3]:https://www.cyberciti.biz/tips/bash-aliases-mac-centos-linux-unix.html
|
||||
[4]:https://bash.cyberciti.biz/guide/~/.bashrc
|
||||
[5]:https://www.cyberciti.biz/faq/linux-unix-vim-save-and-quit-command/
|
||||
[6]:https://www.cyberciti.biz/media/new/faq/2016/01/color-ls-for-Mac-OS-X.jpg
|
||||
[7]:https://www.cyberciti.biz/faq/apple-mac-osx-terminal-color-ls-output-option/
|
||||
[8]:https://www.cyberciti.biz/faq/bash-shell-temporarily-disable-an-alias/
|
||||
[9]:https://twitter.com/nixcraft
|
||||
[10]:https://facebook.com/nixcraft
|
||||
[11]:https://plus.google.com/+CybercitiBiz
|
||||
@ -1,173 +0,0 @@
|
||||
#Translating by qhwdw [Tail Calls, Optimization, and ES6][1]
|
||||
|
||||
|
||||
In this penultimate post about the stack, we take a quick look at tail calls, compiler optimizations, and the proper tail calls landing in the newest version of JavaScript.
|
||||
|
||||
A tail call happens when a function F makes a function call as its final action. At that point F will do absolutely no more work: it passes the ball to whatever function is being called and vanishes from the game. This is notable because it opens up the possibility of tail call optimization: instead of [creating a new stack frame][6] for the function call, we can simply reuse F's stack frame, thereby saving stack space and avoiding the work involved in setting up a new frame. Here are some examples in C and their results compiled with [mild optimization][7]:
|
||||
|
||||
Simple Tail Calls[download][2]
|
||||
|
||||
```
|
||||
int add5(int a)
|
||||
{
|
||||
return a + 5;
|
||||
}
|
||||
|
||||
int add10(int a)
|
||||
{
|
||||
int b = add5(a); // not tail
|
||||
return add5(b); // tail
|
||||
}
|
||||
|
||||
int add5AndTriple(int a){
|
||||
int b = add5(a); // not tail
|
||||
return 3 * add5(a); // not tail, doing work after the call
|
||||
}
|
||||
|
||||
int finicky(int a){
|
||||
if (a > 10){
|
||||
return add5AndTriple(a); // tail
|
||||
}
|
||||
|
||||
if (a > 5){
|
||||
int b = add5(a); // not tail
|
||||
return finicky(b); // tail
|
||||
}
|
||||
|
||||
return add10(a); // tail
|
||||
}
|
||||
```
|
||||
|
||||
You can normally spot tail call optimization (hereafter, TCO) in compiler output by seeing a [jump][8] instruction where a [call][9] would have been expected. At runtime TCO leads to a reduced call stack.
|
||||
|
||||
A common misconception is that tail calls are necessarily [recursive][10]. That's not the case: a tail call may be recursive, such as in finicky() above, but it need not be. As long as caller F is completely done at the call site, we've got ourselves a tail call. Whether it can be optimized is a different question whose answer depends on your programming environment.
|
||||
|
||||
"Yes, it can, always!" is the best answer we can hope for, which is famously the case for Scheme, as discussed in [SICP][11] (by the way, if when you program you don't feel like "a Sorcerer conjuring the spirits of the computer with your spells," I urge you to read that book). It's also the case for [Lua][12]. And most importantly, it is the case for the next version of JavaScript, ES6, whose spec does a good job defining [tail position][13] and clarifying the few conditions required for optimization, such as [strict mode][14]. When a language guarantees TCO, it supports proper tail calls.
|
||||
|
||||
Now some of us can't kick that C habit, heart bleed and all, and the answer there is a more complicated "sometimes" that takes us into compiler optimization territory. We've seen the [simple examples][15] above; now let's resurrect our factorial from [last post][16]:
|
||||
|
||||
Recursive Factorial[download][3]
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
|
||||
int factorial(int n)
|
||||
{
|
||||
int previous = 0xdeadbeef;
|
||||
|
||||
if (n == 0 || n == 1) {
|
||||
return 1;
|
||||
}
|
||||
|
||||
previous = factorial(n-1);
|
||||
return n * previous;
|
||||
}
|
||||
|
||||
int main(int argc)
|
||||
{
|
||||
int answer = factorial(5);
|
||||
printf("%d\n", answer);
|
||||
}
|
||||
```
|
||||
|
||||
So, is line 11 a tail call? It's not, because of the multiplication by n afterwards. But if you're not used to optimizations, gcc's [result][17] with [O2 optimization][18] might shock you: not only it transforms factorial into a [recursion-free loop][19], but the factorial(5) call is eliminated entirely and replaced by a [compile-time constant][20] of 120 (5! == 120). This is why debugging optimized code can be hard sometimes. On the plus side, if you call this function it will use a single stack frame regardless of n's initial value. Compiler algorithms are pretty fun, and if you're interested I suggest you check out [Building an Optimizing Compiler][21] and [ACDI][22].
|
||||
|
||||
However, what happened here was not tail call optimization, since there was no tail call to begin with. gcc outsmarted us by analyzing what the function does and optimizing away the needless recursion. The task was made easier by the simple, deterministic nature of the operations being done. By adding a dash of chaos (e.g., getpid()) we can throw gcc off:
|
||||
|
||||
Recursive PID Factorial[download][4]
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
#include <sys/types.h>
|
||||
#include <unistd.h>
|
||||
|
||||
int pidFactorial(int n)
|
||||
{
|
||||
if (1 == n) {
|
||||
return getpid(); // tail
|
||||
}
|
||||
|
||||
return n * pidFactorial(n-1) * getpid(); // not tail
|
||||
}
|
||||
|
||||
int main(int argc)
|
||||
{
|
||||
int answer = pidFactorial(5);
|
||||
printf("%d\n", answer);
|
||||
}
|
||||
```
|
||||
|
||||
Optimize that, unix fairies! So now we have a regular [recursive call][23] and this function allocates O(n) stack frames to do its work. Heroically, gcc still does [TCO for getpid][24] in the recursion base case. If we now wished to make this function tail recursive, we'd need a slight change:
|
||||
|
||||
tailPidFactorial.c[download][5]
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
#include <sys/types.h>
|
||||
#include <unistd.h>
|
||||
|
||||
int tailPidFactorial(int n, int acc)
|
||||
{
|
||||
if (1 == n) {
|
||||
return acc * getpid(); // not tail
|
||||
}
|
||||
|
||||
acc = (acc * getpid() * n);
|
||||
return tailPidFactorial(n-1, acc); // tail
|
||||
}
|
||||
|
||||
int main(int argc)
|
||||
{
|
||||
int answer = tailPidFactorial(5, 1);
|
||||
printf("%d\n", answer);
|
||||
}
|
||||
```
|
||||
|
||||
The accumulation of the result is now [a loop][25] and we've achieved true TCO. But before you go out partying, what can we say about the general case in C? Sadly, while good C compilers do TCO in a number of cases, there are many situations where they cannot do it. For example, as we saw in our [function epilogues][26], the caller is responsible for cleaning up the stack after a function call using the standard C calling convention. So if function F takes two arguments, it can only make TCO calls to functions taking two or fewer arguments. This is one among many restrictions. Mark Probst wrote an excellent thesis discussing [Proper Tail Recursion in C][27] where he discusses these issues along with C stack behavior. He also does [insanely cool juggling][28].
|
||||
|
||||
"Sometimes" is a rocky foundation for any relationship, so you can't rely on TCO in C. It's a discrete optimization that may or may not take place, rather than a language feature like proper tail calls, though in practice the compiler will optimize the vast majority of cases. But if you must have it, say for transpiling Scheme into C, you will [suffer][29].
|
||||
|
||||
Since JavaScript is now the most popular transpilation target, proper tail calls become even more important there. So kudos to ES6 for delivering it along with many other significant improvements. It's like Christmas for JS programmers.
|
||||
|
||||
This concludes our brief tour of tail calls and compiler optimization. Thanks for reading and see you next time.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:https://manybutfinite.com/post/tail-calls-optimization-es6/
|
||||
|
||||
作者:[Gustavo Duarte][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://duartes.org/gustavo/blog/about/
|
||||
[1]:https://manybutfinite.com/post/tail-calls-optimization-es6/
|
||||
[2]:https://manybutfinite.com/code/x86-stack/tail.c
|
||||
[3]:https://manybutfinite.com/code/x86-stack/factorial.c
|
||||
[4]:https://manybutfinite.com/code/x86-stack/pidFactorial.c
|
||||
[5]:https://manybutfinite.com/code/x86-stack/tailPidFactorial.c
|
||||
[6]:https://manybutfinite.com/post/journey-to-the-stack
|
||||
[7]:https://github.com/gduarte/blog/blob/master/code/x86-stack/asm-tco.sh
|
||||
[8]:https://github.com/gduarte/blog/blob/master/code/x86-stack/tail-tco.s#L27
|
||||
[9]:https://github.com/gduarte/blog/blob/master/code/x86-stack/tail.s#L37-L39
|
||||
[10]:https://manybutfinite.com/post/recursion/
|
||||
[11]:http://mitpress.mit.edu/sicp/full-text/book/book-Z-H-11.html
|
||||
[12]:http://www.lua.org/pil/6.3.html
|
||||
[13]:https://people.mozilla.org/~jorendorff/es6-draft.html#sec-tail-position-calls
|
||||
[14]:https://people.mozilla.org/~jorendorff/es6-draft.html#sec-strict-mode-code
|
||||
[15]:https://github.com/gduarte/blog/blob/master/code/x86-stack/tail.c
|
||||
[16]:https://manybutfinite.com/post/recursion/
|
||||
[17]:https://github.com/gduarte/blog/blob/master/code/x86-stack/factorial-o2.s
|
||||
[18]:https://gcc.gnu.org/onlinedocs/gcc/Optimize-Options.html
|
||||
[19]:https://github.com/gduarte/blog/blob/master/code/x86-stack/factorial-o2.s#L16-L19
|
||||
[20]:https://github.com/gduarte/blog/blob/master/code/x86-stack/factorial-o2.s#L38
|
||||
[21]:http://www.amazon.com/Building-Optimizing-Compiler-Bob-Morgan-ebook/dp/B008COCE9G/
|
||||
[22]:http://www.amazon.com/Advanced-Compiler-Design-Implementation-Muchnick-ebook/dp/B003VM7GGK/
|
||||
[23]:https://github.com/gduarte/blog/blob/master/code/x86-stack/pidFactorial-o2.s#L20
|
||||
[24]:https://github.com/gduarte/blog/blob/master/code/x86-stack/pidFactorial-o2.s#L43
|
||||
[25]:https://github.com/gduarte/blog/blob/master/code/x86-stack/tailPidFactorial-o2.s#L22-L27
|
||||
[26]:https://manybutfinite.com/post/epilogues-canaries-buffer-overflows/
|
||||
[27]:http://www.complang.tuwien.ac.at/schani/diplarb.ps
|
||||
[28]:http://www.complang.tuwien.ac.at/schani/jugglevids/index.html
|
||||
[29]:http://en.wikipedia.org/wiki/Tail_call#Through_trampolining
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by MjSeven
|
||||
How To Install And Setup Vagrant
|
||||
======
|
||||
Vagrant is a powerful tool when it comes to virtual machines, here we will look at how to setup and use Vagrant with Virtualbox on Ubuntu to provision reproducible virtual machines.
|
||||
|
||||
@ -1,112 +0,0 @@
|
||||
Translating by Yinr
|
||||
|
||||
Multimedia Apps for the Linux Console
|
||||
======
|
||||
|
||||

|
||||
The Linux console supports multimedia, so you can enjoy music, movies, photos, and even read PDF files.
|
||||
|
||||
When last we met, we learned that the Linux console supports multimedia. Yes, really! You can enjoy music, movies, photos, and even read PDF files without being in an X session with MPlayer, fbi, and fbgs. And, as a bonus, you can enjoy a Matrix-style screensaver for the console, CMatrix.
|
||||
|
||||
You will probably have make some tweaks to your system to make this work. The examples used here are for Ubuntu Linux 16.04.
|
||||
|
||||
### MPlayer
|
||||
|
||||
You're probably familiar with the amazing and versatile MPlayer, which supports almost every video and audio format, and runs on nearly everything, including Linux, Android, Windows, Mac, Kindle, OS/2, and AmigaOS. Using MPLayer in your console will probably require some tweaking, depending on your Linux distribution. To start, try playing a video:
|
||||
```
|
||||
$ mplayer [video name]
|
||||
|
||||
```
|
||||
|
||||
If it works, then hurrah, and you can invest your time in learning useful MPlayer options, such as controlling the size of the video screen. However, some Linux distributions are managing the framebuffer differently than in the olden days, and you may have to adjust some settings to make it work. This is how to make it work on recent Ubuntu releases.
|
||||
|
||||
First, add yourself to the video group.
|
||||
|
||||
Second, verify that `/etc/modprobe.d/blacklist-framebuffer.conf` has this line: `#blacklist vesafb`. It should already be commented out, and if it isn't then comment it. All the other module lines should be un-commented, which prevents them from loading. Side note: if you want to dig more deeply into managing your framebuffer, the module for your video card may give better performance.
|
||||
|
||||
Add these two modules to the end of `/etc/initramfs-tools/modules`, `vesafb` and `fbcon`, then rebuild the initramfs image:
|
||||
```
|
||||
$ sudo nano /etc/initramfs-tools/modules
|
||||
# List of modules that you want to include in your initramfs.
|
||||
# They will be loaded at boot time in the order below.
|
||||
fbcon
|
||||
vesafb
|
||||
|
||||
$ sudo update-initramfs -u
|
||||
|
||||
```
|
||||
|
||||
[fbcon][1] is the Linux framebuffer console. It runs on top of the framebuffer and adds graphical features. It requires a framebuffer device, which is supplied by the `vesafb` module.
|
||||
|
||||
Now you must edit your GRUB2 configuration. In `/etc/default/grub` you should see a line like this:
|
||||
```
|
||||
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash"
|
||||
|
||||
```
|
||||
|
||||
It may have some other options, but it should be there. Add `vga=789`:
|
||||
```
|
||||
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash vga=789"
|
||||
|
||||
```
|
||||
|
||||
Reboot and enter your console (Ctrl+Alt+F1), and try playing a video. This command selects the `fbdev2` video device; I haven't learned yet how to know which one to use, but I had to use it to play the video. The default screen size is 320x240, so I scaled it to 960:
|
||||
```
|
||||
$ mplayer -vo fbdev2 -vf scale -zoom -xy 960 AlienSong_mp4.mov
|
||||
```
|
||||
|
||||
And behold Figure 1. It's grainy because I have a low-fi copy of this video, not because MPlayer is making it grainy.
|
||||
|
||||
MPLayer plays CDs, DVDs, network streams, and has a giant batch of playback options, which I shall leave as your homework to explore.
|
||||
|
||||
### fbi Image Viewer
|
||||
|
||||
`fbi`, the framebuffer image viewer, comes in the [fbida][2] package on most Linuxes. It has native support for the common image file formats, and uses `convert` (from Image Magick), if it is installed, for other formats. Its simplest use is to view a single image file:
|
||||
```
|
||||
$ fbi filename
|
||||
|
||||
```
|
||||
|
||||
Use the arrow keys to scroll a large image, + and - to zoom, and r and l to rotate 90 degress right and left. Press the Escape key to close the image. You can play a slideshow by giving `fbi` a list of files:
|
||||
```
|
||||
$ fbi --list file-list.txt
|
||||
|
||||
```
|
||||
|
||||
`fbi` supports autozoom. With `-a` `fbi` controls the zoom factor. `--autoup` and `--autodown` tell `fbi` to only zoom up or down. Control the blend time between images with `--blend [time]`, in milliseconds. Press the k and j keys to jump behind and ahead in your file list.
|
||||
|
||||
`fbi` has commands for creating file lists from images you have viewed, and for exporting your commands to a file, and a host of other cool options. Check out `man fbi` for complete options.
|
||||
|
||||
### CMatrix Console Screensaver
|
||||
|
||||
The Matrix screensaver is still my favorite (Figure 2), second only to the bouncing cow. [CMatrix][3] runs on the console. Simply type `cmatrix` to start it, and Ctrl+C stops it. Run `cmatrix -s` to launch it in screensaver mode, which exits on any keypress. `-C` changes the color. Your choices are green, red, blue, yellow, white, magenta, cyan, and black.
|
||||
|
||||
CMatrix supports asynchronous key presses, which means you can change options while it's running.
|
||||
|
||||
`-B` is all bold text, and `-B` is partially bold.
|
||||
|
||||
### fbgs PDF Viewer
|
||||
|
||||
It seems that the addiction to PDF documents is pandemic and incurable, though PDFs are better than they used to be, with live hyperlinks, copy-paste, and good text search. The `fbgs` console PDF viewer is part of the `fbida` package. Options include page size, resolution, page selections, and most `fbi` options, with the exceptions listed in `man fbgs`. The main option I use is page size; you get `-l`, `xl`, and `xxl` to choose from:
|
||||
```
|
||||
$ fbgs -xl annoyingpdf.pdf
|
||||
|
||||
```
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][4]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/1/multimedia-apps-linux-console
|
||||
|
||||
作者:[Carla Schroder][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.mjmwired.net/kernel/Documentation/fb/fbcon.txt
|
||||
[2]:https://www.kraxel.org/blog/linux/fbida/
|
||||
[3]:http://www.asty.org/cmatrix/
|
||||
[4]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,63 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
How To Boot Into Linux Command Line
|
||||
======
|
||||

|
||||
|
||||
There may be times where you need or want to boot up a [Linux][1] system without using a GUI, that is with no X, but rather opt for the command line. Whatever the reason, fortunately, booting straight into the Linux **command-line** is very simple. It requires a simple change to the boot parameter after the other kernel options. This change specifies the runlevel to boot the system into.
|
||||
|
||||
### Why Do This?
|
||||
|
||||
If your system does not run Xorg because the configuration is invalid, or if the display manager is broken, or whatever may prevent the GUI from starting properly, booting into the command-line will allow you to troubleshoot by logging into a terminal (assuming you know what you’re doing to start with) and do whatever you need to do. Booting into the command-line is also a great way to become more familiar with the terminal, otherwise, you can do it just for fun.
|
||||
|
||||
### Accessing GRUB Menu
|
||||
|
||||
On startup, you will need access to the GRUB boot menu. You may need to hold the SHIFT key down before the system boots if the menu isn’t set to display every time the computer is started. In the menu, the [Linux distribution][2] entry must be selected. Once highlighted, press ‘e’ to edit the boot parameters.
|
||||
|
||||
[][3]
|
||||
|
||||
Older GRUB versions follow a similar mechanism. The boot manager should provide instructions on how to edit the boot parameters.
|
||||
|
||||
### Specify the Runlevel
|
||||
|
||||
An editor will appear and you will see the options that GRUB parses to the kernel. Navigate to the line that starts with ‘linux’ (older GRUB versions may be ‘kernel’; select that and follow the instructions). This specifies parameters to parse into the kernel. At the end of that line (may appear to span multiple lines, depending on resolution), you simply specify the runlevel to boot into, which is 3 (multi-user mode, text-only).
|
||||
|
||||
[][4]
|
||||
|
||||
Pressing Ctrl-X or F10 will boot the system using those parameters. Boot-up will continue as normal. The only thing that has changed is the runlevel to boot into.
|
||||
|
||||
|
||||
|
||||
This is what was started up:
|
||||
|
||||
[][5]
|
||||
|
||||
### Runlevels
|
||||
|
||||
You can specify different runlevels to boot into with runlevel 5 being the default one. 1 boots into “single-user” mode, which boots into a root shell. 3 provides a multi-user, command-line only system.
|
||||
|
||||
### Switch From Command-Line
|
||||
|
||||
At some point, you may want to run the display manager again to use a GUI, and the quickest way to do that is running this:
|
||||
```
|
||||
$ sudo init 5
|
||||
```
|
||||
|
||||
And it is as simple as that. Personally, I find the command-line much more exciting and hands-on than using GUI tools; however, that’s just my preference.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/how-to-boot-into-linux-command-line
|
||||
|
||||
作者:[LinuxAndUbuntu][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com
|
||||
[1]:http://www.linuxandubuntu.com/home/category/linux
|
||||
[2]:http://www.linuxandubuntu.com/home/category/distros
|
||||
[3]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/gnu-grub_orig.png
|
||||
[4]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/runlevel_orig.png
|
||||
[5]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/runlevel_1_orig.png
|
||||
@ -0,0 +1,324 @@
|
||||
Creating an Adventure Game in the Terminal with ncurses
|
||||
======
|
||||
How to use curses functions to read the keyboard and manipulate the screen.
|
||||
|
||||
My [previous article][1] introduced the ncurses library and provided a simple program that demonstrated a few curses functions to put text on the screen. In this follow-up article, I illustrate how to use a few other curses functions.
|
||||
|
||||
### An Adventure
|
||||
|
||||
When I was growing up, my family had an Apple II computer. It was on this machine that my brother and I taught ourselves how to write programs in AppleSoft BASIC. After writing a few math puzzles, I moved on to creating games. Having grown up in the 1980s, I already was a fan of the Dungeons and Dragons tabletop games, where you role-played as a fighter or wizard on some quest to defeat monsters and plunder loot in strange lands. So it shouldn't be surprising that I also created a rudimentary adventure game.
|
||||
|
||||
The AppleSoft BASIC programming environment supported a neat feature: in standard resolution graphics mode (GR mode), you could probe the color of a particular pixel on the screen. This allowed a shortcut to create an adventure game. Rather than create and update an in-memory map that was transferred to the screen periodically, I could rely on GR mode to maintain the map for me, and my program could query the screen as the player's character moved around the screen. Using this method, I let the computer do most of the hard work. Thus, my top-down adventure game used blocky GR mode graphics to represent my game map.
|
||||
|
||||
My adventure game used a simple map that represented a large field with a mountain range running down the middle and a large lake on the upper-left side. I might crudely draw this map for a tabletop gaming campaign to include a narrow path through the mountains, allowing the player to pass to the far side.
|
||||
|
||||

|
||||
|
||||
Figure 1. A simple Tabletop Game Map with a Lake and Mountains
|
||||
|
||||
You can draw this map in cursesusing characters to represent grass, mountains and water. Next, I describe how to do just that using curses functions and how to create and play a similar adventure game in the Linux terminal.
|
||||
|
||||
### Constructing the Program
|
||||
|
||||
In my last article, I mentioned that most curses programs start with the same set of instructions to determine the terminal type and set up the curses environment:
|
||||
|
||||
```
|
||||
initscr();
|
||||
cbreak();
|
||||
noecho();
|
||||
|
||||
```
|
||||
|
||||
For this program, I add another statement:
|
||||
|
||||
```
|
||||
keypad(stdscr, TRUE);
|
||||
|
||||
```
|
||||
|
||||
The TRUE flag allows curses to read the keypad and function keys from the user's terminal. If you want to use the up, down, left and right arrow keys in your program, you need to use keypad(stdscr, TRUE) here.
|
||||
|
||||
Having done that, you now can start drawing to the terminal screen. The curses functions include several ways to draw text on the screen. In my previous article, I demonstrated the addch() and addstr() functions and their associated mvaddch() and mvaddstr() counterparts that first moved to a specific location on the screen before adding text. To create the adventure game map on the terminal, you can use another set of functions: vline() and hline(), and their partner functions mvvline() and mvhline(). These mv functions accept screen coordinates, a character to draw and how many times to repeat that character. For example, mvhline(1, 2, '-', 20) will draw a line of 20 dashes starting at line 1, column 2.
|
||||
|
||||
To draw the map to the terminal screen programmatically, let's define this draw_map() function:
|
||||
|
||||
```
|
||||
#define GRASS ' '
|
||||
#define EMPTY '.'
|
||||
#define WATER '~'
|
||||
#define MOUNTAIN '^'
|
||||
#define PLAYER '*'
|
||||
|
||||
void draw_map(void)
|
||||
{
|
||||
int y, x;
|
||||
|
||||
/* draw the quest map */
|
||||
|
||||
/* background */
|
||||
|
||||
for (y = 0; y < LINES; y++) {
|
||||
mvhline(y, 0, GRASS, COLS);
|
||||
}
|
||||
|
||||
/* mountains, and mountain path */
|
||||
|
||||
for (x = COLS / 2; x < COLS * 3 / 4; x++) {
|
||||
mvvline(0, x, MOUNTAIN, LINES);
|
||||
}
|
||||
|
||||
mvhline(LINES / 4, 0, GRASS, COLS);
|
||||
|
||||
/* lake */
|
||||
|
||||
for (y = 1; y < LINES / 2; y++) {
|
||||
mvhline(y, 1, WATER, COLS / 3);
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
In drawing this map, note the use of mvvline() and mvhline() to fill large chunks of characters on the screen. I created the fields of grass by drawing horizontal lines (mvhline) of characters starting at column 0, for the entire height and width of the screen. I added the mountains on top of that by drawing vertical lines (mvvline), starting at row 0, and a mountain path by drawing a single horizontal line (mvhline). And, I created the lake by drawing a series of short horizontal lines (mvhline). It may seem inefficient to draw overlapping rectangles in this way, but remember that curses doesn't actually update the screen until I call the refresh() function later.
|
||||
|
||||
Having drawn the map, all that remains to create the game is to enter a loop where the program waits for the user to press one of the up, down, left or right direction keys and then moves a player icon appropriately. If the space the player wants to move into is unoccupied, it allows the player to go there.
|
||||
|
||||
You can use curses as a shortcut. Rather than having to instantiate a version of the map in the program and replicate this map to the screen, you can let the screen keep track of everything for you. The inch() function, and associated mvinch() function, allow you to probe the contents of the screen. This allows you to query curses to find out whether the space the player wants to move into is already filled with water or blocked by mountains. To do this, you'll need a helper function that you'll use later:
|
||||
|
||||
```
|
||||
int is_move_okay(int y, int x)
|
||||
{
|
||||
int testch;
|
||||
|
||||
/* return true if the space is okay to move into */
|
||||
|
||||
testch = mvinch(y, x);
|
||||
return ((testch == GRASS) || (testch == EMPTY));
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
As you can see, this function probes the location at column y, row x and returns true if the space is suitably unoccupied, or false if not.
|
||||
|
||||
That makes it really easy to write a navigation loop: get a key from the keyboard and move the user's character around depending on the up, down, left and right arrow keys. Here's a simplified version of that loop:
|
||||
|
||||
```
|
||||
|
||||
do {
|
||||
ch = getch();
|
||||
|
||||
/* test inputted key and determine direction */
|
||||
|
||||
switch (ch) {
|
||||
case KEY_UP:
|
||||
if ((y > 0) && is_move_okay(y - 1, x)) {
|
||||
y = y - 1;
|
||||
}
|
||||
break;
|
||||
case KEY_DOWN:
|
||||
if ((y < LINES - 1) && is_move_okay(y + 1, x)) {
|
||||
y = y + 1;
|
||||
}
|
||||
break;
|
||||
case KEY_LEFT:
|
||||
if ((x > 0) && is_move_okay(y, x - 1)) {
|
||||
x = x - 1;
|
||||
}
|
||||
break;
|
||||
case KEY_RIGHT
|
||||
if ((x < COLS - 1) && is_move_okay(y, x + 1)) {
|
||||
x = x + 1;
|
||||
}
|
||||
break;
|
||||
}
|
||||
}
|
||||
while (1);
|
||||
|
||||
```
|
||||
|
||||
To use this in a game, you'll need to add some code inside the loop to allow other keys (for example, the traditional WASD movement keys), provide a method for the user to quit the game and move the player's character around the screen. Here's the program in full:
|
||||
|
||||
```
|
||||
|
||||
/* quest.c */
|
||||
|
||||
#include
|
||||
#include
|
||||
|
||||
#define GRASS ' '
|
||||
#define EMPTY '.'
|
||||
#define WATER '~'
|
||||
#define MOUNTAIN '^'
|
||||
#define PLAYER '*'
|
||||
|
||||
int is_move_okay(int y, int x);
|
||||
void draw_map(void);
|
||||
|
||||
int main(void)
|
||||
{
|
||||
int y, x;
|
||||
int ch;
|
||||
|
||||
/* initialize curses */
|
||||
|
||||
initscr();
|
||||
keypad(stdscr, TRUE);
|
||||
cbreak();
|
||||
noecho();
|
||||
|
||||
clear();
|
||||
|
||||
/* initialize the quest map */
|
||||
|
||||
draw_map();
|
||||
|
||||
/* start player at lower-left */
|
||||
|
||||
y = LINES - 1;
|
||||
x = 0;
|
||||
|
||||
do {
|
||||
/* by default, you get a blinking cursor - use it to indicate player */
|
||||
|
||||
mvaddch(y, x, PLAYER);
|
||||
move(y, x);
|
||||
refresh();
|
||||
|
||||
ch = getch();
|
||||
|
||||
/* test inputted key and determine direction */
|
||||
|
||||
switch (ch) {
|
||||
case KEY_UP:
|
||||
case 'w':
|
||||
case 'W':
|
||||
if ((y > 0) && is_move_okay(y - 1, x)) {
|
||||
mvaddch(y, x, EMPTY);
|
||||
y = y - 1;
|
||||
}
|
||||
break;
|
||||
case KEY_DOWN:
|
||||
case 's':
|
||||
case 'S':
|
||||
if ((y < LINES - 1) && is_move_okay(y + 1, x)) {
|
||||
mvaddch(y, x, EMPTY);
|
||||
y = y + 1;
|
||||
}
|
||||
break;
|
||||
case KEY_LEFT:
|
||||
case 'a':
|
||||
case 'A':
|
||||
if ((x > 0) && is_move_okay(y, x - 1)) {
|
||||
mvaddch(y, x, EMPTY);
|
||||
x = x - 1;
|
||||
}
|
||||
break;
|
||||
case KEY_RIGHT:
|
||||
case 'd':
|
||||
case 'D':
|
||||
if ((x < COLS - 1) && is_move_okay(y, x + 1)) {
|
||||
mvaddch(y, x, EMPTY);
|
||||
x = x + 1;
|
||||
}
|
||||
break;
|
||||
}
|
||||
}
|
||||
while ((ch != 'q') && (ch != 'Q'));
|
||||
|
||||
endwin();
|
||||
|
||||
exit(0);
|
||||
}
|
||||
|
||||
int is_move_okay(int y, int x)
|
||||
{
|
||||
int testch;
|
||||
|
||||
/* return true if the space is okay to move into */
|
||||
|
||||
testch = mvinch(y, x);
|
||||
return ((testch == GRASS) || (testch == EMPTY));
|
||||
}
|
||||
|
||||
void draw_map(void)
|
||||
{
|
||||
int y, x;
|
||||
|
||||
/* draw the quest map */
|
||||
|
||||
/* background */
|
||||
|
||||
for (y = 0; y < LINES; y++) {
|
||||
mvhline(y, 0, GRASS, COLS);
|
||||
}
|
||||
|
||||
/* mountains, and mountain path */
|
||||
|
||||
for (x = COLS / 2; x < COLS * 3 / 4; x++) {
|
||||
mvvline(0, x, MOUNTAIN, LINES);
|
||||
}
|
||||
|
||||
mvhline(LINES / 4, 0, GRASS, COLS);
|
||||
|
||||
/* lake */
|
||||
|
||||
for (y = 1; y < LINES / 2; y++) {
|
||||
mvhline(y, 1, WATER, COLS / 3);
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
In the full program listing, you can see the complete arrangement of curses functions to create the game:
|
||||
|
||||
1) Initialize the curses environment.
|
||||
|
||||
2) Draw the map.
|
||||
|
||||
3) Initialize the player coordinates (lower-left).
|
||||
|
||||
4) Loop:
|
||||
|
||||
* Draw the player's character.
|
||||
|
||||
* Get a key from the keyboard.
|
||||
|
||||
* Adjust the player's coordinates up, down, left or right, accordingly.
|
||||
|
||||
* Repeat.
|
||||
|
||||
5) When done, close the curses environment and exit.
|
||||
|
||||
### Let's Play
|
||||
|
||||
When you run the game, the player's character starts in the lower-left corner. As the player moves around the play area, the program creates a "trail" of dots. This helps show where the player has been before, so the player can avoid crossing the path unnecessarily.
|
||||
|
||||

|
||||
|
||||
Figure 2\. The player starts the game in the lower-left corner.
|
||||
|
||||

|
||||
|
||||
Figure 3\. The player can move around the play area, such as around the lake and through the mountain pass.
|
||||
|
||||
To create a complete adventure game on top of this, you might add random encounters with various monsters as the player navigates his or her character around the play area. You also could include special items the player could discover or loot after defeating enemies, which would enhance the player's abilities further.
|
||||
|
||||
But to start, this is a good program for demonstrating how to use the curses functions to read the keyboard and manipulate the screen.
|
||||
|
||||
### Next Steps
|
||||
|
||||
This program is a simple example of how to use the curses functions to update and read the screen and keyboard. You can do so much more with curses, depending on what you need your program to do. In a follow up article, I plan to show how to update this sample program to use colors. In the meantime, if you are interested in learning more about curses, I encourage you to read Pradeep Padala's [NCURSES Programming HOWTO][2] at the Linux Documentation Project.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxjournal.com/content/creating-adventure-game-terminal-ncurses
|
||||
|
||||
作者:[Jim Hall][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxjournal.com/users/jim-hall
|
||||
[1]:http://www.linuxjournal.com/content/getting-started-ncurses
|
||||
[2]:http://tldp.org/HOWTO/NCURSES-Programming-HOWTO
|
||||
372
sources/tech/20180126 How To Manage NodeJS Packages Using Npm.md
Normal file
372
sources/tech/20180126 How To Manage NodeJS Packages Using Npm.md
Normal file
@ -0,0 +1,372 @@
|
||||
How To Manage NodeJS Packages Using Npm
|
||||
======
|
||||
|
||||

|
||||
|
||||
A while ago, we have published a guide to [**manage Python packages using PIP**][1]. Today, we are going to discuss how to manage NodeJS packages using Npm. NPM is the largest software registry that contains over 600,000 packages. Everyday, developers across the world shares and downloads packages through npm. In this guide, I will explain the the basics of working with npm, such as installing packages(locally and globally), installing certain version of a package, updating, removing and managing NodeJS packages and so on.
|
||||
|
||||
### Manage NodeJS Packages Using Npm
|
||||
|
||||
##### Installing NPM
|
||||
|
||||
Since npm is written in NodeJS, we need to install NodeJS in order to use npm. To install NodeJS on different Linux distributions, refer the following link.
|
||||
|
||||
Once installed, ensure that NodeJS and NPM have been properly installed. There are couple ways to do this.
|
||||
|
||||
To check where node has been installed:
|
||||
```
|
||||
$ which node
|
||||
/home/sk/.nvm/versions/node/v9.4.0/bin/node
|
||||
```
|
||||
|
||||
Check its version:
|
||||
```
|
||||
$ node -v
|
||||
v9.4.0
|
||||
```
|
||||
|
||||
Log in to Node REPL session:
|
||||
```
|
||||
$ node
|
||||
> .help
|
||||
.break Sometimes you get stuck, this gets you out
|
||||
.clear Alias for .break
|
||||
.editor Enter editor mode
|
||||
.exit Exit the repl
|
||||
.help Print this help message
|
||||
.load Load JS from a file into the REPL session
|
||||
.save Save all evaluated commands in this REPL session to a file
|
||||
> .exit
|
||||
```
|
||||
|
||||
Check where npm installed:
|
||||
```
|
||||
$ which npm
|
||||
/home/sk/.nvm/versions/node/v9.4.0/bin/npm
|
||||
```
|
||||
|
||||
And the version:
|
||||
```
|
||||
$ npm -v
|
||||
5.6.0
|
||||
```
|
||||
|
||||
Great! Node and NPM have been installed and are working! As you may have noticed, I have installed NodeJS and NPM in my $HOME directory to avoid permission issues while installing modules globally. This is the recommended method by NodeJS team.
|
||||
|
||||
Well, let us go ahead to see managing NodeJS modules (or packages) using npm.
|
||||
|
||||
##### Installing NodeJS modules
|
||||
|
||||
NodeJS modules can either be installed locally or globally(system wide). Now I am going to show how to install a package locally.
|
||||
|
||||
**Install packages locally**
|
||||
|
||||
To manage packages locally, we normally use **package.json** file.
|
||||
|
||||
First, let us create our project directory.
|
||||
```
|
||||
$ mkdir demo
|
||||
```
|
||||
```
|
||||
$ cd demo
|
||||
```
|
||||
|
||||
Create a package.json file inside your project's directory. To do so, run:
|
||||
```
|
||||
$ npm init
|
||||
```
|
||||
|
||||
Enter the details of your package such as name, version, author, github page etc., or just hit ENTER key to accept the default values and type **YES** to confirm.
|
||||
```
|
||||
This utility will walk you through creating a package.json file.
|
||||
It only covers the most common items, and tries to guess sensible defaults.
|
||||
|
||||
See `npm help json` for definitive documentation on these fields
|
||||
and exactly what they do.
|
||||
|
||||
Use `npm install <pkg>` afterwards to install a package and
|
||||
save it as a dependency in the package.json file.
|
||||
|
||||
Press ^C at any time to quit.
|
||||
package name: (demo)
|
||||
version: (1.0.0)
|
||||
description: demo nodejs app
|
||||
entry point: (index.js)
|
||||
test command:
|
||||
git repository:
|
||||
keywords:
|
||||
author:
|
||||
license: (ISC)
|
||||
About to write to /home/sk/demo/package.json:
|
||||
|
||||
{
|
||||
"name": "demo",
|
||||
"version": "1.0.0",
|
||||
"description": "demo nodejs app",
|
||||
"main": "index.js",
|
||||
"scripts": {
|
||||
"test": "echo \"Error: no test specified\" && exit 1"
|
||||
},
|
||||
"author": "",
|
||||
"license": "ISC"
|
||||
}
|
||||
|
||||
Is this ok? (yes) yes
|
||||
```
|
||||
|
||||
The above command initializes your project and create package.json file.
|
||||
|
||||
You can also do this non-interactively using command:
|
||||
```
|
||||
npm init --y
|
||||
```
|
||||
|
||||
This will create a package.json file quickly with default values without the user interaction.
|
||||
|
||||
Now let us install package named [**commander**][2].
|
||||
```
|
||||
$ npm install commander
|
||||
```
|
||||
|
||||
Sample output:
|
||||
```
|
||||
npm notice created a lockfile as package-lock.json. You should commit this file.
|
||||
npm WARN demo@1.0.0 No repository field.
|
||||
|
||||
+ commander@2.13.0
|
||||
added 1 package in 2.519s
|
||||
```
|
||||
|
||||
This will create a directory named **" node_modules"** (if it doesn't exist already) in the project's root directory and download the packages in it.
|
||||
|
||||
Let us check the package.json file.
|
||||
```
|
||||
$ cat package.json
|
||||
{
|
||||
"name": "demo",
|
||||
"version": "1.0.0",
|
||||
"description": "demo nodejs app",
|
||||
"main": "index.js",
|
||||
"scripts": {
|
||||
"test": "echo \"Error: no test specified\" && exit 1"
|
||||
},
|
||||
"author": "",
|
||||
"license": "ISC",
|
||||
**"dependencies": {**
|
||||
**"commander": "^2.13.0"**
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
You will see the dependencies have been added. The caret ( **^** ) at the front of the version number indicates that when installing, npm will pull the highest version of the package it can find.
|
||||
```
|
||||
$ ls node_modules/
|
||||
commander
|
||||
```
|
||||
|
||||
The advantage of package.json file is if you had the package.json file in your project's directory, you can just type "npm install", then npm will look into the dependencies that listed in the file and download all of them. You can even share it with other developers or push into your GitHub repository, so when they type "npm install", they will get all the same packages that you have.
|
||||
|
||||
You may also noticed another json file named **package-lock.json**. This file ensures that the dependencies remain the same on all systems the project is installed on.
|
||||
|
||||
To use the installed package in your program, create a file **index.js** (or any name of you choice) in the project's directory with the actual code, and then run it using command:
|
||||
```
|
||||
$ node index.js
|
||||
```
|
||||
|
||||
**Install packages globally**
|
||||
|
||||
If you want to use a package as a command line tool, then it is better to install it globally. This way, it works no matter which directory is your current directory.
|
||||
```
|
||||
$ npm install async -g
|
||||
+ async@2.6.0
|
||||
added 2 packages in 4.695s
|
||||
```
|
||||
|
||||
Or,
|
||||
```
|
||||
$ npm install async --global
|
||||
```
|
||||
|
||||
To install a specific version of a package, we do:
|
||||
```
|
||||
$ npm install async@2.6.0 --global
|
||||
```
|
||||
|
||||
##### Updating NodeJS modules
|
||||
|
||||
To update the local packages, go the the project's directory where the package.json is located and run:
|
||||
```
|
||||
$ npm update
|
||||
```
|
||||
|
||||
Then, run the following command to ensure all packages were updated.
|
||||
```
|
||||
$ npm outdated
|
||||
```
|
||||
|
||||
If there is no update, then it returns nothing.
|
||||
|
||||
To find out which global packages need to be updated, run:
|
||||
```
|
||||
$ npm outdated -g --depth=0
|
||||
```
|
||||
|
||||
If there is no output, then all packages are updated.
|
||||
|
||||
To update the a single global package, run:
|
||||
```
|
||||
$ npm update -g <package-name>
|
||||
```
|
||||
|
||||
To update all global packages, run:
|
||||
```
|
||||
$ npm update -g <package>
|
||||
```
|
||||
|
||||
##### Listing NodeJS modules
|
||||
|
||||
To list the local packages, go the project's directory and run:
|
||||
```
|
||||
$ npm list
|
||||
demo@1.0.0 /home/sk/demo
|
||||
└── commander@2.13.0
|
||||
```
|
||||
|
||||
As you see, I have installed "commander" package in local mode.
|
||||
|
||||
To list global packages, run this command from any location:
|
||||
```
|
||||
$ npm list -g
|
||||
```
|
||||
|
||||
Sample output:
|
||||
```
|
||||
/home/sk/.nvm/versions/node/v9.4.0/lib
|
||||
├─┬ async@2.6.0
|
||||
│ └── lodash@4.17.4
|
||||
└─┬ npm@5.6.0
|
||||
├── abbrev@1.1.1
|
||||
├── ansi-regex@3.0.0
|
||||
├── ansicolors@0.3.2
|
||||
├── ansistyles@0.1.3
|
||||
├── aproba@1.2.0
|
||||
├── archy@1.0.0
|
||||
[...]
|
||||
```
|
||||
|
||||
This command will list all modules and their dependencies.
|
||||
|
||||
To list only the top level modules, use -depth=0 option:
|
||||
```
|
||||
$ npm list -g --depth=0
|
||||
/home/sk/.nvm/versions/node/v9.4.0/lib
|
||||
├── async@2.6.0
|
||||
└── npm@5.6.0
|
||||
```
|
||||
|
||||
##### Searching NodeJS modules
|
||||
|
||||
To search for a module, use "npm search" command:
|
||||
```
|
||||
npm search <search-string>
|
||||
```
|
||||
|
||||
Example:
|
||||
```
|
||||
$ npm search request
|
||||
```
|
||||
|
||||
This command will display all modules that contains the search string "request".
|
||||
|
||||
##### Removing NodeJS modules
|
||||
|
||||
To remove a local package, go to the project's directory and run following command to remove the package from your **node_modules** directory:
|
||||
```
|
||||
$ npm uninstall <package-name>
|
||||
```
|
||||
|
||||
To remove it from the dependencies in **package.json** file, use the **save** flag like below:
|
||||
```
|
||||
$ npm uninstall --save <package-name>
|
||||
|
||||
```
|
||||
|
||||
To remove the globally installed packages, run:
|
||||
```
|
||||
$ npm uninstall -g <package>
|
||||
```
|
||||
|
||||
##### Cleaning NPM cache
|
||||
|
||||
By default, NPM keeps the copy of a installed package in the cache folder named npm in your $HOME directory when installing it. So, you can install it next time without having to download again.
|
||||
|
||||
To view the cached modules:
|
||||
```
|
||||
$ ls ~/.npm
|
||||
```
|
||||
|
||||
The cache folder gets flooded with all old packages over time. It is better to clean the cache from time to time.
|
||||
|
||||
As of npm@5, the npm cache self-heals from corruption issues and data extracted from the cache is guaranteed to be valid. If you want to make sure everything is consistent, run:
|
||||
```
|
||||
$ npm cache verify
|
||||
```
|
||||
|
||||
To clear the entire cache, run:
|
||||
```
|
||||
$ npm cache clean --force
|
||||
```
|
||||
|
||||
##### Viewing NPM configuration
|
||||
|
||||
To view the npm configuration, type:
|
||||
```
|
||||
$ npm config list
|
||||
```
|
||||
|
||||
Or,
|
||||
```
|
||||
$ npm config ls
|
||||
```
|
||||
|
||||
Sample output:
|
||||
```
|
||||
; cli configs
|
||||
metrics-registry = "https://registry.npmjs.org/"
|
||||
scope = ""
|
||||
user-agent = "npm/5.6.0 node/v9.4.0 linux x64"
|
||||
|
||||
; node bin location = /home/sk/.nvm/versions/node/v9.4.0/bin/node
|
||||
; cwd = /home/sk
|
||||
; HOME = /home/sk
|
||||
; "npm config ls -l" to show all defaults.
|
||||
```
|
||||
|
||||
To display the current global location:
|
||||
```
|
||||
$ npm config get prefix
|
||||
/home/sk/.nvm/versions/node/v9.4.0
|
||||
```
|
||||
|
||||
And, that's all for now. What we have just covered here is just the basics. NPM is a vast topic. For more details, head over to the the [**NPM Getting Started**][3] guide.
|
||||
|
||||
Hope this was useful. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/manage-nodejs-packages-using-npm/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/manage-python-packages-using-pip/
|
||||
[2]:https://www.npmjs.com/package/commander
|
||||
[3]:https://docs.npmjs.com/getting-started/
|
||||
@ -0,0 +1,416 @@
|
||||
How to Make a Minecraft Server – ThisHosting.Rocks
|
||||
======
|
||||
We’ll show you how to make a Minecraft server with beginner-friendly step-by-step instructions. It will be a persistent multiplayer server that you can play on with your friends from all around the world. You don’t have to be in a LAN.
|
||||
|
||||
### How to Make a Minecraft Server – Quick Guide
|
||||
|
||||
This is our “Table of contents” if you’re in a hurry and want to go straight to the point. We recommend reading everything though.
|
||||
|
||||
* [Learn stuff][1] (optional)
|
||||
|
||||
* [Learn more stuff][2] (optional)
|
||||
|
||||
* [Requirements][3] (required)
|
||||
|
||||
* [Install and start the Minecraft server][4] (required)
|
||||
|
||||
* [Run the server even after you log out of your VPS][5] (optional)
|
||||
|
||||
* [Make the server automatically start at boot][6] (optional)
|
||||
|
||||
* [Configure your Minecraft server][7] (required)
|
||||
|
||||
* [FAQs][8] (optional)
|
||||
|
||||
Before going into the actual instructions, a few things you should know:
|
||||
|
||||
#### Reasons why you would NOT use a specialized Minecraft server hosting provider
|
||||
|
||||
Since you’re here, you’re obviously interested in hosting your own Minecraft server. There are more reasons why you would not use a specialized Minecraft hosting provider, but here are a few:
|
||||
|
||||
* They’re slow most of the time. This is because you actually share the resources with multiple users. It becomes overloaded at some point. Most of them oversell their servers too.
|
||||
|
||||
* You don’t have full control over the Minecraft server or the actual server. You cannot customize anything you want to.
|
||||
|
||||
* You’re limited. Those kinds of hosting plans are always limited in one way or another.
|
||||
|
||||
Of course, there are positives to using a Minecraft hosting provider. The best upside is that you don’t actually have to do all the stuff we’ll write about below. But where’s the fun in that?
|
||||

|
||||
|
||||
#### Why you should NOT use your personal computer to make a Minecraft server
|
||||
|
||||
We noticed lots of tutorials showing you how to host a server on your own computer. There are downsides to doing that, like:
|
||||
|
||||
* Your home internet is not secured enough to handle DDoS attacks. Game servers are often prone to DDoS attacks, and your home network setup is most probably not secured enough to handle them. It’s most likely not powerful enough to handle a small attack.
|
||||
|
||||
* You’ll need to handle port forwarding. If you’ve tried making a Minecraft server on your home network, you’ve surely stumbled upon port forwarding and had issues with it.
|
||||
|
||||
* You’ll need to keep your computer on at all times. Your electricity bill will sky-rocket and you’ll add unnecessary load to your hardware. The hardware most servers use is enterprise-grade and designed to handle loads, with improved stability and longevity.
|
||||
|
||||
* Your home internet is not fast enough. Home networks are not designed to handle multiplayer games. You’ll need a much larger internet plan to even consider making a small server. Luckily, data centers have multiple high-speed, enterprise-grade internet connections making sure they have (or strive to have) 100% uptime.
|
||||
|
||||
* Your hardware is most likely not good enough. Again, servers use enterprise-grade hardware, latest and fastest CPUs, SSDs, and much more. Your personal computer most likely does not.
|
||||
|
||||
* You probably use Windows/MacOS on your personal computer. Though this is debatable, we believe that Linux is much better for game hosting. Don’t worry, you don’t really need to know everything about Linux to make a Minecraft server (though it’s recommended). We’ll show you everything you need to know.
|
||||
|
||||
Our tip is not to use your personal computer, though technically you can. It’s not expensive to buy a cloud server. We’ll show you how to make a Minecraft server on cloud hosting below. It’s easy if you carefully follow the steps.
|
||||
|
||||
### Making a Minecraft Server – Requirements
|
||||
|
||||
There are a few requirements. You should have and know all of this before continuing to the tutorial:
|
||||
|
||||
* You’ll need a [Linux cloud server][9]. We recommend [Vultr][10]. Their prices are cheap, services are high-quality, customer support is great, all server hardware is high-end. Check the [Minecraft server requirements][11] to find out what kind of server you should get (resources like RAM and Disk space). We recommend getting the $20 per month server. They support hourly pricing so if you only need the server temporary for playing with friends, you’ll pay less. Choose the Ubuntu 16.04 distro during signup. Choose the closest server location to where your players live during the signup process. Keep in mind that you’ll be responsible for your server. So you’ll have to secure it and manage it. If you don’t want to do that, you can get a [managed server][12], in which case the hosting provider will likely make a Minecraft server for you.
|
||||
|
||||
* You’ll need an SSH client to connect to the Linux cloud server. [PuTTy][13] is often recommended for beginners, but we also recommend [MobaXTerm][14]. There are many other SSH clients to choose from, so pick your favorite.
|
||||
|
||||
* You’ll need to setup your server (basic security setup at least). Google it and you’ll find many tutorials. You can use [Linode’s Security Guide][15] and follow the exact steps on your [Vultr][16] server.
|
||||
|
||||
* We’ll handle the software requirements like Java below.
|
||||
|
||||
And finally, onto our actual tutorial:
|
||||
|
||||
### How to Make a Minecraft Server on Ubuntu (Linux)
|
||||
|
||||
These instructions are written for and tested on an Ubuntu 16.04 server from [Vultr][17]. Though they’ll also work on Ubuntu 14.04, [Ubuntu 18.04][18], and any other Ubuntu-based distro, and any other server provider.
|
||||
|
||||
We’re using the default Vanilla server from Minecraft. You can use alternatives like CraftBukkit or Spigot that allow more customizations and plugins. Though if you use too many plugins you’ll essentially ruin the server. There are pros and cons to each one. Nevertheless, the instructions below are for the default Vanilla server to keep things simple and beginner-friendly. We may publish a tutorial for CraftBukkit soon if there’s an interest.
|
||||
|
||||
#### 1. Login to your server
|
||||
|
||||
We’ll use the root user. If you use a limited-user, you’ll have to execute most commands with ‘sudo’. You’ll get a warning if you’re doing something you don’t have enough permissions for.
|
||||
|
||||
You can login to your server via your SSH client. Use your server IP and your port (most likely 22).
|
||||
|
||||
After you log in, make sure you [secure your server][19].
|
||||
|
||||
#### 2. Update Ubuntu
|
||||
|
||||
You should always first update your Ubuntu before you do anything else. You can update it with the following commands:
|
||||
|
||||
```
|
||||
apt-get update && apt-get upgrade
|
||||
```
|
||||
|
||||
Hit “enter” and/or “y” when prompted.
|
||||
|
||||
#### 3. Install necessary tools
|
||||
|
||||
You’ll need a few packages and tools for various things in this tutorial like text editing, making your server persistent etc. Install them with the following command:
|
||||
|
||||
```
|
||||
apt-get install nano wget screen bash default-jdk ufw
|
||||
```
|
||||
|
||||
Some of them may already be installed.
|
||||
|
||||
#### 4. Download Minecraft Server
|
||||
|
||||
First, create a directory where you’ll store your Minecraft server and all other files:
|
||||
|
||||
```
|
||||
mkdir /opt/minecraft
|
||||
```
|
||||
|
||||
And navigate to the new directory:
|
||||
|
||||
```
|
||||
cd /opt/minecraft
|
||||
```
|
||||
|
||||
Now you can download the Minecraft Server file. Go to the [download page][20] and get the link there. Download the file with wget:
|
||||
|
||||
```
|
||||
wget https://s3.amazonaws.com/Minecraft.Download/versions/1.12.2/minecraft_server.1.12.2.jar
|
||||
```
|
||||
|
||||
#### 5. Install the Minecraft server
|
||||
|
||||
Once you’ve downloaded the server .jar file, you need to run it once and it will generate some files, including an eula.txt license file. The first time you run it, it will return an error and exit. That’s supposed to happen. Run in with the following command:
|
||||
|
||||
```
|
||||
java -Xms2048M -Xmx3472M -jar minecraft_server.1.12.2.jar nogui
|
||||
```
|
||||
|
||||
“-Xms2048M” is the minimum RAM that your Minecraft server can use and “-Xmx3472M” is the maximum. [Adjust][21] this based on your server’s resources. If you got the 4GB RAM server from [Vultr][22] you can leave them as-is, if you don’t use the server for anything else other than Minecraft.
|
||||
|
||||
After that command ends and returns an error, a new eula.txt file will be generated. You need to accept the license in that file. You can do that by adding “eula=true” to the file with the following command:
|
||||
|
||||
```
|
||||
sed -i.orig 's/eula=false/eula=true/g' eula.txt
|
||||
```
|
||||
|
||||
You can now start the server again and access the Minecraft server console with that same java command from before:
|
||||
|
||||
```
|
||||
java -Xms2048M -Xmx3472M -jar minecraft_server.1.12.2.jar nogui
|
||||
```
|
||||
|
||||
Make sure you’re in the /opt/minecraft directory, or the directory where you installed your MC server.
|
||||
|
||||
You’re free to stop here if you’re just testing this and need it for the short-term. If you’re having trouble loggin into the server, you’ll need to [configure your firewall][23].
|
||||
|
||||
The first time you successfully start the server it will take a bit longer to generate
|
||||
|
||||
We’ll show you how to create a script so you can start the server with it.
|
||||
|
||||
#### 6. Start the Minecraft server with a script, make it persistent, and enable it at boot
|
||||
|
||||
To make things easier, we’ll create a bash script that will start the server automatically.
|
||||
|
||||
So first, create a bash script with nano:
|
||||
|
||||
```
|
||||
nano /opt/minecraft/startminecraft.sh
|
||||
```
|
||||
|
||||
A new (blank) file will open. Paste the following:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
cd /opt/minecraft/ && java -Xms2048M -Xmx3472M -jar minecraft_server.1.12.2.jar nogui
|
||||
```
|
||||
|
||||
If you’re new to nano – you can save and close the file with “CTRL + X”, then “Y”, and hitting enter. This script navigates to your Minecraft server directory you created previously and runs the java command for starting the server. You need to make it executable with the following command:
|
||||
|
||||
```
|
||||
chmod +x startminecraft.sh
|
||||
```
|
||||
|
||||
Then, you can start the server anytime with the following command:
|
||||
|
||||
```
|
||||
/opt/minecraft/startminecraft.sh
|
||||
```
|
||||
|
||||
But, if/when you log out of the SSH session the server will turn off. To keep the server up without being logged in all the time, you can use a screen session. A screen session basically means that it will keep running until the actual server reboots or turns off.
|
||||
|
||||
Start a screen session with this command:
|
||||
|
||||
```
|
||||
screen -S minecraft
|
||||
```
|
||||
|
||||
Once you’re in the screen session (looks like you would start a new ssh session), you can use the bash script from earlier to start the server:
|
||||
|
||||
```
|
||||
/opt/minecraft/startminecraft.sh
|
||||
```
|
||||
|
||||
To get out of the screen session, you should press CTRL + A-D. Even after you get out of the screen session (detach), the server will keep running. You can safely log off your Ubuntu server now, and the Minecraft server you created will keep running.
|
||||
|
||||
But, if the Ubuntu server reboots or shuts off, the screen session won’t work anymore. So **to do everything we did before automatically at boot** , do the following:
|
||||
|
||||
Open the /etc/rc.local file:
|
||||
|
||||
```
|
||||
nano /etc/rc.local
|
||||
```
|
||||
|
||||
and add the following line above the “exit 0” line:
|
||||
|
||||
```
|
||||
screen -dm -S minecraft /opt/minecraft/startminecraft.sh
|
||||
exit 0
|
||||
```
|
||||
|
||||
Save and close the file.
|
||||
|
||||
To access the Minecraft server console, just run the following command to attach to the screen session:
|
||||
|
||||
```
|
||||
screen -r minecraft
|
||||
```
|
||||
|
||||
That’s it for now. Congrats and have fun! You can now connect to your Minecraft server or configure/modify it.
|
||||
|
||||
### Configure your Ubuntu Server
|
||||
|
||||
You’ll, of course, need to set up your Ubuntu server and secure it if you haven’t already done so. Follow the [guide we mentioned earlier][24] and google it for more info. The configurations you need to do for your Minecraft server on your Ubuntu server are:
|
||||
|
||||
#### Enable and configure the firewall
|
||||
|
||||
First, if it’s not already enabled, you should enable UFW that you previously installed:
|
||||
|
||||
```
|
||||
ufw enable
|
||||
```
|
||||
|
||||
You should allow the default Minecraft server port:
|
||||
|
||||
```
|
||||
ufw allow 25565/tcp
|
||||
```
|
||||
|
||||
You should allow and deny other rules depending on how you use your server. You should deny ports like 80 and 443 if you don’t use the server for hosting websites. Google a UFW/Firewall guide for Ubuntu and you’ll get recommendations. Be careful when setting up your firewall, you may lock yourself out of your server if you block the SSH port.
|
||||
|
||||
Since this is the default port, it often gets automatically scanned and attacked. You can prevent attacks by blocking access to anyone that’s not of your whitelist.
|
||||
|
||||
First, you need to enable the whitelist mode in your [server.properties][25] file. To do that, open the file:
|
||||
|
||||
```
|
||||
nano /opt/minecraft/server.properties
|
||||
```
|
||||
|
||||
And change “white-list” line to “true”:
|
||||
|
||||
```
|
||||
white-list=true
|
||||
```
|
||||
|
||||
Save and close the file.
|
||||
|
||||
Then restart your server (either by restarting your Ubuntu server or by running the start bash script again):
|
||||
|
||||
```
|
||||
/opt/minecraft/startminecraft.sh
|
||||
```
|
||||
|
||||
Access the Minecraft server console:
|
||||
|
||||
```
|
||||
screen -r minecraft
|
||||
```
|
||||
|
||||
And if you want someone to be able to join your server, you need to add them to the whitelist with the following command:
|
||||
|
||||
```
|
||||
whitelist add PlayerUsername
|
||||
```
|
||||
|
||||
To remove them from the whitelist, use:
|
||||
|
||||
```
|
||||
whitelist remove PlayerUsername
|
||||
```
|
||||
|
||||
Exit the screen session (server console) with CTRL + A-D. It’s worth noting that this will deny access to everyone but the whitelisted usernames.
|
||||
|
||||
[][26]
|
||||
|
||||
### How to Make a Minecraft Server – FAQs
|
||||
|
||||
We’ll answer some frequently asked questions about Minecraft Servers and our guide.
|
||||
|
||||
#### How do I restart the Minecraft server?
|
||||
|
||||
If you followed every step from our tutorial, including enabling the server to start on boot, you can just reboot your Ubuntu server. If you didn’t set it up to start at boot, you can just run the start script again which will restart the Minecraft server:
|
||||
|
||||
```
|
||||
/opt/minecraft/startminecraft.sh
|
||||
```
|
||||
|
||||
#### How do I configure my Minecraft server?
|
||||
|
||||
You can configure your server using the [server.properties][27] file. Check the Minecraft Wiki for more info, though you can leave everything as-is and it will work perfectly fine.
|
||||
|
||||
If you want to change the game mode, difficulty and stuff like that, you can use the server console. Access the server console by running:
|
||||
|
||||
```
|
||||
screen -r minecraft
|
||||
```
|
||||
|
||||
And execute [commands][28] there. Commands like:
|
||||
|
||||
```
|
||||
difficulty hard
|
||||
```
|
||||
|
||||
```
|
||||
gamemode survival @a
|
||||
```
|
||||
|
||||
You may need to restart the server depending on what command you used. There are many more commands you can use, check the [wiki][29] for more.
|
||||
|
||||
#### How do I upgrade my Minecraft server?
|
||||
|
||||
If there’s a new release, you need to do this:
|
||||
|
||||
Navigate to the minecraft directory:
|
||||
|
||||
```
|
||||
cd /opt/minecraft
|
||||
```
|
||||
|
||||
Download the latest version, example 1.12.3 with wget:
|
||||
|
||||
```
|
||||
wget https://s3.amazonaws.com/Minecraft.Download/versions/1.12.3/minecraft_server.1.12.3.jar
|
||||
```
|
||||
|
||||
Next, run and build the new server:
|
||||
|
||||
```
|
||||
java -Xms2048M -Xmx3472M -jar minecraft_server.1.12.3.jar nogui
|
||||
```
|
||||
|
||||
Finally, update your start script:
|
||||
|
||||
```
|
||||
nano /opt/minecraft/startminecraft.sh
|
||||
```
|
||||
|
||||
And update the version number accordingly:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
cd /opt/minecraft/ && java -Xms2048M -Xmx3472M -jar minecraft_server.1.12.3.jar nogui
|
||||
```
|
||||
|
||||
Now you can restart the server and everything should go well.
|
||||
|
||||
#### Why is your Minecraft server tutorial so long, and yet others are only 2 lines long?!
|
||||
|
||||
We tried to make this beginner-friendly and be as detailed as possible. We also showed you how to make the Minecraft server persistent and start it automatically at boot, we showed you how to configure your server and everything. I mean, sure, you can start a Minecraft server with a couple of lines, but it would definitely suck, for more than one reason.
|
||||
|
||||
#### I don’t know Linux or anything you wrote about here, how do I make a Minecraft server?
|
||||
|
||||
Just read all of our article and copy and paste the commands. If you really don’t know how to do it all, [we can do it for you][30], or just get a [managed][31] server [provider][32] and let them do it for you.
|
||||
|
||||
#### How do I install mods on my server? How do I install plugins?
|
||||
|
||||
Our article is intended to be a starting guide. You should check the [Minecraft wiki][33] for more info, or just google it. There are plenty of tutorials online
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://thishosting.rocks/how-to-make-a-minecraft-server/
|
||||
|
||||
作者:[ThisHosting.Rocks][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://thishosting.rocks
|
||||
[1]:https://thishosting.rocks/how-to-make-a-minecraft-server/#reasons
|
||||
[2]:https://thishosting.rocks/how-to-make-a-minecraft-server/#not-pc
|
||||
[3]:https://thishosting.rocks/how-to-make-a-minecraft-server/#requirements
|
||||
[4]:https://thishosting.rocks/how-to-make-a-minecraft-server/#make-minecraft-server
|
||||
[5]:https://thishosting.rocks/how-to-make-a-minecraft-server/#persistent
|
||||
[6]:https://thishosting.rocks/how-to-make-a-minecraft-server/#boot
|
||||
[7]:https://thishosting.rocks/how-to-make-a-minecraft-server/#configure-minecraft-server
|
||||
[8]:https://thishosting.rocks/how-to-make-a-minecraft-server/#faqs
|
||||
[9]:https://thishosting.rocks/cheap-cloud-hosting-providers-comparison/
|
||||
[10]:https://thishosting.rocks/go/vultr/
|
||||
[11]:https://minecraft.gamepedia.com/Server/Requirements/Dedicated
|
||||
[12]:https://thishosting.rocks/best-cheap-managed-vps/
|
||||
[13]:https://www.chiark.greenend.org.uk/~sgtatham/putty/
|
||||
[14]:https://mobaxterm.mobatek.net/
|
||||
[15]:https://www.linode.com/docs/security/securing-your-server/
|
||||
[16]:https://thishosting.rocks/go/vultr/
|
||||
[17]:https://thishosting.rocks/go/vultr/
|
||||
[18]:https://thishosting.rocks/ubuntu-18-04-new-features-release-date/
|
||||
[19]:https://www.linode.com/docs/security/securing-your-server/
|
||||
[20]:https://minecraft.net/en-us/download/server
|
||||
[21]:https://minecraft.gamepedia.com/Commands
|
||||
[22]:https://thishosting.rocks/go/vultr/
|
||||
[23]:https://thishosting.rocks/how-to-make-a-minecraft-server/#configure-minecraft-server
|
||||
[24]:https://www.linode.com/docs/security/securing-your-server/
|
||||
[25]:https://minecraft.gamepedia.com/Server.properties
|
||||
[26]:https://thishosting.rocks/wp-content/uploads/2018/01/create-a-minecraft-server.jpg
|
||||
[27]:https://minecraft.gamepedia.com/Server.properties
|
||||
[28]:https://minecraft.gamepedia.com/Commands
|
||||
[29]:https://minecraft.gamepedia.com/Commands
|
||||
[30]:https://thishosting.rocks/support/
|
||||
[31]:https://thishosting.rocks/best-cheap-managed-vps/
|
||||
[32]:https://thishosting.rocks/best-cheap-managed-vps/
|
||||
[33]:https://minecraft.gamepedia.com/Minecraft_Wiki
|
||||
@ -0,0 +1,113 @@
|
||||
Linux kill Command Tutorial for Beginners (5 Examples)
|
||||
======
|
||||
|
||||
Sometimes, while working on a Linux machine, you'll see that an application or a command line process gets stuck (becomes unresponsive). Then in those cases, terminating it is the only way out. Linux command line offers a utility that you can use in these scenarios. It's called **kill**.
|
||||
|
||||
In this tutorial, we will discuss the basics of kill using some easy to understand examples. But before we do that, it's worth mentioning that all examples in the article have been tested on an Ubuntu 16.04 machine.
|
||||
|
||||
#### Linux kill command
|
||||
|
||||
The kill command is usually used to kill a process. Internally it sends a signal, and depending on what you want to do, there are different signals that you can send using this tool. Following is the command's syntax:
|
||||
|
||||
```
|
||||
kill [options] <pid> [...]
|
||||
```
|
||||
|
||||
And here's how the tool's man page describes it:
|
||||
```
|
||||
The default signal for kill is TERM. Use -l or -L to list available signals. Particularly useful
|
||||
signals include HUP, INT, KILL, STOP, CONT, and 0. Alternate signals may be specified in three ways:
|
||||
-9, -SIGKILL or -KILL. Negative PID values may be used to choose whole process groups; see the PGID
|
||||
column in ps command output. A PID of -1 is special; it indicates all processes except the kill
|
||||
process itself and init.
|
||||
```
|
||||
|
||||
The following Q&A-styled examples should give you a better idea of how the kill command works.
|
||||
|
||||
#### Q1. How to terminate a process using kill command?
|
||||
|
||||
This is very easy - all you need to do is to get the pid of the process you want to kill, and then pass it to the kill command.
|
||||
|
||||
```
|
||||
kill [pid]
|
||||
```
|
||||
|
||||
For example, I wanted to kill the 'gthumb' process on my system. So i first used the ps command to fetch the application's pid, and then passed it to the kill command to terminate it. Here's the screenshot showing all this:
|
||||
|
||||
[![How to terminate a process using kill command][1]][2]
|
||||
|
||||
#### Q2. How to send a custom signal?
|
||||
|
||||
As already mentioned in the introduction section, TERM is the default signal that kill sends to the application/process in question. However, if you want, you can send any other signal that kill supports using the **-s** command line option.
|
||||
|
||||
```
|
||||
kill -s [signal] [pid]
|
||||
```
|
||||
|
||||
For example, if a process isn't responding to the TERM signal (which allows the process to do final cleanup before quitting), you can go for the KILL signal (which doesn't let process do any cleanup). Following is the command you need to run in that case.
|
||||
|
||||
```
|
||||
kill -s KILL [pid]
|
||||
```
|
||||
|
||||
#### Q3. What all signals you can send using kill?
|
||||
|
||||
Of course, the next logical question that'll come to your mind is how to know which all signals you can send using kill. Well, thankfully, there exists a command line option **-l** that lists all supported signals.
|
||||
|
||||
```
|
||||
kill -l
|
||||
```
|
||||
|
||||
Following is the output the above command produced on our system:
|
||||
|
||||
[![What all signals you can send using kill][3]][4]
|
||||
|
||||
#### Q4. What are the other ways in which signal can be sent?
|
||||
|
||||
In one of the previous examples, we told you if you want to send the KILL signal, you can do it in the following way:
|
||||
|
||||
```
|
||||
kill -s KILL [pid]
|
||||
```
|
||||
|
||||
However, there are a couple of other alternatives as well:
|
||||
|
||||
```
|
||||
kill -s SIGKILL [pid]
|
||||
|
||||
kill -s 9 [pid]
|
||||
```
|
||||
|
||||
The corresponding number can be known using the -l option we've already discussed in the previous example.
|
||||
|
||||
#### Q5. How to kill all running process in one go?
|
||||
|
||||
In case a user wants to kill all processes that they can (this depends on their privilege level), then instead of specifying a large number of process IDs, they can simply pass the -1 option to kill.
|
||||
|
||||
For example:
|
||||
|
||||
```
|
||||
kill -s KILL -1
|
||||
```
|
||||
|
||||
#### Conclusion
|
||||
|
||||
The kill command is pretty straightforward to understand and use. There's a slight learning curve in terms of the list of signal options it offers, but as we explained in here, there's an option to take a quick look at that list as well. Just practice whatever we've discussed and you should be good to go. For more information, head to the tool's [man page][5].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/linux-kill-command/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:https://www.howtoforge.com/images/usage_of_pfsense_to_block_dos_attack_/kill-default.png
|
||||
[2]:https://www.howtoforge.com/images/usage_of_pfsense_to_block_dos_attack_/big/kill-default.png
|
||||
[3]:https://www.howtoforge.com/images/usage_of_pfsense_to_block_dos_attack_/kill-l-option.png
|
||||
[4]:https://www.howtoforge.com/images/usage_of_pfsense_to_block_dos_attack_/big/kill-l-option.png
|
||||
[5]:https://linux.die.net/man/1/kill
|
||||
@ -0,0 +1,342 @@
|
||||
How to install KVM on CentOS 7 / RHEL 7 Headless Server
|
||||
======
|
||||
|
||||
|
||||
How do I install and configure KVM (Kernel-based Virtual Machine) on a CentOS 7 or RHEL (Red Hat Enterprise Linux) 7 server? How can I setup KMV on a CentOS 7 and use cloud images/cloud-init for installing guest VM?
|
||||
|
||||
|
||||
Kernel-based Virtual Machine (KVM) is virtualization software for CentOS or RHEL 7. KVM turn your server into a hypervisor. This page shows how to setup and manage a virtualized environment with KVM in CentOS 7 or RHEL 7. It also described how to install and administer Virtual Machines (VMs) on a physical server using the CLI. Make sure that **Virtualization Technology (VT)** is enabled in your server 's BIOS. You can also run the following command [to test if CPU Support Intel VT and AMD-V Virtualization tech][1]
|
||||
```
|
||||
$ lscpu | grep Virtualization
|
||||
Virtualization: VT-x
|
||||
```
|
||||
|
||||
|
||||
|
||||
### Follow installation steps of KVM on CentOS 7/RHEL 7 headless sever
|
||||
|
||||
#### Step 1: Install kvm
|
||||
|
||||
Type the following [yum command][2]:
|
||||
`# yum install qemu-kvm libvirt libvirt-python libguestfs-tools virt-install`
|
||||
[![How to install KVM on CentOS 7 RHEL 7 Headless Server][3]][3]
|
||||
Start the libvirtd service:
|
||||
```
|
||||
# systemctl enable libvirtd
|
||||
# systemctl start libvirtd
|
||||
```
|
||||
|
||||
#### Step 2: Verify kvm installation
|
||||
|
||||
Make sure KVM module loaded using lsmod command and [grep command][4]:
|
||||
`# lsmod | grep -i kvm`
|
||||
|
||||
#### Step 3: Configure bridged networking
|
||||
|
||||
By default dhcpd based network bridge configured by libvirtd. You can verify that with the following commands:
|
||||
```
|
||||
# brctl show
|
||||
# virsh net-list
|
||||
```
|
||||
[![KVM default networking][5]][5]
|
||||
All VMs (guest machine) only have network access to other VMs on the same server. A private network 192.168.122.0/24 created for you. Verify it:
|
||||
`# virsh net-dumpxml default`
|
||||
If you want your VMs avilable to other servers on your LAN, setup a a network bridge on the server that connected to the your LAN. Update your nic config file such as ifcfg-enp3s0 or em1:
|
||||
`# vi /etc/sysconfig/network-scripts/enp3s0 `
|
||||
Add line:
|
||||
```
|
||||
BRIDGE=br0
|
||||
```
|
||||
|
||||
[Save and close the file in vi][6]. Edit /etc/sysconfig/network-scripts/ifcfg-br0 and add:
|
||||
`# vi /etc/sysconfig/network-scripts/ifcfg-br0`
|
||||
Append the following:
|
||||
```
|
||||
DEVICE="br0"
|
||||
# I am getting ip from DHCP server #
|
||||
BOOTPROTO="dhcp"
|
||||
IPV6INIT="yes"
|
||||
IPV6_AUTOCONF="yes"
|
||||
ONBOOT="yes"
|
||||
TYPE="Bridge"
|
||||
DELAY="0"
|
||||
```
|
||||
|
||||
Restart the networking service (warning ssh command will disconnect, it is better to reboot the box):
|
||||
`# systemctl restart NetworkManager`
|
||||
Verify it with brctl command:
|
||||
`# brctl show`
|
||||
|
||||
#### Step 4: Create your first virtual machine
|
||||
|
||||
I am going to create a CentOS 7.x VM. First, grab CentOS 7.x latest ISO image using the wget command:
|
||||
```
|
||||
# cd /var/lib/libvirt/boot/
|
||||
# wget https://mirrors.kernel.org/centos/7.4.1708/isos/x86_64/CentOS-7-x86_64-Minimal-1708.iso
|
||||
```
|
||||
Verify ISO images:
|
||||
```
|
||||
# wget https://mirrors.kernel.org/centos/7.4.1708/isos/x86_64/sha256sum.txt
|
||||
# sha256sum -c sha256sum.txt
|
||||
```
|
||||
|
||||
##### Create CentOS 7.x VM
|
||||
|
||||
In this example, I'm creating CentOS 7.x VM with 2GB RAM, 2 CPU core, 1 nics and 40GB disk space, enter:
|
||||
```
|
||||
# virt-install \
|
||||
--virt-type=kvm \
|
||||
--name centos7 \
|
||||
--ram 2048 \
|
||||
--vcpus=1 \
|
||||
--os-variant=centos7.0 \
|
||||
--cdrom=/var/lib/libvirt/boot/CentOS-7-x86_64-Minimal-1708.iso \
|
||||
--network=bridge=br0,model=virtio \
|
||||
--graphics vnc \
|
||||
--disk path=/var/lib/libvirt/images/centos7.qcow2,size=40,bus=virtio,format=qcow2
|
||||
```
|
||||
To configure vnc login from another terminal over ssh and type:
|
||||
```
|
||||
# virsh dumpxml centos7 | grep vnc
|
||||
<graphics type='vnc' port='5901' autoport='yes' listen='127.0.0.1'>
|
||||
```
|
||||
Please note down the port value (i.e. 5901). You need to use an SSH client to setup tunnel and a VNC client to access the remote vnc server. Type the following SSH port forwarding command from your client/desktop/macbook pro system:
|
||||
`$ ssh vivek@server1.cyberciti.biz -L 5901:127.0.0.1:5901`
|
||||
Once you have ssh tunnel established, you can point your VNC client at your own 127.0.0.1 (localhost) address and port 5901 as follows:
|
||||
[![][7]][7]
|
||||
You should see CentOS Linux 7 guest installation screen as follows:
|
||||
[![][8]][8]
|
||||
Now just follow on screen instructions and install CentOS 7. Once installed, go ahead and click the reboot button. The remote server closed the connection to our VNC client. You can reconnect via KVM client to configure the rest of the server including SSH based session or firewall.
|
||||
|
||||
#### Step 5: Using cloud images
|
||||
|
||||
The above installation method is okay for learning purpose or a single VM. Do you need to deploy lots of VMs? Try cloud images. You can modify pre built cloud images as per your needs. For example, add users, ssh keys, setup time zone, and more using [Cloud-init][9] which is the defacto multi-distribution package that handles early initialization of a cloud instance. Let us see how to create CentOS 7 vm with 1024MB ram, 20GB disk space, and 1 vCPU.
|
||||
|
||||
##### Grab CentOS 7 cloud image
|
||||
|
||||
```
|
||||
# cd /var/lib/libvirt/boot
|
||||
# wget http://cloud.centos.org/centos/7/images/CentOS-7-x86_64-GenericCloud.qcow2
|
||||
```
|
||||
|
||||
##### Create required directories
|
||||
|
||||
```
|
||||
# D=/var/lib/libvirt/images
|
||||
# VM=centos7-vm1 ## vm name ##
|
||||
# mkdir -vp $D/$VM
|
||||
mkdir: created directory '/var/lib/libvirt/images/centos7-vm1'
|
||||
```
|
||||
|
||||
##### Create meta-data file
|
||||
|
||||
```
|
||||
# cd $D/$VM
|
||||
# vi meta-data
|
||||
```
|
||||
Append the following:
|
||||
```
|
||||
instance-id: centos7-vm1
|
||||
local-hostname: centos7-vm1
|
||||
```
|
||||
|
||||
##### Crete user-data file
|
||||
|
||||
I am going to login into VM using ssh keys. So make sure you have ssh-keys in place:
|
||||
`# ssh-keygen -t ed25519 -C "VM Login ssh key"`
|
||||
[![ssh-keygen command][10]][11]
|
||||
See "[How To Setup SSH Keys on a Linux / Unix System][12]" for more info. Edit user-data as follows:
|
||||
```
|
||||
# cd $D/$VM
|
||||
# vi user-data
|
||||
```
|
||||
Add as follows (replace hostname, users, ssh-authorized-keys as per your setup):
|
||||
```
|
||||
#cloud-config
|
||||
|
||||
# Hostname management
|
||||
preserve_hostname: False
|
||||
hostname: centos7-vm1
|
||||
fqdn: centos7-vm1.nixcraft.com
|
||||
|
||||
# Users
|
||||
users:
|
||||
- default
|
||||
- name: vivek
|
||||
groups: ['wheel']
|
||||
shell: /bin/bash
|
||||
sudo: ALL=(ALL) NOPASSWD:ALL
|
||||
ssh-authorized-keys:
|
||||
- ssh-ed25519 AAAAC3NzaC1lZDI1NTE5AAAAIIMP3MOF2ot8MOdNXCpHem0e2Wemg4nNmL2Tio4Ik1JY VM Login ssh key
|
||||
|
||||
# Configure where output will go
|
||||
output:
|
||||
all: ">> /var/log/cloud-init.log"
|
||||
|
||||
# configure interaction with ssh server
|
||||
ssh_genkeytypes: ['ed25519', 'rsa']
|
||||
|
||||
# Install my public ssh key to the first user-defined user configured
|
||||
# in cloud.cfg in the template (which is centos for CentOS cloud images)
|
||||
ssh_authorized_keys:
|
||||
- ssh-ed25519 AAAAC3NzaC1lZDI1NTE5AAAAIIMP3MOF2ot8MOdNXCpHem0e2Wemg4nNmL2Tio4Ik1JY VM Login ssh key
|
||||
|
||||
# set timezone for VM
|
||||
timezone: Asia/Kolkata
|
||||
|
||||
# Remove cloud-init
|
||||
runcmd:
|
||||
- systemctl stop network && systemctl start network
|
||||
- yum -y remove cloud-init
|
||||
```
|
||||
|
||||
##### Copy cloud image
|
||||
|
||||
```
|
||||
# cd $D/$VM
|
||||
# cp /var/lib/libvirt/boot/CentOS-7-x86_64-GenericCloud.qcow2 $VM.qcow2
|
||||
```
|
||||
|
||||
##### Create 20GB disk image
|
||||
|
||||
```
|
||||
# cd $D/$VM
|
||||
# export LIBGUESTFS_BACKEND=direct
|
||||
# qemu-img create -f qcow2 -o preallocation=metadata $VM.new.image 20G
|
||||
# virt-resize --quiet --expand /dev/sda1 $VM.qcow2 $VM.new.image
|
||||
```
|
||||
[![Set VM image disk size][13]][13]
|
||||
Overwrite it resized image:
|
||||
```
|
||||
# cd $D/$VM
|
||||
# mv $VM.new.image $VM.qcow2
|
||||
```
|
||||
|
||||
##### Creating a cloud-init ISO
|
||||
|
||||
`# mkisofs -o $VM-cidata.iso -V cidata -J -r user-data meta-data`
|
||||
[![Creating a cloud-init ISO][14]][14]
|
||||
|
||||
##### Creating a pool
|
||||
|
||||
```
|
||||
# virsh pool-create-as --name $VM --type dir --target $D/$VM
|
||||
Pool centos7-vm1 created
|
||||
```
|
||||
|
||||
##### Installing a CentOS 7 VM
|
||||
|
||||
```
|
||||
# cd $D/$VM
|
||||
# virt-install --import --name $VM \
|
||||
--memory 1024 --vcpus 1 --cpu host \
|
||||
--disk $VM.qcow2,format=qcow2,bus=virtio \
|
||||
--disk $VM-cidata.iso,device=cdrom \
|
||||
--network bridge=virbr0,model=virtio \
|
||||
--os-type=linux \
|
||||
--os-variant=centos7.0 \
|
||||
--graphics spice \
|
||||
--noautoconsole
|
||||
```
|
||||
Delete unwanted files:
|
||||
```
|
||||
# cd $D/$VM
|
||||
# virsh change-media $VM hda --eject --config
|
||||
# rm meta-data user-data centos7-vm1-cidata.iso
|
||||
```
|
||||
|
||||
##### Find out IP address of VM
|
||||
|
||||
`# virsh net-dhcp-leases default`
|
||||
[![CentOS7-VM1- Created][15]][15]
|
||||
|
||||
##### Log in to your VM
|
||||
|
||||
Use ssh command:
|
||||
`# ssh vivek@192.168.122.85`
|
||||
[![Sample VM session][16]][16]
|
||||
|
||||
### Useful commands
|
||||
|
||||
Let us see some useful commands for managing VMs.
|
||||
|
||||
#### List all VMs
|
||||
|
||||
`# virsh list --all`
|
||||
|
||||
#### Get VM info
|
||||
|
||||
```
|
||||
# virsh dominfo vmName
|
||||
# virsh dominfo centos7-vm1
|
||||
```
|
||||
|
||||
#### Stop/shutdown a VM
|
||||
|
||||
`# virsh shutdown centos7-vm1`
|
||||
|
||||
#### Start VM
|
||||
|
||||
`# virsh start centos7-vm1`
|
||||
|
||||
#### Mark VM for autostart at boot time
|
||||
|
||||
`# virsh autostart centos7-vm1`
|
||||
|
||||
#### Reboot (soft & safe reboot) VM
|
||||
|
||||
`# virsh reboot centos7-vm1`
|
||||
Reset (hard reset/not safe) VM
|
||||
`# virsh reset centos7-vm1`
|
||||
|
||||
#### Delete VM
|
||||
|
||||
```
|
||||
# virsh shutdown centos7-vm1
|
||||
# virsh undefine centos7-vm1
|
||||
# virsh pool-destroy centos7-vm1
|
||||
# D=/var/lib/libvirt/images
|
||||
# VM=centos7-vm1
|
||||
# rm -ri $D/$VM
|
||||
```
|
||||
To see a complete list of virsh command type
|
||||
```
|
||||
# virsh help | less
|
||||
# virsh help | grep reboot
|
||||
```
|
||||
|
||||
|
||||
### About the author
|
||||
|
||||
The author is the creator of nixCraft and a seasoned sysadmin and a trainer for the Linux operating system/Unix shell scripting. He has worked with global clients and in various industries, including IT, education, defense and space research, and the nonprofit sector. Follow him on [Twitter][17], [Facebook][18], [Google+][19].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/how-to-install-kvm-on-centos-7-rhel-7-headless-server/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/faq/linux-xen-vmware-kvm-intel-vt-amd-v-support/
|
||||
[2]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/ (See Linux/Unix yum command examples for more info)
|
||||
[3]:https://www.cyberciti.biz/media/new/faq/2018/01/How-to-install-KVM-on-CentOS-7-RHEL-7-Headless-Server.jpg
|
||||
[4]:https://www.cyberciti.biz/faq/howto-use-grep-command-in-linux-unix/ (See Linux/Unix grep command examples for more info)
|
||||
[5]:https://www.cyberciti.biz/media/new/faq/2018/01/KVM-default-networking.jpg
|
||||
[6]:https://www.cyberciti.biz/faq/linux-unix-vim-save-and-quit-command/
|
||||
[7]:https://www.cyberciti.biz/media/new/faq/2016/01/vnc-client.jpg
|
||||
[8]:https://www.cyberciti.biz/media/new/faq/2016/01/centos7-guest-vnc.jpg
|
||||
[9]:https://cloudinit.readthedocs.io/en/latest/index.html
|
||||
[10]:https://www.cyberciti.biz/media/new/faq/2018/01/ssh-keygen-pub-key.jpg
|
||||
[11]:https://www.cyberciti.biz/faq/linux-unix-generating-ssh-keys/
|
||||
[12]:https://www.cyberciti.biz/faq/how-to-set-up-ssh-keys-on-linux-unix/
|
||||
[13]:https://www.cyberciti.biz/media/new/faq/2018/01/Set-VM-image-disk-size.jpg
|
||||
[14]:https://www.cyberciti.biz/media/new/faq/2018/01/Creating-a-cloud-init-ISO.jpg
|
||||
[15]:https://www.cyberciti.biz/media/new/faq/2018/01/CentOS7-VM1-Created.jpg
|
||||
[16]:https://www.cyberciti.biz/media/new/faq/2018/01/Sample-VM-session.jpg
|
||||
[17]:https://twitter.com/nixcraft
|
||||
[18]:https://facebook.com/nixcraft
|
||||
[19]:https://plus.google.com/+CybercitiBiz
|
||||
98
sources/tech/20180128 Getting Linux Jobs.md
Normal file
98
sources/tech/20180128 Getting Linux Jobs.md
Normal file
@ -0,0 +1,98 @@
|
||||
Getting Linux Jobs
|
||||
======
|
||||
|
||||
In a qualitative review of job posting websites, even highly skilled Linux administrators would be hamstrung to succeed in getting to the stage of an interview.
|
||||
|
||||
All of this results in hundreds of decent and skilled people being snubbed without cause simply because today's job market requires a few extra tools to increase the odds.
|
||||
|
||||
I have two colleagues and a cousin who have all received certifications with RedHat, managed quite extensive server rooms, and received earnest recommendations from former employers.
|
||||
|
||||
All of these skills, certifications and experience come to naught as they apply to employer ads that are crudely constructed by someone hurriedly cutting and pasting snippets of "skill words" from a list of technical terms.
|
||||
|
||||
Not surprisingly, today's politeness has gone the way of the bird, and a **non-response** from companies posting ads seems to be the new way of communicating.
|
||||
|
||||
Unfortunately, it also means that these recruiters/HR personnel probably did **not** get the best candidate.
|
||||
|
||||
The reason I can say this with such conviction is because of the type of buffoonery that takes place so often when creating job ads in the first place.
|
||||
|
||||
Walter, another [Reallylinux.com][3] guest writer, presented how [**Job Want Ads Have Gone Mad**][4].
|
||||
|
||||
Perhaps he's right. However, I believe every Linux job seeker can avoid pitfalls of a job hunt by keeping in mind **three key facts** about job ads.
|
||||
|
||||
First, few advertisements for Linux administrators are exclusively about Linux.
|
||||
|
||||
Bear in mind the occasional Linux system administrator job, where you would actually be using Linux on servers. Instead, many jobs that rise up on a "Linux administrator" search are actually referring to a plethora of 'NX operating systems.
|
||||
|
||||
For example, here is a quote from a **"Linux Administrator"** job posting:
|
||||
This role will provide support for build system integration, especially operating system installation support for BSD applications...
|
||||
|
||||
Or another ad declares in the bowels of its content:
|
||||
Windows administration experience required.
|
||||
|
||||
Ironically, if you show up to interview for any of these types of jobs and focus on Linux, they probably will not choose you.
|
||||
|
||||
Even more importantly, if you simply include Linux as your expertise, they may not even bother with your resume, because they can't tell the difference between UNIX, BSD, Linux, etc.
|
||||
|
||||
As a result, if you are conscientious and only include Linux on your resume, you are automatically out. But change that Linux to UNIX/Linux and you end up getting a bit farther in the human resources bureaucracy.
|
||||
|
||||
I had two colleagues that ended up changing this on their resumes and getting a much better hit ratio for interviews, which were still slim pickings because most job ads are tailored with some particular person already in mind. The main intent behind such job ads being a cover for the ass of the department making the claim of having an open job.
|
||||
|
||||
Second, the only person at the company who cares at all about the system administrator position is the technical lead/manager hiring for the slot. Others at the company, including the HR contact or the management could not care less.
|
||||
|
||||
I remember sitting in a board room as a fly on the wall, hearing one executive vice president refer to server administrators as "dime a dozen geeks." How wrong they are to suggest this.
|
||||
|
||||
Ironically, one day should the mail system fail, or the PBX connectivity hiccup, or perhaps core business files disappear from the intranet, these same executives are the first to get on the phone and threaten to fire the system admins.
|
||||
|
||||
Perhaps if they would stop leaving so many hot air telephone messages, or filling their emails with 35MB photographs of another vice president's fishing trip and wife, the servers wouldn't be so problematic.
|
||||
|
||||
Be aware that a Linux administrator ad, or any job posting for server administrator is placed because someone at the TECHNICAL level sees an urgent need for staffing. You're not going to get any empathy talking to HR or any leader of the company. Instead, take the time to find out who the hiring technical manager is and try to telephone them.
|
||||
|
||||
You can always call them directly because you have some "specific technical questions" you know the HR person could not answer. This opens the dialogue with the person who actually cares that the position is filled and ensures you get a foot in because you took the time for personal contact, even if it was a 60 second phone call.
|
||||
|
||||
What if the HR beauracracy won't let you through?
|
||||
|
||||
Start asking as many tech questions as possible direct to the HR hiring contact, such as how their Linux clusters are setup and do they run VMs exclusively? Anything relatively technical will send these HR people in a tizzy and allow you the question: "may I contact the technical manager of the team?"
|
||||
|
||||
If the response is a fluffy "maybe" or "I'll get back to you on that" they already filled the slot in their mind with someone else two weeks earlier, such as the HR staff member's fiance. They simply wanted it to look less like nepotism and more like indeterminism with a dash of egoism.
|
||||
|
||||
```
|
||||
"They simply wanted it to look less like nepotism and more like indeterminism with a dash of egoism."
|
||||
```
|
||||
|
||||
So take the time to find out who is the direct TECHNICAL leader hiring for the position and talk to them. It can make a difference and get you past some of the baloney.
|
||||
|
||||
Third, few job ads today include any semblance of reality.
|
||||
|
||||
I've seen enough ads requiring a junior system administrator with expertise that senior level experts don't have, to know the plan is to list the blue sky wish list and then find out who applies.
|
||||
|
||||
In this situation, the Linux administrator ad you apply for, should include some key phrases for which you already have experience or certifications.
|
||||
|
||||
The trick is to so overload your resume with the key phrases that MATCH their ad, it becomes almost impossible for them to determine which phrases you left out.
|
||||
|
||||
This doesn't necessarily translate to a job, but it often adds enough intrigue to get you an interview, which now a days is a major step.
|
||||
|
||||
By understanding and applying these three techniques, hopefully those seeking Linux administrator jobs have a head start on those who have only a slim chance in hell.
|
||||
|
||||
Even if these tips don't get you interviews right away, you can use the experience and awareness when you go to the next trade show, or company sponsored technical conference.
|
||||
|
||||
I strongly recommend you regularly attend these as well, especially if they are reasonably close, as they always provide a kick start to networking.
|
||||
|
||||
Remember that job networking now a days is a pseudonym for "getting the gossip on which companies are actually hiring and which ones are just lying about jobs to give the appearance of growth for shareholders."
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://reallylinux.com/docs/gettinglinuxjobs.shtml
|
||||
|
||||
作者:[Andrea W.Codingly][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://reallylinux.com
|
||||
[1]:http://www.reallylinux.com
|
||||
[2]:http://reallylinux.com/docs/linuxrecessionproof.shtml
|
||||
[3]:http://reallylinux.com
|
||||
[4]:http://reallylinux.com/docs/wantadsmad.shtml
|
||||
@ -0,0 +1,146 @@
|
||||
How to add network bridge with nmcli (NetworkManager) on Linux
|
||||
======
|
||||
|
||||
I am using Debian Linux 9 "stretch" on the desktop. I would like to create network bridge with NetworkManager. But, I am unable to find the option to add br0. How can I create or add network bridge with nmcli for NetworkManager on Linux?
|
||||
|
||||
A bridge is nothing but a device which joins two local networks into one network. It works at the data link layer, i.e., layer 2 of the OSI model. Network bridge often used with virtualization and other software. Disabling NetworkManager for a simple bridge especially on Linux Laptop/desktop doesn't make any sense. The nmcli tool can create Persistent bridge configuration without editing any files. **This page shows how to create a bridge interface using the Network Manager command line tool called nmcli**.
|
||||
|
||||
|
||||
|
||||
### How to create/add network bridge with nmcli
|
||||
|
||||
The procedure to add a bridge interface on Linux is as follows when you want to use Network Manager:
|
||||
|
||||
1. Open the Terminal app
|
||||
2. Get info about the current connection:
|
||||
```
|
||||
nmcli con show
|
||||
```
|
||||
3. Add a new bridge:
|
||||
```
|
||||
nmcli con add type bridge ifname br0
|
||||
```
|
||||
4. Create a slave interface:
|
||||
```
|
||||
nmcli con add type bridge-slave ifname eno1 master br0
|
||||
```
|
||||
5. Turn on br0:
|
||||
```
|
||||
nmcli con up br0
|
||||
```
|
||||
|
||||
Let us see how to create a bridge, named br0 in details.
|
||||
|
||||
### Get current network config
|
||||
|
||||
You can view connection from the Network Manager GUI in settings:
|
||||
[![Getting Network Info on Linux][1]][1]
|
||||
Another option is to type the following command:
|
||||
```
|
||||
$ nmcli con show
|
||||
$ nmcli connection show --active
|
||||
```
|
||||
[![View the connections with nmcli][2]][2]
|
||||
I have a "Wired connection 1" which uses the eno1 Ethernet interface. My system has a VPN interface too. I am going to setup a bridge interface named br0 and add, (or enslave) an interface to eno1.
|
||||
|
||||
### How to create a bridge, named br0
|
||||
|
||||
```
|
||||
$ sudo nmcli con add ifname br0 type bridge con-name br0
|
||||
$ sudo nmcli con add type bridge-slave ifname eno1 master br0
|
||||
$ nmcli connection show
|
||||
```
|
||||
[![Create bridge interface using nmcli on Linux][3]][3]
|
||||
You can disable STP too:
|
||||
```
|
||||
$ sudo nmcli con modify br0 bridge.stp no
|
||||
$ nmcli con show
|
||||
$ nmcli -f bridge con show br0
|
||||
```
|
||||
The last command shows the bridge settings including disabled STP:
|
||||
```
|
||||
bridge.mac-address: --
|
||||
bridge.stp: no
|
||||
bridge.priority: 32768
|
||||
bridge.forward-delay: 15
|
||||
bridge.hello-time: 2
|
||||
bridge.max-age: 20
|
||||
bridge.ageing-time: 300
|
||||
bridge.multicast-snooping: yes
|
||||
```
|
||||
|
||||
|
||||
### How to turn on bridge interface
|
||||
|
||||
You must turn off "Wired connection 1" and turn on br0:
|
||||
```
|
||||
$ sudo nmcli con down "Wired connection 1"
|
||||
$ sudo nmcli con up br0
|
||||
$ nmcli con show
|
||||
```
|
||||
Use [ip command][4] to view the IP settings:
|
||||
```
|
||||
$ ip a s
|
||||
$ ip a s br0
|
||||
```
|
||||
[![Build a network bridge with nmcli on Linux][5]][5]
|
||||
|
||||
### Optional: How to use br0 with KVM
|
||||
|
||||
Now you can connect VMs (virtual machine) created with KVM/VirtualBox/VMware workstation to a network directly without using NAT. Create a file named br0.xml for KVM using vi command or [cat command][6]:
|
||||
`$ cat /tmp/br0.xml`
|
||||
Append the following code:
|
||||
```
|
||||
<network>
|
||||
<name>br0</name>
|
||||
<forward mode="bridge"/>
|
||||
<bridge name="br0" />
|
||||
</network>
|
||||
```
|
||||
|
||||
Run virsh command as follows:
|
||||
```
|
||||
# virsh net-define /tmp/br0.xml
|
||||
# virsh net-start br0
|
||||
# virsh net-autostart br0
|
||||
# virsh net-list --all
|
||||
```
|
||||
Sample outputs:
|
||||
```
|
||||
Name State Autostart Persistent
|
||||
----------------------------------------------------------
|
||||
br0 active yes yes
|
||||
default inactive no yes
|
||||
```
|
||||
|
||||
|
||||
For more info read the following man page:
|
||||
```
|
||||
$ man ip
|
||||
$ man nmcli
|
||||
```
|
||||
|
||||
### about the author
|
||||
|
||||
The author is the creator of nixCraft and a seasoned sysadmin and a trainer for the Linux operating system/Unix shell scripting. He has worked with global clients and in various industries, including IT, education, defense and space research, and the nonprofit sector. Follow him on [Twitter][7], [Facebook][8], [Google+][9].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/how-to-add-network-bridge-with-nmcli-networkmanager-on-linux/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/media/new/faq/2018/01/Getting-Network-Info-on-Linux.jpg
|
||||
[2]:https://www.cyberciti.biz/media/new/faq/2018/01/View-the-connections-with-nmcli.jpg
|
||||
[3]:https://www.cyberciti.biz/media/new/faq/2018/01/Create-bridge-interface-using-nmcli-on-Linux.jpg
|
||||
[4]:https://www.cyberciti.biz/faq/linux-ip-command-examples-usage-syntax/ (See Linux/Unix ip command examples for more info)
|
||||
[5]:https://www.cyberciti.biz/media/new/faq/2018/01/Build-a-network-bridge-with-nmcli-on-Linux.jpg
|
||||
[6]:https://www.cyberciti.biz/faq/linux-unix-appleosx-bsd-cat-command-examples/ (See Linux/Unix cat command examples for more info)
|
||||
[7]:https://twitter.com/nixcraft
|
||||
[8]:https://facebook.com/nixcraft
|
||||
[9]:https://plus.google.com/+CybercitiBiz
|
||||
363
sources/tech/20180129 Advanced Python Debugging with pdb.md
Normal file
363
sources/tech/20180129 Advanced Python Debugging with pdb.md
Normal file
@ -0,0 +1,363 @@
|
||||
translating by lujun9972
|
||||
Advanced Python Debugging with pdb
|
||||
======
|
||||
|
||||
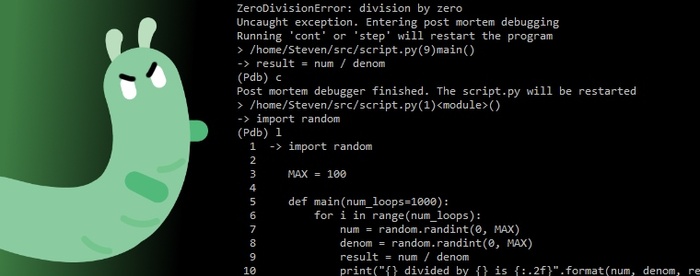
|
||||
|
||||
Python's built-in [`pdb`][1] module is extremely useful for interactive debugging, but has a bit of a learning curve. For a long time, I stuck to basic `print`-debugging and used `pdb` on a limited basis, which meant I missed out on a lot of features that would have made debugging faster and easier.
|
||||
|
||||
In this post I will show you a few tips I've picked up over the years to level up my interactive debugging skills.
|
||||
|
||||
## Print debugging vs. interactive debugging
|
||||
|
||||
First, why would you want to use an interactive debugger instead of inserting `print` or `logging` statements into your code?
|
||||
|
||||
With `pdb`, you have a lot more flexibility to run, resume, and alter the execution of your program without touching the underlying source. Once you get good at this, it means more time spent diving into issues and less time context switching back and forth between your editor and the command line.
|
||||
|
||||
Also, by not touching the underlying source code, you will have the ability to step into third party code (e.g. modules installed from PyPI) and the standard library.
|
||||
|
||||
## Post-mortem debugging
|
||||
|
||||
The first workflow I used after moving away from `print` debugging was `pdb`'s "post-mortem debugging" mode. This is where you run your program as usual, but whenever an unhandled exception is thrown, you drop down into the debugger to poke around in the program state. After that, you attempt to make a fix and repeat the process until the problem is resolved.
|
||||
|
||||
You can run an existing script with the post-mortem debugger by using Python's `-mpdb` option:
|
||||
```
|
||||
python3 -mpdb path/to/script.py
|
||||
|
||||
```
|
||||
|
||||
From here, you are dropped into a `(Pdb)` prompt. To start execution, you use the `continue` or `c` command. If the program executes successfully, you will be taken back to the `(Pdb)` prompt where you can restart the execution again. At this point, you can use `quit` / `q` or Ctrl+D to exit the debugger.
|
||||
|
||||
If the program throws an unhandled exception, you'll also see a `(Pdb)` prompt, but with the program execution stopped at the line that threw the exception. From here, you can run Python code and debugger commands at the prompt to inspect the current program state.
|
||||
|
||||
## Testing our basic workflow
|
||||
|
||||
To see how these basic debugging steps work, I'll be using this (buggy) program:
|
||||
```
|
||||
import random
|
||||
|
||||
MAX = 100
|
||||
|
||||
def main(num_loops=1000):
|
||||
for i in range(num_loops):
|
||||
num = random.randint(0, MAX)
|
||||
denom = random.randint(0, MAX)
|
||||
result = num / denom
|
||||
print("{} divided by {} is {:.2f}".format(num, denom, result))
|
||||
|
||||
if __name__ == "__main__":
|
||||
import sys
|
||||
arg = sys.argv[-1]
|
||||
if arg.isdigit():
|
||||
main(arg)
|
||||
else:
|
||||
main()
|
||||
|
||||
```
|
||||
|
||||
We're expecting the program to do some basic math operations on random numbers in a loop and print the result. Try running it normally and you will see one of the bugs:
|
||||
```
|
||||
$ python3 script.py
|
||||
2 divided by 30 is 0.07
|
||||
65 divided by 41 is 1.59
|
||||
0 divided by 70 is 0.00
|
||||
...
|
||||
38 divided by 26 is 1.46
|
||||
Traceback (most recent call last):
|
||||
File "script.py", line 16, in <module>
|
||||
main()
|
||||
File "script.py", line 7, in main
|
||||
result = num / denom
|
||||
ZeroDivisionError: division by zero
|
||||
|
||||
```
|
||||
|
||||
Let's try post-mortem debugging this error:
|
||||
```
|
||||
$ python3 -mpdb script.py
|
||||
> ./src/script.py(1)<module>()
|
||||
-> import random
|
||||
(Pdb) c
|
||||
49 divided by 46 is 1.07
|
||||
...
|
||||
Traceback (most recent call last):
|
||||
File "/usr/lib/python3.4/pdb.py", line 1661, in main
|
||||
pdb._runscript(mainpyfile)
|
||||
File "/usr/lib/python3.4/pdb.py", line 1542, in _runscript
|
||||
self.run(statement)
|
||||
File "/usr/lib/python3.4/bdb.py", line 431, in run
|
||||
exec(cmd, globals, locals)
|
||||
File "<string>", line 1, in <module>
|
||||
File "./src/script.py", line 1, in <module>
|
||||
import random
|
||||
File "./src/script.py", line 7, in main
|
||||
result = num / denom
|
||||
ZeroDivisionError: division by zero
|
||||
Uncaught exception. Entering post mortem debugging
|
||||
Running 'cont' or 'step' will restart the program
|
||||
> ./src/script.py(7)main()
|
||||
-> result = num / denom
|
||||
(Pdb) num
|
||||
76
|
||||
(Pdb) denom
|
||||
0
|
||||
(Pdb) random.randint(0, MAX)
|
||||
56
|
||||
(Pdb) random.randint(0, MAX)
|
||||
79
|
||||
(Pdb) random.randint(0, 1)
|
||||
0
|
||||
(Pdb) random.randint(1, 1)
|
||||
1
|
||||
|
||||
```
|
||||
|
||||
Once the post-mortem debugger kicks in, we can inspect all of the variables in the current frame and even run new code to help us figure out what's wrong and attempt to make a fix.
|
||||
|
||||
## Dropping into the debugger from Python code using `pdb.set_trace`
|
||||
|
||||
Another technique that I used early on, after starting to use `pdb`, was forcing the debugger to run at a certain line of code before an error occurred. This is a common next step after learning post-mortem debugging because it feels similar to debugging with `print` statements.
|
||||
|
||||
For example, in the above code, if we want to stop execution before the division operation, we could add a `pdb.set_trace` call to our program here:
|
||||
```
|
||||
import pdb; pdb.set_trace()
|
||||
result = num / denom
|
||||
|
||||
```
|
||||
|
||||
And then run our program without `-mpdb`:
|
||||
```
|
||||
$ python3 script.py
|
||||
> ./src/script.py(10)main()
|
||||
-> result = num / denom
|
||||
(Pdb) num
|
||||
94
|
||||
(Pdb) denom
|
||||
19
|
||||
|
||||
```
|
||||
|
||||
The problem with this method is that you have to constantly drop these statements into your source code, remember to remove them afterwards, and switch between running your code with `python` vs. `python -mpdb`.
|
||||
|
||||
Using `pdb.set_trace` gets the job done, but **breakpoints** are an even more flexible way to stop the debugger at any line (even third party or standard library code), without needing to modify any source code. Let's learn about breakpoints and a few other useful commands.
|
||||
|
||||
## Debugger commands
|
||||
|
||||
There are over 30 commands you can give to the interactive debugger, a list that can be seen by using the `help` command when at the `(Pdb)` prompt:
|
||||
```
|
||||
(Pdb) help
|
||||
|
||||
Documented commands (type help <topic>):
|
||||
========================================
|
||||
EOF c d h list q rv undisplay
|
||||
a cl debug help ll quit s unt
|
||||
alias clear disable ignore longlist r source until
|
||||
args commands display interact n restart step up
|
||||
b condition down j next return tbreak w
|
||||
break cont enable jump p retval u whatis
|
||||
bt continue exit l pp run unalias where
|
||||
|
||||
```
|
||||
|
||||
You can use `help <topic>` for more information on a given command.
|
||||
|
||||
Instead of walking through each command, I'll list out the ones I've found most useful and what arguments they take.
|
||||
|
||||
**Setting breakpoints** :
|
||||
|
||||
* `l(ist)`: displays the source code of the currently running program, with line numbers, for the 10 lines around the current statement.
|
||||
* `l 1,999`: displays the source code of lines 1-999. I regularly use this to see the source for the entire program. If your program only has 20 lines, it'll just show all 20 lines.
|
||||
* `b(reakpoint)`: displays a list of current breakpoints.
|
||||
* `b 10`: set a breakpoint at line 10. Breakpoints are referred to by a numeric ID, starting at 1.
|
||||
* `b main`: set a breakpoint at the function named `main`. The function name must be in the current scope. You can also set breakpoints on functions in other modules in the current scope, e.g. `b random.randint`.
|
||||
* `b script.py:10`: sets a breakpoint at line 10 in `script.py`. This gives you another way to set breakpoints in another module.
|
||||
* `clear`: clears all breakpoints.
|
||||
* `clear 1`: clear breakpoint 1.
|
||||
|
||||
|
||||
|
||||
**Stepping through execution** :
|
||||
|
||||
* `c(ontinue)`: execute until the program finishes, an exception is thrown, or a breakpoint is hit.
|
||||
* `s(tep)`: execute the next line, whatever it is (your code, stdlib, third party code, etc.). Use this when you want to step down into function calls you're interested in.
|
||||
* `n(ext)`: execute the next line in the current function (will not step into downstream function calls). Use this when you're only interested in the current function.
|
||||
* `r(eturn)`: execute the remaining lines in the current function until it returns. Use this to skip over the rest of the function and go up a level. For example, if you've stepped down into a function by mistake.
|
||||
* `unt(il) [lineno]`: execute until the current line exceeds the current line number. This is useful when you've stepped into a loop but want to let the loop continue executing without having to manually step through every iteration. Without any argument, this command behaves like `next` (with the loop skipping behavior, once you've stepped through the loop body once).
|
||||
|
||||
|
||||
|
||||
**Moving up and down the stack** :
|
||||
|
||||
* `w(here)`: shows an annotated view of the stack trace, with your current frame marked by `>`.
|
||||
* `u(p)`: move up one frame in the current stack trace. For example, when post-mortem debugging, you'll start off on the lowest level of the stack and typically want to move `up` a few times to help figure out what went wrong.
|
||||
* `d(own)`: move down one frame in the current stack trace.
|
||||
|
||||
|
||||
|
||||
**Additional commands and tips** :
|
||||
|
||||
* `pp <expression>`: This will "pretty print" the result of the given expression using the [`pprint`][2] module. Example:
|
||||
|
||||
|
||||
```
|
||||
(Pdb) stuff = "testing the pp command in pdb with a big list of strings"
|
||||
(Pdb) pp [(i, x) for (i, x) in enumerate(stuff.split())]
|
||||
[(0, 'testing'),
|
||||
(1, 'the'),
|
||||
(2, 'pp'),
|
||||
(3, 'command'),
|
||||
(4, 'in'),
|
||||
(5, 'pdb'),
|
||||
(6, 'with'),
|
||||
(7, 'a'),
|
||||
(8, 'big'),
|
||||
(9, 'list'),
|
||||
(10, 'of'),
|
||||
(11, 'strings')]
|
||||
|
||||
```
|
||||
|
||||
* `!<python code>`: sometimes the Python code you run in the debugger will be confused for a command. For example `c = 1` will trigger the `continue` command. To force the debugger to execute Python code, prefix the line with `!`, e.g. `!c = 1`.
|
||||
|
||||
* Pressing the Enter key at the `(Pdb)` prompt will execute the previous command again. This is most useful after the `s`/`n`/`r`/`unt` commands to quickly step through execution line-by-line.
|
||||
|
||||
* You can run multiple commands on one line by separating them with `;;`, e.g. `b 8 ;; c`.
|
||||
|
||||
* The `pdb` module can take multiple `-c` arguments on the command line to execute commands as soon as the debugger starts.
|
||||
|
||||
|
||||
|
||||
|
||||
Example:
|
||||
```
|
||||
python3 -mpdb -cc script.py # run the program without you having to enter an initial "c" at the prompt
|
||||
python3 -mpdb -c "b 8" -cc script.py # sets a breakpoint on line 8 and runs the program
|
||||
|
||||
```
|
||||
|
||||
## Restart behavior
|
||||
|
||||
Another thing that can shave time off debugging is understanding how `pdb`'s restart behavior works. You may have noticed that after execution stops, `pdb` will give a message like, "The program finished and will be restarted," or "The script will be restarted." When I first started using `pdb`, I would always quit and re-run `python -mpdb ...` to make sure that my code changes were getting picked up, which was unnecessary in most cases.
|
||||
|
||||
When `pdb` says it will restart the program, or when you use the `restart` command, code changes to the script you're debugging will be reloaded automatically. Breakpoints will still be set after reloading, but may need to be cleared and re-set due to line numbers shifting. Code changes to other imported modules will not be reloaded -- you will need to `quit` and re-run the `-mpdb` command to pick those up.
|
||||
|
||||
## Watches
|
||||
|
||||
One feature you may miss from other interactive debuggers is the ability to "watch" a variable change throughout the program's execution. `pdb` does not include a watch command by default, but you can get something similar by using `commands`, which lets you run arbitrary Python code whenever a breakpoint is hit.
|
||||
|
||||
To watch what happens to the `denom` variable in our example program:
|
||||
```
|
||||
$ python3 -mpdb script.py
|
||||
> ./src/script.py(1)<module>()
|
||||
-> import random
|
||||
(Pdb) b 9
|
||||
Breakpoint 1 at ./src/script.py:9
|
||||
(Pdb) commands
|
||||
(com) silent
|
||||
(com) print("DENOM: {}".format(denom))
|
||||
(com) c
|
||||
(Pdb) c
|
||||
DENOM: 77
|
||||
71 divided by 77 is 0.92
|
||||
DENOM: 27
|
||||
100 divided by 27 is 3.70
|
||||
DENOM: 10
|
||||
82 divided by 10 is 8.20
|
||||
DENOM: 20
|
||||
...
|
||||
|
||||
```
|
||||
|
||||
We first set a breakpoint (which is assigned ID 1), then use `commands` to start entering a block of commands. These commands function as if you had typed them at the `(Pdb)` prompt. They can be either Python code or additional `pdb` commands.
|
||||
|
||||
Once we start the `commands` block, the prompt changes to `(com)`. The `silent` command means the following commands will not be echoed back to the screen every time they're executed, which makes reading the output a little easier.
|
||||
|
||||
After that, we run a `print` statement to inspect the variable, similar to what we might do when `print` debugging. Finally, we end with a `c` to continue execution, which ends the command block. Typing `c` again at the `(Pdb)` prompt starts execution and we see our new `print` statement running.
|
||||
|
||||
If you'd rather stop execution instead of continuing, you can use `end` instead of `c` in the command block.
|
||||
|
||||
## Running pdb from the interpreter
|
||||
|
||||
Another way to run `pdb` is via the interpreter, which is useful when you're experimenting interactively and would like to drop into `pdb` without running a standalone script.
|
||||
|
||||
For post-mortem debugging, all you need is a call to `pdb.pm()` after an exception has occurred:
|
||||
```
|
||||
$ python3
|
||||
>>> import script
|
||||
>>> script.main()
|
||||
17 divided by 60 is 0.28
|
||||
...
|
||||
56 divided by 94 is 0.60
|
||||
Traceback (most recent call last):
|
||||
File "<stdin>", line 1, in <module>
|
||||
File "./src/script.py", line 9, in main
|
||||
result = num / denom
|
||||
ZeroDivisionError: division by zero
|
||||
>>> import pdb
|
||||
>>> pdb.pm()
|
||||
> ./src/script.py(9)main()
|
||||
-> result = num / denom
|
||||
(Pdb) num
|
||||
4
|
||||
(Pdb) denom
|
||||
0
|
||||
|
||||
```
|
||||
|
||||
If you want to step through normal execution instead, use the `pdb.run()` function:
|
||||
```
|
||||
$ python3
|
||||
>>> import script
|
||||
>>> import pdb
|
||||
>>> pdb.run("script.main()")
|
||||
> <string>(1)<module>()
|
||||
(Pdb) b script:6
|
||||
Breakpoint 1 at ./src/script.py:6
|
||||
(Pdb) c
|
||||
> ./src/script.py(6)main()
|
||||
-> for i in range(num_loops):
|
||||
(Pdb) n
|
||||
> ./src/script.py(7)main()
|
||||
-> num = random.randint(0, MAX)
|
||||
(Pdb) n
|
||||
> ./src/script.py(8)main()
|
||||
-> denom = random.randint(0, MAX)
|
||||
(Pdb) n
|
||||
> ./src/script.py(9)main()
|
||||
-> result = num / denom
|
||||
(Pdb) n
|
||||
> ./src/script.py(10)main()
|
||||
-> print("{} divided by {} is {:.2f}".format(num, denom, result))
|
||||
(Pdb) n
|
||||
66 divided by 70 is 0.94
|
||||
> ./src/script.py(6)main()
|
||||
-> for i in range(num_loops):
|
||||
|
||||
```
|
||||
|
||||
This one is a little trickier than `-mpdb` because you don't have the ability to step through an entire program. Instead, you'll need to manually set a breakpoint, e.g. on the first statement of the function you're trying to execute.
|
||||
|
||||
## Conclusion
|
||||
|
||||
Hopefully these tips have given you a few new ideas on how to use `pdb` more effectively. After getting a handle on these, you should be able to pick up the [other commands][3] and start customizing `pdb` via a `.pdbrc` file ([example][4]).
|
||||
|
||||
You can also look into other front-ends for debugging, like [pdbpp][5], [pudb][6], and [ipdb][7], or GUI debuggers like the one included in PyCharm. Happy debugging!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.codementor.io/stevek/advanced-python-debugging-with-pdb-g56gvmpfa
|
||||
|
||||
作者:[Steven Kryskalla][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.codementor.io/stevek
|
||||
[1]:https://docs.python.org/3/library/pdb.html
|
||||
[2]:https://docs.python.org/3/library/pprint.html
|
||||
[3]:https://docs.python.org/3/library/pdb.html#debugger-commands
|
||||
[4]:https://nedbatchelder.com/blog/200704/my_pdbrc.html
|
||||
[5]:https://pypi.python.org/pypi/pdbpp/
|
||||
[6]:https://pypi.python.org/pypi/pudb/
|
||||
[7]:https://pypi.python.org/pypi/ipdb
|
||||
@ -0,0 +1,115 @@
|
||||
Create your own personal Cloud: Install OwnCloud
|
||||
======
|
||||
Cloud is what everyone is talking about. We have a number of major players in the market that are offering cloud storage as well as other cloud based services. But we can also create a personal cloud for ourselves.
|
||||
|
||||
In this tutorial we are going to discuss how to create a personal cloud using OwnCloud. OwnCloud is a web application, that we can install on our Linux machines, to store & serve data. It can be used for sharing calender, Contacts and Bookmark sharing and Personal Audio/Video Streaming etc.
|
||||
|
||||
For this tutorial, we will be using CentOS 7 machine but this tutorial can also be used to install ownCloud on other Linux distributions as well. Let's start with pre-requisites for installing ownCloud,
|
||||
|
||||
**(Recommended Read:[How to use Apache as Reverse Proxy on CentOS & RHEL][1])**
|
||||
|
||||
**(Also Read:[Real Time Linux server monitoring with GLANCES monitoring tool][2])**
|
||||
|
||||
### Pre-requisites
|
||||
|
||||
* We need to have LAMP stack configured on our machines. Please go through our articles '[ Easiest guide for setting up LAMP server for CentOS/RHEL ][3] & [Create LAMP stack on Ubuntu][4].
|
||||
|
||||
* We will also need the following php packages installed on our machines,' php-mysql php-json php-xml php-mbstring php-zip php-gd curl php-curl php-pdo'. Install them using the package manager.
|
||||
|
||||
```
|
||||
$ sudo yum install php-mysql php-json php-xml php-mbstring php-zip php-gd curl php-curl php-pdo
|
||||
```
|
||||
|
||||
### Installation
|
||||
|
||||
To install owncloud, we will now download the ownCloud package on our server. Use the following command to download the latest package (10.0.4-1) from ownCloud official website,
|
||||
|
||||
```
|
||||
$ wget https://download.owncloud.org/community/owncloud-10.0.4.tar.bz2
|
||||
```
|
||||
|
||||
Extract it using the following command,
|
||||
|
||||
```
|
||||
$ tar -xvf owncloud-10.0.4.tar.bz2
|
||||
```
|
||||
|
||||
Now move all the contents of extracted folder to '/var/www/html'
|
||||
|
||||
```
|
||||
$ mv owncloud/* /var/www/html
|
||||
```
|
||||
|
||||
Next thing we need to do is to make a change in apache configuration file 'httpd.conf',
|
||||
|
||||
```
|
||||
$ sudo vim /etc/httpd/conf/httpd.com
|
||||
```
|
||||
|
||||
& change the following option,
|
||||
|
||||
```
|
||||
AllowOverride All
|
||||
```
|
||||
|
||||
Now save the file & change the permissions for owncloud folder,
|
||||
|
||||
```
|
||||
$ sudo chown -R apache:apache /var/www/html/
|
||||
$ sudo chmod 777 /var/www/html/config/
|
||||
```
|
||||
|
||||
Now restart the apache service to implement the changes made,
|
||||
|
||||
```
|
||||
$ sudo systemctl restart httpd
|
||||
```
|
||||
|
||||
Now we need to create a database on mariadb to store all the data from owncloud. Create a database & a db user with the following commands,
|
||||
|
||||
```
|
||||
$ mysql -u root -p
|
||||
MariaDB [(none)] > create database owncloud;
|
||||
MariaDB [(none)] > GRANT ALL ON owncloud.* TO ocuser@localhost IDENTIFIED BY 'owncloud';
|
||||
MariaDB [(none)] > flush privileges;
|
||||
MariaDB [(none)] > exit
|
||||
```
|
||||
|
||||
Configuration part on server is completed, we can now access the owncloud from a web browser. Open a browser of your choosing & enter the IP address of the server, which in our case is 10.20.30.100,
|
||||
|
||||
![install owncloud][7]
|
||||
|
||||
As soon as the URL loads, we will be presented with the above mentioned page. Here we will create our admin user & will also provide our database information. Once all the information has been provided, click on 'Finish setup'.
|
||||
|
||||
We will than be redirected to login page, where we need to enter the credentials we created in previous step,
|
||||
|
||||
![install owncloud][9]
|
||||
|
||||
Upon successful authentication, we will enter into the ownCloud dashboard,
|
||||
|
||||
![install owncloud][11]
|
||||
|
||||
We can than use mobile apps or can also upload our data using the web interface. We now have our own personal cloud ready. We now end this tutorial on how to install ownCloud to create your own cloud. Please do leave your questions or suggestions in the comment box below.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/create-personal-cloud-install-owncloud/
|
||||
|
||||
作者:[SHUSAIN][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:http://linuxtechlab.com/apache-as-reverse-proxy-centos-rhel/
|
||||
[2]:http://linuxtechlab.com/linux-server-glances-monitoring-tool/
|
||||
[3]:http://linuxtechlab.com/easiest-guide-creating-lamp-server/
|
||||
[4]:http://linuxtechlab.com/install-lamp-stack-on-ubuntu/
|
||||
[6]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=400%2C647
|
||||
[7]:https://i1.wp.com/linuxtechlab.com/wp-content/uploads/2018/01/owncloud1-compressor.jpg?resize=400%2C647
|
||||
[8]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=876%2C541
|
||||
[9]:https://i1.wp.com/linuxtechlab.com/wp-content/uploads/2018/01/owncloud2-compressor1.jpg?resize=876%2C541
|
||||
[10]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=981%2C474
|
||||
[11]:https://i0.wp.com/linuxtechlab.com/wp-content/uploads/2018/01/owncloud3-compressor1.jpg?resize=981%2C474
|
||||
225
sources/tech/20180129 How to use LXD instance types.md
Normal file
225
sources/tech/20180129 How to use LXD instance types.md
Normal file
@ -0,0 +1,225 @@
|
||||
How to use LXD instance types
|
||||
======
|
||||
**Background** : LXD is a hypervisor that manages machine containers on Linux distributions. You install LXD on your Linux distribution and then you can launch machine containers into your distribution running all sort of (other) Linux distributions.
|
||||
|
||||
When you launch a new LXD container, there is a parameter for an instance type. Here it is,
|
||||
```
|
||||
$ lxc launch --help
|
||||
Usage: lxc launch [ <remote>:]<image> [<remote>:][<name>] [--ephemeral|-e] [--profile|-p <profile>...] [--config|-c <key=value>...] [--type|-t <instance type>]
|
||||
|
||||
Create and start containers from images.
|
||||
|
||||
Not specifying -p will result in the default profile.
|
||||
Specifying "-p" with no argument will result in no profile.
|
||||
|
||||
Examples:
|
||||
lxc launch ubuntu:16.04 u1
|
||||
|
||||
Options:
|
||||
-c, --config (= map[]) Config key/value to apply to the new container
|
||||
--debug (= false) Enable debug mode
|
||||
-e, --ephemeral (= false) Ephemeral container
|
||||
--force-local (= false) Force using the local unix socket
|
||||
--no-alias (= false) Ignore aliases when determining what command to run
|
||||
-p, --profile (= []) Profile to apply to the new container
|
||||
**-t (= "") Instance type**
|
||||
--verbose (= false) Enable verbose mode
|
||||
```
|
||||
|
||||
What do we put for Instance type? Here is the documentation,
|
||||
|
||||
<https://lxd.readthedocs.io/en/latest/containers/#instance-types>
|
||||
|
||||
Simply put, an instance type is just a mnemonic shortcut for specific pair of CPU cores and RAM memory settings. For CPU you specify the number of cores and for RAM memory the amount in GB (assuming your own computer has enough cores and RAM so that LXD can allocate them to the newly created container).
|
||||
|
||||
You would need an instance type if you want to create a machine container that resembles in the specs as close as possible what you will be installing later on, on AWS (Amazon), Azure (Microsoft) or GCE (Google).
|
||||
|
||||
The instance type can have any of the following forms,
|
||||
|
||||
* `<instance type>` for example: **t2.micro** (LXD figures out that this refers to AWS t2.micro, therefore 1 core, 1GB RAM).
|
||||
* `<cloud>:<instance type>` for example, **aws:t2.micro** (LXD quickly looks into the AWS types, therefore 1core, 1GB RAM).
|
||||
* `c<CPU>-m<RAM in GB>` for example, **c1-m1** (LXD explicitly allocates one core, and 1GB RAM).
|
||||
|
||||
|
||||
|
||||
Where do these mnemonics like **t2.micro** come from? The documentation says from <https://github.com/dustinkirkland/instance-type/tree/master/yaml>
|
||||
|
||||
[![][1]][2]
|
||||
|
||||
There are three sets of instance types, **aws** , **azure** and **gce**. Their names are listed in [the LXD instance type index file ][3]**.yaml,**
|
||||
```
|
||||
aws: "aws.yaml"
|
||||
gce: "gce.yaml"
|
||||
azure: "azure.yaml"
|
||||
|
||||
```
|
||||
|
||||
Over there, there are YAML configuration files for each of AWS, Azure and GCE, and in them there are settings for CPU cores and RAM memory.
|
||||
|
||||
The actual URLs that the LXD client will be using, are
|
||||
|
||||
<https://uk.images.linuxcontainers.org/meta/instance-types/aws.yaml>
|
||||
|
||||
Sample for AWS:
|
||||
```
|
||||
t2.large:
|
||||
cpu: 2.0
|
||||
mem: 8.0
|
||||
t2.medium:
|
||||
cpu: 2.0
|
||||
mem: 4.0
|
||||
t2.micro:
|
||||
cpu: 1.0
|
||||
mem: 1.0
|
||||
t2.nano:
|
||||
cpu: 1.0
|
||||
mem: 0.5
|
||||
t2.small:
|
||||
cpu: 1.0
|
||||
mem: 2.0
|
||||
```
|
||||
|
||||
<https://uk.images.linuxcontainers.org/meta/instance-types/azure.yaml>
|
||||
|
||||
Sample for Azure:
|
||||
```
|
||||
ExtraSmall:
|
||||
cpu: 1.0
|
||||
mem: 0.768
|
||||
Large:
|
||||
cpu: 4.0
|
||||
mem: 7.0
|
||||
Medium:
|
||||
cpu: 2.0
|
||||
mem: 3.5
|
||||
Small:
|
||||
cpu: 1.0
|
||||
mem: 1.75
|
||||
Standard_A1_v2:
|
||||
cpu: 1.0
|
||||
mem: 2.0
|
||||
```
|
||||
|
||||
<https://uk.images.linuxcontainers.org/meta/instance-types/gce.yaml>
|
||||
|
||||
Sample for GCE:
|
||||
```
|
||||
f1-micro:
|
||||
cpu: 0.2
|
||||
mem: 0.6
|
||||
g1-small:
|
||||
cpu: 0.5
|
||||
mem: 1.7
|
||||
n1-highcpu-16:
|
||||
cpu: 16.0
|
||||
mem: 14.4
|
||||
n1-highcpu-2:
|
||||
cpu: 2.0
|
||||
mem: 1.8
|
||||
n1-highcpu-32:
|
||||
cpu: 32.0
|
||||
mem: 28.8
|
||||
```
|
||||
|
||||
Let's see an example. Here, all of the following are all equivalent! Just run one of them to get a 1 CPU core/1GB RAM container.
|
||||
```
|
||||
$ lxc launch ubuntu:x -t t2.micro aws-t2-micro
|
||||
|
||||
$ lxc launch ubuntu:x -t aws:t2.micro aws-t2-micro
|
||||
|
||||
$ lxc launch ubuntu:x -t c1-m1 aws-t2-micro
|
||||
```
|
||||
|
||||
Let's verify that the constraints have been actually set for the container.
|
||||
```
|
||||
$ lxc config get aws-t2-micro limits.cpu
|
||||
1
|
||||
|
||||
$ lxc config get aws-t2-micro limits.cpu.allowance
|
||||
|
||||
|
||||
$ lxc config get aws-t2-micro limits.memory
|
||||
1024MB
|
||||
|
||||
$ lxc config get aws-t2-micro limits.memory.enforce
|
||||
|
||||
|
||||
```
|
||||
|
||||
There are generic limits for 1 CPU core and 1024MB/1GB RAM. For more, see [LXD resource control][4].
|
||||
|
||||
If you already have a running container and you wanted to set limits live (no need to restart it), here is how you would do that.
|
||||
```
|
||||
$ lxc launch ubuntu:x mycontainer
|
||||
Creating mycontainer
|
||||
Starting mycontainer
|
||||
|
||||
$ lxc config set mycontainer limits.cpu 1
|
||||
$ lxc config set mycontainer limits.memory 1GB
|
||||
```
|
||||
|
||||
Let's see the config with the limits,
|
||||
```
|
||||
$ lxc config show mycontainer
|
||||
architecture: x86_64
|
||||
config:
|
||||
image.architecture: amd64
|
||||
image.description: ubuntu 16.04 LTS amd64 (release) (20180126)
|
||||
image.label: release
|
||||
image.os: ubuntu
|
||||
image.release: xenial
|
||||
image.serial: "20180126"
|
||||
image.version: "16.04"
|
||||
limits.cpu: "1"
|
||||
limits.memory: 1GB
|
||||
...
|
||||
```
|
||||
|
||||
### Troubleshooting
|
||||
|
||||
#### I tried to the the memory limit but I get an error!
|
||||
|
||||
I got this error,
|
||||
```
|
||||
$ lxc config set mycontainer limits.memory 1
|
||||
error: Failed to set cgroup memory.limit_in_bytes="1": setting cgroup item for the container failed
|
||||
Exit 1
|
||||
```
|
||||
|
||||
When you set the memory limit ( **limits.memory** ), you need to append a specifier like **GB** (as in 1GB). Because the number there is in bytes if no specifier is present, and one byte of memory is not going to work.
|
||||
|
||||
#### I cannot set the limits in lxc launch -config!
|
||||
|
||||
How do I use **lxc launch -config ConfigurationGoesHere**?
|
||||
|
||||
Here is the documentation:
|
||||
```
|
||||
$ lxc launch --help
|
||||
Usage: lxc launch [ <remote>:]<image> ... [--config|-c <key=value>...]
|
||||
```
|
||||
|
||||
Here it is,
|
||||
```
|
||||
$ lxc launch ubuntu:x --config limits.cpu=1 --config limits.memory=1GB mycontainer
|
||||
Creating mycontainer
|
||||
Starting mycontainer
|
||||
```
|
||||
|
||||
That is, use multiple **- config** parameters.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.simos.info/how-to-use-lxd-instance-types/
|
||||
|
||||
作者:[Simos Xenitellis][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.simos.info/author/simos/
|
||||
[1]:https://i1.wp.com/blog.simos.info/wp-content/uploads/2018/01/lxd-instance-types.png?resize=750%2C277&ssl=1
|
||||
[2]:https://i1.wp.com/blog.simos.info/wp-content/uploads/2018/01/lxd-instance-types.png?ssl=1
|
||||
[3]:https://uk.images.linuxcontainers.org/meta/instance-types/.yaml
|
||||
[4]:https://stgraber.org/2016/03/26/lxd-2-0-resource-control-412/
|
||||
@ -0,0 +1,401 @@
|
||||
Install Zabbix Monitoring Server and Agent on Debian 9
|
||||
======
|
||||
|
||||
Monitoring tools are used to continuously keep track of the status of the system and send out alerts and notifications if anything goes wrong. Also, monitoring tools help you to ensure that your critical systems, applications and services are always up and running. Monitoring tools are a supplement for your network security, allowing you to detect malicious traffic, where it's coming from and how to cancel it.
|
||||
|
||||
Zabbix is a free, open source and the ultimate enterprise-level monitoring tool designed for real-time monitoring of millions of metrics collected from tens of thousands of servers, virtual machines and network devices. Zabbix has been designed to skill from small environment to large environment. Its web front-end is written in PHP, backend is written in C and uses MySQL, PostgreSQL, SQLite, Oracle or IBM DB2 to store data. Zabbix provides graphing functionality that allows you to get an overview of the current state of specific nodes and the network
|
||||
|
||||
Some of the major features of the Zabbix are listed below:
|
||||
|
||||
* Monitoring Servers, Databases, Applications, Network Devices, Vmware hypervisor, Virtual Machines and much more.
|
||||
* Special designed to support small to large environments to improve the quality of your services and reduce operating costs by avoiding downtime.
|
||||
* Fully open source, so you don't need to pay anything.
|
||||
* Provide user friendly web interface to do everything from a central location.
|
||||
* Comes with SNMP to monitor Network device and IPMI to monitor Hardware device.
|
||||
* Web-based front end that allows full system control from a browser.
|
||||
|
||||
This tutorial will walk you through the step by step instruction of how to install Zabbix Server and Zabbix agent on Debian 9 server. We will also explain how to add the Zabbix agent to the Zabbix server for monitoring.
|
||||
|
||||
#### Requirements
|
||||
|
||||
* Two system with Debian 9 installed.
|
||||
* Minimum 1 GB of RAM and 10 DB of disk space required. Amount of RAM and Disk space depends on the number of hosts and the parameters that are being monitored.
|
||||
* A non-root user with sudo privileges setup on your server.
|
||||
|
||||
|
||||
|
||||
#### Getting Started
|
||||
|
||||
Before starting, it is necessary to update your server's package repository to the latest stable version. You can update it by just running the following command on both instances:
|
||||
|
||||
```
|
||||
sudo apt-get update -y
|
||||
sudo apt-get upgrade -y
|
||||
```
|
||||
|
||||
Next, restart your system to apply these changes.
|
||||
|
||||
#### Install Apache, PHP and MariaDB
|
||||
|
||||
Zabbix runs on Apache web server, written in PHP and uses MariaDB/MySQL to store their data. So in order to install Zabbix, you will require Apache, MariaDB and PHP to work. First, install Apache, PHP and Other PHP modules by running the following command:
|
||||
|
||||
```
|
||||
sudo apt-get install apache2 libapache2-mod-php7.0 php7.0 php7.0-xml php7.0-bcmath php7.0-mbstring -y
|
||||
```
|
||||
|
||||
Next, you will need to add MariaDB repository to your system. Because, latest version of the MariaDB is not available in Debian 9 default repository.
|
||||
|
||||
You can add the repository by running the following command:
|
||||
|
||||
```
|
||||
sudo apt-get install software-properties-common -y
|
||||
sudo apt-key adv --recv-keys --keyserver keyserver.ubuntu.com 0xF1656F24C74CD1D8
|
||||
sudo add-apt-repository 'deb [arch=amd64] http://www.ftp.saix.net/DB/mariadb/repo/10.1/debian stretch main'
|
||||
```
|
||||
|
||||
Next, update the repository by running the following command:
|
||||
|
||||
```
|
||||
sudo apt-get update -y
|
||||
```
|
||||
|
||||
Finally, install the MariaDB server with the following command:
|
||||
|
||||
```
|
||||
sudo apt-get install mariadb-server -y
|
||||
```
|
||||
|
||||
By default, MariaDB installation is not secured. So you will need to secure it first. You can do this by running the mysql_secure_installation script.
|
||||
|
||||
```
|
||||
sudo mysql_secure_installation
|
||||
```
|
||||
|
||||
Answer all the questions as shown below:
|
||||
```
|
||||
|
||||
Enter current password for root (enter for none): Enter
|
||||
Set root password? [Y/n]: Y
|
||||
New password:
|
||||
Re-enter new password:
|
||||
Remove anonymous users? [Y/n]: Y
|
||||
Disallow root login remotely? [Y/n]: Y
|
||||
Remove test database and access to it? [Y/n]: Y
|
||||
Reload privilege tables now? [Y/n]: Y
|
||||
|
||||
```
|
||||
|
||||
The above script will set the root password, remove test database, remove anonymous user and Disallow root login from a remote location.
|
||||
|
||||
Once the MariaDB installation is secured, start the Apache and MariaDB service and enable them to start on boot time by running the following command:
|
||||
|
||||
```
|
||||
sudo systemctl start apache2
|
||||
sudo systemctl enable apache2
|
||||
sudo systemctl start mysql
|
||||
sudo systemctl enable mysql
|
||||
```
|
||||
|
||||
#### Installing Zabbix Server
|
||||
|
||||
By default, Zabbix is available in the Debian 9 repository, but it might be outdated. So it is recommended to install most recent version from the official Zabbix repositories. You can download and add the latest version of the Zabbix repository with the following command:
|
||||
|
||||
```
|
||||
wget http://repo.zabbix.com/zabbix/3.0/debian/pool/main/z/zabbix-release/zabbix-release_3.0-2+stretch_all.deb
|
||||
```
|
||||
|
||||
Next, install the downloaded repository with the following command:
|
||||
|
||||
```
|
||||
sudo dpkg -i zabbix-release_3.0-2+stretch_all.deb
|
||||
```
|
||||
|
||||
Next, update the package cache and install Zabbix server with web front-end and Mysql support by running the following command:
|
||||
|
||||
```
|
||||
sudo apt-get update -y
|
||||
sudo apt-get install zabbix-server-mysql zabbix-frontend-php -y
|
||||
```
|
||||
|
||||
You will also need to install the Zabbix agent to collect data about the Zabbix server status itself:
|
||||
|
||||
```
|
||||
sudo apt-get install zabbix-agent -y
|
||||
```
|
||||
|
||||
After installing Zabbix agent, start the Zabbix agent service and enable it to start on boot time by running the following command:
|
||||
|
||||
```
|
||||
sudo systemctl start zabbix-agent
|
||||
sudo systemctl enable zabbix-agent
|
||||
```
|
||||
|
||||
#### Configuring Zabbix Database
|
||||
|
||||
Zabbix uses MariaDB/MySQL as a database backend. So, you will need to create a MySQL database and User for zabbix installation:
|
||||
|
||||
First, log into MySQL shell with the following command:
|
||||
|
||||
```
|
||||
mysql -u root -p
|
||||
```
|
||||
|
||||
Enter your root password, then create a database for Zabbix with the following command:
|
||||
|
||||
```
|
||||
MariaDB [(none)]> CREATE DATABASE zabbixdb character set utf8 collate utf8_bin;
|
||||
```
|
||||
|
||||
Next, create a user for Zabbix, assign a password and grant all privileges on Zabbix database with the following command:
|
||||
|
||||
```
|
||||
MariaDB [(none)]> CREATE user zabbix identified by 'password';
|
||||
MariaDB [(none)]> GRANT ALL PRIVILEGES on zabbixdb.* to zabbixuser@localhost identified by 'password';
|
||||
```
|
||||
|
||||
Next, flush the privileges with the following command:
|
||||
|
||||
```
|
||||
MariaDB [(none)]> FLUSH PRIVILEGES;
|
||||
```
|
||||
|
||||
Finally, exit from the MySQL shell with the following command:
|
||||
|
||||
```
|
||||
MariaDB [(none)]> exit;
|
||||
```
|
||||
|
||||
Next, import initial schema and data to the newly created database with the following command:
|
||||
|
||||
```
|
||||
cd /usr/share/doc/zabbix-server-mysql*/
|
||||
zcat create.sql.gz | mysql -u zabbix -p zabbixdb
|
||||
```
|
||||
|
||||
#### Configuring Zabbix
|
||||
|
||||
Zabbix creates its own configuration file at `/etc/zabbix/apache.conf`. Edit this file and update the Timezone and PHP setting as per your need:
|
||||
|
||||
```
|
||||
sudo nano /etc/zabbix/apache.conf
|
||||
```
|
||||
|
||||
Change the file as shown below:
|
||||
```
|
||||
php_value max_execution_time 300
|
||||
php_value memory_limit 128M
|
||||
php_value post_max_size 32M
|
||||
php_value upload_max_filesize 8M
|
||||
php_value max_input_time 300
|
||||
php_value always_populate_raw_post_data -1
|
||||
php_value date.timezone Asia/Kolkata
|
||||
|
||||
```
|
||||
|
||||
Save the file when you are finished.
|
||||
|
||||
Next, you will need to update the database details for Zabbix. You can do this by editing `/etc/zabbix/zabbix_server.conf` file:
|
||||
|
||||
```
|
||||
sudo nano /etc/zabbix/zabbix_server.conf
|
||||
```
|
||||
|
||||
Change the following lines:
|
||||
```
|
||||
DBHost=localhost
|
||||
DBName=zabbixdb
|
||||
DBUser=zabbixuser
|
||||
DBPassword=password
|
||||
|
||||
```
|
||||
|
||||
Save and close the file when you are finished. Then restart all the services with the following command:
|
||||
|
||||
```
|
||||
sudo systemctl restart apache2
|
||||
sudo systemctl restart mysql
|
||||
sudo systemctl restart zabbix-server
|
||||
```
|
||||
|
||||
#### Configuring Firewall
|
||||
|
||||
Before proceeding, you will need to configure the UFW firewall to secure Zabbix server.
|
||||
|
||||
First, make sure UFW is installed on your system. Otherewise, you can install it by running the following command:
|
||||
|
||||
```
|
||||
sudo apt-get install ufw -y
|
||||
```
|
||||
|
||||
Next, enable the UFW firewall:
|
||||
|
||||
```
|
||||
sudo ufw enable
|
||||
```
|
||||
|
||||
Next, allow port 10050, 10051 and 80 through UFW with the following command:
|
||||
|
||||
```
|
||||
sudo ufw allow 10050/tcp
|
||||
sudo ufw allow 10051/tcp
|
||||
sudo ufw allow 80/tcp
|
||||
```
|
||||
|
||||
Finally, reload the firewall to apply these changes with the following command:
|
||||
|
||||
```
|
||||
sudo ufw reload
|
||||
```
|
||||
|
||||
Once the UFW firewall is configured you can proceed to install the Zabbix server via web interface.
|
||||
|
||||
#### Accessing Zabbix Web Installation Wizard
|
||||
|
||||
Once everything is fine, it's time to access Zabbix web installation wizard.
|
||||
|
||||
Open your web browser and navigate the <http://zabbix-server-ip/zabbix> URL , you will be redirected to the following page:
|
||||
|
||||
[![Zabbix 3.0][2]][3]
|
||||
|
||||
Click on the **Next step** button, you should see the following page:
|
||||
|
||||
[![Zabbix Prerequisites][4]][5]
|
||||
|
||||
Here, all the Zabbix pre-requisites are checked and verified, then click on the **Next step** button you should see the following page:
|
||||
|
||||
[![Database Configuration][6]][7]
|
||||
|
||||
Here, provide the Zabbix database name, database user and password then click on the **Next step** button, you should see the following page:
|
||||
|
||||
[![Zabbix Server Details][8]][9]
|
||||
|
||||
Here, specify the Zabbix server details and Port number then click on the **Next step** button, you should see the pre-installation summary of Zabbix Server in following page:
|
||||
|
||||
[![Installation summary][10]][11]
|
||||
|
||||
Next, click on the **Next step** button to start the Zabbix installation. Once the Zabbix installation is completed successfully, you should see the following page:
|
||||
|
||||
[![Zabbix installed successfully][12]][13]
|
||||
|
||||
Here, click on the **Finish** button, it will redirect to the Zabbix login page as shown below:
|
||||
|
||||
[![Login to Zabbix][14]][15]
|
||||
|
||||
Here, provide username as Admin and password as zabbix then click on the **Sign in** button. You should see the Zabbix server dashboard in the following image:
|
||||
|
||||
[![Zabbix Dashboard][16]][17]
|
||||
|
||||
Your Zabbix web installation is now finished.
|
||||
|
||||
#### Install Zabbix Agent
|
||||
|
||||
Now your Zabbix server is up and functioning. It's time to add Zabbix agent node to the Zabbix Server for Monitoring.
|
||||
|
||||
First, log into Zabbix agent instance and add the Zabbix repository with the following command:
|
||||
|
||||
```
|
||||
wget http://repo.zabbix.com/zabbix/3.0/debian/pool/main/z/zabbix-release/zabbix-release_3.0-2+stretch_all.deb
|
||||
sudo dpkg -i zabbix-release_3.0-2+stretch_all.deb
|
||||
sudo apt-get update -y
|
||||
```
|
||||
|
||||
Once you have configured Zabbix repository on your system, install the Zabbix agent by just running the following command:
|
||||
|
||||
```
|
||||
sudo apt-get install zabbix-agent -y
|
||||
```
|
||||
|
||||
Once the Zabbix agent is installed, you will need to configure Zabbix agent to communicate with Zabbix server. You can do this by editing the Zabbix agent configuration file:
|
||||
|
||||
```
|
||||
sudo nano /etc/zabbix/zabbix_agentd.conf
|
||||
```
|
||||
|
||||
Change the file as shown below:
|
||||
```
|
||||
#Zabbix Server IP Address / Hostname
|
||||
|
||||
Server=192.168.0.103
|
||||
|
||||
#Zabbix Agent Hostname
|
||||
|
||||
Hostname=zabbix-agent
|
||||
|
||||
|
||||
```
|
||||
|
||||
Save and close the file when you are finished, then restart the Zabbix agent service and enable it to start on boot time with the following command:
|
||||
|
||||
```
|
||||
sudo systemctl restart zabbix-agent
|
||||
sudo systemctl enable zabbix-agent
|
||||
```
|
||||
|
||||
#### Add Zabbix Agent Node to Zabbix Server
|
||||
|
||||
Next, you will need to add the Zabbix agent node to the Zabbix server for monitoring. First, log in to the Zabbix server web interface.
|
||||
|
||||
[![Zabbix UI][18]][19]
|
||||
|
||||
Next, Click on **Configuration --> Hosts -> Create Host**, you should see the following page:
|
||||
|
||||
[![Create Host in Zabbix][20]][21]
|
||||
|
||||
Here, specify the Hostname, IP address and Group names of Zabbix agent. Then navigate to Templates tab, you should see the following page:
|
||||
|
||||
[![specify the Hostname, IP address and Group name][22]][23]
|
||||
|
||||
Here, search appropriate templates and click on **Add** button, you should see the following page:
|
||||
|
||||
[![OS Template][24]][25]
|
||||
|
||||
Finally, click on **Add** button again. You will see your new host with green labels indicating that everything is working fine.
|
||||
|
||||
[![Hast successfully added to Zabbix][26]][27]
|
||||
|
||||
If you have extra servers and network devices that you want to monitor, log into each host, install the Zabbix agent and add each host from the Zabbix web interface.
|
||||
|
||||
#### Conclusion
|
||||
|
||||
Congratulations! you have successfully installed the Zabbix server and Zabbix agent in Debian 9 server. You have also added Zabbix agent node to the Zabbix server for monitoring. You can now easily list the current issue and past history, get the latest data of hosts, list the current problems and also visualized the collected resource statistics such as CPU load, CPU utilization, Memory usage, etc via graphs. I hope you can now easily install and configure Zabbix on Debian 9 server and deploy it on production environment. Compared to other monitoring software, Zabbix allows you to build your own maps of different network segments while monitoring many hosts. You can also monitor Windows host using Zabbix windows agent. For more information, you can refer the [Zabbix Documentation Page][28]. Feel free to ask me if you have any questions.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/install-zabbix-monitoring-server-and-agent-on-debian-9/
|
||||
|
||||
作者:[Hitesh Jethva][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:/cdn-cgi/l/email-protection
|
||||
[2]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/Screenshot-of-zabbix-welcome-page.png
|
||||
[3]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/big/Screenshot-of-zabbix-welcome-page.png
|
||||
[4]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/Screenshot-of-zabbix-pre-requisite-check-page.png
|
||||
[5]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/big/Screenshot-of-zabbix-pre-requisite-check-page.png
|
||||
[6]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/Screenshot-of-zabbix-db-config-page.png
|
||||
[7]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/big/Screenshot-of-zabbix-db-config-page.png
|
||||
[8]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/Screenshot-of-zabbix-server-details.png
|
||||
[9]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/big/Screenshot-of-zabbix-server-details.png
|
||||
[10]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/Screenshot-of-pre-installation-summary.png
|
||||
[11]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/big/Screenshot-of-pre-installation-summary.png
|
||||
[12]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/Screenshot-of-zabbix-install-success.png
|
||||
[13]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/big/Screenshot-of-zabbix-install-success.png
|
||||
[14]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/Screenshot-of-zabbix-login-page.png
|
||||
[15]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/big/Screenshot-of-zabbix-login-page.png
|
||||
[16]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/Screenshot-of-zabbix-welcome-dashboard.png
|
||||
[17]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/big/Screenshot-of-zabbix-welcome-dashboard.png
|
||||
[18]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/Screenshot-of-zabbix-welcome-dashboard1.png
|
||||
[19]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/big/Screenshot-of-zabbix-welcome-dashboard1.png
|
||||
[20]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/Screenshot-of-zabbix-agent-host1.png
|
||||
[21]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/big/Screenshot-of-zabbix-agent-host1.png
|
||||
[22]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/Screenshot-of-zabbix-agent-add-templates.png
|
||||
[23]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/big/Screenshot-of-zabbix-agent-add-templates.png
|
||||
[24]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/Screenshot-of-zabbix-agent-select-templates.png
|
||||
[25]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/big/Screenshot-of-zabbix-agent-select-templates.png
|
||||
[26]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/Screenshot-of-zabbix-agent-dashboard.png
|
||||
[27]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/big/Screenshot-of-zabbix-agent-dashboard.png
|
||||
[28]:https://www.zabbix.com/documentation/3.2/
|
||||
205
sources/tech/20180129 Parsing HTML with Python.md
Normal file
205
sources/tech/20180129 Parsing HTML with Python.md
Normal file
@ -0,0 +1,205 @@
|
||||
Parsing HTML with Python
|
||||
======
|
||||
|
||||

|
||||
|
||||
Image by : Jason Baker for Opensource.com.
|
||||
|
||||
As a long-time member of the documentation team at Scribus, I keep up-to-date with the latest updates of the source so I can help make updates and additions to the documentation. When I recently did a "checkout" using Subversion on a computer I had just upgraded to Fedora 27, I was amazed at how long it took to download the documentation, which consists of HTML pages and associated images. I became concerned that the project's documentation seemed much larger than it should be and suspected that some of the content was "zombie" documentation--HTML files that aren't used anymore and images that have lost all references in the currently used HTML.
|
||||
|
||||
I decided to create a project for myself to figure this out. One way to do this is to search for existing image files that aren't used. If I could scan through all the HTML files for image references, then compare that list to the actual image files, chances are I would see a mismatch.
|
||||
|
||||
Here is a typical image tag:
|
||||
```
|
||||
<img src="images/edit_shapes.png" ALT="Edit examples" ALIGN=left>
|
||||
```
|
||||
|
||||
I'm interested in the part between the first set of quotation marks, after `src=`. After some searching for a solution, I found a Python module called [BeautifulSoup][1]. The tasty part of the script I wrote looks like this:
|
||||
```
|
||||
soup = BeautifulSoup(all_text, 'html.parser')
|
||||
match = soup.findAll("img")
|
||||
if len(match) > 0:
|
||||
for m in match:
|
||||
imagelist.append(str(m))
|
||||
```
|
||||
|
||||
We can use this `findAll` method to pluck out the image tags. Here is a tiny piece of the output:
|
||||
```
|
||||
|
||||
|
||||
<img src="images/pdf-form-ht3.png"/><img src="images/pdf-form-ht4.png"/><img src="images/pdf-form-ht5.png"/><img src="images/pdf-form-ht6.png"/><img align="middle" alt="GSview - Advanced Options Panel" src="images/gsadv1.png" title="GSview - Advanced Options Panel"/><img align="middle" alt="Scribus External Tools Preferences" src="images/gsadv2.png" title="Scribus External Tools Preferences"/>
|
||||
```
|
||||
|
||||
So far, so good. I thought that the next step might be to just carve this down, but when I tried some string methods in the script, it returned errors about this being tags and not strings. I saved the output to a file and went through the process of editing in [KWrite][2]. One nice thing about KWrite is that you can do a "find & replace" using regular expressions (regex), so I could replace `<img` with `\n<img`, which made it easier to see how to carve this down from there. Another nice thing with KWrite is that, if you make an injudicious choice with regex, you can undo it.
|
||||
|
||||
But I thought, surely there is something better than this, so I turned to regex, or more specifically the `re` module for Python. The relevant part of this new script looks like this:
|
||||
```
|
||||
match = re.findall(r'src="(.*)/>', all_text)
|
||||
if len(match)>0:
|
||||
for m in match:
|
||||
imagelist.append(m)
|
||||
```
|
||||
|
||||
And a tiny piece of its output looks like this:
|
||||
```
|
||||
images/cmcanvas.png" title="Context Menu for the document canvas" alt="Context Menu for the document canvas" /></td></tr></table><br images/eps-imp1.png" title="EPS preview in a file dialog" alt="EPS preview in a file dialog" images/eps-imp5.png" title="Colors imported from an EPS file" alt="Colors imported from an EPS file" images/eps-imp4.png" title="EPS font substitution" alt="EPS font substitution" images/eps-imp2.png" title="EPS import progress" alt="EPS import progress" images/eps-imp3.png" title="Bitmap conversion failure" alt="Bitmap conversion failure"
|
||||
```
|
||||
|
||||
At first glance, it looks similar to the output above, and has the nice feature of trimming out parts of the image tag, but there are puzzling inclusions of table tags and other content. I think this relates to this regex expression `src="(.*)/>`, which is termed greedy, meaning it doesn't necessarily stop at the first instance of `/>` it encounters. I should add that I also tried `src="(.*)"` which was really no better. Not being a regexpert (just made this up), my searching around for various ideas to improve this didn't help.
|
||||
|
||||
After a series of other things, even trying out `HTML::Parser` with Perl, I finally tried to compare this to the situation of some scripts that I wrote for Scribus that analyze the contents of a text frame, character by character, then take some action. For my purposes, what I finally came up with improves on all these methods and requires no regex or HTML parser at all. Let's go back to that example `img` tag I showed.
|
||||
```
|
||||
<img src="images/edit_shapes.png" ALT="Edit examples" ALIGN=left>
|
||||
```
|
||||
|
||||
I decided to home in on the `src=` piece. One way would be to wait for an occurrence of `s`, then see if the next character is `r`, the next `c`, and the next `=`. If so, bingo! Then what follows between two sets of double quotation marks is what I need. The problem with this is the structure it takes to hang onto these. One way of looking at a string of characters representing a line of HTML text would be:
|
||||
```
|
||||
for c in all_text:
|
||||
```
|
||||
|
||||
But the logic was just too messy to hang onto the previous `c`, and the one before that, the one before that, and the one before that.
|
||||
|
||||
In the end, I decided to focus on the `=` and to use an indexing method whereby I could easily reference any prior or future character in the string. Here is the searching part:
|
||||
```
|
||||
index = 3
|
||||
while index < linelength:
|
||||
if (all_text[index] == '='):
|
||||
if (all_text[index-3] == 's') and (all_text[index-2] == 'r') and (all_text[index-1] == 'c'):
|
||||
imagefound(all_text, imagelist, index)
|
||||
index += 1
|
||||
else:
|
||||
index += 1
|
||||
else:
|
||||
index += 1
|
||||
```
|
||||
|
||||
I start the search with the fourth character (indexing starts at 0), so I don't get an indexing error down below, and realistically, there will not be an equal sign before the fourth character of a line. The first test is to see if we find `=` as we're marching through the string, and if not, we march on. If we do see one, then we ask if the three previous characters were `s`, `r`, and `c`, in that order. If that happens, we call the function `imagefound`:
|
||||
```
|
||||
def imagefound(all_text, imagelist, index):
|
||||
end = 0
|
||||
index += 2
|
||||
newimage = ''
|
||||
while end == 0:
|
||||
if (all_text[index] != '"'):
|
||||
newimage = newimage + all_text[index]
|
||||
index += 1
|
||||
else:
|
||||
newimage = newimage + '\n'
|
||||
imagelist.append(newimage)
|
||||
end = 1
|
||||
return
|
||||
```
|
||||
|
||||
We're sending the function the current index, which represents the `=`. We know the next character will be `"`, so we jump two characters and begin adding characters to a holding string named `newimage`, until we reach the following `"`, at which point we're done. We add the string plus a `newline` character to our list `imagelist` and `return`, keeping in mind there may be more image tags in this remaining string of HTML, so we're right back in the middle of our searching loop.
|
||||
|
||||
Here's what our output looks like now:
|
||||
```
|
||||
images/text-frame-link.png
|
||||
images/text-frame-unlink.png
|
||||
images/gimpoptions1.png
|
||||
images/gimpoptions3.png
|
||||
images/gimpoptions2.png
|
||||
images/fontpref3.png
|
||||
images/font-subst.png
|
||||
images/fontpref2.png
|
||||
images/fontpref1.png
|
||||
images/dtp-studio.png
|
||||
```
|
||||
|
||||
Ahhh, much cleaner, and this only took a few seconds to run. I could have jumped seven more index spots to cut out the `images/` part, but I like having it there to make sure I haven't chopped off the first letter of the image filename, and this is so easy to edit out with KWrite--you don't even need regex. After doing that and saving the file, the next step was to run another script I wrote called `sortlist.py`:
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
# sortlist.py
|
||||
|
||||
import os
|
||||
|
||||
imagelist = []
|
||||
for line in open('/tmp/imagelist_parse4.txt').xreadlines():
|
||||
imagelist.append(line)
|
||||
|
||||
imagelist.sort()
|
||||
|
||||
outfile = open('/tmp/imagelist_parse4_sorted.txt', 'w')
|
||||
outfile.writelines(imagelist)
|
||||
outfile.close()
|
||||
```
|
||||
|
||||
This pulls in the file contents as a list, sorts it, then saves it as another file. After that I could just do the following:
|
||||
```
|
||||
ls /home/gregp/development/Scribus15x/doc/en/images/*.png > '/tmp/actual_images.txt'
|
||||
```
|
||||
|
||||
Then I need to run `sortlist.py` on that file too, since the method `ls` uses to sort is different from Python. I could have run a comparison script on these files, but I preferred to do this visually. In the end, I ended up with 42 images that had no HTML reference from the documentation.
|
||||
|
||||
Here is my parsing script in its entirety:
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
# parseimg4.py
|
||||
|
||||
import os
|
||||
|
||||
def imagefound(all_text, imagelist, index):
|
||||
end = 0
|
||||
index += 2
|
||||
newimage = ''
|
||||
while end == 0:
|
||||
if (all_text[index] != '"'):
|
||||
newimage = newimage + all_text[index]
|
||||
index += 1
|
||||
else:
|
||||
newimage = newimage + '\n'
|
||||
imagelist.append(newimage)
|
||||
end = 1
|
||||
return
|
||||
|
||||
htmlnames = []
|
||||
imagelist = []
|
||||
tempstring = ''
|
||||
filenames = os.listdir('/home/gregp/development/Scribus15x/doc/en/')
|
||||
for name in filenames:
|
||||
if name.endswith('.html'):
|
||||
htmlnames.append(name)
|
||||
#print htmlnames
|
||||
for htmlfile in htmlnames:
|
||||
all_text = open('/home/gregp/development/Scribus15x/doc/en/' + htmlfile).read()
|
||||
linelength = len(all_text)
|
||||
index = 3
|
||||
while index < linelength:
|
||||
if (all_text[index] == '='):
|
||||
if (all_text[index-3] == 's') and (all_text[index-2] == 'r') and
|
||||
(all_text[index-1] == 'c'):
|
||||
imagefound(all_text, imagelist, index)
|
||||
index += 1
|
||||
else:
|
||||
index += 1
|
||||
else:
|
||||
index += 1
|
||||
|
||||
outfile = open('/tmp/imagelist_parse4.txt', 'w')
|
||||
outfile.writelines(imagelist)
|
||||
outfile.close()
|
||||
imageno = len(imagelist)
|
||||
print str(imageno) + " images were found and saved"
|
||||
```
|
||||
|
||||
Its name, `parseimg4.py`, doesn't really reflect the number of scripts I wrote along the way, with both minor and major rewrites, plus discards and starting over. Notice that I've hardcoded these directory and filenames, but it would be easy enough to generalize, asking for user input for these pieces of information. Also as they were working scripts, I sent the output to `/tmp`, so they disappear once I reboot my system.
|
||||
|
||||
This wasn't the end of the story, since the next question was: What about zombie HTML files? Any of these files that are not used might reference images not picked up by the previous method. We have a `menu.xml` file that serves as the table of contents for the online manual, but I also needed to consider that some files listed in the TOC might reference files not in the TOC, and yes, I did find some.
|
||||
|
||||
I'll conclude by saying that this was a simpler task than this image search, and it was greatly helped by the processes I had already developed.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/parsing-html-python
|
||||
|
||||
作者:[Greg Pittman][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/greg-p
|
||||
[1]:https://www.crummy.com/software/BeautifulSoup/
|
||||
[2]:https://www.kde.org/applications/utilities/kwrite/
|
||||
91
translated/tech/20141029 What does an idle CPU do.md
Normal file
91
translated/tech/20141029 What does an idle CPU do.md
Normal file
@ -0,0 +1,91 @@
|
||||
[当 CPU 空闲时它都在做什么?][1]
|
||||
============================================================
|
||||
|
||||
在 [上篇文章中][2] 我说了操作系统行为的基本原理是,在任何一个给定的时刻,在一个 CPU 上有且只有一个任务是活动的。但是,如果 CPU 无事可做的时候,又会是什么样的呢?
|
||||
|
||||
事实证明,这种情况是非常普遍的,对于绝大多数的个人电脑来说,这确实是一种常态:大量的睡眠进程,它们都在等待某种情况下被唤醒,差不多在 100% 的 CPU 时间中,它们都处于虚构的“空闲任务”中。事实上,如果一个普通用户的 CPU 处于持续的繁忙中,它可能意味着有一个错误、bug、或者运行了恶意软件。
|
||||
|
||||
因为我们不能违反我们的原理,一些任务需要在一个 CPU 上激活。首先是因为,这是一个良好的设计:持续很长时间去遍历内核,检查是否有一个活动任务,这种特殊情况是不明智的做法。最好的设计是没有任何例外的情况。无论何时,你写一个 `if` 语句,Nyan 猫就会叫。其次,我们需要使用空闲的 CPU 去做一些事情,让它们充满活力,并且,你懂得,创建天网卫星计划。
|
||||
|
||||
因此,保持这种设计的连续性,并领先于恶魔(devil)一步,操作系统开发者创建了一个空闲任务,当没有其它任务可做时就调度它去运行。我们可以在 Linux 的 [引导进程][3] 中看到,这个空闲任务就是进程 0,它是由计算机打开电源时运行的第一个指令直接派生出来的。它在 [rest_init][4] 中初始化,在 [init_idle_bootup_task][5] 中初始化空闲调度类。
|
||||
|
||||
简而言之,Linux 支持像实时进程、普通用户进程、等等的不同调度类。当选择一个进程变成活动任务时,这些类是被优先询问的。通过这种方式,核反应堆的控制代码总是优先于 web 浏览器运行。尽管在通常情况下,这些类返回 `NULL`,意味着它们没有合适的任务需要去运行 —— 它们总是处于睡眠状态。但是空闲调度类,它是持续运行的,从不会失败:它总是返回空闲任务。
|
||||
|
||||
好吧,我们来看一下这个空闲任务到底做了些什么。下面是 [cpu_idle_loop][6],感谢开源能让我们看到它的代码:
|
||||
|
||||
cpu_idle_loop
|
||||
|
||||
```
|
||||
while (1) {
|
||||
while(!need_resched()) {
|
||||
cpuidle_idle_call();
|
||||
}
|
||||
|
||||
/*
|
||||
[Note: Switch to a different task. We will return to this loop when the idle task is again selected to run.]
|
||||
*/
|
||||
schedule_preempt_disabled();
|
||||
}
|
||||
```
|
||||
|
||||
我省略了很多的细节,稍后我们将去了解任务切换,但是,如果你阅读了源代码,你就会找到它的要点:由于这里不需要重新调度 —— 改变活动任务,它一直处于空闲状态。以经过的时间来计算,这个循环和操作系统中它的“堂兄弟们”相比,在计算的历史上它是运行的最多的代码片段。对于 Intel 处理器来说,处于空闲状态意味着运行着一个 [halt][7] 指令:
|
||||
|
||||
native_halt
|
||||
|
||||
```
|
||||
static inline void native_halt(void)
|
||||
{
|
||||
asm volatile("hlt": : :"memory");
|
||||
}
|
||||
```
|
||||
|
||||
`halt` 指令停止处理器中运行的代码,并将它置于 `halt` 的状态。奇怪的是,全世界各地数以百万计的像 Intel 这样的 CPU 们花费大量的时间让它们处于 `halt` 的状态,直到它们被激活。这并不是高效、节能的做法,这促使芯片制造商们去开发处理器的深度睡眠状态,它意味着更少的功耗和更长的唤醒延迟。内核的 [cpuidle 子系统][8] 是这些节能模式能够产生好处的原因。
|
||||
|
||||
现在,一旦我们告诉 CPU 去 `halt` 或者睡眠之后,我们需要以某种方式去将它t重新带回(back to life)。如果你读过 [上篇文章][9],(译者注:指的是《你的操作系统什么时候运行?》) 你可能会猜到中断会参与其中,而事实确实如此。中断促使 CPU 离开 `halt` 状态返回到激活状态。因此,将这些拼到一起,下图是当你阅读一个完全呈现的 web 网页时,你的系统主要做的事情:
|
||||
|
||||
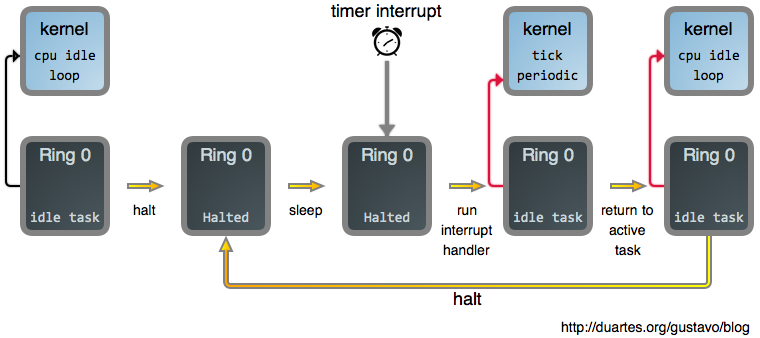
|
||||
|
||||
|
||||
|
||||
除定时器中断外的其它中断也会使处理器再次发生变化。如果你再次点击一个 web 页面就会产生这种变化,例如:你的鼠标发出一个中断,它会导致系统去处理它,并且使处理器因为它产生了一个新的输入而突然地可运行。在那个时刻, `need_resched()` 返回 `true`,然后空闲任务因你的浏览器而被踢出终止运行。
|
||||
|
||||
如果我们阅读这篇文章,而不做任何事情。那么随着时间的推移,这个空闲循环就像下图一样:
|
||||
|
||||
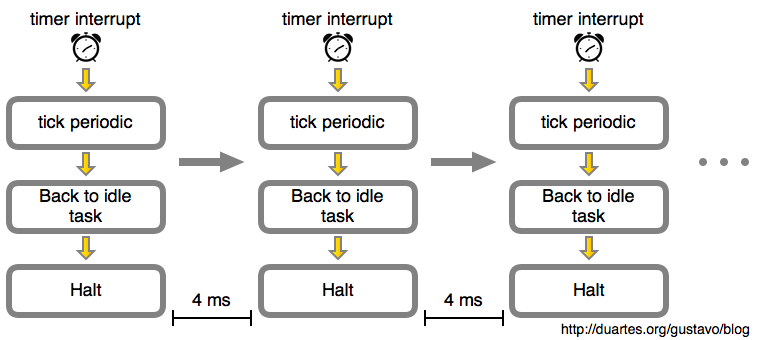
|
||||
|
||||
在这个示例中,由内核计划的定时器中断会每 4 毫秒发生一次。这就是滴答周期。也就是说每秒钟将有 250 个滴答,因此,这个滴答速率或者频率是 250 Hz。这是运行在 Intel 处理器上的 Linux 的典型值,而很多人喜欢使用 100 Hz。这是由你构建内核时在 `CONFIG_HZ` 选项中定义的。
|
||||
|
||||
对于一个空闲 CPU 来说,它看起来似乎是个无意义的工作。如果外部世界没有新的输入,在你的笔记本电脑的电池耗尽之前,CPU 将始终处于这种每秒钟被唤醒 250 次的地狱般折磨的小憩中。如果它运行在一个虚拟机中,那我们正在消耗着宿主机 CPU 的性能和宝贵的时钟周期。
|
||||
|
||||
在这里的解决方案是拥有一个 [动态滴答][10] ,因此,当 CPU 处于空闲状态时,定时器中断要么被 [暂停要么被重计划][11],直到内核知道将有事情要做时(例如,一个进程的定时器可能要在 5 秒内过期,因此,我们不能再继续睡眠了),定时器中断才会重新发出。这也被称为无滴答模式。
|
||||
|
||||
最后,假设在一个系统中你有一个活动进程,例如,一个长周期运行的 CPU 密集型任务。那样几乎就和一个空闲系统是相同的:这些示意图仍然是相同的,只是将空闲任务替换为这个进程,并且描述也是准确的。在那种情况下,每 4 毫秒去中断一次任务仍然是无意义的:它只是操作系统的抖动,甚至会使你的工作变得更慢而已。Linux 也可以在这种单一进程的场景中停止这种固定速率的滴答,这被称为 [adaptive-tick][12] 模式。最终,这种固定速率的滴答可能会 [完全消失][13]。
|
||||
|
||||
对于阅读一篇文章来说,CPU 基本是无事可做的。内核的这种空闲行为是操作系统难题的一个重要部分,并且它与我们看到的其它情况非常相似,因此,这将帮助我们构建一个运行中的内核的蓝图。更多的内容将发布在下周的 [RSS][14] 和 [Twitter][15] 上。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:https://manybutfinite.com/post/what-does-an-idle-cpu-do/
|
||||
|
||||
作者:[Gustavo Duarte][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://duartes.org/gustavo/blog/about/
|
||||
[1]:https://manybutfinite.com/post/what-does-an-idle-cpu-do/
|
||||
[2]:https://manybutfinite.com/post/when-does-your-os-run
|
||||
[3]:https://manybutfinite.com/post/kernel-boot-process
|
||||
[4]:https://github.com/torvalds/linux/blob/v3.17/init/main.c#L393
|
||||
[5]:https://github.com/torvalds/linux/blob/v3.17/kernel/sched/core.c#L4538
|
||||
[6]:https://github.com/torvalds/linux/blob/v3.17/kernel/sched/idle.c#L183
|
||||
[7]:https://github.com/torvalds/linux/blob/v3.17/arch/x86/include/asm/irqflags.h#L52
|
||||
[8]:http://lwn.net/Articles/384146/
|
||||
[9]:https://manybutfinite.com/post/when-does-your-os-run
|
||||
[10]:https://github.com/torvalds/linux/blob/v3.17/Documentation/timers/NO_HZ.txt#L17
|
||||
[11]:https://github.com/torvalds/linux/blob/v3.17/Documentation/timers/highres.txt#L215
|
||||
[12]:https://github.com/torvalds/linux/blob/v3.17/Documentation/timers/NO_HZ.txt#L100
|
||||
[13]:http://lwn.net/Articles/549580/
|
||||
[14]:https://manybutfinite.com/feed.xml
|
||||
[15]:http://twitter.com/manybutfinite
|
||||
@ -7,15 +7,15 @@
|
||||
|
||||
[][2]
|
||||
|
||||
在 IT 领域,作为操作系统为我们为我们所知的 Unix ,是 1969 年 AT& 公司在美国新泽西所开发的,目前它的商标权由国际开放标准组织所拥有。大多数的操作系统都受 Unix 的启发,但 Unix 也受到了未完成的 Multics 系统的启发。 Unix 的另一版本是来自贝尔实验室的 Play 9。
|
||||
在 IT 领域,作为操作系统为我们所知的 Unix,是 1969 年 AT& 公司在美国新泽西所开发的,目前它的商标权由国际开放标准组织所拥有。大多数的操作系统都受 Unix 的启发,而 Unix 也受到了未完成的 Multics 系统的启发。Unix 的另一版本是来自贝尔实验室的 Play 9。
|
||||
|
||||
### Unix 被用于哪里?
|
||||
|
||||
作为一个操作系统,Unix 大多被用在服务器、工作站且现在也有用在个人计算机上。它在创建互联网、创建计算机网络或客户端服务器模型方面发挥着非常重要的作用。
|
||||
作为一个操作系统,Unix 大多被用在服务器、工作站且现在也有用在个人计算机上。它在创建互联网、创建计算机网络或客户端/服务器模型方面发挥着非常重要的作用。
|
||||
|
||||
#### Unix 系统的特点
|
||||
|
||||
* 支持多任务(multitasking)
|
||||
* 支持多任务(multitasking)
|
||||
|
||||
* 相比 Multics 操作更加简单
|
||||
|
||||
@ -37,11 +37,11 @@
|
||||
|
||||
[][4]
|
||||
|
||||
这是一个基于 Unix 系统原理的开源操作系统。正如开源的含义一样,它是一个可以自由下载的系统。也可以干涉系统的编辑、添加,然后扩充其源代码。这是它最大的好处之一,而不像今天的其他操作系统(Windows、Mac OS X....)需要付费。Linux 系统的开发不仅是因为 Unix 系统提供了一个模板,其中还有一个重要的因素是 MINIX 系统的启发。不像 Linus,此版本被创造者(Andrew Tanenbaum)用于商业系统 。1991 年 **Linus Torvalds** 开始把对 Linux 系统的开发当做个人兴趣。其中,Linux 开始处理 Unix 的原因是系统的简单性。Linux(0.01)第一个官方版本发布于 1991年9月17日。虽然这个系统并不是很完美和完整,但 Linus 对它产生很大的兴趣。在接下来的几天,Linus 开始写关于 Linux 源代码扩展以及其他想法的电子邮件。看起来,此操作系统的正式名取自 Linus 的创造者的名字。其中,操作系统名称的结尾“x” 与 Unix 操作系统相名称相关联。
|
||||
这是一个基于 Unix 系统原理的开源操作系统。正如开源的含义一样,它是一个可以自由下载的系统。也可以干涉系统的编辑、添加,然后扩充其源代码。这是它最大的好处之一,而不像今天的其他操作系统(Windows、Mac OS X....)需要付费。Linux 系统的开发不仅是因为 Unix 系统提供了一个模板,其中还有一个重要的因素是 MINIX 系统的启发。不像 Linus,此版本被创造者(Andrew Tanenbaum)用于商业系统 。1991 年 **Linus Torvalds** 开始把对 Linux 系统的开发当做个人兴趣。其中,Linux 开始处理 Unix 的原因是系统的简单性。Linux(0.01)第一个官方版本发布于 1991年9月17日。虽然这个系统并不是很完美和完整,但 Linus 对它产生很大的兴趣。在接下来的几天,Linus 开始写关于 Linux 源代码扩展以及其他想法的电子邮件。
|
||||
|
||||
### Linux 的特点
|
||||
|
||||
Linux 内核是 Unix 内核,基于 Unix 的基本特点以及 **POSIX** 和 Single **UNIX 规范标准**。看起来那操作系统官方名字取自于 **Linus**,其中其操作系统名称的尾部"x"跟 **Unix 系统**相联系。
|
||||
Linux 内核是 Unix 内核,基于 Unix 的基本特点以及 **POSIX** 和 Single **UNIX 规范标准**。看起来那操作系统官方名字取自于 **Linus**,其中其操作系统名称的尾部"x"跟 **Unix 系统**相联系。
|
||||
|
||||
#### 主要特点:
|
||||
|
||||
@ -51,7 +51,7 @@ Linux 内核是 Unix 内核,基于 Unix 的基本特点以及 **POSIX** 和 Si
|
||||
|
||||
* 多用户,因此它可以运行多个用户程序。
|
||||
|
||||
* 个人帐户受适当授权的保护
|
||||
* 个人帐户受适当授权的保护。
|
||||
|
||||
* 因此账户准确地定义了系统控制权。
|
||||
|
||||
@ -63,8 +63,8 @@ Linux 内核是 Unix 内核,基于 Unix 的基本特点以及 **POSIX** 和 Si
|
||||
via: http://www.linuxandubuntu.com/home/linux-vs-unix
|
||||
|
||||
作者:[linuxandubuntu][a]
|
||||
译者:[译者ID](https://github.com/HardworkFish)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[HardworkFish](https://github.com/HardworkFish)
|
||||
校对:[imquanquan](https://github.com/imquanquan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -0,0 +1,116 @@
|
||||
Linux 终端下的多媒体应用
|
||||
======
|
||||
|
||||

|
||||
|
||||
Linux 终端是支持多媒体的,所以你可以在终端里听音乐,看电影,看图片,甚至是阅读 PDF。
|
||||
|
||||
在我的上一篇文章里,我们了解到 Linux 终端是可以支持多媒体的。是的,这是真的!你可以使用 Mplayer、fbi 和 fbgs 来实现不打开 X 进程就听音乐、看电影、看照片,甚至阅读 PDF。此外,你还可以通过 CMatrix 来体验黑客帝国(Matrix)风格的屏幕保护。
|
||||
|
||||
不过你可能需要对系统进行一些修改才能达到前面这些目的。下文的操作都是在 Ubuntu 16.04 上进行的。
|
||||
|
||||
### MPlayer
|
||||
|
||||
你可能会比较熟悉功能丰富的 MPlayer。它支持几乎所有格式的视频与音频,并且能在绝大部分现有的平台上运行,像 Linux,Android,Windows,Mac,Kindle,OS/2 甚至是 AmigaOS。不过,要在你的终端运行 MPlayer 可能需要多做一点工作,这些工作与你使用的 Linux 发行版有关。来,我们先试着播放一个视频:
|
||||
|
||||
```
|
||||
$ mplayer [视频文件名]
|
||||
```
|
||||
|
||||
如果上面的命令正常执行了,那么很好,接下来你可以把时间放在了解 MPlayer 的常用选项上了,譬如设定视频大小等。但是,有些 Linux 发行版在对帧缓冲(framebuffer)的处理方式上与早期的不同,那么你就需要进行一些额外的设置才能让其正常工作了。下面是在最近的 Ubuntu 发行版上需要做的一些操作。
|
||||
|
||||
首先,将你自己添加到 video 用户组。
|
||||
|
||||
其次,确认 `/etc/modprobe.d/blacklist-framebuffer.conf` 文件中包含这样一行:`#blacklist vesafb`。这一行应该默认被注释掉了,如果不是的话,那就手动把它注释掉。此外的其他模块行需要确认没有被注释,这样设置才能保证其他那些模块不会被载入。注:如果你想要对控制帧缓冲(framebuffer)有更深入的了解,可以从针对你的显卡的这些模块里获取更深入的认识。
|
||||
|
||||
然后,在 `/etc/initramfs-tools/modules` 的结尾增加两个模块:`vesafb` 和 `fbcon`,并且更新 iniramfs 镜像:
|
||||
|
||||
```
|
||||
$ sudo nano /etc/initramfs-tools/modules
|
||||
# List of modules that you want to include in your initramfs.
|
||||
# They will be loaded at boot time in the order below.
|
||||
fbcon
|
||||
vesafb
|
||||
|
||||
$ sudo update-initramfs -u
|
||||
```
|
||||
|
||||
[fbcon][1] 是 Linux 帧缓冲(framebuffer)终端,它运行在帧缓冲(framebuffer)之上并为其增加图形功能。而它需要一个帧缓冲(framebuffer)设备,这则是由 `vesafb` 模块来提供的。
|
||||
|
||||
接下来,你需要修改你的 GRUB2 配置。在 `/etc/default/grub` 中你将会看到类似下面的一行:
|
||||
|
||||
```
|
||||
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash"
|
||||
```
|
||||
|
||||
它也可能还会有一些别的参数,不用管它,在其后加上 `vga=789`:
|
||||
|
||||
```
|
||||
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash vga=789"
|
||||
```
|
||||
|
||||
重启之后进入你的终端(Ctrl+Alt+F1)(LCTT 译注:在某些发行版中 Ctrl+Alt+F1 默认为图形界面,可以尝试 Ctrl+Alt+F2),然后就可以尝试播放一个视频了。下面的命令指定了 `fbdev2` 为视频输出设备,虽然我还没弄明白如何去选择用哪个输入设备,但是我用它成功过。默认的视频大小是 320x240,在此我给缩放到了 960:
|
||||
|
||||
```
|
||||
$ mplayer -vo fbdev2 -vf scale -zoom -xy 960 AlienSong_mp4.mov
|
||||
```
|
||||
|
||||
来看图 1。粗糙的画面是由于我原视频的质量不高,而不是 MPlayer 的显示问题。
|
||||
|
||||

|
||||
|
||||
MPlayer 可以播放 CD、DVD 以及网络视频流,并且还有一系列的回放选项,这些将作为作业留给大家自己去发现。
|
||||
|
||||
### fbi 图片查看器
|
||||
|
||||
`fbi` 是一个帧缓冲图片查看器。在大部分的 Linux 发行版中,它被包含在 [fbida][2] 包里。它原生支持一些常见的图片格式,而如果你安装了 `convert`(来自于 Image Magick),那么它还能借此打开一些其他格式。最简单的用法是用来查看一个图片文件:
|
||||
|
||||
```
|
||||
$ fbi 文件名
|
||||
```
|
||||
|
||||
你可以使用方向键来在大图片中移动视野,使用 + 和 - 来缩放,或者使用 r 或 l 来向右或向左旋转 90 度。Escape 键则可以关闭查看的图片。此外,你还可以给 `fbi` 一个文件列表来实现幻灯播放:
|
||||
|
||||
```
|
||||
$ fbi --list 文件列表.txt
|
||||
```
|
||||
|
||||
`fbi` 还支持自动缩放。还可以使用 `-a` 选项来控制缩放比例。`--autoup` 和 `--autodown` 则是用于告知 `fbi` 只进行放大或者缩小。要调整图片切换时淡入淡出的时间则可以使用 `--blend [时间]` 来指定一个以毫秒为单位的时间长度。使用 k 和 j 键则可以切换文件列表中的上一张或下一张图片。
|
||||
|
||||
`fbi` 还提供了命令来为你浏览过的文件创建文件列表,或者将你的命令导出到文件中,以及一系列其它很棒的选项。你可以通过 `man fbi` 来查阅完整的选项列表。
|
||||
|
||||
### CMatrix 终端屏保
|
||||
|
||||
黑客帝国(The Matrix)屏保仍然是我非常喜欢的屏保之一(如图 2),仅次于弹跳牛(bouncing cow)。[CMatrix][3] 可以在终端运行。要运行它只需输入 `cmatrix`,然后可以用 Ctrl+C 来停止运行。执行 `cmatrix -s` 则会启动屏保模式,这样的话,按任意键都会直接退出。`-C` 参数可以设定颜色,譬如绿色(green)、红色(red)、蓝色(blue)、黄色(yellow)、白色(white)、紫色(magenta)、青色(cyan)或者黑色(black)。
|
||||
|
||||

|
||||
|
||||
CMatrix 还支持异步按键,这意味着你可以在它运行的时候改变设置选项。
|
||||
|
||||
`-B` 设置全部使用粗体,而 `-b`(LCTT 译注:原文误为 `-B`)则可以设置部分字体加粗。
|
||||
|
||||
### fbgs PDF 阅读器
|
||||
|
||||
看起来,PDF 文档的流行是普遍且无法阻止的,而且 PDF 比它之前好了很多,譬如超链接、复制粘贴以及更好的文本搜索功能等。`fbgs` 是 `fbida` 包中提供的一个 PDF 阅读器。它可以设置页面大小、分辨率、指定页码以及绝大部分 `fbi` 所提供的选项,当然除了一些在 `man fbgs` 中列举出来的不可用选项。我主要用到的选项是页面大小,你可以选择 `-l`、`xl` 或者 `xxl`:
|
||||
|
||||
```
|
||||
$ fbgs -xl annoyingpdf.pdf
|
||||
```
|
||||
|
||||
欢迎通过 Linux 基金会与 edX 免费提供的[“Linux 入门”][4]课程学习更多 Linux 知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/1/multimedia-apps-linux-console
|
||||
|
||||
作者:[Carla Schroder][a]
|
||||
译者:[Yinr](https://github.com/Yinr)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.mjmwired.net/kernel/Documentation/fb/fbcon.txt
|
||||
[2]:https://www.kraxel.org/blog/linux/fbida/
|
||||
[3]:http://www.asty.org/cmatrix/
|
||||
[4]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -0,0 +1,61 @@
|
||||
如何启动进入 Linux 命令行
|
||||
======
|
||||

|
||||
|
||||
可能有时候你需要或者不想使用 GUI,也就是没有 X,而是选择命令行启动 [Linux][1]。不管是什么原因,幸运的是,直接启动进入 Linux **命令行** 非常简单。在其他内核选项之后,它需要对引导参数进行简单的更改。此更改将系统引导到指定的运行级别。
|
||||
|
||||
### 为什么要这样做?
|
||||
|
||||
如果你的系统由于无效配置或者显示管理器损坏或任何可能导致 GUI 无法正常启动的情况而无法运行 Xorg,那么启动到命令行将允许你通过登录到终端进行故障排除(假设你知道要怎么开始),并能做任何你需要做的东西。引导到命令行也是一个很好的熟悉终端的方式,不然,你也可以为了好玩这么做。
|
||||
|
||||
### 访问 GRUB 菜单
|
||||
|
||||
在启动时,你需要访问 GRUB 启动菜单。如果在每次启动计算机时菜单未设置为显示,那么可能需要在系统启动之前按住 SHIFT 键。在菜单中,需要选择 [Linux 发行版][2]条目。高亮显示后,按下 “e” 编辑引导参数。
|
||||
|
||||
[][3]
|
||||
|
||||
较老的 GRUB 版本遵循类似的机制。启动管理器应提供有关如何编辑启动参数的说明。
|
||||
|
||||
### 指定运行级别
|
||||
|
||||
编辑器将出现,你将看到 GRUB 解析到内核的选项。移动到以 “linux” 开头的行(旧的 GRUB 版本可能是 “kernel”,选择它并按照说明操作)。这指定了解析到内核的参数。在该行的末尾(可能会出现跨越多行,具体取决于分辨率),只需指定要引导的运行级别,即 3(多用户模式,纯文本)。
|
||||
|
||||
[][4]
|
||||
|
||||
按下 Ctrl-X 或 F10 将使用这些参数启动系统。开机和以前一样。唯一改变的是启动的运行级别。
|
||||
|
||||
|
||||
|
||||
这是启动后的页面:
|
||||
|
||||
[][5]
|
||||
|
||||
### 运行级别
|
||||
|
||||
你可以指定不同的运行级别,默认运行级别是 5。1 启动到“单用户”模式,它会启动进入 root shell。3 提供了一个多用户命令行系统。
|
||||
|
||||
### 从命令行切换
|
||||
|
||||
在某个时候,你可能想要再次运行显示管理器来使用 GUI,最快的方法是运行这个:
|
||||
```
|
||||
$ sudo init 5
|
||||
```
|
||||
|
||||
就这么简单。就我个人而言,我发现命令行比使用 GUI 工具更令人兴奋和上手。不过,这只是我的个人偏好。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/how-to-boot-into-linux-command-line
|
||||
|
||||
作者:[LinuxAndUbuntu][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com
|
||||
[1]:http://www.linuxandubuntu.com/home/category/linux
|
||||
[2]:http://www.linuxandubuntu.com/home/category/distros
|
||||
[3]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/gnu-grub_orig.png
|
||||
[4]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/runlevel_orig.png
|
||||
[5]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/runlevel_1_orig.png
|
||||
Loading…
Reference in New Issue
Block a user