mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-28 01:01:09 +08:00
commit
2711118e4c
@ -1,168 +0,0 @@
|
||||
translation by strugglingyouth
|
||||
How to Recover Data and Rebuild Failed Software RAID’s – Part 8
|
||||
================================================================================
|
||||
In the previous articles of this [RAID series][1] you went from zero to RAID hero. We reviewed several software RAID configurations and explained the essentials of each one, along with the reasons why you would lean towards one or the other depending on your specific scenario.
|
||||
|
||||

|
||||
|
||||
Recover Rebuild Failed Software RAID’s – Part 8
|
||||
|
||||
In this guide we will discuss how to rebuild a software RAID array without data loss when in the event of a disk failure. For brevity, we will only consider a RAID 1 setup – but the concepts and commands apply to all cases alike.
|
||||
|
||||
#### RAID Testing Scenario ####
|
||||
|
||||
Before proceeding further, please make sure you have set up a RAID 1 array following the instructions provided in Part 3 of this series: [How to set up RAID 1 (Mirror) in Linux][2].
|
||||
|
||||
The only variations in our present case will be:
|
||||
|
||||
1) a different version of CentOS (v7) than the one used in that article (v6.5), and
|
||||
|
||||
2) different disk sizes for /dev/sdb and /dev/sdc (8 GB each).
|
||||
|
||||
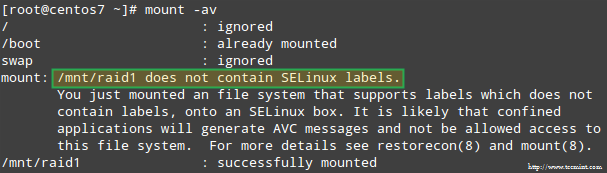
In addition, if SELinux is enabled in enforcing mode, you will need to add the corresponding labels to the directory where you’ll mount the RAID device. Otherwise, you’ll run into this warning message while attempting to mount it:
|
||||
|
||||
|
||||
|
||||
SELinux RAID Mount Error
|
||||
|
||||
You can fix this by running:
|
||||
|
||||
# restorecon -R /mnt/raid1
|
||||
|
||||
### Setting up RAID Monitoring ###
|
||||
|
||||
There is a variety of reasons why a storage device can fail (SSDs have greatly reduced the chances of this happening, though), but regardless of the cause you can be sure that issues can occur anytime and you need to be prepared to replace the failed part and to ensure the availability and integrity of your data.
|
||||
|
||||
A word of advice first. Even when you can inspect /proc/mdstat in order to check the status of your RAIDs, there’s a better and time-saving method that consists of running mdadm in monitor + scan mode, which will send alerts via email to a predefined recipient.
|
||||
|
||||
To set this up, add the following line in /etc/mdadm.conf:
|
||||
|
||||
MAILADDR user@<domain or localhost>
|
||||
|
||||
In my case:
|
||||
|
||||
MAILADDR gacanepa@localhost
|
||||
|
||||

|
||||
|
||||
RAID Monitoring Email Alerts
|
||||
|
||||
To run mdadm in monitor + scan mode, add the following crontab entry as root:
|
||||
|
||||
@reboot /sbin/mdadm --monitor --scan --oneshot
|
||||
|
||||
By default, mdadm will check the RAID arrays every 60 seconds and send an alert if it finds an issue. You can modify this behavior by adding the `--delay` option to the crontab entry above along with the amount of seconds (for example, `--delay` 1800 means 30 minutes).
|
||||
|
||||
Finally, make sure you have a Mail User Agent (MUA) installed, such as [mutt or mailx][3]. Otherwise, you will not receive any alerts.
|
||||
|
||||
In a minute we will see what an alert sent by mdadm looks like.
|
||||
|
||||
### Simulating and Replacing a failed RAID Storage Device ###
|
||||
|
||||
To simulate an issue with one of the storage devices in the RAID array, we will use the `--manage` and `--set-faulty` options as follows:
|
||||
|
||||
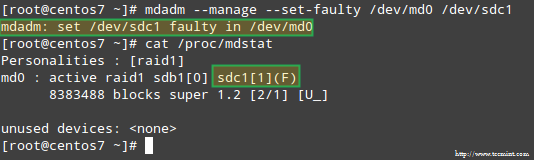
# mdadm --manage --set-faulty /dev/md0 /dev/sdc1
|
||||
|
||||
This will result in /dev/sdc1 being marked as faulty, as we can see in /proc/mdstat:
|
||||
|
||||
|
||||
|
||||
Stimulate Issue with RAID Storage
|
||||
|
||||
More importantly, let’s see if we received an email alert with the same warning:
|
||||
|
||||

|
||||
|
||||
Email Alert on Failed RAID Device
|
||||
|
||||
In this case, you will need to remove the device from the software RAID array:
|
||||
|
||||
# mdadm /dev/md0 --remove /dev/sdc1
|
||||
|
||||
Then you can physically remove it from the machine and replace it with a spare part (/dev/sdd, where a partition of type fd has been previously created):
|
||||
|
||||
# mdadm --manage /dev/md0 --add /dev/sdd1
|
||||
|
||||
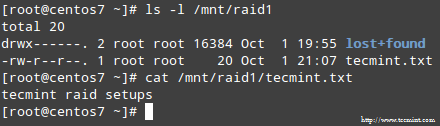
Luckily for us, the system will automatically start rebuilding the array with the part that we just added. We can test this by marking /dev/sdb1 as faulty, removing it from the array, and making sure that the file tecmint.txt is still accessible at /mnt/raid1:
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
# mount | grep raid1
|
||||
# ls -l /mnt/raid1 | grep tecmint
|
||||
# cat /mnt/raid1/tecmint.txt
|
||||
|
||||

|
||||
|
||||
Confirm Rebuilding RAID Array
|
||||
|
||||
The image above clearly shows that after adding /dev/sdd1 to the array as a replacement for /dev/sdc1, the rebuilding of data was automatically performed by the system without intervention on our part.
|
||||
|
||||
Though not strictly required, it’s a great idea to have a spare device in handy so that the process of replacing the faulty device with a good drive can be done in a snap. To do that, let’s re-add /dev/sdb1 and /dev/sdc1:
|
||||
|
||||
# mdadm --manage /dev/md0 --add /dev/sdb1
|
||||
# mdadm --manage /dev/md0 --add /dev/sdc1
|
||||
|
||||

|
||||
|
||||
Replace Failed Raid Device
|
||||
|
||||
### Recovering from a Redundancy Loss ###
|
||||
|
||||
As explained earlier, mdadm will automatically rebuild the data when one disk fails. But what happens if 2 disks in the array fail? Let’s simulate such scenario by marking /dev/sdb1 and /dev/sdd1 as faulty:
|
||||
|
||||
# umount /mnt/raid1
|
||||
# mdadm --manage --set-faulty /dev/md0 /dev/sdb1
|
||||
# mdadm --stop /dev/md0
|
||||
# mdadm --manage --set-faulty /dev/md0 /dev/sdd1
|
||||
|
||||
Attempts to re-create the array the same way it was created at this time (or using the `--assume-clean` option) may result in data loss, so it should be left as a last resort.
|
||||
|
||||
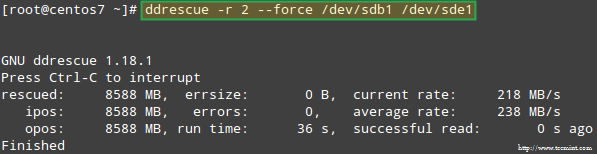
Let’s try to recover the data from /dev/sdb1, for example, into a similar disk partition (/dev/sde1 – note that this requires that you create a partition of type fd in /dev/sde before proceeding) using ddrescue:
|
||||
|
||||
# ddrescue -r 2 /dev/sdb1 /dev/sde1
|
||||
|
||||
|
||||
|
||||
Recovering Raid Array
|
||||
|
||||
Please note that up to this point, we haven’t touched /dev/sdb or /dev/sdd, the partitions that were part of the RAID array.
|
||||
|
||||
Now let’s rebuild the array using /dev/sde1 and /dev/sdf1:
|
||||
|
||||
# mdadm --create /dev/md0 --level=mirror --raid-devices=2 /dev/sd[e-f]1
|
||||
|
||||
Please note that in a real situation, you will typically use the same device names as with the original array, that is, /dev/sdb1 and /dev/sdc1 after the failed disks have been replaced with new ones.
|
||||
|
||||
In this article I have chosen to use extra devices to re-create the array with brand new disks and to avoid confusion with the original failed drives.
|
||||
|
||||
When asked whether to continue writing array, type Y and press Enter. The array should be started and you should be able to watch its progress with:
|
||||
|
||||
# watch -n 1 cat /proc/mdstat
|
||||
|
||||
When the process completes, you should be able to access the content of your RAID:
|
||||
|
||||
|
||||
|
||||
Confirm Raid Content
|
||||
|
||||
### Summary ###
|
||||
|
||||
In this article we have reviewed how to recover from RAID failures and redundancy losses. However, you need to remember that this technology is a storage solution and DOES NOT replace backups.
|
||||
|
||||
The principles explained in this guide apply to all RAID setups alike, as well as the concepts that we will cover in the next and final guide of this series (RAID management).
|
||||
|
||||
If you have any questions about this article, feel free to drop us a note using the comment form below. We look forward to hearing from you!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/recover-data-and-rebuild-failed-software-raid/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/understanding-raid-setup-in-linux/
|
||||
[2]:http://www.tecmint.com/create-raid1-in-linux/
|
||||
[3]:http://www.tecmint.com/send-mail-from-command-line-using-mutt-command/
|
||||
@ -0,0 +1,169 @@
|
||||
|
||||
当软件 RAID 故障时如何恢复和重建数据 – 第 8 部分
|
||||
================================================================================
|
||||
|
||||
在阅读过 [RAID 系列][1] 前面的文章后你已经对 RAID 略微熟悉了。回顾前面几个软件 RAID 的配置,我们对每一个做了详细的解释,使用哪一个取决与你的具体情况。
|
||||
|
||||

|
||||
|
||||
恢复并重建故障的软件 RAID - 第8部分
|
||||
|
||||
在本文中,我们将讨论当一个磁盘发生故障时如何重建软件 RAID 阵列并且不会丢失数据。为方便起见,我们仅考虑RAID 1 的配置 - 但其方法和概念适用于所有情况。
|
||||
|
||||
#### RAID 测试方案 ####
|
||||
|
||||
在进一步讨论之前,请确保你已经配置了 RAID 1 阵列,可以按照本系列第3部分提供的方法:[在 Linux 中如何组建 RAID 1(镜像)][2]。
|
||||
|
||||
在目前的情况下,仅有的变化是:
|
||||
|
||||
1)使用不同版本 CentOS(v7),而不是前面文章中的(v6.5)。
|
||||
|
||||
2) 磁盘容量发生改变, /dev/sdb 和 /dev/sdc(各8GB)。
|
||||
|
||||
此外,如果 SELinux 是 enforcing 模式,你需要将相应的标签添加到挂载 RAID 设备的目录中。否则,当你试图挂载时,你会碰到这样的警告信息:
|
||||
|
||||

|
||||
|
||||
启用 SELinux 时 RAID 挂载错误
|
||||
|
||||
通过以下命令来解决:
|
||||
|
||||
# restorecon -R /mnt/raid1
|
||||
|
||||
### 配置 RAID 监控 ###
|
||||
|
||||
存储设备损坏的原因很多(尽管固态硬盘大大减少了这种情况发生的可能性),但不管是什么原因,可以肯定问题随时可能发生,你需要准备好替换发生故障的部分,并确保数据的可用性和完整性。
|
||||
|
||||
首先建议是。虽然你可以查看 /proc/mdstat 来检查 RAID 的状态,但有一个更好的和节省时间的方法,使用监控 + 扫描模式运行 mdadm,它将警报通过电子邮件发送到一个预定义的收件人。
|
||||
|
||||
要这样设置,在 /etc/mdadm.conf 添加以下行:
|
||||
|
||||
MAILADDR user@<domain or localhost>
|
||||
|
||||
我自己的设置:
|
||||
|
||||
MAILADDR gacanepa@localhost
|
||||
|
||||

|
||||
|
||||
监控 RAID 并使用电子邮件进行报警
|
||||
|
||||
要运行 mdadm 在监控 + 扫描模式中,以 root 用户添加以下 crontab 条目:
|
||||
|
||||
@reboot /sbin/mdadm --monitor --scan --oneshot
|
||||
|
||||
默认情况下,mdadm 每隔60秒会检查 RAID 阵列,如果发现问题将发出警报。你可以通过添加 `--delay` 选项到crontab 条目上面,后面跟上秒数,来修改默认行为(例如,`--delay` 1800意味着30分钟)。
|
||||
|
||||
最后,确保你已经安装了一个邮件用户代理(MUA),如[mutt or mailx][3]。否则,你将不会收到任何警报。
|
||||
|
||||
在一分钟内,我们就会看到 mdadm 发送的警报。
|
||||
|
||||
### 模拟和更换发生故障的 RAID 存储设备 ###
|
||||
|
||||
为了给 RAID 阵列中的存储设备模拟一个故障,我们将使用 `--manage` 和 `--set-faulty` 选项,如下所示:
|
||||
|
||||
# mdadm --manage --set-faulty /dev/md0 /dev/sdc1
|
||||
|
||||
这将导致的 /dev/sdc1 被标记为 faulty,我们可以在 /proc/mdstat 看到:
|
||||
|
||||

|
||||
|
||||
在 RAID 存储设备上模拟问题
|
||||
|
||||
更重要的是,如果我们收到了同样的警报邮件:
|
||||
|
||||

|
||||
|
||||
RAID 设备故障时发送邮件警报
|
||||
|
||||
在这种情况下,你需要从软件 RAID 阵列中删除该设备:
|
||||
|
||||
# mdadm /dev/md0 --remove /dev/sdc1
|
||||
|
||||
然后,你可以直接从机器中取出,并将其使用备用设备来取代(/dev/sdd 中类型为 fd 的分区以前已被创建):
|
||||
|
||||
# mdadm --manage /dev/md0 --add /dev/sdd1
|
||||
|
||||
幸运的是,该系统会使用我们刚才添加的磁盘自动重建阵列。我们可以通过标记 dev/sdb1 为 faulty 来进行测试,从阵列中取出后,并确保 tecmint.txt 文件仍然在/mnt/raid1 是可访问的:
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
# mount | grep raid1
|
||||
# ls -l /mnt/raid1 | grep tecmint
|
||||
# cat /mnt/raid1/tecmint.txt
|
||||
|
||||

|
||||
|
||||
确认 RAID 重建
|
||||
|
||||
上面图片清楚的显示,添加 /dev/sdd1 到阵列中来替代 /dev/sdc1,数据的重建是系统自动完成的,不需要干预。
|
||||
|
||||
虽然要求不是很严格,有一个备用设备是个好主意,这样更换故障的设备就可以在瞬间完成了。要做到这一点,先让我们重新添加 /dev/sdb1 和 /dev/sdc1:
|
||||
|
||||
# mdadm --manage /dev/md0 --add /dev/sdb1
|
||||
# mdadm --manage /dev/md0 --add /dev/sdc1
|
||||
|
||||

|
||||
|
||||
取代故障的 Raid 设备
|
||||
|
||||
### 从冗余丢失中恢复数据 ###
|
||||
|
||||
如前所述,当一个磁盘发生故障 mdadm 将自动重建数据。但是,如果阵列中的2个磁盘都故障时会发生什么?让我们来模拟这种情况,通过标记 /dev/sdb1 和 /dev/sdd1 为 faulty:
|
||||
|
||||
# umount /mnt/raid1
|
||||
# mdadm --manage --set-faulty /dev/md0 /dev/sdb1
|
||||
# mdadm --stop /dev/md0
|
||||
# mdadm --manage --set-faulty /dev/md0 /dev/sdd1
|
||||
|
||||
此时尝试以同样的方式重新创建阵列就(或使用 `--assume-clean` 选项)可能会导致数据丢失,因此不到万不得已不要使用。
|
||||
|
||||
|
||||
让我们试着从 /dev/sdb1 恢复数据,例如,在一个类似的磁盘分区(/dev/sde1 - 注意,这需要你执行前在/dev/sde 上创建一个 fd 类型的分区)上使用 ddrescue:
|
||||
|
||||
# ddrescue -r 2 /dev/sdb1 /dev/sde1
|
||||
|
||||

|
||||
|
||||
恢复 Raid 阵列
|
||||
|
||||
请注意,到现在为止,我们还没有触及 /dev/sdb 和 /dev/sdd,这是 RAID 阵列的一部分分区。
|
||||
|
||||
现在,让我们使用 /dev/sde1 和 /dev/sdf1 来重建阵列:
|
||||
|
||||
# mdadm --create /dev/md0 --level=mirror --raid-devices=2 /dev/sd[e-f]1
|
||||
|
||||
请注意,在真实的情况下,你需要使用与原来的阵列中相同的设备名称,即把 /dev/sdb1 和 /dev/sdc1 替换了的磁盘。
|
||||
|
||||
在本文中,我选择了使用额外的设备来重新创建全新的磁盘阵列,为了避免与原来的故障磁盘混淆。
|
||||
|
||||
当被问及是否继续写入阵列时,键入 Y,然后按 Enter。阵列被启动,你也可以查看它的进展:
|
||||
|
||||
# watch -n 1 cat /proc/mdstat
|
||||
|
||||
当这个过程完成后,你应该能够访问 RAID 的数据:
|
||||
|
||||

|
||||
|
||||
确认 Raid 数据
|
||||
|
||||
### 总结 ###
|
||||
|
||||
在本文中,我们回顾了从 RAID 故障和冗余丢失中恢复数据。但是,你要记住,这种技术是一种存储解决方案,不能取代备份。
|
||||
|
||||
本文中介绍的方法适用于所有 RAID 中,还有其中的理念,我将在本系列的最后一篇(RAID 管理)中涵盖它。
|
||||
|
||||
如果你对本文有任何疑问,随时给我们以评论的形式说明。我们期待倾听阁下的心声!
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/recover-data-and-rebuild-failed-software-raid/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/understanding-raid-setup-in-linux/
|
||||
[2]:http://www.tecmint.com/create-raid1-in-linux/
|
||||
[3]:http://www.tecmint.com/send-mail-from-command-line-using-mutt-command/
|
||||
Loading…
Reference in New Issue
Block a user