It's and its.
- ``` 其输出为: + ``` @@ -135,7 +141,7 @@ via: https://opensource.com/article/18/8/gawk-script-convert-smart-quotes 作者:[Jim Hall][a] 选题:[lujun9972](https://github.com/lujun9972) 译者:[lujun9972](https://github.com/lujun9972) -校对:[校对者ID](https://github.com/校对者ID) +校对:[wxy](https://github.com/wxy) 本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出 diff --git a/published/20180806 Learn Python programming the easy way with EduBlocks.md b/published/201808/20180806 Learn Python programming the easy way with EduBlocks.md similarity index 100% rename from published/20180806 Learn Python programming the easy way with EduBlocks.md rename to published/201808/20180806 Learn Python programming the easy way with EduBlocks.md diff --git a/published/20180806 What is CI-CD.md b/published/201808/20180806 What is CI-CD.md similarity index 100% rename from published/20180806 What is CI-CD.md rename to published/201808/20180806 What is CI-CD.md diff --git a/published/20180809 How To Switch Between Multiple PHP Versions In Ubuntu.md b/published/201808/20180809 How To Switch Between Multiple PHP Versions In Ubuntu.md similarity index 100% rename from published/20180809 How To Switch Between Multiple PHP Versions In Ubuntu.md rename to published/201808/20180809 How To Switch Between Multiple PHP Versions In Ubuntu.md diff --git a/published/20180810 Image creation applications for Fedora.md b/published/201808/20180810 Image creation applications for Fedora.md similarity index 100% rename from published/20180810 Image creation applications for Fedora.md rename to published/201808/20180810 Image creation applications for Fedora.md diff --git a/published/20180812 Ubuntu 18.04 Vs. Fedora 28.md b/published/201808/20180812 Ubuntu 18.04 Vs. Fedora 28.md similarity index 100% rename from published/20180812 Ubuntu 18.04 Vs. Fedora 28.md rename to published/201808/20180812 Ubuntu 18.04 Vs. Fedora 28.md diff --git a/published/20180813 Convert file systems with Fstransform.md b/published/201808/20180813 Convert file systems with Fstransform.md similarity index 100% rename from published/20180813 Convert file systems with Fstransform.md rename to published/201808/20180813 Convert file systems with Fstransform.md diff --git a/published/20180813 How To Switch Between Different Versions Of Commands In Linux.md b/published/201808/20180813 How To Switch Between Different Versions Of Commands In Linux.md similarity index 100% rename from published/20180813 How To Switch Between Different Versions Of Commands In Linux.md rename to published/201808/20180813 How To Switch Between Different Versions Of Commands In Linux.md diff --git a/published/20180813 How to display data in a human-friendly way on Linux.md b/published/201808/20180813 How to display data in a human-friendly way on Linux.md similarity index 100% rename from published/20180813 How to display data in a human-friendly way on Linux.md rename to published/201808/20180813 How to display data in a human-friendly way on Linux.md diff --git a/published/20180813 Tips for using the top command in Linux.md b/published/201808/20180813 Tips for using the top command in Linux.md similarity index 100% rename from published/20180813 Tips for using the top command in Linux.md rename to published/201808/20180813 Tips for using the top command in Linux.md diff --git a/published/20180814 How To Record Terminal Sessions As SVG Animations In Linux.md b/published/201808/20180814 How To Record Terminal Sessions As SVG Animations In Linux.md similarity index 100% rename from published/20180814 How To Record Terminal Sessions As SVG Animations In Linux.md rename to published/201808/20180814 How To Record Terminal Sessions As SVG Animations In Linux.md diff --git a/published/20180815 How the L1 Terminal Fault vulnerability affects Linux systems.md b/published/201808/20180815 How the L1 Terminal Fault vulnerability affects Linux systems.md similarity index 100% rename from published/20180815 How the L1 Terminal Fault vulnerability affects Linux systems.md rename to published/201808/20180815 How the L1 Terminal Fault vulnerability affects Linux systems.md diff --git a/published/20180819 How to define and use functions in Linux Shell Script.md b/published/201808/20180819 How to define and use functions in Linux Shell Script.md similarity index 100% rename from published/20180819 How to define and use functions in Linux Shell Script.md rename to published/201808/20180819 How to define and use functions in Linux Shell Script.md diff --git a/published/20180821 A Collection Of More Useful Unix Utilities.md b/published/201808/20180821 A Collection Of More Useful Unix Utilities.md similarity index 100% rename from published/20180821 A Collection Of More Useful Unix Utilities.md rename to published/201808/20180821 A Collection Of More Useful Unix Utilities.md diff --git a/published/20180802 Distrochooser Helps Linux Beginners To Choose A Suitable Linux Distribution.md b/published/20180802 Distrochooser Helps Linux Beginners To Choose A Suitable Linux Distribution.md new file mode 100644 index 0000000000..1cb44b2ed1 --- /dev/null +++ b/published/20180802 Distrochooser Helps Linux Beginners To Choose A Suitable Linux Distribution.md @@ -0,0 +1,76 @@ +Distrochooser 帮助 Linux 初学者选择合适的 Linux 发行版 +====== + + + +你好 Linux 新手!今天,我为你们带来了一个好消息!你也许想知道如何选择合适的 Linux 发行版。当然,你可能已经咨询过一些 Linux 专家来帮助你的需要选择 Linux 发行版。你们中的一些人可能已经用 Google 搜索并浏览了各种资源、Linux 论坛、网站和博客来寻找完美的发行版。好了,你不必再那样做了。有了 **Distrochooser**,一个帮助你轻松找到 Linux 发行版的网站。 + +### Distrochooser 如何帮助 Linux 初学者选择合适的 Linux 发行版? + +Distrochooser 会根据你的答案向你询问一系列问题并建议你尝试不同的 Linux 发行版。激动吗?太好了!让我们继续看看如何找到合适的 Linux 发行版。单击以下链接开始。 + +![][2] + +你将被重定向到 Distrochooser 主页,其中有一个小测试在等待你注册。 + + + +你需要回答一系列问题(准确地说是 16 个问题)。问题同时有单选和多选。以下是完整的问题列表。 + + 1. 软件:使用情况 + 2. 计算机知识 + 3. Linux 知识 + 4. 安装:预设 + 5. 安装:需要 Live 测试么? + 6. 安装:硬件支持 + 7. 配置:帮助源 + 8. 发行版:用户体验概念 + 9. 发行版:价格 + 10. 发行版:范围 + 11. 发行版:意识形态 + 12. 发行版:隐私 + 13. 发行版:预设主题,图标和壁纸 + 14. 发行版:特色 + 15. 软件:管理 + 16. 软件:更新 + +仔细阅读问题并在相应问题下面选择合适的答案。Distrochooser 提供了更多选择来选择接近完美的发行版。 + + * 你总是可以跳过问题, + * 你可以随时点击“获取结果”, + * 你可以任意顺序回答, + * 你可以随时删除答案, + * 你可以在测试结束时对属性进行加权,以强调对你来说重要的内容。 + +选择问题的答案后,单击“Proceed”以转到下一个问题。完成后,单击“Get Result”按钮。你也可以通过单击答案下面的“Clear”按钮随时清除选择。 + +### 结果? + +我以前不相信 Distrochooser 会找到我想要的东西。哦,我错了!令我惊讶的是,它确实做得很好。结果对我来说几乎是准确的。我期待 Arch Linux 在结果中,结果确实是在推荐第一位,接下来是其他 11 个建议,如 NixOS、Void Linux、Qubes OS、Scientific Linux、Devuan、Gentoo Linux、Bedrock Linux、Slackware、CentOS、Linux from scratch、Redhat Enterprise Linux。总共有 12 个推荐,每个结果都非常详细,带有发行版的描述和主页。 + + + +我在 Reddit 上发布了 Distrochooser 链接,80% 的用户可以找到合适的 Linux 发行版。但是,我不会声称 Distrochooser 足以为每个人找到好结果。一些用户对调查结果感到失望,甚至结果与他们使用中或者想要使用的一点不接近。因此,我强烈建议你在尝试任何 Linux 之前咨询其他 Linux 专家、网站和论坛。你可以在[**这里**][3]阅读完整的 Reddit 讨论。 + +你在等什么?进入 Distrochooser 网站并为你选择合适的 Linux 发行版吧。 + +就是这些了。还有更多好东西。敬请期待! + +干杯! + + + +-------------------------------------------------------------------------------- + +via: https://www.ostechnix.com/distrochooser-helps-linux-beginners-to-choose-a-suitable-linux-distribution/ + +作者:[SK][a] +选题:[lujun9972](https://github.com/lujun9972) +译者:[geekpi](https://github.com/geekpi) +校对:[wxy](https://github.com/wxy) + +本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出 + +[a]:https://www.ostechnix.com/author/sk/ +[2]:https://distrochooser.de/en +[3]:https://www.reddit.com/r/linux/comments/93p6az/distrochooser_helps_linux_beginners_to_choose_a/ diff --git a/translated/tech/20180803 10 Popular Windows Apps That Are Also Available on Linux.md b/published/20180803 10 Popular Windows Apps That Are Also Available on Linux.md similarity index 72% rename from translated/tech/20180803 10 Popular Windows Apps That Are Also Available on Linux.md rename to published/20180803 10 Popular Windows Apps That Are Also Available on Linux.md index f6ad7b42ea..7e49ec1195 100644 --- a/translated/tech/20180803 10 Popular Windows Apps That Are Also Available on Linux.md +++ b/published/20180803 10 Popular Windows Apps That Are Also Available on Linux.md @@ -1,114 +1,116 @@ -10 个在 Linux 上也有的流行 Windows 程序 +10 个在 Linux 上也有的流行的 Windows 程序 ====== + + 回顾过去,2018 年是 Linux 社区的好年景。许多仅在 Windows 和/或 Mac上 有的程序可在 Linux 平台上使用了,而且不用麻烦。向 [Snap][3] 和 [Flatpak][4] 技术致敬,这些技术已经为 Linux 用户带来了许多“受限制”的程序。 -**另请阅读**:[所有很酷的 Linux 程序和工具][5] +**另请阅读**:[很酷的 Linux 程序和工具大全][5] 今天,我们为你提供了一个有名的 Windows 程序列表,你不需要寻找它们的替代品,因为它们已经在 Linux 上可用。 -### 1\. Skype +### 1、Skype + +它可以说是世界上最受欢迎的 VoIP 程序,**Skype** 提供出色的视频和语音通话质量,以及其他功能,如拨打本地和国际电话、固定电话、即时消息、表情符号等功能。 -可以说是世界上最受欢迎的 VoIP 程序,**Skype** 提供出色的视频和语音通话质量,以及其他功能,如拨打本地和国际电话、固定电话、即时消息、表情符号等功能。 ``` $ sudo snap install skype --classic - ``` -### 2\. Spotify +### 2、Spotify + +**Spotify** 是最流行的音乐流媒体平台,在很长一段时间里,Linux 用户需要使用脚本和一些手段才能在他们的机器上设置该程序,感谢 snap,安装和使用 Spotify 就像点击一个按钮那样简单。 -**Spotify** 是最流行的音乐流媒体平台,在很长一段时间里,Linux 用户需要使用脚本和黑客技巧在他们的机器上设置程序,感谢 snap,安装和使用 Spotify 就像点击一个按钮那样简单。 ``` $ sudo snap install spotify - ``` -### 3\. Minecraft +### 3、Minecraft + +**Minecraft** 被证明是一款年度好游戏。更酷的是,它持续地得到维护。如果你不了解 Minecraft,它是一款冒险游戏,它可以让你在一个无限无边的虚拟世界中使用积木创建任何你想创建的虚拟事物。 -**Minecraft** 被证明是一款年度好游戏。更酷的是,它持续地得到维护。如果你不了解 Mincraft,它是一款冒险游戏,它可以让你在一个无限无边的虚拟世界中使用积木创建任何你想创建的虚拟事物。 ``` $ sudo snap install minecraft - ``` -### 4\. JetBrains Dev Suite +### 4、JetBrains Dev Suite -**JetBrains** 以其高级开发 IDE 套件而闻名,其最受欢迎的程序声称可在 Linux 上使用而不会有任何麻烦。 +**JetBrains** 以其高级的开发 IDE 套件而闻名,他们这个最受欢迎的程序声称可在 Linux 上使用而不会有任何麻烦。 #### 安装 IDEA Community – Java IDE + ``` $ sudo snap install intellij-idea-community --classic - ``` #### 安装 PyCharm EDU – Python IDE + ``` $ sudo snap install pycharm-educational --classic - ``` #### 安装 PhpStorm – PHP IDE + ``` $ sudo snap install phpstorm --classic - ``` #### 安装 WebStorm – JavaScript IDE + ``` $ sudo snap install webstorm --classic - ``` #### 安装 RubyMine – Ruby and Rails IDE + ``` $ sudo snap install rubymine --classic - ``` -### 5\. PowerShell +### 5、PowerShell **PowerShell** 是一个用于管理 PC 自动化和配置的平台,它提供了一个带有相关脚本语言的命令行 shell。如果你认为它仅在 Windows 上可用,那么请再想一想。 + ``` $ sudo snap install powershell --classic - ``` -### 6\. Ghost +### 6、Ghost **Ghost** 是一款现代桌面程序,可让用户在无干扰的环境中管理多个 Ghost 博客、杂志、在线出版物等。 + ``` $ sudo snap install ghost-desktop - ``` -### 7\. MySQL Workbench +### 7、MySQL Workbench **MySQL Workbench** 是一个 GUI 程序,用于设计和管理集成 SQL 功能的数据库。 -[**下载 MySQL Workbench**][6] +- [**下载 MySQL Workbench**][6] -### 8\. PlayOnLinux 中的 Adobe App Suite +### 8、PlayOnLinux 中的 Adobe App Suite 你可能错过了我们在 [PlayOnLinux][7] 上发表的文章,所以这是另一个了解的机会。 -PlayOnLinux 基本上是 **wine** 的改进实现,允许用户更轻松地安装 Adobe 的创意云程序。请注意,试用和订阅限制仍然适用。 +PlayOnLinux 基本上是 **wine** 的改进版本,允许用户更轻松地安装 Adobe 的创意云程序。请注意,试用和订阅限制仍然适用。 -[**如何使用 PlayOnLinux**][8] +- [**如何使用 PlayOnLinux**][8] -### 9\. Slack +### 9、Slack 这据说是开发人员和项目经理之间最常用的团队沟通软件,**Slack** 提供了每个人似乎无法满足的有各种文档和消息管理功能的工作空间。 + ``` $ sudo snap install slack --classic - ``` -### 10\. Blender +### 10、Blender **Blender** 是最受欢迎的 3D 创作程序之一。它是免费的、开源的,并且支持完整 3D 管道。 + ``` $ sudo snap install blender --classic - ``` 就是这些了!我们知道列表还有很多,但我们只能列出这么多。我们是否省略了你认为应该将其列入清单的任何程序?在下面的评论栏添加你的建议。 @@ -117,10 +119,10 @@ $ sudo snap install blender --classic via: https://www.fossmint.com/install-popular-windows-apps-on-linux/ -作者:[Martins D. Okoi;View All Posts][a] +作者:[Martins D. Okoi][a] 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) -校对:[校对者ID](https://github.com/校对者ID) +校对:[wxy](https://github.com/wxy) 本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出 diff --git a/published/20180804 Installing Andriod on VirtualBox.md b/published/20180804 Installing Andriod on VirtualBox.md new file mode 100644 index 0000000000..5f69eee83a --- /dev/null +++ b/published/20180804 Installing Andriod on VirtualBox.md @@ -0,0 +1,162 @@ +在 VirtualBox 中安装 Android 系统 +====== + +如果你正在开发 Android 应用,也许会遇到小麻烦。诚然,ios 移动开发有 macOS 系统平台为其提供友好便利性, Android 开发仅有支持少部分 Android 系统(其中还包括可穿戴设备系统)的 Android Studio 工具。 + +毋庸置疑,所有的二进制工具、SDK 工具、开发框架工具以及调试器都会产生大量日志和其他各种文件,使得你的文件系统很混乱。一个有效的解决方法就是在 VirtualBox 中安装 Android 系统,这样还解决了 Android 开发中最为棘手问题之一 —— 设备模拟器。你可以在该虚拟机里测试应用程序,也可以使用 Android 的内部功能。因此,让我们迫不及待的开始吧! + +### 准备工作 + +首先,你需要在你的系统上安装 VirtualBox,可从[这里][1]下载 Windows 版本、macOS 版本或者各种 Linux 版本的 VitualBox。然后,你需要一个能在 x86 平台运行的 Android 镜像,因为 VirtualBox 为虚拟机提供运行 x86 或者 x86\_64(即 AMD64)平台的功能。 + +虽然大部分 Android 设备都在 ARM 上运行,但我们依然可以从 [Android on x86 项目][2] 中获得帮助。这些优秀的开发者已经将 Android 移植到 x86 平台上运行(包括实体机和虚拟机),我们可以下载最新版本的 Android 7.1。你也可以用之前更为稳定的版本,本文写作时最新稳定版是 Android 6.0。 + +### 创建 VM 虚拟机 + +打开 VirtualBox,单击左上角的 “新建” 按钮,在弹出的窗口中选择 “类型:Linux” ,然后根据下载的 ISO 镜像来确定版本,x86 对应 “32-bit”,x86_64 对应 “64-bit”,此处选择 “Linux 2.6 / 3.x / 4.x (64-bit)”。 + +RAM 大小设置为 2 GB 到你系统能提供的最大内存之间。如果你想模拟真实的使用环境你可以设置 6 GB RAM 和 32 GB ROM。 + +![][3] + +![][4] + +创建完成后,你还需要做一些设置,添加更多的处理器核心,提高开机显示内存。在 VM 上打开设置选项,“设置 -> 系统 -> 处理器”,如果硬件条件允许,可以多分配一些处理器。 + +![][5] + +在 “设置 -> 显示 -> 显存大小” 中,你可以分配一大块内存并开启 3D 加速功能。 + +![][6] + +现在我们可以启动 VM 虚拟机了。 + +### 安装 Android + +首次启动 VM 虚拟机,VirtualBox 会提示你需要提供启动媒介,选择之前下载好的Android 镜像。 + +![][7] + +下一步,如果想长时间使用 Android,选择 “Installation” 选项,你也可以选择 Live 模式体验 Android 环境。 + +![][8] + +按回车键。 + +#### 分区 + +分区是通过文本界面操作,并没有友好的 GUI 界面,所以每个操作都需要小心对待。例如,在第一屏中还没有创建分区并且只检测到原始(虚拟)硬盘时显示如下。 + +![][9] + +红色字母 `C` 和 `D` 表明 `C` 开头选项可以创建或者修改分区,`D` 开头选项可以检测设备。你可以选择 `D` 开头选项,然后它就会检测硬盘,也可不进行这步操作,因为在启动的时候它会自动检测。 + +我们选择 `C` 开头选项,在虚拟盘中创建分区。官方不推荐使用 GPT 格式,所以我们选择 “No” 并按回车键。 + +![][10] + +现在你被引导到 fdisk 工具页面。 + +![][11] + +为了简洁起见,我们就只创建一个较大的分区,使用方向键来选择 “New” ,然后选择 “Primary”,按回车键以确认。 + +![][12] + +分区大小系统已经为你计算好了,按回车键确认。 + +![][13] + +这个分区就是 Android 系统所在的分区,所以需要它是可启动的。选择 “Bootable”,然后按回车键(上方表格中 “Flags” 标志下面会出现 “boot” 标志),进一步,选择 “Write” 选项,保存刚才的操作记录并写入分区表。 + +![][14] + +现在你可以选择退出分区工具,然后继续安装过程。 + +![][15] + +#### 文件系统格式化为 EXT4 并安装 Android + +在“Choose Partition”分区页面上会出现一个刚刚我们创建的分区,选择它并点击“OK”进入。 + +![][16] + +在下一个菜单中选择 Ext4 作为实际的文件系统,在下一页中选择 “Yes” 然后格式化开始。会提示是否安装 GRUB 引导工具以及是否允许在目录 `/system` 进行读写,都选择 “Yes” 。现在,安装进程开始。 + +安装完成后,当系统提示可以重启的时候你可以安全地重启系统。在重启之前,你可以先关机,然后在 VitualBox 的 “设置 -> 存储” 中检查 Android iso 镜像是否还连接在虚拟机上,如果在,将它移除。 + +![][17] + +移除安装媒介并保存修改,再去启动 VM 虚拟机。 + +#### 运行 Android + +在 GRUB 引导界面,有调试模式和普通模式的选项。我们选择默认选项,如下图所示。 + +![][18] + +如果一切正常,你将会看到如下界面: + +![][19] + +如今的 Android 系统使用触摸交互而不是鼠标。不过 Android-x86 平台提供了鼠标操作支持,但开始时可能需要方向键来辅助操作。 + +![][20] + +移动到”let’s go“按钮并按下回车键。选择 “Set up as new” 选项,回车确认。 + +![][21] + +在提示用谷歌账户登陆之前,系统检查更新并检测设备信息。你可以跳过这一步,直接去设置日期和时间、用户名等。 + +还有一些其他的选项,和让你设置一个新的 Android 设备类似。选择 “I Agree” 选项同意有关更新、服务等的相应的选项,当然谷歌的服务条款是不得不同意的。 + +![][22] + +在这之后,因为它是个虚拟机,所以可能需要添加额外的 email 账户来设置 “On-body detection”,大部分的选项对我们来说都没有多大作用,因此可以选择 ”All Set“。 + +接下来,它会提示你选择主屏应用,这个根据个人需求选择。现在我们进入了一个虚拟的 Android 系统。 + +![][23] + +如果你需要在 VM 做一些交互测试,有个可触摸屏幕会提供很大的方便,因为那样才更接近真实使用环境。 + +希望这篇教程会给你带来帮助。 + +-------------------------------------------------------------------------------- + +via: https://linuxhint.com/install_android_virtualbox/ + +作者:[Ranvir Singh][a] +选题:[lujun9972](https://github.com/lujun9972) +译者:[jrglinux](https://github.com/jrglinux) +校对:[wxy](https://github.com/wxy) + +本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出 + +[a]:https://linuxhint.com/author/sranvir155/ +[1]:https://www.virtualbox.org/wiki/Downloads +[2]:http://www.android-x86.org/ +[3]:https://linuxhint.com/wp-content/uploads/2018/08/a.png +[4]:https://linuxhint.com/wp-content/uploads/2018/08/a1.png +[5]:https://linuxhint.com/wp-content/uploads/2018/08/a2.png +[6]:https://linuxhint.com/wp-content/uploads/2018/08/a3.png +[7]:https://linuxhint.com/wp-content/uploads/2018/08/a4.png +[8]:https://linuxhint.com/wp-content/uploads/2018/08/a5.png +[9]:https://linuxhint.com/wp-content/uploads/2018/08/a6.png +[10]:https://linuxhint.com/wp-content/uploads/2018/08/a7.png +[11]:https://linuxhint.com/wp-content/uploads/2018/08/a8.png +[12]:https://linuxhint.com/wp-content/uploads/2018/08/a9.png +[13]:https://linuxhint.com/wp-content/uploads/2018/08/a10.png +[14]:https://linuxhint.com/wp-content/uploads/2018/08/a11.png +[15]:https://linuxhint.com/wp-content/uploads/2018/08/a12.png +[16]:https://linuxhint.com/wp-content/uploads/2018/08/a13.png +[17]:https://linuxhint.com/wp-content/uploads/2018/08/a14.png +[18]:https://linuxhint.com/wp-content/uploads/2018/08/a16.png +[19]:https://linuxhint.com/wp-content/uploads/2018/08/a17.png +[20]:https://linuxhint.com/wp-content/uploads/2018/08/a18.png +[21]:https://linuxhint.com/wp-content/uploads/2018/08/a19.png +[22]:https://linuxhint.com/wp-content/uploads/2018/08/a20.png +[23]:https://linuxhint.com/wp-content/uploads/2018/08/a21.png + + diff --git a/published/20180806 Installing and using Git and GitHub on Ubuntu Linux- A beginner-s guide.md b/published/20180806 Installing and using Git and GitHub on Ubuntu Linux- A beginner-s guide.md new file mode 100644 index 0000000000..5c2e7d40b5 --- /dev/null +++ b/published/20180806 Installing and using Git and GitHub on Ubuntu Linux- A beginner-s guide.md @@ -0,0 +1,158 @@ +初学者指南:在 Ubuntu Linux 上安装和使用 Git 和 GitHub +====== + +Github 是一个存放着世界上最棒的一些软件项目的宝藏,这些软件项目由全世界的开发者无私贡献。这个看似简单,实则非常强大的平台因为大大帮助了那些对开发大规模软件感兴趣的开发者而被开源社区所称道。 + +这篇向导是对于安装和使用 GitHub 的的一个快速说明,本文还将涉及诸如创建本地仓库,如何链接这个本地仓库到包含你的项目的远程仓库(这样每个人都能看到你的项目了),以及如何提交改变并最终推送所有的本地内容到 Github。 + +请注意这篇向导假设你对 Git 术语有基本的了解,如推送、拉取请求(PR)、提交、仓库等等。并且希望你在 GitHub 上已注册成功并记下了你的 GitHub 用户名,那么我们这就进入正题吧: + +### 1、在 Linux 上安装 Git + +下载并安装 Git: + +``` +sudo apt-get install git +``` + +上面的命令适用于 Ubuntu 并且应该在所有最新版的 Ubuntu 上都能工作,它们在 Ubuntu 16.04 和 Ubuntu 18.04 LTS(Bionic Beaver)上都测试过,在将来的版本上应该也能工作。 + +### 2、配置 GitHub + +一旦安装完成,接下去就是配置 GitHub 用户的详细配置信息。请使用下面的两条命令,并确保用你自己的 GitHub 用户名替换 `user_name`,用你创建 GitHub 账户的电子邮件替换 `email_id`。 + +``` +git config --global user.name "user_name" +git config --global user.email "email_id" +``` + +下面的图片显示的例子是如何用我的 GitHub 用户名:“akshaypai” 和我的邮件地址 “abc123@gmail.com” 来配置上面的命令。 + +[![Git config][3]][4] + +### 3、创建本地仓库 + +在你的系统上创建一个目录。它将会被作为本地仓库使用,稍后它会被推送到 GitHub 的远程仓库。请使用如下命令: + +``` +git init Mytest +``` + +如果目录被成功创建,你会看到如下信息: + +``` +Initialized empty Git repository in /home/akshay/Mytest/.git/ +``` + +这行信息可能随你的系统不同而变化。 + +这里,`Mytest` 是创建的目录,而 `init` 将其转化为一个 GitHub 仓库。将当前目录改为这个新创建的目录。 + +``` +cd Mytest +``` + +### 4、新建一个 README 文件来描述仓库 + +现在创建一个 `README` 文件并输入一些文本,如 “this is git setup on linux”。README 文件一般用于描述这个仓库用来放置什么内容或这个项目是关于什么的。例如: + +``` +gedit README +``` + +你可以使用任何文本编辑器。我喜欢使用 gedit。`README` 文件的内容可以为: + +``` +This is a git repo +``` + +### 5、将仓库里的文件加入一个索引 + +这是很重要的一步。这里我们会将所有需要推送到 GitHub 的内容都加入一个索引。这些内容可能包括你第一次加入仓库的文本文件或者应用程序,也有可能是对已存在文件的一些编辑(文件的一个更新版本)。 + +既然我们已经有了 `README` 文件,那么让我们创建一个别的文件吧,如一个简单的 C 程序,我们叫它 `sample.c`。文件内容是: + +``` +#include
- Hello {name}
-
- );
- }
- return (
-
- Please sign in
-
- );
-};
-```
-
-Pretty straightforward. But we can do better. Here’s the same component written using a conditional ternary operator.
-
-```
-const MyComponent = ({ name }) => (
-
- {name ? `Hello ${name}` : 'Please sign in'}
-
-);
-```
-
-Notice how concise this code is compared to the example above.
-
-A few things to note. Because we are using the single statement form of the arrow function, the `return` statement is implied. Also, using a ternary allowed us to DRY up the duplicate `` markup. 🎉
-
-### Ternary vs Logical AND
-
-As you can see, ternaries are wonderful for `if/else` conditions. But what about simple `if` conditions?
-
-Let’s look at another example. If `isPro` (a boolean) is `true`, we are to display a trophy emoji. We are also to render the number of stars (if not zero). We could go about it like this.
-
-```
-const MyComponent = ({ name, isPro, stars}) => (
- . And URL shorteners can come in handy if you want to pre-share a link but don't know the final destination yet.
-
-Like any technology, URL shorteners aren't all positive. By masking the ultimate destination, shortened links can be used to direct people to malicious or offensive content. But if you surf carefully, URL shorteners are a useful tool.
-
-We [covered shorteners previously][3] on this site, but maybe you want to run something simple that's powered by a text file. In this article, we'll show how to use the Apache HTTP server's mod_rewrite feature to set up your own URL shortener. If you're not familiar with the Apache HTTP server, check out David Both's article on [installing and configuring][4] it.
-
-### Create a VirtualHost
-
-In this tutorial, I'm assuming you bought a cool domain that you'll use exclusively for the URL shortener. For example, my website is [funnelfiasco.com][5] , so I bought [funnelfias.co][6] to use for my URL shortener (okay, it's not exactly short, but it feeds my vanity). If you won't run the shortener as a separate domain, skip to the next section.
-
-The first step is to set up the VirtualHost that will be used for the URL shortener. For more information on VirtualHosts, see [David Both's article][7]. This setup requires just a few basic lines:
-```
-
-
- ServerName funnelfias.co
-
-
-
-```
-
-### Create the rewrites
-
-This service uses HTTPD's rewrite engine to rewrite the URLs. If you created a VirtualHost in the section above, the configuration below goes into your VirtualHost section. Otherwise, it goes in the VirtualHost or main HTTPD configuration for your server.
-```
- RewriteEngine on
-
- RewriteMap shortlinks txt:/data/web/shortlink/links.txt
-
- RewriteRule ^/(.+)$ ${shortlinks:$1} [R=temp,L]
-
-```
-
-The first line simply enables the rewrite engine. The second line builds a map of the short links from a text file. The path above is only an example; you will need to use a valid path on your system (make sure it's readable by the user account that runs HTTPD). The last line rewrites the URL. In this example, it takes any characters and looks them up in the rewrite map. You may want to have your rewrites use a particular string at the beginning. For example, if you wanted all your shortened links to be of the form "slX" (where X is a number), you would replace `(.+)` above with `(sl\d+)`.
-
-I used a temporary (HTTP 302) redirect here. This allows me to update the destination URL later. If you want the short link to always point to the same target, you can use a permanent (HTTP 301) redirect instead. Replace `temp` on line three with `permanent`.
-
-### Build your map
-
-Edit the file you specified on the `RewriteMap` line of the configuration. The format is a space-separated key-value store. Put one link on each line:
-```
- osdc https://opensource.com/users/bcotton
-
- twitter https://twitter.com/funnelfiasco
-
- swody1 https://www.spc.noaa.gov/products/outlook/day1otlk.html
-
-```
-
-### Restart HTTPD
-
-The last step is to restart the HTTPD process. This is done with `systemctl restart httpd` or similar (the command and daemon name may differ by distribution). Your link shortener is now up and running. When you're ready to edit your map, you don't need to restart the web server. All you have to do is save the file, and the web server will pick up the differences.
-
-### Future work
-
-This example gives you a basic URL shortener. It can serve as a good starting point if you want to develop your own management interface as a learning project. Or you can just use it to share memorable links to forgettable URLs.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/7/apache-url-shortener
-
-作者:[Ben Cotton][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/bcotton
-[1]:http://t.co
-[2]:http://bit.ly/INtravel
-[3]:https://opensource.com/article/17/3/url-link-shortener
-[4]:https://opensource.com/article/18/2/how-configure-apache-web-server
-[5]:http://funnelfiasco.com
-[6]:http://funnelfias.co
-[7]:https://opensource.com/article/18/3/configuring-multiple-web-sites-apache
diff --git a/sources/tech/20180725 How do private keys work in PKI and cryptography.md b/sources/tech/20180725 How do private keys work in PKI and cryptography.md
deleted file mode 100644
index 7bb1528a71..0000000000
--- a/sources/tech/20180725 How do private keys work in PKI and cryptography.md
+++ /dev/null
@@ -1,103 +0,0 @@
-pinewall translating
-
-How do private keys work in PKI and cryptography?
-======
-
-
-
-In [a previous article][1], I gave an overview of cryptography and discussed the core concepts of confidentiality (keeping data secret), integrity (protecting data from tampering), and authentication (knowing the identity of the data's source). Since authentication relates so closely to all the messiness of identity in the real world, a complex technological ecosystem has evolved around establishing that someone is who they claim to be. In this article, I'll describe in broad strokes how these systems work.
-
-### A quick review of public key cryptography and digital signatures
-
-Authentication in the online world relies on public key cryptography where a key has two parts: a private key kept secret by the owner and a public key shared with the world. After the public key encrypts data, only the private key can decrypt it. This feature is useful if a whistleblower wanted to establish contact with a [journalist][2], for example. More importantly for this article, a private key can be combined with a message to create a digital signature that provides integrity and authentication.
-
-In practice, what is signed is not the actual message, but a digest of a message attained by sending the message through a cryptographic hash function. Instead of signing an entire zip file of source code, the sender signs the 256-bit [SHA-256][3] digest of that zip file and sends the zip file in the clear. Recipients independently calculate the SHA-256 digest of the file they received. They input their digest, the signature they received, and the sender's public key into a signature verification algorithm. The verification process varies depending on the encryption algorithm, and there are enough subtleties that signature verification [vulnerabilities][4] still [pop up][5] . If the verification succeeds, the file has not been modified in transit and must have originated from the sender since only the sender has the private key that created the signature.
-
-### The missing piece of the puzzle
-
-There's one major detail missing from this scenario. Where do we get the sender's public key? The sender could send the public key along with a message, but then we have no proof of their identity beyond their own assertion. Imagine being a bank teller and a customer walks up and says, "Hello, I'm Jane Doe, and I'd like to make a withdrawal." When you ask for identification, she points to a name tag sticker on her shirt that says "Jane Doe." Personally, I would politely turn "Jane" away.
-
-If you already know the sender, you could meet in person and exchange public keys. If you don't, you could meet in person, examine their passport, and once you are satisfied it is authentic, accept their public key. To make the process more efficient, you could throw a [party][6], invite a bunch of people, examine all their passports, and accept all their public keys. Building off that, if you know Jane Doe and trust her (despite her unusual banking practices), Jane could go to the party, get the public keys, and give them to you. In fact, Jane could just sign the other public keys using her own private key, and then you could use [an online repository][7] of public keys, trusting the ones signed by Jane. If a person's public key is signed by multiple people you trust, then you might decide to trust that person as well (even though you don't know them). In this fashion, you can build a [web of trust][8].
-
-But now things have gotten complicated: We need to decide on a standard way to encode a key and the identity associated with that key into a digital bundle we can sign. More properly, these digital bundles are called certificates. We'll also need tooling that can create, use, and manage these certificates. The way we solve these and other requirements is what constitutes a public key infrastructure (PKI).
-
-### Beyond the web of trust
-
-You can think of the web of trust as a network of people. A network with many interconnections between the people makes it easy to find a short path of trust: a social circle, for example. [GPG][9]-encrypted email relies on a web of trust, and it functions ([in theory][10]) since most of us communicate primarily with a relatively small group of friends, family, and co-workers.
-
-In practice, the web of trust has some [significant problems][11], many of them around scaling. When the network starts to get larger and there are few connections between people, the web of trust starts to break down. If the path of trust is attenuated across a long chain of people, you face a higher chance of encountering someone who carelessly or maliciously signed a key. And if there is no path at all, you have to create one by contacting the other party and verifying their key to your satisfaction. Imagine going to an online store that you and your friends have never used. Before you establish a secure communications channel to place an order, you'd need to verify the site's public key belongs to the company and not an impostor. That vetting would entail going to a physical store, making telephone calls, or some other laborious process. Online shopping would be a lot less convenient (or a lot less secure since many people would cut corners and accept the key without verifying it).
-
-What if the world had some exceptionally trustworthy people constantly verifying and signing keys for websites? You could just trust them, and browsing the internet would be much smoother. At a high level, that's how things work today. These "exceptionally trustworthy people" are companies called certificate authorities (CAs). When a website wants to get its public key signed, it submits a certificate signing request (CSR) to the CA.
-
-CSRs are like stub certificates that contain a public key and an identity (in this case, the hostname of the server), but are not signed by a CA. Before signing, the CA performs some verification steps. In some cases, the CA merely verifies that the requester controls the domain for the hostname listed in the CSR (via a challenge-and-response email exchange with the address in the WHOIS entry, for example). [In other cases][12], the CA inspects legal documents, like business licenses. Once the CA is satisfied (and usually after the requester has paid a fee), it takes the data from the CSR and signs it with its own private key to create a certificate. The CA then sends the certificate to the requester. The requester installs the certificate on their site's web server, and the certificate is delivered to users when they connect over HTTPS (or any other protocol secured with [TLS][13]).
-
-When users connect to the site, their browser looks at the certificate, checks that the hostname in the certificate is the same as the hostname it is connected to (more on this in a moment), and verifies the CA's signature. If any of these steps fail, the browser will show a warning and break off the connection. Otherwise, the browser uses the public key in the certificate to verify some signed information sent from the server to ensure that the server possesses the certificate's private key. These messages also serve as steps in one of several algorithms used to establish a shared secret key that will encrypt subsequent messages. Key exchange algorithms are beyond the scope of this article, but there's a good discussion of one of them in [this video][14].
-
-### Creating trust
-
-You're probably wondering, "If the CA's private key signs a certificate, that means to verify a certificate we need the CA's public key. Where does it come from and who signs it?" The answer is the CA signs for itself! A certificate can be signed using the private key associated with the same certificate's public key. These certificates are said to be self-signed; they are the PKI equivalent of saying, "Trust me." (People often say, as a form of shorthand, that a certificate has signed something even though it's the private key—which isn't in the certificate at all—doing the actual signing.)
-
-By adhering to policies established by [web browser][15] and [operating system][16] vendors, CAs demonstrate they are trustworthy enough to be placed into a group of self-signed certificates built into the browser or operating system. These certificates are called trust anchors or root CA certificates, and they are placed in a root certificate store where they are trusted implicitly.
-
-A CA can also issue a certificate endowed with the ability to act as a CA itself. In this way, they can create a chain of certificates. To verify the chain, a program starts at the trust anchor and verifies (among other things) the signature on the next certificate using the public key of the current certificate. It continues down the chain, verifying each link until it reaches the end. If there are no problems along the way, a chain of trust is established. When a website pays a CA to sign a certificate for it, they are paying for the privilege of being placed at the end of that chain. CAs mark certificates sold to websites as not being allowed to sign subsequent certificates; this is so they can terminate the chain of trust at the appropriate place.
-
-Why would a chain ever be more than two links long? After all, a site just needs its certificate signed by a CA's root certificate. In practice, CAs create intermediate CA certificates for convenience (among other reasons). The private keys for a CA's root certificates are so valuable that they reside in a specialized device, a [hardware security module][17] (HSM), that requires multiple people to unlock it, is completely offline, and is kept inside a [vault][18] wired with alarms and cameras.
-
-CAB Forum, the association that governs CAs, [requires][19] any interaction with a CA's root certificate to be performed directly by a human. Issuing certificates for dozens of websites a day would be tedious if every certificate request required an employee to place the request on secure media, enter a vault, unlock the HSM with a coworker, sign the certificate, exit the vault, and then copy the signed certificate off the media. Instead, CAs create internal, intermediate CAs used to sign certificates automatically.
-
-You can see this chain in Firefox by clicking the lock icon in the URL bar, opening up the page information, and clicking the "View Certificate" button on the "Security" tab. As of this writing, [opensource.com][20] had the following chain:
-```
-DigiCert High Assurance EV Root CA
-
- DigiCert SHA2 High Assurance Server CA
-
- opensource.com
-
-```
-
-### The man in the middle
-
-I mentioned earlier that a browser needs to check that the hostname in the certificate is the same as the hostname it connected to. Why? The answer has to do with what's called a [man-in-the-middle (MITM) attack][21]. These are [network attacks][22] that allow an attacker to insert itself between a client and a server, masquerading as the server to the client and vice versa. If the traffic is over HTTPS, it's encrypted and eavesdropping is fruitless. Instead, the attacker can create a proxy that will accept HTTPS connections from the victim, decrypt the information, and then form an HTTPS connection with the original destination. To create the phony HTTPS connection, the proxy must return a certificate that our attacker has the private key for. Our attacker could generate self-signed certificates, but the victim's browser won't trust anything not signed by a CA's root certificate in the browser's root certificate store. What if instead, the attacker uses a certificate signed by a trusted CA for a domain it owns?
-
-Imagine we're back to our job in the bank. A man walks in and asks to withdraw money from Jane Doe's account. When asked for identification, the man hands us a valid driver's license for Joe Smith. We would be rightfully fired if we allowed the transaction to continue. If a browser detects a mismatch between the certificate hostname and the connection hostname, it will show a warning that says something like "Your connection is not secure" and an option to show additional details. In Firefox, this error is called SSL_ERROR_BAD_CERT_DOMAIN.
-
-If there's one lesson I want you to remember from this article, it's: If you see these warnings, **do not disregard them**! They signal that the site is either configured so erroneously that you shouldn't use it or that you're the potential victim of a MITM attack.
-
-### Final thoughts
-
-I've only scratched the surface of the PKI world in this article, but I hope that I've given you a map that you can use to guide your further explorations. Cryptography and PKI are fractal-like in their beauty and complexity. The further you dive in, the more there is to discover.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/7/private-keys
-
-作者:[Alex Wood][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/awood
-[1]:https://opensource.com/article/18/5/cryptography-pki
-[2]:https://theintercept.com/2014/10/28/smuggling-snowden-secrets/
-[3]:https://en.wikipedia.org/wiki/SHA-2
-[4]:https://www.ietf.org/mail-archive/web/openpgp/current/msg00999.html
-[5]:https://www.imperialviolet.org/2014/09/26/pkcs1.html
-[6]:https://en.wikipedia.org/wiki/Key_signing_party
-[7]:https://en.wikipedia.org/wiki/Key_server_(cryptographic)
-[8]:https://en.wikipedia.org/wiki/Web_of_trust
-[9]:https://www.gnupg.org/gph/en/manual/x547.html
-[10]:https://blog.cryptographyengineering.com/2014/08/13/whats-matter-with-pgp/
-[11]:https://lists.torproject.org/pipermail/tor-talk/2013-September/030235.html
-[12]:https://en.wikipedia.org/wiki/Extended_Validation_Certificate
-[13]:https://en.wikipedia.org/wiki/Transport_Layer_Security
-[14]:https://www.youtube.com/watch?v=YEBfamv-_do
-[15]:https://www.mozilla.org/en-US/about/governance/policies/security-group/certs/policy/
-[16]:https://technet.microsoft.com/en-us/library/cc751157.aspx
-[17]:https://en.wikipedia.org/wiki/Hardware_security_module
-[18]:https://arstechnica.com/information-technology/2012/11/inside-symantecs-ssl-certificate-vault/
-[19]:https://cabforum.org/baseline-requirements-documents/
-[20]:http://opensource.com
-[21]:https://en.wikipedia.org/wiki/Man-in-the-middle_attack
-[22]:http://www.shortestpathfirst.net/2010/11/18/man-in-the-middle-mitm-attacks-explained-arp-poisoining/
diff --git a/sources/tech/20180727 How to analyze your system with perf and Python.md b/sources/tech/20180727 How to analyze your system with perf and Python.md
index c1be98cc0e..ccc66b04a7 100644
--- a/sources/tech/20180727 How to analyze your system with perf and Python.md
+++ b/sources/tech/20180727 How to analyze your system with perf and Python.md
@@ -1,3 +1,5 @@
+pinewall translating
+
How to analyze your system with perf and Python
======
diff --git a/sources/tech/20180730 7 Python libraries for more maintainable code.md b/sources/tech/20180730 7 Python libraries for more maintainable code.md
deleted file mode 100644
index 24b3daa886..0000000000
--- a/sources/tech/20180730 7 Python libraries for more maintainable code.md
+++ /dev/null
@@ -1,121 +0,0 @@
-7 Python libraries for more maintainable code
-======
-
-
-
-> Readability counts.
-> — [The Zen of Python][1], Tim Peters
-
-It's easy to let readability and coding standards fall by the wayside when a software project moves into "maintenance mode." (It's also easy to never establish those standards in the first place.) But maintaining consistent style and testing standards across a codebase is an important part of decreasing the maintenance burden, ensuring that future developers are able to quickly grok what's happening in a new-to-them project and safeguarding the health of the app over time.
-
-### Check your code style
-
-A great way to protect the future maintainability of a project is to use external libraries to check your code health for you. These are a few of our favorite libraries for [linting code][2] (checking for PEP 8 and other style errors), enforcing a consistent style, and ensuring acceptable test coverage as a project reaches maturity.
-
-[PEP 8][3] is the Python code style guide, and it sets out rules for things like line length, indentation, multi-line expressions, and naming conventions. Your team might also have your own style rules that differ slightly from PEP 8. The goal of any code style guide is to enforce consistent standards across a codebase to make it more readable, and thus more maintainable. Here are three libraries to help prettify your code.
-
-#### 1\. Pylint
-
-[Pylint][4] is a library that checks for PEP 8 style violations and common errors. It integrates well with several popular [editors and IDEs][5] and can also be run from the command line.
-
-To install, run `pip install pylint`.
-
-To use Pylint from the command line, run `pylint [options] path/to/dir` or `pylint [options] path/to/module.py`. Pylint will output warnings about style violations and other errors to the console.
-
-You can customize what errors Pylint checks for with a [configuration file][6] called `pylintrc`.
-
-#### 2\. Flake8
-
-[Flake8][7] is a "Python tool that glues together PEP8, Pyflakes (similar to Pylint), McCabe (code complexity checker), and third-party plugins to check the style and quality of some Python code."
-
-To use Flake8, run `pip install flake8`. Then run `flake8 [options] path/to/dir` or `flake8 [options] path/to/module.py` to see its errors and warnings.
-
-Like Pylint, Flake8 permits some customization for what it checks for with a [configuration file][8]. It has very clear docs, including some on useful [commit hooks][9] to automatically check your code as part of your development workflow.
-
-Flake8 integrates with popular editors and IDEs, but those instructions generally aren't found in the docs. To integrate Flake8 with your favorite editor or IDE, search online for plugins (for example, [Flake8 plugin for Sublime Text][10]).
-
-#### 3\. Isort
-
-[Isort][11] is a library that sorts your imports alphabetically and breaks them up into [appropriate sections][12] (e.g., standard library imports, third-party library imports, imports from your own project, etc.). This increases readability and makes it easier to locate imports if you have a lot of them in your module.
-
-Install isort with `pip install isort`, and run it with `isort path/to/module.py`. More configuration options are in the [documentation][13]. For example, you can [configure][14] how isort handles multi-line imports from one library in an `.isort.cfg` file.
-
-Like Flake8 and Pylint, isort also provides plugins that integrate it with popular [editors and IDEs][15].
-
-### Outsource your code style
-
-Remembering to run linters manually from the command line for each file you change is a pain, and you might not like how a particular plugin behaves with your IDE. Also, your colleagues might prefer different linters or might not have plugins for their favorite editors, or you might be less meticulous about always running the linter and correcting the warnings. Over time, the codebase you all share will get messy and harder to read.
-
-A great solution is to use a library that automatically reformats your code into something that passes PEP 8 for you. The three libraries we recommend all have different levels of customization and different defaults for how they format code. Some of these are more opinionated than others, so like with Pylint and Flake8, you'll want to test these out to see which offers the customizations you can't live without… and the unchangeable defaults you can live with.
-
-#### 4\. Autopep8
-
-[Autopep8][16] automatically formats the code in the module you specify. It will re-indent lines, fix indentation, remove extraneous whitespace, and refactor common comparison mistakes (like with booleans and `None`). See a full [list of corrections][17] in the docs.
-
-To install, run `pip install --upgrade autopep8`. To reformat code in place, run `autopep8 --in-place --aggressive --aggressive `. The `aggressive` flags (and the number of them) indicate how much control you want to give autopep8 over your code style. Read more about [aggressive][18] options.
-
-#### 5\. Yapf
-
-[Yapf][19] is yet another option for reformatting code that comes with its own list of [configuration options][20]. It differs from autopep8 in that it doesn't just address PEP 8 violations. It also reformats code that doesn't violate PEP 8 specifically but isn't styled consistently or could be formatted better for readability.
-
-To install, run `pip install yapf`. To reformat code, run, `yapf [options] path/to/dir` or `yapf [options] path/to/module.py`. There is also a full list of [customization options][20].
-
-#### 6\. Black
-
-[Black][21] is the new kid on the block for linters that reformat code in place. It's similar to autopep8 and Yapf, but way more opinionated. It has very few options for customization, which is kind of the point. The idea is that you shouldn't have to make decisions about code style; the only decision to make is to let Black decide for you. You can read about [limited customization options][22] and instructions on [storing them in a configuration file][23].
-
-Black requires Python 3.6+ but can format Python 2 code. To use, run `pip install black`. To prettify your code, run: `black path/to/dir` or `black path/to/module.py`.
-
-### Check your test coverage
-
-You're writing tests, right? Then you will want to make sure new code committed to your codebase is tested and doesn't drop your overall amount of test coverage. While percentage of test coverage is not the only metric you should use to measure the effectiveness and sufficiency of your tests, it is one way to ensure basic testing standards are being followed in your project. For measuring test coverage, we have one recommendation: Coverage.
-
-#### 7\. Coverage
-
-[Coverage][24] has several options for the way it reports your test coverage to you, including outputting results to the console or to an HTML page and indicating which line numbers are missing test coverage. You can set up a [configuration file][25] to customize what Coverage checks for and make it easier to run.
-
-To install, run `pip install coverage`. To run a program and see its output, run `coverage run [path/to/module.py] [args]`, and you will see your program's output. To see a report of which lines of code are missing coverage, run `coverage report -m`.
-
-Continuous integration (CI) is a series of processes you can run to automatically check for linter errors and test coverage minimums before you merge and deploy code. There are lots of free or paid tools to automate this process, and a thorough walkthrough is beyond the scope of this article. But because setting up a CI process is an important step in removing blocks to more readable and maintainable code, you should investigate continuous integration tools in general; check out [Travis CI][26] and [Jenkins][27] in particular.
-
-These are only a handful of the libraries available to check your Python code. If you have a favorite that's not on this list, please share it in the comments.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/7/7-python-libraries-more-maintainable-code
-
-作者:[Jeff Triplett][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/laceynwilliams
-[1]:https://www.python.org/dev/peps/pep-0020/
-[2]:https://en.wikipedia.org/wiki/Lint_(software)
-[3]:https://www.python.org/dev/peps/pep-0008/
-[4]:https://www.pylint.org/
-[5]:https://pylint.readthedocs.io/en/latest/user_guide/ide-integration.html
-[6]:https://pylint.readthedocs.io/en/latest/user_guide/run.html#command-line-options
-[7]:http://flake8.pycqa.org/en/latest/
-[8]:http://flake8.pycqa.org/en/latest/user/configuration.html#configuration-locations
-[9]:http://flake8.pycqa.org/en/latest/user/using-hooks.html
-[10]:https://github.com/SublimeLinter/SublimeLinter-flake8
-[11]:https://github.com/timothycrosley/isort
-[12]:https://github.com/timothycrosley/isort#how-does-isort-work
-[13]:https://github.com/timothycrosley/isort#using-isort
-[14]:https://github.com/timothycrosley/isort#configuring-isort
-[15]:https://github.com/timothycrosley/isort/wiki/isort-Plugins
-[16]:https://github.com/hhatto/autopep8
-[17]:https://github.com/hhatto/autopep8#id4
-[18]:https://github.com/hhatto/autopep8#id5
-[19]:https://github.com/google/yapf
-[20]:https://github.com/google/yapf#usage
-[21]:https://github.com/ambv/black
-[22]:https://github.com/ambv/black#command-line-options
-[23]:https://github.com/ambv/black#pyprojecttoml
-[24]:https://coverage.readthedocs.io/en/latest/
-[25]:https://coverage.readthedocs.io/en/latest/config.html
-[26]:https://travis-ci.org/
-[27]:https://jenkins.io/
diff --git a/sources/tech/20180802 Distrochooser Helps Linux Beginners To Choose A Suitable Linux Distribution.md b/sources/tech/20180802 Distrochooser Helps Linux Beginners To Choose A Suitable Linux Distribution.md
deleted file mode 100644
index fb2df2e1f5..0000000000
--- a/sources/tech/20180802 Distrochooser Helps Linux Beginners To Choose A Suitable Linux Distribution.md
+++ /dev/null
@@ -1,77 +0,0 @@
-Distrochooser Helps Linux Beginners To Choose A Suitable Linux Distribution
-======
-
-Howdy Linux newbies! Today, I have come up with a good news for you!! You might wondering how to choose a suitable Linux distribution for you. Of course, you might already have consulted some Linux experts to help you to select a Linux distribution for your needs. And some of you might have googled and gone through various resources, Linux forums, websites and blogs in the pursuit of finding perfect distro. Well, you need not to do that anymore. Meet **Distrochooser** , a website that helps you to easily find out a Linux distribution.
-
-### How Distrochooser will help Linux beginners choose a suitable Linux distribution?
-
-The Distrochooser will ask you a series of questions and suggests you different suitable Linux distributions to try, based on your answers. Excited? Great! Let us go ahead and see how to find out a suitable Linux distribution. Click on the following link to get started.
-
-![][2]
-
-You will be now redirected to Distrochooser home page where a small test is awaiting for you to enroll.
-
-
-You need to answer a series of questions (16 questions to be precise). Both single choice and multiple choice questions are provided there. Here are the complete list of questions.
-
- 1. Software: Use case
- 2. Computer knowledge
- 3. Linux Knowledge
- 4. Installation: Presets
- 5. Installation: Live-Test needed?
- 6. Installation: Hardware support
- 7. Configuration: Help source
- 8. Distributions: User experience concept
- 9. Distributions: Price
- 10. Distributions: Scope
- 11. Distributions: Ideology
- 12. Distributions: Privacy
- 13. Distributions: Preset themes, icons and wallpapers
- 14. Distribution: Special features
- 15. Software: Administration
- 16. Software: Updates
-
-
-
-Carefully read the questions and choose the appropriate answer(s) below the respective questions. Distrochooser gives more options to choose a near-perfect distribution.
-
- * You can always skip questions,
- * You can always click on ‘get result’,
- * You can answer in arbitrary order,
- * You can delete answers at any time,
- * You can weight properties at the end of the test to emphasize what is important to you.
-
-
-
-After choosing the answer(s) for a question, click **Proceed** to move to the next question. Once you are done, click on **Get result** button. You can also clear the selection at any time by clicking on the **“Clear”** button below the answers.
-
-### Results?
-
-I didn’t believe Distrochooser will exactly find what I am looking for. Oh boy, I was wrong! To my surprise, it did indeed a good job. The results were almost accurate to me. I was expecting Arch Linux in the result and indeed it was my top recommendation, followed by 11 other recommendations such as NixOS, Void Linux, Qubes OS, Scientific Linux, Devuan, Gentoo Linux, Bedrock Linux, Slackware, CentOS, Linux from scratch and Redhat Enterprise Linux. Totally, I got 12 recommendations and each result is very detailed along with distribution’s description and home page link for each distribution.
-
-
-
-I posted Distrochooser link on Reddit and 80% of the users could be able to find suitable Linux distribution for them. However, I won’t claim Distrochooser alone is enough to find good results for everyone. Some users disappointed about the survey result and the result wasn’t even close to what they use or want to use. So, I strongly recommend you to consult other Linux experts, websites, forums before trying any Linux. You can read the full Reddit discussion [**here**][3].
-
-What are you waiting for? Go to the Distrochooser site and choose a suitable Linux distribution for you.
-
-And, that’s all for now, folks. More good stuffs to come. Stay tuned!
-
-Cheers!
-
-
-
---------------------------------------------------------------------------------
-
-via: https://www.ostechnix.com/distrochooser-helps-linux-beginners-to-choose-a-suitable-linux-distribution/
-
-作者:[SK][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.ostechnix.com/author/sk/
-[2]:https://distrochooser.de/en
-[3]:https://www.reddit.com/r/linux/comments/93p6az/distrochooser_helps_linux_beginners_to_choose_a/
diff --git a/sources/tech/20180804 Installing Android on VirtualBox.md b/sources/tech/20180804 Installing Android on VirtualBox.md
deleted file mode 100644
index 2ed0af3105..0000000000
--- a/sources/tech/20180804 Installing Android on VirtualBox.md
+++ /dev/null
@@ -1,159 +0,0 @@
-Installing Android on VirtualBox
-======
-If you are developing mobile apps Android can be a bit of a hassle. While iOS comes with its niceties, provided you are using macOS, Android comes with just Android Studio which is designed to support more than a few Android version, including wearables.
-
-Needless to say, all the binaries, SDKs, frameworks and debuggers are going to pollute your filesystem with lots and lots of files, logs and other miscellaneous objects. An efficient work around for this is installing Android on your VirtualBox which takes away one of the sluggiest aspect of Android development — The device emulator. You can use this VM to run your test application or just fiddle with Android’s internals. So without further ado let’s set on up!
-
-### Getting Started
-
-To get started we will need to have VirtualBox installed on our system, you can get a copy for Windows, macOS or any major distro of Linux [here][1]. Next you would need a copy of Android meant to run on x86 hardware, because that’s what VirtualBox is going to offer to a Virtual Machine an x86 or an x86_64 (a.k.a AMD64) platform to run.
-
-While most Android devices run on ARM, we can take help of the project [Android on x86][2]. These fine folks have ported Android to run on x86 hardware (both real and virtual) and we can get a copy of the latest release candidate (Android 7.1) for our purposes. You may prefer using a more stable release but in that case Android 6.0 is about as latest as you can get, at the time of this writing.
-
-#### Creating VM
-
-Open VirtualBox and click on “New” (top-left corner) and in the Create Virtual Machine window select the type to be Linux and version Linux 2.6 / 3.x /4.x (64-bit) or (32-bit) depending upon whether the ISO you downloaded was x86_64 or x86 respectively.
-
-RAM size could be anywhere from 2 GB to as much as your system resources can allow. Although if you want to emulate real world devices you should allocate upto 6GB for memory and 32GB for disk size which are typical in Android devices.
-
-![][3]
-
-![][4]
-
-Upon creation, you might want to tweak a few additional settings, add in an additional processor core and improve display memory for starters. To do this, right-click on the VM and open up settings. In the Settings → System → Processor section you can allocate a few more cores if your desktop can pull it off.
-
-![][5]
-
-And in Settings → Display → Video Memory you can allocate a decent chunk of memory and enable 3D acceleration for a more responsive experience.
-
-![][6]
-
-Now we are ready to boot the VM.
-
-#### Installing Android
-
-Starting the VM for the first time, VirtualBox will insist you to supply it with a bootable media. Select the Android iso that you previously downloaded to boot the machine of with.
-
-![][7]
-
-Next, select the Installation option if you wish to install Android on the VM for a long term use, otherwise feel free to log into the live media and play around with the environment.
-
-![][8]
-
-Hit .
-
-##### Partitioning the Drive
-
-Partitioning is done using a textual interface, which means we don’t get the niceties of a GUI and we will have to use the follow careful at what is being shown on the screen. For example, in the first screen when no partition has been created and just a raw (virtual) disk is detected you will see the following.
-
-![][9]
-
-The red lettered C and D indicates that if you hit the key C you can create or modify partitions and D will detect additional devices. You can press D and the live media will detect the disks attached, but that is optional since it did a check during the boot.
-
-Let’s hit C and create partitions in the virtual disk. The offical page recommends against using GPT so we will not use that scheme. Select No using the arrow keys and hit .
-
-![][10]
-
-And now you will be ushered into the fdisk utility.
-
-![][11]
-
-We will create just a single giant partition so as to keep things simple. Using arrow keys navigate to the New option and hit . Select primary as the type of partition, and hit to confirm
-
-![][12]
-
-The maximum size will already be selected for you, hit to confirm that.
-
-![][13]
-
-This partition is where Android OS will reside, so of course we want it to be bootable. So select Bootable and hit enter (Boot will appear in the flags section in the table above) and then you can navigate to the Write section and hit to write the changes to the partitioning table.
-
-![][14]
-
-Then you can Quit the partitioning utility and move on with the installation.
-
-![][15]
-
-##### Formatting with Ext4 and installing Android
-
-A new partition will come in the Choose Partition menu where we were before we down the partitioning digression. Let’s select this partition and hit OK.
-
-![][16]
-
-Select ext4 as the de facto file system in the next menu. Confirm the changes in the next window by selecting **Yes** and the formatting will begin. When asked, say **Yes** to the GRUB boot loader installation. Similarly, say **Yes** to allowing read-write operations on the /system directory. Now the installation will begin.
-
-Once it is installed, you can safely reboot the system when prompted to reboot. You may have to power down the machine before the next reboot happens, go to Settings → Storage and remove the android iso if it is still attached to the VM.
-
-![][17]
-
-Remove the media and save the changes, before starting up the VM.
-
-##### Running Android
-
-In the GRUB menu you will get options for running the OS in debug mode or the normal way. Let’s take a tour of Android in a VM using the default option, as shown below:
-
-![][18]
-
-And if everything works fine, you will see this:
-
-![][19]
-
-Now Android uses touch screen as an interface instead of a mouse, as far as its normal use is concerned. While the x86 port does come with a mouse point-and-click support you may have to use arrow keys a lot in the beginning.
-
-![][20]
-
-Navigate to let’s go, and hit enter, if you are using arrow keys and then select Setup as New.
-
-![][21]
-
-It will check for updates and device info, before asking you to sign in using a Google account. You can skip this if you want and move on to setting up Data and Time and give your username to the device after that.
-
-A few other options would be presented, similar to the options you see when setting up a new Android device. Select appropriate options for privacy, updates, etc and of course Terms of Service, which we might have to Agree to.
-
-![][22]
-
-After this, it may ask you to add another email account or set up “On-body detection” since it is a VM, neither of the options are of much use to us and we can click on “All Set”
-
-It would ask you to select Home App after that, which is upto you to decide, as it is a matter of Preference and you will finally be in a virtualized Android system.
-
-![][23]
-
-You may benefit greatly from a touch screen laptop if you desire to do some intensive testing on this VM, since that would emulate a real world use case much closely.
-
-Hope you have found this tutorial useful in case, you have any other similar request for us to write about, please feel free to reach out to us.
-
---------------------------------------------------------------------------------
-
-via: https://linuxhint.com/install_android_virtualbox/
-
-作者:[Ranvir Singh][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://linuxhint.com/author/sranvir155/
-[1]:https://www.virtualbox.org/wiki/Downloads
-[2]:http://www.android-x86.org/
-[3]:https://linuxhint.com/wp-content/uploads/2018/08/a.png
-[4]:https://linuxhint.com/wp-content/uploads/2018/08/a1.png
-[5]:https://linuxhint.com/wp-content/uploads/2018/08/a2.png
-[6]:https://linuxhint.com/wp-content/uploads/2018/08/a3.png
-[7]:https://linuxhint.com/wp-content/uploads/2018/08/a4.png
-[8]:https://linuxhint.com/wp-content/uploads/2018/08/a5.png
-[9]:https://linuxhint.com/wp-content/uploads/2018/08/a6.png
-[10]:https://linuxhint.com/wp-content/uploads/2018/08/a7.png
-[11]:https://linuxhint.com/wp-content/uploads/2018/08/a8.png
-[12]:https://linuxhint.com/wp-content/uploads/2018/08/a9.png
-[13]:https://linuxhint.com/wp-content/uploads/2018/08/a10.png
-[14]:https://linuxhint.com/wp-content/uploads/2018/08/a11.png
-[15]:https://linuxhint.com/wp-content/uploads/2018/08/a12.png
-[16]:https://linuxhint.com/wp-content/uploads/2018/08/a13.png
-[17]:https://linuxhint.com/wp-content/uploads/2018/08/a14.png
-[18]:https://linuxhint.com/wp-content/uploads/2018/08/a16.png
-[19]:https://linuxhint.com/wp-content/uploads/2018/08/a17.png
-[20]:https://linuxhint.com/wp-content/uploads/2018/08/a18.png
-[21]:https://linuxhint.com/wp-content/uploads/2018/08/a19.png
-[22]:https://linuxhint.com/wp-content/uploads/2018/08/a20.png
-[23]:https://linuxhint.com/wp-content/uploads/2018/08/a21.png
diff --git a/sources/tech/20180806 Anatomy of a Linux DNS Lookup - Part IV.md b/sources/tech/20180806 Anatomy of a Linux DNS Lookup - Part IV.md
deleted file mode 100644
index 03b763fd44..0000000000
--- a/sources/tech/20180806 Anatomy of a Linux DNS Lookup - Part IV.md
+++ /dev/null
@@ -1,182 +0,0 @@
-pinewall is translating
-
-[Anatomy of a Linux DNS Lookup – Part IV][2]
-============================================
-
-In [Anatomy of a Linux DNS Lookup – Part I][3], [Part II][4], and [Part III][5] I covered:
-
-* `nsswitch`
-
-* `/etc/hosts`
-
-* `/etc/resolv.conf`
-
-* `ping` vs `host` style lookups
-
-* `systemd` and its `networking` service
-
-* `ifup` and `ifdown`
-
-* `dhclient`
-
-* `resolvconf`
-
-* `NetworkManager`
-
-* `dnsmasq`
-
-In Part IV I’ll cover how containers do DNS. Yes, that’s not simple either…
-
-* * *
-
-1) Docker and DNS
-============================================================
-
-In [part III][6] we looked at DNSMasq, and learned that it works by directing DNS queries to the localhost address `127.0.0.1`, and a process listening on port 53 there will accept the request.
-
-So when you run up a Docker container, on a host set up like this, what do you expect to see in its `/etc/resolv.conf`?
-
-Have a think, and try and guess what it will be.
-
-Here’s the default output if you run a default Docker setup:
-
-```
-$ docker run ubuntu cat /etc/resolv.conf
-# Dynamic resolv.conf(5) file for glibc resolver(3) generated by resolvconf(8)
-# DO NOT EDIT THIS FILE BY HAND -- YOUR CHANGES WILL BE OVERWRITTEN
-# 127.0.0.53 is the systemd-resolved stub resolver.
-# run "systemd-resolve --status" to see details about the actual nameservers.
-
-search home
-nameserver 8.8.8.8
-nameserver 8.8.4.4
-```
-
-Hmmm.
-
-#### Where did the addresses `8.8.8.8` and `8.8.4.4` come from?
-
-When I pondered this question, my first thought was that the container would inherit the `/etc/resolv.conf` settings from the host. But a little thought shows that that won’t always work.
-
-If you have DNSmasq set up on the host, the `/etc/resolv.conf` file will be pointed at the `127.0.0.1` loopback address. If this were passed through to the container, the container would look up DNS addresses from within its own networking context, and there’s no DNS server available within the container context, so the DNS lookups would fail.
-
-‘A-ha!’ you might think: we can always use the host’s DNS server by using the _host’s_ IP address, available from within the container as the default route:
-
-```
-root@79a95170e679:/# ip route
-default via 172.17.0.1 dev eth0
-172.17.0.0/16 dev eth0 proto kernel scope link src 172.17.0.2
-```
-
-#### Use the host?
-
-From that we can work out that the ‘host’ is on the ip address: `172.17.0.1`, so we could try manually pointing DNS at that using dig (you could also update the `/etc/resolv.conf` and then run `ping`, this just seems like a good time to introduce `dig` and its `@` flag, which points the request at the ip address you specify):
-
-```
-root@79a95170e679:/# dig @172.17.0.1 google.com | grep -A1 ANSWER.SECTION
-;; ANSWER SECTION:
-google.com. 112 IN A 172.217.23.14
-```
-
-However: that might work if you use DNSMasq, but if you don’t it won’t, as there’s no DNS server on the host to look up.
-
-So Docker’s solution to this quandary is to bypass all that complexity and point your DNS lookups to Google’s DNS servers at `8.8.8.8` and `8.8.4.4`, ignoring whatever the host context is.
-
- _Anecdote: This was the source of my first problem with Docker back in 2013\. Our corporate network blocked access to those IP addresses, so my containers couldn’t resolve URLs._
-
-So that’s Docker containers, but container _orchestrators_ such as Kubernetes can do different things again…
-
-# 2) Kubernetes and DNS
-
-The unit of container deployment in Kubernetes is a Pod. A pod is a set of co-located containers that (among other things) share the same IP address.
-
-An extra challenge with Kubernetes is to forward requests for Kubernetes services to the right resolver (eg `myservice.kubernetes.io`) to the private network allocated to those service addresses. These addresses are said to be on the ‘cluster domain’. This cluster domain is configurable by the administrator, so it might be `cluster.local` or `myorg.badger` depending on the configuration you set up.
-
-In Kubernetes you have four options for configuring how DNS lookup works within your pod.
-
-* Default
-
-This (misleadingly-named) option takes the same DNS resolution path as the host the pod runs on, as in the ‘naive’ DNS lookup described earlier. It’s misleadingly named because it’s not the default! ClusterFirst is.
-
-If you want to override the `/etc/resolv.conf` entries, you can in your config for the kubelet.
-
-* ClusterFirst
-
-ClusterFirst does selective forwarding on the DNS request. This is achieved in one of two ways based on the configuration.
-
-In the first, older and simpler setup, a rule was followed where if the cluster domain was not found in the request, then it was forwarded to the host.
-
-In the second, newer approach, you can configure selective forwarding on an internal DNS
-
-Here’s what the config looks like and a diagram lifted from the [Kubernetes docs][7] which shows the flow:
-
-```
-apiVersion: v1
-kind: ConfigMap
-metadata:
- name: kube-dns
- namespace: kube-system
-data:
- stubDomains: |
- {"acme.local": ["1.2.3.4"]}
- upstreamNameservers: |
- ["8.8.8.8", "8.8.4.4"]
-```
-
-The `stubDomains` entry defines specific DNS servers to use for specific domains. The upstream servers are the servers we defer to when nothing else has picked up the DNS request.
-
-This is achieved with our old friend DNSMasq running in a pod.
-
-
-
-The other two options are more niche:
-
-* ClusterFirstWithHostNet
-
-This applies if you use host network for your pods, ie you bypass the Docker networking setup to use the same network as you would directly on the host the pod is running on.
-
-* None
-
-None does nothing to DNS but forces you to specify the DNS settings in the `dnsConfig` field in the pod specification.
-
-### CoreDNS Coming
-
-And if that wasn’t enough, this is set to change again as CoreDNS comes to Kubernetes, replacing kube-dns. CoreDNS will offer a few benefits over kube-dns, being more configurabe and more efficient.
-
-Find out more [here][8].
-
-If you’re interested in OpenShift networking, I wrote a post on that [here][9]. But that was for 3.6 so is likely out of date now.
-
-### End of Part IV
-
-That’s part IV done. In it we covered.
-
-* Docker DNS lookups
-
-* Kubernetes DNS lookups
-
-* Selective forwarding (stub domains)
-
-* kube-dns
-
-
---------------------------------------------------------------------------------
-
-via: https://zwischenzugs.com/2018/08/06/anatomy-of-a-linux-dns-lookup-part-iv/
-
-作者:[zwischenzugs][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://zwischenzugs.com/
-[1]:https://zwischenzugs.com/2018/08/06/anatomy-of-a-linux-dns-lookup-part-iv/
-[2]:https://zwischenzugs.com/2018/08/06/anatomy-of-a-linux-dns-lookup-part-iv/
-[3]:https://zwischenzugs.com/2018/06/08/anatomy-of-a-linux-dns-lookup-part-i/
-[4]:https://zwischenzugs.com/2018/06/18/anatomy-of-a-linux-dns-lookup-part-ii/
-[5]:https://zwischenzugs.com/2018/07/06/anatomy-of-a-linux-dns-lookup-part-iii/
-[6]:https://zwischenzugs.com/2018/07/06/anatomy-of-a-linux-dns-lookup-part-iii/
-[7]:https://kubernetes.io/docs/tasks/administer-cluster/dns-custom-nameservers/#impacts-on-pods
-[8]:https://coredns.io/
-[9]:https://zwischenzugs.com/2017/10/21/openshift-3-6-dns-in-pictures/
diff --git a/sources/tech/20180806 Installing and using Git and GitHub on Ubuntu Linux- A beginner-s guide.md b/sources/tech/20180806 Installing and using Git and GitHub on Ubuntu Linux- A beginner-s guide.md
deleted file mode 100644
index e8d4cb8a98..0000000000
--- a/sources/tech/20180806 Installing and using Git and GitHub on Ubuntu Linux- A beginner-s guide.md
+++ /dev/null
@@ -1,162 +0,0 @@
-Translating by DavidChenLiang
-
-Installing and using Git and GitHub on Ubuntu Linux: A beginner's guide
-======
-
-GitHub is a treasure trove of some of the world's best projects, built by the contributions of developers all across the globe. This simple, yet extremely powerful platform helps every individual interested in building or developing something big to contribute and get recognized in the open source community.
-
-This tutorial is a quick setup guide for installing and using GitHub and how to perform its various functions of creating a repository locally, connecting this repo to the remote host that contains your project (where everyone can see), committing the changes and finally pushing all the content in the local system to GitHub.
-
-Please note that this tutorial assumes that you have a basic knowledge of the terms used in Git such as push, pull requests, commit, repository, etc. It also requires you to register to GitHub [here][1] and make a note of your GitHub username. So let's begin:
-
-### 1 Installing Git for Linux
-
-Download and install Git for Linux:
-
-```
-sudo apt-get install git
-```
-
-The above command is for Ubuntu and works on all Recent Ubuntu versions, tested from Ubuntu 16.04 to Ubuntu 18.04 LTS (Bionic Beaver) and it's likely to work the same way on future versions.
-
-### 2 Configuring GitHub
-
-Once the installation has successfully completed, the next thing to do is to set up the configuration details of the GitHub user. To do this use the following two commands by replacing "user_name" with your GitHub username and replacing "email_id" with your email-id you used to create your GitHub account.
-
-```
-git config --global user.name "user_name"
-
-git config --global user.email "email_id"
-```
-
-The following image shows an example of my configuration with my "user_name" being "akshaypai" and my "email_id" being "[[email protected]][2]"
-
-[![Git config][3]][4]
-
-### 3 Creating a local repository
-
-Create a folder on your system. This will serve as a local repository which will later be pushed onto the GitHub website. Use the following command:
-
-```
-git init Mytest
-```
-
-If the repository is created successfully, then you will get the following line:
-
-Initialized empty Git repository in /home/akshay/Mytest/.git/
-
-This line may vary depending on your system.
-
-So here, Mytest is the folder that is created and "init" makes the folder a GitHub repository. Change the directory to this newly created folder:
-
-```
-cd Mytest
-```
-
-### 4 Creating a README file to describe the repository
-
-Now create a README file and enter some text like "this is a git setup on Linux". The README file is generally used to describe what the repository contains or what the project is all about. Example:
-
-```
-gedit README
-```
-
-You can use any other text editors. I use gedit. The content of the README file will be:
-
-This is a git repo
-
-### 5 Adding repository files to an index
-
-This is an important step. Here we add all the things that need to be pushed onto the website into an index. These things might be the text files or programs that you might add for the first time into the repository or it could be adding a file that already exists but with some changes (a newer version/updated version).
-
-Here we already have the README file. So, let's create another file which contains a simple C program and call it sample.c. The contents of it will be:
-```
-
-#include
-int main()
-{
-printf("hello world");
-return 0;
-}
-
-```
-
-So, now that we have 2 files
-
-README and sample.c
-
-add it to the index by using the following 2 commands:
-
-```
-git add README
-
-git add smaple.c
-```
-
-Note that the "git add" command can be used to add any number of files and folders to the index. Here, when I say index, what I am referring to is a buffer like space that stores the files/folders that have to be added into the Git repository.
-
-### 6 Committing changes made to the index
-
-Once all the files are added, we can commit it. This means that we have finalized what additions and/or changes have to be made and they are now ready to be uploaded to our repository. Use the command :
-
-```
-git commit -m "some_message"
-```
-
-"some_message" in the above command can be any simple message like "my first commit" or "edit in readme", etc.
-
-### 7 Creating a repository on GitHub
-
-Create a repository on GitHub. Notice that the name of the repository should be the same as the repository's on the local system. In this case, it will be "Mytest". To do this login to your account on . Then click on the "plus(+)" symbol at the top right corner of the page and select "create new repository". Fill the details as shown in the image below and click on "create repository" button.
-
-[![Creating a repository on GitHub][5]][6]
-
-Once this is created, we can push the contents of the local repository onto the GitHub repository in your profile. Connect to the repository on GitHub using the command:
-
-Important Note: Make sure you replace 'user_name' and 'Mytest' in the path with your Github username and folder before running the command!
-
-```
-git remote add origin
-```
-
-### 8 Pushing files in local repository to GitHub repository
-
-The final step is to push the local repository contents into the remote host repository (GitHub), by using the command:
-
-```
-git push origin master
-```
-
-Enter the login credentials [user_name and password].
-
-The following image shows the procedure from step 5 to step 8
-
-[![Pushing files in local repository to GitHub repository][7]][8]
-
-So this adds all the contents of the 'Mytest' folder (my local repository) to GitHub. For subsequent projects or for creating repositories, you can start off with step 3 directly. Finally, if you log in to your GitHub account and click on your Mytest repository, you can see that the 2 files README and sample.c have been uploaded and are visible to all as shown in the following image.
-
-[![Content uploaded to Github][9]][10]
-
-
---------------------------------------------------------------------------------
-
-via: https://www.howtoforge.com/tutorial/install-git-and-github-on-ubuntu/
-
-作者:[Akshay Pai][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.howtoforge.com/tutorial/installing-tensorflow-neural-network-software-for-cpu-and-gpu-on-ubuntu-16-04/
-[1]:https://github.com/
-[2]:https://www.howtoforge.com/cdn-cgi/l/email-protection
-[3]:https://www.howtoforge.com/images/ubuntu_github_getting_started/config.png
-[4]:https://www.howtoforge.com/images/ubuntu_github_getting_started/big/config.png
-[5]:https://www.howtoforge.com/images/ubuntu_github_getting_started/details.png
-[6]:https://www.howtoforge.com/images/ubuntu_github_getting_started/big/details.png
-[7]:https://www.howtoforge.com/images/ubuntu_github_getting_started/steps.png
-[8]:https://www.howtoforge.com/images/ubuntu_github_getting_started/big/steps.png
-[9]:https://www.howtoforge.com/images/ubuntu_github_getting_started/final.png
-[10]:https://www.howtoforge.com/images/ubuntu_github_getting_started/big/final.png
diff --git a/sources/tech/20180810 How To Quickly Serve Files And Folders Over HTTP In Linux.md b/sources/tech/20180810 How To Quickly Serve Files And Folders Over HTTP In Linux.md
new file mode 100644
index 0000000000..c4adc3ac07
--- /dev/null
+++ b/sources/tech/20180810 How To Quickly Serve Files And Folders Over HTTP In Linux.md
@@ -0,0 +1,168 @@
+How To Quickly Serve Files And Folders Over HTTP In Linux
+======
+
+
+
+Today, I came across a whole bunch of methods to serve a single file or entire directory with other systems in your local area network via a web browser. I tested all of them in my Ubuntu test machine, and everything worked just fine as described below. If you ever wondered how to easily and quickly serve files and folders over HTTP in Unix-like operating systems, one of the following methods will definitely help.
+
+### Serve Files And Folders Over HTTP In Linux
+
+**Disclaimer:** All the methods given here are meant to be used within a secure local area network. Since these methods doesn’t have any security mechanism, it is **not recommended to use them in production**. You have been warned!
+
+#### Method 1 – Using simpleHTTPserver (Python)
+
+We already have written a brief guide to setup a simple http server to share files and directories instantly in the following link. If you have a system with Python installed, this method is quite handy.
+
+#### Method 2 – Using Quickserve (Python)
+
+This method is specifically for Arch Linux and its variants. Check the following link for more details.
+
+#### Method 3 – Using Ruby**
+
+In this method, we use Ruby to serve files and folders over HTTP in Unix-like systems. Install Ruby and Rails as described in the following link.
+
+Once Ruby installed, go to the directory, for example ostechnix, that you want to share over the network:
+```
+$ cd ostechnix
+
+```
+
+And, run the following command:
+```
+$ ruby -run -ehttpd . -p8000
+[2018-08-10 16:02:55] INFO WEBrick 1.4.2
+[2018-08-10 16:02:55] INFO ruby 2.5.1 (2018-03-29) [x86_64-linux]
+[2018-08-10 16:02:55] INFO WEBrick::HTTPServer#start: pid=5859 port=8000
+
+```
+
+Make sure the port 8000 is opened in your router or firewall . If the port has already been used by some other services use different port.
+
+You can now access the contents of this folder from any remote system using URL – **http:// :8000/**.
+
+
+
+To stop sharing press **CTRL+C**.
+
+#### Method 4 – Using Http-server (NodeJS)
+
+[**Http-server**][1] is a simple, production ready command line http-server written in NodeJS. It requires zero configuration and can be used to instantly share files and directories via web browser.
+
+Install NodeJS as described below.
+
+Once NodeJS installed, run the following command to install http-server.
+```
+$ npm install -g http-server
+
+```
+
+Now, go to any directory and share its contents over HTTP as shown below.
+```
+$ cd ostechnix
+
+$ http-server -p 8000
+Starting up http-server, serving ./
+Available on:
+ http://127.0.0.1:8000
+ http://192.168.225.24:8000
+ http://192.168.225.20:8000
+Hit CTRL-C to stop the server
+
+```
+
+Now, you can access the contents of this directory from local or remote systems in the network using URL – **http:// :8000**.
+
+
+
+To stop sharing, press **CTRL+C**.
+
+#### Method 5 – Using Miniserve (Rust)
+
+[**Miniserve**][2] is yet another command line utility that allows you to quickly serve files over HTTP. It is very fast, easy-to-use, and cross-platform utility written in **Rust** programming language. Unlike the above utilities/methods, it provides authentication support, so you can setup username and password to the shares.
+
+Install Rust in your Linux system as described in the following link.
+
+After installing Rust, run the following command to install miniserve:
+```
+$ cargo install miniserve
+
+```
+
+Alternatively, you can download the binaries from [**the releases page**][3] and make it executable.
+```
+$ chmod +x miniserve-linux
+
+```
+
+And, then you can run it using command (assuming miniserve binary file is downloaded in the current working directory):
+```
+$ ./miniserve-linux
+
+```
+
+**Usage**
+
+To serve a directory:
+```
+$ miniserve
+
+```
+
+**Example:**
+```
+$ miniserve /home/sk/ostechnix/
+miniserve v0.2.0
+Serving path /home/sk/ostechnix at http://[::]:8080, http://localhost:8080
+Quit by pressing CTRL-C
+
+```
+
+Now, you can access the share from local system itself using URL – **** and/or from remote system with URL – **http:// :8080**.
+
+To serve a single file:
+```
+$ miniserve
+
+```
+
+**Example:**
+```
+$ miniserve ostechnix/file.txt
+
+```
+
+Serve file/folder with username and password:
+```
+$ miniserve --auth joe:123
+
+```
+
+Bind to multiple interfaces:
+```
+$ miniserve -i 192.168.225.1 -i 10.10.0.1 -i ::1 --
+
+```
+
+As you can see, I have given only 5 methods. But, there are few more methods given in the link attached at the end of this guide. Go and test them as well. Also, bookmark and revisit it from time to time to check if there are any new additions to the list in future.
+
+And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
+
+Cheers!
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/how-to-quickly-serve-files-and-folders-over-http-in-linux/
+
+作者:[SK][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.ostechnix.com/author/sk/
+[1]:https://www.npmjs.com/package/http-server
+[2]:https://github.com/svenstaro/miniserve
+[3]:https://github.com/svenstaro/miniserve/releases
diff --git a/sources/tech/20180813 5 of the Best Linux Educational Software and Games for Kids.md b/sources/tech/20180813 5 of the Best Linux Educational Software and Games for Kids.md
deleted file mode 100644
index f6013baab2..0000000000
--- a/sources/tech/20180813 5 of the Best Linux Educational Software and Games for Kids.md
+++ /dev/null
@@ -1,81 +0,0 @@
-5 of the Best Linux Educational Software and Games for Kids
-======
-
-
-
-Linux is a very powerful operating system, and that explains why it powers most of the servers on the Internet. Though it may not be the best OS in terms of user friendliness, its diversity is commendable. Everyone has their own need for Linux. Be it for coding, educational purposes or the internet of things (IoT), you’ll always find a suitable Linux distro for every use. To that end, many have dubbed Linux as the OS for future computing.
-
-Because the future belongs to the kids of today, introducing them to Linux is the best way to prepare them for what the future holds. This OS may not have a reputation for popular games such as FIFA or PES; however, it offers the best educational software and games for kids. These are five of the best Linux educational software to keep your kids ahead of the game.
-
-**Related** : [The Beginner’s Guide to Using a Linux Distro][1]
-
-### 1. GCompris
-
-If you’re looking for the best educational software for kids, [GCompris][2] should be your starting point. This software is specifically designed for kids education and is ideal for kids between two and ten years old. As the pinnacle of all Linux educational software suites for children, GCompris offers about 100 activities for kids. It packs everything you want for your kids from reading practice to science, geography, drawing, algebra, quizzes, and more.
-
-![Linux educational software and games][3]
-
-GCompris even has activities for helping your kids learn computer peripherals. If your kids are young and you want them to learn alphabets, colors, and shapes, GCompris has programmes for those, too. What’s more, it also comes with helpful games for kids such as chess, tic-tac-toe, memory, and hangman. GCompris is not a Linux-only app. It’s also available for Windows and Android.
-
-### 2. TuxMath
-
-Most students consider math a tough subject. You can change that perception by acquainting your kids with mathematical skills through Linux software applications such as [TuxMath][4]. TuxMath is a top-rated educational Math tutorial game for kids. In this game your role is to help Tux the penguin of Linux protect his planet from a rain of mathematical problems.
-
-![linux-educational-software-tuxmath-1][5]
-
-By finding the answer, you help Tux save the planet by destroying the asteroids with your laser before they make an impact. The difficulty of the math problems increases with each level you pass. This game is ideal for kids, as it can help them rack their brains for solutions. Besides making them good at math, it also helps them improve their mental agility.
-
-### 3. Sugar on a Stick
-
-[Sugar on a Stick][6] is a dedicated learning program for kids – a brand new pedagogy that has gained a lot of traction. This program provides your kids with a fully-fledged learning platform where they can gain skills in creating, exploring, discovering and also reflecting on ideas. Just like GCompris, Sugar on a Stick comes with a host of learning resources for kids, including games and puzzles.
-
-![linux-educational-software-sugar-on-a-stick][7]
-
-The best thing about Sugar on a Stick is that you can set it up on a USB Drive. All you need is an X86-based PC, then plug in the USB, and boot the distro from it. Sugar on a Stick is a project by Sugar Labs – a non-profit organization that is run by volunteers.
-
-### 4. KDE Edu Suite
-
-[KDE Edu Suite][8] is a package of software for different user purposes. With a host of applications from different fields, the KDE community has proven that it isn’t just serious about empowering adults; it also cares about bringing the young generation to speed with everything surrounding them. It comes packed with various applications for kids ranging from science to math, geography, and more.
-
-![linux-educational-software-kde-1][9]
-
-The KDE Suite can be used for adult needs based on necessities, as a school teaching software, or as a kid’s leaning app. It offers a huge software package and is free to download. The KDE Edu suite can be installed on most GNU/Linux Distros.
-
-### 5. Tux Paint
-
-![linux-educational-software-tux-paint-2][10]
-
-[Tux Paint][11] is another great Linux educational software for kids. This award-winning drawing program is used in schools around the world to help children nurture the art of drawing. It comes with a clean, easy-to-use interface and fun sound effects that help children use the program. There is also an encouraging cartoon mascot that guides kids as they use the program. Tux Paint comes with a variety of drawing tools that help kids unleash their creativity.
-
-### Summing Up
-
-Due to the popularity of these educational software for kids, many institutions have embraced these programs as teaching aids in schools and kindergartens. A typical example is [Edubuntu][12], an Ubuntu-derived distro that is widely used by teachers and parents for educating kids.
-
-Tux Paint is another great example that has grown in popularity over the years and is being used in schools to teach children how to draw. This list is by no means exhaustive. There are hundreds of other Linux educational software and games that can be very useful for your kids.
-
-If you know of any other great Linux educational software and games for kids, share with us in the comments section below.
-
---------------------------------------------------------------------------------
-
-via: https://www.maketecheasier.com/5-best-linux-software-packages-for-kids/
-
-作者:[Kenneth Kimari][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.maketecheasier.com/author/kennkimari/
-[1]:https://www.maketecheasier.com/beginner-guide-to-using-linux-distro/ (The Beginner’s Guide to Using a Linux Distro)
-[2]:http://www.gcompris.net/downloads-en.html
-[3]:https://www.maketecheasier.com/assets/uploads/2018/07/Linux-educational-software-gcompris.jpg (Linux educational software and games)
-[4]:https://tuxmath.en.uptodown.com/ubuntu
-[5]:https://www.maketecheasier.com/assets/uploads/2018/07/Linux-educational-software-tuxmath-1.jpg (linux-educational-software-tuxmath-1)
-[6]:http://wiki.sugarlabs.org/go/Sugar_on_a_Stick/Downloads
-[7]:https://www.maketecheasier.com/assets/uploads/2018/07/Linux-educational-software-sugar-on-a-stick.png (linux-educational-software-sugar-on-a-stick)
-[8]:https://edu.kde.org/
-[9]:https://www.maketecheasier.com/assets/uploads/2018/07/Linux-educational-software-kde-1.jpg (linux-educational-software-kde-1)
-[10]:https://www.maketecheasier.com/assets/uploads/2018/07/Linux-educational-software-tux-paint-2.jpg (linux-educational-software-tux-paint-2)
-[11]:http://www.tuxpaint.org/
-[12]:http://edubuntu.org/
diff --git a/sources/tech/20180814 Automating backups on a Raspberry Pi NAS.md b/sources/tech/20180814 Automating backups on a Raspberry Pi NAS.md
deleted file mode 100644
index 6d9f74be63..0000000000
--- a/sources/tech/20180814 Automating backups on a Raspberry Pi NAS.md
+++ /dev/null
@@ -1,221 +0,0 @@
-Automating backups on a Raspberry Pi NAS
-======
-
-
-In the [first part][1] of this three-part series using a Raspberry Pi for network-attached storage (NAS), we covered the fundamentals of the NAS setup, attached two 1TB hard drives (one for data and one for backups), and mounted the data drive on a remote device via the network filesystem (NFS). In part two, we will look at automating backups. Automated backups allow you to continually secure your data and recover from a hardware defect or accidental file removal.
-
-
-
-### Backup strategy
-
-Let's get started by coming up with with a backup strategy for our small NAS. I recommend creating daily backups of your data and scheduling them for a time they won't interfere with other NAS activities, including when you need to access or store your files. For example, you could trigger the backup activities each day at 2am.
-
-You also need to decide how long you'll keep each backup, since you would quickly run out of storage if you kept each daily backup indefinitely. Keeping your daily backups for one week allows you to travel back into your recent history if you realize something went wrong over the previous seven days. But what if you need something from further in the past? Keeping each Monday backup for a month and one monthly backup for a longer period of time should be sufficient. Let's keep the monthly backups for a year and one backup every year for long-distance time travels, e.g., for the last five years.
-
-This results in a bunch of backups on your backup drive over a five-year period:
-
- * 7 daily backups
- * 4 (approx.) weekly backups
- * 12 monthly backups
- * 5 annual backups
-
-
-
-You may recall that your backup drive and your data drive are of equal size (1TB each). How will more than 10 backups of 1TB from your data drive fit onto a 1TB backup disk? If you create full backups, they won't. Instead, you will create incremental backups, reusing the data from the last backup if it didn't change and creating replicas of new or changed files. That way, the backup doesn't double every night, but only grows a little bit depending on the changes that happen to your data over a day.
-
-Here is my situation: My NAS has been running since August 2016, and 20 backups are on the backup drive. Currently, I store 406GB of files on the data drive. The backups take up 726GB on my backup drive. Of course, this depends heavily on your data's change frequency, but as you can see, the incremental backups don't consume as much space as 20 full backups would. Nevertheless, over time the 1TB disk will probably become insufficient for your backups. Once your data grows close to the 1TB limit (or whatever your backup drive capacity), you should choose a bigger backup drive and move your data there.
-
-### Creating backups with rsync
-
-To create a full backup, you can use the rsync command line tool. Here is an example command to create the initial full backup.
-```
-pi@raspberrypi:~ $ rsync -a /nas/data/ /nas/backup/2018-08-01
-
-```
-
-This command creates a full replica of all data stored on the data drive, mounted on `/nas/data`, on the backup drive. There, it will create the folder `2018-08-01` and create the backup inside it. The `-a` flag starts rsync in archive-mode, which means it preserves all kinds of metadata, like modification dates, permissions, and owners, and copies soft links as soft links.
-
-Now that you have created your full, initial backup as of August 1, on August 2, you will create your first daily incremental backup.
-```
-pi@raspberrypi:~ $ rsync -a --link-dest /nas/backup/2018-08-01/ /nas/data/ /nas/backup/2018-08-02
-
-```
-
-This command tells rsync to again create a backup of `/nas/data`. The target directory this time is `/nas/backup/2018-08-02`. The script also specified the `--link-dest` option and passed the location of the last backup as an argument. With this option specified, rsync looks at the folder `/nas/backup/2018-08-01` and checks what data files changed compared to that folder's content. Unchanged files will not be copied, rather they will be hard-linked to their counterparts in yesterday's backup folder.
-
-When using a hard-linked file from a backup, you won't notice any difference between the initial copy and the link. They behave exactly the same, and if you delete either the link or the initial file, the other will still exist. You can imagine them as two equal entry points to the same file. Here is an example:
-
-
-
-The left box reflects the state shortly after the second backup. The box in the middle is yesterday's replica. The `file2.txt` didn't exist yesterday, but the image `file1.jpg` did and was copied to the backup drive. The box on the right reflects today's incremental backup. The incremental backup command created `file2.txt`, which didn't exist yesterday. Since `file1.jpg` didn't change since yesterday, today a hard link is created so it doesn't take much additional space on the disk.
-
-### Automate your backups
-
-You probably don't want to execute your daily backup command by hand at 2am each day. Instead, you can automate your backup by using a script like the following, which you may want to start with a cron job.
-```
-#!/bin/bash
-
-
-
-TODAY=$(date +%Y-%m-%d)
-
-DATADIR=/nas/data/
-
-BACKUPDIR=/nas/backup/
-
-SCRIPTDIR=/nas/data/backup_scripts
-
-LASTDAYPATH=${BACKUPDIR}/$(ls ${BACKUPDIR} | tail -n 1)
-
-TODAYPATH=${BACKUPDIR}/${TODAY}
-
-if [[ ! -e ${TODAYPATH} ]]; then
-
- mkdir -p ${TODAYPATH}
-
-fi
-
-
-
-rsync -a --link-dest ${LASTDAYPATH} ${DATADIR} ${TODAYPATH} $@
-
-
-
-${SCRIPTDIR}/deleteOldBackups.sh
-
-```
-
-The first block calculates the last backup's folder name to use for links and the name of today's backup folder. The second block has the rsync command (as described above). The last block executes a `deleteOldBackups.sh` script. It will clean up the old, unnecessary backups based on the backup strategy outlined above. You could also execute the cleanup script independently from the backup script if you want it to run less frequently.
-
-The following script is an example implementation of the backup strategy in this how-to article.
-```
-#!/bin/bash
-
-BACKUPDIR=/nas/backup/
-
-
-
-function listYearlyBackups() {
-
- for i in 0 1 2 3 4 5
-
- do ls ${BACKUPDIR} | egrep "$(date +%Y -d "${i} year ago")-[0-9]{2}-[0-9]{2}" | sort -u | head -n 1
-
- done
-
-}
-
-
-
-function listMonthlyBackups() {
-
- for i in 0 1 2 3 4 5 6 7 8 9 10 11 12
-
- do ls ${BACKUPDIR} | egrep "$(date +%Y-%m -d "${i} month ago")-[0-9]{2}" | sort -u | head -n 1
-
- done
-
-}
-
-
-
-function listWeeklyBackups() {
-
- for i in 0 1 2 3 4
-
- do ls ${BACKUPDIR} | grep "$(date +%Y-%m-%d -d "last monday -${i} weeks")"
-
- done
-
-}
-
-
-
-function listDailyBackups() {
-
- for i in 0 1 2 3 4 5 6
-
- do ls ${BACKUPDIR} | grep "$(date +%Y-%m-%d -d "-${i} day")"
-
- done
-
-}
-
-
-
-function getAllBackups() {
-
- listYearlyBackups
-
- listMonthlyBackups
-
- listWeeklyBackups
-
- listDailyBackups
-
-}
-
-
-
-function listUniqueBackups() {
-
- getAllBackups | sort -u
-
-}
-
-
-
-function listBackupsToDelete() {
-
- ls ${BACKUPDIR} | grep -v -e "$(echo -n $(listUniqueBackups) |sed "s/ /\\\|/g")"
-
-}
-
-
-
-cd ${BACKUPDIR}
-
-listBackupsToDelete | while read file_to_delete; do
-
- rm -rf ${file_to_delete}
-
-done
-
-```
-
-This script will first list all the backups to keep (according to our backup strategy), then it will delete all the backup folders that are not necessary anymore.
-
-To execute the scripts every night to create daily backups, schedule the backup script by running `crontab -e` as the root user. (You need to be in root to make sure it has permission to read all the files on the data drive, no matter who created them.) Add a line like the following, which starts the script every night at 2am.
-```
-0 2 * * * /nas/data/backup_scripts/daily.sh
-
-```
-
-For more information, read about [scheduling tasks with cron][2].
-
- * Unmount your backup drive or mount it as read-only when no backups are running
- * Attach the backup drive to a remote server and sync the files over the internet
-
-
-
-There are additional things you can do to fortify your backups against accidental removal or damage, including the following:
-
-This example backup strategy enables you to back up your valuable data to make sure it won't get lost. You can also easily adjust this technique for your personal needs and preferences.
-
-In part three of this series, we will talk about [Nextcloud][3], a convenient way to store and access data on your NAS system that also provides offline access as it synchronizes your data to the client devices.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/8/automate-backups-raspberry-pi
-
-作者:[Manuel Dewald][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/ntlx
-[1]:https://opensource.com/article/18/7/network-attached-storage-Raspberry-Pi
-[2]:https://opensource.com/article/17/11/how-use-cron-linux
-[3]:https://nextcloud.com/
diff --git a/sources/tech/20180815 How To Enable Hardware Accelerated Video Decoding In Chromium On Ubuntu Or Linux Mint.md b/sources/tech/20180815 How To Enable Hardware Accelerated Video Decoding In Chromium On Ubuntu Or Linux Mint.md
deleted file mode 100644
index 563e724c0f..0000000000
--- a/sources/tech/20180815 How To Enable Hardware Accelerated Video Decoding In Chromium On Ubuntu Or Linux Mint.md
+++ /dev/null
@@ -1,113 +0,0 @@
-How To Enable Hardware Accelerated Video Decoding In Chromium On Ubuntu Or Linux Mint
-======
-You may have noticed that watching HD videos from Youtube and other similar websites in Google Chrome or Chromium browsers on Linux considerably increases your CPU usage and, if you use a laptop, it gets quite hot and the battery drains very quickly. That's because Chrome / Chromium (Firefox too but there's no way to force this) doesn't support hardware accelerated video decoding on Linux.
-
-**This article explains how to install a Chromium development build which includes a patch that enables VA-API on Linux, bringing support for GPU accelerated video decoding, which should significantly decrease the CPU usage when watching HD videos online. The instructions cover only Intel and Nvidia graphics cards, as I don't have an ATI/AMD graphics card to try this, nor do I have experience with such graphics cards.**
-
-This is Chromium from the Ubuntu (18.04) repositories without GPU accelerated video decoding playing a 1080p YouTube video:
-
-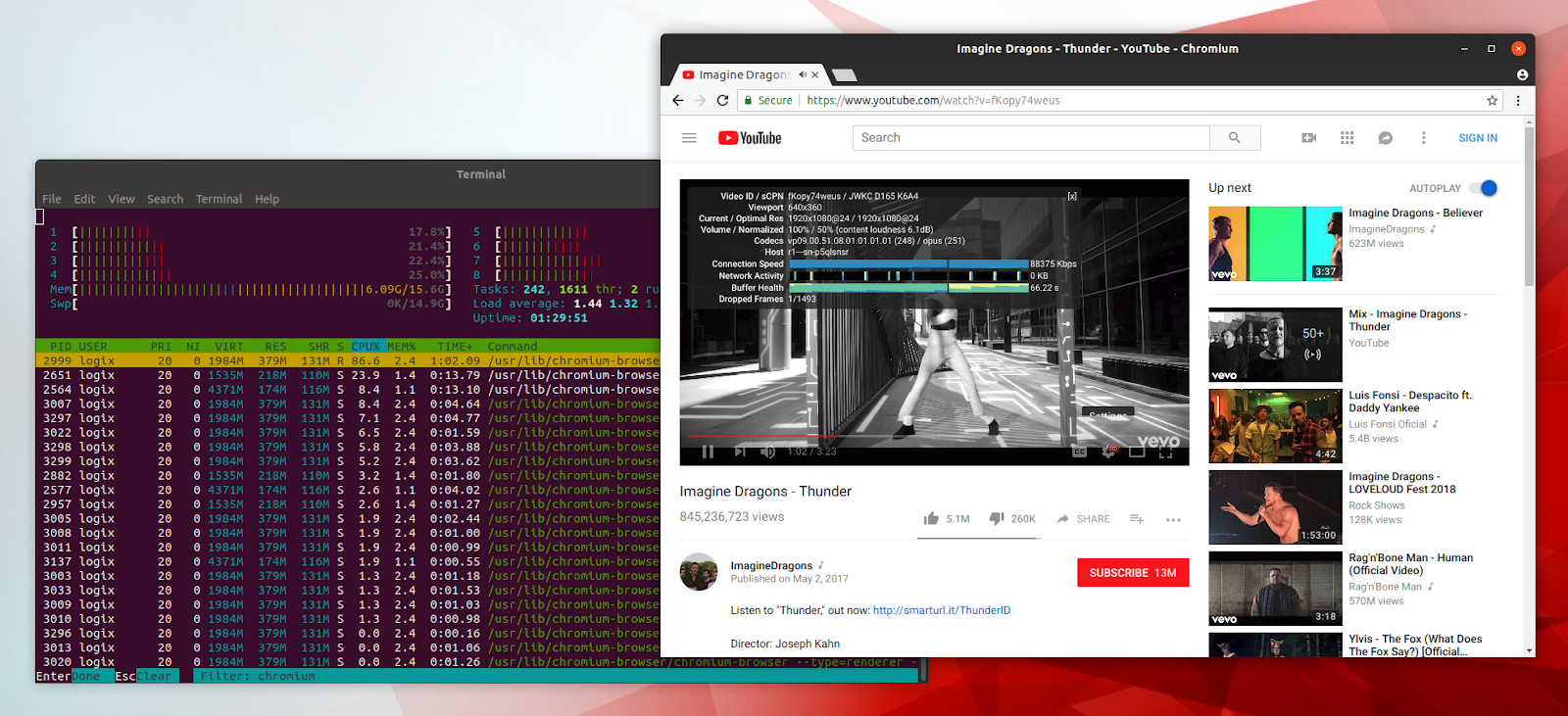
-
-The same 1080p YouTube video playing in Chromium with the VA-API patch and hardware accelerated video decode enabled on Ubuntu 18.04:
-
-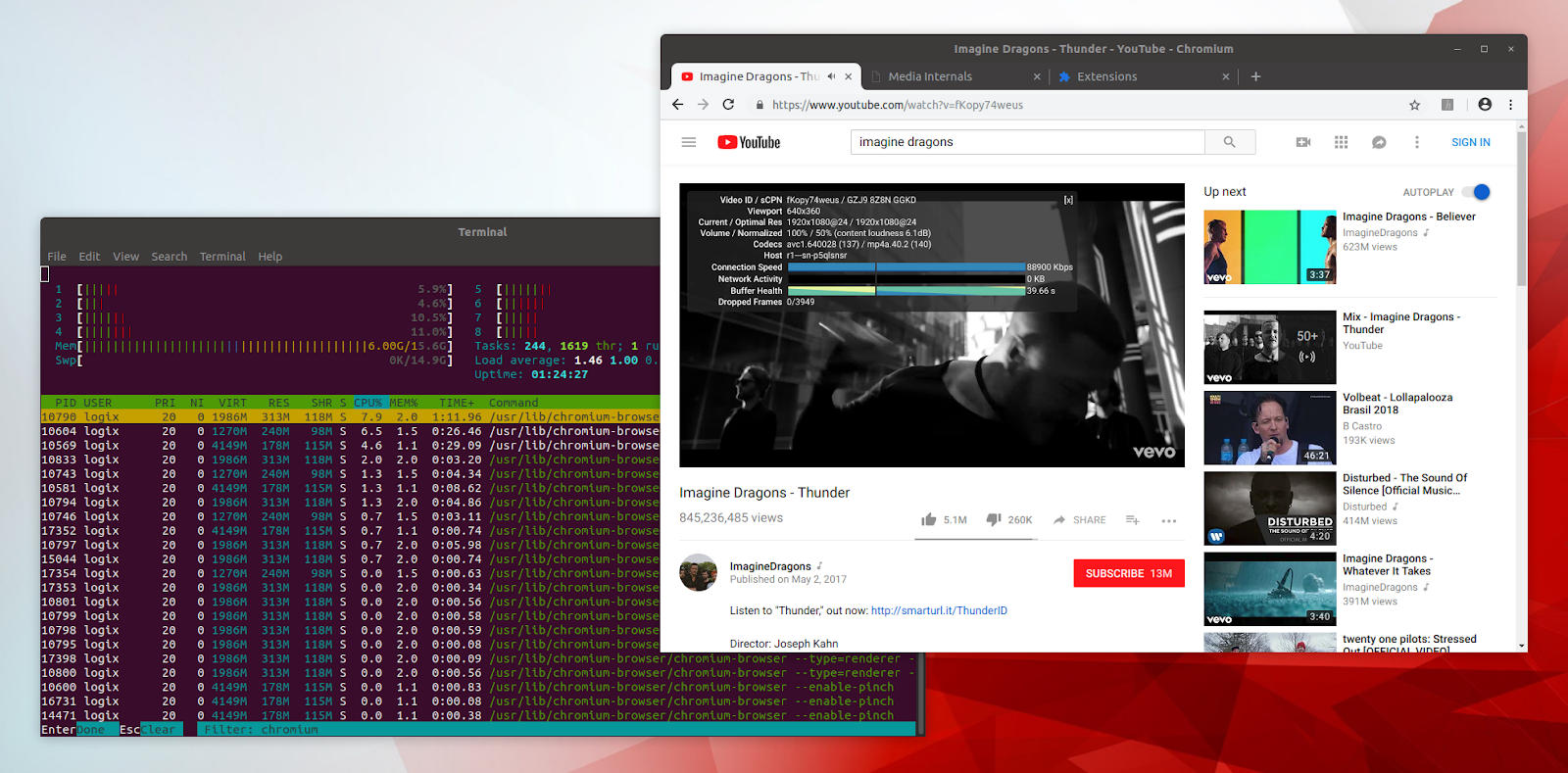
-
-Notice the CPU usage in the screenshots. Both screenshots were taken on my old, but still quite powerful desktop. On my laptop, the Chromium CPU usage without hardware acceleration goes way higher.
-
-The _Enable VAVDA, VAVEA and VAJDA on linux with VAAPI only_ " was was initially submitted to Chromium more than a year ago, but it has yet to be merged.
-
-Chrome has an option to override the software rendering list (
-
-`#ignore-gpu-blacklist`
-
-), but this option does not enable hardware accelerated video decoding. After enabling this option, you may find the following when visiting
-
-`chrome://gpu`
-
-: " _Video Decode: Hardware accelerated_ ", but this does not mean it actually works. Open a HD video on YouTube and check the CPU usage in a tool such as
-
-`htop`
-
-(this is what I'm using in the screenshots above to check the CPU usage) - you should see high CPU usage because GPU video decoding is not actually enabled. There's also a section below for how to check if you're actually using hardware accelerated video decoding.
-
-**The patches used by the Chromium Ubuntu builds with VA-API enabled used in this article are available[here][1].**
-
-### Installing and using Chromium browser with VA-API support on Ubuntu or Linux Mint
-
-**It should be clear to everyone reading this that Chromium Dev Branch is not considered stable. So you might find bugs, it may crash, etc. It works fine right now but who knows what may happen after some update.**
-
-**What's more, the Chromium Dev Branch PPA requires you to perform some extra steps if you want to enable Widevine support** (so you can play Netflix videos and paid YouTube videos, etc.), **or if you need features like Sync** (which needs registering an API key and setting it up on your system). Instructions for performing these tweaks are explained in the
-
-Chromium with the VA-API patch is also available for some other Linux distributions, in third-party repositories, like
-
-**1\. Install Chromium Dev Branch with VA-API support.**
-
-There's a Chromium Beta PPA with the VA-API patch, but it lacks vdpau-video for Ubuntu 18.04. If you want, you can use the `vdpau-va-driver` from the You can add the Chromium
-```
-sudo add-apt-repository ppa:saiarcot895/chromium-dev
-sudo apt-get update
-sudo apt install chromium-browser
-
-```
-
-**2\. Install the VA-API driver**
-
-For Intel graphics cards, you'll need to install the `i965-va-driver` package (it may already be installed):
-```
-sudo apt install i965-va-driver
-
-```
-
-For Nvidia graphics cards (it should work with both the open source Nouveau drivers and the proprietary Nvidia drivers), install `vdpau-va-driver` :
-```
-sudo apt install vdpau-va-driver
-
-```
-
-**3\. Enable the Hardware-accelerated video option in Chromium.**
-
-Copy and paste the following in the Chrome URL bar: `chrome://flags/#enable-accelerated-video` (or search for the `Hardware-accelerated video` option in `chrome://flags`) and enable it, then restart Chromium browser.
-
-On a default Google Chrome / Chromium build, this option shows as unavailable, but you'll be able to enable it now because we've used the VA-API enabled Chromium build.
-
-**4\. Install[h264ify][2] Chrome extension.**
-
-YouTube (and probably some other websites as well) uses VP8 or VP9 video codecs by default, and many GPUs don't support hardware decoding for this codec. The h264ify extension will force YouTube to use H.264, which should be supported by most GPUs, instead of VP8/VP9.
-
-This extension can also block 60fps videos, useful on lower end machines.
-
-You can check the codec used by a YouTube video by right clicking on the video and selecting `Stats for nerds` . With the h264ify extension enabled, you should see avc / mp4a as the codecs. Without this extension, the codec should be something like vp09 / opus.
-
-### How to check if Chromium is using GPU video decoding
-
-Open a video on YouTube. Next, open a new tab in Chromium and enter the following in the URL bar: `chrome://media-internals` .
-
-On the `chrome://media-internals` tab, click on the video url (in order to expand it), scroll down and look under `Player Properties` , and you should find the `video_decoder` property. If the `video_decoder` value is `GpuVideoDecoder` it means that the video that's currently playing on YouTube in the other tab is using hardware-accelerated video decoding.
-
-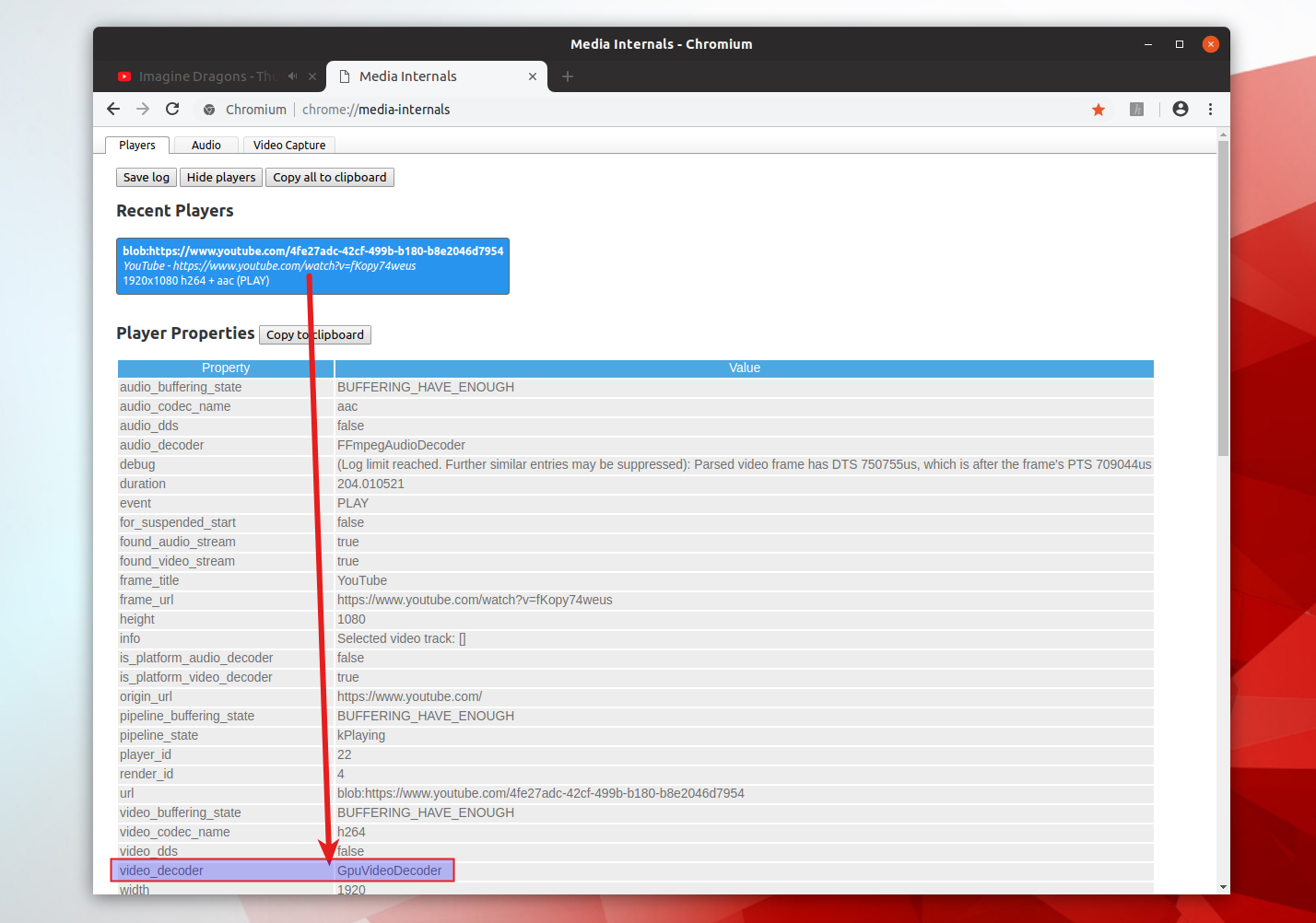
-
-If it says `FFmpegVideoDecoder` or `VpxVideoDecoder` , accelerated video decoding is not working, or maybe you forgot to install or disabled the h264ify Chrome extension.
-
-If it's not working, you could try to debug it by running `chromium-browser` from the command line and see if it shows any VA-API related errors. You can also run `vainfo` (install it in Ubuntu or Linux Mint: `sudo apt install vainfo`) and `vdpauinfo` (for Nvidia; install it in Ubuntu or Linux Mint: `sudo apt install vdpauinfo`) and see if it shows an error.
-
-
---------------------------------------------------------------------------------
-
-via: https://www.linuxuprising.com/2018/08/how-to-enable-hardware-accelerated.html
-
-作者:[Logix][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://plus.google.com/118280394805678839070
-[1]:https://github.com/saiarcot895/chromium-ubuntu-build/tree/master/debian/patches
-[2]:https://chrome.google.com/webstore/detail/h264ify/aleakchihdccplidncghkekgioiakgal
-[3]:https://chromium-review.googlesource.com/c/chromium/src/+/532294
-[4]:https://launchpad.net/~saiarcot895/+archive/ubuntu/chromium-dev
-[5]:https://aur.archlinux.org/packages/?O=0&SeB=nd&K=chromium+vaapi&outdated=&SB=n&SO=a&PP=50&do_Search=Go
-[6]:https://aur.archlinux.org/packages/libva-vdpau-driver-chromium/
-[7]:https://launchpad.net/~saiarcot895/+archive/ubuntu/chromium-beta
-[8]:https://launchpad.net/~saiarcot895/+archive/ubuntu/chromium-dev/+packages
diff --git a/sources/tech/20180816 Add YouTube Player Controls To Your Linux Desktop With browser-mpris2 (Chrome Extension).md b/sources/tech/20180816 Add YouTube Player Controls To Your Linux Desktop With browser-mpris2 (Chrome Extension).md
index 1a0f1e9dbe..acc8f56e0c 100644
--- a/sources/tech/20180816 Add YouTube Player Controls To Your Linux Desktop With browser-mpris2 (Chrome Extension).md
+++ b/sources/tech/20180816 Add YouTube Player Controls To Your Linux Desktop With browser-mpris2 (Chrome Extension).md
@@ -1,3 +1,5 @@
+translating---geekpi
+
Add YouTube Player Controls To Your Linux Desktop With browser-mpris2 (Chrome Extension)
======
A Unity feature that I miss (it only actually worked for a short while though) is automatically getting player controls in the Ubuntu Sound Indicator when visiting a website like YouTube in a web browser, so you could pause or stop the video directly from the top bar, as well as see the video / song information and a preview.
diff --git a/sources/tech/20180822 How To Switch Between TTYs Without Using Function Keys In Linux.md b/sources/tech/20180822 How To Switch Between TTYs Without Using Function Keys In Linux.md
deleted file mode 100644
index 6a260c291f..0000000000
--- a/sources/tech/20180822 How To Switch Between TTYs Without Using Function Keys In Linux.md
+++ /dev/null
@@ -1,108 +0,0 @@
-translating---geekpi
-
-How To Switch Between TTYs Without Using Function Keys In Linux
-======
-
-
-
-This brief guide describes how to switch between TTYs without function keys in Unix-like operating systems. Before going further, we will see what TTY is. As mentioned in an [**answer**][1] in AskUbuntu forum, the word **TTY** came from **T** ele **TY** pewriter. Back in the early days of Unix, the user terminals connected to computers were electromechanical teleprinters or teletypewriters( tty in short). Since then, the name TTY has continued to be used for text-only consoles. Nowadays, all text consoles represents virtual consoles, not physical consoles. The TTY command prints the file name of the terminal connected to standard input.
-
-### Switch Between TTYs In Linux
-
-By default, there are 7 ttys in Linux. They are known as tty1, tty2….. tty7. The 1 to 6 ttys are command line only. The 7th tty is GUI (your X desktop session). You can switch between different TTYs by using **CTRL+ALT+Fn** keys. For example to switch to tty1, we type CTRL+ALT+F1. This is how tty1 looks in Ubuntu 18.04 LTS server.
-
-
-
-If your system has no X session,
-
-In some Linux editions (Eg. from Ubuntu 17.10 onwards), the login screen now uses virtual console 1 . So, you need to press CTRL+ALT+F3 up to CTRL+ALT+F6 for accessing the virtual consoles. To go back to desktop environment, press CTRL+ALT+F2 or CTRL+ALT+F7 on Ubuntu 17.10 and later.
-
-What we have seen so far is we can easily switch between TTYs using CTRL+ALT+Function_Key(F1-F7). However, if you don’t want to use the functions keys for any reason, there is a simple command named **“chvt”** in Linux.
-
-The “chvt N” command allows you to switch to foreground terminal N, the same as pressing CTRL+ALT+Fn. The corresponding screen is created if it did not exist yet.
-
-Let us see print the current tty:
-```
-$ tty
-
-```
-
-Sample output from my Ubuntu 18.04 LTS server.
-
-Now let us switch to tty2. To do so, type:
-```
-$ sudo chvt 2
-
-```
-
-Remember you need to use “sudo” with chvt command.
-
-Now, check the current tty using command:
-```
-$ tty
-
-```
-
-You will see that the tty has changed now.
-
-Similarly, you can switch to tty3 using “sudo chvt 3”, tty4 using “sudo chvt 4” and so on.
-
-Chvt command can be useful when any one of your function keys doesn’t work.
-
-To view the total number of active virtual consoles, run:
-```
-$ fgconsole
-2
-
-```
-
-As you can see, there are two active VTs in my system.
-
-You can see the next unallocated virtual terminal using command:
-```
-$ fgconsole --next-available
-3
-
-```
-
-A virtual console is unused if it is not the foreground console, and no process has it open for reading or writing, and no text has been selected on its screen.
-
-To get rid of unused VTs, just type:
-```
-$ deallocvt
-
-```
-
-The above command deallocates kernel memory and data structures for all unused virtual consoles. To put this simply, this command will free all resources connected to the unused virtual consoles.
-
-For more details, refer the respective command’s man pages.
-```
-$ man tty
-
-$ man chvt
-
-$ man fgconsole
-
-$ man deallocvt
-
-```
-
-And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
-
-Cheers!
-
-
-
---------------------------------------------------------------------------------
-
-via: https://www.ostechnix.com/how-to-switch-between-ttys-without-using-function-keys-in-linux/
-
-作者:[SK][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.ostechnix.com/author/sk/
-[1]:https://askubuntu.com/questions/481906/what-does-tty-stand-for
diff --git a/sources/tech/20180822 What is a Makefile and how does it work.md b/sources/tech/20180822 What is a Makefile and how does it work.md
deleted file mode 100644
index cf168cc44d..0000000000
--- a/sources/tech/20180822 What is a Makefile and how does it work.md
+++ /dev/null
@@ -1,322 +0,0 @@
-What is a Makefile and how does it work?
-======
-
-
-If you want to run or update a task when certain files are updated, the `make` utility can come in handy. The `make` utility requires a file, `Makefile` (or `makefile`), which defines set of tasks to be executed. You may have used `make` to compile a program from source code. Most open source projects use `make` to compile a final executable binary, which can then be installed using `make install`.
-
-In this article, we'll explore `make` and `Makefile` using basic and advanced examples. Before you start, ensure that `make` is installed in your system.
-
-### Basic examples
-
-Let's start by printing the classic "Hello World" on the terminal. Create a empty directory `myproject` containing a file `Makefile` with this content:
-```
-say_hello:
-
- echo "Hello World"
-
-```
-
-Now run the file by typing `make` inside the directory `myproject`. The output will be:
-```
-$ make
-
-echo "Hello World"
-
-Hello World
-
-```
-
-In the example above, `say_hello` behaves like a function name, as in any programming language. This is called the target. The prerequisites or dependencies follow the target. For the sake of simplicity, we have not defined any prerequisites in this example. The command `echo "Hello World"` is called the recipe. The recipe uses prerequisites to make a target. The target, prerequisites, and recipes together make a rule.
-
-To summarize, below is the syntax of a typical rule:
-```
-target: prerequisites
-
- recipe
-
-```
-
-As an example, a target might be a binary file that depends on prerequisites (source files). On the other hand, a prerequisite can also be a target that depends on other dependencies:
-```
-final_target: sub_target final_target.c
-
- Recipe_to_create_final_target
-
-
-
-sub_target: sub_target.c
-
- Recipe_to_create_sub_target
-
-```
-
-It is not necessary for the target to be a file; it could be just a name for the recipe, as in our example. We call these "phony targets."
-
-Going back to the example above, when `make` was executed, the entire command `echo "Hello World"` was displayed, followed by actual command output. We often don't want that. To suppress echoing the actual command, we need to start `echo` with `@`:
-```
-say_hello:
-
- @echo "Hello World"
-
-```
-
-Now try to run `make` again. The output should display only this:
-```
-$ make
-
-Hello World
-
-```
-
-Let's add a few more phony targets: `generate` and `clean` to the `Makefile`:
-```
-say_hello:
- @echo "Hello World"
-
-generate:
- @echo "Creating empty text files..."
- touch file-{1..10}.txt
-
-clean:
- @echo "Cleaning up..."
- rm *.txt
-```
-
-If we try to run `make` after the changes, only the target `say_hello` will be executed. That's because only the first target in the makefile is the default target. Often called the default goal, this is the reason you will see `all` as the first target in most projects. It is the responsibility of `all` to call other targets. We can override this behavior using a special phony target called `.DEFAULT_GOAL`.
-
-Let's include that at the beginning of our makefile:
-```
-.DEFAULT_GOAL := generate
-```
-
-This will run the target `generate` as the default:
-```
-$ make
-Creating empty text files...
-touch file-{1..10}.txt
-```
-
-As the name suggests, the phony target `.DEFAULT_GOAL` can run only one target at a time. This is why most makefiles include `all` as a target that can call as many targets as needed.
-
-Let's include the phony target `all` and remove `.DEFAULT_GOAL`:
-```
-all: say_hello generate
-
-say_hello:
- @echo "Hello World"
-
-generate:
- @echo "Creating empty text files..."
- touch file-{1..10}.txt
-
-clean:
- @echo "Cleaning up..."
- rm *.txt
-```
-
-Before running `make`, let's include another special phony target, `.PHONY`, where we define all the targets that are not files. `make` will run its recipe regardless of whether a file with that name exists or what its last modification time is. Here is the complete makefile:
-```
-.PHONY: all say_hello generate clean
-
-all: say_hello generate
-
-say_hello:
- @echo "Hello World"
-
-generate:
- @echo "Creating empty text files..."
- touch file-{1..10}.txt
-
-clean:
- @echo "Cleaning up..."
- rm *.txt
-```
-
-The `make` should call `say_hello` and `generate`:
-```
-$ make
-Hello World
-Creating empty text files...
-touch file-{1..10}.txt
-```
-
-It is a good practice not to call `clean` in `all` or put it as the first target. `clean` should be called manually when cleaning is needed as a first argument to `make`:
-```
-$ make clean
-Cleaning up...
-rm *.txt
-```
-
-Now that you have an idea of how a basic makefile works and how to write a simple makefile, let's look at some more advanced examples.
-
-### Advanced examples
-
-#### Variables
-
-In the above example, most target and prerequisite values are hard-coded, but in real projects, these are replaced with variables and patterns.
-
-The simplest way to define a variable in a makefile is to use the `=` operator. For example, to assign the command `gcc` to a variable `CC`:
-```
-CC = gcc
-```
-
-This is also called a recursive expanded variable, and it is used in a rule as shown below:
-```
-hello: hello.c
- ${CC} hello.c -o hello
-```
-
-As you may have guessed, the recipe expands as below when it is passed to the terminal:
-```
-gcc hello.c -o hello
-```
-
-Both `${CC}` and `$(CC)` are valid references to call `gcc`. But if one tries to reassign a variable to itself, it will cause an infinite loop. Let's verify this:
-```
-CC = gcc
-CC = ${CC}
-
-all:
- @echo ${CC}
-```
-
-Running `make` will result in:
-```
-$ make
-Makefile:8: *** Recursive variable 'CC' references itself (eventually). Stop.
-```
-
-To avoid this scenario, we can use the `:=` operator (this is also called the simply expanded variable). We should have no problem running the makefile below:
-```
-CC := gcc
-CC := ${CC}
-
-all:
- @echo ${CC}
-```
-
-#### Patterns and functions
-
-The following makefile can compile all C programs by using variables, patterns, and functions. Let's explore it line by line:
-```
-# Usage:
-# make # compile all binary
-# make clean # remove ALL binaries and objects
-
-.PHONY = all clean
-
-CC = gcc # compiler to use
-
-LINKERFLAG = -lm
-
-SRCS := $(wildcard *.c)
-BINS := $(SRCS:%.c=%)
-
-all: ${BINS}
-
-%: %.o
- @echo "Checking.."
- ${CC} ${LINKERFLAG} $< -o $@
-
-%.o: %.c
- @echo "Creating object.."
- ${CC} -c $<
-
-clean:
- @echo "Cleaning up..."
- rm -rvf *.o ${BINS}
-```
-
- * Lines starting with `#` are comments.
-
- * Line `.PHONY = all clean` defines phony targets `all` and `clean`.
-
- * Variable `LINKERFLAG` defines flags to be used with `gcc` in a recipe.
-
- * `SRCS := $(wildcard *.c)`: `$(wildcard pattern)` is one of the functions for filenames. In this case, all files with the `.c` extension will be stored in a variable `SRCS`.
-
- * `BINS := $(SRCS:%.c=%)`: This is called as substitution reference. In this case, if `SRCS` has values `'foo.c bar.c'`, `BINS` will have `'foo bar'`.
-
- * Line `all: ${BINS}`: The phony target `all` calls values in`${BINS}` as individual targets.
-
- * Rule:
-```
-%: %.o
- @echo "Checking.."
- ${CC} ${LINKERFLAG} $< -o $@
-```
-
-Let's look at an example to understand this rule. Suppose `foo` is one of the values in `${BINS}`. Then `%` will match `foo`(`%` can match any target name). Below is the rule in its expanded form:
-```
-foo: foo.o
- @echo "Checking.."
- gcc -lm foo.o -o foo
-
-```
-
-As shown, `%` is replaced by `foo`. `$<` is replaced by `foo.o`. `$<` is patterned to match prerequisites and `$@` matches the target. This rule will be called for every value in `${BINS}`
-
- * Rule:
-```
-%.o: %.c
- @echo "Creating object.."
- ${CC} -c $<
-```
-
-Every prerequisite in the previous rule is considered a target for this rule. Below is the rule in its expanded form:
-```
-foo.o: foo.c
- @echo "Creating object.."
- gcc -c foo.c
-```
-
- * Finally, we remove all binaries and object files in target `clean`.
-
-
-
-
-Below is the rewrite of the above makefile, assuming it is placed in the directory having a single file `foo.c:`
-```
-# Usage:
-# make # compile all binary
-# make clean # remove ALL binaries and objects
-
-.PHONY = all clean
-
-CC = gcc # compiler to use
-
-LINKERFLAG = -lm
-
-SRCS := foo.c
-BINS := foo
-
-all: foo
-
-foo: foo.o
- @echo "Checking.."
- gcc -lm foo.o -o foo
-
-foo.o: foo.c
- @echo "Creating object.."
- gcc -c foo.c
-
-clean:
- @echo "Cleaning up..."
- rm -rvf foo.o foo
-```
-
-For more on makefiles, refer to the [GNU Make manual][1], which offers a complete reference and examples.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/8/what-how-makefile
-
-作者:[Sachin Patil][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/psachin
-[1]:https://www.gnu.org/software/make/manual/make.pdf
diff --git a/sources/tech/20180823 An introduction to pipes and named pipes in Linux.md b/sources/tech/20180823 An introduction to pipes and named pipes in Linux.md
deleted file mode 100644
index ab6a8cf932..0000000000
--- a/sources/tech/20180823 An introduction to pipes and named pipes in Linux.md
+++ /dev/null
@@ -1,60 +0,0 @@
-translating---geekpi
-
-An introduction to pipes and named pipes in Linux
-======
-
-
-
-In Linux, the `pipe` command lets you sends the output of one command to another. Piping, as the term suggests, can redirect the standard output, input, or error of one process to another for further processing.
-
-The syntax for the `pipe` or `unnamed pipe` command is the `|` character between any two commands:
-
-`Command-1 | Command-2 | …| Command-N`
-
-Here, the pipe cannot be accessed via another session; it is created temporarily to accommodate the execution of `Command-1` and redirect the standard output. It is deleted after successful execution.
-
-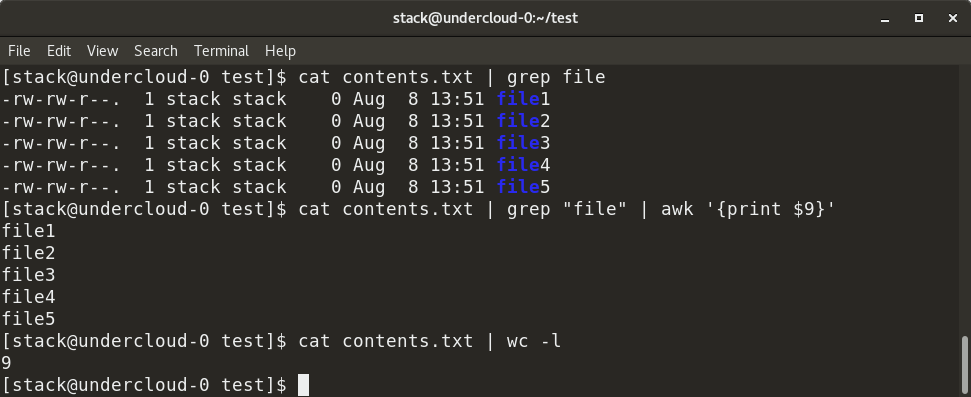
-
-In the example above, contents.txt contains a list of all files in a particular directory—specifically, the output of the ls -al command. We first grep the filenames with the "file" keyword from contents.txt by piping (as shown), so the output of the cat command is provided as the input for the grep command. Next, we add piping to execute the awk command, which displays the 9th column from the filtered output from the grep command. We can also count the number of rows in contents.txt using the wc -l command.
-
-A named pipe can last until as long as the system is up and running or until it is deleted. It is a special file that follows the [FIFO][1] (first in, first out) mechanism. It can be used just like a normal file; i.e., you can write to it, read from it, and open or close it. To create a named pipe, the command is:
-```
-mkfifo
-
-```
-
-This creates a named pipe file that can be used even over multiple shell sessions.
-
-Another way to create a FIFO named pipe is to use this command:
-```
-mknod p
-
-```
-
-To redirect a standard output of any command to another process, use the `>` symbol. To redirect a standard input of any command, use the `<` symbol.
-
-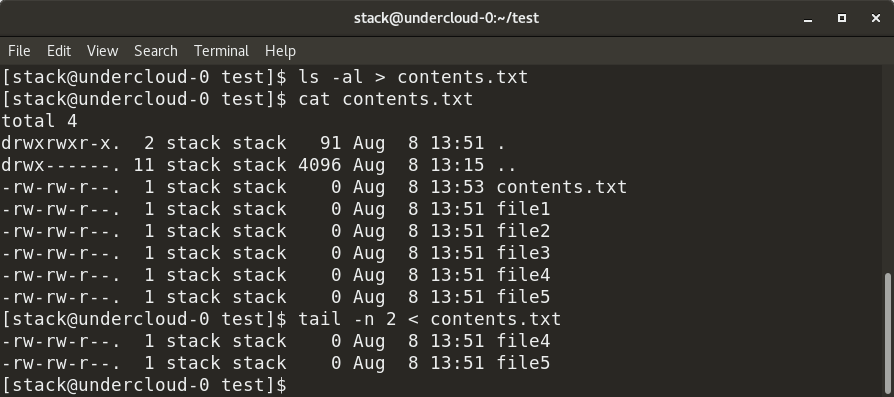
-
-As shown above, the output of the `ls -al` command is redirected to `contents.txt` and inserted in the file. Similarly, the input for the `tail` command is provided as `contents.txt` via the `<` symbol.
-
-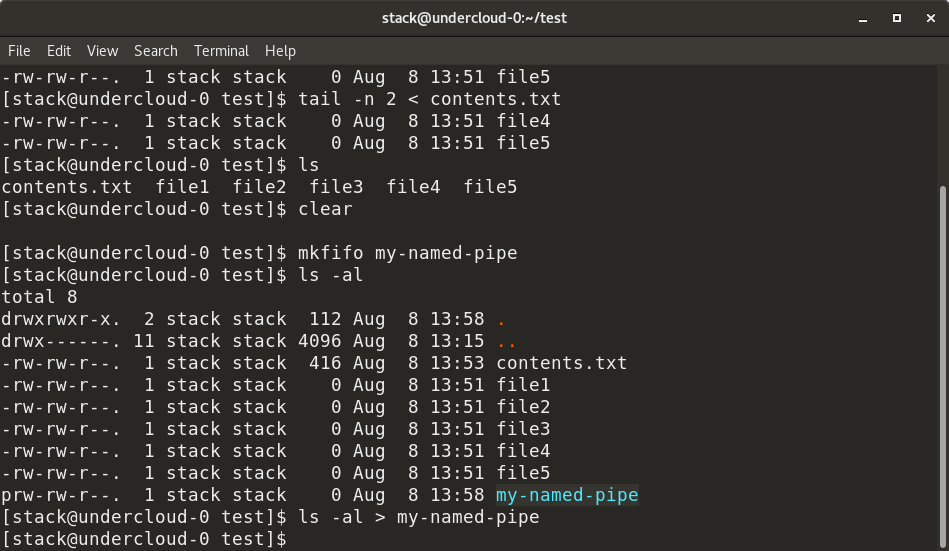
-
-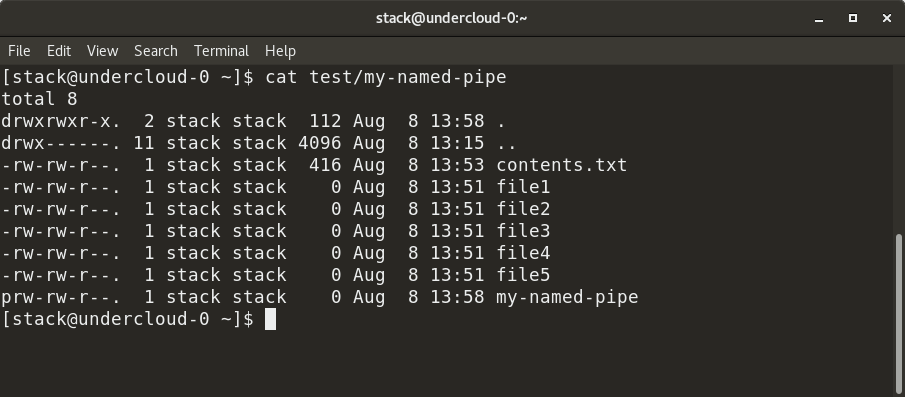
-
-Here, we have created a named pipe, `my-named-pipe`, and redirected the output of the `ls -al` command into the named pipe. We can the open a new shell session and `cat` the contents of the named pipe, which shows the output of the `ls -al` command, as previously supplied. Notice the size of the named pipe is zero and it has a designation of "p".
-
-So, next time you're working with commands at the Linux terminal and find yourself moving data between commands, hopefully a pipe will make the process quick and easy.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/8/introduction-pipes-linux
-
-作者:[Archit Modi][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/architmodi
-[1]:https://en.wikipedia.org/wiki/FIFO_(computing_and_electronics)
diff --git a/sources/tech/20180823 CLI- improved.md b/sources/tech/20180823 CLI- improved.md
new file mode 100644
index 0000000000..d06bb1b2aa
--- /dev/null
+++ b/sources/tech/20180823 CLI- improved.md
@@ -0,0 +1,297 @@
+CLI: improved
+======
+I'm not sure many web developers can get away without visiting the command line. As for me, I've been using the command line since 1997, first at university when I felt both super cool l33t-hacker and simultaneously utterly out of my depth.
+
+Over the years my command line habits have improved and I often search for smarter tools for the jobs I commonly do. With that said, here's my current list of improved CLI tools.
+
+
+### Ignoring my improvements
+
+In a number of cases I've aliased the new and improved command line tool over the original (as with `cat` and `ping`).
+
+If I want to run the original command, which is sometimes I do need to do, then there's two ways I can do this (I'm on a Mac so your mileage may vary):
+```
+$ \cat # ignore aliases named "cat" - explanation: https://stackoverflow.com/a/16506263/22617
+$ command cat # ignore functions and aliases
+
+```
+
+### bat > cat
+
+`cat` is used to print the contents of a file, but given more time spent in the command line, features like syntax highlighting come in very handy. I found [ccat][3] which offers highlighting then I found [bat][4] which has highlighting, paging, line numbers and git integration.
+
+The `bat` command also allows me to search during output (only if the output is longer than the screen height) using the `/` key binding (similarly to `less` searching).
+
+![Simple bat output][5]
+
+I've also aliased `bat` to the `cat` command:
+```
+alias cat='bat'
+
+```
+
+💾 [Installation directions][4]
+
+### prettyping > ping
+
+`ping` is incredibly useful, and probably my goto tool for the "oh crap is X down/does my internet work!!!". But `prettyping` ("pretty ping" not "pre typing"!) gives ping a really nice output and just makes me feel like the command line is a bit more welcoming.
+
+![/images/cli-improved/ping.gif][6]
+
+I've also aliased `ping` to the `prettyping` command:
+```
+alias ping='prettyping --nolegend'
+
+```
+
+💾 [Installation directions][7]
+
+### fzf > ctrl+r
+
+In the terminal, using `ctrl+r` will allow you to [search backwards][8] through your history. It's a nice trick, albeit a bit fiddly.
+
+The `fzf` tool is a **huge** enhancement on `ctrl+r`. It's a fuzzy search against the terminal history, with a fully interactive preview of the possible matches.
+
+In addition to searching through the history, `fzf` can also preview and open files, which is what I've done in the video below:
+
+For this preview effect, I created an alias called `preview` which combines `fzf` with `bat` for the preview and a custom key binding to open VS Code:
+```
+alias preview="fzf --preview 'bat --color \"always\" {}'"
+# add support for ctrl+o to open selected file in VS Code
+export FZF_DEFAULT_OPTS="--bind='ctrl-o:execute(code {})+abort'"
+
+```
+
+💾 [Installation directions][9]
+
+### htop > top
+
+`top` is my goto tool for quickly diagnosing why the CPU on the machine is running hard or my fan is whirring. I also use these tools in production. Annoyingly (to me!) `top` on the Mac is vastly different (and inferior IMHO) to `top` on linux.
+
+However, `htop` is an improvement on both regular `top` and crappy-mac `top`. Lots of colour coding, keyboard bindings and different views which have helped me in the past to understand which processes belong to which.
+
+Handy key bindings include:
+
+ * P - sort by CPU
+ * M - sort by memory usage
+ * F4 - filter processes by string (to narrow to just "node" for instance)
+ * space - mark a single process so I can watch if the process is spiking
+
+
+
+![htop output][10]
+
+There is a weird bug in Mac Sierra that can be overcome by running `htop` as root (I can't remember exactly what the bug is, but this alias fixes it - though annoying that I have to enter my password every now and again):
+```
+alias top="sudo htop" # alias top and fix high sierra bug
+
+```
+
+💾 [Installation directions][11]
+
+### diff-so-fancy > diff
+
+I'm pretty sure I picked this one up from Paul Irish some years ago. Although I rarely fire up `diff` manually, my git commands use diff all the time. `diff-so-fancy` gives me both colour coding but also character highlight of changes.
+
+![diff so fancy][12]
+
+Then in my `~/.gitconfig` I have included the following entry to enable `diff-so-fancy` on `git diff` and `git show`:
+```
+[pager]
+ diff = diff-so-fancy | less --tabs=1,5 -RFX
+ show = diff-so-fancy | less --tabs=1,5 -RFX
+
+```
+
+💾 [Installation directions][13]
+
+### fd > find
+
+Although I use a Mac, I've never been a fan of Spotlight (I found it sluggish, hard to remember the keywords, the database update would hammer my CPU and generally useless!). I use [Alfred][14] a lot, but even the finder feature doesn't serve me well.
+
+I tend to turn the command line to find files, but `find` is always a bit of a pain to remember the right expression to find what I want (and indeed the Mac flavour is slightly different non-mac find which adds to frustration).
+
+`fd` is a great replacement (by the same individual who wrote `bat`). It is very fast and the common use cases I need to search with are simple to remember.
+
+A few handy commands:
+```
+$ fd cli # all filenames containing "cli"
+$ fd -e md # all with .md extension
+$ fd cli -x wc -w # find "cli" and run `wc -w` on each file
+
+```
+
+![fd output][15]
+
+💾 [Installation directions][16]
+
+### ncdu > du
+
+Knowing where disk space is being taking up is a fairly important task for me. I've used the Mac app [Disk Daisy][17] but I find that it can be a little slow to actually yield results.
+
+The `du -sh` command is what I'll use in the terminal (`-sh` means summary and human readable), but often I'll want to dig into the directories taking up the space.
+
+`ncdu` is a nice alternative. It offers an interactive interface and allows for quickly scanning which folders or files are responsible for taking up space and it's very quick to navigate. (Though any time I want to scan my entire home directory, it's going to take a long time, regardless of the tool - my directory is about 550gb).
+
+Once I've found a directory I want to manage (to delete, move or compress files), I'll use the cmd + click the pathname at the top of the screen in [iTerm2][18] to launch finder to that directory.
+
+![ncdu output][19]
+
+There's another [alternative called nnn][20] which offers a slightly nicer interface and although it does file sizes and usage by default, it's actually a fully fledged file manager.
+
+My `ncdu` is aliased to the following:
+```
+alias du="ncdu --color dark -rr -x --exclude .git --exclude node_modules"
+
+```
+
+The options are:
+
+ * `--color dark` \- use a colour scheme
+ * `-rr` \- read-only mode (prevents delete and spawn shell)
+ * `--exclude` ignore directories I won't do anything about
+
+
+
+💾 [Installation directions][21]
+
+### tldr > man
+
+It's amazing that nearly every single command line tool comes with a manual via `man `, but navigating the `man` output can be sometimes a little confusing, plus it can be daunting given all the technical information that's included in the manual output.
+
+This is where the TL;DR project comes in. It's a community driven documentation system that's available from the command line. So far in my own usage, I've not come across a command that's not been documented, but you can [also contribute too][22].
+
+![TLDR output for 'fd'][23]
+
+As a nicety, I've also aliased `tldr` to `help` (since it's quicker to type!):
+```
+alias help='tldr'
+
+```
+
+💾 [Installation directions][24]
+
+### ack || ag > grep
+
+`grep` is no doubt a powerful tool on the command line, but over the years it's been superseded by a number of tools. Two of which are `ack` and `ag`.
+
+I personally flitter between `ack` and `ag` without really remembering which I prefer (that's to say they're both very good and very similar!). I tend to default to `ack` only because it rolls of my fingers a little easier. Plus, `ack` comes with the mega `ack --bar` argument (I'll let you experiment)!
+
+Both `ack` and `ag` will (by default) use a regular expression to search, and extremely pertinent to my work, I can specify the file types to search within using flags like `--js` or `--html` (though here `ag` includes more files in the js filter than `ack`).
+
+Both tools also support the usual `grep` options, like `-B` and `-A` for before and after context in the grep.
+
+![ack in action][25]
+
+Since `ack` doesn't come with markdown support (and I write a lot in markdown), I've got this customisation in my `~/.ackrc` file:
+```
+--type-set=md=.md,.mkd,.markdown
+--pager=less -FRX
+
+```
+
+💾 Installation directions: [ack][26], [ag][27]
+
+[Futher reading on ack & ag][28]
+
+### jq > grep et al
+
+I'm a massive fanboy of [jq][29]. At first I struggled with the syntax, but I've since come around to the query language and use `jq` on a near daily basis (whereas before I'd either drop into node, use grep or use a tool called [json][30] which is very basic in comparison).
+
+I've even started the process of writing a jq tutorial series (2,500 words and counting) and have published a [web tool][31] and a native mac app (yet to be released).
+
+`jq` allows me to pass in JSON and transform the source very easily so that the JSON result fits my requirements. One such example allows me to update all my node dependencies in one command (broken into multiple lines for readability):
+```
+$ npm i $(echo $(\
+ npm outdated --json | \
+ jq -r 'to_entries | .[] | "\(.key)@\(.value.latest)"' \
+))
+
+```
+
+The above command will list all the node dependencies that are out of date, and use npm's JSON output format, then transform the source JSON from this:
+```
+{
+ "node-jq": {
+ "current": "0.7.0",
+ "wanted": "0.7.0",
+ "latest": "1.2.0",
+ "location": "node_modules/node-jq"
+ },
+ "uuid": {
+ "current": "3.1.0",
+ "wanted": "3.2.1",
+ "latest": "3.2.1",
+ "location": "node_modules/uuid"
+ }
+}
+
+```
+
+…to this:
+
+That result is then fed into the `npm install` command and voilà, I'm all upgraded (using the sledgehammer approach).
+
+### Honourable mentions
+
+Some of the other tools that I've started poking around with, but haven't used too often (with the exception of ponysay, which appears when I start a new terminal session!):
+
+ * [ponysay][32] > cowsay
+ * [csvkit][33] > awk et al
+ * [noti][34] > `display notification`
+ * [entr][35] > watch
+
+
+
+### What about you?
+
+So that's my list. How about you? What daily command line tools have you improved? I'd love to know.
+
+
+--------------------------------------------------------------------------------
+
+via: https://remysharp.com/2018/08/23/cli-improved
+
+作者:[Remy Sharp][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://remysharp.com
+[1]: https://remysharp.com/images/terminal-600.jpg
+[2]: https://training.leftlogic.com/buy/terminal/cli2?coupon=READERS-DISCOUNT&utm_source=blog&utm_medium=banner&utm_campaign=remysharp-discount
+[3]: https://github.com/jingweno/ccat
+[4]: https://github.com/sharkdp/bat
+[5]: https://remysharp.com/images/cli-improved/bat.gif (Sample bat output)
+[6]: https://remysharp.com/images/cli-improved/ping.gif (Sample ping output)
+[7]: http://denilson.sa.nom.br/prettyping/
+[8]: https://lifehacker.com/278888/ctrl%252Br-to-search-and-other-terminal-history-tricks
+[9]: https://github.com/junegunn/fzf
+[10]: https://remysharp.com/images/cli-improved/htop.jpg (Sample htop output)
+[11]: http://hisham.hm/htop/
+[12]: https://remysharp.com/images/cli-improved/diff-so-fancy.jpg (Sample diff output)
+[13]: https://github.com/so-fancy/diff-so-fancy
+[14]: https://www.alfredapp.com/
+[15]: https://remysharp.com/images/cli-improved/fd.png (Sample fd output)
+[16]: https://github.com/sharkdp/fd/
+[17]: https://daisydiskapp.com/
+[18]: https://www.iterm2.com/
+[19]: https://remysharp.com/images/cli-improved/ncdu.png (Sample ncdu output)
+[20]: https://github.com/jarun/nnn
+[21]: https://dev.yorhel.nl/ncdu
+[22]: https://github.com/tldr-pages/tldr#contributing
+[23]: https://remysharp.com/images/cli-improved/tldr.png (Sample tldr output for 'fd')
+[24]: http://tldr-pages.github.io/
+[25]: https://remysharp.com/images/cli-improved/ack.png (Sample ack output with grep args)
+[26]: https://beyondgrep.com
+[27]: https://github.com/ggreer/the_silver_searcher
+[28]: http://conqueringthecommandline.com/book/ack_ag
+[29]: https://stedolan.github.io/jq
+[30]: http://trentm.com/json/
+[31]: https://jqterm.com
+[32]: https://github.com/erkin/ponysay
+[33]: https://csvkit.readthedocs.io/en/1.0.3/
+[34]: https://github.com/variadico/noti
+[35]: http://www.entrproject.org/
diff --git a/sources/tech/20180823 How to publish a WordPress blog to a static GitLab Pages site.md b/sources/tech/20180823 How to publish a WordPress blog to a static GitLab Pages site.md
deleted file mode 100644
index fd52def010..0000000000
--- a/sources/tech/20180823 How to publish a WordPress blog to a static GitLab Pages site.md
+++ /dev/null
@@ -1,92 +0,0 @@
-translating---geekpi
-
-How to publish a WordPress blog to a static GitLab Pages site
-======
-
-
-
-A long time ago, I set up a WordPress blog for a family member. There are lots of options these days, but back then there were few decent choices if you needed a web-based CMS with a WYSIWYG editor. An unfortunate side effect of things working well is that the blog has generated a lot of content over time. That means I was also regularly updating WordPress to protect against the exploits that are constantly popping up.
-
-So I decided to convince the family member that switching to [Hugo][1] would be relatively easy, and the blog could then be hosted on [GitLab][2]. But trying to extract all that content and convert it to [Markdown][3] turned into a huge hassle. There were automated scripts that got me 95% there, but nothing worked perfectly. Manually updating all the posts was not something I wanted to do, so eventually, I gave up trying to move the blog.
-
-Recently, I started thinking about this again and realized there was a solution I hadn't considered: I could continue maintaining the WordPress server but set it up to publish a static mirror and serve that with [GitLab Pages][4] (or [GitHub Pages][5] if you like). This would allow me to automate [Let's Encrypt][6] certificate renewals as well as eliminate the security concerns associated with hosting a WordPress site. This would, however, mean comments would stop working, but that feels like a minor loss in this case because the blog did not garner many comments.
-
-Here's the solution I came up with, which so far seems to be working well:
-
- * Host WordPress site at URL that is not linked to or from anywhere else to reduce the odds of it being exploited. In this example, we'll use (even though this site is actually built with Pelican).
- * [Set up hosting on GitLab Pages][7] for the public URL .
- * Add a [cron job][8] that determines when the last-built date differs between the two URLs; if the build dates differ, mirror the WordPress version.
- * After mirroring with `wget`, update all links from "private" version to "public" version.
- * Do a `git push` to publish the new content.
-
-
-
-These are the two scripts I use:
-
-`check-diff.sh` (called by cron every 15 minutes)
-```
-#!/bin/bash
-
-ORIGINDATE="$(curl -v --silent http://private.localconspiracy.com/feed/ 2>&1|grep lastBuildDate)"
-PUBDATE="$(curl -v --silent https://www.localconspiracy.com/feed/ 2>&1|grep lastBuildDate)"
-
-if [ "$ORIGINDATE" != "$PUBDATE" ]
-then
- /home/doc/repos/localconspiracy/mirror.sh
-fi
-```
-
-`mirror.sh:`
-```
-#!/bin/sh
-
-cd /home/doc/repos/localconspiracy
-
-wget \
---mirror \
---convert-links \
---adjust-extension \
---page-requisites \
---retry-connrefused \
---exclude-directories=comments \
---execute robots=off \
-http://private.localconspiracy.com
-
-git rm -rf public/*
-mv private.localconspiracy.com/* public/.
-rmdir private.localconspiracy.com
-find ./public/ -type f -exec sed -i -e 's|http://private.localconspiracy|https://www.localconspiracy|g' {} \;
-find ./public/ -type f -exec sed -i -e 's|http://www.localconspiracy|https://www.localconspiracy|g' {} \;
-git add public/*
-git commit -m "new snapshot"
-git push origin master
-```
-
-That's it! Now, when the blog is changed, within 15 minutes the site is mirrored to a static version and pushed up to the repo where it will be reflected in GitLab pages.
-
-This concept could be extended a little further if you wanted to [run WordPress locally][9]. In that case, you would not need a server to host your WordPress blog; you could just run it on your local machine. In that scenario, there's no chance of your blog getting exploited. As long as you can run `wget` against it locally, you could use the approach outlined above to have a WordPress site hosted on GitLab Pages.
-
-_This article was originally posted at[Local Conspiracy][10]. Reposted with permission._
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/8/publish-wordpress-static-gitlab-pages-site
-
-作者:[Christopher Aedo][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/docaedo
-[1]:https://gohugo.io/
-[2]:https://gitlab.com/
-[3]:https://en.wikipedia.org/wiki/Markdown
-[4]:https://docs.gitlab.com/ee/user/project/pages/
-[5]:https://pages.github.com/
-[6]:https://letsencrypt.org/
-[7]:https://about.gitlab.com/2016/04/07/gitlab-pages-setup/
-[8]:https://en.wikipedia.org/wiki/Cron
-[9]:https://codex.wordpress.org/Installing_WordPress_Locally_on_Your_Mac_With_MAMP
-[10]:https://localconspiracy.com/2018/08/wp-on-gitlab.html
diff --git a/sources/tech/20180824 5 cool music player apps.md b/sources/tech/20180824 5 cool music player apps.md
index 3a8d90400c..fbacc8f8b4 100644
--- a/sources/tech/20180824 5 cool music player apps.md
+++ b/sources/tech/20180824 5 cool music player apps.md
@@ -1,3 +1,5 @@
+translating---geekpi
+
5 cool music player apps
======
diff --git a/sources/tech/20180824 How to install software from the Linux command line.md b/sources/tech/20180824 How to install software from the Linux command line.md
deleted file mode 100644
index 012ed3fece..0000000000
--- a/sources/tech/20180824 How to install software from the Linux command line.md
+++ /dev/null
@@ -1,106 +0,0 @@
-How to install software from the Linux command line
-======
-
-
-
-If you use Linux for any amount of time, you'll soon learn there are many different ways to do the same thing. This includes installing applications on a Linux machine via the command line. I have been a Linux user for roughly 25 years, and time and time again I find myself going back to the command line to install my apps.
-
-The most common method of installing apps from the command line is through software repositories (a place where software is stored) using what's called a package manager. All Linux apps are distributed as packages, which are nothing more than files associated with a package management system. Every Linux distribution comes with a package management system, but they are not all the same.
-
-### What is a package management system?
-
-A package management system is comprised of sets of tools and file formats that are used together to install, update, and uninstall Linux apps. The two most common package management systems are from Red Hat and Debian. Red Hat, CentOS, and Fedora all use the `rpm` system (.rpm files), while Debian, Ubuntu, Mint, and Ubuntu use `dpkg` (.deb files). Gentoo Linux uses a system called Portage, and Arch Linux uses nothing but tarballs (.tar files). The primary difference between these systems is how they install and maintain apps.
-
-You might be wondering what's inside an `.rpm`, `.deb`, or `.tar` file. You might be surprised to learn that all are nothing more than plain old archive files (like `.zip`) that contain an application's code, instructions on how to install it, dependencies (what other apps it may depend on), and where its configuration files should be placed. The software that reads and executes all of those instructions is called a package manager.
-
-### Debian, Ubuntu, Mint, and others
-
-Debian, Ubuntu, Mint, and other Debian-based distributions all use `.deb` files and the `dpkg` package management system. There are two ways to install apps via this system. You can use the `apt` application to install from a repository, or you can use the `dpkg` app to install apps from `.deb` files. Let's take a look at how to do both.
-
-Installing apps using `apt` is as easy as:
-```
-$ sudo apt install app_name
-
-```
-
-Uninstalling an app via `apt` is also super easy:
-```
-$ sudo apt remove app_name
-
-```
-
-To upgrade your installed apps, you'll first need to update the app repository:
-```
-$ sudo apt update
-
-```
-
-Once finished, you can update any apps that need updating with the following:
-```
-$ sudo apt upgrade
-
-```
-
-What if you want to update only a single app? No problem.
-```
-$ sudo apt update app_name
-
-```
-
-Finally, let's say the app you want to install is not available in the Debian repository, but it is available as a `.deb` download.
-```
-$ sudo dpkg -i app_name.deb
-
-```
-
-### Red Hat, CentOS, and Fedora
-
-Red Hat, by default, uses several package management systems. These systems, while using their own terminology, are still very similar to each other and to the one used in Debian. For example, we can use either the `yum` or `dnf` manager to install apps.
-```
-$ sudo yum install app_name
-
-$ sudo dnf install app_name
-
-```
-
-Apps in the `.rpm` format can also be installed with the `rpm` command.
-```
-$ sudo rpm -i app_name.rpm
-
-```
-
-Removing unwanted applications is just as easy.
-```
-$ sudo yum remove app_name
-
-$ sudo dnf remove app_name
-
-```
-
-Updating apps is similarly easy.
-```
-$ yum update
-
-$ sudo dnf upgrade --refresh
-
-```
-
-As you can see, installing, uninstalling, and updating Linux apps from the command line isn't hard at all. In fact, once you get used to it, you'll find it's faster than using desktop GUI-based management tools!
-
-For more information on installing apps from the command line, please visit the Debian [Apt wiki][1], the [Yum cheat sheet][2], and the [DNF wiki][3].
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/8/how-install-software-linux-command-line
-
-作者:[Patrick H.Mullins][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/pmullins
-[1]:https://wiki.debian.org/Apt
-[2]:https://access.redhat.com/articles/yum-cheat-sheet
-[3]:https://fedoraproject.org/wiki/DNF?rd=Dnf
diff --git a/sources/tech/20180824 Joplin- Encrypted Open Source Note Taking And To-Do Application.md b/sources/tech/20180824 Joplin- Encrypted Open Source Note Taking And To-Do Application.md
new file mode 100644
index 0000000000..5c520c8021
--- /dev/null
+++ b/sources/tech/20180824 Joplin- Encrypted Open Source Note Taking And To-Do Application.md
@@ -0,0 +1,78 @@
+Joplin: Encrypted Open Source Note Taking And To-Do Application
+======
+**[Joplin][1] is a free and open source note taking and to-do application available for Linux, Windows, macOS, Android and iOS. Its key features include end-to-end encryption, Markdown support, and synchronization via third-party services like NextCloud, Dropbox, OneDrive or WebDAV.**
+
+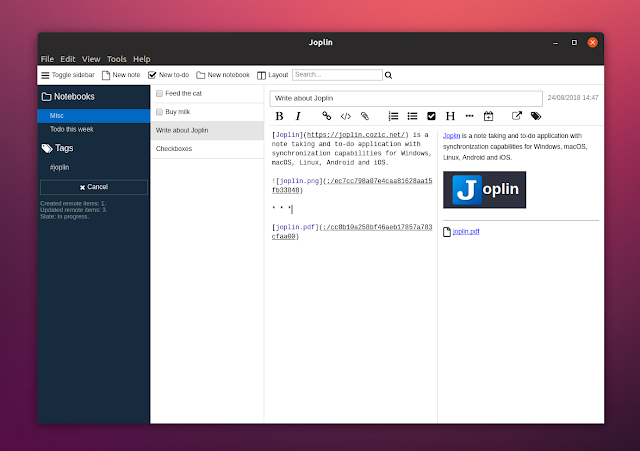
+
+With Joplin you can write your notes in the **Markdown format** (with support for math notations and checkboxes) and the desktop app comes with 3 views: Markdown code, Markdown preview, or both side by side. **You can add attachments to your notes (with image previews) or edit them in an external Markdown editor** and have them automatically updated in Joplin each time you save the file.
+
+The application should handle a large number of notes pretty well by allowing you to **organizing notes into notebooks, add tags, and search in notes**. You can also sort notes by updated date, creation date or title. **Each notebook can contain notes, to-do items, or both** , and you can easily add links to other notes (in the desktop app right click on a note and select `Copy Markdown link` , then paste the link in a note).
+
+**Do-do items in Joplin support alarms** , but this feature didn't work for me on Ubuntu 18.04.
+
+**Other Joplin features include:**
+
+ * **Optional Web Clipper extension** for Firefox and Chrome (in the Joplin desktop application go to `Tools > Web clipper options` to enable the clipper service and find download links for the Chrome / Firefox extension) which can clip simplified or complete pages, clip a selection or screenshot.
+
+ * **Optional command line client**.
+
+ * **Import Enex files (Evernote export format) and Markdown files**.
+
+ * **Export JEX files (Joplin Export format), PDF and raw files**.
+
+ * **Offline first, so the entire data is always available on the device even without an internet connection**.
+
+ * **Geolocation support**.
+
+
+
+[![Joplin notes checkboxes link to other note][2]][3]
+Joplin with hidden sidebar showing checkboxes and a link to another note
+
+While it doesn't offer as many features as Evernote, Joplin is a robust open source Evernote alternative. Joplin includes all the basic features, and on top of that it's open source software, it includes encryption support, and you also get to choose the service you want to use for synchronization.
+
+The application was actually designed as an Evernote alternative so it can import complete Evernote notebooks, notes, tags, attachments, and note metadata like the author, creation and updated time, or geolocation.
+
+Another aspect on which the Joplin development was focused was to avoid being tied to a particular company or service. This is why the application offers multiple synchronization solutions, like NextCloud, Dropbox, oneDrive and WebDav, while also making it easy to support new services. It's also easy to switch from one service to another if you change your mind.
+
+**I should note that Joplin doesn't use encryption by default and you must enable this from its settings. Go to** `Tools > Encryption options` and enable the Joplin end-to-end encryption from there.
+
+### Download Joplin
+
+[Download Joplin][7]
+
+**Joplin is available for Linux, Windows, macOS, Android and iOS. On Linux, there's an AppImage as well as an Aur package available.**
+
+To run the Joplin AppImage on Linux, double click it and select `Make executable and run` if your file manager supports this. If not, you'll need to make it executable either using your file manager (should be something like: `right click > Properties > Permissions > Allow executing file as program` , but this may vary depending on the file manager you use), or from the command line:
+```
+chmod +x /path/to/Joplin-*-x86_64.AppImage
+
+```
+
+Replacing `/path/to/` with the path to where you downloaded Joplin. Now you can double click the Joplin Appimage file to launch it.
+
+**TIP:** If you integrate Joplin to your menu and `~/.local/share/applications/appimagekit-joplin.desktop`) and adding `StartupWMClass=Joplin` at the end of the file on a new line, without modifying anything else.
+
+Joplin has a **command line client** that can be [installed using npm][5] (for Debian, Ubuntu or Linux Mint, see [how to install and configure Node.js and npm][6] ).
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.linuxuprising.com/2018/08/joplin-encrypted-open-source-note.html
+
+作者:[Logix][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://plus.google.com/118280394805678839070
+[1]:https://joplin.cozic.net/
+[2]:https://3.bp.blogspot.com/-y9JKL1F89Vo/W3_0dkZjzQI/AAAAAAAABcI/hQI7GAx6i_sMcel4mF0x4uxBrMO88O59wCLcBGAs/s640/joplin-notes-markdown.png (Joplin notes checkboxes link to other note)
+[3]:https://3.bp.blogspot.com/-y9JKL1F89Vo/W3_0dkZjzQI/AAAAAAAABcI/hQI7GAx6i_sMcel4mF0x4uxBrMO88O59wCLcBGAs/s1600/joplin-notes-markdown.png
+[4]:https://github.com/laurent22/joplin/issues/338
+[5]:https://joplin.cozic.net/terminal/
+[6]:https://www.linuxuprising.com/2018/04/how-to-install-and-configure-nodejs-and.html
+
+[7]: https://joplin.cozic.net/#installation
diff --git a/sources/tech/20180824 Steam Makes it Easier to Play Windows Games on Linux.md b/sources/tech/20180824 Steam Makes it Easier to Play Windows Games on Linux.md
deleted file mode 100644
index 07d22aaad0..0000000000
--- a/sources/tech/20180824 Steam Makes it Easier to Play Windows Games on Linux.md
+++ /dev/null
@@ -1,72 +0,0 @@
-Steam Makes it Easier to Play Windows Games on Linux
-======
-![Steam Wallpaper][1]
-
-It’s no secret that the [Linux gaming][2] library offers only a fraction of what the Windows library offers. In fact, many people wouldn’t even consider [switching to Linux][3] simply because most of the games they want to play aren’t available on the platform.
-
-At the time of writing this article, Linux has just over 5,000 games available on Steam compared to the library’s almost 27,000 total games. Now, 5,000 games may be a lot, but it isn’t 27,000 games, that’s for sure.
-
-And though almost every new indie game seems to launch with a Linux release, we are still left without a way to play many [Triple-A][4] titles. For me, though there are many titles I would love the opportunity to play, this has never been a make-or-break problem since almost all of my favorite titles are available on Linux since I primarily play indie and [retro games][5] anyway.
-
-### Meet Proton: a WINE Fork by Steam
-
-Now, that problem is a thing of the past since this week Valve [announced][6] a new update to Steam Play that adds a forked version of Wine to the Linux and Mac Steam clients called Proton. Yes, the tool is open-source, and Valve has made the source code available on [Github][7]. The feature is still in beta though, so you must opt into the beta Steam client in order to take advantage of this functionality.
-
-#### With proton, more Windows games are available for Linux on Steam
-
-What does that actually mean for us Linux users? In short, it means that both Linux and Mac computers can now play all 27,000 of those games without needing to configure something like [PlayOnLinux][8] or [Lutris][9] to do so! Which, let me tell you, can be quite the headache at times.
-
-The more complicated answer to this is that it sounds too good to be true for a reason. Though, in theory, you can play literally every Windows game on Linux this way, there is only a short list of games that are officially supported at launch, including DOOM, Final Fantasy VI, Tekken 7, Star Wars: Battlefront 2, and several more.
-
-#### You can play all Windows games on Linux (in theory)
-
-Though the list only has about 30 games thus far, you can force enable Steam to install and play any game through Proton by marking the “Enable Steam Play for all titles” checkbox. But don’t get your hopes too high. They do not guarantee the stability and performance you may be hoping for, so keep your expectations reasonable.
-
-![Steam Play][10]
-
-#### Experiencing Proton: Not as bad as I expected
-
-For example, I installed a few moderately taxing games to put Proton through its paces. One of which was The Elder Scrolls IV: Oblivion, and in the two hours I played the game, it only crashed once, and it was almost immediately after an autosave point during the tutorial.
-
-I have an Nvidia Gtx 1050 Ti, so I was able to play the game at 1080p with high settings, and I didn’t see a single problem outside of that one crash. The only negative feedback I really have is that the framerate was not nearly as high as it would have been if it was a native game. I got above 60 frames 90% of the time, but I admit it could have been better.
-
-Every other game that I have installed and launched has also worked flawlessly, granted I haven’t played any of them for an extended amount of time yet. Some games I installed include The Forest, Dead Rising 4, H1Z1, and Assassin’s Creed II (can you tell I like horror games?).
-
-#### Why is Steam (still) betting on Linux?
-
-Now, this is all fine and dandy, but why did this happen? Why would Valve spend the time, money, and resources needed to implement something like this? I like to think they did so because they value the Linux community, but if I am honest, I don’t believe we had anything to do with it.
-
-If I had to put money on it, I would say Valve has developed Proton because they haven’t given up on [Steam machines][11] yet. And since [Steam OS][12] is running on Linux, it is in their best interest financially to invest in something like this. The more games available on Steam OS, the more people might be willing to buy a Steam Machine.
-
-Maybe I am wrong, but I bet this means we will see a new wave of Steam machines coming in the not-so-distant future. Maybe we will see them in one year, or perhaps we won’t see them for another five, who knows!
-
-Either way, all I know is that I am beyond excited to finally play the games from my Steam library that I have slowly accumulated over the years from all of the Humble Bundles, promo codes, and random times I bought a game on sale just in case I wanted to try to get it running in Lutris.
-
-#### Excited for more gaming on Linux?
-
-What do you think? Are you excited about this, or are you afraid fewer developers will create native Linux games because there is almost no need to now? Does Valve love the Linux community, or do they love money? Let us know what you think in the comment section below, and check back in for more FOSS content like this.
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/steam-play-proton/
-
-作者:[Phillip Prado][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://itsfoss.com/author/phillip/
-[1]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/steam-wallpaper.jpeg
-[2]:https://itsfoss.com/linux-gaming-guide/
-[3]:https://itsfoss.com/reasons-switch-linux-windows-xp/
-[4]:https://itsfoss.com/triplea-game-review/
-[5]:https://itsfoss.com/play-retro-games-linux/
-[6]:https://steamcommunity.com/games/221410
-[7]:https://github.com/ValveSoftware/Proton/
-[8]:https://www.playonlinux.com/en/
-[9]:https://lutris.net/
-[10]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/SteamProton.jpg
-[11]:https://store.steampowered.com/sale/steam_machines
-[12]:https://itsfoss.com/valve-annouces-linux-based-gaming-operating-system-steamos/
diff --git a/sources/tech/20180824 [Solved] -sub process usr bin dpkg returned an error code 1- Error in Ubuntu.md b/sources/tech/20180824 [Solved] -sub process usr bin dpkg returned an error code 1- Error in Ubuntu.md
index 3cde4c7e9e..0200dfffdb 100644
--- a/sources/tech/20180824 [Solved] -sub process usr bin dpkg returned an error code 1- Error in Ubuntu.md
+++ b/sources/tech/20180824 [Solved] -sub process usr bin dpkg returned an error code 1- Error in Ubuntu.md
@@ -1,3 +1,5 @@
+translating---geekpi
+
[Solved] “sub process usr bin dpkg returned an error code 1″ Error in Ubuntu
======
If you are encountering “sub process usr bin dpkg returned an error code 1” while installing software on Ubuntu Linux, here is how you can fix it.
diff --git a/sources/tech/20180827 An introduction to diffs and patches.md b/sources/tech/20180827 An introduction to diffs and patches.md
deleted file mode 100644
index 1c81b97bf6..0000000000
--- a/sources/tech/20180827 An introduction to diffs and patches.md
+++ /dev/null
@@ -1,112 +0,0 @@
-An introduction to diffs and patches
-======
-
-
-If you’ve ever worked on a large codebase with a distributed development model, you’ve probably heard people say things like “Sue just sent a patch,” or “Rajiv is checking out the diff.” Maybe those terms were new to you and you wondered what they meant. Open source has had an impact here, as the main development model of large projects from Apache web server to the Linux kernel have been “patch-based” development projects throughout their lifetime. In fact, did you know that Apache’s name originated from the set of patches that were collected and collated against the original [NCSA HTTPd server source code][1]?
-
-You might think this is folklore, but an early [capture of the Apache website][2] claims that the name was derived from this original “patch” collection; hence **APA** t **CH** y server, which was then simplified to Apache.
-
-But enough history trivia. What exactly are these patches and diffs that developers talk about?
-
-First, for the sake of this article, let’s assume that these two terms reference one and the same thing. “Diff” is simply short for “difference;” a Unix utility by the same name reveals the difference between one or more files. We will look at a diff utility example below.
-
-A “patch” refers to a specific collection of differences between files that can be applied to a source code tree using the Unix diff utility. So we can create diffs (or patches) using the diff tool and apply them to an unpatched version of that same source code using the patch tool. As an aside (and breaking my rule of no more history trivia), the word “patch” comes from the physical covering of punchcard holes to make software changes in the early computing days, when punchcards represented the program executed by the computer’s processor. The image below, found on this [Wikipedia page][3] describing software patches, shows this original “patching” concept:
-
-
-
-Now that you have a basic understanding of patches and diffs, let’s explore how software developers use these tools. If you haven’t used a source code control system like [Git][4] or [Subversion][5], I will set the stage for how most non-trivial software projects are developed. If you think of the life of a software project as a set of actions along a timeline, you might visualize changes to the software—such as adding a feature or a function to a source code file or fixing a bug—appearing at different points on the timeline, with each discrete point representing the state of all the source code files at that time. We will call these points of change “commits,” using the same nomenclature that today’s most popular source code control tool, Git, uses. When you want to see the difference between the source code before and after a certain commit, or between many commits, you can use a tool to show us diffs, or differences.
-
-If you are developing software using this same source code control tool, Git, you may have changes in your local system that you want to provide for others to potentially add as commits to their own tree. One way to provide local changes to others is to create a diff of your local tree's changes and send this “patch” to others who are working on the same source code. This lets others patch their tree and see the source code tree with your changes applied.
-
-### Linux, Git, and GitHub
-
-This model of sharing patch files is how the Linux kernel community operates regarding proposed changes today. If you look at the archives for any of the popular Linux kernel mailing lists—[LKML][6] is the primary one, but others include [linux-containers][7], [fs-devel][8], [Netdev][9], to name a few—you’ll find many developers posting patches that they wish to have others review, test, and possibly bring into the official Linux kernel Git tree at some point. It is outside of the scope of this article to discuss Git, the source code control system written by Linus Torvalds, in more detail, but it's worth noting that Git enables this distributed development model, allowing patches to live separately from a main repository, pushing and pulling into different trees and following their specific development flow.
-
-Before moving on, we can’t ignore the most popular service in which patches and diffs are relevant: [GitHub][10]. Given its name, you can probably guess that GitHub is based on Git, but it offers a web- and API-based workflow around the Git tool for distributed open source project development. One of the main ways that patches are shared in GitHub is not via email, like the Linux kernel, but by creating a **pull request**. When you commit changes on your own copy of a source code tree, you can share those changes by creating a pull request against a commonly shared repository for that software project. GitHub is used by many active and popular open source projects today, such as [Kubernetes][11], [Docker][12], [the Container Network Interface (CNI)][13], [Istio][14], and many others. In the GitHub world, users tend to use the web-based interface to review the diffs or patches that comprise a pull request, but you can still access the raw patch files and use them at the command line with the patch utility.
-
-### Getting down to business
-
-Now that we’ve covered patches and diffs and how they are used in popular open source communities or tools, let's look at a few examples.
-
-The first example includes two copies of a source tree, and one has changes that we want to visualize using the diff utility. In our examples, we will look at “unified” diffs because that is the expected view for patches in most of the modern software development world. Check the diff manual page for more information on options and ways to produce differences. The original source code is located in sources-orig and our second, modified codebase is located in a directory named sources-fixed. To show the differences in a unified diff format in your terminal, use the following command:
-```
-$ diff -Naur sources-orig/ sources-fixed/
-```
-
-...which then shows the following diff command output:
-```
-diff -Naur sources-orig/officespace/interest.go sources-fixed/officespace/interest.go
---- sources-orig/officespace/interest.go 2018-08-10 16:39:11.000000000 -0400
-+++ sources-fixed/officespace/interest.go 2018-08-10 16:39:40.000000000 -0400
-@@ -11,15 +11,13 @@
- InterestRate float64
- }
-
-+// compute the rounded interest for a transaction
- func computeInterest(acct *Account, t Transaction) float64 {
-
- interest := t.Amount 选题模板.txt 中文排版指北.md comic core.md Dict.md lctt2014.md lctt2016.md LCTT翻译规范.md LICENSE Makefile published README.md sign.md sources translated t.InterestRate
- roundedInterest := math.Floor(interest*100) / 100.0
- remainingInterest := interest - roundedInterest
-
-- // a little extra..
-- remainingInterest *= 1000
--
- // Save the remaining interest into an account we control:
- acct.Balance = acct.Balance + remainingInterest
-```
-
-The first few lines of the diff command output could use some explanation: The three `---` signs show the original filename; any lines that exist in the original file but not in the compared new file will be prefixed with a single `-` to note that this line was “subtracted” from the sources. The `+++` signs show the opposite: The compared new file and additions found in this file are marked with a single `+` symbol to show they were added in the new version of the file. Each “hunk” (that’s what sections prefixed by `@@` are called) of the difference patch file has contextual line numbers that help the patch tool (or other processors) know where to apply this change. You can see from the "Office Space" movie reference function that we’ve corrected (by removing three lines) the greed of one of our software developers, who added a bit to the rounded-out interest calculation along with a comment to our function.
-
-If you want someone else to test the changes from this tree, you could save this output from diff into a patch file:
-```
-$ diff -Naur sources-orig/ sources-fixed/ >myfixes.patch
-```
-
-Now you have a patch file, myfixes.patch, which can be shared with another developer to apply and test this set of changes. A fellow developer can apply the changes using the patch tool, given that their current working directory is in the base of the source code tree:
-```
-$ patch -p1 < ../myfixes.patch
-patching file officespace/interest.go
-```
-
-Now your fellow developer’s source tree is patched and ready to build and test the changes that were applied via the patch. What if this developer had made changes to interest.go separately? As long as the changes do not conflict directly—for example, change the same exact lines—the patch tool should be able to solve where to merge the changes in. As an example, an interest.go file with several other changes is used in the following example run of patch:
-```
-$ patch -p1 < ../myfixes.patch
-patching file officespace/interest.go
-Hunk #1 succeeded at 26 (offset 15 lines).
-```
-
-In this case, patch warns that the changes did not apply at the original location in the file, but were offset by 15 lines. If you have heavily changed files, patch may give up trying to find where the changes fit, but it does provide options (with requisite warnings in the documentation) for turning up the matching “fuzziness” (which are beyond the scope of this article).
-
-If you are using Git and/or GitHub, you will probably not use the diff or patch tools as standalone tools. Git offers much of this functionality so you can use the built-in capabilities of working on a shared source tree with merging and pulling other developer’s changes. One similar capability is to use git diff to provide the unified diff output in your local tree or between any two references (a commit identifier, the name of a tag or branch, and so on). You can even create a patch file that someone not using Git might find useful by simply piping the git diff output to a file, given that it uses the exact format of the diffcommand that patch can consume. Of course, GitHub takes these capabilities into a web-based user interface so you can view file changes on a pull request. In this view, you will note that it is effectively a unified diff view in your web browser, and GitHub allows you to download these changes as a raw patch file.
-
-### Summary
-
-You’ve learned what a diff and a patch are, as well as the common Unix/Linux command line tools that interact with them. Unless you are a developer on a project still using a patch file-based development method—like the Linux kernel—you will consume these capabilities primarily through a source code control system like Git. But it’s helpful to know the background and underpinnings of features many developers use daily through higher-level tools like GitHub. And who knows—they may come in handy someday when you need to work with patches from a mailing list in the Linux world.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/8/diffs-patches
-
-作者:[Phil Estes][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/estesp
-[1]:https://github.com/TooDumbForAName/ncsa-httpd
-[2]:https://web.archive.org/web/19970615081902/http:/www.apache.org/info.html
-[3]:https://en.wikipedia.org/wiki/Patch_(computing)
-[4]:https://git-scm.com/
-[5]:https://subversion.apache.org/
-[6]:https://lkml.org/
-[7]:https://lists.linuxfoundation.org/pipermail/containers/
-[8]:https://patchwork.kernel.org/project/linux-fsdevel/list/
-[9]:https://www.spinics.net/lists/netdev/
-[10]:https://github.com/
-[11]:https://kubernetes.io/
-[12]:https://www.docker.com/
-[13]:https://github.com/containernetworking/cni
-[14]:https://istio.io/
diff --git a/sources/tech/20180827 Top 10 Raspberry Pi blogs to follow.md b/sources/tech/20180827 Top 10 Raspberry Pi blogs to follow.md
index 243442906c..a6f4e965c5 100644
--- a/sources/tech/20180827 Top 10 Raspberry Pi blogs to follow.md
+++ b/sources/tech/20180827 Top 10 Raspberry Pi blogs to follow.md
@@ -1,3 +1,5 @@
+Translating by jlztan
+
Top 10 Raspberry Pi blogs to follow
======
diff --git a/sources/tech/20180828 A Cat Clone With Syntax Highlighting And Git Integration.md b/sources/tech/20180828 A Cat Clone With Syntax Highlighting And Git Integration.md
index bddc4cac5b..d71bf7f93a 100644
--- a/sources/tech/20180828 A Cat Clone With Syntax Highlighting And Git Integration.md
+++ b/sources/tech/20180828 A Cat Clone With Syntax Highlighting And Git Integration.md
@@ -1,3 +1,6 @@
+Translating by z52527
+
+
A Cat Clone With Syntax Highlighting And Git Integration
======
diff --git a/sources/tech/20180828 How to Play Windows-only Games on Linux with Steam Play.md b/sources/tech/20180828 How to Play Windows-only Games on Linux with Steam Play.md
deleted file mode 100644
index e0eea91e8b..0000000000
--- a/sources/tech/20180828 How to Play Windows-only Games on Linux with Steam Play.md
+++ /dev/null
@@ -1,91 +0,0 @@
-How to Play Windows-only Games on Linux with Steam Play
-======
-The new experimental feature of Steam allows you to play Windows-only games on Linux. Here’s how to use this feature in Steam right now.
-
-You have heard the news. Game distribution platform [Steam is implementing a fork of WINE to allow you to play games that are available on Windows only][1]. This is definitely a great news for us Linux users for we have complained about the lack of the number of games for Linux.
-
-This new feature is still in beta but you can try it out and play Windows-only games on Linux right now. Let’s see how to do that.
-
-### Play Windows-only games in Linux with Steam Play
-
-![Play Windows-only games on Linux][2]
-
-You need to install Steam first. Steam is available for all major Linux distributions. I have written in detail about [installing Steam on Ubuntu][3] and you may refer to that article if you don’t have Steam installed yet.
-
-Once you have Steam installed and you have logged into your Steam account, it’s time to see how to enable Windows games in Steam Linux client.
-
-#### Step 1: Go to Account Settings
-
-Run Steam client. On the top left, click on Steam and then on Settings.
-
-![Enable steam play beta on Linux][4]
-
-#### Step 2: Opt in to the beta program
-
-In the Settings, select Account from left side pane and then click on the CHANGE button under Beta participation.
-
-![Enable beta feature in Steam Linux][5]
-
-You should select Steam Beta Update here.
-
-![Enable beta feature in Steam Linux][6]
-
-Once you save the settings here, Steam will restart and download the new beta updates.
-
-#### Step 3: Enable Steam Play beta
-
-Once Steam has downloaded the new beta updates, it will be restarted. Now you are almost set.
-
-Go to Settings once again. You’ll see a new option Steam Play in the left side pane now. Click on it and check the boxes:
-
- * Enable Steam Play for supported titles (You can play the whitelisted Windows-only games)
- * Enable Steam Play for all titles (You can try to play all Windows-only games)
-
-
-
-![Play Windows games on Linux using Steam Play][7]
-
-I don’t remember if Steam restarts at this point again or not but I guess that’s trivial. You should now see the option to install Windows-only games on Linux.
-
-For example, I have Age of Empires in my Steam library which is not available on Linux normally. But after I enabled Steam Play beta for all Windows titles, it now gives me the option for installing Age of Empires on Linux.
-
-![Install Windows-only games on Linux using Steam][8]
-Windows-only games can now be installed on Linux
-
-### Things to know about Steam Play beta feature
-
-There are a few things you should know and keep in mind about using Windows-only games on Linux with Steam Play beta.
-
- * At present, [only 27 Windows-games are whitelisted][9] for Steam Play. These whitelisted games work seamlessly on Linux.
- * You can try any Windows game with Steam Play beta but it might not work all the time. Some games will crash sometimes while some game might not run at all.
- * While in beta, you won’t see the Windows-only games available for Linux in the Steam store. You’ll have to either try the game on your own or refer to [this community maintained list][10] to see the compatibility status of the said Windows game. You can also contribute to the list by filling [this form][11].
- * If you have games downloaded on Windows via Steam, you can save some download data by [sharing Steam game files between Linux and Windows][12].
-
-
-
-I hope this tutorial helped you in running Windows-only games on Linux. Which game(s) are you looking forward to play on Linux?
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/steam-play/
-
-作者:[Abhishek Prakash][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://itsfoss.com/author/abhishek/
-[1]:https://itsfoss.com/steam-play-proton/
-[2]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/play-windows-games-on-linux-featured.jpeg
-[3]:https://itsfoss.com/install-steam-ubuntu-linux/
-[4]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/enable-steam-play-beta.jpeg
-[5]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/enable-steam-play-beta-2.jpeg
-[6]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/enable-steam-play-beta-3.jpeg
-[7]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/enable-steam-play-beta-4.jpeg
-[8]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/install-windows-games-linux.jpeg
-[9]:https://steamcommunity.com/games/221410
-[10]:https://docs.google.com/spreadsheets/d/1DcZZQ4HL_Ol969UbXJmFG8TzOHNnHoj8Q1f8DIFe8-8/htmlview?sle=true#
-[11]:https://docs.google.com/forms/d/e/1FAIpQLSeefaYQduMST_lg0IsYxZko8tHLKe2vtVZLFaPNycyhY4bidQ/viewform
-[12]:https://itsfoss.com/share-steam-files-linux-windows/
diff --git a/sources/tech/20180828 Linux for Beginners- Moving Things Around.md b/sources/tech/20180828 Linux for Beginners- Moving Things Around.md
new file mode 100644
index 0000000000..abefc7c6f5
--- /dev/null
+++ b/sources/tech/20180828 Linux for Beginners- Moving Things Around.md
@@ -0,0 +1,201 @@
+Linux for Beginners: Moving Things Around
+======
+
+
+
+In previous installments of this series, [you learned about directories][1] and how [permissions to access directories work][2]. Most of what you learned in those articles can be applied to files, except how to make a file executable.
+
+So let's deal with that before moving on.
+
+### No _.exe_ Needed
+
+In other operating systems, the nature of a file is often determined by its extension. If a file has a _.jpg_ extension, the OS guesses it is an image; if it ends in _.wav_ , it is an audio file; and if it has an _.exe_ tacked onto the end of the file name, it is a program you can execute.
+
+This leads to serious problems, like trojans posing as documents. Fortunately, that is not how things work in Linux. Sure, you may see occasional executable file endings in _.sh_ that indicate they are runnable shell scripts, but this is mostly for the benefit of humans eyeballing files, the same way when you use `ls --color`, the names of executable files show up in bright green.
+
+The fact is most applications have no extension at all. What determines whether a file is really program is the _x_ (for _executable_ ) bit. You can make any file executable by running
+```
+chmod a+x some_program
+
+```
+
+regardless of its extension or lack thereof. The `x` in the command above sets the _x_ bit and the `a` says you are setting it for _all_ users. You could also set it only for the group of users that own the file (`g+x`), or for only one user, the owner (`u+x`).
+
+Although we will be covering creating and running scripts from the command line later in this series, know that you can run a program by writing the path to it and then tacking on the name of the program on the end:
+```
+path/to/directory/some_program
+
+```
+
+Or, if you are currently in the same directory, you can use:
+```
+./some_program
+
+```
+
+There are other ways of making your program available from anywhere in the directory tree (hint: look up the `$PATH` environment variable), but you will be reading about those when we talk about shell scripting.
+
+### Copying, Moving, Linking
+
+Obviously, there are more ways of modifying and handling files from the command line than just playing around with their permissions. Most applications will create a new file if you still try to open a file that doesn't exist. Both
+```
+nano test.txt
+
+```
+
+and
+```
+vim test.txt
+
+```
+
+([nano][3] and [vim][4] being to popular command line text editors) will create an empty _test.txt_ file for you to edit if _test.txt_ didn't exist beforehand.
+
+You can also create an empty file by _touching_ it:
+```
+touch test.txt
+
+```
+
+Will create a file, but not open it in any application.
+
+You can use `cp` to make a copy of a file in another location or under a new name:
+```
+cp test.txt copy_of_test.txt
+
+```
+
+You can also copy a whole bunch of files:
+```
+cp *.png /home/images
+
+```
+
+The instruction above copies all the PNG files in the current directory into an _images/_ directory hanging off of your home directory. The _images/_ directory has to exist before you try this, or `cp` will show an error. Also, be warned that, if you copy a file to a directory that contains another file with the same name, `cp` will silently overwrite the old file with the new one.
+
+You can use
+```
+cp -i *.png /home/images
+
+```
+
+If you want `cp` to warn you of any dangers (the `-i` options stands for _interactive_ ).
+
+You can also copy whole directories, but you need the `-r` option for that:
+```
+cp -rv directory_a/ directory_b
+
+```
+
+The `-r` option stands for _recursive_ , meaning that `cp` will drill down into _directory_a_ , copying over all the files and subdirectories contained within. I personally like to include the `-v` option, as it makes `cp` _verbose_ , meaning that it will show you what it is doing instead of just copying silently and then exiting.
+
+The `mv` command moves stuff. That is, it changes files from one location to another. In its simplest form, `mv` looks a lot like `cp`:
+```
+mv test.txt new_test.txt
+
+```
+
+The command above makes _new_test.txt_ appear and _test.txt_ disappear.
+```
+mv *.png /home/images
+
+```
+
+Moves all the PNG files in the current directory to a directory called _images/_ hanging of your home directory. Again you have to be careful you do not overwrite existing files by accident. Use
+```
+mv -i *.png /home/images
+
+```
+
+the same way you would with `cp` if you want to be on the safe side.
+
+Apart from moving versus copying, another difference between `mv` and `cp`is when you move a directory:
+```
+mv directory_a/ directory_b
+
+```
+
+No need for a recursive flag here. This is because what you are really doing is renaming the directory, the same way in the first example, you were renaming the file*. In fact, even when you "move" a file from one directory to another, as long as both directories are on the same storage device and partition, you are renaming the file.
+
+You can do an experiment to prove it. `time` is a tool that lets you measure how long a command takes to execute. Look for a hefty file, something that weighs several hundred MBs or even some GBs (say, something like a long video) and try copying it from one directory to another like this:
+```
+$ time cp hefty_file.mkv another_directory/
+real 0m3,868s
+user 0m0,016s
+sys 0m0,887s
+
+```
+
+In bold is what you have to type into the terminal and below what `time` outputs. The number to focus on is the one on the first line, _real_ time. It takes nearly 4 seconds to copy the 355 MBs of _hefty_file.mkv_ to _another_directory/_.
+
+Now let's try moving it:
+```
+$ time mv hefty_file.mkv another_directory/
+real 0m0,004s
+user 0m0,000s
+sys 0m0,003s
+
+```
+
+Moving is nearly instantaneous! This is counterintuitive, since it would seem that `mv` would have to copy the file and then delete the original. That is two things `mv` has to do versus `cp`'s one. But, somehow, `mv` is 1000 times faster.
+
+That is because the file system's structure, with all its tree of directories, only exists for the users convenience. At the beginning of each partition there is something called a _partition table_ that tells the operating system where to find each file on the actual physical disk. On the disk, data is not split up into directories or even files. [There are tracks, sectors and clusters instead][5]. When you "move" a file within the same partition, what the operating system does is just change the entry for that file in the partition table, but it still points to the same cluster of information on the disk.
+
+Yes! Moving is a lie! At least within the same partition that is. If you try and move a file to a different partition or a different device, `mv` is still fast, but is noticeably slower than moving stuff around within the same partition. That is because this time there is actually copying and erasing of data going on.
+
+### Renaming
+
+There are several distinct command line `rename` utilities around. None are fixtures like `cp` or `mv` and they can work in slightly different ways. What they all have in common is that they are used to change _parts_ of the names of files.
+
+In Debian and Ubuntu, the default `rename` utility uses [regular expressions][6] (patterns of strings of characters) to mass change files in a directory. The instruction:
+```
+rename 's/\.JPEG$/.jpg/' *
+
+```
+
+will change all the extensions of files with the extension _JPEG_ to _jpg_. The file _IMG001.JPEG_ becomes _IMG001.jpg_ , _my_pic.JPEG_ becomes _my_pic.jpg_ , and so on.
+
+Another version of `rename` available by default in Manjaro, a derivative of Arch, is much simpler, but arguably less powerful:
+```
+rename .JPEG .jpg *
+
+```
+
+This does the same renaming as you saw above. In this version, `.JPEG` is the string of characters you want to change, `.jpg` is what you want to change it to, and `*` represents all the files in the current directory.
+
+The bottom line is that you are better off using `mv` if all you want to do is rename one file or directory, and that's because `mv` is realiably the same in all distributions everywhere.
+
+### Learning more
+
+Check out the both `mv` and `cp`'s _man_ pages to learn more. Run
+```
+man cp
+
+```
+
+or
+```
+man mv
+
+```
+
+to read about all the options these commands come with and which make them more powerful and safer to use.
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/blog/2018/8/linux-beginners-moving-things-around
+
+作者:[Paul Brown][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.linux.com/users/bro66
+[1]: https://www.linux.com/blog/learn/2018/5/manipulating-directories-linux
+[2]: https://www.linux.com/blog/learn/intro-to-linux/2018/7/users-groups-and-other-linux-beasts-part-2
+[3]: https://www.nano-editor.org/
+[4]: https://www.vim.org/
+[5]: https://en.wikipedia.org/wiki/Disk_sector
+[6]: https://en.wikipedia.org/wiki/Regular_expression
diff --git a/sources/tech/20180829 Add GUIs to your programs and scripts easily with PySimpleGUI.md b/sources/tech/20180829 Add GUIs to your programs and scripts easily with PySimpleGUI.md
deleted file mode 100644
index 383d4c514f..0000000000
--- a/sources/tech/20180829 Add GUIs to your programs and scripts easily with PySimpleGUI.md
+++ /dev/null
@@ -1,325 +0,0 @@
-Add GUIs to your programs and scripts easily with PySimpleGUI
-======
-
-
-
-Few people run Python programs by double-clicking the .py file as if it were a .exe file. When a typical user (non-programmer types) double-clicks an .exe file, they expect it to pop open with a window they can interact with. While GUIs, using tkinter, are possible using standard Python installations, it's unlikely many programs do this.
-
-What if it were so easy to open a Python program into a GUI that complete beginners could do it? Would anyone care? Would anyone use it? It's difficult to answer because to date it's not been easy to build a custom GUI.
-
-There seems to be a gap in the ability to add a GUI onto a Python program/script. Complete beginners are left using only the command line and many advanced programmers don't want to take the time required to code up a tkinter GUI.
-
-### GUI frameworks
-
-There is no shortage of GUI frameworks for Python. Tkinter, WxPython, Qt, and Kivy are a few of the major packages. In addition, there are a good number of dumbed-down GUI packages that "wrap" one of the major packages, including EasyGUI, PyGUI, and Pyforms.
-
-The problem is that beginners (those with less than six weeks of experience) can't learn even the simplest of the major packages. That leaves the wrapper packages as a potential option, but it will still be difficult or impossible for most new users to build a custom GUI layout. Even if it's possible, the wrappers still require pages of code.
-
-[PySimpleGUI][1] attempts to address these GUI challenges by providing a super-simple, easy-to-understand interface to GUIs that can be easily customized. Even many complex GUIs require less than 20 lines of code when PySimpleGUI is used.
-
-### The secret
-
-What makes PySimpleGUI superior for newcomers is that the package contains the majority of the code that the user is normally expected to write. Button callbacks are handled by PySimpleGUI, not the user's code. Beginners struggle to grasp the concept of a function, and expecting them to understand a call-back function in the first few weeks is a stretch.
-
-With most GUIs, arranging GUI widgets often requires several lines of code… at least one or two lines per widget. PySimpleGUI uses an "auto-packer" that automatically creates the layout. No pack or grid system is needed to lay out a GUI window.
-
-Finally, PySimpleGUI leverages the Python language constructs in clever ways that shorten the amount of code and return the GUI data in a straightforward manner. When a widget is created in a form layout, it is configured in place, not several lines of code away.
-
-### What is a GUI?
-
-Most GUIs do one thing: collect information from the user and return it. From a programmer's viewpoint, this could be summed up as a function call that looks like this:
-```
-button, values = GUI_Display(gui_layout)
-
-```
-
-What's expected from most GUIs is the button that was clicked (e.g., OK, cancel, save, yes, no, etc.) and the values input by the user. The essence of a GUI can be boiled down to a single line of code.
-
-This is exactly how PySimpleGUI works (for simple GUIs). When the call is made to display the GUI, nothing executes until a button is clicked that closes the form.
-
-There are more complex GUIs, such as those that don't close after a button is clicked. Examples include a remote control interface for a robot and a chat window. These complex forms can also be created with PySimpleGUI.
-
-### Making a quick GUI
-
-When is PySimpleGUI useful? Immediately, whenever you need a GUI. It takes less than five minutes to create and try a GUI. The quickest way to make a GUI is to copy one from the [PySimpleGUI Cookbook][2]. Follow these steps:
-
- * Find a GUI that looks similar to what you want to create
- * Copy code from the Cookbook
- * Paste it into your IDE and run it
-
-
-
-Let's look at the first recipe from the book.
-```
-import PySimpleGUI as sg
-
-# Very basic form. Return values as a list
-form = sg.FlexForm('Simple data entry form') # begin with a blank form
-
-layout = [
- [sg.Text('Please enter your Name, Address, Phone')],
- [sg.Text('Name', size=(15, 1)), sg.InputText('name')],
- [sg.Text('Address', size=(15, 1)), sg.InputText('address')],
- [sg.Text('Phone', size=(15, 1)), sg.InputText('phone')],
- [sg.Submit(), sg.Cancel()]
- ]
-
-button, values = form.LayoutAndRead(layout)
-
-print(button, values[0], values[1], values[2])
-```
-It's a reasonably sized form.
-
-
-
-If you just need to collect a few values and they're all basically strings, you could copy this recipe and modify it to suit your needs.
-
-You can even create a custom GUI layout in just five lines of code.
-```
-import PySimpleGUI as sg
-
-form = sg.FlexForm('My first GUI')
-
-layout = [ [sg.Text('Enter your name'), sg.InputText()],
- [sg.OK()] ]
-
-button, (name,) = form.LayoutAndRead(layout)
-```
-
-
-
-### Making a custom GUI in five minutes
-
-If you have a straightforward layout, you should be able create a custom layout in PySimpleGUI in less than five minutes by modifying code from the Cookbook.
-
-Widgets are called elements in PySimpleGUI. These elements are spelled exactly as you would type them into your Python code.
-
-#### Core elements
-```
-Text
-InputText
-Multiline
-InputCombo
-Listbox
-Radio
-Checkbox
-Spin
-Output
-SimpleButton
-RealtimeButton
-ReadFormButton
-ProgressBar
-Image
-Slider
-Column
-```
-
-#### Shortcut list
-
-PySimpleGUI also has two types of element shortcuts. One type is simply other names for the exact same element (e.g., `T` instead of `Text`). The second type configures an element with a particular setting, sparing you from specifying all parameters (e.g., `Submit` is a button with the text "Submit" on it)
-```
-T = Text
-Txt = Text
-In = InputText
-Input = IntputText
-Combo = InputCombo
-DropDown = InputCombo
-Drop = InputCombo
-```
-
-#### Button shortcuts
-
-A number of common buttons have been implemented as shortcuts. These include:
-```
-FolderBrowse
-FileBrowse
-FileSaveAs
-Save
-Submit
-OK
-Ok
-Cancel
-Quit
-Exit
-Yes
-No
-```
-
-There are also shortcuts for more generic button functions.
-```
-SimpleButton
-ReadFormButton
-RealtimeButton
-```
-
-These are all the GUI widgets you can choose from in PySimpleGUI. If one isn't on these lists, it doesn't go in your form layout.
-
-#### GUI design pattern
-
-The stuff that tends not to change in GUIs are the calls that set up and show a window. The layout of the elements is what changes from one program to another.
-
-Here is the code from the example above with the layout removed:
-```
-import PySimpleGUI as sg
-
-form = sg.FlexForm('Simple data entry form')
-# Define your form here (it's a list of lists)
-button, values = form.LayoutAndRead(layout)
-```
-
-The flow for most GUIs is:
-
- * Create the form object
- * Define the GUI as a list of lists
- * Show the GUI and get results
-
-
-
-These are line-for-line what you see in PySimpleGUI's design pattern.
-
-#### GUI layout
-
-To create your custom GUI, first break your form down into rows, because forms are defined one row at a time. Then place one element after another, working from left to right.
-
-The result is a "list of lists" that looks something like this:
-```
-layout = [ [Text('Row 1')],
- [Text('Row 2'), Checkbox('Checkbox 1', OK()), Checkbox('Checkbox 2'), OK()] ]
-
-```
-
-This layout produces this window:
-
-
-
-### Displaying the GUI
-
-Once you have your layout complete and you've copied the lines of code that set up and show the form, it's time to display the form and get values from the user.
-
-This is the line of code that displays the form and provides the results:
-```
-button, values = form.LayoutAndRead(layout)
-```
-
-Forms return two values: the text of the button that is clicked and a list of values the user enters into the form.
-
-If the example form is displayed and the user does nothing other than clicking the OK button, the results would be:
-```
-button == 'OK'
-values == [False, False]
-```
-
-Checkbox elements return a value of True or False. Because the checkboxes defaulted to unchecked, both the values returned were False.
-
-### Displaying results
-
-Once you have the values from the GUI, it's nice to check what values are in the variables. Rather than printing them out using a `print` statement, let's stick with the GUI idea and output the data to a window.
-
-PySimpleGUI has a number of message boxes to choose from. The data passed to the message box is displayed in a window. The function takes any number of arguments. You can simply indicate all the variables you want to see in the call.
-
-The most commonly used message box in PySimpleGUI is MsgBox. To display the results from the previous example, write:
-```
-MsgBox('The GUI returned:', button, values)
-```
-
-### Putting it all together
-
-Now that you know the basics, let's put together a form that contains as many of PySimpleGUI's elements as possible. Also, to give it a nice appearance, we'll change the "look and feel" to a green and tan color scheme.
-```
-import PySimpleGUI as sg
-
-sg.ChangeLookAndFeel('GreenTan')
-
-form = sg.FlexForm('Everything bagel', default_element_size=(40, 1))
-
-column1 = [[sg.Text('Column 1', background_color='#d3dfda', justification='center', size=(10,1))],
- [sg.Spin(values=('Spin Box 1', '2', '3'), initial_value='Spin Box 1')],
- [sg.Spin(values=('Spin Box 1', '2', '3'), initial_value='Spin Box 2')],
- [sg.Spin(values=('Spin Box 1', '2', '3'), initial_value='Spin Box 3')]]
-layout = [
- [sg.Text('All graphic widgets in one form!', size=(30, 1), font=("Helvetica", 25))],
- [sg.Text('Here is some text.... and a place to enter text')],
- [sg.InputText('This is my text')],
- [sg.Checkbox('My first checkbox!'), sg.Checkbox('My second checkbox!', default=True)],
- [sg.Radio('My first Radio! ', "RADIO1", default=True), sg.Radio('My second Radio!', "RADIO1")],
- [sg.Multiline(default_text='This is the default Text should you decide not to type anything', size=(35, 3)),
- sg.Multiline(default_text='A second multi-line', size=(35, 3))],
- [sg.InputCombo(('Combobox 1', 'Combobox 2'), size=(20, 3)),
- sg.Slider(range=(1, 100), orientation='h', size=(34, 20), default_value=85)],
- [sg.Listbox(values=('Listbox 1', 'Listbox 2', 'Listbox 3'), size=(30, 3)),
- sg.Slider(range=(1, 100), orientation='v', size=(5, 20), default_value=25),
- sg.Slider(range=(1, 100), orientation='v', size=(5, 20), default_value=75),
- sg.Slider(range=(1, 100), orientation='v', size=(5, 20), default_value=10),
- sg.Column(column1, background_color='#d3dfda')],
- [sg.Text('_' * 80)],
- [sg.Text('Choose A Folder', size=(35, 1))],
- [sg.Text('Your Folder', size=(15, 1), auto_size_text=False, justification='right'),
- sg.InputText('Default Folder'), sg.FolderBrowse()],
- [sg.Submit(), sg.Cancel()]
- ]
-
-button, values = form.LayoutAndRead(layout)
-sg.MsgBox(button, values)
-```
-
-This may seem like a lot of code, but try coding this same GUI layout directly in tkinter and you'll quickly realize how tiny it is.
-
-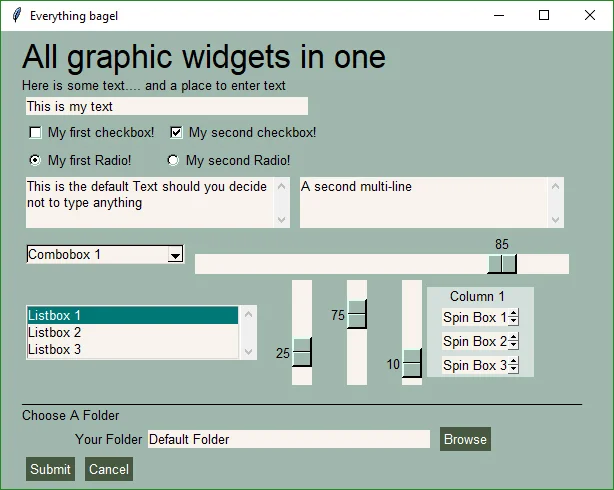
-
-The last line of code opens a message box. This is how it looks:
-
-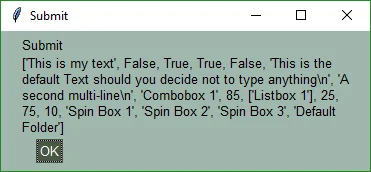
-
-Each parameter to the message box call is displayed on a new line. There are two lines of text in the message box; the second line is very long and wrapped a number of times
-
-Take a moment and pair up the results values with the GUI to get an understanding of how results are created and returned.
-
-### Adding a GUI to Your Program or Script
-
-If you have a script that uses the command line, you don't have to abandon it in order to add a GUI. An easy solution is that if there are zero parameters given on the command line, then the GUI is run. Otherwise, execute the command line as you do today.
-
-This kind of logic is all that's needed:
-```
-if len(sys.argv) == 1:
- # collect arguments from GUI
-else:
- # collect arguements from sys.argv
-```
-
-The easiest way to get a GUI up and running quickly is to copy and modify one of the recipes from the [PySimpleGUI Cookbook][2].
-
-Have some fun! Spice up the scripts you're tired of running by hand. Spend 5 or 10 minutes playing with the demo scripts. You may find one already exists that does exactly what you need. If not, you will find it's simple to create your own. If you really get lost, you've only invested 10 minutes.
-
-### Resources
-
-#### Installation
-
-PySimpleGUI works on all systems that run tkinter, including Raspberry Pi, and it requires Python 3
-```
-pip install PySimpleGUI
-```
-
-#### Documentation
-
-+ [Manual][3]
-+ [Cookbook][4]
-+ [GitHub repository][5]
-
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/8/pysimplegui
-
-作者:[Mike Barnett][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/pysimplegui
-[1]: https://github.com/MikeTheWatchGuy/PySimpleGUI
-[2]: https://pysimplegui.readthedocs.io/en/latest/cookbook/
-[3]: https://pysimplegui.readthedocs.io/en/latest/cookbook/
-[4]: https://pysimplegui.readthedocs.io/en/latest/cookbook/
-[5]: https://github.com/MikeTheWatchGuy/PySimpleGUI
diff --git a/sources/tech/20180830 6 places to host your git repository.md b/sources/tech/20180830 6 places to host your git repository.md
new file mode 100644
index 0000000000..671b120a39
--- /dev/null
+++ b/sources/tech/20180830 6 places to host your git repository.md
@@ -0,0 +1,57 @@
+6 places to host your git repository
+======
+
+
+
+Perhaps you're one of the few people who didn't notice, but a few months back, [Microsoft bought GitHub][1]. Nothing against either company. Microsoft has become a vocal supporter of open source in recent years, and GitHub has been the de facto code repository for a heaping large number of open source projects almost since its inception.
+
+However, the recent(-ish) purchase may have gotten you a little itchy. After all, there's nothing quite like a corporate buy-out to make you realize you've had your open source code sitting on a commercial platform. Maybe you're not quite ready to jump ship just yet, but it would at least be helpful to know your options. Let's have a look around the web and see what's available.
+
+### Option 1: GitHub
+
+Seriously, this is a valid option. [GitHub][2] doesn't have a history of acting in bad faith, and Microsoft certainly has been smiling on open source of late. There's nothing wrong with keeping your project on GitHub and taking a wait-and-see perspective. It's still the largest community website for software development, and it still has some of the best tools for issue tracking, code review, continuous integration, and general code management. And its underpinnings are still on Git, everyone's favorite open source distributed version control system. Your code is still your code. There's nothing wrong with leaving things where they are if nothing is broken.
+
+### Option 2: GitLab
+
+[GitLab][3] is probably the leading contender when it comes to alternative code platforms. It's fully open source. You can host your code right on GitLab's site much like you would on GitHub, but you can also choose to self-host a GitLab instance of your own on your own server and have full control over who has access to everything there and how things are managed. GitLab pretty much has feature parity with GitHub, and some folks might even say its continuous integration and testing tools are superior. Although the community of developers on GitLab is certainly smaller than the one on GitHub, it's still nothing to sneeze at. And it's possible that you'll find more like-minded developers among the population there.
+
+### Option 3: Bitbucket
+
+[Bitbucket][4] has been around for many years. In some ways, it could serve as a looking glass into the future of GitHub. Bitbucket was acquired by a larger corporation (Atlassian) eight years ago and has already been through some of that change-over process. It's still a commercial platform like GitHub, but it's far from being a startup, and it's on pretty stable footing, organizationally speaking. Bitbucket shares most of the features available on GitHub and GitLab, plus a few novel features of its own, like native support for [Mercurial][5] repositories.
+
+### Option 4: SourceForge
+
+The granddaddy of open source code repository sites is [SourceForge][6]. It used to be that if you had an open source project, SourceForge was the place to host your code and share your releases. It took a little while to migrate to Git for version control, and it had its own rash of commercial acquiring and re-acquiring events, coupled with a few unfortunate bundling decisions for a few open source projects. That said, SourceForge seems to have recovered since then, and the site is still a place where quite a few open source projects live. A lot of folks still feel a bit burned, though, and some people aren't huge fans of its various attempts to monetize the platform, so be sure you go in with open eyes.
+
+### Option 5: Roll your own
+
+If you want full control of your project's destiny (and no one to blame but yourself), then doing it all yourself may be the best option for you. It is a good alternative for both large and small projects. Git is open source, so it's easily self-hosted. If you want issue tracking and code review, you can run an instance of GitLab or [Phabricator][7]. For continuous integration, you can set up your own instance of the [Jenkins][8] automation server. Yes, you'll need to take responsibility for your own infrastructure overhead and the associated security requirements. However, it's not that hard to get yourself set up. And if you want a sure-fire way to avoid being beholden to the whims of anyone else's platform, this is the way to do it.
+
+### Option 6: All of the above
+
+Here's the beauty of all of this: Despite the proprietary drapery strewn over some of these platforms, they're still built on top of solid open source technology. And not just open source, but explicitly designed to be distributed across multiple nodes on a large network (like the internet). You're not required to use just one. You can use a couple… or all of them. Roll your own setup as a guaranteed home base using GitLab and have clone repositories on GitHub and Bitbucket for issue tracking and continuous integration. Keep your main codebase on GitHub but have "backup" clones sitting on GitLab for your own piece of mind.
+
+The key thing is you have options. And we have those options thanks to open source licensing on very useful and powerful projects. The future is bright.
+
+Of course, I'm bound to have missed some of the open source options available out there. Feel free to pipe up with your favorites. Are you using multiple platforms? What's your setup? Let everyone know in the comments!
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/8/github-alternatives
+
+作者:[Jason van Gumster][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/mairin
+[1]: https://www.theverge.com/2018/6/4/17422788/microsoft-github-acquisition-official-deal
+[2]: https://github.com/
+[3]: https://gitlab.com
+[4]: https://bitbucket.org
+[5]: https://www.mercurial-scm.org/wiki/Repository
+[6]: https://sourceforge.net
+[7]: https://phacility.com/phabricator/
+[8]: https://jenkins.io
diff --git a/sources/tech/20180830 A quick guide to DNF for yum users.md b/sources/tech/20180830 A quick guide to DNF for yum users.md
new file mode 100644
index 0000000000..559591b516
--- /dev/null
+++ b/sources/tech/20180830 A quick guide to DNF for yum users.md
@@ -0,0 +1,131 @@
+A quick guide to DNF for yum users
+======
+
+
+
+Dandified yum, better known as [DNF][1], is a software package manager for RPM-based Linux distributions that installs, updates, and removes packages. It was first introduced in Fedora 18 in a testable state (i.e., tech preview), but it's been Fedora's default package manager since Fedora 22.
+
+ * Dependency calculation based on modern dependency-solving technology
+ * Optimized memory-intensive operations
+ * The ability to run in Python 2 and Python 3
+ * Complete documentation available for Python APIs
+
+
+
+Since it is the next-generation version of the traditional yum package manager, it has more advanced and robust features than you'll find in yum. Some of the features that distinguish DNF from yum are:
+
+DNF uses [hawkey][2] libraries, which resolve RPM dependencies for running queries on client machines. These are built on top of libsolv, a package-dependency solver that uses a satisfiability algorithm. You can find more details on the algorithm in [libsolv's GitHub][3] repository.
+
+### CLI commands that differ in DNF and yum
+
+Following are some of the changes to yum's command-line interface (CLI) you will find in DNF.
+
+**dnf update** or **dnf upgrade:** Executing either dnf update or dnf upgrade has the same effect in the system: both update installed packages. However, dnf upgrade is preferred since it works exactly like **yum --obsoletes update**.
+
+**resolvedep:** This command doesn't exist in DNF. Instead, execute **dnf provides** to find out which package provides a particular file.
+
+**deplist:** Yum's deplist command, which lists RPM dependencies, was removed in DNF because it uses the package-dependency solver algorithm to solve the dependency query.
+
+**dnf remove :** You must specify concrete versions of whatever you want to remove. For example, **dnf remove kernel** will delete all packages called "kernel," so make sure to use something like **dnf remove kernel-4.16.x**.
+
+**dnf history rollback:** This check, which undoes transactions after the one you specifiy, was dropped since not all the possible changes in the RPM Database Tool are stored in the history of the transaction.
+
+**--skip-broken:** This install command, which checks packages for dependency problems, is triggered in yum with --skip-broken. However, now it is part of dnf update by default, so there is no longer any need for it.
+
+**-b, --best:** These switches select the best available package versions in transactions. During dnf upgrade, which by default skips over updates that cannot be installed for dependency reasons, this switch forces DNF to consider only the latest packages. Use **dnf upgrade --best**.
+
+**--allowerasing:** Allows erasing of installed packages to resolve dependencies. This option could be used as an alternative to the **yum swap X Y** command, in which the packages to remove are not explicitly defined.
+
+For example: **dnf --allowerasing install Y**.
+
+**\--enableplugin:** This switch is not recognized and has been dropped.
+
+### DNF Automatic
+
+The [DNF Automatic][4] tool is an alternative CLI to dnf upgrade. It can execute automatically and regularly from systemd timers, cron jobs, etc. for auto-notification, downloads, or updates.
+
+To start, install dnf-automatic rpm and enable the systemd timer unit (dnf-automatic.timer). It behaves as specified by the default configuration file (which is /etc/dnf/automatic.conf).
+```
+# yum install dnf-automatic
+# systemctl enable dnf-automatic.timer
+# systemctl start dnf-automatic.timer
+# systemctl status dnf-automatic.timer
+```
+
+
+
+Other timer units that override the default configuration are listed below. Select the one that meets your system requirements.
+
+ * **dnf-automatic-notifyonly.timer:** Notifies the available updates
+ * **dnf-automatic-download.timer:** Downloads packages, but doesn't install them
+ * **dnf-automatic-install.timer:** Downloads and installs updates
+
+
+
+### Basic DNF commands useful for package management
+
+**# yum install dnf:** This installs DNF RPM from the yum package manager.
+
+
+
+**# dnf –version:** This specifies the DNF version.
+
+
+
+**# dnf list all** or **# dnf list :** This lists all or specific packages; this example lists the kernel RPM available in the system.
+
+
+
+**# dnf check-update** or **# dnf check-update kernel:** This views updates in the system.
+
+
+
+**# dnf search :** When you search for a specific package via DNF, it will search for an exact match as well as all wildcard searches available in the repository.
+
+
+
+**# dnf repolist all:** This downloads and lists all enabled repositories in the system.
+
+
+
+**# dnf list --recent** or **# dnf list --recent :** The **\--recent** option dumps all recently added packages in the system. Other list options are **\--extras** , **\--upgrades** , and **\--obsoletes**.
+
+
+
+**# dnf updateinfo list available** or **# dnf updateinfo list available sec:** These list all the advisories available in the system; including the sec option will list all advisories labeled "security fix."
+
+
+
+**# dnf updateinfo list available sec --sec-severity Critical:** This lists all the security advisories in the system marked "critical."
+
+
+
+**# dnf updateinfo FEDORA-2018-a86100a264 –info:** This verifies the information of any advisory via the **\--info** switch.
+
+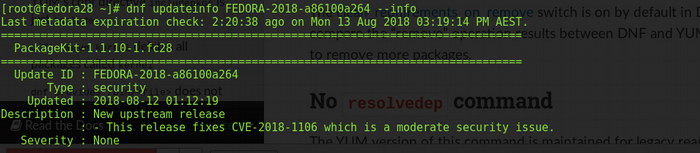
+
+**# dnf upgrade --security** or **# dnf upgrade --sec-severity Critical:** This applies all the security advisories available in the system. With the **\--sec-severity** option, you can include the packages with severity marked either Critical, Important, Moderate, or Low.
+
+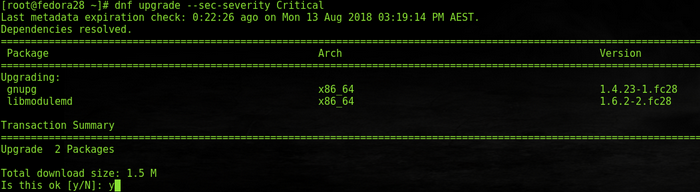
+
+### Summary
+
+These are just a small number of DNF's features, changes, and commands. For complete information about DNF's CLI, new plugins, and hook APIs, refer to the [DNF guide][5].
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/8/guide-yum-dnf
+
+作者:[Amit Das][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/amit-das
+[1]: https://fedoraproject.org/wiki/DNF?rd=Dnf
+[2]: https://fedoraproject.org/wiki/Features/Hawkey
+[3]: https://github.com/openSUSE/libsolv
+[4]: https://dnf.readthedocs.io/en/latest/automatic.html
+[5]: https://dnf.readthedocs.io/en/latest/index.html
diff --git a/sources/tech/20180830 How to scale your website across all mobile devices.md b/sources/tech/20180830 How to scale your website across all mobile devices.md
new file mode 100644
index 0000000000..ad36b9017a
--- /dev/null
+++ b/sources/tech/20180830 How to scale your website across all mobile devices.md
@@ -0,0 +1,85 @@
+How to scale your website across all mobile devices
+======
+
+
+
+Most of us surf the internet, make online purchases, and even pay bills using our mobile devices because they are handy and easily accessible. According to a Forrester study, [The Digital Business Imperative][1], 43% of banking customers in the US used mobile phones to complete banking transactions in a three-month period.
+
+The significant year-over-year growth of online business transactions done via mobile devices has encouraged companies to build websites and e-commerce sites that look, feel, and function identically on computers and smart mobile devices. However, many users still find the experience of browsing a website on a smartphone isn’t the same as on a computer. In order to develop websites that scale effectively and smoothly across different devices, it's important to understand what causes these differences across platforms.
+
+Web pages are usually composed of one or more of the following components: Header and footer, main content (text), images, forms, videos, and tables. Devices differ on features such as screen dimension (length x width), screen resolution (pixel density), compute power (CPU and memory), and operating system (iOS, Android, Windows, etc.). These differences contribute significantly to the overall performance and rendering of web components such as images, videos, and text across different devices. Another important factor is that mobile users may not always be connected to a high-speed network, so web pages should be carefully designed to work effectively on low-bandwidth connections.
+
+### The most troublesome issues on mobile platforms
+
+Here are some of the most common issues that can affect the performance and scalability of websites across devices:
+
+ * **Sites do not automatically adapt to different screen sizes.** Some websites are designed to format for variable screen sizes, but their elements may not auto-scale. This would result in the site automatically adjusting itself for various screen sizes, but the elements in the site may look too large on smaller devices. Some sites may not be designed to adjust for variable screen sizes, causing the elements to look extremely small on devices with smaller screens.
+ * **Sites have too much content for mobile devices.** Some websites are loaded with content to fill empty space on a desktop screen. Websites developed without considering mobile users generally fall under this category. These sites take more time and bandwidth to load, and if the pages aren’t designed appropriately for mobile devices, some content may not even appear.
+ * **Sites take too long to load images.** Websites with too many images or heavy image files are likely to take a long time to load, especially if the images were not optimized during the design phase.
+ * **Data in tables looks complex and takes too long to load.** Many websites present data in a tabular fashion (for example, comparisons of competing products, airfare data from different travel sites, flight schedules, etc.), and on mobile devices, these tables can be slow and difficult to comprehend.
+ * **Websites host videos that don’t play on some devices.** Not all mobile devices support all video formats. Some websites host media that require licenses, Adobe Flash, or other players that some mobile devices may not support. This causes frustration and a poor overall user experience.
+
+
+
+### Design your sites to adapt to different devices
+
+All these issues can be addressed through proper design and by adopting a [mobile-first][2] approach. When working with limitations such as screen size, bandwidth, etc., focus on the right quantity and quality of content. A mobile-first strategy places content as the primary object and designs for the smallest devices, ensuring that a site includes only the most essential features. Address the design challenges for mobile devices first, and then progressively enhance the design for larger devices.
+
+Here are a few best practices to consider when designing websites that need to scale on different devices.
+
+* **Adapting to any screen size**. At a minimum, a web page needs to be scaled to fit the screen size of any mobile device. Today's mobile devices come with very high screen resolutions. The pixel density on mobile devices is much higher than that of desktop screens, so it is important to format pages to match the mobile screen’s width in device-independent pixels. The “meta viewport” tag included in the HTML document addresses this requirement.
+
+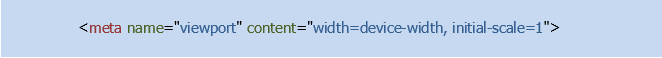
+
+The meta viewport value, as shown above, helps format the entire HTML page and render the content to match any screen size.
+
+* **" Content is king."** Content should determine the design of a website, not vice versa. Websites with too many elements such as tables, forms, charts, etc., become challenging when they need to scale on mobile devices. Developers end up hiding content for mobile users, and the desktop version and the mobile version become inconsistent. The design should focus on the core structure and content rather than decorative elements. The mobile-first methodology ensures a single version of content for both desktop and mobile users, so web designers should carefully consider, craft, and optimize content so that it not only satisfies business goals but also appeals to mobile users. Content that doesn’t appear in the mobile version may not even need to appear in the desktop version.
+* **Responsive images**. The design should consider small hand-held devices operating in areas with low signal strength. Large photos and complex graphics are not suitable for mobile devices operating under such conditions. Make sure all images are optimized for different sizes of viewports and pixel densities. A recommended approach is [resolution switching][3], which enables the browser to select an appropriately sized image file, depending on the screen size of a device. Resolution switching uses two attributes—`srcset` and `sizes` (shown in the code snippet shown below)—which enable the browser to use the device width to select the most suitable media condition provided in the sizes list, choose the slot size based on that condition, and load the image referenced in the `srcset` that most closely matches the chosen slot size.
+
+
+
+For example, if a device with a viewport of 320px loads the page, the media condition (max-width: 320px) in the sizes list will be true, and the corresponding 280px slot will be chosen. The width of the first image listed in `srcset` (elephant-320w.jpg) is the closest to this slot. Browsers that don’t support resolution switching display the image listed in the src attribute as the default image. This approach not only picks the right image for your device viewport, but it also prevents loading unnecessarily large images that consume significant bandwidth.
+
+
+
+* **Responsive tables.** As the world becomes more data-driven, bringing critical, time-sensitive data to handheld devices provides power and freedom to users. The challenge is to present data in a way that is easy to load and read on mobile devices. Some data needs to be presented in the form of a table, but when data tables get too large and unwieldy, it can be frustrating for users to interpret them on a mobile device with a small screen. If the screen is much narrower than the width of the table, for example, users are forced to zoom out, making the text too small to read. Conversely, if the screen is wider than the table, users must zoom in to view the data, which requires constant vertical and horizontal scrolling.
+
+Fortunately, there are several ways to build [responsive tables][4]. Here is one of the most effective:
+
+ * The table's columns are transposed into rows. Each column is sized to the same width as the screen, preventing the need to scroll horizontally. Use of color helps users clearly distinguish each individual row of data. In this case, for each “cell,” the CSS-generated content `(:before)` should be used to apply the label so that each piece of data can be identified clearly.
+ * Another approach is to display the data in one of two formats, based on screen width: chart format (for narrow screens) or complete table format (for wider screens). If the user wants to click the chart to see the complete table, the approach described above can be used to show the data in tabular form.(:before)
+ * A third approach is to show a mini-graphic in a narrow screen to indicate the presence of a table. The user can click on the graphic to expand and display the table.
+* **Videos that always play.** [Video files][5] generally won’t play on mobile devices if their formats are unsupported or if they require a proprietary video player. The recommended approach is to use standard HTML5 tags for videos and animations. The video element in HTML5 can be used to load, decode, and play videos on your website. Produce video in multiple formats to suit different mobile platforms, and be sure to size videos appropriately so that they play within their containers.
+
+The example below shows the use of tags to specify different video formats (indicated by the type element). In this approach, the switch to the correct format happens at the client side, and only one request is made to the server. This reduces network latency and lets the browser select the most appropriate video format without first downloading it.
+
+
+
+The `videoWidth` and `videoHeight` properties of the video element help identify the encoded size of a video. Video dimensions can be controlled using JavaScript or CSS. `max-width: 100%` helps size the videos to fit the screen. CSS media queries can be used to set the size based on the viewport dimensions. There are also several JavaScript libraries and plugins that can maintain the aspect ratio and size of videos.
+
+### All things considered…
+
+These days, users regularly surf the web and perform business transactions with their smartphones and tablets. The web is becoming the primary business channel for many businesses worldwide. Consequently, it is important to develop websites that work and scale well on mobile devices. The goal is to enhance the mobile user experience so that it mirrors the functionality and performance of desktop computers and large monitors.
+
+The mobile-first approach helps web designers create sites that operate well on small mobile devices. Design should focus on content that satisfies business requirements while also considering technical limitations such as screen size, processor speed, memory, and operating conditions (e.g., poor network signal strength). It must also ensure that pictures, videos, and data are responsive across all mobile devices while remaining sensitive to breakpoints, touch targets, etc.
+
+A well-designed website that works and scales on a small device can always be progressively enhanced to work on larger devices.
+
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/8/how-scale-your-website-across-all-devices
+
+作者:[Sridhar Asvathanarayanan][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/sasvathanarayanangmailcom
+[1]: https://www.forrester.com/report/The+Digital+Business+Imperative/-/E-RES115784#
+[2]: https://www.uxpin.com/studio/blog/a-hands-on-guide-to-mobile-first-design/
+[3]: https://developer.mozilla.org/en-US/docs/Learn/HTML/Multimedia_and_embedding/Responsive_images
+[4]: https://css-tricks.com/responsive-data-tables/
+[5]: https://developers.google.com/web/fundamentals/media/video
diff --git a/sources/tech/20180831 3 innovative open source projects for the new school year.md b/sources/tech/20180831 3 innovative open source projects for the new school year.md
new file mode 100644
index 0000000000..e8493ed501
--- /dev/null
+++ b/sources/tech/20180831 3 innovative open source projects for the new school year.md
@@ -0,0 +1,59 @@
+3 innovative open source projects for the new school year
+======
+
+
+
+I first wrote about open source learning software for educators in the fall of 2013. Fast-forward five years—today, open source software and principles have moved from outsiders in the education industry to the popular crowd.
+
+Since Penn Manor School District has [adopted open software][1] and cultivated a learning community built on trust, we've watched student creativity, ingenuity, and engagement soar. Here are three free and open source software tools we’ve used during the past school year. All three have enabled great student projects and may spark cool classroom ideas for open-minded educators.
+
+### Catch a wave: Software-defined radio
+
+Students may love the modern sounds of Spotify and Soundcloud, but there's an old-school charm to snatching noise from the atmosphere. Penn Manor help desk student apprentices had serious fun with [software-defined radio][2] (SDR). With an inexpensive software-defined radio kit, students can capture much more than humdrum FM radio stations. One of our help desk apprentices, JR, discovered everything from local emergency radio chatter to unencrypted pager messages.
+
+Our basic setup involved a student’s Linux laptop running [gqrx software][3] paired with a [USB RTL-SDR tuner and a simple antenna][4]. It was light enough to fit in a student backpack for SDR on the go. And the kit was great for creative hacking, which JR demonstrated when he improvised all manner of antennas, including a frying pan, in an attempt to capture signals from the U.S. weather satellite [NOAA-18][5].
+
+Former Penn Manor IT specialist Tom Swartz maintains an excellent [quick-start resource for SDR][6].
+
+### Stream far for a middle school crowd: OBS Studio
+
+Remember live morning TV announcements in school? Amateur weather reports, daily news updates, middle school puns... In-house video studios are an excellent opportunity for fun collaboration and technical learning. But many schools are stuck running proprietary broadcast and video mixing software, and many more are unable to afford costly production hardware such as [NewTek’s TriCaster][7].
+
+Cue [OBS Studio][8], a free, open source, real-time broadcasting program ideally suited for school projects as well as professional video streaming. During the past six months, several Penn Manor schools successfully upgraded to OBS Studio running on Linux. OBS handles our multi-source video and audio mixing, chroma key compositing, transitions, and just about anything else students need to run a surprising polished video broadcast.
+
+Penn Manor students stream a live morning show via UDP multicast to staff and students tuned in via the [mpv][9] media player. OBS also supports live streaming to YouTube, Facebook Live, and Twitch, which means students can broadcast daily school lunch menus and other vital updates to the world.
+
+### Self-drive by light: TurtleBot3 and Lidar
+
+Of course, robots are cool, but robots with lasers are ace. The newest star of the Penn Manor student help desk is Patch, a petite educational robot built with the [TurtleBot3][10] open hardware and software kit. The Turtlebot platform is extensible and great for hardware hacking, but we were most interested in creating a self-driving gadget.
+
+We used the Turtlebot3 Burger, the entry-level kit powered by a Raspberry PI and loaded with a laser distance sensor. New student tech apprentices Aiden, Alex, and Tristen were challenged to make the robot autonomously navigate down one Penn Manor High School hallway and back to the technology center. It was a tall order: The team spent several months building the bot, and then working through the [ROS][11]-based programming, [rviz][12] (a 3D environment visualizer) and mapping for simultaneous localization and mapping (SLAM).
+
+Building the robot was a joy, but without a doubt, the programming challenged the students, none of whom had previously touched any of the ROS software tools. However, after much persistence, trial and error, and tenacity, Aiden and Tristen succeeded in achieving both the hallway navigation goal and in confusing fellow students with a tiny robot transversing school corridors and magically avoiding objects and people in its path.
+
+I recommend the TurtleBot3, but educators should be aware of the cost (approximately US$ 500) and the complexity. However, the kit is an outstanding resource for students aspiring to technology careers or those who want to build something amazing.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/8/back-school-project-ideas
+
+作者:[Charlie Reisinger][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/charlie
+[1]: https://opensource.com/education/14/9/interview-charlie-reisinger-penn-manor
+[2]: https://en.wikipedia.org/wiki/Software-defined_radio
+[3]: http://gqrx.dk/
+[4]: https://www.amazon.com/JahyShow%C2%AE-RTL2832U-RTL-SDR-Receiver-Compatible/dp/B01H830YQ6
+[5]: https://en.wikipedia.org/wiki/NOAA-18
+[6]: https://github.com/tomswartz07/CPOSC2017
+[7]: https://www.newtek.com/tricaster/
+[8]: https://obsproject.com/
+[9]: https://mpv.io/
+[10]: https://www.turtlebot.com/
+[11]: http://www.ros.org/
+[12]: http://wiki.ros.org/rviz
diff --git a/sources/tech/20180831 Publishing Markdown to HTML with MDwiki.md b/sources/tech/20180831 Publishing Markdown to HTML with MDwiki.md
new file mode 100644
index 0000000000..c25239b7ba
--- /dev/null
+++ b/sources/tech/20180831 Publishing Markdown to HTML with MDwiki.md
@@ -0,0 +1,73 @@
+Publishing Markdown to HTML with MDwiki
+======
+
+
+
+There are plenty of reasons to like Markdown, a simple language with an easy-to-learn syntax that can be used with any text editor. Using tools like [Pandoc][1], you can convert Markdown text to [a variety of popular formats][2], including HTML. You can also automate that conversion process in a web server. An HTML5 and JavaScript application called [MDwiki][3], created by Timo Dörr, can take a stack of Markdown files and turn them into a website when requested from a browser. The MDwiki site includes a how-to guide and other information to help you get started:
+
+![MDwiki site getting started][5]
+
+What an Mdwiki site looks like.
+
+Inside the web server, a basic MDwiki site looks like this:
+
+![MDwiki site inside web server][7]
+
+What the webserver folder for that site looks like.
+
+I renamed the MDwiki HTML file `START.HTML` for this project. There is also one Markdown file that deals with navigation and a JSON file to hold a few configuration settings. Everything else is site content.
+
+While the overall website design is pretty much fixed by MDwiki, the content, styling, and number of pages are not. You can view a selection of different sites generated by MDwiki at [the MDwiki site][8]. It is fair to say that MDwiki sites lack the visual appeal that a web designer could achieve—but they are functional, and users should balance their simple appearance against the speed and ease of creating and editing them.
+
+Markdown comes in various flavors that extend a stable core functionality for different specific purposes. MDwiki uses GitHub flavor [Markdown][9], which adds features such as formatted code blocks and syntax highlighting for popular programming languages, making it well-suited for producing program documentation and tutorials.
+
+MDwiki also supports what it calls "gimmicks," which add extra functionality such as embedding YouTube video content and displaying mathematical formulas. These are worth exploring if you need them for specific projects. I find MDwiki an ideal tool for creating technical documentation and educational resources. I have also discovered some tricks and hacks that might not be immediately apparent.
+
+MDwiki works with any modern web browser when deployed in a web server; however, you do not need a web server if you access MDwiki with Mozilla Firefox. Most MDwiki users will opt to deploy completed projects on a web server to avoid excluding potential users, but development and testing can be done with just a text editor and Firefox. Completed MDwiki projects that are loaded into a Moodle Virtual Learning Environment (VLE) can be read by any modern browser, which could be useful in educational contexts. (This is probably also true for other VLE software, but you should test that.)
+
+MDwiki's default color scheme is not ideal for all projects, but you can replace it with another theme downloaded from [Bootswatch.com][10]. To do this, simply open the MDwiki HTML file in an editor, take out the `extlib/css/bootstrap-3.0.0.min.css` code, and insert the downloaded Bootswatch theme. There is also an MDwiki gimmick that lets users choose a Bootswatch theme to replace the default after MDwiki loads in their browser. I often work with users who have visual impairments, and they tend to prefer high-contrast themes, with white text on a dark background.
+
+![MDwiki screen with Bootswatch Superhero theme][12]
+
+MDwiki screen using the Bootswatch Superhero theme
+
+MDwiki, Markdown files, and static images are fine for many purposes. However, you might sometimes want to include, say, a JavaScript slideshow or a feedback form. Markdown files can include HTML code, but mixing Markdown with HTML can get confusing. One solution is to create the feature you want in a separate HTML file and display it inside a Markdown file with an iframe tag. I took this idea from the [Twine Cookbook][13], a support site for the Twine interactive fiction engine. The Twine Cookbook doesn’t actually use MDwiki, but combining Markdown and iframe tags opens up a wide range of creative possibilities.
+
+Here is an example:
+
+This HTML will display an HTML page created by the Twine interactive fiction engine inside a Markdown file.
+```
+
+```
+
+The result in an MDwiki-generated site looks like this:
+
+
+
+In short, MDwiki is an excellent small application that achieves its purpose extremely well.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/8/markdown-html-publishing
+
+作者:[Peter Cheer][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/petercheer
+[1]: https://pandoc.org/
+[2]: https://opensource.com/downloads/pandoc-cheat-sheet
+[3]: http://dynalon.github.io/mdwiki/#!index.md
+[4]: https://opensource.com/file/407306
+[5]: https://opensource.com/sites/default/files/uploads/1_-_mdwiki_screenshot.png (MDwiki site getting started)
+[6]: https://opensource.com/file/407311
+[7]: https://opensource.com/sites/default/files/uploads/2_-_mdwiki_inside_web_server.png (MDwiki site inside web server)
+[8]: http://dynalon.github.io/mdwiki/#!examples.md
+[9]: https://guides.github.com/features/mastering-markdown/
+[10]: https://bootswatch.com/
+[11]: https://opensource.com/file/407316
+[12]: https://opensource.com/sites/default/files/uploads/3_-_mdwiki_bootswatch_superhero.png (MDwiki screen with Bootswatch Superhero theme)
+[13]: https://github.com/iftechfoundation/twine-cookbook
diff --git a/sources/tech/20180831 Test containers with Python and Conu.md b/sources/tech/20180831 Test containers with Python and Conu.md
new file mode 100644
index 0000000000..e28ca4674e
--- /dev/null
+++ b/sources/tech/20180831 Test containers with Python and Conu.md
@@ -0,0 +1,164 @@
+Test containers with Python and Conu
+======
+
+
+
+More and more developers are using containers to develop and deploy their applications. This means that easily testing containers is also becoming important. [Conu][1] (short for container utilities) is a Python library that makes it easy to write tests for your containers. This article shows you how to use it to test your containers.
+
+### Getting started
+
+First you need a container application to test. For that, the following commands create a new directory with a container Dockerfile, and a Flask application to be served by the container.
+```
+$ mkdir container_test
+$ cd container_test
+$ touch Dockerfile
+$ touch app.py
+
+```
+
+Copy the following code inside the app.py file. This is the customary basic Flask application that returns the string “Hello Container World!”
+```
+from flask import Flask
+app = Flask(__name__)
+
+@app.route('/')
+def hello_world():
+ return 'Hello Container World!'
+
+if __name__ == '__main__':
+ app.run(debug=True,host='0.0.0.0')
+
+```
+
+### Create and Build a Test Container
+
+To build the test container, add the following instructions to the Dockerfile.
+```
+FROM registry.fedoraproject.org/fedora-minimal:latest
+RUN microdnf -y install python3-flask && microdnf clean all
+ADD ./app.py /srv
+CMD ["python3", "/srv/app.py"]
+
+```
+
+Then build the container using the Docker CLI tool.
+```
+$ sudo dnf -y install docker
+$ sudo systemctl start docker
+$ sudo docker build . -t flaskapp_container
+
+```
+
+Note : The first two commands are only needed if Docker is not installed on your system.
+
+After the build use the following command to run the container.
+```
+$ sudo docker run -p 5000:5000 --rm flaskapp_container
+* Running on http://0.0.0.0:5000/ (Press CTRL+C to quit)
+* Restarting with stat
+* Debugger is active!
+* Debugger PIN: 473-505-51
+
+```
+
+Finally, use curl to check that the Flask application is correctly running inside the container:
+```
+$ curl http://127.0.0.1:5000
+Hello Container World!
+
+```
+
+With the flaskapp_container now running and ready for testing, you can stop it using **Ctrl+C**.
+
+### Create a test script
+
+Before you write the test script, you must install conu. Inside the previously created container_test directory run the following commands.
+```
+$ python3 -m venv .venv
+$ source .venv/bin/activate
+(.venv)$ pip install --upgrade pip
+(.venv)$ pip install conu
+
+$ touch test_container.py
+
+```
+
+Then copy and save the following script in the test_container.py file.
+```
+import conu
+
+PORT = 5000
+
+with conu.DockerBackend() as backend:
+ image = backend.ImageClass("flaskapp_container")
+ options = ["-p", "5000:5000"]
+ container = image.run_via_binary(additional_opts=options)
+
+ try:
+ # Check that the container is running and wait for the flask application to start.
+ assert container.is_running()
+ container.wait_for_port(PORT)
+
+ # Run a GET request on / port 5000.
+ http_response = container.http_request(path="/", port=PORT)
+
+ # Check the response status code is 200
+ assert http_response.ok
+
+ # Get the response content
+ response_content = http_response.content.decode("utf-8")
+
+ # Check that the "Hello Container World!" string is served.
+ assert "Hello Container World!" in response_content
+
+ # Get the logs from the container
+ logs = [line for line in container.logs()]
+ # Check the the Flask application saw the GET request.
+ assert b'"GET / HTTP/1.1" 200 -' in logs[-1]
+
+ finally:
+ container.stop()
+ container.delete()
+
+```
+
+#### Test Setup
+
+The script starts by setting conu to use Docker as a backend to run the container. Then it sets the container image to use the flaskapp_container you built in the first part of this tutorial.
+
+The next step is to configure the options needed to run the container. In this example, the Flask application serves the content on port 5000. Therefore you need to expose this port and map it to the same port on the host.
+
+Finally, the script starts the container, and it’s now ready to be tested.
+
+#### Testing methods
+
+Before testing a container, check that the container is running and ready. The example script is using container.is_running and container.wait_for_port. These methods ensure the container is running and the service is available on the expected port.
+
+The container.http_request is a wrapper around the [requests][2] library which makes it convenient to send HTTP requests during the tests. This method returns a [requests.Response][3]object, so it’s easy to access the content of the response for testing.
+
+Conu also gives access to the container logs. Once again, this can be useful during testing. In the example above, the container.logs method returns the container logs. You can use them to assert that a specific log was printed, or for example that no exceptions were raised during testing.
+
+Conu provides many other useful methods to interface with containers. A full list of the APIs is available in the [documentation][4]. You can also consult the examples available on [GitHub][5].
+
+All the code and files needed to run this tutorial are available on [GitHub][6] as well. For readers who want to take this example further, you can look at using [pytest][7] to run the tests and build a container test suite.
+
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/test-containers-python-conu/
+
+作者:[Clément Verna][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://fedoramagazine.org/author/cverna/
+[1]: https://github.com/user-cont/conu
+[2]: http://docs.python-requests.org/en/master/
+[3]: http://docs.python-requests.org/en/master/api/#requests.Response
+[4]: https://conu.readthedocs.io/en/latest/index.html
+[5]: https://github.com/user-cont/conu/tree/master/docs/source/examples
+[6]: https://github.com/cverna/container_test_script
+[7]: https://docs.pytest.org/en/latest/
diff --git a/sources/tech/20180901 Flameshot - A Simple, Yet Powerful Feature-rich Screenshot Tool.md b/sources/tech/20180901 Flameshot - A Simple, Yet Powerful Feature-rich Screenshot Tool.md
new file mode 100644
index 0000000000..f6bec82f02
--- /dev/null
+++ b/sources/tech/20180901 Flameshot - A Simple, Yet Powerful Feature-rich Screenshot Tool.md
@@ -0,0 +1,168 @@
+Flameshot – A Simple, Yet Powerful Feature-rich Screenshot Tool
+======
+
+
+
+Capturing screenshots is part of my job. I have been using Deepin-screenshot tool for taking screenshots. It’s a simple, light-weight and quite neat screenshot tool. It comes with all options such as mart window identification, shortcuts supporting, image editing, delay screenshot, social sharing, smart saving, and image resolution adjusting etc. Today, I stumbled upon yet another screenshot tool that ships with many features. Say hello to **Flameshot** , a simple and powerful, feature-rich screenshot tool for Unix-like operating systems. It is easy to use, customizable and has an option to upload your screenshots to **imgur** , an online image sharing website. And also, Flameshot has a CLI version, so you can take screenshots from commandline as well. Flameshot is completely free and open source tool. In this guide, we will see how to install Flameshot and how to take screenshots using it.
+
+### Install Flameshot
+
+**On Arch Linux:**
+
+Flameshot is available [community] repository in Arch Linux. Make sure you have enabled community repository and install Flameshot using pacman as shown below.
+```
+$ sudo pacman -S flameshot
+
+```
+
+It is also available in [**AUR**][1], so you can install it using any AUR helper programs, for example [**Yay**][2], in Arch-based systems.
+```
+$ yay -S flameshot-git
+
+```
+
+**On Fedora:**
+```
+$ sudo dnf install flameshot
+
+```
+
+On **Debian 10+** and **Ubuntu 18.04+** , install it using APT package manager.
+```
+$ sudo apt install flameshot
+
+```
+
+**On openSUSE:**
+```
+$ sudo zypper install flameshot
+
+```
+
+On other distributions, compile and install it from source code. The compilation requires **Qt version 5.3** or higher and **GCC 4.9.2** or higher.
+
+### Usage
+
+Launch Flameshot from menu or application launcher. On MATE desktop environment, It usually found under **Applications - > Graphics**.
+
+Once you opened it, you will see Flameshot systray icon in your system’s panel.
+
+**Note:**
+
+If you are using Gnome you need to install the [TopIcons][3] extension in order to see the systemtray icon.
+
+Right click on the tray icon and you’ll see some menu items to open the configuration window and the information window or quit the application.
+
+To capture screenshot, just click on the tray icon. You will see help window that says how to use Flameshot. Choose an area to capture and hit **ENTER** key to capture the screen. Press right click to show the color picker, hit spacebar to view the side panel. You can use increase or decrease the pointer’s thickness by using the Mouse scroll button.
+
+Flameshot comes with quite good set of features, such as,
+
+ * Free hand writing
+ * Line drawing
+ * Rectangle / Circle drawing
+ * Rectangle selection
+ * Arrows
+ * Marker to highlight important points
+ * Add text
+ * Blur the image/text
+ * Show the dimension of the image
+ * Undo/Redo the changes while editing images
+ * Copy the selection to the clipboard
+ * Save the selection
+ * Leave the capture screen
+ * Choose an app to open images
+ * Upload the selection to imgur site
+ * Pin image to desktop
+
+
+
+Here is a sample demo:
+
+
+
+**Keyboard shortcuts**
+
+Frameshot supports keyboard shortcuts. Right click on Flameshot tray icon and click **Information** window to see all the available shortcuts in the graphical capture mode. Here is the list of available keyboard shortcuts in GUI mode.
+
+| Keys | Description |
+|------------------------|------------------------------|
+| ←, ↓, ↑, → | Move selection 1px |
+| Shift + ←, ↓, ↑, → | Resize selection 1px |
+| Esc | Quit capture |
+| Ctrl + C | Copy to clipboard |
+| Ctrl + S | Save selection as a file |
+| Ctrl + Z | Undo the last modification |
+| Right Click | Show color picker |
+| Mouse Wheel | Change the tool’s thickness |
+
+Shift + drag a handler of the selection area: mirror redimension in the opposite handler.
+
+**Command line options**
+
+Flameshot also has a set of command line options to delay the screenshots and save images in custom paths.
+
+To capture screen with Flameshot GUI, run:
+```
+$ flameshot gui
+
+```
+
+To capture screen with GUI and save it in a custom path of your choice:
+```
+$ flameshot gui -p ~/myStuff/captures
+
+```
+
+To open GUI with a delay of 2 seconds:
+```
+$ flameshot gui -d 2000
+
+```
+
+To capture fullscreen with custom save path (no GUI) with a delay of 2 seconds:
+```
+$ flameshot full -p ~/myStuff/captures -d 2000
+
+```
+
+To capture fullscreen with custom save path copying to clipboard:
+```
+$ flameshot full -c -p ~/myStuff/captures
+
+```
+
+To capture the screen containing the mouse and print the image (bytes) in **PNG** format:
+```
+$ flameshot screen -r
+
+```
+
+To capture the screen number 1 and copy it to the clipboard:
+```
+$ flameshot screen -n 1 -c
+
+```
+
+What do you need? Flameshot has almost all features for capturing pictures, adding annotations, editing images, blur or highlight important points and a lot more. I think I will stick with Flameshot for a while as find it best replacement for my current screenshot tool. Give it a try and you won’t be disappointed.
+
+And, that’s all for now. More good stuffs to come. Stay tuned!
+
+Cheers!
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/flameshot-a-simple-yet-powerful-feature-rich-screenshot-tool/
+
+作者:[SK][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/sk/
+[1]: https://aur.archlinux.org/packages/flameshot-git
+[2]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
+[3]: https://extensions.gnome.org/extension/1031/topicons/
diff --git a/sources/tech/20180903 A Cross-platform High-quality GIF Encoder.md b/sources/tech/20180903 A Cross-platform High-quality GIF Encoder.md
new file mode 100644
index 0000000000..7a7f79064b
--- /dev/null
+++ b/sources/tech/20180903 A Cross-platform High-quality GIF Encoder.md
@@ -0,0 +1,160 @@
+A Cross-platform High-quality GIF Encoder
+======
+
+
+
+As a content writer, I needed to add images in my articles. Sometimes, it is better to add videos or gif images to explain the concept a bit easier. The readers can easily understand the guide much better by watching the output in video or gif format than the text. The day before, I have written about [**Flameshot**][1], a feature-rich and powerful screenshot tool for Linux. Today, I will show you how to make high quality gif images either from a video or set of images. Meet **Gifski** , a cross-platform, open source, command line High-quality GIF encoder based on **Pngquant**.
+
+For those wondering, pngquant is a command line lossy PNG image compressor. Trust me, pngquant is one of the best loss-less PNG compressor that I ever use. It compresses PNG images **upto 70%** without losing the original quality and and preserves full alpha transparency. The compressed images are compatible with all web browsers and operating systems. Since Gifski is based on Pngquant, it uses pngquant’s features for creating efficient GIF animations. Gifski is capable of creating animated GIFs that use thousands of colors per frame. Gifski is also requires **ffmpeg** to convert video into PNG images.
+
+### **Installing Gifski**
+
+Make sure you have installed FFMpeg and Pngquant.
+
+FFmpeg is available in the default repositories of most Linux distributions, so you can install it using the default package manager. For installation instructions, refer the following guide.
+
+Pngquant is available in [**AUR**][2]. To install it in Arch-based systems, use any AUR helper programs like [**Yay**][3].
+```
+$ yay -S pngquant
+
+```
+
+On Debian-based systems, run:
+```
+$ sudo apt install pngquant
+
+```
+
+If pngquant is not available for your distro, compile and install it from source. You will need **`libpng-dev`** package installed with development headers.
+```
+$ git clone --recursive https://github.com/kornelski/pngquant.git
+
+$ make
+
+$ sudo make install
+
+```
+
+After installing the prerequisites, install Gifski. You can install it using **cargo** if you have installed [**Rust**][4] programming language.
+```
+$ cargo install gifski
+
+```
+
+You can also get it with [**Linuxbrew**][5] package manager.
+```
+$ brew install gifski
+
+```
+
+If you don’t want to install cargo or Linuxbrew, download the latest binary executables from [**releases page**][6] and compile and install gifski manually.
+
+### Create high-quality GIF animations using Gifski high-quality GIF encoder
+
+Go to the location where you have kept the PNG images and run the following command to create GIF animation from the set of images:
+```
+$ gifski -o file.gif *.png
+
+```
+
+Here file.gif is the final output gif animation.
+
+Gifski has also some other additional features, like;
+
+ * Create GIF animation with specific dimension
+ * Show specific number of animations per second
+ * Encode with a specific quality
+ * Encode faster
+ * Encode images exactly in the order given, rather than sorted
+
+
+
+To create GIF animation with specific dimension, for example width=800 and height=400, use the following command:
+```
+$ gifski -o file.gif -W 800 -H 400 *.png
+
+```
+
+You can set how many number of animation frames per second you want in the gif animation. The default value is **20**. To do so, run:
+```
+$ gifski -o file.gif --fps 1 *.png
+
+```
+
+In the above example, I have used one animation frame per second.
+
+We can encode with specific quality on the scale of 1-100. Obviously, the lower quality may give smaller file and higher quality give bigger seize gif animation.
+```
+$ gifski -o file.gif --quality 50 *.png
+
+```
+
+Gifski will take more time when you encode large number of images. To make the encoding process 3 times faster than usual speed, run:
+```
+$ gifski -o file.gif --fast *.png
+
+```
+
+Please note that it will reduce quality to 10% and create bigger animation file.
+
+To encode images exactly in the order given (rather than sorted), use **`--nosort`** option.
+```
+$ gifski -o file.gif --nosort *.png
+
+```
+
+If you do not to loop the GIF, simple use **`--once`** option.
+```
+$ gifski -o file.gif --once *.png
+
+```
+
+**Create GIF animation from Video file**
+
+Some times you might want to an animated file from a video. It is also possible. This is where FFmpeg comes in help. First convert the video into PNG frames first like below.
+```
+$ ffmpeg -i video.mp4 frame%04d.png
+
+```
+
+The above command makes image files namely “frame0001.png”, “frame0002.png”, “frame0003.png”…, etc. from video.mp4 (%04d makes the frame number) and save them in the current working directory.
+
+After converting the image files, simply run the following command to make the animated GIF file.
+```
+$ gifski -o file.gif *.png
+
+```
+
+For more details, refer the help section.
+```
+$ gifski -h
+
+```
+
+Here is the sample animated file created using Gifski.
+
+As you can see, the quality of the GIF file is really great.
+
+And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
+
+Cheers!
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/gifski-a-cross-platform-high-quality-gif-encoder/
+
+作者:[SK][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/sk/
+[1]: https://www.ostechnix.com/flameshot-a-simple-yet-powerful-feature-rich-screenshot-tool/
+[2]: https://aur.archlinux.org/packages/pngquant/
+[3]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
+[4]: https://www.ostechnix.com/install-rust-programming-language-in-linux/
+[5]: https://www.ostechnix.com/linuxbrew-common-package-manager-linux-mac-os-x/
+[6]: https://github.com/ImageOptim/gifski/releases
diff --git a/sources/tech/20180905 How To Run MS-DOS Games And Programs In Linux.md b/sources/tech/20180905 How To Run MS-DOS Games And Programs In Linux.md
new file mode 100644
index 0000000000..0552fb3d09
--- /dev/null
+++ b/sources/tech/20180905 How To Run MS-DOS Games And Programs In Linux.md
@@ -0,0 +1,253 @@
+How To Run MS-DOS Games And Programs In Linux
+======
+
+
+
+If you ever wanted to try some good-old MS-DOS games and defunct C++ compilers like Turbo C++ in Linux? Good! This tutorial will teach you how to run MS-DOS games and programs under Linux environment using **DOSBox**. It is an x86 PC DOS-emulator that can be used to run classic DOS games or programs. DOSBox emulates an Intel x86 PC with sound, graphics, mouse, joystick, and modem etc., that allows you to run many old MS-DOS games and programs that simply cannot be run on any modern PCs and operating systems, such as Microsoft Windows XP and later, Linux and FreeBSD. It is free, written using C++ programming language and distributed under GPL.
+
+### Install DOSBox In Linux
+
+DOSBox is available in the default repositories of most Linux distributions.
+
+On Arch Linux and its variants like Antergos, Manjaro Linux:
+```
+$ sudo pacman -S dosbox
+
+```
+
+On Debian, Ubuntu, Linux Mint:
+```
+$ sudo apt-get install dosbox
+
+```
+
+On Fedora:
+```
+$ sudo dnf install dosbox
+
+```
+
+### Configure DOSBox
+
+There is no initial configuration required to use DOSBox and it just works out of the box. The default configuration file named `dosbox-x.xx.conf` exists in your **`~/.dosbox`** folder. In this configuration file, you can edit/modify various settings, such as starting DOSBox in fullscreen mode, use double buffering in fullscreen, set preferred resolution to use for fullscreen, mouse sensitivity, enable or disable sound, speaker, joystick and a lot more. As I mentioned earlier, the default settings will work just fine. You need not to make any changes.
+
+### Run MS-DOS Games And Programs In Linux
+
+To launch DOSBox, run the following command from the Terminal:
+```
+$ dosbox
+
+```
+
+This is how DOSBox interface looks like.
+
+
+
+As you can see, DOSBox comes with its own DOS-like command prompt with a virtual `Z:\` Drive, so if you’re familiar with MS-DOS, you wouldn’t find any difficulties to work in DOSBox environment.
+
+Here is the output of `dir`command (Equivalent of `ls` command in Linux) output:
+
+
+
+If you’re a new user and it is the first time you use DOSBox, you can view the short introduction about DOSBox by entering the following command in DOSBox prompt:
+```
+intro
+
+```
+
+Press ENTER to go through next page of the introduction section.
+
+To view the list of most often used commands in DOS, use this command:
+```
+help
+
+```
+
+To view list of all supported commands in DOSBox, type:
+```
+help /all
+
+```
+
+Remember, these commands should be used in the DOSBox prompt, not in your Linux Terminal.
+
+DOSBox also supports a good set of keyboard bindings. Here is the default keyboard shortcuts to effectively use DOSBox.
+
+
+
+To exit from DOSBox, simply type and hit ENTER:
+```
+exit
+
+```
+
+By default, DOSBox starts with a normal window-sized screen like above.
+
+To start dosbox directly in fullscreen, edit your `dosbox-x.xx.conf` file and set the value of **fullscreen** variable as **enable**. Now, DosBox will start in fullscreen mode. To go back to normal screen, press **ALT+ENTER**.
+
+Hope you get the basic usage of DOSBox.
+
+Let us go ahead and install some DOS programs and games.
+
+First, we need to create directories to save the programs and games in our Linux system. I am going to create two directories named **`~/dosprograms`** and **`~/dosgames`** , the first one for storing programs and latter for storing games.
+```
+$ mkdir ~/dosprograms ~/dosgames
+
+```
+
+For the purpose of this guide, I will show you how to install **Turbo C++** program and Mario game. First, we will see how to install Turbo.
+
+Download the latest Turbo C++ compiler, extract it and save the contents file in **`~/dosprograms`** directory. I have save the contents turbo c++ in my **~/dosprograms/TC/** directory.
+```
+$ ls dosprograms/tc/
+BGI BIN CLASSLIB DOC EXAMPLES FILELIST.DOC INCLUDE LIB README README.COM
+
+```
+
+Start Dosbox:
+```
+$ dosbox
+
+```
+
+And mount the **`~/dosprograms`** directory as virtual drive **C:\** in DOSBox.
+```
+Z:\>mount c ~/dosprograms
+
+```
+
+You will see an output something like below.
+```
+Drive C is mounted as local directory /home/sk/dosprograms.
+
+```
+
+
+
+Now, change to the C drive using command:
+```
+Z:\>c:
+
+```
+
+And then, switch to **tc/bin** directory:
+```
+Z:\>cd tc/bin
+
+```
+
+Finally, run turbo c++ executable file:
+```
+Z:\>tc.exe
+
+```
+
+**Note:** Just type first few letters and hit ENTER to autocomplete the file name.
+
+
+
+You will now be in Turbo C++ console.
+
+
+
+Create new file (ATL+F) and start coding:
+
+
+
+Similarly, you can install and run other classic DOS programs.
+
+**Troubleshooting:**
+
+You might be encountered with following error while running turbo c++ or any other dos programs:
+```
+DOSBox switched to max cycles, because of the setting: cycles=auto. If the game runs too fast try a fixed cycles amount in DOSBox's options. Exit to error: DRC64:Unhandled memory reference
+
+```
+
+To fix this, edit your **~/.dosbox/dosbox-x.xx.conf** file:
+```
+$ nano ~/.dosbox/dosbox-0.74.conf
+
+```
+
+Find the following variable and change its value from:
+```
+core=auto
+
+```
+
+to
+```
+core=normal
+
+```
+
+Save and close the file. Now you can be able to run the dos programs without any problems.
+
+Now, let us see how to run a dos-based game, for example **Mario Bros VGA**.
+
+Download Mario game from [**here**][1] and extract the contents in **~/dosgames** directory in your Linux machine.
+
+Start DOSBox:
+```
+$ dosbox
+
+```
+
+We have used virtual drive **c:** for dos programs. For games, let us use **d:** as virtual drive.
+
+At the DOSBox prompt, run the following command to mount **~/dosgames** directory as virtuald drive **d**.
+```
+Z:\>mount d ~/dosgames
+
+```
+
+Switch to D: drive:
+```
+Z:\>d:
+
+```
+
+And then go to mario game directory and run the **mario.exe** file to launch the game.
+```
+Z:\>cd mario
+
+Z:\>mario.exe
+
+```
+
+
+
+Start playing the game:
+
+
+
+Similarly, you can run any dos-based games as described above. You can view the complete list of supported games that can be run using DOSBox [**here**][2].
+
+### Conclusion
+
+Even though DOSBOX is not a complete replacement for MS-DOS and it lacks many of the features found in MS-DOS, it is just enough to install and run most DOS games and programs.
+
+For more details, refer the official [**DOSBox manual**][3].
+
+And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
+
+Cheers!
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/how-to-run-ms-dos-games-and-programs-in-linux/
+
+作者:[SK][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/sk/
+[1]: https://www.dosgames.com/game/mario-bros-vga
+[2]: https://www.dosbox.com/comp_list.php
+[3]: https://www.dosbox.com/DOSBoxManual.html
diff --git a/sources/tech/20180906 How To Limit Network Bandwidth In Linux Using Wondershaper.md b/sources/tech/20180906 How To Limit Network Bandwidth In Linux Using Wondershaper.md
new file mode 100644
index 0000000000..11d266e163
--- /dev/null
+++ b/sources/tech/20180906 How To Limit Network Bandwidth In Linux Using Wondershaper.md
@@ -0,0 +1,196 @@
+How To Limit Network Bandwidth In Linux Using Wondershaper
+======
+
+
+
+This tutorial will help you to easily limit network bandwidth and shape your network traffic in Unix-like operating systems. By limiting the network bandwidth usage, you can save unnecessary bandwidth consumption’s by applications, such as package managers (pacman, yum, apt), web browsers, torrent clients, download managers etc., and prevent the bandwidth abuse by a single or multiple users in the network. For the purpose of this tutorial, we will be using a command line utility named **Wondershaper**. Trust me, it is not that hard as you may think. It is one of the easiest and quickest way ever I have come across to limit the Internet or local network bandwidth usage in your own Linux system. Read on.
+
+Please be mindful that the aforementioned utility can only limit the incoming and outgoing traffic of your local network interfaces, not the interfaces of your router or modem. In other words, Wondershaper will only limit the network bandwidth in your local system itself, not any other systems in the network. These utility is mainly designed for limiting the bandwidth of one or more network adapters in your local system. Hope you got my point.
+
+Let us see how to use Wondershaper to shape the network traffic.
+
+### Limit Network Bandwidth In Linux Using Wondershaper
+
+**Wondershaper** is simple script used to limit the bandwidth of your system’s network adapter(s). It limits the bandwidth iproute’s tc command, but greatly simplifies its operation.
+
+**Installing Wondershaper**
+
+To install the latest version, git clone wondershaoer repository:
+
+```
+$ git clone https://github.com/magnific0/wondershaper.git
+
+```
+
+Go to the wondershaper directory and install it as show below
+
+```
+$ cd wondershaper
+
+$ sudo make install
+
+```
+
+And, run the following command to start wondershaper service automatically on every reboot.
+
+```
+$ sudo systemctl enable wondershaper.service
+
+$ sudo systemctl start wondershaper.service
+
+```
+
+You can also install using your distribution’s package manager (official or non-official) if you don’t mind the latest version.
+
+Wondershaper is available in [**AUR**][1], so you can install it in Arch-based systems using AUR helper programs such as [**Yay**][2].
+
+```
+$ yay -S wondershaper-git
+
+```
+
+On Debian, Ubuntu, Linux Mint:
+
+```
+$ sudo apt-get install wondershaper
+
+```
+
+On Fedora:
+
+```
+$ sudo dnf install wondershaper
+
+```
+
+On RHEL, CentOS, enable EPEL repository and install wondershaper as shown below.
+
+```
+$ sudo yum install epel-release
+
+$ sudo yum install wondershaper
+
+```
+
+Finally, start wondershaper service automatically on every reboot.
+
+```
+$ sudo systemctl enable wondershaper.service
+
+$ sudo systemctl start wondershaper.service
+
+```
+
+**Usage**
+
+First, find the name of your network interface. Here are some common ways to find the details of a network card.
+
+```
+$ ip addr
+
+$ route
+
+$ ifconfig
+
+```
+
+Once you find the network card name, you can limit the bandwidth rate as shown below.
+
+```
+$ sudo wondershaper -a -d -u
+
+```
+
+For instance, if your network card name is **enp0s8** and you wanted to limit the bandwidth to **1024 Kbps** for **downloads** and **512 kbps** for **uploads** , the command would be:
+
+```
+$ sudo wondershaper -a enp0s8 -d 1024 -u 512
+
+```
+
+Where,
+
+ * **-a** : network card name
+ * **-d** : download rate
+ * **-u** : upload rate
+
+
+
+To clear the limits from a network adapter, simply run:
+
+```
+$ sudo wondershaper -c -a enp0s8
+
+```
+
+Or
+
+```
+$ sudo wondershaper -c enp0s8
+
+```
+
+Just in case, there are more than one network card available in your system, you need to manually set the download/upload rates for each network interface card as described above.
+
+If you have installed Wondershaper by cloning its GitHub repository, there is a configuration named **wondershaper.conf** exists in **/etc/conf.d/** location. Make sure you have set the download or upload rates by modifying the appropriate values(network card name, download/upload rate) in this file.
+
+```
+$ sudo nano /etc/conf.d/wondershaper.conf
+
+[wondershaper]
+# Adapter
+#
+IFACE="eth0"
+
+# Download rate in Kbps
+#
+DSPEED="2048"
+
+# Upload rate in Kbps
+#
+USPEED="512"
+
+```
+
+Here is the sample before Wondershaper:
+
+After enabling Wondershaper:
+
+As you can see, the download rate has been tremendously reduced after limiting the bandwidth using WOndershaper in my Ubuntu 18.o4 LTS server.
+
+For more details, view the help section by running the following command:
+
+```
+$ wondershaper -h
+
+```
+
+Or, refer man pages.
+
+```
+$ man wondershaper
+
+```
+
+As far as tested, Wondershaper worked just fine as described above. Give it a try and let us know what do you think about this utility.
+
+And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned.
+
+Cheers!
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/how-to-limit-network-bandwidth-in-linux-using-wondershaper/
+
+作者:[SK][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/sk/
+[1]: https://aur.archlinux.org/packages/wondershaper-git/
+[2]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
diff --git a/sources/tech/20180906 What a shell dotfile can do for you.md b/sources/tech/20180906 What a shell dotfile can do for you.md
new file mode 100644
index 0000000000..35593e1e32
--- /dev/null
+++ b/sources/tech/20180906 What a shell dotfile can do for you.md
@@ -0,0 +1,238 @@
+What a shell dotfile can do for you
+======
+
+
+
+Ask not what you can do for your shell dotfile, but what a shell dotfile can do for you!
+
+I've been all over the OS map, but for the past several years my daily drivers have been Macs. For a long time, I used Bash, but when a few friends started proselytizing [zsh][1], I gave it a shot. It didn't take long for me to appreciate it, and several years later, I strongly prefer it for many of the little things that it does.
+
+I've been using zsh (provided via [Homebrew][2], not the system installed), and the [Oh My Zsh enhancement][3].
+
+The examples in this article are for my personal `.zshrc`. Most will work directly in Bash, and I don't believe that any rely on Oh My Zsh, but your mileage may vary. There was a period when I was maintaining a shell dotfile for both zsh and Bash, but I did eventually give up on my `.bashrc`.
+
+### We're all mad here
+
+If you want the possibility of using the same dotfile across OS's, you'll want to give your dotfile a little smarts.
+```
+### Mac Specifics
+if [[ "$OSTYPE" == "darwin"* ]]; then
+ # Mac-specific stuff here.
+fi
+```
+
+For instance, I expect the Alt + arrow keys to move the cursor by the word rather than by a single space. To make this happen in [iTerm2][4] (my preferred shell), I add this snippet to the Mac-specific portion of my .zshrc:
+```
+### Mac Specifics
+if [[ "$OSTYPE" == "darwin"* ]]; then
+ ### Mac cursor commands for iTerm2; map ctrl+arrows or alt+arrows to fast-move
+ bindkey -e
+ bindkey '^[[1;9C' forward-word
+ bindkey '^[[1;9D' backward-word
+ bindkey '\e\e[D' backward-word
+ bindkey '\e\e[C' forward-word
+fi
+```
+
+### What about Bob?
+
+While I came to love my shell dotfile, I didn't always want the same things available on my home machines as on my work machines. One way to solve this is to have supplementary dotfiles to use at home but not at work. Here's how I accomplished this:
+```
+if [[ `egrep 'dnssuffix1|dnssuffix2' /etc/resolv.conf` ]]; then
+ if [ -e $HOME/.work ]
+ source $HOME/.work
+ else
+ echo "This looks like a work machine, but I can't find the ~/.work file"
+ fi
+fi
+```
+
+In this case, I key off of my work dns suffix (or multiple suffixes, depending on your situation) and source a separate file that makes my life at work a little better.
+
+### That thing you do
+
+Now is probably a good time to quit using the tilde (`~`) to represent your home directory when writing scripts. You'll find that there are some contexts where it's not recognized. Getting in the habit of using the environment variable `$HOME` will save you a lot of troubleshooting time and headaches later on.
+
+The logical extension would be to have OS-specific dotfiles to include if you are so inclined.
+
+### Memory, all alone in the moonlight
+
+I've written embarrassing amounts of shell, and I've come to the conclusion that I really don't want to write more. It's not that shell can't do what I need most of the time, but I find that if I'm writing shell, I'm probably slapping together a duct-tape solution rather than permanently solving the problem.
+
+Likewise, I hate memorizing things, and throughout my career, I have had to do radical context shifting during the course of a day. The practical consequence is that I've had to re-learn many things several times over the years. ("Wait... which for-loop structure does this language use?")
+
+So, every so often I decide that I'm tired of looking up how to do something again. One way that I improve my life is by adding aliases.
+
+A common scenario for anyone who works with systems is finding out what's taking up all of the disk. Unfortunately, I have never been able to remember this incantation, so I made a shell alias, creatively called `bigdirs`:
+```
+alias bigdirs='du --max-depth=1 2> /dev/null | sort -n -r | head -n20'
+```
+
+While I could be less lazy and actually memorize it, well, that's just not the Unix way...
+
+### Typos, and the people who love them
+
+Another way that using shell aliases improves my life is by saving me from typos. I don't know why, but I've developed this nasty habit of typing a `w` after the sequence `ea`, so if I want to clear my terminal, I'll often type `cleawr`. Unfortunately, that doesn't mean anything to my shell. Until I add this little piece of gold:
+```
+alias cleawr='clear'
+```
+
+In one instance of Windows having an equivalent, but better, command, I find myself typing `cls`. It's frustrating to see your shell throw up its hands, so I add:
+```
+alias cls='clear'
+```
+
+Yes, I'm aware of `ctrl + l`, but I never use it.
+
+### Amuse yourself
+
+Work can be stressful. Sometimes you just need to have a little fun. If your shell doesn't know the command that it clearly should just do, maybe you want to shrug your shoulders right back at it! You can do this with a function:
+```
+shrug() { echo "¯\_(ツ)_/¯"; }
+```
+
+If that doesn't work, maybe you need to flip a table:
+```
+fliptable() { echo "(╯°□°)╯ ┻━┻"; } # Flip a table. Example usage: fsck -y /dev/sdb1 || fliptable
+```
+
+Imagine my chagrin and frustration when I needed to flip a desk and I couldn't remember what I had called it. So I added some more shell aliases:
+```
+alias flipdesk='fliptable'
+alias deskflip='fliptable'
+alias tableflip='fliptable'
+```
+
+And sometimes you need to celebrate:
+```
+disco() {
+ echo "(•_•)"
+ echo "<) )╯"
+ echo " / \ "
+ echo ""
+ echo "\(•_•)"
+ echo " ( (>"
+ echo " / \ "
+ echo ""
+ echo " (•_•)"
+ echo "<) )>"
+ echo " / \ "
+}
+```
+
+Typically, I'll pipe the output of these commands to `pbcopy `and paste it into the relevant chat tool I'm using.
+
+I got this fun function from a Twitter account that I follow called "Command Line Magic:" [@climagic][5]. Since I live in Florida now, I'm very happy that this is the only snow in my life:
+```
+snow() {
+ clear;while :;do echo $LINES $COLUMNS $(($RANDOM%$COLUMNS));sleep 0.1;done|gawk '{a[$3]=0;for(x in a) {o=a[x];a[x]=a[x]+1;printf "\033[%s;%sH ",o,x;printf "\033[%s;%sH*\033[0;0H",a[x],x;}}'
+}
+
+```
+
+### Fun with functions
+
+We've seen some examples of functions that I use. Since few of these examples require an argument, they could be done as aliases. I use functions out of personal preference when it's more than a single short statement.
+
+At various times in my career, I've run [Graphite][6], an open-source, scalable, time-series metrics solution. There have been enough instances where I needed to transpose a metric path (delineated with periods) to a filesystem path (delineated with slashes), or vice versa, that it became useful to have dedicated functions for these tasks:
+```
+# Useful for converting between Graphite metrics and file paths
+function dottoslash() {
+ echo $1 | sed 's/\./\//g'
+}
+function slashtodot() {
+ echo $1 | sed 's/\//\./g'
+}
+```
+
+During another time in my career, I was running a lot of Kubernetes. If you aren't familiar with running Kubernetes, you need to write a lot of YAML. Unfortunately, it's not hard to write invalid YAML. Worse, Kubernetes doesn't validate YAML before trying to apply it, so you won't find out it's invalid until you apply it. Unless you validate it first:
+```
+function yamllint() {
+ for i in $(find . -name '*.yml' -o -name '*.yaml'); do echo $i; ruby -e "require 'yaml';YAML.load_file(\"$i\")"; done
+}
+```
+
+Because I got tired of embarrassing myself and occasionally breaking a customer's setup, I wrote this little snippet and added it as a pre-commit hook to all of my relevant repos. Something similar would be very helpful as part of your continuous integration process, especially if you're working as part of a team.
+
+### Oh, fingers, where art thou?
+
+I was once an excellent touch-typist. Those days are long gone. I typo more than I would have believed possible.
+
+At different times, I have used a fair amount of either Chef or Kubernetes. Fortunately for me, I never used both at the same time.
+
+Part of the Chef ecosystem is Test Kitchen, a suite of tools that facilitate testing, which is invoked with the commands `kitchen test`. Kubernetes is managed with a CLI tool `kubectl`. Both commands require several subcommands, and neither rolls off the fingers particularly fluidly.
+
+Rather than create a bunch of "typo aliases," I aliased those commands to `k`:
+```
+alias k='kitchen test $@'
+```
+
+or
+```
+alias k='kubectl $@'
+```
+
+### Timesplitters
+
+The last half of my career has involved writing more code with other people. I've worked in many environments where we have forked copies of repos on our account and use pull requests as part of the review process. When I want to make sure that my fork of a given repo is up to date with the parent, I use `fetchupstream`:
+```
+alias fetchupstream='git fetch upstream && git checkout master && git merge upstream/master && git push'
+```
+
+### Mine eyes have seen the glory of the coming of color
+
+I like color. It can make things like diffs easier to use.
+```
+alias diff='colordiff'
+```
+
+I thought that colorized man pages was a neat trick, so I incorporated this function:
+```
+# Colorized man pages, from:
+# http://boredzo.org/blog/archives/2016-08-15/colorized-man-pages-understood-and-customized
+man() {
+ env \
+ LESS_TERMCAP_md=$(printf "\e[1;36m") \
+ LESS_TERMCAP_me=$(printf "\e[0m") \
+ LESS_TERMCAP_se=$(printf "\e[0m") \
+ LESS_TERMCAP_so=$(printf "\e[1;44;33m") \
+ LESS_TERMCAP_ue=$(printf "\e[0m") \
+ LESS_TERMCAP_us=$(printf "\e[1;32m") \
+ man "$@"
+}
+```
+
+I love the command `which`. It simply tells you where in the filesystem the command you're running comes from—unless it's a shell function. After multiple cascading dotfiles, sometimes it's not clear where a function is defined or what it does. It turns out that the `whence` and `type` commands can help with that.
+```
+# Where is a function defined?
+whichfunc() {
+ whence -v $1
+ type -a $1
+}
+```
+
+### Conclusion
+
+I hope this article helps and inspires you to find ways to improve your daily shell-using experience. They don't need to be huge, novel, or complex. They might solve a minor but frequent bit of friction, create a shortcut, or even offer a solution to reducing common typos.
+
+You're welcome to look through my [dotfiles repo][7], but I warn you that it could use a lot of cleaning up. Feel free to use anything that you find helpful, and please be excellent to one another.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/9/shell-dotfile
+
+作者:[H.Waldo Grunenwald][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/gwaldo
+[1]: http://www.zsh.org/
+[2]: https://brew.sh/
+[3]: https://github.com/robbyrussell/oh-my-zsh
+[4]: https://www.iterm2.com/
+[5]: https://twitter.com/climagic
+[6]: https://github.com/graphite-project/
+[7]: https://github.com/gwaldo/dotfiles
diff --git a/sources/tech/20180907 6 open source tools for writing a book.md b/sources/tech/20180907 6 open source tools for writing a book.md
new file mode 100644
index 0000000000..3a2328e7f1
--- /dev/null
+++ b/sources/tech/20180907 6 open source tools for writing a book.md
@@ -0,0 +1,68 @@
+KevinSJ 翻译中
+6 open source tools for writing a book
+======
+
+
+
+I first used and contributed to free and open source software in 1993, and since then I've been an open source software developer and evangelist. I've written or contributed to dozens of open source software projects, although the one that I'll be remembered for is the [FreeDOS Project][1], an open source implementation of the DOS operating system.
+
+I recently wrote a book about FreeDOS. [_Using FreeDOS_][2] is my celebration of the 24th anniversary of FreeDOS. It is a collection of how-to's about installing and using FreeDOS, essays about my favorite DOS applications, and quick-reference guides to the DOS command line and DOS batch programming. I've been working on this book for the last few months, with the help of a great professional editor.
+
+_Using FreeDOS_ is available under the Creative Commons Attribution (cc-by) International Public License. You can download the EPUB and PDF versions at no charge from the [FreeDOS e-books][2] website. (I'm also planning a print version, for those who prefer a bound copy.)
+
+The book was produced almost entirely with open source software. I'd like to share a brief insight into the tools I used to create, edit, and produce _Using FreeDOS_.
+
+### Google Docs
+
+[Google Docs][3] is the only tool I used that isn't open source software. I uploaded my first drafts to Google Docs so my editor and I could collaborate. I'm sure there are open source collaboration tools, but Google Doc's ability to let two people edit the same document at the same time, make comments, edit suggestions, and change tracking—not to mention its use of paragraph styles and the ability to download the finished document—made it a valuable part of the editing process.
+
+### LibreOffice
+
+I started on [LibreOffice][4] 6.0 but I finished the book using LibreOffice 6.1. I love LibreOffice's rich support of styles. Paragraph styles made it easy to apply a style for titles, headers, body text, sample code, and other text. Character styles let me modify the appearance of text within a paragraph, such as inline sample code or a different style to indicate a filename. Graphics styles let me apply certain styling to screenshots and other images. And page styles allowed me to easily modify the layout and appearance of the page.
+
+### GIMP
+
+My book includes a lot of DOS program screenshots, website screenshots, and FreeDOS logos. I used [GIMP][5] to modify these images for the book. Usually, this was simply cropping or resizing an image, but as I prepare the print edition of the book, I'm using GIMP to create a few images that will be simpler for print layout.
+
+### Inkscape
+
+Most of the FreeDOS logos and fish mascots are in SVG format, and I used [Inkscape][6] for any image tweaking here. And in preparing the PDF version of the ebook, I wanted a simple blue banner at top of the page, with the FreeDOS logo in the corner. After some experimenting, I found it easier to create an SVG image in Inkscape that looked like the banner I wanted, and I pasted that into the header.
+
+### ImageMagick
+
+While it's great to use GIMP to do the fine work, sometimes it's faster to run an [ImageMagick][7] command over a set of images, such as to convert into PNG format or to resize images.
+
+### Sigil
+
+LibreOffice can export directly to EPUB format, but it wasn't a great transfer. I haven't tried creating an EPUB with LibreOffice 6.1, but LibreOffice 6.0 didn't include my images. It also added styles in a weird way. I used [Sigil][8] to tweak the EPUB file and make everything look right. Sigil even has a preview function so you can see what the EPUB will look like.
+
+### QEMU
+
+Because this book is about installing and running FreeDOS, I needed to actually run FreeDOS. You can boot FreeDOS inside any PC emulator, including VirtualBox, QEMU, GNOME Boxes, PCem, and Bochs. But I like the simplicity of [QEMU][9]. And the QEMU console lets you issue a screen dump in PPM format, which is ideal for grabbing screenshots to include in the book.
+
+Of course, I have to mention running [GNOME][10] on [Linux][11]. I use the [Fedora][12] distribution of Linux.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/9/writing-book-open-source-tools
+
+作者:[Jim Hall][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/jim-hall
+[1]: http://www.freedos.org/
+[2]: http://www.freedos.org/ebook/
+[3]: https://www.google.com/docs/about/
+[4]: https://www.libreoffice.org/
+[5]: https://www.gimp.org/
+[6]: https://inkscape.org/
+[7]: https://www.imagemagick.org/
+[8]: https://sigil-ebook.com/
+[9]: https://www.qemu.org/
+[10]: https://www.gnome.org/
+[11]: https://www.kernel.org/
+[12]: https://getfedora.org/
diff --git a/sources/tech/20180907 How to Use the Netplan Network Configuration Tool on Linux.md b/sources/tech/20180907 How to Use the Netplan Network Configuration Tool on Linux.md
new file mode 100644
index 0000000000..a9d3eb0895
--- /dev/null
+++ b/sources/tech/20180907 How to Use the Netplan Network Configuration Tool on Linux.md
@@ -0,0 +1,230 @@
+LuuMing translating
+How to Use the Netplan Network Configuration Tool on Linux
+======
+
+
+
+For years Linux admins and users have configured their network interfaces in the same way. For instance, if you’re a Ubuntu user, you could either configure the network connection via the desktop GUI or from within the /etc/network/interfaces file. The configuration was incredibly easy and never failed to work. The configuration within that file looked something like this:
+
+```
+auto enp10s0
+
+iface enp10s0 inet static
+
+address 192.168.1.162
+
+netmask 255.255.255.0
+
+gateway 192.168.1.100
+
+dns-nameservers 1.0.0.1,1.1.1.1
+
+```
+
+Save and close that file. Restart networking with the command:
+
+```
+sudo systemctl restart networking
+
+```
+
+Or, if you’re not using a non-systemd distribution, you could restart networking the old fashioned way like so:
+
+```
+sudo /etc/init.d/networking restart
+
+```
+
+Your network will restart and the newly configured interface is good to go.
+
+That’s how it’s been done for years. Until now. With certain distributions (such as Ubuntu Linux 18.04), the configuration and control of networking has changed considerably. Instead of that interfaces file and using the /etc/init.d/networking script, we now turn to [Netplan][1]. Netplan is a command line utility for the configuration of networking on certain Linux distributions. Netplan uses YAML description files to configure network interfaces and, from those descriptions, will generate the necessary configuration options for any given renderer tool.
+
+I want to show you how to use Netplan on Linux, to configure a static IP address and a DHCP address. I’ll be demonstrating on Ubuntu Server 18.04. I will give you one word of warning, the .yaml files you create for Netplan must be consistent in spacing, otherwise they’ll fail to work. You don’t have to use a specific spacing for each line, it just has to remain consistent.
+
+### The new configuration files
+
+Open a terminal window (or log into your Ubuntu Server via SSH). You will find the new configuration files for Netplan in the /etc/netplan directory. Change into that directory with the command cd /etc/netplan. Once in that directory, you will probably only see a single file:
+
+```
+01-netcfg.yaml
+
+```
+
+You can create a new file or edit the default. If you opt to edit the default, I suggest making a copy with the command:
+
+```
+sudo cp /etc/netplan/01-netcfg.yaml /etc/netplan/01-netcfg.yaml.bak
+
+```
+
+With your backup in place, you’re ready to configure.
+
+### Network Device Name
+
+Before you configure your static IP address, you’ll need to know the name of device to be configured. To do that, you can issue the command ip a and find out which device is to be used (Figure 1).
+
+![netplan][3]
+
+Figure 1: Finding our device name with the ip a command.
+
+[Used with permission][4]
+
+I’ll be configuring ens5 for a static IP address.
+
+### Configuring a Static IP Address
+
+Open the original .yaml file for editing with the command:
+
+```
+sudo nano /etc/netplan/01-netcfg.yaml
+
+```
+
+The layout of the file looks like this:
+
+network:
+
+Version: 2
+
+Renderer: networkd
+
+ethernets:
+
+DEVICE_NAME:
+
+Dhcp4: yes/no
+
+Addresses: [IP/NETMASK]
+
+Gateway: GATEWAY
+
+Nameservers:
+
+Addresses: [NAMESERVER, NAMESERVER]
+
+Where:
+
+ * DEVICE_NAME is the actual device name to be configured.
+
+ * yes/no is an option to enable or disable dhcp4.
+
+ * IP is the IP address for the device.
+
+ * NETMASK is the netmask for the IP address.
+
+ * GATEWAY is the address for your gateway.
+
+ * NAMESERVER is the comma-separated list of DNS nameservers.
+
+
+
+
+Here’s a sample .yaml file:
+
+```
+network:
+
+ version: 2
+
+ renderer: networkd
+
+ ethernets:
+
+ ens5:
+
+ dhcp4: no
+
+ addresses: [192.168.1.230/24]
+
+ gateway4: 192.168.1.254
+
+ nameservers:
+
+ addresses: [8.8.4.4,8.8.8.8]
+
+```
+
+Edit the above to fit your networking needs. Save and close that file.
+
+Notice the netmask is no longer configured in the form 255.255.255.0. Instead, the netmask is added to the IP address.
+
+### Testing the Configuration
+
+Before we apply the change, let’s test the configuration. To do that, issue the command:
+
+```
+sudo netplan try
+
+```
+
+The above command will validate the configuration before applying it. If it succeeds, you will see Configuration accepted. In other words, Netplan will attempt to apply the new settings to a running system. Should the new configuration file fail, Netplan will automatically revert to the previous working configuration. Should the new configuration work, it will be applied.
+
+### Applying the New Configuration
+
+If you are certain of your configuration file, you can skip the try option and go directly to applying the new options. The command for this is:
+
+```
+sudo netplan apply
+
+```
+
+At this point, you can issue the command ip a to see that your new address configurations are in place.
+
+### Configuring DHCP
+
+Although you probably won’t be configuring your server for DHCP, it’s always good to know how to do this. For example, you might not know what static IP addresses are currently available on your network. You could configure the device for DHCP, get an IP address, and then reconfigure that address as static.
+
+To use DHCP with Netplan, the configuration file would look something like this:
+
+```
+network:
+
+ version: 2
+
+ renderer: networkd
+
+ ethernets:
+
+ ens5:
+
+ Addresses: []
+
+ dhcp4: true
+
+ optional: true
+
+```
+
+Save and close that file. Test the file with:
+
+```
+sudo netplan try
+
+```
+
+Netplan should succeed and apply the DHCP configuration. You could then issue the ip a command, get the dynamically assigned address, and then reconfigure a static address. Or, you could leave it set to use DHCP (but seeing as how this is a server, you probably won’t want to do that).
+
+Should you have more than one interface, you could name the second .yaml configuration file 02-netcfg.yaml. Netplan will apply the configuration files in numerical order, so 01 will be applied before 02. Create as many configuration files as needed for your server.
+
+### That’s All There Is
+
+Believe it or not, that’s all there is to using Netplan. Although it is a significant change to how we’re accustomed to configuring network addresses, it’s not all that hard to get used to. But this style of configuration is here to stay… so you will need to get used to it.
+
+Learn more about Linux through the free ["Introduction to Linux" ][5]course from The Linux Foundation and edX.
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/learn/intro-to-linux/2018/9/how-use-netplan-network-configuration-tool-linux
+
+作者:[Jack Wallen][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.linux.com/users/jlwallen
+[1]: https://netplan.io/
+[3]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/netplan_1.jpg?itok=XuIsXWbV (netplan)
+[4]: /licenses/category/used-permission
+[5]: https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/sources/tech/20180910 How To List An Available Package Groups In Linux.md b/sources/tech/20180910 How To List An Available Package Groups In Linux.md
new file mode 100644
index 0000000000..754c2d0c3a
--- /dev/null
+++ b/sources/tech/20180910 How To List An Available Package Groups In Linux.md
@@ -0,0 +1,644 @@
+How To List An Available Package Groups In Linux
+======
+As we know, if we want to install any packages in Linux we need to use the distribution package manager to get it done.
+
+Package manager is playing major role in Linux as this used most of the time by admin.
+
+If you would like to install group of package in one shot what would be the possible option.
+
+Is it possible in Linux? if so, what would be the command for it.
+
+Yes, this can be done in Linux by using the package manager. Each package manager has their own option to perform this task, as i know apt or apt-get package manager doesn’t has this option.
+
+For Debian based system we need to use tasksel command instead of official package managers called apt or apt-get.
+
+What is the benefit if we install group of package in Linux? Yes, there is lot of benefit is available in Linux when we install group of package because if you want to install LAMP separately we need to include so many packages but that can be done using single package when we use group of package command.
+
+Say for example, as you get a request from Application team to install LAMP but you don’t know what are the packages needs to be installed, this is where group of package comes into picture.
+
+Group option is a handy tool for Linux systems which will install Group of Software in a single click on your system without headache.
+
+A package group is a collection of packages that serve a common purpose, for instance System Tools or Sound and Video. Installing a package group pulls a set of dependent packages, saving time considerably.
+
+**Suggested Read :**
+**(#)** [How To List Installed Packages By Size (Largest) On Linux][1]
+**(#)** [How To View/List The Available Packages Updates In Linux][2]
+**(#)** [How To View A Particular Package Installed/Updated/Upgraded/Removed/Erased Date On Linux][3]
+**(#)** [How To View Detailed Information About A Package In Linux][4]
+**(#)** [How To Search If A Package Is Available On Your Linux Distribution Or Not][5]
+**(#)** [Newbies corner – A Graphical frontend tool for Linux Package Manager][6]
+**(#)** [Linux Expert should knows, list of Command line Package Manager & Usage][7]
+
+### How To List An Available Package Groups In CentOS/RHEL Systems
+
+RHEL & CentOS systems are using RPM packages hence we can use the `Yum Package Manager` to get this information.
+
+YUM stands for Yellowdog Updater, Modified is an open-source command-line front-end package-management utility for RPM based systems such as Red Hat Enterprise Linux (RHEL) and CentOS.
+
+Yum is the primary tool for getting, installing, deleting, querying, and managing RPM packages from distribution repositories, as well as other third-party repositories.
+
+**Suggested Read :** [YUM Command To Manage Packages on RHEL/CentOS Systems][8]
+
+```
+# yum grouplist
+Loaded plugins: fastestmirror, security
+Setting up Group Process
+Loading mirror speeds from cached hostfile
+ * epel: epel.mirror.constant.com
+Installed Groups:
+ Base
+ E-mail server
+ Graphical Administration Tools
+ Hardware monitoring utilities
+ Legacy UNIX compatibility
+ Milkymist
+ Networking Tools
+ Performance Tools
+ Perl Support
+ Security Tools
+Available Groups:
+ Additional Development
+ Backup Client
+ Backup Server
+ CIFS file server
+ Client management tools
+ Compatibility libraries
+ Console internet tools
+ Debugging Tools
+ Desktop
+.
+.
+Available Language Groups:
+ Afrikaans Support [af]
+ Albanian Support [sq]
+ Amazigh Support [ber]
+ Arabic Support [ar]
+ Armenian Support [hy]
+ Assamese Support [as]
+ Azerbaijani Support [az]
+.
+.
+Done
+
+```
+
+If you would like to list what are the packages is associated on it, run the below command. In this example we are going to list what are the packages is associated with “Performance Tools” group.
+
+```
+# yum groupinfo "Performance Tools"
+Loaded plugins: fastestmirror, security
+Setting up Group Process
+Loading mirror speeds from cached hostfile
+ * epel: ewr.edge.kernel.org
+
+Group: Performance Tools
+ Description: Tools for diagnosing system and application-level performance problems.
+ Mandatory Packages:
+ blktrace
+ sysstat
+ Default Packages:
+ dstat
+ iotop
+ latencytop
+ latencytop-tui
+ oprofile
+ perf
+ powertop
+ seekwatcher
+ Optional Packages:
+ oprofile-jit
+ papi
+ sdparm
+ sg3_utils
+ tiobench
+ tuned
+ tuned-utils
+
+```
+
+### How To List An Available Package Groups In Fedora
+
+Fedora system uses DNF package manager hence we can use the Dnf Package Manager to get this information.
+
+DNF stands for Dandified yum. We can tell DNF, the next generation of yum package manager (Fork of Yum) using hawkey/libsolv library for backend. Aleš Kozumplík started working on DNF since Fedora 18 and its implemented/launched in Fedora 22 finally.
+
+Dnf command is used to install, update, search & remove packages on Fedora 22 and later system. It automatically resolve dependencies and make it smooth package installation without any trouble.
+
+Yum replaced by DNF due to several long-term problems in Yum which was not solved. Asked why ? he did not patches the Yum issues. Aleš Kozumplík explains that patching was technically hard and YUM team wont accept the changes immediately and other major critical, YUM is 56K lines but DNF is 29K lies. So, there is no option for further development, except to fork.
+
+**Suggested Read :** [DNF (Fork of YUM) Command To Manage Packages on Fedora System][9]
+
+```
+# dnf grouplist
+Last metadata expiration check: 0:00:00 ago on Sun 09 Sep 2018 07:10:36 PM IST.
+Available Environment Groups:
+ Fedora Custom Operating System
+ Minimal Install
+ Fedora Server Edition
+ Fedora Workstation
+ Fedora Cloud Server
+ KDE Plasma Workspaces
+ Xfce Desktop
+ LXDE Desktop
+ Hawaii Desktop
+ LXQt Desktop
+ Cinnamon Desktop
+ MATE Desktop
+ Sugar Desktop Environment
+ Development and Creative Workstation
+ Web Server
+ Infrastructure Server
+ Basic Desktop
+Installed Groups:
+ C Development Tools and Libraries
+ Development Tools
+Available Groups:
+ 3D Printing
+ Administration Tools
+ Ansible node
+ Audio Production
+ Authoring and Publishing
+ Books and Guides
+ Cloud Infrastructure
+ Cloud Management Tools
+ Container Management
+ D Development Tools and Libraries
+.
+.
+ RPM Development Tools
+ Security Lab
+ Text-based Internet
+ Window Managers
+ GNOME Desktop Environment
+ Graphical Internet
+ KDE (K Desktop Environment)
+ Fonts
+ Games and Entertainment
+ Hardware Support
+ Sound and Video
+ System Tools
+
+```
+
+If you would like to list what are the packages is associated on it, run the below command. In this example we are going to list what are the packages is associated with “Editor” group.
+
+```
+
+# dnf groupinfo Editors
+Last metadata expiration check: 0:04:57 ago on Sun 09 Sep 2018 07:10:36 PM IST.
+
+Group: Editors
+ Description: Sometimes called text editors, these are programs that allow you to create and edit text files. This includes Emacs and Vi.
+ Optional Packages:
+ code-editor
+ cssed
+ emacs
+ emacs-auctex
+ emacs-bbdb
+ emacs-ess
+ emacs-vm
+ geany
+ gobby
+ jed
+ joe
+ leafpad
+ nedit
+ poedit
+ psgml
+ vim-X11
+ vim-enhanced
+ xemacs
+ xemacs-packages-base
+ xemacs-packages-extra
+ xemacs-xft
+ xmlcopyeditor
+ zile
+```
+
+### How To List An Available Package Groups In openSUSE System
+
+openSUSE system uses zypper package manager hence we can use the zypper Package Manager to get this information.
+
+Zypper is a command line package manager for suse & openSUSE distributions. It’s used to install, update, search & remove packages & manage repositories, perform various queries, and more. Zypper command-line interface to ZYpp system management library (libzypp).
+
+**Suggested Read :** [Zypper Command To Manage Packages On openSUSE & suse Systems][10]
+
+```
+# zypper patterns
+Loading repository data...
+Warning: Repository 'Update Repository (Non-Oss)' appears to be outdated. Consider using a different mirror or server.
+Warning: Repository 'Main Update Repository' appears to be outdated. Consider using a different mirror or server.
+Reading installed packages...
+S | Name | Version | Repository | Dependency
+---|----------------------|---------------|-----------------------|-----------
+ | 64bit | 20150918-25.1 | Main Repository (OSS) |
+ | apparmor | 20150918-25.1 | Main Repository (OSS) |
+i | apparmor | 20150918-25.1 | @System |
+ | base | 20150918-25.1 | Main Repository (OSS) |
+i+ | base | 20150918-25.1 | @System |
+ | books | 20150918-25.1 | Main Repository (OSS) |
+ | console | 20150918-25.1 | Main Repository (OSS) |
+ | devel_C_C++ | 20150918-25.1 | Main Repository (OSS) |
+i | enhanced_base | 20150918-25.1 | @System |
+ | enlightenment | 20150918-25.1 | Main Repository (OSS) |
+ | file_server | 20150918-25.1 | Main Repository (OSS) |
+ | fonts | 20150918-25.1 | Main Repository (OSS) |
+i | fonts | 20150918-25.1 | @System |
+ | games | 20150918-25.1 | Main Repository (OSS) |
+i | games | 20150918-25.1 | @System |
+ | gnome | 20150918-25.1 | Main Repository (OSS) |
+ | gnome_basis | 20150918-25.1 | Main Repository (OSS) |
+i | imaging | 20150918-25.1 | @System |
+ | kde | 20150918-25.1 | Main Repository (OSS) |
+i+ | kde | 20150918-25.1 | @System |
+ | kde_plasma | 20150918-25.1 | Main Repository (OSS) |
+i | kde_plasma | 20150918-25.1 | @System |
+ | lamp_server | 20150918-25.1 | Main Repository (OSS) |
+ | laptop | 20150918-25.1 | Main Repository (OSS) |
+i+ | laptop | 20150918-25.1 | @System |
+ | lxde | 20150918-25.1 | Main Repository (OSS) |
+ | lxqt | 20150918-25.1 | Main Repository (OSS) |
+i | multimedia | 20150918-25.1 | @System |
+ | network_admin | 20150918-25.1 | Main Repository (OSS) |
+ | non_oss | 20150918-25.1 | Main Repository (OSS) |
+i | non_oss | 20150918-25.1 | @System |
+ | office | 20150918-25.1 | Main Repository (OSS) |
+i | office | 20150918-25.1 | @System |
+ | print_server | 20150918-25.1 | Main Repository (OSS) |
+ | remote_desktop | 20150918-25.1 | Main Repository (OSS) |
+ | x11 | 20150918-25.1 | Main Repository (OSS) |
+i+ | x11 | 20150918-25.1 | @System |
+ | x86 | 20150918-25.1 | Main Repository (OSS) |
+ | xen_server | 20150918-25.1 | Main Repository (OSS) |
+ | xfce | 20150918-25.1 | Main Repository (OSS) |
+ | xfce_basis | 20150918-25.1 | Main Repository (OSS) |
+ | yast2_basis | 20150918-25.1 | Main Repository (OSS) |
+i | yast2_basis | 20150918-25.1 | @System |
+ | yast2_install_wf | 20150918-25.1 | Main Repository (OSS) |
+```
+
+If you would like to list what are the packages is associated on it, run the below command. In this example we are going to list what are the packages is associated with “file_server” group.
+Additionally zypper command allows a user to perform the same action with different options.
+
+```
+# zypper info file_server
+Loading repository data...
+Warning: Repository 'Update Repository (Non-Oss)' appears to be outdated. Consider using a different mirror or server.
+Warning: Repository 'Main Update Repository' appears to be outdated. Consider using a different mirror or server.
+Reading installed packages...
+
+Information for pattern file_server:
+------------------------------------
+Repository : Main Repository (OSS)
+Name : file_server
+Version : 20150918-25.1
+Arch : x86_64
+Vendor : openSUSE
+Installed : No
+Visible to User : Yes
+Summary : File Server
+Description :
+ File services to host files so that they may be accessed or retrieved by other computers on the same network. This includes the FTP, SMB, and NFS protocols.
+Contents :
+ S | Name | Type | Dependency
+ ---|-------------------------------|---------|------------
+ i+ | patterns-openSUSE-base | package | Required
+ | patterns-openSUSE-file_server | package | Required
+ | nfs-kernel-server | package | Recommended
+ i | nfsidmap | package | Recommended
+ i | samba | package | Recommended
+ i | samba-client | package | Recommended
+ i | samba-winbind | package | Recommended
+ | tftp | package | Recommended
+ | vsftpd | package | Recommended
+ | yast2-ftp-server | package | Recommended
+ | yast2-nfs-server | package | Recommended
+ i | yast2-samba-server | package | Recommended
+ | yast2-tftp-server | package | Recommended
+```
+
+If you would like to list what are the packages is associated on it, run the below command.
+
+```
+# zypper pattern-info file_server
+Loading repository data...
+Warning: Repository 'Update Repository (Non-Oss)' appears to be outdated. Consider using a different mirror or server.
+Warning: Repository 'Main Update Repository' appears to be outdated. Consider using a different mirror or server.
+Reading installed packages...
+
+
+Information for pattern file_server:
+------------------------------------
+Repository : Main Repository (OSS)
+Name : file_server
+Version : 20150918-25.1
+Arch : x86_64
+Vendor : openSUSE
+Installed : No
+Visible to User : Yes
+Summary : File Server
+Description :
+ File services to host files so that they may be accessed or retrieved by other computers on the same network. This includes the FTP, SMB, and NFS protocols.
+Contents :
+ S | Name | Type | Dependency
+ ---|-------------------------------|---------|------------
+ i+ | patterns-openSUSE-base | package | Required
+ | patterns-openSUSE-file_server | package | Required
+ | nfs-kernel-server | package | Recommended
+ i | nfsidmap | package | Recommended
+ i | samba | package | Recommended
+ i | samba-client | package | Recommended
+ i | samba-winbind | package | Recommended
+ | tftp | package | Recommended
+ | vsftpd | package | Recommended
+ | yast2-ftp-server | package | Recommended
+ | yast2-nfs-server | package | Recommended
+ i | yast2-samba-server | package | Recommended
+ | yast2-tftp-server | package | Recommended
+```
+
+If you would like to list what are the packages is associated on it, run the below command.
+
+```
+# zypper info pattern file_server
+Loading repository data...
+Warning: Repository 'Update Repository (Non-Oss)' appears to be outdated. Consider using a different mirror or server.
+Warning: Repository 'Main Update Repository' appears to be outdated. Consider using a different mirror or server.
+Reading installed packages...
+
+Information for pattern file_server:
+------------------------------------
+Repository : Main Repository (OSS)
+Name : file_server
+Version : 20150918-25.1
+Arch : x86_64
+Vendor : openSUSE
+Installed : No
+Visible to User : Yes
+Summary : File Server
+Description :
+ File services to host files so that they may be accessed or retrieved by other computers on the same network. This includes the FTP, SMB, and NFS protocols.
+Contents :
+ S | Name | Type | Dependency
+ ---|-------------------------------|---------|------------
+ i+ | patterns-openSUSE-base | package | Required
+ | patterns-openSUSE-file_server | package | Required
+ | nfs-kernel-server | package | Recommended
+ i | nfsidmap | package | Recommended
+ i | samba | package | Recommended
+ i | samba-client | package | Recommended
+ i | samba-winbind | package | Recommended
+ | tftp | package | Recommended
+ | vsftpd | package | Recommended
+ | yast2-ftp-server | package | Recommended
+ | yast2-nfs-server | package | Recommended
+ i | yast2-samba-server | package | Recommended
+ | yast2-tftp-server | package | Recommended
+```
+
+If you would like to list what are the packages is associated on it, run the below command.
+
+```
+# zypper info -t pattern file_server
+Loading repository data...
+Warning: Repository 'Update Repository (Non-Oss)' appears to be outdated. Consider using a different mirror or server.
+Warning: Repository 'Main Update Repository' appears to be outdated. Consider using a different mirror or server.
+Reading installed packages...
+
+
+Information for pattern file_server:
+------------------------------------
+Repository : Main Repository (OSS)
+Name : file_server
+Version : 20150918-25.1
+Arch : x86_64
+Vendor : openSUSE
+Installed : No
+Visible to User : Yes
+Summary : File Server
+Description :
+ File services to host files so that they may be accessed or retrieved by other computers on the same network. This includes the FTP, SMB, and NFS protocols.
+Contents :
+ S | Name | Type | Dependency
+ ---|-------------------------------|---------|------------
+ i+ | patterns-openSUSE-base | package | Required
+ | patterns-openSUSE-file_server | package | Required
+ | nfs-kernel-server | package | Recommended
+ i | nfsidmap | package | Recommended
+ i | samba | package | Recommended
+ i | samba-client | package | Recommended
+ i | samba-winbind | package | Recommended
+ | tftp | package | Recommended
+ | vsftpd | package | Recommended
+ | yast2-ftp-server | package | Recommended
+ | yast2-nfs-server | package | Recommended
+ i | yast2-samba-server | package | Recommended
+ | yast2-tftp-server | package | Recommended
+```
+
+### How To List An Available Package Groups In Debian/Ubuntu Systems
+
+Since APT or APT-GET package manager doesn’t offer this option for Debian/Ubuntu based systems hence, we are using tasksel command to get this information.
+
+[Tasksel][11] is a handy tool for Debian/Ubuntu systems which will install Group of Software in a single click on your system. Tasks are defined in `.desc` files and located at `/usr/share/tasksel`.
+
+By default, tasksel tool installed on Debian system as part of Debian installer but it’s not installed on Ubuntu desktop editions. This functionality is similar to that of meta-packages, like how package managers have.
+
+Tasksel tool offer a simple user interface based on zenity (popup Graphical dialog box in command line).
+
+**Suggested Read :** [Tasksel – Install Group of Software in A Single Click on Debian/Ubuntu][12]
+
+```
+# tasksel --list-task
+u kubuntu-live Kubuntu live CD
+u lubuntu-live-gtk Lubuntu live CD (GTK part)
+u ubuntu-budgie-live Ubuntu Budgie live CD
+u ubuntu-live Ubuntu live CD
+u ubuntu-mate-live Ubuntu MATE Live CD
+u ubuntustudio-dvd-live Ubuntu Studio live DVD
+u vanilla-gnome-live Ubuntu GNOME live CD
+u xubuntu-live Xubuntu live CD
+u cloud-image Ubuntu Cloud Image (instance)
+u dns-server DNS server
+u kubuntu-desktop Kubuntu desktop
+u kubuntu-full Kubuntu full
+u lamp-server LAMP server
+u lubuntu-core Lubuntu minimal installation
+u lubuntu-desktop Lubuntu Desktop
+u lubuntu-gtk-core Lubuntu minimal installation (GTK part)
+u lubuntu-gtk-desktop Lubuntu Desktop (GTK part)
+u lubuntu-qt-core Lubuntu minimal installation (Qt part)
+u lubuntu-qt-desktop Lubuntu Qt Desktop (Qt part)
+u mail-server Mail server
+u postgresql-server PostgreSQL database
+i print-server Print server
+u samba-server Samba file server
+u tomcat-server Tomcat Java server
+u ubuntu-budgie-desktop Ubuntu Budgie desktop
+i ubuntu-desktop Ubuntu desktop
+u ubuntu-mate-core Ubuntu MATE minimal
+u ubuntu-mate-desktop Ubuntu MATE desktop
+i ubuntu-usb Ubuntu desktop USB
+u ubuntustudio-audio Audio recording and editing suite
+u ubuntustudio-desktop Ubuntu Studio desktop
+u ubuntustudio-desktop-core Ubuntu Studio minimal DE installation
+u ubuntustudio-fonts Large selection of font packages
+u ubuntustudio-graphics 2D/3D creation and editing suite
+u ubuntustudio-photography Photograph touchup and editing suite
+u ubuntustudio-publishing Publishing applications
+u ubuntustudio-video Video creation and editing suite
+u vanilla-gnome-desktop Vanilla GNOME desktop
+u xubuntu-core Xubuntu minimal installation
+u xubuntu-desktop Xubuntu desktop
+u openssh-server OpenSSH server
+u server Basic Ubuntu server
+```
+
+If you would like to list what are the packages is associated on it, run the below command. In this example we are going to list what are the packages is associated with “file_server” group.
+
+```
+# tasksel --task-desc "lamp-server"
+Selects a ready-made Linux/Apache/MySQL/PHP server.
+```
+
+### How To List An Available Package Groups In Arch Linux based Systems
+
+Arch Linux based systems are using pacman package manager hence we can use the pacman Package Manager to get this information.
+
+pacman stands for package manager utility (pacman). pacman is a command-line utility to install, build, remove and manage Arch Linux packages. pacman uses libalpm (Arch Linux Package Management (ALPM) library) as a back-end to perform all the actions.
+
+**Suggested Read :** [Pacman Command To Manage Packages On Arch Linux Based Systems][13]
+
+```
+# pacman -Sg
+base-devel
+base
+multilib-devel
+gnome-extra
+kde-applications
+kdepim
+kdeutils
+kdeedu
+kf5
+kdemultimedia
+gnome
+plasma
+kdegames
+kdesdk
+kdebase
+xfce4
+fprint
+kdegraphics
+kdenetwork
+kdeadmin
+kf5-aids
+kdewebdev
+.
+.
+dlang-ldc
+libretro
+ring
+lxqt
+non-daw
+non
+alsa
+qtcurve
+realtime
+sugar-fructose
+tesseract-data
+vim-plugins
+
+```
+
+If you would like to list what are the packages is associated on it, run the below command. In this example we are going to list what are the packages is associated with “gnome” group.
+
+```
+# pacman -Sg gnome
+gnome baobab
+gnome cheese
+gnome eog
+gnome epiphany
+gnome evince
+gnome file-roller
+gnome gdm
+gnome gedit
+gnome gnome-backgrounds
+gnome gnome-calculator
+gnome gnome-calendar
+gnome gnome-characters
+gnome gnome-clocks
+gnome gnome-color-manager
+gnome gnome-contacts
+gnome gnome-control-center
+gnome gnome-dictionary
+gnome gnome-disk-utility
+gnome gnome-documents
+gnome gnome-font-viewer
+.
+.
+gnome sushi
+gnome totem
+gnome tracker
+gnome tracker-miners
+gnome vino
+gnome xdg-user-dirs-gtk
+gnome yelp
+gnome gnome-boxes
+gnome gnome-software
+gnome simple-scan
+
+```
+
+Alternatively we can check the same by running following command.
+
+```
+# pacman -S gnome
+:: There are 64 members in group gnome:
+:: Repository extra
+ 1) baobab 2) cheese 3) eog 4) epiphany 5) evince 6) file-roller 7) gdm 8) gedit 9) gnome-backgrounds 10) gnome-calculator 11) gnome-calendar 12) gnome-characters 13) gnome-clocks
+ 14) gnome-color-manager 15) gnome-contacts 16) gnome-control-center 17) gnome-dictionary 18) gnome-disk-utility 19) gnome-documents 20) gnome-font-viewer 21) gnome-getting-started-docs
+ 22) gnome-keyring 23) gnome-logs 24) gnome-maps 25) gnome-menus 26) gnome-music 27) gnome-photos 28) gnome-screenshot 29) gnome-session 30) gnome-settings-daemon 31) gnome-shell
+ 32) gnome-shell-extensions 33) gnome-system-monitor 34) gnome-terminal 35) gnome-themes-extra 36) gnome-todo 37) gnome-user-docs 38) gnome-user-share 39) gnome-video-effects 40) grilo-plugins
+ 41) gvfs 42) gvfs-afc 43) gvfs-goa 44) gvfs-google 45) gvfs-gphoto2 46) gvfs-mtp 47) gvfs-nfs 48) gvfs-smb 49) mousetweaks 50) mutter 51) nautilus 52) networkmanager 53) orca 54) rygel
+ 55) sushi 56) totem 57) tracker 58) tracker-miners 59) vino 60) xdg-user-dirs-gtk 61) yelp
+:: Repository community
+ 62) gnome-boxes 63) gnome-software 64) simple-scan
+
+Enter a selection (default=all): ^C
+Interrupt signal received
+
+```
+
+To know exactly how many packages is associated on it, run the following command.
+
+```
+# pacman -Sg gnome | wc -l
+64
+
+```
+
+--------------------------------------------------------------------------------
+
+via: https://www.2daygeek.com/how-to-list-an-available-package-groups-in-linux/
+
+作者:[Prakash Subramanian][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.2daygeek.com/author/prakash/
+[1]: https://www.2daygeek.com/how-to-list-installed-packages-by-size-largest-on-linux/
+[2]: https://www.2daygeek.com/how-to-view-list-the-available-packages-updates-in-linux/
+[3]: https://www.2daygeek.com/how-to-view-a-particular-package-installed-updated-upgraded-removed-erased-date-on-linux/
+[4]: https://www.2daygeek.com/how-to-view-detailed-information-about-a-package-in-linux/
+[5]: https://www.2daygeek.com/how-to-search-if-a-package-is-available-on-your-linux-distribution-or-not/
+[6]: https://www.2daygeek.com/list-of-graphical-frontend-tool-for-linux-package-manager/
+[7]: https://www.2daygeek.com/list-of-command-line-package-manager-for-linux/
+[8]: https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
+[9]: https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
+[10]: https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
+[11]: https://wiki.debian.org/tasksel
+[12]: https://www.2daygeek.com/tasksel-install-group-of-software-in-a-single-click-or-single-command-on-debian-ubuntu/
+[13]: https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
diff --git a/sources/tech/20180911 Know Your Storage- Block, File - Object.md b/sources/tech/20180911 Know Your Storage- Block, File - Object.md
new file mode 100644
index 0000000000..186b41d41a
--- /dev/null
+++ b/sources/tech/20180911 Know Your Storage- Block, File - Object.md
@@ -0,0 +1,63 @@
+translating by name1e5s
+Know Your Storage: Block, File & Object
+======
+
+
+
+Dealing with the tremendous amount of data generated today presents a big challenge for companies who create or consume such data. It’s a challenge for tech companies that are dealing with related storage issues.
+
+“Data is growing exponentially each year, and we find that the majority of data growth is due to increased consumption and industries adopting transformational projects to expand value. Certainly, the Internet of Things (IoT) has contributed greatly to data growth, but the key challenge for software-defined storage is how to address the use cases associated with data growth,” said Michael St. Jean, principal product marketing manager, Red Hat Storage.
+
+Every challenge is an opportunity. “The deluge of data being generated by old and new sources today is certainly presenting us with opportunities to meet our customers escalating needs in the areas of scale, performance, resiliency, and governance,” said Tad Brockway, General Manager for Azure Storage, Media and Edge.
+
+### Trinity of modern software-defined storage
+
+There are three different kinds of storage solutions -- block, file, and object -- each serving a different purpose while working with the others.
+
+Block storage is the oldest form of data storage, where data is stored in fixed-length blocks or chunks of data. Block storage is used in enterprise storage environments and usually is accessed using Fibre Channel or iSCSI interface. “Block storage requires an application to map where the data is stored on the storage device,” according to SUSE’s Larry Morris, Sr. Product Manager, Software Defined Storage.
+
+Block storage is virtualized in storage area network and software defined storage systems, which are abstracted logical devices that reside on a shared hardware infrastructure and are created and presented to the host operating system of a server, virtual server, or hypervisor via protocols like SCSI, SATA, SAS, FCP, FCoE, or iSCSI.
+
+“Block storage splits a single storage volume (like a virtual or cloud storage node, or a good old fashioned hard disk) into individual instances known as blocks,” said St. Jean.
+
+Each block exists independently and can be formatted with its own data transfer protocol and operating system — giving users complete configuration autonomy. Because block storage systems aren’t burdened with the same investigative file-finding duties as the file storage systems, block storage is a faster storage system. Pairing that speed with configuration flexibility makes block storage ideal for raw server storage or rich media databases.
+
+Block storage can be used to host operating systems, applications, databases, entire virtual machines and containers. Traditionally, block storage can only be accessed by individual machine, or machines in a cluster, to which it has been presented.
+
+### File-based storage
+
+File-based storage uses a filesystem to map where the data is stored on the storage device. It’s a dominant technology used on direct- and networked-attached storage system, and it takes care of two things: organizing data and representing it to users. “With file storage, data is arranged on the server side in the exact same format as the clients see it. This allows the user to request a file by some unique identifier — like a name, location, or URL — which is communicated to the storage system using specific data transfer protocols,” said St. Jean.
+
+The result is a type of hierarchical file structure that can be navigated from top to bottom. File storage is layered on top of block storage, allowing users to see and access data as files and folders, but restricting access to the blocks that stand up those files and folders.
+
+“File storage is typically represented by shared filesystems like NFS and CIFS/SMB that can be accessed by many servers over an IP network. Access can be controlled at a file, directory, and export level via user and group permissions. File storage can be used to store files needed by multiple users and machines, application binaries, databases, virtual machines, and can be used by containers,” explained Brockway.
+
+### Object storage
+
+Object storage is the newest form of data storage, and it provides a repository for unstructured data which separates the content from the indexing and allows the concatenation of multiple files into an object. An object is a piece of data paired with any associated metadata that provides context about the bytes contained within the object (things like how old or big the data is). Those two things together — the data and metadata — make an object.
+
+One advantage of object storage is the unique identifier associated with each piece of data. Accessing the data involves using the unique identifier and does not require the application or user to know where the data is actually stored. Object data is accessed through APIs.
+
+“The data stored in objects is uncompressed and unencrypted, and the objects themselves are arranged in object stores (a central repository filled with many other objects) or containers (a package that contains all of the files an application needs to run). Objects, object stores, and containers are very flat in nature — compared to the hierarchical structure of file storage systems — which allow them to be accessed very quickly at huge scale,” explained St. Jean.
+
+Object stores can scale to many petabytes to accommodate the largest datasets and are a great choice for images, audio, video, logs, backups, and data used by analytics services.
+
+### Conclusion
+
+Now you know about the various types of storage and how they are used. Stay tuned to learn more about software-defined storage as we examine the topic in the future.
+
+Join us at [Open Source Summit + Embedded Linux Conference Europe][1] in Edinburgh, UK on October 22-24, 2018, for 100+ sessions on Linux, Cloud, Containers, AI, Community, and more.
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/blog/2018/9/know-your-storage-block-file-object
+
+作者:[Swapnil Bhartiya][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.linux.com/users/arnieswap
+[1]: https://events.linuxfoundation.org/events/elc-openiot-europe-2018/
diff --git a/sources/tech/20180912 How subroutine signatures work in Perl 6.md b/sources/tech/20180912 How subroutine signatures work in Perl 6.md
new file mode 100644
index 0000000000..79606380bd
--- /dev/null
+++ b/sources/tech/20180912 How subroutine signatures work in Perl 6.md
@@ -0,0 +1,335 @@
+How subroutine signatures work in Perl 6
+======
+In the fourth article in this series comparing Perl 5 to Perl 6, learn how signatures work in Perl 6.
+
+
+
+In the [first article][1] in this series comparing Perl 5 to Perl 6, we looked into some of the issues you might encounter when migrating code into Perl 6. In the [second article][2], we examined how garbage collection works in Perl 6, and in the [third article][3], we looked at how containers replaced references in Perl 6. Here in the fourth article, we will focus on (subroutine) signatures in Perl 6 and how they differ from those in Perl 5.
+
+### Experimental signatures in Perl 5
+
+If you're migrating from Perl 5 code to Perl 6, you're probably not using the [experimental signature feature][4] that became available in Perl 5.20 or any of the older CPAN modules like [signatures][5], [Function::Parameters][6], or any of the other Perl 5 modules on CPAN with ["signature" in their name][7].
+
+Also, in my experience, [prototypes][8] haven't been used very often in the Perl programs out in the world (e.g., the [DarkPAN][9] ).
+
+For these reasons, I will compare Perl 6 functionality only with the most common use of "classic" Perl 5 argument passing.
+
+### Argument passing in Perl 5
+
+All arguments you pass to a Perl 5 subroutine are flattened and put into the automatically defined `@_` array variable inside. That is basically all Perl 5 does with passing arguments to subroutines. Nothing more, nothing less. There are, however, several idioms in Perl 5 that take it from there. The most common (I would say "standard") idiom in my experience is:
+
+```
+# Perl 5
+sub do_something {
+ my ($foo, $bar) = @_;
+ # actually do something with $foo and $bar
+}
+```
+
+This idiom performs a list assignment (copy) to two (new) lexical variables. This way of accessing the arguments to a subroutine is also supported in Perl 6, but it's intended just as a way to make migrations easier.
+
+If you expect a fixed number of arguments followed by a variable number of arguments, the following idiom is typically used:
+
+```
+# Perl 5
+sub do_something {
+ my $foo = shift;
+ my $bar = shift;
+ for (@_) {
+ # do something for each element in @_
+ }
+}do_something
+```
+
+This idiom depends on the magic behavior of [shift][10], which shifts from `@_` in this context. If the subroutine is intended to be called as a method, something like this is usually seen:
+
+```
+# Perl 5
+sub do_something {
+ my $self = shift;
+ # do something with $self
+}do_something
+```
+
+as the first argument passed is the [invocant][11] in Perl 5.
+
+By the way, this idiom can also be written in the first idiom:
+
+```
+# Perl 5
+sub do_something {
+ my ($foo, $bar, @rest) = @_;
+ for (@rest) {
+ # do something for each element in @rest
+ }
+}
+```
+
+But that would be less efficient, as it would involve copying a potentially long list of values.
+
+The third idiom revolves on directly accessing the `@_` array.
+
+```
+# Perl 5
+sub sum_two {
+ return $_[0] + $_[1]; # return the sum of the two parameters
+}sum_two
+```
+
+This idiom is typically used for small, one-line subroutines, as it is one of the most efficient ways of handling arguments because no copying takes place.
+
+This idiom is also used if you want to change any variable that is passed as a parameter. Since the elements in `@_` are aliases to any variables specified (in Perl 6 you would say: "are bound to the variables"), it is possible to change the contents:
+
+```
+# Perl 5
+sub make42 {
+ $_[0] = 42;
+}
+my $a = 666;
+make42($a);
+say $a; # 42
+```
+
+### Named arguments in Perl 5
+
+Named arguments (as such) don't exist in Perl 5. But there is an often-used idiom that effectively mimics named arguments:
+
+```
+# Perl 5
+sub do_something {
+ my %named = @_;
+ if (exists %named{bar}) {
+ # do stuff if named variable "bar" exists
+ }
+}do_somethingbar
+```
+
+This initializes the hash `%named` by alternately taking a key and a value from the `@_` array. If you call a subroutine with arguments using the fat-comma syntax:
+
+```
+# Perl 5
+frobnicate( bar => 42 );
+```
+
+it will pass two values, `"foo"` and `42`, which will be placed into the `%named` hash as the value `42` associated with key `"foo"`. But the same thing would have happened if you had specified:
+
+```
+# Perl 5
+frobnicate( "bar", 42 );
+```
+
+The `=>` is syntactic sugar for automatically quoting the left side. Otherwise, it functions just like a comma (hence the name "fat comma").
+
+If a subroutine is called as a method with named arguments, this idiom is combined with the standard idiom:
+
+```
+# Perl 5
+sub do_something {
+ my ($self, %named) = @_;
+ # do something with $self and %named
+}
+```
+
+alternatively:
+
+```
+# Perl 5
+sub do_something {
+ my $self = shift;
+ my %named = @_;
+ # do something with $self and %named
+}do_something
+```
+
+### Argument passing in Perl 6
+
+In their simplest form, subroutine signatures in Perl 6 are very much like the "standard" idiom of Perl 5. But instead of being part of the code, they are part of the definition of the subroutine, and you don't need to do the assignment:
+
+```
+# Perl 6
+sub do-something($foo, $bar) {
+ # actually do something with $foo and $bar
+}
+```
+
+versus:
+
+```
+# Perl 5
+sub do_something {
+ my ($foo, $bar) = @_;
+ # actually do something with $foo and $bar
+}
+```
+
+In Perl 6, the `($foo, $bar)` part is called the signature of the subroutine.
+
+Since Perl 6 has an actual `method` keyword, it is not necessary to take the invocant into account, as that is automatically available with the `self` term:
+
+```
+# Perl 6
+class Foo {
+ method do-something-else($foo, $bar) {
+ # do something else with self, $foo and $bar
+ }
+}
+```
+
+Such parameters are called positional parameters in Perl 6. Unless indicated otherwise, positional parameters must be specified when calling the subroutine.
+
+If you need the aliasing behavior of using `$_[0]` directly in Perl 5, you can mark the parameter as writable by specifying the `is rw` trait:
+
+```
+# Perl 6
+sub make42($foo is rw) {
+ $foo = 42;
+}
+my $a = 666;
+make42($a);
+say $a; # 42
+```
+
+When you pass an array as an argument to a subroutine, it doesn't get flattened in Perl 6. You only need to accept an array as an array in the signature:
+
+```
+# Perl 6
+sub handle-array(@a) {
+ # do something with @a
+}
+my @foo = "a" .. "z";
+handle-array(@foo);
+```
+
+You can pass any number of arrays:
+
+```
+# Perl 6
+sub handle-two-arrays(@a, @b) {
+ # do something with @a and @b
+}
+my @bar = 1..26;
+handle-two-arrays(@foo, @bar);
+```
+
+If you want the ([variadic][12]) flattening semantics of Perl 5, you can indicate this with a so-called "slurpy array" by prefixing the array with an asterisk in the signature:
+
+```
+# Perl 6
+sub slurp-an-array(*@values) {
+ # do something with @values
+}
+slurp-an-array("foo", 42, "baz");slurpanarrayslurpanarray
+```
+
+A slurpy array can occur only as the last positional parameter in a signature.
+
+If you prefer to use the Perl 5 way of specifying parameters in Perl 6, you can do this by specifying a slurpy array `*@_` in the signature:
+
+```
+# Perl 6
+sub do-like-5(*@_) {
+ my ($foo, $bar) = @_;
+}
+```
+
+### Named arguments in Perl 6
+
+On the calling side, named arguments in Perl 6 can be expressed very similarly to how they are expressed in Perl 5:
+
+```
+# Perl 5 and Perl 6
+frobnicate( bar => 42 );
+```
+
+However, on the definition side of the subroutine, things are very different:
+
+```
+# Perl 6
+sub frobnicate(:$bar) {
+ # do something with $bar
+}
+```
+
+The difference between an ordinary (positional) parameter and a named parameter is the colon, which precedes the [sigil][13] and the variable name in the definition:
+
+```
+$foo # positional parameter, receives in $foo
+:$bar # named parameter "bar", receives in $bar
+```
+
+Unless otherwise specified, named parameters are optional. If a named argument is not specified, the associated variable will contain the default value, which usually is the type object `Any`.
+
+If you want to catch any (other) named arguments, you can use a so-called "slurpy hash." Just like the slurpy array, it is indicated with an asterisk before a hash:
+
+```
+# Perl 6
+sub slurp-nameds(*%nameds) {
+ say "Received: " ~ join ", ", sort keys %nameds;
+}
+slurp-nameds(foo => 42, bar => 666); # Received: bar, fooslurpnamedssayslurpnamedsfoobar
+```
+
+As with the slurpy array, there can be only one slurpy hash in a signature, and it must be specified after any other named parameters.
+
+Often you want to pass a named argument to a subroutine from a variable with the same name. In Perl 5 this looks like: `do_something(bar => $bar)`. In Perl 6, you can specify this in the same way: `do-something(bar => $bar)`. But you can also use a shortcut: `do-something(:$bar)`. This means less typing–and less chance of typos.
+
+### Default values in Perl 6
+
+Perl 5 has the following idiom for making parameters optional with a default value:
+
+```
+# Perl 5
+sub dosomething_with_defaults {
+ my $foo = @_ ? shift : 42;
+ my $bar = @_ ? shift : 666;
+ # actually do something with $foo and $bar
+}dosomething_with_defaults
+```
+
+In Perl 6, you can specify default values as part of the signature by specifying an equal sign and an expression:
+
+```
+# Perl 6
+sub dosomething-with-defaults($foo = 42, :$bar = 666) {
+ # actually do something with $foo and $bar
+}
+```
+
+Positional parameters become optional if a default value is specified for them. Named parameters stay optional regardless of any default value.
+
+### Summary
+
+Perl 6 has a way of describing how arguments to a subroutine should be captured into parameters of that subroutine. Positional parameters are indicated by their name and the appropriate sigil (e.g., `$foo`). Named parameters are prefixed with a colon (e.g. `:$bar`). Positional parameters can be marked as `is rw` to allow changing variables in the caller's scope.
+
+Positional arguments can be flattened in a slurpy array, which is prefixed by an asterisk (e.g., `*@values`). Unexpected named arguments can be collected using a slurpy hash, which is also prefixed with an asterisk (e.g., `*%nameds`).
+
+Default values can be specified inside the signature by adding an expression after an equal sign (e.g., `$foo = 42`), which makes that parameter optional.
+
+Signatures in Perl 6 have many other interesting features, aside from the ones summarized here; if you want to know more about them, check out the Perl 6 [signature object documentation][14].
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/9/signatures-perl-6
+
+作者:[Elizabeth Mattijsen][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/lizmat
+[1]: https://opensource.com/article/18/7/migrating-perl-5-perl-6
+[2]: https://opensource.com/article/18/7/garbage-collection-perl-6
+[3]: https://opensource.com/article/18/7/containers-perl-6
+[4]: https://metacpan.org/pod/distribution/perl/pod/perlsub.pod#Signatures
+[5]: https://metacpan.org/pod/signatures
+[6]: https://metacpan.org/pod/Function::Parameters
+[7]: https://metacpan.org/search?q=signature
+[8]: https://metacpan.org/pod/perlsub#Prototypes
+[9]: http://modernperlbooks.com/mt/2009/02/the-darkpan-dependency-management-and-support-problem.html
+[10]: https://perldoc.perl.org/functions/shift.html
+[11]: https://docs.perl6.org/routine/invocant
+[12]: https://en.wikipedia.org/wiki/Variadic_function
+[13]: https://www.perl.com/article/on-sigils/
+[14]: https://docs.perl6.org/type/Signature
diff --git a/sources/tech/20180912 How to build rpm packages.md b/sources/tech/20180912 How to build rpm packages.md
new file mode 100644
index 0000000000..97b630707d
--- /dev/null
+++ b/sources/tech/20180912 How to build rpm packages.md
@@ -0,0 +1,395 @@
+How to build rpm packages
+======
+
+Save time and effort installing files and scripts across multiple hosts.
+
+
+
+I have used rpm-based package managers to install software on Red Hat and Fedora Linux since I started using Linux more than 20 years ago. I have used the **rpm** program itself, **yum** , and **DNF** , which is a close descendant of yum, to install and update packages on my Linux hosts. The yum and DNF tools are wrappers around the rpm utility that provide additional functionality, such as the ability to find and install package dependencies.
+
+Over the years I have created a number of Bash scripts, some of which have separate configuration files, that I like to install on most of my new computers and virtual machines. It reached the point that it took a great deal of time to install all of these packages, so I decided to automate that process by creating an rpm package that I could copy to the target hosts and install all of these files in their proper locations. Although the **rpm** tool was formerly used to build rpm packages, that function was removed and a new tool,was created to build new rpms.
+
+When I started this project, I found very little information about creating rpm packages, but I managed to find a book, Maximum RPM, that helped me figure it out. That book is now somewhat out of date, as is the vast majority of information I have found. It is also out of print, and used copies go for hundreds of dollars. The online version of [Maximum RPM][1] is available at no charge and is kept up to date. The [RPM website][2] also has links to other websites that have a lot of documentation about rpm. What other information there is tends to be brief and apparently assumes that you already have a good deal of knowledge about the process.
+
+In addition, every one of the documents I found assumes that the code needs to be compiled from sources as in a development environment. I am not a developer. I am a sysadmin, and we sysadmins have different needs because we don’t—or we shouldn’t—compile code to use for administrative tasks; we should use shell scripts. So we have no source code in the sense that it is something that needs to be compiled into binary executables. What we have is a source that is also the executable.
+
+For the most part, this project should be performed as the non-root user student. Rpms should never be built by root, but only by non-privileged users. I will indicate which parts should be performed as root and which by a non-root, unprivileged user.
+
+### Preparation
+
+First, open one terminal session and `su` to root. Be sure to use the `-` option to ensure that the complete root environment is enabled. I do not believe that sysadmins should use `sudo` for any administrative tasks. Find out why in my personal blog post: [Real SysAdmins don’t sudo][3].
+
+```
+[student@testvm1 ~]$ su -
+Password:
+[root@testvm1 ~]#
+```
+
+Create a student user that can be used for this project and set a password for that user.
+
+```
+[root@testvm1 ~]# useradd -c "Student User" student
+[root@testvm1 ~]# passwd student
+Changing password for user student.
+New password:
+Retype new password:
+passwd: all authentication tokens updated successfully.
+[root@testvm1 ~]#
+```
+
+Building rpm packages requires the `rpm-build` package, which is likely not already installed. Install it now as root. Note that this command will also install several dependencies. The number may vary, depending upon the packages already installed on your host; it installed a total of 17 packages on my test VM, which is pretty minimal.
+
+```
+dnf install -y rpm-build
+```
+
+The rest of this project should be performed as the user student unless otherwise explicitly directed. Open another terminal session and use `su` to switch to that user to perform the rest of these steps. Download a tarball that I have prepared of a development directory structure, utils.tar, from GitHub using the following command:
+
+```
+wget https://github.com/opensourceway/how-to-rpm/raw/master/utils.tar
+```
+
+This tarball includes all of the files and Bash scripts that will be installed by the final rpm. There is also a complete spec file, which you can use to build the rpm. We will go into detail about each section of the spec file.
+
+As user student, using your home directory as your present working directory (pwd), untar the tarball.
+
+```
+[student@testvm1 ~]$ cd ; tar -xvf utils.tar
+```
+
+Use the `tree` command to verify that the directory structure of ~/development and the contained files looks like the following output:
+
+```
+[student@testvm1 ~]$ tree development/
+development/
+├── license
+│ ├── Copyright.and.GPL.Notice.txt
+│ └── GPL_LICENSE.txt
+├── scripts
+│ ├── create_motd
+│ ├── die
+│ ├── mymotd
+│ └── sysdata
+└── spec
+ └── utils.spec
+
+3 directories, 7 files
+[student@testvm1 ~]$
+```
+
+The `mymotd` script creates a “Message Of The Day” data stream that is sent to stdout. The `create_motd` script runs the `mymotd` scripts and redirects the output to the /etc/motd file. This file is used to display a daily message to users who log in remotely using SSH.
+
+The `die` script is my own script that wraps the `kill` command in a bit of code that can find running programs that match a specified string and kill them. It uses `kill -9` to ensure that they cannot ignore the kill message.
+
+The `sysdata` script can spew tens of thousands of lines of data about your computer hardware, the installed version of Linux, all installed packages, and the metadata of your hard drives. I use it to document the state of a host at a point in time. I can later use it for reference. I used to do this to maintain a record of hosts that I installed for customers.
+
+You may need to change ownership of these files and directories to student.student. Do this, if necessary, using the following command:
+
+```
+chown -R student.student development
+```
+
+Most of the files and directories in this tree will be installed on Fedora systems by the rpm you create during this project.
+
+### Creating the build directory structure
+
+The `rpmbuild` command requires a very specific directory structure. You must create this directory structure yourself because no automated way is provided. Create the following directory structure in your home directory:
+
+```
+~ ─ rpmbuild
+ ├── RPMS
+ │ └── noarch
+ ├── SOURCES
+ ├── SPECS
+ └── SRPMS
+```
+
+We will not create the rpmbuild/RPMS/X86_64 directory because that would be architecture-specific for 64-bit compiled binaries. We have shell scripts that are not architecture-specific. In reality, we won’t be using the SRPMS directory either, which would contain source files for the compiler.
+
+### Examining the spec file
+
+Each spec file has a number of sections, some of which may be ignored or omitted, depending upon the specific circumstances of the rpm build. This particular spec file is not an example of a minimal file required to work, but it is a good example of a moderately complex spec file that packages files that do not need to be compiled. If a compile were required, it would be performed in the `%build` section, which is omitted from this spec file because it is not required.
+
+#### Preamble
+
+This is the only section of the spec file that does not have a label. It consists of much of the information you see when the command `rpm -qi [Package Name]` is run. Each datum is a single line which consists of a tag, which identifies it and text data for the value of the tag.
+
+```
+###############################################################################
+# Spec file for utils
+################################################################################
+# Configured to be built by user student or other non-root user
+################################################################################
+#
+Summary: Utility scripts for testing RPM creation
+Name: utils
+Version: 1.0.0
+Release: 1
+License: GPL
+URL: http://www.both.org
+Group: System
+Packager: David Both
+Requires: bash
+Requires: screen
+Requires: mc
+Requires: dmidecode
+BuildRoot: ~/rpmbuild/
+
+# Build with the following syntax:
+# rpmbuild --target noarch -bb utils.spec
+```
+
+Comment lines are ignored by the `rpmbuild` program. I always like to add a comment to this section that contains the exact syntax of the `rpmbuild` command required to create the package. The Summary tag is a short description of the package. The Name, Version, and Release tags are used to create the name of the rpm file, as in utils-1.00-1.rpm. Incrementing the release and version numbers lets you create rpms that can be used to update older ones.
+
+The License tag defines the license under which the package is released. I always use a variation of the GPL. Specifying the license is important to clarify the fact that the software contained in the package is open source. This is also why I included the license and GPL statement in the files that will be installed.
+
+The URL is usually the web page of the project or project owner. In this case, it is my personal web page.
+
+The Group tag is interesting and is usually used for GUI applications. The value of the Group tag determines which group of icons in the applications menu will contain the icon for the executable in this package. Used in conjunction with the Icon tag (which we are not using here), the Group tag allows adding the icon and the required information to launch a program into the applications menu structure.
+
+The Packager tag is used to specify the person or organization responsible for maintaining and creating the package.
+
+The Requires statements define the dependencies for this rpm. Each is a package name. If one of the specified packages is not present, the DNF installation utility will try to locate it in one of the defined repositories defined in /etc/yum.repos.d and install it if it exists. If DNF cannot find one or more of the required packages, it will throw an error indicating which packages are missing and terminate.
+
+The BuildRoot line specifies the top-level directory in which the `rpmbuild` tool will find the spec file and in which it will create temporary directories while it builds the package. The finished package will be stored in the noarch subdirectory that we specified earlier. The comment showing the command syntax used to build this package includes the option `–target noarch`, which defines the target architecture. Because these are Bash scripts, they are not associated with a specific CPU architecture. If this option were omitted, the build would be targeted to the architecture of the CPU on which the build is being performed.
+
+The `rpmbuild` program can target many different architectures, and using the `--target` option allows us to build architecture-specific packages on a host with a different architecture from the one on which the build is performed. So I could build a package intended for use on an i686 architecture on an x86_64 host, and vice versa.
+
+Change the packager name to yours and the URL to your own website if you have one.
+
+#### %description
+
+The `%description` section of the spec file contains a description of the rpm package. It can be very short or can contain many lines of information. Our `%description` section is rather terse.
+
+```
+%description
+A collection of utility scripts for testing RPM creation.
+```
+
+#### %prep
+
+The `%prep` section is the first script that is executed during the build process. This script is not executed during the installation of the package.
+
+This script is just a Bash shell script. It prepares the build directory, creating directories used for the build as required and copying the appropriate files into their respective directories. This would include the sources required for a complete compile as part of the build.
+
+The $RPM_BUILD_ROOT directory represents the root directory of an installed system. The directories created in the $RPM_BUILD_ROOT directory are fully qualified paths, such as /user/local/share/utils, /usr/local/bin, and so on, in a live filesystem.
+
+In the case of our package, we have no pre-compile sources as all of our programs are Bash scripts. So we simply copy those scripts and other files into the directories where they belong in the installed system.
+
+```
+%prep
+################################################################################
+# Create the build tree and copy the files from the development directories #
+# into the build tree. #
+################################################################################
+echo "BUILDROOT = $RPM_BUILD_ROOT"
+mkdir -p $RPM_BUILD_ROOT/usr/local/bin/
+mkdir -p $RPM_BUILD_ROOT/usr/local/share/utils
+
+cp /home/student/development/utils/scripts/* $RPM_BUILD_ROOT/usr/local/bin
+cp /home/student/development/utils/license/* $RPM_BUILD_ROOT/usr/local/share/utils
+cp /home/student/development/utils/spec/* $RPM_BUILD_ROOT/usr/local/share/utils
+
+exit
+```
+
+Note that the exit statement at the end of this section is required.
+
+#### %files
+
+This section of the spec file defines the files to be installed and their locations in the directory tree. It also specifies the file attributes and the owner and group owner for each file to be installed. The file permissions and ownerships are optional, but I recommend that they be explicitly set to eliminate any chance for those attributes to be incorrect or ambiguous when installed. Directories are created as required during the installation if they do not already exist.
+
+```
+%files
+%attr(0744, root, root) /usr/local/bin/*
+%attr(0644, root, root) /usr/local/share/utils/*
+```
+
+#### %pre
+
+This section is empty in our lab project’s spec file. This would be the place to put any scripts that are required to run during installation of the rpm but prior to the installation of the files.
+
+#### %post
+
+This section of the spec file is another Bash script. This one runs after the installation of files. This section can be pretty much anything you need or want it to be, including creating files, running system commands, and restarting services to reinitialize them after making configuration changes. The `%post` script for our rpm package performs some of those tasks.
+
+```
+%post
+################################################################################
+# Set up MOTD scripts #
+################################################################################
+cd /etc
+# Save the old MOTD if it exists
+if [ -e motd ]
+then
+ cp motd motd.orig
+fi
+# If not there already, Add link to create_motd to cron.daily
+cd /etc/cron.daily
+if [ ! -e create_motd ]
+then
+ ln -s /usr/local/bin/create_motd
+fi
+# create the MOTD for the first time
+/usr/local/bin/mymotd > /etc/motd
+```
+
+The comments included in this script should make its purpose clear.
+
+#### %postun
+
+This section contains a script that would be run after the rpm package is uninstalled. Using rpm or DNF to remove a package removes all of the files listed in the `%files` section, but it does not remove files or links created by the `%post` section, so we need to handle that in this section.
+
+This script usually consists of cleanup tasks that simply erasing the files previously installed by the rpm cannot accomplish. In the case of our package, it includes removing the link created by the `%post` script and restoring the saved original of the motd file.
+
+```
+%postun
+# remove installed files and links
+rm /etc/cron.daily/create_motd
+
+# Restore the original MOTD if it was backed up
+if [ -e /etc/motd.orig ]
+then
+ mv -f /etc/motd.orig /etc/motd
+fi
+```
+
+#### %clean
+
+This Bash script performs cleanup after the rpm build process. The two lines in the `%clean` section below remove the build directories created by the `rpm-build` command. In many cases, additional cleanup may also be required.
+
+```
+%clean
+rm -rf $RPM_BUILD_ROOT/usr/local/bin
+rm -rf $RPM_BUILD_ROOT/usr/local/share/utils
+```
+
+#### %changelog
+
+This optional text section contains a list of changes to the rpm and files it contains. The newest changes are recorded at the top of this section.
+
+```
+%changelog
+* Wed Aug 29 2018 Your Name
+ - The original package includes several useful scripts. it is
+ primarily intended to be used to illustrate the process of
+ building an RPM.
+```
+
+Replace the data in the header line with your own name and email address.
+
+### Building the rpm
+
+The spec file must be in the SPECS directory of the rpmbuild tree. I find it easiest to create a link to the actual spec file in that directory so that it can be edited in the development directory and there is no need to copy it to the SPECS directory. Make the SPECS directory your pwd, then create the link.
+
+```
+cd ~/rpmbuild/SPECS/
+ln -s ~/development/spec/utils.spec
+```
+
+Run the following command to build the rpm. It should only take a moment to create the rpm if no errors occur.
+
+```
+rpmbuild --target noarch -bb utils.spec
+```
+
+Check in the ~/rpmbuild/RPMS/noarch directory to verify that the new rpm exists there.
+
+```
+[student@testvm1 ~]$ cd rpmbuild/RPMS/noarch/
+[student@testvm1 noarch]$ ll
+total 24
+-rw-rw-r--. 1 student student 24364 Aug 30 10:00 utils-1.0.0-1.noarch.rpm
+[student@testvm1 noarch]$
+```
+
+### Testing the rpm
+
+As root, install the rpm to verify that it installs correctly and that the files are installed in the correct directories. The exact name of the rpm will depend upon the values you used for the tags in the Preamble section, but if you used the ones in the sample, the rpm name will be as shown in the sample command below:
+
+```
+[root@testvm1 ~]# cd /home/student/rpmbuild/RPMS/noarch/
+[root@testvm1 noarch]# ll
+total 24
+-rw-rw-r--. 1 student student 24364 Aug 30 10:00 utils-1.0.0-1.noarch.rpm
+[root@testvm1 noarch]# rpm -ivh utils-1.0.0-1.noarch.rpm
+Preparing... ################################# [100%]
+Updating / installing...
+ 1:utils-1.0.0-1 ################################# [100%]
+```
+
+Check /usr/local/bin to ensure that the new files are there. You should also verify that the create_motd link in /etc/cron.daily has been created.
+
+Use the `rpm -q --changelog utils` command to view the changelog. View the files installed by the package using the `rpm -ql utils` command (that is a lowercase L in `ql`.)
+
+```
+[root@testvm1 noarch]# rpm -q --changelog utils
+* Wed Aug 29 2018 Your Name
+- The original package includes several useful scripts. it is
+ primarily intended to be used to illustrate the process of
+ building an RPM.
+
+[root@testvm1 noarch]# rpm -ql utils
+/usr/local/bin/create_motd
+/usr/local/bin/die
+/usr/local/bin/mymotd
+/usr/local/bin/sysdata
+/usr/local/share/utils/Copyright.and.GPL.Notice.txt
+/usr/local/share/utils/GPL_LICENSE.txt
+/usr/local/share/utils/utils.spec
+[root@testvm1 noarch]#
+```
+
+Remove the package.
+
+```
+rpm -e utils
+```
+
+### Experimenting
+
+Now you will change the spec file to require a package that does not exist. This will simulate a dependency that cannot be met. Add the following line immediately under the existing Requires line:
+
+```
+Requires: badrequire
+```
+
+Build the package and attempt to install it. What message is displayed?
+
+We used the `rpm` command to install and delete the `utils` package. Try installing the package with yum or DNF. You must be in the same directory as the package or specify the full path to the package for this to work.
+
+### Conclusion
+
+There are many tags and a couple sections that we did not cover in this look at the basics of creating an rpm package. The resources listed below can provide more information. Building rpm packages is not difficult; you just need the right information. I hope this helps you—it took me months to figure things out on my own.
+
+We did not cover building from source code, but if you are a developer, that should be a simple step from this point.
+
+Creating rpm packages is another good way to be a lazy sysadmin and save time and effort. It provides an easy method for distributing and installing the scripts and other files that we as sysadmins need to install on many hosts.
+
+### Resources
+
+ * Edward C. Baily, Maximum RPM, Sams Publishing, 2000, ISBN 0-672-31105-4
+
+ * Edward C. Baily, [Maximum RPM][1], updated online version
+
+ * [RPM Documentation][4]: This web page lists most of the available online documentation for rpm. It includes many links to other websites and information about rpm.
+
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/9/how-build-rpm-packages
+
+作者:[David Both][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/dboth
+[1]: http://ftp.rpm.org/max-rpm/
+[2]: http://rpm.org/index.html
+[3]: http://www.both.org/?p=960
+[4]: http://rpm.org/documentation.html
diff --git a/sources/tech/20180912 How to turn on an LED with Fedora IoT.md b/sources/tech/20180912 How to turn on an LED with Fedora IoT.md
new file mode 100644
index 0000000000..007cfc27ab
--- /dev/null
+++ b/sources/tech/20180912 How to turn on an LED with Fedora IoT.md
@@ -0,0 +1,201 @@
+How to turn on an LED with Fedora IoT
+======
+
+
+
+Do you enjoy running Fedora, containers, and have a Raspberry Pi? What about using all three together to play with LEDs? This article introduces Fedora IoT and shows you how to install a preview image on a Raspberry Pi. You’ll also learn how to interact with GPIO in order to light up an LED.
+
+### What is Fedora IoT?
+
+Fedora IoT is one of the current Fedora Project objectives, with a plan to become a full Fedora Edition. The result will be a system that runs on ARM (aarch64 only at the moment) devices such as the Raspberry Pi, as well as on the x86_64 architecture.
+
+![][1]
+
+Fedora IoT is based on OSTree, like [Fedora Silverblue][2] and the former [Atomic Host][3].
+
+### Download and install Fedora IoT
+
+The official Fedora IoT images are coming with the Fedora 29 release. However, in the meantime you can download a [Fedora 28-based image][4] for this experiment.
+
+You have two options to install the system: either flash the SD card using a dd command, or use a fedora-arm-installer tool. The Fedora Wiki offers more information about [setting up a physical device][5] for IoT. Also, remember that you might need to resize the third partition.
+
+Once you insert the SD card into the device, you’ll need to complete the installation by creating a user. This step requires either a serial connection, or a HDMI display with a keyboard to interact with the device.
+
+When the system is installed and ready, the next step is to configure a network connection. Log in to the system with the user you have just created choose one of the following options:
+
+ * If you need to configure your network manually, run a command similar to the following. Remember to use the right addresses for your network:
+```
+ $ nmcli connection add con-name cable ipv4.addresses \
+ 192.168.0.10/24 ipv4.gateway 192.168.0.1 \
+ connection.autoconnect true ipv4.dns "8.8.8.8,1.1.1.1" \
+ type ethernet ifname eth0 ipv4.method manual
+
+```
+
+ * If there’s a DHCP service on your network, run a command like this:
+
+```
+ $ nmcli con add type ethernet con-name cable ifname eth0
+```
+
+
+
+
+### **The GPIO interface in Fedora**
+
+Many tutorials about GPIO on Linux focus on a legacy GPIO sysfis interface. This interface is deprecated, and the upstream Linux kernel community plan to remove it completely, due to security and other issues.
+
+The Fedora kernel is already compiled without this legacy interface, so there’s no /sys/class/gpio on the system. This tutorial uses a new character device /dev/gpiochipN provided by the upstream kernel. This is the current way of interacting with GPIO.
+
+To interact with this new device, you need to use a library and a set of command line interface tools. The common command line tools such as echo or cat won’t work with this device.
+
+You can install the CLI tools by installing the libgpiod-utils package. A corresponding Python library is provided by the python3-libgpiod package.
+
+### **Creating a container with Podman**
+
+[Podman][6] is a container runtime with a command line interface similar to Docker. The big advantage of Podman is it doesn’t run any daemon in the background. That’s especially useful for devices with limited resources. Podman also allows you to start containerized services with systemd unit files. Plus, it has many additional features.
+
+We’ll create a container in these two steps:
+
+ 1. Create a layered image containing the required packages.
+ 2. Create a new container starting from our image.
+
+
+
+First, create a file Dockerfile with the content below. This tells podman to build an image based on the latest Fedora image available in the registry. Then it updates the system inside and installs some packages:
+
+```
+FROM fedora:latest
+RUN dnf -y update
+RUN dnf -y install libgpiod-utils python3-libgpiod
+
+```
+
+You have created a build recipe of a container image based on the latest Fedora with updates, plus packages to interact with GPIO.
+
+Now, run the following command to build your base image:
+
+```
+$ sudo podman build --tag fedora:gpiobase -f ./Dockerfile
+
+```
+
+You have just created your custom image with all the bits in place. You can play with this base container images as many times as you want without installing the packages every time you run it.
+
+### Working with Podman
+
+To verify the image is present, run the following command:
+
+```
+$ sudo podman images
+REPOSITORY TAG IMAGE ID CREATED SIZE
+localhost/fedora gpiobase 67a2b2b93b4b 10 minutes ago 488MB
+docker.io/library/fedora latest c18042d7fac6 2 days ago 300MB
+
+```
+
+Now, start the container and do some actual experiments. Containers are normally isolated and don’t have an access to the host system, including the GPIO interface. Therefore, you need to mount it inside while starting the container. To do this, use the –device option in the following command:
+
+```
+$ sudo podman run -it --name gpioexperiment --device=/dev/gpiochip0 localhost/fedora:gpiobase /bin/bash
+
+```
+
+You are now inside the running container. Before you move on, here are some more container commands. For now, exit the container by typing exit or pressing **Ctrl+D**.
+
+To list the the existing containers, including those not currently running, such as the one you just created, run:
+
+```
+$ sudo podman container ls -a
+CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
+64e661d5d4e8 localhost/fedora:gpiobase /bin/bash 37 seconds ago Exited (0) Less than a second ago gpioexperiment
+
+```
+
+To create a new container, run this command:
+
+```
+$ sudo podman run -it --name newexperiment --device=/dev/gpiochip0 localhost/fedora:gpiobase /bin/bash
+
+```
+
+Delete it with the following command:
+
+```
+$ sudo podman rm newexperiment
+
+```
+
+### **Turn on an LED**
+
+Now you can use the container you already created. If you exited from the container, start it again with this command:
+
+```
+$ sudo podman start -ia gpioexperiment
+
+```
+
+As already discussed, you can use the CLI tools provided by the libgpiod-utils package in Fedora. To list the available GPIO chips, run:
+
+```
+$ gpiodetect
+gpiochip0 [pinctrl-bcm2835] (54 lines)
+
+```
+
+To get the list of the lines exposed by a specific chip, run:
+
+```
+$ gpioinfo gpiochip0
+
+```
+
+Notice there’s no correlation between the number of physical pins and the number of lines printed by the previous command. What’s important is the BCM number, as shown on [pinout.xyz][7]. It is not advised to play with the lines that don’t have a corresponding BCM number.
+
+Now, connect an LED to the physical pin 40, that is BCM 21. Remember: the shorter leg of the LED (the negative leg, called the cathode) must be connected to a GND pin of the Raspberry Pi with a 330 ohm resistor, and the long leg (the anode) to the physical pin 40.
+
+To turn the LED on, run the following command. It will stay on until you press **Ctrl+C** :
+
+```
+$ gpioset --mode=wait gpiochip0 21=1
+
+```
+
+To light it up for a certain period of time, add the -b (run in the background) and -s NUM (how many seconds) parameters, as shown below. For example, to light the LED for 5 seconds, run:
+
+```
+$ gpioset -b -s 5 --mode=time gpiochip0 21=1
+
+```
+
+Another useful command is gpioget. It gets the status of a pin (high or low), and can be useful to detect buttons and switches.
+
+![Closeup of LED connection with GPIO][8]
+
+### **Conclusion**
+
+You can also play with LEDs using Python — [there are some examples here][9]. And you can also use the i2c devices inside the container as well. In addition, Podman is not strictly related to this Fedora edition. You can install it on any existing Fedora Edition, or try it on the two new OSTree-based systems in Fedora: [Fedora Silverblue][2] and [Fedora CoreOS][10].
+
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/turnon-led-fedora-iot/
+
+作者:[Alessio Ciregia][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: http://alciregi.id.fedoraproject.org/
+[1]: https://fedoramagazine.org/wp-content/uploads/2018/08/oled-1024x768.png
+[2]: https://teamsilverblue.org/
+[3]: https://www.projectatomic.io/
+[4]: https://kojipkgs.fedoraproject.org/compose/iot/latest-Fedora-IoT-28/compose/IoT/
+[5]: https://fedoraproject.org/wiki/InternetOfThings/GettingStarted#Setting_up_a_Physical_Device
+[6]: https://github.com/containers/libpod
+[7]: https://pinout.xyz/
+[8]: https://fedoramagazine.org/wp-content/uploads/2018/08/breadboard-1024x768.png
+[9]: https://github.com/brgl/libgpiod/tree/master/bindings/python/examples
+[10]: https://coreos.fedoraproject.org/
diff --git a/sources/tech/20180914 A day in the life of a log message.md b/sources/tech/20180914 A day in the life of a log message.md
new file mode 100644
index 0000000000..8d60ec9fe6
--- /dev/null
+++ b/sources/tech/20180914 A day in the life of a log message.md
@@ -0,0 +1,57 @@
+A day in the life of a log message
+======
+
+Navigating a modern distributed system from the perspective of a log message.
+
+
+
+Chaotic systems tend to be unpredictable. This is especially evident when architecting something as complex as a distributed system. Left unchecked, this unpredictability can waste boundless amounts of time. This is why every single component of a distributed system, no matter how small, must be designed to fit together in a streamlined way.
+
+[Kubernetes][1] provides a promising model for abstracting compute resources—but even it must be reconciled with other distributed platforms such as [Apache Kafka][2] to ensure reliable data delivery. If someone were to integrate these two platforms, how would it work? Furthermore, if you were to trace something as simple as a log message through such a system, what would it look like? This article will focus on how a log message from an application running inside [OKD][3], the Origin Community Distribution of Kubernetes that powers Red Hat OpenShift, gets to a data warehouse through Kafka.
+
+### OKD-defined environment
+
+Such a journey begins in OKD, since the container platform completely overlays the hardware it abstracts. This means that the log message waits to be written to **stdout** or **stderr** streams by an application residing in a container. From there, the log message is redirected onto the node's filesystem by a container engine such as [CRI-O][4].
+
+
+
+ithin OpenShift, one or more containers are encapsulated within virtual compute nodes known as pods. In fact, all applications running within OKD are abstracted as pods. This allows the applications to be manipulated in a uniform way. This also greatly simplifies communication between distributed components, since pods are systematically addressable through IP addresses and [load-balanced services][5] . So when the log message is taken from the node's filesystem by a log-collector application, it can easily be delivered to another pod running within OpenShift.
+
+### Two peas in a pod
+
+To ensure ubiquitous dispersal of the log message throughout the distributed system, the log collector needs to deliver the log message into a Kafka cluster data hub running within OpenShift. Through Kafka, the log message can be delivered to the consuming applications in a reliable and fault-tolerant way with low latency. However, in order to reap the benefits of Kafka within an OKD-defined environment, Kafka needs to be fully integrated into OKD.
+
+Running a [Strimzi operator][6] will instantiate all Kafka components as pods and integrate them to run within an OKD environment. This includes Kafka brokers for queuing log messages, Kafka connectors for reading and writing from Kafka brokers, and Zookeeper nodes for managing the Kafka cluster state. Strimzi can also instantiate the log collector to double as a Kafka connector, allowing the log collector to feed the log messages directly into a Kafka broker pod running within OKD.
+
+### Kafka inside OKD
+
+When the log-collector pod delivers the log message to a Kafka broker, the collector writes to a single broker partition, appending the message to the end of the partition. One of the advantages of using Kafka is that it decouples the log collector from the log's final destination. Thanks to the decoupling, the log collector doesn't care whether the logs end up in [Elasticsearch][7], Hadoop, Amazon S3, or all of them at the same time. Kafka is well-connected to all infrastructure, so the Kafka connectors can take the log message wherever it needs to go.
+
+Once written to a Kafka broker's partition, the log message is replicated across the broker partitions within the Kafka cluster. This is a very powerful concept on its own; combined with the self-healing features of the platform, it creates a very resilient distributed system. For example, when a node becomes unavailable, the applications running on the node are almost instantaneously spawned on healthy node(s). So even if a node with the Kafka broker is lost or damaged, the log message is guaranteed to survive as many deaths as it was replicated and a new Kafka broker will quickly take the original's place.
+
+### Off to storage
+
+After it is committed to a Kafka topic, the log message waits to be consumed by a Kafka connector sink, which relays the log message to either an analytics engine or logging warehouse. Upon delivery to its final destination, the log message could be studied for anomaly detection, queried for immediate root-cause analysis, or used for other purposes. Either way, the log message is delivered by Kafka to its destination in a safe and reliable manner.
+
+OKD and Kafka are powerful distributed platforms that are evolving rapidly. It is vital to create systems that can abstract the complicated nature of distributed computing without compromising performance. After all, how can we boast of systemwide efficiency if we cannot simplify the journey of a single log message?
+
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/9/life-log-message
+
+作者:[Josef Karásek][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/jkarasek
+[1]: https://kubernetes.io/
+[2]: https://kafka.apache.org/
+[3]: https://www.okd.io/
+[4]: http://cri-o.io/
+[5]: https://kubernetes.io/docs/concepts/services-networking/service/
+[6]: http://strimzi.io/
+[7]: https://www.elastic.co/
diff --git a/sources/tech/20180914 Convert files at the command line with Pandoc.md b/sources/tech/20180914 Convert files at the command line with Pandoc.md
new file mode 100644
index 0000000000..7b72da76a5
--- /dev/null
+++ b/sources/tech/20180914 Convert files at the command line with Pandoc.md
@@ -0,0 +1,394 @@
+Convert files at the command line with Pandoc
+======
+
+This guide shows you how to use Pandoc to convert your documents into many different file formats
+
+
+
+Pandoc is a command-line tool for converting files from one markup language to another. Markup languages use tags to annotate sections of a document. Commonly used markup languages include Markdown, ReStructuredText, HTML, LaTex, ePub, and Microsoft Word DOCX.
+
+In plain English, [Pandoc][1] allows you to convert a bunch of files from one markup language into another one. Typical examples include converting a Markdown file into a presentation, LaTeX, PDF, or even ePub.
+
+This article will explain how to produce documentation in multiple formats from a single markup language (in this case Markdown) using Pandoc. It will guide you through Pandoc installation, show how to create several types of documents, and offer tips on how to write documentation that is easy to port to other formats. It will also explain the value of using meta-information files to create a separation between the content and the meta-information (e.g., author name, template used, bibliographic style, etc.) of your documentation.
+
+### Installation and requirements
+
+Pandoc is installed by default in most Linux distributions. This tutorial uses pandoc-2.2.3.2 and pandoc-citeproc-0.14.3. If you don't intend to generate PDFs, those two packages are enough. However, I recommend installing texlive as well, so you have the option to generate PDFs.
+
+To install these programs on Linux, type the following on the command line:
+
+```
+sudo apt-get install pandoc pandoc-citeproc texlive
+```
+
+You can find [installation instructions][2] for other platforms on Pandoc's website.
+
+I highly recommend installing [pandoc][3][-crossref][3], a "filter for numbering figures, equations, tables, and cross-references to them." The easiest option is to download a [prebuilt executable][4], but you can install it from Haskell's package manager, cabal, by typing:
+
+```
+cabal update
+cabal install pandoc-crossref
+```
+
+Consult pandoc-crossref's GitHub repository if you need additional Haskell [installation information][5].
+
+### Some examples
+
+I'll demonstrate how Pandoc works by explaining how to produce three types of documents:
+
+ * A website from a LaTeX file containing math formulas
+ * A Reveal.js slideshow from a Markdown file
+ * A contract agreement document that mixes Markdown and LaTeX
+
+
+
+#### Create a website with math formulas
+
+One of the ways Pandoc excels is displaying math formulas in different output file formats. For instance, let's generate a website from a LaTeX document (named math.tex) containing some math symbols (written in LaTeX).
+
+The math.tex document looks like:
+
+```
+% Pandoc math demos
+
+$a^2 + b^2 = c^2$
+
+$v(t) = v_0 + \frac{1}{2}at^2$
+
+$\gamma = \frac{1}{\sqrt{1 - v^2/c^2}}$
+
+$\exists x \forall y (Rxy \equiv Ryx)$
+
+$p \wedge q \models p$
+
+$\Box\diamond p\equiv\diamond p$
+
+$\int_{0}^{1} x dx = \left[ \frac{1}{2}x^2 \right]_{0}^{1} = \frac{1}{2}$
+
+$e^x = \sum_{n=0}^\infty \frac{x^n}{n!} = \lim_{n\rightarrow\infty} (1+x/n)^n$
+```
+
+Convert the LaTeX document into a website named mathMathML.html by entering the following command:
+
+```
+pandoc math.tex -s --mathml -o mathMathML.html
+```
+
+The flag **-s** tells Pandoc to generate a standalone website (instead of a fragment, so it will include the head and body HTML tags), and the **–mathml** flag forces Pandoc to convert the math in LaTeX to MathML, which can be rendered by modern browsers.
+
+
+
+Take a look at the [website result][6] and the [code][7]; the code repository contains a Makefile to make things even simpler.
+
+#### Make a Reveal.js slideshow
+
+It's easy to generate simple presentations from a Markdown file using Pandoc. The slides contain top-level slides and nested slides underneath. The presentation can be controlled from the keyboard, and you can jump from one top-level slide to the next top-level slide or show the nested slides on a per-top-level basis. This structure is typical in HTML-based presentation frameworks.
+
+Let's create a slide document named SLIDES (see the [code repository][8]). First, add the slides' meta-information (e.g., title, author, and date) prepended by the **%** symbol:
+
+```
+% Case Study
+% Kiko Fernandez Reyes
+% Sept 27, 2017
+```
+
+This meta-information also creates the first slide. To add more slides, declare top-level slides using Markdown heading H1 (line 5 in the example below, [heading 1 in Markdown][9] , designated by).
+
+For example, if we want to create a presentation with the title Case Study that starts with a top-level slide titled Wine Management System, write:
+
+```
+% Case Study
+% Kiko Fernandez Reyes
+% Sept 27, 2017
+
+# Wine Management System
+```
+
+To put content (such as slides that explain a new management system and its implementation) inside this top-level section, use a Markdown header H2. Let's add two more slides (lines 7 and 14 below, [heading 2 in Markdown][9], designated by **##** ):
+
+ * The first second-level slide has the title Idea and shows an image of the Swiss flag
+ * The second second-level slide has the title Implementation
+
+
+
+```
+% Case Study
+% Kiko Fernandez Reyes
+% Sept 27, 2017
+
+# Wine Management System
+
+##  Idea
+
+## Implementation
+```
+
+We now have a top-level slide ( **# Wine Management System** ) that contains two slides ( **## Idea** and **## Implementation** ).
+
+Let's put some content in these two slides using incremental bulleted lists by creating a Markdown list prepended by the symbol **>**. Continuing from above, add two items in the first slide (lines 9–10 below) and five items in the second slide (lines 16–20):
+
+```
+% Case Study
+% Kiko Fernandez Reyes
+% Sept 27, 2017
+
+# Wine Management System
+
+## Idea
+
+>- Swiss love their **wine** and cheese
+>- Create a *simple* wine tracker system
+
+
+
+## Implementation
+
+>- Bottles have a RFID tag
+>- RFID reader (emits and read signal)
+>- **Raspberry Pi**
+>- **Server (online shop)**
+>- Mobile app
+```
+
+We added an image of the Matterhorn mountain. Your slides can be improved by using plain Markdown or adding plain HTML.
+
+To generate the slides, Pandoc needs to point to the Reveal.js library, so it must be in the same folder as the SLIDES file. The command to generate the slides is:
+
+```
+pandoc -t revealjs -s --self-contained SLIDES \
+-V theme=white -V slideNumber=true -o index.html
+```
+
+
+
+The above Pandoc command uses the following flags:
+
+ * **-t revealjs** specifies we are going to output a **revealjs** presentation
+ * **-s** tells Pandoc to generate a standalone document
+ * **\--self-contained** produces HTML with no external dependencies
+ * **-V** sets the following variables:
+– **theme=white** sets the theme of the slideshow to **white**
+– **slideNumber=true** shows the slide number
+ * **-o index.html** generates the slides in the file named **index.html**
+
+
+
+To make things simpler and avoid typing this long command, create the following Makefile:
+
+```
+all: generate
+
+generate:
+ pandoc -t revealjs -s --self-contained SLIDES \
+ -V theme=white -V slideNumber=true -o index.html
+
+clean: index.html
+ rm index.html
+
+.PHONY: all clean generate
+```
+
+You can find all the code in [this repository][8].
+
+#### Make a multi-format contract
+
+Let's say you are preparing a document and (as things are nowadays) some people want it in Microsoft Word format, others use free software and would like an ODT, and others need a PDF. You do not have to use OpenOffice nor LibreOffice to generate the DOCX or PDF file. You can create your document in Markdown (with some bits of LaTeX if you need advanced formatting) and generate any of these file types.
+
+As before, begin by declaring the document's meta-information (title, author, and date):
+
+```
+% Contract Agreement for Software X
+% Kiko Fernandez-Reyes
+% August 28th, 2018
+```
+
+Then write the document in Markdown (and add LaTeX if you require advanced formatting). For example, create a table that needs fixed separation space (declared in LaTeX with **\hspace{3cm}** ) and a line where a client and a contractor should sign (declared in LaTeX with **\hrulefill** ). After that, add a table written in Markdown.
+
+Here's what the document will look like:
+
+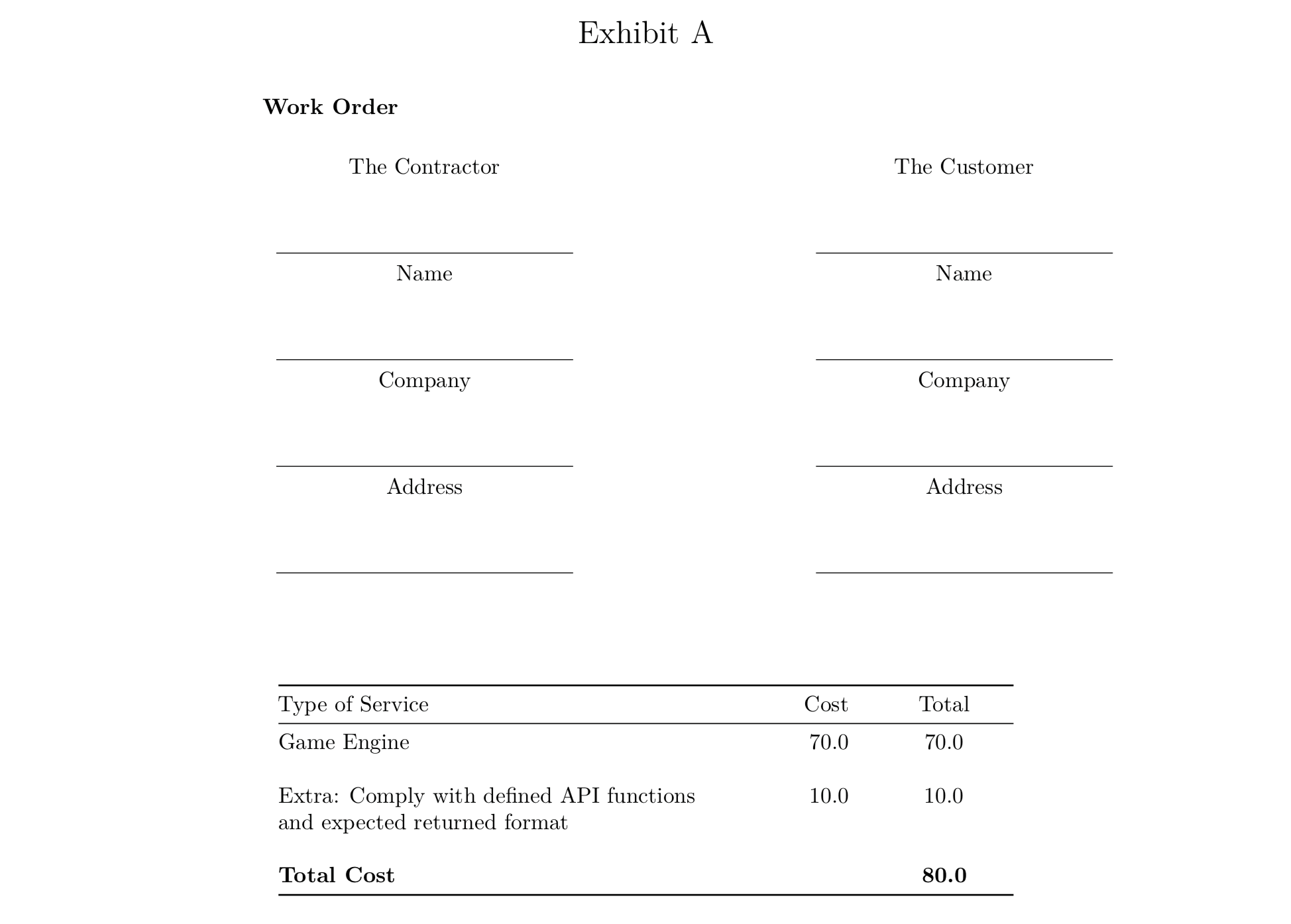
+
+The code to create this document is:
+
+```
+% Contract Agreement for Software X
+% Kiko Fernandez-Reyes
+% August 28th, 2018
+
+...
+
+### Work Order
+
+\begin{table}[h]
+\begin{tabular}{ccc}
+The Contractor & \hspace{3cm} & The Customer \\
+& & \\
+& & \\
+\hrulefill & \hspace{3cm} & \hrulefill \\
+%
+Name & \hspace{3cm} & Name \\
+& & \\
+& & \\
+\hrulefill & \hspace{3cm} & \hrulefill \\
+...
+\end{tabular}
+\end{table}
+
+\vspace{1cm}
+
++--------------------------------------------|----------|-------------+
+| Type of Service | Cost | Total |
++:===========================================+=========:+:===========:+
+| Game Engine | 70.0 | 70.0 |
+| | | |
++--------------------------------------------|----------|-------------+
+| | | |
++--------------------------------------------|----------|-------------+
+| Extra: Comply with defined API functions | 10.0 | 10.0 |
+| and expected returned format | | |
++--------------------------------------------|----------|-------------+
+| | | |
++--------------------------------------------|----------|-------------+
+| **Total Cost** | | **80.0** |
++--------------------------------------------|----------|-------------+
+```
+
+To generate the three different output formats needed for this document, write a Makefile:
+
+```
+DOCS=contract-agreement.md
+
+all: $(DOCS)
+ pandoc -s $(DOCS) -o $(DOCS:md=pdf)
+ pandoc -s $(DOCS) -o $(DOCS:md=docx)
+ pandoc -s $(DOCS) -o $(DOCS:md=odt)
+
+clean:
+ rm *.pdf *.docx *.odt
+
+.PHONY: all clean
+```
+
+Lines 4–7 contain the commands to generate the different outputs.
+
+If you have several Markdown files and want to merge them into one document, issue a command with the files in the order you want them to appear. For example, when writing this article, I created three documents: an introduction document, three examples, and some advanced uses. The following tells Pandoc to merge these files together in the specified order and produce a PDF named document.pdf.
+
+```
+pandoc -s introduction.md examples.md advanced-uses.md -o document.pdf
+```
+
+### Templates and meta-information
+
+Writing a complex document is no easy task. You need to stick to a set of rules that are independent from your content, such as using a specific template, writing an abstract, embedding specific fonts, and maybe even declaring keywords. All of this has nothing to do with your content: simply put, it is meta-information.
+
+Pandoc uses templates to generate different output formats. There is a template for LaTeX, another for ePub, etc. These templates have unfulfilled variables that are set with the meta-information given to Pandoc. To find out what meta-information is available in a Pandoc template, type:
+
+```
+pandoc -D FORMAT
+```
+
+For example, the template for LaTeX would be:
+
+```
+pandoc -D latex
+```
+
+Which outputs something along these lines:
+
+```
+$if(title)$
+\title{$title$$if(thanks)$\thanks{$thanks$}$endif$}
+$endif$
+$if(subtitle)$
+\providecommand{\subtitle}[1]{}
+\subtitle{$subtitle$}
+$endif$
+$if(author)$
+\author{$for(author)$$author$$sep$ \and $endfor$}
+$endif$
+$if(institute)$
+\providecommand{\institute}[1]{}
+\institute{$for(institute)$$institute$$sep$ \and $endfor$}
+$endif$
+\date{$date$}
+$if(beamer)$
+$if(titlegraphic)$
+\titlegraphic{\includegraphics{$titlegraphic$}}
+$endif$
+$if(logo)$
+\logo{\includegraphics{$logo$}}
+$endif$
+$endif$
+
+\begin{document}
+```
+
+As you can see, there are **title** , **thanks** , **author** , **subtitle** , and **institute** template variables (and many others are available). These are easily set using YAML metablocks. In lines 1–5 of the example below, we declare a YAML metablock and set some of those variables (using the contract agreement example above):
+
+```
+---
+title: Contract Agreement for Software X
+author: Kiko Fernandez-Reyes
+date: August 28th, 2018
+---
+
+(continue writing document as in the previous example)
+```
+
+This works like a charm and is equivalent to the previous code:
+
+```
+% Contract Agreement for Software X
+% Kiko Fernandez-Reyes
+% August 28th, 2018
+```
+
+However, this ties the meta-information to the content; i.e., Pandoc will always use this information to output files in the new format. If you know you need to produce multiple file formats, you better be careful. For example, what if you need to produce the contract in ePub and in HTML, and the ePub and HTML need specific and different styling rules?
+
+Let's consider the cases:
+
+ * If you simply try to embed the YAML variable **css: style-epub.css** , you would be excluding the one from the HTML version. This does not work.
+ * Duplicating the document is obviously not a good solution either, as changes in one version would not be in sync with the other copy.
+ * You can add variables to the Pandoc command line as follows:
+
+
+
+```
+pandoc -s -V css=style-epub.css document.md document.epub
+pandoc -s -V css=style-html.css document.md document.html
+```
+
+My opinion is that it is easy to overlook these variables from the command line, especially when you need to set tens of these (which can happen in complex documents). Now, if you put them all together under the same roof (a meta.yaml file), you only need to update or create a new meta-information file to produce the desired output. You would then write:
+
+```
+pandoc -s meta-pub.yaml document.md document.epub
+pandoc -s meta-html.yaml document.md document.html
+```
+
+This is a much cleaner version, and you can update all the meta-information from a single file without ever having to update the content of your document.
+
+### Wrapping up
+
+With these basic examples, I have shown how Pandoc can do a really good job at converting Markdown documents into other formats.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/9/intro-pandoc
+
+作者:[Kiko Fernandez-Reyes][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/kikofernandez
+[1]: https://pandoc.org/
+[2]: http://pandoc.org/installing.html
+[3]: https://hackage.haskell.org/package/pandoc-crossref
+[4]: https://github.com/lierdakil/pandoc-crossref/releases/tag/v0.3.2.1
+[5]: https://github.com/lierdakil/pandoc-crossref#installation
+[6]: http://pandoc.org/demo/mathMathML.html
+[7]: https://github.com/kikofernandez/pandoc-examples/tree/master/math
+[8]: https://github.com/kikofernandez/pandoc-examples/tree/master/slides
+[9]: https://daringfireball.net/projects/markdown/syntax#header
diff --git a/sources/tech/20180914 Freespire Linux- A Great Desktop for the Open Source Purist.md b/sources/tech/20180914 Freespire Linux- A Great Desktop for the Open Source Purist.md
new file mode 100644
index 0000000000..baaf08e92d
--- /dev/null
+++ b/sources/tech/20180914 Freespire Linux- A Great Desktop for the Open Source Purist.md
@@ -0,0 +1,114 @@
+Freespire Linux: A Great Desktop for the Open Source Purist
+======
+
+
+
+Quick. Click on your Linux desktop menu and scan through the list of installed software. How much of that software is strictly open sources To make matters a bit more complicated, have you installed closed source media codecs (to play the likes of MP3 files perhaps)? Is everything fully open, or do you have a mixture of open and closed source tools?
+
+If you’re a purist, you probably strive to only use open source tools on your desktop. But how do you know, for certain, that your distribution only includes open source software? Fortunately, a few distributions go out of their way to only include applications that are 100% open. One such distro is [Freespire][1].
+
+Does that name sound familiar? It should, as it is closely related to[Linspire][2]. Now we’re talking familiarity. Remember back in the early 2000s, when Walmart sold Linux desktop computers? Those computers were powered by the Linspire operating system. Linspire went above and beyond to create an experience that would be similar to that of Windows—even including the tools to install Windows apps on Linux. That experiment failed, mostly because consumers thought they were getting a Windows desktop machine for a dirt cheap price. After that debacle, Linspire went away for a while. It’s now back, thanks to [PC/OpenSystems LLC][3]. Their goal isn’t to recreate the past but to offer two different flavors of Linux:
+
+ * Linspire—a commercial distribution of Linux that includes proprietary software and does have an associated cost ($39.99 USD for a single license).
+
+ * Freespire—a non-commercial distribution of Linux that only includes open source software and is free to download.
+
+
+
+
+We’re here to discuss Freespire and why it is an outstanding addition to the Linux community, especially those who strive to use only free and open source software. This version of Freespire (4.0) was released on August 20, 2018, so it’s fresh and ready to go.
+
+Let’s dig into the operating system and see what makes this a viable candidate for open source fans.
+
+### Installation
+
+In keeping with my usual approach, there’s very little reason to even mention the installation of Freespire Linux. There is nothing out of the ordinary here. Download the ISO image, burn it to a USB Drive (or CD/DVD if you’re dealing with older hardware), boot the drive, click the Install icon, answer a few simple questions, and wait for the installation to prompt for a reboot. That’s how far we’ve come with Linux installations… they are simple, and rarely will you have a single issue with the process. In the end, you’ll be presented with a simple (modified) Mate desktop (Figure 1) that makes it easy for any user (of any skill level) to feel right at home.
+
+
+
+### Software Titles
+
+Once you’ve logged into the desktop, you’ll find a main menu where you can view all of the installed applications. That list of software includes:
+
+ * Geary
+
+ * Chromium Browser
+
+ * Abiword
+
+ * Gnumeric
+
+ * Calendar
+
+ * Audacious
+
+ * Totem Video Player
+
+ * Software Center
+
+ * Synaptic
+
+ * G-Debi
+
+
+
+
+Also rolled into the system is support for both Flatpak and Snap applications, so you shouldn’t miss out on any software you need, which brings me to the part when purists might want to look away.
+
+Just because Freespire is marketed as a purely open source distribution, it doesn’t mean users are locked down to only open source software. In fact, if you open the Software Center, you can do a quick search for Spotify (a closed source application with an available Linux desktop client) and there it is! (Figure 2).
+
+![Spotify][5]
+
+Figure 2: The closed source Spotify client available for installation.
+
+[Used with permission][6]
+
+Fortunately, for those productive-minded folks, the likes of LibreOffice (which is not installed by default) is open source and can be installed easily from the Software Center. That doesn’t mean you must install other software, but those who need to do serious business-centric work (such as collaborating on documents), will likely want/need to install a more powerful office suite (as Abiword won’t cut it as a business-level word processor).
+
+For those who tend to work long hours on the Linux desktop and want to protect their eyes from extended strain, Freespire does include a nightlight tool that can adjust the color temperature of the interface. To open this tool, click on the main desktop menu and type night in the Search bar (Figure 3).
+
+![Night Light][8]
+
+Figure 3: Opening the Night Light tool.
+
+[Used with permission][6]
+
+Once opened, Night Light will automatically adjust the color temperature, based on the time of day. From the notification tray, you can click the icon to suspend Night Light, set it to autostart, and close the service (Figure 4).
+
+![Night Light controls.][10]
+
+Figure 4: The Night Light controls.
+
+[Used with permission][6]
+
+### Beyond the Mate Desktop
+
+As is, Mate fans might not exactly recognize the Freespire desktop. The developers have clearly given Mate a significant set of tweaks to make it slightly resemble the Mac OS desktop. It’s not quite as elegant as, say, Elementary OS, but this is certainly an outstanding take on the Linux desktop. Whether you’re a fan of Mate or Mac OS, you should feel immediately at home on the desktop. On the top bar, the developers have included an appmenu that changes, based on what application you have open. Start any app and you’ll find that app’s menu appears in the top bar. This active menu makes the desktop quite efficient.
+
+### Are you ready for Freespire?
+
+Every piece of the Freespire puzzle is equally as user-friendly as it is intuitive. The developers of Freespire have gone to great lengths to make this pure open source distribution a treat to use. Even if a 100% open source desktop isn’t your thing, Freespire is still a worthy contender in the world of desktop Linux. It’s clean and stable (as it’s based on Ubuntu 18.04) and able to help you be efficient and productive on the desktop.
+
+Learn more about Linux through the free ["Introduction to Linux" ][11]course from The Linux Foundation and edX.
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/learn/intro-to-linux/2018/9/freespire-linux-great-desktop-open-source-purist
+
+作者:[Jack Wallen][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.linux.com/users/jlwallen
+[1]: https://www.freespirelinux.com/
+[2]: https://www.linspirelinux.com/
+[3]: https://www.pc-opensystems.com
+[5]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/freespire_2.jpg?itok=zcr94Dk6 (Spotify)
+[6]: /licenses/category/used-permission
+[8]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/freespire_3.jpg?itok=aZYtBPgE (Night Light)
+[9]: /files/images/freespire4jpg
+[10]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/freespire_4.jpg?itok=JCcQwmJ5 (Night Light controls.)
+[11]: https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/sources/tech/20180915 Backup Installed Packages And Restore Them On Freshly Installed Ubuntu.md b/sources/tech/20180915 Backup Installed Packages And Restore Them On Freshly Installed Ubuntu.md
new file mode 100644
index 0000000000..c775fd5040
--- /dev/null
+++ b/sources/tech/20180915 Backup Installed Packages And Restore Them On Freshly Installed Ubuntu.md
@@ -0,0 +1,109 @@
+translating---geekpi
+
+Backup Installed Packages And Restore Them On Freshly Installed Ubuntu
+======
+
+
+
+Installing the same set of packages on multiple Ubuntu systems is time consuming and boring task. You don’t want to spend your time to install the same packages over and over on multiple systems. When it comes to install packages on similar architecture Ubuntu systems, there are many methods available to make this task easier. You could simply migrate your old Ubuntu system’s applications, settings and data to a newly installed system with a couple mouse clicks using [**Aptik**][1]. Or, you can take the [**backup entire list of installed packages**][2] using your package manager (Eg. APT), and install them later on a freshly installed system. Today, I learned that there is also yet another dedicated utility available to do this job. Say hello to **apt-clone** , a simple tool that lets you to create a list of installed packages for Debian/Ubuntu systems that can be restored on freshly installed systems or containers or into a directory.
+
+Apt-clone will help you on situations where you want to,
+
+ * Install consistent applications across multiple systems running with similar Ubuntu (and derivatives) OS.
+ * Install same set of packages on multiple systems often.
+ * Backup the entire list of installed applications and restore them on demand wherever and whenever necessary.
+
+
+
+In this brief guide, we will be discussing how to install and use Apt-clone on Debian-based systems. I tested this utility on Ubuntu 18.04 LTS system, however it should work on all Debian and Ubuntu-based systems.
+
+### Backup Installed Packages And Restore Them Later On Freshly Installed Ubuntu System
+
+Apt-clone is available in the default repositories. To install it, just enter the following command from the Terminal:
+
+```
+$ sudo apt install apt-clone
+```
+
+Once installed, simply create the list of installed packages and save them in any location of your choice.
+
+```
+$ mkdir ~/mypackages
+
+$ sudo apt-clone clone ~/mypackages
+```
+
+The above command saved all installed packages in my Ubuntu system in a file named **apt-clone-state-ubuntuserver.tar.gz** under **~/mypackages** directory.
+
+To view the details of the backup file, run:
+
+```
+$ apt-clone info mypackages/apt-clone-state-ubuntuserver.tar.gz
+Hostname: ubuntuserver
+Arch: amd64
+Distro: bionic
+Meta:
+Installed: 516 pkgs (33 automatic)
+Date: Sat Sep 15 10:23:05 2018
+```
+
+As you can see, I have 516 packages in total in my Ubuntu server.
+
+Now, copy this file on your USB or external drive and go to any other system that want to install the same set of packages. Or you can also transfer the backup file to the system on the network and install the packages by using the following command:
+
+```
+$ sudo apt-clone restore apt-clone-state-ubuntuserver.tar.gz
+```
+
+Please be mindful that this command will overwrite your existing **/etc/apt/sources.list** and will install/remove packages. You have been warned! Also, just make sure the destination system is on same arch and same OS. For example, if the source system is running with 18.04 LTS 64bit, the destination system must also has the same.
+
+If you don’t want to restore packages on the system, you can simply use `--destination /some/location` option to debootstrap the clone into this directory.
+
+```
+$ sudo apt-clone restore apt-clone-state-ubuntuserver.tar.gz --destination ~/oldubuntu
+```
+
+In this case, the above command will restore the packages in a folder named **~/oldubuntu**.
+
+For more details, refer help section:
+
+```
+$ apt-clone -h
+```
+
+Or, man pages:
+
+```
+$ man apt-clone
+```
+
+**Suggested read:**
+
++ [Systemback – Restore Ubuntu Desktop and Server to previous state][3]
++ [Cronopete – An Apple’s Time Machine Clone For Linux][4]
+
+And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
+
+Cheers!
+
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/backup-installed-packages-and-restore-them-on-freshly-installed-ubuntu-system/
+
+作者:[SK][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/sk/
+[1]: https://www.ostechnix.com/how-to-migrate-system-settings-and-data-from-an-old-system-to-a-newly-installed-ubuntu-system/
+[2]: https://www.ostechnix.com/create-list-installed-packages-install-later-list-centos-ubuntu/#comment-12598
+
+[3]: https://www.ostechnix.com/systemback-restore-ubuntu-desktop-and-server-to-previous-state/
+
+[4]: https://www.ostechnix.com/cronopete-apples-time-machine-clone-linux/
diff --git a/sources/tech/20180917 4 scanning tools for the Linux desktop.md b/sources/tech/20180917 4 scanning tools for the Linux desktop.md
new file mode 100644
index 0000000000..a239c87768
--- /dev/null
+++ b/sources/tech/20180917 4 scanning tools for the Linux desktop.md
@@ -0,0 +1,72 @@
+4 scanning tools for the Linux desktop
+======
+Go paperless by driving your scanner with one of these open source applications.
+
+
+
+While the paperless world isn't here quite yet, more and more people are getting rid of paper by scanning documents and photos. Having a scanner isn't enough to do the deed, though. You need software to drive that scanner.
+
+But the catch is many scanner makers don't have Linux versions of the software they bundle with their devices. For the most part, that doesn't matter. Why? Because there are good scanning applications available for the Linux desktop. They work with a variety of scanners and do a good job.
+
+Let's take a look at four simple but flexible open source Linux scanning tools. I've used each of these tools (and even wrote about three of them [back in 2014][1]) and found them very useful. You might, too.
+
+### Simple Scan
+
+One of my longtime favorites, [Simple Scan][2] is small, quick, efficient, and easy to use. If you've seen it before, that's because Simple Scan is the default scanner application on the GNOME desktop, as well as for a number of Linux distributions.
+
+Scanning a document or photo takes one click. After scanning something, you can rotate or crop it and save it as an image (JPEG or PNG only) or as a PDF. That said, Simple Scan can be slow, even if you scan documents at lower resolutions. On top of that, Simple Scan uses a set of global defaults for scanning, like 150dpi for text and 300dpi for photos. You need to go into Simple Scan's preferences to change those settings.
+
+If you've scanned something with more than a couple of pages, you can reorder the pages before you save. And if necessary—say you're submitting a signed form—you can email from within Simple Scan.
+
+### Skanlite
+
+In many ways, [Skanlite][3] is Simple Scan's cousin in the KDE world. Skanlite has few features, but it gets the job done nicely.
+
+The software has options that you can configure, including automatically saving scanned files, setting the quality of the scan, and identifying where to save your scans. Skanlite can save to these image formats: JPEG, PNG, BMP, PPM, XBM, and XPM.
+
+One nifty feature is the software's ability to save portions of what you've scanned to separate files. That comes in handy when, say, you want to excise someone or something from a photo.
+
+### Gscan2pdf
+
+Another old favorite, [gscan2pdf][4] might be showing its age, but it still packs a few more features than some of the other applications mentioned here. Even so, gscan2pdf is still comparatively light.
+
+In addition to saving scans in various image formats (JPEG, PNG, and TIFF), gscan2pdf also saves them as PDF or [DjVu][5] files. You can set the scan's resolution, whether it's black and white or color, and paper size before you click the Scan button. That beats going into gscan2pdf's preferences every time you want to change any of those settings. You can also rotate, crop, and delete pages.
+
+While none of those features are truly killer, they give you a bit more flexibility.
+
+### GIMP
+
+You probably know [GIMP][6] as an image-editing tool. But did you know you can use it to drive your scanner?
+
+You'll need to install the [XSane][7] scanner software and the GIMP XSane plugin. Both of those should be available from your Linux distro's package manager. From there, select File > Create > Scanner/Camera. From there, click on your scanner and then the Scan button.
+
+If that's not your cup of tea, or if it doesn't work, you can combine GIMP with a plugin called [QuiteInsane][8]. With either plugin, GIMP becomes a powerful scanning application that lets you set a number of options like whether to scan in color or black and white, the resolution of the scan, and whether or not to compress results. You can also use GIMP's tools to touch up or apply effects to your scans. This makes it great for scanning photos and art.
+
+### Do they really just work?
+
+All of this software works well for the most part and with a variety of hardware. I've used them with several multifunction printers that I've owned over the years—whether connecting using a USB cable or over wireless.
+
+You might have noticed that I wrote "works well for the most part" in the previous paragraph. I did run into one exception: an inexpensive Canon multifunction printer. None of the software I used could detect it. I had to download and install Canon's Linux scanner software, which did work.
+
+What's your favorite open source scanning tool for Linux? Share your pick by leaving a comment.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/9/linux-scanner-tools
+
+作者:[Scott Nesbitt][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/scottnesbitt
+[1]: https://opensource.com/life/14/8/3-tools-scanners-linux-desktop
+[2]: https://gitlab.gnome.org/GNOME/simple-scan
+[3]: https://www.kde.org/applications/graphics/skanlite/
+[4]: http://gscan2pdf.sourceforge.net/
+[5]: http://en.wikipedia.org/wiki/DjVu
+[6]: http://www.gimp.org/
+[7]: https://en.wikipedia.org/wiki/Scanner_Access_Now_Easy#XSane
+[8]: http://sourceforge.net/projects/quiteinsane/
diff --git a/sources/tech/20180918 Cozy Is A Nice Linux Audiobook Player For DRM-Free Audio Files.md b/sources/tech/20180918 Cozy Is A Nice Linux Audiobook Player For DRM-Free Audio Files.md
new file mode 100644
index 0000000000..8450d6fd11
--- /dev/null
+++ b/sources/tech/20180918 Cozy Is A Nice Linux Audiobook Player For DRM-Free Audio Files.md
@@ -0,0 +1,72 @@
+Cozy Is A Nice Linux Audiobook Player For DRM-Free Audio Files
+======
+[Cozy][1] **is a free and open source audiobook player for the Linux desktop. The application lets you listen to DRM-free audiobooks (mp3, m4a, flac, ogg and wav) using a modern Gtk3 interface.**
+
+
+
+You could use any audio player to listen to audiobooks, but a specialized audiobook player like Cozy makes everything easier, by **remembering your playback position and continuing from where you left off for each audiobook** , or by letting you **set the playback speed of each book individually** , among others.
+
+The Cozy interface lets you browse books by author, reader or recency, while also providing search functionality. **Books front covers are supported by Cozy** \- either by using embedded images, or by adding a cover.jpg or cover.png image in the book folder, which is automatically picked up and displayed by Cozy.
+
+When you click on an audiobook, Cozy lists the book chapters on the right, while displaying the book cover (if available) on the left, along with the book name, author and the last played time, along with total and remaining time:
+
+
+
+From the application toolbar you can easily **go back 30 seconds** by clicking the rewind icon from its top left-hand side corner. Besides regular controls, cover and title, you'll also find a playback speed button on the toolbar, which lets you increase the playback speed up to 2X.
+
+**A sleep timer is also available**. It can be set to stop after the current chapter or after a given number of minutes.
+
+Other Cozy features worth mentioning:
+
+ * **Mpris integration** (Media keys & playback info)
+ * **Supports multiple storage locations**
+ * **Drag'n'drop support for importing new audiobooks**
+ * **Offline Mode**. If your audiobooks are on an external or network drive, you can switch the download button to keep a local cached copy of the book to listen to on the go. To enable this feature you have to set your storage location to external in the settings
+ * **Prevents your system from suspend during playback**
+ * **Dark mode**
+
+
+
+What I'd like to see in Cozy is a way to get audiobooks metadata, including the book cover, automatically. A feature to retrieve metadata from Audible.com was proposed on the Cozy GitHub project page and the developer seems interested in this, but it's not clear when or if this will be implemented.
+
+Like I was mentioning in the beginning of the article, Cozy only supports DRM-free audio files. Currently it supports mp3, m4a, flac, ogg and wav. Support for more formats will probably come in the future, with m4b being listed on the Cozy 0.7.0 todo list.
+
+Cozy cannot play Audible audiobooks due to DRM. But you'll find some solutions out there for converting Audible (.aa/.aax) audiobooks to mp3, like
+
+### Install Cozy
+
+**Any Linux distribution / Flatpak** : Cozy is available as a Flatpak on FlatHub. To install it, follow the quick Flatpak [setup][4], then go to the Cozy FlaHub [page][5] and click the install button, or use the install command at the bottom if its page.
+
+**elementary OS** : Cozy is available in the [AppCenter][6].
+
+**Ubuntu 18.04 / Linux Mint 19** : you can install Cozy from its repository:
+
+```
+wget -nv https://download.opensuse.org/repositories/home:geigi/Ubuntu_18.04/Release.key -O Release.key
+sudo apt-key add - < Release.key
+sudo sh -c "echo 'deb http://download.opensuse.org/repositories/home:/geigi/Ubuntu_18.04/ /' > /etc/apt/sources.list.d/home:geigi.list"
+sudo apt update
+sudo apt install com.github.geigi.cozy
+```
+
+**For other ways of installing Cozy check out its[website][2].**
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.linuxuprising.com/2018/09/cozy-is-nice-linux-audiobook-player-for.html
+
+作者:[Logix][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://plus.google.com/118280394805678839070
+[1]: https://cozy.geigi.de/
+[2]: https://cozy.geigi.de/#how-can-i-get-it
+[3]: https://gitlab.com/ReverendJ1/audiblefreedom/blob/master/audiblefreedom
+[4]: https://flatpak.org/setup/
+[5]: https://flathub.org/apps/details/com.github.geigi.cozy
+[6]: https://appcenter.elementary.io/com.github.geigi.cozy/
diff --git a/sources/tech/20180918 Linux firewalls- What you need to know about iptables and firewalld.md b/sources/tech/20180918 Linux firewalls- What you need to know about iptables and firewalld.md
new file mode 100644
index 0000000000..98e38a02cd
--- /dev/null
+++ b/sources/tech/20180918 Linux firewalls- What you need to know about iptables and firewalld.md
@@ -0,0 +1,170 @@
+heguangzhi translating
+
+Linux firewalls: What you need to know about iptables and firewalld
+======
+Here's how to use the iptables and firewalld tools to manage Linux firewall connectivity rules.
+
+
+This article is excerpted from my book, [Linux in Action][1], and a second Manning project that’s yet to be released.
+
+### The firewall
+
+A firewall is a set of rules. When a data packet moves into or out of a protected network space, its contents (in particular, information about its origin, target, and the protocol it plans to use) are tested against the firewall rules to see if it should be allowed through. Here’s a simple example:
+
+![firewall filtering request][3]
+
+A firewall can filter requests based on protocol or target-based rules.
+
+On the one hand, [iptables][4] is a tool for managing firewall rules on a Linux machine.
+
+On the other hand, [firewalld][5] is also a tool for managing firewall rules on a Linux machine.
+
+You got a problem with that? And would it spoil your day if I told you that there was another tool out there, called [nftables][6]?
+
+OK, I’ll admit that the whole thing does smell a bit funny, so let me explain. It all starts with Netfilter, which controls access to and from the network stack at the Linux kernel module level. For decades, the primary command-line tool for managing Netfilter hooks was the iptables ruleset.
+
+Because the syntax needed to invoke those rules could come across as a bit arcane, various user-friendly implementations like [ufw][7] and firewalld were introduced as higher-level Netfilter interpreters. Ufw and firewalld are, however, primarily designed to solve the kinds of problems faced by stand-alone computers. Building full-sized network solutions will often require the extra muscle of iptables or, since 2014, its replacement, nftables (through the nft command line tool).
+
+iptables hasn’t gone anywhere and is still widely used. In fact, you should expect to run into iptables-protected networks in your work as an admin for many years to come. But nftables, by adding on to the classic Netfilter toolset, has brought some important new functionality.
+
+From here on, I’ll show by example how firewalld and iptables solve simple connectivity problems.
+
+### Configure HTTP access using firewalld
+
+As you might have guessed from its name, firewalld is part of the [systemd][8] family. Firewalld can be installed on Debian/Ubuntu machines, but it’s there by default on Red Hat and CentOS. If you’ve got a web server like Apache running on your machine, you can confirm that the firewall is working by browsing to your server’s web root. If the site is unreachable, then firewalld is doing its job.
+
+You’ll use the `firewall-cmd` tool to manage firewalld settings from the command line. Adding the `–state` argument returns the current firewall status:
+
+```
+# firewall-cmd --state
+running
+```
+
+By default, firewalld will be active and will reject all incoming traffic with a couple of exceptions, like SSH. That means your website won’t be getting too many visitors, which will certainly save you a lot of data transfer costs. As that’s probably not what you had in mind for your web server, though, you’ll want to open the HTTP and HTTPS ports that by convention are designated as 80 and 443, respectively. firewalld offers two ways to do that. One is through the `–add-port` argument that references the port number directly along with the network protocol it’ll use (TCP in this case). The `–permanent` argument tells firewalld to load this rule each time the server boots:
+
+```
+# firewall-cmd --permanent --add-port=80/tcp
+# firewall-cmd --permanent --add-port=443/tcp
+```
+
+The `–reload` argument will apply those rules to the current session:
+
+```
+# firewall-cmd --reload
+```
+
+Curious as to the current settings on your firewall? Run `–list-services`:
+
+```
+# firewall-cmd --list-services
+dhcpv6-client http https ssh
+```
+
+Assuming you’ve added browser access as described earlier, the HTTP, HTTPS, and SSH ports should now all be open—along with `dhcpv6-client`, which allows Linux to request an IPv6 IP address from a local DHCP server.
+
+### Configure a locked-down customer kiosk using iptables
+
+I’m sure you’ve seen kiosks—they’re the tablets, touchscreens, and ATM-like PCs in a box that airports, libraries, and business leave lying around, inviting customers and passersby to browse content. The thing about most kiosks is that you don’t usually want users to make themselves at home and treat them like their own devices. They’re not generally meant for browsing, viewing YouTube videos, or launching denial-of-service attacks against the Pentagon. So to make sure they’re not misused, you need to lock them down.
+
+One way is to apply some kind of kiosk mode, whether it’s through clever use of a Linux display manager or at the browser level. But to make sure you’ve got all the holes plugged, you’ll probably also want to add some hard network controls through a firewall. In the following section, I'll describe how I would do it using iptables.
+
+There are two important things to remember about using iptables: The order you give your rules is critical, and by themselves, iptables rules won’t survive a reboot. I’ll address those here one at a time.
+
+### The kiosk project
+
+To illustrate all this, let’s imagine we work for a store that’s part of a larger chain called BigMart. They’ve been around for decades; in fact, our imaginary grandparents probably grew up shopping there. But these days, the guys at BigMart corporate headquarters are probably just counting the hours before Amazon drives them under for good.
+
+Nevertheless, BigMart’s IT department is doing its best, and they’ve just sent you some WiFi-ready kiosk devices that you’re expected to install at strategic locations throughout your store. The idea is that they’ll display a web browser logged into the BigMart.com products pages, allowing them to look up merchandise features, aisle location, and stock levels. The kiosks will also need access to bigmart-data.com, where many of the images and video media are stored.
+
+Besides those, you’ll want to permit updates and, whenever necessary, package downloads. Finally, you’ll want to permit inbound SSH access only from your local workstation, and block everyone else. The figure below illustrates how it will all work:
+
+![kiosk traffic flow ip tables][10]
+
+The kiosk traffic flow being controlled by iptables.
+
+### The script
+
+Here’s how that will all fit into a Bash script:
+
+```
+#!/bin/bash
+iptables -A OUTPUT -p tcp -d bigmart.com -j ACCEPT
+iptables -A OUTPUT -p tcp -d bigmart-data.com -j ACCEPT
+iptables -A OUTPUT -p tcp -d ubuntu.com -j ACCEPT
+iptables -A OUTPUT -p tcp -d ca.archive.ubuntu.com -j ACCEPT
+iptables -A OUTPUT -p tcp --dport 80 -j DROP
+iptables -A OUTPUT -p tcp --dport 443 -j DROP
+iptables -A INPUT -p tcp -s 10.0.3.1 --dport 22 -j ACCEPT
+iptables -A INPUT -p tcp -s 0.0.0.0/0 --dport 22 -j DROP
+```
+
+The basic anatomy of our rules starts with `-A`, telling iptables that we want to add the following rule. `OUTPUT` means that this rule should become part of the OUTPUT chain. `-p` indicates that this rule will apply only to packets using the TCP protocol, where, as `-d` tells us, the destination is [bigmart.com][11]. The `-j` flag points to `ACCEPT` as the action to take when a packet matches the rule. In this first rule, that action is to permit, or accept, the request. But further down, you can see requests that will be dropped, or denied.
+
+Remember that order matters. And that’s because iptables will run a request past each of its rules, but only until it gets a match. So an outgoing browser request for, say, [youtube.com][12] will pass the first four rules, but when it gets to either the `–dport 80` or `–dport 443` rule—depending on whether it’s an HTTP or HTTPS request—it’ll be dropped. iptables won’t bother checking any further because that was a match.
+
+On the other hand, a system request to ubuntu.com for a software upgrade will get through when it hits its appropriate rule. What we’re doing here, obviously, is permitting outgoing HTTP or HTTPS requests to only our BigMart or Ubuntu destinations and no others.
+
+The final two rules will deal with incoming SSH requests. They won’t already have been denied by the two previous drop rules since they don’t use ports 80 or 443, but 22. In this case, login requests from my workstation will be accepted but requests for anywhere else will be dropped. This is important: Make sure the IP address you use for your port 22 rule matches the address of the machine you’re using to log in—if you don’t do that, you’ll be instantly locked out. It's no big deal, of course, because the way it’s currently configured, you could simply reboot the server and the iptables rules will all be dropped. If you’re using an LXC container as your server and logging on from your LXC host, then use the IP address your host uses to connect to the container, not its public address.
+
+You’ll need to remember to update this rule if my machine’s IP ever changes; otherwise, you’ll be locked out.
+
+Playing along at home (hopefully on a throwaway VM of some sort)? Great. Create your own script. Now I can save the script, use `chmod` to make it executable, and run it as `sudo`. Don’t worry about that `bigmart-data.com not found` error—of course it’s not found; it doesn’t exist.
+
+```
+chmod +X scriptname.sh
+sudo ./scriptname.sh
+```
+
+You can test your firewall from the command line using `cURL`. Requesting ubuntu.com works, but [manning.com][13] fails.
+
+```
+curl ubuntu.com
+curl manning.com
+```
+
+### Configuring iptables to load on system boot
+
+Now, how do I get these rules to automatically load each time the kiosk boots? The first step is to save the current rules to a .rules file using the `iptables-save` tool. That’ll create a file in the root directory containing a list of the rules. The pipe, followed by the tee command, is necessary to apply my `sudo` authority to the second part of the string: the actual saving of a file to the otherwise restricted root directory.
+
+I can then tell the system to run a related tool called `iptables-restore` every time it boots. A regular cron job of the kind we saw in the previous module won’t help because they’re run at set times, but we have no idea when our computer might decide to crash and reboot.
+
+There are lots of ways to handle this problem. Here’s one:
+
+On my Linux machine, I’ll install a program called [anacron][14] that will give us a file in the /etc/ directory called anacrontab. I’ll edit the file and add this `iptables-restore` command, telling it to load the current values of that .rules file into iptables each day (when necessary) one minute after a boot. I’ll give the job an identifier (`iptables-restore`) and then add the command itself. Since you’re playing along with me at home, you should test all this out by rebooting your system.
+
+```
+sudo iptables-save | sudo tee /root/my.active.firewall.rules
+sudo apt install anacron
+sudo nano /etc/anacrontab
+1 1 iptables-restore iptables-restore < /root/my.active.firewall.rules
+
+```
+
+I hope these practical examples have illustrated how to use iptables and firewalld for managing connectivity issues on Linux-based firewalls.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/9/linux-iptables-firewalld
+
+作者:[David Clinton][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/remyd
+[1]: https://www.manning.com/books/linux-in-action?a_aid=bootstrap-it&a_bid=4ca15fc9&chan=opensource
+[2]: /file/409116
+[3]: https://opensource.com/sites/default/files/uploads/iptables1.jpg (firewall filtering request)
+[4]: https://en.wikipedia.org/wiki/Iptables
+[5]: https://firewalld.org/
+[6]: https://wiki.nftables.org/wiki-nftables/index.php/Main_Page
+[7]: https://en.wikipedia.org/wiki/Uncomplicated_Firewall
+[8]: https://en.wikipedia.org/wiki/Systemd
+[9]: /file/409121
+[10]: https://opensource.com/sites/default/files/uploads/iptables2.jpg (kiosk traffic flow ip tables)
+[11]: http://bigmart.com/
+[12]: http://youtube.com/
+[13]: http://manning.com/
+[14]: https://sourceforge.net/projects/anacron/
diff --git a/sources/tech/20180919 Streama - Setup Your Own Streaming Media Server In Minutes.md b/sources/tech/20180919 Streama - Setup Your Own Streaming Media Server In Minutes.md
new file mode 100644
index 0000000000..521a8f5b95
--- /dev/null
+++ b/sources/tech/20180919 Streama - Setup Your Own Streaming Media Server In Minutes.md
@@ -0,0 +1,171 @@
+Streama – Setup Your Own Streaming Media Server In Minutes
+======
+
+
+
+**Streama** is a free, open source application that helps to setup your own personal streaming media server in minutes in Unix-like operating systems. It’s like Netflix, but self-hostable. You can deploy it on your local system or VPS or dedicated server and stream the media files across multiple devices. The media files can be accessed from a web-browser from any system on your network. If you have deployed on your VPS, you can access it from anywhere. Streama works like your own personal Netflix system to stream your TV shows, videos, audios and movies. Streama is a web-based application written using Grails 3 (server-side) with SpringSecurity and all frond-end components are written in AngularJS. The built-in player is completely HTML5-based.
+
+### Prominent Features
+
+Streama ships with a lot features as listed below.
+
+ * Easy to install configure. You can either download docker instance and fire up your media server in minutes or install vanilla version on your local or VPS or dedicated server.
+ * Drag and drop support to upload media files.
+ * Live sync watching support. You can watch videos with your friends, family remotely. It doesn’t matter where they are. You can all watch the same video at a time.
+ * Built-in beautiful video player to watch/listen video and audio.
+ * Built-in browser to access the media files in the server.
+ * Multi-user support. You can create individual user accounts to your family members and access the media server simultaneously.
+ * Streama supports pause-play option. Pause the playback at any time and Streama remembers where you left off last time.
+ * Streama can be able to detect similar movies and videos and shows for you to add.
+ * Self-hostable
+ * It is completely free and open source.
+
+
+
+What do you need more? Streama has everything you to need to setup a full-fledged streaming media server in your Linux box.
+
+### Setup Your Own Streaming Media Server Using Streama
+
+Streama requires JAVA 8 or later, preferably **OpenJDK**. And, the recommended OS is **Ubuntu**. For the purpose of this guide, I will be using Ubuntu 18.04 LTS.
+
+By default, the latest Ubuntu 18.04 includes Open JDK 11. To install default openJDK in Ubuntu 18.04 or later, run:
+
+```
+$ sudo apt install default-jdk
+
+```
+
+Java 8 is the latest stable Long Time Support version. If you prefer to use Java LTS, run:
+
+```
+$ sudo apt install openjdk-8-jdk
+```
+
+I have installed openjdk-8-jdk. To check the installed Java version, run:
+
+```
+$ java -version
+openjdk version "1.8.0_181"
+OpenJDK Runtime Environment (build 1.8.0_181-8u181-b13-0ubuntu0.18.04.1-b13)
+OpenJDK 64-Bit Server VM (build 25.181-b13, mixed mode)
+```
+
+Once java installed, create a directory to save Streama executable and yml files.
+
+```
+$ sudo mkdir /data
+
+$ sudo mkdir /data/streama
+```
+
+I followed the official documentation, so I used this path – /data/streama. It is optional. You’re free to use any location of your choice.
+
+Switch to streama directory:
+
+```
+$ cd /data/streama
+```
+
+Download the latest Streama executable file from [**releases page**][1]. As of writing this guide, the latest version was **v1.6.0-RC8**.
+
+```
+$ sudo wget https://github.com/streamaserver/streama/releases/download/v1.6.0-RC8/streama-1.6.0-RC8.war
+```
+
+Make it executable:
+
+```
+$ sudo chmod +x streama-1.6.0-RC8.war
+```
+
+Now, run Streama application using command:
+
+```
+$ sudo ./streama-1.6.0-RC8.war
+```
+
+If you an output something like below, Streama is working!
+
+```
+INFO streama.Application - Starting Application on ubuntuserver with PID 26714 (/data/streama/streama-1.6.0-RC8.war started by root in /data/streama)
+DEBUG streama.Application - Running with Spring Boot v1.4.4.RELEASE, Spring v4.3.6.RELEASE
+INFO streama.Application - The following profiles are active: production
+
+Configuring Spring Security Core ...
+... finished configuring Spring Security Core
+
+INFO streama.Application - Started Application in 92.003 seconds (JVM running for 98.66)
+Grails application running at http://localhost:8080 in environment: production
+```
+
+Open your web browser and navigate to URL – **
Idea
+
+## Implementation
+```
+
+We now have a top-level slide ( **# Wine Management System** ) that contains two slides ( **## Idea** and **## Implementation** ).
+
+Let's put some content in these two slides using incremental bulleted lists by creating a Markdown list prepended by the symbol **>**. Continuing from above, add two items in the first slide (lines 9–10 below) and five items in the second slide (lines 16–20):
+
+```
+% Case Study
+% Kiko Fernandez Reyes
+% Sept 27, 2017
+
+# Wine Management System
+
+## Idea
+
+>- Swiss love their **wine** and cheese
+>- Create a *simple* wine tracker system
+
+
+
+## Implementation
+
+>- Bottles have a RFID tag
+>- RFID reader (emits and read signal)
+>- **Raspberry Pi**
+>- **Server (online shop)**
+>- Mobile app
+```
+
+We added an image of the Matterhorn mountain. Your slides can be improved by using plain Markdown or adding plain HTML.
+
+To generate the slides, Pandoc needs to point to the Reveal.js library, so it must be in the same folder as the SLIDES file. The command to generate the slides is:
+
+```
+pandoc -t revealjs -s --self-contained SLIDES \
+-V theme=white -V slideNumber=true -o index.html
+```
+
+
+
+The above Pandoc command uses the following flags:
+
+ * **-t revealjs** specifies we are going to output a **revealjs** presentation
+ * **-s** tells Pandoc to generate a standalone document
+ * **\--self-contained** produces HTML with no external dependencies
+ * **-V** sets the following variables:
+– **theme=white** sets the theme of the slideshow to **white**
+– **slideNumber=true** shows the slide number
+ * **-o index.html** generates the slides in the file named **index.html**
+
+
+
+To make things simpler and avoid typing this long command, create the following Makefile:
+
+```
+all: generate
+
+generate:
+ pandoc -t revealjs -s --self-contained SLIDES \
+ -V theme=white -V slideNumber=true -o index.html
+
+clean: index.html
+ rm index.html
+
+.PHONY: all clean generate
+```
+
+You can find all the code in [this repository][8].
+
+#### Make a multi-format contract
+
+Let's say you are preparing a document and (as things are nowadays) some people want it in Microsoft Word format, others use free software and would like an ODT, and others need a PDF. You do not have to use OpenOffice nor LibreOffice to generate the DOCX or PDF file. You can create your document in Markdown (with some bits of LaTeX if you need advanced formatting) and generate any of these file types.
+
+As before, begin by declaring the document's meta-information (title, author, and date):
+
+```
+% Contract Agreement for Software X
+% Kiko Fernandez-Reyes
+% August 28th, 2018
+```
+
+Then write the document in Markdown (and add LaTeX if you require advanced formatting). For example, create a table that needs fixed separation space (declared in LaTeX with **\hspace{3cm}** ) and a line where a client and a contractor should sign (declared in LaTeX with **\hrulefill** ). After that, add a table written in Markdown.
+
+Here's what the document will look like:
+
+
+
+The code to create this document is:
+
+```
+% Contract Agreement for Software X
+% Kiko Fernandez-Reyes
+% August 28th, 2018
+
+...
+
+### Work Order
+
+\begin{table}[h]
+\begin{tabular}{ccc}
+The Contractor & \hspace{3cm} & The Customer \\
+& & \\
+& & \\
+\hrulefill & \hspace{3cm} & \hrulefill \\
+%
+Name & \hspace{3cm} & Name \\
+& & \\
+& & \\
+\hrulefill & \hspace{3cm} & \hrulefill \\
+...
+\end{tabular}
+\end{table}
+
+\vspace{1cm}
+
++--------------------------------------------|----------|-------------+
+| Type of Service | Cost | Total |
++:===========================================+=========:+:===========:+
+| Game Engine | 70.0 | 70.0 |
+| | | |
++--------------------------------------------|----------|-------------+
+| | | |
++--------------------------------------------|----------|-------------+
+| Extra: Comply with defined API functions | 10.0 | 10.0 |
+| and expected returned format | | |
++--------------------------------------------|----------|-------------+
+| | | |
++--------------------------------------------|----------|-------------+
+| **Total Cost** | | **80.0** |
++--------------------------------------------|----------|-------------+
+```
+
+To generate the three different output formats needed for this document, write a Makefile:
+
+```
+DOCS=contract-agreement.md
+
+all: $(DOCS)
+ pandoc -s $(DOCS) -o $(DOCS:md=pdf)
+ pandoc -s $(DOCS) -o $(DOCS:md=docx)
+ pandoc -s $(DOCS) -o $(DOCS:md=odt)
+
+clean:
+ rm *.pdf *.docx *.odt
+
+.PHONY: all clean
+```
+
+Lines 4–7 contain the commands to generate the different outputs.
+
+If you have several Markdown files and want to merge them into one document, issue a command with the files in the order you want them to appear. For example, when writing this article, I created three documents: an introduction document, three examples, and some advanced uses. The following tells Pandoc to merge these files together in the specified order and produce a PDF named document.pdf.
+
+```
+pandoc -s introduction.md examples.md advanced-uses.md -o document.pdf
+```
+
+### Templates and meta-information
+
+Writing a complex document is no easy task. You need to stick to a set of rules that are independent from your content, such as using a specific template, writing an abstract, embedding specific fonts, and maybe even declaring keywords. All of this has nothing to do with your content: simply put, it is meta-information.
+
+Pandoc uses templates to generate different output formats. There is a template for LaTeX, another for ePub, etc. These templates have unfulfilled variables that are set with the meta-information given to Pandoc. To find out what meta-information is available in a Pandoc template, type:
+
+```
+pandoc -D FORMAT
+```
+
+For example, the template for LaTeX would be:
+
+```
+pandoc -D latex
+```
+
+Which outputs something along these lines:
+
+```
+$if(title)$
+\title{$title$$if(thanks)$\thanks{$thanks$}$endif$}
+$endif$
+$if(subtitle)$
+\providecommand{\subtitle}[1]{}
+\subtitle{$subtitle$}
+$endif$
+$if(author)$
+\author{$for(author)$$author$$sep$ \and $endfor$}
+$endif$
+$if(institute)$
+\providecommand{\institute}[1]{}
+\institute{$for(institute)$$institute$$sep$ \and $endfor$}
+$endif$
+\date{$date$}
+$if(beamer)$
+$if(titlegraphic)$
+\titlegraphic{\includegraphics{$titlegraphic$}}
+$endif$
+$if(logo)$
+\logo{\includegraphics{$logo$}}
+$endif$
+$endif$
+
+\begin{document}
+```
+
+As you can see, there are **title** , **thanks** , **author** , **subtitle** , and **institute** template variables (and many others are available). These are easily set using YAML metablocks. In lines 1–5 of the example below, we declare a YAML metablock and set some of those variables (using the contract agreement example above):
+
+```
+---
+title: Contract Agreement for Software X
+author: Kiko Fernandez-Reyes
+date: August 28th, 2018
+---
+
+(continue writing document as in the previous example)
+```
+
+This works like a charm and is equivalent to the previous code:
+
+```
+% Contract Agreement for Software X
+% Kiko Fernandez-Reyes
+% August 28th, 2018
+```
+
+However, this ties the meta-information to the content; i.e., Pandoc will always use this information to output files in the new format. If you know you need to produce multiple file formats, you better be careful. For example, what if you need to produce the contract in ePub and in HTML, and the ePub and HTML need specific and different styling rules?
+
+Let's consider the cases:
+
+ * If you simply try to embed the YAML variable **css: style-epub.css** , you would be excluding the one from the HTML version. This does not work.
+ * Duplicating the document is obviously not a good solution either, as changes in one version would not be in sync with the other copy.
+ * You can add variables to the Pandoc command line as follows:
+
+
+
+```
+pandoc -s -V css=style-epub.css document.md document.epub
+pandoc -s -V css=style-html.css document.md document.html
+```
+
+My opinion is that it is easy to overlook these variables from the command line, especially when you need to set tens of these (which can happen in complex documents). Now, if you put them all together under the same roof (a meta.yaml file), you only need to update or create a new meta-information file to produce the desired output. You would then write:
+
+```
+pandoc -s meta-pub.yaml document.md document.epub
+pandoc -s meta-html.yaml document.md document.html
+```
+
+This is a much cleaner version, and you can update all the meta-information from a single file without ever having to update the content of your document.
+
+### Wrapping up
+
+With these basic examples, I have shown how Pandoc can do a really good job at converting Markdown documents into other formats.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/9/intro-pandoc
+
+作者:[Kiko Fernandez-Reyes][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/kikofernandez
+[1]: https://pandoc.org/
+[2]: http://pandoc.org/installing.html
+[3]: https://hackage.haskell.org/package/pandoc-crossref
+[4]: https://github.com/lierdakil/pandoc-crossref/releases/tag/v0.3.2.1
+[5]: https://github.com/lierdakil/pandoc-crossref#installation
+[6]: http://pandoc.org/demo/mathMathML.html
+[7]: https://github.com/kikofernandez/pandoc-examples/tree/master/math
+[8]: https://github.com/kikofernandez/pandoc-examples/tree/master/slides
+[9]: https://daringfireball.net/projects/markdown/syntax#header
diff --git a/sources/tech/20180914 Freespire Linux- A Great Desktop for the Open Source Purist.md b/sources/tech/20180914 Freespire Linux- A Great Desktop for the Open Source Purist.md
new file mode 100644
index 0000000000..baaf08e92d
--- /dev/null
+++ b/sources/tech/20180914 Freespire Linux- A Great Desktop for the Open Source Purist.md
@@ -0,0 +1,114 @@
+Freespire Linux: A Great Desktop for the Open Source Purist
+======
+
+
+
+Quick. Click on your Linux desktop menu and scan through the list of installed software. How much of that software is strictly open sources To make matters a bit more complicated, have you installed closed source media codecs (to play the likes of MP3 files perhaps)? Is everything fully open, or do you have a mixture of open and closed source tools?
+
+If you’re a purist, you probably strive to only use open source tools on your desktop. But how do you know, for certain, that your distribution only includes open source software? Fortunately, a few distributions go out of their way to only include applications that are 100% open. One such distro is [Freespire][1].
+
+Does that name sound familiar? It should, as it is closely related to[Linspire][2]. Now we’re talking familiarity. Remember back in the early 2000s, when Walmart sold Linux desktop computers? Those computers were powered by the Linspire operating system. Linspire went above and beyond to create an experience that would be similar to that of Windows—even including the tools to install Windows apps on Linux. That experiment failed, mostly because consumers thought they were getting a Windows desktop machine for a dirt cheap price. After that debacle, Linspire went away for a while. It’s now back, thanks to [PC/OpenSystems LLC][3]. Their goal isn’t to recreate the past but to offer two different flavors of Linux:
+
+ * Linspire—a commercial distribution of Linux that includes proprietary software and does have an associated cost ($39.99 USD for a single license).
+
+ * Freespire—a non-commercial distribution of Linux that only includes open source software and is free to download.
+
+
+
+
+We’re here to discuss Freespire and why it is an outstanding addition to the Linux community, especially those who strive to use only free and open source software. This version of Freespire (4.0) was released on August 20, 2018, so it’s fresh and ready to go.
+
+Let’s dig into the operating system and see what makes this a viable candidate for open source fans.
+
+### Installation
+
+In keeping with my usual approach, there’s very little reason to even mention the installation of Freespire Linux. There is nothing out of the ordinary here. Download the ISO image, burn it to a USB Drive (or CD/DVD if you’re dealing with older hardware), boot the drive, click the Install icon, answer a few simple questions, and wait for the installation to prompt for a reboot. That’s how far we’ve come with Linux installations… they are simple, and rarely will you have a single issue with the process. In the end, you’ll be presented with a simple (modified) Mate desktop (Figure 1) that makes it easy for any user (of any skill level) to feel right at home.
+
+
+
+### Software Titles
+
+Once you’ve logged into the desktop, you’ll find a main menu where you can view all of the installed applications. That list of software includes:
+
+ * Geary
+
+ * Chromium Browser
+
+ * Abiword
+
+ * Gnumeric
+
+ * Calendar
+
+ * Audacious
+
+ * Totem Video Player
+
+ * Software Center
+
+ * Synaptic
+
+ * G-Debi
+
+
+
+
+Also rolled into the system is support for both Flatpak and Snap applications, so you shouldn’t miss out on any software you need, which brings me to the part when purists might want to look away.
+
+Just because Freespire is marketed as a purely open source distribution, it doesn’t mean users are locked down to only open source software. In fact, if you open the Software Center, you can do a quick search for Spotify (a closed source application with an available Linux desktop client) and there it is! (Figure 2).
+
+![Spotify][5]
+
+Figure 2: The closed source Spotify client available for installation.
+
+[Used with permission][6]
+
+Fortunately, for those productive-minded folks, the likes of LibreOffice (which is not installed by default) is open source and can be installed easily from the Software Center. That doesn’t mean you must install other software, but those who need to do serious business-centric work (such as collaborating on documents), will likely want/need to install a more powerful office suite (as Abiword won’t cut it as a business-level word processor).
+
+For those who tend to work long hours on the Linux desktop and want to protect their eyes from extended strain, Freespire does include a nightlight tool that can adjust the color temperature of the interface. To open this tool, click on the main desktop menu and type night in the Search bar (Figure 3).
+
+![Night Light][8]
+
+Figure 3: Opening the Night Light tool.
+
+[Used with permission][6]
+
+Once opened, Night Light will automatically adjust the color temperature, based on the time of day. From the notification tray, you can click the icon to suspend Night Light, set it to autostart, and close the service (Figure 4).
+
+![Night Light controls.][10]
+
+Figure 4: The Night Light controls.
+
+[Used with permission][6]
+
+### Beyond the Mate Desktop
+
+As is, Mate fans might not exactly recognize the Freespire desktop. The developers have clearly given Mate a significant set of tweaks to make it slightly resemble the Mac OS desktop. It’s not quite as elegant as, say, Elementary OS, but this is certainly an outstanding take on the Linux desktop. Whether you’re a fan of Mate or Mac OS, you should feel immediately at home on the desktop. On the top bar, the developers have included an appmenu that changes, based on what application you have open. Start any app and you’ll find that app’s menu appears in the top bar. This active menu makes the desktop quite efficient.
+
+### Are you ready for Freespire?
+
+Every piece of the Freespire puzzle is equally as user-friendly as it is intuitive. The developers of Freespire have gone to great lengths to make this pure open source distribution a treat to use. Even if a 100% open source desktop isn’t your thing, Freespire is still a worthy contender in the world of desktop Linux. It’s clean and stable (as it’s based on Ubuntu 18.04) and able to help you be efficient and productive on the desktop.
+
+Learn more about Linux through the free ["Introduction to Linux" ][11]course from The Linux Foundation and edX.
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/learn/intro-to-linux/2018/9/freespire-linux-great-desktop-open-source-purist
+
+作者:[Jack Wallen][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.linux.com/users/jlwallen
+[1]: https://www.freespirelinux.com/
+[2]: https://www.linspirelinux.com/
+[3]: https://www.pc-opensystems.com
+[5]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/freespire_2.jpg?itok=zcr94Dk6 (Spotify)
+[6]: /licenses/category/used-permission
+[8]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/freespire_3.jpg?itok=aZYtBPgE (Night Light)
+[9]: /files/images/freespire4jpg
+[10]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/freespire_4.jpg?itok=JCcQwmJ5 (Night Light controls.)
+[11]: https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/sources/tech/20180915 Backup Installed Packages And Restore Them On Freshly Installed Ubuntu.md b/sources/tech/20180915 Backup Installed Packages And Restore Them On Freshly Installed Ubuntu.md
new file mode 100644
index 0000000000..c775fd5040
--- /dev/null
+++ b/sources/tech/20180915 Backup Installed Packages And Restore Them On Freshly Installed Ubuntu.md
@@ -0,0 +1,109 @@
+translating---geekpi
+
+Backup Installed Packages And Restore Them On Freshly Installed Ubuntu
+======
+
+
+
+Installing the same set of packages on multiple Ubuntu systems is time consuming and boring task. You don’t want to spend your time to install the same packages over and over on multiple systems. When it comes to install packages on similar architecture Ubuntu systems, there are many methods available to make this task easier. You could simply migrate your old Ubuntu system’s applications, settings and data to a newly installed system with a couple mouse clicks using [**Aptik**][1]. Or, you can take the [**backup entire list of installed packages**][2] using your package manager (Eg. APT), and install them later on a freshly installed system. Today, I learned that there is also yet another dedicated utility available to do this job. Say hello to **apt-clone** , a simple tool that lets you to create a list of installed packages for Debian/Ubuntu systems that can be restored on freshly installed systems or containers or into a directory.
+
+Apt-clone will help you on situations where you want to,
+
+ * Install consistent applications across multiple systems running with similar Ubuntu (and derivatives) OS.
+ * Install same set of packages on multiple systems often.
+ * Backup the entire list of installed applications and restore them on demand wherever and whenever necessary.
+
+
+
+In this brief guide, we will be discussing how to install and use Apt-clone on Debian-based systems. I tested this utility on Ubuntu 18.04 LTS system, however it should work on all Debian and Ubuntu-based systems.
+
+### Backup Installed Packages And Restore Them Later On Freshly Installed Ubuntu System
+
+Apt-clone is available in the default repositories. To install it, just enter the following command from the Terminal:
+
+```
+$ sudo apt install apt-clone
+```
+
+Once installed, simply create the list of installed packages and save them in any location of your choice.
+
+```
+$ mkdir ~/mypackages
+
+$ sudo apt-clone clone ~/mypackages
+```
+
+The above command saved all installed packages in my Ubuntu system in a file named **apt-clone-state-ubuntuserver.tar.gz** under **~/mypackages** directory.
+
+To view the details of the backup file, run:
+
+```
+$ apt-clone info mypackages/apt-clone-state-ubuntuserver.tar.gz
+Hostname: ubuntuserver
+Arch: amd64
+Distro: bionic
+Meta:
+Installed: 516 pkgs (33 automatic)
+Date: Sat Sep 15 10:23:05 2018
+```
+
+As you can see, I have 516 packages in total in my Ubuntu server.
+
+Now, copy this file on your USB or external drive and go to any other system that want to install the same set of packages. Or you can also transfer the backup file to the system on the network and install the packages by using the following command:
+
+```
+$ sudo apt-clone restore apt-clone-state-ubuntuserver.tar.gz
+```
+
+Please be mindful that this command will overwrite your existing **/etc/apt/sources.list** and will install/remove packages. You have been warned! Also, just make sure the destination system is on same arch and same OS. For example, if the source system is running with 18.04 LTS 64bit, the destination system must also has the same.
+
+If you don’t want to restore packages on the system, you can simply use `--destination /some/location` option to debootstrap the clone into this directory.
+
+```
+$ sudo apt-clone restore apt-clone-state-ubuntuserver.tar.gz --destination ~/oldubuntu
+```
+
+In this case, the above command will restore the packages in a folder named **~/oldubuntu**.
+
+For more details, refer help section:
+
+```
+$ apt-clone -h
+```
+
+Or, man pages:
+
+```
+$ man apt-clone
+```
+
+**Suggested read:**
+
++ [Systemback – Restore Ubuntu Desktop and Server to previous state][3]
++ [Cronopete – An Apple’s Time Machine Clone For Linux][4]
+
+And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
+
+Cheers!
+
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/backup-installed-packages-and-restore-them-on-freshly-installed-ubuntu-system/
+
+作者:[SK][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/sk/
+[1]: https://www.ostechnix.com/how-to-migrate-system-settings-and-data-from-an-old-system-to-a-newly-installed-ubuntu-system/
+[2]: https://www.ostechnix.com/create-list-installed-packages-install-later-list-centos-ubuntu/#comment-12598
+
+[3]: https://www.ostechnix.com/systemback-restore-ubuntu-desktop-and-server-to-previous-state/
+
+[4]: https://www.ostechnix.com/cronopete-apples-time-machine-clone-linux/
diff --git a/sources/tech/20180917 4 scanning tools for the Linux desktop.md b/sources/tech/20180917 4 scanning tools for the Linux desktop.md
new file mode 100644
index 0000000000..a239c87768
--- /dev/null
+++ b/sources/tech/20180917 4 scanning tools for the Linux desktop.md
@@ -0,0 +1,72 @@
+4 scanning tools for the Linux desktop
+======
+Go paperless by driving your scanner with one of these open source applications.
+
+
+
+While the paperless world isn't here quite yet, more and more people are getting rid of paper by scanning documents and photos. Having a scanner isn't enough to do the deed, though. You need software to drive that scanner.
+
+But the catch is many scanner makers don't have Linux versions of the software they bundle with their devices. For the most part, that doesn't matter. Why? Because there are good scanning applications available for the Linux desktop. They work with a variety of scanners and do a good job.
+
+Let's take a look at four simple but flexible open source Linux scanning tools. I've used each of these tools (and even wrote about three of them [back in 2014][1]) and found them very useful. You might, too.
+
+### Simple Scan
+
+One of my longtime favorites, [Simple Scan][2] is small, quick, efficient, and easy to use. If you've seen it before, that's because Simple Scan is the default scanner application on the GNOME desktop, as well as for a number of Linux distributions.
+
+Scanning a document or photo takes one click. After scanning something, you can rotate or crop it and save it as an image (JPEG or PNG only) or as a PDF. That said, Simple Scan can be slow, even if you scan documents at lower resolutions. On top of that, Simple Scan uses a set of global defaults for scanning, like 150dpi for text and 300dpi for photos. You need to go into Simple Scan's preferences to change those settings.
+
+If you've scanned something with more than a couple of pages, you can reorder the pages before you save. And if necessary—say you're submitting a signed form—you can email from within Simple Scan.
+
+### Skanlite
+
+In many ways, [Skanlite][3] is Simple Scan's cousin in the KDE world. Skanlite has few features, but it gets the job done nicely.
+
+The software has options that you can configure, including automatically saving scanned files, setting the quality of the scan, and identifying where to save your scans. Skanlite can save to these image formats: JPEG, PNG, BMP, PPM, XBM, and XPM.
+
+One nifty feature is the software's ability to save portions of what you've scanned to separate files. That comes in handy when, say, you want to excise someone or something from a photo.
+
+### Gscan2pdf
+
+Another old favorite, [gscan2pdf][4] might be showing its age, but it still packs a few more features than some of the other applications mentioned here. Even so, gscan2pdf is still comparatively light.
+
+In addition to saving scans in various image formats (JPEG, PNG, and TIFF), gscan2pdf also saves them as PDF or [DjVu][5] files. You can set the scan's resolution, whether it's black and white or color, and paper size before you click the Scan button. That beats going into gscan2pdf's preferences every time you want to change any of those settings. You can also rotate, crop, and delete pages.
+
+While none of those features are truly killer, they give you a bit more flexibility.
+
+### GIMP
+
+You probably know [GIMP][6] as an image-editing tool. But did you know you can use it to drive your scanner?
+
+You'll need to install the [XSane][7] scanner software and the GIMP XSane plugin. Both of those should be available from your Linux distro's package manager. From there, select File > Create > Scanner/Camera. From there, click on your scanner and then the Scan button.
+
+If that's not your cup of tea, or if it doesn't work, you can combine GIMP with a plugin called [QuiteInsane][8]. With either plugin, GIMP becomes a powerful scanning application that lets you set a number of options like whether to scan in color or black and white, the resolution of the scan, and whether or not to compress results. You can also use GIMP's tools to touch up or apply effects to your scans. This makes it great for scanning photos and art.
+
+### Do they really just work?
+
+All of this software works well for the most part and with a variety of hardware. I've used them with several multifunction printers that I've owned over the years—whether connecting using a USB cable or over wireless.
+
+You might have noticed that I wrote "works well for the most part" in the previous paragraph. I did run into one exception: an inexpensive Canon multifunction printer. None of the software I used could detect it. I had to download and install Canon's Linux scanner software, which did work.
+
+What's your favorite open source scanning tool for Linux? Share your pick by leaving a comment.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/9/linux-scanner-tools
+
+作者:[Scott Nesbitt][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/scottnesbitt
+[1]: https://opensource.com/life/14/8/3-tools-scanners-linux-desktop
+[2]: https://gitlab.gnome.org/GNOME/simple-scan
+[3]: https://www.kde.org/applications/graphics/skanlite/
+[4]: http://gscan2pdf.sourceforge.net/
+[5]: http://en.wikipedia.org/wiki/DjVu
+[6]: http://www.gimp.org/
+[7]: https://en.wikipedia.org/wiki/Scanner_Access_Now_Easy#XSane
+[8]: http://sourceforge.net/projects/quiteinsane/
diff --git a/sources/tech/20180918 Cozy Is A Nice Linux Audiobook Player For DRM-Free Audio Files.md b/sources/tech/20180918 Cozy Is A Nice Linux Audiobook Player For DRM-Free Audio Files.md
new file mode 100644
index 0000000000..8450d6fd11
--- /dev/null
+++ b/sources/tech/20180918 Cozy Is A Nice Linux Audiobook Player For DRM-Free Audio Files.md
@@ -0,0 +1,72 @@
+Cozy Is A Nice Linux Audiobook Player For DRM-Free Audio Files
+======
+[Cozy][1] **is a free and open source audiobook player for the Linux desktop. The application lets you listen to DRM-free audiobooks (mp3, m4a, flac, ogg and wav) using a modern Gtk3 interface.**
+
+
+
+You could use any audio player to listen to audiobooks, but a specialized audiobook player like Cozy makes everything easier, by **remembering your playback position and continuing from where you left off for each audiobook** , or by letting you **set the playback speed of each book individually** , among others.
+
+The Cozy interface lets you browse books by author, reader or recency, while also providing search functionality. **Books front covers are supported by Cozy** \- either by using embedded images, or by adding a cover.jpg or cover.png image in the book folder, which is automatically picked up and displayed by Cozy.
+
+When you click on an audiobook, Cozy lists the book chapters on the right, while displaying the book cover (if available) on the left, along with the book name, author and the last played time, along with total and remaining time:
+
+
+
+From the application toolbar you can easily **go back 30 seconds** by clicking the rewind icon from its top left-hand side corner. Besides regular controls, cover and title, you'll also find a playback speed button on the toolbar, which lets you increase the playback speed up to 2X.
+
+**A sleep timer is also available**. It can be set to stop after the current chapter or after a given number of minutes.
+
+Other Cozy features worth mentioning:
+
+ * **Mpris integration** (Media keys & playback info)
+ * **Supports multiple storage locations**
+ * **Drag'n'drop support for importing new audiobooks**
+ * **Offline Mode**. If your audiobooks are on an external or network drive, you can switch the download button to keep a local cached copy of the book to listen to on the go. To enable this feature you have to set your storage location to external in the settings
+ * **Prevents your system from suspend during playback**
+ * **Dark mode**
+
+
+
+What I'd like to see in Cozy is a way to get audiobooks metadata, including the book cover, automatically. A feature to retrieve metadata from Audible.com was proposed on the Cozy GitHub project page and the developer seems interested in this, but it's not clear when or if this will be implemented.
+
+Like I was mentioning in the beginning of the article, Cozy only supports DRM-free audio files. Currently it supports mp3, m4a, flac, ogg and wav. Support for more formats will probably come in the future, with m4b being listed on the Cozy 0.7.0 todo list.
+
+Cozy cannot play Audible audiobooks due to DRM. But you'll find some solutions out there for converting Audible (.aa/.aax) audiobooks to mp3, like
+
+### Install Cozy
+
+**Any Linux distribution / Flatpak** : Cozy is available as a Flatpak on FlatHub. To install it, follow the quick Flatpak [setup][4], then go to the Cozy FlaHub [page][5] and click the install button, or use the install command at the bottom if its page.
+
+**elementary OS** : Cozy is available in the [AppCenter][6].
+
+**Ubuntu 18.04 / Linux Mint 19** : you can install Cozy from its repository:
+
+```
+wget -nv https://download.opensuse.org/repositories/home:geigi/Ubuntu_18.04/Release.key -O Release.key
+sudo apt-key add - < Release.key
+sudo sh -c "echo 'deb http://download.opensuse.org/repositories/home:/geigi/Ubuntu_18.04/ /' > /etc/apt/sources.list.d/home:geigi.list"
+sudo apt update
+sudo apt install com.github.geigi.cozy
+```
+
+**For other ways of installing Cozy check out its[website][2].**
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.linuxuprising.com/2018/09/cozy-is-nice-linux-audiobook-player-for.html
+
+作者:[Logix][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://plus.google.com/118280394805678839070
+[1]: https://cozy.geigi.de/
+[2]: https://cozy.geigi.de/#how-can-i-get-it
+[3]: https://gitlab.com/ReverendJ1/audiblefreedom/blob/master/audiblefreedom
+[4]: https://flatpak.org/setup/
+[5]: https://flathub.org/apps/details/com.github.geigi.cozy
+[6]: https://appcenter.elementary.io/com.github.geigi.cozy/
diff --git a/sources/tech/20180918 Linux firewalls- What you need to know about iptables and firewalld.md b/sources/tech/20180918 Linux firewalls- What you need to know about iptables and firewalld.md
new file mode 100644
index 0000000000..98e38a02cd
--- /dev/null
+++ b/sources/tech/20180918 Linux firewalls- What you need to know about iptables and firewalld.md
@@ -0,0 +1,170 @@
+heguangzhi translating
+
+Linux firewalls: What you need to know about iptables and firewalld
+======
+Here's how to use the iptables and firewalld tools to manage Linux firewall connectivity rules.
+
+
+This article is excerpted from my book, [Linux in Action][1], and a second Manning project that’s yet to be released.
+
+### The firewall
+
+A firewall is a set of rules. When a data packet moves into or out of a protected network space, its contents (in particular, information about its origin, target, and the protocol it plans to use) are tested against the firewall rules to see if it should be allowed through. Here’s a simple example:
+
+![firewall filtering request][3]
+
+A firewall can filter requests based on protocol or target-based rules.
+
+On the one hand, [iptables][4] is a tool for managing firewall rules on a Linux machine.
+
+On the other hand, [firewalld][5] is also a tool for managing firewall rules on a Linux machine.
+
+You got a problem with that? And would it spoil your day if I told you that there was another tool out there, called [nftables][6]?
+
+OK, I’ll admit that the whole thing does smell a bit funny, so let me explain. It all starts with Netfilter, which controls access to and from the network stack at the Linux kernel module level. For decades, the primary command-line tool for managing Netfilter hooks was the iptables ruleset.
+
+Because the syntax needed to invoke those rules could come across as a bit arcane, various user-friendly implementations like [ufw][7] and firewalld were introduced as higher-level Netfilter interpreters. Ufw and firewalld are, however, primarily designed to solve the kinds of problems faced by stand-alone computers. Building full-sized network solutions will often require the extra muscle of iptables or, since 2014, its replacement, nftables (through the nft command line tool).
+
+iptables hasn’t gone anywhere and is still widely used. In fact, you should expect to run into iptables-protected networks in your work as an admin for many years to come. But nftables, by adding on to the classic Netfilter toolset, has brought some important new functionality.
+
+From here on, I’ll show by example how firewalld and iptables solve simple connectivity problems.
+
+### Configure HTTP access using firewalld
+
+As you might have guessed from its name, firewalld is part of the [systemd][8] family. Firewalld can be installed on Debian/Ubuntu machines, but it’s there by default on Red Hat and CentOS. If you’ve got a web server like Apache running on your machine, you can confirm that the firewall is working by browsing to your server’s web root. If the site is unreachable, then firewalld is doing its job.
+
+You’ll use the `firewall-cmd` tool to manage firewalld settings from the command line. Adding the `–state` argument returns the current firewall status:
+
+```
+# firewall-cmd --state
+running
+```
+
+By default, firewalld will be active and will reject all incoming traffic with a couple of exceptions, like SSH. That means your website won’t be getting too many visitors, which will certainly save you a lot of data transfer costs. As that’s probably not what you had in mind for your web server, though, you’ll want to open the HTTP and HTTPS ports that by convention are designated as 80 and 443, respectively. firewalld offers two ways to do that. One is through the `–add-port` argument that references the port number directly along with the network protocol it’ll use (TCP in this case). The `–permanent` argument tells firewalld to load this rule each time the server boots:
+
+```
+# firewall-cmd --permanent --add-port=80/tcp
+# firewall-cmd --permanent --add-port=443/tcp
+```
+
+The `–reload` argument will apply those rules to the current session:
+
+```
+# firewall-cmd --reload
+```
+
+Curious as to the current settings on your firewall? Run `–list-services`:
+
+```
+# firewall-cmd --list-services
+dhcpv6-client http https ssh
+```
+
+Assuming you’ve added browser access as described earlier, the HTTP, HTTPS, and SSH ports should now all be open—along with `dhcpv6-client`, which allows Linux to request an IPv6 IP address from a local DHCP server.
+
+### Configure a locked-down customer kiosk using iptables
+
+I’m sure you’ve seen kiosks—they’re the tablets, touchscreens, and ATM-like PCs in a box that airports, libraries, and business leave lying around, inviting customers and passersby to browse content. The thing about most kiosks is that you don’t usually want users to make themselves at home and treat them like their own devices. They’re not generally meant for browsing, viewing YouTube videos, or launching denial-of-service attacks against the Pentagon. So to make sure they’re not misused, you need to lock them down.
+
+One way is to apply some kind of kiosk mode, whether it’s through clever use of a Linux display manager or at the browser level. But to make sure you’ve got all the holes plugged, you’ll probably also want to add some hard network controls through a firewall. In the following section, I'll describe how I would do it using iptables.
+
+There are two important things to remember about using iptables: The order you give your rules is critical, and by themselves, iptables rules won’t survive a reboot. I’ll address those here one at a time.
+
+### The kiosk project
+
+To illustrate all this, let’s imagine we work for a store that’s part of a larger chain called BigMart. They’ve been around for decades; in fact, our imaginary grandparents probably grew up shopping there. But these days, the guys at BigMart corporate headquarters are probably just counting the hours before Amazon drives them under for good.
+
+Nevertheless, BigMart’s IT department is doing its best, and they’ve just sent you some WiFi-ready kiosk devices that you’re expected to install at strategic locations throughout your store. The idea is that they’ll display a web browser logged into the BigMart.com products pages, allowing them to look up merchandise features, aisle location, and stock levels. The kiosks will also need access to bigmart-data.com, where many of the images and video media are stored.
+
+Besides those, you’ll want to permit updates and, whenever necessary, package downloads. Finally, you’ll want to permit inbound SSH access only from your local workstation, and block everyone else. The figure below illustrates how it will all work:
+
+![kiosk traffic flow ip tables][10]
+
+The kiosk traffic flow being controlled by iptables.
+
+### The script
+
+Here’s how that will all fit into a Bash script:
+
+```
+#!/bin/bash
+iptables -A OUTPUT -p tcp -d bigmart.com -j ACCEPT
+iptables -A OUTPUT -p tcp -d bigmart-data.com -j ACCEPT
+iptables -A OUTPUT -p tcp -d ubuntu.com -j ACCEPT
+iptables -A OUTPUT -p tcp -d ca.archive.ubuntu.com -j ACCEPT
+iptables -A OUTPUT -p tcp --dport 80 -j DROP
+iptables -A OUTPUT -p tcp --dport 443 -j DROP
+iptables -A INPUT -p tcp -s 10.0.3.1 --dport 22 -j ACCEPT
+iptables -A INPUT -p tcp -s 0.0.0.0/0 --dport 22 -j DROP
+```
+
+The basic anatomy of our rules starts with `-A`, telling iptables that we want to add the following rule. `OUTPUT` means that this rule should become part of the OUTPUT chain. `-p` indicates that this rule will apply only to packets using the TCP protocol, where, as `-d` tells us, the destination is [bigmart.com][11]. The `-j` flag points to `ACCEPT` as the action to take when a packet matches the rule. In this first rule, that action is to permit, or accept, the request. But further down, you can see requests that will be dropped, or denied.
+
+Remember that order matters. And that’s because iptables will run a request past each of its rules, but only until it gets a match. So an outgoing browser request for, say, [youtube.com][12] will pass the first four rules, but when it gets to either the `–dport 80` or `–dport 443` rule—depending on whether it’s an HTTP or HTTPS request—it’ll be dropped. iptables won’t bother checking any further because that was a match.
+
+On the other hand, a system request to ubuntu.com for a software upgrade will get through when it hits its appropriate rule. What we’re doing here, obviously, is permitting outgoing HTTP or HTTPS requests to only our BigMart or Ubuntu destinations and no others.
+
+The final two rules will deal with incoming SSH requests. They won’t already have been denied by the two previous drop rules since they don’t use ports 80 or 443, but 22. In this case, login requests from my workstation will be accepted but requests for anywhere else will be dropped. This is important: Make sure the IP address you use for your port 22 rule matches the address of the machine you’re using to log in—if you don’t do that, you’ll be instantly locked out. It's no big deal, of course, because the way it’s currently configured, you could simply reboot the server and the iptables rules will all be dropped. If you’re using an LXC container as your server and logging on from your LXC host, then use the IP address your host uses to connect to the container, not its public address.
+
+You’ll need to remember to update this rule if my machine’s IP ever changes; otherwise, you’ll be locked out.
+
+Playing along at home (hopefully on a throwaway VM of some sort)? Great. Create your own script. Now I can save the script, use `chmod` to make it executable, and run it as `sudo`. Don’t worry about that `bigmart-data.com not found` error—of course it’s not found; it doesn’t exist.
+
+```
+chmod +X scriptname.sh
+sudo ./scriptname.sh
+```
+
+You can test your firewall from the command line using `cURL`. Requesting ubuntu.com works, but [manning.com][13] fails.
+
+```
+curl ubuntu.com
+curl manning.com
+```
+
+### Configuring iptables to load on system boot
+
+Now, how do I get these rules to automatically load each time the kiosk boots? The first step is to save the current rules to a .rules file using the `iptables-save` tool. That’ll create a file in the root directory containing a list of the rules. The pipe, followed by the tee command, is necessary to apply my `sudo` authority to the second part of the string: the actual saving of a file to the otherwise restricted root directory.
+
+I can then tell the system to run a related tool called `iptables-restore` every time it boots. A regular cron job of the kind we saw in the previous module won’t help because they’re run at set times, but we have no idea when our computer might decide to crash and reboot.
+
+There are lots of ways to handle this problem. Here’s one:
+
+On my Linux machine, I’ll install a program called [anacron][14] that will give us a file in the /etc/ directory called anacrontab. I’ll edit the file and add this `iptables-restore` command, telling it to load the current values of that .rules file into iptables each day (when necessary) one minute after a boot. I’ll give the job an identifier (`iptables-restore`) and then add the command itself. Since you’re playing along with me at home, you should test all this out by rebooting your system.
+
+```
+sudo iptables-save | sudo tee /root/my.active.firewall.rules
+sudo apt install anacron
+sudo nano /etc/anacrontab
+1 1 iptables-restore iptables-restore < /root/my.active.firewall.rules
+
+```
+
+I hope these practical examples have illustrated how to use iptables and firewalld for managing connectivity issues on Linux-based firewalls.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/9/linux-iptables-firewalld
+
+作者:[David Clinton][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/remyd
+[1]: https://www.manning.com/books/linux-in-action?a_aid=bootstrap-it&a_bid=4ca15fc9&chan=opensource
+[2]: /file/409116
+[3]: https://opensource.com/sites/default/files/uploads/iptables1.jpg (firewall filtering request)
+[4]: https://en.wikipedia.org/wiki/Iptables
+[5]: https://firewalld.org/
+[6]: https://wiki.nftables.org/wiki-nftables/index.php/Main_Page
+[7]: https://en.wikipedia.org/wiki/Uncomplicated_Firewall
+[8]: https://en.wikipedia.org/wiki/Systemd
+[9]: /file/409121
+[10]: https://opensource.com/sites/default/files/uploads/iptables2.jpg (kiosk traffic flow ip tables)
+[11]: http://bigmart.com/
+[12]: http://youtube.com/
+[13]: http://manning.com/
+[14]: https://sourceforge.net/projects/anacron/
diff --git a/sources/tech/20180919 Streama - Setup Your Own Streaming Media Server In Minutes.md b/sources/tech/20180919 Streama - Setup Your Own Streaming Media Server In Minutes.md
new file mode 100644
index 0000000000..521a8f5b95
--- /dev/null
+++ b/sources/tech/20180919 Streama - Setup Your Own Streaming Media Server In Minutes.md
@@ -0,0 +1,171 @@
+Streama – Setup Your Own Streaming Media Server In Minutes
+======
+
+
+
+**Streama** is a free, open source application that helps to setup your own personal streaming media server in minutes in Unix-like operating systems. It’s like Netflix, but self-hostable. You can deploy it on your local system or VPS or dedicated server and stream the media files across multiple devices. The media files can be accessed from a web-browser from any system on your network. If you have deployed on your VPS, you can access it from anywhere. Streama works like your own personal Netflix system to stream your TV shows, videos, audios and movies. Streama is a web-based application written using Grails 3 (server-side) with SpringSecurity and all frond-end components are written in AngularJS. The built-in player is completely HTML5-based.
+
+### Prominent Features
+
+Streama ships with a lot features as listed below.
+
+ * Easy to install configure. You can either download docker instance and fire up your media server in minutes or install vanilla version on your local or VPS or dedicated server.
+ * Drag and drop support to upload media files.
+ * Live sync watching support. You can watch videos with your friends, family remotely. It doesn’t matter where they are. You can all watch the same video at a time.
+ * Built-in beautiful video player to watch/listen video and audio.
+ * Built-in browser to access the media files in the server.
+ * Multi-user support. You can create individual user accounts to your family members and access the media server simultaneously.
+ * Streama supports pause-play option. Pause the playback at any time and Streama remembers where you left off last time.
+ * Streama can be able to detect similar movies and videos and shows for you to add.
+ * Self-hostable
+ * It is completely free and open source.
+
+
+
+What do you need more? Streama has everything you to need to setup a full-fledged streaming media server in your Linux box.
+
+### Setup Your Own Streaming Media Server Using Streama
+
+Streama requires JAVA 8 or later, preferably **OpenJDK**. And, the recommended OS is **Ubuntu**. For the purpose of this guide, I will be using Ubuntu 18.04 LTS.
+
+By default, the latest Ubuntu 18.04 includes Open JDK 11. To install default openJDK in Ubuntu 18.04 or later, run:
+
+```
+$ sudo apt install default-jdk
+
+```
+
+Java 8 is the latest stable Long Time Support version. If you prefer to use Java LTS, run:
+
+```
+$ sudo apt install openjdk-8-jdk
+```
+
+I have installed openjdk-8-jdk. To check the installed Java version, run:
+
+```
+$ java -version
+openjdk version "1.8.0_181"
+OpenJDK Runtime Environment (build 1.8.0_181-8u181-b13-0ubuntu0.18.04.1-b13)
+OpenJDK 64-Bit Server VM (build 25.181-b13, mixed mode)
+```
+
+Once java installed, create a directory to save Streama executable and yml files.
+
+```
+$ sudo mkdir /data
+
+$ sudo mkdir /data/streama
+```
+
+I followed the official documentation, so I used this path – /data/streama. It is optional. You’re free to use any location of your choice.
+
+Switch to streama directory:
+
+```
+$ cd /data/streama
+```
+
+Download the latest Streama executable file from [**releases page**][1]. As of writing this guide, the latest version was **v1.6.0-RC8**.
+
+```
+$ sudo wget https://github.com/streamaserver/streama/releases/download/v1.6.0-RC8/streama-1.6.0-RC8.war
+```
+
+Make it executable:
+
+```
+$ sudo chmod +x streama-1.6.0-RC8.war
+```
+
+Now, run Streama application using command:
+
+```
+$ sudo ./streama-1.6.0-RC8.war
+```
+
+If you an output something like below, Streama is working!
+
+```
+INFO streama.Application - Starting Application on ubuntuserver with PID 26714 (/data/streama/streama-1.6.0-RC8.war started by root in /data/streama)
+DEBUG streama.Application - Running with Spring Boot v1.4.4.RELEASE, Spring v4.3.6.RELEASE
+INFO streama.Application - The following profiles are active: production
+
+Configuring Spring Security Core ...
+... finished configuring Spring Security Core
+
+INFO streama.Application - Started Application in 92.003 seconds (JVM running for 98.66)
+Grails application running at http://localhost:8080 in environment: production
+```
+
+Open your web browser and navigate to URL – ****
+
+You should see Streama login screen. Login with default credentials – **admin/admin**
+
+
+
+Now, You need to fill out some required base-settings. Click OK button in the next screen and you will be redirected to the settings page. In the Settings page, you need to set some parameters such as the location of the Uploads directory, Streama logo, name of the media server, base URL, allow anonymous access, allow users to download videos. All fields marked with ***** is necessary to fill. Once you provided the details, click **Save settings** button.
+
+
+
+Congratulations! Your media server is ready to use!
+
+Here is how Stream dashboard looks like.
+
+
+
+And, this is the contents management page where you can upload movies, shows, access files via file manager, view the notifications and highlights.
+
+
+
+### Adding movies/shows
+
+Let me show you how to add a movie.
+
+Go to the **“Manage Content”** page from the dashboard and click **“Create New Movie”** link.
+
+Enter the movie details, such as name, release date, IMDB ID and movie description and click **Save**. These are all optional, you can simply ignore them if you don’t know about the details.
+
+
+
+We have added the movie details, but we haven’t added the actual movie yet. To do so, click on the red box in the bottom that says – **“No video file yet! Drop file or Click here to add”**.
+
+
+
+You could either drag and drop the movie file inside this dashboard or click on the red box to manually upload it.
+
+Choose the movie file to upload and click Upload.
+
+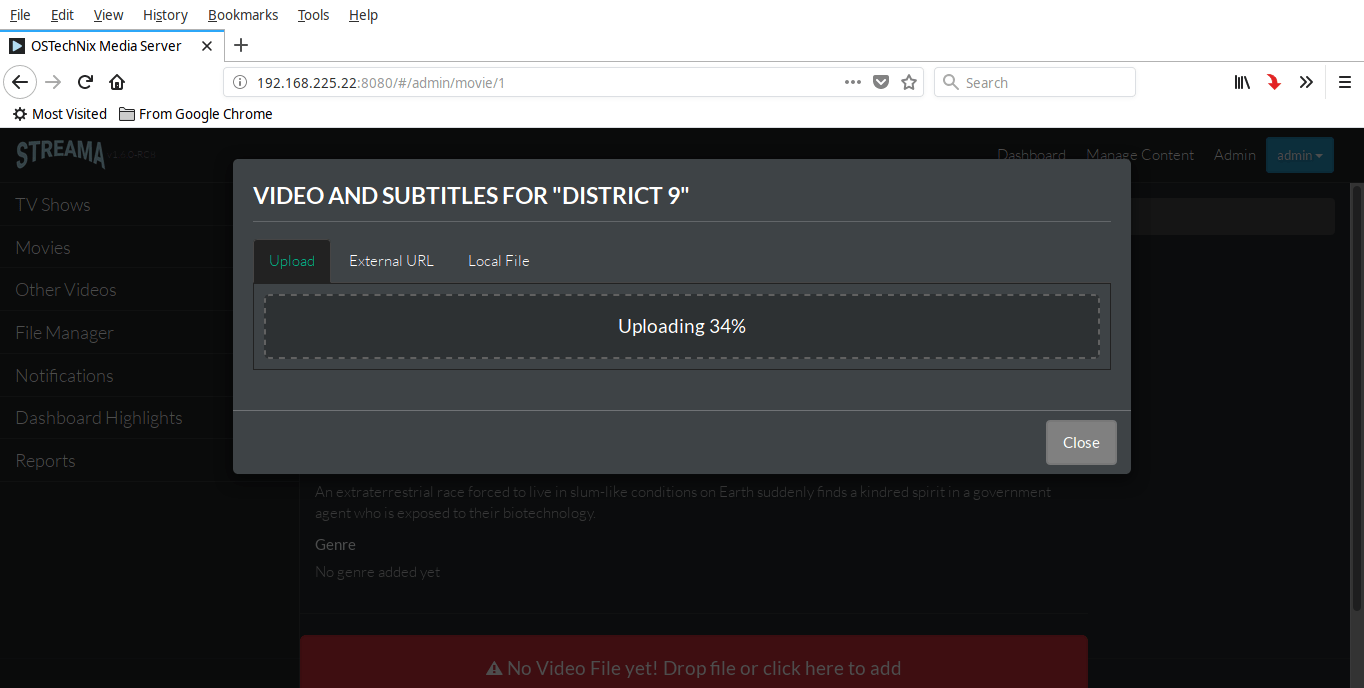
+
+Once the upload is completed, you could see the uploaded movie details. Click on the three horizontal lines next to the movie if you want to edit/modify movie details.
+
+
+
+Similarly, you can create TV shows, videos and audios.
+
+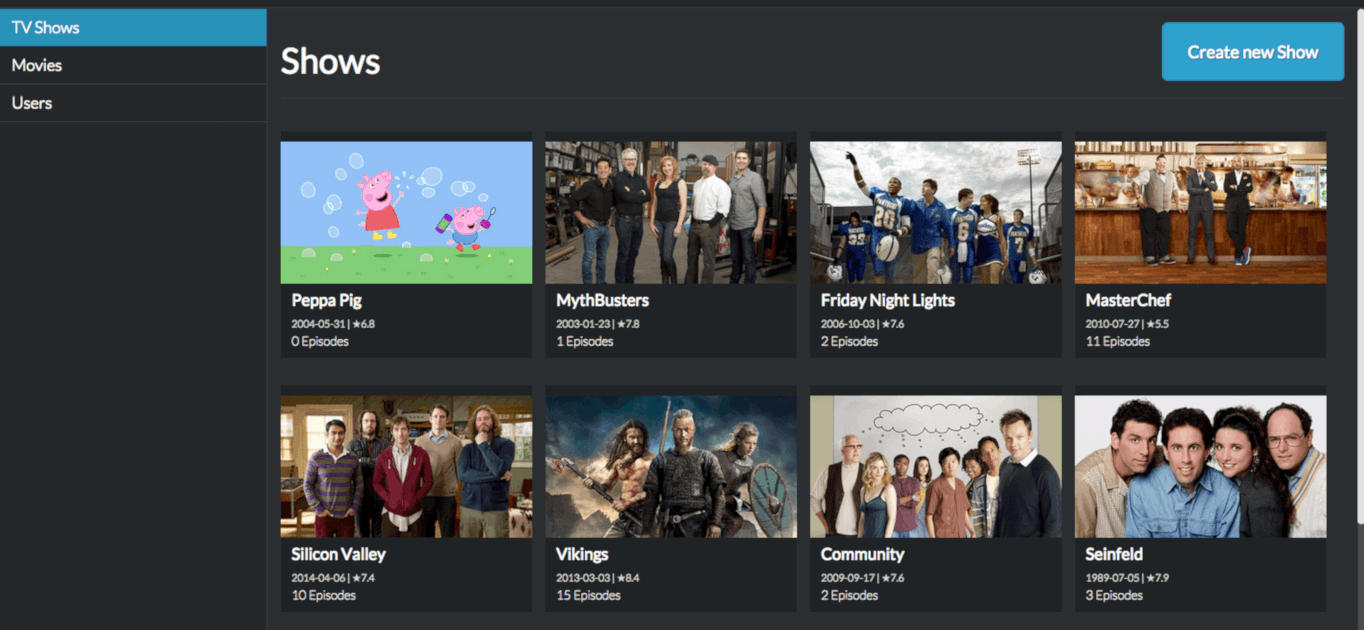
+
+And also the movies/shows are started to appear in the home screen of your dashboard. Simply click on it to play the video and enjoy Netflix experience right from your Linux desktop.
+
+For more details, refer the product’s official website.
+
+And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
+
+Cheers!
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/streama-setup-your-own-streaming-media-server-in-minutes/
+
+作者:[SK][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/sk/
+[1]: https://github.com/streamaserver/streama/releases
diff --git a/sources/tech/20180920 Distributed tracing in a microservices world.md b/sources/tech/20180920 Distributed tracing in a microservices world.md
new file mode 100644
index 0000000000..1b39a5e30a
--- /dev/null
+++ b/sources/tech/20180920 Distributed tracing in a microservices world.md
@@ -0,0 +1,113 @@
+Distributed tracing in a microservices world
+======
+What is distributed tracing and why is it so important in a microservices environment?
+
+
+
+[Microservices][1] have become the default choice for greenfield applications. After all, according to practitioners, microservices provide the type of decoupling required for a full digital transformation, allowing individual teams to innovate at a far greater speed than ever before.
+
+Microservices are nothing more than regular distributed systems, only at a larger scale. Therefore, they exacerbate the well-known problems that any distributed system faces, like lack of visibility into a business transaction across process boundaries.
+
+Given that it's extremely common to have multiple versions of a single service running in production at the same time—be it in a [A/B testing][2] scenario or as part of rolling out a new release following the [Canary release][3] technique—when we account for the fact that we are talking about hundreds of services, it's clear that what we have is chaos. It's almost impossible to map the interdependencies and understand the path of a business transaction across services and their versions.
+
+### Observability
+
+This chaos ends up being a good thing, as long as we can observe what's going on and diagnose the problems that will eventually occur.
+
+A system is said to be observable when we can understand its state based on the [metrics, logs, and traces][4] it emits. Given that we are talking about distributed systems, knowing the state of a single instance of a single service isn't enough; we need to be able to aggregate the metrics for all instances of a given service, perhaps grouped by version. Metrics solutions like [Prometheus][5] are very popular in tackling this aspect of the observability problem. Similarly, we need logs to be stored in a central location, as it's impossible to analyze the logs from the individual instances of each service. [Logstash][6] is usually applied here, in combination with a backing storage like [Elasticsearch][7]. And finally, we need to get end-to-end traces to understand the path a given transaction has taken. This is where distributed tracing solutions come into play.
+
+### Distributed tracing
+
+In monolithic web applications, logging frameworks provide enough capabilities to do a basic root-cause analysis when something fails. A developer just needs to place log statements in the code. Information like "context" (usually "thread") and "timestamp" are automatically added to the log entry, making it easier to understand the execution of a given request and correlate the entries.
+
+```
+Thread-1 2018-09-03T15:52:54+02:00 Request started
+Thread-2 2018-09-03T15:52:55+02:00 Charging credit card x321
+Thread-1 2018-09-03T15:52:55+02:00 Order submitted
+Thread-1 2018-09-03T15:52:56+02:00 Charging credit card x123
+Thread-1 2018-09-03T15:52:57+02:00 Changing order status
+Thread-1 2018-09-03T15:52:58+02:00 Dispatching event to inventory
+Thread-1 2018-09-03T15:52:59+02:00 Request finished
+```
+
+We can safely say that the second log entry above is not related to the other entries, as it's being executed in a different thread.
+
+In microservices architectures, logging alone fails to deliver the complete picture. Is this service the first one in the call chain? And what happened at the inventory service (where we apparently dispatched an event)?
+
+A common strategy to answer this question is creating an identifier at the very first building block of our transaction and propagating this identifier across all the calls, probably by sending it as an HTTP header whenever a remote call is made.
+
+In a central log collector, we could then see entries like the ones below. Note how we could log the correlation ID (the first column in our example), so we know that the second entry is not related to the other entries.
+
+```
+abc123 Order 2018-09-03T15:52:58+02:00 Dispatching event to inventory
+def456 Order 2018-09-03T15:52:58+02:00 Dispatching event to inventory
+abc123 Inventory 2018-09-03T15:52:59+02:00 Received `order-submitted` event
+abc123 Inventory 2018-09-03T15:53:00+02:00 Checking inventory status
+abc123 Inventory 2018-09-03T15:53:01+02:00 Updating inventory
+abc123 Inventory 2018-09-03T15:53:02+02:00 Preparing order manifest
+```
+
+This technique is one of the concepts at the core of any modern distributed tracing solution, but it's not really new; correlating log entries is decades old, probably as old as "distributed systems" itself.
+
+What sets distributed tracing apart from regular logging is that the data structure that holds tracing data is more specialized, so we can also identify causality. Looking at the log entries above, it's hard to tell if the last step was caused by the previous entry, if they were performed concurrently, or if they share the same caller. Having a dedicated data structure also allows distributed tracing to record not only a message in a single point in time but also the start and end time of a given procedure.
+
+![Trace showing spans][9]
+
+Trace showing spans similar to the logs described above
+
+[Click to enlarge][10]
+
+Most of the modern distributed tracing tools are inspired by a 2010 [paper about Dapper][11], the distributed tracing solution used at Google. In that paper, the data structure described above was called a span, and you can see nine of them in the image above. This particular "forest" of spans is called a trace and is equivalent to the correlated log entries we've seen before.
+
+The image above is a screenshot of a trace displayed in [Jaeger][12], an open source distributed tracing solution hosted by the [Cloud Native Computing Foundation (CNCF)][13]. It marks each service with a color to make it easier to see the process boundaries. Timing information can be easily visualized, both by looking at the macro timeline at the top of the screen or at the individual spans, giving a sense of how long each span takes and how impactful it is in this particular execution. It's also easy to observe when processes are asynchronous and therefore may outlive the initial request.
+
+Like with logging, we need to annotate or instrument our code with the data we want to record. Unlike logging, we record spans instead of messages and do some demarcation to know when the span starts and finishes so we can get accurate timing information. As we would probably like to have our business code independent from a specific distributed tracing implementation, we can use an API such as [OpenTracing][14], leaving the decision about the concrete implementation as a packaging or runtime concern. Following is pseudo-Java code showing such demarcation.
+
+```
+try (Scope scope = tracer.buildSpan("submitOrder").startActive(true)) {
+ scope.span().setTag("order-id", "c85b7644b6b5");
+ chargeCreditCard();
+ changeOrderStatus();
+ dispatchEventToInventory();
+}
+```
+
+Given the nature of the distributed tracing concept, it's clear the code executed "between" our business services can also be part of the trace. For instance, we could [turn on][15] the distributed tracing integration for [Istio][16], a service mesh solution that helps in the communication between microservices, and we'll suddenly have a better picture about the network latency and routing decisions made at this layer. Another example is the work done in the OpenTracing community to provide instrumentation for popular stacks, frameworks, and APIs, such as Java's [JAX-RS][17], [Spring Cloud][18], or [JDBC][19]. This enables us to see how our business code interacts with the rest of the middleware, understand where a potential problem might be happening, and identify the best areas to improve. In fact, today's middleware instrumentation is so rich that it's common to get started with distributed tracing by using only the so-called "framework instrumentation," leaving the business code free from any tracing-related code.
+
+While a microservices architecture is almost unavoidable nowadays for established companies to innovate faster and for ambitious startups to achieve web scale, it's easy to feel helpless while conducting a root cause analysis when something eventually fails and the right tools aren't available. The good news is tools like Prometheus, Logstash, OpenTracing, and Jaeger provide the pieces to bring observability to your application.
+
+Juraci Paixão Kröhling will present [What are My Microservices Doing?][20] at [Open Source Summit Europe][21], October 22-24 in Edinburgh, Scotland.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/9/distributed-tracing-microservices-world
+
+作者:[Juraci Paixão Kröhling][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/jpkroehling
+[1]: https://en.wikipedia.org/wiki/Microservices
+[2]: https://en.wikipedia.org/wiki/A/B_testing
+[3]: https://martinfowler.com/bliki/CanaryRelease.html
+[4]: https://blog.twitter.com/engineering/en_us/a/2016/observability-at-twitter-technical-overview-part-i.html
+[5]: https://prometheus.io/
+[6]: https://github.com/elastic/logstash
+[7]: https://github.com/elastic/elasticsearch
+[8]: /file/409621
+[9]: https://opensource.com/sites/default/files/uploads/distributed-trace.png (Trace showing spans)
+[10]: /sites/default/files/uploads/trace.png
+[11]: https://ai.google/research/pubs/pub36356
+[12]: https://www.jaegertracing.io/
+[13]: https://www.cncf.io/
+[14]: http://opentracing.io/
+[15]: https://istio.io/docs/tasks/telemetry/distributed-tracing/
+[16]: https://istio.io/
+[17]: https://github.com/opentracing-contrib/java-jaxrs
+[18]: https://github.com/opentracing-contrib/java-spring-cloud
+[19]: https://github.com/opentracing-contrib/java-jdbc
+[20]: https://osseu18.sched.com/event/FxW3/what-are-my-microservices-doing-juraci-paixao-krohling-red-hat#
+[21]: https://osseu18.sched.com/
diff --git a/sources/tech/20180920 Record Screen in Ubuntu Linux With Kazam -Beginner-s Guide.md b/sources/tech/20180920 Record Screen in Ubuntu Linux With Kazam -Beginner-s Guide.md
new file mode 100644
index 0000000000..a2f57f592a
--- /dev/null
+++ b/sources/tech/20180920 Record Screen in Ubuntu Linux With Kazam -Beginner-s Guide.md
@@ -0,0 +1,185 @@
+Record Screen in Ubuntu Linux With Kazam [Beginner’s Guide]
+======
+**This tutorial shows you how to install Kazam screen recorder and explains how to record screen in Ubuntu. The guide also lists useful shortcuts and handy tips for using Kazam.**
+
+![How to record your screen in Ubuntu Linux with Kazam][1]
+
+[Kazam][2] is one of the [best screen recorders for Linux][3]. To me, it’s the best screen recording tool. I have been using it for years. All the video tutorials on YouTube have been recorded with Kazam.
+
+Some of the main features of Kazam are:
+
+ * Record entire screen, part of screen, application window or all screens (for multi-monitor setup)
+ * Take screenshots
+ * Keyboard shortcut support for easily pausing and resuming while recording screen
+ * Record in various file formats such as MP4, AVI and more.
+ * Capture audio from speaker or microphone while recording the screen
+ * Capture mouse clicks and key presses
+ * Capture video from webcam
+ * Insert a webcam window on the side
+ * Broadcast to YouTube live video
+
+
+
+Like the screenshot tool [Shutter][4], Kazam is also not being actively developed for the last couple of years. And like Shutter, the present Kazam release works just fine.
+
+I am using Ubuntu in the tutorial. The installation instructions should work for other Ubuntu-based distributions such as Linux Mint, elementary OS etc. For all the other distributions, you can still read about using Kazam and its features.
+
+### Install Kazam in Ubuntu
+
+Kazam is available in the official repository in Ubuntu. However, the official repository consists Kazam version 1.4.5, the last stable version of Kazam.
+
+![Kazam Version 1.4.5][5]
+Kazam Version 1.4.5
+
+Kazam developer(s) also worked on a newer release, Kazam 1.5.3. The version was almost sable and ready to release, but for unknown reasons, the development stopped after this. There have been [no updates][6] since then.
+
+You can use either of Kazam 1.4.5 and 1.5.3 without hesitating. Kazam 1.5 provides additional features like recording mouse clicks and key presses, webcam support, live broadcast support, and a refreshed countdown timer.
+
+![Kazam Version 1.5.3][7]
+Kazam Version 1.5.3
+
+It’s up to you to decide which version you want to use. I would suggest go for version 1.5.3 because it has more features.
+
+You can install the older Kazam 1.4.5 from the Software Center. You can also use the command below:
+
+```
+sudo apt install kazam
+```
+
+If you want to install the newer Kazam 1.5.3, you can use this [unofficial PPA][8] that is available for Ubuntu 18.04 and 16.04:
+
+```
+sudo add-apt-repository ppa:sylvain-pineau/kazam
+sudo apt-get update
+sudo apt install kazam
+```
+
+You also need to install a few libraries in order to record the mouse clicks and keyboard presses.
+
+```
+sudo apt install python3-cairo python3-xlib
+```
+
+### Recording your screen with Kazam
+
+Once you have installed Kazam, search for it in the application menu and start it. You should see a screen like this with some options on it. You can check the options as per your need and click on capture to start recording screen with Kazam.
+
+![Screen recording with Kazam][9]
+Screen recording with Kazam
+
+It will show you a countdown before recording the screen. The default wait time is 5 seconds and you can change it from Kazam interface (see the previous image). It gives you a breathing time so that you can prepare for your recording.
+
+![Countdown before screen recording][10]
+Countdown before screen recording
+
+Once the recording starts,the main Kazam interface disappears and an indicator appears in the panel. If you want to pause the recording or finish the recording, you can do it from this indicator.
+
+![Pause or finish screen recording][11]
+Pause or finish screen recording
+
+If you choose to finish the recording, it will give you the option to “Save for later”. If you have a [video editor installed in Linux][12], you can also start editing the recording from this point.
+
+![Save screen recording in Kazam][13]
+Save recording
+
+By default it prompts you to install the recording in Videos folder but you can change the location and save it elsewhere as well.
+
+That’s the basic you need to know about screen recording in Linux with Kazam.
+
+Now let me give you a few tips on how to utilize more features in Kazam.
+
+### Getting more out of Kazam screen recorder
+
+Kazam is a featureful screen recorder for Linux. You can access its advanced or additional features from the preferences.
+
+![Accessing Kazam preferences][14]
+Accessing Kazam preferences
+
+#### Autosave screen recording in a specified location
+
+You can choose to automatically save the screen recordings in Kazam. The default location is Videos but you can change it to any other location.
+
+![Autosave screen recordings in a chosen location][15]
+Autosave in a chosen location
+
+#### Avoid screen recording in RAW mode
+
+You can save your screen recordings in file formats like WEBM, MP4, AVI etc. You are free to choose what you want. However, I would advise avoiding RAW (AVI) file format. If you use RAW file format, the recorded files will be in GBs even for a few minutes of recordings.
+
+It’s wise to verify that Kazam is not using the RAW file format for recording. If you ask my suggestion, prefer H264 with MP4 file format.
+
+![file format in Kazam][16]
+Don’t use RAW files
+
+#### Capture mouse clicks and key presses while screen recording
+
+If you want to highlight when a mouse was clicked, you can easily do that in the newer version of Kazam.
+
+![Record mouse clicks while screen recording with Kazam][17]
+Record mouse clicks
+
+All you have to do is to check the “Key presses and mouse clicks” option on the Kazam interface (the same screen where you press Capture).
+
+#### Use keyboard shortcuts for more efficient screen recordings
+
+Imagine you are recording screen in Linux and suddenly you realized that you have to pause the recording for some reasons. Now, you can pause the recording by going to the Kazam indicator and selecting the pause option. But this activity of selecting the pause option will also be recorded.
+
+You can edit out this part later but it unnecessarily adds to the already cumbersome editing task.
+
+A better option will be to use the [keyboard shortcuts in Ubuntu][18]. Screen recording becomes a lot better if you use the shortcuts.
+
+While Kazam is running, you can use the following hotkeys:
+
+ * Super+Ctrl+R: Start recording
+ * Super+Ctrl+P: Pause recording, press again for resuming the recording
+ * Super+Ctrl+F: Finish recording
+ * Super+Ctrl+Q: Quit recording
+
+
+
+Super key is the Windows key on your keyboard.
+
+The most important is Super+Ctrl+P for pausing and resuming the recording.
+
+You can further explore the Kazam preferences for webcam recording and YouTube live broadcasting options.
+
+### Do you like Kazam?
+
+I am repeating myself here. I love Kazam. I have used other screen recorders like [SimpleScreenRecorder][19] or [Green Recorder][20] but I feel a lot more comfortable with Kazam.
+
+I hope you like Kazam for screen recording in Ubuntu or any other Linux distribution. I have tried highlighting some of the additional features here to help you with a better screen recording.
+
+What features do you like about Kazam? Do you use some other screen recorder? Do they work better than Kazam? Please share your views in the comments section below.
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/kazam-screen-recorder/
+
+作者:[Abhishek Prakash][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/abhishek/
+[1]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/screen-recording-kazam-ubuntu-linux.png
+[2]: https://launchpad.net/kazam
+[3]: https://itsfoss.com/best-linux-screen-recorders/
+[4]: http://shutter-project.org/
+[5]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/kazam-1-4-5.png
+[6]: https://launchpad.net/~kazam-team/+archive/ubuntu/unstable-series
+[7]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/kazam-1-5-3.png
+[8]: https://launchpad.net/~sylvain-pineau/+archive/ubuntu/kazam
+[9]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/kazam-start-recording.png
+[10]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/kazam-countdown.jpg
+[11]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/kazam-finish-recording.png
+[12]: https://itsfoss.com/best-video-editing-software-linux/
+[13]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/kazam-save-recording.jpg
+[14]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/kazam-preferences.png
+[15]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/kazam-auto-save.jpg
+[16]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/select-file-type-kazam.jpg
+[17]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/record-mouse-clicks-kazam.jpeg
+[18]: https://itsfoss.com/ubuntu-shortcuts/
+[19]: https://itsfoss.com/record-screen-ubuntu-simplescreenrecorder/
+[20]: https://itsfoss.com/green-recorder-3/
diff --git a/sources/tech/20180921 Clinews - Read News And Latest Headlines From Commandline.md b/sources/tech/20180921 Clinews - Read News And Latest Headlines From Commandline.md
new file mode 100644
index 0000000000..24ae89f461
--- /dev/null
+++ b/sources/tech/20180921 Clinews - Read News And Latest Headlines From Commandline.md
@@ -0,0 +1,136 @@
+Clinews – Read News And Latest Headlines From Commandline
+======
+
+
+
+A while ago, we have written about a CLI news client named [**InstantNews**][1] that helps you to read news and latest headlines from commandline instantly. Today, I stumbled upon a similar utility named **Clinews** which serves the same purpose – reading news and latest headlines from popular websites, blogs from Terminal. You don’t need to install GUI applications or mobile apps. You can read what’s happening in the world right from your Terminal. It is free, open source utility written using **NodeJS**.
+
+### Installing Clinews
+
+Since Clinews is written using NodeJS, you can install it using NPM package manager. If you haven’t install NodeJS, install it as described in the following link.
+
+Once node installed, run the following command to install Clinews:
+
+```
+$ npm i -g clinews
+```
+
+You can also install Clinews using **Yarn** :
+
+```
+$ yarn global add clinews
+```
+
+Yarn itself can installed using npm
+
+```
+$ npm -i yarn
+```
+
+### Configure News API
+
+Clinews retrieves all news headlines from [**News API**][2]. News API is a simple and easy-to-use API that returns JSON metadata for the headlines currently published on a range of news sources and blogs. It currently provides live headlines from 70 popular sources, including Ars Technica, BBC, Blooberg, CNN, Daily Mail, Engadget, ESPN, Financial Times, Google News, hacker News, IGN, Mashable, National Geographic, Reddit r/all, Reuters, Speigel Online, Techcrunch, The Guardian, The Hindu, The Huffington Post, The Newyork Times, The Next Web, The Wall street Journal, USA today and [**more**][3].
+
+First, you need an API key from News API. Go to [**https://newsapi.org/register**][4] URL and register a free account to get the API key.
+
+Once you got the API key from News API site, edit your **.bashrc** file:
+
+```
+$ vi ~/.bashrc
+
+```
+
+Add newsapi API key at the end like below:
+
+```
+export IN_API_KEY="Paste-API-key-here"
+
+```
+
+Please note that you need to paste the key inside the double quotes. Save and close the file.
+
+Run the following command to update the changes.
+
+```
+$ source ~/.bashrc
+
+```
+
+Done. Now let us go ahead and fetch the latest headlines from new sources.
+
+### Read News And Latest Headlines From Commandline
+
+To read news and latest headlines from specific new source, for example **The Hindu** , run:
+
+```
+$ news fetch the-hindu
+
+```
+
+Here, **“the-hindu”** is the new source id (fetch id).
+
+The above command will fetch latest 10 headlines from The Hindu news portel and display them in the Terminal. Also, it displays a brief description of the news, the published date and time, and the actual link to the source.
+
+**Sample output:**
+
+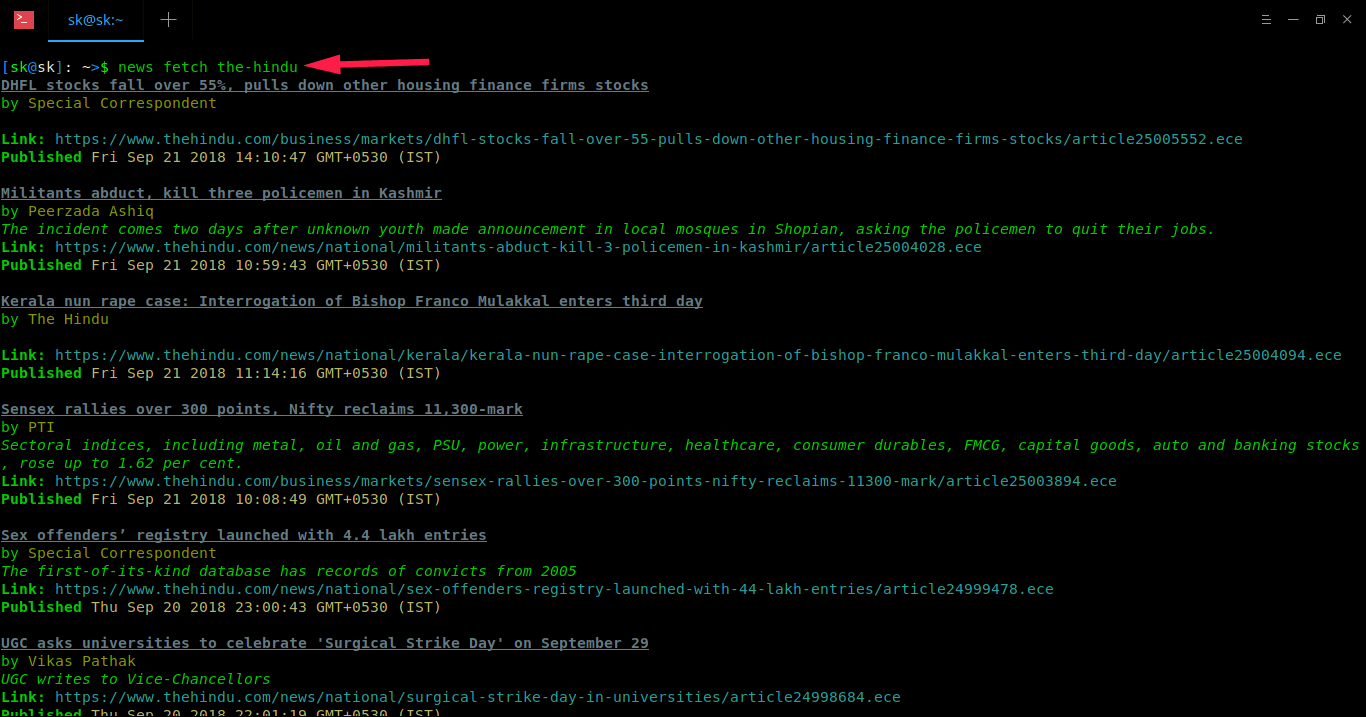
+
+To read a news in your browser, hold Ctrl key and click on the URL. It will open in your default web browser.
+
+To view all the sources you can get news from, run:
+
+```
+$ news sources
+
+```
+
+**Sample output:**
+
+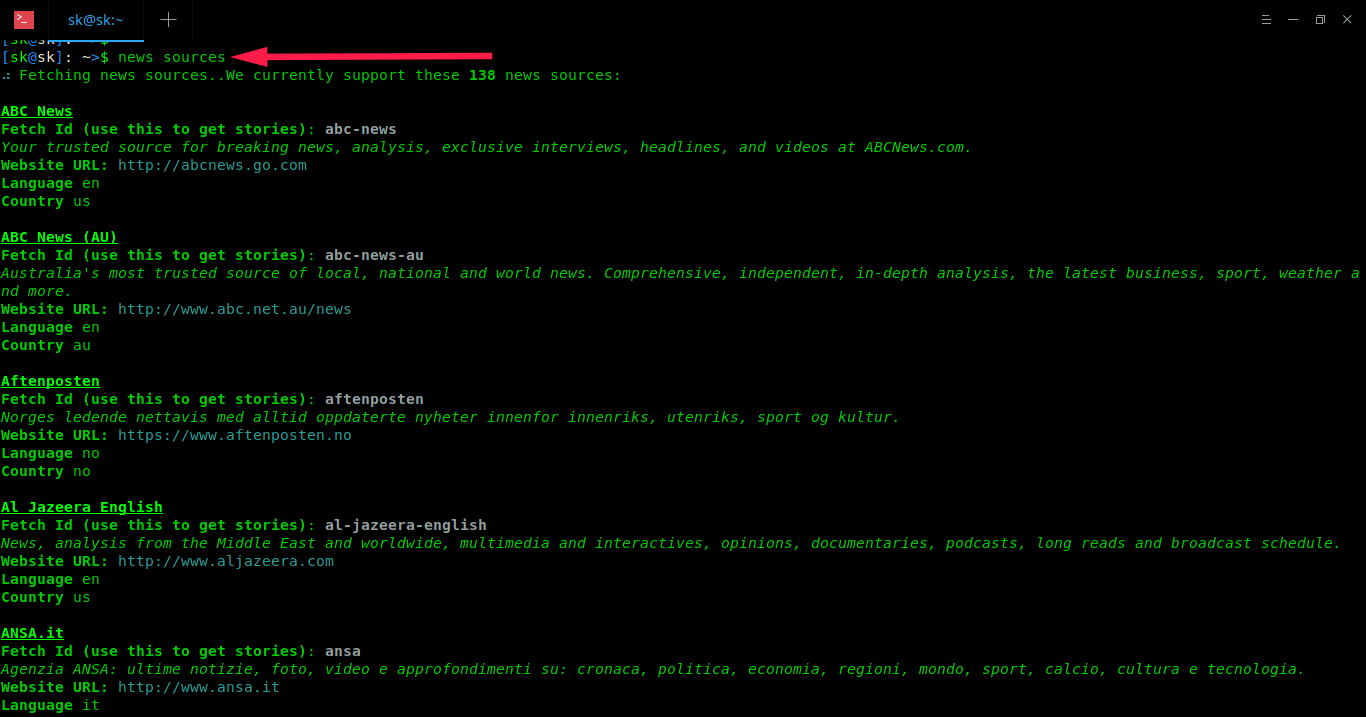
+
+As you see in the above screenshot, Clinews lists all news sources including the name of the news source, fetch id, description of the site, website URL and the country where it is located. As of writing this guide, Clinews currently supports 70+ news sources.
+
+Clinews can also able to search for news stories across all sources matching search criteria/term. Say for example, to list all news stories with titles containing the words **“Tamilnadu”** , use the following command:
+
+```
+$ news search "Tamilnadu"
+```
+
+This command will scrap all news sources for stories that match term **Tamilnadu**.
+
+Clinews has some extra flags that helps you to
+
+ * limit the amount of news stories you want to see,
+ * sort news stories (top, latest, popular),
+ * display news stories category wise (E.g. business, entertainment, gaming, general, music, politics, science-and-nature, sport, technology)
+
+
+
+For more details, see the help section:
+
+```
+$ clinews -h
+```
+
+And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
+
+Cheers!
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/clinews-read-news-and-latest-headlines-from-commandline/
+
+作者:[SK][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/sk/
+[1]: https://www.ostechnix.com/get-news-instantly-commandline-linux/
+[2]: https://newsapi.org/
+[3]: https://newsapi.org/sources
+[4]: https://newsapi.org/register
diff --git a/sources/tech/20180921 Control your data with Syncthing- An open source synchronization tool.md b/sources/tech/20180921 Control your data with Syncthing- An open source synchronization tool.md
new file mode 100644
index 0000000000..32be152b4c
--- /dev/null
+++ b/sources/tech/20180921 Control your data with Syncthing- An open source synchronization tool.md
@@ -0,0 +1,108 @@
+Control your data with Syncthing: An open source synchronization tool
+======
+Decide how to store and share your personal information.
+
+
+
+These days, some of our most important possessions—from pictures and videos of family and friends to financial and medical documents—are data. And even as cloud storage services are booming, so there are concerns about privacy and lack of control over our personal data. From the PRISM surveillance program to Google [letting app developers scan your personal emails][1], the news is full of reports that should give us all pause regarding the security of our personal information.
+
+[Syncthing][2] can help put your mind at ease. An open source peer-to-peer file synchronization tool that runs on Linux, Windows, Mac, Android, and others (sorry, no iOS), Syncthing uses its own protocol, called [Block Exchange Protocol][3]. In brief, Syncthing lets you synchronize your data across many devices without owning a server.
+
+### Linux
+
+In this post, I will explain how to install and synchronize files between a Linux computer and an Android phone.
+
+Syncthing is readily available for most popular distributions. Fedora 28 includes the latest version.
+
+To install Syncthing in Fedora, you can either search for it in Software Center or execute the following command:
+
+```
+sudo dnf install syncthing syncthing-gtk
+
+```
+
+Once it’s installed, open it. You’ll be welcomed by an assistant to help configure Syncthing. Click **Next** until it asks to configure the WebUI. The safest option is to keep the option **Listen on localhost**. That will disable the web interface and keep unauthorized users away.
+
+![Syncthing in Setup WebUI dialog box][5]
+
+Syncthing in Setup WebUI dialog box
+
+Close the dialog. Now that Syncthing is installed, it’s time to share a folder, connect a device, and start syncing. But first, let’s continue with your other client.
+
+### Android
+
+Syncthing is available in Google Play and in F-Droid app stores.
+
+
+
+Once the application is installed, you’ll be welcomed by a wizard. Grant Syncthing permissions to your storage. You might be asked to disable battery optimization for this application. It is safe to do so as we will optimize the app to synchronize only when plugged in and connected to a wireless network.
+
+Click on the main menu icon and go to **Settings** , then **Run Conditions**. Tick **Always run in** **the background** , **Run only when charging** , and **Run only on wifi**. Now your Android client is ready to exchange files with your devices.
+
+There are two important concepts to remember in Syncthing: folders and devices. Folders are what you want to share, but you must have a device to share with. Syncthing allows you to share individual folders with different devices. Devices are added by exchanging device IDs. A device ID is a unique, cryptographically secure identifier that is created when Syncthing starts for the first time.
+
+### Connecting devices
+
+Now let’s connect your Linux machine and your Android client.
+
+In your Linux computer, open Syncthing, click on the **Settings** icon and click **Show ID**. A QR code will show up.
+
+In your Android mobile, open Syncthing. In the main screen, click the **Devices** tab and press the **+** symbol. In the first field, press the QR code symbol to open the QR scanner.
+
+Point your mobile camera to the computer QR code. The Device ID** **field will be populated with your desktop client Device ID. Give it a friendly name and save. Because adding a device goes two ways, you now need to confirm on the computer client that you want to add the Android mobile. It might take a couple of minutes for your computer client to ask for confirmation. When it does, click **Add**.
+
+
+
+In the **New Device** window, you can verify and configure some options about your new device, like the **Device Name** and **Addresses**. If you keep dynamic, it will try to auto-discover the device IP, but if you want to force one, you can add it in this field. If you already created a folder (more on this later), you can also share it with this new device.
+
+
+
+Your computer and Android are now paired and ready to exchange files. (If you have more than one computer or mobile phone, simply repeat these steps.)
+
+### Sharing folders
+
+Now that the devices you want to sync are already connected, it’s time to share a folder. You can share folders on your computer and the devices you add to that folder will get a copy.
+
+To share a folder, go to **Settings** and click **Add Shared Folder** :
+
+
+
+In the next window, enter the information of the folder you want to share:
+
+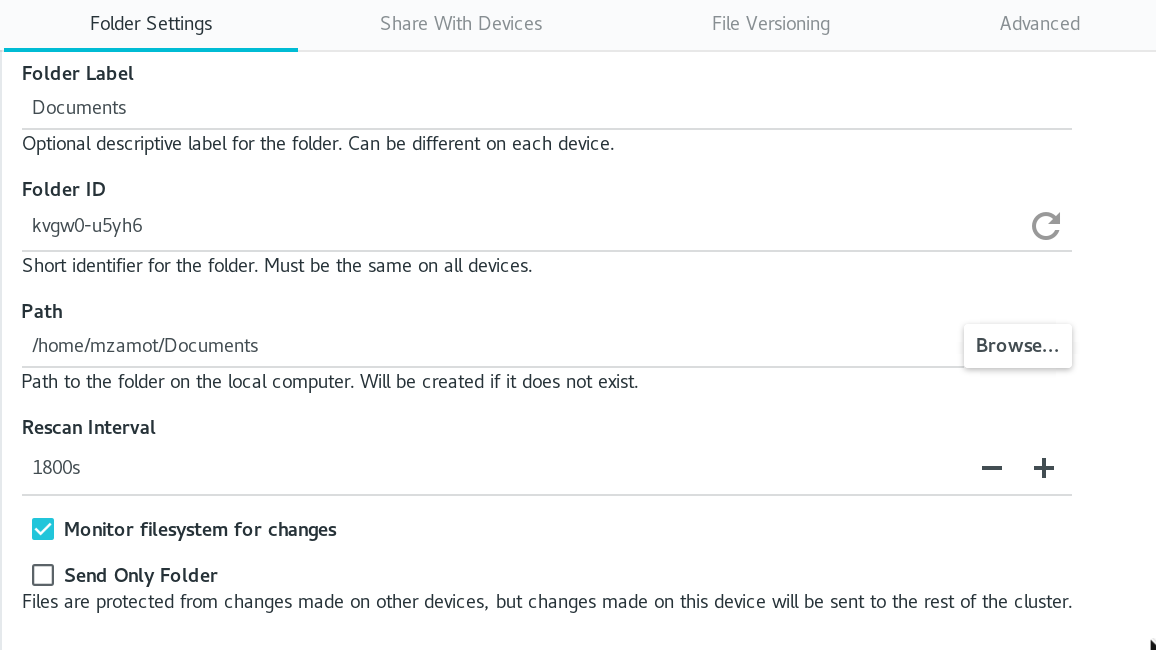
+
+You can use any label you want. **Folder ID** will be generated randomly and will be used to identify the folder between the clients. In **Path** , click **Browse** and locate the folder you want to share. If you want Syncthing to monitor the folder for changes (such as deletes, new files, etc.), click **Monitor filesystem for changes**.
+
+Remember, when you share a folder, any change that happens on the other clients will be reflected on every single device. That means that if you share a folder containing pictures with other computers or mobile devices, changes in these other clients will be reflected everywhere. If this is not what you want, you can make your folder “Send Only” so it will send files to the clients, but the other clients’ changes won’t be synced.
+
+When this is done, go to **Share with Devices** and select the hosts you want to sync with your folder:
+
+All the devices you select will need to accept the share request; you will get a notification from the devices:
+
+Just as when you shared the folder, you must configure the new shared folder:
+
+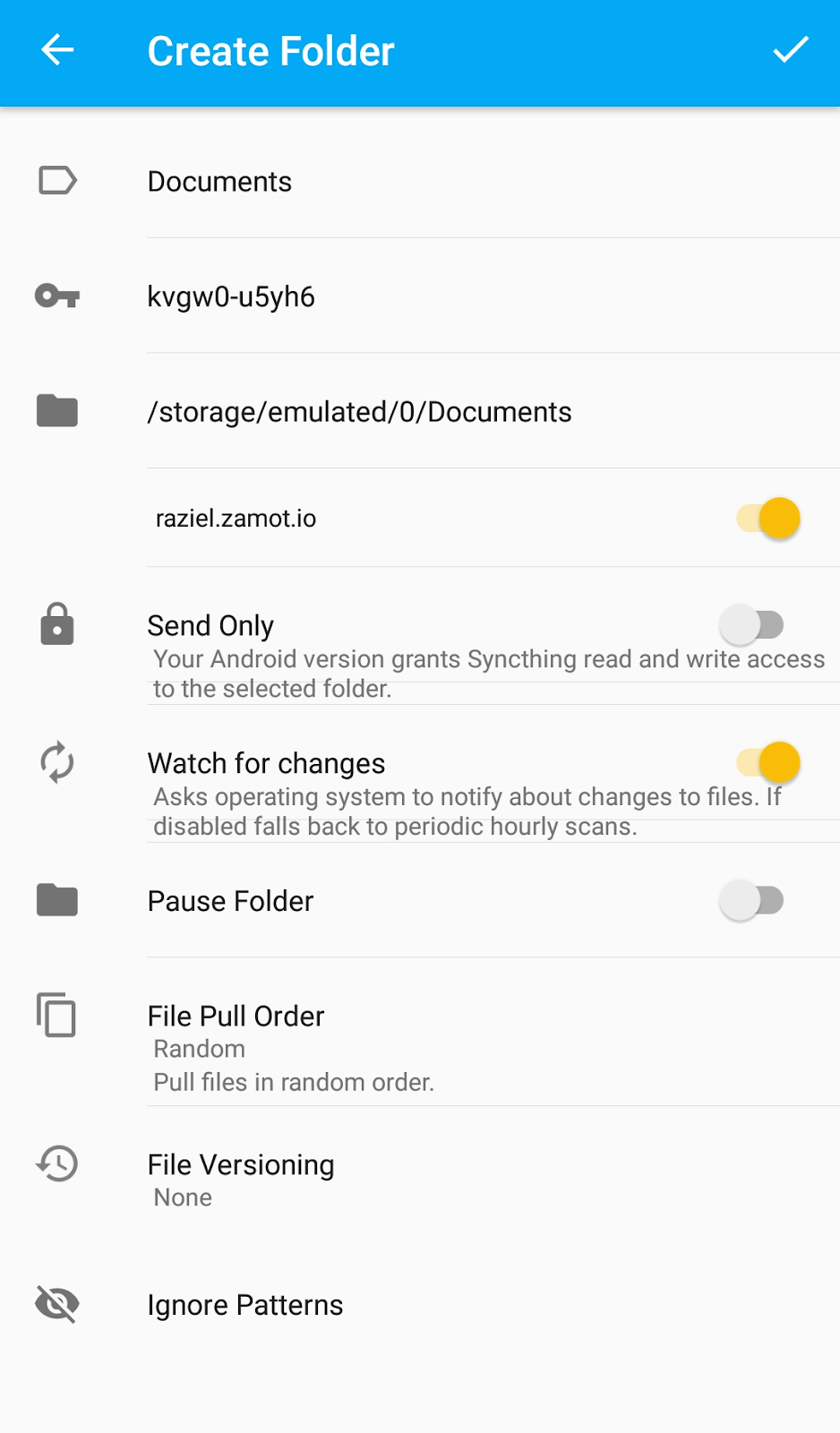
+
+Again, here you can define any label, but the ID must match each client. In the folder option, select the destination for the folder and its files. Remember that any change done in this folder will be reflected with every device allowed in the folder.
+
+These are the steps to connect devices and share folders with Syncthing. It might take a few minutes to start copying, depending on your network settings or if you are not on the same network.
+
+Syncthing offers many more great features and options. Try it—and take control of your data.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/9/take-control-your-data-syncthing
+
+作者:[Michael Zamot][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/mzamot
+[1]: https://gizmodo.com/google-says-it-doesnt-go-through-your-inbox-anymore-bu-1827299695
+[2]: https://syncthing.net/
+[3]: https://docs.syncthing.net/specs/bep-v1.html
+[4]: /file/410191
+[5]: https://opensource.com/sites/default/files/uploads/syncthing1.png (Syncthing in Setup WebUI dialog box)
diff --git a/sources/tech/20180923 Gunpoint is a Delight for Stealth Game Fans.md b/sources/tech/20180923 Gunpoint is a Delight for Stealth Game Fans.md
new file mode 100644
index 0000000000..3ff6857f78
--- /dev/null
+++ b/sources/tech/20180923 Gunpoint is a Delight for Stealth Game Fans.md
@@ -0,0 +1,104 @@
+Gunpoint is a Delight for Stealth Game Fans
+======
+Gunpoint is a 2D stealth game in which you play as a spy stealing secrets and hacking networks like Ethan Hunt of Mission Impossible movie series.
+
+
+
+Hi, Fellow Linux gamers. Let’s take a look at a fun stealth game. Let’s take a look at [Gunpoint][1].
+
+Gunpoint is neither free nor open source. It is an independent game you can purchase directly from the creator or from Steam.
+
+![][2]
+
+### The Interesting History of Gunpoint
+
+> The instant success of Gunpoint enabled its creator to become a full time game developer.
+
+Gunpoint is a stealth game created by [Tom Francis][3]. Francis was inspired to create the game after he heard about Spelunky, which was created by one person. Francis played games as part of his day job, as an editor for PC Gamer UK magazine. He had no previous programming experience but used the easy-to-use Game Maker. He planned to create a demo with the hopes of getting a job as a developer.
+
+He released his first prototype in May 2010 under the name Private Dick. Based on the response, Francis continued to work on the game. The final version was released in June of 2013 to high praise.
+
+In a [blog post][4] weeks after Gunpoint’s launch, Francis revealed that he made back all the money he spent on development ($30 for Game Maker 8) in 64 seconds. Francis didn’t reveal Gunpoint’s sales figures, but he did quit his job and today creates [games][5] full time.
+
+### Experiencing the Gunpoint Gameplay
+
+![Gunpoint Gameplay][6]
+
+Like I said earlier, Gunpoint is a stealth game. You play a freelance spy named Richard Conway. As Conway, you will use a pair of Bullfrog hypertrousers to infiltrate buildings for clients. The hypertrousers allow you to jump very high, even through windows. You can also cling to walls or ceilings like a ninja.
+
+Another tool you have is the Crosslink, which allows you to rewire circuits. Often you will need to use the Crosslink to reroute motion detections to unlock doors instead of setting off an alarm or rewire a light switch to turn off the light on another floor to distract a guard.
+
+When you sneak into a building, your biggest concern is the on-site security guards. If they see Conway, they will shoot and in this game, it’s one shot one kill. You can jump off a three-story building no problem, but bullets will take you down. Thankfully, if Conway is killed you can just jump back a few seconds and try again.
+
+Along the way, you will earn money to upgrade your tools and unlock new features. For example, I just unlocked the ability to rewire a guard’s gun. Don’t ask me how that works.
+
+### Minimum System Requirements
+
+Here are the minimum system requirements for Gunpoint:
+
+##### Linux
+
+ * Processor: 2GHz
+ * Memory: 1GB RAM
+ * Video card: 512MB
+ * Hard Drive: 700MB HD space
+
+
+
+##### Windows
+
+ * OS: Windows XP, Visa, 7 or 8
+ * Processor: 2GHz
+ * Memory: 1GB RAM
+ * Video card: 512MB
+ * DirectX®: 9.0
+ * Hard Drive: 700MB HD space
+
+
+
+##### macOS
+
+ * OS: OS X 10.7 or later
+ * Processor: 2GHz
+ * Memory: 1GB RAM
+ * Video card: 512MB
+ * Hard Drive: 700MB HD space
+
+
+
+### Thoughts on Gunpoint
+
+![Gunpoint game on Linux][7]
+Image Courtesy: Steam Community
+
+Gunpoint is a very fun game. The early levels are easy to get through, but the later levels make you put your thinking cap on. The hypertrousers and Crosslink are fun to play with. There is nothing like turning the lights off on a guard and bouncing over his head to hack a terminal.
+
+Besides the fun mechanics, it also has an interesting [noir][8] murder mystery story. Several different (and conflicting) clients hire you to look into different aspects of the case. Some of them seem to have ulterior motives that are not in your best interest.
+
+I always enjoy good mysteries and this one is no different. If you like noir or platforming games, be sure to check out [Gunpoint][1].
+
+Have you every played Gunpoint? What other games should we review for your entertainment? Let us know in the comments below.
+
+If you found this article interesting, please take a minute to share it on social media, Hacker News or [Reddit][9].
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/gunpoint-game-review/
+
+作者:[John Paul][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/john/
+[1]: http://www.gunpointgame.com/
+[2]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/gunpoint.jpg
+[3]: https://www.pentadact.com/
+[4]: https://www.pentadact.com/2013-06-18-gunpoint-recoups-development-costs-in-64-seconds/
+[5]: https://www.pentadact.com/2014-08-09-what-im-working-on-and-what-ive-done/
+[6]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/gunpoint-gameplay-1.jpeg
+[7]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/gunpoint-game-1.jpeg
+[8]: https://en.wikipedia.org/wiki/Noir_fiction
+[9]: http://reddit.com/r/linuxusersgroup
diff --git a/sources/tech/20180924 5 ways to play old-school games on a Raspberry Pi.md b/sources/tech/20180924 5 ways to play old-school games on a Raspberry Pi.md
new file mode 100644
index 0000000000..539ac42082
--- /dev/null
+++ b/sources/tech/20180924 5 ways to play old-school games on a Raspberry Pi.md
@@ -0,0 +1,169 @@
+5 ways to play old-school games on a Raspberry Pi
+======
+
+Relive the golden age of gaming with these open source platforms for Raspberry Pi.
+
+
+
+They don't make 'em like they used to, do they? Video games, I mean.
+
+Sure, there's a bit more grunt in the gear now. Princess Zelda used to be 16 pixels in each direction; there's now enough graphics power for every hair on her head. Today's processors could beat up 1988's processors in a cage-fight deathmatch without breaking a sweat.
+
+But you know what's missing? The fun.
+
+You've got a squillion and one buttons to learn just to get past the tutorial mission. There's probably a storyline, too. You shouldn't need a backstory to kill bad guys. All you need is jump and shoot. So, it's little wonder that one of the most enduring popular uses for a Raspberry Pi is to relive the 8- and 16-bit golden age of gaming in the '80s and early '90s. But where to start?
+
+There are a few ways to play old-school games on the Pi. Each has its strengths and weaknesses, which I'll discuss here.
+
+### Retropie
+
+[Retropie][1] is probably the most popular retro-gaming platform for the Raspberry Pi. It's a solid all-rounder and a great default option for emulating classic desktop and console gaming systems.
+
+#### What is it?
+
+Retropie is built to run on [Raspbian][2]. It can also be installed over an existing Raspbian image if you'd prefer. It uses [EmulationStation][3] as a graphical front-end for a library of open source emulators, including the [Libretro][4] emulators.
+
+You don't need to understand a word of that to play your games, though.
+
+#### What's great about it
+
+It's very easy to get started. All you need to do is burn the image to an SD card, configure your controllers, copy your games over, and start killing bad guys.
+
+The huge user base means that there is a wealth of support and information out there, and active online communities to turn to for questions.
+
+In addition to the emulators that come installed with the Retropie image, there's a huge library of emulators you can install from the package manager, and it's growing all the time. Retropie also offers a user-friendly menu system to manage this, saving you time.
+
+From the Retropie menu, it's easy to add Kodi and the Raspbian desktop, which comes with the Chromium web browser. This means your retro-gaming rig is also good for home theatre, [YouTube][5], [SoundCloud][6], and all those other “lounge room computer” goodies.
+
+Retropie also has a number of other customization options: You can change the graphics in the menus, set up different control pad configurations for different emulators, make your Raspberry Pi file system visible to your local Windows network—all sorts of stuff.
+
+Retropie is built on Raspbian, which means you have the Raspberry Pi's most popular operating system to explore. Most Raspberry Pi projects and tutorials you find floating around are written for Raspbian, making it easy to customize and install new things on it. I've used my Retropie rig as a wireless bridge, installed MIDI synthesizers on it, taught myself a bit of Python, and more—all without compromising its use as a gaming machine.
+
+#### What's not so great about it
+
+Retropie's simple installation and ease of use is, in a way, a double-edged sword. You can go for a long time with Retropie without ever learning simple stuff like `sudo apt-get`, which means you're missing out on a lot of the Raspberry Pi experience.
+
+It doesn't have to be this way; the command line is still there under the hood when you want it, but perhaps users are a bit too insulated from a Bash shell that's ultimately a lot less scary than it looks. Retropie's main menu is operable only with a control pad, which can be annoying when you don't have one plugged in because you've been using the system for things other than gaming.
+
+#### Who's it for?
+
+Anyone who wants to get straight into some gaming, anyone who wants the biggest and best library of emulators, and anyone who wants a great way to start exploring Linux when they're not playing games.
+
+### Recalbox
+
+[Recalbox][7] is a newer open source suite of emulators for the Raspberry Pi. It also supports other ARM-based small-board computers.
+
+#### What is it?
+
+Like Retropie, Recalbox is built on EmulationStation and Libretro. Where it differs is that it's not built on Raspbian, but on its own flavor of Linux: RecalboxOS.
+
+#### What's great about it
+
+The setup for Recalbox is even easier than for Retropie. You don't even need to image an SD card; simply copy some files over and go. It also has out-of-the-box support for some game controllers, getting you to Level 1 that little bit faster. Kodi comes preinstalled. This is a ready-to-go gaming and media rig.
+
+#### What's not so great about it
+
+Recalbox has fewer emulators than Retropie, fewer customization options, and a smaller user community.
+
+Your Recalbox rig is probably always just going to be for emulators and Kodi, the same as when you installed it. If you feel like getting deeper into Linux, you'll probably want a new SD card for Raspbian.
+
+#### Who's it for?
+
+Recalbox is great if you want the absolute easiest retro gaming experience and can happily go without some of the more obscure gaming platforms, or if you are intimidated by the idea of doing anything a bit technical (and have no interest in growing out of that).
+
+For most opensource.com readers, Recalbox will probably come in most handy to recommend to your not-so-technical friend or relative. Its super-simple setup and overall lack of options might even help you avoid having to help them with it.
+
+### Roll your own
+
+Ok, if you've been paying attention, you might have noticed that both Retropie and Recalbox are built from many of the same open source components. So what's to stop you from putting them together yourself?
+
+#### What is it?
+
+Whatever you want it to be, baby. The nature of open source software means you could use an existing emulator suite as a starting point, or pilfer from them at will.
+
+#### What's great about it
+
+If you have your own custom interface in mind, I guess there's nothing to do but roll your sleeves up and get to it. This is also a way to install emulators that haven't quite found their way into Retropie yet, such as [BeebEm][8] or [ArcEm][9].
+
+#### What's not so great about it
+
+Well, it's a bit of work, isn't it?
+
+#### Who's it for?
+
+Hackers, tinkerers, builders, seasoned hobbyists, and such.
+
+### Native RISC OS gaming
+
+Now here's a dark horse: [RISC OS][10], the original operating system for ARM devices.
+
+#### What is it?
+
+Before ARM went on to become the world's most popular CPU architecture, it was originally built to be the heart of the Acorn Archimedes. That's kind of a forgotten beast nowadays, but for a few years it was light years ahead as the most powerful desktop computer in the world, and it attracted a lot of games development.
+
+Because the ARM processor in the Pi is the great-grandchild of the one in the Archimedes, we can still install RISC OS on it, and with a little bit of work, get these games running. This is different to the emulator options we've covered so far because we're playing our games on the operating system and CPU architecture for which they were written.
+
+#### What's great about it
+
+It's the perfect introduction to RISC OS. This is an absolute gem of an operating system and well worth checking out in its own right.
+
+The fact that you're using much the same operating system as back in the day to load and play your games makes your retro gaming rig just that little bit more of a time machine. This definitely adds some charm and retro value to the project.
+
+There are a few superb games that were released only on the Archimedes. The massive hardware advantage of the Archimedes also means that it often had the best graphics and smoothest gameplay of a lot of multi-platform titles. The rights holders to many of these games have been generous enough to make them legally available for free download.
+
+#### What's not so great about it
+
+Once you have installed RISC OS, it still takes a bit of elbow grease to get the games working. Here's a [guide to getting started][11].
+
+This is definitely not a great all-rounder for the lounge room. There's nothing like [Kodi][12]. There's a web browser, [NetSurf][13], but it's struggling to catch up to the modern web. You won't get the range of titles to play as you would with an emulator suite. RISC OS Open is free for hobbyists to download and use and much of the source code has been made open. But despite the name, it's not a 100% open source operating system.
+
+#### Who's it for?
+
+This one's for novelty seekers, absolute retro heads, people who want to explore an interesting operating system from the '80s, people who are nostalgic for Acorn machines from back in the day, and people who want a totally different retro gaming project.
+
+### Command line gaming
+
+Do you really need to install an emulator or an exotic operating system just to relive the glory days? Why not just install some native linux games from the command line?
+
+#### What is it?
+
+There's a whole range of native Linux games tested to work on the [Raspberry Pi][14].
+
+#### What's great about it
+
+You can install most of these from packages using the command line and start playing. Easy. If you've already got Raspbian up and running, it's probably your fastest path to getting a game running.
+
+#### What's not so great about it
+
+This isn't, strictly speaking, actual retro gaming. Linux was born in 1991 and took a while longer to come together as a gaming platform. This isn't quite gaming from the classic 8- and 16-bit era; these are ports and retro-influenced games that were built later.
+
+#### Who's it for?
+
+If you're just after a bucket of fun, no problem. But if you're trying to relive the actual era, this isn't quite it.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/9/retro-gaming-raspberry-pi
+
+作者:[James Mawson][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/dxmjames
+[1]: https://retropie.org.uk/
+[2]: https://www.raspbian.org/
+[3]: https://emulationstation.org/
+[4]: https://www.libretro.com/
+[5]: https://www.youtube.com/
+[6]: https://soundcloud.com/
+[7]: https://www.recalbox.com/
+[8]: http://www.mkw.me.uk/beebem/
+[9]: http://arcem.sourceforge.net/
+[10]: https://opensource.com/article/18/7/gentle-intro-risc-os
+[11]: https://blog.dxmtechsupport.com.au/playing-badass-acorn-archimedes-games-on-a-raspberry-pi/
+[12]: https://kodi.tv/
+[13]: https://www.netsurf-browser.org/
+[14]: https://www.raspberrypi.org/forums/viewtopic.php?f=78&t=51794
diff --git a/sources/tech/20180924 A Simple, Beautiful And Cross-platform Podcast App.md b/sources/tech/20180924 A Simple, Beautiful And Cross-platform Podcast App.md
new file mode 100644
index 0000000000..ae9f91b548
--- /dev/null
+++ b/sources/tech/20180924 A Simple, Beautiful And Cross-platform Podcast App.md
@@ -0,0 +1,112 @@
+A Simple, Beautiful And Cross-platform Podcast App
+======
+
+
+
+Podcasts have become very popular in the last few years. Podcasts are what’s called “infotainment”, they are generally light-hearted, but they generally give you valuable information. Podcasts have blown up in the last few years, and if you like something, chances are there is a podcast about it. There are a lot of podcast players out there for the Linux desktop, but if you want something that is visually beautiful, has slick animations, and works on every platform, there aren’t a lot of alternatives to **CPod**. CPod (formerly known as **Cumulonimbus** ) is an open source and slickest podcast app that works on Linux, MacOS and Windows.
+
+CPod runs on something called **Electron** – a tool that allows developers to build cross-platform (E.g Windows, MacOs and Linux) desktop GUI applications. In this brief guide, we will be discussing – how to install and use CPod podcast app in Linux.
+
+### Installing CPod
+
+Go to the [**releases page**][1] of CPod. Download and Install the binary for your platform of choice. If you use Ubuntu/Debian, you can just download and install the .deb file from the releases page as shown below.
+
+```
+$ wget https://github.com/z-------------/CPod/releases/download/v1.25.7/CPod_1.25.7_amd64.deb
+
+$ sudo apt update
+
+$ sudo apt install gdebi
+
+$ sudo gdebi CPod_1.25.7_amd64.deb
+```
+
+If you use any other distribution, you probably should use the **AppImage** in the releases page.
+
+Download the AppImage file from the releases page.
+
+Open your terminal, and go to the directory where the AppImage file has been stored. Change the permissions to allow execution:
+
+```
+$ chmod +x CPod-1.25.7-x86_64.AppImage
+```
+
+Execute the AppImage File:
+
+```
+$ ./CPod-1.25.7-x86_64.AppImage
+```
+
+You’ll be presented a dialog asking whether to integrate the app with the system. Click **Yes** if you want to do so.
+
+### Features
+
+**Explore Tab**
+
+
+
+CPod uses the Apple iTunes database to find podcasts. This is good, because the iTunes database is the biggest one out there. If there is a podcast out there, chances are it’s on iTunes. To find podcasts, just use the top search bar in the Explore section. The Explore Section also shows a few popular podcasts.
+
+**Home Tab**
+
+
+
+The Home Tab is the tab that opens by default when you open the app. The Home Tab shows a chronological list of all the episodes of all the podcasts that you have subscribed to.
+
+From the home tab, you can:
+
+ 1. Mark episodes read.
+ 2. Download them for offline playing
+ 3. Add them to the queue.
+
+
+
+**Subscriptions Tab**
+
+
+
+You can of course, subscribe to podcasts that you like. A few other things you can do in the Subscriptions Tab is:
+
+ 1. Refresh Podcast Artwork
+ 2. Export and Import Subscriptions to/from an .OPML file.
+
+
+
+**The Player**
+
+
+
+The player is perhaps the most beautiful part of CPod. The app changes the overall look and feel according to the banner of the podcast. There’s a sound visualiser at the bottom. To the right, you can see and search for other episodes of this podcast.
+
+**Cons/Missing Features**
+
+While I love this app, there are a few features and disadvantages that CPod does have:
+
+ 1. Poor MPRIS Integration – You can play/pause the podcast from the media player dialog of your desktop environment, but not much more. The name of the podcast is not shown, and you can go to the next/previous episode.
+ 2. No support for chapters.
+ 3. No auto-downloading – you have to manually download episodes.
+ 4. CPU usage during use is pretty high (even for an Electron app).
+
+
+
+### Verdict
+
+While it does have its cons, CPod is clearly the most aesthetically pleasing podcast player app out there, and it has most basic features down. If you love using visually beautiful apps, and don’t need the advanced features, this is the perfect app for you. I know for a fact that I’m going to use it.
+
+Do you like CPod? Please put your opinions on the comments below!
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/cpod-a-simple-beautiful-and-cross-platform-podcast-app/
+
+作者:[EDITOR][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/editor/
+[1]: https://github.com/z-------------/CPod/releases
diff --git a/sources/tech/20180924 How To Find Out Which Port Number A Process Is Using In Linux.md b/sources/tech/20180924 How To Find Out Which Port Number A Process Is Using In Linux.md
new file mode 100644
index 0000000000..add3ce719e
--- /dev/null
+++ b/sources/tech/20180924 How To Find Out Which Port Number A Process Is Using In Linux.md
@@ -0,0 +1,280 @@
+HankChow translating
+
+How To Find Out Which Port Number A Process Is Using In Linux
+======
+As a Linux administrator, you should know whether the corresponding service is binding/listening with correct port or not.
+
+This will help you to easily troubleshoot further when you are facing port related issues.
+
+A port is a logical connection that identifies a specific process on Linux. There are two kind of port are available like, physical and software.
+
+Since Linux operating system is a software hence, we are going to discuss about software port.
+
+Software port is always associated with an IP address of a host and the relevant protocol type for communication. The port is used to distinguish the application.
+
+Most of the network related services have to open up a socket to listen incoming network requests. Socket is unique for every service.
+
+**Suggested Read :**
+**(#)** [4 Easiest Ways To Find Out Process ID (PID) In Linux][1]
+**(#)** [3 Easy Ways To Kill Or Terminate A Process In Linux][2]
+
+Socket is combination of IP address, software Port and protocol. The port numbers area available for both TCP and UDP protocol.
+
+The Transmission Control Protocol (TCP) and the User Datagram Protocol (UDP) use port numbers for communication. It is a value from 0 to 65535.
+
+Below are port assignments categories.
+
+ * `0-1023:` Well Known Ports or System Ports
+ * `1024-49151:` Registered Ports for applications
+ * `49152-65535:` Dynamic Ports or Private Ports
+
+
+
+You can check the details of the reserved ports in the /etc/services file on Linux.
+
+```
+# less /etc/services
+# /etc/services:
+# $Id: services,v 1.55 2013/04/14 ovasik Exp $
+#
+# Network services, Internet style
+# IANA services version: last updated 2013-04-10
+#
+# Note that it is presently the policy of IANA to assign a single well-known
+# port number for both TCP and UDP; hence, most entries here have two entries
+# even if the protocol doesn't support UDP operations.
+# Updated from RFC 1700, ``Assigned Numbers'' (October 1994). Not all ports
+# are included, only the more common ones.
+#
+# The latest IANA port assignments can be gotten from
+# http://www.iana.org/assignments/port-numbers
+# The Well Known Ports are those from 0 through 1023.
+# The Registered Ports are those from 1024 through 49151
+# The Dynamic and/or Private Ports are those from 49152 through 65535
+#
+# Each line describes one service, and is of the form:
+#
+# service-name port/protocol [aliases ...] [# comment]
+
+tcpmux 1/tcp # TCP port service multiplexer
+tcpmux 1/udp # TCP port service multiplexer
+rje 5/tcp # Remote Job Entry
+rje 5/udp # Remote Job Entry
+echo 7/tcp
+echo 7/udp
+discard 9/tcp sink null
+discard 9/udp sink null
+systat 11/tcp users
+systat 11/udp users
+daytime 13/tcp
+daytime 13/udp
+qotd 17/tcp quote
+qotd 17/udp quote
+msp 18/tcp # message send protocol (historic)
+msp 18/udp # message send protocol (historic)
+chargen 19/tcp ttytst source
+chargen 19/udp ttytst source
+ftp-data 20/tcp
+ftp-data 20/udp
+# 21 is registered to ftp, but also used by fsp
+ftp 21/tcp
+ftp 21/udp fsp fspd
+ssh 22/tcp # The Secure Shell (SSH) Protocol
+ssh 22/udp # The Secure Shell (SSH) Protocol
+telnet 23/tcp
+telnet 23/udp
+# 24 - private mail system
+lmtp 24/tcp # LMTP Mail Delivery
+lmtp 24/udp # LMTP Mail Delivery
+
+```
+
+This can be achieved using the below six methods.
+
+ * `ss:` ss is used to dump socket statistics.
+ * `netstat:` netstat is displays a list of open sockets.
+ * `lsof:` lsof – list open files.
+ * `fuser:` fuser – list process IDs of all processes that have one or more files open
+ * `nmap:` nmap – Network exploration tool and security / port scanner
+ * `systemctl:` systemctl – Control the systemd system and service manager
+
+
+
+In this tutorial we are going to find out which port number the SSHD daemon is using.
+
+### Method-1: Using ss Command
+
+ss is used to dump socket statistics. It allows showing information similar to netstat. It can display more TCP and state informations than other tools.
+
+It can display stats for all kind of sockets such as PACKET, TCP, UDP, DCCP, RAW, Unix domain, etc.
+
+```
+# ss -tnlp | grep ssh
+LISTEN 0 128 *:22 *:* users:(("sshd",pid=997,fd=3))
+LISTEN 0 128 :::22 :::* users:(("sshd",pid=997,fd=4))
+```
+
+Alternatively you can check this with port number as well.
+
+```
+# ss -tnlp | grep ":22"
+LISTEN 0 128 *:22 *:* users:(("sshd",pid=997,fd=3))
+LISTEN 0 128 :::22 :::* users:(("sshd",pid=997,fd=4))
+```
+
+### Method-2: Using netstat Command
+
+netstat – Print network connections, routing tables, interface statistics, masquerade connections, and multicast memberships.
+
+By default, netstat displays a list of open sockets. If you don’t specify any address families, then the active sockets of all configured address families will be printed. This program is obsolete. Replacement for netstat is ss.
+
+```
+# netstat -tnlp | grep ssh
+tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 997/sshd
+tcp6 0 0 :::22 :::* LISTEN 997/sshd
+```
+
+Alternatively you can check this with port number as well.
+
+```
+# netstat -tnlp | grep ":22"
+tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1208/sshd
+tcp6 0 0 :::22 :::* LISTEN 1208/sshd
+```
+
+### Method-3: Using lsof Command
+
+lsof – list open files. The Linux lsof command lists information about files that are open by processes running on the system.
+
+```
+# lsof -i -P | grep ssh
+COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
+sshd 11584 root 3u IPv4 27625 0t0 TCP *:22 (LISTEN)
+sshd 11584 root 4u IPv6 27627 0t0 TCP *:22 (LISTEN)
+sshd 11592 root 3u IPv4 27744 0t0 TCP vps.2daygeek.com:ssh->103.5.134.167:49902 (ESTABLISHED)
+```
+
+Alternatively you can check this with port number as well.
+
+```
+# lsof -i tcp:22
+COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
+sshd 1208 root 3u IPv4 20919 0t0 TCP *:ssh (LISTEN)
+sshd 1208 root 4u IPv6 20921 0t0 TCP *:ssh (LISTEN)
+sshd 11592 root 3u IPv4 27744 0t0 TCP vps.2daygeek.com:ssh->103.5.134.167:49902 (ESTABLISHED)
+```
+
+### Method-4: Using fuser Command
+
+The fuser utility shall write to standard output the process IDs of processes running on the local system that have one or more named files open.
+
+```
+# fuser -v 22/tcp
+ USER PID ACCESS COMMAND
+22/tcp: root 1208 F.... sshd
+ root 12388 F.... sshd
+ root 49339 F.... sshd
+```
+
+### Method-5: Using nmap Command
+
+Nmap (“Network Mapper”) is an open source tool for network exploration and security auditing. It was designed to rapidly scan large networks, although it works fine against single hosts.
+
+Nmap uses raw IP packets in novel ways to determine what hosts are available on the network, what services (application name and version) those hosts are offering, what operating systems (and OS versions) they are running, what type of packet filters/firewalls are in use, and dozens of other characteristics.
+
+```
+# nmap -sV -p 22 localhost
+
+Starting Nmap 6.40 ( http://nmap.org ) at 2018-09-23 12:36 IST
+Nmap scan report for localhost (127.0.0.1)
+Host is up (0.000089s latency).
+Other addresses for localhost (not scanned): 127.0.0.1
+PORT STATE SERVICE VERSION
+22/tcp open ssh OpenSSH 7.4 (protocol 2.0)
+
+Service detection performed. Please report any incorrect results at http://nmap.org/submit/ .
+Nmap done: 1 IP address (1 host up) scanned in 0.44 seconds
+```
+
+### Method-6: Using systemctl Command
+
+systemctl – Control the systemd system and service manager. This is the replacement of old SysV init system management and most of the modern Linux operating systems were adapted systemd.
+
+**Suggested Read :**
+**(#)** [chkservice – A Tool For Managing Systemd Units From Linux Terminal][3]
+**(#)** [How To Check All Running Services In Linux][4]
+
+```
+# systemctl status sshd
+● sshd.service - OpenSSH server daemon
+ Loaded: loaded (/usr/lib/systemd/system/sshd.service; enabled; vendor preset: enabled)
+ Active: active (running) since Sun 2018-09-23 02:08:56 EDT; 6h 11min ago
+ Docs: man:sshd(8)
+ man:sshd_config(5)
+ Main PID: 11584 (sshd)
+ CGroup: /system.slice/sshd.service
+ └─11584 /usr/sbin/sshd -D
+
+Sep 23 02:08:56 vps.2daygeek.com systemd[1]: Starting OpenSSH server daemon...
+Sep 23 02:08:56 vps.2daygeek.com sshd[11584]: Server listening on 0.0.0.0 port 22.
+Sep 23 02:08:56 vps.2daygeek.com sshd[11584]: Server listening on :: port 22.
+Sep 23 02:08:56 vps.2daygeek.com systemd[1]: Started OpenSSH server daemon.
+Sep 23 02:09:15 vps.2daygeek.com sshd[11589]: Connection closed by 103.5.134.167 port 49899 [preauth]
+Sep 23 02:09:41 vps.2daygeek.com sshd[11592]: Accepted password for root from 103.5.134.167 port 49902 ssh2
+```
+
+The above out will be showing the actual listening port of SSH service when you start the SSHD service recently. Otherwise it won’t because it updates recent logs in the output frequently.
+
+```
+# systemctl status sshd
+● sshd.service - OpenSSH server daemon
+ Loaded: loaded (/usr/lib/systemd/system/sshd.service; enabled; vendor preset: enabled)
+ Active: active (running) since Thu 2018-09-06 07:40:59 IST; 2 weeks 3 days ago
+ Docs: man:sshd(8)
+ man:sshd_config(5)
+ Main PID: 1208 (sshd)
+ CGroup: /system.slice/sshd.service
+ ├─ 1208 /usr/sbin/sshd -D
+ ├─23951 sshd: [accepted]
+ └─23952 sshd: [net]
+
+Sep 23 12:50:36 vps.2daygeek.com sshd[23909]: Invalid user pi from 95.210.113.142 port 51666
+Sep 23 12:50:36 vps.2daygeek.com sshd[23909]: input_userauth_request: invalid user pi [preauth]
+Sep 23 12:50:37 vps.2daygeek.com sshd[23911]: pam_unix(sshd:auth): check pass; user unknown
+Sep 23 12:50:37 vps.2daygeek.com sshd[23911]: pam_unix(sshd:auth): authentication failure; logname= uid=0 euid=0 tty=ssh ruser= rhost=95.210.113.142
+Sep 23 12:50:37 vps.2daygeek.com sshd[23909]: pam_unix(sshd:auth): check pass; user unknown
+Sep 23 12:50:37 vps.2daygeek.com sshd[23909]: pam_unix(sshd:auth): authentication failure; logname= uid=0 euid=0 tty=ssh ruser= rhost=95.210.113.142
+Sep 23 12:50:39 vps.2daygeek.com sshd[23911]: Failed password for invalid user pi from 95.210.113.142 port 51670 ssh2
+Sep 23 12:50:39 vps.2daygeek.com sshd[23909]: Failed password for invalid user pi from 95.210.113.142 port 51666 ssh2
+Sep 23 12:50:40 vps.2daygeek.com sshd[23911]: Connection closed by 95.210.113.142 port 51670 [preauth]
+Sep 23 12:50:40 vps.2daygeek.com sshd[23909]: Connection closed by 95.210.113.142 port 51666 [preauth]
+```
+
+Most of the time the above output won’t shows the process actual port number. in this case i would suggest you to check the details using the below command from the journalctl log file.
+
+```
+# journalctl | grep -i "openssh\|sshd"
+Sep 23 02:08:56 vps138235.vps.ovh.ca sshd[997]: Received signal 15; terminating.
+Sep 23 02:08:56 vps138235.vps.ovh.ca systemd[1]: Stopping OpenSSH server daemon...
+Sep 23 02:08:56 vps138235.vps.ovh.ca systemd[1]: Starting OpenSSH server daemon...
+Sep 23 02:08:56 vps138235.vps.ovh.ca sshd[11584]: Server listening on 0.0.0.0 port 22.
+Sep 23 02:08:56 vps138235.vps.ovh.ca sshd[11584]: Server listening on :: port 22.
+Sep 23 02:08:56 vps138235.vps.ovh.ca systemd[1]: Started OpenSSH server daemon.
+```
+
+--------------------------------------------------------------------------------
+
+via: https://www.2daygeek.com/how-to-find-out-which-port-number-a-process-is-using-in-linux/
+
+作者:[Prakash Subramanian][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.2daygeek.com/author/prakash/
+[1]: https://www.2daygeek.com/how-to-check-find-the-process-id-pid-ppid-of-a-running-program-in-linux/
+[2]: https://www.2daygeek.com/kill-terminate-a-process-in-linux-using-kill-pkill-killall-command/
+[3]: https://www.2daygeek.com/chkservice-a-tool-for-managing-systemd-units-from-linux-terminal/
+[4]: https://www.2daygeek.com/how-to-check-all-running-services-in-linux/
diff --git a/sources/tech/20180924 Why Linux users should try Rust.md b/sources/tech/20180924 Why Linux users should try Rust.md
new file mode 100644
index 0000000000..db60883eb9
--- /dev/null
+++ b/sources/tech/20180924 Why Linux users should try Rust.md
@@ -0,0 +1,171 @@
+Why Linux users should try Rust
+======
+
+
+
+Rust is a fairly young and modern programming language with a lot of features that make it incredibly flexible and very secure. It's also becoming quite popular, having won first place for the "most loved programming language" in the Stack Overflow Developer Survey three years in a row — [2016][1], [2017][2], and [2018][3].
+
+Rust is also an _open-source_ language with a suite of special features that allow it to be adapted to many different programming projects. It grew out of what was a personal project of a Mozilla employee back in 2006, was picked up as a special project by Mozilla a few years later (2009), and then announced for public use in 2010.
+
+Rust programs run incredibly fast, prevent segfaults, and guarantee thread safety. These attributes make the language tremendously appealing to developers focused on application security. Rust is also a very readable language and one that can be used for anything from simple programs to very large and complex projects.
+
+Rust is:
+
+ * Memory safe — Rust will not suffer from dangling pointers, buffer overflows, or other memory-related errors. And it provides memory safety without garbage collection.
+ * General purpose — Rust is an appropriate language for any type of programming
+ * Fast — Rust is comparable in performance to C/C++ but with far better security features.
+ * Efficient — Rust is built to facilitate concurrent programming.
+ * Project-oriented — Rust has a built-in dependency and build management system called Cargo.
+ * Well supported — Rust has an impressive [support community][4].
+
+
+
+Rust also enforces RAII (Resource Acquisition Is Initialization). That means when an object goes out of scope, its destructor will be called and its resources will be freed, providing a shield against resource leaks. It provides functional abstractions and a great [type system][5] together with speed and mathematical soundness.
+
+In short, Rust is an impressive systems programming language with features that other most languages lack, making it a serious contender for languages like C, C++ and Objective-C that have been used for years.
+
+### Installing Rust
+
+Installing Rust is a fairly simple process.
+
+```
+$ curl https://sh.rustup.rs -sSf | sh
+```
+
+Once Rust in installed, calling rustc with the **\--version** argument or using the **which** command displays version information.
+
+```
+$ which rustc
+rustc 1.27.2 (58cc626de 2018-07-18)
+$ rustc --version
+rustc 1.27.2 (58cc626de 2018-07-18)
+```
+
+### Getting started with Rust
+
+The simplest code example is not all that different from what you'd enter if you were using one of many scripting languages.
+
+```
+$ cat hello.rs
+fn main() {
+ // Print a greeting
+ println!("Hello, world!");
+}
+```
+
+In these lines, we are setting up a function (main), adding a comment describing the function, and using a println statement to create output. You could compile and then run a program like this using the command shown below.
+
+```
+$ rustc hello.rs
+$ ./hello
+Hello, world!
+```
+
+Alternately, you might create a "project" (generally used only for more complex programs than this one!) to keep your code organized.
+
+```
+$ mkdir ~/projects
+$ cd ~/projects
+$ mkdir hello_world
+$ cd hello_world
+```
+
+Notice that even a simple program, once compiled, becomes a fairly large executable.
+
+```
+$ ./hello
+Hello, world!
+$ ls -l hello*
+-rwxrwxr-x 1 shs shs 5486784 Sep 23 19:02 hello <== executable
+-rw-rw-r-- 1 shs shs 68 Sep 23 15:25 hello.rs
+```
+
+And, of course, that's just a start — the traditional "Hello, world!" program. The Rust language has a suite of features to get you moving quickly to advanced levels of programming skill.
+
+### Learning Rust
+
+![rust programming language book cover][6]
+No Starch Press
+
+The Rust Programming Language book by Steve Klabnik and Carol Nichols (2018) provides one of the best ways to learn Rust. Written by two members of the core development team, this book is available in print from [No Starch Press][7] or in ebook format at [rust-lang.org][8]. It has earned its reference as "the book" among the Rust developer community.
+
+Among the many topics covered, you will learn about these advanced topics:
+
+ * Ownership and borrowing
+ * Safety guarantees
+ * Testing and error handling
+ * Smart pointers and multi-threading
+ * Advanced pattern matching
+ * Using Cargo (the built-in package manager)
+ * Using Rust's advanced compiler
+
+
+
+#### Table of Contents
+
+The table of contents is shown below.
+
+```
+Foreword by Nicholas Matsakis and Aaron Turon
+Acknowledgements
+Introduction
+Chapter 1: Getting Started
+Chapter 2: Guessing Game
+Chapter 3: Common Programming Concepts
+Chapter 4: Understanding Ownership
+Chapter 5: Structs
+Chapter 6: Enums and Pattern Matching
+Chapter 7: Modules
+Chapter 8: Common Collections
+Chapter 9: Error Handling
+Chapter 10: Generic Types, Traits, and Lifetimes
+Chapter 11: Testing
+Chapter 12: An Input/Output Project
+Chapter 13: Iterators and Closures
+Chapter 14: More About Cargo and Crates.io
+Chapter 15: Smart Pointers
+Chapter 16: Concurrency
+Chapter 17: Is Rust Object Oriented?
+Chapter 18: Patterns
+Chapter 19: More About Lifetimes
+Chapter 20: Advanced Type System Features
+Appendix A: Keywords
+Appendix B: Operators and Symbols
+Appendix C: Derivable Traits
+Appendix D: Macros
+Index
+
+```
+
+[The Rust Programming Language][7] takes you from basic installation and language syntax to complex topics, such as modules, error handling, crates (synonymous with a ‘library’ or ‘package’ in other languages), modules (allowing you to partition your code within the crate itself), lifetimes, etc.
+
+Probably the most important thing to say is that the book can move you from basic programming skills to building and compiling complex, secure and very useful programs.
+
+### Wrap-up
+
+If you're ready to get into some serious programming with a language that's well worth the time and effort to study and becoming increasingly popular, Rust is a good bet!
+
+Join the Network World communities on [Facebook][9] and [LinkedIn][10] to comment on topics that are top of mind.
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3308162/linux/why-you-should-try-rust.html
+
+作者:[Sandra Henry-Stocker][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
+[1]: https://insights.stackoverflow.com/survey/2016#technology-most-loved-dreaded-and-wanted
+[2]: https://insights.stackoverflow.com/survey/2017#technology-most-loved-dreaded-and-wanted-languages
+[3]: https://insights.stackoverflow.com/survey/2018#technology-most-loved-dreaded-and-wanted-languages
+[4]: https://www.rust-lang.org/en-US/community.html
+[5]: https://doc.rust-lang.org/reference/type-system.html
+[6]: https://images.idgesg.net/images/article/2018/09/rust-programming-language_book-cover-100773679-small.jpg
+[7]: https://nostarch.com/Rust
+[8]: https://doc.rust-lang.org/book/2018-edition/index.html
+[9]: https://www.facebook.com/NetworkWorld/
+[10]: https://www.linkedin.com/company/network-world
diff --git a/sources/tech/20180925 9 Easiest Ways To Find Out Process ID (PID) In Linux.md b/sources/tech/20180925 9 Easiest Ways To Find Out Process ID (PID) In Linux.md
new file mode 100644
index 0000000000..ae353bf11f
--- /dev/null
+++ b/sources/tech/20180925 9 Easiest Ways To Find Out Process ID (PID) In Linux.md
@@ -0,0 +1,208 @@
+9 Easiest Ways To Find Out Process ID (PID) In Linux
+======
+Everybody knows about PID, Exactly what is PID? Why you want PID? What are you going to do using PID? Are you having the same questions on your mind? If so, you are in the right place to get all the details.
+
+Mainly, we are looking PID to kill an unresponsive program and it’s similar to Windows task manager. Linux GUI also offering the same feature but CLI is an efficient way to perform the kill operation.
+
+### What Is Process ID?
+
+PID stands for process identification number which is generally used by most operating system kernels such as Linux, Unix, macOS and Windows. It is a unique identification number that is automatically assigned to each process when it is created in an operating system. A process is a running instance of a program.
+
+**Suggested Read :**
+**(#)** [How To Find Out Which Port Number A Process Is Using In Linux][1]
+**(#)** [3 Easy Ways To Kill Or Terminate A Process In Linux][2]
+
+Each time process ID will be getting change to all the processes except init because init is always the first process on the system and is the ancestor of all other processes. It’s PID is 1.
+
+The default maximum value of PIDs is `32,768`. The same has been verified by running the following command on your system `cat /proc/sys/kernel/pid_max`. On 32-bit systems 32768 is the maximum value but we can set to any value up to 2^22 (approximately 4 million) on 64-bit systems.
+
+You may ask, why we need such amount of PIDs? because we can’t reused the PIDs immediately that’s why. Also in order to prevent possible errors.
+
+The PID for the running processes on the system can be found by using the below nine methods such as pidof command, pgrep command, ps command, pstree command, ss command, netstat command, lsof command, fuser command and systemctl command.
+
+This can be achieved using the below six methods.
+
+ * `pidof:` pidof — find the process ID of a running program.
+ * `pgrep:` pgre – look up or signal processes based on name and other attributes.
+ * `ps:` ps – report a snapshot of the current processes.
+ * `pstree:` pstree – display a tree of processes.
+ * `ss:` ss is used to dump socket statistics.
+ * `netstat:` netstat is displays a list of open sockets.
+ * `lsof:` lsof – list open files.
+ * `fuser:` fuser – list process IDs of all processes that have one or more files open
+ * `systemctl:` systemctl – Control the systemd system and service manager
+
+
+
+In this tutorial we are going to find out the Apache process id to test this article. Make sure your need to input your process name instead of us.
+
+### Method-1 : Using pidof Command
+
+pidof used to find the process ID of a running program. It’s prints those id’s on the standard output. To demonstrate this, we are going to find out the Apache2 process id from Debian 9 (stretch) system.
+
+```
+# pidof apache2
+3754 2594 2365 2364 2363 2362 2361
+
+```
+
+From the above output you may face difficulties to identify the Process ID because it’s shows all the PIDs (included Parent and Childs) aginst the process name. Hence we need to find out the parent PID (PPID), which is the one we are looking. It could be the first number. In my case it’s `3754` and it’s shorted in descending order.
+
+### Method-2 : Using pgrep Command
+
+pgrep looks through the currently running processes and lists the process IDs which match the selection criteria to stdout.
+
+```
+# pgrep apache2
+2361
+2362
+2363
+2364
+2365
+2594
+3754
+
+```
+
+This also similar to the above output but it’s shorting the results in ascending order, which clearly says that the parent PID is the last one. In my case it’s `3754`.
+
+**Note :** If you have more than one process id of the process, you may face trouble to identify the parent process id when using pidof & pgrep command.
+
+### Method-3 : Using pstree Command
+
+pstree shows running processes as a tree. The tree is rooted at either pid or init if pid is omitted. If a user name is specified in the pstree command then it’s shows all the process owned by the corresponding user.
+
+pstree visually merges identical branches by putting them in square brackets and prefixing them with the repetition count.
+
+```
+# pstree -p | grep "apache2"
+ |-apache2(3754)-|-apache2(2361)
+ | |-apache2(2362)
+ | |-apache2(2363)
+ | |-apache2(2364)
+ | |-apache2(2365)
+ | `-apache2(2594)
+
+```
+
+To get parent process alone, use the following format.
+
+```
+# pstree -p | grep "apache2" | head -1
+ |-apache2(3754)-|-apache2(2361)
+
+```
+
+pstree command is very simple because it’s segregating the Parent and Child processes separately but it’s not easy when using pidof & pgrep command.
+
+### Method-4 : Using ps Command
+
+ps displays information about a selection of the active processes. It displays the process ID (pid=PID), the terminal associated with the process (tname=TTY), the cumulated CPU time in [DD-]hh:mm:ss format (time=TIME), and the executable name (ucmd=CMD). Output is unsorted by default.
+
+```
+# ps aux | grep "apache2"
+www-data 2361 0.0 0.4 302652 9732 ? S 06:25 0:00 /usr/sbin/apache2 -k start
+www-data 2362 0.0 0.4 302652 9732 ? S 06:25 0:00 /usr/sbin/apache2 -k start
+www-data 2363 0.0 0.4 302652 9732 ? S 06:25 0:00 /usr/sbin/apache2 -k start
+www-data 2364 0.0 0.4 302652 9732 ? S 06:25 0:00 /usr/sbin/apache2 -k start
+www-data 2365 0.0 0.4 302652 8400 ? S 06:25 0:00 /usr/sbin/apache2 -k start
+www-data 2594 0.0 0.4 302652 8400 ? S 06:55 0:00 /usr/sbin/apache2 -k start
+root 3754 0.0 1.4 302580 29324 ? Ss Dec11 0:23 /usr/sbin/apache2 -k start
+root 5648 0.0 0.0 12784 940 pts/0 S+ 21:32 0:00 grep apache2
+
+```
+
+From the above output we can easily identify the parent process id (PPID) based on the process start date. In my case apache2 process was started @ `Dec11` which is the parent and others are child’s. PID of apache2 is `3754`.
+
+### Method-5: Using ss Command
+
+ss is used to dump socket statistics. It allows showing information similar to netstat. It can display more TCP and state informations than other tools.
+
+It can display stats for all kind of sockets such as PACKET, TCP, UDP, DCCP, RAW, Unix domain, etc.
+
+```
+# ss -tnlp | grep apache2
+LISTEN 0 128 :::80 :::* users:(("apache2",pid=3319,fd=4),("apache2",pid=3318,fd=4),("apache2",pid=3317,fd=4))
+
+```
+
+### Method-6: Using netstat Command
+
+netstat – Print network connections, routing tables, interface statistics, masquerade connections, and multicast memberships.
+By default, netstat displays a list of open sockets.
+
+If you don’t specify any address families, then the active sockets of all configured address families will be printed. This program is obsolete. Replacement for netstat is ss.
+
+```
+# netstat -tnlp | grep apache2
+tcp6 0 0 :::80 :::* LISTEN 3317/apache2
+
+```
+
+### Method-7: Using lsof Command
+
+lsof – list open files. The Linux lsof command lists information about files that are open by processes running on the system.
+
+```
+# lsof -i -P | grep apache2
+apache2 3317 root 4u IPv6 40518 0t0 TCP *:80 (LISTEN)
+apache2 3318 www-data 4u IPv6 40518 0t0 TCP *:80 (LISTEN)
+apache2 3319 www-data 4u IPv6 40518 0t0 TCP *:80 (LISTEN)
+
+```
+
+### Method-8: Using fuser Command
+
+The fuser utility shall write to standard output the process IDs of processes running on the local system that have one or more named files open.
+
+```
+# fuser -v 80/tcp
+ USER PID ACCESS COMMAND
+80/tcp: root 3317 F.... apache2
+ www-data 3318 F.... apache2
+ www-data 3319 F.... apache2
+
+```
+
+### Method-9: Using systemctl Command
+
+systemctl – Control the systemd system and service manager. This is the replacement of old SysV init system management and
+most of the modern Linux operating systems were adapted systemd.
+
+```
+# systemctl status apache2
+● apache2.service - The Apache HTTP Server
+ Loaded: loaded (/lib/systemd/system/apache2.service; disabled; vendor preset: enabled)
+ Drop-In: /lib/systemd/system/apache2.service.d
+ └─apache2-systemd.conf
+ Active: active (running) since Tue 2018-09-25 10:03:28 IST; 3s ago
+ Process: 3294 ExecStart=/usr/sbin/apachectl start (code=exited, status=0/SUCCESS)
+ Main PID: 3317 (apache2)
+ Tasks: 55 (limit: 4915)
+ Memory: 7.9M
+ CPU: 71ms
+ CGroup: /system.slice/apache2.service
+ ├─3317 /usr/sbin/apache2 -k start
+ ├─3318 /usr/sbin/apache2 -k start
+ └─3319 /usr/sbin/apache2 -k start
+
+Sep 25 10:03:28 ubuntu systemd[1]: Starting The Apache HTTP Server...
+Sep 25 10:03:28 ubuntu systemd[1]: Started The Apache HTTP Server.
+
+```
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.2daygeek.com/9-methods-to-check-find-the-process-id-pid-ppid-of-a-running-program-in-linux/
+
+作者:[Magesh Maruthamuthu][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.2daygeek.com/author/magesh/
+[1]: https://www.2daygeek.com/how-to-find-out-which-port-number-a-process-is-using-in-linux/
+[2]: https://www.2daygeek.com/kill-terminate-a-process-in-linux-using-kill-pkill-killall-command/
diff --git a/sources/tech/20180925 Hegemon - A Modular System Monitor Application Written In Rust.md b/sources/tech/20180925 Hegemon - A Modular System Monitor Application Written In Rust.md
new file mode 100644
index 0000000000..14f6a2e947
--- /dev/null
+++ b/sources/tech/20180925 Hegemon - A Modular System Monitor Application Written In Rust.md
@@ -0,0 +1,78 @@
+Hegemon – A Modular System Monitor Application Written In Rust
+======
+
+
+
+When it comes to monitor running processes in Unix-like systems, the most commonly used applications are **top** and **htop** , which is an enhanced version of top. My personal favorite is htop. However, the developers are releasing few alternatives to these applications every now and then. One such alternative to top and htop utilities is **Hegemon**. It is a modular system monitor application written using **Rust** programming language.
+
+Concerning about the features of Hegemon, we can list the following:
+
+ * Hegemon will monitor the usage of CPU, memory and Swap.
+ * It monitors the system’s temperature and fan speed.
+ * The update interval time can be adjustable. The default value is 3 seconds.
+ * We can reveal more detailed graph and additional information by expanding the data streams.
+ * Unit tests
+ * Clean interface
+ * Free and open source.
+
+
+
+### Installing Hegemon
+
+Make sure you have installed **Rust 1.26** or later version. To install Rust in your Linux distribution, refer the following guide:
+
+[Install Rust Programming Language In Linux][2]
+
+Also, install [libsensors][1] library. It is available in the default repositories of most Linux distributions. For example, you can install it in RPM based systems such as Fedora using the following command:
+
+```
+$ sudo dnf install lm_sensors-devel
+```
+
+On Debian-based systems like Ubuntu, Linux Mint, it can be installed using command:
+
+```
+$ sudo apt-get install libsensors4-dev
+```
+
+Once you installed Rust and libsensors, install Hegemon using command:
+
+```
+$ cargo install hegemon
+```
+
+Once hegemon installed, start monitoring the running processes in your Linux system using command:
+
+```
+$ hegemon
+```
+
+Here is the sample output from my Arch Linux desktop.
+
+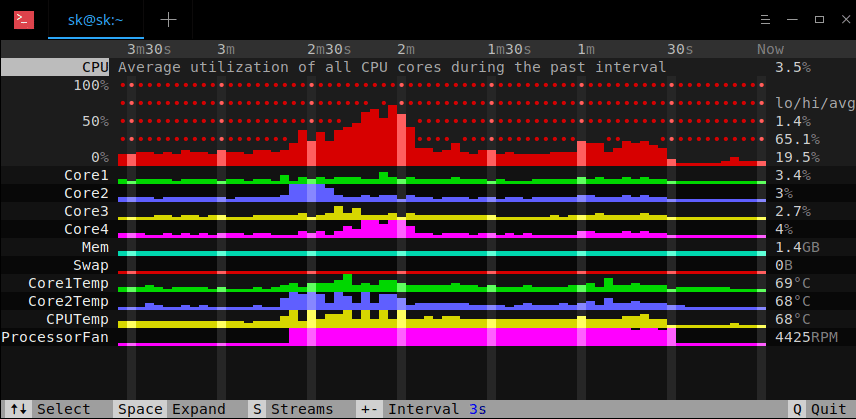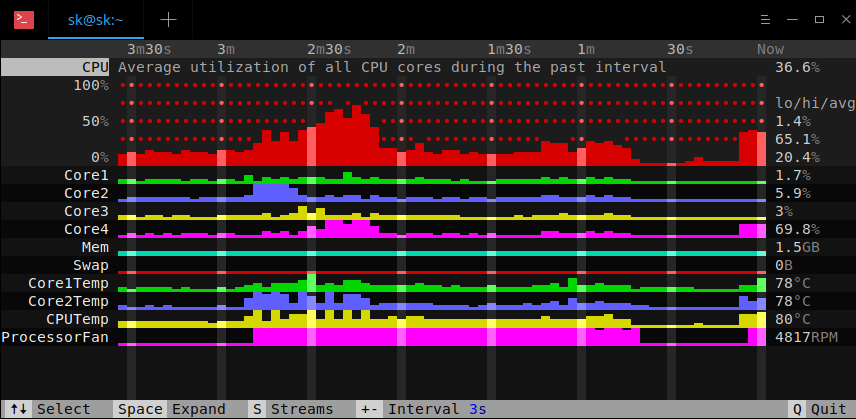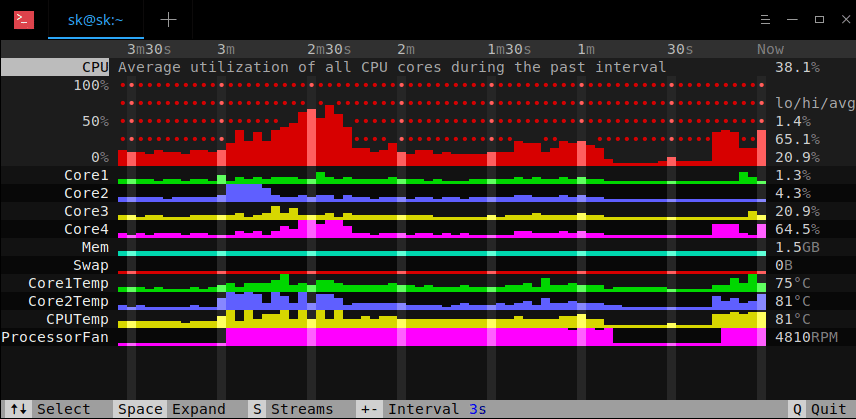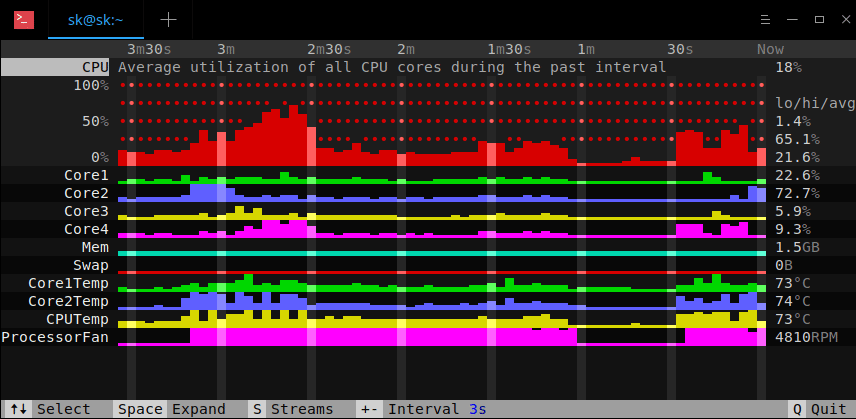
+
+To exit, press **Q**.
+
+
+Please be mindful that hegemon is still in its early development stage and it is not complete replacement for **top** command. There might be bugs and missing features. If you came across any bugs, report them in the project’s github page. The developer is planning to bring more features in the upcoming versions. So, keep an eye on this project.
+
+And, that’s all for now. Hope this helps. More good stuffs to come. Stay tuned!
+
+Cheers!
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/hegemon-a-modular-system-monitor-application-written-in-rust/
+
+作者:[SK][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/sk/
+[1]: https://github.com/lm-sensors/lm-sensors
+[2]: https://www.ostechnix.com/install-rust-programming-language-in-linux/
diff --git a/sources/tech/20180925 How to Boot Ubuntu 18.04 - Debian 9 Server in Rescue (Single User mode) - Emergency Mode.md b/sources/tech/20180925 How to Boot Ubuntu 18.04 - Debian 9 Server in Rescue (Single User mode) - Emergency Mode.md
new file mode 100644
index 0000000000..ff33e7c175
--- /dev/null
+++ b/sources/tech/20180925 How to Boot Ubuntu 18.04 - Debian 9 Server in Rescue (Single User mode) - Emergency Mode.md
@@ -0,0 +1,88 @@
+How to Boot Ubuntu 18.04 / Debian 9 Server in Rescue (Single User mode) / Emergency Mode
+======
+Booting a Linux Server into a single user mode or **rescue mode** is one of the important troubleshooting that a Linux admin usually follow while recovering the server from critical conditions. In Ubuntu 18.04 and Debian 9, single user mode is known as a rescue mode.
+
+Apart from the rescue mode, Linux servers can be booted in **emergency mode** , the main difference between them is that, emergency mode loads a minimal environment with read only root file system file system, also it does not enable any network or other services. But rescue mode try to mount all the local file systems & try to start some important services including network.
+
+In this article we will discuss how we can boot our Ubuntu 18.04 LTS / Debian 9 Server in rescue mode and emergency mode.
+
+#### Booting Ubuntu 18.04 LTS Server in Single User / Rescue Mode:
+
+Reboot your server and go to boot loader (Grub) screen and Select “ **Ubuntu** “, bootloader screen would look like below,
+
+
+
+Press “ **e** ” and then go the end of line which starts with word “ **linux** ” and append “ **systemd.unit=rescue.target** “. Remove the word “ **$vt_handoff** ” if it exists.
+
+
+
+Now Press Ctrl-x or F10 to boot,
+
+
+
+Now press enter and then you will get the shell where all file systems will be mounted in read-write mode and do the troubleshooting. Once you are done with troubleshooting, you can reboot your server using “ **reboot** ” command.
+
+#### Booting Ubuntu 18.04 LTS Server in emergency mode
+
+Reboot the server and go the boot loader screen and select “ **Ubuntu** ” and then press “ **e** ” and go to the end of line which starts with word linux, and append “ **systemd.unit=emergency.target** ”
+
+
+
+Now Press Ctlr-x or F10 to boot in emergency mode, you will get a shell and do the troubleshooting from there. As we had already discussed that in emergency mode, file systems will be mounted in read-only mode and also there will be no networking in this mode,
+
+
+
+Use below command to mount the root file system in read-write mode,
+
+```
+# mount -o remount,rw /
+
+```
+
+Similarly, you can remount rest of file systems in read-write mode .
+
+#### Booting Debian 9 into Rescue & Emergency Mode
+
+Reboot your Debian 9.x server and go to grub screen and select “ **Debian GNU/Linux** ”
+
+
+
+Press “ **e** ” and go to end of line which starts with word linux and append “ **systemd.unit=rescue.target** ” to boot the system in rescue mode and to boot in emergency mode then append “ **systemd.unit=emergency.target** ”
+
+#### Rescue mode :
+
+
+
+Now press Ctrl-x or F10 to boot in rescue mode
+
+
+
+Press Enter to get the shell and from there you can start troubleshooting.
+
+#### Emergency Mode:
+
+
+
+Now press ctrl-x or F10 to boot your system in emergency mode
+
+
+
+Press enter to get the shell and use “ **mount -o remount,rw /** ” command to mount the root file system in read-write mode.
+
+**Note:** In case root password is already set in Ubuntu 18.04 and Debian 9 Server then you must enter root password to get shell in rescue and emergency mode
+
+That’s all from this article, please do share your feedback and comments in case you like this article.
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.linuxtechi.com/boot-ubuntu-18-04-debian-9-rescue-emergency-mode/
+
+作者:[Pradeep Kumar][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: http://www.linuxtechi.com/author/pradeep/
diff --git a/sources/tech/20180925 How to Replace one Linux Distro With Another in Dual Boot -Guide.md b/sources/tech/20180925 How to Replace one Linux Distro With Another in Dual Boot -Guide.md
new file mode 100644
index 0000000000..ab9fa8acc3
--- /dev/null
+++ b/sources/tech/20180925 How to Replace one Linux Distro With Another in Dual Boot -Guide.md
@@ -0,0 +1,160 @@
+How to Replace one Linux Distro With Another in Dual Boot [Guide]
+======
+**If you have a Linux distribution installed, you can replace it with another distribution in the dual boot. You can also keep your personal documents while switching the distribution.**
+
+![How to Replace One Linux Distribution With Another From Dual Boot][1]
+
+Suppose you managed to [successfully dual boot Ubuntu and Windows][2]. But after reading the [Linux Mint versus Ubuntu discussion][3], you realized that [Linux Mint][4] is more suited for your needs. What would you do now? How would you [remove Ubuntu][5] and [install Mint in dual boot][6]?
+
+You might think that you need to uninstall [Ubuntu][7] from dual boot first and then repeat the dual booting steps with Linux Mint. Let me tell you something. You don’t need to do all of that.
+
+If you already have a Linux distribution installed in dual boot, you can easily replace it with another. You don’t have to uninstall the existing Linux distribution. You simply delete its partition and install the new distribution on the disk space vacated by the previous distribution.
+
+Another good news is that you may be able to keep your Home directory with all your documents and pictures while switching the Linux distributions.
+
+Let me show you how to switch Linux distributions.
+
+### Replace one Linux with another from dual boot
+
+
+
+Let me describe the scenario I am going to use here. I have Linux Mint 19 installed on my system in dual boot mode with Windows 10. I am going to replace it with elementary OS 5. I’ll also keep my personal files (music, pictures, videos, documents from my home directory) while switching distributions.
+
+Let’s first take a look at the requirements:
+
+ * A system with Linux and Windows dual boot
+ * Live USB of Linux you want to install
+ * Backup of your important files in Windows and in Linux on an external disk (optional yet recommended)
+
+
+
+#### Things to keep in mind for keeping your home directory while changing Linux distribution
+
+If you want to keep your files from existing Linux install as it is, you must have a separate root and home directory. You might have noticed that in my [dual boot tutorials][8], I always go for ‘Something Else’ option and then manually create root and home partitions instead of choosing ‘Install alongside Windows’ option. This is where all the troubles in manually creating separate home partition pay off.
+
+Keeping Home on a separate partition is helpful in situations when you want to replace your existing Linux install with another without losing your files.
+
+Note: You must remember the exact username and password of your existing Linux install in order to use the same home directory as it is in the new distribution.
+
+If you don’t have a separate Home partition, you may create it later as well BUT I won’t recommend that. That process is slightly complicated and I don’t want you to mess up your system.
+
+With that much background information, it’s time to see how to replace a Linux distribution with another.
+
+#### Step 1: Create a live USB of the new Linux distribution
+
+Alright! I already mentioned it in the requirements but I still included it in the main steps to avoid confusion.
+
+You can create a live USB using a start up disk creator like [Etcher][9] in Windows or Linux. The process is simple so I am not going to list the steps here.
+
+#### Step 2: Boot into live USB and proceed to installing Linux
+
+Since you have already dual booted before, you probably know the drill. Plugin the live USB, restart your system and at the boot time, press F10 or F12 repeatedly to enter BIOS settings.
+
+In here, choose to boot from the USB. And then you’ll see the option to try the live environment or installing it immediately.
+
+You should start the installation procedure. When you reach the ‘Installation type’ screen, choose the ‘Something else’ option.
+
+![Replacing one Linux with another from dual boot][10]
+Select ‘Something else’ here
+
+#### Step 3: Prepare the partition
+
+You’ll see the partitioning screen now. Look closely and you’ll see your Linux installation with Ext4 file system type.
+
+![Identifying Linux partition in dual boot][11]
+Identify where your Linux is installed
+
+In the above picture, the Ext4 partition labeled as Linux Mint 19 is the root partition. The second Ext4 partition of 82691 MB is the Home partition. I [haven’t used any swap space][12] here.
+
+Now, if you have just one Ext4 partition, that means that your home directory is on the same partition as root. In this case, you won’t be able to keep your Home directory. I suggest that you copy the important files to an external disk else you’ll lose them forever.
+
+It’s time to delete the root partition. Select the root partition and click the – sign. This will create some free space.
+
+![Delete root partition of your existing Linux install][13]
+Delete root partition
+
+When you have the free space, click on + sign.
+
+![Create root partition for the new Linux][14]
+Create a new root partition
+
+Now you should create a new partition out of this free space. If you had just one root partition in your previous Linux install, you should create root and home partitions here. You can also create the swap partition if you want to.
+
+If you had root and home partition separately, just create a root partition from the deleted root partition.
+
+![Create root partition for the new Linux][15]
+Creating root partition
+
+You may ask why did I use delete and add instead of using the ‘change’ option. It’s because a few years ago, using change didn’t work for me. So I prefer to do a – and +. Is it superstition? Maybe.
+
+One important thing to do here is to mark the newly created partition for format. f you don’t change the size of the partition, it won’t be formatted unless you explicitly ask it to format. And if the partition is not formatted, you’ll have issues.
+
+![][16]
+It’s important to format the root partition
+
+Now if you already had a separate Home partition on your existing Linux install, you should select it and click on change.
+
+![Recreate home partition][17]
+Retouch the already existing home partition (if any)
+
+You just have to specify that you are mounting it as home partition.
+
+![Specify the home mount point][18]
+Specify the home mount point
+
+If you had a swap partition, you can repeat the same steps as the home partition. This time specify that you want to use the space as swap.
+
+At this stage, you should have a root partition (with format option selected) and a home partition (and a swap if you want to). Hit the install now button to start the installation.
+
+![Verify partitions while replacing one Linux with another][19]
+Verify the partitions
+
+The next few screens would be familiar to you. What matters is the screen where you are asked to create user and password.
+
+If you had a separate home partition previously and you want to use the same home directory, you MUST use the same username and password that you had before. Computer name doesn’t matter.
+
+![To keep the home partition intact, use the previous user and password][20]
+To keep the home partition intact, use the previous user and password
+
+Your struggle is almost over. You don’t have to do anything else other than waiting for the installation to finish.
+
+![Wait for installation to finish][21]
+Wait for installation to finish
+
+Once the installation is over, restart your system. You’ll have a new Linux distribution or version.
+
+In my case, I had the entire home directory of Linux Mint 19 as it is in the elementary OS. All the videos, pictures I had remained as it is. Isn’t that nice?
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/replace-linux-from-dual-boot/
+
+作者:[Abhishek Prakash][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/abhishek/
+[1]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/Replace-Linux-Distro-from-dual-boot.png
+[2]: https://itsfoss.com/install-ubuntu-1404-dual-boot-mode-windows-8-81-uefi/
+[3]: https://itsfoss.com/linux-mint-vs-ubuntu/
+[4]: https://www.linuxmint.com/
+[5]: https://itsfoss.com/uninstall-ubuntu-linux-windows-dual-boot/
+[6]: https://itsfoss.com/guide-install-linux-mint-16-dual-boot-windows/
+[7]: https://www.ubuntu.com/
+[8]: https://itsfoss.com/guide-install-elementary-os-luna/
+[9]: https://etcher.io/
+[10]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/replace-linux-with-another-1.jpg
+[11]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/replace-linux-with-another-2.jpg
+[12]: https://itsfoss.com/swap-size/
+[13]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/replace-linux-with-another-3.jpg
+[14]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/replace-linux-with-another-4.jpg
+[15]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/replace-linux-with-another-5.jpg
+[16]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/replace-linux-with-another-6.jpg
+[17]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/replace-linux-with-another-7.jpg
+[18]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/replace-linux-with-another-8.jpg
+[19]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/replace-linux-with-another-9.jpg
+[20]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/replace-linux-with-another-10.jpg
+[21]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/replace-linux-with-another-11.jpg
diff --git a/sources/tech/20180925 Taking the Audiophile Linux distro for a spin.md b/sources/tech/20180925 Taking the Audiophile Linux distro for a spin.md
new file mode 100644
index 0000000000..1c813cb30a
--- /dev/null
+++ b/sources/tech/20180925 Taking the Audiophile Linux distro for a spin.md
@@ -0,0 +1,161 @@
+Taking the Audiophile Linux distro for a spin
+======
+
+This lightweight open source audio OS offers a rich feature set and high-quality digital sound.
+
+
+
+I recently stumbled on the [Audiophile Linux project][1], one of a number of special-purpose music-oriented Linux distributions. Audiophile Linux:
+
+ 1. is based on [ArchLinux][2]
+
+ 2. provides a real-time Linux kernel customized for playing music
+
+ 3. uses the lightweight [Fluxbox][3] window manager
+
+ 4. avoids unnecessary daemons and services
+
+ 5. allows playback of DSF and supports the usual PCM formats
+
+ 6. supports various music players, including one of my favorite combos: MPD + Cantata
+
+
+
+
+The Audiophile Linux site hasn’t shown a lot of activity since April 2017, but it does contain some updates and commentary from this year. Given its orientation and feature set, I decided to take it for a spin on my old Toshiba laptop.
+
+### Installing Audiophile Linux
+
+The site provides [a clear set of install instructions][4] that require the use of the terminal. The first step after downloading the .iso is burning it to a USB stick. I used the GNOME Disks utility’s Restore Disk Image for this purpose. Once I had the USB set up and ready to go, I plugged it into the Toshiba and booted it. When the splash screen came up, I set the boot device to the USB stick and a minute or so later, the Arch Grub menu was displayed. I booted Linux from that menu, which put me in a root shell session, where I could carry out the install to the hard drive:
+
+
+
+I was willing to sacrifice the 320-GB hard drive in the Toshiba for this test, so I was able to use the previous Linux partitioning (from the last experiment). I then proceeded as follows:
+
+```
+fdisk -l # find the disk / partition, in my case /dev/sda and /dev/sda1
+mkfs.ext4 /dev/sda1 # build the ext4 filesystem in the root partition
+mount /dev/sda1 /mnt # mount the new file system
+time cp -ax / /mnt # copy over the OS
+ # reported back cp -ax / /mnt 1.36s user 136.54s system 88% cpu 2:36.37 total
+arch-chroot /mnt /bin/bash # run in the new system root
+cd /etc/apl-files
+./runme.sh # do the rest of the install
+grub-install --target=i386-pc /dev/sda # make the new OS bootable part 1
+grub-mkconfig -o /boot/grub/grub.cfg # part 2
+passwd root # set root’s password
+ln -s /usr/share/zoneinfo/America/Vancouver /etc/localtime # set my time zone
+hwclock --systohc --utc # update the hardware clock
+./autologin.sh # set the system up so that it automatically logs in
+exit # done with the chroot session
+genfstab -U /mnt >> /mnt/etc/fstab # create the fstab for the new system
+```
+
+At that point, I was ready to boot the new operating system, so I did—and voilà, up came the system!
+
+
+
+### Finishing the configuration
+
+Once Audiophile Linux was up and running, I needed to [finish the configuration][4] and load some music. Grabbing the application menu by right-clicking on the screen background, I started **X-terminal** and entered the remaining configuration commands:
+
+```
+ping 8.8.8.8 # check connectivity (works fine)
+su # become root
+pacman-key –init # create pacman’s encryption data part 1
+pacman-key --populate archlinux # part 2
+pacman -Sy # part 3
+pacman -S archlinux-keyring # part 4
+```
+
+At this point, the install instructions note that there is a problem with updating software with the `pacman -Suy` command, and that first the **libxfont** package must be removed using `pacman -Rc libxfont`. I followed this instruction, but the second run of `pacman -Suy` led to another dependency error, this time with the **x265** package. I looked further down the page in the install instructions and saw this recommendation:
+
+_Again there is an error in upstream repo of Arch packages. Try to remove conflicting packages with “pacman -R ffmpeg2.8” and then do pacman -Suy later._
+
+I chose to use `pacman -Rc ffmpeg2.8`, and then reran `pacman -Suy`. (As an aside, typing all these **pacman** commands made me realize how familiar I am with **apt** , and how much this whole process made me feel like I was trying to write an email in some language I don’t know using an online translator.)
+
+To be clear, here was my sequence of operations:
+
+```
+pacman -Suy # failed
+pacman -Rc libxfont
+pacman -Suy # failed, again
+pacman -Rc ffmpeg2.8 # uninstalled Cantata, have to fix that later!
+pacman -Suy # worked!
+```
+
+Now back to the rest of the instructions:
+
+```
+pacman -S terminus-font
+pacman -S xorg-server
+pacman -S firefox # the docs suggested installing chromium but I prefer FF
+reboot
+```
+
+And the last little bit, fiddling `/etc/fstab` to avoid access time modifications. I also thought I’d try installing [Cantata][5] once more using `pacman -S cantata`, and it worked just fine (no `ffmpeg2.8` problems).
+
+I found the `DAC Setup > List cards` on the application menu, which showed the built-in Intel sound hardware plus my USB DAC that I had plugged in earlier. Then I selected `DAC Setup > Edit mpd.conf` and adjusted the output stanza of `mpd.conf`. I used `scp` to copy an album over from my main music server into **~/Music**. And finally, I used the application menu `DAC Setup > Restart mpd`. And… nothing… the **conky** info on the screen indicated “MPD not responding”. So I scanned again through the comments at the bottom of the installation instructions and spotted this:
+
+_After every update of mpd, you have to do:
+1. Become root
+```
+$su
+```
+2. run this commands
+```
+# cat /etc/apl-files/mpd.service > /usr/lib/systemd/system/mpd.service
+# systemctl daemon-reload
+# systemctl restart mpd.service_
+```
+_And this will be fixed._
+
+
+
+And it works! Right now I’m enjoying [Nils Frahm’s "All Melody"][6] from the album of the same name, playing over my [Schiit Fulla 2][7] in glorious high-resolution sound. Time to copy in some more music so I can give it a better listen.
+
+So… does it sound better than the same DAC connected to my regular work laptop and playing back through [Guayadeque][8] or [GogglesMM][9]? I’m going to see if I can detect a difference at some point, but right now all I can say is it sounds just wonderful; plus [I like the Cantata / mpd combo a lot][10], and I really enjoy having the heads-up display in the upper right of the screen.
+
+### As for the music...
+
+The other day I was reorganizing my work hard drive a bit and I decided to check to make sure that 1) all the music on it was also on the house music servers and 2) _vice versa_ (gotta set up `rsync` for that purpose one day soon). In doing so, I found some music I hadn’t enjoyed for a while, which is kind of like buying a brand-new album, except it costs much less.
+
+[Six Degrees Records][11] has long been one of my favorite purveyors of unusual music. A great example is the group [Zuco 103][12]'s album [Whaa!][13], whose CD version I purchased from Six Degrees’ online store some years ago. Check out [this fun documentary about the group][14].
+
+
+
+For a completely different experience, take a look at the [Ragazze Quartet’s performance of Terry Riley’s "Four Four Three."][15] I picked up ahigh-resolutionn version of this fascinating music from [Channel Classics][16], which operates a Linux-friendly download store (no bloatware to install on your computer).
+
+And finally, I was saddened to hear of the recent passing of [Rachid Taha][17], whose wonderful blend of North African and French musical traditions, along with his frank confrontation of the challenges of being North African and living in Europe, has made some powerful—and fun—music. Check out [Taha’s version of "Rock the Casbah."][18] I have a few of his songs scattered around various compilation albums, and some time ago bought the CD version of [Rachid Taha: The Definitive Collection][19], which I’ve been enjoying again recently.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/9/audiophile-linux-distro
+
+作者:[Chris Hermansen][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/clhermansen
+[1]: https://www.ap-linux.com/
+[2]: https://www.archlinux.org/
+[3]: http://fluxbox.org/
+[4]: https://www.ap-linux.com/documentation/ap-linux-v4-install-instructions/
+[5]: https://github.com/CDrummond/cantata
+[6]: https://www.youtube.com/watch?v=1PTj1qIqcWM
+[7]: https://www.audiostream.com/content/listening-session-history-lesson-bw-schiit-and-shinola-together-last
+[8]: http://www.guayadeque.org/
+[9]: https://gogglesmm.github.io/
+[10]: https://opensource.com/article/17/8/cantata-music-linux
+[11]: https://www.sixdegreesrecords.com/
+[12]: https://www.sixdegreesrecords.com/?s=zuco+103
+[13]: https://www.musicomh.com/reviews/albums/zuco-103-whaa
+[14]: https://www.youtube.com/watch?v=ncaqD92cjQ8
+[15]: https://www.youtube.com/watch?v=DwMaO7bMVD4
+[16]: https://www.channelclassics.com/catalogue/37816-Riley-Four-Four-Three/
+[17]: https://en.wikipedia.org/wiki/Rachid_Taha
+[18]: https://www.youtube.com/watch?v=n1p_dkJo6Y8
+[19]: http://www.bbc.co.uk/music/reviews/26rg/
diff --git a/sources/tech/20180926 An introduction to swap space on Linux systems.md b/sources/tech/20180926 An introduction to swap space on Linux systems.md
new file mode 100644
index 0000000000..036890ef4b
--- /dev/null
+++ b/sources/tech/20180926 An introduction to swap space on Linux systems.md
@@ -0,0 +1,300 @@
+An introduction to swap space on Linux systems
+======
+
+
+
+Swap space is a common aspect of computing today, regardless of operating system. Linux uses swap space to increase the amount of virtual memory available to a host. It can use one or more dedicated swap partitions or a swap file on a regular filesystem or logical volume.
+
+There are two basic types of memory in a typical computer. The first type, random access memory (RAM), is used to store data and programs while they are being actively used by the computer. Programs and data cannot be used by the computer unless they are stored in RAM. RAM is volatile memory; that is, the data stored in RAM is lost if the computer is turned off.
+
+Hard drives are magnetic media used for long-term storage of data and programs. Magnetic media is nonvolatile; the data stored on a disk remains even when power is removed from the computer. The CPU (central processing unit) cannot directly access the programs and data on the hard drive; it must be copied into RAM first, and that is where the CPU can access its programming instructions and the data to be operated on by those instructions. During the boot process, a computer copies specific operating system programs, such as the kernel and init or systemd, and data from the hard drive into RAM, where it is accessed directly by the computer’s processor, the CPU.
+
+### Swap space
+
+Swap space is the second type of memory in modern Linux systems. The primary function of swap space is to substitute disk space for RAM memory when real RAM fills up and more space is needed.
+
+For example, assume you have a computer system with 8GB of RAM. If you start up programs that don’t fill that RAM, everything is fine and no swapping is required. But suppose the spreadsheet you are working on grows when you add more rows, and that, plus everything else that's running, now fills all of RAM. Without swap space available, you would have to stop working on the spreadsheet until you could free up some of your limited RAM by closing down some other programs.
+
+The kernel uses a memory management program that detects blocks, aka pages, of memory in which the contents have not been used recently. The memory management program swaps enough of these relatively infrequently used pages of memory out to a special partition on the hard drive specifically designated for “paging,” or swapping. This frees up RAM and makes room for more data to be entered into your spreadsheet. Those pages of memory swapped out to the hard drive are tracked by the kernel’s memory management code and can be paged back into RAM if they are needed.
+
+The total amount of memory in a Linux computer is the RAM plus swap space and is referred to as virtual memory.
+
+### Types of Linux swap
+
+Linux provides for two types of swap space. By default, most Linux installations create a swap partition, but it is also possible to use a specially configured file as a swap file. A swap partition is just what its name implies—a standard disk partition that is designated as swap space by the `mkswap` command.
+
+A swap file can be used if there is no free disk space in which to create a new swap partition or space in a volume group where a logical volume can be created for swap space. This is just a regular file that is created and preallocated to a specified size. Then the `mkswap` command is run to configure it as swap space. I don’t recommend using a file for swap space unless absolutely necessary.
+
+### Thrashing
+
+Thrashing can occur when total virtual memory, both RAM and swap space, become nearly full. The system spends so much time paging blocks of memory between swap space and RAM and back that little time is left for real work. The typical symptoms of this are obvious: The system becomes slow or completely unresponsive, and the hard drive activity light is on almost constantly.
+
+If you can manage to issue a command like `free` that shows CPU load and memory usage, you will see that the CPU load is very high, perhaps as much as 30 to 40 times the number of CPU cores in the system. Another symptom is that both RAM and swap space are almost completely allocated.
+
+After the fact, looking at SAR (system activity report) data can also show these symptoms. I install SAR on every system I work on and use it for post-repair forensic analysis.
+
+### What is the right amount of swap space?
+
+Many years ago, the rule of thumb for the amount of swap space that should be allocated on the hard drive was 2X the amount of RAM installed in the computer (of course, that was when most computers' RAM was measured in KB or MB). So if a computer had 64KB of RAM, a swap partition of 128KB would be an optimum size. This rule took into account the facts that RAM sizes were typically quite small at that time and that allocating more than 2X RAM for swap space did not improve performance. With more than twice RAM for swap, most systems spent more time thrashing than actually performing useful work.
+
+RAM has become an inexpensive commodity and most computers these days have amounts of RAM that extend into tens of gigabytes. Most of my newer computers have at least 8GB of RAM, one has 32GB, and my main workstation has 64GB. My older computers have from 4 to 8 GB of RAM.
+
+When dealing with computers having huge amounts of RAM, the limiting performance factor for swap space is far lower than the 2X multiplier. The Fedora 28 online Installation Guide, which can be found online at [Fedora Installation Guide][1], defines current thinking about swap space allocation. I have included below some discussion and the table of recommendations from that document.
+
+The following table provides the recommended size of a swap partition depending on the amount of RAM in your system and whether you want sufficient memory for your system to hibernate. The recommended swap partition size is established automatically during installation. To allow for hibernation, however, you will need to edit the swap space in the custom partitioning stage.
+
+_Table 1: Recommended system swap space in Fedora 28 documentation_
+
+| **Amount of system RAM** | **Recommended swap space** | **Recommended swap with hibernation** |
+|--------------------------|-----------------------------|---------------------------------------|
+| less than 2 GB | 2 times the amount of RAM | 3 times the amount of RAM |
+| 2 GB - 8 GB | Equal to the amount of RAM | 2 times the amount of RAM |
+| 8 GB - 64 GB | 0.5 times the amount of RAM | 1.5 times the amount of RAM |
+| more than 64 GB | workload dependent | hibernation not recommended |
+
+At the border between each range listed above (for example, a system with 2 GB, 8 GB, or 64 GB of system RAM), use discretion with regard to chosen swap space and hibernation support. If your system resources allow for it, increasing the swap space may lead to better performance.
+
+Of course, most Linux administrators have their own ideas about the appropriate amount of swap space—as well as pretty much everything else. Table 2, below, contains my recommendations based on my personal experiences in multiple environments. These may not work for you, but as with Table 1, they may help you get started.
+
+_Table 2: Recommended system swap space per the author_
+
+| Amount of RAM | Recommended swap space |
+|---------------|------------------------|
+| ≤ 2GB | 2X RAM |
+| 2GB – 8GB | = RAM |
+| >8GB | 8GB |
+
+One consideration in both tables is that as the amount of RAM increases, beyond a certain point adding more swap space simply leads to thrashing well before the swap space even comes close to being filled. If you have too little virtual memory while following these recommendations, you should add more RAM, if possible, rather than more swap space. As with all recommendations that affect system performance, use what works best for your specific environment. This will take time and effort to experiment and make changes based on the conditions in your Linux environment.
+
+#### Adding more swap space to a non-LVM disk environment
+
+Due to changing requirements for swap space on hosts with Linux already installed, it may become necessary to modify the amount of swap space defined for the system. This procedure can be used for any general case where the amount of swap space needs to be increased. It assumes sufficient available disk space is available. This procedure also assumes that the disks are partitioned in “raw” EXT4 and swap partitions and do not use logical volume management (LVM).
+
+The basic steps to take are simple:
+
+ 1. Turn off the existing swap space.
+
+ 2. Create a new swap partition of the desired size.
+
+ 3. Reread the partition table.
+
+ 4. Configure the partition as swap space.
+
+ 5. Add the new partition/etc/fstab.
+
+ 6. Turn on swap.
+
+
+
+
+A reboot should not be necessary.
+
+For safety's sake, before turning off swap, at the very least you should ensure that no applications are running and that no swap space is in use. The `free` or `top` commands can tell you whether swap space is in use. To be even safer, you could revert to run level 1 or single-user mode.
+
+Turn off the swap partition with the command which turns off all swap space:
+
+```
+swapoff -a
+
+```
+
+Now display the existing partitions on the hard drive.
+
+```
+fdisk -l
+
+```
+
+This displays the current partition tables on each drive. Identify the current swap partition by number.
+
+Start `fdisk` in interactive mode with the command:
+
+```
+fdisk /dev/
+
+```
+
+For example:
+
+```
+fdisk /dev/sda
+
+```
+
+At this point, `fdisk` is now interactive and will operate only on the specified disk drive.
+
+Use the fdisk `p` sub-command to verify that there is enough free space on the disk to create the new swap partition. The space on the hard drive is shown in terms of 512-byte blocks and starting and ending cylinder numbers, so you may have to do some math to determine the available space between and at the end of allocated partitions.
+
+Use the `n` sub-command to create a new swap partition. fdisk will ask you the starting cylinder. By default, it chooses the lowest-numbered available cylinder. If you wish to change that, type in the number of the starting cylinder.
+
+The `fdisk` command now allows you to enter the size of the partitions in a number of formats, including the last cylinder number or the size in bytes, KB or MB. Type in 4000M, which will give about 4GB of space on the new partition (for example), and press Enter.
+
+Use the `p` sub-command to verify that the partition was created as you specified it. Note that the partition will probably not be exactly what you specified unless you used the ending cylinder number. The `fdisk` command can only allocate disk space in increments on whole cylinders, so your partition may be a little smaller or larger than you specified. If the partition is not what you want, you can delete it and create it again.
+
+Now it is necessary to specify that the new partition is to be a swap partition. The sub-command `t` allows you to specify the type of partition. So enter `t`, specify the partition number, and when it asks for the hex code partition type, type 82, which is the Linux swap partition type, and press Enter.
+
+When you are satisfied with the partition you have created, use the `w` sub-command to write the new partition table to the disk. The `fdisk` program will exit and return you to the command prompt after it completes writing the revised partition table. You will probably receive the following message as `fdisk` completes writing the new partition table:
+
+```
+The partition table has been altered!
+Calling ioctl() to re-read partition table.
+WARNING: Re-reading the partition table failed with error 16: Device or resource busy.
+The kernel still uses the old table.
+The new table will be used at the next reboot.
+Syncing disks.
+```
+
+At this point, you use the `partprobe` command to force the kernel to re-read the partition table so that it is not necessary to perform a reboot.
+
+```
+partprobe
+```
+
+Now use the command `fdisk -l` to list the partitions and the new swap partition should be among those listed. Be sure that the new partition type is “Linux swap”.
+
+It will be necessary to modify the /etc/fstab file to point to the new swap partition. The existing line may look like this:
+
+```
+LABEL=SWAP-sdaX swap swap defaults 0 0
+
+```
+
+where `X` is the partition number. Add a new line that looks similar this, depending upon the location of your new swap partition:
+
+```
+/dev/sdaY swap swap defaults 0 0
+
+```
+
+Be sure to use the correct partition number. Now you can perform the final step in creating the swap partition. Use the `mkswap` command to define the partition as a swap partition.
+
+```
+mkswap /dev/sdaY
+
+```
+
+The final step is to turn swap on using the command:
+
+```
+swapon -a
+
+```
+
+Your new swap partition is now online along with the previously existing swap partition. You can use the `free` or `top` commands to verify this.
+
+#### Adding swap to an LVM disk environment
+
+If your disk setup uses LVM, changing swap space will be fairly easy. Again, this assumes that space is available in the volume group in which the current swap volume is located. By default, the installation procedures for Fedora Linux in an LVM environment create the swap partition as a logical volume. This makes it easy because you can simply increase the size of the swap volume.
+
+Here are the steps required to increase the amount of swap space in an LVM environment:
+
+ 1. Turn off all swap.
+
+ 2. Increase the size of the logical volume designated for swap.
+
+ 3. Configure the resized volume as swap space.
+
+ 4. Turn on swap.
+
+
+
+
+First, let’s verify that swap exists and is a logical volume using the `lvs` command (list logical volume).
+
+```
+[root@studentvm1 ~]# lvs
+ LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
+ home fedora_studentvm1 -wi-ao---- 2.00g
+ pool00 fedora_studentvm1 twi-aotz-- 2.00g 8.17 2.93
+ root fedora_studentvm1 Vwi-aotz-- 2.00g pool00 8.17
+ swap fedora_studentvm1 -wi-ao---- 8.00g
+ tmp fedora_studentvm1 -wi-ao---- 5.00g
+ usr fedora_studentvm1 -wi-ao---- 15.00g
+ var fedora_studentvm1 -wi-ao---- 10.00g
+[root@studentvm1 ~]#
+```
+
+You can see that the current swap size is 8GB. In this case, we want to add 2GB to this swap volume. First, stop existing swap. You may have to terminate running programs if swap space is in use.
+
+```
+swapoff -a
+
+```
+
+Now increase the size of the logical volume.
+
+```
+[root@studentvm1 ~]# lvextend -L +2G /dev/mapper/fedora_studentvm1-swap
+ Size of logical volume fedora_studentvm1/swap changed from 8.00 GiB (2048 extents) to 10.00 GiB (2560 extents).
+ Logical volume fedora_studentvm1/swap successfully resized.
+[root@studentvm1 ~]#
+```
+
+Run the `mkswap` command to make this entire 10GB partition into swap space.
+
+```
+[root@studentvm1 ~]# mkswap /dev/mapper/fedora_studentvm1-swap
+mkswap: /dev/mapper/fedora_studentvm1-swap: warning: wiping old swap signature.
+Setting up swapspace version 1, size = 10 GiB (10737414144 bytes)
+no label, UUID=3cc2bee0-e746-4b66-aa2d-1ea15ef1574a
+[root@studentvm1 ~]#
+```
+
+Turn swap back on.
+
+```
+[root@studentvm1 ~]# swapon -a
+[root@studentvm1 ~]#
+```
+
+Now verify the new swap space is present with the list block devices command. Again, a reboot is not required.
+
+```
+[root@studentvm1 ~]# lsblk
+NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
+sda 8:0 0 60G 0 disk
+|-sda1 8:1 0 1G 0 part /boot
+`-sda2 8:2 0 59G 0 part
+ |-fedora_studentvm1-pool00_tmeta 253:0 0 4M 0 lvm
+ | `-fedora_studentvm1-pool00-tpool 253:2 0 2G 0 lvm
+ | |-fedora_studentvm1-root 253:3 0 2G 0 lvm /
+ | `-fedora_studentvm1-pool00 253:6 0 2G 0 lvm
+ |-fedora_studentvm1-pool00_tdata 253:1 0 2G 0 lvm
+ | `-fedora_studentvm1-pool00-tpool 253:2 0 2G 0 lvm
+ | |-fedora_studentvm1-root 253:3 0 2G 0 lvm /
+ | `-fedora_studentvm1-pool00 253:6 0 2G 0 lvm
+ |-fedora_studentvm1-swap 253:4 0 10G 0 lvm [SWAP]
+ |-fedora_studentvm1-usr 253:5 0 15G 0 lvm /usr
+ |-fedora_studentvm1-home 253:7 0 2G 0 lvm /home
+ |-fedora_studentvm1-var 253:8 0 10G 0 lvm /var
+ `-fedora_studentvm1-tmp 253:9 0 5G 0 lvm /tmp
+sr0 11:0 1 1024M 0 rom
+[root@studentvm1 ~]#
+```
+
+You can also use the `swapon -s` command, or `top`, `free`, or any of several other commands to verify this.
+
+```
+[root@studentvm1 ~]# free
+ total used free shared buff/cache available
+Mem: 4038808 382404 2754072 4152 902332 3404184
+Swap: 10485756 0 10485756
+[root@studentvm1 ~]#
+```
+
+Note that the different commands display or require as input the device special file in different forms. There are a number of ways in which specific devices are accessed in the /dev directory. My article, [Managing Devices in Linux][2], includes more information about the /dev directory and its contents.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/9/swap-space-linux-systems
+
+作者:[David Both][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/dboth
+[1]: https://docs.fedoraproject.org/en-US/fedora/f28/install-guide/
+[2]: https://opensource.com/article/16/11/managing-devices-linux
diff --git a/sources/tech/20180926 How to use the Scikit-learn Python library for data science projects.md b/sources/tech/20180926 How to use the Scikit-learn Python library for data science projects.md
new file mode 100644
index 0000000000..4f5d9aedf6
--- /dev/null
+++ b/sources/tech/20180926 How to use the Scikit-learn Python library for data science projects.md
@@ -0,0 +1,258 @@
+How to use the Scikit-learn Python library for data science projects
+======
+
+
+
+The Scikit-learn Python library, initially released in 2007, is commonly used in solving machine learning and data science problems—from the beginning to the end. The versatile library offers an uncluttered, consistent, and efficient API and thorough online documentation.
+
+### What is Scikit-learn?
+
+[Scikit-learn][1] is an open source Python library that has powerful tools for data analysis and data mining. It's available under the BSD license and is built on the following machine learning libraries:
+
+ * **NumPy** , a library for manipulating multi-dimensional arrays and matrices. It also has an extensive compilation of mathematical functions for performing various calculations.
+ * **SciPy** , an ecosystem consisting of various libraries for completing technical computing tasks.
+ * **Matplotlib** , a library for plotting various charts and graphs.
+
+
+
+Scikit-learn offers an extensive range of built-in algorithms that make the most of data science projects.
+
+Here are the main ways the Scikit-learn library is used.
+
+#### 1. Classification
+
+The [classification][2] tools identify the category associated with provided data. For example, they can be used to categorize email messages as either spam or not.
+
+ * Support vector machines (SVMs)
+ * Nearest neighbors
+ * Random forest
+
+
+
+#### 2. Regression
+
+Classification algorithms in Scikit-learn include:
+
+Regression involves creating a model that tries to comprehend the relationship between input and output data. For example, regression tools can be used to understand the behavior of stock prices.
+
+Regression algorithms include:
+
+ * SVMs
+ * Ridge regression
+ * Lasso
+
+
+
+#### 3. Clustering
+
+The Scikit-learn clustering tools are used to automatically group data with the same characteristics into sets. For example, customer data can be segmented based on their localities.
+
+Clustering algorithms include:
+
+ * K-means
+ * Spectral clustering
+ * Mean-shift
+
+
+
+#### 4. Dimensionality reduction
+
+Dimensionality reduction lowers the number of random variables for analysis. For example, to increase the efficiency of visualizations, outlying data may not be considered.
+
+Dimensionality reduction algorithms include:
+
+ * Principal component analysis (PCA)
+ * Feature selection
+ * Non-negative matrix factorization
+
+
+
+#### 5. Model selection
+
+Model selection algorithms offer tools to compare, validate, and select the best parameters and models to use in your data science projects.
+
+Model selection modules that can deliver enhanced accuracy through parameter tuning include:
+
+ * Grid search
+ * Cross-validation
+ * Metrics
+
+
+
+#### 6. Preprocessing
+
+The Scikit-learn preprocessing tools are important in feature extraction and normalization during data analysis. For example, you can use these tools to transform input data—such as text—and apply their features in your analysis.
+
+Preprocessing modules include:
+
+ * Preprocessing
+ * Feature extraction
+
+
+
+### A Scikit-learn library example
+
+Let's use a simple example to illustrate how you can use the Scikit-learn library in your data science projects.
+
+We'll use the [Iris flower dataset][3], which is incorporated in the Scikit-learn library. The Iris flower dataset contains 150 details about three flower species:
+
+ * Setosa—labeled 0
+ * Versicolor—labeled 1
+ * Virginica—labeled 2
+
+
+
+The dataset includes the following characteristics of each flower species (in centimeters):
+
+ * Sepal length
+ * Sepal width
+ * Petal length
+ * Petal width
+
+
+
+#### Step 1: Importing the library
+
+Since the Iris dataset is included in the Scikit-learn data science library, we can load it into our workspace as follows:
+
+```
+from sklearn import datasets
+iris = datasets.load_iris()
+```
+
+These commands import the **datasets** module from **sklearn** , then use the **load_digits()** method from **datasets** to include the data in the workspace.
+
+#### Step 2: Getting dataset characteristics
+
+The **datasets** module contains several methods that make it easier to get acquainted with handling data.
+
+In Scikit-learn, a dataset refers to a dictionary-like object that has all the details about the data. The data is stored using the **.data** key, which is an array list.
+
+For instance, we can utilize **iris.data** to output information about the Iris flower dataset.
+
+```
+print(iris.data)
+```
+
+Here is the output (the results have been truncated):
+
+```
+[[5.1 3.5 1.4 0.2]
+ [4.9 3. 1.4 0.2]
+ [4.7 3.2 1.3 0.2]
+ [4.6 3.1 1.5 0.2]
+ [5. 3.6 1.4 0.2]
+ [5.4 3.9 1.7 0.4]
+ [4.6 3.4 1.4 0.3]
+ [5. 3.4 1.5 0.2]
+ [4.4 2.9 1.4 0.2]
+ [4.9 3.1 1.5 0.1]
+ [5.4 3.7 1.5 0.2]
+ [4.8 3.4 1.6 0.2]
+ [4.8 3. 1.4 0.1]
+ [4.3 3. 1.1 0.1]
+ [5.8 4. 1.2 0.2]
+ [5.7 4.4 1.5 0.4]
+ [5.4 3.9 1.3 0.4]
+ [5.1 3.5 1.4 0.3]
+```
+
+Let's also use **iris.target** to give us information about the different labels of the flowers.
+
+```
+print(iris.target)
+```
+
+Here is the output:
+
+```
+[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
+ 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
+ 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
+ 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
+ 2 2]
+
+```
+
+If we use **iris.target_names** , we'll output an array of the names of the labels found in the dataset.
+
+```
+print(iris.target_names)
+```
+
+Here is the result after running the Python code:
+
+```
+['setosa' 'versicolor' 'virginica']
+```
+
+#### Step 3: Visualizing the dataset
+
+We can use the [box plot][4] to produce a visual depiction of the Iris flower dataset. The box plot illustrates how the data is distributed over the plane through their quartiles.
+
+Here's how to achieve this:
+
+```
+import seaborn as sns
+box_data = iris.data #variable representing the data array
+box_target = iris.target #variable representing the labels array
+sns.boxplot(data = box_data,width=0.5,fliersize=5)
+sns.set(rc={'figure.figsize':(2,15)})
+```
+
+Let's see the result:
+
+
+
+On the horizontal axis:
+
+ * 0 is sepal length
+ * 1 is sepal width
+ * 2 is petal length
+ * 3 is petal width
+
+
+
+The vertical axis is dimensions in centimeters.
+
+### Wrapping up
+
+Here is the entire code for this simple Scikit-learn data science tutorial.
+
+```
+from sklearn import datasets
+iris = datasets.load_iris()
+print(iris.data)
+print(iris.target)
+print(iris.target_names)
+import seaborn as sns
+box_data = iris.data #variable representing the data array
+box_target = iris.target #variable representing the labels array
+sns.boxplot(data = box_data,width=0.5,fliersize=5)
+sns.set(rc={'figure.figsize':(2,15)})
+```
+
+Scikit-learn is a versatile Python library you can use to efficiently complete data science projects.
+
+If you want to learn more, check out the tutorials on [LiveEdu][5], such as Andrey Bulezyuk's video on using the Scikit-learn library to create a [machine learning application][6].
+
+Do you have any questions or comments? Feel free to share them below.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/9/how-use-scikit-learn-data-science-projects
+
+作者:[Dr.Michael J.Garbade][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/drmjg
+[1]: http://scikit-learn.org/stable/index.html
+[2]: https://blog.liveedu.tv/regression-versus-classification-machine-learning-whats-the-difference/
+[3]: https://en.wikipedia.org/wiki/Iris_flower_data_set
+[4]: https://en.wikipedia.org/wiki/Box_plot
+[5]: https://www.liveedu.tv/guides/data-science/
+[6]: https://www.liveedu.tv/andreybu/REaxr-machine-learning-model-python-sklearn-kera/oPGdP-machine-learning-model-python-sklearn-kera/
diff --git a/translated/talk/20180117 How to get into DevOps.md b/translated/talk/20180117 How to get into DevOps.md
new file mode 100644
index 0000000000..ec169be76f
--- /dev/null
+++ b/translated/talk/20180117 How to get into DevOps.md
@@ -0,0 +1,145 @@
+
+DevOps 实践指南
+======
+
+
+
+在去年大概一年的时间里,我注意到对“Devops 实践”感兴趣的开发人员和系统管理员突然有了明显的增加。这样的变化也合理:现在开发者只要花很少的钱,调用一些 API, 就能单枪匹马地在一整套分布式基础设施上运行自己的应用, 在这个时代,开发和运维的紧密程度前所未有。我看过许多博客和文章介绍很酷的 DevOps 工具和相关思想,但是给那些希望践行 DevOps 的人以指导和建议的内容,我却很少看到。
+
+这篇文章的目的就是描述一下如何去实践。我的想法基于 Reddit 上 [devops][1] 的一些访谈、聊天和深夜讨论,还有一些随机谈话,一般都发生在享受啤酒和美食的时候。如果你已经开始这样实践,我对你的反馈很感兴趣,请通过 [我的博客][2] 或者 [Twitter][3] 联系我,也可以直接在下面评论。我很乐意听到你们的想法和故事。
+
+### 古代的 IT
+
+了解历史是搞清楚未来的关键,DevOps 也不例外。想搞清楚 DevOps 运动的普及和流行,去了解一下上世纪 90 年代后期和 21 世纪前十年 IT 的情况会有帮助。这是我的经验。
+
+我的第一份工作是在一家大型跨国金融服务公司做 Windows 系统管理员。当时给计算资源扩容需要给 Dell 打电话 (或者像我们公司那样打给 CDW ),并下一个价值数十万美元的订单,包含服务器、网络设备、电缆和软件,所有这些都要运到在线或离线的数据中心去。虽然 VMware 仍在尝试说服企业使用虚拟机运行他们的“性能敏感”型程序是更划算的,但是包括我们在内的很多公司都还忠于使用他们的物理机运行应用。
+
+在我们技术部门,有一个专门做数据中心工程和操作的完整团队,他们的工作包括价格谈判,让荒唐的租赁月费能够下降一点点,还包括保证我们的系统能够正常冷却(如果设备太多,这个事情的难度会呈指数增长)。如果这个团队足够幸运足够有钱,境外数据中心的工作人员对我们所有的服务器型号又都有足够的了解,就能避免在盘后交易中不小心扯错东西。那时候亚马逊 AWS 和 Rackspace 逐渐开始加速扩张,但还远远没到临界规模。
+
+当时我们还有专门的团队来保证硬件上运行着的操作系统和软件能够按照预期工作。这些工程师负责设计可靠的架构以方便给系统打补丁,监控和报警,还要定义基础镜像 (gold image) 的内容。这些大都是通过很多手工实验完成的,很多手工实验是为了编写一个运行说明书 (runbook) 来描述要做的事情,并确保按照它执行后的结果确实在预期内。在我们这么大的组织里,这样做很重要,因为一线和二线的技术支持都是境外的,而他们的培训内容只覆盖到了这些运行说明而已。
+
+(这是我职业生涯前三年的世界。我那时候的梦想是成为制定金本位制的人!)
+
+软件发布则完全是另外一头怪兽。无可否认,我在这方面并没有积累太多经验。但是,从我收集的故事(和最近的经历)来看,当时大部分软件开发的日常大概是这样:
+
+ * 开发人员按照技术和功能需求来编写代码,这些需求来自于业务分析人员的会议,但是会议并没有邀请开发人员参加。
+ * 开发人员可以选择为他们的代码编写单元测试,以确保在代码里没有任何明显的疯狂行为,比如除以 0 但不抛出异常。
+ * 然后开发者会把他们的代码标记为 "Ready for QA."(准备好了接受测试),质量保障的成员会把这个版本的代码发布到他们自己的环境中,这个环境和生产环境可能相似,也可能不相似,甚至和开发环境相比也不一定相似。
+ * 故障会在几天或者几个星期内反馈到开发人员那里,这个时长取决于其他业务活动和优先事项。
+
+
+
+虽然系统管理员和开发人员经常有不一致的意见,但是对“变更管理”的痛恨却是一致的。变更管理由高度规范的(就我当时的雇主而言)和非常有必要的规则和程序组成,用来管理一家公司应该什么时候做技术变更,以及如何做。很多公司都按照 [ITIL][4] 来操作, 简单的说,ITIL 问了很多和事情发生的原因、时间、地点和方式相关的问题,而且提供了一个过程,对产生最终答案的决定做审计跟踪。
+
+你可能从我的简短历史课上了解到,当时 IT 的很多很多事情都是手工完成的。这导致了很多错误。错误又导致了很多财产损失。变更管理的工作就是尽量减少这些损失,它常常以这样的形式出现:不管变更的影响和规模大小,每两周才能发布部署一次。周五下午 4 点到周一早上 5 点 59 分这段时间,需要排队等候发布窗口。(讽刺的是,这种流程导致了更多错误,通常还是更严重的那种错误)
+
+### DevOps 不是专家团
+
+你可能在想 "Carlos 你在讲啥啊,什么时候才能说到 Ansible playbooks? ",我热爱 Ansible, 但是请再等一会;下面这些很重要。
+
+你有没有过被分配到过需要跟"DevOps"小组打交道的项目?你有没有依赖过“配置管理”或者“持续集成/持续交付”小组来保证业务流水线设置正确?你有没有在代码开发完的数周之后才参加发布部署的会议?
+
+如果有过,那么你就是在重温历史,这个历史是由上面所有这些导致的。
+
+出于本能,我们喜欢和像自己的人一起工作,这会导致[筒仓][5]的行成。很自然,这种人类特质也会在工作场所表现出来是不足为奇的。我甚至在一个 250 人的创业公司里见到过这样的现象,当时我在那里工作。刚开始的时候,开发人员都在聚在一起工作,彼此深度协作。随着代码变得复杂,开发相同功能的人自然就坐到了一起,解决他们自己的复杂问题。然后按功能划分的小组很快就正式形成了。
+
+在我工作过的很多公司里,系统管理员和开发人员不仅像这样形成了天然的筒仓,而且彼此还有激烈的对抗。开发人员的环境出问题了或者他们的权限太小了,就会对系统管理员很恼火。系统管理员怪开发者无时不刻的不在用各种方式破坏他们的环境,怪开发人员申请的计算资源严重超过他们的需要。双方都不理解对方,更糟糕的是,双方都不愿意去理解对方。
+
+大部分开发人员对操作系统,内核或计算机硬件都不感兴趣。同样的,大部分系统管理员,即使是 Linux 的系统管理员,也都不愿意学习编写代码,他们在大学期间学过一些 C 语言,然后就痛恨它,并且永远都不想再碰 IDE. 所以,开发人员把运行环境的问题甩给围墙外的系统管理员,系统管理员把这些问题和甩过来的其他上百个问题放在一起,做一个优先级安排。每个人都很忙,心怀怨恨的等待着。DevOps 的目的就是解决这种矛盾。
+
+DevOps 不是一个团队,CI/CD 也不是 Jira 系统的一个用户组。DevOps 是一种思考方式。根据这个运动来看,在理想的世界里,开发人员、系统管理员和业务相关人将作为一个团队工作。虽然他们可能不完全了解彼此的世界,可能没有足够的知识去了解彼此的积压任务,但他们在大多数情况下能有一致的看法。
+
+把所有基础设施和业务逻辑都代码化,再串到一个发布部署流水线里,就像是运行在这之上的应用一样。这个理念的基础就是 DevOps. 因为大家都理解彼此,所以人人都是赢家。聊天机器人和易用的监控工具、可视化工具的兴起,背后的基础也是 DevOps.
+
+[Adam Jacob][6] 说的最好:"DevOps 就是企业往软件导向型过渡时我们用来描述操作的词"
+
+### 要实践 DevOps 我需要知道些什么
+
+我经常被问到这个问题,它的答案,和同属于开放式的其他大部分问题一样:视情况而定。
+
+现在“DevOps 工程师”在不同的公司有不同的含义。在软件开发人员比较多但是很少有人懂基础设施的小公司,他们很可能是在找有更多系统管理经验的人。而其他公司,通常是大公司或老公司或又大又老的公司,已经有一个稳固的系统管理团队了,他们在向类似于谷歌 [SRE][7] 的方向做优化,也就是“设计操作功能的软件工程师”。但是,这并不是金科玉律,就像其他技术类工作一样,这个决定很大程度上取决于他的招聘经理。
+
+也就是说,我们一般是在找对深入学习以下内容感兴趣的工程师:
+
+ * 如何管理和设计安全、可扩展的云上的平台(通常是在 AWS 上,不过微软的 Azure, 谷歌的 Cloud Platform,还有 DigitalOcean 和 Heroku 这样的 PaaS 提供商,也都很流行)
+ * 如何用流行的 [CI/CD][8] 工具,比如 Jenkins,Gocd,还有基于云的 Travis CI 或者 CircleCI,来构造一条优化的发布部署流水线,和发布部署策略。
+ * 如何在你的系统中使用基于时间序列的工具,比如 Kibana,Grafana,Splunk,Loggly 或者 Logstash,来监控,记录,并在变化的时候报警,还有
+ * 如何使用配置管理工具,例如 Chef,Puppet 或者 Ansible 做到“基础设施即代码”,以及如何使用像 Terraform 或 CloudFormation 的工具发布这些基础设施。
+
+
+
+容器也变得越来越受欢迎。尽管有人对大规模使用 Docker 的现状[表示不满][9],但容器正迅速地成为一种很好的方式来实现在更少的操作系统上运行超高密度的服务和应用,同时提高它们的可靠性。(像 Kubernetes 或者 Mesos 这样的容器编排工具,能在宿主机故障的时候,几秒钟之内重新启动新的容器。)考虑到这些,掌握 Docker 或者 rkt 以及容器编排平台的知识会对你大有帮助。
+
+如果你是希望做 DevOps 实践的系统管理员,你还需要知道如何写代码。Python 和 Ruby 是 DevOps 领域的流行语言,因为他们是可移植的(也就是说可以在任何操作系统上运行),快速的,而且易读易学。它们还支撑着这个行业最流行的配置管理工具(Ansible 是使用 Python 写的,Chef 和 Puppet 是使用 Ruby 写的)以及云平台的 API 客户端(亚马逊 AWS, 微软 Azure, 谷歌 Cloud Platform 的客户端通常会提供 Python 和 Ruby 语言的版本)。
+
+如果你是开发人员,也希望做 DevOps 的实践,我强烈建议你去学习 Unix,Windows 操作系统以及网络基础知识。虽然云计算把很多系统管理的难题抽象化了,但是对慢应用的性能做 debug 的时候,你知道操作系统如何工作的就会有很大的帮助。下文包含了一些这个主题的图书。
+
+如果你觉得这些东西听起来内容太多,大家都是这么想的。幸运的是,有很多小项目可以让你开始探索。其中一个启动项目是 Gary Stafford 的[选举服务](https://github.com/garystafford/voter-service), 一个基于 Java 的简单投票平台。我们要求面试候选人通过一个流水线将该服务从 GitHub 部署到生产环境基础设施上。你可以把这个服务与 Rob Mile 写的了不起的 DevOps [入门教程](https://github.com/maxamg/cd-office-hours)结合起来,学习如何编写流水线。
+
+还有一个熟悉这些工具的好方法,找一个流行的服务,然后只使用 AWS 和配置管理工具来搭建这个服务所需要的基础设施。第一次先手动搭建,了解清楚要做的事情,然后只用 CloudFormation (或者 Terraform) 和 Ansible 重写刚才的手动操作。令人惊讶的是,这就是我们基础设施开发人员为客户所做的大部分日常工作,我们的客户认为这样的工作非常有意义!
+
+### 需要读的书
+
+如果你在找 DevOps 的其他资源,下面这些理论和技术书籍值得一读。
+
+#### 理论书籍
+
+ * Gene Kim 写的 [The Phoenix Project (凤凰项目)][10]。这是一本很不错的书,内容涵盖了我上文解释过的历史(写的更生动形象),描述了一个运行在敏捷和 DevOps 之上的公司向精益前进的过程。
+ * Terrance Ryan 写的 [Driving Technical Change (布道之道)][11]。非常好的一小本书,讲了大多数技术型组织内的常见性格特点以及如何和他们打交道。这本书对我的帮助比我想象的更多。
+ * Tom DeMarco 和 Tim Lister 合著的 [Peopleware (人件)][12]。管理工程师团队的经典图书,有一点过时,但仍然很有价值。
+ * Tom Limoncelli 写的 [Time Management for System Administrators (时间管理: 给系统管理员)][13]。这本书主要面向系统管理员,它对很多大型组织内的系统管理员生活做了深入的展示。如果你想了解更多系统管理员和开发人员之间的冲突,这本书可能解释了更多。
+ * Eric Ries 写的 [The Lean Startup (精益创业)][14]。描述了 Eric 自己的 3D 虚拟形象公司,IMVU, 发现了如何精益工作,快速失败和更快盈利。
+ * Jez Humble 和他的朋友写的[Lean Enterprise (精益企业)][15]。这本书是对精益创业做的改编,以更适应企业,两本书都很棒,都很好的解释了 DevOps 背后的商业动机。
+ * Kief Morris 写的 [Infrastructure As Code (基础设施即代码)][16]。关于 "基础设施即代码" 的非常好的入门读物!很好的解释了为什么所有公司都有必要采纳这种做法。
+ * Betsy Beyer, Chris Jones, Jennifer Petoff 和 Niall Richard Murphy 合著的 [Site Reliability Engineering (站点可靠性工程师)][17]。一本解释谷歌 SRE 实践的书,也因为是 "DevOps 诞生之前的 DevOps" 被人熟知。在如何处理运行时间、时延和保持工程师快乐方面提供了有趣的看法。
+
+
+
+#### 技术书籍
+
+如果你想找的是让你直接跟代码打交道的书,看这里就对了。
+
+ * W. Richard Stevens 的 [TCP/IP Illustrated (TCP/IP 详解)][18]。这是一套经典的(也可以说是最全面的)讲解基本网络协议的巨著,重点介绍了 TCP/IP 协议族。如果你听说过 1,2, 3,4 层网络,而且对深入学习他们感兴趣,那么你需要这本书。
+ * Evi Nemeth, Trent Hein 和 Ben Whaley 合著的 [UNIX and Linux System Administration Handbook (UNIX/Linux 系统管理员手册)][19]。一本很好的入门书,介绍 Linux/Unix 如何工作以及如何使用。
+ * Don Jones 和 Jeffrey Hicks 合著的 [Learn Windows Powershell In A Month of Lunches (Windows PowerShell实战指南)][20]. 如果你在 Windows 系统下做自动化任务,你需要学习怎么使用 Powershell。这本书能够帮助你。Don Jones 是这方面著名的 MVP。
+ * 几乎所有 [James Turnbull][21] 写的东西,针对流行的 DevOps 工具,他发表了很好的技术入门读物。
+
+
+
+不管是在那些把所有应用都直接部署在物理机上的公司,(现在很多公司仍然有充分的理由这样做)还是在那些把所有应用都做成 serverless 的先驱公司,DevOps 都很可能会持续下去。这部分工作很有趣,产出也很有影响力,而且最重要的是,它搭起桥梁衔接了技术和业务之间的缺口。DevOps 是一个值得期待的美好事物。
+
+首次发表在 [Neurons Firing on a Keyboard][22]。使用 CC-BY-SA 协议。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/1/getting-devops
+
+作者:[Carlos Nunez][a]
+译者:[belitex](https://github.com/belitex)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/carlosonunez
+[1]:https://www.reddit.com/r/devops/
+[2]:https://carlosonunez.wordpress.com/
+[3]:https://twitter.com/easiestnameever
+[4]:https://en.wikipedia.org/wiki/ITIL
+[5]:https://www.psychologytoday.com/blog/time-out/201401/getting-out-your-silo
+[6]:https://twitter.com/adamhjk/status/572832185461428224
+[7]:https://landing.google.com/sre/interview/ben-treynor.html
+[8]:https://en.wikipedia.org/wiki/CI/CD
+[9]:https://thehftguy.com/2016/11/01/docker-in-production-an-history-of-failure/
+[10]:https://itrevolution.com/book/the-phoenix-project/
+[11]:https://pragprog.com/book/trevan/driving-technical-change
+[12]:https://en.wikipedia.org/wiki/Peopleware:_Productive_Projects_and_Teams
+[13]:http://shop.oreilly.com/product/9780596007836.do
+[14]:http://theleanstartup.com/
+[15]:https://info.thoughtworks.com/lean-enterprise-book.html
+[16]:http://infrastructure-as-code.com/book/
+[17]:https://landing.google.com/sre/book.html
+[18]:https://en.wikipedia.org/wiki/TCP/IP_Illustrated
+[19]:http://www.admin.com/
+[20]:https://www.manning.com/books/learn-windows-powershell-in-a-month-of-lunches-third-edition
+[21]:https://jamesturnbull.net/
+[22]:https://carlosonunez.wordpress.com/2017/03/02/getting-into-devops/
diff --git a/translated/talk/20180308 What is open source programming.md b/translated/talk/20180308 What is open source programming.md
deleted file mode 100644
index 5b4427f46c..0000000000
--- a/translated/talk/20180308 What is open source programming.md
+++ /dev/null
@@ -1,89 +0,0 @@
-何为开源?
-======
-
-
-
-简单来说,开源项目就是书写一些大家可以随意取用、修改的代码。但你肯定听过关于Go语言的那个笑话,说 Go 语言简单到看一眼就可以明白规则,但需要一辈子去学会运用它。其实写开源代码也是这样的。往 GitHub, Bitbucket, SourceForge 等网站或者是你自己的博客,网站上丢几行代码不是难事,但想要有效地操作,还需要个人的努力付出,和高瞻远瞩。
-
-
-
-### 我们对开源项目的误解
-
-首先我要说清楚一点:把你的代码写在 GitHub 的公开资源库中并不意味着把你的代码开源化了。在几乎全世界,根本不用创作者做什么,只要作品形成,版权就随之而生了。在创作者进行授权之前,只有作者可以行使版权相关的权力。未经创作者授权的代码,不论有多少人在使用,都是一颗定时炸弹,只有愚蠢的人才会去用它。
-
-有些创作者很善良,认为“很明显我的代码是免费提供给大家使用的。”,他也并不想起诉那些用了他的代码的人,但这并不意味着这些代码可以放心使用。不论在你眼中创作者们多么善良,他们都是有权力起诉任何使用、修改代码,或未经明确授权就将代码嵌入的人。
-
-很明显,你不应该在没有指定开源许可证的情况下将你的源代码发布到网上然后期望别人使用它并为其做出贡献,我建议你也尽量避免使用这种代码,甚至疑似未授权的也不要使用。如果你开发了一个函数和实现,它和之前一个疑似未授权代码很像,源代码作者就可以对你就侵权提起诉讼。
-
-举个例子, Jill Schmill 写了 AwesomeLib 然后未明确授权就把它放到了 GitHub 上,就算 Jill Schmill 不起诉任何人,只要她把 AwesomeLib 的完整版权都卖给 EvilCorp,EvilCorp 就会起诉之前违规使用这段代码的人。这种行为就好像是埋下了计算机安全隐患,总有一天会为人所用。
-
-没有许可证的代码的危险的,以上。
-
-### 选择恰当的开源许可证
-
-假设你证要写一个新程序,而且打算把它放在开源平台上,你需要选择最贴合你需求的[许可证][1]。和宣传中说的一样,你可以从 [GitHub-curated][2] 上得到你想要的信息。这个网站设置得像个小问卷,特别方便快捷,点几下就能找到合适的许可证。
-
-没有许可证的代码的危险的,切记。
-
-在选择许可证时不要过于自负,如果你选的是 [Apache License][3] 或者 [GPLv3][4] 这种广为使用的许可证,人们很容易理解其对于权利的规划,你也不需要请律师来排查其中的漏洞。你选择的许可证使用的人越少,带来的麻烦越多。
-
-最重要的一点是:千万不要试图自己编造许可证!自己编造许可证会给大家带来更多的困惑和困扰,不要这样做。如果在现有的许可证中确实找不到你需要的程式,你可以在现有的许可证中附加上你的要求,并且重点标注出来,提醒使用者们注意。
-
-我知道有些人会说:“我才懒得管什么许可证,我已经把代码发到公共域了。”但问题是,公共域的法律效力并不是受全世界认可的。在不同的国家,公共域的效力和表现形式不同。有些国家的政府管控下,你甚至不可以把自己的源代码发到公共域中。万幸,[Unlicense][5] 可以弥补这些漏洞,它语言简洁,但其效力为全世界认可。
-
-### 怎样引入许可证
-
-确定使用哪个许可证之后,你需要明文指定它。如果你是在 GitHub 、 GitLab 或 BitBucket 这几个网站发布,你需要构建很多个文件夹,在根文件夹中,你应把许可证创建为一个以 LICENSE 命名的 txt 格式明文文件。
-
-创建 LICENSE.txt 这个文件之后还有其他事要做。你需要在每个有效文件的页眉中添加注释块来申明许可证。如果你使用的是一现有的许可证,这一步对你来说十分简便。一个 `# 项目名 (c)2018作者名, GPLv3 许可证,详情见 https://www.gnu.org/licenses/gpl-3.0.en.html` 这样的注释块比隐约指代的许可证的效力要强得多。
-
-如果你是要发布在自己的网站上,步骤也差不多。先创建 LICENSE.txt 文件,放入许可证,再表明许可证出处。
-
-### 开源代码的不同之处
-
-开源代码和专有代码的一个区别的开源代码写出来就是为了给别人看的。我是个40多岁的系统管理员,已经写过许许多多的代码。最开始我写代码是为了工作,为了解决公司的问题,所以其中大部分代码都是专有代码。这种代码的目的很简单,只要能在特定场合通过特定方式发挥作用就行。
-
-开源代码则大不相同。在写开源代码时,你知道它可能会被用于各种各样的环境中。也许你的使用案例的环境条件很局限,但你仍旧希望它能在各种环境下发挥理想的效果。不同的人使用这些代码时,你会看到各类冲突,还有你没有考虑过的思路。虽然代码不一定要满足所有人,但最少它们可以顺利解决使用者遇到的问题,就算解决不了,也可以转换回常见的逻辑,不会给使用者添麻烦。(例如“第583行的内容除以零”就不能作为命令行参数正确的结果)
-
-你的源代码也可能逼疯你,尤其是在你一遍又一遍地修改错误的函数或是子过程后,终于出现了你希望的结果,这时你不会叹口气就继续下一个任务,你会把过程清理干净,因为你不会愿意别人看出你一遍遍尝试的痕迹。比如你会把 `$variable` `$lol`全都换成有意义的 `$iterationcounter` 和 `$modelname`。这意味着你要认真专业地进行注释(尽管对于头脑风暴中的你来说它并不难懂),但为了之后有更多的人可以使用你的代码,你会尽力去注释,但注意适可而止。
-
-这个过程难免有些痛苦沮丧,毕竟这不是你常做的事,会有些不习惯。但它会使你成为一位更好的程序员,也会让你的代码升华。即使你的项目只有你在贡献,清理代码也会节约你后期的很多工作,相信我一年后你更新 app 时,你会庆幸自己现在写下的是 `$modelname`,还有清晰的注释,而不是什么不知名的数列,甚至连 `$lol`也不是。
-
-### 你并不是为你一人而写
-
-开源的真正核心并不是那些代码,是社区。更大的社区的项目维持的时间更长,也更容易为人们接受。因此不仅要加入社区,还要多多为社区发展贡献思路,让自己的项目能够为社区所用。
-
-蝙蝠侠为了完成目标暗中独自花了很大功夫,你用不着这样,你可以登录 Twitter , Reddit, 或者给你项目的相关人士发邮件,发布你正在筹备新项目的消息,仔细聊聊项目的设计初衷和你的计划,让大家一起帮忙,向大家征集数据输入,类似的使用案例,把这些信息整合起来,用在你的代码里。你不用看所有的回复,但你要对它有个大概把握,这样在你之后完善时可以躲过一些陷阱。
-
-不发首次通告这个过程还不算完整。如果你希望大家能够接受你的作品,并且使用它,你就要以此为初衷来设计。公众说不定可以帮到你,你不必对公开这件事如临大敌。所以不要闭门造车,既然你是为大家而写,那就开设一个真实、公开的项目,想象你在社区的监督下,认真地一步步完成它。
-
-### 建立项目的方式
-
-你可以在 GitHub, GitLab, or BitBucket 上免费注册账号来管理你的项目。注册之后,创建知识库,建立 README 文件,分配一个许可证,一步步写入代码。这样可以帮你建立好习惯,让你之后和现实中的团队一起工作时,也能目的清晰地朝着目标稳妥地进行工作。这样你做得越久,就越有兴趣。
-
-用户们会开始对你产生兴趣,这会让你开心也会让你不爽,但你应该亲切礼貌地对待他们,就算他们很多人根本不知道你的项目做的是什么,你可以把文件给他们看,让他们了解你在干什么。有些还在犹豫的用户可以给你提个醒,告诉你最开始设计的用户范围中落下了哪些人。
-
-如果你的项目很受用户青睐,总会有开发者出现,并表示出兴趣。这也许是好事,也可能激怒你。最开始你可能只会做简单的错误修正,但总有一天你会收到拉请求,有可能是特殊利基案例,它可能改变你项目的作用域,甚至改变你项目的初衷。你需要学会分辨哪个有贡献,根据这个决定合并哪个,婉拒哪个。
-
-### 我们为什么要开源?
-
-开源听起来任务繁重,它也确实是这样。但它对你也有很多好处。它可以在无形之中磨练你,让你写出纯净持久的代码,也教会你与人沟通,团队协作。对于一位志向远大的专业开发者来说,它是最好的简历书写者。你的未来雇主很有可能点开你的知识库,了解你的能力范围;而你的开发者也有可能想带你进全球信息网络工作。
-
-最后,为开源工作,意味着个人的提升,因为你在做的事不是为了你一个人,这比养活自己重要得多。
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/3/what-open-source-programming
-
-作者:[Jim Salter][a]
-译者:[Valoniakim](https://github.com/Valoniakim)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/jim-salter
-[1]:https://opensource.com/tags/licensing
-[2]:https://choosealicense.com/
-[3]:https://choosealicense.com/licenses/apache-2.0/
-[4]:https://choosealicense.com/licenses/gpl-3.0/
-[5]:https://choosealicense.com/licenses/unlicense/
diff --git a/translated/talk/20180402 Understanding Linux filesystems- ext4 and beyond.md b/translated/talk/20180402 Understanding Linux filesystems- ext4 and beyond.md
deleted file mode 100644
index b437df4350..0000000000
--- a/translated/talk/20180402 Understanding Linux filesystems- ext4 and beyond.md
+++ /dev/null
@@ -1,272 +0,0 @@
-
-理解 Linux 文件系统:ext4 以及更多文件系统
-==========================================
-
-
-
-目前的大部分 Linux 文件系统都默认采用 ext4 文件系统, 正如以前的 Linux 发行版默认使用 ext3、ext2 以及更久前的 ext。对于不熟悉 Linux 或文件系统的朋友而言,你可能不清楚 ext4 相对于上一版本 ext3 带来了什么变化。你可能还想知道在一连串关于可替代文件系统例如 btrfs、xfs 和 zfs 不断被发布的情况下,ext4 是否仍然能得到进一步的发展 。
-
-在一篇文章中,我们不可能讲述文件系统的所有方面,但我们尝试让您尽快了解 Linux 默认文件系统的发展历史,包括它的产生以及未来发展。我仔细研究了维基百科里的各种关于 ext 文件系统文章、kernel.org‘s wiki 中关于 ext4 的条目以及结合自己的经验写下这篇文章。
-
-### ext 简史
-
-#### MINIX 文件系统
-
-在有 ext 之前, 使用的是 MINIX 文件系统。如果你不熟悉 Linux 历史, 那么可以理解为 MINIX 相对于 IBM PC/AT 微型计算机来说是一个非常小的类 Unix 系统。Andrew Tannenbaum 为了教学的目的而开发了它并于 1987 年发布了源代码(印刷版!)。
-
-
-
-
-
-虽然你可以读阅 MINIX 的源代码,但实际上它并不是免费的开源软件(FOSS)。出版 Tannebaum 著作的出版商要求你花 69 美元的许可费来获得 MINIX 的操作权,而这笔费用包含在书籍的费用中。尽管如此,在那时来说非常便宜,并且 MINIX 的使用得到迅速发展,很快超过了 Tannebaum 当初使用它来教授操作系统编码的意图。在整个 20 世纪 90 年代,你可以发现 MINIX 的安装在世界各个大学里面非常流行。
-而此时,年轻的 Lius Torvalds 使用 MINIX 来开发原始 Linux 内核,并于 1991 年首次公布。而后在 1992 年 12 月在 GPL 开源协议下发布。
-
-但是等等,这是一篇以*文件系统*为主题的文章不是吗?是的,MINIX 有自己的文件系统,早期的 Linux 版本依赖于它。跟 MINIX 一样,Linux 的文件系统也如同玩具那般小 —— MINX 文件系统最多能处理 14 个字符的文件名,并且只能处理 64MB 的存储空间。到了 1991 年,一般的硬盘尺寸已经达到了 40-140MB。很显然,Linux 需要一个更好的文件系统。
-
-#### ext
-
-当 Linus 开发出刚起步的 Linux 内核时,Rémy Card 从事第一代的 ext 文件系统的开发工作。 ext 文件系统在 1992 首次实现并发布 —— 仅在 Linux 首次发布后的一年! —— ext 解决了 MINIX 文件系统中最糟糕的问题。
-
-1992年的 ext 使用在 Linux 内核中的新虚拟文件系统(VFS)抽象层。与之前的 MINIX 文件系统不同的是,ext 可以处理高达 2GB 存储空间并处理 255 个字符的文件名。
-
-但 ext 并没有长时间占统治地位,主要是由于它的原始时间戳(每个文件仅有一个时间戳,而不是今天我们所熟悉的有 inode 、最近文件访问时间和最新文件修改时间的时间戳。)仅仅一年后,ext2 就替代了它。
-
-#### ext2
-
-Rémy 很快就意识到 ext 的局限性,所以一年后他设计出 ext2 替代它。当 ext 仍然根植于 "玩具” 操作系统时,ext2 从一开始就被设计为一个商业级文件系统,沿用 BSD 的 Berkeley 文件系统的设计原理。
-
-Ext2 提供了 GB 级别的最大文件大小和 TB 级别的文件系统大小,使其在 20 世纪 90 年代的地位牢牢巩固在文件系统大联盟中。很快它被广泛地使用,无论是在 Linux 内核中还是最终在 MINIX 中,且利用第三方模块可以使其应用于 MacOs 和 Windows。
-
-但这里仍然有一些问题需要解决:ext2 文件系统与 20 世纪 90 年代的大多数文件系统一样,如果在将数据写入到磁盘的时候,系统发生奔溃或断电,则容易发生灾难性的数据损坏。随着时间的推移,由于碎片(单个文件存储在多个位置,物理上其分散在旋转的磁盘上),它们也遭受了严重的性能损失。
-
-尽管存在这些问题,但今天 ext2 还是用在某些特殊的情况下 —— 最常见的是,作为便携式 USB 拇指驱动器的文件系统格式。
-
-#### ext3
-
-1998 年, 在 ext2 被采用后的 6 年后,Stephen Tweedie 宣布他正在致力于改进 ext2。这成了 ext3,并于 2001 年 11 月在 2.4.15 内核版本中被采用到 Linux 内核主线中。
-
-
-![Packard Bell 计算机][2]
-
-20世纪90年代中期的 Packard Bell 计算机, [Spacekid][3], [CC0][4]
-
-在大部分情况下,Ext2 在 Linux 发行版中做得很好,但像 FAT、FAT32、HFS 和当时的其他文件系统一样 —— 在断电时容易发生灾难性的破坏。如果在将数据写入文件系统时候发生断电,则可能会将其留在所谓 *不一致* 的状态 —— 事情只完成一半而另一半未完成。这可能导致大量文件丢失或损坏,这些文件与正在保存的文件无关甚至导致整个文件系统无法卸载。
-
-Ext3 和 20 世纪 90 年代后期的其他文件系统,如微软的 NTFS ,使用*日志*来解决这个问题。 日志是磁盘上的一种特殊分配,其写入存储在事务中;如果事务完成写入磁盘,则日志中的数据将提交给文件系统它本身。如果文件在它提交操作前崩溃,则重新启动的系统识别其为未完成的事务而将其进行回滚,就像从未发生过一样。这意味着正在处理的文件可能依然会丢失,但文件系统本身保持一致,且其他所有数据都是安全的。
-
-在使用 ext3 文件系统的 Linux 内核中实现了三个级别的日志记录方式:**日记(journal)** , **顺序(ordered)** , 和 **回写(writeback)**。
-
- * **日记(Journal)** 是最低风险模式,在将数据和元数据提交给文件系统之前将其写入日志。这可以保证正在写入的文件与整个文件系统的一致性,但其显著降低了性能。
- * **顺序(Ordered)** 是大多数 Linux 发行版默认模式;ordered 模式将元数据写入日志且直接将数据提交到文件系统。顾名思义,这里的操作顺序是固定的:首先,元数据提交到日志;其次,数据写入文件系统,然后才将日志中关联的元数据更新到文件系统。这确保了在发生奔溃时,与未完整写入相关联的元数据仍在日志中,且文件系统可以在回滚日志时清理那些不完整的写入事务。在 ordered 模式下,系统崩溃可能导致在崩溃期间文件被主动写入或损坏,但文件系统它本身 —— 以及未被主动写入的文件 —— 确保是安全的。
- * **回写(Writeback)** 是第三种模式 —— 也是最不安全的日志模式。在 writeback 模式下,像 ordered 模式一样,元数据会被记录,但数据不会。与 ordered 模式不同,元数据和数据都可以以任何有利于获得最佳性能的顺序写入。这可以显著提高性能,但安全性低很多。尽管 wireteback 模式仍然保证文件系统本身的安全性,但在奔溃或之前写入的文件很容易丢失或损坏。
-
-
-跟之前的 ext2 类似,ext3 使用 16 位内部寻址。这意味着对于有着 4K 块大小的 ext3 在最大规格为 16TiB 的文件系统中可以处理的最大文件大小为 2TiB。
-
-#### ext4
-
-Theodore Ts'o (是当时 ext3 主要开发人员) 在 2006 年发表的 ext4 ,于两年后在 2.6.28 内核版本中被加入到了 Linux 主线。
-
-Ts’o 将 ext4 描述为一个显著扩展 ext3 的临时技术,但它仍然依赖于旧技术。他预计 ext4 终将会被真正的下一代文件系统所取代。
-
-
-
-Ext4 在功能上与 Ext3 在功能上非常相似,但大大支持文件系统、提高了对碎片的抵抗力,有更高的性能以及更好的时间戳。
-
-### Ext4 vs ext3
-
-Ext3 和 Ext4 有一些非常明确的差别,在这里集中讨论下。
-
-#### 向后兼容性
-
-Ext4 特地设计为尽可能地向后兼容 ext3。这不仅允许 ext3 文件系统升级到 ext4;也允许 ext4 驱动程序在 ext3 模式下自动挂载 ext3 文件系统,因此使它无需单独维护两个代码库。
-
-#### 大文件系统
-
-Ext3 文进系统使用 32 为寻址,这限制它仅支持 2TiB 文件大小和 16TiB 文件系统系统大小(这是假设在块大小为 4KiB 的情况下,一些 ext3 文件系统使用更小的块大小,因此对其进一步做了限制)。
-
-Ext4 使用 48 位的内部寻址,理论上可以在文件系统上分配高达 16TiB 大小的文件,其中文件系统大小最高可达 1000 000 TiB(1EiB)。在早期 ext4 的实现中 有些用户空间的程序仍然将其限制为最大大小为 16TiB 的文件系统,但截至 2011 年,e2fsprogs 已经直接支持大于 16TiB 大小的 ext4 文件系统。例如,红帽企业 Linux 合同上仅支持最高 50TiB 的 ext4 文件系统,并建议 ext4 卷不超过 100TiB。
-
-#### 分配改进
-
-Ext4 在将存储块写入磁盘之前对存储块的分配方式进行了大量改进,这可以显著提高读写性能。
-
-##### 区段(extent)
-
-extent 是一系列连续的物理块大小 (最多达 128 MiB,假设块大小为 4KiB),可以一次性保留和寻址。使用区段可以减少给定未见所需的 inode 数量,并显著减少碎片并提高写入大文件时的性能。
-
-##### 多块分配
-
-Ext3 为每一个新分配的块调用一次块分配器。当多个块调用同时打开分配器时,很容易导致严重的碎片。然而,ext4 使用延迟分配,这允许它合并写入并更好地决定如何为尚未提交的写入分配块。
-
-##### 持续的预分配
-
-在为文件预分配磁盘空间时,大部分文件系统必须在创建时将零写入该文件的块中。Ext4 允许使用 `fallocate()`,它保证了空间的可用性(并试图为它找到连续的空间),而不需要县写入它。
-这显著提高了写入和将来读取流和数据库应用程序的写入数据的性能。
-
-##### 延迟分配
-
-这是一个耐人嚼味而有争议性的功能。延迟分配允许 ext4 等待分配将写入数据的实际块,直到它准备好将数据提交到磁盘。(相比之下,即使数据仍然在写入缓存,ext3 也会立即分配块。)
-
-当缓存中的数据累积时,延迟分配块允许文件系统做出更好的选择。然而不幸的是,当程序员想确保数据完全刷新到磁盘时,它增加了在还没有专门编写调用 ‘fsync()’方法的程序中的数据丢失的可能性。
-
-假设一个程序完全重写了一个文件:
-
-`fd=open("file" ,O_TRUNC); write(fd, data); close(fd);`
-
-使用旧的文件系统, `close(fd);` 足以保证 `file` 中的内存刷新到磁盘。即使严格来说,写不是事务性的,但如果文件关闭后发生崩溃,则丢失数据的风险很小。如果写入不成功(由于程序上的错误、磁盘上的错误、断电等),文件的原始版本和较新版本都可能丢失数据或损坏。如果其他进程在写入文件时访问文件,则会看到损坏的版本。
-如果其他进程打开文件并且不希望其内容发生更改 —— 例如,映射到多个正在运行的程序的共享库。这些进程可能会崩溃。
-
-为了避免这些问题,一些程序员完全避免使用 `O_TRUNC`。相反,他们可能会写入一个新文件,关闭它,然后将其重命名为旧文件名:
-
-`fd=open("newfile"); write(fd, data); close(fd); rename("newfile", "file");`
-
-在没有延迟分配的文件系统下,这足以避免上面列出的潜在的损坏和崩溃问题:因为`rename()` 是原子操作,所以它不会被崩溃中断;并且运行的程序将引用旧的。现在 `file` 的未链接版本主要有一个打开的文件文件句柄即可。
-但是因为 ext4 的延迟分配会导致写入被延迟和重新排序,`rename("newfile","file")` 可以在 `newfile` 的内容实际写入磁盘内容之前执行,这打开了并行进行再次获得 `file` 坏版本的问题。
-
-
-为了缓解这种情况,Linux 内核(自版本 2.6.30 )尝试检测这些常见代码情况并强制立即分配。这减少但不能防止数据丢失的可能性 —— 并且它对新文件没有任何帮助。如果你是一位开发人员,请注意:
-
-保证数据立即写入磁盘的方法是正确调用 `fsync()` 。
-
-#### 无限制的子目录
-
-Ext3 仅限于 32000 个子目录;ext4 允许无限数量的子目录。从 2.6.23 内核版本开始,ext4 使用 HTree 索引来减少大量子目录的性能损失。
-
-#### 日志校验
-
-Ext3 没有对日志进行校验,这给内核直接控制之外的磁盘或控制器设备带来了自己的缓存问题。如果控制器或具有子集对缓存的磁盘确实无序写入,则可能会破坏 ext3 的日记事务顺序,
-从而可能破坏在崩溃期间(或之前一段时间)写入的文件。
-
-理论上,这个问题可以使用 write barriers —— 在安装文件系统时,你在挂载选项设置 `barrier=1` ,然后将设备 `fsync` 一直向下调用直到 metal。通过实践,可以发现存储设备和控制器经常不遵守 write barriers —— 提高性能(和 benchmarks,跟竞争对手比较),但增加了本应该防止数据损坏的可能性。
-
-对日志进行校验和允许文件系统奔溃后意识到其某些条目在第一次安装时无效或无序。因此,这避免了即使部分存储设备不存在 barriers ,也会回滚部分或无序日志条目和进一步损坏的文件系统的错误。
-
-#### 快速文件系统检查
-
-在 ext3 下,整个文件系统 —— 包括已删除或空文件 —— 在 `fsck` 被调用时需要检查。相比之下,ext4 标记了未分配块和 inode 表的小部分,从而允许 `fsck` 完全跳过它们。
-这大大减少了在大多数文件系统上运行 `fsck` 的时间,并从内核 2.6.24 开始实现。
-
-#### 改进的时间戳
-
-Ext3 提供粒度为一秒的时间戳。虽然足以满足大多数用途,但任务关键型应用程序经常需要更严格的时间控制。Ext4 通过提供纳秒级的时间戳,使其可用于那些企业,科学以及任务关键型的应用程序。
-
-Ext3文件系统也没有提供足够的位来存储 2038 年 1 月 18 日以后的日期。Ext4 在这里增加了两位,将 [the Unix epoch][5] 扩展了 408 年。如果你在公元 2446 年读到这篇文章,
-你很有可能已经转移到一个更好的文件系统 —— 如果你还在测量 UTC 00:00,1970 年 1 月 1 日以来的时间,这会让我非常非常高兴。
-
-#### 在线碎片整理
-
-ext2 和 ext3 都不直接支持在线碎片整理 —— 即在挂载时会对文件系统进行碎片整理。Ext2 有一个包含的实用程序,**e2defrag**,它的名字暗示 —— 它需要在文件系统未挂载时脱机运行。(显然,这对于根文件系统来说非常有问题。)在 ext3 中的情况甚至更糟糕 —— 虽然 ext3 比 ext2 更不容易受到严重碎片的影响,但 ext3 文件系统运行 **e2defrag** 可能会导致灾难性损坏和数据丢失。
-
-尽管 ext3 最初被认为“不受碎片影响”,但对同一文件(例如 BitTorrent)采用大规模并行写入过程的过程清楚地表明情况并非完全如此。一些用户空间攻击和解决方法,例如 [Shake][6],
-以这种或那种方式解决了这个问题 —— 但它们比真正的、文件系统感知的、内核级碎片整理过程更慢并且在各方面都不太令人满意。
-
-Ext4通过 **e4defrag** 解决了这个问题,且是一个在线、内核模式、文件系统感知、块和范围级别的碎片整理实用程序。
-
-### 正在进行的ext4开发
-
-Ext4,正如 Monty Python 中瘟疫感染者曾经说过的那样,“我还没死呢!” 虽然它的[主要开发人员][7]认为它只是一个真正的[下一代文件系统][8]的权宜之计,但是在一段时间内,没有任何可能的候选人准备好(由于技术或许可问题)部署为根文件系统。
-
-在未来的 ext4 版本中仍然有一些关键功能,包括元数据校验和、一流的配额支持和大型分配块。
-
-#### 元数据校验和
-
-由于 ext4 具有冗余超级块,因此为文件系统校验其中的元数据提供了一种方法,可以自行确定主超级块是否已损坏并需要使用备用块。可以在没有校验和的情况下,从损坏的超级块恢复 —— 但是用户首先需要意识到它已损坏,然后尝试使用备用方法手动挂载文件系统。由于在某些情况下,使用损坏的主超级块安装文件系统读写可能会造成进一步的损坏,即使是经验丰富的用户也无法避免,这也不是一个完美的解决方案!
-
-与 btrfs 或 zfs 等下一代文件系统提供的极其强大的每块校验和相比,ext4 的元数据校验和功能非常弱。但它总比没有好。虽然校验和所有的事情都听起来很简单!—— 事实上,将校验和连接到文件系统有一些重大的挑战; 请参阅[设计文档][9]了解详细信息。
-
-#### 一流的配额支持
-
-等等,配额?!从 ext2 出现的那条开始我们就有了这些!是的,但他们一直都是事后的想法,而且他们总是有点傻逼。这里可能不值得详细介绍,
-但[设计文档][10]列出了配额将从用户空间移动到内核中的方式,并且能够更加正确和高效地执行。
-
-#### 大分配块
-随着时间的推移,那些讨厌的存储系统不断变得越来越大。由于一些固态硬盘已经使用 8K 硬件模块,因此 ext4 对 4K 模块的当前限制越来越受到限制。
-较大的存储块可以显着减少碎片并提高性能,代价是增加“松弛”空间(当您只需要块的一部分来存储文件或文件的最后一块时留下的空间)。
-
-您可以在[设计文档][11]中查看详细说明。
-
-### ext4的实际限制
-
-Ext4 是一个健壮,稳定的文件系统。它是大多数人应该都在 2018 年用它作为根文件系统,但它无法处理所有需求。让我们简单地谈谈你不应该期待的一些事情 —— 现在或可能在未来。
-
-虽然 ext4 可以处理高达 1 EiB 大小相当于 1,000,000 TiB 大小的数据,但你真的、真的不应该尝试这样做。除了仅仅能够记住更多块的地址之外,还存在规模上的问题
-并且现在 ext4 不会处理(并且可能永远不会)超过 50 —— 100TiB 的数据。
-
-Ext4 也不足以保证数据的完整性。随着日志记录的重大进展又回到了前 3 天,它并未涵盖数据损坏的许多常见原因。如果数据已经在磁盘上被[破坏][12]——由于故障硬件,
-宇宙射线的影响(是的,真的),或者数据随时间的简单降级 —— ext4无法检测或修复这种损坏。
-
-最后两点是,ext4 只是一个纯文件系统,而不是存储卷管理器。这意味着,即使你有多个磁盘 ——也就是奇偶校验或冗余,理论上你可以从 ext4 中恢复损坏的数据,但无法知道使用它是否对你有利。虽然理论上可以在离散层中分离文件系统和存储卷管理系统而不会丢失自动损坏检测和修复功能,但这不是当前存储系统的设计方式,并且它将给新设计带来重大挑战。
-
-### 备用文件系统
-在我们开始之前,提醒一句:要非常小心这是没有内置任何备用的文件系统,并直接支持为您分配的主线内核的一部分!
-
-即使文件系统是安全的,如果在内核升级期间出现问题,使用它作为根文件系统也是非常可怕的。如果你没有充分的想法通过一个 chroot 去使用介质引导,耐心地操作内核模块和 grub 配置,
-和 DKMS...不要在一个很重要的系统中去掉对根文件的备份。
-
-可能有充分的理由使用您的发行版不直接支持的文件系统 —— 但如果您这样做,我强烈建议您在系统启动并可用后再安装它。
-(例如,您可能有一个 ext4 根文件系统,但是将大部分数据存储在 zfs 或 btrfs 池中。)
-
-#### XFS
-
-XFS 与 非 ext 文件系统在Linux下的主线一样。它是一个 64 位的日志文件系统,自 2001 年以来内置于 Linux 内核中,为大型文件系统和高度并发性提供了高性能
-(即,大量的进程都会立即写入文件系统)。
-
-从 RHEL 7开始,XFS 成为 Red Hat Enterprise Linux 的默认文件系统。对于家庭或小型企业用户来说,它仍然有一些缺点 —— 最值得注意的是,重新调整现有 XFS 文件系统
-是一件非常痛苦的事情,不如创建另一个并复制数据更有意义。
-
-虽然 XFS 是稳定且是高性能的,但它和 ext4 之间没有足够的具体的最终用途差异来推荐它在非默认值的任何地方使用(例如,RHEL7),除非它解决了对 ext4 的特定问题,例如> 50 TiB容量的文件系统。
-
-XFS 在任何方面都不是 ZFS,btrfs 甚至 WAFL(专有 SAN 文件系统)的“下一代”文件系统。就像 ext4 一样,它应该被视为一种更好的方式的权宜之计。
-
-#### ZFS
-
-ZFS 由 Sun Microsystems 开发,以 zettabyte 命名 —— 相当于 1 万亿 GB —— 因为它理论上可以解决大型存储系统。
-
-作为真正的下一代文件系统,ZFS 提供卷管理(能够在单个文件系统中处理多个单独的存储设备),块级加密校验和(允许以极高的准确率检测数据损坏),
-[自动损坏修复][12](其中冗余或奇偶校验存储可用),[快速异步增量复制][13],内联压缩等,[还有更多][14]。
-
-从 Linux 用户的角度来看,ZFS 的最大问题是许可证问题。ZFS 许可证是 CDDL 许可证,这是一种与 GPL 冲突的半许可许可证。关于在 Linux 内核中使用 ZFS 的意义存在很多争议,
-其争议范围从“它是 GPL 违规”到“它是 CDDL 违规”到“它完全没问题,它还没有在法庭上进行过测试。 “ 最值得注意的是,自2016 年以来,Canonical 已将 ZFS 代码内联
-在其默认内核中,而且目前尚无法律挑战。
-
-此时,即使我作为一个非常狂热于 ZFS 的用户,我也不建议将 ZFS 作为 Linux的 root 文件系统。如果你想在 Linux 上利用 ZFS 的优势,在 ext4 上设置一个小的根文件系统,
-然后将 ZFS 放在你剩余的存储上,把数据,应用程序以及你喜欢的东西放在它上面 —— 但在 ext4 上保持 root,直到你的发行版明显支持 zfs 根目录。
-
-#### BTRFS
-
-Btrfs 是 B-Tree Filesystem 的简称,通常发音为 “butter” —— 由 Chris Mason 于 2007 年在 Oracle 任职期间宣布。BTRFS 旨在跟 ZFS 有大部分相同的目标,
-提供多种设备管理,每块校验、异步复制、直列压缩等,[还有更多][8]。
-
-截至 2018 年,btrfs 相当稳定,可用作标准的单磁盘文件系统,但可能不应该依赖于卷管理器。与许多常见用例中的 ext4,XFS 或 ZFS 相比,它存在严重的性能问题,
-其下一代功能 —— 复制(replication),多磁盘拓扑和快照管理 —— 可能非常多,其结果可能是从灾难性地性能降低到实际数据的丢失。
-
-btrfs 的持续状态是有争议的; SUSE Enterprise Linux 在 2015 年采用它作为默认文件系统,而 Red Hat 宣布它将不再支持从 2017 年开始使用 RHEL 7.4 的 btrfs。
-可能值得注意的是,生产,支持的 btrfs 部署将其用作单磁盘文件系统,而不是作为一个多磁盘卷管理器 —— a la ZFS —— 甚至 Synology 在它的存储设备使用 BTRFS,
-但是它在传统 Linux 内核 RAID(mdraid)之上分层来管理磁盘。
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/4/ext4-filesystem
-
-作者:[Jim Salter][a]
-译者:[HardworkFish](https://github.com/HardworkFish)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/jim-salter
-[1]:https://opensource.com/file/391546
-[2]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/packard_bell_pc.jpg?itok=VI8dzcwp (Packard Bell computer)
-[3]:https://commons.wikimedia.org/wiki/File:Old_packard_bell_pc.jpg
-[4]:https://creativecommons.org/publicdomain/zero/1.0/deed.en
-[5]:https://en.wikipedia.org/wiki/Unix_time
-[6]:https://vleu.net/shake/
-[7]:http://www.linux-mag.com/id/7272/
-[8]:https://arstechnica.com/information-technology/2014/01/bitrot-and-atomic-cows-inside-next-gen-filesystems/
-[9]:https://ext4.wiki.kernel.org/index.php/Ext4_Metadata_Checksums
-[10]:https://ext4.wiki.kernel.org/index.php/Design_For_1st_Class_Quota_in_Ext4
-[11]:https://ext4.wiki.kernel.org/index.php/Design_for_Large_Allocation_Blocks
-[12]:https://en.wikipedia.org/wiki/Data_degradation#Visual_example_of_data_degradation
-[13]:https://arstechnica.com/information-technology/2015/12/rsync-net-zfs-replication-to-the-cloud-is-finally-here-and-its-fast/
-[14]:https://arstechnica.com/information-technology/2014/02/ars-walkthrough-using-the-zfs-next-gen-filesystem-on-linux/
diff --git a/translated/tech/20140114 Caffeinated 6.828:Lab 2 Memory Management.md b/translated/tech/20140114 Caffeinated 6.828:Lab 2 Memory Management.md
new file mode 100644
index 0000000000..0e2a348679
--- /dev/null
+++ b/translated/tech/20140114 Caffeinated 6.828:Lab 2 Memory Management.md
@@ -0,0 +1,232 @@
+# Caffeinated 6.828:实验 2:内存管理
+
+### 简介
+
+在本实验中,你将为你的操作系统写内存管理方面的代码。内存管理有两部分组成。
+
+第一部分是内核的物理内存分配器,内核通过它来分配内存,以及在不需要时释放所分配的内存。分配器以页为单位分配内存,每个页的大小为 4096 字节。你的任务是去维护那个数据结构,它负责记录物理页的分配和释放,以及每个分配的页有多少进程共享它。本实验中你将要写出分配和释放内存页的全套代码。
+
+第二个部分是虚拟内存的管理,它负责由内核和用户软件使用的虚拟内存地址到物理内存地址之间的映射。当使用内存时,x86 架构的硬件是由内存管理单元(MMU)负责执行映射操作来查阅一组页表。接下来你将要修改 JOS,以根据我们提供的特定指令去设置 MMU 的页表。
+
+### 预备知识
+
+在本实验及后面的实验中,你将逐步构建你的内核。我们将会为你提供一些附加的资源。使用 Git 去获取这些资源、提交自实验 1 以来的改变(如有需要的话)、获取课程仓库的最新版本、以及在我们的实验 2 (origin/lab2)的基础上创建一个称为 lab2 的本地分支:
+
+```
+athena% cd ~/6.828/lab
+athena% add git
+athena% git pull
+Already up-to-date.
+athena% git checkout -b lab2 origin/lab2
+Branch lab2 set up to track remote branch refs/remotes/origin/lab2.
+Switched to a new branch "lab2"
+athena%
+```
+
+现在,你需要将你在 lab1 分支中的改变合并到 lab2 分支中,命令如下:
+
+```
+athena% git merge lab1
+Merge made by recursive.
+ kern/kdebug.c | 11 +++++++++--
+ kern/monitor.c | 19 +++++++++++++++++++
+ lib/printfmt.c | 7 +++----
+ 3 files changed, 31 insertions(+), 6 deletions(-)
+athena%
+```
+
+实验 2 包含如下的新源代码,后面你将遍历它们:
+
+- inc/memlayout.h
+- kern/pmap.c
+- kern/pmap.h
+- kern/kclock.h
+- kern/kclock.c
+
+`memlayout.h` 描述虚拟地址空间的布局,这个虚拟地址空间是通过修改 `pmap.c`、`memlayout.h` 和 `pmap.h` 所定义的 *PageInfo* 数据结构来实现的,这个数据结构用于跟踪物理内存页面是否被释放。`kclock.c` 和 `kclock.h` 维护 PC 基于电池的时钟和 CMOS RAM 硬件,在 BIOS 中记录了 PC 上安装的物理内存数量,以及其它的一些信息。在 `pmap.c` 中的代码需要去读取这个设备硬件信息,以算出在这个设备上安装了多少物理内存,这些只是由你来完成的一部分代码:你不需要知道 CMOS 硬件工作原理的细节。
+
+特别需要注意的是 `memlayout.h` 和 `pmap.h`,因为本实验需要你去使用和理解的大部分内容都包含在这两个文件中。你或许还需要去复习 `inc/mmu.h` 这个文件,因为它也包含了本实验中用到的许多定义。
+
+开始本实验之前,记得去添加 `exokernel` 以获取 QEMU 的 6.828 版本。
+
+### 实验过程
+
+在你准备进行实验和写代码之前,先添加你的 `answers-lab2.txt` 文件到 Git 仓库,提交你的改变然后去运行 `make handin`。
+
+```
+athena% git add answers-lab2.txt
+athena% git commit -am "my answer to lab2"
+[lab2 a823de9] my answer to lab2 4 files changed, 87 insertions(+), 10 deletions(-)
+athena% make handin
+```
+
+### 第 1 部分:物理页面管理
+
+操作系统必须跟踪物理内存页是否使用的状态。JOS 以页为最小粒度来管理 PC 的物理内存,以便于它使用 MMU 去映射和保护每个已分配的内存片段。
+
+现在,你将要写内存的物理页分配器的代码。它使用链接到 `PageInfo` 数据结构的一组列表来保持对物理页的状态跟踪,每个列表都对应到一个物理内存页。在你能够写出剩下的虚拟内存实现之前,你需要先写出物理内存页面分配器,因为你的页表管理代码将需要去分配物理内存来存储页表。
+
+> 练习 1
+>
+> 在文件 `kern/pmap.c` 中,你需要去实现以下函数的代码(或许要按给定的顺序来实现)。
+>
+> boot_alloc()
+>
+> mem_init()(只要能够调用 check_page_free_list() 即可)
+>
+> page_init()
+>
+> page_alloc()
+>
+> page_free()
+>
+> `check_page_free_list()` 和 `check_page_alloc()` 可以测试你的物理内存页分配器。你将需要引导 JOS 然后去看一下 `check_page_alloc()` 是否报告成功即可。如果没有报告成功,修复你的代码直到成功为止。你可以添加你自己的 `assert()` 以帮助你去验证是否符合你的预期。
+
+本实验以及所有的 6.828 实验中,将要求你做一些检测工作,以便于你搞清楚它们是否按你的预期来工作。这个任务不需要详细描述你添加到 JOS 中的代码的细节。查找 JOS 源代码中你需要去修改的那部分的注释;这些注释中经常包含有技术规范和提示信息。你也可能需要去查阅 JOS、和 Intel 的技术手册、以及你的 6.004 或 6.033 课程笔记的相关部分。
+
+### 第 2 部分:虚拟内存
+
+在你开始动手之前,需要先熟悉 x86 内存管理架构的保护模式:即分段和页面转换。
+
+> 练习 2
+>
+> 如果你对 x86 的保护模式还不熟悉,可以查看 Intel 80386 参考手册的第 5 章和第 6 章。阅读这些章节(5.2 和 6.4)中关于页面转换和基于页面的保护。我们建议你也去了解关于段的章节;在虚拟内存和保护模式中,JOS 使用了分页、段转换、以及在 x86 上不能禁用的基于段的保护,因此你需要去理解这些基础知识。
+
+### 虚拟地址、线性地址和物理地址
+
+在 x86 的专用术语中,一个虚拟地址是由一个段选择器和在段中的偏移量组成。一个线性地址是在页面转换之前、段转换之后得到的一个地址。一个物理地址是段和页面转换之后得到的最终地址,它最终将进入你的物理内存中的硬件总线。
+
+
+
+回顾实验 1 中的第 3 部分,我们安装了一个简单的页表,这样内核就可以在 0xf0100000 链接的地址上运行,尽管它实际上是加载在 0x00100000 处的 ROM BIOS 的物理内存上。这个页表仅映射了 4MB 的内存。在实验中,你将要为 JOS 去设置虚拟内存布局,我们将从虚拟地址 0xf0000000 处开始扩展它,首先将物理内存扩展到 256MB,并映射许多其它区域的虚拟内存。
+
+> 练习 3
+>
+> 虽然 GDB 能够通过虚拟地址访问 QEMU 的内存,它经常用于在配置虚拟内存期间检查物理内存。在实验工具指南中复习 QEMU 的监视器命令,尤其是 `xp` 命令,它可以让你去检查物理内存。访问 QEMU 监视器,可以在终端中按 `Ctrl-a c`(相同的绑定返回到串行控制台)。
+>
+> 使用 QEMU 监视器的 `xp` 命令和 GDB 的 `x` 命令去检查相应的物理内存和虚拟内存,以确保你看到的是相同的数据。
+>
+> 我们的打过补丁的 QEMU 版本提供一个非常有用的 `info pg` 命令:它可以展示当前页表的一个简单描述,包括所有已映射的内存范围、权限、以及标志。Stock QEMU 也提供一个 `info mem` 命令用于去展示一个概要信息,这个信息包含了已映射的虚拟内存范围和使用了什么权限。
+
+在 CPU 上运行的代码,一旦处于保护模式(这是在 boot/boot.S 中所做的第一件事情)中,是没有办法去直接使用一个线性地址或物理地址的。所有的内存引用都被解释为虚拟地址,然后由 MMU 来转换,这意味着在 C 语言中的指针都是虚拟地址。
+
+例如在物理内存分配器中,JOS 内存经常需要在不反向引用的情况下,去维护作为地址的一个很难懂的值或一个整数。有时它们是虚拟地址,而有时是物理地址。为便于在代码中证明,JOS 源文件中将它们区分为两种:类型 `uintptr_t` 表示一个难懂的虚拟地址,而类型 `physaddr_trepresents` 表示物理地址。这些类型其实不过是 32 位整数(uint32_t)的同义词,因此编译器不会阻止你将一个类型的数据指派为另一个类型!因为它们都是整数(而不是指针)类型,如果你想去反向引用它们,编译器将报错。
+
+JOS 内核能够通过将它转换为指针类型的方式来反向引用一个 `uintptr_t` 类型。相反,内核不能反向引用一个物理地址,因为这是由 MMU 来转换所有的内存引用。如果你转换一个 `physaddr_t` 为一个指针类型,并反向引用它,你或许能够加载和存储最终结果地址(硬件将它解释为一个虚拟地址),但你并不会取得你想要的内存位置。
+
+总结如下:
+
+| C type | Address type |
+| ------------ | ------------ |
+| `T*` | Virtual |
+| `uintptr_t` | Virtual |
+| `physaddr_t` | Physical |
+
+>问题:
+>
+>假设下面的 JOS 内核代码是正确的,那么变量 `x` 应该是什么类型?uintptr_t 还是 physaddr_t ?
+>
+>
+>
+
+JOS 内核有时需要去读取或修改它知道物理地址的内存。例如,添加一个映射到页表,可以要求分配物理内存去存储一个页目录,然后去初始化它们。然而,内核也和其它的软件一样,并不能跳过虚拟地址转换,内核并不能直接加载和存储物理地址。一个原因是 JOS 将重映射从虚拟地址 0xf0000000 处物理地址 0 开始的所有的物理地址,以帮助内核去读取和写入它知道物理地址的内存。为转换一个物理地址为一个内核能够真正进行读写操作的虚拟地址,内核必须添加 0xf0000000 到物理地址以找到在重映射区域中相应的虚拟地址。你应该使用 KADDR(pa) 去做那个添加操作。
+
+JOS 内核有时也需要能够通过给定的内核数据结构中存储的虚拟地址找到内存中的物理地址。内核全局变量和通过 `boot_alloc()` 分配的内存是加载到内核的这些区域中,从 0xf0000000 处开始,到全部物理内存映射的区域。因此,在这些区域中转变一个虚拟地址为物理地址时,内核能够只是简单地减去 0xf0000000 即可得到物理地址。你应该使用 PADDR(va) 去做那个减法操作。
+
+### 引用计数
+
+在以后的实验中,你将会经常遇到多个虚拟地址(或多个环境下的地址空间中)同时映射到相同的物理页面上。你将在 PageInfo 数据结构中用 pp_ref 字段来提供一个引用到每个物理页面的计数器。如果一个物理页面的这个计数器为 0,表示这个页面已经被释放,因为它不再被使用了。一般情况下,这个计数器应该等于相应的物理页面出现在所有页表下面的 UTOP 的次数(UTOP 上面的映射大都是在引导时由内核设置的,并且它从不会被释放,因此不需要引用计数器)。我们也使用它去跟踪到页目录的指针数量,反过来就是,页目录到页表的数量。
+
+使用 `page_alloc` 时要注意。它返回的页面引用计数总是为 0,因此,一旦对返回页做了一些操作(比如将它插入到页表),`pp_ref` 就应该增加。有时这需要通过其它函数(比如,`page_instert`)来处理,而有时这个函数是直接调用 `page_alloc` 来做的。
+
+### 页表管理
+
+现在,你将写一套管理页表的代码:去插入和删除线性地址到物理地址的映射表,并且在需要的时候去创建页表。
+
+> 练习 4
+>
+> 在文件 `kern/pmap.c` 中,你必须去实现下列函数的代码。
+>
+> pgdir_walk()
+>
+> boot_map_region()
+>
+> page_lookup()
+>
+> page_remove()
+>
+> page_insert()
+>
+> `check_page()`,调用 `mem_init()`,测试你的页表管理动作。在进行下一步流程之前你应该确保它成功运行。
+
+### 第 3 部分:内核地址空间
+
+JOS 分割处理器的 32 位线性地址空间为两部分:用户环境(进程),我们将在实验 3 中开始加载和运行,它将控制其上的布局和低位部分的内容,而内核总是维护对高位部分的完全控制。线性地址的定义是在 `inc/memlayout.h` 中通过符号 ULIM 来划分的,它为内核保留了大约 256MB 的虚拟地址空间。这就解释了为什么我们要在实验 1 中给内核这样的一个高位链接地址的原因:如是不这样做的话,内核的虚拟地址空间将没有足够的空间去同时映射到下面的用户空间中。
+
+你可以在 `inc/memlayout.h` 中找到一个图表,它有助于你去理解 JOS 内存布局,这在本实验和后面的实验中都会用到。
+
+### 权限和缺页隔离
+
+由于内核和用户的内存都存在于它们各自环境的地址空间中,因此我们需要在 x86 的页表中使用权限位去允许用户代码只能访问用户所属地址空间的部分。否则的话,用户代码中的 bug 可能会覆写内核数据,导致系统崩溃或者发生各种莫名其妙的的故障;用户代码也可能会偷窥其它环境的私有数据。
+
+对于 ULIM 以上部分的内存,用户环境没有任何权限,只有内核才可以读取和写入这部分内存。对于 [UTOP,ULIM] 地址范围,内核和用户都有相同的权限:它们可以读取但不能写入这个地址范围。这个地址范围是用于向用户环境暴露某些只读的内核数据结构。最后,低于 UTOP 的地址空间是为用户环境所使用的;用户环境将为访问这些内核设置权限。
+
+### 初始化内核地址空间
+
+现在,你将去配置 UTOP 以上的地址空间:内核部分的地址空间。`inc/memlayout.h` 中展示了你将要使用的布局。我将使用函数去写相关的线性地址到物理地址的映射配置。
+
+> 练习 5
+>
+> 完成调用 `check_page()` 之后在 `mem_init()` 中缺失的代码。
+
+现在,你的代码应该通过了 `check_kern_pgdir()` 和 `check_page_installed_pgdir()` 的检查。
+
+> 问题:
+>
+> 1、在这个时刻,页目录中的条目(行)是什么?它们映射的址址是什么?以及它们映射到哪里了?换句话说就是,尽可能多地填写这个表:
+>
+> EntryBase Virtual AddressPoints to (logically):
+>
+> 1023 ? Page table for top 4MB of phys memory
+>
+> 1022 ? ?
+>
+> . ? ?
+>
+> . ? ?
+>
+> . ? ?
+>
+> 2 0x00800000 ?
+>
+> 1 0x00400000 ?
+>
+> 0 0x00000000 [see next question]
+>
+> 2、(来自课程 3) 我们将内核和用户环境放在相同的地址空间中。为什么用户程序不能去读取和写入内核的内存?有什么特殊机制保护内核内存?
+>
+> 3、这个操作系统能够支持的最大的物理内存数量是多少?为什么?
+>
+> 4、我们真实地拥有最大数量的物理内存吗?管理内存的开销有多少?这个开销可以减少吗?
+>
+> 5、复习在 `kern/entry.S` 和 `kern/entrypgdir.c` 中的页表设置。一旦我们打开分页,EIP 中是一个很小的数字(稍大于 1MB)。在什么情况下,我们转而去运行在 KERNBASE 之上的一个 EIP?当我们启用分页并开始在 KERNBASE 之上运行一个 EIP 时,是什么让我们能够持续运行一个很低的 EIP?为什么这种转变是必需的?
+
+### 地址空间布局的其它选择
+
+在 JOS 中我们使用的地址空间布局并不是我们唯一的选择。一个操作系统可以在低位的线性地址上映射内核,而为用户进程保留线性地址的高位部分。然而,x86 内核一般并不采用这种方法,而 x86 向后兼容模式是不这样做的其中一个原因,这种模式被称为“虚拟 8086 模式”,处理器使用线性地址空间的最下面部分是“不可改变的”,所以,如果内核被映射到这里是根本无法使用的。
+
+虽然很困难,但是设计这样的内核是有这种可能的,即:不为处理器自身保留任何固定的线性地址或虚拟地址空间,而有效地允许用户级进程不受限制地使用整个 4GB 的虚拟地址空间 —— 同时还要在这些进程之间充分保护内核以及不同的进程之间相互受保护!
+
+将内核的内存分配系统进行概括类推,以支持二次幂为单位的各种页大小,从 4KB 到一些你选择的合理的最大值。你务必要有一些方法,将较大的分配单位按需分割为一些较小的单位,以及在需要时,将多个较小的分配单位合并为一个较大的分配单位。想一想在这样的一个系统中可能会出现些什么样的问题。
+
+这个实验做完了。确保你通过了所有的等级测试,并记得在 `answers-lab2.txt` 中写下你对上述问题的答案。提交你的改变(包括添加 `answers-lab2.txt` 文件),并在 `lab` 目录下输入 `make handin` 去提交你的实验。
+
+------
+
+via:
-
-);
-```
-
-But notice the “else” conditions return `null`. This is becasue a ternary expects an else condition.
-
-For simple `if` conditions, we could use something a little more fitting: the logical AND operator. Here’s the same code written using a logical AND.
-
-```
-const MyComponent = ({ name, isPro, stars}) => (
-
- Hello {name}
- {isPro ? '🏆' : null}
-
- {stars ? (
-
- Stars:{'⭐️'.repeat(stars)}
-
- ) : null}
-
-
-);
-```
-
-Not too different, but notice how we eliminated the `: null` (i.e. else condition) at the end of each ternary. Everything should render just like it did before.
-
-
-Hey! What gives with John? There is a `0` when nothing should be rendered. That’s the gotcha that I was referring to above. Here’s why.
-
-[According to MDN][3], a Logical AND (i.e. `&&`):
-
-> `expr1 && expr2`
-
-> Returns `expr1` if it can be converted to `false`; otherwise, returns `expr2`. Thus, when used with Boolean values, `&&` returns `true` if both operands are true; otherwise, returns `false`.
-
-OK, before you start pulling your hair out, let me break it down for you.
-
-In our case, `expr1` is the variable `stars`, which has a value of `0`. Because zero is falsey, `0` is returned and rendered. See, that wasn’t too bad.
-
-I would write this simply.
-
-> If `expr1` is falsey, returns `expr1`, else returns `expr2`.
-
-So, when using a logical AND with non-boolean values, we must make the falsey value return something that React won’t render. Say, like a value of `false`.
-
-There are a few ways that we can accomplish this. Let’s try this instead.
-
-```
-{!!stars && (
-
- Hello {name}
- {isPro && '🏆'}
-
- {stars && (
-
- Stars:{'⭐️'.repeat(stars)}
-
- )}
-
- {'⭐️'.repeat(stars)}
-
-)}
-```
-
-Notice the double bang operator (i.e. `!!`) in front of `stars`. (Well, actually there is no “double bang operator”. We’re just using the bang operator twice.)
-
-The first bang operator will coerce the value of `stars` into a boolean and then perform a NOT operation. If `stars` is `0`, then `!stars` will produce `true`.
-
-Then we perform a second NOT operation, so if `stars` is 0, `!!stars` would produce `false`. Exactly what we want.
-
-If you’re not a fan of `!!`, you can also force a boolean like this (which I find a little wordy).
-
-```
-{Boolean(stars) && (
-```
-
-Or simply give a comparator that results in a boolean value (which some might say is even more semantic).
-
-```
-{stars > 0 && (
-```
-
-#### A word on strings
-
-Empty string values suffer the same issue as numbers. But because a rendered empty string is invisible, it’s not a problem that you will likely have to deal with, or will even notice. However, if you are a perfectionist and don’t want an empty string on your DOM, you should take similar precautions as we did for numbers above.
-
-### Another solution
-
-A possible solution, and one that scales to other variables in the future, would be to create a separate `shouldRenderStars` variable. Then you are dealing with boolean values in your logical AND.
-
-```
-const shouldRenderStars = stars > 0;
-```
-
-```
-return (
-
- {shouldRenderStars && (
-
-);
-```
-
-Then, if in the future, the business rule is that you also need to be logged in, own a dog, and drink light beer, you could change how `shouldRenderStars` is computed, and what is returned would remain unchanged. You could also place this logic elsewhere where it’s testable and keep the rendering explicit.
-
-```
-const shouldRenderStars =
- stars > 0 && loggedIn && pet === 'dog' && beerPref === 'light`;
-```
-
-```
-return (
-
- {'⭐️'.repeat(stars)}
-
- )}
-
- {shouldRenderStars && (
-
-);
-```
-
-### Conclusion
-
-I’m of the opinion that you should make best use of the language. And for JavaScript, this means using conditional ternary operators for `if/else`conditions and logical AND operators for simple `if` conditions.
-
-While we could just retreat back to our safe comfy place where we use the ternary operator everywhere, you now possess the knowledge and power to go forth AND prosper.
-
---------------------------------------------------------------------------------
-
-作者简介:
-
-Managing Editor at the American Express Engineering Blog http://aexp.io and Director of Engineering @AmericanExpress. MyViews !== ThoseOfMyEmployer.
-
-----------------
-
-via: https://medium.freecodecamp.org/conditional-rendering-in-react-using-ternaries-and-logical-and-7807f53b6935
-
-作者:[Donavon West][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://medium.freecodecamp.org/@donavon
-[1]:https://unsplash.com/photos/pKeF6Tt3c08?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
-[2]:https://unsplash.com/search/photos/road-sign?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
-[3]:https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Operators/Logical_Operators
\ No newline at end of file
diff --git a/sources/tech/20180201 Here are some amazing advantages of Go that you dont hear much about.md b/sources/tech/20180201 Here are some amazing advantages of Go that you dont hear much about.md
deleted file mode 100644
index efa3c4e653..0000000000
--- a/sources/tech/20180201 Here are some amazing advantages of Go that you dont hear much about.md
+++ /dev/null
@@ -1,225 +0,0 @@
-Translatin by imquanquan
-
-Here are some amazing advantages of Go that you don’t hear much about
-============================================================
-
-
-
-Artwork from [https://github.com/ashleymcnamara/gophers][1]
-
-In this article, I discuss why you should give Go a chance and where to start.
-
-Golang is a programming language you might have heard about a lot during the last couple years. Even though it was created back in 2009, it has started to gain popularity only in recent years.
-
-
-
-Golang popularity according to Google Trends
-
-This article is not about the main selling points of Go that you usually see.
-
-Instead, I would like to present to you some rather small but still significant features that you only get to know after you’ve decided to give Go a try.
-
-These are amazing features that are not laid out on the surface, but they can save you weeks or months of work. They can also make software development more enjoyable.
-
-Don’t worry if Go is something new for you. This article does not require any prior experience with the language. I have included a few extra links at the bottom, in case you would like to learn a bit more.
-
-We will go through such topics as:
-
-* GoDoc
-
-* Static code analysis
-
-* Built-in testing and profiling framework
-
-* Race condition detection
-
-* Learning curve
-
-* Reflection
-
-* Opinionatedness
-
-* Culture
-
-Please, note that the list doesn’t follow any particular order. It is also opinionated as hell.
-
-### GoDoc
-
-Documentation in code is taken very seriously in Go. So is simplicity.
-
-[GoDoc][4] is a static code analyzing tool that creates beautiful documentation pages straight out of your code. A remarkable thing about GoDoc is that it doesn’t use any extra languages, like JavaDoc, PHPDoc, or JSDoc to annotate constructions in your code. Just English.
-
-It uses as much information as it can get from the code to outline, structure, and format the documentation. And it has all the bells and whistles, such as cross-references, code samples, and direct links to your version control system repository.
-
-All you can do is to add a good old `// MyFunc transforms Foo into Bar` kind of comment which would be reflected in the documentation, too. You can even add [code examples][5] which are actually runnable via the web interface or locally.
-
-GoDoc is the only documentation engine for Go that is used by the whole community. This means that every library or application written in Go has the same format of documentation. In the long run, it saves you tons of time while browsing those docs.
-
-Here, for example, is the GoDoc page for my recent pet project: [pullkee — GoDoc][6].
-
-### Static code analysis
-
-Go heavily relies on static code analysis. Examples include [godoc][7] for documentation, [gofmt][8] for code formatting, [golint][9] for code style linting, and many others.
-
-There are so many of them that there’s even an everything-included-kind-of project called [gometalinter][10] to compose them all into a single utility.
-
-Those tools are commonly implemented as stand-alone command line applications and integrate easily with any coding environment.
-
-Static code analysis isn’t actually something new to modern programming, but Go sort of brings it to the absolute. I can’t overestimate how much time it saved me. Also, it gives you a feeling of safety, as though someone is covering your back.
-
-It’s very easy to create your own analyzers, as Go has dedicated built-in packages for parsing and working with Go sources.
-
-You can learn more from this talk: [GothamGo Kickoff Meetup: Go Static Analysis Tools by Alan Donovan][11].
-
-### Built-in testing and profiling framework
-
-Have you ever tried to pick a testing framework for a Javascript project you are starting from scratch? If so, you might understand that struggle of going through such an analysis paralysis. You might have also realized that you were not using like 80% of the framework you have chosen.
-
-The issue repeats over again once you need to do some reliable profiling.
-
-Go comes with a built-in testing tool designed for simplicity and efficiency. It provides you the simplest API possible, and makes minimum assumptions. You can use it for different kinds of testing, profiling, and even to provide executable code examples.
-
-It produces CI-friendly output out-of-box, and the usage is usually as easy as running `go test`. Of course, it also supports advanced features like running tests in parallel, marking them skipped, and many more.
-
-### Race condition detection
-
-You might already know about Goroutines, which are used in Go to achieve concurrent code execution. If you don’t, [here’s][12] a really brief explanation.
-
-Concurrent programming in complex applications is never easy regardless of the specific technique, partly due to the possibility of race conditions.
-
-Simply put, race conditions happen when several concurrent operations finish in an unpredicted order. It might lead to a huge number of bugs, which are particularly hard to chase down. Ever spent a day debugging an integration test which only worked in about 80% of executions? It probably was a race condition.
-
-All that said, concurrent programming is taken very seriously in Go and, luckily, we have quite a powerful tool to hunt those race conditions down. It is fully integrated into Go’s toolchain.
-
-You can read more about it and learn how to use it here: [Introducing the Go Race Detector — The Go Blog][13].
-
-### Learning curve
-
-You can learn ALL Go’s language features in one evening. I mean it. Of course, there are also the standard library, and the best practices in different, more specific areas. But two hours would totally be enough time to get you confidently writing a simple HTTP server, or a command-line app.
-
-The project has [marvelous documentation][14], and most of the advanced topics have already been covered on their blog: [The Go Programming Language Blog][15].
-
-Go is much easier to bring to your team than Java (and the family), Javascript, Ruby, Python, or even PHP. The environment is easy to setup, and the investment your team needs to make is much smaller before they can complete your first production code.
-
-### Reflection
-
-Code reflection is essentially an ability to sneak under the hood and access different kinds of meta-information about your language constructs, such as variables or functions.
-
-Given that Go is a statically typed language, it’s exposed to a number of various limitations when it comes to more loosely typed abstract programming. Especially compared to languages like Javascript or Python.
-
-Moreover, Go [doesn’t implement a concept called Generics][16] which makes it even more challenging to work with multiple types in an abstract way. Nevertheless, many people think it’s actually beneficial for the language because of the amount of complexity Generics bring along. And I totally agree.
-
-According to Go’s philosophy (which is a separate topic itself), you should try hard to not over-engineer your solutions. And this also applies to dynamically-typed programming. Stick to static types as much as possible, and use interfaces when you know exactly what sort of types you’re dealing with. Interfaces are very powerful and ubiquitous in Go.
-
-However, there are still cases in which you can’t possibly know what sort of data you are facing. A great example is JSON. You convert all the kinds of data back and forth in your applications. Strings, buffers, all sorts of numbers, nested structs and more.
-
-In order to pull that off, you need a tool to examine all the data in runtime that acts differently depending on its type and structure. Reflection to rescue! Go has a first-class [reflect][17] package to enable your code to be as dynamic as it would be in a language like Javascript.
-
-An important caveat is to know what price you pay for using it — and only use it when there is no simpler way.
-
-You can read more about it here: [The Laws of Reflection — The Go Blog][18].
-
-You can also read some real code from the JSON package sources here: [src/encoding/json/encode.go — Source Code][19]
-
-### Opinionatedness
-
-Is there such a word, by the way?
-
-Coming from the Javascript world, one of the most daunting processes I faced was deciding which conventions and tools I needed to use. How should I style my code? What testing library should I use? How should I go about structure? What programming paradigms and approaches should I rely on?
-
-Which sometimes basically got me stuck. I was doing this instead of writing the code and satisfying the users.
-
-To begin with, I should note that I totally get where those conventions should come from. It’s always you and your team. Anyway, even a group of experienced Javascript developers can easily find themselves having most of the experience with entirely different tools and paradigms to achieve kind of the same results.
-
-This makes the analysis paralysis cloud explode over the whole team, and also makes it harder for the individuals to integrate with each other.
-
-Well, Go is different. You have only one style guide that everyone follows. You have only one testing framework which is built into the basic toolchain. You have a lot of strong opinions on how to structure and maintain your code. How to pick names. What structuring patterns to follow. How to do concurrency better.
-
-While this might seem too restrictive, it saves tons of time for you and your team. Being somewhat limited is actually a great thing when you are coding. It gives you a more straightforward way to go when architecting new code, and makes it easier to reason about the existing one.
-
-As a result, most of the Go projects look pretty alike code-wise.
-
-### Culture
-
-People say that every time you learn a new spoken language, you also soak in some part of the culture of the people who speak that language. Thus, the more languages you learn, more personal changes you might experience.
-
-It’s the same with programming languages. Regardless of how you are going to apply a new programming language in the future, it always gives you a new perspective on programming in general, or on some specific techniques.
-
-Be it functional programming, pattern matching, or prototypal inheritance. Once you’ve learned it, you carry these approaches with you which broadens the problem-solving toolset that you have as a software developer. It also changes the way you see high-quality programming in general.
-
-And Go is a terrific investment here. The main pillar of Go’s culture is keeping simple, down-to-earth code without creating many redundant abstractions and putting the maintainability at the top. It’s also a part of the culture to spend the most time actually working on the codebase, instead of tinkering with the tools and the environment. Or choosing between different variations of those.
-
-Go is also all about “there should be only one way of doing a thing.”
-
-A little side note. It’s also partially true that Go usually gets in your way when you need to build relatively complex abstractions. Well, I’d say that’s the tradeoff for its simplicity.
-
-If you really need to write a lot of abstract code with complex relationships, you’d be better off using languages like Java or Python. However, even when it’s not obvious, it’s very rarely the case.
-
-Always use the best tool for the job!
-
-### Conclusion
-
-You might have heard of Go before. Or maybe it’s something that has been staying out of your radar for a while. Either way, chances are, Go can be a very decent choice for you or your team when starting a new project or improving the existing one.
-
-This is not a complete list of all the amazing things about Go. Just the undervalued ones.
-
-Please, give Go a try with [A Tour of Go][20] which is an incredible place to start.
-
-If you wish to learn more about Go’s benefits, you can check out these links:
-
-* [Why should you learn Go? — Keval Patel — Medium][2]
-
-* [Farewell Node.js — TJ Holowaychuk — Medium][3]
-
-Share your observations down in the comments!
-
-Even if you are not specifically looking for a new language to use, it’s worth it to spend an hour or two getting the feel of it. And maybe it can become quite useful for you in the future.
-
-Always be looking for the best tools for your craft!
-
-* * *
-
-If you like this article, please consider following me for more, and clicking on those funny green little hands right below this text for sharing. 👏👏👏
-
-Check out my [Github][21] and follow me on [Twitter][22]!
-
---------------------------------------------------------------------------------
-
-作者简介:
-
-Software Engineer and Traveler. Coding for fun. Javascript enthusiast. Tinkering with Golang. A lot into SOA and Docker. Architect at Velvica.
-
-------------
-
-
-via: https://medium.freecodecamp.org/here-are-some-amazing-advantages-of-go-that-you-dont-hear-much-about-1af99de3b23a
-
-作者:[Kirill Rogovoy][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:
-[1]:https://github.com/ashleymcnamara/gophers
-[2]:https://medium.com/@kevalpatel2106/why-should-you-learn-go-f607681fad65
-[3]:https://medium.com/@tjholowaychuk/farewell-node-js-4ba9e7f3e52b
-[4]:https://godoc.org/
-[5]:https://blog.golang.org/examples
-[6]:https://godoc.org/github.com/kirillrogovoy/pullkee
-[7]:https://godoc.org/
-[8]:https://golang.org/cmd/gofmt/
-[9]:https://github.com/golang/lint
-[10]:https://github.com/alecthomas/gometalinter#supported-linters
-[11]:https://vimeo.com/114736889
-[12]:https://gobyexample.com/goroutines
-[13]:https://blog.golang.org/race-detector
-[14]:https://golang.org/doc/
-[15]:https://blog.golang.org/
-[16]:https://golang.org/doc/faq#generics
-[17]:https://golang.org/pkg/reflect/
-[18]:https://blog.golang.org/laws-of-reflection
-[19]:https://golang.org/src/encoding/json/encode.go
-[20]:https://tour.golang.org/
-[21]:https://github.com/kirillrogovoy/
-[22]:https://twitter.com/krogovoy
diff --git a/sources/tech/20180205 Writing eBPF tracing tools in Rust.md b/sources/tech/20180205 Writing eBPF tracing tools in Rust.md
index 18b8eb5742..093d3de215 100644
--- a/sources/tech/20180205 Writing eBPF tracing tools in Rust.md
+++ b/sources/tech/20180205 Writing eBPF tracing tools in Rust.md
@@ -1,3 +1,4 @@
+Zafiry translating...
Writing eBPF tracing tools in Rust
============================================================
diff --git a/sources/tech/20180226 Linux Virtual Machines vs Linux Live Images.md b/sources/tech/20180226 Linux Virtual Machines vs Linux Live Images.md
deleted file mode 100644
index 5367ccf9db..0000000000
--- a/sources/tech/20180226 Linux Virtual Machines vs Linux Live Images.md
+++ /dev/null
@@ -1,59 +0,0 @@
-## sober-wang 翻译中
-Linux Virtual Machines vs Linux Live Images
-======
-I'll be the first to admit that I tend to try out new [Linux distros][1] on a far too frequent basis. Yet the method I use to test them, does vary depending on my goals for each instance. In this article, we're going to look at both running Linux virtual machines and running Linux live images. There are advantages to each method, but there are some hurdles with each method as well.
-
-### Testing out a new Linux distro for the first time
-
-When I test out a brand new Linux distro for the first time, the method I use depends heavily on the resources of the PC I'm currently on. If I have access to my desktop PC, I'm going to run the distro to be tested in a virtual machine. The reason for this approach is that I can download and test the distro in not only a live environment, but also as an installed product with persistent storage abilities.
-
-On the other hand, if I am working with much less robust hardware on a PC, then testing out a distro with a virtual machine installation of Linux is counter-productive. I'd be pushing that PC to its limits and honestly would be better off using a live Linux image instead running from a flash drive.
-
-### Touring software on a new Linux distro
-
-If you're interested in checking out a distro's desktop environment or the available software, you can't go wrong with a live image of the distro. A live environment provides you with a birds eye view of what to expect in terms of overall layout, applications provided and how the user experience flows overall.
-
-To be fair, you could do the same thing with a virtual machine installation, but it may be a bit overkill if you would rather avoid filling up hard drive space with yet more data. After all, this is a simple tour of the distro. Remember what I said in the first section – I like to run Linux in a virtual machine to test it. This means I'm going to see how it installs, what the partition options look like and other elements you wouldn't see from using a live image of any given distro.
-
-Touring usually indicates that you're only looking to take a quick look at a distro, so in this case the method that can be done with the least amount of resistance and time investment is a good course of action.
-
-### Taking a Linux distro with you
-
-While it's not as common as it was a few years ago, the ability to take a Linux distro with you may be a consideration for some users. Obviously, virtual machine installations don't necessarily lend themselves favorably to portability. However a live image of a Linux distro is actually quite portable. A live image can be written to a DVD or copied onto a flash drive for easy traveling.
-
-Expanding on this concept of Linux portability, it's also beneficial to have a live image on a flash drive when showing off how Linux works on a friend's computer. This empowers you to demonstrate how Linux can enrich their life while not relying on running a virtual machine on their PC. It's a bit of a win-win in favor of using a live image.
-
-### Alternative to dual-booting Linux
-
-This next item is a huge one. Consider this – perhaps you're a Windows user. You like playing with Linux, but would rather not take the plunge. Dual-booting is out of the question in case something goes wrong or perhaps you're not comfortable identifying individual partitions. Whatever the case may be, both using Linux in a virtual machine or from a live image might be a great option for you.
-
-Now I'm going to take a rather odd stance on something. I think you'll get far more value in the long term running Linux on a flash drive using a live image than with a virtual machine. There are two reasons for this. First of all, you'll get used to truly running Linux vs running it inside of a virtual machine on top of Windows. Second, you can setup your flash drive to contain user data with persistent storage.
-
-I'll grant you the same could be said with a virtual machine running Linux, however you will never have an update break anything using the live image approach. Why? Because you're not updating a host OS or the guest OS. Remember there are entire distros that are designed to be nothing more than persistent storage Linux distros. Puppy Linux is one great example. Not only can it run on PCs that would otherwise be recycled or thrown away, it allows you to never be bothered again with tedious system updates thanks to the way the distro handles security. It's not a normal Linux distro and it's walled off in such a way that the persistent live image is free from anything scary.
-
-### When a Linux virtual machine is absolutely the best option
-
-As I bring this article to a close, let me leave you with this. There is one instance where using a virtual machine such as Virtual Box is absolutely better than using a live image – recording the desktop environment of any Linux distro.
-
-For example, I make videos that provide a tour and review of a variety of Linux distros. Doing this with live images would require me to capture the screen with a hardware device or install a software capture device from the live image's repositories. Clearly, a virtual machine is better suited for this job than a live image of a Linux distro.
-
-Once you toss audio capture into the mix, there is no question that if you're going to use software to capture your review, you really want to have a host OS that has all the basic needs covered for a reasonably decent capture environment. Again, you could do all of this with a hardware device...but that might be cost prohibitive if you're only do video/audio capturing as a part time endeavor.
-
-### A Linux virtual machine vs a Linux live image
-
-What is your preferred method of trying out new distros? Perhaps you're someone who is fine with formatting their hard drive and throwing caution to the wind, thus, making the idea of any of this unneeded?
-
-Most people I've interacted with online tend to follow much of the methodology I've touched on above, but I'd love to hear what approach works best for you. Hit the comments, let me know which method you prefer when checking out the greatest and latest from the Linux distro world.
-
---------------------------------------------------------------------------------
-
-via: https://www.datamation.com/open-source/linux-virtual-machines-vs-linux-live-images.html
-
-作者:[Matt Hartley][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.datamation.com/author/Matt-Hartley-3080.html
-[1]:https://www.datamation.com/open-source/best-linux-distro.html
diff --git a/sources/tech/20180316 How to Encrypt Files From Within a File Manager.md b/sources/tech/20180316 How to Encrypt Files From Within a File Manager.md
deleted file mode 100644
index 491c18eb04..0000000000
--- a/sources/tech/20180316 How to Encrypt Files From Within a File Manager.md
+++ /dev/null
@@ -1,179 +0,0 @@
-How to Encrypt Files From Within a File Manager
-======
-
-
-The Linux desktop and server enjoys a remarkable level of security. That doesn’t mean, however, you should simply rest easy. You should always consider that your data is always a quick hack away from being compromised. That being said, you might want to employ various tools for encryption, such as GnuPG, which lets you encrypt and decrypt files and much more. One problem with GnuPG is that some users don’t want to mess with the command line. If that’s the case, you can turn to a desktop file manager. Many Linux desktops include the ability to easily encrypt or decrypt files, and if that capability is not built in, it’s easy to add.
-
-I will walk you through the process of encrypting and decrypting a file from within three popular Linux file managers:
-
- * Nautilus (aka GNOME Files)
-
- * Dolphin
-
- * Thunar
-
-
-
-
-### Installing GnuPG
-
-Before we get into the how to of this, we have to ensure your system includes the necessary base component… [GnuPG][1]. Most distributions ship with GnuPG included. On the off chance you use a distribution that doesn’t ship with GnuPG, here’s how to install it:
-
- * Ubuntu-based distribution: sudo apt install gnupg
-
- * Fedora-based distribution: sudo yum install gnupg
-
- * openSUSE: sudo zypper in gnupg
-
- * Arch-based distribution: sudo pacman -S gnupg
-
-
-
-
-Whether you’ve just now installed GnuPG or it was installed by default, you will have to create a GPG key for this to work. Each desktop uses a different GUI tool for this (or may not even include a GUI tool for the task), so let’s create that key from the command line. Open up your terminal window and issue the following command:
-```
-gpg --gen-key
-
-```
-
-You will then be asked to answer the following questions. Unless you have good reason, you can accept the defaults:
-
- * What kind of key do you want?
-
- * What key size do you want?
-
- * Key is valid for?
-
-
-
-
-Once you’ve answered these questions, type y to indicate the answers are correct. Next you’ll need to supply the following information:
-
- * Real name.
-
- * Email address.
-
- * Comment.
-
-
-
-
-Complete the above and then, when prompted, type O (for Okay). You will then be required to type a passphrase for the new key. Once the system has collected enough entropy (you’ll need to do some work on the desktop so this can happen), your key will have been created and you’re ready to go.
-
-Let’s see how to encrypt/decrypt files from within the file managers.
-
-### Nautilus
-
-We start with the default GNOME file manager because it is the easiest. Nautilus requires no extra installation or extra work to encrypt/decrypt files from within it’s well-designed interface. Once you have your gpg key created, you can open up the file manager, navigate to the directory housing the file to be encrypted, right-click the file in question, and select Encrypt from the menu (Figure 1).
-
-
-![nautilus][3]
-
-Figure 1: Encrypting a file from within Nautilus.
-
-[Used with permission][4]
-
-You will be asked to select a recipient (or list of recipients — Figure 2). NOTE: Recipients will be those users whose public keys you have imported. Select the necessary keys and then select your key (email address) from the Sign message as drop-down.
-
-![nautilus][6]
-
-Figure 2: Selecting recipients and a signer.
-
-[Used with permission][4]
-
-Notice you can also opt to encrypt the file with only a passphrase. This is important if the file will remain on your local machine (more on this later). Once you’ve set up the encryption, click OK and (when prompted) type the passphrase for your key. The file will be encrypted (now ending in .gpg) and saved in the working directory. You can now send that encrypted file to the recipients you selected during the encryption process.
-
-Say someone (who has your public key) has sent you an encrypted file. Save that file, open the file manager, navigate to the directory housing that file, right-click the encrypted file, select Open With Decrypt File, give the file a new name (without the .gpg extension), and click Save. When prompted, type your gpg key passphrase and the file will be decrypted and ready to use.
-
-### Dolphin
-
-On the KDE front, there’s a package that must be installed in order to encrypt/decrypt from with the Dolphin file manager. Log into your KDE desktop, open the terminal window, and issue the following command (I’m demonstrating with Neon. If your distribution isn’t Ubuntu-based, you’ll have to alter the command accordingly):
-```
-sudo apt install kgpg
-
-```
-
-Once that installs, logout and log back into the KDE desktop. You can open up Dolphin and right-click a file to be encrypted. Since this is the first time you’ve used kgpg, you’ll have to walk through a quick setup wizard (which self-explanatory). When you’ve completed the wizard, you can go back to that file, right-click it (Figure 3), and select Encrypt File.
-
-
-![Dolphin][8]
-
-Figure 3: Encrypting a file within Dolphin.
-
-[Used with permission][4]
-
-You’ll be prompted to select the key to use for encryption (Figure 4). Make your selection and click OK. The file will encrypt and you’re ready to send it to the recipient.
-
-Note: With KDE’s Dolphin file manager, you cannot encrypt with a passphrase only.
-
-
-![Dolphin][10]
-
-Figure 4: Selecting your recipients for encryption.
-
-[Used with permission][4]
-
-If you receive an encrypted file from a user who has your public key (or you have a file you’ve encrypted yourself), open up Dolphin, navigate to the file in question, double-click the file, give the file a new name, type the encryption passphrase, and click OK. You can now read your newly decrypted file. If you’ve encrypted the file with your own key, you won’t be prompted to type the passphrase (as it has already been stored).
-
-### Thunar
-
-The Thunar file manager is a bit trickier. There aren’t any extra packages to install; instead, you need to create new custom action for Encrypt. Once you’ve done this, you’ll have the ability to do this from within the file manager.
-
-To create the custom actions, open up the Thunar file manager and click Edit > Configure Custom Actions. In the resulting window, click the + button (Figure 5) and enter the following for an Encrypt action:
-
-Name: Encrypt
-
-Description: File Encryption
-
-Command: gnome-terminal -x gpg --encrypt --recipient %f
-
-Click OK to save this action.
-
-
-![Thunar][12]
-
-Figure 5: Creating an custom action within Thunar.
-
-[Used with permission][4]
-
-NOTE: If gnome-terminal isn’t your default terminal, substitute the command to open your default terminal in.
-
-You can also create an action that encrypts with a passphrase only (not a key). To do this, the details for the action would be:
-
-Name: Encrypt Passphrase
-
-Description: Encrypt with Passphrase only
-
-Command: gnome-terminal -x gpg -c %f
-
-You don’t need to create a custom action for the decryption process, as Thunar already knows what to do with an encrypted file. To decrypt a file, simply right-click it (within Thunar), select Open With Decrypt File, give the decrypted file a name, and (when/if prompted) type the encryption passphrase. Viola, your encrypted file has been decrypted and is ready to use.
-
-### One caveat
-
-Do note: If you encrypt your own files, using your own keys, you won’t need to enter an encryption passphrase to decrypt them (because your public keys are stored). If, however, you receive files from others (who have your public key) you will be required to enter your passphrase. If you’re wanting to store your own encrypted files, instead of encrypting them with a key, encrypt them with a passphrase only. This is possible with Nautilus and Thunar (but not KDE). By opting for passphrase encryption (over key encryption), when you go to decrypt the file, it will always prompt you for the passphrase.
-
-### Other file managers
-
-There are plenty of other file managers out there, some of them can work with encryption, some cannot. Chances are, you’re using one of these three tools, so the ability to add encryption/decryption to the contextual menu is not only possible, it’s pretty easy. Give this a try and see if it doesn’t make the process of encryption and decryption much easier.
-
-Learn more about Linux through the free ["Introduction to Linux" ][13] course from The Linux Foundation and edX.
-
---------------------------------------------------------------------------------
-
-via: https://www.linux.com/learn/intro-to-linux/2018/3/how-encrypt-files-within-file-manager
-
-作者:[JACK WALLEN][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.linux.com/users/jlwallen
-[1]:https://www.gnupg.org/
-[3]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/nautilus.jpg?itok=ae7Gtj60 (nautilus)
-[4]:https://www.linux.com/licenses/category/used-permission
-[6]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/nautilus_2.jpg?itok=3ht7j63n (nautilus)
-[8]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/kde_0.jpg?itok=KSTctVw0 (Dolphin)
-[10]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/kde_2.jpg?itok=CeqWikNl (Dolphin)
-[12]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/thunar.jpg?itok=fXcHk08B (Thunar)
-[13]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/sources/tech/20180324 How To Compress And Decompress Files In Linux.md b/sources/tech/20180324 How To Compress And Decompress Files In Linux.md
deleted file mode 100644
index 8766b9e39b..0000000000
--- a/sources/tech/20180324 How To Compress And Decompress Files In Linux.md
+++ /dev/null
@@ -1,210 +0,0 @@
-How To Compress And Decompress Files In Linux
-======
-
-
-Compressing is quite useful when backing up important files and also sending large files over Internet. Please note that compressing an already compressed file adds extra overhead, hence you will get a slightly bigger file. So, stop compressing a compressed file. There are many programs to compress and decompress files in GNU/Linux. In this tutorial, we’re going to learn about two applications only.
-
-### Compress and decompress files
-
-The most common programs used to compress files in Unix-like systems are:
-
- 1. gzip
- 2. bzip2
-
-
-
-##### 1\. Compress and decompress files using Gzip program
-
-The gzip is an utility to compress and decompress files using Lempel-Ziv coding (LZ77) algorithm.
-
-**1.1 Compress files**
-
-To compress a file named **ostechnix.txt** , replacing it with a gzipped compressed version, run:
-```
-$ gzip ostechnix.txt
-
-```
-
-Gzip will replace the original file **ostechnix.txt** with a gzipped compressed version named **ostechnix.txt.gz**.
-
-The gzip command can also be used in other ways too. One fine example is we can create a compressed version of a specific command’s output. Look at the following command.
-```
-$ ls -l Downloads/ | gzip > ostechnix.txt.gz
-
-```
-
-The above command creates compressed version of the directory listing of Downloads folder.
-
-**1.2 Compress files and write the output to different files (Don’t replace the original file)
-**
-
-By default, gzip program will compress the given file, replacing it with a gzipped compressed version. You can, however, keep the original file and write the output to standard output. For example, the following command, compresses **ostechnix.txt** and writes the output to **output.txt.gz**.
-```
-$ gzip -c ostechnix.txt > output.txt.gz
-
-```
-
-Similarly, to decompress a gzipped file specifying the output filename:
-```
-$ gzip -c -d output.txt.gz > ostechnix1.txt
-
-```
-
-The above command decompresses the **output.txt.gz** file and writes the output to **ostechnix1.txt** file. In both cases, it won’t delete the original file.
-
-**1.3 Decompress files**
-
-To decompress the file **ostechnix.txt.gz** , replacing it with the original uncompressed version, we do:
-```
-$ gzip -d ostechnix.txt.gz
-
-```
-
-We can also use gunzip to decompress the files.
-```
-$ gunzip ostechnix.txt.gz
-
-```
-
-**1.4 View contents of compressed files without decompressing them**
-
-To view the contents of the compressed file using gzip without decompressing it, use **-c** flag as shown below:
-```
-$ gunzip -c ostechnix1.txt.gz
-
-```
-
-Alternatively, use **zcat** utility like below.
-```
-$ zcat ostechnix.txt.gz
-
-```
-
-You can also pipe the output to “less” command to view the output page by page like below.
-```
-$ gunzip -c ostechnix1.txt.gz | less
-
-$ zcat ostechnix.txt.gz | less
-
-```
-
-Alternatively, there is a **zless** program which performs the same function as the pipeline above.
-```
-$ zless ostechnix1.txt.gz
-
-```
-
-**1.5 Compress file with gzip by specifying compression level**
-
-Another notable advantage of gzip is it supports compression level. It supports 3 compression levels as given below.
-
- * **1** – Fastest (Worst)
- * **9** – Slowest (Best)
- * **6** – Default level
-
-
-
-To compress a file named **ostechnix.txt** , replacing it with a gzipped compressed version with **best** compression level, we use:
-```
-$ gzip -9 ostechnix.txt
-
-```
-
-**1.6 Concatenate multiple compressed files**
-
-It is also possible to concatenate multiple compressed files into one. How? Have a look at the following example.
-```
-$ gzip -c ostechnix1.txt > output.txt.gz
-
-$ gzip -c ostechnix2.txt >> output.txt.gz
-
-```
-
-The above two commands will compress ostechnix1.txt and ostechnix2.txt and saves them in one file named **output.txt.gz**.
-
-You can view the contents of both files (ostechnix1.txt and ostechnix2.txt) without extracting them using any one of the following commands:
-```
-$ gunzip -c output.txt.gz
-
-$ gunzip -c output.txt
-
-$ zcat output.txt.gz
-
-$ zcat output.txt
-
-```
-
-For more details, refer the man pages.
-```
-$ man gzip
-
-```
-
-##### 2\. Compress and decompress files using bzip2 program
-
-The **bzip2** is very similar to gzip program, but uses different compression algorithm named the Burrows-Wheeler block sorting text compression algorithm, and Huffman coding. The files compressed using bzip2 will end with **.bz2** extension.
-
-Like I said, the usage of bzip2 is almost same as gzip. Just replace **gzip** in the above examples with **bzip2** , **gunzip** with **bunzip2** , **zcat** with **bzcat** and so on.
-
-To compress a file using bzip2, replacing it with compressed version, run:
-```
-$ bzip2 ostechnix.txt
-
-```
-
-If you don’t want to replace the original file, use **-c** flag and write the output to a new file.
-```
-$ bzip2 -c ostechnix.txt > output.txt.bz2
-
-```
-
-To decompress a compressed file:
-```
-$ bzip2 -d ostechnix.txt.bz2
-
-```
-
-Or,
-```
-$ bunzip2 ostechnix.txt.bz2
-
-```
-
-To view the contents of a compressed file without decompressing it:
-```
-$ bunzip2 -c ostechnix.txt.bz2
-
-```
-
-Or,
-```
-$ bzcat ostechnix.txt.bz2
-
-```
-
-For more details, refer man pages.
-```
-$ man bzip2
-
-```
-
-##### Summary
-
-In this tutorial, we learned what is gzip and bzip2 programs and how to use them to compress and decompress files with some examples in GNU/Linux. In this next, guide we are going to learn how to archive files and directories in Linux.
-
-Cheers!
-
-
-
---------------------------------------------------------------------------------
-
-via: https://www.ostechnix.com/how-to-compress-and-decompress-files-in-linux/
-
-作者:[SK][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-选题:[lujun9972](https://github.com/lujun9972)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.ostechnix.com/author/sk/
diff --git a/sources/tech/20180326 Start a blog in 30 minutes with Hugo, a static site generator written in Go.md b/sources/tech/20180326 Start a blog in 30 minutes with Hugo, a static site generator written in Go.md
deleted file mode 100644
index 465941491c..0000000000
--- a/sources/tech/20180326 Start a blog in 30 minutes with Hugo, a static site generator written in Go.md
+++ /dev/null
@@ -1,191 +0,0 @@
-Start a blog in 30 minutes with Hugo, a static site generator written in Go
-======
-
-
-Do you want to start a blog to share your latest adventures with various software frameworks? Do you love a project that is poorly documented and want to fix that? Or do you just want to create a personal website?
-
-Many people who want to start a blog have a significant caveat: lack of knowledge about a content management system (CMS) or time to learn. Well, what if I said you don't need to spend days learning a new CMS, setting up a basic website, styling it, and hardening it against attackers? What if I said you could create a blog in 30 minutes, start to finish, with [Hugo][1]?
-
-
-
-Hugo is a static site generator written in Go. Why use Hugo, you ask?
-
- * Because there is no database, no plugins requiring any permissions, and no underlying platform running on your server, there's no added security concern.
- * The blog is a set of static websites, which means lightning-fast serve time. Additionally, all pages are rendered at deploy time, so your server's load is minimal.
- * Version control is easy. Some CMS platforms use their own version control system (VCS) or integrate Git into their interface. With Hugo, all your source files can live natively on the VCS of your choice.
-
-
-
-### Minutes 0-5: Download Hugo and generate a site
-
-To put it bluntly, Hugo is here to make writing a website fun again. Let's time the 30 minutes, shall we?
-
-To simplify the installation of Hugo, download the binary file. To do so:
-
- 1. Download the appropriate [archive][2] for your operating system.
-
- 2. Unzip the archive into a directory of your choice, for example `C:\hugo_dir` or `~/hugo_dir`; this path will be referred to as `${HUGO_HOME}`.
-
- 3. Open the command line and change into your directory: `cd ${HUGO_HOME}`.
-
- 4. Verify that Hugo is working:
-
- * On Unix: `${HUGO_HOME}/[hugo version]`
- * On Windows: `${HUGO_HOME}\[hugo.exe version]`
-For example, `c:\hugo_dir\hugo version`.
-
-For simplicity, I'll refer to the path to the Hugo binary (including the binary) as `hugo`. For example, `hugo version` would translate to `C:\hugo_dir\hugo version` on your computer.
-
-If you get an error message, you may have downloaded the wrong version. Also note there are many possible ways to install Hugo. See the [official documentation][3] for more information. Ideally, you put the Hugo binary on PATH. For this quick start, it's fine to use the full path of the Hugo binary.
-
-
-
- 5. Create a new site that will become your blog: `hugo new site awesome-blog`.
- 6. Change into the newly created directory: `cd awesome-blog`.
-
-
-
-Congratulations! You have just created your new blog.
-
-### Minutes 5-10: Theme your blog
-
-With Hugo, you can either theme your blog yourself or use one of the beautiful, ready-made [themes][4]. I chose [Kiera][5] because it is deliciously simple. To install the theme:
-
- 1. Change into the themes directory: `cd themes`.
- 2. Clone your theme: `git clone https://github.com/avianto/hugo-kiera kiera`. If you do not have Git installed:
- * Download the .zip file from [GitHub][5].
- * Unzip it to your site's `themes` directory.
- * Rename the directory from `hugo-kiera-master` to `kiera`.
- 3. Change the directory to the awesome-blog level: `cd awesome-blog`.
- 4. Activate the theme. Themes (including Kiera) often come with a directory called `exampleSite`, which contains example content and an example settings file. To activate Kiera, copy the provided `config.toml` file to your blog:
- * On Unix: `cp themes/kiera/exampleSite/config.toml .`
- * On Windows: `copy themes\kiera\exampleSite\config.toml .`
- * Confirm `Yes` to override the old `config.toml`
- 5. (Optional) You can start your server to visually verify the theme is activated: `hugo server -D` and access `http://localhost:1313` in your web browser. Once you've reviewed your blog, you can turn off the server by pressing `Ctrl+C` in the command line. Your blog is empty, but we're getting someplace. It should look something like this:
-
-
-
-You have just themed your blog! You can find hundreds of beautiful themes on the official [Hugo themes][4] site.
-
-### Minutes 10-20: Add content to your blog
-
-Whereas a bowl is most useful when it is empty, this is not the case for a blog. In this step, you'll add content to your blog. Hugo and the Kiera theme simplify this process. To add your first post:
-
- 1. Article archetypes are templates for your content.
- 2. Add theme archetypes to your blog site:
- * On Unix: `cp themes/kiera/archetypes/* archetypes/`
- * On Windows: `copy themes\kiera\archetypes\* archetypes\`
- * Confirm `Yes` to override the `default.md` archetype
- 3. Create a new directory for your blog posts:
- * On Unix: `mkdir content/posts`
- * On Windows: `mkdir content\posts`
- 4. Use Hugo to generate your post:
- * On Unix: `hugo new posts/first-post.md`
- * On Windows: `hugo new posts\first-post.md`
- 5. Open the new post in a text editor of your choice:
- * On Unix: `gedit content/posts/first-post.md`
- * On Windows: `notepad content\posts\first-post.md`
-
-
-
-At this point, you can go wild. Notice that your post consists of two sections. The first one is separated by `+++`. It contains metadata about your post, such as its title. In Hugo, this is called front matter. After the front matter, the article begins. Create the first post:
-```
-+++
-
-title = "First Post"
-
-date = 2018-03-03T13:23:10+01:00
-
-draft = false
-
-tags = ["Getting started"]
-
-categories = []
-
-+++
-
-
-
-Hello Hugo world! No more excuses for having no blog or documentation now!
-
-```
-
-All you need to do now is start the server: `hugo server -D`. Open your browser and enter: `http://localhost:1313/`.
-
-
-### Minutes 20-30: Tweak your site
-
-What we've done is great, but there are still a few niggles to iron out. For example, naming your site is simple:
-
- 1. Stop your server by pressing `Ctrl+C` on the command line.
- 2. Open `config.toml` and edit settings such as the blog's title, copyright, name, your social network links, etc.
-
-
-
-When you start your server again, you'll see your blog has a bit more personalization. One more basic thing is missing: menus. That's a quick fix as well. Back in `config.toml`, insert the following at the bottom:
-```
-[[menu.main]]
-
- name = "Home" #Name in the navigation bar
-
- weight = 10 #The larger the weight, the more on the right this item will be
-
- url = "/" #URL address
-
-[[menu.main]]
-
- name = "Posts"
-
- weight = 20
-
- url = "/posts/"
-
-```
-
-This adds menus for Home and Posts. You still need an About page. Instead of referencing it from the `config.toml` file, reference it from a markdown file:
-
- 1. Create an About file: `hugo new about.md`. Notice that it's `about.md`, not `posts/about.md`. The About page is not a blog post, so you don't want it displayed in the Posts section.
- 2. Open the file in a text editor and enter the following:
-
-
-```
-+++
-
-title = "About"
-
-date = 2018-03-03T13:50:49+01:00
-
-menu = "main" #Display this page on the nav menu
-
-weight = "30" #Right-most nav item
-
-meta = "false" #Do not display tags or categories
-
-+++
-
-
-
-> Waves are the practice of the water. Shunryu Suzuki
-
-```
-
-When you start your Hugo server and open `http://localhost:1313/`, you should see your new blog ready to be used. (Check out [my example][6] on my GitHub page.) If you'd like to change the active style of menu items to make the padding slightly nicer (like the GitHub live version), apply [this patch][7] to your `themes/kiera/static/css/styles.css` file.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/3/start-blog-30-minutes-hugo
-
-作者:[Marek Czernek][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/mczernek
-[1]:https://gohugo.io/
-[2]:https://github.com/gohugoio/hugo/releases
-[3]:https://gohugo.io/getting-started/installing/
-[4]:https://themes.gohugo.io/
-[5]:https://github.com/avianto/hugo-kiera
-[6]:https://m-czernek.github.io/awesome-blog/
-[7]:https://github.com/avianto/hugo-kiera/pull/18/files
diff --git a/sources/tech/20180516 Manipulating Directories in Linux.md b/sources/tech/20180516 Manipulating Directories in Linux.md
index 9c6df23e43..4cc8ca4ea1 100644
--- a/sources/tech/20180516 Manipulating Directories in Linux.md
+++ b/sources/tech/20180516 Manipulating Directories in Linux.md
@@ -1,3 +1,4 @@
+Translating by way-ww
Manipulating Directories in Linux
======
diff --git a/sources/tech/20180522 Free Resources for Securing Your Open Source Code.md b/sources/tech/20180522 Free Resources for Securing Your Open Source Code.md
deleted file mode 100644
index 4a7522ff9f..0000000000
--- a/sources/tech/20180522 Free Resources for Securing Your Open Source Code.md
+++ /dev/null
@@ -1,83 +0,0 @@
-Free Resources for Securing Your Open Source Code
-======
-
-
-
-While the widespread adoption of open source continues at a healthy rate, the recent [2018 Open Source Security and Risk Analysis Report][1] from Black Duck and Synopsys reveals some common concerns and highlights the need for sound security practices. The report examines findings from the anonymized data of over 1,100 commercial codebases with represented Industries from automotive, Big Data, enterprise software, financial services, healthcare, IoT, manufacturing, and more.
-
-The report highlights a massive uptick in open source adoption, with 96 percent of the applications scanned containing open source components. However, the report also includes warnings about existing vulnerabilities. Among the [findings][2]:
-
- * “What is worrisome is that 78 percent of the codebases examined contained at least one open source vulnerability, with an average 64 vulnerabilities per codebase.”
-
- * “Over 54 percent of the vulnerabilities found in audited codebases are considered high-risk vulnerabilities.”
-
- * Seventeen percent of the codebases contained a highly publicized vulnerability such as Heartbleed, Logjam, Freak, Drown, or Poodle.
-
-
-
-
-"The report clearly demonstrates that with the growth in open source use, organizations need to ensure they have the tools to detect vulnerabilities in open source components and manage whatever license compliance their use of open source may require," said Tim Mackey, technical evangelist at Black Duck by Synopsys.
-
-Indeed, with ever more impactful security threats emerging,the need for fluency with security tools and practices has never been more pronounced. Most organizations are aware that network administrators and sysadmins need to have strong security skills, and, in many cases security certifications. [In this article,][3] we explored some of the tools, certifications and practices that many of them wisely embrace.
-
-The Linux Foundation has also made available many informational and educational resources on security. Likewise, the Linux community offers many free resources for specific platforms and tools. For example, The Linux Foundation has published a [Linux workstation security checklist][4] that covers a lot of good ground. Online publications ranging from the [Fedora security guide][5] to the[Securing Debian Manual][6] can also help users protect against vulnerabilities within specific platforms.
-
-The widespread use of cloud platforms such as OpenStack is also stepping up the need for cloud-centric security smarts. According to The Linux Foundation’s[Guide to the Open Cloud][7]: “Security is still a top concern among companies considering moving workloads to the public cloud, according to Gartner, despite a strong track record of security and increased transparency from cloud providers. Rather, security is still an issue largely due to companies’ inexperience and improper use of cloud services.”
-
-For both organizations and individuals, the smallest holes in implementation of routers, firewalls, VPNs, and virtual machines can leave room for big security problems. Here is a collection of free tools that can plug these kinds of holes:
-
- * [Wireshark][8], a packet analyzer
-
- * [KeePass Password Safe][9], a free open source password manager
-
- * [Malwarebytes][10], a free anti-malware and antivirus tool
-
- * [NMAP][11], a powerful security scanner
-
- * [NIKTO][12], an open source web server scanner
-
- * [Ansible][13], a tool for automating secure IT provisioning
-
- * [Metasploit][14], a tool for understanding attack vectors and doing penetration testing
-
-
-
-
-Instructional videos abound for these tools. You’ll find a whole[tutorial series][15] for Metasploit, and [video tutorials][16] for Wireshark. Quite a few free ebooks provide good guidance on security as well. For example, one of the common ways for security threats to invade open source platforms occurs in M&A scenarios, where technology platforms are merged—often without proper open source audits. In an ebook titled [Open Source Audits in Merger and Acquisition Transactions][17], from Ibrahim Haddad and The Linux Foundation, you’ll find an overview of the open source audit process and important considerations for code compliance, preparation, and documentation.
-
-Meanwhile, we’ve[previously covered][18] a free ebook from the editors at[The New Stack][19] called Networking, Security & Storage with Docker & Containers. It covers the latest approaches to secure container networking, as well as native efforts by Docker to create efficient and secure networking practices. The ebook is loaded with best practices for locking down security at scale.
-
-All of these tools and resources, and many more, can go a long way toward preventing security problems, and an ounce of prevention is, as they say, worth a pound of cure. With security breaches continuing, now is an excellent time to look into the many security and compliance resources for open source tools and platforms available. Learn more about security, compliance, and open source project health [here][20].
-
---------------------------------------------------------------------------------
-
-via: https://www.linux.com/blog/2018/5/free-resources-securing-your-open-source-code
-
-作者:[Sam Dean][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.linux.com/users/sam-dean
-[1]:https://www.blackducksoftware.com/open-source-security-risk-analysis-2018
-[2]:https://www.prnewswire.com/news-releases/synopsys-report-finds-majority-of-software-plagued-by-known-vulnerabilities-and-license-conflicts-as-open-source-adoption-soars-300648367.html
-[3]:https://www.linux.com/blog/sysadmin-ebook/2017/8/future-proof-your-sysadmin-career-locking-down-security
-[4]:http://go.linuxfoundation.org/ebook_workstation_security
-[5]:https://docs.fedoraproject.org/en-US/Fedora/19/html/Security_Guide/index.html
-[6]:https://www.debian.org/doc/manuals/securing-debian-howto/index.en.html
-[7]:https://www.linux.com/publications/2016-guide-open-cloud
-[8]:https://www.wireshark.org/
-[9]:http://keepass.info/
-[10]:https://www.malwarebytes.com/
-[11]:http://searchsecurity.techtarget.co.uk/tip/Nmap-tutorial-Nmap-scan-examples-for-vulnerability-discovery
-[12]:https://cirt.net/Nikto2
-[13]:https://www.ansible.com/
-[14]:https://www.metasploit.com/
-[15]:http://www.computerweekly.com/tutorial/The-Metasploit-Framework-Tutorial-PDF-compendium-Your-ready-reckoner
-[16]:https://www.youtube.com/watch?v=TkCSr30UojM
-[17]:https://www.linuxfoundation.org/resources/open-source-audits-merger-acquisition-transactions/
-[18]:https://www.linux.com/news/networking-security-storage-docker-containers-free-ebook-covers-essentials
-[19]:http://thenewstack.io/ebookseries/
-[20]:https://www.linuxfoundation.org/projects/security-compliance/
diff --git a/sources/tech/20180531 How to create shortcuts in vi.md b/sources/tech/20180531 How to create shortcuts in vi.md
index 0e9772e402..ba856e745a 100644
--- a/sources/tech/20180531 How to create shortcuts in vi.md
+++ b/sources/tech/20180531 How to create shortcuts in vi.md
@@ -1,4 +1,4 @@
-How to create shortcuts in vi
+【sd886393认领翻译中】How to create shortcuts in vi
======

diff --git a/sources/tech/20180618 What-s all the C Plus Fuss- Bjarne Stroustrup warns of dangerous future plans for his C.md b/sources/tech/20180618 What-s all the C Plus Fuss- Bjarne Stroustrup warns of dangerous future plans for his C.md
index 04644aebb2..2f9a6636e7 100644
--- a/sources/tech/20180618 What-s all the C Plus Fuss- Bjarne Stroustrup warns of dangerous future plans for his C.md
+++ b/sources/tech/20180618 What-s all the C Plus Fuss- Bjarne Stroustrup warns of dangerous future plans for his C.md
@@ -1,3 +1,4 @@
+Translating by qhwdw
What's all the C Plus Fuss? Bjarne Stroustrup warns of dangerous future plans for his C++
======
diff --git a/sources/tech/20180709 How To Configure SSH Key-based Authentication In Linux.md b/sources/tech/20180709 How To Configure SSH Key-based Authentication In Linux.md
deleted file mode 100644
index 06ca1b9178..0000000000
--- a/sources/tech/20180709 How To Configure SSH Key-based Authentication In Linux.md
+++ /dev/null
@@ -1,225 +0,0 @@
-How To Configure SSH Key-based Authentication In Linux
-======
-
-
-
-### What is SSH Key-based authentication?
-
-As we all know, **Secure Shell** , shortly **SSH** , is the cryptographic network protocol that allows you to securely communicate/access a remote system over unsecured network, for example Internet. Whenever you send a data over an unsecured network using SSH, the data will be automatically encrypted in the source system, and decrypted in the destination side. SSH provides four authentication methods namely **password-based authentication** , **key-based authentication** , **Host-based authentication** , and **Keyboard authentication**. The most commonly used authentication methods are password-based and key-based authentication.
-
-In password-based authentication, all you need is the password of the remote system’s user. If you know the password of remote user, you can access the respective system using **“ssh[[email protected]][1]”**. On the other hand, in key-based authentication, you need to generate SSH key pairs and upload the SSH public key to the remote system in order to communicate it via SSH. Each SSH key pair consists of a private key and public key. The private key should be kept within the client system, and the public key should uploaded to the remote systems. You shouldn’t disclose the private key to anyone. Hope you got the basic idea about SSH and its authentication methods.
-
-In this tutorial, we will be discussing how to configure SSH key-based authentication in Linux.
-
-### Configure SSH Key-based Authentication In Linux
-
-For the purpose of this guide, I will be using Arch Linux system as local system and Ubuntu 18.04 LTS as remote system.
-
-Local system details:
-
- * **OS** : Arch Linux Desktop
- * **IP address** : 192.168.225.37 /24
-
-
-
-Remote system details:
-
- * **OS** : Ubuntu 18.04 LTS Server
- * **IP address** : 192.168.225.22/24
-
-
-
-### Local system configuration
-
-Like I said already, in SSH key-based authentication method, the public key should be uploaded to the remote system that you want to access via SSH. The public keys will usually be stored in a file called **~/.ssh/authorized_keys** in the remote SSH systems.
-
-**Important note:** Do not generate key pairs as **root** , as only root would be able to use those keys. Create key pairs as normal user.
-
-Now, let us create the SSH key pair in the local system. To do so, run the following command in your client system.
-```
-$ ssh-keygen
-
-```
-
-The above command will create 2048 bit RSA key pair. Enter the passphrase twice. More importantly, Remember your passphrase. You’ll need it later.
-
-**Sample output:**
-```
-Generating public/private rsa key pair.
-Enter file in which to save the key (/home/sk/.ssh/id_rsa):
-Enter passphrase (empty for no passphrase):
-Enter same passphrase again:
-Your identification has been saved in /home/sk/.ssh/id_rsa.
-Your public key has been saved in /home/sk/.ssh/id_rsa.pub.
-The key fingerprint is:
-SHA256:wYOgvdkBgMFydTMCUI3qZaUxvjs+p2287Tn4uaZ5KyE [email protected]
-The key's randomart image is:
-+---[RSA 2048]----+
-|+=+*= + |
-|o.o=.* = |
-|.oo * o + |
-|. = + . o |
-|. o + . S |
-| . E . |
-| + o |
-| +.*o+o |
-| .o*=OO+ |
-+----[SHA256]-----+
-
-```
-
-In case you have already created the key pair, you will see the following message. Just type “y” to create overwrite the existing key .
-```
-/home/username/.ssh/id_rsa already exists.
-Overwrite (y/n)?
-
-```
-
-Please note that **passphrase is optional**. If you give one, you’ll be asked to enter the password every time when you try to SSH a remote system unless you are using any SSH agent to store the password. If you don’t want passphrase(not safe though), simply press ENTER key twice when you’ll be asked to enter the passphrase. However, we recommend you to use passphrase. Using a password-less ssh key is generally not a good idea from a security point of view. They should be limited to very specific cases such as services having to access a remote system without the user intervention (e.g. remote backups with rsync, …).
-
-If you already have a ssh key without a passphrase in private file **~/.ssh/id_rsa** and wanted to update key with passphrase, use the following command:
-```
-$ ssh-keygen -p -f ~/.ssh/id_rsa
-
-```
-
-Sample output:
-```
-Enter new passphrase (empty for no passphrase):
-Enter same passphrase again:
-Your identification has been saved with the new passphrase.
-
-```
-
-Now, we have created the key pair in the local system. Now, copy the SSH public key to your remote SSH server using command:
-
-Here, I will be copying the local (Arch Linux) system’s public key to the remote system (Ubuntu 18.04 LTS in my case). Technically speaking, the above command will copy the contents of local system’s **~/.ssh/id_rsa.pub key** into remote system’s **~/.ssh/authorized_keys** file. Clear? Good.
-
-Type **yes** to continue connecting to your remote SSH server. And, then Enter the root user’s password of the remote system.
-```
-/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
-/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
-[email protected]2.168.225.22's password:
-
-Number of key(s) added: 1
-
-Now try logging into the machine, with: "ssh '[email protected]'"
-and check to make sure that only the key(s) you wanted were added.
-
-```
-
-If you have already copied the key, but want to update the key with new passphrase, use **-f** option to overwrite the existing key like below.
-
-We have now successfully added the local system’s SSH public key to the remote system. Now, let us disable the password-based authentication completely in the remote system. Because, we have configured key-based authentication, so we don’t need password-base authentication anymore.
-
-### Disable SSH Password-based authentication in remote system
-
-You need to perform the following commands as root or sudo user.
-
-To disable password-based authentication, go to your remote system’s console and edit **/etc/ssh/sshd_config** configuration file using any editor:
-```
-$ sudo vi /etc/ssh/sshd_config
-
-```
-
-Find the following line. Uncomment it and set it’s value as **no**.
-```
-PasswordAuthentication no
-
-```
-
-Restart ssh service to take effect the changes.
-```
-$ sudo systemctl restart sshd
-
-```
-
-### Access Remote system from local system
-
-Go to your local system and SSH into your remote server using command:
-
-Enter the passphrase.
-
-**Sample output:**
-```
-Enter passphrase for key '/home/sk/.ssh/id_rsa':
-Last login: Mon Jul 9 09:59:51 2018 from 192.168.225.37
-[email protected]:~$
-
-```
-
-Now, you’ll be able to SSH into your remote system. As you noticed, we have logged-in to the remote system’s account using passphrase which we created earlier using **ssh-keygen** command, not using the actual account’s password.
-
-If you try to ssh from another client system, you will get this error message. Say for example, I am tried to SSH into my Ubuntu system from my CentOS using command:
-
-**Sample output:**
-```
-The authenticity of host '192.168.225.22 (192.168.225.22)' can't be established.
-ECDSA key fingerprint is 67:fc:69:b7:d4:4d:fd:6e:38:44:a8:2f:08:ed:f4:21.
-Are you sure you want to continue connecting (yes/no)? yes
-Warning: Permanently added '192.168.225.22' (ECDSA) to the list of known hosts.
-Permission denied (publickey).
-
-```
-
-As you see in the above output, I can’t SSH into my remote Ubuntu 18.04 systems from any other systems, except the CentOS system.
-
-### Adding more Client system’s keys to SSH server
-
-This is very important. Like I said already, you can’t access the remote system via SSH, except the one you configured (In our case, it’s Ubuntu). I want to give permissions to more clients to access the remote SSH server. What should I do? Simple. You need to generate the SSH key pair in all your client systems and copy the ssh public key manually to the remote server that you want to access via SSH.
-
-To create SSH key pair on your client system’s, run:
-```
-$ ssh-keygen
-
-```
-
-Enter the passphrase twice. Now, the ssh key pair is generated. You need to copy the public ssh key (not private key) to your remote server manually.
-
-Display the pub key using command:
-```
-$ cat ~/.ssh/id_rsa.pub
-
-```
-
-You should an output something like below.
-
-Copy the entire contents (via USB drive or any medium) and go to your remote server’s console. Create a directory called **ssh** in the home directory as shown below. You need to execute the following commands as root user.
-```
-$ mkdir -p ~/.ssh
-
-```
-
-Now, append the your client system’s pub key which you generated in the previous step in a file called
-```
-echo {Your_public_key_contents_here} >> ~/.ssh/authorized_keys
-
-```
-
-Restart ssh service on the remote system. Now, you’ll be able to SSH to your server from the new client.
-
-If manually adding ssh pubkey seems difficult, enable password-based authentication temporarily in the remote system and copy the key using “ssh-copy-id” command from your local system and finally disable the password-based authentication.
-
-**Suggested read:**
-
-And, that’s all for now. SSH Key-based authentication provides an extra layer protection from brute-force attacks. As you can see, configuring key-based authentication is not that difficult either. It is one of the recommended method to keep your Linux servers safe and secure.
-
-I will be here soon with another useful article. Until then, stay tuned with OSTechNix.
-
-Cheers!
-
-
-
---------------------------------------------------------------------------------
-
-via: https://www.ostechnix.com/configure-ssh-key-based-authentication-linux/
-
-作者:[SK][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.ostechnix.com/author/sk/
-[1]:https://www.ostechnix.com/cdn-cgi/l/email-protection
diff --git a/sources/tech/20180720 An Introduction to Using Git.md b/sources/tech/20180720 An Introduction to Using Git.md
deleted file mode 100644
index 2a91406721..0000000000
--- a/sources/tech/20180720 An Introduction to Using Git.md
+++ /dev/null
@@ -1,193 +0,0 @@
-translating by distant1219
-
-An Introduction to Using Git
-======
-
-If you’re a developer, then you know your way around development tools. You’ve spent years studying one or more programming languages and have perfected your skills. You can develop with GUI tools or from the command line. On your own, nothing can stop you. You code as if your mind and your fingers are one to create elegant, perfectly commented, source for an app you know will take the world by storm.
-
-But what happens when you’re tasked with collaborating on a project? Or what about when that app you’ve developed becomes bigger than just you? What’s the next step? If you want to successfully collaborate with other developers, you’ll want to make use of a distributed version control system. With such a system, collaborating on a project becomes incredibly efficient and reliable. One such system is [Git][1]. Along with Git comes a handy repository called [GitHub][2], where you can house your projects, such that a team can check out and check in code.
-
-I will walk you through the very basics of getting Git up and running and using it with GitHub, so the development on your game-changing app can be taken to the next level. I’ll be demonstrating on Ubuntu 18.04, so if your distribution of choice is different, you’ll only need to modify the Git install commands to suit your distribution’s package manager.
-
-### Git and GitHub
-
-The first thing to do is create a free GitHub account. Head over to the [GitHub signup page][3] and fill out the necessary information. Once you’ve done that, you’re ready to move on to installing Git (you can actually do these two steps in any order).
-
-Installing Git is simple. Open up a terminal window and issue the command:
-```
-sudo apt install git-all
-
-```
-
-This will include a rather large number of dependencies, but you’ll wind up with everything you need to work with Git and GitHub.
-
-On a side note: I use Git quite a bit to download source for application installation. There are times when a piece of software isn’t available via the built-in package manager. Instead of downloading the source files from a third-party location, I’ll often go the project’s Git page and clone the package like so:
-```
-git clone ADDRESS
-
-```
-
-Where ADDRESS is the URL given on the software’s Git page.
-Doing this most always ensures I am installing the latest release of a package.
-
-Create a local repository and add a file
-
-The next step is to create a local repository on your system (we’ll call it newproject and house it in ~/). Open up a terminal window and issue the commands:
-```
-cd ~/
-
-mkdir newproject
-
-cd newproject
-
-```
-
-Now we must initialize the repository. In the ~/newproject folder, issue the command git init. When the command completes, you should see that the empty Git repository has been created (Figure 1).
-
-![new repository][5]
-
-Figure 1: Our new repository has been initialized.
-
-[Used with permission][6]
-
-Next we need to add a file to the project. From within the root folder (~/newproject) issue the command:
-```
-touch readme.txt
-
-```
-
-You will now have an empty file in your repository. Issue the command git status to verify that Git is aware of the new file (Figure 2).
-
-![readme][8]
-
-Figure 2: Git knows about our readme.txt file.
-
-[Used with permission][6]
-
-Even though Git is aware of the file, it hasn’t actually been added to the project. To do that, issue the command:
-```
-git add readme.txt
-
-```
-
-Once you’ve done that, issue the git status command again to see that readme.txt is now considered a new file in the project (Figure 3).
-
-![file added][10]
-
-Figure 3: Our file now has now been added to the staging environment.
-
-[Used with permission][6]
-
-### Your first commit
-
-With the new file in the staging environment, you are now ready to create your first commit. What is a commit? Easy: A commit is a record of the files you’ve changed within the project. Creating the commit is actually quite simple. It is important, however, that you include a descriptive message for the commit. By doing this, you are adding notes about what the commit contains (such as what changes you’ve made to the file). Before we do this, however, we have to inform Git who we are. To do this, issue the command:
-```
-git config --global user.email EMAIL
-
-git config --global user.name “FULL NAME”
-
-```
-
-Where EMAIL is your email address and FULL NAME is your name.
-
-Now we can create the commit by issuing the command:
-```
-git commit -m “Descriptive Message”
-
-```
-
-Where Descriptive Message is your message about the changes within the commit. For example, since this is the first commit for the readme.txt file, the commit could be:
-```
-git commit -m “First draft of readme.txt file”
-
-```
-
-You should see output indicating that 1 file has changed and a new mode was created for readme.txt (Figure 4).
-
-![success][12]
-
-Figure 4: Our commit was successful.
-
-[Used with permission][6]
-
-### Create a branch and push it to GitHub
-
-Branches are important, as they allow you to move between project states. Let’s say you want to create a new feature for your game-changing app. To do that, create a new branch. Once you’ve completed work on the feature you can merge this feature from the branch to the master branch. To create the new branch, issue the command:
-
-git checkout -b BRANCH
-
-where BRANCH is the name of the new branch. Once the command completes, issue the command git branch to see that it has been created (Figure 5).
-
-![featureX][14]
-
-Figure 5: Our new branch, called featureX.
-
-[Used with permission][6]
-
-Next we need to create a repository on GitHub. If you log into your GitHub account, click the New Repository button from your account main page. Fill out the necessary information and click Create repository (Figure 6).
-
-![new repository][16]
-
-Figure 6: Creating the new repository on GitHub.
-
-[Used with permission][6]
-
-After creating the repository, you will be presented with a URL to use for pushing our local repository. To do this, go back to the terminal window (still within ~/newproject) and issue the commands:
-```
-git remote add origin URL
-
-git push -u origin master
-
-```
-
-Where URL is the url for our new GitHub repository.
-
-You will be prompted for your GitHub username and password. Once you successfully authenticate, the project will be pushed to your GitHub repository and you’re ready to go.
-
-### Pulling the project
-
-Say your collaborators make changes to the code on the GitHub project and have merged those changes. You will then need to pull the project files to your local machine, so the files you have on your system match those on the remote account. To do this, issue the command (from within ~/newproject):
-```
-git pull origin master
-
-```
-
-The above command will pull down any new or changed files to your local repository.
-
-### The very basics
-
-And that is the very basics of using Git from the command line to work with a project stored on GitHub. There is quite a bit more to learn, so I highly recommend you issue the commands man git, man git-push, and man git-pull to get a more in-depth understanding of what the git command can do.
-
-Happy developing!
-
-Learn more about Linux through the free ["Introduction to Linux" ][17]course from The Linux Foundation and edX.
-
---------------------------------------------------------------------------------
-
-via: https://www.linux.com/learn/intro-to-linux/2018/7/introduction-using-git
-
-作者:[Jack Wallen][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.linux.com/users/jlwallen
-[1]:https://git-scm.com/
-[2]:https://github.com/
-[3]:https://github.com/join?source=header-home
-[4]:/files/images/git1jpg
-[5]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/git_1.jpg?itok=FKkr5Mrk (new repository)
-[6]:https://www.linux.com/licenses/category/used-permission
-[7]:/files/images/git2jpg
-[8]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/git_2.jpg?itok=54G9KBHS (readme)
-[9]:/files/images/git3jpg
-[10]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/git_3.jpg?itok=KAJwRJIB (file added)
-[11]:/files/images/git4jpg
-[12]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/git_4.jpg?itok=qR0ighDz (success)
-[13]:/files/images/git5jpg
-[14]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/git_5.jpg?itok=6m9RTWg6 (featureX)
-[15]:/files/images/git6jpg
-[16]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/git_6.jpg?itok=d2toRrUq (new repository)
-[17]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/sources/tech/20180720 How to build a URL shortener with Apache.md b/sources/tech/20180720 How to build a URL shortener with Apache.md
deleted file mode 100644
index ede90814af..0000000000
--- a/sources/tech/20180720 How to build a URL shortener with Apache.md
+++ /dev/null
@@ -1,82 +0,0 @@
-How to build a URL shortener with Apache
-======
-
-
-
-Long ago, folks started sharing links on Twitter. The 140-character limit meant that URLs might consume most (or all) of a tweet, so people turned to URL shorteners. Eventually, Twitter added a built-in URL shortener ([t.co][1]).
-
-Character count isn't as important now, but there are still other reasons to shorten links. For one, the shortening service may provide analytics—you can see how popular the links are that you share. It also simplifies making easy-to-remember URLs. For example, [bit.ly/INtravel][2] is much easier to remember than
- {'⭐️'.repeat(stars)}
-
- )}
- Idea
+
+## Implementation
+```
+
+We now have a top-level slide ( **# Wine Management System** ) that contains two slides ( **## Idea** and **## Implementation** ).
+
+Let's put some content in these two slides using incremental bulleted lists by creating a Markdown list prepended by the symbol **>**. Continuing from above, add two items in the first slide (lines 9–10 below) and five items in the second slide (lines 16–20):
+
+```
+% Case Study
+% Kiko Fernandez Reyes
+% Sept 27, 2017
+
+# Wine Management System
+
+## Idea
+
+>- Swiss love their **wine** and cheese
+>- Create a *simple* wine tracker system
+
+
+
+## Implementation
+
+>- Bottles have a RFID tag
+>- RFID reader (emits and read signal)
+>- **Raspberry Pi**
+>- **Server (online shop)**
+>- Mobile app
+```
+
+We added an image of the Matterhorn mountain. Your slides can be improved by using plain Markdown or adding plain HTML.
+
+To generate the slides, Pandoc needs to point to the Reveal.js library, so it must be in the same folder as the SLIDES file. The command to generate the slides is:
+
+```
+pandoc -t revealjs -s --self-contained SLIDES \
+-V theme=white -V slideNumber=true -o index.html
+```
+
+
+
+The above Pandoc command uses the following flags:
+
+ * **-t revealjs** specifies we are going to output a **revealjs** presentation
+ * **-s** tells Pandoc to generate a standalone document
+ * **\--self-contained** produces HTML with no external dependencies
+ * **-V** sets the following variables:
+– **theme=white** sets the theme of the slideshow to **white**
+– **slideNumber=true** shows the slide number
+ * **-o index.html** generates the slides in the file named **index.html**
+
+
+
+To make things simpler and avoid typing this long command, create the following Makefile:
+
+```
+all: generate
+
+generate:
+ pandoc -t revealjs -s --self-contained SLIDES \
+ -V theme=white -V slideNumber=true -o index.html
+
+clean: index.html
+ rm index.html
+
+.PHONY: all clean generate
+```
+
+You can find all the code in [this repository][8].
+
+#### Make a multi-format contract
+
+Let's say you are preparing a document and (as things are nowadays) some people want it in Microsoft Word format, others use free software and would like an ODT, and others need a PDF. You do not have to use OpenOffice nor LibreOffice to generate the DOCX or PDF file. You can create your document in Markdown (with some bits of LaTeX if you need advanced formatting) and generate any of these file types.
+
+As before, begin by declaring the document's meta-information (title, author, and date):
+
+```
+% Contract Agreement for Software X
+% Kiko Fernandez-Reyes
+% August 28th, 2018
+```
+
+Then write the document in Markdown (and add LaTeX if you require advanced formatting). For example, create a table that needs fixed separation space (declared in LaTeX with **\hspace{3cm}** ) and a line where a client and a contractor should sign (declared in LaTeX with **\hrulefill** ). After that, add a table written in Markdown.
+
+Here's what the document will look like:
+
+
+
+The code to create this document is:
+
+```
+% Contract Agreement for Software X
+% Kiko Fernandez-Reyes
+% August 28th, 2018
+
+...
+
+### Work Order
+
+\begin{table}[h]
+\begin{tabular}{ccc}
+The Contractor & \hspace{3cm} & The Customer \\
+& & \\
+& & \\
+\hrulefill & \hspace{3cm} & \hrulefill \\
+%
+Name & \hspace{3cm} & Name \\
+& & \\
+& & \\
+\hrulefill & \hspace{3cm} & \hrulefill \\
+...
+\end{tabular}
+\end{table}
+
+\vspace{1cm}
+
++--------------------------------------------|----------|-------------+
+| Type of Service | Cost | Total |
++:===========================================+=========:+:===========:+
+| Game Engine | 70.0 | 70.0 |
+| | | |
++--------------------------------------------|----------|-------------+
+| | | |
++--------------------------------------------|----------|-------------+
+| Extra: Comply with defined API functions | 10.0 | 10.0 |
+| and expected returned format | | |
++--------------------------------------------|----------|-------------+
+| | | |
++--------------------------------------------|----------|-------------+
+| **Total Cost** | | **80.0** |
++--------------------------------------------|----------|-------------+
+```
+
+To generate the three different output formats needed for this document, write a Makefile:
+
+```
+DOCS=contract-agreement.md
+
+all: $(DOCS)
+ pandoc -s $(DOCS) -o $(DOCS:md=pdf)
+ pandoc -s $(DOCS) -o $(DOCS:md=docx)
+ pandoc -s $(DOCS) -o $(DOCS:md=odt)
+
+clean:
+ rm *.pdf *.docx *.odt
+
+.PHONY: all clean
+```
+
+Lines 4–7 contain the commands to generate the different outputs.
+
+If you have several Markdown files and want to merge them into one document, issue a command with the files in the order you want them to appear. For example, when writing this article, I created three documents: an introduction document, three examples, and some advanced uses. The following tells Pandoc to merge these files together in the specified order and produce a PDF named document.pdf.
+
+```
+pandoc -s introduction.md examples.md advanced-uses.md -o document.pdf
+```
+
+### Templates and meta-information
+
+Writing a complex document is no easy task. You need to stick to a set of rules that are independent from your content, such as using a specific template, writing an abstract, embedding specific fonts, and maybe even declaring keywords. All of this has nothing to do with your content: simply put, it is meta-information.
+
+Pandoc uses templates to generate different output formats. There is a template for LaTeX, another for ePub, etc. These templates have unfulfilled variables that are set with the meta-information given to Pandoc. To find out what meta-information is available in a Pandoc template, type:
+
+```
+pandoc -D FORMAT
+```
+
+For example, the template for LaTeX would be:
+
+```
+pandoc -D latex
+```
+
+Which outputs something along these lines:
+
+```
+$if(title)$
+\title{$title$$if(thanks)$\thanks{$thanks$}$endif$}
+$endif$
+$if(subtitle)$
+\providecommand{\subtitle}[1]{}
+\subtitle{$subtitle$}
+$endif$
+$if(author)$
+\author{$for(author)$$author$$sep$ \and $endfor$}
+$endif$
+$if(institute)$
+\providecommand{\institute}[1]{}
+\institute{$for(institute)$$institute$$sep$ \and $endfor$}
+$endif$
+\date{$date$}
+$if(beamer)$
+$if(titlegraphic)$
+\titlegraphic{\includegraphics{$titlegraphic$}}
+$endif$
+$if(logo)$
+\logo{\includegraphics{$logo$}}
+$endif$
+$endif$
+
+\begin{document}
+```
+
+As you can see, there are **title** , **thanks** , **author** , **subtitle** , and **institute** template variables (and many others are available). These are easily set using YAML metablocks. In lines 1–5 of the example below, we declare a YAML metablock and set some of those variables (using the contract agreement example above):
+
+```
+---
+title: Contract Agreement for Software X
+author: Kiko Fernandez-Reyes
+date: August 28th, 2018
+---
+
+(continue writing document as in the previous example)
+```
+
+This works like a charm and is equivalent to the previous code:
+
+```
+% Contract Agreement for Software X
+% Kiko Fernandez-Reyes
+% August 28th, 2018
+```
+
+However, this ties the meta-information to the content; i.e., Pandoc will always use this information to output files in the new format. If you know you need to produce multiple file formats, you better be careful. For example, what if you need to produce the contract in ePub and in HTML, and the ePub and HTML need specific and different styling rules?
+
+Let's consider the cases:
+
+ * If you simply try to embed the YAML variable **css: style-epub.css** , you would be excluding the one from the HTML version. This does not work.
+ * Duplicating the document is obviously not a good solution either, as changes in one version would not be in sync with the other copy.
+ * You can add variables to the Pandoc command line as follows:
+
+
+
+```
+pandoc -s -V css=style-epub.css document.md document.epub
+pandoc -s -V css=style-html.css document.md document.html
+```
+
+My opinion is that it is easy to overlook these variables from the command line, especially when you need to set tens of these (which can happen in complex documents). Now, if you put them all together under the same roof (a meta.yaml file), you only need to update or create a new meta-information file to produce the desired output. You would then write:
+
+```
+pandoc -s meta-pub.yaml document.md document.epub
+pandoc -s meta-html.yaml document.md document.html
+```
+
+This is a much cleaner version, and you can update all the meta-information from a single file without ever having to update the content of your document.
+
+### Wrapping up
+
+With these basic examples, I have shown how Pandoc can do a really good job at converting Markdown documents into other formats.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/9/intro-pandoc
+
+作者:[Kiko Fernandez-Reyes][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/kikofernandez
+[1]: https://pandoc.org/
+[2]: http://pandoc.org/installing.html
+[3]: https://hackage.haskell.org/package/pandoc-crossref
+[4]: https://github.com/lierdakil/pandoc-crossref/releases/tag/v0.3.2.1
+[5]: https://github.com/lierdakil/pandoc-crossref#installation
+[6]: http://pandoc.org/demo/mathMathML.html
+[7]: https://github.com/kikofernandez/pandoc-examples/tree/master/math
+[8]: https://github.com/kikofernandez/pandoc-examples/tree/master/slides
+[9]: https://daringfireball.net/projects/markdown/syntax#header
diff --git a/sources/tech/20180914 Freespire Linux- A Great Desktop for the Open Source Purist.md b/sources/tech/20180914 Freespire Linux- A Great Desktop for the Open Source Purist.md
new file mode 100644
index 0000000000..baaf08e92d
--- /dev/null
+++ b/sources/tech/20180914 Freespire Linux- A Great Desktop for the Open Source Purist.md
@@ -0,0 +1,114 @@
+Freespire Linux: A Great Desktop for the Open Source Purist
+======
+
+
+
+Quick. Click on your Linux desktop menu and scan through the list of installed software. How much of that software is strictly open sources To make matters a bit more complicated, have you installed closed source media codecs (to play the likes of MP3 files perhaps)? Is everything fully open, or do you have a mixture of open and closed source tools?
+
+If you’re a purist, you probably strive to only use open source tools on your desktop. But how do you know, for certain, that your distribution only includes open source software? Fortunately, a few distributions go out of their way to only include applications that are 100% open. One such distro is [Freespire][1].
+
+Does that name sound familiar? It should, as it is closely related to[Linspire][2]. Now we’re talking familiarity. Remember back in the early 2000s, when Walmart sold Linux desktop computers? Those computers were powered by the Linspire operating system. Linspire went above and beyond to create an experience that would be similar to that of Windows—even including the tools to install Windows apps on Linux. That experiment failed, mostly because consumers thought they were getting a Windows desktop machine for a dirt cheap price. After that debacle, Linspire went away for a while. It’s now back, thanks to [PC/OpenSystems LLC][3]. Their goal isn’t to recreate the past but to offer two different flavors of Linux:
+
+ * Linspire—a commercial distribution of Linux that includes proprietary software and does have an associated cost ($39.99 USD for a single license).
+
+ * Freespire—a non-commercial distribution of Linux that only includes open source software and is free to download.
+
+
+
+
+We’re here to discuss Freespire and why it is an outstanding addition to the Linux community, especially those who strive to use only free and open source software. This version of Freespire (4.0) was released on August 20, 2018, so it’s fresh and ready to go.
+
+Let’s dig into the operating system and see what makes this a viable candidate for open source fans.
+
+### Installation
+
+In keeping with my usual approach, there’s very little reason to even mention the installation of Freespire Linux. There is nothing out of the ordinary here. Download the ISO image, burn it to a USB Drive (or CD/DVD if you’re dealing with older hardware), boot the drive, click the Install icon, answer a few simple questions, and wait for the installation to prompt for a reboot. That’s how far we’ve come with Linux installations… they are simple, and rarely will you have a single issue with the process. In the end, you’ll be presented with a simple (modified) Mate desktop (Figure 1) that makes it easy for any user (of any skill level) to feel right at home.
+
+
+
+### Software Titles
+
+Once you’ve logged into the desktop, you’ll find a main menu where you can view all of the installed applications. That list of software includes:
+
+ * Geary
+
+ * Chromium Browser
+
+ * Abiword
+
+ * Gnumeric
+
+ * Calendar
+
+ * Audacious
+
+ * Totem Video Player
+
+ * Software Center
+
+ * Synaptic
+
+ * G-Debi
+
+
+
+
+Also rolled into the system is support for both Flatpak and Snap applications, so you shouldn’t miss out on any software you need, which brings me to the part when purists might want to look away.
+
+Just because Freespire is marketed as a purely open source distribution, it doesn’t mean users are locked down to only open source software. In fact, if you open the Software Center, you can do a quick search for Spotify (a closed source application with an available Linux desktop client) and there it is! (Figure 2).
+
+![Spotify][5]
+
+Figure 2: The closed source Spotify client available for installation.
+
+[Used with permission][6]
+
+Fortunately, for those productive-minded folks, the likes of LibreOffice (which is not installed by default) is open source and can be installed easily from the Software Center. That doesn’t mean you must install other software, but those who need to do serious business-centric work (such as collaborating on documents), will likely want/need to install a more powerful office suite (as Abiword won’t cut it as a business-level word processor).
+
+For those who tend to work long hours on the Linux desktop and want to protect their eyes from extended strain, Freespire does include a nightlight tool that can adjust the color temperature of the interface. To open this tool, click on the main desktop menu and type night in the Search bar (Figure 3).
+
+![Night Light][8]
+
+Figure 3: Opening the Night Light tool.
+
+[Used with permission][6]
+
+Once opened, Night Light will automatically adjust the color temperature, based on the time of day. From the notification tray, you can click the icon to suspend Night Light, set it to autostart, and close the service (Figure 4).
+
+![Night Light controls.][10]
+
+Figure 4: The Night Light controls.
+
+[Used with permission][6]
+
+### Beyond the Mate Desktop
+
+As is, Mate fans might not exactly recognize the Freespire desktop. The developers have clearly given Mate a significant set of tweaks to make it slightly resemble the Mac OS desktop. It’s not quite as elegant as, say, Elementary OS, but this is certainly an outstanding take on the Linux desktop. Whether you’re a fan of Mate or Mac OS, you should feel immediately at home on the desktop. On the top bar, the developers have included an appmenu that changes, based on what application you have open. Start any app and you’ll find that app’s menu appears in the top bar. This active menu makes the desktop quite efficient.
+
+### Are you ready for Freespire?
+
+Every piece of the Freespire puzzle is equally as user-friendly as it is intuitive. The developers of Freespire have gone to great lengths to make this pure open source distribution a treat to use. Even if a 100% open source desktop isn’t your thing, Freespire is still a worthy contender in the world of desktop Linux. It’s clean and stable (as it’s based on Ubuntu 18.04) and able to help you be efficient and productive on the desktop.
+
+Learn more about Linux through the free ["Introduction to Linux" ][11]course from The Linux Foundation and edX.
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/learn/intro-to-linux/2018/9/freespire-linux-great-desktop-open-source-purist
+
+作者:[Jack Wallen][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.linux.com/users/jlwallen
+[1]: https://www.freespirelinux.com/
+[2]: https://www.linspirelinux.com/
+[3]: https://www.pc-opensystems.com
+[5]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/freespire_2.jpg?itok=zcr94Dk6 (Spotify)
+[6]: /licenses/category/used-permission
+[8]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/freespire_3.jpg?itok=aZYtBPgE (Night Light)
+[9]: /files/images/freespire4jpg
+[10]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/freespire_4.jpg?itok=JCcQwmJ5 (Night Light controls.)
+[11]: https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/sources/tech/20180915 Backup Installed Packages And Restore Them On Freshly Installed Ubuntu.md b/sources/tech/20180915 Backup Installed Packages And Restore Them On Freshly Installed Ubuntu.md
new file mode 100644
index 0000000000..c775fd5040
--- /dev/null
+++ b/sources/tech/20180915 Backup Installed Packages And Restore Them On Freshly Installed Ubuntu.md
@@ -0,0 +1,109 @@
+translating---geekpi
+
+Backup Installed Packages And Restore Them On Freshly Installed Ubuntu
+======
+
+
+
+Installing the same set of packages on multiple Ubuntu systems is time consuming and boring task. You don’t want to spend your time to install the same packages over and over on multiple systems. When it comes to install packages on similar architecture Ubuntu systems, there are many methods available to make this task easier. You could simply migrate your old Ubuntu system’s applications, settings and data to a newly installed system with a couple mouse clicks using [**Aptik**][1]. Or, you can take the [**backup entire list of installed packages**][2] using your package manager (Eg. APT), and install them later on a freshly installed system. Today, I learned that there is also yet another dedicated utility available to do this job. Say hello to **apt-clone** , a simple tool that lets you to create a list of installed packages for Debian/Ubuntu systems that can be restored on freshly installed systems or containers or into a directory.
+
+Apt-clone will help you on situations where you want to,
+
+ * Install consistent applications across multiple systems running with similar Ubuntu (and derivatives) OS.
+ * Install same set of packages on multiple systems often.
+ * Backup the entire list of installed applications and restore them on demand wherever and whenever necessary.
+
+
+
+In this brief guide, we will be discussing how to install and use Apt-clone on Debian-based systems. I tested this utility on Ubuntu 18.04 LTS system, however it should work on all Debian and Ubuntu-based systems.
+
+### Backup Installed Packages And Restore Them Later On Freshly Installed Ubuntu System
+
+Apt-clone is available in the default repositories. To install it, just enter the following command from the Terminal:
+
+```
+$ sudo apt install apt-clone
+```
+
+Once installed, simply create the list of installed packages and save them in any location of your choice.
+
+```
+$ mkdir ~/mypackages
+
+$ sudo apt-clone clone ~/mypackages
+```
+
+The above command saved all installed packages in my Ubuntu system in a file named **apt-clone-state-ubuntuserver.tar.gz** under **~/mypackages** directory.
+
+To view the details of the backup file, run:
+
+```
+$ apt-clone info mypackages/apt-clone-state-ubuntuserver.tar.gz
+Hostname: ubuntuserver
+Arch: amd64
+Distro: bionic
+Meta:
+Installed: 516 pkgs (33 automatic)
+Date: Sat Sep 15 10:23:05 2018
+```
+
+As you can see, I have 516 packages in total in my Ubuntu server.
+
+Now, copy this file on your USB or external drive and go to any other system that want to install the same set of packages. Or you can also transfer the backup file to the system on the network and install the packages by using the following command:
+
+```
+$ sudo apt-clone restore apt-clone-state-ubuntuserver.tar.gz
+```
+
+Please be mindful that this command will overwrite your existing **/etc/apt/sources.list** and will install/remove packages. You have been warned! Also, just make sure the destination system is on same arch and same OS. For example, if the source system is running with 18.04 LTS 64bit, the destination system must also has the same.
+
+If you don’t want to restore packages on the system, you can simply use `--destination /some/location` option to debootstrap the clone into this directory.
+
+```
+$ sudo apt-clone restore apt-clone-state-ubuntuserver.tar.gz --destination ~/oldubuntu
+```
+
+In this case, the above command will restore the packages in a folder named **~/oldubuntu**.
+
+For more details, refer help section:
+
+```
+$ apt-clone -h
+```
+
+Or, man pages:
+
+```
+$ man apt-clone
+```
+
+**Suggested read:**
+
++ [Systemback – Restore Ubuntu Desktop and Server to previous state][3]
++ [Cronopete – An Apple’s Time Machine Clone For Linux][4]
+
+And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
+
+Cheers!
+
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/backup-installed-packages-and-restore-them-on-freshly-installed-ubuntu-system/
+
+作者:[SK][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/sk/
+[1]: https://www.ostechnix.com/how-to-migrate-system-settings-and-data-from-an-old-system-to-a-newly-installed-ubuntu-system/
+[2]: https://www.ostechnix.com/create-list-installed-packages-install-later-list-centos-ubuntu/#comment-12598
+
+[3]: https://www.ostechnix.com/systemback-restore-ubuntu-desktop-and-server-to-previous-state/
+
+[4]: https://www.ostechnix.com/cronopete-apples-time-machine-clone-linux/
diff --git a/sources/tech/20180917 4 scanning tools for the Linux desktop.md b/sources/tech/20180917 4 scanning tools for the Linux desktop.md
new file mode 100644
index 0000000000..a239c87768
--- /dev/null
+++ b/sources/tech/20180917 4 scanning tools for the Linux desktop.md
@@ -0,0 +1,72 @@
+4 scanning tools for the Linux desktop
+======
+Go paperless by driving your scanner with one of these open source applications.
+
+
+
+While the paperless world isn't here quite yet, more and more people are getting rid of paper by scanning documents and photos. Having a scanner isn't enough to do the deed, though. You need software to drive that scanner.
+
+But the catch is many scanner makers don't have Linux versions of the software they bundle with their devices. For the most part, that doesn't matter. Why? Because there are good scanning applications available for the Linux desktop. They work with a variety of scanners and do a good job.
+
+Let's take a look at four simple but flexible open source Linux scanning tools. I've used each of these tools (and even wrote about three of them [back in 2014][1]) and found them very useful. You might, too.
+
+### Simple Scan
+
+One of my longtime favorites, [Simple Scan][2] is small, quick, efficient, and easy to use. If you've seen it before, that's because Simple Scan is the default scanner application on the GNOME desktop, as well as for a number of Linux distributions.
+
+Scanning a document or photo takes one click. After scanning something, you can rotate or crop it and save it as an image (JPEG or PNG only) or as a PDF. That said, Simple Scan can be slow, even if you scan documents at lower resolutions. On top of that, Simple Scan uses a set of global defaults for scanning, like 150dpi for text and 300dpi for photos. You need to go into Simple Scan's preferences to change those settings.
+
+If you've scanned something with more than a couple of pages, you can reorder the pages before you save. And if necessary—say you're submitting a signed form—you can email from within Simple Scan.
+
+### Skanlite
+
+In many ways, [Skanlite][3] is Simple Scan's cousin in the KDE world. Skanlite has few features, but it gets the job done nicely.
+
+The software has options that you can configure, including automatically saving scanned files, setting the quality of the scan, and identifying where to save your scans. Skanlite can save to these image formats: JPEG, PNG, BMP, PPM, XBM, and XPM.
+
+One nifty feature is the software's ability to save portions of what you've scanned to separate files. That comes in handy when, say, you want to excise someone or something from a photo.
+
+### Gscan2pdf
+
+Another old favorite, [gscan2pdf][4] might be showing its age, but it still packs a few more features than some of the other applications mentioned here. Even so, gscan2pdf is still comparatively light.
+
+In addition to saving scans in various image formats (JPEG, PNG, and TIFF), gscan2pdf also saves them as PDF or [DjVu][5] files. You can set the scan's resolution, whether it's black and white or color, and paper size before you click the Scan button. That beats going into gscan2pdf's preferences every time you want to change any of those settings. You can also rotate, crop, and delete pages.
+
+While none of those features are truly killer, they give you a bit more flexibility.
+
+### GIMP
+
+You probably know [GIMP][6] as an image-editing tool. But did you know you can use it to drive your scanner?
+
+You'll need to install the [XSane][7] scanner software and the GIMP XSane plugin. Both of those should be available from your Linux distro's package manager. From there, select File > Create > Scanner/Camera. From there, click on your scanner and then the Scan button.
+
+If that's not your cup of tea, or if it doesn't work, you can combine GIMP with a plugin called [QuiteInsane][8]. With either plugin, GIMP becomes a powerful scanning application that lets you set a number of options like whether to scan in color or black and white, the resolution of the scan, and whether or not to compress results. You can also use GIMP's tools to touch up or apply effects to your scans. This makes it great for scanning photos and art.
+
+### Do they really just work?
+
+All of this software works well for the most part and with a variety of hardware. I've used them with several multifunction printers that I've owned over the years—whether connecting using a USB cable or over wireless.
+
+You might have noticed that I wrote "works well for the most part" in the previous paragraph. I did run into one exception: an inexpensive Canon multifunction printer. None of the software I used could detect it. I had to download and install Canon's Linux scanner software, which did work.
+
+What's your favorite open source scanning tool for Linux? Share your pick by leaving a comment.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/9/linux-scanner-tools
+
+作者:[Scott Nesbitt][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/scottnesbitt
+[1]: https://opensource.com/life/14/8/3-tools-scanners-linux-desktop
+[2]: https://gitlab.gnome.org/GNOME/simple-scan
+[3]: https://www.kde.org/applications/graphics/skanlite/
+[4]: http://gscan2pdf.sourceforge.net/
+[5]: http://en.wikipedia.org/wiki/DjVu
+[6]: http://www.gimp.org/
+[7]: https://en.wikipedia.org/wiki/Scanner_Access_Now_Easy#XSane
+[8]: http://sourceforge.net/projects/quiteinsane/
diff --git a/sources/tech/20180918 Cozy Is A Nice Linux Audiobook Player For DRM-Free Audio Files.md b/sources/tech/20180918 Cozy Is A Nice Linux Audiobook Player For DRM-Free Audio Files.md
new file mode 100644
index 0000000000..8450d6fd11
--- /dev/null
+++ b/sources/tech/20180918 Cozy Is A Nice Linux Audiobook Player For DRM-Free Audio Files.md
@@ -0,0 +1,72 @@
+Cozy Is A Nice Linux Audiobook Player For DRM-Free Audio Files
+======
+[Cozy][1] **is a free and open source audiobook player for the Linux desktop. The application lets you listen to DRM-free audiobooks (mp3, m4a, flac, ogg and wav) using a modern Gtk3 interface.**
+
+
+
+You could use any audio player to listen to audiobooks, but a specialized audiobook player like Cozy makes everything easier, by **remembering your playback position and continuing from where you left off for each audiobook** , or by letting you **set the playback speed of each book individually** , among others.
+
+The Cozy interface lets you browse books by author, reader or recency, while also providing search functionality. **Books front covers are supported by Cozy** \- either by using embedded images, or by adding a cover.jpg or cover.png image in the book folder, which is automatically picked up and displayed by Cozy.
+
+When you click on an audiobook, Cozy lists the book chapters on the right, while displaying the book cover (if available) on the left, along with the book name, author and the last played time, along with total and remaining time:
+
+
+
+From the application toolbar you can easily **go back 30 seconds** by clicking the rewind icon from its top left-hand side corner. Besides regular controls, cover and title, you'll also find a playback speed button on the toolbar, which lets you increase the playback speed up to 2X.
+
+**A sleep timer is also available**. It can be set to stop after the current chapter or after a given number of minutes.
+
+Other Cozy features worth mentioning:
+
+ * **Mpris integration** (Media keys & playback info)
+ * **Supports multiple storage locations**
+ * **Drag'n'drop support for importing new audiobooks**
+ * **Offline Mode**. If your audiobooks are on an external or network drive, you can switch the download button to keep a local cached copy of the book to listen to on the go. To enable this feature you have to set your storage location to external in the settings
+ * **Prevents your system from suspend during playback**
+ * **Dark mode**
+
+
+
+What I'd like to see in Cozy is a way to get audiobooks metadata, including the book cover, automatically. A feature to retrieve metadata from Audible.com was proposed on the Cozy GitHub project page and the developer seems interested in this, but it's not clear when or if this will be implemented.
+
+Like I was mentioning in the beginning of the article, Cozy only supports DRM-free audio files. Currently it supports mp3, m4a, flac, ogg and wav. Support for more formats will probably come in the future, with m4b being listed on the Cozy 0.7.0 todo list.
+
+Cozy cannot play Audible audiobooks due to DRM. But you'll find some solutions out there for converting Audible (.aa/.aax) audiobooks to mp3, like
+
+### Install Cozy
+
+**Any Linux distribution / Flatpak** : Cozy is available as a Flatpak on FlatHub. To install it, follow the quick Flatpak [setup][4], then go to the Cozy FlaHub [page][5] and click the install button, or use the install command at the bottom if its page.
+
+**elementary OS** : Cozy is available in the [AppCenter][6].
+
+**Ubuntu 18.04 / Linux Mint 19** : you can install Cozy from its repository:
+
+```
+wget -nv https://download.opensuse.org/repositories/home:geigi/Ubuntu_18.04/Release.key -O Release.key
+sudo apt-key add - < Release.key
+sudo sh -c "echo 'deb http://download.opensuse.org/repositories/home:/geigi/Ubuntu_18.04/ /' > /etc/apt/sources.list.d/home:geigi.list"
+sudo apt update
+sudo apt install com.github.geigi.cozy
+```
+
+**For other ways of installing Cozy check out its[website][2].**
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.linuxuprising.com/2018/09/cozy-is-nice-linux-audiobook-player-for.html
+
+作者:[Logix][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://plus.google.com/118280394805678839070
+[1]: https://cozy.geigi.de/
+[2]: https://cozy.geigi.de/#how-can-i-get-it
+[3]: https://gitlab.com/ReverendJ1/audiblefreedom/blob/master/audiblefreedom
+[4]: https://flatpak.org/setup/
+[5]: https://flathub.org/apps/details/com.github.geigi.cozy
+[6]: https://appcenter.elementary.io/com.github.geigi.cozy/
diff --git a/sources/tech/20180918 Linux firewalls- What you need to know about iptables and firewalld.md b/sources/tech/20180918 Linux firewalls- What you need to know about iptables and firewalld.md
new file mode 100644
index 0000000000..98e38a02cd
--- /dev/null
+++ b/sources/tech/20180918 Linux firewalls- What you need to know about iptables and firewalld.md
@@ -0,0 +1,170 @@
+heguangzhi translating
+
+Linux firewalls: What you need to know about iptables and firewalld
+======
+Here's how to use the iptables and firewalld tools to manage Linux firewall connectivity rules.
+
+
+This article is excerpted from my book, [Linux in Action][1], and a second Manning project that’s yet to be released.
+
+### The firewall
+
+A firewall is a set of rules. When a data packet moves into or out of a protected network space, its contents (in particular, information about its origin, target, and the protocol it plans to use) are tested against the firewall rules to see if it should be allowed through. Here’s a simple example:
+
+![firewall filtering request][3]
+
+A firewall can filter requests based on protocol or target-based rules.
+
+On the one hand, [iptables][4] is a tool for managing firewall rules on a Linux machine.
+
+On the other hand, [firewalld][5] is also a tool for managing firewall rules on a Linux machine.
+
+You got a problem with that? And would it spoil your day if I told you that there was another tool out there, called [nftables][6]?
+
+OK, I’ll admit that the whole thing does smell a bit funny, so let me explain. It all starts with Netfilter, which controls access to and from the network stack at the Linux kernel module level. For decades, the primary command-line tool for managing Netfilter hooks was the iptables ruleset.
+
+Because the syntax needed to invoke those rules could come across as a bit arcane, various user-friendly implementations like [ufw][7] and firewalld were introduced as higher-level Netfilter interpreters. Ufw and firewalld are, however, primarily designed to solve the kinds of problems faced by stand-alone computers. Building full-sized network solutions will often require the extra muscle of iptables or, since 2014, its replacement, nftables (through the nft command line tool).
+
+iptables hasn’t gone anywhere and is still widely used. In fact, you should expect to run into iptables-protected networks in your work as an admin for many years to come. But nftables, by adding on to the classic Netfilter toolset, has brought some important new functionality.
+
+From here on, I’ll show by example how firewalld and iptables solve simple connectivity problems.
+
+### Configure HTTP access using firewalld
+
+As you might have guessed from its name, firewalld is part of the [systemd][8] family. Firewalld can be installed on Debian/Ubuntu machines, but it’s there by default on Red Hat and CentOS. If you’ve got a web server like Apache running on your machine, you can confirm that the firewall is working by browsing to your server’s web root. If the site is unreachable, then firewalld is doing its job.
+
+You’ll use the `firewall-cmd` tool to manage firewalld settings from the command line. Adding the `–state` argument returns the current firewall status:
+
+```
+# firewall-cmd --state
+running
+```
+
+By default, firewalld will be active and will reject all incoming traffic with a couple of exceptions, like SSH. That means your website won’t be getting too many visitors, which will certainly save you a lot of data transfer costs. As that’s probably not what you had in mind for your web server, though, you’ll want to open the HTTP and HTTPS ports that by convention are designated as 80 and 443, respectively. firewalld offers two ways to do that. One is through the `–add-port` argument that references the port number directly along with the network protocol it’ll use (TCP in this case). The `–permanent` argument tells firewalld to load this rule each time the server boots:
+
+```
+# firewall-cmd --permanent --add-port=80/tcp
+# firewall-cmd --permanent --add-port=443/tcp
+```
+
+The `–reload` argument will apply those rules to the current session:
+
+```
+# firewall-cmd --reload
+```
+
+Curious as to the current settings on your firewall? Run `–list-services`:
+
+```
+# firewall-cmd --list-services
+dhcpv6-client http https ssh
+```
+
+Assuming you’ve added browser access as described earlier, the HTTP, HTTPS, and SSH ports should now all be open—along with `dhcpv6-client`, which allows Linux to request an IPv6 IP address from a local DHCP server.
+
+### Configure a locked-down customer kiosk using iptables
+
+I’m sure you’ve seen kiosks—they’re the tablets, touchscreens, and ATM-like PCs in a box that airports, libraries, and business leave lying around, inviting customers and passersby to browse content. The thing about most kiosks is that you don’t usually want users to make themselves at home and treat them like their own devices. They’re not generally meant for browsing, viewing YouTube videos, or launching denial-of-service attacks against the Pentagon. So to make sure they’re not misused, you need to lock them down.
+
+One way is to apply some kind of kiosk mode, whether it’s through clever use of a Linux display manager or at the browser level. But to make sure you’ve got all the holes plugged, you’ll probably also want to add some hard network controls through a firewall. In the following section, I'll describe how I would do it using iptables.
+
+There are two important things to remember about using iptables: The order you give your rules is critical, and by themselves, iptables rules won’t survive a reboot. I’ll address those here one at a time.
+
+### The kiosk project
+
+To illustrate all this, let’s imagine we work for a store that’s part of a larger chain called BigMart. They’ve been around for decades; in fact, our imaginary grandparents probably grew up shopping there. But these days, the guys at BigMart corporate headquarters are probably just counting the hours before Amazon drives them under for good.
+
+Nevertheless, BigMart’s IT department is doing its best, and they’ve just sent you some WiFi-ready kiosk devices that you’re expected to install at strategic locations throughout your store. The idea is that they’ll display a web browser logged into the BigMart.com products pages, allowing them to look up merchandise features, aisle location, and stock levels. The kiosks will also need access to bigmart-data.com, where many of the images and video media are stored.
+
+Besides those, you’ll want to permit updates and, whenever necessary, package downloads. Finally, you’ll want to permit inbound SSH access only from your local workstation, and block everyone else. The figure below illustrates how it will all work:
+
+![kiosk traffic flow ip tables][10]
+
+The kiosk traffic flow being controlled by iptables.
+
+### The script
+
+Here’s how that will all fit into a Bash script:
+
+```
+#!/bin/bash
+iptables -A OUTPUT -p tcp -d bigmart.com -j ACCEPT
+iptables -A OUTPUT -p tcp -d bigmart-data.com -j ACCEPT
+iptables -A OUTPUT -p tcp -d ubuntu.com -j ACCEPT
+iptables -A OUTPUT -p tcp -d ca.archive.ubuntu.com -j ACCEPT
+iptables -A OUTPUT -p tcp --dport 80 -j DROP
+iptables -A OUTPUT -p tcp --dport 443 -j DROP
+iptables -A INPUT -p tcp -s 10.0.3.1 --dport 22 -j ACCEPT
+iptables -A INPUT -p tcp -s 0.0.0.0/0 --dport 22 -j DROP
+```
+
+The basic anatomy of our rules starts with `-A`, telling iptables that we want to add the following rule. `OUTPUT` means that this rule should become part of the OUTPUT chain. `-p` indicates that this rule will apply only to packets using the TCP protocol, where, as `-d` tells us, the destination is [bigmart.com][11]. The `-j` flag points to `ACCEPT` as the action to take when a packet matches the rule. In this first rule, that action is to permit, or accept, the request. But further down, you can see requests that will be dropped, or denied.
+
+Remember that order matters. And that’s because iptables will run a request past each of its rules, but only until it gets a match. So an outgoing browser request for, say, [youtube.com][12] will pass the first four rules, but when it gets to either the `–dport 80` or `–dport 443` rule—depending on whether it’s an HTTP or HTTPS request—it’ll be dropped. iptables won’t bother checking any further because that was a match.
+
+On the other hand, a system request to ubuntu.com for a software upgrade will get through when it hits its appropriate rule. What we’re doing here, obviously, is permitting outgoing HTTP or HTTPS requests to only our BigMart or Ubuntu destinations and no others.
+
+The final two rules will deal with incoming SSH requests. They won’t already have been denied by the two previous drop rules since they don’t use ports 80 or 443, but 22. In this case, login requests from my workstation will be accepted but requests for anywhere else will be dropped. This is important: Make sure the IP address you use for your port 22 rule matches the address of the machine you’re using to log in—if you don’t do that, you’ll be instantly locked out. It's no big deal, of course, because the way it’s currently configured, you could simply reboot the server and the iptables rules will all be dropped. If you’re using an LXC container as your server and logging on from your LXC host, then use the IP address your host uses to connect to the container, not its public address.
+
+You’ll need to remember to update this rule if my machine’s IP ever changes; otherwise, you’ll be locked out.
+
+Playing along at home (hopefully on a throwaway VM of some sort)? Great. Create your own script. Now I can save the script, use `chmod` to make it executable, and run it as `sudo`. Don’t worry about that `bigmart-data.com not found` error—of course it’s not found; it doesn’t exist.
+
+```
+chmod +X scriptname.sh
+sudo ./scriptname.sh
+```
+
+You can test your firewall from the command line using `cURL`. Requesting ubuntu.com works, but [manning.com][13] fails.
+
+```
+curl ubuntu.com
+curl manning.com
+```
+
+### Configuring iptables to load on system boot
+
+Now, how do I get these rules to automatically load each time the kiosk boots? The first step is to save the current rules to a .rules file using the `iptables-save` tool. That’ll create a file in the root directory containing a list of the rules. The pipe, followed by the tee command, is necessary to apply my `sudo` authority to the second part of the string: the actual saving of a file to the otherwise restricted root directory.
+
+I can then tell the system to run a related tool called `iptables-restore` every time it boots. A regular cron job of the kind we saw in the previous module won’t help because they’re run at set times, but we have no idea when our computer might decide to crash and reboot.
+
+There are lots of ways to handle this problem. Here’s one:
+
+On my Linux machine, I’ll install a program called [anacron][14] that will give us a file in the /etc/ directory called anacrontab. I’ll edit the file and add this `iptables-restore` command, telling it to load the current values of that .rules file into iptables each day (when necessary) one minute after a boot. I’ll give the job an identifier (`iptables-restore`) and then add the command itself. Since you’re playing along with me at home, you should test all this out by rebooting your system.
+
+```
+sudo iptables-save | sudo tee /root/my.active.firewall.rules
+sudo apt install anacron
+sudo nano /etc/anacrontab
+1 1 iptables-restore iptables-restore < /root/my.active.firewall.rules
+
+```
+
+I hope these practical examples have illustrated how to use iptables and firewalld for managing connectivity issues on Linux-based firewalls.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/9/linux-iptables-firewalld
+
+作者:[David Clinton][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/remyd
+[1]: https://www.manning.com/books/linux-in-action?a_aid=bootstrap-it&a_bid=4ca15fc9&chan=opensource
+[2]: /file/409116
+[3]: https://opensource.com/sites/default/files/uploads/iptables1.jpg (firewall filtering request)
+[4]: https://en.wikipedia.org/wiki/Iptables
+[5]: https://firewalld.org/
+[6]: https://wiki.nftables.org/wiki-nftables/index.php/Main_Page
+[7]: https://en.wikipedia.org/wiki/Uncomplicated_Firewall
+[8]: https://en.wikipedia.org/wiki/Systemd
+[9]: /file/409121
+[10]: https://opensource.com/sites/default/files/uploads/iptables2.jpg (kiosk traffic flow ip tables)
+[11]: http://bigmart.com/
+[12]: http://youtube.com/
+[13]: http://manning.com/
+[14]: https://sourceforge.net/projects/anacron/
diff --git a/sources/tech/20180919 Streama - Setup Your Own Streaming Media Server In Minutes.md b/sources/tech/20180919 Streama - Setup Your Own Streaming Media Server In Minutes.md
new file mode 100644
index 0000000000..521a8f5b95
--- /dev/null
+++ b/sources/tech/20180919 Streama - Setup Your Own Streaming Media Server In Minutes.md
@@ -0,0 +1,171 @@
+Streama – Setup Your Own Streaming Media Server In Minutes
+======
+
+
+
+**Streama** is a free, open source application that helps to setup your own personal streaming media server in minutes in Unix-like operating systems. It’s like Netflix, but self-hostable. You can deploy it on your local system or VPS or dedicated server and stream the media files across multiple devices. The media files can be accessed from a web-browser from any system on your network. If you have deployed on your VPS, you can access it from anywhere. Streama works like your own personal Netflix system to stream your TV shows, videos, audios and movies. Streama is a web-based application written using Grails 3 (server-side) with SpringSecurity and all frond-end components are written in AngularJS. The built-in player is completely HTML5-based.
+
+### Prominent Features
+
+Streama ships with a lot features as listed below.
+
+ * Easy to install configure. You can either download docker instance and fire up your media server in minutes or install vanilla version on your local or VPS or dedicated server.
+ * Drag and drop support to upload media files.
+ * Live sync watching support. You can watch videos with your friends, family remotely. It doesn’t matter where they are. You can all watch the same video at a time.
+ * Built-in beautiful video player to watch/listen video and audio.
+ * Built-in browser to access the media files in the server.
+ * Multi-user support. You can create individual user accounts to your family members and access the media server simultaneously.
+ * Streama supports pause-play option. Pause the playback at any time and Streama remembers where you left off last time.
+ * Streama can be able to detect similar movies and videos and shows for you to add.
+ * Self-hostable
+ * It is completely free and open source.
+
+
+
+What do you need more? Streama has everything you to need to setup a full-fledged streaming media server in your Linux box.
+
+### Setup Your Own Streaming Media Server Using Streama
+
+Streama requires JAVA 8 or later, preferably **OpenJDK**. And, the recommended OS is **Ubuntu**. For the purpose of this guide, I will be using Ubuntu 18.04 LTS.
+
+By default, the latest Ubuntu 18.04 includes Open JDK 11. To install default openJDK in Ubuntu 18.04 or later, run:
+
+```
+$ sudo apt install default-jdk
+
+```
+
+Java 8 is the latest stable Long Time Support version. If you prefer to use Java LTS, run:
+
+```
+$ sudo apt install openjdk-8-jdk
+```
+
+I have installed openjdk-8-jdk. To check the installed Java version, run:
+
+```
+$ java -version
+openjdk version "1.8.0_181"
+OpenJDK Runtime Environment (build 1.8.0_181-8u181-b13-0ubuntu0.18.04.1-b13)
+OpenJDK 64-Bit Server VM (build 25.181-b13, mixed mode)
+```
+
+Once java installed, create a directory to save Streama executable and yml files.
+
+```
+$ sudo mkdir /data
+
+$ sudo mkdir /data/streama
+```
+
+I followed the official documentation, so I used this path – /data/streama. It is optional. You’re free to use any location of your choice.
+
+Switch to streama directory:
+
+```
+$ cd /data/streama
+```
+
+Download the latest Streama executable file from [**releases page**][1]. As of writing this guide, the latest version was **v1.6.0-RC8**.
+
+```
+$ sudo wget https://github.com/streamaserver/streama/releases/download/v1.6.0-RC8/streama-1.6.0-RC8.war
+```
+
+Make it executable:
+
+```
+$ sudo chmod +x streama-1.6.0-RC8.war
+```
+
+Now, run Streama application using command:
+
+```
+$ sudo ./streama-1.6.0-RC8.war
+```
+
+If you an output something like below, Streama is working!
+
+```
+INFO streama.Application - Starting Application on ubuntuserver with PID 26714 (/data/streama/streama-1.6.0-RC8.war started by root in /data/streama)
+DEBUG streama.Application - Running with Spring Boot v1.4.4.RELEASE, Spring v4.3.6.RELEASE
+INFO streama.Application - The following profiles are active: production
+
+Configuring Spring Security Core ...
+... finished configuring Spring Security Core
+
+INFO streama.Application - Started Application in 92.003 seconds (JVM running for 98.66)
+Grails application running at http://localhost:8080 in environment: production
+```
+
+Open your web browser and navigate to URL – **
+ Hello {name}
+
+ );
+ }
+ return (
+
+ Please sign in
+
+ );
+};
+```
+
+这个很简单但是我们可以做得更好。这是使用三元运算符编写的相同组件。
+
+```
+const MyComponent = ({ name }) => (
+
+ {name ? `Hello ${name}` : 'Please sign in'}
+
+);
+```
+
+请注意这段代码与上面的例子相比是多么简洁。
+
+有几点需要注意。因为我们使用了箭头函数的单语句形式,所以隐含了return语句。另外,使用三元运算符允许我们省略掉重复的 `` 标记。🎉
+
+### 三元表达式 vs &&
+
+正如您所看到的,三元表达式用于表达 if/else 条件式非常好。但是对于简单的 if 条件式怎么样呢?
+
+让我们看另一个例子。如果 isPro(一个布尔值)为真,我们将显示一个奖杯表情符号。我们也要渲染星星的数量(如果不是0)。我们可以这样写。
+
+```
+const MyComponent = ({ name, isPro, stars}) => (
+ ` 就可以重新格式化你的代码。`aggressive` 标记的数量表示 auotopep8 在代码风格控制上有多少控制权。在这里可以详细了解 [aggressive][18] 选项。
+
+#### 5\. Yapf
+
+[Yapf][19] 是另一种有自己的[配置项][20]列表的重新格式化代码的工具。它与 autopep8 的不同之处在于它不仅会指出代码中违反 PEP 8 规范的地方,还会对没有违反 PEP 8 但代码风格不一致的地方重新格式化,旨在令代码的可读性更强。
+
+执行`pip install yapf` 安装 Yapf,然后执行 `yapf [options] path/to/dir` 或 `yapf [options] path/to/module.py` 可以对代码重新格式化。
+
+#### 6\. Black
+
+[Black][21] 在代码检查工具当中算是比较新的一个。它与 autopep8 和 Yapf 类似,但限制较多,没有太多的自定义选项。这样的好处是你不需要去决定使用怎么样的代码风格,让 black 来给你做决定就好。你可以在这里查阅 black 的[自定义选项][22]以及[如何在配置文件中对其进行设置][23]。
+
+Black 依赖于 Python 3.6+,但它可以格式化用 Python 2 编写的代码。执行 `pip install black` 安装 black,然后执行 `black path/to/dir` 或 `black path/to/module.py` 就可以使用 black 优化你的代码。
+
+### 检查你的测试覆盖率
+
+如果你正在进行测试工作,你需要确保提交到代码库的新代码都已经测试通过,并且不会降低测试覆盖率。虽然测试覆盖率不是衡量测试有效性和充分性的唯一指标,但它是确保项目遵循基本测试标准的一种方法。对于计算测试覆盖率,我们推荐使用 Coverage 这个库。
+
+#### 7\. Coverage
+
+[Coverage][24] 有数种显示测试覆盖率的方式,包括将结果输出到控制台或 HTML 页面,并指出哪些具体哪些地方没有被覆盖到。你可以通过配置文件自定义 Coverage 检查的内容,让你更方便使用。
+
+执行 `pip install coverage` 安装 Converage 。然后执行 `coverage [path/to/module.py] [args]` 可以运行程序并查看输出结果。如果要查看哪些代码行没有被覆盖,执行 `coverage report -m` 即可。
+
+持续集成(Continuous integration, CI)是在合并和部署代码之前自动检查代码风格错误和测试覆盖率最小值的过程。很多免费或付费的工具都可以用于执行这项工作,具体的过程不在本文中赘述,但 CI 过程是令代码更易读和更易维护的重要步骤,关于这一部分可以参考 [Travis CI][26] 和 [Jenkins][27]。
+
+以上这些只是用于检查 Python 代码的各种工具中的其中几个。如果你有其它喜爱的工具,欢迎在评论中分享。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/7/7-python-libraries-more-maintainable-code
+
+作者:[Jeff Triplett][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[HankChow](https://github.com/HankChow)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/laceynwilliams
+[1]:https://www.python.org/dev/peps/pep-0020/
+[2]:https://en.wikipedia.org/wiki/Lint_(software)
+[3]:https://www.python.org/dev/peps/pep-0008/
+[4]:https://www.pylint.org/
+[5]:https://pylint.readthedocs.io/en/latest/user_guide/ide-integration.html
+[6]:https://pylint.readthedocs.io/en/latest/user_guide/run.html#command-line-options
+[7]:http://flake8.pycqa.org/en/latest/
+[8]:http://flake8.pycqa.org/en/latest/user/configuration.html#configuration-locations
+[9]:http://flake8.pycqa.org/en/latest/user/using-hooks.html
+[10]:https://github.com/SublimeLinter/SublimeLinter-flake8
+[11]:https://github.com/timothycrosley/isort
+[12]:https://github.com/timothycrosley/isort#how-does-isort-work
+[13]:https://github.com/timothycrosley/isort#using-isort
+[14]:https://github.com/timothycrosley/isort#configuring-isort
+[15]:https://github.com/timothycrosley/isort/wiki/isort-Plugins
+[16]:https://github.com/hhatto/autopep8
+[17]:https://github.com/hhatto/autopep8#id4
+[18]:https://github.com/hhatto/autopep8#id5
+[19]:https://github.com/google/yapf
+[20]:https://github.com/google/yapf#usage
+[21]:https://github.com/ambv/black
+[22]:https://github.com/ambv/black#command-line-options
+[23]:https://github.com/ambv/black#pyprojecttoml
+[24]:https://coverage.readthedocs.io/en/latest/
+[25]:https://coverage.readthedocs.io/en/latest/config.html
+[26]:https://travis-ci.org/
+[27]:https://jenkins.io/
+
diff --git a/translated/tech/20180806 Anatomy of a Linux DNS Lookup - Part IV.md b/translated/tech/20180806 Anatomy of a Linux DNS Lookup - Part IV.md
new file mode 100644
index 0000000000..9f3dd93437
--- /dev/null
+++ b/translated/tech/20180806 Anatomy of a Linux DNS Lookup - Part IV.md
@@ -0,0 +1,165 @@
+Linux DNS 查询剖析(第四部分)
+============================================
+
+在 [Linux DNS 查询剖析(第一部分)][1],[Linux DNS 查询剖析(第二部分)][2] 和 [Linux DNS 查询剖析(第三部分)][3] 中,我们已经介绍了以下内容:
+
+* `nsswitch`
+* `/etc/hosts`
+* `/etc/resolv.conf`
+* `ping` 与 `host` 查询方式的对比
+* `systemd` 和对应的 `networking` 服务
+* `ifup` 和 `ifdown`
+* `dhclient`
+* `resolvconf`
+* `NetworkManager`
+* `dnsmasq`
+
+在第四部分中,我将介绍容器如何完成 DNS 查询。你想的没错,也不是那么简单。
+
+* * *
+
+### 1) Docker 和 DNS
+
+============================================================
+
+在 [Linux DNS 查询剖析(第三部分)][3] 中,我们介绍了 `dnsmasq`,其工作方式如下:将 DNS 查询指向到 localhost 地址 `127.0.0.1`,同时启动一个进程监听 `53` 端口并处理查询请求。
+
+在按上述方式配置 DNS 的主机上,如果运行了一个 Docker 容器,容器内的 `/etc/resolv.conf` 文件会是怎样的呢?
+
+我们来动手试验一下吧。
+
+按照默认 Docker 创建流程,可以看到如下的默认输出:
+
+```
+$ docker run ubuntu cat /etc/resolv.conf
+# Dynamic resolv.conf(5) file for glibc resolver(3) generated by resolvconf(8)
+# DO NOT EDIT THIS FILE BY HAND -- YOUR CHANGES WILL BE OVERWRITTEN
+# 127.0.0.53 is the systemd-resolved stub resolver.
+# run "systemd-resolve --status" to see details about the actual nameservers.
+
+search home
+nameserver 8.8.8.8
+nameserver 8.8.4.4
+```
+
+奇怪!
+
+#### 地址 `8.8.8.8` 和 `8.8.4.4` 从何而来呢?
+
+当我思考容器内的 `/etc/resolv.conf` 配置时,我的第一反应是继承主机的 `/etc/resolv.conf`。但只要稍微进一步分析,就会发现这样并不总是有效的。
+
+如果在主机上配置了 `dnsmasq`,那么 `/etc/resolv.conf` 文件总会指向 `127.0.0.1` 这个回环地址。如果这个地址被容器继承,容器会在其本身的网络上下文中使用;由于容器内并没有运行(在 `127.0.0.1` 地址的)DNS 服务器,因此 DNS 查询都会失败。
+
+“有了!”你可能有了新主意:将 _主机的_ 的 IP 地址用作 DNS 服务器地址,其中这个 IP 地址可以从容器的默认路由中获取:
+
+```
+root@79a95170e679:/# ip route
+default via 172.17.0.1 dev eth0
+172.17.0.0/16 dev eth0 proto kernel scope link src 172.17.0.2
+```
+
+#### 使用主机 IP 地址真的可行吗?
+
+从默认路由中,我们可以找到主机的 IP 地址 `172.17.0.1`,进而可以通过手动指定 DNS 服务器的方式进行测试(你也可以更新 `/etc/resolv.conf` 文件并使用 `ping` 进行测试;但我觉得这里很适合介绍新的 `dig` 工具及其 `@` 参数,后者用于指定需要查询的 DNS 服务器地址):
+
+```
+root@79a95170e679:/# dig @172.17.0.1 google.com | grep -A1 ANSWER.SECTION
+;; ANSWER SECTION:
+google.com. 112 IN A 172.217.23.14
+```
+
+但是还有一个问题,这种方式仅适用于主机配置了 `dnsmasq` 的情况;如果主机没有配置 `dnsmasq`,主机上并不存在用于查询的 DNS 服务器。
+
+在这个问题上,Docker 的解决方案是忽略所有可能的复杂情况,即无论主机中使用什么 DNS 服务器,容器内都使用 Google 的 DNS 服务器 `8.8.8.8` 和 `8.8.4.4` 完成 DNS 查询。
+
+ _我的经历:在 2013 年,我遇到了使用 Docker 以来的第一个问题,与 Docker 的这种 DNS 解决方案密切相关。我们公司的网络屏蔽了 `8.8.8.8` 和 `8.8.4.4`,导致容器无法解析域名。_
+
+这就是 Docker 容器的情况,但对于包括 Kubernetes 在内的容器 _编排引擎_,情况又有些不同。
+
+### 2) Kubernetes 和 DNS
+
+在 Kubernetes 中,最小部署单元是 `pod`;`pod` 是一组相互协作的容器,共享 IP 地址(和其它资源)。
+
+Kubernetes 面临的一个额外的挑战是,将 Kubernetes 服务请求(例如,`myservice.kubernetes.io`)通过对应的解析器,转发到具体服务地址对应的内网地址。这里提到的服务地址被称为归属于“集群域”。集群域可由管理员配置,根据配置可以是 `cluster.local` 或 `myorg.badger` 等。
+
+在 Kubernetes 中,你可以为 `pod` 指定如下四种 `pod` 内 DNS 查询的方式。
+
+* Default
+
+在这种(名称容易让人误解)的方式中,`pod` 与其所在的主机采用相同的 DNS 查询路径,与前面介绍的主机 DNS 查询一致。我们说这种方式的名称容易让人误解,因为该方式并不是默认选项!`ClusterFirst` 才是默认选项。
+
+如果你希望覆盖 `/etc/resolv.conf` 中的条目,你可以添加到 `kubelet` 的配置中。
+
+* ClusterFirst
+
+在 `ClusterFirst` 方式中,遇到 DNS 查询请求会做有选择的转发。根据配置的不同,有以下两种方式:
+
+第一种方式配置相对古老但更简明,即采用一个规则:如果请求的域名不是集群域的子域,那么将其转发到 `pod` 所在的主机。
+
+第二种方式相对新一些,你可以在内部 DNS 中配置选择性转发。
+
+下面给出示例配置并从 [Kubernetes 文档][4]中选取一张图说明流程:
+
+```
+apiVersion: v1
+kind: ConfigMap
+metadata:
+ name: kube-dns
+ namespace: kube-system
+data:
+ stubDomains: |
+ {"acme.local": ["1.2.3.4"]}
+ upstreamNameservers: |
+ ["8.8.8.8", "8.8.4.4"]
+```
+
+在 `stubDomains` 条目中,可以为特定域名指定特定的 DNS 服务器;而 `upstreamNameservers` 条目则给出,待查询域名不是集群域子域情况下用到的 DNS 服务器。
+
+这是通过在一个 `pod` 中运行我们熟知的 `dnsmasq` 实现的。
+
+
+
+剩下两种选项都比较小众:
+
+* ClusterFirstWithHostNet
+
+适用于 `pod` 使用主机网络的情况,例如绕开 Docker 网络配置,直接使用与 `pod` 对应主机相同的网络。
+
+* None
+
+`None` 意味着不改变 DNS,但强制要求你在 `pod` 规范文件的 `dnsConfig` 条目中指定 DNS 配置。
+
+### CoreDNS 即将到来
+
+除了上面提到的那些,一旦 `CoreDNS` 取代Kubernetes 中的 `kube-dns`,情况还会发生变化。`CoreDNS` 相比 `kube-dns` 具有可配置性更高、效率更高等优势。
+
+如果想了解更多,参考[这里][5]。
+
+如果你对 OpenShift 的网络感兴趣,我曾写过一篇[文章][6]可供你参考。但文章中 OpenShift 的版本是 `3.6`,可能有些过时。
+
+### 第四部分总结
+
+第四部分到此结束,其中我们介绍了:
+
+* Docker DNS 查询
+* Kubernetes DNS 查询
+* 选择性转发(子域不转发)
+* kube-dns
+
+--------------------------------------------------------------------------------
+
+via: https://zwischenzugs.com/2018/08/06/anatomy-of-a-linux-dns-lookup-part-iv/
+
+作者:[zwischenzugs][a]
+译者:[pinewall](https://github.com/pinewall)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://zwischenzugs.com/
+[1]:https://zwischenzugs.com/2018/06/08/anatomy-of-a-linux-dns-lookup-part-i/
+[2]:https://zwischenzugs.com/2018/06/18/anatomy-of-a-linux-dns-lookup-part-ii/
+[3]:https://zwischenzugs.com/2018/07/06/anatomy-of-a-linux-dns-lookup-part-iii/
+[4]:https://kubernetes.io/docs/tasks/administer-cluster/dns-custom-nameservers/#impacts-on-pods
+[5]:https://coredns.io/
+[6]:https://zwischenzugs.com/2017/10/21/openshift-3-6-dns-in-pictures/
diff --git a/translated/tech/20180808 5 open source role-playing games for Linux.md b/translated/tech/20180808 5 open source role-playing games for Linux.md
deleted file mode 100644
index 50a091ce14..0000000000
--- a/translated/tech/20180808 5 open source role-playing games for Linux.md
+++ /dev/null
@@ -1,107 +0,0 @@
-
-五个 Linux 上的开源角色扮演游戏
-======
-
-
-
-游戏是 Linux 的传统弱点之一,感谢 Stean、GOG 和其他的游戏开发商将商业游戏移植到了多个操作系统,Linux 的这个弱点在近几年有所改观,但是这些游戏通常都不是开源的。当然,这些游戏可以在开源系统上运行,但是对于开源的纯粹主义者来说这还不够好。
-
-那么,有没有一款能让只使用免费和开源软件的人在不影响他们开源理念的情况下也能享受到可靠游戏体验的精致游戏呢?
-
-当然有啦!虽然开源游戏不太可能和拥有大量开发预算的 3A 级大作相媲美,但有许多类型的开源游戏也很有趣,而且他们可以直接从大多数主要的 Linux 发行版的仓库中进行安装。即使某个游戏没有被某些仓库打包,你也可以很简单地从这个游戏的官网下载它,并进行安装和运行。
-
-这篇文章着眼于角色扮演游戏,我已经写过关于街机游戏,棋牌游戏,益智游戏,以及赛车和飞行游戏。在本系列的最后一篇文章中,我打算覆盖战略游戏和模拟游戏这两方面。
-
-### Endless Sky
-
-
-
-Endless Sky 是 Ambrosia Software 的 Escape Velocity 系列的开源克隆。玩家乘坐一艘宇宙飞船,在不同的世界之间旅行来运送货物和乘客,并在沿途中承接其他任务,或者玩家也可以变成海盗,并从其他货船中偷取货物。这个游戏让玩家自己决定要如何去体验这个游戏,以太阳系为背景的超大地图是非常具有探索性的。Endless Sky 是那些违背正常游戏类别分类的游戏之一。但这个兼具动作、角色扮演、太空模拟和交易这四种类型的游戏非常值得一试。
-
-如果要安装 Endless Sky ,请运行下面的命令:
-
-在 Fedora 上: `dnf install endless-sky`
-
-在 Debian/Ubuntu 上: `apt install endless-sky`
-
-### FreeDink
-
-
-
-FreeDink 是 Dink Smallwood 的开源版本,Dink Smallwood 是一个由 RTSoft 在1997 年发售的动作角色扮演游戏。Dink Smallwood 在 1999 年时变为了免费游戏,并在 2003 年时公布了源代码。在 2008 年时,游戏的数据除了少部分的声音文件,都在开源协议下进行了开源。FreeDink 用一些替代的声音文件替换了缺少的那部分文件,来提供了一个完整的游戏。游戏的玩法类似于任天堂的塞尔达传说系列。玩家控制的角色和 Dink Smallwood 同名,他在从一个任务地点移动到下一个任务地点的时候,探索这个充满隐藏物品和隐藏洞穴的世界地图。由于这个游戏的年龄,FreeDink 不能和现代的商业游戏相抗衡,但它仍然是一个拥有着有趣故事的有趣的游戏。游戏可以通过 D-Mods 进行扩展,D-Mods 是提供额外任务的附加模块,但是 D-Mods 在复杂性,质量,和年龄适应性上确实有很大的差异。游戏主要适合青少年,但也有部分额外组件适用于成年玩家。
-
-要安装 FreeDink ,请运行下面的命令:
-
-在 Fedora 上: `dnf install freedink`
-
-在 Debian/Ubuntu 上: `apt install freedink`
-
-### ManaPlus
-
-
-
-从技术上讲,ManaPlus 本身并不是一个游戏,它是一个访问各种大型多人在线角色扮演游戏的客户端。The Mana World 和 Evol Online 是两款可以通过 ManaPlus 访问的开源游戏,但是游戏的服务器不在那里。这个游戏的 2D 精灵图像让人想起超级任天堂游戏,虽然 ManaPlus 支持的游戏没有一款能像商业游戏那样受欢迎的,但他们都有一个有趣的世界,并且在绝大部分时间里都有至少一小部分玩家在线。一个玩家不太可能遇到很多的其他玩家,但通常都能有足够的人一起在这个 MMORPG 游戏里进行冒险,而不是一个需要连接到服务器的单机游戏。Mana World 和 Evol Online 的开发者联合起来进行未来的开发,但是对于目前而言,Mana World 的历史服务器和 Evol Online 提供了不同的游戏体验。
-
-要安装 ManaPlus,请运行下面的命令:
-
-在 Fedora 上: `dnf install manaplus`
-
-在 Debian/Ubuntu 上: `apt install manaplus`
-
-### Minetest
-
-
-
-使用 Minetest 来在一个开放式世界里进行探索和创造,Minetest 是 Minecraft 的克隆,就像它所基于的游戏一样,Minetest 提供了一个开放的世界,玩家可以在这个世界里探索和创造他们想要的一切。Minetest 提供了各种各样的方块和工具,对于想要一个比 Minecraft 更加开放的游戏的人来说,Minetest 是一个很好的替代品。除了基本的游戏之外,Minetest 还可以通过额外的模块进行可扩展,增加更多的选项。
-
-如果要安装 Minetest ,请运行下面的命令:
-
-在 Fedora 上: `dnf install minetest`
-
-在 Debian/Ubuntu 上: `apt install minetest`
-
-### NetHack
-
-
-
-NetHack 是一款经典的 Roguelike 类型的角色扮演游戏,玩家可以从不同的角色种族、层次和路线中进行选择,来探索这个多层次的地下层。这个游戏的目的就是找回 Yendor 的护身符,玩家从地下层的第一层开始探索,并尝试向下一层移动,每一层都是随机生成的,这样每次都能获得不同的游戏体验。虽然这个游戏只具有 ASCII 图形和基本图形,但是游戏玩法的深度能够弥补画面的不足。玩家如果想要更好一些的画面的话,可能就需要去查看 NetHack 中的 Vulture 了,这个选项可以提供更好的图像、声音和背景音乐。
-
-如果要安装 NetHack ,请运行下面的命令:
-
-在 Fedora 上: `dnf install nethack`
-
-在 Debian/Ubuntu 上: `apt install nethack-x11 or apt install nethack-console`
-
-我有错过了你最喜欢的角色扮演游戏吗?请在下面的评论区分享出来。
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/8/role-playing-games-linux
-
-作者:[Joshua Allen Holm][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[hopefully2333](https://github.com/hopefully2333)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/holmja
-[1]:https://opensource.com/article/18/1/arcade-games-linux
-[2]:https://opensource.com/article/18/3/card-board-games-linux
-[3]:https://opensource.com/article/18/6/puzzle-games-linux
-[4]:https://opensource.com/article/18/7/racing-flying-games-linux
-[5]:https://endless-sky.github.io/
-[6]:https://en.wikipedia.org/wiki/Escape_Velocity_(video_game)
-[7]:http://www.gnu.org/software/freedink/
-[8]:http://www.rtsoft.com/pages/dink.php
-[9]:https://en.wikipedia.org/wiki/The_Legend_of_Zelda
-[10]:http://www.dinknetwork.com/files/category_dmod/
-[11]:http://manaplus.org/
-[12]:http://www.themanaworld.org/
-[13]:http://evolonline.org/
-[14]:https://en.wikipedia.org/wiki/Massively_multiplayer_online_role-playing_game
-[15]:https://www.minetest.net/
-[16]:https://wiki.minetest.net/Mods
-[17]:https://www.nethack.org/
-[18]:https://en.wikipedia.org/wiki/Roguelike
-[19]:http://www.darkarts.co.za/vulture-for-nethack
diff --git a/translated/tech/20180810 6 Reasons Why Linux Users Switch to BSD.md b/translated/tech/20180810 6 Reasons Why Linux Users Switch to BSD.md
deleted file mode 100644
index a5755a68ee..0000000000
--- a/translated/tech/20180810 6 Reasons Why Linux Users Switch to BSD.md
+++ /dev/null
@@ -1,76 +0,0 @@
-Linux 用户选择 BSD 的 6 个理由
-======
-
-迄今我因 BSD 是 FOSS 已经写了数篇关于它的文章。但总有人会问:"为什么要纠结于 BSD?"。我认为最好的办法是写一篇关于这个话题的文章。
-
-### 为什么在 Linux 上使用 BSD?
-
-为了准备这篇文章,我与几位使用了多年 Linux 而后转入 BSD 的用户聊了聊。因而这篇文章的观点都来源于真实的 BSD 用户。本文希望提出一个不同的观点。
-![why use bsd over linux][2]
-
-#### 1\. BSD 不仅仅是一个内核
-
-几个人都指出 BSD 提供的操作系统对于终端用户来说就是一个巨大的内建的软件包。他们指出 "Linux" 仅仅说的是内核。一个 Linux 发行版由上述的内核与许多由发行者所选取的不同的应用与软件包组成。有时候安装新的软件包所导致的不兼容会使系统产生崩溃。
-
-一个典型的 BSD 由内核和许多必要的软件包组成。这些包里的大多数是通过活跃的项目所开发。因此其具备高集成度与高响应度的特点。
-
-#### 2\. 软件包更值得信赖
-
-说起软件包,BSD 用户提出的另一点是软件包的可信度。在 Linux 上,软件包可以从一堆不同源上获得,一些是发行版的开发者,另一些是第三方。[Ubuntu][3] 和[其他发行版][4]就遇到了在第三方应用里隐藏了恶意软件的问题。
-
-在 BSD 上,所有的软件包由“每个软件包都作为单个仓库的一部分并且每一步都设有安全系统的集中式软件包/端口系统”所提供。这就确保了黑客不能将恶意软件潜入看似稳定的应用程序中,保障了 BSD 的长期稳定性。
-
-#### 3\. 更新缓慢 = 更好的长期稳定性
-
-如果更新是一场竞赛,那么 Linux 就是兔子, BSD 就是乌龟。甚至最慢的 Linux 发行版每年至少发布一个新版本(当然,除了 Debian)。在 BSD 的世界里,主要版本的发布需要更长时间。这就意味着可以更加集中于将事情做完善之后再将它推送给用户。
-
-这也意味着操作系统的变化会随着时间的推移而发生。Linux 世界经历了数次快速而重大的变化,我们至今仍感觉如此(咳咳, [systemD][5],咳咳)。就像 Debian 那样,长时间的开发周期帮助 BSD 去测试新的想法,保证在它永久化之前正常工作。它也有助于生产出不太可能出现问题的代码。
-
-#### 4\. Linux 太乱了
-
-没有一个 BSD 用户直截了当地指出这一点,但这是他们许多经验所显示出的情况。很多用户从一个 Linux 发行版跳到另一个发行版去寻找适合他的版本。很多情况下,他们无法使所有的软件或硬件正常工作。这时,他们决定尝试使用 BSD,接着,所有的东西都正常工作了。
-
-当考虑到如何选择 BSD 时,一切就变得相当简单。目前只有一半的 BSD 在积极开发。这些 BSD中的每一个都有特定的用途。“[OpenBSD][6] 更安全,[FreeBSD][7] 适用于桌面或服务器, [NetBSD][8] 无所不包,[DragonFlyBSD][9] 精简高效“。与此同时,Linux 世界充满的许多版本仅仅是在现有的发行版上增加了主题或者图标。BSD 项目数量之少意味着它重复性低并且更加专注。
-
-#### 5\. ZFS 支持
-
-一个 BSD 用户说到他选择 BSD 最主要的原因是 [ZFS][10]。事实上,几乎所有我谈过的人都提到 BSD 支持 ZFS 是他们没有返回 Linux 的原因。
-
-这一点是 Linux 从一开始就处于下风的地方。虽然在一些 Linux 发行版上可以使用 [OpenZFS][11],但是 ZFS 已经内置在了 BSD 的内核中。这意味着 ZFS 在 BSD 上将会有更好地性能。尽管数次尝试将 ZFS 加入到 Linux 内核中,但协议问题依旧无法解决。
-
-#### 6\. 协议
-
-就协议而言也有不同的看法。大多数人所持有的想法是, GPL 不是真正的自由,因为它限制了如何使用软件。一些人也认为 GPL 太庞大而复杂以至于无法作出解释,会在开发过程中不仔细遵守协议而导致法律问题。
-
-另一方面,BSD 协议只有 3 条,并且允许任何人“使用软件、进行修改、做任何事,并且对开发者提供保护”。
-
-#### 总结
-
-这些仅仅只是一小部分人们使用 BSD 而不使用 Linux 的原因。如果你感兴趣,你可以[在这][12]阅读其他人的评论。如果你是 BSD 用户并且觉得我错过什么重要的地方,请在评论里说出你的想法。
-
-如果你觉得这篇文章有意思,请在社交媒体上、技术资讯或者 [Reddit][13] 上分享它。
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/why-use-bsd/
-
-作者:[John Paul][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[LuuMing](https://github.com/LuuMing)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://itsfoss.com/author/john/
-[1]:https://itsfoss.com/category/bsd/
-[2]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/why-BSD.png
-[3]:https://itsfoss.com/snapstore-cryptocurrency-saga/
-[4]:https://www.bleepingcomputer.com/news/security/malware-found-in-arch-linux-aur-package-repository/
-[5]:https://www.freedesktop.org/wiki/Software/systemd/
-[6]:https://www.openbsd.org/
-[7]:https://www.freebsd.org/
-[8]:http://netbsd.org/
-[9]:http://www.dragonflybsd.org/
-[10]:https://en.wikipedia.org/wiki/ZFS
-[11]:http://open-zfs.org/wiki/Main_Page
-[12]:https://discourse.trueos.org/t/why-do-you-guys-use-bsd/2601
-[13]:http://reddit.com/r/linuxusersgroup
diff --git a/translated/tech/20180813 5 of the Best Linux Educational Software and Games for Kids.md b/translated/tech/20180813 5 of the Best Linux Educational Software and Games for Kids.md
new file mode 100644
index 0000000000..3a1981f0bc
--- /dev/null
+++ b/translated/tech/20180813 5 of the Best Linux Educational Software and Games for Kids.md
@@ -0,0 +1,80 @@
+# 5 个给孩子的非常好的 Linux 教育软件和游戏
+
+
+
+Linux 是一个非常强大的操作系统,因此因特网上的大多数服务器都使用它。尽管它算不上是对用户友好的最佳操作系统,但它的多元化还是值的称赞的。对于 Linux 来说,每个人都能在它上面找到他们自己的所需。不论你是用它来写代码、还是用于教学或物联网(IoT),你总能找到一个适合你用的 Linux 发行版。为此,许多人认为 Linux 是未来计算的最佳操作系统。
+
+未来是属于孩子们的,让孩子们了解 Linux 是他们掌控未来的最佳方式。这个操作系统上或许并没有一些像 FIFA 或 PES 那样的声名赫赫的游戏;但是,它为孩子们提供了一些非常好的教育软件和游戏。这里有五款最好的 Linux 教育软件,可以让你的孩子远离游戏。
+
+**相关阅读**:[使用一个 Linux 发行版的新手指南][1]
+
+### 1. GCompris
+
+如果你正在为你的孩子寻找一款最佳的教育软件,[GCompris][2] 将是你的最好的开端。这款软件专门为 2 到 10 岁的孩子所设计。作为所有的 Linux 教育软件套装的巅峰之作,GCompris 为孩子们提供了大约 100 项活动。它囊括了你期望你的孩子学习的所有内容,从阅读材料到科学、地理、绘画、代数、测验、等等。
+
+![Linux educational software and games][3]
+
+GCompris 甚至有一项活动可以帮你的孩子学习计算机的相关知识。如果你的孩子还很小,你希望他去学习字母、颜色、和形状,GCompris 也有这方面的相关内容。更重要的是,它也为孩子们准备了一些益智类游戏,比如国际象棋、井字棋、好记性、以及猜词游戏。GCompris 并不是一个仅在 Linux 上可运行的游戏。它也可以运行在 Windows 和 Android 上。
+
+### 2. TuxMath
+
+很多学生认为数学是们非常难的课程。你可以通过 Linux 教育软件如 [TuxMath][4] 来让你的孩子了解数学技能,从而来改变这种看法。TuxMath 是为孩子开发的顶级的数学教育辅助游戏。在这个游戏中,你的角色是在如雨点般下降的数学问题中帮助 Linux 企鹅 Tux 来保护它的星球。
+
+![linux-educational-software-tuxmath-1][5]
+
+在它们落下来毁坏 Tux 的星球之前,找到问题的答案,就可以使用你的激光去帮助 Tux 拯救它的星球。数字问题的难度每过一关就会提升一点。这个游戏非常适合孩子,因为它可以让孩子们去开动脑筋解决问题。而且还有助他们学好数学,以及帮助他们开发智力。
+
+### 3. Sugar on a Stick
+
+[Sugar on a Stick][6] 是献给孩子们的学习程序 —— 一个广受好评的全新教学法。这个程序为你的孩子提供一个成熟的教学平台,在那里,他们可以收获创造、探索、发现和思考方面的技能。和 GCompris 一样,Sugar on a Stick 为孩子们带来了包括游戏和谜题在内的大量学习资源。
+
+![linux-educational-software-sugar-on-a-stick][7]
+
+关于 Sugar on a Stick 最大的一个好处是你可以将它配置在一个 U 盘上。你只要有一台 X86 的 PC,插入那个 U 盘,然后就可以从 U 盘引导这个发行版。Sugar on a Stick 是由 Sugar 实验室提供的一个项目 —— 这个实验室是一个由志愿者运作的非盈利组织。
+
+### 4. KDE Edu Suite
+
+[KDE Edu Suite][8] 是一个用途与众不同的软件包。带来了大量不同领域的应用程序,KDE 社区已经证实,它不仅是一系列成年人授权的问题;它还关心年青一代如何适应他们周围的一切。它囊括了一系列孩子们使用的应用程序,从科学到数学、地理等等。
+
+![linux-educational-software-kde-1][9]
+
+KDE Edu 套件根据长大后所必需的知识为基础,既能够用作学校的教学软件,也能够作为孩子们的学习 APP。它提供了大量的可免费下载的软件包。KDE Edu 套件在主流的 GNU/Linux 发行版都能安装。
+
+### 5. Tux Paint
+
+![linux-educational-software-tux-paint-2][10]
+
+[Tux Paint][11] 是给孩子们的另一个非常好的 Linux 教育软件。这个屡获殊荣的绘画软件在世界各地被用于帮助培养孩子们的绘画技能,它有一个简洁的、易于使用的界面和有趣的音效,可以高效地帮助孩子去使用这个程序。它也有一个卡通吉祥物去鼓励孩子们使用这个程序。Tux Paint 中有许多绘画工具,它们可以帮助孩子们放飞他们的创意。
+
+### 总结
+
+由于这些教育软件深受孩子们的欢迎,许多学校和幼儿园都使用这些程序进行辅助教学。典型的一个例子就是 [Edubuntu][12],它是儿童教育领域中广受老师和家长们欢迎的一个基于 Ubuntu 的发行版。
+
+Tux Paint 是另一个非常好的例子,它在这些年越来越流行,它大量地用于学校中教孩子们如何绘画。以上的这个清单并不很详细。还有成百上千的对孩子有益的其它 Linux 教育软件和游戏。
+
+如果你还知道给孩子们的其它非常好的 Linux 教育软件和游戏,在下面的评论区分享给我们吧。
+
+------
+
+via: https://www.maketecheasier.com/5-best-linux-software-packages-for-kids/
+
+作者:[Kenneth Kimari][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.maketecheasier.com/author/kennkimari/
+[1]: https://www.maketecheasier.com/beginner-guide-to-using-linux-distro/ "The Beginner’s Guide to Using a Linux Distro"
+[2]: http://www.gcompris.net/downloads-en.html
+[3]: https://www.maketecheasier.com/assets/uploads/2018/07/Linux-educational-software-gcompris.jpg "Linux educational software and games"
+[4]: https://tuxmath.en.uptodown.com/ubuntu
+[5]: https://www.maketecheasier.com/assets/uploads/2018/07/Linux-educational-software-tuxmath-1.jpg "linux-educational-software-tuxmath-1"
+[6]: http://wiki.sugarlabs.org/go/Sugar_on_a_Stick/Downloads
+[7]: https://www.maketecheasier.com/assets/uploads/2018/07/Linux-educational-software-sugar-on-a-stick.png "linux-educational-software-sugar-on-a-stick"
+[8]: https://edu.kde.org/
+[9]: https://www.maketecheasier.com/assets/uploads/2018/07/Linux-educational-software-kde-1.jpg "linux-educational-software-kde-1"
+[10]: https://www.maketecheasier.com/assets/uploads/2018/07/Linux-educational-software-tux-paint-2.jpg "linux-educational-software-tux-paint-2"
+[11]: http://www.tuxpaint.org/
+[12]: http://edubuntu.org/
\ No newline at end of file
diff --git a/translated/tech/20180814 Automating backups on a Raspberry Pi NAS.md b/translated/tech/20180814 Automating backups on a Raspberry Pi NAS.md
new file mode 100644
index 0000000000..111b508245
--- /dev/null
+++ b/translated/tech/20180814 Automating backups on a Raspberry Pi NAS.md
@@ -0,0 +1,229 @@
+Part-II 树莓派自建 NAS 云盘之数据自动备份
+======
+
+
+
+在《树莓派自建 NAS 云盘》系列的 [第一篇][1] 文章中,我们讨论了建立 NAS 的一些基本步骤,添加了两块 1TB 的存储硬盘驱动(一个用于数据存储,一个用于数据备份),并且通过 网络文件系统(NFS)将数据存储盘挂载到远程终端上。本文是此系列的第二篇文章,我们将探讨数据自动备份。数据自动备份保证了数据的安全,为硬件损坏后的数据恢复提供便利以及减少了文件误操作带来的不必要的麻烦。
+
+
+
+
+
+
+
+### 备份策略
+
+我们就从为小型 NAS 构想一个备份策略着手开始吧。我建议每天有时间节点有计划的去备份数据,以防止干扰到我们正常的访问 NAS,比如备份时间点避开正在访问 NAS 并写入文件的时间点。举个例子,你可以每天凌晨 2 点去进行数据备份。
+
+另外,你还得决定每天的备份需要被保留的时间长短,因为如果没有时间限制,存储空间很快就会被用完。一般每天的备份保留一周便可以,如果数据出了问题,你便可以很方便的从备份中恢复出来原数据。但是如果需要恢复数据到更久之前怎么办?可以将每周一的备份文件保留一个月、每个月的备份保留更长时间。让我们把每月的备份保留一年时间,每一年的备份保留更长时间、例如五年。
+
+这样,五年内在备份盘上产生大量备份:
+
+* 每周 7 个日备份
+* 每月 4 个周备份
+* 每年 12 个月备份
+* 每五年 5 个年备份
+
+
+你应该还记得,我们搭建的备份盘和数据盘大小相同(每个 1 TB)。如何将不止 10 个 1TB 数据的备份从数据盘存放到只有 1TB 大小的备份盘呢?如果你创建的是完整备份,这显然不可能。因此,你需要创建增量备份,它是每一份备份都基于上一份备份数据而创建的。增量备份方式不会每隔一天就成倍的去占用存储空间,它每天只会增加一点占用空间。
+
+以下是我的情况:我的 NAS 自 2016 年 8 月开始运行,备份盘上有 20 个备份。目前,我在数据盘上存储了 406GB 的文件。我的备份盘用了 726GB。当然,备份盘空间使用率在很大程度上取决于数据的更改频率,但正如你所看到的,增量备份不会占用 20 个完整备份所需的空间。然而,随着时间的推移,1TB 空间也可能不足以进行备份。一旦数据增长接近 1TB 限制(或任何备份盘容量),应该选择更大的备份盘空间并将数据移动转移过去。
+
+### 利用 rsync 进行数据备份
+
+利用 rsync 命令行工具可以生成完整备份。
+
+```
+pi@raspberrypi:~ $ rsync -a /nas/data/ /nas/backup/2018-08-01
+
+```
+
+这段命令将挂载在 /nas/data/ 目录下的数据盘中的数据进行了完整的复制备份。备份文件保存在 /nas/backup/2018-08-01 目录下。`-a` 参数是以归档模式进行备份,这将会备份所有的元数据,例如文件的修改日期、权限、拥有者以及软连接文件。
+
+现在,你已经在 8 月 1 日创建了完整的初始备份,你将在 8 月 2 日创建第一个增量备份。
+
+```
+pi@raspberrypi:~ $ rsync -a --link-dest /nas/backup/2018-08-01/ /nas/data/ /nas/backup/2018-08-02
+
+```
+
+上面这行代码又创建了一个关于 `/nas/data` 目录中数据的备份。备份路径是 `/nas/backup/2018-08-02`。这里的参数 `--link-dest` 指定了一个备份文件所在的路径。这样,这次备份会与 `/nas/backup/2018-08-01` 的备份进行比对,只备份已经修改过的文件,未做修改的文件将不会被复制,而是创建一个到上一个备份文件中它们的硬链接。
+
+使用备份文件中的硬链接文件时,你一般不会注意到硬链接和初始拷贝之间的差别。它们表现的完全一样,如果删除其中一个硬链接或者文件,其他的依旧存在。你可以把它们看做是同一个文件的两个不同入口。下面就是一个例子:
+
+
+
+左侧框是在进行了第二次备份后的原数据状态。中间的盒子是昨天的备份。昨天的备份中只有图片 `file1.jpg` 并没有 `file2.txt` 。右侧的框反映了今天的增量备份。增量备份命令创建昨天不存在的 `file2.txt`。由于 `file1.jpg` 自昨天以来没有被修改,所以今天创建了一个硬链接,它不会额外占用磁盘上的空间。
+
+### 自动化备份
+
+你肯定也不想每天凌晨去输入命令进行数据备份吧。你可以创建一个任务定时去调用下面的脚本让它自动化备份
+
+```
+#!/bin/bash
+
+
+
+TODAY=$(date +%Y-%m-%d)
+
+DATADIR=/nas/data/
+
+BACKUPDIR=/nas/backup/
+
+SCRIPTDIR=/nas/data/backup_scripts
+
+LASTDAYPATH=${BACKUPDIR}/$(ls ${BACKUPDIR} | tail -n 1)
+
+TODAYPATH=${BACKUPDIR}/${TODAY}
+
+if [[ ! -e ${TODAYPATH} ]]; then
+
+ mkdir -p ${TODAYPATH}
+
+fi
+
+
+
+rsync -a --link-dest ${LASTDAYPATH} ${DATADIR} ${TODAYPATH} $@
+
+
+
+${SCRIPTDIR}/deleteOldBackups.sh
+
+```
+
+第一段代码指定了数据路径、备份路劲、脚本路径以及昨天和今天的备份路径。第二段代码调用 rsync 命令。最后一段代码执行 `deleteOldBackups.sh` 脚本,它会清除一些过期的没有必要的备份数据。如果不想频繁的调用 `deleteOldBackups.sh`,你也可以手动去执行它。
+
+下面是今天讨论的备份策略的一个简单完整的示例脚本。
+
+```
+#!/bin/bash
+
+BACKUPDIR=/nas/backup/
+
+
+
+function listYearlyBackups() {
+
+ for i in 0 1 2 3 4 5
+
+ do ls ${BACKUPDIR} | egrep "$(date +%Y -d "${i} year ago")-[0-9]{2}-[0-9]{2}" | sort -u | head -n 1
+
+ done
+
+}
+
+
+
+function listMonthlyBackups() {
+
+ for i in 0 1 2 3 4 5 6 7 8 9 10 11 12
+
+ do ls ${BACKUPDIR} | egrep "$(date +%Y-%m -d "${i} month ago")-[0-9]{2}" | sort -u | head -n 1
+
+ done
+
+}
+
+
+
+function listWeeklyBackups() {
+
+ for i in 0 1 2 3 4
+
+ do ls ${BACKUPDIR} | grep "$(date +%Y-%m-%d -d "last monday -${i} weeks")"
+
+ done
+
+}
+
+
+
+function listDailyBackups() {
+
+ for i in 0 1 2 3 4 5 6
+
+ do ls ${BACKUPDIR} | grep "$(date +%Y-%m-%d -d "-${i} day")"
+
+ done
+
+}
+
+
+
+function getAllBackups() {
+
+ listYearlyBackups
+
+ listMonthlyBackups
+
+ listWeeklyBackups
+
+ listDailyBackups
+
+}
+
+
+
+function listUniqueBackups() {
+
+ getAllBackups | sort -u
+
+}
+
+
+
+function listBackupsToDelete() {
+
+ ls ${BACKUPDIR} | grep -v -e "$(echo -n $(listUniqueBackups) |sed "s/ /\\\|/g")"
+
+}
+
+
+
+cd ${BACKUPDIR}
+
+listBackupsToDelete | while read file_to_delete; do
+
+ rm -rf ${file_to_delete}
+
+done
+
+```
+
+这段脚本会首先根据你的备份策略列出所有需要保存的备份文件,然后它会删除那些再也不需要了的备份目录。
+
+下面创建一个定时任务去执行上面这段代码。以 root 用户权限打开 `crontab -e`,输入以下这段命令,它将会创建一个每天凌晨 2 点去执行 `/nas/data/backup_scripts/daily.sh` 的定时任务。
+
+```
+0 2 * * * /nas/data/backup_scripts/daily.sh
+
+```
+
+有关创建定时任务请参考 [cron 创建定时任务][2]。
+
+* 当没有备份任务时,卸载你的备份盘或者将它挂载为只读盘;
+* 利用远程服务器作为你的备份盘,这样就可以通过互联网同步数据
+
+你也可用下面的方法来加强你的备份策略,以防止备份数据的误删除或者被破坏:
+
+本文中备份策略示例是备份一些我觉得有价值的数据,你也可以根据个人需求去修改这些策略。
+
+我将会在 《树莓派自建 NAS 云盘》 系列的第三篇文章中讨论 [Nextcloud][3]。Nextcloud 提供了更方便的方式去访问 NAS 云盘上的数据并且它还提供了离线操作,你还可以在客户端中同步你的数据。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/8/automate-backups-raspberry-pi
+
+作者:[Manuel Dewald][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[jrg](https://github.com/jrglinux)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/ntlx
+[1]: https://opensource.com/article/18/7/network-attached-storage-Raspberry-Pi
+[2]: https://opensource.com/article/17/11/how-use-cron-linux
+[3]: https://nextcloud.com/
+
diff --git a/translated/tech/20180828 How to Play Windows-only Games on Linux with Steam Play.md b/translated/tech/20180828 How to Play Windows-only Games on Linux with Steam Play.md
new file mode 100644
index 0000000000..52a919ea57
--- /dev/null
+++ b/translated/tech/20180828 How to Play Windows-only Games on Linux with Steam Play.md
@@ -0,0 +1,92 @@
+如何使用 Steam Play 在 Linux 上玩仅限 Windows 的游戏
+======
+Steam 的新实验功能允许你在 Linux 上玩仅限 Windows 的游戏。以下是如何在 Steam 中使用此功能。
+
+你已经听说过这个消息。游戏发行平台[ Steam 正在实现一个 WINE 分支来允许你玩仅在 Windows 上的游戏][1]。对于 Linux 用户来说,这绝对是一个好消息,因为我们抱怨 Linux 的游戏数量不足。
+
+这个新功能仍处于测试阶段,但你现在可以在 Linux 上试用它并在 Linux 上玩仅限 Windows 的游戏。让我们看看如何做到这一点。
+
+### 使用 Steam Play 在 Linux 中玩仅限 Windows 的游戏
+
+![Play Windows-only games on Linux][2]
+
+你需要先安装 Steam。Steam 适用于所有主要 Linux 发行版。我已经详细介绍了[在 Ubuntu 上安装 Steam][3],如果你还没有安装 Steam,你可以参考那篇文章。
+
+安装了 Steam 并且你已登录到 Steam 帐户,就可以了解如何在 Steam Linux 客户端中启用 Windows 游戏。
+
+
+#### 步骤 1:进入帐户设置
+
+运行 Steam 客户端。在左上角,单击 Steam,然后单击 Settings。
+
+![Enable steam play beta on Linux][4]
+
+#### 步骤 2:选择加入测试计划
+
+在“设置”中,从左侧窗口中选择“帐户”,然后单击 “Beta participation” 下的 “CHANGE” 按钮。
+
+![Enable beta feature in Steam Linux][5]
+
+你应该在此处选择 Steam Beta Update。
+
+![Enable beta feature in Steam Linux][6]
+
+在此处保存设置后,Steam 将重新启动并下载新的测试版更新。
+
+#### 步骤 3:启用 Steam Play 测试版
+
+下载好 Steam 新的测试版更新后,它将重新启动。到这里就差不多了。
+
+再次进入“设置”。你现在可以在左侧窗口看到新的 Steam Play 选项。单击它并选中复选框:
+
+ * Enable Steam Play for supported titles (你可以玩列入白名单的 Windows 游戏)
+ * Enable Steam Play for all titles (你可以尝试玩所有仅限 Windows 的游戏)
+
+
+
+![Play Windows games on Linux using Steam Play][7]
+
+我不记得 Steam 是否会再次重启,但我想这是微不足道的。你现在应该可以在 Linux 上看到安装仅限 Windows 的游戏的选项了。
+
+比如,我的 Steam 库中有 Age of Empires,正常情况下这个在 Linux 中没有。但我在 Steam Play 测试版启用所有 Windows 游戏后,现在我可以选择在 Linux 上安装 Age of Empires 了。
+
+![Install Windows-only games on Linux using Steam][8]
+现在可以在 Linux 上安装仅限 Windows 的游戏
+
+### 有关 Steam Play 测试版功能的信息
+
+在 Linux 上使用 Steam Play 测试版玩仅限 Windows 的游戏有一些事情你需要知道并且牢记。
+
+ * If you have games downloaded on Windows via Steam, you can save some download data by [sharing Steam game files between Linux and Windows][12].
+ * 目前,[只有 27 个 Steam Play 中的 Windows 游戏被列入白名单][9]。这些白名单游戏在 Linux 上无缝运行。
+ * 你可以使用 Steam Play 测试版尝试任何 Windows 游戏,但它可能无法一直运行。有些游戏有时会崩溃,而某些游戏可能根本无法运行。
+ * 在测试版中,你无法 Steam 商店中看到适用于 Linux 的 Windows 限定游戏。你必须自己尝试游戏或参考[这个社区维护的列表][10]以查看该 Windows 游戏的兼容性状态。你也可以通过填写[此表][11]来为列表做出贡献。
+ * 如果你通过 Steam 在 Windows 上下载游戏,那么可以通过[在 Linux 和 Windows 之间共享 Steam 游戏文件][12]来保存一些下载数据。
+
+
+我希望本教程能帮助你在 Linux 上运行仅限 Windows 的游戏。你期待在 Linux 上玩哪些游戏?
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/steam-play/
+
+作者:[Abhishek Prakash][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[geekpi](https://github.com/geekpi)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/abhishek/
+[1]:https://itsfoss.com/steam-play-proton/
+[2]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/play-windows-games-on-linux-featured.jpeg
+[3]:https://itsfoss.com/install-steam-ubuntu-linux/
+[4]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/enable-steam-play-beta.jpeg
+[5]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/enable-steam-play-beta-2.jpeg
+[6]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/enable-steam-play-beta-3.jpeg
+[7]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/enable-steam-play-beta-4.jpeg
+[8]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/install-windows-games-linux.jpeg
+[9]:https://steamcommunity.com/games/221410
+[10]:https://docs.google.com/spreadsheets/d/1DcZZQ4HL_Ol969UbXJmFG8TzOHNnHoj8Q1f8DIFe8-8/htmlview?sle=true#
+[11]:https://docs.google.com/forms/d/e/1FAIpQLSeefaYQduMST_lg0IsYxZko8tHLKe2vtVZLFaPNycyhY4bidQ/viewform
+[12]:https://itsfoss.com/share-steam-files-linux-windows/
diff --git a/translated/tech/20180901 5 Ways to Take Screenshot in Linux GUI and Terminal.md b/translated/tech/20180901 5 Ways to Take Screenshot in Linux GUI and Terminal.md
new file mode 100644
index 0000000000..b8872981fe
--- /dev/null
+++ b/translated/tech/20180901 5 Ways to Take Screenshot in Linux GUI and Terminal.md
@@ -0,0 +1,211 @@
+5 种在 Linux 图形界面或命令行界面截图的方法
+======
+下面介绍几种获取屏幕截图并对其编辑的方法,而且其中的屏幕截图工具在 Ubuntu 和其它主流 Linux 发行版中都能够使用。
+
+![在 Ubuntu Linux 中如何获取屏幕截图][1]
+
+当我的主力操作系统从 Windows 转换到 Ubuntu 的时候,首要考虑的就是屏幕截图工具的可用性。尽管使用默认的键盘快捷键也可以获取屏幕截图,但如果使用屏幕截图工具,可以更方便地对屏幕截图进行编辑。
+
+本文将会介绍在不适用第三方工具的情况下,如何通过系统自带的方法和工具获取屏幕截图,另外还会介绍一些可用于 Linux 的最佳截图工具。
+
+### 方法 1: 在 Linux 中截图的默认方式
+
+你是否需要截取整个屏幕?屏幕中的某个区域?某个特定的窗口?
+
+如果只需要获取一张屏幕截图,不对其进行编辑的话,那么键盘的默认快捷键就可以满足要求了。而且不仅仅是 Ubuntu ,绝大部分的 Linux 发行版和桌面环境都支持以下这些快捷键:
+
+**PrtSc** – 获取整个屏幕的截图并保存到 Pictures 目录。
+**Shift + PrtSc** – 获取屏幕的某个区域截图并保存到 Pictures 目录。
+**Alt + PrtSc** –获取当前窗口的截图并保存到 Pictures 目录。
+**Ctrl + PrtSc** – 获取整个屏幕的截图并存放到剪贴板。
+**Shift + Ctrl + PrtSc** – 获取屏幕的某个区域截图并存放到剪贴板。
+**Ctrl + Alt + PrtSc** – 获取当前窗口的 截图并存放到剪贴板。
+
+如上所述,在 Linux 中使用默认的快捷键获取屏幕截图是相当简单的。但如果要在不把屏幕截图导入到其它应用程序的情况下对屏幕截图进行编辑,还是使用屏幕截图工具比较方便。
+
+#### **方法 2: 在 Linux 中使用 Flameshot 获取屏幕截图并编辑**
+
+![flameshot][2]
+
+功能概述
+
+ * 注释 (高亮、标示、添加文本、框选)
+ * 图片模糊
+ * 图片裁剪
+ * 上传到 Imgur
+ * 用另一个应用打开截图
+
+
+
+Flameshot 在去年发布到 [GitHub][3],并成为一个引人注目的工具。如果你需要的是一个能够用于标注、模糊、上传到 imgur 的新式截图工具,那么 Flameshot 是一个好的选择。
+
+下面将会介绍如何安装 Flameshot 并根据你的偏好进行配置。
+
+如果你用的是 Ubuntu,那么只需要在 Ubuntu 软件中心上搜索,就可以找到 Flameshot 进而完成安装了。要是你想使用终端来安装,可以执行以下命令:
+```
+sudo apt install flameshot
+
+```
+
+如果你在安装过程中遇到问题,可以按照[官方的安装说明][4]进行操作。安装完成后,你还需要进行配置。尽管可以通过搜索来随时启动 Flameshot,但如果想使用 PrtSc 键触发启动,则需要指定对应的键盘快捷键。以下是相关配置步骤:
+
+ * 进入系统设置中的键盘设置
+ * 页面中会列出所有现有的键盘快捷键,拉到底部就会看见一个 **+** 按钮
+ * 点击 “+” 按钮添加自定义快捷键并输入以下两个字段:
+**名称:** 任意名称均可
+**命令:** /usr/bin/flameshot gui
+ * 最后将这个快捷操作绑定到 **PrtSc** 键上,可能会提示与系统的截图功能相冲突,但可以忽略掉这个警告。
+
+
+
+配置之后,你的自定义快捷键页面大概会是以下这样:
+
+![][5]
+将键盘快捷键映射到 Flameshot
+
+### **方法 3: 在 Linux 中使用 Shutter 获取屏幕截图并编辑**
+
+![][6]
+
+功能概述:
+
+ * 注释 (高亮、标示、添加文本、框选)
+ * 图片模糊
+ * 图片裁剪
+ * 上传到图片网站
+
+
+
+[Shutter][7] 是一个对所有主流 Linux 发行版都适用的屏幕截图工具。尽管最近已经不太更新了,但仍然是操作屏幕截图的一个优秀工具。
+
+在使用过程中可能会遇到这个工具的一些缺陷。Shutter 在任何一款最新的 Linux 发行版上最常见的问题就是由于缺少了任务栏上的程序图标,导致默认禁用了编辑屏幕截图的功能。 对于这个缺陷,还是有解决方案的。下面介绍一下如何[在 Shutter 中重新打开这个功能并将程序图标在任务栏上显示出来][8]。问题修复后,就可以使用 Shutter 来快速编辑屏幕截图了。
+
+同样地,在软件中心搜索也可以找到进而安装 Shutter,也可以在基于 Ubuntu 的发行版中执行以下命令使用命令行安装:
+```
+sudo apt install shutter
+
+```
+
+类似 Flameshot,你可以通过搜索 Shutter 手动启动它,也可以按照相似的方式设置自定义快捷方式以 **PrtSc** 键唤起 Shutter。
+
+如果要指定自定义键盘快捷键,只需要执行以下命令:
+```
+shutter -f
+
+```
+
+### 方法 4: 在 Linux 中使用 GIMP 获取屏幕截图
+
+![][9]
+
+功能概述:
+
+ * 高级图像编辑功能(缩放、添加滤镜、颜色校正、添加图层、裁剪等)
+ * 截取某一区域的屏幕截图
+
+
+
+如果需要对屏幕截图进行一些预先编辑,GIMP 是一个不错的选择。
+
+通过软件中心可以安装 GIMP。如果在安装时遇到问题,可以参考其[官方网站的安装说明][10]。
+
+要使用 GIMP 获取屏幕截图,需要先启动程序,然后通过 **File-> Create-> Screenshot** 导航。
+
+打开 Screenshot 选项后,会看到几个控制点来控制屏幕截图范围。点击 **Snap** 截取屏幕截图,图像将自动显示在 GIMP 中可供编辑。
+
+### 方法 5: 在 Linux 中使用命令行工具获取屏幕截图
+
+这一节内容仅适用于终端爱好者。如果你也喜欢使用终端,可以使用 **GNOME 截图工具**或 **ImageMagick** 或 **Deepin Scrot**,大部分流行的 Linux 发行版中都自带这些工具。
+
+要立即获取屏幕截图,可以执行以下命令:
+
+#### GNOME Screenshot(可用于 GNOME 桌面)
+```
+gnome-screenshot
+
+```
+
+GNOME Screenshot 是使用 GNOME 桌面的 Linux 发行版中都自带的一个默认工具。如果需要延时获取屏幕截图,可以执行以下命令(这里的 **5** 是需要延迟的秒数):
+
+```
+gnome-screenshot -d -5
+
+```
+
+#### ImageMagick
+
+如果你的操作系统是 Ubuntu、Mint 或其它流行的 Linux 发行版,一般会自带 [ImageMagick][11] 这个工具。如果没有这个工具,也可以按照[官方安装说明][12]使用安装源来安装。你也可以在终端中执行这个命令:
+```
+sudo apt-get install imagemagick
+
+```
+
+安装完成后,执行下面的命令就可以获取到屏幕截图(截取整个屏幕):
+
+```
+import -window root image.png
+
+```
+
+这里的“image.png”就是屏幕截图文件保存的名称。
+
+要获取屏幕一个区域的截图,可以执行以下命令:
+```
+import image.png
+
+```
+
+#### Deepin Scrot
+
+Deepin Scrot 是基于终端的一个较新的截图工具。和前面两个工具类似,一般自带于 Linux 发行版中。如果需要自行安装,可以执行以下命令:
+```
+sudo apt-get install scrot
+
+```
+
+安装完成后,使用下面这些命令可以获取屏幕截图。
+
+获取整个屏幕的截图:
+```
+scrot myimage.png
+
+```
+
+获取屏幕某一区域的截图:
+```
+scrot -s myimage.png
+
+```
+
+### 总结
+
+以上是一些在 Linux 上的优秀截图工具。当然还有很多截图工具没有提及(例如 [Spectacle][13] for KDE-distros),但相比起来还是上面几个工具更为好用。
+
+如果你有比文章中提到的更好的截图工具,欢迎讨论!
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/take-screenshot-linux/
+
+作者:[Ankush Das][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/ankush/
+[1]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/Taking-Screenshots-in-Linux.png
+[2]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/flameshot-pic.png
+[3]: https://github.com/lupoDharkael/flameshot
+[4]: https://github.com/lupoDharkael/flameshot#installation
+[5]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/flameshot-config-default.png
+[6]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/shutter-screenshot.jpg
+[7]: http://shutter-project.org/
+[8]: https://itsfoss.com/shutter-edit-button-disabled/
+[9]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/gimp-screenshot.jpg
+[10]: https://www.gimp.org/downloads/
+[11]: https://www.imagemagick.org/script/index.php
+[12]: https://www.imagemagick.org/script/install-source.php
+[13]: https://www.kde.org/applications/graphics/spectacle/
+
diff --git a/translated/tech/20180913 ScreenCloud- The Screenshot-- App.md b/translated/tech/20180913 ScreenCloud- The Screenshot-- App.md
new file mode 100644
index 0000000000..a7002183c3
--- /dev/null
+++ b/translated/tech/20180913 ScreenCloud- The Screenshot-- App.md
@@ -0,0 +1,77 @@
+ScreenCloud:一个截屏程序
+======
+[ScreenCloud][1]是一个很棒的小程序,你甚至不知道你需要它。桌面 Linux 的默认屏幕截图流程很好(Prt Scr 按钮),我们甚至有一些[强大的截图工具][2],如 [Shutter][3]。但是,ScreenCloud 有一个非常简单但非常方便的功能,让我爱上了它。在我们深入它之前,让我们先看一个背景故事。
+
+我截取了很多截图。远远超过平均水平。收据、注册详细信息、开发工作、文章中程序的截图等等。我接下来要做的就是打开浏览器,浏览我最喜欢的云存储并将重要的内容转储到那里,以便我可以在手机上以及 PC 上的多个操作系统上访问它们。这也让我可以轻松与我的团队分享我正在使用的程序的截图。
+
+我对这个标准的截图流程没有抱怨,打开浏览器并登录我的云,然后手动上传屏幕截图,直到我遇到 ScreenCloud。
+
+### ScreenCloud
+
+ScreenCloud 是跨平台的程序,它提供简单的屏幕截图和灵活的[云备份选项][4]管理。这包括使用你自己的[ FTP 服务器][5]。
+
+![][6]
+
+ScreenCloud 很精简,投入了大量的注意力给小的东西。它为你提供了非常容易记住的热键来捕获全屏、活动窗口或捕获用鼠标选择的区域。
+
+![][7]ScreenCloud 的默认键盘快捷键
+
+截取屏幕截图后,你可以设置 ScreenCloud 如何处理图像或直接将其上传到你选择的云服务。它甚至支持 SFTP。截图上传后(通常在几秒钟内),图像链接就会被自动复制到剪贴板,这让你可以轻松共享。
+
+![][8]
+
+你还可以使用 ScreenCloud 进行一些基本编辑。为此,你需要将 “Save to” 设置为 “Ask me”。此设置在下拉框中有并且通常是默认设置。当使用它时,当你截取屏幕截图时,你会看到编辑文件的选项。在这里,你可以在屏幕截图中添加箭头、文本和数字。
+
+![Editing screenshots with ScreenCloud][9]Editing screenshots with ScreenCloud
+
+### 在 Linux 上安装 ScreenCloud
+
+ScreenCloud 可在[ Snap 商店][10]中找到。因此,你可以通过访问[ Snap 商店][12]或运行以下命令,轻松地将其安装在 Ubuntu 和其他[启用 Snap ][11]的发行版上。
+
+```
+sudo snap install screencloud
+
+```
+
+对于无法通过 Snap 安装程序的 Linux 发行版,你可以[在这里][1]下载 AppImage。进入下载文件夹,右键单击并在那里打开终端。然后运行以下命令。
+
+```
+sudo chmod +x ScreenCloud-v1.4.0-x86_64.AppImage
+
+```
+
+然后,你可以通过双击下载的文件来启动程序。
+
+![][13]
+
+### 总结
+
+ScreenCloud 适合所有人吗?可能不会。它比默认屏幕截图更好吗?可能是。如果你正在截某些屏幕,有可能它是重要的或是你想分享的。ScreenCloud 可以更轻松,更快速地备份或共享屏幕截图。所以,如果你想要这些功能,你应该试试 ScreenCloud。
+
+欢迎在用下面的评论栏提出你的想法和意见。还有不要忘记与朋友分享这篇文章。干杯。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/screencloud-app/
+
+作者:[Aquil Roshan][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[geekpi](https://github.com/geekpi)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/aquil/
+[1]: https://screencloud.net
+[2]: https://itsfoss.com/take-screenshot-linux/
+[3]: http://shutter-project.org
+[4]: https://itsfoss.com/cloud-services-linux/
+[5]: https://itsfoss.com/set-ftp-server-linux/
+[6]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/screencloud3.jpg
+[7]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/screencloud2.jpg
+[8]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/ScrenCloud6.jpg
+[9]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/editing-with-screencloud.png
+[10]: https://snapcraft.io/
+[11]: https://itsfoss.com/install-snap-linux/
+[12]: https://snapcraft.io/screencloud
+[13]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/ScrenCloud4.jpg
diff --git a/translated/tech/20180917 Getting started with openmediavault- A home NAS solution.md b/translated/tech/20180917 Getting started with openmediavault- A home NAS solution.md
new file mode 100644
index 0000000000..833180811a
--- /dev/null
+++ b/translated/tech/20180917 Getting started with openmediavault- A home NAS solution.md
@@ -0,0 +1,74 @@
+openmediavault入门:一个家庭NAS解决方案
+======
+这个网络附加文件服务提供了一序列功能,并且易于安装和配置。
+
+
+
+面对许多可供选择的云存储方案,一些人可能会质疑一个家庭网络附加存储服务的价值。毕竟,当所有你的文件存储在云上,你不需要为你自己云服务的维护,更新,和安全担忧。
+
+但是,这不完全对,是不是?你有一个家庭网络,所以你不得不负责维护网络的健康和安全。假定你已经维护一个家庭网络,那么[一个家庭NAS][1]并不会增加额外负担。反而你能从少量的工作中得到许多的好处。
+
+你可以为你家里所有的计算机备份(你也可以备份离线网站).构架一个存储电影,音乐和照片的媒体服务器,无需担心网络连接是否连接。在家里的多台计算机处理大型文件,不需要等待从网络其他随机的计算机传输这些文件过来。另外,可以让NAS与其他服务一起进行双重任务,如托管本地邮件或者家庭Wiki。也许最重要的是,构架家庭NAS,数据完全是你的,始终在控制下和随时可访问的。
+
+接下来的问题是如何选择NAS方案。当然,你可以购买预先建立的解决方案,并在某一天打电话购买,但是这会有什么乐趣呢?实际上,尽管拥有一个能处理一切的设备很棒,但最好还是有一个可以修复和升级的钻机。这是一个我近期发现的解决方案。我选择安装和配置[openmediavault][2]。
+
+### 为什么选择openmediavault?
+
+市面上有不少开源的NAS解决方案,其中有些无可争议的比openmediavault流行。当我询问周遭,例如,[freeNAS][3]最常被推荐给我。那么为什么我不采纳他们的建议呢?毕竟,它被大范围的使用,包含很多的功能,并且提供许多支持选项,[基于FreeNAS官网的一份对比数据][4]。当然这些全部是对的。但是openmediavault也不差。它是基于FreeNAS早期版本,虽然它在下载和功能方面的数量较低,但是对于我的需求而言,它已经相当足够了。
+
+另外一个因素是它让我感到很舒适。openmediavault的底层操作系统是[Debian][5],然而FreeNAS是[FreeBSD][6]。由于我个人对FressBSD不是很熟悉,因此如果我的NAS出现故障,必定会很难在FreeBSD上修复故障。同样的,也会让我觉得很难微调配置或添加服务到机器上。当然,我可以学习FreeBSD和更熟悉它,但是我已经在家里构架了这个NAS;我发现,如果限制给定自己完成构建NAS的“学习机会”的数量,构建NAS往往会更成功。
+
+当然,每个情况都不同,所以你要自己调研,然后作出最适合自己方案的决定。FreeNAS对于许多人似乎都是不错的解决方案。Openmediavault正是适合我的解决方案。
+
+### 安装与配置
+
+在[openmediavault文档]里详细记录了安装步骤,所以我不在这里重述了。如果你曾经安装过任何一个linux版本,大部分安装步骤都是很类似的(虽然在相对丑陋的[Ucurses][9]界面,不像你可能在现代版本的相对美观的安装界面)。我通过使用[专用驱动器][9]指令来安装它。然而,这些指令不但很好,而且相当精炼的。当你搞定这些指令,你安装了一个基本的系统,但是你还需要做很多才能真正构建好NAS来存储任何文件。例如,专用驱动器指令在硬盘驱动上安装openmediavault,但那是操作系统的驱动,而不是和网络上其他计算机共享空间的那个驱动。你需要自己把这些建立起来并且配置好。
+
+你要做的第一件事是加载用来管理的网页界面和修改默认密码。这个密码和之前你安装过程设置的根密码是不同的。这是网页洁面的管理员账号,和默认的账户和密码分别是 `admin` 和 `openmediavault`,当你登入后自然而然地会修改这些配置属性。
+
+#### 设置你的驱动
+
+一旦你安装好openmediavault,你需要它为你做一些工作。逻辑上的第一个步骤是设置好你即将用来作为存储的驱动。在这里,我假定你已经物理上安装好它们了,所以接下来你要做的就是让openmediavault识别和配置它们。第一步是确保这些磁盘是可见的。侧边栏菜单有很多选项,而且被精心的归类了。选择**存储 - > 磁盘**。一旦你点击该菜单,你应该能够看到所有你已经安装到该服务器的驱动,包括那个你已经用来安装openmediavault的驱动。如果你没有在那里看到所有驱动,点击扫描按钮去看它能够接载它们。通常,这不会是一个问题。
+
+当你的文件共享时,你可以独立的挂载和设置这些驱动,但是对于一个文件服务器,你将想要一些冗余驱动。你想要能够把很多驱动当作一个单一卷和能够在某一个驱动出现故障或者空间不足下安装新驱动的情况下恢复你的数据。这意味你将需要一个[RAID][10]。你想要的什么特定类型的RAID的主题是一个深深的兔子洞,是一个值得另写一片文章专门来讲述它(而且已经有很多关于该主题的文章了),但是简而言之是你将需要不仅仅一个驱动和最好的情况下,你的所有驱动都存储一样数量的数据。
+
+openmedia支持所有标准的RAID级别,所以多了解RAID对你很有好处的。可以在**存储 - > RAID管理**配置你的RAID。配置是相当简单:点击创建按钮,在你的RAID阵列里选择你想要的磁盘和你想要使用的RAID级别,和给这个阵列一个名字。openmediavault为你处理剩下的工作。没有混乱的命令行,试图记住‘mdadm'命令的一些标志参数。在我特别的例子,我有六个2TB驱动,并被设置为RAID 10.
+
+当你的RAID构建好了,基本上你已经有一个地方可以存储东西了。你仅仅需要设置一个文件系统。正如你的桌面系统,一个硬盘驱动在没有格式化情况下是没什么用处的。所以下一个你要去的地方的是位于openmediavault控制面板里的 **存储 - > 文件系统**。和配置你的RAID一样,点击创建按钮,然后跟着提示操作。如果你只有一个RAID在你的服务器上,你应该可以看到一个像 `md0`的东西。你也需要选择文件系统的类别。如果你不能确定,选择标准的ext4类型即可。
+
+#### 定义你的共享
+
+亲爱的!你有个地方可以存储文件了。现在你只需要让它在你的家庭网络中可见。可以从在openmediavault控制面板上的**服务**部分上配置。当谈到在网络上设置文件共享,有两个主要的选择:NFS或者SMB/CIFS. 根据以往经验,如果你网络上的所有计算机都是Linux系统,那么你使用NFS会更好。然而,当你家庭网络是一个混合环境,是一个包含Linux,Windows,苹果系统和嵌入式设备的组合,那么SMB/CIF可能会是你合适的选择。
+
+这些选项不是互斥的。实际上,你可以在服务器上运行这些服务和同时拥有这些服务的好处。或者你可以混合起来,如果你有一个特定的设备做特定的任务。不管你的使用场景是怎样,配置这些服务是相当简单。点击你想要的服务,从它配置中激活它,和在网络中设定你想要的共享文件夹为可见。在基于SMB/CIFS共享的情况下,相对于NFS多了一些可用的配置,但是一般用默认配置就挺好的,接着可以在默认基础上修改配置。最酷的事情是它很容易配置,同时也很容易在需要的时候修改配置。
+
+#### 用户配置
+
+基本上已将完成了。你已经在RAID配置你的驱动。你已经用一种文件系统格式化了RAID。和你已经在格式化的RAID上设定了共享文件夹。剩下来的一件事情是配置那些人可以访问这些共享和可以访问多少。这个可以在 **访问权限管理** 配置区设置。使用 **用户** 和 **群组** 选项来设定可以连接到你共享文件加的用户和设定这些共享文件的访问权限。
+
+一旦你完成用户配置,你几乎准备好了。你需要从不同客户端机器访问你的共享,但是这是另外一个可以单独写个文章的话题了。
+
+玩得开心!
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/9/openmediavault
+
+作者:[Jason van Gumster][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[jamelouis](https://github.com/jamelouis)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/mairin
+[1]: https://opensource.com/article/18/8/automate-backups-raspberry-pi
+[2]: https://openmediavault.org
+[3]: https://freenas.org
+[4]: http://www.freenas.org/freenas-vs-openmediavault/
+[5]: https://www.debian.org/
+[6]: https://www.freebsd.org/
+[7]: https://openmediavault.readthedocs.io/en/latest/installation/index.html
+[8]: https://invisible-island.net/ncurses/
+[9]: https://openmediavault.readthedocs.io/en/latest/installation/via_iso.html
+[10]: https://en.wikipedia.org/wiki/RAID
diff --git a/translated/tech/20180917 Linux tricks that can save you time and trouble.md b/translated/tech/20180917 Linux tricks that can save you time and trouble.md
new file mode 100644
index 0000000000..1dbc81bfbd
--- /dev/null
+++ b/translated/tech/20180917 Linux tricks that can save you time and trouble.md
@@ -0,0 +1,170 @@
+让你提高效率的 Linux 技巧
+======
+想要在 Linux 命令行工作中提高效率,你需要使用一些技巧。
+
+
+
+巧妙的 Linux 命令行技巧能让你节省时间、避免出错,还能让你记住和复用各种复杂的命令,专注在需要做的事情本身,而不是做事的方式。以下介绍一些好用的命令行技巧。
+
+### 命令编辑
+
+如果要对一个已输入的命令进行修改,可以使用 ^a(ctrl + a)或 ^e(ctrl + e)将光标快速移动到命令的开头或命令的末尾。
+
+还可以使用 `^` 字符实现对上一个命令的文本替换并重新执行命令,例如 `^before^after^` 相当于把上一个命令中的 `before` 替换为 `after` 然后重新执行一次。
+
+```
+$ eho hello world <== 错误的命令
+
+Command 'eho' not found, did you mean:
+
+ command 'echo' from deb coreutils
+ command 'who' from deb coreutils
+
+Try: sudo apt install
+
+$ ^e^ec^ <== 替换
+echo hello world
+hello world
+
+```
+
+### 使用远程机器的名称登录到机器上
+
+如果使用命令行登录其它机器上,可以考虑添加别名。在别名中,可以填入需要登录的用户名(与本地系统上的用户名可能相同,也可能不同)以及远程机器的登录信息。例如使用 `server_name ='ssh -v -l username IP-address'` 这样的别名命令:
+
+```
+$ alias butterfly=”ssh -v -l jdoe 192.168.0.11”
+```
+
+也可以通过在 `/etc/hosts` 文件中添加记录或者在 DNS 服务器中加入解析记录来把 IP 地址替换成易记的机器名称。
+
+执行 `alias` 命令可以列出机器上已有的别名。
+
+```
+$ alias
+alias butterfly='ssh -v -l jdoe 192.168.0.11'
+alias c='clear'
+alias egrep='egrep --color=auto'
+alias fgrep='fgrep --color=auto'
+alias grep='grep --color=auto'
+alias l='ls -CF'
+alias la='ls -A'
+alias list_repos='grep ^[^#] /etc/apt/sources.list /etc/apt/sources.list.d/*'
+alias ll='ls -alF'
+alias ls='ls --color=auto'
+alias show_dimensions='xdpyinfo | grep '\''dimensions:'\'''
+```
+
+只要将新的别名添加到 `~/.bashrc` 或类似的文件中,就可以让别名在每次登录后都能立即生效。
+
+### 冻结、解冻终端界面
+
+^s(ctrl + s)将通过执行流量控制命令 XOFF 来停止终端输出内容,这会对 PuTTY 会话和桌面终端窗口产生影响。如果误输入了这个命令,可以使用 ^q(ctrl + q)让终端重新响应。所以只需要记住^q 这个组合键就可以了,毕竟这种情况并不多见。
+
+### 复用命令
+
+Linux 提供了很多让用户复用命令的方法,其核心是通过历史缓冲区收集执行过的命令。复用命令的最简单方法是输入 `!` 然后接最近使用过的命令的开头字母;当然也可以按键盘上的向上箭头,直到看到要复用的命令,然后按 Enter 键。还可以先使用 `history` 显示命令历史,然后输入 `!` 后面再接命令历史记录中需要复用的命令旁边的数字。
+
+```
+!! <== 复用上一条命令
+!ec <== 复用上一条以 “ec” 开头的命令
+!76 <== 复用命令历史中的 76 号命令
+```
+
+### 查看日志文件并动态显示更新内容
+
+使用形如 `tail -f /var/log/syslog` 的命令可以查看指定的日志文件,并动态显示文件中增加的内容,需要监控向日志文件中追加内容的的事件时相当有用。这个命令会输出文件内容的末尾部分,并逐渐显示新增的内容。
+
+```
+$ tail -f /var/log/auth.log
+Sep 17 09:41:01 fly CRON[8071]: pam_unix(cron:session): session closed for user smmsp
+Sep 17 09:45:01 fly CRON[8115]: pam_unix(cron:session): session opened for user root
+Sep 17 09:45:01 fly CRON[8115]: pam_unix(cron:session): session closed for user root
+Sep 17 09:47:00 fly sshd[8124]: Accepted password for shs from 192.168.0.22 port 47792
+Sep 17 09:47:00 fly sshd[8124]: pam_unix(sshd:session): session opened for user shs by
+Sep 17 09:47:00 fly systemd-logind[776]: New session 215 of user shs.
+Sep 17 09:55:01 fly CRON[8208]: pam_unix(cron:session): session opened for user root
+Sep 17 09:55:01 fly CRON[8208]: pam_unix(cron:session): session closed for user root
+ <== 等待显示追加的内容
+```
+
+### 寻求帮助
+
+对于大多数 Linux 命令,都可以通过在输入命令后加上选项 `--help` 来获得这个命令的作用、用法以及它的一些相关信息。除了 `man` 命令之外, `--help` 选项可以让你在不使用所有扩展选项的情况下获取到所需要的内容。
+
+```
+$ mkdir --help
+Usage: mkdir [OPTION]... DIRECTORY...
+Create the DIRECTORY(ies), if they do not already exist.
+
+Mandatory arguments to long options are mandatory for short options too.
+ -m, --mode=MODE set file mode (as in chmod), not a=rwx - umask
+ -p, --parents no error if existing, make parent directories as needed
+ -v, --verbose print a message for each created directory
+ -Z set SELinux security context of each created directory
+ to the default type
+ --context[=CTX] like -Z, or if CTX is specified then set the SELinux
+ or SMACK security context to CTX
+ --help display this help and exit
+ --version output version information and exit
+
+GNU coreutils online help:
+or available locally via: info '(coreutils) mkdir invocation'
+```
+
+### 谨慎删除文件
+
+如果要谨慎使用 `rm` 命令,可以为它设置一个别名,在删除文件之前需要进行确认才能删除。有些系统管理员会默认使用这个别名,对于这种情况,你可能需要看看下一个技巧。
+
+```
+$ rm -i <== 请求确认
+```
+
+### 关闭别名
+
+你可以使用 `unalias` 命令以交互方式禁用别名。它不会更改别名的配置,而仅仅是暂时禁用,直到下次登录或重新设置了这一个别名才会重新生效。
+
+```
+$ unalias rm
+```
+
+如果已经将 `rm -i` 默认设置为 `rm` 的别名,但你希望在删除文件之前不必进行确认,则可以将 `unalias` 命令放在一个启动文件(例如 ~/.bashrc)中。
+
+### 使用 sudo
+
+如果你经常在只有 root 用户才能执行的命令前忘记使用 `sudo`,这里有两个方法可以解决。一是利用命令历史记录,可以使用 `sudo !!`(使用 `!!` 来运行最近的命令,并在前面添加 `sudo`)来重复执行,二是设置一些附加了所需 `sudo` 的命令别名。
+
+```
+$ alias update=’sudo apt update’
+```
+
+### 更复杂的技巧
+
+有时命令行技巧并不仅仅是一个别名。毕竟,别名能帮你做的只有替换命令以及增加一些命令参数,节省了输入的时间。但如果需要比别名更复杂功能,可以通过编写脚本、向 `.bashrc` 或其他启动文件添加函数来实现。例如,下面这个函数会在创建一个目录后进入到这个目录下。在设置完毕后,执行 `source .bashrc`,就可以使用 `md temp` 这样的命令来创建目录立即进入这个目录下。
+
+```
+md () { mkdir -p "$@" && cd "$1"; }
+```
+
+### 总结
+
+使用 Linux 命令行是在 Linux 系统上工作最有效也最有趣的方法,但配合命令行技巧和巧妙的别名可以让你获得更好的体验。
+
+加入 [Facebook][1] 和 [LinkedIn][2] 上的 Network World 社区可以和我们一起讨论。
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3305811/linux/linux-tricks-that-even-you-can-love.html
+
+作者:[Sandra Henry-Stocker][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[HankChow](https://github.com/HankChow)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
+[1]: https://www.facebook.com/NetworkWorld/
+[2]: https://www.linkedin.com/company/network-world
+
diff --git a/translated/tech/20180918 How To Force APT Package Manager To Use IPv4 In Ubuntu 16.04.md b/translated/tech/20180918 How To Force APT Package Manager To Use IPv4 In Ubuntu 16.04.md
new file mode 100644
index 0000000000..02bc39addc
--- /dev/null
+++ b/translated/tech/20180918 How To Force APT Package Manager To Use IPv4 In Ubuntu 16.04.md
@@ -0,0 +1,47 @@
+如何在 Ubuntu 16.04 强制 APT 包管理器使用 IPv4
+======
+
+
+
+**APT**, 是 **A** dvanced **P** ackage **T** ool 的缩写,是基于 Debian 的系统的默认包管理器。我们可以使用 APT 安装、更新、升级和删除应用程序。最近,我一直遇到一个奇怪的错误。每当我尝试更新我的 Ubuntu 16.04 时,我都会收到此错误 - **“0% [Connecting to in.archive.ubuntu.com (2001:67c:1560:8001::14)]”** ,同时更新流程会卡住很长时间。我的网络连接没问题,我可以 ping 通所有网站,包括 Ubuntu 官方网站。在搜索了一番谷歌后,我意识到 Ubuntu 镜像有时无法通过 IPv6 访问。在我强制将 APT 包管理器在更新系统时使用 IPv4 代替 IPv6 访问 Ubuntu 镜像后,此问题得以解决。如果你遇到过此错误,可以按照以下说明解决。
+
+### 强制 APT 包管理器在 Ubuntu 16.04 中使用 IPv4
+
+要在更新和升级 Ubuntu 16.04 LTS 系统时强制 APT 使用 IPv4 代替 IPv6,只需使用以下命令:
+
+```
+$ sudo apt-get -o Acquire::ForceIPv4=true update
+
+$ sudo apt-get -o Acquire::ForceIPv4=true upgrade
+```
+
+瞧!这次更新很快就完成了。
+
+你还可以使用以下命令在 **/etc/apt/apt.conf.d/99force-ipv4** 中添加以下行,以便将来对所有 **apt-get** 事务保持持久性:
+
+```
+$ echo 'Acquire::ForceIPv4 "true";' | sudo tee /etc/apt/apt.conf.d/99force-ipv4
+```
+
+**免责声明:**
+
+我不知道最近是否有人遇到这个问题,但我今天在我的 Ubuntu 16.04 LTS 虚拟机中遇到了至少四五次这样的错误,我按照上面的说法解决了这个问题。我不确定这是推荐的解决方案。请浏览 Ubuntu 论坛来确保此方法合法。由于我只是一个 VM,我只将它用于测试和学习目的,我不介意这种方法的真实性。请自行承担使用风险。
+
+希望这有帮助。还有更多的好东西。敬请关注!
+
+干杯!
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/how-to-force-apt-package-manager-to-use-ipv4-in-ubuntu-16-04/
+
+作者:[SK][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[geekpi](https://github.com/geekpi)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/sk/
diff --git a/translated/tech/20180918 Top 3 Python libraries for data science.md b/translated/tech/20180918 Top 3 Python libraries for data science.md
new file mode 100644
index 0000000000..4026b751d5
--- /dev/null
+++ b/translated/tech/20180918 Top 3 Python libraries for data science.md
@@ -0,0 +1,246 @@
+3 个用于数据科学的顶级 Python 库
+======
+
+>使用这些库把 Python 变成一个科学数据分析和建模工具。
+
+![][7]
+
+Python 的许多特性,比如开发效率、代码可读性、速度等使之成为了数据科学爱好者的首选编程语言。对于想要升级应用程序功能的数据科学家和机器学习专家来说,Python 通常是最好的选择(比如,Andrey Bulezyuk 使用 Python 语言创造了一个优秀的[机器学习应用程序][1])。
+
+由于 Python 的广泛使用,因此它拥有大量的库,使得数据科学家能够很容易地完成复杂的任务,而且不会遇到许多编码困难。下面列出 3 个用于数据科学的顶级 Python 库。如果你想在数据科学这一领域开始你的职业生涯,就去了解一下它们吧。
+
+### NumPy
+
+[NumPy][2](数值 Python 的简称)是其中一个顶级数据科学库,它拥有许多有用的资源,从而帮助数据科学家把 Python 变成一个强大的科学分析和建模工具。NumPy 是在 BSD 许可证的许可下开源的,它是在科学计算中执行任务的基础 Python 库。SciPy 是一个更大的基于 Python 生态系统的开源工具,而 NumPy 是 SciPy 非常重要的一部分。
+
+NumPy 为 Python 提供了大量数据结构,从而能够轻松地执行多维数组和矩阵运算。除了用于求解线性代数方程和其它数学计算之外,NumPy 还可以用做不同类型通用数据的多维容器。
+
+此外,NumPy 还可以和其他编程语言无缝集成,比如 C/C++ 和 Fortran。NumPy 的多功能性使得它可以简单而快速地与大量数据库和工具结合。比如,让我们来看一下如何使用 NumPy(缩写成 `np`)来实现两个矩阵的乘法运算。
+
+我们首先导入 NumPy 库(在这些例子中,我将使用 Jupyter notebook):
+
+```
+import numpy as np
+```
+
+接下来,使用 `eye()` 函数来生成指定维数的单位矩阵:
+
+```
+matrix_one = np.eye(3)
+matrix_one
+```
+
+输出如下:
+
+```
+array([[1., 0., 0.],
+ [0., 1., 0.],
+ [0., 0., 1.]])
+```
+
+让我们生成另一个 3x3 矩阵。
+
+我们使用 `arange([starting number], [stopping number])` 函数来排列数字。注意,函数中的第一个参数是需要列出的初始数字,而后一个数字不包含在生成的结果中。
+
+另外,使用 `reshape()` 函数把原始生成的矩阵的维度改成我们需要的维度。为了使两个矩阵“可乘”,它们需要有相同的维度。
+
+```
+matrix_two = np.arange(1,10).reshape(3,3)
+matrix_two
+```
+
+Here is the output:
+输出如下:
+
+```
+array([[1, 2, 3],
+ [4, 5, 6],
+ [7, 8, 9]])
+```
+
+接下来,使用 `dot()` 函数将两个矩阵相乘。
+
+```
+matrix_multiply = np.dot(matrix_one, matrix_two)
+
+matrix_multiply
+
+```
+
+相乘后的输出如下:
+
+```
+array([[1., 2., 3.],
+ [4., 5., 6.],
+ [7., 8., 9.]])
+```
+
+太好了!
+
+我们成功使用 NumPy 完成了两个矩阵的相乘,而不是使用普通冗长的 Python 代码。
+
+下面是这个例子的完整代码:
+
+```
+import numpy as np
+#生成一个 3x3 单位矩阵
+matrix_one = np.eye(3)
+matrix_one
+#生成另一个 3x3 矩阵以用来做乘法运算
+matrix_two = np.arange(1,10).reshape(3,3)
+matrix_two
+#将两个矩阵相乘
+matrix_multiply = np.dot(matrix_one, matrix_two)
+matrix_multiply
+```
+
+### Pandas
+
+[Pandas][3] 是另一个可以提高你的 Python 数据科学技能的优秀库。就和 NumPy 一样,它属于 SciPy 开源软件家族,可以在 BSD 免费许可证许可下使用。
+
+Pandas 提供了多功能并且很强大的工具用于管理数据结构和执行大量数据分析。该库能够很好的处理不完整、非结构化和无序的真实世界数据,并且提供了用于整形、聚合、分析和可视化数据集的工具
+
+Pandas 中有三种类型的数据结构:
+
+ * Series: 一维、相同数据类型的数组
+ * DataFrame: 二维异型矩阵
+ * Panel: 三维大小可变数组
+
+
+
+例如,我们来看一下如何使用 Panda 库(缩写成 `pd`)来执行一些描述性统计计算。
+
+首先导入该库:
+
+```
+import pandas as pd
+```
+
+然后,创建一个序列字典:
+
+```
+d = {'Name':pd.Series(['Alfrick','Michael','Wendy','Paul','Dusan','George','Andreas',
+ 'Irene','Sagar','Simon','James','Rose']),
+ 'Years of Experience':pd.Series([5,9,1,4,3,4,7,9,6,8,3,1]),
+ 'Programming Language':pd.Series(['Python','JavaScript','PHP','C++','Java','Scala','React','Ruby','Angular','PHP','Python','JavaScript'])
+ }
+```
+
+接下来,再创建一个数据框:
+
+```
+df = pd.DataFrame(d)
+```
+
+输出是一个非常规整的表:
+
+```
+ Name Programming Language Years of Experience
+0 Alfrick Python 5
+1 Michael JavaScript 9
+2 Wendy PHP 1
+3 Paul C++ 4
+4 Dusan Java 3
+5 George Scala 4
+6 Andreas React 7
+7 Irene Ruby 9
+8 Sagar Angular 6
+9 Simon PHP 8
+10 James Python 3
+11 Rose JavaScript 1
+```
+
+下面是这个例子的完整代码:
+
+```
+import pandas as pd
+#创建一个序列字典
+d = {'Name':pd.Series(['Alfrick','Michael','Wendy','Paul','Dusan','George','Andreas',
+ 'Irene','Sagar','Simon','James','Rose']),
+ 'Years of Experience':pd.Series([5,9,1,4,3,4,7,9,6,8,3,1]),
+ 'Programming Language':pd.Series(['Python','JavaScript','PHP','C++','Java','Scala','React','Ruby','Angular','PHP','Python','JavaScript'])
+ }
+
+#创建一个数据框
+df = pd.DataFrame(d)
+print(df)
+```
+
+### Matplotlib
+
+[Matplotlib][4] 也是 Scipy 核心包的一部分,并且在 BSD 许可证下可用。它是一个非常流行的科学库,用于实现简单而强大的可视化。你可以使用这个 Python 数据科学框架来生成曲线图、柱状图、直方图以及各种不同形状的图表,并且不用担心需要写很多行的代码。例如,我们来看一下如何使用 Matplotlib 库来生成一个简单的柱状图。
+
+首先导入该库:
+
+```
+from matplotlib import pyplot as plt
+```
+
+然后生成 x 轴和 y 轴的数值:
+
+```
+x = [2, 4, 6, 8, 10]
+y = [10, 11, 6, 7, 4]
+```
+
+接下来,调用函数来绘制柱状图:
+
+```
+plt.bar(x,y)
+```
+
+最后,显示图表:
+
+```
+plt.show()
+```
+
+柱状图如下:
+
+![][6]
+
+下面是这个例子的完整代码:
+
+```
+#导入 Matplotlib 库
+from matplotlib import pyplot as plt
+#和 import matplotlib.pyplot as plt 一样
+
+#生成 x 轴的数值
+x = [2, 4, 6, 8, 10]
+
+#生成 y 轴的数值
+y = [10, 11, 6, 7, 4]
+
+#调用函数来绘制柱状图
+plt.bar(x,y)
+
+#显示图表
+plt.show()
+```
+
+### 总结
+
+Python 编程语言非常擅长数据处理和准备,但是在科学数据分析和建模方面就没有那么优秀了。幸好有这些用于[数据科学][5]的顶级 Python 框架填补了这一空缺,从而你能够进行复杂的数学计算以及创建复杂模型,进而让数据变得更有意义。
+
+你还知道其它的 Python 数据挖掘库吗?你的使用经验是什么样的?请在下面的评论中和我们分享。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/9/top-3-python-libraries-data-science
+
+作者:[Dr.Michael J.Garbade][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[ucasFL](https://github.com/ucasFL)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/drmjg
+[1]: https://www.liveedu.tv/andreybu/REaxr-machine-learning-model-python-sklearn-kera/oPGdP-machine-learning-model-python-sklearn-kera/
+[2]: http://www.numpy.org/
+[3]: http://pandas.pydata.org/
+[4]: https://matplotlib.org/
+[5]: https://www.liveedu.tv/guides/data-science/
+[6]: https://opensource.com/sites/default/files/uploads/matplotlib_barchart.png
+[7]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/data_metrics_analytics_desktop_laptop.png?itok=9QXd7AUr
diff --git a/translated/tech/20180919 Host your own cloud with Raspberry Pi NAS.md b/translated/tech/20180919 Host your own cloud with Raspberry Pi NAS.md
new file mode 100644
index 0000000000..312fed7c4c
--- /dev/null
+++ b/translated/tech/20180919 Host your own cloud with Raspberry Pi NAS.md
@@ -0,0 +1,112 @@
+Part-III 树莓派自建 NAS 云盘之云盘构建
+======
+
+用树莓派 NAS 云盘来保护数据的安全!
+
+在前面两篇文章中(译注:文章链接 [Part-I][1],[Part-II][2]),我们讨论了用树莓派搭建一个 NAS(network-attached storage) 所需要的一些 [软硬件环境及其操作步骤][1]。我们还制定了适当的 [备份策略][2] 来保护NAS上的数据。本文中,我们将介绍讨论利用 [Nestcloud][3] 来方便快捷的存储、获取以及分享你的数据。
+
+### 必要的准备工作
+
+想要方便的使用 Nextcloud,需要一些必要的准备工作。首先,你需要一个指向 Nextcloud 的域名。方便起见,本文将使用 **nextcloud.pi-nas.com** 。如果你是在家庭网络里运行,你需要为该域名配置 DNS 服务(动态域名解析服务)并在路由器中开启 80 端口和 443 端口转发功能(如果需要使用 https,则需要开启 443 端口转发,如果只用 http,80 端口足以)。
+
+你可以使用 [ddclient][4] 在树莓派中自动更新 DNS。
+
+### 安装 Nextcloud
+
+为了在树莓派(参考 [Part-I][1] 中步骤设置)中运行 Nextcloud,首先用命令 **apt** 安装 以下的一些依赖软件包。
+
+```
+sudo apt install unzip wget php apache2 mysql-server php-zip php-mysql php-dom php-mbstring php-gd php-curl
+```
+
+其次,下载 Nextcloud。在树莓派中利用 **wget** 下载其 [最新的版本][5]。在 [Part-I] 文章中,我们将两个磁盘驱动器连接到树莓派,一个用于存储当前数据,另一个用于备份。这里在数据存储盘上安装 Nextcloud,以确保每晚自动备份数据。
+
+```
+sudo mkdir -p /nas/data/nextcloud
+sudo chown pi /nas/data/nextcloud
+cd /nas/data/
+wget https://download.nextcloud.com/server/releases/nextcloud-14.0.0.zip -O /nas/data/nextcloud.zip
+unzip nextcloud.zip
+sudo ln -s /nas/data/nextcloud /var/www/nextcloud
+sudo chown -R www-data:www-data /nas/data/nextcloud
+```
+
+截止到写作本文时,Nextcloud 最新版更新到如上述代码中所示的 14.0.0 版本。Nextcloud 正在快速的迭代更新中,所以你可以在你的树莓派中安装更新一点的版本。
+
+### 配置数据库
+
+如上所述,Nextcloud 安装完毕。之前安装依赖软件包时就已经安装了 MySQL 数据库来存储 Nextcloud 的一些重要数据(例如,那些你创建的可以访问 Nextcloud 的用户的信息)。如果你更愿意使用 Pstgres 数据库,则上面的依赖软件包需要做一些调整。
+
+以 root 权限启动 MySQL:
+
+```
+sudo mysql
+```
+
+这将会打开 SQL 提示符界面,在那里可以插入如下指令--使用数据库连接密码替换其中的占位符--为 Nextcloud 创建一个数据库。
+
+```
+CREATE USER nextcloud IDENTIFIED BY '';
+CREATE DATABASE nextcloud;
+GRANT ALL ON nextcloud.* TO nextcloud;
+```
+
+按 **Ctrl+D** 或输入 **quit** 退出 SQL 提示符界面。
+
+### Web 服务器配置
+
+Nextcloud 可以配置以适配于 Nginx 服务器或者其他 Web 服务器运行的环境。但本文中,我决定在我的树莓派 NAS 中运行 Apache 服务器(如果你有其他效果更好的服务器选择方案,不妨也跟我分享一下)。
+
+首先为你的 Nextcloud 域名创建一个虚拟主机,创建配置文件 **/etc/apache2/sites-available/001-netxcloud.conf**,在其中输入下面的参数内容。修改其中 ServerName 为你的域名。
+
+```
+
+ServerName nextcloud.pi-nas.com
+ServerAdmin admin@pi-nas.com
+DocumentRoot /var/www/nextcloud/
+
+
+```
+
+使用下面的命令来启动该虚拟主机。
+
+```
+a2ensite 001-nextcloud
+sudo systemctl reload apache2
+```
+
+现在,你应该可以通过浏览器中输入域名访问到 web 服务器了。这里我推荐使用 HTTPS 协议而不是 HTTP 协议来访问 Nextcloud。一个简单而且免费的方法就是利用 [Certbot][7] 下载 [Let's Encrypt][6] 证书,然后设置定时任务自动刷新。这样就避免了自签证书等的麻烦。参考 [如何在树莓派中安装][8] Certbot 。在配置 Certbot 的时候,你甚至可以配置将 HTTP 自动转到 HTTPS ,例如访问 **** 自动跳转到 ****。注意,如果你的树莓派 NAS 运行在家庭路由器的下面,别忘了设置路由器的 443 端口和 80 端口转发。
+
+### 配置 Nextcloud
+
+最后一步,通过浏览器访问 Nextcloud 来配置它。在浏览器中输入域名地址,插入上文中的数据库设置信息。这里,你可以创建 Nextcloud 管理员用户。默认情况下,数据保存目录在在 Nextcloud 目录下,所以你也无需修改我们在 [Part-II][2] 一文中设置的备份策略。
+
+然后,页面会跳转到 Nextcloud 登陆界面,用刚才创建的管理员用户登陆。在设置页面中会有基础操作教程和安全安装教程(这里是访问
+
+);
+```
+
+请注意 “else” 条件返回 null 。 这是因为三元表达式要有"否则"条件。
+
+对于简单的 “if” 条件式,我们可以使用更合适的东西:&& 运算符。这是使用 “&&” 编写的相同代码。
+
+```
+const MyComponent = ({ name, isPro, stars}) => (
+
+ Hello {name}
+ {isPro ? '🏆' : null}
+
+ {stars ? (
+
+ Stars:{'⭐️'.repeat(stars)}
+
+ ) : null}
+
+
+);
+```
+
+没有太多区别,但是注意我们消除了每个三元表达式最后面的 `: null` (else 条件式)。一切都应该像以前一样渲染。
+
+
+嘿!约翰得到了什么?当什么都不应该渲染时,只有一个0。这就是我上面提到的陷阱。这里有解释为什么。
+
+[根据 MDN][3],一个逻辑运算符“和”(也就是`&&`):
+
+> `expr1 && expr2`
+
+> 如果 `expr1` 可以被转换成 `false` ,返回 `expr1`;否则返回 `expr2`。 如此,当与布尔值一起使用时,如果两个操作数都是 true,`&&` 返回 `true` ;否则,返回 `false`。
+
+好的,在你开始拔头发之前,让我为你解释它。
+
+在我们这个例子里, `expr1` 是变量 `stars`,它的值是 `0`,因为0是 falsey 的值, `0` 会被返回和渲染。看,这还不算太坏。
+
+我会简单地这么写。
+
+> 如果 `expr1` 是 falsey,返回 `expr1` ,否则返回 `expr2`
+
+所以,当对非布尔值使用 “&&” 时,我们必须让 falsy 的值返回 React 无法渲染的东西,比如说,`false` 这个值。
+
+我们可以通过几种方式实现这一目标。让我们试试吧。
+
+```
+{!!stars && (
+
+ Hello {name}
+ {isPro && '🏆'}
+
+ {stars && (
+
+ Stars:{'⭐️'.repeat(stars)}
+
+ )}
+
+ {'⭐️'.repeat(stars)}
+
+)}
+```
+
+注意 `stars` 前的双感叹操作符( `!!`)(呃,其实没有双感叹操作符。我们只是用了感叹操作符两次)。
+
+第一个感叹操作符会强迫 `stars` 的值变成布尔值并且进行一次“非”操作。如果 `stars` 是 `0` ,那么 `!stars` 会 是 `true`。
+
+然后我们执行第二个`非`操作,所以如果 `stars` 是0,`!!stars` 会是 `false`。正好是我们想要的。
+
+如果你不喜欢 `!!`,那么你也可以强制转换出一个布尔数比如这样(这种方式我觉得有点冗长)。
+
+```
+{Boolean(stars) && (
+```
+
+或者只是用比较符产生一个布尔值(有些人会说这样甚至更加语义化)。
+
+```
+{stars > 0 && (
+```
+
+#### 关于字符串
+
+空字符串与数字有一样的毛病。但是因为渲染后的空字符串是不可见的,所以这不是那种你很可能会去处理的难题,甚至可能不会注意到它。然而,如果你是完美主义者并且不希望DOM上有空字符串,你应采取我们上面对数字采取的预防措施。
+
+### 其它解决方案
+
+一种可能的将来可扩展到其他变量的解决方案,是创建一个单独的 `shouldRenderStars` 变量。然后你用“&&”处理布尔值。
+
+```
+const shouldRenderStars = stars > 0;
+```
+
+```
+return (
+
+ {shouldRenderStars && (
+
+);
+```
+
+之后,在将来,如果业务规则要求你还需要已登录,拥有一条狗以及喝淡啤酒,你可以改变 `shouldRenderStars` 的得出方式,而返回的内容保持不变。你还可以把这个逻辑放在其它可测试的地方,并且保持渲染明晰。
+
+```
+const shouldRenderStars =
+ stars > 0 && loggedIn && pet === 'dog' && beerPref === 'light`;
+```
+
+```
+return (
+
+ {'⭐️'.repeat(stars)}
+
+ )}
+
+ {shouldRenderStars && (
+
+);
+```
+
+### 结论
+
+我认为你应该充分利用这种语言。对于 JavaScript,这意味着为 `if/else` 条件式使用三元表达式,以及为 `if` 条件式使用 `&&` 操作符。
+
+我们可以回到每处都使用三元运算符的舒适区,但你现在消化了这些知识和力量,可以继续前进 && 取得成功了。
+
+--------------------------------------------------------------------------------
+
+作者简介:
+
+美国运通工程博客的执行编辑 http://aexp.io 以及 @AmericanExpress 的工程总监。MyViews !== ThoseOfMyEmployer.
+
+----------------
+
+via: https://medium.freecodecamp.org/conditional-rendering-in-react-using-ternaries-and-logical-and-7807f53b6935
+
+作者:[Donavon West][a]
+译者:[GraveAccent](https://github.com/GraveAccent)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://medium.freecodecamp.org/@donavon
+[1]:https://unsplash.com/photos/pKeF6Tt3c08?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
+[2]:https://unsplash.com/search/photos/road-sign?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
+[3]:https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Operators/Logical_Operators
diff --git a/translated/tech/20180201 Here are some amazing advantages of Go that you dont hear much about.md b/translated/tech/20180201 Here are some amazing advantages of Go that you dont hear much about.md
new file mode 100644
index 0000000000..954d800b25
--- /dev/null
+++ b/translated/tech/20180201 Here are some amazing advantages of Go that you dont hear much about.md
@@ -0,0 +1,223 @@
+你没听说过的 Go 语言惊人优点
+============================================================
+
+
+
+来自 [https://github.com/ashleymcnamara/gophers][1] 的图稿
+
+在这篇文章中,我将讨论为什么你需要尝试一下 Go,以及应该从哪里学起。
+
+Golang 是可能是最近几年里你经常听人说起的编程语言。尽管它在 2009 年已经发布,但它最近才开始流行起来。
+
+
+
+根据 Google 趋势,Golang 语言非常流行。
+
+这篇文章不会讨论一些你经常看到的 Golang 的主要特性。
+
+相反,我想向您介绍一些相当小众但仍然很重要的功能。在您决定尝试Go后,您才会知道这些功能。
+
+这些都是表面上没有体现出来的惊人特性,但它们可以为您节省数周或数月的工作量。而且这些特性还可以使软件开发更加愉快。
+
+阅读本文不需要任何语言经验,所以不比担心 Golang 对你来说是新的事物。如果你想了解更多,可以看看我在底部列出的一些额外的链接,。
+
+我们将讨论以下主题:
+
+* GoDoc
+
+* 静态代码分析
+
+* 内置的测试和分析框架
+
+* 竞争条件检测
+
+* 学习曲线
+
+* 反射(Reflection)
+
+* Opinionatedness(专制独裁的 Go)
+
+* 文化
+
+请注意,这个列表不遵循任何特定顺序来讨论。
+
+### GoDoc
+
+Golang 非常重视代码中的文档,简洁也是如此。
+
+[GoDoc][4] 是一个静态代码分析工具,可以直接从代码中创建漂亮的文档页面。GoDoc 的一个显着特点是它不使用任何其他的语言,如 JavaDoc,PHPDoc 或 JSDoc 来注释代码中的结构,只需要用英语。
+
+它使用从代码中获取的尽可能多的信息来概述、构造和格式化文档。它有多而全的功能,比如:交叉引用,代码示例以及一个指向版本控制系统仓库的链接。
+
+而你需要做的只有添加一些好的,像 `// MyFunc transforms Foo into Bar` 这样子的注释,而这些注释也会反映在的文档中。你甚至可以添加一些通过网络接口或者在本地可以实际运行的 [代码示例][5]。
+
+GoDoc 是 Go 的唯一文档引擎,供整个社区使用。这意味着用 Go 编写的每个库或应用程序都具有相同的文档格式。从长远来看,它可以帮你在浏览这些文档时节省大量时间。
+
+例如,这是我最近一个小项目的 GoDoc 页面:[pullkee — GoDoc][6]。
+
+### 静态代码分析
+
+Go 严重依赖于静态代码分析。例子包括 godoc 文档,gofmt 代码格式化,golint 代码风格统一,等等。
+
+其中有很多甚至全部包含在类似 [gometalinter][10] 的项目中,这些将它们全部组合成一个实用程序。
+
+这些工具通常作为独立的命令行应用程序实现,并可轻松与任何编码环境集成。
+
+静态代码分析实际上并不是现代编程的新概念,但是 Go 将其带入了绝对的范畴。我无法估量它为我节省了多少时间。此外,它给你一种安全感,就像有人在你背后支持你一样。
+
+创建自己的分析器非常简单,因为 Go 有专门的内置包来解析和加工 Go 源码。
+
+你可以从这个链接中了解到更多相关内容: [GothamGo Kickoff Meetup: Go Static Analysis Tools by Alan Donovan][11].
+
+### 内置的测试和分析框架
+
+您是否曾尝试为一个从头开始的 Javascript 项目选择测试框架?如果是这样,你可能会明白经历这种分析瘫痪的斗争。您可能也意识到您没有使用其中 80% 的框架。
+
+一旦您需要进行一些可靠的分析,问题就会重复出现。
+
+Go 附带内置测试工具,旨在简化和提高效率。它为您提供了最简单的 API,并做出最小的假设。您可以将它用于不同类型的测试,分析,甚至可以提供可执行代码示例。
+
+它可以开箱即用地生成持续集成友好的输出,而且它的用法很简单,只需运行 `go test`。当然,它还支持高级功能,如并行运行测试,跳过标记代码,以及其他更多功能。
+
+### 竞争条件检测
+
+您可能已经了解了 Goroutines,它们在 Go 中用于实现并发代码执行。如果你未曾了解过,[这里][12]有一个非常简短的解释。
+
+无论具体技术如何,复杂应用中的并发编程都不容易,部分原因在于竞争条件的可能性。
+
+简单地说,当几个并发操作以不可预测的顺序完成时,竞争条件就会发生。它可能会导致大量的错误,特别难以追查。如果你曾经花了一天时间调试集成测试,该测试仅在大约 80% 的执行中起作用?这可能是竞争条件引起的。
+
+总而言之,在 Go 中非常重视并发编程,幸运的是,我们有一个强大的工具来捕捉这些竞争条件。它完全集成到 Go 的工具链中。
+
+您可以在这里阅读更多相关信息并了解如何使用它:[介绍 Go 中的竞争条件检测 - Go Blog][13]。
+
+### 学习曲线
+
+您可以在一个晚上学习所有 Go 的语言功能。我是认真的。当然,还有标准库,以及不同,更具体领域的最佳实践。但是两个小时就足以让你自信地编写一个简单的 HTTP 服务器或命令行应用程序。
+
+Golang 拥有[出色的文档][14],大部分高级主题已经在博客上进行了介绍:[The Go Programming Language Blog][15]。
+
+比起 Java(以及 Java 家族的语言),Javascript,Ruby,Python 甚至 PHP,你可以更轻松地把 Go 语言带到你的团队中。由于环境易于设置,您的团队在完成第一个生产代码之前需要进行的投资要小得多。
+
+### 反射(Reflection)
+
+代码反射本质上是一种隐藏在编译器下并访问有关语言结构的各种元信息的能力,例如变量或函数。
+
+鉴于 Go 是一种静态类型语言,当涉及更松散类型的抽象编程时,它会受到许多各种限制。特别是与 Javascript 或 Python 等语言相比。
+
+此外,Go [没有实现一个名为泛型的概念][16],这使得以抽象方式处理多种类型更具挑战性。然而,由于泛型带来的复杂程度,许多人认为不实现泛型对语言实际上是有益的。我完全同意。
+
+根据 Go 的理念(这是一个单独的主题),您应该努力不要过度设计您的解决方案。这也适用于动态类型编程。尽可能坚持使用静态类型,并在确切知道要处理的类型时使用接口(interfaces)。接口在 Go 中非常强大且无处不在。
+
+但是,仍然存在一些情况,你无法知道你处理的数据类型。一个很好的例子是 JSON。您可以在应用程序中来回转换所有类型的数据。字符串,缓冲区,各种数字,嵌套结构等。
+
+为了解决这个问题,您需要一个工具来检查运行时的数据并根据其类型和结构采取不同行为。反射(Reflect)可以帮到你。Go 拥有一流的反射包,使您的代码能够像 Javascript 这样的语言一样动态。
+
+一个重要的警告是知道你使用它所带来的代价 - 并且只有知道在没有更简单的方法时才使用它。
+
+你可以在这里阅读更多相关信息: [反射的法则 — Go 博客][18].
+
+您还可以在此处阅读 JSON 包源码中的一些实际代码: [src/encoding/json/encode.go — Source Code][19]
+
+### Opinionatedness
+
+顺便问一下,有这样一个单词吗?
+
+来自 Javascript 世界,我面临的最艰巨的困难之一是决定我需要使用哪些约定和工具。我应该如何设计代码?我应该使用什么测试库?我该怎么设计结构?我应该依赖哪些编程范例和方法?
+
+这有时候基本上让我卡住了。我需要花时间思考这些事情而不是编写代码并满足用户。
+
+首先,我应该注意到我完全可以得到这些惯例的来源,它总是来源于你或者你的团队。无论如何,即使是一群经验丰富的 Javascript 开发人员也可以轻松地发现自己拥有完全不同的工具和范例的大部分经验,以实现相同的结果。
+
+这导致整个团队中分析的瘫痪,并且使得个体之间更难以相互协作。
+
+嗯,Go 是不同的。即使您对如何构建和维护代码有很多强烈的意见,例如:如何命名,要遵循哪些结构模式,如何更好地实现并发。但你只有一个每个人都遵循的风格指南。你只有一个内置在基本工具链中的测试框架。
+
+虽然这似乎过于严格,但它为您和您的团队节省了大量时间。当你写代码时,受一点限制实际上是一件好事。在构建新代码时,它为您提供了一种更直接的方法,并且可以更容易地调试现有代码。
+
+因此,大多数 Go 项目在代码方面看起来非常相似。
+
+### 文化
+
+人们说,每当你学习一门新的口语时,你也会沉浸在说这种语言的人的某些文化中。因此,您学习的语言越多,您可能会有更多的变化。
+
+编程语言也是如此。无论您将来如何应用新的编程语言,它总能给的带来新的编程视角或某些特别的技术。
+
+无论是函数式编程,模式匹配(pattern matching)还是原型继承(prototypal inheritance)。一旦你学会了它们,你就可以随身携带这些编程思想,这扩展了你作为软件开发人员所拥有的问题解决工具集。它们也改变了你阅读高质量代码的方式。
+
+而 Go 在方面有一项了不起的财富。Go 文化的主要支柱是保持简单,脚踏实地的代码,而不会产生许多冗余的抽象概念,并将可维护性放在首位。大部分时间花费在代码的编写工作上,而不是在修补工具和环境或者选择不同的实现方式上,这也是 Go文化的一部分。
+
+Go 文化也可以总结为:“应当只用一种方法去做一件事”。
+
+一点注意事项。当你需要构建相对复杂的抽象代码时,Go 通常会妨碍你。好吧,我会说这是简单的权衡。
+
+如果你真的需要编写大量具有复杂关系的抽象代码,那么最好使用 Java 或 Python 等语言。然而,这种情况却很少。
+
+在工作时始终使用最好的工具!
+
+### 总结
+
+你或许之前听说过 Go,或者它暂时在你圈子以外的地方。但无论怎样,在开始新项目或改进现有项目时,Go 可能是您或您团队的一个非常不错的选择。
+
+这不是 Go 的所有惊人的优点的完整列表,只是一些被人低估的特性。
+
+请尝试一下从 [Go 之旅(A Tour of Go)][20]来开始学习 Go,这将是一个令人惊叹的开始。
+
+如果您想了解有关 Go 的优点的更多信息,可以查看以下链接:
+
+* [你为什么要学习 Go? - Keval Patel][2]
+
+* [告别Node.js - TJ Holowaychuk][3]
+
+并在评论中分享您的阅读感悟!
+
+即使您不是为了专门寻找新的编程语言语言,也值得花一两个小时来感受它。也许它对你来说可能会变得非常有用。
+
+不断为您的工作寻找最好的工具!
+
+* * *
+
+If you like this article, please consider following me for more, and clicking on those funny green little hands right below this text for sharing. 👏👏👏
+
+Check out my [Github][21] and follow me on [Twitter][22]!
+
+--------------------------------------------------------------------------------
+
+作者简介:
+
+Software Engineer and Traveler. Coding for fun. Javascript enthusiast. Tinkering with Golang. A lot into SOA and Docker. Architect at Velvica.
+
+------------
+
+
+via: https://medium.freecodecamp.org/here-are-some-amazing-advantages-of-go-that-you-dont-hear-much-about-1af99de3b23a
+
+作者:[Kirill Rogovoy][a]
+译者:[译者ID](https://github.com/imquanquan)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:
+[1]:https://github.com/ashleymcnamara/gophers
+[2]:https://medium.com/@kevalpatel2106/why-should-you-learn-go-f607681fad65
+[3]:https://medium.com/@tjholowaychuk/farewell-node-js-4ba9e7f3e52b
+[4]:https://godoc.org/
+[5]:https://blog.golang.org/examples
+[6]:https://godoc.org/github.com/kirillrogovoy/pullkee
+[7]:https://godoc.org/
+[8]:https://golang.org/cmd/gofmt/
+[9]:https://github.com/golang/lint
+[10]:https://github.com/alecthomas/gometalinter#supported-linters
+[11]:https://vimeo.com/114736889
+[12]:https://gobyexample.com/goroutines
+[13]:https://blog.golang.org/race-detector
+[14]:https://golang.org/doc/
+[15]:https://blog.golang.org/
+[16]:https://golang.org/doc/faq#generics
+[17]:https://golang.org/pkg/reflect/
+[18]:https://blog.golang.org/laws-of-reflection
+[19]:https://golang.org/src/encoding/json/encode.go
+[20]:https://tour.golang.org/
+[21]:https://github.com/kirillrogovoy/
+[22]:https://twitter.com/krogovoy
diff --git a/translated/tech/20180226 Linux Virtual Machines vs Linux Live Images.md b/translated/tech/20180226 Linux Virtual Machines vs Linux Live Images.md
deleted file mode 100644
index 9b927bb348..0000000000
--- a/translated/tech/20180226 Linux Virtual Machines vs Linux Live Images.md
+++ /dev/null
@@ -1,66 +0,0 @@
-## sober-wang 翻译中
-
-Linux Virtual Machines vs Linux Live Images
-Linxu 虚拟机 vs Linux 实体机
-======
-I'll be the first to admit(认可) that I tend(照顾) to try out new [Linux distros(发行版本)][1] on a far(远) too frequent(频繁) basis. Yet the method(方法) I use to test them, does vary depending(依赖) on my goals(目标) for each instance(每一个). In this article(文章), we're going to look at both(两个) running Linux virtual machines and running Linux live images. There are advantages(优势/促进/有利于) to each method(方法), but there are some hurdles(障碍) with each method(方法/函数) as well(同样的).
-
-首先我得承认,我非常倾向于频繁尝试新的[ linux 发行版本 ][1],我的目标是为了解决每一个 Linux 发行版的依赖,所以我用一些方法来测试它们。在一些文章中,我们将会看到两种运行 Linux 的模式,虚拟机或实体机。每一种方式都存在优势,但是有一些障碍会伴随着这两种方式。
-
-### Testing out a new Linux distro for the first time
-### 第一时间测试一个新的 Linux 发行版
-
-When I test out a brand new Linux distro for the first time, the method I use depends heavily(沉重的) on the resources(资源) of the PC I'm currently(目前的) on. If I have access to my desktop PC, I'm going to run the distro to be tested in a virtual machine. The reason(理由) for this approach(靠近) is that I can download and test the distro in not only a live environment(环境), but also(也) as an installed product with persistent(稳定的) storage abilities(能力).
-
-为了第一时间去做 Linux 发型版本的依赖测试,我把它们运行在我目前所拥有的所有类型的 PC 上。如果我用我的台式机,我将运行一个 Linux 虚拟机做测试。
-
-On the other hand, if I am working with much less robust hardware on a PC, then testing out a distro with a virtual machine installation of Linux is counter-productive. I'd be pushing that PC to its limits and honestly would be better off using a live Linux image instead running from a flash drive.
-
-### Touring software on a new Linux distro
-
-If you're interested in checking out a distro's desktop environment or the available software, you can't go wrong with a live image of the distro. A live environment provides you with a birds eye view of what to expect in terms of overall layout, applications provided and how the user experience flows overall.
-
-To be fair, you could do the same thing with a virtual machine installation, but it may be a bit overkill if you would rather avoid filling up hard drive space with yet more data. After all, this is a simple tour of the distro. Remember what I said in the first section – I like to run Linux in a virtual machine to test it. This means I'm going to see how it installs, what the partition options look like and other elements you wouldn't see from using a live image of any given distro.
-
-Touring usually indicates that you're only looking to take a quick look at a distro, so in this case the method that can be done with the least amount of resistance and time investment is a good course of action.
-
-### Taking a Linux distro with you
-
-While it's not as common as it was a few years ago, the ability to take a Linux distro with you may be a consideration for some users. Obviously, virtual machine installations don't necessarily lend themselves favorably to portability. However a live image of a Linux distro is actually quite portable. A live image can be written to a DVD or copied onto a flash drive for easy traveling.
-
-Expanding on this concept of Linux portability, it's also beneficial to have a live image on a flash drive when showing off how Linux works on a friend's computer. This empowers you to demonstrate how Linux can enrich their life while not relying on running a virtual machine on their PC. It's a bit of a win-win in favor of using a live image.
-
-### Alternative to dual-booting Linux
-
-This next item is a huge one. Consider this – perhaps you're a Windows user. You like playing with Linux, but would rather not take the plunge. Dual-booting is out of the question in case something goes wrong or perhaps you're not comfortable identifying individual partitions. Whatever the case may be, both using Linux in a virtual machine or from a live image might be a great option for you.
-
-Now I'm going to take a rather odd stance on something. I think you'll get far more value in the long term running Linux on a flash drive using a live image than with a virtual machine. There are two reasons for this. First of all, you'll get used to truly running Linux vs running it inside of a virtual machine on top of Windows. Second, you can setup your flash drive to contain user data with persistent storage.
-
-I'll grant you the same could be said with a virtual machine running Linux, however you will never have an update break anything using the live image approach. Why? Because you're not updating a host OS or the guest OS. Remember there are entire distros that are designed to be nothing more than persistent storage Linux distros. Puppy Linux is one great example. Not only can it run on PCs that would otherwise be recycled or thrown away, it allows you to never be bothered again with tedious system updates thanks to the way the distro handles security. It's not a normal Linux distro and it's walled off in such a way that the persistent live image is free from anything scary.
-
-### When a Linux virtual machine is absolutely the best option
-
-As I bring this article to a close, let me leave you with this. There is one instance where using a virtual machine such as Virtual Box is absolutely better than using a live image – recording the desktop environment of any Linux distro.
-
-For example, I make videos that provide a tour and review of a variety of Linux distros. Doing this with live images would require me to capture the screen with a hardware device or install a software capture device from the live image's repositories. Clearly, a virtual machine is better suited for this job than a live image of a Linux distro.
-
-Once you toss audio capture into the mix, there is no question that if you're going to use software to capture your review, you really want to have a host OS that has all the basic needs covered for a reasonably decent capture environment. Again, you could do all of this with a hardware device...but that might be cost prohibitive if you're only do video/audio capturing as a part time endeavor.
-
-### A Linux virtual machine vs a Linux live image
-
-What is your preferred method of trying out new distros? Perhaps you're someone who is fine with formatting their hard drive and throwing caution to the wind, thus, making the idea of any of this unneeded?
-
-Most people I've interacted with online tend to follow much of the methodology I've touched on above, but I'd love to hear what approach works best for you. Hit the comments, let me know which method you prefer when checking out the greatest and latest from the Linux distro world.
-
---------------------------------------------------------------------------------
-
-via: https://www.datamation.com/open-source/linux-virtual-machines-vs-linux-live-images.html
-
-作者:[Matt Hartley][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.datamation.com/author/Matt-Hartley-3080.html
-[1]:https://www.datamation.com/open-source/best-linux-distro.html
diff --git a/translated/tech/20180522 Free Resources for Securing Your Open Source Code.md b/translated/tech/20180522 Free Resources for Securing Your Open Source Code.md
new file mode 100644
index 0000000000..4e63a64e43
--- /dev/null
+++ b/translated/tech/20180522 Free Resources for Securing Your Open Source Code.md
@@ -0,0 +1,83 @@
+一些提高你开源源码安全性的工具
+======
+
+
+
+虽然目前开源依然发展势头较好,并被广大的厂商所采用,然而最近由 Black Duck 和 Synopsys 发布的[2018开源安全与风险评估报告][1]指出了一些存在的风险并重点阐述了对于健全安全措施的需求。这份报告的分析资料素材来自经过脱敏后的 1100 个商业代码库,这些代码所涉及:自动化、大数据、企业级软件、金融服务业、健康医疗、物联网、制造业等多个领域。
+
+这份报告强调开源软件正在被大量的使用,扫描结果中有 96% 的应用都使用了开源组件。然而,报告还指出许多其中存在很多漏洞。具体在 [这里][2]:
+
+ * 令人担心的是扫描的所有结果中,有 78% 的代码库存在至少一个开源的漏洞,平均每个代码库有 64 个漏洞。
+
+ * 在经过代码审计过后代码库中,发现超过 54% 的漏洞经验证是高危漏洞。
+
+ * 17% 的代码库包括一种已经早已公开的漏洞,包括:Heartbleed、Logjam、Freak、Drown、Poddle。
+
+
+
+
+Tim Mackey,Synopsys 旗下 Black Duck 的技术负责人称,"这份报告清楚的阐述了:随着开源软件正在被企业广泛的使用,企业与组织也应当使用一些工具来检测可能出现在这些开源软件中的漏洞,并且管理其所使用的开源软件的方式是否符合相应的许可证规则"
+
+确实,随着越来越具有影响力的安全威胁出现,历史上从未有过我们目前对安全工具和实践的需求。大多数的组织已经意识到网络与系统管理员需要具有相应的较强的安全技能和安全证书。[在这篇文章中,][3] 我们给出一些具有较大影响力的工具、认证和实践。
+
+Linux 基金会已经在安全方面提供了许多关于安全的信息与教育资源。比如,Linux 社区提供许多免费的用来针对一些平台的工具,其中[Linux 服务器安全检查表][4] 其中提到了很多有用的基础信息。线上的一些发表刊物也可以提升用户针对某些平台对于漏洞的保护,如:[Fedora 安全指南][5],[Debian 安全手册][6]。
+
+目前被广泛使用的私有云平台 OpenStack 也加强了关于基于云的智能安全需求。根据 Linux 基金会发布的 [公有云指南][7]:“据 Gartner 的调研结果,尽管公有云的服务商在安全和审查方面做的都还不错,安全问题是企业考虑向公有云转移的最重要的考量之一”
+
+无论是对于组织还是个人,千里之堤毁于蚁穴,这些“蚁穴”无论是来自路由器、防火墙、VPNs或虚拟机都可能导致灾难性的后果。以下是一些免费的工具可能对于检测这些漏洞提供帮助:
+
+ * [Wireshark][8], 流量包分析工具
+
+ * [KeePass Password Safe][9], 免费开源的密码管理器
+
+ * [Malwarebytes][10], 免费的反病毒和勒索软件工具
+
+ * [NMAP][11], 安全扫描器
+
+ * [NIKTO][12], 开源 web 扫描器
+
+ * [Ansible][13], 自动化的配置运维工具,可以辅助做安全基线
+
+ * [Metasploit][14], 渗透测试工具,可辅助理解攻击向量
+
+
+
+这里有一些对上面工具讲解的视频。比如[Metasploit 教学][15]、[Wireshark 教学][16]。还有一些传授安全技能的免费电子书,比如:由 Ibrahim Haddad 博士和 Linux 基金会共同出版的[并购过程中的开源审计][17],里面阐述了多条在技术平台合并过程中,因没有较好的进行开源审计,从而引发的安全问题。当然,书中也记录了如何在这一过程中进行代码合规检查、准备以及文档编写。
+
+同时,我们 [之前提到的一个免费的电子书][18], 由来自[The New Stack][19] 编写的“Docker与容器中的网络、安全和存储”,里面也提到了关于加强容器网络安全的最新技术,以及Docker本身可提供的关于,提升其网络的安全与效率的最佳实践。这本电子书还记录了关于如何构建安全容器集群的最佳实践。
+
+所有这些工具和资源,可以在很大的程度上预防安全问题,正如人们所说的未雨绸缪,考虑到一直存在的安全问题,现在就应该开始学习这些安全合规资料与工具。
+想要了解更多的安全、合规以及开源项目问题,点击[这里][20]
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/blog/2018/5/free-resources-securing-your-open-source-code
+
+作者:[Sam Dean][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/sd886393)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.linux.com/users/sam-dean
+[1]:https://www.blackducksoftware.com/open-source-security-risk-analysis-2018
+[2]:https://www.prnewswire.com/news-releases/synopsys-report-finds-majority-of-software-plagued-by-known-vulnerabilities-and-license-conflicts-as-open-source-adoption-soars-300648367.html
+[3]:https://www.linux.com/blog/sysadmin-ebook/2017/8/future-proof-your-sysadmin-career-locking-down-security
+[4]:http://go.linuxfoundation.org/ebook_workstation_security
+[5]:https://docs.fedoraproject.org/en-US/Fedora/19/html/Security_Guide/index.html
+[6]:https://www.debian.org/doc/manuals/securing-debian-howto/index.en.html
+[7]:https://www.linux.com/publications/2016-guide-open-cloud
+[8]:https://www.wireshark.org/
+[9]:http://keepass.info/
+[10]:https://www.malwarebytes.com/
+[11]:http://searchsecurity.techtarget.co.uk/tip/Nmap-tutorial-Nmap-scan-examples-for-vulnerability-discovery
+[12]:https://cirt.net/Nikto2
+[13]:https://www.ansible.com/
+[14]:https://www.metasploit.com/
+[15]:http://www.computerweekly.com/tutorial/The-Metasploit-Framework-Tutorial-PDF-compendium-Your-ready-reckoner
+[16]:https://www.youtube.com/watch?v=TkCSr30UojM
+[17]:https://www.linuxfoundation.org/resources/open-source-audits-merger-acquisition-transactions/
+[18]:https://www.linux.com/news/networking-security-storage-docker-containers-free-ebook-covers-essentials
+[19]:http://thenewstack.io/ebookseries/
+[20]:https://www.linuxfoundation.org/projects/security-compliance/
diff --git a/translated/tech/20180529 How To Add Additional IP (Secondary IP) In Ubuntu System.md b/translated/tech/20180529 How To Add Additional IP (Secondary IP) In Ubuntu System.md
deleted file mode 100644
index 53d9a090ba..0000000000
--- a/translated/tech/20180529 How To Add Additional IP (Secondary IP) In Ubuntu System.md
+++ /dev/null
@@ -1,336 +0,0 @@
-如何在 Ubuntu 系统中添加一个辅助 IP 地址
-======
-
-Linux 管理员应该意识到这一点,因为这是一项例行任务。很多人想知道为什么我们需要在服务器中添加多个 IP 地址,以及为什么我们需要将它添加到单块网卡中?我说的对吗?
-
-你可能也会有类似的问题:在 Linux 中如何为单块网卡分配多个 IP 地址?在本文中,你可以得到答案。
-
-当我们对一个新服务器进行设置时,理想情况下它将有一个 IP 地址,即服务器主 IP 地址,它与服务器主机名对应。
-
-我们不应在服务器主 IP 地址上托管任何应用程序,这是不可取的。如果要在服务器上托管任何应用程序,我们应该为此添加辅助 IP。
-
-这是业界的最佳实践,它允许用户安装 SSL 证书。大多数系统都配有单块网卡,这足以添加额外的 IP 地址。
-
-**建议阅读:**
-**(#)** [在 Linux 命令行中 9 种方法检查公共 IP 地址][1]
-**(#)** [在 Linux 终端中 3 种简单的方式来检查 DNS(域名服务器)记录][2]
-**(#)** [在 Linux 上使用 Dig 命令检查 DNS(域名服务器)记录][3]
-**(#)** [在 Linux 上使用 Nslookup 命令检查 DNS(域名服务器)记录][4]
-**(#)** [在 Linux 上使用 Host 命令检查 DNS(域名服务器)记录][5]
-
-我们可以在同一个接口上添加 IP 地址,或者在同一设备上创建子接口,然后在其中添加 IP。默认情况下,一直到 Ubuntu 14.04 LTS,接口给名称为 `ethX (eth0)`,但是从 Ubuntu 15.10 之后网络接口名称已从 `ethX` 更改为 `enXXXXX`(对于服务器是 ens33,桌面版是 enp0s3)。
-
-在本文中,我们将教你如何在 Ubuntu 上执行此操作,并且衍生到其它发行版(to 校正:这句自己加的)。
-
-**`注意:`**别在 DNS 详细信息后添加 IP 地址。如果是这样,DNS 将无法正常工作。
-
-### 如何在 Ubuntu 14.04 LTS 中添加临时辅助 IP 地址
-
-在系统中添加 IP 地址之前,运行以下任一命令即可验证服务器主 IP 地址:
-```
-# ifconfig
-
-or
-
-# ip addr
-
-eth0 Link encap:Ethernet HWaddr 08:00:27:98:b7:36
- inet addr:192.168.56.150 Bcast:192.168.56.255 Mask:255.255.255.0
- inet6 addr: fe80::a00:27ff:fe98:b736/64 Scope:Link
- UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
- RX packets:4 errors:0 dropped:0 overruns:0 frame:0
- TX packets:105 errors:0 dropped:0 overruns:0 carrier:0
- collisions:0 txqueuelen:1000
- RX bytes:902 (902.0 B) TX bytes:16423 (16.4 KB)
-
-eth1 Link encap:Ethernet HWaddr 08:00:27:6a:cf:d3
- inet addr:10.0.3.15 Bcast:10.0.3.255 Mask:255.255.255.0
- inet6 addr: fe80::a00:27ff:fe6a:cfd3/64 Scope:Link
- UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
- RX packets:80 errors:0 dropped:0 overruns:0 frame:0
- TX packets:146 errors:0 dropped:0 overruns:0 carrier:0
- collisions:0 txqueuelen:1000
- RX bytes:8698 (8.6 KB) TX bytes:17047 (17.0 KB)
-
-lo Link encap:Local Loopback
- inet addr:127.0.0.1 Mask:255.0.0.0
- inet6 addr: ::1/128 Scope:Host
- UP LOOPBACK RUNNING MTU:65536 Metric:1
- RX packets:25 errors:0 dropped:0 overruns:0 frame:0
- TX packets:25 errors:0 dropped:0 overruns:0 carrier:0
- collisions:0 txqueuelen:1
- RX bytes:1730 (1.7 KB) TX bytes:1730 (1.7 KB)
-
-```
-
-如我所见,服务器主 IP 地址是 `192.168.56.150`,我将下一个 IP `192.168.56.151` 作为辅助 IP,使用以下方法完成:
-```
-# ip addr add 192.168.56.151/24 broadcast 192.168.56.255 dev eth0 label eth0:1
-
-```
-
-输入以下命令以检查新添加的 IP 地址。如果你重新启动服务器,那么新添加的 IP 地址会消失,因为我们的 IP 是临时添加的。
-```
-# ip addr
-1: lo: mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1
- link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
- inet 127.0.0.1/8 scope host lo
- valid_lft forever preferred_lft forever
- inet6 ::1/128 scope host
- valid_lft forever preferred_lft forever
-2: eth0: mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
- link/ether 08:00:27:98:b7:36 brd ff:ff:ff:ff:ff:ff
- inet 192.168.56.150/24 brd 192.168.56.255 scope global eth0
- valid_lft forever preferred_lft forever
- inet 192.168.56.151/24 brd 192.168.56.255 scope global secondary eth0:1
- valid_lft forever preferred_lft forever
- inet6 fe80::a00:27ff:fe98:b736/64 scope link
- valid_lft forever preferred_lft forever
-3: eth1: mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
- link/ether 08:00:27:6a:cf:d3 brd ff:ff:ff:ff:ff:ff
- inet 10.0.3.15/24 brd 10.0.3.255 scope global eth1
- valid_lft forever preferred_lft forever
- inet6 fe80::a00:27ff:fe6a:cfd3/64 scope link
- valid_lft forever preferred_lft forever
-
-```
-
-### 如何在 Ubuntu 14.04 LTS 中添加永久辅助 IP 地址
-
-要在 Ubuntu 系统上添加永久辅助 IP 地址,只需编辑 `/etc/network/interfaces` 文件并添加所需的 IP 详细信息。
-```
-# vi /etc/network/interfaces
-
-# The loopback network interface
-auto lo
-iface lo inet loopback
-
-# The primary network interface
-auto eth0
-iface eth0 inet static
- address 192.168.56.150
- netmask 255.255.255.0
- network 192.168.56.0
- broadcast 192.168.56.255
- gateway 192.168.56.1
-
-auto eth0:1
-iface eth0:1 inet static
- address 192.168.56.151
- netmask 255.255.255.0
-
-```
-
-保存并关闭文件,然后重启网络接口服务。
-```
-# service networking restart
-or
-# ifdown eth0:1 && ifup eth0:1
-
-```
-
-验证新添加的 IP 地址:
-```
-# ifconfig
-eth0 Link encap:Ethernet HWaddr 08:00:27:98:b7:36
- inet addr:192.168.56.150 Bcast:192.168.56.255 Mask:255.255.255.0
- inet6 addr: fe80::a00:27ff:fe98:b736/64 Scope:Link
- UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
- RX packets:5 errors:0 dropped:0 overruns:0 frame:0
- TX packets:84 errors:0 dropped:0 overruns:0 carrier:0
- collisions:0 txqueuelen:1000
- RX bytes:962 (962.0 B) TX bytes:11905 (11.9 KB)
-
-eth0:1 Link encap:Ethernet HWaddr 08:00:27:98:b7:36
- inet addr:192.168.56.151 Bcast:192.168.56.255 Mask:255.255.255.0
- UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
-
-eth1 Link encap:Ethernet HWaddr 08:00:27:6a:cf:d3
- inet addr:10.0.3.15 Bcast:10.0.3.255 Mask:255.255.255.0
- inet6 addr: fe80::a00:27ff:fe6a:cfd3/64 Scope:Link
- UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
- RX packets:4924 errors:0 dropped:0 overruns:0 frame:0
- TX packets:3185 errors:0 dropped:0 overruns:0 carrier:0
- collisions:0 txqueuelen:1000
- RX bytes:4037636 (4.0 MB) TX bytes:422516 (422.5 KB)
-
-lo Link encap:Local Loopback
- inet addr:127.0.0.1 Mask:255.0.0.0
- inet6 addr: ::1/128 Scope:Host
- UP LOOPBACK RUNNING MTU:65536 Metric:1
- RX packets:0 errors:0 dropped:0 overruns:0 frame:0
- TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
- collisions:0 txqueuelen:1
- RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
-
-```
-
-### 如何在 Ubuntu 16.04 LTS 中临时添加辅助 IP 地址
-
-正如本文开头所述,网络接口名称从 Ubuntu 15.10 就开始从 ‘ethX’ 更改为 ‘enXXXX’ (enp0s3),所以,替换你的接口名称。
-
-在执行此操作之前,先检查系统上的 IP 信息:
-```
-# ifconfig
-or
-# ip addr
-
-enp0s3: flags=4163 mtu 1500
- inet 192.168.56.201 netmask 255.255.255.0 broadcast 192.168.56.255
- inet6 fe80::a00:27ff:fe97:132e prefixlen 64 scopeid 0x20
- ether 08:00:27:97:13:2e txqueuelen 1000 (Ethernet)
- RX packets 7 bytes 420 (420.0 B)
- RX errors 0 dropped 0 overruns 0 frame 0
- TX packets 294 bytes 24747 (24.7 KB)
- TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
-
-enp0s8: flags=4163 mtu 1500
- inet 10.0.3.15 netmask 255.255.255.0 broadcast 10.0.3.255
- inet6 fe80::344b:6259:4dbe:eabb prefixlen 64 scopeid 0x20
- ether 08:00:27:12:e8:c1 txqueuelen 1000 (Ethernet)
- RX packets 1 bytes 590 (590.0 B)
- RX errors 0 dropped 0 overruns 0 frame 0
- TX packets 97 bytes 10209 (10.2 KB)
- TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
-
-lo: flags=73 mtu 65536
- inet 127.0.0.1 netmask 255.0.0.0
- inet6 ::1 prefixlen 128 scopeid 0x10
- loop txqueuelen 1000 (Local Loopback)
- RX packets 325 bytes 24046 (24.0 KB)
- RX errors 0 dropped 0 overruns 0 frame 0
- TX packets 325 bytes 24046 (24.0 KB)
- TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
-
-```
-
-如我所见,服务器主 IP 地址是 `192.168.56.201`,所以,我将下一个 IP `192.168.56.202` 作为辅助 IP,使用以下命令完成。
-```
-# ip addr add 192.168.56.202/24 broadcast 192.168.56.255 dev enp0s3
-
-```
-
-运行以下命令来检查是否已分配了新的 IP。当你重启机器时,它会消失。
-```
-# ip addr
-1: lo: mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
- link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
- inet 127.0.0.1/8 scope host lo
- valid_lft forever preferred_lft forever
- inet6 ::1/128 scope host
- valid_lft forever preferred_lft forever
-2: enp0s3: mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
- link/ether 08:00:27:97:13:2e brd ff:ff:ff:ff:ff:ff
- inet 192.168.56.201/24 brd 192.168.56.255 scope global enp0s3
- valid_lft forever preferred_lft forever
- inet 192.168.56.202/24 brd 192.168.56.255 scope global secondary enp0s3
- valid_lft forever preferred_lft forever
- inet6 fe80::a00:27ff:fe97:132e/64 scope link
- valid_lft forever preferred_lft forever
-3: enp0s8: mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
- link/ether 08:00:27:12:e8:c1 brd ff:ff:ff:ff:ff:ff
- inet 10.0.3.15/24 brd 10.0.3.255 scope global dynamic enp0s8
- valid_lft 86353sec preferred_lft 86353sec
- inet6 fe80::344b:6259:4dbe:eabb/64 scope link
- valid_lft forever preferred_lft forever
-
-```
-
-### 如何在 Ubuntu 16.04 LTS 中添加永久辅助 IP 地址
-
-要在 Ubuntu 系统上添加永久辅助 IP 地址,只需编辑 `/etc/network/interfaces` 文件并添加所需 IP 的详细信息。
-
-我们不应该在 dns-nameservers 之后添加辅助 IP 地址,因为它不会起作用,应该以下面的格式添加 IP 详情。
-
-此外,我们不需要添加子接口(我们之前在 Ubuntu 14.04 LTS 中的做法):
-```
-# vi /etc/network/interfaces
-
-# interfaces(5) file used by ifup(8) and ifdown(8)
-auto lo
-iface lo inet loopback
-
-# The primary network interface
-auto enp0s3
-iface enp0s3 inet static
-address 192.168.56.201
-netmask 255.255.255.0
-
-iface enp0s3 inet static
-address 192.168.56.202
-netmask 255.255.255.0
-
-gateway 192.168.56.1
-network 192.168.56.0
-broadcast 192.168.56.255
-dns-nameservers 8.8.8.8 8.8.4.4
-dns-search 2daygeek.local
-
-```
-
-保存并关闭文件,然后重启网络接口服务:
-```
-# systemctl restart networking
-or
-# ifdown enp0s3 && ifup enp0s3
-
-```
-
-运行以下命令来检查是否已经分配了新的 IP:
-```
-# ip addr
-1: lo: mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
- link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
- inet 127.0.0.1/8 scope host lo
- valid_lft forever preferred_lft forever
- inet6 ::1/128 scope host
- valid_lft forever preferred_lft forever
-2: enp0s3: mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
- link/ether 08:00:27:97:13:2e brd ff:ff:ff:ff:ff:ff
- inet 192.168.56.201/24 brd 192.168.56.255 scope global enp0s3
- valid_lft forever preferred_lft forever
- inet 192.168.56.202/24 brd 192.168.56.255 scope global secondary enp0s3
- valid_lft forever preferred_lft forever
- inet6 fe80::a00:27ff:fe97:132e/64 scope link
- valid_lft forever preferred_lft forever
-3: enp0s8: mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
- link/ether 08:00:27:12:e8:c1 brd ff:ff:ff:ff:ff:ff
- inet 10.0.3.15/24 brd 10.0.3.255 scope global dynamic enp0s8
- valid_lft 86353sec preferred_lft 86353sec
- inet6 fe80::344b:6259:4dbe:eabb/64 scope link
- valid_lft forever preferred_lft forever
-
-```
-
-让我来 ping 一下新 IP 地址:
-```
-# ping 192.168.56.202 -c 4
-PING 192.168.56.202 (192.168.56.202) 56(84) bytes of data.
-64 bytes from 192.168.56.202: icmp_seq=1 ttl=64 time=0.019 ms
-64 bytes from 192.168.56.202: icmp_seq=2 ttl=64 time=0.087 ms
-64 bytes from 192.168.56.202: icmp_seq=3 ttl=64 time=0.034 ms
-64 bytes from 192.168.56.202: icmp_seq=4 ttl=64 time=0.042 ms
-
---- 192.168.56.202 ping statistics ---
-4 packets transmitted, 4 received, 0% packet loss, time 3068ms
-rtt min/avg/max/mdev = 0.019/0.045/0.087/0.026 ms
-
-```
-
---------------------------------------------------------------------------------
-
-via: https://www.2daygeek.com/how-to-add-additional-ip-secondary-ip-in-ubuntu-debian-system/
-
-作者:[Prakash Subramanian][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[MjSeven](https://github.com/MjSeven)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.2daygeek.com/author/prakash/
-[1]:https://www.2daygeek.com/check-find-server-public-ip-address-linux/
-[2]:https://www.2daygeek.com/check-find-dns-records-of-domain-in-linux-terminal/
-[3]:https://www.2daygeek.com/dig-command-check-find-dns-records-lookup-linux/
-[4]:https://www.2daygeek.com/nslookup-command-check-find-dns-records-lookup-linux/
-[5]:https://www.2daygeek.com/host-command-check-find-dns-records-lookup-linux/
diff --git a/translated/tech/20180709 How To Configure SSH Key-based Authentication In Linux.md b/translated/tech/20180709 How To Configure SSH Key-based Authentication In Linux.md
new file mode 100644
index 0000000000..5c69d6a92b
--- /dev/null
+++ b/translated/tech/20180709 How To Configure SSH Key-based Authentication In Linux.md
@@ -0,0 +1,235 @@
+如何在 Linux 中配置基于密钥认证的 SSH
+======
+
+
+
+### 什么是基于 SSH密钥的认证?
+
+众所周知,**Secure Shell**,又称 **SSH**,是允许你通过无安全网络(例如 Internet)和远程系统之间安全访问/通信的加密网络协议。无论何时使用 SSH 在无安全网络上发送数据,它都会在源系统上自动地被加密,并且在目的系统上解密。SSH 提供了四种加密方式,**基于密码认证**,**基于密钥认证**,**基于主机认证**和**键盘认证**。最常用的认证方式是基于密码认证和基于密钥认证。
+
+在基于密码认证中,你需要的仅仅是远程系统上用户的密码。如果你知道远程用户的密码,你可以使用**“ssh[[email protected]][1]”**访问各自的系统。另一方面,在基于密钥认证中,为了通过 SSH 通信,你需要生成 SSH 密钥对,并且为远程系统上传 SSH 公钥。每个 SSH 密钥对由私钥与公钥组成。私钥应该保存在客户系统上,公钥应该上传给远程系统。你不应该将私钥透露给任何人。希望你已经对 SSH 和它的认证方式有了基本的概念。
+
+这篇教程,我们将讨论如何在 linux 上配置基于密钥认证的 SSH。
+
+### 在 Linux 上配置基于密钥认证的SSH
+
+为本篇教程起见,我将使用 Arch Linux 为本地系统,Ubuntu 18.04 LTS 为远程系统。
+
+本地系统详情:
+ * **OS** : Arch Linux Desktop
+ * **IP address** : 192.168.225.37 /24
+
+远程系统详情:
+ * **OS** : Ubuntu 18.04 LTS Server
+ * **IP address** : 192.168.225.22/24
+
+### 本地系统配置
+
+就像我之前所说,在基于密钥认证的方法中,想要通过 SSH 访问远程系统,就应该将公钥上传给它。公钥通常会被保存在远程系统的一个文件**~/.ssh/authorized_keys** 中。
+
+**注意事项:**不要使用**root** 用户生成密钥对,这样只有 root 用户才可以使用。使用普通用户创建密钥对。
+
+现在,让我们在本地系统上创建一个 SSH 密钥对。只需要在客户端系统上运行下面的命令。
+
+```
+$ ssh-keygen
+```
+
+上面的命令将会创建一个 2048 位的 RSA 密钥对。输入两次密码。更重要的是,记住你的密码。后面将会用到它。
+
+**样例输出**
+
+```
+Generating public/private rsa key pair.
+Enter file in which to save the key (/home/sk/.ssh/id_rsa):
+Enter passphrase (empty for no passphrase):
+Enter same passphrase again:
+Your identification has been saved in /home/sk/.ssh/id_rsa.
+Your public key has been saved in /home/sk/.ssh/id_rsa.pub.
+The key fingerprint is:
+SHA256:wYOgvdkBgMFydTMCUI3qZaUxvjs+p2287Tn4uaZ5KyE [email protected]
+The key's randomart image is:
++---[RSA 2048]----+
+|+=+*= + |
+|o.o=.* = |
+|.oo * o + |
+|. = + . o |
+|. o + . S |
+| . E . |
+| + o |
+| +.*o+o |
+| .o*=OO+ |
++----[SHA256]-----+
+```
+
+如果你已经创建了密钥对,你将看到以下信息。输入 ‘y’ 就会覆盖已存在的密钥。
+
+```
+/home/username/.ssh/id_rsa already exists.
+Overwrite (y/n)?
+```
+
+请注意**密码是可选的**。如果你输入了密码,那么每次通过 SSH 访问远程系统时都要求输入密码,除非你使用了 SSH 代理保存了密码。如果你不想要密码(虽然不安全),简单地输入两次 ENTER。不过,我们建议你使用密码。从安全的角度来看,使用无密码的 ssh 密钥对大体上不是一个很好的主意。 这种方式应该限定在特殊的情况下使用,例如,没有用户介入的服务访问远程系统。(例如,用 rsync 远程备份...)
+
+如果你已经在个人文件 **~/.ssh/id_rsa** 中有了无密码的密钥对,但想要更新为带密码的密钥。使用下面的命令:
+
+```
+$ ssh-keygen -p -f ~/.ssh/id_rsa
+```
+
+样例输出:
+
+```
+Enter new passphrase (empty for no passphrase):
+Enter same passphrase again:
+Your identification has been saved with the new passphrase.
+```
+
+现在,我们已经在本地系统上创建了密钥对。接下来,使用下面的命令将 SSH 公钥拷贝到你的远程 SSH 服务端上。
+
+```
+$ ssh-copy-id sk@192.168.225.22
+```
+
+在这,我把本地(Arch Linux)系统上的公钥拷贝到了远程系统(Ubuntu 18.04 LTS)上。从技术上讲,上面的命令会把本地系统 **~/.ssh/id_rsa.pub key** 文件中的内容拷贝到远程系统**~/.ssh/authorized_keys** 中。明白了吗?非常棒。
+
+输入 **yes** 来继续连接你的远程 SSH 服务端。接着,输入远程系统 root 用户的密码。
+
+```
+/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
+/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
+[email protected]2.168.225.22's password:
+
+Number of key(s) added: 1
+
+Now try logging into the machine, with: "ssh '[email protected]'"
+and check to make sure that only the key(s) you wanted were added.
+```
+
+如果你已经拷贝了密钥,但想要替换为新的密码,使用 **-f** 选项覆盖已有的密钥。
+
+```
+$ ssh-copy-id -f sk@192.168.225.22
+```
+
+我们现在已经成功地将本地系统的 SSH 公钥添加进了远程系统。现在,让我们在远程系统上完全禁用掉基于密码认证的方式。因为,我们已经配置了密钥认证,因此我们不再需要密码认证了。
+
+### 在远程系统上禁用基于密码认证的 SSH
+
+你需要在 root 或者 sudo 用户下执行下面的命令。
+
+为了禁用基于密码的认证,你需要在远程系统的控制台上编辑 **/etc/ssh/sshd_config** 配置文件:
+
+```
+$ sudo vi /etc/ssh/sshd_config
+```
+
+找到下面这一行,去掉注释然后将值设为 **no**
+
+```
+PasswordAuthentication no
+```
+
+重启 ssh 服务让它生效。
+
+```
+$ sudo systemctl restart sshd
+```
+
+### 从本地系统访问远程系统
+
+在本地系统上使用命令 SSH 你的远程服务端:
+
+```
+$ ssh sk@192.168.225.22
+```
+
+输入密码。
+
+**样例输出:**
+
+```
+Enter passphrase for key '/home/sk/.ssh/id_rsa':
+Last login: Mon Jul 9 09:59:51 2018 from 192.168.225.37
+[email protected]:~$
+```
+
+现在,你就能 SSH 你的远程系统了。如你所见,我们已经使用之前 **ssh-keygen** 创建的密码登录进了远程系统的账户,而不是使用账户实际的密码。
+
+如果你试图从其他客户端系统 ssh (远程系统),你将会得到这条错误信息。比如,我试图通过命令从 CentOS SSH 访问 Ubuntu 系统:
+
+**样例输出:**
+
+```
+The authenticity of host '192.168.225.22 (192.168.225.22)' can't be established.
+ECDSA key fingerprint is 67:fc:69:b7:d4:4d:fd:6e:38:44:a8:2f:08:ed:f4:21.
+Are you sure you want to continue connecting (yes/no)? yes
+Warning: Permanently added '192.168.225.22' (ECDSA) to the list of known hosts.
+Permission denied (publickey).
+```
+
+如你所见,除了 CentOS (译注:根据上文,这里应该是 Arch) 系统外,我不能通过其他任何系统 SSH 访问我的远程系统 Ubuntu 18.04。
+
+### 为 SSH 服务端添加更多客户端系统的密钥
+
+这点非常重要。就像我说过的那样,除非你配置过(在之前的例子中,是 Ubuntu),否则你不能通过 SSH 访问到远程系统。如果我希望给更多客户端予以权限去访问远程 SSH 服务端,我应该怎么做?很简单。你需要在所有的客户端系统上生成 SSH 密钥对并且手动拷贝 ssh 公钥到想要通过 ssh 访问的远程服务端上。
+
+在客户端系统上创建 SSH 密钥对,运行:
+
+```
+$ ssh-keygen
+```
+
+输入两次密码。现在, ssh 密钥对已经生成了。你需要手动把公钥(不是私钥)拷贝到远程服务端上。
+
+使用命令查看公钥:
+
+```
+$ cat ~/.ssh/id_rsa.pub
+```
+
+应该会输出如下信息:
+
+```
+ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQCt3a9tIeK5rPx9p74/KjEVXa6/OODyRp0QLS/sLp8W6iTxFL+UgALZlupVNgFjvRR5luJ9dLHWwc+d4umavAWz708e6Na9ftEPQtC28rTFsHwmyLKvLkzcGkC5+A0NdbiDZLaK3K3wgq1jzYYKT5k+IaNS6vtrx5LDObcPNPEBDt4vTixQ7GZHrDUUk5586IKeFfwMCWguHveTN7ykmo2EyL2rV7TmYq+eY2ZqqcsoK0fzXMK7iifGXVmuqTkAmZLGZK8a3bPb6VZd7KFum3Ezbu4BXZGp7FVhnOMgau2kYeOH/ItKPzpCAn+dg3NAAziCCxnII9b4nSSGz3mMY4Y7 ostechnix@centosserver
+```
+
+拷贝所有内容(通过 USB 驱动器或者其它任何介质),然后去你的远程服务端的控制台。像下面那样,在 home 下创建文件夹叫做 **ssh**。你需要以 root 身份执行命令。
+
+```
+$ mkdir -p ~/.ssh
+```
+
+现在,将前几步创建的客户端系统的公钥添加进文件中。
+
+```
+echo {Your_public_key_contents_here} >> ~/.ssh/authorized_keys
+```
+
+在远程系统上重启 ssh 服务。现在,你可以在新的客户端上 SSH 远程服务端了。
+
+如果觉得手动添加 ssh 公钥有些困难,在远程系统上暂时性启用密码认证,使用 “ssh-copy-id“ 命令从本地系统上拷贝密钥,最后关闭密码认证。
+
+**推荐阅读:**
+
+(译者注:在原文中此处有超链接)
+
+好了,到此为止。基于密钥认证的 SSH 提供了一层防止暴力破解的额外保护。如你所见,配置密钥认证一点也不困难。这是一个非常好的方法让你的 Linux 服务端安全可靠。
+
+不久我就会带来另一篇有用的文章。到那时,继续关注 OSTechNix。
+
+干杯!
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/configure-ssh-key-based-authentication-linux/
+
+作者:[SK][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[LuuMing](https://github.com/LuuMing)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.ostechnix.com/author/sk/
+[1]:https://www.ostechnix.com/cdn-cgi/l/email-protection
diff --git a/translated/tech/20180710 How To View Detailed Information About A Package In Linux.md b/translated/tech/20180710 How To View Detailed Information About A Package In Linux.md
deleted file mode 100644
index 2ef1d008ac..0000000000
--- a/translated/tech/20180710 How To View Detailed Information About A Package In Linux.md
+++ /dev/null
@@ -1,432 +0,0 @@
-
-如何在Linux上检查一个包(package)的详细信息
-======
-
-
-我们可以就这个已经被广泛讨论的话题写出大量的文档,大多数情况下,因为各种各样的原因,我们都愿意让包管理器(package manager)来帮我们做这些事情。
-
-每个Linux发行版都有自己的包管理器,并且每个都有各自有不同的特性,这些特性包括允许用户执行安装新软件包,删除无用的软件包,更新现存的软件包,搜索某些具体的软件包,以及更新整个系统到其最新的状态之类的操作。
-
-习惯于命令行的用户大多数时间都会使用基于命令行方式的包管理器。对于Linux而言,这些基于命令行的包管理器有Yum,Dnf, Rpm, Apt, Apt-Get, Deb, pacman 和zypper.
-
-
-**推荐阅读**
-**(#)** [List of Command line Package Managers For Linux & Usage][1]
-**(#)** [A Graphical frontend tool for Linux Package Manager][2]
-**(#)** [How To Search If A Package Is Available On Your Linux Distribution Or Not][3]
-**(#)** [How To Add, Enable And Disable A Repository By Using The DNF/YUM Config Manager Command On Linux][4]
-
-
-作为一个系统管理员你应该熟知以下事实:安装包来自何方,具体来自哪个软件仓库,包的具体版本,包的大小,发行版的版本,包的源URL,包的许可证信息,等等等等。
-
-
-这篇短文将用尽可能简单的方式帮你理解包管理器的用法,这些用法正是来自随包自带的总结和描述文件。按你所使用的Linux发行版的不同,运行下面相应的命令,你能得到你所使用的发行版下的包的详细信息。
-
-### [YUM 命令][5] : 在RHEL和CentOS系统上获得包的信息
-
-
-YUM 英文直译是黄狗更新器--修改版,它是一个开源的基于命令行的包管理器前端实用工具。它被广泛应用在基于RPM的系统上,例如:RHEL和CentOS。
-
-Yum是用于在官方发行版仓库以及其他第三方发行版仓库下获取,安装,删除,查询RPM包的主要工具。
-
-```
-# yum info python(LCTT译注:用yum info 获取python包的信息)
-Loaded plugins: fastestmirror, security
-Loading mirror speeds from cached hostfile
- * epel: epel.mirror.constant.com
-Installed Packages
-Name : python
-Arch : x86_64
-Version : 2.6.6
-Release : 66.el6_8
-Size : 78 k
-Repo : installed
-From repo : updates
-Summary : An interpreted, interactive, object-oriented programming language
-URL : http://www.python.org/
-License : Python
-Description : Python is an interpreted, interactive, object-oriented programming
- : language often compared to Tcl, Perl, Scheme or Java. Python includes
- : modules, classes, exceptions, very high level dynamic data types and
- : dynamic typing. Python supports interfaces to many system calls and
- : libraries, as well as to various windowing systems (X11, Motif, Tk,
- : Mac and MFC).
- :
- : Programmers can write new built-in modules for Python in C or C++.
- : Python can be used as an extension language for applications that need
- : a programmable interface.
- :
- : Note that documentation for Python is provided in the python-docs
- : package.
- :
- : This package provides the "python" executable; most of the actual
- : implementation is within the "python-libs" package.
-
-```
-
-### YUMDB 命令: 查看RHEL和CentOS系统上的包信息
-
-
-Yumdb info这个命令提供与yum info相类似的的信息,不过它还额外提供了诸如包校验值,包类型,用户信息(由何人安装)。从yum 3.2.26版本后,yum开始在rpm数据库外储存额外的信息了(下文输出的用户信息指该python由该用户安装,而dep说明该包是被作为被依赖的包而被安装的)。
-
-```
-# yumdb info python(LCTT译注:用yumdb info 来获取Python的信息)
-Loaded plugins: fastestmirror
-python-2.6.6-66.el6_8.x86_64
- changed_by = 4294967295
- checksum_data = 53c75a1756e5b4f6564c5229a37948c9b4561e0bf58076bd7dab7aff85a417f2
- checksum_type = sha256
- command_line = update -y
- from_repo = updates
- from_repo_revision = 1488370672
- from_repo_timestamp = 1488371100
- installed_by = 4294967295
- reason = dep
- releasever = 6
-
-
-```
-
-### [RPM 命令][6] : 在RHEL/CentOS/Fedora系统上查看包的信息
-
-
-RPM 英文直译为红帽包管理器,这是一个在RedHat以及其变种发行版(如RHEL, CentOS, Fedora, openSUSE,Megeia)下的功能强大的命令行包管理工具。它能让你轻松的安装,升级,删除,查询以及校验你的系统或服务器上的软件。RPM文件以.rpm结尾。RPM包由它所依赖的软件库以及其他依赖构成,它不会与系统上已经安装的包冲突。
-
-```
-# rpm -qi nano (LCTT译注:用RPM -qi 查询nano包的具体信息)
-Name : nano Relocations: (not relocatable)
-Version : 2.0.9 Vendor: CentOS
-Release : 7.el6 Build Date: Fri 12 Nov 2010 02:18:36 AM EST
-Install Date: Fri 03 Mar 2017 08:57:47 AM EST Build Host: c5b2.bsys.dev.centos.org
-Group : Applications/Editors Source RPM: nano-2.0.9-7.el6.src.rpm
-Size : 1588347 License: GPLv3+
-Signature : RSA/8, Sun 03 Jul 2011 12:46:50 AM EDT, Key ID 0946fca2c105b9de
-Packager : CentOS BuildSystem
-URL : http://www.nano-editor.org
-Summary : A small text editor
-Description :
-GNU nano is a small and friendly text editor.
-
-```
-
-### [DNF 命令][7] : 在Fedora系统上查看报信息
-
-
-DNF指时髦版的Yum,我们也可以认为DNF是下一代的YUM包管理器(Yum的一个分支),它在后台使用了hawkey/libsolv库。Aleš Kozumplík在Fedora 18上开始开发DNF,在Fedora 22上正式最后发布。 DNF命令用来在Fedora 22及以后系统安装, 更新,搜索以及删除包。它能自动的解决包安装过程中的包依赖问题。
-
-```
-$ dnf info tilix (LCTT译注: 用dnf info 查看tilix的包信息)
-Last metadata expiration check: 27 days, 10:00:23 ago on Wed 04 Oct 2017 06:43:27 AM IST.
-Installed Packages
-Name : tilix
-Version : 1.6.4
-Release : 1.fc26
-Arch : x86_64
-Size : 3.6 M
-Source : tilix-1.6.4-1.fc26.src.rpm
-Repo : @System
-From repo : @commandline
-Summary : Tiling terminal emulator
-URL : https://github.com/gnunn1/tilix
-License : MPLv2.0 and GPLv3+ and CC-BY-SA
-Description : Tilix is a tiling terminal emulator with the following features:
- :
- : - Layout terminals in any fashion by splitting them horizontally or vertically
- : - Terminals can be re-arranged using drag and drop both within and between
- : windows
- : - Terminals can be detached into a new window via drag and drop
- : - Input can be synchronized between terminals so commands typed in one
- : terminal are replicated to the others
- : - The grouping of terminals can be saved and loaded from disk
- : - Terminals support custom titles
- : - Color schemes are stored in files and custom color schemes can be created by
- : simply creating a new file
- : - Transparent background
- : - Supports notifications when processes are completed out of view
- :
- : The application was written using GTK 3 and an effort was made to conform to
- : GNOME Human Interface Guidelines (HIG).
-
-```
-
-### [Zypper 命令][8] : 在openSUSE系统上查看包信息
-
-
-Zypper是一个使用libzypp库的命令行包管理器。Zypper提供诸如软件仓库访问,安装依赖解决,软件包安装等等功能。
-
-```
-$ zypper info nano (译注: 用zypper info查询nano的信息)
-
-Loading repository data...
-Reading installed packages...
-
-
-Information for package nano:
------------------------------
-Repository : Main Repository (OSS)
-Name : nano
-Version : 2.4.2-5.3
-Arch : x86_64
-Vendor : openSUSE
-Installed Size : 1017.8 KiB
-Installed : No
-Status : not installed
-Source package : nano-2.4.2-5.3.src
-Summary : Pico editor clone with enhancements
-Description :
- GNU nano is a small and friendly text editor. It aims to emulate
- the Pico text editor while also offering a few enhancements.
-
-```
-
-### [pacman 命令][9] :在ArchLinux及Manjaro系统上查看包信息
-
-Pacman指包管理器实用工具。pacman是一个用于安装,构建,删除,管理Arch Linux上包的命令行工具。它后端使用libalpm(Arch Linux package Manager(ALPM)库)来完成所有功能。
-
-```
-$ pacman -Qi bash (LCTT译注: 用pacman -Qi 来查询bash)
-Name : bash
-Version : 4.4.012-2
-Description : The GNU Bourne Again shell
-Architecture : x86_64
-URL : http://www.gnu.org/software/bash/bash.html
-Licenses : GPL
-Groups : base
-Provides : sh
-Depends On : readline>=7.0 glibc ncurses
-Optional Deps : bash-completion: for tab completion
-Required By : autoconf automake bison bzip2 ca-certificates-utils db
- dhcpcd diffutils e2fsprogs fakeroot figlet findutils
- flex freetype2 gawk gdbm gettext gmp grub gzip icu
- iptables keyutils libgpg-error libksba libpcap libpng
- libtool lvm2 m4 man-db mkinitcpio nano neofetch nspr
- nss openresolv os-prober pacman pcre pcre2 shadow
- systemd texinfo vte-common which xdg-user-dirs xdg-utils
- xfsprogs xorg-mkfontdir xorg-xpr xz
-Optional For : None
-Conflicts With : None
-Replaces : None
-Installed Size : 7.13 MiB
-Packager : Jan Alexander Steffens (heftig)
-Build Date : Tue 14 Feb 2017 01:16:51 PM UTC
-Install Date : Thu 24 Aug 2017 06:08:12 AM UTC
-Install Reason : Explicitly installed
-Install Script : No
-Validated By : Signature
-
-```
-
-### [Apt-Cache 命令][10] :在Debian/Ubuntu/Mint系统上查看包信息
-
-
-apt-cache命令能显示Apt内部数据库中的大量信息。这些信息是从sources.list中的不同的软件源中搜集而来,因此从某种意义上这些信息也可以被认为是某种缓存。
-这些信息搜集工作是在运行apt update命令时执行的。
-
-```
-$ sudo apt-cache show apache2 (LCTT译注:用管理员权限查询apache2的信息)
-Package: apache2
-Priority: optional
-Section: web
-Installed-Size: 473
-Maintainer: Ubuntu Developers
-Original-Maintainer: Debian Apache Maintainers
-Architecture: amd64
-Version: 2.4.12-2ubuntu2
-Replaces: apache2.2-common
-Provides: httpd, httpd-cgi
-Depends: lsb-base, procps, perl, mime-support, apache2-bin (= 2.4.12-2ubuntu2), apache2-utils (>= 2.4), apache2-data (= 2.4.12-2ubuntu2)
-Pre-Depends: dpkg (>= 1.17.14)
-Recommends: ssl-cert
-Suggests: www-browser, apache2-doc, apache2-suexec-pristine | apache2-suexec-custom, ufw
-Conflicts: apache2.2-common (<< 2.3~)
-Filename: pool/main/a/apache2/apache2_2.4.12-2ubuntu2_amd64.deb
-Size: 91348
-MD5sum: ab0ee0b0d1c6b3d19bd87aa2a9537125
-SHA1: 350c9a1a954906088ed032aebb77de3d5bb24004
-SHA256: 03f515f7ebc3b67b050b06e82ebca34b5e83e34a528868498fce020bf1dbbe34
-Description-en: Apache HTTP Server
- The Apache HTTP Server Project's goal is to build a secure, efficient and
- extensible HTTP server as standards-compliant open source software. The
- result has long been the number one web server on the Internet.
- .
- Installing this package results in a full installation, including the
- configuration files, init scripts and support scripts.
-Description-md5: d02426bc360345e5acd45367716dc35c
-Homepage: http://httpd.apache.org/
-Bugs: https://bugs.launchpad.net/ubuntu/+filebug
-Origin: Ubuntu
-Supported: 9m
-Task: lamp-server, mythbuntu-frontend, mythbuntu-desktop, mythbuntu-backend-slave, mythbuntu-backend-master, mythbuntu-backend-master
-
-```
-
-### [APT 命令][11] : 查看Debian/Ubuntu/Mint系统上的包信息
-
-
-APT意为高级打包工具,就像DNF将如何替代YUM一样,APT是apt-get的替代物。它功能丰富的命令行工具包括了如下所有命令的功能如apt-cache,apt-search,dpkg, apt-cdrom, apt-config, apt-key等等,我们可以方便的通过apt来安装.dpkg包,但是我们却不能通过apt-get来完成这一点,还有一些其他的类似的功能也不能用apt-get来完成,所以apt-get因为没有解决上述功能缺乏的原因而被apt所取代。
-
-```
-$ apt show nano (LCTT译注: 用apt show查看nano)
-Package: nano
-Version: 2.8.6-3
-Priority: standard
-Section: editors
-Origin: Ubuntu
-Maintainer: Ubuntu Developers
-Original-Maintainer: Jordi Mallach
-Bugs: https://bugs.launchpad.net/ubuntu/+filebug
-Installed-Size: 766 kB
-Depends: libc6 (>= 2.14), libncursesw5 (>= 6), libtinfo5 (>= 6)
-Suggests: spell
-Conflicts: pico
-Breaks: nano-tiny (<< 2.8.6-2)
-Replaces: nano-tiny (<< 2.8.6-2), pico
-Homepage: https://www.nano-editor.org/
-Task: standard, ubuntu-touch-core, ubuntu-touch
-Supported: 9m
-Download-Size: 222 kB
-APT-Manual-Installed: yes
-APT-Sources: http://in.archive.ubuntu.com/ubuntu artful/main amd64 Packages
-Description: small, friendly text editor inspired by Pico
- GNU nano is an easy-to-use text editor originally designed as a replacement
- for Pico, the ncurses-based editor from the non-free mailer package Pine
- (itself now available under the Apache License as Alpine).
- .
- However, GNU nano also implements many features missing in pico, including:
- - undo/redo
- - line numbering
- - syntax coloring
- - soft-wrapping of overlong lines
- - selecting text by holding Shift
- - interactive search and replace (with regular expression support)
- - a go-to line (and column) command
- - support for multiple file buffers
- - auto-indentation
- - tab completion of filenames and search terms
- - toggling features while running
- - and full internationalization support
-
-```
-
-### [dpkg 命令][12] : 查看Debian/Ubuntu/Mint系统上的包信息
-
-
-dpkg意指Debian包管理器(dpkg)。dpkg用于Debian系统上的安装,构建,移除以及管理Debian包的命令行工具。dpkg 使用Aptitude(因为它更为主流及用户友好)作为前端工具来完成所有的功能。其他的工具如dpkg-deb和dpkg-query使用dpkg做为前端来实现功能。尽管系统管理员还是时不时会在必要时使用dpkg来完成一些软件安装的任务,他大多数情况下还是会因为APt,Apt-Get以及Aptitude的健壮性而使用后者。
-
-```
-$ dpkg -s python (LCTT译注: 用dpkg -s查看python)
-Package: python
-Status: install ok installed
-Priority: optional
-Section: python
-Installed-Size: 626
-Maintainer: Ubuntu Developers
-Architecture: amd64
-Multi-Arch: allowed
-Source: python-defaults
-Version: 2.7.14-2ubuntu1
-Replaces: python-dev (<< 2.6.5-2)
-Provides: python-ctypes, python-email, python-importlib, python-profiler, python-wsgiref
-Depends: python2.7 (>= 2.7.14-1~), libpython-stdlib (= 2.7.14-2ubuntu1)
-Pre-Depends: python-minimal (= 2.7.14-2ubuntu1)
-Suggests: python-doc (= 2.7.14-2ubuntu1), python-tk (>= 2.7.14-1~)
-Breaks: update-manager-core (<< 0.200.5-2)
-Conflicts: python-central (<< 0.5.5)
-Description: interactive high-level object-oriented language (default version)
- Python, the high-level, interactive object oriented language,
- includes an extensive class library with lots of goodies for
- network programming, system administration, sounds and graphics.
- .
- This package is a dependency package, which depends on Debian's default
- Python version (currently v2.7).
-Homepage: http://www.python.org/
-Original-Maintainer: Matthias Klose
-
-```
-
-
-我们也可使用dpkg的‘-p’选项,这个选项提供和‘dpkg -s’相类似的信息,但是它还提供了包的校验值和包类型。
-
-```
-$ dpkg -p python3 (LCTT译注: 用dpkg -p查看python3的信息)
-Package: python3
-Priority: important
-Section: python
-Installed-Size: 67
-Origin: Ubuntu
-Maintainer: Ubuntu Developers
-Bugs: https://bugs.launchpad.net/ubuntu/+filebug
-Architecture: amd64
-Multi-Arch: allowed
-Source: python3-defaults
-Version: 3.6.3-0ubuntu2
-Replaces: python3-minimal (<< 3.1.2-2)
-Provides: python3-profiler
-Depends: python3.6 (>= 3.6.3-1~), libpython3-stdlib (= 3.6.3-0ubuntu2), dh-python
-Pre-Depends: python3-minimal (= 3.6.3-0ubuntu2)
-Suggests: python3-doc (>= 3.6.3-0ubuntu2), python3-tk (>= 3.6.3-1~), python3-venv (>= 3.6.3-0ubuntu2)
-Filename: pool/main/p/python3-defaults/python3_3.6.3-0ubuntu2_amd64.deb
-Size: 8712
-MD5sum: a8bae494c6e5d1896287675faf40d373
-Description: interactive high-level object-oriented language (default python3 version)
-Original-Maintainer: Matthias Klose
-SHA1: 2daec885cea7d4dc83c284301c3bebf42b23e095
-SHA256: 865e509c91d2504a16c4b573dbe27e260c36fceec2add3fa43a30c1751d7e9bb
-Homepage: http://www.python.org/
-Task: minimal, ubuntu-core, ubuntu-core
-Description-md5: 950ebd8122c0a7340f0a740c295b9eab
-Supported: 9m
-
-```
-
-### Aptitude 命令 : 查看Debian/Ubuntu/Mint 系统上的包信息
-
-
-aptitude是Debian GNU/Linux包管理系统的面向文本的接口。它允许用户查看已安装的包的列表,以及完成诸如安装,升级,删除包之类的包管理任务。这些管理行为也能从图形接口来执行。
-
-```
-$ aptitude show htop (LCTT译注: 用aptitude show查看htop信息)
-Package: htop
-Version: 2.0.2-1
-State: installed
-Automatically installed: no
-Priority: optional
-Section: universe/utils
-Maintainer: Ubuntu Developers
-Architecture: amd64
-Uncompressed Size: 216 k
-Depends: libc6 (>= 2.15), libncursesw5 (>= 6), libtinfo5 (>= 6)
-Suggests: lsof, strace
-Conflicts: htop:i386
-Description: interactive processes viewer
- Htop is an ncursed-based process viewer similar to top, but it allows one to scroll the list vertically and horizontally to see all processes and their full command lines.
-
- Tasks related to processes (killing, renicing) can be done without entering their PIDs.
-Homepage: http://hisham.hm/htop/
-
-```
-
---------------------------------------------------------------------------------
-
-via: https://www.2daygeek.com/how-to-view-detailed-information-about-a-package-in-linux/
-
-作者:[Prakash Subramanian][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[DavidChenLiang](https://github.com/davidchenliang)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.2daygeek.com/author/prakash/
-[1]:https://www.2daygeek.com/list-of-command-line-package-manager-for-linux/
-[2]:https://www.2daygeek.com/list-of-graphical-frontend-tool-for-linux-package-manager/
-[3]:https://www.2daygeek.com/how-to-search-if-a-package-is-available-on-your-linux-distribution-or-not/
-[4]:https://www.2daygeek.com/how-to-add-enable-disable-a-repository-dnf-yum-config-manager-on-linux/
-[5]:https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
-[6]:https://www.2daygeek.com/rpm-command-examples/
-[7]:https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
-[8]:https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
-[9]:https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
-[10]:https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
-[11]:https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
-[12]:https://www.2daygeek.com/dpkg-command-to-manage-packages-on-debian-ubuntu-linux-mint-systems/
diff --git a/translated/tech/20180730 7 Python libraries for more maintainable code.md b/translated/tech/20180730 7 Python libraries for more maintainable code.md
new file mode 100644
index 0000000000..de08df9304
--- /dev/null
+++ b/translated/tech/20180730 7 Python libraries for more maintainable code.md
@@ -0,0 +1,120 @@
+这 7 个 Python 库让你写出更易维护的代码
+======
+
+
+
+> 可读性很重要。
+> — [Python 之禅(The Zen of Python)][1], Tim Peters
+
+尽管很多项目一开始的时候就有可读性和编码标准的要求,但随着项目进入“维护模式”,这些要求都会变得虎头蛇尾。然而,在代码库中保持一致的代码风格和测试标准能够显著减轻维护的压力,也能确保新的开发者能够快速了解项目的情况,同时能更好地保持应用程序的运行良好。
+
+### 检查你的代码风格
+
+使用外部库来检查代码运行情况不失为保护项目未来可维护性的一个好方法。以下会推荐一些我们最喜爱的[检查代码][2](包括检查 PEP 8 和其它代码风格错误)的库,用它们来强制保持代码风格一致,并确保在项目成熟时有一个可接受的测试覆盖率。
+
+[PEP 8][3]是Python代码风格规范,规定了行长度,缩进,多行表达式、变量命名约定等内容。尽管你的团队自身可能也会有不同于 PEP 8 的代码风格规范,但任何代码风格规范的目标都是在代码库中强制实施一致的标准,使代码的可读性更强、更易于维护。下面三个库就可以用来帮助你美化代码。
+
+#### 1\. Pylint
+
+[Pylint][4] 是一个检查违反 PEP 8 规范和常见错误的库。它在一些流行的编辑器和 IDE 中都有集成,也可以单独从命令行运行。
+
+执行 `pip install pylint`安装 Pylint 。然后运行 `pylint [options] path/to/dir` 或者 `pylint [options] path/to/module.py` 就可以在命令行中使用 Pylint,它会向控制台输出代码中违反规范和出现错误的地方。
+
+你还可以使用 `pylintrc` [配置文件][6]来自定义 Pylint 对哪些代码错误进行检查。
+
+#### 2\. Flake8
+
+对 [Flake8][7] 的描述是“将 PEP 8、Pyflakes(类似 Pylint)、McCabe(代码复杂性检查器)、第三方插件整合到一起,以检查 Python 代码风格和质量的一个 Python 工具”。
+
+执行 `pip install flake8` 安装 flake8 ,然后执行 `flake8 [options] path/to/dir` 或者 `flake8 [options] path/to/module.py` 可以查看报出的错误和警告。
+
+和 Pylint 类似,Flake8 允许通过[配置文件][8]来自定义检查的内容。它有非常清晰的文档,包括一些有用的[提交钩子][9],可以将自动检查代码纳入到开发工作流程之中。
+
+Flake8 也允许集成到一些流行的编辑器和 IDE 当中,但在文档中并没有详细说明。要将 Flake8 集成到喜欢的编辑器或 IDE 中,可以搜索插件(例如 [Sublime Text 的 Flake8 插件][10])。
+
+#### 3\. Isort
+
+[Isort][11] 这个库能将你在项目中导入的库按字母顺序,并将其[正确划分为不同部分][12](例如标准库、第三方库,自建的库等)。这样提高了代码的可读性,并且可以在导入的库较多的时候轻松找到各个库。
+
+执行 `pip install isort` 安装 isort,然后执行 `isort path/to/module.py` 就可以运行了。文档中还提供了更多的配置项,例如通过配置 `.isort.cfg` 文件来决定 isort 如何处理一个库的多行导入。
+
+和 Flake8、Pylint 一样,isort 也提供了将其与流行的[编辑器和 IDE][15] 集成的插件。
+
+### 共享代码风格
+
+每次文件发生变动之后都用命令行手动检查代码是一件痛苦的事,你可能也不太喜欢通过运行 IDE 中某个插件来实现这个功能。同样地,你的同事可能会用不同的代码检查方式,也许他们的编辑器中也没有安装插件,甚至自己可能也不会严格检查代码和按照警告来更正代码。总之,你共享的代码库将会逐渐地变得混乱且难以阅读。
+
+一个很好的解决方案是使用一个库,自动将代码按照 PEP 8 规范进行格式化。我们推荐的三个库都有不同的自定义级别来控制如何格式化代码。其中有一些设置较为特殊,例如 Pylint 和 Flake8 ,你需要先行测试,看看是否有你无法忍受蛋有不能修改的默认配置。
+
+#### 4\. Autopep8
+
+[Autopep8][16] 可以自动格式化指定的模块中的代码,包括重新缩进行,修复缩进,删除多余的空格,并重构常见的比较错误(例如布尔值和 `None` 值)。你可以查看文档中完整的[更正列表][17]。
+
+运行 `pip install --upgrade autopep8` 安装 autopep8。然后执行 `autopep8 --in-place --aggressive --aggressive
+ {'⭐️'.repeat(stars)}
+
+ )}
+