mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-21 02:10:11 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject
This commit is contained in:
commit
265a1c0f0d
@ -1,12 +1,14 @@
|
||||
|
||||
自动化部署基于Docker的Rails应用
|
||||
================================================================================
|
||||

|
||||
|
||||
[TL;DR] 这是系列文章的第三篇,讲述了我的公司是如何将基础设施从PaaS移植到Docker上的。
|
||||
|
||||
- [第一部分][1]:谈论了我接触Docker之前的经历;
|
||||
- [第二部分][2]:一步步搭建一个安全而又私有的registry。
|
||||
|
||||
----------
|
||||
|
||||
在系列文章的最后一篇里,我们将用一个实例来学习如何自动化整个部署过程。
|
||||
|
||||
### 基本的Rails应用程序###
|
||||
@ -18,99 +20,97 @@
|
||||
$ rvm use 2.2.0
|
||||
$ rails new && cd docker-test
|
||||
|
||||
创建一个基础控制器:
|
||||
创建一个基本的控制器:
|
||||
|
||||
$ rails g controller welcome index
|
||||
|
||||
……然后编辑 `routes.rb` ,以便让工程的根指向我们新创建的welcome#index方法:(这句话理解不太理解)
|
||||
……,然后编辑 `routes.rb` ,以便让该项目的根指向我们新创建的welcome#index方法:
|
||||
|
||||
root 'welcome#index'
|
||||
|
||||
在终端运行 `rails s` ,然后打开浏览器,登录[http://localhost:3000][3],你会进入到索引界面当中。我们不准备给应用加上多么神奇的东西,这只是一个基础实例,用来验证当我们将要创建并部署容器的时候,一切运行正常。
|
||||
在终端运行 `rails s` ,然后打开浏览器,登录[http://localhost:3000][3],你会进入到索引界面当中。我们不准备给应用加上多么神奇的东西,这只是一个基础的实例,当我们将要创建并部署容器的时候,用它来验证一切是否运行正常。
|
||||
|
||||
### 安装webserver ###
|
||||
|
||||
我们打算使用Unicorn当做我们的webserver。在Gemfile中添加 `gem 'unicorn'`和 `gem 'foreman'`然后将它bundle起来(运行 `bundle install`命令)。
|
||||
|
||||
在Rails应用启动的伺候,需要配置Unicorn,所以我们将一个**unicorn.rb**文件放在**config**目录下。[这里有一个Unicorn配置文件的例子][4]你可以直接复制粘贴Gist的内容。
|
||||
启动Rails应用时,需要先配置好Unicorn,所以我们将一个**unicorn.rb**文件放在**config**目录下。[这里有一个Unicorn配置文件的例子][4],你可以直接复制粘贴Gist的内容。
|
||||
|
||||
Let's also add a Procfile with the following content inside the root of the project so that we will be able to start the app with foreman:
|
||||
接下来,在工程的根目录下添加一个Procfile,以便可以使用foreman启动应用,内容为下:
|
||||
接下来,在项目的根目录下添加一个Procfile,以便可以使用foreman启动应用,内容为下:
|
||||
|
||||
web: bundle exec unicorn -p $PORT -c ./config/unicorn.rb
|
||||
|
||||
现在运行**foreman start**命令启动应用,一切都将正常运行,并且你将能够在[http://localhost:5000][5]上看到一个正在运行的应用。
|
||||
|
||||
### 创建一个Docker映像 ###
|
||||
### 构建一个Docker镜像 ###
|
||||
|
||||
现在我们创建一个映像来运行我们的应用。在Rails工程的跟目录下,创建一个名为**Dockerfile**的文件,然后粘贴进以下内容:
|
||||
现在我们构建一个镜像来运行我们的应用。在这个Rails项目的根目录下,创建一个名为**Dockerfile**的文件,然后粘贴进以下内容:
|
||||
|
||||
# Base image with ruby 2.2.0
|
||||
# 基于镜像 ruby 2.2.0
|
||||
FROM ruby:2.2.0
|
||||
|
||||
# Install required libraries and dependencies
|
||||
# 安装所需的库和依赖
|
||||
RUN apt-get update && apt-get install -qy nodejs postgresql-client sqlite3 --no-install-recommends && rm -rf /var/lib/apt/lists/*
|
||||
|
||||
# Set Rails version
|
||||
# 设置 Rails 版本
|
||||
ENV RAILS_VERSION 4.1.1
|
||||
|
||||
# Install Rails
|
||||
# 安装 Rails
|
||||
RUN gem install rails --version "$RAILS_VERSION"
|
||||
|
||||
# Create directory from where the code will run
|
||||
# 创建代码所运行的目录
|
||||
RUN mkdir -p /usr/src/app
|
||||
WORKDIR /usr/src/app
|
||||
|
||||
# Make webserver reachable to the outside world
|
||||
# 使 webserver 可以在容器外面访问
|
||||
EXPOSE 3000
|
||||
|
||||
# Set ENV variables
|
||||
# 设置环境变量
|
||||
ENV PORT=3000
|
||||
|
||||
# Start the web app
|
||||
# 启动 web 应用
|
||||
CMD ["foreman","start"]
|
||||
|
||||
# Install the necessary gems
|
||||
# 安装所需的 gems
|
||||
ADD Gemfile /usr/src/app/Gemfile
|
||||
ADD Gemfile.lock /usr/src/app/Gemfile.lock
|
||||
RUN bundle install --without development test
|
||||
|
||||
# Add rails project (from same dir as Dockerfile) to project directory
|
||||
# 将 rails 项目(和 Dockerfile 同一个目录)添加到项目目录
|
||||
ADD ./ /usr/src/app
|
||||
|
||||
# Run rake tasks
|
||||
# 运行 rake 任务
|
||||
RUN RAILS_ENV=production rake db:create db:migrate
|
||||
|
||||
使用提供的Dockerfile,执行下列命令创建一个映像[1][7]:
|
||||
使用上述Dockerfile,执行下列命令创建一个镜像(确保**boot2docker**已经启动并在运行当中):
|
||||
|
||||
$ docker build -t localhost:5000/your_username/docker-test .
|
||||
|
||||
然后,如果一切正常,长日志输出的最后一行应该类似于:
|
||||
然后,如果一切正常,长长的日志输出的最后一行应该类似于:
|
||||
|
||||
Successfully built 82e48769506c
|
||||
$ docker images
|
||||
REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE
|
||||
localhost:5000/your_username/docker-test latest 82e48769506c About a minute ago 884.2 MB
|
||||
|
||||
来运行容器吧!
|
||||
让我们运行一下容器试试!
|
||||
|
||||
$ docker run -d -p 3000:3000 --name docker-test localhost:5000/your_username/docker-test
|
||||
|
||||
You should be able to reach your Rails app running inside the Docker container at port 3000 of your boot2docker VM[2][8] (in my case [http://192.168.59.103:3000][6]).
|
||||
通过你的boot2docker虚拟机[2][8]的3000号端口(我的是[http://192.168.59.103:3000][6]),你可以观察你的Rails应用。
|
||||
通过你的boot2docker虚拟机的3000号端口(我的是[http://192.168.59.103:3000][6]),你可以观察你的Rails应用。(如果不清楚你的boot2docker虚拟地址,输入` $ boot2docker ip`命令查看。)
|
||||
|
||||
### 使用shell脚本进行自动化部署 ###
|
||||
|
||||
前面的文章(指文章1和文章2)已经告诉了你如何将新创建的映像推送到私有registry中,并将其部署在服务器上,所以我们跳过这一部分直接开始自动化进程。
|
||||
前面的文章(指文章1和文章2)已经告诉了你如何将新创建的镜像推送到私有registry中,并将其部署在服务器上,所以我们跳过这一部分直接开始自动化进程。
|
||||
|
||||
我们将要定义3个shell脚本,然后最后使用rake将它们捆绑在一起。
|
||||
|
||||
### 清除 ###
|
||||
|
||||
每当我们创建映像的时候,
|
||||
每当我们创建镜像的时候,
|
||||
|
||||
- 停止并重启boot2docker;
|
||||
- 去除Docker孤儿映像(那些没有标签,并且不再被容器所使用的映像们)。
|
||||
- 去除Docker孤儿镜像(那些没有标签,并且不再被容器所使用的镜像们)。
|
||||
|
||||
在你的工程根目录下的**clean.sh**文件中输入下列命令。
|
||||
|
||||
@ -132,22 +132,22 @@ You should be able to reach your Rails app running inside the Docker container a
|
||||
|
||||
$ chmod +x clean.sh
|
||||
|
||||
### 创建 ###
|
||||
### 构建 ###
|
||||
|
||||
创建的过程基本上和之前我们所做的(docker build)内容相似。在工程的根目录下创建一个**build.sh**脚本,填写如下内容:
|
||||
构建的过程基本上和之前我们所做的(docker build)内容相似。在工程的根目录下创建一个**build.sh**脚本,填写如下内容:
|
||||
|
||||
docker build -t localhost:5000/your_username/docker-test .
|
||||
|
||||
给脚本执行权限。
|
||||
记得给脚本执行权限。
|
||||
|
||||
### 部署 ###
|
||||
|
||||
最后,创建一个**deploy.sh**脚本,在里面填进如下内容:
|
||||
|
||||
# Open SSH connection from boot2docker to private registry
|
||||
# 打开 boot2docker 到私有注册库的 SSH 连接
|
||||
boot2docker ssh "ssh -o 'StrictHostKeyChecking no' -i /Users/username/.ssh/id_boot2docker -N -L 5000:localhost:5000 root@your-registry.com &" &
|
||||
|
||||
# Wait to make sure the SSH tunnel is open before pushing...
|
||||
# 在推送前先确认该 SSH 通道是开放的。
|
||||
echo Waiting 5 seconds before pushing image.
|
||||
|
||||
echo 5...
|
||||
@ -165,7 +165,7 @@ You should be able to reach your Rails app running inside the Docker container a
|
||||
echo Starting push!
|
||||
docker push localhost:5000/username/docker-test
|
||||
|
||||
如果你不理解这其中的含义,请先仔细阅读这部分[part 2][9]。
|
||||
如果你不理解这其中的含义,请先仔细阅读这部分[第二部分][2]。
|
||||
|
||||
给脚本加上执行权限。
|
||||
|
||||
@ -179,10 +179,9 @@ You should be able to reach your Rails app running inside the Docker container a
|
||||
|
||||
这一点都不费工夫,可是事实上开发者比你想象的要懒得多!那么咱们就索性再懒一点!
|
||||
|
||||
我们最后再把工作好好整理一番,我们现在要将三个脚本捆绑在一起,通过rake。
|
||||
|
||||
为了更简单一点,你可以在工程根目录下已经存在的Rakefile中添加几行代码,打开Rakefile文件——pun intended——把下列内容粘贴进去。
|
||||
我们最后再把工作好好整理一番,我们现在要将三个脚本通过rake捆绑在一起。
|
||||
|
||||
为了更简单一点,你可以在工程根目录下已经存在的Rakefile中添加几行代码,打开Rakefile文件,把下列内容粘贴进去。
|
||||
|
||||
namespace :docker do
|
||||
desc "Remove docker container"
|
||||
@ -221,34 +220,27 @@ Deploy独立于build,build独立于clean。所以每次我们输入命令运
|
||||
|
||||
$ rake docker:deploy
|
||||
|
||||
接下来就是见证奇迹的时刻了。一旦映像文件被上传(第一次可能花费较长的时间),你就可以ssh登录产品服务器,并且(通过SSH管道)把docker映像拉取到服务器并运行了。多么简单!
|
||||
接下来就是见证奇迹的时刻了。一旦镜像文件被上传(第一次可能花费较长的时间),你就可以ssh登录产品服务器,并且(通过SSH管道)把docker镜像拉取到服务器并运行了。多么简单!
|
||||
|
||||
也许你需要一段时间来习惯,但是一旦成功,它几乎与用Heroku部署一样简单。
|
||||
|
||||
备注:像往常一样,请让我了解到你的意见。我不敢保证这种方法是最好,最快,或者最安全的Docker开发的方法,但是这东西对我们确实奏效。
|
||||
|
||||
- 确保**boot2docker**已经启动并在运行当中。
|
||||
- 如果你不了解你的boot2docker虚拟地址,输入` $ boot2docker ip`命令查看。
|
||||
- 点击[here][10],教你怎样搭建私有的registry。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://cocoahunter.com/2015/01/23/docker-3/
|
||||
|
||||
作者:[Michelangelo Chasseur][a]
|
||||
译者:[DongShuaike](https://github.com/DongShuaike)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://cocoahunter.com/author/michelangelo/
|
||||
[1]:http://cocoahunter.com/docker-1
|
||||
[2]:http://cocoahunter.com/2015/01/23/docker-2/
|
||||
[1]:https://linux.cn/article-5339-1.html
|
||||
[2]:https://linux.cn/article-5379-1.html
|
||||
[3]:http://localhost:3000/
|
||||
[4]:https://gist.github.com/chasseurmic/0dad4d692ff499761b20
|
||||
[5]:http://localhost:5000/
|
||||
[6]:http://192.168.59.103:3000/
|
||||
[7]:http://cocoahunter.com/2015/01/23/docker-3/#fn:1
|
||||
[8]:http://cocoahunter.com/2015/01/23/docker-3/#fn:2
|
||||
[9]:http://cocoahunter.com/2015/01/23/docker-2/
|
||||
[10]:http://cocoahunter.com/2015/01/23/docker-2/
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
如何修复:apt-get update无法添加新的CD-ROM
|
||||
如何修复 apt-get update 无法添加新的 CD-ROM 的错误
|
||||
================================================================================
|
||||

|
||||
|
||||
@ -63,8 +63,8 @@
|
||||
via: http://itsfoss.com/fix-failed-fetch-cdrom-aptget-update-add-cdroms/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -10,12 +10,14 @@
|
||||
|
||||
#### 在 64位 Ubuntu 15.04 ####
|
||||
|
||||
$ wget http://kernel.ubuntu.com/~kernel-ppa/mainline/v4.0-vivid/linux-image-4.0.0-040000-generic_4.0.0-040000.201504121935_amd64.deb
|
||||
$ wget http://kernel.ubuntu.com/~kernel-ppa/mainline/v4.0-vivid/linux-headers-4.0.0-040000-generic_4.0.0-040000.201504121935_amd64.deb
|
||||
|
||||
$ sudo dpkg -i linux-headers-4.0.0*.deb linux-image-4.0.0*.deb
|
||||
|
||||
#### 在 32位 Ubuntu 15.04 ####
|
||||
|
||||
$ wget http://kernel.ubuntu.com/~kernel-ppa/mainline/v4.0-vivid/linux-image-4.0.0-040000-generic_4.0.0-040000.201504121935_i386.deb
|
||||
$ wget http://kernel.ubuntu.com/~kernel-ppa/mainline/v4.0-vivid/linux-headers-4.0.0-040000-generic_4.0.0-040000.201504121935_i386.deb
|
||||
|
||||
$ sudo dpkg -i linux-headers-4.0.0*.deb linux-image-4.0.0*.deb
|
||||
|
||||
@ -0,0 +1,41 @@
|
||||
EvilAP_Defender:可以警示和攻击 WIFI 热点陷阱的工具
|
||||
===============================================================================
|
||||
|
||||
**开发人员称,EvilAP_Defender甚至可以攻击流氓Wi-Fi接入点**
|
||||
|
||||
这是一个新的开源工具,可以定期扫描一个区域,以防出现恶意 Wi-Fi 接入点,同时如果发现情况会提醒网络管理员。
|
||||
|
||||
这个工具叫做 EvilAP_Defender,是为监测攻击者所配置的恶意接入点而专门设计的,这些接入点冒用合法的名字诱导用户连接上。
|
||||
|
||||
这类接入点被称做假面猎手(evil twin),使得黑客们可以从所接入的设备上监听互联网信息流。这可以被用来窃取证书、钓鱼网站等等。
|
||||
|
||||
大多数用户设置他们的计算机和设备可以自动连接一些无线网络,比如家里的或者工作地方的网络。通常,当面对两个同名的无线网络时,即SSID相同,有时候甚至连MAC地址(BSSID)也相同,这时候大多数设备会自动连接信号较强的一个。
|
||||
|
||||
这使得假面猎手攻击容易实现,因为SSID和BSSID都可以伪造。
|
||||
|
||||
[EvilAP_Defender][1]是一个叫Mohamed Idris的人用Python语言编写,公布在GitHub上面。它可以使用一个计算机的无线网卡来发现流氓接入点,这些坏蛋们复制了一个真实接入点的SSID,BSSID,甚至是其他的参数如通道,密码,隐私协议和认证信息等等。
|
||||
|
||||
该工具首先以学习模式运行,以便发现合法的接入点[AP],并且将其加入白名单。然后可以切换到正常模式,开始扫描未认证的接入点。
|
||||
|
||||
如果一个恶意[AP]被发现了,该工具会用电子邮件提醒网络管理员,但是开发者也打算在未来加入短信提醒功能。
|
||||
|
||||
该工具还有一个保护模式,在这种模式下,应用会发起一个denial-of-service [DoS]攻击反抗恶意接入点,为管理员采取防卫措施赢得一些时间。
|
||||
|
||||
“DoS 将仅仅针对有着相同SSID的而BSSID(AP的MAC地址)不同或者不同信道的流氓 AP,”Idris在这款工具的文档中说道。“这是为了避免攻击到你的正常网络。”
|
||||
|
||||
尽管如此,用户应该切记在许多国家,攻击别人的接入点很多时候都是非法的,甚至是一个看起来像是攻击者操控的恶意接入点。
|
||||
|
||||
要能够运行这款工具,需要Aircrack-ng无线网套装,一个支持Aircrack-ng的无线网卡,MySQL和Python运行环境。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoworld.com/article/2905725/security0/this-tool-can-alert-you-about-evil-twin-access-points-in-the-area.html
|
||||
|
||||
作者:[Lucian Constantin][a]
|
||||
译者:[wi-cuckoo](https://github.com/wi-cuckoo)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.infoworld.com/author/Lucian-Constantin/
|
||||
[1]:https://github.com/moha99sa/EvilAP_Defender/blob/master/README.TXT
|
||||
@ -1,8 +1,8 @@
|
||||
在 RedHat/CentOS 7.x 中使用 cmcli 命令管理网络
|
||||
在 RedHat/CentOS 7.x 中使用 nmcli 命令管理网络
|
||||
===============
|
||||
[**Red Hat Enterprise Linux 7** 与 **CentOS 7**][1] 中默认的网络服务由 **NetworkManager** 提供,这是动态控制及配置网络的守护进程,它用于保持当前网络设备及连接处于工作状态,同时也支持传统的 ifcfg 类型的配置文件。
|
||||
NetworkManager 可以用于以下类型的连接:
|
||||
Ethernet,VLANS,Bridges,Bonds,Teams,Wi-Fi,mobile boradband(如移动3G)以及 IP-over-InfiniBand。针对与这些网络类型,NetworkManager 可以配置他们的网络别名,IP 地址,静态路由,DNS,VPN连接以及很多其它的特殊参数。
|
||||
|
||||
NetworkManager 可以用于以下类型的连接:Ethernet,VLANS,Bridges,Bonds,Teams,Wi-Fi,mobile boradband(如移动3G)以及 IP-over-InfiniBand。针对与这些网络类型,NetworkManager 可以配置他们的网络别名,IP 地址,静态路由,DNS,VPN连接以及很多其它的特殊参数。
|
||||
|
||||
可以用命令行工具 nmcli 来控制 NetworkManager。
|
||||
|
||||
@ -24,19 +24,21 @@ Ethernet,VLANS,Bridges,Bonds,Teams,Wi-Fi,mobile boradband(如移
|
||||
|
||||
显示所有连接。
|
||||
|
||||
# nmcli connection show -a
|
||||
# nmcli connection show -a
|
||||
|
||||
仅显示当前活动的连接。
|
||||
|
||||
# nmcli device status
|
||||
|
||||
列出通过 NetworkManager 验证的设备列表及他们的状态。
|
||||
列出 NetworkManager 识别出的设备列表及他们的状态。
|
||||
|
||||

|
||||
|
||||
### 启动/停止 网络接口###
|
||||
|
||||
使用 nmcli 工具启动或停止网络接口,与 ifconfig 的 up/down 是一样的。使用下列命令停止某个接口:
|
||||
使用 nmcli 工具启动或停止网络接口,与 ifconfig 的 up/down 是一样的。
|
||||
|
||||
使用下列命令停止某个接口:
|
||||
|
||||
# nmcli device disconnect eno16777736
|
||||
|
||||
@ -50,7 +52,7 @@ Ethernet,VLANS,Bridges,Bonds,Teams,Wi-Fi,mobile boradband(如移
|
||||
|
||||
# nmcli connection add type ethernet con-name NAME_OF_CONNECTION ifname interface-name ip4 IP_ADDRESS gw4 GW_ADDRESS
|
||||
|
||||
根据你需要的配置更改 NAME_OF_CONNECTION,IP_ADDRESS, GW_ADDRESS参数(如果不需要网关的话可以省略最后一部分)。
|
||||
根据你需要的配置更改 NAME\_OF\_CONNECTION,IP\_ADDRESS, GW\_ADDRESS参数(如果不需要网关的话可以省略最后一部分)。
|
||||
|
||||
# nmcli connection add type ethernet con-name NEW ifname eno16777736 ip4 192.168.1.141 gw4 192.168.1.1
|
||||
|
||||
@ -68,9 +70,11 @@ Ethernet,VLANS,Bridges,Bonds,Teams,Wi-Fi,mobile boradband(如移
|
||||
|
||||

|
||||
|
||||
###增加一个使用 DHCP 的新连接
|
||||
|
||||
增加新的连接,使用DHCP自动分配IP地址,网关,DNS等,你要做的就是将命令行后 ip/gw 地址部分去掉就行了,DHCP会自动分配这些参数。
|
||||
|
||||
例,在 eno 16777736 设备上配置一个 名为 NEW_DHCP 的 DHCP 连接
|
||||
例,在 eno 16777736 设备上配置一个 名为 NEW\_DHCP 的 DHCP 连接
|
||||
|
||||
# nmcli connection add type ethernet con-name NEW_DHCP ifname eno16777736
|
||||
|
||||
@ -79,8 +83,8 @@ Ethernet,VLANS,Bridges,Bonds,Teams,Wi-Fi,mobile boradband(如移
|
||||
via: http://linoxide.com/linux-command/nmcli-tool-red-hat-centos-7/
|
||||
|
||||
作者:[Adrian Dinu][a]
|
||||
译者:[SPccman](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[SPccman](https://github.com/SPccman)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
[translating by KayGuoWhu]
|
||||
Enjoy Android Apps on Ubuntu using ARChon Runtime
|
||||
================================================================================
|
||||
Before, we gave try to many android app emulating tools like Genymotion, Virtualbox, Android SDK, etc to try to run android apps on it. But, with this new Chrome Android Runtime, we are able to run Android Apps on our Chrome Browser. So, here are the steps we'll need to follow to install Android Apps on Ubuntu using ARChon Runtime.
|
||||
|
||||
@ -1,161 +0,0 @@
|
||||
[bazz222]
|
||||
How to set up networking between Docker containers
|
||||
================================================================================
|
||||
As you may be aware, Docker container technology has emerged as a viable lightweight alternative to full-blown virtualization. There are a growing number of use cases of Docker that the industry adopted in different contexts, for example, enabling rapid build environment, simplifying configuration of your infrastructure, isolating applications in multi-tenant environment, and so on. While you can certainly deploy an application sandbox in a standalone Docker container, many real-world use cases of Docker in production environments may involve deploying a complex multi-tier application in an ensemble of multiple containers, where each container plays a specific role (e.g., load balancer, LAMP stack, database, UI).
|
||||
|
||||
There comes the problem of **Docker container networking**: How can we interconnect different Docker containers spawned potentially across different hosts when we do not know beforehand on which host each container will be created?
|
||||
|
||||
One pretty neat open-source solution for this is [weave][1]. This tool makes interconnecting multiple Docker containers pretty much hassle-free. When I say this, I really mean it.
|
||||
|
||||
In this tutorial, I am going to demonstrate **how to set up Docker networking across different hosts using weave**.
|
||||
|
||||
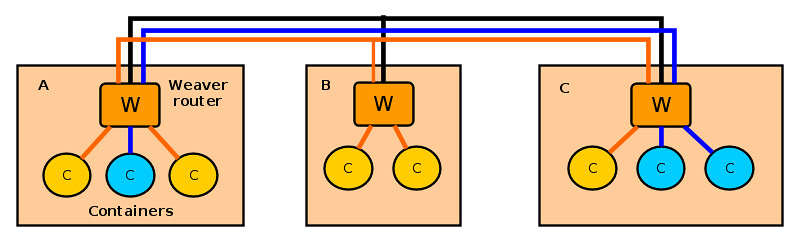
### How Weave Works ###
|
||||
|
||||
|
||||
|
||||
Let's first see how weave works. Weave creates a network of "peers", where each peer is a virtual router container called "weave router" residing on a distinct host. The weave routers on different hosts maintain TCP connections among themselves to exchange topology information. They also establish UDP connections among themselves to carry inter-container traffic. A weave router on each host is then connected via a bridge to all other Docker containers created on the host. When two containers on different hosts want to exchange traffic, a weave router on each host captures their traffic via a bridge, encapsulates the traffic with UDP, and forwards it to the other router over a UDP connection.
|
||||
|
||||
Each weave router maintains up-to-date weave router topology information, as well as container's MAC address information (similar to switch's MAC learning), so that it can make forwarding decision on container traffic. Weave is able to route traffic between containers created on hosts which are not directly reachable, as long as two hosts are interconnected via an intermediate weave router on weave topology. Optionally, weave routers can be set to encrypt both TCP control data and UDP data traffic based on public key cryptography.
|
||||
|
||||
### Prerequisite ###
|
||||
|
||||
Before using weave on Linux, of course you need to set up Docker environment on each host where you want to run [Docker][2] containers. Check out [these][3] [tutorials][4] on how to create Docker containers on Ubuntu or CentOS/Fedora.
|
||||
|
||||
Once Docker environment is set up, install weave on Linux as follows.
|
||||
|
||||
$ wget https://github.com/zettio/weave/releases/download/latest_release/weave
|
||||
$ chmod a+x weave
|
||||
$ sudo cp weave /usr/local/bin
|
||||
|
||||
Make sure that /usr/local/bin is include in your PATH variable by appending the following in /etc/profile.
|
||||
|
||||
export PATH="$PATH:/usr/local/bin"
|
||||
|
||||
Repeat weave installation on every host where Docker containers will be deployed.
|
||||
|
||||
Weave uses TCP/UDP 6783 port. If you are using firewall, make sure that these port numbers are not blocked by the firewall.
|
||||
|
||||
### Launch Weave Router on Each Host ###
|
||||
|
||||
When you want to interconnect Docker containers across multiple hosts, the first step is to launch a weave router on every host.
|
||||
|
||||
On the first host, run the following command, which will create and start a weave router container.
|
||||
|
||||
$ sudo weave launch
|
||||
|
||||
The first time you run this command, it will take a couple of minutes to download a weave image before launching a router container. On successful launch, it will print the ID of a launched weave router.
|
||||
|
||||
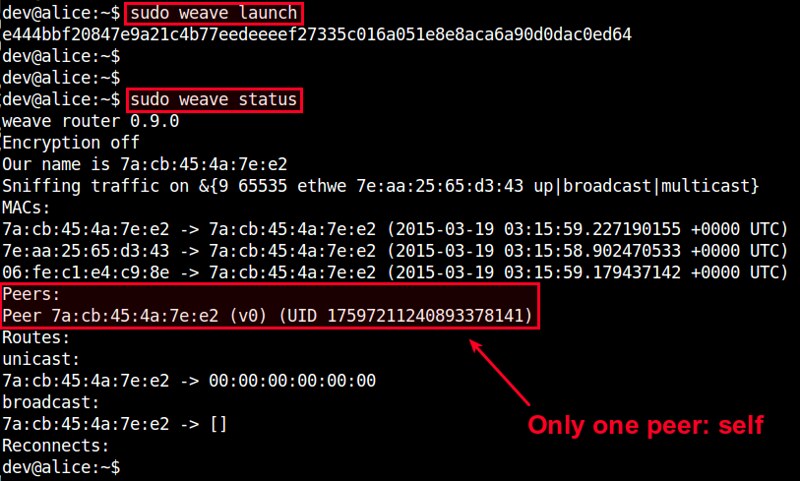
To check the status of the router, use this command:
|
||||
|
||||
$ sudo weave status
|
||||
|
||||
|
||||
|
||||
Since this is the first weave router launched, there will be only one peer in the peer list.
|
||||
|
||||
You can also verify the launch of a weave router by using docker command.
|
||||
|
||||
$ docker ps
|
||||
|
||||

|
||||
|
||||
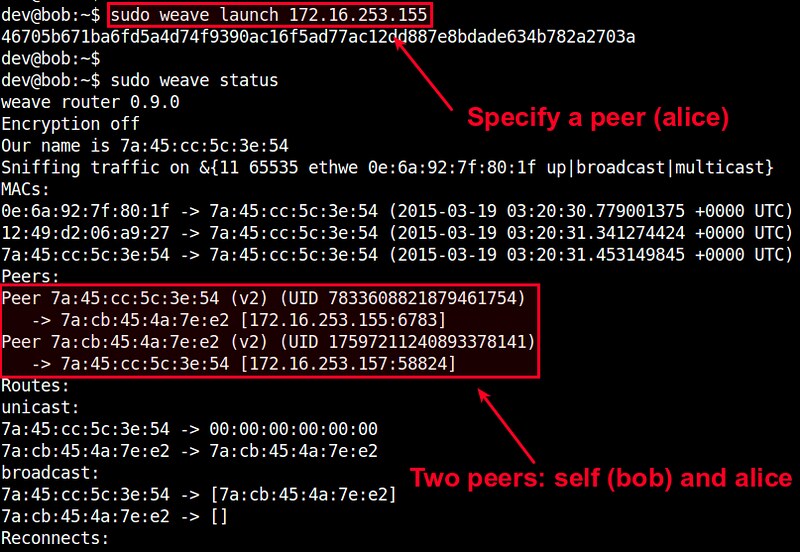
On the second host, run the following command, where we specify the IP address of the first host as a peer to join.
|
||||
|
||||
$ sudo weave launch <first-host-IP-address>
|
||||
|
||||
When you check the status of the router, you will see two peers: the current host and the first host.
|
||||
|
||||
|
||||
|
||||
As you launch more routers on subsequent hosts, the peer list will grow accordingly. When launching a router, just make sure that you specify any previously launched peer's IP address.
|
||||
|
||||
At this point, you should have a weave network up and running, which consists of multiple weave routers across different hosts.
|
||||
|
||||
### Interconnect Docker Containers across Multiple Hosts ###
|
||||
|
||||
Now it is time to launch Docker containers on different hosts, and interconnect them on a virtual network.
|
||||
|
||||
Let's say we want to create a private network 10.0.0.0/24, to interconnect two Docker containers. We will assign random IP addressses from this subnet to the containers.
|
||||
|
||||
When you create a Docker container to deploy on a weave network, you need to use weave command, not docker command. Internally, the weave command uses docker command to create a container, and then sets up Docker networking on it.
|
||||
|
||||
Here is how to create a Ubuntu container on hostA, and attach the container to 10.0.0.0/24 subnet with an IP addresss 10.0.0.1.
|
||||
|
||||
hostA:~$ sudo weave run 10.0.0.1/24 -t -i ubuntu
|
||||
|
||||
On successful run, it will print the ID of a created container. You can use this ID to attach to the running container and access its console as follows.
|
||||
|
||||
hostA:~$ docker attach <container-id>
|
||||
|
||||
Move to hostB, and let's create another container. Attach it to the same subnet (10.0.0.0/24) with a different IP address 10.0.0.2.
|
||||
|
||||
hostB:~$ sudo weave run 10.0.0.2/24 -t -i ubuntu
|
||||
|
||||
Let's attach to the second container's console as well:
|
||||
|
||||
hostB:~$ docker attach <container-id>
|
||||
|
||||
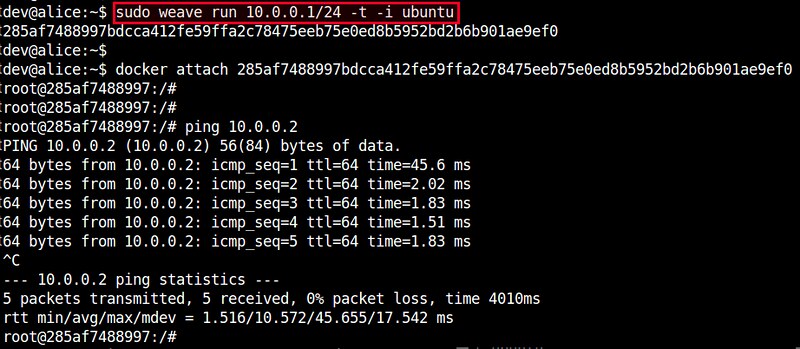
At this point, those two containers should be able to ping each other via the other's IP address. Verify that from each container's console.
|
||||
|
||||
|
||||
|
||||
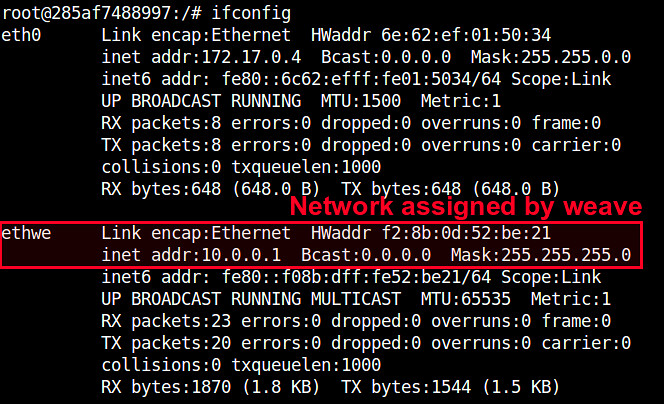
If you check the interfaces of each container, you will see an interface named "ethwe" which is assigned an IP address (e.g., 10.0.0.1 and 10.0.0.2) you specified.
|
||||
|
||||
|
||||
|
||||
### Other Advanced Usages of Weave ###
|
||||
|
||||
Weave offers a number of pretty neat features. Let me briefly cover a few here.
|
||||
|
||||
#### Application Isolation ####
|
||||
|
||||
Using weave, you can create multiple virtual networks and dedicate each network to a distinct application. For example, create 10.0.0.0/24 for one group of containers, and 10.10.0.0/24 for another group of containers, and so on. Weave automatically takes care of provisioning these networks, and isolating container traffic on each network. Going further, you can flexibly detach a container from one network, and attach it to another network without restarting containers. For example:
|
||||
|
||||
First launch a container on 10.0.0.0/24:
|
||||
|
||||
$ sudo weave run 10.0.0.2/24 -t -i ubuntu
|
||||
|
||||
Detach the container from 10.0.0.0/24:
|
||||
|
||||
$ sudo weave detach 10.0.0.2/24 <container-id>
|
||||
|
||||
Re-attach the container to another network 10.10.0.0/24:
|
||||
|
||||
$ sudo weave attach 10.10.0.2/24 <container-id>
|
||||
|
||||

|
||||
|
||||
Now this container should be able to communicate with other containers on 10.10.0.0/24. This is a pretty useful feature when network information is not available at the time you create a container.
|
||||
|
||||
#### Integrate Weave Networks with Host Network ####
|
||||
|
||||
Sometimes you may need to allow containers on a virtual weave network to access physical host network. Conversely, hosts may want to access containers on a weave network. To support this requirement, weave allows weave networks to be integrated with host network.
|
||||
|
||||
For example, on hostA where a container is running on network 10.0.0.0/24, run the following command.
|
||||
|
||||
hostA:~$ sudo weave expose 10.0.0.100/24
|
||||
|
||||
This will assign IP address 10.0.0.100 to hostA, so that hostA itself is also connected to 10.0.0.0/24 network. Obviously, you need to choose an IP address which is not used by any other containers on the network.
|
||||
|
||||
At this point, hostA should be able to access any containers on 10.0.0.0/24, whether or not the containers are residing on hostA. Pretty neat!
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
As you can see, weave is a pretty useful Docker networking tool. This tutorial only covers a glimpse of [its powerful features][5]. If you are more ambitious, you can try its multi-hop routing, which can be pretty useful in multi-cloud environment, dynamic re-routing, which is a neat fault-tolerance feature, or even its distributed DNS service which allows you to name containers on weave networks. If you decide to use this gem in your environment, feel free to share your use case!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/networking-between-docker-containers.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:https://github.com/zettio/weave
|
||||
[2]:http://xmodulo.com/recommend/dockerbook
|
||||
[3]:http://xmodulo.com/manage-linux-containers-docker-ubuntu.html
|
||||
[4]:http://xmodulo.com/docker-containers-centos-fedora.html
|
||||
[5]:http://zettio.github.io/weave/features.html
|
||||
@ -1,57 +0,0 @@
|
||||
Vic020
|
||||
|
||||
Linux FAQs with Answers--How to configure PCI-passthrough on virt-manager
|
||||
================================================================================
|
||||
> **Question**: I would like to dedicate a physical network interface card to one of my guest VMs created by KVM. For that, I am trying to enable PCI passthrough of the NIC for the VM. How can I add a PCI device to a guest VM with PCI passthrough on virt-manager?
|
||||
|
||||
Modern hypervisors enable efficient resource sharing among multiple guest operating systems by virtualizing and emulating hardware resources. However, such virtualized resource sharing may not always be desirable, or even should be avoided when VM performance is a great concern, or when a VM requires full DMA control of a hardware device. One technique used in this case is so-called "PCI passthrough," where a guest VM is granted an exclusive access to a PCI device (e.g., network/sound/video card). Essentially, PCI passthrough bypasses the virtualization layer, and directly exposes a PCI device to a VM. No other VM can access the PCI device.
|
||||
|
||||
### Requirement for Enabling PCI Passthrough ###
|
||||
|
||||
If you want to enable PCI passthrough for an HVM guest (e.g., a fully-virtualized VM created by KVM), your system (both CPU and motherboard) must meet the following requirement. If your VM is paravirtualized (created by Xen), you can skip this step.
|
||||
|
||||
In order to enable PCI passthrough for an HVM guest VM, your system must support **VT-d** (for Intel processors) or **AMD-Vi** (for AMD processors). Intel's VT-d ("Intel Virtualization Technology for Directed I/O") is available on most high-end Nehalem processors and its successors (e.g., Westmere, Sandy Bridge, Ivy Bridge). Note that VT-d and VT-x are two independent features. A list of Intel/AMD processors with VT-d/AMD-Vi capability can be found [here][1].
|
||||
|
||||
After you verify that your host hardware supports VT-d/AMD-Vi, you then need to do two things on your system. First, make sure that VT-d/AMD-Vi is enabled in system BIOS. Second, enable IOMMU on your kernel during booting. The IOMMU service, which is provided by VT-d,/AMD-Vi, protects host memory access by a guest VM, and is a requirement for PCI passthrough for fully-virtualized guest VMs.
|
||||
|
||||
To enable IOMMU on the kernel for Intel processors, pass "**intel_iommu=on**" boot parameter on your Linux. Follow [this tutorial][2] to find out how to add a kernel boot parameter via GRUB.
|
||||
|
||||
After configuring the boot parameter, reboot your host.
|
||||
|
||||
### Add a PCI Device to a VM on Virt-Manager ###
|
||||
|
||||
Now we are ready to enable PCI passthrough. In fact, assigning a PCI device to a guest VM is straightforward on virt-manager.
|
||||
|
||||
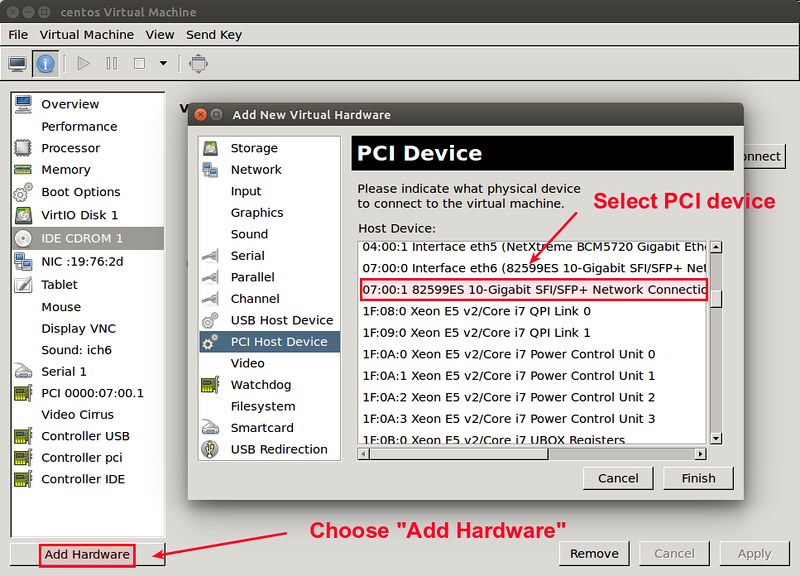
Open the VM's settings on virt-manager, and click on "Add Hardware" button on the left sidebar.
|
||||
|
||||
Choose a PCI device to assign from a PCI device list, and click on "Finish" button.
|
||||
|
||||
|
||||
|
||||
Finally, power on the guest. At this point, the host PCI device should be directly visible inside the guest VM.
|
||||
|
||||
### Troubleshooting ###
|
||||
|
||||
If you see either of the following errors while powering on a guest VM, the error may be because VT-d (or IOMMU) is not enabled on your host.
|
||||
|
||||
Error starting domain: unsupported configuration: host doesn't support passthrough of host PCI devices
|
||||
|
||||
----------
|
||||
|
||||
Error starting domain: Unable to read from monitor: Connection reset by peer
|
||||
|
||||
Make sure that "**intel_iommu=on**" boot parameter is passed to the kernel during boot as described above.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/pci-passthrough-virt-manager.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:http://wiki.xenproject.org/wiki/VTdHowTo
|
||||
[2]:http://xmodulo.com/add-kernel-boot-parameters-via-grub-linux.html
|
||||
@ -1,3 +1,5 @@
|
||||
translating by createyuan
|
||||
|
||||
How to access a Linux server behind NAT via reverse SSH tunnel
|
||||
================================================================================
|
||||
You are running a Linux server at home, which is behind a NAT router or restrictive firewall. Now you want to SSH to the home server while you are away from home. How would you set that up? SSH port forwarding will certainly be an option. However, port forwarding can become tricky if you are dealing with multiple nested NAT environment. Besides, it can be interfered with under various ISP-specific conditions, such as restrictive ISP firewalls which block forwarded ports, or carrier-grade NAT which shares IPv4 addresses among users.
|
||||
@ -127,4 +129,4 @@ via: http://xmodulo.com/access-linux-server-behind-nat-reverse-ssh-tunnel.html
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/go/digitalocean
|
||||
[2]:http://xmodulo.com/how-to-enable-ssh-login-without.html
|
||||
[3]:http://ask.xmodulo.com/install-autossh-linux.html
|
||||
[3]:http://ask.xmodulo.com/install-autossh-linux.html
|
||||
|
||||
@ -0,0 +1,40 @@
|
||||
Bodhi Linux Introduces Moksha Desktop
|
||||
================================================================================
|
||||

|
||||
|
||||
Ubuntu based lightweight Linux distribution [Bodhi Linux][1] is working on a desktop environment of its own. This new desktop environment will be called Moksha (Sanskrit for ‘complete freedom’). Moksha will be replacing the usual [Enlightenment desktop environment][2].
|
||||
|
||||
### Why Moksha instead of Enlightenment? ###
|
||||
|
||||
Jeff Hoogland of Bodhi Linux [says][3] that he had been unhappy with the newer versions of Enlightenment in the recent past. Until E17, Enlightenment was very stable and complemented well to the need of a lightweight Linux OS, but the E18 was so full of bugs that Bodhi Linux skipped it altogether.
|
||||
|
||||
While the latest [Bodhi Linux 3.0.0 release][4] uses E19 (except the legacy mode, meant for older hardware, still uses E17), Jeff is not happy with E19 as well. He quotes:
|
||||
|
||||
> On top of the performance issues, E19 did not allow for me personally to have the same workflow I enjoyed under E17 due to features it no longer had. Because of this I had changed to using the E17 on all of my Bodhi 3 computers – even my high end ones. This got me to thinking how many of our existing Bodhi users felt the same way, so I [opened a discussion about it on our user forums][5].
|
||||
|
||||
### Moksha is continuation of the E17 desktop ###
|
||||
|
||||
Moksha will be a continuation of Bodhi’s favorite E17 desktop. Jeff further mentions:
|
||||
|
||||
> We will start by integrating all of the Bodhi changes we have simply been patching into the source code over the years and fixing the few issues the desktop has. Once this is done we will begin back porting a few of the more useful features E18 and E19 introduced to the Enlightenment desktop and finally, we will introduce a few new things we think will improve the end user experience.
|
||||
|
||||
### When will Moksha release? ###
|
||||
|
||||
The next update to Bodhi will be Bodhi 3.1.0 in August this year. This new release will bring Moksha on all of its default ISOs. Let’s wait and watch to see if Moksha turns out to be a good decision or not.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/bodhi-linux-introduces-moksha-desktop/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://www.bodhilinux.com/
|
||||
[2]:https://www.enlightenment.org/
|
||||
[3]:http://www.bodhilinux.com/2015/04/28/introducing-the-moksha-desktop/
|
||||
[4]:http://itsfoss.com/bodhi-linux-3/
|
||||
[5]:http://forums.bodhilinux.com/index.php?/topic/12322-e17-vs-e19-which-are-you-using-and-why/
|
||||
@ -0,0 +1,459 @@
|
||||
First Step Guide for Learning Shell Scripting
|
||||
================================================================================
|
||||

|
||||
|
||||
Usually when people say "shell scripting" they have on mind bash, ksh, sh, ash or similar linux/unix scripting language. Scripting is another way to communicate with computer. Using graphic windows interface (not matter windows or linux) user can move mouse and clicking on the various objects like, buttons, lists, check boxes and so on. But it is very inconvenient way witch requires user participation and accuracy each time he would like to ask computer / server to do the same tasks (lets say to convert photos or download new movies, mp3 etc). To make all these things easy accessible and automated we could use shell scripts.
|
||||
|
||||
Some programming languages like pascal, foxpro, C, java needs to be compiled before they could be executed. They needs appropriate compiler to make our code to do some job.
|
||||
|
||||
Another programming languages like php, javascript, visualbasic do not needs compiler. So they need interpretersand we could run our program without compiling the code.
|
||||
|
||||
The shell scripts is also like interpreters, but it is usually used to call external compiled programs. Then captures the outputs, exit codes and act accordingly.
|
||||
|
||||
One of the most popular shell scripting language in the linux world is the bash. And i think (this is my own opinion) this is because bash shell allows user easily navigate through the history commands (previously executed) by default, in opposite ksh which requires some tuning in .profile or remember some "magic" key combination to walk through history and amend commands.
|
||||
|
||||
Ok, i think this is enough for introduction and i leaving for your judge which environment is most comfortable for you. Since now i will speak only about bash and scripting. In the following examples i will use the CentOS 6.6 and bash-4.1.2. Just make sure you have the same or greater version.
|
||||
|
||||
### Shell Script Streams ###
|
||||
|
||||
The shell scripting it is something similar to conversation of several persons. Just imagine that all command like the persons who able to do something if you properly ask them. Lets say you would like to write the document. First of all you need the paper, then you need to say the content to someone to write it, and finally you would like to store it somewhere. Or you would like build a house, so you will ask appropriate persons to cleanup the space. After they say "its done" then other engineers could build for you the walls. And finally, when engineers also tell "Its done" you can ask the painters to color your house. And what would happen if you ask the painters coloring your walls before they are built? I think they will start to complain. Almost all commands like the persons could speak and if they did its job without any issues they speaks to "standard output". If they can't to what you asking - they speaking to the "standard error". So finally all commands listening for you through "standard input".
|
||||
|
||||
Quick example- when you opening linux terminal and writing some text - you speaking to bash through "standard input". So ask the bash shell **who am i**
|
||||
|
||||
root@localhost ~]# who am i <--- you speaking through the standard input to bash shell
|
||||
root pts/0 2015-04-22 20:17 (192.168.1.123) <--- bash shell answering to you through the standard output
|
||||
|
||||
Now lets ask something that bash will not understand us:
|
||||
|
||||
[root@localhost ~]# blablabla <--- and again, you speaking through standard input
|
||||
-bash: blablabla: command not found <--- bash complaining through standard error
|
||||
|
||||
The first word before ":" usually is the command which complaining to you. Actually each of these streams has their own index number:
|
||||
|
||||
- standard input (**stdin**) - 0
|
||||
- standard output (**stdout**) - 1
|
||||
- standard error (**stderr**) - 2
|
||||
|
||||
If you really would like to know to witch output command said something - you need to redirect (to use "greater than ">" symbol after command and stream index) that speech to file:
|
||||
|
||||
[root@localhost ~]# blablabla 1> output.txt
|
||||
-bash: blablabla: command not found
|
||||
|
||||
In this example we tried to redirect 1 (**stdout**) stream to file named output.txt. Lets look does to the content of that file. We use the command cat for that:
|
||||
|
||||
[root@localhost ~]# cat output.txt
|
||||
[root@localhost ~]#
|
||||
|
||||
Seams that is empty. Ok now lets try to redirect 2 (**stderr**) streem:
|
||||
|
||||
[root@localhost ~]# blablabla 2> error.txt
|
||||
[root@localhost ~]#
|
||||
|
||||
Ok, we see that complains gone. Lets chec the file:
|
||||
|
||||
[root@localhost ~]# cat error.txt
|
||||
-bash: blablabla: command not found
|
||||
[root@localhost ~]#
|
||||
|
||||
Exactly! We see that all complains was recorded to the errors.txt file.
|
||||
|
||||
Sometimes commands produces **stdout** and **stderr** simultaniously. To redirect them to separate files we can use the following syntax:
|
||||
|
||||
command 1>out.txt 2>err.txt
|
||||
|
||||
To shorten this syntax a bit we can skip the "1" as by default the **stdout** stream will be redirected:
|
||||
|
||||
command >out.txt 2>err.txt
|
||||
|
||||
Ok, lets try to do something "bad". lets remove the file1 and folder1 with the rm command:
|
||||
|
||||
[root@localhost ~]# rm -vf folder1 file1 > out.txt 2>err.txt
|
||||
|
||||
Now check our output files:
|
||||
|
||||
[root@localhost ~]# cat out.txt
|
||||
removed `file1'
|
||||
[root@localhost ~]# cat err.txt
|
||||
rm: cannot remove `folder1': Is a directory
|
||||
[root@localhost ~]#
|
||||
|
||||
As we see the streams was separated to different files. Sometimes it is not handy as usually we want to see the sequence when the errors appeared - before or after some actions. For that we can redirect both streams to the same file:
|
||||
|
||||
command >>out_err.txt 2>>out_err.txt
|
||||
|
||||
Note : Please notice that i use ">>" instead of ">". It allows us to append file instead of overwrite.
|
||||
|
||||
We can redirect one stream to another:
|
||||
|
||||
command >out_err.txt 2>&1
|
||||
|
||||
Let me explain. All stdout of the command will be redirected to the out_err.txt. The errout will be redirected to the 1-st stream which (as i already explained above) will be redirected to the same file. Let see the example:
|
||||
|
||||
[root@localhost ~]# rm -fv folder2 file2 >out_err.txt 2>&1
|
||||
[root@localhost ~]# cat out_err.txt
|
||||
rm: cannot remove `folder2': Is a directory
|
||||
removed `file2'
|
||||
[root@localhost ~]#
|
||||
|
||||
Looking at the combined output we can state that first of all **rm** command tried to remove the folder2 and it was not success as linux require the **-r** key for **rm** command to allow remove folders. At the second the file2 was removed. By providing the **-v** (verbose) key for the **rm** command we asking rm command to inform as about each removed file or folder.
|
||||
|
||||
This is almost all you need to know about redirection. I say almost, because there is one more very important redirection which called "piping". By using | (pipe) symbol we usually redirecting **stdout** streem.
|
||||
|
||||
Lets say we have the text file:
|
||||
|
||||
[root@localhost ~]# cat text_file.txt
|
||||
This line does not contain H e l l o word
|
||||
This lilne contains Hello
|
||||
This also containd Hello
|
||||
This one no due to HELLO all capital
|
||||
Hello bash world!
|
||||
|
||||
and we need to find the lines in it with the words "Hello". Linux has the **grep** command for that:
|
||||
|
||||
[root@localhost ~]# grep Hello text_file.txt
|
||||
This lilne contains Hello
|
||||
This also containd Hello
|
||||
Hello bash world!
|
||||
[root@localhost ~]#
|
||||
|
||||
This is ok when we have file and would like to sech in it. But what to do if we need to find something in the output of another command? Yes, of course we can redirect the output to the file and then look in it:
|
||||
|
||||
[root@localhost ~]# fdisk -l>fdisk.out
|
||||
[root@localhost ~]# grep "Disk /dev" fdisk.out
|
||||
Disk /dev/sda: 8589 MB, 8589934592 bytes
|
||||
Disk /dev/mapper/VolGroup-lv_root: 7205 MB, 7205814272 bytes
|
||||
Disk /dev/mapper/VolGroup-lv_swap: 855 MB, 855638016 bytes
|
||||
[root@localhost ~]#
|
||||
|
||||
If you going to grep something with white spaces embrace that with " quotes!
|
||||
|
||||
Note : fdisk command shows information about Linux OS disk drives
|
||||
|
||||
As we see this way is not very handy as soon we will mess the space with temporary files. For that we can use the pipes. They allow us redirect one command **stdout** to another command **stdin** streams:
|
||||
|
||||
[root@localhost ~]# fdisk -l | grep "Disk /dev"
|
||||
Disk /dev/sda: 8589 MB, 8589934592 bytes
|
||||
Disk /dev/mapper/VolGroup-lv_root: 7205 MB, 7205814272 bytes
|
||||
Disk /dev/mapper/VolGroup-lv_swap: 855 MB, 855638016 bytes
|
||||
[root@localhost ~]#
|
||||
|
||||
As we see, we get the same result without any temporary files. We have redirected **frisk stdout** to the **grep stdin**.
|
||||
|
||||
**Note** : Pipe redirection is always from left to right.
|
||||
|
||||
There are several other redirections but we will speak about them later.
|
||||
|
||||
### Displaying custom messages in the shell ###
|
||||
|
||||
As we already know usually communication with and within shell is going as dialog. So lets create some real script which also will speak with us. It will allow you to learn some simple commands and better understand the scripting concept.
|
||||
|
||||
Imagine we are working in some company as help desk manager and we would like to create some shell script to register the call information: phone number, User name and brief description about issue. We going to store it in the plain text file data.txt for future statistics. Script it self should work in dialog way to make live easy for help desk workers. So first of all we need to display the questions. For displaying any messages there is echo and printf commands. Both of them displaying messages, but printf is more powerful as we can nicely form output to align it to the right, left or leave dedicated space for message. Lets start from simple one. For file creation please use your favorite text editor (kate, nano, vi, ...) and create the file named note.sh with the command inside:
|
||||
|
||||
echo "Phone number ?"
|
||||
|
||||
### Script execution ###
|
||||
|
||||
After you have saved the file we can run it with bash command by providing our file as an argument:
|
||||
|
||||
[root@localhost ~]# bash note.sh
|
||||
Phone number ?
|
||||
|
||||
Actually to use this way for script execution is not handy. It would be more comfortable just execute the script without any **bash** command as a prefix. To make it executable we can use **chmod** command:
|
||||
|
||||
[root@localhost ~]# ls -la note.sh
|
||||
-rw-r--r--. 1 root root 22 Apr 23 20:52 note.sh
|
||||
[root@localhost ~]# chmod +x note.sh
|
||||
[root@localhost ~]# ls -la note.sh
|
||||
-rwxr-xr-x. 1 root root 22 Apr 23 20:52 note.sh
|
||||
[root@localhost ~]#
|
||||
|
||||

|
||||
|
||||
**Note** : ls command displays the files in the current folder. By adding the keys -la it will display a bit more information about files.
|
||||
|
||||
As we see, before **chmod** command execution, script has only read (r) and write (w) permissions. After **chmod +x** it got execute (x) permissions. (More details about permissions i am going to describe in next article.) Now we can simply run it:
|
||||
|
||||
[root@localhost ~]# ./note.sh
|
||||
Phone number ?
|
||||
|
||||
Before script name i have added ./ combination. . (dot) in the unix world means current position (current folder), the / (slash) is the folder separator. (In Windows OS we use \ (backslash) for the same). So whole this combination means: "from the current folder execute the note.sh script". I think it will be more clear for you if i run this script with full path:
|
||||
|
||||
[root@localhost ~]# /root/note.sh
|
||||
Phone number ?
|
||||
[root@localhost ~]#
|
||||
|
||||
It also works.
|
||||
|
||||
Everything would be ok if all linux users would have the same default shell. If we simply execute this script default user shell will be used to parse script content and run the commands. Different shells have a bit different syntax, internal commands, etc. So to guarantee the **bash** will be used for our script we should add **#!/bin/bash** as the first line. In this way default user shell will call **/bin/bash** and only then will execute following shell commands in the script:
|
||||
|
||||
[root@localhost ~]# cat note.sh
|
||||
#!/bin/bash
|
||||
echo "Phone number ?"
|
||||
|
||||
Only now we will be 100% sure that **bash** will be used to parse our script content. Lets move on.
|
||||
|
||||
### Reading the inputs ###
|
||||
|
||||
After we have displayed the message script should wait for answer from user. There is the command **read**:
|
||||
|
||||
#!/bin/bash
|
||||
echo "Phone number ?"
|
||||
read phone
|
||||
|
||||
After execution script will wait for the user input until he press the [ENTER] key:
|
||||
|
||||
[root@localhost ~]# ./note.sh
|
||||
Phone number ?
|
||||
12345 <--- here is my input
|
||||
[root@localhost ~]#
|
||||
|
||||
Everything you have input will be stored to the variable **phone**. To display the value of variable we can use the same **echo** command:
|
||||
|
||||
[root@localhost ~]# cat note.sh
|
||||
#!/bin/bash
|
||||
echo "Phone number ?"
|
||||
read phone
|
||||
echo "You have entered $phone as a phone number"
|
||||
[root@localhost ~]# ./note.sh
|
||||
Phone number ?
|
||||
123456
|
||||
You have entered 123456 as a phone number
|
||||
[root@localhost ~]#
|
||||
|
||||
In **bash** shell we using **$** (dollar) sign as variable indication, except when reading into variable and few other moments (will describe later).
|
||||
|
||||
Ok, now we are ready to add the rest questions:
|
||||
|
||||
#!/bin/bash
|
||||
echo "Phone number?"
|
||||
read phone
|
||||
echo "Name?"
|
||||
read name
|
||||
echo "Issue?"
|
||||
read issue
|
||||
[root@localhost ~]# ./note.sh
|
||||
Phone number?
|
||||
123
|
||||
Name?
|
||||
Jim
|
||||
Issue?
|
||||
script is not working.
|
||||
[root@localhost ~]#
|
||||
|
||||
### Using stream redirection ###
|
||||
|
||||
Perfect! There is left to redirect everything to the file data.txt. As a field separator we going to use / (slash) symbol.
|
||||
|
||||
**Note** : You can chose any which you think is the best, bat be sure that content will not have thes symbols inside. It will cause extra fields in the line.
|
||||
|
||||
Do not forget to use ">>" instead of ">" as we would like to append the output to the end of file!
|
||||
|
||||
[root@localhost ~]# tail -2 note.sh
|
||||
read issue
|
||||
echo "$phone/$name/$issue">>data.txt
|
||||
[root@localhost ~]# ./note.sh
|
||||
Phone number?
|
||||
987
|
||||
Name?
|
||||
Jimmy
|
||||
Issue?
|
||||
Keybord issue.
|
||||
[root@localhost ~]# cat data.txt
|
||||
987/Jimmy/Keybord issue.
|
||||
[root@localhost ~]#
|
||||
|
||||
**Note** : The command **tail** displays the last **-n** lines of the file.
|
||||
|
||||
Bingo. Lets run once again:
|
||||
|
||||
[root@localhost ~]# ./note.sh
|
||||
Phone number?
|
||||
556
|
||||
Name?
|
||||
Janine
|
||||
Issue?
|
||||
Mouse was broken.
|
||||
[root@localhost ~]# cat data.txt
|
||||
987/Jimmy/Keybord issue.
|
||||
556/Janine/Mouse was broken.
|
||||
[root@localhost ~]#
|
||||
|
||||
Our file is growing. Lets add the date in the front of each line. This will be useful later when playing with data while calculating statistic. For that we can use command date and give it some format as i do not like default one:
|
||||
|
||||
[root@localhost ~]# date
|
||||
Thu Apr 23 21:33:14 EEST 2015 <---- default output of dta command
|
||||
[root@localhost ~]# date "+%Y.%m.%d %H:%M:%S"
|
||||
2015.04.23 21:33:18 <---- formated output
|
||||
|
||||
There are several ways to read the command output to the variable. In this simple situation we will use ` (back quotes):
|
||||
|
||||
[root@localhost ~]# cat note.sh
|
||||
#!/bin/bash
|
||||
now=`date "+%Y.%m.%d %H:%M:%S"`
|
||||
echo "Phone number?"
|
||||
read phone
|
||||
echo "Name?"
|
||||
read name
|
||||
echo "Issue?"
|
||||
read issue
|
||||
echo "$now/$phone/$name/$issue">>data.txt
|
||||
[root@localhost ~]# ./note.sh
|
||||
Phone number?
|
||||
123
|
||||
Name?
|
||||
Jim
|
||||
Issue?
|
||||
Script hanging.
|
||||
[root@localhost ~]# cat data.txt
|
||||
2015.04.23 21:38:56/123/Jim/Script hanging.
|
||||
[root@localhost ~]#
|
||||
|
||||
Hmmm... Our script looks a bit ugly. Lets prettify it a bit. If you would read manual about **read** command you would find that read command also could display some messages. For this we should use -p key and message:
|
||||
|
||||
[root@localhost ~]# cat note.sh
|
||||
#!/bin/bash
|
||||
now=`date "+%Y.%m.%d %H:%M:%S"`
|
||||
read -p "Phone number: " phone
|
||||
read -p "Name: " name
|
||||
read -p "Issue: " issue
|
||||
echo "$now/$phone/$name/$issue">>data.txt
|
||||
|
||||
You can fine a lots of interesting about each command directly from the console. Just type: **man read, man echo, man date, man ....**
|
||||
|
||||
Agree it looks much better!
|
||||
|
||||
[root@localhost ~]# ./note.sh
|
||||
Phone number: 321
|
||||
Name: Susane
|
||||
Issue: Mouse was stolen
|
||||
[root@localhost ~]# cat data.txt
|
||||
2015.04.23 21:38:56/123/Jim/Script hanging.
|
||||
2015.04.23 21:43:50/321/Susane/Mouse was stolen
|
||||
[root@localhost ~]#
|
||||
|
||||
And the cursor is right after the message (not in new line) what makes a bit sense.
|
||||
Loop
|
||||
|
||||
Time to improve our script. If user works all day with the calls it is not very handy to run it each time. Lets add all these actions in the never-ending loop:
|
||||
|
||||
[root@localhost ~]# cat note.sh
|
||||
#!/bin/bash
|
||||
while true
|
||||
do
|
||||
read -p "Phone number: " phone
|
||||
now=`date "+%Y.%m.%d %H:%M:%S"`
|
||||
read -p "Name: " name
|
||||
read -p "Issue: " issue
|
||||
echo "$now/$phone/$name/$issue">>data.txt
|
||||
done
|
||||
|
||||
I have swapped **read phone** and **now=`date** lines. This is because i would like to get the time right after the phone number will be entered. If i would left it as the first line in the loop **- the** now variable will get the time right after the data was stored in the file. And it is not good as the next call could be after 20 mins or so.
|
||||
|
||||
[root@localhost ~]# ./note.sh
|
||||
Phone number: 123
|
||||
Name: Jim
|
||||
Issue: Script still not works.
|
||||
Phone number: 777
|
||||
Name: Daniel
|
||||
Issue: I broke my monitor
|
||||
Phone number: ^C
|
||||
[root@localhost ~]# cat data.txt
|
||||
2015.04.23 21:38:56/123/Jim/Script hanging.
|
||||
2015.04.23 21:43:50/321/Susane/Mouse was stolen
|
||||
2015.04.23 21:47:55/123/Jim/Script still not works.
|
||||
2015.04.23 21:48:16/777/Daniel/I broke my monitor
|
||||
[root@localhost ~]#
|
||||
|
||||
NOTE: To exit from the never-ending loop you can by pressing [Ctrl]+[C] keys. Shell will display ^ as the Ctrl key.
|
||||
|
||||
### Using pipe redirection ###
|
||||
|
||||
Lets add more functionality to our "Frankenstein" I would like the script will display some statistic after each call. Lets say we want to see the how many times each number called us. For that we should cat the data.txt file:
|
||||
|
||||
[root@localhost ~]# cat data.txt
|
||||
2015.04.23 21:38:56/123/Jim/Script hanging.
|
||||
2015.04.23 21:43:50/321/Susane/Mouse was stolen
|
||||
2015.04.23 21:47:55/123/Jim/Script still not works.
|
||||
2015.04.23 21:48:16/777/Daniel/I broke my monitor
|
||||
2015.04.23 22:02:14/123/Jimmy/New script also not working!!!
|
||||
[root@localhost ~]#
|
||||
|
||||
Now all this output we can redirect to the **cut** command to **cut** each line into the chunks (our delimiter "/") and print the second field:
|
||||
|
||||
[root@localhost ~]# cat data.txt | cut -d"/" -f2
|
||||
123
|
||||
321
|
||||
123
|
||||
777
|
||||
123
|
||||
[root@localhost ~]#
|
||||
|
||||
Now this output we can redirect to another command to **sort**:
|
||||
|
||||
[root@localhost ~]# cat data.txt | cut -d"/" -f2|sort
|
||||
123
|
||||
123
|
||||
123
|
||||
321
|
||||
777
|
||||
[root@localhost ~]#
|
||||
|
||||
and leave only unique lines. To count unique entries just add **-c** key for **uniq** command:
|
||||
|
||||
[root@localhost ~]# cat data.txt | cut -d"/" -f2 | sort | uniq -c
|
||||
3 123
|
||||
1 321
|
||||
1 777
|
||||
[root@localhost ~]#
|
||||
|
||||
Just add this to end of our loop:
|
||||
|
||||
#!/bin/bash
|
||||
while true
|
||||
do
|
||||
read -p "Phone number: " phone
|
||||
now=`date "+%Y.%m.%d %H:%M:%S"`
|
||||
read -p "Name: " name
|
||||
read -p "Issue: " issue
|
||||
echo "$now/$phone/$name/$issue">>data.txt
|
||||
echo "===== We got calls from ====="
|
||||
cat data.txt | cut -d"/" -f2 | sort | uniq -c
|
||||
echo "--------------------------------"
|
||||
done
|
||||
|
||||
Run it:
|
||||
|
||||
[root@localhost ~]# ./note.sh
|
||||
Phone number: 454
|
||||
Name: Malini
|
||||
Issue: Windows license expired.
|
||||
===== We got calls from =====
|
||||
3 123
|
||||
1 321
|
||||
1 454
|
||||
1 777
|
||||
--------------------------------
|
||||
Phone number: ^C
|
||||
|
||||

|
||||
|
||||
Current scenario is going through well-known steps like:
|
||||
|
||||
- Display message
|
||||
- Get user input
|
||||
- Store values to the file
|
||||
- Do something with stored data
|
||||
|
||||
But what if user has several responsibilities and he needs sometimes to input data, sometimes to do statistic calculations, or might be to find something in stored data? For that we need to implement switches / cases. In next article i will show you how to use them and how to nicely form the output. It is useful while "drawing" the tables in the shell.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-shell-script/guide-start-learning-shell-scripting-scratch/
|
||||
|
||||
作者:[Petras Liumparas][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/petrasl/
|
||||
@ -0,0 +1,170 @@
|
||||
Translating by wwy-hust
|
||||
|
||||
|
||||
How to Securely Store Passwords and Api Keys Using Vault
|
||||
================================================================================
|
||||
Vault is a tool that is used to access secret information securely, it may be password, API key, certificate or anything else. Vault provides a unified interface to secret information through strong access control mechanism and extensive logging of events.
|
||||
|
||||
Granting access to critical information is quite a difficult problem when we have multiple roles and individuals across different roles requiring various critical information like, login details to databases with different privileges, API keys for external services, credentials for service oriented architecture communication etc. Situation gets even worse when access to secret information is managed across different platforms with custom settings, so rolling, secure storage and managing the audit logs is almost impossible. But Vault provides a solution to such a complex situation.
|
||||
|
||||
### Salient Features ###
|
||||
|
||||
Data Encryption: Vault can encrypt and decrypt data with no requirement to store it. Developers can now store encrypted data without developing their own encryption techniques and it allows security teams to define security parameters.
|
||||
|
||||
**Secure Secret Storage**: Vault encrypts the secret information (API keys, passwords or certificates) before storing it on to the persistent (secondary) storage. So even if somebody gets access to the stored information by chance, it will be of no use until it is decrypted.
|
||||
|
||||
**Dynamic Secrets**: On demand secrets are generated for systems like AWS and SQL databases. If an application needs to access S3 bucket, for instance, it requests AWS keypair from Vault, which grants the required secret information along with a lease time. The secret information won’t work once the lease time is expired.
|
||||
|
||||
**Leasing and Renewal**: Vault grants secrets with a lease limit, it revokes the secrets as soon as lease expires which can further be renewed through APIs if required.
|
||||
|
||||
**Revocation**: Upon expiring the lease period Vault can revoke a single secret or a tree of secrets.
|
||||
|
||||
### Installing Vault ###
|
||||
|
||||
There are two ways to use Vault.
|
||||
|
||||
**1. Pre-compiled Vault Binary** can be downloaded for all Linux flavors from the following source, once done, unzip it and place it on a system PATH where other binaries are kept so that it can be accessed/invoked easily.
|
||||
|
||||
- [Download Precompiled Vault Binary (32-bit)][1]
|
||||
- [Download Precompiled Vault Binary (64-bit)][2]
|
||||
- [Download Precompiled Vault Binary (ARM)][3]
|
||||
|
||||
Download the desired precompiled Vault binary.
|
||||
|
||||

|
||||
|
||||
Unzip the downloaded binary.
|
||||
|
||||

|
||||
|
||||
unzipCongratulations! Vault is ready to be used.
|
||||
|
||||

|
||||
|
||||
**2. Compiling from source** is another way of installing Vault on the system. GO and GIT are required to be installed and configured properly on the system before we start the installation process.
|
||||
|
||||
To **install GO on Redhat systems** use the following command.
|
||||
|
||||
sudo yum install go
|
||||
|
||||
To **install GO on Debian systems** use the following commands.
|
||||
|
||||
sudo apt-get install golang
|
||||
|
||||
OR
|
||||
|
||||
sudo add-apt-repository ppa:gophers/go
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
sudo apt-get install golang-stable
|
||||
|
||||
To **install GIT on Redhat systems** use the following command.
|
||||
|
||||
sudo yum install git
|
||||
|
||||
To **install GIT on Debian systems** use the following commands.
|
||||
|
||||
sudo apt-get install git
|
||||
|
||||
Once both GO and GIT are installed we start the Vault installation process by compiling from the source.
|
||||
|
||||
> Clone following Vault repository into the GOPATH
|
||||
|
||||
https://github.com/hashicorp/vault
|
||||
|
||||
> Verify if the following clone file exist, if it doesn’t then Vault wasn’t cloned to the proper path.
|
||||
|
||||
$GOPATH/src/github.com/hashicorp/vault/main.go
|
||||
|
||||
> Run following command to build Vault in the current system and put binary in the bin directory.
|
||||
|
||||
make dev
|
||||
|
||||

|
||||
|
||||
### An introductory tutorial of Vault ###
|
||||
|
||||
We have compiled Vault’s official interactive tutorial along with its output on SSH.
|
||||
|
||||
**Overview**
|
||||
|
||||
This tutorial will cover the following steps:
|
||||
|
||||
- Initializing and unsealing your Vault
|
||||
- Authorizing your requests to Vault
|
||||
- Reading and writing secrets
|
||||
- Sealing your Vault
|
||||
|
||||
**Initialize your Vault**
|
||||
|
||||
To get started, we need to initialize an instance of Vault for you to work with.
|
||||
While initializing, you can configure the seal behavior of Vault.
|
||||
Initialize Vault now, with 1 unseal key for simplicity, using the command:
|
||||
|
||||
vault init -key-shares=1 -key-threshold=1
|
||||
|
||||
You'll notice Vault prints out several keys here. Don't clear your terminal, as these are needed in the next few steps.
|
||||
|
||||

|
||||
|
||||
**Unsealing your Vault**
|
||||
|
||||
When a Vault server is started, it starts in a sealed state. In this state, Vault is configured to know where and how to access the physical storage, but doesn't know how to decrypt any of it.
|
||||
Vault encrypts data with an encryption key. This key is encrypted with the "master key", which isn't stored. Decrypting the master key requires a threshold of shards. In this example, we use one shard to decrypt this master key.
|
||||
|
||||
vault unseal <key 1>
|
||||
|
||||

|
||||
|
||||
**Authorize your requests**
|
||||
|
||||
Before performing any operation with Vault, the connecting client must be authenticated. Authentication is the process of verifying a person or machine is who they say they are and assigning an identity to them. This identity is then used when making requests with Vault.
|
||||
For simplicity, we'll use the root token we generated on init in Step 2. This output should be available in the scrollback.
|
||||
Authorize with a client token:
|
||||
|
||||
vault auth <root token>
|
||||
|
||||

|
||||
|
||||
**Read and write secrets**
|
||||
|
||||
Now that Vault has been set-up, we can start reading and writing secrets with the default mounted secret backend. Secrets written to Vault are encrypted and then written to the backend storage. The backend storage mechanism never sees the unencrypted value and doesn't have the means necessary to decrypt it without Vault.
|
||||
|
||||
vault write secret/hello value=world
|
||||
|
||||
Of course, you can then read this data too:
|
||||
|
||||
vault read secret/hello
|
||||
|
||||

|
||||
|
||||
**Seal your Vault**
|
||||
|
||||
There is also an API to seal the Vault. This will throw away the encryption key and require another unseal process to restore it. Sealing only requires a single operator with root privileges. This is typically part of a rare "break glass procedure".
|
||||
This way, if there is a detected intrusion, the Vault data can be locked quickly to try to minimize damages. It can't be accessed again without access to the master key shards.
|
||||
|
||||
vault seal
|
||||
|
||||

|
||||
|
||||
That is the end of introductory tutorial.
|
||||
|
||||
### Summary ###
|
||||
|
||||
Vault is a very useful application mainly because of providing a reliable and secure way of storing critical information. Furthermore it encrypts the critical information before storing, maintains audit logs, grants secret information for limited lease time and revokes it once lease is expired. It is platform independent and freely available to download and install. To discover more about Vault, readers are encouraged to visit the official website.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/how-tos/secure-secret-store-vault/
|
||||
|
||||
作者:[Aun Raza][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunrz/
|
||||
[1]:https://dl.bintray.com/mitchellh/vault/vault_0.1.0_linux_386.zip
|
||||
[2]:https://dl.bintray.com/mitchellh/vault/vault_0.1.0_linux_amd64.zip
|
||||
[3]:https://dl.bintray.com/mitchellh/vault/vault_0.1.0_linux_arm.zip
|
||||
@ -0,0 +1,112 @@
|
||||
How to Setup OpenERP (Odoo) on CentOS 7.x
|
||||
================================================================================
|
||||
Hi everyone, this tutorial is all about how we can setup Odoo (formerly known as OpenERP) on our CentOS 7 Server. Are you thinking to get an awesome ERP (Enterprise Resource Planning) app for your business ?. Then, OpenERP is the best app you are searching as it is a Free and Open Source Software which provides an outstanding features for your business or company.
|
||||
|
||||
[OpenERP][1] is a free and open source traditional OpenERP (Enterprise Resource Planning) app which includes Open Source CRM, Website Builder, eCommerce, Project Management, Billing & Accounting, Point of Sale, Human Resources, Marketing, Manufacturing, Purchase Management and many more modules included for a better way to boost the productivity and sales. Odoo Apps can be used as stand-alone applications, but they also integrate seamlessly so you get a full-featured Open Source ERP when you install several Apps.
|
||||
|
||||
So, here are some quick and easy steps to get your copy of OpenERP installed on your CentOS machine.
|
||||
|
||||
### 1. Installing PostgreSQL ###
|
||||
|
||||
First of all, we'll want to update the packages installed in our CentOS 7 machine to ensure that the latest packages, patches and security are up to date. To update our sytem, we should run the following command in a shell or terminal.
|
||||
|
||||
# yum clean all
|
||||
# yum update
|
||||
|
||||
Now, we'll want to install PostgreSQL Database System as OpenERP uses PostgreSQL for its database system. To install it, we'll need to run the following command.
|
||||
|
||||
# yum install postgresql postgresql-server postgresql-libs
|
||||
|
||||

|
||||
|
||||
After it is installed, we'll need to initialize the database with the following command
|
||||
|
||||
# postgresql-setup initdb
|
||||
|
||||

|
||||
|
||||
We'll then set PostgreSQL to start on every boot and start the PostgreSQL Database server.
|
||||
|
||||
# systemctl enable postgresql
|
||||
# systemctl start postgresql
|
||||
|
||||
As we haven't set a password for the user "postgresql", we'll want to set it now.
|
||||
|
||||
# su - postgres
|
||||
$ psql
|
||||
postgres=# \password postgres
|
||||
postgres=# \q
|
||||
# exit
|
||||
|
||||

|
||||
|
||||
### 2. Configuring Odoo Repository ###
|
||||
|
||||
After our Database Server has been installed correctly, we'll want add EPEL (Extra Packages for Enterprise Linux) to our CentOS server. Odoo (or OpenERP) depends on Python run-time and many other packages that are not included in default standard repository. As such, we'll want to add the Extra Packages for Enterprise Linux (or EPEL) repository support so that Odoo can get the required dependencies. To install, we'll need to run the following command.
|
||||
|
||||
# yum install epel-release
|
||||
|
||||

|
||||
|
||||
Now, after we install EPEL, we'll now add repository of Odoo (OpenERP) using yum-config-manager.
|
||||
|
||||
# yum install yum-utils
|
||||
|
||||
# yum-config-manager --add-repo=https://nightly.odoo.com/8.0/nightly/rpm/odoo.repo
|
||||
|
||||

|
||||
|
||||
### 3. Installing Odoo 8 (OpenERP) ###
|
||||
|
||||
Finally after adding repository of Odoo 8 (OpenERP) in our CentOS 7 machine. We'll can install Odoo 8 (OpenERP) using the following command.
|
||||
|
||||
# yum install -y odoo
|
||||
|
||||
The above command will install odoo along with the necessary dependency packages.
|
||||
|
||||

|
||||
|
||||
Now, we'll enable automatic startup of Odoo in every boot and will start our Odoo service using the command below.
|
||||
|
||||
# systemctl enable odoo
|
||||
# systemctl start odoo
|
||||
|
||||

|
||||
|
||||
### 4. Allowing Firewall ###
|
||||
|
||||
As Odoo uses port 8069, we'll need to allow firewall for remote access. We can allow firewall to port 8069 by running the following command.
|
||||
|
||||
# firewall-cmd --zone=public --add-port=8069/tcp --permanent
|
||||
# firewall-cmd --reload
|
||||
|
||||

|
||||
|
||||
**Note: By default, only connections from localhost are allowed. If we want to allow remote access to PostgreSQL databases, we'll need to add the line shown in the below image to pg_hba.conf configuration file:**
|
||||
|
||||
# nano /var/lib/pgsql/data/pg_hba.conf
|
||||
|
||||

|
||||
|
||||
### 5. Web Interface ###
|
||||
|
||||
Finally, as we have successfully installed our latest Odoo 8 (OpenERP) on our CentOS 7 Server, we can now access our Odoo by browsing to http://ip-address:8069 http://my-site.com:8069 using our favorite web browser. Then, first thing we'll gonna do is we'll create a new database and create a new password for it. Note, the master password is admin by default. Then, we can login to our panel with that username and password.
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Odoo 8 (formerly OpenERP) is the best ERP app available in the world of Open Source. We did an excellent work on installing it because OpenERP is a set of many modules which are essential for a complete ERP app for business and company. So, if you have any questions, suggestions, feedback please write them in the comment box below. Thank you ! Enjoy OpenERP (Odoo 8) :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/setup-openerp-odoo-centos-7/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:https://www.odoo.com/
|
||||
@ -0,0 +1,96 @@
|
||||
Linux FAQs with Answers--How to configure a Linux bridge with Network Manager on Ubuntu
|
||||
================================================================================
|
||||
> **Question**: I need to set up a Linux bridge on my Ubuntu box to share a NIC with several other virtual machines or containers created on the box. I am currently using Network Manager on my Ubuntu, so preferrably I would like to configure a bridge using Network Manager. How can I do that?
|
||||
|
||||
Network bridge is a hardware equipment used to interconnect two or more Layer-2 network segments, so that network devices on different segments can talk to each other. A similar bridging concept is needed within a Linux host, when you want to interconnect multiple VMs or Ethernet interfaces within a host. That is one use case of a software Linux bridge.
|
||||
|
||||
There are several different ways to configure a Linux bridge. For example, in a headless server environment, you can use [brctl][1] to manually configure a bridge. In desktop environment, bridge support is available in Network Manager. Let's examine how to configure a bridge with Network Manager.
|
||||
|
||||
### Requirement ###
|
||||
|
||||
To avoid [any issue][2], it is recommended that you have Network Manager 0.9.9 and higher, which is the case for Ubuntu 15.04 and later.
|
||||
|
||||
$ apt-cache show network-manager | grep Version
|
||||
|
||||
----------
|
||||
|
||||
Version: 0.9.10.0-4ubuntu15.1
|
||||
Version: 0.9.10.0-4ubuntu15
|
||||
|
||||
### Create a Bridge ###
|
||||
|
||||
The easiest way to create a bridge with Network Manager is via nm-connection-editor. This GUI tool allows you to configure a bridge in easy-to-follow steps.
|
||||
|
||||
To start, invoke nm-connection-editor.
|
||||
|
||||
$ nm-connection-editor
|
||||
|
||||
The editor window will show you a list of currently configured network connections. Click on "Add" button in the top right to create a bridge.
|
||||
|
||||
|
||||
|
||||
Next, choose "Bridge" as a connection type.
|
||||
|
||||
|
||||
|
||||
Now it's time to configure a bridge, including its name and bridged connection(s). With no other bridges created, the default bridge interface will be named bridge0.
|
||||
|
||||
Recall that the goal of creating a bridge is to share your Ethernet interface via the bridge. So you need to add the Ethernet interface to the bridge. This is achieved by adding a new "bridged connection" in the GUI. Click on "Add" button.
|
||||
|
||||
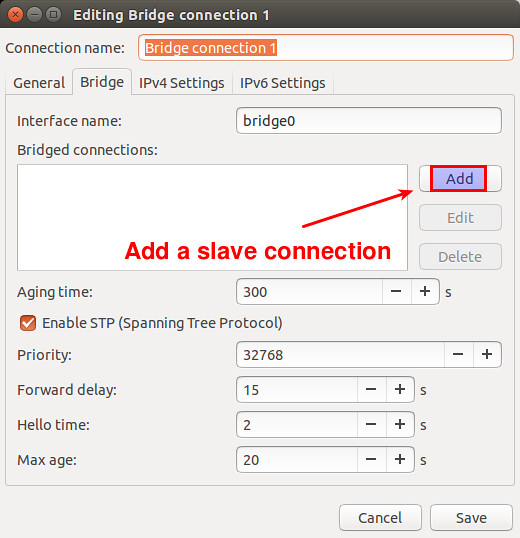
|
||||
|
||||
Choose "Ethernet" as a connection type.
|
||||
|
||||
|
||||
|
||||
In "Device MAC address" field, choose the interface that you want to enslave into the bridge. In this example, assume that this interface is eth0.
|
||||
|
||||

|
||||
|
||||
Click on "General" tab, and enable both checkboxes that say "Automatically connect to this network when it is available" and "All users may connect to this network".
|
||||
|
||||
|
||||
|
||||
Save the change.
|
||||
|
||||
Now you will see a new slave connection created in the bridge.
|
||||
|
||||
|
||||
|
||||
Click on "General" tab of the bridge, and make sure that top-most two checkboxes are enabled.
|
||||
|
||||
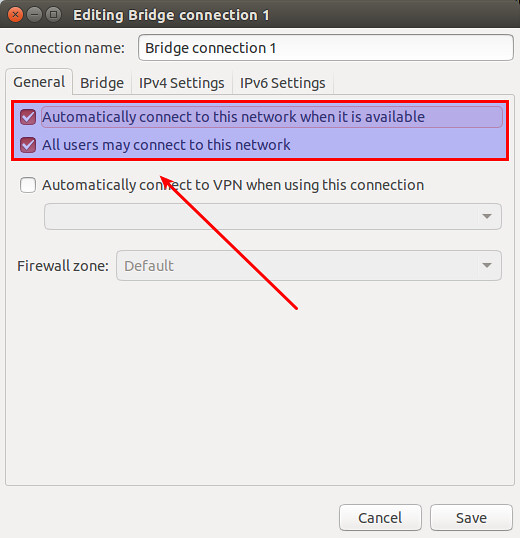
|
||||
|
||||
Go to "IPv4 Settings" tab, and configure either DHCP or static IP address for the bridge. Note that you should use the same IPv4 settings as the enslaved Ethernet interface eth0. In this example, we assume that eth0 is configured via DHCP. Thus choose "Automatic (DHCP)" here. If eth0 is assigned a static IP address, you should assign the same IP address to the bridge.
|
||||
|
||||
|
||||
|
||||
Finally, save the bridge settings.
|
||||
|
||||
Now you will see an additional bridge connection created in "Network Connections" window. You no longer need a previously-configured wired connection for the enslaved interface eth0. So go ahead and delete the original wired connection.
|
||||
|
||||
|
||||
|
||||
At this point, the bridge connection will automatically be activated. You will momentarily lose a connection, since the IP address assigned to eth0 is taken over by the bridge. Once an IP address is assigned to the bridge, you will be connected back to your Ethernet interface via the bridge. You can confirm that by checking "Network" settings.
|
||||
|
||||
|
||||
|
||||
Also, check the list of available interfaces. As mentioned, the bridge interface must have taken over whatever IP address was possessed by your Ethernet interface.
|
||||
|
||||
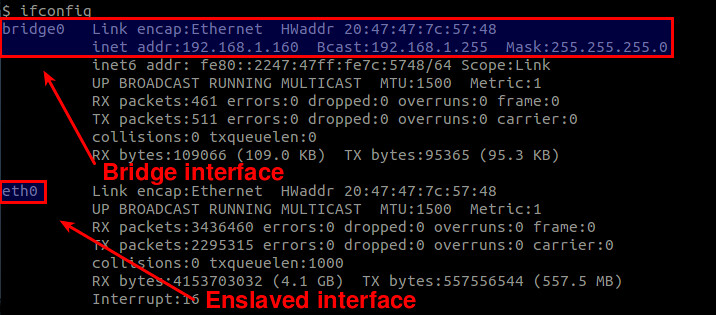
|
||||
|
||||
That's it, and now the bridge is ready to use!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/configure-linux-bridge-network-manager-ubuntu.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/how-to-configure-linux-bridge-interface.html
|
||||
[2]:https://bugs.launchpad.net/ubuntu/+source/network-manager/+bug/1273201
|
||||
@ -0,0 +1,78 @@
|
||||
Vic020
|
||||
|
||||
Linux FAQs with Answers--How to install autossh on Linux
|
||||
================================================================================
|
||||
> **Question**: I would like to install autossh on [insert your Linux distro]. How can I do that?
|
||||
|
||||
[autossh][1] is an open-source tool that allows you to monitor an SSH session and restart it automatically should it gets disconnected or stops forwarding traffic. autossh assumes that [passwordless SSH login][2] for a destination host is already setup, so that it can restart a broken SSH session without user's involvement.
|
||||
|
||||
autossh comes in handy when you want to set up [reverse SSH tunnels][3] or [mount remote folders over SSH][4]. Essentially in any situation where persistent SSH sessions are required, autossh can be useful.
|
||||
|
||||
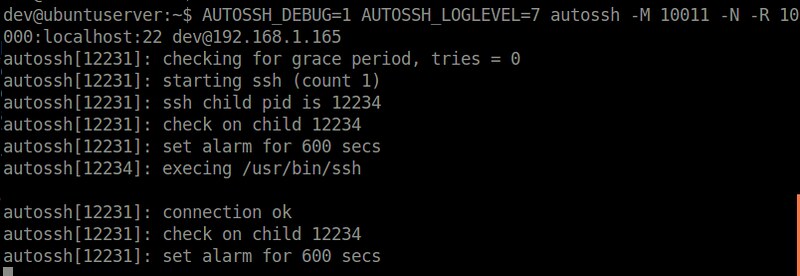
|
||||
|
||||
Here is how to install autossh on various Linux distributions.
|
||||
|
||||
### Install Autossh on Debian or Ubuntu ###
|
||||
|
||||
autossh is available in base repositories of Debian based systems, so installation is easy.
|
||||
|
||||
$ sudo apt-get install autossh
|
||||
|
||||
### Install Autossh on Fedora ###
|
||||
|
||||
Fedora repositories also carry autossh package. So simply use yum command.
|
||||
|
||||
$ sudo yum install autossh
|
||||
|
||||
### Install Autossh on CentOS or RHEL ###
|
||||
|
||||
For CentOS/RHEL 6 or earlier, enable [Repoforge repository][5] first, and then use yum command.
|
||||
|
||||
$ sudo yum install autossh
|
||||
|
||||
For CentOS/RHEL 7, autossh is no longer available in Repoforge repository. You will need to build it from the source (explained below).
|
||||
|
||||
### Install Autossh on Arch Linux ###
|
||||
|
||||
$ sudo pacman -S autossh
|
||||
|
||||
### Compile Autossh from the Source on Debian or Ubuntu ###
|
||||
|
||||
If you would like to try the latest version of autossh, you can build it from the source as follows.
|
||||
|
||||
$ sudo apt-get install gcc make
|
||||
$ wget http://www.harding.motd.ca/autossh/autossh-1.4e.tgz
|
||||
$ tar -xf autossh-1.4e.tgz
|
||||
$ cd autossh-1.4e
|
||||
$ ./configure
|
||||
$ make
|
||||
$ sudo make install
|
||||
|
||||
### Compile Autossh from the Source on CentOS, Fedora or RHEL ###
|
||||
|
||||
On CentOS/RHEL 7, autossh is not available as a pre-built package. So you'll need to compile it from the source as follows.
|
||||
|
||||
$ sudo yum install wget gcc make
|
||||
$ wget http://www.harding.motd.ca/autossh/autossh-1.4e.tgz
|
||||
$ tar -xf autossh-1.4e.tgz
|
||||
$ cd autossh-1.4e
|
||||
$ ./configure
|
||||
$ make
|
||||
$ sudo make install
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/install-autossh-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:http://www.harding.motd.ca/autossh/
|
||||
[2]:http://xmodulo.com/how-to-enable-ssh-login-without.html
|
||||
[3]:http://xmodulo.com/access-linux-server-behind-nat-reverse-ssh-tunnel.html
|
||||
[4]:http://xmodulo.com/how-to-mount-remote-directory-over-ssh-on-linux.html
|
||||
[5]:http://xmodulo.com/how-to-set-up-rpmforge-repoforge-repository-on-centos.html
|
||||
@ -0,0 +1,134 @@
|
||||
Install uGet Download Manager 2.0 in Debian, Ubuntu, Linux Mint and Fedora
|
||||
================================================================================
|
||||
After a long development period, which includes more than 11 developement releases, finally uGet project team pleased to announce the immediate availability of the latest stable version of uGet 2.0. The latest version includes numerous attractive features, such as a new setting dialog, improved BitTorrent and Metalink support added in the aria2 plugin, as well as better support for uGet RSS messages in the banner, other features include:
|
||||
|
||||
- A new “Check for Updates” button informs you about new released versions.
|
||||
- Added new languages & updated existing languages.
|
||||
- Added a new “Message Banner” that allows developers to easily provide uGet related information to all users.
|
||||
- Enhanced the Help Menu by including links to the Documentation, to submit Feedback & Bug Reports and more.
|
||||
- Integrated uGet download manager into the two major browsers on the Linux platform, Firefox and Google Chrome.
|
||||
- Improved support for Firefox Addon ‘FlashGot’.
|
||||
|
||||
### What is uGet ###
|
||||
|
||||
uGet (formerly known ad UrlGfe) is an open source, free and very powerful multi-platform GTK based download manager application was written in C language, that released and licensed under GPL. It offers large collection of features such as resuming downloads, multiple download support, categories support with an independent configuration, clipboard monitoring, download scheduler, import URLs from HTML files, integrated Flashgot plugin with Firefox and download torrent and metalink files using aria2 (a command-line download manager) that integrated with uGet.
|
||||
|
||||
I have listed down all the key features of uGet Download Manager in detailed explanation.
|
||||
|
||||
#### Key Features of uGet Download Manager ####
|
||||
|
||||
- Downloads Queue: Place all your downloads into a Queue. As downloads finishes, the remaining queue files will automatically start downloading.
|
||||
- Resume Downloads: If in case, your network connection disconnected, don’t worry you can start or resume download where it was left.
|
||||
- Download Categories: Support for unlimited categories to manage downloads.
|
||||
- Clipboard Monitor: Add the types of files to clipboard that automatically prompt you to download copied files.
|
||||
- Batch Downloads: Allows you to easily add unlimited number of files at once for downloading.
|
||||
- Multi-Protocol: Allows you to easily download files through HTTP, HTTPS, FTP, BitTorrent and Metalink using arial2 command-line plugin.
|
||||
- Multi-Connection: Support for up to 20 simultaneous connections per download using aria2 plugin.
|
||||
- FTP Login & Anonymous FTP: Added support for FTP login using username and password, as well as anonymous FTP.
|
||||
- Scheduler: Added support for scheduled downloads, now you can schedule all your downloads.
|
||||
- FireFox Integration via FlashGot: Integrated FlashGot as an independent supported Firefox extension that handles single or massive selection of files for downloading.
|
||||
- CLI / Terminal Support: Offers command line or terminal option to download files.
|
||||
- Folder Auto-Creation: If you have provided the save path for the download, but the save path doesn’t exist, uget will automatically create them.
|
||||
- Download History Management: Keeps a track of finished download and recycled entries, per list 9,999 files. Entries which are older than the custom limit will be deleted automatically.
|
||||
- Multi-Language Support: By default uGet uses English, but it support more than 23 languages.
|
||||
- Aria2 Plugin: uGet integrated with Aria2 plugin to give more user friendly GUI.
|
||||
|
||||
If you want to know a complete list of available features, see the official uGet [features page][1].
|
||||
|
||||
### Install uGet in Debian, Ubuntu, Linux Mint and Fedora ###
|
||||
|
||||
The uGet developers added latest version in various repos throughout the Linux platform, so you can able to install or upgrade uGet using supported repository under your Linux distribution.
|
||||
|
||||
Currently, a few Linux distributions are not up-to-date, but you can get the status of your distribution by going to the [uGet Download page][2] and selecting your preferred distro from there for more details.
|
||||
|
||||
#### On Debian ####
|
||||
|
||||
In Debian Testing (Jessie) and Debian Unstable (Sid), you can easily install and update using the official repository on a fairly reliable basis.
|
||||
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install uget
|
||||
|
||||
#### On Ubuntu & Linux Mint ####
|
||||
|
||||
In Ubuntu and Linux Mint, you can install and update uGet using official PPA repository ‘ppa:plushuang-tw/uget-stable‘. By using this PPA, you automatically be kept up-to-date with the latest versions.
|
||||
|
||||
$ sudo add-apt-repository ppa:plushuang-tw/uget-stable
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install uget
|
||||
|
||||
#### On Fedora ####
|
||||
|
||||
In Fedora 20 – 21, latest version of uGet (2.0) available from the official repositories, installing from these repo is fairly reliable.
|
||||
|
||||
$ sudo yum install uget
|
||||
|
||||
**Note**: On older versions of Debian, Ubuntu, Linux Mint and Fedora, users can also install uGet. but the available version is 1.10.4. If you are looking for updated version (i.e. 2.0) you need to upgrade your system and add uGet PPA to get latest stable version.
|
||||
|
||||
### Installing aria2 plugin ###
|
||||
|
||||
[aria2][3] is a excellent command-line download utility, that is used by uGet as a aria2 plugin to add even more great functionality such as downloading torrent files, metalinks, multi-protocol & multi-source download.
|
||||
|
||||
By default uGet uses CURL as backend in most of the today’s Linux systems, but the aria2 Plugin replaces CURL with aria2 as the backend.
|
||||
|
||||
aria2 is a separate package that needs to be installed separately. You can easily install latest version of aria2 using supported repository under your Linux distribution or you can also use [downloads-aria2][4] that explains how to install aria2 on each distro.
|
||||
|
||||
#### On Debian, Ubuntu and Linux Mint ####
|
||||
|
||||
Use the official aria2 PPA repository to install latest version of aria2 using the following commands.
|
||||
|
||||
$ sudo add-apt-repository ppa:t-tujikawa/ppa
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install aria2
|
||||
|
||||
#### On Fedora ####
|
||||
|
||||
Fedora’s official repositories already added aria2 package, so you can easily install it using the following yum command.
|
||||
|
||||
$ sudo yum install aria2
|
||||
|
||||
#### Starting uGet ####
|
||||
|
||||
To start uGet application, from the desktop “Menu” on search bar type “uget“. Refer below screenshot.
|
||||
|
||||

|
||||
Start uGet Download Manager
|
||||
|
||||

|
||||
uGet Version: 2.0
|
||||
|
||||
#### Activate aria2 Plugin in uGet ####
|
||||
|
||||
To active the aria2 plugin, from the uGet menu go to Edit –> Settings –> Plug-in tab, from the drop-down select “arial2“.
|
||||
|
||||

|
||||
Enable Aria2 Plugin for uGet
|
||||
|
||||
### uGet 2.0 Screenshot Tour ###
|
||||
|
||||

|
||||
Download Files Using Aria2
|
||||
|
||||

|
||||
Download Torrent File Using uGet
|
||||
|
||||

|
||||
Batch Downloads Using uGet
|
||||
|
||||
uGet source files and RPM packages also available for other Linux distributions and Windows at [download page][5].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-uget-download-manager-in-linux/
|
||||
|
||||
作者:[Ravi Saive][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/admin/
|
||||
[1]:http://uget.visuex.com/features
|
||||
[2]:http://ugetdm.com/downloads
|
||||
[3]:http://www.tecmint.com/install-aria2-a-multi-protocol-command-line-download-manager-in-rhel-centos-fedora/
|
||||
[4]:http://ugetdm.com/downloads-aria2
|
||||
[5]:http://ugetdm.com/downloads
|
||||
@ -0,0 +1,176 @@
|
||||
translating by cvsher
|
||||
Linux grep command with 14 different examples
|
||||
================================================================================
|
||||
### Overview : ###
|
||||
|
||||
Linux like operating system provides a searching tool known as **grep (global regular expression print)**. grep command is useful for searching the content of one more files based on the pattern. A pattern may be a single character, bunch of characters, single word or a sentence.
|
||||
|
||||
When we execute the grep command with specified pattern, if its is matched, then it will display the line of file containing the pattern without modifying the contents of existing file.
|
||||
|
||||
In this tutorial we will discuss 14 different examples of grep command
|
||||
|
||||
### Example:1 Search the pattern (word) in a file ###
|
||||
|
||||
Search the “linuxtechi” word in the file /etc/passwd file
|
||||
|
||||
root@Linux-world:~# grep linuxtechi /etc/passwd
|
||||
linuxtechi:x:1000:1000:linuxtechi,,,:/home/linuxtechi:/bin/bash
|
||||
root@Linux-world:~#
|
||||
|
||||
### Example:2 Search the pattern in the multiple files. ###
|
||||
|
||||
root@Linux-world:~# grep linuxtechi /etc/passwd /etc/shadow /etc/gshadow
|
||||
/etc/passwd:linuxtechi:x:1000:1000:linuxtechi,,,:/home/linuxtechi:/bin/bash
|
||||
/etc/shadow:linuxtechi:$6$DdgXjxlM$4flz4JRvefvKp0DG6re:16550:0:99999:7:::/etc/gshadow:adm:*::syslog,linuxtechi
|
||||
/etc/gshadow:cdrom:*::linuxtechi
|
||||
/etc/gshadow:sudo:*::linuxtechi
|
||||
/etc/gshadow:dip:*::linuxtechi
|
||||
/etc/gshadow:plugdev:*::linuxtechi
|
||||
/etc/gshadow:lpadmin:!::linuxtechi
|
||||
/etc/gshadow:linuxtechi:!::
|
||||
/etc/gshadow:sambashare:!::linuxtechi
|
||||
root@Linux-world:~#
|
||||
|
||||
### Example:3 List the name of those files which contain a specified pattern using -l option. ###
|
||||
|
||||
root@Linux-world:~# grep -l linuxtechi /etc/passwd /etc/shadow /etc/fstab /etc/mtab
|
||||
/etc/passwd
|
||||
/etc/shadow
|
||||
root@Linux-world:~#
|
||||
|
||||
### Example:4 Search the pattern in the file along with associated line number(s) using the -n option ###
|
||||
|
||||
root@Linux-world:~# grep -n linuxtechi /etc/passwd
|
||||
39:linuxtechi:x:1000:1000:linuxtechi,,,:/home/linuxtechi:/bin/bash
|
||||
root@Linux-world:~#
|
||||
|
||||
root@Linux-world:~# grep -n root /etc/passwd /etc/shadow
|
||||
|
||||

|
||||
|
||||
### Example:5 Print the line excluding the pattern using -v option ###
|
||||
|
||||
List all the lines of the file /etc/passwd that does not contain specific word “linuxtechi”.
|
||||
|
||||
root@Linux-world:~# grep -v linuxtechi /etc/passwd
|
||||
|
||||
|
||||
|
||||
### Example:6 Display all the lines that starts with specified pattern using ^ symbol ###
|
||||
|
||||
Bash shell treats carrot symbol (^) as a special character which marks the beginning of line or a word. Let’s display the lines which starts with “root” word in the file /etc/passwd.
|
||||
|
||||
root@Linux-world:~# grep ^root /etc/passwd
|
||||
root:x:0:0:root:/root:/bin/bash
|
||||
root@Linux-world:~#
|
||||
|
||||
### Example: 7 Display all the lines that ends with specified pattern using $ symbol. ###
|
||||
|
||||
List all the lines of /etc/passwd that ends with “bash” word.
|
||||
|
||||
root@Linux-world:~# grep bash$ /etc/passwd
|
||||
root:x:0:0:root:/root:/bin/bash
|
||||
linuxtechi:x:1000:1000:linuxtechi,,,:/home/linuxtechi:/bin/bash
|
||||
root@Linux-world:~#
|
||||
|
||||
Bash shell treats dollar ($) symbol as a special character which marks the end of line or word.
|
||||
|
||||
### Example:8 Search the pattern recursively using -r option ###
|
||||
|
||||
root@Linux-world:~# grep -r linuxtechi /etc/
|
||||
/etc/subuid:linuxtechi:100000:65536
|
||||
/etc/group:adm:x:4:syslog,linuxtechi
|
||||
/etc/group:cdrom:x:24:linuxtechi
|
||||
/etc/group:sudo:x:27:linuxtechi
|
||||
/etc/group:dip:x:30:linuxtechi
|
||||
/etc/group:plugdev:x:46:linuxtechi
|
||||
/etc/group:lpadmin:x:115:linuxtechi
|
||||
/etc/group:linuxtechi:x:1000:
|
||||
/etc/group:sambashare:x:131:linuxtechi
|
||||
/etc/passwd-:linuxtechi:x:1000:1000:linuxtechi,,,:/home/linuxtechi:/bin/bash
|
||||
/etc/passwd:linuxtechi:x:1000:1000:linuxtechi,,,:/home/linuxtechi:/bin/bash
|
||||
............................................................................
|
||||
|
||||
Above command will search linuxtechi in the “/etc” directory recursively.
|
||||
|
||||
### Example:9 Search all the empty or blank lines of a file using grep ###
|
||||
|
||||
root@Linux-world:~# grep ^$ /etc/shadow
|
||||
root@Linux-world:~#
|
||||
|
||||
As there is no empty line in /etc/shadow file , so nothing is displayed.
|
||||
|
||||
### Example:10 Search the pattern using ‘grep -i’ option. ###
|
||||
|
||||
-i option in the grep command ignores the letter case i.e it will ignore upper case or lower case letters while searching
|
||||
|
||||
Lets take an example , i want to search “LinuxTechi” word in the passwd file.
|
||||
|
||||
nextstep4it@localhost:~$ grep -i LinuxTechi /etc/passwd
|
||||
linuxtechi:x:1001:1001::/home/linuxtechi:/bin/bash
|
||||
nextstep4it@localhost:~$
|
||||
|
||||
### Example:11 Search multiple patterns using -e option ###
|
||||
|
||||
For example i want to search ‘linuxtechi’ and ‘root’ word in a single grep command , then using -e option we can search multiple patterns .
|
||||
|
||||
root@Linux-world:~# grep -e "linuxtechi" -e "root" /etc/passwd
|
||||
root:x:0:0:root:/root:/bin/bash
|
||||
linuxtechi:x:1000:1000:linuxtechi,,,:/home/linuxtechi:/bin/bash
|
||||
root@Linux-world:~#
|
||||
|
||||
### Example:12 Getting Search pattern from a file using “grep -f” ###
|
||||
|
||||
First create a search pattern file “grep_pattern” in your current working directory. In my case i have put the below contents.
|
||||
|
||||
root@Linux-world:~# cat grep_pattern
|
||||
^linuxtechi
|
||||
root
|
||||
false$
|
||||
root@Linux-world:~#
|
||||
|
||||
Now try to search using grep_pattern file.
|
||||
|
||||
root@Linux-world:~# grep -f grep_pattern /etc/passwd
|
||||
|
||||
|
||||
|
||||
### Example:13 Count the number of matching patterns using -c option ###
|
||||
|
||||
Let take the above example , we can count the number of matching patterns using -c option in grep command.
|
||||
|
||||
root@Linux-world:~# grep -c -f grep_pattern /etc/passwd
|
||||
22
|
||||
root@Linux-world:~#
|
||||
|
||||
### Example:14 Display N number of lines before & after pattern matching ###
|
||||
|
||||
a) Display Four lines before patten matching using -B option
|
||||
|
||||
root@Linux-world:~# grep -B 4 "games" /etc/passwd
|
||||
|
||||
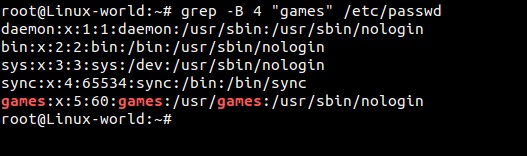
|
||||
|
||||
b) Display Four lines after pattern matching using -A option
|
||||
|
||||
root@Linux-world:~# grep -A 4 "games" /etc/passwd
|
||||
|
||||
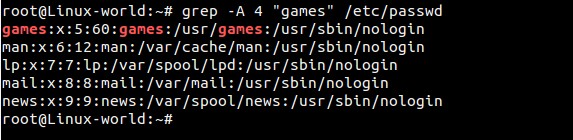
|
||||
|
||||
c) Display Four lines around the pattern matching using -C option
|
||||
|
||||
root@Linux-world:~# grep -C 4 "games" /etc/passwd
|
||||
|
||||
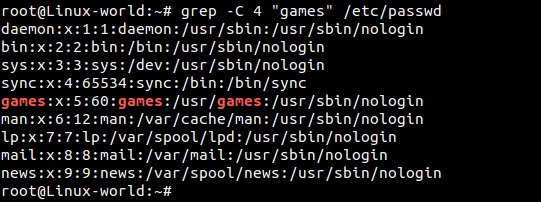
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxtechi.com/linux-grep-command-with-14-different-examples/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxtechi.com/author/pradeep/
|
||||
@ -1,40 +0,0 @@
|
||||
这个工具可以提醒你一个区域内的假面猎手接入点 (注:evil twin暂无相关翻译)
|
||||
===============================================================================
|
||||
**开发人员称,EvilAP_Defender甚至可以攻击流氓Wi-Fi接入点**
|
||||
|
||||
一个新的开源工具可以定期扫描一个区域,以防流氓Wi-Fi接入点,同时如果发现情况会提醒网络管理员。
|
||||
|
||||
这个工具叫做EvilAP_Defender,是为监测攻击者配置的恶意接入点而专门设计的,这些接入点冒用合法的名字诱导用户连接上。
|
||||
|
||||
这类接入点被称做假面猎手,使得黑客们从接入的设备上监听互联网信息流。这可以被用来窃取证书,破坏网站等等。
|
||||
|
||||
大多数用户设置他们的计算机和设备可以自动连接一些无线网络,比如家里的或者工作地方的网络。尽管如此,当面对两个同名的无线网络时,即SSID相同,有时候甚至时MAC地址也相同,这时候大多数设备会自动连接信号较强的一个。
|
||||
|
||||
这使得假面猎手的攻击容易实现,因为SSID和BSSID都可以伪造。
|
||||
|
||||
[EvilAP_Defender][1]是一个叫Mohamed Idris的人用Python语言编写,公布在GitHub上面。它可以使用一个计算机的无线网卡来发现流氓接入点,这些接入点复制了一个真实接入点的SSID,BSSID,甚至是其他的参数如通道,密码,隐私协议和认证信息。
|
||||
|
||||
该工具首先以学习模式运行,为了发现合法的接入点[AP],并且加入白名单。然后切换到正常模式,开始扫描未认证的接入点。
|
||||
|
||||
如果一个恶意[AP]被发现了,该工具会用电子邮件提醒网络管理员,但是开发者也打算在未来加入短信提醒功能。
|
||||
|
||||
该工具还有一个保护模式,在这种模式下,应用会发起一个denial-of-service [DoS]攻击反抗恶意接入点,为管理员采取防卫措施赢得一些时间。
|
||||
|
||||
“DoS不仅针对有着相同SSID的恶意AP,也针对BSSID(AP的MAC地址)不同或者不同信道的,”Idris在这款工具的文档中说道。“这是避免攻击你的合法网络。”
|
||||
|
||||
尽管如此,用户应该切记在许多国家,攻击别人的接入点,甚至一个可能一个攻击者操控的恶意的接入点,很多时候都是非法的。
|
||||
|
||||
为了能够运行这款工具,需要Aircrack-ng无线网套装,一个支持Aircrack-ng的无线网卡,MySQL和Python运行环境。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoworld.com/article/2905725/security0/this-tool-can-alert-you-about-evil-twin-access-points-in-the-area.html
|
||||
|
||||
作者:[Lucian Constantin][a]
|
||||
译者:[wi-cuckoo](https://github.com/wi-cuckoo)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.infoworld.com/author/Lucian-Constantin/
|
||||
[1] https://github.com/moha99sa/EvilAP_Defender/blob/master/README.TXT
|
||||
@ -0,0 +1,160 @@
|
||||
如何在 Docker 容器之间设置网络
|
||||
================================================================================
|
||||
你也许已经知道了,Docker 容器技术是现有的成熟虚拟化技术的一个替代方案。它被企业应用在越来越多的领域中,比如快速部署环境、简化基础设施的配置流程、多客户环境间的互相隔离等等。当你开始在真实的生产环境使用 Docker 容器去部署应用沙箱时,你可能需要用到多个容器部署一套复杂的多层应用系统,其中每个容器负责一个特定的功能(例如负载均衡、LAMP 栈、数据库、UI 等)。
|
||||
|
||||
那么问题来了:有多台宿主机,我们事先不知道会在哪台宿主机上创建容器,如果保证在这些宿主机上创建的容器们可以互相联网?
|
||||
|
||||
联网技术哪家强?开源方案找 [weave][1]。这个工具可以为你省下不少烦恼。听我的准没错,谁用谁知道。
|
||||
|
||||
于是本教程的主题就变成了“**如何使用 weave 在不同主机上的 Docker 容器之间设置网络**”。
|
||||
|
||||
### Weave 是如何工作的 ###
|
||||
|
||||

|
||||
|
||||
让我们先来看看 weave 怎么工作:先创建一个由多个 peer 组成的对等网络,每个 peer 是一个虚拟路由器容器,叫做“weave 路由器”,它们分布在不同的宿主机上。这个对等网络的每个 peer 之间会维持一个 TCP 链接,用于互相交换拓扑信息,它们也会建立 UDP 链接用于容器间通信。一个 weave 路由器通过桥接技术连接到其他本宿主机上的其他容器。当处于不同宿主机上的两个容器想要通信,一台宿主机上的 weave 路由器通过网桥截获数据包,使用 UDP 协议封装后发给另一台宿主机上的 weave 路由器。
|
||||
|
||||
每个 weave 路由器会刷新整个对等网络的拓扑信息,像容器的 MAC 地址(就像交换机的 MAC 地址学习一样获取其他容器的 MAC 地址),因此它可以决定数据包的下一跳是往哪个容器的。weave 能让两个处于不同宿主机的容器进行通信,只要这两台宿主机在 weave 拓扑结构内连到同一个 weave 路由器。另外,weave 路由器还能使用公钥加密技术将 TCP 和 UDP 数据包进行加密。
|
||||
|
||||
### 准备工作 ###
|
||||
|
||||
在使用 weave 之前,你需要在所有宿主机上安装 Docker[2] 环境,参考[这些][3][教程][4],在 Ubuntu 或 CentOS/Fedora 发行版中安装 Docker。
|
||||
|
||||
Docker 环境部署完成后,使用下面的命令安装 weave:
|
||||
|
||||
$ wget https://github.com/zettio/weave/releases/download/latest_release/weave
|
||||
$ chmod a+x weave
|
||||
$ sudo cp weave /usr/local/bin
|
||||
|
||||
注意你的 PATH 环境变量要包含 /usr/local/bin 这个路径,请在 /etc/profile 文件中加入一行(LCTT 注:要使环境变量生效,你需要执行这个命令: src /etc/profile):
|
||||
|
||||
export PATH="$PATH:/usr/local/bin"
|
||||
|
||||
在每台宿主机上重复上面的操作。
|
||||
|
||||
Weave 在 TCP 和 UDP 上都使用 6783 端口,如果你的系统开启了防火墙,请确保这两个端口不会被防火墙挡住。
|
||||
|
||||
### 在每台宿主机上开启 Weave 路由器 ###
|
||||
|
||||
当你想要让处于在不同宿主机上的容器能够互相通信,第一步要做的就是在每台宿主机上开启 weave 路由器。
|
||||
|
||||
第一台宿主机,运行下面的命令,就会创建并开启一个 weave 路由器容器(LCTT 注:前面说过了,weave 路由器也是一个容器):
|
||||
|
||||
$ sudo weave launch
|
||||
|
||||
第一次运行这个命令的时候,它会下载一个 weave 镜像,这会花一些时间。下载完成后就会自动运行这个镜像。成功启动后,终端会打印这个 weave 路由器的 ID 号。
|
||||
|
||||
下面的命令用于查看路由器状态:
|
||||
|
||||
$ sudo weave status
|
||||
|
||||

|
||||
|
||||
第一个 weave 路由器就绪了,目前为止整个 peer 对等网络中只有一个 peer 成员。
|
||||
|
||||
你也可以使用 doceker 的命令来查看 weave 路由器的状态:
|
||||
|
||||
$ docker ps
|
||||
|
||||

|
||||
|
||||
第二台宿主机部署步骤稍微有点不同,我们需要为这台宿主机的 weave 路由器指定第一台宿主机的 IP 地址,命令如下:
|
||||
|
||||
$ sudo weave launch <first-host-IP-address>
|
||||
|
||||
当你查看路由器状态,你会看到两个 peer 成员:当前宿主机和第一个宿主机。
|
||||
|
||||

|
||||
|
||||
当你开启更多路由器,这个 peer 成员列表会更长。当你新开一个路由器时,要指定前一个宿主机的 IP 地址,请注意不是第一个宿主机的 IP 地址。
|
||||
|
||||
现在你已经有了一个 weave 网络了,它由位于不同宿主机的 weave 路由器组成。
|
||||
|
||||
### 把不同宿主机上的容器互联起来 ###
|
||||
|
||||
接下来要做的就是在不同宿主机上开启 Docker 容器,并使用虚拟网络将它们互联起来。
|
||||
|
||||
假设我们创建一个私有网络 10.0.0.0/24 来互联 Docker 容器,并为这些容器随机分配 IP 地址。
|
||||
|
||||
如果你想新建一个能加入 weave 网络的容器,你就需要使用 weave 命令来创建,而不是 docker 命令。原因是 weave 命令内部会调用 docker 命令来新建容器然后为它设置网络。
|
||||
|
||||
下面的命令是在宿主机 hostA 上建立一个 Ubuntu 容器,然后将它放到 10.0.0.0/24 网络中,分配的 IP 地址为 10.0.0.1:
|
||||
|
||||
hostA:~$ sudo weave run 10.0.0.1/24 -t -i ubuntu
|
||||
|
||||
成功运行后,终端会打印出容器的 ID 号。你可以使用这个 ID 来访问这个容器:
|
||||
|
||||
hostA:~$ docker attach <container-id>
|
||||
|
||||
在宿主机 hostB 上,也创建一个 Ubuntu 容器,IP 地址为 10.0.0.2:
|
||||
|
||||
hostB:~$ sudo weave run 10.0.0.2/24 -t -i ubuntu
|
||||
|
||||
访问下这个容器的控制台:
|
||||
|
||||
hostB:~$ docker attach <container-id>
|
||||
|
||||
这两个容器能够互相 ping 通,你可以通过容器的控制台检查一下。
|
||||
|
||||

|
||||
|
||||
如果你检查一下每个容器的网络配置,你会发现有一块名为“ethwe”的网卡,你分配给容器的 IP 地址出现在它们那里(比如这里分别是 10.0.0.1 和 10.0.0.2)。
|
||||
|
||||

|
||||
|
||||
### Weave 的其他高级用法 ###
|
||||
|
||||
weave 提供了一些非常巧妙的特性,我在这里作下简单的介绍。
|
||||
|
||||
#### 应用分离 ####
|
||||
|
||||
使用 weave,你可以创建多个虚拟网络,并为每个网络设置不同的应用。比如你可以为一群容器创建 10.0.0.0/24 网络,为另一群容器创建 10.10.0.0/24 网络,weave 会自动帮你维护这些网络,并将这两个网络互相隔离。另外,你可以灵活地将一个容器从一个网络移到另一个网络而不需要重启容器。举个例子:
|
||||
|
||||
首先开启一个容器,运行在 10.0.0.0/24 网络上:
|
||||
|
||||
$ sudo weave run 10.0.0.2/24 -t -i ubuntu
|
||||
|
||||
然后让它脱离这个网络:
|
||||
|
||||
$ sudo weave detach 10.0.0.2/24 <container-id>
|
||||
|
||||
最后将它加入到 10.10.0.0/24 网络中:
|
||||
|
||||
$ sudo weave attach 10.10.0.2/24 <container-id>
|
||||
|
||||

|
||||
|
||||
现在这个容器可以与 10.10.0.0/24 网络上的其它容器进行通信了。当你要把容器加入一个网络,而这个网络暂时不可用时,上面的步骤就很有帮助了。
|
||||
|
||||
#### 将 weave 网络与宿主机网络整合起来 ####
|
||||
|
||||
有时候你想让虚拟网络中的容器能访问物理主机的网络。或者相反,宿主机需要访问容器。为满足这个功能,weave 允许虚拟网络与宿主机网络整合。
|
||||
|
||||
举个例子,在宿主机 hostA 上一个容器运行在 10.0.0.0/24 中,运行使用下面的命令:
|
||||
|
||||
hostA:~$ sudo weave expose 10.0.0.100/24
|
||||
|
||||
这个命令把 IP 地址 10.0.0.100 分配给宿主机 hostA,这样一来 hostA 也连到了 10.0.0.0/24 网络上了。很明显,你在为宿主机选择 IP 地址的时候,需要选一个没有被其他容器使用的地址。
|
||||
|
||||
现在 hostA 就可以访问 10.0.0.0/24 上的所有容器了,不管这些容器是否位于 hostA 上。好巧妙的设定啊,32 个赞!
|
||||
|
||||
### 总结 ###
|
||||
|
||||
如你所见,weave 是一个很有用的 docker 网络配置工具。这个教程只是[它强悍功能][5]的冰山一角。如果你想进一步玩玩,你可以试试它的以下功能:多跳路由功能,这个在 multi-cloud 环境(LCTT 注:多云,企业使用多个不同的云服务提供商的产品,比如 IaaS 和 SaaS,来承载不同的业务)下还是很有用的;动态重路由功能是一个很巧妙的容错技术;或者它的分布式 DNS 服务,它允许你为你的容器命名。如果你决定使用这个好东西,欢迎分享你的使用心得。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/networking-between-docker-containers.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[bazz2](https://github.com/bazz2)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:https://github.com/zettio/weave
|
||||
[2]:http://xmodulo.com/recommend/dockerbook
|
||||
[3]:http://xmodulo.com/manage-linux-containers-docker-ubuntu.html
|
||||
[4]:http://xmodulo.com/docker-containers-centos-fedora.html
|
||||
[5]:http://zettio.github.io/weave/features.html
|
||||
@ -0,0 +1,56 @@
|
||||
Linux有问必答:如何在虚拟机上配置PCI-passthrough
|
||||
================================================================================
|
||||
> **提问**:我想要设置一块物理网卡到用KVM创建的虚拟机上。我打算开启网卡的PCI passthrough给这台虚拟机。请问,我如何才能增加一个PCI设备通过PCI直通到虚拟机上?
|
||||
|
||||
如今的hypervisor能够高效地在多个虚拟操作系统分享和模拟硬件资源。然而,虚拟资源分享,虚拟机的性能,或者是虚拟机需要硬件DMA的完全控制,不是总能使人满意。一项名叫“PCI passthrough”的技术可以用在一个虚拟机需要独享PCI设备时(例如:network/sound/video card)。本质上,PCI passthrough越过了虚拟层,直接扩展PCI设备到虚拟机。但是其他虚拟机不能同时共享。
|
||||
|
||||
|
||||
### 开启“PCI Passthrough”的准备 ###
|
||||
|
||||
如果你想要为一台HVM实例开启PCI passthrough(例如,一台KVM创建的full虚拟机),你的母系统(包括CPU和主板)必须满足以下条件。但是如果你的虚拟机是para-V(由Xen创建),你可以挑过这步。
|
||||
|
||||
为了开启PCI passthrough,系统需要支持**VT-d** (Intel处理器)或者**AMD-Vi** (AMD处理器)。Intel的VT-D(“英特尔虚拟化技术支持直接I/ O”)是适用于最高端的Nehalem处理器和它的后继者(例如,Westmere、Sandy Bridge的,Ivy Bridge)。注意:VT-d和VT-x是两个独立功能。intel/AMD处理器支持VT-D/AMD-VI功能的列表可以[点击这里][1]。
|
||||
|
||||
完成验证你的设备支持VT-d/AMD-Vi后,还有两件事情需要做。首先,确保VT-d/AMD-Vi已经在BIOS中开启。然后,在内核启动过程中开启IOMMU。IOMMU服务,是VT-d,/AMD-Vi提供,可以保护虚拟机访问的主机内存,同时它也是full虚拟机支持PCI passthrough的前提。
|
||||
|
||||
Intel处理器中,内核开启IOMMU通过在启动参数中修改“**intel_iommu=on**”。参看[这篇教程][2]获得如何通过GRUB修改内核启动参数。
|
||||
|
||||
配置完成启动参数后,重启电脑。
|
||||
|
||||
### 添加PCI设备到虚拟机 ###
|
||||
|
||||
我们已经完成了开启PCI Passthrough的准备。事实上,只需通过虚拟机管理就可以给虚拟机分配一个PCI设备。
|
||||
|
||||
打开虚拟机设置,在左边工具栏点击‘增加硬件’按钮。
|
||||
|
||||
选择从PCI设备表一个PCI设备来分配,点击“完成”按钮
|
||||
|
||||

|
||||
|
||||
最后,开启实例。目前为止,主机的PCI设备已经可以由虚拟机直接访问了。
|
||||
|
||||
### 常见问题 ###
|
||||
|
||||
在虚拟机启动时,如果你看见下列任何一个错误,这个错误有可能由于母机VT-d (或 IOMMU)未开启导致。
|
||||
|
||||
Error starting domain: unsupported configuration: host doesn't support passthrough of host PCI devices
|
||||
|
||||
----------
|
||||
|
||||
Error starting domain: Unable to read from monitor: Connection reset by peer
|
||||
|
||||
请确保"**intel_iommu=on**"启动参数已经按上文叙述开启。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/pci-passthrough-virt-manager.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[Vic020/VicYu](http://vicyu.net)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:http://wiki.xenproject.org/wiki/VTdHowTo
|
||||
[2]:http://xmodulo.com/add-kernel-boot-parameters-via-grub-linux.html
|
||||
@ -0,0 +1,579 @@
|
||||
在Linux中使用‘Systemctl’管理‘Systemd’服务和单元
|
||||
================================================================================
|
||||
Systemctl是一个systemd工具,主要负责控制systemd系统和服务管理器。
|
||||
|
||||
Systemd是一个系统管理守护进程、工具和库的集合,用于取代System V初始进程。Systemd的功能是用于集中管理和配置类UNIX系统。
|
||||
|
||||
在Linux生态系统中,Systemd被部署到了大多数的标准Linux发行版中,只有位数不多的几个尚未部署。Systemd通常是所有其它守护进程的父进程,但并非总是如此。
|
||||
|
||||

|
||||
使用Systemctl管理Linux服务
|
||||
|
||||
本文旨在阐明在运行systemd的系统上“如何控制系统和服务”。
|
||||
|
||||
### Systemd初体验和Systemctl基础 ###
|
||||
|
||||
#### 1. 首先检查你的系统中是否安装有systemd并确定当前安装的版本 ####
|
||||
|
||||
# systemd --version
|
||||
|
||||
systemd 215
|
||||
+PAM +AUDIT +SELINUX +IMA +SYSVINIT +LIBCRYPTSETUP +GCRYPT +ACL +XZ -SECCOMP -APPARMOR
|
||||
|
||||
上例中很清楚地表明,我们安装了215版本的systemd。
|
||||
|
||||
#### 2. 检查systemd和systemctl的二进制文件和库文件的安装位置 ####
|
||||
|
||||
# whereis systemd
|
||||
systemd: /usr/lib/systemd /etc/systemd /usr/share/systemd /usr/share/man/man1/systemd.1.gz
|
||||
|
||||
|
||||
# whereis systemctl
|
||||
systemctl: /usr/bin/systemctl /usr/share/man/man1/systemctl.1.gz
|
||||
|
||||
#### 3. 检查systemd是否运行 ####
|
||||
|
||||
# ps -eaf | grep [s]ystemd
|
||||
|
||||
root 1 0 0 16:27 ? 00:00:00 /usr/lib/systemd/systemd --switched-root --system --deserialize 23
|
||||
root 444 1 0 16:27 ? 00:00:00 /usr/lib/systemd/systemd-journald
|
||||
root 469 1 0 16:27 ? 00:00:00 /usr/lib/systemd/systemd-udevd
|
||||
root 555 1 0 16:27 ? 00:00:00 /usr/lib/systemd/systemd-logind
|
||||
dbus 556 1 0 16:27 ? 00:00:00 /bin/dbus-daemon --system --address=systemd: --nofork --nopidfile --systemd-activation
|
||||
|
||||
**注意**:systemd是作为父进程(PID=1)运行的。在上面带(-e)参数的ps命令输出中,选择所有进程,(-
|
||||
|
||||
a)选择除会话前导外的所有进程,并使用(-f)参数输出完整格式列表(如 -eaf)。
|
||||
|
||||
也请注意上例中后随的方括号和样例剩余部分。方括号表达式是grep的字符类表达式的一部分。
|
||||
|
||||
#### 4. 分析systemd启动进程 ####
|
||||
|
||||
# systemd-analyze
|
||||
Startup finished in 487ms (kernel) + 2.776s (initrd) + 20.229s (userspace) = 23.493s
|
||||
|
||||
#### 5. 分析启动时各个进程花费的时间 ####
|
||||
|
||||
# systemd-analyze blame
|
||||
|
||||
8.565s mariadb.service
|
||||
7.991s webmin.service
|
||||
6.095s postfix.service
|
||||
4.311s httpd.service
|
||||
3.926s firewalld.service
|
||||
3.780s kdump.service
|
||||
3.238s tuned.service
|
||||
1.712s network.service
|
||||
1.394s lvm2-monitor.service
|
||||
1.126s systemd-logind.service
|
||||
....
|
||||
|
||||
#### 6. 分析启动时的关键链 ####
|
||||
|
||||
# systemd-analyze critical-chain
|
||||
|
||||
The time after the unit is active or started is printed after the "@" character.
|
||||
The time the unit takes to start is printed after the "+" character.
|
||||
|
||||
multi-user.target @20.222s
|
||||
└─mariadb.service @11.657s +8.565s
|
||||
└─network.target @11.168s
|
||||
└─network.service @9.456s +1.712s
|
||||
└─NetworkManager.service @8.858s +596ms
|
||||
└─firewalld.service @4.931s +3.926s
|
||||
└─basic.target @4.916s
|
||||
└─sockets.target @4.916s
|
||||
└─dbus.socket @4.916s
|
||||
└─sysinit.target @4.905s
|
||||
└─systemd-update-utmp.service @4.864s +39ms
|
||||
└─auditd.service @4.563s +301ms
|
||||
└─systemd-tmpfiles-setup.service @4.485s +69ms
|
||||
└─rhel-import-state.service @4.342s +142ms
|
||||
└─local-fs.target @4.324s
|
||||
└─boot.mount @4.286s +31ms
|
||||
└─systemd-fsck@dev-disk-by\x2duuid-79f594ad\x2da332\x2d4730\x2dbb5f\x2d85d19608096
|
||||
└─dev-disk-by\x2duuid-79f594ad\x2da332\x2d4730\x2dbb5f\x2d85d196080964.device @4
|
||||
|
||||
**重要**:Systemctl接受服务(.service),挂载点(.mount),套接口(.socket)和设备(.device)作为单元。
|
||||
|
||||
#### 7. 列出所有可用单元 ####
|
||||
|
||||
# systemctl list-unit-files
|
||||
|
||||
UNIT FILE STATE
|
||||
proc-sys-fs-binfmt_misc.automount static
|
||||
dev-hugepages.mount static
|
||||
dev-mqueue.mount static
|
||||
proc-sys-fs-binfmt_misc.mount static
|
||||
sys-fs-fuse-connections.mount static
|
||||
sys-kernel-config.mount static
|
||||
sys-kernel-debug.mount static
|
||||
tmp.mount disabled
|
||||
brandbot.path disabled
|
||||
.....
|
||||
|
||||
#### 8. 列出所有运行中单元 ####
|
||||
|
||||
# systemctl list-units
|
||||
|
||||
UNIT LOAD ACTIVE SUB DESCRIPTION
|
||||
proc-sys-fs-binfmt_misc.automount loaded active waiting Arbitrary Executable File Formats File Syste
|
||||
sys-devices-pc...0-1:0:0:0-block-sr0.device loaded active plugged VBOX_CD-ROM
|
||||
sys-devices-pc...:00:03.0-net-enp0s3.device loaded active plugged PRO/1000 MT Desktop Adapter
|
||||
sys-devices-pc...00:05.0-sound-card0.device loaded active plugged 82801AA AC'97 Audio Controller
|
||||
sys-devices-pc...:0:0-block-sda-sda1.device loaded active plugged VBOX_HARDDISK
|
||||
sys-devices-pc...:0:0-block-sda-sda2.device loaded active plugged LVM PV Qzyo3l-qYaL-uRUa-Cjuk-pljo-qKtX-VgBQ8
|
||||
sys-devices-pc...0-2:0:0:0-block-sda.device loaded active plugged VBOX_HARDDISK
|
||||
sys-devices-pl...erial8250-tty-ttyS0.device loaded active plugged /sys/devices/platform/serial8250/tty/ttyS0
|
||||
sys-devices-pl...erial8250-tty-ttyS1.device loaded active plugged /sys/devices/platform/serial8250/tty/ttyS1
|
||||
sys-devices-pl...erial8250-tty-ttyS2.device loaded active plugged /sys/devices/platform/serial8250/tty/ttyS2
|
||||
sys-devices-pl...erial8250-tty-ttyS3.device loaded active plugged /sys/devices/platform/serial8250/tty/ttyS3
|
||||
sys-devices-virtual-block-dm\x2d0.device loaded active plugged /sys/devices/virtual/block/dm-0
|
||||
sys-devices-virtual-block-dm\x2d1.device loaded active plugged /sys/devices/virtual/block/dm-1
|
||||
sys-module-configfs.device loaded active plugged /sys/module/configfs
|
||||
...
|
||||
|
||||
#### 9. 列出所有失败单元 ####
|
||||
|
||||
# systemctl --failed
|
||||
|
||||
UNIT LOAD ACTIVE SUB DESCRIPTION
|
||||
kdump.service loaded failed failed Crash recovery kernel arming
|
||||
|
||||
LOAD = Reflects whether the unit definition was properly loaded.
|
||||
ACTIVE = The high-level unit activation state, i.e. generalization of SUB.
|
||||
SUB = The low-level unit activation state, values depend on unit type.
|
||||
|
||||
1 loaded units listed. Pass --all to see loaded but inactive units, too.
|
||||
To show all installed unit files use 'systemctl list-unit-files'.
|
||||
|
||||
#### 10. 检查某个单元(cron.service)是否启用 ####
|
||||
|
||||
# systemctl is-enabled crond.service
|
||||
|
||||
enabled
|
||||
|
||||
#### 11. 检查某个单元或服务是否运行 ####
|
||||
|
||||
# systemctl status firewalld.service
|
||||
|
||||
firewalld.service - firewalld - dynamic firewall daemon
|
||||
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; enabled)
|
||||
Active: active (running) since Tue 2015-04-28 16:27:55 IST; 34min ago
|
||||
Main PID: 549 (firewalld)
|
||||
CGroup: /system.slice/firewalld.service
|
||||
└─549 /usr/bin/python -Es /usr/sbin/firewalld --nofork --nopid
|
||||
|
||||
Apr 28 16:27:51 tecmint systemd[1]: Starting firewalld - dynamic firewall daemon...
|
||||
Apr 28 16:27:55 tecmint systemd[1]: Started firewalld - dynamic firewall daemon.
|
||||
|
||||
### 使用Systemctl控制并管理服务 ###
|
||||
|
||||
#### 12. 列出所有服务(包括启用的和禁用的) ####
|
||||
|
||||
# systemctl list-unit-files --type=service
|
||||
|
||||
UNIT FILE STATE
|
||||
arp-ethers.service disabled
|
||||
auditd.service enabled
|
||||
autovt@.service disabled
|
||||
blk-availability.service disabled
|
||||
brandbot.service static
|
||||
collectd.service disabled
|
||||
console-getty.service disabled
|
||||
console-shell.service disabled
|
||||
cpupower.service disabled
|
||||
crond.service enabled
|
||||
dbus-org.fedoraproject.FirewallD1.service enabled
|
||||
....
|
||||
|
||||
#### 13. Linux中如何启动、重启、停止、重载服务以及检查服务(httpd.service)状态 ####
|
||||
|
||||
# systemctl start httpd.service
|
||||
# systemctl restart httpd.service
|
||||
# systemctl stop httpd.service
|
||||
# systemctl reload httpd.service
|
||||
# systemctl status httpd.service
|
||||
|
||||
httpd.service - The Apache HTTP Server
|
||||
Loaded: loaded (/usr/lib/systemd/system/httpd.service; enabled)
|
||||
Active: active (running) since Tue 2015-04-28 17:21:30 IST; 6s ago
|
||||
Process: 2876 ExecStop=/bin/kill -WINCH ${MAINPID} (code=exited, status=0/SUCCESS)
|
||||
Main PID: 2881 (httpd)
|
||||
Status: "Processing requests..."
|
||||
CGroup: /system.slice/httpd.service
|
||||
├─2881 /usr/sbin/httpd -DFOREGROUND
|
||||
├─2884 /usr/sbin/httpd -DFOREGROUND
|
||||
├─2885 /usr/sbin/httpd -DFOREGROUND
|
||||
├─2886 /usr/sbin/httpd -DFOREGROUND
|
||||
├─2887 /usr/sbin/httpd -DFOREGROUND
|
||||
└─2888 /usr/sbin/httpd -DFOREGROUND
|
||||
|
||||
Apr 28 17:21:30 tecmint systemd[1]: Starting The Apache HTTP Server...
|
||||
Apr 28 17:21:30 tecmint httpd[2881]: AH00558: httpd: Could not reliably determine the server's fully q...ssage
|
||||
Apr 28 17:21:30 tecmint systemd[1]: Started The Apache HTTP Server.
|
||||
Hint: Some lines were ellipsized, use -l to show in full.
|
||||
|
||||
**注意**:当我们使用systemctl的start,restart,stop和reload命令时,我们不会不会从终端获取到任何输出内容,只有status命令可以打印输出。
|
||||
|
||||
#### 14. 如何激活服务并在启动时启用或禁用服务(系统启动时自动启动服务) ####
|
||||
|
||||
# systemctl is-active httpd.service
|
||||
# systemctl enable httpd.service
|
||||
# systemctl disable httpd.service
|
||||
|
||||
#### 15. 如何屏蔽(让它不能启动)或显示服务(httpd.service) ####
|
||||
|
||||
# systemctl mask httpd.service
|
||||
ln -s '/dev/null' '/etc/systemd/system/httpd.service'
|
||||
|
||||
# systemctl unmask httpd.service
|
||||
rm '/etc/systemd/system/httpd.service'
|
||||
|
||||
#### 16. 使用systemctl命令杀死服务 ####
|
||||
|
||||
# systemctl kill httpd
|
||||
# systemctl status httpd
|
||||
|
||||
httpd.service - The Apache HTTP Server
|
||||
Loaded: loaded (/usr/lib/systemd/system/httpd.service; enabled)
|
||||
Active: failed (Result: exit-code) since Tue 2015-04-28 18:01:42 IST; 28min ago
|
||||
Main PID: 2881 (code=exited, status=0/SUCCESS)
|
||||
Status: "Total requests: 0; Current requests/sec: 0; Current traffic: 0 B/sec"
|
||||
|
||||
Apr 28 17:37:29 tecmint systemd[1]: httpd.service: Got notification message from PID 2881, but recepti...bled.
|
||||
Apr 28 17:37:29 tecmint systemd[1]: httpd.service: Got notification message from PID 2881, but recepti...bled.
|
||||
Apr 28 17:37:39 tecmint systemd[1]: httpd.service: Got notification message from PID 2881, but recepti...bled.
|
||||
Apr 28 17:37:39 tecmint systemd[1]: httpd.service: Got notification message from PID 2881, but recepti...bled.
|
||||
Apr 28 17:37:49 tecmint systemd[1]: httpd.service: Got notification message from PID 2881, but recepti...bled.
|
||||
Apr 28 17:37:49 tecmint systemd[1]: httpd.service: Got notification message from PID 2881, but recepti...bled.
|
||||
Apr 28 17:37:59 tecmint systemd[1]: httpd.service: Got notification message from PID 2881, but recepti...bled.
|
||||
Apr 28 17:37:59 tecmint systemd[1]: httpd.service: Got notification message from PID 2881, but recepti...bled.
|
||||
Apr 28 18:01:42 tecmint systemd[1]: httpd.service: control process exited, code=exited status=226
|
||||
Apr 28 18:01:42 tecmint systemd[1]: Unit httpd.service entered failed state.
|
||||
Hint: Some lines were ellipsized, use -l to show in full.
|
||||
|
||||
### 使用Systemctl控制并管理挂载点 ###
|
||||
|
||||
#### 17. 列出所有系统挂载点 ####
|
||||
|
||||
# systemctl list-unit-files --type=mount
|
||||
|
||||
UNIT FILE STATE
|
||||
dev-hugepages.mount static
|
||||
dev-mqueue.mount static
|
||||
proc-sys-fs-binfmt_misc.mount static
|
||||
sys-fs-fuse-connections.mount static
|
||||
sys-kernel-config.mount static
|
||||
sys-kernel-debug.mount static
|
||||
tmp.mount disabled
|
||||
|
||||
#### 18. 挂载、卸载、重新挂载、重载系统挂载点并检查系统中挂载点状态 ####
|
||||
|
||||
# systemctl start tmp.mount
|
||||
# systemctl stop tmp.mount
|
||||
# systemctl restart tmp.mount
|
||||
# systemctl reload tmp.mount
|
||||
# systemctl status tmp.mount
|
||||
|
||||
tmp.mount - Temporary Directory
|
||||
Loaded: loaded (/usr/lib/systemd/system/tmp.mount; disabled)
|
||||
Active: active (mounted) since Tue 2015-04-28 17:46:06 IST; 2min 48s ago
|
||||
Where: /tmp
|
||||
What: tmpfs
|
||||
Docs: man:hier(7)
|
||||
|
||||
http://www.freedesktop.org/wiki/Software/systemd/APIFileSystems
|
||||
|
||||
Process: 3908 ExecMount=/bin/mount tmpfs /tmp -t tmpfs -o mode=1777,strictatime (code=exited, status=0/SUCCESS)
|
||||
|
||||
Apr 28 17:46:06 tecmint systemd[1]: Mounting Temporary Directory...
|
||||
Apr 28 17:46:06 tecmint systemd[1]: tmp.mount: Directory /tmp to mount over is not empty, mounting anyway.
|
||||
Apr 28 17:46:06 tecmint systemd[1]: Mounted Temporary Directory.
|
||||
|
||||
#### 19. 在启动时激活、启用或禁用挂载点(系统启动时自动挂载) ####
|
||||
|
||||
# systemctl is-active tmp.mount
|
||||
# systemctl enable tmp.mount
|
||||
# systemctl disable tmp.mount
|
||||
|
||||
#### 20. 在Linux中屏蔽(让它不能启动)或显示挂载点 ####
|
||||
|
||||
# systemctl mask tmp.mount
|
||||
|
||||
ln -s '/dev/null' '/etc/systemd/system/tmp.mount'
|
||||
|
||||
# systemctl unmask tmp.mount
|
||||
|
||||
rm '/etc/systemd/system/tmp.mount'
|
||||
|
||||
### 使用Systemctl控制并管理套接口 ###
|
||||
|
||||
#### 21. 列出所有可用系统套接口 ####
|
||||
|
||||
# systemctl list-unit-files --type=socket
|
||||
|
||||
UNIT FILE STATE
|
||||
dbus.socket static
|
||||
dm-event.socket enabled
|
||||
lvm2-lvmetad.socket enabled
|
||||
rsyncd.socket disabled
|
||||
sshd.socket disabled
|
||||
syslog.socket static
|
||||
systemd-initctl.socket static
|
||||
systemd-journald.socket static
|
||||
systemd-shutdownd.socket static
|
||||
systemd-udevd-control.socket static
|
||||
systemd-udevd-kernel.socket static
|
||||
|
||||
11 unit files listed.
|
||||
|
||||
#### 22. 在Linux中启动、重启、停止、重载套接口并检查其状态####
|
||||
|
||||
# systemctl start cups.socket
|
||||
# systemctl restart cups.socket
|
||||
# systemctl stop cups.socket
|
||||
# systemctl reload cups.socket
|
||||
# systemctl status cups.socket
|
||||
|
||||
cups.socket - CUPS Printing Service Sockets
|
||||
Loaded: loaded (/usr/lib/systemd/system/cups.socket; enabled)
|
||||
Active: active (listening) since Tue 2015-04-28 18:10:59 IST; 8s ago
|
||||
Listen: /var/run/cups/cups.sock (Stream)
|
||||
|
||||
Apr 28 18:10:59 tecmint systemd[1]: Starting CUPS Printing Service Sockets.
|
||||
Apr 28 18:10:59 tecmint systemd[1]: Listening on CUPS Printing Service Sockets.
|
||||
|
||||
#### 23. 在启动时激活套接口,并启用或禁用它(系统启动时自启动) ####
|
||||
|
||||
# systemctl is-active cups.socket
|
||||
# systemctl enable cups.socket
|
||||
# systemctl disable cups.socket
|
||||
|
||||
#### 24. 屏蔽(使它不能启动)或显示套接口 ####
|
||||
|
||||
# systemctl mask cups.socket
|
||||
ln -s '/dev/null' '/etc/systemd/system/cups.socket'
|
||||
|
||||
# systemctl unmask cups.socket
|
||||
rm '/etc/systemd/system/cups.socket'
|
||||
|
||||
### 服务的CPU利用率(分配额) ###
|
||||
|
||||
#### 25. 获取当前某个服务的CPU分配额(如httpd) ####
|
||||
|
||||
# systemctl show -p CPUShares httpd.service
|
||||
|
||||
CPUShares=1024
|
||||
|
||||
**注意**:各个服务的默认CPU分配份额=1024,你可以增加/减少某个进程的CPU分配份额。
|
||||
|
||||
#### 26. 将某个服务(httpd.service)的CPU分配份额限制为2000 CPUShares/ ####
|
||||
|
||||
# systemctl set-property httpd.service CPUShares=2000
|
||||
# systemctl show -p CPUShares httpd.service
|
||||
|
||||
CPUShares=2000
|
||||
|
||||
**注意**:当你为某个服务设置CPUShares,会自动创建一个以服务名命名的目录(httpd.service),里面包含了一个名为90-CPUShares.conf的文件,该文件含有CPUShare限制信息,你可以通过以下方式查看该文件:
|
||||
|
||||
# vi /etc/systemd/system/httpd.service.d/90-CPUShares.conf
|
||||
|
||||
[Service]
|
||||
CPUShares=2000
|
||||
|
||||
#### 27. 检查某个服务的所有配置细节 ####
|
||||
|
||||
# systemctl show httpd
|
||||
|
||||
Id=httpd.service
|
||||
Names=httpd.service
|
||||
Requires=basic.target
|
||||
Wants=system.slice
|
||||
WantedBy=multi-user.target
|
||||
Conflicts=shutdown.target
|
||||
Before=shutdown.target multi-user.target
|
||||
After=network.target remote-fs.target nss-lookup.target systemd-journald.socket basic.target system.slice
|
||||
Description=The Apache HTTP Server
|
||||
LoadState=loaded
|
||||
ActiveState=active
|
||||
SubState=running
|
||||
FragmentPath=/usr/lib/systemd/system/httpd.service
|
||||
....
|
||||
|
||||
#### 28. 分析某个服务(httpd)的关键链 ####
|
||||
|
||||
# systemd-analyze critical-chain httpd.service
|
||||
|
||||
The time after the unit is active or started is printed after the "@" character.
|
||||
The time the unit takes to start is printed after the "+" character.
|
||||
|
||||
httpd.service +142ms
|
||||
└─network.target @11.168s
|
||||
└─network.service @9.456s +1.712s
|
||||
└─NetworkManager.service @8.858s +596ms
|
||||
└─firewalld.service @4.931s +3.926s
|
||||
└─basic.target @4.916s
|
||||
└─sockets.target @4.916s
|
||||
└─dbus.socket @4.916s
|
||||
└─sysinit.target @4.905s
|
||||
└─systemd-update-utmp.service @4.864s +39ms
|
||||
└─auditd.service @4.563s +301ms
|
||||
└─systemd-tmpfiles-setup.service @4.485s +69ms
|
||||
└─rhel-import-state.service @4.342s +142ms
|
||||
└─local-fs.target @4.324s
|
||||
└─boot.mount @4.286s +31ms
|
||||
└─systemd-fsck@dev-disk-by\x2duuid-79f594ad\x2da332\x2d4730\x2dbb5f\x2d85d196080964.service @4.092s +149ms
|
||||
└─dev-disk-by\x2duuid-79f594ad\x2da332\x2d4730\x2dbb5f\x2d85d196080964.device @4.092s
|
||||
|
||||
#### 29. 获取某个服务(httpd)的依赖性列表 ####
|
||||
|
||||
# systemctl list-dependencies httpd.service
|
||||
|
||||
httpd.service
|
||||
├─system.slice
|
||||
└─basic.target
|
||||
├─firewalld.service
|
||||
├─microcode.service
|
||||
├─rhel-autorelabel-mark.service
|
||||
├─rhel-autorelabel.service
|
||||
├─rhel-configure.service
|
||||
├─rhel-dmesg.service
|
||||
├─rhel-loadmodules.service
|
||||
├─paths.target
|
||||
├─slices.target
|
||||
│ ├─-.slice
|
||||
│ └─system.slice
|
||||
├─sockets.target
|
||||
│ ├─dbus.socket
|
||||
....
|
||||
|
||||
#### 30. 按等级列出控制组 ####
|
||||
|
||||
# systemd-cgls
|
||||
|
||||
├─1 /usr/lib/systemd/systemd --switched-root --system --deserialize 23
|
||||
├─user.slice
|
||||
│ └─user-0.slice
|
||||
│ └─session-1.scope
|
||||
│ ├─2498 sshd: root@pts/0
|
||||
│ ├─2500 -bash
|
||||
│ ├─4521 systemd-cgls
|
||||
│ └─4522 systemd-cgls
|
||||
└─system.slice
|
||||
├─httpd.service
|
||||
│ ├─4440 /usr/sbin/httpd -DFOREGROUND
|
||||
│ ├─4442 /usr/sbin/httpd -DFOREGROUND
|
||||
│ ├─4443 /usr/sbin/httpd -DFOREGROUND
|
||||
│ ├─4444 /usr/sbin/httpd -DFOREGROUND
|
||||
│ ├─4445 /usr/sbin/httpd -DFOREGROUND
|
||||
│ └─4446 /usr/sbin/httpd -DFOREGROUND
|
||||
├─polkit.service
|
||||
│ └─721 /usr/lib/polkit-1/polkitd --no-debug
|
||||
....
|
||||
|
||||
#### 31. 按CPU、内存、输入和输出列出控制组 ####
|
||||
|
||||
# systemd-cgtop
|
||||
|
||||
Path Tasks %CPU Memory Input/s Output/s
|
||||
|
||||
/ 83 1.0 437.8M - -
|
||||
/system.slice - 0.1 - - -
|
||||
/system.slice/mariadb.service 2 0.1 - - -
|
||||
/system.slice/tuned.service 1 0.0 - - -
|
||||
/system.slice/httpd.service 6 0.0 - - -
|
||||
/system.slice/NetworkManager.service 1 - - - -
|
||||
/system.slice/atop.service 1 - - - -
|
||||
/system.slice/atopacct.service 1 - - - -
|
||||
/system.slice/auditd.service 1 - - - -
|
||||
/system.slice/crond.service 1 - - - -
|
||||
/system.slice/dbus.service 1 - - - -
|
||||
/system.slice/firewalld.service 1 - - - -
|
||||
/system.slice/lvm2-lvmetad.service 1 - - - -
|
||||
/system.slice/polkit.service 1 - - - -
|
||||
/system.slice/postfix.service 3 - - - -
|
||||
/system.slice/rsyslog.service 1 - - - -
|
||||
/system.slice/system-getty.slice/getty@tty1.service 1 - - - -
|
||||
/system.slice/systemd-journald.service 1 - - - -
|
||||
/system.slice/systemd-logind.service 1 - - - -
|
||||
/system.slice/systemd-udevd.service 1 - - - -
|
||||
/system.slice/webmin.service 1 - - - -
|
||||
/user.slice/user-0.slice/session-1.scope 3 - - - -
|
||||
|
||||
### 控制系统运行等级 ###
|
||||
|
||||
#### 32. 启动系统救援模式 ####
|
||||
|
||||
# systemctl rescue
|
||||
|
||||
Broadcast message from root@tecmint on pts/0 (Wed 2015-04-29 11:31:18 IST):
|
||||
|
||||
The system is going down to rescue mode NOW!
|
||||
|
||||
#### 33. 进入紧急模式 ####
|
||||
|
||||
# systemctl emergency
|
||||
|
||||
Welcome to emergency mode! After logging in, type "journalctl -xb" to view
|
||||
system logs, "systemctl reboot" to reboot, "systemctl default" to try again
|
||||
to boot into default mode.
|
||||
|
||||
#### 34. 列出当前使用的运行等级 ####
|
||||
|
||||
# systemctl get-default
|
||||
|
||||
multi-user.target
|
||||
|
||||
#### 35. 启动运行等级5,即图形模式 ####
|
||||
|
||||
# systemctl isolate runlevel5.target
|
||||
OR
|
||||
# systemctl isolate graphical.target
|
||||
|
||||
#### 36. 启动运行等级3,即多用户模式(命令行) ####
|
||||
|
||||
# systemctl isolate runlevel3.target
|
||||
OR
|
||||
# systemctl isolate multiuser.target
|
||||
|
||||
#### 36. 设置多用户模式或图形模式为默认运行等级 ####
|
||||
|
||||
# systemctl set-default runlevel3.target
|
||||
|
||||
# systemctl set-default runlevel5.target
|
||||
|
||||
#### 37. 重启、停止、挂起、休眠系统或使系统进入混合睡眠 ####
|
||||
|
||||
# systemctl reboot
|
||||
|
||||
# systemctl halt
|
||||
|
||||
# systemctl suspend
|
||||
|
||||
# systemctl hibernate
|
||||
|
||||
# systemctl hybrid-sleep
|
||||
|
||||
对于不知运行等级为何物的人,说明如下。
|
||||
|
||||
- Runlevel 0 : 关闭系统
|
||||
- Runlevel 1 : 救援?维护模式
|
||||
- Runlevel 3 : 多用户,无图形系统
|
||||
- Runlevel 4 : 多用户,无图形系统
|
||||
- Runlevel 5 : 多用户,图形化系统
|
||||
- Runlevel 6 : 关闭并重启机器
|
||||
|
||||
到此为止吧。保持连线,进行评论。别忘了在下面的评论中为我们提供一些有价值的反馈哦。喜欢我们、与我们分享,求扩散。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/manage-services-using-systemd-and-systemctl-in-linux/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
@ -0,0 +1,54 @@
|
||||
Linux有问必答——Ubuntu桌面上如何禁用默认的密钥环解锁密码输入
|
||||
================================================================================
|
||||
>**问题**:当我启动我的Ubuntu桌面时,出现了一个弹出对话框,要求我输入密码来解锁默认的密钥环。我怎样才能禁用这个“解锁默认密钥环”弹出窗口,并自动解锁我的密钥环?
|
||||
|
||||
密钥环被认为是用来以加密方式存储你的登录信息的本地数据库。各种桌面应用(如浏览器、电子邮件客户端)使用密钥环来安全地存储并管理你的登录凭证、机密、密码、证书或密钥。对于那些需要检索存储在密钥环中的信息的应用程序,需要解锁该密钥环。
|
||||
|
||||
Ubuntu桌面所使用的GNOME密钥环被整合到了桌面登录中,该密钥环会在你验证进入桌面后自动解锁。但是,如果你设置了自动登录桌面或者是从休眠中唤醒,你默认的密钥环仍然可能“被锁定”的。在这种情况下,你会碰到这一提示:
|
||||
|
||||
>“为密钥环‘默认密钥环’输入密码来解锁。某个应用想要访问密钥环‘默认密钥环’,但它被锁定了。”
|
||||
>
|
||||
|
||||
|
||||
如果你想要避免在每次弹出对话框出现时输入密码来解锁默认密钥环,那么你可以这样做。
|
||||
|
||||
在做之前,请先了解禁用密码提示后可能出现的结果。通过自动解锁默认密钥环,你可以让任何使用你桌面的人无需知道你的密码而能获取你的密钥环(以及存储在密钥环中的任何信息)。
|
||||
|
||||
### 禁用默认密钥环解锁密码 ###
|
||||
|
||||
打开Dash,然后输入“密码”来启动“密码和密钥”应用。
|
||||
|
||||
|
||||
|
||||
或者,使用seahorse命令从命令行启动图形界面。
|
||||
|
||||
$ seahorse
|
||||
|
||||
在左侧面板中,右击“默认密钥环”,并选择“修改密码”。
|
||||
|
||||
|
||||
|
||||
输入你的当前登录密码。
|
||||
|
||||
|
||||
在设置“默认”密钥环新密码的密码框中留空。
|
||||
|
||||
|
||||
|
||||
在询问是否不加密存储密码对话框中点击“继续”。
|
||||
|
||||

|
||||
|
||||
搞定。从今往后,那个该死的解锁密钥环提示对话框再也不会来烦你了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/disable-entering-password-unlock-default-keyring.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
@ -0,0 +1,98 @@
|
||||
Linux有问必答——Linux上如何安装Shrew Soft IPsec VPN
|
||||
================================================================================
|
||||
> **Question**: I need to connect to an IPSec VPN gateway. For that, I'm trying to use Shrew Soft VPN client, which is available for free. How can I install Shrew Soft VPN client on [insert your Linux distro]?
|
||||
> **问题**:我需要连接到一个IPSec VPN网关,鉴于此,我尝试使用Shrew Soft VPN客户端,它是一个免费版本。我怎样才能安装Shrew Soft VPN客户端到[插入你的Linux发行版]?
|
||||
|
||||
市面上有许多商业VPN网关,同时附带有他们自己的专有VPN客户端软件。虽然也有许多开源的VPN服务器/客户端备选方案,但它们通常缺乏复杂的IPsec支持,比如互联网密钥交换(IKE),这是一个标准的IPsec协议,用于加固VPN密钥交换和验证安全。Shrew Soft VPN是一个免费的IPsec VPN客户端,它支持多种验证方法、密钥交换、加密以及防火墙穿越选项。
|
||||
|
||||
下面介绍如何安装Shrew Soft VPN客户端到Linux平台。
|
||||
|
||||
首先,从[官方站点][1]下载它的源代码。
|
||||
|
||||
### 安装Shrew VPN客户端到Debian, Ubuntu或者Linux Mint ###
|
||||
|
||||
Shrew Soft VPN客户端图形界面要求使用Qt 4.x。所以,作为依赖,你需要安装其开发文件。
|
||||
|
||||
$ sudo apt-get install cmake libqt4-core libqt4-dev libqt4-gui libedit-dev libssl-dev checkinstall flex bison
|
||||
$ wget https://www.shrew.net/download/ike/ike-2.2.1-release.tbz2
|
||||
$ tar xvfvj ike-2.2.1-release.tbz2
|
||||
$ cd ike
|
||||
$ cmake -DCMAKE_INSTALL_PREFIX=/usr -DQTGUI=YES -DETCDIR=/etc -DNATT=YES .
|
||||
$ make
|
||||
$ sudo make install
|
||||
$ cd /etc/
|
||||
$ sudo mv iked.conf.sample iked.conf
|
||||
|
||||
### 安装Shrew VPN客户端到CentOS, Fedora或者RHEL ###
|
||||
|
||||
与基于Debian的系统类似,在编译前你需要安装一堆依赖包,包括Qt4。
|
||||
|
||||
$ sudo yum install qt-devel cmake gcc-c++ openssl-devel libedit-devel flex bison
|
||||
$ wget https://www.shrew.net/download/ike/ike-2.2.1-release.tbz2
|
||||
$ tar xvfvj ike-2.2.1-release.tbz2
|
||||
$ cd ike
|
||||
$ cmake -DCMAKE_INSTALL_PREFIX=/usr -DQTGUI=YES -DETCDIR=/etc -DNATT=YES .
|
||||
$ make
|
||||
$ sudo make install
|
||||
$ cd /etc/
|
||||
$ sudo mv iked.conf.sample iked.conf
|
||||
|
||||
在基于Red Hat的系统中,最后一步需要用文本编辑器打开/etc/ld.so.conf文件,并添加以下行。
|
||||
|
||||
$ sudo vi /etc/ld.so.conf
|
||||
|
||||
----------
|
||||
|
||||
include /usr/lib/
|
||||
|
||||
重新加载运行时绑定的共享库文件,以容纳新安装的共享库:
|
||||
|
||||
$ sudo ldconfig
|
||||
|
||||
### 启动Shrew VPN客户端 ###
|
||||
|
||||
首先,启动IKE守护进程(iked)。该守护进作为VPN客户端程通过IKE协议与远程主机经由IPSec通信。
|
||||
|
||||
$ sudo iked
|
||||
|
||||
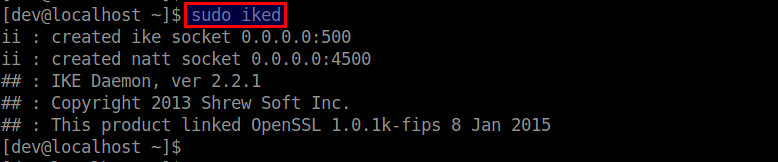
|
||||
|
||||
现在,启动qikea,它是一个IPsec VPN客户端前端。该GUI应用允许你管理远程站点配置并初始化VPN连接。
|
||||
|
||||
|
||||
|
||||
要创建一个新的VPN配置,点击“添加”按钮,然后填入VPN站点配置。创建配置后,你可以通过点击配置来初始化VPN连接。
|
||||
|
||||
|
||||
|
||||
### 故障排除 ###
|
||||
|
||||
1. 我在运行iked时碰到了如下错误。
|
||||
|
||||
iked: error while loading shared libraries: libss_ike.so.2.2.1: cannot open shared object file: No such file or directory
|
||||
|
||||
要解决该问题,你需要更新动态链接器来容纳libss_ike库。对于此,请添加库文件的位置路径到/etc/ld.so.conf文件中,然后运行ldconfig命令。
|
||||
|
||||
$ sudo ldconfig
|
||||
|
||||
验证libss_ike是否添加到了库路径:
|
||||
|
||||
$ ldconfig -p | grep ike
|
||||
|
||||
----------
|
||||
|
||||
libss_ike.so.2.2.1 (libc6,x86-64) => /lib/libss_ike.so.2.2.1
|
||||
libss_ike.so (libc6,x86-64) => /lib/libss_ike.so
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/install-shrew-soft-ipsec-vpn-client-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:https://www.shrew.net/download/ike
|
||||
@ -0,0 +1,192 @@
|
||||
监控Linux容器性能的命令行神器
|
||||
================================================================================
|
||||
ctop是一个新的基于命令行的工具,它可用于在容器层级监控进程。容器通过利用控制器组(cgroup)的资源管理功能,提供了操作系统层级的虚拟化环境。该工具收集来自cgroup的与内存、CPU、块输入输出和诸如拥有者、开机时间等相关的元数据,并以人性化的格式呈现给用户,这样就可以快速对系统健康状况进行评估。基于所获得的数据,它可以尝试推测潜在的容器技术。ctop也有助于在低内存环境中检测出谁在消耗大量的内存。
|
||||
|
||||
### 功能 ###
|
||||
|
||||
ctop的一些功能如下:
|
||||
|
||||
- 收集CPU、内存和块输入输出的度量值
|
||||
- 收集与拥有者、容器技术和任务统计相关的信息
|
||||
- 使用任何栏目对信息排序
|
||||
- 以树状视图显示信息
|
||||
- 折叠/展开cgroup树
|
||||
- 选择并跟踪cgroup/容器
|
||||
- 选择显示数据刷新时间框架
|
||||
- 暂停刷新数据
|
||||
- 检测基于systemd、Docker和LXC的容器
|
||||
- 基于Docker和LXC的容器的高级特性
|
||||
- 打开/连接shell以进行深度诊断
|
||||
- 停止/杀死容器类型
|
||||
|
||||
### 安装 ###
|
||||
|
||||
**ctop**是由Python写成的,因此,除了需要Python 2.6或其更高版本外(支持内建光标),别无其它外部依赖。推荐使用Python的pip进行安装,如果还没有安装pip,请先安装,然后使用pip安装ctop。
|
||||
|
||||
*注意:本文样例来自Ubuntu(14.10)系统*
|
||||
|
||||
$ sudo apt-get install python-pip
|
||||
|
||||
使用pip安装ctop:
|
||||
|
||||
poornima@poornima-Lenovo:~$ sudo pip install ctop
|
||||
|
||||
[sudo] password for poornima:
|
||||
|
||||
Downloading/unpacking ctop
|
||||
|
||||
Downloading ctop-0.4.0.tar.gz
|
||||
|
||||
Running setup.py (path:/tmp/pip_build_root/ctop/setup.py) egg_info for package ctop
|
||||
|
||||
Installing collected packages: ctop
|
||||
|
||||
Running setup.py install for ctop
|
||||
|
||||
changing mode of build/scripts-2.7/ctop from 644 to 755
|
||||
|
||||
changing mode of /usr/local/bin/ctop to 755
|
||||
|
||||
Successfully installed ctop
|
||||
|
||||
Cleaning up...
|
||||
|
||||
如果不选择使用pip安装,你也可以使用wget直接从github安装:
|
||||
|
||||
poornima@poornima-Lenovo:~$ wget https://raw.githubusercontent.com/yadutaf/ctop/master/cgroup_top.py -O ctop
|
||||
|
||||
--2015-04-29 19:32:53-- https://raw.githubusercontent.com/yadutaf/ctop/master/cgroup_top.py
|
||||
|
||||
Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 199.27.78.133
|
||||
|
||||
Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|199.27.78.133|:443... connected.
|
||||
|
||||
HTTP request sent, awaiting response... 200 OK Length: 27314 (27K) [text/plain]
|
||||
|
||||
Saving to: ctop
|
||||
|
||||
100%[======================================>] 27,314 --.-K/s in 0s
|
||||
|
||||
2015-04-29 19:32:59 (61.0 MB/s) - ctop saved [27314/27314]
|
||||
|
||||
----------
|
||||
|
||||
poornima@poornima-Lenovo:~$ chmod +x ctop
|
||||
|
||||
如果cgroup-bin包没有安装,你可能会碰到一个错误消息,你可以通过安装需要的包来解决。
|
||||
|
||||
poornima@poornima-Lenovo:~$ ./ctop
|
||||
|
||||
[ERROR] Failed to locate cgroup mountpoints.
|
||||
|
||||
poornima@poornima-Lenovo:~$ sudo apt-get install cgroup-bin
|
||||
|
||||
下面是ctop的输出样例:
|
||||
|
||||

|
||||
ctop屏幕
|
||||
|
||||
### 用法选项 ###
|
||||
|
||||
ctop [--tree] [--refresh=] [--columns=] [--sort-col=] [--follow=] [--fold=, ...] ctop (-h | --help)
|
||||
|
||||
一旦你进入ctop屏幕,使用上(↑)和下(↓)箭头键在容器间导航。点击某个容器就选定了该容器,按q或Ctrl+C退出容器。
|
||||
|
||||
现在,让我们来看看上面列出的那一堆选项究竟是怎么用的吧。
|
||||
|
||||
-h / --help - Show the help screen
|
||||
|
||||
----------
|
||||
|
||||
poornima@poornima-Lenovo:~$ ctop -h
|
||||
Usage: ctop [options]
|
||||
|
||||
Options:
|
||||
-h, --help show this help message and exit
|
||||
--tree show tree view by default
|
||||
--refresh=REFRESH Refresh display every <seconds>
|
||||
--follow=FOLLOW Follow cgroup path
|
||||
--columns=COLUMNS List of optional columns to display. Always includes
|
||||
'name'
|
||||
--sort-col=SORT_COL Select column to sort by initially. Can be changed
|
||||
dynamically.
|
||||
|
||||
----------
|
||||
|
||||
--tree - Display tree view of the containers
|
||||
|
||||
默认情况下,会显示列表视图
|
||||
|
||||
一旦你进入ctop窗口,你可以使用F5按钮在树状/列表视图间切换。
|
||||
|
||||
--fold=<name> - Fold the <name> cgroup path in the tree view.
|
||||
|
||||
This option needs to be used in combination with --tree.
|
||||
|
||||
----------
|
||||
|
||||
Eg: ctop --tree --fold=/user.slice
|
||||
|
||||

|
||||
‘ctop --fold’的输出
|
||||
|
||||
在ctop窗口中,使用+/-键来展开或折叠子cgroup。
|
||||
|
||||
注意:在写本文时,pip仓库中还没有最新版的ctop,还不支持命令行的‘--fold’选项
|
||||
|
||||
--follow= - Follow/Highlight the cgroup path.
|
||||
|
||||
----------
|
||||
|
||||
Eg: ctop --follow=/user.slice/user-1000.slice
|
||||
|
||||
正如你在下面屏幕中所见到的那样,带有“/user.slice/user-1000.slice”路径的cgroup被高亮显示,这让用户易于跟踪,就算显示位置变了也一样。
|
||||
|
||||

|
||||
‘ctop --follow’的输出
|
||||
|
||||
你也可以使用‘f’按钮来让高亮的行跟踪选定的容器。默认情况下,跟踪是关闭的。
|
||||
|
||||
--refresh= - Refresh the display at the given rate. Default 1 sec
|
||||
|
||||
这对于按每用户需求来显示改变刷新率时很有用。使用‘p’按钮可以暂停刷新并选择文本。
|
||||
|
||||
--columns=<columns> - Can limit the display to selected <columns>. 'name' should be the first entry followed by other columns. By default, the columns include owner, processes,memory, cpu-sys, cpu-user, blkio, cpu-time.
|
||||
|
||||
----------
|
||||
|
||||
Eg: ctop --columns=name,owner,type,memory
|
||||
|
||||

|
||||
‘ctop --column’的输出
|
||||
|
||||
-sort-col=<sort-col> - column using which the displayed data should be sorted. By default it is sorted using cpu-user
|
||||
|
||||
----------
|
||||
|
||||
Eg: ctop --sort-col=blkio
|
||||
|
||||
如果有Docker和LXC支持的额外容器,跟踪选项也是可用的:
|
||||
|
||||
press 'a' - attach to console output
|
||||
|
||||
press 'e' - open a shell in the container context
|
||||
|
||||
press 's' – stop the container (SIGTERM)
|
||||
|
||||
press 'k' - kill the container (SIGKILL)
|
||||
|
||||
[ctop][1]当前还处于Jean-Tiare Le Bigot的开发中,希望我们能在该工具中见到像本地top命令一样的特性 :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/how-tos/monitor-linux-containers-performance/
|
||||
|
||||
作者:[B N Poornima][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/bnpoornima/
|
||||
[1]:https://github.com/yadutaf/ctop
|
||||
Loading…
Reference in New Issue
Block a user