mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-15 01:50:08 +08:00
commit
26405f6faf
@ -1,22 +1,18 @@
|
||||
GHLandy Translated
|
||||
|
||||
LFCS 系列第五讲:如何在 Linux 中挂载/卸载本地文件系统和网络文件系统(Samba 和 NFS)
|
||||
|
||||
================================================================================
|
||||
|
||||
Linux 基金会已经发起了一个全新的 LFCS(Linux Foundation Certified Sysadmin,Linux 基金会认证系统管理员)认证,旨在让来自世界各地的人有机会参加到 LFCS 测试,获得关于有能力在 Linux 系统中执行中间系统管理任务的认证。该认证包括:维护正在运行的系统和服务的能力、全面监控和分析的能力以及何时上游团队请求支持的决策能力。
|
||||
Linux 基金会已经发起了一个全新的 LFCS(Linux Foundation Certified Sysadmin,Linux 基金会认证系统管理员)认证,旨在让来自世界各地的人有机会参加到 LFCS 测试,获得关于有能力在 Linux 系统中执行中间系统管理任务的认证。该认证包括:维护正在运行的系统和服务的能力、全面监控和分析的能力以及何时向上游团队请求支持的决策能力。
|
||||
|
||||

|
||||
|
||||
LFCS 系列第五讲
|
||||
*LFCS 系列第五讲*
|
||||
|
||||
请看以下视频,这里边介绍了 Linux 基金会认证程序。
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="720" height="405" frameborder="0" allowfullscreen="allowfullscreen" src="//www.youtube.com/embed/Y29qZ71Kicg"></iframe>
|
||||
|
||||
本讲是《十套教程》系列中的第三讲,在这一讲里边,我们会解释如何在 Linux 中挂载/卸载本地和网络文件系统。这些都是 LFCS 认证中的必备知识。
|
||||
|
||||
本讲是系列教程中的第五讲,在这一讲里边,我们会解释如何在 Linux 中挂载/卸载本地和网络文件系统。这些都是 LFCS 认证中的必备知识。
|
||||
|
||||
### 挂载文件系统 ###
|
||||
|
||||
@ -26,20 +22,19 @@ LFCS 系列第五讲
|
||||
|
||||
换句话说,管理存储设备的第一步就是把设备关联到文件系统树。要完成这一步,通常可以这样:用 mount 命令来进行临时挂载(用完的时候,使用 umount 命令来卸载),或者通过编辑 /etc/fstab 文件之后重启系统来永久性挂载,这样每次开机都会进行挂载。
|
||||
|
||||
|
||||
不带任何选项的 mount 命令,可以显示当前已挂载的文件系统。
|
||||
|
||||
# mount
|
||||
|
||||

|
||||
|
||||
检查已挂载的文件系统
|
||||
*检查已挂载的文件系统*
|
||||
|
||||
另外,mount 命令通常用来挂载文件系统。其基本语法如下:
|
||||
|
||||
# mount -t type device dir -o options
|
||||
|
||||
该命令会指引内核在设备上找到的文件系统(如已格式化为指定类型的文件系统)挂载到指定目录。像这样的形式,mount 命令不会再到 /etc/fstab 文件中进行确认。
|
||||
该命令会指引内核将在设备上找到的文件系统(如已格式化为指定类型的文件系统)挂载到指定目录。像这样的形式,mount 命令不会再到 /etc/fstab 文件中进行确认。
|
||||
|
||||
除非像下面,挂载指定的目录或者设备:
|
||||
|
||||
@ -59,20 +54,17 @@ mount 命令会尝试寻找挂载点,如果找不到就会查找设备(上
|
||||
|
||||
读作:
|
||||
|
||||
设备 dev/mapper/debian-home 的格式为 ext4,挂载在 /home 下,并且有以下挂载选项: rw,relatime,user_xattr,barrier=1,data=ordered。
|
||||
设备 dev/mapper/debian-home 挂载在 /home 下,它被格式化为 ext4,并且有以下挂载选项: rw,relatime,user_xattr,barrier=1,data=ordered。
|
||||
|
||||
**mount 命令选项**
|
||||
|
||||
下面列出 mount 命令的常用选项
|
||||
|
||||
|
||||
- async:运许在将要挂载的文件系统上进行异步 I/O 操作
|
||||
- auto:标志文件系统通过 mount -a 命令挂载,与 noauto 相反。
|
||||
|
||||
- defaults:该选项为 async,auto,dev,exec,nouser,rw,suid 的一个别名。注意,多个选项必须由逗号隔开并且中间没有空格。倘若你不小心在两个选项中间输入了一个空格,mount 命令会把后边的字符解释为另一个参数。
|
||||
- async:允许在将要挂载的文件系统上进行异步 I/O 操作
|
||||
- auto:标示该文件系统通过 mount -a 命令挂载,与 noauto 相反。
|
||||
- defaults:该选项相当于 `async,auto,dev,exec,nouser,rw,suid` 的组合。注意,多个选项必须由逗号隔开并且中间没有空格。倘若你不小心在两个选项中间输入了一个空格,mount 命令会把后边的字符解释为另一个参数。
|
||||
- loop:将镜像文件(如 .iso 文件)挂载为 loop 设备。该选项可以用来模拟显示光盘中的文件内容。
|
||||
- noexec:阻止该文件系统中可执行文件的执行。与 exec 选项相反。
|
||||
|
||||
- nouser:阻止任何用户(除 root 用户外) 挂载或卸载文件系统。与 user 选项相反。
|
||||
- remount:重新挂载文件系统。
|
||||
- ro:只读模式挂载。
|
||||
@ -91,7 +83,7 @@ mount 命令会尝试寻找挂载点,如果找不到就会查找设备(上
|
||||
|
||||

|
||||
|
||||
可读写模式挂载设备
|
||||
*可读写模式挂载设备*
|
||||
|
||||
**以默认模式挂载设备**
|
||||
|
||||
@ -102,26 +94,25 @@ mount 命令会尝试寻找挂载点,如果找不到就会查找设备(上
|
||||
|
||||

|
||||
|
||||
挂载设备
|
||||
*挂载设备*
|
||||
|
||||
在这个例子中,我们发现写入文件和命令都完美执行了。
|
||||
|
||||
### 卸载设备 ###
|
||||
|
||||
使用 umount 命令卸载设备,意味着将所有的“在使用”数据全部写入到文件系统了,然后可以安全移除文件系统。请注意,倘若你移除一个没有事先正确卸载的文件系统,就会有造成设备损坏和数据丢失的风险。
|
||||
使用 umount 命令卸载设备,意味着将所有的“在使用”数据全部写入到文件系统,然后可以安全移除文件系统。请注意,倘若你移除一个没有事先正确卸载的设备,就会有造成设备损坏和数据丢失的风险。
|
||||
|
||||
也就是说,你必须设备的盘符或者挂载点中退出,才能卸载设备。换言之,当前工作目录不能是需要卸载设备的挂载点。否则,系统将返回设备繁忙的提示信息。
|
||||
也就是说,你必须“离开”设备的块设备描述符或者挂载点,才能卸载设备。换言之,你的当前工作目录不能是需要卸载设备的挂载点。否则,系统将返回设备繁忙的提示信息。
|
||||
|
||||
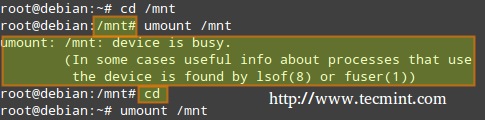
|
||||
|
||||
卸载设备
|
||||
*卸载设备*
|
||||
|
||||
离开需卸载设备的挂载点最简单的方法就是,运行不带任何选项的 cd 命令,这样会回到当前用户的家目录。
|
||||
|
||||
|
||||
### 挂载常见的网络文件系统 ###
|
||||
最常用的两种网络文件系统是 SMB(Server Message Block,服务器消息块)和 NFS(Network File System,网络文件系统)。如果你只向类 Unix 客户端提供共享,用 NFS 就可以了,如果是向 Windows 和其他类 Unix客户端提供共享服务,就需要用到 Samba 了。
|
||||
|
||||
最常用的两种网络文件系统是 SMB(Server Message Block,服务器消息块)和 NFS(Network File System,网络文件系统)。如果你只向类 Unix 客户端提供共享,用 NFS 就可以了,如果是向 Windows 和其他类 Unix 客户端提供共享服务,就需要用到 Samba 了。
|
||||
|
||||
扩展阅读
|
||||
|
||||
@ -130,13 +121,13 @@ mount 命令会尝试寻找挂载点,如果找不到就会查找设备(上
|
||||
|
||||
下面的例子中,假设 Samba 和 NFS 已经在地址为 192.168.0.10 的服务器上架设好了(请注意,架设 NFS 服务器也是 LFCS 考试中需要考核的能力,我们会在后边中提到)。
|
||||
|
||||
|
||||
#### 在 Linux 中挂载 Samba 共享 ####
|
||||
|
||||
第一步:在 Red Hat 以 Debian 系发行版中安装 samba-client、samba-common 和 cifs-utils 软件包,如下:
|
||||
|
||||
# yum update && yum install samba-client samba-common cifs-utils
|
||||
# aptitude update && aptitude install samba-client samba-common cifs-utils
|
||||
|
||||
然后运行下列命令,查看服务器上可用的 Samba 共享。
|
||||
|
||||
# smbclient -L 192.168.0.10
|
||||
@ -145,7 +136,7 @@ mount 命令会尝试寻找挂载点,如果找不到就会查找设备(上
|
||||
|
||||

|
||||
|
||||
挂载 Samba 共享
|
||||
*挂载 Samba 共享*
|
||||
|
||||
上图中,已经对可以挂载到我们本地系统上的共享进行高亮显示。你只需要与一个远程服务器上的合法用户名及密码就可以访问共享了。
|
||||
|
||||
@ -164,7 +155,7 @@ mount 命令会尝试寻找挂载点,如果找不到就会查找设备(上
|
||||
|
||||

|
||||
|
||||
挂载有密码保护的 Samba 共享
|
||||
*挂载有密码保护的 Samba 共享*
|
||||
|
||||
#### 在 Linux 系统中挂载 NFS 共享 ####
|
||||
|
||||
@ -185,7 +176,7 @@ mount 命令会尝试寻找挂载点,如果找不到就会查找设备(上
|
||||
|
||||
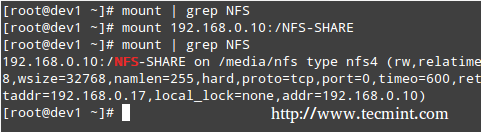
|
||||
|
||||
挂载 NFS 共享
|
||||
*挂载 NFS 共享*
|
||||
|
||||
### 永久性挂载文件系统 ###
|
||||
|
||||
@ -197,13 +188,12 @@ mount 命令会尝试寻找挂载点,如果找不到就会查找设备(上
|
||||
|
||||
其中:
|
||||
|
||||
- <file system>: 第一个字段指定挂载的设备。大多数发行版本都通过分区的标卷(label)或者 UUID 来指定。这样做可以避免分区号改变是带来的错误。
|
||||
- <mount point>: 第二字段指定挂载点。
|
||||
- <type> :文件系统的类型代码与 mount 命令挂载文件系统时使用的类型代码是一样的。通过 auto 类型代码可以让内核自动检测文件系统,这对于可移动设备来说非常方便。注意,该选项可能不是对所有文件系统可用。
|
||||
- <options>: 一个(或多个)挂载选项。
|
||||
- <dump>: 你可能把这个字段设置为 0(否则设置为 1),使得系统启动时禁用 dump 工具(dump 程序曾经是一个常用的备份工具,但现在越来越少用了)对文件系统进行备份。
|
||||
|
||||
- <pass>: 这个字段指定启动系统是是否通过 fsck 来检查文件系统的完整性。0 表示 fsck 不对文件系统进行检查。数字越大,优先级越低。因此,根分区(/)最可能使用数字 1,其他所有需要检查的分区则是以数字 2.
|
||||
- \<file system>: 第一个字段指定挂载的设备。大多数发行版本都通过分区的标卷(label)或者 UUID 来指定。这样做可以避免分区号改变时带来的错误。
|
||||
- \<mount point>: 第二个字段指定挂载点。
|
||||
- \<type> :文件系统的类型代码与 mount 命令挂载文件系统时使用的类型代码是一样的。通过 auto 类型代码可以让内核自动检测文件系统,这对于可移动设备来说非常方便。注意,该选项可能不是对所有文件系统可用。
|
||||
- \<options>: 一个(或多个)挂载选项。
|
||||
- \<dump>: 你可能把这个字段设置为 0(否则设置为 1),使得系统启动时禁用 dump 工具(dump 程序曾经是一个常用的备份工具,但现在越来越少用了)对文件系统进行备份。
|
||||
- \<pass>: 这个字段指定启动系统是是否通过 fsck 来检查文件系统的完整性。0 表示 fsck 不对文件系统进行检查。数字越大,优先级越低。因此,根分区(/)最可能使用数字 1,其他所有需要检查的分区则是以数字 2.
|
||||
|
||||
**Mount 命令例示**
|
||||
|
||||
@ -211,7 +201,7 @@ mount 命令会尝试寻找挂载点,如果找不到就会查找设备(上
|
||||
|
||||
LABEL=TECMINT /mnt ext4 rw,noexec 0 0
|
||||
|
||||
2. 若你想在系统启动时挂载 DVD 光驱中的内容,添加已下语句。
|
||||
2. 若你想在系统启动时挂载 DVD 光驱中的内容,添加以下语句。
|
||||
|
||||
/dev/sr0 /media/cdrom0 iso9660 ro,user,noauto 0 0
|
||||
|
||||
@ -219,7 +209,7 @@ mount 命令会尝试寻找挂载点,如果找不到就会查找设备(上
|
||||
|
||||
### 总结 ###
|
||||
|
||||
可以放心,在命令行中挂载/卸载本地和网络文件系统将是你作为系统管理员的日常责任的一部分。同时,你需要掌握 /etc/fstab 文件的编写。希望本文对你有帮助。随时在下边发表评论(或者提问),并分享本文到你的朋友圈。
|
||||
不用怀疑,在命令行中挂载/卸载本地和网络文件系统将是你作为系统管理员的日常责任的一部分。同时,你需要掌握 /etc/fstab 文件的编写。希望本文对你有帮助。随时在下边发表评论(或者提问),并分享本文到你的朋友圈。
|
||||
|
||||
|
||||
参考链接
|
||||
@ -234,7 +224,7 @@ via: http://www.tecmint.com/mount-filesystem-in-linux/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[GHLandy](https://github.com/GHLandy)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,110 +0,0 @@
|
||||
alim0x translating
|
||||
|
||||
8 things to do after installing openSUSE Leap 42.1
|
||||
================================================================================
|
||||

|
||||
Credit: [Metropolitan Transportation/Flicrk][1]
|
||||
|
||||
> You've installed openSUSE on your PC. Here's what to do next.
|
||||
|
||||
[openSUSE Leap is indeed a huge leap][2], allowing users to run a distro that has the same DNA of SUSE Linux Enterprise. Like any other operating system, some work is needed to get it set up for optimal use.
|
||||
|
||||
Following are some of the things that I did after installing openSUSE Leap on my PC (these are not applicable for server installations). None of them are mandatory, and you may be fine with the basic install. But if you need more out of your openSUSE Leap, follow me.
|
||||
|
||||
### 1. Adding Packman repository ###
|
||||
|
||||
Due to software patents and licences, openSUSE, like many Linux distributions, doesn't offer many applications, codecs, and drivers through official repositories (repos). Instead, these are made available through 3rd party or community repos. The first and most important repository is 'Packman'. Since these repos are not enabled by default, we have to add them. You can do so either using YaST (one of the gems of openSUSE) or by command line (instructions below).
|
||||
|
||||
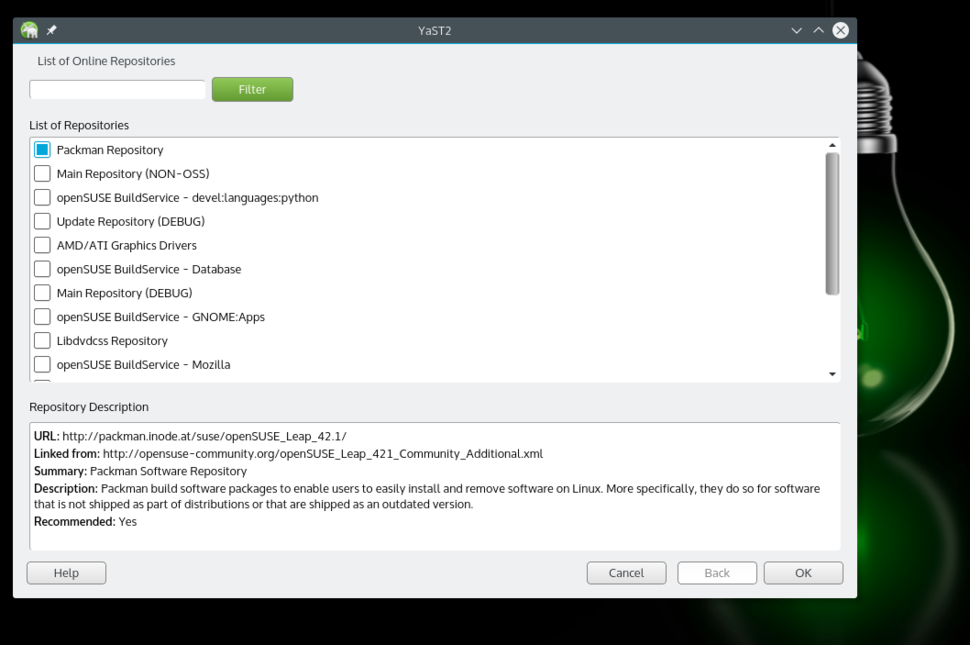
|
||||
Adding Packman repositories.
|
||||
|
||||
Using YaST, go to the Software Repositories section. Click on the 'Add’ button and select 'Community Repositories.' Click 'next.' And once the repos are loaded, select the Packman Repository. Click 'OK,' then import the trusted GnuPG key by clicking on the 'Trust' button.
|
||||
|
||||
Or, using the terminal you can add and enable the Packman repo using the following command:
|
||||
|
||||
zypper ar -f -n packmanhttp://ftp.gwdg.de/pub/linux/misc/packman/suse/openSUSE_Leap_42.1/ packman
|
||||
|
||||
Once the repo is added, you have access to many more packages. To install any application or package, open YaST Software Manager, search for the package and install it.
|
||||
|
||||
### 2. Install VLC ###
|
||||
|
||||
VLC is the Swiss Army knife of media players and can play virtually any media file. You can install VLC from YaST Software Manager or from software.opensuse.org. You will need to install two packages: vlc and vlc-codecs.
|
||||
|
||||
If using terminal, run the following command:
|
||||
|
||||
sudo zypper install vlc vlc-codecs
|
||||
|
||||
### 3. Install Handbrake ###
|
||||
|
||||
If you need to transcode or convert your video files from one format to another, [Handbrake is the tools for you][3]. Handbrake is available through repositories we enabled, so just search for it in YaST and install.
|
||||
|
||||
If you are using the terminal, run the following command:
|
||||
|
||||
sudo zypper install handbrake-cli handbrake-gtk
|
||||
|
||||
(Pro tip: VLC can also transcode audio and video files.)
|
||||
|
||||
### 4. Install Chrome ###
|
||||
|
||||
OpenSUSE comes with Firefox as the default browser. But since Firefox isn't capable of playing restricted media such as Netflix, I recommend installing Chrome. This takes some extra work. First you need to import the trusted key from Google. Open the terminal app and run the 'wget' command to download the key:
|
||||
|
||||
wget https://dl.google.com/linux/linux_signing_key.pub
|
||||
|
||||
Then import the key:
|
||||
|
||||
sudo rpm --import linux_signing_key.pub
|
||||
|
||||
Now head over to the [Google Chrome website][4] and download the 64 bit .rpm file. Once downloaded run the following command to install the browser:
|
||||
|
||||
sudo zypper install /PATH_OF_GOOGLE_CHROME.rpm
|
||||
|
||||
### 5. Install Nvidia drivers ###
|
||||
|
||||
OpenSUSE Leap will work out of the box even if you have Nvidia or ATI graphics cards. However, if you do need the proprietary drivers for gaming or any other purpose, you can install such drivers, but some extra work is needed.
|
||||
|
||||
First you need to add the Nvidia repositories; it's the same procedure we used to add Packman repositories using YaST. The only difference is that you will choose Nvidia from the Community Repositories section. Once it's added, go to **Software Management > Extras** and select 'Extras/Install All Matching Recommended Packages'.
|
||||
|
||||
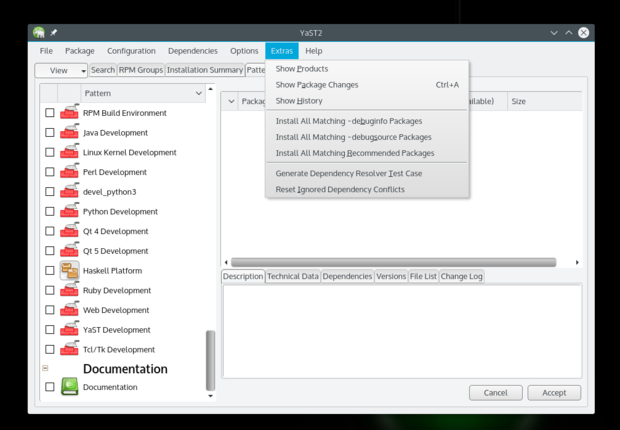
|
||||
|
||||
It will open a dialogue box showing all the packages it's going to install, click OK and follow the instructions. You can also run the following command after adding the Nvidia repository to install the needed Nvidia drivers:
|
||||
|
||||
sudo zypper inr
|
||||
|
||||
(Note: I have never used AMD/ATI cards so I have no experience with them.)
|
||||
|
||||
### 6. Install media codecs ###
|
||||
|
||||
Once you have VLC installed you won't need to install media codecs, but if you are using other apps for media playback you will need to install such codecs. Some developers have written scripts/tools which makes it a much easier process. Just go to [this page][5] and install the entire pack by clicking on the appropriate button. It will open YaST and install the packages automatically (of source you will have to give the root password and trust the GnuPG key, as usual).
|
||||
|
||||
### 7. Install your preferred email client ###
|
||||
|
||||
OpenSUSE comes with Kmail or Evolution, depending on the Desktop Environment you installed on the system. I run Plasma, which comes with Kmail, and this email client leaves a lot to be desired. I suggest trying Thunderbird or Evolution mail. All major email clients are available through official repositories. You can also check my [handpicked list of the best email clients for Linux][7].
|
||||
|
||||
### 8. Enable Samba services from Firewall ###
|
||||
|
||||
OpenSUSE offers a much more secure system out of the box, compared to other distributions. But it also requires a little bit more work for a new user. If you are using Samba protocol to share files within your local network then you will have to allow that service from the Firewall.
|
||||
|
||||
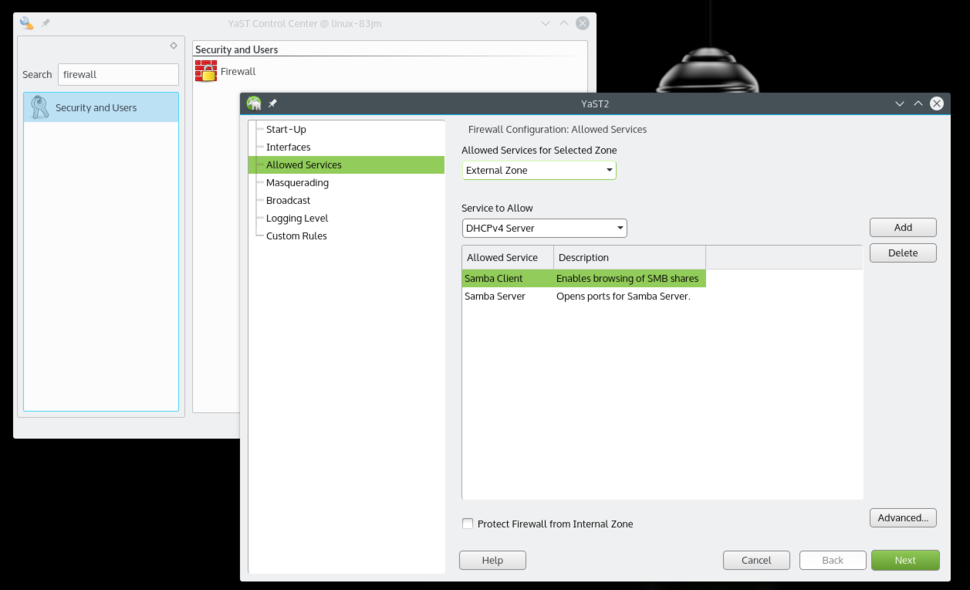
|
||||
Allow Samba Client and Server from Firewall settings.
|
||||
|
||||
Open YaST and search for Firewall. Once in Firewall settings, go to 'Allowed Services' where you will see a drop down list under 'Service to allow.' Select 'Samba Client,' then click 'Add.' Do the same with the 'Samba Server' option. Once both are added, click 'Next,' then click 'Finish,' and now you will be able to share folders from your openSUSE system and also access other machines over the local network.
|
||||
|
||||
That's pretty much all that I did on my new openSUSE system to set it up just the way I like it. If you have any questions, please feel free to ask in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.itworld.com/article/3003865/open-source-tools/8-things-to-do-after-installing-opensuse-leap-421.html
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.itworld.com/author/Swapnil-Bhartiya/
|
||||
[1]:https://www.flickr.com/photos/mtaphotos/11200079265/
|
||||
[2]:https://www.linux.com/news/software/applications/865760-opensuse-leap-421-review-the-most-mature-linux-distribution
|
||||
[3]:https://www.linux.com/learn/tutorials/857788-how-to-convert-videos-in-linux-using-the-command-line
|
||||
[4]:https://www.google.com/intl/en/chrome/browser/desktop/index.html#brand=CHMB&utm_campaign=en&utm_source=en-ha-na-us-sk&utm_medium=ha
|
||||
[5]:http://opensuse-community.org/
|
||||
[6]:http://www.itworld.com/article/2875981/the-5-best-open-source-email-clients-for-linux.html
|
||||
@ -1,217 +0,0 @@
|
||||
Vic020
|
||||
|
||||
How to use Python to hack your Eclipse IDE
|
||||
==============================================
|
||||
|
||||

|
||||
|
||||
The Eclipse Advanced Scripting Environment ([EASE][1]) project is a new but powerful set of plugins that enables you to quickly hack your Eclipse IDE.
|
||||
|
||||
Eclipse is a powerful framework that can be extended in many different ways by using its built-in plugin mechanism. However, writing and deploying a new plugin can be cumbersome if all you want is a bit of additional functionality. Now, using EASE, there's a better way to do that, without having to write a single line of Java code. EASE provides a way to easily automate workbench functionality using scripting languages such as Python or Javascript.
|
||||
|
||||
In this article, based on my [talk][2] at EclipseCon North America this year, I'll cover the basics of how to set up your Eclipse environment with Python and EASE and look at a few ideas to supercharge your IDE with the power of Python.
|
||||
|
||||
### Setup and run "Hello World"
|
||||
|
||||
The examples in this article are based on the Java-implementation of Python, Jython. You can install EASE directly into your existing Eclipse IDE. In this example we use Eclipse [Mars][3] and install EASE itself, its modules and the Jython engine.
|
||||
|
||||
From within the Eclipse Install Dialog (`Help>Install New Software`...), install EASE: [http://download.eclipse.org/ease/update/nightly][4]
|
||||
|
||||
And, select the following components:
|
||||
|
||||
- EASE Core feature
|
||||
|
||||
- EASE core UI feature
|
||||
|
||||
- EASE Python Developer Resources
|
||||
|
||||
- EASE modules (Incubation)
|
||||
|
||||
This will give you EASE and its modules. The main one we are interested in is the Resource module that gives you access to the Eclipse workspace, projects, and files API.
|
||||
|
||||
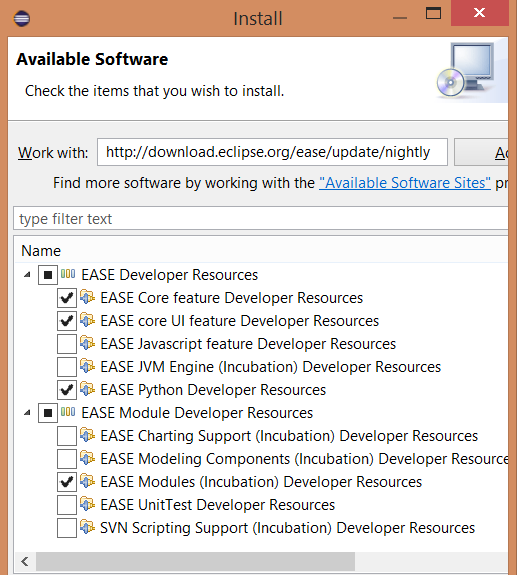
|
||||
|
||||
|
||||
After those have been successfully installed, next install the EASE Jython engine: [https://dl.bintray.com/pontesegger/ease-jython/][5]. Once the plugins are installed, test EASE out. Create a new project and add in a new file called hello.py with this content:
|
||||
|
||||
```
|
||||
print "hello world"
|
||||
```
|
||||
|
||||
Select the file, right click, and select 'Run as -> EASE script'. You should see "Hello World" appear in the console.
|
||||
|
||||
Now you can start writing Python scripts that can access the workspace and projects. This power can be used for all sorts of hacks, below are just a few ideas.
|
||||
|
||||
### Improve your code quality
|
||||
|
||||
Maintaining good code quality can be a tiresome job especially when dealing with a large codebase or when lots of developers are involved. Some of this pain can be made easier with a script, such as for batch formatting for a set of files, or even fixing certain files to [remove unix line endings][6] for easy comparison in source control like git. Another nice thing to do is use a script to generate Eclipse markers to highlight code that could do with improving. Here's an example script that you could use to add task markers for all "printStackTrace" methods it detects in Java files. See the source code: [markers.py][7]
|
||||
|
||||
To run, copy the file to your workspace, then right click and select 'Run as -> EASE script'.
|
||||
|
||||
```
|
||||
loadModule('/System/Resources')
|
||||
```
|
||||
|
||||
from org.eclipse.core.resources import IMarker
|
||||
|
||||
```
|
||||
for ifile in findFiles("*.java"):
|
||||
file_name = str(ifile.getLocation())
|
||||
print "Processing " + file_name
|
||||
with open(file_name) as f:
|
||||
for line_no, line in enumerate(f, start=1):
|
||||
if "printStackTrace" in line:
|
||||
marker = ifile.createMarker(IMarker.TASK)
|
||||
marker.setAttribute(IMarker.TRANSIENT, True)
|
||||
marker.setAttribute(IMarker.LINE_NUMBER, line_no)
|
||||
marker.setAttribute(IMarker.MESSAGE, "Fix in Sprint 2: " + line.strip())
|
||||
|
||||
```
|
||||
|
||||
If you have any java files with printStackTraces you will be able to see the newly created markers in the Tasks view and in the editor margin.
|
||||
|
||||
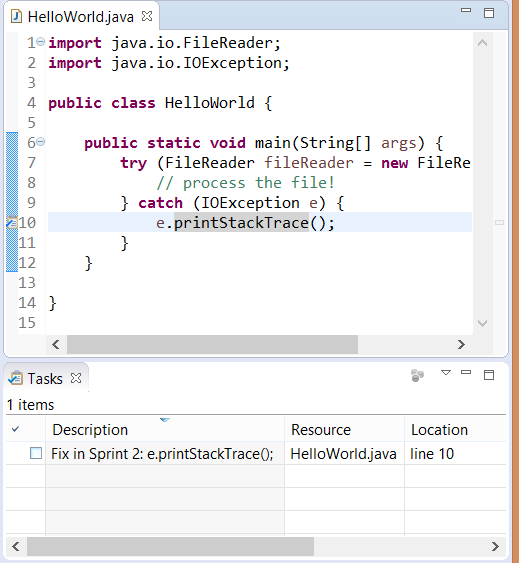
|
||||
|
||||
### Automate tedious tasks
|
||||
|
||||
When you are working with several projects you may want to automate some tedious, repetitive tasks. Perhaps you need to add in a copyright header to the beginning of each source file, or update source files when adopting a new framework. For instance, when we first switched to using Tycho and Maven, we had to add a pom.xml to each project. This is easily done using a few lines of Python. Then when Tycho provided support for pom-less builds, we wanted to remove unnecessary pom files. Again, a few lines of Python script enabled this. As an example, here is a script which adds a README.md file to every open project in your workspace, noting if they are Java or Python projects. See the source code: [add_readme.py][8].
|
||||
|
||||
To run, copy the file to your workspace, then right click and select 'Run as -> EASE script'.
|
||||
|
||||
loadModule('/System/Resources')
|
||||
|
||||
```
|
||||
for iproject in getWorkspace().getProjects():
|
||||
if not iproject.isOpen():
|
||||
continue
|
||||
|
||||
ifile = iproject.getFile("README.md")
|
||||
|
||||
if not ifile.exists():
|
||||
contents = "# " + iproject.getName() + "\n\n"
|
||||
if iproject.hasNature("org.eclipse.jdt.core.javanature"):
|
||||
contents += "A Java Project\n"
|
||||
elif iproject.hasNature("org.python.pydev.pythonNature"):
|
||||
contents += "A Python Project\n"
|
||||
writeFile(ifile, contents)
|
||||
```
|
||||
|
||||
The result should be that every open project will have a README.md file, with Java and Python projects having an additional descriptive line.
|
||||
|
||||
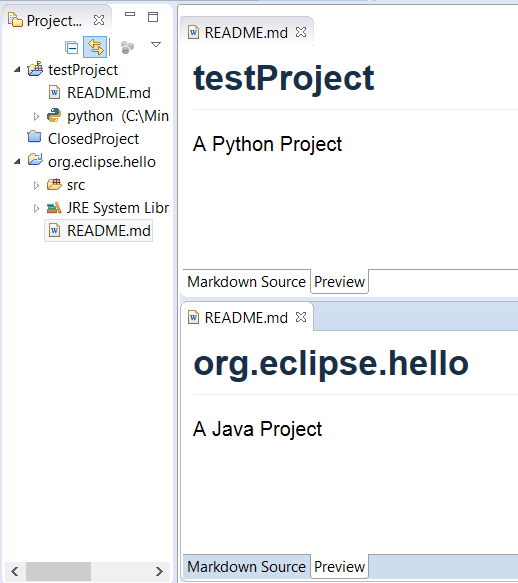
|
||||
|
||||
### Prototype new features
|
||||
|
||||
You can also use a Python script to hack a quick-fix for some much wanted functionality, or as a prototype to help demonstrate to your team or users how you envision a feature. For instance, one feature Eclipse IDE doesn't currently support is auto-save on the current file you are working on. Although this feature is in the works for future releases, you can have a quick and dirty version that autosaves every 30 seconds or when the editor is deactivated. Below is a snippet of the main method. See the full source: [autosave.py][9]
|
||||
|
||||
```
|
||||
def save_dirty_editors():
|
||||
workbench = getService(org.eclipse.ui.IWorkbench)
|
||||
for window in workbench.getWorkbenchWindows():
|
||||
for page in window.getPages():
|
||||
for editor_ref in page.getEditorReferences():
|
||||
part = editor_ref.getPart(False)
|
||||
if part and part.isDirty():
|
||||
print "Auto-Saving", part.getTitle()
|
||||
part.doSave(None)
|
||||
```
|
||||
|
||||
Before running this script you will need to turn on the 'Allow Scripts to run code in UI thread' setting by checking the box under Window > Preferences > Scripting. Then you can add the file to your workspace, right click on it and select 'Run As>EASE Script'. A save message is printed out in the Console view every time an editor is saved. To turn off the autosave just stop the script by pressing the 'Terminate' red square button in the Console view.
|
||||
|
||||
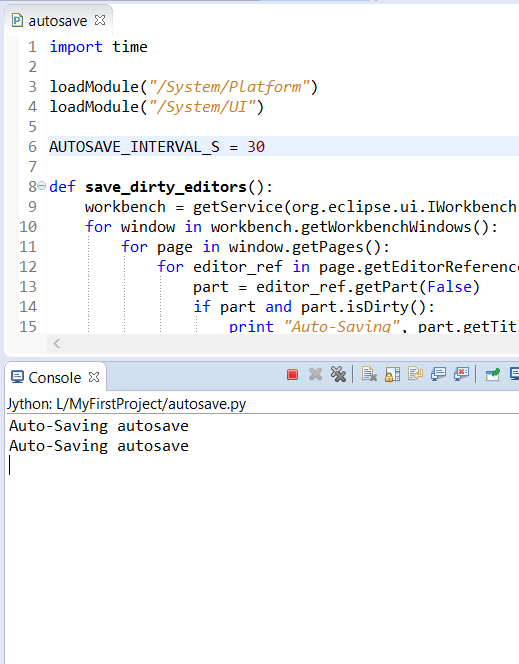
|
||||
|
||||
### Quickly extend the user interface with custom buttons, menus, etc
|
||||
|
||||
One of the best things about EASE is that it allows you to take your scripts and quickly hook them into UI elements of the IDE, for example, as a new button or new menu item. No need to write Java or have a new plugin, just add a couple of lines to your script header—it's that simple.
|
||||
|
||||
Here's an example for a simplistic script that creates us three new projects.
|
||||
|
||||
```
|
||||
# name : Create fruit projects
|
||||
# toolbar : Project Explorer
|
||||
# description : Create fruit projects
|
||||
|
||||
loadModule("/System/Resources")
|
||||
|
||||
for name in ["banana", "pineapple", "mango"]:
|
||||
createProject(name)
|
||||
```
|
||||
|
||||
The comment lines specify to EASE to add a button to the Project Explorer toolbar. Here's another script that adds a button to the same toolbar to delete those three projects. See the source files: [createProjects.py][10] and [deleteProjects.py][11]
|
||||
|
||||
```
|
||||
# name :Delete fruit projects
|
||||
# toolbar : Project Explorer
|
||||
# description : Get rid of the fruit projects
|
||||
|
||||
loadModule("/System/Resources")
|
||||
|
||||
for name in ["banana", "pineapple", "mango"]:
|
||||
project = getProject(name)
|
||||
project.delete(0, None)
|
||||
```
|
||||
|
||||
To get the buttons to appear, add the two script files to a new project—let's call it 'ScriptsProject'. Then go to Windows > Preference > Scripting > Script Locations. Click on the 'Add Workspace' button and select the ScriptsProject. This project now becomes a default location for locating script files. You should see the buttons show up in the Project Explorer without needing to restart your IDE. You should be able to quickly create and delete the projects using your newly added buttons.
|
||||
|
||||
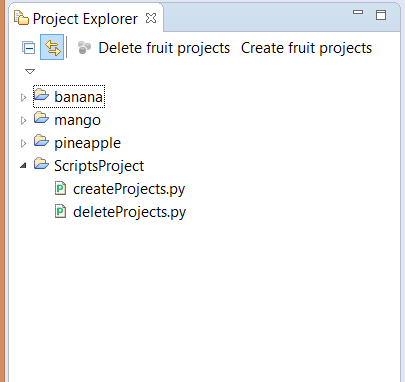
|
||||
|
||||
### Integrate with third-party tools
|
||||
|
||||
Every now and then you may need to use a tool outside the Eclipse ecosystem (sad but true, it has a lot but it does not do everything). For those occasions it might be quite handy to wrap calling that call to the tool in a script. Here's an example that allows you to integrate with explorer.exe, and add it to the content menu so you could instantly open a file browser using the current selection. See the source code: [explorer.py][12]
|
||||
|
||||
```
|
||||
# name : Explore from here
|
||||
# popup : enableFor(org.eclipse.core.resources.IResource)
|
||||
# description : Start a file browser using current selection
|
||||
loadModule("/System/Platform")
|
||||
loadModule('/System/UI')
|
||||
|
||||
selection = getSelection()
|
||||
if isinstance(selection, org.eclipse.jface.viewers.IStructuredSelection):
|
||||
selection = selection.getFirstElement()
|
||||
|
||||
if not isinstance(selection, org.eclipse.core.resources.IResource):
|
||||
selection = adapt(selection, org.eclipse.core.resources.IResource)
|
||||
|
||||
if isinstance(selection, org.eclipse.core.resources.IFile):
|
||||
selection = selection.getParent()
|
||||
|
||||
if isinstance(selection, org.eclipse.core.resources.IContainer):
|
||||
runProcess("explorer.exe", [selection.getLocation().toFile().toString()])
|
||||
```
|
||||
|
||||
To get the menu to appear, add the script to a new project—let's call it 'ScriptsProject'. Then go to Windows > Preference > Scripting > Script Locations. Click on the 'Add Workspace' button and select the ScriptsProject. You should see the new menu item show up in the context menu when you right-click on a file. Select this action to bring up a file browser. (Note this functionality already exists in Eclipse but this example is one you could adapt to other third-party tools).
|
||||
|
||||
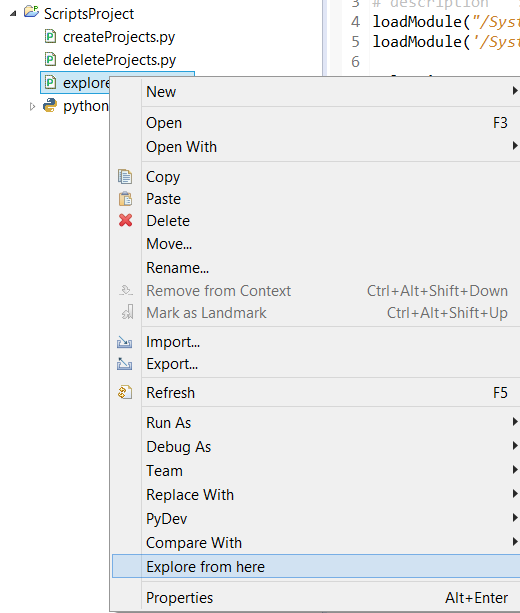
|
||||
|
||||
The Eclipse Advanced Scripting Environment provides a great way to get more out of your Eclipse IDE by leveraging the power of Python. It is a project in its infancy so there is so much more to come. Learn more [about the project][13] and get involved by signing up for the [forum][14].
|
||||
|
||||
I'll be talking more about EASE at [Eclipsecon North America][15] 2016. My talk [Scripting Eclipse with Python][16] will go into how you can use not just Jython, but C-Python and how this functionality can be extended specifically for scientific use-cases.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/2/how-use-python-hack-your-ide
|
||||
|
||||
作者:[Tracy Miranda][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/tracymiranda
|
||||
[1]: https://eclipse.org/ease/
|
||||
[2]: https://www.eclipsecon.org/na2016/session/scripting-eclipse-python
|
||||
[3]: https://www.eclipse.org/downloads/packages/eclipse-ide-eclipse-committers-451/mars1
|
||||
[4]: http://download.eclipse.org/ease/update/nightly
|
||||
[5]: https://dl.bintray.com/pontesegger/ease-jython/
|
||||
[6]: http://code.activestate.com/recipes/66434-change-line-endings/
|
||||
[7]: https://gist.github.com/tracymiranda/6556482e278c9afc421d
|
||||
[8]: https://gist.github.com/tracymiranda/f20f233b40f1f79b1df2
|
||||
[9]: https://gist.github.com/tracymiranda/e9588d0976c46a987463
|
||||
[10]: https://gist.github.com/tracymiranda/55995daaea9a4db584dc
|
||||
[11]: https://gist.github.com/tracymiranda/baa218fc2c1a8e898194
|
||||
[12]: https://gist.github.com/tracymiranda/8aa3f0fc4bf44f4a5cd3
|
||||
[13]: https://eclipse.org/ease/
|
||||
[14]: https://dev.eclipse.org/mailman/listinfo/ease-dev
|
||||
[15]: https://www.eclipsecon.org/na2016
|
||||
[16]: https://www.eclipsecon.org/na2016/session/scripting-eclipse-python
|
||||
@ -1,3 +1,4 @@
|
||||
Translating By willowyoung
|
||||
Image processing at NASA with open source tools
|
||||
=======================================================
|
||||
|
||||
|
||||
@ -0,0 +1,206 @@
|
||||
Part 11 - How to Manage and Create LVM Using vgcreate, lvcreate and lvextend Commands
|
||||
============================================================================================
|
||||
|
||||
Because of the changes in the LFCS exam requirements effective Feb. 2, 2016, we are adding the necessary topics to the [LFCS series][1] published here. To prepare for this exam, your are highly encouraged to use the [LFCE series][2] as well.
|
||||
|
||||

|
||||
>LFCS: Manage LVM and Create LVM Partition – Part 11
|
||||
|
||||
One of the most important decisions while installing a Linux system is the amount of storage space to be allocated for system files, home directories, and others. If you make a mistake at that point, growing a partition that has run out of space can be burdensome and somewhat risky.
|
||||
|
||||
**Logical Volumes Management** (also known as **LVM**), which have become a default for the installation of most (if not all) Linux distributions, have numerous advantages over traditional partitioning management. Perhaps the most distinguishing feature of LVM is that it allows logical divisions to be resized (reduced or increased) at will without much hassle.
|
||||
|
||||
The structure of the LVM consists of:
|
||||
|
||||
* One or more entire hard disks or partitions are configured as physical volumes (PVs).
|
||||
* A volume group (**VG**) is created using one or more physical volumes. You can think of a volume group as a single storage unit.
|
||||
* Multiple logical volumes can then be created in a volume group. Each logical volume is somewhat equivalent to a traditional partition – with the advantage that it can be resized at will as we mentioned earlier.
|
||||
|
||||
In this article we will use three disks of **8 GB** each (**/dev/sdb**, **/dev/sdc**, and **/dev/sdd**) to create three physical volumes. You can either create the PVs directly on top of the device, or partition it first.
|
||||
|
||||
Although we have chosen to go with the first method, if you decide to go with the second (as explained in [Part 4 – Create Partitions and File Systems in Linux][3] of this series) make sure to configure each partition as type `8e`.
|
||||
|
||||
### Creating Physical Volumes, Volume Groups, and Logical Volumes
|
||||
|
||||
To create physical volumes on top of **/dev/sdb**, **/dev/sdc**, and **/dev/sdd**, do:
|
||||
|
||||
```
|
||||
# pvcreate /dev/sdb /dev/sdc /dev/sdd
|
||||
```
|
||||
|
||||
You can list the newly created PVs with:
|
||||
|
||||
```
|
||||
# pvs
|
||||
```
|
||||
|
||||
and get detailed information about each PV with:
|
||||
|
||||
```
|
||||
# pvdisplay /dev/sdX
|
||||
```
|
||||
|
||||
(where **X** is b, c, or d)
|
||||
|
||||
If you omit `/dev/sdX` as parameter, you will get information about all the PVs.
|
||||
|
||||
To create a volume group named `vg00` using `/dev/sdb` and `/dev/sdc` (we will save `/dev/sdd` for later to illustrate the possibility of adding other devices to expand storage capacity when needed):
|
||||
|
||||
```
|
||||
# vgcreate vg00 /dev/sdb /dev/sdc
|
||||
```
|
||||
|
||||
As it was the case with physical volumes, you can also view information about this volume group by issuing:
|
||||
|
||||
```
|
||||
# vgdisplay vg00
|
||||
```
|
||||
|
||||
Since `vg00` is formed with two **8 GB** disks, it will appear as a single **16 GB** drive:
|
||||
|
||||

|
||||
>List LVM Volume Groups
|
||||
|
||||
When it comes to creating logical volumes, the distribution of space must take into consideration both current and future needs. It is considered good practice to name each logical volume according to its intended use.
|
||||
|
||||
For example, let’s create two LVs named `vol_projects` (**10 GB**) and `vol_backups` (remaining space), which we can use later to store project documentation and system backups, respectively.
|
||||
|
||||
The `-n` option is used to indicate a name for the LV, whereas `-L` sets a fixed size and `-l` (lowercase L) is used to indicate a percentage of the remaining space in the container VG.
|
||||
|
||||
```
|
||||
# lvcreate -n vol_projects -L 10G vg00
|
||||
# lvcreate -n vol_backups -l 100%FREE vg00
|
||||
```
|
||||
|
||||
As before, you can view the list of LVs and basic information with:
|
||||
|
||||
```
|
||||
# lvs
|
||||
```
|
||||
|
||||
and detailed information with
|
||||
|
||||
```
|
||||
# lvdisplay
|
||||
```
|
||||
|
||||
To view information about a single **LV**, use **lvdisplay** with the **VG** and **LV** as parameters, as follows:
|
||||
|
||||
```
|
||||
# lvdisplay vg00/vol_projects
|
||||
```
|
||||
|
||||

|
||||
>List Logical Volume
|
||||
|
||||
In the image above we can see that the LVs were created as storage devices (refer to the LV Path line). Before each logical volume can be used, we need to create a filesystem on top of it.
|
||||
|
||||
We’ll use ext4 as an example here since it allows us both to increase and reduce the size of each LV (as opposed to xfs that only allows to increase the size):
|
||||
|
||||
```
|
||||
# mkfs.ext4 /dev/vg00/vol_projects
|
||||
# mkfs.ext4 /dev/vg00/vol_backups
|
||||
```
|
||||
|
||||
In the next section we will explain how to resize logical volumes and add extra physical storage space when the need arises to do so.
|
||||
|
||||
### Resizing Logical Volumes and Extending Volume Groups
|
||||
|
||||
Now picture the following scenario. You are starting to run out of space in `vol_backups`, while you have plenty of space available in `vol_projects`. Due to the nature of LVM, we can easily reduce the size of the latter (say **2.5 GB**) and allocate it for the former, while resizing each filesystem at the same time.
|
||||
|
||||
Fortunately, this is as easy as doing:
|
||||
|
||||
```
|
||||
# lvreduce -L -2.5G -r /dev/vg00/vol_projects
|
||||
# lvextend -l +100%FREE -r /dev/vg00/vol_backups
|
||||
```
|
||||
|
||||

|
||||
>Resize Reduce Logical Volume and Volume Group
|
||||
|
||||
It is important to include the minus `(-)` or plus `(+)` signs while resizing a logical volume. Otherwise, you’re setting a fixed size for the LV instead of resizing it.
|
||||
|
||||
It can happen that you arrive at a point when resizing logical volumes cannot solve your storage needs anymore and you need to buy an extra storage device. Keeping it simple, you will need another disk. We are going to simulate this situation by adding the remaining PV from our initial setup (`/dev/sdd`).
|
||||
|
||||
To add `/dev/sdd` to `vg00`, do
|
||||
|
||||
```
|
||||
# vgextend vg00 /dev/sdd
|
||||
```
|
||||
|
||||
If you run vgdisplay `vg00` before and after the previous command, you will see the increase in the size of the VG:
|
||||
|
||||
```
|
||||
# vgdisplay vg00
|
||||
```
|
||||
|
||||
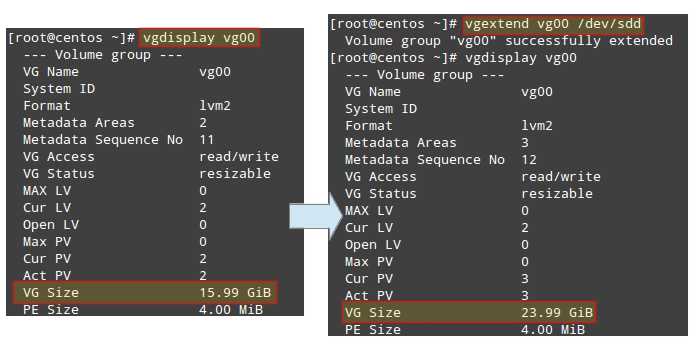
|
||||
>Check Volume Group Disk Size
|
||||
|
||||
Now you can use the newly added space to resize the existing LVs according to your needs, or to create additional ones as needed.
|
||||
|
||||
### Mounting Logical Volumes on Boot and on Demand
|
||||
|
||||
Of course there would be no point in creating logical volumes if we are not going to actually use them! To better identify a logical volume we will need to find out what its `UUID` (a non-changing attribute that uniquely identifies a formatted storage device) is.
|
||||
|
||||
To do that, use blkid followed by the path to each device:
|
||||
|
||||
```
|
||||
# blkid /dev/vg00/vol_projects
|
||||
# blkid /dev/vg00/vol_backups
|
||||
```
|
||||
|
||||

|
||||
>Find Logical Volume UUID
|
||||
|
||||
Create mount points for each LV:
|
||||
|
||||
```
|
||||
# mkdir /home/projects
|
||||
# mkdir /home/backups
|
||||
```
|
||||
|
||||
and insert the corresponding entries in `/etc/fstab` (make sure to use the UUIDs obtained before):
|
||||
|
||||
```
|
||||
UUID=b85df913-580f-461c-844f-546d8cde4646 /home/projects ext4 defaults 0 0
|
||||
UUID=e1929239-5087-44b1-9396-53e09db6eb9e /home/backups ext4 defaults 0 0
|
||||
```
|
||||
|
||||
Then save the changes and mount the LVs:
|
||||
|
||||
```
|
||||
# mount -a
|
||||
# mount | grep home
|
||||
```
|
||||
|
||||

|
||||
>Find Logical Volume UUID
|
||||
|
||||
When it comes to actually using the LVs, you will need to assign proper `ugo+rwx` permissions as explained in [Part 8 – Manage Users and Groups in Linux][4] of this series.
|
||||
|
||||
### Summary
|
||||
|
||||
In this article we have introduced [Logical Volume Management][5], a versatile tool to manage storage devices that provides scalability. When combined with RAID (which we explained in [Part 6 – Create and Manage RAID in Linux][6] of this series), you can enjoy not only scalability (provided by LVM) but also redundancy (offered by RAID).
|
||||
|
||||
In this type of setup, you will typically find `LVM` on top of `RAID`, that is, configure RAID first and then configure LVM on top of it.
|
||||
|
||||
If you have questions about this article, or suggestions to improve it, feel free to reach us using the comment form below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-basic-shell-scripting-and-linux-filesystem-troubleshooting/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/gacanepa/
|
||||
[1]: http://www.tecmint.com/sed-command-to-create-edit-and-manipulate-files-in-linux/
|
||||
[2]: http://www.tecmint.com/installing-network-services-and-configuring-services-at-system-boot/
|
||||
[3]: http://www.tecmint.com/create-partitions-and-filesystems-in-linux/
|
||||
[4]: http://www.tecmint.com/manage-users-and-groups-in-linux/
|
||||
[5]: http://www.tecmint.com/create-lvm-storage-in-linux/
|
||||
[6]: http://www.tecmint.com/creating-and-managing-raid-backups-in-linux/
|
||||
@ -0,0 +1,273 @@
|
||||
Part 14 - Monitor Linux Processes Resource Usage and Set Process Limits on a Per-User Basis
|
||||
=============================================================================================
|
||||
|
||||
Because of the changes in the LFCS exam requirements effective Feb. 2, 2016, we are adding the necessary topics to the [LFCS series][1] published here. To prepare for this exam, your are highly encouraged to use the [LFCE series][2] as well.
|
||||
|
||||

|
||||
>Monitor Linux Processes and Set Process Limits Per User – Part 14
|
||||
|
||||
Every Linux system administrator needs to know how to verify the integrity and availability of hardware, resources, and key processes. In addition, setting resource limits on a per-user basis must also be a part of his / her skill set.
|
||||
|
||||
In this article we will explore a few ways to ensure that the system both hardware and the software is behaving correctly to avoid potential issues that may cause unexpected production downtime and money loss.
|
||||
|
||||
### Linux Reporting Processors Statistics
|
||||
|
||||
With **mpstat** you can view the activities for each processor individually or the system as a whole, both as a one-time snapshot or dynamically.
|
||||
|
||||
In order to use this tool, you will need to install **sysstat**:
|
||||
|
||||
```
|
||||
# yum update && yum install sysstat [On CentOS based systems]
|
||||
# aptitutde update && aptitude install sysstat [On Ubuntu based systems]
|
||||
# zypper update && zypper install sysstat [On openSUSE systems]
|
||||
```
|
||||
|
||||
Read more about sysstat and it’s utilities at [Learn Sysstat and Its Utilities mpstat, pidstat, iostat and sar in Linux][3]
|
||||
|
||||
Once you have installed **mpstat**, use it to generate reports of processors statistics.
|
||||
|
||||
To display **3** global reports of CPU utilization (`-u`) for all CPUs (as indicated by `-P` ALL) at a 2-second interval, do:
|
||||
|
||||
```
|
||||
# mpstat -P ALL -u 2 3
|
||||
```
|
||||
|
||||
### Sample Output
|
||||
|
||||
```
|
||||
Linux 3.19.0-32-generic (tecmint.com) Wednesday 30 March 2016 _x86_64_ (4 CPU)
|
||||
|
||||
11:41:07 IST CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
|
||||
11:41:09 IST all 5.85 0.00 1.12 0.12 0.00 0.00 0.00 0.00 0.00 92.91
|
||||
11:41:09 IST 0 4.48 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 94.53
|
||||
11:41:09 IST 1 2.50 0.00 0.50 0.00 0.00 0.00 0.00 0.00 0.00 97.00
|
||||
11:41:09 IST 2 6.44 0.00 0.99 0.00 0.00 0.00 0.00 0.00 0.00 92.57
|
||||
11:41:09 IST 3 10.45 0.00 1.99 0.00 0.00 0.00 0.00 0.00 0.00 87.56
|
||||
|
||||
11:41:09 IST CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
|
||||
11:41:11 IST all 11.60 0.12 1.12 0.50 0.00 0.00 0.00 0.00 0.00 86.66
|
||||
11:41:11 IST 0 10.50 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 88.50
|
||||
11:41:11 IST 1 14.36 0.00 1.49 2.48 0.00 0.00 0.00 0.00 0.00 81.68
|
||||
11:41:11 IST 2 2.00 0.50 1.00 0.00 0.00 0.00 0.00 0.00 0.00 96.50
|
||||
11:41:11 IST 3 19.40 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 79.60
|
||||
|
||||
11:41:11 IST CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
|
||||
11:41:13 IST all 5.69 0.00 1.24 0.00 0.00 0.00 0.00 0.00 0.00 93.07
|
||||
11:41:13 IST 0 2.97 0.00 1.49 0.00 0.00 0.00 0.00 0.00 0.00 95.54
|
||||
11:41:13 IST 1 10.78 0.00 1.47 0.00 0.00 0.00 0.00 0.00 0.00 87.75
|
||||
11:41:13 IST 2 2.00 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 97.00
|
||||
11:41:13 IST 3 6.93 0.00 0.50 0.00 0.00 0.00 0.00 0.00 0.00 92.57
|
||||
|
||||
Average: CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
|
||||
Average: all 7.71 0.04 1.16 0.21 0.00 0.00 0.00 0.00 0.00 90.89
|
||||
Average: 0 5.97 0.00 1.16 0.00 0.00 0.00 0.00 0.00 0.00 92.87
|
||||
Average: 1 9.24 0.00 1.16 0.83 0.00 0.00 0.00 0.00 0.00 88.78
|
||||
Average: 2 3.49 0.17 1.00 0.00 0.00 0.00 0.00 0.00 0.00 95.35
|
||||
Average: 3 12.25 0.00 1.16 0.00 0.00 0.00 0.00 0.00 0.00 86.59
|
||||
```
|
||||
|
||||
To view the same statistics for a specific **CPU** (**CPU 0** in the following example), use:
|
||||
|
||||
```
|
||||
# mpstat -P 0 -u 2 3
|
||||
```
|
||||
|
||||
### Sample Output
|
||||
|
||||
```
|
||||
Linux 3.19.0-32-generic (tecmint.com) Wednesday 30 March 2016 _x86_64_ (4 CPU)
|
||||
|
||||
11:42:08 IST CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
|
||||
11:42:10 IST 0 3.00 0.00 0.50 0.00 0.00 0.00 0.00 0.00 0.00 96.50
|
||||
11:42:12 IST 0 4.08 0.00 0.00 2.55 0.00 0.00 0.00 0.00 0.00 93.37
|
||||
11:42:14 IST 0 9.74 0.00 0.51 0.00 0.00 0.00 0.00 0.00 0.00 89.74
|
||||
Average: 0 5.58 0.00 0.34 0.85 0.00 0.00 0.00 0.00 0.00 93.23
|
||||
```
|
||||
|
||||
The output of the above commands shows these columns:
|
||||
|
||||
* `CPU`: Processor number as an integer, or the word all as an average for all processors.
|
||||
* `%usr`: Percentage of CPU utilization while running user level applications.
|
||||
* `%nice`: Same as `%usr`, but with nice priority.
|
||||
* `%sys`: Percentage of CPU utilization that occurred while executing kernel applications. This does not include time spent dealing with interrupts or handling hardware.
|
||||
* `%iowait`: Percentage of time when the given CPU (or all) was idle, during which there was a resource-intensive I/O operation scheduled on that CPU. A more detailed explanation (with examples) can be found [here][4].
|
||||
* `%irq`: Percentage of time spent servicing hardware interrupts.
|
||||
* `%soft`: Same as `%irq`, but with software interrupts.
|
||||
* `%steal`: Percentage of time spent in involuntary wait (steal or stolen time) when a virtual machine, as guest, is “winning” the hypervisor’s attention while competing for the CPU(s). This value should be kept as small as possible. A high value in this field means the virtual machine is stalling – or soon will be.
|
||||
* `%guest`: Percentage of time spent running a virtual processor.
|
||||
* `%idle`: percentage of time when CPU(s) were not executing any tasks. If you observe a low value in this column, that is an indication of the system being placed under a heavy load. In that case, you will need to take a closer look at the process list, as we will discuss in a minute, to determine what is causing it.
|
||||
|
||||
To put the place the processor under a somewhat high load, run the following commands and then execute mpstat (as indicated) in a separate terminal:
|
||||
|
||||
```
|
||||
# dd if=/dev/zero of=test.iso bs=1G count=1
|
||||
# mpstat -u -P 0 2 3
|
||||
# ping -f localhost # Interrupt with Ctrl + C after mpstat below completes
|
||||
# mpstat -u -P 0 2 3
|
||||
```
|
||||
|
||||
Finally, compare to the output of **mpstat** under “normal” circumstances:
|
||||
|
||||

|
||||
>Report Linux Processors Related Statistics
|
||||
|
||||
As you can see in the image above, **CPU 0** was under a heavy load during the first two examples, as indicated by the `%idle` column.
|
||||
|
||||
In the next section we will discuss how to identify these resource-hungry processes, how to obtain more information about them, and how to take appropriate action.
|
||||
|
||||
### Reporting Linux Processes
|
||||
|
||||
To list processes sorting them by CPU usage, we will use the well known `ps` command with the `-eo` (to select all processes with user-defined format) and `--sort` (to specify a custom sorting order) options, like so:
|
||||
|
||||
```
|
||||
# ps -eo pid,ppid,cmd,%cpu,%mem --sort=-%cpu
|
||||
```
|
||||
|
||||
The above command will only show the `PID`, `PPID`, the command associated with the process, and the percentage of CPU and RAM usage sorted by the percentage of CPU usage in descending order. When executed during the creation of the .iso file, here’s the first few lines of the output:
|
||||
|
||||

|
||||
>Find Linux Processes By CPU Usage
|
||||
|
||||
Once we have identified a process of interest (such as the one with `PID=2822`), we can navigate to `/proc/PID` (`/proc/2822` in this case) and do a directory listing.
|
||||
|
||||
This directory is where several files and subdirectories with detailed information about this particular process are kept while it is running.
|
||||
|
||||
#### For example:
|
||||
|
||||
* `/proc/2822/io` contains IO statistics for the process (number of characters and bytes read and written, among others, during IO operations).
|
||||
* `/proc/2822/attr/current` shows the current SELinux security attributes of the process.
|
||||
* `/proc/2822/cgroup` describes the control groups (cgroups for short) to which the process belongs if the CONFIG_CGROUPS kernel configuration option is enabled, which you can verify with:
|
||||
|
||||
```
|
||||
# cat /boot/config-$(uname -r) | grep -i cgroups
|
||||
```
|
||||
|
||||
If the option is enabled, you should see:
|
||||
|
||||
```
|
||||
CONFIG_CGROUPS=y
|
||||
```
|
||||
|
||||
Using `cgroups` you can manage the amount of allowed resource usage on a per-process basis as explained in Chapters 1 through 4 of the [Red Hat Enterprise Linux 7 Resource Management guide][5], in Chapter 9 of the [openSUSE System Analysis and Tuning guide][6], and in the [Control Groups section of the Ubuntu 14.04 Server documentation][7].
|
||||
|
||||
The `/proc/2822/fd` is a directory that contains one symbolic link for each file descriptor the process has opened. The following image shows this information for the process that was started in tty1 (the first terminal) to create the **.iso** image:
|
||||
|
||||

|
||||
>Find Linux Process Information
|
||||
|
||||
The above image shows that **stdin** (file descriptor **0**), **stdout** (file descriptor **1**), and **stderr** (file descriptor **2**) are mapped to **/dev/zero**, **/root/test.iso**, and **/dev/tty1**, respectively.
|
||||
|
||||
More information about `/proc` can be found in “The `/proc` filesystem” document kept and maintained by Kernel.org, and in the Linux Programmer’s Manual.
|
||||
|
||||
### Setting Resource Limits on a Per-User Basis in Linux
|
||||
|
||||
If you are not careful and allow any user to run an unlimited number of processes, you may eventually experience an unexpected system shutdown or get locked out as the system enters an unusable state. To prevent this from happening, you should place a limit on the number of processes users can start.
|
||||
|
||||
To do this, edit **/etc/security/limits.conf** and add the following line at the bottom of the file to set the limit:
|
||||
|
||||
```
|
||||
* hard nproc 10
|
||||
```
|
||||
|
||||
The first field can be used to indicate either a user, a group, or all of them `(*)`, whereas the second field enforces a hard limit on the number of process (nproc) to **10**. To apply changes, logging out and back in is enough.
|
||||
|
||||
Thus, let’s see what happens if a certain user other than root (either a legitimate one or not) attempts to start a shell fork bomb. If we had not implemented limits, this would initially launch two instances of a function, and then duplicate each of them in a neverending loop. Thus, it would eventually bringing your system to a crawl.
|
||||
|
||||
However, with the above restriction in place, the fork bomb does not succeed but the user will still get locked out until the system administrator kills the process associated with it:
|
||||
|
||||
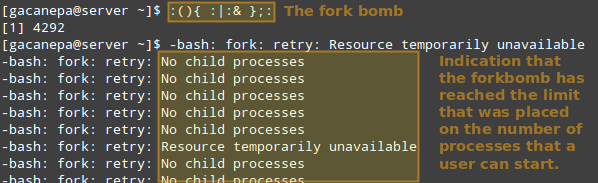
|
||||
>Run Shell Fork Bomb
|
||||
|
||||
**TIP**: Other possible restrictions made possible by **ulimit** are documented in the `limits.conf` file.
|
||||
|
||||
### Linux Other Process Management Tools
|
||||
|
||||
In addition to the tools discussed previously, a system administrator may also need to:
|
||||
|
||||
**a)** Modify the execution priority (use of system resources) of a process using **renice**. This means that the kernel will allocate more or less system resources to the process based on the assigned priority (a number commonly known as “**niceness**” in a range from `-20` to `19`).
|
||||
|
||||
The lower the value, the greater the execution priority. Regular users (other than root) can only modify the niceness of processes they own to a higher value (meaning a lower execution priority), whereas root can modify this value for any process, and may increase or decrease it.
|
||||
|
||||
The basic syntax of renice is as follows:
|
||||
|
||||
```
|
||||
# renice [-n] <new priority> <UID, GID, PGID, or empty> identifier
|
||||
```
|
||||
|
||||
If the argument after the new priority value is not present (empty), it is set to PID by default. In that case, the niceness of process with **PID=identifier** is set to `<new priority>`.
|
||||
|
||||
**b)** Interrupt the normal execution of a process when needed. This is commonly known as [“killing” the process][9]. Under the hood, this means sending the process a signal to finish its execution properly and release any used resources in an orderly manner.
|
||||
|
||||
To [kill a process][10], use the **kill** command as follows:
|
||||
|
||||
```
|
||||
# kill PID
|
||||
```
|
||||
|
||||
Alternatively, you can use [pkill to terminate all processes][11] of a given owner `(-u)`, or a group owner `(-G)`, or even those processes which have a PPID in common `(-P)`. These options may be followed by the numeric representation or the actual name as identifier:
|
||||
|
||||
```
|
||||
# pkill [options] identifier
|
||||
```
|
||||
|
||||
For example,
|
||||
|
||||
```
|
||||
# pkill -G 1000
|
||||
```
|
||||
|
||||
will kill all processes owned by group with `GID=1000`.
|
||||
|
||||
And,
|
||||
|
||||
```
|
||||
# pkill -P 4993
|
||||
```
|
||||
|
||||
will kill all processes whose `PPID is 4993`.
|
||||
|
||||
Before running a `pkill`, it is a good idea to test the results with `pgrep` first, perhaps using the `-l` option as well to list the processes’ names. It takes the same options but only returns the PIDs of processes (without taking any further action) that would be killed if `pkill` is used.
|
||||
|
||||
```
|
||||
# pgrep -l -u gacanepa
|
||||
```
|
||||
|
||||
This is illustrated in the next image:
|
||||
|
||||

|
||||
>Find User Running Processes in Linux
|
||||
|
||||
### Summary
|
||||
|
||||
In this article we have explored a few ways to monitor resource usage in order to verify the integrity and availability of critical hardware and software components in a Linux system.
|
||||
|
||||
We have also learned how to take appropriate action (either by adjusting the execution priority of a given process or by terminating it) under unusual circumstances.
|
||||
|
||||
We hope the concepts explained in this tutorial have been helpful. If you have any questions or comments, feel free to reach us using the contact form below.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-basic-shell-scripting-and-linux-filesystem-troubleshooting/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/gacanepa/
|
||||
[1]: http://www.tecmint.com/sed-command-to-create-edit-and-manipulate-files-in-linux/
|
||||
[2]: http://www.tecmint.com/installing-network-services-and-configuring-services-at-system-boot/
|
||||
[3]: http://www.tecmint.com/sysstat-commands-to-monitor-linux/
|
||||
[4]: http://veithen.github.io/2013/11/18/iowait-linux.html
|
||||
[5]: https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/7/html/Resource_Management_Guide/index.html
|
||||
[6]: https://doc.opensuse.org/documentation/leap/tuning/html/book.sle.tuning/cha.tuning.cgroups.html
|
||||
[7]: https://help.ubuntu.com/lts/serverguide/cgroups.html
|
||||
[8]: http://man7.org/linux/man-pages/man5/proc.5.html
|
||||
[9]: http://www.tecmint.com/kill-processes-unresponsive-programs-in-ubuntu/
|
||||
[10]: http://www.tecmint.com/find-and-kill-running-processes-pid-in-linux/
|
||||
[11]: http://www.tecmint.com/how-to-kill-a-process-in-linux/
|
||||
@ -0,0 +1,43 @@
|
||||
Ubuntu Budgie 将在 Ubuntu 16.10 中成为新官方分支发行版
|
||||
===
|
||||
|
||||
> Budgie-Remix Beta 2 已经就绪以供测试。
|
||||
|
||||
上个月我们介绍了一个新 GNU/Linux 发行版 [Budgie-Remix][1],它的终极目标是成为一个 Ubuntu 官方分支发行版,可能会使用 Ubuntu Budgie 这个名字。
|
||||
|
||||

|
||||
|
||||
今天,Budgie-Remix 的开发者 David Mohammed 向 Softpedia 通报了项目进度,以及为即将到来的 16.04 发布的第二个 Beta 版本。Cononical 的创始人 [Mark Shuttleworth 说过][2]如果能够有围绕这个包的社区,它肯定会得到支持。
|
||||
|
||||
自我们[最初的报道][3]以来,David Mohammed 似乎与 Ubuntu MATE 项目的领导者 Martin Wimpress 取得了联系,后者敦促他以 Ubuntu 16.10 作为他还未正式命名的 Ubuntu 分支的官方版本目标。这个分支发行版构建于 Budgie 桌面环境之上,它是超赞的 [Solus][4] 开发者团队创建的。
|
||||
|
||||
“我们本周完成了 Beta 2 版本的开发以及很多其它东西,而且我们还有 Martin Wimpress (Ubuntu MATE 项目领导者)的支持,”David Mohammed 对 Softpedia 独家爆料。”他还敦促我们以 16.10 作为成为官方版本的目标——那当然是个主要的挑战——并且我们还需要社区的帮助/加入我们来让这一切成为现实!”
|
||||
|
||||
### Ubuntu Budgie 16.10 可能在 2016 年 10 月到来 ###
|
||||
|
||||
4 月 21 日,Canonical 将会发布 Ubuntu Linux 的下一个 LTS(Long Term Support,长期支持)版本,Xenial Xerus 好客的非洲地松鼠,也就是 Ubuntu 16.04,并且我们有可能能够以 Budgie-Remix 16.04 的名义提前尝试将成为官方分支的 Ubuntu Budgie。但在那之前,你可以帮助开发者[测试 Beta 2 版本][5]。
|
||||
|
||||
在 Ubuntu 16.04 LTS(Xenial Xerus)发布之后,Ubuntu 的开发者们就会立即将注意力转移到下一个版本的开发上。下一个版本 Ubuntu 16.10 应该会在 10 月底到来,并且 Ubuntu Budgie 也可能宣布成为 Ubuntu 官方分支发行版。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
----------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/ubuntu-budgie-could-be-the-new-flavor-of-ubuntu-linux-as-part-of-ubuntu-16-10-502573.shtml
|
||||
|
||||
作者:Marius Nestor
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]: https://launchpad.net/budgie-remix
|
||||
[2]: https://plus.google.com/+programmerslab/posts/CSvbSvgcdcv
|
||||
[3]: http://news.softpedia.com/news/budgie-remix-could-become-ubuntu-budgie-download-and-test-it-501231.shtml
|
||||
[4]: https://solus-project.com/
|
||||
[5]: https://sourceforge.net/projects/budgie-remix/files/beta2/
|
||||
@ -1,208 +1,207 @@
|
||||
10 Tips for 10x Application Performance
|
||||
|
||||
将程序性能提高十倍的10条建议
|
||||
================================================================================
|
||||
|
||||
提高web 应用的性能从来没有比现在更关键过。网络经济的比重一直在增长;全球经济超过5% 的价值是在因特网上产生的(数据参见下面的资料)。我们的永远在线、超级连接的世界意味着用户的期望值也处于历史上的最高点。如果你的网站不能及时的响应,或者你的app 不能无延时的工作,用户会很快的投奔到你的竞争对手那里。
|
||||
提高 web 应用的性能从来没有比现在更重要过。网络经济的比重一直在增长;全球经济超过 5% 的价值是在因特网上产生的(数据参见下面的资料)。这个时刻在线的超连接世界意味着用户对其的期望值也处于历史上的最高点。如果你的网站不能及时的响应,或者你的 app 不能无延时的工作,用户会很快的投奔到你的竞争对手那里。
|
||||
|
||||
举一个例子,一份亚马逊十年前做过的研究可以证明,甚至在那个时候,网页加载时间每减少100毫秒,收入就会增加1%。另一个最近的研究特别强调一个事实,即超过一半的网站拥有着在调查中说他们会因为应用程序性能的问题流失用户。
|
||||
举一个例子,一份亚马逊十年前做过的研究可以证明,甚至在那个时候,网页加载时间每减少100毫秒,收入就会增加1%。另一个最近的研究特别强调一个事实,即超过一半的网站拥有者在调查中承认它们会因为应用程序性能的问题流失用户。
|
||||
|
||||
网站到底需要多块呢?对于页面加载,每增加1秒钟就有4%的用户放弃使用。顶级的电子商务站点的页面在第一次交互时可以做到1秒到3秒加载时间,而这是提供最高舒适度的速度。很明显这种利害关系对于web 应用来说很高,而且在不断的增加。
|
||||
网站到底需要多快呢?对于页面加载,每增加1秒钟就有4%的用户放弃使用。顶级的电子商务站点的页面在第一次交互时可以做到1秒到3秒加载时间,而这是提供最高舒适度的速度。很明显这种利害关系对于 web 应用来说很高,而且在不断的增加。
|
||||
|
||||
想要提高效率很简单,但是看到实际结果很难。要在旅途上帮助你,这篇blog 会给你提供10条最高可以10倍的提升网站性能的建议。这是系列介绍提高应用程序性能的第一篇文章,包括测试充分的优化技术和一点NGIX 的帮助。这个系列给出了潜在的提高安全性的帮助。
|
||||
想要提高效率很简单,但是看到实际结果很难。为了在你的探索之旅上帮助到你,这篇文章会给你提供10条最高可以提升10倍网站性能的建议。这是系列介绍提高应用程序性能的第一篇文章,包括充分测试的优化技术和一点 NGINX 的帮助。这个系列也给出了潜在的提高安全性的帮助。
|
||||
|
||||
### Tip #1: 通过反向代理来提高性能和增加安全性 ###
|
||||
|
||||
如果你的web 应用运行在单个机器上,那么这个办法会明显的提升性能:只需要添加一个更快的机器,更好的处理器,更多的内存,更快的磁盘阵列,等等。然后新机器就可以更快的运行你的WordPress 服务器, Node.js 程序, Java 程序,以及其它程序。(如果你的程序要访问数据库服务器,那么这个办法还是很简单:添加两个更快的机器,以及在两台电脑之间使用一个更快的链路。)
|
||||
如果你的 web 应用运行在单个机器上,那么这个办法会明显的提升性能:只需要换一个更快的机器,更好的处理器,更多的内存,更快的磁盘阵列,等等。然后新机器就可以更快的运行你的 WordPress 服务器, Node.js 程序, Java 程序,以及其它程序。(如果你的程序要访问数据库服务器,那么解决方法依然很简单:添加两个更快的机器,以及在两台电脑之间使用一个更快的链路。)
|
||||
|
||||
问题是,机器速度可能并不是问题。web 程序运行慢经常是因为计算机一直在不同的任务之间切换:和用户的成千上万的连接,从磁盘访问文件,运行代码,等等。应用服务器可能会抖动-内存不足,将内存数据写会磁盘,以及多个请求等待一个任务完成,如磁盘I/O。
|
||||
问题是,机器速度可能并不是问题。web 程序运行慢经常是因为计算机一直在不同的任务之间切换:通过成千上万的连接和用户交互,从磁盘访问文件,运行代码,等等。应用服务器可能会抖动(thrashing)-比如说内存不足、将内存数据交换到磁盘,以及有多个请求要等待某个任务完成,如磁盘I/O。
|
||||
|
||||
你可以采取一个完全不同的方案来替代升级硬件:添加一个反向代理服务器来分担部分任务。[反向代理服务器][1] 位于运行应用的机器的前端,是用来处理网络流量的。只有反向代理服务器是直接连接到互联网的;和程序的通讯都是通过一个快速的内部网络完成的。
|
||||
你可以采取一个完全不同的方案来替代升级硬件:添加一个反向代理服务器来分担部分任务。[反向代理服务器][1] 位于运行应用的机器的前端,是用来处理网络流量的。只有反向代理服务器是直接连接到互联网的;和应用服务器的通讯都是通过一个快速的内部网络完成的。
|
||||
|
||||
使用反向代理服务器可以将应用服务器从等待用户与web 程序交互解放出来,这样应用服务器就可以专注于为反向代理服务器构建网页,让其能够传输到互联网上。而应用服务器就不需要在能带客户端的响应,可以运行与接近优化过的性能水平。
|
||||
使用反向代理服务器可以将应用服务器从等待用户与 web 程序交互解放出来,这样应用服务器就可以专注于为反向代理服务器构建网页,让其能够传输到互联网上。而应用服务器就不需要等待客户端的响应,其运行速度可以接近于优化后的性能水平。
|
||||
|
||||
添加方向代理服务器还可以给你的web 服务器安装带来灵活性。比如,一个已知类型的服务器已经超载了,那么就可以轻松的添加另一个相同的服务器;如果某个机器宕机了,也可以很容易的被替代。
|
||||
添加反向代理服务器还可以给你的 web 服务器安装带来灵活性。比如,一个某种类型的服务器已经超载了,那么就可以轻松的添加另一个相同的服务器;如果某个机器宕机了,也可以很容易替代一个新的。
|
||||
|
||||
因为反向代理带来的灵活性,所以方向代理也是一些性能加速功能的必要前提,比如:
|
||||
因为反向代理带来的灵活性,所以反向代理也是一些性能加速功能的必要前提,比如:
|
||||
|
||||
- **负载均衡** (参见 [Tip #2][2]) – 负载均衡运行在方向代理服务器上,用来将流量均衡分配给一批应用。有了合适的负载均衡,你就可以在不改变程序的前提下添加应用服务器。
|
||||
- **缓存静态文件** (参见 [Tip #3][3]) – 直接读取的文件,比如图像或者代码,可以保存在方向代理服务器,然后直接发给客户端,这样就可以提高速度、分担应用服务器的负载,可以让应用运行的更快
|
||||
- **网站安全** – 反响代理服务器可以提高网站安全性,以及快速的发现和响应攻击,保证应用服务器处于被保护状态。
|
||||
- **负载均衡** (参见 [Tip #2][2]) – 负载均衡运行在反向代理服务器上,用来将流量均衡分配给一批应用。有了合适的负载均衡,你就可以添加应用服务器而根本不用修改应用。
|
||||
- **缓存静态文件** (参见 [Tip #3][3]) – 直接读取的文件,比如图片或者客户端代码,可以保存在反向代理服务器,然后直接发给客户端,这样就可以提高速度、分担应用服务器的负载,可以让应用运行的更快。
|
||||
- **网站安全** – 反向代理服务器可以提高网站安全性,以及快速的发现和响应攻击,保证应用服务器处于被保护状态。
|
||||
|
||||
NGINX 软件是一个专门设计的反响代理服务器,也包含了上述的多种功能。NGINX 使用事件驱动的方式处理问题,着回避传统的服务器更加有效率。NGINX plus 天价了更多高级的反向代理特性,比如程序[健康度检查][4],专门用来处理request 路由,高级缓冲和相关支持。
|
||||
NGINX 软件为用作反向代理服务器而专门设计,也包含了上述的多种功能。NGINX 使用事件驱动的方式处理请求,这会比传统的服务器更加有效率。NGINX plus 添加了更多高级的反向代理特性,比如应用的[健康度检查][4],专门用来处理请求路由、高级缓冲和相关支持。
|
||||
|
||||
|
||||
|
||||
### Tip #2: 添加负载平衡 ###
|
||||
|
||||
添加一个[负载均衡服务器][5] 是一个相当简单的用来提高性能和网站安全性的的方法。使用负载均衡讲流量分配到多个服务器,是用来替代只使用一个巨大且高性能web 服务器的方案。即使程序写的不好,或者在扩容方面有困难,只使用负载均衡服务器就可以很好的提高用户体验。
|
||||
添加一个[负载均衡服务器][5] 是一个相当简单的用来提高性能和网站安全性的的方法。与其将核心 Web 服务器变得越来越大和越来越强,不如使用负载均衡将流量分配到多个服务器。即使程序写的不好,或者在扩容方面有困难,仅是使用负载均衡服务器就可以很好的提高用户体验。
|
||||
|
||||
负载均衡服务器首先是一个反响代理服务器(参见[Tip #1][6])——它接收来自互联网的流量,然后转发请求给另一个服务器。小戏法是负载均衡服务器支持两个或多个应用服务器,使用[分配算法][7]将请求转发给不同服务器。最简单的负载均衡方法是轮转法,只需要将新的请求发给列表里的下一个服务器。其它的方法包括将请求发给负载最小的活动连接。NGINX plus 拥有将特定用户的会话分配给同一个服务器的[能力][8].
|
||||
负载均衡服务器首先是一个反向代理服务器(参见[Tip #1][6])——它接受来自互联网的流量,然后转发请求给另一个服务器。特别是负载均衡服务器支持两个或多个应用服务器,使用[分配算法][7]将请求转发给不同服务器。最简单的负载均衡方法是轮转法(round robin),每个新的请求都会发给列表里的下一个服务器。其它的复制均衡方法包括将请求发给活动连接最少的服务器。NGINX plus 拥有将特定用户的会话分配给同一个服务器的[能力][8]。
|
||||
|
||||
负载均衡可以很好的提高性能是因为它可以避免某个服务器过载而另一些服务器却没有流量来处理。它也可以简单的扩展服务器规模,因为你可以添加多个价格相对便宜的服务器并且保证它们被充分利用了。
|
||||
负载均衡可以很好的提高性能是因为它可以避免某个服务器过载而另一些服务器却没有需要处理的流量。它也可以简单的扩展服务器规模,因为你可以添加多个价格相对便宜的服务器并且保证它们被充分利用了。
|
||||
|
||||
可以进行负载均衡的协议包括HTTP, HTTPS, SPDY, HTTP/2, WebSocket,[FastCGI][9],SCGI,uwsgi, memcached,以及集中其它的应用类型,包括采用TCP 第4层协议的程序。分析你的web 应用来决定那些你要使用以及那些地方的性能不足。
|
||||
可以进行负载均衡的协议包括 HTTP、HTTPS、SPDY、HTTP/2、WebSocket、[FastCGI][9]、SCGI、uwsgi、 memcached 等,以及几种其它的应用类型,包括基于 TCP 的应用和其它的第4层协议的程序。分析你的 web 应用来决定你要使用哪些以及哪些地方性能不足。
|
||||
|
||||
相同的服务器或服务器群可以被用来进行负载均衡,也可以用来处理其它的任务,如SSL 终止,提供对客户端使用的HTTP/1/x 和 HTTP/2 ,以及缓存静态文件。
|
||||
相同的服务器或服务器群可以被用来进行负载均衡,也可以用来处理其它的任务,如 SSL 末端服务器,支持客户端的 HTTP/1.x 和 HTTP/2 请求,以及缓存静态文件。
|
||||
|
||||
NGINX 经常被用来进行负载均衡;要想了解更多的情况可以访问我们的[overview blog post][10], [configuration blog post][11], [ebook][12] 以及相关网站 [webinar][13], 和 [documentation][14]。我们的商业版本 [NGINX Plus][15] 支持更多优化了的负载均衡特性,如基于服务器响应时间的加载路由和Microsoft’s NTLM 协议上的负载均衡。
|
||||
NGINX 经常被用于进行负载均衡;要想了解更多的情况,可以下载我们的电子书 [选择软件负载均衡器的五个理由][10]。你也可以从 [使用 NGINX 和 NGINX Plus 配置负载均衡,第一部分][11] 中了解基本的配置指导,在 NGINX Plus 管理员指南中有完整的 [NGINX 负载均衡][12]的文档。。我们的商业版本 [NGINX Plus][15] 支持更多优化了的负载均衡特性,如基于服务器响应时间的加载路由和Microsoft’s NTLM 协议上的负载均衡。
|
||||
|
||||
### Tip #3: 缓存静态和动态的内容 ###
|
||||
|
||||
缓存通过加速内容的传输速度来提高web 应用的性能。它可以采用一下集中策略:当需要的时候预处理要传输的内容,保存数据到速度更快的设备,把数据存储在距离客户端更近的位置,或者结合起来使用。
|
||||
缓存可以通过加速内容的传输速度来提高 web 应用的性能。它可以采用以下几种策略:当需要的时候预处理要传输的内容,保存数据到速度更快的设备,把数据存储在距离客户端更近的位置,或者将这几种方法结合起来使用。
|
||||
|
||||
下面要考虑两种不同类型数据的缓冲:
|
||||
有两种不同类型数据的缓冲:
|
||||
|
||||
- **静态内容缓存**。不经常变化的文件,比如图像(JPEG,PNG) 和代码(CSS,JavaScript),可以保存在边缘服务器,这样就可以快速的从内存和磁盘上提取。
|
||||
- **动态内容缓存**。很多web 应用回针对每个网页请求生成不同的HTML 页面。在短时间内简单的缓存每个生成HTML 内容,就可以很好的减少要生成的内容的数量,这完全可以达到你的要求。
|
||||
- **静态内容缓存**。不经常变化的文件,比如图像(JPEG、PNG) 和代码(CSS,JavaScript),可以保存在外围服务器上,这样就可以快速的从内存和磁盘上提取。
|
||||
- **动态内容缓存**。很多 web 应用会针对每次网页请求生成一个新的 HTML 页面。在短时间内简单的缓存生成的 HTML 内容,就可以很好的减少要生成的内容的数量,而且这些页面足够新,可以满足你的需要。
|
||||
|
||||
举个例子,如果一个页面每秒会被浏览10次,你将它缓存1 秒,99%请求的页面都会直接从缓存提取。如果你将将数据分成静态内容,甚至新生成的页面可能都是由这些缓存构成的。
|
||||
举个例子,如果一个页面每秒会被浏览10次,你将它缓存 1 秒,90%请求的页面都会直接从缓存提取。如果你分开缓存静态内容,甚至新生成的页面可能都是由这些缓存构成的。
|
||||
|
||||
下面由是web 应用发明的三种主要的缓存技术:
|
||||
下面由是 web 应用发明的三种主要的缓存技术:
|
||||
|
||||
- **缩短数据与用户的距离**。把一份内容的拷贝放的离用户更近点来减少传输时间。
|
||||
- **缩短数据与用户的网络距离**。把一份内容的拷贝放的离用户更近的节点来减少传输时间。
|
||||
- **提高内容服务器的速度**。内容可以保存在一个更快的服务器上来减少提取文件的时间。
|
||||
- **从过载服务器拿走数据**。机器经常因为要完成某些其它的任务而造成某个任务的执行速度比测试结果要差。将数据缓存在不同的机器上可以提高缓存资源和非缓存资源的效率,而这知识因为主机没有被过度使用。
|
||||
- **从过载服务器上移走数据**。机器经常因为要完成某些其它的任务而造成某个任务的执行速度比测试结果要差。将数据缓存在不同的机器上可以提高缓存资源和非缓存资源的性能,而这是因为主机没有被过度使用。
|
||||
|
||||
对web 应用的缓存机制可以web 应用服务器内部实现。第一,缓存动态内容是用来减少应用服务器加载动态内容的时间。然后,缓存静态内容(包括动态内容的临时拷贝)是为了更进一步的分担应用服务器的负载。而且缓存之后会从应用服务器转移到对用户而言更快、更近的机器,从而减少应用服务器的压力,减少提取数据和传输数据的时间。
|
||||
对 web 应用的缓存机制可以在 web 应用服务器内部实现。首先,缓存动态内容是用来减少应用服务器加载动态内容的时间。其次,缓存静态内容(包括动态内容的临时拷贝)是为了更进一步的分担应用服务器的负载。而且缓存之后会从应用服务器转移到对用户而言更快、更近的机器,从而减少应用服务器的压力,减少提取数据和传输数据的时间。
|
||||
|
||||
改进过的缓存方案可以极大的提高应用的速度。对于大多数网页来说,静态数据,比如大图像文件,构成了超过一半的内容。如果没有缓存,那么这可能会花费几秒的时间来提取和传输这类数据,但是采用了缓存之后不到1秒就可以完成。
|
||||
|
||||
举一个在实际中缓存是如何使用的例子, NGINX 和NGINX Plus使用了两条指令来[设置缓存机制][16]:proxy_cache_path 和 proxy_cache。你可以指定缓存的位置和大小,文件在缓存中保存的最长时间和其他一些参数。使用第三条(而且是相当受欢迎的一条)指令,proxy_cache_use_stale,如果服务器提供新鲜内容是忙或者挂掉之类的信息,你甚至可以让缓存提供旧的内容,这样客户端就不会一无所得。从用户的角度来看这可以很好的提高你的网站或者应用的上线时间。
|
||||
举一个在实际中缓存是如何使用的例子, NGINX 和 NGINX Plus 使用了两条指令来[设置缓存机制][16]:proxy_cache_path 和 proxy_cache。你可以指定缓存的位置和大小、文件在缓存中保存的最长时间和其它一些参数。使用第三条(而且是相当受欢迎的一条)指令 proxy_cache_use_stale,如果提供新鲜内容的服务器忙碌或者挂掉了,你甚至可以让缓存提供较旧的内容,这样客户端就不会一无所得。从用户的角度来看这可以很好的提高你的网站或者应用的可用时间。
|
||||
|
||||
NGINX plus 拥有[高级缓存特性][17],包括对[缓存清除][18]的支持和在[仪表盘][19]上显示缓存状态信息。
|
||||
NGINX plus 有个[高级缓存特性][17],包括对[缓存清除][18]的支持和在[仪表盘][19]上显示缓存状态信息。
|
||||
|
||||
要想获得更多关于NGINX 的缓存机制的信息可以浏览NGINX Plus 管理员指南中的 [reference documentation][20] 和 [NGINX Content Caching][21] 。
|
||||
要想获得更多关于 NGINX 的缓存机制的信息可以浏览 NGINX Plus 管理员指南中的 [参考文档][20] 和 [NGINX 内容缓存][21] 。
|
||||
|
||||
**注意**:缓存机制分布于应用开发者、投资决策者以及实际的系统运维人员之间。本文提到的一些复杂的缓存机制从[DevOps 的角度][23]来看很具有价值,即对集应用开发者、架构师以及运维操作人员的功能为一体的工程师来说可以满足他们对站点功能性、响应时间、安全性和商业结果,如完成的交易数。
|
||||
**注意**:缓存机制分布于应用开发者、投资决策者以及实际的系统运维人员之间。本文提到的一些复杂的缓存机制从[DevOps 的角度][23]来看很具有价值,即对集应用开发者、架构师以及运维操作人员的功能为一体的工程师来说可以满足它们对站点功能性、响应时间、安全性和商业结果(如完成的交易数)等需要。
|
||||
|
||||
### Tip #4: 压缩数据 ###
|
||||
|
||||
压缩是一个具有很大潜力的提高性能的加速方法。现在已经有一些针对照片(JPEG 和PNG)、视频(MPEG-4)和音乐(MP3)等各类文件精心设计和高压缩率的标准。每一个标准都或多或少的减少了文件的大小。
|
||||
|
||||
文本数据 —— 包括HTML(包含了纯文本和HTL 标签),CSS和代码,比如Javascript —— 经常是未经压缩就传输的。压缩这类数据会在对应用程序性能的感觉上,特别是处于慢速或受限的移动网络的客户端,产生不成比例的影响。
|
||||
文本数据 —— 包括HTML(包含了纯文本和 HTML 标签),CSS 和代码,比如 Javascript —— 经常是未经压缩就传输的。压缩这类数据会在对应用程序性能的感觉上,特别是处于慢速或受限的移动网络的客户端,产生更大的影响。
|
||||
|
||||
这是因为文本数据经常是用户与网页交互的有效数据,而多媒体数据可能更多的是起提供支持或者装饰的作用。聪明的内容压缩可以减少HTML,Javascript,CSS和其他文本内容对贷款的要求,通常可以减少30% 甚至更多的带宽和相应的页面加载时间。
|
||||
这是因为文本数据经常是用户与网页交互的有效数据,而多媒体数据可能更多的是起提供支持或者装饰的作用。智能的内容压缩可以减少 HTML,Javascript,CSS和其它文本内容对带宽的要求,通常可以减少 30% 甚至更多的带宽和相应的页面加载时间。
|
||||
|
||||
如果你是用SSL,压缩可以减少需要进行SSL 编码的的数据量,而这些编码操作会占用一些CPU时间而抵消了压缩数据减少的时间。
|
||||
如果你使用 SSL,压缩可以减少需要进行 SSL 编码的的数据量,而这些编码操作会占用一些 CPU 时间而抵消了压缩数据减少的时间。
|
||||
|
||||
压缩文本数据的方法很多,举个例子,在定义小说文本压缩模式的[HTTP/2 部分]就专门为适应头数据。另一个例子是可以在NGINX 里打开使用GZIP 压缩文本。你在你的服务里[预压缩文本数据][25]之后,你就可以直接使用gzip_static 指令来处理压缩过的.gz 版本。
|
||||
压缩文本数据的方法很多,举个例子,在定义小说文本压缩模式的 [HTTP/2 部分]就对于头数据来特别适合。另一个例子是可以在 NGINX 里打开使用 GZIP 压缩。你在你的服务里[预先压缩文本数据][25]之后,你就可以直接使用 gzip_static 指令来处理压缩过的 .gz 版本。
|
||||
|
||||
### Tip #5: 优化 SSL/TLS ###
|
||||
|
||||
安全套接字([SSL][26]) 协议和它的继承者,传输层安全(TLS)协议正在被越来越多的网站采用。SSL/TLS 对从原始服务器发往用户的数据进行加密提高了网站的安全性。影响这个趋势的部分原因是Google 正在使用SSL/TLS,这在搜索引擎排名上是一个正面的影响因素。
|
||||
安全套接字([SSL][26]) 协议和它的下一代版本传输层安全(TLS)协议正在被越来越多的网站采用。SSL/TLS 对从原始服务器发往用户的数据进行加密提高了网站的安全性。影响这个趋势的部分原因是 Google 正在使用 SSL/TLS,这在搜索引擎排名上是一个正面的影响因素。
|
||||
|
||||
尽管SSL/TLS 越来越流行,但是使用加密对速度的影响也让很多网站望而却步。SSL/TLS 之所以让网站变的更慢,原因有二:
|
||||
尽管 SSL/TLS 越来越流行,但是使用加密对速度的影响也让很多网站望而却步。SSL/TLS 之所以让网站变的更慢,原因有二:
|
||||
|
||||
1. 任何一个连接第一次连接时的握手过程都需要传递密钥。而采用HTTP/1.x 协议的浏览器在建立多个连接时会对每个连接重复上述操作。
|
||||
2. 数据在传输过程中需要不断的在服务器加密、在客户端解密。
|
||||
1. 任何一个连接第一次连接时的握手过程都需要传递密钥。而采用 HTTP/1.x 协议的浏览器在建立多个连接时会对每个连接重复上述操作。
|
||||
2. 数据在传输过程中需要不断的在服务器端加密、在客户端解密。
|
||||
|
||||
要鼓励使用SSL/TLS,HTTP/2 和SPDY(在[下一章][27]会描述)的作者设计新的协议来让浏览器只需要对一个浏览器会话使用一个连接。这会大大的减少上述两个原因中的一个浪费的时间。然而现在可以用来提高应用程序使用SSL/TLS 传输数据的性能的方法不止这些。
|
||||
为了鼓励使用 SSL/TLS,HTTP/2 和 SPDY(在[下一章][27]会描述)的作者设计了新的协议来让浏览器只需要对一个浏览器会话使用一个连接。这会大大的减少上述第一个原因所浪费的时间。然而现在可以用来提高应用程序使用 SSL/TLS 传输数据的性能的方法不止这些。
|
||||
|
||||
web 服务器有对应的机制优化SSL/TLS 传输。举个例子,NGINX 使用[OpenSSL][28]运行在普通的硬件上提供接近专用硬件的传输性能。NGINX [SSL 性能][29] 有详细的文档,而且把对SSL/TLS 数据进行加解密的时间和CPU 占用率降低了很多。
|
||||
web 服务器有对应的机制优化 SSL/TLS 传输。举个例子,NGINX 使用 [OpenSSL][28] 运行在普通的硬件上提供了接近专用硬件的传输性能。NGINX 的 [SSL 性能][29] 有详细的文档,而且把对 SSL/TLS 数据进行加解密的时间和 CPU 占用率降低了很多。
|
||||
|
||||
更进一步,在这篇[blog][30]有详细的说明如何提高SSL/TLS 性能,可以总结为一下几点:
|
||||
更进一步,参考这篇[文章][30]了解如何提高 SSL/TLS 性能的更多细节,可以总结为一下几点:
|
||||
|
||||
- **会话缓冲**。使用指令[ssl_session_cache][31]可以缓存每个新的SSL/TLS 连接使用的参数。
|
||||
- **会话票据或者ID**。把SSL/TLS 的信息保存在一个票据或者ID 里可以流畅的复用而不需要重新握手。
|
||||
- **OCSP 分割**。通过缓存SSL/TLS 证书信息来减少握手时间。
|
||||
- **会话缓冲**。使用指令 [ssl_session_cache][31] 可以缓存每个新的 SSL/TLS 连接使用的参数。
|
||||
- **会话票据或者 ID**。把 SSL/TLS 的信息保存在一个票据或者 ID 里可以流畅的复用而不需要重新握手。
|
||||
- **OCSP 分割**。通过缓存 SSL/TLS 证书信息来减少握手时间。
|
||||
|
||||
NGINX 和NGINX Plus 可以被用作SSL/TLS 终结——处理客户端流量的加密和解密,而同时和其他服务器进行明文通信。使用[这几步][32] 来设置NGINX 和NGINX Plus 处理SSL/TLS 终止。同时,这里还有一些NGINX Plus 和接收TCP 连接的服务器一起使用时的[特有的步骤][33]
|
||||
NGINX 和 NGINX Plus 可以被用作 SSL/TLS 服务端,用于处理客户端流量的加密和解密,而同时以明文方式和其它服务器进行通信。要设置 NGINX 和 NGINX Plus 作为 SSL/TLS 服务端,参看 [HTTPS 连接][32] 和[加密的 TCP 连接][33]
|
||||
|
||||
### Tip #6: 使用 HTTP/2 或 SPDY ###
|
||||
|
||||
对于已经使用了SSL/TLS 的站点,HTTP/2 和SPDY 可以很好的提高性能,因为每个连接只需要一次握手。而对于没有使用SSL/TLS 的站点来说,HTTP/2 和SPDY会在响应速度上有些影响(通常会将度效率)。
|
||||
对于已经使用了 SSL/TLS 的站点,HTTP/2 和 SPDY 可以很好的提高性能,因为每个连接只需要一次握手。而对于没有使用 SSL/TLS 的站点来说,从响应速度的角度来说 HTTP/2 和 SPDY 将让迁移到 SSL/TLS 没有什么压力(原本会降低效率)。
|
||||
|
||||
Google 在2012年开始把SPDY 作为一个比HTTP/1.x 更快速的协议来推荐。HTTP/2 是目前IETF 标准,他也基于SPDY。SPDY 已经被广泛的支持了,但是很快就会被HTTP/2 替代。
|
||||
Google 在2012年开始把 SPDY 作为一个比 HTTP/1.x 更快速的协议来推荐。HTTP/2 是目前 IETF 通过的标准,是基于 SPDY 的。SPDY 已经被广泛的支持了,但是很快就会被 HTTP/2 替代。
|
||||
|
||||
SPDY 和HTTP/2 的关键是用单连接来替代多路连接。单个连接是被复用的,所以它可以同时携带多个请求和响应的分片。
|
||||
SPDY 和 HTTP/2 的关键是用单一连接来替代多路连接。单个连接是被复用的,所以它可以同时携带多个请求和响应的分片。
|
||||
|
||||
通过使用一个连接这些协议可以避免过多的设置和管理多个连接,就像浏览器实现了HTTP/1.x 一样。单连接在对SSL 特别有效,这是因为它可以最小化SSL/TLS 建立安全链接时的握手时间。
|
||||
通过使用单一连接,这些协议可以避免像在实现了 HTTP/1.x 的浏览器中一样建立和管理多个连接。单一连接在对 SSL 特别有效,这是因为它可以最小化 SSL/TLS 建立安全链接时的握手时间。
|
||||
|
||||
SPDY 协议需要使用SSL/TLS, 而HTTP/2 官方并不需要,但是目前所有支持HTTP/2的浏览器只有在使能了SSL/TLS 的情况下才会使用它。这就意味着支持HTTP/2 的浏览器只有在网站使用了SSL 并且服务器接收HTTP/2 流量的情况下才会启用HTTP/2。否则的话浏览器就会使用HTTP/1.x 协议。
|
||||
SPDY 协议需要使用 SSL/TLS,而 HTTP/2 官方标准并不需要,但是目前所有支持 HTTP/2 的浏览器只有在启用了 SSL/TLS 的情况下才能使用它。这就意味着支持 HTTP/2 的浏览器只有在网站使用了 SSL 并且服务器接收 HTTP/2 流量的情况下才会启用 HTTP/2。否则的话浏览器就会使用 HTTP/1.x 协议。
|
||||
|
||||
当你实现SPDY 或者HTTP/2时,你不再需要通常的HTTP 性能优化方案,比如域分隔资源聚合,以及图像登记。这些改变可以让你的代码和部署变得更简单和更易于管理。要了解HTTP/2 带来的这些变化可以浏览我们的[白皮书][34]。
|
||||
当你实现 SPDY 或者 HTTP/2 时,你不再需要那些常规的 HTTP 性能优化方案,比如按域分割、资源聚合,以及图像拼合。这些改变可以让你的代码和部署变得更简单和更易于管理。要了解 HTTP/2 带来的这些变化可以浏览我们的[白皮书][34]。
|
||||
|
||||

|
||||
|
||||
作为支持这些协议的一个样例,NGINX 已经从一开始就支持了SPDY,而且[大部分使用SPDY 协议的网站][35]都运行的是NGINX。NGINX 同时也[很早][36]对HTTP/2 的提供了支持,从2015 年9月开始开源NGINX 和NGINX Plus 就[支持][37]它了。
|
||||
作为支持这些协议的一个样例,NGINX 已经从一开始就支持了 SPDY,而且[大部分使用 SPDY 协议的网站][35]都运行的是 NGINX。NGINX 同时也[很早][36]对 HTTP/2 的提供了支持,从2015 年9月开始,开源版 NGINX 和 NGINX Plus 就[支持][37]它了。
|
||||
|
||||
经过一段时间,我们NGINX 希望更多的站点完全是能SSL 并且向HTTP/2 迁移。这将会提高安全性,同时新的优化手段也会被发现和实现,更简单的代码表现的更加优异。
|
||||
经过一段时间,我们 NGINX 希望更多的站点完全启用 SSL 并且向 HTTP/2 迁移。这将会提高安全性,同时也会找到并实现新的优化手段,简化的代码表现的会更加优异。
|
||||
|
||||
### Tip #7: 升级软件版本 ###
|
||||
|
||||
一个提高应用性能的简单办法是根据软件的稳定性和性能的评价来选在你的软件栈。进一步说,因为高性能组件的开发者更愿意追求更高的性能和解决bug ,所以值得使用最新版本的软件。新版本往往更受开发者和用户社区的关注。更新的版本往往会利用到新的编译器优化,包括对新硬件的调优。
|
||||
一个提高应用性能的简单办法是根据软件的稳定性和性能的评价来选在你的软件栈。进一步说,因为高性能组件的开发者更愿意追求更高的性能和解决 bug ,所以值得使用最新版本的软件。新版本往往更受开发者和用户社区的关注。更新的版本往往会利用到新的编译器优化,包括对新硬件的调优。
|
||||
|
||||
稳定的新版本通常比旧版本具有更好的兼容性和更高的性能。一直进行软件更新,可以非常简单的保持软件保持最佳的优化,解决掉bug,以及安全性的提高。
|
||||
稳定的新版本通常比旧版本具有更好的兼容性和更高的性能。一直进行软件更新,可以非常简单的保持软件保持最佳的优化,解决掉 bug,以及提高安全性。
|
||||
|
||||
一直使用旧版软件也会组织你利用新的特性。比如上面说到的HTTP/2,目前要求OpenSSL 1.0.1.在2016 年中期开始将会要求1.0.2 ,而这是在2015年1月才发布的。
|
||||
一直使用旧版软件也会阻止你利用新的特性。比如上面说到的 HTTP/2,目前要求 OpenSSL 1.0.1。在2016 年中期开始将会要求1.0.2 ,而它是在2015年1月才发布的。
|
||||
|
||||
NGINX 用户可以开始迁移到[NGINX 最新的开源软件][38] 或者[NGINX Plus][39];他们都包含了罪行的能力,如socket分区和线程池(见下文),这些都已经为性能优化过了。然后好好看看的你软件栈,把他们升级到你能能升级道德最新版本吧。
|
||||
NGINX 用户可以开始迁移到 [NGINX 最新的开源软件][38] 或者 [NGINX Plus][39];它们都包含了最新的能力,如 socket 分割和线程池(见下文),这些都已经为性能优化过了。然后好好看看的你软件栈,把它们升级到你能升级到的最新版本吧。
|
||||
|
||||
### Tip #8: linux 系统性能调优 ###
|
||||
### Tip #8: Linux 系统性能调优 ###
|
||||
|
||||
linux 是大多数web 服务器使用操作系统,而且作为你的架构的基础,Linux 表现出明显可以提高性能的机会。默认情况下,很多linux 系统都被设置为使用很少的资源,匹配典型的桌面应用负载。这就意味着web 应用需要最少一些等级的调优才能达到最大效能。
|
||||
Linux 是大多数 web 服务器使用的操作系统,而且作为你的架构的基础,Linux 显然有不少提高性能的可能。默认情况下,很多 Linux 系统都被设置为使用很少的资源,以符合典型的桌面应用使用。这就意味着 web 应用需要一些微调才能达到最大效能。
|
||||
|
||||
Linux 优化是转变们针对web 服务器方面的。以NGINX 为例,这里有一些在加速linux 时需要强调的变化:
|
||||
这里的 Linux 优化是专门针对 web 服务器方面的。以 NGINX 为例,这里有一些在加速 Linux 时需要强调的变化:
|
||||
|
||||
- **缓冲队列**。如果你有挂起的连接,那么你应该考虑增加net.core.somaxconn 的值,它代表了可以缓存的连接的最大数量。如果连接线直太小,那么你将会看到错误信息,而你可以逐渐的增加这个参数知道错误信息停止出现。
|
||||
- **文件描述符**。NGINX 对一个连接使用最多2个文件描述符。如果你的系统有很多连接,你可能就需要提高sys.fs.file_max ,增加系统对文件描述符数量整体的限制,这样子才能支持不断增加的负载需求。
|
||||
- **临时端口**。当使用代理时,NGINX 会为每个上游服务器创建临时端口。你可以设置net.ipv4.ip_local_port_range 来提高这些端口的范围,增加可用的端口。你也可以减少非活动的端口的超时判断来重复使用端口,这可以通过net.ipv4.tcp_fin_timeout 来设置,这可以快速的提高流量。
|
||||
- **缓冲队列**。如果你有挂起的连接,那么你应该考虑增加 net.core.somaxconn 的值,它代表了可以缓存的连接的最大数量。如果连接限制太小,那么你将会看到错误信息,而你可以逐渐的增加这个参数直到错误信息停止出现。
|
||||
- **文件描述符**。NGINX 对一个连接使用最多2个文件描述符。如果你的系统有很多连接请求,你可能就需要提高sys.fs.file_max ,以增加系统对文件描述符数量整体的限制,这样才能支持不断增加的负载需求。
|
||||
- **临时端口**。当使用代理时,NGINX 会为每个上游服务器创建临时端口。你可以设置net.ipv4.ip_local_port_range 来提高这些端口的范围,增加可用的端口号。你也可以减少非活动的端口的超时判断来重复使用端口,这可以通过 net.ipv4.tcp_fin_timeout 来设置,这可以快速的提高流量。
|
||||
|
||||
对于NGINX 来说,可以查阅[NGINX 性能调优指南][40]来学习如果优化你的Linux 系统,这样子它就可以很好的适应大规模网络流量而不会超过工作极限。
|
||||
对于 NGINX 来说,可以查阅 [NGINX 性能调优指南][40]来学习如果优化你的 Linux 系统,这样它就可以很好的适应大规模网络流量而不会超过工作极限。
|
||||
|
||||
### Tip #9: web 服务器性能调优 ###
|
||||
|
||||
无论你是用哪种web 服务器,你都需要对它进行优化来提高性能。下面的推荐手段可以用于任何web 服务器,但是一些设置是针对NGINX的。关键的优化手段包括:
|
||||
无论你是用哪种 web 服务器,你都需要对它进行优化来提高性能。下面的推荐手段可以用于任何 web 服务器,但是一些设置是针对 NGINX 的。关键的优化手段包括:
|
||||
|
||||
- **f访问日志**。不要把每个请求的日志都直接写回磁盘,你可以在内存将日志缓存起来然后一批写回磁盘。对于NGINX 来说添加给指令*access_log* 添加参数 *buffer=size* 可以让系统在缓存满了的情况下才把日志写到此哦按。如果你添加了参数**flush=time** ,那么缓存内容会每隔一段时间再写回磁盘。
|
||||
- **缓存**。缓存掌握了内存中的部分资源知道满了位置,这可以让与客户端的通信更加高效。与内存中缓存不匹配的响应会写回磁盘,而这就会降低效能。当NGINX [启用][42]了缓存机制后,你可以使用指令*proxy_buffer_size* 和 *proxy_buffers* 来管理缓存。
|
||||
- **客户端保活**。保活连接可以减少开销,特别是使用SSL/TLS时。对于NGINX 来说,你可以增加*keepalive_requests* 的值,从默认值100 开始修改,这样一个客户端就可以转交一个指定的连接,而且你也可以通过增加*keepalive_timeout* 的值来允许保活连接存活更长时间,结果就是让后来的请求处理的更快速。
|
||||
- **上游保活**。上游的连接——即连接到应用服务器、数据库服务器等机器的连接——同样也会收益于连接保活。对于上游连接老说,你可以增加*保活时间*,即每个工人进程的空闲保活连接个数。这就可以提高连接的复用次数,减少需要重新打开全新的连接次数。更多关于保活连接的信息可以参见[blog][41].
|
||||
- **限制**。限制客户端使用的资源可以提高性能和安全性。对于NGINX 来说指令*limit_conn* 和 *limit_conn_zone* 限制了每个源的连接数量,而*limit_rate* 限制了带宽。这些限制都可以阻止合法用户*攫取* 资源,同时夜避免了攻击。指令*limit_req* 和 *limit_req_zone* 限制了客户端请求。对于上游服务器来说,可以在上游服务器的配置块里使用max_conns 可以限制连接到上游服务器的连接。 这样可以避免服务器过载。关联的队列指令会创建一个队列来在连接数抵达*max_conn* 限制时在指定的长度的时间内保存特定数量的请求。
|
||||
- **工人进程**。工人进程负责处理请求。NGINX 采用事件驱动模型和依赖操作系统的机制来有效的讲请求分发给不同的工人进程。这条建议推荐设置每个CPU 的参数*worker_processes* 。如果需要的话,工人连接的最大数(默认512)可以安全在大部分系统增加,是指找到最适合你的系统的值。
|
||||
- **套接字分割**。通常一个套接字监听器会把新连接分配给所有工人进程。套接字分割会未每个工人进程创建一个套接字监听器,这样一来以内核分配连接给套接字就成为可能了。折可以减少锁竞争,并且提高多核系统的性能,要使能[套接字分隔][43]需要在监听指令里面加上复用端口参数。
|
||||
- **线程池**。一个计算机进程可以处理一个缓慢的操作。对于web 服务器软件来说磁盘访问会影响很多更快的操作,比如计算或者在内存中拷贝。使用了线程池之后慢操作可以分配到不同的任务集,而主进程可以一直运行快速操作。当磁盘操作完成后结果会返回给主进程的循环。在NGINX理有两个操作——read()系统调用和sendfile() ——被分配到了[线程池][44]
|
||||
- **访问日志**。不要把每个请求的日志都直接写回磁盘,你可以在内存将日志缓存起来然后批量写回磁盘。对于NGINX 来说,给指令 **access_log** 添加参数 **buffer=size** 可以让系统在缓存满了的情况下才把日志写到磁盘。如果你添加了参数 **flush=time** ,那么缓存内容会每隔一段时间再写回磁盘。
|
||||
- **缓存**。缓存会在内存中存放部分响应,直到满了为止,这可以让与客户端的通信更加高效。内存放不下的响应会写回磁盘,而这就会降低效能。当 NGINX [启用][42]了缓存机制后,你可以使用指令 **proxy_buffer_size** 和 **proxy_buffers** 来管理缓存。
|
||||
- **客户端保活**。保活连接可以减少开销,特别是使用 SSL/TLS 时。对于 NGINX 来说,你可以从 **keepalive_requests** 的默认值 100 开始增加最大连接数,这样一个客户端就可以在一个指定的连接上请求多次,而且你也可以通过增加 **keepalive_timeout** 的值来允许保活连接存活更长时间,这样就可以让后来的请求处理的更快速。
|
||||
- **上游保活**。上游的连接——即连接到应用服务器、数据库服务器等机器的连接——同样也会受益于连接保活。对于上游连接来说,你可以增加 **keepalive**,即每个工人进程的空闲保活连接个数。这就可以提高连接的复用次数,减少需要重新打开全新连接的次数。更多关于保活连接的信息可以参见[这篇“ HTTP 保活连接和性能”][41]。
|
||||
- **限制**。限制客户端使用的资源可以提高性能和安全性。对于 NGINX 来说,指令 **limit_conn** 和 **limit_conn_zone** 限制了给定来源的连接数量,而 **limit_rate** 限制了带宽。这些限制都可以阻止合法用户*扒取*资源,同时也避免了攻击。指令 **limit_req** 和 **limit_req_zone** 限制了客户端请求。对于上游服务器来说,可以在 upstream 的配置块里的 server 指令使用 max_conns 参数来限制连接到上游服务器的连接数。 这样可以避免服务器过载。关联的 queue 指令会创建一个队列来在连接数抵达 **max_conn** 限制时在指定长度的时间内保存特定数量的请求。
|
||||
- **工人进程**。工人进程负责处理请求。NGINX 采用事件驱动模型和操作系统特定的机制来有效的将请求分发给不同的工人进程。这条建议推荐设置 **worker_processes** 为每个 CPU 一个 。worker_connections 的最大数(默认512)可以在大部分系统上根据需要增加,实验性地找到最适合你的系统的值。
|
||||
- **套接字分割**。通常一个套接字监听器会把新连接分配给所有工人进程。套接字分割会为每个工人进程创建一个套接字监听器,这样一来以当套接字监听器可用时,内核就会将连接分配给它。这可以减少锁竞争,并且提高多核系统的性能,要启用[套接字分隔][43]需要在 **listen** 指令里面加上 **reuseport** 参数。
|
||||
- **线程池**。计算机进程可能被一个单一的缓慢的操作所占用。对于 web 服务器软件来说,磁盘访问会影响很多更快的操作,比如计算或者在内存中拷贝。使用了线程池之后慢操作可以分配到不同的任务集,而主进程可以一直运行快速操作。当磁盘操作完成后结果会返回给主进程的循环。在 NGINX 里有两个操作——read() 系统调用和 sendfile() ——被分配到了[线程池][44]
|
||||
|
||||
|
||||
|
||||
**技巧**。当改变任务操作系统或支持服务的设置时,一次只改变一个参数然后测试性能。如果修改引起问题了,或者不能让你的系统更快那么就改回去。
|
||||
**技巧**。当改变任何操作系统或支持服务的设置时,一次只改变一个参数然后测试性能。如果修改引起问题了,或者不能让你的系统更快,那么就改回去。
|
||||
|
||||
在[blog][45]可以看到更详细的NGINX 调优方法。
|
||||
在[文章“调优 NGINX 性能”][45]里可以看到更详细的 NGINX 调优方法。
|
||||
|
||||
### Tip #10: 监视系统活动来解决问题和瓶颈 ###
|
||||
|
||||
在应用开发中要使得系统变得非常高效的关键是监视你的系统在现实世界运行的性能。你必须能通过特定的设备和你的web 基础设施上监控程序活动。
|
||||
在应用开发中要使得系统变得非常高效的关键是监视你的系统在现实世界运行的性能。你必须能通过特定的设备和你的 web 基础设施上监控程序活动。
|
||||
|
||||
监视活动是最积极的——他会告诉你发生了什么,把问题留给你发现和最终解决掉。
|
||||
监视活动是最积极的——它会告诉你发生了什么,把问题留给你发现和最终解决掉。
|
||||
|
||||
监视可以发现集中不同的问题。它们包括:
|
||||
监视可以发现几种不同的问题。它们包括:
|
||||
|
||||
- 服务器宕机。
|
||||
- 服务器出问题一直在丢失连接。
|
||||
- 服务器出现大量的缓存未命中。
|
||||
- 服务器没有发送正确的内容。
|
||||
|
||||
应用的总体性能监控工具,比如New Relic 和Dynatrace,可以帮助你监控到从远处加载网页的时间,二NGINX 可以帮助你监控到应用发送的时 间。当你需要考虑为基础设施添加容量以满足流量需求时,应用性能数据可以告诉你你的优化措施的确起作用了。
|
||||
应用的总体性能监控工具,比如 New Relic 和 Dynatrace,可以帮助你监控到从远程加载网页的时间,而 NGINX 可以帮助你监控到应用交付端。当你需要考虑为基础设施添加容量以满足流量需求时,应用性能数据可以告诉你你的优化措施的确起作用了。
|
||||
|
||||
为了帮助开发者快速的发现、解决问题,NGINX Plus 增加了[应用感知健康度检查][46] ——对重复出现的常规事件进行综合分析并在问题出现时向你发出警告。NGINX Plus 同时提供[会话过滤][47] 功能,折可以组织当前任务未完成之前不接受新的连接,另一个功能是慢启动,允许一个从错误恢复过来的服务器追赶上负载均衡服务器群的速度。当有使用得当时,健康度检查可以让你在问题变得严重到影响用户体验前就发现它,而会话过滤和慢启动可以让你替换服务器,并且这个过程不会对性能和正常运行时间产生负面影响。这个表格就展示了NGINX Plus 内建模块在web 基础设施[监视活活动][48]的仪表盘,包括了服务器群,TCP 连接和缓存等信息。
|
||||
为了帮助开发者快速的发现、解决问题,NGINX Plus 增加了[应用感知健康度检查][46] ——对重复出现的常规事件进行综合分析并在问题出现时向你发出警告。NGINX Plus 同时提供[会话过滤][47] 功能,这可以阻止当前任务完成之前接受新的连接,另一个功能是慢启动,允许一个从错误恢复过来的服务器追赶上负载均衡服务器群的进度。当使用得当时,健康度检查可以让你在问题变得严重到影响用户体验前就发现它,而会话过滤和慢启动可以让你替换服务器,并且这个过程不会对性能和正常运行时间产生负面影响。下图就展示了内建的 NGINX Plus 模块[实时活动监视][48]的仪表盘,包括了服务器群,TCP 连接和缓存信息等 Web 架构信息。
|
||||
|
||||

|
||||
|
||||
### 总结: 看看10倍性能提升的效果 ###
|
||||
|
||||
这些性能提升方案对任何一个web 应用都可用并且效果都很好,而实际效果取决于你的预算,如你能花费的时间,目前实现方案的差距。所以你该如何对你自己的应用实现10倍性能提升?
|
||||
这些性能提升方案对任何一个 web 应用都可用并且效果都很好,而实际效果取决于你的预算、你能花费的时间、目前实现方案的差距。所以你该如何对你自己的应用实现10倍性能提升?
|
||||
|
||||
为了指导你了解每种优化手段的潜在影响,这里是是上面详述的每个优化方法的关键点,虽然你的里程肯定大不相同:
|
||||
为了指导你了解每种优化手段的潜在影响,这里是上面详述的每个优化方法的关键点,虽然你的情况肯定大不相同:
|
||||
|
||||
- **反向代理服务器和负载均衡**。没有负载均衡或者负载均衡很差都会造成间断的极低性能。增加一个反向代理,比如NGINX可以避免web应用程序在内存和磁盘之间抖动。负载均衡可以将过载服务器的任务转移到空闲的服务器,还可以轻松的进行扩容。这些改变都可以产生巨大的性能提升,很容易就可以比你现在的实现方案的最差性能提高10倍,对于总体性能来说可能提高的不多,但是也是有实质性的提升。
|
||||
- **缓存动态和静态数据**。如果你又一个web 服务器负担过重,那么毫无疑问肯定是你的应用服务器,只通过缓存动态数据就可以在峰值时间提高10倍的性能。缓存静态文件可以提高个位数倍的性能。
|
||||
- **压缩数据**。使用媒体文件压缩格式,比如图像格式JPEG,图形格式PNG,视频格式MPEG-4,音乐文件格式MP3可以极大的提高性能。一旦这些都用上了,然后压缩文件数据可以提高初始页面加载速度提高两倍。
|
||||
- **优化SSL/TLS**。安全握手会对性能产生巨大的影响,对他们的优化可能会对初始响应特别是重文本站点产生2倍的提升。优化SSL/TLS 下媒体文件只会产生很小的性能提升。
|
||||
- **使用HTTP/2 和SPDY*。当你使用了SSL/TLS,这些协议就可以提高整个站点的性能。
|
||||
- **对linux 和web 服务器软件进行调优**。比如优化缓存机制,使用保活连接,分配时间敏感型任务到不同的线程池可以明显的提高性能;举个例子,线程池可以加速对磁盘敏感的任务[近一个数量级][49].
|
||||
- **反向代理服务器和负载均衡**。没有负载均衡或者负载均衡很差都会造成间歇的性能低谷。增加一个反向代理,比如 NGINX ,可以避免 web 应用程序在内存和磁盘之间波动。负载均衡可以将过载服务器的任务转移到空闲的服务器,还可以轻松的进行扩容。这些改变都可以产生巨大的性能提升,很容易就可以比你现在的实现方案的最差性能提高10倍,对于总体性能来说可能提高的不多,但是也是有实质性的提升。
|
||||
- **缓存动态和静态数据**。如果你有一个负担过重的 web 服务器,那么毫无疑问肯定是你的应用服务器,只通过缓存动态数据就可以在峰值时间提高10倍的性能。缓存静态文件可以提高几倍的性能。
|
||||
- **压缩数据**。使用媒体文件压缩格式,比如图像格式 JPEG,图形格式 PNG,视频格式 MPEG-4,音乐文件格式 MP3 可以极大的提高性能。一旦这些都用上了,然后压缩文件数据可以将初始页面加载速度提高两倍。
|
||||
- **优化 SSL/TLS**。安全握手会对性能产生巨大的影响,对它们的优化可能会对初始响应产生2倍的提升,特别是对于大量文本的站点。优化 SSL/TLS 下媒体文件只会产生很小的性能提升。
|
||||
- **使用 HTTP/2 和 SPDY*。当你使用了 SSL/TLS,这些协议就可以提高整个站点的性能。
|
||||
- **对 Linux 和 web 服务器软件进行调优**。比如优化缓存机制,使用保活连接,分配时间敏感型任务到不同的线程池可以明显的提高性能;举个例子,线程池可以加速对磁盘敏感的任务[近一个数量级][49]。
|
||||
|
||||
我们希望你亲自尝试这些技术。我们希望知道你说取得的各种性能提升案例。请在下面评论栏分享你的结果或者在标签 #NGINX 和 #webperf 下 tweet 你的故事。
|
||||
|
||||
我们希望你亲自尝试这些技术。我们希望这些提高应用性能的手段可以被你实现。请在下面评论栏分享你的结果 或者在标签#NGINX 和#webperf 下tweet 你的故事。
|
||||
### 网上资源 ###
|
||||
|
||||
[Statista.com – Share of the internet economy in the gross domestic product in G-20 countries in 2016][50]
|
||||
@ -215,11 +214,11 @@ Linux 优化是转变们针对web 服务器方面的。以NGINX 为例,这里
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.nginx.com/blog/10-tips-for-10x-application-performance/?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io
|
||||
via: https://www.nginx.com/blog/10-tips-for-10x-application-performance/
|
||||
|
||||
作者:[Floyd Smith][a]
|
||||
译者:[Ezio]](https://github.com/oska874)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[Ezio](https://github.com/oska874)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -233,11 +232,9 @@ via: https://www.nginx.com/blog/10-tips-for-10x-application-performance/?hmsr=to
|
||||
[7]:https://www.nginx.com/resources/admin-guide/load-balancer/
|
||||
[8]:https://www.nginx.com/blog/load-balancing-with-nginx-plus/
|
||||
[9]:https://www.digitalocean.com/community/tutorials/understanding-and-implementing-fastcgi-proxying-in-nginx
|
||||
[10]:https://www.nginx.com/blog/five-reasons-use-software-load-balancer/
|
||||
[10]:https://www.nginx.com/resources/library/five-reasons-choose-software-load-balancer/
|
||||
[11]:https://www.nginx.com/blog/load-balancing-with-nginx-plus/
|
||||
[12]:https://www.nginx.com/resources/ebook/five-reasons-choose-software-load-balancer/
|
||||
[13]:https://www.nginx.com/resources/webinars/choose-software-based-load-balancer-45-min/
|
||||
[14]:https://www.nginx.com/resources/admin-guide/load-balancer/
|
||||
[12]:https://www.nginx.com/resources/admin-guide/load-balancer//
|
||||
[15]:https://www.nginx.com/products/
|
||||
[16]:https://www.nginx.com/blog/nginx-caching-guide/
|
||||
[17]:https://www.nginx.com/products/content-caching-nginx-plus/
|
||||
|
||||
@ -0,0 +1,108 @@
|
||||
装好 openSUSE Leap 42.1 之后要做的 8 件事
|
||||
================================================================================
|
||||

|
||||
致谢:[Metropolitan Transportation/Flicrk][1]
|
||||
|
||||
> 你已经在你的电脑上安装了 openSUSE。这是你接下来要做的。
|
||||
|
||||
[openSUSE Leap 确实是个巨大的飞跃][2],它允许用户运行一个和 SUSE Linux 企业版拥有一样基因的发行版。和其它系统一样,在使用它之前需要做些优化设置。
|
||||
|
||||
下面是一些我在安装 openSUSE 到我的电脑上之后做的一些事情(不适用于服务器)。这里面没有强制性要求的设置,基本安装对来说你也可能足够了。但如果你想获得更好的 openSUSE Leap 体验,那就跟着我往下看吧。
|
||||
|
||||
### 1. 添加 Packman 仓库 ###
|
||||
|
||||
由于专利和授权等原因,openSUSE 和许多 Linux 发行版一样,不通过官方仓库(repos)提供一些软件,解码器,以及驱动等。取而代之的是通过第三方或社区仓库来提供。第一个也是最重要的仓库是“Packman”。因为这些仓库不是默认启用的,我们需要添加它们。你可以通过 YaST (openSUSE 的特色之一)或者命令行完成(如下方介绍)。
|
||||
|
||||

|
||||
添加 Packman 仓库。
|
||||
|
||||
使用 YsST,打开软件源部分。点击“添加”按钮并选择“社区仓库(Community Repositories)”。点击“下一步”。一旦仓库列表加载出来了,选择 Packman 仓库。点击“确认”,然后点击“信任”导入信任的 GnuPG 密钥。
|
||||
|
||||
或者在终端里使用以下命令添加并启用 Packman 仓库:
|
||||
|
||||
zypper ar -f -n packmanhttp://ftp.gwdg.de/pub/linux/misc/packman/suse/openSUSE_Leap_42.1/ packman
|
||||
|
||||
仓库添加之后,你就能接触到更多的包了。想安装任意软件或包,打开 YaST 软件管理器,搜索并安装即可。
|
||||
|
||||
### 2. 安装 VLC ###
|
||||
|
||||
VLC 是媒体播放器里的瑞士军刀,几乎可以播放任何媒体文件。你可以从 YaST 软件管理器 或 software.opensuse.org 安装 VLC。你需要安装两个包:vlc 和 vlc-codecs。
|
||||
|
||||
如果你用终端,运行以下命令:
|
||||
|
||||
sudo zypper install vlc vlc-codecs
|
||||
|
||||
### 3. 安装 Handbrake ###
|
||||
|
||||
如果你需要转码或转换视频文件格式,[Handbrake 是你的不二之选][3]。Handbrake 就在我们启用的仓库中,所以只要在 YaST 中搜索并安装它。
|
||||
|
||||
如果你用终端,运行以下命令:
|
||||
|
||||
sudo zypper install handbrake-cli handbrake-gtk
|
||||
|
||||
(提示:VLC 也能转码音频和视频文件。)
|
||||
|
||||
### 4. 安装 Chrome ###
|
||||
|
||||
openSUSE 的默认浏览器是 Firefox。但是因为 Firefox 不能胜任播放专有媒体,比如 Netflix,我推荐安装 Chrome。这需要额外的工作。首先你需要从谷歌导入信任密钥。打开终端执行“wget”命令下载密钥:
|
||||
|
||||
wget https://dl.google.com/linux/linux_signing_key.pub
|
||||
|
||||
然后导入密钥:
|
||||
|
||||
sudo rpm --import linux_signing_key.pub
|
||||
|
||||
现在到 [Google Chrome 网站][4] 去,下载 64 位 .rpm 文件。下载完成后执行以下命令安装浏览器:
|
||||
|
||||
sudo zypper install /PATH_OF_GOOGLE_CHROME.rpm
|
||||
|
||||
### 5. 安装 Nvidia 驱动 ###
|
||||
|
||||
即便你有 Nvidia 或 ATI 显卡,openSUSE Leap 也能够开箱即用。但是,如果你需要专有驱动来游戏或其它目的,你可以安装这些驱动,但需要一点额外的工作。
|
||||
|
||||
首先你需要添加 Nvidia 源;它的步骤和使用 YaST 添加 Packman 仓库是一样的。唯一的不同是你需要在社区仓库部分选择 Nvidia。添加好了之后,到 **软件管理 > 附加** 去并选择“附加/安装所有匹配的推荐包”。
|
||||
|
||||

|
||||
|
||||
它会打开一个对话框,显示所有将要安装的包,点击确认后按介绍操作。添加了 Nvidia 源之后你也可以通过命令安装需要的 Nvidia 驱动:
|
||||
|
||||
sudo zypper inr
|
||||
|
||||
(注:我没使用过 AMD/ATI 显卡,所以这方面我没有经验。)
|
||||
|
||||
### 6. 安装媒体解码器 ###
|
||||
|
||||
你安装 VLC 之后就不需要安装媒体解码器了,但如果你要使用其它软件来播放媒体的话就需要安装了。一些开发者写了脚本/工具来简化这个过程。打开[这个页面][5]并点击合适的按钮安装完整的包。他会打开 YaST 并自动安装包(当然通常你还需要提供 root 权限密码并信任 GnuPG 密钥)。
|
||||
|
||||
### 7. 安装你偏好的电子邮件客户端 ###
|
||||
|
||||
openSUSE 自带 Kmail 或 Evolution,这取决于你安装的桌面环境。我用的是 Plasma,自带 Kmail,这个邮件客户端还有许多地方有待改进。我建议可以试试 Thunderbird 或 Evolution。所有主要的邮件客户端都能在官方仓库找到。你还可以看看我的[精心挑选的 Linux 最佳邮件客户端][7]。
|
||||
|
||||
### 8. 在防火墙允许 Samba 服务 ###
|
||||
|
||||
相比于其它发行版,openSUSE 默认提供了更加安全的系统。但对新用户来说它也需要一点设置。如果你正在使用 Samba 协议分享文件到本地网络的话,你需要在防火墙允许该服务。
|
||||
|
||||

|
||||
在防火墙设置里允许 Samba 客户端和服务端
|
||||
|
||||
打开 YaST 并搜索 Firewall。在防火墙设置里,到“允许的服务”那里你会在“要允许的服务”下面看到一个下拉列表。选择“Samba 客户端”,然后点击“添加”。对“Samba 服务端”也一样地添加。都添加了之后,点击“下一步”,然后点击“完成”,现在你就可以通过本地网络从你的 openSUSE 分享文件以及访问其它机器了。
|
||||
|
||||
这差不多就是我以我喜欢的方式对我的新 openSUSE 系统做的所有设置了。如果你有任何问题,欢迎在评论区提问。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.itworld.com/article/3003865/open-source-tools/8-things-to-do-after-installing-opensuse-leap-421.html
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.itworld.com/author/Swapnil-Bhartiya/
|
||||
[1]:https://www.flickr.com/photos/mtaphotos/11200079265/
|
||||
[2]:https://www.linux.com/news/software/applications/865760-opensuse-leap-421-review-the-most-mature-linux-distribution
|
||||
[3]:https://www.linux.com/learn/tutorials/857788-how-to-convert-videos-in-linux-using-the-command-line
|
||||
[4]:https://www.google.com/intl/en/chrome/browser/desktop/index.html#brand=CHMB&utm_campaign=en&utm_source=en-ha-na-us-sk&utm_medium=ha
|
||||
[5]:http://opensuse-community.org/
|
||||
[6]:http://www.itworld.com/article/2875981/the-5-best-open-source-email-clients-for-linux.html
|
||||
@ -0,0 +1,215 @@
|
||||
用Python打造你的Eclipse
|
||||
==============================================
|
||||
|
||||

|
||||
|
||||
Eclipse高级脚本环境([EASE][1])项目虽然还在开发中,但是不是不得承认它非常强大,让我们可以快速打造自己的Eclipse开发环境.
|
||||
|
||||
依据Eclipse强大的框架,可以通过其内建的插件系统全方面的扩展Eclipse.然而,编写和部署一个新的插件还是十分笨重,即使只是需要一个额外的小功能。但是,现在依托EASE,可以方便实用Python或者Javascript脚本语言来扩展。
|
||||
|
||||
本文中,根据我在今年北美的EclipseCon大会上的[演讲][2],我介绍包括安装Eclipse的Python和EASE环境,并包括使用强力Python来增压你的IDE。
|
||||
|
||||
### 安装并运行 "Hello World"
|
||||
|
||||
本文中的例子使用Java实现的Python解释,Jython。Eclipse可以直接安装EASE环境。本例中使用Eclipse[Mars][3],它已经自带了EASE环境,包和Jython引擎。
|
||||
|
||||
使用Eclipse安装对话框(`Help>Install New Software`...),安装EASE[http://download.eclipse.org/ease/update/nightly][4]
|
||||
|
||||
选择下列组件:
|
||||
|
||||
- EASE Core feature
|
||||
|
||||
- EASE core UI feature
|
||||
|
||||
- EASE Python Developer Resources
|
||||
|
||||
- EASE modules (Incubation)
|
||||
|
||||
包括了EASE和模组。但是我们比较关心Resource包,此包可以访问Eclipse工作空间,项目和文件API。
|
||||
|
||||

|
||||
|
||||
|
||||
成功安装后,接下来安装Jython引擎[https://dl.bintray.com/pontesegger/ease-jython/][5].完成后,测试下。新建一个项目并新建一个hello.py文件,输入:
|
||||
|
||||
```
|
||||
print "hello world"
|
||||
```
|
||||
|
||||
选中这个文件,右击,选中'Run as -> EASE script'.这样就可以在控制台看到"Hello world"的输出.
|
||||
|
||||
配置完成,现在就可以轻松使用Python来控制工作空间和项目了.
|
||||
|
||||
### 提升你的代码质量
|
||||
|
||||
管理良好的代码质量本身是一件非常烦恼的事情,尤其是当需要处理一个大量代码库和要许多工程师参与的时候.而这些痛苦可以通过脚本来减轻,比如大量文字排版,或者[去掉文件中的unix行结束符][6]来使更容易比较.其他很棒的事情包括使用脚本让Eclipse markers高亮代码.这里有一些例子,你可以加入到task markers ,用"printStackTrace"方法在java文件中探测.请看[源码][7]
|
||||
|
||||
运行,拷贝文件到工作空间,右击运行.
|
||||
|
||||
```
|
||||
loadModule('/System/Resources')
|
||||
```
|
||||
|
||||
from org.eclipse.core.resources import IMarker
|
||||
|
||||
```
|
||||
for ifile in findFiles("*.java"):
|
||||
file_name = str(ifile.getLocation())
|
||||
print "Processing " + file_name
|
||||
with open(file_name) as f:
|
||||
for line_no, line in enumerate(f, start=1):
|
||||
if "printStackTrace" in line:
|
||||
marker = ifile.createMarker(IMarker.TASK)
|
||||
marker.setAttribute(IMarker.TRANSIENT, True)
|
||||
marker.setAttribute(IMarker.LINE_NUMBER, line_no)
|
||||
marker.setAttribute(IMarker.MESSAGE, "Fix in Sprint 2: " + line.strip())
|
||||
|
||||
```
|
||||
|
||||
如果你的任何java文件中包含了printStackTraces,你就可以看见编辑器的侧边栏上自动加上的标记.
|
||||
|
||||

|
||||
|
||||
### 自动构建繁琐任务
|
||||
|
||||
当同时工作在多个项目的时候,肯定需要需要完成许多繁杂,重复的任务.可能你需要在所有源文件头上加入CopyRight, 或者采用新框架时候自动更新文件.例如,当从Tycho迁移到Maven时候,我们给每一个项目必须添加pom.xml文件.使用Python可以很轻松的完成这个任务.只从Tycho提供无pom构建后,我们也需要移除不要的pom文件.同样,只需要几行代码就可以完成这个任务.例如,这里有个脚本可以在每一个打开的工作空间项目上加入README.md.请看源代码[add_readme.py][8].
|
||||
|
||||
拷贝文件到工作空间,右击并选择"Run as -> EASE script"
|
||||
|
||||
loadModule('/System/Resources')
|
||||
|
||||
```
|
||||
for iproject in getWorkspace().getProjects():
|
||||
if not iproject.isOpen():
|
||||
continue
|
||||
|
||||
ifile = iproject.getFile("README.md")
|
||||
|
||||
if not ifile.exists():
|
||||
contents = "# " + iproject.getName() + "\n\n"
|
||||
if iproject.hasNature("org.eclipse.jdt.core.javanature"):
|
||||
contents += "A Java Project\n"
|
||||
elif iproject.hasNature("org.python.pydev.pythonNature"):
|
||||
contents += "A Python Project\n"
|
||||
writeFile(ifile, contents)
|
||||
```
|
||||
|
||||
脚本结果会在打开的项目中加入README.md,java和Python项目还会自动加上一行描述.
|
||||
|
||||

|
||||
|
||||
### 构建新功能
|
||||
|
||||
Python脚本可以快速构建一些需要的附加功能,或者给团队和用户快速构建demo.例如,一个现在Eclipse目前不支持的功能,自动保存工作的文件.即使这个功能将会很快提供,但是你现在就可以马上拥有一个能30秒自动保存的编辑器.以下是主方法的片段.请看下列代码:[autosave.py][9]
|
||||
|
||||
```
|
||||
def save_dirty_editors():
|
||||
workbench = getService(org.eclipse.ui.IWorkbench)
|
||||
for window in workbench.getWorkbenchWindows():
|
||||
for page in window.getPages():
|
||||
for editor_ref in page.getEditorReferences():
|
||||
part = editor_ref.getPart(False)
|
||||
if part and part.isDirty():
|
||||
print "Auto-Saving", part.getTitle()
|
||||
part.doSave(None)
|
||||
```
|
||||
|
||||
在运行脚本之前,你需要勾选'Allow Scripts to run code in UI thread'设定,这个设定在Window > Preferences > Scripting中.然后添加脚本到工作空间,右击和选择"Run as > EASE Script".每10秒自动保存的信息就会在控制台输出.关掉自动保存脚本,只需要在点击控制台的红色方框.
|
||||
|
||||

|
||||
|
||||
### 快速扩展用户界面
|
||||
|
||||
EASE最棒的事情是可以通过脚本与UI元素挂钩,可以调整你的IDE,例如,在菜单中新建一个按钮.不需要编写java代码或者新的插件,只需要增加几行代码.
|
||||
|
||||
下面是一个简单的基脚本示例,用来产生三个新项目.
|
||||
|
||||
```
|
||||
# name : Create fruit projects
|
||||
# toolbar : Project Explorer
|
||||
# description : Create fruit projects
|
||||
|
||||
loadModule("/System/Resources")
|
||||
|
||||
for name in ["banana", "pineapple", "mango"]:
|
||||
createProject(name)
|
||||
```
|
||||
|
||||
上述特别的EASE增加了一个按钮到项目浏览工具条.下面这个脚本是用来删除这三个项目.请看源码[createProjects.py][10]和[deleteProjects.py][11].
|
||||
|
||||
```
|
||||
# name :Delete fruit projects
|
||||
# toolbar : Project Explorer
|
||||
# description : Get rid of the fruit projects
|
||||
|
||||
loadModule("/System/Resources")
|
||||
|
||||
for name in ["banana", "pineapple", "mango"]:
|
||||
project = getProject(name)
|
||||
project.delete(0, None)
|
||||
```
|
||||
|
||||
为了使脚本启动生效按钮,增加脚本到'ScriptsProject'文件夹.然后选择Windows > Preference > Scripting > Script 中定位到文件夹.点击'Add Workspace'按钮和选择ScriptProject项目.这个项目现在将会在启动时默认加载.你可以发现Project Explorer上出现了这两个按钮,这样你就可以通过这两个按钮快速增加删除项目.
|
||||
|
||||

|
||||
|
||||
### 整合三方工具
|
||||
|
||||
无论何时,你可能需要除了Eclipse生态系统以外的工具.这些时候你会发将他们包装在一个脚本来调用会非常方便.这里有一个简单的例子让你整合explorer.exe,并加入它到右键菜单栏,这样点击图标就可以打开浏览器浏览当前文件.请看源码[explorer.py][12]
|
||||
|
||||
```
|
||||
# name : Explore from here
|
||||
# popup : enableFor(org.eclipse.core.resources.IResource)
|
||||
# description : Start a file browser using current selection
|
||||
loadModule("/System/Platform")
|
||||
loadModule('/System/UI')
|
||||
|
||||
selection = getSelection()
|
||||
if isinstance(selection, org.eclipse.jface.viewers.IStructuredSelection):
|
||||
selection = selection.getFirstElement()
|
||||
|
||||
if not isinstance(selection, org.eclipse.core.resources.IResource):
|
||||
selection = adapt(selection, org.eclipse.core.resources.IResource)
|
||||
|
||||
if isinstance(selection, org.eclipse.core.resources.IFile):
|
||||
selection = selection.getParent()
|
||||
|
||||
if isinstance(selection, org.eclipse.core.resources.IContainer):
|
||||
runProcess("explorer.exe", [selection.getLocation().toFile().toString()])
|
||||
```
|
||||
|
||||
为了让菜单显示增加,像之前一样加入'ScriptProject'.在文件上右击,你看弹出菜单是不是出现了图标.选择Explore from here.
|
||||
|
||||

|
||||
|
||||
Eclipse高级基本环境提供一套很棒的扩展功能,使得Eclipse IDE能使用Python来轻易扩展.虽然这个项目还在婴儿期,但是[关于这个项目][13]更多更棒的功能也正在加紧开发中,如果你想为这个贡献,请到[论坛][14]讨论.
|
||||
|
||||
2016年[Eclipsecon North America][15]会议将会发布更多EASE细节.我的演讲[Scripting Eclipse with Python][16]也会不单介绍Jython,也包括C-Python和其他功能性扩展的实战例子.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/2/how-use-python-hack-your-ide
|
||||
|
||||
作者:[Tracy Miranda][a]
|
||||
译者:[VicYu/Vic020](http://vicyu.net)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/tracymiranda
|
||||
[1]: https://eclipse.org/ease/
|
||||
[2]: https://www.eclipsecon.org/na2016/session/scripting-eclipse-python
|
||||
[3]: https://www.eclipse.org/downloads/packages/eclipse-ide-eclipse-committers-451/mars1
|
||||
[4]: http://download.eclipse.org/ease/update/nightly
|
||||
[5]: https://dl.bintray.com/pontesegger/ease-jython/
|
||||
[6]: http://code.activestate.com/recipes/66434-change-line-endings/
|
||||
[7]: https://gist.github.com/tracymiranda/6556482e278c9afc421d
|
||||
[8]: https://gist.github.com/tracymiranda/f20f233b40f1f79b1df2
|
||||
[9]: https://gist.github.com/tracymiranda/e9588d0976c46a987463
|
||||
[10]: https://gist.github.com/tracymiranda/55995daaea9a4db584dc
|
||||
[11]: https://gist.github.com/tracymiranda/baa218fc2c1a8e898194
|
||||
[12]: https://gist.github.com/tracymiranda/8aa3f0fc4bf44f4a5cd3
|
||||
[13]: https://eclipse.org/ease/
|
||||
[14]: https://dev.eclipse.org/mailman/listinfo/ease-dev
|
||||
[15]: https://www.eclipsecon.org/na2016
|
||||
[16]: https://www.eclipsecon.org/na2016/session/scripting-eclipse-python
|
||||
Loading…
Reference in New Issue
Block a user