mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-21 02:10:11 +08:00
commit
25ed163c39
@ -2,8 +2,6 @@
|
||||
================================================================================
|
||||

|
||||
|
||||
图片来源 : opensource.com
|
||||
|
||||
经过了一整天的Opensource.com[社区版主][1]年会,最后一项日程提了上来,内容只有“特邀嘉宾:待定”几个字。作为[Opensource.com][3]的项目负责人和社区管理员,[Jason Hibbets][2]起身解释道,“因为这个嘉宾有可能无法到场,因此我不想提前说是谁。在几个月前我问他何时有空过来,他给了我两个时间点,我选了其中一个。今天是这三周中Jim唯一能来的一天”。(译者注:Jim是指下文中提到的Jim Whitehurst,即红帽公司总裁兼首席执行官)
|
||||
|
||||
这句话在版主们(Moderators)中引起一阵轰动,他们从世界各地赶来参加此次的[拥抱开源大会(All Things Open Conference)][4]。版主们纷纷往前挪动椅子,仔细聆听。
|
||||
@ -14,7 +12,7 @@
|
||||
|
||||
“大家好!”,这个家伙开口了。他没穿正装,只是衬衫和休闲裤。
|
||||
|
||||
这时会场中第二高个子的人,红帽全球意识部门(Global Awareness)的高级主管[Jeff Mackanic][5],告诉他大部分社区版本今天都在场,然后让每个人开始作简单的自我介绍。
|
||||
这时会场中第二高个子的人,红帽全球意识部门(Global Awareness)的高级主管[Jeff Mackanic][5],告诉他大部分社区版主今天都在场,然后让每个人开始作简单的自我介绍。
|
||||
|
||||
“我叫[Jen Wike Huger][6],负责Opensource.com的内容管理,很高兴见到大家。”
|
||||
|
||||
@ -22,13 +20,13 @@
|
||||
|
||||
“我叫[Robin][9],从2013年开始参与版主项目。我在OSDC做了一些事情,工作是在[City of the Hague][10]维护[网站][11]。”
|
||||
|
||||
“我叫[Marcus Hanwell][12],来自英格兰,在[Kitware][13]工作。同时,我是FOSS科学软件的技术总监,和国家实验室在[Titan][14] Z和[Gpu programming][15]方面合作。我主要使用[Gentoo][16]和[KDE][17]。最后,我很激动能加入FOSS和开源科学。”
|
||||
“我叫[Marcus Hanwell][12],来自英格兰,在[Kitware][13]工作。同时,我是FOSS science software的技术总监,和国家实验室在[Titan][14] Z和[Gpu programming][15]方面合作。我主要使用[Gentoo][16]和[KDE][17]。最后,我很激动能参与到FOSS和开源科学。”
|
||||
|
||||
“我叫[Phil Shapiro][18],是华盛顿的一个小图书馆28个Linux工作站的管理员。我视各位为我的同事。非常高兴能一起交流分享,贡献力量。我主要关注FOSS和自豪感的关系,以及FOSS如何提升自豪感。”
|
||||
“我叫[Phil Shapiro][18],是华盛顿的一个小图书馆的28个Linux工作站的管理员。我视各位为我的同事。非常高兴能一起交流分享,贡献力量。我主要关注FOSS和自豪感的关系,以及FOSS如何提升自豪感。”
|
||||
|
||||
“我叫[Joshua Holm][19]。我大多数时间都在关注系统更新,以及帮助人们在网上找工作。”
|
||||
|
||||
“我叫[Mel Chernoff][20],在红帽工作,和[Jason Hibbets]和[Mark Bohannon]一起主要关注政府渠道方面。”
|
||||
“我叫[Mel Chernoff][20],在红帽工作,和[Jason Hibbets][22]和[Mark Bohannon][23]一起主要关注[政府][21]渠道方面。”
|
||||
|
||||
“我叫[Scott Nesbitt][24],写过很多东西,使用FOSS很久了。我是个普通人,不是系统管理员,也不是程序员,只希望能更加高效工作。我帮助人们在商业和生活中使用FOSS。”
|
||||
|
||||
@ -38,41 +36,41 @@
|
||||
|
||||
“你在[新FOSS Minor][30]教书?!”,Jim说道,“很酷!”
|
||||
|
||||
“我叫[Jason Baker][31]。我是红慢的一个云专家,主要做[OpenStack][32]方面的工作。”
|
||||
“我叫[Jason Baker][31]。我是红帽的一个云专家,主要做[OpenStack][32]方面的工作。”
|
||||
|
||||
“我叫[Mark Bohannan][33],是红帽全球开放协议的一员,在华盛顿外工作。和Mel一样,我花了相当多时间写作,也从法律和政府部门中找合作者。我做了一个很好的小册子来讨论正在发生在政府中的积极变化。”
|
||||
|
||||
“我叫[Jason Hibbets][34],我组织了这次会议。”
|
||||
“我叫[Jason Hibbets][34],我组织了这次讨论。”
|
||||
|
||||
会场中一片笑声。
|
||||
|
||||
“我也组织了这片讨论,可以这么说,”这个棕红色头发笑容灿烂的家伙说道。笑声持续一会逐渐平息。
|
||||
“我也组织了这个讨论,可以这么说,”这个棕红色头发笑容灿烂的家伙说道。笑声持续一会逐渐平息。
|
||||
|
||||
我当时在他左边,时不时从转录空隙中抬头看一眼,然后从眼神中注意到微笑背后暗示的那个自2008年1月起开始领导公司的人,红帽的CEO[Jim Whitehurst][35]。
|
||||
我当时在他左边,时不时从记录的间隙中抬头看一眼,我注意到淡淡微笑背后的那个令人瞩目的人,是自2008年1月起开始领导红帽公司的CEO [Jim Whitehurst][35]。
|
||||
|
||||
“我有世界上最好的工作,”稍稍向后靠、叉腿抱头,Whitehurst开始了演讲。“我开始领导红帽,在世界各地旅行到处看看情况。在这里的七年中,FOSS和广泛的开源创新所发生的美好的事情是开源已经脱离了条条框框。我现在认为,IT正处在FOSS之前所在的位置。我们可以预见FOSS从一个替代走向创新驱动力。”用户也看到了这一点。他们用FOSS并不是因为它便宜,而是因为它能提供和创新的解决方案。这也十一个全球现象。比如,我刚才还在印度,然后发现那里的用户拥抱开源的两个理由:一个是创新,另一个是那里的市场有些特殊,需要完全的控制。
|
||||
“我有世界上最好的工作,”稍稍向后靠、叉腿抱头,Whitehurst开始了演讲。“我开始领导红帽,在世界各地旅行到处看看情况。在这里的七年中,FOSS和广泛的开源创新所发生的最美好的事情是开源已经脱离了条条框框。我现在认为,信息技术正处在FOSS之前所在的位置。我们可以预见FOSS从一个替代品走向创新驱动力。我们的用户也看到了这一点。他们用FOSS并不是因为它便宜,而是因为它能带来可控和创新的解决方案。这也是个全球现象。比如,我刚才还在印度,然后发现那里的用户拥抱开源的两个理由:一个是创新,另一个是那里的市场有些特殊,需要完全的可控。”
|
||||
|
||||
“[孟买证券交易所][36]想得到源代码并加以控制,五年前这在证券交易领域闻所未闻。那时FOSS正在重复发明轮子。今天看来,FOSS正在做几乎所有的结合了大数据的事物。几乎所有的新框架,语言和方法论,包括流动(尽管不包括设备),都首先发生在开源世界。”
|
||||
“[孟买证券交易所][36]想得到源代码并加以控制,五年前这种事情在证券交易领域就没有听说过。那时FOSS正在重复发明轮子。今天看来,实际上大数据的每件事情都出现在FOSS领域。几乎所有的新框架,语言和方法论,包括移动通讯(尽管不包括设备),都首先发生在开源世界。”
|
||||
|
||||
“这是因为用户数量已经达到了相当的规模。这不只是红帽遇到的情况,[Google][37],[Amazon][38],[Facebook][39]等也出现这样的情况。他们想解决自己的问题,用开源的方式。忘掉协议吧,开源绝不仅如此。我们建立了一个交通工具,一套规则,例如[Hadoop][40],[Cassandra][41]和其他工具。事实上,开源驱动创新。例如,Hadoop在厂商们意识的规模带来的问题。他们实际上有足够的资和资源金来解决自己的问题。”开源是许多领域的默认技术方案。这在一个更加注重内容的世界中更是如此,例如[3D打印][42]和其他使用信息内容的物理产品。”
|
||||
“这是因为用户数量已经达到了相当的规模。这不只是红帽遇到的情况,[Google][37],[Amazon][38],[Facebook][39]等也出现这样的情况。他们想解决自己的问题,用开源的方式。忘掉许可协议吧,开源绝不仅如此。我们建立了一个交通工具,一套规则,例如[Hadoop][40],[Cassandra][41]和其他工具。事实上,开源驱动创新。例如,Hadoop是在厂商们意识到规模带来的问题时的一个解决方案。他们实际上有足够的资金和资源来解决自己的问题。开源是许多领域的默认技术方案。这在一个更加注重内容的世界中更是如此,例如[3D打印][42]和其他使用信息内容的实体产品。”
|
||||
|
||||
“源代码的开源确实很酷,但开源不应当仅限于此。在各行各业不同领域开源仍有可以用武之地。我们要问下自己:‘开源能够为教育,政府,法律带来什么?其它的呢?其它的领域如何能学习我们?’”
|
||||
|
||||
“还有内容的问题。内容在现在是免费的,当然我们可以投资更多的免费内容,不过我们也需要商业模式围绕的内容。这是我们更应该关注的。如果你相信开放的创新能带来更好,那么我们需要更多的商业模式。”
|
||||
“还有内容的问题。内容在现在是免费的,当然我们可以投资更多的免费内容,不过我们也需要商业模式围绕的内容。这是我们更应该关注的。如果你相信开放的创新更好,那么我们需要更多的商业模式。”
|
||||
|
||||
“教育让我担心其相比与‘社区’它更关注‘内容’。例如,无论我走到哪里,大学校长们都会说,‘等等,难道教育将会免费?!’对于下游来说FOSS免费很棒,但别忘了上游很强大。免费课程很棒,但我们同样需要社区来不断迭代和完善。这是很多人都在做的事情,Opensource.com是一个提供交流的社区。问题不是‘我们如何控制内容’,也不是‘如何建立和分发内容’,而是要确保它处在不断的完善当中,而且能给其他领域提供有价值的参考。”
|
||||
“教育让我担心,其相比与‘社区’它更关注‘内容’。例如,无论我走到哪里,大学的校长们都会说,‘等等,难道教育将会免费?!’对于下游来说FOSS免费很棒,但别忘了上游很强大。免费课程很棒,但我们同样需要社区来不断迭代和完善。这是很多人都在做的事情,Opensource.com是一个提供交流的社区。问题不是‘我们如何控制内容’,也不是‘如何建立和分发内容’,而是要确保它处在不断的完善当中,而且能给其他领域提供有价值的参考。”
|
||||
|
||||
“改变世界的潜力是无穷无尽的,我们已经取得了很棒的进步。”六年前我们痴迷于制定宣言,我们说‘我们是领导者’。我们用错词了,因为那潜在意味着控制。积极的参与者们同样也不能很好理解……[Máirín Duffy][43]提出了[催化剂][44]这个词。然后我们组成了红帽,不断地促进行动,指引方向。”
|
||||
|
||||
“Opensource.com也是其他领域的催化剂,而这正是它的本义所在,我希望你们也这样认为。当时的内容质量和现在比起来都令人难以置信。你可以看到每季度它都在进步。谢谢你们的时间!谢谢成为了催化剂!这是一个让世界变得更好的机会。我想听听你们的看法。”
|
||||
“Opensource.com也是其他领域的催化剂,而这正是它的本义所在,我希望你们也这样认为。当时的内容质量和现在比起来都令人难以置信。你可以看到每季度它都在进步。谢谢你们付出的时间!谢谢成为了催化剂!这是一个让世界变得更好的机会。我想听听你们的看法。”
|
||||
|
||||
我瞥了一下桌子,发现几个人眼中带泪。
|
||||
|
||||
然后Whitehurst又回顾了大会的开放教育议题。“极端一点看,如果你有一门[Ulysses][45]的公开课。在这里你能和一群人一起合作体验课堂。这样就和代码块一样的:大家一起努力,代码随着时间不断改进。”
|
||||
|
||||
在这一点上,我有发言权。当谈论其FOSS和学术团体之间的差异,向基础和可能的不调和这些词语都跳了出来。
|
||||
在这一点上,我有发言权。当谈论其FOSS和学术团体之间的差异,像“基础”和“可能不调和”这些词语都跳了出来。
|
||||
|
||||
**Remy**: “倒退带来死亡。如果你在论文或者发布的代码中烦了一个错误,有可能带来十分严重的后果。学校一直都是避免失败寻求正确答案的地方。复制意味着抄袭。轮子在一遍遍地教条地被发明。FOSS你能快速失败,但在学术界,你只能带来无效的结果。”
|
||||
**Remy**: “倒退带来死亡。如果你在论文或者发布的代码中犯了一个错误,有可能带来十分严重的后果。学校一直都是避免失败寻求正确答案的地方。复制意味着抄袭。轮子在一遍遍地教条地被发明。FOSS让你能快速失败,但在学术界,你只能带来无效的结果。”
|
||||
|
||||
**Nicole**: “学术界有太多自我的家伙,你们需要一个发布经理。”
|
||||
|
||||
@ -80,20 +78,21 @@
|
||||
|
||||
**Luis**: “团队和分享应该优先考虑,红帽可以多向它们强调这一点。”
|
||||
|
||||
**Jim**: “还有公司在其中扮演积极角色吗?”
|
||||
**Jim**: “还有公司在其中扮演积极角色了吗?”
|
||||
|
||||
[Phil Shapiro][46]: “我对FOSS的临界点感兴趣。联邦没有改用[LibreOffice][47]把我逼疯了。我们没有在软件上花税款,也不应当在字处理软件或者微软的Office上浪费税钱。”
|
||||
[Phil Shapiro][46]: “我对FOSS的临界点感兴趣。Fed没有改用[LibreOffice][47]把我逼疯了。我们没有在软件上花税款,也不应当在字处理软件或者微软的Office上浪费税钱。”
|
||||
|
||||
**Jim**: “我们经常提倡这一点。我们能做更多吗?这是个问题。首先,我们在我们的产品涉足的地方取得了进步。我们在政府中有坚实的专营权。我们比私有公司平均话费更多。银行和电信业都和政府挨着。我们在欧洲做的更好,我认为在那工作又更低的税。下一代计算就像‘终结者’,我们到处取得了进步,但仍然需要忧患意识。”
|
||||
**Jim**: “我们经常提倡这一点。我们能做更多吗?这是个问题。首先,我们在我们的产品涉足的地方取得了进步。我们在政府中有坚实的专营权。我们比私有公司平均花费更多。银行和电信业都和政府挨着。我们在欧洲做的更好,我认为在那工作有更低的税。下一代计算就像‘终结者’,我们到处取得了进步,但仍然需要忧患意识。”
|
||||
|
||||
突然,门开了。Jim转身向门口站着的执行助理点头。他要去参加下一场会了。他并拢双腿,站着向前微倾。然后,他再次向每个人的工作和奉献表示感谢,微笑着出了门……留给我们更多的激励。
|
||||
|
||||
突然,门开了。Jim转身向门口站着的执行助理点头。他要去参加下一场会了。他并拢双腿,站着向前微倾。然后,他再次向每个人的工作和奉献表示感谢,微笑着除了门……留给我们更多的激励。
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/business/14/12/jim-whitehurst-inspiration-open-source
|
||||
|
||||
作者:[Remy][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[fyh](https://github.com/fyh)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
Linux 日志基础
|
||||
================================================================================
|
||||
首先,我们将描述有关 Linux 日志是什么,到哪儿去找它们以及它们是如何创建的基础知识。如果你已经知道这些,请随意跳至下一节。
|
||||
首先,我们将描述有关 Linux 日志是什么,到哪儿去找它们,以及它们是如何创建的基础知识。如果你已经知道这些,请随意跳至下一节。
|
||||
|
||||
### Linux 系统日志 ###
|
||||
|
||||
@ -10,71 +10,69 @@ Linux 日志基础
|
||||
|
||||
一些最为重要的 Linux 系统日志包括:
|
||||
|
||||
- `/var/log/syslog` 或 `/var/log/messages` 存储所有的全局系统活动数据,包括开机信息。基于 Debian 的系统如 Ubuntu 在 `/var/log/syslog` 目录中存储它们,而基于 RedHat 的系统如 RHEL 或 CentOS 则在 `/var/log/messages` 中存储它们。
|
||||
- `/var/log/syslog` 或 `/var/log/messages` 存储所有的全局系统活动数据,包括开机信息。基于 Debian 的系统如 Ubuntu 在 `/var/log/syslog` 中存储它们,而基于 RedHat 的系统如 RHEL 或 CentOS 则在 `/var/log/messages` 中存储它们。
|
||||
- `/var/log/auth.log` 或 `/var/log/secure` 存储来自可插拔认证模块(PAM)的日志,包括成功的登录,失败的登录尝试和认证方式。Ubuntu 和 Debian 在 `/var/log/auth.log` 中存储认证信息,而 RedHat 和 CentOS 则在 `/var/log/secure` 中存储该信息。
|
||||
- `/var/log/kern` 存储内核错误和警告数据,这对于排除与自定义内核相关的故障尤为实用。
|
||||
- `/var/log/kern` 存储内核的错误和警告数据,这对于排除与定制内核相关的故障尤为实用。
|
||||
- `/var/log/cron` 存储有关 cron 作业的信息。使用这个数据来确保你的 cron 作业正成功地运行着。
|
||||
|
||||
Digital Ocean 有一个完整的关于这些文件及 rsyslog 如何在常见的发行版本如 RedHat 和 CentOS 中创建它们的 [教程][1] 。
|
||||
Digital Ocean 有一个关于这些文件的完整[教程][1],介绍了 rsyslog 如何在常见的发行版本如 RedHat 和 CentOS 中创建它们。
|
||||
|
||||
应用程序也会在这个目录中写入日志文件。例如像 Apache,Nginx,MySQL 等常见的服务器程序可以在这个目录中写入日志文件。其中一些日志文件由应用程序自己创建,其他的则通过 syslog (具体见下文)来创建。
|
||||
|
||||
### 什么是 Syslog? ###
|
||||
|
||||
Linux 系统日志文件是如何创建的呢?答案是通过 syslog 守护程序,它在 syslog
|
||||
套接字 `/dev/log` 上监听日志信息,然后将它们写入适当的日志文件中。
|
||||
Linux 系统日志文件是如何创建的呢?答案是通过 syslog 守护程序,它在 syslog 套接字 `/dev/log` 上监听日志信息,然后将它们写入适当的日志文件中。
|
||||
|
||||
单词“syslog” 是一个重载的条目,并经常被用来简称如下的几个名称之一:
|
||||
单词“syslog” 代表几个意思,并经常被用来简称如下的几个名称之一:
|
||||
|
||||
1. **Syslog 守护进程** — 一个用来接收,处理和发送 syslog 信息的程序。它可以[远程发送 syslog][2] 到一个集中式的服务器或写入一个本地文件。常见的例子包括 rsyslogd 和 syslog-ng。在这种使用方式中,人们常说 "发送到 syslog."
|
||||
1. **Syslog 协议** — 一个指定日志如何通过网络来传送的传输协议和一个针对 syslog 信息(具体见下文) 的数据格式的定义。它在 [RFC-5424][3] 中被正式定义。对于文本日志,标准的端口是 514,对于加密日志,端口是 6514。在这种使用方式中,人们常说"通过 syslog 传送."
|
||||
1. **Syslog 信息** — syslog 格式的日志信息或事件,它包括一个带有几个标准域的文件头。在这种使用方式中,人们常说"发送 syslog."
|
||||
1. **Syslog 守护进程** — 一个用来接收、处理和发送 syslog 信息的程序。它可以[远程发送 syslog][2] 到一个集中式的服务器或写入到一个本地文件。常见的例子包括 rsyslogd 和 syslog-ng。在这种使用方式中,人们常说“发送到 syslog”。
|
||||
1. **Syslog 协议** — 一个指定日志如何通过网络来传送的传输协议和一个针对 syslog 信息(具体见下文) 的数据格式的定义。它在 [RFC-5424][3] 中被正式定义。对于文本日志,标准的端口是 514,对于加密日志,端口是 6514。在这种使用方式中,人们常说“通过 syslog 传送”。
|
||||
1. **Syslog 信息** — syslog 格式的日志信息或事件,它包括一个带有几个标准字段的消息头。在这种使用方式中,人们常说“发送 syslog”。
|
||||
|
||||
Syslog 信息或事件包括一个带有几个标准域的 header ,使得分析和路由更方便。它们包括时间戳,应用程序的名称,在系统中信息来源的分类或位置,以及事件的优先级。
|
||||
Syslog 信息或事件包括一个带有几个标准字段的消息头,可以使分析和路由更方便。它们包括时间戳、应用程序的名称、在系统中信息来源的分类或位置、以及事件的优先级。
|
||||
|
||||
下面展示的是一个包含 syslog header 的日志信息,它来自于 sshd 守护进程,它控制着到该系统的远程登录,这个信息描述的是一次失败的登录尝试:
|
||||
下面展示的是一个包含 syslog 消息头的日志信息,它来自于控制着到该系统的远程登录的 sshd 守护进程,这个信息描述的是一次失败的登录尝试:
|
||||
|
||||
<34>1 2003-10-11T22:14:15.003Z server1.com sshd - - pam_unix(sshd:auth): authentication failure; logname= uid=0 euid=0 tty=ssh ruser= rhost=10.0.2.2
|
||||
|
||||
### Syslog 格式和域 ###
|
||||
### Syslog 格式和字段 ###
|
||||
|
||||
每条 syslog 信息包含一个带有域的 header,这些域是结构化的数据,使得分析和路由事件更加容易。下面是我们使用的用来产生上面的 syslog 例子的格式,你可以将每个值匹配到一个特定的域的名称上。
|
||||
每条 syslog 信息包含一个带有字段的信息头,这些字段是结构化的数据,使得分析和路由事件更加容易。下面是我们使用的用来产生上面的 syslog 例子的格式,你可以将每个值匹配到一个特定的字段的名称上。
|
||||
|
||||
<%pri%>%protocol-version% %timestamp:::date-rfc3339% %HOSTNAME% %app-name% %procid% %msgid% %msg%n
|
||||
|
||||
下面,你将看到一些在查找或排错时最常使用的 syslog 域:
|
||||
下面,你将看到一些在查找或排错时最常使用的 syslog 字段:
|
||||
|
||||
#### 时间戳 ####
|
||||
|
||||
[时间戳][4] (上面的例子为 2003-10-11T22:14:15.003Z) 暗示了在系统中发送该信息的时间和日期。这个时间在另一系统上接收该信息时可能会有所不同。上面例子中的时间戳可以分解为:
|
||||
|
||||
- **2003-10-11** 年,月,日.
|
||||
- **T** 为时间戳的必需元素,它将日期和时间分离开.
|
||||
- **22:14:15.003** 是 24 小时制的时间,包括进入下一秒的毫秒数(**003**).
|
||||
- **Z** 是一个可选元素,指的是 UTC 时间,除了 Z,这个例子还可以包括一个偏移量,例如 -08:00,这意味着时间从 UTC 偏移 8 小时,即 PST 时间.
|
||||
- **2003-10-11** 年,月,日。
|
||||
- **T** 为时间戳的必需元素,它将日期和时间分隔开。
|
||||
- **22:14:15.003** 是 24 小时制的时间,包括进入下一秒的毫秒数(**003**)。
|
||||
- **Z** 是一个可选元素,指的是 UTC 时间,除了 Z,这个例子还可以包括一个偏移量,例如 -08:00,这意味着时间从 UTC 偏移 8 小时,即 PST 时间。
|
||||
|
||||
#### 主机名 ####
|
||||
|
||||
[主机名][5] 域(在上面的例子中对应 server1.com) 指的是主机的名称或发送信息的系统.
|
||||
[主机名][5] 字段(在上面的例子中对应 server1.com) 指的是主机的名称或发送信息的系统.
|
||||
|
||||
#### 应用名 ####
|
||||
|
||||
[应用名][6] 域(在上面的例子中对应 sshd:auth) 指的是发送信息的程序的名称.
|
||||
[应用名][6] 字段(在上面的例子中对应 sshd:auth) 指的是发送信息的程序的名称.
|
||||
|
||||
#### 优先级 ####
|
||||
|
||||
优先级域或缩写为 [pri][7] (在上面的例子中对应 <34>) 告诉我们这个事件有多紧急或多严峻。它由两个数字域组成:设备域和紧急性域。紧急性域从代表 debug 类事件的数字 7 一直到代表紧急事件的数字 0 。设备域描述了哪个进程创建了该事件。它从代表内核信息的数字 0 到代表本地应用使用的 23 。
|
||||
优先级字段或缩写为 [pri][7] (在上面的例子中对应 <34>) 告诉我们这个事件有多紧急或多严峻。它由两个数字字段组成:设备字段和紧急性字段。紧急性字段从代表 debug 类事件的数字 7 一直到代表紧急事件的数字 0 。设备字段描述了哪个进程创建了该事件。它从代表内核信息的数字 0 到代表本地应用使用的 23 。
|
||||
|
||||
Pri 有两种输出方式。第一种是以一个单独的数字表示,可以这样计算:先用设备字段的值乘以 8,再加上紧急性字段的值:(设备字段)(8) + (紧急性字段)。第二种是 pri 文本,将以“设备字段.紧急性字段” 的字符串格式输出。后一种格式更方便阅读和搜索,但占据更多的存储空间。
|
||||
|
||||
Pri 有两种输出方式。第一种是以一个单独的数字表示,可以这样计算:先用设备域的值乘以 8,再加上紧急性域的值:(设备域)(8) + (紧急性域)。第二种是 pri 文本,将以“设备域.紧急性域” 的字符串格式输出。后一种格式更方便阅读和搜索,但占据更多的存储空间。
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.loggly.com/ultimate-guide/logging/linux-logging-basics/
|
||||
|
||||
作者:[Jason Skowronski][a1]
|
||||
作者:[Amy Echeverri][a2]
|
||||
作者:[Sadequl Hussain][a3]
|
||||
作者:[Jason Skowronski][a1],[Amy Echeverri][a2],[Sadequl Hussain][a3]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating by xiaoyu33
|
||||
|
||||
Tickr Is An Open-Source RSS News Ticker for Linux Desktops
|
||||
================================================================================
|
||||

|
||||
@ -92,4 +94,4 @@ via: http://www.omgubuntu.co.uk/2015/06/tickr-open-source-desktop-rss-news-ticke
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:apt://tickr
|
||||
[1]:apt://tickr
|
||||
|
||||
@ -1,349 +0,0 @@
|
||||
translating wi-cuckoo
|
||||
Shilpa Nair Shares Her Interview Experience on RedHat Linux Package Management
|
||||
================================================================================
|
||||
**Shilpa Nair has just graduated in the year 2015. She went to apply for Trainee position in a National News Television located in Noida, Delhi. When she was in the last year of graduation and searching for help on her assignments she came across Tecmint. Since then she has been visiting Tecmint regularly.**
|
||||
|
||||

|
||||
|
||||
Linux Interview Questions on RPM
|
||||
|
||||
All the questions and answers are rewritten based upon the memory of Shilpa Nair.
|
||||
|
||||
> “Hi friends! I am Shilpa Nair from Delhi. I have completed my graduation very recently and was hunting for a Trainee role soon after my degree. I have developed a passion for UNIX since my early days in the collage and I was looking for a role that suits me and satisfies my soul. I was asked a lots of questions and most of them were basic questions related to RedHat Package Management.”
|
||||
|
||||
Here are the questions, that I was asked and their corresponding answers. I am posting only those questions that are related to RedHat GNU/Linux Package Management, as they were mainly asked.
|
||||
|
||||
### 1. How will you find if a package is installed or not? Say you have to find if ‘nano’ is installed or not, what will you do? ###
|
||||
|
||||
> **Answer** : To find the package nano, weather installed or not, we can use rpm command with the option -q is for query and -a stands for all the installed packages.
|
||||
>
|
||||
> # rpm -qa nano
|
||||
> OR
|
||||
> # rpm -qa | grep -i nano
|
||||
>
|
||||
> nano-2.3.1-10.el7.x86_64
|
||||
>
|
||||
> Also the package name must be complete, an incomplete package name will return the prompt without printing anything which means that package (incomplete package name) is not installed. It can be understood easily by the example below:
|
||||
>
|
||||
> We generally substitute vim command with vi. But if we find package vi/vim we will get no result on the standard output.
|
||||
>
|
||||
> # vi
|
||||
> # vim
|
||||
>
|
||||
> However we can clearly see that the package is installed by firing vi/vim command. Here is culprit is incomplete file name. If we are not sure of the exact file-name we can use wildcard as:
|
||||
>
|
||||
> # rpm -qa vim*
|
||||
>
|
||||
> vim-minimal-7.4.160-1.el7.x86_64
|
||||
>
|
||||
> This way we can find information about any package, if installed or not.
|
||||
|
||||
### 2. How will you install a package XYZ using rpm? ###
|
||||
|
||||
> **Answer** : We can install any package (*.rpm) using rpm command a shown below, here options -i (install), -v (verbose or display additional information) and -h (print hash mark during package installation).
|
||||
>
|
||||
> # rpm -ivh peazip-1.11-1.el6.rf.x86_64.rpm
|
||||
>
|
||||
> Preparing... ################################# [100%]
|
||||
> Updating / installing...
|
||||
> 1:peazip-1.11-1.el6.rf ################################# [100%]
|
||||
>
|
||||
> If upgrading a package from earlier version -U switch should be used, option -v and -h follows to make sure we get a verbose output along with hash Mark, that makes it readable.
|
||||
|
||||
### 3. You have installed a package (say httpd) and now you want to see all the files and directories installed and created by the above package. What will you do? ###
|
||||
|
||||
> **Answer** : We can list all the files (Linux treat everything as file including directories) installed by the package httpd using options -l (List all the files) and -q (is for query).
|
||||
>
|
||||
> # rpm -ql httpd
|
||||
>
|
||||
> /etc/httpd
|
||||
> /etc/httpd/conf
|
||||
> /etc/httpd/conf.d
|
||||
> ...
|
||||
|
||||
### 4. You are supposed to remove a package say postfix. What will you do? ###
|
||||
|
||||
> **Answer** : First we need to know postfix was installed by what package. Find the package name that installed postfix using options -e erase/uninstall a package) and –v (verbose output).
|
||||
>
|
||||
> # rpm -qa postfix*
|
||||
>
|
||||
> postfix-2.10.1-6.el7.x86_64
|
||||
>
|
||||
> and then remove postfix as:
|
||||
>
|
||||
> # rpm -ev postfix-2.10.1-6.el7.x86_64
|
||||
>
|
||||
> Preparing packages...
|
||||
> postfix-2:3.0.1-2.fc22.x86_64
|
||||
|
||||
### 5. Get detailed information about an installed package, means information like Version, Release, Install Date, Size, Summary and a brief description. ###
|
||||
|
||||
> **Answer** : We can get detailed information about an installed package by using option -qa with rpm followed by package name.
|
||||
>
|
||||
> For example to find details of package openssh, all I need to do is:
|
||||
>
|
||||
> # rpm -qi openssh
|
||||
>
|
||||
> [root@tecmint tecmint]# rpm -qi openssh
|
||||
> Name : openssh
|
||||
> Version : 6.8p1
|
||||
> Release : 5.fc22
|
||||
> Architecture: x86_64
|
||||
> Install Date: Thursday 28 May 2015 12:34:50 PM IST
|
||||
> Group : Applications/Internet
|
||||
> Size : 1542057
|
||||
> License : BSD
|
||||
> ....
|
||||
|
||||
### 6. You are not sure about what are the configuration files provided by a specific package say httpd. How will you find list of all the configuration files provided by httpd and their location. ###
|
||||
|
||||
> **Answer** : We need to run option -c followed by package name with rpm command and it will list the name of all the configuration file and their location.
|
||||
>
|
||||
> # rpm -qc httpd
|
||||
>
|
||||
> /etc/httpd/conf.d/autoindex.conf
|
||||
> /etc/httpd/conf.d/userdir.conf
|
||||
> /etc/httpd/conf.d/welcome.conf
|
||||
> /etc/httpd/conf.modules.d/00-base.conf
|
||||
> /etc/httpd/conf/httpd.conf
|
||||
> /etc/sysconfig/httpd
|
||||
>
|
||||
> Similarly we can list all the associated document files as:
|
||||
>
|
||||
> # rpm -qd httpd
|
||||
>
|
||||
> /usr/share/doc/httpd/ABOUT_APACHE
|
||||
> /usr/share/doc/httpd/CHANGES
|
||||
> /usr/share/doc/httpd/LICENSE
|
||||
> ...
|
||||
>
|
||||
> also, we can list the associated License file as:
|
||||
>
|
||||
> # rpm -qL openssh
|
||||
>
|
||||
> /usr/share/licenses/openssh/LICENCE
|
||||
>
|
||||
> Not to mention that the option -d and option -L in the above command stands for ‘documents‘ and ‘License‘, respectively.
|
||||
|
||||
### 7. You came across a configuration file located at ‘/usr/share/alsa/cards/AACI.conf’ and you are not sure this configuration file is associated with what package. How will you find out the parent package name? ###
|
||||
|
||||
> **Answer** : When a package is installed, the relevant information gets stored in the database. So it is easy to trace what provides the above package using option -qf (-f query packages owning files).
|
||||
>
|
||||
> # rpm -qf /usr/share/alsa/cards/AACI.conf
|
||||
> alsa-lib-1.0.28-2.el7.x86_64
|
||||
>
|
||||
> Similarly we can find (what provides) information about any sub-packge, document files and License files.
|
||||
|
||||
### 8. How will you find list of recently installed software’s using rpm? ###
|
||||
|
||||
> **Answer** : As said earlier, everything being installed is logged in database. So it is not difficult to query the rpm database and find the list of recently installed software’s.
|
||||
>
|
||||
> We can do this by running the below commands using option –last (prints the most recent installed software’s).
|
||||
>
|
||||
> # rpm -qa --last
|
||||
>
|
||||
> The above command will print all the packages installed in a order such that, the last installed software appears at the top.
|
||||
>
|
||||
> If our concern is to find out specific package, we can grep that package (say sqlite) from the list, simply as:
|
||||
>
|
||||
> # rpm -qa --last | grep -i sqlite
|
||||
>
|
||||
> sqlite-3.8.10.2-1.fc22.x86_64 Thursday 18 June 2015 05:05:43 PM IST
|
||||
>
|
||||
> We can also get a list of 10 most recently installed software simply as:
|
||||
>
|
||||
> # rpm -qa --last | head
|
||||
>
|
||||
> We can refine the result to output a more custom result simply as:
|
||||
>
|
||||
> # rpm -qa --last | head -n 2
|
||||
>
|
||||
> In the above command -n represents number followed by a numeric value. The above command prints a list of 2 most recent installed software.
|
||||
|
||||
### 9. Before installing a package, you are supposed to check its dependencies. What will you do? ###
|
||||
|
||||
> **Answer** : To check the dependencies of a rpm package (XYZ.rpm), we can use switches -q (query package), -p (query a package file) and -R (Requires / List packages on which this package depends i.e., dependencies).
|
||||
>
|
||||
> # rpm -qpR gedit-3.16.1-1.fc22.i686.rpm
|
||||
>
|
||||
> /bin/sh
|
||||
> /usr/bin/env
|
||||
> glib2(x86-32) >= 2.40.0
|
||||
> gsettings-desktop-schemas
|
||||
> gtk3(x86-32) >= 3.16
|
||||
> gtksourceview3(x86-32) >= 3.16
|
||||
> gvfs
|
||||
> libX11.so.6
|
||||
> ...
|
||||
|
||||
### 10. Is rpm a front-end Package Management Tool? ###
|
||||
|
||||
> **Answer** : No! rpm is a back-end package management for RPM based Linux Distribution.
|
||||
>
|
||||
> [YUM][1] which stands for Yellowdog Updater Modified is the front-end for rpm. YUM automates the overall process of resolving dependencies and everything else.
|
||||
>
|
||||
> Very recently [DNF][2] (Dandified YUM) replaced YUM in Fedora 22. Though YUM is still available to be used in RHEL and CentOS, we can install dnf and use it alongside of YUM. DNF is said to have a lots of improvement over YUM.
|
||||
>
|
||||
> Good to know, you keep yourself updated. Lets move to the front-end part.
|
||||
|
||||
### 11. How will you list all the enabled repolist on a system. ###
|
||||
|
||||
> **Answer** : We can list all the enabled repos on a system simply using following commands.
|
||||
>
|
||||
> # yum repolist
|
||||
> or
|
||||
> # dnf repolist
|
||||
>
|
||||
> Last metadata expiration check performed 0:30:03 ago on Mon Jun 22 16:50:00 2015.
|
||||
> repo id repo name status
|
||||
> *fedora Fedora 22 - x86_64 44,762
|
||||
> ozonos Repository for Ozon OS 61
|
||||
> *updates Fedora 22 - x86_64 - Updates
|
||||
>
|
||||
> The above command will only list those repos that are enabled. If we need to list all the repos, enabled or not, we can do.
|
||||
>
|
||||
> # yum repolist all
|
||||
> or
|
||||
> # dnf repolist all
|
||||
>
|
||||
> Last metadata expiration check performed 0:29:45 ago on Mon Jun 22 16:50:00 2015.
|
||||
> repo id repo name status
|
||||
> *fedora Fedora 22 - x86_64 enabled: 44,762
|
||||
> fedora-debuginfo Fedora 22 - x86_64 - Debug disabled
|
||||
> fedora-source Fedora 22 - Source disabled
|
||||
> ozonos Repository for Ozon OS enabled: 61
|
||||
> *updates Fedora 22 - x86_64 - Updates enabled: 5,018
|
||||
> updates-debuginfo Fedora 22 - x86_64 - Updates - Debug
|
||||
|
||||
### 12. How will you list all the available and installed packages on a system? ###
|
||||
|
||||
> **Answer** : To list all the available packages on a system, we can do:
|
||||
>
|
||||
> # yum list available
|
||||
> or
|
||||
> # dnf list available
|
||||
>
|
||||
> ast metadata expiration check performed 0:34:09 ago on Mon Jun 22 16:50:00 2015.
|
||||
> Available Packages
|
||||
> 0ad.x86_64 0.0.18-1.fc22 fedora
|
||||
> 0ad-data.noarch 0.0.18-1.fc22 fedora
|
||||
> 0install.x86_64 2.6.1-2.fc21 fedora
|
||||
> 0xFFFF.x86_64 0.3.9-11.fc22 fedora
|
||||
> 2048-cli.x86_64 0.9-4.git20141214.723738c.fc22 fedora
|
||||
> 2048-cli-nocurses.x86_64 0.9-4.git20141214.723738c.fc22 fedora
|
||||
> ....
|
||||
>
|
||||
> To list all the installed Packages on a system, we can do.
|
||||
>
|
||||
> # yum list installed
|
||||
> or
|
||||
> # dnf list installed
|
||||
>
|
||||
> Last metadata expiration check performed 0:34:30 ago on Mon Jun 22 16:50:00 2015.
|
||||
> Installed Packages
|
||||
> GeoIP.x86_64 1.6.5-1.fc22 @System
|
||||
> GeoIP-GeoLite-data.noarch 2015.05-1.fc22 @System
|
||||
> NetworkManager.x86_64 1:1.0.2-1.fc22 @System
|
||||
> NetworkManager-libnm.x86_64 1:1.0.2-1.fc22 @System
|
||||
> aajohan-comfortaa-fonts.noarch 2.004-4.fc22 @System
|
||||
> ....
|
||||
>
|
||||
> To list all the available and installed packages on a system, we can do.
|
||||
>
|
||||
> # yum list
|
||||
> or
|
||||
> # dnf list
|
||||
>
|
||||
> Last metadata expiration check performed 0:32:56 ago on Mon Jun 22 16:50:00 2015.
|
||||
> Installed Packages
|
||||
> GeoIP.x86_64 1.6.5-1.fc22 @System
|
||||
> GeoIP-GeoLite-data.noarch 2015.05-1.fc22 @System
|
||||
> NetworkManager.x86_64 1:1.0.2-1.fc22 @System
|
||||
> NetworkManager-libnm.x86_64 1:1.0.2-1.fc22 @System
|
||||
> aajohan-comfortaa-fonts.noarch 2.004-4.fc22 @System
|
||||
> acl.x86_64 2.2.52-7.fc22 @System
|
||||
> ....
|
||||
|
||||
### 13. How will you install and update a package and a group of packages separately on a system using YUM/DNF? ###
|
||||
|
||||
> Answer : To Install a package (say nano), we can do,
|
||||
>
|
||||
> # yum install nano
|
||||
>
|
||||
> To Install a Group of Package (say Haskell), we can do.
|
||||
>
|
||||
> # yum groupinstall 'haskell'
|
||||
>
|
||||
> To update a package (say nano), we can do.
|
||||
>
|
||||
> # yum update nano
|
||||
>
|
||||
> To update a Group of Package (say Haskell), we can do.
|
||||
>
|
||||
> # yum groupupdate 'haskell'
|
||||
|
||||
### 14. How will you SYNC all the installed packages on a system to stable release? ###
|
||||
|
||||
> **Answer** : We can sync all the packages on a system (say CentOS or Fedora) to stable release as,
|
||||
>
|
||||
> # yum distro-sync [On CentOS/RHEL]
|
||||
> or
|
||||
> # dnf distro-sync [On Fedora 20 Onwards]
|
||||
|
||||
Seems you have done a good homework before coming for the interview,Good!. Before proceeding further I just want to ask one more question.
|
||||
|
||||
### 15. Are you familiar with YUM local repository? Have you tried making a Local YUM repository? Let me know in brief what you will do to create a local YUM repo. ###
|
||||
|
||||
> **Answer** : First I would like to Thank you Sir for appreciation. Coming to question, I must admit that I am quiet familiar with Local YUM repositories and I have already implemented it for testing purpose in my local machine.
|
||||
>
|
||||
> 1. To set up Local YUM repository, we need to install the below three packages as:
|
||||
>
|
||||
> # yum install deltarpm python-deltarpm createrepo
|
||||
>
|
||||
> 2. Create a directory (say /home/$USER/rpm) and copy all the RPMs from RedHat/CentOS DVD to that folder.
|
||||
>
|
||||
> # mkdir /home/$USER/rpm
|
||||
> # cp /path/to/rpm/on/DVD/*.rpm /home/$USER/rpm
|
||||
>
|
||||
> 3. Create base repository headers as.
|
||||
>
|
||||
> # createrepo -v /home/$USER/rpm
|
||||
>
|
||||
> 4. Create the .repo file (say abc.repo) at the location /etc/yum.repos.d simply as:
|
||||
>
|
||||
> cd /etc/yum.repos.d && cat << EOF > abc.repo
|
||||
> [local-installation]name=yum-local
|
||||
> baseurl=file:///home/$USER/rpm
|
||||
> enabled=1
|
||||
> gpgcheck=0
|
||||
> EOF
|
||||
|
||||
**Important**: Make sure to remove $USER with user_name.
|
||||
|
||||
That’s all we need to do to create a Local YUM repository. We can now install applications from here, that is relatively fast, secure and most important don’t need an Internet connection.
|
||||
|
||||
Okay! It was nice interviewing you. I am done. I am going to suggest your name to HR. You are a young and brilliant candidate we would like to have in our organization. If you have any question you may ask me.
|
||||
|
||||
**Me**: Sir, it was really a very nice interview and I feel very lucky today, to have cracked the interview..
|
||||
|
||||
Obviously it didn’t end here. I asked a lots of questions like the project they are handling. What would be my role and responsibility and blah..blah..blah
|
||||
|
||||
Friends, by the time all these were documented I have been called for HR round which is 3 days from now. Hope I do my best there as well. All your blessings will count.
|
||||
|
||||
Thankyou friends and Tecmint for taking time and documenting my experience. Mates I believe Tecmint is doing some really extra-ordinary which must be praised. When we share ours experience with other, other get to know many things from us and we get to know our mistakes.
|
||||
|
||||
It enhances our confidence level. If you have given any such interview recently, don’t keep it to yourself. Spread it! Let all of us know that. You may use the below form to share your experience with us.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-rpm-package-management-interview-questions/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
|
||||
[2]:http://www.tecmint.com/dnf-commands-for-fedora-rpm-package-management/
|
||||
@ -1,151 +0,0 @@
|
||||
translation by strugglingyouth
|
||||
How to monitor NGINX with Datadog - Part 3
|
||||
================================================================================
|
||||

|
||||
|
||||
If you’ve already read [our post on monitoring NGINX][1], you know how much information you can gain about your web environment from just a handful of metrics. And you’ve also seen just how easy it is to start collecting metrics from NGINX on ad hoc basis. But to implement comprehensive, ongoing NGINX monitoring, you will need a robust monitoring system to store and visualize your metrics, and to alert you when anomalies happen. In this post, we’ll show you how to set up NGINX monitoring in Datadog so that you can view your metrics on customizable dashboards like this:
|
||||
|
||||

|
||||
|
||||
Datadog allows you to build graphs and alerts around individual hosts, services, processes, metrics—or virtually any combination thereof. For instance, you can monitor all of your NGINX hosts, or all hosts in a certain availability zone, or you can monitor a single key metric being reported by all hosts with a certain tag. This post will show you how to:
|
||||
|
||||
- Monitor NGINX metrics on Datadog dashboards, alongside all your other systems
|
||||
- Set up automated alerts to notify you when a key metric changes dramatically
|
||||
|
||||
### Configuring NGINX ###
|
||||
|
||||
To collect metrics from NGINX, you first need to ensure that NGINX has an enabled status module and a URL for reporting its status metrics. Step-by-step instructions [for configuring open-source NGINX][2] and [NGINX Plus][3] are available in our companion post on metric collection.
|
||||
|
||||
### Integrating Datadog and NGINX ###
|
||||
|
||||
#### Install the Datadog Agent ####
|
||||
|
||||
The Datadog Agent is [the open-source software][4] that collects and reports metrics from your hosts so that you can view and monitor them in Datadog. Installing the agent usually takes [just a single command][5].
|
||||
|
||||
As soon as your Agent is up and running, you should see your host reporting metrics [in your Datadog account][6].
|
||||
|
||||

|
||||
|
||||
#### Configure the Agent ####
|
||||
|
||||
Next you’ll need to create a simple NGINX configuration file for the Agent. The location of the Agent’s configuration directory for your OS can be found [here][7].
|
||||
|
||||
Inside that directory, at conf.d/nginx.yaml.example, you will find [a sample NGINX config file][8] that you can edit to provide the status URL and optional tags for each of your NGINX instances:
|
||||
|
||||
init_config:
|
||||
|
||||
instances:
|
||||
|
||||
- nginx_status_url: http://localhost/nginx_status/
|
||||
tags:
|
||||
- instance:foo
|
||||
|
||||
Once you have supplied the status URLs and any tags, save the config file as conf.d/nginx.yaml.
|
||||
|
||||
#### Restart the Agent ####
|
||||
|
||||
You must restart the Agent to load your new configuration file. The restart command varies somewhat by platform—see the specific commands for your platform [here][9].
|
||||
|
||||
#### Verify the configuration settings ####
|
||||
|
||||
To check that Datadog and NGINX are properly integrated, run the Datadog info command. The command for each platform is available [here][10].
|
||||
|
||||
If the configuration is correct, you will see a section like this in the output:
|
||||
|
||||
Checks
|
||||
======
|
||||
|
||||
[...]
|
||||
|
||||
nginx
|
||||
-----
|
||||
- instance #0 [OK]
|
||||
- Collected 8 metrics & 0 events
|
||||
|
||||
#### Install the integration ####
|
||||
|
||||
Finally, switch on the NGINX integration inside your Datadog account. It’s as simple as clicking the “Install Integration” button under the Configuration tab in the [NGINX integration settings][11].
|
||||
|
||||

|
||||
|
||||
### Metrics! ###
|
||||
|
||||
Once the Agent begins reporting NGINX metrics, you will see [an NGINX dashboard][12] among your list of available dashboards in Datadog.
|
||||
|
||||
The basic NGINX dashboard displays a handful of graphs encapsulating most of the key metrics highlighted [in our introduction to NGINX monitoring][13]. (Some metrics, notably request processing time, require log analysis and are not available in Datadog.)
|
||||
|
||||
You can easily create a comprehensive dashboard for monitoring your entire web stack by adding additional graphs with important metrics from outside NGINX. For example, you might want to monitor host-level metrics on your NGINX hosts, such as system load. To start building a custom dashboard, simply clone the default NGINX dashboard by clicking on the gear near the upper right of the dashboard and selecting “Clone Dash”.
|
||||
|
||||

|
||||
|
||||
You can also monitor your NGINX instances at a higher level using Datadog’s [Host Maps][14]—for instance, color-coding all your NGINX hosts by CPU usage to identify potential hotspots.
|
||||
|
||||

|
||||
|
||||
### Alerting on NGINX metrics ###
|
||||
|
||||
Once Datadog is capturing and visualizing your metrics, you will likely want to set up some monitors to automatically keep tabs on your metrics—and to alert you when there are problems. Below we’ll walk through a representative example: a metric monitor that alerts on sudden drops in NGINX throughput.
|
||||
|
||||
#### Monitor your NGINX throughput ####
|
||||
|
||||
Datadog metric alerts can be threshold-based (alert when the metric exceeds a set value) or change-based (alert when the metric changes by a certain amount). In this case we’ll take the latter approach, alerting when our incoming requests per second drop precipitously. Such drops are often indicative of problems.
|
||||
|
||||
1.**Create a new metric monitor**. Select “New Monitor” from the “Monitors” dropdown in Datadog. Select “Metric” as the monitor type.
|
||||
|
||||

|
||||
|
||||
2.**Define your metric monitor**. We want to know when our total NGINX requests per second drop by a certain amount. So we define the metric of interest to be the sum of nginx.net.request_per_s across our infrastructure.
|
||||
|
||||

|
||||
|
||||
3.**Set metric alert conditions**. Since we want to alert on a change, rather than on a fixed threshold, we select “Change Alert.” We’ll set the monitor to alert us whenever the request volume drops by 30 percent or more. Here we use a one-minute window of data to represent the metric’s value “now” and alert on the average change across that interval, as compared to the metric’s value 10 minutes prior.
|
||||
|
||||

|
||||
|
||||
4.**Customize the notification**. If our NGINX request volume drops, we want to notify our team. In this case we will post a notification in the ops team’s chat room and page the engineer on call. In “Say what’s happening”, we name the monitor and add a short message that will accompany the notification to suggest a first step for investigation. We @mention the Slack channel that we use for ops and use @pagerduty to [route the alert to PagerDuty][15]
|
||||
|
||||

|
||||
|
||||
5.**Save the integration monitor**. Click the “Save” button at the bottom of the page. You’re now monitoring a key NGINX [work metric][16], and your on-call engineer will be paged anytime it drops rapidly.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
In this post we’ve walked you through integrating NGINX with Datadog to visualize your key metrics and notify your team when your web infrastructure shows signs of trouble.
|
||||
|
||||
If you’ve followed along using your own Datadog account, you should now have greatly improved visibility into what’s happening in your web environment, as well as the ability to create automated monitors tailored to your environment, your usage patterns, and the metrics that are most valuable to your organization.
|
||||
|
||||
If you don’t yet have a Datadog account, you can sign up for [a free trial][17] and start monitoring your infrastructure, your applications, and your services today.
|
||||
|
||||
----------
|
||||
|
||||
Source Markdown for this post is available [on GitHub][18]. Questions, corrections, additions, etc.? Please [let us know][19].
|
||||
|
||||
------------------------------------------------------------
|
||||
|
||||
via: https://www.datadoghq.com/blog/how-to-monitor-nginx-with-datadog/
|
||||
|
||||
作者:K Young
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://www.datadoghq.com/blog/how-to-monitor-nginx/
|
||||
[2]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#open-source
|
||||
[3]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#plus
|
||||
[4]:https://github.com/DataDog/dd-agent
|
||||
[5]:https://app.datadoghq.com/account/settings#agent
|
||||
[6]:https://app.datadoghq.com/infrastructure
|
||||
[7]:http://docs.datadoghq.com/guides/basic_agent_usage/
|
||||
[8]:https://github.com/DataDog/dd-agent/blob/master/conf.d/nginx.yaml.example
|
||||
[9]:http://docs.datadoghq.com/guides/basic_agent_usage/
|
||||
[10]:http://docs.datadoghq.com/guides/basic_agent_usage/
|
||||
[11]:https://app.datadoghq.com/account/settings#integrations/nginx
|
||||
[12]:https://app.datadoghq.com/dash/integration/nginx
|
||||
[13]:https://www.datadoghq.com/blog/how-to-monitor-nginx/
|
||||
[14]:https://www.datadoghq.com/blog/introducing-host-maps-know-thy-infrastructure/
|
||||
[15]:https://www.datadoghq.com/blog/pagerduty/
|
||||
[16]:https://www.datadoghq.com/blog/monitoring-101-collecting-data/#metrics
|
||||
[17]:https://www.datadoghq.com/blog/how-to-monitor-nginx-with-datadog/#sign-up
|
||||
[18]:https://github.com/DataDog/the-monitor/blob/master/nginx/how_to_monitor_nginx_with_datadog.md
|
||||
[19]:https://github.com/DataDog/the-monitor/issues
|
||||
@ -1,62 +0,0 @@
|
||||
Darkstat is a Web Based Network Traffic Analyzer – Install it on Linux
|
||||
================================================================================
|
||||
Darkstat is a simple, web based network traffic analyzer application. It works on many popular operating systems like Linux, Solaris, Mac and AIX. It keeps running in the background as a daemon and continues collecting and sniffing network data and presents it in easily understandable format within its web interface. It can generate traffic reports for hosts, identify which ports are open on some particular host and is IPV 6 complaint application. Let’s see how we can install and configure it on Linux operating system.
|
||||
|
||||
### Installing Darkstat on Linux ###
|
||||
|
||||
**Install Darkstat on Fedora/CentOS/RHEL:**
|
||||
|
||||
In order to install it on Fedora/RHEL and CentOS Linux distributions, run following command on the terminal.
|
||||
|
||||
sudo yum install darkstat
|
||||
|
||||
**Install Darkstat on Ubuntu/Debian:**
|
||||
|
||||
Run following on the terminal to install it on Ubuntu and Debian.
|
||||
|
||||
sudo apt-get install darkstat
|
||||
|
||||
Congratulations, Darkstat has been installed on your Linux system now.
|
||||
|
||||
### Configuring Darkstat ###
|
||||
|
||||
In order to run this application properly, we need to perform some basic configurations. Edit /etc/darkstat/init.cfg file in Gedit text editor by running the following command on the terminal.
|
||||
|
||||
sudo gedit /etc/darkstat/init.cfg
|
||||
|
||||

|
||||
Edit Darkstat
|
||||
|
||||
Change START_DARKSTAT parameter to “yes” and provide your network interface in “INTERFACE”. Make sure to uncomment DIR, PORT, BINDIP, and LOCAL parameters here. If you wish to bind the web interface for Darkstat to some specific IP, provide it in BINDIP section.
|
||||
|
||||
### Starting Darkstat Daemon ###
|
||||
|
||||
Once the installation and configuration for Darkstat is complete, run following command to start its daemon.
|
||||
|
||||
sudo /etc/init.d/darkstat start
|
||||
|
||||

|
||||
|
||||
You can configure Darkstat to start on system boot by running the following command:
|
||||
|
||||
chkconfig darkstat on
|
||||
|
||||
Launch your browser and load **http://localhost:666** and it will display the web based graphical interface for Darkstat. Start using this tool to analyze your network traffic.
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
It is a lightweight tool with very low memory footprints. The key reason for the popularity of this tool is simplicity, ease of configuration and usage. It is a must-have application for System and Network Administrators.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxpitstop.com/install-darkstat-on-ubuntu-linux/
|
||||
|
||||
作者:[Aun][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxpitstop.com/author/aun/
|
||||
@ -1,101 +0,0 @@
|
||||
FSSlc translating
|
||||
|
||||
How to download apk files from Google Play Store on Linux
|
||||
================================================================================
|
||||
Suppose you want to install an Android app on your Android device. However, for whatever reason, you cannot access Google Play Store on the Android device. What can you do then? One way to install the app without Google Play Store access is to download its APK file using some other means, and then [install the APK][1] file on the Android device manually.
|
||||
|
||||
There are several ways to download official APK files from Google Play Store on non-Android devices such as regular computers and laptops. For example, there are browser plugins (e.g., for [Chrome][2] or [Firefox][3]) or online APK archives that allow you to download APK files using a web browser. If you do not trust these closed-source plugins or third-party APK repositories, there is yet another way to download official APK files manually, and that is via an open-source Linux app called [GooglePlayDownloader][4].
|
||||
|
||||
GooglePlayDownloader is a Python-based GUI application that enables you to search and download APK files from Google Play Store. Since this is completely open-source, you can be assured while using it. In this tutorial, I am going to show how to download an APK file from Google Play Store using GooglePlayDownloader in Linux environment.
|
||||
|
||||
### Python requirement ###
|
||||
|
||||
GooglePlayDownloader requires Python with SNI (Server Name Indication) support for SSL/TLS communication. This feature comes with Python 2.7.9 or higher. This leaves out older distributions such as Debian 7 Wheezy or earlier, Ubuntu 14.04 or earlier, or CentOS/RHEL 7 or earlier. Assuming that you have a Linux distribution with Python 2.7.9 or higher, proceed to install GooglePlayDownloader as follows.
|
||||
|
||||
### Install GooglePlayDownloader on Ubuntu ###
|
||||
|
||||
On Ubuntu, you can use the official deb build. One catch is that you may need to install one required dependency manually.
|
||||
|
||||
#### On Ubuntu 14.10 ####
|
||||
|
||||
Download [python-ndg-httpsclient][5] deb package, which is a missing dependency on older Ubuntu distributions. Also download GooglePlayDownloader's official deb package.
|
||||
|
||||
$ wget http://mirrors.kernel.org/ubuntu/pool/main/n/ndg-httpsclient/python-ndg-httpsclient_0.3.2-1ubuntu4_all.deb
|
||||
$ wget http://codingteam.net/project/googleplaydownloader/download/file/googleplaydownloader_1.7-1_all.deb
|
||||
|
||||
We are going to use [gdebi command][6] to install those two deb files as follows. The gdebi command will automatically handle any other dependencies.
|
||||
|
||||
$ sudo apt-get install gdebi-core
|
||||
$ sudo gdebi python-ndg-httpsclient_0.3.2-1ubuntu4_all.deb
|
||||
$ sudo gdebi googleplaydownloader_1.7-1_all.deb
|
||||
|
||||
#### On Ubuntu 15.04 or later ####
|
||||
|
||||
Recent Ubuntu distributions ship all required dependencies, and thus the installation is straightforward as follows.
|
||||
|
||||
$ wget http://codingteam.net/project/googleplaydownloader/download/file/googleplaydownloader_1.7-1_all.deb
|
||||
$ sudo apt-get install gdebi-core
|
||||
$ sudo gdebi googleplaydownloader_1.7-1_all.deb
|
||||
|
||||
### Install GooglePlayDownloader on Debian ###
|
||||
|
||||
Due to its Python requirement, GooglePlayDownloader cannot be installed on Debian 7 Wheezy or earlier unless you upgrade its stock Python.
|
||||
|
||||
#### On Debian 8 Jessie and higher: ####
|
||||
|
||||
$ wget http://codingteam.net/project/googleplaydownloader/download/file/googleplaydownloader_1.7-1_all.deb
|
||||
$ sudo apt-get install gdebi-core
|
||||
$ sudo gdebi googleplaydownloader_1.7-1_all.deb
|
||||
|
||||
### Install GooglePlayDownloader on Fedora ###
|
||||
|
||||
Since GooglePlayDownloader was originally developed for Debian based distributions, you need to install it from the source if you want to use it on Fedora.
|
||||
|
||||
First, install necessary dependencies.
|
||||
|
||||
$ sudo yum install python-pyasn1 wxPython python-ndg_httpsclient protobuf-python python-requests
|
||||
|
||||
Then install it as follows.
|
||||
|
||||
$ wget http://codingteam.net/project/googleplaydownloader/download/file/googleplaydownloader_1.7.orig.tar.gz
|
||||
$ tar -xvf googleplaydownloader_1.7.orig.tar.gz
|
||||
$ cd googleplaydownloader-1.7
|
||||
$ chmod o+r -R .
|
||||
$ sudo python setup.py install
|
||||
$ sudo sh -c "echo 'python /usr/lib/python2.7/site-packages/googleplaydownloader-1.7-py2.7.egg/googleplaydownloader/googleplaydownloader.py' > /usr/bin/googleplaydownloader"
|
||||
|
||||
### Download APK Files from Google Play Store with GooglePlayDownloader ###
|
||||
|
||||
Once you installed GooglePlayDownloader, you can download APK files from Google Play Store as follows.
|
||||
|
||||
First launch the app by typing:
|
||||
|
||||
$ googleplaydownloader
|
||||
|
||||

|
||||
|
||||
At the search bar, type the name of the app you want to download from Google Play Store.
|
||||
|
||||
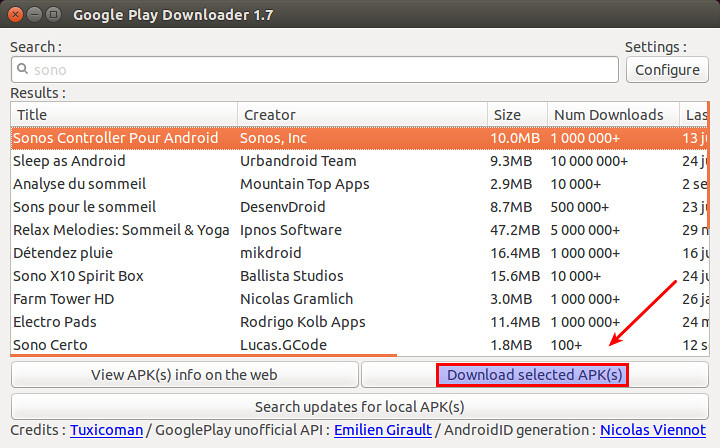
|
||||
|
||||
Once you find the app in the search list, choose the app, and click on "Download selected APK(s)" button. You will find the downloaded APK file in your home directory. Now you can move the APK file to the Android device of your choice, and install it manually.
|
||||
|
||||
Hope this helps.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/download-apk-files-google-play-store.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/how-to-install-apk-file-on-android-phone-or-tablet.html
|
||||
[2]:https://chrome.google.com/webstore/detail/apk-downloader/cgihflhdpokeobcfimliamffejfnmfii
|
||||
[3]:https://addons.mozilla.org/en-us/firefox/addon/apk-downloader/
|
||||
[4]:http://codingteam.net/project/googleplaydownloader
|
||||
[5]:http://packages.ubuntu.com/vivid/python-ndg-httpsclient
|
||||
[6]:http://xmodulo.com/how-to-install-deb-file-with-dependencies.html
|
||||
@ -0,0 +1,143 @@
|
||||
Linux Tricks: Play Game in Chrome, Text-to-Speech, Schedule a Job and Watch Commands in Linux
|
||||
================================================================================
|
||||
Here again, I have compiled a list of four things under [Linux Tips and Tricks][1] series you may do to remain more productive and entertained with Linux Environment.
|
||||
|
||||

|
||||
|
||||
Linux Tips and Tricks Series
|
||||
|
||||
The topics I have covered includes Google-chrome inbuilt small game, Text-to-speech in Linux Terminal, Quick job scheduling using ‘at‘ command and watch a command at regular interval.
|
||||
|
||||
### 1. Play A Game in Google Chrome Browser ###
|
||||
|
||||
Very often when there is a power shedding or no network due to some other reason, I don’t put my Linux box into maintenance mode. I keep myself engage in a little fun game by Google Chrome. I am not a gamer and hence I have not installed third-party creepy games. Security is another concern.
|
||||
|
||||
So when there is Internet related issue and my web page seems something like this:
|
||||
|
||||

|
||||
|
||||
Unable to Connect Internet
|
||||
|
||||
You may play the Google-chrome inbuilt game simply by hitting the space-bar. There is no limitation for the number of times you can play. The best thing is you need not break a sweat installing and using it.
|
||||
|
||||
No third-party application/plugin required. It should work well on other platforms like Windows and Mac but our niche is Linux and I’ll talk about Linux only and mind it, it works well on Linux. It is a very simple game (a kind of time pass).
|
||||
|
||||
Use Space-Bar/Navigation-up-key to jump. A glimpse of the game in action.
|
||||
|
||||

|
||||
|
||||
Play Game in Google Chrome
|
||||
|
||||
### 2. Text to Speech in Linux Terminal ###
|
||||
|
||||
For those who may not be aware of espeak utility, It is a Linux command-line text to speech converter. Write anything in a variety of languages and espeak utility will read it loud for you.
|
||||
|
||||
Espeak should be installed in your system by default, however it is not installed for your system, you may do:
|
||||
|
||||
# apt-get install espeak (Debian)
|
||||
# yum install espeak (CentOS)
|
||||
# dnf install espeak (Fedora 22 onwards)
|
||||
|
||||
You may ask espeak to accept Input Interactively from standard Input device and convert it to speech for you. You may do:
|
||||
|
||||
$ espeak [Hit Return Key]
|
||||
|
||||
For detailed output you may do:
|
||||
|
||||
$ espeak --stdout | aplay [Hit Return Key][Double - Here]
|
||||
|
||||
espeak is flexible and you can ask espeak to accept input from a text file and speak it loud for you. All you need to do is:
|
||||
|
||||
$ espeak --stdout /path/to/text/file/file_name.txt | aplay [Hit Enter]
|
||||
|
||||
You may ask espeak to speak fast/slow for you. The default speed is 160 words per minute. Define your preference using switch ‘-s’.
|
||||
|
||||
To ask espeak to speak 30 words per minute, you may do:
|
||||
|
||||
$ espeak -s 30 -f /path/to/text/file/file_name.txt | aplay
|
||||
|
||||
To ask espeak to speak 200 words per minute, you may do:
|
||||
|
||||
$ espeak -s 200 -f /path/to/text/file/file_name.txt | aplay
|
||||
|
||||
To use another language say Hindi (my mother tongue), you may do:
|
||||
|
||||
$ espeak -v hindi --stdout 'टेकमिंट विश्व की एक बेहतरीन लाइंक्स आधारित वेबसाइट है|' | aplay
|
||||
|
||||
You may choose any language of your preference and ask to speak in your preferred language as suggested above. To get the list of all the languages supported by espeak, you need to run:
|
||||
|
||||
$ espeak --voices
|
||||
|
||||
### 3. Quick Schedule a Job ###
|
||||
|
||||
Most of us are already familiar with [cron][2] which is a daemon to execute scheduled commands.
|
||||
|
||||
Cron is an advanced command often used by Linux SYSAdmins to schedule a job such as Backup or practically anything at certain time/interval.
|
||||
|
||||
Are you aware of ‘at’ command in Linux which lets you schedule a job/command to run at specific time? You can tell ‘at’ what to do and when to do and everything else will be taken care by command ‘at’.
|
||||
|
||||
For an example, say you want to print the output of uptime command at 11:02 AM, All you need to do is:
|
||||
|
||||
$ at 11:02
|
||||
uptime >> /home/$USER/uptime.txt
|
||||
Ctrl+D
|
||||
|
||||

|
||||
|
||||
Schedule Job in Linux
|
||||
|
||||
To check if the command/script/job has been set or not by ‘at’ command, you may do:
|
||||
|
||||
$ at -l
|
||||
|
||||

|
||||
|
||||
View Scheduled Jobs
|
||||
|
||||
You may schedule more than one command in one go using at, simply as:
|
||||
|
||||
$ at 12:30
|
||||
Command – 1
|
||||
Command – 2
|
||||
…
|
||||
command – 50
|
||||
…
|
||||
Ctrl + D
|
||||
|
||||
### 4. Watch a Command at Specific Interval ###
|
||||
|
||||
We need to run some command for specified amount of time at regular interval. Just for example say we need to print the current time and watch the output every 3 seconds.
|
||||
|
||||
To see current time we need to run the below command in terminal.
|
||||
|
||||
$ date +"%H:%M:%S
|
||||
|
||||

|
||||
|
||||
Check Date and Time in Linux
|
||||
|
||||
and to check the output of this command every three seconds, we need to run the below command in Terminal.
|
||||
|
||||
$ watch -n 3 'date +"%H:%M:%S"'
|
||||
|
||||

|
||||
|
||||
Watch Command in Linux
|
||||
|
||||
The switch ‘-n’ in watch command is for Interval. In the above example we defined Interval to be 3 sec. You may define yours as required. Also you may pass any command/script with watch command to watch that command/script at the defined interval.
|
||||
|
||||
That’s all for now. Hope you are like this series that aims at making you more productive with Linux and that too with fun inside. All the suggestions are welcome in the comments below. Stay tuned for more such posts. Keep connected and Enjoy…
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/text-to-speech-in-terminal-schedule-a-job-and-watch-commands-in-linux/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/tag/linux-tricks/
|
||||
[2]:http://www.tecmint.com/11-cron-scheduling-task-examples-in-linux/
|
||||
138
sources/tech/20150813 How to Install Logwatch on Ubuntu 15.04.md
Normal file
138
sources/tech/20150813 How to Install Logwatch on Ubuntu 15.04.md
Normal file
@ -0,0 +1,138 @@
|
||||
(translating by runningwater)
|
||||
How to Install Logwatch on Ubuntu 15.04
|
||||
================================================================================
|
||||
Hi, Today we are going to illustrate the setup of Logwatch on Ubuntu 15.04 Operating system where as it can be used for any Linux and UNIX like operating systems. Logwatch is a customizable system log analyzer and reporting log-monitoring system that go through your logs for a given period of time and make a report in the areas that you wish with the details you want. Its an easy tool to install, configure, review and to take actions that will improve security from data it provides. Logwatch scans the log files of major operating system components, like SSH, Web Server and forwards a summary that contains the valuable items in it that needs to be looked at.
|
||||
|
||||
### Pre-installation Setup ###
|
||||
|
||||
We will be using Ubuntu 15.04 operating system to deploy Logwatch on it so as a perquisite for the installation of Logwatch, make sure that your emails setup is working as it will be used to send email to the administrators for daily reports on the gathered reports.Your system repositories should be enabled as we will be installing it from its available universal repositories.
|
||||
|
||||
Then open the terminal of your ubuntu operating system and login with root user to update your system packages before moving to Logwatch installation.
|
||||
|
||||
root@ubuntu-15:~# apt-get update
|
||||
|
||||
### Installing Logwatch ###
|
||||
|
||||
Once your system is updated and your have fulfilled all its prerequisites then run the following command to start the installation of Logwatch in your server.
|
||||
|
||||
root@ubuntu-15:~# apt-get install logwatch
|
||||
|
||||
The logwatch installation process will starts with addition of some extra required packages as shown once you press “Y” to accept the required changes to the system.
|
||||
|
||||
During the installation process you will be prompted to configure the Postfix Configurations according to your mail server’s setup. Here we used “Local only” in the tutorial for ease, we can choose from the other available options as per your infrastructure requirements and then press “OK” to proceed.
|
||||
|
||||

|
||||
|
||||
Then you have to choose your mail server’s name that will also be used by other programs, so it should be single fully qualified domain name (FQDN).
|
||||
|
||||

|
||||
|
||||
Once you press “OK” after postfix configurations, then it will completes the Logwatch installation process with default configurations of Postfix.
|
||||
|
||||

|
||||
|
||||
You can check the status of Logwatch by issuing the following command in the terminal that should be in active state.
|
||||
|
||||
root@ubuntu-15:~# service postfix status
|
||||
|
||||

|
||||
|
||||
To confirm the installation of Logwatch with its default configurations, issue the simple “logwatch” command as shown.
|
||||
|
||||
root@ubuntu-15:~# logwatch
|
||||
|
||||
The output from the above executed command will results in following compiled report form in the terminal.
|
||||
|
||||

|
||||
|
||||
### Logwatch Configurations ###
|
||||
|
||||
Now after successful installation of Logwatch, we need to make few configuration changes in its configuration file located under following shown path. So, let’s open it with the file editor to update its configurations as required.
|
||||
|
||||
root@ubuntu-15:~# vim /usr/share/logwatch/default.conf/logwatch.conf
|
||||
|
||||
**Output/Format Options**
|
||||
|
||||
By default Logwatch will print to stdout in text with no encoding.To make email Default set “Output = mail” and to save to file set “Output = file”. So you can comment out the its default configurations as per your required settings.
|
||||
|
||||
Output = stdout
|
||||
|
||||
To make Html the default formatting update the following line if you are using Internet email configurations.
|
||||
|
||||
Format = text
|
||||
|
||||
Now add the default person to mail reports should be sent to, it could be a local account or a complete email address that you are free to mention in this line
|
||||
|
||||
MailTo = root
|
||||
#MailTo = user@test.com
|
||||
|
||||
Default person to mail reports sent from can be a local account or any other you wish to use.
|
||||
|
||||
# complete email address.
|
||||
MailFrom = Logwatch
|
||||
|
||||
Save the changes made in the configuration file of Logwatch while leaving the other parameter as default.
|
||||
|
||||
**Cronjob Configuration**
|
||||
|
||||
Now edit the "00logwatch" file in daily crons directory to configure your desired email address to forward reports from logwatch.
|
||||
|
||||
root@ubuntu-15:~# vim /etc/cron.daily/00logwatch
|
||||
|
||||
Here you need to use "--mailto" user@test.com instead of --output mail and save the file.
|
||||
|
||||

|
||||
|
||||
### Using Logwatch Report ###
|
||||
|
||||
Now we generate the test report by executing the "logwatch" command in the terminal to get its result shown in the Text format within the terminal.
|
||||
|
||||
root@ubuntu-15:~#logwatch
|
||||
|
||||
The generated report starts with showing its execution time and date, it will be comprising of different sections that starts with its begin status and closed with end status after showing the complete information about its logs of the mentioned sections.
|
||||
|
||||
Here is its starting point looks like, where it starts by showing all the installed packages in the system as shown below.
|
||||
|
||||

|
||||
|
||||
The following sections shows the logs informmation about the login sessions, rsyslogs and SSH connections about the current and last sessions enabled on the system.
|
||||
|
||||

|
||||
|
||||
The logwatch report will ends up by showing the secure sudo logs and the disk space usage of the root diretory as shown below.
|
||||
|
||||

|
||||
|
||||
You can also check for the generated emails about the logwatch reports by opening the following file.
|
||||
|
||||
root@ubuntu-15:~# vim /var/mail/root
|
||||
|
||||
Here you will be able to see all the generated emails to your configured users with their message delivery status.
|
||||
|
||||
### More about Logwatch ###
|
||||
|
||||
Logwatch is a great tool to lern more about it, so if your more interested to learn more about its logwatch then you can also get much help from the below few commands.
|
||||
|
||||
root@ubuntu-15:~# man logwatch
|
||||
|
||||
The above command contains all the users manual about the logwatch, so read it carefully and to exit from the manuals section simply press "q".
|
||||
|
||||
To get help about the logwatch commands usage you can run the following help command for further information in details.
|
||||
|
||||
root@ubuntu-15:~# logwatch --help
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
At the end of this tutorial you learn about the complete setup of Logwatch on Ubuntu 15.04 that includes with its installation and configurations guide. Now you can start monitoring your logs in a customize able form, whether you monitor the logs of all the services rnning on your system or you customize it to send you the reports about the specific services on the scheduled days. So, let's use this tool and feel free to leave us a comment if you face any issue or need to know more about logwatch usage.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/install-use-logwatch-ubuntu-15-04/
|
||||
|
||||
作者:[Kashif Siddique][a]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/kashifs/
|
||||
@ -0,0 +1,69 @@
|
||||
KevinSJ Translating
|
||||
How to get Public IP from Linux Terminal?
|
||||
================================================================================
|
||||

|
||||
|
||||
Public addresses are assigned by InterNIC and consist of class-based network IDs or blocks of CIDR-based addresses (called CIDR blocks) that are guaranteed to be globally unique to the Internet. How to get Public IP from Linux Terminal - blackMORE OpsWhen the public addresses are assigned, routes are programmed into the routers of the Internet so that traffic to the assigned public addresses can reach their locations. Traffic to destination public addresses are reachable on the Internet. For example, when an organization is assigned a CIDR block in the form of a network ID and subnet mask, that [network ID, subnet mask] pair also exists as a route in the routers of the Internet. IP packets destined to an address within the CIDR block are routed to the proper destination. In this post I will show several ways to find your public IP address from Linux terminal. This though seems like a waste for normal users, but when you are in a terminal of a headless Linux server(i.e. no GUI or you’re connected as a user with minimal tools). Either way, being able to getHow to get Public IP from Linux Terminal public IP from Linux terminal can be useful in many cases or it could be one of those things that might just come in handy someday.
|
||||
|
||||
There’s two main commands we use, curl and wget. You can use them interchangeably.
|
||||
|
||||
### Curl output in plain text format: ###
|
||||
|
||||
curl icanhazip.com
|
||||
curl ifconfig.me
|
||||
curl curlmyip.com
|
||||
curl ip.appspot.com
|
||||
curl ipinfo.io/ip
|
||||
curl ipecho.net/plain
|
||||
curl www.trackip.net/i
|
||||
|
||||
### curl output in JSON format: ###
|
||||
|
||||
curl ipinfo.io/json
|
||||
curl ifconfig.me/all.json
|
||||
curl www.trackip.net/ip?json (bit ugly)
|
||||
|
||||
### curl output in XML format: ###
|
||||
|
||||
curl ifconfig.me/all.xml
|
||||
|
||||
### curl all IP details – The motherload ###
|
||||
|
||||
curl ifconfig.me/all
|
||||
|
||||
### Using DYNDNS (Useful when you’re using DYNDNS service) ###
|
||||
|
||||
curl -s 'http://checkip.dyndns.org' | sed 's/.*Current IP Address: \([0-9\.]*\).*/\1/g'
|
||||
curl -s http://checkip.dyndns.org/ | grep -o "[[:digit:].]\+"
|
||||
|
||||
### Using wget instead of curl ###
|
||||
|
||||
wget http://ipecho.net/plain -O - -q ; echo
|
||||
wget http://observebox.com/ip -O - -q ; echo
|
||||
|
||||
### Using host and dig command (cause we can) ###
|
||||
|
||||
You can also use host and dig command assuming they are available or installed
|
||||
|
||||
host -t a dartsclink.com | sed 's/.*has address //'
|
||||
dig +short myip.opendns.com @resolver1.opendns.com
|
||||
|
||||
### Sample bash script: ###
|
||||
|
||||
#!/bin/bash
|
||||
|
||||
PUBLIC_IP=`wget http://ipecho.net/plain -O - -q ; echo`
|
||||
echo $PUBLIC_IP
|
||||
|
||||
Quite a few to pick from.
|
||||
|
||||
I was actually writing a small script to track all the IP changes of my router each day and save those into a file. I found these nifty commands and sites to use while doing some online research. Hope they help someone else someday too. Thanks for reading, please Share and RT.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.blackmoreops.com/2015/06/14/how-to-get-public-ip-from-linux-terminal/
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,102 @@
|
||||
Howto Run JBoss Data Virtualization GA with OData in Docker Container
|
||||
================================================================================
|
||||
Hi everyone, today we'll learn how to run JBoss Data Virtualization 6.0.0.GA with OData in a Docker Container. JBoss Data Virtualization is a data supply and integration solution platform that transforms various scatered multiple sources data, treats them as single source and delivers the required data into actionable information at business speed to any applications or users. JBoss Data Virtualization can help us easily combine and transform data into reusable business friendly data models and make unified data easily consumable through open standard interfaces. It offers comprehensive data abstraction, federation, integration, transformation, and delivery capabilities to combine data from one or multiple sources into reusable for agile data utilization and sharing.For more information about JBoss Data Virtualization, we can check out [its official page][1]. Docker is an open source platform that provides an open platform to pack, ship and run any application as a lightweight container. Running JBoss Data Virtualization with OData in Docker Container makes us easy to handle and launch.
|
||||
|
||||
Here are some easy to follow tutorial on how we can run JBoss Data Virtualization with OData in Docker Container.
|
||||
|
||||
### 1. Cloning the Repository ###
|
||||
|
||||
First of all, we'll wanna clone the repository of OData with Data Virtualization ie [https://github.com/jbossdemocentral/dv-odata-docker-integration-demo][2] using git command. As we have an Ubuntu 15.04 distribution of linux running in our machine. We'll need to install git initially using apt-get command.
|
||||
|
||||
# apt-get install git
|
||||
|
||||
Then after installing git, we'll wanna clone the repository by running the command below.
|
||||
|
||||
# git clone https://github.com/jbossdemocentral/dv-odata-docker-integration-demo
|
||||
|
||||
Cloning into 'dv-odata-docker-integration-demo'...
|
||||
remote: Counting objects: 96, done.
|
||||
remote: Total 96 (delta 0), reused 0 (delta 0), pack-reused 96
|
||||
Unpacking objects: 100% (96/96), done.
|
||||
Checking connectivity... done.
|
||||
|
||||
### 2. Downloading JBoss Data Virtualization Installer ###
|
||||
|
||||
Now, we'll need to download JBoss Data Virtualization Installer from the Download Page ie [http://www.jboss.org/products/datavirt/download/][3] . After we download **jboss-dv-installer-6.0.0.GA-redhat-4.jar**, we'll need to keep it under the directory named **software**.
|
||||
|
||||
### 3. Building the Docker Image ###
|
||||
|
||||
Next, after we have downloaded the JBoss Data Virtualization installer, we'll then go for building the docker image using the Dockerfile and its resources we had just cloned from the repository.
|
||||
|
||||
# cd dv-odata-docker-integration-demo/
|
||||
# docker build -t jbossdv600 .
|
||||
|
||||
...
|
||||
Step 22 : USER jboss
|
||||
---> Running in 129f701febd0
|
||||
---> 342941381e37
|
||||
Removing intermediate container 129f701febd0
|
||||
Step 23 : EXPOSE 8080 9990 31000
|
||||
---> Running in 61e6d2c26081
|
||||
---> 351159bb6280
|
||||
Removing intermediate container 61e6d2c26081
|
||||
Step 24 : CMD $JBOSS_HOME/bin/standalone.sh -c standalone.xml -b 0.0.0.0 -bmanagement 0.0.0.0
|
||||
---> Running in a9fed69b3000
|
||||
---> 407053dc470e
|
||||
Removing intermediate container a9fed69b3000
|
||||
Successfully built 407053dc470e
|
||||
|
||||
Note: Here, we assume that you have already installed docker and is running in your machine.
|
||||
|
||||
### 4. Starting the Docker Container ###
|
||||
|
||||
As we have built the Docker Image of JBoss Data Virtualization with oData, we'll now gonna run the docker container and expose its port with -P flag. To do so, we'll run the following command.
|
||||
|
||||
# docker run -p 8080:8080 -d -t jbossdv600
|
||||
|
||||
7765dee9cd59c49ca26850e88f97c21f46859d2dc1d74166353d898773214c9c
|
||||
|
||||
### 5. Getting the Container IP ###
|
||||
|
||||
After we have started the Docker Container, we'll wanna get the IP address of the running docker container. To do so, we'll run the docker inspect command followed by the running container id.
|
||||
|
||||
# docker inspect <$containerID>
|
||||
|
||||
...
|
||||
"NetworkSettings": {
|
||||
"Bridge": "",
|
||||
"EndpointID": "3e94c5900ac5954354a89591a8740ce2c653efde9232876bc94878e891564b39",
|
||||
"Gateway": "172.17.42.1",
|
||||
"GlobalIPv6Address": "",
|
||||
"GlobalIPv6PrefixLen": 0,
|
||||
"HairpinMode": false,
|
||||
"IPAddress": "172.17.0.8",
|
||||
"IPPrefixLen": 16,
|
||||
"IPv6Gateway": "",
|
||||
"LinkLocalIPv6Address": "",
|
||||
"LinkLocalIPv6PrefixLen": 0,
|
||||
|
||||
### 6. Web Interface ###
|
||||
|
||||
Now, if everything went as expected as done above, we'll gonna see the login screen of JBoss Data Virtualization with oData when pointing our web browser to http://container-ip:8080/ and the JBoss Management from http://container-ip:9990. The Management credentials for username is admin and password is redhat1! whereas the Data virtualization credentials for username is user and password is user . After that, we can navigate the contents via the web interface.
|
||||
|
||||
**Note**: It is strongly recommended to change the password as soon as possible after the first login. Thanks :)
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Finally we've successfully run Docker Container running JBoss Data Virtualization with OData Multisource Virtual Database. JBoss Data Virtualization is really an awesome platform for the virtualization of data from different multiple source and transform them into reusable business friendly data models and produces data easily consumable through open standard interfaces. The deployment of JBoss Data Virtualization with OData Multisource Virtual Database has been very easy, secure and fast to setup with the Docker Technology. If you have any questions, suggestions, feedback please write them in the comment box below so that we can improve or update our contents. Thank you ! Enjoy :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/run-jboss-data-virtualization-ga-odata-docker-container/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://www.redhat.com/en/technologies/jboss-middleware/data-virtualization
|
||||
[2]:https://github.com/jbossdemocentral/dv-odata-docker-integration-demo
|
||||
[3]:http://www.jboss.org/products/datavirt/download/
|
||||
@ -0,0 +1,164 @@
|
||||
DongShuaike is translating.
|
||||
|
||||
Linux and Unix Test Disk I/O Performance With dd Command
|
||||
================================================================================
|
||||
How can I use dd command on a Linux to test I/O performance of my hard disk drive? How do I check the performance of a hard drive including the read and write speed on a Linux operating systems?
|
||||
|
||||
You can use the following commands on a Linux or Unix-like systems for simple I/O performance test:
|
||||
|
||||
- **dd command** : It is used to monitor the writing performance of a disk device on a Linux and Unix-like system
|
||||
- **hdparm command** : It is used to get/set hard disk parameters including test the reading and caching performance of a disk device on a Linux based system.
|
||||
|
||||
In this tutorial you will learn how to use the dd command to test disk I/O performance.
|
||||
|
||||
### Use dd command to monitor the reading and writing performance of a disk device: ###
|
||||
|
||||
- Open a shell prompt.
|
||||
- Or login to a remote server via ssh.
|
||||
- Use the dd command to measure server throughput (write speed) `dd if=/dev/zero of=/tmp/test1.img bs=1G count=1 oflag=dsync`
|
||||
- Use the dd command to measure server latency `dd if=/dev/zero of=/tmp/test2.img bs=512 count=1000 oflag=dsync`
|
||||
|
||||
#### Understanding dd command options ####
|
||||
|
||||
In this example, I'm using RAID-10 (Adaptec 5405Z with SAS SSD) array running on a Ubuntu Linux 14.04 LTS server. The basic syntax is
|
||||
|
||||
dd if=/dev/input.file of=/path/to/output.file bs=block-size count=number-of-blocks oflag=dsync
|
||||
## GNU dd syntax ##
|
||||
dd if=/dev/zero of=/tmp/test1.img bs=1G count=1 oflag=dsync
|
||||
## OR alternate syntax for GNU/dd ##
|
||||
dd if=/dev/zero of=/tmp/testALT.img bs=1G count=1 conv=fdatasync
|
||||
|
||||
Sample outputs:
|
||||
|
||||

|
||||
Fig.01: Ubuntu Linux Server with RAID10 and testing server throughput with dd
|
||||
|
||||
Please note that one gigabyte was written for the test and 135 MB/s was server throughput for this test. Where,
|
||||
|
||||
- `if=/dev/zero (if=/dev/input.file)` : The name of the input file you want dd the read from.
|
||||
- `of=/tmp/test1.img (of=/path/to/output.file)` : The name of the output file you want dd write the input.file to.
|
||||
- `bs=1G (bs=block-size)` : Set the size of the block you want dd to use. 1 gigabyte was written for the test.
|
||||
- `count=1 (count=number-of-blocks)`: The number of blocks you want dd to read.
|
||||
- `oflag=dsync (oflag=dsync)` : Use synchronized I/O for data. Do not skip this option. This option get rid of caching and gives you good and accurate results
|
||||
- `conv=fdatasyn`: Again, this tells dd to require a complete "sync" once, right before it exits. This option is equivalent to oflag=dsync.
|
||||
|
||||
In this example, 512 bytes were written one thousand times to get RAID10 server latency time:
|
||||
|
||||
dd if=/dev/zero of=/tmp/test2.img bs=512 count=1000 oflag=dsync
|
||||
|
||||
Sample outputs:
|
||||
|
||||
1000+0 records in
|
||||
1000+0 records out
|
||||
512000 bytes (512 kB) copied, 0.60362 s, 848 kB/s
|
||||
|
||||
Please note that server throughput and latency time depends upon server/application load too. So I recommend that you run these tests on a newly rebooted server as well as peak time to get better idea about your workload. You can now compare these numbers with all your devices.
|
||||
|
||||
#### But why the server throughput and latency time are so low? ####
|
||||
|
||||
Low values does not mean you are using slow hardware. The value can be low because of the HARDWARE RAID10 controller's cache.
|
||||
|
||||
Use hdparm command to see buffered and cached disk read speed
|
||||
|
||||
I suggest you run the following commands 2 or 3 times Perform timings of device reads for benchmark and comparison purposes:
|
||||
|
||||
### Buffered disk read test for /dev/sda ##
|
||||
hdparm -t /dev/sda1
|
||||
## OR ##
|
||||
hdparm -t /dev/sda
|
||||
|
||||
To perform timings of cache reads for benchmark and comparison purposes again run the following command 2-3 times (note the -T option):
|
||||
|
||||
## Cache read benchmark for /dev/sda ###
|
||||
hdparm -T /dev/sda1
|
||||
## OR ##
|
||||
hdparm -T /dev/sda
|
||||
|
||||
OR combine both tests:
|
||||
|
||||
hdparm -Tt /dev/sda
|
||||
|
||||
Sample outputs:
|
||||
|
||||
|
||||
Fig.02: Linux hdparm command to test reading and caching disk performance
|
||||
|
||||
Again note that due to filesystems caching on file operations, you will always see high read rates.
|
||||
|
||||
**Use dd command on Linux to test read speed**
|
||||
|
||||
To get accurate read test data, first discard caches before testing by running the following commands:
|
||||
|
||||
flush
|
||||
echo 3 | sudo tee /proc/sys/vm/drop_caches
|
||||
time time dd if=/path/to/bigfile of=/dev/null bs=8k
|
||||
|
||||
**Linux Laptop example**
|
||||
|
||||
Run the following command:
|
||||
|
||||
### Debian Laptop Throughput With Cache ##
|
||||
dd if=/dev/zero of=/tmp/laptop.bin bs=1G count=1 oflag=direct
|
||||
|
||||
### Deactivate the cache ###
|
||||
hdparm -W0 /dev/sda
|
||||
|
||||
### Debian Laptop Throughput Without Cache ##
|
||||
dd if=/dev/zero of=/tmp/laptop.bin bs=1G count=1 oflag=direct
|
||||
|
||||
**Apple OS X Unix (Macbook pro) example**
|
||||
|
||||
GNU dd has many more options but OS X/BSD and Unix-like dd command need to run as follows to test real disk I/O and not memory add sync option as follows:
|
||||
|
||||
## Run command 2-3 times to get good results ###
|
||||
time sh -c "dd if=/dev/zero of=/tmp/testfile bs=100k count=1k && sync"
|
||||
|
||||
Sample outputs:
|
||||
|
||||
1024+0 records in
|
||||
1024+0 records out
|
||||
104857600 bytes transferred in 0.165040 secs (635346520 bytes/sec)
|
||||
|
||||
real 0m0.241s
|
||||
user 0m0.004s
|
||||
sys 0m0.113s
|
||||
|
||||
So I'm getting 635346520 bytes (635.347 MB/s) write speed on my MBP.
|
||||
|
||||
**Not a fan of command line...?**
|
||||
|
||||
You can use disk utility (gnome-disk-utility) on a Linux or Unix based system to get the same information. The following screenshot is taken from my Fedora Linux v22 VM.
|
||||
|
||||
**Graphical method**
|
||||
|
||||
Click on the "Activities" or press the "Super" key to switch between the Activities overview and desktop. Type "Disks"
|
||||
|
||||
|
||||
Fig.03: Start the Gnome disk utility
|
||||
|
||||
Select your hard disk at left pane and click on configure button and click on "Benchmark partition":
|
||||
|
||||
|
||||
Fig.04: Benchmark disk/partition
|
||||
|
||||
Finally, click on the "Start Benchmark..." button (you may be promoted for the admin username and password):
|
||||
|
||||
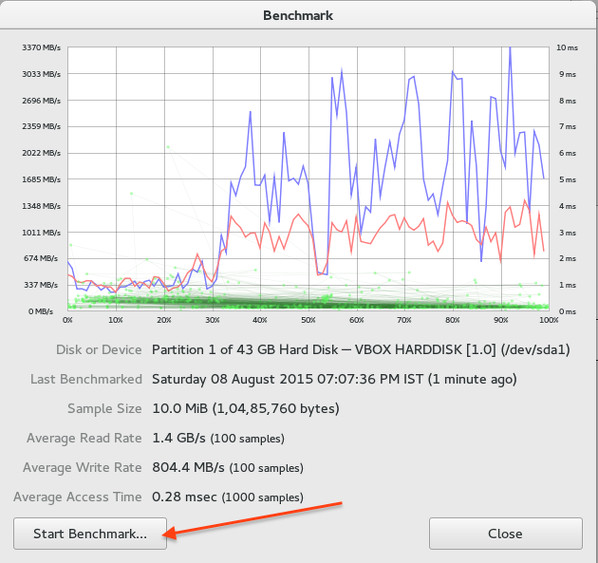
|
||||
Fig.05: Final benchmark result
|
||||
|
||||
Which method and command do you recommend to use?
|
||||
|
||||
- I recommend dd command on all Unix-like systems (`time sh -c "dd if=/dev/zero of=/tmp/testfile bs=100k count=1k && sync`"
|
||||
- If you are using GNU/Linux use the dd command (`dd if=/dev/zero of=/tmp/testALT.img bs=1G count=1 conv=fdatasync`)
|
||||
- Make sure you adjust count and bs arguments as per your setup to get a good set of result.
|
||||
- The GUI method is recommended only for Linux/Unix laptop users running Gnome2 or 3 desktop.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cyberciti.biz/faq/howto-linux-unix-test-disk-performance-with-dd-command/
|
||||
|
||||
作者:Vivek Gite
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
441
sources/tech/20150813 Linux file system hierarchy v2.0.md
Normal file
441
sources/tech/20150813 Linux file system hierarchy v2.0.md
Normal file
@ -0,0 +1,441 @@
|
||||
|
||||
Translating by dingdongnigetou
|
||||
|
||||
Linux file system hierarchy v2.0
|
||||
================================================================================
|
||||
What is a file in Linux? What is file system in Linux? Where are all the configuration files? Where do I keep my downloaded applications? Is there really a filesystem standard structure in Linux? Well, the above image explains Linux file system hierarchy in a very simple and non-complex way. It’s very useful when you’re looking for a configuration file or a binary file. I’ve added some explanation and examples below, but that’s TL;DR.
|
||||
|
||||
Another issue is when you got configuration and binary files all over the system that creates inconsistency and if you’re a large organization or even an end user, it can compromise your system (binary talking with old lib files etc.) and when you do [security audit of your Linux system][1], you find it is vulnerable to different exploits. So keeping a clean operating system (no matter Windows or Linux) is important.
|
||||
|
||||
### What is a file in Linux? ###
|
||||
|
||||
A simple description of the UNIX system, also applicable to Linux, is this:
|
||||
|
||||
> On a UNIX system, everything is a file; if something is not a file, it is a process.
|
||||
|
||||
This statement is true because there are special files that are more than just files (named pipes and sockets, for instance), but to keep things simple, saying that everything is a file is an acceptable generalization. A Linux system, just like UNIX, makes no difference between a file and a directory, since a directory is just a file containing names of other files. Programs, services, texts, images, and so forth, are all files. Input and output devices, and generally all devices, are considered to be files, according to the system.
|
||||
|
||||

|
||||
|
||||
- Version 2.0 – 17-06-2015
|
||||
- – Improved: Added title and version history.
|
||||
- – Improved: Added /srv, /media and /proc.
|
||||
- – Improved: Updated descriptions to reflect modern Linux File Systems.
|
||||
- – Fixed: Multiple typo’s.
|
||||
- – Fixed: Appearance and colour.
|
||||
- Version 1.0 – 14-02-2015
|
||||
- – Created: Initial diagram.
|
||||
- – Note: Discarded lowercase version.
|
||||
|
||||
### Download Links ###
|
||||
|
||||
Following are two links for download. If you need this in any other format, let me know and I will try to create that and upload it somewhere.
|
||||
|
||||
- [Large (PNG) Format – 2480×1755 px – 184KB][2]
|
||||
- [Largest (PDF) Format – 9919x7019 px – 1686KB][3]
|
||||
|
||||
**Note**: PDF Format is best for printing and very high in quality
|
||||
|
||||
### Linux file system description ###
|
||||
|
||||
In order to manage all those files in an orderly fashion, man likes to think of them in an ordered tree-like structure on the hard disk, as we know from `MS-DOS` (Disk Operating System) for instance. The large branches contain more branches, and the branches at the end contain the tree’s leaves or normal files. For now we will use this image of the tree, but we will find out later why this is not a fully accurate image.
|
||||
|
||||
注:表格
|
||||
<table cellspacing="2" border="4" style="border-collapse: collapse; width: 731px; height: 2617px;">
|
||||
<thead>
|
||||
<tr>
|
||||
<th scope="col">Directory</th>
|
||||
<th scope="col">Description</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/</code></dd>
|
||||
</dl></td>
|
||||
<td><i>Primary hierarchy</i> root and root directory of the entire file system hierarchy.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/bin</code></dd>
|
||||
</dl></td>
|
||||
<td>Essential command binaries that need to be available in single user mode; for all users, <i>e.g.</i>, cat, ls, cp.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/boot</code></dd>
|
||||
</dl></td>
|
||||
<td>Boot loader files, <i>e.g.</i>, kernels, initrd.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/dev</code></dd>
|
||||
</dl></td>
|
||||
<td>Essential devices, <i>e.g.</i>, <code>/dev/null</code>.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/etc</code></dd>
|
||||
</dl></td>
|
||||
<td>Host-specific system-wide configuration filesThere has been controversy over the meaning of the name itself. In early versions of the UNIX Implementation Document from Bell labs, /etc is referred to as the <i>etcetera directory</i>, as this directory historically held everything that did not belong elsewhere (however, the FHS restricts /etc to static configuration files and may not contain binaries). Since the publication of early documentation, the directory name has been re-designated in various ways. Recent interpretations include backronyms such as “Editable Text Configuration” or “Extended Tool Chest”.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/opt</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Configuration files for add-on packages that are stored in <code>/opt/</code>.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/sgml</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Configuration files, such as catalogs, for software that processes SGML.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/X11</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Configuration files for the X Window System, version 11.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/xml</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Configuration files, such as catalogs, for software that processes XML.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/home</code></dd>
|
||||
</dl></td>
|
||||
<td>Users’ home directories, containing saved files, personal settings, etc.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/lib</code></dd>
|
||||
</dl></td>
|
||||
<td>Libraries essential for the binaries in <code>/bin/</code> and <code>/sbin/</code>.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/lib<qual></code></dd>
|
||||
</dl></td>
|
||||
<td>Alternate format essential libraries. Such directories are optional, but if they exist, they have some requirements.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/media</code></dd>
|
||||
</dl></td>
|
||||
<td>Mount points for removable media such as CD-ROMs (appeared in FHS-2.3).</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/mnt</code></dd>
|
||||
</dl></td>
|
||||
<td>Temporarily mounted filesystems.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/opt</code></dd>
|
||||
</dl></td>
|
||||
<td>Optional application software packages.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/proc</code></dd>
|
||||
</dl></td>
|
||||
<td>Virtual filesystem providing process and kernel information as files. In Linux, corresponds to a procfs mount.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/root</code></dd>
|
||||
</dl></td>
|
||||
<td>Home directory for the root user.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/sbin</code></dd>
|
||||
</dl></td>
|
||||
<td>Essential system binaries, <i>e.g.</i>, init, ip, mount.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/srv</code></dd>
|
||||
</dl></td>
|
||||
<td>Site-specific data which are served by the system.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/tmp</code></dd>
|
||||
</dl></td>
|
||||
<td>Temporary files (see also <code>/var/tmp</code>). Often not preserved between system reboots.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/usr</code></dd>
|
||||
</dl></td>
|
||||
<td><i>Secondary hierarchy</i> for read-only user data; contains the majority of (multi-)user utilities and applications.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/bin</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Non-essential command binaries (not needed in single user mode); for all users.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/include</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Standard include files.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/lib</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Libraries for the binaries in <code>/usr/bin/</code> and <code>/usr/sbin/</code>.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/lib<qual></code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Alternate format libraries (optional).</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/local</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td><i>Tertiary hierarchy</i> for local data, specific to this host. Typically has further subdirectories, <i>e.g.</i>, <code>bin/</code>, <code>lib/</code>, <code>share/</code>.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/sbin</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Non-essential system binaries, <i>e.g.</i>, daemons for various network-services.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/share</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Architecture-independent (shared) data.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/src</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Source code, <i>e.g.</i>, the kernel source code with its header files.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/X11R6</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>X Window System, Version 11, Release 6.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/var</code></dd>
|
||||
</dl></td>
|
||||
<td>Variable files—files whose content is expected to continually change during normal operation of the system—such as logs, spool files, and temporary e-mail files.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/cache</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Application cache data. Such data are locally generated as a result of time-consuming I/O or calculation. The application must be able to regenerate or restore the data. The cached files can be deleted without loss of data.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/lib</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>State information. Persistent data modified by programs as they run, <i>e.g.</i>, databases, packaging system metadata, etc.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/lock</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Lock files. Files keeping track of resources currently in use.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/log</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Log files. Various logs.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/mail</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Users’ mailboxes.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/opt</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Variable data from add-on packages that are stored in <code>/opt/</code>.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/run</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Information about the running system since last boot, <i>e.g.</i>, currently logged-in users and running <a href="http://en.wikipedia.org/wiki/Daemon_%28computing%29">daemons</a>.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/spool</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Spool for tasks waiting to be processed, <i>e.g.</i>, print queues and outgoing mail queue.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/mail</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Deprecated location for users’ mailboxes.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/tmp</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Temporary files to be preserved between reboots.</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
### Types of files in Linux ###
|
||||
|
||||
Most files are just files, called `regular` files; they contain normal data, for example text files, executable files or programs, input for or output from a program and so on.
|
||||
|
||||
While it is reasonably safe to suppose that everything you encounter on a Linux system is a file, there are some exceptions.
|
||||
|
||||
- `Directories`: files that are lists of other files.
|
||||
- `Special files`: the mechanism used for input and output. Most special files are in `/dev`, we will discuss them later.
|
||||
- `Links`: a system to make a file or directory visible in multiple parts of the system’s file tree. We will talk about links in detail.
|
||||
- `(Domain) sockets`: a special file type, similar to TCP/IP sockets, providing inter-process networking protected by the file system’s access control.
|
||||
- `Named pipes`: act more or less like sockets and form a way for processes to communicate with each other, without using network socket semantics.
|
||||
|
||||
### File system in reality ###
|
||||
|
||||
For most users and for most common system administration tasks, it is enough to accept that files and directories are ordered in a tree-like structure. The computer, however, doesn’t understand a thing about trees or tree-structures.
|
||||
|
||||
Every partition has its own file system. By imagining all those file systems together, we can form an idea of the tree-structure of the entire system, but it is not as simple as that. In a file system, a file is represented by an `inode`, a kind of serial number containing information about the actual data that makes up the file: to whom this file belongs, and where is it located on the hard disk.
|
||||
|
||||
Every partition has its own set of inodes; throughout a system with multiple partitions, files with the same inode number can exist.
|
||||
|
||||
Each inode describes a data structure on the hard disk, storing the properties of a file, including the physical location of the file data. When a hard disk is initialized to accept data storage, usually during the initial system installation process or when adding extra disks to an existing system, a fixed number of inodes per partition is created. This number will be the maximum amount of files, of all types (including directories, special files, links etc.) that can exist at the same time on the partition. We typically count on having 1 inode per 2 to 8 kilobytes of storage.At the time a new file is created, it gets a free inode. In that inode is the following information:
|
||||
|
||||
- Owner and group owner of the file.
|
||||
- File type (regular, directory, …)
|
||||
- Permissions on the file
|
||||
- Date and time of creation, last read and change.
|
||||
- Date and time this information has been changed in the inode.
|
||||
- Number of links to this file (see later in this chapter).
|
||||
- File size
|
||||
- An address defining the actual location of the file data.
|
||||
|
||||
The only information not included in an inode, is the file name and directory. These are stored in the special directory files. By comparing file names and inode numbers, the system can make up a tree-structure that the user understands. Users can display inode numbers using the -i option to ls. The inodes have their own separate space on the disk.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.blackmoreops.com/2015/06/18/linux-file-system-hierarchy-v2-0/
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.blackmoreops.com/2015/02/15/in-light-of-recent-linux-exploits-linux-security-audit-is-a-must/
|
||||
[2]:http://www.blackmoreops.com/wp-content/uploads/2015/06/Linux-file-system-hierarchy-v2.0-2480px-blackMORE-Ops.png
|
||||
[3]:http://www.blackmoreops.com/wp-content/uploads/2015/06/Linux-File-System-Hierarchy-blackMORE-Ops.pdf
|
||||
@ -0,0 +1,63 @@
|
||||
Ubuntu Want To Make It Easier For You To Install The Latest Nvidia Linux Driver
|
||||
================================================================================
|
||||

|
||||
Ubuntu Gamers are on the rise -and so is demand for the latest drivers
|
||||
|
||||
**Installing the latest upstream NVIDIA graphics driver on Ubuntu could be about to get much easier. **
|
||||
|
||||
Ubuntu developers are considering the creation of a brand new ‘official’ PPA to distribute the latest closed-source NVIDIA binary drivers to desktop users.
|
||||
|
||||
The move would benefit Ubuntu gamers **without** risking the stability of the OS for everyone else.
|
||||
|
||||
New upstream drivers would be installed and updated from this new PPA **only** when a user explicitly opts-in to it. Everyone else would continue to receive and use the more recent stable NVIDIA Linux driver snapshot included in the Ubuntu archive.
|
||||
|
||||
### Why Is This Needed? ###
|
||||
|
||||
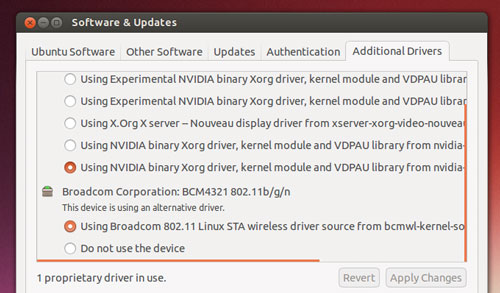
|
||||
Ubuntu provides drivers – but they’re not the latest
|
||||
|
||||
The closed-source NVIDIA graphics drivers that are available to install on Ubuntu from the archive (using the command line, synaptic or through the additional drivers tool) work fine for most and can handle the composited Unity desktop shell with ease.
|
||||
|
||||
For gaming needs it’s a different story.
|
||||
|
||||
If you want to squeeze every last frame and HD texture out of the latest big-name Steam game you’ll need the latest binary drivers blob.
|
||||
|
||||
> ‘Installing the very latest Nvidia Linux driver on Ubuntu is not easy and not always safe.’
|
||||
|
||||
The more recent the driver the more likely it is to support the latest features and technologies, or come pre-packed with game-specific tweaks and bug fixes too.
|
||||
|
||||
The problem is that installing the very latest Nvidia Linux driver on Ubuntu is not easy and not always safe.
|
||||
|
||||
To fill the void many third-party PPAs maintained by enthusiasts have emerged. Since many of these PPAs also distribute other experimental or bleeding-edge software their use is **not without risk**. Adding a bleeding edge PPA is often the fastest way to entirely hose a system!
|
||||
|
||||
A solution that lets Ubuntu users install the latest propriety graphics drivers as offered in third-party PPAs is needed **but** with the safety catch of being able to roll-back to the stable archive version if needed.
|
||||
|
||||
### ‘Demand for fresh drivers is hard to ignore’ ###
|
||||
|
||||
> ‘A solution that lets Ubuntu users get the latest hardware drivers safely is coming.’
|
||||
|
||||
‘The demand for fresh drivers in a fast developing market is becoming hard to ignore, users are going to want the latest upstream has to offer,’ Castro explains in an e-mail to the Ubuntu Desktop mailing list.
|
||||
|
||||
‘[NVIDIA] can deliver a kickass experience with almost no effort from the user [in Windows 10]. Until we can convince NVIDIA to do the same with Ubuntu we’re going to have to pick up the slack.’
|
||||
|
||||
Castro’s proposition of a “blessed” NVIDIA PPA is the easiest way to do this.
|
||||
|
||||
Gamers would be able to opt-in to receive new drivers from the PPA straight from Ubuntu’s default proprietary hardware drivers tool — no need for them to copy and paste terminal commands from websites or wiki pages.
|
||||
|
||||
The drivers within this PPA would be packaged and maintained by a select band of community members and receive benefits from being a semi-official option, namely **automated testing**.
|
||||
|
||||
As Castro himself puts it: ‘People want the latest bling, and no matter what they’re going to do it. We might as well put a framework around it so people can get what they want without breaking their computer.’
|
||||
|
||||
**Would you make use of this PPA? How would you rate the performance of the default Nvidia drivers on Ubuntu? Share your thoughts in the comments, folks! **
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/08/ubuntu-easy-install-latest-nvidia-linux-drivers
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
@ -0,0 +1,228 @@
|
||||
Translating by ictlyh
|
||||
Part 1 - RHCE Series: How to Setup and Test Static Network Routing
|
||||
================================================================================
|
||||
RHCE (Red Hat Certified Engineer) is a certification from Red Hat company, which gives an open source operating system and software to the enterprise community, It also gives training, support and consulting services for the companies.
|
||||
|
||||

|
||||
|
||||
RHCE Exam Preparation Guide
|
||||
|
||||
This RHCE (Red Hat Certified Engineer) is a performance-based exam (codename EX300), who possesses the additional skills, knowledge, and abilities required of a senior system administrator responsible for Red Hat Enterprise Linux (RHEL) systems.
|
||||
|
||||
**Important**: [Red Hat Certified System Administrator][1] (RHCSA) certification is required to earn RHCE certification.
|
||||
|
||||
Following are the exam objectives based on the Red Hat Enterprise Linux 7 version of the exam, which will going to cover in this RHCE series:
|
||||
|
||||
- Part 1: How to Setup and Test Static Routing in RHEL 7
|
||||
- Part 2: How to Perform Packet Filtering, Network Address Translation and Set Kernel Runtime Parameters
|
||||
- Part 3: How to Produce and Deliver System Activity Reports Using Linux Toolsets
|
||||
- Part 4: Automate System Maintenance Tasks Using Shell Scripts
|
||||
- Part 5: How to Configure Local and Remote System Logging
|
||||
- Part 6: How to Configure a Samba Server and a NFS Server
|
||||
- Part 7: Setting Up Complete SMTP Server for Mailing
|
||||
- Part 8: Setting Up HTTPS and TLS on RHEL 7
|
||||
- Part 9: Setting Up Network Time Protocol
|
||||
- Part 10: How to Configure a Cache-Only DNS Server
|
||||
|
||||
To view fees and register for an exam in your country, check the [RHCE Certification][2] page.
|
||||
|
||||
In this Part 1 of the RHCE series and the next, we will present basic, yet typical, cases where the principles of static routing, packet filtering, and network address translation come into play.
|
||||
|
||||

|
||||
|
||||
RHCE: Setup and Test Network Static Routing – Part 1
|
||||
|
||||
Please note that we will not cover them in depth, but rather organize these contents in such a way that will be helpful to take the first steps and build from there.
|
||||
|
||||
### Static Routing in Red Hat Enterprise Linux 7 ###
|
||||
|
||||
One of the wonders of modern networking is the vast availability of devices that can connect groups of computers, whether in relatively small numbers and confined to a single room or several machines in the same building, city, country, or across continents.
|
||||
|
||||
However, in order to effectively accomplish this in any situation, network packets need to be routed, or in other words, the path they follow from source to destination must be ruled somehow.
|
||||
|
||||
Static routing is the process of specifying a route for network packets other than the default, which is provided by a network device known as the default gateway. Unless specified otherwise through static routing, network packets are directed to the default gateway; with static routing, other paths are defined based on predefined criteria, such as the packet destination.
|
||||
|
||||
Let us define the following scenario for this tutorial. We have a Red Hat Enterprise Linux 7 box connecting to router #1 [192.168.0.1] to access the Internet and machines in 192.168.0.0/24.
|
||||
|
||||
A second router (router #2) has two network interface cards: enp0s3 is also connected to router #1 to access the Internet and to communicate with the RHEL 7 box and other machines in the same network, whereas the other (enp0s8) is used to grant access to the 10.0.0.0/24 network where internal services reside, such as a web and / or database server.
|
||||
|
||||
This scenario is illustrated in the diagram below:
|
||||
|
||||

|
||||
|
||||
Static Routing Network Diagram
|
||||
|
||||
In this article we will focus exclusively on setting up the routing table on our RHEL 7 box to make sure that it can both access the Internet through router #1 and the internal network via router #2.
|
||||
|
||||
In RHEL 7, you will use the [ip command][3] to configure and show devices and routing using the command line. These changes can take effect immediately on a running system but since they are not persistent across reboots, we will use ifcfg-enp0sX and route-enp0sX files inside /etc/sysconfig/network-scripts to save our configuration permanently.
|
||||
|
||||
To begin, let’s print our current routing table:
|
||||
|
||||
# ip route show
|
||||
|
||||

|
||||
|
||||
Check Current Routing Table
|
||||
|
||||
From the output above, we can see the following facts:
|
||||
|
||||
- The default gateway’s IP address is 192.168.0.1 and can be accessed via the enp0s3 NIC.
|
||||
- When the system booted up, it enabled the zeroconf route to 169.254.0.0/16 (just in case). In few words, if a machine is set to obtain an IP address through DHCP but fails to do so for some reason, it is automatically assigned an address in this network. Bottom line is, this route will allow us to communicate, also via enp0s3, with other machines who have failed to obtain an IP address from a DHCP server.
|
||||
- Last, but not least, we can communicate with other boxes inside the 192.168.0.0/24 network through enp0s3, whose IP address is 192.168.0.18.
|
||||
|
||||
These are the typical tasks that you would have to perform in such a setting. Unless specified otherwise, the following tasks should be performed in router #2:
|
||||
|
||||
Make sure all NICs have been properly installed:
|
||||
|
||||
# ip link show
|
||||
|
||||
If one of them is down, bring it up:
|
||||
|
||||
# ip link set dev enp0s8 up
|
||||
|
||||
and assign an IP address in the 10.0.0.0/24 network to it:
|
||||
|
||||
# ip addr add 10.0.0.17 dev enp0s8
|
||||
|
||||
Oops! We made a mistake in the IP address. We will have to remove the one we assigned earlier and then add the right one (10.0.0.18):
|
||||
|
||||
# ip addr del 10.0.0.17 dev enp0s8
|
||||
# ip addr add 10.0.0.18 dev enp0s8
|
||||
|
||||
Now, please note that you can only add a route to a destination network through a gateway that is itself already reachable. For that reason, we need to assign an IP address within the 192.168.0.0/24 range to enp0s3 so that our RHEL 7 box can communicate with it:
|
||||
|
||||
# ip addr add 192.168.0.19 dev enp0s3
|
||||
|
||||
Finally, we will need to enable packet forwarding:
|
||||
|
||||
# echo "1" > /proc/sys/net/ipv4/ip_forward
|
||||
|
||||
and stop / disable (just for the time being – until we cover packet filtering in the next article) the firewall:
|
||||
|
||||
# systemctl stop firewalld
|
||||
# systemctl disable firewalld
|
||||
|
||||
Back in our RHEL 7 box (192.168.0.18), let’s configure a route to 10.0.0.0/24 through 192.168.0.19 (enp0s3 in router #2):
|
||||
|
||||
# ip route add 10.0.0.0/24 via 192.168.0.19
|
||||
|
||||
After that, the routing table looks as follows:
|
||||
|
||||
# ip route show
|
||||
|
||||

|
||||
|
||||
Confirm Network Routing Table
|
||||
|
||||
Likewise, add the corresponding route in the machine(s) you’re trying to reach in 10.0.0.0/24:
|
||||
|
||||
# ip route add 192.168.0.0/24 via 10.0.0.18
|
||||
|
||||
You can test for basic connectivity using ping:
|
||||
|
||||
In the RHEL 7 box, run
|
||||
|
||||
# ping -c 4 10.0.0.20
|
||||
|
||||
where 10.0.0.20 is the IP address of a web server in the 10.0.0.0/24 network.
|
||||
|
||||
In the web server (10.0.0.20), run
|
||||
|
||||
# ping -c 192.168.0.18
|
||||
|
||||
where 192.168.0.18 is, as you will recall, the IP address of our RHEL 7 machine.
|
||||
|
||||
Alternatively, we can use [tcpdump][4] (you may need to install it with yum install tcpdump) to check the 2-way communication over TCP between our RHEL 7 box and the web server at 10.0.0.20.
|
||||
|
||||
To do so, let’s start the logging in the first machine with:
|
||||
|
||||
# tcpdump -qnnvvv -i enp0s3 host 10.0.0.20
|
||||
|
||||
and from another terminal in the same system let’s telnet to port 80 in the web server (assuming Apache is listening on that port; otherwise, indicate the right port in the following command):
|
||||
|
||||
# telnet 10.0.0.20 80
|
||||
|
||||
The tcpdump log should look as follows:
|
||||
|
||||

|
||||
|
||||
Check Network Communication between Servers
|
||||
|
||||
Where the connection has been properly initialized, as we can tell by looking at the 2-way communication between our RHEL 7 box (192.168.0.18) and the web server (10.0.0.20).
|
||||
|
||||
Please remember that these changes will go away when you restart the system. If you want to make them persistent, you will need to edit (or create, if they don’t already exist) the following files, in the same systems where we performed the above commands.
|
||||
|
||||
Though not strictly necessary for our test case, you should know that /etc/sysconfig/network contains system-wide network parameters. A typical /etc/sysconfig/network looks as follows:
|
||||
|
||||
# Enable networking on this system?
|
||||
NETWORKING=yes
|
||||
# Hostname. Should match the value in /etc/hostname
|
||||
HOSTNAME=yourhostnamehere
|
||||
# Default gateway
|
||||
GATEWAY=XXX.XXX.XXX.XXX
|
||||
# Device used to connect to default gateway. Replace X with the appropriate number.
|
||||
GATEWAYDEV=enp0sX
|
||||
|
||||
When it comes to setting specific variables and values for each NIC (as we did for router #2), you will have to edit /etc/sysconfig/network-scripts/ifcfg-enp0s3 and /etc/sysconfig/network-scripts/ifcfg-enp0s8.
|
||||
|
||||
Following our case,
|
||||
|
||||
TYPE=Ethernet
|
||||
BOOTPROTO=static
|
||||
IPADDR=192.168.0.19
|
||||
NETMASK=255.255.255.0
|
||||
GATEWAY=192.168.0.1
|
||||
NAME=enp0s3
|
||||
ONBOOT=yes
|
||||
|
||||
and
|
||||
|
||||
TYPE=Ethernet
|
||||
BOOTPROTO=static
|
||||
IPADDR=10.0.0.18
|
||||
NETMASK=255.255.255.0
|
||||
GATEWAY=10.0.0.1
|
||||
NAME=enp0s8
|
||||
ONBOOT=yes
|
||||
|
||||
for enp0s3 and enp0s8, respectively.
|
||||
|
||||
As for routing in our client machine (192.168.0.18), we will need to edit /etc/sysconfig/network-scripts/route-enp0s3:
|
||||
|
||||
10.0.0.0/24 via 192.168.0.19 dev enp0s3
|
||||
|
||||
Now reboot your system and you should see that route in your table.
|
||||
|
||||
### Summary ###
|
||||
|
||||
In this article we have covered the essentials of static routing in Red Hat Enterprise Linux 7. Although scenarios may vary, the case presented here illustrates the required principles and the procedures to perform this task. Before wrapping up, I would like to suggest you to take a look at [Chapter 4][5] of the Securing and Optimizing Linux section in The Linux Documentation Project site for further details on the topics covered here.
|
||||
|
||||
Free ebook on Securing & Optimizing Linux: The Hacking Solution (v.3.0) – This 800+ eBook contains comprehensive collection of Linux security tips and how to use them safely and easily to configure Linux-based applications and services.
|
||||
|
||||

|
||||
|
||||
Linux Security and Optimization Book
|
||||
|
||||
[Download Now][6]
|
||||
|
||||
In the next article we will talk about packet filtering and network address translation to sum up the networking basic skills needed for the RHCE certification.
|
||||
|
||||
As always, we look forward to hearing from you, so feel free to leave your questions, comments, and suggestions using the form below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/how-to-setup-and-configure-static-network-routing-in-rhel/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/rhcsa-exam-reviewing-essential-commands-system-documentation/
|
||||
[2]:https://www.redhat.com/en/services/certification/rhce
|
||||
[3]:http://www.tecmint.com/ip-command-examples/
|
||||
[4]:http://www.tecmint.com/12-tcpdump-commands-a-network-sniffer-tool/
|
||||
[5]:http://www.tldp.org/LDP/solrhe/Securing-Optimizing-Linux-RH-Edition-v1.3/net-manage.html
|
||||
[6]:http://tecmint.tradepub.com/free/w_opeb01/prgm.cgi
|
||||
@ -0,0 +1,178 @@
|
||||
Translating by ictlyh
|
||||
Part 2 - How to Perform Packet Filtering, Network Address Translation and Set Kernel Runtime Parameters
|
||||
================================================================================
|
||||
As promised in Part 1 (“[Setup Static Network Routing][1]”), in this article (Part 2 of RHCE series) we will begin by introducing the principles of packet filtering and network address translation (NAT) in Red Hat Enterprise Linux 7, before diving into setting runtime kernel parameters to modify the behavior of a running kernel if certain conditions change or needs arise.
|
||||
|
||||

|
||||
|
||||
RHCE: Network Packet Filtering – Part 2
|
||||
|
||||
### Network Packet Filtering in RHEL 7 ###
|
||||
|
||||
When we talk about packet filtering, we refer to a process performed by a firewall in which it reads the header of each data packet that attempts to pass through it. Then, it filters the packet by taking the required action based on rules that have been previously defined by the system administrator.
|
||||
|
||||
As you probably know, beginning with RHEL 7, the default service that manages firewall rules is [firewalld][2]. Like iptables, it talks to the netfilter module in the Linux kernel in order to examine and manipulate network packets. Unlike iptables, updates can take effect immediately without interrupting active connections – you don’t even have to restart the service.
|
||||
|
||||
Another advantage of firewalld is that it allows us to define rules based on pre-configured service names (more on that in a minute).
|
||||
|
||||
In Part 1, we used the following scenario:
|
||||
|
||||

|
||||
|
||||
Static Routing Network Diagram
|
||||
|
||||
However, you will recall that we disabled the firewall on router #2 to simplify the example since we had not covered packet filtering yet. Let’s see now how we can enable incoming packets destined for a specific service or port in the destination.
|
||||
|
||||
First, let’s add a permanent rule to allow inbound traffic in enp0s3 (192.168.0.19) to enp0s8 (10.0.0.18):
|
||||
|
||||
# firewall-cmd --permanent --direct --add-rule ipv4 filter FORWARD 0 -i enp0s3 -o enp0s8 -j ACCEPT
|
||||
|
||||
The above command will save the rule to /etc/firewalld/direct.xml:
|
||||
|
||||
# cat /etc/firewalld/direct.xml
|
||||
|
||||

|
||||
|
||||
Check Firewalld Saved Rules
|
||||
|
||||
Then enable the rule for it to take effect immediately:
|
||||
|
||||
# firewall-cmd --direct --add-rule ipv4 filter FORWARD 0 -i enp0s3 -o enp0s8 -j ACCEPT
|
||||
|
||||
Now you can telnet to the web server from the RHEL 7 box and run [tcpdump][3] again to monitor the TCP traffic between the two machines, this time with the firewall in router #2 enabled.
|
||||
|
||||
# telnet 10.0.0.20 80
|
||||
# tcpdump -qnnvvv -i enp0s3 host 10.0.0.20
|
||||
|
||||
What if you want to only allow incoming connections to the web server (port 80) from 192.168.0.18 and block connections from other sources in the 192.168.0.0/24 network?
|
||||
|
||||
In the web server’s firewall, add the following rules:
|
||||
|
||||
# firewall-cmd --add-rich-rule 'rule family="ipv4" source address="192.168.0.18/24" service name="http" accept'
|
||||
# firewall-cmd --add-rich-rule 'rule family="ipv4" source address="192.168.0.18/24" service name="http" accept' --permanent
|
||||
# firewall-cmd --add-rich-rule 'rule family="ipv4" source address="192.168.0.0/24" service name="http" drop'
|
||||
# firewall-cmd --add-rich-rule 'rule family="ipv4" source address="192.168.0.0/24" service name="http" drop' --permanent
|
||||
|
||||
Now you can make HTTP requests to the web server, from 192.168.0.18 and from some other machine in 192.168.0.0/24. In the first case the connection should complete successfully, whereas in the second it will eventually timeout.
|
||||
|
||||
To do so, any of the following commands will do the trick:
|
||||
|
||||
# telnet 10.0.0.20 80
|
||||
# wget 10.0.0.20
|
||||
|
||||
I strongly advise you to check out the [Firewalld Rich Language][4] documentation in the Fedora Project Wiki for further details on rich rules.
|
||||
|
||||
### Network Address Translation in RHEL 7 ###
|
||||
|
||||
Network Address Translation (NAT) is the process where a group of computers (it can also be just one of them) in a private network are assigned an unique public IP address. As result, they are still uniquely identified by their own private IP address inside the network but to the outside they all “seem” the same.
|
||||
|
||||
In addition, NAT makes it possible that computers inside a network sends requests to outside resources (like the Internet) and have the corresponding responses be sent back to the source system only.
|
||||
|
||||
Let’s now consider the following scenario:
|
||||
|
||||

|
||||
|
||||
Network Address Translation
|
||||
|
||||
In router #2, we will move the enp0s3 interface to the external zone, and enp0s8 to the internal zone, where masquerading, or NAT, is enabled by default:
|
||||
|
||||
# firewall-cmd --list-all --zone=external
|
||||
# firewall-cmd --change-interface=enp0s3 --zone=external
|
||||
# firewall-cmd --change-interface=enp0s3 --zone=external --permanent
|
||||
# firewall-cmd --change-interface=enp0s8 --zone=internal
|
||||
# firewall-cmd --change-interface=enp0s8 --zone=internal --permanent
|
||||
|
||||
For our current setup, the internal zone – along with everything that is enabled in it will be the default zone:
|
||||
|
||||
# firewall-cmd --set-default-zone=internal
|
||||
|
||||
Next, let’s reload firewall rules and keep state information:
|
||||
|
||||
# firewall-cmd --reload
|
||||
|
||||
Finally, let’s add router #2 as default gateway in the web server:
|
||||
|
||||
# ip route add default via 10.0.0.18
|
||||
|
||||
You can now verify that you can ping router #1 and an external site (tecmint.com, for example) from the web server:
|
||||
|
||||
# ping -c 2 192.168.0.1
|
||||
# ping -c 2 tecmint.com
|
||||
|
||||

|
||||
|
||||
Verify Network Routing
|
||||
|
||||
### Setting Kernel Runtime Parameters in RHEL 7 ###
|
||||
|
||||
In Linux, you are allowed to change, enable, and disable the kernel runtime parameters, and RHEL is no exception. The /proc/sys interface (sysctl) lets you set runtime parameters on-the-fly to modify the system’s behavior without much hassle when operating conditions change.
|
||||
|
||||
To do so, the echo shell built-in is used to write to files inside /proc/sys/<category>, where <category> is most likely one of the following directories:
|
||||
|
||||
- dev: parameters for specific devices connected to the machine.
|
||||
- fs: filesystem configuration (quotas and inodes, for example).
|
||||
- kernel: kernel-specific configuration.
|
||||
- net: network configuration.
|
||||
- vm: use of the kernel’s virtual memory.
|
||||
|
||||
To display the list of all the currently available values, run
|
||||
|
||||
# sysctl -a | less
|
||||
|
||||
In Part 1, we changed the value of the net.ipv4.ip_forward parameter by doing
|
||||
|
||||
# echo 1 > /proc/sys/net/ipv4/ip_forward
|
||||
|
||||
in order to allow a Linux machine to act as router.
|
||||
|
||||
Another runtime parameter that you may want to set is kernel.sysrq, which enables the Sysrq key in your keyboard to instruct the system to perform gracefully some low-level functions, such as rebooting the system if it has frozen for some reason:
|
||||
|
||||
# echo 1 > /proc/sys/kernel/sysrq
|
||||
|
||||
To display the value of a specific parameter, use sysctl as follows:
|
||||
|
||||
# sysctl <parameter.name>
|
||||
|
||||
For example,
|
||||
|
||||
# sysctl net.ipv4.ip_forward
|
||||
# sysctl kernel.sysrq
|
||||
|
||||
Some parameters, such as the ones mentioned above, require only one value, whereas others (for example, fs.inode-state) require multiple values:
|
||||
|
||||

|
||||
|
||||
Check Kernel Parameters
|
||||
|
||||
In either case, you need to read the kernel’s documentation before making any changes.
|
||||
|
||||
Please note that these settings will go away when the system is rebooted. To make these changes permanent, we will need to add .conf files inside the /etc/sysctl.d as follows:
|
||||
|
||||
# echo "net.ipv4.ip_forward = 1" > /etc/sysctl.d/10-forward.conf
|
||||
|
||||
(where the number 10 indicates the order of processing relative to other files in the same directory).
|
||||
|
||||
and enable the changes with
|
||||
|
||||
# sysctl -p /etc/sysctl.d/10-forward.conf
|
||||
|
||||
### Summary ###
|
||||
|
||||
In this tutorial we have explained the basics of packet filtering, network address translation, and setting kernel runtime parameters on a running system and persistently across reboots. I hope you have found this information useful, and as always, we look forward to hearing from you!
|
||||
Don’t hesitate to share with us your questions, comments, or suggestions using the form below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/perform-packet-filtering-network-address-translation-and-set-kernel-runtime-parameters-in-rhel/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/how-to-setup-and-configure-static-network-routing-in-rhel/
|
||||
[2]:http://www.tecmint.com/firewalld-rules-for-centos-7/
|
||||
[3]:http://www.tecmint.com/12-tcpdump-commands-a-network-sniffer-tool/
|
||||
[4]:https://fedoraproject.org/wiki/Features/FirewalldRichLanguage
|
||||
@ -0,0 +1,183 @@
|
||||
Translating by ictlyh
|
||||
Part 3 - How to Produce and Deliver System Activity Reports Using Linux Toolsets
|
||||
================================================================================
|
||||
As a system engineer, you will often need to produce reports that show the utilization of your system’s resources in order to make sure that: 1) they are being utilized optimally, 2) prevent bottlenecks, and 3) ensure scalability, among other reasons.
|
||||
|
||||

|
||||
|
||||
RHCE: Monitor Linux Performance Activity Reports – Part 3
|
||||
|
||||
Besides the well-known native Linux tools that are used to check disk, memory, and CPU usage – to name a few examples, Red Hat Enterprise Linux 7 provides two additional toolsets to enhance the data you can collect for your reports: sysstat and dstat.
|
||||
|
||||
In this article we will describe both, but let’s first start by reviewing the usage of the classic tools.
|
||||
|
||||
### Native Linux Tools ###
|
||||
|
||||
With df, you will be able to report disk space and inode usage of by filesystem. You need to monitor both because a lack of space will prevent you from being able to save further files (and may even cause the system to crash), just like running out of inodes will mean you can’t link further files with their corresponding data structures, thus producing the same effect: you won’t be able to save those files to disk.
|
||||
|
||||
# df -h [Display output in human-readable form]
|
||||
# df -h --total [Produce a grand total]
|
||||
|
||||
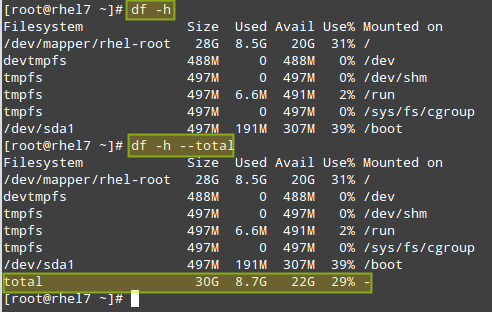
|
||||
|
||||
Check Linux Total Disk Usage
|
||||
|
||||
# df -i [Show inode count by filesystem]
|
||||
# df -i --total [Produce a grand total]
|
||||
|
||||

|
||||
|
||||
Check Linux Total inode Numbers
|
||||
|
||||
With du, you can estimate file space usage by either file, directory, or filesystem.
|
||||
|
||||
For example, let’s see how much space is used by the /home directory, which includes all of the user’s personal files. The first command will return the overall space currently used by the entire /home directory, whereas the second will also display a disaggregated list by sub-directory as well:
|
||||
|
||||
# du -sch /home
|
||||
# du -sch /home/*
|
||||
|
||||

|
||||
|
||||
Check Linux Directory Disk Size
|
||||
|
||||
Don’t Miss:
|
||||
|
||||
- [12 ‘df’ Command Examples to Check Linux Disk Space Usage][1]
|
||||
- [10 ‘du’ Command Examples to Find Disk Usage of Files/Directories][2]
|
||||
|
||||
Another utility that can’t be missing from your toolset is vmstat. It will allow you to see at a quick glance information about processes, CPU and memory usage, disk activity, and more.
|
||||
|
||||
If run without arguments, vmstat will return averages since the last reboot. While you may use this form of the command once in a while, it will be more helpful to take a certain amount of system utilization samples, one after another, with a defined time separation between samples.
|
||||
|
||||
For example,
|
||||
|
||||
# vmstat 5 10
|
||||
|
||||
will return 10 samples taken every 5 seconds:
|
||||
|
||||

|
||||
|
||||
Check Linux System Performance
|
||||
|
||||
As you can see in the above picture, the output of vmstat is divided by columns: procs (processes), memory, swap, io, system, and cpu. The meaning of each field can be found in the FIELD DESCRIPTION sections in the man page of vmstat.
|
||||
|
||||
Where can vmstat come in handy? Let’s examine the behavior of the system before and during a yum update:
|
||||
|
||||
# vmstat -a 1 5
|
||||
|
||||

|
||||
|
||||
Vmstat Linux Performance Monitoring
|
||||
|
||||
Please note that as files are being modified on disk, the amount of active memory increases and so does the number of blocks written to disk (bo) and the CPU time that is dedicated to user processes (us).
|
||||
|
||||
Or during the saving process of a large file directly to disk (caused by dsync):
|
||||
|
||||
# vmstat -a 1 5
|
||||
# dd if=/dev/zero of=dummy.out bs=1M count=1000 oflag=dsync
|
||||
|
||||

|
||||
|
||||
VmStat Linux Disk Performance Monitoring
|
||||
|
||||
In this case, we can see a yet larger number of blocks being written to disk (bo), which was to be expected, but also an increase of the amount of CPU time that it has to wait for I/O operations to complete before processing tasks (wa).
|
||||
|
||||
**Don’t Miss**: [Vmstat – Linux Performance Monitoring][3]
|
||||
|
||||
### Other Linux Tools ###
|
||||
|
||||
As mentioned in the introduction of this chapter, there are other tools that you can use to check the system status and utilization (they are not only provided by Red Hat but also by other major distributions from their officially supported repositories).
|
||||
|
||||
The sysstat package contains the following utilities:
|
||||
|
||||
- sar (collect, report, or save system activity information).
|
||||
- sadf (display data collected by sar in multiple formats).
|
||||
- mpstat (report processors related statistics).
|
||||
- iostat (report CPU statistics and I/O statistics for devices and partitions).
|
||||
- pidstat (report statistics for Linux tasks).
|
||||
- nfsiostat (report input/output statistics for NFS).
|
||||
- cifsiostat (report CIFS statistics) and
|
||||
- sa1 (collect and store binary data in the system activity daily data file.
|
||||
- sa2 (write a daily report in the /var/log/sa directory) tools.
|
||||
|
||||
whereas dstat adds some extra features to the functionality provided by those tools, along with more counters and flexibility. You can find an overall description of each tool by running yum info sysstat or yum info dstat, respectively, or checking the individual man pages after installation.
|
||||
|
||||
To install both packages:
|
||||
|
||||
# yum update && yum install sysstat dstat
|
||||
|
||||
The main configuration file for sysstat is /etc/sysconfig/sysstat. You will find the following parameters in that file:
|
||||
|
||||
# How long to keep log files (in days).
|
||||
# If value is greater than 28, then log files are kept in
|
||||
# multiple directories, one for each month.
|
||||
HISTORY=28
|
||||
# Compress (using gzip or bzip2) sa and sar files older than (in days):
|
||||
COMPRESSAFTER=31
|
||||
# Parameters for the system activity data collector (see sadc manual page)
|
||||
# which are used for the generation of log files.
|
||||
SADC_OPTIONS="-S DISK"
|
||||
# Compression program to use.
|
||||
ZIP="bzip2"
|
||||
|
||||
When sysstat is installed, two cron jobs are added and enabled in /etc/cron.d/sysstat. The first job runs the system activity accounting tool every 10 minutes and stores the reports in /var/log/sa/saXX where XX is the day of the month.
|
||||
|
||||
Thus, /var/log/sa/sa05 will contain all the system activity reports from the 5th of the month. This assumes that we are using the default value in the HISTORY variable in the configuration file above:
|
||||
|
||||
*/10 * * * * root /usr/lib64/sa/sa1 1 1
|
||||
|
||||
The second job generates a daily summary of process accounting at 11:53 pm every day and stores it in /var/log/sa/sarXX files, where XX has the same meaning as in the previous example:
|
||||
|
||||
53 23 * * * root /usr/lib64/sa/sa2 -A
|
||||
|
||||
For example, you may want to output system statistics from 9:30 am through 5:30 pm of the sixth of the month to a .csv file that can easily be viewed using LibreOffice Calc or Microsoft Excel (this approach will also allow you to create charts or graphs):
|
||||
|
||||
# sadf -s 09:30:00 -e 17:30:00 -dh /var/log/sa/sa06 -- | sed 's/;/,/g' > system_stats20150806.csv
|
||||
|
||||
You could alternatively use the -j flag instead of -d in the sadf command above to output the system stats in JSON format, which could be useful if you need to consume the data in a web application, for example.
|
||||
|
||||

|
||||
|
||||
Linux System Statistics
|
||||
|
||||
Finally, let’s see what dstat has to offer. Please note that if run without arguments, dstat assumes -cdngy by default (short for CPU, disk, network, memory pages, and system stats, respectively), and adds one line every second (execution can be interrupted anytime with Ctrl + C):
|
||||
|
||||
# dstat
|
||||
|
||||

|
||||
|
||||
Linux Disk Statistics Monitoring
|
||||
|
||||
To output the stats to a .csv file, use the –output flag followed by a file name. Let’s see how this looks on LibreOffice Calc:
|
||||
|
||||

|
||||
|
||||
Monitor Linux Statistics Output
|
||||
|
||||
I strongly advise you to check out the man page of dstat, included with this article along with the man page of sysstat in PDF format for your reading convenience. You will find several other options that will help you create custom and detailed system activity reports.
|
||||
|
||||
**Don’t Miss**: [Sysstat – Linux Usage Activity Monitoring Tool][4]
|
||||
|
||||
### Summary ###
|
||||
|
||||
In this guide we have explained how to use both native Linux tools and specific utilities provided with RHEL 7 in order to produce reports on system utilization. At one point or another, you will come to rely on these reports as best friends.
|
||||
|
||||
You will probably have used other tools that we have not covered in this tutorial. If so, feel free to share them with the rest of the community along with any other suggestions / questions / comments that you may have- using the form below.
|
||||
|
||||
We look forward to hearing from you.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-performance-monitoring-and-file-system-statistics-reports/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/how-to-check-disk-space-in-linux/
|
||||
[2]:http://www.tecmint.com/check-linux-disk-usage-of-files-and-directories/
|
||||
[3]:http://www.tecmint.com/linux-performance-monitoring-with-vmstat-and-iostat-commands/
|
||||
[4]:http://www.tecmint.com/install-sysstat-in-linux/
|
||||
@ -1,3 +1,5 @@
|
||||
FSSlc translating
|
||||
|
||||
RHCSA Series: Process Management in RHEL 7: Boot, Shutdown, and Everything in Between – Part 5
|
||||
================================================================================
|
||||
We will start this article with an overall and brief revision of what happens since the moment you press the Power button to turn on your RHEL 7 server until you are presented with the login screen in a command line interface.
|
||||
@ -213,4 +215,4 @@ via: http://www.tecmint.com/rhcsa-exam-boot-process-and-process-management/
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/dmesg-commands/
|
||||
[2]:http://www.tecmint.com/systemd-replaces-init-in-linux/
|
||||
[3]:http://www.tecmint.com/how-to-kill-a-process-in-linux/
|
||||
[3]:http://www.tecmint.com/how-to-kill-a-process-in-linux/
|
||||
|
||||
@ -0,0 +1,348 @@
|
||||
Shilpa Nair 分享了她面试 RedHat Linux 包管理方面的经验
|
||||
========================================================================
|
||||
**Shilpa Nair 刚于2015年毕业。她之后去了一家位于 Noida,Delhi 的国家新闻电视台,应聘实习生的岗位。在她去年毕业季的时候,常逛 Tecmint 寻求作业上的帮助。从那时开始,她就常去 Tecmint。**
|
||||
|
||||

|
||||
|
||||
有关 RPM 方面的 Linux 面试题
|
||||
|
||||
所有的问题和回答都是 Shilpa Nair 根据回忆重写的。
|
||||
|
||||
> “大家好!我是来自 Delhi 的Shilpa Nair。我不久前才顺利毕业,正寻找一个实习的机会。在大学早期的时候,我就对 UNIX 十分喜爱,所以我也希望这个机会能适合我,满足我的兴趣。我被提问了很多问题,大部分都是关于 RedHat 包管理的基础问题。”
|
||||
|
||||
下面就是我被问到的问题,和对应的回答。我仅贴出了与 RedHat GNU/Linux 包管理相关的,也是主要被提问的。
|
||||
|
||||
### 1,里如何查找一个包安装与否?假设你需要确认 ‘nano’ 有没有安装,你怎么做? ###
|
||||
|
||||
> **回答**:为了确认 nano 软件包有没有安装,我们可以使用 rpm 命令,配合 -q 和 -a 选项来查询所有已安装的包
|
||||
>
|
||||
> # rpm -qa nano
|
||||
> OR
|
||||
> # rpm -qa | grep -i nano
|
||||
>
|
||||
> nano-2.3.1-10.el7.x86_64
|
||||
>
|
||||
> 同时包的名字必须是完成的,不完整的包名返回提示,不打印任何东西,就是说这包(包名字不全)未安装。下面的例子会更好理解些:
|
||||
>
|
||||
> 我们通常使用 vim 替代 vi 命令。当时如果我们查找安装包 vi/vim 的时候,我们就会看到标准输出上没有任何结果。
|
||||
>
|
||||
> # vi
|
||||
> # vim
|
||||
>
|
||||
> 尽管如此,我们仍然可以通过使用 vi/vim 命令来清楚地知道包有没有安装。Here is ... name(这句不知道)。如果我们不确切知道完整的文件名,我们可以使用通配符:
|
||||
>
|
||||
> # rpm -qa vim*
|
||||
>
|
||||
> vim-minimal-7.4.160-1.el7.x86_64
|
||||
>
|
||||
> 通过这种方式,我们可以获得任何软件包的信息,安装与否。
|
||||
|
||||
### 2. 你如何使用 rpm 命令安装 XYZ 软件包? ###
|
||||
|
||||
> **回答**:我们可以使用 rpm 命令安装任何的软件包(*.rpm),像下面这样,选项 -i(install),-v(冗余或者显示额外的信息)和 -h(打印#号显示进度,在安装过程中)。
|
||||
>
|
||||
> # rpm -ivh peazip-1.11-1.el6.rf.x86_64.rpm
|
||||
>
|
||||
> Preparing... ################################# [100%]
|
||||
> Updating / installing...
|
||||
> 1:peazip-1.11-1.el6.rf ################################# [100%]
|
||||
>
|
||||
> 如果要升级一个早期版本的包,应加上 -U 选项,选项 -v 和 -h 可以确保我们得到用 # 号表示的冗余输出,这增加了可读性。
|
||||
|
||||
### 3. 你已经安装了一个软件包(假设是 httpd),现在你想看看软件包创建并安装的所有文件和目录,你会怎么做? ###
|
||||
|
||||
> **回答**:使用选项 -l(列出所有文件)和 -q(查询)列出 httpd 软件包安装的所有文件(Linux哲学:所有的都是文件,包括目录)。
|
||||
>
|
||||
> # rpm -ql httpd
|
||||
>
|
||||
> /etc/httpd
|
||||
> /etc/httpd/conf
|
||||
> /etc/httpd/conf.d
|
||||
> ...
|
||||
|
||||
### 4. 假如你要移除一个软件包,叫 postfix。你会怎么做? ###
|
||||
|
||||
> **回答**:首先我们需要知道什么包安装了 postfix。查找安装 postfix 的包名后,使用 -e(擦除/卸载软件包)和 -v(冗余输出)两个选项来实现。
|
||||
>
|
||||
> # rpm -qa postfix*
|
||||
>
|
||||
> postfix-2.10.1-6.el7.x86_64
|
||||
>
|
||||
> 然后移除 postfix,如下:
|
||||
>
|
||||
> # rpm -ev postfix-2.10.1-6.el7.x86_64
|
||||
>
|
||||
> Preparing packages...
|
||||
> postfix-2:3.0.1-2.fc22.x86_64
|
||||
|
||||
### 5. 获得一个已安装包的具体信息,如版本,发行号,安装日期,大小,总结和一个间短的描述。 ###
|
||||
|
||||
> **回答**:我们通过使用 rpm 的选项 -qi,后面接包名,可以获得关于一个已安装包的具体信息。
|
||||
>
|
||||
> 举个例子,为了获得 openssh 包的具体信息,我需要做的就是:
|
||||
>
|
||||
> # rpm -qi openssh
|
||||
>
|
||||
> [root@tecmint tecmint]# rpm -qi openssh
|
||||
> Name : openssh
|
||||
> Version : 6.8p1
|
||||
> Release : 5.fc22
|
||||
> Architecture: x86_64
|
||||
> Install Date: Thursday 28 May 2015 12:34:50 PM IST
|
||||
> Group : Applications/Internet
|
||||
> Size : 1542057
|
||||
> License : BSD
|
||||
> ....
|
||||
|
||||
### 6. 假如你不确定一个指定包的配置文件在哪,比如 httpd。你如何找到所有 httpd 提供的配置文件列表和位置。 ###
|
||||
|
||||
> **回答**: 我们需要用选项 -c 接包名,这会列出所有配置文件的名字和他们的位置。
|
||||
>
|
||||
> # rpm -qc httpd
|
||||
>
|
||||
> /etc/httpd/conf.d/autoindex.conf
|
||||
> /etc/httpd/conf.d/userdir.conf
|
||||
> /etc/httpd/conf.d/welcome.conf
|
||||
> /etc/httpd/conf.modules.d/00-base.conf
|
||||
> /etc/httpd/conf/httpd.conf
|
||||
> /etc/sysconfig/httpd
|
||||
>
|
||||
> 相似地,我们可以列出所有相关的文档文件,如下:
|
||||
>
|
||||
> # rpm -qd httpd
|
||||
>
|
||||
> /usr/share/doc/httpd/ABOUT_APACHE
|
||||
> /usr/share/doc/httpd/CHANGES
|
||||
> /usr/share/doc/httpd/LICENSE
|
||||
> ...
|
||||
>
|
||||
> 我们也可以列出所有相关的证书文件,如下:
|
||||
>
|
||||
> # rpm -qL openssh
|
||||
>
|
||||
> /usr/share/licenses/openssh/LICENCE
|
||||
>
|
||||
> 忘了说明上面的选项 -d 和 -L 分别表示 “文档” 和 “证书”,抱歉。
|
||||
|
||||
### 7. 你进入了一个配置文件,位于‘/usr/share/alsa/cards/AACI.conf’,现在你不确定该文件属于哪个包。你如何查找出包的名字? ###
|
||||
|
||||
> **回答**:当一个包被安装后,相关的信息就存储在了数据库里。所以使用选项 -qf(-f 查询包拥有的文件)很容易追踪谁提供了上述的包。
|
||||
>
|
||||
> # rpm -qf /usr/share/alsa/cards/AACI.conf
|
||||
> alsa-lib-1.0.28-2.el7.x86_64
|
||||
>
|
||||
> 类似地,我们可以查找(谁提供的)关于任何子包,文档和证书文件的信息。
|
||||
|
||||
### 8. 你如何使用 rpm 查找最近安装的软件列表? ###
|
||||
|
||||
> **回答**:如刚刚说的,每一样被安装的文件都记录在了数据库里。所以这并不难,通过查询 rpm 的数据库,找到最近安装软件的列表。
|
||||
>
|
||||
> 我们通过运行下面的命令,使用选项 -last(打印出最近安装的软件)达到目的。
|
||||
>
|
||||
> # rpm -qa --last
|
||||
>
|
||||
> 上面的命令会打印出所有安装的软件,最近一次安装的软件在列表的顶部。
|
||||
>
|
||||
> 如果我们关心的是找出特定的包,我们可以使用 grep 命令从列表中匹配包(假设是 sqlite ),简单如下:
|
||||
>
|
||||
> # rpm -qa --last | grep -i sqlite
|
||||
>
|
||||
> sqlite-3.8.10.2-1.fc22.x86_64 Thursday 18 June 2015 05:05:43 PM IST
|
||||
>
|
||||
> 我们也可以获得10个最近安装的软件列表,简单如下:
|
||||
>
|
||||
> # rpm -qa --last | head
|
||||
>
|
||||
> 我们可以重定义一下,输出想要的结果,简单如下:
|
||||
>
|
||||
> # rpm -qa --last | head -n 2
|
||||
>
|
||||
> 上面的命令中,-n 代表数目,后面接一个常数值。该命令是打印2个最近安装的软件的列表。
|
||||
|
||||
### 9. 安装一个包之前,你如果要检查其依赖。你会怎么做? ###
|
||||
|
||||
> **回答**:检查一个 rpm 包(XYZ.rpm)的依赖,我们可以使用选项 -q(查询包),-p(指定包名)和 -R(查询/列出该包依赖的包,嗯,就是依赖)。
|
||||
>
|
||||
> # rpm -qpR gedit-3.16.1-1.fc22.i686.rpm
|
||||
>
|
||||
> /bin/sh
|
||||
> /usr/bin/env
|
||||
> glib2(x86-32) >= 2.40.0
|
||||
> gsettings-desktop-schemas
|
||||
> gtk3(x86-32) >= 3.16
|
||||
> gtksourceview3(x86-32) >= 3.16
|
||||
> gvfs
|
||||
> libX11.so.6
|
||||
> ...
|
||||
|
||||
### 10. rpm 是不是一个前端的包管理工具呢? ###
|
||||
|
||||
> **回答**:不是!rpm 是一个后端管理工具,适用于基于 Linux 发行版的 RPM (此处指 Redhat Package Management)。
|
||||
>
|
||||
> [YUM][1],全称 Yellowdog Updater Modified,是一个 RPM 的前端工具。YUM 命令自动完成所有工作,包括解决依赖和其他一切事务。
|
||||
>
|
||||
> 最近,[DNF][2](YUM命令升级版)在Fedora 22发行版中取代了 YUM。尽管 YUM 仍然可以在 RHEL 和 CentOS 平台使用,我们也可以安装 dnf,与 YUM 命令共存使用。据说 DNF 较于 YUM 有很多提高。
|
||||
>
|
||||
> 知道更多总是好的,保持自我更新。现在我们移步到前端部分来谈谈。
|
||||
|
||||
### 11. 你如何列出一个系统上面所有可用的仓库列表。 ###
|
||||
|
||||
> **回答**:简单地使用下面的命令,我们就可以列出一个系统上所有可用的仓库列表。
|
||||
>
|
||||
> # yum repolist
|
||||
> 或
|
||||
> # dnf repolist
|
||||
>
|
||||
> Last metadata expiration check performed 0:30:03 ago on Mon Jun 22 16:50:00 2015.
|
||||
> repo id repo name status
|
||||
> *fedora Fedora 22 - x86_64 44,762
|
||||
> ozonos Repository for Ozon OS 61
|
||||
> *updates Fedora 22 - x86_64 - Updates
|
||||
>
|
||||
> 上面的命令仅会列出可用的仓库。如果你需要列出所有的仓库,不管可用与否,可以这样做。
|
||||
>
|
||||
> # yum repolist all
|
||||
> or
|
||||
> # dnf repolist all
|
||||
>
|
||||
> Last metadata expiration check performed 0:29:45 ago on Mon Jun 22 16:50:00 2015.
|
||||
> repo id repo name status
|
||||
> *fedora Fedora 22 - x86_64 enabled: 44,762
|
||||
> fedora-debuginfo Fedora 22 - x86_64 - Debug disabled
|
||||
> fedora-source Fedora 22 - Source disabled
|
||||
> ozonos Repository for Ozon OS enabled: 61
|
||||
> *updates Fedora 22 - x86_64 - Updates enabled: 5,018
|
||||
> updates-debuginfo Fedora 22 - x86_64 - Updates - Debug
|
||||
|
||||
### 12. 你如何列出一个系统上所有可用并且安装了的包? ###
|
||||
|
||||
> **回答**:列出一个系统上所有可用的包,我们可以这样做:
|
||||
>
|
||||
> # yum list available
|
||||
> 或
|
||||
> # dnf list available
|
||||
>
|
||||
> ast metadata expiration check performed 0:34:09 ago on Mon Jun 22 16:50:00 2015.
|
||||
> Available Packages
|
||||
> 0ad.x86_64 0.0.18-1.fc22 fedora
|
||||
> 0ad-data.noarch 0.0.18-1.fc22 fedora
|
||||
> 0install.x86_64 2.6.1-2.fc21 fedora
|
||||
> 0xFFFF.x86_64 0.3.9-11.fc22 fedora
|
||||
> 2048-cli.x86_64 0.9-4.git20141214.723738c.fc22 fedora
|
||||
> 2048-cli-nocurses.x86_64 0.9-4.git20141214.723738c.fc22 fedora
|
||||
> ....
|
||||
>
|
||||
> 而列出一个系统上所有已安装的包,我们可以这样做。
|
||||
>
|
||||
> # yum list installed
|
||||
> or
|
||||
> # dnf list installed
|
||||
>
|
||||
> Last metadata expiration check performed 0:34:30 ago on Mon Jun 22 16:50:00 2015.
|
||||
> Installed Packages
|
||||
> GeoIP.x86_64 1.6.5-1.fc22 @System
|
||||
> GeoIP-GeoLite-data.noarch 2015.05-1.fc22 @System
|
||||
> NetworkManager.x86_64 1:1.0.2-1.fc22 @System
|
||||
> NetworkManager-libnm.x86_64 1:1.0.2-1.fc22 @System
|
||||
> aajohan-comfortaa-fonts.noarch 2.004-4.fc22 @System
|
||||
> ....
|
||||
>
|
||||
> 而要同时满足两个要求的时候,我们可以这样做。
|
||||
>
|
||||
> # yum list
|
||||
> 或
|
||||
> # dnf list
|
||||
>
|
||||
> Last metadata expiration check performed 0:32:56 ago on Mon Jun 22 16:50:00 2015.
|
||||
> Installed Packages
|
||||
> GeoIP.x86_64 1.6.5-1.fc22 @System
|
||||
> GeoIP-GeoLite-data.noarch 2015.05-1.fc22 @System
|
||||
> NetworkManager.x86_64 1:1.0.2-1.fc22 @System
|
||||
> NetworkManager-libnm.x86_64 1:1.0.2-1.fc22 @System
|
||||
> aajohan-comfortaa-fonts.noarch 2.004-4.fc22 @System
|
||||
> acl.x86_64 2.2.52-7.fc22 @System
|
||||
> ....
|
||||
|
||||
### 13. 你会怎么分别安装和升级一个包与一组包,在一个系统上面使用 YUM/DNF? ###
|
||||
|
||||
> **回答**:安装一个包(假设是 nano),我们可以这样做,
|
||||
>
|
||||
> # yum install nano
|
||||
>
|
||||
> 而安装一组包(假设是 Haskell),我们可以这样做,
|
||||
>
|
||||
> # yum groupinstall 'haskell'
|
||||
>
|
||||
> 升级一个包(还是 nano),我们可以这样做,
|
||||
>
|
||||
> # yum update nano
|
||||
>
|
||||
> 而为了升级一组包(还是 haskell),我们可以这样做,
|
||||
>
|
||||
> # yum groupupdate 'haskell'
|
||||
|
||||
### 14. 你会如何同步一个系统上面的所有安装软件到稳定发行版? ###
|
||||
|
||||
> **回答**:我们可以一个系统上(假设是 CentOS 或者 Fedora)的所有包到稳定发行版,如下,
|
||||
>
|
||||
> # yum distro-sync [On CentOS/ RHEL]
|
||||
> 或
|
||||
> # dnf distro-sync [On Fedora 20之后版本]
|
||||
|
||||
似乎来面试之前你做了相当不多的功课,很好!在进一步交谈前,我还想问一两个问题。
|
||||
|
||||
### 15. 你对 YUM 本地仓库熟悉吗?你尝试过建立一个本地 YUM 仓库吗?让我们简单看看你会怎么建立一个本地 YUM 仓库。 ###
|
||||
|
||||
> **回答**:首先,感谢你的夸奖。回到问题,我必须承认我对本地 YUM 仓库十分熟悉,并且在我的本地主机上也部署过,作为测试用。
|
||||
>
|
||||
> 1. 为了建立本地 YUM 仓库,我们需要安装下面三个包:
|
||||
>
|
||||
> # yum install deltarpm python-deltarpm createrepo
|
||||
>
|
||||
> 2. 新建一个目录(假设 /home/$USER/rpm),然后复制 RedHat/CentOS DVD 上的 RPM 包到这个文件夹下
|
||||
>
|
||||
> # mkdir /home/$USER/rpm
|
||||
> # cp /path/to/rpm/on/DVD/*.rpm /home/$USER/rpm
|
||||
>
|
||||
> 3. 新建基本的库头文件如下。
|
||||
>
|
||||
> # createrepo -v /home/$USER/rpm
|
||||
>
|
||||
> 4. 在路径 /etc/yum.repo.d 下创建一个 .repo 文件(如 abc.repo):
|
||||
>
|
||||
> cd /etc/yum.repos.d && cat << EOF > abc.repo
|
||||
> [local-installation]name=yum-local
|
||||
> baseurl=file:///home/$USER/rpm
|
||||
> enabled=1
|
||||
> gpgcheck=0
|
||||
> EOF
|
||||
|
||||
**重要**:用你的用户名替换掉 $USER。
|
||||
|
||||
以上就是创建一个本地 YUM 仓库所要做的全部工作。我们现在可以从这里安装软件了,相对快一些,安全一些,并且最重要的是不需要 Internet 连接。
|
||||
|
||||
好了!面试过程很愉快。我已经问完了。我会将你推荐给 HR。你是一个年轻且十分聪明的候选者,我们很愿意你加入进来。如果你有任何问题,你可以问我。
|
||||
|
||||
**我**:谢谢,这确实是一次愉快的面试,我感到非常幸运今天,然后这次面试就毁了。。。
|
||||
|
||||
显然,不会在这里结束。我问了很多问题,比如他们正在做的项目。我会担任什么角色,负责什么,,,balabalabala
|
||||
|
||||
小伙伴们,3天以前 HR 轮的所有问题到时候也会被写成文档。希望我当时表现不错。感谢你们所有的祝福。
|
||||
|
||||
谢谢伙伴们和 Tecmint,花时间来编辑我的面试经历。我相信 Tecmint 好伙伴们做了很大的努力,必要要赞一个。当我们与他人分享我们的经历的时候,其他人从我们这里知道了更多,而我们自己则发现了自己的不足。
|
||||
|
||||
这增加了我们的信心。如果你最近也有任何类似的面试经历,别自己蔵着。分享出来!让我们所有人都知道。你可以使用如下的格式来与我们分享你的经历。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-rpm-package-management-interview-questions/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[wi-cuckoo](https://github.com/wi-cuckoo)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
|
||||
[2]:http://www.tecmint.com/dnf-commands-for-fedora-rpm-package-management/
|
||||
@ -0,0 +1,154 @@
|
||||
|
||||
如何使用 Datadog 监控 NGINX - 第3部分
|
||||
================================================================================
|
||||

|
||||
|
||||
如果你已经阅读了[前面的如何监控 NGINX][1],你应该知道从你网络环境的几个指标中可以获取多少信息。而且你也看到了从 NGINX 特定的基础中收集指标是多么容易的。但要实现全面,持续的监控 NGINX,你需要一个强大的监控系统来存储并将指标可视化,当异常发生时能提醒你。在这篇文章中,我们将向你展示如何使用 Datadog 安装 NGINX 监控,以便你可以在定制的仪表盘中查看这些指标:
|
||||
|
||||

|
||||
|
||||
Datadog 允许你建立单个主机,服务,流程,度量,或者几乎任何它们的组合图形周围和警报。例如,你可以在一定的可用性区域监控所有NGINX主机,或所有主机,或者您可以监视被报道具有一定标签的所有主机的一个关键指标。本文将告诉您如何:
|
||||
|
||||
Datadog 允许你来建立图表并报告周围的主机,进程,指标或其他的。例如,你可以在特定的可用性区域监控所有 NGINX 主机,或所有主机,或者你可以监视一个关键指标并将它报告给周围所有标记的主机。本文将告诉你如何做:
|
||||
|
||||
- 在 Datadog 仪表盘上监控 NGINX 指标,对其他所有系统
|
||||
- 当一个关键指标急剧变化时设置自动警报来通知你
|
||||
|
||||
### 配置 NGINX ###
|
||||
|
||||
为了收集 NGINX 指标,首先需要确保 NGINX 已启用 status 模块和一个URL 来报告 status 指标。下面将一步一步展示[配置开源 NGINX ][2]和[NGINX Plus][3]。
|
||||
|
||||
### 整合 Datadog 和 NGINX ###
|
||||
|
||||
#### 安装 Datadog 代理 ####
|
||||
|
||||
Datadog 代理是 [一个开源软件][4] 能收集和报告你主机的指标,这样就可以使用 Datadog 查看和监控他们。安装代理通常 [仅需要一个命令][5]
|
||||
|
||||
只要你的代理启动并运行着,你会看到你主机的指标报告[在你 Datadog 账号下][6]。
|
||||
|
||||

|
||||
|
||||
#### 配置 Agent ####
|
||||
|
||||
|
||||
接下来,你需要为代理创建一个简单的 NGINX 配置文件。在你系统中代理的配置目录应该 [在这儿][7]。
|
||||
|
||||
在目录里面的 conf.d/nginx.yaml.example 中,你会发现[一个简单的配置文件][8],你可以编辑并提供 status URL 和可选的标签为每个NGINX 实例:
|
||||
|
||||
init_config:
|
||||
|
||||
instances:
|
||||
|
||||
- nginx_status_url: http://localhost/nginx_status/
|
||||
tags:
|
||||
- instance:foo
|
||||
|
||||
一旦你修改了 status URLs 和其他标签,将配置文件保存为 conf.d/nginx.yaml。
|
||||
|
||||
#### 重启代理 ####
|
||||
|
||||
|
||||
你必须重新启动代理程序来加载新的配置文件。重新启动命令 [在这里][9] 根据平台的不同而不同。
|
||||
|
||||
#### 检查配置文件 ####
|
||||
|
||||
要检查 Datadog 和 NGINX 是否正确整合,运行 Datadog 的信息命令。每个平台使用的命令[看这儿][10]。
|
||||
|
||||
如果配置是正确的,你会看到这样的输出:
|
||||
|
||||
Checks
|
||||
======
|
||||
|
||||
[...]
|
||||
|
||||
nginx
|
||||
-----
|
||||
- instance #0 [OK]
|
||||
- Collected 8 metrics & 0 events
|
||||
|
||||
#### 安装整合 ####
|
||||
|
||||
最后,在你的 Datadog 帐户里面整合 Nginx。这非常简单,你只要点击“Install Integration”按钮在 [NGINX 集成设置][11] 配置表中。
|
||||
|
||||

|
||||
|
||||
### 指标! ###
|
||||
|
||||
一旦代理开始报告 NGINX 指标,你会看到 [一个 NGINX 仪表盘][12] 在你 Datadog 可用仪表盘的列表中。
|
||||
|
||||
基本的 NGINX 仪表盘显示了几个关键指标 [在我们介绍的 NGINX 监控中][13] 的最大值。 (一些指标,特别是请求处理时间,日志分析,Datadog 不提供。)
|
||||
|
||||
你可以轻松创建一个全面的仪表盘来监控你的整个网站区域通过增加额外的图形与 NGINX 外部的重要指标。例如,你可能想监视你 NGINX 主机的host-level 指标,如系统负载。你需要构建一个自定义的仪表盘,只需点击靠近仪表盘的右上角的选项并选择“Clone Dash”来克隆一个默认的 NGINX 仪表盘。
|
||||
|
||||

|
||||
|
||||
你也可以更高级别的监控你的 NGINX 实例通过使用 Datadog 的 [Host Maps][14] -对于实例,color-coding 你所有的 NGINX 主机通过 CPU 使用率来辨别潜在热点。
|
||||
|
||||

|
||||
|
||||
### NGINX 指标 ###
|
||||
|
||||
一旦 Datadog 捕获并可视化你的指标,你可能会希望建立一些监控自动密切的关注你的指标,并当有问题提醒你。下面将介绍一个典型的例子:一个提醒你 NGINX 吞吐量突然下降时的指标监控器。
|
||||
|
||||
#### 监控 NGINX 吞吐量 ####
|
||||
|
||||
Datadog 指标警报可以是 threshold-based(当指标超过设定值会警报)或 change-based(当指标的变化超过一定范围会警报)。在这种情况下,我们会采取后一种方式,当每秒传入的请求急剧下降时会提醒我们。下降往往意味着有问题。
|
||||
|
||||
1.**创建一个新的指标监控**. 从 Datadog 的“Monitors”下拉列表中选择“New Monitor”。选择“Metric”作为监视器类型。
|
||||
|
||||

|
||||
|
||||
2.**定义你的指标监视器**. 我们想知道 NGINX 每秒总的请求量下降的数量。所以我们在基础设施中定义我们感兴趣的 nginx.net.request_per_s度量和。
|
||||
|
||||

|
||||
|
||||
3.**设置指标警报条件**.我们想要在变化时警报,而不是一个固定的值,所以我们选择“Change Alert”。我们设置监控为无论何时请求量下降了30%以上时警报。在这里,我们使用一个 one-minute 数据窗口来表示“now” 指标的值,警报横跨该间隔内的平均变化,和之前 10 分钟的指标值作比较。
|
||||
|
||||

|
||||
|
||||
4.**自定义通知**.如果 NGINX 的请求量下降,我们想要通知我们的团队。在这种情况下,我们将给 ops 队的聊天室发送通知,网页呼叫工程师。在“Say what’s happening”中,我们将其命名为监控器并添加一个短消息将伴随该通知并建议首先开始调查。我们使用 @mention 作为一般警告,使用 ops 并用 @pagerduty [专门给 PagerDuty 发警告][15]。
|
||||
|
||||

|
||||
|
||||
5.**保存集成监控**.点击页面底部的“Save”按钮。你现在监控的关键指标NGINX [work 指标][16],它边打电话给工程师并在它迅速下时随时分页。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
在这篇文章中,我们已经通过整合 NGINX 与 Datadog 来可视化你的关键指标,并当你的网络基础架构有问题时会通知你的团队。
|
||||
|
||||
如果你一直使用你自己的 Datadog 账号,你现在应该在 web 环境中有了很大的可视化提高,也有能力根据你的环境创建自动监控,你所使用的模式,指标应该是最有价值的对你的组织。
|
||||
|
||||
如果你还没有 Datadog 帐户,你可以注册[免费试用][17],并开始监视你的基础架构,应用程序和现在的服务。
|
||||
|
||||
----------
|
||||
这篇文章的来源在 [on GitHub][18]. 问题,错误,补充等?请[联系我们][19].
|
||||
|
||||
------------------------------------------------------------
|
||||
|
||||
via: https://www.datadoghq.com/blog/how-to-monitor-nginx-with-datadog/
|
||||
|
||||
作者:K Young
|
||||
译者:[strugglingyouth](https://github.com/译者ID)
|
||||
校对:[strugglingyouth](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://www.datadoghq.com/blog/how-to-monitor-nginx/
|
||||
[2]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#open-source
|
||||
[3]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#plus
|
||||
[4]:https://github.com/DataDog/dd-agent
|
||||
[5]:https://app.datadoghq.com/account/settings#agent
|
||||
[6]:https://app.datadoghq.com/infrastructure
|
||||
[7]:http://docs.datadoghq.com/guides/basic_agent_usage/
|
||||
[8]:https://github.com/DataDog/dd-agent/blob/master/conf.d/nginx.yaml.example
|
||||
[9]:http://docs.datadoghq.com/guides/basic_agent_usage/
|
||||
[10]:http://docs.datadoghq.com/guides/basic_agent_usage/
|
||||
[11]:https://app.datadoghq.com/account/settings#integrations/nginx
|
||||
[12]:https://app.datadoghq.com/dash/integration/nginx
|
||||
[13]:https://www.datadoghq.com/blog/how-to-monitor-nginx/
|
||||
[14]:https://www.datadoghq.com/blog/introducing-host-maps-know-thy-infrastructure/
|
||||
[15]:https://www.datadoghq.com/blog/pagerduty/
|
||||
[16]:https://www.datadoghq.com/blog/monitoring-101-collecting-data/#metrics
|
||||
[17]:https://www.datadoghq.com/blog/how-to-monitor-nginx-with-datadog/#sign-up
|
||||
[18]:https://github.com/DataDog/the-monitor/blob/master/nginx/how_to_monitor_nginx_with_datadog.md
|
||||
[19]:https://github.com/DataDog/the-monitor/issues
|
||||
@ -0,0 +1,62 @@
|
||||
Darkstat一个基于网络的流量分析器 - 在Linux中安装
|
||||
================================================================================
|
||||
Darkstat是一个简易的,基于网络的流量分析程序。它可以在主流的操作系统如Linux、Solaris、MAC、AIX上工作。它以守护进程的形式持续工作在后台并不断地嗅探网络数据并以简单易懂的形式展现在网页上。它可以为主机生成流量报告,鉴别特定主机上哪些端口打开并且兼容IPv6。让我们看下如何在Linux中安装和配置它。
|
||||
|
||||
### 在Linux中安装配置Darkstat ###
|
||||
|
||||
** 在Fedora/CentOS/RHEL中安装Darkstat:**
|
||||
|
||||
要在Fedora/RHEL和CentOS中安装,运行下面的命令。
|
||||
|
||||
sudo yum install darkstat
|
||||
|
||||
**在Ubuntu/Debian中安装Darkstat:**
|
||||
|
||||
运行下面的命令在Ubuntu和Debian中安装。
|
||||
|
||||
sudo apt-get install darkstat
|
||||
|
||||
恭喜你,Darkstat已经在你的Linux中安装了。
|
||||
|
||||
### 配置 Darkstat ###
|
||||
|
||||
为了正确运行这个程序,我恩需要执行一些基本的配置。运行下面的命令用gedit编辑器打开/etc/darkstat/init.cfg文件。
|
||||
|
||||
sudo gedit /etc/darkstat/init.cfg
|
||||
|
||||

|
||||
编辑 Darkstat
|
||||
|
||||
修改START_DARKSTAT这个参数为yes,并在“INTERFACE”中提供你的网络接口。确保取消了DIR、PORT、BINDIP和LOCAL这些参数的注释。如果你希望绑定Darkstat到特定的IP,在BINDIP中提供它
|
||||
|
||||
### 启动Darkstat守护进程 ###
|
||||
|
||||
安装并配置完Darkstat后,运行下面的命令启动它的守护进程。
|
||||
|
||||
sudo /etc/init.d/darkstat start
|
||||
|
||||

|
||||
|
||||
你可以用下面的命令来在开机时启动Darkstat:
|
||||
|
||||
chkconfig darkstat on
|
||||
|
||||
打开浏览器并打开**http://localhost:666**,它会显示Darkstat的网页界面。使用这个工具来分析你的网络流量。
|
||||
|
||||

|
||||
|
||||
### 总结 ###
|
||||
|
||||
它是一个占用很少内存的轻量级工具。这个工具流行的原因是简易、易于配置和使用。这是一个对系统管理员而言必须拥有的程序
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxpitstop.com/install-darkstat-on-ubuntu-linux/
|
||||
|
||||
作者:[Aun][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxpitstop.com/author/aun/
|
||||
@ -0,0 +1,99 @@
|
||||
如何在 Linux 中从 Google Play 商店里下载 apk 文件
|
||||
================================================================================
|
||||
假设你想在你的 Android 设备中安装一个 Android 应用,然而由于某些原因,你不能在 Andor 设备上访问 Google Play 商店。接着你该怎么做呢?在不访问 Google Play 商店的前提下安装应用的一种可能的方法是使用其他的手段下载该应用的 APK 文件,然后手动地在 Android 设备上 [安装 APK 文件][1]。
|
||||
|
||||
在非 Android 设备如常规的电脑和笔记本电脑上,有着几种方式来从 Google Play 商店下载到官方的 APK 文件。例如,使用浏览器插件(例如, 针对 [Chrome][2] 或针对 [Firefox][3] 的插件) 或利用允许你使用浏览器下载 APK 文件的在线的 APK 存档等。假如你不信任这些闭源的插件或第三方的 APK 仓库,这里有另一种手动下载官方 APK 文件的方法,它使用一个名为 [GooglePlayDownloader][4] 的开源 Linux 应用。
|
||||
|
||||
GooglePlayDownloader 是一个基于 Python 的 GUI 应用,使得你可以从 Google Play 商店上搜索和下载 APK 文件。由于它是完全开源的,你可以放心地使用它。在本篇教程中,我将展示如何在 Linux 环境下,使用 GooglePlayDownloader 来从 Google Play 商店下载 APK 文件。
|
||||
|
||||
### Python 需求 ###
|
||||
|
||||
GooglePlayDownloader 需要使用 Python 中 SSL 模块的扩展 SNI(服务器名称指示) 来支持 SSL/TLS 通信,该功能由 Python 2.7.9 或更高版本带来。这使得一些旧的发行版本如 Debian 7 Wheezy 及早期版本,Ubuntu 14.04 及早期版本或 CentOS/RHEL 7 及早期版本均不能满足该要求。假设你已经有了一个带有 Python 2.7.9 或更高版本的发行版本,可以像下面这样接着安装 GooglePlayDownloader。
|
||||
|
||||
### 在 Ubuntu 上安装 GooglePlayDownloader ###
|
||||
|
||||
在 Ubuntu 上,你可以使用官方构建的 deb 包。有一个条件是你可能需要手动地安装一个必需的依赖。
|
||||
|
||||
#### 在 Ubuntu 14.10 上 ####
|
||||
|
||||
下载 [python-ndg-httpsclient][5] deb 软件包,这在旧一点的 Ubuntu 发行版本中是一个缺失的依赖。同时还要下载 GooglePlayDownloader 的官方 deb 软件包。
|
||||
|
||||
$ wget http://mirrors.kernel.org/ubuntu/pool/main/n/ndg-httpsclient/python-ndg-httpsclient_0.3.2-1ubuntu4_all.deb
|
||||
$ wget http://codingteam.net/project/googleplaydownloader/download/file/googleplaydownloader_1.7-1_all.deb
|
||||
|
||||
如下所示,我们将使用 [gdebi 命令][6] 来安装这两个 deb 文件。 gedbi 命令将自动地处理任何其他的依赖。
|
||||
|
||||
$ sudo apt-get install gdebi-core
|
||||
$ sudo gdebi python-ndg-httpsclient_0.3.2-1ubuntu4_all.deb
|
||||
$ sudo gdebi googleplaydownloader_1.7-1_all.deb
|
||||
|
||||
#### 在 Ubuntu 15.04 或更新的版本上 ####
|
||||
|
||||
最近的 Ubuntu 发行版本上已经配备了所有需要的依赖,所以安装过程可以如下面那样直接进行。
|
||||
|
||||
$ wget http://codingteam.net/project/googleplaydownloader/download/file/googleplaydownloader_1.7-1_all.deb
|
||||
$ sudo apt-get install gdebi-core
|
||||
$ sudo gdebi googleplaydownloader_1.7-1_all.deb
|
||||
|
||||
### 在 Debian 上安装 GooglePlayDownloader ###
|
||||
|
||||
由于其 Python 需求, Googleplaydownloader 不能被安装到 Debian 7 Wheezy 或早期版本上,除非你升级了它自备的 Python 版本。
|
||||
|
||||
#### 在 Debian 8 Jessie 及更高版本上: ####
|
||||
|
||||
$ wget http://codingteam.net/project/googleplaydownloader/download/file/googleplaydownloader_1.7-1_all.deb
|
||||
$ sudo apt-get install gdebi-core
|
||||
$ sudo gdebi googleplaydownloader_1.7-1_all.deb
|
||||
|
||||
### 在 Fedora 上安装 GooglePlayDownloader ###
|
||||
|
||||
由于 GooglePlayDownloader 原本是针对基于 Debian 的发行版本所开发的,假如你想在 Fedora 上使用它,你需要从它的源码开始安装。
|
||||
|
||||
首先安装必需的依赖。
|
||||
|
||||
$ sudo yum install python-pyasn1 wxPython python-ndg_httpsclient protobuf-python python-requests
|
||||
|
||||
然后像下面这样安装它。
|
||||
|
||||
$ wget http://codingteam.net/project/googleplaydownloader/download/file/googleplaydownloader_1.7.orig.tar.gz
|
||||
$ tar -xvf googleplaydownloader_1.7.orig.tar.gz
|
||||
$ cd googleplaydownloader-1.7
|
||||
$ chmod o+r -R .
|
||||
$ sudo python setup.py install
|
||||
$ sudo sh -c "echo 'python /usr/lib/python2.7/site-packages/googleplaydownloader-1.7-py2.7.egg/googleplaydownloader/googleplaydownloader.py' > /usr/bin/googleplaydownloader"
|
||||
|
||||
### 使用 GooglePlayDownloader 从 Google Play 商店下载 APK 文件 ###
|
||||
|
||||
一旦你安装好 GooglePlayDownloader 后,你就可以像下面那样从 Google Play 商店下载 APK 文件。
|
||||
|
||||
首先通过输入下面的命令来启动该应用:
|
||||
|
||||
$ googleplaydownloader
|
||||
|
||||

|
||||
|
||||
在搜索栏中,输入你想从 Google Play 商店下载的应用的名称。
|
||||
|
||||

|
||||
|
||||
一旦你从搜索列表中找到了该应用,就选择该应用,接着点击 "下载选定的 APK 文件" 按钮。最后你将在你的家目录中找到下载的 APK 文件。现在,你就可以将下载到的 APK 文件转移到你所选择的 Android 设备上,然后手动安装它。
|
||||
|
||||
希望这篇教程对你有所帮助。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/download-apk-files-google-play-store.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/how-to-install-apk-file-on-android-phone-or-tablet.html
|
||||
[2]:https://chrome.google.com/webstore/detail/apk-downloader/cgihflhdpokeobcfimliamffejfnmfii
|
||||
[3]:https://addons.mozilla.org/en-us/firefox/addon/apk-downloader/
|
||||
[4]:http://codingteam.net/project/googleplaydownloader
|
||||
[5]:http://packages.ubuntu.com/vivid/python-ndg-httpsclient
|
||||
[6]:http://xmodulo.com/how-to-install-deb-file-with-dependencies.html
|
||||
Loading…
Reference in New Issue
Block a user