mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-13 22:30:37 +08:00
commit
259425c35e
@ -1,8 +1,11 @@
|
|||||||
修复Linux中的提供最小化类BASH命令行编辑GRUB错误
|
修复Linux中的“提供类似行编辑的袖珍BASH...”的GRUB错误
|
||||||
================================================================================
|
================================================================================
|
||||||
|
|
||||||
这两天我[安装了Elementary OS和Windows双系统][1],在启动的时候遇到了一个Grub错误。命令行中呈现如下信息:
|
这两天我[安装了Elementary OS和Windows双系统][1],在启动的时候遇到了一个Grub错误。命令行中呈现如下信息:
|
||||||
|
|
||||||
**提供最小化类BASH命令行编辑。对于第一个词,TAB键补全可以使用的命令。除此之外,TAB键补全可用的设备或文件。**
|
**Minimal BASH like line editing is supported. For the first word, TAB lists possible command completions. anywhere else TAB lists possible device or file completions.**
|
||||||
|
|
||||||
|
**提供类似行编辑的袖珍 BASH。TAB键补全第一个词,列出可以使用的命令。除此之外,TAB键补全可以列出可用的设备或文件。**
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
@ -10,7 +13,7 @@
|
|||||||
|
|
||||||
通过这篇文章里我们可以学到基于Linux系统**如何修复Ubuntu中出现的“minimal BASH like line editing is supported” Grub错误**。
|
通过这篇文章里我们可以学到基于Linux系统**如何修复Ubuntu中出现的“minimal BASH like line editing is supported” Grub错误**。
|
||||||
|
|
||||||
> 你可以参阅这篇教程来修复类似的高频问题,[错误:分区未找到Linux grub救援模式][3]。
|
> 你可以参阅这篇教程来修复类似的常见问题,[错误:分区未找到Linux grub救援模式][3]。
|
||||||
|
|
||||||
### 先决条件 ###
|
### 先决条件 ###
|
||||||
|
|
||||||
@ -19,11 +22,11 @@
|
|||||||
- 一个包含相同版本、相同OS的LiveUSB或磁盘
|
- 一个包含相同版本、相同OS的LiveUSB或磁盘
|
||||||
- 当前会话的Internet连接正常工作
|
- 当前会话的Internet连接正常工作
|
||||||
|
|
||||||
在确认了你拥有先决条件了之后,让我们看看如何修复Linux的死亡黑屏(如果我可以这样的称呼它的话;))。
|
在确认了你拥有先决条件了之后,让我们看看如何修复Linux的死亡黑屏(如果我可以这样的称呼它的话 ;) )。
|
||||||
|
|
||||||
### 如何在基于Ubuntu的Linux中修复“minimal BASH like line editing is supported” Grub错误 ###
|
### 如何在基于Ubuntu的Linux中修复“minimal BASH like line editing is supported” Grub错误 ###
|
||||||
|
|
||||||
我知道你一定疑问这种Grub错误并不局限于在基于Ubuntu的Linux发行版上发生,那为什么我要强调在基于Ubuntu的发行版上呢?原因是,在这里我们将采用一个简单的方法并叫作**Boot Repair**的工具来修复我们的问题。我并不确定在其他的诸如Fedora的发行版中是否有这个工具可用。不再浪费时间,我们来看如何修复minimal BASH like line editing is supported Grub错误。
|
我知道你一定疑问这种Grub错误并不局限于在基于Ubuntu的Linux发行版上发生,那为什么我要强调在基于Ubuntu的发行版上呢?原因是,在这里我们将采用一个简单的方法,用个叫做**Boot Repair**的工具来修复我们的问题。我并不确定在其他的诸如Fedora的发行版中是否有这个工具可用。不再浪费时间,我们来看如何修复“minimal BASH like line editing is supported” Grub错误。
|
||||||
|
|
||||||
### 步骤 1: 引导进入lives会话 ###
|
### 步骤 1: 引导进入lives会话 ###
|
||||||
|
|
||||||
@ -75,7 +78,7 @@ via: http://itsfoss.com/fix-minimal-bash-line-editing-supported-grub-error-linux
|
|||||||
|
|
||||||
作者:[Abhishek][a]
|
作者:[Abhishek][a]
|
||||||
译者:[martin2011qi](https://github.com/martin2011qi)
|
译者:[martin2011qi](https://github.com/martin2011qi)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
177
published/20150616 LINUX 101--POWER UP YOUR SHELL.md
Normal file
177
published/20150616 LINUX 101--POWER UP YOUR SHELL.md
Normal file
@ -0,0 +1,177 @@
|
|||||||
|
LINUX 101: 让你的 SHELL 更强大
|
||||||
|
================================================================================
|
||||||
|
> 在我们的关于 shell 基础的指导下, 得到一个更灵活,功能更强大且多彩的命令行界面
|
||||||
|
|
||||||
|
**为何要这样做?**
|
||||||
|
|
||||||
|
- 使得在 shell 提示符下过得更轻松,高效
|
||||||
|
- 在失去连接后恢复先前的会话
|
||||||
|
- Stop pushing around that fiddly rodent!
|
||||||
|
|
||||||
|
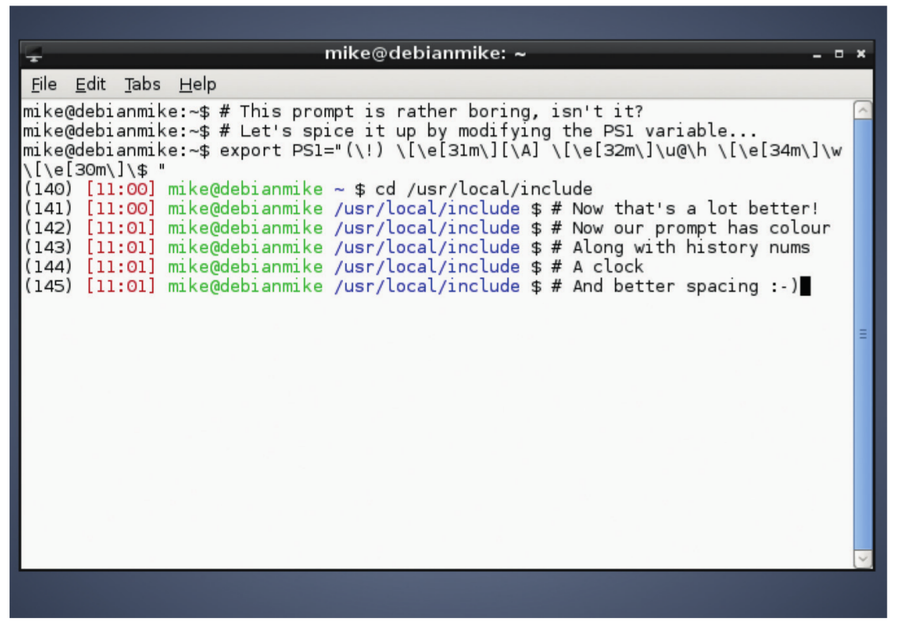
|
||||||
|
|
||||||
|
这是我的命令行提示符的设置。对于这个小的终端窗口来说,这或许有些长。但你可以根据你的喜好来调整它。
|
||||||
|
|
||||||
|
作为一个 Linux 用户, 你可能熟悉 shell (又名为命令行)。 或许你需要时不时的打开终端来完成那些不能在 GUI 下处理的必要任务,抑或是因为你处在一个将窗口铺满桌面的环境中,而 shell 是你与你的 linux 机器交互的主要方式。
|
||||||
|
|
||||||
|
在上面那些情况下,你可能正在使用你所使用的发行版本自带的 Bash 配置。 尽管对于大多数的任务而言,它足够好了,但它可以更加强大。 在本教程中,我们将向你展示如何使得你的 shell 提供更多有用信息、更加实用且更适合工作。 我们将对提示符进行自定义,让它比默认情况下提供更好的反馈,并向你展示如何使用炫酷的 `tmux` 工具来管理会话并同时运行多个程序。 并且,为了让眼睛舒服一点,我们还将关注配色方案。那么,进击吧,少女!
|
||||||
|
|
||||||
|
### 让提示符更美妙 ###
|
||||||
|
|
||||||
|
大多数的发行版本配置有一个非常简单的提示符,它们大多向你展示了一些基本信息, 但提示符可以为你提供更多的内容。例如,在 Debian 7 下,默认的提示符是这样的:
|
||||||
|
|
||||||
|
mike@somebox:~$
|
||||||
|
|
||||||
|
上面的提示符展示出了用户、主机名、当前目录和账户类型符号(假如你切换到 root 账户, **$** 会变为 **#**)。 那这些信息是在哪里存储的呢? 答案是:在 **PS1** 环境变量中。 假如你键入 `echo $PS1`, 你将会在这个命令的输出字符串的最后有如下的字符:
|
||||||
|
|
||||||
|
\u@\h:\w$
|
||||||
|
|
||||||
|
这看起来有一些丑陋,并在瞥见它的第一眼时,你可能会开始尖叫,认为它是令人恐惧的正则表达式,但我们不打算用这些复杂的字符来煎熬我们的大脑。这不是正则表达式,这里的斜杠是转义序列,它告诉提示符进行一些特别的处理。 例如,上面的 **u** 部分,告诉提示符展示用户名, 而 w 则展示工作路径.
|
||||||
|
|
||||||
|
下面是一些你可以在提示符中用到的字符的列表:
|
||||||
|
|
||||||
|
- d 当前的日期
|
||||||
|
- h 主机名
|
||||||
|
- n 代表换行的字符
|
||||||
|
- A 当前的时间 (HH:MM)
|
||||||
|
- u 当前的用户
|
||||||
|
- w (小写) 整个工作路径的全称
|
||||||
|
- W (大写) 工作路径的简短名称
|
||||||
|
- $ 一个提示符号,对于 root 用户为 # 号
|
||||||
|
- ! 当前命令在 shell 历史记录中的序号
|
||||||
|
|
||||||
|
下面解释 **w** 和 **W** 选项的区别: 对于前者,你将看到你所在的工作路径的完整地址,(例如 **/usr/local/bin**),而对于后者, 它则只显示 **bin** 这一部分。
|
||||||
|
|
||||||
|
现在,我们该怎样改变提示符呢? 你需要更改 **PS1** 环境变量的内容,试试下面这个:
|
||||||
|
|
||||||
|
export PS1="I am \u and it is \A $"
|
||||||
|
|
||||||
|
现在,你的提示符将会像下面这样:
|
||||||
|
|
||||||
|
I am mike and it is 11:26 $
|
||||||
|
|
||||||
|
从这个例子出发,你就可以按照你的想法来试验一下上面列出的其他转义序列。 但等等 – 当你登出后,你的这些努力都将消失,因为在你每次打开终端时,**PS1** 环境变量的值都会被重置。解决这个问题的最简单方式是打开 **.bashrc** 配置文件(在你的家目录下) 并在这个文件的最下方添加上完整的 `export` 命令。在每次你启动一个新的 shell 会话时,这个 **.bashrc** 会被 `Bash` 读取, 所以你的加强的提示符就可以一直出现。你还可以使用额外的颜色来装扮提示符。刚开始,这将有点棘手,因为你必须使用一些相当奇怪的转义序列,但结果是非常漂亮的。 将下面的字符添加到你的 **PS1**字符串中的某个位置,最终这将把文本变为红色:
|
||||||
|
|
||||||
|
\[\e[31m\]
|
||||||
|
|
||||||
|
你可以将这里的 31 更改为其他的数字来获得不同的颜色:
|
||||||
|
|
||||||
|
- 30 黑色
|
||||||
|
- 32 绿色
|
||||||
|
- 33 黄色
|
||||||
|
- 34 蓝色
|
||||||
|
- 35 洋红色
|
||||||
|
- 36 青色
|
||||||
|
- 37 白色
|
||||||
|
|
||||||
|
所以,让我们使用先前看到的转义序列和颜色来创造一个提示符,以此来结束这一小节的内容。深吸一口气,弯曲你的手指,然后键入下面这只“野兽”:
|
||||||
|
|
||||||
|
export PS1="(\!) \[\e[31m\] \[\A\] \[\e[32m\]\u@\h \[\e[34m\]\w \[\e[30m\]$"
|
||||||
|
|
||||||
|
上面的命令提供了一个 Bash 命令历史序号、当前的时间、彩色的用户或主机名组合、以及工作路径。假如你“野心勃勃”,利用一些惊人的组合,你还可以更改提示符的背景色和前景色。非常有用的 Arch wiki 有一个关于颜色代码的完整列表:[http://tinyurl.com/3gvz4ec][1]。
|
||||||
|
|
||||||
|
> **Shell 精要**
|
||||||
|
>
|
||||||
|
> 假如你是一个彻底的 Linux 新手并第一次阅读这份杂志,或许你会发觉阅读这些教程有些吃力。 所以这里有一些基础知识来让你熟悉一些 shell。 通常在你的菜单中, shell 指的是 Terminal、 XTerm 或 Konsole, 当你启动它后, 最为实用的命令有这些:
|
||||||
|
>
|
||||||
|
> **ls** (列出文件名); **cp one.txt two.txt** (复制文件); **rm file.txt** (移除文件); **mv old.txt new.txt** (移动或重命名文件);
|
||||||
|
>
|
||||||
|
> **cd /some/directory** (改变目录); **cd ..** (回到上级目录); **./program** (在当前目录下运行一个程序); **ls > list.txt** (重定向输出到一个文件)。
|
||||||
|
>
|
||||||
|
> 几乎每个命令都有一个手册页用来解释其选项(例如 **man ls** – 按 Q 来退出)。在那里,你可以知晓命令的选项,这样你就知道 **ls -la** 展示一个详细的列表,其中也列出了隐藏文件, 并且在键入一个文件或目录的名字的一部分后, 可以使用 Tab 键来自动补全。
|
||||||
|
|
||||||
|
### Tmux: 针对 shell 的窗口管理器 ###
|
||||||
|
|
||||||
|
在文本模式的环境中使用一个窗口管理器 – 这听起来有点不可思议, 是吧? 然而,你应该记得当 Web 浏览器第一次实现分页浏览的时候吧? 在当时, 这是在可用性上的一个重大进步,它减少了桌面任务栏的杂乱无章和繁多的窗口列表。 对于你的浏览器来说,你只需要一个按钮便可以在浏览器中切换到你打开的每个单独网站, 而不是针对每个网站都有一个任务栏或导航图标。 这个功能非常有意义。
|
||||||
|
|
||||||
|
若有时你同时运行着几个虚拟终端,你便会遇到相似的情况; 在这些终端之间跳转,或每次在任务栏或窗口列表中找到你所需要的那一个终端,都可能会让你觉得麻烦。 拥有一个文本模式的窗口管理器不仅可以让你像在同一个终端窗口中运行多个 shell 会话,而且你甚至还可以将这些窗口排列在一起。
|
||||||
|
|
||||||
|
另外,这样还有另一个好处:可以将这些窗口进行分离和重新连接。想要看看这是如何运行的最好方式是自己尝试一下。在一个终端窗口中,输入 `screen` (在大多数发行版本中,它已经默认安装了或者可以在软件包仓库中找到)。 某些欢迎的文字将会出现 – 只需敲击 Enter 键这些文字就会消失。 现在运行一个交互式的文本模式的程序,例如 `nano`, 并关闭这个终端窗口。
|
||||||
|
|
||||||
|
在一个正常的 shell 对话中, 关闭窗口将会终止所有在该终端中运行的进程 – 所以刚才的 Nano 编辑对话也就被终止了, 但对于 screen 来说,并不是这样的。打开一个新的终端并输入如下命令:
|
||||||
|
|
||||||
|
screen -r
|
||||||
|
|
||||||
|
瞧,你刚开打开的 Nano 会话又回来了!
|
||||||
|
|
||||||
|
当刚才你运行 **screen** 时, 它会创建了一个新的独立的 shell 会话, 它不与某个特定的终端窗口绑定在一起,所以可以在后面被分离并重新连接(即 **-r** 选项)。
|
||||||
|
|
||||||
|
当你正使用 SSH 去连接另一台机器并做着某些工作时, 但并不想因为一个脆弱的连接而影响你的进度,这个方法尤其有用。假如你在一个 **screen** 会话中做着某些工作,并且你的连接突然中断了(或者你的笔记本没电了,又或者你的电脑报废了——不是这么悲催吧),你只需重新连接或给电脑充电或重新买一台电脑,接着运行 **screen -r** 来重新连接到远程的电脑,并在刚才掉线的地方接着开始。
|
||||||
|
|
||||||
|
现在,我们都一直在讨论 GNU 的 **screen**,但这个小节的标题提到的是 tmux。 实质上, **tmux** (terminal multiplexer) 就像是 **screen** 的一个进阶版本,带有许多有用的额外功能,所以现在我们开始关注 tmux。 某些发行版本默认包含了 **tmux**; 在其他的发行版本上,通常只需要一个 **apt-get、 yum install** 或 **pacman -S** 命令便可以安装它。
|
||||||
|
|
||||||
|
一旦你安装了它过后,键入 **tmux** 来启动它。接着你将注意到,在终端窗口的底部有一条绿色的信息栏,它非常像传统的窗口管理器中的任务栏: 上面显示着一个运行着的程序的列表、机器的主机名、当前时间和日期。 现在运行一个程序,同样以 Nano 为例, 敲击 Ctrl+B 后接着按 C 键, 这将在 tmux 会话中创建一个新的窗口,你便可以在终端的底部的任务栏中看到如下的信息:
|
||||||
|
|
||||||
|
0:nano- 1:bash*
|
||||||
|
|
||||||
|
每一个窗口都有一个数字,当前呈现的程序被一个星号所标记。 Ctrl+B 是与 tmux 交互的标准方式, 所以若你敲击这个按键组合并带上一个窗口序号, 那么就会切换到对应的那个窗口。你也可以使用 Ctrl+B 再加上 N 或 P 来分别切换到下一个或上一个窗口 – 或者使用 Ctrl+B 加上 L 来在最近使用的两个窗口之间来进行切换(有点类似于桌面中的经典的 Alt+Tab 组合键的效果)。 若需要知道窗口列表,使用 Ctrl+B 再加上 W。
|
||||||
|
|
||||||
|
目前为止,一切都还好:现在你可以在一个单独的终端窗口中运行多个程序,避免混乱(尤其是当你经常与同一个远程主机保持多个 SSH 连接时)。 当想同时看两个程序又该怎么办呢?
|
||||||
|
|
||||||
|
针对这种情况, 可以使用 tmux 中的窗格。 敲击 Ctrl+B 再加上 % , 则当前窗口将分为两个部分:一个在左一个在右。你可以使用 Ctrl+B 再加上 O 来在这两个部分之间切换。 这尤其在你想同时看两个东西时非常实用, – 例如一个窗格看指导手册,另一个窗格里用编辑器看一个配置文件。
|
||||||
|
|
||||||
|
有时,你想对一个单独的窗格进行缩放,而这需要一定的技巧。 首先你需要敲击 Ctrl+B 再加上一个 :(冒号),这将使得位于底部的 tmux 栏变为深橙色。 现在,你进入了命令模式,在这里你可以输入命令来操作 tmux。 输入 **resize-pane -R** 来使当前窗格向右移动一个字符的间距, 或使用 **-L** 来向左移动。 对于一个简单的操作,这些命令似乎有些长,但请注意,在 tmux 的命令模式(前面提到的一个分号开始的模式)下,可以使用 Tab 键来补全命令。 另外需要提及的是, **tmux** 同样也有一个命令历史记录,所以若你想重复刚才的缩放操作,可以先敲击 Ctrl+B 再跟上一个分号,并使用向上的箭头来取回刚才输入的命令。
|
||||||
|
|
||||||
|
最后,让我们看一下分离和重新连接 - 即我们刚才介绍的 screen 的特色功能。 在 tmux 中,敲击 Ctrl+B 再加上 D 来从当前的终端窗口中分离当前的 tmux 会话。这使得这个会话的一切工作都在后台中运行、使用 `tmux a` 可以再重新连接到刚才的会话。但若你同时有多个 tmux 会话在运行时,又该怎么办呢? 我们可以使用下面的命令来列出它们:
|
||||||
|
|
||||||
|
tmux ls
|
||||||
|
|
||||||
|
这个命令将为每个会话分配一个序号; 假如你想重新连接到会话 1, 可以使用 `tmux a -t 1`. tmux 是可以高度定制的,你可以自定义按键绑定并更改配色方案, 所以一旦你适应了它的主要功能,请钻研指导手册以了解更多的内容。
|
||||||
|
|
||||||
|
|
||||||
|
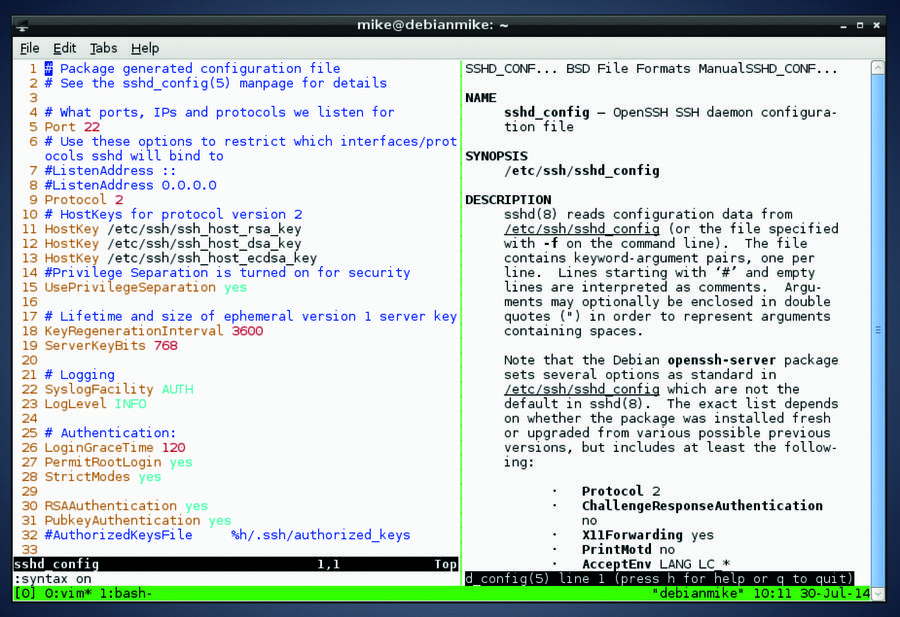
|
||||||
|
|
||||||
|
上图中, tmux 开启了两个窗格: 左边是 Vim 正在编辑一个配置文件,而右边则展示着指导手册页。
|
||||||
|
|
||||||
|
> **Zsh: 另一个 shell**
|
||||||
|
>
|
||||||
|
> 选择是好的,但标准同样重要。 你要知道几乎每个主流的 Linux 发行版本都默认使用 Bash shell – 尽管还存在其他的 shell。 Bash 为你提供了一个 shell 能够给你提供的几乎任何功能,包括命令历史记录,文件名补全和许多脚本编程的能力。它成熟、可靠并文档丰富 – 但它不是你唯一的选择。
|
||||||
|
>
|
||||||
|
> 许多高级用户热衷于 Zsh, 即 Z shell。 这是 Bash 的一个替代品并提供了 Bash 的几乎所有功能,另外还提供了一些额外的功能。 例如, 在 Zsh 中,你输入 **ls** ,并敲击 Tab 键可以得到 **ls** 可用的各种不同选项的一个大致描述。 而不需要再打开 man page 了!
|
||||||
|
>
|
||||||
|
> Zsh 还支持其他强大的自动补全功能: 例如,输入 **cd /u/lo/bi** 再敲击 Tab 键, 则完整的路径名 **/usr/local/bin** 就会出现(这里假设没有其他的路径包含 **u**, **lo** 和 **bi** 等字符)。 或者只输入 **cd** 再跟上 Tab 键,则你将看到着色后的路径名的列表 – 这比 Bash 给出的简单的结果好看得多。
|
||||||
|
>
|
||||||
|
> Zsh 在大多数的主要发行版本上都可以得到了; 安装它后并输入 **zsh** 便可启动它。 要将你的默认 shell 从 Bash 改为 Zsh, 可以使用 **chsh** 命令。 若需了解更多的信息,请访问 [www.zsh.org][2]。
|
||||||
|
|
||||||
|
### “未来”的终端 ###
|
||||||
|
|
||||||
|
你或许会好奇为什么包含你的命令行提示符的应用被叫做终端。 这需要追溯到 Unix 的早期, 那时人们一般工作在一个多用户的机器上,这个巨大的电脑主机将占据一座建筑中的一个房间, 人们通过某些线路,使用屏幕和键盘来连接到这个主机, 这些终端机通常被称为“哑终端”, 因为它们不能靠自己做任何重要的执行任务 – 它们只展示通过线路从主机传来的信息,并输送回从键盘的敲击中得到的输入信息。
|
||||||
|
|
||||||
|
今天,我们在自己的机器上执行几乎所有的实际操作,所以我们的电脑不是传统意义下的终端,这就是为什么诸如 **XTerm**、 Gnome Terminal、 Konsole 等程序被称为“终端模拟器” 的原因 – 他们提供了同昔日的物理终端一样的功能。事实上,在许多方面它们并没有改变多少。诚然,现在我们有了反锯齿字体,更好的颜色和点击网址的能力,但总的来说,几十年来我们一直以同样的方式在工作。
|
||||||
|
|
||||||
|
所以某些程序员正尝试改变这个状况。 **Terminology** ([http://tinyurl.com/osopjv9][3]), 它来自于超级时髦的 Enlightenment 窗口管理器背后的团队,旨在让终端步入到 21 世纪,例如带有在线媒体显示功能。你可以在一个充满图片的目录里输入 **ls** 命令,便可以看到它们的缩略图,或甚至可以直接在你的终端里播放视频。 这使得一个终端有点类似于一个文件管理器,意味着你可以快速地检查媒体文件的内容而不必用另一个应用来打开它们。
|
||||||
|
|
||||||
|
接着还有 Xiki ([www.xiki.org][4]),它自身的描述为“命令的革新”。它就像是一个传统的 shell、一个 GUI 和一个 wiki 之间的过渡;你可以在任何地方输入命令,并在后面将它们的输出存储为笔记以作为参考,并可以创建非常强大的自定义命令。用几句话是很能描述它的,所以作者们已经创作了一个视频来展示它的潜力是多么的巨大(请看 **Xiki** 网站的截屏视频部分)。
|
||||||
|
|
||||||
|
并且 Xiki 绝不是那种在几个月之内就消亡的昙花一现的项目,作者们成功地进行了一次 Kickstarter 众筹,在七月底已募集到超过 $84,000。 是的,你没有看错 – $84K 来支持一个终端模拟器。这可能是最不寻常的集资活动了,因为某些疯狂的家伙已经决定开始创办它们自己的 Linux 杂志 ......
|
||||||
|
|
||||||
|
### 下一代终端 ###
|
||||||
|
|
||||||
|
许多命令行和基于文本的程序在功能上与它们的 GUI 程序是相同的,并且常常更加快速和高效。我们的推荐有:
|
||||||
|
**Irssi** (IRC 客户端); **Mutt** (mail 客户端); **rTorrent** (BitTorrent); **Ranger** (文件管理器); **htop** (进程监视器)。 若给定在终端的限制下来进行 Web 浏览, Elinks 确实做的很好,并且对于阅读那些以文字为主的网站例如 Wikipedia 来说。它非常实用。
|
||||||
|
|
||||||
|
> **微调配色方案**
|
||||||
|
>
|
||||||
|
> 在《Linux Voice》杂志社中,我们并不迷恋那些养眼的东西,但当你每天花费几个小时盯着屏幕看东西时,我们确实认识到美学的重要性。我们中的许多人都喜欢调整我们的桌面和窗口管理器来达到完美的效果,调整阴影效果、摆弄不同的配色方案,直到我们 100% 的满意(然后出于习惯,摆弄更多的东西)。
|
||||||
|
>
|
||||||
|
> 但我们倾向于忽视终端窗口,它理应也获得我们的喜爱,并且在 [http://ciembor.github.io/4bit][5] 你将看到一个极其棒的配色方案设计器,对于所有受欢迎的终端模拟器(**XTerm, Gnome Terminal, Konsole 和 Xfce4 Terminal 等都是支持的应用。**),它可以输出其设定。移动滑块直到你看到配色方案最佳, 然后点击位于该页面右上角的 `得到方案` 按钮。
|
||||||
|
>
|
||||||
|
> 相似的,假如你在一个文本编辑器,如 Vim 或 Emacs 上花费了很多的时间,使用一个精心设计的调色板也是非常值得的。 **Solarized** [http://ethanschoonover.com/solarized][6] 是一个卓越的方案,它不仅漂亮,而且因追求最大的可用性而设计,在其背后有着大量的研究和测试。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://www.linuxvoice.com/linux-101-power-up-your-shell-8/
|
||||||
|
|
||||||
|
作者:[Ben Everard][a]
|
||||||
|
译者:[FSSlc](https://github.com/FSSlc)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://www.linuxvoice.com/author/ben_everard/
|
||||||
|
[1]:http://tinyurl.com/3gvz4ec
|
||||||
|
[2]:http://www.zsh.org/
|
||||||
|
[3]:http://tinyurl.com/osopjv9
|
||||||
|
[4]:http://www.xiki.org/
|
||||||
|
[5]:http://ciembor.github.io/4bit
|
||||||
|
[6]:http://ethanschoonover.com/solarized
|
||||||
@ -0,0 +1,83 @@
|
|||||||
|
监控 Linux 系统的 7 个命令行工具
|
||||||
|
================================================================================
|
||||||
|
**这里有一些基本的命令行工具,让你能更简单地探索和操作Linux。**
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 深入 ###
|
||||||
|
|
||||||
|
关于Linux最棒的一件事之一是你能深入操作系统,来探索它是如何工作的,并寻找机会来微调性能或诊断问题。这里有一些基本的命令行工具,让你能更简单地探索和操作Linux。大多数的这些命令是在你的Linux系统中已经内建的,但假如它们没有的话,就用谷歌搜索命令名和你的发行版名吧,你会找到哪些包需要安装(注意,一些命令是和其它命令捆绑起来打成一个包的,你所找的包可能写的是其它的名字)。如果你知道一些你所使用的其它工具,欢迎评论。
|
||||||
|
|
||||||
|
|
||||||
|
### 我们怎么开始 ###
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
须知: 本文中的截图取自一台[Debian Linux 8.1][1] (“Jessie”),其运行在[OS X 10.10.3][3] (“Yosemite”)操作系统下的[Oracle VirtualBox 4.3.28][2]中的一台虚拟机里。想要建立你的Debian虚拟机,可以看看我的这篇教程——“[如何在 VirtualBox VM 下安装 Debian][4]”。
|
||||||
|
|
||||||
|
|
||||||
|
### Top ###
|
||||||
|
|
||||||
|
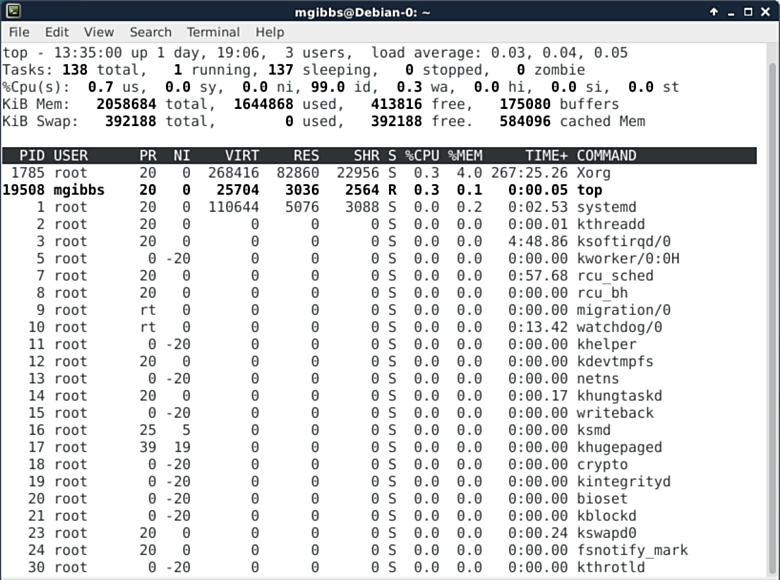
|
||||||
|
|
||||||
|
作为Linux系统监控工具中比较易用的一个,**top命令**能带我们一览Linux中的几乎每一处。以下这张图是它的默认界面,但是按“z”键可以切换不同的显示颜色。其它热键和命令则有其它的功能,例如显示概要信息和内存信息(第四行第二个),根据各种不一样的条件排序、终止进程任务等等(你可以在[这里][5]找到完整的列表)。
|
||||||
|
|
||||||
|
|
||||||
|
### htop ###
|
||||||
|
|
||||||
|
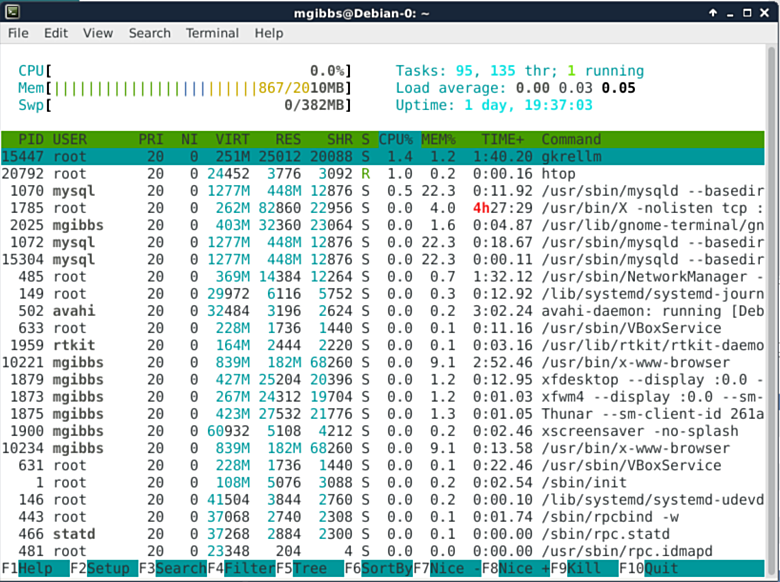
|
||||||
|
|
||||||
|
相比top,它的替代品Htop则更为精致。维基百科是这样描述的:“用户经常会部署htop以免Unix top不能提供关于系统进程的足够信息,比如说当你在尝试发现应用程序里的一个小的内存泄露问题,Htop一般也能作为一个系统监听器来使用。相比top,它提供了一个更方便的光标控制界面来向进程发送信号。” (想了解更多细节猛戳[这里][6])
|
||||||
|
|
||||||
|
|
||||||
|
### Vmstat ###
|
||||||
|
|
||||||
|
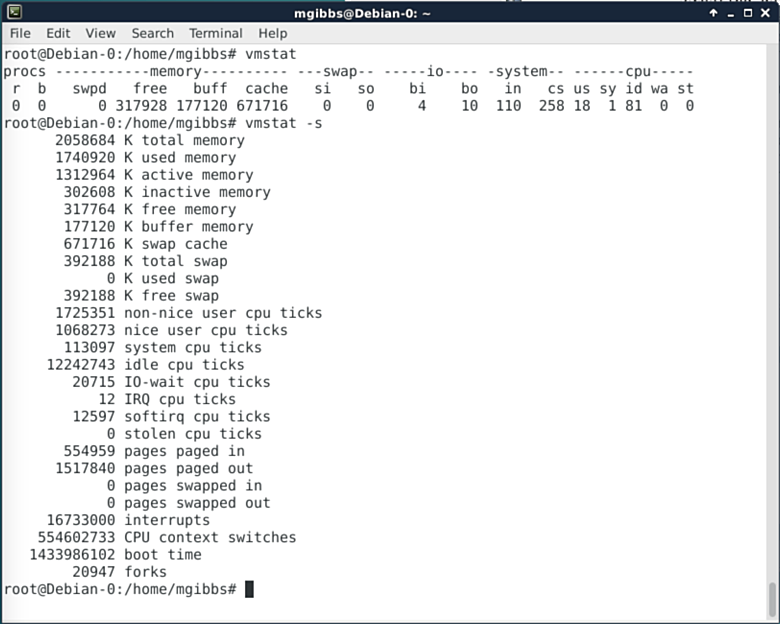
|
||||||
|
|
||||||
|
Vmstat是一款监控Linux系统性能数据的简易工具,这让它更合适使用在shell脚本中。使出你的正则表达式绝招,用vmstat和cron作业来做一些激动人心的事情吧。“后面的报告给出的是上一次系统重启之后的均值,另外一份报告给出的则是从前一个报告起间隔周期中的信息。其它的进程和内存报告是那个瞬态的情况”(猛戳[这里][7]获取更多信息)。
|
||||||
|
|
||||||
|
### ps ###
|
||||||
|
|
||||||
|
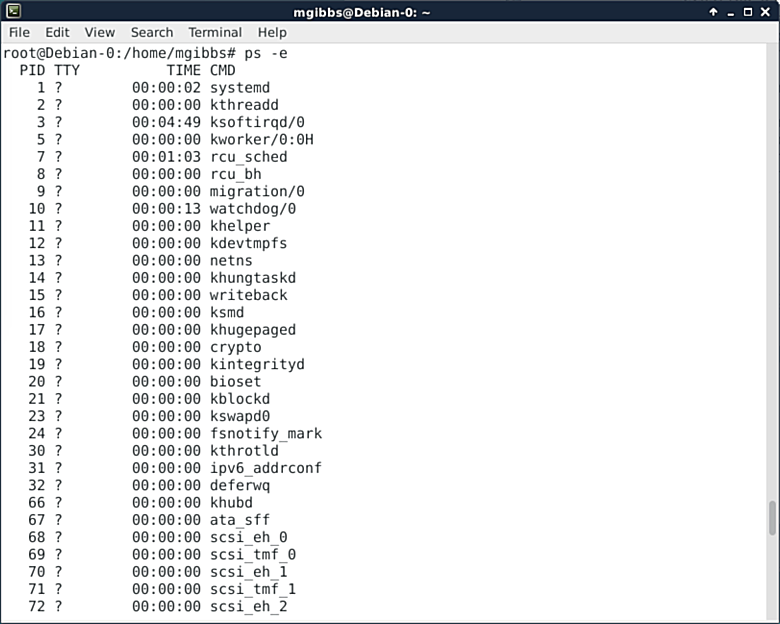
|
||||||
|
|
||||||
|
ps命令展现的是正在运行中的进程列表。在这种情况下,我们用“-e”选项来显示每个进程,也就是所有正在运行的进程了(我把列表滚动到了前面,否则列名就看不到了)。这个命令有很多选项允许你去按需格式化输出。只要使用上述一点点的正则表达式技巧,你就能得到一个强大的工具了。猛戳[这里][8]获取更多信息。
|
||||||
|
|
||||||
|
### Pstree ###
|
||||||
|
|
||||||
|
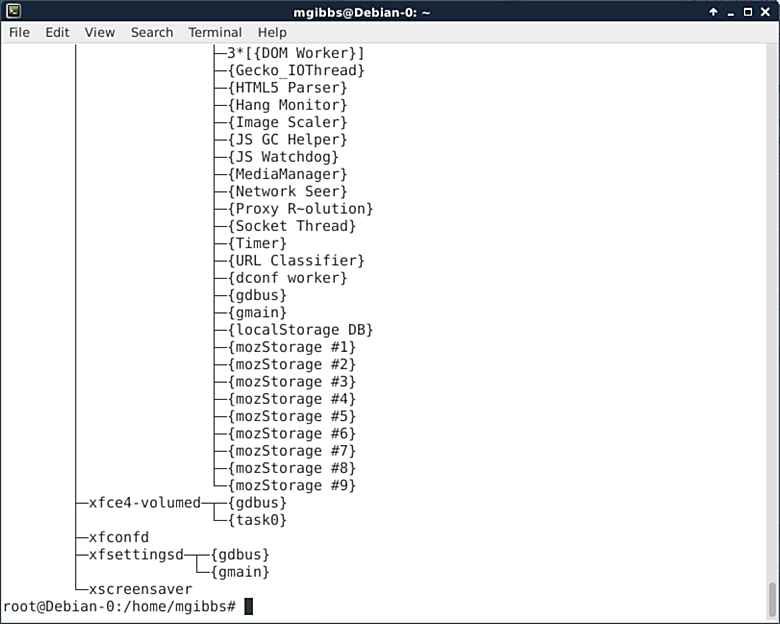
|
||||||
|
|
||||||
|
Pstree“以树状图显示正在运行中的进程。这个进程树是以某个 pid 为根节点的,如果pid被省略的话那树是以init为根节点的。如果指定用户名,那所有进程树都会以该用户所属的进程为父进程进行显示。”以树状图来帮你将进程之间的所属关系进行分类,这的确是个很有效的工具(戳[这里][9])。
|
||||||
|
|
||||||
|
### pmap ###
|
||||||
|
|
||||||
|
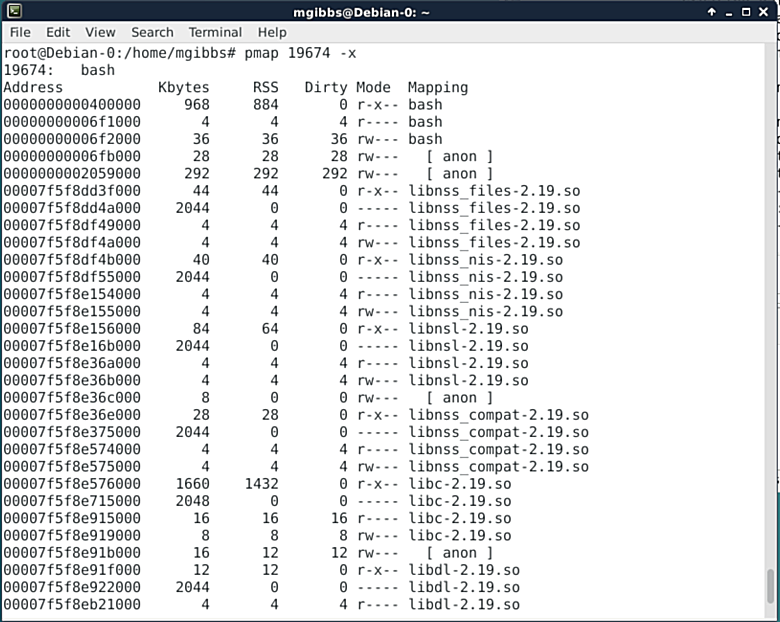
|
||||||
|
|
||||||
|
在调试过程中,理解一个应用程序如何使用内存是至关重要的,而pmap的作用就是当给出一个进程ID时显示出相关信息。上面的截图展示的是使用“-x”选项所产生的部分输出,你也可以用pmap的“-X”选项来获取更多的细节信息,但是前提是你要有个更宽的终端窗口。
|
||||||
|
|
||||||
|
### iostat ###
|
||||||
|
|
||||||
|
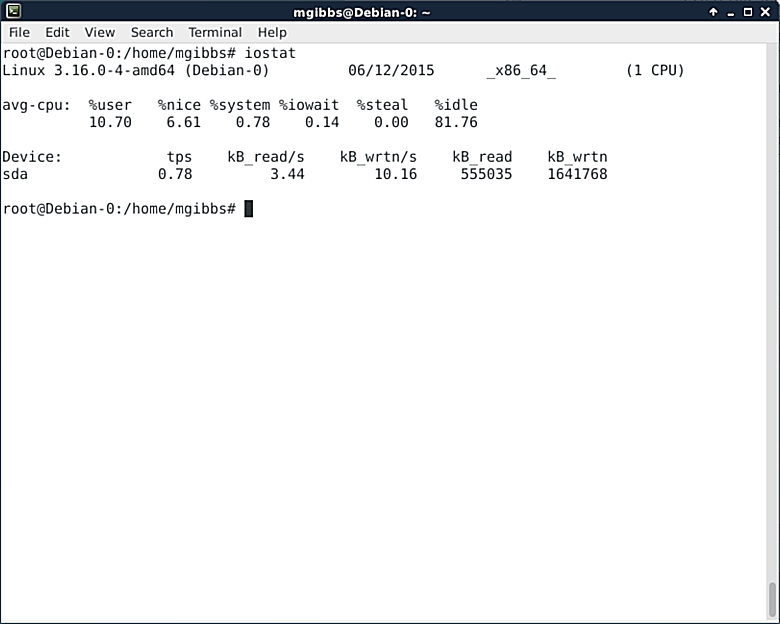
|
||||||
|
|
||||||
|
Linux系统的一个至关重要的性能指标是处理器和存储的使用率,它也是iostat命令所报告的内容。如同ps命令一样,iostat有很多选项允许你选择你需要的输出格式,除此之外还可以在某一段时间范围内的重复采样几次。详情请戳[这里][10]。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://www.networkworld.com/article/2937219/linux/7-command-line-tools-for-monitoring-your-linux-system.html
|
||||||
|
|
||||||
|
作者:[Mark Gibbs][a]
|
||||||
|
译者:[ZTinoZ](https://github.com/ZTinoZ)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://www.networkworld.com/author/Mark-Gibbs/
|
||||||
|
[1]:https://www.debian.org/releases/stable/
|
||||||
|
[2]:https://www.virtualbox.org/
|
||||||
|
[3]:http://www.apple.com/osx/
|
||||||
|
[4]:http://www.networkworld.com/article/2937148/how-to-install-debian-linux-8-1-in-a-virtualbox-vm
|
||||||
|
[5]:http://linux.die.net/man/1/top
|
||||||
|
[6]:http://linux.die.net/man/1/htop
|
||||||
|
[7]:http://linuxcommand.org/man_pages/vmstat8.html
|
||||||
|
[8]:http://linux.die.net/man/1/ps
|
||||||
|
[9]:http://linux.die.net/man/1/pstree
|
||||||
|
[10]:http://linux.die.net/man/1/iostat
|
||||||
@ -1,24 +1,25 @@
|
|||||||
在 Linux 中安装 Google 环聊桌面客户端
|
在 Linux 中安装 Google 环聊桌面客户端
|
||||||
================================================================================
|
================================================================================
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
先前,我们已经介绍了如何[在 Linux 中安装 Facebook Messenger][1] 和[WhatsApp 桌面客户端][2]。这些应用都是非官方的应用。今天,我将为你推荐另一款非官方的应用,它就是 [Google 环聊][3]
|
先前,我们已经介绍了如何[在 Linux 中安装 Facebook Messenger][1] 和[WhatsApp 桌面客户端][2]。这些应用都是非官方的应用。今天,我将为你推荐另一款非官方的应用,它就是 [Google 环聊][3]
|
||||||
|
|
||||||
当然,你可以在 Web 浏览器中使用 Google 环聊,但相比于此,使用桌面客户端会更加有趣。好奇吗?那就跟着我看看如何 **在 Linux 中安装 Google 环聊** 以及如何使用它把。
|
当然,你可以在 Web 浏览器中使用 Google 环聊,但相比于此,使用桌面客户端会更加有趣。好奇吗?那就跟着我看看如何 **在 Linux 中安装 Google 环聊** 以及如何使用它吧。
|
||||||
|
|
||||||
### 在 Linux 中安装 Google 环聊 ###
|
### 在 Linux 中安装 Google 环聊 ###
|
||||||
|
|
||||||
我们将使用一个名为 [yakyak][4] 的开源项目,它是一个针对 Linux,Windows 和 OS X 平台的非官方 Google 环聊客户端。我将向你展示如何在 Ubuntu 中使用 yakyak,但我相信在其他的 Linux 发行版本中,你可以使用同样的方法来使用它。在了解如何使用它之前,让我们先看看 yakyak 的主要特点:
|
我们将使用一个名为 [yakyak][4] 的开源项目,它是一个针对 Linux,Windows 和 OS X 平台的非官方 Google 环聊客户端。我将向你展示如何在 Ubuntu 中使用 yakyak,但我相信在其他的 Linux 发行版本中,你可以使用同样的方法来使用它。在了解如何使用它之前,让我们先看看 yakyak 的主要特点:
|
||||||
|
|
||||||
- 发送和接受聊天信息
|
- 发送和接受聊天信息
|
||||||
- 创建和更改对话 (重命名, 添加人物)
|
- 创建和更改对话 (重命名, 添加参与者)
|
||||||
- 离开或删除对话
|
- 离开或删除对话
|
||||||
- 桌面提醒通知
|
- 桌面提醒通知
|
||||||
- 打开或关闭通知
|
- 打开或关闭通知
|
||||||
- 针对图片上传,支持拖放,复制粘贴或使用上传按钮
|
- 对于图片上传,支持拖放,复制粘贴或使用上传按钮
|
||||||
- Hangupsbot 房间同步(实际的用户图片) (注: 这里翻译不到位,希望改善一下)
|
- Hangupsbot 房间同步(使用用户实际的图片)
|
||||||
- 展示行内图片
|
- 展示行内图片
|
||||||
- 历史回放
|
- 翻阅历史
|
||||||
|
|
||||||
听起来不错吧,你可以从下面的链接下载到该软件的安装文件:
|
听起来不错吧,你可以从下面的链接下载到该软件的安装文件:
|
||||||
|
|
||||||
@ -36,7 +37,7 @@
|
|||||||
|
|
||||||

|

|
||||||
|
|
||||||
假如你想看看对话的配置图,你可以选择 `查看-> 展示对话缩略图`
|
假如你想在联系人里面显示用户头像,你可以选择 `查看-> 展示对话缩略图`
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
@ -54,7 +55,7 @@ via: http://itsfoss.com/install-google-hangouts-linux/
|
|||||||
|
|
||||||
作者:[Abhishek][a]
|
作者:[Abhishek][a]
|
||||||
译者:[FSSlc](https://github.com/FSSlc)
|
译者:[FSSlc](https://github.com/FSSlc)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
@ -1,10 +1,9 @@
|
|||||||
|
如何修复 ubuntu 中检测到系统程序错误的问题
|
||||||
如何修复ubuntu 14.04中检测到系统程序错误的问题
|
|
||||||
================================================================================
|
================================================================================
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
|
在过去的几个星期,(几乎)每次都有消息 **Ubuntu 15.04在启动时检测到系统程序错误** 跑出来“欢迎”我。那时我是直接忽略掉它的,但是这种情况到了某个时刻,它就让人觉得非常烦人了!
|
||||||
在过去的几个星期,(几乎)每次都有消息 **Ubuntu 15.04在启动时检测到系统程序错误(system program problem detected on startup in Ubuntu 15.04)** 跑出来“欢迎”我。那时我是直接忽略掉它的,但是这种情况到了某个时刻,它就让人觉得非常烦人了!
|
|
||||||
|
|
||||||
> 检测到系统程序错误(System program problem detected)
|
> 检测到系统程序错误(System program problem detected)
|
||||||
>
|
>
|
||||||
@ -18,15 +17,16 @@
|
|||||||
|
|
||||||
#### 那么这个通知到底是关于什么的? ####
|
#### 那么这个通知到底是关于什么的? ####
|
||||||
|
|
||||||
大体上讲,它是在告知你,你的系统的一部分崩溃了。可别因为“崩溃”这个词而恐慌。这不是一个严重的问题,你的系统还是完完全全可用的。只是在以前的某个时刻某个程序崩溃了,而Ubuntu想让你决定要不要把这个问题报告给开发者,这样他们就能够修复这个问题。
|
大体上讲,它是在告知你,你的系统的一部分崩溃了。可别因为“崩溃”这个词而恐慌。这不是一个严重的问题,你的系统还是完完全全可用的。只是在之前的某个时刻某个程序崩溃了,而Ubuntu想让你决定要不要把这个问题报告给开发者,这样他们就能够修复这个问题。
|
||||||
|
|
||||||
#### 那么,我们点了“报告错误”的按钮后,它以后就不再显示了?####
|
#### 那么,我们点了“报告错误”的按钮后,它以后就不再显示了?####
|
||||||
|
|
||||||
|
不,不是的!即使你点了“报告错误”按钮,最后你还是会被一个如下的弹窗再次“欢迎”一下:
|
||||||
|
|
||||||
不,不是的!即使你点了“报告错误”按钮,最后你还是会被一个如下的弹窗再次“欢迎”:
|
|
||||||

|

|
||||||
|
|
||||||
[对不起,Ubuntu发生了一个内部错误(Sorry, Ubuntu has experienced an internal error)][1]是一个Apport(Apport是Ubuntu中错误信息的收集报告系统,详见Ubuntu Wiki中的Apport篇,译者注),它将会进一步的打开网页浏览器,然后你可以通过登录或创建[Launchpad][2]帐户来填写一份漏洞(Bug)报告文件。你看,这是一个复杂的过程,它要花整整四步来完成.
|
[对不起,Ubuntu发生了一个内部错误][1]是个Apport(LCTT 译注:Apport是Ubuntu中错误信息的收集报告系统,详见Ubuntu Wiki中的Apport篇),它将会进一步的打开网页浏览器,然后你可以通过登录或创建[Launchpad][2]帐户来填写一份漏洞(Bug)报告文件。你看,这是一个复杂的过程,它要花整整四步来完成。
|
||||||
|
|
||||||
#### 但是我想帮助开发者,让他们知道这个漏洞啊 !####
|
#### 但是我想帮助开发者,让他们知道这个漏洞啊 !####
|
||||||
|
|
||||||
你这样想的确非常地周到体贴,而且这样做也是正确的。但是这样做的话,存在两个问题。第一,存在非常高的概率,这个漏洞已经被报告过了;第二,即使你报告了个这次崩溃,也无法保证你不会再看到它。
|
你这样想的确非常地周到体贴,而且这样做也是正确的。但是这样做的话,存在两个问题。第一,存在非常高的概率,这个漏洞已经被报告过了;第二,即使你报告了个这次崩溃,也无法保证你不会再看到它。
|
||||||
@ -34,35 +34,38 @@
|
|||||||
#### 那么,你的意思就是说别报告这次崩溃了?####
|
#### 那么,你的意思就是说别报告这次崩溃了?####
|
||||||
|
|
||||||
对,也不对。如果你想的话,在你第一次看到它的时候报告它。你可以在上面图片显示的“显示细节(Show Details)”中,查看崩溃的程序。但是如果你总是看到它,或者你不想报告漏洞(Bug),那么我建议你还是一次性摆脱这个问题吧。
|
对,也不对。如果你想的话,在你第一次看到它的时候报告它。你可以在上面图片显示的“显示细节(Show Details)”中,查看崩溃的程序。但是如果你总是看到它,或者你不想报告漏洞(Bug),那么我建议你还是一次性摆脱这个问题吧。
|
||||||
|
|
||||||
### 修复Ubuntu中“检测到系统程序错误”的错误 ###
|
### 修复Ubuntu中“检测到系统程序错误”的错误 ###
|
||||||
|
|
||||||
这些错误报告被存放在Ubuntu中目录/var/crash中。如果你翻看这个目录的话,应该可以看到有一些以crash结尾的文件。
|
这些错误报告被存放在Ubuntu中目录/var/crash中。如果你翻看这个目录的话,应该可以看到有一些以crash结尾的文件。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
我的建议是删除这些错误报告。打开一个终端,执行下面的命令:
|
我的建议是删除这些错误报告。打开一个终端,执行下面的命令:
|
||||||
|
|
||||||
sudo rm /var/crash/*
|
sudo rm /var/crash/*
|
||||||
|
|
||||||
这个操作会删除所有在/var/crash目录下的所有内容。这样你就不会再被这些报告以前程序错误的弹窗所扰。但是如果有一个程序又崩溃了,你就会再次看到“检测到系统程序错误”的错误。你可以再次删除这些报告文件,或者你可以禁用Apport来彻底地摆脱这个错误弹窗。
|
这个操作会删除所有在/var/crash目录下的所有内容。这样你就不会再被这些报告以前程序错误的弹窗所扰。但是如果又有一个程序崩溃了,你就会再次看到“检测到系统程序错误”的错误。你可以再次删除这些报告文件,或者你可以禁用Apport来彻底地摆脱这个错误弹窗。
|
||||||
|
|
||||||
#### 彻底地摆脱Ubuntu中的系统错误弹窗 ####
|
#### 彻底地摆脱Ubuntu中的系统错误弹窗 ####
|
||||||
|
|
||||||
如果你这样做,系统中任何程序崩溃时,系统都不会再通知你。如果你想问问我的看法的话,我会说,这不是一件坏事,除非你愿意填写错误报告。如果你不想填写错误报告,那么这些错误通知存不存在都不会有什么区别。
|
如果你这样做,系统中任何程序崩溃时,系统都不会再通知你。如果你想问问我的看法的话,我会说,这不是一件坏事,除非你愿意填写错误报告。如果你不想填写错误报告,那么这些错误通知存不存在都不会有什么区别。
|
||||||
|
|
||||||
要禁止Apport,并且彻底地摆脱Ubuntu系统中的程序崩溃报告,打开一个终端,输入以下命令:
|
要禁止Apport,并且彻底地摆脱Ubuntu系统中的程序崩溃报告,打开一个终端,输入以下命令:
|
||||||
|
|
||||||
gksu gedit /etc/default/apport
|
gksu gedit /etc/default/apport
|
||||||
|
|
||||||
这个文件的内容是:
|
这个文件的内容是:
|
||||||
|
|
||||||
# set this to 0 to disable apport, or to 1 to enable it
|
# 设置0表示禁用Apportw,或者1开启它。
|
||||||
# 设置0表示禁用Apportw,或者1开启它。译者注,下同。
|
|
||||||
# you can temporarily override this with
|
|
||||||
# 你可以用下面的命令暂时关闭它:
|
# 你可以用下面的命令暂时关闭它:
|
||||||
# sudo service apport start force_start=1
|
# sudo service apport start force_start=1
|
||||||
enabled=1
|
enabled=1
|
||||||
|
|
||||||
把**enabled=1**改为**enabled=0**.保存并关闭文件。完成之后你就再也不会看到弹窗报告错误了。很显然,如果我们想重新开启错误报告功能,只要再打开这个文件,把enabled设置为1就可以了。
|
把**enabled=1**改为**enabled=0**。保存并关闭文件。完成之后你就再也不会看到弹窗报告错误了。很显然,如果我们想重新开启错误报告功能,只要再打开这个文件,把enabled设置为1就可以了。
|
||||||
|
|
||||||
#### 你的有效吗? ####
|
#### 你的有效吗? ####
|
||||||
|
|
||||||
我希望这篇教程能够帮助你修复Ubuntu 14.04和Ubuntu 15.04中检测到系统程序错误的问题。如果这个小窍门帮你摆脱了这个烦人的问题,请让我知道。
|
我希望这篇教程能够帮助你修复Ubuntu 14.04和Ubuntu 15.04中检测到系统程序错误的问题。如果这个小窍门帮你摆脱了这个烦人的问题,请让我知道。
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
--------------------------------------------------------------------------------
|
||||||
@ -71,7 +74,7 @@ via: http://itsfoss.com/how-to-fix-system-program-problem-detected-ubuntu/
|
|||||||
|
|
||||||
作者:[Abhishek][a]
|
作者:[Abhishek][a]
|
||||||
译者:[XLCYun](https://github.com/XLCYun)
|
译者:[XLCYun](https://github.com/XLCYun)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
@ -1,10 +1,12 @@
|
|||||||
Linux命令行中使用和执行PHP代码——第一部分
|
在 Linux 命令行中使用和执行 PHP 代码(一)
|
||||||
================================================================================
|
================================================================================
|
||||||
PHP是一个开元服务器端脚本语言,最初这三个字母代表的是“Personal Home Page”,而现在则代表的是“PHP:Hypertext Preprocessor”,它是个递归首字母缩写。它是一个跨平台脚本语言,深受C、C++和Java的影响。
|
PHP是一个开源服务器端脚本语言,最初这三个字母代表的是“Personal Home Page”,而现在则代表的是“PHP:Hypertext Preprocessor”,它是个递归首字母缩写。它是一个跨平台脚本语言,深受C、C++和Java的影响。
|
||||||

|
|
||||||
Linux命令行中运行PHP代码——第一部分
|
|
||||||
|
|
||||||
PHP的语法和C、Java以及带有一些PHP特性的Perl变成语言中的语法十分相似,它眼下大约正被2.6亿个网站所使用,当前最新的稳定版本是PHP版本5.6.10。
|

|
||||||
|
|
||||||
|
*在 Linux 命令行中运行 PHP 代码*
|
||||||
|
|
||||||
|
PHP的语法和C、Java以及带有一些PHP特性的Perl变成语言中的语法十分相似,它当下大约正被2.6亿个网站所使用,当前最新的稳定版本是PHP版本5.6.10。
|
||||||
|
|
||||||
PHP是HTML的嵌入脚本,它便于开发人员快速写出动态生成的页面。PHP主要用于服务器端(而Javascript则用于客户端)以通过HTTP生成动态网页,然而,当你知道可以在Linux终端中不需要网页浏览器来执行PHP时,你或许会大为惊讶。
|
PHP是HTML的嵌入脚本,它便于开发人员快速写出动态生成的页面。PHP主要用于服务器端(而Javascript则用于客户端)以通过HTTP生成动态网页,然而,当你知道可以在Linux终端中不需要网页浏览器来执行PHP时,你或许会大为惊讶。
|
||||||
|
|
||||||
@ -12,40 +14,44 @@ PHP是HTML的嵌入脚本,它便于开发人员快速写出动态生成的页
|
|||||||
|
|
||||||
**1. 在安装完PHP和Apache2后,我们需要安装PHP命令行解释器。**
|
**1. 在安装完PHP和Apache2后,我们需要安装PHP命令行解释器。**
|
||||||
|
|
||||||
# apt-get install php5-cli [Debian and alike System)
|
# apt-get install php5-cli [Debian 及类似系统]
|
||||||
# yum install php-cli [CentOS and alike System)
|
# yum install php-cli [CentOS 及类似系统]
|
||||||
|
|
||||||
接下来我们通常要做的是,在‘/var/www/html‘(这是 Apache2 在大多数发行版中的工作目录)这个位置创建一个内容为 ‘<?php phpinfo(); ?>‘,名为 ‘infophp.php‘ 的文件来测试(是否安装正确),执行以下命令即可。
|
接下来我们通常要做的是,在`/var/www/html`(这是 Apache2 在大多数发行版中的工作目录)这个位置创建一个内容为 `<?php phpinfo(); ?>`,名为 `infophp.php` 的文件来测试(PHP是否安装正确),执行以下命令即可。
|
||||||
|
|
||||||
# echo '<?php phpinfo(); ?>' > /var/www/html/infophp.php
|
# echo '<?php phpinfo(); ?>' > /var/www/html/infophp.php
|
||||||
|
|
||||||
然后,将浏览器指向http://127.0.0.1/infophp.php, 这将会在网络浏览器中打开该文件。
|
然后,将浏览器访问 http://127.0.0.1/infophp.php ,这将会在网络浏览器中打开该文件。
|
||||||
|
|
||||||

|

|
||||||
检查PHP信息
|
|
||||||
|
|
||||||
不需要任何浏览器,在Linux终端中也可以获得相同的结果。在Linux命令行中执行‘/var/www/html/infophp.php‘,如:
|
*检查PHP信息*
|
||||||
|
|
||||||
|
不需要任何浏览器,在Linux终端中也可以获得相同的结果。在Linux命令行中执行`/var/www/html/infophp.php`,如:
|
||||||
|
|
||||||
# php -f /var/www/html/infophp.php
|
# php -f /var/www/html/infophp.php
|
||||||
|
|
||||||

|

|
||||||
从命令行检查PHP信息
|
|
||||||
|
|
||||||
由于输出结果太大,我们可以通过管道将上述输出结果输送给 ‘less‘ 命令,这样就可以一次输出一屏了,命令如下:
|
*从命令行检查PHP信息*
|
||||||
|
|
||||||
|
由于输出结果太大,我们可以通过管道将上述输出结果输送给 `less` 命令,这样就可以一次输出一屏了,命令如下:
|
||||||
|
|
||||||
# php -f /var/www/html/infophp.php | less
|
# php -f /var/www/html/infophp.php | less
|
||||||
|
|
||||||

|

|
||||||
检查所有PHP信息
|
|
||||||
|
|
||||||
这里,‘-f‘选项解析病执行命令后跟随的文件。
|
*检查所有PHP信息*
|
||||||
|
|
||||||
|
这里,‘-f‘选项解析并执行命令后跟随的文件。
|
||||||
|
|
||||||
**2. 我们可以直接在Linux命令行使用`phpinfo()`这个十分有价值的调试工具而不需要从文件来调用,只需执行以下命令:**
|
**2. 我们可以直接在Linux命令行使用`phpinfo()`这个十分有价值的调试工具而不需要从文件来调用,只需执行以下命令:**
|
||||||
|
|
||||||
# php -r 'phpinfo();'
|
# php -r 'phpinfo();'
|
||||||
|
|
||||||

|

|
||||||
PHP调试工具
|
|
||||||
|
*PHP调试工具*
|
||||||
|
|
||||||
这里,‘-r‘ 选项会让PHP代码在Linux终端中不带`<`和`>`标记直接执行。
|
这里,‘-r‘ 选项会让PHP代码在Linux终端中不带`<`和`>`标记直接执行。
|
||||||
|
|
||||||
@ -74,13 +80,14 @@ PHP调试工具
|
|||||||
输入 ‘exit‘ 或者按下 ‘ctrl+c‘ 来关闭PHP交互模式。
|
输入 ‘exit‘ 或者按下 ‘ctrl+c‘ 来关闭PHP交互模式。
|
||||||
|
|
||||||

|

|
||||||
启用PHP交互模式
|
|
||||||
|
*启用PHP交互模式*
|
||||||
|
|
||||||
**4. 你可以仅仅将PHP脚本作为shell脚本来运行。首先,创建在你当前工作目录中创建一个PHP样例脚本。**
|
**4. 你可以仅仅将PHP脚本作为shell脚本来运行。首先,创建在你当前工作目录中创建一个PHP样例脚本。**
|
||||||
|
|
||||||
# echo -e '#!/usr/bin/php\n<?php phpinfo(); ?>' > phpscript.php
|
# echo -e '#!/usr/bin/php\n<?php phpinfo(); ?>' > phpscript.php
|
||||||
|
|
||||||
注意,我们在该PHP脚本的第一行使用#!/usr/bin/php,就像在shell脚本中那样(/bin/bash)。第一行的#!/usr/bin/php告诉Linux命令行将该脚本文件解析到PHP解释器中。
|
注意,我们在该PHP脚本的第一行使用`#!/usr/bin/php`,就像在shell脚本中那样(`/bin/bash`)。第一行的`#!/usr/bin/php`告诉Linux命令行用 PHP 解释器来解析该脚本文件。
|
||||||
|
|
||||||
其次,让该脚本可执行:
|
其次,让该脚本可执行:
|
||||||
|
|
||||||
@ -96,7 +103,7 @@ PHP调试工具
|
|||||||
|
|
||||||
# php -a
|
# php -a
|
||||||
|
|
||||||
创建一个函授,将它命名为 addition。同时,声明两个变量 $a 和 $b。
|
创建一个函数,将它命名为 `addition`。同时,声明两个变量 `$a` 和 `$b`。
|
||||||
|
|
||||||
php > function addition ($a, $b)
|
php > function addition ($a, $b)
|
||||||
|
|
||||||
@ -133,7 +140,8 @@ PHP调试工具
|
|||||||
12.3NULL
|
12.3NULL
|
||||||
|
|
||||||

|

|
||||||
创建PHP函数
|
|
||||||
|
*创建PHP函数*
|
||||||
|
|
||||||
你可以一直运行该函数,直至退出交互模式(ctrl+z)。同时,你也应该注意到了,上面输出结果中返回的数据类型为 NULL。这个问题可以通过要求 php 交互 shell用 return 代替 echo 返回结果来修复。
|
你可以一直运行该函数,直至退出交互模式(ctrl+z)。同时,你也应该注意到了,上面输出结果中返回的数据类型为 NULL。这个问题可以通过要求 php 交互 shell用 return 代替 echo 返回结果来修复。
|
||||||
|
|
||||||
@ -152,11 +160,12 @@ PHP调试工具
|
|||||||
这里是一个样例,在该样例的输出结果中返回了正确的数据类型。
|
这里是一个样例,在该样例的输出结果中返回了正确的数据类型。
|
||||||
|
|
||||||

|

|
||||||
PHP函数
|
|
||||||
|
*PHP函数*
|
||||||
|
|
||||||
永远都记住,用户定义的函数不会从一个shell会话保留到下一个shell会话,因此,一旦你退出交互shell,它就会丢失了。
|
永远都记住,用户定义的函数不会从一个shell会话保留到下一个shell会话,因此,一旦你退出交互shell,它就会丢失了。
|
||||||
|
|
||||||
希望你喜欢此次会话。保持连线,你会获得更多此类文章。保持关注,保持健康。请在下面的评论中为我们提供有价值的反馈。点赞并分享,帮助我们扩散。
|
希望你喜欢此次教程。保持连线,你会获得更多此类文章。保持关注,保持健康。请在下面的评论中为我们提供有价值的反馈。点赞并分享,帮助我们扩散。
|
||||||
|
|
||||||
还请阅读: [12个Linux终端中有用的的PHP命令行用法——第二部分][1]
|
还请阅读: [12个Linux终端中有用的的PHP命令行用法——第二部分][1]
|
||||||
|
|
||||||
@ -164,9 +173,9 @@ PHP函数
|
|||||||
|
|
||||||
via: http://www.tecmint.com/run-php-codes-from-linux-commandline/
|
via: http://www.tecmint.com/run-php-codes-from-linux-commandline/
|
||||||
|
|
||||||
作者:[vishek Kumar][a]
|
作者:[Avishek Kumar][a]
|
||||||
译者:[GOLinux](https://github.com/GOLinux)
|
译者:[GOLinux](https://github.com/GOLinux)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
@ -1,74 +0,0 @@
|
|||||||
2015 will be the year Linux takes over the enterprise (and other predictions)
|
|
||||||
================================================================================
|
|
||||||
> Jack Wallen removes his rose-colored glasses and peers into the crystal ball to predict what 2015 has in store for Linux.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
The crystal ball has been vague and fuzzy for quite some time. Every pundit and voice has opined on what the upcoming year will mean to whatever topic it is they hold dear to their heart. In my case, we're talking Linux and open source.
|
|
||||||
|
|
||||||
In previous years, I'd don the rose-colored glasses and make predictions that would shine a fantastic light over the Linux landscape and proclaim 20** will be the year of Linux on the _____ (name your platform). Many times, those predictions were wrong, and Linux would wind up grinding on in the background.
|
|
||||||
|
|
||||||
This coming year, however, there are some fairly bold predictions to be made, some of which are sure things. Read on and see if you agree.
|
|
||||||
|
|
||||||
### Linux takes over big data ###
|
|
||||||
|
|
||||||
This should come as no surprise, considering the advancements Linux and open source has made over the previous few years. With the help of SuSE, Red Hat, and SAP Hana, Linux will hold powerful sway over big data in 2015. In-memory computing and live kernel patching will be the thing that catapults big data into realms of uptime and reliability never before known. SuSE will lead this charge like a warrior rushing into a battle it cannot possibly lose.
|
|
||||||
|
|
||||||
This rise of Linux in the world of big data will have serious trickle down over the rest of the business world. We already know how fond enterprise businesses are of Linux and big data. What we don't know is how this relationship will alter the course of Linux with regards to the rest of the business world.
|
|
||||||
|
|
||||||
My prediction is that the success of Linux with big data will skyrocket the popularity of Linux throughout the business landscape. More contracts for SuSE and Red Hat will equate to more deployments of Linux servers that handle more tasks within the business world. This will especially apply to the cloud, where OpenStack should easily become an overwhelming leader.
|
|
||||||
|
|
||||||
As the end of 2015 draws to a close, Linux will continue its take over of more backend services, which may include the likes of collaboration servers, security, and much more.
|
|
||||||
|
|
||||||
### Smart machines ###
|
|
||||||
|
|
||||||
Linux is already leading the trend for making homes and autos more intelligent. With improvements in the likes of Nest (which currently uses an embedded Linux), the open source platform is poised to take over your machines. Because 2015 should see a massive rise in smart machines, it goes without saying that Linux will be a huge part of that growth. I firmly believe more homes and businesses will take advantage of such smart controls, and that will lead to more innovations (all of which will be built on Linux).
|
|
||||||
|
|
||||||
One of the issues facing Nest, however, is that it was purchased by Google. What does this mean for the thermostat controller? Will Google continue using the Linux platform -- or will it opt to scrap that in favor of Android? Of course, a switch would set the Nest platform back a bit.
|
|
||||||
|
|
||||||
The upcoming year will see Linux lead the rise in popularity of home automation. Wink, Iris, Q Station, Staples Connect, and more (similar) systems will help to bridge Linux and home users together.
|
|
||||||
|
|
||||||
### The desktop ###
|
|
||||||
|
|
||||||
The big question, as always, is one that tends to hang over the heads of the Linux community like a dark cloud. That question is in relation to the desktop. Unfortunately, my predictions here aren't nearly as positive. I believe that the year 2015 will remain quite stagnant for Linux on the desktop. That complacency will center around Ubuntu.
|
|
||||||
|
|
||||||
As much as I love Ubuntu (and the Unity desktop), this particular distribution will continue to drag the Linux desktop down. Why?
|
|
||||||
|
|
||||||
Convergence... or the lack thereof.
|
|
||||||
|
|
||||||
Canonical has been so headstrong about converging the desktop and mobile experience that they are neglecting the current state of the desktop. The last two releases of Ubuntu (one being an LTS release) have been stagnant (at best). The past year saw two of the most unexciting releases of Ubuntu that I can recall. The reason? Because the developers of Ubuntu are desperately trying to make Unity 8/Mir and the ubiquitous Ubuntu Phone a reality. The vaporware that is the Ubuntu Phone will continue on through 2015, and Unity 8/Mir may or may not be released.
|
|
||||||
|
|
||||||
When the new iteration of the Ubuntu Unity desktop is finally released, it will suffer a serious setback, because there will be so little hardware available to truly show it off. [System76][1] will sell their outstanding [Sable Touch][2], which will probably become the flagship system for Unity 8/Mir. As for the Ubuntu Phone? How many reports have you read that proclaimed "Ubuntu Phone will ship this year"?
|
|
||||||
|
|
||||||
I'm now going on the record to predict that the Ubuntu Phone will not ship in 2015. Why? Canonical created partnerships with two OEMs over a year ago. Those partnerships have yet to produce a single shippable product. The closest thing to a shippable product is the Meizu MX4 phone. The "Pro" version of that phone was supposed to have a formal launch of Sept 25. Like everything associated with the Ubuntu Phone, it didn't happen.
|
|
||||||
|
|
||||||
Unless Canonical stops putting all of its eggs in one vaporware basket, desktop Linux will take a major hit in 2015. Ubuntu needs to release something major -- something to make heads turn -- otherwise, 2015 will be just another year where we all look back and think "we could have done something special."
|
|
||||||
|
|
||||||
Outside of Ubuntu, I do believe there are some outside chances that Linux could still make some noise on the desktop. I think two distributions, in particular, will bring something rather special to the table:
|
|
||||||
|
|
||||||
- [Evolve OS][3] -- a ChromeOS-like Linux distribution
|
|
||||||
- [Quantum OS][4] -- a Linux distribution that uses Android's Material Design specs
|
|
||||||
|
|
||||||
Both of these projects are quite exciting and offer unique, user-friendly takes on the Linux desktop. This is quickly become a necessity in a landscape being dragged down by out-of-date design standards (think the likes of Cinnamon, Mate, XFCE, LXCE -- all desperately clinging to the past).
|
|
||||||
|
|
||||||
This is not to say that Linux on the desktop doesn't have a chance in 2015. It does. In order to grasp the reins of that chance, it will have to move beyond the past and drop the anchors that prevent it from moving out to deeper, more viable waters.
|
|
||||||
|
|
||||||
Linux stands to make more waves in 2015 than it has in a very long time. From enterprise to home automation -- the world could be the oyster that Linux uses as a springboard to the desktop and beyond.
|
|
||||||
|
|
||||||
What are your predictions for Linux and open source in 2015? Share your thoughts in the discussion thread below.
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: http://www.techrepublic.com/article/2015-will-be-the-year-linux-takes-over-the-enterprise-and-other-predictions/
|
|
||||||
|
|
||||||
作者:[Jack Wallen][a]
|
|
||||||
译者:[barney-ro](https://github.com/barney-ro)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:http://www.techrepublic.com/search/?a=jack+wallen
|
|
||||||
[1]:https://system76.com/
|
|
||||||
[2]:https://system76.com/desktops/sable
|
|
||||||
[3]:https://evolve-os.com/
|
|
||||||
[4]:http://quantum-os.github.io/
|
|
||||||
@ -1,120 +0,0 @@
|
|||||||
The Curious Case of the Disappearing Distros
|
|
||||||
================================================================================
|
|
||||||

|
|
||||||
|
|
||||||
"Linux is a big game now, with billions of dollars of profit, and it's the best thing since sliced bread, but corporations are taking control, and slowly but systematically, community distros are being killed," said Google+ blogger Alessandro Ebersol. "Linux is slowly becoming just like BSD, where companies use and abuse it and give very little in return."
|
|
||||||
|
|
||||||
Well the holidays are pretty much upon us at last here in the Linux blogosphere, and there's nowhere left to hide. The next two weeks or so promise little more than a blur of forced social occasions and too-large meals, punctuated only -- for the luckier ones among us -- by occasional respite down at the Broken Windows Lounge.
|
|
||||||
|
|
||||||
Perhaps that's why Linux bloggers seized with such glee upon the good old-fashioned mystery that came up recently -- delivered in the nick of time, as if on cue.
|
|
||||||
|
|
||||||
"Why is the Number of Linux Distros Declining?" is the [question][1] posed over at Datamation, and it's just the distraction so many FOSS fans have been needing.
|
|
||||||
|
|
||||||
"Until about 2011, the number of active distributions slowly increased by a few each year," wrote author Bruce Byfield. "By contrast, the last three years have seen a 12 percent decline -- a decrease too high to be likely to be coincidence.
|
|
||||||
|
|
||||||
"So what's happening?" Byfield wondered.
|
|
||||||
|
|
||||||
It would be difficult to imagine a more thought-provoking question with which to spend the Northern hemisphere's shortest days.
|
|
||||||
|
|
||||||
### 'There Are Too Many Distros' ###
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
"That's an easy question," began blogger [Robert Pogson][2]. "There are too many distros."
|
|
||||||
|
|
||||||
After all, "if a fanatic like me can enjoy life having sampled only a dozen distros, why have any more?" Pogson explained. "If someone has a concept different from the dozen or so most common distros, that concept can likely be demonstrated by documenting the tweaks and package-lists and, perhaps, some code."
|
|
||||||
|
|
||||||
Trying to compete with some 40,000 package repositories like Debian's, however, is "just silly," he said.
|
|
||||||
|
|
||||||
"No startup can compete with such a distro," Pogson asserted. "Why try? Just use it to do what you want and tell the world about it."
|
|
||||||
|
|
||||||
### 'I Don't Distro-Hop Anymore' ###
|
|
||||||
|
|
||||||
The major existing distros are doing a good job, so "we don't need so many derivative works," Google+ blogger Kevin O'Brien agreed.
|
|
||||||
|
|
||||||
"I know I don't 'distro-hop' anymore, and my focus is on using my computer to get work done," O'Brien added.
|
|
||||||
|
|
||||||
"If my apps run fine every day, that is all that I need," he said. "Right now I am sticking with Ubuntu LTS 14.04, and probably will until 2016."
|
|
||||||
|
|
||||||
### 'The More Distros, the Better' ###
|
|
||||||
|
|
||||||
It stands to reason that "as distros get better, there will be less reasons to roll your own," concurred [Linux Rants][3] blogger Mike Stone.
|
|
||||||
|
|
||||||
"I think the modern Linux distros cover the bases of a larger portion of the Linux-using crowd, so fewer and fewer people are starting their own distribution to compensate for something that the others aren't satisfying," he explained. "Add to that the fact that corporations are more heavily involved in the development of Linux now than they ever have been, and they're going to focus their resources."
|
|
||||||
|
|
||||||
So, the decline isn't necessarily a bad thing, as it only points to the strength of the current offerings, he asserted.
|
|
||||||
|
|
||||||
At the same time, "I do think there are some negative consequences as well," Stone added. "Variation in the distros is a way that Linux grows and evolves, and with a narrower field, we're seeing less opportunity to put new ideas out there. In my mind, the more distros, the better -- hopefully the trend reverses soon."
|
|
||||||
|
|
||||||
### 'I Hope Some Diversity Survives' ###
|
|
||||||
|
|
||||||
Indeed, "the era of novelty and experimentation is over," Google+ blogger Gonzalo Velasco C. told Linux Girl.
|
|
||||||
|
|
||||||
"Linux is 20+ years old and got professional," he noted. "There is always room for experimentation, but the top 20 are here since more than a decade ago.
|
|
||||||
|
|
||||||
"Godspeed GNU/Linux," he added. "I hope some diversity survives -- especially distros without Systemd; on the other hand, some standards are reached through consensus."
|
|
||||||
|
|
||||||
### A Question of Package Managers ###
|
|
||||||
|
|
||||||
There are two trends at work here, suggested consultant and [Slashdot][4] blogger Gerhard Mack.
|
|
||||||
|
|
||||||
First, "there are fewer reasons to start a new distro," he said. "The basic nuts and bolts are mostly done, installation is pretty easy across most distros, and it's not difficult on most hardware to get a working system without having to resort to using the command line."
|
|
||||||
|
|
||||||
The second thing is that "we are seeing a reduction of distros with inferior package managers," Mack suggested. "It is clear that .deb-based distros had fewer losses and ended up with a larger overall share."
|
|
||||||
|
|
||||||
### Survival of the Fittest ###
|
|
||||||
|
|
||||||
It's like survival of the fittest, suggested consultant Rodolfo Saenz, who is certified in Linux, IBM Tivoli Storage Manager and Microsoft Active Directory.
|
|
||||||
|
|
||||||
"I prefer to see a strong Linux with less distros," Saenz added. "Too many distros dilutes development efforts and can confuse potential future users."
|
|
||||||
|
|
||||||
Fewer distros, on the other hand, "focuses development efforts into the stronger distros and also attracts new potential users with clear choices for their needs," he said.
|
|
||||||
|
|
||||||
### All About the Money ###
|
|
||||||
|
|
||||||
Google+ blogger Alessandro Ebersol also saw survival of the fittest at play, but he took a darker view.
|
|
||||||
|
|
||||||
"Linux is a big game now, with billions of dollars of profit, and it's the best thing since sliced bread," Ebersol began. "But corporations are taking control, and slowly but systematically, community distros are being killed."
|
|
||||||
|
|
||||||
It's difficult for community distros to keep pace with the ever-changing field, and cash is a necessity, he conceded.
|
|
||||||
|
|
||||||
Still, "Linux is slowly becoming just like BSD, where companies use and abuse it and give very little in return," Ebersol said. "It saddens me, but GNU/Linux's best days were 10 years ago, circa 2002 to 2004. Now, it's the survival of the fittest -- and of course, the ones with more money will prevail."
|
|
||||||
|
|
||||||
### 'Fewer Devs Care' ###
|
|
||||||
|
|
||||||
SoylentNews blogger hairyfeet focused on today's altered computing landscape.
|
|
||||||
|
|
||||||
"The reason there are fewer distros is simple: With everybody moving to the Google Playwall of Android, and Windows 10 looking to be the next XP, fewer devs care," hairyfeet said.
|
|
||||||
|
|
||||||
"Why should they?" he went on. "The desktop wars are over, MSFT won, and the mobile wars are gonna be proprietary Google, proprietary Apple and proprietary MSFT. The money is in apps and services, and with a slow economy, there just isn't time for pulling a Taco Bell and rerolling yet another distro.
|
|
||||||
|
|
||||||
"For the few that care about Linux desktops you have Ubuntu, Mint and Cent, and that is plenty," hairyfeet said.
|
|
||||||
|
|
||||||
### 'No Less Diversity' ###
|
|
||||||
|
|
||||||
Last but not least, Chris Travers, a [blogger][5] who works on the [LedgerSMB][6] project, took an optimistic view.
|
|
||||||
|
|
||||||
"Ever since I have been around Linux, there have been a few main families -- [SuSE][7], [Red Hat][8], Debian, Gentoo, Slackware -- and a number of forks of these," Travers said. "The number of major families of distros has been declining for some time -- Mandrake and Connectiva merging, for example, Caldera disappearing -- but each of these families is ending up with fewer members as well.
|
|
||||||
|
|
||||||
"I think this is a good thing," he concluded.
|
|
||||||
|
|
||||||
"The big community distros -- Debian, Slackware, Gentoo, Fedora -- are going strong and picking up a lot of the niche users that other distros catered to," he pointed out. "Many of these distros are making it easier to come up with customized variants for niche markets. So what you have is a greater connectedness within the big distros, and no less diversity."
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: http://www.linuxinsider.com/story/The-Curious-Case-of-the-Disappearing-Distros-81518.html
|
|
||||||
|
|
||||||
作者:Katherine Noyes
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[1]:http://www.datamation.com/open-source/why-is-the-number-of-linux-distros-declining.html
|
|
||||||
[2]:http://mrpogson.com/
|
|
||||||
[3]:http://linuxrants.com/
|
|
||||||
[4]:http://slashdot.org/
|
|
||||||
[5]:http://ledgersmbdev.blogspot.com/
|
|
||||||
[6]:http://www.ledgersmb.org/
|
|
||||||
[7]:http://www.novell.com/linux
|
|
||||||
[8]:http://www.redhat.com/
|
|
||||||
@ -1,36 +0,0 @@
|
|||||||
diff -u: What's New in Kernel Development
|
|
||||||
================================================================================
|
|
||||||
**David Drysdale** wanted to add Capsicum security features to Linux after he noticed that FreeBSD already had Capsicum support. Capsicum defines fine-grained security privileges, not unlike filesystem capabilities. But as David discovered, Capsicum also has some controversy surrounding it.
|
|
||||||
|
|
||||||
Capsicum has been around for a while and was described in a USENIX paper in 2010: [http://www.cl.cam.ac.uk/research/security/capsicum/papers/2010usenix-security-capsicum-website.pdf][1].
|
|
||||||
|
|
||||||
Part of the controversy is just because of the similarity with capabilities. As Eric Biderman pointed out during the discussion, it would be possible to implement features approaching Capsicum's as an extension of capabilities, but implementing Capsicum directly would involve creating a whole new (and extensive) abstraction layer in the kernel. Although David argued that capabilities couldn't actually be extended far enough to match Capsicum's fine-grained security controls.
|
|
||||||
|
|
||||||
Capsicum also was controversial within its own developer community. For example, as Eric described, it lacked a specification for how to revoke privileges. And, David pointed out that this was because the community couldn't agree on how that could best be done. David quoted an e-mail sent by Ben Laurie to the cl-capsicum-discuss mailing list in 2011, where Ben said, "It would require additional book-keeping to find and revoke outstanding capabilities, which requires knowing how to reach capabilities, and then whether they are derived from the capability being revoked. It also requires an authorization model for revocation. The former two points mean additional overhead in terms of data structure operations and synchronisation."
|
|
||||||
|
|
||||||
Given the ongoing controversy within the Capsicum developer community and the corresponding lack of specification of key features, and given the existence of capabilities that already perform a similar function in the kernel and the invasiveness of Capsicum patches, Eric was opposed to David implementing Capsicum in Linux.
|
|
||||||
|
|
||||||
But, given the fact that capabilities are much coarser-grained than Capsicum's security features, to the point that capabilities can't really be extended far enough to mimic Capsicum's features, and given that FreeBSD already has Capsicum implemented in its kernel, showing that it can be done and that people might want it, it seems there will remain a lot of folks interested in getting Capsicum into the Linux kernel.
|
|
||||||
|
|
||||||
Sometimes it's unclear whether there's a bug in the code or just a bug in the written specification. Henrique de Moraes Holschuh noticed that the Intel Software Developer Manual (vol. 3A, section 9.11.6) said quite clearly that microcode updates required 16-byte alignment for the P6 family of CPUs, the Pentium 4 and the Xeon. But, the code in the kernel's microcode driver didn't enforce that alignment.
|
|
||||||
|
|
||||||
In fact, Henrique's investigation uncovered the fact that some Intel chips, like the Xeon X5550 and the second-generation i5 chips, needed only 4-byte alignment in practice, and not 16. However, to conform to the documented specification, he suggested fixing the kernel code to match the spec.
|
|
||||||
|
|
||||||
Borislav Petkov objected to this. He said Henrique was looking for problems where there weren't any. He said that Henrique simply had discovered a bug in Intel's documentation, because the alignment issue clearly wasn't a problem in the real world. He suggested alerting the Intel folks to the documentation problem and moving on. As he put it, "If the processor accepts the non-16-byte-aligned update, why do you care?"
|
|
||||||
|
|
||||||
But, as H. Peter Anvin remarked, the written spec was Intel's guarantee that certain behaviors would work. If the kernel ignored the spec, it could lead to subtle bugs later on. And, Bill Davidsen said that if the kernel ignored the alignment requirement, and "if the requirement is enforced in some future revision, and updates then fail in some insane way, the vendor is justified in claiming 'I told you so'."
|
|
||||||
|
|
||||||
The end result was that Henrique sent in some patches to make the microcode driver enforce the 16-byte alignment requirement.
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: http://www.linuxjournal.com/content/diff-u-whats-new-kernel-development-6
|
|
||||||
|
|
||||||
作者:[Zack Brown][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:http://www.linuxjournal.com/user/801501
|
|
||||||
[1]:http://www.cl.cam.ac.uk/research/security/capsicum/papers/2010usenix-security-capsicum-website.pdf
|
|
||||||
@ -1,91 +0,0 @@
|
|||||||
Did this JavaScript break the console?
|
|
||||||
---------
|
|
||||||
|
|
||||||
#Q:
|
|
||||||
|
|
||||||
Just doing some JavaScript stuff in google chrome (don't want to try in other browsers for now, in case this is really doing real damage) and I'm not sure why this seemed to break my console.
|
|
||||||
|
|
||||||
```javascript
|
|
||||||
>var x = "http://www.foo.bar/q?name=%%this%%";
|
|
||||||
<undefined
|
|
||||||
>x
|
|
||||||
```
|
|
||||||
|
|
||||||
After x (and enter) the console stops working... I restarted chrome and now when I do a simple
|
|
||||||
|
|
||||||
```javascript
|
|
||||||
console.clear();
|
|
||||||
```
|
|
||||||
|
|
||||||
It's giving me
|
|
||||||
|
|
||||||
```javascript
|
|
||||||
Console was cleared
|
|
||||||
```
|
|
||||||
|
|
||||||
And not clearing the console. Now in my scripts console.log's do not register and I'm wondering what is going on. 99% sure it has to do with the double percent signs (%%).
|
|
||||||
|
|
||||||
Anyone know what I did wrong or better yet, how to fix the console?
|
|
||||||
|
|
||||||
[A bug report for this issue has been filed here.][1]
|
|
||||||
Edit: Feeling pretty dumb, but I had Preserve log checked... That's why the console wasn't clearing.
|
|
||||||
|
|
||||||
#A:
|
|
||||||
|
|
||||||
As discussed in the comments, there are actually many different ways of constructing a string that causes this issue, and it is not necessary for there to be two percent signs in most cases.
|
|
||||||
|
|
||||||
```TXT
|
|
||||||
http://example.com/%
|
|
||||||
http://%%%
|
|
||||||
http://ab%
|
|
||||||
http://%ab
|
|
||||||
http://%zz
|
|
||||||
```
|
|
||||||
|
|
||||||
However, it's not just the presence of a percent sign that breaks the Chrome console, as when we enter the following well-formed URL, the console continues to work properly and produces a clickable link.
|
|
||||||
|
|
||||||
```TXT
|
|
||||||
http://ab%20cd
|
|
||||||
```
|
|
||||||
|
|
||||||
Additionally, the strings `http://%`, and `http://%%` will also print properly, since Chrome will not auto-link a URL-link string unless the [`http://`][2] is followed by at least 3 characters.
|
|
||||||
|
|
||||||
From here I hypothesized that the issue must be in the process of linking a URL string in the console, likely in the process of decoding a malformed URL. I remembered that the JavaScript function `decodeURI` will throw an exception if given a malformed URL, and since Chrome's developer tools are largely written in JavaScript, could this be the issue that is evidently crashing the developer console?
|
|
||||||
|
|
||||||
To test this theory, I ran Chrome by the command link, to see if any errors were being logged.
|
|
||||||
|
|
||||||
Indeed, the same error you would see if you ran decodeURI on a malformed URL (i.e. decodeURI('http://example.com/%')) was being printed to the console:
|
|
||||||
|
|
||||||
>[4810:1287:0107/164725:ERROR:CONSOLE(683)] "Uncaught URIError: URI malformed", source: chrome-devtools://devtools/bundled/devtools.js (683)
|
|
||||||
>So, I opened the URL 'chrome-devtools://devtools/bundled/devtools.js' in Chrome, and on line 683, I found the following.
|
|
||||||
|
|
||||||
```javascript
|
|
||||||
{var parsedURL=new WebInspector.ParsedURL(decodeURI(url));var origin;var folderPath;var name;if(parsedURL.isValid){origin=parsedURL.scheme+"://"+parsedURL.host;if(parsedURL.port)
|
|
||||||
```
|
|
||||||
|
|
||||||
As we can see, `decodeURI(url)` is being called on the URL without any error checking, thus throwing the exception and crashing the developer console.
|
|
||||||
|
|
||||||
A real fix for this issue will come from adding error handling to the Chrome console code, but in the meantime, one way to avoid the issue would be to wrap the string in a complex data type like an array to prevent parsing when logging.
|
|
||||||
|
|
||||||
```javascript
|
|
||||||
var x = "http://example.com/%";
|
|
||||||
console.log([x]);
|
|
||||||
```
|
|
||||||
|
|
||||||
Thankfully, the broken console issue does not persist once the tab is closed, and will not affect other tabs.
|
|
||||||
|
|
||||||
###Update:
|
|
||||||
|
|
||||||
Apparently, the issue can persist across tabs and restarts if Preserve Log is checked. Uncheck this if you are having this issue.
|
|
||||||
|
|
||||||
via:[stackoverflow](http://stackoverflow.com/questions/27828804/did-this-javascript-break-the-console/27830948#27830948)
|
|
||||||
|
|
||||||
作者:[Alexander O'Mara][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:http://stackoverflow.com/users/3155639/alexander-omara
|
|
||||||
[1]:https://code.google.com/p/chromium/issues/detail?id=446975
|
|
||||||
[2]:https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/decodeURI
|
|
||||||
@ -1,66 +0,0 @@
|
|||||||
Revealed: The best and worst of Docker
|
|
||||||
================================================================================
|
|
||||||

|
|
||||||
Credit: [Shutterstock][1]
|
|
||||||
|
|
||||||
> Docker experts talk about the good, the bad, and the ugly of the ubiquitous application container system
|
|
||||||
|
|
||||||
No question about it: Docker's app container system has made its mark and become a staple in many IT environments. With its accelerating adoption, it's bound to stick around for a good long time.
|
|
||||||
|
|
||||||
But there's no end to the debate about what Docker's best for, where it falls short, or how to most sensibly move it forward without alienating its existing users or damaging its utility. Here, we've turned to a few of the folks who have made Docker their business to get their takes on Docker's good, bad, and ugly sides.
|
|
||||||
|
|
||||||
### The good ###
|
|
||||||
|
|
||||||
One hardly expects Steve Francia, chief of operations of the Docker open source project, to speak of Docker in anything less than glowing terms. When asked by email about Docker's best attributes, he didn't disappoint: "I think the best thing about Docker is that it enables people, enables developers, enables users to very easily run an application anywhere," he said. "It's almost like the Holy Grail of development in that you can run an application on your desktop, and the exact same application without any changes can run on the server. That's never been done before."
|
|
||||||
|
|
||||||
Alexis Richardson of [Weaveworks][2], a virtual networking product, praised Docker for enabling simplicity. "Docker offers immense potential to radically simplify and speed up how software gets built," he replied in an email. "This is why it has delivered record-breaking initial mind share and traction."
|
|
||||||
|
|
||||||
Bob Quillin, CEO of [StackEngine][3], which makes Docker management and automation solutions, noted in an email that Docker (the company) has done a fine job of maintaining Docker's (the product) appeal to its audience. "Docker has been best at delivering strong developer support and focused investment in its product," he wrote. "Clearly, they know they have to keep the momentum, and they are doing that by putting intense effort into product functionality." He also mentioned that Docker's commitment to open source has accelerated adoption by "[allowing] people to build around their features as they are being built."
|
|
||||||
|
|
||||||
Though containerization itself isn't new, as Rob Markovich of IT monitoring-service makers [Moogsoft][4] pointed out, Docker's implementation makes it new. "Docker is considered a next-generation virtualization technology given its more modern, lightweight form [of containerization]," he wrote in an email. "[It] brings an opportunity for an order-of-magnitude leap forward for software development teams seeking to deploy code faster."
|
|
||||||
|
|
||||||
### The bad ###
|
|
||||||
|
|
||||||
What's less appealing about Docker boils down to two issues: the complexity of using the product, and the direction of the company behind it.
|
|
||||||
|
|
||||||
Samir Ghosh, CEO of enterprise PaaS outfit [WaveMaker][5], gave Docker a thumbs-up for simplifying the complex scripting typically needed for continuous delivery. That said, he added, "That doesn't mean Docker is simple. Implementing Docker is complicated. There are a lot of supporting technologies needed for things like container management, orchestration, app stack packaging, intercontainer networking, data snapshots, and so on."
|
|
||||||
|
|
||||||
Ghosh noted the ones who feel the most of that pain are enterprises that want to leverage Docker for continuous delivery, but "it's even more complicated for enterprises that have diverse workloads, various app stacks, heterogenous infrastructures, and limited resources, not to mention unique IT needs for visibility, control and security."
|
|
||||||
|
|
||||||
Complexity also becomes an issue in troubleshooting and analysis, and Markovich cited the fact that Docker provides application abstraction as the reason why. "It is nearly impossible to relate problems with application performance running on Docker to the performance of the underlying infrastructure domains," he said in an email. "IT teams are going to need visibility -- a new class of monitoring and analysis tools that can correlate across and relate how everything is working up and down the Docker stack, from the applications down to the private or public infrastructure."
|
|
||||||
|
|
||||||
Quillin is most concerned about Docker's direction vis-à-vis its partner community: "Where will Docker make money, and where will their partners? If [Docker] wants to be the next VMware, it will need to take a page out of VMware's playbook in how to build and support a thriving partner ecosystem.
|
|
||||||
|
|
||||||
"Additionally, to drive broader adoption, especially in the enterprise, Docker needs to start acting like a market leader by releasing more fully formed capabilities that organizations can count on, versus announcements of features with 'some assembly required,' that don't exist yet, or that require you to 'submit a pull request' to fix it yourself."
|
|
||||||
|
|
||||||
Francia pointed to Docker's rapid ascent for creating its own difficulties. "[Docker] caught on so quickly that there's definitely places that we're focused on to add some features that a lot of users are looking forward to."
|
|
||||||
|
|
||||||
One such feature, he noted, was having a GUI. "Right now to use Docker," he said, "you have to be comfortable with the command line. There's no visual interface to using Docker. Right now it's all command line-based. And we know if we want to really be as successful as we think we can be, we need to be more approachable and a lot of people when they see a command line, it's a bit intimidating for a lot of users."
|
|
||||||
|
|
||||||
### The future ###
|
|
||||||
|
|
||||||
In that last respect, Docker recently started to make advances. Last week it [bought the startup Kitematic][6], whose product gave Docker a convenient GUI on Mac OS X (and will eventually do the same for Windows). Another acqui-hire, [SocketPlane][7], is being spun in to work on Docker's networking.
|
|
||||||
|
|
||||||
What remains to be seen is whether Docker's proposed solutions to its problems will be adopted, or whether another party -- say, [Red Hat][8] -- will provide a more immediately useful solution for enterprise customers who can't wait around for the chips to stop falling.
|
|
||||||
|
|
||||||
"Good technology is hard and takes time to build," said Richardson. "The big risk is that expectations spin wildly out of control and customers are disappointed."
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: http://www.infoworld.com/article/2896895/application-virtualization/best-and-worst-about-docker.html
|
|
||||||
|
|
||||||
作者:[Serdar Yegulalp][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:http://www.infoworld.com/author/Serdar-Yegulalp/
|
|
||||||
[1]:http://shutterstock.com/
|
|
||||||
[2]:http://weave.works/
|
|
||||||
[3]:http://stackengine.com/
|
|
||||||
[4]:http://www.moogsoft.com/
|
|
||||||
[5]:http://www.wavemaker.com/
|
|
||||||
[6]:http://www.infoworld.com/article/2896099/application-virtualization/dockers-new-acquisition-does-containers-on-the-desktop.html
|
|
||||||
[7]:http://www.infoworld.com/article/2892916/application-virtualization/docker-snaps-up-socketplane-to-fix-networking-flaws.html
|
|
||||||
[8]:http://www.infoworld.com/article/2895804/application-virtualization/red-hat-wants-to-do-for-containers-what-its-done-for-linux.html
|
|
||||||
@ -1,3 +1,4 @@
|
|||||||
|
zpl1025
|
||||||
Interviews: Linus Torvalds Answers Your Question
|
Interviews: Linus Torvalds Answers Your Question
|
||||||
================================================================================
|
================================================================================
|
||||||
Last Thursday you had a chance to [ask Linus Torvalds][1] about programming, hardware, and all things Linux. You can read his answers to those questions below. If you'd like to see what he had to say the last time we sat down with him, [you can do so here][2].
|
Last Thursday you had a chance to [ask Linus Torvalds][1] about programming, hardware, and all things Linux. You can read his answers to those questions below. If you'd like to see what he had to say the last time we sat down with him, [you can do so here][2].
|
||||||
@ -181,4 +182,4 @@ via: http://linux.slashdot.org/story/15/06/30/0058243/interviews-linus-torvalds-
|
|||||||
[a]:samzenpus@slashdot.org
|
[a]:samzenpus@slashdot.org
|
||||||
[1]:http://interviews.slashdot.org/story/15/06/24/1718247/interview-ask-linus-torvalds-a-question
|
[1]:http://interviews.slashdot.org/story/15/06/24/1718247/interview-ask-linus-torvalds-a-question
|
||||||
[2]:http://meta.slashdot.org/story/12/10/11/0030249/linus-torvalds-answers-your-questions
|
[2]:http://meta.slashdot.org/story/12/10/11/0030249/linus-torvalds-answers-your-questions
|
||||||
[3]:https://lwn.net/Articles/604695/
|
[3]:https://lwn.net/Articles/604695/
|
||||||
|
|||||||
@ -1,4 +1,3 @@
|
|||||||
2q1w2007申领
|
|
||||||
How to access a Linux server behind NAT via reverse SSH tunnel
|
How to access a Linux server behind NAT via reverse SSH tunnel
|
||||||
================================================================================
|
================================================================================
|
||||||
You are running a Linux server at home, which is behind a NAT router or restrictive firewall. Now you want to SSH to the home server while you are away from home. How would you set that up? SSH port forwarding will certainly be an option. However, port forwarding can become tricky if you are dealing with multiple nested NAT environment. Besides, it can be interfered with under various ISP-specific conditions, such as restrictive ISP firewalls which block forwarded ports, or carrier-grade NAT which shares IPv4 addresses among users.
|
You are running a Linux server at home, which is behind a NAT router or restrictive firewall. Now you want to SSH to the home server while you are away from home. How would you set that up? SSH port forwarding will certainly be an option. However, port forwarding can become tricky if you are dealing with multiple nested NAT environment. Besides, it can be interfered with under various ISP-specific conditions, such as restrictive ISP firewalls which block forwarded ports, or carrier-grade NAT which shares IPv4 addresses among users.
|
||||||
|
|||||||
@ -1,193 +0,0 @@
|
|||||||
Translating by dingdongnigetou
|
|
||||||
|
|
||||||
Install Plex Media Server On Ubuntu / CentOS 7.1 / Fedora 22
|
|
||||||
================================================================================
|
|
||||||
In this article we will show you how easily you can setup Plex Home Media Server on major Linux distributions with their latest releases. After its successful installation of Plex you will be able to use your centralized home media playback system that streams its media to many Plex player Apps and the Plex Home will allows you to setup your environment by adding your devices and to setup a group of users that all can use Plex Together. So let’s start its installation first on Ubuntu 15.04.
|
|
||||||
|
|
||||||
### Basic System Resources ###
|
|
||||||
|
|
||||||
System resources mainly depend on the type and number of devices that you are planning to connect with the server. So according to our requirements we will be using as following system resources and software for a standalone server.
|
|
||||||
|
|
||||||
注:表格
|
|
||||||
<table width="666" style="height: 181px;">
|
|
||||||
<tbody>
|
|
||||||
<tr>
|
|
||||||
<td width="670" colspan="2"><b>Plex Home Media Server</b></td>
|
|
||||||
</tr>
|
|
||||||
<tr>
|
|
||||||
<td width="236"><b>Base Operating System</b></td>
|
|
||||||
<td width="425">Ubuntu 15.04 / CentOS 7.1 / Fedora 22 Work Station</td>
|
|
||||||
</tr>
|
|
||||||
<tr>
|
|
||||||
<td width="236"><b>Plex Media Server</b></td>
|
|
||||||
<td width="425">Version 0.9.12.3.1173-937aac3</td>
|
|
||||||
</tr>
|
|
||||||
<tr>
|
|
||||||
<td width="236"><b>RAM and CPU</b></td>
|
|
||||||
<td width="425">1 GB , 2.0 GHZ</td>
|
|
||||||
</tr>
|
|
||||||
<tr>
|
|
||||||
<td width="236"><b>Hard Disk</b></td>
|
|
||||||
<td width="425">30 GB</td>
|
|
||||||
</tr>
|
|
||||||
</tbody>
|
|
||||||
</table>
|
|
||||||
|
|
||||||
### Plex Media Server 0.9.12.3 on Ubuntu 15.04 ###
|
|
||||||
|
|
||||||
We are now ready to start the installations process of Plex Media Server on Ubuntu so let’s start with the following steps to get it ready.
|
|
||||||
|
|
||||||
#### Step 1: System Update ####
|
|
||||||
|
|
||||||
Login to your server with root privileges Make your that your system is upto date if not then do by using below command.
|
|
||||||
|
|
||||||
root@ubuntu-15:~#apt-get update
|
|
||||||
|
|
||||||
#### Step 2: Download the Latest Plex Media Server Package ####
|
|
||||||
|
|
||||||
Create a new directory and download .deb plex Media Package in it from the official website of Plex for Ubuntu using wget command.
|
|
||||||
|
|
||||||
root@ubuntu-15:~# cd /plex/
|
|
||||||
root@ubuntu-15:/plex#
|
|
||||||
root@ubuntu-15:/plex# wget https://downloads.plex.tv/plex-media-server/0.9.12.3.1173-937aac3/plexmediaserver_0.9.12.3.1173-937aac3_amd64.deb
|
|
||||||
|
|
||||||
#### Step 3: Install the Debian Package of Plex Media Server ####
|
|
||||||
|
|
||||||
Now within the same directory run following command to start installation of debian package and then check the status of plekmediaserver.
|
|
||||||
|
|
||||||
root@ubuntu-15:/plex# dpkg -i plexmediaserver_0.9.12.3.1173-937aac3_amd64.deb
|
|
||||||
|
|
||||||
----------
|
|
||||||
|
|
||||||
root@ubuntu-15:~# service plexmediaserver status
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### Plex Home Media Web App Setup on Ubuntu 15.04 ###
|
|
||||||
|
|
||||||
Let's open your web browser within your localhost network and open the Web Interface with your localhost IP and port 32400 and do following steps to configure it:
|
|
||||||
|
|
||||||
http://172.25.10.179:32400/web
|
|
||||||
http://localhost:32400/web
|
|
||||||
|
|
||||||
#### Step 1:Sign UP before Login ####
|
|
||||||
|
|
||||||
After you have access to the web interface of Plesk Media Server make sure to Sign Up and set your username email ID and Password to login as.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
#### Step 2: Enter Your Pin to Secure Your Plex Media Home User ####
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
Now you have successfully configured your user under Plex Home Media.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### Opening Plex Web App on Devices Other than Localhost Server ###
|
|
||||||
|
|
||||||
As we have seen in our Plex media home page that it indicates that "You do not have permissions to access this server". Its because of we are on a different network than the Server computer.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
Now we need to resolve this permissions issue so that we can have access to server on the devices other than the hosted server by doing following setup.
|
|
||||||
|
|
||||||
### Setup SSH Tunnel for Windows System to access Linux Server ###
|
|
||||||
|
|
||||||
First we need to set up a SSH tunnel so that we can access things as if they were local. This is only necessary for the initial setup.
|
|
||||||
|
|
||||||
If you are using Windows as your local system and server on Linux then we can setup SSH-Tunneling using Putty as shown.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
**Once you have the SSH tunnel set up:**
|
|
||||||
|
|
||||||
Open your Web browser window and type following URL in the address bar.
|
|
||||||
|
|
||||||
http://localhost:8888/web
|
|
||||||
|
|
||||||
The browser will connect to the server and load the Plex Web App with same functionality as on local.
|
|
||||||
Agree to the terms of Services and start
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
Now a fully functional Plex Home Media Server is ready to add new media libraries, channels, playlists etc.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### Plex Media Server 0.9.12.3 on CentOS 7.1 ###
|
|
||||||
|
|
||||||
We will follow the same steps on CentOS-7.1 that we did for the installation of Plex Home Media Server on Ubuntu 15.04.
|
|
||||||
|
|
||||||
So lets start with Plex Media Servers Package Installation.
|
|
||||||
|
|
||||||
#### Step 1: Plex Media Server Installation ####
|
|
||||||
|
|
||||||
To install Plex Media Server on centOS 7.1 we need to download the .rpm package from the official website of Plex. So we will use wget command to download .rpm package for this purpose in a new directory.
|
|
||||||
|
|
||||||
[root@linux-tutorials ~]# cd /plex
|
|
||||||
[root@linux-tutorials plex]# wget https://downloads.plex.tv/plex-media-server/0.9.12.3.1173-937aac3/plexmediaserver-0.9.12.3.1173-937aac3.x86_64.rpm
|
|
||||||
|
|
||||||
#### Step 2: Install .RPM Package ####
|
|
||||||
|
|
||||||
After completion of complete download package we will install this package using rpm command within the same direcory where we installed the .rpm package.
|
|
||||||
|
|
||||||
[root@linux-tutorials plex]# ls
|
|
||||||
plexmediaserver-0.9.12.3.1173-937aac3.x86_64.rpm
|
|
||||||
[root@linux-tutorials plex]# rpm -i plexmediaserver-0.9.12.3.1173-937aac3.x86_64.rpm
|
|
||||||
|
|
||||||
#### Step 3: Start Plexmediaservice ####
|
|
||||||
|
|
||||||
We have successfully installed Plex Media Server Now we just need to restart its service and then enable it permanently.
|
|
||||||
|
|
||||||
[root@linux-tutorials plex]# systemctl start plexmediaserver.service
|
|
||||||
[root@linux-tutorials plex]# systemctl enable plexmediaserver.service
|
|
||||||
[root@linux-tutorials plex]# systemctl status plexmediaserver.service
|
|
||||||
|
|
||||||
### Plex Home Media Web App Setup on CentOS-7.1 ###
|
|
||||||
|
|
||||||
Now we just need to repeat all steps that we performed during the Web app setup of Ubuntu.
|
|
||||||
So let's Open a new window in your web browser and access the Plex Media Server Web app using localhost or IP or your Plex server.
|
|
||||||
|
|
||||||
http://172.20.3.174:32400/web
|
|
||||||
http://localhost:32400/web
|
|
||||||
|
|
||||||
Then to get full permissions on the server you need to repeat the steps to create the SSH-Tunnel.
|
|
||||||
After signing up with new user account we will be able to access its all features and can add new users, add new libraries and setup it per our needs.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### Plex Media Server 0.9.12.3 on Fedora 22 Work Station ###
|
|
||||||
|
|
||||||
The Basic steps to download and install Plex Media Server are the same as its we did for in CentOS 7.1.
|
|
||||||
We just need to download its .rpm package and then install it with rpm command.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### Plex Home Media Web App Setup on Fedora 22 Work Station ###
|
|
||||||
|
|
||||||
We had setup Plex Media Server on the same host so we don't need to setup SSH-Tunnel in this time scenario. Just open the web browser in your Fedora 22 Workstation with default port 32400 of Plex Home Media Server and accept the Plex Terms of Services Agreement.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
**Welcome to Plex Home Media Server on Fedora 22 Workstation**
|
|
||||||
|
|
||||||
Lets login with your plex account and start with adding your libraries for your favorite movie channels , create your playlists, add your photos and enjoy with many other features of Plex Home Media Server.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### Conclusion ###
|
|
||||||
|
|
||||||
We had successfully installed and configured Plex Media Server on Major Linux Distributions. So, Plex Home Media Server has always been a best choice for media management. Its so simple to setup on cross platform as we did for Ubuntu, CentOS and Fedora. It has simplifies the tasks of organizing your media content and streaming to other computers and devices then to share it with your friends.
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: http://linoxide.com/tools/install-plex-media-server-ubuntu-centos-7-1-fedora-22/
|
|
||||||
|
|
||||||
作者:[Kashif Siddique][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:http://linoxide.com/author/kashifs/
|
|
||||||
@ -1,4 +1,4 @@
|
|||||||
translating by zhangboyue
|
ictlyh Translating
|
||||||
Analyzing Linux Logs
|
Analyzing Linux Logs
|
||||||
================================================================================
|
================================================================================
|
||||||
There’s a great deal of information waiting for you within your logs, although it’s not always as easy as you’d like to extract it. In this section we will cover some examples of basic analysis you can do with your logs right away (just search what’s there). We’ll also cover more advanced analysis that may take some upfront effort to set up properly, but will save you time on the back end. Examples of advanced analysis you can do on parsed data include generating summary counts, filtering on field values, and more.
|
There’s a great deal of information waiting for you within your logs, although it’s not always as easy as you’d like to extract it. In this section we will cover some examples of basic analysis you can do with your logs right away (just search what’s there). We’ll also cover more advanced analysis that may take some upfront effort to set up properly, but will save you time on the back end. Examples of advanced analysis you can do on parsed data include generating summary counts, filtering on field values, and more.
|
||||||
|
|||||||
@ -1,209 +0,0 @@
|
|||||||
translating by wwy-hust
|
|
||||||
|
|
||||||
Nishita Agarwal Shares Her Interview Experience on Linux ‘iptables’ Firewall
|
|
||||||
================================================================================
|
|
||||||
Nishita Agarwal, a frequent Tecmint Visitor shared her experience (Question and Answer) with us regarding the job interview she had just given in a privately owned hosting company in Pune, India. She was asked a lot of questions on a variety of topics however she is an expert in iptables and she wanted to share those questions and their answer (she gave) related to iptables to others who may be going to give interview in near future.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
All the questions and their Answer are rewritten based upon the memory of Nishita Agarwal.
|
|
||||||
|
|
||||||
> “Hello Friends! My name is **Nishita Agarwal**. I have Pursued Bachelor Degree in Technology. My area of Specialization is UNIX and Variants of UNIX (BSD, Linux) fascinates me since the time I heard it. I have 1+ years of experience in storage. I was looking for a job change which ended with a hosting company in Pune, India.”
|
|
||||||
|
|
||||||
Here is the collection of what I was asked during the Interview. I’ve documented only those questions and their answer that were related to iptables based upon my memory. Hope this will help you in cracking your Interview.
|
|
||||||
|
|
||||||
### 1. Have you heard of iptables and firewall in Linux? Any idea of what they are and for what it is used? ###
|
|
||||||
|
|
||||||
> **Answer** : I’ve been using iptables for quite long time and I am aware of both iptables and firewall. Iptables is an application program mostly written in C Programming Language and is released under GNU General Public License. Written for System administration point of view, the latest stable release if iptables 1.4.21.iptables may be considered as firewall for UNIX like operating system which can be called as iptables/netfilter, more accurately. The Administrator interact with iptables via console/GUI front end tools to add and define firewall rules into predefined tables. Netfilter is a module built inside of kernel that do the job of filtering.
|
|
||||||
>
|
|
||||||
> Firewalld is the latest implementation of filtering rules in RHEL/CentOS 7 (may be implemented in other distributions which I may not be aware of). It has replaced iptables interface and connects to netfilter.
|
|
||||||
|
|
||||||
### 2. Have you used some kind of GUI based front end tool for iptables or the Linux Command Line? ###
|
|
||||||
|
|
||||||
> **Answer** : Though I have used both the GUI based front end tools for iptables like Shorewall in conjugation of [Webmin][1] in GUI and Direct access to iptables via console.And I must admit that direct access to iptables via Linux console gives a user immense power in the form of higher degree of flexibility and better understanding of what is going on in the background, if not anything other. GUI is for novice administrator while console is for experienced.
|
|
||||||
|
|
||||||
### 3. What are the basic differences between between iptables and firewalld? ###
|
|
||||||
|
|
||||||
> **Answer** : iptables and firewalld serves the same purpose (Packet Filtering) but with different approach. iptables flush the entire rules set each time a change is made unlike firewalld. Typically the location of iptables configuration lies at ‘/etc/sysconfig/iptables‘ whereas firewalld configuration lies at ‘/etc/firewalld/‘, which is a set of XML files.Configuring a XML based firewalld is easier as compared to configuration of iptables, however same task can be achieved using both the packet filtering application ie., iptables and firewalld. Firewalld runs iptables under its hood along with it’s own command line interface and configuration file that is XML based and said above.
|
|
||||||
|
|
||||||
### 4. Would you replace iptables with firewalld on all your servers, if given a chance? ###
|
|
||||||
|
|
||||||
> **Answer** : I am familiar with iptables and it’s working and if there is nothing that requires dynamic aspect of firewalld, there seems no reason to migrate all my configuration from iptables to firewalld.In most of the cases, so far I have never seen iptables creating an issue. Also the general rule of Information technology says “why fix if it is not broken”. However this is my personal thought and I would never mind implementing firewalld if the Organization is going to replace iptables with firewalld.
|
|
||||||
|
|
||||||
### 5. You seems confident with iptables and the plus point is even we are using iptables on our server. ###
|
|
||||||
|
|
||||||
What are the tables used in iptables? Give a brief description of the tables used in iptables and the chains they support.
|
|
||||||
|
|
||||||
> **Answer** : Thanks for the recognition. Moving to question part, There are four tables used in iptables, namely they are:
|
|
||||||
>
|
|
||||||
> Nat Table
|
|
||||||
> Mangle Table
|
|
||||||
> Filter Table
|
|
||||||
> Raw Table
|
|
||||||
>
|
|
||||||
> Nat Table : Nat table is primarily used for Network Address Translation. Masqueraded packets get their IP address altered as per the rules in the table. Packets in the stream traverse Nat Table only once. ie., If a packet from a jet of Packets is masqueraded they rest of the packages in the stream will not traverse through this table again. It is recommended not to filter in this table. Chains Supported by NAT Table are PREROUTING Chain, POSTROUTING Chain and OUTPUT Chain.
|
|
||||||
>
|
|
||||||
> Mangle Table : As the name suggests, this table serves for mangling the packets. It is used for Special package alteration. It can be used to alter the content of different packets and their headers. Mangle table can’t be used for Masquerading. Supported chains are PREROUTING Chain, OUTPUT Chain, Forward Chain, INPUT Chain, POSTROUTING Chain.
|
|
||||||
>
|
|
||||||
> Filter Table : Filter Table is the default table used in iptables. It is used for filtering Packets. If no rules are defined, Filter Table is taken as default table and filtering is done on the basis of this table. Supported Chains are INPUT Chain, OUTPUT Chain, FORWARD Chain.
|
|
||||||
>
|
|
||||||
> Raw Table : Raw table comes into action when we want to configure packages that were exempted earlier. It supports PREROUTING Chain and OUTPUT Chain.
|
|
||||||
|
|
||||||
### 6. What are the target values (that can be specified in target) in iptables and what they do, be brief! ###
|
|
||||||
|
|
||||||
> **Answer** : Following are the target values that we can specify in target in iptables:
|
|
||||||
>
|
|
||||||
> ACCEPT : Accept Packets
|
|
||||||
> QUEUE : Paas Package to user space (place where application and drivers reside)
|
|
||||||
> DROP : Drop Packets
|
|
||||||
> RETURN : Return Control to calling chain and stop executing next set of rules for the current Packets in the chain.
|
|
||||||
|
|
||||||
|
|
||||||
### 7. Lets move to the technical aspects of iptables, by technical I means practical. ###
|
|
||||||
|
|
||||||
How will you Check iptables rpm that is required to install iptables in CentOS?.
|
|
||||||
|
|
||||||
> **Answer** : iptables rpm are included in standard CentOS installation and we do not need to install it separately. We can check the rpm as:
|
|
||||||
>
|
|
||||||
> # rpm -qa iptables
|
|
||||||
>
|
|
||||||
> iptables-1.4.21-13.el7.x86_64
|
|
||||||
>
|
|
||||||
> If you need to install it, you may do yum to get it.
|
|
||||||
>
|
|
||||||
> # yum install iptables-services
|
|
||||||
|
|
||||||
### 8. How to Check and ensure if iptables service is running? ###
|
|
||||||
|
|
||||||
> **Answer** : To check the status of iptables, you may run the following command on the terminal.
|
|
||||||
>
|
|
||||||
> # service status iptables [On CentOS 6/5]
|
|
||||||
> # systemctl status iptables [On CentOS 7]
|
|
||||||
>
|
|
||||||
> If it is not running, the below command may be executed.
|
|
||||||
>
|
|
||||||
> ---------------- On CentOS 6/5 ----------------
|
|
||||||
> # chkconfig --level 35 iptables on
|
|
||||||
> # service iptables start
|
|
||||||
>
|
|
||||||
> ---------------- On CentOS 7 ----------------
|
|
||||||
> # systemctl enable iptables
|
|
||||||
> # systemctl start iptables
|
|
||||||
>
|
|
||||||
> We may also check if the iptables module is loaded or not, as:
|
|
||||||
>
|
|
||||||
> # lsmod | grep ip_tables
|
|
||||||
|
|
||||||
### 9. How will you review the current Rules defined in iptables? ###
|
|
||||||
|
|
||||||
> **Answer** : The current rules in iptables can be review as simple as:
|
|
||||||
>
|
|
||||||
> # iptables -L
|
|
||||||
>
|
|
||||||
> Sample Output
|
|
||||||
>
|
|
||||||
> Chain INPUT (policy ACCEPT)
|
|
||||||
> target prot opt source destination
|
|
||||||
> ACCEPT all -- anywhere anywhere state RELATED,ESTABLISHED
|
|
||||||
> ACCEPT icmp -- anywhere anywhere
|
|
||||||
> ACCEPT all -- anywhere anywhere
|
|
||||||
> ACCEPT tcp -- anywhere anywhere state NEW tcp dpt:ssh
|
|
||||||
> REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
|
|
||||||
>
|
|
||||||
> Chain FORWARD (policy ACCEPT)
|
|
||||||
> target prot opt source destination
|
|
||||||
> REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
|
|
||||||
>
|
|
||||||
> Chain OUTPUT (policy ACCEPT)
|
|
||||||
> target prot opt source destination
|
|
||||||
|
|
||||||
### 10. How will you flush all iptables rules or a particular chain? ###
|
|
||||||
|
|
||||||
> **Answer** : To flush a particular iptables chain, you may use following commands.
|
|
||||||
>
|
|
||||||
>
|
|
||||||
> # iptables --flush OUTPUT
|
|
||||||
>
|
|
||||||
> To Flush all the iptables rules.
|
|
||||||
>
|
|
||||||
> # iptables --flush
|
|
||||||
|
|
||||||
### 11. Add a rule in iptables to accept packets from a trusted IP Address (say 192.168.0.7) ###
|
|
||||||
|
|
||||||
> **Answer** : The above scenario can be achieved simply by running the below command.
|
|
||||||
>
|
|
||||||
> # iptables -A INPUT -s 192.168.0.7 -j ACCEPT
|
|
||||||
>
|
|
||||||
> We may include standard slash or subnet mask in the source as:
|
|
||||||
>
|
|
||||||
> # iptables -A INPUT -s 192.168.0.7/24 -j ACCEPT
|
|
||||||
> # iptables -A INPUT -s 192.168.0.7/255.255.255.0 -j ACCEPT
|
|
||||||
|
|
||||||
### 12. How to add rules to ACCEPT, REJECT, DENY and DROP ssh service in iptables. ###
|
|
||||||
|
|
||||||
> **Answer** : Hoping ssh is running on port 22, which is also the default port for ssh, we can add rule to iptables as:To ACCEPT tcp packets for ssh service (port 22).
|
|
||||||
>
|
|
||||||
> # iptables -A INPUT -s -p tcp - -dport -j ACCEPT
|
|
||||||
>
|
|
||||||
> To REJECT tcp packets for ssh service (port 22).
|
|
||||||
>
|
|
||||||
> # iptables -A INPUT -s -p tcp - -dport -j REJECT
|
|
||||||
>
|
|
||||||
> To DENY tcp packets for ssh service (port 22).
|
|
||||||
>
|
|
||||||
>
|
|
||||||
> # iptables -A INPUT -s -p tcp - -dport -j DENY
|
|
||||||
>
|
|
||||||
> To DROP tcp packets for ssh service (port 22).
|
|
||||||
>
|
|
||||||
>
|
|
||||||
> # iptables -A INPUT -s -p tcp - -dport -j DROP
|
|
||||||
|
|
||||||
### 13. Let me give you a scenario. Say there is a machine the local ip address of which is 192.168.0.6. You need to block connections on port 21, 22, 23, and 80 to your machine. What will you do? ###
|
|
||||||
|
|
||||||
> **Answer** : Well all I need to use is the ‘multiport‘ option with iptables followed by port numbers to be blocked and the above scenario can be achieved in a single go as.
|
|
||||||
>
|
|
||||||
> # iptables -A INPUT -s 192.168.0.6 -p tcp -m multiport --dport 22,23,80,8080 -j DROP
|
|
||||||
>
|
|
||||||
> The written rules can be checked using the below command.
|
|
||||||
>
|
|
||||||
> # iptables -L
|
|
||||||
>
|
|
||||||
> Chain INPUT (policy ACCEPT)
|
|
||||||
> target prot opt source destination
|
|
||||||
> ACCEPT all -- anywhere anywhere state RELATED,ESTABLISHED
|
|
||||||
> ACCEPT icmp -- anywhere anywhere
|
|
||||||
> ACCEPT all -- anywhere anywhere
|
|
||||||
> ACCEPT tcp -- anywhere anywhere state NEW tcp dpt:ssh
|
|
||||||
> REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
|
|
||||||
> DROP tcp -- 192.168.0.6 anywhere multiport dports ssh,telnet,http,webcache
|
|
||||||
>
|
|
||||||
> Chain FORWARD (policy ACCEPT)
|
|
||||||
> target prot opt source destination
|
|
||||||
> REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
|
|
||||||
>
|
|
||||||
> Chain OUTPUT (policy ACCEPT)
|
|
||||||
> target prot opt source destination
|
|
||||||
|
|
||||||
**Interviewer** : That’s all I wanted to ask. You are a valuable employee we won’t like to miss. I will recommend your name to the HR. If you have any question you may ask me.
|
|
||||||
|
|
||||||
As a candidate I don’t wanted to kill the conversation hence keep asking about the projects I would be handling if selected and what are the other openings in the company. Not to mention HR round was not difficult to crack and I got the opportunity.
|
|
||||||
|
|
||||||
Also I would like to thank Avishek and Ravi (whom I am a friend since long) for taking the time to document my interview.
|
|
||||||
|
|
||||||
Friends! If you had given any such interview and you would like to share your interview experience to millions of Tecmint readers around the globe? then send your questions and answers to admin@tecmint.com.
|
|
||||||
|
|
||||||
Thank you! Keep Connected. Also let me know if I could have answered a question more correctly than what I did.
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: http://www.tecmint.com/linux-firewall-iptables-interview-questions-and-answers/
|
|
||||||
|
|
||||||
作者:[Avishek Kumar][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:http://www.tecmint.com/author/avishek/
|
|
||||||
[1]:http://www.tecmint.com/install-webmin-web-based-system-administration-tool-for-rhel-centos-fedora/
|
|
||||||
@ -1,96 +0,0 @@
|
|||||||
Translating by GOLinux!
|
|
||||||
How to Configure Swarm Native Clustering for Docker
|
|
||||||
================================================================================
|
|
||||||
Hi everyone, today we'll learn about Swarm and how we can create native clusters using Docker with Swarm. [Docker Swarm][1] is a native clustering program for Docker which turns a pool of Docker hosts into a single virtual host. Swarm serves the standard Docker API, so any tool which can communicate with a Docker daemon can use Swarm to transparently scale to multiple hosts. Swarm follows the "batteries included but removable" principle as other Docker Projects. It ships with a simple scheduling backend out of the box, and as initial development settles, an API will develop to enable pluggable backends. The goal is to provide a smooth out-of-box experience for simple use cases, and allow swapping in more powerful backends, like Mesos, for large scale production deployments. Swarm is extremely easy to setup and get started.
|
|
||||||
|
|
||||||
So, here are some features of Swarm 0.2 out of the box.
|
|
||||||
|
|
||||||
1. Swarm 0.2.0 is about 85% compatible with the Docker Engine.
|
|
||||||
2. It supports Resource Management.
|
|
||||||
3. It has Advanced Scheduling feature with constraints and affinities.
|
|
||||||
4. It supports multiple Discovery Backends (hubs, consul, etcd, zookeeper)
|
|
||||||
5. It uses TLS encryption method for security and authentication.
|
|
||||||
|
|
||||||
So, here are some very simple and easy steps on how we can use Swarm.
|
|
||||||
|
|
||||||
### 1. Pre-requisites to run Swarm ###
|
|
||||||
|
|
||||||
We must install Docker 1.4.0 or later on all nodes. While each node's IP need not be public, the Swarm manager must be able to access each node across the network.
|
|
||||||
|
|
||||||
Note: Swarm is currently in beta, so things are likely to change. We don't recommend you use it in production yet.
|
|
||||||
|
|
||||||
### 2. Creating Swarm Cluster ###
|
|
||||||
|
|
||||||
Now, we'll create swarm cluster by running the below command. Each node will run a swarm node agent. The agent registers the referenced Docker daemon, monitors it, and updates the discovery backend with the node's status. The below command returns a token which is a unique cluster id, it will be used when starting the Swarm Agent on nodes.
|
|
||||||
|
|
||||||
# docker run swarm create
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### 3. Starting the Docker Daemon in each nodes ###
|
|
||||||
|
|
||||||
We'll need to login into each node that we'll use to create clusters and start the Docker Daemon into it using flag -H . It ensures that the docker remote API on the node is available over TCP for the Swarm Manager. To do start the docker daemon, we'll need to run the following command inside the nodes.
|
|
||||||
|
|
||||||
# docker -H tcp://0.0.0.0:2375 -d
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### 4. Adding the Nodes ###
|
|
||||||
|
|
||||||
After enabling Docker Daemon, we'll need to add the Swarm Nodes to the discovery service. We must ensure that node's IP must be accessible from the Swarm Manager. To do so, we'll need to run the following command.
|
|
||||||
|
|
||||||
# docker run -d swarm join --addr=<node_ip>:2375 token://<cluster_id>
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
**Note**: Here, we'll need to replace <node_ip> and <cluster_id> with the IP address of the Node and the cluster ID we got from step 2.
|
|
||||||
|
|
||||||
### 5. Starting the Swarm Manager ###
|
|
||||||
|
|
||||||
Now, as we have got the nodes connected to the cluster. Now, we'll start the swarm manager, we'll need to run the following command in the node.
|
|
||||||
|
|
||||||
# docker run -d -p <swarm_port>:2375 swarm manage token://<cluster_id>
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### 6. Checking the Configuration ###
|
|
||||||
|
|
||||||
Once the manager is running, we can check the configuration by running the following command.
|
|
||||||
|
|
||||||
# docker -H tcp://<manager_ip:manager_port> info
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
**Note**: We'll need to replace <manager_ip:manager_port> with the ip address and port of the host running the swarm manager.
|
|
||||||
|
|
||||||
### 7. Using the docker CLI to access nodes ###
|
|
||||||
|
|
||||||
After everything is done perfectly as explained above, this part is the most important part of the Docker Swarm. We can use Docker CLI to access the nodes and run containers on them.
|
|
||||||
|
|
||||||
# docker -H tcp://<manager_ip:manager_port> info
|
|
||||||
# docker -H tcp://<manager_ip:manager_port> run ...
|
|
||||||
|
|
||||||
### 8. Listing nodes in the cluster ###
|
|
||||||
|
|
||||||
We can get a list of all of the running nodes using the swarm list command.
|
|
||||||
|
|
||||||
# docker run --rm swarm list token://<cluster_id>
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### Conclusion ###
|
|
||||||
|
|
||||||
Swarm is really an awesome feature of docker that can be used for creating and managing clusters. It is pretty easy to setup and use. It is more beautiful when we use constraints and affinities on top of it. Advanced Scheduling is an awesome feature of it which applies filters to exclude nodes with ports, labels, health and it uses strategies to pick the best node. So, if you have any questions, comments, feedback please do write on the comment box below and let us know what stuffs needs to be added or improved. Thank You! Enjoy :-)
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: http://linoxide.com/linux-how-to/configure-swarm-clustering-docker/
|
|
||||||
|
|
||||||
作者:[Arun Pyasi][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:http://linoxide.com/author/arunp/
|
|
||||||
[1]:https://docs.docker.com/swarm/
|
|
||||||
@ -0,0 +1,91 @@
|
|||||||
|
Translating by GOLinux!
|
||||||
|
Easy Backup, Restore and Migrate Containers in Docker
|
||||||
|
================================================================================
|
||||||
|
Today we'll learn how we can easily backup, restore and migrate docker containers out of the box. [Docker][1] is an open source platform that automates the deployment of applications with fast and easy way to pack, ship and run it under a lightweight layer of software called container. It makes the applications platform independent as it acts an additional layer of abstraction and automation of operating system level virtualization on Linux. It utilizes resource isolation features of Linux Kernel with its components cgroups and namespace for avoiding the overhead of virtual machines. It makes the great building blocks for deploying and scaling web apps, databases, and back-end services without depending on a particular stack or provider. Containers are those software layers which are created from a docker image that contains the respective linux filesystem and applications out of the box. If we have a docker container running in our box and need to backup those containers for future use or wanna migrate those containers, then this tutorial will help you how we can backup, restore and migrate docker containers in linux operating system.
|
||||||
|
|
||||||
|
Here are some easy steps on how we can backup, restore and migrate the docker containers in linux.
|
||||||
|
|
||||||
|
### 1. Backing up the Containers ###
|
||||||
|
|
||||||
|
First of all, in order to backup the containers in docker, we'll wanna see the list of containers that we wanna backup. To do so, we'll need to run docker ps in our linux machine running docker engine with containers already created.
|
||||||
|
|
||||||
|
# docker ps
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
After that, we'll choose the containers we wanna backup and then we'll go for creating the snapshot of the container. We can use docker commit command in order to create the snapshot.
|
||||||
|
|
||||||
|
# docker commit -p 30b8f18f20b4 container-backup
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
This will generated a snapshot of the container as the docker image. We can see the docker image by running the command docker images as shown below.
|
||||||
|
|
||||||
|
# docker images
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
As we can see the snapshot that was taken above has been preserved as docker image. Now, inorder to backup that snapshot, we have two options, one is that we can login into the docker registry hub and push the image and the next is that we can backup the docker image as tarballs for further use.
|
||||||
|
|
||||||
|
If we wanna upload or backup the image in the [docker registry hub][2], we can simply run docker login command to login into the docker registry hub and then push the required image.
|
||||||
|
|
||||||
|
# docker login
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
# docker tag a25ddfec4d2a arunpyasi/container-backup:test
|
||||||
|
# docker push arunpyasi/container-backup
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
If we don't wanna backup to the docker registry hub and wanna save the image for future use in the machine locally then we can backup the image as tarballs. To do so, we'll need to run the following docker save command.
|
||||||
|
|
||||||
|
# docker save -o ~/container-backup.tar container-backup
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
To verify if the tarball has been generated or not, we can simply run docker ls inside the directory where we saved the tarball.
|
||||||
|
|
||||||
|
### 2. Restoring the Containers ###
|
||||||
|
|
||||||
|
Next, after we have successfully backed up our docker containers, we'll now go for restoring those contianers which are snapshotted as docker images. If we have pushed those docker images in the registry hub, then we can simply pull that docker image and run it out of the box.
|
||||||
|
|
||||||
|
# docker pull arunpyasi/container-backup:test
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
But if we have backed up those docker images locally as tarball file, then we can easy load that docker image using docker load command followed by the backed up tarball.
|
||||||
|
|
||||||
|
# docker load -i ~/container-backup.tar
|
||||||
|
|
||||||
|
Now, to ensure that those docker images have been loaded successfully, we'll run docker images command.
|
||||||
|
|
||||||
|
# docker images
|
||||||
|
|
||||||
|
After the images have been loaded, we'll gonna run the docker container from the loaded image.
|
||||||
|
|
||||||
|
# docker run -d -p 80:80 container-backup
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 3. Migrating the Docker Containers ###
|
||||||
|
|
||||||
|
Migrating the containers involve both the above process ie Backup and Restore. We can migrate any docker container from one machine to another. In the process of migration, first we take the backup of the container as snapshot docker image. Then, that docker image is either pushed to the docker registry hub or saved as tarball files in the locally. If we have pushed the image to the docker registry hub, we can easily restore and run the container using docker run command from any machine we want. But if we have saved the image as tarballs locally, we can simply copy or move the image to the machine where we want to load image and run the required container.
|
||||||
|
|
||||||
|
### Conclusion ###
|
||||||
|
|
||||||
|
Finally, we have learned how we can backup, restore and migrate the docker containers out of the box. This tutorial is exactly same for every platform of operating system where docker runs successfully. Really, docker is pretty simple and easy to use but very powerful tool. It has pretty easy to remember commands which are short enough with many simple but powerful flags and parameters. The above methods makes us comfortable to backup our containers so that we can restore them when needed in future. This can help us recover our containers and images even if our host system crashes or gets wiped out accidentally. If you have any questions, suggestions, feedback please write them in the comment box below so that we can improve or update our contents. Thank you ! Enjoy :-)
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://linoxide.com/linux-how-to/backup-restore-migrate-containers-docker/
|
||||||
|
|
||||||
|
作者:[Arun Pyasi][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://linoxide.com/author/arunp/
|
||||||
|
[1]:http://docker.com/
|
||||||
|
[2]:https://registry.hub.docker.com/
|
||||||
@ -0,0 +1,127 @@
|
|||||||
|
How to Update Linux Kernel for Improved System Performance
|
||||||
|
================================================================================
|
||||||
|

|
||||||
|
|
||||||
|
The rate of development for [the Linux kernel][1] is unprecedented, with a new major release approximately every two to three months. Each release offers several new features and improvements that a lot of people could take advantage of to make their computing experience faster, more efficient, or better in other ways.
|
||||||
|
|
||||||
|
The problem, however, is that you usually can’t take advantage of these new kernel releases as soon as they come out — you have to wait until your distribution comes out with a new release that packs a newer kernel with it. We’ve previously laid out [the benefits for regularly updating your kernel][2], and you don’t have to wait to get your hands on them. We’ll show you how.
|
||||||
|
|
||||||
|
> Disclaimer: As some of our literature may have mentioned before, updating your kernel does carry a (small) risk of breaking your system. If this is the case, it’s usually easy to pick an older kernel at boot time that works, but something may always go wrong. Therefore, we’re not responsible for any damage to your system — use at your own risk!
|
||||||
|
|
||||||
|
### Prep Work ###
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
To update your kernel, you’ll first need to determine whether you’re using a 32-bit or 64-bit system. Open up a terminal window and run
|
||||||
|
|
||||||
|
uname -a
|
||||||
|
|
||||||
|
Then check to see if the output says x86_64 or i686. If it’s x86_64, then you’re running the 64-bit version; otherwise, you’re running the 32-bit version. Remember this, because it will be important.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Next, visit the [official Linux kernel website][3]. This will tell you what the current stable version of the kernel is. You can try out release candidates if you’d like, but they are a lot less tested than the stable releases. Stick with the stable kernel unless you are certain you need a release candidate version.
|
||||||
|
|
||||||
|
### Ubuntu Instructions ###
|
||||||
|
|
||||||
|
It’s quite easy for Ubuntu and Ubuntu-derivative users to update their kernel, thanks to the Ubuntu Mainline Kernel PPA. Although it’s officially called a PPA, you cannot use it like other PPAs by adding them to your software sources list and expecting it to automatically update the kernel for you. Instead, it’s simply a webpage you navigate through to download the kernel you want.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Now, visit the [kernel PPA webpage][4] and scroll all the way to the bottom. The absolute bottom of the list will probably contain some release candidate versions (which you can see by the “rc” in the name), but just above them should be the latest stable kernel (to make this easier to explain, at the time of writing the stable version was 4.1.2). Click on that, and you’ll be presented with several options. You’ll need to grab three files and save them in their own folder (within the Downloads folder if you’d like) so that they’re isolated from all other files:
|
||||||
|
|
||||||
|
- The “generic” header file for your architecture (in my case, 64-bit or “amd64″)
|
||||||
|
- The header file in the middle that has “all” towards the end of the filename
|
||||||
|
- The “generic” kernel file for your architecture (again, I would pick “amd64″ but if you use 32-bit you’ll need “i686″)
|
||||||
|
|
||||||
|
You’ll notice that there are also “lowlatency” files available to download, but it’s fine to ignore this. These files are relatively unstable and are only made available for people who need their low-latency benefits if the general files don’t suffice for tasks such as audio recording. Again, the recommendation is to always use generic first and only try lowlatency if your performance isn’t good enough for certain tasks. No, gaming or Internet browsing aren’t excuses to try lowlatency.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
You put these files into their own folder, right? Now open up the Terminal, use the
|
||||||
|
|
||||||
|
cd
|
||||||
|
|
||||||
|
command to go to your newly-created folder, such as
|
||||||
|
|
||||||
|
cd /home/user/Downloads/Kernel
|
||||||
|
|
||||||
|
and then run:
|
||||||
|
|
||||||
|
sudo dpkg -i *.deb
|
||||||
|
|
||||||
|
This command marks all .deb files within the folder as “to be installed” and then performs the installation. This is the recommended way to install these files because otherwise it’s easy to pick one file to install and it’ll complain about dependency issues. This approach avoids that problem. If you’re not sure what cd or sudo are, get a quick crash course on [essential Linux commands][5].
|
||||||
|
|
||||||
|
Once the installation is complete, **Restart** your system and you should be running the just-installed kernel! You can check this by running uname -a in the Terminal and checking the output.
|
||||||
|
|
||||||
|
### Fedora Instructions ###
|
||||||
|
|
||||||
|
If you use Fedora or one of its derivatives, the process is very similar to Ubuntu. There’s just a different location to grab different files, and a different command to install them.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
VIew the list of the most [recent kernel builds for Fedora][6]. Pick the latest stable version out of the list, and then scroll down to either the i686 or x86_64 section, depending on your system’s architecture. In this section, you’ll need to grab the following files and save them in their own folder (such as “Kernel” within your Downloads folder, as an example):
|
||||||
|
|
||||||
|
- kernel
|
||||||
|
- kernel-core
|
||||||
|
- kernel-headers
|
||||||
|
- kernel-modules
|
||||||
|
- kernel-modules-extra
|
||||||
|
- kernel-tools
|
||||||
|
- perf and python-perf (optional)
|
||||||
|
|
||||||
|
If your system is i686 (32-bit) and you have 4GB of RAM or more, you’ll need to grab the PAE version of all of these files where available. PAE is an address extension technique used for 32-bit system to allow them to use more than 3GB of RAM.
|
||||||
|
|
||||||
|
Now, use the
|
||||||
|
|
||||||
|
cd
|
||||||
|
|
||||||
|
command to go to that folder, such as
|
||||||
|
|
||||||
|
cd /home/user/Downloads/Kernel
|
||||||
|
|
||||||
|
and then run the following command to install all the files:
|
||||||
|
|
||||||
|
yum --nogpgcheck localinstall *.rpm
|
||||||
|
|
||||||
|
Finally **Restart** your computer and you should be running a new kernel!
|
||||||
|
|
||||||
|
### Using Rawhide ###
|
||||||
|
|
||||||
|
Alternatively, Fedora users can also simply [switch to Rawhide][7] and it’ll automatically update every package to the latest version, including the kernel. However, Rawhide is known to break quite often (especially early on in the development cycle) and should **not** be used on a system that you need to rely on.
|
||||||
|
|
||||||
|
### Arch Instructions ###
|
||||||
|
|
||||||
|
[Arch users][8] should always have the latest and greatest stable kernel available (or one pretty close to it). If you want to get even closer to the latest-released stable kernel, you can enable the testing repo which will give you access to major new releases roughly two to four weeks early.
|
||||||
|
|
||||||
|
To do this, open the file located at
|
||||||
|
|
||||||
|
/etc/pacman.conf
|
||||||
|
|
||||||
|
with sudo permissions in [your favorite terminal text editor][9], and then uncomment (delete the pound symbols from the front of each line) the three lines associated with testing. If you have the multilib repository enabled, then do the same for the multilib-testing repository. See [this Arch Linux wiki page][10] if you need more information.
|
||||||
|
|
||||||
|
Upgrading your kernel isn’t easy (done so intentionally), but it can give you a lot of benefits. So long as your new kernel didn’t break anything, you can now enjoy improved performance, better efficiency, support for more hardware, and potential new features. Especially if you’re running relatively new hardware, upgrading the kernel can really help out.
|
||||||
|
|
||||||
|
**How has upgraded the kernel helped you? Do you think your favorite distribution’s policy on kernel releases is what it should be?** Let us know in the comments!
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://www.makeuseof.com/tag/update-linux-kernel-improved-system-performance/
|
||||||
|
|
||||||
|
作者:[Danny Stieben][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://www.makeuseof.com/tag/author/danny/
|
||||||
|
[1]:http://www.makeuseof.com/tag/linux-kernel-explanation-laymans-terms/
|
||||||
|
[2]:http://www.makeuseof.com/tag/5-reasons-update-kernel-linux/
|
||||||
|
[3]:http://www.kernel.org/
|
||||||
|
[4]:http://kernel.ubuntu.com/~kernel-ppa/mainline/
|
||||||
|
[5]:http://www.makeuseof.com/tag/an-a-z-of-linux-40-essential-commands-you-should-know/
|
||||||
|
[6]:http://koji.fedoraproject.org/koji/packageinfo?packageID=8
|
||||||
|
[7]:http://www.makeuseof.com/tag/bleeding-edge-linux-fedora-rawhide/
|
||||||
|
[8]:http://www.makeuseof.com/tag/arch-linux-letting-you-build-your-linux-system-from-scratch/
|
||||||
|
[9]:http://www.makeuseof.com/tag/nano-vs-vim-terminal-text-editors-compared/
|
||||||
|
[10]:https://wiki.archlinux.org/index.php/Pacman#Repositories
|
||||||
674
sources/tech/20150728 Process of the Linux kernel building.md
Normal file
674
sources/tech/20150728 Process of the Linux kernel building.md
Normal file
@ -0,0 +1,674 @@
|
|||||||
|
Process of the Linux kernel building
|
||||||
|
================================================================================
|
||||||
|
Introduction
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
I will not tell you how to build and install custom Linux kernel on your machine, you can find many many [resources](https://encrypted.google.com/search?q=building+linux+kernel#q=building+linux+kernel+from+source+code) that will help you to do it. Instead, we will know what does occur when you are typed `make` in the directory with Linux kernel source code in this part. When I just started to learn source code of the Linux kernel, the [Makefile](https://github.com/torvalds/linux/blob/master/Makefile) file was a first file that I've opened. And it was scary :) This [makefile](https://en.wikipedia.org/wiki/Make_%28software%29) contains `1591` lines of code at the time when I wrote this part and it was [third](https://github.com/torvalds/linux/commit/52721d9d3334c1cb1f76219a161084094ec634dc) release candidate.
|
||||||
|
|
||||||
|
This makefile is the the top makefile in the Linux kernel source code and kernel build starts here. Yes, it is big, but moreover, if you've read the source code of the Linux kernel you can noted that all directories with a source code has an own makefile. Of course it is not real to describe how each source files compiled and linked. So, we will see compilation only for the standard case. You will not find here building of the kernel's documentation, cleaning of the kernel source code, [tags](https://en.wikipedia.org/wiki/Ctags) generation, [cross-compilation](https://en.wikipedia.org/wiki/Cross_compiler) related stuff and etc. We will start from the `make` execution with the standard kernel configuration file and will finish with the building of the [bzImage](https://en.wikipedia.org/wiki/Vmlinux#bzImage).
|
||||||
|
|
||||||
|
It would be good if you're already familiar with the [make](https://en.wikipedia.org/wiki/Make_%28software%29) util, but I will anyway try to describe all code that will be in this part.
|
||||||
|
|
||||||
|
So let's start.
|
||||||
|
|
||||||
|
Preparation before the kernel compilation
|
||||||
|
---------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
There are many things to preparate before the kernel compilation will be started. The main point here is to find and configure
|
||||||
|
the type of compilation, to parse command line arguments that are passed to the `make` util and etc. So let's dive into the top `Makefile` of the Linux kernel.
|
||||||
|
|
||||||
|
The Linux kernel top `Makefile` is responsible for building two major products: [vmlinux](https://en.wikipedia.org/wiki/Vmlinux) (the resident kernel image) and the modules (any module files). The [Makefile](https://github.com/torvalds/linux/blob/master/Makefile) of the Linux kernel starts from the definition of the following variables:
|
||||||
|
|
||||||
|
```Makefile
|
||||||
|
VERSION = 4
|
||||||
|
PATCHLEVEL = 2
|
||||||
|
SUBLEVEL = 0
|
||||||
|
EXTRAVERSION = -rc3
|
||||||
|
NAME = Hurr durr I'ma sheep
|
||||||
|
```
|
||||||
|
|
||||||
|
These variables determine the current version of the Linux kernel and are used in the different places, for example in the forming of the `KERNELVERSION` variable:
|
||||||
|
|
||||||
|
```Makefile
|
||||||
|
KERNELVERSION = $(VERSION)$(if $(PATCHLEVEL),.$(PATCHLEVEL)$(if $(SUBLEVEL),.$(SUBLEVEL)))$(EXTRAVERSION)
|
||||||
|
```
|
||||||
|
|
||||||
|
After this we can see a couple of the `ifeq` condition that check some of the parameters passed to `make`. The Linux kernel `makefiles` provides a special `make help` target that prints all available targets and some of the command line arguments that can be passed to `make`. For example: `make V=1` - provides verbose builds. The first `ifeq` condition checks if the `V=n` option is passed to make:
|
||||||
|
|
||||||
|
```Makefile
|
||||||
|
ifeq ("$(origin V)", "command line")
|
||||||
|
KBUILD_VERBOSE = $(V)
|
||||||
|
endif
|
||||||
|
ifndef KBUILD_VERBOSE
|
||||||
|
KBUILD_VERBOSE = 0
|
||||||
|
endif
|
||||||
|
|
||||||
|
ifeq ($(KBUILD_VERBOSE),1)
|
||||||
|
quiet =
|
||||||
|
Q =
|
||||||
|
else
|
||||||
|
quiet=quiet_
|
||||||
|
Q = @
|
||||||
|
endif
|
||||||
|
|
||||||
|
export quiet Q KBUILD_VERBOSE
|
||||||
|
```
|
||||||
|
|
||||||
|
If this option is passed to `make` we set the `KBUILD_VERBOSE` variable to the value of the `V` option. Otherwise we set the `KBUILD_VERBOSE` variable to zero. After this we check value of the `KBUILD_VERBOSE` variable and set values of the `quiet` and `Q` variables depends on the `KBUILD_VERBOSE` value. The `@` symbols suppress the output of the command and if it will be set before a command we will see something like this: `CC scripts/mod/empty.o` instead of the `Compiling .... scripts/mod/empty.o`. In the end we just export all of these variables. The next `ifeq` statement checks that `O=/dir` option was passed to the `make`. This option allows to locate all output files in the given `dir`:
|
||||||
|
|
||||||
|
```Makefile
|
||||||
|
ifeq ($(KBUILD_SRC),)
|
||||||
|
|
||||||
|
ifeq ("$(origin O)", "command line")
|
||||||
|
KBUILD_OUTPUT := $(O)
|
||||||
|
endif
|
||||||
|
|
||||||
|
ifneq ($(KBUILD_OUTPUT),)
|
||||||
|
saved-output := $(KBUILD_OUTPUT)
|
||||||
|
KBUILD_OUTPUT := $(shell mkdir -p $(KBUILD_OUTPUT) && cd $(KBUILD_OUTPUT) \
|
||||||
|
&& /bin/pwd)
|
||||||
|
$(if $(KBUILD_OUTPUT),, \
|
||||||
|
$(error failed to create output directory "$(saved-output)"))
|
||||||
|
|
||||||
|
sub-make: FORCE
|
||||||
|
$(Q)$(MAKE) -C $(KBUILD_OUTPUT) KBUILD_SRC=$(CURDIR) \
|
||||||
|
-f $(CURDIR)/Makefile $(filter-out _all sub-make,$(MAKECMDGOALS))
|
||||||
|
|
||||||
|
skip-makefile := 1
|
||||||
|
endif # ifneq ($(KBUILD_OUTPUT),)
|
||||||
|
endif # ifeq ($(KBUILD_SRC),)
|
||||||
|
```
|
||||||
|
|
||||||
|
We check the `KBUILD_SRC` that represent top directory of the source code of the linux kernel and if it is empty (it is empty every time while makefile executes first time) and the set the `KBUILD_OUTPUT` variable to the value that passed with the `O` option (if this option was passed). In the next step we check this `KBUILD_OUTPUT` variable and if we set it, we do following things:
|
||||||
|
|
||||||
|
* Store value of the `KBUILD_OUTPUT` in the temp `saved-output` variable;
|
||||||
|
* Try to create given output directory;
|
||||||
|
* Check that directory created, in other way print error;
|
||||||
|
* If custom output directory created sucessfully, execute `make` again with the new directory (see `-C` option).
|
||||||
|
|
||||||
|
The next `ifeq` statements checks that `C` or `M` options was passed to the make:
|
||||||
|
|
||||||
|
```Makefile
|
||||||
|
ifeq ("$(origin C)", "command line")
|
||||||
|
KBUILD_CHECKSRC = $(C)
|
||||||
|
endif
|
||||||
|
ifndef KBUILD_CHECKSRC
|
||||||
|
KBUILD_CHECKSRC = 0
|
||||||
|
endif
|
||||||
|
|
||||||
|
ifeq ("$(origin M)", "command line")
|
||||||
|
KBUILD_EXTMOD := $(M)
|
||||||
|
endif
|
||||||
|
```
|
||||||
|
|
||||||
|
The first `C` option tells to the `makefile` that need to check all `c` source code with a tool provided by the `$CHECK` environment variable, by default it is [sparse](https://en.wikipedia.org/wiki/Sparse). The second `M` option provides build for the external modules (will not see this case in this part). As we set this variables we make a check of the `KBUILD_SRC` variable and if it is not set we set `srctree` variable to `.`:
|
||||||
|
|
||||||
|
```Makefile
|
||||||
|
ifeq ($(KBUILD_SRC),)
|
||||||
|
srctree := .
|
||||||
|
endif
|
||||||
|
|
||||||
|
objtree := .
|
||||||
|
src := $(srctree)
|
||||||
|
obj := $(objtree)
|
||||||
|
|
||||||
|
export srctree objtree VPATH
|
||||||
|
```
|
||||||
|
|
||||||
|
That tells to `Makefile` that source tree of the Linux kernel will be in the current directory where `make` command was executed. After this we set `objtree` and other variables to this directory and export these variables. The next step is the getting value for the `SUBARCH` variable that will represent tewhat the underlying archicecture is:
|
||||||
|
|
||||||
|
```Makefile
|
||||||
|
SUBARCH := $(shell uname -m | sed -e s/i.86/x86/ -e s/x86_64/x86/ \
|
||||||
|
-e s/sun4u/sparc64/ \
|
||||||
|
-e s/arm.*/arm/ -e s/sa110/arm/ \
|
||||||
|
-e s/s390x/s390/ -e s/parisc64/parisc/ \
|
||||||
|
-e s/ppc.*/powerpc/ -e s/mips.*/mips/ \
|
||||||
|
-e s/sh[234].*/sh/ -e s/aarch64.*/arm64/ )
|
||||||
|
```
|
||||||
|
|
||||||
|
As you can see it executes [uname](https://en.wikipedia.org/wiki/Uname) utils that prints information about machine, operating system and architecture. As it will get output of the `uname` util, it will parse it and assign to the `SUBARCH` variable. As we got `SUBARCH`, we set the `SRCARCH` variable that provides directory of the certain architecture and `hfr-arch` that provides directory for the header files:
|
||||||
|
|
||||||
|
```Makefile
|
||||||
|
ifeq ($(ARCH),i386)
|
||||||
|
SRCARCH := x86
|
||||||
|
endif
|
||||||
|
ifeq ($(ARCH),x86_64)
|
||||||
|
SRCARCH := x86
|
||||||
|
endif
|
||||||
|
|
||||||
|
hdr-arch := $(SRCARCH)
|
||||||
|
```
|
||||||
|
|
||||||
|
Note that `ARCH` is the alias for the `SUBARCH`. In the next step we set the `KCONFIG_CONFIG` variable that represents path to the kernel configuration file and if it was not set before, it will be `.config` by default:
|
||||||
|
|
||||||
|
```Makefile
|
||||||
|
KCONFIG_CONFIG ?= .config
|
||||||
|
export KCONFIG_CONFIG
|
||||||
|
```
|
||||||
|
|
||||||
|
and the [shell](https://en.wikipedia.org/wiki/Shell_%28computing%29) that will be used during kernel compilation:
|
||||||
|
|
||||||
|
```Makefile
|
||||||
|
CONFIG_SHELL := $(shell if [ -x "$$BASH" ]; then echo $$BASH; \
|
||||||
|
else if [ -x /bin/bash ]; then echo /bin/bash; \
|
||||||
|
else echo sh; fi ; fi)
|
||||||
|
```
|
||||||
|
|
||||||
|
The next set of variables related to the compiler that will be used during Linux kernel compilation. We set the host compilers for the `c` and `c++` and flags for it:
|
||||||
|
|
||||||
|
```Makefile
|
||||||
|
HOSTCC = gcc
|
||||||
|
HOSTCXX = g++
|
||||||
|
HOSTCFLAGS = -Wall -Wmissing-prototypes -Wstrict-prototypes -O2 -fomit-frame-pointer -std=gnu89
|
||||||
|
HOSTCXXFLAGS = -O2
|
||||||
|
```
|
||||||
|
|
||||||
|
Next we will meet the `CC` variable that represent compiler too, so why do we need in the `HOST*` variables? The `CC` is the target compiler that will be used during kernel compilation, but `HOSTCC` will be used during compilation of the set of the `host` programs (we will see it soon). After this we can see definition of the `KBUILD_MODULES` and `KBUILD_BUILTIN` variables that are used for the determination of the what to compile (kernel, modules or both):
|
||||||
|
|
||||||
|
```Makefile
|
||||||
|
KBUILD_MODULES :=
|
||||||
|
KBUILD_BUILTIN := 1
|
||||||
|
|
||||||
|
ifeq ($(MAKECMDGOALS),modules)
|
||||||
|
KBUILD_BUILTIN := $(if $(CONFIG_MODVERSIONS),1)
|
||||||
|
endif
|
||||||
|
```
|
||||||
|
|
||||||
|
Here we can see definition of these variables and the value of the `KBUILD_BUILTIN` will depens on the `CONFIG_MODVERSIONS` kernel configuration parameter if we pass only `modules` to the `make`. The next step is including of the:
|
||||||
|
|
||||||
|
```Makefile
|
||||||
|
include scripts/Kbuild.include
|
||||||
|
```
|
||||||
|
|
||||||
|
`kbuild` file. The [Kbuild](https://github.com/torvalds/linux/blob/master/Documentation/kbuild/kbuild.txt) or `Kernel Build System` is the special infrastructure to manage building of the kernel and its modules. The `kbuild` files has the same syntax that makefiles. The [scripts/Kbuild.include](https://github.com/torvalds/linux/blob/master/scripts/Kbuild.include) file provides some generic definitions for the `kbuild` system. As we included this `kbuild` files we can see definition of the variables that are related to the different tools that will be used during kernel and modules compilation (like linker, compilers, utils from the [binutils](http://www.gnu.org/software/binutils/) and etc...):
|
||||||
|
|
||||||
|
```Makefile
|
||||||
|
AS = $(CROSS_COMPILE)as
|
||||||
|
LD = $(CROSS_COMPILE)ld
|
||||||
|
CC = $(CROSS_COMPILE)gcc
|
||||||
|
CPP = $(CC) -E
|
||||||
|
AR = $(CROSS_COMPILE)ar
|
||||||
|
NM = $(CROSS_COMPILE)nm
|
||||||
|
STRIP = $(CROSS_COMPILE)strip
|
||||||
|
OBJCOPY = $(CROSS_COMPILE)objcopy
|
||||||
|
OBJDUMP = $(CROSS_COMPILE)objdump
|
||||||
|
AWK = awk
|
||||||
|
...
|
||||||
|
...
|
||||||
|
...
|
||||||
|
```
|
||||||
|
|
||||||
|
After definition of these variables we define two variables: `USERINCLUDE` and `LINUXINCLUDE`. They will contain paths of the directories with headers (public for users in the first case and for kernel in the second case):
|
||||||
|
|
||||||
|
```Makefile
|
||||||
|
USERINCLUDE := \
|
||||||
|
-I$(srctree)/arch/$(hdr-arch)/include/uapi \
|
||||||
|
-Iarch/$(hdr-arch)/include/generated/uapi \
|
||||||
|
-I$(srctree)/include/uapi \
|
||||||
|
-Iinclude/generated/uapi \
|
||||||
|
-include $(srctree)/include/linux/kconfig.h
|
||||||
|
|
||||||
|
LINUXINCLUDE := \
|
||||||
|
-I$(srctree)/arch/$(hdr-arch)/include \
|
||||||
|
...
|
||||||
|
```
|
||||||
|
|
||||||
|
And the standard flags for the C compiler:
|
||||||
|
|
||||||
|
```Makefile
|
||||||
|
KBUILD_CFLAGS := -Wall -Wundef -Wstrict-prototypes -Wno-trigraphs \
|
||||||
|
-fno-strict-aliasing -fno-common \
|
||||||
|
-Werror-implicit-function-declaration \
|
||||||
|
-Wno-format-security \
|
||||||
|
-std=gnu89
|
||||||
|
```
|
||||||
|
|
||||||
|
It is the not last compiler flags, they can be updated by the other makefiles (for example kbuilds from `arch/`). After all of these, all variables will be exported to be available in the other makefiles. The following two the `RCS_FIND_IGNORE` and the `RCS_TAR_IGNORE` variables will contain files that will be ignored in the version control system:
|
||||||
|
|
||||||
|
```Makefile
|
||||||
|
export RCS_FIND_IGNORE := \( -name SCCS -o -name BitKeeper -o -name .svn -o \
|
||||||
|
-name CVS -o -name .pc -o -name .hg -o -name .git \) \
|
||||||
|
-prune -o
|
||||||
|
export RCS_TAR_IGNORE := --exclude SCCS --exclude BitKeeper --exclude .svn \
|
||||||
|
--exclude CVS --exclude .pc --exclude .hg --exclude .git
|
||||||
|
```
|
||||||
|
|
||||||
|
That's all. We have finished with the all preparations, next point is the building of `vmlinux`.
|
||||||
|
|
||||||
|
Directly to the kernel build
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
As we have finished all preparations, next step in the root makefile is related to the kernel build. Before this moment we will not see in the our terminal after the execution of the `make` command. But now first steps of the compilation are started. In this moment we need to go on the [598](https://github.com/torvalds/linux/blob/master/Makefile#L598) line of the Linux kernel top makefile and we will see `vmlinux` target there:
|
||||||
|
|
||||||
|
```Makefile
|
||||||
|
all: vmlinux
|
||||||
|
include arch/$(SRCARCH)/Makefile
|
||||||
|
```
|
||||||
|
|
||||||
|
Don't worry that we have missed many lines in Makefile that are placed after `export RCS_FIND_IGNORE.....` and before `all: vmlinux.....`. This part of the makefile is responsible for the `make *.config` targets and as I wrote in the beginning of this part we will see only building of the kernel in a general way.
|
||||||
|
|
||||||
|
The `all:` target is the default when no target is given on the command line. You can see here that we include architecture specific makefile there (in our case it will be [arch/x86/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/Makefile)). From this moment we will continue from this makefile. As we can see `all` target depends on the `vmlinux` target that defined a little lower in the top makefile:
|
||||||
|
|
||||||
|
```Makefile
|
||||||
|
vmlinux: scripts/link-vmlinux.sh $(vmlinux-deps) FORCE
|
||||||
|
```
|
||||||
|
|
||||||
|
The `vmlinux` is is the Linux kernel in an statically linked executable file format. The [scripts/link-vmlinux.sh](https://github.com/torvalds/linux/blob/master/scripts/link-vmlinux.sh) script links combines different compiled subsystems into vmlinux. The second target is the `vmlinux-deps` that defined as:
|
||||||
|
|
||||||
|
```Makefile
|
||||||
|
vmlinux-deps := $(KBUILD_LDS) $(KBUILD_VMLINUX_INIT) $(KBUILD_VMLINUX_MAIN)
|
||||||
|
```
|
||||||
|
|
||||||
|
and consists from the set of the `built-in.o` from the each top directory of the Linux kernel. Later, when we will go through all directories in the Linux kernel, the `Kbuild` will compile all the `$(obj-y)` files. It then calls `$(LD) -r` to merge these files into one `built-in.o` file. For this moment we have no `vmlinux-deps`, so the `vmlinux` target will not be executed now. For me `vmlinux-deps` contains following files:
|
||||||
|
|
||||||
|
```
|
||||||
|
arch/x86/kernel/vmlinux.lds arch/x86/kernel/head_64.o
|
||||||
|
arch/x86/kernel/head64.o arch/x86/kernel/head.o
|
||||||
|
init/built-in.o usr/built-in.o
|
||||||
|
arch/x86/built-in.o kernel/built-in.o
|
||||||
|
mm/built-in.o fs/built-in.o
|
||||||
|
ipc/built-in.o security/built-in.o
|
||||||
|
crypto/built-in.o block/built-in.o
|
||||||
|
lib/lib.a arch/x86/lib/lib.a
|
||||||
|
lib/built-in.o arch/x86/lib/built-in.o
|
||||||
|
drivers/built-in.o sound/built-in.o
|
||||||
|
firmware/built-in.o arch/x86/pci/built-in.o
|
||||||
|
arch/x86/power/built-in.o arch/x86/video/built-in.o
|
||||||
|
net/built-in.o
|
||||||
|
```
|
||||||
|
|
||||||
|
The next target that can be executed is following:
|
||||||
|
|
||||||
|
```Makefile
|
||||||
|
$(sort $(vmlinux-deps)): $(vmlinux-dirs) ;
|
||||||
|
$(vmlinux-dirs): prepare scripts
|
||||||
|
$(Q)$(MAKE) $(build)=$@
|
||||||
|
```
|
||||||
|
|
||||||
|
As we can see the `vmlinux-dirs` depends on the two targets: `prepare` and `scripts`. The first `prepare` defined in the top `Makefile` of the Linux kernel and executes three stages of preparations:
|
||||||
|
|
||||||
|
```Makefile
|
||||||
|
prepare: prepare0
|
||||||
|
prepare0: archprepare FORCE
|
||||||
|
$(Q)$(MAKE) $(build)=.
|
||||||
|
archprepare: archheaders archscripts prepare1 scripts_basic
|
||||||
|
|
||||||
|
prepare1: prepare2 $(version_h) include/generated/utsrelease.h \
|
||||||
|
include/config/auto.conf
|
||||||
|
$(cmd_crmodverdir)
|
||||||
|
prepare2: prepare3 outputmakefile asm-generic
|
||||||
|
```
|
||||||
|
|
||||||
|
The first `prepare0` expands to the `archprepare` that exapnds to the `archheaders` and `archscripts` that defined in the `x86_64` specific [Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/Makefile). Let's look on it. The `x86_64` specific makefile starts from the definition of the variables that are related to the archicteture-specific configs ([defconfig](https://github.com/torvalds/linux/tree/master/arch/x86/configs) and etc.). After this it defines flags for the compiling of the [16-bit](https://en.wikipedia.org/wiki/Real_mode) code, calculating of the `BITS` variable that can be `32` for `i386` or `64` for the `x86_64` flags for the assembly source code, flags for the linker and many many more (all definitions you can find in the [arch/x86/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/Makefile)). The first target is `archheaders` in the makefile generates syscall table:
|
||||||
|
|
||||||
|
```Makefile
|
||||||
|
archheaders:
|
||||||
|
$(Q)$(MAKE) $(build)=arch/x86/entry/syscalls all
|
||||||
|
```
|
||||||
|
|
||||||
|
And the second target is `archscripts` in this makefile is:
|
||||||
|
|
||||||
|
```Makefile
|
||||||
|
archscripts: scripts_basic
|
||||||
|
$(Q)$(MAKE) $(build)=arch/x86/tools relocs
|
||||||
|
```
|
||||||
|
|
||||||
|
We can see that it depends on the `scripts_basic` target from the top [Makefile](https://github.com/torvalds/linux/blob/master/Makefile). At the first we can see the `scripts_basic` target that executes make for the [scripts/basic](https://github.com/torvalds/linux/blob/master/scripts/basic/Makefile) makefile:
|
||||||
|
|
||||||
|
```Maklefile
|
||||||
|
scripts_basic:
|
||||||
|
$(Q)$(MAKE) $(build)=scripts/basic
|
||||||
|
```
|
||||||
|
|
||||||
|
The `scripts/basic/Makefile` contains targets for compilation of the two host programs: `fixdep` and `bin2`:
|
||||||
|
|
||||||
|
```Makefile
|
||||||
|
hostprogs-y := fixdep
|
||||||
|
hostprogs-$(CONFIG_BUILD_BIN2C) += bin2c
|
||||||
|
always := $(hostprogs-y)
|
||||||
|
|
||||||
|
$(addprefix $(obj)/,$(filter-out fixdep,$(always))): $(obj)/fixdep
|
||||||
|
```
|
||||||
|
|
||||||
|
First program is `fixdep` - optimizes list of dependencies generated by the [gcc](https://gcc.gnu.org/) that tells make when to remake a source code file. The second program is `bin2c` depends on the value of the `CONFIG_BUILD_BIN2C` kernel configuration option and very little C program that allows to convert a binary on stdin to a C include on stdout. You can note here strange notation: `hostprogs-y` and etc. This notation is used in the all `kbuild` files and more about it you can read in the [documentation](https://github.com/torvalds/linux/blob/master/Documentation/kbuild/makefiles.txt). In our case the `hostprogs-y` tells to the `kbuild` that there is one host program named `fixdep` that will be built from the will be built from `fixdep.c` that located in the same directory that `Makefile`. The first output after we will execute `make` command in our terminal will be result of this `kbuild` file:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ make
|
||||||
|
HOSTCC scripts/basic/fixdep
|
||||||
|
```
|
||||||
|
|
||||||
|
As `script_basic` target was executed, the `archscripts` target will execute `make` for the [arch/x86/tools](https://github.com/torvalds/linux/blob/master/arch/x86/tools/Makefile) makefile with the `relocs` target:
|
||||||
|
|
||||||
|
```Makefile
|
||||||
|
$(Q)$(MAKE) $(build)=arch/x86/tools relocs
|
||||||
|
```
|
||||||
|
|
||||||
|
The `relocs_32.c` and the `relocs_64.c` will be compiled that will contain [relocation](https://en.wikipedia.org/wiki/Relocation_%28computing%29) information and we will see it in the `make` output:
|
||||||
|
|
||||||
|
```Makefile
|
||||||
|
HOSTCC arch/x86/tools/relocs_32.o
|
||||||
|
HOSTCC arch/x86/tools/relocs_64.o
|
||||||
|
HOSTCC arch/x86/tools/relocs_common.o
|
||||||
|
HOSTLD arch/x86/tools/relocs
|
||||||
|
```
|
||||||
|
|
||||||
|
There is checking of the `version.h` after compiling of the `relocs.c`:
|
||||||
|
|
||||||
|
```Makefile
|
||||||
|
$(version_h): $(srctree)/Makefile FORCE
|
||||||
|
$(call filechk,version.h)
|
||||||
|
$(Q)rm -f $(old_version_h)
|
||||||
|
```
|
||||||
|
|
||||||
|
We can see it in the output:
|
||||||
|
|
||||||
|
```
|
||||||
|
CHK include/config/kernel.release
|
||||||
|
```
|
||||||
|
|
||||||
|
and the building of the `generic` assembly headers with the `asm-generic` target from the `arch/x86/include/generated/asm` that generated in the top Makefile of the Linux kernel. After the `asm-generic` target the `archprepare` will be done, so the `prepare0` target will be executed. As I wrote above:
|
||||||
|
|
||||||
|
```Makefile
|
||||||
|
prepare0: archprepare FORCE
|
||||||
|
$(Q)$(MAKE) $(build)=.
|
||||||
|
```
|
||||||
|
|
||||||
|
Note on the `build`. It defined in the [scripts/Kbuild.include](https://github.com/torvalds/linux/blob/master/scripts/Kbuild.include) and looks like this:
|
||||||
|
|
||||||
|
```Makefile
|
||||||
|
build := -f $(srctree)/scripts/Makefile.build obj
|
||||||
|
```
|
||||||
|
|
||||||
|
or in our case it is current source directory - `.`:
|
||||||
|
|
||||||
|
```Makefile
|
||||||
|
$(Q)$(MAKE) -f $(srctree)/scripts/Makefile.build obj=.
|
||||||
|
```
|
||||||
|
|
||||||
|
The [scripts/Makefile.build](https://github.com/torvalds/linux/blob/master/scripts/Makefile.build) tries to find the `Kbuild` file by the given directory via the `obj` parameter, include this `Kbuild` files:
|
||||||
|
|
||||||
|
```Makefile
|
||||||
|
include $(kbuild-file)
|
||||||
|
```
|
||||||
|
|
||||||
|
and build targets from it. In our case `.` contains the [Kbuild](https://github.com/torvalds/linux/blob/master/Kbuild) file that generates the `kernel/bounds.s` and the `arch/x86/kernel/asm-offsets.s`. After this the `prepare` target finished to work. The `vmlinux-dirs` also depends on the second target - `scripts` that compiles following programs: `file2alias`, `mk_elfconfig`, `modpost` and etc... After scripts/host-programs compilation our `vmlinux-dirs` target can be executed. First of all let's try to understand what does `vmlinux-dirs` contain. For my case it contains paths of the following kernel directories:
|
||||||
|
|
||||||
|
```
|
||||||
|
init usr arch/x86 kernel mm fs ipc security crypto block
|
||||||
|
drivers sound firmware arch/x86/pci arch/x86/power
|
||||||
|
arch/x86/video net lib arch/x86/lib
|
||||||
|
```
|
||||||
|
|
||||||
|
We can find definition of the `vmlinux-dirs` in the top [Makefile](https://github.com/torvalds/linux/blob/master/Makefile) of the Linux kernel:
|
||||||
|
|
||||||
|
```Makefile
|
||||||
|
vmlinux-dirs := $(patsubst %/,%,$(filter %/, $(init-y) $(init-m) \
|
||||||
|
$(core-y) $(core-m) $(drivers-y) $(drivers-m) \
|
||||||
|
$(net-y) $(net-m) $(libs-y) $(libs-m)))
|
||||||
|
|
||||||
|
init-y := init/
|
||||||
|
drivers-y := drivers/ sound/ firmware/
|
||||||
|
net-y := net/
|
||||||
|
libs-y := lib/
|
||||||
|
...
|
||||||
|
...
|
||||||
|
...
|
||||||
|
```
|
||||||
|
|
||||||
|
Here we remove the `/` symbol from the each directory with the help of the `patsubst` and `filter` functions and put it to the `vmlinux-dirs`. So we have list of directories in the `vmlinux-dirs` and the following code:
|
||||||
|
|
||||||
|
```Makefile
|
||||||
|
$(vmlinux-dirs): prepare scripts
|
||||||
|
$(Q)$(MAKE) $(build)=$@
|
||||||
|
```
|
||||||
|
|
||||||
|
The `$@` represents `vmlinux-dirs` here that means that it will go recursively over all directories from the `vmlinux-dirs` and its internal directories (depens on configuration) and will execute `make` in there. We can see it in the output:
|
||||||
|
|
||||||
|
```
|
||||||
|
CC init/main.o
|
||||||
|
CHK include/generated/compile.h
|
||||||
|
CC init/version.o
|
||||||
|
CC init/do_mounts.o
|
||||||
|
...
|
||||||
|
CC arch/x86/crypto/glue_helper.o
|
||||||
|
AS arch/x86/crypto/aes-x86_64-asm_64.o
|
||||||
|
CC arch/x86/crypto/aes_glue.o
|
||||||
|
...
|
||||||
|
AS arch/x86/entry/entry_64.o
|
||||||
|
AS arch/x86/entry/thunk_64.o
|
||||||
|
CC arch/x86/entry/syscall_64.o
|
||||||
|
```
|
||||||
|
|
||||||
|
Source code in each directory will be compiled and linked to the `built-in.o`:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ find . -name built-in.o
|
||||||
|
./arch/x86/crypto/built-in.o
|
||||||
|
./arch/x86/crypto/sha-mb/built-in.o
|
||||||
|
./arch/x86/net/built-in.o
|
||||||
|
./init/built-in.o
|
||||||
|
./usr/built-in.o
|
||||||
|
...
|
||||||
|
...
|
||||||
|
```
|
||||||
|
|
||||||
|
Ok, all buint-in.o(s) built, now we can back to the `vmlinux` target. As you remember, the `vmlinux` target is in the top Makefile of the Linux kernel. Before the linking of the `vmlinux` it builds [samples](https://github.com/torvalds/linux/tree/master/samples), [Documentation](https://github.com/torvalds/linux/tree/master/Documentation) and etc., but I will not describe it in this part as I wrote in the beginning of this part.
|
||||||
|
|
||||||
|
```Makefile
|
||||||
|
vmlinux: scripts/link-vmlinux.sh $(vmlinux-deps) FORCE
|
||||||
|
...
|
||||||
|
...
|
||||||
|
+$(call if_changed,link-vmlinux)
|
||||||
|
```
|
||||||
|
|
||||||
|
As you can see main purpose of it is a call of the [scripts/link-vmlinux.sh](https://github.com/torvalds/linux/blob/master/scripts/link-vmlinux.sh) script is linking of the all `built-in.o`(s) to the one statically linked executable and creation of the [System.map](https://en.wikipedia.org/wiki/System.map). In the end we will see following output:
|
||||||
|
|
||||||
|
```
|
||||||
|
LINK vmlinux
|
||||||
|
LD vmlinux.o
|
||||||
|
MODPOST vmlinux.o
|
||||||
|
GEN .version
|
||||||
|
CHK include/generated/compile.h
|
||||||
|
UPD include/generated/compile.h
|
||||||
|
CC init/version.o
|
||||||
|
LD init/built-in.o
|
||||||
|
KSYM .tmp_kallsyms1.o
|
||||||
|
KSYM .tmp_kallsyms2.o
|
||||||
|
LD vmlinux
|
||||||
|
SORTEX vmlinux
|
||||||
|
SYSMAP System.map
|
||||||
|
```
|
||||||
|
|
||||||
|
and `vmlinux` and `System.map` in the root of the Linux kernel source tree:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ls vmlinux System.map
|
||||||
|
System.map vmlinux
|
||||||
|
```
|
||||||
|
|
||||||
|
That's all, `vmlinux` is ready. The next step is creation of the [bzImage](https://en.wikipedia.org/wiki/Vmlinux#bzImage).
|
||||||
|
|
||||||
|
Building bzImage
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
The `bzImage` is the compressed Linux kernel image. We can get it with the execution of the `make bzImage` after the `vmlinux` built. In other way we can just execute `make` without arguments and will get `bzImage` anyway because it is default image:
|
||||||
|
|
||||||
|
```Makefile
|
||||||
|
all: bzImage
|
||||||
|
```
|
||||||
|
|
||||||
|
in the [arch/x86/kernel/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/Makefile). Let's look on this target, it will help us to understand how this image builds. As I already said the `bzImage` target defined in the [arch/x86/kernel/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/Makefile) and looks like this:
|
||||||
|
|
||||||
|
```Makefile
|
||||||
|
bzImage: vmlinux
|
||||||
|
$(Q)$(MAKE) $(build)=$(boot) $(KBUILD_IMAGE)
|
||||||
|
$(Q)mkdir -p $(objtree)/arch/$(UTS_MACHINE)/boot
|
||||||
|
$(Q)ln -fsn ../../x86/boot/bzImage $(objtree)/arch/$(UTS_MACHINE)/boot/$@
|
||||||
|
```
|
||||||
|
|
||||||
|
We can see here, that first of all called `make` for the boot directory, in our case it is:
|
||||||
|
|
||||||
|
```Makefile
|
||||||
|
boot := arch/x86/boot
|
||||||
|
```
|
||||||
|
|
||||||
|
The main goal now to build source code in the `arch/x86/boot` and `arch/x86/boot/compressed` directories, build `setup.bin` and `vmlinux.bin`, and build the `bzImage` from they in the end. First target in the [arch/x86/boot/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/boot/Makefile) is the `$(obj)/setup.elf`:
|
||||||
|
|
||||||
|
```Makefile
|
||||||
|
$(obj)/setup.elf: $(src)/setup.ld $(SETUP_OBJS) FORCE
|
||||||
|
$(call if_changed,ld)
|
||||||
|
```
|
||||||
|
|
||||||
|
We already have the `setup.ld` linker script in the `arch/x86/boot` directory and the `SETUP_OBJS` expands to the all source files from the `boot` directory. We can see first output:
|
||||||
|
|
||||||
|
```Makefile
|
||||||
|
AS arch/x86/boot/bioscall.o
|
||||||
|
CC arch/x86/boot/cmdline.o
|
||||||
|
AS arch/x86/boot/copy.o
|
||||||
|
HOSTCC arch/x86/boot/mkcpustr
|
||||||
|
CPUSTR arch/x86/boot/cpustr.h
|
||||||
|
CC arch/x86/boot/cpu.o
|
||||||
|
CC arch/x86/boot/cpuflags.o
|
||||||
|
CC arch/x86/boot/cpucheck.o
|
||||||
|
CC arch/x86/boot/early_serial_console.o
|
||||||
|
CC arch/x86/boot/edd.o
|
||||||
|
```
|
||||||
|
|
||||||
|
The next source code file is the [arch/x86/boot/header.S](https://github.com/torvalds/linux/blob/master/arch/x86/boot/header.S), but we can't build it now because this target depends on the following two header files:
|
||||||
|
|
||||||
|
```Makefile
|
||||||
|
$(obj)/header.o: $(obj)/voffset.h $(obj)/zoffset.h
|
||||||
|
```
|
||||||
|
|
||||||
|
The first is `voffset.h` generated by the `sed` script that gets two addresses from the `vmlinux` with the `nm` util:
|
||||||
|
|
||||||
|
```C
|
||||||
|
#define VO__end 0xffffffff82ab0000
|
||||||
|
#define VO__text 0xffffffff81000000
|
||||||
|
```
|
||||||
|
|
||||||
|
They are start and end of the kernel. The second is `zoffset.h` depens on the `vmlinux` target from the [arch/x86/boot/compressed/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/boot/compressed/Makefile):
|
||||||
|
|
||||||
|
```Makefile
|
||||||
|
$(obj)/zoffset.h: $(obj)/compressed/vmlinux FORCE
|
||||||
|
$(call if_changed,zoffset)
|
||||||
|
```
|
||||||
|
|
||||||
|
The `$(obj)/compressed/vmlinux` target depends on the `vmlinux-objs-y` that compiles source code files from the [arch/x86/boot/compressed](https://github.com/torvalds/linux/tree/master/arch/x86/boot/compressed) directory and generates `vmlinux.bin`, `vmlinux.bin.bz2`, and compiles programm - `mkpiggy`. We can see this in the output:
|
||||||
|
|
||||||
|
```Makefile
|
||||||
|
LDS arch/x86/boot/compressed/vmlinux.lds
|
||||||
|
AS arch/x86/boot/compressed/head_64.o
|
||||||
|
CC arch/x86/boot/compressed/misc.o
|
||||||
|
CC arch/x86/boot/compressed/string.o
|
||||||
|
CC arch/x86/boot/compressed/cmdline.o
|
||||||
|
OBJCOPY arch/x86/boot/compressed/vmlinux.bin
|
||||||
|
BZIP2 arch/x86/boot/compressed/vmlinux.bin.bz2
|
||||||
|
HOSTCC arch/x86/boot/compressed/mkpiggy
|
||||||
|
```
|
||||||
|
|
||||||
|
Where the `vmlinux.bin` is the `vmlinux` with striped debuging information and comments and the `vmlinux.bin.bz2` compressed `vmlinux.bin.all` + `u32` size of `vmlinux.bin.all`. The `vmlinux.bin.all` is `vmlinux.bin + vmlinux.relocs`, where `vmlinux.relocs` is the `vmlinux` that was handled by the `relocs` program (see above). As we got these files, the `piggy.S` assembly files will be generated with the `mkpiggy` program and compiled:
|
||||||
|
|
||||||
|
```Makefile
|
||||||
|
MKPIGGY arch/x86/boot/compressed/piggy.S
|
||||||
|
AS arch/x86/boot/compressed/piggy.o
|
||||||
|
```
|
||||||
|
|
||||||
|
This assembly files will contain computed offset from a compressed kernel. After this we can see that `zoffset` generated:
|
||||||
|
|
||||||
|
```Makefile
|
||||||
|
ZOFFSET arch/x86/boot/zoffset.h
|
||||||
|
```
|
||||||
|
|
||||||
|
As the `zoffset.h` and the `voffset.h` are generated, compilation of the source code files from the [arch/x86/boot](https://github.com/torvalds/linux/tree/master/arch/x86/boot/) can be continued:
|
||||||
|
|
||||||
|
```Makefile
|
||||||
|
AS arch/x86/boot/header.o
|
||||||
|
CC arch/x86/boot/main.o
|
||||||
|
CC arch/x86/boot/mca.o
|
||||||
|
CC arch/x86/boot/memory.o
|
||||||
|
CC arch/x86/boot/pm.o
|
||||||
|
AS arch/x86/boot/pmjump.o
|
||||||
|
CC arch/x86/boot/printf.o
|
||||||
|
CC arch/x86/boot/regs.o
|
||||||
|
CC arch/x86/boot/string.o
|
||||||
|
CC arch/x86/boot/tty.o
|
||||||
|
CC arch/x86/boot/video.o
|
||||||
|
CC arch/x86/boot/video-mode.o
|
||||||
|
CC arch/x86/boot/video-vga.o
|
||||||
|
CC arch/x86/boot/video-vesa.o
|
||||||
|
CC arch/x86/boot/video-bios.o
|
||||||
|
```
|
||||||
|
|
||||||
|
As all source code files will be compiled, they will be linked to the `setup.elf`:
|
||||||
|
|
||||||
|
```Makefile
|
||||||
|
LD arch/x86/boot/setup.elf
|
||||||
|
```
|
||||||
|
|
||||||
|
or:
|
||||||
|
|
||||||
|
```
|
||||||
|
ld -m elf_x86_64 -T arch/x86/boot/setup.ld arch/x86/boot/a20.o arch/x86/boot/bioscall.o arch/x86/boot/cmdline.o arch/x86/boot/copy.o arch/x86/boot/cpu.o arch/x86/boot/cpuflags.o arch/x86/boot/cpucheck.o arch/x86/boot/early_serial_console.o arch/x86/boot/edd.o arch/x86/boot/header.o arch/x86/boot/main.o arch/x86/boot/mca.o arch/x86/boot/memory.o arch/x86/boot/pm.o arch/x86/boot/pmjump.o arch/x86/boot/printf.o arch/x86/boot/regs.o arch/x86/boot/string.o arch/x86/boot/tty.o arch/x86/boot/video.o arch/x86/boot/video-mode.o arch/x86/boot/version.o arch/x86/boot/video-vga.o arch/x86/boot/video-vesa.o arch/x86/boot/video-bios.o -o arch/x86/boot/setup.elf
|
||||||
|
```
|
||||||
|
|
||||||
|
The last two things is the creation of the `setup.bin` that will contain compiled code from the `arch/x86/boot/*` directory:
|
||||||
|
|
||||||
|
```
|
||||||
|
objcopy -O binary arch/x86/boot/setup.elf arch/x86/boot/setup.bin
|
||||||
|
```
|
||||||
|
|
||||||
|
and the creation of the `vmlinux.bin` from the `vmlinux`:
|
||||||
|
|
||||||
|
```
|
||||||
|
objcopy -O binary -R .note -R .comment -S arch/x86/boot/compressed/vmlinux arch/x86/boot/vmlinux.bin
|
||||||
|
```
|
||||||
|
|
||||||
|
In the end we compile host program: [arch/x86/boot/tools/build.c](https://github.com/torvalds/linux/blob/master/arch/x86/boot/tools/build.c) that will create our `bzImage` from the `setup.bin` and the `vmlinux.bin`:
|
||||||
|
|
||||||
|
```
|
||||||
|
arch/x86/boot/tools/build arch/x86/boot/setup.bin arch/x86/boot/vmlinux.bin arch/x86/boot/zoffset.h arch/x86/boot/bzImage
|
||||||
|
```
|
||||||
|
|
||||||
|
Actually the `bzImage` is the concatenated `setup.bin` and the `vmlinux.bin`. In the end we will see the output which familiar to all who once build the Linux kernel from source:
|
||||||
|
|
||||||
|
```
|
||||||
|
Setup is 16268 bytes (padded to 16384 bytes).
|
||||||
|
System is 4704 kB
|
||||||
|
CRC 94a88f9a
|
||||||
|
Kernel: arch/x86/boot/bzImage is ready (#5)
|
||||||
|
```
|
||||||
|
|
||||||
|
That's all.
|
||||||
|
|
||||||
|
Conclusion
|
||||||
|
================================================================================
|
||||||
|
|
||||||
|
It is the end of this part and here we saw all steps from the execution of the `make` command to the generation of the `bzImage`. I know, the Linux kernel makefiles and process of the Linux kernel building may seem confusing at first glance, but it is not so hard. Hope this part will help you to understand process of the Linux kernel building.
|
||||||
|
|
||||||
|
Links
|
||||||
|
================================================================================
|
||||||
|
|
||||||
|
* [GNU make util](https://en.wikipedia.org/wiki/Make_%28software%29)
|
||||||
|
* [Linux kernel top Makefile](https://github.com/torvalds/linux/blob/master/Makefile)
|
||||||
|
* [cross-compilation](https://en.wikipedia.org/wiki/Cross_compiler)
|
||||||
|
* [Ctags](https://en.wikipedia.org/wiki/Ctags)
|
||||||
|
* [sparse](https://en.wikipedia.org/wiki/Sparse)
|
||||||
|
* [bzImage](https://en.wikipedia.org/wiki/Vmlinux#bzImage)
|
||||||
|
* [uname](https://en.wikipedia.org/wiki/Uname)
|
||||||
|
* [shell](https://en.wikipedia.org/wiki/Shell_%28computing%29)
|
||||||
|
* [Kbuild](https://github.com/torvalds/linux/blob/master/Documentation/kbuild/kbuild.txt)
|
||||||
|
* [binutils](http://www.gnu.org/software/binutils/)
|
||||||
|
* [gcc](https://gcc.gnu.org/)
|
||||||
|
* [Documentation](https://github.com/torvalds/linux/blob/master/Documentation/kbuild/makefiles.txt)
|
||||||
|
* [System.map](https://en.wikipedia.org/wiki/System.map)
|
||||||
|
* [Relocation](https://en.wikipedia.org/wiki/Relocation_%28computing%29)
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://github.com/0xAX/linux-insides/blob/master/Misc/how_kernel_compiled.md
|
||||||
|
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
@ -0,0 +1,130 @@
|
|||||||
|
translation by strugglingyouth
|
||||||
|
Tips to Create ISO from CD, Watch User Activity and Check Memory Usages of Browser
|
||||||
|
================================================================================
|
||||||
|
Here again, I have written another post on [Linux Tips and Tricks][1] series. Since beginning the objective of this post is to make you aware of those small tips and hacks that lets you manage your system/server efficiently.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Create Cdrom ISO Image and Monitor Users in Linux
|
||||||
|
|
||||||
|
In this post we will see how to create ISO image from the contents of CD/DVD loaded in the drive, Open random man pages for learning, know details of other logged-in users and what they are doing and monitoring the memory usages of a browser, and all these using native tools/commands without any third-party application/utility. Here we go…
|
||||||
|
|
||||||
|
### Create ISO image from a CD ###
|
||||||
|
|
||||||
|
Often we need to backup/copy the content of CD/DVD. If you are on Linux platform you do not need any additional software. All you need is the access to Linux console.
|
||||||
|
|
||||||
|
To create ISO image of the files in your CD/DVD ROM, you need two things. The first thing is you need to find the name of your CD/DVD drive. To find the name of your CD/DVD drive, you may choose any of the below three methods.
|
||||||
|
|
||||||
|
**1. Run command lsblk (list block devices) from your terminal/console.**
|
||||||
|
|
||||||
|
$ lsblk
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Find Block Devices
|
||||||
|
|
||||||
|
**2. To see information about CD-ROM, you may use commands like less or more.**
|
||||||
|
|
||||||
|
$ less /proc/sys/dev/cdrom/info
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Check Cdrom Information
|
||||||
|
|
||||||
|
**3. You may get the same information from [dmesg command][2] and customize the output using egrep.**
|
||||||
|
|
||||||
|
The command ‘dmesg‘ print/control the kernel buffer ring. ‘egrep‘ command is used to print lines that matches a pattern. Option -i and –color with egrep is used to ignore case sensitive search and highlight the matching string respectively.
|
||||||
|
|
||||||
|
$ dmesg | egrep -i --color 'cdrom|dvd|cd/rw|writer'
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Find Device Information
|
||||||
|
|
||||||
|
Once you know the name of your CD/DVD, you can use following command to create a ISO image of your cdrom in Linux.
|
||||||
|
|
||||||
|
$ cat /dev/sr0 > /path/to/output/folder/iso_name.iso
|
||||||
|
|
||||||
|
Here ‘sr0‘ is the name of my CD/DVD drive. You should replace this with the name of your CD/DVD. This will help you in creating ISO image and backup contents of CD/DVD without any third-party application.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Create ISO Image of CDROM
|
||||||
|
|
||||||
|
### Open a man page randomly for Reading ###
|
||||||
|
|
||||||
|
If you are new to Linux and want to learn commands and switches, this tweak is for you. Put the below line of code at the end of your `~/.bashrc` file.
|
||||||
|
|
||||||
|
/use/bin/man $(ls /bin | shuf | head -1)
|
||||||
|
|
||||||
|
Remember to put the above one line script in users’s `.bashrc` file and not in the .bashrc file of root. So when the next you login either locally or remotely using SSH you will see a man page randomly opened for you to read. For the newbies who want to learn commands and command-line switches, this will prove helpful.
|
||||||
|
|
||||||
|
Here is what I got in my terminal after logging in to session for two times back-to-back.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
LoadKeys Man Pages
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Zgrep Man Pages
|
||||||
|
|
||||||
|
### Check Activity of Logged-in Users ###
|
||||||
|
|
||||||
|
Know what other users are doing on your shared server.
|
||||||
|
|
||||||
|
In most general case, either you are a user of Shared Linux Server or the Admin. If you are concerned about your server and want to check what other users are doing, you may try command ‘w‘.
|
||||||
|
|
||||||
|
This command lets you know if someone is executing any malicious code or tampering the server, slowing it down or anything else. ‘w‘ is the preferred way of keeping an eye on logged on users and what they are doing.
|
||||||
|
|
||||||
|
To see logged on users and what they re doing, run command ‘w’ from terminal, preferably as root.
|
||||||
|
|
||||||
|
# w
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Check Linux User Activity
|
||||||
|
|
||||||
|
### Check Memory usages by Browser ###
|
||||||
|
|
||||||
|
These days a lot of jokes are cracked on Google-chrome and its demand of memory. If you want to know the memory usages of a browser, you can list the name of the process, its PID and Memory usages of it. To check memory usages of a browser, just enter the “about:memory” in the address bar without quotes.
|
||||||
|
|
||||||
|
I have tested it on Google-Chrome and Mozilla Firefox web browser. If you can check it on any other browser and it works well you may acknowledge us in the comments below. Also you may kill the browser process simply as if you have done for any Linux terminal process/service.
|
||||||
|
|
||||||
|
In Google Chrome, type `about:memory` in address bar, you should get something similar to below image.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Check Chrome Memory Usage
|
||||||
|
|
||||||
|
In Mozilla Firefox, type `about:memory` in address bar, you should get something similar to below image.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Check Firefox Memory Usage
|
||||||
|
|
||||||
|
Out of these options you may select any of them, if you understand what it is. To check memory usages, click the left most option ‘Measure‘.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Firefox Main Process
|
||||||
|
|
||||||
|
It shows tree like process-memory usages by browser.
|
||||||
|
|
||||||
|
That’s all for now. Hope all the above tips will help you at some point of time. If you have one (or more) tips/tricks that will help Linux Users to manage their Linux System/Server more efficiently ans is lesser known, you may like to share it with us.
|
||||||
|
|
||||||
|
I’ll be here with another post soon, till then stay tuned and connected to TecMint. Provide us with your valuable feedback in the comments below. Like and share us and help us get spread.
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://www.tecmint.com/creating-cdrom-iso-image-watch-user-activity-in-linux/
|
||||||
|
|
||||||
|
作者:[Avishek Kumar][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://www.tecmint.com/author/avishek/
|
||||||
|
[1]:http://www.tecmint.com/tag/linux-tricks/
|
||||||
|
[2]:http://www.tecmint.com/dmesg-commands/
|
||||||
@ -0,0 +1,121 @@
|
|||||||
|
|
||||||
|
Translating by dingdongnigetou
|
||||||
|
|
||||||
|
Understanding Shell Commands Easily Using “Explain Shell” Script in Linux
|
||||||
|
================================================================================
|
||||||
|
While working on Linux platform all of us need help on shell commands, at some point of time. Although inbuilt help like man pages, whatis command is helpful, but man pages output are too lengthy and until and unless one has some experience with Linux, it is very difficult to get any help from massive man pages. The output of whatis command is rarely more than one line which is not sufficient for newbies.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Explain Shell Commands in Linux Shell
|
||||||
|
|
||||||
|
There are third-party application like ‘cheat‘, which we have covered here “[Commandline Cheat Sheet for Linux Users][1]. Although Cheat is an exceptionally good application which shows help on shell command even when computer is not connected to Internet, it shows help on predefined commands only.
|
||||||
|
|
||||||
|
There is a small piece of code written by Jackson which is able to explain shell commands within the bash shell very effectively and guess what the best part is you don’t need to install any third party package. He named the file containing this piece of code as `'explain.sh'`.
|
||||||
|
|
||||||
|
#### Features of Explain Utility ####
|
||||||
|
|
||||||
|
- Easy Code Embedding.
|
||||||
|
- No third-party utility needed to be installed.
|
||||||
|
- Output just enough information in course of explanation.
|
||||||
|
- Requires internet connection to work.
|
||||||
|
- Pure command-line utility.
|
||||||
|
- Able to explain most of the shell commands in bash shell.
|
||||||
|
- No root Account involvement required.
|
||||||
|
|
||||||
|
**Prerequisite**
|
||||||
|
|
||||||
|
The only requirement is `'curl'` package. In most of the today’s latest Linux distributions, curl package comes pre-installed, if not you can install it using package manager as shown below.
|
||||||
|
|
||||||
|
# apt-get install curl [On Debian systems]
|
||||||
|
# yum install curl [On CentOS systems]
|
||||||
|
|
||||||
|
### Installation of explain.sh Utility in Linux ###
|
||||||
|
|
||||||
|
We have to insert the below piece of code as it is in the `~/.bashrc` file. The code should be inserted for each user and each `.bashrc` file. It is suggested to insert the code to the user’s .bashrc file only and not in the .bashrc of root user.
|
||||||
|
|
||||||
|
Notice the first line of code that starts with hash `(#)` is optional and added just to differentiate rest of the codes of .bashrc.
|
||||||
|
|
||||||
|
# explain.sh marks the beginning of the codes, we are inserting in .bashrc file at the bottom of this file.
|
||||||
|
|
||||||
|
# explain.sh begins
|
||||||
|
explain () {
|
||||||
|
if [ "$#" -eq 0 ]; then
|
||||||
|
while read -p "Command: " cmd; do
|
||||||
|
curl -Gs "https://www.mankier.com/api/explain/?cols="$(tput cols) --data-urlencode "q=$cmd"
|
||||||
|
done
|
||||||
|
echo "Bye!"
|
||||||
|
elif [ "$#" -eq 1 ]; then
|
||||||
|
curl -Gs "https://www.mankier.com/api/explain/?cols="$(tput cols) --data-urlencode "q=$1"
|
||||||
|
else
|
||||||
|
echo "Usage"
|
||||||
|
echo "explain interactive mode."
|
||||||
|
echo "explain 'cmd -o | ...' one quoted command to explain it."
|
||||||
|
fi
|
||||||
|
}
|
||||||
|
|
||||||
|
### Working of explain.sh Utility ###
|
||||||
|
|
||||||
|
After inserting the code and saving it, you must logout of the current session and login back to make the changes taken into effect. Every thing is taken care of by the ‘curl’ command which transfer the input command and flag that need explanation to the mankier server and then print just necessary information to the Linux command-line. Not to mention to use this utility you must be connected to internet always.
|
||||||
|
|
||||||
|
Let’s test few examples of command which I don’t know the meaning with explain.sh script.
|
||||||
|
|
||||||
|
**1. I forgot what ‘du -h‘ does. All I need to do is:**
|
||||||
|
|
||||||
|
$ explain 'du -h'
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Get Help on du Command
|
||||||
|
|
||||||
|
**2. If you forgot what ‘tar -zxvf‘ does, you may simply do:**
|
||||||
|
|
||||||
|
$ explain 'tar -zxvf'
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Tar Command Help
|
||||||
|
|
||||||
|
**3. One of my friend often confuse the use of ‘whatis‘ and ‘whereis‘ command, so I advised him.**
|
||||||
|
|
||||||
|
Go to Interactive Mode by simply typing explain command on the terminal.
|
||||||
|
|
||||||
|
$ explain
|
||||||
|
|
||||||
|
and then type the commands one after another to see what they do in one window, as:
|
||||||
|
|
||||||
|
Command: whatis
|
||||||
|
Command: whereis
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Whatis Whereis Commands Help
|
||||||
|
|
||||||
|
To exit interactive mode he just need to do Ctrl + c.
|
||||||
|
|
||||||
|
**4. You can ask to explain more than one command chained by pipeline.**
|
||||||
|
|
||||||
|
$ explain 'ls -l | grep -i Desktop'
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Get Help on Multiple Commands
|
||||||
|
|
||||||
|
Similarly you can ask your shell to explain any shell command. All you need is a working Internet connection. The output is generated based upon the explanation needed from the server and hence the output result is not customizable.
|
||||||
|
|
||||||
|
For me this utility is really helpful and it has been honored being added to my .bashrc. Let me know what is your thought on this project? How it can useful for you? Is the explanation satisfactory?
|
||||||
|
|
||||||
|
Provide us with your valuable feedback in the comments below. Like and share us and help us get spread.
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://www.tecmint.com/explain-shell-commands-in-the-linux-shell/
|
||||||
|
|
||||||
|
作者:[Avishek Kumar][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://www.tecmint.com/author/avishek/
|
||||||
|
[1]:http://www.tecmint.com/cheat-command-line-cheat-sheet-for-linux-users/
|
||||||
@ -1,79 +0,0 @@
|
|||||||
监控你的Linux系统的7个命令行工具
|
|
||||||
================================================================================
|
|
||||||
**这里有一些基本的命令行工具,让你能更简单地探索和操作Linux。**
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### 深入 ###
|
|
||||||
|
|
||||||
关于Linux最棒的一件事之一是你能深入操作系统多深,来探索它是如何工作的并寻找机会来微调性能或诊断问题。这里有一些基本的命令行工具,让你能更简单地探索和操作Linux。大多数的这些命令是在你的Linux系统中已经内建的,但假设它们不是,就用谷歌搜索命令名和你的发行版名吧,你会找到哪些包需要安装(注意,一些命令是和其它命令捆绑起来打成一个包的,你所找的包可能写的是其它的名字)。如果你知道一些你所使用的其它工具,欢迎评论。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### 我们怎么做 ###
|
|
||||||
|
|
||||||
须知: 本文中的截图取自[Debian Linux 8.1][1] (“Jessie”),其运行在[OS X 10.10.3][3] (“Yosemite”)操作系统下[Oracle VirtualBox 4.3.28][2]中的一台虚拟机里。想要建立你的Debian虚拟机,可以看看我的这篇教程——“[How to install Debian Linux in a VirtualBox VM][4]”。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### Top ###
|
|
||||||
|
|
||||||
作为Linux系统监控工具中比较易用的一个,**top命令**能带我们一览Linux中的几乎每一处。以下这张图是它的默认界面,但是按“z”键可以切换不同的显示颜色。其它热键和命令则有其它的功能,例如显示概要信息和内存信息(第四行第二个),根据各种不一样的条件排序、终止进程任务等等(你可以在[这里][5]找到完整的列表)。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### htop ###
|
|
||||||
|
|
||||||
相比top,它的替代品Htop则更为精致。维基百科是这样描述的:“用户经常会部署htop以防Unix top不能提供关于系统进程的足够信息,比如说当你在尝试发现应用程序里的一个小的内存泄露问题,Htop一般也能作为一个系统监听器来使用。相比top,它提供了一个更方便的光标控制界面来向进程发送信号。” (想了解更多细节猛戳[这里][6].)
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### Vmstat ###
|
|
||||||
|
|
||||||
Vmstat是一款监控Linux系统性能数据的简易工具,这让它在shell脚本中使用更合适。打开你的regex-fu,用vmstat和cron作业来做一些激动人心的事情吧。“产出的第一份报告给出的是上一次系统重启之后的均值,另外其一份报告给出的则是从前一个报告起间隔周期中的信息。进程和内存报告在任何情况下都是不停更新的”(猛戳[这里][7]获取更多信息)。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### ps ###
|
|
||||||
|
|
||||||
ps命令展现的是正在运行中的进程列表。在这种情况下,我们用“-e”选项来显示每个进程,也就是所有正在运行的进程了(我把列表滚动到了头部否则列名就看不到了)。这个命令有很多选项允许你去按需格式化输出。只要使用上述一点点的regex-fu你就能得到一个强大的工具了。猛戳[这里][8]获取更多信息。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### Pstree ###
|
|
||||||
|
|
||||||
Pstree“以树状图显示正在运行中的进程。如果pid被省略的话那树结构是以pid或init为父进程,如果用户名指定,那所有进程树都会以该用户所属的进程为父进程进行显示。”以树状图来帮你将进程之间的所属关系进行分类,这的确是个很有效的工具(戳[这里][9])。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### pmap ###
|
|
||||||
|
|
||||||
理解一个应用程序在调试过程中如何使用内存是至关重要的,而pmap的作用就是当给出一个进程ID(PID)时显示出相关信息。上面的截图展示的是使用“-x”选项所产生的部分输出,你也可以用pmap的“-X”选项来获取更多的细节信息但是前提是你要有个更宽的终端窗口。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### iostat ###
|
|
||||||
|
|
||||||
Linux系统的一个至关重要的性能指标是处理器和存储的使用率,它也是iostat命令所报告的内容。如同ps命令一样,iostat有很多选项允许你选择你需要的输出格式,除此之外还有某一段时间范围内的简单性能输出并在报告之前重复抽样多次。详情戳[这里][10]。
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: http://www.networkworld.com/article/2937219/linux/7-command-line-tools-for-monitoring-your-linux-system.html
|
|
||||||
|
|
||||||
作者:[Mark Gibbs][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:http://www.networkworld.com/author/Mark-Gibbs/
|
|
||||||
[1]:https://www.debian.org/releases/stable/
|
|
||||||
[2]:https://www.virtualbox.org/
|
|
||||||
[3]:http://www.apple.com/osx/
|
|
||||||
[4]:http://www.networkworld.com/article/2937148/how-to-install-debian-linux-8-1-in-a-virtualbox-vm
|
|
||||||
[5]:http://linux.die.net/man/1/top
|
|
||||||
[6]:http://linux.die.net/man/1/htop
|
|
||||||
[7]:http://linuxcommand.org/man_pages/vmstat8.html
|
|
||||||
[8]:http://linux.die.net/man/1/ps
|
|
||||||
[9]:http://linux.die.net/man/1/pstree
|
|
||||||
[10]:http://linux.die.net/man/1/iostat
|
|
||||||
@ -0,0 +1,95 @@
|
|||||||
|
为Docker配置Swarm本地集群
|
||||||
|
================================================================================
|
||||||
|
嗨,大家好。今天我们来学一学Swarm相关的内容吧,我们将学习通过Swarm来创建Docker本地集群。[Docker Swarm][1]是用于Docker的本地集群项目,它可以将Docker主机池转换成单个的虚拟主机。Swarm提供了标准的Docker API,所以任何可以和Docker守护进程通信的工具都可以使用Swarm来透明地规模化多个主机。Swarm遵循“包含电池并可拆卸”的原则,就像其它Docker项目一样。它附带有一个开箱即用的简单的后端调度程序,而且作为初始开发套件,也为其开发了一个可启用即插即用后端的API。其目标在于为一些简单的使用情况提供一个平滑的、开箱即用的体验,并且它允许在更强大的后端,如Mesos,中开启交换,以达到大量生产部署的目的。Swarm配置和使用极其简单。
|
||||||
|
|
||||||
|
这里给大家提供Swarm 0.2开箱的即用一些特性。
|
||||||
|
|
||||||
|
1. Swarm 0.2.0大约85%与Docker引擎兼容。
|
||||||
|
2. 它支持资源管理。
|
||||||
|
3. 它具有一些带有限制器和类同器高级调度特性。
|
||||||
|
4. 它支持多个发现后端(hubs,consul,etcd,zookeeper)
|
||||||
|
5. 它使用TLS加密方法进行安全通信和验证。
|
||||||
|
|
||||||
|
那么,我们来看一看Swarm的一些相当简单而简易的使用步骤吧。
|
||||||
|
|
||||||
|
### 1. 运行Swarm的先决条件 ###
|
||||||
|
|
||||||
|
我们必须在所有节点安装Docker 1.4.0或更高版本。虽然哥哥节点的IP地址不需要要公共地址,但是Swarm管理器必须可以通过网络访问各个节点。
|
||||||
|
|
||||||
|
注意:Swarm当前还处于beta版本,因此功能特性等还有可能发生改变,我们不推荐你在生产环境中使用。
|
||||||
|
|
||||||
|
### 2. 创建Swarm集群 ###
|
||||||
|
|
||||||
|
现在,我们将通过运行下面的命令来创建Swarm集群。各个节点都将运行一个swarm节点代理,该代理会注册、监控相关的Docker守护进程,并更新发现后端获取的节点状态。下面的命令会返回一个唯一的集群ID标记,在启动节点上的Swarm代理时会用到它。
|
||||||
|
|
||||||
|
# docker run swarm create
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 3. 启动各个节点上的Docker守护进程 ###
|
||||||
|
|
||||||
|
我们需要使用-H标记登陆进我们将用来创建几圈和启动Docker守护进程的各个节点,它会保证Swarm管理器能够通过TCP访问到各个节点上的Docker远程API。要启动Docker守护进程,我们需要在各个节点内部运行以下命令。
|
||||||
|
|
||||||
|
# docker -H tcp://0.0.0.0:2375 -d
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 4. 添加节点 ###
|
||||||
|
|
||||||
|
在启用Docker守护进程后,我们需要添加Swarm节点到发现服务,我们必须确保节点IP可从Swarm管理器访问到。要完成该操作,我们需要运行以下命令。
|
||||||
|
|
||||||
|
# docker run -d swarm join --addr=<node_ip>:2375 token://<cluster_id>
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
** 注意**:我们需要用步骤2中获取到的节点IP地址和集群ID替换这里的<node_ip>和<cluster_id>。
|
||||||
|
|
||||||
|
### 5. 开启Swarm管理器 ###
|
||||||
|
|
||||||
|
现在,由于我们已经获得了连接到集群的节点,我们将启动swarm管理器。我们需要在节点中运行以下命令。
|
||||||
|
|
||||||
|
# docker run -d -p <swarm_port>:2375 swarm manage token://<cluster_id>
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 6. 检查配置 ###
|
||||||
|
|
||||||
|
一旦管理运行起来后,我们可以通过运行以下命令来检查配置。
|
||||||
|
|
||||||
|
# docker -H tcp://<manager_ip:manager_port> info
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
** 注意**:我们需要替换<manager_ip:manager_port>为运行swarm管理器的主机的IP地址和端口。
|
||||||
|
|
||||||
|
### 7. 使用docker CLI来访问节点 ###
|
||||||
|
|
||||||
|
在一切都像上面说得那样完美地完成后,这一部分是Docker Swarm最为重要的部分。我们可以使用Docker CLI来访问节点,并在节点上运行容器。
|
||||||
|
|
||||||
|
# docker -H tcp://<manager_ip:manager_port> info
|
||||||
|
# docker -H tcp://<manager_ip:manager_port> run ...
|
||||||
|
|
||||||
|
### 8. 监听集群中的节点 ###
|
||||||
|
|
||||||
|
我们可以使用swarm list命令来获取所有运行中节点的列表。
|
||||||
|
|
||||||
|
# docker run --rm swarm list token://<cluster_id>
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 尾声 ###
|
||||||
|
|
||||||
|
Swarm真的是一个有着相当不错的功能的docker,它可以用于创建和管理集群。它相当易于配置和使用,当我们在它上面使用限制器和类同器师它更为出色。高级调度程序是一个相当不错的特性,它可以应用过滤器来通过端口、标签、健康状况来排除节点,并且它使用策略来挑选最佳节点。那么,如果你有任何问题、评论、反馈,请在下面的评论框中写出来吧,好让我们知道哪些材料需要补充或改进。谢谢大家了!尽情享受吧 :-)
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://linoxide.com/linux-how-to/configure-swarm-clustering-docker/
|
||||||
|
|
||||||
|
作者:[Arun Pyasi][a]
|
||||||
|
译者:[GOLinux](https://github.com/GOLinux)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://linoxide.com/author/arunp/
|
||||||
|
[1]:https://docs.docker.com/swarm/
|
||||||
@ -1,177 +0,0 @@
|
|||||||
LINUX 101: 让你的 SHELL 更强大
|
|
||||||
================================================================================
|
|
||||||
> 在我们的有关 shell 基础的指导下, 得到一个更灵活,功能更强大且多彩的命令行界面
|
|
||||||
|
|
||||||
**为何要这样做?**
|
|
||||||
|
|
||||||
- 使得在 shell 提示符下过得更轻松,高效
|
|
||||||
- 在失去连接后恢复先前的会话
|
|
||||||
- Stop pushing around that fiddly rodent! (注: 我不知道这句该如何翻译)
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
Here’s our souped-up prompt on steroids.(注: 我不知道该如何翻译这句)对于这个细小的终端窗口来说,这或许有些长.但你可以根据你的喜好来调整它的大小.
|
|
||||||
|
|
||||||
作为一个 Linux 用户, 对 shell (又名为命令行),你可能会熟悉. 或许你需要时不时的打开终端来完成那些不能在 GUI 下处理的必要任务,抑或是因为你处在一个平铺窗口管理器的环境中, 而 shell 是你与你的 linux 机器交互的主要方式.
|
|
||||||
|
|
||||||
在上面的任一情况下,你可能正在使用你所使用的发行版本自带的 Bash 配置. 尽管对于大多数的任务而言,它足够强大,但它可以更加强大. 在本教程中,我们将向你展示如何使得你的 shell 更具信息性,更加实用且更适于在其中工作. 我们将对提示符进行自定义,让它比默认情况下提供更好的反馈,并向你展示如何使用炫酷的 `tmux` 工具来管理会话并同时运行多个程序. 并且,为了让眼睛舒服一点,我们还将关注配色方案. 接着,就让我们向前吧!
|
|
||||||
|
|
||||||
### 让提示符 "唱歌" ###
|
|
||||||
|
|
||||||
大多数的发行版本配置有一个非常简单的提示符 – 它们大多向你展示了一些基本信息, 但提示符可以为你提供更多的内容.例如,在 Debian 7 下,默认的提示符是这样的:
|
|
||||||
|
|
||||||
mike@somebox:~$
|
|
||||||
|
|
||||||
上面的提示符展示出了用户,主机名,当前目录和账户类型符号(假如你切换到 root 账户, **$** 会变为 # ). 那这些信息是在哪里存储的呢? 答案是:在 **PS1** 环境变量中. 假如你键入 **echo $PS1**, 你将会在这个命令的输出字符串的最后有如下的字符:
|
|
||||||
|
|
||||||
\u@\h:\w$ (注:这里没有加上斜杠 \,应该是没有转义 ,下面的有些命令也一样,我把 \ 都加上了,发表的时候也得注意一下)
|
|
||||||
|
|
||||||
这看起来有一些丑陋,并在瞥见它的第一眼时,你可能会开始尖叫,认为它是令人恐惧的正则表达式,但我们不打算用这些复杂的字符来煎熬我们的大脑. 这不是正则表达式, 这里的斜杠是转义序列,它告诉提示符进行一些特别的处理. 例如,上面的 **u** 部分,告诉提示符展示用户名, 而 w 则展示工作路径.
|
|
||||||
|
|
||||||
下面是一些你可以在提示符中用到的字符的列表:
|
|
||||||
|
|
||||||
- d 当前的日期.
|
|
||||||
- h 主机名.
|
|
||||||
- n 代表新的一行的字符.
|
|
||||||
- A 当前的时间 (HH:MM).
|
|
||||||
- u 当前的用户.
|
|
||||||
- w (小写) 整个工作路径的全称.
|
|
||||||
- W (大写) 工作路径的简短名称.
|
|
||||||
- $ 一个提示符号,对于 root 用户为 # 号.
|
|
||||||
- ! 当前命令在 shell 历史记录中的序号.
|
|
||||||
|
|
||||||
下面解释 **w** 和 **W** 选项的区别: 对于前者,你将看到你所在的工作路径的完整地址,(例如 **/usr/local/bin**), 而对于后者, 它则只显示 **bin** 这一部分.
|
|
||||||
|
|
||||||
现在, 我们该怎样改变提示符呢? 你需要更改 **PS1** 环境变量的内容, 试试下面这个:
|
|
||||||
|
|
||||||
export PS1=”I am \u and it is \A $”
|
|
||||||
|
|
||||||
现在, 你的提示符将会像下面这样:
|
|
||||||
|
|
||||||
I am mike and it is 11:26 $
|
|
||||||
|
|
||||||
从这个例子出发, 你就可以按照你的想法来试验一下上面列出的其他转义序列. 但稍等片刻 – 当你登出后,你的这些努力都将消失,因为在你每次打开终端时, **PS1** 环境变量的值都会被重置. 解决这个问题的最简单方式是打开 **.bashrc** 配置文件(在你的家目录下) 并在这个文件的最下方添加上完整的 `export` 命令.在每次你启动一个新的 shell 会话时,这个 **.bashrc** 会被 `Bash` 读取, 所以你的被加强了的提示符就可以一直出现.你还可以使用额外的颜色来装扮提示符.刚开始,这将有点棘手,因为你必须使用一些相当奇怪的转义序列,但结果是非常漂亮的. 将下面的字符添加到你的 **PS1**字符串中的某个位置,最终这将把文本变为红色:
|
|
||||||
|
|
||||||
\[\e[31m\]
|
|
||||||
|
|
||||||
你可以将这里的 31 更改为其他的数字来获得不同的颜色:
|
|
||||||
|
|
||||||
- 30 黑色
|
|
||||||
- 32 绿色
|
|
||||||
- 33 黄色
|
|
||||||
- 34 蓝色
|
|
||||||
- 35 洋红色
|
|
||||||
- 36 青色
|
|
||||||
- 37 白色
|
|
||||||
|
|
||||||
所以,让我们使用先前看到的转义序列和颜色来创造一个提示符,以此来结束这一小节的内容. 深吸一口气,弯曲你的手指,然后键入下面这只"野兽":
|
|
||||||
|
|
||||||
export PS1="(\!) \[\e[31m\] \[\A\] \[\e[32m\]\u@\h \[\e[34m\]\w \[\e[30m\]$"
|
|
||||||
|
|
||||||
上面的命令提供了一个 Bash 命令历史序号, 当前的时间,用户或主机名与颜色之间的组合,以及工作路径.假如你"野心勃勃",利用一些惊人的组合,你还可以更改提示符的背景色和前景色.先前实用的 Arch wiki 有一个关于颜色代码的完整列表:[http://tinyurl.com/3gvz4ec][1].
|
|
||||||
|
|
||||||
> ### Shell 精要 ###
|
|
||||||
>
|
|
||||||
> 假如你是一个彻底的 Linux 新手并第一次阅读这份杂志,或许你会发觉阅读这些教程有些吃力. 所以这里有一些基础知识来让你熟悉一些 shell. 通常在你的菜单中, shell 指的是 Terminal, XTerm 或 Konsole, 但你启动它后, 最为实用的命令有这些:
|
|
||||||
>
|
|
||||||
> **ls** (列出文件名); **cp one.txt two.txt** (复制文件); **rm file.txt** (移除文件); **mv old.txt new.txt** (移动或重命名文件);
|
|
||||||
>
|
|
||||||
> **cd /some/directory** (改变目录); **cd ..** (回到上级目录); **./program** (在当前目录下运行一个程序); **ls > list.txt** (重定向输出到一个文件).
|
|
||||||
>
|
|
||||||
> 几乎每个命令都有一个手册页用来解释其选项(例如 **man ls** – 按 Q 来退出).在那里,你可以知晓命令的选项,这样你就知道 **ls -la** 展示一个详细的列表,其中也列出了隐藏文件, 并且在键入一个文件或目录的名字的一部分后, 可以使用 Tab 键来自动补全.
|
|
||||||
|
|
||||||
### Tmux: 针对 shell 的窗口管理器 ###
|
|
||||||
|
|
||||||
在文本模式的环境中使用一个窗口管理器 – 这听起来有点不可思议, 是吧? 然而,你应该记得当 Web 浏览器第一次实现分页浏览的时候吧? 在当时, 这是在可用性上的一个重大进步,它减少了桌面任务栏的杂乱无章和繁多的窗口列表. 对于你的浏览器来说,你只需要一个按钮便可以在浏览器中切换到你打开的每个单独网站, 而不是针对每个网站都有一个任务栏或导航图标. 这个功能非常有意义.
|
|
||||||
|
|
||||||
若有时你同时运行着几个虚拟终端,你便会遇到相似的情况; 在这些终端之间跳转,或每次在任务栏或窗口列表中找到你所需要的那一个终端,都可能会让你觉得麻烦. 拥有一个文本模式的窗口管理器不仅可以让你像在同一个终端窗口中运行多个 shell 会话,而且你甚至还可以将这些窗口排列在一起.
|
|
||||||
|
|
||||||
另外,这样还有另一个好处:可以将这些窗口进行分离和重新连接.想要看看这是如何运行的最好方式是自己尝试一下. 在一个终端窗口中,输入 **screen** (在大多数发行版本中,它被默认安装了或者可以在软件包仓库中找到). 某些欢迎的文字将会出现 – 只需敲击 Enter 键这些文字就会消失. 现在运行一个交互式的文本模式的程序,例如 **nano**, 并关闭这个终端窗口.
|
|
||||||
|
|
||||||
在一个正常的 shell 对话中, 关闭窗口将会终止所有在该终端中运行的进程 – 所以刚才的 Nano 编辑对话也就被终止了, 但对于 screen 来说,并不是这样的. 打开一个新的终端并输入如下命令:
|
|
||||||
|
|
||||||
screen -r
|
|
||||||
|
|
||||||
瞧, 你刚开打开的 Nano 会话又回来了!
|
|
||||||
|
|
||||||
当刚才你运行 **screen** 时, 它会创建了一个新的独立的 shell 会话, 它不与某个特定的终端窗口绑定在一起,所以可以在后面被分离并重新连接( 即 **-r** 选项).
|
|
||||||
|
|
||||||
当你正使用 SSH 去连接另一台机器并做着某些工作, 但并不想因为一个单独的连接而毁掉你的所有进程时,这个方法尤其有用.假如你在一个 **screen** 会话中做着某些工作,并且你的连接突然中断了(或者你的笔记本没电了,又或者你的电脑报废了),你只需重新连接一个新的电脑或给电脑充电或重新买一台电脑,接着运行 **screen -r** 来重新连接到远程的电脑,并在刚才掉线的地方接着开始.
|
|
||||||
|
|
||||||
现在,我们都一直在讨论 GNU 的 **screen**,但这个小节的标题提到的是 tmux. 实质上, **tmux** (terminal multiplexer) 就像是 **screen** 的一个进阶版本,带有许多有用的额外功能,所以现在我们开始关注 tmux. 某些发行版本默认包含了 **tmux**; 在其他的发行版本上,通常只需要一个 **apt-get, yum install** 或 **pacman -S** 命令便可以安装它.
|
|
||||||
|
|
||||||
一旦你安装了它过后,键入 **tmux** 来启动它.接着你将注意到,在终端窗口的底部有一条绿色的信息栏,它非常像传统的窗口管理器中的任务栏: 上面显示着一个运行着的程序的列表,机器的主机名,当前时间和日期. 现在运行一个程序,又以 Nano 为例, 敲击 Ctrl+B 后接着按 C 键, 这将在 tmux 会话中创建一个新的窗口,你便可以在终端的底部的任务栏中看到如下的信息:
|
|
||||||
|
|
||||||
0:nano- 1:bash*
|
|
||||||
|
|
||||||
每一个窗口都有一个数字,当前呈现的程序被一个星号所标记. Ctrl+B 是与 tmux 交互的标准方式, 所以若你敲击这个按键组合并带上一个窗口序号, 那么就会切换到对应的那个窗口.你也可以使用 Ctrl+B 再加上 N 或 P 来分别切换到下一个或上一个窗口 – 或者使用 Ctrl+B 加上 L 来在最近使用的两个窗口之间来进行切换(有点类似于桌面中的经典的 Alt+Tab 组合键的效果). 若需要知道窗口列表,使用 Ctrl+B 再加上 W.
|
|
||||||
|
|
||||||
目前为止,一切都还好:现在你可以在一个单独的终端窗口中运行多个程序,避免混乱(尤其是当你经常与同一个远程主机保持多个 SSH 连接时.). 当想同时看两个程序又该怎么办呢?
|
|
||||||
|
|
||||||
针对这种情况, 可以使用 tmux 中的窗格. 敲击 Ctrl+B 再加上 % , 则当前窗口将分为两个部分,一个在左一个在右.你可以使用 Ctrl+B 再加上 O 来在这两个部分之间切换. 这尤其在你想同时看两个东西时非常实用, – 例如一个窗格看指导手册,另一个窗格里用编辑器看一个配置文件.
|
|
||||||
|
|
||||||
有时,你想对一个单独的窗格进行缩放,而这需要一定的技巧. 首先你需要敲击 Ctrl+B 再加上一个 :(分号),这将使得位于底部的 tmux 栏变为深橙色. 现在,你进入了命令模式,在这里你可以输入命令来操作 tmux. 输入 **resize-pane -R** 来使当前窗格向右移动一个字符的间距, 或使用 **-L** 来向左移动. 对于一个简单的操作,这些命令似乎有些长,但请注意,在 tmux 的命令模式(以前面提到的一个分号开始的模式)下,可以使用 Tab 键来补全命令. 另外需要提及的是, **tmux** 同样也有一个命令历史记录,所以若你想重复刚才的缩放操作,可以先敲击 Ctrl+B 再跟上一个分号并使用向上的箭头来取回刚才输入的命令.
|
|
||||||
|
|
||||||
最后,让我们看一下分离和重新连接 - 即我们刚才介绍的 screen 的特色功能. 在 tmux 中,敲击 Ctrl+B 再加上 D 来从当前的终端窗口中分离当前的 tmux 会话, 这使得这个会话的一切工作都在后台中运行.使用 **tmux a** 可以再重新连接到刚才的会话. 但若你同时有多个 tmux 会话在运行时,又该怎么办呢? 我们可以使用下面的命令来列出它们:
|
|
||||||
|
|
||||||
tmux ls
|
|
||||||
|
|
||||||
这个命令将为每个会话分配一个序号; 假如你想重新连接到会话 1, 可以使用 `tmux a -t 1`. tmux 是可以高度定制的,你可以自定义按键绑定并更改配色方案, 所以一旦你适应了它的主要功能,请钻研指导手册以了解更多的内容.
|
|
||||||
|
|
||||||
tmux: 一个针对 shell 的窗口管理器
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
上图中, tmux 开启了两个窗格: 左边是 Vim 正在编辑一个配置文件,而右边则展示着指导手册页.
|
|
||||||
|
|
||||||
> ### Zsh: 另一个 shell ###
|
|
||||||
>
|
|
||||||
> 选择是好的,但标准同样重要. 你要知道几乎每个主流的 Linux 发行版本都默认使用 Bash shell – 尽管还存在其他的 shell. Bash 为你提供了一个 shell 能够给你提供的几乎任何功能,包括命令历史记录,文件名补全和许多脚本编程的能力.它成熟,可靠并文档丰富 – 但它不是你唯一的选择.
|
|
||||||
>
|
|
||||||
> 许多高级用户热衷于 Zsh, 即 Z shell. 这是 Bash 的一个替代品并提供了 Bash 的几乎所有功能,令外还提供了一些额外的功能. 例如, 在 Zsh 中,你输入 **ls** - 并敲击 Tab 键可以得到 **ls** 可用的各种不同选项的一个大致描述. 而不需要再打开 man page 了!
|
|
||||||
>
|
|
||||||
> Zsh 还支持其他强大的自动补全功能: 例如,输入 **cd /u/lo/bi** 再敲击 Tab 键, 则完整的路径名 **/usr/local/bin** 就会出现(这里假设没有其他的路径包含 **u**, **lo** 和 **bi** 等字符.). 或者只输入 **cd** 再跟上 Tab 键,则你将看到着色后的路径名的列表 – 这比 Bash 给出的简单的结果好看得多.
|
|
||||||
>
|
|
||||||
> Zsh 在大多数的主要发行版本上都可以得到; 安装它后并输入 **zsh** 便可启动它. 要将你的默认 shell 从 Bash 改为 Zsh, 可以使用 **chsh** 命令. 若需了解更多的信息,请访问 [www.zsh.org][2].
|
|
||||||
|
|
||||||
### "未来" 的终端 ###
|
|
||||||
|
|
||||||
你或许会好奇为什么包含你的命令行提示符的应用被叫做终端. 这需要追溯到 Unix 的早期, 那时人们一般工作在一个多用户的机器上,这个巨大的电脑主机将占据一座建筑中的一个房间, 人们在某些线路的配合下,使用屏幕和键盘来连接到这个主机, 这些终端机通常被称为 "哑终端", 因为它们不能靠自己做任何重要的执行任务 – 它们只展示通过线路从主机传来的信息,并输送回从键盘的敲击中得到的输入信息.
|
|
||||||
|
|
||||||
今天,几乎所有的我们在自己的机器上执行实际的操作,所以我们的电脑不是传统意义下的终端, 这就是为什么诸如 **XTerm**, Gnome Terminal, Konsole 等程序被称为 "终端模拟器" 的原因 – 他们提供了同昔日的物理终端一样的功能.事实上,在许多方面它们并没有改变多少.诚然,现在我们有了反锯齿字体,更好的颜色和点击网址的能力,但总的来说,几十年来我们一直以同样的方式在工作.
|
|
||||||
|
|
||||||
所以某些程序员正尝试改变这个状况. **Terminology** ([http://tinyurl.com/osopjv9][3]), 它来自于超级时髦的 Enlightenment 窗口管理器背后的团队,旨在将终端引入 21 世纪,例如带有在线媒体显示功能.你可以在一个充满图片的目录里输入 **ls** 命令,便可以看到它们的缩略图,或甚至可以直接在你的终端里播放视频. 这使得一个终端有点类似于一个文件管理器,意味着你可以快速地检查媒体文件的内容而不必用另一个应用来打开它们.
|
|
||||||
|
|
||||||
接着还有 Xiki ([www.xiki.org][4]),它自身的描述为 "命令的革新".它就像是一个传统的 shell, 一个 GUI 和一个 wiki 之间的过渡; 你可以在任何地方输入命令,并在后面将它们的输出存储为笔记以作为参考,并可以创建非常强大的自定义命令.用几句话是很能描述它的,所以作者们已经创作了一个视频来展示它的潜力是多么的巨大(请看 **Xiki** 网站的截屏视频部分).
|
|
||||||
|
|
||||||
并且 Xiki 绝不是那种在几个月之内就消亡的昙花一现的项目,作者们成功地进行了一次 Kickstarter 众筹,在七月底已募集到超过 $84,000. 是的,你没有看错 – $84K 来支持一个终端模拟器.这可能是最不寻常的集资活动,因为某些疯狂的家伙已经决定开始创办它们自己的 Linux 杂志 ......
|
|
||||||
|
|
||||||
### 下一代终端 ###
|
|
||||||
|
|
||||||
许多命令行和基于文本的程序在功能上与它们的 GUI 程序是相同的,并且常常更加快速和高效. 我们的推荐有:
|
|
||||||
**Irssi** (IRC 客户端); **Mutt** (mail 客户端); **rTorrent** (BitTorrent); **Ranger** (文件管理器); **htop** (进程监视器). 若给定在终端的限制下来进行 Web 浏览, Elinks 确实做的很好,并且对于阅读那些以文字为主的网站例如 Wikipedia 来说,它非常实用.
|
|
||||||
|
|
||||||
> ### 微调配色方案 ###
|
|
||||||
>
|
|
||||||
> 在 Linux Voice 中,我们并不迷恋养眼的东西,但当你每天花费几个小时盯着屏幕看东西时,我们确实认识到美学的重要性.我们中的许多人都喜欢调整我们的桌面和窗口管理器来达到完美的效果,调整阴影效果,摆弄不同的配色方案,直到我们 100% 的满意.(然后出于习惯,摆弄更多的东西.)
|
|
||||||
>
|
|
||||||
> 但我们倾向于忽视终端窗口,它理应也获得我们的喜爱, 并且在 [http://ciembor.github.io/4bit][5] 你将看到一个极其棒的配色方案设计器,对于所有受欢迎的终端模拟器(**XTerm, Gnome Terminal, Konsole and Xfce4 Terminal are among the apps supported.**),它可以色设定.移动滑动条直到你看到配色方案 norvana, 然后点击位于该页面右上角的 `得到方案` 按钮.
|
|
||||||
>
|
|
||||||
> 相似的,假如你在一个文本编辑器,如 Vim 或 Emacs 上花费很多的时间,使用一个精心设计的调色板也是非常值得的. **Solarized at** [http://ethanschoonover.com/solarized][6] 是一个卓越的方案,它不仅漂亮,而且因追求最大的可用性而设计,在其背后有着大量的研究和测试.
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: http://www.linuxvoice.com/linux-101-power-up-your-shell-8/
|
|
||||||
|
|
||||||
作者:[Ben Everard][a]
|
|
||||||
译者:[FSSlc](https://github.com/FSSlc)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:http://www.linuxvoice.com/author/ben_everard/
|
|
||||||
[1]:http://tinyurl.com/3gvz4ec
|
|
||||||
[2]:http://www.zsh.org/
|
|
||||||
[3]:http://tinyurl.com/osopjv9
|
|
||||||
[4]:http://www.xiki.org/
|
|
||||||
[5]:http://ciembor.github.io/4bit
|
|
||||||
[6]:http://ethanschoonover.com/solarized
|
|
||||||
@ -0,0 +1,51 @@
|
|||||||
|
如何修复:There is no command installed for 7-zip archive files
|
||||||
|
================================================================================
|
||||||
|
### 问题 ###
|
||||||
|
|
||||||
|
我试着在Ubuntu中安装Emerald图标主题,而这个主题被打包成了.7z归档包。和以往一样,我试着通过在GUI中右击并选择“提取到这里”来将它解压缩。但是Ubuntu 15.04却并没有解压文件,取而代之的,却是丢给了我一个下面这样的错误信息:
|
||||||
|
|
||||||
|
> Could not open this file
|
||||||
|
> 无法打开该文件
|
||||||
|
>
|
||||||
|
> There is no command installed for 7-zip archive files. Do you want to search for a command to open this file?
|
||||||
|
> 没有安装用于7-zip归档文件的命令。你是否想要搜索命令来打开该文件?
|
||||||
|
|
||||||
|
错误信息看上去是这样的:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 原因 ###
|
||||||
|
|
||||||
|
发生该错误的原因从错误信息本身来看就十分明了。7Z,称之为[7-zip][1]更好,该程序没有安装,因此7Z压缩文件就无法解压缩。这也暗示着Ubuntu默认不支持7-zip文件。
|
||||||
|
|
||||||
|
### 解决方案:在Ubuntu中安装 7zip ###
|
||||||
|
|
||||||
|
要解决该问题也十分简单,在Ubuntu中安装7-Zip包即可。现在,你也许想知道如何在Ubuntu中安装 7Zip吧?好吧,在前面的错误对话框中,如果你右击“Search Command”搜索命令,它会查找可用的 p7zip 包。只要点击“Install”安装,如下图:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 可选方案:在终端中安装 7Zip ###
|
||||||
|
|
||||||
|
如果偏好使用终端,你可以使用以下命令在终端中安装 7zip:
|
||||||
|
|
||||||
|
sudo apt-get install p7zip-full
|
||||||
|
|
||||||
|
注意:在Ubuntu中,你会发现有3个7zip包:p7zip,p7zip-full 和 p7zip-rar。p7zip和p7zip-full的区别在于,p7zip是一个更轻量化的版本,仅仅提供了对 .7z 和 .7za 文件的支持,而完整版则提供了对更多(用于音频文件等的) 7z 压缩算法的支持。对于 p7zip-rar,它除了对 7z 文件的支持外,也提供了对 .rar 文件的支持。
|
||||||
|
|
||||||
|
事实上,相同的错误也会发生在[Ubuntu中的RAR文件][2]身上。解决方案也一样,安装正确的程序即可。
|
||||||
|
|
||||||
|
希望这篇快文帮助你解决了**Ubuntu 14.04中如何打开 7zip**的谜团。如有任何问题或建议,我们将无任欢迎。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://itsfoss.com/fix-there-is-no-command-installed-for-7-zip-archive-files/
|
||||||
|
|
||||||
|
作者:[Abhishek][a]
|
||||||
|
译者:[GOLinux](https://github.com/GOLinux)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://itsfoss.com/author/abhishek/
|
||||||
|
[1]:http://www.7-zip.org/
|
||||||
|
[2]:http://itsfoss.com/fix-there-is-no-command-installed-for-rar-archive-files/
|
||||||
@ -0,0 +1,190 @@
|
|||||||
|
|
||||||
|
如何在 Ubuntu/CentOS7.1/Fedora22 上安装 Plex Media Server ?
|
||||||
|
================================================================================
|
||||||
|
在本文中我们将会向你展示如何容易地在主流的最新发布的Linux发行版上安装Plex Home Media Server。在Plex安装成功后你将可以使用你的集中式家庭媒体播放系统,该系统能让多个Plex播放器App共享它的媒体资源,并且该系统允许你设置你的环境,通过增加你的设备以及设置一个可以一起使用Plex的用户组。让我们首先在Ubuntu15.04上开始Plex的安装。
|
||||||
|
|
||||||
|
### 基本的系统资源 ###
|
||||||
|
|
||||||
|
系统资源主要取决于你打算用来连接服务的设备类型和数量, 所以根据我们的需求我们将会在一个单独的服务器上使用以下系统资源。
|
||||||
|
|
||||||
|
注:表格
|
||||||
|
<table width="666" style="height: 181px;">
|
||||||
|
<tbody>
|
||||||
|
<tr>
|
||||||
|
<td width="670" colspan="2"><b>Plex Home Media Server</b></td>
|
||||||
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td width="236"><b>Base Operating System</b></td>
|
||||||
|
<td width="425">Ubuntu 15.04 / CentOS 7.1 / Fedora 22 Work Station</td>
|
||||||
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td width="236"><b>Plex Media Server</b></td>
|
||||||
|
<td width="425">Version 0.9.12.3.1173-937aac3</td>
|
||||||
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td width="236"><b>RAM and CPU</b></td>
|
||||||
|
<td width="425">1 GB , 2.0 GHZ</td>
|
||||||
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td width="236"><b>Hard Disk</b></td>
|
||||||
|
<td width="425">30 GB</td>
|
||||||
|
</tr>
|
||||||
|
</tbody>
|
||||||
|
</table>
|
||||||
|
|
||||||
|
### 在Ubuntu 15.04上安装Plex Media Server 0.9.12.3 ###
|
||||||
|
|
||||||
|
我们现在准备开始在Ubuntu上安装Plex Media Server,让我们从下面的步骤开始来让Plex做好准备。
|
||||||
|
|
||||||
|
#### 步骤 1: 系统更新 ####
|
||||||
|
|
||||||
|
用root权限登陆你的服务器。确保你的系统是最新的,如果不是就使用下面的命令。
|
||||||
|
|
||||||
|
root@ubuntu-15:~#apt-get update
|
||||||
|
|
||||||
|
#### 步骤 2: 下载最新的Plex Media Server包 ####
|
||||||
|
|
||||||
|
创建一个新目录,用wget命令从Plex官网下载为Ubuntu提供的.deb包并放入该目录中。
|
||||||
|
|
||||||
|
root@ubuntu-15:~# cd /plex/
|
||||||
|
root@ubuntu-15:/plex#
|
||||||
|
root@ubuntu-15:/plex# wget https://downloads.plex.tv/plex-media-server/0.9.12.3.1173-937aac3/plexmediaserver_0.9.12.3.1173-937aac3_amd64.deb
|
||||||
|
|
||||||
|
#### 步骤 3: 安装Plex Media Server的Debian包 ####
|
||||||
|
|
||||||
|
现在在相同的目录下执行下面的命令来开始debian包的安装, 然后检查plexmediaserver(译者注: 原文plekmediaserver, 明显笔误)的状态。
|
||||||
|
|
||||||
|
root@ubuntu-15:/plex# dpkg -i plexmediaserver_0.9.12.3.1173-937aac3_amd64.deb
|
||||||
|
|
||||||
|
----------
|
||||||
|
|
||||||
|
root@ubuntu-15:~# service plexmediaserver status
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 在Ubuntu 15.04上设置Plex Home Media Web应用 ###
|
||||||
|
|
||||||
|
让我们在你的本地网络主机中打开web浏览器, 并用你的本地主机IP以及端口32400来打开Web界面并完成以下步骤来配置Plex。
|
||||||
|
|
||||||
|
http://172.25.10.179:32400/web
|
||||||
|
http://localhost:32400/web
|
||||||
|
|
||||||
|
#### 步骤 1: 登陆前先注册 ####
|
||||||
|
|
||||||
|
在你访问到Plex Media Server的Web界面之后(译者注: 原文是Plesk, 应该是笔误), 确保注册并填上你的用户名(译者注: 原文username email ID感觉怪怪:))和密码来登陆。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
#### 输入你的PIN码来保护你的Plex Home Media用户(译者注: 原文Plex Media Home, 个人觉得专业称谓应该保持一致) ####
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
现在你已经成功的在Plex Home Media下配置你的用户。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 在设备上而不是本地服务器上打开Plex Web应用 ###
|
||||||
|
|
||||||
|
正如我们在Plex Media主页看到的表明"你没有权限访问这个服务"。 这是因为我们跟服务器计算机不在同个网络。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
现在我们需要解决这个权限问题以便我们通过设备访问服务器而不是通过托管服务器(Plex服务器), 通过完成下面的步骤。
|
||||||
|
|
||||||
|
### 设置SSH隧道使Windows系统访问到Linux服务器 ###
|
||||||
|
|
||||||
|
首先我们需要建立一条SSH隧道以便我们访问远程服务器资源,就好像资源在本地一样。 这仅仅是必要的初始设置。
|
||||||
|
|
||||||
|
如果你正在使用Windows作为你的本地系统,Linux作为服务器,那么我们可以参照下图通过Putty来设置SSH隧道。
|
||||||
|
(译者注: 首先要在Putty的Session中用Plex服务器IP配置一个SSH的会话,才能进行下面的隧道转发规则配置。
|
||||||
|
然后点击“Open”,输入远端服务器用户名密码, 来保持SSH会话连接。)
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
**一旦你完成SSH隧道设置:**
|
||||||
|
|
||||||
|
打开你的Web浏览器窗口并在地址栏输入下面的URL。
|
||||||
|
|
||||||
|
http://localhost:8888/web
|
||||||
|
|
||||||
|
浏览器将会连接到Plex服务器并且加载与服务器本地功能一致的Plex Web应用。 同意服务条款并开始。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
现在一个功能齐全的Plex Home Media Server已经准备好添加新的媒体库、频道、播放列表等资源。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 在CentOS 7.1上安装Plex Media Server 0.9.12.3 ###
|
||||||
|
|
||||||
|
我们将会按照上述在Ubuntu15.04上安装Plex Home Media Server的步骤来将Plex安装到CentOS 7.1上。
|
||||||
|
|
||||||
|
让我们从安装Plex Media Server开始。
|
||||||
|
|
||||||
|
#### 步骤1: 安装Plex Media Server ####
|
||||||
|
|
||||||
|
为了在CentOS7.1上安装Plex Media Server,我们需要从Plex官网下载rpm安装包。 因此我们使用wget命令来将rpm包下载到一个新的目录下。
|
||||||
|
|
||||||
|
[root@linux-tutorials ~]# cd /plex
|
||||||
|
[root@linux-tutorials plex]# wget https://downloads.plex.tv/plex-media-server/0.9.12.3.1173-937aac3/plexmediaserver-0.9.12.3.1173-937aac3.x86_64.rpm
|
||||||
|
|
||||||
|
#### 步骤2: 安装RPM包 ####
|
||||||
|
|
||||||
|
在完成安装包完整的下载之后, 我们将会使用rpm命令在相同的目录下安装这个rpm包。
|
||||||
|
|
||||||
|
[root@linux-tutorials plex]# ls
|
||||||
|
plexmediaserver-0.9.12.3.1173-937aac3.x86_64.rpm
|
||||||
|
[root@linux-tutorials plex]# rpm -i plexmediaserver-0.9.12.3.1173-937aac3.x86_64.rpm
|
||||||
|
|
||||||
|
#### 步骤3: 启动Plexmediaservice ####
|
||||||
|
|
||||||
|
我们已经成功地安装Plex Media Server, 现在我们只需要重启它的服务然后让它永久地启用。
|
||||||
|
|
||||||
|
[root@linux-tutorials plex]# systemctl start plexmediaserver.service
|
||||||
|
[root@linux-tutorials plex]# systemctl enable plexmediaserver.service
|
||||||
|
[root@linux-tutorials plex]# systemctl status plexmediaserver.service
|
||||||
|
|
||||||
|
### 在CentOS-7.1上设置Plex Home Media Web应用 ###
|
||||||
|
|
||||||
|
现在我们只需要重复在Ubuntu上设置Plex Web应用的所有步骤就可以了。 让我们在Web浏览器上打开一个新窗口并用localhost或者Plex服务器的IP(译者注: 原文为or your Plex server, 明显的笔误)来访问Plex Home Media Web应用(译者注:称谓一致)。
|
||||||
|
|
||||||
|
http://172.20.3.174:32400/web
|
||||||
|
http://localhost:32400/web
|
||||||
|
|
||||||
|
为了获取服务的完整权限你需要重复创建SSH隧道的步骤。 在你用新账户注册后我们将可以访问到服务的所有特性,并且可以添加新用户、添加新的媒体库以及根据我们的需求来设置它。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 在Fedora 22工作站上安装Plex Media Server 0.9.12.3 ###
|
||||||
|
|
||||||
|
基本的下载和安装Plex Media Server步骤跟在CentOS 7.1上安装的步骤一致。我们只需要下载对应的rpm包然后用rpm命令来安装它。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 在Fedora 22工作站上配置Plex Home Media Web应用 ###
|
||||||
|
|
||||||
|
我们在(与Plex服务器)相同的主机上配置Plex Media Server,因此不需要设置SSH隧道。只要在你的Fedora 22工作站上用Plex Home Media Server的默认端口号32400打开Web浏览器并同意Plex的服务条款即可。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
**欢迎来到Fedora 22工作站上的Plex Home Media Server**
|
||||||
|
|
||||||
|
让我们用你的Plex账户登陆,并且开始将你喜欢的电影频道添加到媒体库、创建你的播放列表、添加你的图片以及享用更多其他的特性。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 总结 ###
|
||||||
|
|
||||||
|
我们已经成功完成Plex Media Server在主流Linux发行版上安装和配置。Plex Home Media Server永远都是媒体管理的最佳选择。 它在跨平台上的设置是如此的简单,就像我们在Ubuntu,CentOS以及Fedora上的设置一样。它简化了你组织媒体内容的工作,并将媒体内容“流”向其他计算机以及设备以便你跟你的朋友分享媒体内容。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://linoxide.com/tools/install-plex-media-server-ubuntu-centos-7-1-fedora-22/
|
||||||
|
|
||||||
|
作者:[Kashif Siddique][a]
|
||||||
|
译者:[dingdongnigetou](https://github.com/dingdongnigetou)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://linoxide.com/author/kashifs/
|
||||||
Loading…
Reference in New Issue
Block a user