mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-25 00:50:15 +08:00
commit
2586a20f2a
@ -0,0 +1,129 @@
|
||||
Ubunsys:面向 Ubuntu 资深用户的一个高级系统配置工具
|
||||
======
|
||||
|
||||

|
||||
|
||||
|
||||
**Ubunsys** 是一个面向 Ubuntu 及其衍生版的基于 Qt 的高级系统工具。高级用户可以使用命令行轻松完成大多数配置。不过为了以防万一某天,你突然不想用命令行了,就可以用 Ubnusys 这个程序来配置你的系统或其衍生系统,如 Linux Mint、Elementary OS 等。Ubunsys 可用来修改系统配置,安装、删除、更新包和旧内核,启用或禁用 `sudo` 权限,安装主线内核,更新软件安装源,清理垃圾文件,将你的 Ubuntu 系统升级到最新版本等等。以上提到的所有功能都可以通过鼠标点击完成。你不需要再依赖于命令行模式,下面是你能用 Ubunsys 做到的事:
|
||||
|
||||
* 安装、删除、更新包
|
||||
* 更新和升级软件源
|
||||
* 安装主线内核
|
||||
* 删除旧的和不再使用的内核
|
||||
* 系统整体更新
|
||||
* 将系统升级到下一个可用的版本
|
||||
* 将系统升级到最新的开发版本
|
||||
* 清理系统垃圾文件
|
||||
* 在不输入密码的情况下启用或者禁用 `sudo` 权限
|
||||
* 当你在终端输入密码时使 `sudo` 密码可见
|
||||
* 启用或禁用系统休眠
|
||||
* 启用或禁用防火墙
|
||||
* 打开、备份和导入 `sources.list.d` 和 `sudoers` 文件
|
||||
* 显示或者隐藏启动项
|
||||
* 启用或禁用登录音效
|
||||
* 配置双启动
|
||||
* 启用或禁用锁屏
|
||||
* 智能系统更新
|
||||
* 使用脚本管理器更新/一次性执行脚本
|
||||
* 从 `git` 执行常规用户安装脚本
|
||||
* 检查系统完整性和缺失的 GPG 密钥
|
||||
* 修复网络
|
||||
* 修复已破损的包
|
||||
* 还有更多功能在开发中
|
||||
|
||||
**重要提示:** Ubunsys 不适用于 Ubuntu 新手。它很危险并且仍然不是稳定版。它可能会使你的系统崩溃。如果你刚接触 Ubuntu 不久,不要使用。但如果你真的很好奇这个应用能做什么,仔细浏览每一个选项,并确定自己能承担风险。在使用这一应用之前记着备份你自己的重要数据。
|
||||
|
||||
### 安装 Ubunsys
|
||||
|
||||
Ubunsys 开发者制作了一个 PPA 来简化安装过程,Ubunsys 现在可以在 Ubuntu 16.04 LTS、 Ubuntu 17.04 64 位版本上使用。
|
||||
|
||||
逐条执行下面的命令,将 Ubunsys 的 PPA 添加进去,并安装它。
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:adgellida/ubunsys
|
||||
sudo apt-get update
|
||||
sudo apt-get install ubunsys
|
||||
```
|
||||
|
||||
如果 PPA 无法使用,你可以在[发布页面][1]根据你自己当前系统,选择正确的安装包,直接下载并安装 Ubunsys。
|
||||
|
||||
### 用途
|
||||
|
||||
一旦安装完成,从菜单栏启动 Ubunsys。下图是 Ubunsys 主界面。
|
||||
|
||||
![][3]
|
||||
|
||||
你可以看到,Ubunsys 有四个主要部分,分别是 Packages、Tweaks、System 和 Repair。在每一个标签项下面都有一个或多个子标签项以对应不同的操作。
|
||||
|
||||
**Packages**
|
||||
|
||||
这一部分允许你安装、删除和更新包。
|
||||
|
||||
![][4]
|
||||
|
||||
**Tweaks**
|
||||
|
||||
在这一部分,我们可以对系统进行多种调整,例如:
|
||||
|
||||
* 打开、备份和导入 `sources.list.d` 和 `sudoers` 文件;
|
||||
* 配置双启动;
|
||||
* 启用或禁用登录音效、防火墙、锁屏、系统休眠、`sudo` 权限(在不需要密码的情况下)同时你还可以针对某一用户启用或禁用 `sudo` 权限(在不需要密码的情况下);
|
||||
* 在终端中输入密码时可见(禁用星号)。
|
||||
|
||||
![][5]
|
||||
|
||||
**System**
|
||||
|
||||
这一部分被进一步分成 3 个部分,每个都是针对某一特定用户类型。
|
||||
|
||||
**Normal user** 这一标签下的选项可以:
|
||||
|
||||
* 更新、升级包和软件源
|
||||
* 清理系统
|
||||
* 执行常规用户安装脚本
|
||||
|
||||
**Advanced user** 这一标签下的选项可以:
|
||||
|
||||
* 清理旧的/无用的内核
|
||||
* 安装主线内核
|
||||
* 智能包更新
|
||||
* 升级系统
|
||||
|
||||
**Developer** 这一部分可以将系统升级到最新的开发版本。
|
||||
|
||||
![][6]
|
||||
|
||||
**Repair**
|
||||
|
||||
这是 Ubunsys 的第四个也是最后一个部分。正如名字所示,这一部分能让我们修复我们的系统、网络、缺失的 GPG 密钥,和已经缺失的包。
|
||||
|
||||
![][7]
|
||||
|
||||
正如你所见,Ubunsys 可以在几次点击下就能完成诸如系统配置、系统维护和软件维护之类的任务。你不需要一直依赖于终端。Ubunsys 能帮你完成任何高级任务。再次声明,我警告你,这个应用不适合新手,而且它并不稳定。所以当你使用的时候,能会出现 bug 或者系统崩溃。在仔细研究过每一个选项的影响之后再使用它。
|
||||
|
||||
谢谢阅读!
|
||||
|
||||
### 参考资源
|
||||
|
||||
- [Ubunsys GitHub Repository][8]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/ubunsys-advanced-system-configuration-utility-ubuntu-power-users/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[wenwensnow](https://github.com/wenwensnow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://github.com/adgellida/ubunsys/releases
|
||||
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-1.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-2.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-5.png
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-9.png
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-11.png
|
||||
[8]:https://github.com/adgellida/ubunsys
|
||||
@ -0,0 +1,132 @@
|
||||
IT 自动化的下一步是什么: 6 大趋势
|
||||
======
|
||||
|
||||
> 自动化专家分享了一点对 [自动化][6]不远的将来的看法。请将这些保留在你的视线之内。
|
||||
|
||||

|
||||
|
||||
我们最近讨论了 [推动 IT 自动化的因素][1],可以看到[当前趋势][2]正在增长,以及那些给刚开始使用自动化部分流程的组织的 [有用的技巧][3] 。
|
||||
|
||||
噢,我们也分享了如何在贵公司[进行自动化的案例][4]及 [长期成功的关键][5]的专家建议。
|
||||
|
||||
现在,只有一个问题:自动化的下一步是什么? 我们邀请一系列专家分享一下 [自动化][6]不远的将来的看法。 以下是他们建议 IT 领域领导需密切关注的六大趋势。
|
||||
|
||||
### 1、 机器学习的成熟
|
||||
|
||||
对于关于 [机器学习][7](与“自我学习系统”相似的定义)的讨论,对于绝大多数组织的项目来说,实际执行起来它仍然为时过早。但预计这将发生变化,机器学习将在下一次 IT 自动化浪潮中将扮演着至关重要的角色。
|
||||
|
||||
[Advanced Systems Concepts, Inc.][8] 公司的工程总监 Mehul Amin 指出机器学习是 IT 自动化下一个关键增长领域之一。
|
||||
|
||||
“随着数据化的发展,自动化软件理应可以自我决策,否则这就是开发人员的责任了”,Amin 说。 “例如,开发者构建了需要执行的内容,但通过使用来自系统内部分析的软件,可以确定执行该流程的最佳系统。”
|
||||
|
||||
假设将这个系统延伸到其他地方中。Amin 指出,机器学习可以使自动化系统在必要的时候提供额外的资源,以需要满足时间线或 SLA,同样在不需要资源以及其他的可能性的时候退出。
|
||||
|
||||
显然不只有 Amin 一个人这样认为。
|
||||
|
||||
“IT 自动化正在走向自我学习的方向” ,[Sungard Availability Services][9] 公司首席架构师 Kiran Chitturi 表示,“系统将会能测试和监控自己,加强业务流程和软件交付能力。”
|
||||
|
||||
Chitturi 指出自动化测试就是个例子。脚本测试已经被广泛采用,但很快这些自动化测试流程将会更容易学习,更快发展,例如开发出新的代码或将更为广泛地影响生产环境。
|
||||
|
||||
### 2、 人工智能催生的自动化
|
||||
|
||||
上述原则同样适合与相关的(但是独立的) [人工智能][10]的领域。根据对人工智能的定义,机器学习在短时间内可能会对 IT 领域产生巨大的影响(并且我们可能会看到这两个领域的许多重叠的定义和理解)。假定新兴的人工智能技术将也会产生新的自动化机会。
|
||||
|
||||
[SolarWinds][11] 公司技术负责人 Patrick Hubbard 说,“人工智能和机器学习的整合普遍被认为对未来几年的商业成功起至关重要的作用。”
|
||||
|
||||
### 3、 这并不意味着不再需要人力
|
||||
|
||||
让我们试着安慰一下那些不知所措的人:前两种趋势并不一定意味着我们将失去工作。
|
||||
|
||||
这很可能意味着各种角色的改变,以及[全新角色][12]的创造。
|
||||
|
||||
但是在可预见的将来,至少,你不必需要对机器人鞠躬。
|
||||
|
||||
“一台机器只能运行在给定的环境变量中——它不能选择包含新的变量,在今天只有人类可以这样做,” Hubbard 解释说。“但是,对于 IT 专业人员来说,这将需要培养 AI 和自动化技能,如对程序设计、编程、管理人工智能和机器学习功能算法的基本理解,以及用强大的安全状态面对更复杂的网络攻击。”
|
||||
|
||||
Hubbard 分享一些新的工具或功能例子,例如支持人工智能的安全软件或机器学习的应用程序,这些应用程序可以远程发现石油管道中的维护需求。两者都可以提高效益和效果,自然不会代替需要信息安全或管道维护的人员。
|
||||
|
||||
“许多新功能仍需要人工监控,”Hubbard 说。“例如,为了让机器确定一些‘预测’是否可能成为‘规律’,人为的管理是必要的。”
|
||||
|
||||
即使你把机器学习和 AI 先放在一边,看待一般的 IT 自动化,同样原理也是成立的,尤其是在软件开发生命周期中。
|
||||
|
||||
[Juniper Networks][13] 公司自动化首席架构师 Matthew Oswalt ,指出 IT 自动化增长的根本原因是它通过减少操作基础设施所需的人工工作量来创造直接价值。
|
||||
|
||||
> 在代码上,操作工程师可以使用事件驱动的自动化提前定义他们的工作流程,而不是在凌晨 3 点来应对基础设施的问题。
|
||||
|
||||
“它也将操作工作流程作为代码而不再是容易过时的文档或系统知识阶段,”Oswalt 解释说。“操作人员仍然需要在[自动化]工具响应事件方面后发挥积极作用。采用自动化的下一个阶段是建立一个能够跨 IT 频谱识别发生的有趣事件的系统,并以自主方式进行响应。在代码上,操作工程师可以使用事件驱动的自动化提前定义他们的工作流程,而不是在凌晨 3 点来应对基础设施的问题。他们可以依靠这个系统在任何时候以同样的方式作出回应。”
|
||||
|
||||
### 4、 对自动化的焦虑将会减少
|
||||
|
||||
SolarWinds 公司的 Hubbard 指出,“自动化”一词本身就产生大量的不确定性和担忧,不仅仅是在 IT 领域,而且是跨专业领域,他说这种担忧是合理的。但一些随之而来的担忧可能被夸大了,甚至与科技产业本身共存。现实可能实际上是这方面的镇静力:当自动化的实际实施和实践帮助人们认识到这个列表中的第 3 项时,我们将看到第 4 项的出现。
|
||||
|
||||
“今年我们可能会看到对自动化焦虑的减少,更多的组织开始接受人工智能和机器学习作为增加现有人力资源的一种方式,”Hubbard 说。“自动化历史上为更多的工作创造了空间,通过降低成本和时间来完成较小任务,并将劳动力重新集中到无法自动化并需要人力的事情上。人工智能和机器学习也是如此。”
|
||||
|
||||
自动化还将减少令 IT 领导者神经紧张的一些焦虑:安全。正如[红帽][14]公司首席架构师 Matt Smith 最近[指出][15]的那样,自动化将越来越多地帮助 IT 部门降低与维护任务相关的安全风险。
|
||||
|
||||
他的建议是:“首先在维护活动期间记录和自动化 IT 资产之间的交互。通过依靠自动化,您不仅可以消除之前需要大量手动操作和手术技巧的任务,还可以降低人为错误的风险,并展示当您的 IT 组织采纳变更和新工作方法时可能发生的情况。最终,这将迅速减少对应用安全补丁的抵制。而且它还可以帮助您的企业在下一次重大安全事件中摆脱头条新闻。”
|
||||
|
||||
**[ 阅读全文: [12个企业安全坏习惯要打破。][16] ] **
|
||||
|
||||
### 5、 脚本和自动化工具将持续发展
|
||||
|
||||
许多组织看到了增加自动化的第一步,通常以脚本或自动化工具(有时称为配置管理工具)的形式作为“早期”工作。
|
||||
|
||||
但是随着各种自动化技术的使用,对这些工具的观点也在不断发展。
|
||||
|
||||
[DataVision][18] 首席运营官 Mark Abolafia 表示:“数据中心环境中存在很多重复性过程,容易出现人为错误,[Ansible][17] 等技术有助于缓解这些问题。“通过 Ansible ,人们可以为一组操作编写特定的步骤,并输入不同的变量,例如地址等,使过去长时间的过程链实现自动化,而这些过程以前都需要人为触摸和更长的交付时间。”
|
||||
|
||||
**[想了解更多关于 Ansible 这个方面的知识吗?阅读相关文章:[使用 Ansible 时的成功秘诀][19]。 ]**
|
||||
|
||||
另一个因素是:工具本身将继续变得更先进。
|
||||
|
||||
“使用先进的 IT 自动化工具,开发人员将能够在更短的时间内构建和自动化工作流程,减少易出错的编码,” ASCI 公司的 Amin 说。“这些工具包括预先构建的、预先测试过的拖放式集成,API 作业,丰富的变量使用,参考功能和对象修订历史记录。”
|
||||
|
||||
### 6、 自动化开创了新的指标机会
|
||||
|
||||
正如我们在此前所说的那样,IT 自动化不是万能的。它不会修复被破坏的流程,或者以其他方式为您的组织提供全面的灵丹妙药。这也是持续不断的:自动化并不排除衡量性能的必要性。
|
||||
|
||||
**[ 参见我们的相关文章 [DevOps 指标:你在衡量什么重要吗?][20] ]**
|
||||
|
||||
实际上,自动化应该打开了新的机会。
|
||||
|
||||
[Janeiro Digital][21] 公司架构师总裁 Josh Collins 说,“随着越来越多的开发活动 —— 源代码管理、DevOps 管道、工作项目跟踪等转向 API 驱动的平台,将这些原始数据拼接在一起以描绘组织效率提升的机会和图景”。
|
||||
|
||||
Collins 认为这是一种可能的新型“开发组织度量指标”。但不要误认为这意味着机器和算法可以突然预测 IT 所做的一切。
|
||||
|
||||
“无论是衡量个人资源还是整体团队,这些指标都可以很强大 —— 但应该用大量的背景来衡量。”Collins 说,“将这些数据用于高层次趋势并确认定性观察 —— 而不是临床评级你的团队。”
|
||||
|
||||
**想要更多这样知识, IT 领导者?[注册我们的每周电子邮件通讯][22]。**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2018/3/what-s-next-it-automation-6-trends-watch
|
||||
|
||||
作者:[Kevin Casey][a]
|
||||
译者:[MZqk](https://github.com/MZqk)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://enterprisersproject.com/user/kevin-casey
|
||||
[1]:https://enterprisersproject.com/article/2017/12/5-factors-fueling-automation-it-now
|
||||
[2]:https://enterprisersproject.com/article/2017/12/4-trends-watch-it-automation-expands
|
||||
[3]:https://enterprisersproject.com/article/2018/1/getting-started-automation-6-tips
|
||||
[4]:https://enterprisersproject.com/article/2018/1/how-make-case-it-automation
|
||||
[5]:https://enterprisersproject.com/article/2018/1/it-automation-best-practices-7-keys-long-term-success
|
||||
[6]:https://enterprisersproject.com/tags/automation
|
||||
[7]:https://enterprisersproject.com/article/2018/2/how-spot-machine-learning-opportunity
|
||||
[8]:https://www.advsyscon.com/en-us/
|
||||
[9]:https://www.sungardas.com/en/
|
||||
[10]:https://enterprisersproject.com/tags/artificial-intelligence
|
||||
[11]:https://www.solarwinds.com/
|
||||
[12]:https://enterprisersproject.com/article/2017/12/8-emerging-ai-jobs-it-pros
|
||||
[13]:https://www.juniper.net/
|
||||
[14]:https://www.redhat.com/en?intcmp=701f2000000tjyaAAA
|
||||
[15]:https://enterprisersproject.com/article/2018/2/12-bad-enterprise-security-habits-break
|
||||
[16]:https://enterprisersproject.com/article/2018/2/12-bad-enterprise-security-habits-break?sc_cid=70160000000h0aXAAQ
|
||||
[17]:https://opensource.com/tags/ansible
|
||||
[18]:https://datavision.com/
|
||||
[19]:https://opensource.com/article/18/2/tips-success-when-getting-started-ansible?intcmp=701f2000000tjyaAAA
|
||||
[20]:https://enterprisersproject.com/article/2017/7/devops-metrics-are-you-measuring-what-matters?sc_cid=70160000000h0aXAAQ
|
||||
[21]:https://www.janeirodigital.com/
|
||||
[22]:https://enterprisersproject.com/email-newsletter?intcmp=701f2000000tsjPAAQ
|
||||
@ -1,133 +1,106 @@
|
||||
3 个实用的 Python 工具:魔术方法,迭代器和生成器,以及方法魔术
|
||||
日常 Python 编程优雅之道
|
||||
======
|
||||
(to 校正者:magic)
|
||||
|
||||
> 3 个可以使你的 Python 代码更优雅、可读、直观和易于维护的工具。
|
||||
|
||||

|
||||
Python 提供了一组独特的工具和语言特性来帮助你使代码更加优雅,可读和直观。通过为正确的问题选择合适的工具,你的代码将更易于维护。在本文中,我们将研究其中的三个工具:魔术方法,迭代器和生成器,以及方法魔术。
|
||||
|
||||
Python 提供了一组独特的工具和语言特性来使你的代码更加优雅、可读和直观。为正确的问题选择合适的工具,你的代码将更易于维护。在本文中,我们将研究其中的三个工具:魔术方法、迭代器和生成器,以及方法魔术。
|
||||
|
||||
### 魔术方法
|
||||
|
||||
魔术方法可以看作是 Python 的管道。它们被称为“底层”方法,用于某些内置的方法、符号和操作。你可能熟悉的常见魔术方法是 `__init__()`,当我们想要初始化一个类的新实例时,它会被调用。
|
||||
|
||||
你可能已经看过其他常见的魔术方法,如 `__str__` 和 `__repr__`。Python 中有一整套魔术方法,通过实现其中的一些方法,我们可以修改一个对象的行为,甚至使其行为类似于内置数据类型,例如数字,列表或字典。
|
||||
你可能已经看过其他常见的魔术方法,如 `__str__` 和 `__repr__`。Python 中有一整套魔术方法,通过实现其中的一些方法,我们可以修改一个对象的行为,甚至使其行为类似于内置数据类型,例如数字、列表或字典。
|
||||
|
||||
让我们创建一个 `Money` 类来示例:
|
||||
|
||||
```
|
||||
class Money:
|
||||
|
||||
currency_rates = {
|
||||
currency_rates = {
|
||||
'$': 1,
|
||||
'€': 0.88,
|
||||
}
|
||||
|
||||
'$': 1,
|
||||
def __init__(self, symbol, amount):
|
||||
self.symbol = symbol
|
||||
self.amount = amount
|
||||
|
||||
'€': 0.88,
|
||||
def __repr__(self):
|
||||
return '%s%.2f' % (self.symbol, self.amount)
|
||||
|
||||
}
|
||||
|
||||
def __init__(self, symbol, amount):
|
||||
|
||||
self.symbol = symbol
|
||||
|
||||
self.amount = amount
|
||||
|
||||
def __repr__(self):
|
||||
|
||||
return '%s%.2f' % (self.symbol, self.amount)
|
||||
|
||||
def convert(self, other):
|
||||
|
||||
""" Convert other amount to our currency """
|
||||
|
||||
new_amount = (
|
||||
|
||||
other.amount / self.currency_rates[other.symbol]
|
||||
|
||||
* self.currency_rates[self.symbol])
|
||||
|
||||
return Money(self.symbol, new_amount)
|
||||
def convert(self, other):
|
||||
""" Convert other amount to our currency """
|
||||
new_amount = (
|
||||
other.amount / self.currency_rates[other.symbol]
|
||||
* self.currency_rates[self.symbol])
|
||||
|
||||
return Money(self.symbol, new_amount)
|
||||
```
|
||||
|
||||
该类定义为给定的符号和汇率定义了一个货币汇率,指定了一个初始化器(也称为构造函数),并实现 `__repr__`,因此当我们打印这个类时,我们会看到一个友好的表示,例如 `$2.00` ,一个带有货币符号和金额的 `Money('$', 2.00)` 实例。最重要的是,它定义了一种方法,允许你使用不同的汇率在不同的货币之间进行转换。
|
||||
该类定义为给定的货币符号和汇率定义了一个货币汇率,指定了一个初始化器(也称为构造函数),并实现 `__repr__`,因此当我们打印这个类时,我们会看到一个友好的表示,例如 `$2.00` ,这是一个带有货币符号和金额的 `Money('$', 2.00)` 实例。最重要的是,它定义了一种方法,允许你使用不同的汇率在不同的货币之间进行转换。
|
||||
|
||||
打开 Python shell,假设我们已经定义了使用两种不同货币的食品的成本,如下所示:
|
||||
|
||||
```
|
||||
>>> soda_cost = Money('$', 5.25)
|
||||
|
||||
>>> soda_cost
|
||||
|
||||
$5.25
|
||||
$5.25
|
||||
|
||||
>>> pizza_cost = Money('€', 7.99)
|
||||
|
||||
>>> pizza_cost
|
||||
|
||||
€7.99
|
||||
|
||||
€7.99
|
||||
```
|
||||
|
||||
我们可以使用魔术方法使得这个类的实例之间可以相互交互。假设我们希望能够将这个类的两个实例一起加在一起,即使它们是不同的货币。为了实现这一点,我们可以在 `Money` 类上实现 `__add__` 这个魔术方法:
|
||||
|
||||
```
|
||||
class Money:
|
||||
|
||||
# ... previously defined methods ...
|
||||
|
||||
def __add__(self, other):
|
||||
|
||||
""" Add 2 Money instances using '+' """
|
||||
|
||||
new_amount = self.amount + self.convert(other).amount
|
||||
|
||||
return Money(self.symbol, new_amount)
|
||||
# ... previously defined methods ...
|
||||
|
||||
def __add__(self, other):
|
||||
""" Add 2 Money instances using '+' """
|
||||
new_amount = self.amount + self.convert(other).amount
|
||||
return Money(self.symbol, new_amount)
|
||||
```
|
||||
|
||||
现在我们可以以非常直观的方式使用这个类:
|
||||
|
||||
```
|
||||
>>> soda_cost = Money('$', 5.25)
|
||||
|
||||
>>> pizza_cost = Money('€', 7.99)
|
||||
|
||||
>>> soda_cost + pizza_cost
|
||||
|
||||
$14.33
|
||||
|
||||
$14.33
|
||||
>>> pizza_cost + soda_cost
|
||||
|
||||
€12.61
|
||||
|
||||
€12.61
|
||||
```
|
||||
|
||||
当我们将两个实例加在一起时,我们得到第一个定义的货币的符号所表示的结果(to 校正者:这里意思是:得到的结果是第一个对象的符号所表示的。)。所有的转换都是在底层无缝完成的。如果我们想的话,我们也可以为减法实现 `__sub__`,为乘法实现 `__mul__` 等等。阅读[模拟数字类型][1]或[魔术方法指南][2]来获得更多信息。
|
||||
当我们将两个实例加在一起时,我们得到以第一个定义的货币符号所表示的结果。所有的转换都是在底层无缝完成的。如果我们想的话,我们也可以为减法实现 `__sub__`,为乘法实现 `__mul__` 等等。阅读[模拟数字类型][1]或[魔术方法指南][2]来获得更多信息。
|
||||
|
||||
我们学习到 `__add__` 映射到内置运算符 `+`。其他魔术方法可以映射到像 `[]` 这样的符号。例如,在字典中通过索引或键来获得一项,其实是使用了 `__getitem__` 方法:
|
||||
|
||||
```
|
||||
>>> d = {'one': 1, 'two': 2}
|
||||
|
||||
>>> d['two']
|
||||
|
||||
2
|
||||
|
||||
>>> d.__getitem__('two')
|
||||
|
||||
2
|
||||
|
||||
```
|
||||
|
||||
一些魔术方法甚至映射到内置函数,例如 `__len__()` 映射到 `len()`。
|
||||
|
||||
```
|
||||
class Alphabet:
|
||||
letters = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
|
||||
|
||||
letters = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
|
||||
|
||||
def __len__(self):
|
||||
|
||||
return len(self.letters)
|
||||
def __len__(self):
|
||||
return len(self.letters)
|
||||
|
||||
>>> my_alphabet = Alphabet()
|
||||
|
||||
>>> len(my_alphabet)
|
||||
|
||||
26
|
||||
|
||||
26
|
||||
```
|
||||
|
||||
### 自定义迭代器
|
||||
@ -135,15 +108,14 @@ class Alphabet:
|
||||
对于新的和经验丰富的 Python 开发者来说,自定义迭代器是一个非常强大的但令人迷惑的主题。
|
||||
|
||||
许多内置类型,例如列表、集合和字典,已经实现了允许它们在底层迭代的协议。这使我们可以轻松地遍历它们。
|
||||
|
||||
```
|
||||
>>> for food in ['Pizza', 'Fries']:
|
||||
|
||||
print(food + '. Yum!')
|
||||
|
||||
Pizza. Yum!
|
||||
|
||||
Fries. Yum!
|
||||
|
||||
```
|
||||
|
||||
我们如何迭代我们自己的自定义类?首先,让我们来澄清一些术语。
|
||||
@ -155,70 +127,52 @@ Fries. Yum!
|
||||
呼!这听起来很复杂,但是一旦你记住了这些基本概念,你就可以在任何时候进行迭代。
|
||||
|
||||
我们什么时候想使用自定义迭代器?让我们想象一个场景,我们有一个 `Server` 实例在不同的端口上运行不同的服务,如 `http` 和 `ssh`。其中一些服务处于 `active` 状态,而其他服务则处于 `inactive` 状态。
|
||||
|
||||
```
|
||||
class Server:
|
||||
|
||||
services = [
|
||||
|
||||
{'active': False, 'protocol': 'ftp', 'port': 21},
|
||||
|
||||
{'active': True, 'protocol': 'ssh', 'port': 22},
|
||||
|
||||
{'active': True, 'protocol': 'http', 'port': 80},
|
||||
|
||||
]
|
||||
|
||||
services = [
|
||||
{'active': False, 'protocol': 'ftp', 'port': 21},
|
||||
{'active': True, 'protocol': 'ssh', 'port': 22},
|
||||
{'active': True, 'protocol': 'http', 'port': 80},
|
||||
]
|
||||
```
|
||||
|
||||
当我们遍历 `Server` 实例时,我们只想遍历那些处于 `active` 的服务。让我们创建一个 `IterableServer` 类:
|
||||
|
||||
```
|
||||
class IterableServer:
|
||||
|
||||
def __init__(self):
|
||||
|
||||
self.current_pos = 0
|
||||
|
||||
def __next__(self):
|
||||
|
||||
pass # TODO: 实现并记得抛出 StopIteration
|
||||
|
||||
```
|
||||
|
||||
首先,我们将当前位置初始化为 `0`。然后,我们定义一个 `__next__()` 方法来返回下一项。我们还将确保在没有更多项返回时抛出 `StopIteration`。到目前为止都很好!现在,让我们实现这个 `__next__()` 方法。
|
||||
|
||||
```
|
||||
class IterableServer:
|
||||
|
||||
def __init__(self):
|
||||
|
||||
self.current_pos = 0. # 我们初始化当前位置为 0
|
||||
|
||||
def __iter__(self): # 我们可以在这里返回 self,因为实现了 __next__
|
||||
|
||||
return self
|
||||
|
||||
def __next__(self):
|
||||
|
||||
while self.current_pos < len(self.services):
|
||||
|
||||
service = self.services[self.current_pos]
|
||||
|
||||
self.current_pos += 1
|
||||
|
||||
if service['active']:
|
||||
|
||||
return service['protocol'], service['port']
|
||||
|
||||
raise StopIteration
|
||||
|
||||
next = __next__ # 可选的 Python2 兼容性
|
||||
|
||||
```
|
||||
|
||||
我们对列表中的服务进行遍历,而当前的位置小于服务的个数,但只有在服务处于活动状态时才返回。一旦我们遍历完服务,就会抛出一个 `StopIteration` 异常。
|
||||
|
||||
因为我们实现了 `__next __()` 方法,当它耗尽时,它会抛出 `StopIteration`。我们可以从 `__iter __()` 返回 `self`,因为 `IterableServer` 类遵循 `iterable` 协议。
|
||||
|
||||
因为我们实现了 `__next__()` 方法,当它耗尽时,它会抛出 `StopIteration`。我们可以从 `__iter__()` 返回 `self`,因为 `IterableServer` 类遵循 `iterable` 协议。
|
||||
|
||||
现在我们可以遍历一个 `IterableServer` 实例,这将允许我们查看每个处于活动的服务,如下所示:
|
||||
|
||||
```
|
||||
>>> for protocol, port in IterableServer():
|
||||
|
||||
@ -231,274 +185,190 @@ service http is running on port 21
|
||||
```
|
||||
|
||||
太棒了,但我们可以做得更好!在这样类似的实例中,我们的迭代器不需要维护大量的状态,我们可以简化代码并使用 [generator(生成器)][4] 来代替。
|
||||
|
||||
```
|
||||
class Server:
|
||||
|
||||
services = [
|
||||
|
||||
{'active': False, 'protocol': 'ftp', 'port': 21},
|
||||
|
||||
{'active': True, 'protocol': 'ssh', 'port': 22},
|
||||
|
||||
{'active': True, 'protocol': 'http', 'port': 21},
|
||||
|
||||
]
|
||||
|
||||
def __iter__(self):
|
||||
|
||||
for service in self.services:
|
||||
|
||||
if service['active']:
|
||||
|
||||
yield service['protocol'], service['port']
|
||||
|
||||
```
|
||||
|
||||
`yield` 关键字到底是什么?在定义生成器函数时使用 yield。这有点像 `return`,虽然 `return` 返回值后退出函数,但 `yield` 会暂停执行直到下次调用它。这允许你的生成器功能在它恢复之前保持状态。查看 [yield 的文档][5]以了解更多信息。使用生成器,我们不必通过记住我们的位置来手动维护状态。生成器只知道两件事:它现在需要做什么以及计算下一个项目需要做什么。一旦我们到达执行点,即 `yield` 不再被调用,我们就知道停止迭代。
|
||||
`yield` 关键字到底是什么?在定义生成器函数时使用 yield。这有点像 `return`,虽然 `return` 在返回值后退出函数,但 `yield` 会暂停执行直到下次调用它。这允许你的生成器的功能在它恢复之前保持状态。查看 [yield 的文档][5]以了解更多信息。使用生成器,我们不必通过记住我们的位置来手动维护状态。生成器只知道两件事:它现在需要做什么以及计算下一个项目需要做什么。一旦我们到达执行点,即 `yield` 不再被调用,我们就知道停止迭代。
|
||||
|
||||
这是因为一些内置的 Python 魔法。在 [Python 关于 `__iter__()` 的文档][6]中我们可以看到,如果 `__iter __()` 是作为一个生成器实现的,它将自动返回一个迭代器对象,该对象提供 `__iter __()` 和 `__next __( )` 方法。阅读这篇很棒的文章,深入了解[迭代器,可迭代对象和生成器][7]。
|
||||
这是因为一些内置的 Python 魔法。在 [Python 关于 `__iter__()` 的文档][6]中我们可以看到,如果 `__iter__()` 是作为一个生成器实现的,它将自动返回一个迭代器对象,该对象提供 `__iter__()` 和 `__next__()` 方法。阅读这篇很棒的文章,深入了解[迭代器,可迭代对象和生成器][7]。
|
||||
|
||||
### 方法魔法
|
||||
|
||||
由于其独特的方面,Python 提供了一些有趣的方法魔法作为语言的一部分。
|
||||
|
||||
其中一个例子是别名功能。因为函数只是对象,所以我们可以将它们赋值给多个变量。例如:
|
||||
|
||||
```
|
||||
>>> def foo():
|
||||
|
||||
return 'foo'
|
||||
|
||||
>>> foo()
|
||||
|
||||
'foo'
|
||||
|
||||
>>> bar = foo
|
||||
|
||||
>>> bar()
|
||||
|
||||
'foo'
|
||||
|
||||
```
|
||||
|
||||
我们稍后会看到它的作用。
|
||||
|
||||
Python 提供了一个方便的内置函数[称为 `getattr()`][8],它接受 `object, name, default` 参数并在 `object` 上返回属性 `name`。这种编程方式允许我们访问实例变量和方法。例如:
|
||||
|
||||
```
|
||||
>>> class Dog:
|
||||
|
||||
sound = 'Bark'
|
||||
|
||||
def speak(self):
|
||||
|
||||
print(self.sound + '!', self.sound + '!')
|
||||
|
||||
sound = 'Bark'
|
||||
def speak(self):
|
||||
print(self.sound + '!', self.sound + '!')
|
||||
|
||||
>>> fido = Dog()
|
||||
|
||||
>>> fido.sound
|
||||
|
||||
'Bark'
|
||||
|
||||
>>> getattr(fido, 'sound')
|
||||
|
||||
'Bark'
|
||||
|
||||
>>> fido.speak
|
||||
|
||||
<bound method Dog.speak of <__main__.Dog object at 0x102db8828>>
|
||||
|
||||
>>> getattr(fido, 'speak')
|
||||
|
||||
<bound method Dog.speak of <__main__.Dog object at 0x102db8828>>
|
||||
|
||||
|
||||
>>> fido.speak()
|
||||
|
||||
Bark! Bark!
|
||||
|
||||
>>> speak_method = getattr(fido, 'speak')
|
||||
|
||||
>>> speak_method()
|
||||
|
||||
Bark! Bark!
|
||||
|
||||
```
|
||||
|
||||
这是一个很酷的技巧,但是我们如何在实际中使用 `getattr` 呢?让我们看一个例子,我们编写一个小型命令行工具来动态处理命令。
|
||||
|
||||
```
|
||||
class Operations:
|
||||
|
||||
def say_hi(self, name):
|
||||
|
||||
print('Hello,', name)
|
||||
|
||||
def say_bye(self, name):
|
||||
|
||||
print ('Goodbye,', name)
|
||||
|
||||
def default(self, arg):
|
||||
|
||||
print ('This operation is not supported.')
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
|
||||
operations = Operations()
|
||||
|
||||
# 假设我们做了错误处理
|
||||
|
||||
command, argument = input('> ').split()
|
||||
|
||||
func_to_call = getattr(operations, command, operations.default)
|
||||
|
||||
func_to_call(argument)
|
||||
|
||||
```
|
||||
|
||||
脚本的输出是:
|
||||
|
||||
```
|
||||
$ python getattr.py
|
||||
|
||||
> say_hi Nina
|
||||
|
||||
Hello, Nina
|
||||
|
||||
> blah blah
|
||||
|
||||
This operation is not supported.
|
||||
|
||||
```
|
||||
|
||||
接下来,我们来看看 `partial`。例如,**`functool.partial(func, *args, **kwargs)`** 允许你返回一个新的 [partial 对象][9],它的行为类似 `func`,参数是 `args` 和 `kwargs`。如果传入更多的 `args`,它们会被附加到 `args`。如果传入更多的 `kwargs`,它们会扩展并覆盖 `kwargs`。让我们通过一个简短的例子来看看:
|
||||
接下来,我们来看看 `partial`。例如,`functool.partial(func, *args, **kwargs)` 允许你返回一个新的 [partial 对象][9],它的行为类似 `func`,参数是 `args` 和 `kwargs`。如果传入更多的 `args`,它们会被附加到 `args`。如果传入更多的 `kwargs`,它们会扩展并覆盖 `kwargs`。让我们通过一个简短的例子来看看:
|
||||
|
||||
```
|
||||
>>> from functools import partial
|
||||
|
||||
>>> basetwo = partial(int, base=2)
|
||||
|
||||
>>> basetwo
|
||||
|
||||
<functools.partial object at 0x1085a09f0>
|
||||
|
||||
>>> basetwo('10010')
|
||||
|
||||
18
|
||||
|
||||
|
||||
# 这等同于
|
||||
|
||||
>>> int('10010', base=2)
|
||||
|
||||
```
|
||||
|
||||
让我们看看这个方法魔术如何在我喜欢的一个[名为 `agithub`][10] 的库中的一些示例代码结合在一起的,这是一个(poorly name)REST API 客户端。它具有透明的语法,允许你以最小的配置快速构建任何 REST API 原型(不仅仅是 GitHub)。我发现这个项目很有趣,因为它非常强大,但只有大约 400 行 Python 代码。你可以在大约 30 行配置代码中添加对任何 REST API 的支持。`agithub` 知道协议所需的一切(`REST`、`HTTP`、`TCP`),但它不考虑上游 API。让我们深入到它的实现中。
|
||||
让我们看看在我喜欢的一个[名为 `agithub`][10] 的库中的一些示例代码中,这个方法魔术是如何结合在一起的,这是一个(名字起得很 low 的) REST API 客户端,它具有透明的语法,允许你以最小的配置快速构建任何 REST API 原型(不仅仅是 GitHub)。我发现这个项目很有趣,因为它非常强大,但只有大约 400 行 Python 代码。你可以在大约 30 行配置代码中添加对任何 REST API 的支持。`agithub` 知道协议所需的一切(`REST`、`HTTP`、`TCP`),但它不考虑上游 API。让我们深入到它的实现中。
|
||||
|
||||
以下是我们如何为 GitHub API 和任何其他相关连接属性定义端点 URL 的简化版本。在这里查看[完整代码][11]。
|
||||
|
||||
```
|
||||
class GitHub(API):
|
||||
|
||||
def __init__(self, token=None, *args, **kwargs):
|
||||
|
||||
props = ConnectionProperties(api_url = kwargs.pop('api_url', 'api.github.com'))
|
||||
|
||||
self.setClient(Client(*args, **kwargs))
|
||||
|
||||
self.setConnectionProperties(props)
|
||||
|
||||
```
|
||||
|
||||
然后,一旦配置了[访问令牌][12],就可以开始使用 [GitHub API][13]。
|
||||
|
||||
```
|
||||
>>> gh = GitHub('token')
|
||||
|
||||
>>> status, data = gh.user.repos.get(visibility='public', sort='created')
|
||||
|
||||
>>> # ^ 映射到 GET /user/repos
|
||||
|
||||
>>> data
|
||||
|
||||
... ['tweeter', 'snipey', '...']
|
||||
|
||||
```
|
||||
|
||||
请注意,由你决定拼写正确的 URL,因为我们没有验证 URL。如果 URL 不存在或出现了其他任何错误,将返回 API 抛出的错误。那么,这一切是如何运作的呢?让我们找出答案。首先,我们将查看一个 [`API` 类][14]的简化示例:
|
||||
请注意,你要确保 URL 拼写正确,因为我们没有验证 URL。如果 URL 不存在或出现了其他任何错误,将返回 API 抛出的错误。那么,这一切是如何运作的呢?让我们找出答案。首先,我们将查看一个 [`API` 类][14]的简化示例:
|
||||
|
||||
```
|
||||
class API:
|
||||
|
||||
# ... other methods ...
|
||||
|
||||
def __getattr__(self, key):
|
||||
|
||||
return IncompleteRequest(self.client).__getattr__(key)
|
||||
|
||||
__getitem__ = __getattr__
|
||||
|
||||
```
|
||||
|
||||
在 `API` 类上的每次调用都会调用 [`IncompleteRequest` 类][15]作为指定的 `key`。
|
||||
|
||||
```
|
||||
class IncompleteRequest:
|
||||
|
||||
# ... other methods ...
|
||||
|
||||
def __getattr__(self, key):
|
||||
|
||||
if key in self.client.http_methods:
|
||||
|
||||
htmlMethod = getattr(self.client, key)
|
||||
|
||||
return partial(htmlMethod, url=self.url)
|
||||
|
||||
else:
|
||||
|
||||
self.url += '/' + str(key)
|
||||
|
||||
return self
|
||||
|
||||
__getitem__ = __getattr__
|
||||
|
||||
|
||||
class Client:
|
||||
|
||||
http_methods = ('get') # 还有 post, put, patch 等等。
|
||||
|
||||
def get(self, url, headers={}, **params):
|
||||
|
||||
return self.request('GET', url, None, headers)
|
||||
|
||||
```
|
||||
|
||||
如果最后一次调用不是 HTTP 方法(如 'get'、'post' 等),则返回带有附加路径的 `IncompleteRequest`。否则,它从[ `Client` 类][16]获取 HTTP 方法对应的正确函数,并返回 `partial`。
|
||||
如果最后一次调用不是 HTTP 方法(如 `get`、`post` 等),则返回带有附加路径的 `IncompleteRequest`。否则,它从[`Client` 类][16]获取 HTTP 方法对应的正确函数,并返回 `partial`。
|
||||
|
||||
如果我们给出一个不存在的路径会发生什么?
|
||||
|
||||
```
|
||||
>>> status, data = this.path.doesnt.exist.get()
|
||||
|
||||
>>> status
|
||||
|
||||
... 404
|
||||
|
||||
```
|
||||
|
||||
因为 `__getattr__` 别名为 `__getitem__`:
|
||||
|
||||
```
|
||||
>>> owner, repo = 'nnja', 'tweeter'
|
||||
|
||||
>>> status, data = gh.repos[owner][repo].pulls.get()
|
||||
|
||||
>>> # ^ Maps to GET /repos/nnja/tweeter/pulls
|
||||
|
||||
>>> data
|
||||
|
||||
.... # {....}
|
||||
|
||||
```
|
||||
|
||||
以上是一些认真的方法魔术!(to 校正:这句话真的翻译得不行 )
|
||||
这真心是一些方法魔术!
|
||||
|
||||
### 了解更多
|
||||
|
||||
Python 提供了大量工具,使你的代码更优雅,更易于阅读和理解。挑战在于找到合适的工具来完成工作,但我希望本文为你的工具箱添加了一些新工具。而且,如果你想更进一步,你可以在我的博客 [nnja.io][17] 上阅读有关装饰器,上下文管理器,上下文生成器和 `NamedTuple(译注:这是命名元组)` 的内容。随着你成为一名更好的 Python 开发人员,我鼓励你到那里阅读一些设计良好的项目的源代码。[Requests][18] 和 [Flask][19] 是两个很好的代码库来开始。
|
||||
|
||||
Python 提供了大量工具,使你的代码更优雅,更易于阅读和理解。挑战在于找到合适的工具来完成工作,但我希望本文为你的工具箱添加了一些新工具。而且,如果你想更进一步,你可以在我的博客 [nnja.io][17] 上阅读有关装饰器、上下文管理器、上下文生成器和命名元组的内容。随着你成为一名更好的 Python 开发人员,我鼓励你到那里阅读一些设计良好的项目的源代码。[Requests][18] 和 [Flask][19] 是两个很好的起步的代码库。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -508,7 +378,7 @@ via: https://opensource.com/article/18/4/elegant-solutions-everyday-python-probl
|
||||
作者:[Nina Zakharenko][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
246
published/20180522 How to Run Your Own Git Server.md
Normal file
246
published/20180522 How to Run Your Own Git Server.md
Normal file
@ -0,0 +1,246 @@
|
||||
搭建属于你自己的 Git 服务器
|
||||
======
|
||||
|
||||
|
||||
|
||||
> 在本文中,我们的目的是让你了解如何设置属于自己的Git服务器。
|
||||
|
||||
[Git][1] 是由 [Linux Torvalds 开发][2]的一个版本控制系统,现如今正在被全世界大量开发者使用。许多公司喜欢使用基于 Git 版本控制的 GitHub 代码托管。[根据报道,GitHub 是现如今全世界最大的代码托管网站][3]。GitHub 宣称已经有 920 万用户和 2180 万个仓库。许多大型公司现如今也将代码迁移到 GitHub 上。[甚至于谷歌,一家搜索引擎公司,也正将代码迁移到 GitHub 上][4]。
|
||||
|
||||
### 运行你自己的 Git 服务器
|
||||
|
||||
GitHub 能提供极佳的服务,但却有一些限制,尤其是你是单人或是一名 coding 爱好者。GitHub 其中之一的限制就是其中免费的服务没有提供代码私有托管业务。[你不得不支付每月 7 美金购买 5 个私有仓库][5],并且想要更多的私有仓库则要交更多的钱。
|
||||
|
||||
万一你想要私有仓库或需要更多权限控制,最好的方法就是在你的服务器上运行 Git。不仅你能够省去一笔钱,你还能够在你的服务器有更多的操作。在大多数情况下,大多数高级 Linux 用户已经拥有自己的服务器,并且在这些服务器上方式 Git 就像“啤酒一样免费”(LCTT 译注:指免费软件)。
|
||||
|
||||
在这篇教程中,我们主要讲在你的服务器上,使用两种代码管理的方法。一种是运行一个纯 Git 服务器,另一个是使用名为 [GitLab][6] 的 GUI 工具。在本教程中,我在 VPS 上运行的操作系统是 Ubuntu 14.04 LTS。
|
||||
|
||||
### 在你的服务器上安装 Git
|
||||
|
||||
在本篇教程中,我们考虑一个简单案例,我们有一个远程服务器和一台本地服务器,现在我们需要使用这两台机器来工作。为了简单起见,我们就分别叫它们为远程服务器和本地服务器。
|
||||
|
||||
首先,在两边的机器上安装 Git。你可以从依赖包中安装 Git,在本文中,我们将使用更简单的方法:
|
||||
|
||||
```
|
||||
sudo apt-get install git-core
|
||||
```
|
||||
|
||||
为 Git 创建一个用户。
|
||||
|
||||
```
|
||||
sudo useradd git
|
||||
passwd git
|
||||
```
|
||||
|
||||
为了容易的访问服务器,我们设置一个免密 ssh 登录。首先在你本地电脑上创建一个 ssh 密钥:
|
||||
|
||||
```
|
||||
ssh-keygen -t rsa
|
||||
```
|
||||
|
||||
这时会要求你输入保存密钥的路径,这时只需要点击回车保存在默认路径。第二个问题是输入访问远程服务器所需的密码。它生成两个密钥——公钥和私钥。记下您在下一步中需要使用的公钥的位置。
|
||||
|
||||
现在您必须将这些密钥复制到服务器上,以便两台机器可以相互通信。在本地机器上运行以下命令:
|
||||
|
||||
```
|
||||
cat ~/.ssh/id_rsa.pub | ssh git@remote-server "mkdir -p ~/.ssh && cat >> ~/.ssh/authorized_keys"
|
||||
```
|
||||
|
||||
现在,用 `ssh` 登录进服务器并为 Git 创建一个项目路径。你可以为你的仓库设置一个你想要的目录。
|
||||
|
||||
现在跳转到该目录中:
|
||||
|
||||
```
|
||||
cd /home/swapnil/project-1.git
|
||||
```
|
||||
|
||||
现在新建一个空仓库:
|
||||
|
||||
```
|
||||
git init --bare
|
||||
Initialized empty Git repository in /home/swapnil/project-1.git
|
||||
```
|
||||
|
||||
现在我们需要在本地机器上新建一个基于 Git 版本控制仓库:
|
||||
|
||||
```
|
||||
mkdir -p /home/swapnil/git/project
|
||||
```
|
||||
|
||||
进入我们创建仓库的目录:
|
||||
|
||||
```
|
||||
cd /home/swapnil/git/project
|
||||
```
|
||||
|
||||
现在在该目录中创建项目所需的文件。留在这个目录并启动 `git`:
|
||||
|
||||
```
|
||||
git init
|
||||
Initialized empty Git repository in /home/swapnil/git/project
|
||||
```
|
||||
|
||||
把所有文件添加到仓库中:
|
||||
|
||||
```
|
||||
git add .
|
||||
```
|
||||
|
||||
现在,每次添加文件或进行更改时,都必须运行上面的 `add` 命令。 您还需要为每个文件更改都写入提交消息。提交消息基本上说明了我们所做的更改。
|
||||
|
||||
```
|
||||
git commit -m "message" -a
|
||||
[master (root-commit) 57331ee] message
|
||||
2 files changed, 2 insertions(+)
|
||||
create mode 100644 GoT.txt
|
||||
create mode 100644 writing.txt
|
||||
```
|
||||
|
||||
在这种情况下,我有一个名为 GoT(《权力的游戏》的点评)的文件,并且我做了一些更改,所以当我运行命令时,它指定对文件进行更改。 在上面的命令中 `-a` 选项意味着提交仓库中的所有文件。 如果您只更改了一个,则可以指定该文件的名称而不是使用 `-a`。
|
||||
|
||||
举一个例子:
|
||||
|
||||
```
|
||||
git commit -m "message" GoT.txt
|
||||
[master e517b10] message
|
||||
1 file changed, 1 insertion(+)
|
||||
```
|
||||
|
||||
到现在为止,我们一直在本地服务器上工作。现在我们必须将这些更改推送到远程服务器上,以便通过互联网访问,并且可以与其他团队成员进行协作。
|
||||
|
||||
```
|
||||
git remote add origin ssh://git@remote-server/repo-<wbr< a="">>path-on-server..git
|
||||
```
|
||||
|
||||
现在,您可以使用 `pull` 或 `push` 选项在服务器和本地计算机之间推送或拉取:
|
||||
|
||||
```
|
||||
git push origin master
|
||||
```
|
||||
|
||||
如果有其他团队成员想要使用该项目,则需要将远程服务器上的仓库克隆到其本地计算机上:
|
||||
|
||||
```
|
||||
git clone git@remote-server:/home/swapnil/project.git
|
||||
```
|
||||
|
||||
这里 `/home/swapnil/project.git` 是远程服务器上的项目路径,在你本机上则会改变。
|
||||
|
||||
然后进入本地计算机上的目录(使用服务器上的项目名称):
|
||||
|
||||
```
|
||||
cd /project
|
||||
```
|
||||
|
||||
现在他们可以编辑文件,写入提交更改信息,然后将它们推送到服务器:
|
||||
|
||||
```
|
||||
git commit -m 'corrections in GoT.txt story' -a
|
||||
```
|
||||
|
||||
然后推送改变:
|
||||
|
||||
```
|
||||
git push origin master
|
||||
```
|
||||
|
||||
我认为这足以让一个新用户开始在他们自己的服务器上使用 Git。 如果您正在寻找一些 GUI 工具来管理本地计算机上的更改,则可以使用 GUI 工具,例如 QGit 或 GitK for Linux。
|
||||
|
||||
|
||||
|
||||
### 使用 GitLab
|
||||
|
||||
这是项目所有者和协作者的纯命令行解决方案。这当然不像使用 GitHub 那么简单。不幸的是,尽管 GitHub 是全球最大的代码托管商,但是它自己的软件别人却无法使用。因为它不是开源的,所以你不能获取源代码并编译你自己的 GitHub。这与 WordPress 或 Drupal 不同,您无法下载 GitHub 并在您自己的服务器上运行它。
|
||||
|
||||
像往常一样,在开源世界中,是没有终结的尽头。GitLab 是一个非常优秀的项目。这是一个开源项目,允许用户在自己的服务器上运行类似于 GitHub 的项目管理系统。
|
||||
|
||||
您可以使用 GitLab 为团队成员或公司运行类似于 GitHub 的服务。您可以使用 GitLab 在公开发布之前开发私有项目。
|
||||
|
||||
GitLab 采用传统的开源商业模式。他们有两种产品:免费的开源软件,用户可以在自己的服务器上安装,以及类似于 GitHub 的托管服务。
|
||||
|
||||
可下载版本有两个版本,免费的社区版和付费企业版。企业版基于社区版,但附带针对企业客户的其他功能。它或多或少与 WordPress.org 或 Wordpress.com 提供的服务类似。
|
||||
|
||||
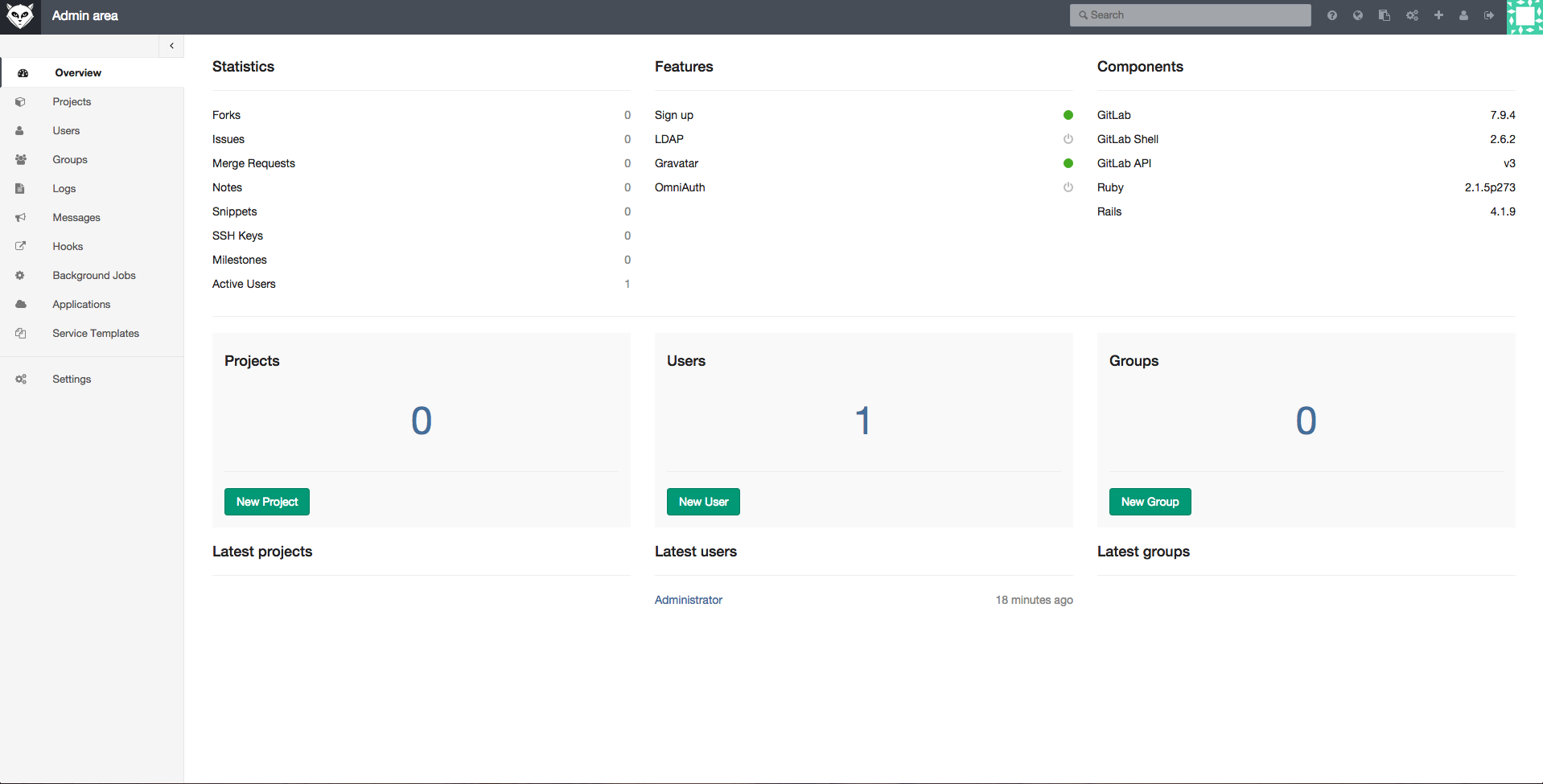
社区版具有高度可扩展性,可以在单个服务器或群集上支持 25000 个用户。GitLab 的一些功能包括:Git 仓库管理,代码评论,问题跟踪,活动源和维基。它配备了 GitLab CI,用于持续集成和交付。
|
||||
|
||||
Digital Ocean 等许多 VPS 提供商会为用户提供 GitLab 服务。 如果你想在你自己的服务器上运行它,你可以手动安装它。GitLab 为不同的操作系统提供了软件包。 在我们安装 GitLab 之前,您可能需要配置 SMTP 电子邮件服务器,以便 GitLab 可以在需要时随时推送电子邮件。官方推荐使用 Postfix。所以,先在你的服务器上安装 Postfix:
|
||||
|
||||
```
|
||||
sudo apt-get install postfix
|
||||
```
|
||||
|
||||
在安装 Postfix 期间,它会问你一些问题,不要跳过它们。 如果你一不小心跳过,你可以使用这个命令来重新配置它:
|
||||
|
||||
```
|
||||
sudo dpkg-reconfigure postfix
|
||||
```
|
||||
|
||||
运行此命令时,请选择 “Internet Site”并为使用 Gitlab 的域名提供电子邮件 ID。
|
||||
|
||||
我是这样输入的:
|
||||
|
||||
```
|
||||
xxx@x.com
|
||||
```
|
||||
|
||||
用 Tab 键并为 postfix 创建一个用户名。接下来将会要求你输入一个目标邮箱。
|
||||
|
||||
在剩下的步骤中,都选择默认选项。当我们安装且配置完成后,我们继续安装 GitLab。
|
||||
|
||||
我们使用 `wget` 来下载软件包(用 [最新包][7] 替换下载链接):
|
||||
|
||||
```
|
||||
wget https://downloads-packages.s3.amazonaws.com/ubuntu-14.04/gitlab_7.9.4-omnibus.1-1_amd64.deb
|
||||
```
|
||||
|
||||
然后安装这个包:
|
||||
|
||||
```
|
||||
sudo dpkg -i gitlab_7.9.4-omnibus.1-1_amd64.deb
|
||||
```
|
||||
|
||||
现在是时候配置并启动 GitLab 了。
|
||||
|
||||
```
|
||||
sudo gitlab-ctl reconfigure
|
||||
```
|
||||
|
||||
您现在需要在配置文件中配置域名,以便您可以访问 GitLab。打开文件。
|
||||
|
||||
```
|
||||
nano /etc/gitlab/gitlab.rb
|
||||
```
|
||||
|
||||
在这个文件中编辑 `external_url` 并输入服务器域名。保存文件,然后从 Web 浏览器中打开新建的一个 GitLab 站点。
|
||||
|
||||
|
||||
|
||||
默认情况下,它会以系统管理员的身份创建 `root`,并使用 `5iveL!fe` 作为密码。 登录到 GitLab 站点,然后更改密码。
|
||||
|
||||
|
||||
|
||||
密码更改后,登录该网站并开始管理您的项目。
|
||||
|
||||

|
||||
|
||||
GitLab 有很多选项和功能。最后,我借用电影“黑客帝国”中的经典台词:“不幸的是,没有人知道 GitLab 可以做什么。你必须亲自尝试一下。”
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/how-run-your-own-git-server
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[wyxplus](https://github.com/wyxplus)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/arnieswap
|
||||
[1]:https://github.com/git/git
|
||||
[2]:https://www.linuxfoundation.org/blog/10-years-of-git-an-interview-with-git-creator-linus-torvalds/
|
||||
[3]:https://github.com/about/press
|
||||
[4]:http://google-opensource.blogspot.com/2015/03/farewell-to-google-code.html
|
||||
[5]:https://github.com/pricing
|
||||
[6]:https://about.gitlab.com/
|
||||
[7]:https://about.gitlab.com/downloads/
|
||||
59
published/20180615 BLUI- An easy way to create game UI.md
Normal file
59
published/20180615 BLUI- An easy way to create game UI.md
Normal file
@ -0,0 +1,59 @@
|
||||
BLUI:创建游戏 UI 的简单方法
|
||||
======
|
||||
|
||||
> 开源游戏开发插件运行虚幻引擎的用户使用基于 Web 的编程方式创建独特的用户界面元素。
|
||||
|
||||

|
||||
|
||||
游戏开发引擎在过去几年中变得越来越易于使用。像 Unity 这样一直免费使用的引擎,以及最近从基于订阅的服务切换到免费服务的<ruby>虚幻引擎<rt>Unreal Engine</rt></ruby>,允许独立开发者使用 AAA 发行商相同达到行业标准的工具。虽然这些引擎都不是开源的,但每个引擎都能够促进其周围的开源生态系统的发展。
|
||||
|
||||
这些引擎中可以包含插件以允许开发人员通过添加特定程序来增强引擎的基本功能。这些程序的范围可以从简单的资源包到更复杂的事物,如人工智能 (AI) 集成。这些插件来自不同的创作者。有些是由引擎开发工作室和有些是个人提供的。后者中的很多是开源插件。
|
||||
|
||||
### 什么是 BLUI?
|
||||
|
||||
作为独立游戏开发工作室的一员,我体验到了在专有游戏引擎上使用开源插件的好处。Aaron Shea 开发的一个开源插件 [BLUI][1] 对我们团队的开发过程起到了重要作用。它允许我们使用基于 Web 的编程(如 HTML/CSS 和 JavaScript)创建用户界面 (UI) 组件。尽管<ruby>虚幻引擎<rt>Unreal Engine</rt></ruby>(我们选择的引擎)有一个实现了类似目的的内置 UI 编辑器,我们也选择使用这个开源插件。我们选择使用开源替代品有三个主要原因:它们的可访问性、易于实现以及伴随的开源程序活跃的、支持性好的在线社区。
|
||||
|
||||
在虚幻引擎的最早版本中,我们在游戏中创建 UI 的唯一方法是通过引擎的原生 UI 集成,使用 Autodesk 的 Scaleform 程序,或通过在虚幻社区中传播的一些选定的基于订阅的虚幻引擎集成。在这些情况下,这些解决方案要么不能为独立开发者提供有竞争力的 UI 解决方案,对于小型团队来说太昂贵,要么只能为大型团队和 AAA 开发者提供。
|
||||
|
||||
在商业产品和虚幻引擎的原生整合失败后,我们向独立社区寻求解决方案。我们在那里发现了 BLUI。它不仅与虚幻引擎无缝集成,而且还保持了一个强大且活跃的社区,经常推出更新并确保独立开发人员可以轻松访问文档。BLUI 使开发人员能够将 HTML 文件导入虚幻引擎,并在程序内部对其进行编程。这使得通过 web 语言创建的 UI 能够集成到游戏的代码、资源和其他元素中,并拥有所有 HTML、CSS、Javascript 和其他网络语言的能力。它还为开源 [Chromium Embedded Framework][2] 提供全面支持。
|
||||
|
||||
### 安装和使用 BLUI
|
||||
|
||||
使用 BLUI 的基本过程包括首先通过 HTML 创建 UI。开发人员可以使用任何工具来实现此目的,包括<ruby>自举<rt>bootstrapped</rt> JavaScript 代码、外部 API 或任何数据库代码。一旦这个 HTML 页面完成,你可以像安装任何虚幻引擎插件那样安装它,并加载或创建一个项目。项目加载后,你可以将 BLUI 函数放在虚幻引擎 UI 图纸中的任何位置,或者通过 C++ 进行硬编码。开发人员可以通过其 HTML 页面调用函数,或使用 BLUI 的内部函数轻松更改变量。
|
||||
|
||||
![Integrating BLUI into Unreal Engine 4 blueprints][4]
|
||||
|
||||
*将 BLUI 集成到虚幻 4 图纸中。*
|
||||
|
||||
在我们当前的项目中,我们使用 BLUI 将 UI 元素与游戏中的音轨同步,为游戏机制的节奏方面提供视觉反馈。将定制引擎编程与 BLUI 插件集成很容易。
|
||||
|
||||
![Using BLUI to sync UI elements with the soundtrack.][6]
|
||||
|
||||
*使用 BLUI 将 UI 元素与音轨同步。*
|
||||
|
||||
通过 BLUI GitHub 页面上的[文档][7],将 BLUI 集成到虚幻 4 中是一个轻松的过程。还有一个由支持虚幻引擎开发人员组成的[论坛][8],他们乐于询问和回答关于插件以及实现该工具时出现的任何问题。
|
||||
|
||||
### 开源优势
|
||||
|
||||
开源插件可以在专有游戏引擎的范围内扩展创意。他们继续降低进入游戏开发的障碍,并且可以产生前所未有的游戏内的机制和资源。随着对专有游戏开发引擎的访问持续增长,开源插件社区将变得更加重要。不断增长的创造力必将超过专有软件,开源代码将会填补这些空白,并促进开发真正独特的游戏。而这种新颖性正是让独立游戏如此美好的原因!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/blui-game-development-plugin
|
||||
|
||||
作者:[Uwana lkaiddi][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/uwikaiddi
|
||||
[1]:https://github.com/AaronShea/BLUI
|
||||
[2]:https://bitbucket.org/chromiumembedded/cef
|
||||
[3]:/file/400616
|
||||
[4]:https://opensource.com/sites/default/files/uploads/blui_gaming_plugin-integratingblui.png (Integrating BLUI into Unreal Engine 4 blueprints)
|
||||
[5]:/file/400621
|
||||
[6]:https://opensource.com/sites/default/files/uploads/blui_gaming_plugin-syncui.png (Using BLUI to sync UI elements with the soundtrack.)
|
||||
[7]:https://github.com/AaronShea/BLUI/wiki
|
||||
[8]:https://forums.unrealengine.com/community/released-projects/29036-blui-open-source-html5-js-css-hud-ui
|
||||
122
published/20180618 5 open source alternatives to Dropbox.md
Normal file
122
published/20180618 5 open source alternatives to Dropbox.md
Normal file
@ -0,0 +1,122 @@
|
||||
可代替 Dropbox 的 5 个开源软件
|
||||
=====
|
||||
|
||||
> 寻找一个不会破坏你的安全、自由或银行资产的文件共享应用。
|
||||
|
||||

|
||||
|
||||
Dropbox 在文件共享应用中是个 800 磅的大猩猩。尽管它是个极度流行的工具,但你可能仍想使用一个软件去替代它。
|
||||
|
||||
也行你出于各种好的理由,包括安全和自由,这使你决定用[开源方式][1]。亦或是你已经被数据泄露吓坏了,或者定价计划不能满足你实际需要的存储量。
|
||||
|
||||
幸运的是,有各种各样的开源文件共享应用,可以提供给你更多的存储容量,更好的安全性,并且以低于 Dropbox 很多的价格来让你掌控你自己的数据。有多低呢?如果你有一定的技术和一台 Linux 服务器可供使用,那尝试一下免费的应用吧。
|
||||
|
||||
这里有 5 个最好的可以代替 Dropbox 的开源应用,以及其他一些,你可能想考虑使用。
|
||||
|
||||
### ownCloud
|
||||
|
||||
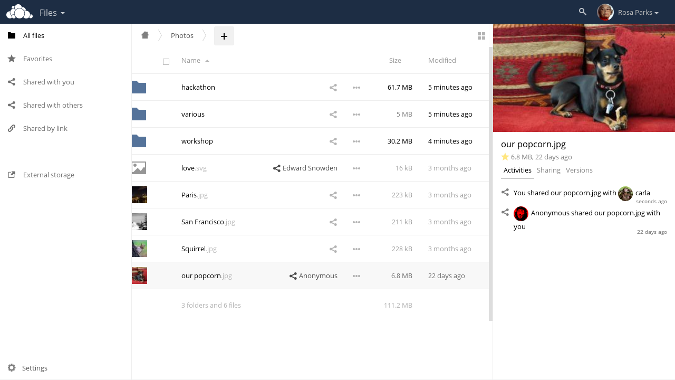
|
||||
|
||||
[ownCloud][2] 发布于 2010 年,是本文所列应用中最老的,但是不要被这件事蒙蔽:它仍然十分流行(根据该公司统计,有超过 150 万用户),并且由由 1100 个参与者的社区积极维护,定期发布更新。
|
||||
|
||||
它的主要特点——文件共享和文档写作功能和 Dropbox 的功能相似。它们的主要区别(除了它的[开源协议][3])是你的文件可以托管在你的私人 Linux 服务器或云上,给予用户对自己数据完全的控制权。(自托管是本文所列应用的一个普遍的功能。)
|
||||
|
||||
使用 ownCloud,你可以通过 Linux、MacOS 或 Windows 的客户端和安卓、iOS 的移动应用程序来同步和访问文件。你还可以通过带有密码保护的链接分享给其他人来协作或者上传和下载。数据传输通过端到端加密(E2EE)和 SSL 加密来保护安全。你还可以通过使用它的 [市场][4] 中的各种各样的第三方应用来扩展它的功能。当然,它也提供付费的、商业许可的企业版本。
|
||||
|
||||
ownCloud 提供了详尽的[文档][5],包括安装指南和针对用户、管理员、开发者的手册。你可以从 GitHub 仓库中获取它的[源码][6]。
|
||||
|
||||
### NextCloud
|
||||
|
||||
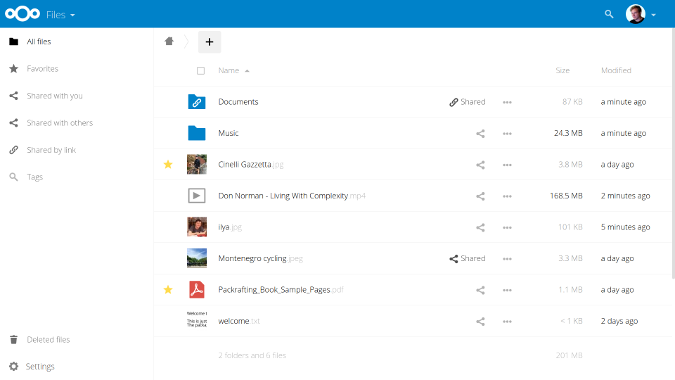
|
||||
|
||||
[NextCloud][7] 在 2016 年从 ownCloud 分裂出来,并且具有很多相同的功能。 NextCloud 以它的高安全性和法规遵从性作为它的一个独特的[推崇的卖点][8]。它具有 HIPAA (医疗) 和 GDPR (隐私)法规遵从功能,并提供广泛的数据策略约束、加密、用户管理和审核功能。它还在传输和存储期间对数据进行加密,并且集成了移动设备管理和身份验证机制 (包括 LDAP/AD、单点登录、双因素身份验证等)。
|
||||
|
||||
像本文列表里的其他应用一样, NextCloud 是自托管的,但是如果你不想在自己的 Linux 上安装 NextCloud 服务器,该公司与几个[提供商][9]达成了伙伴合作,提供安装和托管,并销售服务器、设备和服务支持。在[市场][10]中提供了大量的apps 来扩展它的功能。
|
||||
|
||||
NextCloud 的[文档][11]为用户、管理员和开发者提供了详细的信息,并且它的论坛、IRC 频道和社交媒体提供了基于社区的支持。如果你想贡献或者获取它的源码、报告一个错误、查看它的 AGPLv3 许可,或者想了解更多,请访问它的[GitHub 项目主页][12]。
|
||||
|
||||
### Seafile
|
||||
|
||||
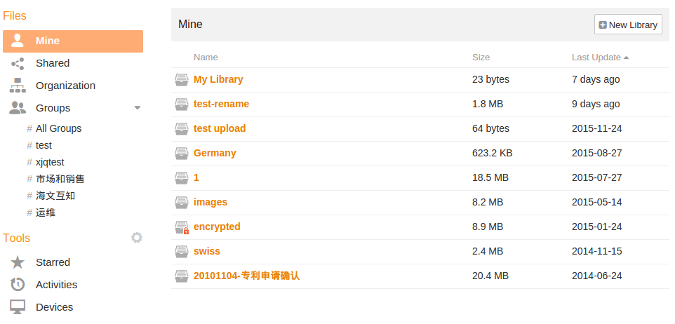
|
||||
|
||||
与 ownCloud 或 NextCloud 相比,[Seafile][13] 或许没有花里胡哨的卖点(app 生态),但是它能完成任务。实质上, 它充当了 Linux 服务器上的虚拟驱动器,以扩展你的桌面存储,并允许你使用密码保护和各种级别的权限(即只读或读写) 有选择地共享文件。
|
||||
|
||||
它的协作功能包括文件夹权限控制,密码保护的下载链接和像 Git 一样的版本控制和记录。文件使用双因素身份验证、文件加密和 AD/LDAP 集成进行保护,并且可以从 Windows、MacOS、Linux、iOS 或 Android 设备进行访问。
|
||||
|
||||
更多详细信息, 请访问 Seafile 的 [GitHub 仓库][14]、[服务手册][15]、[wiki][16] 和[论坛][17]。请注意, Seafile 的社区版在 [GPLv2][18] 下获得许可,但其专业版不是开源的。
|
||||
|
||||
### OnionShare
|
||||
|
||||
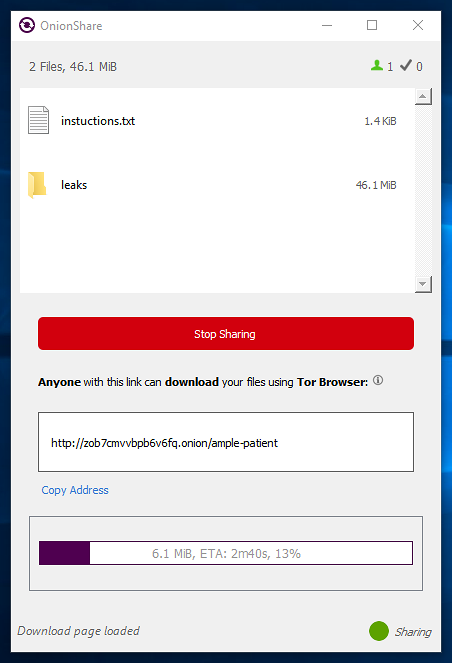
|
||||
|
||||
[OnionShare][19] 是一个很酷的应用:如果你想匿名,它允许你安全地共享单个文件或文件夹。不需要设置或维护服务器,所有你需要做的就是[下载和安装][20],无论是在 MacOS, Windows 还是 Linux 上。文件始终在你自己的计算机上; 当你共享文件时,OnionShare 创建一个 web 服务器,使其可作为 Tor 洋葱服务访问,并生成一个不可猜测的 .onion URL,这个 URL 允许收件人通过 [Tor 浏览器][21]获取文件。
|
||||
|
||||
你可以设置文件共享的限制,例如限制可以下载的次数或使用自动停止计时器,这会设置一个严格的过期日期/时间,超过这个期限便不可访问(即使尚未访问该文件)。
|
||||
|
||||
OnionShare 在 [GPLv3][22] 之下被许可;有关详细信息,请查阅其 [GitHub 仓库][22],其中还包括[文档][23],介绍了这个易用的文件共享软件的特点。
|
||||
|
||||
### Pydio Cells
|
||||
|
||||
|
||||
|
||||
[Pydio Cells][24] 在 2018 年 5 月推出了稳定版,是对 Pydio 共享应用程序的核心服务器代码的彻底大修。由于 Pydio 的基于 PHP 的后端的限制,开发人员决定用 Go 服务器语言和微服务体系结构重写后端。(前端仍然是基于 PHP 的)。
|
||||
|
||||
Pydio Cells 包括通常的共享和版本控制功能,以及应用程序中的消息接受、移动应用程序(Android 和 iOS),以及一种社交网络风格的协作方法。安全性包括基于 OpenID 连接的身份验证、rest 加密、安全策略等。企业发行版中包含着高级功能,但在社区(家庭)版本中,对于大多数中小型企业和家庭用户来说,依然是足够的。
|
||||
|
||||
您可以 在 Linux 和 MacOS 里[下载][25] Pydio Cells。有关详细信息, 请查阅 [文档常见问题][26]、[源码库][27] 和 [AGPLv3 许可证][28]
|
||||
|
||||
### 其他
|
||||
|
||||
如果以上选择不能满足你的需求,你可能想考虑其他开源的文件共享型应用。
|
||||
|
||||
* 如果你的主要目的是在设备间同步文件而不是分享文件,考察一下 [Syncthing][29]。
|
||||
* 如果你是一个 Git 的粉丝而不需要一个移动应用。你可能更喜欢 [SparkleShare][30]。
|
||||
* 如果你主要想要一个地方聚合所有你的个人数据, 看看 [Cozy][31]。
|
||||
* 如果你想找一个轻量级的或者专注于文件共享的工具,考察一下 [Scott Nesbitt's review][32]——一个罕为人知的工具。
|
||||
|
||||
哪个是你最喜欢的开源文件共享应用?在评论中让我们知悉。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/alternatives/dropbox
|
||||
|
||||
作者:[Opensource.com][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[distant1219](https://github.com/distant1219)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com
|
||||
[1]:https://opensource.com/open-source-way
|
||||
[2]:https://owncloud.org/
|
||||
[3]:https://www.gnu.org/licenses/agpl-3.0.html
|
||||
[4]:https://marketplace.owncloud.com/
|
||||
[5]:https://doc.owncloud.com/
|
||||
[6]:https://github.com/owncloud
|
||||
[7]:https://nextcloud.com/
|
||||
[8]:https://nextcloud.com/secure/
|
||||
[9]:https://nextcloud.com/providers/
|
||||
[10]:https://apps.nextcloud.com/
|
||||
[11]:https://nextcloud.com/support/
|
||||
[12]:https://github.com/nextcloud
|
||||
[13]:https://www.seafile.com/en/home/
|
||||
[14]:https://github.com/haiwen/seafile
|
||||
[15]:https://manual.seafile.com/
|
||||
[16]:https://seacloud.cc/group/3/wiki/
|
||||
[17]:https://forum.seafile.com/
|
||||
[18]:https://github.com/haiwen/seafile/blob/master/LICENSE.txt
|
||||
[19]:https://onionshare.org/
|
||||
[20]:https://onionshare.org/#downloads
|
||||
[21]:https://www.torproject.org/
|
||||
[22]:https://github.com/micahflee/onionshare/blob/develop/LICENSE
|
||||
[23]:https://github.com/micahflee/onionshare/wiki
|
||||
[24]:https://pydio.com/en
|
||||
[25]:https://pydio.com/download/
|
||||
[26]:https://pydio.com/en/docs/faq
|
||||
[27]:https://github.com/pydio/cells
|
||||
[28]:https://github.com/pydio/pydio-core/blob/develop/LICENSE
|
||||
[29]:https://syncthing.net/
|
||||
[30]:http://www.sparkleshare.org/
|
||||
[31]:https://cozy.io/en/
|
||||
[32]:https://opensource.com/article/17/3/file-sharing-tools
|
||||
@ -1,15 +1,17 @@
|
||||
开始使用 Perlbrew
|
||||
Perlbrew 入门
|
||||
======
|
||||
|
||||
> 用 Perlbrew 在你系统上安装多个版本的 Perl。
|
||||
|
||||

|
||||
|
||||
什么比在系统上安装 Perl 更好?在系统中安装多个版本的 Perl。使用 [Perlbrew][1] 你可以做到这一点。但是为什么,除了让你包围在 Perl 下之外,你想要那样做吗?
|
||||
有比在系统上安装了 Perl 更好的事情吗?那就是在系统中安装了多个版本的 Perl。使用 [Perlbrew][1] 你可以做到这一点。但是为什么呢,除了让你包围在 Perl 下之外,有什么好处吗?
|
||||
|
||||
简短的回答是不同版本的 Perl 是......不同的。程序 A 可能依赖于较新版本中不推荐使用的行为,而程序 B 需要去年无法使用的新功能。如果你安装了多个版本的 Perl,则每个脚本都可以使用最适合它的版本。如果您是开发人员,这也会派上用场,你可以针对多个版本的 Perl 测试你的程序,这样无论你的用户运行什么,你都知道它是否工作。
|
||||
简短的回答是,不同版本的 Perl 是......不同的。程序 A 可能依赖于较新版本中不推荐使用的行为,而程序 B 需要去年无法使用的新功能。如果你安装了多个版本的 Perl,则每个脚本都可以使用最适合它的版本。如果您是开发人员,这也会派上用场,你可以针对多个版本的 Perl 测试你的程序,这样无论你的用户运行什么,你都知道它能否工作。
|
||||
|
||||
### 安装 Perlbrew
|
||||
|
||||
另一个好处是 Perlbrew 安装到用户的家目录。这意味着每个用户都可以管理他们的 Perl 版本(以及相关的 CPAN 包),而无需与系统管理员联系。自助服务意味着为用户提供更快的安装,并为系统管理员提供更多时间来解决难题。
|
||||
另一个好处是 Perlbrew 会安装 Perl 到用户的家目录。这意味着每个用户都可以管理他们的 Perl 版本(以及相关的 CPAN 包),而无需与系统管理员联系。自助服务意味着为用户提供更快的安装,并为系统管理员提供更多时间来解决难题。
|
||||
|
||||
第一步是在你的系统上安装 Perlbrew。许多 Linux 发行版已经在包仓库中拥有它,因此你只需要 `dnf install perlbrew`(或者适用于你的发行版的命令)。你还可以使用 `cpan App::perlbrew` 从 CPAN 安装 `App::perlbrew` 模块。或者你可以在 [install.perlbrew.pl][2] 下载并运行安装脚本。
|
||||
|
||||
@ -18,56 +20,56 @@
|
||||
### 安装新的 Perl 版本
|
||||
|
||||
假设你想尝试最新的开发版本(撰写本文时为 5.27.11)。首先,你需要安装包:
|
||||
|
||||
```
|
||||
perlbrew install 5.27.11
|
||||
|
||||
```
|
||||
|
||||
### 切换 Perl 版本
|
||||
|
||||
现在你已经安装了新版本,你可以将它用于该 shell:
|
||||
|
||||
```
|
||||
perlbrew use 5.27.11
|
||||
|
||||
```
|
||||
|
||||
或者你可以将其设置为你帐户的默认 Perl 版本(假设你按照 `perlbrew init` 的输出设置了你的配置文件):
|
||||
|
||||
```
|
||||
perlbrew switch 5.27.11
|
||||
|
||||
```
|
||||
|
||||
### 运行单个脚本
|
||||
|
||||
你也可以用特定版本的 Perl 运行单个命令:
|
||||
|
||||
```
|
||||
perlberew exec 5.27.11 myscript.pl
|
||||
|
||||
```
|
||||
|
||||
或者,你可以针对所有已安装的版本运行命令。如果你想针对各种版本运行测试,这尤其方便。在这种情况下,请将 Perl 指定版本:
|
||||
```
|
||||
.plperlbrew exec perl myscriptpl
|
||||
或者,你可以针对所有已安装的版本运行命令。如果你想针对各种版本运行测试,这尤其方便。在这种情况下,请指定版本为 `perl`:
|
||||
|
||||
```
|
||||
plperlbrew exec perl myscriptpl
|
||||
```
|
||||
|
||||
### 安装 CPAN 模块
|
||||
|
||||
如果你想安装 CPAN 模块,`cpanm` 包是一个易于使用的界面,可以很好地与 Perlbrew 一起使用。用下面命令安装它:
|
||||
```
|
||||
perlbrew install-cpamn
|
||||
|
||||
```
|
||||
perlbrew install-cpanm
|
||||
```
|
||||
|
||||
然后,你可以使用 `cpanm` 命令安装 CPAN 模块:
|
||||
|
||||
```
|
||||
cpanm CGI::simple
|
||||
|
||||
```
|
||||
|
||||
### 但是等下,还有更多!
|
||||
|
||||
本文介绍了基本的 Perlbrew 用法。还有更多功能和选项可供选择。从查看 `perlbrew help` 的输出开始,或查看[ App::perlbrew 文档][3]。你还喜欢 Perlbrew 的其他什么功能?让我们在评论中知道。
|
||||
本文介绍了基本的 Perlbrew 用法。还有更多功能和选项可供选择。从查看 `perlbrew help` 的输出开始,或查看[App::perlbrew 文档][3]。你还喜欢 Perlbrew 的其他什么功能?让我们在评论中知道。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -76,7 +78,7 @@ via: https://opensource.com/article/18/7/perlbrew
|
||||
作者:[Ben Cotton][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,23 +1,24 @@
|
||||
在 Ubuntu 18.04 LTS 上安装 Microsoft Windows 字体
|
||||
在 Ubuntu 18.04 LTS 上安装 Microsoft Windows 字体
|
||||
======
|
||||
|
||||

|
||||
|
||||
大多数教育机构仍在使用 Microsoft 字体, 我不清楚其他国家是什么情况。但在泰米尔纳德邦(印度的一个州), **Times New Roman** 和 **Arial** 字体主要被用于大学和学校的几乎所有文档工作,项目和作业。不仅是教育机构,而且一些小型组织,办公室和商店仍在使用 MS Windows 字体。以防万一,如果你需要在 Ubuntu 桌面版上使用 Microsoft 字体,请按照以下步骤安装。
|
||||
大多数教育机构仍在使用 Microsoft 字体, 我不清楚其他国家是什么情况。但在泰米尔纳德邦(印度的一个州), **Times New Roman** 和 **Arial** 字体主要被用于大学和学校的几乎所有文档工作、项目和作业。不仅是教育机构,而且一些小型组织、办公室和商店仍在使用 MS Windows 字体。以防万一,如果你需要在 Ubuntu 桌面版上使用 Microsoft 字体,请按照以下步骤安装。
|
||||
|
||||
**免责声明**: Microsoft 已免费发布其核心字体。 但**请不要在其他操作系统中禁止使用 Microsoft 字体**。在任何 Linux 操作系统中安装 MS 字体之前请仔细阅读 EULA 。我们(OSTechNix)不负责这种任何种类的盗版行为。
|
||||
**免责声明**: Microsoft 已免费发布其核心字体。 但**请注意 Microsoft 字体是禁止使用在其他操作系统中**。在任何 Linux 操作系统中安装 MS 字体之前请仔细阅读 EULA 。我们不负责这种任何种类的盗版行为。
|
||||
|
||||
(LCTT 译注:本文只做技术探讨,并不代表作者、译者和本站鼓励任何行为。)
|
||||
|
||||
### 在 Ubuntu 18.04 LTS 桌面版上安装 MS 字体
|
||||
|
||||
如下所示安装 MS TrueType 字体:
|
||||
|
||||
```
|
||||
$ sudo apt update
|
||||
|
||||
$ sudo apt install ttf-mscorefonts-installer
|
||||
|
||||
```
|
||||
|
||||
然后将会出现 Microsoft 的最终用户协议向导,点击 **OK** 以继续。
|
||||
然后将会出现 Microsoft 的最终用户协议向导,点击 **OK** 以继续。
|
||||
|
||||
![][2]
|
||||
|
||||
@ -26,12 +27,13 @@ $ sudo apt install ttf-mscorefonts-installer
|
||||
![][3]
|
||||
|
||||
安装字体之后, 我们需要使用命令行来更新字体缓存:
|
||||
|
||||
```
|
||||
$ sudo fc-cache -f -v
|
||||
|
||||
```
|
||||
|
||||
**示例输出:**
|
||||
**示例输出:**
|
||||
|
||||
```
|
||||
/usr/share/fonts: caching, new cache contents: 0 fonts, 6 dirs
|
||||
/usr/share/fonts/X11: caching, new cache contents: 0 fonts, 4 dirs
|
||||
@ -106,60 +108,54 @@ $ sudo fc-cache -f -v
|
||||
/home/sk/.cache/fontconfig: cleaning cache directory
|
||||
/home/sk/.fontconfig: not cleaning non-existent cache directory
|
||||
fc-cache: succeeded
|
||||
|
||||
```
|
||||
|
||||
### 在 Linux 和 Windows 双启动的机器上安装 MS 字体
|
||||
### 在 Linux 和 Windows 双启动的机器上安装 MS 字体
|
||||
|
||||
如果你有 Linux 和 Windows 的双启动系统,你可以轻松地从 Windows C 驱动器上安装 MS 字体。
|
||||
你所要做的就是挂载 Windows 分区(C:/windows)。
|
||||
|
||||
我假设你已经在 Linux 中将 **C:\Windows** 分区挂载在了 **/Windowsdrive** 目录下。
|
||||
我假设你已经在 Linux 中将 `C:\Windows` 分区挂载在了 `/Windowsdrive` 目录下。
|
||||
|
||||
现在,将字体位置链接到你的 Linux 系统的字体文件夹,如下所示:
|
||||
|
||||
现在,将字体位置链接到你的 Linux 系统的字体文件夹,如下所示。
|
||||
```
|
||||
ln -s /Windowsdrive/Windows/Fonts /usr/share/fonts/WindowsFonts
|
||||
|
||||
```
|
||||
|
||||
链接字体文件之后,使用命令行重新生成 fontconfig 缓存::
|
||||
链接字体文件之后,使用命令行重新生成 fontconfig 缓存:
|
||||
|
||||
```
|
||||
fc-cache
|
||||
|
||||
```
|
||||
|
||||
或者,将所有的 Windows 字体复制到 **/usr/share/fonts** 目录下并使用一下命令安装字体:
|
||||
或者,将所有的 Windows 字体复制到 `/usr/share/fonts` 目录下并使用一下命令安装字体:
|
||||
|
||||
```
|
||||
mkdir /usr/share/fonts/WindowsFonts
|
||||
|
||||
cp /Windowsdrive/Windows/Fonts/* /usr/share/fonts/WindowsFonts
|
||||
|
||||
chmod 755 /usr/share/fonts/WindowsFonts/*
|
||||
|
||||
```
|
||||
|
||||
最后,使用命令行重新生成 fontconfig 缓存:
|
||||
|
||||
```
|
||||
fc-cache
|
||||
|
||||
```
|
||||
|
||||
|
||||
### 测试 Windows 字体
|
||||
|
||||
|
||||
安装 MS 字体后打开 LibreOffice 或 GIMP。 现在,你将会看到 Microsoft coretype 字体。
|
||||
|
||||
![][4]
|
||||
|
||||
就是这样, 希望这本指南有用。我再次警告你,在其他操作系统中使用 MS 字体是被禁止的。在安装 MS 字体之前请先阅读 Microsoft 许可协议。
|
||||
|
||||
如果你觉得我们的指南有用,请在你的社区、专业网络上分享并支持 OSTechNix。还有更多好东西在等着我们。持续访问!
|
||||
如果你觉得我们的指南有用,请在你的社区、专业网络上分享并支持我们。还有更多好东西在等着我们。持续访问!
|
||||
|
||||
庆祝吧!!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/install-microsoft-windows-fonts-ubuntu-16-04/
|
||||
@ -167,7 +163,7 @@ via: https://www.ostechnix.com/install-microsoft-windows-fonts-ubuntu-16-04/
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[Auk7F7](https://github.com/Auk7F7)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,6 +1,8 @@
|
||||
如何检查 Linux 中的可用磁盘空间
|
||||
======
|
||||
|
||||
> 用这里列出的方便的工具来跟踪你的磁盘利用率。
|
||||
|
||||

|
||||
|
||||
跟踪磁盘利用率信息是系统管理员(和其他人)的日常待办事项列表之一。Linux 有一些内置的使用程序来帮助提供这些信息。
|
||||
@ -11,45 +13,48 @@
|
||||
|
||||
`df -h` 以人类可读的格式显示磁盘空间。
|
||||
|
||||
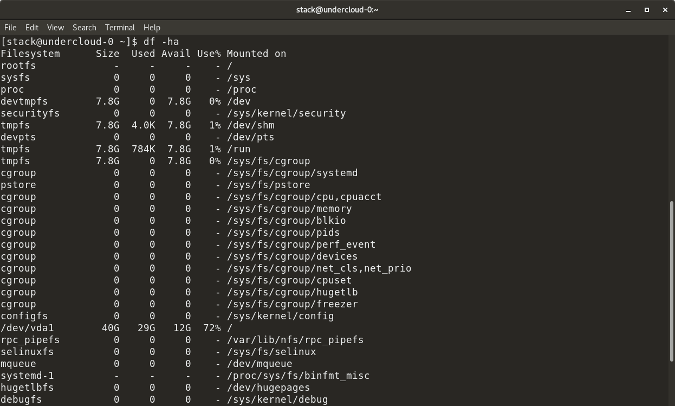
`df -a` 显示文件系统的完整磁盘使用情况,即使 Available(可用) 字段为 0
|
||||
`df -a` 显示文件系统的完整磁盘使用情况,即使 Available(可用) 字段为 0。
|
||||
|
||||
|
||||
|
||||
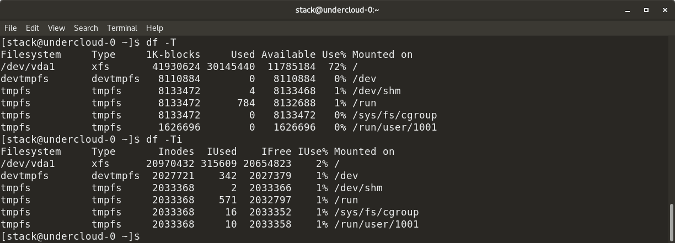
`df -T` 显示磁盘使用情况以及每个块的文件系统类型(例如,xfs, ext2, ext3, btrfs 等)
|
||||
`df -T` 显示磁盘使用情况以及每个块的文件系统类型(例如,xfs、ext2、ext3、btrfs 等)。
|
||||
|
||||
`df -i` 显示已使用和未使用的 inode。
|
||||
|
||||
`df -i` 显示已使用和未使用的 inodes
|
||||
|
||||
|
||||
### du
|
||||
|
||||
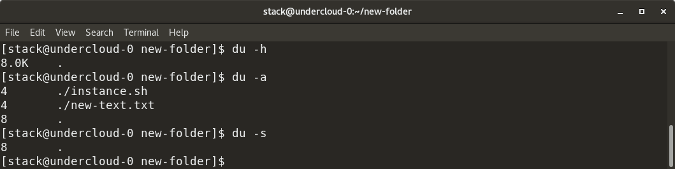
`du` 显示文件,目录等的磁盘使用情况,默认情况下以 kb 为单位显示
|
||||
`du` 显示文件,目录等的磁盘使用情况,默认情况下以 kb 为单位显示。
|
||||
|
||||
`du -h` 以人类可读的方式显示所有目录和子目录的磁盘使用情况
|
||||
`du -h` 以人类可读的方式显示所有目录和子目录的磁盘使用情况。
|
||||
|
||||
`du -a` 显示所有文件的磁盘使用情况
|
||||
`du -a` 显示所有文件的磁盘使用情况。
|
||||
|
||||
`du -s` 提供特定文件或目录使用的总磁盘空间。
|
||||
|
||||
`du -s` 提供特定文件或目录使用的总磁盘空间
|
||||
|
||||
|
||||
以下命令将检查 Linux 系统的总空间和使用空间。
|
||||
|
||||
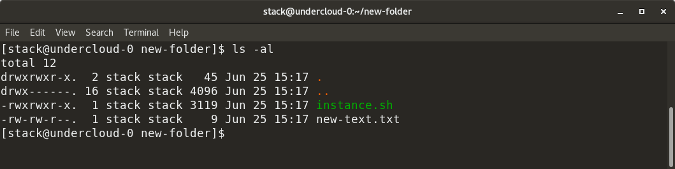
### ls -al
|
||||
|
||||
`ls -al` 列出了特定目录的全部内容及大小。
|
||||
|
||||
|
||||
|
||||
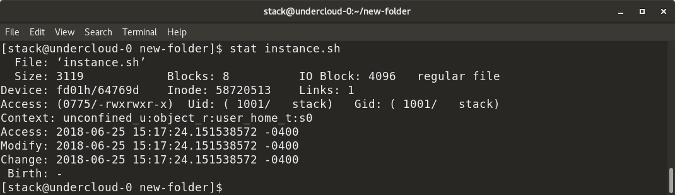
### stat
|
||||
|
||||
`stat <文件/目录> `显示文件/目录或文件系统的大小和其他统计信息。
|
||||
|
||||
|
||||
|
||||
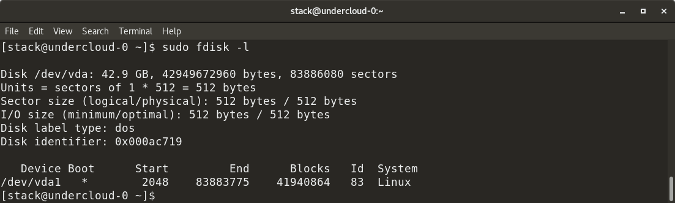
### fdisk -l
|
||||
|
||||
`fdisk -l` 显示磁盘大小以及磁盘分区信息。
|
||||
|
||||
|
||||
|
||||
这些是用于检查 Linux 文件空间的大多数内置实用程序。有许多类似的工具,如 [Disks][1](GUI 工具),[Ncdu][2] 等,它们也显示磁盘空间的利用率。你有你最喜欢的工具而它不在这个列表上吗?请在评论中分享。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/how-check-free-disk-space-linux
|
||||
@ -57,7 +62,7 @@ via: https://opensource.com/article/18/7/how-check-free-disk-space-linux
|
||||
作者:[Archit Modi][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
translating by wyxplus
|
||||
CIP: Keeping the Lights On with Linux
|
||||
======
|
||||
|
||||
|
||||
@ -0,0 +1,450 @@
|
||||
MjSeven is translating
|
||||
|
||||
|
||||
Docker Guide: Dockerizing Python Django Application
|
||||
============================================================
|
||||
|
||||
### On this page
|
||||
|
||||
1. [What we will do?][6]
|
||||
|
||||
2. [Step 1 - Install Docker-ce][7]
|
||||
|
||||
3. [Step 2 - Install Docker-compose][8]
|
||||
|
||||
4. [Step 3 - Configure Project Environment][9]
|
||||
1. [Create a New requirements.txt file][1]
|
||||
|
||||
2. [Create the Nginx virtual host file django.conf][2]
|
||||
|
||||
3. [Create the Dockerfile][3]
|
||||
|
||||
4. [Create Docker-compose script][4]
|
||||
|
||||
5. [Configure Django project][5]
|
||||
|
||||
5. [Step 4 - Build and Run the Docker image][10]
|
||||
|
||||
6. [Step 5 - Testing][11]
|
||||
|
||||
7. [Reference][12]
|
||||
|
||||
Docker is an open-source project that provides an open platform for developers and sysadmins to build, package, and run applications anywhere as a lightweight container. Docker automates the deployment of applications inside software containers.
|
||||
|
||||
Django is a web application framework written in python that follows the MVC (Model-View-Controller) architecture. It is available for free and released under an open source license. It is fast and designed to help developers get their application online as quickly as possible.
|
||||
|
||||
In this tutorial, I will show you step-by-step how to create a docker image for an existing Django application project in Ubuntu 16.04\. We will learn about dockerizing a python Django application, and then deploy the application as a container to the docker environment using a docker-compose script.
|
||||
|
||||
In order to deploy our python Django application, we need additional docker images. We need an nginx docker image for the web server and PostgreSQL image for the database.
|
||||
|
||||
### What we will do?
|
||||
|
||||
1. Install Docker-ce
|
||||
|
||||
2. Install Docker-compose
|
||||
|
||||
3. Configure Project Environment
|
||||
|
||||
4. Build and Run
|
||||
|
||||
5. Testing
|
||||
|
||||
### Step 1 - Install Docker-ce
|
||||
|
||||
In this tutorial, we will install docker-ce community edition from the docker repository. We will install docker-ce community edition and docker-compose that support compose file version 3.
|
||||
|
||||
Before installing docker-ce, install docker dependencies needed using the apt command.
|
||||
|
||||
```
|
||||
sudo apt install -y \
|
||||
apt-transport-https \
|
||||
ca-certificates \
|
||||
curl \
|
||||
software-properties-common
|
||||
```
|
||||
|
||||
Now add the docker key and repository by running commands below.
|
||||
|
||||
```
|
||||
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
|
||||
sudo add-apt-repository \
|
||||
"deb [arch=amd64] https://download.docker.com/linux/ubuntu \
|
||||
$(lsb_release -cs) \
|
||||
stable"
|
||||
```
|
||||
|
||||
[][14]
|
||||
|
||||
Update the repository and install docker-ce.
|
||||
|
||||
```
|
||||
sudo apt update
|
||||
sudo apt install -y docker-ce
|
||||
```
|
||||
|
||||
After the installation is complete, start the docker service and enable it to launch every time at system boot.
|
||||
|
||||
```
|
||||
systemctl start docker
|
||||
systemctl enable docker
|
||||
```
|
||||
|
||||
Next, we will add a new user named 'omar' and add it to the docker group.
|
||||
|
||||
```
|
||||
useradd -m -s /bin/bash omar
|
||||
usermod -a -G docker omar
|
||||
```
|
||||
|
||||
[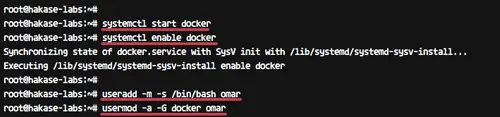][15]
|
||||
|
||||
Login as the omar user and run docker command as shown below.
|
||||
|
||||
```
|
||||
su - omar
|
||||
docker run hello-world
|
||||
```
|
||||
|
||||
Make sure you get the hello-world message from Docker.
|
||||
|
||||
[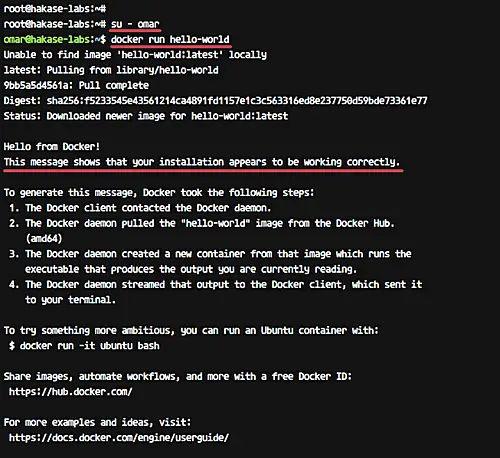][16]
|
||||
|
||||
Docker-ce installation has been completed.
|
||||
|
||||
### Step 2 - Install Docker-compose
|
||||
|
||||
In this tutorial, we will be using the latest docker-compose support for compose file version 3\. We will install docker-compose manually.
|
||||
|
||||
Download the latest version of docker-compose using curl command to the '/usr/local/bin' directory and make it executable using chmod.
|
||||
|
||||
Run commands below.
|
||||
|
||||
```
|
||||
sudo curl -L https://github.com/docker/compose/releases/download/1.21.0/docker-compose-$(uname -s)-$(uname -m) -o /usr/local/bin/docker-compose
|
||||
sudo chmod +x /usr/local/bin/docker-compose
|
||||
```
|
||||
|
||||
Now check the docker-compose version.
|
||||
|
||||
```
|
||||
docker-compose version
|
||||
```
|
||||
|
||||
And make sure you get the latest version of the docker-compose 1.21.
|
||||
|
||||
[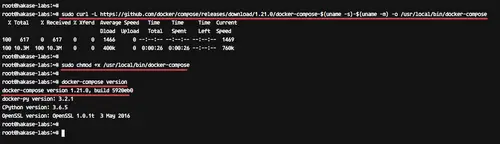][17]
|
||||
|
||||
The docker-compose latest version that supports compose file version 3 has been installed.
|
||||
|
||||
### Step 3 - Configure Project Environment
|
||||
|
||||
In this step, we will configure the python Django project environment. We will create new directory 'guide01' and make it as the main directory for our project files, such as a Dockerfile, Django project, nginx configuration file etc.
|
||||
|
||||
Login to the 'omar' user.
|
||||
|
||||
```
|
||||
su - omar
|
||||
```
|
||||
|
||||
Create new directory 'guide01' and go to the directory.
|
||||
|
||||
```
|
||||
mkdir -p guide01
|
||||
cd guide01/
|
||||
```
|
||||
|
||||
Now inside the 'guide01' directory, create new directories 'project' and 'config'.
|
||||
|
||||
```
|
||||
mkdir project/ config/
|
||||
```
|
||||
|
||||
Note:
|
||||
|
||||
* Directory 'project': All our python Django project files will be placed in that directory.
|
||||
|
||||
* Directory 'config': Directory for the project configuration files, including nginx configuration file, python pip requirements file etc.
|
||||
|
||||
### Create a New requirements.txt file
|
||||
|
||||
Next, create new file 'requirements.txt' inside the 'config' directory using vim command.
|
||||
|
||||
```
|
||||
vim config/requirements.txt
|
||||
```
|
||||
|
||||
Paste the configuration below.
|
||||
|
||||
```
|
||||
Django==2.0.4
|
||||
gunicorn==19.7.0
|
||||
psycopg2==2.7.4
|
||||
```
|
||||
|
||||
Save and exit.
|
||||
|
||||
### Create the Nginx virtual host file django.conf
|
||||
|
||||
Under the config directory, create the 'nginx' configuration directory and add the virtual host configuration file django.conf.
|
||||
|
||||
```
|
||||
mkdir -p config/nginx/
|
||||
vim config/nginx/django.conf
|
||||
```
|
||||
|
||||
Paste the following configuration there.
|
||||
|
||||
```
|
||||
upstream web {
|
||||
ip_hash;
|
||||
server web:8000;
|
||||
}
|
||||
|
||||
# portal
|
||||
server {
|
||||
location / {
|
||||
proxy_pass http://web/;
|
||||
}
|
||||
listen 8000;
|
||||
server_name localhost;
|
||||
|
||||
location /static {
|
||||
autoindex on;
|
||||
alias /src/static/;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Save and exit.
|
||||
|
||||
### Create the Dockerfile
|
||||
|
||||
Create new 'Dockerfile' inside the 'guide01' directory.
|
||||
|
||||
Run the command below.
|
||||
|
||||
```
|
||||
vim Dockerfile
|
||||
```
|
||||
|
||||
Now paste Dockerfile script below.
|
||||
|
||||
```
|
||||
FROM python:3.5-alpine
|
||||
ENV PYTHONUNBUFFERED 1
|
||||
|
||||
RUN apk update && \
|
||||
apk add --virtual build-deps gcc python-dev musl-dev && \
|
||||
apk add postgresql-dev bash
|
||||
|
||||
RUN mkdir /config
|
||||
ADD /config/requirements.txt /config/
|
||||
RUN pip install -r /config/requirements.txt
|
||||
RUN mkdir /src
|
||||
WORKDIR /src
|
||||
```
|
||||
|
||||
Save and exit.
|
||||
|
||||
Note:
|
||||
|
||||
We want to build the Docker images for our Django project based on Alpine Linux, the smallest size of Linux. Our Django project will run Alpine Linux with python 3.5 installed on top of it and add the postgresql-dev package for the PostgreSQL database support. And then we will install all python packages listed on the 'requirements.txt' file using python pip command, and create new '/src' for our project.
|
||||
|
||||
### Create Docker-compose script
|
||||
|
||||
Create the 'docker-compose.yml' file under the 'guide01' directory using [vim][18] command below.
|
||||
|
||||
```
|
||||
vim docker-compose.yml
|
||||
```
|
||||
|
||||
Paste the following configuration there.
|
||||
|
||||
```
|
||||
version: '3'
|
||||
services:
|
||||
db:
|
||||
image: postgres:10.3-alpine
|
||||
container_name: postgres01
|
||||
nginx:
|
||||
image: nginx:1.13-alpine
|
||||
container_name: nginx01
|
||||
ports:
|
||||
- "8000:8000"
|
||||
volumes:
|
||||
- ./project:/src
|
||||
- ./config/nginx:/etc/nginx/conf.d
|
||||
depends_on:
|
||||
- web
|
||||
web:
|
||||
build: .
|
||||
container_name: django01
|
||||
command: bash -c "python manage.py makemigrations && python manage.py migrate && python manage.py collectstatic --noinput && gunicorn hello_django.wsgi -b 0.0.0.0:8000"
|
||||
depends_on:
|
||||
- db
|
||||
volumes:
|
||||
- ./project:/src
|
||||
expose:
|
||||
- "8000"
|
||||
restart: always
|
||||
```
|
||||
|
||||
Save and exit.
|
||||
|
||||
Note:
|
||||
|
||||
With this docker-compose file script, we will create three services. Create the database service named 'db' using the PostgreSQL alpine Linux, create the 'nginx' service using the Nginx alpine Linux again, and create our python Django container using the custom docker images generated from our Dockerfile.
|
||||
|
||||
[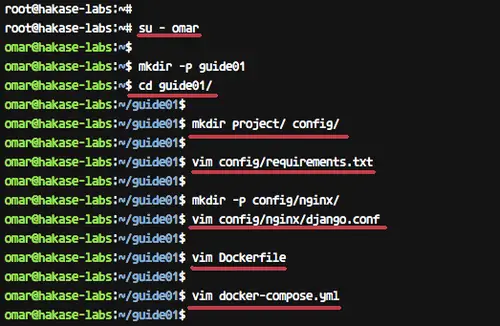][19]
|
||||
|
||||
### Configure Django project
|
||||
|
||||
Copy your Django project files to the 'project' directory.
|
||||
|
||||
```
|
||||
cd ~/django
|
||||
cp -r * ~/guide01/project/
|
||||
```
|
||||
|
||||
Go to the 'project' directory and edit the application setting 'settings.py'.
|
||||
|
||||
```
|
||||
cd ~/guide01/project/
|
||||
vim hello_django/settings.py
|
||||
```
|
||||
|
||||
Note:
|
||||
|
||||
We will deploy simple Django application called 'hello_django' app.
|
||||
|
||||
On the 'ALLOW_HOSTS' line, add the service name 'web'.
|
||||
|
||||
```
|
||||
ALLOW_HOSTS = ['web']
|
||||
```
|
||||
|
||||
Now change the database settings. We will be using the PostgreSQL database that runs as a service named 'db' with default user and password.
|
||||
|
||||
```
|
||||
DATABASES = {
|
||||
'default': {
|
||||
'ENGINE': 'django.db.backends.postgresql_psycopg2',
|
||||
'NAME': 'postgres',
|
||||
'USER': 'postgres',
|
||||
'HOST': 'db',
|
||||
'PORT': 5432,
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
And for the 'STATIC_ROOT' configuration directory, add this line to the end of the line of the file.
|
||||
|
||||
```
|
||||
STATIC_ROOT = os.path.join(BASE_DIR, 'static/')
|
||||
```
|
||||
|
||||
Save and exit.
|
||||
|
||||
[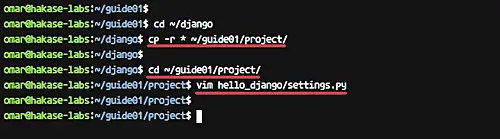][20]
|
||||
|
||||
Now we're ready to build and run the Django project under the docker container.
|
||||
|
||||
### Step 4 - Build and Run the Docker image
|
||||
|
||||
In this step, we want to build a Docker image for our Django project using the configuration on the 'guide01' directory.
|
||||
|
||||
Go to the 'guide01' directory.
|
||||
|
||||
```
|
||||
cd ~/guide01/
|
||||
```
|
||||
|
||||
Now build the docker images using the docker-compose command.
|
||||
|
||||
```
|
||||
docker-compose build
|
||||
```
|
||||
|
||||
[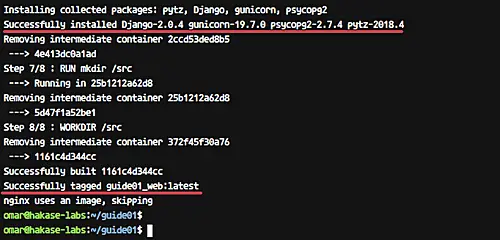][21]
|
||||
|
||||
Start all services inside the docker-compose script.
|
||||
|
||||
```
|
||||
docker-compose up -d
|
||||
```
|
||||
|
||||
Wait for some minutes for Docker to build our Python image and download the nginx and postgresql docker images.
|
||||
|
||||
[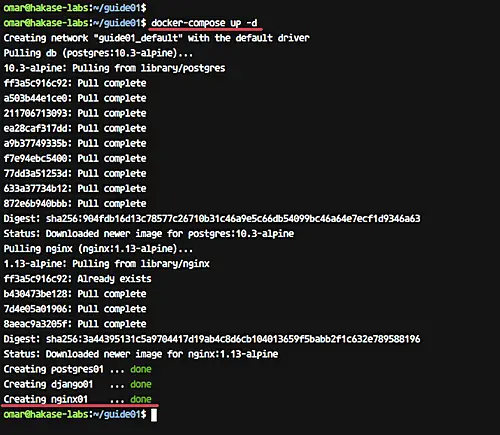][22]
|
||||
|
||||
And when it's complete, check running container and list docker images on the system using following commands.
|
||||
|
||||
```
|
||||
docker-compose ps
|
||||
docker-compose images
|
||||
```
|
||||
|
||||
And now you will get three containers running and list of Docker images on the system as shown below.
|
||||
|
||||
[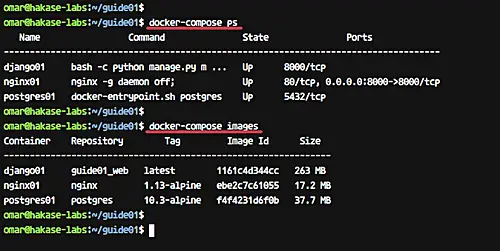][23]
|
||||
|
||||
Our Python Django Application is now running inside the docker container, and docker images for our service have been created.
|
||||
|
||||
### Step 5 - Testing
|
||||
|
||||
Open your web browser and type the server address with port 8000, mine is: http://ovh01:8000/
|
||||
|
||||
Now you will get the default Django home page.
|
||||
|
||||
[][24]
|
||||
|
||||
Next, test the admin page by adding the '/admin' path on the URL.
|
||||
|
||||
http://ovh01:8000/admin/
|
||||
|
||||
And you will see the Django admin login page.
|
||||
|
||||
[][25]
|
||||
|
||||
The Dockerizing Python Django Application has been completed successfully.
|
||||
|
||||
### Reference
|
||||
|
||||
* [https://docs.docker.com/][13]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/
|
||||
|
||||
作者:[Muhammad Arul][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/
|
||||
[1]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/#create-a-new-requirementstxt-file
|
||||
[2]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/#create-the-nginx-virtual-host-file-djangoconf
|
||||
[3]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/#create-the-dockerfile
|
||||
[4]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/#create-dockercompose-script
|
||||
[5]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/#configure-django-project
|
||||
[6]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/#what-we-will-do
|
||||
[7]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/#step-install-dockerce
|
||||
[8]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/#step-install-dockercompose
|
||||
[9]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/#step-configure-project-environment
|
||||
[10]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/#step-build-and-run-the-docker-image
|
||||
[11]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/#step-testing
|
||||
[12]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/#reference
|
||||
[13]:https://docs.docker.com/
|
||||
[14]:https://www.howtoforge.com/images/docker_guide_dockerizing_python_django_application/big/1.png
|
||||
[15]:https://www.howtoforge.com/images/docker_guide_dockerizing_python_django_application/big/2.png
|
||||
[16]:https://www.howtoforge.com/images/docker_guide_dockerizing_python_django_application/big/3.png
|
||||
[17]:https://www.howtoforge.com/images/docker_guide_dockerizing_python_django_application/big/4.png
|
||||
[18]:https://www.howtoforge.com/vim-basics
|
||||
[19]:https://www.howtoforge.com/images/docker_guide_dockerizing_python_django_application/big/5.png
|
||||
[20]:https://www.howtoforge.com/images/docker_guide_dockerizing_python_django_application/big/6.png
|
||||
[21]:https://www.howtoforge.com/images/docker_guide_dockerizing_python_django_application/big/7.png
|
||||
[22]:https://www.howtoforge.com/images/docker_guide_dockerizing_python_django_application/big/8.png
|
||||
[23]:https://www.howtoforge.com/images/docker_guide_dockerizing_python_django_application/big/9.png
|
||||
[24]:https://www.howtoforge.com/images/docker_guide_dockerizing_python_django_application/big/10.png
|
||||
[25]:https://www.howtoforge.com/images/docker_guide_dockerizing_python_django_application/big/11.png
|
||||
File diff suppressed because it is too large
Load Diff
@ -1,233 +0,0 @@
|
||||
translating by wyxplus
|
||||
How to Run Your Own Git Server
|
||||
======
|
||||
**Learn how to set up your own Git server in this tutorial from our archives.**
|
||||
|
||||
[Git ][1]is a versioning system [developed by Linus Torvalds][2], that is used by millions of users around the globe. Companies like GitHub offer code hosting services based on Git. [According to reports, GitHub, a code hosting site, is the world's largest code hosting service.][3] The company claims that there are 9.2M people collaborating right now across 21.8M repositories on GitHub. Big companies are now moving to GitHub. [Even Google, the search engine giant, is shutting it's own Google Code and moving to GitHub.][4]
|
||||
|
||||
### Run your own Git server
|
||||
|
||||
GitHub is a great service, however there are some limitations and restrictions, especially if you are an individual or a small player. One of the limitations of GitHub is that the free service doesn’t allow private hosting of the code. [You have to pay a monthly fee of $7 to host 5 private repositories][5], and the expenses go up with more repos.
|
||||
|
||||
In cases like these or when you want more control, the best path is to run Git on your own server. Not only do you save costs, you also have more control over your server. In most cases a majority of advanced Linux users already have their own servers and pushing Git on those servers is like ‘free as in beer’.
|
||||
|
||||
In this tutorial we are going to talk about two methods of managing your code on your own server. One is running a bare, basic Git server and and the second one is via a GUI tool called [GitLab][6]. For this tutorial I used a fully patched Ubuntu 14.04 LTS server running on a VPS.
|
||||
|
||||
### Install Git on your server
|
||||
|
||||
In this tutorial we are considering a use-case where we have a remote server and a local server and we will work between these machines. For the sake of simplicity we will call them remote-server and local-server.
|
||||
|
||||
First, install Git on both machines. You can install Git from the packages already available via the repos or your distros, or you can do it manually. In this article we will use the simpler method:
|
||||
```
|
||||
sudo apt-get install git-core
|
||||
|
||||
```
|
||||
|
||||
Then add a user for Git.
|
||||
```
|
||||
sudo useradd git
|
||||
passwd git
|
||||
|
||||
```
|
||||
|
||||
In order to ease access to the server let's set-up a password-less ssh login. First create ssh keys on your local machine:
|
||||
```
|
||||
ssh-keygen -t rsa
|
||||
|
||||
```
|
||||
|
||||
It will ask you to provide the location for storing the key, just hit Enter to use the default location. The second question will be to provide it with a pass phrase which will be needed to access the remote server. It generates two keys - a public key and a private key. Note down the location of the public key which you will need in the next step.
|
||||
|
||||
Now you have to copy these keys to the server so that the two machines can talk to each other. Run the following command on your local machine:
|
||||
```
|
||||
cat ~/.ssh/id_rsa.pub | ssh git@remote-server "mkdir -p ~/.ssh && cat >> ~/.ssh/authorized_keys"
|
||||
|
||||
```
|
||||
|
||||
Now ssh into the server and create a project directory for Git. You can use the desired path for the repo.
|
||||
|
||||
Then change to this directory:
|
||||
```
|
||||
cd /home/swapnil/project-1.git
|
||||
|
||||
```
|
||||
|
||||
Then create an empty repo:
|
||||
```
|
||||
git init --bare
|
||||
Initialized empty Git repository in /home/swapnil/project-1.git
|
||||
|
||||
```
|
||||
|
||||
We now need to create a Git repo on the local machine.
|
||||
```
|
||||
mkdir -p /home/swapnil/git/project
|
||||
|
||||
```
|
||||
|
||||
And change to this directory:
|
||||
```
|
||||
cd /home/swapnil/git/project
|
||||
|
||||
```
|
||||
|
||||
Now create the files that you need for the project in this directory. Stay in this directory and initiate git:
|
||||
```
|
||||
git init
|
||||
Initialized empty Git repository in /home/swapnil/git/project
|
||||
|
||||
```
|
||||
|
||||
Now add files to the repo:
|
||||
```
|
||||
git add .
|
||||
|
||||
```
|
||||
|
||||
Now every time you add a file or make changes you have to run the add command above. You also need to write a commit message with every change in a file. The commit message basically tells what changes were made.
|
||||
```
|
||||
git commit -m "message" -a
|
||||
[master (root-commit) 57331ee] message
|
||||
2 files changed, 2 insertions(+)
|
||||
create mode 100644 GoT.txt
|
||||
create mode 100644 writing.txt
|
||||
|
||||
```
|
||||
|
||||
In this case I had a file called GoT (Game of Thrones review) and I made some changes, so when I ran the command it specified that changes were made to the file. In the above command '-a' option means commits for all files in the repo. If you made changes to only one you can specify the name of that file instead of using '-a'.
|
||||
|
||||
An example:
|
||||
```
|
||||
git commit -m "message" GoT.txt
|
||||
[master e517b10] message
|
||||
1 file changed, 1 insertion(+)
|
||||
|
||||
```
|
||||
|
||||
Until now we have been working on the local server. Now we have to push these changes to the server so the work is accessible over the Internet and you can collaborate with other team members.
|
||||
```
|
||||
git remote add origin ssh://git@remote-server/repo-<wbr< a="">>path-on-server..git
|
||||
|
||||
```
|
||||
|
||||
Now you can push or pull changes between the server and local machine using the 'push' or 'pull' option:
|
||||
```
|
||||
git push origin master
|
||||
|
||||
```
|
||||
|
||||
If there are other team members who want to work with the project they need to clone the repo on the server to their local machine:
|
||||
```
|
||||
git clone git@remote-server:/home/swapnil/project.git
|
||||
|
||||
```
|
||||
|
||||
Here /home/swapnil/project.git is the project path on the remote server, exchange the values for your own server.
|
||||
|
||||
Then change directory on the local machine (exchange project with the name of project on your server):
|
||||
```
|
||||
cd /project
|
||||
|
||||
```
|
||||
|
||||
Now they can edit files, write commit change messages and then push them to the server:
|
||||
```
|
||||
git commit -m 'corrections in GoT.txt story' -a
|
||||
And then push changes:
|
||||
|
||||
git push origin master
|
||||
|
||||
```
|
||||
|
||||
I assume this is enough for a new user to get started with Git on their own servers. If you are looking for some GUI tools to manage changes on local machines, you can use GUI tools such as QGit or GitK for Linux.
|
||||
|
||||
### Using GitLab
|
||||
|
||||
This was a pure command line solution for project owner and collaborator. It's certainly not as easy as using GitHub. Unfortunately, while GitHub is the world's largest code hosting service; its own software is not available for others to use. It's not open source so you can't grab the source code and compile your own GitHub. Unlike WordPress or Drupal you can't download GitHub and run it on your own servers.
|
||||
|
||||
As usual in the open source world there is no end to the options. GitLab is a nifty project which does exactly that. It's an open source project which allows users to run a project management system similar to GitHub on their own servers.
|
||||
|
||||
You can use GitLab to run a service similar to GitHub for your team members or your company. You can use GitLab to work on private projects before releasing them for public contributions.
|
||||
|
||||
GitLab employs the traditional Open Source business model. They have two products: free of cost open source software, which users can install on their own servers, and a hosted service similar to GitHub.
|
||||
|
||||
The downloadable version has two editions - the free of cost community edition and the paid enterprise edition. The enterprise edition is based on the community edition but comes with additional features targeted at enterprise customers. It’s more or less similar to what WordPress.org or Wordpress.com offer.
|
||||
|
||||
The community edition is highly scalable and can support 25,000 users on a single server or cluster. Some of the features of GitLab include: Git repository management, code reviews, issue tracking, activity feeds, and wikis. It comes with GitLab CI for continuous integration and delivery.
|
||||
|
||||
Many VPS providers such as Digital Ocean offer GitLab droplets for users. If you want to run it on your own server, you can install it manually. GitLab offers an Omnibus package for different operating systems. Before we install GitLab, you may want to configure an SMTP email server so that GitLab can push emails as and when needed. They recommend Postfix. So, install Postfix on your server:
|
||||
```
|
||||
sudo apt-get install postfix
|
||||
|
||||
```
|
||||
|
||||
During installation of Postfix it will ask you some questions; don't skip them. If you did miss it you can always re-configure it using this command:
|
||||
```
|
||||
sudo dpkg-reconfigure postfix
|
||||
|
||||
```
|
||||
|
||||
When you run this command choose "Internet Site" and provide the email ID for the domain which will be used by Gitlab.
|
||||
|
||||
In my case I provided it with:
|
||||
```
|
||||
This e-mail address is being protected from spambots. You need JavaScript enabled to view it
|
||||
|
||||
|
||||
```
|
||||
|
||||
Use Tab and create a username for postfix. The Next page will ask you to provide a destination for mail.
|
||||
|
||||
In the rest of the steps, use the default options. Once Postfix is installed and configured, let's move on to install GitLab.
|
||||
|
||||
Download the packages using wget (replace the download link with the [latest packages from here][7]) :
|
||||
```
|
||||
wget https://downloads-packages.s3.amazonaws.com/ubuntu-14.04/gitlab_7.9.4-omnibus.1-1_amd64.deb
|
||||
|
||||
```
|
||||
|
||||
Then install the package:
|
||||
```
|
||||
sudo dpkg -i gitlab_7.9.4-omnibus.1-1_amd64.deb
|
||||
|
||||
```
|
||||
|
||||
Now it's time to configure and start GitLabs.
|
||||
```
|
||||
sudo gitlab-ctl reconfigure
|
||||
|
||||
```
|
||||
|
||||
You now need to configure the domain name in the configuration file so you can access GitLab. Open the file.
|
||||
```
|
||||
nano /etc/gitlab/gitlab.rb
|
||||
|
||||
```
|
||||
|
||||
In this file edit the 'external_url' and give the server domain. Save the file and then open the newly created GitLab site from a web browser.
|
||||
|
||||
By default it creates 'root' as the system admin and uses '5iveL!fe' as the password. Log into the GitLab site and then change the password.
|
||||
|
||||
Once the password is changed, log into the site and start managing your project.
|
||||
|
||||
GitLab is overflowing with features and options. I will borrow popular lines from the movie, The Matrix: "Unfortunately, no one can be told what all GitLab can do. You have to try it for yourself."
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/how-run-your-own-git-server
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/arnieswap
|
||||
[1]:https://github.com/git/git
|
||||
[2]:https://www.linuxfoundation.org/blog/10-years-of-git-an-interview-with-git-creator-linus-torvalds/
|
||||
[3]:https://github.com/about/press
|
||||
[4]:http://google-opensource.blogspot.com/2015/03/farewell-to-google-code.html
|
||||
[5]:https://github.com/pricing
|
||||
[6]:https://about.gitlab.com/
|
||||
[7]:https://about.gitlab.com/downloads/
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
GitLab’s Ultimate & Gold Plans Are Now Free For Open-Source Projects
|
||||
======
|
||||
A lot has happened in the open-source community recently. First, [Microsoft acquired GitHub][1] and then people started to look for [GitHub alternatives][2] without even taking a second to think about it while Linus Torvalds released the [Linux Kernel 4.17][3]. Well, if you’ve been following us, I assume that you know all that.
|
||||
|
||||
@ -1,45 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Malware Found On The Arch User Repository (AUR)
|
||||
======
|
||||
|
||||
On July 7, an AUR package was modified with some malicious code, reminding [Arch Linux][1] users (and Linux users in general) that all user-generated packages should be checked (when possible) before installation.
|
||||
|
||||
[AUR][3] , or the Arch (Linux) User Repository contains package descriptions, also known as PKGBUILDs, which make compiling packages from source easier. While these packages are very useful, they should never be treated as safe, and users should always check their contents before using them, when possible. After all, the AUR webpage states in bold that "AUR packages are user produced content. Any use of the provided files is at your own risk."
|
||||
|
||||
The [discovery][4] of an AUR package containing malicious code proves this. [acroread][5] was modified on July 7 (it appears it was previously "orphaned", meaning it had no maintainer) by an user named "xeactor" to include a `curl` command that downloaded a script from a pastebin. The script then downloaded another script and installed a systemd unit to run that script periodically.
|
||||
|
||||
**It appears [two other][2] AUR packages were modified in the same way. All the offending packages were removed and the user account (which was registered in the same day those packages were updated) that was used to upload them was suspended.**
|
||||
|
||||
The malicious code didn't do anything truly harmful - it only tried to upload some system information, like the machine ID, the output of `uname -a` (which includes the kernel version, architecture, etc.), CPU information, pacman information, and the output of `systemctl list-units` (which lists systemd units information) to pastebin.com. I'm saying "tried" because no system information was actually uploaded due to an error in the second script (the upload function is called "upload", but the script tried to call it using a different name, "uploader").
|
||||
|
||||
Also, the person adding these malicious scripts to AUR left the personal Pastebin API key in the script in cleartext, proving once again that they don't know exactly what they are doing.
|
||||
|
||||
The purpose for trying to upload this information to Pastebin is not clear, especially since much more sensitive data could have been uploaded, like GPG / SSH keys.
|
||||
|
||||
**Update:** Reddit user u/xanaxdroid_ [mentions][6] that the same user named "xeactor" also had some cryptocurrency mining packages posted, so he speculates that "xeactor" was probably planning on adding some hidden cryptocurrency mining software to AUR (this was also the case with some Ubuntu Snap packages [two months ago][7]). That's why "xeactor" was probably trying to obtain various system information. All the packages uploaded by this AUR user have been removed so I cannot check this.
|
||||
|
||||
**Another update:**
|
||||
|
||||
What exactly should you check in user-generated packages such as those found in AUR? This varies and I can't tell you exactly but you can start by looking for anything that tries to download something using `curl` , `wget` and other similar tools, and see what exactly they are attempting to download. Also check the server from which the package source is downloaded from and make sure it's the official source. Unfortunately this is not an exact 'science'. For Launchpad PPAs for example, things get more complicated as you must know how Debian packaging works, and the source can be altered directly as it's hosted in the PPA and uploaded by the user. It gets even more complicated with Snap packages, because you cannot check such packages before installation (as far as I know). In these latter cases, and as a generic solution, I guess you should only install user-generated packages if you trust the uploader / packager.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxuprising.com/2018/07/malware-found-on-arch-user-repository.html
|
||||
|
||||
作者:[Logix][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/118280394805678839070
|
||||
[1]:https://www.archlinux.org/
|
||||
[2]:https://lists.archlinux.org/pipermail/aur-general/2018-July/034153.html
|
||||
[3]:https://aur.archlinux.org/
|
||||
[4]:https://lists.archlinux.org/pipermail/aur-general/2018-July/034152.html
|
||||
[5]:https://aur.archlinux.org/cgit/aur.git/commit/?h=acroread&id=b3fec9f2f16703c2dae9e793f75ad6e0d98509bc
|
||||
[6]:https://www.reddit.com/r/archlinux/comments/8x0p5z/reminder_to_always_read_your_pkgbuilds/e21iugg/
|
||||
[7]:https://www.linuxuprising.com/2018/05/malware-found-in-ubuntu-snap-store.html
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
Display Weather Forecast In Your Terminal With Wttr.in
|
||||
======
|
||||
**[wttr.in][1] is a feature-packed weather forecast service that supports displaying the weather from the command line**. It can automatically detect your location (based on your IP address), supports specifying the location or searching for a geographical location (like a site in a city, a mountain and so on), and much more. Oh, and **you don't have to install it - all you need to use it is cURL or Wget** (see below).
|
||||
|
||||
@ -1,65 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
4 add-ons to improve your privacy on Thunderbird
|
||||
======
|
||||
|
||||

|
||||
Thunderbird is a popular free email client developed by [Mozilla][1]. Similar to Firefox, Thunderbird offers a large choice of add-ons for extra features and customization. This article focuses on four add-ons to improve your privacy.
|
||||
|
||||
### Enigmail
|
||||
|
||||
Encrypting emails using GPG (GNU Privacy Guard) is the best way to keep their contents private. If you aren’t familiar with GPG, [check out our primer right here][2] on the Magazine.
|
||||
|
||||
[Enigmail][3] is the go-to add-on for using OpenPGP with Thunderbird. Indeed, Enigmail integrates well with Thunderbird, and lets you encrypt, decrypt, and digitally sign and verify emails.
|
||||
|
||||
### Paranoia
|
||||
|
||||
[Paranoia][4] gives you access to critical information about your incoming emails. An emoticon shows the encryption state between servers an email traveled through before reaching your inbox.
|
||||
|
||||
A yellow, happy emoticon tells you all connections were encrypted. A blue, sad emoticon means one connection was not encrypted. Finally, a red, scared emoticon shows on more than one connection the message wasn’t encrypted.
|
||||
|
||||
More details about these connections are available, so you can check which servers were used to deliver the email.
|
||||
|
||||
### Sensitivity Header
|
||||
|
||||
[Sensitivity Header][5] is a simple add-on that lets you select the privacy level of an outgoing email. Using the option menu, you can select a sensitivity: Normal, Personal, Private and Confidential.
|
||||
|
||||
Adding this header doesn’t add extra security to email. However, some email clients or mail transport/user agents (MTA/MUA) can use this header to process the message differently based on the sensitivity.
|
||||
|
||||
Note that this add-on is marked as experimental by its developers.
|
||||
|
||||
### TorBirdy
|
||||
|
||||
If you’re really concerned about your privacy, [TorBirdy][6] is the add-on for you. It configures Thunderbird to use the [Tor][7] network.
|
||||
|
||||
TorBirdy offers less privacy on email accounts that have been used without Tor before, as noted in the [documentation][8].
|
||||
|
||||
> Please bear in mind that email accounts that have been used without Tor before offer **less** privacy/anonymity/weaker pseudonyms than email accounts that have always been accessed with Tor. But nevertheless, TorBirdy is still useful for existing accounts or real-name email addresses. For example, if you are looking for location anonymity — you travel a lot and don’t want to disclose all your locations by sending emails — TorBirdy works wonderfully!
|
||||
|
||||
Note that to use this add-on, you must have Tor installed on your system.
|
||||
|
||||
Photo by [Braydon Anderson][9] on [Unsplash][10].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/4-addons-privacy-thunderbird/
|
||||
|
||||
作者:[Clément Verna][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org
|
||||
[1]:https://www.mozilla.org/en-US/
|
||||
[2]:https://fedoramagazine.org/gnupg-a-fedora-primer/
|
||||
[3]:https://addons.mozilla.org/en-US/thunderbird/addon/enigmail/
|
||||
[4]:https://addons.mozilla.org/en-US/thunderbird/addon/paranoia/?src=cb-dl-users
|
||||
[5]:https://addons.mozilla.org/en-US/thunderbird/addon/sensitivity-header/?src=cb-dl-users
|
||||
[6]:https://addons.mozilla.org/en-US/thunderbird/addon/torbirdy/?src=cb-dl-users
|
||||
[7]:https://www.torproject.org/
|
||||
[8]:https://trac.torproject.org/projects/tor/wiki/torbirdy
|
||||
[9]:https://unsplash.com/photos/wOHH-NUTvVc?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[10]:https://unsplash.com/search/photos/privacy?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
@ -1,130 +0,0 @@
|
||||
IT自动化的下一步是什么: 6 大趋势
|
||||
======
|
||||
|
||||

|
||||
|
||||
我们最近介绍了 [促进自动化的因素][1] ,目前正在被人们采用的 [趋势][2], 以及那些刚开始使用自动化部分流程组织 [有用的技巧][3] 。
|
||||
|
||||
噢, 我们也分享了在你的公司[如何使用自动化的案例][4] , 以及 [长期成功的关键][5].
|
||||
|
||||
现在, 只有一个问题: 自动化的下一步是什么? 我们邀请一系列专家分享一下 [自动化][6]不远的将来。 以下是他们建议IT领域领导需密切关注的六大趋势。
|
||||
|
||||
### 1. 机器学习的成熟
|
||||
|
||||
对于关于 [机器学习][7]的讨论 (与“自我学习系统”相似的定义),对于绝大多数组织的项目来说,实际执行起来它仍然为时过早。但预计这将发生变化,机器学习将在下一次IT自动化浪潮中将扮演着至关重要的角色。
|
||||
|
||||
[Advanced Systems Concepts, Inc.][8]公司工程总监 Mehul Amin 指出机器学习是IT自动化下一个关键增长领域之一。
|
||||
|
||||
“随着数据化的发展, 自动化软件理应可以自我决策,否则这就是开发人员的责任了”, Amin 说。 “例如, 开发者需要执行构建内容, 但是识别系统最佳执行流程的,可能是由系统内软件分析完成。”
|
||||
|
||||
假设将这个系统延伸到其他地方中。Amin 指出,机器学习可以使自动化系统在必要的时候提供额外的资源,以需要满足时间线或SLA,同样在不需要资源的时候退出以及其他的可能性。
|
||||
|
||||
显然不只有 Amin 一个人这样认为。
|
||||
|
||||
[Sungard Availability Services][9] 公司首席架构师 Kiran Chitturi 表示,“IT自动化正在走向自我学习的方向” 。“系统将会能测试和监控自己,加强业务流程和软件交付能力。”
|
||||
|
||||
Chitturi 指出自动化测试就是个例子。脚本测试已经被广泛采用,但很快这些自动化测试流程将会更容易学习,更快发展,例如开发出新的代码或将更为广泛地影响生产环境。
|
||||
|
||||
### 2. 人工智能催生的自动化
|
||||
|
||||
上述原则同样适合 [人工智能][10](但是为独立)的领域。假定新兴的人工智能技术将也会产生新的自动化机会。根据对人工智能的定义,机器学习在短时间内可能会对IT领域产生巨大的影响(并且我们可能会看到这两个领域的许多重叠的定义和理解)。
|
||||
|
||||
[SolarWinds][11]公司技术负责人 Patrick Hubbard说,“人工智能(AI)和机器学习的整合普遍被认为对未来几年的商业成功起至关重要的作用。”
|
||||
|
||||
### 3. 这并不意味着不再需要人力
|
||||
|
||||
让我们试着安慰一下那些不知所措的人:前两种趋势并不一定意味着我们将失去工作。
|
||||
|
||||
这很可能意味着各种角色的改变以及[全新角色][12]的创造。
|
||||
|
||||
但是在可预见的将来,至少,你不必需要机器人鞠躬。
|
||||
|
||||
“一台机器只能运行在给定的环境变量中它不能选择包含新的变量,在今天只有人类可以这样做,” Hubbard 解释说。“但是,对于IT专业人员来说,这将是需要培养AI和自动化技能的时代。如对程序设计、编程、管理人工智能和机器学习功能算法的基本理解,以及用强大的安全状态面对更复杂的网络攻击。”
|
||||
|
||||
Hubbard 分享一些新的工具或功能例子,例如支持人工智能的安全软件或机器学习的应用程序,这些应用程序可以远程发现石油管道中的维护需求。两者都可以提高效益和效果,自然不会代替需要信息安全或管道维护的人员。
|
||||
|
||||
“许多新功能仍需要人工监控,”Hubbard 说。“例如,为了让机器确定一些‘预测’是否可能成为‘规律’,人为的管理是必要的。”
|
||||
|
||||
即使你把机器学习和AI先放在一边,看待一般地IT自动化,同样原理也是成立的,尤其是在软件开发生命周期中。
|
||||
|
||||
[Juniper Networks][13]公司自动化首席架构师 Matthew Oswalt ,指出IT自动化增长的根本原因是它通过减少操作基础设施所需的人工工作量来创造直接价值。
|
||||
|
||||
在代码上,操作工程师可以使用事件驱动的自动化提前定义他们的工作流程,而不是在凌晨3点来应对基础设施的问题。
|
||||
|
||||
“它也将操作工作流程作为代码而不再是容易过时的文档或系统知识阶段,”Oswalt解释说。“操作人员仍然需要在[自动化]工具响应事件方面后发挥积极作用。采用自动化的下一个阶段是建立一个能够跨IT频谱识别发生的有趣事件的系统,并以自主方式进行响应。在代码上,操作工程师可以使用事件驱动的自动化提前定义他们的工作流程,而不是在凌晨3点来应对基础设施的问题。他们可以依靠这个系统在任何时候以同样的方式作出回应。”
|
||||
|
||||
### 4. 对自动化的焦虑将会减少
|
||||
|
||||
SolarWinds公司的 Hubbard 指出,“自动化”一词本身就产生大量的不确定性和担忧,不仅仅是在IT领域,而且是跨专业领域,他说这种担忧是合理的。但一些随之而来的担忧可能被夸大了,甚至是科技产业本身。现实可能实际上是这方面的镇静力:当自动化的实际实施和实践帮助人们认识到这个列表中的“3”时,我们将看到“4”的出现。
|
||||
|
||||
“今年我们可能会看到对自动化焦虑的减少,更多的组织开始接受人工智能和机器学习作为增加现有人力资源的一种方式,”Hubbard说。“自动化历史上的今天为更多的工作创造了空间,通过降低成本和时间来完成较小任务,并将劳动力重新集中到无法自动化并需要人力的事情上。人工智能和机器学习也是如此。”
|
||||
|
||||
自动化还将减少IT领导者神经紧张主题的一些焦虑:安全。正如[红帽][14]公司首席架构师 Matt Smith 最近[指出][15]的那样,自动化将越来越多地帮助IT部门降低与维护任务相关的安全风险。
|
||||
|
||||
他的建议是:“首先在维护活动期间记录和自动化IT资产之间的交互。通过依靠自动化,您不仅可以消除历史上需要大量手动操作和手术技巧的任务,还可以降低人为错误的风险,并展示当您的IT组织采纳变更和新工作方法时可能发生的情况。最终,这将迅速减少对应用安全补丁的抵制。而且它还可以帮助您的企业在下一次重大安全事件中摆脱头条新闻。”
|
||||
|
||||
**[ 阅读全文: [12个企业安全坏习惯要打破。][16] ] **
|
||||
|
||||
### 5. 脚本和自动化工具将持续发展
|
||||
|
||||
看到许多组织增加自动化的第一步 - 通常以脚本或自动化工具(有时称为配置管理工具)的形式 - 作为“早期”工作。
|
||||
|
||||
但是随着各种自动化技术的使用,对这些工具的观点也在不断发展。
|
||||
|
||||
[DataVision][18]首席运营官 Mark Abolafia 表示:“数据中心环境中存在很多重复性过程,容易出现人为错误,[Ansible][17]等技术有助于缓解这些问题。“通过 Ansible ,人们可以为一组操作编写特定的步骤,并输入不同的变量,例如地址等,使过去长时间的过程链实现自动化,而这些过程以前都需要人为触摸和更长的交货时间。”
|
||||
|
||||
**[想了解更多关于Ansible这个方面的知识吗?阅读相关文章:[使用Ansible时的成功秘诀][19]。 ]**
|
||||
|
||||
另一个因素是:工具本身将继续变得更先进。
|
||||
|
||||
“使用先进的IT自动化工具,开发人员将能够在更短的时间内构建和自动化工作流程,减少易出错的编码,” ASCI 公司的 Amin 说。“这些工具包括预先构建的,预先测试过的拖放式集成,API作业,丰富的变量使用,参考功能和对象修订历史记录。”
|
||||
|
||||
### 6. 自动化开创了新的指标机会
|
||||
|
||||
正如我们在此前所说的那样,IT自动化不是万能的。它不会修复被破坏的流程,或者以其他方式为您的组织提供全面的灵丹妙药。这也是持续不断的:自动化并不排除衡量性能的必要性。
|
||||
|
||||
**[ 参见我们的相关文章 [DevOps指标:你在衡量什么重要吗?][20] ]**
|
||||
|
||||
实际上,自动化应该打开新的机会。
|
||||
|
||||
[Janeiro Digital][21]公司架构师总裁 Josh Collins 说,“随着越来越多的开发活动 - 源代码管理,DevOps管道,工作项目跟踪 - 转向API驱动的平台 - 将这些原始数据拼接在一起以描绘组织效率提升的机会和图景”。
|
||||
|
||||
Collins 认为这是一种可能的新型“开发组织度量指标”。但不要误认为这意味着机器和算法可以突然预测IT所做的一切。
|
||||
|
||||
“无论是衡量个人资源还是整体团队,这些指标都可以很强大 - 但应该用大量的背景来衡量。”Collins说,“将这些数据用于高层次趋势并确认定性观察 - 而不是临床评级你的团队。”
|
||||
|
||||
**想要更多这样知识, IT领导者?[注册我们的每周电子邮件通讯][22]。**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2018/3/what-s-next-it-automation-6-trends-watch
|
||||
|
||||
作者:[Kevin Casey][a]
|
||||
译者:[MZqk](https://github.com/MZqk)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://enterprisersproject.com/user/kevin-casey
|
||||
[1]:https://enterprisersproject.com/article/2017/12/5-factors-fueling-automation-it-now
|
||||
[2]:https://enterprisersproject.com/article/2017/12/4-trends-watch-it-automation-expands
|
||||
[3]:https://enterprisersproject.com/article/2018/1/getting-started-automation-6-tips
|
||||
[4]:https://enterprisersproject.com/article/2018/1/how-make-case-it-automation
|
||||
[5]:https://enterprisersproject.com/article/2018/1/it-automation-best-practices-7-keys-long-term-success
|
||||
[6]:https://enterprisersproject.com/tags/automation
|
||||
[7]:https://enterprisersproject.com/article/2018/2/how-spot-machine-learning-opportunity
|
||||
[8]:https://www.advsyscon.com/en-us/
|
||||
[9]:https://www.sungardas.com/en/
|
||||
[10]:https://enterprisersproject.com/tags/artificial-intelligence
|
||||
[11]:https://www.solarwinds.com/
|
||||
[12]:https://enterprisersproject.com/article/2017/12/8-emerging-ai-jobs-it-pros
|
||||
[13]:https://www.juniper.net/
|
||||
[14]:https://www.redhat.com/en?intcmp=701f2000000tjyaAAA
|
||||
[15]:https://enterprisersproject.com/article/2018/2/12-bad-enterprise-security-habits-break
|
||||
[16]:https://enterprisersproject.com/article/2018/2/12-bad-enterprise-security-habits-break?sc_cid=70160000000h0aXAAQ
|
||||
[17]:https://opensource.com/tags/ansible
|
||||
[18]:https://datavision.com/
|
||||
[19]:https://opensource.com/article/18/2/tips-success-when-getting-started-ansible?intcmp=701f2000000tjyaAAA
|
||||
[20]:https://enterprisersproject.com/article/2017/7/devops-metrics-are-you-measuring-what-matters?sc_cid=70160000000h0aXAAQ
|
||||
[21]:https://www.janeirodigital.com/
|
||||
[22]:https://enterprisersproject.com/email-newsletter?intcmp=701f2000000tsjPAAQ
|
||||
File diff suppressed because it is too large
Load Diff
@ -1,146 +0,0 @@
|
||||
对Ubuntu标准用户的一个高级系统配置程序
|
||||
======
|
||||
|
||||

|
||||
|
||||
|
||||
**Ubunsys** 是一个基于Qt 的高级系统程序,可以在Ubuntu和其他Ubuntu系列衍生系统上使用.大多数情况下,高级用户可以使用命令行轻松完成大多数配置.
|
||||
不过为了以防万一某天,你突然不想用命令行了,就可以用 Ubnusys 这个程序来配置你的系统或其衍生系统,如Linux Mint,Elementary OS 等. Ubunsys 可用来修改系统配置,安装,删除,更新包和旧内核,启用或禁用sudo 权限,安装主线内核,更新软件安装源,清理垃圾文件,将你的Ubuntu 系统升级到最新版本等等
|
||||
以上提到的所有功能都可以通过鼠标点击完成.你不需要再依赖于命令行模式,下面是你能用Ubunsys 做到的事:
|
||||
|
||||
|
||||
* 安装,删除,更新包
|
||||
* 更新和升级软件源
|
||||
* 安装主线内核
|
||||
* 删除旧的和不再使用的内核
|
||||
* 系统整体更新
|
||||
* 将系统升级到下一个可用的版本
|
||||
* 将系统升级到最新的开发版本
|
||||
* 清理系统垃圾文件
|
||||
* 在不输入密码的情况下启用或者禁用sudo 权限
|
||||
* 当你在terminal输入密码时使Sudo 密码可见
|
||||
* 启用或禁用系统冬眠
|
||||
* 启用或禁用防火墙
|
||||
* 打开,备份和导入 sources.list.d 和sudoers 文件.
|
||||
* 显示或者隐藏启动项
|
||||
* 启用或禁用登录音效
|
||||
* 配置双启动
|
||||
* 启用或禁用锁屏
|
||||
* 智能系统更新
|
||||
* 使用脚本管理器更新/一次性执行脚本
|
||||
* 从git执行常规用户安装脚本
|
||||
* 检查系统完整性和缺失的GPG keys.
|
||||
* 修复网络
|
||||
* 修复已破损的包
|
||||
* 还有更多功能在开发中
|
||||
|
||||
**重要提示:** Ubunsys 不适用于Ubuntu 新手.它很危险并且没有一个稳定的版本.它可能会使你的系统崩溃.如果你刚接触Ubuntu不久,不要使用.但如果你真的很好奇这个应用能做什么,仔细浏览每一个选项,并确定自己能承担风险.在使用这一应用之前记着备份你自己的重要数据
|
||||
|
||||
### Ubunsys - 对Ubuntu标准用户的一个高级系统配置程序
|
||||
|
||||
#### 安装 Ubunsys
|
||||
|
||||
|
||||
Ubunusys 开发者制作了一个ppa 来简化安装过程,Ubunusys现在可以在Ubuntu 16.04 LTS, Ubuntu 17.04 64 位版本上使用.
|
||||
|
||||
逐条执行下面的命令,将Ubunsys的PPA 添加进去,并安装它
|
||||
```
|
||||
sudo add-apt-repository ppa:adgellida/ubunsys
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
sudo apt-get install ubunsys
|
||||
|
||||
```
|
||||
|
||||
|
||||
如果ppa 无法使用,你可以在[**发布页面**][1]根据你自己当前系统,选择正确的安装包,直接下载并安装Ubunsys
|
||||
|
||||
#### 用途
|
||||
|
||||
一旦安装完成,从菜单栏启动Ubunsys.下图是Ubunsys 主界面
|
||||
|
||||
![][3]
|
||||
|
||||
你可以看到,Ubunusys 有四个主要部分,分别是 **Packages** , **Tweaks** , **System** ,和**Repair**. 在每一个标签项下面都有一个或多个子标签项以对应不同的操作
|
||||
|
||||
|
||||
**Packages**
|
||||
|
||||
这一部分允许你安装,删除和更新包
|
||||
|
||||
![][4]
|
||||
|
||||
**Tweaks**
|
||||
|
||||
在这一部分,我们可以对系统进行多种调整,例如,
|
||||
|
||||
* 打开,备份和导入 sources.list.d 和sudoers 文件;
|
||||
* 配置双启动;
|
||||
* 启用或禁用登录音效,防火墙,锁屏,系统冬眠,sudo 权限(在不需要密码的情况下)同时你还可以针对某一用户启用或禁用sudo 权限(在不需要密码的情况下)
|
||||
* 在terminal 中输入密码时可见(禁用Asterisk).
|
||||
|
||||
|
||||
|
||||
![][5]
|
||||
|
||||
**System**
|
||||
|
||||
这一部分被进一步分成3个部分,每个都是针对某一特定用户.
|
||||
|
||||
**Normal user** 这一标签下的选项可以,
|
||||
|
||||
* 更新,升级包和软件源
|
||||
* 清理系统
|
||||
* 执行常规用户安装脚本
|
||||
|
||||
|
||||
|
||||
**Advanced user** 这一标签下的选项可以,
|
||||
|
||||
* 清理旧的/无用的内核
|
||||
* 安装主线内核
|
||||
* 智能包更新
|
||||
* 升级系统
|
||||
|
||||
|
||||
|
||||
|
||||
**Developer** 这一部分可以将系统升级到最新的开发版本
|
||||
|
||||
![][6]
|
||||
|
||||
**Repair**
|
||||
|
||||
这是Ubunsys 的第四个也是最后一个部分.正如名字所示,这一部分能让我们修复我们的系统,网络,缺失的GPG keys,和已经缺失的包
|
||||
|
||||
![][7]
|
||||
|
||||
|
||||
正如你所见,Ubunsys可以在几次点击下就能完成诸如系统配置,系统维护和软件维护之类的任务.你不需要一直依赖于Terminal. Ubunsys 能帮你完成任何高级任务.再次声明,我警告你,这个应用不适合新手,而且它并不稳定.所以当你使用的时候,可能会出现bug或者系统崩溃.在仔细研究过每一个选项的影响之后再使用它.
|
||||
|
||||
谢谢阅读!
|
||||
|
||||
**参考资源:**
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/ubunsys-advanced-system-configuration-utility-ubuntu-power-users/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://github.com/adgellida/ubunsys/releases
|
||||
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-1.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-2.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-5.png
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-9.png
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-11.png
|
||||
@ -1,170 +1,183 @@
|
||||
streams:一个新的 Redis 通用数据结构
|
||||
==================================
|
||||
|
||||
直到几个月以前,对于我来说,在消息传递的环境中,streams 只是一个有趣且相对简单的概念。在 Kafka 流行这个概念之后,我主要研究它们在 Disque 实例中的用途。Disque 是一个将会转变为 Redis 4.2 模块的消息队列。后来我发现 Disque 全都是 AP 消息,它将在不需要客户端过多参与的情况下实现容错和保证送达,因此,我认为 streams 的概念在那种情况下并不适用。
|
||||
|
||||
然而同时,在 Redis 中有一个问题,那就是缺省情况下导出数据结构并不轻松。它在 Redis 列表、排序集和发布/订阅(Pub/Sub)能力之间有某些缺陷。你可以权衡使用这些工具去模拟一个消息或事件的序列。
|
||||
Streams:一个新的 Redis 通用数据结构
|
||||
==================================
|
||||
|
||||
排序集是大量耗费内存的,不能自然的模拟一次又一次的相同消息的传递,客户端不能阻塞新消息。因为一个排序集并不是一个序列化的数据结构,它是一个元素可以根据它们量的变化而移动的集合:它不是很像时间系列一样的东西。
|
||||
直到几个月以前,对于我来说,在消息传递的环境中,streams 只是一个有趣且相对简单的概念。这个概念在 Kafka 流行之后,我主要研究它们在 Disque 案例中的效能。Disque 是一个消息队列,它将在 Redis 4.2 中被转换为 Redis 的一个模块。后来我决定用 Disque 来做全部的 AP 消息,也就是说,它将在不需要客户端过多参与的情况下实现容错和保证送达,这样一来,我更加确定地认为 streams 的概念在那种情况下并不适用。
|
||||
|
||||
列表有另外的问题,它在某些特定的用例中产生类似的适用性问题:你无法浏览列表中部是什么,因为在那种情况下,访问时间是线性的。此外,没有任何的指定输出功能,列表上的阻塞操作仅为单个客户端提供单个元素。列表中没有固定的元素标识,也就是说,不能指定从哪个元素开始给我提供内容。
|
||||
然而在那时,在 Redis 中还存在一个问题,那就是缺省情况下导出数据结构并不轻松。在 Redis 列表、有序集和发布/订阅能力之间有某些缺陷。你可以权衡使用这些工具对一系列消息或事件进行建模。
|
||||
|
||||
对于一到多的工作任务,有发布/订阅机制,它在大多数情况下是非常好的,但是,对于某些不想“即发即弃”的东西:保留一个历史是很重要的,而不是断开之后重新获得消息,也因为某些消息列表,像时间系列,用范围查询浏览是非常重要的:在这 10 秒范围内我的温度读数是多少?
|
||||
|
||||
这有一种方法可以尝试处理上面的问题,我计划对排序集进行通用化,并列入一个唯一的、更灵活的数据结构,然而,我的设计尝试最终以生成一个比当前的数据结构更加矫揉造作的结果而结束。一个关于 Redis 数据结构导出的更好的想法是,让它更像天然的计算机科学的数据结构,而不是,“Salvatore 发明的 API”。因此,在最后我停止了我的尝试,并且说,“ok,这是我们目前能提供的”,或许,我将为发布/订阅增加一些历史信息,或者将来对列表访问增加一些更灵活的方式。然而,每次在会议上有用户对我说“你如何在 Redis 中模拟时间系列” 或者类似的问题时,我的脸就绿了。
|
||||
|
||||
### 起源
|
||||
|
||||
在 Redis 4.0 中引入模块之后,用户开始去看他们自己怎么去修复这些问题。他们中的一个,Timothy Downs,通过 IRC 写信给我:
|
||||
|
||||
\<forkfork> 这个模块,我计划去增加一个事务日志式的数据类型 —— 这意味着大量的订阅者可以在没有大量增加 redis 内存使用的情况下做一些像发布/订阅那样的事情
|
||||
\<forkfork> 订阅者保持它在消息队列中的位置,而不是让 Redis 必须维护每个消费者的位置和为每个订阅者复制消息
|
||||
|
||||
这激发了我的想像力。我想了几天,并且意识到这可能是我们立刻同时解决上面所有问题的契机。我需要去重新构想 “日志” 的概念是什么。它是个基本的编程元素,每个人都使用过它,因为它只是简单地以追加模式打开一个文件,并以一定的格式写入数据。然而 Redis 数据结构必须是抽象的。它们在内存中,并且我们使用内存并不是因为我们懒,而是因为使用一些指针,我们可以概念化数据结构并把它们抽象,以允许它们摆脱明显的限制。对于正常的例子来说,日志有几个问题:偏移不是逻辑的,而是真实的字节偏移,如果你想要与条目插入的时间相关的逻辑偏移,我们有范围查询可用。同样的,日志通常很难进行垃圾收集:在一个只追加的数据结构中怎么去删除旧的元素?好吧,在我们理想的日志中,我们只是说,我想要编号最大的那个条目,而旧的元素一个也不要,等等。
|
||||
|
||||
当我从 Timothy 的想法萌芽,去尝试着写一个规范的时候,我使用了我用于 Redis 集群中的 radix 树实现,优化了它内部的某些部分。这为实现一个有效利用空间的日志提供了基础,而仍然可以用对数时间来访问范围。同时,我开始去读关于 Kafka 流以获得另外的灵感,它也非常适合我的设计,并且产生了一个 Kafka 消费组的概念,并且,理想化的话,它可以用于 Redis 和内存用例。然而,该规范仅维持了几个月,在一段时间后我几乎把它从头到尾重写了一遍,以便将我与别人讨论的即将增加到 Redis 中的内容所得到的许多建议一起升级。我希望 Redis 流是非常有用的,尤其对于时间序列,而不仅是用于事件和消息类的应用程序。
|
||||
|
||||
### 让我们写一些代码
|
||||
|
||||
从 Redis 大会回来后,在整个夏天,我实现了一个称为 “listpack” 的库。这个库是 ziplist.c 的继任者,那是一个表示在单个分配中的字符串元素列表的数据结构。它是一个非常特殊的序列化格式,其特点在于也能够以逆序(从右到左)解析:需要它以便在各种用例中替代 ziplists。
|
||||
|
||||
结合 radix 树和 listpacks,它可以很容易地去构建一个日志,它同时也是非常空间高效的,并且是索引化的,这意味着允许通过 ID 和时间进行随机访问。自从这些就绪后,我开始去写一些代码以实现流数据结构。我最终完成了该实现,不管怎样,现在,在 Github 上的 Redis 的 “streams” 分支里面,它已经可以跑起来了。我并没有声称那个 API 是 100% 的最终版本,但是,这有两个有趣的事实:一是,在那时,只有消费组是缺失的,加上一些不那么重要的命令去操作流,但是,所有的大的方面都已经实现了。二是,一旦各个方面比较稳定了之后 ,决定大概用两个月的时间将所有的流的工作向后移植到 4.0 分支。这意味着 Redis 用户为了使用流,不用等待 Redis 4.2,它们在生产环境马上就可用了。这是可能的,因为作为一个新的数据结构,几乎所有的代码改变都出现在新的代码里面。除了阻塞列表操作之外:该代码被重构了,我们对于流和列表阻塞操作共享了相同的代码,而极大地简化了 Redis 内部。
|
||||
|
||||
教程:欢迎使用 Redis 流
|
||||
==================================
|
||||
|
||||
在某种程序上,你应该感谢流作为 Redis 列表的一个增强版本。流元素不再是一个单一的字符串,它们更多是一个域(fields)和值(values)组成的对象。范围查询更适用而且更快。流中的每个条目都有一个 ID,它是一个逻辑偏移量。不同的客户端可以阻塞等待(blocking-wait)比指定的 IDs 更大的元素。Redis 流的一个基本的命令是 XADD。是的,所有的 Redis 命令都是以一个“X”为前缀的。
|
||||
|
||||
> XADD mystream * sensor-id 1234 temperature 10.5
|
||||
1506871964177.0
|
||||
|
||||
这个 XADD 命令将追加指定的条目作为一个新元素到一个指定的流 “mystream” 中。在上面的示例中的这个条目有两个域:sensor-id 和 temperature,然而,每个条目在同一个流中可以有不同的域。使用相同的域名字将导致更多的内存使用。一个有趣的事情是,域的排序是保证保存的。XADD 仅返回插入的条目的 ID,因为在第三个参数中有星号(*),我们请求命令去自动生成 ID。这几乎总是你想要的,但是,它也可能去强制指定一个 ID,实例为了去复制这个命令到被动服务器和 AOF 文件。
|
||||
|
||||
这个 ID 是由两部分组成的:一个毫秒时间和一个序列号。1506871964177 是毫秒时间,它仅是一个使用毫秒解决方案的 UNIX 时间。圆点(.)后面的数字 0,是一个序列号,它是为了区分相同毫秒数的条目增加上去的。所有的数字都是 64 位的无符号整数。这意味着在流中,我们可以增加所有我们想要的条目,在相同毫秒数中的事件。ID 的毫秒部分使用 Redis 服务器的当前本地时间生成的 ID 和流中的最后一个条目之间的最大值来获取。因此,对实例来说,即使是计算机时间向后跳,这个 IDs 仍然是增加的。在某些情况下,你可能想流条目的 IDs 作为完整的 128 位数字。然而,现实是,它们与被添加的实例的本地时间有关,意味着我们有毫秒级的精确的范围查询。
|
||||
|
||||
如你想像的那样,以一个快速的方式去添加两个条目,结果是仅序列号增加。我可以使用一个 MULTI/EXEC 块去简单模拟“快速插入”,如下:
|
||||
|
||||
> MULTI
|
||||
OK
|
||||
> XADD mystream * foo 10
|
||||
QUEUED
|
||||
> XADD mystream * bar 20
|
||||
QUEUED
|
||||
> EXEC
|
||||
1) 1506872463535.0
|
||||
2) 1506872463535.1
|
||||
|
||||
在上面的示例中,也展示了无需在开始时指定任何模式(schema)的情况下,对不同的条目,使用不同的域。会发生什么呢?每个块(它通常包含 50 - 150 个消息范围的内容)的每一个信息被用作参考。并且,有相同域的连续条目被使用一个标志进行压缩,这个标志表明“这个块中的第一个条目的相同域”。因此,对于连续消息使用相同域可以节省许多内存,即使是域的集合随着时间发生缓慢变化。
|
||||
|
||||
为了从流中检索数据,这里有两种方法:范围查询,它是通过 XRANGE 命令实现的,并且对于正在变化的流,通过 XREAD 命令去实现。XRANGE 命令仅取得包括从开始到停止范围内的条目。因此,对于实例,如果我知道它的 ID,我可以取得单个条目,像这样:
|
||||
|
||||
> XRANGE mystream 1506871964177.0 1506871964177.0
|
||||
1) 1) 1506871964177.0
|
||||
2) 1) "sensor-id"
|
||||
2) "1234"
|
||||
3) "temperature"
|
||||
4) "10.5"
|
||||
|
||||
然而,你可以使用指定的开始符号 “-” 和停止符号 “+” 去表示可能的最小和最大 ID。为了限制返回条目的数量,它也可以使用 COUNT 选项。下面是一个更复杂的 XRANGE 示例:
|
||||
|
||||
> XRANGE mystream - + COUNT 2
|
||||
1) 1) 1506871964177.0
|
||||
2) 1) "sensor-id"
|
||||
2) "1234"
|
||||
3) "temperature"
|
||||
4) "10.5"
|
||||
2) 1) 1506872463535.0
|
||||
2) 1) "foo"
|
||||
2) "10"
|
||||
|
||||
这里我们讲的是 IDs 的范围,然后,为了在一个给定时间范围内取得特定元素的范围,你可以使用 XRANGE,因为你可以省略 IDs 的“序列” 部分。因此,你可以做的仅是指定“毫秒”时间,下面的命令的意思是: “从 UNIX 时间 1506872463 开始给我 10 个条目”:
|
||||
|
||||
127.0.0.1:6379> XRANGE mystream 1506872463000 + COUNT 10
|
||||
1) 1) 1506872463535.0
|
||||
2) 1) "foo"
|
||||
2) "10"
|
||||
2) 1) 1506872463535.1
|
||||
2) 1) "bar"
|
||||
2) "20"
|
||||
|
||||
关于 XRANGE 注意的最重要的事情是,由于我们在回复中收到了 IDs,并且连续 ID 是无法直接获得的,因为 ID 的序列部分是增加的,它可以使用 XRANGE 去遍历整个流,接收每个调用的元素的特定个数。在 Redis 中的*SCAN*系列命令之后,那是允许 Redis 数据结构迭代的,尽管事实上它们不是为迭代设计的,我以免再次产生相同的错误。
|
||||
|
||||
使用 XREAD 处理变化的流:阻塞新的数据
|
||||
===========================================
|
||||
|
||||
XRANGE 用于,当我们想通过 ID 或时间去访问流中的一个范围或者是通过 ID 去得到单个元素时,是非常完美的。然而,在当数据到达时,不同的客户端必须同时使用流的情况下,它就不是一个很好的解决方案,并且它是需要某种形式的“池”的。(对于*某些*应用程序来说,这可能是个好主意,因为它们仅是偶尔连接取数的)。
|
||||
|
||||
XREAD 命令是为读设计的,同时从多个流中仅指定我们得到的流中的最后条目的 ID。此外,如果没有数据可用,我们可以要求阻塞,当数据到达时,去解除阻塞。类似于阻塞列表操作产生的效果,但是,这里的数据是从流中得到的。并且多个客户端可以在同时访问相同的数据。
|
||||
|
||||
这里有一个关于 XREAD 调用的规范示例:
|
||||
|
||||
> XREAD BLOCK 5000 STREAMS mystream otherstream $ $
|
||||
|
||||
它的意思是:从 “mystream” 和 “otherstream” 取得数据。如果没有数据可用,阻塞客户端 5000 毫秒。之后我们用关键字 STREAMS 指定我们想要监听的流,和最后的 ID,指定的 ID “$” 意思是:假设我现在已经有了流中的所有元素,因此,从下一个到达的元素开始给我。
|
||||
|
||||
如果,从另外一个客户端,我发出这样的命令:
|
||||
|
||||
> XADD otherstream * message “Hi There”
|
||||
|
||||
在 XREAD 侧会出现什么情况呢?
|
||||
|
||||
1) 1) "otherstream"
|
||||
2) 1) 1) 1506935385635.0
|
||||
2) 1) "message"
|
||||
2) "Hi There"
|
||||
|
||||
和到过的数据一起,我们得到了最新到达的数据的 key,在下次的调用中,我们将使用接收到的最新消息的 ID:
|
||||
|
||||
> XREAD BLOCK 5000 STREAMS mystream otherstream $ 1506935385635.0
|
||||
|
||||
依次类推。然而需要注意的是使用方式,有可能客户端在一个非常大的延迟(因为它处理消息需要时间,或者其它什么原因)之后再次连接。在这种情况下,同时会有很多消息堆积,为了确保客户端不被消息淹没,并且服务器不会丢失太多时间的提供给单个客户端的大量消息,所以,总是使用 XREAD 的 COUNT 选项是明智的。
|
||||
|
||||
流封顶
|
||||
==============
|
||||
|
||||
到现在为止,一直还都不错… 然而,有些时候,流需要去删除一些旧的消息。幸运的是,这可以使用 XADD 命令的 MAXLEN 选项去做:
|
||||
|
||||
> XADD mystream MAXLEN 1000000 * field1 value1 field2 value2
|
||||
|
||||
它是基本意思是,如果流添加的新元素被发现超过 1000000 个消息,那么,删除旧的消息,以便于长度回到 1000000 个元素以内。它很像是使用 RPUSH + LTRIM 的列表,但是,这是我们使用了一个内置机制去完成的。然而,需要注意的是,上面的意思是每次我们增加一个新的消息时,我们还需要另外的工作去从流中删除旧的消息。这将使用一些 CPU 资源,所以,在计算 MAXLEN 的之前,尽可能使用 “~” 符号,为了表明我们不是要求非常*精确*的 1000000 个消息。但是,这里有很多,它还不是一个大的问题:
|
||||
|
||||
> XADD mystream MAXLEN ~ 1000000 * foo bar
|
||||
|
||||
这种方式的 XADD 删除消息,仅用于当它可以删除整个节点的时候。相比 vanilla XADD,这种方式几乎可以自由地对流进行封顶。
|
||||
|
||||
(进程内工作的)客户组
|
||||
==================================
|
||||
|
||||
这是不在 Redis 中实现的第一个特性,但是,它是在进程内工作的。它也是来自 Kafka 的灵感,尽管在这里以不同的方式去实现的。重点是使用了 XREAD,客户端也可以增加一个 “GROUP <name>” 选项。 在相同组的所有客户端自动调用,以得到*不同的*消息。当然,这里不能从同一个流中被多个组读。在这种情况下,所有的组将收到流中到达的消息的相同副本。但是,在不同的组,消息是不会重复的。
|
||||
|
||||
当指定组时,尽可能指定一个 “RETRY <milliseconds>” 选项去扩展组:在这种情况下,如果消息没有使用 XACK 去进行确认,它将在指定的毫秒数后进行再次投递。这种情况下,客户端没有私有的方法去标记已处理的消息,这也是一项正在进行中的工作。
|
||||
|
||||
内存使用和节省的加载时间
|
||||
=====================================
|
||||
|
||||
因为被设计用来模拟 Redis 流,所以,根据它们的域的数量、值和长度,内存使用是显著降低的。但对于简单的消息,每 100 MB 内存使用可以有几百万条消息,此外,设想中的格式去需要极少的系列化:是存储为 radix 树节点的 listpack 块,在磁盘上和内存中是用同一个来表示的,因此,它们被琐碎地存储和读取。在一个实例中,Redis 能在 0.3 秒内可以从 RDB 文件中读取 500 万个条目。这使的流的复制和持久存储是非常高效的。
|
||||
|
||||
它也被计划允许从条目中间删除。现在仅部分实现,策略是整个条目标记中删除的条目被标记为已删除条目,并且,当达到设置的已删除条目占全部条目的比例时,这个块将被回收重写,并且,如果需要,它将被连到相邻的另一个块上,以避免碎片化。
|
||||
|
||||
最终发布时间的结论
|
||||
===================
|
||||
|
||||
Redis 流将包含在年底前推出的 Redis 4.0 系列的稳定版中。我认为这个通用的数据结构将为 Redis 提供一个巨大的补丁,为了用于解决很多现在很难去解决的情况:那意味着你需要创造性地滥用当前提供的数据结构去解决那些问题。一个非常重要的使用情况是时间系列,但是,我的感觉是,对于其它案例来说,通过 TREAD 来传递消息将是非常有趣的,因为它可以替代那些需要更高可靠性的发布/订阅的应用程序,而不是“即用即弃”,以及全新的使用案例。现在,如果你想在你的有问题的环境中,去评估新的数据结构的能力,可以在 GitHub 上去获得 “streams” 分支,开始去玩吧。欢迎向我们报告所有的 bug 。 :-)
|
||||
|
||||
如果你喜欢这个视频,展示这个 streams 的实时会话在这里: https://www.youtube.com/watch?v=ELDzy9lCFHQ
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://antirez.com/news/114
|
||||
|
||||
作者:[antirez ][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://antirez.com/
|
||||
[1]:http://antirez.com/news/114
|
||||
[2]:http://antirez.com/user/antirez
|
||||
[3]:https://www.youtube.com/watch?v=ELDzy9lCFHQ
|
||||
有序集是非常耗费内存的,那自然就不能对投递的相同消息进行一次又一次的建模,客户端不能阻塞新消息。因为有序集并不是一个序列化的数据结构,它是一个可以根据元素分数的变化而移动位置的集合:难怪它不适合像时间序列这样的东西。
|
||||
|
||||
列表也有不同的问题,它在某些特定的用例中产生类似的适用性问题:你无法浏览列表中间的内容,因为在那种情况下,访问时间是线性的。此外,有可能是没有输出的,列表上的阻塞操作仅为单个客户端提供单个元素。而不是为列表中的元素提供固定的标识符,也就是说,无法做到从指定的那个元素开始给我提供内容。
|
||||
|
||||
对于一到多的负载,它有发布/订阅机制,它在大多数情况下是非常好的,但是,对于某些你不希望“即发即弃”的东西:保留一个历史是很重要的,而不是断开之后重新获得消息,也因为某些消息列表,像时间序列,用范围查询浏览是非常重要的:在这 10 秒范围内我的温度读数是多少?
|
||||
|
||||
我尝试去解决上面的问题所使用的一种方法是,规划一个通用的有序集合,并列入到一个唯一的、更灵活的数据结构中,然而,我的设计尝试最终以生成一个比当前的数据结构更加矫揉造作的结果而结束。一个关于 Redis 数据结构导出的更好的事情是,让它更像天然的计算机科学的数据结构,而不是,“Salvatore 发明的 API”。因此,在最后我停止了我的尝试,并且说,“ok,这是我们目前能提供的东西了”,或许,我将为发布/订阅增加一些历史,或者将来对列表访问增加一些更灵活的方式。然而,每次在会议上有用户对我说“你如何在 Redis 中建模时间序列” 或者类似的问题时,我就感到很惶恐。
|
||||
|
||||
### 起源
|
||||
|
||||
在 Redis 4.0 中引入模块之后,用户开始去看,他们自己如何去修复这些问题。他们中的一个 —— Timothy Downs,通过 IRC 写信给我:
|
||||
|
||||
\<forkfork> 这个模块,我计划去增加一个事务日志式的数据类型 —— 这意味着大量的订阅者可以在不大量增加 redis 内存使用的情况下做一些像发布/订阅那样的事情
|
||||
\<forkfork> 订阅者持有他们在消息队列中的位置,而不是让 Redis 必须维护每个消费者的位置和为每个订阅者复制消息
|
||||
|
||||
他的思路启发了我。我想了几天,并且意识到这可能是我们马上同时解决上面所有问题的一个契机。我需要去重新构思 “日志” 的概念。日志是个基本的编程元素,每个人都使用过它,因为它只是简单地以追加模式打开一个文件,并以一定的格式写入数据。然而 Redis 数据结构必须是抽象的。它们在内存中,并且我们使用内存并不是因为我们懒,而是因为使用一些指针,我们可以概念化数据结构并把它们抽象,以使它们摆脱明确的限制。例如,一般来说日志有几个问题:偏移不是逻辑化的,而是真实的字节偏移,如果你希望找到与条目插入时间相关的逻辑偏移量是多少?我们有范围查询可用。同样的,日志通常很难进行垃圾收集:在一个只能进行追加操作的数据结构中怎么去删除旧的元素?好吧,在我们理想的日志中,我们只需要说,我想要数字最大的那个条目,而旧的元素一个也不要,等等。
|
||||
|
||||
当我从 Timothy 的想法中受到启发,去尝试着写一个规范的时候,我使用了 Redis 集群中的 radix 树去实现,优化了它内部的某些部分。这为实现一个有效利用空间的日志提供了基础,而且仍然有可能在<ruby>对数时间<rt>logarithmic time</rt></ruby>内访问日志得到该范围。就在那时,我开始去读关于 Kafka 的 streams 相关的内容,以获得适合我的设计的其它灵感,最后的结果是借鉴了 Kafka 消费组的概念,并且再次针对 Redis 进行优化,以适用于 Redis 在内存中使用的情况。然而,该规范仅停留在纸面上,在一段时间后我几乎把它从头到尾重写了一遍,以便将我与别人讨论所得到的许多建议一起增加到即将到来的 Redis 升级中。我希望 Redis 的 streams 是非常有用的,尤其对于时间序列来说,而不仅是用于事件和消息类的应用程序。
|
||||
|
||||
### 让我们写一些代码吧
|
||||
|
||||
从 Redis 大会回来后,在那个夏天,我实现了一个称为 “listpack” 的库。这个库是 `ziplist.c` 的继任者,它是表示在单个分配中的字符串元素列表的一个数据结构。它是一个非常专业的序列化格式,其特点在于也能够以逆序(从右到左)进行解析:在所有的案例中是用于代替 ziplists 所做的事情。
|
||||
|
||||
结合 radix 树和 listpacks 的特性,它可以很容易地去构建一个空间高效的日志,并且还是索引化的,这意味着允许通过 ID 和时间进行随机访问。自从这些准备就绪后,我开始去写一些代码以实现流数据结构。我最终完成了该实现,不管怎样,现在,Redis 在 Github 上的 “streams” 分支里面,它已经可以跑的很好了。我并没有声称那个 API 是 100% 的最终版本,但是,这有两个有趣的事实:一是,在那时,只有消费组是不行的,再加上一些不那么重要的命令去操作流,但是,所有的大的方面都已经实现了。二是,一旦各个方面比较稳定了之后 ,决定大概用两个月的时间将所有的流的工作<ruby>回迁<rt>backport</rt></ruby>到 4.0 分支。这意味着 Redis 用户为了使用 streams,不用等到 Redis 4.2 发布,它们在生产环境中马上就可以使用了。这是可能的,因为作为一个新的数据结构,几乎所有的代码改变都出现在新的代码里面。除了阻塞列表操作之外:该代码被重构了,我们对于 streams 和列表阻塞操作共享了相同的代码,从而极大地简化了 Redis 内部。
|
||||
|
||||
### 教程:欢迎使用 Redis 的 streams
|
||||
|
||||
在某些方面,你可以认为 streams 是 Redis 中列表的一个增强版本。streams 元素不再是一个单一的字符串,它们更多是一个<ruby>字段<rt>field</rt></ruby>和<ruby>值<rt>value</rt></ruby>组成的对象。范围查询成为可能而且还更快。流中的每个条目都有一个 ID,它是个逻辑偏移量。不同的客户端可以<ruby>阻塞等待<rt>blocking-wait</rt></ruby>比指定的 ID 更大的元素。Redis 中 streams 的一个基本命令是 XADD。是的,所有 Redis 的流命令都是以一个“X”为前缀的。
|
||||
|
||||
```
|
||||
> XADD mystream * sensor-id 1234 temperature 10.5
|
||||
1506871964177.0
|
||||
```
|
||||
|
||||
这个 `XADD` 命令将追加指定的条目作为一个指定的流 —— “mystream” 的新元素。在上面的示例中的这个条目有两个字段:`sensor-id` 和 `temperature`,每个条目在同一个流中可以有不同的字段。使用相同的字段名字可以更好地利用内存。需要记住的一个有趣的事情是,字段是保证排序的。XADD 仅返回插入的条目的 ID,因为在第三个参数中是星号(`*`),表示我们要求命令自动生成 ID。大多数情况下需要如此,但是,也可以去强制指定一个 ID,这种情况用于复制这个命令到被动服务器和 AOF 文件。
|
||||
|
||||
这个 ID 是由两部分组成的:一个毫秒时间和一个序列号。`1506871964177` 是毫秒时间,它仅是一个毫秒级的 UNIX 时间。圆点(`.`)后面的数字 `0`,是一个序列号,它是为了区分相同毫秒数的条目增加上去的。这两个数字都是 64 位的无符号整数。这意味着在流中,我们可以增加所有我们想要的条目,即使是在同一毫秒中。ID 的毫秒部分使用 Redis 服务器的当前本地时间生成的 ID 和流中的最后一个条目 ID 两者间的最大的一个。因此,举例来说,即使是计算机时间回跳,这个 ID 仍然是增加的。在某些情况下,你可以认为流条目的 ID 是完整的 128 位数字。然而,事实是,它们与被添加的实例的本地时间有关,这意味着我们可以在毫秒级的精度范围内随意查询。
|
||||
|
||||
正如你想的那样,以一个速度非常快的方式去添加两个条目,结果是仅一个序列号增加了。我可以使用一个 `MULTI`/`EXEC` 块去简单模拟“快速插入”,如下:
|
||||
|
||||
```
|
||||
> MULTI
|
||||
OK
|
||||
> XADD mystream * foo 10
|
||||
QUEUED
|
||||
> XADD mystream * bar 20
|
||||
QUEUED
|
||||
> EXEC
|
||||
1) 1506872463535.0
|
||||
2) 1506872463535.1
|
||||
```
|
||||
|
||||
在上面的示例中,也展示了无需指定任何初始<ruby>模式<rt>schema</rt></ruby>的情况下,对不同的条目使用不同的字段。会发生什么呢?就像前面提到的一样,只有每个块(它通常包含 50 - 150 个消息内容)的第一个信息被使用。并且,相同字段的连续条目都使用了一个标志进行了压缩,这个标志表示与“它们与这个块中的第一个条目的字段相同”。因此,对于使用了相同字段的连续消息可以节省许多内存,即使是字段集随着时间发生缓慢变化的情况下也很节省内存。
|
||||
|
||||
为了从流中检索数据,这里有两种方法:范围查询,它是通过 `XRANGE` 命令实现的;和<ruby>流播<rt>streaming</rt></ruby>,它是通过 XREAD 命令实现的。`XRANGE` 命令仅取得包括从开始到停止范围内的全部条目。因此,举例来说,如果我知道它的 ID,我可以使用如下的命名取得单个条目:
|
||||
|
||||
```
|
||||
> XRANGE mystream 1506871964177.0 1506871964177.0
|
||||
1) 1) 1506871964177.0
|
||||
2) 1) "sensor-id"
|
||||
2) "1234"
|
||||
3) "temperature"
|
||||
4) "10.5"
|
||||
```
|
||||
|
||||
不管怎样,你都可以使用指定的开始符号 `-` 和停止符号 `+` 去表示最小和最大的 ID。为了限制返回条目的数量,也可以使用 `COUNT` 选项。下面是一个更复杂的 `XRANGE` 示例:
|
||||
|
||||
```
|
||||
> XRANGE mystream - + COUNT 2
|
||||
1) 1) 1506871964177.0
|
||||
2) 1) "sensor-id"
|
||||
2) "1234"
|
||||
3) "temperature"
|
||||
4) "10.5"
|
||||
2) 1) 1506872463535.0
|
||||
2) 1) "foo"
|
||||
2) "10"
|
||||
```
|
||||
|
||||
这里我们讲的是 ID 的范围,然后,为了取得在一个给定时间范围内的特定范围的元素,你可以使用 `XRANGE`,因为你可以省略 ID 的“序列” 部分。因此,你可以做的仅是指定“毫秒”时间,下面的命令的意思是: “从 UNIX 时间 1506872463 开始给我 10 个条目”:
|
||||
|
||||
```
|
||||
127.0.0.1:6379> XRANGE mystream 1506872463000 + COUNT 10
|
||||
1) 1) 1506872463535.0
|
||||
2) 1) "foo"
|
||||
2) "10"
|
||||
2) 1) 1506872463535.1
|
||||
2) 1) "bar"
|
||||
2) "20"
|
||||
```
|
||||
|
||||
关于 `XRANGE` 需要注意的最重要的事情是,假设我们在回复中收到 ID,并且随后连续的 ID 只是增加了 ID 的序列部分,所以可以使用 `XRANGE` 去遍历整个流,接收每个调用的指定个数的元素。在 Redis 中的`*SCAN` 系列命令之后,它允许 Redis 数据结构迭代,尽管事实上它们不是为迭代设计的,但这样我可以避免再犯相同的错误。
|
||||
|
||||
### 使用 XREAD 处理流播:阻塞新的数据
|
||||
|
||||
当我们想通过 ID 或时间去访问流中的一个范围或者是通过 ID 去获取单个元素时,使用 XRANGE 是非常完美的。然而,在 streams 的案例中,当数据到达时,它必须由不同的客户端来消费时,这就不是一个很好的解决方案,这需要某种形式的“汇聚池”。(对于*某些*应用程序来说,这可能是个好主意,因为它们仅是偶尔连接取数的)
|
||||
|
||||
`XREAD` 命令是为读取设计的,在同一个时间,从多个 streams 中仅指定我们从该流中得到的最后条目的 ID。此外,如果没有数据可用,我们可以要求阻塞,当数据到达时,去解除阻塞。类似于阻塞列表操作产生的效果,但是这里并没有消费从流中得到的数据。并且多个客户端可以同时访问相同的数据。
|
||||
|
||||
这里有一个关于 `XREAD` 调用的规范示例:
|
||||
|
||||
```
|
||||
> XREAD BLOCK 5000 STREAMS mystream otherstream $ $
|
||||
```
|
||||
|
||||
它的意思是:从 `mystream` 和 `otherstream` 取得数据。如果没有数据可用,阻塞客户端 5000 毫秒。在 `STREAMS` 选项之后指定我们想要监听的关键字,最后的是指定想要监听的 ID,指定的 ID 为 `$` 的意思是:假设我现在需要流中的所有元素,因此,只需要从下一个到达的元素开始给我。
|
||||
|
||||
如果,从另外一个客户端,我发出这样的命令:
|
||||
|
||||
```
|
||||
> XADD otherstream * message “Hi There”
|
||||
```
|
||||
在 XREAD 侧会出现什么情况呢?
|
||||
```
|
||||
1) 1) "otherstream"
|
||||
2) 1) 1) 1506935385635.0
|
||||
2) 1) "message"
|
||||
2) "Hi There"
|
||||
```
|
||||
|
||||
与收到的数据一起,我们得到了所收到数据的关键字,在下次的调用中,我们将使用接收到的最新消息的 ID:
|
||||
|
||||
```
|
||||
> XREAD BLOCK 5000 STREAMS mystream otherstream $ 1506935385635.0
|
||||
```
|
||||
|
||||
依次类推。然而需要注意的是使用方式,客户端有可能在一个非常大的延迟(因为它处理消息需要时间,或者其它什么原因)之后再次连接。在这种情况下,期间会有很多消息堆积,为了确保客户端不被消息淹没,以及服务器不会因为给单个客户端提供大量消息而浪费太多的时间,使用 `XREAD` 的 `COUNT` 选项是非常明智的。
|
||||
|
||||
### 流封顶
|
||||
|
||||
到现在为止,一直还都不错…… 然而,有些时候,streams 需要去删除一些旧的消息。幸运的是,这可以使用 `XADD` 命令的 `MAXLEN` 选项去做:
|
||||
|
||||
```
|
||||
> XADD mystream MAXLEN 1000000 * field1 value1 field2 value2
|
||||
```
|
||||
|
||||
它是基本意思是,如果流上添加新元素后发现,它的消息数量超过了 `1000000` 个,那么,删除旧的消息,以便于长度重新回到 `1000000` 个元素以内。它很像是在列表中使用的 `RPUSH` + `LTRIM`,但是,这次我们是使用了一个内置机制去完成的。然而,需要注意的是,上面的意思是每次我们增加一个新的消息时,我们还需要另外的工作去从流中删除旧的消息。这将使用一些 CPU 资源,所以,在计算 MAXLEN 之前,尽可能使用 `~` 符号,以表明我们不要求非常*精确*的 1000000 个消息,就是稍微多一些也不是个大问题:
|
||||
|
||||
```
|
||||
> XADD mystream MAXLEN ~ 1000000 * foo bar
|
||||
```
|
||||
|
||||
这种方式的 XADD 仅当它可以删除整个节点的时候才会删除消息。相比普通的 `XADD`,这种方式几乎可以自由地对流进行封顶。
|
||||
|
||||
### 消费组(开发中)
|
||||
|
||||
这是第一个 Redis 中尚未实现而在开发中的特性。它也是来自 Kafka 的灵感,尽管在这里以不同的方式去实现的。重点是使用了 `XREAD`,客户端也可以增加一个 `GROUP <name>` 选项。 在相同组的所有客户端,将自动地得到*不同的*消息。当然,同一个流可以被多个组读取。在这种情况下,所有的组将收到流中到达的消息的相同副本。但是,在每个组内,消息是不会重复的。
|
||||
|
||||
当指定组时,能够指定一个 “RETRY <milliseconds>” 选项去扩展组:在这种情况下,如果消息没有使用 XACK 去进行确认,它将在指定的毫秒数后进行再次投递。这将为消息投递提供更佳的可靠性,这种情况下,客户端没有私有的方法将消息标记为已处理。这一部分也正在开发中。
|
||||
|
||||
### 内存使用和加载时间节省
|
||||
|
||||
因为设计用来建模 Redis 的 streams,内存使用是非常低的。这取决于它们的字段、值的数量和它们的长度,对于简单的消息,每使用 100 MB 内存可以有几百万条消息,此外,格式设想为需要极少的序列化:listpack 块以 radix 树节点方式存储,在磁盘上和内存中都以相同方式表示的,因此,它们可以很轻松地存储和读取。例如,Redis 可以在 0.3 秒内从 RDB 文件中读取 500 万个条目。这使得 streams 的复制和持久存储非常高效。
|
||||
|
||||
也计划允许从条目中间进行部分删除。现在仅实现了一部分,策略是在条目在标记中标识为已删除条目,并且,当已删除条目占全部条目的比率达到给定值时,这个块将被回收重写,并且,如果需要,它将被连到相邻的另一个块上,以避免碎片化。
|
||||
|
||||
### 关于最终发布时间的结论
|
||||
|
||||
Redis 的 streams 将包含在年底前(LCTT 译注:本文原文发布于 2017 年 10 月)推出的 Redis 4.0 系列的稳定版中。我认为这个通用的数据结构将为 Redis 提供一个巨大的补丁,以用于解决很多现在很难去解决的情况:那意味着你(之前)需要创造性地滥用当前提供的数据结构去解决那些问题。一个非常重要的使用案例是时间序列,但是,我的感觉是,对于其它用例来说,通过 `TREAD` 来流播消息将是非常有趣的,因为对于那些需要更高可靠性的应用程序,可以使用发布/订阅模式来替换“即用即弃”,还有其它全新的使用案例。现在,如果你想在你的有问题环境中评估新数据结构的能力,可以在 GitHub 上去获得 “streams” 分支,开始去玩吧。欢迎向我们报告所有的 bug 。 :-)
|
||||
|
||||
如果你喜欢这个视频,展示这个 streams 的实时会话在这里: https://www.youtube.com/watch?v=ELDzy9lCFHQ
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://antirez.com/news/114
|
||||
|
||||
作者:[antirez][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://antirez.com/
|
||||
[1]:http://antirez.com/news/114
|
||||
[2]:http://antirez.com/user/antirez
|
||||
[3]:https://www.youtube.com/watch?v=ELDzy9lCFHQ
|
||||
|
||||
@ -1,57 +0,0 @@
|
||||
BLUI:创建游戏 UI 的简单方法
|
||||
======
|
||||
|
||||

|
||||
|
||||
游戏开发引擎在过去几年中变得越来越易于使用。像 Unity 这样一直免费使用的引擎,以及最近从基于订阅的服务切换到免费服务的 Unreal,允许独立开发者使用 AAA 发布商使用的相同行业标准工具。虽然这些引擎都不是开源的,但每个引擎都能够促进其周围的开源生态系统的发展。
|
||||
|
||||
这些引擎中包含的插件允许开发人员通过添加特定程序来增强引擎的基本功能。这些程序的范围可以从简单的资源包到更复杂的事物,如人工智能 (AI) 集成。这些插件来自不同的创作者。有些是由引擎开发工作室和有些是个人提供的。后者中的很多是开源插件。
|
||||
|
||||
### 什么是 BLUI?
|
||||
|
||||
作为独立游戏开发工作室的一部分,我体验到了在专有游戏引擎上使用开源插件的好处。Aaron Shea 开发的一个开源插件 [BLUI][1] 对我们团队的开发过程起到了重要作用。它允许我们使用基于 Web 的编程(如 HTML/CSS 和 JavaScript)创建用户界面 (UI) 组件。尽管虚幻引擎(我们选择的引擎)有一个内置的 UI 编辑器实现了类似目的,我们也选择使用这个开源插件。我们选择使用开源替代品有三个主要原因:它们的可访问性、易于实现以及伴随的开源程序活跃的、支持性好的在线社区。
|
||||
|
||||
在虚幻引擎的最早版本中,我们在游戏中创建 UI 的唯一方法是通过引擎的原生 UI 集成,使用 Autodesk 的 Scaleform 程序,或通过在虚幻社区中传播的一些选定的基于订阅的 Unreal 集成。在这些情况下,这些解决方案要么不能为独立开发者提供有竞争力的 UI 解决方案,要么对于小型团队来说太昂贵,要么只能为大型团队和 AAA 开发者提供。
|
||||
|
||||
在商业产品和 Unreal 的原生整合失败后,我们向独立社区寻求解决方案。我们在那里发现了 BLUI。它不仅与虚幻引擎无缝集成,而且还保持了一个强大且活跃的社区,经常推出更新并确保独立开发人员可以轻松访问文档。BLUI 使开发人员能够将 HTML 文件导入虚幻引擎,并在程序内部对其进行编程。这使得通过网络语言创建的 UI 能够集成到游戏的代码、资源和其他元素中,并拥有所有 HTML、CSS、Javascript 和其他网络语言的能力。它还为开源 [Chromium Embedded Framework][2] 提供全面支持。
|
||||
|
||||
### 安装和使用 BLUI
|
||||
|
||||
使用 BLUI 的基本过程包括首先通过 HTML 创建 UI。开发人员可以使用任何工具来实现此目的,包括自举 JavaScript 代码,外部 API 或任何数据库代码。一旦这个 HTML 页面完成,你可以像安装任何 Unreal 插件那样安装它并加载或创建一个项目。项目加载后,你可以将 BLUI 函数放在 Unreal UI 图纸中的任何位置,或者通过 C++ 进行硬编码。开发人员可以通过其 HTML 页面调用函数,或使用 BLUI 的内部函数轻松更改变量。
|
||||
|
||||
![Integrating BLUI into Unreal Engine 4 blueprints][4]
|
||||
|
||||
将 BLUI 集成到虚幻 4 图纸中。
|
||||
|
||||
在我们当前的项目中,我们使用 BLUI 将 UI 元素与游戏中的音轨同步,为游戏机制的节奏方面提供视觉反馈。将定制引擎编程与 BLUI 插件集成很容易。
|
||||
|
||||
![Using BLUI to sync UI elements with the soundtrack.][6]
|
||||
|
||||
使用 BLUI 将 UI 元素与音轨同步。
|
||||
|
||||
通过 BLUI GitHub 页面上的[文档][7],将 BLUI 集成到虚幻 4 中是一个微不足道的过程。还有一个由支援虚幻引擎开发人员组成的[论坛][8],他们乐于询问和回答关于插件以及实现该工具时出现的任何问题。
|
||||
|
||||
### 开源优势
|
||||
|
||||
开源插件可以在专有游戏引擎的范围内扩展创意。他们继续降低进入游戏开发的障碍,并且可以产生前所未有的游戏内机制和资源。随着对专有游戏开发引擎的访问持续增长,开源插件社区将变得更加重要。不断增长的创造力必将超过专有软件,开源代码将会填补这些空白,并促进开发真正独特的游戏。而这种新颖性正是让独立游戏如此美好的原因!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/blui-game-development-plugin
|
||||
|
||||
作者:[Uwana lkaiddi][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/uwikaiddi
|
||||
[1]:https://github.com/AaronShea/BLUI
|
||||
[2]:https://bitbucket.org/chromiumembedded/cef
|
||||
[3]:/file/400616
|
||||
[4]:https://opensource.com/sites/default/files/uploads/blui_gaming_plugin-integratingblui.png (Integrating BLUI into Unreal Engine 4 blueprints)
|
||||
[5]:/file/400621
|
||||
[6]:https://opensource.com/sites/default/files/uploads/blui_gaming_plugin-syncui.png (Using BLUI to sync UI elements with the soundtrack.)
|
||||
[7]:https://github.com/AaronShea/BLUI/wiki
|
||||
[8]:https://forums.unrealengine.com/community/released-projects/29036-blui-open-source-html5-js-css-hud-ui
|
||||
@ -1,115 +0,0 @@
|
||||
可代替Dropbox的5个开源软件
|
||||
=====
|
||||

|
||||
|
||||
Dropbox 在文件共享应用中是个 800 磅的大猩猩。尽管它是个极度流行的工具,但你可能仍想使用一个软件去替代它。
|
||||
|
||||
出于所有的好的原因, 包括安全和自由,这使你决定用[开源方式][1]。或许你已经被数据泄露吓坏了。或者定价计划不能满足你实际需要的存储量。
|
||||
|
||||
幸运的是,有各种各样的开源文件共享应用,可以提供给你更多的存储容量,更好的安全性,并且以低于 Dropbox 很多的价格来让你掌控你自己的数据。有多低呢?如果你有一定的技术和一台 Linux 服务器可供使用,那尝试一下免费的应用吧。
|
||||
|
||||
这里有5个最好的可以代替 Dropbox 的开源应用,以及其他一些,你可能想考虑使用。
|
||||
|
||||
### ownCloud
|
||||
|
||||

|
||||
|
||||
[ownCloud][2]发布于 2010 年,是本文所列应用中最老的,但是不要被这件事蒙蔽:它仍然十分流行(根据公司统计,有超过 150 万用户),并且由 1100 个参与者的社区积极维护, 定期发布更新。
|
||||
|
||||
它的主要特点——文件共享和文档写作功能和 Dropbox 的功能相似。它们的主要区别(除了它的[开源协议][3])是你的文件可以托管在你的私人 Linux 服务器或云上,给予用户对自己数据完全的控制权。(自托管是本文所列应用的一个普遍的功能。)
|
||||
|
||||
使用 ownCloud,你可以通过 Linux、MacOS 或 Windows 的客户端和安卓、iOS 的移动应用程序来同步和访问文件。你还可以通过密码保护的链接分享给其他人来协作或者上传和下载。数据传输通过端到端加密(E2EE)和 SSL 加密来保护安全。你还可以通过使用它[marketplace][4]中的各种各样的第三方应用来扩展它的功能。当然,他也提供付费的,商业许可的企业版本。
|
||||
|
||||
ownCloud 提供了详尽的[文档][5],包括安装指南和这对用户、管理员、开发者的手册。你可以从 GitHub 仓库中获取它的[源码][6]。
|
||||
|
||||
### NextCloud
|
||||
|
||||

|
||||
|
||||
[NextCloud][7]在2016年从 ownCloud 脱离出来,并且具有很多相同的功能。 NextCloud 以它的高安全性和法规遵守作为它们的一个独特的[推崇的卖点][8]。它具有 HIPAA (healthcare) 和 GDPR (隐私) 法规遵守功能, 并提供广泛的数据政策执行、加密、用户管理和审核功能。它还在传输和暂停期间对数据进行加密, 并且集成了移动设备管理和身份验证机制 (包括 LDAP/AD、单点登录、双因素身份验证等)。
|
||||
像本文列表里的其他应用一样, NextCloud 是自托管的,但是如果你不想在自己的 Linux 上安装 NextCloud 服务器,公司与几个[提供商][9]伙伴合作,提供安装和托管, 并销售服务器、设备和服务支持。
|
||||
在[marketplace][10]中提供了大量的apps来扩展它的功能。
|
||||
|
||||
NextCloud 的[文档][11]为用户、管理员和开发者提供了详细的信息,并且向它的论坛、IRC 频道和社交媒体提供了基于社区的支持。如果你想贡献或者获取它的源码,报告一个错误,查看它的 AGPLv3 许可,或者通过它的[GitHub 项目主页][12]了解更多。
|
||||
### Seafile
|
||||
|
||||

|
||||
与ownCloud或NextCloud相比,[Seafile][13]或许没有花里胡哨的卖点(或者 app 生态),但是它能完成任务。实质上, 它充当了 Linux 服务器上的虚拟驱动器, 以扩展你的桌面存储, 并允许你有选择地使用密码保护和各种级别的权限 (即只读或读写) 共享文件。
|
||||
|
||||
它的协作的功能包括文件夹权限控制,密码保护的下载链接和像Git一样的版本控制和保留。文件使用双因素身份验证、文件加密和 AD/LDAP 集成进行保护, 并且可以从 Windows、MacOS、Linux、iOS 或 Android 设备进行访问。
|
||||
|
||||
更多详细信息, 请访问 Seafile 的[GitHub仓库][14]、[服务手册][15]、[wiki][16]和[论坛][17]。请注意, Seafile 的社区版在[GPLv2][18]下获得许可, 但其专业版不是开源的。
|
||||
### OnionShare
|
||||
|
||||

|
||||
|
||||
[OnionShare][19]是一个很酷的应用: 如果你想匿名,它允许你安全地共享单个文件或文件夹。不需要设置或维护服务器,所有你需要做的就是[下载和安装][20] 无论是在 MacOS, Windows 还是 Linux 上。文件始终在你自己的计算机上; 当你共享文件时, OnionShare创建一个 web 服务器, 使其可作为 Tor 洋葱服务访问, 并生成一个不可猜测的 .onion URL, 这个URL允许收件人通过[ Tor 浏览器][21]获取文件。
|
||||
|
||||
你可以设置文件共享的限制, 例如限制可以下载的次数或使用自动停止计时器, 这会设置一个严格的过期日期/时间,超过这个期限便不可访问 (即使尚未访问该文件)。
|
||||
|
||||
OnionShare 在 [GPLv3][22] 之下被许可; 有关详细信息, 请查阅其 [GitHub 仓库][22], 其中还包括[文档][23], 介绍了这个易用文件共享软件的特点。
|
||||
|
||||
### Pydio Cells
|
||||
|
||||

|
||||
|
||||
[Pydio Cells][24]在2018年5月推出了稳定版, 是对 Pydio 共享应用程序的核心服务器代码的全面检修。由于 Pydio 的基于 PHP 的后端的限制, 开发人员决定用 Go 服务器语言和微服务体系结构重写后端。(前端仍然是基于 PHP 的)。
|
||||
|
||||
Pydio Cells 包括通常的共享和版本控制功能, 以及应用程序中的消息接受、移动应用程序 (Android 和 iOS), 以及一种社交网络风格的协作方法。安全性包括基于 OpenID 连接的身份验证、rest 加密、安全策略等。企业发行版中包含着高级功能, 但在社区(家庭)版本中,对于大多数中小型企业和家庭用户来说,依然是足够的。
|
||||
|
||||
您可以 在Linux 和 MacOS[下载][25] Pydio Cells。有关详细信息, 请查阅 [文档常见问题][26]、[源码库][27] 和 [AGPLv3 许可证][28]
|
||||
|
||||
### 其他
|
||||
如果以上选择不能满足你的需求,你可能想考虑其他开源的文件共享型应用。
|
||||
* 如果你的主要目的是在设备间同步文件而不是分享文件,考察一下 [Syncthing][29]。
|
||||
* 如果你是一个Git的粉丝而不需要一个移动应用。你可能更喜欢 [SparkleShare][30]。
|
||||
* 如果你主要想要一个地方聚合所有你的个人数据, 看看 [Cozy][31]。
|
||||
* 如果你想找一个轻量级的或者专注于文件共享的工具,考察一下 [Scott Nesbitt's review][32]——一个罕为人知的工具。
|
||||
|
||||
|
||||
哪个是你最喜欢的开源文件共享应用?在评论中让我们知悉。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/alternatives/dropbox
|
||||
|
||||
作者:[OPensource.com][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[distant1219](https://github.com/distant1219)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com
|
||||
[1]:https://opensource.com/open-source-way
|
||||
[2]:https://owncloud.org/
|
||||
[3]:https://www.gnu.org/licenses/agpl-3.0.html
|
||||
[4]:https://marketplace.owncloud.com/
|
||||
[5]:https://doc.owncloud.com/
|
||||
[6]:https://github.com/owncloud
|
||||
[7]:https://nextcloud.com/
|
||||
[8]:https://nextcloud.com/secure/
|
||||
[9]:https://nextcloud.com/providers/
|
||||
[10]:https://apps.nextcloud.com/
|
||||
[11]:https://nextcloud.com/support/
|
||||
[12]:https://github.com/nextcloud
|
||||
[13]:https://www.seafile.com/en/home/
|
||||
[14]:https://github.com/haiwen/seafile
|
||||
[15]:https://manual.seafile.com/
|
||||
[16]:https://seacloud.cc/group/3/wiki/
|
||||
[17]:https://forum.seafile.com/
|
||||
[18]:https://github.com/haiwen/seafile/blob/master/LICENSE.txt
|
||||
[19]:https://onionshare.org/
|
||||
[20]:https://onionshare.org/#downloads
|
||||
[21]:https://www.torproject.org/
|
||||
[22]:https://github.com/micahflee/onionshare/blob/develop/LICENSE
|
||||
[23]:https://github.com/micahflee/onionshare/wiki
|
||||
[24]:https://pydio.com/en
|
||||
[25]:https://pydio.com/download/
|
||||
[26]:https://pydio.com/en/docs/faq
|
||||
[27]:https://github.com/pydio/cells
|
||||
[28]:https://github.com/pydio/pydio-core/blob/develop/LICENSE
|
||||
[29]:https://syncthing.net/
|
||||
[30]:http://www.sparkleshare.org/
|
||||
[31]:https://cozy.io/en/
|
||||
[32]:https://opensource.com/article/17/3/file-sharing-tools
|
||||
@ -0,0 +1,44 @@
|
||||
在 Arch 用户仓库(AUR)中发现恶意软件
|
||||
======
|
||||
|
||||
7 月 7 日,AUR 软件包被修改了一些恶意代码,提醒 [Arch Linux][1] 用户(以及一般 Linux 用户)在安装之前应该检查所有用户生成的软件包(如果可能)。
|
||||
|
||||
[AUR][3] 或者称 Arch(Linux)用户仓库包含包描述,也称为 PKGBUILD,它使得从源代码编译包变得更容易。虽然这些包非常有用,但它们永远不应被视为安全,并且用户应尽可能在使用之前检查其内容。毕竟,AUR在网页中以粗体显示 “AUR 包是用户制作的内容。任何使用提供的文件的风险由你自行承担。”
|
||||
|
||||
|
||||
包含恶意代码的 AUR 包的[发现][4]证明了这一点。[acroread][5] 于 7 月 7 日(看起来它以前是“孤儿”,意思是它没有维护者)被一位名为 “xeactor” 的用户修改,它包含了一行从 pastebin 使用 `curl` 下载脚本的命令。然后,该脚本下载了另一个脚本并安装了systemd 单元以定期运行该脚本。
|
||||
|
||||
**看来[另外两个][2] AUR 包以同样的方式被修改。所有违规软件包都已删除,并暂停了用于上传它们的用户帐户(在更新软件包同一天注册了那些帐户)。**
|
||||
|
||||
恶意代码没有做任何真正有害的事情 - 它只是试图上传一些系统信息,比如机器 ID、`uname -a` 的输出(包括内核版本、架构等)、CPU 信息、pacman 信息,以及 `systemctl list-units`(列出 systemd 单位信息)的输出到 pastebin.com。我说“尝试”是因为第二个脚本中存在错误而没有实际上传系统信息(上传函数为 “upload”,但脚本试图使用其他名称 “uploader” 调用它)。
|
||||
|
||||
此外,将这些恶意脚本添加到 AUR 的人将脚本中的个人 Pastebin API 密钥以明文形式留下,再次证明他们不确切地知道他们在做什么。
|
||||
|
||||
尝试将此信息上传到 Pastebin 的目的尚不清楚,特别是原本可以上传更加敏感信息的情况下,如 GPG / SSH 密钥。
|
||||
|
||||
**更新:** Reddit用户 u/xanaxdroid_ [提及][6]同一个名为 “xeactor” 的用户也发布了一些加密货币挖矿软件包,因此他推测 “xeactor” 可能正计划添加一些隐藏的加密货币挖矿软件到 AUR([两个月][7]前的一些 Ubuntu Snap 软件包也是如此)[7]。这就是 “xeactor” 可能试图获取各种系统信息的原因。此 AUR 用户上传的所有包都已删除,因此我无法检查。
|
||||
|
||||
**另一个更新:**
|
||||
|
||||
你究竟应该在那些用户生成的软件包 (如 AUR 中找到的) 检查什么?情况各有相同,我无法准确地告诉你,但你可以从寻找任何尝试使用 `curl`、`wget`和其他类似工具下载内容的东西开始,看看他们究竟想要下载什么。还要检查从中下载软件包源的服务器,并确保它是官方来源。不幸的是,这不是一个确切的“科学”。例如,对于 Launchpad PPA,事情变得更加复杂,因为你必须知道 Debian 打包,并且可以直接更改源,因为它在 PPA 中托管并由用户上传。使用 Snap 软件包会变得更加复杂,因为在安装之前你无法检查这些软件包(据我所知)。在后面这些情况下,作为通用解决方案,我猜你应该只安装你信任的用户/打包器生成的软件包。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxuprising.com/2018/07/malware-found-on-arch-user-repository.html
|
||||
|
||||
作者:[Logix][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/118280394805678839070
|
||||
[1]:https://www.archlinux.org/
|
||||
[2]:https://lists.archlinux.org/pipermail/aur-general/2018-July/034153.html
|
||||
[3]:https://aur.archlinux.org/
|
||||
[4]:https://lists.archlinux.org/pipermail/aur-general/2018-July/034152.html
|
||||
[5]:https://aur.archlinux.org/cgit/aur.git/commit/?h=acroread&id=b3fec9f2f16703c2dae9e793f75ad6e0d98509bc
|
||||
[6]:https://www.reddit.com/r/archlinux/comments/8x0p5z/reminder_to_always_read_your_pkgbuilds/e21iugg/
|
||||
[7]:https://www.linuxuprising.com/2018/05/malware-found-in-ubuntu-snap-store.html
|
||||
@ -0,0 +1,63 @@
|
||||
4 个提高你在 Thunderbird 上隐私的加载项
|
||||
======
|
||||
|
||||

|
||||
Thunderbird 是由 [Mozilla][1] 开发的流行免费电子邮件客户端。与 Firefox 类似,Thunderbird 提供了大量加载项来用于额外功能和自定义。本文重点介绍四个加载项,以改善你的隐私。
|
||||
|
||||
### Enigmail
|
||||
|
||||
使用 GPG(GNU Privacy Guard)加密电子邮件是保持其内容私密性的最佳方式。如果你不熟悉 GPG,请[查看我们在 Magazine 上的入门介绍][2]。
|
||||
|
||||
[Enigmail][3] 是使用 OpenPGP 和 Thunderbird 的首选加载项。实际上,Enigmail 与 Thunderbird 集成良好,可让你加密、解密、数字签名和验证电子邮件。
|
||||
|
||||
### Paranoia
|
||||
|
||||
[Paranoia][4] 可让你查看有关收到的电子邮件的重要信息。表情符号显示电子邮件在到达收件箱之前经过的服务器之间的加密状态。
|
||||
|
||||
黄色,快乐的表情告诉你所有连接都已加密。蓝色,悲伤的表情意味着一个连接未加密。最后,红色的,害怕的表情表示在多个连接上该消息未加密。
|
||||
|
||||
还有更多有关这些连接的详细信息,你可以用来检查哪台服务器用于投递邮件。
|
||||
|
||||
### Sensitivity Header
|
||||
|
||||
[Sensitivity Header][5] 是一个简单的加载项,可让你选择外发电子邮件的隐私级别。使用选项菜单,你可以选择敏感度:正常、个人、隐私和机密。
|
||||
|
||||
添加此标头不会为电子邮件添加额外的安全性。但是,某些电子邮件客户端或邮件传输/用户代理(MTA/MUA)可以使用此标头根据敏感度以不同方式处理邮件。
|
||||
|
||||
请注意,开发人员将此加载项标记为实验性的。
|
||||
|
||||
### TorBirdy
|
||||
|
||||
如果你真的担心自己的隐私,[TorBirdy][6] 就是给你设计的加载项。它将 Thunderbird 配置为使用 [Tor][7] 网络。
|
||||
|
||||
据其[文档][8]所述,TorBirdy 在以前没有使用 Tor 的电子邮件帐户上提供较少的隐私。
|
||||
|
||||
>请记住,跟之前使用 Tor 访问的电子邮件帐户相比,之前没有使用 Tor 访问的电子邮件帐户提供**更少**的隐私/匿名/更弱的假名。但是,TorBirdy 仍然对现有帐户或实名电子邮件地址有用。例如,如果你正在寻求隐匿位置 - 你经常旅行并且不想通过发送电子邮件来披露你的所有位置--TorBirdy 非常有效!
|
||||
|
||||
请注意,要使用此加载项,必须在系统上安装 Tor。
|
||||
|
||||
照片由 [Braydon Anderson][9] 在 [Unsplash][10] 上发布。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/4-addons-privacy-thunderbird/
|
||||
|
||||
作者:[Clément Verna][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org
|
||||
[1]:https://www.mozilla.org/en-US/
|
||||
[2]:https://fedoramagazine.org/gnupg-a-fedora-primer/
|
||||
[3]:https://addons.mozilla.org/en-US/thunderbird/addon/enigmail/
|
||||
[4]:https://addons.mozilla.org/en-US/thunderbird/addon/paranoia/?src=cb-dl-users
|
||||
[5]:https://addons.mozilla.org/en-US/thunderbird/addon/sensitivity-header/?src=cb-dl-users
|
||||
[6]:https://addons.mozilla.org/en-US/thunderbird/addon/torbirdy/?src=cb-dl-users
|
||||
[7]:https://www.torproject.org/
|
||||
[8]:https://trac.torproject.org/projects/tor/wiki/torbirdy
|
||||
[9]:https://unsplash.com/photos/wOHH-NUTvVc?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[10]:https://unsplash.com/search/photos/privacy?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
Loading…
Reference in New Issue
Block a user