mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-21 02:10:11 +08:00
20140928-2 选题
This commit is contained in:
parent
aa02c137da
commit
246dcbf034
@ -0,0 +1,52 @@
|
||||
Oracle Linux 5.11 Features Updated Unbreakable Linux Kernel
|
||||
================================================================================
|
||||
> A lot of packages have been updated in this release
|
||||
|
||||

|
||||
|
||||
This is the last release for this branch
|
||||
|
||||
> **Oracle has announced that Oracle Linux Release 5.11 has been made available for download, but this is the enterprise version, so users will have to register in order to get the download.**
|
||||
|
||||
The new Oracle Linux update is probably the last one in the series. This operating system is based on Red Hat and the company has just pushed out the last update for the RHEL 5x branch, which means that this is the end of the line for the Oracle version as well.
|
||||
|
||||
Oracle Linux also comes with a series of features that make it very interesting, like zero-downtime kernel updates with the help of a tool called Ksplice that was originally developed for OpenSUSE, inclusion of the Oracle Database and Oracle Applications, and it's used in all x86-based Oracle Engineered Systems.
|
||||
|
||||
### What's so special about Oracle Linux ###
|
||||
|
||||
|
||||
Despite the fact that Oracle Linux is based on Red Hat, its developers have actually made a list of reasons why you shouldn't use RHEL. There are quite a lot of them, but the main one is that anyone can download Oracle Linux (after registering) and RHEL is actually off limits for non-paying members.
|
||||
|
||||
"Providing advanced scalability and reliability for enterprise applications and systems, Oracle Linux delivers extreme performance and is used in all x86-based Oracle Engineered Systems. Oracle Linux is free to use, free to distribute, free to update, and easy to download. It is the only Linux distribution with production support for zero-downtime kernel updates with Oracle Ksplice, allowing customers the ability to apply patches for security and other updates without a reboot, as well as providing diagnostic features for debugging kernel issues on production systems," say the developers on their website.
|
||||
|
||||
One of the most interesting features for Oracle Linux and unique for this distribution is its unbreakable kernel. This is the actual name used by the developers. It's based on an older Linux kernel from the 3.0.36 branch. Users also have access to a Red Hat-compatible Kernel (kernel-2.6.18-398.el5), which is provided by default in the distro.
|
||||
|
||||
Also, the Unbreakable Enterprise Kernel available in the Oracle Linux Release 5.11 features a ton of drivers for hardware and devices, but this latest update brought even better support.
|
||||
|
||||
You can check the comprehensive [release notes][1] for Oracle Linux 5.11, which will probably take you the rest of the day.
|
||||
|
||||
You can also download Oracle Linux 5.11:
|
||||
|
||||
- [Oracle Enterprise Linux 6.5 (ISO) 64-bit][2]
|
||||
- [Oracle Enterprise Linux 6.5 (ISO) 32-bit][3]
|
||||
- [Oracle Enterprise Linux 7.0 (ISO) 64-bit][4]
|
||||
- [Oracle Enterprise Linux 5.11 (ISO) 64-bit][5]
|
||||
- [Oracle Enterprise Linux 5.11 (ISO) 32-bit][6]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/Oracle-Linux-5-11-Features-Updated-Unbreakable-Linux-Kernel-460129.shtml
|
||||
|
||||
作者:[Silviu Stahie][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
[1]:https://oss.oracle.com/ol5/docs/RELEASE-NOTES-U11-en.html#Kernel_and_Driver_Updates
|
||||
[2]:http://mirrors.dotsrc.org/oracle-linux/OL6/U5/i386/OracleLinux-R6-U5-Server-i386-dvd.iso
|
||||
[3]:http://mirrors.dotsrc.org/oracle-linux/OL6/U5/x86_64/OracleLinux-R6-U5-Server-x86_64-dvd.iso
|
||||
[4]:https://edelivery.oracle.com/linux/
|
||||
[5]:http://ftp5.gwdg.de/pub/linux/oracle/EL5/U11/x86_64/Enterprise-R5-U11-Server-x86_64-dvd.iso
|
||||
[6]:http://ftp5.gwdg.de/pub/linux/oracle/EL5/U11/i386/Enterprise-R5-U11-Server-i386-dvd.iso
|
||||
@ -0,0 +1,64 @@
|
||||
What is a good subtitle editor on Linux
|
||||
================================================================================
|
||||
If you watch foreign movies regularly, chances are you prefer having subtitles rather than the dub. Grown up in France, I know that most Disney movies during my childhood sounded weird because of the French dub. If now I have the chance to be able to watch them in their original version, I know that for a lot of people subtitles are still required. And I surprise myself sometimes making subtitles for my family. Hopefully for me, Linux is not devoid of fancy and open source subtitle editors. In short, this is the non-exhaustive list of open source subtitle editors for Linux. Share your opinion on what you think of the best subtitle editor.
|
||||
|
||||
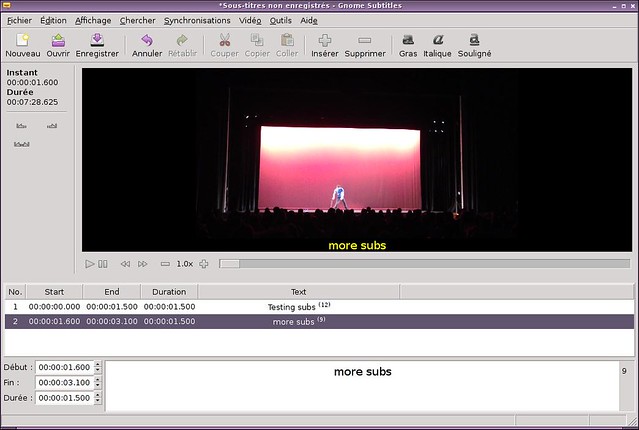
### 1. Gnome Subtitles ###
|
||||
|
||||
|
||||
|
||||
[Gnome Subtitles][2] is a bit my go to when it comes to quickly editing some existing subtitles. You can load the video, load the subtitle text files and instantly get going. I appreciate its balance between ease of use and advanced features. It comes with a synchronization tool as well as a spell check. Finally, last but not least, the shortcuts are what makes it good in the end: when you edit a lot of lines, you prefer to keep your hands on the keyboard, and use the built in shortcuts to move around.
|
||||
|
||||
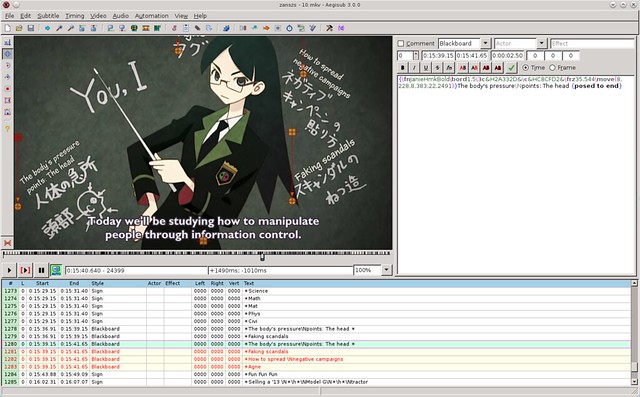
### 2. Aegisub ###
|
||||
|
||||
|
||||
|
||||
[Aegisub][2] is already one level of complexity higher. Just the interface reflects a learning curve. But besides its intimidating aspect, Aegisub is very complete software, providing tools beyond anything I could have imagined before. Like Gnome Subtitles, Aegisub has a WYSIWYG approach, but to a whole new level: it is possible to drag and drop the subtitles on the screen, see the audio spectrum on the side, and do everything with shortcuts. In addition to that, it comes with a Kanji tool, a karaoke mode, and the possibility to import lua script to automate some tasks. I really invite you to go read the [manual page][3] before starting using it.
|
||||
|
||||
### 3. Gaupol ###
|
||||
|
||||

|
||||
|
||||
At the other end of the complexity spectrum is [Gaupol][4]. Unlike Aegisub, Gaupol is quick to pick up and adopts an interface very close to Gnome Subtitles. But behind this relative simplicity, it comes with all the necessary tools: shortcuts, third party extension, spell checking, and even speech recognition (courtesy of [CMU Sphinx][5]). As a downside, however, I did notice some slow-downs while testing it, nothing too serious, but just enough to make me prefer Gnome Subtitles still.
|
||||
|
||||
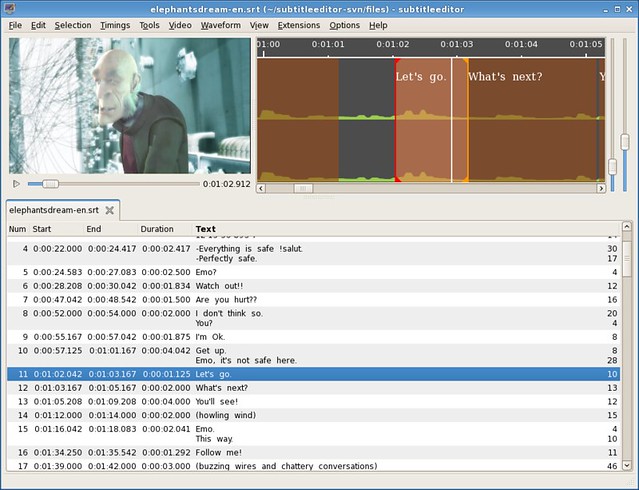
### 4. Subtitle Editor ###
|
||||
|
||||
|
||||
|
||||
[Subtitle Editor][6] is very close to Gaupol. However, the interface is a little bit less intuitive, and the features are slightly more advanced. I appreciate the possibility to define "key frames" and all the given synchronization options. However, maybe more icons and less text would enhance the interface. As a goodie, Subtitle Editor can simulate a "type writer" effect, while I am not sure if it is extremely useful. And last but not least, the possibility to redefine the shortcuts is always handy.
|
||||
|
||||
### 5. Jubler ###
|
||||
|
||||

|
||||
|
||||
Written in Java, [Jubler][7] is a multi-platform subtitle editor. I was actually very impressed by its interface. I definitely see the Java-ish aspect of it, but it remains well conceived and clear. Like Aegisub, you can drag and drop the subtitles on the image, making the experience far more pleasant than just typing. It is also possible to define a style for subtitles, play sound from another track, translate the subtitles, or use the spell checker. However, be careful as you will need MPlayer installed and correctly configured beforehand if you want to use Jubler fully. Oh and I give it a special credit for its easy installation process after downloading the script from the [official page][8].
|
||||
|
||||
### 6. Subtitle Composer ###
|
||||
|
||||

|
||||
|
||||
Defined as a "KDE subtitle composer," [Subtitle Composer][9] comes with most of the traditional features evoked previously, but with the KDE interface that we expect. This comes naturally with the option to redefine the shortcuts, which is very dear to me. But beyond all of this, what differentiates Subtitle Composer from all the previously mentioned programs is its ability to follow scripts written in JavaScript, Python, and even Ruby. A few examples are packaged with the software, and will definitely help you pick up the syntax and the usefulness of such feature.
|
||||
|
||||
To conclude, whether you, like me, just edit a few subtitles for your family, re-synchronize the entire track, or write everything from scratch, Linux has the tools for you. For me in the end, the shortcuts and the ease-of-use make all the difference, but for any higher usage, scripting or speech recognition can become super handy.
|
||||
|
||||
Which subtitle editor do you use and why? Or is there another one that you prefer not mentioned here? Let us know in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/good-subtitle-editor-linux.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/adrien
|
||||
[1]:http://gnomesubtitles.org/
|
||||
[2]:http://www.aegisub.org/
|
||||
[3]:http://docs.aegisub.org/3.2/Main_Page/
|
||||
[4]:http://home.gna.org/gaupol/
|
||||
[5]:http://cmusphinx.sourceforge.net/
|
||||
[6]:http://home.gna.org/subtitleeditor/
|
||||
[7]:http://www.jubler.org/
|
||||
[8]:http://www.jubler.org/download.html
|
||||
[9]:http://sourceforge.net/projects/subcomposer/
|
||||
@ -0,0 +1,223 @@
|
||||
How to turn your CentOS box into an OSPF router using Quagga
|
||||
================================================================================
|
||||
[Quagga][1] is an open source routing software suite that can be used to turn your Linux box into a fully-fledged router that supports major routing protocols like RIP, OSPF, BGP or ISIS router. It has full provisions for IPv4 and IPv6, and supports route/prefix filtering. Quagga can be a life saver in case your production router is down, and you don't have a spare one at your disposal, so are waiting for a replacement. With proper configurations, Quagga can even be provisioned as a production router.
|
||||
|
||||
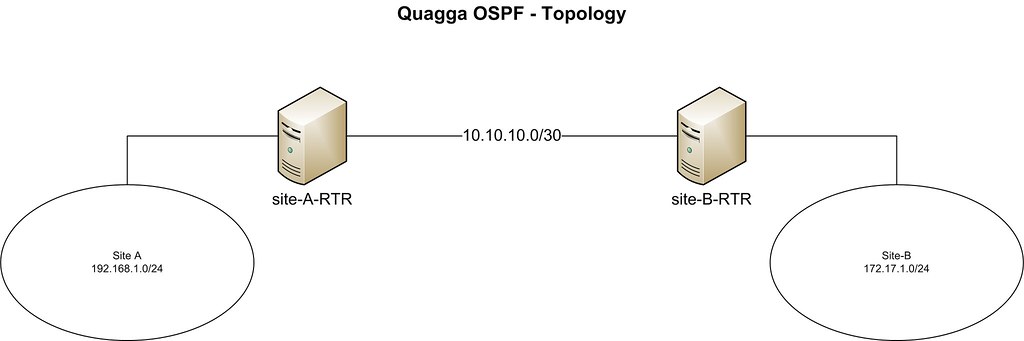
In this tutorial, we will connect two hypothetical branch office networks (e.g., 192.168.1.0/24 and 172.17.1.0/24) that have a dedicated link between them.
|
||||
|
||||
|
||||
|
||||
Our CentOS boxes are located at both ends of the dedicated link. The hostnames of the two boxes are set as 'site-A-RTR' and 'site-B-RTR' respectively. IP address details are provided below.
|
||||
|
||||
- **Site-A**: 192.168.1.0/24
|
||||
- **Site-B**: 172.16.1.0/24
|
||||
- **Peering between 2 Linux boxes**: 10.10.10.0/30
|
||||
|
||||
The Quagga package consists of several daemons that work together. In this tutorial, we will focus on setting up the following daemons.
|
||||
|
||||
1. **Zebra**: a core daemon, responsible for kernel interfaces and static routes.
|
||||
1. **Ospfd**: an IPv4 OSPF daemon.
|
||||
|
||||
### Install Quagga on CentOS ###
|
||||
|
||||
We start the process by installing Quagga using yum.
|
||||
|
||||
# yum install quagga
|
||||
|
||||
On CentOS 7, SELinux prevents /usr/sbin/zebra from writing to its configuration directory by default. This SELinux policy interferes with the setup procedure we are going to describe, so we want to disable this policy. For that, either [turn off SELinux][2] (which is not recommended), or enable the 'zebra_write_config' boolean as follows. Skip this step if you are using CentOS 6.
|
||||
|
||||
# setsebool -P zebra_write_config 1
|
||||
|
||||
Without this change, we will see the following error when attempting to save Zebra configuration from inside Quagga's command shell.
|
||||
|
||||
Can't open configuration file /etc/quagga/zebra.conf.OS1Uu5.
|
||||
|
||||
After Quagga is installed, we configure necessary peering IP addresses, and update OSPF settings. Quagga comes with a command line shell called vtysh. The Quagga commands used inside vtysh are similar to those of major router vendors such as Cisco or Juniper.
|
||||
|
||||
### Phase 1: Configuring Zebra ###
|
||||
|
||||
We start by creating a Zebra configuration file, and launching Zebra daemon.
|
||||
|
||||
# cp /usr/share/doc/quagga-XXXXX/zebra.conf.sample /etc/quagga/zebra.conf
|
||||
# service zebra start
|
||||
# chkconfig zebra on
|
||||
|
||||
Launch vtysh command shell:
|
||||
|
||||
# vtysh
|
||||
|
||||
First, we configure the log file for Zebra. For that, enter the global configuration mode in vtysh by typing:
|
||||
|
||||
site-A-RTR# configure terminal
|
||||
|
||||
and specify log file location, then exit the mode:
|
||||
|
||||
site-A-RTR(config)# log file /var/log/quagga/quagga.log
|
||||
site-A-RTR(config)# exit
|
||||
|
||||
Save configuration permanently:
|
||||
|
||||
site-A-RTR# write
|
||||
|
||||
Next, we identify available interfaces and configure their IP addresses as necessary.
|
||||
|
||||
site-A-RTR# show interface
|
||||
|
||||
----------
|
||||
|
||||
Interface eth0 is up, line protocol detection is disabled
|
||||
. . . . .
|
||||
Interface eth1 is up, line protocol detection is disabled
|
||||
. . . . .
|
||||
|
||||
Configure eth0 parameters:
|
||||
|
||||
site-A-RTR# configure terminal
|
||||
site-A-RTR(config)# interface eth0
|
||||
site-A-RTR(config-if)# ip address 10.10.10.1/30
|
||||
site-A-RTR(config-if)# description to-site-B
|
||||
site-A-RTR(config-if)# no shutdown
|
||||
|
||||
Go ahead and configure eth1 parameters:
|
||||
|
||||
site-A-RTR(config)# interface eth1
|
||||
site-A-RTR(config-if)# ip address 192.168.1.1/24
|
||||
site-A-RTR(config-if)# description to-site-A-LAN
|
||||
site-A-RTR(config-if)# no shutdown
|
||||
|
||||
Now verify configuration:
|
||||
|
||||
site-A-RTR(config-if)# do show interface
|
||||
|
||||
----------
|
||||
|
||||
Interface eth0 is up, line protocol detection is disabled
|
||||
. . . . .
|
||||
inet 10.10.10.1/30 broadcast 10.10.10.3
|
||||
. . . . .
|
||||
Interface eth1 is up, line protocol detection is disabled
|
||||
. . . . .
|
||||
inet 192.168.1.1/24 broadcast 192.168.1.255
|
||||
. . . . .
|
||||
|
||||
----------
|
||||
|
||||
site-A-RTR(config-if)# do show interface description
|
||||
|
||||
----------
|
||||
|
||||
Interface Status Protocol Description
|
||||
eth0 up unknown to-site-B
|
||||
eth1 up unknown to-site-A-LAN
|
||||
|
||||
Save configuration permanently:
|
||||
|
||||
site-A-RTR(config-if)# do write
|
||||
|
||||
Repeat the IP address configuration step on site-B server as well.
|
||||
|
||||
If all goes well, you should be able to ping site-B's peering IP 10.10.10.2 from site-A server.
|
||||
|
||||
Note that once Zebra daemon has started, any change made with vtysh's command line interface takes effect immediately. There is no need to restart Zebra daemon after configuration change.
|
||||
|
||||
### Phase 2: Configuring OSPF ###
|
||||
|
||||
We start by creating an OSPF configuration file, and starting the OSPF daemon:
|
||||
|
||||
# cp /usr/share/doc/quagga-XXXXX/ospfd.conf.sample /etc/quagga/ospfd.conf
|
||||
# service ospfd start
|
||||
# chkconfig ospfd on
|
||||
|
||||
Now launch vtysh shell to continue with OSPF configuration:
|
||||
|
||||
# vtysh
|
||||
|
||||
Enter router configuration mode:
|
||||
|
||||
site-A-RTR# configure terminal
|
||||
site-A-RTR(config)# router ospf
|
||||
|
||||
Optionally, set the router-id manually:
|
||||
|
||||
site-A-RTR(config-router)# router-id 10.10.10.1
|
||||
|
||||
Add the networks that will participate in OSPF:
|
||||
|
||||
site-A-RTR(config-router)# network 10.10.10.0/30 area 0
|
||||
site-A-RTR(config-router)# network 192.168.1.0/24 area 0
|
||||
|
||||
Save configuration permanently:
|
||||
|
||||
site-A-RTR(config-router)# do write
|
||||
|
||||
Repeat the similar OSPF configuration on site-B as well:
|
||||
|
||||
site-B-RTR(config-router)# network 10.10.10.0/30 area 0
|
||||
site-B-RTR(config-router)# network 172.16.1.0/24 area 0
|
||||
site-B-RTR(config-router)# do write
|
||||
|
||||
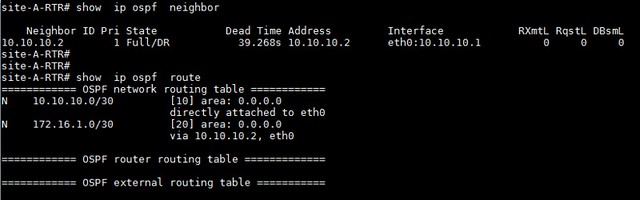
The OSPF neighbors should come up now. As long as ospfd is running, any OSPF related configuration change made via vtysh shell takes effect immediately without having to restart ospfd.
|
||||
|
||||
In the next section, we are going to verify our Quagga setup.
|
||||
|
||||
### Verification ###
|
||||
|
||||
#### 1. Test with ping ####
|
||||
|
||||
To begin with, you should be able to ping the LAN subnet of site-B from site-A. Make sure that your firewall does not block ping traffic.
|
||||
|
||||
[root@site-A-RTR ~]# ping 172.16.1.1 -c 2
|
||||
|
||||
#### 2. Check routing tables ####
|
||||
|
||||
Necessary routes should be present in both kernel and Quagga routing tables.
|
||||
|
||||
[root@site-A-RTR ~]# ip route
|
||||
|
||||
----------
|
||||
|
||||
10.10.10.0/30 dev eth0 proto kernel scope link src 10.10.10.1
|
||||
172.16.1.0/30 via 10.10.10.2 dev eth0 proto zebra metric 20
|
||||
192.168.1.0/24 dev eth1 proto kernel scope link src 192.168.1.1
|
||||
|
||||
----------
|
||||
|
||||
[root@site-A-RTR ~]# vtysh
|
||||
site-A-RTR# show ip route
|
||||
|
||||
----------
|
||||
|
||||
Codes: K - kernel route, C - connected, S - static, R - RIP, O - OSPF,
|
||||
I - ISIS, B - BGP, > - selected route, * - FIB route
|
||||
|
||||
O 10.10.10.0/30 [110/10] is directly connected, eth0, 00:14:29
|
||||
C>* 10.10.10.0/30 is directly connected, eth0
|
||||
C>* 127.0.0.0/8 is directly connected, lo
|
||||
O>* 172.16.1.0/30 [110/20] via 10.10.10.2, eth0, 00:14:14
|
||||
C>* 192.168.1.0/24 is directly connected, eth1
|
||||
|
||||
#### 3. Verifying OSPF neighbors and routes ####
|
||||
|
||||
Inside vtysh shell, you can check if necessary neighbors are up, and proper routes are being learnt.
|
||||
|
||||
[root@site-A-RTR ~]# vtysh
|
||||
site-A-RTR# show ip ospf neighbor
|
||||
|
||||
|
||||
|
||||
In this tutorial, we focused on configuring basic OSPF using Quagga. In general, Quagga allows us to easily configure a regular Linux box to speak dynamic routing protocols such as OSPF, RIP or BGP. Quagga-enabled boxes will be able to communicate and exchange routes with any other router that you may have in your network. Since it supports major open standard routing protocols, it may be a preferred choice in many scenarios. Better yet, Quagga's command line interface is almost identical to that of major router vendors like Cisco or Juniper, which makes deploying and maintaining Quagga boxes very easy.
|
||||
|
||||
Hope this helps.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/turn-centos-box-into-ospf-router-quagga.html
|
||||
|
||||
作者:[Sarmed Rahman][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/sarmed
|
||||
[1]:http://www.nongnu.org/quagga/
|
||||
[2]:http://xmodulo.com/how-to-disable-selinux.html
|
||||
116
sources/tech/20140928 How to use xargs command in Linux.md
Normal file
116
sources/tech/20140928 How to use xargs command in Linux.md
Normal file
@ -0,0 +1,116 @@
|
||||
How to use xargs command in Linux
|
||||
================================================================================
|
||||
Have you ever been in the situation where you are running the same command over and over again for multiple files? If so, you know how tedious and inefficient this can feel. The good news is that there is an easier way, made possible through the xargs command in Unix-based operating systems. With this command you can process multiple files efficiently, saving you time and energy. In this tutorial, you will learn how to execute a command or script for multiple files at once, avoiding the daunting task of processing numerous log files or data files individually.
|
||||
|
||||
There are two ingredients for the xargs command. First, you must specify the files of interest. Second, you must indicate which command or script will be executed for each of the files you specified.
|
||||
|
||||
This tutorial will cover three scenarios in which the xargs command can be used to process files located within several different directories:
|
||||
|
||||
1. Count the number of lines in all files
|
||||
1. Print the first line of specific files
|
||||
1. Process each file using a custom script
|
||||
|
||||
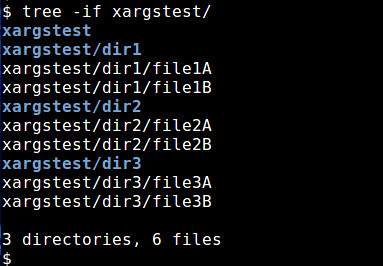
Consider the following directory named xargstest (the directory tree can be displayed using the tree command with the combined -i and -f options, which print the results without indentation and with the full path prefix for each file):
|
||||
|
||||
$ tree -if xargstest/
|
||||
|
||||
|
||||
|
||||
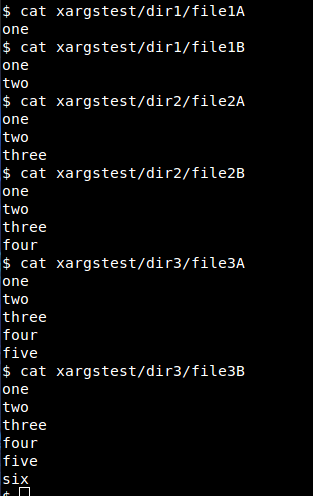
The contents of each of the six files are as follows:
|
||||
|
||||
|
||||
|
||||
The **xargstest** directory, its subdirectories and files will be used in the following examples.
|
||||
|
||||
### Scenario 1: Count the number of lines in all files ###
|
||||
|
||||
As mentioned earlier, the first ingredient for the xargs command is a list of files for which the command or script will be run. We can use the find command to identify and list the files that we are interested in. The **-name 'file??'** option specifies that only files with names beginning with "file" followed by any two characters will be matched within the xargstest directory. This search is recursive by default, which means that the find command will search for matching files within xargstest and all of its sub-directories.
|
||||
|
||||
$ find xargstest/ -name 'file??'
|
||||
|
||||
----------
|
||||
|
||||
xargstest/dir3/file3B
|
||||
xargstest/dir3/file3A
|
||||
xargstest/dir1/file1A
|
||||
xargstest/dir1/file1B
|
||||
xargstest/dir2/file2B
|
||||
xargstest/dir2/file2A
|
||||
|
||||
We can pipe the results to the sort command to order the filenames sequentially:
|
||||
|
||||
$ find xargstest/ -name 'file??' | sort
|
||||
|
||||
----------
|
||||
|
||||
xargstest/dir1/file1A
|
||||
xargstest/dir1/file1B
|
||||
xargstest/dir2/file2A
|
||||
xargstest/dir2/file2B
|
||||
xargstest/dir3/file3A
|
||||
xargstest/dir3/file3B
|
||||
|
||||
We now need the second ingredient, which is the command to execute. We use the wc command with the -l option to count the number of newlines in each file (printed at the beginning of each output line):
|
||||
|
||||
$ find xargstest/ -name 'file??' | sort | xargs wc -l
|
||||
|
||||
----------
|
||||
|
||||
1 xargstest/dir1/file1A
|
||||
2 xargstest/dir1/file1B
|
||||
3 xargstest/dir2/file2A
|
||||
4 xargstest/dir2/file2B
|
||||
5 xargstest/dir3/file3A
|
||||
6 xargstest/dir3/file3B
|
||||
21 total
|
||||
|
||||
You'll see that instead of manually running the wc -l command for each of these files, the xargs command allows you to complete this operation in a single step. Tasks that may have previously seemed unmanageable, such as processing hundreds of files individually, can now be performed quite easily.
|
||||
|
||||
### Scenario 2: Print the first line of specific files ###
|
||||
|
||||
Now that you know the basics of how to use the xargs command, you have the freedom to choose which command you want to execute. Sometimes, you may want to run commands for only a subset of files and ignore others. In this case, you can use the find command with the -name option and the ? globbing character (matches any single character) to select specific files to pipe into the xargs command. For example, if you want to print the first line of all files that end with a "B" character and ignore the files that end with an "A" character, use the following combination of the find, xargs, and head commands (head -n1 will print the first line in a file):
|
||||
|
||||
$ find xargstest/ -name 'file?B' | sort | xargs head -n1
|
||||
|
||||
----------
|
||||
|
||||
==> xargstest/dir1/file1B <==
|
||||
one
|
||||
|
||||
==> xargstest/dir2/file2B <==
|
||||
one
|
||||
|
||||
==> xargstest/dir3/file3B <==
|
||||
one
|
||||
|
||||
You'll see that only the files with names that end with a "B" character were processed, and all files that end with an "A" character were ignored.
|
||||
|
||||
### Scenario 3: Process each file using a custom script ###
|
||||
|
||||
Finally, you may want to run a custom script (in Bash, Python, or Perl for example) for the files. To do this, simply substitute the name of your custom script in place of the wc and head commands shown previously:
|
||||
|
||||
$ find xargstest/ -name 'file??' | xargs myscript.sh
|
||||
|
||||
The custom script **myscript.sh** needs to be written to take a file name as an argument and process the file. The above command will then invoke the script for every file found by find command.
|
||||
|
||||
Note that the above examples include file names that do not contain spaces. Generally speaking, life in a Linux environment is much more pleasant when using file names without spaces. If you do need to handle file names with spaces, the above commands will not work, and should be tweaked to accommodate them. This is accomplished with the -print0 option for find command (which prints the full file name to stdout, followed by a null character), and -0 option for xargs command (which interprets a null character as the end of a string), as shown below:
|
||||
|
||||
$ find xargstest/ -name 'file*' -print0 | xargs -0 myscript.sh
|
||||
|
||||
Note that the argument for the -name option has been changed to 'file*', which means any files with names beginning with "file" and trailed by any number of characters will be matched.
|
||||
|
||||
### Summary ###
|
||||
|
||||
After reading this tutorial you will understand the capabilities of the xargs command and how you can implement this into your workflow. Soon you'll be spending more time enjoying the efficiency offered by this command, and less time doing repetitive tasks. For more details and additional options you can read the xargs documentation by entering the 'man xargs' command in your terminal.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/xargs-command-linux.html
|
||||
|
||||
作者:[Joshua Reed][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/joshua
|
||||
Loading…
Reference in New Issue
Block a user