mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-12 01:40:10 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
22bd8d5320
@ -0,0 +1,67 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11664-1.html)
|
||||
[#]: subject: (Dell XPS 13 7390 Review: The Best Laptop For Desktop Linux Users)
|
||||
[#]: via: (https://www.linux.com/articles/dell-xps-13-7390-review-the-best-laptop-for-desktop-linux-user/)
|
||||
[#]: author: (Swapnil Bhartiya https://www.linux.com/author/swapnil/)
|
||||
|
||||
Dell XPS 13 7390:最好的 Linux 桌面笔记本
|
||||
======
|
||||
|
||||

|
||||
|
||||
曾经,我们必须进行大量研究、阅读大量评论,才能找到一种在所选的 Linux 桌面发行版上可以以最少的麻烦工作的机器。而如今,这种日子已经一去不复返了,几乎每台机器都可以运行 Linux。Linux 内核社区在设备驱动程序支持方面做得非常出色,可以使一切都开箱即用。
|
||||
|
||||
不过,有的是**可以**运行 Linux d 机器,有的是运行 Linux 的机器。戴尔计算机属于后一类。五年前,Barton George 在戴尔内部启动了一项计划,将桌面版 Linux 引入到消费级的高端戴尔系统。从一台机器开始,到现在整套从产品线的高端笔记本电脑和台式机都可以运行 Linux。
|
||||
|
||||
在这些机器中,XPS 13 是我的最爱。尽管我需要一个功能强大的台式机来处理 4K UHD、多机位视频制作,但我还需要一台超便携的笔记本电脑,可以随身携带,而不必担心笨重的背包和充电器。XPS 13 也是我的第一台笔记本电脑,陪了我 7 年多。因此,是的,这还有一个怀旧因素。
|
||||
|
||||
戴尔几乎每年都会更新其 XPS 产品线,并且最新的[产品展示宣布于 10 月][3]。[XPS 13(7390)] [4] 是该系列的增量更新,而且戴尔非常乐意向我寄来一台测评设备。
|
||||
|
||||

|
||||
|
||||
它由 6 核 Core i7-10710U CPU 所支持。它配备 16GB 内存和 1TB SSD。在 1.10 GHz 的基本频率(可以超频到 4.1 GHz)的情况下,这是一台用于常规工作负载的出色机器。它没有使用任何专用的 GPU,因此它并不适合进行游戏或从源代码进行编译的 Gentoo Linux 或 Arch Linux。但是,我确实设法在上面运行了一些 Steam 游戏。
|
||||
|
||||
如果你想运行 Kubernetes 集群、AI 框架或虚拟现实,那么 Precision 系列中还有更强大的机器,这些机器可以运行 Red Hat Enterprise Linux 和 Ubuntu。
|
||||
|
||||
该机器的底盘与上一代相同。边框保持与上一代一样的薄,依旧比 MacBook 和微软的 Surface Pro 薄。
|
||||
|
||||
它具有三个端口,其中两个是 USB-C Thunderbolt 3,可用于连接 4K 显示器、USB 附件以及用于对等网络的计算机之间的高速数据传输。
|
||||
|
||||
它还具有一个 microSD 插槽。作为视频记者,SD 卡插槽会更有用。大量使用树莓派的用户也会喜欢这种卡。
|
||||
|
||||
它具有 4 个麦克风和一个改进的摄像头,该摄像头现在位于顶部(再见,鼻孔摄像头!)。
|
||||
|
||||
XPS 13(7390)光滑纤薄。它的重量仅为 2.7 磅(1.2kg),可以与苹果的 MacBook Air 相提并论。 这台机器可以成为你的旅行伴侣,并且可以执行日常任务,例如检查电子邮件、浏览网络和写作。
|
||||
|
||||
其 4K UHD 屏幕支持 HDR,这意味着你将可以尽享《The Mandalorian》的全部美妙之处。另外,车载扬声器并没有那么好,听起来有些沉闷。它们适合进行视频聊天或休闲的 YouTube 观看,但是如果你想在今年晚些时候观看《The Witcher》剧集,或者想欣赏 Amazon、Apple Music 或 YouTube Music 的音乐,则需要耳机或外接扬声器。
|
||||
|
||||

|
||||
|
||||
但是,在插入充电线之前,你可以能使用这台机器多少时间?在正常工作量的情况下,它为我提供了大约 7-8 个小时的电池续航时间:我打开了几个选项卡浏览网络,只是看看电影或听音乐。多任务处理,尤其是各种 Web 活动,都会加速消耗电池电量。在 Linux 上进行一些微调可能会给你带来更多的续航时间,而在 Windows 10 上,我可以使用 10 多个小时呢!
|
||||
|
||||
作为仍在从事大量写作工作的视频记者,我非常喜欢键盘。但是,我们这么多年来在 Linux 台式机上听到的触控板故事一直没变:它与 MacBook 或 Windows 上的品质相差甚远。这或许有一天能改变。值得称道的是,他们确实发布了可增强体验的触控板驱动程序,但我没有运行此系统随附的提供的 Ubuntu 18.04 LTS。我全新安装了 Ubuntu 19.10,因为 Gnome 在 18.04 中的运行速度非常慢。我尝试过 openSUSE Tumbleweed、Zorin OS、elementary OS、Fedora、KDE neon 和 Arch Linux。一切正常,尽管有些需要额外的努力才能运行。
|
||||
|
||||
那么,该系统适用于谁?显然,这是给那些想要设计精良的、他们信赖的品牌的高端机器的专业人士打造的。适用于喜欢 MacBook Air,但更喜欢 Linux 台式机生态系统的用户。适用于那些希望使用 Linux 来工作,而不是使 Linux 可以工作的人。
|
||||
|
||||
我使用这台机器一周的时间,进一步说明了为什么我如此喜欢戴尔的 XPS 系列。它们是目前最好的 Linux 笔记本电脑。这款 XPS 13(7390),你值得拥有!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/articles/dell-xps-13-7390-review-the-best-laptop-for-desktop-linux-user/
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/author/swapnil/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.linux.com/wp-content/uploads/2019/12/dell-xps-13-7390-1068x665.jpg (dell-xps-13-7390)
|
||||
[2]: https://www.linux.com/wp-content/uploads/2019/12/dell-xps-13-7390.jpg
|
||||
[3]: https://bartongeorge.io/2019/08/21/please-welcome-the-9th-generation-of-the-xps-13-developer-edition/
|
||||
[4]: https://blog.dell.com/en-us/dells-new-consumer-pc-portfolio-unveiled-ifa-2019/
|
||||
@ -0,0 +1,225 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lxbwolf)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11663-1.html)
|
||||
[#]: subject: (6 Ways to Send Email from the Linux Command Line)
|
||||
[#]: via: (https://www.2daygeek.com/6-ways-to-send-email-from-the-linux-command-line/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
Linux 命令行发送邮件的 5 种方法
|
||||
======
|
||||
|
||||
当你需要在 shell 脚本中创建邮件时,就需要用到命令行发送邮件的知识。Linux 中有很多命令可以实现发送邮件。本教程中包含了最流行的 5 个命令行邮件客户端,你可以选择其中一个。这 5 个命令分别是:
|
||||
|
||||
* `mail` / `mailx`
|
||||
* `mutt`
|
||||
* `mpack`
|
||||
* `sendmail`
|
||||
* `ssmtp`
|
||||
|
||||
### 工作原理
|
||||
|
||||
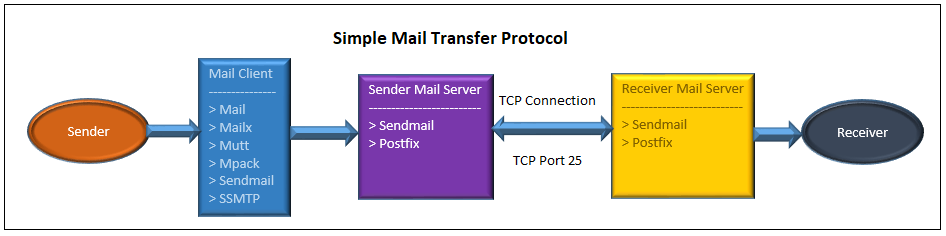
我先从整体上来解释下 Linux 中邮件命令怎么把邮件传递给收件人的。邮件命令撰写邮件并发送给一个本地邮件传输代理(MTA,如 sendmail、Postfix)。邮件服务器和远程邮件服务器之间通信以实际发送和接收邮件。下面的流程可以看得更详细。
|
||||
|
||||
|
||||
|
||||
### 1) 如何在 Linux 上安装 mail/mailx 命令
|
||||
|
||||
`mail` 命令是 Linux 终端发送邮件用的最多的命令。`mailx` 是 `mail` 命令的更新版本,基于 Berkeley Mail 8.1,意在提供 POSIX `mailx` 命令的功能,并支持 MIME、IMAP、POP3、SMTP 和 S/MIME 扩展。mailx 在某些交互特性上更加强大,如缓冲邮件消息、垃圾邮件评分和过滤等。在 Linux 发行版上,`mail` 命令是 `mailx` 命令的软链接。可以运行下面的命令从官方发行版仓库安装 `mail` 命令。
|
||||
|
||||
对于 Debian/Ubuntu 系统,使用 [APT-GET 命令][3] 或 [APT 命令][4] 安装 mailutils。
|
||||
|
||||
```
|
||||
$ sudo apt-get install mailutils
|
||||
```
|
||||
|
||||
对于 RHEL/CentOS 系统,使用 [YUM 命令][5] 安装 mailx。
|
||||
|
||||
```
|
||||
$ sudo yum install mailx
|
||||
```
|
||||
|
||||
对于 Fedora 系统,使用 [DNF 命令][6] 安装 mailx。
|
||||
|
||||
```
|
||||
$ sudo dnf install mailx
|
||||
```
|
||||
|
||||
#### 1a) 如何在 Linux 上使用 mail 命令发送邮件
|
||||
|
||||
`mail` 命令简单易用。如果你不需要发送附件,使用下面的 `mail` 命令格式就可以发送邮件了:
|
||||
|
||||
```
|
||||
$ echo "This is the mail body" | mail -s "Subject" 2daygeek@gmail.com
|
||||
```
|
||||
|
||||
如果你要发送附件,使用下面的 `mail` 命令格式:
|
||||
|
||||
```
|
||||
$ echo "This is the mail body" | mail -a test1.txt -s "Subject" 2daygeek@gmail.com
|
||||
```
|
||||
|
||||
- `-a`:用于在基于 Red Hat 的系统上添加附件。
|
||||
- `-A`:用于在基于 Debian 的系统上添加附件。
|
||||
- `-s`:指定消息标题。
|
||||
|
||||
### 2) 如何在 Linux 上安装 mutt 命令
|
||||
|
||||
`mutt` 是另一个很受欢迎的在 Linux 终端发送邮件的命令。`mutt` 是一个小而强大的基于文本的程序,用来在 unix 操作系统下阅读和发送电子邮件,并支持彩色终端、MIME、OpenPGP 和按邮件线索排序的模式。可以运行下面的命令从官方发行版仓库安装 `mutt` 命令。
|
||||
|
||||
对于 Debian/Ubuntu 系统,使用 [APT-GET 命令][3] 或 [APT 命令][4] 安装 mutt。
|
||||
|
||||
```
|
||||
$ sudo apt-get install mutt
|
||||
```
|
||||
|
||||
对于 RHEL/CentOS 系统,使用 [YUM 命令][5] 安装 mutt。
|
||||
|
||||
```
|
||||
$ sudo yum install mutt
|
||||
```
|
||||
|
||||
对于 Fedora 系统,使用 [DNF 命令][6] 安装 mutt。
|
||||
|
||||
```
|
||||
$ sudo dnf install mutt
|
||||
```
|
||||
|
||||
#### 2b) 如何在 Linux 上使用 mutt 命令发送邮件
|
||||
|
||||
`mutt` 一样简单易用。如果你不需要发送附件,使用下面的 `mutt` 命令格式就可以发送邮件了:
|
||||
|
||||
```
|
||||
$ echo "This is the mail body" | mutt -s "Subject" 2daygeek@gmail.com
|
||||
```
|
||||
|
||||
如果你要发送附件,使用下面的 `mutt` 命令格式:
|
||||
|
||||
```
|
||||
$ echo "This is the mail body" | mutt -s "Subject" 2daygeek@gmail.com -a test1.txt
|
||||
```
|
||||
|
||||
### 3) 如何在 Linux 上安装 mpack 命令
|
||||
|
||||
`mpack` 是另一个很受欢迎的在 Linux 终端上发送邮件的命令。`mpack` 程序会在一个或多个 MIME 消息中对命名的文件进行编码。编码后的消息被发送到一个或多个收件人。可以运行下面的命令从官方发行版仓库安装 `mpack` 命令。
|
||||
|
||||
对于 Debian/Ubuntu 系统,使用 [APT-GET 命令][3] 或 [APT 命令][4] 安装 mpack。
|
||||
|
||||
```
|
||||
$ sudo apt-get install mpack
|
||||
```
|
||||
|
||||
对于 RHEL/CentOS 系统,使用 [YUM 命令][5] 安装 mpack。
|
||||
|
||||
```
|
||||
$ sudo yum install mpack
|
||||
```
|
||||
|
||||
对于 Fedora 系统,使用 [DNF 命令][6] 安装 mpack。
|
||||
|
||||
```
|
||||
$ sudo dnf install mpack
|
||||
```
|
||||
|
||||
#### 3a) 如何在 Linux 上使用 mpack 命令发送邮件
|
||||
|
||||
`mpack` 同样简单易用。如果你不需要发送附件,使用下面的 `mpack` 命令格式就可以发送邮件了:
|
||||
|
||||
```
|
||||
$ echo "This is the mail body" | mpack -s "Subject" 2daygeek@gmail.com
|
||||
```
|
||||
|
||||
如果你要发送附件,使用下面的 mpack 命令格式:
|
||||
|
||||
```
|
||||
$ echo "This is the mail body" | mpack -s "Subject" 2daygeek@gmail.com -a test1.txt
|
||||
```
|
||||
|
||||
### 4) 如何在 Linux 上安装 sendmail 命令
|
||||
|
||||
sendmail 是一个上广泛使用的通用 SMTP 服务器,你也可以从命令行用 `sendmail` 发邮件。可以运行下面的命令从官方发行版仓库安装 `sendmail` 命令。
|
||||
|
||||
对于 Debian/Ubuntu 系统,使用 [APT-GET 命令][3] 或 [APT 命令][4]安装 sendmail。
|
||||
|
||||
```
|
||||
$ sudo apt-get install sendmail
|
||||
```
|
||||
|
||||
对于 RHEL/CentOS 系统,使用 [YUM 命令][5] 安装 sendmail。
|
||||
|
||||
```
|
||||
$ sudo yum install sendmail
|
||||
```
|
||||
|
||||
对于 Fedora 系统,使用 [DNF 命令][6] 安装 sendmail。
|
||||
|
||||
```
|
||||
$ sudo dnf install sendmail
|
||||
```
|
||||
|
||||
#### 4a) 如何在 Linux 上使用 sendmail 命令发送邮件
|
||||
|
||||
`sendmail` 同样简单易用。使用下面的 `sendmail` 命令发送邮件。
|
||||
|
||||
```
|
||||
$ echo -e "Subject: Test Mail\nThis is the mail body" > /tmp/send-mail.txt
|
||||
```
|
||||
|
||||
```
|
||||
$ sendmail 2daygeek@gmail.com < send-mail.txt
|
||||
```
|
||||
|
||||
### 5) 如何在 Linux 上安装 ssmtp 命令
|
||||
|
||||
`ssmtp` 是类似 `sendmail` 的一个只发送不接收的工具,可以把邮件从本地计算机传递到配置好的 邮件主机(mailhub)。用户可以在 Linux 命令行用 `ssmtp` 把邮件发送到 SMTP 服务器。可以运行下面的命令从官方发行版仓库安装 `ssmtp` 命令。
|
||||
|
||||
对于 Debian/Ubuntu 系统,使用 [APT-GET 命令][3] 或 [APT 命令][4]安装 ssmtp。
|
||||
|
||||
```
|
||||
$ sudo apt-get install ssmtp
|
||||
```
|
||||
|
||||
对于 RHEL/CentOS 系统,使用 [YUM 命令][5] 安装 ssmtp。
|
||||
|
||||
```
|
||||
$ sudo yum install ssmtp
|
||||
```
|
||||
|
||||
对于 Fedora 系统,使用 [DNF 命令][6] 安装 ssmtp。
|
||||
|
||||
```
|
||||
$ sudo dnf install ssmtp
|
||||
```
|
||||
|
||||
### 5a) 如何在 Linux 上使用 ssmtp 命令发送邮件
|
||||
|
||||
`ssmtp` 同样简单易用。使用下面的 `ssmtp` 命令格式发送邮件。
|
||||
|
||||
```
|
||||
$ echo -e "Subject: Test Mail\nThis is the mail body" > /tmp/ssmtp-mail.txt
|
||||
```
|
||||
|
||||
```
|
||||
$ ssmtp 2daygeek@gmail.com < /tmp/ssmtp-mail.txt
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/6-ways-to-send-email-from-the-linux-command-line/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lxbwolf](https://github.com/lxbwolf)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]: https://www.2daygeek.com/wp-content/uploads/2019/12/smtp-simple-mail-transfer-protocol.png
|
||||
[3]: https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[4]: https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[5]: https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||
[6]: https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
@ -0,0 +1,65 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (KubeCon gets bigger, the kernel gets better, and more industry trends)
|
||||
[#]: via: (https://opensource.com/article/19/12/kubecon-bigger-kernel-better-more-industry-trends)
|
||||
[#]: author: (Tim Hildred https://opensource.com/users/thildred)
|
||||
|
||||
KubeCon gets bigger, the kernel gets better, and more industry trends
|
||||
======
|
||||
A weekly look at open source community, market, and industry trends.
|
||||
![Person standing in front of a giant computer screen with numbers, data][1]
|
||||
|
||||
As part of my role as a senior product marketing manager at an enterprise software company with an open source development model, I publish a regular update about open source community, market, and industry trends for product marketers, managers, and other influencers. Here are five of my and their favorite articles from that update.
|
||||
|
||||
## [KubeCon showed Kubernetes is big, but is it a Unicorn?][2]
|
||||
|
||||
> It’s hard to remember now but there was a time when Kubernetes was a distant No. 3 in terms of container orchestrators being used in the market. It’s also eye opening to now realize that [the firms][3] that hatched the two platforms that [towered over][4] Kubernetes have had to completely re-jigger their business models under the Kubernetes onslaught.
|
||||
>
|
||||
> And full credit to the CNCF for attempting to diffuse some of that attention from Kubernetes by spending the vast majority of the KubeCon opening keynote address touting some of the nearly two dozen graduated, incubating, and sandbox projects it also hosts. But, it was really the Big K that stole the show.
|
||||
|
||||
**The impact:** Open source is way more than the source code; governance is a big deal and can be the difference between longevity and irrelevance. Gathering, organizing, and maintaining humans is an entirely different skill set than doing the same for bits, but can have just as big an influence on the success of a project.
|
||||
|
||||
## [Report: Kubernetes use on the rise][5]
|
||||
|
||||
> At the same time, the Datadog report notes that container churn rates are approximately 10 times higher in orchestrated environments. Churn rates in container environments that lack an orchestration platform such as Kubernetes have increased in the last year as well. The average container lifespan at a typical company running infrastructure without orchestration is about two days, down from about six days in mid-2018. In 19% of those environments not running orchestration, the average container lifetime exceeded 30 days. That compares to only 3% of organizations running containers longer than 30 days in Kubernetes environments, according to the report’s findings.
|
||||
|
||||
**The impact**: If your containers aren't churning, you're probably not getting the full benefit of the technology you've adopted.
|
||||
|
||||
## [Upcoming Linux 5.5 kernel improves live patching, scheduling][6]
|
||||
|
||||
> A new WFX Wi-Fi driver for the Silicon Labs WF200 ASIC transceiver is coming to Linux kernel 5.5. This particular wireless transceiver is geared toward low-power IoT devices and uses a 2.4 GHz 802.11b/g/n radio optimized for low power RF performance in crowded RF environments. This new driver can interface via both Serial Peripheral Interface (SPI) and Secure Digital Input Output (SDIO).
|
||||
|
||||
**The impact**: The kernel's continued relevance is a direct result of the never-ending grind to keep being where people need it to be (i.e. basically everywhere).
|
||||
|
||||
## [DigitalOcean Currents: December 2019][7]
|
||||
|
||||
> In that spirit, this fall’s installment of our seasonal Currents report is dedicated to open source for the second year running. We surveyed more than 5800 developers around the world on the overall health and direction of the open source community. When we last checked in with the community in [2018][8], more than half of developers reported contributing to open source projects, and most felt the community was healthy and growing.
|
||||
|
||||
**The impact**: While the good news outweighs the bad, there are a couple of things to keep an eye on: namely, making open source more inclusive and mitigating potential negative impact of big money.
|
||||
|
||||
_I hope you enjoyed this list of what stood out to me from last week and come back next Monday for more open source community, market, and industry trends._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/kubecon-bigger-kernel-better-more-industry-trends
|
||||
|
||||
作者:[Tim Hildred][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/thildred
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/data_metrics_analytics_desktop_laptop.png?itok=9QXd7AUr (Person standing in front of a giant computer screen with numbers, data)
|
||||
[2]: https://www.sdxcentral.com/articles/opinion-editorial/kubecon-showed-kubernetes-is-big-but-is-it-a-unicorn/2019/11/
|
||||
[3]: https://www.sdxcentral.com/articles/news/docker-unloads-enterprise-biz-to-mirantis/2019/11/
|
||||
[4]: https://www.sdxcentral.com/articles/news/mesosphere-is-now-d2iq-and-kubernetes-is-its-game/2019/08/
|
||||
[5]: https://containerjournal.com/topics/container-ecosystems/report-kubernetes-use-on-the-rise/
|
||||
[6]: https://thenewstack.io/upcoming-linux-5-5-kernel-improves-live-patching-scheduling/
|
||||
[7]: https://blog.digitalocean.com/digitalocean-currents-december-2019/
|
||||
[8]: https://www.digitalocean.com/currents/october-2018/
|
||||
@ -0,0 +1,103 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (LibreCorps mentors humanitarian startups on how to run the open source way)
|
||||
[#]: via: (https://opensource.com/article/19/12/humanitarian-startups-open-source)
|
||||
[#]: author: (Justin W. Flory https://opensource.com/users/jflory)
|
||||
|
||||
LibreCorps mentors humanitarian startups on how to run the open source way
|
||||
======
|
||||
NGOs and nonprofits can increase their reach by building open source
|
||||
communities.
|
||||
![Two diverse hands holding a globe][1]
|
||||
|
||||
Free and open source software are no longer workplace taboos, at least not in the same way they were fifteen years ago. Today, distributed collaboration platforms and tools empower people around the world to contribute code, documentation, design, leadership, and other skills to open source projects. But do newcomers actually have a deep understanding of free and open source software?
|
||||
|
||||
If you hang around in open source communities for long enough, you realize there is more to open source than slapping a free software license on a project and throwing it over an imaginary fence to wait for contributors who never come. To address this problem in the humanitarian sector, the LibreCorps program, led by Rochester Institute of Technology's FOSS initiative at the [Center for Media, Arts, Interaction & Creativity][2] (MAGIC,) partnered with UNICEF to develop a set of resources to help new open source maintainers chart an "open source roadmap" to build a community.
|
||||
|
||||
![Grassroots presentation in UNICEF office ][3]
|
||||
|
||||
### What is LibreCorps?
|
||||
|
||||
[LibreCorps][4] connects RIT students interested in open source to humanitarian and civic coding opportunities; specifically, opportunities for co-operative education placements (co-ops,) which are full-time paid internships included in the university's graduation requirements.
|
||||
|
||||
LibreCorps students work in two major areas on co-ops. The first, not surprisingly, is technology. The second is FOSS community and processes. Many NGOs and civic organizations put openly licensed work in repositories but need a plan to build and maintain a community of contributors around their technology.
|
||||
|
||||
LibreCorps has worked with numerous humanitarian projects over the years. Recently, LibreCorps was contracted by [UNICEF Innovation][5] to support the [Innovation Fund][6] by mentoring several cohorts of international start-ups in adopting best practices to meet the open source requirement of their funding.
|
||||
|
||||
Periodically, the UNICEF Innovation Fund invites the companies together for cohort workshops, with hands-on mentorship a primary component of the workshop. [Stephen Jacobs][7] and [Justin W. Flory][8] represented LibreCorps at [two UNICEF Innovation Fund workshops][9] to help these teams better understand free and open source, as well as how to successfully build communities and teams that operate as [open organizatio][10][ns][10]. Most of these teams have either never worked in open source projects or only have a basic understanding of licenses and GitHub. Often, for these teams, working on your code in a way where anyone can see what you are doing is a radical shift in process.
|
||||
|
||||
UNICEF Innovation has engaged with open source for years and currently provides funded teams with a course on [open source business models][11].
|
||||
|
||||
> "We'd approached open-source pretty tentatively and definitely naively. We were keen to move to open source for transparency and perception but, beyond that, had no plans around deriving or creating value, and we were nervous about the perceived risks. The mentorship from Mike Nolan has given us clear direction and a deeper understanding that open source isn't a compromise but a communication channel and a way to build a community, and he's giving us the tools that enable that." — Michael Nunan, Director at Tupaia.
|
||||
|
||||
### How do we create workable community strategy guides?
|
||||
|
||||
This past summer, LibreCorps began developing and evolving resources to help these teams take the complex and difficult challenge of building an open source community and break it down into smaller, more manageable steps. [Mike Nolan][12] and [Kent Reese][13] developed a roadmap template for teams to evaluate their current status in maintainership best practices and chart out milestones for where to go next. For a cohort working in open source for the first time, the LibreCorps team offers advice and suggestions on crafting a mission statement, choosing the right license for your project, and more. The rubrics provide an interactive, color-coded reference to unlock a deeper understanding of their progress towards each milestone.
|
||||
|
||||
Let's explore each resource in more detail to understand how they work:
|
||||
|
||||
### Roadmap template
|
||||
|
||||
The [roadmap template][14] is a resource that gets hands-on and personal to a specific open source project. There are five tracks within the roadmaps with different tasks to gradually ramp up the areas of focus for community management.
|
||||
|
||||
The first track includes milestones like writing a mission statement, choosing a free software license, and establishing a code of conduct, and provides a set of open source tools or frameworks for users to learn more about. The second track includes gradually more advanced milestones like documenting how to set up a development environment, learning the pull request workflow, choosing a project hosting platform, and more. Further tracks include milestones like implementing continuous integration (CI,) organizing community events, and gathering user testimonials.
|
||||
|
||||
The LibreCorps team works with each Innovation Fund team within the cohort to create a rubric specific to their projects. The cohort identifies their current position based on which milestone they are currently working toward. Then, we work together to determine next steps for growing their open source community, then create a strategy to reach and accomplish those goals.
|
||||
|
||||
### Self-evaluation rubric
|
||||
|
||||
The milestone template provides high-level guidance on which direction to go, but the [self-evaluation rubric][15] is a feedback mechanism to give cohorts a picture of exceptional, acceptable, and poor implementations for each assigned task. The self-evaluation rubrics enable LibreCorps cohorts to independently self-evaluate progress towards building a sustainable and open community.
|
||||
|
||||
The rubric is organized into five tracks:
|
||||
|
||||
* Community outreach
|
||||
* Continuous integration and health checks
|
||||
* Documentation
|
||||
* Project management
|
||||
* Workflow
|
||||
|
||||
|
||||
|
||||
Each track includes detailed sets of sub-tasks or specific components of building an open source community. For example, documentation includes writing guidelines for how to contribute, and community outreach includes maintaining a project website and engaging with an upstream project community, if one exists.
|
||||
|
||||
The LibreCorps team mostly works with the rubric to evaluate whether Innovation Fund cohort teams sufficiently meet the open source requirement for their project. Some teams make use of the rubric to get a more detailed understanding of whether they are heading in the right direction with their community work.
|
||||
|
||||
### Contribute to these resources
|
||||
|
||||
Do these resources sound useful or interesting? Fortunately, the LibreCorps content is licensed under Creative Commons licenses. Learn more about LibreCorps on the [FOSS@MAGIC website][4] and keep up with what we are doing on [our GitHub][16]. To get in touch with us, visit our community Discourse forums on [fossrit.community][17].
|
||||
|
||||
A few months ago, we profiled open source projects working to make the world a better place. In...
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/humanitarian-startups-open-source
|
||||
|
||||
作者:[Justin W. Flory][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jflory
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/world_hands_diversity.png?itok=zm4EDxgE (Two diverse hands holding a globe)
|
||||
[2]: https://www.rit.edu/magic/
|
||||
[3]: https://opensource.com/sites/default/files/uploads/unicef-flory_0.jpg (Grassroots presentation in UNICEF office )
|
||||
[4]: https://fossrit.github.io/librecorps/
|
||||
[5]: https://www.wired.com/story/wired25-stories-people-racing-to-save-us/
|
||||
[6]: https://unicefinnovationfund.org/
|
||||
[7]: https://www.rit.edu/magic/affiliate-spotlight-stephen-jacobs
|
||||
[8]: https://justinwflory.com/
|
||||
[9]: https://fossrit.github.io/announcements/2019/04/01/unicef-foss-community-building/
|
||||
[10]: https://opensource.com/open-organization/resources/open-org-maturity-model
|
||||
[11]: https://www.google.com/url?q=https://agora.unicef.org/course/info.php?id%3D18096&sa=D&ust=1573658770972000&usg=AFQjCNGemgWoJ3kCoKImLCDok7opIo2RCA
|
||||
[12]: https://nolski.rocks/
|
||||
[13]: https://kentr.itch.io/
|
||||
[14]: https://docs.google.com/document/d/1M2nVwh7ArjAU31M7QZWP4AQz1cOyMhw90iP8Wg9lZNo/edit?usp=sharing
|
||||
[15]: https://docs.google.com/spreadsheets/d/11DaQxbiOv9_EiZEozEkUapf2AsVQ4vBFelhnZ0a8R4w/edit?usp=sharing
|
||||
[16]: https://github.com/librecorps/
|
||||
[17]: https://fossrit.community/
|
||||
@ -0,0 +1,106 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Italian job: Translating our mission statement in the open)
|
||||
[#]: via: (https://opensource.com/open-organization/19/12/translating-mission-statement)
|
||||
[#]: author: (Antonella Iecle https://opensource.com/users/aiecle)
|
||||
|
||||
Italian job: Translating our mission statement in the open
|
||||
======
|
||||
A seemingly straightforward translation exercise turned into a lesson
|
||||
about the power of open decision making.
|
||||
![Yellow arrows going both ways with texture][1]
|
||||
|
||||
At Red Hat, part of my job is to ensure that company messages maintain their meaning and effectiveness in my native language—Italian—so that customers in my region can learn not only about our products and services but also about [our organizational values][2].
|
||||
|
||||
The work tends to be simple and straightforward. But in an open organization, even the tasks that seem small can present big opportunities for learning about the power of working the open way.
|
||||
|
||||
That was the case for me recently, when what I thought would be a quick translation exercise turned into a lesson in the [benefits of open decision making][3].
|
||||
|
||||
### A crowdsourced decision
|
||||
|
||||
A few months ago, I noticed a post on our company's internal collaboration platform that seemed to be calling my name. Colleagues from around the world were leaving comments on translated versions of one particular (and very important) corporate message: the [company's mission statement][4]. And they had questions about the Italian translation.
|
||||
|
||||
So I joined the conversation with no hesitation, assuming I'd engage in a quick exchange of opinions and reach a conclusion about the best way to translate Red Hat's mission statement:
|
||||
|
||||
_To be the catalyst in communities of customers, contributors, and partners creating better technology the open source way._
|
||||
|
||||
That's a single sentence consisting of less than 20 words. Translating it into another language should be a no-brainer, right? If anything, the work should take no longer than a few minutes: Read it out loud, spot room for improvement, swap a word for a more effective synonym, maybe rephrase a bit, and you're done!
|
||||
|
||||
As a matter of fact, that's not always the case.
|
||||
|
||||
Translations of the mission statement in a few languages were already available, but comments from colleagues reflected a need for some review. And as more Red Hatters from different parts of the globe joined the discussion and shared their perspectives, I began to see many possibilities for solving this translation problem—and the challenges that come with this abundance of ideas.
|
||||
|
||||
Seeing so many inspiring comments can make reaching a decision much more complicated. One might put concepts into words in a _number_ of ways, but how do we all agree on the _best_ way? How do we deliver a message that reflects our common goal? How do we make sure that all employees can identify with it? And how do we ensure that our customers understand how we can help them grow?
|
||||
|
||||
It's true: When you're about to make a decision that has an impact on other people, you have to ask yourself—and each other—a lot of questions.
|
||||
|
||||
It's true: When you're about to make a decision that has an impact on other people, you have to ask yourself—and each other—a lot of questions.
|
||||
|
||||
### Found in translation
|
||||
|
||||
Localising a message for our readers around the world means more than just translating it word by word. A literal translation may not be fully understandable, especially when the original message was written with English native speakers in mind. On the other hand, a creative translation may be just one of many possible interpretations of the original text. And then there are personal preferences: Which translation sounds better to me? Is there a particular reason? If so, how do I get my point across?
|
||||
|
||||
Linguistic debates can highlight complex aspects of communication, from the subtle nuances in the meaning of a particular word to the cultural traits, mindsets, and levels of familiarity with a topic that define how the same message can be perceived by readers from different countries. Our own conversations delved into known linguistic dilemmas like the use of anglicisms and the disambiguation of expressions that can have more than one interpretation.
|
||||
|
||||
Localisation teams must ensure that messages are delivered accurately and consistently. Working collaboratively is essential to achieving this goal.
|
||||
|
||||
To get started, we only had to look at how our original mission statement had come together in the first place. Since we were trying to do something that someone else had done before, we needed to ask: "[How did Red Hat find its mission][5]?"
|
||||
|
||||
The answer? By asking the whole company what it should be.
|
||||
|
||||
Opening up the conversation doesn't always accelerate the decision making process.
|
||||
|
||||
It may be counterintuitive, but engaging the broader community can be a very efficient way to overcome uncertainties and address problems you weren't even aware of. Opening up the conversation doesn't always accelerate the decision making process, but by bringing people together you allow them to draw a clearer picture of the problem and provide you with the elements you need to make better decisions.
|
||||
|
||||
With that in mind, all you have to do is ask other teams to contribute, then give them a reasonable amount of time to make room in their busy schedule and think about how they can help. Suggestions will come, and how you will channel the incoming information is up to you.
|
||||
|
||||
Surveys are often a great way to gather feedback and keep track of incoming responses, and this is the approach we chose. We submitted a new translation, and asked our teams in Italy to tell us if they were happy with it. The majority of the respondents were. However, a few participants had their own versions to share (and valid comments to add).
|
||||
|
||||
After considering everyone's input, we submitted a second survey. We asked the participants to choose between the solution we offered in the first survey and a _newer_ version, one we obtained by incorporating the feedback we'd received from our recent collaborative discussion.
|
||||
|
||||
The second option was the winner.
|
||||
|
||||
The initial translation did not represent Red Hat's mission as clearly and faithfully as the improved statement did. For example, in the original version, Red Hat was a “point of reference” rather than a "catalyst," and worked with "a community" rather than a larger and more diverse number of "communities." We were using the word "collaborators" instead of "contributors," and our actions were following a set of "principles" rather than the open source "way."
|
||||
|
||||
The changes we made reaffirmed Red Hat's role in the communities and its commitment to open source technology, but also to open source as a way of working.
|
||||
|
||||
Don't be afraid to jump into a conversation—or even to take the lead—if you think you can help to make better decisions.
|
||||
|
||||
So here is some advice this experience taught me: Don't be afraid to jump into a conversation—or even to take the lead—if you think you can help to make better decisions. Because as Jim Whitehurst likes to say, in the open source world, we believe [the best ideas should win][6], no matter where they come from.
|
||||
|
||||
In short, here is my five-point checklist for open decision-making, regardless of the task you face:
|
||||
|
||||
1. Encourage wide participation.
|
||||
2. Welcome all responses as they arrive.
|
||||
3. Identify the best ideas and get the most out of everyone's suggestions.
|
||||
4. Answer questions and address concerns.
|
||||
5. Communicate the outcome, and summarize the steps of the decision process. In doing so, reassert the value of broad collaboration.
|
||||
|
||||
|
||||
|
||||
One more thing (I know I said I only had five more points, but don't switch off yet): Keep listening to what people might have to say about the decision you just made together.
|
||||
|
||||
The best ideas may take longer to brew.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/19/12/translating-mission-statement
|
||||
|
||||
作者:[Antonella Iecle][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/aiecle
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/arrows_translation_lead.jpg?itok=S4vAh9CP (Yellow arrows going both ways with texture)
|
||||
[2]: https://www.redhat.com/en/book-of-red-hat#our-values
|
||||
[3]: https://opensource.com/open-organization/resources/open-decision-framework
|
||||
[4]: https://www.redhat.com/en/book-of-red-hat#our-vision-intro
|
||||
[5]: https://www.managementexchange.com/blog/how-red-hat-used-open-source-way-develop-company-mission
|
||||
[6]: https://opensource.com/open-organization/16/8/how-make-meritocracy-work
|
||||
@ -1,241 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (14 SCP Command Examples to Securely Transfer Files in Linux)
|
||||
[#]: via: (https://www.linuxtechi.com/scp-command-examples-in-linux/)
|
||||
[#]: author: (Pradeep Kumar https://www.linuxtechi.com/author/pradeep/)
|
||||
|
||||
14 SCP Command Examples to Securely Transfer Files in Linux
|
||||
======
|
||||
|
||||
**SCP** (Secure Copy) is command line tool in Linux and Unix like systems which is used to transfer files and directories across the systems securely over the network. When we use scp command to copy files and directories from our local system to remote system then in the backend it makes **ssh connection** to remote system. In other words, we can say scp uses the same **SSH security mechanism** in the backend, it needs either password or keys for authentication.
|
||||
|
||||
[![scp-command-examples-linux][1]][2]
|
||||
|
||||
In this tutorial we will discuss 14 useful Linux scp command examples.
|
||||
|
||||
**Syntax of scp command:**
|
||||
|
||||
### scp <options> <files_or_directories> [root@linuxtechi][3]_host:/<folder>
|
||||
|
||||
### scp <options> [root@linuxtechi][3]_host:/files <folder_local_system>
|
||||
|
||||
First syntax of scp command demonstrate how to copy files or directories from local system to target host under the specific folder.
|
||||
|
||||
Second syntax of scp command demonstrate how files from target host is copied into local system.
|
||||
|
||||
Some of the most widely used options in scp command are listed below,
|
||||
|
||||
* -C Enable Compression
|
||||
* -i identity File or private key
|
||||
* -l limit the bandwidth while copying
|
||||
* -P ssh port number of target host
|
||||
* -p Preserves permissions, modes and access time of files while copying
|
||||
* -q Suppress warning message of SSH
|
||||
* -r Copy files and directories recursively
|
||||
* -v verbose output
|
||||
|
||||
|
||||
|
||||
Let’s jump into the examples now!!!!
|
||||
|
||||
###### Example:1) Copy a file from local system to remote system using scp
|
||||
|
||||
Let’s assume we want to copy jdk rpm package from our local Linux system to remote system (172.20.10.8) using scp command, use the following command,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]$ scp jdk-linux-x64_bin.rpm root@linuxtechi:/opt
|
||||
root@linuxtechi's password:
|
||||
jdk-linux-x64_bin.rpm 100% 10MB 27.1MB/s 00:00
|
||||
[root@linuxtechi ~]$
|
||||
```
|
||||
|
||||
Above command will copy jdk rpm package file to remote system under /opt folder.
|
||||
|
||||
###### Example:2) Copy a file from remote System to local system using scp
|
||||
|
||||
Let’s suppose we want to copy a file from remote system to our local system under the /tmp folder, execute the following scp command,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]$ scp root@linuxtechi:/root/Technical-Doc-RHS.odt /tmp
|
||||
root@linuxtechi's password:
|
||||
Technical-Doc-RHS.odt 100% 1109KB 31.8MB/s 00:00
|
||||
[root@linuxtechi ~]$ ls -l /tmp/Technical-Doc-RHS.odt
|
||||
-rwx------. 1 pkumar pkumar 1135521 Oct 19 11:12 /tmp/Technical-Doc-RHS.odt
|
||||
[root@linuxtechi ~]$
|
||||
```
|
||||
|
||||
###### Example:3) Verbose Output while transferring files using scp (-v)
|
||||
|
||||
In scp command, we can enable the verbose output using -v option, using verbose output we can easily find what exactly is happening in the background. This becomes very useful in **debugging connection**, **authentication** and **configuration problems**.
|
||||
|
||||
```
|
||||
root@linuxtechi ~]$ scp -v jdk-linux-x64_bin.rpm root@linuxtechi:/opt
|
||||
Executing: program /usr/bin/ssh host 172.20.10.8, user root, command scp -v -t /opt
|
||||
OpenSSH_7.8p1, OpenSSL 1.1.1 FIPS 11 Sep 2018
|
||||
debug1: Reading configuration data /etc/ssh/ssh_config
|
||||
debug1: Reading configuration data /etc/ssh/ssh_config.d/05-redhat.conf
|
||||
debug1: Reading configuration data /etc/crypto-policies/back-ends/openssh.config
|
||||
debug1: /etc/ssh/ssh_config.d/05-redhat.conf line 8: Applying options for *
|
||||
debug1: Connecting to 172.20.10.8 [172.20.10.8] port 22.
|
||||
debug1: Connection established.
|
||||
…………
|
||||
debug1: Next authentication method: password
|
||||
root@linuxtechi's password:
|
||||
```
|
||||
|
||||
###### Example:4) Transfer multiple files to remote system
|
||||
|
||||
Multiple files can be copied / transferred to remote system using scp command in one go, in scp command specify the multiple files separated by space, example is shown below
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]$ scp install.txt index.html jdk-linux-x64_bin.rpm root@linuxtechi:/mnt
|
||||
root@linuxtechi's password:
|
||||
install.txt 100% 0 0.0KB/s 00:00
|
||||
index.html 100% 85KB 7.2MB/s 00:00
|
||||
jdk-linux-x64_bin.rpm 100% 10MB 25.3MB/s 00:00
|
||||
[root@linuxtechi ~]$
|
||||
```
|
||||
|
||||
###### Example:5) Transfer files across two remote hosts
|
||||
|
||||
Using scp command we can copy files and directories between two remote hosts, let’s suppose we have a local Linux system which can connect to two remote Linux systems, so from my local linux system I can use scp command to copy files across these two systems,
|
||||
|
||||
Syntax:
|
||||
|
||||
### scp [root@linuxtechi][3]_hosts1:/<files_to_transfer> [root@linuxtechi][3]_host2:/<folder>
|
||||
|
||||
Example is shown below,
|
||||
|
||||
```
|
||||
# scp root@linuxtechi:~/backup-Oct.zip root@linuxtechi:/tmp
|
||||
# ssh root@linuxtechi "ls -l /tmp/backup-Oct.zip"
|
||||
-rwx------. 1 root root 747438080 Oct 19 12:02 /tmp/backup-Oct.zip
|
||||
```
|
||||
|
||||
###### Example:6) Copy files and directories recursively (-r)
|
||||
|
||||
Use -r option in scp command to recursively copy the entire directory from one system to another, example is shown below,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]$ scp -r Downloads root@linuxtechi:/opt
|
||||
```
|
||||
|
||||
Use below command to verify whether Download folder is copied to remote system or not,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]$ ssh root@linuxtechi "ls -ld /opt/Downloads"
|
||||
drwxr-xr-x. 2 root root 75 Oct 19 12:10 /opt/Downloads
|
||||
[root@linuxtechi ~]$
|
||||
```
|
||||
|
||||
###### Example:7) Increase transfer speed by enabling compression (-C)
|
||||
|
||||
In scp command, we can increase the transfer speed by enabling the compression using -C option, it will automatically enable compression at source and decompression at destination host.
|
||||
|
||||
```
|
||||
root@linuxtechi ~]$ scp -r -C Downloads root@linuxtechi:/mnt
|
||||
```
|
||||
|
||||
In the above example we are transferring the Download directory with compression enabled.
|
||||
|
||||
###### Example:8) Limit bandwidth while copying ( -l )
|
||||
|
||||
Use ‘-l’ option in scp command to put limit on bandwidth usage while copying. Bandwidth is specified in Kbit/s, example is shown below,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]$ scp -l 500 jdk-linux-x64_bin.rpm root@linuxtechi:/var
|
||||
```
|
||||
|
||||
###### Example:9) Specify different ssh port while scp ( -P)
|
||||
|
||||
There can be some scenario where ssh port is changed on destination host, so while using scp command we can specify the ssh port number using ‘-P’ option.
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]$ scp -P 2022 jdk-linux-x64_bin.rpm root@linuxtechi:/var
|
||||
```
|
||||
|
||||
In above example, ssh port for remote host is “2022”
|
||||
|
||||
###### Example:10) Preserves permissions, modes and access time of files while copying (-p)
|
||||
|
||||
Use “-p” option in scp command to preserve permissions, access time and modes while copying from source to destination
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]$ scp -p jdk-linux-x64_bin.rpm root@linuxtechi:/var/tmp
|
||||
jdk-linux-x64_bin.rpm 100% 10MB 13.5MB/s 00:00
|
||||
[root@linuxtechi ~]$
|
||||
```
|
||||
|
||||
###### Example:11) Transferring files in quiet mode ( -q) in scp
|
||||
|
||||
Use ‘-q’ option in scp command to suppress transfer progress, warning and diagnostic messages of ssh. Example is shown below,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]$ scp -q -r Downloads root@linuxtechi:/var/tmp
|
||||
[root@linuxtechi ~]$
|
||||
```
|
||||
|
||||
###### Example:12) Use Identify file in scp while transferring ( -i )
|
||||
|
||||
In most of the Linux environments, keys-based authentication is preferred. In scp command we specify the identify file or private key file using ‘-i’ option, example is shown below,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]$ scp -i my_key.pem -r Downloads root@linuxtechi:/root
|
||||
```
|
||||
|
||||
In above example, “my_key.pem” is the identity file or private key file.
|
||||
|
||||
###### Example:13) Use different ‘ssh_config’ file in scp ( -F)
|
||||
|
||||
There are some scenarios where you use different networks to connect to Linux systems, may be some network is behind proxy servers, so in that case we must have different **ssh_config** file.
|
||||
|
||||
Different ssh_config file in scp command is specified via ‘-F’ option, example is shown below
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]$ scp -F /home/pkumar/new_ssh_config -r Downloads root@linuxtechi:/root
|
||||
root@linuxtechi's password:
|
||||
jdk-linux-x64_bin.rpm 100% 10MB 16.6MB/s 00:00
|
||||
backup-Oct.zip 100% 713MB 41.9MB/s 00:17
|
||||
index.html 100% 85KB 6.6MB/s 00:00
|
||||
[root@linuxtechi ~]$
|
||||
```
|
||||
|
||||
###### Example:14) Use Different Cipher in scp command (-c)
|
||||
|
||||
By default, scp uses ‘AES-128’ cipher to encrypt the files. If you want to use another cipher in scp command then use ‘-c’ option followed by cipher name,
|
||||
|
||||
Let’s suppose we want to use ‘3des-cbc’ cipher in scp command while transferring the files, run the following scp command
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# scp -c 3des-cbc -r Downloads root@linuxtechi:/root
|
||||
```
|
||||
|
||||
Use the below command to list ssh and scp ciphers,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# ssh -Q cipher localhost | paste -d , -s -
|
||||
3des-cbc,aes128-cbc,aes192-cbc,aes256-cbc,root@linuxtechi,aes128-ctr,aes192-ctr,aes256-ctr,root@linuxtechi,root@linuxtechi,root@linuxtechi
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
That’s all from this tutorial, to get more details about scp command, kindly refer its man page. Please do share your feedback and comments in comments section below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxtechi.com/scp-command-examples-in-linux/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linuxtechi.com/author/pradeep/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]: https://www.linuxtechi.com/wp-content/uploads/2019/10/scp-command-examples-linux.jpg
|
||||
[3]: https://www.linuxtechi.com/cdn-cgi/l/email-protection
|
||||
@ -1,65 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Dell XPS 13 7390 Review: The Best Laptop For Desktop Linux Users)
|
||||
[#]: via: (https://www.linux.com/articles/dell-xps-13-7390-review-the-best-laptop-for-desktop-linux-user/)
|
||||
[#]: author: (Swapnil Bhartiya https://www.linux.com/author/swapnil/)
|
||||
|
||||
Dell XPS 13 7390 Review: The Best Laptop For Desktop Linux Users
|
||||
======
|
||||
|
||||
[![][1]][2]
|
||||
|
||||
[![][1]][2]
|
||||
|
||||
Gone are the days when we had to do a lot of research and read a lot of reviews to find a machine that would work with the least amount of trouble with the desktop Linux distribution of choice. Today, almost every machine out there can run Linux. The kernel community has done an incredible job with device driver support to make everything work out of the box.
|
||||
|
||||
Still, there are machines that can run Linux, and then there are machines that run Linux. Dell machines fall in the latter category. Five years ago, Barton George started a program within Dell to bring desktop Linux to consumer grade, high-end Dell systems. What started as one machine is now an entire line of high-end laptops and desktops.
|
||||
|
||||
Among these machines, XPS 13 is my favorite. While I need a really powerful desktop to handle my 4K UHD, multicam video production, I also need an ultra-portable laptop that I can bring with me anywhere without having to worry about a bulky backpack and charger. XPS 13 was also my very first laptop, which lasted me more than 7 years. So, yes, there is that nostalgic factor, too.
|
||||
|
||||
Dell updates the XPS line almost every year and the latest [rollout was announced in October][3] (link to video interview). [XPS 13 (7390)][4] is an incremental update to the series, and Dell was kind enough to send me a review unit.
|
||||
|
||||
It is powered by a 6-core, Core i7-10710U CPU. It comes with 16GB of memory and 1TB SSD. At the base frequency of 1.10 GHz, which can boost to 4.1 GHz, this is a great machine for average workloads. It doesn’t have any dedicated GPU, so it’s not meant for gaming or compiling from source for Gentoo Linux or Arch Linux. However, I did manage to run some Steam games on it.
|
||||
|
||||
If you are looking to run your Kubernetes clusters, AI frameworks or Virtual Reality, then there are more powerful machines from the Precision line, which are certified to run Red Hat Enterprise Linux and Ubuntu.
|
||||
|
||||
The machine’s chassis is identical to the previous generation. The bezels remains as thin as they were in the previous generation, still thinner than MacBook and Microsoft’s Surface Pro.
|
||||
|
||||
It has three ports, two of which are USB-C Thunderbolt 3, which can be used to connect to 4K monitors, USB accessories, and high-speed data transfer between machines with peer-to-peer networking.
|
||||
|
||||
It also has a microSD slot. As a video journalist, a slot for an SD card would have been more useful. Heavy users of Raspberry Pis would also love this card.
|
||||
|
||||
It has 4 microphones and an improved camera, which is now located at the top (goodbye, nosecam!).
|
||||
|
||||
XPS 13 (7390) is sleek and slim. At 2.7 lbs, it is certainly comparable to Apple’s MacBook Air. This machine is meant to be your travel companion and for everyday tasks like checking emails, browsing the web, and writing.
|
||||
|
||||
Its 4K UHD screen supports HDR, which means you will be able to enjoy Mandalorian in all its full glory. That said, the on-board speakers are not that great and sound muffled. They are OK for video chats or casual YouTube viewing, but if you want to enjoy the The Witcher later this year, or if you want to enjoy music from Amazon, Apple Music or YouTube Music, you need headphones or external speakers.
|
||||
|
||||
But how much fun can you get out of this machine before you reach for charging cable? It gave me around 7-8 hours of battery life with average workload: browsing the web with a few tabs, just watching a movie or listening to music. Multi-tasking, especially any kind of web activity, will drain the battery. Some fine-tuning on Linux may give you even more life. On Windows 10, I was able to get more than 10 hours!
|
||||
|
||||
As a video journalist who is still doing a fair amount of writing, I really like the keyboard. However, the trackpad is the same story that we have been hearing on desktop Linux for ages: it’s nowhere near the quality on MacBook or Windows machines. Maybe one day. To Dell’s credit, they do release drivers for the trackpad that enhances the experience, but I am not running the stock Ubuntu 18.04 LTS that came with this system. I did a fresh install of Ubuntu 19.10 because Gnome is painfully slow in 18.04. I tried openSUSE Tumbleweed, Zorin OS, elementary OS, Fedora, KDE’s neon and Arch Linux. All worked, although some needed extra effort to run.
|
||||
|
||||
So, who is this system for? It’s certainly for professionals who want a well designed, high-end machine from a brand they can trust. It’s for those who like a MacBook Air, but prefer the desktop Linux ecosystem. It’s for those who want to use Linux for work, instead of working on it to make it work.
|
||||
|
||||
Spending a week with this machine reinforced why I love Dell’s XPS series so much. They are the best Linux laptops out there. And this XPS 13 (7390) packs a punch.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/articles/dell-xps-13-7390-review-the-best-laptop-for-desktop-linux-user/
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/author/swapnil/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.linux.com/wp-content/uploads/2019/12/dell-xps-13-7390-1068x665.jpg (dell-xps-13-7390)
|
||||
[2]: https://www.linux.com/wp-content/uploads/2019/12/dell-xps-13-7390.jpg
|
||||
[3]: https://bartongeorge.io/2019/08/21/please-welcome-the-9th-generation-of-the-xps-13-developer-edition/
|
||||
[4]: https://blog.dell.com/en-us/dells-new-consumer-pc-portfolio-unveiled-ifa-2019/
|
||||
@ -1,95 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Pekwm: A lightweight Linux desktop)
|
||||
[#]: via: (https://opensource.com/article/19/12/pekwm-linux-desktop)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
Pekwm: A lightweight Linux desktop
|
||||
======
|
||||
This article is part of a special series of 24 days of Linux desktops.
|
||||
If you're a minimalist who finds traditional desktops get in your way,
|
||||
try the Pekwm Linux desktop.
|
||||
![Penguin with green background][1]
|
||||
|
||||
Let's say you want a lightweight desktop environment, with just enough to get graphics on the screen, move some windows around, and not much else. You find traditional desktops get in your way, with their notifications and taskbars and system trays. You want to live your life primarily from a terminal, but you also want the luxury of launching graphical applications. If that sounds like you, then [Pekwm][2] may be what you've been looking for all along.
|
||||
|
||||
Pekwm is, presumably, inspired by the likes of Window Maker and Fluxbox. It provides an application menu, window decoration, and not a whole lot more. It's ideal for minimalists—users who want to conserve resources and users who prefer to work from a terminal.
|
||||
|
||||
Install Pekwm from your distribution's software repository. After installing, log out of your current desktop session so you can log into your new desktop. By default, your session manager (KDM, GDM, LightDM, or XDM, depending on your setup) will continue to log you into your previous desktop, so you must override that before logging in.
|
||||
|
||||
To override the previous desktop on GDM:
|
||||
|
||||
![Selecting your desktop in GDM][3]
|
||||
|
||||
And on KDM:
|
||||
|
||||
![Selecting your desktop in KDM][4]
|
||||
|
||||
The first time you log into Pekwm, you may encounter nothing but a black screen. Believe it or not, that's normal. What you're seeing is a blank desktop without background wallpaper. You can set a wallpaper with the **feh** command (you may need to install it from your repository). This command has a few options for setting the background, including **\--bg-fill** to fill the screen with your wallpaper, **\--bg-scale** to scale it to fit, and so on.
|
||||
|
||||
|
||||
```
|
||||
`$ feh --bg-fill ~/Pictures/wallpapers/mybackground.jpg`
|
||||
```
|
||||
|
||||
### Application menu
|
||||
|
||||
By default, Pekwm auto-generates a menu, available with a right-click anywhere on the desktop, that gives you access to applications. This menu also provides a few preference settings, such as the ability to pick a theme and to log out of your Pekwm session.
|
||||
|
||||
![Pekwm running on Fedora][5]
|
||||
|
||||
### Configuration
|
||||
|
||||
Pekwm is primarily configured in text config files stored in **$HOME/.pekwm**. The **menu** file defines your application menu, the **keys** file defines keyboard shortcuts, and so on.
|
||||
|
||||
The **start** file is a shell script that is executed after Pekwm launches. It is analogous to the **rc.local** file on a traditional Unix system; it's intentionally last in line, so whatever you put into it overrides everything that came before it. This is an important file—it's probably where you want to set your background so that _your_ choice overrides the default on the theme you're using.
|
||||
|
||||
The **start** file is also where you can launch dockapps. Dockapps are tiny applets that rose to prominence with Window Maker and Fluxbox. They usually provide network monitors, a clock, audio settings, and other things you might be used to seeing in a system tray or as a KDE plasmoid or widget in a full desktop environment. You might find some dockapps in your distribution's repository, or you can look for them online at [dockapps.net][6].
|
||||
|
||||
You can launch dockapps at startup by listing them in the **start** file followed by an **&** symbol:
|
||||
|
||||
|
||||
```
|
||||
feh --bg-fill ~/Pictures/wallpapers/mybackground.jpg
|
||||
wmnd &
|
||||
bubblemon -d &
|
||||
```
|
||||
|
||||
The **start** file must be [marked executable][7] for it to run when Pekwm starts.
|
||||
|
||||
|
||||
```
|
||||
`$ chmod +x $HOME/.pekwm/start`
|
||||
```
|
||||
|
||||
### Features
|
||||
|
||||
There's not much to Pekwm, and that's the beauty of it. If you want extra services to run on your desktop, it's up to you to launch them. If you're still learning Linux, this is a great way to learn about the minute GUI components you usually don't think about when they come bundled with a complete desktop environment (like [a taskbar][8]). It's also a good way to get used to some of the Linux commands, like [nmcli][9], that you've been meaning to learn.
|
||||
|
||||
Pekwm is a fun window manager. It's sparse, terse, and very lightweight. Give it a try!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/pekwm-linux-desktop
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/linux_penguin_green.png?itok=ENdVzW22 (Penguin with green background)
|
||||
[2]: http://www.pekwm.org/
|
||||
[3]: https://opensource.com/sites/default/files/uploads/advent-gdm_1.jpg (Selecting your desktop in GDM)
|
||||
[4]: https://opensource.com/sites/default/files/uploads/advent-enlightenment-kdm_0.jpg (Selecting your desktop in KDM)
|
||||
[5]: https://opensource.com/sites/default/files/uploads/advent-pekwm.jpg (Pekwm running on Fedora)
|
||||
[6]: http://dockapps.net
|
||||
[7]: https://opensource.com/article/19/6/understanding-linux-permissions
|
||||
[8]: https://opensource.com/article/19/1/productivity-tool-tint2
|
||||
[9]: https://opensource.com/article/19/5/set-static-network-connection-linux
|
||||
@ -0,0 +1,74 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (What's your favorite terminal emulator?)
|
||||
[#]: via: (https://opensource.com/article/19/12/favorite-terminal-emulator)
|
||||
[#]: author: (Opensource.com https://opensource.com/users/admin)
|
||||
|
||||
What's your favorite terminal emulator?
|
||||
======
|
||||
We asked our community to tell us about their experience with terminal
|
||||
emulators. Here are a few of the responses we received. Take our poll to
|
||||
weigh in on your favorite.
|
||||
![Terminal window with green text][1]
|
||||
|
||||
Preference of a terminal emulator can say a lot about a person's workflow. Is the ability to drive mouseless a must-have? Do you like to navigate between tabs or windows? There's something to be said about how it makes you feel, too. Does it have that cool factor? Tell us about your favorite terminal emulator by taking our poll or leaving us a comment. How many have you tried?
|
||||
|
||||
We asked our community to tell us about their experience with terminal emulators. Here are a few of the responses we received.
|
||||
|
||||
"My favorite terminal emulator is Tilix, customized with Powerline. I love that it supports multiple terminals open in a single window." —Dan Arel
|
||||
|
||||
"urxvt ([rxvt-unicode][2]). It's simple to configure via files, is lightweight, and readily available in most package manager repositories." —Brian Tomlinson
|
||||
|
||||
"gnome-terminal is still my go-to even though I don't use GNOME anymore. :)" —Justin W. Flory
|
||||
|
||||
"Terminator at this point on FC31. I just started using it but like the split screen feature and it seems light enough for me. Investigating plugins." —Marc Maxwell
|
||||
|
||||
"I switched over to Tilix a while back and it does everything I need terminals to do. :) Multiple panes, notifications, lean and runs my tmux sessions great." —Kevin Fenzi
|
||||
|
||||
"alacritty. It's optimized for speed, implemented in Rust and generally feature packed, but, honestly speaking, I only care about one feature: configurable inter-glyph spacing that allows me to further condense my font. I'm so-o hooked." —Alexander Sosedkin
|
||||
|
||||
|
||||
"I am old and grumpy: KDE Konsole. With tmux in it if session is remote." —Marcin Juszkiewicz
|
||||
|
||||
"iTerm2 for macOS. Yes, it's open source. :-) Terminator on Linux." —Patrick Mullins
|
||||
|
||||
"I've been using alacritty for a year or two now, but recently I started also using cool-retro-term in fullscreen mode whenever I have to run a script that has a lot of output because it looks cool and makes me feel cool. This is important to me." —Nick Childers
|
||||
|
||||
"I love Tilix, partly because it's good at staying out of the way (I usually just run it full screen with tmux inside), but also for the custom hotlinking support: in my terminal, text like "rhbz#1234" is a hotlink that takes me to bugzilla. Similar for LaunchPad issues, Gerrit change ids for OpenStack, etc." —Lars Kellogg-Stedman
|
||||
|
||||
"Eterm, also presentations look best in cool-retro-term with Vintage profile." —Ivan Horvath
|
||||
|
||||
"+1 for Tilix. It’s the best for an option for GNOME users, IMO!" —Eric Rich
|
||||
|
||||
"urxvt. Fast. Small. Configurable. Extendable via perl plugins, which can make it mouseless." —Roman Dobosz
|
||||
|
||||
"Konsole is the best, the only app I use from KDE project. The highlight of all search result occurrences is a killer feature which afaik does not have any other Linux terminal (glad if you prove me wrong). Best for searching compilation errors and output logs." —Jan Horak
|
||||
|
||||
"I use Terminator in past a lot. Now I cloned the theme (dark one) in Tilix and I didn't miss a thing. Is easy to move between tabs. That's all." —Alberto Fanjul Alonso
|
||||
|
||||
"Started my journey in using Terminator, I have since (in the past 3 years or so) completely switched over to Tilix." —Mike Harris
|
||||
|
||||
"I use Drop Down Terminal X. It's a very simple extension for GNOME 3 that lets me have a terminal always at the stroke of a single key (F12 for me). And it also supports tabs, which is kind of all I need." —Germán Pulido
|
||||
|
||||
"xfce4-terminal: wayland support, zoom, no borders, no title bar, no scroll bar - that's all I want from terminal emulator, for everything else I have tmux. I want my terminal emulator to use as much screen space as possible as I usually have editor (Vim) and repl side by side in tmux panes." —Martin Kourim
|
||||
|
||||
"Fish! Don’t ask! ;-)" —Eric Schabell
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/favorite-terminal-emulator
|
||||
|
||||
作者:[Opensource.com][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/admin
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/osdc_terminals_0.png?itok=XwIRERsn (Terminal window with green text)
|
||||
[2]: https://opensource.com/article/19/10/why-use-rxvt-terminal
|
||||
@ -0,0 +1,63 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Why choose Xfce for your lightweight Linux desktop)
|
||||
[#]: via: (https://opensource.com/article/19/12/xfce-linux-desktop)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
Why choose Xfce for your lightweight Linux desktop
|
||||
======
|
||||
This article is part of a special series of 24 days of Linux desktops.
|
||||
Looking for for a lightweight Linux distribution with plenty of
|
||||
features? The Xfce Linux desktop has been the standard for a long time.
|
||||
![Woman sitting in front of her laptop][1]
|
||||
|
||||
The [Xfce desktop][2] has a specific, self-stated goal: to be fast on a system with low resources while being visually appealing and user-friendly. It's been the de facto choice for lightweight Linux distributions (or remixes) for years and is often cited by its fans as a desktop that provides just enough to be useful, but never so much as to be a burden.
|
||||
|
||||
You may find Xfce included in the software repository of your Linux distribution, or you can download and install a distribution that ships Xfce as an available desktop (like the Xfce [Mageia][3] or [Fedora][4] spins or [Slackware][5]). Before you install it, be aware that, while it's lightweight, it is intended to provide a full desktop experience, so many Xfce apps are installed along with the desktop. If you're already running a different desktop, you may find yourself with redundant applications (two PDF readers, two file managers, and so on). If you just want to try the Xfce desktop, you can install an Xfce-based distribution in a virtual machine, such as [GNOME Boxes][6].
|
||||
|
||||
### Xfce desktop tour
|
||||
|
||||
True to the Unix philosophy, Xfce keeps its desktop modular. Many different components, such as the xfwm4 window manager, xfce4-panel, xfdesktop, Thunar, Xfconf, and so on, are bundled together to form the Xfce desktop environment. That may seem a pedantic way of defining a bunch of components that are always bundled together as a desktop, but in the case of Xfce, it's significant because these components truly are separate. You can run the Xfce panel over your Openbox or PekWM window manager, or use Xfce applets in your Fluxbox toolbar, and run Thunar as your file manager in Cinnamon or Pantheon. The possibilities are endless, but together they form the Xfce desktop.
|
||||
|
||||
The design of the Xfce desktop is clean, direct, and true to its Unix origins. Xfce began as some desktop widgets written with the XForms framework, even before GNOME existed. It was based conceptually upon the CDE desktop, which was the ubiquitous desktop at the time. Neither CDE nor XForms were open source, but Xfce was distributed freely. Eventually, Xfce was rewritten using the open source GTK toolkit, was included in several distributions, became a popular CDE and GNOME alternative, and eventually became the dominant choice of "lightweight" distributions.
|
||||
|
||||
Here's what it looked like on [Alan Formy-Duval's][7] desktop back in 2003:
|
||||
|
||||
![XFCE in 2003][8]
|
||||
|
||||
Xfce isn't necessarily a simple desktop: its application menu is in the upper-left corner (a tradition familiar to Linux users but probably foreign to newcomers), and it has a place for pinned application launchers, a system tray, virtual desktops, and a taskbar. It's a proper control panel for the GUI side of a Linux computer, with all the essential knobs and switches exposed for easy access. And it does all of that without making much of an impact on your system resources.
|
||||
|
||||
![XFCE in 2019 on Mageia Linux][9]
|
||||
|
||||
Significantly, Xfce uses GTK libraries to accomplish a lightweight desktop, and in doing so, it looks good, it looks familiar, and it can be themed to look really beautiful. The [Xfce screenshot forum][10] affords users the opportunity to show off their themes and configurations.
|
||||
|
||||
### Using the Xfce desktop
|
||||
|
||||
Xfce is an ideal desktop for a server or when you want quick access to important settings on a desktop that you rarely _look_ at. It's also ideal for Linux power users who want to adjust common settings quickly, but otherwise rarely deals with the GUI. Then again, it's a good-looking lightweight desktop, it can be themed easily, and it's got plenty of features. It may be the perfect desktop for you, no matter how you use your Linux computer. The only way to find out is to try!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/xfce-linux-desktop
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/OSDC_women_computing_4.png?itok=VGZO8CxT (Woman sitting in front of her laptop)
|
||||
[2]: http://xfce.org
|
||||
[3]: http://mageia.org
|
||||
[4]: http://fedoraproject.org
|
||||
[5]: http://slackware.com
|
||||
[6]: https://opensource.com/article/19/5/getting-started-gnome-boxes-virtualization
|
||||
[7]: https://opensource.com/users/alanfdoss
|
||||
[8]: https://opensource.com/sites/default/files/advent-xfce-2003.jpg (XFCE in 2003)
|
||||
[9]: https://opensource.com/sites/default/files/advent-xfce.jpg (XFCE on Mageia Linux in 2019)
|
||||
[10]: https://forum.xfce.org/viewtopic.php?id=12676
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -0,0 +1,12 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to change colors and themes in Vim)
|
||||
[#]: via: (https://opensource.com/article/19/12/colors-themes-vim)
|
||||
[#]: author: (Rashan Smith https://opensource.com/users/rsmith)
|
||||
|
||||
How to change colors and themes in Vim
|
||||
======
|
||||
Style your command line Vim with your favorite color scheme.
|
||||
@ -0,0 +1,164 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Use the Fluxbox Linux desktop as your window manager)
|
||||
[#]: via: (https://opensource.com/article/19/12/fluxbox-linux-desktop)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
Use the Fluxbox Linux desktop as your window manager
|
||||
======
|
||||
This article is part of a special series of 24 days of Linux desktops.
|
||||
Fluxbox is very light on system resources, yet it has vital Linux
|
||||
desktop features to make your user experience easy, blazingly efficient,
|
||||
and unduly fast.
|
||||
![Text editor on a browser, in blue][1]
|
||||
|
||||
The concept of a desktop may differ from one computer user to another. Many people see the desktop as a home base, or a comfy living room, or even a literal desktop where they place frequently used notepads, their best pens and pencils, and their favorite coffee mug. KDE, GNOME, Pantheon (and so on) provide that kind of comfort on Linux.
|
||||
|
||||
But for some users, the desktop is just empty monitor space, a side effect of not yet having any free-floating application windows projected directly onto their retina. For these users, the desktop is a void over which they can run applications—whether big office and graphic suites, or a simple terminal window, or docked applets—to manage services. This model of operating a [POSIX][2] computer has a long history, and one branch of that family tree is the *box window managers: Blackbox, Fluxbox, and Openbox.
|
||||
|
||||
[Fluxbox][3] is a window manager for X11 systems that's based on an older project called Blackbox. Blackbox development was waning when I discovered Linux, so I fell into Fluxbox, and I've used it ever since on at least one of my active systems. It is written in C++ and is licensed under the MIT open source license.
|
||||
|
||||
### Installing Fluxbox
|
||||
|
||||
You are likely to find Fluxbox included in the software repository of your Linux distribution, but you can also find it on [Fluxbox.org][4]. If you're already running a different desktop, it's safe to install Fluxbox on the same system because Fluxbox doesn't predetermine any configuration or accompanying applications.
|
||||
|
||||
After installing Fluxbox, log out of your current desktop session so you can log into your new one. By default, your session manager (KDM, GDM, LightDM, or XDM, depending on your setup) will continue to log you into your previous desktop, so you must override that before logging in.
|
||||
|
||||
To override the desktop with GDM:
|
||||
|
||||
![Select your desktop session in GDM][5]
|
||||
|
||||
Or with KDM:
|
||||
|
||||
![Select your desktop session with KDM][6]
|
||||
|
||||
### Configuring the Fluxbox desktop
|
||||
|
||||
When you first log in, the screen is mostly empty because all Fluxbox provides are panels (for a taskbar, system tray, and so on) and window decoration for application windows.
|
||||
|
||||
![Default Fluxbox configuration on CentOS 7][7]
|
||||
|
||||
If your distribution delivers a plain Fluxbox desktop, you can set a background for your desktop using the **feh** command (you may need to install it from your distribution's repository). This command has a few options for setting the background, including **\--bg-fill** to fill the screen with your wallpaper of choice, **\--bg-scale** to scale it to fit, and so on.
|
||||
|
||||
|
||||
```
|
||||
`$ feh --bg-fill ~/photo/oamaru/leaf-spiral.jpg`
|
||||
```
|
||||
|
||||
![Fluxbox with a theme applied][8]
|
||||
|
||||
By default, Fluxbox auto-generates a menu, available with a right-click anywhere on the desktop, that gives you access to applications. Depending on your distribution, this menu may be very minimal, or it may list all the launchers in your **/usr/share/applications** directory.
|
||||
|
||||
Fluxbox configuration is set in text files, and those text files are contained in the **$HOME/.fluxbox** directory. You can:
|
||||
|
||||
* Set keyboard shortcuts in **keys**
|
||||
* Set startup services and applications in **startup**
|
||||
* Set desktop preferences (such as the number of workspaces, locations of panels, and so on) in **init**
|
||||
* Set menu items in **menu**
|
||||
|
||||
|
||||
|
||||
The text configuration files are easy to reverse-engineer, but you also can (and should) read the Fluxbox [documentation][9].
|
||||
|
||||
For example, this is my typical menu (or at least the basic structure of it):
|
||||
|
||||
|
||||
```
|
||||
# to use your own menu, copy this to ~/.fluxbox/menu, then edit
|
||||
# ~/.fluxbox/init and change the session.menuFile path to ~/.fluxbox/menu
|
||||
|
||||
[begin] (fluxkbox)
|
||||
[submenu] (apps) {}
|
||||
[submenu] (txt) {}
|
||||
[exec] (Emacs 23 (text\\)) { x-terminal-emulator -T "Emacs (text)" -e /usr/bin/emacs -nw} <>
|
||||
[exec] (Emacs (X11\\)) {/usr/bin/emacs} <>
|
||||
[exec] (LibreOffice) {/usr/bin/libreoffice}
|
||||
[end]
|
||||
[submenu] (code) {}
|
||||
[exec] (qtCreator) {/usr/bin/qtcreator}
|
||||
[exec] (eclipse) {/usr/bin/eclipse}
|
||||
[end]
|
||||
[submenu] (graphics) {}
|
||||
[exec] (ksnapshot) {/usr/bin/ksnapshot}
|
||||
[exec] (gimp) {/usr/bin/gimp}
|
||||
[exec] (blender) {/usr/bin/blender}
|
||||
[end]
|
||||
[submenu] (files) {}
|
||||
[exec] (dolphin) {/usr/bin/dolphin}
|
||||
[exec] (konqueror) { /usr/bin/kfmclient openURL $HOME }
|
||||
[end]
|
||||
[submenu] (network) {}
|
||||
[exec] (firefox) {/usr/bin/firefox}
|
||||
[exec] (konqueror) {/usr/bin/konqueror}
|
||||
[end]
|
||||
[end]
|
||||
## change window manager or work env
|
||||
[submenu] (environments) {}
|
||||
[restart] (flux) {/usr/bin/startfluxbox}
|
||||
[restart] (ratpoison) {/usr/bin/ratpoison}
|
||||
[exec] (openIndiana) {/home/kenlon/qemu/startSolaris.sh}
|
||||
[end]
|
||||
|
||||
[config] (config)
|
||||
[submenu] (styles) {}
|
||||
[stylesdir] (/usr/share/fluxbox/styles)
|
||||
[stylesdir] (~/.fluxbox/styles)
|
||||
[end]
|
||||
[workspaces] (workspaces)
|
||||
[reconfig] (reconfigure)
|
||||
[restart] (restart)
|
||||
[exit] (exeunt)
|
||||
[end]
|
||||
```
|
||||
|
||||
The menu also provides a few preference settings, such as the ability to pick a theme and restart or log out from your Fluxbox session.
|
||||
|
||||
I launch most applications using keyboard shortcuts, which are entered into the **keys** configuration file. Here are some examples (the **Mod4** key is the Super key, which I use to designate global shortcuts):
|
||||
|
||||
|
||||
```
|
||||
# open apps
|
||||
Mod4 t :Exec konsole
|
||||
Mod4 k :Exec konqueror
|
||||
Mod4 z :Exec fbrun
|
||||
Mod4 e :Exec emacs
|
||||
Mod4 f :Exec firefox
|
||||
Mod4 x :Exec urxvt
|
||||
Mod4 d :Exec dolphin
|
||||
Mod4 q :Exec xscreensaver-command -activate
|
||||
Mod4 3 :Exec ksnapshot
|
||||
```
|
||||
|
||||
Between these shortcuts and an open terminal, I have little use for a mouse during most of my workday, so there's no wasted time switching from one controller to another. And because Fluxbox stays well out of the way, there's little distraction.
|
||||
|
||||
### Why you should use Fluxbox
|
||||
|
||||
Fluxbox is very light on system resources, yet it has vital features to make your user experience easy, blazingly efficient, and unduly fast. It's simple to customize, and it allows you to define your own workflow. You don't have to use Fluxbox's panels, because there are other excellent panels out there. You can even middle-click and drag two separate application windows into one another so that they become one window, each in its own tab.
|
||||
|
||||
The possibilities are endless, so try the steady simplicity that is Fluxbox on your Linux box today!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/fluxbox-linux-desktop
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/browser_blue_text_editor_web.png?itok=lcf-m6N7 (Text editor on a browser, in blue)
|
||||
[2]: https://opensource.com/article/19/7/what-posix-richard-stallman-explains
|
||||
[3]: http://fluxbox.org
|
||||
[4]: http://fluxbox.org/download/
|
||||
[5]: https://opensource.com/sites/default/files/advent-gdm_0.jpg (Select your desktop session in GDM)
|
||||
[6]: https://opensource.com/sites/default/files/advent-kdm.jpg (Select your desktop session with KDM)
|
||||
[7]: https://opensource.com/sites/default/files/advent-fluxbox-default.jpg (Default Fluxbox configuration on CentOS 7)
|
||||
[8]: https://opensource.com/sites/default/files/advent-fluxbox-green.jpg (Fluxbox with a theme applied)
|
||||
[9]: http://fluxbox.org/features/
|
||||
@ -0,0 +1,164 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (3 easy steps to update your apps to Python 3)
|
||||
[#]: via: (https://opensource.com/article/19/12/update-apps-python-3)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
3 easy steps to update your apps to Python 3
|
||||
======
|
||||
Python 2 has reached its end of life, so it's past time to convert your
|
||||
Python 2 project to Python 3.
|
||||
![Hands on a keyboard with a Python book ][1]
|
||||
|
||||
The 2.x series of Python is [officially over][2], but converting code to Python 3 is easier than you think. Over the weekend, I spent an evening converting the frontend code of a 3D renderer (and its corresponding [PySide][3] version) to Python 3, and it was surprisingly simple in retrospect, although it seemed relatively hopeless during the refactoring process. The conversion process can seem a little like a labyrinth, with every change you make revealing a dozen more changes you need to make.
|
||||
|
||||
You may or may not _want_ to do the conversion, but—whether it's because you procrastinated too long or you rely on a module that won't be maintained unless you convert—sometimes you just don't have a choice. And if you're looking for an easy task to start your contribution to open source, converting a Python 2 app to Python 3 is a great way to make an easy but meaningful impression.
|
||||
|
||||
Whatever your reason for refactoring Python 2 code into Python 3, it's an important job. Here are three steps to approach the task with clarity.
|
||||
|
||||
### 1\. Run 2to3
|
||||
|
||||
For the past several years, Python has shipped with a script called [**2to3**][4], which does the bulk of the conversion from Python 2 to Python 3 for you. Automatically. And you already have it installed (whether you realize it or not).
|
||||
|
||||
Here's a short snippet of code written in Python 2.6:
|
||||
|
||||
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
mystring = u'abcdé'
|
||||
print ord(mystring[-1])
|
||||
```
|
||||
|
||||
Run the **2to3** script:
|
||||
|
||||
|
||||
```
|
||||
$ 2to3 example.py
|
||||
RefactoringTool: Refactored example.py
|
||||
\--- example.py (original)
|
||||
+++ example.py (refactored)
|
||||
@@ -1,5 +1,5 @@
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
-mystring = u'abcdé'
|
||||
-print ord(mystring[-1])
|
||||
+mystring = 'abcdé'
|
||||
+print(ord(mystring[-1]))
|
||||
RefactoringTool: Files that need to be modified:
|
||||
RefactoringTool: example.py
|
||||
```
|
||||
|
||||
By default, **2to3** prints only the changes required to bring old Python code up to Python 3 standards. The output is a usable patch you can use to change your file, but it's easier to just let Python do that for you, using the **\--write** (or **-w**) option:
|
||||
|
||||
|
||||
```
|
||||
$ 2to3 -w example.py
|
||||
[...]
|
||||
RefactoringTool: Files that were modified:
|
||||
RefactoringTool: example.py
|
||||
```
|
||||
|
||||
The **2to3** script doesn't work on just a single file. You can run it on an entire directory of Python files, with or without the **\--write** option, to process all ***.py** files in the directory and its subdirectories.
|
||||
|
||||
### 2\. Use Pylint or Pyflakes
|
||||
|
||||
It's not uncommon to discover code quirks that ran without issue in Python 2 but don't work so well in Python 3. Because these quirks can't be fixed by converting syntax, they get past **2to3** unchanged, but they fail once you try to run the code.
|
||||
|
||||
To detect such issues, you can use an application like [Pylint][5] or a tool like [Pyflakes][6] (or the [flake8][7] wrapper). I prefer Pyflakes because, unlike Pylint, it ignores deviations in the _style_ of your code. While the "prettiness" of Python is often praised as one of its strong points, when porting someone else's code from 2 to 3, treating style and function as two separate bugs is a matter of prioritization.
|
||||
|
||||
Here's example output from Pyflakes:
|
||||
|
||||
|
||||
```
|
||||
$ pyflakes example/maths
|
||||
example/maths/enum.py:19: undefined name 'cmp'
|
||||
example/maths/enum.py:105: local variable 'e' is assigned to but never used
|
||||
example/maths/enum.py:109: undefined name 'basestring'
|
||||
example/maths/enum.py:208: undefined name 'EnumValueCompareError'
|
||||
example/maths/enum.py:208: local variable 'e' is assigned to but never used
|
||||
```
|
||||
|
||||
This output (compared to 143 lines from Pylint, most of which were complaints about indentation) clearly displays the problems in the code that you should repair.
|
||||
|
||||
The most interesting error here is the first one, on line 19. It's a little misleading because you might think that **cmp** is a variable that was never defined, but **cmp** is really a function from Python 2 that doesn't exist in Python 3. It's wrapped in a **try** statement, so the issue could easily go unnoticed until it becomes obvious that the **try** result is not getting produced.
|
||||
|
||||
|
||||
```
|
||||
try:
|
||||
result = cmp(self.index, other.index)
|
||||
except:
|
||||
result = 42
|
||||
|
||||
return result
|
||||
```
|
||||
|
||||
There are countless examples of functions that no longer exist or that have changed between when an application was maintained as a Python 2 codebase and when you decide to port it. PySide(2) bindings have changed, Python functions have disappeared or been transformed (**imp** to **importlib**, for example), and so on. Fix them one by one as you encounter them. Even though it's up to you to reimplement or replace those missing functions, by now, most of these issues are known and [well-documented][8]. The real challenge is more about catching the errors than fixing them, so use Pyflakes or a similar tool.
|
||||
|
||||
### 3\. Repair broken Python 2 code
|
||||
|
||||
The **2to3** script gets your code Python 3 compliant, but it only knows about differences between Python 2 and 3. It generally can't make adjustments to account for changes in libraries that worked one way back in 2010 but have had major revisions since then. You must update that code manually.
|
||||
|
||||
For instance, this code apparently worked back in the days of Python 2.6:
|
||||
|
||||
|
||||
```
|
||||
class CLOCK_SPEED:
|
||||
TICKS_PER_SECOND = 16
|
||||
TICK_RATES = [int(i * TICKS_PER_SECOND)
|
||||
for i in (0.5, 1, 2, 3, 4, 6, 8, 11, 20)]
|
||||
|
||||
class FPS:
|
||||
STATS_UPDATE_FREQUENCY = CLOCK_SPEED.TICKS_PER_SECOND
|
||||
```
|
||||
|
||||
Automated tools like **2to3** and **Pyflakes** don't detect the problem, but Python 3 doesn't see **GAME_SPEED.TICKS_PER_SECOND** as a valid statement because the function being called was never explicitly declared. Adjusting the code is a simple exercise in object-oriented programming:
|
||||
|
||||
|
||||
```
|
||||
class CLOCK_SPEED:
|
||||
def TICKS_PER_SECOND():
|
||||
TICKS_PER_SECOND = 16
|
||||
TICK_RATES = [int(i * TICKS_PER_SECOND)
|
||||
for i in (0.5, 1, 2, 3, 4, 6, 8, 11, 20)]
|
||||
return TICKS_PER_SECOND
|
||||
|
||||
class FPS:
|
||||
STATS_UPDATE_FREQUENCY = CLOCK_SPEED.TICKS_PER_SECOND()
|
||||
```
|
||||
|
||||
You may be inclined to make it cleaner still by replacing the **TICKS_PER_SECOND** function with a constructor (an **__init__** function to set default values), but that would change the required call from **CLOCK_SPEED.TICKS_PER_SECOND()** to just **CLOCK_SPEED()**, which may or may not have ramifications elsewhere in the codebase. If you know the code well, then you can use your better judgment about how
|
||||
|
||||
much alteration is _required_ and how much would just be pleasant, but generally, I prefer to assume every change I make inevitably demands at least three changes to every other file in the project, so I try to work within its existing structure.
|
||||
|
||||
### Don't stop believing
|
||||
|
||||
If you're porting a very large project, it sometimes starts to feel like there's no end in sight. It can seem like forever before you see a useful error message that's _not_ about a Python 2 quirk that slipped past the scripts and linters, and once you get to that point, you'll start to suspect it would be easier to just start from scratch. The bright side is that you (presumably) know that the codebase you're porting works (or worked) in Python 2, and once you make your adjustments, it will work again in Python 3; it's just a matter of conversion.
|
||||
|
||||
Once you've done the legwork, you'll have a Python 3 module or application, and regular maintenance (and those style changes to make Pylint happy) can begin anew!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/update-apps-python-3
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/python-programming-code-keyboard.png?itok=fxiSpmnd (Hands on a keyboard with a Python book )
|
||||
[2]: https://opensource.com/article/19/11/end-of-life-python-2
|
||||
[3]: https://pypi.org/project/PySide/
|
||||
[4]: https://docs.python.org/3.1/library/2to3.html
|
||||
[5]: https://opensource.com/article/19/10/python-pylint-introduction
|
||||
[6]: https://pypi.org/project/pyflakes/
|
||||
[7]: https://opensource.com/article/19/5/python-flake8
|
||||
[8]: https://docs.python.org/3.0/whatsnew/3.0.html
|
||||
@ -0,0 +1,120 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Breaking Linux files into pieces with the split command)
|
||||
[#]: via: (https://www.networkworld.com/article/3489256/breaking-linux-files-into-pieces-with-the-split-command.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
Breaking Linux files into pieces with the split command
|
||||
======
|
||||
Some simple Linux commands allow you to break up files and reassemble them as needed in order to accommodate size restrictions on file size for storage or email attachments
|
||||
[Marco Verch][1] [(CC BY 2.0)][2]
|
||||
|
||||
Linux systems provide a very easy-to-use command for breaking files into pieces. This is something that you might need to do prior to uploading your files to some storage site that limits file sizes or emailing them as attachments. To split a file into pieces, you simply use the split command.
|
||||
|
||||
```
|
||||
$ split bigfile
|
||||
```
|
||||
|
||||
By default, the split command uses a very simple naming scheme. The file chunks will be named xaa, xab, xac, etc., and, presumably, if you break up a file that is sufficiently large, you might even get chunks named xza and xzz.
|
||||
|
||||
[[Get regularly scheduled insights by signing up for Network World newsletters.]][3]
|
||||
|
||||
Unless you ask, the command runs without giving you any feedback. You can, however, use the --verbose option if you would like to see the file chunks as they are being created.
|
||||
|
||||
[][4]
|
||||
|
||||
BrandPost Sponsored by HPE
|
||||
|
||||
[Take the Intelligent Route with Consumption-Based Storage][4]
|
||||
|
||||
Combine the agility and economics of HPE storage with HPE GreenLake and run your IT department with efficiency.
|
||||
|
||||
```
|
||||
$ split –-verbose bigfile
|
||||
creating file 'xaa'
|
||||
creating file 'xab'
|
||||
creating file 'xac'
|
||||
```
|
||||
|
||||
You can also contribute to the file naming by providing a prefix. For example, to name all the pieces of your original file bigfile.xaa, bigfile.xab and so on, you would add your prefix to the end of your split command like so:
|
||||
|
||||
```
|
||||
$ split –-verbose bigfile bigfile.
|
||||
creating file 'bigfile.aa'
|
||||
creating file 'bigfile.ab'
|
||||
creating file 'bigfile.ac'
|
||||
```
|
||||
|
||||
Note that a dot is added to the end of the prefix shown in the above command. Otherwise, the files would have names like bigfilexaa rather than bigfile.xaa.
|
||||
|
||||
Note that the split command does _not_ remove your original file, just creates the chunks. If you want to specify the size of the file chunks, you can add that to your command using the -b option. For example:
|
||||
|
||||
```
|
||||
$ split -b100M bigfile
|
||||
```
|
||||
|
||||
File sizes can be specified in kilobytes, megabytes, gigabytes … up to yottabytes! Just use the appropriate letter from K, M, G, T, P, E, Z and Y.
|
||||
|
||||
If you want your file to be split based on the number of lines in each chunk rather than the number of bytes, you can use the -l (lines) option. In this example, each file will have 1,000 lines except, of course, for the last one which may have fewer lines.
|
||||
|
||||
```
|
||||
$ split --verbose -l1000 logfile log.
|
||||
creating file 'log.aa'
|
||||
creating file 'log.ab'
|
||||
creating file 'log.ac'
|
||||
creating file 'log.ad'
|
||||
creating file 'log.ae'
|
||||
creating file 'log.af'
|
||||
creating file 'log.ag'
|
||||
creating file 'log.ah'
|
||||
creating file 'log.ai'
|
||||
creating file 'log.aj'
|
||||
```
|
||||
|
||||
If you need to reassemble your file from pieces on a remote site, you can do that fairly easily using a cat command like one of these:
|
||||
|
||||
```
|
||||
$ cat x?? > original.file
|
||||
$ cat log.?? > original.file
|
||||
```
|
||||
|
||||
Splitting and reassembling with the commands shown above should work for binary files as well as text files. In this example, we’ve split the zip binary into 50 kilobyte chunks, used cat to reassemble them and then compared the assembled and original files. The diff command verifies that the files are the same.
|
||||
|
||||
```
|
||||
$ split --verbose -b50K zip zip.
|
||||
creating file 'zip.aa'
|
||||
creating file 'zip.ab'
|
||||
creating file 'zip.ac'
|
||||
creating file 'zip.ad'
|
||||
creating file 'zip.ae'
|
||||
$ cat zip.a? > zip.new
|
||||
$ diff zip zip.new
|
||||
$ <== no output = no difference
|
||||
```
|
||||
|
||||
The only caution I have to give at this point is that, if you use split often and use the default naming, you will likely end up overwriting some chunks with others and maybe sometimes having more chunks than you were expecting because some were left over from some earlier split.
|
||||
|
||||
Join the Network World communities on [Facebook][5] and [LinkedIn][6] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3489256/breaking-linux-files-into-pieces-with-the-split-command.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.flickr.com/photos/30478819@N08/34879296673/in/photolist-V9avJ2-LysA9-qVeu6t-dV4dkC-RWNeA5-LFKPG-aLpKTg-aLpJoK-4rN35a-97zDK4-7fevx8-mBSVT-64r2D4-8TbXFw-4g2Wgv-4pAdnq-4g6Ycf-9pt9t9-ceyN2u-LYckrJ-23sDdLH-dAQgiK-25eyt6N-UuAEk9-koNDTn-dAVK2j-ea8feG-bWpNKQ-bzJNPM-dAQ22K-dnkd1e-8qkaFp-dnCtBr-dnknKi-TKXaei-dnkjzV-RxvhHd-pQXTfa-c3crQf-dnkwXG-dnfW2K-2SKdMh-efHTUr-5mMzpp-XdMr5c-88H1s3-d67Gth-aMuG6v-Uio4v1-KZt3M
|
||||
[2]: https://creativecommons.org/licenses/by/2.0/legalcode
|
||||
[3]: https://www.networkworld.com/newsletters/signup.html
|
||||
[4]: https://www.networkworld.com/article/3440100/take-the-intelligent-route-with-consumption-based-storage.html?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE20773&utm_content=sidebar ( Take the Intelligent Route with Consumption-Based Storage)
|
||||
[5]: https://www.facebook.com/NetworkWorld/
|
||||
[6]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,78 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Customize your Linux desktop with FVWM)
|
||||
[#]: via: (https://opensource.com/article/19/12/fvwm-linux-desktop)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
Customize your Linux desktop with FVWM
|
||||
======
|
||||
This article is part of a special series of 24 days of Linux desktops.
|
||||
If you're looking for a lightweight, fast, and simple Linux window
|
||||
manager, FVWM qualifies. But if you're looking for something to dig
|
||||
into, explore, and hack, then FVWM is a must.
|
||||
![Coding on a computer][1]
|
||||
|
||||
The [FVWM][2] window manager started out as modifications to [TWM][3], back in 1993. After several years of iteration, what emerged is an extremely customizable environment where any behavior, action, or event is configurable. It has support for custom key bindings, mouse gestures, theming, scripting, and much more.
|
||||
|
||||
While FVWM is usable immediately after installation, its default distribution provides only the absolute minimum configuration. It's a great foundation to start your own custom desktop environment, but if you just want to use it as a desktop, then you probably want to install a full configuration distributed by another user. There are a few different distributions of FVWM, including FVWM95, which mimics Windows 95 (at least in appearance and layout). I tried [FVWM-Crystal][4], a modern-looking theme with some common Linux desktop conventions.
|
||||
|
||||
Install the FVWM distribution you want to try from your Linux distribution's software repository. If you can't find a specific FVWM distribution, it's safe to install the base FVWM2 package and then go to [Box-Look.org][5] to download a theme package manually. It's a little more work that way, but not nearly as much as building your own workspace from scratch.
|
||||
|
||||
After installing, log out of your current desktop session so you can log into FVWM. By default, your session manager (KDM, GDM, LightDM, or XDM, depending on your setup) will continue to log you into your previous desktop, so you must override that before logging in.
|
||||
|
||||
To do so with GDM:
|
||||
|
||||
![Select your desktop session in GDM][6]
|
||||
|
||||
And with KDM:
|
||||
|
||||
![Select your desktop session with KDM][7]
|
||||
|
||||
### FVWM desktop
|
||||
|
||||
Regardless of what theme and configuration you're using, FVWM, at minimum, provides a menu when you left-click on the desktop. The contents of this menu vary depending on what you've installed. The menu in the FVWM-Crystal distribution contains quick access to common preferences, such as screen resolution, wallpaper settings, window decorations, and so on.
|
||||
|
||||
As with pretty much everything in FVWM, the menu can be edited to include whatever you want, but FVWM-Crystal favors the application menu bar. The application menu is located at the top-left of the screen, and each icon contains a menu of related application launchers. For example, the GIMP icon reveals image editors, the KDevelop icon reveals integrated development environments (IDEs), the GNU icon reveals text editors, and so on, depending on what you have installed on your system.
|
||||
|
||||
![FVWM-crystal running on Slackware 14.2][8]
|
||||
|
||||
FVWM-Crystal also provides virtual desktops, a taskbar, a clock, and an application bar.
|
||||
|
||||
For your background, you can use the wallpapers bundled with FVWM-Crystal or set your own with the **feh** command (you may need to install it from your repository). This command has a few options for setting the background, including **\--bg-scale** to fill the screen with a scaled version of your wallpaper of choice, **\--bg-fill** to fill the screen without adjusting the size of the image, and so on.
|
||||
|
||||
|
||||
```
|
||||
`$ feh --bg-scale ~/Pictures/wallpapers/mybackground.jpg`
|
||||
```
|
||||
|
||||
Most configuration files are contained in **$HOME/.fvwm-crystal**, with some systemwide defaults located in **/usr/share/fvwm-crystal**.
|
||||
|
||||
### Do it yourself
|
||||
|
||||
FVWM is as much a desktop-building platform as it is a window manager. It doesn't do anything for you, and it expects you to configure anything—and possibly everything.
|
||||
If you're looking for a lightweight, fast, and simple window manager, FVWM qualifies. But if you're looking for something to dig into, explore, and hack, then FVWM is a must.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/fvwm-linux-desktop
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/code_computer_laptop_hack_work.png?itok=aSpcWkcl (Coding on a computer)
|
||||
[2]: http://www.fvwm.org/
|
||||
[3]: https://en.wikipedia.org/wiki/Twm
|
||||
[4]: https://www.box-look.org/p/1018270/
|
||||
[5]: http://box-look.org
|
||||
[6]: https://opensource.com/sites/default/files/advent-gdm_0.jpg (Select your desktop session in GDM)
|
||||
[7]: https://opensource.com/sites/default/files/advent-kdm.jpg (Select your desktop session with KDM)
|
||||
[8]: https://opensource.com/sites/default/files/advent-fvwm-crystal.jpg (FVWM-crystal running on Slackware 14.2)
|
||||
334
sources/tech/20191210 Lessons learned from programming in Go.md
Normal file
334
sources/tech/20191210 Lessons learned from programming in Go.md
Normal file
@ -0,0 +1,334 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Lessons learned from programming in Go)
|
||||
[#]: via: (https://opensource.com/article/19/12/go-common-pitfalls)
|
||||
[#]: author: (Eduardo Ferreira https://opensource.com/users/edufgf)
|
||||
|
||||
Lessons learned from programming in Go
|
||||
======
|
||||
Prevent future concurrent processing headaches by learning how to
|
||||
address these common pitfalls.
|
||||
![Goland gopher illustration][1]
|
||||
|
||||
When you are working with complex distributed systems, you will likely come across the need for concurrent processing. At [Mode.net][2], we deal daily with real-time, fast and resilient software. Building a global private network that dynamically routes packets at the millisecond scale wouldn’t be possible without a highly concurrent system. This dynamic routing is based on the state of the network and, while there are many parameters to consider here, our focus is on link [metrics][3]. In our context, link metrics can be anything related to the status or current properties of a network link (e.g.: link latency).
|
||||
|
||||
### Concurrent probing for link metrics
|
||||
|
||||
[H.A.L.O.][4] (Hop-by-Hop Adaptive Link-State Optimal Routing), our dynamic routing algorithm relies partially on link metrics to compute its routing table. Those metrics are collected by an independent component that sits on each [PoP][5] (Point of Presence). PoPs are machines that represent a single routing entity in our networks, connected by links and spread around multiple locations shaping our network. This component probes neighboring machines using network packets, and those neighbors will bounce back the initial probe. Link latency values can be derived from the received probes. Because each PoP has more than one neighbor, the nature of such a task is intrinsically concurrent: we need to measure latency for each neighboring link in real-time. We can’t afford sequential processing; each probe must be processed as soon as possible in order to compute this metric.
|
||||
|
||||
![latency computation graph][6]
|
||||
|
||||
### Sequence numbers and resets: A reordering situation
|
||||
|
||||
Our probing component exchanges packets and relies on sequence numbers for packet processing. This aims to avoid processing of packet duplication or out-of-order packets. Our first implementation relied on a special sequence number 0 to reset sequence numbers. Such a number was only used during initialization of a component. The main problem was that we were considering an increasing sequence number value that always started at 0. After the component restarts, packet reordering could happen, and a packet could easily replace the sequence number with the value that was being used before the reset. This meant that the following packets would be ignored until it reaches the sequence number that was in use just before the reset.
|
||||
|
||||
### UDP handshake and finite state machine
|
||||
|
||||
The problem here was proper agreement of a sequence number after a component restarts. There are a few ways to handle this and, after discussing our options, we chose to implement a 3-way handshake protocol with a clear definition of states. This handshake establishes sessions over links during initialization. This guarantees that nodes are communicating over the same session and using the appropriate sequence number for it.
|
||||
|
||||
To properly implement this, we have to define a finite state machine with clear states and transitions. This allows us to properly manage all corner cases for the handshake formation.
|
||||
|
||||
![finite state machine diagram][7]
|
||||
|
||||
Session IDs are generated by the handshake initiator. A full exchange sequence is as follows:
|
||||
|
||||
1. The sender sends out a **SYN (ID)*** *packet.
|
||||
2. The receiver stores the received **ID** and sends a **SYN-ACK (ID)**.
|
||||
3. The sender receives the **SYN-ACK (ID) *_and sends out an **ACK (ID)**._ *It also starts sending packets starting with sequence number 0.
|
||||
4. The receiver checks the last received **ID*** _and accepts the **ACK (ID)**_ *if the ID matches. It also starts accepting packets with sequence number 0.
|
||||
|
||||
|
||||
|
||||
### Handling state timeouts
|
||||
|
||||
Basically, at each state, you need to handle, at most, three types of events: link events, packet events, and timeout events. And those events show up concurrently, so here you have to handle concurrency properly.
|
||||
|
||||
* Link events are either link up or link down updates. This can either initiate a link session or break an existing session.
|
||||
* Packet events are control packets **(SYN/SYN-ACK/ACK)** or just probe responses.
|
||||
* Timeout events are the ones triggered after a scheduled timeout expires for the current session state.
|
||||
|
||||
|
||||
|
||||
The main challenge here is how to handle concurrent timeout expiration and other events. And this is where one can easily fall into the traps of deadlocks and race conditions.
|
||||
|
||||
### A first approach
|
||||
|
||||
The language used for this project is [Golang][8]. It does provide native synchronization mechanisms such as native channels and locks and is able to spin lightweight threads for concurrent processing.
|
||||
|
||||
![gophers hacking together][9]
|
||||
|
||||
gophers hacking together
|
||||
|
||||
You can start first by designing a structure that represents our **Session** and **Timeout Handlers**.
|
||||
|
||||
|
||||
```
|
||||
type Session struct {
|
||||
State SessionState
|
||||
Id SessionId
|
||||
RemoteIp string
|
||||
}
|
||||
|
||||
type TimeoutHandler struct {
|
||||
callback func(Session)
|
||||
session Session
|
||||
duration int
|
||||
timer *timer.Timer
|
||||
}
|
||||
```
|
||||
|
||||
**Session** identifies the connection session, with the session ID, neighboring link IP, and the current session state.
|
||||
|
||||
**TimeoutHandler** holds the callback function, the session for which it should run, the duration, and a pointer to the scheduled timer.
|
||||
|
||||
There is a global map that will store, per neighboring link session, the scheduled timeout handler.
|
||||
|
||||
|
||||
```
|
||||
`SessionTimeout map[Session]*TimeoutHandler`
|
||||
```
|
||||
|
||||
Registering and canceling a timeout is achieved by the following methods:
|
||||
|
||||
|
||||
```
|
||||
// schedules the timeout callback function.
|
||||
func (timeout* TimeoutHandler) Register() {
|
||||
timeout.timer = time.AfterFunc(time.Duration(timeout.duration) * time.Second, func() {
|
||||
timeout.callback(timeout.session)
|
||||
})
|
||||
}
|
||||
|
||||
func (timeout* TimeoutHandler) Cancel() {
|
||||
if timeout.timer == nil {
|
||||
return
|
||||
}
|
||||
timeout.timer.Stop()
|
||||
}
|
||||
```
|
||||
|
||||
For the timeouts creation and storage, you can use a method like the following:
|
||||
|
||||
|
||||
```
|
||||
func CreateTimeoutHandler(callback func(Session), session Session, duration int) *TimeoutHandler {
|
||||
if sessionTimeout[session] == nil {
|
||||
sessionTimeout[session] := new(TimeoutHandler)
|
||||
}
|
||||
|
||||
timeout = sessionTimeout[session]
|
||||
timeout.session = session
|
||||
timeout.callback = callback
|
||||
timeout.duration = duration
|
||||
return timeout
|
||||
}
|
||||
```
|
||||
|
||||
Once the timeout handler is created and registered, it runs the callback after _duration_ seconds have elapsed. However, some events will require you to reschedule a timeout handler (as it happens at **SYN** state — every 3 seconds).
|
||||
|
||||
For that, you can have the callback rescheduling a new timeout:
|
||||
|
||||
|
||||
```
|
||||
func synCallback(session Session) {
|
||||
sendSynPacket(session)
|
||||
|
||||
// reschedules the same callback.
|
||||
newTimeout := NewTimeoutHandler(synCallback, session, SYN_TIMEOUT_DURATION)
|
||||
newTimeout.Register()
|
||||
|
||||
sessionTimeout[state] = newTimeout
|
||||
}
|
||||
```
|
||||
|
||||
This callback reschedules itself in a new timeout handler and updates the global **sessionTimeout** map.
|
||||
|
||||
### **Data race and references**
|
||||
|
||||
Your solution is ready. One simple test is to check that a timeout callback is executed after the timer has expired. To do this, register a timeout, sleep for its duration, and then check whether the callback actions were done. After the test is executed, it is a good idea to cancel the scheduled timeout (as it reschedules), so it won’t have side effects between tests.
|
||||
|
||||
Surprisingly, this simple test found a bug in the solution. Canceling timeouts using the cancel method was just not doing its job. The following order of events would cause a data race condition:
|
||||
|
||||
1. You have one scheduled timeout handler.
|
||||
2. Thread 1:
|
||||
a) You receive a control packet, and you now want to cancel the registered timeout and move on to the next session state. (e.g. received a **SYN-ACK** **after you sent a **SYN**).
|
||||
b) You call **timeout.Cancel()**, which calls a **timer.Stop()**. (Note that a Golang timer stop doesn’t prevent an already expired timer from running.)
|
||||
3. Thread 2:
|
||||
a) Right before that cancel call, the timer has expired, and the callback was about to execute.
|
||||
b) The callback is executed, it schedules a new timeout and updates the global map.
|
||||
4. Thread 1:
|
||||
a) Transitions to a new session state and registers a new timeout, updating the global map.
|
||||
|
||||
|
||||
|
||||
Both threads were updating the timeout map concurrently. The end result is that you failed to cancel the registered timeout, and then you also lost the reference to the rescheduled timeout done by thread 2. This results in a handler that keeps executing and rescheduling for a while, doing unwanted behavior.
|
||||
|
||||
### When locking is not enough
|
||||
|
||||
Using locks also doesn’t fix the issue completely. If you add locks before processing any event and before executing a callback, it still doesn’t prevent an expired callback to run:
|
||||
|
||||
|
||||
```
|
||||
func (timeout* TimeoutHandler) Register() {
|
||||
timeout.timer = time.AfterFunc(time.Duration(timeout.duration) * time._Second_, func() {
|
||||
stateLock.Lock()
|
||||
defer stateLock.Unlock()
|
||||
|
||||
timeout.callback(timeout.session)
|
||||
})
|
||||
}
|
||||
```
|
||||
|
||||
The difference now is that the updates in the global map are synchronized, but this doesn’t prevent the callback from running after you call the **timeout.Cancel() **— This is the case if the scheduled timer expired but didn’t grab the lock yet. You should again lose reference to one of the registered timeouts.
|
||||
|
||||
### Using cancellation channels
|
||||
|
||||
Instead of relying on golang’s **timer.Stop()**, which doesn’t prevent an expired timer to execute, you can use cancellation channels.
|
||||
|
||||
It is a slightly different approach. Now you won’t do a recursive re-scheduling through callbacks; instead, you register an infinite loop that waits for cancellation signals or timeout events.
|
||||
|
||||
The new **Register()** spawns a new go thread that runs your callback after a timeout and schedules a new timeout after the previous one has been executed. A cancellation channel is returned to the caller to control when the loop should stop.
|
||||
|
||||
|
||||
```
|
||||
func (timeout *TimeoutHandler) Register() chan struct{} {
|
||||
cancelChan := make(chan struct{})
|
||||
|
||||
go func () {
|
||||
select {
|
||||
case _ = <\- cancelChan:
|
||||
return
|
||||
case _ = <\- time.AfterFunc(time.Duration(timeout.duration) * time.Second):
|
||||
func () {
|
||||
stateLock.Lock()
|
||||
defer stateLock.Unlock()
|
||||
|
||||
timeout.callback(timeout.session)
|
||||
} ()
|
||||
}
|
||||
} ()
|
||||
|
||||
return cancelChan
|
||||
}
|
||||
|
||||
func (timeout* TimeoutHandler) Cancel() {
|
||||
if timeout.cancelChan == nil {
|
||||
return
|
||||
}
|
||||
timeout.cancelChan <\- struct{}{}
|
||||
}
|
||||
```
|
||||
|
||||
This approach gives you a cancellation channel for each timeout you register. A cancel call sends an empty struct to the channel and triggers the cancellation. However, this doesn’t resolve the previous issue; the timeout can expire right before you call cancel over the channel, and before the lock is grabbed by the timeout thread.
|
||||
|
||||
The solution here is to check the cancellation channel inside the timeout scope after you grab the lock.
|
||||
|
||||
|
||||
```
|
||||
case _ = <\- time.AfterFunc(time.Duration(timeout.duration) * time.Second):
|
||||
func () {
|
||||
stateLock.Lock()
|
||||
defer stateLock.Unlock()
|
||||
|
||||
select {
|
||||
case _ = <\- handler.cancelChan:
|
||||
return
|
||||
default:
|
||||
timeout.callback(timeout.session)
|
||||
}
|
||||
} ()
|
||||
}
|
||||
```
|
||||
|
||||
Finally, this guarantees that the callback is only executed after you grab the lock and no cancellation was triggered.
|
||||
|
||||
### Beware of deadlocks
|
||||
|
||||
This solution seems to work; however, there is one hidden pitfall here: [deadlocks][10].
|
||||
|
||||
Please read the code above again and try to find it yourself. Think of concurrent calls to any of the methods described.
|
||||
|
||||
The last problem here is with the cancellation channel itself. We made it an unbuffered channel, which means that sending is a blocking call. Once you call cancel in a timeout handler, you only proceed once that handler is canceled. The problem here is when you have multiple calls to the same cancelation channel, where a cancel request is only consumed once. And this can easily happen if concurrent events were to cancel the same timeout handler, like a link down or control packet event. This results in a deadlock situation, possibly bringing the application to a halt.
|
||||
|
||||
![gophers on a wire, talking][11]
|
||||
|
||||
Is anyone listening?
|
||||
|
||||
By Trevor Forrey. Used with permission.
|
||||
|
||||
The solution here is to at least make the channel buffered by one, so sends are not always blocking, and also explicitly make the send non-blocking in case of concurrent calls. This guarantees the cancellation is sent once and won’t block the subsequent cancel calls.
|
||||
|
||||
|
||||
```
|
||||
func (timeout* TimeoutHandler) Cancel() {
|
||||
if timeout.cancelChan == nil {
|
||||
return
|
||||
}
|
||||
|
||||
select {
|
||||
case timeout.cancelChan <\- struct{}{}:
|
||||
default:
|
||||
// can’t send on the channel, someone has already requested the cancellation.
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### Conclusion
|
||||
|
||||
You learned in practice how common mistakes can show up while working with concurrent code. Due to their non-deterministic nature, those issues can go easily undetected, even with extensive testing. Here are the three main problems we encountered in the initial implementation.
|
||||
|
||||
#### Updating shared data without synchronization
|
||||
|
||||
This seems like an obvious one, but it’s actually hard to spot if your concurrent updates happen in different locations. The result is data race, where multiple updates to the same data can cause update loss, due to one update overriding another. In our case, we were updating the scheduled timeout reference on the same shared map. (Interestingly, if Go detects a concurrent read/write on the same Map object, it throws a fatal error —you can try to run Go’s [data race detector][12]). This eventually results in losing a timeout reference and making it impossible to cancel that given timeout. Always remember to use locks when they are needed.
|
||||
|
||||
![gopher assembly line][13]
|
||||
|
||||
don’t forget to synchronize gophers’ work
|
||||
|
||||
#### Missing condition checks
|
||||
|
||||
Condition checks are needed in situations where you can’t rely only on the lock exclusivity. Our situation is a bit different, but the core idea is the same as [condition variables][14]. Imagine a classic situation where you have one producer and multiple consumers working with a shared queue. A producer can add one item to the queue and wake up all consumers. The wake-up call means that some data is available at the queue, and because the queue is shared, access must be synchronized through a lock. Every consumer has a chance to grab the lock; however, you still need to check if there are items in the queue. A condition check is needed because you don’t know the queue status by the time you grab the lock.
|
||||
|
||||
In our example, the timeout handler got a ‘wake up’ call from a timer expiration, but it still needed to check if a cancel signal was sent to it before it could proceed with the callback execution.
|
||||
|
||||
![gopher boot camp][15]
|
||||
|
||||
condition checks might be needed if you wake up multiple gophers
|
||||
|
||||
#### Deadlocks
|
||||
|
||||
This happens when one thread is stuck, waiting indefinitely for a signal to wake up, but this signal will never arrive. Those can completely kill your application by halting your entire program execution.
|
||||
|
||||
In our case, this happened due to multiple send calls to a non-buffered and blocking channel. This meant that the send call would only return after a receive is done on the same channel. Our timeout thread loop was promptly receiving signals on the cancellation channel; however, after the first signal is received, it would break off the loop and never read from that channel again. The remaining callers are stuck forever. To avoid this situation, you need to carefully think through your code, handle blocking calls with care, and guarantee that thread starvation doesn’t happen. The fix in our example was to make the cancellation calls non-blocking—we didn’t need a blocking call for our needs.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/go-common-pitfalls
|
||||
|
||||
作者:[Eduardo Ferreira][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/edufgf
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/go-golang.png?itok=OAW9BXny (Goland gopher illustration)
|
||||
[2]: http://mode.net
|
||||
[3]: https://en.wikipedia.org/wiki/Metrics_%28networking%29
|
||||
[4]: https://people.ece.cornell.edu/atang/pub/15/HALO_ToN.pdf
|
||||
[5]: https://en.wikipedia.org/wiki/Point_of_presence
|
||||
[6]: https://opensource.com/sites/default/files/uploads/image2_0_3.png (latency computation graph)
|
||||
[7]: https://opensource.com/sites/default/files/uploads/image3_0.png (finite state machine diagram)
|
||||
[8]: https://golang.org/
|
||||
[9]: https://opensource.com/sites/default/files/uploads/image4.png (gophers hacking together)
|
||||
[10]: https://en.wikipedia.org/wiki/Deadlock
|
||||
[11]: https://opensource.com/sites/default/files/uploads/image5_0_0.jpg (gophers on a wire, talking)
|
||||
[12]: https://golang.org/doc/articles/race_detector.html
|
||||
[13]: https://opensource.com/sites/default/files/uploads/image6.jpeg (gopher assembly line)
|
||||
[14]: https://en.wikipedia.org/wiki/Monitor_%28synchronization%29#Condition_variables
|
||||
[15]: https://opensource.com/sites/default/files/uploads/image7.png (gopher boot camp)
|
||||
@ -0,0 +1,196 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to Find High CPU Consumption Processes in Linux)
|
||||
[#]: via: (https://www.2daygeek.com/how-to-find-high-cpu-consumption-processes-in-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
How to Find High CPU Consumption Processes in Linux
|
||||
======
|
||||
|
||||
We have already described in our previous article **[how to find high memory consumption processes in Linux][1]**.
|
||||
|
||||
There are situations where you might see more CPU usage on a Linux system.
|
||||
|
||||
If so, you should identify a list of processes that consume more CPU on the system.
|
||||
|
||||
I believe there are only two ways for you to check this.
|
||||
|
||||
This can be done using the **[top command][2]** and the **[ps command][3]**.
|
||||
|
||||
I’d like to go with the top command for most reasons instead of ps.
|
||||
|
||||
But both will give you the same results, so you can choose the one you like.
|
||||
|
||||
Both of these options are widely used by Linux administrators.
|
||||
|
||||
### 1) How to Find High CPU Consumption Process in Linux Using the top Command
|
||||
|
||||
The Linux top command is the best and most well known command that everyone uses to monitor Linux system performance.
|
||||
|
||||
The top command provides a dynamic real-time view of the running process on a Linux system.
|
||||
|
||||
It display system summary information, the list of processes currently being managed by the Linux kernel.
|
||||
|
||||
It displays various system information such as CPU usage, Memory usage, Swap Memory, Number of running processes, system uptime, system load, Buffer Size, Cache Size, Process PID, etc.
|
||||
|
||||
By default, it sorts the top output with the CPU usage and updates the top command data every 5 seconds.
|
||||
|
||||
If you want to see a clear view of the top command output for further analysis, this is a best way to **[run the top command in the batch mode][4]**.
|
||||
|
||||
Also, you need to **[understand the top command output][5]** to fix the performance problem on the system.
|
||||
|
||||
```
|
||||
# top -c -b | head -50
|
||||
|
||||
top - 00:19:17 up 14:23, 1 user, load average: 2.46, 2.18, 1.97
|
||||
Tasks: 306 total, 1 running, 305 sleeping, 0 stopped, 0 zombie
|
||||
%Cpu0 : 10.4 us, 3.0 sy, 0.0 ni, 83.9 id, 0.0 wa, 1.3 hi, 1.3 si, 0.0 st
|
||||
%Cpu1 : 17.0 us, 3.0 sy, 0.0 ni, 78.7 id, 0.0 wa, 0.3 hi, 1.0 si, 0.0 st
|
||||
%Cpu2 : 13.0 us, 4.0 sy, 0.0 ni, 81.3 id, 0.0 wa, 0.3 hi, 1.3 si, 0.0 st
|
||||
%Cpu3 : 12.3 us, 3.3 sy, 0.0 ni, 82.5 id, 0.3 wa, 0.7 hi, 1.0 si, 0.0 st
|
||||
%Cpu4 : 12.2 us, 3.0 sy, 0.0 ni, 82.8 id, 0.7 wa, 0.3 hi, 1.0 si, 0.0 st
|
||||
%Cpu5 : 6.4 us, 2.7 sy, 0.0 ni, 89.2 id, 0.0 wa, 0.7 hi, 1.0 si, 0.0 st
|
||||
%Cpu6 : 26.7 us, 3.4 sy, 0.0 ni, 68.6 id, 0.0 wa, 0.7 hi, 0.7 si, 0.0 st
|
||||
%Cpu7 : 15.6 us, 4.0 sy, 0.0 ni, 78.8 id, 0.0 wa, 0.7 hi, 1.0 si, 0.0 st
|
||||
KiB Mem : 16248556 total, 1448920 free, 8571484 used, 6228152 buff/cache
|
||||
KiB Swap: 17873388 total, 17873388 free, 0 used. 4596044 avail Mem
|
||||
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
|
||||
2179 daygeek 20 3106324 613584 327564 S 79.5 3.8 14:19.76 Web Content
|
||||
1714 daygeek 20 4603372 974600 403504 S 20.2 6.0 65:18.91 firefox
|
||||
1227 daygeek 20 4192012 376332 180348 S 13.9 2.3 20:43.26 gnome-shell
|
||||
18324 daygeek 20 3296192 766040 127948 S 6.3 4.7 9:18.12 Web Content
|
||||
1170 daygeek 20 1008264 572036 546180 S 6.0 3.5 18:07.85 Xorg
|
||||
4684 daygeek 20 3363708 1.1g 1.0g S 3.6 7.2 13:49.92 VirtualBoxVM
|
||||
4607 daygeek 20 4591040 1.7g 1.6g S 3.0 11.0 14:09.65 VirtualBoxVM
|
||||
1211 daygeek 9 -11 2865268 21032 16588 S 2.0 0.1 10:46.37 pulseaudio
|
||||
4562 daygeek 20 1096888 28812 21044 S 1.7 0.2 4:42.93 VBoxSVC
|
||||
1783 daygeek 20 3123888 376896 134788 S 1.3 2.3 39:32.56 Web Content
|
||||
3286 daygeek 20 3089736 404088 184968 S 1.0 2.5 41:57.44 Web Content
|
||||
```
|
||||
|
||||
Details of the above command:
|
||||
|
||||
* **top :** This is a command.
|
||||
* **-b :** Batch mode.
|
||||
* **head -50:** Display first 50 lines in the output.
|
||||
* **PID :** Unique ID of the process.
|
||||
* **USER :** Owner of the process.
|
||||
* **PR :** priority of the process.
|
||||
* **NI :** The NICE value of the process.
|
||||
* **VIRT :** How much virtual memory used by the process.
|
||||
* **RES :** How much physical memory used by the process.
|
||||
* **SHR :** How much shared memory used by the process.
|
||||
* **S :** This indicates the status of the process: S=sleep R=running Z=zombie.
|
||||
* **%CPU :** The percentage of CPU used by the process.
|
||||
* **%MEM :** The percentage of RAM used by the process.
|
||||
* **TIME+ :** How long the process being running.
|
||||
* **COMMAND :** Name of the process.
|
||||
|
||||
|
||||
|
||||
If you want to see the full path of the command instead of the command name, run the following top command format.
|
||||
|
||||
```
|
||||
# top -b | head -50
|
||||
|
||||
top - 00:28:49 up 14:33, 1 user, load average: 2.43, 2.49, 2.23
|
||||
Tasks: 305 total, 1 running, 304 sleeping, 0 stopped, 0 zombie
|
||||
%Cpu0 : 11.7 us, 3.7 sy, 0.0 ni, 82.3 id, 0.0 wa, 1.0 hi, 1.3 si, 0.0 st
|
||||
%Cpu1 : 13.6 us, 3.3 sy, 0.0 ni, 81.1 id, 0.7 wa, 0.3 hi, 1.0 si, 0.0 st
|
||||
%Cpu2 : 10.9 us, 2.6 sy, 0.0 ni, 85.1 id, 0.0 wa, 0.3 hi, 1.0 si, 0.0 st
|
||||
%Cpu3 : 16.0 us, 2.6 sy, 0.0 ni, 80.1 id, 0.0 wa, 0.3 hi, 1.0 si, 0.0 st
|
||||
%Cpu4 : 9.2 us, 3.6 sy, 0.0 ni, 85.9 id, 0.0 wa, 0.3 hi, 1.0 si, 0.0 st
|
||||
%Cpu5 : 15.6 us, 2.9 sy, 0.0 ni, 80.5 id, 0.0 wa, 0.3 hi, 0.7 si, 0.0 st
|
||||
%Cpu6 : 11.6 us, 4.3 sy, 0.0 ni, 82.7 id, 0.0 wa, 0.3 hi, 1.0 si, 0.0 st
|
||||
%Cpu7 : 8.0 us, 3.0 sy, 0.0 ni, 87.3 id, 0.0 wa, 0.7 hi, 1.0 si, 0.0 st
|
||||
KiB Mem : 16248556 total, 1022456 free, 8778508 used, 6447592 buff/cache
|
||||
KiB Swap: 17873388 total, 17873388 free, 0 used. 4201560 avail Mem
|
||||
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
|
||||
18527 daygeek 20 3151820 624808 325748 S 52.8 3.8 59:26.72 /usr/lib/firefox/firefox -contentproc -childID 18 -isForBrowser -prefsLen 10002 -prefMapSize 213431 -parentBuildID 20191031132559 -greomni /+
|
||||
1714 daygeek 20 4764668 910940 443228 S 21.5 5.6 68:59.33 /usr/lib/firefox/firefox --new-window
|
||||
1227 daygeek 20 4193108 377344 181404 S 11.6 2.3 21:47.36 /usr/bin/gnome-shell
|
||||
1170 daygeek 20 1008820 572700 546844 S 5.6 3.5 19:05.10 /usr/lib/Xorg vt2 -displayfd 3 -auth /run/user/1000/gdm/Xauthority -nolisten tcp -background none -noreset -keeptty -verbose 3
|
||||
18324 daygeek 20 3300288 789344 127948 S 5.0 4.9 9:46.89 /usr/lib/firefox/firefox -contentproc -childID 16 -isForBrowser -prefsLen 10002 -prefMapSize 213431 -parentBuildID 20191031132559 -greomni /+
|
||||
4684 daygeek 20 3363708 1.1g 1.0g S 3.6 7.2 14:10.18 /usr/lib/virtualbox/VirtualBoxVM --comment CentOS7 --startvm 002f47b8-2af2-48f5-be1d-67b67e03514c --no-startvm-errormsgbox
|
||||
4607 daygeek 20 4591040 1.7g 1.6g S 3.0 11.0 14:28.86 /usr/lib/virtualbox/VirtualBoxVM --comment Ubuntu-18.04 --startvm e8c32dbb-8b01-41b0-977a-bf28b9db1117 --no-startvm-errormsgbox
|
||||
1783 daygeek 20 3132640 451924 132168 S 2.6 2.8 39:49.66 /usr/lib/firefox/firefox -contentproc -childID 1 -isForBrowser -prefsLen 1 -prefMapSize 213431 -parentBuildID 20191031132559 -greomni /usr/l+
|
||||
1211 daygeek 9 -11 2865268 21272 16828 S 2.0 0.1 11:01.29 /usr/bin/pulseaudio --daemonize=no
|
||||
4562 daygeek 20 1096888 28812 21044 S 1.7 0.2 4:49.33 /usr/lib/virtualbox/VBoxSVC --auto-shutdown
|
||||
16865 daygeek 20 3073364 430596 124652 S 1.3 2.7 8:04.02 /usr/lib/firefox/firefox -contentproc -childID 15 -isForBrowser -prefsLen 10002 -prefMapSize 213431 -parentBuildID 20191031132559 -greomni /+
|
||||
2179 daygeek 20 2945348 429644 172940 S 1.0 2.6 15:20.90 /usr/lib/firefox/firefox -contentproc -childID 6 -isForBrowser -prefsLen 7821 -prefMapSize 213431 -parentBuildID 20191031132559 -greomni /us+
|
||||
```
|
||||
|
||||
### 2) How to Find High CPU Consumption Process in Linux Using the ps Command
|
||||
|
||||
ps stands for processes status, it display the information about the active/running processes on the system.
|
||||
|
||||
It provides a snapshot of the current processes along with detailed information like username, user id, cpu usage, memory usage, process start date and time command name etc.
|
||||
|
||||
```
|
||||
# ps -eo pid,ppid,%mem,%cpu,cmd --sort=-%cpu | head
|
||||
|
||||
PID PPID %MEM %CPU CMD
|
||||
18527 1714 4.2 40.3 /usr/lib/firefox/firefox -contentproc -childID 18 -isForBrowser -prefsLen 10002 -prefMapSize 213431 -parentBuildID 20191031132559 -greomni /usr/lib/firefox/omni.ja -appomni /usr/lib/firefox/browser/omni.ja -appdir /usr/lib/firefox/browser 1714 true tab
|
||||
1714 1152 5.6 8.0 /usr/lib/firefox/firefox --new-window
|
||||
18324 1714 4.9 6.3 /usr/lib/firefox/firefox -contentproc -childID 16 -isForBrowser -prefsLen 10002 -prefMapSize 213431 -parentBuildID 20191031132559 -greomni /usr/lib/firefox/omni.ja -appomni /usr/lib/firefox/browser/omni.ja -appdir /usr/lib/firefox/browser 1714 true tab
|
||||
3286 1714 2.0 5.1 /usr/lib/firefox/firefox -contentproc -childID 14 -isForBrowser -prefsLen 8078 -prefMapSize 213431 -parentBuildID 20191031132559 -greomni /usr/lib/firefox/omni.ja -appomni /usr/lib/firefox/browser/omni.ja -appdir /usr/lib/firefox/browser 1714 true tab
|
||||
1783 1714 3.0 4.5 /usr/lib/firefox/firefox -contentproc -childID 1 -isForBrowser -prefsLen 1 -prefMapSize 213431 -parentBuildID 20191031132559 -greomni /usr/lib/firefox/omni.ja -appomni /usr/lib/firefox/browser/omni.ja -appdir /usr/lib/firefox/browser 1714 true tab
|
||||
1227 1152 2.3 2.5 /usr/bin/gnome-shell
|
||||
1170 1168 3.5 2.2 /usr/lib/Xorg vt2 -displayfd 3 -auth /run/user/1000/gdm/Xauthority -nolisten tcp -background none -noreset -keeptty -verbose 3
|
||||
16865 1714 2.5 2.1 /usr/lib/firefox/firefox -contentproc -childID 15 -isForBrowser -prefsLen 10002 -prefMapSize 213431 -parentBuildID 20191031132559 -greomni /usr/lib/firefox/omni.ja -appomni /usr/lib/firefox/browser/omni.ja -appdir /usr/lib/firefox/browser 1714 true tab
|
||||
2179 1714 2.7 1.8 /usr/lib/firefox/firefox -contentproc -childID 6 -isForBrowser -prefsLen 7821 -prefMapSize 213431 -parentBuildID 20191031132559 -greomni /usr/lib/firefox/omni.ja -appomni /usr/lib/firefox/browser/omni.ja -appdir /usr/lib/firefox/browser 1714 true tab
|
||||
```
|
||||
|
||||
Details of the above command:
|
||||
|
||||
* **ps :** This is a command.
|
||||
* **-e :** Select all processes.
|
||||
* **-o :** To customize a output format.
|
||||
* **–sort=-%cpu :** Sort the ouput based on CPU usage.
|
||||
* **head :** To display first 10 lines of the output
|
||||
* **PID :** Unique ID of the process.
|
||||
* **PPID :** Unique ID of the parent process.
|
||||
* **%MEM :** The percentage of RAM used by the process.
|
||||
* **%CPU :** The percentage of CPU used by the process.
|
||||
* **Command :** Name of the process.
|
||||
|
||||
|
||||
|
||||
If you only want to see the command name instead of the absolute path of the command, use the ps command format below.
|
||||
|
||||
```
|
||||
# ps -eo pid,ppid,%mem,%cpu,comm --sort=-%cpu | head
|
||||
|
||||
PID PPID %MEM %CPU COMMAND
|
||||
18527 1714 4.1 40.4 Web Content
|
||||
1714 1152 5.7 8.0 firefox
|
||||
18324 1714 4.9 6.3 Web Content
|
||||
3286 1714 2.0 5.1 Web Content
|
||||
1783 1714 3.0 4.5 Web Content
|
||||
1227 1152 2.3 2.5 gnome-shell
|
||||
1170 1168 3.5 2.2 Xorg
|
||||
16865 1714 2.4 2.1 Web Content
|
||||
2179 1714 2.7 1.8 Web Content
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-find-high-cpu-consumption-processes-in-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/linux-find-top-memory-consuming-processes/
|
||||
[2]: https://www.2daygeek.com/linux-top-command-linux-system-performance-monitoring-tool/
|
||||
[3]: https://www.2daygeek.com/linux-ps-command-find-running-process-monitoring/
|
||||
[4]: https://www.2daygeek.com/linux-run-execute-top-command-in-batch-mode/
|
||||
[5]: https://www.2daygeek.com/understanding-linux-top-command-output-usage/
|
||||
@ -0,0 +1,243 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (14 SCP Command Examples to Securely Transfer Files in Linux)
|
||||
[#]: via: (https://www.linuxtechi.com/scp-command-examples-in-linux/)
|
||||
[#]: author: (Pradeep Kumar https://www.linuxtechi.com/author/pradeep/)
|
||||
|
||||
在 Linux 上安全传输文件的 14 SCP 命令示例
|
||||
======
|
||||
|
||||
SCP(Secure Copy)是 Linux 和 Unix 之类的系统中的命令行工具,用于通过网络安全地跨系统传输文件和目录。当我们使用 `scp` 命令将文件和目录从本地系统复制到远程系统时,则在后端与远程系统建立 ssh 连接。换句话说,我们可以说 `scp` 在后端使用了相同的 SSH 安全机制,它需要密码或密钥进行身份验证。
|
||||
|
||||
![scp-command-examples-linux][2]
|
||||
|
||||
在本教程中,我们将讨论 14 个有用的 Linux `scp` 命令示例。
|
||||
|
||||
`scp` 命令语法:
|
||||
|
||||
```
|
||||
# scp <选项> <文件或目录> 用户名@目标主机:/<文件夹>
|
||||
|
||||
# scp <选项> 用户名@目标主机:/文件 <本地文件夹>
|
||||
```
|
||||
|
||||
`scp` 命令的第一个语法演示了如何将文件或目录从本地系统复制到特定文件夹下的目标主机。
|
||||
|
||||
`scp` 命令的第二种语法演示了如何将目标主机中的文件复制到本地系统中。
|
||||
|
||||
下面列出了 `scp` 命令中使用最广泛的一些选项,
|
||||
|
||||
* `-C` 启用压缩
|
||||
* `-i` 指定识别文件或私钥
|
||||
* `-l` 复制时限制带宽
|
||||
* `-P` 目标主机的 ssh 端口号
|
||||
* `-p` 复制时保留文件的权限、模式和访问时间
|
||||
* `-q` 禁止 SSH 警告消息
|
||||
* `-r` 递归复制文件和目录
|
||||
* `-v` 详细输出
|
||||
|
||||
现在让我们跳入示例!!!!
|
||||
|
||||
### 示例:1)使用 scp 将文件从本地系统复制到远程系统
|
||||
|
||||
假设我们要使用 `scp` 命令将 jdk 的 rpm 软件包从本地 Linux 系统复制到远程系统(172.20.10.8),请使用以下命令,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]$ scp jdk-linux-x64_bin.rpm root@linuxtechi:/opt
|
||||
root@linuxtechi's password:
|
||||
jdk-linux-x64_bin.rpm 100% 10MB 27.1MB/s 00:00
|
||||
[root@linuxtechi ~]$
|
||||
```
|
||||
|
||||
上面的命令会将 jdk 的 rpm 软件包文件复制到 `/opt` 文件夹下的远程系统。
|
||||
|
||||
### 示例:2)使用 scp 将文件从远程系统复制到本地系统
|
||||
|
||||
假设我们想将文件从远程系统复制到 `/tmp` 文件夹下的本地系统,执行以下 `scp` 命令,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]$ scp root@linuxtechi:/root/Technical-Doc-RHS.odt /tmp
|
||||
root@linuxtechi's password:
|
||||
Technical-Doc-RHS.odt 100% 1109KB 31.8MB/s 00:00
|
||||
[root@linuxtechi ~]$ ls -l /tmp/Technical-Doc-RHS.odt
|
||||
-rwx------. 1 pkumar pkumar 1135521 Oct 19 11:12 /tmp/Technical-Doc-RHS.odt
|
||||
[root@linuxtechi ~]$
|
||||
```
|
||||
|
||||
### 示例:3)使用 scp 传输文件时的详细输出(-v)
|
||||
|
||||
在 `scp` 命令中,我们可以使用 `-v` 选项启用详细输出,使用详细输出,我们可以轻松地发现后台确切发生了什么。这对于调试连接、认证和配置问题非常有用。
|
||||
|
||||
```
|
||||
root@linuxtechi ~]$ scp -v jdk-linux-x64_bin.rpm root@linuxtechi:/opt
|
||||
Executing: program /usr/bin/ssh host 172.20.10.8, user root, command scp -v -t /opt
|
||||
OpenSSH_7.8p1, OpenSSL 1.1.1 FIPS 11 Sep 2018
|
||||
debug1: Reading configuration data /etc/ssh/ssh_config
|
||||
debug1: Reading configuration data /etc/ssh/ssh_config.d/05-redhat.conf
|
||||
debug1: Reading configuration data /etc/crypto-policies/back-ends/openssh.config
|
||||
debug1: /etc/ssh/ssh_config.d/05-redhat.conf line 8: Applying options for *
|
||||
debug1: Connecting to 172.20.10.8 [172.20.10.8] port 22.
|
||||
debug1: Connection established.
|
||||
…………
|
||||
debug1: Next authentication method: password
|
||||
root@linuxtechi's password:
|
||||
```
|
||||
|
||||
### 示例:4)将多个文件传输到远程系统
|
||||
|
||||
可以使用 `scp` 命令一次性将多个文件复制/传输到远程系统,在 `scp` 命令中指定多个文件,并用空格隔开,示例如下所示
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]$ scp install.txt index.html jdk-linux-x64_bin.rpm root@linuxtechi:/mnt
|
||||
root@linuxtechi's password:
|
||||
install.txt 100% 0 0.0KB/s 00:00
|
||||
index.html 100% 85KB 7.2MB/s 00:00
|
||||
jdk-linux-x64_bin.rpm 100% 10MB 25.3MB/s 00:00
|
||||
[root@linuxtechi ~]$
|
||||
```
|
||||
|
||||
### 示例:5)在两个远程主机之间传输文件
|
||||
|
||||
使用 `scp` 命令,我们可以在两个远程主机之间复制文件和目录,假设我们有一个可以连接到两个远程 Linux 系统的本地 Linux 系统,因此从我的本地 Linux 系统中,我可以使用 `scp` 命令在这两个系统之间复制文件,
|
||||
|
||||
命令语法:
|
||||
|
||||
```
|
||||
# scp 用户名@远程主机1:/<要传输的文件> 用户名@远程主机2:/<文件夹>
|
||||
```
|
||||
|
||||
示例如下:
|
||||
|
||||
```
|
||||
# scp root@linuxtechi:~/backup-Oct.zip root@linuxtechi:/tmp
|
||||
# ssh root@linuxtechi "ls -l /tmp/backup-Oct.zip"
|
||||
-rwx------. 1 root root 747438080 Oct 19 12:02 /tmp/backup-Oct.zip
|
||||
```
|
||||
|
||||
### 示例:6)递归复制文件和目录(-r)
|
||||
|
||||
在 `scp` 命令中使用 `-r` 选项将整个目录从一个系统递归复制到另一个系统,示例如下所示:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]$ scp -r Downloads root@linuxtechi:/opt
|
||||
```
|
||||
|
||||
使用以下命令验证 `Downloads` 文件夹是否已复制到远程系统,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]$ ssh root@linuxtechi "ls -ld /opt/Downloads"
|
||||
drwxr-xr-x. 2 root root 75 Oct 19 12:10 /opt/Downloads
|
||||
[root@linuxtechi ~]$
|
||||
```
|
||||
|
||||
### 示例:7)通过启用压缩来提高传输速度(-C)
|
||||
|
||||
在 `scp` 命令中,我们可以通过使用 `-C` 选项启用压缩来提高传输速度,它将自动在源上启用压缩并在目标主机上启用解压缩。
|
||||
|
||||
```
|
||||
root@linuxtechi ~]$ scp -r -C Downloads root@linuxtechi:/mnt
|
||||
```
|
||||
|
||||
在以上示例中,我们正在启用压缩的情况下传输下载目录。
|
||||
|
||||
### 示例:8)复制时限制带宽(-l)
|
||||
|
||||
在 `scp` 命令中使用 `-l` 选项设置复制时对带宽使用的限制。带宽以 Kbit/s 为单位指定,示例如下所示,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]$ scp -l 500 jdk-linux-x64_bin.rpm root@linuxtechi:/var
|
||||
```
|
||||
|
||||
### 示例:9)在 scp 时指定其他 ssh 端口(-P)
|
||||
|
||||
在某些情况下,目标主机上的 ssh 端口会更改,因此在使用 `scp` 命令时,我们可以使用 `-P` 选项指定 ssh 端口号。
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]$ scp -P 2022 jdk-linux-x64_bin.rpm root@linuxtechi:/var
|
||||
```
|
||||
|
||||
在上面的示例中,远程主机的 ssh 端口为 “2022”
|
||||
|
||||
### 示例:10)复制时保留文件的权限、模式和访问时间(-p)
|
||||
|
||||
从源复制到目标时,在 `scp` 命令中使用 `-p` 选项保留权限、访问时间和模式。
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]$ scp -p jdk-linux-x64_bin.rpm root@linuxtechi:/var/tmp
|
||||
jdk-linux-x64_bin.rpm 100% 10MB 13.5MB/s 00:00
|
||||
[root@linuxtechi ~]$
|
||||
```
|
||||
|
||||
### 示例:11)在 scp 中以安静模式传输文件(-q)
|
||||
|
||||
在 `scp` 命令中使用 `-q` 选项可禁止显示 ssh 的传输进度、警告和诊断消息。示例如下所示:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]$ scp -q -r Downloads root@linuxtechi:/var/tmp
|
||||
[root@linuxtechi ~]$
|
||||
```
|
||||
|
||||
### 示例:12)在传输时使用 scp 中的识别文件(-i)
|
||||
|
||||
在大多数 Linux 环境中,首选基于密钥的身份验证。在 scp 命令中,我们使用 `-i` 选项指定识别文件(私钥文件),示例如下所示:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]$ scp -i my_key.pem -r Downloads root@linuxtechi:/root
|
||||
```
|
||||
|
||||
在上面的示例中,`my_key.pem` 是识别文件或私钥文件。
|
||||
|
||||
### 示例:13)在 scp 中使用其他 ssh_config 文件(-F)
|
||||
|
||||
在某些情况下,你使用不同的网络连接到 Linux 系统,可能某些网络位于代理服务器后面,因此在这种情况下,我们必须具有不同的 `ssh_config` 文件。
|
||||
|
||||
通过 `-F` 选项在 `scp` 命令中指定了不同的 `ssh_config` 文件,示例如下所示:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]$ scp -F /home/pkumar/new_ssh_config -r Downloads root@linuxtechi:/root
|
||||
root@linuxtechi's password:
|
||||
jdk-linux-x64_bin.rpm 100% 10MB 16.6MB/s 00:00
|
||||
backup-Oct.zip 100% 713MB 41.9MB/s 00:17
|
||||
index.html 100% 85KB 6.6MB/s 00:00
|
||||
[root@linuxtechi ~]$
|
||||
```
|
||||
|
||||
### 示例:14)在 scp 命令中使用其他加密方式(-c)
|
||||
|
||||
默认情况下,`scp` 使用 AES-128 加密方式来加密文件。如果你想在 `scp` 命令中使用其他加密方式,请使用 `-c` 选项,后接加密方式名称,
|
||||
|
||||
假设我们要在用 `scp`命令传输文件时使用 3des-cbc 加密方式,请运行以下 `scp` 命令:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# scp -c 3des-cbc -r Downloads root@linuxtechi:/root
|
||||
```
|
||||
|
||||
使用以下命令列出 `ssh` 和 `scp` 加密方式:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# ssh -Q cipher localhost | paste -d , -s -
|
||||
3des-cbc,aes128-cbc,aes192-cbc,aes256-cbc,root@linuxtechi,aes128-ctr,aes192-ctr,aes256-ctr,root@linuxtechi,root@linuxtechi,root@linuxtechi
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
以上就是本教程的全部内容,要获取有关 `scp` 命令的更多详细信息,请参考其手册页。请在下面的评论部分中分享你的反馈和评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxtechi.com/scp-command-examples-in-linux/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linuxtechi.com/author/pradeep/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]: https://www.linuxtechi.com/wp-content/uploads/2019/10/scp-command-examples-linux.jpg
|
||||
[3]: https://www.linuxtechi.com/cdn-cgi/l/email-protection
|
||||
@ -1,258 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lxbwolf)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (6 Ways to Send Email from the Linux Command Line)
|
||||
[#]: via: (https://www.2daygeek.com/6-ways-to-send-email-from-the-linux-command-line/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
Linux 命令行发送邮件的 6 种方法
|
||||
======
|
||||
|
||||
当你需要在 shell 脚本中创建邮件时,就需要用到命令行发送邮件的知识。Linux 中有很多命令可以实现发送邮件。本教程中包含了命令行邮件客户端的 Top 6,你可以选择其中一个。6 个命令分别是:
|
||||
|
||||
* mail
|
||||
* mailx
|
||||
* mutt
|
||||
* mpack
|
||||
* sendmail
|
||||
* ssmtp
|
||||
|
||||
|
||||
|
||||
### 工作原理
|
||||
|
||||
我先从整体上来解释下Linux中邮件命令怎么把邮件传递给收件人的。邮件命令(如 sendmail,postfix)生成邮件并发送给一个本地的邮件传输代理(MTA)。本质上发送和接收邮件时邮件服务器和远程邮件服务器之间的通信。下面的流程可以看得更详细。
|
||||
|
||||

|
||||
|
||||
### 1) Linux 安装 mail 命令
|
||||
|
||||
mail 命令是 Linux 终端发送邮件使用次数最多的命令。可以运行下面的命令从官方发行库安装 mail 命令。对于 **”Debian/Ubuntu“** 系统,使用 **[APT-GET 命令][3]** 或 **[APT 命令][4]** 安装 mailutils。
|
||||
|
||||
```
|
||||
$ sudo apt-get install mailutils
|
||||
```
|
||||
|
||||
对于 **“RHEL/CentOS”** 系统,使用 **[YUM 命令][5]** 安装 mailx。
|
||||
|
||||
```
|
||||
$ sudo yum install mailx
|
||||
```
|
||||
|
||||
对于 **“Fedora”** 系统,使用 **[DNF 命令][6]** 安装 mailx。
|
||||
|
||||
```
|
||||
$ sudo dnf install mailx
|
||||
```
|
||||
|
||||
### 1a) Linux 安装 mail 命令后发送邮件
|
||||
|
||||
mail 命令简单易用。如果你不需要发送附件,使用下面的 mail 命令格式就可以发送邮件了。
|
||||
|
||||
```
|
||||
$ echo "This is the mail body" | mail -s "Subject" [email protected]
|
||||
```
|
||||
|
||||
如果你要发送附件,使用下面的 mail 命令格式。
|
||||
|
||||
```
|
||||
$ echo "This is the mail body" | mail -a test1.txt -s "Subject" [email protected]
|
||||
```
|
||||
|
||||
```
|
||||
+---------+----------------------------------------------------+
|
||||
| Options | Description |
|
||||
+---------+----------------------------------------------------+
|
||||
| -a | It's used for attachment on Red Hat based systems. |
|
||||
| -A | It's used for attachment on Debian based systems. |
|
||||
| -s | Specify the subject of the message |
|
||||
+--------------------------------------------------------------+
|
||||
```
|
||||
|
||||
### 2) Linux 安装 mutt 命令
|
||||
|
||||
mutt 是另一个 Linux 终端发送邮件很受欢迎的命令。mutt 是一个小而强大的基于文本的程序,用来阅读和发送 unix 操作系统的电子邮件,功能支持多彩终端、MIME、OpenPGP和按邮件线索排序的模式。可以运行下面的命令从官方发行库安装 mutt 命令。对于 **”Debian/Ubuntu“** 系统,使用 **[APT-GET 命令][3]** 或 **[APT 命令][4]** 安装 mutt。
|
||||
|
||||
```
|
||||
$ sudo apt-get install mutt
|
||||
```
|
||||
|
||||
对于 **“RHEL/CentOS”** 系统,使用 **[YUM 命令][5]** 安装 mutt。
|
||||
|
||||
```
|
||||
$ sudo yum install mutt
|
||||
```
|
||||
|
||||
对于 **“Fedora”** 系统,使用 **[DNF 命令][6]** 安装 mutt。
|
||||
|
||||
```
|
||||
$ sudo dnf install mutt
|
||||
```
|
||||
|
||||
### 2b) Linux 使用 mutt 命令发送邮件
|
||||
|
||||
mutt 也是简单易用的。如果你不需要发送附件,使用下面的 mutt 命令格式就可以发送邮件了。
|
||||
|
||||
```
|
||||
$ echo "This is the mail body" | mutt -s "Subject" [email protected]
|
||||
```
|
||||
|
||||
如果你要发送附件,使用下面的 mutt 命令格式。
|
||||
|
||||
```
|
||||
$ echo "This is the mail body" | mutt -s "Subject" [email protected] -a test1.txt
|
||||
```
|
||||
|
||||
### 3) Linux 安装 mpack 命令
|
||||
|
||||
mpack 是另一个 Linux 终端发送邮件很受欢迎的命令。mpack 程序会对 MIME 消息中文件进行编码。编码后的消息被发送到一个或多个收件人。可以运行下面的命令从官方发行库安装 mpack 命令。对于 **”Debian/Ubuntu“** 系统,使用 **[APT-GET 命令][3]** 或 **[APT 命令][4]** 安装 mpack。
|
||||
|
||||
```
|
||||
$ sudo apt-get install mpack
|
||||
```
|
||||
|
||||
对于 **“RHEL/CentOS”** 系统,使用 **[YUM 命令][5]** 安装 mpack。
|
||||
|
||||
```
|
||||
$ sudo yum install mpack
|
||||
```
|
||||
|
||||
对于 **“Fedora”** 系统,使用 **[DNF 命令][6]** 安装 mpack。
|
||||
|
||||
```
|
||||
$ sudo dnf install mpack
|
||||
```
|
||||
|
||||
### 3a) Linux 使用 mpack 命令发送邮件
|
||||
|
||||
mpack 也是简单易用的。如果你不需要发送附件,使用下面的 mpack 命令格式就可以发送邮件了。
|
||||
|
||||
```
|
||||
$ echo "This is the mail body" | mpack -s "Subject" [email protected]
|
||||
```
|
||||
|
||||
如果你要发送附件,使用下面的 mpack 命令格式。
|
||||
|
||||
```
|
||||
$ echo "This is the mail body" | mpack -s "Subject" [email protected] -a test1.txt
|
||||
```
|
||||
|
||||
### 4) Linux 安装 mailx 命令
|
||||
|
||||
mailx 是 mail 命令的更新版本,基于 Berkeley Mail 8.1,意在提供 POSIX mailx 命令的功能和支持MIME、IMAP、POP3、SMTP和S/MIME 的扩展。mailx 在某些交互特性上更加强大,如缓冲邮件消息、排序和过滤等。可以运行下面的命令从官方发行库安装 mailx 命令。对于 **”Debian/Ubuntu“** 系统,使用 **[APT-GET 命令][3]** 或 **[APT 命令][4]** 安装 mailutils。
|
||||
|
||||
```
|
||||
$ sudo apt-get install mailutils
|
||||
```
|
||||
|
||||
对于 **“RHEL/CentOS”** 系统,使用 **[YUM 命令][5]** 安装 mailx。
|
||||
|
||||
```
|
||||
$ sudo yum install mailx
|
||||
```
|
||||
|
||||
对于 **“Fedora”** 系统,使用 **[DNF 命令][6]** 安装 mailx。
|
||||
|
||||
```
|
||||
$ sudo dnf install mailx
|
||||
```
|
||||
|
||||
### 4a) Linux 使用 mailx 命令发送邮件
|
||||
|
||||
mailx 也是简单易用的。如果你不需要发送附件,使用下面的 mail 命令格式就可以发送邮件了。
|
||||
|
||||
```
|
||||
$ echo "This is the mail body" | mail -s "Subject" [email protected]
|
||||
```
|
||||
|
||||
如果你要发送附件,使用下面的 mail 命令格式。
|
||||
|
||||
```
|
||||
$ echo "This is the mail body" | mail -a test1.txt -s "Subject" [email protected]
|
||||
```
|
||||
|
||||
### 5) Linux 安装 sendmail 命令
|
||||
|
||||
sendmail 是一个 Linux 上广泛使用的 SMTP 服务器,你也可以从命令行用 sendmail 发邮件。可以运行下面的命令从官方发行库安装 sendmail 命令。对于 **”Debian/Ubuntu“** 系统,使用 **[APT-GET 命令][3]** 或 **[APT 命令][4]** 安装 sendmail。
|
||||
|
||||
```
|
||||
$ sudo apt-get install sendmail
|
||||
```
|
||||
|
||||
对于 **“RHEL/CentOS”** 系统,使用 **[YUM 命令][5]** 安装 sendmail。
|
||||
|
||||
```
|
||||
$ sudo yum install sendmail
|
||||
```
|
||||
|
||||
对于 **“Fedora”** 系统,使用 **[DNF 命令][6]** 安装 sendmail。
|
||||
|
||||
```
|
||||
$ sudo dnf install sendmail
|
||||
```
|
||||
|
||||
### 5a) Linux 使用 sendmail 命令发送邮件
|
||||
|
||||
sendmail 也是简单易用的。使用下面的 sendmail 命令格式发送邮件。
|
||||
|
||||
```
|
||||
$ echo -e "Subject: Test Mail\nThis is the mail body" > /tmp/send-mail.txt
|
||||
```
|
||||
|
||||
```
|
||||
$ sendmail [email protected] < send-mail.txt
|
||||
```
|
||||
|
||||
### 6) Linux 安装 ssmtp 命令
|
||||
|
||||
ssmtp 是类似 sendmail 的一个只发送不接收的工具,可以把邮件从本地计算机传递到配置好的 mailhost(mailhub)。用户可以在 Linux 命令行用 SSMTP 把邮件发送到 SMTP 服务器。可以运行下面的命令从官方发行库安装 ssmtp 命令。对于 **”Debian/Ubuntu“** 系统,使用 **[APT-GET 命令][3]** 或 **[APT 命令][4]** 安装 ssmtp。
|
||||
|
||||
```
|
||||
$ sudo apt-get install ssmtp
|
||||
```
|
||||
|
||||
对于 **“RHEL/CentOS”** 系统,使用 **[YUM 命令][5]** 安装 ssmtp。
|
||||
|
||||
```
|
||||
$ sudo yum install ssmtp
|
||||
```
|
||||
|
||||
对于 **“Fedora”** 系统,使用 **[DNF 命令][6]** 安装 ssmtp。
|
||||
|
||||
```
|
||||
$ sudo dnf install ssmtp
|
||||
```
|
||||
|
||||
### 6a) Linux 使用 ssmtp 命令发送邮件
|
||||
|
||||
ssmtp 也是简单易用的。使用下面的 sendmail 命令格式发送邮件。
|
||||
|
||||
```
|
||||
$ echo -e "Subject: Test Mail\nThis is the mail body" > /tmp/ssmtp-mail.txt
|
||||
```
|
||||
|
||||
```
|
||||
$ ssmtp [email protected] < /tmp/ssmtp-mail.txt
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/6-ways-to-send-email-from-the-linux-command-line/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lxbwolf](https://github.com/lxbwolf)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]: https://www.2daygeek.com/wp-content/uploads/2019/12/smtp-simple-mail-transfer-protocol.png
|
||||
[3]: https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[4]: https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[5]: https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||
[6]: https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
@ -0,0 +1,91 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Pekwm: A lightweight Linux desktop)
|
||||
[#]: via: (https://opensource.com/article/19/12/pekwm-linux-desktop)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
Pekwm:一个轻量级的 Linux 桌面
|
||||
======
|
||||
本文是 24 天 Linux 桌面特别系列的一部分。如果你是一个觉得传统桌面会妨碍你的极简主义者,那么试试 Pekwm Linux 桌面。
|
||||
![Penguin with green background][1]
|
||||
|
||||
假设你想要一个轻量级桌面环境,它的功能足以在屏幕上显示图形,移动一些窗口,而没有其他东西。你会发现传统桌面的通知、任务栏和系统托盘会妨碍你的工作。你想主要通过终端工作,但也希望运行图形应用。如果听起来像你,那么 [Pekwm][2] 可能是你一直在寻找的东西。
|
||||
|
||||
Pekwm 的灵感大概来自于 Window Maker 和 Fluxbox 等。它提供了一个应用菜单,窗口装饰,而不是一大堆其他东西。它非常适合极简主义者,即那些希望节省资源的用户和喜欢在终端工作的用户。
|
||||
|
||||
从发行版仓库安装 Pekwm。安装后,请先退出当前桌面会话,以便可以登录到新桌面。默认情况下,会话管理器(KDM、GDM、LightDM 或 XDM,具体取决于你的设置)将继续登录到以前的桌面,因此需要在登录之前修改它。
|
||||
|
||||
在 GDM 中覆盖之前的桌面:
|
||||
|
||||
![Selecting your desktop in GDM][3]
|
||||
|
||||
在 KDM 中:
|
||||
|
||||
![Selecting your desktop in KDM][4]
|
||||
|
||||
第一次登录 Pekwm 时,你可能会看到黑屏。信不信由你,这是正常的。你看到的是一个空白桌面,没有背景壁纸。你可以使用 **feh** 命令设置壁纸(你可能需要从仓库中安装它)。此命令有几个用于设置背景的选项,包括 **\--bg-fill** 用壁纸填充屏幕,**\--bg-scale** 缩放到合适大小,等等。
|
||||
|
||||
```
|
||||
`$ feh --bg-fill ~/Pictures/wallpapers/mybackground.jpg`
|
||||
```
|
||||
|
||||
### 应用菜单
|
||||
|
||||
默认情况下,Pekwm 自动生成一个菜单,可在桌面上的任意位置右键单击,从而可让你运行应用。此菜单还提供一些首选项设置,例如选择主题和注销 Pekwm 会话。
|
||||
|
||||
![Pekwm running on Fedora][5]
|
||||
|
||||
### 配置
|
||||
|
||||
Pekwm 主要通过保存在 **$HOME/.pekwm**. 的文本配置文件配置。**menu** 文件定义你的应用菜单,**keys** 文件定义键盘快捷键,等等。
|
||||
|
||||
**start** 文件是在 Pekwm 启动后执行的 shell 脚本。它类似于传统 Unix 系统上的 **rc.local**。它故意放在最后一行,因此这里的东西将覆盖之前的一切。这是一个重要文件,它可能是你要设置背景的地方,以便_你的_选择会覆盖正在使用的主题的默认值。
|
||||
|
||||
**start** 文件也是可以启动 dockapp 的地方。dockapp 是 一种小程序,它在 Window Maker 和 Fluxbox 引起了人们的关注。它们通常有网络监视器、时钟、音频设置和其他你能会在系统托盘或作为一个 KDE plasmoid 或者完整桌面环境中看到的小部件。你可能会在发行版仓库中找到一些 dockapp,或者可以在 [dockapps.net][6] 上在线查找它们。
|
||||
|
||||
你可以在启动时运行 dockapp,将它们列在 **start** 文件中,跟上 **&** 符号:
|
||||
|
||||
|
||||
```
|
||||
feh --bg-fill ~/Pictures/wallpapers/mybackground.jpg
|
||||
wmnd &
|
||||
bubblemon -d &
|
||||
```
|
||||
|
||||
**start** 文件必须[设置为可执行][7],才能在 Pekwm 启动时运行。
|
||||
|
||||
```
|
||||
`$ chmod +x $HOME/.pekwm/start`
|
||||
```
|
||||
|
||||
### 功能
|
||||
|
||||
Pekwm 的功能不多,但这就是它的美。如果你希望在桌面上运行额外的服务,那么由你来启动这些服务。如果你仍在学习 Linux,这是了解那些与完整的桌面环境捆绑在一起时通常不会考虑的微小 GUI 组件的好方法(像是[任务栏][8])。这也习惯一些 Linux 命令(例如 [nmcli][9])的好方法。
|
||||
|
||||
Pekwm 是一个有趣的窗口管理器。它分散、简洁、轻巧。请试试看!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/pekwm-linux-desktop
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/linux_penguin_green.png?itok=ENdVzW22 (Penguin with green background)
|
||||
[2]: http://www.pekwm.org/
|
||||
[3]: https://opensource.com/sites/default/files/uploads/advent-gdm_1.jpg (Selecting your desktop in GDM)
|
||||
[4]: https://opensource.com/sites/default/files/uploads/advent-enlightenment-kdm_0.jpg (Selecting your desktop in KDM)
|
||||
[5]: https://opensource.com/sites/default/files/uploads/advent-pekwm.jpg (Pekwm running on Fedora)
|
||||
[6]: http://dockapps.net
|
||||
[7]: https://opensource.com/article/19/6/understanding-linux-permissions
|
||||
[8]: https://opensource.com/article/19/1/productivity-tool-tint2
|
||||
[9]: https://opensource.com/article/19/5/set-static-network-connection-linux
|
||||
Loading…
Reference in New Issue
Block a user