mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-21 02:10:11 +08:00
commit
21193a7dcd
@ -1,12 +1,15 @@
|
||||
如何提升自动化的 ROI:4 个小提示
|
||||
======
|
||||
|
||||
> 想要在你的自动化项目上达成强 RIO?采取如下步骤来规避失败。
|
||||
|
||||

|
||||
在过去的几年间,有关自动化技术的讨论已经很多了。COO 们和运营团队(事实上还有其它的业务部门)对成本随着工作量的增加而增加的这一事实可以重新定义而感到震惊。
|
||||
|
||||
机器人流程自动化(RPA)似乎预示着运营的圣杯(Holy Grail):“我们提供了开箱即用的功能来满足你的日常操作所需 —— 检查电子邮件、保存附件、取数据、更新表格、生成报告、文件以及目录操作。构建一个机器人就像配置这些功能一样简单,然后用机器人将这些操作链接到一起,而不用去请求 IT 部门来构建它们。”这是一个多么诱人的话题。
|
||||
在过去的几年间,有关自动化技术的讨论已经很多了。COO 们和运营团队(事实上还有其它的业务部门)对于可以重新定义成本随着工作量的增加而增加的这一事实而感到震惊。
|
||||
|
||||
低成本、几乎不出错、非常遵守流程 —— 对 COO 们和运营领导来说,这些好处即实用可行度又高。RPA 工具承诺,它从运营中节省下来的费用就足够支付它的成本(有一个短的回报期),这一事实使得业务的观点更具有吸引力。
|
||||
<ruby>机器人流程自动化<rt>Robotic Process Automation</rt></ruby>(RPA)似乎预示着运营的<ruby>圣杯<rt>Holy Grail</rt></ruby>:“我们提供了开箱即用的功能来满足你的日常操作所需 —— 检查电子邮件、保存附件、取数据、更新表格、生成报告、文件以及目录操作。构建一个机器人就像配置这些功能一样简单,然后用机器人将这些操作链接到一起,而不用去请求 IT 部门来构建它们。”这是一个多么诱人的话题。
|
||||
|
||||
低成本、几乎不出错、非常遵守流程 —— 对 COO 们和运营领导来说,这些好处真实可及。RPA 工具承诺,它从运营中节省下来的费用就足够支付它的成本(有一个短的回报期),这一事实使得业务的观点更具有吸引力。
|
||||
|
||||
自动化的谈论都趋向于类似的话题:COO 们和他们的团队想知道,自动化操作能够给他们带来什么好处。他们想知道 RPA 平台特性和功能,以及自动化在现实中的真实案例。从这一点到概念验证的实现过程通常很短暂。
|
||||
|
||||
@ -14,7 +17,7 @@
|
||||
|
||||
但是自动化带来的现实好处有时候可能比你所预期的时间要晚。采用 RPA 的公司在其实施后可能会对它们自身的 ROI 提出一些质疑。一些人没有看到预期之中的成本节省,并对其中的原因感到疑惑。
|
||||
|
||||
## 你是不是自动化了错误的东西?
|
||||
### 你是不是自动化了错误的东西?
|
||||
|
||||
在这些情况下,自动化的愿景和现实之间的差距是什么呢?我们来分析一下它,在决定去继续进行一个自动化验证项目(甚至是一个成熟的实践)之后,我们来看一下通常会发生什么。
|
||||
|
||||
@ -26,7 +29,7 @@
|
||||
|
||||
那么,对于领导们来说,怎么才能确保实施自动化能够带来他们想要的 ROI 呢?实现这个目标有四步:
|
||||
|
||||
## 1. 教育团队
|
||||
### 1. 教育团队
|
||||
|
||||
在你的团队中,从 COO 职位以下的人中,很有可能都听说过 RPA 和运营自动化。同样很有可能他们都有许多的问题和担心。在你开始启动实施之前解决这些问题和担心是非常重要的。
|
||||
|
||||
@ -36,23 +39,23 @@
|
||||
|
||||
“实施自动化的第一步是更好地理解你的流程。”
|
||||
|
||||
## 2. 审查内部流程
|
||||
### 2. 审查内部流程
|
||||
|
||||
实施自动化的第一步是更好地理解你的流程。每个 RPA 实施之前都应该进行流程清单、动作分析、以及成本/价值的绘制练习。
|
||||
|
||||
这些练习对于理解流程中何处价值产生(或成本,如果没有价值的情况下)是至关重要的。并且这些练习需要在每个流程或者每个任务这样的粒度级别上来做。
|
||||
这些练习对于理解流程中何处产生价值(或成本,如果没有价值的情况下)是至关重要的。并且这些练习需要在每个流程或者每个任务这样的粒度级别上来做。
|
||||
|
||||
这将有助你去识别和优先考虑最合适的自动化候选者。由于能够或者可能需要自动化的任务数量较多,流程一般需要分段实施自动化,因此优先级很重要。
|
||||
|
||||
**建议**:设置一个小的工作团队,每个运营团队都参与其中。从每个运营团队中提名一个协调人 —— 一般是运营团队的领导或者团队管理者。在团队级别上组织一次研讨会,去构建流程清单、识别候选流程、以及推动购买。你的自动化合作伙伴很可能有“加速器” —— 调查问卷、计分卡等等 —— 这些将帮助你加速完成这项活动。
|
||||
|
||||
## 3. 为优先业务提供强有力的指导
|
||||
### 3. 为优先业务提供强有力的指导
|
||||
|
||||
实施自动化经常会涉及到在运营团队之间,基于业务价值对流程选择和自动化优先级上要达成共识(有时候是打破平衡)虽然团队的参与仍然是分析和实施的关键部分,但是领导仍然应该是最终的决策者。
|
||||
|
||||
**建议**:安排定期会议从工作团队中获取最新信息。除了像推动达成共识和购买之外,工作团队还应该在团队层面上去查看领导们关于 ROI、平台选择、以及自动化优先级上的指导性决定。
|
||||
|
||||
## 4. 应该推动 CIO 和 COO 的紧密合作
|
||||
### 4. 应该推动 CIO 和 COO 的紧密合作
|
||||
|
||||
当运营团队和技术团队紧密合作时,自动化的实施将异常顺利。COO 需要去帮助推动与 CIO 团队的合作。
|
||||
|
||||
@ -68,7 +71,7 @@ via: https://enterprisersproject.com/article/2017/11/how-improve-roi-automation-
|
||||
|
||||
作者:[Rajesh Kamath][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,134 @@
|
||||
如何轻松地检查 Ubuntu 版本以及其它系统信息
|
||||
======
|
||||
|
||||
> 摘要:想知道你正在使用的 Ubuntu 具体是什么版本吗?这篇文档将告诉你如何检查你的 Ubuntu 版本、桌面环境以及其他相关的系统信息。
|
||||
|
||||
通常,你能非常容易的通过命令行或者图形界面获取你正在使用的 Ubuntu 的版本。当你正在尝试学习一篇互联网上的入门教材或者正在从各种各样的论坛里获取帮助的时候,知道当前正在使用的 Ubuntu 确切的版本号、桌面环境以及其他的系统信息将是尤为重要的。
|
||||
|
||||
在这篇简短的文章中,作者将展示各种检查 [Ubuntu][1] 版本以及其他常用的系统信息的方法。
|
||||
|
||||
### 如何在命令行检查 Ubuntu 版本
|
||||
|
||||
这个是获得 Ubuntu 版本的最好的办法。我本想先展示如何用图形界面做到这一点,但是我决定还是先从命令行方法说起,因为这种方法不依赖于你使用的任何[桌面环境][2]。 你可以在 Ubuntu 的任何变种系统上使用这种方法。
|
||||
|
||||
打开你的命令行终端 (`Ctrl+Alt+T`), 键入下面的命令:
|
||||
|
||||
```
|
||||
lsb_release -a
|
||||
```
|
||||
|
||||
上面命令的输出应该如下:
|
||||
|
||||
```
|
||||
No LSB modules are available.
|
||||
Distributor ID: Ubuntu
|
||||
Description: Ubuntu 16.04.4 LTS
|
||||
Release: 16.04
|
||||
Codename: xenial
|
||||
```
|
||||
|
||||
![How to check Ubuntu version in command line][3]
|
||||
|
||||
正像你所看到的,当前我的系统安装的 Ubuntu 版本是 Ubuntu 16.04, 版本代号: Xenial。
|
||||
|
||||
且慢!为什么版本描述中显示的是 Ubuntu 16.04.4 而发行版本是 16.04?到底哪个才是正确的版本?16.04 还是 16.04.4? 这两者之间有什么区别?
|
||||
|
||||
如果言简意赅的回答这个问题的话,那么答案应该是你正在使用 Ubuntu 16.04。这个是基准版本,而 16.04.4 进一步指明这是 16.04 的第四个补丁版本。你可以将补丁版本理解为 Windows 世界里的服务包。在这里,16.04 和 16.04.4 都是正确的版本号。
|
||||
|
||||
那么输出的 Xenial 又是什么?那正是 Ubuntu 16.04 的版本代号。你可以阅读下面这篇文章获取更多信息:[了解 Ubuntu 的命名惯例][4]。
|
||||
|
||||
#### 其他一些获取 Ubuntu 版本的方法
|
||||
|
||||
你也可以使用下面任意的命令得到 Ubuntu 的版本:
|
||||
|
||||
```
|
||||
cat /etc/lsb-release
|
||||
```
|
||||
|
||||
输出如下信息:
|
||||
|
||||
```
|
||||
DISTRIB_ID=Ubuntu
|
||||
DISTRIB_RELEASE=16.04
|
||||
DISTRIB_CODENAME=xenial
|
||||
DISTRIB_DESCRIPTION="Ubuntu 16.04.4 LTS"
|
||||
```
|
||||
|
||||
![How to check Ubuntu version in command line][5]
|
||||
|
||||
|
||||
你还可以使用下面的命令来获得 Ubuntu 版本:
|
||||
|
||||
```
|
||||
cat /etc/issue
|
||||
```
|
||||
|
||||
|
||||
命令行的输出将会如下:
|
||||
|
||||
```
|
||||
Ubuntu 16.04.4 LTS \n \l
|
||||
```
|
||||
|
||||
不要介意输出末尾的\n \l. 这里 Ubuntu 版本就是 16.04.4,或者更加简单:16.04。
|
||||
|
||||
|
||||
### 如何在图形界面下得到 Ubuntu 版本
|
||||
|
||||
在图形界面下获取 Ubuntu 版本更是小事一桩。这里我使用了 Ubuntu 18.04 的图形界面系统 GNOME 的屏幕截图来展示如何做到这一点。如果你在使用 Unity 或者别的桌面环境的话,显示可能会有所不同。这也是为什么我推荐使用命令行方式来获得版本的原因:你不用依赖形形色色的图形界面。
|
||||
|
||||
下面我来展示如何在桌面环境获取 Ubuntu 版本。
|
||||
|
||||
进入‘系统设置’并点击下面的‘详细信息’栏。
|
||||
|
||||
![Finding Ubuntu version graphically][6]
|
||||
|
||||
你将会看到系统的 Ubuntu 版本和其他和桌面系统有关的系统信息 这里的截图来自 [GNOME][7] 。
|
||||
|
||||
![Finding Ubuntu version graphically][8]
|
||||
|
||||
### 如何知道桌面环境以及其他的系统信息
|
||||
|
||||
你刚才学习的是如何得到 Ubuntu 的版本信息,那么如何知道桌面环境呢? 更进一步, 如果你还想知道当前使用的 Linux 内核版本呢?
|
||||
|
||||
有各种各样的命令你可以用来得到这些信息,不过今天我想推荐一个命令行工具, 叫做 [Neofetch][9]。 这个工具能在命令行完美展示系统信息,包括 Ubuntu 或者其他 Linux 发行版的系统图标。
|
||||
|
||||
用下面的命令安装 Neofetch:
|
||||
|
||||
```
|
||||
sudo apt install neofetch
|
||||
```
|
||||
|
||||
安装成功后,运行 `neofetch` 将会优雅的展示系统的信息如下。
|
||||
|
||||
![System information in Linux terminal][10]
|
||||
|
||||
如你所见,`neofetch` 完全展示了 Linux 内核版本、Ubuntu 的版本、桌面系统版本以及环境、主题和图标等等信息。
|
||||
|
||||
|
||||
希望我如上展示方法能帮到你更快的找到你正在使用的 Ubuntu 版本和其他系统信息。如果你对这篇文章有其他的建议,欢迎在评论栏里留言。
|
||||
|
||||
再见。:)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/how-to-know-ubuntu-unity-version/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[DavidChenLiang](https://github.com/davidchenliang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]:https://www.ubuntu.com/
|
||||
[2]:https://en.wikipedia.org/wiki/Desktop_environment
|
||||
[3]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2013/03/check-ubuntu-version-command-line-1-800x216.jpeg
|
||||
[4]:https://itsfoss.com/linux-code-names/
|
||||
[5]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2013/03/check-ubuntu-version-command-line-2-800x185.jpeg
|
||||
[6]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2013/03/ubuntu-version-system-settings.jpeg
|
||||
[7]:https://www.gnome.org/
|
||||
[8]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2013/03/checking-ubuntu-version-gui.jpeg
|
||||
[9]:https://itsfoss.com/display-linux-logo-in-ascii/
|
||||
[10]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2013/03/ubuntu-system-information-terminal-800x400.jpeg
|
||||
@ -2,7 +2,8 @@ Android 工程师的一年
|
||||
============================================================
|
||||
|
||||

|
||||
>妙绝的绘画来自 [Miquel Beltran][0]
|
||||
|
||||
> 这幅妙绝的绘画来自 [Miquel Beltran][0]
|
||||
|
||||
我的技术生涯,从两年前算起。开始是 QA 测试员,一年后就转入开发人员角色。没怎么努力,也没有投入过多的个人时间。
|
||||
|
||||
@ -12,7 +13,7 @@ Android 工程师的一年
|
||||
|
||||
我的第一个职位角色, Android 开发者,开始于一年前。我工作的这家公司,可以花一半的时间去尝试其它角色的工作,这给我从 QA 职位转到 Android 开发者职位创造了机会。
|
||||
|
||||
这一转变归功于我在晚上和周末投入学习 Android 的时间。我通过了[ Android 基础纳米学位][3]、[Andriod 工程师纳米学位][4]课程,也获得了[ Google 开发者认证][5]。这部分的详细故事在[这儿][6]。
|
||||
这一转变归功于我在晚上和周末投入学习 Android 的时间。我通过了 [Android 基础纳米学位][3]、[Andriod 工程师纳米学位][4]课程,也获得了 [Google 开发者认证][5]。这部分的详细故事在[这儿][6]。
|
||||
|
||||
两个月后,公司雇佣了另一位 QA,我转向全职工作。挑战从此开始!
|
||||
|
||||
@ -46,29 +47,27 @@ Android 工程师的一年
|
||||
|
||||
一个例子就是拉取代码进行公开展示和代码审查。有是我会请同事私下检查我的代码,并不想被公开拉取,向任何人展示。
|
||||
|
||||
其他时候,当我做代码审查时,会花好几分钟盯着"批准"按纽犹豫不决,在担心审查通过的会被其他同事找出毛病。
|
||||
其他时候,当我做代码审查时,会花好几分钟盯着“批准”按纽犹豫不决,在担心审查通过的代码会被其他同事找出毛病。
|
||||
|
||||
当我在一些事上持反对意见时,由于缺乏相关知识,担心被坐冷板凳,从来没有大声说出来过。
|
||||
|
||||
> 某些时间我会请同事私下[...]检查我的代码,以避免被公开展示。
|
||||
|
||||
* * *
|
||||
|
||||
### 新的公司,新的挑战
|
||||
|
||||
后来,我手边有了个新的机会。感谢曾经和我共事的朋友,我被[ Babbel ][7]邀请去参加初级 Android 工程师职位的招聘流程。
|
||||
后来,我手边有了个新的机会。感谢曾经和我共事的朋友,我被 [Babbel][7] 邀请去参加初级 Android 工程师职位的招聘流程。
|
||||
|
||||
我见到了他们的团队,同时自告奋勇的在他们办公室主持了一次本地会议。此事让我下定决心要申请这个职位。我喜欢公司的箴言:全民学习。其次,公司每个人都非常友善,在那儿工作看起来很愉快!但我没有马上申请,因为我认为自己不够好,所以为什么能申请呢?
|
||||
|
||||
还好我的朋友和搭档推动我这样做,他们给了我发送简历的力量和勇气。过后不久就进入了面试流程。这很简单:以很小的应该程序来进行编码挑战,随后是和团队一起的技术面试,之后是和招聘经理间关于团队合作的面试。
|
||||
还好我的朋友和搭档推动我这样做,他们给了我发送简历的力量和勇气。过后不久就进入了面试流程。这很简单:以很小的程序的形式来进行编码挑战,随后是和团队一起的技术面试,之后是和招聘经理间关于团队合作的面试。
|
||||
|
||||
#### 招聘过程
|
||||
|
||||
我用周未的时间来完成编码挑战的项目,并在周一就立即发送过去。不久就受邀去当场面试。
|
||||
|
||||
技术面试是关于编程挑战本身,我们谈论了 Android 好的不好的、我为什么以这种方式实现这功能,以及如何改进等等。随后是招聘经理进行的一次简短的关于团队合作面试,也有涉及到编程挑战的事,我们谈到了我面临的挑战,我如何解决这些问题,等等。
|
||||
技术面试是关于编程挑战本身,我们谈论了 Android 好的不好的地方、我为什么以这种方式实现这功能,以及如何改进等等。随后是招聘经理进行的一次简短的关于团队合作面试,也有涉及到编程挑战的事,我们谈到了我面临的挑战,我如何解决这些问题,等等。
|
||||
|
||||
最后,通过面试,得到 offer, 我授受了!
|
||||
最后,通过面试,得到 offer,我授受了!
|
||||
|
||||
我的 Android 工程师生涯的第一年,有九个月在一个公司,后面三个月在当前的公司。
|
||||
|
||||
@ -88,7 +87,7 @@ Android 工程师的一年
|
||||
|
||||
两次三次后,压力就堵到胸口。为什么我还不知道?为什么就那么难理解?这种状态让我焦虑万分。
|
||||
|
||||
我意识到我需要承认我确实不懂某个特定的主题,但第一步是要知道有这么个概念!有是,仅仅需要的就是更多的时间、更多的练习,最终会"在大脑中完全演绎" :-)
|
||||
我意识到我需要承认我确实不懂某个特定的主题,但第一步是要知道有这么个概念!有时,仅仅需要的就是更多的时间、更多的练习,最终会“在大脑中完全演绎” :-)
|
||||
|
||||
例如,我常常为 Java 的接口类和抽象类所困扰,不管看了多少的例子,还是不能完全明白他们之间的区别。但一旦我使用后,即使还不能解释其工作原理,也知道了怎么使用以及什么时候使用。
|
||||
|
||||
@ -102,19 +101,13 @@ Android 工程师的一年
|
||||
|
||||
工程师的角色不仅仅是编码,而是广泛的技能。 我仍然处于旅程的起点,在掌握它的道路上,我想着重于以下几点:
|
||||
|
||||
* 交流:因为英文不是我的母语,所以有的时候我会努力传达我的想法,这在我工作中是至关重要的。我可以通过写作,阅读和交谈来解决这个问题。
|
||||
|
||||
* 提有建设性的反馈意见: 我想给同事有意义的反馈,这样我们一起共同发展。
|
||||
|
||||
* 为我的成就感到骄傲: 我需要创建一个列表来跟踪各种成就,无论大小,或整体进步,所以当我挣扎时我可以回顾并感觉良好。
|
||||
|
||||
* 不要着迷于不知道的事情: 当有很多新事物出现时很难做到都知道,所以只关注必须的,及手头项目需要的东西,这非常重要的。
|
||||
|
||||
* 多和同事分享知识。我是初级的并不意味着没有可以分享的!我需要持续分享我感兴趣的的文章及讨论话题。我知道同事们会感激我的。
|
||||
|
||||
* 耐心和持续学习: 和现在一样的保持不断学习,但对自己要有更多耐心。
|
||||
|
||||
* 自我保健: 随时注意休息,不要为难自己。 放松也富有成效。
|
||||
* 交流:因为英文不是我的母语,所以有的时候我需要努力传达我的想法,这在我工作中是至关重要的。我可以通过写作,阅读和交谈来解决这个问题。
|
||||
* 提有建设性的反馈意见:我想给同事有意义的反馈,这样我们一起共同发展。
|
||||
* 为我的成就感到骄傲:我需要创建一个列表来跟踪各种成就,无论大小,或整体进步,所以当我挣扎时我可以回顾并感觉良好。
|
||||
* 不要着迷于不知道的事情:当有很多新事物出现时很难做到都知道,所以只关注必须的,及手头项目需要的东西,这非常重要的。
|
||||
* 多和同事分享知识:我是初级的并不意味着没有可以分享的!我需要持续分享我感兴趣的的文章及讨论话题。我知道同事们会感激我的。
|
||||
* 耐心和持续学习:和现在一样的保持不断学习,但对自己要有更多耐心。
|
||||
* 自我保健:随时注意休息,不要为难自己。 放松也富有成效。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -122,7 +115,7 @@ via: https://proandroiddev.com/a-year-as-android-engineer-55e2a428dfc8
|
||||
|
||||
作者:[Lara Martín][a]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,34 +1,35 @@
|
||||
使用 Xenlism 主题为你的 Linux 桌面带来令人惊叹的改造
|
||||
使用 Xenlism 主题对你的 Linux 桌面进行令人惊叹的改造
|
||||
============================================================
|
||||
|
||||
|
||||
_简介:Xenlism 主题包提供了一个美观的 GTK 主题、彩色图标和简约壁纸,将你的 Linux 桌面转变为引人注目的设置._
|
||||
> 简介:Xenlism 主题包提供了一个美观的 GTK 主题、彩色图标和简约的壁纸,将你的 Linux 桌面转变为引人注目的操作系统。
|
||||
|
||||
除非我找到一些非常棒的东西,否则我不会每天都把整篇文章献给一个主题。我曾经经常发布主题和图标。但最近,我更喜欢列出[最佳 GTK 主题][6]和图标主题。这对我和你来说都更方便,你可以在一个地方看到许多美丽的主题。
|
||||
|
||||
在[ Pop OS 主题][7]套件之后,Xenlism 是另一个让我对它的外观感到震惊的主题。
|
||||
在 [Pop OS 主题][7]套件之后,Xenlism 是另一个让我对它的外观感到震惊的主题。
|
||||
|
||||

|
||||
|
||||
Xenlism GTK 主题基于 Arc 主题,这后面有许多主题的灵感。GTK 主题提供类似于 macOS 的 Windows 按钮,我既没有喜欢,也没有不喜欢。GTK 主题采用扁平、简约的布局,我喜欢这样。
|
||||
Xenlism GTK 主题基于 Arc 主题,其得益于许多主题的灵感。GTK 主题提供类似于 macOS 的 Windows 按钮,我既不特别喜欢,也没有特别不喜欢。GTK 主题采用扁平、简约的布局,我喜欢这样。
|
||||
|
||||
Xenlism 套件中有两个图标主题。Xenlism Wildfire是以前的,已经进入我们的[最佳图标主题][8]列表。
|
||||
Xenlism 套件中有两个图标主题。Xenlism Wildfire 是以前的,已经进入我们的[最佳图标主题][8]列表。
|
||||
|
||||

|
||||
Xenlism Wildfire 图标
|
||||
|
||||
*Xenlism Wildfire 图标*
|
||||
|
||||
Xenlsim Storm 是一个相对较新的图标主题,但同样美观。
|
||||
|
||||

|
||||
Xenlism Storm 图标
|
||||
|
||||
Xenlism 主题在 GPL 许可下的开源。
|
||||
*Xenlism Storm 图标*
|
||||
|
||||
Xenlism 主题在 GPL 许可下开源。
|
||||
|
||||
### 如何在 Ubuntu 18.04 上安装 Xenlism 主题包
|
||||
|
||||
Xenlism 开发提供了一种通过 PPA 安装主题包的更简单方法。尽管 PPA 可用于 Ubuntu 16.04,但我发现 GTK 主题不适用于 Unity。它适用于 Ubuntu 18.04 中的 GNOME 桌面。
|
||||
|
||||
打开终端(Ctrl+Alt+T)并逐个使用以下命令:
|
||||
打开终端(`Ctrl+Alt+T`)并逐个使用以下命令:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:xenatt/xenlism
|
||||
@ -38,11 +39,8 @@ sudo apt update
|
||||
该 PPA 提供四个包:
|
||||
|
||||
* xenlism-finewalls:一组壁纸,可直接在 Ubuntu 的壁纸中使用。截图中使用了其中一个壁纸。
|
||||
|
||||
* xenlism-minimalism-theme:GTK主题
|
||||
|
||||
* xenlism-minimalism-theme:GTK 主题
|
||||
* xenlism-storm:一个图标主题(见前面的截图)
|
||||
|
||||
* xenlism-wildfire-icon-theme:具有多种颜色变化的另一个图标主题(文件夹颜色在变体中更改)
|
||||
|
||||
你可以自己决定要安装的主题组件。就个人而言,我认为安装所有组件没有任何损害。
|
||||
@ -65,7 +63,7 @@ sudo apt install xenlism-minimalism-theme xenlism-storm-icon-theme xenlism-wild
|
||||
|
||||
你喜欢 Xenlism 主题吗?如果不喜欢,你最喜欢什么主题?在下面的评论部分分享你的意见。
|
||||
|
||||
#### 关于作者
|
||||
### 关于作者
|
||||
|
||||
我是一名专业软件开发人员,也是 It's FOSS 的创始人。我是一名狂热的 Linux 爱好者和开源爱好者。我使用 Ubuntu 并相信分享知识。除了Linux,我喜欢经典侦探之谜。我是 Agatha Christie 作品的忠实粉丝。
|
||||
|
||||
@ -73,9 +71,9 @@ sudo apt install xenlism-minimalism-theme xenlism-storm-icon-theme xenlism-wild
|
||||
|
||||
via: https://itsfoss.com/xenlism-theme/
|
||||
|
||||
作者:[Abhishek Prakash ][a]
|
||||
作者:[Abhishek Prakash][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,127 @@
|
||||
如何在 Android 上借助 Wine 来运行 Windows Apps
|
||||
======
|
||||
|
||||

|
||||
|
||||
Wine(一种 Linux 上的程序,不是你喝的葡萄酒)是在类 Unix 操作系统上运行 Windows 程序的一个自由开源的兼容层。创建于 1993 年,借助它你可以在 Linux 和 macOS 操作系统上运行很多 Windows 程序,虽然有时可能还需要做一些小修改。现在,Wine 项目已经发布了 3.0 版本,这个版本兼容 Android 设备。
|
||||
|
||||
在本文中,我们将向你展示,在你的 Android 设备上如何借助 Wine 来运行 Windows Apps。
|
||||
|
||||
**相关阅读** : [如何使用 Winepak 在 Linux 上轻松安装 Windows 游戏][1]
|
||||
|
||||
### 在 Wine 上你可以运行什么?
|
||||
|
||||
Wine 只是一个兼容层,而不是一个全功能的仿真器,因此,你需要一个 x86 的 Android 设备才能完全发挥出它的优势。但是,大多数消费者手中的 Android 设备都是基于 ARM 的。
|
||||
|
||||
因为大多数人使用的是基于 ARM 的 Android 设备,所以有一个限制,只有适配在 Windows RT 上运行的那些 App 才能够使用 Wine 在基于 ARM 的 Android 上运行。但是随着发展,能够在 ARM 设备上运行的 App 数量越来越多。你可以在 XDA 开发者论坛上的这个 [帖子][2] 中找到兼容的这些 App 的清单。
|
||||
|
||||
在 ARM 上能够运行的一些 App 的例子如下:
|
||||
|
||||
* [Keepass Portable][3]: 一个密码钱包
|
||||
* [Paint.NET][4]: 一个图像处理程序
|
||||
* [SumatraPDF][5]: 一个 PDF 文档阅读器,也能够阅读一些其它的文档类型
|
||||
* [Audacity][6]: 一个数字录音和编辑程序
|
||||
|
||||
也有一些再度流行的开源游戏,比如,[Doom][7] 和 [Quake 2][8],以及它们的开源克隆,比如 [OpenTTD][9] 和《运输大亨》的一个版本。
|
||||
|
||||
随着 Wine 在 Android 上越来越普及,能够在基于 ARM 的 Android 设备上的 Wine 中运行的程序越来越多。Wine 项目致力于在 ARM 上使用 QEMU 去仿真 x86 的 CPU 指令,在该项目完成后,能够在 Android 上运行的 App 将会迅速增加。
|
||||
|
||||
### 安装 Wine
|
||||
|
||||
在安装 Wine 之前,你首先需要去确保你的设备的设置 “允许从 Play 商店之外的其它源下载和安装 APK”。对于本文的用途,你需要去许可你的设备从未知源下载 App。
|
||||
|
||||
1、 打开你手机上的设置,然后选择安全选项。
|
||||
|
||||
![wine-android-security][10]
|
||||
|
||||
2、 向下拉并点击 “Unknown Sources” 的开关。
|
||||
|
||||
![wine-android-unknown-sources][11]
|
||||
|
||||
3、 接受风险警告。
|
||||
|
||||
![wine-android-unknown-sources-warning][12]
|
||||
|
||||
4、 打开 [Wine 安装站点][13],并点选列表中的第一个选择框。下载将自动开始。
|
||||
|
||||
![wine-android-download-button][14]
|
||||
|
||||
5、 下载完成后,从下载目录中打开它,或者下拉通知菜单并点击这里的已完成的下载。
|
||||
|
||||
6、 开始安装程序。它将提示你它需要访问和记录音频,并去修改、删除、和读取你的 SD 卡。你也可为程序中使用的一些 App 授予访问音频的权利。
|
||||
|
||||
![wine-android-app-access][15]
|
||||
|
||||
7、 安装完成后,点击程序图标去打开它。
|
||||
|
||||
![wine-android-icon-small][16]
|
||||
|
||||
当你打开 Wine 后,它模仿的是 Windows 7 的桌面。
|
||||
|
||||
![wine-android-desktop][17]
|
||||
|
||||
Wine 有一个缺点是,你得有一个外接键盘去进行输入。如果你在一个小屏幕上运行它,并且触摸非常小的按钮很困难,你也可以使用一个外接鼠标。
|
||||
|
||||
你可以通过触摸 “开始” 按钮去打开两个菜单 —— “控制面板”和“运行”。
|
||||
|
||||
![wine-android-start-button][18]
|
||||
|
||||
### 使用 Wine 来工作
|
||||
|
||||
当你触摸 “控制面板” 后你将看到三个选项 —— 添加/删除程序、游戏控制器、和 Internet 设定。
|
||||
|
||||
使用 “运行”,你可以打开一个对话框去运行命令。例如,通过输入 `iexplore` 来启动 “Internet Explorer”。
|
||||
|
||||
![wine-android-run][19]
|
||||
|
||||
### 在 Wine 中安装程序
|
||||
|
||||
1、 在你的 Android 设备上下载应用程序(或通过云来同步)。一定要记住下载的程序保存的位置。
|
||||
|
||||
2、 打开 Wine 命令提示符窗口。
|
||||
|
||||
3、 输入程序的位置路径。如果你把下载的文件保存在 SD 卡上,输入:
|
||||
|
||||
```
|
||||
cd sdcard/Download/[filename.exe]
|
||||
```
|
||||
|
||||
4、 在 Android 上运行 Wine 中的文件,只需要简单地输入 EXE 文件的名字即可。
|
||||
|
||||
如果这个支持 ARM 的文件是兼容的,它将会运行。如果不兼容,你将看到一大堆错误信息。在这种情况下,在 Android 上的 Wine 中安装的 Windows 软件可能会损坏或丢失。
|
||||
|
||||
这个在 Android 上使用的新版本的 Wine 仍然有许多问题。它并不能在所有的 Android 设备上正常工作。它可以在我的 Galaxy S6 Edge 上运行的很好,但是在我的 Galaxy Tab 4 上却不能运行。许多游戏也不能正常运行,因为图形驱动还不支持 Direct3D。因为触摸屏还不是全扩展的,所以你需要一个外接的键盘和鼠标才能很轻松地操作它。
|
||||
|
||||
即便是在早期阶段的发布版本中存在这样那样的问题,但是这种技术还是值得深思的。当然了,你要想在你的 Android 智能手机上运行 Windows 程序而不出问题,可能还需要等待一些时日。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/run-windows-apps-android-with-wine/
|
||||
|
||||
作者:[Tracey Rosenberger][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/traceyrosenberger/
|
||||
[1]:https://www.maketecheasier.com/winepak-install-windows-games-linux/ "How to Easily Install Windows Games on Linux with Winepak"
|
||||
[2]:https://forum.xda-developers.com/showthread.php?t=2092348
|
||||
[3]:http://downloads.sourceforge.net/keepass/KeePass-2.20.1.zip
|
||||
[4]:http://forum.xda-developers.com/showthread.php?t=2411497
|
||||
[5]:http://forum.xda-developers.com/showthread.php?t=2098594
|
||||
[6]:http://forum.xda-developers.com/showthread.php?t=2103779
|
||||
[7]:http://forum.xda-developers.com/showthread.php?t=2175449
|
||||
[8]:http://forum.xda-developers.com/attachment.php?attachmentid=1640830&amp;d=1358070370
|
||||
[9]:http://forum.xda-developers.com/showpost.php?p=36674868&amp;postcount=151
|
||||
[10]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-security.png "wine-android-security"
|
||||
[11]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-unknown-sources.jpg "wine-android-unknown-sources"
|
||||
[12]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-unknown-sources-warning.png "wine-android-unknown-sources-warning"
|
||||
[13]:https://dl.winehq.org/wine-builds/android/
|
||||
[14]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-download-button.png "wine-android-download-button"
|
||||
[15]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-app-access.jpg "wine-android-app-access"
|
||||
[16]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-icon-small.jpg "wine-android-icon-small"
|
||||
[17]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-desktop.png "wine-android-desktop"
|
||||
[18]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-start-button.png "wine-android-start-button"
|
||||
[19]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-Run.png "wine-android-run"
|
||||
@ -3,11 +3,11 @@
|
||||
|
||||

|
||||
|
||||
Fedora 28 Workstation 添加了一个功能允许你使用键盘快速搜索、选择和输入 emoji。emoji,可爱的表意文字是 Unicode 的一部分,在消息传递中使用得相当广泛,特别是在移动设备上。你可能听过这样的成语:“一张图片胜过千言万语。”这正是 emoji 所提供的:简单的图像供你在交流中使用。Unicode 的每个版本都增加了更多,在过去的 Unicode 版本中添加了 200 多个 emoji。本文向你展示如何使它们在你的 Fedora 系统中易于使用。
|
||||
Fedora 28 Workstation 添加了一个功能允许你使用键盘快速搜索、选择和输入 emoji。emoji,这种可爱的表意文字是 Unicode 的一部分,在消息传递中使用得相当广泛,特别是在移动设备上。你可能听过这样的成语:“一图胜千言”。这正是 emoji 所提供的:简单的图像供你在交流中使用。Unicode 的每个版本都增加了更多 emoji,在最近的 Unicode 版本中添加了 200 多个 emoji。本文向你展示如何使它们在你的 Fedora 系统中易于使用。
|
||||
|
||||
很高兴看到 emoji 数字在增长。但与此同时,它带来了如何在计算设备中输入它们的挑战。许多人已经将这些符号用于移动设备或社交网站中的输入。
|
||||
很高兴看到 emoji 的数量在增长。但与此同时,它带来了如何在计算设备中输入它们的挑战。许多人已经将这些符号用于移动设备或社交网站中的输入。
|
||||
|
||||
[ **编者注:**本文是对此主题以前发表过的文章的更新]。
|
||||
[**编者注:**本文是对此主题以前发表过的文章的更新]。
|
||||
|
||||
### 在 Fedora 28 Workstation 上启用 emoji 输入
|
||||
|
||||
@ -15,32 +15,31 @@ Fedora 28 Workstation 添加了一个功能允许你使用键盘快速搜索、
|
||||
|
||||
[![Region & Language settings tool][1]][2]
|
||||
|
||||
选择 + 控件添加输入源。出现以下对话框:
|
||||
选择 `+` 控件添加输入源。出现以下对话框:
|
||||
|
||||
[![Adding an input source][3]][4]
|
||||
|
||||
选择最后选项(三个点)来完全展开选择。然后,在列表底部找到“其他”并选择它:
|
||||
选择最后选项(三个点)来完全展开选择。然后,在列表底部找到“Other”并选择它:
|
||||
|
||||
[![Selecting other input sources][5]][6]
|
||||
|
||||
在下面的对话框中,找到 ”Typing Booster“ 选项并选择它:
|
||||
在下面的对话框中,找到 “Typing Booster” 选项并选择它:
|
||||
|
||||
[![][7]][8]
|
||||
|
||||
这个高级输入法由 iBus 在背后支持。高级输入方法可通过列表右侧的齿轮图标在列表中识别。
|
||||
这个高级输入法由 iBus 在背后支持。该高级输入法可通过列表右侧的齿轮图标在列表中识别。
|
||||
|
||||
输入法下拉菜单自动出现在 GNOME Shell 顶部栏中。确认你的默认输入法 - 在此示例中为英语(美国) - 被选为当前输入法,你就可以输入了。
|
||||
输入法下拉菜单自动出现在 GNOME Shell 顶部栏中。确认你的默认输入法 —— 在此示例中为英语(美国) - 被选为当前输入法,你就可以输入了。
|
||||
|
||||
[![Input method dropdown in Shell top bar][9]][10]
|
||||
|
||||
## 使用新的表情符号输入法
|
||||
### 使用新的表情符号输入法
|
||||
|
||||
现在 emoji 输入法启用了,按键盘快捷键 **Ctrl+Shift+E** 搜索 emoji。将出现一个弹出对话框,你可以在其中输入搜索词,例如 smile 来查找匹配的符号。
|
||||
现在 emoji 输入法启用了,按键盘快捷键 `Ctrl+Shift+E` 搜索 emoji。将出现一个弹出对话框,你可以在其中输入搜索词,例如 “smile” 来查找匹配的符号。
|
||||
|
||||
[![Searching for smile emoji][11]][12]
|
||||
|
||||
使用箭头键翻页列表。然后按 **Enter** 进行选择,字形将作为输入。
|
||||
|
||||
使用箭头键翻页列表。然后按回车进行选择,字形将替换输入内容。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -49,7 +48,7 @@ via: https://fedoramagazine.org/boost-typing-emoji-fedora-28-workstation/
|
||||
作者:[Paul W. Frields][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,137 @@
|
||||
学习如何使用 Python 构建你自己的 Twitter 机器人
|
||||
======
|
||||
|
||||

|
||||
|
||||
Twitter 允许用户将博客帖子和文章[分享][1]给全世界。使用 Python 和 Tweepy 库使得创建一个 Twitter 机器人来接管你的所有的推特变得非常简单。这篇文章告诉你如何去构建这样一个机器人。希望你能将这些概念也同样应用到其他的在线服务的项目中去。
|
||||
|
||||
### 开始
|
||||
|
||||
[tweepy][2] 库可以让创建一个 Twitter 机器人的过程更加容易上手。它包含了 Twitter 的 API 调用和一个很简单的接口。
|
||||
|
||||
下面这些命令使用 `pipenv` 在一个虚拟环境中安装 tweepy。如果你没有安装 `pipenv`,可以看一看我们之前的文章[如何在 Fedora 上安装 Pipenv][3]。
|
||||
|
||||
```
|
||||
$ mkdir twitterbot
|
||||
$ cd twitterbot
|
||||
$ pipenv --three
|
||||
$ pipenv install tweepy
|
||||
$ pipenv shell
|
||||
```
|
||||
|
||||
### Tweepy —— 开始
|
||||
|
||||
要使用 Twitter API ,机器人需要通过 Twitter 的授权。为了解决这个问题, tweepy 使用了 OAuth 授权标准。你可以通过在 <https://apps.twitter.com/> 创建一个新的应用来获取到凭证。
|
||||
|
||||
|
||||
#### 创建一个新的 Twitter 应用
|
||||
|
||||
当你填完了表格并点击了“<ruby>创建你自己的 Twitter 应用<rt>Create your Twitter application</rt></ruby>”的按钮后,你可以获取到该应用的凭证。 Tweepy 需要<ruby>用户密钥<rt>API Key</rt></ruby>和<ruby>用户密码<rt>API Secret</rt></ruby>,这些都可以在 “<ruby>密钥和访问令牌<rt>Keys and Access Tokens</rt></ruby>” 中找到。
|
||||
|
||||
![][4]
|
||||
|
||||
向下滚动页面,使用“<ruby>创建我的访问令牌<rt>Create my access token</rt></ruby>”按钮生成一个“<ruby>访问令牌<rt>Access Token</rt></ruby>” 和一个“<ruby>访问令牌密钥<rt>Access Token Secret</rt></ruby>”。
|
||||
|
||||
#### 使用 Tweppy —— 输出你的时间线
|
||||
|
||||
现在你已经有了所需的凭证了,打开一个文件,并写下如下的 Python 代码。
|
||||
|
||||
```
|
||||
import tweepy
|
||||
auth = tweepy.OAuthHandler("your_consumer_key", "your_consumer_key_secret")
|
||||
auth.set_access_token("your_access_token", "your_access_token_secret")
|
||||
api = tweepy.API(auth)
|
||||
public_tweets = api.home_timeline()
|
||||
for tweet in public_tweets:
|
||||
print(tweet.text)
|
||||
```
|
||||
|
||||
在确保你正在使用你的 Pipenv 虚拟环境后,执行你的程序。
|
||||
|
||||
```
|
||||
$ python tweet.py
|
||||
```
|
||||
|
||||
上述程序调用了 `home_timeline` 方法来获取到你时间线中的 20 条最近的推特。现在这个机器人能够使用 tweepy 来获取到 Twitter 的数据,接下来尝试修改代码来发送 tweet。
|
||||
|
||||
#### 使用 Tweepy —— 发送一条推特
|
||||
|
||||
要发送一条推特 ,有一个容易上手的 API 方法 `update_status` 。它的用法很简单:
|
||||
|
||||
```
|
||||
api.update_status("The awesome text you would like to tweet")
|
||||
```
|
||||
|
||||
Tweepy 拓展为制作 Twitter 机器人准备了非常多不同有用的方法。要获取 API 的详细信息,请查看[文档][5]。
|
||||
|
||||
|
||||
### 一个杂志机器人
|
||||
|
||||
接下来我们来创建一个搜索 Fedora Magazine 的推特并转推这些的机器人。
|
||||
|
||||
为了避免多次转推相同的内容,这个机器人存放了最近一条转推的推特的 ID 。 两个助手函数 `store_last_id` 和 `get_last_id` 将会帮助存储和保存这个 ID。
|
||||
|
||||
然后,机器人使用 tweepy 搜索 API 来查找 Fedora Magazine 的最近的推特并存储这个 ID。
|
||||
|
||||
```
|
||||
import tweepy
|
||||
|
||||
def store_last_id(tweet_id):
|
||||
""" Stores a tweet id in text file """
|
||||
with open('lastid', 'w') as fp:
|
||||
fp.write(str(tweet_id))
|
||||
|
||||
|
||||
def get_last_id():
|
||||
""" Retrieve the list of tweets that were
|
||||
already retweeted """
|
||||
|
||||
with open('lastid') as fp:
|
||||
return fp.read()
|
||||
|
||||
if __name__ == '__main__':
|
||||
|
||||
auth = tweepy.OAuthHandler("your_consumer_key", "your_consumer_key_secret")
|
||||
auth.set_access_token("your_access_token", "your_access_token_secret")
|
||||
|
||||
api = tweepy.API(auth)
|
||||
|
||||
try:
|
||||
last_id = get_last_id()
|
||||
except FileNotFoundError:
|
||||
print("No retweet yet")
|
||||
last_id = None
|
||||
|
||||
for tweet in tweepy.Cursor(api.search, q="fedoramagazine.org", since_id=last_id).items():
|
||||
if tweet.user.name == 'Fedora Project':
|
||||
store_last_id(tweet.id)
|
||||
#tweet.retweet()
|
||||
print(f'"{tweet.text}" was retweeted')
|
||||
```
|
||||
|
||||
为了只转推 Fedora Magazine 的推特 ,机器人搜索内容包含 fedoramagazine.org 和由 「Fedora Project」 Twitter 账户发布的推特。
|
||||
|
||||
### 结论
|
||||
|
||||
在这篇文章中你看到了如何使用 tweepy 的 Python 库来创建一个自动阅读、发送和搜索推特的 Twitter 应用。现在,你能使用你自己的创造力来创造一个你自己的 Twitter 机器人。
|
||||
|
||||
这篇文章的演示源码可以在 [Github][6] 找到。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/learn-build-twitter-bot-python/
|
||||
|
||||
作者:[Clément Verna][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[Bestony](https://github.com/bestony)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org
|
||||
[1]:https://twitter.com
|
||||
[2]:https://tweepy.readthedocs.io/en/v3.5.0/
|
||||
[3]:https://linux.cn/article-9827-1.html
|
||||
[4]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-19-20-17-17.png
|
||||
[5]:http://docs.tweepy.org/en/v3.5.0/api.html#id1
|
||||
[6]:https://github.com/cverna/magabot
|
||||
@ -1,3 +1,4 @@
|
||||
translating by aiwhj
|
||||
3 tips for organizing your open source project's workflow on GitHub
|
||||
======
|
||||
|
||||
|
||||
@ -1,53 +0,0 @@
|
||||
translating by wyxplus
|
||||
CIP: Keeping the Lights On with Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
Modern civil infrastructure is all around us -- in power plants, radar systems, traffic lights, dams, weather systems, and so on. Many of these infrastructure projects exist for decades, if not longer, so security and longevity are paramount.
|
||||
|
||||
And, many of these systems are powered by Linux, which offers technology providers more control over these issues. However, if every provider is building their own solution, this can lead to fragmentation and duplication of effort. Thus, the primary goal of [Civil Infrastructure Platform (CIP)][1] is to create an open source base layer for industrial use-cases in these systems, such as embedded controllers and gateway devices.
|
||||
|
||||
“We have a very conservative culture in this area because once we create a system, it has to be supported for more than ten years; in some cases for over 60 years. That’s why this project was created, because every player in this industry had the same issue of being able to use Linux for a long time,” says Yoshitake Kobayashi is Technical Steering Committee Chair of CIP.
|
||||
|
||||
CIP’s concept is to create a very fundamental system to use open source software on controllers. This base layer comprises the Linux kernel and a small set of common open source software like libc, busybox, and so on. Because longevity of software is a primary concern, CIP chose Linux kernel 4.4, which is the LTS release of the kernel maintained by Greg Kroah-Hartman.
|
||||
|
||||
### Collaboration
|
||||
|
||||
Since CIP has an upstream first policy, the code that they want in the project must be in the upstream kernel. To create a proactive feedback loop with the kernel community, CIP hired Ben Hutchings as the official maintainer of CIP. Hutchings is known for the work he has done on Debian LTS release, which also led to an official collaboration between CIP and the Debian project.
|
||||
|
||||
Under the newly forged collaboration, CIP will use Debian LTS to build the platform. CIP will also help Debian Long Term Support (LTS) to extend the lifetime of all Debian stable releases. CIP will work closely with Freexian, a company that offers commercial services around Debian LTS. The two organizations will focus on interoperability, security, and support for open source software for embedded systems. CIP will also provide funding for some of the Debian LTS activities.
|
||||
|
||||
“We are excited about this collaboration as well as the CIP’s support of the Debian LTS project, which aims to extend the support lifetime to more than five years. Together, we are committed to long-term support for our users and laying the ‘foundation’ for the cities of the future.” said Chris Lamb, Debian Project Leader.
|
||||
|
||||
### Security
|
||||
|
||||
Security is the biggest concern, said Kobayashi. Although most of the civil infrastructure is not connected to the Internet for obvious security reasons (you definitely don’t want a nuclear power plant to be connected to the Internet), there are many other risks.
|
||||
|
||||
Just because the system itself is not connected to the Internet, that doesn’t mean it’s immune to all threats. Other systems -- like user’s laptops -- may connect to the Internet and then be plugged into the local systems. If someone receives a malicious file as an attachment with email, it can “contaminate” the internal infrastructure.
|
||||
|
||||
Thus, it’s critical to keep all software running on such controllers up to date and fully patched. To ensure security, CIP has also backported many components of the Kernel Self Protection project. CIP also follows one of the strictest cybersecurity standards -- IEC 62443 -- which defines processes and tests to ensure the system is more secure.
|
||||
|
||||
### Going forward
|
||||
|
||||
As CIP is maturing, it's extending its collaboration with providers of Linux. In addition to collaboration with Debian and freexian, CIP recently added Cybertrust Japan Co, Ltd., a supplier of enterprise Linux operating system, as a new Silver member.
|
||||
|
||||
Cybertrust joins other industry leaders, such as Siemens, Toshiba, Codethink, Hitachi, Moxa, Plat’Home, and Renesas, in their work to create a reliable and secure Linux-based embedded software platform that is sustainable for decades to come.
|
||||
|
||||
The ongoing work of these companies under the umbrella of CIP will ensure the integrity of the civil infrastructure that runs our modern society.
|
||||
|
||||
Learn more at the [Civil Infrastructure Platform][1] website.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2018/6/cip-keeping-lights-linux
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/arnieswap
|
||||
[1]:https://www.cip-project.org/
|
||||
@ -1,127 +0,0 @@
|
||||
Translating by qhwdw
|
||||
How to Run Windows Apps on Android with Wine
|
||||
======
|
||||
|
||||

|
||||
|
||||
Wine (on Linux, not the one you drink) is a free and open-source compatibility layer for running Windows programs on Unix-like operating systems. Begun in 1993, it could run a wide variety of Windows programs on Linux and macOS, although sometimes with modification. Now the Wine Project has rolled out version 3.0 which is compatible with your Android devices.
|
||||
|
||||
In this article we will show you how you can run Windows apps on your Android device with WINE.
|
||||
|
||||
**Related** : [How to Easily Install Windows Games on Linux with Winepak][1]
|
||||
|
||||
### What can you run on Wine?
|
||||
|
||||
Wine is only a compatibility layer, not a full-blown emulator, so you need an x86 Android device to take full advantage of it. However, most Androids in the hands of consumers are ARM-based.
|
||||
|
||||
Since most of you are using an ARM-based Android device, you will only be able to use Wine to run apps that have been adapted to run on Windows RT. There is a limited, but growing, list of software available for ARM devices. You can find a list of these apps that are compatible in this [thread][2] on XDA Developers Forums.
|
||||
|
||||
Some examples of apps you will be able to run on ARM are:
|
||||
|
||||
* [Keepass Portable][3]: A password storage wallet
|
||||
* [Paint.NET][4]: An image manipulation program
|
||||
* [SumatraPDF][5]: A document reader for PDFs and possibly some other document types
|
||||
* [Audacity][6]: A digital audio recording and editing program
|
||||
|
||||
|
||||
|
||||
There are also some open-source retro games available like [Doom][7] and [Quake 2][8], as well as the open-source clone, [OpenTTD][9], a version of Transport Tycoon.
|
||||
|
||||
The list of programs that Wine can run on Android ARM devices is bound to grow as the popularity of Wine on Android expands. The Wine project is working on using QEMU to emulate x86 CPU instructions on ARM, and when that is complete, the number of apps your Android will be able to run should grow rapidly.
|
||||
|
||||
### Installing Wine
|
||||
|
||||
To install Wine you must first make sure that your device’s settings allow it to download and install APKs from other sources than the Play Store. To do this you’ll need to give your device permission to download apps from unknown sources.
|
||||
|
||||
1\. Open Settings on your phone and select your Security options.
|
||||
|
||||
|
||||
![wine-android-security][10]
|
||||
|
||||
2\. Scroll down and click on the switch next to “Unknown Sources.”
|
||||
|
||||
![wine-android-unknown-sources][11]
|
||||
|
||||
3\. Accept the risks in the warning.
|
||||
|
||||
![wine-android-unknown-sources-warning][12]
|
||||
|
||||
4\. Open the [Wine installation site][13], and tap the first checkbox in the list. The download will automatically begin.
|
||||
|
||||
![wine-android-download-button][14]
|
||||
|
||||
5\. Once the download completes, open it from your Downloads folder, or pull down the notifications menu and click on the completed download there.
|
||||
|
||||
6\. Install the program. It will notify you that it needs access to recording audio and to modify, delete, and read the contents of your SD card. You may also need to give access for audio recording for some apps you will use in the program.
|
||||
|
||||
![wine-android-app-access][15]
|
||||
|
||||
7\. When the installation completes, click on the icon to open the program.
|
||||
|
||||
![wine-android-icon-small][16]
|
||||
|
||||
When you open Wine, the desktop mimics Windows 7.
|
||||
|
||||
![wine-android-desktop][17]
|
||||
|
||||
One drawback of Wine is that you have to have an external keyboard available to type. An external mouse may also be useful if you are running it on a small screen and find it difficult to tap small buttons.
|
||||
|
||||
You can tap the Start button to open two menus – Control Panel and Run.
|
||||
|
||||
![wine-android-start-button][18]
|
||||
|
||||
### Working with Wine
|
||||
|
||||
When you tap “Control panel” you will see three choices – Add/Remove Programs, Game Controllers, and Internet Settings.
|
||||
|
||||
Using “Run,” you can open a dialogue box to issue commands. For instance, launch Internet Explorer by entering `iexplore`.
|
||||
|
||||
![wine-android-run][19]
|
||||
|
||||
### Installing programs on Wine
|
||||
|
||||
1\. Download the application (or sync via the cloud) to your Android device. Take note of where you save it.
|
||||
|
||||
2\. Open the Wine Command Prompt window.
|
||||
|
||||
3\. Type the path to the location of the program. If you have saved it to the Download folder on your SD card, type:
|
||||
|
||||
4\. To run the file in Wine for Android, simply input the name of the EXE file.
|
||||
|
||||
If the ARM-ready file is compatible, it should run. If not, you’ll see a bunch of error messages. At this stage, installing Windows software on Android in Wine can be hit or miss.
|
||||
|
||||
There are still a lot of issues with this new version of Wine for Android. It doesn’t work on all Android devices. It worked on my Galaxy S6 Edge but not on my Galaxy Tab 4. Many games won’t work because the graphics driver doesn’t support Direct3D yet. You need an external keyboard and mouse to be able to easily manipulate the screen because touch-screen is not fully developed yet.
|
||||
|
||||
Even with these issues in the early stages of release, the possibilities for this technology are thought-provoking. It’s certainly likely that it will take some time yet before you can launch Windows programs on your Android smartphone using Wine without a hitch.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/run-windows-apps-android-with-wine/
|
||||
|
||||
作者:[Tracey Rosenberger][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/traceyrosenberger/
|
||||
[1]:https://www.maketecheasier.com/winepak-install-windows-games-linux/ (How to Easily Install Windows Games on Linux with Winepak)
|
||||
[2]:https://forum.xda-developers.com/showthread.php?t=2092348
|
||||
[3]:http://downloads.sourceforge.net/keepass/KeePass-2.20.1.zip
|
||||
[4]:http://forum.xda-developers.com/showthread.php?t=2411497
|
||||
[5]:http://forum.xda-developers.com/showthread.php?t=2098594
|
||||
[6]:http://forum.xda-developers.com/showthread.php?t=2103779
|
||||
[7]:http://forum.xda-developers.com/showthread.php?t=2175449
|
||||
[8]:http://forum.xda-developers.com/attachment.php?attachmentid=1640830&d=1358070370
|
||||
[9]:http://forum.xda-developers.com/showpost.php?p=36674868&postcount=151
|
||||
[10]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-security.png (wine-android-security)
|
||||
[11]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-unknown-sources.jpg (wine-android-unknown-sources)
|
||||
[12]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-unknown-sources-warning.png (wine-android-unknown-sources-warning)
|
||||
[13]:https://dl.winehq.org/wine-builds/android/
|
||||
[14]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-download-button.png (wine-android-download-button)
|
||||
[15]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-app-access.jpg (wine-android-app-access)
|
||||
[16]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-icon-small.jpg (wine-android-icon-small)
|
||||
[17]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-desktop.png (wine-android-desktop)
|
||||
[18]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-start-button.png (wine-android-start-button)
|
||||
[19]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-Run.png (wine-android-run)
|
||||
@ -1,3 +1,5 @@
|
||||
translating by bestony
|
||||
|
||||
Getting Started with Debian Packaging
|
||||
======
|
||||
|
||||
|
||||
@ -1,201 +0,0 @@
|
||||
Translating by qhwdw
|
||||
A sysadmin's guide to network management
|
||||
======
|
||||
|
||||

|
||||
|
||||
If you're a sysadmin, your daily tasks include managing servers and the data center's network. The following Linux utilities and commands—from basic to advanced—will help make network management easier.
|
||||
|
||||
In several of these commands, you'll see `<fqdn>`, which stands for "fully qualified domain name." When you see this, substitute your website URL or your server (e.g., `server-name.company.com`), as the case may be.
|
||||
|
||||
### Ping
|
||||
|
||||
As the name suggests, `ping` is used to check the end-to-end connectivity from your system to the one you are trying to connect to. It uses [ICMP][1] echo packets that travel back to your system when a ping is successful. It's also a good first step to check system/network connectivity. You can use the `ping` command with IPv4 and IPv6 addresses. (Read my article "[How to find your IP address in Linux][2]" to learn more about IP addresses.)
|
||||
|
||||
**Syntax:**
|
||||
|
||||
* IPv4: `ping <ip address>/<fqdn>`
|
||||
* IPv6: `ping6 <ip address>/<fqdn>`
|
||||
|
||||
|
||||
|
||||
You can also use `ping` to resolve names of websites to their corresponding IP address, as shown below:
|
||||
|
||||
|
||||
|
||||
### Traceroute
|
||||
|
||||
`ping` checks end-to-end connectivity, the `traceroute` utility tells you all the router IPs on the path you travel to reach the end system, website, or server. `traceroute` is usually is the second step after `ping` for network connection debugging.
|
||||
|
||||
This is a nice utility for tracing the full network path from your system to another. Wherechecks end-to-end connectivity, theutility tells you all the router IPs on the path you travel to reach the end system, website, or server.is usually is the second step afterfor network connection debugging.
|
||||
|
||||
**Syntax:**
|
||||
|
||||
* `traceroute <ip address>/<fqdn>`
|
||||
|
||||
|
||||
|
||||
### Telnet
|
||||
|
||||
**Syntax:**
|
||||
|
||||
* `telnet <ip address>/<fqdn>` is used to [telnet][3] into any server.
|
||||
|
||||
|
||||
|
||||
### Netstat
|
||||
|
||||
The network statistics (`netstat`) utility is used to troubleshoot network-connection problems and to check interface/port statistics, routing tables, protocol stats, etc. It's any sysadmin's must-have tool.
|
||||
|
||||
**Syntax:**
|
||||
|
||||
* `netstat -l` shows the list of all the ports that are in listening mode.
|
||||
* `netstat -a` shows all ports; to specify only TCP, use `-at` (for UDP use `-au`).
|
||||
* `netstat -r` provides a routing table.
|
||||
|
||||
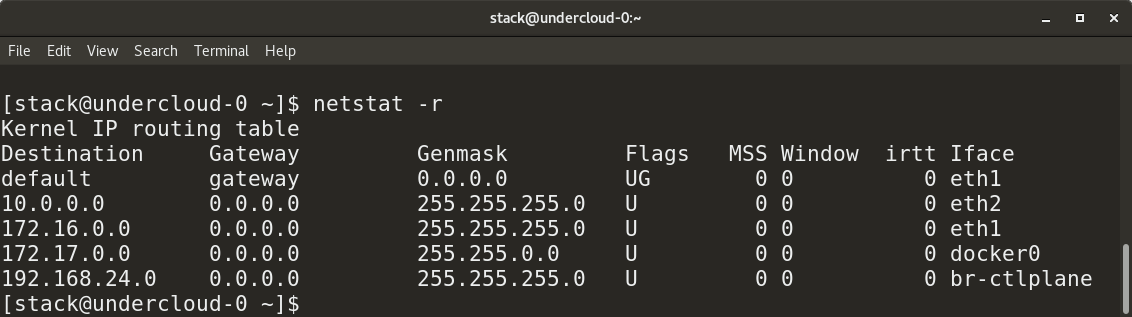
|
||||
|
||||
* `netstat -s` provides a summary of statistics for each protocol.
|
||||
|
||||
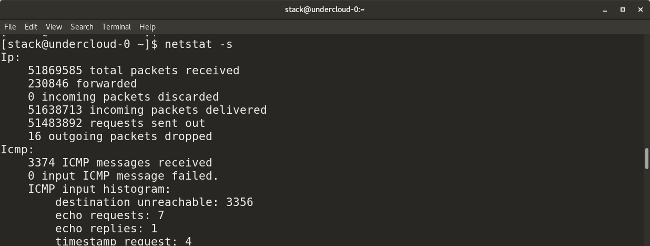
|
||||
|
||||
* `netstat -i` displays transmission/receive (TX/RX) packet statistics for each interface.
|
||||
|
||||
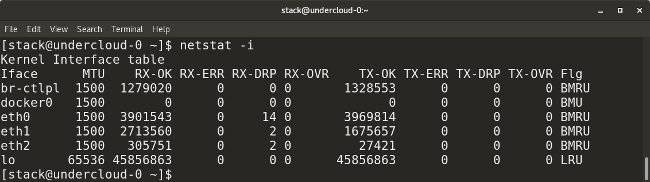
|
||||
|
||||
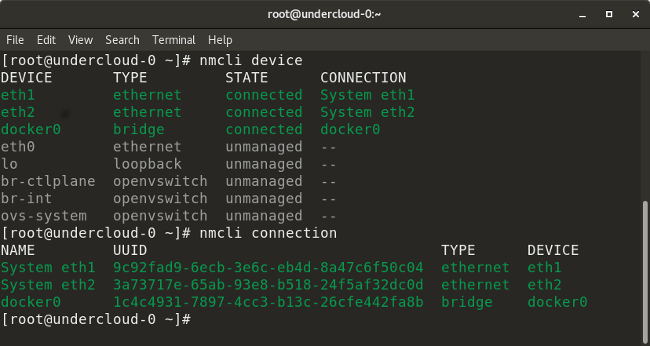
### Nmcli
|
||||
|
||||
`nmcli` is a good utility for managing network connections, configurations, etc. It can be used to control Network Manager and modify any device's network configuration details.
|
||||
|
||||
**Syntax:**
|
||||
|
||||
* `nmcli device` lists all devices on the system.
|
||||
|
||||
* `nmcli device show <interface>` shows network-related details of the specified interface.
|
||||
|
||||
* `nmcli connection` checks a device's connection.
|
||||
|
||||
* `nmcli connection down <interface>` shuts down the specified interface.
|
||||
|
||||
* `nmcli connection up <interface>` starts the specified interface.
|
||||
|
||||
* `nmcli con add type vlan con-name <connection-name> dev <interface> id <vlan-number> ipv4 <ip/cidr> gw4 <gateway-ip>` adds a virtual LAN (VLAN) interface with the specified VLAN number, IP address, and gateway to a particular interface.
|
||||
|
||||
|
||||
|
||||
|
||||
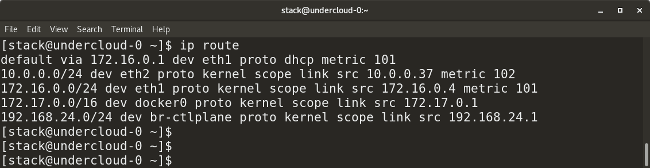
### Routing
|
||||
|
||||
There are many commands you can use to check and configure routing. Here are some useful ones:
|
||||
|
||||
**Syntax:**
|
||||
|
||||
* `ip route` shows all the current routes configured for the respective interfaces.
|
||||
|
||||
|
||||
|
||||
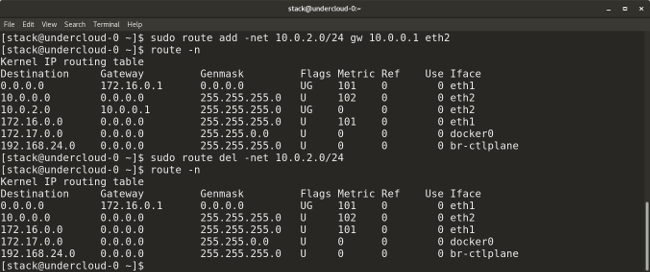
* `route add default gw <gateway-ip>` adds a default gateway to the routing table.
|
||||
* `route add -net <network ip/cidr> gw <gateway ip> <interface>` adds a new network route to the routing table. There are many other routing parameters, such as adding a default route, default gateway, etc.
|
||||
* `route del -net <network ip/cidr>` deletes a particular route entry from the routing table.
|
||||
|
||||
|
||||
|
||||
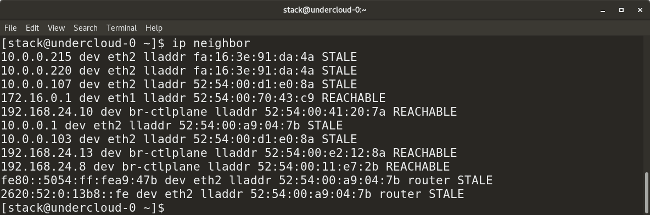
* `ip neighbor` shows the current neighbor table and can be used to add, change, or delete new neighbors.
|
||||
|
||||
|
||||
|
||||
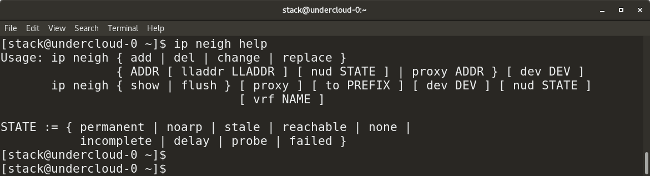
|
||||
|
||||
* `arp` (which stands for address resolution protocol) is similar to `ip neighbor`. `arp` maps a system's IP address to its corresponding MAC (media access control) address.
|
||||
|
||||
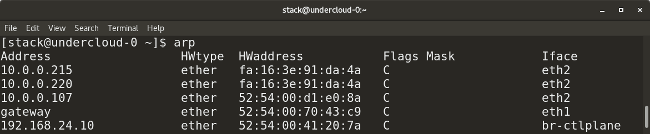
|
||||
|
||||
### Tcpdump and Wireshark
|
||||
|
||||
Linux provides many packet-capturing tools like `tcpdump`, `wireshark`, `tshark`, etc. They are used to capture network traffic in packets that are transmitted/received and hence are very useful for a sysadmin to debug any packet losses or related issues. For command-line enthusiasts, `tcpdump` is a great tool, and for GUI users, `wireshark` is a great utility to capture and analyze packets. `tcpdump` is a built-in Linux utility to capture network traffic. It can be used to capture/show traffic on specific ports, protocols, etc.
|
||||
|
||||
**Syntax:**
|
||||
|
||||
* `tcpdump -i <interface-name>` shows live packets from the specified interface. Packets can be saved in a file by adding the `-w` flag and the name of the output file to the command, for example: `tcpdump -w <output-file.> -i <interface-name>`.
|
||||
|
||||
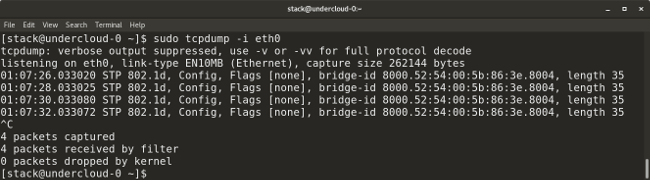
|
||||
|
||||
* `tcpdump -i <interface> src <source-ip>` captures packets from a particular source IP.
|
||||
* `tcpdump -i <interface> dst <destination-ip>` captures packets from a particular destination IP.
|
||||
* `tcpdump -i <interface> port <port-number>` captures traffic for a specific port number like 53, 80, 8080, etc.
|
||||
* `tcpdump -i <interface> <protocol>` captures traffic for a particular protocol, like TCP, UDP, etc.
|
||||
|
||||
|
||||
|
||||
### Iptables
|
||||
|
||||
`iptables` is a firewall-like packet-filtering utility that can allow or block certain traffic. The scope of this utility is very wide; here are some of its most common uses.
|
||||
|
||||
**Syntax:**
|
||||
|
||||
* `iptables -L` lists all existing `iptables` rules.
|
||||
* `iptables -F` deletes all existing rules.
|
||||
|
||||
|
||||
|
||||
The following commands allow traffic from the specified port number to the specified interface:
|
||||
|
||||
* `iptables -A INPUT -i <interface> -p tcp –dport <port-number> -m state –state NEW,ESTABLISHED -j ACCEPT`
|
||||
* `iptables -A OUTPUT -o <interface> -p tcp -sport <port-number> -m state – state ESTABLISHED -j ACCEPT`
|
||||
|
||||
|
||||
|
||||
The following commands allow loopback access to the system:
|
||||
|
||||
* `iptables -A INPUT -i lo -j ACCEPT`
|
||||
* `iptables -A OUTPUT -o lo -j ACCEPT`
|
||||
|
||||
|
||||
|
||||
### Nslookup
|
||||
|
||||
The `nslookup` tool is used to obtain IP address mapping of a website or domain. It can also be used to obtain information on your DNS server, such as all DNS records on a website (see the example below). A similar tool to `nslookup` is the `dig` (Domain Information Groper) utility.
|
||||
|
||||
**Syntax:**
|
||||
|
||||
* `nslookup <website-name.com>` shows the IP address of your DNS server in the Server field, and, below that, gives the IP address of the website you are trying to reach.
|
||||
* `nslookup -type=any <website-name.com>` shows all the available records for the specified website/domain.
|
||||
|
||||
|
||||
|
||||
### Network/interface debugging
|
||||
|
||||
Here is a summary of the necessary commands and files used to troubleshoot interface connectivity or related network issues.
|
||||
|
||||
**Syntax:**
|
||||
|
||||
* `ss` is a utility for dumping socket statistics.
|
||||
* `nmap <ip-address>`, which stands for Network Mapper, scans network ports, discovers hosts, detects MAC addresses, and much more.
|
||||
* `ip addr/ifconfig -a` provides IP addresses and related info on all the interfaces of a system.
|
||||
* `ssh -vvv user@<ip/domain>` enables you to SSH to another server with the specified IP/domain and username. The `-vvv` flag provides "triple-verbose" details of the processes going on while SSH'ing to the server.
|
||||
* `ethtool -S <interface>` checks the statistics for a particular interface.
|
||||
* `ifup <interface>` starts up the specified interface.
|
||||
* `ifdown <interface>` shuts down the specified interface.
|
||||
* `systemctl restart network` restarts a network service for the system.
|
||||
* `/etc/sysconfig/network-scripts/<interface-name>` is an interface configuration file used to set IP, network, gateway, etc. for the specified interface. DHCP mode can be set here.
|
||||
* `/etc/hosts` this file contains custom host/domain to IP mappings.
|
||||
* `/etc/resolv.conf` specifies the DNS nameserver IP of the system.
|
||||
* `/etc/ntp.conf` specifies the NTP server domain.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/sysadmin-guide-networking-commands
|
||||
|
||||
作者:[Archit Modi][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/architmodi
|
||||
[1]:https://en.wikipedia.org/wiki/Internet_Control_Message_Protocol
|
||||
[2]:https://opensource.com/article/18/5/how-find-ip-address-linux
|
||||
[3]:https://en.wikipedia.org/wiki/Telnet
|
||||
@ -1,119 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Display Weather Forecast In Your Terminal With Wttr.in
|
||||
======
|
||||
**[wttr.in][1] is a feature-packed weather forecast service that supports displaying the weather from the command line**. It can automatically detect your location (based on your IP address), supports specifying the location or searching for a geographical location (like a site in a city, a mountain and so on), and much more. Oh, and **you don't have to install it - all you need to use it is cURL or Wget** (see below).
|
||||
|
||||
wttr.in features include:
|
||||
|
||||
* **displays the current weather as well as a 3-day weather forecast, split into morning, noon, evening and night** (includes temperature range, wind speed and direction, viewing distance, precipitation amount and probability)
|
||||
|
||||
* **can display Moon phases**
|
||||
|
||||
* **automatic location detection based on your IP address**
|
||||
|
||||
* **allows specifying a location using the city name, 3-letter airport code, area code, GPS coordinates, IP address, or domain name**. You can also specify a geographical location like a lake, mountain, landmark, and so on)
|
||||
|
||||
* **supports multilingual location names** (the query string must be specified in Unicode)
|
||||
|
||||
* **supports specifying the language** in which the weather forecast should be displayed in (it supports more than 50 languages)
|
||||
|
||||
* **it uses USCS units for queries from the USA and the metric system for the rest of the world** , but you can change this by appending `?u` for USCS, and `?m` for the metric system (SI)
|
||||
|
||||
* **3 output formats: ANSI for the terminal, HTML for the browser, and PNG**.
|
||||
|
||||
|
||||
|
||||
|
||||
Like I mentioned in the beginning of the article, to use wttr.in, all you need is cURL or Wget, but you can also
|
||||
|
||||
**Before using wttr.in, make sure cURL is installed.** In Debian, Ubuntu or Linux Mint (and other Debian or Ubuntu-based Linux distributions), install cURL using this command:
|
||||
```
|
||||
sudo apt install curl
|
||||
|
||||
```
|
||||
|
||||
### wttr.in command line examples
|
||||
|
||||
Get the weather for your location (wttr.in tries to guess your location based on your IP address):
|
||||
```
|
||||
curl wttr.in
|
||||
|
||||
```
|
||||
|
||||
Force cURL to resolve names to IPv4 addresses (in case you're having issues with IPv6 and wttr.in) by adding `-4` after `curl` :
|
||||
```
|
||||
curl -4 wttr.in
|
||||
|
||||
```
|
||||
|
||||
**Wget also works** (instead of cURL) if you want to retrieve the current weather and forecast as a png, or if you use it like this:
|
||||
```
|
||||
wget -O- -q wttr.in
|
||||
|
||||
```
|
||||
|
||||
You can replace `curl` with `wget -O- -q` in all the commands below if you prefer Wget over cURL.
|
||||
|
||||
Specify the location:
|
||||
```
|
||||
curl wttr.in/Dublin
|
||||
|
||||
```
|
||||
|
||||
Display weather information for a landmark (the Eiffel Tower in this example):
|
||||
```
|
||||
curl wttr.in/~Eiffel+Tower
|
||||
|
||||
```
|
||||
|
||||
Get the weather information for an IP address' location (the IP below belongs to GitHub):
|
||||
```
|
||||
curl wttr.in/@192.30.253.113
|
||||
|
||||
```
|
||||
|
||||
Retrieve the weather using USCS units:
|
||||
```
|
||||
curl wttr.in/Paris?u
|
||||
|
||||
```
|
||||
|
||||
Force wttr.in to use the metric system (SI) if you're in the USA:
|
||||
```
|
||||
curl wttr.in/New+York?m
|
||||
|
||||
```
|
||||
|
||||
Use Wget to download the current weather and 3-day forecast as a PNG image:
|
||||
```
|
||||
wget wttr.in/Istanbul.png
|
||||
|
||||
```
|
||||
|
||||
You can specify the PNG
|
||||
|
||||
**For many other examples, check out the wttr.in[project page][2] or type this in a terminal:**
|
||||
```
|
||||
curl wttr.in/:help
|
||||
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxuprising.com/2018/07/display-weather-forecast-in-your.html
|
||||
|
||||
作者:[Logix][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/118280394805678839070
|
||||
[1]:https://wttr.in/
|
||||
[2]:https://github.com/chubin/wttr.in
|
||||
[3]:https://github.com/chubin/wttr.in#installation
|
||||
[4]:https://github.com/schachmat/wego
|
||||
[5]:https://github.com/chubin/wttr.in#supported-formats
|
||||
@ -1,3 +1,4 @@
|
||||
translating by wyxplus
|
||||
Building a network attached storage device with a Raspberry Pi
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geelkpi
|
||||
|
||||
Textricator: Data extraction made simple
|
||||
======
|
||||
|
||||
|
||||
@ -0,0 +1,57 @@
|
||||
CIP:延续 Linux 之光
|
||||
======
|
||||
|
||||

|
||||
|
||||
|
||||
现如今,现代民用基础设施遍及各处 —— 发电厂、雷达系统、交通信号灯、水坝和天气系统等。这些基础设施项目已然存在数十年,这些设施还将继续提供更长时间的服务,所以安全性和使用寿命是至关重要的。
|
||||
|
||||
|
||||
并且,其中许多系统都是由 Linux 提供支持,它为技术提供商提供了对这些问题的更多控制。然而,如果每个提供商都在构建自己的解决方案,这可能会导致分散和重复工作。因此,[民用基础设施平台(CIP)][1]最首要的目标是创造一个开源基础层,提供给工业设施,例如嵌入式控制器或是网关设备。
|
||||
|
||||
Yoshitake Kobayashi,担任 CIP 的技术指导委员会主席说过,“我们在这个领域有一种非常保守的文化,因为一旦我们建立了一个系统,它必须得到长达十多年的支持,在某些情况下超过 60 年。这就是为什么这个项目被创建的原因,因为这个行业的每个使用者都有同样的问题,即能够长时间使用 Linux。”
|
||||
|
||||
CIP 的架构是创建一个基础系统,能够在控制器上使用开源软件。其中,该基础层包括 Linux 内核和一系列常见的开源软件如 libc、busybox 等。由于软件的使用寿命是一个最主要的问题,CIP 选择使用 Linux 4.4 版本的内核,这是一个由 Greg Kroah-Hartman 维护的长期支持版本。
|
||||
|
||||
### 合作
|
||||
|
||||
由于 CIP 有上游优先政策,因此他们在项目中需要的代码必须位于上游内核中。为了与内核社区建立积极的反馈循环,CIP聘请 Ben Hutchings 作为 CIP 的官方维护者。Hutchings以他在Debian LTS 版本上所做的工作而闻名,这也促成了 CIP 与 Debian 项目之间的官方合作。
|
||||
|
||||
在新的合作下,CIP 将使用 Debian LTS 版本构建平台。 CIP 还将支持 Debian 长期支持版本(LTS),延长所有 Debian 稳定版的生命周期。CIP 还将与 Freexian 进行密切合作,后者是一家围绕 Debian LTS 版本提供商业服务的公司。这两个组织将专注于嵌入式系统的开源软件的操作性、安全性和维护。CIP 还会为一些 Debian LTS 版本提供资金支持。
|
||||
|
||||
Chris Lamb,Debian 项目负责人表示,“我们对此次合作以及 CIP 对 Debian LTS 项目的支持感到非常兴奋,这样将使支持生命周期延长至五年以上。我们将一起致力于为用户提供长期支持,并为未来的城市奠定基础。”
|
||||
|
||||
### 安全性
|
||||
|
||||
|
||||
Kobayashi 说过,其中最需要担心的是安全性。虽然出于明显的安全原因,大部分民用基础设施没有接入互联网(你肯定不想让一座核电站连接到互联网),况且也存在其他风险。
|
||||
|
||||
仅仅因为系统本身没有连接到互联网,这并不意味着能避开所有危险。其他系统,比如个人移动电脑也能够通过接入互联网而间接入侵到本地系统中。如若有人收到一封带有恶意文件作为电子邮件的附件,这将会“污染”系统内部的基础设备。
|
||||
|
||||
因此,保持所有软件在这些控制器上运行是最新的并且完全修补是至关重要的。为了确保安全性,CIP 还向后移植了内核自我保护项目的许多组件。CIP还遵循最严格的网络安全标准之一 —— IEC 62443,该标准定义了软件的流程和相应的测试,以确保系统更安全。
|
||||
|
||||
|
||||
### 展望未来
|
||||
|
||||
|
||||
随着 CIP 日趋成熟,官方正在加大与各个 Linux 提供商的合作力度。除了与 Debian 和 freexian 的合作外,CIP最近还邀请了企业 Linux 操作系统供应商 Cybertrust Japan Co., Ltd. 作为新的银牌成员。
|
||||
|
||||
Cybertrust 与其他行业领军者合作,如西门子,东芝,Codethink,日立,Moxa,Plat'Home 和瑞萨,致力于打造在未来数十年里,一个可靠、安全的基于 Linux 的嵌入式软件平台。
|
||||
|
||||
这些公司在 CIP 的保护下所进行的工作,将确保管理我们现代社会中的民用基础设施的完整性。
|
||||
|
||||
想要了解更多信息,请访问 [民用基础设施官网][1]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2018/6/cip-keeping-lights-linux
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[wyxplus](https://github.com/wyxplus)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/arnieswap
|
||||
[1]:https://www.cip-project.org/
|
||||
@ -1,49 +1,41 @@
|
||||
translating by bestony
|
||||
|
||||
How to use Fio (Flexible I/O Tester) to Measure Disk Performance in Linux
|
||||
如何在 Linux 中使用 Fio 来测评硬盘性能
|
||||
======
|
||||

|
||||
|
||||
Fio which stands for Flexible I/O Tester [is a free and open source][1] disk I/O tool used both for benchmark and stress/hardware verification developed by Jens Axboe.
|
||||
Fio(Flexible I/O Tester) 是一款由 Jens Axboe 开发的用于测评和压力/硬件验证的[免费开源][1]的软件
|
||||
|
||||
It has support for 19 different types of I/O engines (sync, mmap, libaio, posixaio, SG v3, splice, null, network, syslet, guasi, solarisaio, and more), I/O priorities (for newer Linux kernels), rate I/O, forked or threaded jobs, and much more. It can work on block devices as well as files.
|
||||
它支持 19 种不同类型的 I/O 引擎 (sync, mmap, libaio, posixaio, SG v3, splice, null, network, syslet, guasi, solarisaio, 以及更多), I/O 优先级(针对较新的 Linux 内核),I/O 速度,复刻或线程任务,和其他更多的东西。它能够在块设备和文件上工作。
|
||||
|
||||
Fio accepts job descriptions in a simple-to-understand text format. Several example job files are included. Fio displays all sorts of I/O performance information, including complete IO latencies and percentiles.
|
||||
Fio 接受一种非常简单易于理解的文本格式作为任务描述。软件默认包含了许多示例任务文件。 Fio 展示了所有类型的 I/O 性能信息,包括完整的 IO 延迟和百分比。
|
||||
|
||||
It is in wide use in many places, for both benchmarking, QA, and verification purposes. It supports Linux, FreeBSD, NetBSD, OpenBSD, OS X, OpenSolaris, AIX, HP-UX, Android, and Windows.
|
||||
它被广泛的应用在非常多的地方,包括测评、QA,以及验证用途。它支持 Linux 、 FreeBSD 、 NetBSD、 OpenBSD、 OS X、 OpenSolaris、 AIX、 HP-UX、 Android 以及 Windows。
|
||||
|
||||
In this tutorial, we will be using Ubuntu 16 and you are required to have sudo or root privileges to the computer. We will go over the installation and use of fio.
|
||||
在这个教程,我们将使用 Ubuntu 16 ,你需要拥有这台电脑的 sudo 或 root 权限。我们将完整的进行安装和 Fio 的使用。
|
||||
|
||||
### Installing fio from Source
|
||||
### 使用源码安装 Fio
|
||||
|
||||
我们要去克隆 Github 上的仓库。安装所需的依赖,然后我们将会从源码构建应用。首先,确保我们安装了 Git 。
|
||||
|
||||
We are going to clone the repo on GitHub. Install the prerequisites, and then we will build the packages from the source code. Lets' start by making sure we have git installed.
|
||||
```
|
||||
|
||||
sudo apt-get install git
|
||||
|
||||
|
||||
```
|
||||
|
||||
For centOS users you can use:
|
||||
CentOS 用户可以执行下述命令:
|
||||
```
|
||||
|
||||
sudo yum install git
|
||||
|
||||
|
||||
```
|
||||
|
||||
Now we change directory to /opt and clone the repo from Github:
|
||||
```
|
||||
现在,我们切换到 /opt 目录,并从 Github 上克隆仓库:
|
||||
|
||||
```
|
||||
cd /opt
|
||||
git clone https://github.com/axboe/fio
|
||||
|
||||
|
||||
```
|
||||
|
||||
You should see the output below:
|
||||
```
|
||||
你应该会看到下面这样的输出
|
||||
|
||||
```
|
||||
Cloning into 'fio'...
|
||||
remote: Counting objects: 24819, done.
|
||||
remote: Compressing objects: 100% (44/44), done.
|
||||
@ -51,72 +43,59 @@ remote: Total 24819 (delta 39), reused 62 (delta 32), pack-reused 24743
|
||||
Receiving objects: 100% (24819/24819), 16.07 MiB | 0 bytes/s, done.
|
||||
Resolving deltas: 100% (16251/16251), done.
|
||||
Checking connectivity... done.
|
||||
|
||||
|
||||
```
|
||||
|
||||
Now, we change directory into the fio codebase by typing the command below inside the opt folder:
|
||||
```
|
||||
现在,我们通过在 opt 目录下输入下方的命令切换到 Fio 的代码目录:
|
||||
|
||||
```
|
||||
cd fio
|
||||
|
||||
|
||||
```
|
||||
|
||||
We can finally build fio from source using the `make` build utility bu using the commands below:
|
||||
```
|
||||
最后,我们可以使用下面的命令来使用 `make` 从源码构建软件:
|
||||
|
||||
```
|
||||
# ./configure
|
||||
# make
|
||||
# make install
|
||||
|
||||
|
||||
```
|
||||
|
||||
### Installing fio on Ubuntu
|
||||
### 在 Ubuntu 上安装 Fio
|
||||
|
||||
For Ubuntu and Debian, fio is available on the main repository. You can easily install fio using the standard package managers such as yum and apt-get.
|
||||
对于 Ubuntu 和 Debian 来说, Fio 已经在主仓库内。你可以很容易的使用类似 yum 和 apt-get 的标准包管理器来安装 Fio。
|
||||
|
||||
对于 Ubuntu 和 Debian ,你只需要简单的执行下述命令:
|
||||
|
||||
For Ubuntu and Debian you can simple use:
|
||||
```
|
||||
|
||||
sudo apt-get install fio
|
||||
|
||||
|
||||
```
|
||||
|
||||
For CentOS/Redhat you can simple use:
|
||||
On CentOS, you might need to install EPEL repository to your system before you can have access to fio. You can install it by running the following command:
|
||||
```
|
||||
对于 CentOS/Redhat 你只需要简单执行下述命令:
|
||||
在 CentOS ,你可能在你能安装 Fio 前需要去安装 EPEL 仓库到你的系统中。你可以通过执行下述命令来安装它:
|
||||
|
||||
```
|
||||
sudo yum install epel-release -y
|
||||
|
||||
|
||||
```
|
||||
|
||||
You can then install fio using the command below:
|
||||
```
|
||||
你可以执行下述命令来安装 Fio:
|
||||
|
||||
```
|
||||
sudo yum install fio -y
|
||||
|
||||
|
||||
```
|
||||
|
||||
### Disk Performace testing with Fio
|
||||
### 使用 Fio 进行磁盘性能测试
|
||||
|
||||
With Fio is installed on your system. It's time to see how to use Fio with some examples below. We are going to perform a random write, read and read and write test.
|
||||
|
||||
### Performing a Random Write Test
|
||||
现在 Fio 已经安装到了你的系统中。现在是时候看一些如何使用 Fio 的例子了。我们将进行随机写、读和读写测试。
|
||||
|
||||
### 执行随机写测试
|
||||
|
||||
执行下面的命令来开始。这个命令将要同一时间执行两个进程,写入共计 4GB( 4 个任务 x 512MB = 2GB) 文件:
|
||||
|
||||
Let's start by running the following command. This command will write a total 4GB file [4 jobs x 512 MB = 2GB] running 2 processes at a time:
|
||||
```
|
||||
|
||||
sudo fio --name=randwrite --ioengine=libaio --iodepth=1 --rw=randwrite --bs=4k --direct=0 --size=512M --numjobs=2 --runtime=240 --group_reporting
|
||||
|
||||
|
||||
```
|
||||
```
|
||||
|
||||
```
|
||||
...
|
||||
fio-2.2.10
|
||||
Starting 2 processes
|
||||
@ -149,9 +128,9 @@ Disk stats (read/write):
|
||||
|
||||
```
|
||||
|
||||
### Performing a Random Read Test
|
||||
### 执行随机读测试
|
||||
|
||||
We are going to perform a random read test now, we will be trying to read a random 2Gb file
|
||||
我们将要执行一个随机读测试,我们将会尝试读取一个随机的 2GB 文件。
|
||||
```
|
||||
|
||||
sudo fio --name=randread --ioengine=libaio --iodepth=16 --rw=randread --bs=4k --direct=0 --size=512M --numjobs=4 --runtime=240 --group_reporting
|
||||
@ -159,7 +138,7 @@ sudo fio --name=randread --ioengine=libaio --iodepth=16 --rw=randread --bs=4k --
|
||||
|
||||
```
|
||||
|
||||
You should see the output below:
|
||||
你应该会看到下面这样的输出
|
||||
```
|
||||
|
||||
...
|
||||
@ -201,21 +180,18 @@ Disk stats (read/write):
|
||||
|
||||
```
|
||||
|
||||
Finally, we want to show a sample read-write test to see how the kind out output that fio returns.
|
||||
最后,我们想要展示一个简单的随机读-写测试来看一看 Fio 返回的输出类型。
|
||||
|
||||
### Read Write Performance Test
|
||||
### 读写性能测试
|
||||
|
||||
下述命令将会测试 USB Pen 驱动器 (/dev/sdc1) 的随机读写性能:
|
||||
|
||||
The command below will measure random read/write performance of USB Pen drive (/dev/sdc1):
|
||||
```
|
||||
|
||||
sudo fio --randrepeat=1 --ioengine=libaio --direct=1 --gtod_reduce=1 --name=test --filename=random_read_write.fio --bs=4k --iodepth=64 --size=4G --readwrite=randrw --rwmixread=75
|
||||
|
||||
|
||||
```
|
||||
|
||||
Below is the outout we get from the command above.
|
||||
下面的内容是我们从上面的命令得到的输出:
|
||||
```
|
||||
|
||||
fio-2.2.10
|
||||
Starting 1 process
|
||||
Jobs: 1 (f=1): [m(1)] [100.0% done] [217.8MB/74452KB/0KB /s] [55.8K/18.7K/0 iops] [eta 00m:00s]
|
||||
@ -235,19 +211,19 @@ Run status group 0 (all jobs):
|
||||
|
||||
Disk stats (read/write):
|
||||
sda: ios=774141/258944, merge=1463/899, ticks=748800/150316, in_queue=900720, util=99.35%
|
||||
|
||||
|
||||
```
|
||||
|
||||
We hope you enjoyed this tutorial and enjoyed following along, Fio is a very useful tool and we hope you can use it in your next debugging activity. If you enjoyed reading this post feel free to leave a comment of questions. Go ahead and clone the repo and play around with the code.
|
||||
|
||||
我们希望你能喜欢这个教程并且享受接下来的内容,Fio 是一个非常有用的工具,并且我们希望你能在你下一次 Debugging 活动中使用到它。如果你喜欢这个文章,欢迎留下评论和问题。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://wpmojo.com/how-to-use-fio-to-measure-disk-performance-in-linux/
|
||||
|
||||
作者:[Alex Pearson][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[Bestony](https://github.com/bestony)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,49 +1,49 @@
|
||||
Streams:一个新的 Redis 通用数据结构
|
||||
==================================
|
||||
======
|
||||
|
||||
直到几个月以前,对于我来说,在消息传递的环境中,streams 只是一个有趣且相对简单的概念。这个概念在 Kafka 流行之后,我主要研究它们在 Disque 案例中的效能。Disque 是一个消息队列,它将在 Redis 4.2 中被转换为 Redis 的一个模块。后来我决定用 Disque 来做全部的 AP 消息,也就是说,它将在不需要客户端过多参与的情况下实现容错和保证送达,这样一来,我更加确定地认为 streams 的概念在那种情况下并不适用。
|
||||
直到几个月以前,对于我来说,在消息传递的环境中,<ruby>流<rt>streams</rt></ruby>只是一个有趣且相对简单的概念。这个概念在 Kafka 流行之后,我主要研究它们在 Disque 案例中的应用,Disque 是一个消息队列,它将在 Redis 4.2 中被转换为 Redis 的一个模块。后来我决定让 Disque 都用 AP 消息[1],也就是说,它将在不需要客户端过多参与的情况下实现容错和可用性,这样一来,我更加确定地认为流的概念在那种情况下并不适用。
|
||||
|
||||
然而在那时,在 Redis 中还存在一个问题,那就是缺省情况下导出数据结构并不轻松。在 Redis 列表、有序集和发布/订阅能力之间有某些缺陷。你可以权衡使用这些工具对一系列消息或事件进行建模。
|
||||
然而在那时 Redis 有个问题,那就是缺省情况下导出数据结构并不轻松。它在 Redis <ruby>列表<rt>list</rt></ruby>、<ruby>有序集合<rt>sorted list</rt></ruby>、<ruby>发布/订阅<rt>Pub/Sub</rt></ruby>功能之间有某些缺陷。你可以权衡使用这些工具对一个消息或事件建模。
|
||||
|
||||
有序集是非常耗费内存的,那自然就不能对投递的相同消息进行一次又一次的建模,客户端不能阻塞新消息。因为有序集并不是一个序列化的数据结构,它是一个可以根据元素分数的变化而移动位置的集合:难怪它不适合像时间序列这样的东西。
|
||||
排序集合是内存消耗大户,那自然就不能对投递相同消息进行一次又一次的建模,客户端不能阻塞新消息。因为有序集合并不是一个序列化的数据结构,它是一个元素可以根据它们量的变化而移动的集合:所以它不像时序性的数据那样。
|
||||
|
||||
列表也有不同的问题,它在某些特定的用例中产生类似的适用性问题:你无法浏览列表中间的内容,因为在那种情况下,访问时间是线性的。此外,有可能是没有输出的,列表上的阻塞操作仅为单个客户端提供单个元素。而不是为列表中的元素提供固定的标识符,也就是说,无法做到从指定的那个元素开始给我提供内容。
|
||||
列表有另外的问题,它在某些特定的用例中产生类似的适用性问题:你无法浏览列表中间的内容,因为在那种情况下,访问时间是线性的。此外,没有任何指定输出的功能,列表上的阻塞操作仅为单个客户端提供单个元素。列表中没有固定的元素标识,也就是说,不能指定从哪个元素开始给我提供内容。
|
||||
|
||||
对于一到多的负载,它有发布/订阅机制,它在大多数情况下是非常好的,但是,对于某些你不希望“即发即弃”的东西:保留一个历史是很重要的,而不是断开之后重新获得消息,也因为某些消息列表,像时间序列,用范围查询浏览是非常重要的:在这 10 秒范围内我的温度读数是多少?
|
||||
对于一对多的工作任务,有发布/订阅机制,它在大多数情况下是非常好的,但是,对于某些不想<ruby>“即发即弃”<rt>fire-and-forget</rt></ruby>的东西:保留一个历史是很重要的,不只是因为是断开之后重新获得消息,也因为某些如时序性的消息列表,用范围查询浏览是非常重要的:在这 10 秒范围内温度读数是多少?
|
||||
|
||||
我尝试去解决上面的问题所使用的一种方法是,规划一个通用的有序集合,并列入到一个唯一的、更灵活的数据结构中,然而,我的设计尝试最终以生成一个比当前的数据结构更加矫揉造作的结果而结束。一个关于 Redis 数据结构导出的更好的事情是,让它更像天然的计算机科学的数据结构,而不是,“Salvatore 发明的 API”。因此,在最后我停止了我的尝试,并且说,“ok,这是我们目前能提供的东西了”,或许,我将为发布/订阅增加一些历史,或者将来对列表访问增加一些更灵活的方式。然而,每次在会议上有用户对我说“你如何在 Redis 中建模时间序列” 或者类似的问题时,我就感到很惶恐。
|
||||
我试图解决上述问题,我想规划一个通用的有序集合,并列入一个独特的、更灵活的数据结构,然而,我的设计尝试最终以生成一个比当前的数据结构更加矫揉造作的结果而告终。Redis 有个好处,它的数据结构导出更像自然的计算机科学的数据结构,而不是 “Salvatore 发明的 API”。因此,我最终停止了我的尝试,并且说,“ok,这是我们目前能提供的”,或许我会为发布/订阅增加一些历史信息,或者为列表访问增加一些更灵活的方式。然而,每次在会议上有用户对我说 “你如何在 Redis 中模拟时间系列” 或者类似的问题时,我的脸就绿了。
|
||||
|
||||
### 起源
|
||||
|
||||
在 Redis 4.0 中引入模块之后,用户开始去看,他们自己如何去修复这些问题。他们中的一个 —— Timothy Downs,通过 IRC 写信给我:
|
||||
在 Redis 4.0 中引入模块之后,用户开始考虑他们自己怎么去修复这些问题。其中一个用户 Timothy Downs 通过 IRC 和我说道:
|
||||
|
||||
\<forkfork> 这个模块,我计划去增加一个事务日志式的数据类型 —— 这意味着大量的订阅者可以在不大量增加 redis 内存使用的情况下做一些像发布/订阅那样的事情
|
||||
\<forkfork> 我计划给这个模块增加一个事务日志式的数据类型 —— 这意味着大量的订阅者可以在不导致 redis 内存激增的情况下做一些像发布/订阅那样的事情
|
||||
\<forkfork> 订阅者持有他们在消息队列中的位置,而不是让 Redis 必须维护每个消费者的位置和为每个订阅者复制消息
|
||||
|
||||
他的思路启发了我。我想了几天,并且意识到这可能是我们马上同时解决上面所有问题的一个契机。我需要去重新构思 “日志” 的概念。日志是个基本的编程元素,每个人都使用过它,因为它只是简单地以追加模式打开一个文件,并以一定的格式写入数据。然而 Redis 数据结构必须是抽象的。它们在内存中,并且我们使用内存并不是因为我们懒,而是因为使用一些指针,我们可以概念化数据结构并把它们抽象,以使它们摆脱明确的限制。例如,一般来说日志有几个问题:偏移不是逻辑化的,而是真实的字节偏移,如果你希望找到与条目插入时间相关的逻辑偏移量是多少?我们有范围查询可用。同样的,日志通常很难进行垃圾收集:在一个只能进行追加操作的数据结构中怎么去删除旧的元素?好吧,在我们理想的日志中,我们只需要说,我想要数字最大的那个条目,而旧的元素一个也不要,等等。
|
||||
他的思路启发了我。我想了几天,并且意识到这可能是我们马上同时解决上面所有问题的契机。我需要去重新构思 “日志” 的概念是什么。日志是个基本的编程元素,每个人都使用过它,因为它只是简单地以追加模式打开一个文件,并以一定的格式写入数据。然而 Redis 数据结构必须是抽象的。它们在内存中,并且我们使用内存并不是因为我们懒,而是因为使用一些指针,我们可以概念化数据结构并把它们抽象,以使它们摆脱明确的限制。例如,一般来说日志有几个问题:偏移不是逻辑化的,而是真实的字节偏移,如果你想要与条目插入的时间相关的逻辑偏移应该怎么办?我们有范围查询可用。同样,日志通常很难进行垃圾回收:在一个只能进行追加操作的数据结构中怎么去删除旧的元素?好吧,在我们理想的日志中,我们只需要说,我想要数字最大的那个条目,而旧的元素一个也不要,等等。
|
||||
|
||||
当我从 Timothy 的想法中受到启发,去尝试着写一个规范的时候,我使用了 Redis 集群中的 radix 树去实现,优化了它内部的某些部分。这为实现一个有效利用空间的日志提供了基础,而且仍然有可能在<ruby>对数时间<rt>logarithmic time</rt></ruby>内访问日志得到该范围。就在那时,我开始去读关于 Kafka 的 streams 相关的内容,以获得适合我的设计的其它灵感,最后的结果是借鉴了 Kafka 消费组的概念,并且再次针对 Redis 进行优化,以适用于 Redis 在内存中使用的情况。然而,该规范仅停留在纸面上,在一段时间后我几乎把它从头到尾重写了一遍,以便将我与别人讨论所得到的许多建议一起增加到即将到来的 Redis 升级中。我希望 Redis 的 streams 是非常有用的,尤其对于时间序列来说,而不仅是用于事件和消息类的应用程序。
|
||||
当我从 Timothy 的想法中受到启发,去尝试着写一个规范的时候,我使用了 Redis 集群中的 radix 树去实现,优化了它内部的某些部分。这为实现一个有效利用空间的日志提供了基础,而且仍然可以用<ruby>对数时间<rt>logarithmic time</rt></ruby>来访问范围。同时,我开始去读关于 Kafka 流以获得另外的灵感,它也非常适合我的设计,最后借鉴了 Kafka <ruby>消费群体<rt>consumer groups</rt></ruby>的概念,并且再次针对 Redis 进行优化,以适用于 Redis 在内存中使用的情况。然而,该规范仅停留在纸面上,在一段时间后我几乎把它从头到尾重写了一遍,以便将我与别人讨论的所得到的许多建议一起增加到 Redis 升级中。我希望 Redis 流能成为对于时间序列有用的特性,而不仅是一个常见的事件和消息类的应用程序。
|
||||
|
||||
### 让我们写一些代码吧
|
||||
|
||||
从 Redis 大会回来后,在那个夏天,我实现了一个称为 “listpack” 的库。这个库是 `ziplist.c` 的继任者,它是表示在单个分配中的字符串元素列表的一个数据结构。它是一个非常专业的序列化格式,其特点在于也能够以逆序(从右到左)进行解析:在所有的案例中是用于代替 ziplists 所做的事情。
|
||||
从 Redis 大会回来后,整个夏天我都在实现一个叫 listpack 的库。这个库是 `ziplist.c` 的继任者,那是一个表示在单个分配中的字符串元素列表的数据结构。它是一个非常特殊的序列化格式,其特点在于也能够以逆序(从右到左)解析:以便在各种用例中替代 ziplists。
|
||||
|
||||
结合 radix 树和 listpacks 的特性,它可以很容易地去构建一个空间高效的日志,并且还是索引化的,这意味着允许通过 ID 和时间进行随机访问。自从这些准备就绪后,我开始去写一些代码以实现流数据结构。我最终完成了该实现,不管怎样,现在,Redis 在 Github 上的 “streams” 分支里面,它已经可以跑的很好了。我并没有声称那个 API 是 100% 的最终版本,但是,这有两个有趣的事实:一是,在那时,只有消费组是不行的,再加上一些不那么重要的命令去操作流,但是,所有的大的方面都已经实现了。二是,一旦各个方面比较稳定了之后 ,决定大概用两个月的时间将所有的流的工作<ruby>回迁<rt>backport</rt></ruby>到 4.0 分支。这意味着 Redis 用户为了使用 streams,不用等到 Redis 4.2 发布,它们在生产环境中马上就可以使用了。这是可能的,因为作为一个新的数据结构,几乎所有的代码改变都出现在新的代码里面。除了阻塞列表操作之外:该代码被重构了,我们对于 streams 和列表阻塞操作共享了相同的代码,从而极大地简化了 Redis 内部。
|
||||
结合 radix 树和 listpacks 的特性,它可以很容易地去构建一个空间高效的日志,并且还是可索引的,这意味着允许通过 ID 和时间进行随机访问。自从这些就绪后,我开始去写一些代码以实现流数据结构。我还在完成这个实现,不管怎样,现在在 Github 上的 Redis 的 streams 分支里它已经可以跑起来了。我并没有声称那个 API 是 100% 的最终版本,但是,这有两个有意思的事实:一,在那时只有消费群组是缺失的,加上一些不太重要的操作流的命令,但是,所有的大的方面都已经实现了。二,一旦各个方面比较稳定了之后,我决定大概用两个月的时间将所有的流的特性<ruby>向后移植<rt>backport</rt></ruby>到 4.0 分支。这意味着 Redis 用户想要使用流,不用等待 Redis 4.2 发布,它们在生产环境马上就可用了。这是可能的,因为作为一个新的数据结构,几乎所有的代码改变都出现在新的代码里面。除了阻塞列表操作之外:该代码被重构了,我们对于流和列表阻塞操作共享了相同的代码,而极大地简化了 Redis 内部实现。
|
||||
|
||||
### 教程:欢迎使用 Redis 的 streams
|
||||
|
||||
在某些方面,你可以认为 streams 是 Redis 中列表的一个增强版本。streams 元素不再是一个单一的字符串,它们更多是一个<ruby>字段<rt>field</rt></ruby>和<ruby>值<rt>value</rt></ruby>组成的对象。范围查询成为可能而且还更快。流中的每个条目都有一个 ID,它是个逻辑偏移量。不同的客户端可以<ruby>阻塞等待<rt>blocking-wait</rt></ruby>比指定的 ID 更大的元素。Redis 中 streams 的一个基本命令是 XADD。是的,所有 Redis 的流命令都是以一个“X”为前缀的。
|
||||
在某些方面,你可以认为流是 Redis 列表的一个增强版本。流元素不再是一个单一的字符串,而是一个<ruby>字段<rt>field</rt></ruby>和<ruby>值<rt>value</rt></ruby>组成的对象。范围查询更适用而且更快。在流中,每个条目都有一个 ID,它是一个逻辑偏移量。不同的客户端可以<ruby>阻塞等待<rt>blocking-wait</rt></ruby>比指定的 ID 更大的元素。Redis 流的一个基本的命令是 `XADD`。是的,所有的 Redis 流命令都是以一个 `X` 为前缀的。
|
||||
|
||||
```
|
||||
> XADD mystream * sensor-id 1234 temperature 10.5
|
||||
1506871964177.0
|
||||
```
|
||||
|
||||
这个 `XADD` 命令将追加指定的条目作为一个指定的流 —— “mystream” 的新元素。在上面的示例中的这个条目有两个字段:`sensor-id` 和 `temperature`,每个条目在同一个流中可以有不同的字段。使用相同的字段名字可以更好地利用内存。需要记住的一个有趣的事情是,字段是保证排序的。XADD 仅返回插入的条目的 ID,因为在第三个参数中是星号(`*`),表示我们要求命令自动生成 ID。大多数情况下需要如此,但是,也可以去强制指定一个 ID,这种情况用于复制这个命令到被动服务器和 AOF 文件。
|
||||
这个 `XADD` 命令将追加指定的条目作为一个指定的流 —— “mystream” 的新元素。上面示例中的这个条目有两个字段:`sensor-id` 和 `temperature`,每个条目在同一个流中可以有不同的字段。使用相同的字段名可以更好地利用内存。有意思的是,字段的排序是可以保证顺序的。`XADD` 仅返回插入的条目的 ID,因为在第三个参数中是星号(`*`),表示由命令自动生成 ID。通常这样做就够了,但是也可以去强制指定一个 ID,这种情况用于复制这个命令到<ruby>从服务器<rt>slave server</rt></ruby>和 <ruby>AOF<rt>append-only file</rt></ruby> 文件。
|
||||
|
||||
这个 ID 是由两部分组成的:一个毫秒时间和一个序列号。`1506871964177` 是毫秒时间,它仅是一个毫秒级的 UNIX 时间。圆点(`.`)后面的数字 `0`,是一个序列号,它是为了区分相同毫秒数的条目增加上去的。这两个数字都是 64 位的无符号整数。这意味着在流中,我们可以增加所有我们想要的条目,即使是在同一毫秒中。ID 的毫秒部分使用 Redis 服务器的当前本地时间生成的 ID 和流中的最后一个条目 ID 两者间的最大的一个。因此,举例来说,即使是计算机时间回跳,这个 ID 仍然是增加的。在某些情况下,你可以认为流条目的 ID 是完整的 128 位数字。然而,事实是,它们与被添加的实例的本地时间有关,这意味着我们可以在毫秒级的精度范围内随意查询。
|
||||
这个 ID 是由两部分组成的:一个毫秒时间和一个序列号。`1506871964177` 是毫秒时间,它只是一个毫秒级的 UNIX 时间戳。圆点(`.`)后面的数字 `0` 是一个序号,它是为了区分相同毫秒数的条目增加上去的。这两个数字都是 64 位的无符号整数。这意味着,我们可以在流中增加所有想要的条目,即使是在同一毫秒中。ID 的毫秒部分使用 Redis 服务器的当前本地时间生成的 ID 和流中的最后一个条目 ID 两者间的最大的一个。因此,举例来说,即使是计算机时间回跳,这个 ID 仍然是增加的。在某些情况下,你可以认为流条目的 ID 是完整的 128 位数字。然而,事实上它们与被添加到的实例的本地时间有关,这意味着我们可以在毫秒级的精度的范围随意查询。
|
||||
|
||||
正如你想的那样,以一个速度非常快的方式去添加两个条目,结果是仅一个序列号增加了。我可以使用一个 `MULTI`/`EXEC` 块去简单模拟“快速插入”,如下:
|
||||
正如你想的那样,快速添加两个条目后,结果是仅一个序号递增了。我们可以用一个 `MULTI`/`EXEC` 块来简单模拟“快速插入”:
|
||||
|
||||
```
|
||||
> MULTI
|
||||
@ -57,9 +57,9 @@ QUEUED
|
||||
2) 1506872463535.1
|
||||
```
|
||||
|
||||
在上面的示例中,也展示了无需指定任何初始<ruby>模式<rt>schema</rt></ruby>的情况下,对不同的条目使用不同的字段。会发生什么呢?就像前面提到的一样,只有每个块(它通常包含 50 - 150 个消息内容)的第一个信息被使用。并且,相同字段的连续条目都使用了一个标志进行了压缩,这个标志表示与“它们与这个块中的第一个条目的字段相同”。因此,对于使用了相同字段的连续消息可以节省许多内存,即使是字段集随着时间发生缓慢变化的情况下也很节省内存。
|
||||
在上面的示例中,也展示了无需指定任何初始<ruby>模式<rt>schema</rt></ruby>的情况下,对不同的条目使用不同的字段。会发生什么呢?就像前面提到的一样,只有每个块(它通常包含 50-150 个消息内容)的第一个消息被使用。并且,相同字段的连续条目都使用了一个标志进行了压缩,这个标志表示与“它们与这个块中的第一个条目的字段相同”。因此,使用相同字段的连续消息可以节省许多内存,即使是字段集随着时间发生缓慢变化的情况下也很节省内存。
|
||||
|
||||
为了从流中检索数据,这里有两种方法:范围查询,它是通过 `XRANGE` 命令实现的;和<ruby>流播<rt>streaming</rt></ruby>,它是通过 XREAD 命令实现的。`XRANGE` 命令仅取得包括从开始到停止范围内的全部条目。因此,举例来说,如果我知道它的 ID,我可以使用如下的命名取得单个条目:
|
||||
为了从流中检索数据,这里有两种方法:范围查询,它是通过 `XRANGE` 命令实现的;<ruby>流播<rt>streaming</rt></ruby>,它是通过 `XREAD` 命令实现的。`XRANGE` 命令仅取得包括从开始到停止范围内的全部条目。因此,举例来说,如果我知道它的 ID,我可以使用如下的命名取得单个条目:
|
||||
|
||||
```
|
||||
> XRANGE mystream 1506871964177.0 1506871964177.0
|
||||
@ -70,7 +70,7 @@ QUEUED
|
||||
4) "10.5"
|
||||
```
|
||||
|
||||
不管怎样,你都可以使用指定的开始符号 `-` 和停止符号 `+` 去表示最小和最大的 ID。为了限制返回条目的数量,也可以使用 `COUNT` 选项。下面是一个更复杂的 `XRANGE` 示例:
|
||||
不管怎样,你都可以使用指定的开始符号 `-` 和停止符号 `+` 表示最小和最大的 ID。为了限制返回条目的数量,也可以使用 `COUNT` 选项。下面是一个更复杂的 `XRANGE` 示例:
|
||||
|
||||
```
|
||||
> XRANGE mystream - + COUNT 2
|
||||
@ -84,7 +84,7 @@ QUEUED
|
||||
2) "10"
|
||||
```
|
||||
|
||||
这里我们讲的是 ID 的范围,然后,为了取得在一个给定时间范围内的特定范围的元素,你可以使用 `XRANGE`,因为你可以省略 ID 的“序列” 部分。因此,你可以做的仅是指定“毫秒”时间,下面的命令的意思是: “从 UNIX 时间 1506872463 开始给我 10 个条目”:
|
||||
这里我们讲的是 ID 的范围,然后,为了取得在一个给定时间范围内的特定范围的元素,你可以使用 `XRANGE`,因为 ID 的“序号” 部分可以省略。因此,你可以只指定“毫秒”时间即可,下面的命令的意思是:“从 UNIX 时间 1506872463 开始给我 10 个条目”:
|
||||
|
||||
```
|
||||
127.0.0.1:6379> XRANGE mystream 1506872463000 + COUNT 10
|
||||
@ -96,15 +96,15 @@ QUEUED
|
||||
2) "20"
|
||||
```
|
||||
|
||||
关于 `XRANGE` 需要注意的最重要的事情是,假设我们在回复中收到 ID,并且随后连续的 ID 只是增加了 ID 的序列部分,所以可以使用 `XRANGE` 去遍历整个流,接收每个调用的指定个数的元素。在 Redis 中的`*SCAN` 系列命令之后,它允许 Redis 数据结构迭代,尽管事实上它们不是为迭代设计的,但这样我可以避免再犯相同的错误。
|
||||
关于 `XRANGE` 需要注意的最重要的事情是,假设我们在回复中收到 ID,随后连续的 ID 只是增加了序号部分,所以可以使用 `XRANGE` 遍历整个流,接收每个调用的指定个数的元素。Redis 中的`*SCAN` 系列命令允许迭代 Redis 数据结构,尽管事实上它们不是为迭代设计的,但这样可以避免再犯相同的错误。
|
||||
|
||||
### 使用 XREAD 处理流播:阻塞新的数据
|
||||
|
||||
当我们想通过 ID 或时间去访问流中的一个范围或者是通过 ID 去获取单个元素时,使用 XRANGE 是非常完美的。然而,在 streams 的案例中,当数据到达时,它必须由不同的客户端来消费时,这就不是一个很好的解决方案,这需要某种形式的“汇聚池”。(对于*某些*应用程序来说,这可能是个好主意,因为它们仅是偶尔连接取数的)
|
||||
当我们想通过 ID 或时间去访问流中的一个范围或者是通过 ID 去获取单个元素时,使用 `XRANGE` 是非常完美的。然而,在使用流的案例中,当数据到达时,它必须由不同的客户端来消费时,这就不是一个很好的解决方案,这需要某种形式的<ruby>汇聚池<rt>pooling</rt></ruby>。(对于 *某些* 应用程序来说,这可能是个好主意,因为它们仅是偶尔连接查询的)
|
||||
|
||||
`XREAD` 命令是为读取设计的,在同一个时间,从多个 streams 中仅指定我们从该流中得到的最后条目的 ID。此外,如果没有数据可用,我们可以要求阻塞,当数据到达时,去解除阻塞。类似于阻塞列表操作产生的效果,但是这里并没有消费从流中得到的数据。并且多个客户端可以同时访问相同的数据。
|
||||
`XREAD` 命令是为读取设计的,在同一个时间,从多个流中仅指定我们从该流中得到的最后条目的 ID。此外,如果没有数据可用,我们可以要求阻塞,当数据到达时,就解除阻塞。类似于阻塞列表操作产生的效果,但是这里并没有消费从流中得到的数据,并且多个客户端可以同时访问同一份数据。
|
||||
|
||||
这里有一个关于 `XREAD` 调用的规范示例:
|
||||
这里有一个典型的 `XREAD` 调用示例:
|
||||
|
||||
```
|
||||
> XREAD BLOCK 5000 STREAMS mystream otherstream $ $
|
||||
@ -112,12 +112,14 @@ QUEUED
|
||||
|
||||
它的意思是:从 `mystream` 和 `otherstream` 取得数据。如果没有数据可用,阻塞客户端 5000 毫秒。在 `STREAMS` 选项之后指定我们想要监听的关键字,最后的是指定想要监听的 ID,指定的 ID 为 `$` 的意思是:假设我现在需要流中的所有元素,因此,只需要从下一个到达的元素开始给我。
|
||||
|
||||
如果,从另外一个客户端,我发出这样的命令:
|
||||
如果我从另一个客户端发送这样的命令:
|
||||
|
||||
```
|
||||
> XADD otherstream * message “Hi There”
|
||||
```
|
||||
在 XREAD 侧会出现什么情况呢?
|
||||
|
||||
在 `XREAD` 侧会出现什么情况呢?
|
||||
|
||||
```
|
||||
1) 1) "otherstream"
|
||||
2) 1) 1) 1506935385635.0
|
||||
@ -125,23 +127,23 @@ QUEUED
|
||||
2) "Hi There"
|
||||
```
|
||||
|
||||
与收到的数据一起,我们得到了所收到数据的关键字,在下次的调用中,我们将使用接收到的最新消息的 ID:
|
||||
与收到的数据一起,我们也得到了数据的关键字。在下次调用中,我们将使用接收到的最新消息的 ID:
|
||||
|
||||
```
|
||||
> XREAD BLOCK 5000 STREAMS mystream otherstream $ 1506935385635.0
|
||||
```
|
||||
|
||||
依次类推。然而需要注意的是使用方式,客户端有可能在一个非常大的延迟(因为它处理消息需要时间,或者其它什么原因)之后再次连接。在这种情况下,期间会有很多消息堆积,为了确保客户端不被消息淹没,以及服务器不会因为给单个客户端提供大量消息而浪费太多的时间,使用 `XREAD` 的 `COUNT` 选项是非常明智的。
|
||||
依次类推。然而需要注意的是使用方式,客户端有可能在一个非常大的延迟之后再次连接(因为它处理消息需要时间,或者其它什么原因)。在这种情况下,期间会有很多消息堆积,为了确保客户端不被消息淹没,以及服务器不会因为给单个客户端提供大量消息而浪费太多的时间,使用 `XREAD` 的 `COUNT` 选项是非常明智的。
|
||||
|
||||
### 流封顶
|
||||
|
||||
到现在为止,一直还都不错…… 然而,有些时候,streams 需要去删除一些旧的消息。幸运的是,这可以使用 `XADD` 命令的 `MAXLEN` 选项去做:
|
||||
目前看起来还不错……然而,有些时候,流需要删除一些旧的消息。幸运的是,这可以使用 `XADD` 命令的 `MAXLEN` 选项去做:
|
||||
|
||||
```
|
||||
> XADD mystream MAXLEN 1000000 * field1 value1 field2 value2
|
||||
```
|
||||
|
||||
它是基本意思是,如果流上添加新元素后发现,它的消息数量超过了 `1000000` 个,那么,删除旧的消息,以便于长度重新回到 `1000000` 个元素以内。它很像是在列表中使用的 `RPUSH` + `LTRIM`,但是,这次我们是使用了一个内置机制去完成的。然而,需要注意的是,上面的意思是每次我们增加一个新的消息时,我们还需要另外的工作去从流中删除旧的消息。这将使用一些 CPU 资源,所以,在计算 MAXLEN 之前,尽可能使用 `~` 符号,以表明我们不要求非常*精确*的 1000000 个消息,就是稍微多一些也不是个大问题:
|
||||
它是基本意思是,如果在流中添加新元素后发现消息数量超过了 `1000000` 个,那么就删除旧的消息,以便于元素总量重新回到 `1000000` 以内。它很像是在列表中使用的 `RPUSH` + `LTRIM`,但是,这次我们是使用了一个内置机制去完成的。然而,需要注意的是,上面的意思是每次我们增加一个新的消息时,我们还需要另外的工作去从流中删除旧的消息。这将消耗一些 CPU 资源,所以在计算 `MAXLEN` 之前,尽可能使用 `~` 符号,以表明我们不要求非常 *精确* 的 1000000 个消息,就是稍微多一些也不是大问题:
|
||||
|
||||
```
|
||||
> XADD mystream MAXLEN ~ 1000000 * foo bar
|
||||
@ -151,33 +153,31 @@ QUEUED
|
||||
|
||||
### 消费组(开发中)
|
||||
|
||||
这是第一个 Redis 中尚未实现而在开发中的特性。它也是来自 Kafka 的灵感,尽管在这里以不同的方式去实现的。重点是使用了 `XREAD`,客户端也可以增加一个 `GROUP <name>` 选项。 在相同组的所有客户端,将自动地得到*不同的*消息。当然,同一个流可以被多个组读取。在这种情况下,所有的组将收到流中到达的消息的相同副本。但是,在每个组内,消息是不会重复的。
|
||||
这是第一个 Redis 中尚未实现而在开发中的特性。灵感也是来自 Kafka,尽管在这里是以不同的方式实现的。重点是使用了 `XREAD`,客户端也可以增加一个 `GROUP <name>` 选项。相同组的所有客户端将自动得到 *不同的* 消息。当然,同一个流可以被多个组读取。在这种情况下,所有的组将收到流中到达的消息的相同副本。但是,在每个组内,消息是不会重复的。
|
||||
|
||||
当指定组时,能够指定一个 “RETRY <milliseconds>” 选项去扩展组:在这种情况下,如果消息没有使用 XACK 去进行确认,它将在指定的毫秒数后进行再次投递。这将为消息投递提供更佳的可靠性,这种情况下,客户端没有私有的方法将消息标记为已处理。这一部分也正在开发中。
|
||||
当指定组时,能够指定一个 `RETRY <milliseconds>` 选项去扩展组:在这种情况下,如果消息没有通过 `XACK` 进行确认,它将在指定的毫秒数后进行再次投递。这将为消息投递提供更佳的可靠性,这种情况下,客户端没有私有的方法将消息标记为已处理。这一部分也正在开发中。
|
||||
|
||||
### 内存使用和加载时间节省
|
||||
### 内存使用和节省加载时间
|
||||
|
||||
因为设计用来建模 Redis 的 streams,内存使用是非常低的。这取决于它们的字段、值的数量和它们的长度,对于简单的消息,每使用 100 MB 内存可以有几百万条消息,此外,格式设想为需要极少的序列化:listpack 块以 radix 树节点方式存储,在磁盘上和内存中都以相同方式表示的,因此,它们可以很轻松地存储和读取。例如,Redis 可以在 0.3 秒内从 RDB 文件中读取 500 万个条目。这使得 streams 的复制和持久存储非常高效。
|
||||
因为用来建模 Redis 流的设计,内存使用率是非常低的。这取决于它们的字段、值的数量和长度,对于简单的消息,每使用 100MB 内存可以有几百万条消息。此外,格式设想为需要极少的序列化:listpack 块以 radix 树节点方式存储,在磁盘上和内存中都以相同方式表示的,因此它们可以很轻松地存储和读取。例如,Redis 可以在 0.3 秒内从 RDB 文件中读取 500 万个条目。这使流的复制和持久存储非常高效。
|
||||
|
||||
也计划允许从条目中间进行部分删除。现在仅实现了一部分,策略是在条目在标记中标识为已删除条目,并且,当已删除条目占全部条目的比率达到给定值时,这个块将被回收重写,并且,如果需要,它将被连到相邻的另一个块上,以避免碎片化。
|
||||
我还计划允许从条目中间进行部分删除。现在仅实现了一部分,策略是在条目在标记中标识条目为已删除,并且,当已删除条目占全部条目的比例达到指定值时,这个块将被回收重写,如果需要,它将被连到相邻的另一个块上,以避免碎片化。
|
||||
|
||||
### 关于最终发布时间的结论
|
||||
|
||||
Redis 的 streams 将包含在年底前(LCTT 译注:本文原文发布于 2017 年 10 月)推出的 Redis 4.0 系列的稳定版中。我认为这个通用的数据结构将为 Redis 提供一个巨大的补丁,以用于解决很多现在很难去解决的情况:那意味着你(之前)需要创造性地滥用当前提供的数据结构去解决那些问题。一个非常重要的使用案例是时间序列,但是,我的感觉是,对于其它用例来说,通过 `TREAD` 来流播消息将是非常有趣的,因为对于那些需要更高可靠性的应用程序,可以使用发布/订阅模式来替换“即用即弃”,还有其它全新的使用案例。现在,如果你想在你的有问题环境中评估新数据结构的能力,可以在 GitHub 上去获得 “streams” 分支,开始去玩吧。欢迎向我们报告所有的 bug 。 :-)
|
||||
Redis 的流特性将包含在年底前(LCTT 译注:本文原文发布于 2017 年 10 月)推出的 Redis 4.0 系列的稳定版中。我认为这个通用的数据结构将为 Redis 提供一个巨大的补丁,以用于解决很多现在很难以解决的情况:那意味着你(之前)需要创造性地“滥用”当前提供的数据结构去解决那些问题。一个非常重要的使用场景是时间序列,但是,我觉得对于其它场景来说,通过 `TREAD` 来流播消息将是非常有趣的,因为对于那些需要更高可靠性的应用程序,可以使用发布/订阅模式来替换“即用即弃”,还有其它全新的使用场景。现在,如果你想在有问题环境中评估这个新数据结构,可以更新 GitHub 上的 streams 分支开始试用。欢迎向我们报告所有的 bug。:-)
|
||||
|
||||
如果你喜欢这个视频,展示这个 streams 的实时会话在这里: https://www.youtube.com/watch?v=ELDzy9lCFHQ
|
||||
如果你喜欢观看视频的方式,这里有一个现场演示:https://www.youtube.com/watch?v=ELDzy9lCFHQ
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
---
|
||||
|
||||
via: http://antirez.com/news/114
|
||||
|
||||
作者:[antirez][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)、[pityonline](https://github.com/pityonline)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://antirez.com/
|
||||
[1]:http://antirez.com/news/114
|
||||
[2]:http://antirez.com/user/antirez
|
||||
[3]:https://www.youtube.com/watch?v=ELDzy9lCFHQ
|
||||
[a]: http://antirez.com/
|
||||
[1]: https://zh.wikipedia.org/wiki/CAP%E5%AE%9A%E7%90%86
|
||||
|
||||
@ -1,34 +1,33 @@
|
||||
Translating by qhwdw
|
||||
Asynchronous Processing with Go using Kafka and MongoDB
|
||||
使用 Kafka 和 MongoDB 进行 Go 异步处理
|
||||
============================================================
|
||||
|
||||
In my previous blog post ["My First Go Microservice using MongoDB and Docker Multi-Stage Builds"][9], I created a Go microservice sample which exposes a REST http endpoint and saves the data received from an HTTP POST to a MongoDB database.
|
||||
在我前面的博客文章 ["使用 MongoDB 和 Docker 多阶段构建我的第一个 Go 微服务][9] 中,我创建了一个 Go 微服务示例,它发布一个 REST 式的 http 端点,并将从 HTTP POST 中接收到的数据保存到 MongoDB 数据库。
|
||||
|
||||
In this example, I decoupled the saving of data to MongoDB and created another microservice to handle this. I also added Kafka to serve as the messaging layer so the microservices can work on its own concerns asynchronously.
|
||||
在这个示例中,我将保存数据到 MongoDB 和创建另一个微服务去处理它解耦了。我还添加了 Kafka 为消息层服务,这样微服务就可以异步地处理它自己关心的东西了。
|
||||
|
||||
> In case you have time to watch, I recorded a walkthrough of this blog post in the [video below][1] :)
|
||||
> 如果你有时间去看,我将这个博客文章的整个过程录制到 [这个视频中了][1] :)
|
||||
|
||||
Here is the high-level architecture of this simple asynchronous processing example wtih 2 microservices.
|
||||
下面是这个使用了两个微服务的简单的异步处理示例的高级架构。
|
||||
|
||||

|
||||
|
||||
Microservice 1 - is a REST microservice which receives data from a /POST http call to it. After receiving the request, it retrieves the data from the http request and saves it to Kafka. After saving, it responds to the caller with the same data sent via /POST
|
||||
微服务 1 —— 是一个 REST 式微服务,它从一个 /POST http 调用中接收数据。接收到请求之后,它从 http 请求中检索数据,并将它保存到 Kafka。保存之后,它通过 /POST 发送相同的数据去响应调用者。
|
||||
|
||||
Microservice 2 - is a microservice which subscribes to a topic in Kafka where Microservice 1 saves the data. Once a message is consumed by the microservice, it then saves the data to MongoDB.
|
||||
微服务 2 —— 是一个在 Kafka 中订阅一个主题的微服务,在这里就是微服务 1 保存的数据。一旦消息被微服务消费之后,它接着保存数据到 MongoDB 中。
|
||||
|
||||
Before you proceed, we need a few things to be able to run these microservices:
|
||||
在你继续之前,我们需要能够去运行这些微服务的几件东西:
|
||||
|
||||
1. [Download Kafka][2] - I used version kafka_2.11-1.1.0
|
||||
1. [下载 Kafka][2] —— 我使用的版本是 kafka_2.11-1.1.0
|
||||
|
||||
2. Install [librdkafka][3] - Unfortunately, this library should be present in the target system
|
||||
2. 安装 [librdkafka][3] —— 不幸的是,这个库应该在目标系统中
|
||||
|
||||
3. Install the [Kafka Go Client by Confluent][4]
|
||||
3. 安装 [Kafka Go 客户端][4]
|
||||
|
||||
4. Run MongoDB. You can check my [previous blog post][5] about this where I used a MongoDB docker image.
|
||||
4. 运行 MongoDB。你可以去看我的 [以前的文章][5] 中关于这一块的内容,那篇文章中我使用了一个 MongoDB docker 镜像。
|
||||
|
||||
Let's get rolling!
|
||||
我们开始吧!
|
||||
|
||||
Start Kafka first, you need Zookeeper running before you run the Kafka server. Here's how
|
||||
首先,启动 Kafka,在你运行 Kafka 服务器之前,你需要运行 Zookeeper。下面是示例:
|
||||
|
||||
```
|
||||
$ cd /<download path>/kafka_2.11-1.1.0
|
||||
@ -36,14 +35,14 @@ $ bin/zookeeper-server-start.sh config/zookeeper.properties
|
||||
|
||||
```
|
||||
|
||||
Then run Kafka - I am using port 9092 to connect to Kafka. If you need to change the port, just configure it in config/server.properties. If you are just a beginner like me, I suggest to just use default ports for now.
|
||||
接着运行 Kafka —— 我使用 9092 端口连接到 Kafka。如果你需要改变端口,只需要在 `config/server.properties` 中配置即可。如果你像我一样是个新手,我建议你现在还是使用默认端口。
|
||||
|
||||
```
|
||||
$ bin/kafka-server-start.sh config/server.properties
|
||||
|
||||
```
|
||||
|
||||
After running Kafka, we need MongoDB. To make it simple, just use this docker-compose.yml.
|
||||
Kafka 跑起来之后,我们需要 MongoDB。它很简单,只需要使用这个 `docker-compose.yml` 即可。
|
||||
|
||||
```
|
||||
version: '3'
|
||||
@ -65,14 +64,14 @@ networks:
|
||||
|
||||
```
|
||||
|
||||
Run the MongoDB docker container using Docker Compose
|
||||
使用 Docker Compose 去运行 MongoDB docker 容器。
|
||||
|
||||
```
|
||||
docker-compose up
|
||||
|
||||
```
|
||||
|
||||
Here is the relevant code of Microservice 1. I just modified my previous example to save to Kafka rather than MongoDB.
|
||||
这里是微服务 1 的相关代码。我只是修改了我前面的示例去保存到 Kafka 而不是 MongoDB。
|
||||
|
||||
[rest-to-kafka/rest-kafka-sample.go][10]
|
||||
|
||||
@ -137,7 +136,7 @@ func saveJobToKafka(job Job) {
|
||||
|
||||
```
|
||||
|
||||
Here is the code of Microservice 2. What is important in this code is the consumption from Kafka, the saving part I already discussed in my previous blog post. Here are the important parts of the code which consumes the data from Kafka.
|
||||
这里是微服务 2 的代码。在这个代码中最重要的东西是从 Kafka 中消耗数据,保存部分我已经在前面的博客文章中讨论过了。这里代码的重点部分是从 Kafka 中消费数据。
|
||||
|
||||
[kafka-to-mongo/kafka-mongo-sample.go][11]
|
||||
|
||||
@ -210,51 +209,51 @@ func saveJobToMongo(jobString string) {
|
||||
|
||||
```
|
||||
|
||||
Let's get down to the demo, run Microservice 1\. Make sure Kafka is running.
|
||||
我们来演示一下,运行微服务 1。确保 Kafka 已经运行了。
|
||||
|
||||
```
|
||||
$ go run rest-kafka-sample.go
|
||||
|
||||
```
|
||||
|
||||
I used Postman to send data to Microservice 1
|
||||
我使用 Postman 向微服务 1 发送数据。
|
||||
|
||||

|
||||
|
||||
Here is the log you will see in Microservice 1\. Once you see this, it means data has been received from Postman and saved to Kafka
|
||||
这里是日志,你可以在微服务 1 中看到。当你看到这些的时候,说明已经接收到了来自 Postman 发送的数据,并且已经保存到了 Kafka。
|
||||
|
||||

|
||||
|
||||
Since we are not running Microservice 2 yet, the data saved by Microservice 1 will just be in Kafka. Let's consume it and save to MongoDB by running Microservice 2.
|
||||
因为我们尚未运行微服务 2,数据被微服务 1 只保存在了 Kafka。我们来消费它并通过运行的微服务 2 来将它保存到 MongoDB。
|
||||
|
||||
```
|
||||
$ go run kafka-mongo-sample.go
|
||||
|
||||
```
|
||||
|
||||
Now you'll see that Microservice 2 consumes the data and saves it to MongoDB
|
||||
现在,你将在微服务 2 上看到消费的数据,并将它保存到了 MongoDB。
|
||||
|
||||

|
||||
|
||||
Check if data is saved in MongoDB. If it is there, we're good!
|
||||
检查一下数据是否保存到了 MongoDB。如果有数据,我们成功了!
|
||||
|
||||

|
||||
|
||||
Complete source code can be found here
|
||||
完整的源代码可以在这里找到
|
||||
[https://github.com/donvito/learngo/tree/master/rest-kafka-mongo-microservice][12]
|
||||
|
||||
Shameless plug! If you like this blog post, please follow me in Twitter [@donvito][6]. I tweet about Docker, Kubernetes, GoLang, Cloud, DevOps, Agile and Startups. Would love to connect in [GitHub][7] and [LinkedIn][8]
|
||||
现在是广告时间:如果你喜欢这篇文章,请在 Twitter [@donvito][6] 上关注我。我的 Twitter 上有关于 Docker、Kubernetes、GoLang、Cloud、DevOps、Agile 和 Startups 的内容。欢迎你们在 [GitHub][7] 和 [LinkedIn][8] 关注我。
|
||||
|
||||
[VIDEO](https://youtu.be/xa0Yia1jdu8)
|
||||
[视频](https://youtu.be/xa0Yia1jdu8)
|
||||
|
||||
Enjoy!
|
||||
开心地玩吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.melvinvivas.com/developing-microservices-using-kafka-and-mongodb/
|
||||
|
||||
作者:[Melvin Vivas ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,175 +0,0 @@
|
||||
|
||||
如何方便的检查Ubuntu版本以及其他系统信息
|
||||
======
|
||||
|
||||
|
||||
**简要:想知道你正在使用的Ubuntu具体是什么版本吗?这篇文档将告诉你如何检查你的Ubuntu版本,桌面环境以及其他相关的系统信息**
|
||||
|
||||
|
||||
|
||||
通常,你能非常容易的通过命令行或者图形界面获取你正在使用的Ubutnu的版本。当你正在尝试学习一篇互联网上的入门教材或者正在从各种各样的论坛里获取帮助的时候,知道当前正在使用的Ubuntu确切的版本号,桌面环境以及其他的系统信息将是尤为重要的。
|
||||
|
||||
|
||||
|
||||
在这篇简短的文章中,作者将展示各种检查[Ubuntu][1] 版本以及其他常用的系统信息的方法。
|
||||
|
||||
|
||||
### 如何在命令行检查Ubuntu版本
|
||||
|
||||
|
||||
这个是获得Ubuntu版本的最好的办法。 我本想先展示如何用图形界面做到这一点但是我决定还是先从命令行方法说起,因为这种方法不依赖于你使用的任何桌面环境[desktop environment][2]。 你可以在任何Ubuntu的变种系统上使用这种方法。
|
||||
|
||||
|
||||
打开你的命令行终端 (Ctrl+Alt+T), 键入下面的命令:
|
||||
|
||||
```
|
||||
lsb_release -a
|
||||
|
||||
```
|
||||
|
||||
|
||||
上面命令的输出应该如下:
|
||||
|
||||
```
|
||||
No LSB modules are available.
|
||||
Distributor ID: Ubuntu
|
||||
Description: Ubuntu 16.04.4 LTS
|
||||
Release: 16.04
|
||||
Codename: xenial
|
||||
|
||||
```
|
||||
|
||||
![How to check Ubuntu version in command line][3]
|
||||
|
||||
|
||||
正像你所看到的,当前我的系统安装的Ubuntu版本是 Ubuntu 16.04, 版本代号: Xenial
|
||||
|
||||
|
||||
且慢!为什么版本描述中显示的是Ubuntu 16.04.4而发行号是16.04?到底哪个才是正确的版本?16.04还是16.04.4? 这两者之间有什么区别?
|
||||
|
||||
|
||||
如果言简意赅的回答这个问题的话,那么答案应该是你正在使用Ubuntu 16.04. 这个是基准版本, 而16.04.4进一步指明这是16.04的第四个补丁版本。你可以将补丁版本理解为Windows世界里的服务包。在这里,16.04和16.04.4都是正确的版本号。
|
||||
|
||||
|
||||
那么输出的Xenial又是什么?那正是Ubuntu 16.04版本代号。你可以阅读下面这篇文章获取更多信息[article to know about Ubuntu naming convention][4].
|
||||
|
||||
|
||||
|
||||
#### 其他一些获取Ubuntu版本的方法
|
||||
|
||||
|
||||
|
||||
你也可以使用下面任意的命令得到Ubuntu的版本:
|
||||
|
||||
```
|
||||
cat /etc/lsb-release
|
||||
|
||||
```
|
||||
|
||||
|
||||
输出如下信息:
|
||||
|
||||
```
|
||||
DISTRIB_ID=Ubuntu
|
||||
DISTRIB_RELEASE=16.04
|
||||
DISTRIB_CODENAME=xenial
|
||||
DISTRIB_DESCRIPTION="Ubuntu 16.04.4 LTS"
|
||||
|
||||
```
|
||||
|
||||
![How to check Ubuntu version in command line][5]
|
||||
|
||||
|
||||
你还可以使用下面的命令来获得Ubuntu版本
|
||||
|
||||
```
|
||||
cat /etc/issue
|
||||
|
||||
```
|
||||
|
||||
|
||||
命令行的输出将会如下:
|
||||
|
||||
```
|
||||
Ubuntu 16.04.4 LTS \n \l
|
||||
|
||||
```
|
||||
|
||||
|
||||
不要介意输出末尾的\n \l. 这里Ubuntu版本就是16.04.4或者更加简单:16.04.
|
||||
|
||||
|
||||
### 如何在图形界面下得到Ubuntu版本
|
||||
|
||||
|
||||
在图形界面下获取Ubuntu版本更是小事一桩。这里我使用了Ubuntu 18.04的图形界面系统GNOME的屏幕截图来展示如何做到这一点。如果你在使用Unity或者别的桌面环境的话,显示可能会有所不同。这也是为什么我推荐使用命令行方式来获得版本的原因:你不用依赖形形色色的图形界面。
|
||||
|
||||
|
||||
|
||||
下面我来展示如何在桌面环境获取Ubuntu版本。
|
||||
|
||||
|
||||
|
||||
进入‘系统设置’并点击下面的‘详细信息’栏。
|
||||
|
||||
![Finding Ubuntu version graphically][6]
|
||||
|
||||
|
||||
|
||||
你将会看到系统的Ubuntu版本和其他和桌面系统有关的系统信息 这里的截图来自[GNOME][7] 。
|
||||
|
||||
![Finding Ubuntu version graphically][8]
|
||||
|
||||
|
||||
|
||||
### 如何知道桌面环境以及其他的系统信息
|
||||
|
||||
|
||||
|
||||
你刚才学习的是如何得到Ubuntu的版本信息,那么如何知道桌面环境呢? 更进一步, 如果你还想知道当前使用的Linux内核版本呢?
|
||||
|
||||
|
||||
有各种各样的命令你可以用来得到这些信息,不过今天我想推荐一个命令行工具, 叫做[Neofetch][9]。 这个工具能在命令行完美展示系统信息,包括Ubuntu或者其他Linux发行版的系统图标。
|
||||
|
||||
|
||||
用下面的命令安装Neofetch:
|
||||
|
||||
```
|
||||
sudo apt install neofetch
|
||||
|
||||
```
|
||||
|
||||
|
||||
安装成功后,运行'neofetch'将会优雅的展示系统的信息如下。
|
||||
|
||||
![System information in Linux terminal][10]
|
||||
|
||||
|
||||
如你所见,neofetch 完全展示了Linux内核版本,Ubuntu的版本,桌面系统版本以及环境,主题和图标等等信息。
|
||||
|
||||
|
||||
希望我如上展示方法能帮到你更快的找到你正在使用的Ubuntu版本和其他系统信息。如果你对这篇文章有其他的建议,欢迎在评论栏里留言。
|
||||
再见。:)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/how-to-know-ubuntu-unity-version/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[DavidChenLiang](https://github.com/davidchenliang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]:https://www.ubuntu.com/
|
||||
[2]:https://en.wikipedia.org/wiki/Desktop_environment
|
||||
[3]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2013/03/check-ubuntu-version-command-line-1-800x216.jpeg
|
||||
[4]:https://itsfoss.com/linux-code-names/
|
||||
[5]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2013/03/check-ubuntu-version-command-line-2-800x185.jpeg
|
||||
[6]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2013/03/ubuntu-version-system-settings.jpeg
|
||||
[7]:https://www.gnome.org/
|
||||
[8]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2013/03/checking-ubuntu-version-gui.jpeg
|
||||
[9]:https://itsfoss.com/display-linux-logo-in-ascii/
|
||||
[10]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2013/03/ubuntu-system-information-terminal-800x400.jpeg
|
||||
@ -0,0 +1,200 @@
|
||||
系统管理员的一个网络管理指南
|
||||
======
|
||||
|
||||

|
||||
|
||||
如果你是一位系统管理员,那么你的日常工作应该包括管理服务器和数据中心的网络。以下的 Linux 实用工具和命令 —— 从基础的到高级的 —— 将帮你更轻松地管理你的网络。
|
||||
|
||||
在几个命令中,你将会看到 `<fqdn>`,它是“完全合格域名”的全称。当你看到它时,你应该用你的网站 URL 或你的服务器来代替它(比如,`server-name.company.com`),具体要视情况而定。
|
||||
|
||||
### Ping
|
||||
|
||||
正如它的名字所表示的那样,`ping` 是用于去检查从你的系统到你想去连接的系统之间端到端的连通性。当一个 ping 成功时,它使用的 [ICMP][1] 的 echo 包将会返回到你的系统中。它是检查系统/网络连通性的一个良好开端。你可以在 IPv4 和 IPv6 地址上使用 `ping` 命令。(阅读我的文章 "[如何在 Linux 系统上找到你的 IP 地址][2]" 去学习更多关于 IP 地址的知识)
|
||||
|
||||
**语法:**
|
||||
|
||||
* IPv4: `ping <ip address>/<fqdn>`
|
||||
* IPv6: `ping6 <ip address>/<fqdn>`
|
||||
|
||||
|
||||
|
||||
你也可以使用 `ping` 去解析出网站所对应的 IP 地址,如下图所示:
|
||||
|
||||

|
||||
|
||||
### Traceroute
|
||||
|
||||
`ping` 是用于检查端到端的连通性,`traceroute` 实用工具将告诉你到达对端系统、网站、或服务器所经过的路径上所有路由器的 IP 地址。`traceroute` 在网络连接调试中经常用于在 `ping` 之后的第二步。
|
||||
|
||||
这是一个跟踪从你的系统到其它对端的全部网络路径的非常好的工具。在检查端到端的连通性时,这个实用工具将告诉你到达对端系统、网站、或服务器上所经历的路径上的全部路由器的 IP 地址。通常用于网络连通性调试的第二步。
|
||||
|
||||
**语法:**
|
||||
|
||||
* `traceroute <ip address>/<fqdn>`
|
||||
|
||||
|
||||
|
||||
### Telnet
|
||||
|
||||
**语法:**
|
||||
|
||||
* `telnet <ip address>/<fqdn>` 是用于 [telnet][3] 进入任何支持该协议的服务器。
|
||||
|
||||
|
||||
|
||||
### Netstat
|
||||
|
||||
这个网络统计(`netstat`)实用工具是用于去分析解决网络连接问题和检查接口/端口统计数据、路由表、协议状态等等的。它是任何管理员都应该必须掌握的工具。
|
||||
|
||||
**语法:**
|
||||
|
||||
* `netstat -l` 显示所有处于监听状态的端口列表。
|
||||
* `netstat -a` 显示所有端口;如果去指定仅显示 TCP 端口,使用 `-at`(指定信显示 UDP 端口,使用 `-au`)。
|
||||
* `netstat -r` 显示路由表。
|
||||
|
||||

|
||||
|
||||
* `netstat -s` 显示每个协议的状态总结。
|
||||
|
||||

|
||||
|
||||
* `netstat -i` 显示每个接口传输/接收(TX/RX)包的统计数据。
|
||||
|
||||

|
||||
|
||||
### Nmcli
|
||||
|
||||
`nmcli` 是一个管理网络连接、配置等工作的非常好的实用工具。它能够去管理网络管理程序和修改任何设备的网络配置详情。
|
||||
|
||||
**语法:**
|
||||
|
||||
* `nmcli device` 列出网络上的所有设备。
|
||||
|
||||
* `nmcli device show <interface>` 显示指定接口的网络相关的详细情况。
|
||||
|
||||
* `nmcli connection` 检查设备的连接情况。
|
||||
|
||||
* `nmcli connection down <interface>` 关闭指定接口。
|
||||
|
||||
* `nmcli connection up <interface>` 打开指定接口。
|
||||
|
||||
* `nmcli con add type vlan con-name <connection-name> dev <interface> id <vlan-number> ipv4 <ip/cidr> gw4 <gateway-ip>` 在特定的接口上使用指定的 VLAN 号添加一个虚拟局域网(VLAN)接口、IP 地址、和网关。
|
||||
|
||||

|
||||
|
||||
|
||||
### 路由
|
||||
|
||||
检查和配置路由的命令很多。下面是其中一些比较有用的:
|
||||
|
||||
**语法:**
|
||||
|
||||
* `ip route` 显示各自接口上所有当前的路由配置。
|
||||
|
||||

|
||||
|
||||
* `route add default gw <gateway-ip>` 在路由表中添加一个默认的网关。
|
||||
* `route add -net <network ip/cidr> gw <gateway ip> <interface>` 在路由表中添加一个新的网络路由。还有许多其它的路由参数,比如,添加一个默认路由,默认网关等等。
|
||||
* `route del -net <network ip/cidr>` 从路由表中删除一个指定的路由条目。
|
||||
|
||||

|
||||
|
||||
* `ip neighbor` 显示当前的邻接表和用于去添加、改变、或删除新的邻居。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
* `arp` (它的全称是 “地址解析协议”)类似于 `ip neighbor`。`arp` 映射一个系统的 IP 地址到它相应的 MAC(介质访问控制)地址。
|
||||
|
||||

|
||||
|
||||
### Tcpdump 和 Wireshark
|
||||
|
||||
Linux 提供了许多包捕获工具,比如 `tcpdump`、`wireshark`、`tshark` 等等。它们被用于去捕获传输/接收的网络流量中的数据包,因此它们对于系统管理员去诊断丢包或相关问题时非常有用。对于热衷于命令行操作的人来说,`tcpdump` 是一个非常好的工具,而对于喜欢 GUI 操作的用户来说,`wireshark` 是捕获和分析数据包的不二选择。`tcpdump` 是一个 Linux 内置的用于去捕获网络流量的实用工具。它能够用于去捕获/显示特定端口、协议等上的流量。
|
||||
|
||||
**语法:**
|
||||
|
||||
* `tcpdump -i <interface-name>` 显示指定接口上实时通过的数据包。通过在命令中添加一个 `-w` 标志和输出文件的名字,可以将数据包保存到一个文件中。例如:`tcpdump -w <output-file.> -i <interface-name>`。
|
||||
|
||||

|
||||
|
||||
* `tcpdump -i <interface> src <source-ip>` 从指定的源 IP 地址上捕获数据包。
|
||||
* `tcpdump -i <interface> dst <destination-ip>` 从指定的目标 IP 地址上捕获数据包。
|
||||
* `tcpdump -i <interface> port <port-number>` 从一个指定的端口号(比如,53、80、8080 等等)上捕获数据包。
|
||||
* `tcpdump -i <interface> <protocol>` 捕获指定协议的数据包,比如:TCP、UDP、等等。
|
||||
|
||||
|
||||
|
||||
### Iptables
|
||||
|
||||
`iptables` 是一个包过滤防火墙工具,它能够允许或阻止某些流量。这个实用工具的应用范围非常广泛;下面是它的其中一些最常用的使用命令。
|
||||
|
||||
**语法:**
|
||||
|
||||
* `iptables -L` 列出所有已存在的 `iptables` 规则。
|
||||
* `iptables -F` 删除所有已存在的规则。
|
||||
|
||||
|
||||
|
||||
下列命令允许流量从指定端口到指定接口:
|
||||
|
||||
* `iptables -A INPUT -i <interface> -p tcp –dport <port-number> -m state –state NEW,ESTABLISHED -j ACCEPT`
|
||||
* `iptables -A OUTPUT -o <interface> -p tcp -sport <port-number> -m state – state ESTABLISHED -j ACCEPT`
|
||||
|
||||
|
||||
|
||||
下列命令允许<ruby>环回<rt>loopback</rt></ruby>接口访问系统:
|
||||
|
||||
* `iptables -A INPUT -i lo -j ACCEPT`
|
||||
* `iptables -A OUTPUT -o lo -j ACCEPT`
|
||||
|
||||
|
||||
|
||||
### Nslookup
|
||||
|
||||
`nslookup` 工具是用于去获得一个网站或域名所映射的 IP 地址。它也能用于去获得你的 DNS 服务器的信息,比如,一个网站的所有 DNS 记录(具体看下面的示例)。与 `nslookup` 类似的一个工具是 `dig`(Domain Information Groper)实用工具。
|
||||
|
||||
**语法:**
|
||||
|
||||
* `nslookup <website-name.com>` 显示你的服务器组中 DNS 服务器的 IP 地址,它后面就是你想去访问网站的 IP 地址。
|
||||
* `nslookup -type=any <website-name.com>` 显示指定网站/域中所有可用记录。
|
||||
|
||||
|
||||
|
||||
### 网络/接口调试
|
||||
|
||||
下面是用于接口连通性或相关网络问题调试所需的命令和文件的汇总。
|
||||
|
||||
**语法:**
|
||||
|
||||
* `ss` 是一个转储套接字统计数据的实用工具。
|
||||
* `nmap <ip-address>`,它的全称是 “Network Mapper”,它用于扫描网络端口、发现主机、检测 MAC 地址,等等。
|
||||
* `ip addr/ifconfig -a` 提供一个系统上所有接口的 IP 地址和相关信息。
|
||||
* `ssh -vvv user@<ip/domain>` 允许你使用指定的 IP/域名和用户名通过 SSH 协议登入到其它服务器。`-vvv` 标志提供 SSH 登入到服务器过程中的 "最详细的" 信息。
|
||||
* `ethtool -S <interface>` 检查指定接口上的统计数据。
|
||||
* `ifup <interface>` 启动指定的接口。
|
||||
* `ifdown <interface>` 关闭指定的接口
|
||||
* `systemctl restart network` 重启动系统上的一个网络服务。
|
||||
* `/etc/sysconfig/network-scripts/<interface-name>` 是一个对指定的接口设置 IP 地址、网络、网关等等的接口配置文件。DHCP 模式也可以在这里设置。
|
||||
* `/etc/hosts` 这个文件包含自定义的主机/域名到 IP 地址的映射。
|
||||
* `/etc/resolv.conf` 指定系统上的 DNS 服务器的 IP 地址。
|
||||
* `/etc/ntp.conf` 指定 NTP 服务器域名。
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/sysadmin-guide-networking-commands
|
||||
|
||||
作者:[Archit Modi][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/architmodi
|
||||
[1]:https://en.wikipedia.org/wiki/Internet_Control_Message_Protocol
|
||||
[2]:https://opensource.com/article/18/5/how-find-ip-address-linux
|
||||
[3]:https://en.wikipedia.org/wiki/Telnet
|
||||
@ -0,0 +1,118 @@
|
||||
使用 Wttr.in 在你的终端中显示天气预报
|
||||
======
|
||||
**[wttr.in][1] 是一个功能丰富的天气预报服务,它支持在命令行显示天气**。它可以自动检测你的位置(根据你的 IP 地址),支持指定位置或搜索地理位置(如城市、山区等)等。哦,另外**你不需要安装它 - 你只需要使用 cURL 或 Wget**(见下文)。
|
||||
|
||||
wttr.in 功能包括:
|
||||
|
||||
* **显示当前天气以及 3 天天气预报,分为早晨、中午、傍晚和夜晚**(包括温度范围、风速和风向、可见度、降水量和概率)
|
||||
|
||||
* **可以显示月相**
|
||||
|
||||
* **基于你的 IP 地址自动检测位置**
|
||||
|
||||
* **允许指定城市名称、3 字母的机场代码、区域代码、GPS 坐标、IP 地址或域名**。你还可以指定地理位置,如湖泊、山脉、地标等)
|
||||
|
||||
* **支持多语言位置名称**(查询字符串必须以 Unicode 指定)
|
||||
|
||||
* **支持指定**天气预报显示的语言(它支持超过 50 种语言)
|
||||
|
||||
* **it uses USCS units for queries from the USA and the metric system for the rest of the world** , but you can change this by appending `?u` for USCS, and `?m` for the metric system (SI)
|
||||
* **来自美国的查询使用 USCS 单位用于,世界其他地方使用公制系统**,但你可以通过附加 `?u` 使用 USCS,附加 `?m` 使用公制系统。 )
|
||||
|
||||
* **3 种输出格式:终端的 ANSI,浏览器的 HTML 和 PNG**。
|
||||
|
||||
|
||||
|
||||
|
||||
就像我在文章开头提到的那样,使用 wttr.in,你只需要 cURL 或 Wget,但你也可以
|
||||
|
||||
**在使用 wttr.in 之前,请确保已安装 cURL。**在 Debian、Ubuntu 或 Linux Mint(以及其他基于 Debian 或 Ubuntu 的 Linux 发行版)中,使用以下命令安装 cURL:
|
||||
```
|
||||
sudo apt install curl
|
||||
|
||||
```
|
||||
|
||||
### wttr.in 命令行示例
|
||||
|
||||
获取你所在位置的天气(wttr.in 会根据你的 IP 地址猜测你的位置):
|
||||
```
|
||||
curl wttr.in
|
||||
|
||||
```
|
||||
|
||||
通过在 `curl` 之后添加 `-4`,强制 cURL 将名称解析为 IPv4 地址(如果你遇到 IPv6 和 wttr.in 问题):
|
||||
```
|
||||
curl -4 wttr.in
|
||||
|
||||
```
|
||||
|
||||
如果你想检索天气预报保存为 png,**还可以使用 Wget**(而不是 cURL),或者你想这样使用它:
|
||||
```
|
||||
wget -O- -q wttr.in
|
||||
|
||||
```
|
||||
|
||||
如果相对 cURL 你更喜欢 Wget ,可以在下面的所有命令中用 `wget -O- -q` 替换 `curl`。
|
||||
|
||||
指定位置:
|
||||
```
|
||||
curl wttr.in/Dublin
|
||||
|
||||
```
|
||||
|
||||
显示地标的天气信息(本例中为艾菲尔铁塔):
|
||||
```
|
||||
curl wttr.in/~Eiffel+Tower
|
||||
|
||||
```
|
||||
|
||||
获取 IP 地址位置的天气信息(以下 IP 属于 GitHub):
|
||||
```
|
||||
curl wttr.in/@192.30.253.113
|
||||
|
||||
```
|
||||
|
||||
使用 USCS 单位检索天气:
|
||||
```
|
||||
curl wttr.in/Paris?u
|
||||
|
||||
```
|
||||
|
||||
如果你在美国,强制 wttr.in 使用公制系统(SI):
|
||||
```
|
||||
curl wttr.in/New+York?m
|
||||
|
||||
```
|
||||
|
||||
使用 Wget 将当前天气和 3 天预报下载为 PNG 图像:
|
||||
```
|
||||
wget wttr.in/Istanbul.png
|
||||
|
||||
```
|
||||
|
||||
你可以指定 PNG 名称
|
||||
|
||||
**对于其他示例,请查看 wttr.in [项目页面][2]或在终端中输入:**
|
||||
```
|
||||
curl wttr.in/:help
|
||||
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxuprising.com/2018/07/display-weather-forecast-in-your.html
|
||||
|
||||
作者:[Logix][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/118280394805678839070
|
||||
[1]:https://wttr.in/
|
||||
[2]:https://github.com/chubin/wttr.in
|
||||
[3]:https://github.com/chubin/wttr.in#installation
|
||||
[4]:https://github.com/schachmat/wego
|
||||
[5]:https://github.com/chubin/wttr.in#supported-formats
|
||||
@ -1,146 +0,0 @@
|
||||
学习如何使用 Python 构建你自己的 Twitter Bot
|
||||
======
|
||||
|
||||

|
||||
|
||||
Twitter 允许用户向这个世界[分享][1]博客文章。使用 Python 和 Tweepy 拓展使得创建一个 Twitter 机器人来接管你的所有 tweeting 变得非常简单。这篇文章告诉你如何去构建这样一个机器人。希望你能将这些概念也同样应用到其他的在线服务的项目中去。
|
||||
|
||||
### 开始
|
||||
|
||||
[tweepy][2] 拓展可以让创建一个 Twitter 机器人的过程更加容易上手。它包含了 Twitter 的 API 调用和一个很简单的接口
|
||||
|
||||
下面这些命令使用 Pipenv 在一个虚拟环境中安装 tweepy。如果你没有安装 Pipenv,可以看一看我们之前的文章[如何在 Fedora 上安装 Pipenv][3]
|
||||
|
||||
```
|
||||
$ mkdir twitterbot
|
||||
$ cd twitterbot
|
||||
$ pipenv --three
|
||||
$ pipenv install tweepy
|
||||
$ pipenv shell
|
||||
|
||||
```
|
||||
|
||||
### Tweepy – 开始
|
||||
|
||||
要使用 Twitter API ,机器人需要通过 Twitter 的授权。为了解决这个问题, tweepy 使用了 OAuth 授权标准。你可以通过在 <https://apps.twitter.com/> 创建一个新的应用来获取到凭证。
|
||||
|
||||
|
||||
#### 创建一个新的 Twitter 应用
|
||||
|
||||
当你填完了表格并点击了创建你自己的应用的按钮后,你可以获取到应用的凭证。 Tweepy 需要用户密钥 (API Key)和用户密码 (API Secret),这些都可以在 the Keys and Access Tokens 中找到
|
||||
|
||||
![][4]
|
||||
|
||||
向下滚动页面,使用创建我的 Access Token 按钮生成一个 Access Token 和一个 Access Token Secret
|
||||
|
||||
#### 使用 Tweppy —— 输出你的时间线
|
||||
|
||||
现在你已经有了所需的凭证了,打开一个文件,并写下如下的 Python 代码。
|
||||
```
|
||||
import tweepy
|
||||
|
||||
auth = tweepy.OAuthHandler("your_consumer_key", "your_consumer_key_secret")
|
||||
|
||||
auth.set_access_token("your_access_token", "your_access_token_secret")
|
||||
|
||||
api = tweepy.API(auth)
|
||||
|
||||
public_tweets = api.home_timeline()
|
||||
|
||||
for tweet in public_tweets:
|
||||
print(tweet.text)
|
||||
|
||||
```
|
||||
|
||||
在确保你正在使用你的 Pipenv 虚拟环境后,执行你的程序
|
||||
|
||||
```
|
||||
$ python tweet.py
|
||||
|
||||
```
|
||||
|
||||
上述程序调用了 home_timeline 方法来获取到你时间线中的 20 条最近的 tweets。现在这个机器人能够使用 tweepy 来获取到 Twitter 的数据,接下来尝试修改代码来发送 tweet。
|
||||
|
||||
#### 使用 Tweepy —— 发送一条 tweet
|
||||
|
||||
要发送一条 tweet ,有一个容易上手的 API 方法 update_status 。它的用法很简单:
|
||||
|
||||
```
|
||||
api.update_status("The awesome text you would like to tweet")
|
||||
```
|
||||
|
||||
Tweepy 拓展为制作 Twitter 机器人准备了非常多不同有用的方法。获取 API 的详细信息,查看[文档][5]。
|
||||
|
||||
|
||||
### 一个杂志机器人
|
||||
|
||||
接下来我们来创建一个搜索 Fedora Magazine 的 tweets 并转推这些 tweets 的机器人。
|
||||
|
||||
为了避免多次转推相同的内容,这个机器人存放了最近一条转推的 tweet 的 ID 。 两个助手函数 store_last_id 和 get_last_id 将会帮助存储和保存这个 ID。
|
||||
|
||||
然后,机器人使用 tweepy 搜索 API 来查找 Fedora Magazine 的最近的 tweets 并存储这个 ID。
|
||||
|
||||
```
|
||||
import tweepy
|
||||
|
||||
|
||||
def store_last_id(tweet_id):
|
||||
""" Store a tweet id in a file """
|
||||
with open("lastid", "w") as fp:
|
||||
fp.write(str(tweet_id))
|
||||
|
||||
|
||||
def get_last_id():
|
||||
""" Read the last retweeted id from a file """
|
||||
with open("lastid", "r") as fp:
|
||||
return fp.read()
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
|
||||
auth = tweepy.OAuthHandler("your_consumer_key", "your_consumer_key_secret")
|
||||
|
||||
auth.set_access_token("your_access_token", "your_access_token_secret") api = tweepy.API(auth)
|
||||
|
||||
try:
|
||||
last_id = get_last_id()
|
||||
except FileNotFoundError:
|
||||
print("No retweet yet")
|
||||
last_id = None
|
||||
|
||||
for tweet in tweepy.Cursor(api.search, q="fedoramagazine.org", since_id=last_id).items():
|
||||
if tweet.user.name == 'Fedora Project':
|
||||
store_last_id(tweet.id)
|
||||
tweet.retweet()
|
||||
print(f'"{tweet.text}" was retweeted'
|
||||
|
||||
```
|
||||
|
||||
为了只转推 Fedora Magazine 的 tweet ,机器人搜索内容包含 fedoramagazine.org 和由 「Fedora Project」 Twitter 账户发布的 tweets。
|
||||
|
||||
|
||||
|
||||
### 结论
|
||||
|
||||
在这篇文章中你看到了如何使用 tweepy Python 拓展来创建一个自动阅读、发送和搜索 tweets 的 Twitter 应用。现在,你能使用你自己的创造力来创造一个你自己的 Twitter 机器人。
|
||||
|
||||
这篇文章的演示源码可以在 [Github][6] 找到。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/learn-build-twitter-bot-python/
|
||||
|
||||
作者:[Clément Verna][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[Bestony](https://github.com/bestony)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org
|
||||
[1]:https://twitter.com
|
||||
[2]:https://tweepy.readthedocs.io/en/v3.5.0/
|
||||
[3]:https://fedoramagazine.org/install-pipenv-fedora/
|
||||
[4]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-19-20-17-17.png
|
||||
[5]:http://docs.tweepy.org/en/v3.5.0/api.html#id1
|
||||
[6]:https://github.com/cverna/magabot
|
||||
Loading…
Reference in New Issue
Block a user