mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-06 01:20:12 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
2051ab6c8b
@ -0,0 +1,64 @@
|
||||
Open Source Certification: Preparing for the Exam
|
||||
======
|
||||
Open source is the new normal in tech today, with open components and platforms driving mission-critical processes at organizations everywhere. As open source has become more pervasive, it has also profoundly impacted the job market. Across industries [the skills gap is widening, making it ever more difficult to hire people][1] with much needed job skills. That’s why open source training and certification are more important than ever, and this series aims to help you learn more and achieve your own certification goals.
|
||||
|
||||
In the [first article in the series][2], we explored why certification matters so much today. In the [second article][3], we looked at the kinds of certifications that are making a difference. This story will focus on preparing for exams, what to expect during an exam, and how testing for open source certification differs from traditional types of testing.
|
||||
|
||||
Clyde Seepersad, General Manager of Training and Certification at The Linux Foundation, stated, “For many of you, if you take the exam, it may well be the first time that you've taken a performance-based exam and it is quite different from what you might have been used to with multiple choice, where the answer is on screen and you can identify it. In performance-based exams, you get what's called a prompt.”
|
||||
|
||||
As a matter of fact, many Linux-focused certification exams literally prompt test takers at the command line. The idea is to demonstrate skills in real time in a live environment, and the best preparation for this kind of exam is practice, backed by training.
|
||||
|
||||
### Know the requirements
|
||||
|
||||
"Get some training," Seepersad emphasized. "Get some help to make sure that you're going to do well. We sometimes find folks have very deep skills in certain areas, but then they're light in other areas. If you go to the website for [Linux Foundation training and certification][4], for the [LFCS][5] and the [LFCE][6] certifications, you can scroll down the page and see the details of the domains and tasks, which represent the knowledge areas you're supposed to know.”
|
||||
|
||||
Once you’ve identified the skills you need, “really spend some time on those and try to identify whether you think there are areas where you have gaps. You can figure out what the right training or practice regimen is going to be to help you get prepared to take the exam," Seepersad said.
|
||||
|
||||
### Practice, practice, practice
|
||||
|
||||
"Practice is important, of course, for all exams," he added. "We deliver the exams in a bit of a unique way -- through your browser. We're using a terminal emulator on your browser and you're being proctored, so there's a live human who is watching you via video cam, your screen is being recorded, and you're having to work through the exam console using the browser window. You're going to be asked to do something live on the system, and then at the end, we're going to evaluate that system to see if you were successful in accomplishing the task"
|
||||
|
||||
What if you run out of time on your exam, or simply don’t pass because you couldn’t perform the required skills? “I like the phrase, exam insurance,” Seepersad said. “The way we take the stress out is by offering a ‘no questions asked’ retake. If you take either exam, LFCS, LFCE and you do not pass on your first attempt, you are automatically eligible to have a free second attempt.”
|
||||
|
||||
The Linux Foundation intentionally maintains separation between its training and certification programs and uses an independent proctoring solution to monitor candidates. It also requires that all certifications be renewed every two years, which gives potential employers confidence that skills are current and have been recently demonstrated.
|
||||
|
||||
### Free certification guide
|
||||
|
||||
Becoming a Linux Foundation Certified System Administrator or Engineer is no small feat, so the Foundation has created [this free certification guide][7] to help you with your preparation. In this guide, you’ll find:
|
||||
|
||||
* Critical things to keep in mind on test day
|
||||
|
||||
|
||||
* An array of both free and paid study resources to help you be as prepared as possible
|
||||
|
||||
* A few tips and tricks that could make the difference at exam time
|
||||
|
||||
* A checklist of all the domains and competencies covered in the exam
|
||||
|
||||
|
||||
|
||||
|
||||
With certification playing a more important role in securing a rewarding long-term career, careful planning and preparation are key. Stay tuned for the next article in this series that will answer frequently asked questions pertaining to open source certification and training.
|
||||
|
||||
[Learn more about Linux training and certification.][8]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/sysadmin-cert/2018/7/open-source-certification-preparing-exam
|
||||
|
||||
作者:[Sam Dean][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/sam-dean
|
||||
[1]:https://www.linux.com/blog/os-jobs-report/2017/9/demand-open-source-skills-rise
|
||||
[2]:https://www.linux.com/blog/sysadmin-cert/2018/7/5-reasons-open-source-certification-matters-more-ever
|
||||
[3]:https://www.linux.com/blog/sysadmin-cert/2018/7/tips-success-open-source-certification
|
||||
[4]:https://training.linuxfoundation.org/
|
||||
[5]:https://training.linuxfoundation.org/certification/linux-foundation-certified-sysadmin-lfcs/
|
||||
[6]:https://training.linuxfoundation.org/certification/linux-foundation-certified-engineer-lfce/
|
||||
[7]:https://training.linuxfoundation.org/download-free-certification-prep-guide
|
||||
[8]:https://training.linuxfoundation.org/certification/
|
||||
@ -0,0 +1,71 @@
|
||||
Why moving all your workloads to the cloud is a bad idea
|
||||
======
|
||||
|
||||

|
||||
|
||||
As we've been exploring in this series, cloud hype is everywhere, telling you that migrating your applications to the cloud—including hybrid cloud and multicloud—is the way to ensure a digital future for your business. This hype rarely dives into the pitfalls of moving to the cloud, nor considers the daily work of enhancing your customer's experience and agile delivery of new and legacy applications.
|
||||
|
||||
In [part one][1] of this series, we covered basic definitions (to level the playing field). We outlined our views on hybrid cloud and multi-cloud, making sure to show the dividing lines between the two. This set the stage for [part two][2], where we discussed the first of three pitfalls: Why cost is not always the obvious motivator for moving to the cloud.
|
||||
|
||||
In part three, we'll look at the second pitfall: Why moving all your workloads to the cloud is a bad idea.
|
||||
|
||||
### Everything's better in the cloud?
|
||||
|
||||
There's a misconception that everything will benefit from running in the cloud. All workloads are not equal, and not all workloads will see a measurable effect on the bottom line from moving to the cloud.
|
||||
|
||||
As [InformationWeek wrote][3], "Not all business applications should migrate to the cloud, and enterprises must determine which apps are best suited to a cloud environment." This is a hard fact that the utility company in part two of this series learned when labor costs rose while trying to move applications to the cloud. Discovering this was not a viable solution, the utility company backed up and reevaluated its applications. It found some applications were not heavily used and others had data ownership and compliance issues. Some of its applications were not certified for use in a cloud environment.
|
||||
|
||||
Sometimes running applications in the cloud is not physically possible, but other times it's not financially viable to run in the cloud.
|
||||
|
||||
Imagine a fictional online travel company. As its business grew, it expanded its on-premises hosting capacity to over 40,000 servers. It eventually became a question of expanding resources by purchasing a data center at a time, not a rack at a time. Its business consumes bandwidth at such volumes that cloud pricing models based on bandwidth usage remain prohibitive.
|
||||
|
||||
### Get a baseline
|
||||
|
||||
Sometimes running applications in the cloud is not physically possible, but other times it's not financially viable to run in the cloud.
|
||||
|
||||
As these examples show, nothing is more important than having a thorough understanding of your application landscape. Along with a having good understanding of what applications need to migrate to the cloud, you also need to understand current IT environments, know your present level of resources, and estimate your costs for moving.
|
||||
|
||||
As these examples show, nothing is more important than having a thorough understanding of your application landscape. Along with a having good understanding of what applications need to migrate to the cloud, you also need to understand current IT environments, know your present level of resources, and estimate your costs for moving.
|
||||
|
||||
Understanding your baseline–each application's current situation and performance requirements (network, storage, CPU, memory, application and infrastructure behavior under load, etc.)–gives you the tools to make the right decision.
|
||||
|
||||
If you're running servers with single-digit CPU utilization due to complex acquisition processes, a cloud with on-demand resourcing might be a great idea. However, first ask these questions:
|
||||
|
||||
* How long did this low-utilization exist?
|
||||
* Why wasn't it caught earlier?
|
||||
* Isn't there a process or effective monitoring in place?
|
||||
* Do you really need a cloud to fix this? Or just a better process for both getting and managing your resources?
|
||||
* Will you have a better process in the cloud?
|
||||
|
||||
|
||||
|
||||
### Are containers necessary?
|
||||
|
||||
Many believe you need containers to be successful in the cloud. This popular [catchphrase][4] sums it up nicely, "We crammed this monolith into a container and called it a microservice."
|
||||
|
||||
Containers are a means to an end, and using containers doesn't mean your organization is capable of running maturely in the cloud. It's not about the technology involved, it's about applications that often were written in days gone by with technology that's now outdated. If you put a tire fire into a container and then put that container on a container platform to ship, it's still functionality that someone is using.
|
||||
|
||||
Is that fire easier to extinguish now? These container fires just create more challenges for your DevOps teams, who are already struggling to keep up with all the changes being pushed through an organization moving everything into the cloud.
|
||||
|
||||
Note, it's not necessarily a bad decision to move legacy workloads into the cloud, nor is it a bad idea to containerize them. It's about weighing the benefits and the downsides, assessing the options available, and making the right choices for each of your workloads.
|
||||
|
||||
### Coming up
|
||||
|
||||
In part four of this series, we'll describe the third and final pitfall everyone should avoid with hybrid multi-cloud. Find out what the cloud means for your data.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/why-you-cant-move-everything-cloud
|
||||
|
||||
作者:[Eric D.Schabell][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/eschabell
|
||||
[1]:https://opensource.com/article/18/4/pitfalls-hybrid-multi-cloud
|
||||
[2]:https://opensource.com/article/18/6/reasons-move-to-cloud
|
||||
[3]:https://www.informationweek.com/cloud/10-cloud-migration-mistakes-to-avoid/d/d-id/1318829
|
||||
[4]:https://speakerdeck.com/caseywest/containercon-north-america-cloud-anti-patterns?slide=22
|
||||
@ -1,450 +0,0 @@
|
||||
MjSeven is translating
|
||||
|
||||
|
||||
Docker Guide: Dockerizing Python Django Application
|
||||
============================================================
|
||||
|
||||
### On this page
|
||||
|
||||
1. [What we will do?][6]
|
||||
|
||||
2. [Step 1 - Install Docker-ce][7]
|
||||
|
||||
3. [Step 2 - Install Docker-compose][8]
|
||||
|
||||
4. [Step 3 - Configure Project Environment][9]
|
||||
1. [Create a New requirements.txt file][1]
|
||||
|
||||
2. [Create the Nginx virtual host file django.conf][2]
|
||||
|
||||
3. [Create the Dockerfile][3]
|
||||
|
||||
4. [Create Docker-compose script][4]
|
||||
|
||||
5. [Configure Django project][5]
|
||||
|
||||
5. [Step 4 - Build and Run the Docker image][10]
|
||||
|
||||
6. [Step 5 - Testing][11]
|
||||
|
||||
7. [Reference][12]
|
||||
|
||||
Docker is an open-source project that provides an open platform for developers and sysadmins to build, package, and run applications anywhere as a lightweight container. Docker automates the deployment of applications inside software containers.
|
||||
|
||||
Django is a web application framework written in python that follows the MVC (Model-View-Controller) architecture. It is available for free and released under an open source license. It is fast and designed to help developers get their application online as quickly as possible.
|
||||
|
||||
In this tutorial, I will show you step-by-step how to create a docker image for an existing Django application project in Ubuntu 16.04\. We will learn about dockerizing a python Django application, and then deploy the application as a container to the docker environment using a docker-compose script.
|
||||
|
||||
In order to deploy our python Django application, we need additional docker images. We need an nginx docker image for the web server and PostgreSQL image for the database.
|
||||
|
||||
### What we will do?
|
||||
|
||||
1. Install Docker-ce
|
||||
|
||||
2. Install Docker-compose
|
||||
|
||||
3. Configure Project Environment
|
||||
|
||||
4. Build and Run
|
||||
|
||||
5. Testing
|
||||
|
||||
### Step 1 - Install Docker-ce
|
||||
|
||||
In this tutorial, we will install docker-ce community edition from the docker repository. We will install docker-ce community edition and docker-compose that support compose file version 3.
|
||||
|
||||
Before installing docker-ce, install docker dependencies needed using the apt command.
|
||||
|
||||
```
|
||||
sudo apt install -y \
|
||||
apt-transport-https \
|
||||
ca-certificates \
|
||||
curl \
|
||||
software-properties-common
|
||||
```
|
||||
|
||||
Now add the docker key and repository by running commands below.
|
||||
|
||||
```
|
||||
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
|
||||
sudo add-apt-repository \
|
||||
"deb [arch=amd64] https://download.docker.com/linux/ubuntu \
|
||||
$(lsb_release -cs) \
|
||||
stable"
|
||||
```
|
||||
|
||||
[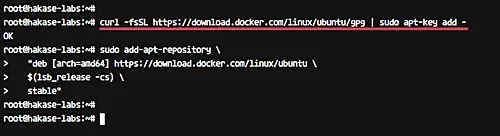][14]
|
||||
|
||||
Update the repository and install docker-ce.
|
||||
|
||||
```
|
||||
sudo apt update
|
||||
sudo apt install -y docker-ce
|
||||
```
|
||||
|
||||
After the installation is complete, start the docker service and enable it to launch every time at system boot.
|
||||
|
||||
```
|
||||
systemctl start docker
|
||||
systemctl enable docker
|
||||
```
|
||||
|
||||
Next, we will add a new user named 'omar' and add it to the docker group.
|
||||
|
||||
```
|
||||
useradd -m -s /bin/bash omar
|
||||
usermod -a -G docker omar
|
||||
```
|
||||
|
||||
[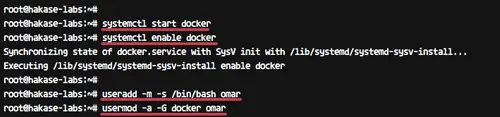][15]
|
||||
|
||||
Login as the omar user and run docker command as shown below.
|
||||
|
||||
```
|
||||
su - omar
|
||||
docker run hello-world
|
||||
```
|
||||
|
||||
Make sure you get the hello-world message from Docker.
|
||||
|
||||
[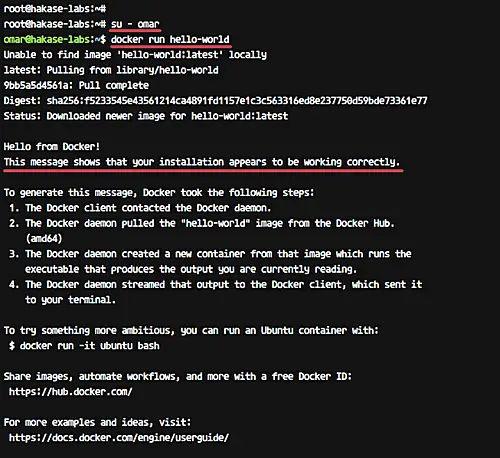][16]
|
||||
|
||||
Docker-ce installation has been completed.
|
||||
|
||||
### Step 2 - Install Docker-compose
|
||||
|
||||
In this tutorial, we will be using the latest docker-compose support for compose file version 3\. We will install docker-compose manually.
|
||||
|
||||
Download the latest version of docker-compose using curl command to the '/usr/local/bin' directory and make it executable using chmod.
|
||||
|
||||
Run commands below.
|
||||
|
||||
```
|
||||
sudo curl -L https://github.com/docker/compose/releases/download/1.21.0/docker-compose-$(uname -s)-$(uname -m) -o /usr/local/bin/docker-compose
|
||||
sudo chmod +x /usr/local/bin/docker-compose
|
||||
```
|
||||
|
||||
Now check the docker-compose version.
|
||||
|
||||
```
|
||||
docker-compose version
|
||||
```
|
||||
|
||||
And make sure you get the latest version of the docker-compose 1.21.
|
||||
|
||||
[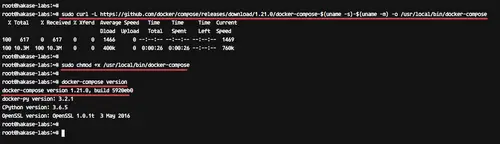][17]
|
||||
|
||||
The docker-compose latest version that supports compose file version 3 has been installed.
|
||||
|
||||
### Step 3 - Configure Project Environment
|
||||
|
||||
In this step, we will configure the python Django project environment. We will create new directory 'guide01' and make it as the main directory for our project files, such as a Dockerfile, Django project, nginx configuration file etc.
|
||||
|
||||
Login to the 'omar' user.
|
||||
|
||||
```
|
||||
su - omar
|
||||
```
|
||||
|
||||
Create new directory 'guide01' and go to the directory.
|
||||
|
||||
```
|
||||
mkdir -p guide01
|
||||
cd guide01/
|
||||
```
|
||||
|
||||
Now inside the 'guide01' directory, create new directories 'project' and 'config'.
|
||||
|
||||
```
|
||||
mkdir project/ config/
|
||||
```
|
||||
|
||||
Note:
|
||||
|
||||
* Directory 'project': All our python Django project files will be placed in that directory.
|
||||
|
||||
* Directory 'config': Directory for the project configuration files, including nginx configuration file, python pip requirements file etc.
|
||||
|
||||
### Create a New requirements.txt file
|
||||
|
||||
Next, create new file 'requirements.txt' inside the 'config' directory using vim command.
|
||||
|
||||
```
|
||||
vim config/requirements.txt
|
||||
```
|
||||
|
||||
Paste the configuration below.
|
||||
|
||||
```
|
||||
Django==2.0.4
|
||||
gunicorn==19.7.0
|
||||
psycopg2==2.7.4
|
||||
```
|
||||
|
||||
Save and exit.
|
||||
|
||||
### Create the Nginx virtual host file django.conf
|
||||
|
||||
Under the config directory, create the 'nginx' configuration directory and add the virtual host configuration file django.conf.
|
||||
|
||||
```
|
||||
mkdir -p config/nginx/
|
||||
vim config/nginx/django.conf
|
||||
```
|
||||
|
||||
Paste the following configuration there.
|
||||
|
||||
```
|
||||
upstream web {
|
||||
ip_hash;
|
||||
server web:8000;
|
||||
}
|
||||
|
||||
# portal
|
||||
server {
|
||||
location / {
|
||||
proxy_pass http://web/;
|
||||
}
|
||||
listen 8000;
|
||||
server_name localhost;
|
||||
|
||||
location /static {
|
||||
autoindex on;
|
||||
alias /src/static/;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Save and exit.
|
||||
|
||||
### Create the Dockerfile
|
||||
|
||||
Create new 'Dockerfile' inside the 'guide01' directory.
|
||||
|
||||
Run the command below.
|
||||
|
||||
```
|
||||
vim Dockerfile
|
||||
```
|
||||
|
||||
Now paste Dockerfile script below.
|
||||
|
||||
```
|
||||
FROM python:3.5-alpine
|
||||
ENV PYTHONUNBUFFERED 1
|
||||
|
||||
RUN apk update && \
|
||||
apk add --virtual build-deps gcc python-dev musl-dev && \
|
||||
apk add postgresql-dev bash
|
||||
|
||||
RUN mkdir /config
|
||||
ADD /config/requirements.txt /config/
|
||||
RUN pip install -r /config/requirements.txt
|
||||
RUN mkdir /src
|
||||
WORKDIR /src
|
||||
```
|
||||
|
||||
Save and exit.
|
||||
|
||||
Note:
|
||||
|
||||
We want to build the Docker images for our Django project based on Alpine Linux, the smallest size of Linux. Our Django project will run Alpine Linux with python 3.5 installed on top of it and add the postgresql-dev package for the PostgreSQL database support. And then we will install all python packages listed on the 'requirements.txt' file using python pip command, and create new '/src' for our project.
|
||||
|
||||
### Create Docker-compose script
|
||||
|
||||
Create the 'docker-compose.yml' file under the 'guide01' directory using [vim][18] command below.
|
||||
|
||||
```
|
||||
vim docker-compose.yml
|
||||
```
|
||||
|
||||
Paste the following configuration there.
|
||||
|
||||
```
|
||||
version: '3'
|
||||
services:
|
||||
db:
|
||||
image: postgres:10.3-alpine
|
||||
container_name: postgres01
|
||||
nginx:
|
||||
image: nginx:1.13-alpine
|
||||
container_name: nginx01
|
||||
ports:
|
||||
- "8000:8000"
|
||||
volumes:
|
||||
- ./project:/src
|
||||
- ./config/nginx:/etc/nginx/conf.d
|
||||
depends_on:
|
||||
- web
|
||||
web:
|
||||
build: .
|
||||
container_name: django01
|
||||
command: bash -c "python manage.py makemigrations && python manage.py migrate && python manage.py collectstatic --noinput && gunicorn hello_django.wsgi -b 0.0.0.0:8000"
|
||||
depends_on:
|
||||
- db
|
||||
volumes:
|
||||
- ./project:/src
|
||||
expose:
|
||||
- "8000"
|
||||
restart: always
|
||||
```
|
||||
|
||||
Save and exit.
|
||||
|
||||
Note:
|
||||
|
||||
With this docker-compose file script, we will create three services. Create the database service named 'db' using the PostgreSQL alpine Linux, create the 'nginx' service using the Nginx alpine Linux again, and create our python Django container using the custom docker images generated from our Dockerfile.
|
||||
|
||||
[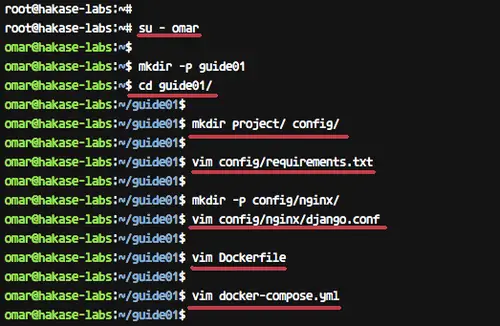][19]
|
||||
|
||||
### Configure Django project
|
||||
|
||||
Copy your Django project files to the 'project' directory.
|
||||
|
||||
```
|
||||
cd ~/django
|
||||
cp -r * ~/guide01/project/
|
||||
```
|
||||
|
||||
Go to the 'project' directory and edit the application setting 'settings.py'.
|
||||
|
||||
```
|
||||
cd ~/guide01/project/
|
||||
vim hello_django/settings.py
|
||||
```
|
||||
|
||||
Note:
|
||||
|
||||
We will deploy simple Django application called 'hello_django' app.
|
||||
|
||||
On the 'ALLOW_HOSTS' line, add the service name 'web'.
|
||||
|
||||
```
|
||||
ALLOW_HOSTS = ['web']
|
||||
```
|
||||
|
||||
Now change the database settings. We will be using the PostgreSQL database that runs as a service named 'db' with default user and password.
|
||||
|
||||
```
|
||||
DATABASES = {
|
||||
'default': {
|
||||
'ENGINE': 'django.db.backends.postgresql_psycopg2',
|
||||
'NAME': 'postgres',
|
||||
'USER': 'postgres',
|
||||
'HOST': 'db',
|
||||
'PORT': 5432,
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
And for the 'STATIC_ROOT' configuration directory, add this line to the end of the line of the file.
|
||||
|
||||
```
|
||||
STATIC_ROOT = os.path.join(BASE_DIR, 'static/')
|
||||
```
|
||||
|
||||
Save and exit.
|
||||
|
||||
[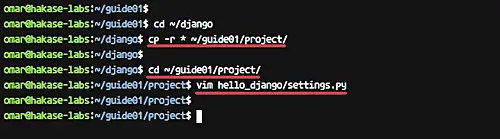][20]
|
||||
|
||||
Now we're ready to build and run the Django project under the docker container.
|
||||
|
||||
### Step 4 - Build and Run the Docker image
|
||||
|
||||
In this step, we want to build a Docker image for our Django project using the configuration on the 'guide01' directory.
|
||||
|
||||
Go to the 'guide01' directory.
|
||||
|
||||
```
|
||||
cd ~/guide01/
|
||||
```
|
||||
|
||||
Now build the docker images using the docker-compose command.
|
||||
|
||||
```
|
||||
docker-compose build
|
||||
```
|
||||
|
||||
[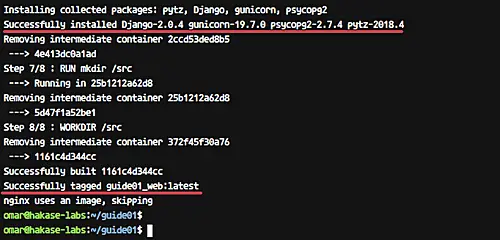][21]
|
||||
|
||||
Start all services inside the docker-compose script.
|
||||
|
||||
```
|
||||
docker-compose up -d
|
||||
```
|
||||
|
||||
Wait for some minutes for Docker to build our Python image and download the nginx and postgresql docker images.
|
||||
|
||||
[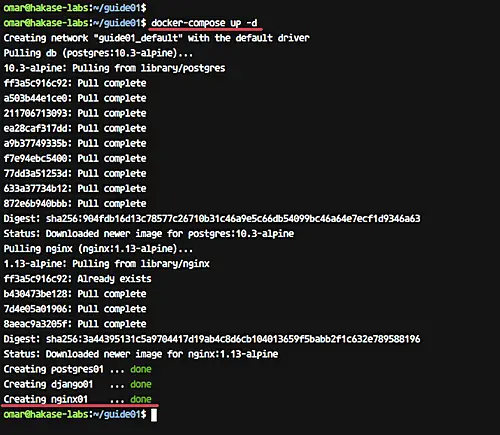][22]
|
||||
|
||||
And when it's complete, check running container and list docker images on the system using following commands.
|
||||
|
||||
```
|
||||
docker-compose ps
|
||||
docker-compose images
|
||||
```
|
||||
|
||||
And now you will get three containers running and list of Docker images on the system as shown below.
|
||||
|
||||
[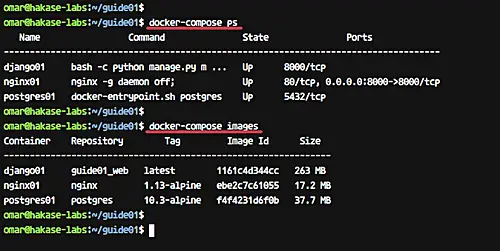][23]
|
||||
|
||||
Our Python Django Application is now running inside the docker container, and docker images for our service have been created.
|
||||
|
||||
### Step 5 - Testing
|
||||
|
||||
Open your web browser and type the server address with port 8000, mine is: http://ovh01:8000/
|
||||
|
||||
Now you will get the default Django home page.
|
||||
|
||||
[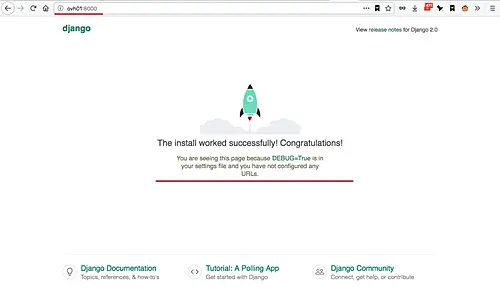][24]
|
||||
|
||||
Next, test the admin page by adding the '/admin' path on the URL.
|
||||
|
||||
http://ovh01:8000/admin/
|
||||
|
||||
And you will see the Django admin login page.
|
||||
|
||||
[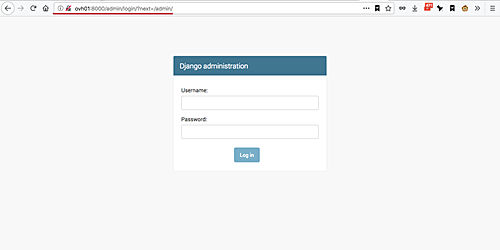][25]
|
||||
|
||||
The Dockerizing Python Django Application has been completed successfully.
|
||||
|
||||
### Reference
|
||||
|
||||
* [https://docs.docker.com/][13]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/
|
||||
|
||||
作者:[Muhammad Arul][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/
|
||||
[1]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/#create-a-new-requirementstxt-file
|
||||
[2]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/#create-the-nginx-virtual-host-file-djangoconf
|
||||
[3]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/#create-the-dockerfile
|
||||
[4]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/#create-dockercompose-script
|
||||
[5]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/#configure-django-project
|
||||
[6]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/#what-we-will-do
|
||||
[7]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/#step-install-dockerce
|
||||
[8]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/#step-install-dockercompose
|
||||
[9]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/#step-configure-project-environment
|
||||
[10]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/#step-build-and-run-the-docker-image
|
||||
[11]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/#step-testing
|
||||
[12]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/#reference
|
||||
[13]:https://docs.docker.com/
|
||||
[14]:https://www.howtoforge.com/images/docker_guide_dockerizing_python_django_application/big/1.png
|
||||
[15]:https://www.howtoforge.com/images/docker_guide_dockerizing_python_django_application/big/2.png
|
||||
[16]:https://www.howtoforge.com/images/docker_guide_dockerizing_python_django_application/big/3.png
|
||||
[17]:https://www.howtoforge.com/images/docker_guide_dockerizing_python_django_application/big/4.png
|
||||
[18]:https://www.howtoforge.com/vim-basics
|
||||
[19]:https://www.howtoforge.com/images/docker_guide_dockerizing_python_django_application/big/5.png
|
||||
[20]:https://www.howtoforge.com/images/docker_guide_dockerizing_python_django_application/big/6.png
|
||||
[21]:https://www.howtoforge.com/images/docker_guide_dockerizing_python_django_application/big/7.png
|
||||
[22]:https://www.howtoforge.com/images/docker_guide_dockerizing_python_django_application/big/8.png
|
||||
[23]:https://www.howtoforge.com/images/docker_guide_dockerizing_python_django_application/big/9.png
|
||||
[24]:https://www.howtoforge.com/images/docker_guide_dockerizing_python_django_application/big/10.png
|
||||
[25]:https://www.howtoforge.com/images/docker_guide_dockerizing_python_django_application/big/11.png
|
||||
@ -1,3 +1,5 @@
|
||||
translating by bestony
|
||||
|
||||
How to use Fio (Flexible I/O Tester) to Measure Disk Performance in Linux
|
||||
======
|
||||

|
||||
|
||||
322
sources/tech/20180705 Testing Node.js in 2018.md
Normal file
322
sources/tech/20180705 Testing Node.js in 2018.md
Normal file
@ -0,0 +1,322 @@
|
||||
BriFuture is translating
|
||||
|
||||
|
||||
Testing Node.js in 2018
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
[Stream][4] powers feeds for over 300+ million end users. With all of those users relying on our infrastructure, we’re very good about testing everything that gets pushed into production. Our primary codebase is written in Go, with some remaining bits of Python.
|
||||
|
||||
Our recent showcase application, [Winds 2.0][5], is built with Node.js and we quickly learned that our usual testing methods in Go and Python didn’t quite fit. Furthermore, creating a proper test suite requires a bit of upfront work in Node.js as the frameworks we are using don’t offer any type of built-in test functionality.
|
||||
|
||||
Setting up a good test framework can be tricky regardless of what language you’re using. In this post, we’ll uncover the hard parts of testing with Node.js, the various tooling we decided to utilize in Winds 2.0, and point you in the right direction for when it comes time for you to write your next set of tests.
|
||||
|
||||
### Why Testing is so Important
|
||||
|
||||
We’ve all pushed a bad commit to production and faced the consequences. It’s not a fun thing to have happen. Writing a solid test suite is not only a good sanity check, but it allows you to completely refactor code and feel confident that your codebase is still functional. This is especially important if you’ve just launched.
|
||||
|
||||
If you’re working with a team, it’s extremely important that you have test coverage. Without it, it’s nearly impossible for other developers on the team to know if their contributions will result in a breaking change (ouch).
|
||||
|
||||
Writing tests also encourage you and your teammates to split up code into smaller pieces. This makes it much easier to understand your code, and fix bugs along the way. The productivity gains are even bigger, due to the fact that you catch bugs early on.
|
||||
|
||||
Finally, without tests, your codebase might as well be a house of cards. There is simply zero certainty that your code is stable.
|
||||
|
||||
### The Hard Parts
|
||||
|
||||
In my opinion, most of the testing problems we ran into with Winds were specific to Node.js. The ecosystem is always growing. For example, if you are on macOS and run “brew upgrade” (with homebrew installed), your chances of seeing a new version of Node.js are quite high. With Node.js moving quickly and libraries following close behind, keeping up to date with the latest libraries is difficult.
|
||||
|
||||
Below are a few pain points that immediately come to mind:
|
||||
|
||||
1. Testing in Node.js is very opinionated and un-opinionated at the same time. Many people have different views on how a test infrastructure should be built and measured for success. The sad part is that there is no golden standard (yet) for how you should approach testing.
|
||||
|
||||
2. There are a large number of frameworks available to use in your application. However, they are generally minimal with no well-defined configuration or boot process. This leads to side effects that are very common, and yet hard to diagnose; so, you’ll likely end up writing your own test runner from scratch.
|
||||
|
||||
3. It’s almost guaranteed that you will be _required_ to write your own test runner (we’ll get to this in a minute).
|
||||
|
||||
The situations listed above are not ideal and it’s something that the Node.js community needs to address sooner rather than later. If other languages have figured it out, I think it’s time for Node.js, a widely adopted language, to figure it out as well.
|
||||
|
||||
### Writing Your Own Test Runner
|
||||
|
||||
So… you’re probably wondering what a test runner _is_ . To be honest, it’s not that complicated. A test runner is the highest component in the test suite. It allows for you to specify global configurations and environments, as well as import fixtures. One would assume this would be simple and easy to do… Right? Not so fast…
|
||||
|
||||
What we learned is that, although there is a solid number of test frameworks out there, not a single one for Node.js provides a unified way to construct your test runner. Sadly, it’s up to the developer to do so. Here’s a quick breakdown of the requirements for a test runner:
|
||||
|
||||
* Ability to load different configurations (e.g. local, test, development) and ensure that you _NEVER_ load a production configuration — you can guess what goes wrong when that happens.
|
||||
|
||||
* Lift and seed a database with dummy data for testing. This must work for various databases, whether it be MySQL, PostgreSQL, MongoDB, or any other, for that matter.
|
||||
|
||||
* Ability to load fixtures (files with seed data for testing in a development environment).
|
||||
|
||||
With Winds, we chose to use Mocha as our test runner. Mocha provides an easy and programmatic way to run tests on an ES6 codebase via command-line tools (integrated with Babel).
|
||||
|
||||
To kick off the tests, we register the Babel module loader ourselves. This provides us with finer grain greater control over which modules are imported before Babel overrides Node.js module loading process, giving us the opportunity to mock modules before any tests are run.
|
||||
|
||||
Additionally, we also use Mocha’s test runner feature to pre-assign HTTP handlers to specific requests. We do this because the normal initialization code is not run during tests (server interactions are mocked by the Chai HTTP plugin) and run some safety check to ensure we are not connecting to production databases.
|
||||
|
||||
While this isn’t part of the test runner, having a fixture loader is an important part of our test suite. We examined existing solutions; however, we settled on writing our own helper so that it was tailored to our requirements. With our solution, we can load fixtures with complex data-dependencies by following an easy ad-hoc convention when generating or writing fixtures by hand.
|
||||
|
||||
### Tooling for Winds
|
||||
|
||||
Although the process was cumbersome, we were able to find the right balance of tools and frameworks to make proper testing become a reality for our backend API. Here’s what we chose to go with:
|
||||
|
||||
### Mocha ☕
|
||||
|
||||
[Mocha][6], described as a “feature-rich JavaScript test framework running on Node.js”, was our immediate choice of tooling for the job. With well over 15k stars, many backers, sponsors, and contributors, we knew it was the right framework for the job.
|
||||
|
||||
### Chai 🥃
|
||||
|
||||
Next up was our assertion library. We chose to go with the traditional approach, which is what works best with Mocha — [Chai][7]. Chai is a BDD and TDD assertion library for Node.js. With a simple API, Chai was easy to integrate into our application and allowed for us to easily assert what we should _expect_ tobe returned from the Winds API. Best of all, writing tests feel natural with Chai. Here’s a short example:
|
||||
|
||||
```
|
||||
describe('retrieve user', () => {
|
||||
let user;
|
||||
|
||||
before(async () => {
|
||||
await loadFixture('user');
|
||||
user = await User.findOne({email: authUser.email});
|
||||
expect(user).to.not.be.null;
|
||||
});
|
||||
|
||||
after(async () => {
|
||||
await User.remove().exec();
|
||||
});
|
||||
|
||||
describe('valid request', () => {
|
||||
it('should return 200 and the user resource, including the email field, when retrieving the authenticated user', async () => {
|
||||
const response = await withLogin(request(api).get(`/users/${user._id}`), authUser);
|
||||
|
||||
expect(response).to.have.status(200);
|
||||
expect(response.body._id).to.equal(user._id.toString());
|
||||
});
|
||||
|
||||
it('should return 200 and the user resource, excluding the email field, when retrieving another user', async () => {
|
||||
const anotherUser = await User.findOne({email: 'another_user@email.com'});
|
||||
|
||||
const response = await withLogin(request(api).get(`/users/${anotherUser.id}`), authUser);
|
||||
|
||||
expect(response).to.have.status(200);
|
||||
expect(response.body._id).to.equal(anotherUser._id.toString());
|
||||
expect(response.body).to.not.have.an('email');
|
||||
});
|
||||
|
||||
});
|
||||
|
||||
describe('invalid requests', () => {
|
||||
|
||||
it('should return 404 if requested user does not exist', async () => {
|
||||
const nonExistingId = '5b10e1c601e9b8702ccfb974';
|
||||
expect(await User.findOne({_id: nonExistingId})).to.be.null;
|
||||
|
||||
const response = await withLogin(request(api).get(`/users/${nonExistingId}`), authUser);
|
||||
expect(response).to.have.status(404);
|
||||
});
|
||||
});
|
||||
|
||||
});
|
||||
```
|
||||
|
||||
### Sinon 🧙
|
||||
|
||||
With the ability to work with any unit testing framework, [Sinon][8] was our first choice for a mocking library. Again, a super clean integration with minimal setup, Sinon turns mocking requests into a simple and easy process. Their website has an extremely friendly user experience and offers up easy steps to integrate Sinon with your test suite.
|
||||
|
||||
### Nock 🔮
|
||||
|
||||
For all external HTTP requests, we use [nock][9], a robust HTTP mocking library that really comes in handy when you have to communicate with a third party API (such as [Stream’s REST API][10]). There’s not much to say about this little library aside from the fact that it is awesome at what it does, and that’s why we like it. Here’s a quick example of us calling our [personalization][11] engine for Stream:
|
||||
|
||||
```
|
||||
nock(config.stream.baseUrl)
|
||||
.get(/winds_article_recommendations/)
|
||||
.reply(200, { results: [{foreign_id:`article:${article.id}`}] });
|
||||
```
|
||||
|
||||
### Mock-require 🎩
|
||||
|
||||
The library [mock-require][12] allows dependencies on external code. In a single line of code, you can replace a module and mock-require will step in when some code attempts to import that module. It’s a small and minimalistic, but robust library, and we’re big fans.
|
||||
|
||||
### Istanbul 🔭
|
||||
|
||||
[Istanbul][13] is a JavaScript code coverage tool that computes statement, line, function and branch coverage with module loader hooks to transparently add coverage when running tests. Although we have similar functionality with CodeCov (see next section), this is a nice tool to have when running tests locally.
|
||||
|
||||
### The End Result — Working Tests
|
||||
|
||||
_With all of the libraries, including the test runner mentioned above, let’s have a look at what a full test looks like (you can have a look at our entire test suite _ [_here_][14] _):_
|
||||
|
||||
```
|
||||
import nock from 'nock';
|
||||
import { expect, request } from 'chai';
|
||||
|
||||
import api from '../../src/server';
|
||||
import Article from '../../src/models/article';
|
||||
import config from '../../src/config';
|
||||
import { dropDBs, loadFixture, withLogin } from '../utils.js';
|
||||
|
||||
describe('Article controller', () => {
|
||||
let article;
|
||||
|
||||
before(async () => {
|
||||
await dropDBs();
|
||||
await loadFixture('initial-data', 'articles');
|
||||
article = await Article.findOne({});
|
||||
expect(article).to.not.be.null;
|
||||
expect(article.rss).to.not.be.null;
|
||||
});
|
||||
|
||||
describe('get', () => {
|
||||
it('should return the right article via /articles/:articleId', async () => {
|
||||
let response = await withLogin(request(api).get(`/articles/${article.id}`));
|
||||
expect(response).to.have.status(200);
|
||||
});
|
||||
});
|
||||
|
||||
describe('get parsed article', () => {
|
||||
it('should return the parsed version of the article', async () => {
|
||||
const response = await withLogin(
|
||||
request(api).get(`/articles/${article.id}`).query({ type: 'parsed' })
|
||||
);
|
||||
expect(response).to.have.status(200);
|
||||
});
|
||||
});
|
||||
|
||||
describe('list', () => {
|
||||
it('should return the list of articles', async () => {
|
||||
let response = await withLogin(request(api).get('/articles'));
|
||||
expect(response).to.have.status(200);
|
||||
});
|
||||
});
|
||||
|
||||
describe('list from personalization', () => {
|
||||
after(function () {
|
||||
nock.cleanAll();
|
||||
});
|
||||
|
||||
it('should return the list of articles', async () => {
|
||||
nock(config.stream.baseUrl)
|
||||
.get(/winds_article_recommendations/)
|
||||
.reply(200, { results: [{foreign_id:`article:${article.id}`}] });
|
||||
|
||||
const response = await withLogin(
|
||||
request(api).get('/articles').query({
|
||||
type: 'recommended',
|
||||
})
|
||||
);
|
||||
expect(response).to.have.status(200);
|
||||
expect(response.body.length).to.be.at.least(1);
|
||||
expect(response.body[0].url).to.eq(article.url);
|
||||
});
|
||||
});
|
||||
});
|
||||
```
|
||||
|
||||
### Continuous Integration
|
||||
|
||||
There are a lot of continuous integration services available, but we like to use [Travis CI][15] because they love the open-source environment just as much as we do. Given that Winds is open-source, it made for a perfect fit.
|
||||
|
||||
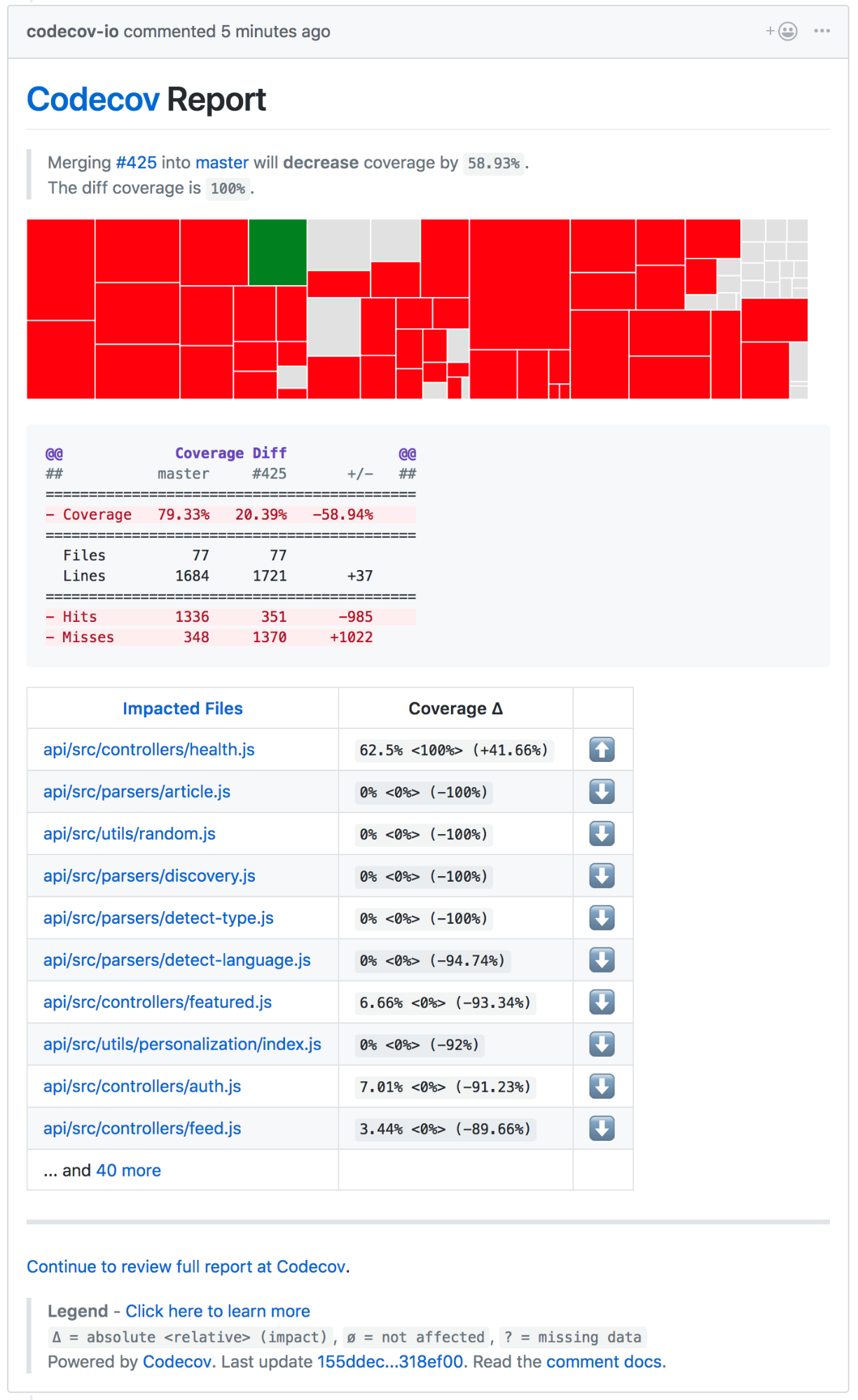
Our integration is rather simple — we have a [.travis.yml][16] file that sets up the environment and kicks off our tests via a simple [npm][17] command. The coverage reports back to GitHub, where we have a clear picture of whether or not our latest codebase or PR passes our tests. The GitHub integration is great, as it is visible without us having to go to Travis CI to look at the results. Below is a screenshot of GitHub when viewing the PR (after tests):
|
||||
|
||||
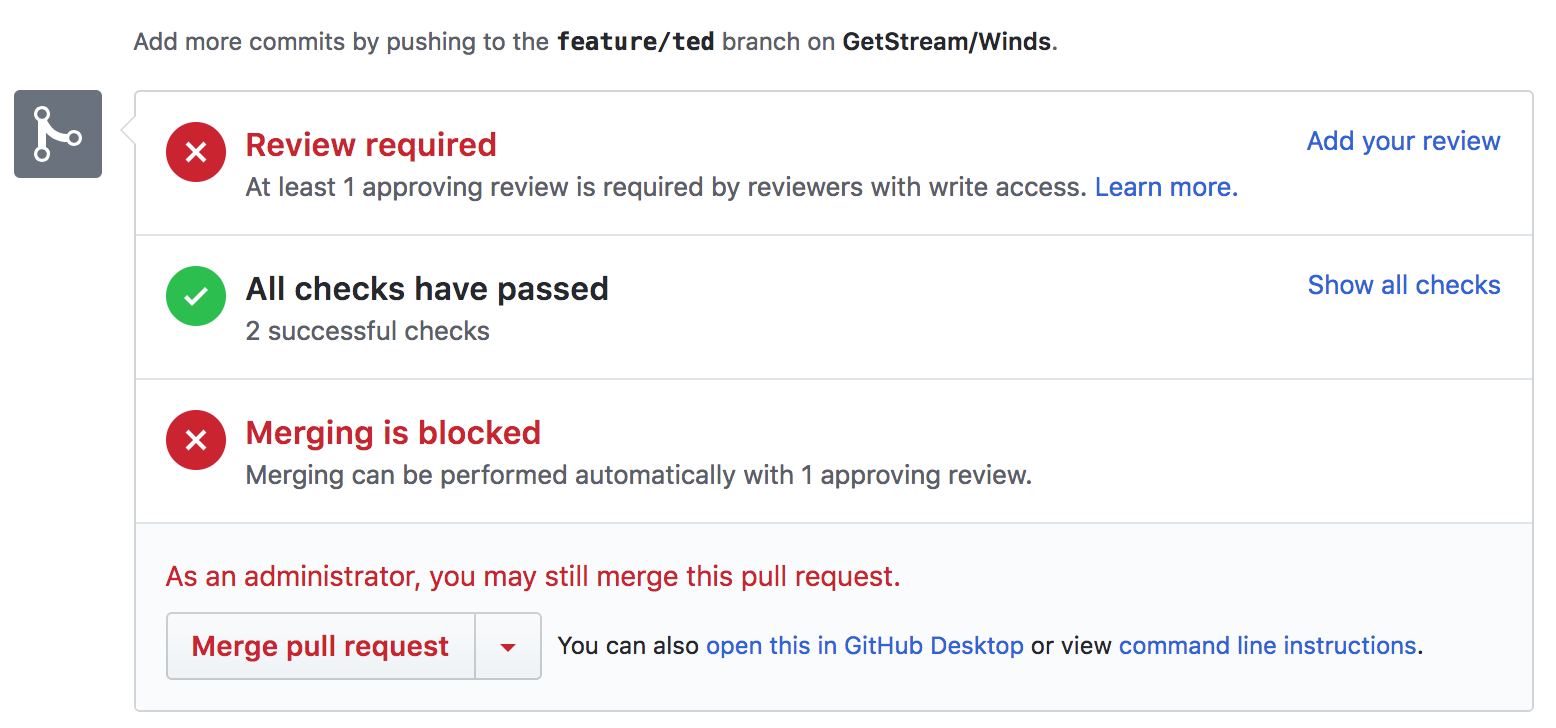
|
||||
|
||||
In addition to Travis CI, we use a tool called [CodeCov][18]. CodeCov is similar to [Istanbul][19], however, it’s a visualization tool that allows us to easily see code coverage, files changed, lines modified, and all sorts of other goodies. Though visualizing this data is possible without CodeCov, it’s nice to have everything in one spot.
|
||||
|
||||
### What We Learned
|
||||
|
||||
|
||||
|
||||
We learned a lot throughout the process of developing our test suite. With no “correct” way of doing things, we decided to set out and create our own test flow by sorting through the available libraries to find ones that were promising enough to add to our toolbox.
|
||||
|
||||
What we ultimately learned is that testing in Node.js is not as easy as it may sound. Hopefully, as Node.js continues to grow, the community will come together and build a rock solid library that handles everything test related in a “correct” manner.
|
||||
|
||||
Until then, we’ll continue to use our test suite, which is open-source on the [Winds GitHub repository][20].
|
||||
|
||||
### Limitations
|
||||
|
||||
#### No Easy Way to Create Fixtures
|
||||
|
||||
Frameworks and languages, such as Python’s Django, have easy ways to create fixtures. With Django, for example, you can use the following commands to automate the creation of fixtures by dumping data into a file:
|
||||
|
||||
The Following command will dump the whole database into a db.json file:
|
||||
./manage.py dumpdata > db.json
|
||||
|
||||
The Following command will dump only the content in django admin.logentry table:
|
||||
./manage.py dumpdata admin.logentry > logentry.json
|
||||
|
||||
The Following command will dump the content in django auth.user table: ./manage.py dumpdata auth.user > user.json
|
||||
|
||||
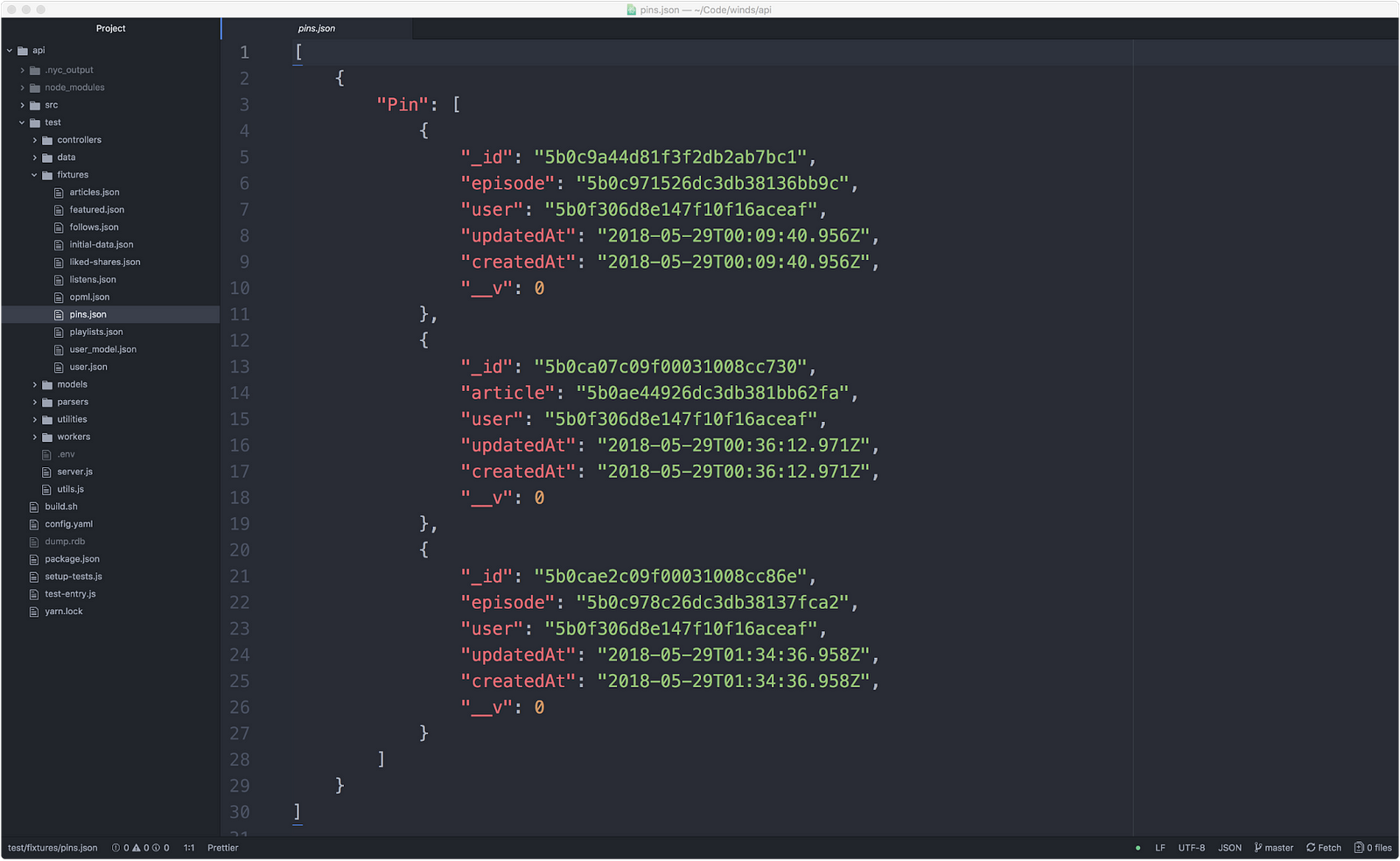
There’s no easy way to create a fixture in Node.js. What we ended up doing is using MongoDB Compass and exporting JSON from there. This resulted in a nice fixture, as shown below (however, it was a tedious process and prone to error):
|
||||
|
||||
|
||||
|
||||
|
||||
#### Unintuitive Module Loading When Using Babel, Mocked Modules, and Mocha Test-Runner
|
||||
|
||||
To support a broader variety of node versions and have access to latest additions to Javascript standard, we are using Babel to transpile our ES6 codebase to ES5\. Node.js module system is based on the CommonJS standard whereas the ES6 module system has different semantics.
|
||||
|
||||
Babel emulates ES6 module semantics on top of the Node.js module system, but because we are interfering with module loading by using mock-require, we are embarking on a journey through weird module loading corner cases, which seem unintuitive and can lead to multiple independent versions of the module imported and initialized and used throughout the codebase. This complicates mocking and global state management during testing.
|
||||
|
||||
#### Inability to Mock Functions Used Within the Module They Are Declared in When Using ES6 Modules
|
||||
|
||||
When a module exports multiple functions where one calls the other, it’s impossible to mock the function being used inside the module. The reason is that when you require an ES6 module you are presented with a separate set of references from the one used inside the module. Any attempt to rebind the references to point to new values does not really affect the code inside the module, which will continue to use the original function.
|
||||
|
||||
### Final Thoughts
|
||||
|
||||
Testing Node.js applications is a complicated process because the ecosystem is always evolving. It’s important to stay on top of the latest and greatest tools so you don’t fall behind.
|
||||
|
||||
There are so many outlets for JavaScript related news these days that it’s hard to keep up to date with all of them. Following email newsletters such as [JavaScript Weekly][21] and [Node Weekly][22] is a good start. Beyond that, joining a subreddit such as [/r/node][23] is a great idea. If you like to stay on top of the latest trends, [State of JS][24] does a great job at helping developers visualize trends in the testing world.
|
||||
|
||||
Lastly, here are a couple of my favorite blogs where articles often popup:
|
||||
|
||||
* [Hacker Noon][1]
|
||||
|
||||
* [Free Code Camp][2]
|
||||
|
||||
* [Bits and Pieces][3]
|
||||
|
||||
Think I missed something important? Let me know in the comments, or on Twitter – [@NickParsons][25].
|
||||
|
||||
Also, if you’d like to check out Stream, we have a great 5 minute tutorial on our website. Give it a shot [here][26].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Nick Parsons
|
||||
|
||||
Dreamer. Doer. Engineer. Developer Evangelist https://getstream.io.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://hackernoon.com/testing-node-js-in-2018-10a04dd77391
|
||||
|
||||
作者:[Nick Parsons][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://hackernoon.com/@nparsons08?source=post_header_lockup
|
||||
[1]:https://hackernoon.com/
|
||||
[2]:https://medium.freecodecamp.org/
|
||||
[3]:https://blog.bitsrc.io/
|
||||
[4]:https://getstream.io/
|
||||
[5]:https://getstream.io/winds
|
||||
[6]:https://github.com/mochajs/mocha
|
||||
[7]:http://www.chaijs.com/
|
||||
[8]:http://sinonjs.org/
|
||||
[9]:https://github.com/node-nock/nock
|
||||
[10]:https://getstream.io/docs_rest/
|
||||
[11]:https://getstream.io/personalization
|
||||
[12]:https://github.com/boblauer/mock-require
|
||||
[13]:https://github.com/gotwarlost/istanbul
|
||||
[14]:https://github.com/GetStream/Winds/tree/master/api/test
|
||||
[15]:https://travis-ci.org/
|
||||
[16]:https://github.com/GetStream/Winds/blob/master/.travis.yml
|
||||
[17]:https://www.npmjs.com/
|
||||
[18]:https://codecov.io/#features
|
||||
[19]:https://github.com/gotwarlost/istanbul
|
||||
[20]:https://github.com/GetStream/Winds/tree/master/api/test
|
||||
[21]:https://javascriptweekly.com/
|
||||
[22]:https://nodeweekly.com/
|
||||
[23]:https://www.reddit.com/r/node/
|
||||
[24]:https://stateofjs.com/2017/testing/results/
|
||||
[25]:https://twitter.com/@nickparsons
|
||||
[26]:https://getstream.io/try-the-api
|
||||
@ -1,127 +0,0 @@
|
||||
Translating by qhwdw
|
||||
How to Run Windows Apps on Android with Wine
|
||||
======
|
||||
|
||||

|
||||
|
||||
Wine (on Linux, not the one you drink) is a free and open-source compatibility layer for running Windows programs on Unix-like operating systems. Begun in 1993, it could run a wide variety of Windows programs on Linux and macOS, although sometimes with modification. Now the Wine Project has rolled out version 3.0 which is compatible with your Android devices.
|
||||
|
||||
In this article we will show you how you can run Windows apps on your Android device with WINE.
|
||||
|
||||
**Related** : [How to Easily Install Windows Games on Linux with Winepak][1]
|
||||
|
||||
### What can you run on Wine?
|
||||
|
||||
Wine is only a compatibility layer, not a full-blown emulator, so you need an x86 Android device to take full advantage of it. However, most Androids in the hands of consumers are ARM-based.
|
||||
|
||||
Since most of you are using an ARM-based Android device, you will only be able to use Wine to run apps that have been adapted to run on Windows RT. There is a limited, but growing, list of software available for ARM devices. You can find a list of these apps that are compatible in this [thread][2] on XDA Developers Forums.
|
||||
|
||||
Some examples of apps you will be able to run on ARM are:
|
||||
|
||||
* [Keepass Portable][3]: A password storage wallet
|
||||
* [Paint.NET][4]: An image manipulation program
|
||||
* [SumatraPDF][5]: A document reader for PDFs and possibly some other document types
|
||||
* [Audacity][6]: A digital audio recording and editing program
|
||||
|
||||
|
||||
|
||||
There are also some open-source retro games available like [Doom][7] and [Quake 2][8], as well as the open-source clone, [OpenTTD][9], a version of Transport Tycoon.
|
||||
|
||||
The list of programs that Wine can run on Android ARM devices is bound to grow as the popularity of Wine on Android expands. The Wine project is working on using QEMU to emulate x86 CPU instructions on ARM, and when that is complete, the number of apps your Android will be able to run should grow rapidly.
|
||||
|
||||
### Installing Wine
|
||||
|
||||
To install Wine you must first make sure that your device’s settings allow it to download and install APKs from other sources than the Play Store. To do this you’ll need to give your device permission to download apps from unknown sources.
|
||||
|
||||
1\. Open Settings on your phone and select your Security options.
|
||||
|
||||
|
||||
![wine-android-security][10]
|
||||
|
||||
2\. Scroll down and click on the switch next to “Unknown Sources.”
|
||||
|
||||
![wine-android-unknown-sources][11]
|
||||
|
||||
3\. Accept the risks in the warning.
|
||||
|
||||
![wine-android-unknown-sources-warning][12]
|
||||
|
||||
4\. Open the [Wine installation site][13], and tap the first checkbox in the list. The download will automatically begin.
|
||||
|
||||
![wine-android-download-button][14]
|
||||
|
||||
5\. Once the download completes, open it from your Downloads folder, or pull down the notifications menu and click on the completed download there.
|
||||
|
||||
6\. Install the program. It will notify you that it needs access to recording audio and to modify, delete, and read the contents of your SD card. You may also need to give access for audio recording for some apps you will use in the program.
|
||||
|
||||
![wine-android-app-access][15]
|
||||
|
||||
7\. When the installation completes, click on the icon to open the program.
|
||||
|
||||
![wine-android-icon-small][16]
|
||||
|
||||
When you open Wine, the desktop mimics Windows 7.
|
||||
|
||||
![wine-android-desktop][17]
|
||||
|
||||
One drawback of Wine is that you have to have an external keyboard available to type. An external mouse may also be useful if you are running it on a small screen and find it difficult to tap small buttons.
|
||||
|
||||
You can tap the Start button to open two menus – Control Panel and Run.
|
||||
|
||||
![wine-android-start-button][18]
|
||||
|
||||
### Working with Wine
|
||||
|
||||
When you tap “Control panel” you will see three choices – Add/Remove Programs, Game Controllers, and Internet Settings.
|
||||
|
||||
Using “Run,” you can open a dialogue box to issue commands. For instance, launch Internet Explorer by entering `iexplore`.
|
||||
|
||||
![wine-android-run][19]
|
||||
|
||||
### Installing programs on Wine
|
||||
|
||||
1\. Download the application (or sync via the cloud) to your Android device. Take note of where you save it.
|
||||
|
||||
2\. Open the Wine Command Prompt window.
|
||||
|
||||
3\. Type the path to the location of the program. If you have saved it to the Download folder on your SD card, type:
|
||||
|
||||
4\. To run the file in Wine for Android, simply input the name of the EXE file.
|
||||
|
||||
If the ARM-ready file is compatible, it should run. If not, you’ll see a bunch of error messages. At this stage, installing Windows software on Android in Wine can be hit or miss.
|
||||
|
||||
There are still a lot of issues with this new version of Wine for Android. It doesn’t work on all Android devices. It worked on my Galaxy S6 Edge but not on my Galaxy Tab 4. Many games won’t work because the graphics driver doesn’t support Direct3D yet. You need an external keyboard and mouse to be able to easily manipulate the screen because touch-screen is not fully developed yet.
|
||||
|
||||
Even with these issues in the early stages of release, the possibilities for this technology are thought-provoking. It’s certainly likely that it will take some time yet before you can launch Windows programs on your Android smartphone using Wine without a hitch.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/run-windows-apps-android-with-wine/
|
||||
|
||||
作者:[Tracey Rosenberger][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/traceyrosenberger/
|
||||
[1]:https://www.maketecheasier.com/winepak-install-windows-games-linux/ (How to Easily Install Windows Games on Linux with Winepak)
|
||||
[2]:https://forum.xda-developers.com/showthread.php?t=2092348
|
||||
[3]:http://downloads.sourceforge.net/keepass/KeePass-2.20.1.zip
|
||||
[4]:http://forum.xda-developers.com/showthread.php?t=2411497
|
||||
[5]:http://forum.xda-developers.com/showthread.php?t=2098594
|
||||
[6]:http://forum.xda-developers.com/showthread.php?t=2103779
|
||||
[7]:http://forum.xda-developers.com/showthread.php?t=2175449
|
||||
[8]:http://forum.xda-developers.com/attachment.php?attachmentid=1640830&d=1358070370
|
||||
[9]:http://forum.xda-developers.com/showpost.php?p=36674868&postcount=151
|
||||
[10]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-security.png (wine-android-security)
|
||||
[11]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-unknown-sources.jpg (wine-android-unknown-sources)
|
||||
[12]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-unknown-sources-warning.png (wine-android-unknown-sources-warning)
|
||||
[13]:https://dl.winehq.org/wine-builds/android/
|
||||
[14]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-download-button.png (wine-android-download-button)
|
||||
[15]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-app-access.jpg (wine-android-app-access)
|
||||
[16]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-icon-small.jpg (wine-android-icon-small)
|
||||
[17]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-desktop.png (wine-android-desktop)
|
||||
[18]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-start-button.png (wine-android-start-button)
|
||||
[19]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-Run.png (wine-android-run)
|
||||
@ -1,70 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Boost your typing with emoji in Fedora 28 Workstation
|
||||
======
|
||||
|
||||

|
||||
|
||||
Fedora 28 Workstation ships with a feature that allows you to quickly search, select and input emoji using your keyboard. Emoji, cute ideograms that are part of Unicode, are used fairly widely in messaging and especially on mobile devices. You may have heard the idiom “A picture is worth a thousand words.” This is exactly what emoji provide: simple images for you to use in communication. Each release of Unicode adds more, with over 200 new ones added in past releases of Unicode. This article shows you how to make them easy to use in your Fedora system.
|
||||
|
||||
It’s great to see emoji numbers growing. But at the same time it brings the challenge of how to input them in a computing device. Many people already use these symbols for input in mobile devices or social networking sites.
|
||||
|
||||
[**Editors’ note: **This article is an update to a previously published piece on this topic.]
|
||||
|
||||
### Enabling Emoji input on Fedora 28 Workstation
|
||||
|
||||
The new emoji input method ships by default in Fedora 28 Workstation. To use it, you must enable it using the Region and Language settings dialog. Open the Region and Language dialog from the main Fedora Workstation settings, or search for it in the Overview.
|
||||
|
||||
[![Region & Language settings tool][1]][2]
|
||||
|
||||
Choose the + control to add an input source. The following dialog appears:
|
||||
|
||||
[![Adding an input source][3]][4]
|
||||
|
||||
Choose the final option (three dots) to expand the selections fully. Then, find Other at the bottom of the list and select it:
|
||||
|
||||
[![Selecting other input sources][5]][6]
|
||||
|
||||
In the next dialog, find the Typing booster choice and select it:
|
||||
|
||||
[![][7]][8]
|
||||
|
||||
This advanced input method is powered behind the scenes by iBus. The advanced input methods are identifiable in the list by the cogs icon on the right of the list.
|
||||
|
||||
The Input Method drop-down automatically appears in the GNOME Shell top bar. Ensure your default method — in this example, English (US) — is selected as the current method, and you’ll be ready to input.
|
||||
|
||||
[![Input method dropdown in Shell top bar][9]][10]
|
||||
|
||||
## Using the new Emoji input method
|
||||
|
||||
Now the Emoji input method is enabled, search for emoji by pressing the keyboard shortcut **Ctrl+Shift+E**. A pop-over dialog appears where you can type a search term, such as smile, to find matching symbols.
|
||||
|
||||
[![Searching for smile emoji][11]][12]
|
||||
|
||||
Use the arrow keys to navigate the list. Then, hit **Enter** to make your selection, and the glyph will be placed as input.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/boost-typing-emoji-fedora-28-workstation/
|
||||
|
||||
作者:[Paul W. Frields][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/pfrields/
|
||||
[1]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-15-02-41-1024x718.png
|
||||
[2]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-15-02-41.png
|
||||
[3]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-33-46-1024x839.png
|
||||
[4]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-33-46.png
|
||||
[5]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-34-15-1024x839.png
|
||||
[6]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-34-15.png
|
||||
[7]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-34-41-1024x839.png
|
||||
[8]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-34-41.png
|
||||
[9]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-15-05-24-300x244.png
|
||||
[10]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-15-05-24.png
|
||||
[11]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-36-31-290x300.png
|
||||
[12]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-36-31.png
|
||||
263
sources/tech/20180712 Slices from the ground up.md
Normal file
263
sources/tech/20180712 Slices from the ground up.md
Normal file
@ -0,0 +1,263 @@
|
||||
name1e5s is translating
|
||||
|
||||
|
||||
Slices from the ground up
|
||||
============================================================
|
||||
|
||||
This blog post was inspired by a conversation with a co-worker about using a slice as a stack. The conversation turned into a wider discussion on the way slices work in Go, so I thought it would be useful to write it up.
|
||||
|
||||
### Arrays
|
||||
|
||||
Every discussion of Go’s slice type starts by talking about something that isn’t a slice, namely, Go’s array type. Arrays in Go have two relevant properties:
|
||||
|
||||
1. They have a fixed size; `[5]int` is both an array of 5 `int`s and is distinct from `[3]int`.
|
||||
|
||||
2. They are value types. Consider this example:
|
||||
```
|
||||
package main
|
||||
|
||||
import "fmt"
|
||||
|
||||
func main() {
|
||||
var a [5]int
|
||||
b := a
|
||||
b[2] = 7
|
||||
fmt.Println(a, b) // prints [0 0 0 0 0] [0 0 7 0 0]
|
||||
}
|
||||
```
|
||||
|
||||
The statement `b := a` declares a new variable, `b`, of type `[5]int`, and _copies _ the contents of `a` to `b`. Updating `b` has no effect on the contents of `a` because `a` and `b` are independent values.[1][1]
|
||||
|
||||
### Slices
|
||||
|
||||
Go’s slice type differs from its array counterpart in two important ways:
|
||||
|
||||
1. Slices do not have a fixed length. A slice’s length is not declared as part of its type, rather it is held within the slice itself and is recoverable with the built-in function `len`.[2][2]
|
||||
|
||||
2. Assigning one slice variable to another _does not_ make a copy of the slices contents. This is because a slice does not directly hold its contents. Instead a slice holds a pointer to its _underlying_ array[3][3] which holds the contents of the slice.
|
||||
|
||||
As a result of the second property, two slices can share the same underlying array. Consider these examples:
|
||||
|
||||
1. Slicing a slice:
|
||||
```
|
||||
package main
|
||||
|
||||
import "fmt"
|
||||
|
||||
func main() {
|
||||
var a = []int{1,2,3,4,5}
|
||||
b := a[2:]
|
||||
b[0] = 0
|
||||
fmt.Println(a, b) // prints [1 2 0 4 5] [0 4 5]
|
||||
}
|
||||
```
|
||||
|
||||
In this example `a` and `b` share the same underlying array–even though `b` starts at a different offset in that array, and has a different length. Changes to the underlying array via `b` are thus visible to `a`.
|
||||
|
||||
2. Passing a slice to a function:
|
||||
```
|
||||
package main
|
||||
|
||||
import "fmt"
|
||||
|
||||
func negate(s []int) {
|
||||
for i := range s {
|
||||
s[i] = -s[i]
|
||||
}
|
||||
}
|
||||
|
||||
func main() {
|
||||
var a = []int{1, 2, 3, 4, 5}
|
||||
negate(a)
|
||||
fmt.Println(a) // prints [-1 -2 -3 -4 -5]
|
||||
}
|
||||
```
|
||||
|
||||
In this example `a` is passed to `negate`as the formal parameter `s.` `negate` iterates over the elements of `s`, negating their sign. Even though `negate` does not return a value, or have any way to access the declaration of `a` in `main`, the contents of `a` are modified when passed to `negate`.
|
||||
|
||||
Most programmers have an intuitive understanding of how a Go slice’s underlying array works because it matches how array-like concepts in other languages tend to work. For example, here’s the first example of this section rewritten in Python:
|
||||
|
||||
```
|
||||
Python 2.7.10 (default, Feb 7 2017, 00:08:15)
|
||||
[GCC 4.2.1 Compatible Apple LLVM 8.0.0 (clang-800.0.34)] on darwin
|
||||
Type "help", "copyright", "credits" or "license" for more information.
|
||||
>>> a = [1,2,3,4,5]
|
||||
>>> b = a
|
||||
>>> b[2] = 0
|
||||
>>> a
|
||||
[1, 2, 0, 4, 5]
|
||||
```
|
||||
|
||||
And also in Ruby:
|
||||
|
||||
```
|
||||
irb(main):001:0> a = [1,2,3,4,5]
|
||||
=> [1, 2, 3, 4, 5]
|
||||
irb(main):002:0> b = a
|
||||
=> [1, 2, 3, 4, 5]
|
||||
irb(main):003:0> b[2] = 0
|
||||
=> 0
|
||||
irb(main):004:0> a
|
||||
=> [1, 2, 0, 4, 5]
|
||||
```
|
||||
|
||||
The same applies to most languages that treat arrays as objects or reference types.[4][8]
|
||||
|
||||
### The slice header value
|
||||
|
||||
The magic that makes a slice behave both as a value and a pointer is to understand that a slice is actually a struct type. This is commonly referred to as a _slice header_ after its [counterpart in the reflect package][20]. The definition of a slice header looks something like this:
|
||||
|
||||
|
||||
|
||||
```
|
||||
package runtime
|
||||
|
||||
type slice struct {
|
||||
ptr unsafe.Pointer
|
||||
len int
|
||||
cap int
|
||||
}
|
||||
```
|
||||
|
||||
This is important because [_unlike_ `map` and `chan`types][21] slices are value types and are _copied_ when assigned or passed as arguments to functions.
|
||||
|
||||
To illustrate this, programmers instinctively understand that `square`‘s formal parameter `v` is an independent copy of the `v` declared in `main`.
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import "fmt"
|
||||
|
||||
func square(v int) {
|
||||
v = v * v
|
||||
}
|
||||
|
||||
func main() {
|
||||
v := 3
|
||||
square(v)
|
||||
fmt.Println(v) // prints 3, not 9
|
||||
}
|
||||
```
|
||||
|
||||
So the operation of `square` on its `v` has no effect on `main`‘s `v`. So too the formal parameter `s` of `double` is an independent copy of the slice `s` declared in `main`, _not_ a pointer to `main`‘s `s` value.
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import "fmt"
|
||||
|
||||
func double(s []int) {
|
||||
s = append(s, s...)
|
||||
}
|
||||
|
||||
func main() {
|
||||
s := []int{1, 2, 3}
|
||||
double(s)
|
||||
fmt.Println(s, len(s)) // prints [1 2 3] 3
|
||||
}
|
||||
```
|
||||
|
||||
The slightly unusual nature of a Go slice variable is it’s passed around as a value, not than a pointer. 90% of the time when you declare a struct in Go, you will pass around a pointer to values of that struct.[5][9] This is quite uncommon, the only other example of passing a struct around as a value I can think of off hand is `time.Time`.
|
||||
|
||||
It is this exceptional behaviour of slices as values, rather than pointers to values, that can confuses Go programmer’s understanding of how slices work. Just remember that any time you assign, subslice, or pass or return, a slice, you’re making a copy of the three fields in the slice header; the pointer to the underlying array, and the current length and capacity.
|
||||
|
||||
### Putting it all together
|
||||
|
||||
I’m going to conclude this post on the example of a slice as a stack that I opened this post with:
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import "fmt"
|
||||
|
||||
func f(s []string, level int) {
|
||||
if level > 5 {
|
||||
return
|
||||
}
|
||||
s = append(s, fmt.Sprint(level))
|
||||
f(s, level+1)
|
||||
fmt.Println("level:", level, "slice:", s)
|
||||
}
|
||||
|
||||
func main() {
|
||||
f(nil, 0)
|
||||
}
|
||||
```
|
||||
|
||||
Starting from `main` we pass a `nil` slice into `f` as `level` 0\. Inside `f` we append to `s` the current `level`before incrementing `level` and recursing. Once `level` exceeds 5, the calls to `f` return, printing their current level and the contents of their copy of `s`.
|
||||
|
||||
```
|
||||
level: 5 slice: [0 1 2 3 4 5]
|
||||
level: 4 slice: [0 1 2 3 4]
|
||||
level: 3 slice: [0 1 2 3]
|
||||
level: 2 slice: [0 1 2]
|
||||
level: 1 slice: [0 1]
|
||||
level: 0 slice: [0]
|
||||
```
|
||||
|
||||
You can see that at each level the value of `s` was unaffected by the operation of other callers of `f`, and that while four underlying arrays were created [6][10] higher levels of `f` in the call stack are unaffected by the copy and reallocation of new underlying arrays as a by-product of `append`.
|
||||
|
||||
### Further reading
|
||||
|
||||
If you want to find out more about how slices work in Go, I recommend these posts from the Go blog:
|
||||
|
||||
* [Go Slices: usage and internals][11] (blog.golang.org)
|
||||
|
||||
* [Arrays, slices (and strings): The mechanics of ‘append’][12] (blog.golang.org)
|
||||
|
||||
### Notes
|
||||
|
||||
1. This is not a unique property of arrays. In Go _every_ assignment is a copy.[][13]
|
||||
|
||||
2. You can also use `len` on array values, but the result is a forgone conclusion.[][14]
|
||||
|
||||
3. This is also known as the backing array or sometimes, less correctly, as the backing slice[][15]
|
||||
|
||||
4. In Go we tend to say value type and pointer type because of the confusion caused by C++’s _reference_ type, but in this case I think calling arrays as objects reference types is appropriate.[][16]
|
||||
|
||||
5. I’d argue if that struct has a [method defined on it and/or is used to satisfy an interface][17]then the percentage that you will pass around a pointer to your struct raises to near 100%.[][18]
|
||||
|
||||
6. Proof of this is left as an exercise to the reader.[][19]
|
||||
|
||||
### Related Posts:
|
||||
|
||||
1. [If a map isn’t a reference variable, what is it?][4]
|
||||
|
||||
2. [What is the zero value, and why is it useful ?][5]
|
||||
|
||||
3. [The empty struct][6]
|
||||
|
||||
4. [Should methods be declared on T or *T][7]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://dave.cheney.net/2018/07/12/slices-from-the-ground-up
|
||||
|
||||
作者:[Dave Cheney][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://dave.cheney.net/
|
||||
[1]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-bottom-1-3265
|
||||
[2]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-bottom-2-3265
|
||||
[3]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-bottom-3-3265
|
||||
[4]:https://dave.cheney.net/2017/04/30/if-a-map-isnt-a-reference-variable-what-is-it
|
||||
[5]:https://dave.cheney.net/2013/01/19/what-is-the-zero-value-and-why-is-it-useful
|
||||
[6]:https://dave.cheney.net/2014/03/25/the-empty-struct
|
||||
[7]:https://dave.cheney.net/2016/03/19/should-methods-be-declared-on-t-or-t
|
||||
[8]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-bottom-4-3265
|
||||
[9]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-bottom-5-3265
|
||||
[10]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-bottom-6-3265
|
||||
[11]:https://blog.golang.org/go-slices-usage-and-internals
|
||||
[12]:https://blog.golang.org/slices
|
||||
[13]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-1-3265
|
||||
[14]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-2-3265
|
||||
[15]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-3-3265
|
||||
[16]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-4-3265
|
||||
[17]:https://dave.cheney.net/2016/03/19/should-methods-be-declared-on-t-or-t
|
||||
[18]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-5-3265
|
||||
[19]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-6-3265
|
||||
[20]:https://golang.org/pkg/reflect/#SliceHeader
|
||||
[21]:https://dave.cheney.net/2017/04/30/if-a-map-isnt-a-reference-variable-what-is-it
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
Incomplete Path Expansion (Completion) For Bash
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating by distant1219
|
||||
|
||||
An Introduction to Using Git
|
||||
======
|
||||

|
||||
|
||||
@ -0,0 +1,265 @@
|
||||
How To Mount Google Drive Locally As Virtual File System In Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
[**Google Drive**][1] is the one of the popular cloud storage provider on the planet. As of 2017, over 800 million users are actively using this service worldwide. Even though the number of users have dramatically increased, Google haven’t released a Google drive client for Linux yet. But it didn’t stop the Linux community. Every now and then, some developers had brought few google drive clients for Linux operating system. In this guide, we will see three unofficial google drive clients for Linux. Using these clients, you can mount Google drive locally as a virtual file system and access your drive files in your Linux box. Read on.
|
||||
|
||||
### 1. Google-drive-ocamlfuse
|
||||
|
||||
The **google-drive-ocamlfuse** is a FUSE filesystem for Google Drive, written in OCaml. For those wondering, FUSE, stands for **F** ilesystem in **Use** rspace, is a project that allows the users to create virtual file systems in user level. **google-drive-ocamlfuse** allows you to mount your Google Drive on Linux system. It features read/write access to ordinary files and folders, read-only access to Google docks, sheets, and slides, support for multiple google drive accounts, duplicate file handling, access to your drive trash directory, and more.
|
||||
|
||||
#### Installing google-drive-ocamlfuse
|
||||
|
||||
google-drive-ocamlfuse is available in the [**AUR**][2], so you can install it using any AUR helper programs, for example [**Yay**][3].
|
||||
```
|
||||
$ yay -S google-drive-ocamlfuse
|
||||
|
||||
```
|
||||
|
||||
On Ubuntu:
|
||||
```
|
||||
$ sudo add-apt-repository ppa:alessandro-strada/ppa
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install google-drive-ocamlfuse
|
||||
|
||||
```
|
||||
|
||||
To install latest beta version, do:
|
||||
```
|
||||
$ sudo add-apt-repository ppa:alessandro-strada/google-drive-ocamlfuse-beta
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install google-drive-ocamlfuse
|
||||
|
||||
```
|
||||
|
||||
#### Usage
|
||||
|
||||
Once installed, run the following command to launch **google-drive-ocamlfuse** utility from your Terminal:
|
||||
```
|
||||
$ google-drive-ocamlfuse
|
||||
|
||||
```
|
||||
|
||||
When you run this first time, the utility will open your web browser and ask your permission to authorize your google drive files. Once you gave authorization, all necessary config files and folders it needs to mount your google drive will be automatically created.
|
||||
|
||||
![][5]
|
||||
|
||||
After successful authentication, you will see the following message in your Terminal.
|
||||
```
|
||||
Access token retrieved correctly.
|
||||
|
||||
```
|
||||
|
||||
You’re good to go now. Close the web browser and then create a mount point to mount your google drive files.
|
||||
```
|
||||
$ mkdir ~/mygoogledrive
|
||||
|
||||
```
|
||||
|
||||
Finally, mount your google drive using command:
|
||||
```
|
||||
$ google-drive-ocamlfuse ~/mygoogledrive
|
||||
|
||||
```
|
||||
|
||||
Congratulations! You can access access your files either from Terminal or file manager.
|
||||
|
||||
From **Terminal** :
|
||||
```
|
||||
$ ls ~/mygoogledrive
|
||||
|
||||
```
|
||||
|
||||
From **File manager** :
|
||||
|
||||
![][6]
|
||||
|
||||
If you have more than one account, use **label** option to distinguish different accounts like below.
|
||||
```
|
||||
$ google-drive-ocamlfuse -label label [mountpoint]
|
||||
|
||||
```
|
||||
|
||||
Once you’re done, unmount the FUSE flesystem using command:
|
||||
```
|
||||
$ fusermount -u ~/mygoogledrive
|
||||
|
||||
```
|
||||
|
||||
For more details, refer man pages.
|
||||
```
|
||||
$ google-drive-ocamlfuse --help
|
||||
|
||||
```
|
||||
|
||||
Also, do check the [**official wiki**][7] and the [**project GitHub repository**][8] for more details.
|
||||
|
||||
### 2. GCSF
|
||||
|
||||
**GCSF** is a FUSE filesystem based on Google Drive, written using **Rust** programming language. The name GCSF has come from the Romanian word “ **G** oogle **C** onduce **S** istem de **F** ișiere”, which means “Google Drive Filesystem” in English. Using GCSF, you can mount your Google drive as a local virtual file system and access the contents from the Terminal or file manager. You might wonder how it differ from other Google Drive FUSE projects, for example **google-drive-ocamlfuse**. The developer of GCSF replied to a similar [comment on Reddit][9] “GCSF tends to be faster in several cases (listing files recursively, reading large files from Drive). The caching strategy it uses also leads to very fast reads (x4-7 improvement compared to google-drive-ocamlfuse) for files that have been cached, at the cost of using more RAM“.
|
||||
|
||||
#### Installing GCSF
|
||||
|
||||
GCSF is available in the [**AUR**][10], so the Arch Linux users can install it using any AUR helper, for example [**Yay**][3].
|
||||
```
|
||||
$ yay -S gcsf-git
|
||||
|
||||
```
|
||||
|
||||
For other distributions, do the following.
|
||||
|
||||
Make sure you have installed Rust on your system.
|
||||
|
||||
Make sure **pkg-config** and the **fuse** packages are installed. They are available in the default repositories of most Linux distributions. For example, on Ubuntu and derivatives, you can install them using command:
|
||||
```
|
||||
$ sudo apt-get install -y libfuse-dev pkg-config
|
||||
|
||||
```
|
||||
|
||||
Once all dependencies installed, run the following command to install GCSF:
|
||||
```
|
||||
$ cargo install gcsf
|
||||
|
||||
```
|
||||
|
||||
#### Usage
|
||||
|
||||
First, we need to authorize our google drive. To do so, simply run:
|
||||
```
|
||||
$ gcsf login ostechnix
|
||||
|
||||
```
|
||||
|
||||
You must specify a session name. Replace **ostechnix** with your own session name. You will see an output something like below with an URL to authorize your google drive account.
|
||||
|
||||
![][11]
|
||||
|
||||
Just copy and navigate to the above URL from your browser and click **allow** to give permission to access your google drive contents. Once you gave the authentication you will see an output like below.
|
||||
```
|
||||
Successfully logged in. Credentials saved to "/home/sk/.config/gcsf/ostechnix".
|
||||
|
||||
```
|
||||
|
||||
GCSF will create a configuration file in **$XDG_CONFIG_HOME/gcsf/gcsf.toml** , which is usually defined as **$HOME/.config/gcsf/gcsf.toml**. Credentials are stored in the same directory.
|
||||
|
||||
Next, create a directory to mount your google drive contents.
|
||||
```
|
||||
$ mkdir ~/mygoogledrive
|
||||
|
||||
```
|
||||
|
||||
Then, edit **/etc/fuse.conf** file:
|
||||
```
|
||||
$ sudo vi /etc/fuse.conf
|
||||
|
||||
```
|
||||
|
||||
Uncomment the following line to allow non-root users to specify the allow_other or allow_root mount options.
|
||||
```
|
||||
user_allow_other
|
||||
|
||||
```
|
||||
|
||||
Save and close the file.
|
||||
|
||||
Finally, mount your google drive using command:
|
||||
```
|
||||
$ gcsf mount ~/mygoogledrive -s ostechnix
|
||||
|
||||
```
|
||||
|
||||
Sample output:
|
||||
```
|
||||
INFO gcsf > Creating and populating file system...
|
||||
INFO gcsf > File sytem created.
|
||||
INFO gcsf > Mounting to /home/sk/mygoogledrive
|
||||
INFO gcsf > Mounted to /home/sk/mygoogledrive
|
||||
INFO gcsf::gcsf::file_manager > Checking for changes and possibly applying them.
|
||||
INFO gcsf::gcsf::file_manager > Checking for changes and possibly applying them.
|
||||
|
||||
```
|
||||
|
||||
Again, replace **ostechnix** with your session name. You can view the existing sessions using command:
|
||||
```
|
||||
$ gcsf list
|
||||
Sessions:
|
||||
- ostechnix
|
||||
|
||||
```
|
||||
|
||||
You can now access your google drive contents either from the Terminal or from File manager.
|
||||
|
||||
From **Terminal** :
|
||||
```
|
||||
$ ls ~/mygoogledrive
|
||||
|
||||
```
|
||||
|
||||
From **File manager** :
|
||||
|
||||
![][12]
|
||||
|
||||
If you don’t know where your Google drive is mounted, use **df** or **mount** command as shown below.
|
||||
```
|
||||
$ df -h
|
||||
Filesystem Size Used Avail Use% Mounted on
|
||||
udev 968M 0 968M 0% /dev
|
||||
tmpfs 200M 1.6M 198M 1% /run
|
||||
/dev/sda1 20G 7.5G 12G 41% /
|
||||
tmpfs 997M 0 997M 0% /dev/shm
|
||||
tmpfs 5.0M 4.0K 5.0M 1% /run/lock
|
||||
tmpfs 997M 0 997M 0% /sys/fs/cgroup
|
||||
tmpfs 200M 40K 200M 1% /run/user/1000
|
||||
GCSF 15G 857M 15G 6% /home/sk/mygoogledrive
|
||||
|
||||
$ mount | grep GCSF
|
||||
GCSF on /home/sk/mygoogledrive type fuse (rw,nosuid,nodev,relatime,user_id=1000,group_id=1000,allow_other)
|
||||
|
||||
```
|
||||
|
||||
Once done, unmount the google drive using command:
|
||||
```
|
||||
$ fusermount -u ~/mygoogledrive
|
||||
|
||||
```
|
||||
|
||||
Check the [**GCSF GitHub repository**][13] for more details.
|
||||
|
||||
### 3. Tuxdrive
|
||||
|
||||
**Tuxdrive** is yet another unofficial google drive client for Linux. We have written a detailed guide about Tuxdrive a while ago. Please check the following link.
|
||||
|
||||
Of course, there were few other unofficial google drive clients available in the past, such as Grive2, Syncdrive. But it seems that they are discontinued now. I will keep updating this list when I come across any active google drive clients.
|
||||
|
||||
And, that’s all for now, folks. Hope this was useful. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-mount-google-drive-locally-as-virtual-file-system-in-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.google.com/drive/
|
||||
[2]:https://aur.archlinux.org/packages/google-drive-ocamlfuse/
|
||||
[3]:https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[4]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/07/google-drive.png
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2018/07/google-drive-2.png
|
||||
[7]:https://github.com/astrada/google-drive-ocamlfuse/wiki/Configuration
|
||||
[8]:https://github.com/astrada/google-drive-ocamlfuse
|
||||
[9]:https://www.reddit.com/r/DataHoarder/comments/8vlb2v/google_drive_as_a_file_system/e1oh9q9/
|
||||
[10]:https://aur.archlinux.org/packages/gcsf-git/
|
||||
[11]:http://www.ostechnix.com/wp-content/uploads/2018/07/google-drive-3.png
|
||||
[12]:http://www.ostechnix.com/wp-content/uploads/2018/07/google-drive-4.png
|
||||
[13]:https://github.com/harababurel/gcsf
|
||||
@ -1,140 +0,0 @@
|
||||
Learn how to build your own Twitter bot with Python
|
||||
======
|
||||
|
||||

|
||||
|
||||
Twitter allows one to [share][1] blog posts and articles with the world. Using Python and the tweepy library makes it easy to create a Twitter bot that takes care of all the tweeting for you. This article shows you how to build such a bot. Hopefully you can take the concepts here and apply them to other projects that use online services.
|
||||
|
||||
### Getting started
|
||||
|
||||
To create a Twitter bot the [tweepy][2] library comes handy. It manages the Twitter API calls and provides a simple interface.
|
||||
|
||||
The following commands use Pipenv to install tweepy into a virtual environment. If you don’t have Pipenv installed, check out our previous article, [How to install Pipenv on Fedora][3].
|
||||
```
|
||||
$ mkdir twitterbot
|
||||
$ cd twitterbot
|
||||
$ pipenv --three
|
||||
$ pipenv install tweepy
|
||||
$ pipenv shell
|
||||
|
||||
```
|
||||
|
||||
### Tweepy – Getting started
|
||||
|
||||
To use the Twitter API the bot needs to authenticate against Twitter. For that, tweepy uses the OAuth authentication standard. You can get credentials by creating a new application at <https://apps.twitter.com/>.
|
||||
|
||||
#### Create a new Twitter application
|
||||
|
||||
After you fill in the following form and click on the Create your Twitter application button, you have access to the application credentials. Tweepy requires the Consumer Key (API Key) and the Consumer Secret (API Secret), both available from the Keys and Access Tokens.
|
||||
|
||||
![][4]
|
||||
|
||||
After scrolling down the page, generate an Access Token and an Access Token Secret using the Create my access token button.
|
||||
|
||||
#### Using Tweepy – print your timeline
|
||||
|
||||
Now that you have all the credentials needed, open a new file and write the following Python code.
|
||||
```
|
||||
import tweepy
|
||||
|
||||
auth = tweepy.OAuthHandler("your_consumer_key", "your_consumer_key_secret")
|
||||
|
||||
auth.set_access_token("your_access_token", "your_access_token_secret")
|
||||
|
||||
api = tweepy.API(auth)
|
||||
|
||||
public_tweets = api.home_timeline()
|
||||
|
||||
for tweet in public_tweets:
|
||||
print(tweet.text)
|
||||
|
||||
```
|
||||
|
||||
After making sure that you are using the Pipenv virtual environment, run your program.
|
||||
```
|
||||
$ python tweet.py
|
||||
|
||||
```
|
||||
|
||||
The above program calls the home_timeline API method to retrieve the 20 most recent tweets from your timeline. Now that the bot is able to use tweepy to get data from Twitter, try changing the code to send a tweet.
|
||||
|
||||
#### Using Tweepy – send a tweet
|
||||
|
||||
To send a tweet, the API method update_status comes in handy. The usage is simple:
|
||||
```
|
||||
api.update_status("The awesome text you would like to tweet")
|
||||
|
||||
```
|
||||
|
||||
The tweepy library has many other methods that can be useful for a Twitter bot. For the full details of the API, check the [documentation][5].
|
||||
|
||||
### A magazine bot
|
||||
|
||||
Let’s create a bot that searches for Fedora Magazine tweets and automatically retweets them.
|
||||
|
||||
To avoid retweeting the same tweet multiple times, the bot stores the tweet ID of the last retweet. Two helper functions, store_last_id and get_last_id, will be used to save and retrieve this ID.
|
||||
|
||||
Then the bot uses the tweepy search API to find the Fedora Magazine tweets that are more recent than the stored ID.
|
||||
```
|
||||
import tweepy
|
||||
|
||||
|
||||
def store_last_id(tweet_id):
|
||||
""" Store a tweet id in a file """
|
||||
with open("lastid", "w") as fp:
|
||||
fp.write(str(tweet_id))
|
||||
|
||||
|
||||
def get_last_id():
|
||||
""" Read the last retweeted id from a file """
|
||||
with open("lastid", "r") as fp:
|
||||
return fp.read()
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
|
||||
auth = tweepy.OAuthHandler("your_consumer_key", "your_consumer_key_secret")
|
||||
|
||||
auth.set_access_token("your_access_token", "your_access_token_secret") api = tweepy.API(auth)
|
||||
|
||||
try:
|
||||
last_id = get_last_id()
|
||||
except FileNotFoundError:
|
||||
print("No retweet yet")
|
||||
last_id = None
|
||||
|
||||
for tweet in tweepy.Cursor(api.search, q="fedoramagazine.org", since_id=last_id).items():
|
||||
if tweet.user.name == 'Fedora Project':
|
||||
store_last_id(tweet.id)
|
||||
tweet.retweet()
|
||||
print(f'"{tweet.text}" was retweeted'
|
||||
|
||||
```
|
||||
|
||||
In order to retweet only tweets from the Fedora Magazine, the bot searches for tweets that contain fedoramagazine.org and are published by the “Fedora Project” Twitter account.
|
||||
|
||||
### Conclusion
|
||||
|
||||
In this article you saw how to create a Twitter application using the tweepy Python library to automate reading, sending and searching tweets. You can now use your creativity to create a Twitter bot of your own.
|
||||
|
||||
The source code of the example in this article is available on [Github][6].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/learn-build-twitter-bot-python/
|
||||
|
||||
作者:[Clément Verna][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org
|
||||
[1]:https://twitter.com
|
||||
[2]:https://tweepy.readthedocs.io/en/v3.5.0/
|
||||
[3]:https://fedoramagazine.org/install-pipenv-fedora/
|
||||
[4]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-19-20-17-17.png
|
||||
[5]:http://docs.tweepy.org/en/v3.5.0/api.html#id1
|
||||
[6]:https://github.com/cverna/magabot
|
||||
@ -0,0 +1,40 @@
|
||||
Textricator: Data extraction made simple
|
||||
======
|
||||
|
||||

|
||||
|
||||
You probably know the feeling: You ask for data and get a positive response, only to open the email and find a whole bunch of PDFs attached. Data, interrupted.
|
||||
|
||||
We understand your frustration, and we’ve done something about it: Introducing [Textricator][1], our first open source product.
|
||||
|
||||
We’re Measures for Justice, a criminal justice research and transparency organization. Our mission is to provide data transparency for the entire justice system, from arrest to post-conviction. We do this by producing a series of up to 32 performance measures covering the entire criminal justice system, county by county. We get our data in many ways—all legal, of course—and while many state and county agencies are data-savvy, giving us quality, formatted data in CSVs, the data is often bundled inside software with no simple way to get it out. PDF reports are the best they can offer.
|
||||
|
||||
Developers Joe Hale and Stephen Byrne have spent the past two years developing Textricator to extract tens of thousands of pages of data for our internal use. Textricator can process just about any text-based PDF format—not just tables, but complex reports with wrapping text and detail sections generated from tools like Crystal Reports. Simply tell Textricator the attributes of the fields you want to collect, and it chomps through the document, collecting and writing out your records.
|
||||
|
||||
Not a software engineer? Textricator doesn’t require programming skills; rather, the user describes the structure of the PDF and Textricator handles the rest. Most users run it via the command line; however, a browser-based GUI is available.
|
||||
|
||||
We evaluated other great open source solutions like [Tabula][2], but they just couldn’t handle the structure of some of the PDFs we needed to scrape. “Textricator is both flexible and powerful and has cut the time we spend to process large datasets from days to hours,” says Andrew Branch, director of technology.
|
||||
|
||||
At MFJ, we’re committed to transparency and knowledge-sharing, which includes making our software available to anyone, especially those trying to free and share data publicly. Textricator is available on [GitHub][3] and released under [GNU Affero General Public License Version 3][4].
|
||||
|
||||
You can see the results of our work, including data processed via Textricator, on our free [online data portal][5]. Textricator is an essential part of our process and we hope civic tech and government organizations alike can unlock more data with this new tool.
|
||||
|
||||
If you use Textricator, let us know how it helped solve your data problem. Want to improve it? Submit a pull request.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/textricator
|
||||
|
||||
作者:[Stephen Byrne][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[1]:https://textricator.mfj.io/
|
||||
[2]:https://tabula.technology/
|
||||
[3]:https://github.com/measuresforjustice/textricator
|
||||
[4]:https://www.gnu.org/licenses/agpl-3.0.en.html
|
||||
[5]:https://www.measuresforjustice.org/portal/
|
||||
@ -0,0 +1,415 @@
|
||||
Docker 指南:Docker 化 Python Django 应用程序
|
||||
======
|
||||
|
||||
### 目录
|
||||
|
||||
1. [我们要做什么?][6]
|
||||
|
||||
2. [步骤 1 - 安装 Docker-ce][7]
|
||||
|
||||
3. [步骤 2 - 安装 Docker-compose][8]
|
||||
|
||||
4. [步骤 3 - 配置项目环境][9]
|
||||
1. [创建一个新的 requirements.txt 文件][1]
|
||||
|
||||
2. [创建 Nginx 虚拟主机文件 django.conf][2]
|
||||
|
||||
3. [创建 Dockerfile][3]
|
||||
|
||||
4. [创建 Docker-compose 脚本][4]
|
||||
|
||||
5. [配置 Django 项目][5]
|
||||
|
||||
5. [步骤 4 - 构建并运行 Docker 镜像][10]
|
||||
|
||||
6. [步骤 5 - 测试][11]
|
||||
|
||||
7. [参考][12]
|
||||
|
||||
|
||||
Docker 是一个开源项目,为开发人员和系统管理员提供了一个开放平台,作为一个轻量级容器,它可以在任何地方构建,打包和运行应用程序。Docker 在软件容器中自动部署应用程序。
|
||||
|
||||
Django 是一个用 Python 编写的 Web 应用程序框架,遵循 MVC(模型-视图-控制器)架构。它是免费的,并在开源许可下发布。它速度很快,旨在帮助开发人员尽快将他们的应用程序上线。
|
||||
|
||||
在本教程中,我将逐步向你展示在 Ubuntu 16.04 如何为现有的 Django 应用程序创建 docker 镜像。我们将学习如何 docker 化一个 Python Django 应用程序,然后使用一个 docker-compose 脚本将应用程序作为容器部署到 docker 环境。
|
||||
|
||||
为了部署我们的 Python Django 应用程序,我们需要其他 docker 镜像:一个用于 Web 服务器的 nginx docker 镜像和用于数据库的 PostgreSQL 镜像。
|
||||
|
||||
### 我们要做什么?
|
||||
|
||||
1. 安装 Docker-ce
|
||||
|
||||
2. 安装 Docker-compose
|
||||
|
||||
3. 配置项目环境
|
||||
|
||||
4. 构建并运行
|
||||
|
||||
5. 测试
|
||||
|
||||
### 步骤 1 - 安装 Docker-ce
|
||||
|
||||
在本教程中,我们将重 docker 仓库安装 docker-ce 社区版。我们将安装 docker-ce 社区版和 docker-compose,其支持 compose 文件版本 3(to 校正者:此处不太明白具体意思)。
|
||||
|
||||
在安装 docker-ce 之前,先使用 apt 命令安装所需的 docker 依赖项。
|
||||
|
||||
```
|
||||
sudo apt install -y \
|
||||
apt-transport-https \
|
||||
ca-certificates \
|
||||
curl \
|
||||
software-properties-common
|
||||
```
|
||||
|
||||
现在通过运行以下命令添加 docker 密钥和仓库。
|
||||
|
||||
```
|
||||
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
|
||||
sudo add-apt-repository \
|
||||
"deb [arch=amd64] https://download.docker.com/linux/ubuntu \
|
||||
$(lsb_release -cs) \
|
||||
stable"
|
||||
```
|
||||
|
||||
[][14]
|
||||
|
||||
更新仓库并安装 docker-ce。
|
||||
|
||||
```
|
||||
sudo apt update
|
||||
sudo apt install -y docker-ce
|
||||
```
|
||||
|
||||
安装完成后,启动 docker 服务并使其能够在每次系统引导时启动。
|
||||
|
||||
```
|
||||
systemctl start docker
|
||||
systemctl enable docker
|
||||
```
|
||||
|
||||
接着,我们将添加一个名为 'omar' 的新用户并将其添加到 docker 组。
|
||||
|
||||
```
|
||||
useradd -m -s /bin/bash omar
|
||||
usermod -a -G docker omar
|
||||
```
|
||||
|
||||
[][15]
|
||||
|
||||
以 omar 用户身份登录并运行 docker 命令,如下所示。
|
||||
|
||||
```
|
||||
su - omar
|
||||
docker run hello-world
|
||||
```
|
||||
|
||||
确保你能从 Docker 获得 hello-world 消息。
|
||||
|
||||
[][16]
|
||||
|
||||
Docker-ce 安装已经完成。
|
||||
|
||||
### 步骤 2 - 安装 Docker-compose
|
||||
|
||||
在本教程中,我们将使用最新的 docker-compose 支持 compose 文件版本 3。我们将手动安装 docker-compose。
|
||||
|
||||
使用 curl 命令将最新版本的 docker-compose 下载到 `/usr/local/bin` 目录,并使用 chmod 命令使其有执行权限。
|
||||
|
||||
运行以下命令:
|
||||
|
||||
```
|
||||
sudo curl -L https://github.com/docker/compose/releases/download/1.21.0/docker-compose-$(uname -s)-$(uname -m) -o /usr/local/bin/docker-compose
|
||||
sudo chmod +x /usr/local/bin/docker-compose
|
||||
```
|
||||
|
||||
现在检查 docker-compose 版本。
|
||||
|
||||
```
|
||||
docker-compose version
|
||||
```
|
||||
|
||||
确保你安装的是最新版本的 docker-compose 1.21。
|
||||
|
||||
[][17]
|
||||
|
||||
已安装支持 compose 文件版本 3 的 docker-compose 最新版本。
|
||||
|
||||
### 步骤 3 - 配置项目环境
|
||||
|
||||
在这一步中,我们将配置 Python Django 项目环境。我们将创建新目录 'guide01',并使其成为我们项目文件的主目录,例如 Dockerfile,Django 项目,nginx 配置文件等。
|
||||
|
||||
登录到 'omar' 用户。
|
||||
|
||||
```
|
||||
su - omar
|
||||
```
|
||||
|
||||
创建一个新目录 'guide01',并进入目录。
|
||||
|
||||
```
|
||||
mkdir -p guide01
|
||||
cd guide01/
|
||||
```
|
||||
|
||||
现在在 'guide01' 目录下,创建两个新目录 'project' 和 'config'。
|
||||
|
||||
```
|
||||
mkdir project/ config/
|
||||
```
|
||||
|
||||
注意:
|
||||
|
||||
* 'project' 目录:我们所有的 python Django 项目文件都将放在该目录中。
|
||||
|
||||
* 'config' 目录:项目配置文件的目录,包括 nginx 配置文件,python pip requirements 文件等。
|
||||
|
||||
### 创建一个新的 requirements.txt 文件
|
||||
|
||||
接下来,使用 vim 命令在 'config' 目录中创建一个新的 requirements.txt 文件
|
||||
|
||||
```
|
||||
vim config/requirements.txt
|
||||
```
|
||||
|
||||
粘贴下面的配置。
|
||||
|
||||
```
|
||||
Django==2.0.4
|
||||
gunicorn==19.7.0
|
||||
psycopg2==2.7.4
|
||||
```
|
||||
|
||||
保存并退出。
|
||||
|
||||
### 创建 Dockerfile
|
||||
|
||||
在 'guide01' 目录下创建新文件 'Dockerfile'。
|
||||
|
||||
运行以下命令。
|
||||
|
||||
```
|
||||
vim Dockerfile
|
||||
```
|
||||
|
||||
现在粘贴下面的 Dockerfile 脚本。
|
||||
|
||||
```
|
||||
FROM python:3.5-alpine
|
||||
ENV PYTHONUNBUFFERED 1
|
||||
|
||||
RUN apk update && \
|
||||
apk add --virtual build-deps gcc python-dev musl-dev && \
|
||||
apk add postgresql-dev bash
|
||||
|
||||
RUN mkdir /config
|
||||
ADD /config/requirements.txt /config/
|
||||
RUN pip install -r /config/requirements.txt
|
||||
RUN mkdir /src
|
||||
WORKDIR /src
|
||||
```
|
||||
|
||||
保存并退出。
|
||||
|
||||
注意:
|
||||
|
||||
我们想要为我们的 Django 项目构建基于 Alpine Linux 的 Docker 镜像,Alpine 是最小的 Linux 版本。我们的 Django 项目将运行在带有 Python3.5 的 Alpine Linux 上,并添加 postgresql-dev 包以支持 PostgreSQL 数据库。然后,我们将使用 python pip 命令安装在 'requirements.txt' 上列出的所有 Python 包,并为我们的项目创建新目录 '/src'。
|
||||
|
||||
### 创建 Docker-compose 脚本
|
||||
|
||||
使用 [vim][18] 命令在 'guide01' 目录下创建 'docker-compose.yml' 文件。
|
||||
|
||||
```
|
||||
vim docker-compose.yml
|
||||
```
|
||||
|
||||
粘贴以下配置内容。
|
||||
|
||||
```
|
||||
version: '3'
|
||||
services:
|
||||
db:
|
||||
image: postgres:10.3-alpine
|
||||
container_name: postgres01
|
||||
nginx:
|
||||
image: nginx:1.13-alpine
|
||||
container_name: nginx01
|
||||
ports:
|
||||
- "8000:8000"
|
||||
volumes:
|
||||
- ./project:/src
|
||||
- ./config/nginx:/etc/nginx/conf.d
|
||||
depends_on:
|
||||
- web
|
||||
web:
|
||||
build: .
|
||||
container_name: django01
|
||||
command: bash -c "python manage.py makemigrations && python manage.py migrate && python manage.py collectstatic --noinput && gunicorn hello_django.wsgi -b 0.0.0.0:8000"
|
||||
depends_on:
|
||||
- db
|
||||
volumes:
|
||||
- ./project:/src
|
||||
expose:
|
||||
- "8000"
|
||||
restart: always
|
||||
```
|
||||
|
||||
保存并退出。
|
||||
|
||||
注意:
|
||||
|
||||
使用这个 docker-compose 文件脚本,我们将创建三个服务。使用 PostgreSQL alpine Linux 创建名为 'db' 的数据库服务,再次使用 Nginx alpine Linux 创建 'nginx' 服务,并使用从 Dockerfile 生成的自定义 docker 镜像创建我们的 python Django 容器。
|
||||
|
||||
[][19]
|
||||
|
||||
### 配置 Django 项目
|
||||
|
||||
将 Django 项目文件复制到 'project' 目录。
|
||||
|
||||
```
|
||||
cd ~/django
|
||||
cp -r * ~/guide01/project/
|
||||
```
|
||||
|
||||
进入 'project' 目录并编辑应用程序设置 'settings.py'。
|
||||
|
||||
```
|
||||
cd ~/guide01/project/
|
||||
vim hello_django/settings.py
|
||||
```
|
||||
|
||||
注意:
|
||||
|
||||
我们将部署名为 'hello_django' 的简单 Django 应用程序。
|
||||
|
||||
在 'ALLOW_HOSTS' 行中,添加服务名称 'web'。
|
||||
|
||||
```
|
||||
ALLOW_HOSTS = ['web']
|
||||
```
|
||||
|
||||
现在更改数据库设置,我们将使用 PostgreSQL 数据库,'db' 数据库作为服务运行,使用默认用户和密码。
|
||||
|
||||
```
|
||||
DATABASES = {
|
||||
'default': {
|
||||
'ENGINE': 'django.db.backends.postgresql_psycopg2',
|
||||
'NAME': 'postgres',
|
||||
'USER': 'postgres',
|
||||
'HOST': 'db',
|
||||
'PORT': 5432,
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
至于 'STATIC_ROOT' 配置目录,将此行添加到文件行的末尾。
|
||||
|
||||
```
|
||||
STATIC_ROOT = os.path.join(BASE_DIR, 'static/')
|
||||
```
|
||||
|
||||
保存并退出。
|
||||
|
||||
[][20]
|
||||
|
||||
现在我们准备在 docker 容器下构建和运行 Django 项目。
|
||||
|
||||
### 步骤 4 - 构建并运行 Docker 镜像
|
||||
|
||||
在这一步中,我们想要使用 'guide01' 目录中的配置为我们的 Django 项目构建一个 Docker 镜像。
|
||||
|
||||
进入 'guide01' 目录。
|
||||
|
||||
```
|
||||
cd ~/guide01/
|
||||
```
|
||||
|
||||
现在使用 docker-compose 命令构建 docker 镜像。
|
||||
|
||||
```
|
||||
docker-compose build
|
||||
```
|
||||
|
||||
[][21]
|
||||
|
||||
启动 docker-compose 脚本中的所有服务。
|
||||
|
||||
```
|
||||
docker-compose up -d
|
||||
```
|
||||
|
||||
等待几分钟让 Docker 构建我们的 Python 镜像并下载 nginx 和 postgresql docker 镜像。
|
||||
|
||||
[][22]
|
||||
|
||||
完成后,使用以下命令检查运行容器并在系统上列出 docker 镜像。
|
||||
|
||||
```
|
||||
docker-compose ps
|
||||
docker-compose images
|
||||
```
|
||||
|
||||
现在,你将在系统上运行三个容器并列出 Docker 镜像,如下所示。
|
||||
|
||||
[][23]
|
||||
|
||||
我们的 Python Django 应用程序现在在 docker 容器内运行,并且已经创建了为我们服务的 docker 镜像。
|
||||
|
||||
### 步骤 5 - 测试
|
||||
|
||||
打开 Web 浏览器并使用端口 8000 键入服务器地址,我的是:http://ovh01:8000/
|
||||
|
||||
现在你将获得默认的 Django 主页。
|
||||
|
||||
[][24]
|
||||
|
||||
接下来,通过在 URL 上添加 “/admin” 路径来测试管理页面。
|
||||
|
||||
http://ovh01:8000/admin/
|
||||
|
||||
然后你将会看到 Django admin 登录页面。
|
||||
|
||||
[][25]
|
||||
|
||||
Docker 化 Python Django 应用程序已成功完成。
|
||||
|
||||
### 参考
|
||||
|
||||
* [https://docs.docker.com/][13]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/
|
||||
|
||||
作者:[Muhammad Arul][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/
|
||||
[1]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/#create-a-new-requirementstxt-file
|
||||
[2]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/#create-the-nginx-virtual-host-file-djangoconf
|
||||
[3]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/#create-the-dockerfile
|
||||
[4]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/#create-dockercompose-script
|
||||
[5]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/#configure-django-project
|
||||
[6]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/#what-we-will-do
|
||||
[7]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/#step-install-dockerce
|
||||
[8]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/#step-install-dockercompose
|
||||
[9]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/#step-configure-project-environment
|
||||
[10]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/#step-build-and-run-the-docker-image
|
||||
[11]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/#step-testing
|
||||
[12]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/#reference
|
||||
[13]:https://docs.docker.com/
|
||||
[14]:https://www.howtoforge.com/images/docker_guide_dockerizing_python_django_application/big/1.png
|
||||
[15]:https://www.howtoforge.com/images/docker_guide_dockerizing_python_django_application/big/2.png
|
||||
[16]:https://www.howtoforge.com/images/docker_guide_dockerizing_python_django_application/big/3.png
|
||||
[17]:https://www.howtoforge.com/images/docker_guide_dockerizing_python_django_application/big/4.png
|
||||
[18]:https://www.howtoforge.com/vim-basics
|
||||
[19]:https://www.howtoforge.com/images/docker_guide_dockerizing_python_django_application/big/5.png
|
||||
[20]:https://www.howtoforge.com/images/docker_guide_dockerizing_python_django_application/big/6.png
|
||||
[21]:https://www.howtoforge.com/images/docker_guide_dockerizing_python_django_application/big/7.png
|
||||
[22]:https://www.howtoforge.com/images/docker_guide_dockerizing_python_django_application/big/8.png
|
||||
[23]:https://www.howtoforge.com/images/docker_guide_dockerizing_python_django_application/big/9.png
|
||||
[24]:https://www.howtoforge.com/images/docker_guide_dockerizing_python_django_application/big/10.png
|
||||
[25]:https://www.howtoforge.com/images/docker_guide_dockerizing_python_django_application/big/11.png
|
||||
@ -1,49 +1,49 @@
|
||||
Streams:一个新的 Redis 通用数据结构
|
||||
==================================
|
||||
======
|
||||
|
||||
直到几个月以前,对于我来说,在消息传递的环境中,streams 只是一个有趣且相对简单的概念。这个概念在 Kafka 流行之后,我主要研究它们在 Disque 案例中的效能。Disque 是一个消息队列,它将在 Redis 4.2 中被转换为 Redis 的一个模块。后来我决定用 Disque 来做全部的 AP 消息,也就是说,它将在不需要客户端过多参与的情况下实现容错和保证送达,这样一来,我更加确定地认为 streams 的概念在那种情况下并不适用。
|
||||
直到几个月以前,对于我来说,在消息传递的环境中,<ruby>流<rt>streams</rt></ruby>只是一个有趣且相对简单的概念。这个概念在 Kafka 流行之后,我主要研究它们在 Disque 案例中的应用,Disque 是一个消息队列,它将在 Redis 4.2 中被转换为 Redis 的一个模块。后来我决定让 Disque 都用 AP 消息[1],也就是说,它将在不需要客户端过多参与的情况下实现容错和可用性,这样一来,我更加确定地认为流的概念在那种情况下并不适用。
|
||||
|
||||
然而在那时,在 Redis 中还存在一个问题,那就是缺省情况下导出数据结构并不轻松。在 Redis 列表、有序集和发布/订阅能力之间有某些缺陷。你可以权衡使用这些工具对一系列消息或事件进行建模。
|
||||
然而在那时 Redis 有个问题,那就是缺省情况下导出数据结构并不轻松。它在 Redis <ruby>列表<rt>list</rt></ruby>、<ruby>有序集合<rt>sorted list</rt></ruby>、<ruby>发布/订阅<rt>Pub/Sub</rt></ruby>功能之间有某些缺陷。你可以权衡使用这些工具对一个消息或事件建模。
|
||||
|
||||
有序集是非常耗费内存的,那自然就不能对投递的相同消息进行一次又一次的建模,客户端不能阻塞新消息。因为有序集并不是一个序列化的数据结构,它是一个可以根据元素分数的变化而移动位置的集合:难怪它不适合像时间序列这样的东西。
|
||||
排序集合是内存消耗大户,那自然就不能对投递相同消息进行一次又一次的建模,客户端不能阻塞新消息。因为有序集合并不是一个序列化的数据结构,它是一个元素可以根据它们量的变化而移动的集合:所以它不像时序性的数据那样。
|
||||
|
||||
列表也有不同的问题,它在某些特定的用例中产生类似的适用性问题:你无法浏览列表中间的内容,因为在那种情况下,访问时间是线性的。此外,有可能是没有输出的,列表上的阻塞操作仅为单个客户端提供单个元素。而不是为列表中的元素提供固定的标识符,也就是说,无法做到从指定的那个元素开始给我提供内容。
|
||||
列表有另外的问题,它在某些特定的用例中产生类似的适用性问题:你无法浏览列表中间的内容,因为在那种情况下,访问时间是线性的。此外,没有任何指定输出的功能,列表上的阻塞操作仅为单个客户端提供单个元素。列表中没有固定的元素标识,也就是说,不能指定从哪个元素开始给我提供内容。
|
||||
|
||||
对于一到多的负载,它有发布/订阅机制,它在大多数情况下是非常好的,但是,对于某些你不希望“即发即弃”的东西:保留一个历史是很重要的,而不是断开之后重新获得消息,也因为某些消息列表,像时间序列,用范围查询浏览是非常重要的:在这 10 秒范围内我的温度读数是多少?
|
||||
对于一对多的工作任务,有发布/订阅机制,它在大多数情况下是非常好的,但是,对于某些不想<ruby>“即发即弃”<rt>fire-and-forget</rt></ruby>的东西:保留一个历史是很重要的,不只是因为是断开之后重新获得消息,也因为某些如时序性的消息列表,用范围查询浏览是非常重要的:在这 10 秒范围内温度读数是多少?
|
||||
|
||||
我尝试去解决上面的问题所使用的一种方法是,规划一个通用的有序集合,并列入到一个唯一的、更灵活的数据结构中,然而,我的设计尝试最终以生成一个比当前的数据结构更加矫揉造作的结果而结束。一个关于 Redis 数据结构导出的更好的事情是,让它更像天然的计算机科学的数据结构,而不是,“Salvatore 发明的 API”。因此,在最后我停止了我的尝试,并且说,“ok,这是我们目前能提供的东西了”,或许,我将为发布/订阅增加一些历史,或者将来对列表访问增加一些更灵活的方式。然而,每次在会议上有用户对我说“你如何在 Redis 中建模时间序列” 或者类似的问题时,我就感到很惶恐。
|
||||
我试图解决上述问题,我想规划一个通用的有序集合,并列入一个独特的、更灵活的数据结构,然而,我的设计尝试最终以生成一个比当前的数据结构更加矫揉造作的结果而告终。Redis 有个好处,它的数据结构导出更像自然的计算机科学的数据结构,而不是 “Salvatore 发明的 API”。因此,我最终停止了我的尝试,并且说,“ok,这是我们目前能提供的”,或许我会为发布/订阅增加一些历史信息,或者为列表访问增加一些更灵活的方式。然而,每次在会议上有用户对我说 “你如何在 Redis 中模拟时间系列” 或者类似的问题时,我的脸就绿了。
|
||||
|
||||
### 起源
|
||||
|
||||
在 Redis 4.0 中引入模块之后,用户开始去看,他们自己如何去修复这些问题。他们中的一个 —— Timothy Downs,通过 IRC 写信给我:
|
||||
在 Redis 4.0 中引入模块之后,用户开始考虑他们自己怎么去修复这些问题。其中一个用户 Timothy Downs 通过 IRC 和我说道:
|
||||
|
||||
\<forkfork> 这个模块,我计划去增加一个事务日志式的数据类型 —— 这意味着大量的订阅者可以在不大量增加 redis 内存使用的情况下做一些像发布/订阅那样的事情
|
||||
\<forkfork> 我计划给这个模块增加一个事务日志式的数据类型 —— 这意味着大量的订阅者可以在不导致 redis 内存激增的情况下做一些像发布/订阅那样的事情
|
||||
\<forkfork> 订阅者持有他们在消息队列中的位置,而不是让 Redis 必须维护每个消费者的位置和为每个订阅者复制消息
|
||||
|
||||
他的思路启发了我。我想了几天,并且意识到这可能是我们马上同时解决上面所有问题的一个契机。我需要去重新构思 “日志” 的概念。日志是个基本的编程元素,每个人都使用过它,因为它只是简单地以追加模式打开一个文件,并以一定的格式写入数据。然而 Redis 数据结构必须是抽象的。它们在内存中,并且我们使用内存并不是因为我们懒,而是因为使用一些指针,我们可以概念化数据结构并把它们抽象,以使它们摆脱明确的限制。例如,一般来说日志有几个问题:偏移不是逻辑化的,而是真实的字节偏移,如果你希望找到与条目插入时间相关的逻辑偏移量是多少?我们有范围查询可用。同样的,日志通常很难进行垃圾收集:在一个只能进行追加操作的数据结构中怎么去删除旧的元素?好吧,在我们理想的日志中,我们只需要说,我想要数字最大的那个条目,而旧的元素一个也不要,等等。
|
||||
他的思路启发了我。我想了几天,并且意识到这可能是我们马上同时解决上面所有问题的契机。我需要去重新构思 “日志” 的概念是什么。日志是个基本的编程元素,每个人都使用过它,因为它只是简单地以追加模式打开一个文件,并以一定的格式写入数据。然而 Redis 数据结构必须是抽象的。它们在内存中,并且我们使用内存并不是因为我们懒,而是因为使用一些指针,我们可以概念化数据结构并把它们抽象,以使它们摆脱明确的限制。例如,一般来说日志有几个问题:偏移不是逻辑化的,而是真实的字节偏移,如果你想要与条目插入的时间相关的逻辑偏移应该怎么办?我们有范围查询可用。同样,日志通常很难进行垃圾回收:在一个只能进行追加操作的数据结构中怎么去删除旧的元素?好吧,在我们理想的日志中,我们只需要说,我想要数字最大的那个条目,而旧的元素一个也不要,等等。
|
||||
|
||||
当我从 Timothy 的想法中受到启发,去尝试着写一个规范的时候,我使用了 Redis 集群中的 radix 树去实现,优化了它内部的某些部分。这为实现一个有效利用空间的日志提供了基础,而且仍然有可能在<ruby>对数时间<rt>logarithmic time</rt></ruby>内访问日志得到该范围。就在那时,我开始去读关于 Kafka 的 streams 相关的内容,以获得适合我的设计的其它灵感,最后的结果是借鉴了 Kafka 消费组的概念,并且再次针对 Redis 进行优化,以适用于 Redis 在内存中使用的情况。然而,该规范仅停留在纸面上,在一段时间后我几乎把它从头到尾重写了一遍,以便将我与别人讨论所得到的许多建议一起增加到即将到来的 Redis 升级中。我希望 Redis 的 streams 是非常有用的,尤其对于时间序列来说,而不仅是用于事件和消息类的应用程序。
|
||||
当我从 Timothy 的想法中受到启发,去尝试着写一个规范的时候,我使用了 Redis 集群中的 radix 树去实现,优化了它内部的某些部分。这为实现一个有效利用空间的日志提供了基础,而且仍然可以用<ruby>对数时间<rt>logarithmic time</rt></ruby>来访问范围。同时,我开始去读关于 Kafka 流以获得另外的灵感,它也非常适合我的设计,最后借鉴了 Kafka <ruby>消费群体<rt>consumer groups</rt></ruby>的概念,并且再次针对 Redis 进行优化,以适用于 Redis 在内存中使用的情况。然而,该规范仅停留在纸面上,在一段时间后我几乎把它从头到尾重写了一遍,以便将我与别人讨论的所得到的许多建议一起增加到 Redis 升级中。我希望 Redis 流能成为对于时间序列有用的特性,而不仅是一个常见的事件和消息类的应用程序。
|
||||
|
||||
### 让我们写一些代码吧
|
||||
|
||||
从 Redis 大会回来后,在那个夏天,我实现了一个称为 “listpack” 的库。这个库是 `ziplist.c` 的继任者,它是表示在单个分配中的字符串元素列表的一个数据结构。它是一个非常专业的序列化格式,其特点在于也能够以逆序(从右到左)进行解析:在所有的案例中是用于代替 ziplists 所做的事情。
|
||||
从 Redis 大会回来后,整个夏天我都在实现一个叫 listpack 的库。这个库是 `ziplist.c` 的继任者,那是一个表示在单个分配中的字符串元素列表的数据结构。它是一个非常特殊的序列化格式,其特点在于也能够以逆序(从右到左)解析:以便在各种用例中替代 ziplists。
|
||||
|
||||
结合 radix 树和 listpacks 的特性,它可以很容易地去构建一个空间高效的日志,并且还是索引化的,这意味着允许通过 ID 和时间进行随机访问。自从这些准备就绪后,我开始去写一些代码以实现流数据结构。我最终完成了该实现,不管怎样,现在,Redis 在 Github 上的 “streams” 分支里面,它已经可以跑的很好了。我并没有声称那个 API 是 100% 的最终版本,但是,这有两个有趣的事实:一是,在那时,只有消费组是不行的,再加上一些不那么重要的命令去操作流,但是,所有的大的方面都已经实现了。二是,一旦各个方面比较稳定了之后 ,决定大概用两个月的时间将所有的流的工作<ruby>回迁<rt>backport</rt></ruby>到 4.0 分支。这意味着 Redis 用户为了使用 streams,不用等到 Redis 4.2 发布,它们在生产环境中马上就可以使用了。这是可能的,因为作为一个新的数据结构,几乎所有的代码改变都出现在新的代码里面。除了阻塞列表操作之外:该代码被重构了,我们对于 streams 和列表阻塞操作共享了相同的代码,从而极大地简化了 Redis 内部。
|
||||
结合 radix 树和 listpacks 的特性,它可以很容易地去构建一个空间高效的日志,并且还是可索引的,这意味着允许通过 ID 和时间进行随机访问。自从这些就绪后,我开始去写一些代码以实现流数据结构。我还在完成这个实现,不管怎样,现在在 Github 上的 Redis 的 streams 分支里它已经可以跑起来了。我并没有声称那个 API 是 100% 的最终版本,但是,这有两个有意思的事实:一,在那时只有消费群组是缺失的,加上一些不太重要的操作流的命令,但是,所有的大的方面都已经实现了。二,一旦各个方面比较稳定了之后,我决定大概用两个月的时间将所有的流的特性<ruby>向后移植<rt>backport</rt></ruby>到 4.0 分支。这意味着 Redis 用户想要使用流,不用等待 Redis 4.2 发布,它们在生产环境马上就可用了。这是可能的,因为作为一个新的数据结构,几乎所有的代码改变都出现在新的代码里面。除了阻塞列表操作之外:该代码被重构了,我们对于流和列表阻塞操作共享了相同的代码,而极大地简化了 Redis 内部实现。
|
||||
|
||||
### 教程:欢迎使用 Redis 的 streams
|
||||
|
||||
在某些方面,你可以认为 streams 是 Redis 中列表的一个增强版本。streams 元素不再是一个单一的字符串,它们更多是一个<ruby>字段<rt>field</rt></ruby>和<ruby>值<rt>value</rt></ruby>组成的对象。范围查询成为可能而且还更快。流中的每个条目都有一个 ID,它是个逻辑偏移量。不同的客户端可以<ruby>阻塞等待<rt>blocking-wait</rt></ruby>比指定的 ID 更大的元素。Redis 中 streams 的一个基本命令是 XADD。是的,所有 Redis 的流命令都是以一个“X”为前缀的。
|
||||
在某些方面,你可以认为流是 Redis 列表的一个增强版本。流元素不再是一个单一的字符串,而是一个<ruby>字段<rt>field</rt></ruby>和<ruby>值<rt>value</rt></ruby>组成的对象。范围查询更适用而且更快。在流中,每个条目都有一个 ID,它是一个逻辑偏移量。不同的客户端可以<ruby>阻塞等待<rt>blocking-wait</rt></ruby>比指定的 ID 更大的元素。Redis 流的一个基本的命令是 `XADD`。是的,所有的 Redis 流命令都是以一个 `X` 为前缀的。
|
||||
|
||||
```
|
||||
> XADD mystream * sensor-id 1234 temperature 10.5
|
||||
1506871964177.0
|
||||
```
|
||||
|
||||
这个 `XADD` 命令将追加指定的条目作为一个指定的流 —— “mystream” 的新元素。在上面的示例中的这个条目有两个字段:`sensor-id` 和 `temperature`,每个条目在同一个流中可以有不同的字段。使用相同的字段名字可以更好地利用内存。需要记住的一个有趣的事情是,字段是保证排序的。XADD 仅返回插入的条目的 ID,因为在第三个参数中是星号(`*`),表示我们要求命令自动生成 ID。大多数情况下需要如此,但是,也可以去强制指定一个 ID,这种情况用于复制这个命令到被动服务器和 AOF 文件。
|
||||
这个 `XADD` 命令将追加指定的条目作为一个指定的流 —— “mystream” 的新元素。上面示例中的这个条目有两个字段:`sensor-id` 和 `temperature`,每个条目在同一个流中可以有不同的字段。使用相同的字段名可以更好地利用内存。有意思的是,字段的排序是可以保证顺序的。`XADD` 仅返回插入的条目的 ID,因为在第三个参数中是星号(`*`),表示由命令自动生成 ID。通常这样做就够了,但是也可以去强制指定一个 ID,这种情况用于复制这个命令到<ruby>从服务器<rt>slave server</rt></ruby>和 <ruby>AOF<rt>append-only file</rt></ruby> 文件。
|
||||
|
||||
这个 ID 是由两部分组成的:一个毫秒时间和一个序列号。`1506871964177` 是毫秒时间,它仅是一个毫秒级的 UNIX 时间。圆点(`.`)后面的数字 `0`,是一个序列号,它是为了区分相同毫秒数的条目增加上去的。这两个数字都是 64 位的无符号整数。这意味着在流中,我们可以增加所有我们想要的条目,即使是在同一毫秒中。ID 的毫秒部分使用 Redis 服务器的当前本地时间生成的 ID 和流中的最后一个条目 ID 两者间的最大的一个。因此,举例来说,即使是计算机时间回跳,这个 ID 仍然是增加的。在某些情况下,你可以认为流条目的 ID 是完整的 128 位数字。然而,事实是,它们与被添加的实例的本地时间有关,这意味着我们可以在毫秒级的精度范围内随意查询。
|
||||
这个 ID 是由两部分组成的:一个毫秒时间和一个序列号。`1506871964177` 是毫秒时间,它只是一个毫秒级的 UNIX 时间戳。圆点(`.`)后面的数字 `0` 是一个序号,它是为了区分相同毫秒数的条目增加上去的。这两个数字都是 64 位的无符号整数。这意味着,我们可以在流中增加所有想要的条目,即使是在同一毫秒中。ID 的毫秒部分使用 Redis 服务器的当前本地时间生成的 ID 和流中的最后一个条目 ID 两者间的最大的一个。因此,举例来说,即使是计算机时间回跳,这个 ID 仍然是增加的。在某些情况下,你可以认为流条目的 ID 是完整的 128 位数字。然而,事实上它们与被添加到的实例的本地时间有关,这意味着我们可以在毫秒级的精度的范围随意查询。
|
||||
|
||||
正如你想的那样,以一个速度非常快的方式去添加两个条目,结果是仅一个序列号增加了。我可以使用一个 `MULTI`/`EXEC` 块去简单模拟“快速插入”,如下:
|
||||
正如你想的那样,快速添加两个条目后,结果是仅一个序号递增了。我们可以用一个 `MULTI`/`EXEC` 块来简单模拟“快速插入”:
|
||||
|
||||
```
|
||||
> MULTI
|
||||
@ -57,9 +57,9 @@ QUEUED
|
||||
2) 1506872463535.1
|
||||
```
|
||||
|
||||
在上面的示例中,也展示了无需指定任何初始<ruby>模式<rt>schema</rt></ruby>的情况下,对不同的条目使用不同的字段。会发生什么呢?就像前面提到的一样,只有每个块(它通常包含 50 - 150 个消息内容)的第一个信息被使用。并且,相同字段的连续条目都使用了一个标志进行了压缩,这个标志表示与“它们与这个块中的第一个条目的字段相同”。因此,对于使用了相同字段的连续消息可以节省许多内存,即使是字段集随着时间发生缓慢变化的情况下也很节省内存。
|
||||
在上面的示例中,也展示了无需指定任何初始<ruby>模式<rt>schema</rt></ruby>的情况下,对不同的条目使用不同的字段。会发生什么呢?就像前面提到的一样,只有每个块(它通常包含 50-150 个消息内容)的第一个消息被使用。并且,相同字段的连续条目都使用了一个标志进行了压缩,这个标志表示与“它们与这个块中的第一个条目的字段相同”。因此,使用相同字段的连续消息可以节省许多内存,即使是字段集随着时间发生缓慢变化的情况下也很节省内存。
|
||||
|
||||
为了从流中检索数据,这里有两种方法:范围查询,它是通过 `XRANGE` 命令实现的;和<ruby>流播<rt>streaming</rt></ruby>,它是通过 XREAD 命令实现的。`XRANGE` 命令仅取得包括从开始到停止范围内的全部条目。因此,举例来说,如果我知道它的 ID,我可以使用如下的命名取得单个条目:
|
||||
为了从流中检索数据,这里有两种方法:范围查询,它是通过 `XRANGE` 命令实现的;<ruby>流播<rt>streaming</rt></ruby>,它是通过 `XREAD` 命令实现的。`XRANGE` 命令仅取得包括从开始到停止范围内的全部条目。因此,举例来说,如果我知道它的 ID,我可以使用如下的命名取得单个条目:
|
||||
|
||||
```
|
||||
> XRANGE mystream 1506871964177.0 1506871964177.0
|
||||
@ -70,7 +70,7 @@ QUEUED
|
||||
4) "10.5"
|
||||
```
|
||||
|
||||
不管怎样,你都可以使用指定的开始符号 `-` 和停止符号 `+` 去表示最小和最大的 ID。为了限制返回条目的数量,也可以使用 `COUNT` 选项。下面是一个更复杂的 `XRANGE` 示例:
|
||||
不管怎样,你都可以使用指定的开始符号 `-` 和停止符号 `+` 表示最小和最大的 ID。为了限制返回条目的数量,也可以使用 `COUNT` 选项。下面是一个更复杂的 `XRANGE` 示例:
|
||||
|
||||
```
|
||||
> XRANGE mystream - + COUNT 2
|
||||
@ -84,7 +84,7 @@ QUEUED
|
||||
2) "10"
|
||||
```
|
||||
|
||||
这里我们讲的是 ID 的范围,然后,为了取得在一个给定时间范围内的特定范围的元素,你可以使用 `XRANGE`,因为你可以省略 ID 的“序列” 部分。因此,你可以做的仅是指定“毫秒”时间,下面的命令的意思是: “从 UNIX 时间 1506872463 开始给我 10 个条目”:
|
||||
这里我们讲的是 ID 的范围,然后,为了取得在一个给定时间范围内的特定范围的元素,你可以使用 `XRANGE`,因为 ID 的“序号” 部分可以省略。因此,你可以只指定“毫秒”时间即可,下面的命令的意思是:“从 UNIX 时间 1506872463 开始给我 10 个条目”:
|
||||
|
||||
```
|
||||
127.0.0.1:6379> XRANGE mystream 1506872463000 + COUNT 10
|
||||
@ -96,15 +96,15 @@ QUEUED
|
||||
2) "20"
|
||||
```
|
||||
|
||||
关于 `XRANGE` 需要注意的最重要的事情是,假设我们在回复中收到 ID,并且随后连续的 ID 只是增加了 ID 的序列部分,所以可以使用 `XRANGE` 去遍历整个流,接收每个调用的指定个数的元素。在 Redis 中的`*SCAN` 系列命令之后,它允许 Redis 数据结构迭代,尽管事实上它们不是为迭代设计的,但这样我可以避免再犯相同的错误。
|
||||
关于 `XRANGE` 需要注意的最重要的事情是,假设我们在回复中收到 ID,随后连续的 ID 只是增加了序号部分,所以可以使用 `XRANGE` 遍历整个流,接收每个调用的指定个数的元素。Redis 中的`*SCAN` 系列命令允许迭代 Redis 数据结构,尽管事实上它们不是为迭代设计的,但这样可以避免再犯相同的错误。
|
||||
|
||||
### 使用 XREAD 处理流播:阻塞新的数据
|
||||
|
||||
当我们想通过 ID 或时间去访问流中的一个范围或者是通过 ID 去获取单个元素时,使用 XRANGE 是非常完美的。然而,在 streams 的案例中,当数据到达时,它必须由不同的客户端来消费时,这就不是一个很好的解决方案,这需要某种形式的“汇聚池”。(对于*某些*应用程序来说,这可能是个好主意,因为它们仅是偶尔连接取数的)
|
||||
当我们想通过 ID 或时间去访问流中的一个范围或者是通过 ID 去获取单个元素时,使用 `XRANGE` 是非常完美的。然而,在使用流的案例中,当数据到达时,它必须由不同的客户端来消费时,这就不是一个很好的解决方案,这需要某种形式的<ruby>汇聚池<rt>pooling</rt></ruby>。(对于 *某些* 应用程序来说,这可能是个好主意,因为它们仅是偶尔连接查询的)
|
||||
|
||||
`XREAD` 命令是为读取设计的,在同一个时间,从多个 streams 中仅指定我们从该流中得到的最后条目的 ID。此外,如果没有数据可用,我们可以要求阻塞,当数据到达时,去解除阻塞。类似于阻塞列表操作产生的效果,但是这里并没有消费从流中得到的数据。并且多个客户端可以同时访问相同的数据。
|
||||
`XREAD` 命令是为读取设计的,在同一个时间,从多个流中仅指定我们从该流中得到的最后条目的 ID。此外,如果没有数据可用,我们可以要求阻塞,当数据到达时,就解除阻塞。类似于阻塞列表操作产生的效果,但是这里并没有消费从流中得到的数据,并且多个客户端可以同时访问同一份数据。
|
||||
|
||||
这里有一个关于 `XREAD` 调用的规范示例:
|
||||
这里有一个典型的 `XREAD` 调用示例:
|
||||
|
||||
```
|
||||
> XREAD BLOCK 5000 STREAMS mystream otherstream $ $
|
||||
@ -112,12 +112,14 @@ QUEUED
|
||||
|
||||
它的意思是:从 `mystream` 和 `otherstream` 取得数据。如果没有数据可用,阻塞客户端 5000 毫秒。在 `STREAMS` 选项之后指定我们想要监听的关键字,最后的是指定想要监听的 ID,指定的 ID 为 `$` 的意思是:假设我现在需要流中的所有元素,因此,只需要从下一个到达的元素开始给我。
|
||||
|
||||
如果,从另外一个客户端,我发出这样的命令:
|
||||
如果我从另一个客户端发送这样的命令:
|
||||
|
||||
```
|
||||
> XADD otherstream * message “Hi There”
|
||||
```
|
||||
在 XREAD 侧会出现什么情况呢?
|
||||
|
||||
在 `XREAD` 侧会出现什么情况呢?
|
||||
|
||||
```
|
||||
1) 1) "otherstream"
|
||||
2) 1) 1) 1506935385635.0
|
||||
@ -125,23 +127,23 @@ QUEUED
|
||||
2) "Hi There"
|
||||
```
|
||||
|
||||
与收到的数据一起,我们得到了所收到数据的关键字,在下次的调用中,我们将使用接收到的最新消息的 ID:
|
||||
与收到的数据一起,我们也得到了数据的关键字。在下次调用中,我们将使用接收到的最新消息的 ID:
|
||||
|
||||
```
|
||||
> XREAD BLOCK 5000 STREAMS mystream otherstream $ 1506935385635.0
|
||||
```
|
||||
|
||||
依次类推。然而需要注意的是使用方式,客户端有可能在一个非常大的延迟(因为它处理消息需要时间,或者其它什么原因)之后再次连接。在这种情况下,期间会有很多消息堆积,为了确保客户端不被消息淹没,以及服务器不会因为给单个客户端提供大量消息而浪费太多的时间,使用 `XREAD` 的 `COUNT` 选项是非常明智的。
|
||||
依次类推。然而需要注意的是使用方式,客户端有可能在一个非常大的延迟之后再次连接(因为它处理消息需要时间,或者其它什么原因)。在这种情况下,期间会有很多消息堆积,为了确保客户端不被消息淹没,以及服务器不会因为给单个客户端提供大量消息而浪费太多的时间,使用 `XREAD` 的 `COUNT` 选项是非常明智的。
|
||||
|
||||
### 流封顶
|
||||
|
||||
到现在为止,一直还都不错…… 然而,有些时候,streams 需要去删除一些旧的消息。幸运的是,这可以使用 `XADD` 命令的 `MAXLEN` 选项去做:
|
||||
目前看起来还不错……然而,有些时候,流需要删除一些旧的消息。幸运的是,这可以使用 `XADD` 命令的 `MAXLEN` 选项去做:
|
||||
|
||||
```
|
||||
> XADD mystream MAXLEN 1000000 * field1 value1 field2 value2
|
||||
```
|
||||
|
||||
它是基本意思是,如果流上添加新元素后发现,它的消息数量超过了 `1000000` 个,那么,删除旧的消息,以便于长度重新回到 `1000000` 个元素以内。它很像是在列表中使用的 `RPUSH` + `LTRIM`,但是,这次我们是使用了一个内置机制去完成的。然而,需要注意的是,上面的意思是每次我们增加一个新的消息时,我们还需要另外的工作去从流中删除旧的消息。这将使用一些 CPU 资源,所以,在计算 MAXLEN 之前,尽可能使用 `~` 符号,以表明我们不要求非常*精确*的 1000000 个消息,就是稍微多一些也不是个大问题:
|
||||
它是基本意思是,如果在流中添加新元素后发现消息数量超过了 `1000000` 个,那么就删除旧的消息,以便于元素总量重新回到 `1000000` 以内。它很像是在列表中使用的 `RPUSH` + `LTRIM`,但是,这次我们是使用了一个内置机制去完成的。然而,需要注意的是,上面的意思是每次我们增加一个新的消息时,我们还需要另外的工作去从流中删除旧的消息。这将消耗一些 CPU 资源,所以在计算 `MAXLEN` 之前,尽可能使用 `~` 符号,以表明我们不要求非常 *精确* 的 1000000 个消息,就是稍微多一些也不是大问题:
|
||||
|
||||
```
|
||||
> XADD mystream MAXLEN ~ 1000000 * foo bar
|
||||
@ -151,33 +153,31 @@ QUEUED
|
||||
|
||||
### 消费组(开发中)
|
||||
|
||||
这是第一个 Redis 中尚未实现而在开发中的特性。它也是来自 Kafka 的灵感,尽管在这里以不同的方式去实现的。重点是使用了 `XREAD`,客户端也可以增加一个 `GROUP <name>` 选项。 在相同组的所有客户端,将自动地得到*不同的*消息。当然,同一个流可以被多个组读取。在这种情况下,所有的组将收到流中到达的消息的相同副本。但是,在每个组内,消息是不会重复的。
|
||||
这是第一个 Redis 中尚未实现而在开发中的特性。灵感也是来自 Kafka,尽管在这里是以不同的方式实现的。重点是使用了 `XREAD`,客户端也可以增加一个 `GROUP <name>` 选项。相同组的所有客户端将自动得到 *不同的* 消息。当然,同一个流可以被多个组读取。在这种情况下,所有的组将收到流中到达的消息的相同副本。但是,在每个组内,消息是不会重复的。
|
||||
|
||||
当指定组时,能够指定一个 “RETRY <milliseconds>” 选项去扩展组:在这种情况下,如果消息没有使用 XACK 去进行确认,它将在指定的毫秒数后进行再次投递。这将为消息投递提供更佳的可靠性,这种情况下,客户端没有私有的方法将消息标记为已处理。这一部分也正在开发中。
|
||||
当指定组时,能够指定一个 `RETRY <milliseconds>` 选项去扩展组:在这种情况下,如果消息没有通过 `XACK` 进行确认,它将在指定的毫秒数后进行再次投递。这将为消息投递提供更佳的可靠性,这种情况下,客户端没有私有的方法将消息标记为已处理。这一部分也正在开发中。
|
||||
|
||||
### 内存使用和加载时间节省
|
||||
### 内存使用和节省加载时间
|
||||
|
||||
因为设计用来建模 Redis 的 streams,内存使用是非常低的。这取决于它们的字段、值的数量和它们的长度,对于简单的消息,每使用 100 MB 内存可以有几百万条消息,此外,格式设想为需要极少的序列化:listpack 块以 radix 树节点方式存储,在磁盘上和内存中都以相同方式表示的,因此,它们可以很轻松地存储和读取。例如,Redis 可以在 0.3 秒内从 RDB 文件中读取 500 万个条目。这使得 streams 的复制和持久存储非常高效。
|
||||
因为用来建模 Redis 流的设计,内存使用率是非常低的。这取决于它们的字段、值的数量和长度,对于简单的消息,每使用 100MB 内存可以有几百万条消息。此外,格式设想为需要极少的序列化:listpack 块以 radix 树节点方式存储,在磁盘上和内存中都以相同方式表示的,因此它们可以很轻松地存储和读取。例如,Redis 可以在 0.3 秒内从 RDB 文件中读取 500 万个条目。这使流的复制和持久存储非常高效。
|
||||
|
||||
也计划允许从条目中间进行部分删除。现在仅实现了一部分,策略是在条目在标记中标识为已删除条目,并且,当已删除条目占全部条目的比率达到给定值时,这个块将被回收重写,并且,如果需要,它将被连到相邻的另一个块上,以避免碎片化。
|
||||
我还计划允许从条目中间进行部分删除。现在仅实现了一部分,策略是在条目在标记中标识条目为已删除,并且,当已删除条目占全部条目的比例达到指定值时,这个块将被回收重写,如果需要,它将被连到相邻的另一个块上,以避免碎片化。
|
||||
|
||||
### 关于最终发布时间的结论
|
||||
|
||||
Redis 的 streams 将包含在年底前(LCTT 译注:本文原文发布于 2017 年 10 月)推出的 Redis 4.0 系列的稳定版中。我认为这个通用的数据结构将为 Redis 提供一个巨大的补丁,以用于解决很多现在很难去解决的情况:那意味着你(之前)需要创造性地滥用当前提供的数据结构去解决那些问题。一个非常重要的使用案例是时间序列,但是,我的感觉是,对于其它用例来说,通过 `TREAD` 来流播消息将是非常有趣的,因为对于那些需要更高可靠性的应用程序,可以使用发布/订阅模式来替换“即用即弃”,还有其它全新的使用案例。现在,如果你想在你的有问题环境中评估新数据结构的能力,可以在 GitHub 上去获得 “streams” 分支,开始去玩吧。欢迎向我们报告所有的 bug 。 :-)
|
||||
Redis 的流特性将包含在年底前(LCTT 译注:本文原文发布于 2017 年 10 月)推出的 Redis 4.0 系列的稳定版中。我认为这个通用的数据结构将为 Redis 提供一个巨大的补丁,以用于解决很多现在很难以解决的情况:那意味着你(之前)需要创造性地“滥用”当前提供的数据结构去解决那些问题。一个非常重要的使用场景是时间序列,但是,我觉得对于其它场景来说,通过 `TREAD` 来流播消息将是非常有趣的,因为对于那些需要更高可靠性的应用程序,可以使用发布/订阅模式来替换“即用即弃”,还有其它全新的使用场景。现在,如果你想在有问题环境中评估这个新数据结构,可以更新 GitHub 上的 streams 分支开始试用。欢迎向我们报告所有的 bug。:-)
|
||||
|
||||
如果你喜欢这个视频,展示这个 streams 的实时会话在这里: https://www.youtube.com/watch?v=ELDzy9lCFHQ
|
||||
如果你喜欢观看视频的方式,这里有一个现场演示:https://www.youtube.com/watch?v=ELDzy9lCFHQ
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
---
|
||||
|
||||
via: http://antirez.com/news/114
|
||||
|
||||
作者:[antirez][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)、[pityonline](https://github.com/pityonline)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://antirez.com/
|
||||
[1]:http://antirez.com/news/114
|
||||
[2]:http://antirez.com/user/antirez
|
||||
[3]:https://www.youtube.com/watch?v=ELDzy9lCFHQ
|
||||
[a]: http://antirez.com/
|
||||
[1]: https://zh.wikipedia.org/wiki/CAP%E5%AE%9A%E7%90%86
|
||||
|
||||
@ -0,0 +1,130 @@
|
||||
如何在 Android 上借助 Wine 来运行 Windows Apps
|
||||
======
|
||||
|
||||

|
||||
|
||||
Wine(是 Linux 上的程序,不是你喝的葡萄酒)是在类 Unix 操作系统上运行 Windows 程序的一个自由开源的兼容层。创建于 1993 年,借助它你可以在 Linux 和 macOS 操作系统上运行很多 Windows 程序,虽然有时可能还需要做一些小修改。现在,Wine 项目已经发布了 3.0 版本,这个版本兼容你的 Android 设备。
|
||||
|
||||
在本文中,我们将向你展示,在你的 Android 设备上如何借助 Wine 来运行 Windows Apps。
|
||||
|
||||
**相关阅读** : [如何使用 Winepak 在 Linux 上轻松安装 Windows 游戏][1]
|
||||
|
||||
### 在 Wine 上你可以运行什么?
|
||||
|
||||
Wine 只是一个兼容层,不是一个全功能的仿真器,因此,你需要一个 x86 的 Android 设备才能完全发挥出它的优势。但是,大多数消费者手中的 Android 设备都是基于 ARM 的。
|
||||
|
||||
因为大多数人使用的是基于 ARM 的 Android 设备,所以有一个限制,只有适配在 Windows RT 上运行的那些 App 才能够使用 Wine 在基于 ARM 的 Android 上运行。但是随着发展,能够在 ARM 设备上运行的软件数量越来越多。你可以在 XDA 开发者论坛上的这个 [帖子][2] 中找到兼容的这些 App 的清单。
|
||||
|
||||
在 ARM 上能够运行的一些 App 的例子如下:
|
||||
|
||||
* [Keepass Portable][3]: 一个密码钱包
|
||||
* [Paint.NET][4]: 一个图像处理程序
|
||||
* [SumatraPDF][5]: 一个 PDF 文档阅读器,也能够阅读一些其它的文档类型
|
||||
* [Audacity][6]: 一个数字录音和编辑程序
|
||||
|
||||
|
||||
|
||||
也有一些再度流行的开源游戏,比如,[Doom][7] 和 [Quake 2][8],以及它们的开源克隆,比如 [OpenTTD][9],和《运输大亨》的一个版本。
|
||||
|
||||
随着 Wine 在 Android 上越来越普及,能够在基于 ARM 的 Android 设备上的 Wine 中运行的程序越来越多。Wine 项目致力于在 ARM 上使用 QEMU 去仿真 x86 的 CPU 指令,并且在项目完成后,能够在 Android 上运行的 App 将会迅速增加。
|
||||
|
||||
### 安装 Wine
|
||||
|
||||
在安装 Wine 之前,你首先需要去确保你的设备的设置是 “允许从 Play 商店之外的其它源下载和安装 APK”。为此,你需要去许可你的设备从未知源下载 App。
|
||||
|
||||
1\. 打开你手机上的设置,然后选择安全选项。
|
||||
|
||||
|
||||
![wine-android-security][10]
|
||||
|
||||
2\. 向下拉并点击 “Unknown Sources” 的开关。
|
||||
|
||||
![wine-android-unknown-sources][11]
|
||||
|
||||
3\. 接受风险警告。
|
||||
|
||||
![wine-android-unknown-sources-warning][12]
|
||||
|
||||
4\. 打开 [Wine 安装站点][13],并点选列表中的第一个选择框。下载将自动开始。
|
||||
|
||||
![wine-android-download-button][14]
|
||||
|
||||
5\. 下载完成后,从下载目录中打开它,或者下拉通知菜单并点击这里的已完成的下载。
|
||||
|
||||
6\. 开始安装程序。它将提示你它需要访问和记录音频,并去修改、删除、和读取你的 SD 卡。你也可能为程序中使用的一些 App 授予访问音频的权利。
|
||||
|
||||
![wine-android-app-access][15]
|
||||
|
||||
7\. 安装完成后,点击程序图标去打开它。
|
||||
|
||||
![wine-android-icon-small][16]
|
||||
|
||||
当你打开 Wine 后,它模仿的是 Windows 7 的桌面。
|
||||
|
||||
![wine-android-desktop][17]
|
||||
|
||||
Wine 有一个缺点是,你得有一个外接键盘去进行输入。如果你在一个小屏幕上运行它,并且触摸非常小的按钮很困难,你也可以使用一个外接鼠标。
|
||||
|
||||
你可以通过触摸 “开始” 按钮去打开两个菜单 —— “控制面板”和“运行”。
|
||||
|
||||
![wine-android-start-button][18]
|
||||
|
||||
### 使用 Wine 来工作
|
||||
|
||||
当你触摸 “控制面板” 后你将看到三个选项 —— 添加/删除程序、游戏控制器、和 Internet 设定。
|
||||
|
||||
使用 “运行”,你可以打开一个对话框去运行命令。例如,通过输入 `iexplore` 来启动 “Internet Explorer”。
|
||||
|
||||
![wine-android-run][19]
|
||||
|
||||
### 在 Wine 中安装程序
|
||||
|
||||
1\. 在你的 Android 设备上下载应用程序(或通过云来同步)。一定要记住下载的程序保存的位置。
|
||||
|
||||
2\. 打开 Wine 命令提示符窗口。
|
||||
|
||||
3\. 输入程序的位置路径。如果你把下载的文件保存在 SD 卡上,输入:
|
||||
|
||||
```
|
||||
cd sdcard/Download/[filename.exe]
|
||||
```
|
||||
|
||||
4\. 在 Android 上运行 Wine 中的文件,只需要简单地输入 EXE 文件的名字即可。
|
||||
|
||||
如果这个 ARM 就绪的文件是兼容的,它将会运行。如果不兼容,你将看到一大堆错误信息。在这种情况下,在 Android 上的 Wine 中安装的 Windows 软件可能会损坏或丢失。
|
||||
|
||||
这个在 Android 上使用的新版本的 Wine 仍然有许多问题。它并不能在所有的 Android 设备上正常工作。它可以在我的 Galaxy S6 Edge 上运行的很好,但是在我的 Galaxy Tab 4 上却不能运行。许多游戏也不能正常运行,因为图形驱动还不支持 Direct3D。因为触摸屏还不是全扩展的,所以你需要一个外接的键盘和鼠标才能很轻松地操作它。
|
||||
|
||||
即便是在早期阶段的发行版中存在这样那样的问题,但是这种技术还是值得深思的。当然了,你要想在你的 Android 智能手机上运行 Windows 程序而不出问题,可能还需要等待一些时日。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/run-windows-apps-android-with-wine/
|
||||
|
||||
作者:[Tracey Rosenberger][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/traceyrosenberger/
|
||||
[1]:https://www.maketecheasier.com/winepak-install-windows-games-linux/ "How to Easily Install Windows Games on Linux with Winepak"
|
||||
[2]:https://forum.xda-developers.com/showthread.php?t=2092348
|
||||
[3]:http://downloads.sourceforge.net/keepass/KeePass-2.20.1.zip
|
||||
[4]:http://forum.xda-developers.com/showthread.php?t=2411497
|
||||
[5]:http://forum.xda-developers.com/showthread.php?t=2098594
|
||||
[6]:http://forum.xda-developers.com/showthread.php?t=2103779
|
||||
[7]:http://forum.xda-developers.com/showthread.php?t=2175449
|
||||
[8]:http://forum.xda-developers.com/attachment.php?attachmentid=1640830&amp;d=1358070370
|
||||
[9]:http://forum.xda-developers.com/showpost.php?p=36674868&amp;postcount=151
|
||||
[10]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-security.png "wine-android-security"
|
||||
[11]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-unknown-sources.jpg "wine-android-unknown-sources"
|
||||
[12]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-unknown-sources-warning.png "wine-android-unknown-sources-warning"
|
||||
[13]:https://dl.winehq.org/wine-builds/android/
|
||||
[14]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-download-button.png "wine-android-download-button"
|
||||
[15]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-app-access.jpg "wine-android-app-access"
|
||||
[16]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-icon-small.jpg "wine-android-icon-small"
|
||||
[17]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-desktop.png "wine-android-desktop"
|
||||
[18]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-start-button.png "wine-android-start-button"
|
||||
[19]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-Run.png "wine-android-run"
|
||||
@ -0,0 +1,68 @@
|
||||
在 Fedora 28 Workstation 使用 emoji 加速输入
|
||||
======
|
||||
|
||||

|
||||
|
||||
Fedora 28 Workstation 添加了一个功能允许你使用键盘快速搜索、选择和输入 emoji。emoji,可爱的表意文字是 Unicode 的一部分,在消息传递中使用得相当广泛,特别是在移动设备上。你可能听过这样的成语:“一张图片胜过千言万语。”这正是 emoji 所提供的:简单的图像供你在交流中使用。Unicode 的每个版本都增加了更多,在过去的 Unicode 版本中添加了 200 多个 emoji。本文向你展示如何使它们在你的 Fedora 系统中易于使用。
|
||||
|
||||
很高兴看到 emoji 数字在增长。但与此同时,它带来了如何在计算设备中输入它们的挑战。许多人已经将这些符号用于移动设备或社交网站中的输入。
|
||||
|
||||
[ **编者注:**本文是对此主题以前发表过的文章的更新]。
|
||||
|
||||
### 在 Fedora 28 Workstation 上启用 emoji 输入
|
||||
|
||||
新的 emoji 输入法默认出现在 Fedora 28 Workstation 中。要使用它,必须使用“区域和语言设置”对话框启用它。从 Fedora Workstation 设置打开“区域和语言”对话框,或在“概要”中搜索它。
|
||||
|
||||
[![Region & Language settings tool][1]][2]
|
||||
|
||||
选择 + 控件添加输入源。出现以下对话框:
|
||||
|
||||
[![Adding an input source][3]][4]
|
||||
|
||||
选择最后选项(三个点)来完全展开选择。然后,在列表底部找到“其他”并选择它:
|
||||
|
||||
[![Selecting other input sources][5]][6]
|
||||
|
||||
在下面的对话框中,找到 ”Typing Booster“ 选项并选择它:
|
||||
|
||||
[![][7]][8]
|
||||
|
||||
这个高级输入法由 iBus 在背后支持。高级输入方法可通过列表右侧的齿轮图标在列表中识别。
|
||||
|
||||
输入法下拉菜单自动出现在 GNOME Shell 顶部栏中。确认你的默认输入法 - 在此示例中为英语(美国) - 被选为当前输入法,你就可以输入了。
|
||||
|
||||
[![Input method dropdown in Shell top bar][9]][10]
|
||||
|
||||
## 使用新的表情符号输入法
|
||||
|
||||
现在 emoji 输入法启用了,按键盘快捷键 **Ctrl+Shift+E** 搜索 emoji。将出现一个弹出对话框,你可以在其中输入搜索词,例如 smile 来查找匹配的符号。
|
||||
|
||||
[![Searching for smile emoji][11]][12]
|
||||
|
||||
使用箭头键翻页列表。然后按 **Enter** 进行选择,字形将作为输入。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/boost-typing-emoji-fedora-28-workstation/
|
||||
|
||||
作者:[Paul W. Frields][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/pfrields/
|
||||
[1]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-15-02-41-1024x718.png
|
||||
[2]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-15-02-41.png
|
||||
[3]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-33-46-1024x839.png
|
||||
[4]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-33-46.png
|
||||
[5]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-34-15-1024x839.png
|
||||
[6]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-34-15.png
|
||||
[7]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-34-41-1024x839.png
|
||||
[8]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-34-41.png
|
||||
[9]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-15-05-24-300x244.png
|
||||
[10]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-15-05-24.png
|
||||
[11]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-36-31-290x300.png
|
||||
[12]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-36-31.png
|
||||
@ -0,0 +1,146 @@
|
||||
学习如何使用 Python 构建你自己的 Twitter Bot
|
||||
======
|
||||
|
||||

|
||||
|
||||
Twitter 允许用户向这个世界[分享][1]博客文章。使用 Python 和 Tweepy 拓展使得创建一个 Twitter 机器人来接管你的所有 tweeting 变得非常简单。这篇文章告诉你如何去构建这样一个机器人。希望你能将这些概念也同样应用到其他的在线服务的项目中去。
|
||||
|
||||
### 开始
|
||||
|
||||
[tweepy][2] 拓展可以让创建一个 Twitter 机器人的过程更加容易上手。它包含了 Twitter 的 API 调用和一个很简单的接口
|
||||
|
||||
下面这些命令使用 Pipenv 在一个虚拟环境中安装 tweepy。如果你没有安装 Pipenv,可以看一看我们之前的文章[如何在 Fedora 上安装 Pipenv][3]
|
||||
|
||||
```
|
||||
$ mkdir twitterbot
|
||||
$ cd twitterbot
|
||||
$ pipenv --three
|
||||
$ pipenv install tweepy
|
||||
$ pipenv shell
|
||||
|
||||
```
|
||||
|
||||
### Tweepy – 开始
|
||||
|
||||
要使用 Twitter API ,机器人需要通过 Twitter 的授权。为了解决这个问题, tweepy 使用了 OAuth 授权标准。你可以通过在 <https://apps.twitter.com/> 创建一个新的应用来获取到凭证。
|
||||
|
||||
|
||||
#### 创建一个新的 Twitter 应用
|
||||
|
||||
当你填完了表格并点击了创建你自己的应用的按钮后,你可以获取到应用的凭证。 Tweepy 需要用户密钥 (API Key)和用户密码 (API Secret),这些都可以在 the Keys and Access Tokens 中找到
|
||||
|
||||
![][4]
|
||||
|
||||
向下滚动页面,使用创建我的 Access Token 按钮生成一个 Access Token 和一个 Access Token Secret
|
||||
|
||||
#### 使用 Tweppy —— 输出你的时间线
|
||||
|
||||
现在你已经有了所需的凭证了,打开一个文件,并写下如下的 Python 代码。
|
||||
```
|
||||
import tweepy
|
||||
|
||||
auth = tweepy.OAuthHandler("your_consumer_key", "your_consumer_key_secret")
|
||||
|
||||
auth.set_access_token("your_access_token", "your_access_token_secret")
|
||||
|
||||
api = tweepy.API(auth)
|
||||
|
||||
public_tweets = api.home_timeline()
|
||||
|
||||
for tweet in public_tweets:
|
||||
print(tweet.text)
|
||||
|
||||
```
|
||||
|
||||
在确保你正在使用你的 Pipenv 虚拟环境后,执行你的程序
|
||||
|
||||
```
|
||||
$ python tweet.py
|
||||
|
||||
```
|
||||
|
||||
上述程序调用了 home_timeline 方法来获取到你时间线中的 20 条最近的 tweets。现在这个机器人能够使用 tweepy 来获取到 Twitter 的数据,接下来尝试修改代码来发送 tweet。
|
||||
|
||||
#### 使用 Tweepy —— 发送一条 tweet
|
||||
|
||||
要发送一条 tweet ,有一个容易上手的 API 方法 update_status 。它的用法很简单:
|
||||
|
||||
```
|
||||
api.update_status("The awesome text you would like to tweet")
|
||||
```
|
||||
|
||||
Tweepy 拓展为制作 Twitter 机器人准备了非常多不同有用的方法。获取 API 的详细信息,查看[文档][5]。
|
||||
|
||||
|
||||
### 一个杂志机器人
|
||||
|
||||
接下来我们来创建一个搜索 Fedora Magazine 的 tweets 并转推这些 tweets 的机器人。
|
||||
|
||||
为了避免多次转推相同的内容,这个机器人存放了最近一条转推的 tweet 的 ID 。 两个助手函数 store_last_id 和 get_last_id 将会帮助存储和保存这个 ID。
|
||||
|
||||
然后,机器人使用 tweepy 搜索 API 来查找 Fedora Magazine 的最近的 tweets 并存储这个 ID。
|
||||
|
||||
```
|
||||
import tweepy
|
||||
|
||||
|
||||
def store_last_id(tweet_id):
|
||||
""" Store a tweet id in a file """
|
||||
with open("lastid", "w") as fp:
|
||||
fp.write(str(tweet_id))
|
||||
|
||||
|
||||
def get_last_id():
|
||||
""" Read the last retweeted id from a file """
|
||||
with open("lastid", "r") as fp:
|
||||
return fp.read()
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
|
||||
auth = tweepy.OAuthHandler("your_consumer_key", "your_consumer_key_secret")
|
||||
|
||||
auth.set_access_token("your_access_token", "your_access_token_secret") api = tweepy.API(auth)
|
||||
|
||||
try:
|
||||
last_id = get_last_id()
|
||||
except FileNotFoundError:
|
||||
print("No retweet yet")
|
||||
last_id = None
|
||||
|
||||
for tweet in tweepy.Cursor(api.search, q="fedoramagazine.org", since_id=last_id).items():
|
||||
if tweet.user.name == 'Fedora Project':
|
||||
store_last_id(tweet.id)
|
||||
tweet.retweet()
|
||||
print(f'"{tweet.text}" was retweeted'
|
||||
|
||||
```
|
||||
|
||||
为了只转推 Fedora Magazine 的 tweet ,机器人搜索内容包含 fedoramagazine.org 和由 「Fedora Project」 Twitter 账户发布的 tweets。
|
||||
|
||||
|
||||
|
||||
### 结论
|
||||
|
||||
在这篇文章中你看到了如何使用 tweepy Python 拓展来创建一个自动阅读、发送和搜索 tweets 的 Twitter 应用。现在,你能使用你自己的创造力来创造一个你自己的 Twitter 机器人。
|
||||
|
||||
这篇文章的演示源码可以在 [Github][6] 找到。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/learn-build-twitter-bot-python/
|
||||
|
||||
作者:[Clément Verna][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[Bestony](https://github.com/bestony)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org
|
||||
[1]:https://twitter.com
|
||||
[2]:https://tweepy.readthedocs.io/en/v3.5.0/
|
||||
[3]:https://fedoramagazine.org/install-pipenv-fedora/
|
||||
[4]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-19-20-17-17.png
|
||||
[5]:http://docs.tweepy.org/en/v3.5.0/api.html#id1
|
||||
[6]:https://github.com/cverna/magabot
|
||||
Loading…
Reference in New Issue
Block a user