mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-24 02:20:09 +08:00
commit
1fb67e2b87
3
.gitmodules
vendored
Normal file
3
.gitmodules
vendored
Normal file
@ -0,0 +1,3 @@
|
||||
[submodule "comic"]
|
||||
path = comic
|
||||
url = https://wxy@github.com/LCTT/comic.git
|
||||
2
.travis.yml
Normal file
2
.travis.yml
Normal file
@ -0,0 +1,2 @@
|
||||
language: c
|
||||
script: make -s check
|
||||
84
Dict.md
84
Dict.md
@ -14,55 +14,55 @@
|
||||
### 2.
|
||||
#### B ####
|
||||
### 1. Backbone:骨干
|
||||
>是一个网络的一部分,其作为所有网络运输的一个基本通道,其需要非常高的带宽。一个骨干网络的服务提供者连接许多企业子网和较小服务提供者的网络。一个企业骨干网络连接许多局域网和数据中心。
|
||||
> 是一个网络的一部分,其作为所有网络运输的一个基本通道,其需要非常高的带宽。一个骨干网络的服务提供者连接许多企业子网和较小服务提供者的网络。一个企业骨干网络连接许多局域网和数据中心。
|
||||
|
||||
### 2. B channel(Bearer channel):承载信道
|
||||
>承载信道(Bearer Channel),也叫做B channel,是一个全双工DS0时间槽(64-kbps),其携带模拟语音或数字资料通过综合服务数字网(ISDN)。
|
||||
> 承载信道(Bearer Channel),也叫做B channel,是一个全双工DS0时间槽(64-kbps),其携带模拟语音或数字资料通过综合服务数字网(ISDN)。
|
||||
|
||||
### 3. Backchannel:反向通道
|
||||
>是指当其他实时在线会话在进行中时,习惯使用网络化的计算机来维持一个实时的在线会话。
|
||||
> 是指当其他实时在线会话在进行中时,习惯使用网络化的计算机来维持一个实时的在线会话。
|
||||
|
||||
### 4. Back End:后台
|
||||
>在一个计算机系统中,是指为一个前台作业提供服务的一个节点或软件程序。前台直接影响用户,后台可能与其他系统相连接,如数据库和其它系统。
|
||||
> 在一个计算机系统中,是指为一个前台作业提供服务的一个节点或软件程序。前台直接影响用户,后台可能与其他系统相连接,如数据库和其它系统。
|
||||
|
||||
### 5. Back-haul:回程线路
|
||||
>是一个通信信道,它使携带信息流到远于最终目的地的地方,然后将它送回。这样做是因为传输到更远的远程区域的代价要远比直接发送的代价低地多。
|
||||
> 是一个通信信道,它使携带信息流到远于最终目的地的地方,然后将它送回。这样做是因为传输到更远的远程区域的代价要远比直接发送的代价低地多。
|
||||
|
||||
### 6. Backoff:退避
|
||||
>是指当一个主机已经在有MAC 协议的网络中经历了一个冲突之后试图去重发之前的等待时期。这个退避时间通常是任意的来最小化相同节点再次冲突的可能性。在每次冲突后增加退避时期也能帮助预防重复碰撞,特别当这个网络负担很重时。
|
||||
> 是指当一个主机已经在有MAC 协议的网络中经历了一个冲突之后试图去重发之前的等待时期。这个退避时间通常是任意的来最小化相同节点再次冲突的可能性。在每次冲突后增加退避时期也能帮助预防重复碰撞,特别当这个网络负担很重时。
|
||||
|
||||
### 7. Backplane:附加卡
|
||||
>在许多网络中是一个物理接口模块,例如,连接在一个界面处理器或卡和在一个总线机箱内数据总线和功率分配总线之间的一个路由器或转换器。
|
||||
> 在许多网络中是一个物理接口模块,例如,连接在一个界面处理器或卡和在一个总线机箱内数据总线和功率分配总线之间的一个路由器或转换器。
|
||||
|
||||
### 8. Back Pressure:背压
|
||||
>在计算机系统中,是指网络拥塞信息逆流通过一个Internet网络。
|
||||
> 在计算机系统中,是指网络拥塞信息逆流通过一个Internet网络。
|
||||
|
||||
### 9. Balun(balanced-unbalanced):不平衡变压器
|
||||
>意味着平衡-非平衡。不平衡变压器是一个设计用来转换平衡和不平衡之间的电信号的设备。
|
||||
> 意味着平衡-非平衡。不平衡变压器是一个设计用来转换平衡和不平衡之间的电信号的设备。
|
||||
|
||||
### 10. Baseband:基带
|
||||
>是一种类型的网络技术,在那里仅仅一种载波频率被使用。在一个基带网中,信息在传送介质中以数字的形式被携带在一个单一的多元信号通道中。
|
||||
> 是一种类型的网络技术,在那里仅仅一种载波频率被使用。在一个基带网中,信息在传送介质中以数字的形式被携带在一个单一的多元信号通道中。
|
||||
|
||||
### 11. Bastion Host:防御主机
|
||||
>是在内部网络和外部网络之间的一个网关,它被设计来防御针对内部网络的攻击。这个系统在非武装区(DMZ)的公共一边,不被防火墙或过滤路由器保护,它对攻击是完全暴露的。
|
||||
> 是在内部网络和外部网络之间的一个网关,它被设计来防御针对内部网络的攻击。这个系统在非武装区(DMZ)的公共一边,不被防火墙或过滤路由器保护,它对攻击是完全暴露的。
|
||||
|
||||
### 12: Bc(Committed Burst):约定资讯讯务
|
||||
>是一个用在帧中继系统的术语,是一个帧中继交互网约定接受和传输和通过一个帧中继网络数据链路控制(DLC)和一个特殊的时帧的最大数据量(用比特表示)。
|
||||
> 是一个用在帧中继系统的术语,是一个帧中继交互网约定接受和传输和通过一个帧中继网络数据链路控制(DLC)和一个特殊的时帧的最大数据量(用比特表示)。
|
||||
|
||||
### 13. BCP(Best Current Practices):最优现行方法
|
||||
>是副系列的IETF RFCs,其被用于描述在Internet上的最优配置技术。
|
||||
> 是副系列的IETF RFCs,其被用于描述在Internet上的最优配置技术。
|
||||
|
||||
### 14. BCU(Balanced Configuration Unit):平衡配置单元
|
||||
>是一个综合的IBM解决方法,它由软件和硬件组成。BCUs是综合的和测试作为数据仓库系统的预配置功能块。
|
||||
> 是一个综合的IBM解决方法,它由软件和硬件组成。BCUs是综合的和测试作为数据仓库系统的预配置功能块。
|
||||
|
||||
### 15. BECN(Backward Explicit Congestion Notification):显式拥塞通知
|
||||
>是在帧中继报头的一个1比特域,其发信号到任何接收帧的事物(转换器和数据终端设备),拥塞就发生在帧的反面(后面)。帧中继转换器和数据终端设备可能遵照显式拥塞通知位来减慢那个方向的数据传输率。
|
||||
> 是在帧中继报头的一个1比特域,其发信号到任何接收帧的事物(转换器和数据终端设备),拥塞就发生在帧的反面(后面)。帧中继转换器和数据终端设备可能遵照显式拥塞通知位来减慢那个方向的数据传输率。
|
||||
|
||||
### 16. BER(Bit Error Rate):误码率
|
||||
>是接收到的位包含错误的比率。BER通常被表示成十足的负面力量。
|
||||
> 是接收到的位包含错误的比率。BER通常被表示成十足的负面力量。
|
||||
|
||||
### 17. BIP(Bit Interleaved Parity):位交叉奇偶校验
|
||||
>一个用在ATM中的术语,是一个通常用来检测链接错误的一种方法。一个检测位或字被嵌入到以前发生阻塞或帧的链接中。位错误在有效载荷中能够作为维护信息被删除和报告。
|
||||
> 一个用在ATM中的术语,是一个通常用来检测链接错误的一种方法。一个检测位或字被嵌入到以前发生阻塞或帧的链接中。位错误在有效载荷中能够作为维护信息被删除和报告。
|
||||
|
||||
#### C ####
|
||||
|
||||
@ -76,76 +76,88 @@
|
||||
#### H ####
|
||||
### 1. Home Directory:家目录
|
||||
#### I ####
|
||||
### 1. issue:工单
|
||||
> 有翻译做“问题”的,但是应该译作“工单”,尤其是用于 GitHub 中。
|
||||
|
||||
#### J ####
|
||||
|
||||
#### K ####
|
||||
|
||||
#### L ####
|
||||
### 1. LTS(Long Term Support):长期支持
|
||||
>该缩写词多见于操作系统发行版或者软件发行版名称中,表明该版本属于长期支持版。
|
||||
### 1. live CD:现场版 CD
|
||||
> 通常不翻译,但是如果翻译,可以译作“现场版”。
|
||||
### 2. live patch: 实时补丁/热补丁
|
||||
> 指 Linux 内核的 live patch 支持。
|
||||
|
||||
### 2. LTS(Long Term Support):长期支持
|
||||
> 该缩写词多见于操作系统发行版或者软件发行版名称中,表明该版本属于长期支持版。
|
||||
|
||||
#### M ####
|
||||
|
||||
#### N ####
|
||||
|
||||
#### O ####
|
||||
### 1. Orchestration:编排
|
||||
> 描述复杂计算机系统、中间件(middleware)和业务的自动化的安排、协调和管理(来自维基百科)。
|
||||
|
||||
#### P ####
|
||||
### 1.P-code(Pseudo-code):伪代码语言
|
||||
>一种解释型语言,执行方式介于编译型语言和解释型语言之间。和解释型语言一样,伪代码编程语言无需编译,在执行时自动转换成二进制形式。然而,和编译型语言不同的是,这种可执行的二进制文件是以伪代码的形式而不是机器语言的形式存储的。伪代码语言的例子有 Java、Python 和 REXX/Object REXX。
|
||||
### 1. P-code(Pseudo-code):伪代码语言
|
||||
> 一种解释型语言,执行方式介于编译型语言和解释型语言之间。和解释型语言一样,伪代码编程语言无需编译,在执行时自动转换成二进制形式。然而,和编译型语言不同的是,这种可执行的二进制文件是以伪代码的形式而不是机器语言的形式存储的。伪代码语言的例子有 Java、Python 和 REXX/Object REXX。
|
||||
|
||||
### 2. PAM(Pluggable Authentication Modules):可插拔认证模块
|
||||
>用于系统安全性的可替换的用户认证模块,它允许在不知道将使用何种认证方案的情况下进行编程。这允许将来用其它模块来替换某个模块,却无需重写软件。
|
||||
> 用于系统安全性的可替换的用户认证模块,它允许在不知道将使用何种认证方案的情况下进行编程。这允许将来用其它模块来替换某个模块,却无需重写软件。
|
||||
|
||||
### 3. Port/Ported/Porting:移植
|
||||
>一个过程,即获取为某个操作系统平台编写的程序,并对其进行修改使之能在另一 OS 上运行,并且具有类似的功能。
|
||||
> 一个过程,即获取为某个操作系统平台编写的程序,并对其进行修改使之能在另一 OS 上运行,并且具有类似的功能。
|
||||
|
||||
### 4. POSIX(Portable Operating System Interface for uniX):UNIX 可移植操作系统接口
|
||||
>一组编程接口标准,它们规定如何编写应用程序源代码以便应用程序可在操作系统之间移植。POSIX 基于 UNIX,它是 The Open Group 的 X/Open 规范的基础。
|
||||
> 一组编程接口标准,它们规定如何编写应用程序源代码以便应用程序可在操作系统之间移植。POSIX 基于 UNIX,它是 The Open Group 的 X/Open 规范的基础。
|
||||
|
||||
#### Q ####
|
||||
|
||||
#### R ####
|
||||
### 1. RCS(Revision Control System):修订控制系统
|
||||
>一组程序,它们控制组环境下文件的共享访问并跟踪文本文件的变化。常用于维护源代码模块的编码工作。
|
||||
> 一组程序,它们控制组环境下文件的共享访问并跟踪文本文件的变化。常用于维护源代码模块的编码工作。
|
||||
|
||||
### 2. RFS(Remote File Sharing):远程文件共享
|
||||
>一个程序,它让用户访问其它计算机上的文件,就好象文件在用户的系统上一样。
|
||||
> 一个程序,它让用户访问其它计算机上的文件,就好象文件在用户的系统上一样。
|
||||
|
||||
#### S ####
|
||||
### 1. shebang [ʃɪ'bæŋ]:释伴
|
||||
>Shebang(也称为Hashbang)是一个由井号和叹号构成的字符序列(#!),出现在文本文件的第一行的前两个字符,后跟解释器路径,如:#!/bin/sh,这通常是Linux中shell脚本的标准起始行。
|
||||
>长期以来,shebang都没有正式的中文名称。Linux中国翻译组将其翻译为:释伴,即解释伴随行的简称,同时又是shebang的音译。
|
||||
> Shebang(也称为Hashbang)是一个由井号和叹号构成的字符序列(#!),出现在文本文件的第一行的前两个字符,后跟解释器路径,如:#!/bin/sh,这通常是Linux中shell脚本的标准起始行。
|
||||
> 长期以来,shebang都没有正式的中文名称。Linux中国翻译组将其翻译为:释伴,即解释伴随行的简称,同时又是shebang的音译。
|
||||
|
||||
### 2. Spool(Simultaneous Peripheral Operation On-Line):假脱机
|
||||
>将数据发送给一个程序,该程序将该数据信息放入队列以备将来使用(例如,打印假脱机程序)
|
||||
> 将数据发送给一个程序,该程序将该数据信息放入队列以备将来使用(例如,打印假脱机程序)
|
||||
|
||||
### 2. Steganography:隐写术
|
||||
>将一段信息隐藏在另一段信息中的做法。一个示例是在数字化照片中放置不可见的数字水印。
|
||||
> 将一段信息隐藏在另一段信息中的做法。一个示例是在数字化照片中放置不可见的数字水印。
|
||||
|
||||
### 3. Swap:交换
|
||||
>暂时将数据(程序和/或数据文件)从随机存取存储器移到磁盘存储器(换出),或反方向移动(换入),以允许处理比物理内存所能容纳的更多的程序和数据。
|
||||
> 暂时将数据(程序和/或数据文件)从随机存取存储器移到磁盘存储器(换出),或反方向移动(换入),以允许处理比物理内存所能容纳的更多的程序和数据。
|
||||
|
||||
### 4. Scheduling:调度
|
||||
> 将任务分配至资源的过程,在计算机或生产处理中尤为重要(来自维基百科)。
|
||||
|
||||
#### T ####
|
||||
### 1. Time-sharing:分时
|
||||
>一种允许多个用户分享处理器的方法,它以时间为基础给每个用户分配一部分处理器资源,按照这些时间段轮流运行每个用户的进程。
|
||||
> 一种允许多个用户分享处理器的方法,它以时间为基础给每个用户分配一部分处理器资源,按照这些时间段轮流运行每个用户的进程。
|
||||
|
||||
### 2. TL;DR:长篇摘要
|
||||
>Too Long;Didn't Read的缩写词,即太长,未阅的意思。该词多见于互联网社区论坛中,用于指出该文太长,没有阅读,或者标示出一篇长文章的摘要。在论坛回复中,该缩写词也多作为灌水用。因此,Linux中国翻译组将其翻译为:长篇摘要。
|
||||
> Too Long;Didn't Read的缩写词,即太长,未阅的意思。该词多见于互联网社区论坛中,用于指出该文太长,没有阅读,或者标示出一篇长文章的摘要。在论坛回复中,该缩写词也多作为灌水用。因此,Linux中国翻译组将其翻译为:长篇摘要。
|
||||
|
||||
#### U ####
|
||||
|
||||
#### V ####
|
||||
### 1. VRML(Virtual Reality Modeling Language):虚拟现实建模语言
|
||||
>一种主要基于 Web 的语言,用于 3D 效果(如构建遍历)。
|
||||
> 一种主要基于 Web 的语言,用于 3D 效果(如构建遍历)。
|
||||
|
||||
#### W ####
|
||||
### 1. Wrapper:封装器
|
||||
>用于启动另一个程序的程序。
|
||||
> 用于启动另一个程序的程序。
|
||||
|
||||
#### X ####
|
||||
|
||||
#### Y ####
|
||||
|
||||
#### Z ####
|
||||
#### Z ####
|
||||
|
||||
51
Makefile
Normal file
51
Makefile
Normal file
@ -0,0 +1,51 @@
|
||||
DIR_PATTERN := (news|talk|tech)
|
||||
NAME_PATTERN := [0-9]{8} [a-zA-Z0-9_.,() -]*\.md
|
||||
|
||||
RULES := rule-source-added \
|
||||
rule-translation-requested \
|
||||
rule-translation-completed \
|
||||
rule-translation-revised \
|
||||
rule-translation-published
|
||||
.PHONY: check match $(RULES)
|
||||
|
||||
CHANGE_FILE := /tmp/changes
|
||||
|
||||
check: $(CHANGE_FILE)
|
||||
echo 'PR #$(TRAVIS_PULL_REQUEST) Changes:'
|
||||
cat $(CHANGE_FILE)
|
||||
echo
|
||||
echo 'Check for rules...'
|
||||
make -k $(RULES) 2>/dev/null | grep '^Rule Matched: '
|
||||
|
||||
$(CHANGE_FILE):
|
||||
git --no-pager diff $(TRAVIS_BRANCH) FETCH_HEAD --no-renames --name-status > $@
|
||||
|
||||
rule-source-added:
|
||||
echo 'Unmatched Files:'
|
||||
egrep -v '^A\s*"?sources/$(DIR_PATTERN)/$(NAME_PATTERN)"?' $(CHANGE_FILE) || true
|
||||
echo '[End of Unmatched Files]'
|
||||
[ $(shell egrep '^A\s*"?sources/$(DIR_PATTERN)/$(NAME_PATTERN)"?' $(CHANGE_FILE) | wc -l) -ge 1 ]
|
||||
[ $(shell egrep -v '^A\s*"?sources/$(DIR_PATTERN)/$(NAME_PATTERN)"?' $(CHANGE_FILE) | wc -l) = 0 ]
|
||||
echo 'Rule Matched: $(@)'
|
||||
|
||||
rule-translation-requested:
|
||||
[ $(shell egrep '^M\s*"?sources/$(DIR_PATTERN)/$(NAME_PATTERN)"?' $(CHANGE_FILE) | wc -l) = 1 ]
|
||||
[ $(shell cat $(CHANGE_FILE) | wc -l) = 1 ]
|
||||
echo 'Rule Matched: $(@)'
|
||||
|
||||
rule-translation-completed:
|
||||
[ $(shell egrep '^D\s*"?sources/$(DIR_PATTERN)/$(NAME_PATTERN)"?' $(CHANGE_FILE) | wc -l) = 1 ]
|
||||
[ $(shell egrep '^A\s*"?translated/$(DIR_PATTERN)/$(NAME_PATTERN)"?' $(CHANGE_FILE) | wc -l) = 1 ]
|
||||
[ $(shell cat $(CHANGE_FILE) | wc -l) = 2 ]
|
||||
echo 'Rule Matched: $(@)'
|
||||
|
||||
rule-translation-revised:
|
||||
[ $(shell egrep '^M\s*"?translated/$(DIR_PATTERN)/$(NAME_PATTERN)"?' $(CHANGE_FILE) | wc -l) = 1 ]
|
||||
[ $(shell cat $(CHANGE_FILE) | wc -l) = 1 ]
|
||||
echo 'Rule Matched: $(@)'
|
||||
|
||||
rule-translation-published:
|
||||
[ $(shell egrep '^D\s*"?translated/$(DIR_PATTERN)/$(NAME_PATTERN)"?' $(CHANGE_FILE) | wc -l) = 1 ]
|
||||
[ $(shell egrep '^A\s*"?published/$(NAME_PATTERN)' $(CHANGE_FILE) | wc -l) = 1 ]
|
||||
[ $(shell cat $(CHANGE_FILE) | wc -l) = 2 ]
|
||||
echo 'Rule Matched: $(@)'
|
||||
@ -60,6 +60,9 @@ LCTT 的组成
|
||||
* 2017/03/13 制作了 LCTT 主页、成员列表和成员主页,LCTT 主页将移动至 https://linux.cn/lctt 。
|
||||
* 2017/03/16 提升 GHLandy、bestony、rusking 为新的 Core 成员。创建 Comic 小组。
|
||||
* 2017/04/11 启用头衔制,为各位重要成员颁发头衔。
|
||||
* 2017/11/21 鉴于 qhwdw 快速而上佳的翻译质量,提升 qhwdw 为新的 Core 成员。
|
||||
* 2017/11/19 wxy 在上海交大举办的 2017 中国开源年会上做了演讲:《[如何以翻译贡献参与开源社区](https://linux.cn/article-9084-1.html)》。
|
||||
* 2018/01/11 提升 lujun9972 成为核心成员,并加入选题组。
|
||||
|
||||
核心成员
|
||||
-------------------------------
|
||||
@ -86,6 +89,8 @@ LCTT 的组成
|
||||
- 核心成员 @Locez,
|
||||
- 核心成员 @ucasFL,
|
||||
- 核心成员 @rusking,
|
||||
- 核心成员 @qhwdw,
|
||||
- 核心成员 @lujun9972
|
||||
- 前任选题 @DeadFire,
|
||||
- 前任校对 @reinoir222,
|
||||
- 前任校对 @PurlingNayuki,
|
||||
|
||||
1
comic
Submodule
1
comic
Submodule
@ -0,0 +1 @@
|
||||
Subproject commit e5db5b880dac1302ee0571ecaaa1f8ea7cf61901
|
||||
@ -0,0 +1,293 @@
|
||||
如何在 Linux 或者 UNIX 下调试 Bash Shell 脚本
|
||||
======
|
||||
|
||||
来自我的邮箱:
|
||||
|
||||
> 我写了一个 hello world 小脚本。我如何能调试运行在 Linux 或者类 UNIX 的系统上的 bash shell 脚本呢?
|
||||
|
||||
这是 Linux / Unix 系统管理员或新用户最常问的问题。shell 脚本调试可能是一项繁琐的工作(不容易阅读)。调试 shell 脚本有多种方法。
|
||||
|
||||
您需要传递 `-x` 或 `-v` 参数,以在 bash shell 中浏览每行代码。
|
||||
|
||||
[![如何在 Linux 或者 UNIX 下调试 Bash Shell 脚本][1]][1]
|
||||
|
||||
让我们看看如何使用各种方法调试 Linux 和 UNIX 上运行的脚本。
|
||||
|
||||
### -x 选项来调试脚本
|
||||
|
||||
用 `-x` 选项来运行脚本:
|
||||
|
||||
```
|
||||
$ bash -x script-name
|
||||
$ bash -x domains.sh
|
||||
```
|
||||
### 使用 set 内置命令
|
||||
|
||||
bash shell 提供调试选项,可以打开或关闭使用 [set 命令][2]:
|
||||
|
||||
* `set -x` : 显示命令及其执行时的参数。
|
||||
* `set -v` : 显示 shell 输入行作为它们读取的
|
||||
|
||||
可以在 shell 脚本本身中使用上面的两个命令:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
clear
|
||||
|
||||
# turn on debug mode
|
||||
set -x
|
||||
for f in *
|
||||
do
|
||||
file $f
|
||||
done
|
||||
# turn OFF debug mode
|
||||
set +x
|
||||
ls
|
||||
# more commands
|
||||
```
|
||||
|
||||
你可以代替 [标准释伴][3] 行:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
```
|
||||
|
||||
用以下代码(用于调试):
|
||||
|
||||
```
|
||||
#!/bin/bash -xv
|
||||
```
|
||||
|
||||
### 使用智能调试功能
|
||||
|
||||
首先添加一个叫做 `_DEBUG` 的特殊变量。当你需要调试脚本的时候,设置 `_DEBUG` 为 `on`:
|
||||
|
||||
```
|
||||
_DEBUG="on"
|
||||
```
|
||||
|
||||
在脚本的开头放置以下函数:
|
||||
|
||||
```
|
||||
function DEBUG()
|
||||
{
|
||||
[ "$_DEBUG" == "on" ] && $@
|
||||
}
|
||||
```
|
||||
|
||||
现在,只要你需要调试,只需使用 `DEBUG` 函数如下:
|
||||
|
||||
```
|
||||
DEBUG echo "File is $filename"
|
||||
```
|
||||
|
||||
或者:
|
||||
|
||||
```
|
||||
DEBUG set -x
|
||||
Cmd1
|
||||
Cmd2
|
||||
DEBUG set +x
|
||||
```
|
||||
|
||||
当调试完(在移动你的脚本到生产环境之前)设置 `_DEBUG` 为 `off`。不需要删除调试行。
|
||||
|
||||
```
|
||||
_DEBUG="off" # 设置为非 'on' 的任何字符
|
||||
```
|
||||
|
||||
示例脚本:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
_DEBUG="on"
|
||||
function DEBUG()
|
||||
{
|
||||
[ "$_DEBUG" == "on" ] && $@
|
||||
}
|
||||
|
||||
DEBUG echo 'Reading files'
|
||||
for i in *
|
||||
do
|
||||
grep 'something' $i > /dev/null
|
||||
[ $? -eq 0 ] && echo "Found in $i file"
|
||||
done
|
||||
DEBUG set -x
|
||||
a=2
|
||||
b=3
|
||||
c=$(( $a + $b ))
|
||||
DEBUG set +x
|
||||
echo "$a + $b = $c"
|
||||
```
|
||||
|
||||
保存并关闭文件。运行脚本如下:
|
||||
|
||||
```
|
||||
$ ./script.sh
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
```
|
||||
Reading files
|
||||
Found in xyz.txt file
|
||||
+ a=2
|
||||
+ b=3
|
||||
+ c=5
|
||||
+ DEBUG set +x
|
||||
+ '[' on == on ']'
|
||||
+ set +x
|
||||
2 + 3 = 5
|
||||
```
|
||||
|
||||
现在设置 `_DEBUG` 为 `off`(你需要编辑该文件):
|
||||
|
||||
```
|
||||
_DEBUG="off"
|
||||
```
|
||||
|
||||
运行脚本:
|
||||
|
||||
```
|
||||
$ ./script.sh
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
```
|
||||
Found in xyz.txt file
|
||||
2 + 3 = 5
|
||||
```
|
||||
|
||||
以上是一个简单但非常有效的技术。还可以尝试使用 `DEBUG` 作为别名而不是函数。
|
||||
|
||||
### 调试 Bash Shell 的常见错误
|
||||
|
||||
Bash 或者 sh 或者 ksh 在屏幕上给出各种错误信息,在很多情况下,错误信息可能不提供详细的信息。
|
||||
|
||||
#### 跳过在文件上应用执行权限
|
||||
|
||||
当你 [编写你的第一个 hello world 脚本][4],您可能会得到一个错误,如下所示:
|
||||
|
||||
```
|
||||
bash: ./hello.sh: Permission denied
|
||||
```
|
||||
|
||||
设置权限使用 `chmod` 命令:
|
||||
|
||||
```
|
||||
$ chmod +x hello.sh
|
||||
$ ./hello.sh
|
||||
$ bash hello.sh
|
||||
```
|
||||
|
||||
#### 文件结束时发生意外的错误
|
||||
|
||||
如果您收到文件结束意外错误消息,请打开脚本文件,并确保它有打开和关闭引号。在这个例子中,`echo` 语句有一个开头引号,但没有结束引号:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
...
|
||||
....
|
||||
|
||||
echo 'Error: File not found
|
||||
^^^^^^^
|
||||
missing quote
|
||||
```
|
||||
|
||||
还要确保你检查缺少的括号和大括号 `{}`:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
.....
|
||||
[ ! -d $DIRNAME ] && { echo "Error: Chroot dir not found"; exit 1;
|
||||
^^^^^^^^^^^^^
|
||||
missing brace }
|
||||
...
|
||||
```
|
||||
|
||||
#### 丢失像 fi,esac,;; 等关键字。
|
||||
|
||||
如果你缺少了结尾的关键字,如 `fi` 或 `;;` 你会得到一个错误,如 “XXX 意外”。因此,确保所有嵌套的 `if` 和 `case` 语句以适当的关键字结束。有关语法要求的页面。在本例中,缺少 `fi`:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
echo "Starting..."
|
||||
....
|
||||
if [ $1 -eq 10 ]
|
||||
then
|
||||
if [ $2 -eq 100 ]
|
||||
then
|
||||
echo "Do something"
|
||||
fi
|
||||
|
||||
for f in $files
|
||||
do
|
||||
echo $f
|
||||
done
|
||||
|
||||
# 注意 fi 丢失了
|
||||
```
|
||||
|
||||
#### 在 Windows 或 UNIX 框中移动或编辑 shell 脚本
|
||||
|
||||
不要在 Linux 上创建脚本并移动到 Windows。另一个问题是编辑 Windows 10上的 shell 脚本并将其移动到 UNIX 服务器上。这将由于换行符不同而导致命令没有发现的错误。你可以使用下列命令 [将 DOS 换行转换为 CR-LF 的Unix/Linux 格式][5] :
|
||||
|
||||
```
|
||||
dos2unix my-script.sh
|
||||
```
|
||||
|
||||
### 技巧
|
||||
|
||||
#### 技巧 1 - 发送调试信息输出到标准错误
|
||||
|
||||
[标准错误] 是默认错误输出设备,用于写所有系统错误信息。因此,将消息发送到默认的错误设备是个好主意:
|
||||
|
||||
```
|
||||
# 写错误到标准输出
|
||||
echo "Error: $1 file not found"
|
||||
#
|
||||
# 写错误到标准错误(注意 1>&2 在 echo 命令末尾)
|
||||
#
|
||||
echo "Error: $1 file not found" 1>&2
|
||||
```
|
||||
|
||||
#### 技巧 2 - 在使用 vim 文本编辑器时,打开语法高亮
|
||||
|
||||
大多数现代文本编辑器允许设置语法高亮选项。这对于检测语法和防止常见错误如打开或关闭引号非常有用。你可以在不同的颜色中看到。这个特性简化了 shell 脚本结构中的编写,语法错误在视觉上截然不同。高亮不影响文本本身的意义,它只为你提示而已。在这个例子中,我的脚本使用了 vim 语法高亮:
|
||||
|
||||
[!如何调试 Bash Shell 脚本,在 Linux 或者 UNIX 使用 Vim 语法高亮特性][7]][7]
|
||||
|
||||
#### 技巧 3 - 使用 shellcheck 检查脚本
|
||||
|
||||
[shellcheck 是一个用于静态分析 shell 脚本的工具][8]。可以使用它来查找 shell 脚本中的错误。这是用 Haskell 编写的。您可以使用这个工具找到警告和建议。你可以看看如何在 Linux 或 类UNIX 系统上安装和使用 shellcheck 来改善你的 shell 脚本,避免错误和高效。
|
||||
|
||||
作者:Vivek Gite
|
||||
|
||||
作者是 nixCraft 创造者,一个经验丰富的系统管理员和一个练习 Linux 操作系统/ UNIX shell 脚本的教练。他曾与全球客户和各种行业,包括 IT,教育,国防和空间研究,以及非营利部门。关注他的 [推特][9],[脸谱网][10],[谷歌+ ][11]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/tips/debugging-shell-script.html
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[zjon](https://github.com/zjon)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/tips/wp-content/uploads/2007/01/How-to-debug-a-bash-shell-script-on-Linux-or-Unix.jpg
|
||||
[2]:https://bash.cyberciti.biz/guide/Set_command
|
||||
[3]:https://bash.cyberciti.biz/guide/Shebang
|
||||
[4]:https://www.cyberciti.biz/faq/hello-world-bash-shell-script/
|
||||
[5]:https://www.cyberciti.biz/faq/howto-unix-linux-convert-dos-newlines-cr-lf-unix-text-format/
|
||||
[6]:https://bash.cyberciti.biz/guide/Standard_error
|
||||
[7]:https://www.cyberciti.biz/media/new/tips/2007/01/bash-vim-debug-syntax-highlighting.png
|
||||
[8]:https://www.cyberciti.biz/programming/improve-your-bashsh-shell-script-with-shellcheck-lint-script-analysis-tool/
|
||||
[9]:https://twitter.com/nixcraft
|
||||
[10]:https://facebook.com/nixcraft
|
||||
[11]:https://plus.google.com/+CybercitiBiz
|
||||
|
||||
|
||||
89
published/20141029 What does an idle CPU do.md
Normal file
89
published/20141029 What does an idle CPU do.md
Normal file
@ -0,0 +1,89 @@
|
||||
当 CPU 空闲时它都在做什么?
|
||||
============================================================
|
||||
|
||||
在 [上篇文章中][2] 我说了操作系统行为的基本原理是,*在任何一个给定的时刻*,在一个 CPU 上**有且只有一个任务是活动的**。但是,如果 CPU 无事可做的时候,又会是什么样的呢?
|
||||
|
||||
事实证明,这种情况是非常普遍的,对于绝大多数的个人电脑来说,这确实是一种常态:大量的睡眠进程,它们都在等待某种情况下被唤醒,差不多在 100% 的 CPU 时间中,都处于虚构的“空闲任务”中。事实上,如果一个普通用户的 CPU 处于持续的繁忙中,它可能意味着有一个错误、bug、或者运行了恶意软件。
|
||||
|
||||
因为我们不能违反我们的原理,*一些任务需要在一个 CPU 上激活*。首先是因为,这是一个良好的设计:持续很长时间去遍历内核,检查是否*有*一个活动任务,这种特殊情况是不明智的做法。最好的设计是*没有任何例外的情况*。无论何时,你写一个 `if` 语句,Nyan Cat 就会喵喵喵。其次,我们需要使用空闲的 CPU 去做*一些事情*,让它们充满活力,你懂得,就是创建天网计划呗。
|
||||
|
||||
因此,保持这种设计的连续性,并领先于那些邪恶计划一步,操作系统开发者创建了一个**空闲任务**,当没有其它任务可做时就调度它去运行。我们可以在 Linux 的 [引导过程][3] 中看到,这个空闲任务就是进程 0,它是由计算机打开电源时运行的第一个指令直接派生出来的。它在 [rest_init][4] 中初始化,在 [init_idle_bootup_task][5] 中初始化空闲<ruby>调度类<rt>scheduling class</rt></ruby>。
|
||||
|
||||
简而言之,Linux 支持像实时进程、普通用户进程等等的不同调度类。当选择一个进程变成活动任务时,这些类按优先级进行查询。通过这种方式,核反应堆的控制代码总是优先于 web 浏览器运行。尽管在通常情况下,这些类返回 `NULL`,意味着它们没有合适的任务需要去运行 —— 它们总是处于睡眠状态。但是空闲调度类,它是持续运行的,从不会失败:它总是返回空闲任务。
|
||||
|
||||
好吧,我们来看一下这个空闲任务*到底做了些什么*。下面是 [cpu_idle_loop][6],感谢开源能让我们看到它的代码:
|
||||
|
||||
```
|
||||
while (1) {
|
||||
while(!need_resched()) {
|
||||
cpuidle_idle_call();
|
||||
}
|
||||
|
||||
/*
|
||||
[Note: Switch to a different task. We will return to this loop when the idle task is again selected to run.]
|
||||
*/
|
||||
schedule_preempt_disabled();
|
||||
}
|
||||
```
|
||||
|
||||
*cpu_idle_loop*
|
||||
|
||||
我省略了很多的细节,稍后我们将去了解任务切换,但是,如果你阅读了这些源代码,你就会找到它的要点:由于这里不需要重新调度(即改变活动任务),它一直处于空闲状态。以所经历的时间来计算,这个循环和其它操作系统中它的“堂兄弟们”相比,在计算的历史上它是运行的最多的代码片段。对于 Intel 处理器来说,处于空闲状态意味着运行着一个 [halt][7] 指令:
|
||||
|
||||
```
|
||||
static inline void native_halt(void)
|
||||
{
|
||||
asm volatile("hlt": : :"memory");
|
||||
}
|
||||
```
|
||||
|
||||
*native_halt*
|
||||
|
||||
`hlt` 指令停止处理器中的代码执行,并将它置于 `halt` 的状态。奇怪的是,全世界各地数以百万计的 Intel 类的 CPU 们花费大量的时间让它们处于 `halt` 的状态,甚至它们在通电的时候也是如此。这并不是高效、节能的做法,这促使芯片制造商们去开发处理器的深度睡眠状态,以带来着更少的功耗和更长休眠时间。内核的 [cpuidle 子系统][8] 是这些节能模式能够产生好处的原因。
|
||||
|
||||
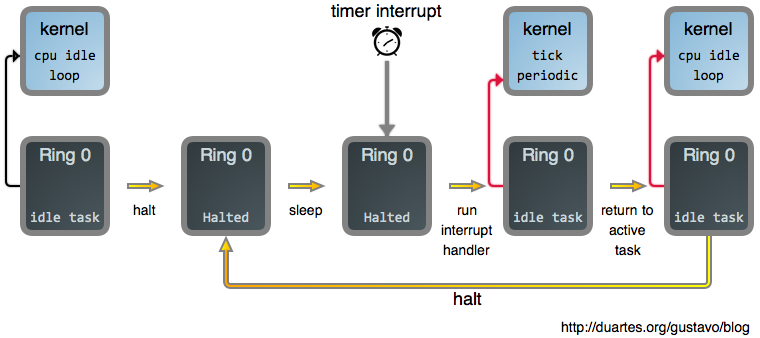
现在,一旦我们告诉 CPU 去 `halt`(睡眠)之后,我们需要以某种方式让它醒来。如果你读过 [上篇文章《你的操作系统什么时候运行?》][9] ,你可能会猜到*中断*会参与其中,而事实确实如此。中断促使 CPU 离开 `halt` 状态返回到激活状态。因此,将这些拼到一起,下图是当你阅读一个完全呈现的 web 网页时,你的系统主要做的事情:
|
||||
|
||||
|
||||
|
||||
除定时器中断外的其它中断也会使处理器再次发生变化。如果你再次点击一个 web 页面就会产生这种变化,例如:你的鼠标发出一个中断,它的驱动会处理它,并且因为它产生了一个新的输入,突然进程就可运行了。在那个时刻, `need_resched()` 返回 `true`,然后空闲任务因你的浏览器而被踢出而终止运行。
|
||||
|
||||
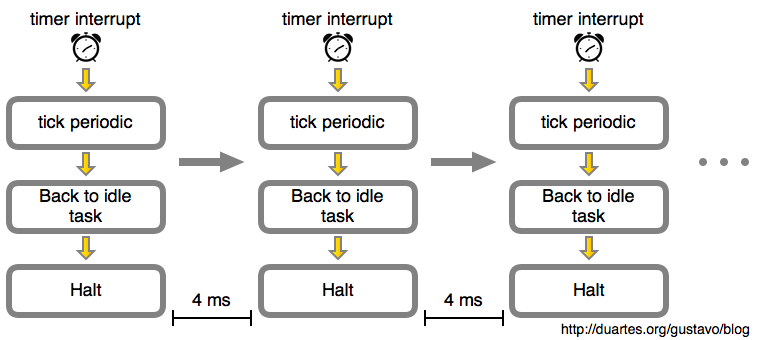
如果我们呆呆地看着这篇文章,而不做任何事情。那么随着时间的推移,这个空闲循环就像下图一样:
|
||||
|
||||
|
||||
|
||||
在这个示例中,由内核计划的定时器中断会每 4 毫秒发生一次。这就是<ruby>滴答<rt>tick</rt></ruby>周期。也就是说每秒钟将有 250 个滴答,因此,这个*滴答速率(频率)*是 250 Hz。这是运行在 Intel 处理器上的 Linux 的典型值,而其它操作系统喜欢使用 100 Hz。这是由你构建内核时在 `CONFIG_HZ` 选项中定义的。
|
||||
|
||||
对于一个*空闲 CPU* 来说,它看起来似乎是个无意义的工作。如果外部世界没有新的输入,在你的笔记本电脑的电池耗尽之前,CPU 将始终处于这种每秒钟被唤醒 250 次的地狱般折磨的小憩中。如果它运行在一个虚拟机中,那我们正在消耗着宿主机 CPU 的性能和宝贵的时钟周期。
|
||||
|
||||
在这里的解决方案是 [动态滴答][10],当 CPU 处于空闲状态时,定时器中断被 [暂停或重计划][11],直到内核*知道*将有事情要做时(例如,一个进程的定时器可能要在 5 秒内过期,因此,我们不能再继续睡眠了),定时器中断才会重新发出。这也被称为*无滴答模式*。
|
||||
|
||||
最后,假设在一个系统中你有一个*活动进程*,例如,一个长时间运行的 CPU 密集型任务。那样几乎就和一个空闲系统是相同的:这些示意图仍然是相同的,只是将空闲任务替换为这个进程,并且相应的描述也是准确的。在那种情况下,每 4 毫秒去中断一次任务仍然是无意义的:它只是操作系统的性能抖动,甚至会使你的工作变得更慢而已。Linux 也可以在这种单一进程的场景中停止这种固定速率的滴答,这被称为 [自适应滴答][12] 模式。最终,这种固定速率的滴答可能会 [完全消失][13]。
|
||||
|
||||
对于阅读一篇文章来说,CPU 基本是无事可做的。内核的这种空闲行为是操作系统难题的一个重要部分,并且它与我们看到的其它情况非常相似,因此,这将帮助我们理解一个运行中的内核。更多的内容将发布在下周的 [RSS][14] 和 [Twitter][15] 上。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://manybutfinite.com/post/what-does-an-idle-cpu-do/
|
||||
|
||||
作者:[Gustavo Duarte][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://duartes.org/gustavo/blog/about/
|
||||
[1]:https://manybutfinite.com/post/what-does-an-idle-cpu-do/
|
||||
[2]:https://linux.cn/article-9095-1.html
|
||||
[3]:https://manybutfinite.com/post/kernel-boot-process
|
||||
[4]:https://github.com/torvalds/linux/blob/v3.17/init/main.c#L393
|
||||
[5]:https://github.com/torvalds/linux/blob/v3.17/kernel/sched/core.c#L4538
|
||||
[6]:https://github.com/torvalds/linux/blob/v3.17/kernel/sched/idle.c#L183
|
||||
[7]:https://github.com/torvalds/linux/blob/v3.17/arch/x86/include/asm/irqflags.h#L52
|
||||
[8]:http://lwn.net/Articles/384146/
|
||||
[9]:https://linux.cn/article-9095-1.html
|
||||
[10]:https://github.com/torvalds/linux/blob/v3.17/Documentation/timers/NO_HZ.txt#L17
|
||||
[11]:https://github.com/torvalds/linux/blob/v3.17/Documentation/timers/highres.txt#L215
|
||||
[12]:https://github.com/torvalds/linux/blob/v3.17/Documentation/timers/NO_HZ.txt#L100
|
||||
[13]:http://lwn.net/Articles/549580/
|
||||
[14]:https://manybutfinite.com/feed.xml
|
||||
[15]:http://twitter.com/manybutfinite
|
||||
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 247 KiB |
@ -1,21 +1,21 @@
|
||||
[调试器的工作原理:第一篇-基础][21]
|
||||
调试器的工作原理(一):基础篇
|
||||
============================================================
|
||||
|
||||
这是调试器工作原理系列文章的第一篇,我不确定这个系列会有多少篇文章,会涉及多少话题,但我仍会从这篇基础开始。
|
||||
|
||||
### 这一篇会讲什么
|
||||
|
||||
我将为大家展示 Linux 中调试器的主要构成模块 - ptrace 系统调用。这篇文章所有代码都是基于 32 位 Ubuntu 操作系统.值得注意的是,尽管这些代码是平台相关的,将他们移植到其他平台应该并不困难。
|
||||
我将为大家展示 Linux 中调试器的主要构成模块 - `ptrace` 系统调用。这篇文章所有代码都是基于 32 位 Ubuntu 操作系统。值得注意的是,尽管这些代码是平台相关的,将它们移植到其它平台应该并不困难。
|
||||
|
||||
### 缘由
|
||||
|
||||
为了理解我们要做什么,让我们先考虑下调试器为了完成调试都需要什么资源。调试器可以开始一个进程并调试这个进程,又或者将自己同某个已经存在的进程关联起来。调试器能够单步执行代码,设定断点并且将程序执行到断点,检查变量的值并追踪堆栈。许多调试器有着更高级的特性,例如在调试器的地址空间内执行表达式或者调用函数,甚至可以在进程执行过程中改变代码并观察效果。
|
||||
为了理解我们要做什么,让我们先考虑下调试器为了完成调试都需要什么资源。调试器可以开始一个进程并调试这个进程,又或者将自己同某个已经存在的进程关联起来。调试器能够单步执行代码,设定断点并且将程序执行到断点,检查变量的值并追踪堆栈。许多调试器有着更高级的特性,例如在调试器的地址空间内执行表达式或者调用函数,甚至可以在进程执行过程中改变代码并观察效果。
|
||||
|
||||
尽管现代的调试器都十分的复杂 [[1]][13],但他们的工作的原理却是十分的简单。调试器的基础是操作系统与编译器 / 链接器提供的一些基础服务,其余的部分只是[简单的编程][14]。
|
||||
尽管现代的调试器都十分的复杂(我没有检查,但我确信 gdb 的代码行数至少有六位数),但它们的工作的原理却是十分的简单。调试器的基础是操作系统与编译器 / 链接器提供的一些基础服务,其余的部分只是[简单的编程][14]而已。
|
||||
|
||||
### Linux 的调试 - ptrace
|
||||
|
||||
Linux 调试器中的瑞士军刀便是 ptrace 系统调用 [[2]][15]。这是一种复杂却强大的工具,可以允许一个进程控制另外一个进程并从内部替换被控制进程的内核镜像的值[[3]][16].。
|
||||
Linux 调试器中的瑞士军刀便是 `ptrace` 系统调用(使用 man 2 ptrace 命令可以了解更多)。这是一种复杂却强大的工具,可以允许一个进程控制另外一个进程并从<ruby>内部替换<rt>Peek and poke</rt></ruby>被控制进程的内核镜像的值(Peek and poke 在系统编程中是很知名的叫法,指的是直接读写内存内容)。
|
||||
|
||||
接下来会深入分析。
|
||||
|
||||
@ -49,7 +49,7 @@ int main(int argc, char** argv)
|
||||
}
|
||||
```
|
||||
|
||||
看起来相当的简单:我们用 fork 命令创建了一个新的子进程。if 语句的分支执行子进程(这里称之为“target”),else if 的分支执行父进程(这里称之为“debugger”)。
|
||||
看起来相当的简单:我们用 `fork` 创建了一个新的子进程(这篇文章假定读者有一定的 Unix/Linux 编程经验。我假定你知道或至少了解 fork、exec 族函数与 Unix 信号)。if 语句的分支执行子进程(这里称之为 “target”),`else if` 的分支执行父进程(这里称之为 “debugger”)。
|
||||
|
||||
下面是 target 进程的代码:
|
||||
|
||||
@ -69,18 +69,18 @@ void run_target(const char* programname)
|
||||
}
|
||||
```
|
||||
|
||||
这段代码中最值得注意的是 ptrace 调用。在 "sys/ptrace.h" 中,ptrace 是如下定义的:
|
||||
这段代码中最值得注意的是 `ptrace` 调用。在 `sys/ptrace.h` 中,`ptrace` 是如下定义的:
|
||||
|
||||
```
|
||||
long ptrace(enum __ptrace_request request, pid_t pid,
|
||||
void *addr, void *data);
|
||||
```
|
||||
|
||||
第一个参数是 _request_,这是许多预定义的 PTRACE_* 常量中的一个。第二个参数为请求分配进程 ID。第三个与第四个参数是地址与数据指针,用于操作内存。上面代码段中的ptrace调用发起了 PTRACE_TRACEME 请求,这意味着该子进程请求系统内核让其父进程跟踪自己。帮助页面上对于 request 的描述很清楚:
|
||||
第一个参数是 `_request_`,这是许多预定义的 `PTRACE_*` 常量中的一个。第二个参数为请求分配进程 ID。第三个与第四个参数是地址与数据指针,用于操作内存。上面代码段中的 `ptrace` 调用发起了 `PTRACE_TRACEME` 请求,这意味着该子进程请求系统内核让其父进程跟踪自己。帮助页面上对于 request 的描述很清楚:
|
||||
|
||||
> 意味着该进程被其父进程跟踪。任何传递给该进程的信号(除了 SIGKILL)都将通过 wait() 方法阻塞该进程并通知其父进程。**此外,该进程的之后所有调用 exec() 动作都将导致 SIGTRAP 信号发送到此进程上,使得父进程在新的程序执行前得到取得控制权的机会**。如果一个进程并不需要它的的父进程跟踪它,那么这个进程不应该发送这个请求。(pid,addr 与 data 暂且不提)
|
||||
> 意味着该进程被其父进程跟踪。任何传递给该进程的信号(除了 `SIGKILL`)都将通过 `wait()` 方法阻塞该进程并通知其父进程。**此外,该进程的之后所有调用 `exec()` 动作都将导致 `SIGTRAP` 信号发送到此进程上,使得父进程在新的程序执行前得到取得控制权的机会**。如果一个进程并不需要它的的父进程跟踪它,那么这个进程不应该发送这个请求。(pid、addr 与 data 暂且不提)
|
||||
|
||||
我高亮了这个例子中我们需要注意的部分。在 ptrace 调用后,run_target 接下来要做的就是通过 execl 传参并调用。如同高亮部分所说明,这将导致系统内核在 execl 创建进程前暂时停止,并向父进程发送信号。
|
||||
我高亮了这个例子中我们需要注意的部分。在 `ptrace` 调用后,`run_target` 接下来要做的就是通过 `execl` 传参并调用。如同高亮部分所说明,这将导致系统内核在 `execl` 创建进程前暂时停止,并向父进程发送信号。
|
||||
|
||||
是时候看看父进程做什么了。
|
||||
|
||||
@ -110,11 +110,11 @@ void run_debugger(pid_t child_pid)
|
||||
}
|
||||
```
|
||||
|
||||
如前文所述,一旦子进程调用了 exec,子进程会停止并被发送 SIGTRAP 信号。父进程会等待该过程的发生并在第一个 wait() 处等待。一旦上述事件发生了,wait() 便会返回,由于子进程停止了父进程便会收到信号(如果子进程由于信号的发送停止了,WIFSTOPPED 就会返回 true)。
|
||||
如前文所述,一旦子进程调用了 `exec`,子进程会停止并被发送 `SIGTRAP` 信号。父进程会等待该过程的发生并在第一个 `wait()` 处等待。一旦上述事件发生了,`wait()` 便会返回,由于子进程停止了父进程便会收到信号(如果子进程由于信号的发送停止了,`WIFSTOPPED` 就会返回 `true`)。
|
||||
|
||||
父进程接下来的动作就是整篇文章最需要关注的部分了。父进程会将 PTRACE_SINGLESTEP 与子进程ID作为参数调用 ptrace 方法。这就会告诉操作系统,“请恢复子进程,但在它执行下一条指令前阻塞”。周而复始地,父进程等待子进程阻塞,循环继续。当 wait() 中传出的信号不再是子进程的停止信号时,循环终止。在跟踪器(父进程)运行期间,这将会是被跟踪进程(子进程)传递给跟踪器的终止信号(如果子进程终止 WIFEXITED 将返回 true)。
|
||||
父进程接下来的动作就是整篇文章最需要关注的部分了。父进程会将 `PTRACE_SINGLESTEP` 与子进程 ID 作为参数调用 `ptrace` 方法。这就会告诉操作系统,“请恢复子进程,但在它执行下一条指令前阻塞”。周而复始地,父进程等待子进程阻塞,循环继续。当 `wait()` 中传出的信号不再是子进程的停止信号时,循环终止。在跟踪器(父进程)运行期间,这将会是被跟踪进程(子进程)传递给跟踪器的终止信号(如果子进程终止 `WIFEXITED` 将返回 `true`)。
|
||||
|
||||
icounter 存储了子进程执行指令的次数。这么看来我们小小的例子也完成了些有用的事情 - 在命令行中指定程序,它将执行该程序并记录它从开始到结束所需要的 cpu 指令数量。接下来就让我们这么做吧。
|
||||
`icounter` 存储了子进程执行指令的次数。这么看来我们小小的例子也完成了些有用的事情 - 在命令行中指定程序,它将执行该程序并记录它从开始到结束所需要的 cpu 指令数量。接下来就让我们这么做吧。
|
||||
|
||||
### 测试
|
||||
|
||||
@ -131,11 +131,11 @@ int main()
|
||||
|
||||
```
|
||||
|
||||
令我惊讶的是,跟踪器花了相当长的时间,并报告整个执行过程共有超过 100,000 条指令执行。仅仅是一条输出语句?什么造成了这种情况?答案很有趣[[5]][18]。Linux 的 gcc 默认会动态的将程序与 c 的运行时库动态地链接。这就意味着任何程序运行前的第一件事是需要动态库加载器去查找程序运行所需要的共享库。这些代码的数量很大 - 别忘了我们的跟踪器要跟踪每一条指令,不仅仅是主函数的,而是“整个过程中的指令”。
|
||||
令我惊讶的是,跟踪器花了相当长的时间,并报告整个执行过程共有超过 100,000 条指令执行。仅仅是一条输出语句?什么造成了这种情况?答案很有趣(至少你同我一样痴迷与机器/汇编语言)。Linux 的 gcc 默认会动态的将程序与 c 的运行时库动态地链接。这就意味着任何程序运行前的第一件事是需要动态库加载器去查找程序运行所需要的共享库。这些代码的数量很大 - 别忘了我们的跟踪器要跟踪每一条指令,不仅仅是主函数的,而是“整个进程中的指令”。
|
||||
|
||||
所以当我将测试程序使用静态编译时(通过比较,可执行文件会多出 500 KB 左右的大小,这部分是 C 运行时库的静态链接),跟踪器提示只有大概 7000 条指令被执行。这个数目仍然不小,但是考虑到在主函数执行前 libc 的初始化以及主函数执行后的清除代码,这个数目已经是相当不错了。此外,printf 也是一个复杂的函数。
|
||||
所以当我将测试程序使用静态编译时(通过比较,可执行文件会多出 500 KB 左右的大小,这部分是 C 运行时库的静态链接),跟踪器提示只有大概 7000 条指令被执行。这个数目仍然不小,但是考虑到在主函数执行前 libc 的初始化以及主函数执行后的清除代码,这个数目已经是相当不错了。此外,`printf` 也是一个复杂的函数。
|
||||
|
||||
仍然不满意的话,我需要的是“可以测试”的东西 - 例如可以完整记录每一个指令运行的程序执行过程。这当然可以通过汇编代码完成。所以我找到了这个版本的“Hello, world!”并编译了它。
|
||||
仍然不满意的话,我需要的是“可以测试”的东西 - 例如可以完整记录每一个指令运行的程序执行过程。这当然可以通过汇编代码完成。所以我找到了这个版本的 “Hello, world!” 并编译了它。
|
||||
|
||||
|
||||
```
|
||||
@ -168,13 +168,11 @@ len equ $ - msg
|
||||
```
|
||||
|
||||
|
||||
当然,现在跟踪器提示 7 条指令被执行了,这样一来很容易区分他们。
|
||||
|
||||
当然,现在跟踪器提示 7 条指令被执行了,这样一来很容易区分它们。
|
||||
|
||||
### 深入指令流
|
||||
|
||||
|
||||
上面那个汇编语言编写的程序使得我可以向你介绍 ptrace 的另外一个强大的用途 - 详细显示被跟踪进程的状态。下面是 run_debugger 函数的另一个版本:
|
||||
上面那个汇编语言编写的程序使得我可以向你介绍 `ptrace` 的另外一个强大的用途 - 详细显示被跟踪进程的状态。下面是 `run_debugger` 函数的另一个版本:
|
||||
|
||||
```
|
||||
void run_debugger(pid_t child_pid)
|
||||
@ -209,24 +207,16 @@ void run_debugger(pid_t child_pid)
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
不同仅仅存在于 while 循环的开始几行。这个版本里增加了两个新的 ptrace 调用。第一条将进程的寄存器值读取进了一个结构体中。 sys/user.h 定义有 user_regs_struct。如果你查看头文件,头部的注释这么写到:
|
||||
不同仅仅存在于 `while` 循环的开始几行。这个版本里增加了两个新的 `ptrace` 调用。第一条将进程的寄存器值读取进了一个结构体中。 `sys/user.h` 定义有 `user_regs_struct`。如果你查看头文件,头部的注释这么写到:
|
||||
|
||||
```
|
||||
/* The whole purpose of this file is for GDB and GDB only.
|
||||
Don't read too much into it. Don't use it for
|
||||
anything other than GDB unless know what you are
|
||||
doing. */
|
||||
```
|
||||
|
||||
```
|
||||
/* 这个文件只为了GDB而创建
|
||||
/* 这个文件只为了 GDB 而创建
|
||||
不用详细的阅读.如果你不知道你在干嘛,
|
||||
不要在除了 GDB 以外的任何地方使用此文件 */
|
||||
```
|
||||
|
||||
|
||||
不知道你做何感想,但这让我觉得我们找对地方了。回到例子中,一旦我们在 regs 变量中取得了寄存器的值,我们就可以通过将 PTRACE_PEEKTEXT 作为参数、 regs.eip(x86 上的扩展指令指针)作为地址,调用 ptrace ,读取当前进程的当前指令。下面是新跟踪器所展示出的调试效果:
|
||||
不知道你做何感想,但这让我觉得我们找对地方了。回到例子中,一旦我们在 `regs` 变量中取得了寄存器的值,我们就可以通过将 `PTRACE_PEEKTEXT` 作为参数、 `regs.eip`(x86 上的扩展指令指针)作为地址,调用 `ptrace` ,读取当前进程的当前指令(警告:如同我上面所说,文章很大程度上是平台相关的。我简化了一些设定 - 例如,x86 指令集不需要调整到 4 字节,我的32位 Ubuntu unsigned int 是 4 字节。事实上,许多平台都不需要。从内存中读取指令需要预先安装完整的反汇编器。我们这里没有,但实际的调试器是有的)。下面是新跟踪器所展示出的调试效果:
|
||||
|
||||
```
|
||||
$ simple_tracer traced_helloworld
|
||||
@ -244,7 +234,7 @@ Hello, world!
|
||||
```
|
||||
|
||||
|
||||
现在,除了 icounter,我们也可以观察到指令指针与它每一步所指向的指令。怎么来判断这个结果对不对呢?使用 objdump -d 处理可执行文件:
|
||||
现在,除了 `icounter`,我们也可以观察到指令指针与它每一步所指向的指令。怎么来判断这个结果对不对呢?使用 `objdump -d` 处理可执行文件:
|
||||
|
||||
```
|
||||
$ objdump -d traced_helloworld
|
||||
@ -263,62 +253,36 @@ Disassembly of section .text:
|
||||
804809b: cd 80 int $0x80
|
||||
```
|
||||
|
||||
|
||||
这个结果和我们跟踪器的结果就很容易比较了。
|
||||
|
||||
|
||||
### 将跟踪器关联到正在运行的进程
|
||||
|
||||
|
||||
如你所知,调试器也能关联到已经运行的进程。现在你应该不会惊讶,ptrace 通过 以PTRACE_ATTACH 为参数调用也可以完成这个过程。这里我不会展示示例代码,通过上文的示例代码应该很容易实现这个过程。出于学习目的,这里使用的方法更简便(因为我们在子进程刚开始就可以让它停止)。
|
||||
|
||||
如你所知,调试器也能关联到已经运行的进程。现在你应该不会惊讶,`ptrace` 通过以 `PTRACE_ATTACH` 为参数调用也可以完成这个过程。这里我不会展示示例代码,通过上文的示例代码应该很容易实现这个过程。出于学习目的,这里使用的方法更简便(因为我们在子进程刚开始就可以让它停止)。
|
||||
|
||||
### 代码
|
||||
|
||||
|
||||
上文中的简单的跟踪器(更高级的,可以打印指令的版本)的完整c源代码可以在[这里][20]找到。它是通过 4.4 版本的 gcc 以 -Wall -pedantic --std=c99 编译的。
|
||||
|
||||
上文中的简单的跟踪器(更高级的,可以打印指令的版本)的完整c源代码可以在[这里][20]找到。它是通过 4.4 版本的 gcc 以 `-Wall -pedantic --std=c99` 编译的。
|
||||
|
||||
### 结论与计划
|
||||
|
||||
诚然,这篇文章并没有涉及很多内容 - 我们距离亲手完成一个实际的调试器还有很长的路要走。但我希望这篇文章至少可以使得调试这件事少一些神秘感。`ptrace` 是功能多样的系统调用,我们目前只展示了其中的一小部分。
|
||||
|
||||
诚然,这篇文章并没有涉及很多内容 - 我们距离亲手完成一个实际的调试器还有很长的路要走。但我希望这篇文章至少可以使得调试这件事少一些神秘感。ptrace 是功能多样的系统调用,我们目前只展示了其中的一小部分。
|
||||
|
||||
|
||||
单步调试代码很有用,但也只是在一定程度上有用。上面我通过c的“Hello World!”做了示例。为了执行主函数,可能需要上万行代码来初始化c的运行环境。这并不是很方便。最理想的是在main函数入口处放置断点并从断点处开始分步执行。为此,在这个系列的下一篇,我打算展示怎么实现断点。
|
||||
|
||||
|
||||
单步调试代码很有用,但也只是在一定程度上有用。上面我通过 C 的 “Hello World!” 做了示例。为了执行主函数,可能需要上万行代码来初始化 C 的运行环境。这并不是很方便。最理想的是在 `main` 函数入口处放置断点并从断点处开始分步执行。为此,在这个系列的下一篇,我打算展示怎么实现断点。
|
||||
|
||||
### 参考
|
||||
|
||||
|
||||
撰写此文时参考了如下文章
|
||||
|
||||
* [Playing with ptrace, Part I][11]
|
||||
* [How debugger works][12]
|
||||
|
||||
|
||||
|
||||
[1] 我没有检查,但我确信 gdb 的代码行数至少有六位数。
|
||||
|
||||
[2] 使用 man 2 ptrace 命令可以了解更多。
|
||||
|
||||
[3] Peek and poke 在系统编程中是很知名的叫法,指的是直接读写内存内容。
|
||||
|
||||
[4] 这篇文章假定读者有一定的 Unix/Linux 编程经验。我假定你知道(至少了解概念)fork,exec 族函数与 Unix 信号。
|
||||
|
||||
[5] 至少你同我一样痴迷与机器/汇编语言。
|
||||
|
||||
[6] 警告:如同我上面所说,文章很大程度上是平台相关的。我简化了一些设定 - 例如,x86指令集不需要调整到 4 字节(我的32位 Ubuntu unsigned int 是 4 字节)。事实上,许多平台都不需要。从内存中读取指令需要预先安装完整的反汇编器。我们这里没有,但实际的调试器是有的。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1
|
||||
|
||||
作者:[Eli Bendersky ][a]
|
||||
译者:[译者ID](https://github.com/YYforymj)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
作者:[Eli Bendersky][a]
|
||||
译者:[YYforymj](https://github.com/YYforymj)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
165
published/201704/20150112 Data-Oriented Hash Table.md
Normal file
165
published/201704/20150112 Data-Oriented Hash Table.md
Normal file
@ -0,0 +1,165 @@
|
||||
深入解析面向数据的哈希表性能
|
||||
============================================================
|
||||
|
||||
最近几年中,面向数据的设计已经受到了很多的关注 —— 一种强调内存中数据布局的编程风格,包括如何访问以及将会引发多少的 cache 缺失。由于在内存读取操作中缺失所占的数量级要大于命中的数量级,所以缺失的数量通常是优化的关键标准。这不仅仅关乎那些对性能有要求的 code-data 结构设计的软件,由于缺乏对内存效益的重视而成为软件运行缓慢、膨胀的一个很大因素。
|
||||
|
||||
|
||||
高效缓存数据结构的中心原则是将事情变得平滑和线性。比如,在大部分情况下,存储一个序列元素更倾向于使用普通数组而不是链表 —— 每一次通过指针来查找数据都会为 cache 缺失增加一份风险;而普通数组则可以预先获取,并使得内存系统以最大的效率运行
|
||||
|
||||
如果你知道一点内存层级如何运作的知识,下面的内容会是想当然的结果——但是有时候即便它们相当明显,测试一下任不失为一个好主意。几年前 [Baptiste Wicht 测试过了 `std::vector` vs `std::list` vs `std::deque`][4],(后者通常使用分块数组来实现,比如:一个数组的数组)。结果大部分会和你预期的保持一致,但是会存在一些违反直觉的东西。作为实例:在序列链表的中间位置做插入或者移除操作被认为会比数组快,但如果该元素是一个 POD 类型,并且不大于 64 字节或者在 64 字节左右(在一个 cache 流水线内),通过对要操作的元素周围的数组元素进行移位操作要比从头遍历链表来的快。这是由于在遍历链表以及通过指针插入/删除元素的时候可能会导致不少的 cache 缺失,相对而言,数组移位则很少会发生。(对于更大的元素,非 POD 类型,或者你已经有了指向链表元素的指针,此时和预期的一样,链表胜出)
|
||||
|
||||
|
||||
多亏了类似 Baptiste 这样的数据,我们知道了内存布局如何影响序列容器。但是关联容器,比如 hash 表会怎么样呢?已经有了些权威推荐:[Chandler Carruth 推荐的带局部探测的开放寻址][5](此时,我们没必要追踪指针),以及[Mike Acton 推荐的在内存中将 value 和 key 隔离][6](这种情况下,我们可以在每一个 cache 流水线中得到更多的 key), 这可以在我们必须查找多个 key 时提高局部性能。这些想法很有意义,但再一次的说明:测试永远是好习惯,但由于我找不到任何数据,所以只好自己收集了。
|
||||
|
||||
### 测试
|
||||
|
||||
我测试了四个不同的 quick-and-dirty 哈希表实现,另外还包括 `std::unordered_map` 。这五个哈希表都使用了同一个哈希函数 —— Bob Jenkins 的 [SpookyHash][8](64 位哈希值)。(由于哈希函数在这里不是重点,所以我没有测试不同的哈希函数;我同样也没有检测我的分析中的总内存消耗。)实现会通过简短的代码在测试结果表中标注出来。
|
||||
|
||||
* **UM**: `std::unordered_map` 。在 VS2012 和 libstdc++-v3 (libstdc++-v3: gcc 和 clang 都会用到这东西)中,UM 是以链表的形式实现,所有的元素都在链表中,bucket 数组中存储了链表的迭代器。VS2012 中,则是一个双链表,每一个 bucket 存储了起始迭代器和结束迭代器;libstdc++ 中,是一个单链表,每一个 bucket 只存储了一个起始迭代器。这两种情况里,链表节点是独立申请和释放的。最大负载因子是 1 。
|
||||
* **Ch**:分离的、链状 buket 指向一个元素节点的单链表。为了避免分开申请每一个节点,元素节点存储在普通数组池中。未使用的节点保存在一个空闲链表中。最大负载因子是 1。
|
||||
* **OL**:开地址线性探测 —— 每一个 bucket 存储一个 62 bit 的 hash 值,一个 2 bit 的状态值(包括 empty,filled,removed 三个状态),key 和 vale 。最大负载因子是 2/3。
|
||||
* **DO1**:“data-oriented 1” —— 和 OL 相似,但是哈希值、状态值和 key、values 分离在两个隔离的平滑数组中。
|
||||
* **DO2**:“data-oriented 2” —— 与 OL 类似,但是哈希/状态,keys 和 values 被分离在 3 个相隔离的平滑数组中。
|
||||
|
||||
|
||||
在我的所有实现中,包括 VS2012 的 UM 实现,默认使用尺寸为 2 的 n 次方。如果超出了最大负载因子,则扩展两倍。在 libstdc++ 中,UM 默认尺寸是一个素数。如果超出了最大负载因子,则扩展为下一个素数大小。但是我不认为这些细节对性能很重要。素数是一种对低 bit 位上没有足够熵的低劣 hash 函数的挽救手段,但是我们正在用的是一个很好的 hash 函数。
|
||||
|
||||
OL,DO1 和 DO2 的实现将共同的被称为 OA(open addressing)——稍后我们将发现它们在性能特性上非常相似。在每一个实现中,单元数从 100 K 到 1 M,有效负载(比如:总的 key + value 大小)从 8 到 4 k 字节我为几个不同的操作记了时间。 keys 和 values 永远是 POD 类型,keys 永远是 8 个字节(除了 8 字节的有效负载,此时 key 和 value 都是 4 字节)因为我的目的是为了测试内存影响而不是哈希函数性能,所以我将 key 放在连续的尺寸空间中。每一个测试都会重复 5 遍,然后记录最小的耗时。
|
||||
|
||||
测试的操作在这里:
|
||||
|
||||
* **Fill**:将一个随机的 key 序列插入到表中(key 在序列中是唯一的)。
|
||||
* **Presized fill**:和 Fill 相似,但是在插入之间我们先为所有的 key 保留足够的内存空间,以防止在 fill 过程中 rehash 或者重申请。
|
||||
* **Lookup**:执行 100 k 次随机 key 查找,所有的 key 都在 table 中。
|
||||
* **Failed lookup**: 执行 100 k 次随机 key 查找,所有的 key 都不在 table 中。
|
||||
* **Remove**:从 table 中移除随机选择的半数元素。
|
||||
* **Destruct**:销毁 table 并释放内存。
|
||||
|
||||
你可以[在这里下载我的测试代码][9]。这些代码只能在 64 机器上编译(包括Windows和Linux)。在 `main()` 函数顶部附近有一些开关,你可把它们打开或者关掉——如果全开,可能会需要一两个小时才能结束运行。我收集的结果也放在了那个打包文件里的 Excel 表中。(注意: Windows 和 Linux 在不同的 CPU 上跑的,所以时间不具备可比较性)代码也跑了一些单元测试,用来验证所有的 hash 表实现都能运行正确。
|
||||
|
||||
我还顺带尝试了附加的两个实现:Ch 中第一个节点存放在 bucket 中而不是 pool 里,二次探测的开放寻址。
|
||||
这两个都不足以好到可以放在最终的数据里,但是它们的代码仍放在了打包文件里面。
|
||||
|
||||
### 结果
|
||||
|
||||
这里有成吨的数据!!
|
||||
这一节我将详细的讨论一下结果,但是如果你对此不感兴趣,可以直接跳到下一节的总结。
|
||||
|
||||
#### Windows
|
||||
|
||||
这是所有的测试的图表结果,使用 Visual Studio 2012 编译,运行于 Windows 8.1 和 Core i7-4710HQ 机器上。(点击可以放大。)
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
从左至右是不同的有效负载大小,从上往下是不同的操作(注意:不是所有的Y轴都是相同的比例!)我将为每一个操作总结一下主要趋向。
|
||||
|
||||
**Fill**:
|
||||
|
||||
在我的 hash 表中,Ch 稍比任何的 OA 变种要好。随着哈希表大小和有效负载的加大,差距也随之变大。我猜测这是由于 Ch 只需要从一个空闲链表中拉取一个元素,然后把它放在 bucket 前面,而 OA 不得不搜索一部分 bucket 来找到一个空位置。所有的 OA 变种的性能表现基本都很相似,当然 DO1 稍微有点优势。
|
||||
|
||||
在小负载的情况,UM 几乎是所有 hash 表中表现最差的 —— 因为 UM 为每一次的插入申请(内存)付出了沉重的代价。但是在 128 字节的时候,这些 hash 表基本相当,大负载的时候 UM 还赢了点。因为,我所有的实现都需要重新调整元素池的大小,并需要移动大量的元素到新池里面,这一点我几乎无能为力;而 UM 一旦为元素申请了内存后便不需要移动了。注意大负载中图表上夸张的跳步!这更确认了重新调整大小带来的问题。相反,UM 只是线性上升 —— 只需要重新调整 bucket 数组大小。由于没有太多隆起的地方,所以相对有效率。
|
||||
|
||||
**Presized fill**:
|
||||
|
||||
大致和 Fill 相似,但是图示结果更加的线性光滑,没有太大的跳步(因为不需要 rehash ),所有的实现差距在这一测试中要缩小了些。大负载时 UM 依然稍快于 Ch,问题还是在于重新调整大小上。Ch 仍是稳步少快于 OA 变种,但是 DO1 比其它的 OA 稍有优势。
|
||||
|
||||
**Lookup**:
|
||||
|
||||
所有的实现都相当的集中。除了最小负载时,DO1 和 OL 稍快,其余情况下 UM 和 DO2 都跑在了前面。(LCTT 译注: 你确定?)真的,我无法描述 UM 在这一步做的多么好。尽管需要遍历链表,但是 UM 还是坚守了面向数据的本性。
|
||||
|
||||
顺带一提,查找时间和 hash 表的大小有着很弱的关联,这真的很有意思。
|
||||
哈希表查找时间期望上是一个常量时间,所以在的渐进视图中,性能不应该依赖于表的大小。但是那是在忽视了 cache 影响的情况下!作为具体的例子,当我们在具有 10 k 条目的表中做 100 k 次查找时,速度会便变快,因为在第一次 10 k - 20 k 次查找后,大部分的表会处在 L3 中。
|
||||
|
||||
**Failed lookup**:
|
||||
|
||||
相对于成功查找,这里就有点更分散一些。DO1 和 DO2 跑在了前面,但 UM 并没有落下,OL 则是捉襟见肘啊。我猜测,这可能是因为 OL 整体上具有更长的搜索路径,尤其是在失败查询时;内存中,hash 值在 key 和 value 之飘来荡去的找不着出路,我也很受伤啊。DO1 和 DO2 具有相同的搜索长度,但是它们将所有的 hash 值打包在内存中,这使得问题有所缓解。
|
||||
|
||||
**Remove**:
|
||||
|
||||
DO2 很显然是赢家,但 DO1 也未落下。Ch 则落后,UM 则是差的不是一丁半点(主要是因为每次移除都要释放内存);差距随着负载的增加而拉大。移除操作是唯一不需要接触数据的操作,只需要 hash 值和 key 的帮助,这也是为什么 DO1 和 DO2 在移除操作中的表现大相径庭,而其它测试中却保持一致。(如果你的值不是 POD 类型的,并需要析构,这种差异应该是会消失的。)
|
||||
|
||||
**Destruct**:
|
||||
|
||||
Ch 除了最小负载,其它的情况都是最快的(最小负载时,约等于 OA 变种)。所有的 OA 变种基本都是相等的。注意,在我的 hash 表中所做的所有析构操作都是释放少量的内存 buffer 。但是 [在Windows中,释放内存的消耗和大小成比例关系][13]。(而且,这是一个很显著的开支 —— 申请 ~1 GB 的内存需要 ~100 ms 的时间去释放!)
|
||||
|
||||
UM 在析构时是最慢的一个(小负载时,慢的程度可以用数量级来衡量),大负载时依旧是稍慢些。对于 UM 来讲,释放每一个元素而不是释放一组数组真的是一个硬伤。
|
||||
|
||||
#### Linux
|
||||
|
||||
我还在装有 Linux Mint 17.1 的 Core i5-4570S 机器上使用 gcc 4.8 和 clang 3.5 来运行了测试。gcc 和 clang 的结果很相像,因此我只展示了 gcc 的;完整的结果集合包含在了代码下载打包文件中,链接在上面。(点击图来缩放)
|
||||
|
||||
[
|
||||

|
||||
][15]
|
||||
|
||||
大部分结果和 Windows 很相似,因此我只高亮了一些有趣的不同点。
|
||||
|
||||
**Lookup**:
|
||||
|
||||
这里 DO1 跑在前头,而在 Windows 中 DO2 更快些。(LCTT 译注: 这里原文写错了吧?)同样,UM 和 Ch 落后于其它所有的实现——过多的指针追踪,然而 OA 只需要在内存中线性的移动即可。至于 Windows 和 Linux 结果为何不同,则不是很清楚。UM 同样比 Ch 慢了不少,特别是大负载时,这很奇怪;我期望的是它们可以基本相同。
|
||||
|
||||
**Failed lookup**:
|
||||
|
||||
UM 再一次落后于其它实现,甚至比 OL 还要慢。我再一次无法理解为何 UM 比 Ch 慢这么多,Linux 和 Windows 的结果为何有着如此大的差距。
|
||||
|
||||
|
||||
**Destruct**:
|
||||
|
||||
在我的实现中,小负载的时候,析构的消耗太少了,以至于无法测量;在大负载中,线性增加的比例和创建的虚拟内存页数量相关,而不是申请到的数量?同样,要比 Windows 中的析构快上几个数量级。但是并不是所有的都和 hash 表有关;我们在这里可以看出不同系统和运行时内存系统的表现。貌似,Linux 释放大内存块是要比 Windows 快上不少(或者 Linux 很好的隐藏了开支,或许将释放工作推迟到了进程退出,又或者将工作推给了其它线程或者进程)。
|
||||
|
||||
UM 由于要释放每一个元素,所以在所有的负载中都比其它慢上几个数量级。事实上,我将图片做了剪裁,因为 UM 太慢了,以至于破坏了 Y 轴的比例。
|
||||
|
||||
### 总结
|
||||
|
||||
好,当我们凝视各种情况下的数据和矛盾的结果时,我们可以得出什么结果呢?我想直接了当的告诉你这些 hash 表变种中有一个打败了其它所有的 hash 表,但是这显然不那么简单。不过我们仍然可以学到一些东西。
|
||||
|
||||
首先,在大多数情况下我们“很容易”做的比 `std::unordered_map` 还要好。我为这些测试所写的所有实现(它们并不复杂;我只花了一两个小时就写完了)要么是符合 `unordered_map` 要么是在其基础上做的提高,除了大负载(超过128字节)中的插入性能, `unordered_map` 为每一个节点独立申请存储占了优势。(尽管我没有测试,我同样期望 `unordered_map` 能在非 POD 类型的负载上取得胜利。)具有指导意义的是,如果你非常关心性能,不要假设你的标准库中的数据结构是高度优化的。它们可能只是在 C++ 标准的一致性上做了优化,但不是性能。:P
|
||||
|
||||
其次,如果不管在小负载还是超负载中,若都只用 DO1 (开放寻址,线性探测,hashes/states 和 key/vaules分别处在隔离的普通数组中),那可能不会有啥好表现。这不是最快的插入,但也不坏(还比 `unordered_map` 快),并且在查找,移除,析构中也很快。你所知道的 —— “面向数据设计”完成了!
|
||||
|
||||
注意,我的为这些哈希表做的测试代码远未能用于生产环境——它们只支持 POD 类型,没有拷贝构造函数以及类似的东西,也未检测重复的 key,等等。我将可能尽快的构建一些实际的 hash 表,用于我的实用库中。为了覆盖基础部分,我想我将有两个变种:一个基于 DO1,用于小的,移动时不需要太大开支的负载;另一个用于链接并且避免重新申请和移动元素(就像 `unordered_map` ),用于大负载或者移动起来需要大开支的负载情况。这应该会给我带来最好的两个世界。
|
||||
|
||||
与此同时,我希望你们会有所启迪。最后记住,如果 Chandler Carruth 和 Mike Acton 在数据结构上给你提出些建议,你一定要听。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
作者简介:
|
||||
|
||||
我是一名图形程序员,目前在西雅图做自由职业者。之前我在 NVIDIA 的 DevTech 软件团队中工作,并在美少女特工队工作室中为 PS3 和 PS4 的 Infamous 系列游戏开发渲染技术。
|
||||
|
||||
自 2002 年起,我对图形非常感兴趣,并且已经完成了一系列的工作,包括:雾、大气雾霾、体积照明、水、视觉效果、粒子系统、皮肤和头发阴影、后处理、镜面模型、线性空间渲染、和 GPU 性能测量和优化。
|
||||
|
||||
你可以在我的博客了解更多和我有关的事,处理图形,我还对理论物理和程序设计感兴趣。
|
||||
|
||||
你可以在 nathaniel.reed@gmail.com 或者在 Twitter(@Reedbeta)/Google+ 上关注我。我也会经常在 StackExchange 上回答计算机图形的问题。
|
||||
|
||||
--------------
|
||||
|
||||
via: http://reedbeta.com/blog/data-oriented-hash-table/
|
||||
|
||||
作者:[Nathan Reed][a]
|
||||
译者:[sanfusu](https://github.com/sanfusu)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://reedbeta.com/about/
|
||||
[1]:http://reedbeta.com/blog/data-oriented-hash-table/
|
||||
[2]:http://reedbeta.com/blog/category/coding/
|
||||
[3]:http://reedbeta.com/blog/data-oriented-hash-table/#comments
|
||||
[4]:http://baptiste-wicht.com/posts/2012/12/cpp-benchmark-vector-list-deque.html
|
||||
[5]:https://www.youtube.com/watch?v=fHNmRkzxHWs
|
||||
[6]:https://www.youtube.com/watch?v=rX0ItVEVjHc
|
||||
[7]:http://reedbeta.com/blog/data-oriented-hash-table/#the-tests
|
||||
[8]:http://burtleburtle.net/bob/hash/spooky.html
|
||||
[9]:http://reedbeta.com/blog/data-oriented-hash-table/hash-table-tests.zip
|
||||
[10]:http://reedbeta.com/blog/data-oriented-hash-table/#the-results
|
||||
[11]:http://reedbeta.com/blog/data-oriented-hash-table/#windows
|
||||
[12]:http://reedbeta.com/blog/data-oriented-hash-table/results-vs2012.png
|
||||
[13]:https://randomascii.wordpress.com/2014/12/10/hidden-costs-of-memory-allocation/
|
||||
[14]:http://reedbeta.com/blog/data-oriented-hash-table/#linux
|
||||
[15]:http://reedbeta.com/blog/data-oriented-hash-table/results-g++4.8.png
|
||||
[16]:http://reedbeta.com/blog/data-oriented-hash-table/#conclusions
|
||||
@ -0,0 +1,314 @@
|
||||
2016 年度顶级开源创作工具
|
||||
============================================================
|
||||
|
||||
> 无论你是想修改图片、编译音频,还是制作动画,这里的自由而开源的工具都能帮你做到。
|
||||
|
||||

|
||||
|
||||
>图片来源 : opensource.com
|
||||
|
||||
几年前,我在 Red Hat 总结会上做了一个简单的演讲,给与会者展示了 [2012 年度开源创作工具][12]。开源软件在过去几年里发展迅速,现在我们来看看 2016 年的相关领域的软件。
|
||||
|
||||
### 核心应用
|
||||
|
||||
这六款应用是开源的设计软件中的最强王者。它们做的很棒,拥有完善的功能特征集、稳定发行版以及活跃的开发者社区,是很成熟的项目。这六款应用都是跨平台的,每一个都能在 Linux、OS X 和 Windows 上使用,不过大多数情况下 Linux 版本一般都是最先更新的。这些应用广为人知,我已经把最新特性的重要部分写进来了,如果你不是非常了解它们的开发情况,你有可能会忽视这些特性。
|
||||
|
||||
如果你想要对这些软件做更深层次的了解,或许你可以帮助测试这四个软件 —— GIMP、Inkscape、Scribus,以及 MyPaint 的最新版本,在 Linux 机器上你可以用 [Flatpak][13] 软件轻松地安装它们。这些应用的每日构建版本可以[按照指令][14] 通过 Flatpak 的“每日构建的绘图应用(Nightly Graphics Apps)”得到。有一件事要注意:如果你要给每个应用的 Flatpak 版本安装笔刷或者其它扩展,用于移除这些扩展的目录将会位于相应应用的目录 **~/.var/app** 下。
|
||||
|
||||
#### GIMP
|
||||
|
||||
[GIMP][15] [在 2015 年迎来了它的 20 周岁][16],使得它成为这里资历最久的开源创造型应用之一。GIMP 是一款强大的应用,可以处理图片,创作简单的绘画,以及插图。你可以通过简单的任务来尝试 GIMP,比如裁剪、缩放图片,然后循序渐进使用它的其它功能。GIMP 可以在 Linux、Mac OS X 以及 Windows 上使用,是一款跨平台的应用,而且能够打开、导出一系列格式的文件,包括在与之相似的软件 Photoshop 上广为应用的那些格式。
|
||||
|
||||
GIMP 开发团队正在忙着 2.10 发行版的工作;[2.8.18][17] 是最新的稳定版本。更振奋人心的是非稳定版,[2.9.4][18],拥有全新的用户界面,旨在节省空间的符号式图标和黑色主题,改进了颜色管理,更多的基于 GEGL 的支持分离预览的过滤器,支持 MyPaint 笔刷(如下图所示),对称绘图,以及命令行批次处理。想了解更多信息,请关注 [完整的发行版注记][19]。
|
||||
|
||||

|
||||
|
||||
#### Inkscape
|
||||
|
||||
[Inkscape][20] 是一款富有特色的矢量绘图设计软件。可以用它来创作简单的图形、图表、布局或者图标。
|
||||
|
||||
最新的稳定版是 [0.91][21] 版本;与 GIMP 相似,能在预发布版 0.92pre3 版本中找到更多有趣的东西,其发布于 2016 年 11 月。最新推出的预发布版的突出特点是 [梯度网格特性(gradient mesh feature)][22](如下图所示);0.91 发行版里介绍的新特性包括:[强力笔触(power stroke)][23] 用于完全可配置的书法笔画(下图的 “opensource.com” 中的 “open” 用的就是强力笔触技术),画布测量工具,以及 [全新的符号对话框][24](如下图右侧所示)。(很多符号库可以从 GitHub 上获得;[Xaviju's inkscape-open-symbols set][25] 就很不错。)_对象_对话框是在改进版或每日构建中可用的新特性,整合了一个文档中的所有对象,提供工具来管理这些对象。
|
||||
|
||||

|
||||
|
||||
#### Scribus
|
||||
|
||||
[Scribus][26] 是一款强大的桌面出版和页面布局工具。Scribus 让你能够创造精致美丽的物品,包括信封、书籍、杂志以及其它印刷品。Scribus 的颜色管理工具可以处理和输出 CMYK 格式,还能给文件配色,可靠地用于印刷车间的重印。
|
||||
|
||||
[1.4.6][27] 是 Scribus 的最新稳定版本;[1.5.x][28] 系列的发行版更令人期待,因为它们是即将到来的 1.6.0 发行版的预览。1.5.3 版本包含了 Krita 文件(*.KRA)导入工具; 1.5.x 系列中其它的改进包括了表格工具、文本框对齐、脚注、导出可选 PDF 格式、改进的字典、可驻留边框的调色盘、符号工具,和丰富的文件格式支持。
|
||||
|
||||

|
||||
|
||||
#### MyPaint
|
||||
|
||||
[MyPaint][29] 是一款用于数位屏的快速绘图和插画工具。它很轻巧,界面虽小,但快捷键丰富,因此你能够不用放下数位笔而专心于绘图。
|
||||
|
||||
[MyPaint 1.2.0][30] 是其最新的稳定版本,包含了一些新特性,诸如 [直观上墨工具][31] 用来跟踪铅笔绘图的轨迹,新的填充工具,层分组,笔刷和颜色的历史面板,用户界面的改进包括暗色主题和小型符号图标,以及可编辑的矢量层。想要尝试 MyPaint 里的最新改进,我建议安装每日构建版的 Flatpak 构建,尽管自从 1.2.0 版本没有添加重要的特性。
|
||||
|
||||

|
||||
|
||||
#### Blender
|
||||
|
||||
[Blender][32] 最初发布于 1995 年 1 月,像 GIMP 一样,已经有 20 多年的历史了。Blender 是一款功能强大的开源 3D 制作套件,包含建模、雕刻、渲染、真实材质、套索、动画、影像合成、视频编辑、游戏创作以及模拟。
|
||||
|
||||
Blender 最新的稳定版是 [2.78a][33]。2.78 版本很庞大,包含的特性有:改进的 2D 蜡笔(Grease Pencil) 动画工具;针对球面立体图片的 VR 渲染支持;以及新的手绘曲线的绘图工具。
|
||||
|
||||

|
||||
|
||||
要尝试最新的 Blender 开发工具,有很多种选择,包括:
|
||||
|
||||
* Blender 基金会在官方网址提供 [非稳定版的每日构建版][2]。
|
||||
* 如果你在寻找特殊的开发中特性,[graphicall.org][3] 是一个适合社区的网站,能够提供特殊版本的 Blender(偶尔还有其它的创造型开源应用),让艺术家能够尝试体验最新的代码。
|
||||
* Mathieu Bridon 通过 Flatpak 做了 Blender 的一个开发版本。查看它的博客以了解详情:[Flatpak 上每日构建版的 Blender][4]
|
||||
|
||||
#### Krita
|
||||
|
||||
[Krita][34] 是一款拥有强大功能的数字绘图应用。这款应用贴合插画师、印象艺术家以及漫画家的需求,有很多附件,比如笔刷、调色板、图案以及模版。
|
||||
|
||||
最新的稳定版是 [Krita 3.0.1][35],于 2016 年 9 月发布。3.0.x 系列的新特性包括 2D 逐帧动画;改进的层管理器和功能;丰富的常用快捷键;改进了网格、向导和图形捕捉;还有软打样。
|
||||
|
||||

|
||||
|
||||
### 视频处理工具
|
||||
|
||||
关于开源的视频编辑工具则有很多很多。这这些工具之中,[Flowblade][36] 是新推出的,而 Kdenlive 则是构建完善、对新手友好、功能最全的竞争者。对你排除某些备选品有所帮助的主要标准是它们所支持的平台,其中一些只支持 Linux 平台。它们的软件上游都很活跃,最新的稳定版都于近期发布,发布时间相差不到一周。
|
||||
|
||||
#### Kdenlive
|
||||
|
||||
[Kdenlive][37],最初于 2002 年发布,是一款强大的非线性视频编辑器,有 Linux 和 OS X 版本(但是 OS X 版本已经过时了)。Kdenlive 有用户友好的、基于拖拽的用户界面,适合初学者,又有专业人员需要的深层次功能。
|
||||
|
||||
可以看看 Seth Kenlon 写的 [Kdenlive 系列教程][38],了解如何使用 Kdenlive。
|
||||
|
||||
* 最新稳定版: 16.08.2 (2016 年 10 月)
|
||||
|
||||

|
||||
|
||||
#### Flowblade
|
||||
|
||||
2012 年发布, [Flowblade][39],只有 Linux 版本的视频编辑器,是个相当不错的后起之秀。
|
||||
|
||||
* 最新稳定版: 1.8 (2016 年 9 月)
|
||||
|
||||
#### Pitivi
|
||||
|
||||
[Pitivi][40] 是用户友好型的自由开源视频编辑器。Pitivi 是用 [Python][41] 编写的(“Pitivi” 中的 “Pi”来源于此),使用了 [GStreamer][42] 多媒体框架,社区活跃。
|
||||
|
||||
* 最新稳定版: 0.97 (2016 年 8 月)
|
||||
* 通过 Flatpak 获取 [最新版本][5]
|
||||
|
||||
#### Shotcut
|
||||
|
||||
[Shotcut][43] 是一款自由开源的跨平台视频编辑器,[早在 2004 年]就发布了,之后由现在的主要开发者 [Dan Dennedy][45] 重写。
|
||||
|
||||
* 最新稳定版: 16.11 (2016 年 11 月)
|
||||
* 支持 4K 分辨率
|
||||
* 仅以 tar 包方式发布
|
||||
|
||||
#### OpenShot Video Editor
|
||||
|
||||
始于 2008 年,[OpenShot Video Editor][46] 是一款自由、开源、易于使用、跨平台的视频编辑器。
|
||||
|
||||
* 最新稳定版: [2.1][6] (2016 年 8 月)
|
||||
|
||||
|
||||
### 其它工具
|
||||
|
||||
#### SwatchBooker
|
||||
|
||||
[SwatchBooker][47] 是一款很方便的工具,尽管它近几年都没有更新了,但它还是很有用。SwatchBooler 能帮助用户从各大制造商那里合法地获取色卡,你可以用其它自由开源的工具处理它导出的格式,包括 Scribus。
|
||||
|
||||
#### GNOME Color Manager
|
||||
|
||||
[GNOME Color Manager][48] 是 GNOME 桌面环境内建的颜色管理器,而 GNOME 是某些 Linux 发行版的默认桌面。这个工具让你能够用色度计为自己的显示设备创建属性文件,还可以为这些设备加载/管理 ICC 颜色属性文件。
|
||||
|
||||
#### GNOME Wacom Control
|
||||
|
||||
[The GNOME Wacom controls][49] 允许你在 GNOME 桌面环境中配置自己的 Wacom 手写板;你可以修改手写板交互的很多选项,包括自定义手写板灵敏度,以及手写板映射到哪块屏幕上。
|
||||
|
||||
#### Xournal
|
||||
|
||||
[Xournal][50] 是一款简单但可靠的应用,可以让你通过手写板手写或者在笔记上涂鸦。Xournal 是一款有用的工具,可以让你签名或注解 PDF 文档。
|
||||
|
||||
#### PDF Mod
|
||||
|
||||
[PDF Mod][51] 是一款编辑 PDF 文件很方便的工具。PDF Mod 让用户可以移除页面、添加页面,将多个 PDF 文档合并成一个单独的 PDF 文件,重新排列页面,旋转页面等。
|
||||
|
||||
#### SparkleShare
|
||||
|
||||
[SparkleShare][52] 是一款基于 git 的文件分享工具,艺术家用来协作和分享资源。它会挂载在 GitLab 仓库上,你能够采用一个精妙的开源架构来进行资源管理。SparkleShare 的前端通过在顶部提供一个类似下拉框界面,避免了使用 git 的复杂性。
|
||||
|
||||
### 摄影
|
||||
|
||||
#### Darktable
|
||||
|
||||
[Darktable][53] 是一款能让你开发数位 RAW 文件的应用,有一系列工具,可以管理工作流、无损编辑图片。Darktable 支持许多流行的相机和镜头。
|
||||
|
||||

|
||||
|
||||
#### Entangle
|
||||
|
||||
[Entangle][54] 允许你将数字相机连接到电脑上,让你能从电脑上完全控制相机。
|
||||
|
||||
#### Hugin
|
||||
|
||||
[Hugin][55] 是一款工具,让你可以拼接照片,从而制作全景照片。
|
||||
|
||||
### 2D 动画
|
||||
|
||||
#### Synfig Studio
|
||||
|
||||
[Synfig Studio][56] 是基于矢量的二维动画套件,支持位图原图,在平板上用起来方便。
|
||||
|
||||
#### Blender Grease Pencil
|
||||
|
||||
我在前面讲过了 Blender,但值得注意的是,最近的发行版里[重构的蜡笔特性][57],添加了创作二维动画的功能。
|
||||
|
||||
#### Krita
|
||||
|
||||
[Krita][58] 现在同样提供了二维动画功能。
|
||||
|
||||
### 音频编辑
|
||||
|
||||
#### Audacity
|
||||
|
||||
[Audacity][59] 在编辑音频文件、记录声音方面很有名,是用户友好型的工具。
|
||||
|
||||
#### Ardour
|
||||
|
||||
[Ardour][60] 是一款数字音频工作软件,界面中间是录音,编辑和混音工作流。使用上它比 Audacity 要稍微难一点,但它允许自动操作,并且更高端。(有 Linux、Mac OS X 和 Windows 版本)
|
||||
|
||||
#### Hydrogen
|
||||
|
||||
[Hydrogen][61] 是一款开源的电子鼓,界面直观。它可以用合成的乐器创作、整理各种乐谱。
|
||||
|
||||
#### Mixxx
|
||||
|
||||
[Mixxx][62] 是四仓 DJ 套件,让你能够以强大操控来 DJ 和混音歌曲,包含节拍循环、时间延长、音高变化,还可以用 DJ 硬件控制器直播混音和衔接。
|
||||
|
||||
### Rosegarden
|
||||
|
||||
[Rosegarden][63] 是一款作曲软件,有乐谱编写和音乐作曲或编辑的功能,提供音频和 MIDI 音序器。(LCTT 译注:MIDI 即 Musical Instrument Digital Interface 乐器数字接口)
|
||||
|
||||
#### MuseScore
|
||||
|
||||
[MuseScore][64] 是乐谱创作、记谱和编辑的软件,它还有个乐谱贡献者社区。
|
||||
|
||||
### 其它具有创造力的工具
|
||||
|
||||
#### MakeHuman
|
||||
|
||||
[MakeHuman][65] 是一款三维绘图工具,可以创造人型的真实模型。
|
||||
|
||||
#### Natron
|
||||
|
||||
[Natron][66] 是基于节点的合成工具,用于视频后期制作、动态图象和设计特效。
|
||||
|
||||
#### FontForge
|
||||
|
||||
[FontForge][67] 是创作和编辑字体的工具。允许你编辑某个字体中的字形,也能够使用这些字形生成字体。
|
||||
|
||||
#### Valentina
|
||||
|
||||
[Valentina][68] 是用来设计缝纫图案的应用。
|
||||
|
||||
#### Calligra Flow
|
||||
|
||||
[Calligra Flow][69] 是一款图表工具,类似 Visio(有 Linux,Mac OS X 和 Windows 版本)。
|
||||
|
||||
### 资源
|
||||
|
||||
这里有很多小玩意和彩蛋值得尝试。需要一点灵感来探索?这些网站和论坛有很多教程和精美的成品能够激发你开始创作:
|
||||
|
||||
1、 [pixls.us][7]: 摄影师 Pat David 管理的博客,他专注于专业摄影师使用的自由开源的软件和工作流。
|
||||
2、 [David Revoy 's Blog][8]: David Revoy 的博客,热爱自由开源,非常有天赋的插画师,概念派画师和开源倡议者,对 Blender 基金会电影有很大贡献。
|
||||
3、 [The Open Source Creative Podcast][9]: 由 Opensource.com 社区版主和专栏作家 [Jason van Gumster][10] 管理,他是 Blender 和 GIMP 的专家, [《Blender for Dummies》][1] 的作者,该文章正好是面向我们这些热爱开源创作工具和这些工具周边的文化的人。
|
||||
4、 [Libre Graphics Meeting][11]: 自由开源创作软件的开发者和使用这些软件的创作者的年度会议。这是个好地方,你可以通过它找到你喜爱的开源创作软件将会推出哪些有意思的特性,还可以了解到这些软件的用户用它们在做什么。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Máirín Duffy - Máirín 是 Red Hat 的首席交互设计师。她热衷于自由软件和开源工具,尤其是在创作领域:她最喜欢的应用是 [Inkscape](http://inkscape.org)。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/16/12/yearbook-top-open-source-creative-tools-2016
|
||||
|
||||
作者:[Máirín Duffy][a]
|
||||
译者:[GitFuture](https://github.com/GitFuture)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/mairin
|
||||
[1]:http://www.blenderbasics.com/
|
||||
[2]:https://builder.blender.org/download/
|
||||
[3]:http://graphicall.org/
|
||||
[4]:https://mathieu.daitauha.fr/blog/2016/09/23/blender-nightly-in-flatpak/
|
||||
[5]:https://pitivi.wordpress.com/2016/07/18/get-pitivi-directly-from-us-with-flatpak/
|
||||
[6]:http://www.openshotvideo.com/2016/08/openshot-21-released.html
|
||||
[7]:http://pixls.us/
|
||||
[8]:http://davidrevoy.com/
|
||||
[9]:http://monsterjavaguns.com/podcast/
|
||||
[10]:https://opensource.com/users/jason-van-gumster
|
||||
[11]:http://libregraphicsmeeting.org/2016/
|
||||
[12]:https://opensource.com/life/12/9/tour-through-open-source-creative-tools
|
||||
[13]:https://opensource.com/business/16/8/flatpak
|
||||
[14]:http://flatpak.org/apps.html
|
||||
[15]:https://opensource.com/tags/gimp
|
||||
[16]:https://linux.cn/article-7131-1.html
|
||||
[17]:https://www.gimp.org/news/2016/07/14/gimp-2-8-18-released/
|
||||
[18]:https://www.gimp.org/news/2016/07/13/gimp-2-9-4-released/
|
||||
[19]:https://www.gimp.org/news/2016/07/13/gimp-2-9-4-released/
|
||||
[20]:https://opensource.com/tags/inkscape
|
||||
[21]:http://wiki.inkscape.org/wiki/index.php/Release_notes/0.91
|
||||
[22]:http://wiki.inkscape.org/wiki/index.php/Mesh_Gradients
|
||||
[23]:https://www.youtube.com/watch?v=IztyV-Dy4CE
|
||||
[24]:https://inkscape.org/cs/~doctormo/%E2%98%85symbols-dialog
|
||||
[25]:https://github.com/Xaviju/inkscape-open-symbols
|
||||
[26]:https://opensource.com/tags/scribus
|
||||
[27]:https://www.scribus.net/scribus-1-4-6-released/
|
||||
[28]:https://www.scribus.net/scribus-1-5-2-released/
|
||||
[29]:http://mypaint.org/
|
||||
[30]:http://mypaint.org/blog/2016/01/15/mypaint-1.2.0-released/
|
||||
[31]:https://github.com/mypaint/mypaint/wiki/v1.2-Inking-Tool
|
||||
[32]:https://opensource.com/tags/blender
|
||||
[33]:http://www.blender.org/features/2-78/
|
||||
[34]:https://opensource.com/tags/krita
|
||||
[35]:https://krita.org/en/item/krita-3-0-1-update-brings-numerous-fixes/
|
||||
[36]:https://opensource.com/life/16/9/10-reasons-flowblade-linux-video-editor
|
||||
[37]:https://opensource.com/tags/kdenlive
|
||||
[38]:https://opensource.com/life/11/11/introduction-kdenlive
|
||||
[39]:http://jliljebl.github.io/flowblade/
|
||||
[40]:http://pitivi.org/
|
||||
[41]:http://wiki.pitivi.org/wiki/Why_Python%3F
|
||||
[42]:https://gstreamer.freedesktop.org/
|
||||
[43]:http://shotcut.org/
|
||||
[44]:http://permalink.gmane.org/gmane.comp.lib.fltk.general/2397
|
||||
[45]:http://www.dennedy.org/
|
||||
[46]:http://openshot.org/
|
||||
[47]:http://www.selapa.net/swatchbooker/
|
||||
[48]:https://help.gnome.org/users/gnome-help/stable/color.html.en
|
||||
[49]:https://help.gnome.org/users/gnome-help/stable/wacom.html.en
|
||||
[50]:http://xournal.sourceforge.net/
|
||||
[51]:https://wiki.gnome.org/Apps/PdfMod
|
||||
[52]:https://www.sparkleshare.org/
|
||||
[53]:https://opensource.com/life/16/4/how-use-darktable-digital-darkroom
|
||||
[54]:https://entangle-photo.org/
|
||||
[55]:http://hugin.sourceforge.net/
|
||||
[56]:https://opensource.com/article/16/12/synfig-studio-animation-software-tutorial
|
||||
[57]:https://wiki.blender.org/index.php/Dev:Ref/Release_Notes/2.78/GPencil
|
||||
[58]:https://opensource.com/tags/krita
|
||||
[59]:https://opensource.com/tags/audacity
|
||||
[60]:https://ardour.org/
|
||||
[61]:http://www.hydrogen-music.org/
|
||||
[62]:http://mixxx.org/
|
||||
[63]:http://www.rosegardenmusic.com/
|
||||
[64]:https://opensource.com/life/16/03/musescore-tutorial
|
||||
[65]:http://makehuman.org/
|
||||
[66]:https://natron.fr/
|
||||
[67]:http://fontforge.github.io/en-US/
|
||||
[68]:http://valentina-project.org/
|
||||
[69]:https://www.calligra.org/flow/
|
||||
@ -1,7 +1,7 @@
|
||||
工程师和市场营销人员之间能够相互学习什么?
|
||||
============================================================
|
||||
|
||||
> 营销人员觉得工程师在工作中都太严谨了;而工程师则认为营销人员都很懒散。但是他们都错了。
|
||||
> 营销人员觉得工程师在工作中都太严谨了;而工程师则认为营销人员毫无用处。但是他们都错了。
|
||||
|
||||

|
||||
|
||||
@ -1,74 +1,59 @@
|
||||
|
||||
2016 Git 新视界
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
|
||||
2016 年 Git 发生了 _惊天动地_ 地变化,发布了五大新特性[¹][57] (从 _v2.7_ 到 _v2.11_ )和十六个补丁[²][58]。189 位作者[³][59]贡献了 3676 个提交[⁴][60]到 `master` 分支,比 2015 年多了 15%[⁵][61]!总计有 1545 个文件被修改,其中增加了 276799 行并移除了 100973 行。
|
||||
|
||||
但是,通过统计提交的数量和代码行数来衡量生产力是一种十分愚蠢的方法。除了深度研究过的开发者可以做到凭直觉来判断代码质量的地步,我们普通人来作仲裁难免会因我们常人的判断有失偏颇。
|
||||
|
||||
谨记这一条于心,我决定整理这一年里六个我最喜爱的 Git 特性涵盖的改进,来做一次分类回顾 。这篇文章作为一篇中篇推文有点太过长了,所以我不介意你们直接跳到你们特别感兴趣的特性去。
|
||||
谨记这一条于心,我决定整理这一年里六个我最喜爱的 Git 特性涵盖的改进,来做一次分类回顾。这篇文章作为一篇中篇推文有点太过长了,所以我不介意你们直接跳到你们特别感兴趣的特性去。
|
||||
|
||||
* [完成][41]`[git worktree][25]`[命令][42]
|
||||
* [更多方便的][43]`[git rebase][26]`[选项][44]
|
||||
* `[git lfs][27]`[梦幻的性能加速][45]
|
||||
* `[git diff][28]`[实验性的算法和更好的默认结果][46]
|
||||
* `[git submodules][29]`[差强人意][47]
|
||||
* `[git stash][30]`的[90 个增强][48]
|
||||
* [完成][41] [`git worktree`][25] [命令][42]
|
||||
* [更多方便的][43] [`git rebase`][26] [选项][44]
|
||||
* [`git lfs`][27] [梦幻的性能加速][45]
|
||||
* [`git diff`][28] [实验性的算法和更好的默认结果][46]
|
||||
* [`git submodules`][29] [差强人意][47]
|
||||
* [`git stash`][30] 的[90 个增强][48]
|
||||
|
||||
在我们开始之前,请注意在大多数操作系统上都自带有 Git 的旧版本,所以你需要检查你是否在使用最新并且最棒的版本。如果在终端运行 `git --version` 返回的结果小于 Git `v2.11.0`,请立刻跳转到 Atlassian 的快速指南 [更新或安装 Git][63] 并根据你的平台做出选择。
|
||||
|
||||
###[所需的“引用”]
|
||||
|
||||
在我们进入高质量内容之前还需要做一个短暂的停顿:我觉得我需要为你展示我是如何从公开文档生成统计信息(以及开篇的封面图片)的。你也可以使用下面的命令来对你自己的仓库做一个快速的 *年度回顾*!
|
||||
|
||||
###[`引用` 是需要的]
|
||||
|
||||
在我们进入高质量内容之前还需要做一个短暂的停顿:我觉得我需要为你展示我是如何从公开文档(以及开篇的封面图片)生成统计信息的。你也可以使用下面的命令来对你自己的仓库做一个快速的 *年度回顾*!
|
||||
|
||||
```
|
||||
¹ Tags from 2016 matching the form vX.Y.0
|
||||
```
|
||||
>¹ Tags from 2016 matching the form vX.Y.0
|
||||
|
||||
```
|
||||
$ git for-each-ref --sort=-taggerdate --format \
|
||||
'%(refname) %(taggerdate)' refs/tags | grep "v\d\.\d*\.0 .* 2016"
|
||||
```
|
||||
|
||||
```
|
||||
² Tags from 2016 matching the form vX.Y.Z
|
||||
```
|
||||
> ² Tags from 2016 matching the form vX.Y.Z
|
||||
|
||||
```
|
||||
$ git for-each-ref --sort=-taggerdate --format '%(refname) %(taggerdate)' refs/tags | grep "v\d\.\d*\.[^0] .* 2016"
|
||||
```
|
||||
|
||||
```
|
||||
³ Commits by author in 2016
|
||||
```
|
||||
> ³ Commits by author in 2016
|
||||
|
||||
```
|
||||
$ git shortlog -s -n --since=2016-01-01 --until=2017-01-01
|
||||
```
|
||||
|
||||
```
|
||||
⁴ Count commits in 2016
|
||||
```
|
||||
> ⁴ Count commits in 2016
|
||||
|
||||
```
|
||||
$ git log --oneline --since=2016-01-01 --until=2017-01-01 | wc -l
|
||||
```
|
||||
|
||||
```
|
||||
⁵ ... and in 2015
|
||||
```
|
||||
> ⁵ ... and in 2015
|
||||
|
||||
```
|
||||
$ git log --oneline --since=2015-01-01 --until=2016-01-01 | wc -l
|
||||
```
|
||||
|
||||
```
|
||||
⁶ Net LOC added/removed in 2016
|
||||
```
|
||||
> ⁶ Net LOC added/removed in 2016
|
||||
|
||||
```
|
||||
$ git diff --shortstat `git rev-list -1 --until=2016-01-01 master` \
|
||||
@ -79,39 +64,36 @@ $ git diff --shortstat `git rev-list -1 --until=2016-01-01 master` \
|
||||
|
||||
现在,让我们开始说好的回顾……
|
||||
|
||||
### 完成 Git worktress
|
||||
`git worktree` 命令首次出现于 Git v2.5 但是在 2016 年有了一些显著的增强。两个有价值的新特性在 v2.7 被引入—— `list` 子命令,和为二分搜索增加了命令空间的 refs——而 `lock`/`unlock` 子命令则是在 v2.10被引入。
|
||||
### 完成 Git 工作树(worktree)
|
||||
|
||||
`git worktree` 命令首次出现于 Git v2.5 ,但是在 2016 年有了一些显著的增强。两个有价值的新特性在 v2.7 被引入:`list` 子命令,和为二分搜索增加了命令空间的 refs。而 `lock`/`unlock` 子命令则是在 v2.10 被引入。
|
||||
|
||||
#### 什么是工作树呢?
|
||||
|
||||
[`git worktree`][49] 命令允许你同步地检出和操作处于不同路径下的同一仓库的多个分支。例如,假如你需要做一次快速的修复工作但又不想扰乱你当前的工作区,你可以使用以下命令在一个新路径下检出一个新分支:
|
||||
|
||||
#### 什么是 worktree 呢?
|
||||
`[git worktree][49]` 命令允许你同步地检出和操作处于不同路径下的同一仓库的多个分支。例如,假如你需要做一次快速的修复工作但又不想扰乱你当前的工作区,你可以使用以下命令在一个新路径下检出一个新分支
|
||||
```
|
||||
$ git worktree add -b hotfix/BB-1234 ../hotfix/BB-1234
|
||||
Preparing ../hotfix/BB-1234 (identifier BB-1234)
|
||||
HEAD is now at 886e0ba Merged in bedwards/BB-13430-api-merge-pr (pull request #7822)
|
||||
```
|
||||
|
||||
Worktree 不仅仅是为分支工作。你可以检出多个里程碑(tags)作为不同的工作树来并行构建或测试它们。例如,我从 Git v2.6 和 v2.7 的里程碑中创建工作树来检验不同版本 Git 的行为特征。
|
||||
工作树不仅仅是为分支工作。你可以检出多个里程碑(tags)作为不同的工作树来并行构建或测试它们。例如,我从 Git v2.6 和 v2.7 的里程碑中创建工作树来检验不同版本 Git 的行为特征。
|
||||
|
||||
```
|
||||
$ git worktree add ../git-v2.6.0 v2.6.0
|
||||
Preparing ../git-v2.6.0 (identifier git-v2.6.0)
|
||||
HEAD is now at be08dee Git 2.6
|
||||
```
|
||||
|
||||
```
|
||||
$ git worktree add ../git-v2.7.0 v2.7.0
|
||||
Preparing ../git-v2.7.0 (identifier git-v2.7.0)
|
||||
HEAD is now at 7548842 Git 2.7
|
||||
```
|
||||
|
||||
```
|
||||
$ git worktree list
|
||||
/Users/kannonboy/src/git 7548842 [master]
|
||||
/Users/kannonboy/src/git-v2.6.0 be08dee (detached HEAD)
|
||||
/Users/kannonboy/src/git-v2.7.0 7548842 (detached HEAD)
|
||||
```
|
||||
|
||||
```
|
||||
$ cd ../git-v2.7.0 && make
|
||||
```
|
||||
|
||||
@ -119,7 +101,7 @@ $ cd ../git-v2.7.0 && make
|
||||
|
||||
#### 列出工作树
|
||||
|
||||
`git worktree list` 子命令(于 Git v2.7引入)显示所有与当前仓库有关的工作树。
|
||||
`git worktree list` 子命令(于 Git v2.7 引入)显示所有与当前仓库有关的工作树。
|
||||
|
||||
```
|
||||
$ git worktree list
|
||||
@ -130,43 +112,41 @@ $ git worktree list
|
||||
|
||||
#### 二分查找工作树
|
||||
|
||||
`[gitbisect][50]` 是一个简洁的 Git 命令,可以让我们对提交记录执行一次二分搜索。通常用来找到哪一次提交引入了一个指定的退化。例如,如果在我的 `master` 分支最后的提交上有一个测试没有通过,我可以使用 `git bisect` 来贯穿仓库的历史来找寻第一次造成这个错误的提交。
|
||||
[`gitbisect`][50] 是一个简洁的 Git 命令,可以让我们对提交记录执行一次二分搜索。通常用来找到哪一次提交引入了一个指定的退化。例如,如果在我的 `master` 分支最后的提交上有一个测试没有通过,我可以使用 `git bisect` 来贯穿仓库的历史来找寻第一次造成这个错误的提交。
|
||||
|
||||
```
|
||||
$ git bisect start
|
||||
```
|
||||
|
||||
```
|
||||
# indicate the last commit known to be passing the tests
|
||||
# (e.g. the latest release tag)
|
||||
# 找到已知通过测试的最后提交
|
||||
# (例如最新的发布里程碑)
|
||||
$ git bisect good v2.0.0
|
||||
```
|
||||
|
||||
```
|
||||
# indicate a known broken commit (e.g. the tip of master)
|
||||
# 找到已知的出问题的提交
|
||||
# (例如在 `master` 上的提示)
|
||||
$ git bisect bad master
|
||||
```
|
||||
|
||||
```
|
||||
# tell git bisect a script/command to run; git bisect will
|
||||
# find the oldest commit between "good" and "bad" that causes
|
||||
# this script to exit with a non-zero status
|
||||
# 告诉 git bisect 要运行的脚本/命令;
|
||||
# git bisect 会在 “good” 和 “bad”范围内
|
||||
# 找到导致脚本以非 0 状态退出的最旧的提交
|
||||
$ git bisect run npm test
|
||||
```
|
||||
|
||||
在后台,bisect 使用 refs 来跟踪 好 与 坏 的提交来作为二分搜索范围的上下界限。不幸的是,对工作树的粉丝来说,这些 refs 都存储在寻常的 `.git/refs/bisect` 命名空间,意味着 `git bisect` 操作如果运行在不同的工作树下可能会互相干扰。
|
||||
在后台,bisect 使用 refs 来跟踪 “good” 与 “bad” 的提交来作为二分搜索范围的上下界限。不幸的是,对工作树的粉丝来说,这些 refs 都存储在寻常的 `.git/refs/bisect` 命名空间,意味着 `git bisect` 操作如果运行在不同的工作树下可能会互相干扰。
|
||||
|
||||
到了 v2.7 版本,bisect 的 refs 移到了 `.git/worktrees/$worktree_name/refs/bisect`, 所以你可以并行运行 bisect 操作于多个工作树中。
|
||||
|
||||
#### 锁定工作树
|
||||
|
||||
当你完成了一颗工作树的工作,你可以直接删除它,然后通过运行 `git worktree prune` 等它被当做垃圾自动回收。但是,如果你在网络共享或者可移除媒介上存储了一颗工作树,如果工作树目录在删除期间不可访问,工作树会被完全清除——不管你喜不喜欢!Git v2.10 引入了 `git worktree lock` 和 `unlock` 子命令来防止这种情况发生。
|
||||
|
||||
```
|
||||
# to lock the git-v2.7 worktree on my USB drive
|
||||
# 在我的 USB 盘上锁定 git-v2.7 工作树
|
||||
$ git worktree lock /Volumes/Flash_Gordon/git-v2.7 --reason \
|
||||
"In case I remove my removable media"
|
||||
```
|
||||
|
||||
```
|
||||
# to unlock (and delete) the worktree when I'm finished with it
|
||||
# 当我完成时,解锁(并删除)该工作树
|
||||
$ git worktree unlock /Volumes/Flash_Gordon/git-v2.7
|
||||
$ rm -rf /Volumes/Flash_Gordon/git-v2.7
|
||||
$ git worktree prune
|
||||
@ -175,32 +155,33 @@ $ git worktree prune
|
||||
`--reason` 标签允许为未来的你留一个记号,描述为什么当初工作树被锁定。`git worktree unlock` 和 `lock` 都要求你指定工作树的路径。或者,你可以 `cd` 到工作树目录然后运行 `git worktree lock .` 来达到同样的效果。
|
||||
|
||||
|
||||
### 更多 Git 变基(rebase)选项
|
||||
|
||||
### 更多 Git `reabse` 选项
|
||||
2016 年三月,Git v2.8 增加了在拉取过程中交互进行 rebase 的命令 `git pull --rebase=interactive` 。对应地,六月份 Git v2.9 发布了通过 `git rebase -x` 命令对执行变基操作而不需要进入交互模式的支持。
|
||||
2016 年三月,Git v2.8 增加了在拉取过程中交互进行变基的命令 `git pull --rebase=interactive` 。对应地,六月份 Git v2.9 发布了通过 `git rebase -x` 命令对执行变基操作而不需要进入交互模式的支持。
|
||||
|
||||
#### Re-啥?
|
||||
|
||||
在我们继续深入前,我假设读者中有些并不是很熟悉或者没有完全习惯变基命令或者交互式变基。从概念上说,它很简单,但是与很多 Git 的强大特性一样,变基散发着听起来很复杂的专业术语的气息。所以,在我们深入前,先来快速的复习一下什么是 rebase。
|
||||
在我们继续深入前,我假设读者中有些并不是很熟悉或者没有完全习惯变基命令或者交互式变基。从概念上说,它很简单,但是与很多 Git 的强大特性一样,变基散发着听起来很复杂的专业术语的气息。所以,在我们深入前,先来快速的复习一下什么是变基(rebase)。
|
||||
|
||||
变基操作意味着将一个或多个提交在一个指定分支上重写。`git rebase` 命令是被深度重载了,但是 rebase 名字的来源事实上还是它经常被用来改变一个分支的基准提交(你基于此提交创建了这个分支)。
|
||||
变基操作意味着将一个或多个提交在一个指定分支上重写。`git rebase` 命令是被深度重载了,但是 rebase 这个名字的来源事实上还是它经常被用来改变一个分支的基准提交(你基于此提交创建了这个分支)。
|
||||
|
||||
从概念上说,rebase 通过将你的分支上的提交存储为一系列补丁包临时释放了它们,接着将这些补丁包按顺序依次打在目标提交之上。
|
||||
从概念上说,rebase 通过将你的分支上的提交临时存储为一系列补丁包,接着将这些补丁包按顺序依次打在目标提交之上。
|
||||
|
||||
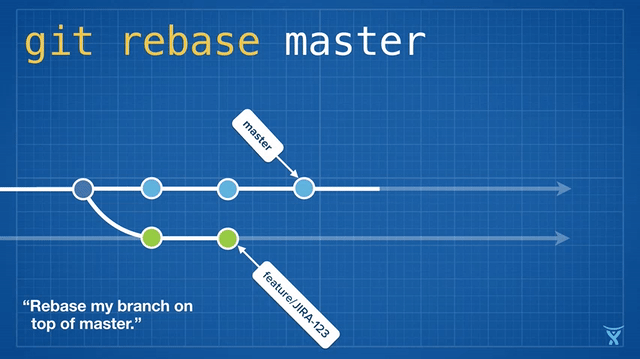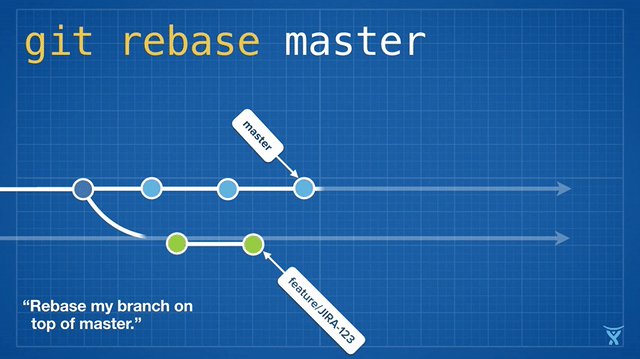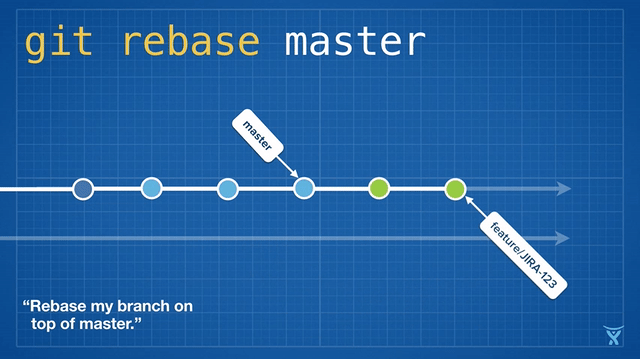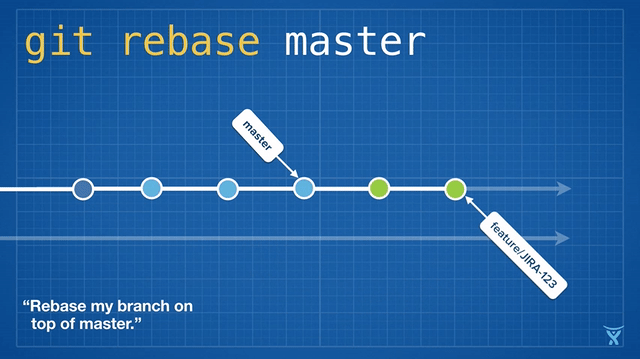
|
||||

|
||||
|
||||
对 master 分支的一个功能分支执行变基操作 (`git reabse master`)是一种通过将 master 分支上最新的改变合并到功能分支的“保鲜法”。对于长期存在的功能分支,规律的变基操作能够最大程度的减少开发过程中出现冲突的可能性和严重性。
|
||||
|
||||
有些团队会选择在合并他们的改动到 master 前立即执行变基操作以实现一次快速合并 (`git merge --ff <feature>`)。对 master 分支快速合并你的提交是通过简单的将 master ref 指向你的重写分支的顶点而不需要创建一个合并提交。
|
||||
|
||||

|
||||

|
||||
|
||||
变基是如此方便和功能强大以致于它已经被嵌入其他常见的 Git 命令中,例如 `git pull`。如果你在本地 master 分支有未推送的提交,运行 `git pull` 命令从 origin 拉取你队友的改动会造成不必要的合并提交。
|
||||
变基是如此方便和功能强大以致于它已经被嵌入其他常见的 Git 命令中,例如拉取操作 `git pull` 。如果你在本地 master 分支有未推送的提交,运行 `git pull` 命令从 origin 拉取你队友的改动会造成不必要的合并提交。
|
||||
|
||||
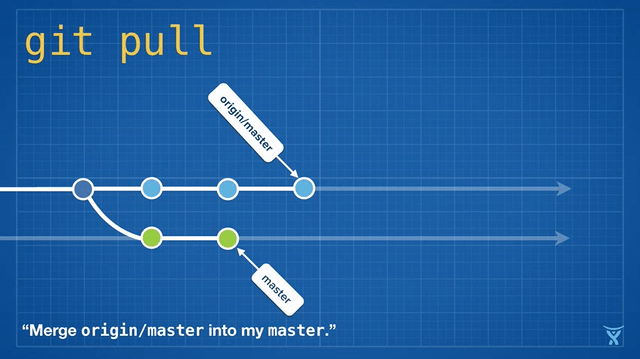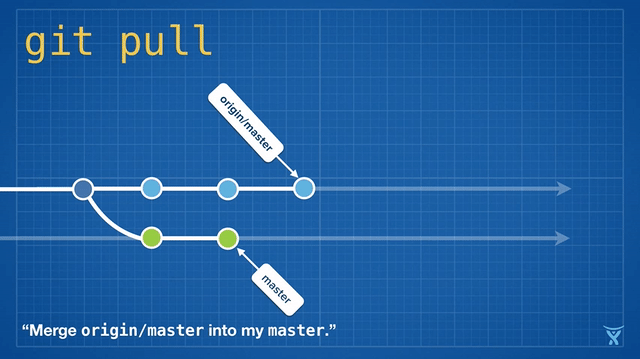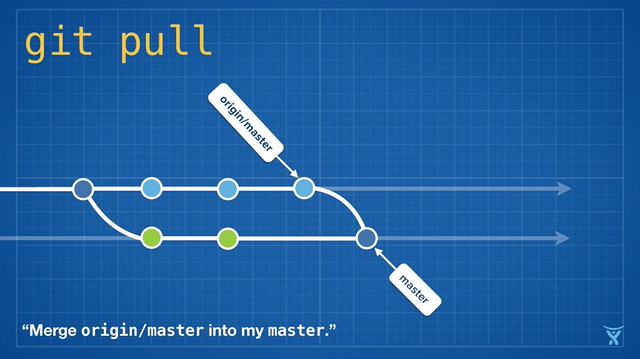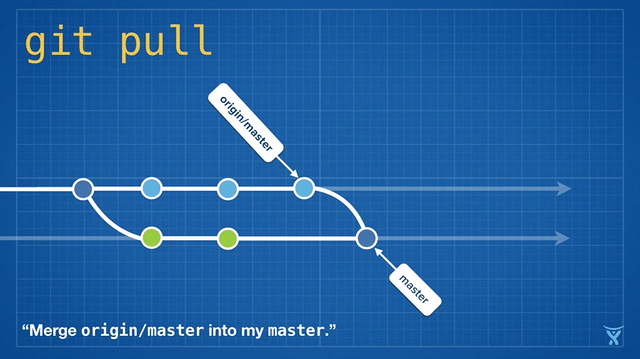
|
||||

|
||||
|
||||
这有点混乱,而且在繁忙的团队,你会获得成堆的不必要的合并提交。`git pull --rebase` 将你本地的提交在你队友的提交上执行变基而不产生一个合并提交。
|
||||
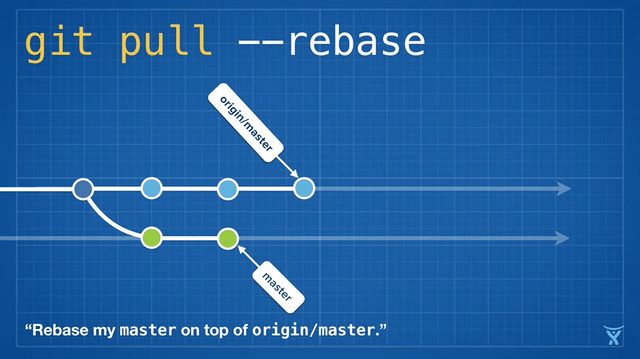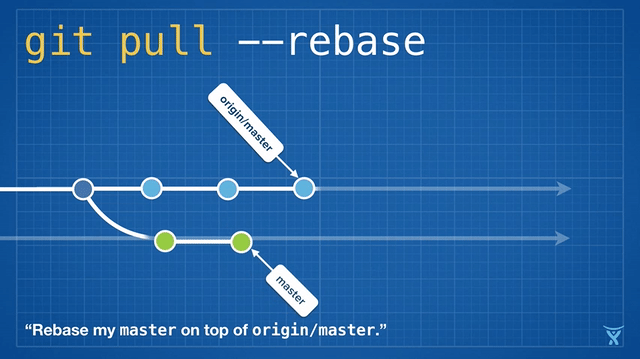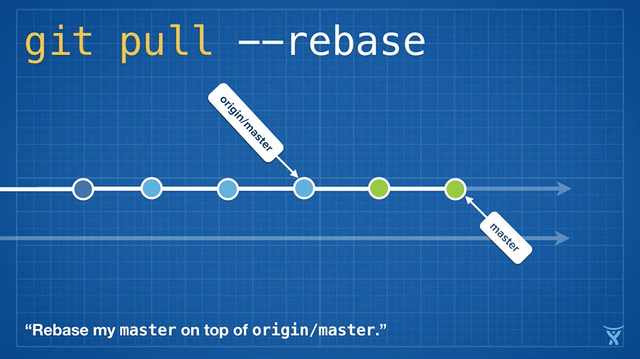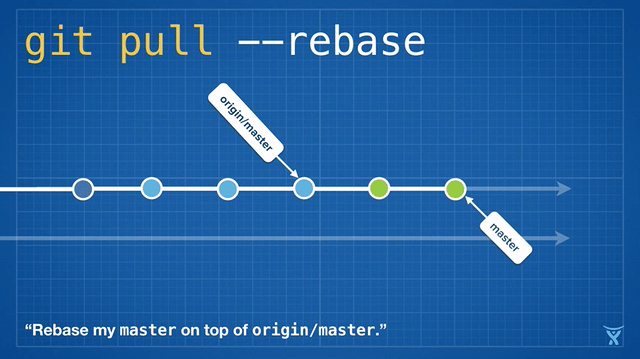
|
||||
|
||||

|
||||
|
||||
这很整洁吧!甚至更酷,Git v2.8 引入了一个新特性,允许你在拉取时 _交互地_ 变基。
|
||||
|
||||
@ -209,18 +190,15 @@ $ git worktree prune
|
||||
交互式变基是变基操作的一种更强大的形态。和标准变基操作相似,它可以重写提交,但它也可以向你提供一个机会让你能够交互式地修改这些将被重新运用在新基准上的提交。
|
||||
|
||||
当你运行 `git rebase --interactive` (或 `git pull --rebase=interactive`)时,你会在你的文本编辑器中得到一个可供选择的提交列表视图。
|
||||
```
|
||||
$ git rebase master --interactive
|
||||
```
|
||||
|
||||
```
|
||||
$ git rebase master --interactive
|
||||
|
||||
pick 2fde787 ACE-1294: replaced miniamalCommit with string in test
|
||||
pick ed93626 ACE-1294: removed pull request service from test
|
||||
pick b02eb9a ACE-1294: moved fromHash, toHash and diffType to batch
|
||||
pick e68f710 ACE-1294: added testing data to batch email file
|
||||
```
|
||||
|
||||
```
|
||||
# Rebase f32fa9d..0ddde5f onto f32fa9d (4 commands)
|
||||
#
|
||||
# Commands:
|
||||
@ -238,27 +216,30 @@ pick e68f710 ACE-1294: added testing data to batch email file
|
||||
# If you remove a line here THAT COMMIT WILL BE LOST.
|
||||
```
|
||||
|
||||
注意到每一条提交旁都有一个 `pick`。这是对 rebase 而言,"照原样留下这个提交"。如果你现在就退出文本编辑器,它会执行一次如上文所述的普通变基操作。但是,如果你将 `pick` 改为 `edit` 或者其他 rebase 命令中的一个,变基操作会允许你在它被重新运用前改变它。有效的变基命令有如下几种:
|
||||
* `reword`: 编辑提交信息。
|
||||
* `edit`: 编辑提交了的文件。
|
||||
* `squash`: 将提交与之前的提交(同在文件中)合并,并将提交信息拼接。
|
||||
* `fixup`: 将本提交与上一条提交合并,并且逐字使用上一条提交的提交信息(这很方便,如果你为一个很小的改动创建了第二个提交,而它本身就应该属于上一条提交,例如,你忘记暂存了一个文件)。
|
||||
* `exec`: 运行一条任意的 shell 命令(我们将会在下一节看到本例一次简洁的使用场景)。
|
||||
注意到每一条提交旁都有一个 `pick`。这是对 rebase 而言,“照原样留下这个提交”。如果你现在就退出文本编辑器,它会执行一次如上文所述的普通变基操作。但是,如果你将 `pick` 改为 `edit` 或者其他 rebase 命令中的一个,变基操作会允许你在它被重新运用前改变它。有效的变基命令有如下几种:
|
||||
|
||||
* `reword`:编辑提交信息。
|
||||
* `edit`:编辑提交了的文件。
|
||||
* `squash`:将提交与之前的提交(同在文件中)合并,并将提交信息拼接。
|
||||
* `fixup`:将本提交与上一条提交合并,并且逐字使用上一条提交的提交信息(这很方便,如果你为一个很小的改动创建了第二个提交,而它本身就应该属于上一条提交,例如,你忘记暂存了一个文件)。
|
||||
* `exec`: 运行一条任意的 shell 命令(我们将会在下一节看到本例一次简洁的使用场景)。
|
||||
* `drop`: 这将丢弃这条提交。
|
||||
|
||||
你也可以在文件内重新整理提交,这样会改变他们被重新运用的顺序。这会很顺手当你对不同的主题创建了交错的提交时,你可以使用 `squash` 或者 `fixup` 来将其合并成符合逻辑的原子提交。
|
||||
你也可以在文件内重新整理提交,这样会改变它们被重新应用的顺序。当你对不同的主题创建了交错的提交时这会很顺手,你可以使用 `squash` 或者 `fixup` 来将其合并成符合逻辑的原子提交。
|
||||
|
||||
当你设置完命令并且保存这个文件后,Git 将递归每一条提交,在每个 `reword` 和 `edit` 命令处为你暂停来执行你设计好的改变并且自动运行 `squash`, `fixup`,`exec` 和 `drop`命令。
|
||||
当你设置完命令并且保存这个文件后,Git 将递归每一条提交,在每个 `reword` 和 `edit` 命令处为你暂停来执行你设计好的改变,并且自动运行 `squash`, `fixup`,`exec` 和 `drop` 命令。
|
||||
|
||||
####非交互性式执行
|
||||
|
||||
当你执行变基操作时,本质上你是在通过将你每一条新提交应用于指定基址的头部来重写历史。`git pull --rebase` 可能会有一点危险,因为根据上游分支改动的事实,你的新建历史可能会由于特定的提交遭遇测试失败甚至编译问题。如果这些改动引起了合并冲突,变基过程将会暂停并且允许你来解决它们。但是,整洁的合并改动仍然有可能打断编译或测试过程,留下破败的提交弄乱你的提交历史。
|
||||
|
||||
但是,你可以指导 Git 为每一个重写的提交来运行你的项目测试套件。在 Git v2.9 之前,你可以通过绑定 `git rebase --interactive` 和 `exec` 命令来实现。例如这样:
|
||||
|
||||
```
|
||||
$ git rebase master −−interactive −−exec=”npm test”
|
||||
```
|
||||
|
||||
...会生成在重写每条提交后执行 `npm test` 这样的一个交互式变基计划,保证你的测试仍然会通过:
|
||||
……这会生成一个交互式变基计划,在重写每条提交后执行 `npm test` ,保证你的测试仍然会通过:
|
||||
|
||||
```
|
||||
pick 2fde787 ACE-1294: replaced miniamalCommit with string in test
|
||||
@ -269,20 +250,17 @@ pick b02eb9a ACE-1294: moved fromHash, toHash and diffType to batch
|
||||
exec npm test
|
||||
pick e68f710 ACE-1294: added testing data to batch email file
|
||||
exec npm test
|
||||
```
|
||||
|
||||
```
|
||||
# Rebase f32fa9d..0ddde5f onto f32fa9d (4 command(s))
|
||||
```
|
||||
|
||||
如果出现了测试失败的情况,变基会暂停并让你修复这些测试(并且将你的修改应用于相应提交):
|
||||
|
||||
```
|
||||
291 passing
|
||||
1 failing
|
||||
```
|
||||
|
||||
```
|
||||
1) Host request “after all” hook:
|
||||
1) Host request "after all" hook:
|
||||
Uncaught Error: connect ECONNRESET 127.0.0.1:3001
|
||||
…
|
||||
npm ERR! Test failed.
|
||||
@ -292,91 +270,96 @@ You can fix the problem, and then run
|
||||
```
|
||||
|
||||
这很方便,但是使用交互式变基有一点臃肿。到了 Git v2.9,你可以这样来实现非交互式变基:
|
||||
|
||||
```
|
||||
$ git rebase master -x “npm test”
|
||||
$ git rebase master -x "npm test"
|
||||
```
|
||||
|
||||
简单替换 `npm test` 为 `make`,`rake`,`mvn clean install`,或者任何你用来构建或测试你的项目的命令。
|
||||
可以简单替换 `npm test` 为 `make`,`rake`,`mvn clean install`,或者任何你用来构建或测试你的项目的命令。
|
||||
|
||||
#### 小小警告
|
||||
|
||||
####小小警告
|
||||
就像电影里一样,重写历史可是一个危险的行当。任何提交被重写为变基操作的一部分都将改变它的 SHA-1 ID,这意味着 Git 会把它当作一个全新的提交对待。如果重写的历史和原来的历史混杂,你将获得重复的提交,而这可能在你的团队中引起不少的疑惑。
|
||||
|
||||
为了避免这个问题,你仅仅需要遵照一条简单的规则:
|
||||
|
||||
> _永远不要变基一条你已经推送的提交!_
|
||||
|
||||
坚持这一点你会没事的。
|
||||
|
||||
### Git LFS 的性能提升
|
||||
|
||||
[Git 是一个分布式版本控制系统][64],意味着整个仓库的历史会在克隆阶段被传送到客户端。对包含大文件的项目——尤其是大文件经常被修改——初始克隆会非常耗时,因为每一个版本的每一个文件都必须下载到客户端。[Git LFS(Large File Storage 大文件存储)][65] 是一个 Git 拓展包,由 Atlassian、GitHub 和其他一些开源贡献者开发,通过需要时才下载大文件的相对版本来减少仓库中大文件的影响。更明确地说,大文件是在检出过程中按需下载的而不是在克隆或抓取过程中。
|
||||
|
||||
### `Git LFS` 的性能提升
|
||||
[Git 是一个分布式版本控制系统][64],意味着整个仓库的历史会在克隆阶段被传送到客户端。对包含大文件的项目——尤其是大文件经常被修改——初始克隆会非常耗时,因为每一个版本的每一个文件都必须下载到客户端。[Git LFS(Large File Storage 大文件存储)][65] 是一个 Git 拓展包,由 Atlassian,GitHub 和其他一些开源贡献者开发,通过消极地下载大文件的相对版本来减少仓库中大文件的影响。更明确地说,大文件是在检出过程中按需下载的而不是在克隆或抓取过程中。
|
||||
|
||||
在 Git 2016 年的五大发布中,Git LFS 自身有四个功能丰富的发布:v1.2 到 v1.5。你可以凭 Git LFS 自身来写一系列回顾文章,但是就这篇文章而言,我将专注于 2016 年解决的一项最重要的主题:速度。一系列针对 Git 和 Git LFS 的改进极大程度地优化了将文件传入/传出服务器的性能。
|
||||
在 Git 2016 年的五大发布中,Git LFS 自身就有四个功能版本的发布:v1.2 到 v1.5。你可以仅对 Git LFS 这一项来写一系列回顾文章,但是就这篇文章而言,我将专注于 2016 年解决的一项最重要的主题:速度。一系列针对 Git 和 Git LFS 的改进极大程度地优化了将文件传入/传出服务器的性能。
|
||||
|
||||
#### 长期过滤进程
|
||||
|
||||
当你 `git add` 一个文件时,Git 的净化过滤系统会被用来在文件被写入 Git 目标存储前转化文件的内容。Git LFS 通过使用净化过滤器将大文件内容存储到 LFS 缓存中以缩减仓库的大小,并且增加一个小“指针”文件到 Git 目标存储中作为替代。
|
||||
当你 `git add` 一个文件时,Git 的净化过滤系统会被用来在文件被写入 Git 目标存储之前转化文件的内容。Git LFS 通过使用净化过滤器(clean filter)将大文件内容存储到 LFS 缓存中以缩减仓库的大小,并且增加一个小“指针”文件到 Git 目标存储中作为替代。
|
||||
|
||||
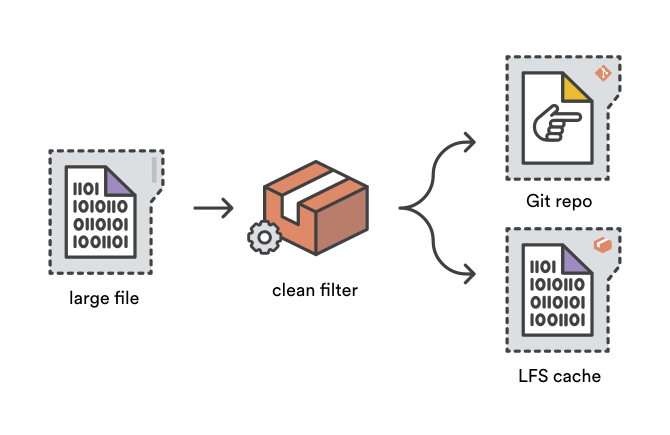
|
||||
|
||||

|
||||
|
||||
污化过滤器是净化过滤器的对立面——正如其名。在 `git checkout` 过程中从一个 Git 目标仓库读取文件内容时,污化过滤系统有机会在文件被写入用户的工作区前将其改写。Git LFS 污化过滤器通过将指针文件替代为对应的大文件将其转化,可以是从 LFS 缓存中获得或者通过读取存储在 Bitbucket 的 Git LFS。
|
||||
污化过滤器(smudge filter)是净化过滤器的对立面——正如其名。在 `git checkout` 过程中从一个 Git 目标仓库读取文件内容时,污化过滤系统有机会在文件被写入用户的工作区前将其改写。Git LFS 污化过滤器通过将指针文件替代为对应的大文件将其转化,可以是从 LFS 缓存中获得或者通过读取存储在 Bitbucket 的 Git LFS。
|
||||
|
||||
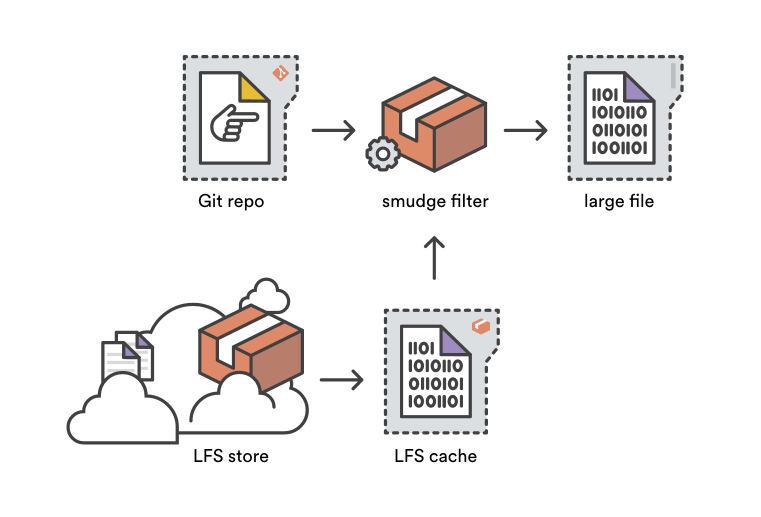
|
||||
|
||||
传统上,污化和净化过滤进程在每个文件被增加和检出时只能被唤起一次。所以,一个项目如果有 1000 个文件在被 Git LFS 追踪 ,做一次全新的检出需要唤起 `git-lfs-smudge` 命令 1000 次。尽管单次操作相对很迅速,但是经常执行 1000 次独立的污化进程总耗费惊人。、
|
||||
|
||||
针对 Git v2.11(和 Git LFS v1.5),污化和净化过滤器可以被定义为长期进程,为第一个需要过滤的文件调用一次,然后为之后的文件持续提供污化或净化过滤直到父 Git 操作结束。[Lars Schneider][66],Git 的长期过滤系统的贡献者,简洁地总结了对 Git LFS 性能改变带来的影响。
|
||||
> 使用 12k 个文件的测试仓库的过滤进程在 macOS 上快了80 倍,在 Windows 上 快了 58 倍。在 Windows 上,这意味着测试运行了 57 秒而不是 55 分钟。
|
||||
> 这真是一个让人印象深刻的性能增强!
|
||||
针对 Git v2.11(和 Git LFS v1.5),污化和净化过滤器可以被定义为长期进程,为第一个需要过滤的文件调用一次,然后为之后的文件持续提供污化或净化过滤直到父 Git 操作结束。[Lars Schneider][66],Git 的长期过滤系统的贡献者,简洁地总结了对 Git LFS 性能改变带来的影响。
|
||||
|
||||
> 使用 12k 个文件的测试仓库的过滤进程在 macOS 上快了 80 倍,在 Windows 上 快了 58 倍。在 Windows 上,这意味着测试运行了 57 秒而不是 55 分钟。
|
||||
|
||||
这真是一个让人印象深刻的性能增强!
|
||||
|
||||
#### LFS 专有克隆
|
||||
|
||||
长期运行的污化和净化过滤器在对向本地缓存读写的加速做了很多贡献,但是对大目标传入/传出 Git LFS 服务器的速度提升贡献很少。 每次 Git LFS 污化过滤器在本地 LFS 缓存中无法找到一个文件时,它不得不使用两个 HTTP 请求来获得该文件:一个用来定位文件,另外一个用来下载它。在一次 `git clone` 过程中,你的本地 LFS 缓存是空的,所以 Git LFS 会天真地为你的仓库中每个 LFS 所追踪的文件创建两个 HTTP 请求:
|
||||
长期运行的污化和净化过滤器在对向本地缓存读写的加速做了很多贡献,但是对大目标传入/传出 Git LFS 服务器的速度提升贡献很少。 每次 Git LFS 污化过滤器在本地 LFS 缓存中无法找到一个文件时,它不得不使用两次 HTTP 请求来获得该文件:一个用来定位文件,另外一个用来下载它。在一次 `git clone` 过程中,你的本地 LFS 缓存是空的,所以 Git LFS 会天真地为你的仓库中每个 LFS 所追踪的文件创建两个 HTTP 请求:
|
||||
|
||||
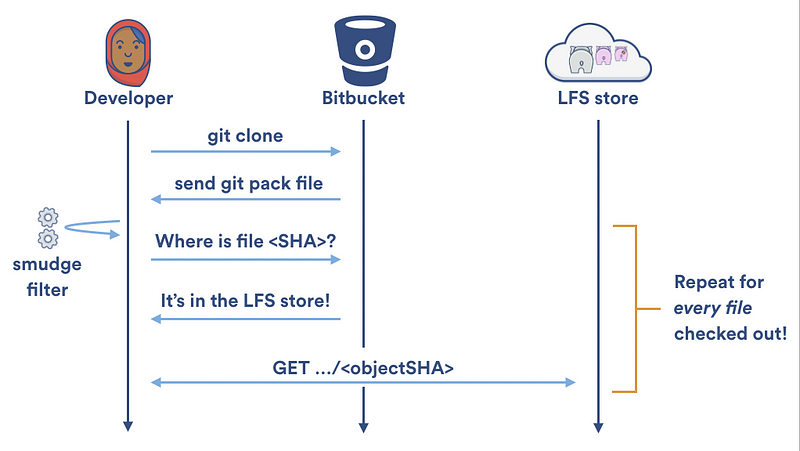
|
||||

|
||||
|
||||
幸运的是,Git LFS v1.2 提供了专门的 `[git lfs clone][51]` 命令。不再是一次下载一个文件; `git lfs clone` 禁止 Git LFS 污化过滤器,等待检出结束,然后从 Git LFS 存储中按批下载任何需要的文件。这允许了并行下载并且将需要的 HTTP 请求数量减半。
|
||||
幸运的是,Git LFS v1.2 提供了专门的 [`git lfs clone`][51] 命令。不再是一次下载一个文件; `git lfs clone` 禁止 Git LFS 污化过滤器,等待检出结束,然后从 Git LFS 存储中按批下载任何需要的文件。这允许了并行下载并且将需要的 HTTP 请求数量减半。
|
||||
|
||||
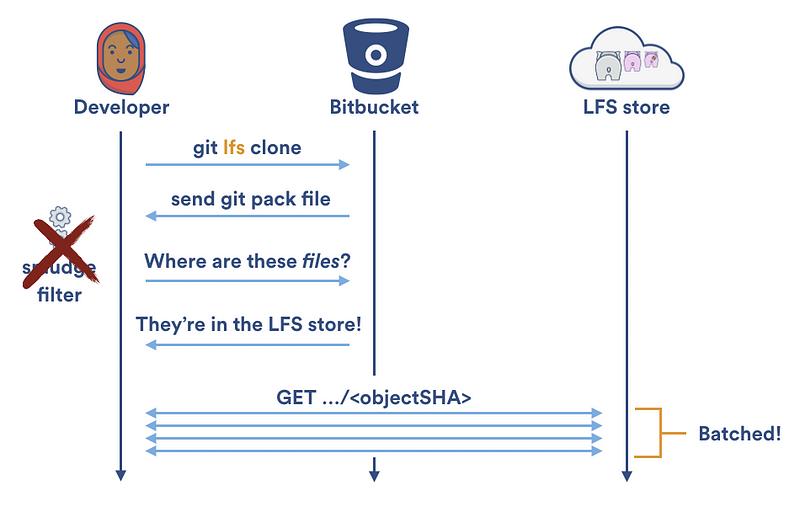
|
||||

|
||||
|
||||
###自定义传输路由器
|
||||
### 自定义传输路由器(Transfer Adapter)
|
||||
|
||||
正如之前讨论过的,Git LFS 在 v1.5 中 发起了对长期过滤进程的支持。不过,对另外一种可插入进程的支持早在今年年初就发布了。 Git LFS 1.3 包含了对可插拔传输路由器的支持,因此不同的 Git LFS 托管服务可以定义属于它们自己的协议来向或从 LFS 存储中传输文件。
|
||||
正如之前讨论过的,Git LFS 在 v1.5 中提供对长期过滤进程的支持。不过,对另外一种类型的可插入进程的支持早在今年年初就发布了。 Git LFS 1.3 包含了对可插拔传输路由器(pluggable transfer adapter)的支持,因此不同的 Git LFS 托管服务可以定义属于它们自己的协议来向或从 LFS 存储中传输文件。
|
||||
|
||||
直到 2016 年底,Bitbucket 是唯一一个执行专属 Git LFS 传输协议 [Bitbucket LFS Media Adapter][67] 的托管服务商。这是为了从 Bitbucket 的一个独特的被称为 chunking 的 LFS 存储 API 特性中获利。Chunking 意味着在上传或下载过程中,大文件被分解成 4MB 的文件块(chunk)。
|
||||

|
||||
直到 2016 年底,Bitbucket 是唯一一个执行专属 Git LFS 传输协议 [Bitbucket LFS Media Adapter][67] 的托管服务商。这是为了从 Bitbucket 的一个被称为 chunking 的 LFS 存储 API 独特特性中获益。Chunking 意味着在上传或下载过程中,大文件被分解成 4MB 的文件块(chunk)。
|
||||
|
||||

|
||||
|
||||
分块给予了 Bitbucket 支持的 Git LFS 三大优势:
|
||||
1. 并行下载与上传。默认地,Git LFS 最多并行传输三个文件。但是,如果只有一个文件被单独传输(这也是 Git LFS 污化过滤器的默认行为),它会在一个单独的流中被传输。Bitbucket 的分块允许同一文件的多个文件块同时被上传或下载,经常能够梦幻地提升传输速度。
|
||||
2. 可恢复文件块传输。文件块都在本地缓存,所以如果你的下载或上传被打断,Bitbucket 的自定义 LFS 流媒体路由器会在下一次你推送或拉取时仅为丢失的文件块恢复传输。
|
||||
3. 免重复。Git LFS,正如 Git 本身,是内容索位;每一个 LFS 文件都由它的内容生成的 SHA-256 哈希值认证。所以,哪怕你稍微修改了一位数据,整个文件的 SHA-256 就会修改而你不得不重新上传整个文件。分块允许你仅仅重新上传文件真正被修改的部分。举个例子,想想一下Git LFS 在追踪一个 41M 的电子游戏精灵表。如果我们增加在此精灵表上增加 2MB 的新层并且提交它,传统上我们需要推送整个新的 43M 文件到服务器端。但是,使用 Bitbucket 的自定义传输路由,我们仅仅需要推送 ~7MB:先是 4MB 文件块(因为文件的信息头会改变)和我们刚刚添加的包含新层的 3MB 文件块!其余未改变的文件块在上传过程中被自动跳过,节省了巨大的带宽和时间消耗。
|
||||
|
||||
可自定义的传输路由器是 Git LFS 一个伟大的特性,它们使得不同服务商在不过载核心项目的前提下体验适合其服务器的优化后的传输协议。
|
||||
1. 并行下载与上传。默认地,Git LFS 最多并行传输三个文件。但是,如果只有一个文件被单独传输(这也是 Git LFS 污化过滤器的默认行为),它会在一个单独的流中被传输。Bitbucket 的分块允许同一文件的多个文件块同时被上传或下载,经常能够神奇地提升传输速度。
|
||||
2. 可续传的文件块传输。文件块都在本地缓存,所以如果你的下载或上传被打断,Bitbucket 的自定义 LFS 流媒体路由器会在下一次你推送或拉取时仅为丢失的文件块恢复传输。
|
||||
3. 免重复。Git LFS,正如 Git 本身,是一种可定位的内容;每一个 LFS 文件都由它的内容生成的 SHA-256 哈希值认证。所以,哪怕你稍微修改了一位数据,整个文件的 SHA-256 就会修改而你不得不重新上传整个文件。分块允许你仅仅重新上传文件真正被修改的部分。举个例子,想想一下 Git LFS 在追踪一个 41M 的精灵表格(spritesheet)。如果我们增加在此精灵表格上增加 2MB 的新的部分并且提交它,传统上我们需要推送整个新的 43M 文件到服务器端。但是,使用 Bitbucket 的自定义传输路由,我们仅仅需要推送大约 7MB:先是 4MB 文件块(因为文件的信息头会改变)和我们刚刚添加的包含新的部分的 3MB 文件块!其余未改变的文件块在上传过程中被自动跳过,节省了巨大的带宽和时间消耗。
|
||||
|
||||
### 更佳的 `git diff` 算法与默认值
|
||||
可自定义的传输路由器是 Git LFS 的一个伟大的特性,它们使得不同服务商在不重载核心项目的前提下体验适合其服务器的优化后的传输协议。
|
||||
|
||||
### 更佳的 git diff 算法与默认值
|
||||
|
||||
不像其他的版本控制系统,Git 不会明确地存储文件被重命名了的事实。例如,如果我编辑了一个简单的 Node.js 应用并且将 `index.js` 重命名为 `app.js`,然后运行 `git diff`,我会得到一个看起来像一个文件被删除另一个文件被新建的结果。
|
||||
|
||||

|
||||

|
||||
|
||||
我猜测移动或重命名一个文件从技术上来讲是一次删除后跟一次新建,但这不是对人类最友好的方式来诉说它。其实,你可以使用 `-M` 标志来指示 Git 在计算差异时抽空尝试检测重命名文件。对之前的例子,`git diff -M` 给我们如下结果:
|
||||

|
||||
我猜测移动或重命名一个文件从技术上来讲是一次删除后跟着一次新建,但这不是对人类最友好的描述方式。其实,你可以使用 `-M` 标志来指示 Git 在计算差异时同时尝试检测是否是文件重命名。对之前的例子,`git diff -M` 给我们如下结果:
|
||||
|
||||
第二行显示的 similarity index 告诉我们文件内容经过比较后的相似程度。默认地,`-M` 会考虑任意两个文件都有超过 50% 相似度。这意味着,你需要编辑少于 50% 的行数来确保它们被识别成一个重命名后的文件。你可以通过加上一个百分比来选择你自己的 similarity index,如,`-M80%`。
|
||||

|
||||
|
||||
到 Git v2.9 版本,如果你使用了 `-M` 标志 `git diff` 和 `git log` 命令都会默认检测重命名。如果不喜欢这种行为(或者,更现实的情况,你在通过一个脚本来解析 diff 输出),那么你可以通过显示的传递 `--no-renames` 标志来禁用它。
|
||||
第二行显示的 similarity index 告诉我们文件内容经过比较后的相似程度。默认地,`-M` 会处理任意两个超过 50% 相似度的文件。这意味着,你需要编辑少于 50% 的行数来确保它们可以被识别成一个重命名后的文件。你可以通过加上一个百分比来选择你自己的 similarity index,如,`-M80%`。
|
||||
|
||||
到 Git v2.9 版本,无论你是否使用了 `-M` 标志, `git diff` 和 `git log` 命令都会默认检测重命名。如果不喜欢这种行为(或者,更现实的情况,你在通过一个脚本来解析 diff 输出),那么你可以通过显式的传递 `--no-renames` 标志来禁用这种行为。
|
||||
|
||||
#### 详细的提交
|
||||
|
||||
你经历过调用 `git commit` 然后盯着空白的 shell 试图想起你刚刚做过的所有改动吗?verbose 标志就为此而来!
|
||||
你经历过调用 `git commit` 然后盯着空白的 shell 试图想起你刚刚做过的所有改动吗?`verbose` 标志就为此而来!
|
||||
|
||||
不像这样:
|
||||
```
|
||||
Ah crap, which dependency did I just rev?
|
||||
```
|
||||
|
||||
```
|
||||
Ah crap, which dependency did I just rev?
|
||||
|
||||
# Please enter the commit message for your changes. Lines starting
|
||||
# with ‘#’ will be ignored, and an empty message aborts the commit.
|
||||
# On branch master
|
||||
@ -387,15 +370,16 @@ Ah crap, which dependency did I just rev?
|
||||
#
|
||||
```
|
||||
|
||||
...你可以调用 `git commit --verbose` 来查看你改动造成的内联差异。不用担心,这不会包含在你的提交信息中:
|
||||
……你可以调用 `git commit --verbose` 来查看你改动造成的行内差异。不用担心,这不会包含在你的提交信息中:
|
||||
|
||||
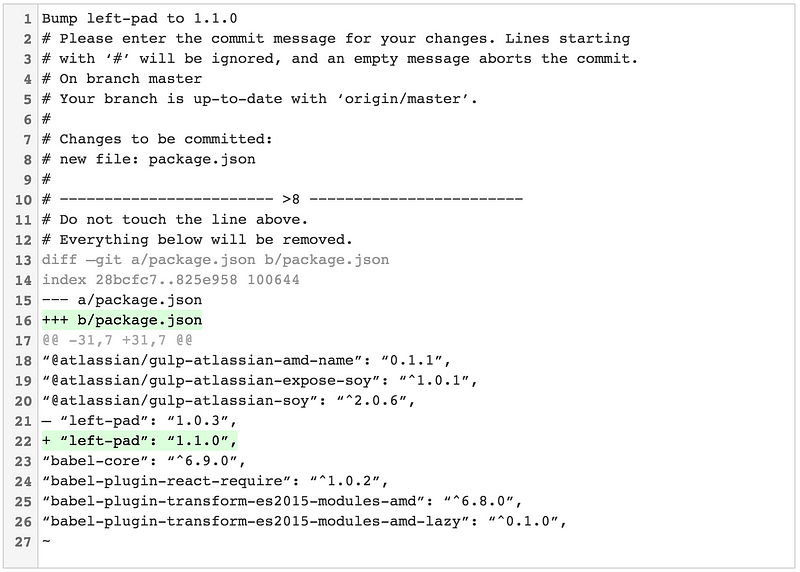
|
||||

|
||||
|
||||
`--verbose` 标志不是最新的,但是直到 Git v2.9 你可以通过 `git config --global commit.verbose true` 永久的启用它。
|
||||
`--verbose` 标志并不是新出现的,但是直到 Git v2.9 你才可以通过 `git config --global commit.verbose true` 永久的启用它。
|
||||
|
||||
#### 实验性的 Diff 改进
|
||||
|
||||
当一个被修改部分前后几行相同时,`git diff` 可能产生一些稍微令人迷惑的输出。如果在一个文件中有两个或者更多相似结构的函数时这可能发生。来看一个有些刻意人为的例子,想象我们有一个 JS 文件包含一个单独的函数:
|
||||
|
||||
```
|
||||
/* @return {string} "Bitbucket" */
|
||||
function productName() {
|
||||
@ -403,15 +387,14 @@ function productName() {
|
||||
}
|
||||
```
|
||||
|
||||
现在想象一下我们刚提交的改动包含一个预谋的 _另一个_可以做相似事情的函数:
|
||||
现在想象一下我们刚提交的改动包含一个我们专门做的 _另一个_可以做相似事情的函数:
|
||||
|
||||
```
|
||||
/* @return {string} "Bitbucket" */
|
||||
function productId() {
|
||||
return "Bitbucket";
|
||||
}
|
||||
```
|
||||
|
||||
```
|
||||
/* @return {string} "Bitbucket" */
|
||||
function productName() {
|
||||
return "Bitbucket";
|
||||
@ -420,32 +403,34 @@ function productName() {
|
||||
|
||||
我们希望 `git diff` 显示开头五行被新增,但是实际上它不恰当地将最初提交的第一行也包含进来。
|
||||
|
||||

|
||||

|
||||
|
||||
错误的注释被包含在了 diff 中!这虽不是世界末日,但每次发生这种事情总免不了花费几秒钟的意识去想 _啊?_
|
||||
在十二月,Git v2.11 介绍了一个新的实验性的 diff 选项,`--indent-heuristic`,尝试生成从美学角度来看更赏心悦目的 diff。
|
||||
|
||||

|
||||

|
||||
|
||||
在后台,`--indent-heuristic` 在每一次改动造成的所有可能的 diff 中循环,并为它们分别打上一个 "不良" 分数。这是基于试探性的如差异文件块是否以不同等级的缩进开始和结束(从美学角度讲不良)以及差异文件块前后是否有空白行(从美学角度讲令人愉悦)。最后,有着最低不良分数的块就是最终输出。
|
||||
在后台,`--indent-heuristic` 在每一次改动造成的所有可能的 diff 中循环,并为它们分别打上一个 “不良” 分数。这是基于启发式的,如差异文件块是否以不同等级的缩进开始和结束(从美学角度讲“不良”),以及差异文件块前后是否有空白行(从美学角度讲令人愉悦)。最后,有着最低不良分数的块就是最终输出。
|
||||
|
||||
这个特性还是实验性的,但是你可以通过应用 `--indent-heuristic` 选项到任何 `git diff` 命令来专门测试它。如果,如果你喜欢尝鲜,你可以这样将其在你的整个系统内启用:
|
||||
|
||||
这个特性还是实验性的,但是你可以通过应用 `--indent-heuristic` 选项到任何 `git diff` 命令来专门测试它。如果,如果你喜欢在刀口上讨生活,你可以这样将其在你的整个系统内使能:
|
||||
```
|
||||
$ git config --global diff.indentHeuristic true
|
||||
```
|
||||
|
||||
### Submodules 差强人意
|
||||
### 子模块(Submodule)差强人意
|
||||
|
||||
子模块允许你从 Git 仓库内部引用和包含其他 Git 仓库。这通常被用在当一些项目管理的源依赖也在被 Git 跟踪时,或者被某些公司用来作为包含一系列相关项目的 [monorepo][68] 的替代品。
|
||||
|
||||
由于某些用法的复杂性以及使用错误的命令相当容易破坏它们的事实,Submodule 得到了一些坏名声。
|
||||
|
||||
|
||||

|
||||
|
||||
但是,它们还是有着它们的用处,而且,我想,仍然对其他方案有依赖时的最好的选择。 幸运的是,2016 对 submodule 用户来说是伟大的一年,在几次发布中落地了许多意义重大的性能和特性提升。
|
||||
但是,它们还是有着它们的用处,而且,我想这仍然是用于需要厂商依赖项的最好选择。 幸运的是,2016 对子模块的用户来说是伟大的一年,在几次发布中落地了许多意义重大的性能和特性提升。
|
||||
|
||||
#### 并行抓取
|
||||
当克隆或则抓取一个仓库时,加上 `--recurse-submodules` 选项意味着任何引用的 submodule 也将被克隆或更新。传统上,这会被串行执行,每次只抓取一个 submodule。直到 Git v2.8,你可以附加 `--jobs=n` 选项来使用 _n_ 个并行线程来抓取 submodules。
|
||||
|
||||
当克隆或则抓取一个仓库时,加上 `--recurse-submodules` 选项意味着任何引用的子模块也将被克隆或更新。传统上,这会被串行执行,每次只抓取一个子模块。直到 Git v2.8,你可以附加 `--jobs=n` 选项来使用 _n_ 个并行线程来抓取子模块。
|
||||
|
||||
我推荐永久的配置这个选项:
|
||||
|
||||
@ -453,30 +438,31 @@ $ git config --global diff.indentHeuristic true
|
||||
$ git config --global submodule.fetchJobs 4
|
||||
```
|
||||
|
||||
...或者你可以选择使用任意程度的平行化。
|
||||
……或者你可以选择使用任意程度的平行化。
|
||||
|
||||
#### 浅层子模块
|
||||
Git v2.9 介绍了 `git clone —shallow-submodules` 标志。它允许你抓取你仓库的完整克隆,然后递归的浅层克隆所有引用的子模块的一个提交。如果你不需要项目的依赖的完整记录时会很有用。
|
||||
#### 浅层化子模块
|
||||
|
||||
例如,一个仓库有着一些混合了的子模块,其中包含有其他方案商提供的依赖和你自己其它的项目。你可能希望初始化时执行浅层子模块克隆然后深度选择几个你想要与之工作的项目。
|
||||
Git v2.9 介绍了 `git clone —shallow-submodules` 标志。它允许你抓取你仓库的完整克隆,然后递归地以一个提交的深度浅层化克隆所有引用的子模块。如果你不需要项目的依赖的完整记录时会很有用。
|
||||
|
||||
另一种情况可能是配置一次持续性的集成或调度工作。Git 需要超级仓库以及每个子模块最新的提交以便能够真正执行构建。但是,你可能并不需要每个子模块全部的历史记录,所以仅仅检索最新的提交可以为你省下时间和带宽。
|
||||
例如,一个仓库有着一些混合了的子模块,其中包含有其他厂商提供的依赖和你自己其它的项目。你可能希望初始化时执行浅层化子模块克隆,然后深度选择几个你想工作与其上的项目。
|
||||
|
||||
另一种情况可能是配置持续集成或部署工作。Git 需要一个包含了子模块的超级仓库以及每个子模块最新的提交以便能够真正执行构建。但是,你可能并不需要每个子模块全部的历史记录,所以仅仅检索最新的提交可以为你省下时间和带宽。
|
||||
|
||||
#### 子模块的替代品
|
||||
|
||||
`--reference` 选项可以和 `git clone` 配合使用来指定另一个本地仓库作为一个目标存储来保存你本地已经存在的又通过网络传输的重复制目标。语法为:
|
||||
`--reference` 选项可以和 `git clone` 配合使用来指定另一个本地仓库作为一个替代的对象存储,来避免跨网络重新复制你本地已经存在的对象。语法为:
|
||||
|
||||
```
|
||||
$ git clone --reference <local repo> <url>
|
||||
```
|
||||
|
||||
直到 Git v2.11,你可以使用 `—reference` 选项与 `—recurse-submodules` 结合来设置子模块替代品从另一个本地仓库指向子模块。其语法为:
|
||||
到 Git v2.11,你可以使用 `—reference` 选项与 `—recurse-submodules` 结合来设置子模块指向一个来自另一个本地仓库的子模块。其语法为:
|
||||
|
||||
```
|
||||
$ git clone --recurse-submodules --reference <local repo> <url>
|
||||
```
|
||||
|
||||
这潜在的可以省下很大数量的带宽和本地磁盘空间,但是如果引用的本地仓库不包含你所克隆自的远程仓库所必需的所有子模块时,它可能会失败。。
|
||||
这潜在的可以省下大量的带宽和本地磁盘空间,但是如果引用的本地仓库不包含你克隆的远程仓库所必需的所有子模块时,它可能会失败。
|
||||
|
||||
幸运的是,方便的 `—-reference-if-able` 选项将会让它优雅地失败,然后为丢失了的被引用的本地仓库的所有子模块回退为一次普通的克隆。
|
||||
|
||||
@ -487,11 +473,11 @@ $ git clone --recurse-submodules --reference-if-able \
|
||||
|
||||
#### 子模块的 diff
|
||||
|
||||
在 Git v2.11 之前,Git 有两种模式来显示对更新了仓库子模块的提交之间的差异。
|
||||
在 Git v2.11 之前,Git 有两种模式来显示对更新你的仓库子模块的提交之间的差异。
|
||||
|
||||
`git diff —-submodule=short` 显示你的项目引用的子模块中的旧提交和新提交( 这也是如果你整体忽略 `--submodule` 选项的默认结果):
|
||||
`git diff —-submodule=short` 显示你的项目引用的子模块中的旧提交和新提交(这也是如果你整体忽略 `--submodule` 选项的默认结果):
|
||||
|
||||
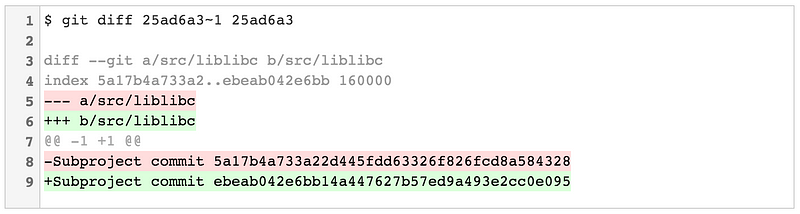
|
||||

|
||||
|
||||
`git diff —submodule=log` 有一点啰嗦,显示更新了的子模块中任意新建或移除的提交的信息中统计行。
|
||||
|
||||
@ -499,15 +485,16 @@ $ git clone --recurse-submodules --reference-if-able \
|
||||
|
||||
Git v2.11 引入了第三个更有用的选项:`—-submodule=diff`。这会显示更新后的子模块所有改动的完整的 diff。
|
||||
|
||||
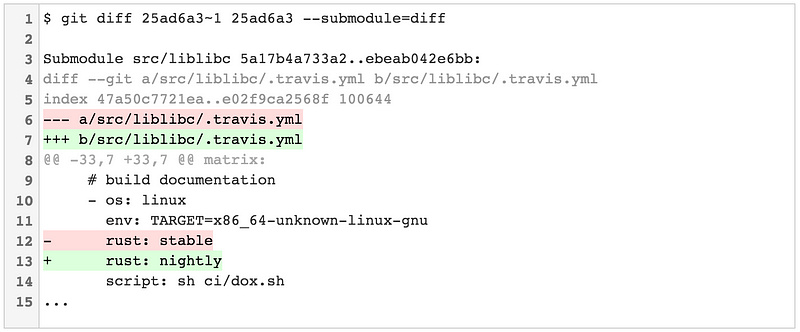
|
||||

|
||||
|
||||
### `git stash` 的 90 个增强
|
||||
### git stash 的 90 个增强
|
||||
|
||||
不像 submodules,几乎没有 Git 用户不钟爱 `[git stash][52]`。 `git stash` 临时搁置(或者 _藏匿_)你对工作区所做的改动使你能够先处理其他事情,结束后重新将搁置的改动恢复到先前状态。
|
||||
不像子模块,几乎没有 Git 用户不钟爱 [`git stash`][52]。 `git stash` 临时搁置(或者 _藏匿_)你对工作区所做的改动使你能够先处理其他事情,结束后重新将搁置的改动恢复到先前状态。
|
||||
|
||||
#### 自动搁置
|
||||
|
||||
如果你是 `git rebase` 的粉丝,你可能很熟悉 `--autostash` 选项。它会在变基之前自动搁置工作区所有本地修改然后等变基结束再将其复用。
|
||||
|
||||
```
|
||||
$ git rebase master --autostash
|
||||
Created autostash: 54f212a
|
||||
@ -516,12 +503,14 @@ First, rewinding head to replay your work on top of it...
|
||||
Applied autostash.
|
||||
```
|
||||
|
||||
这很方便,因为它使得你可以在一个不洁的工作区执行变基。有一个方便的配置标志叫做 `rebase.autostash` 可以将这个特性设为默认,你可以这样来全局使能它:
|
||||
这很方便,因为它使得你可以在一个不洁的工作区执行变基。有一个方便的配置标志叫做 `rebase.autostash` 可以将这个特性设为默认,你可以这样来全局启用它:
|
||||
|
||||
```
|
||||
$ git config --global rebase.autostash true
|
||||
```
|
||||
|
||||
`rebase.autostash` 实际上自从 [Git v1.8.4][69] 就可用了,但是 v2.7 引入了通过 `--no-autostash` 选项来取消这个标志的功能。如果你对未暂存的改动使用这个选项,变基会被一条工作树被污染的警告禁止:
|
||||
|
||||
```
|
||||
$ git rebase master --no-autostash
|
||||
Cannot rebase: You have unstaged changes.
|
||||
@ -531,31 +520,37 @@ Please commit or stash them.
|
||||
#### 补丁式搁置
|
||||
|
||||
说到配置标签,Git v2.7 也引入了 `stash.showPatch`。`git stash show` 的默认行为是显示你搁置文件的汇总。
|
||||
|
||||
```
|
||||
$ git stash show
|
||||
package.json | 2 +-
|
||||
1 file changed, 1 insertion(+), 1 deletion(-)
|
||||
```
|
||||
|
||||
将 `-p` 标志传入会将 `git stash show` 变为 "补丁模式",这将会显示完整的 diff:
|
||||
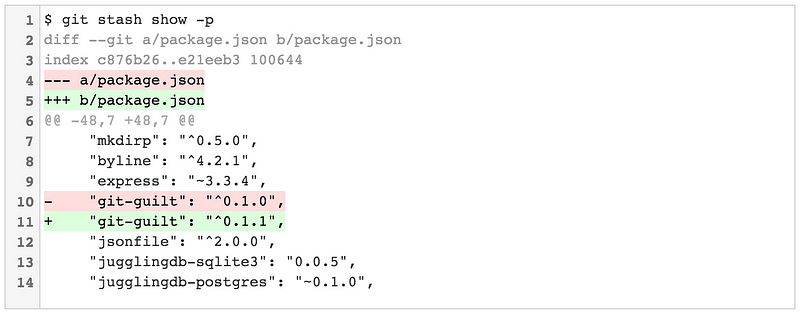
|
||||
将 `-p` 标志传入会将 `git stash show` 变为 “补丁模式”,这将会显示完整的 diff:
|
||||
|
||||

|
||||
|
||||
`stash.showPatch` 将这个行为定为默认。你可以将其全局启用:
|
||||
|
||||
`stash.showPatch` 将这个行为定为默认。你可以将其全局使能:
|
||||
```
|
||||
$ git config --global stash.showPatch true
|
||||
```
|
||||
|
||||
如果你使能 `stash.showPatch` 但却之后决定你仅仅想要查看文件总结,你可以通过传入 `--stat` 选项来重新获得之前的行为。
|
||||
|
||||
```
|
||||
$ git stash show --stat
|
||||
package.json | 2 +-
|
||||
1 file changed, 1 insertion(+), 1 deletion(-)
|
||||
```
|
||||
|
||||
顺便一提:`--no-patch` 是一个有效选项但它不会如你所希望的改写 `stash.showPatch` 的结果。不仅如此,它会传递给用来生成补丁时潜在调用的 `git diff` 命令,然后你会发现完全没有任何输出。
|
||||
顺便一提:`--no-patch` 是一个有效选项但它不会如你所希望的取消 `stash.showPatch`。不仅如此,它会传递给用来生成补丁时潜在调用的 `git diff` 命令,然后你会发现完全没有任何输出。
|
||||
|
||||
#### 简单的搁置标识
|
||||
如果你是 `git stash` 的粉丝,你可能知道你可以搁置多次改动然后通过 `git stash list` 来查看它们:
|
||||
|
||||
如果你惯用 `git stash` ,你可能知道你可以搁置多次改动然后通过 `git stash list` 来查看它们:
|
||||
|
||||
```
|
||||
$ git stash list
|
||||
stash@{0}: On master: crazy idea that might work one day
|
||||
@ -564,11 +559,11 @@ stash@{2}: On master: perf improvement that I forgot I stashed
|
||||
stash@{3}: On master: pop this when we use Docker in production
|
||||
```
|
||||
|
||||
但是,你可能不知道为什么 Git 的搁置有着这么难以理解的标识(`stash@{1}`, `stash@{2}`, 等)也可能将它们勾勒成 "仅仅是 Git 的一个特性吧"。实际上就像很多 Git 特性一样,这些奇怪的标志实际上是 Git 数据模型一个非常巧妙使用(或者说是滥用了的)的特性。
|
||||
但是,你可能不知道为什么 Git 的搁置有着这么难以理解的标识(`stash@{1}`、`stash@{2}` 等),或许你可能将它们勾勒成 “仅仅是 Git 的癖好吧”。实际上就像很多 Git 特性一样,这些奇怪的标志实际上是 Git 数据模型的一个非常巧妙使用(或者说是滥用了的)的结果。
|
||||
|
||||
在后台,`git stash` 命令实际创建了一系列特别的提交目标,这些目标对你搁置的改动做了编码并且维护一个 [reglog][70] 来保存对这些特殊提交的参考。 这也是为什么 `git stash list` 的输出看起来很像 `git reflog` 的输出。当你运行 `git stash apply stash@{1}` 时,你实际上在说,"从stash reflog 的位置 1 上应用这条提交 "
|
||||
在后台,`git stash` 命令实际创建了一系列特定的提交目标,这些目标对你搁置的改动做了编码并且维护一个 [reglog][70] 来保存对这些特殊提交的引用。 这也是为什么 `git stash list` 的输出看起来很像 `git reflog` 的输出。当你运行 `git stash apply stash@{1}` 时,你实际上在说,“从 stash reflog 的位置 1 上应用这条提交。”
|
||||
|
||||
直到 Git v2.11,你不再需要使用完整的 `stash@{n}` 语句。相反,你可以通过一个简单的整数指出搁置在 stash reflog 中的位置来引用它们。
|
||||
到了 Git v2.11,你不再需要使用完整的 `stash@{n}` 语句。相反,你可以通过一个简单的整数指出该搁置在 stash reflog 中的位置来引用它们。
|
||||
|
||||
```
|
||||
$ git stash show 1
|
||||
@ -577,25 +572,26 @@ $ git stash pop 1
|
||||
```
|
||||
|
||||
讲了很多了。如果你还想要多学一些搁置是怎么保存的,我在 [这篇教程][71] 中写了一点这方面的内容。
|
||||
### <2016> <2017>
|
||||
好了,结束了。感谢您的阅读!我希望您享受阅读这份长篇大论,正如我享受在 Git 的源码,发布文档,和 `man` 手册中探险一番来撰写它。如果你认为我忘记了一些重要的事,请留下一条评论或者在 [Twitter][72] 上让我知道,我会努力写一份后续篇章。
|
||||
|
||||
至于 Git 接下来会发生什么,这要靠广大维护者和贡献者了(其中有可能就是你!)。随着日益增长的采用,我猜测简化,改进后的用户体验,和更好的默认结果将会是 2017 年 Git 主要的主题。随着 Git 仓库变得又大又旧,我猜我们也可以看到继续持续关注性能和对大文件、深度树和长历史的改进处理。
|
||||
### </2016> <2017>
|
||||
|
||||
如果你关注 Git 并且很期待能够和一些项目背后的开发者会面,请考虑来 Brussels 花几周时间来参加 [Git Merge][74] 。我会在[那里发言][75]!但是更重要的是,很多维护 Git 的开发者将会出席这次会议而且一年一度的 Git 贡献者峰会很可能会指定来年发展的方向。
|
||||
好了,结束了。感谢您的阅读!我希望您喜欢阅读这份长篇大论,正如我乐于在 Git 的源码、发布文档和 `man` 手册中探险一番来撰写它。如果你认为我忘记了一些重要的事,请留下一条评论或者在 [Twitter][72] 上让我知道,我会努力写一份后续篇章。
|
||||
|
||||
至于 Git 接下来会发生什么,这要靠广大维护者和贡献者了(其中有可能就是你!)。随着 Git 的采用日益增长,我猜测简化、改进的用户体验,和更好的默认结果将会是 2017 年 Git 主要的主题。随着 Git 仓库变得越来越大、越来越旧,我猜我们也可以看到继续持续关注性能和对大文件、深度树和长历史的改进处理。
|
||||
|
||||
如果你关注 Git 并且很期待能够和一些项目背后的开发者会面,请考虑来 Brussels 花几周时间来参加 [Git Merge][74] 。我会在[那里发言][75]!但是更重要的是,很多维护 Git 的开发者将会出席这次会议而且一年一度的 Git 贡献者峰会很可能会指定来年发展的方向。
|
||||
|
||||
或者如果你实在等不及,想要获得更多的技巧和指南来改进你的工作流,请参看这份 Atlassian 的优秀作品: [Git 教程][76] 。
|
||||
|
||||
|
||||
*如果你翻到最下方来找第一节的脚注,请跳转到 [ [引用是需要的] ][77]一节去找生成统计信息的命令。免费的封面图片是由 [ instaco.de ][78] 生成的 ❤️。*
|
||||
封面图片是由 [instaco.de][78] 生成的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://hackernoon.com/git-in-2016-fad96ae22a15#.t5c5cm48f
|
||||
via: https://medium.com/hacker-daily/git-in-2016-fad96ae22a15
|
||||
|
||||
作者:[Tim Pettersen][a]
|
||||
译者:[xiaow6](https://github.com/xiaow6)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,62 @@
|
||||
用 NTP 把控时间(一):使用概览
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
这系列共三部分,首先,Chirs Binnie 探讨了在一个合理的架构中 NTP 服务的重要性。
|
||||
|
||||
鲜有互联网上的服务能如时间服务一样重要。影响你系统计时的小问题可能需要一两天才能被发现,而这些不期而遇的问题所带来的连锁反应几乎总是让人伤脑筋的。
|
||||
|
||||
设想你的备份服务器与网络时间协议(NTP)服务器断开连接,过了几天,引起了几小时的时间偏差。你的同事照常九点上班,发现需要大量带宽的备份服务器消耗了所有网络资源,这也就意味着他们在备份完成之前几乎不能登录工作台开始他们的日常工作。
|
||||
|
||||
这系列共三部分,首先,我将提供简要介绍 NTP 来防止这种困境的发生。从邮件的时间戳到记录你工作的进展,NTP 服务对于一个合理的架构是如此的重要。
|
||||
|
||||
可以把如此重要的 NTP 服务器(其他的服务器从此获取时钟数据)看做是倒置金字塔的底部,它被称之为<ruby>一层<rt>Stratum 1</rt></ruby>服务器(也被称为“<ruby>主<rt>primary</rt></ruby>”服务器)。这些服务器与国家级时间服务(称为<ruby>零层<rt>Stratum 0</rt></ruby>,通常这些设备是是原子钟和 GPS 钟之类的装置)直接交互。与之安全通讯的方法很多,例如通过卫星或者无线电。
|
||||
|
||||
令人惊讶的是,几乎所有的大型企业都会连接<ruby>二层<rt>Stratum 2</rt></ruby>服务器(或“<ruby>次级<rt>secondary</rt></ruby>”服务器)而是不是主服务器。如你所料,二层服务器和一层直接同步。如果你觉得大公司可能有自己的本地 NTP 服务器(至少两个,通常三个,为了灾难恢复之用),这些就是三层服务器。这样,三层服务器将连接上层预定义的次级服务器,负责任地传递时间给客户端和服务器,精确地反馈当前时间。
|
||||
|
||||
由简单设计而构成的 NTP 可以工作的前提是——多亏了通过互联网跨越了大范围的地理距离——在确认时间完全准确之前,来回时间(包什么时候发出和多少秒后被收到)都会被清楚记录。设置电脑的时间的背后要比你想象的复杂得多,如果你不相信,那[这神奇的网页][3]值得一看。
|
||||
|
||||
再次重提一遍,为了确保你的架构如预期般工作,NTP 是如此的关键,你的 NTP 与层次服务器之间的连接必须是完全可信赖并且能提供额外的冗余,才能保持你的内部时钟同步。在 [NTP 主站][4]有一个有用的一层服务器列表。
|
||||
|
||||
正如你在列表所见,一些 NTP 一层服务器以 “ClosedAccount” 状态运行;这些服务器需要事先接受才可以使用。但是只要你完全按照他们的使用引导做,“OpenAccess” 服务器是可以用于轮询使用的。而 “RestrictedAccess” 服务器有时候会因为大量客户端访问或者轮询间隙太小而受限。另外有时候也有一些专供某种类型的组织使用,例如学术界。
|
||||
|
||||
### 尊重我的权威
|
||||
|
||||
在公共 NTP 服务器上,你可能发现遵从某些规则的使用规范。现在让我们看看其中一些。
|
||||
|
||||
“iburst” 选项作用是如果在一个标准的轮询间隔内没有应答,客户端会发送一定数量的包(八个包而不是通常的一个)给 NTP 服务器。如果在短时间内呼叫 NTP 服务器几次,没有出现可辨识的应答,那么本地时间将不会变化。
|
||||
|
||||
不像 “iburst” ,按照 NTP 服务器的通用规则, “burst” 选项一般不允许使用(所以不要用它!)。这个选项不仅在轮询间隔发送大量包(明显又是八个),而且也会在服务器能正常使用时这样做。如果你在高层服务器持续发送包,甚至是它们在正常应答时,你可能会因为使用 “burst” 选项而被拉黑。
|
||||
|
||||
显然,你连接服务器的频率造成了它的负载差异(和少量的带宽占用)。使用 “minpoll” 和 “maxpoll” 选项可以本地设置频率。然而,根据连接 NTP 服务器的规则,你不应该分别修改其默认的 64 秒和 1024 秒。
|
||||
|
||||
此外,需要提出的是客户应该重视那些请求时间的服务器发出的“<ruby>亲一下就死(死亡之吻)<rt>Kiss-Of-Death</rt></ruby>” (KOD)消息。如果 NTP 服务器不想响应某个特定的请求,就像路由和防火墙技术那样,那么它最有可能的就是简单地遗弃或吞没任何相关的包。
|
||||
|
||||
换句话说,接受到这些数据的服务器并不需要特别处理这些包,简单地丢弃这些它认为这不值得回应的包即可。你可以想象,这并不是特别好的做法,有时候礼貌地问客户是否中止或停止比忽略请求更为有效。因此,这种特别的包类型叫做 KOD 包。如果一个客户端被发送了这种不受欢迎的 KOD 包,它应该记住这个发回了拒绝访问标志的服务器。
|
||||
|
||||
如果从该服务器收到不止一个 KOD 包,客户端会猜想服务器上发生了流量限速的情况(或类似的)。这种情况下,客户端一般会写入本地日志,提示与该服务器的交流不太顺利,以备将来排错之用。
|
||||
|
||||
牢记,出于显而易见的原因,关键在于 NTP 服务器的架构应该是动态的。因此,不要给你的 NTP 配置硬编码 IP 地址是非常重要的。通过使用 DNS 域名,个别服务器断开网络时服务仍能继续进行,而 IP 地址空间也能重新分配,并且可引入简单的负载均衡(具有一定程度的弹性)。
|
||||
|
||||
请别忘了我们也需要考虑呈指数增长的物联网(IoT),这最终将包括数以亿万计的新装置,意味着这些设备都需要保持正确时间。硬件卖家无意(或有意)设置他们的设备只能与一个提供者的(甚至一个) NTP 服务器连接终将成为过去,这是一个非常麻烦的问题。
|
||||
|
||||
你可能会想象,随着买入和上线更多的硬件单元,NTP 基础设施的拥有者大概不会为相关的费用而感到高兴,因为他们正被没有实际收入所困扰。这种情形并非杞人忧天。头疼的问题多呢 -- 由于 NTP 流量导致基础架构不堪重负 -- 这在过去几年里已发生过多次。
|
||||
|
||||
在下面两篇文章里,我将着重于一些重要的 NTP 安全配置选项和描述服务器的搭建。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/arrive-time-ntp-part-1-usage-overview
|
||||
|
||||
作者:[CHRIS BINNIE][a]
|
||||
译者:[XYenChi](https://github.com/XYenChi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/chrisbinnie
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/files/images/ntp-timejpg
|
||||
[3]:http://www.ntp.org/ntpfaq/NTP-s-sw-clocks-quality.htm
|
||||
[4]:http://support.ntp.org/bin/view/Servers/StratumOneTimeServers
|
||||
@ -0,0 +1,632 @@
|
||||
如何在 CentOS 7 上安装 Elastic Stack
|
||||
============================================================
|
||||
|
||||
**Elasticsearch** 是基于 Lucene 由 Java 开发的开源搜索引擎。它提供了一个分布式、多租户的全文搜索引擎(LCTT 译注:多租户是指多租户技术,是一种软件架构技术,用来探讨与实现如何在多用户的环境下共用相同的系统或程序组件,并且仍可确保各用户间数据的隔离性。),并带有 HTTP 仪表盘的 Web 界面(Kibana)。数据会被 Elasticsearch 查询、检索,并且使用 JSON 文档方案存储。Elasticsearch 是一个可扩展的搜索引擎,可用于搜索所有类型的文本文档,包括日志文件。Elasticsearch 是 Elastic Stack 的核心,Elastic Stack 也被称为 ELK Stack。
|
||||
|
||||
**Logstash** 是用于管理事件和日志的开源工具。它为数据收集提供实时传递途径。 Logstash 将收集您的日志数据,将数据转换为 JSON 文档,并将其存储在 Elasticsearch 中。
|
||||
|
||||
**Kibana** 是 Elasticsearch 的开源数据可视化工具。Kibana 提供了一个漂亮的仪表盘 Web 界面。 你可以用它来管理和可视化来自 Elasticsearch 的数据。 它不仅美丽,而且强大。
|
||||
|
||||
在本教程中,我将向您展示如何在 CentOS 7 服务器上安装和配置 Elastic Stack 以监视服务器日志。 然后,我将向您展示如何在操作系统为 CentOS 7 和 Ubuntu 16 的客户端上安装 “Elastic beats”。
|
||||
|
||||
**前提条件**
|
||||
|
||||
* 64 位的 CentOS 7,4 GB 内存 - elk 主控机
|
||||
* 64 位的 CentOS 7 ,1 GB 内存 - 客户端 1
|
||||
* 64 位的 Ubuntu 16 ,1 GB 内存 - 客户端 2
|
||||
|
||||
### 步骤 1 - 准备操作系统
|
||||
|
||||
在本教程中,我们将禁用 CentOS 7 服务器上的 SELinux。 编辑 SELinux 配置文件。
|
||||
|
||||
```
|
||||
vim /etc/sysconfig/selinux
|
||||
```
|
||||
|
||||
将 `SELINUX` 的值从 `enforcing` 改成 `disabled` 。
|
||||
|
||||
```
|
||||
SELINUX=disabled
|
||||
```
|
||||
|
||||
然后重启服务器:
|
||||
|
||||
```
|
||||
reboot
|
||||
```
|
||||
|
||||
再次登录服务器并检查 SELinux 状态。
|
||||
|
||||
```
|
||||
getenforce
|
||||
```
|
||||
|
||||
确保结果是 `disabled`。
|
||||
|
||||
### 步骤 2 - 安装 Java
|
||||
|
||||
部署 Elastic stack 依赖于Java,Elasticsearch 需要 Java 8 版本,推荐使用 Oracle JDK 1.8 。我将从官方的 Oracle rpm 包安装 Java 8。
|
||||
|
||||
使用 `wget` 命令下载 Java 8 的 JDK。
|
||||
|
||||
```
|
||||
wget --no-cookies --no-check-certificate --header "Cookie: gpw_e24=http:%2F%2Fwww.oracle.com%2F; oraclelicense=accept-securebackup-cookie" "http://download.oracle.com/otn-pub/java/jdk/8u77-b02/jdk-8u77-linux-x64.rpm"
|
||||
```
|
||||
|
||||
然后使用 `rpm` 命令安装:
|
||||
|
||||
```
|
||||
rpm -ivh jdk-8u77-linux-x64.rpm
|
||||
```
|
||||
|
||||
最后,检查 java JDK 版本,确保它正常工作。
|
||||
|
||||
```
|
||||
java -version
|
||||
```
|
||||
|
||||
您将看到服务器的 Java 版本。
|
||||
|
||||
### 步骤 3 - 安装和配置 Elasticsearch
|
||||
|
||||
在此步骤中,我们将安装和配置 Elasticsearch。 从 elastic.co 网站提供的 rpm 包安装 Elasticsearch,并将其配置运行在 localhost 上(以确保该程序安全,而且不能从外部访问)。
|
||||
|
||||
在安装 Elasticsearch 之前,将 elastic.co 的密钥添加到服务器。
|
||||
|
||||
```
|
||||
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
|
||||
```
|
||||
|
||||
接下来,使用 `wget` 下载 Elasticsearch 5.1,然后安装它。
|
||||
|
||||
```
|
||||
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.1.1.rpm
|
||||
rpm -ivh elasticsearch-5.1.1.rpm
|
||||
```
|
||||
|
||||
Elasticsearch 已经安装好了。 现在进入配置目录编辑 `elasticsaerch.yml` 配置文件。
|
||||
|
||||
```
|
||||
cd /etc/elasticsearch/
|
||||
vim elasticsearch.yml
|
||||
```
|
||||
|
||||
去掉第 40 行的注释,启用 Elasticsearch 的内存锁。这将禁用 Elasticsearch 的内存交换。
|
||||
|
||||
```
|
||||
bootstrap.memory_lock: true
|
||||
```
|
||||
|
||||
在 `Network` 块中,取消注释 `network.host` 和 `http.port` 行。
|
||||
|
||||
```
|
||||
network.host: localhost
|
||||
http.port: 9200
|
||||
```
|
||||
|
||||
保存文件并退出编辑器。
|
||||
|
||||
现在编辑 `elasticsearch.service` 文件的内存锁配置。
|
||||
|
||||
```
|
||||
vim /usr/lib/systemd/system/elasticsearch.service
|
||||
```
|
||||
|
||||
去掉第 60 行的注释,确保该值为 `unlimited`。
|
||||
|
||||
```
|
||||
MAX_LOCKED_MEMORY=unlimited
|
||||
```
|
||||
|
||||
保存并退出。
|
||||
|
||||
Elasticsearch 配置到此结束。Elasticsearch 将在本机的 9200 端口运行,我们通过在 CentOS 服务器上启用 `mlockall` 来禁用内存交换。重新加载 systemd,将 Elasticsearch 置为开机启动,然后启动服务。
|
||||
|
||||
```
|
||||
sudo systemctl daemon-reload
|
||||
sudo systemctl enable elasticsearch
|
||||
sudo systemctl start elasticsearch
|
||||
```
|
||||
|
||||
等待 Eelasticsearch 启动成功,然后检查服务器上打开的端口,确保 9200 端口的状态是 `LISTEN`。
|
||||
|
||||
```
|
||||
netstat -plntu
|
||||
```
|
||||
|
||||
![Check elasticsearch running on port 9200] [10]
|
||||
|
||||
然后检查内存锁以确保启用 `mlockall`,并使用以下命令检查 Elasticsearch 是否正在运行。
|
||||
|
||||
```
|
||||
curl -XGET 'localhost:9200/_nodes?filter_path=**.mlockall&pretty'
|
||||
curl -XGET 'localhost:9200/?pretty'
|
||||
```
|
||||
|
||||
会看到如下结果。
|
||||
|
||||
![Check memory lock elasticsearch and check status] [11]
|
||||
|
||||
### 步骤 4 - 安装和配置 Kibana 和 Nginx
|
||||
|
||||
在这一步,我们将在 Nginx Web 服务器上安装并配置 Kibana。 Kibana 监听在 localhost 上,而 Nginx 作为 Kibana 的反向代理。
|
||||
|
||||
用 `wget` 下载 Kibana 5.1,然后使用 `rpm` 命令安装:
|
||||
|
||||
```
|
||||
wget https://artifacts.elastic.co/downloads/kibana/kibana-5.1.1-x86_64.rpm
|
||||
rpm -ivh kibana-5.1.1-x86_64.rpm
|
||||
```
|
||||
|
||||
编辑 Kibana 配置文件。
|
||||
|
||||
```
|
||||
vim /etc/kibana/kibana.yml
|
||||
```
|
||||
|
||||
去掉配置文件中 `server.port`、`server.host` 和 `elasticsearch.url` 这三行的注释。
|
||||
|
||||
```
|
||||
server.port: 5601
|
||||
server.host: "localhost"
|
||||
elasticsearch.url: "http://localhost:9200"
|
||||
```
|
||||
|
||||
保存并退出。
|
||||
|
||||
将 Kibana 设为开机启动,并且启动 Kibana 。
|
||||
|
||||
```
|
||||
sudo systemctl enable kibana
|
||||
sudo systemctl start kibana
|
||||
```
|
||||
|
||||
Kibana 将作为 node 应用程序运行在端口 5601 上。
|
||||
|
||||
```
|
||||
netstat -plntu
|
||||
```
|
||||
|
||||
![Kibana running as node application on port 5601] [12]
|
||||
|
||||
Kibana 安装到此结束。 现在我们需要安装 Nginx 并将其配置为反向代理,以便能够从公共 IP 地址访问 Kibana。
|
||||
|
||||
Nginx 在 Epel 资源库中可以找到,用 `yum` 安装 epel-release。
|
||||
|
||||
```
|
||||
yum -y install epel-release
|
||||
```
|
||||
|
||||
然后安装 Nginx 和 httpd-tools 这两个包。
|
||||
|
||||
```
|
||||
yum -y install nginx httpd-tools
|
||||
```
|
||||
|
||||
httpd-tools 软件包包含 Web 服务器的工具,可以为 Kibana 添加 htpasswd 基础认证。
|
||||
|
||||
编辑 Nginx 配置文件并删除 `server {}` 块,这样我们可以添加一个新的虚拟主机配置。
|
||||
|
||||
```
|
||||
cd /etc/nginx/
|
||||
vim nginx.conf
|
||||
```
|
||||
|
||||
删除 `server { }` 块。
|
||||
|
||||
![Remove Server Block on Nginx configuration] [13]
|
||||
|
||||
保存并退出。
|
||||
|
||||
现在我们需要在 `conf.d` 目录中创建一个新的虚拟主机配置文件。 用 `vim` 创建新文件 `kibana.conf`。
|
||||
|
||||
```
|
||||
vim /etc/nginx/conf.d/kibana.conf
|
||||
```
|
||||
|
||||
复制下面的配置。
|
||||
|
||||
```
|
||||
server {
|
||||
listen 80;
|
||||
|
||||
server_name elk-stack.co;
|
||||
|
||||
auth_basic "Restricted Access";
|
||||
auth_basic_user_file /etc/nginx/.kibana-user;
|
||||
|
||||
location / {
|
||||
proxy_pass http://localhost:5601;
|
||||
proxy_http_version 1.1;
|
||||
proxy_set_header Upgrade $http_upgrade;
|
||||
proxy_set_header Connection 'upgrade';
|
||||
proxy_set_header Host $host;
|
||||
proxy_cache_bypass $http_upgrade;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
保存并退出。
|
||||
|
||||
然后使用 `htpasswd` 命令创建一个新的基本认证文件。
|
||||
|
||||
```
|
||||
sudo htpasswd -c /etc/nginx/.kibana-user admin
|
||||
“输入你的密码”
|
||||
```
|
||||
|
||||
测试 Nginx 配置,确保没有错误。 然后设定 Nginx 开机启动并启动 Nginx。
|
||||
|
||||
```
|
||||
nginx -t
|
||||
systemctl enable nginx
|
||||
systemctl start nginx
|
||||
```
|
||||
|
||||
![Add nginx virtual host configuration for Kibana Application] [14]
|
||||
|
||||
### 步骤 5 - 安装和配置 Logstash
|
||||
|
||||
在此步骤中,我们将安装 Logstash,并将其配置为:从配置了 filebeat 的 logstash 客户端里集中化服务器的日志,然后过滤和转换 Syslog 数据,并将其移动到存储中心(Elasticsearch)中。
|
||||
|
||||
下载 Logstash 并使用 rpm 进行安装。
|
||||
|
||||
```
|
||||
wget https://artifacts.elastic.co/downloads/logstash/logstash-5.1.1.rpm
|
||||
rpm -ivh logstash-5.1.1.rpm
|
||||
```
|
||||
|
||||
生成新的 SSL 证书文件,以便客户端可以识别 elastic 服务端。
|
||||
|
||||
进入 `tls` 目录并编辑 `openssl.cnf` 文件。
|
||||
|
||||
```
|
||||
cd /etc/pki/tls
|
||||
vim openssl.cnf
|
||||
```
|
||||
|
||||
在 `[v3_ca]` 部分添加服务器标识。
|
||||
|
||||
```
|
||||
[ v3_ca ]
|
||||
|
||||
# Server IP Address
|
||||
subjectAltName = IP: 10.0.15.10
|
||||
```
|
||||
|
||||
保存并退出。
|
||||
|
||||
使用 `openssl` 命令生成证书文件。
|
||||
|
||||
```
|
||||
openssl req -config /etc/pki/tls/openssl.cnf -x509 -days 3650 -batch -nodes -newkey rsa:2048 -keyout /etc/pki/tls/private/logstash-forwarder.key -out /etc/pki/tls/certs/logstash-forwarder.crt
|
||||
```
|
||||
|
||||
证书文件可以在 `/etc/pki/tls/certs/` 和 `/etc/pki/tls/private/` 目录中找到。
|
||||
|
||||
接下来,我们会为 Logstash 创建新的配置文件。创建一个新的 `filebeat-input.conf` 文件来为 filebeat 配置日志源,然后创建一个 `syslog-filter.conf` 配置文件来处理 syslog,再创建一个 `output-elasticsearch.conf` 文件来定义输出日志数据到 Elasticsearch。
|
||||
|
||||
转到 logstash 配置目录,并在 `conf.d` 子目录中创建新的配置文件。
|
||||
|
||||
```
|
||||
cd /etc/logstash/
|
||||
vim conf.d/filebeat-input.conf
|
||||
```
|
||||
|
||||
输入配置,粘贴以下配置:
|
||||
|
||||
```
|
||||
input {
|
||||
beats {
|
||||
port => 5443
|
||||
ssl => true
|
||||
ssl_certificate => "/etc/pki/tls/certs/logstash-forwarder.crt"
|
||||
ssl_key => "/etc/pki/tls/private/logstash-forwarder.key"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
保存并退出。
|
||||
|
||||
创建 `syslog-filter.conf` 文件。
|
||||
|
||||
```
|
||||
vim conf.d/syslog-filter.conf
|
||||
```
|
||||
|
||||
粘贴以下配置:
|
||||
|
||||
```
|
||||
filter {
|
||||
if [type] == "syslog" {
|
||||
grok {
|
||||
match => { "message" => "%{SYSLOGTIMESTAMP:syslog_timestamp} %{SYSLOGHOST:syslog_hostname} %{DATA:syslog_program}(?:\[%{POSINT:syslog_pid}\])?: %{GREEDYDATA:syslog_message}" }
|
||||
add_field => [ "received_at", "%{@timestamp}" ]
|
||||
add_field => [ "received_from", "%{host}" ]
|
||||
}
|
||||
date {
|
||||
match => [ "syslog_timestamp", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ]
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
我们使用名为 `grok` 的过滤器插件来解析 syslog 文件。
|
||||
|
||||
保存并退出。
|
||||
|
||||
创建输出配置文件 `output-elasticsearch.conf`。
|
||||
|
||||
```
|
||||
vim conf.d/output-elasticsearch.conf
|
||||
```
|
||||
|
||||
粘贴以下配置:
|
||||
|
||||
```
|
||||
output {
|
||||
elasticsearch { hosts => ["localhost:9200"]
|
||||
hosts => "localhost:9200"
|
||||
manage_template => false
|
||||
index => "%{[@metadata][beat]}-%{+YYYY.MM.dd}"
|
||||
document_type => "%{[@metadata][type]}"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
保存并退出。
|
||||
|
||||
最后,将 logstash 设定为开机启动并且启动服务。
|
||||
|
||||
```
|
||||
sudo systemctl enable logstash
|
||||
sudo systemctl start logstash
|
||||
```
|
||||
|
||||
![Logstash started on port 5443 with SSL Connection] [15]
|
||||
|
||||
### 步骤 6 - 在 CentOS 客户端上安装并配置 Filebeat
|
||||
|
||||
Beat 作为数据发送人的角色,是一种可以安装在客户端节点上的轻量级代理,将大量数据从客户机发送到 Logstash 或 Elasticsearch 服务器。有 4 种 beat,`Filebeat` 用于发送“日志文件”,`Metricbeat` 用于发送“指标”,`Packetbeat` 用于发送“网络数据”,`Winlogbeat` 用于发送 Windows 客户端的“事件日志”。
|
||||
|
||||
在本教程中,我将向您展示如何安装和配置 `Filebeat`,通过 SSL 连接将数据日志文件传输到 Logstash 服务器。
|
||||
|
||||
登录到客户端1的服务器上。 然后将证书文件从 elastic 服务器复制到客户端1的服务器上。
|
||||
|
||||
```
|
||||
ssh root@client1IP
|
||||
```
|
||||
|
||||
使用 `scp` 命令拷贝证书文件。
|
||||
|
||||
```
|
||||
scp root@elk-serverIP:~/logstash-forwarder.crt .
|
||||
输入 elk-server 的密码
|
||||
```
|
||||
|
||||
创建一个新的目录,将证书移动到这个目录中。
|
||||
|
||||
```
|
||||
sudo mkdir -p /etc/pki/tls/certs/
|
||||
mv ~/logstash-forwarder.crt /etc/pki/tls/certs/
|
||||
```
|
||||
|
||||
接下来,在客户端 1 服务器上导入 elastic 密钥。
|
||||
|
||||
```
|
||||
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
|
||||
```
|
||||
|
||||
下载 Filebeat 并且用 `rpm` 命令安装。
|
||||
|
||||
```
|
||||
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-5.1.1-x86_64.rpm
|
||||
rpm -ivh filebeat-5.1.1-x86_64.rpm
|
||||
```
|
||||
|
||||
Filebeat 已经安装好了,请转到配置目录并编辑 `filebeat.yml` 文件。
|
||||
|
||||
```
|
||||
cd /etc/filebeat/
|
||||
vim filebeat.yml
|
||||
```
|
||||
|
||||
在第 21 行的路径部分,添加新的日志文件。 我们将创建两个文件,记录 ssh 活动的 `/var/log/secure` 文件 ,以及服务器日志 `/var/log/messages` 。
|
||||
|
||||
```
|
||||
paths:
|
||||
- /var/log/secure
|
||||
- /var/log/messages
|
||||
```
|
||||
|
||||
在第 26 行添加一个新配置来定义 syslog 类型的文件。
|
||||
|
||||
```
|
||||
document-type: syslog
|
||||
```
|
||||
|
||||
Filebeat 默认使用 Elasticsearch 作为输出目标。 在本教程中,我们将其更改为 Logshtash。 在 83 行和 85 行添加注释来禁用 Elasticsearch 输出。
|
||||
|
||||
禁用 Elasticsearch 输出:
|
||||
|
||||
```
|
||||
#-------------------------- Elasticsearch output ------------------------------
|
||||
#output.elasticsearch:
|
||||
# Array of hosts to connect to.
|
||||
# hosts: ["localhost:9200"]
|
||||
```
|
||||
|
||||
现在添加新的 logstash 输出配置。 去掉 logstash 输出配置的注释,并将所有值更改为下面配置中的值。
|
||||
|
||||
```
|
||||
output.logstash:
|
||||
# The Logstash hosts
|
||||
hosts: ["10.0.15.10:5443"]
|
||||
bulk_max_size: 1024
|
||||
ssl.certificate_authorities: ["/etc/pki/tls/certs/logstash-forwarder.crt"]
|
||||
template.name: "filebeat"
|
||||
template.path: "filebeat.template.json"
|
||||
template.overwrite: false
|
||||
```
|
||||
|
||||
保存文件并退出 vim。
|
||||
|
||||
将 Filebeat 设定为开机启动并启动。
|
||||
|
||||
```
|
||||
sudo systemctl enable filebeat
|
||||
sudo systemctl start filebeat
|
||||
```
|
||||
|
||||
### 步骤 7 - 在 Ubuntu 客户端上安装并配置 Filebeat
|
||||
|
||||
使用 `ssh` 连接到服务器。
|
||||
|
||||
```
|
||||
ssh root@ubuntu-clientIP
|
||||
```
|
||||
|
||||
使用 `scp` 命令拷贝证书文件。
|
||||
|
||||
```
|
||||
scp root@elk-serverIP:~/logstash-forwarder.crt .
|
||||
```
|
||||
|
||||
创建一个新的目录,将证书移动到这个目录中。
|
||||
|
||||
```
|
||||
sudo mkdir -p /etc/pki/tls/certs/
|
||||
mv ~/logstash-forwarder.crt /etc/pki/tls/certs/
|
||||
```
|
||||
|
||||
在服务器上导入 elastic 密钥。
|
||||
|
||||
```
|
||||
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
|
||||
```
|
||||
|
||||
下载 Filebeat .deb 包并且使用 `dpkg` 命令进行安装。
|
||||
|
||||
```
|
||||
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-5.1.1-amd64.deb
|
||||
dpkg -i filebeat-5.1.1-amd64.deb
|
||||
```
|
||||
|
||||
转到配置目录并编辑 `filebeat.yml` 文件。
|
||||
|
||||
```
|
||||
cd /etc/filebeat/
|
||||
vim filebeat.yml
|
||||
```
|
||||
|
||||
在路径配置部分添加新的日志文件路径。
|
||||
|
||||
```
|
||||
paths:
|
||||
- /var/log/auth.log
|
||||
- /var/log/syslog
|
||||
```
|
||||
|
||||
设定文档类型为 `syslog` 。
|
||||
|
||||
```
|
||||
document-type: syslog
|
||||
```
|
||||
|
||||
将下列几行注释掉,禁用输出到 Elasticsearch。
|
||||
|
||||
```
|
||||
#-------------------------- Elasticsearch output ------------------------------
|
||||
#output.elasticsearch:
|
||||
# Array of hosts to connect to.
|
||||
# hosts: ["localhost:9200"]
|
||||
```
|
||||
|
||||
启用 logstash 输出,去掉以下配置的注释并且按照如下所示更改值。
|
||||
|
||||
```
|
||||
output.logstash:
|
||||
# The Logstash hosts
|
||||
hosts: ["10.0.15.10:5443"]
|
||||
bulk_max_size: 1024
|
||||
ssl.certificate_authorities: ["/etc/pki/tls/certs/logstash-forwarder.crt"]
|
||||
template.name: "filebeat"
|
||||
template.path: "filebeat.template.json"
|
||||
template.overwrite: false
|
||||
```
|
||||
|
||||
保存并退出 vim。
|
||||
|
||||
将 Filebeat 设定为开机启动并启动。
|
||||
|
||||
```
|
||||
sudo systemctl enable filebeat
|
||||
sudo systemctl start filebeat
|
||||
```
|
||||
|
||||
检查服务状态:
|
||||
|
||||
```
|
||||
systemctl status filebeat
|
||||
```
|
||||
|
||||
![Filebeat is running on the client Ubuntu] [16]
|
||||
|
||||
### 步骤 8 - 测试
|
||||
|
||||
打开您的网络浏览器,并访问您在 Nginx 中配置的 elastic stack 域名,我的是“elk-stack.co”。 使用管理员密码登录,然后按 Enter 键登录 Kibana 仪表盘。
|
||||
|
||||
![Login to the Kibana Dashboard with Basic Auth] [17]
|
||||
|
||||
创建一个新的默认索引 `filebeat-*`,然后点击“创建”按钮。
|
||||
|
||||
![Create First index filebeat for Kibana] [18]
|
||||
|
||||
默认索引已创建。 如果 elastic stack 上有多个 beat,您可以在“星形”按钮上点击一下即可配置默认 beat。
|
||||
|
||||
![Filebeat index as default index on Kibana Dashboard] [19]
|
||||
|
||||
转到 “发现” 菜单,您就可以看到 elk-client1 和 elk-client2 服务器上的所有日志文件。
|
||||
|
||||
![Discover all Log Files from the Servers] [20]
|
||||
|
||||
来自 elk-client1 服务器日志中的无效 ssh 登录的 JSON 输出示例。
|
||||
|
||||
![JSON output for Failed SSH Login] [21]
|
||||
|
||||
使用其他的选项,你可以使用 Kibana 仪表盘做更多的事情。
|
||||
|
||||
Elastic Stack 已安装在 CentOS 7 服务器上。 Filebeat 已安装在 CentOS 7 和 Ubuntu 客户端上。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-install-elastic-stack-on-centos-7/
|
||||
|
||||
作者:[Muhammad Arul][a]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.howtoforge.com/tutorial/how-to-install-elastic-stack-on-centos-7/
|
||||
[1]: https://www.howtoforge.com/tutorial/how-to-install-elastic-stack-on-centos-7/#step-nbspprepare-the-operating-system
|
||||
[2]: https://www.howtoforge.com/tutorial/how-to-install-elastic-stack-on-centos-7/#step-install-java
|
||||
[3]: https://www.howtoforge.com/tutorial/how-to-install-elastic-stack-on-centos-7/#step-install-and-configure-elasticsearch
|
||||
[4]: https://www.howtoforge.com/tutorial/how-to-install-elastic-stack-on-centos-7/#step-install-and-configure-kibana-with-nginx
|
||||
[5]: https://www.howtoforge.com/tutorial/how-to-install-elastic-stack-on-centos-7/#step-install-and-configure-logstash
|
||||
[6]: https://www.howtoforge.com/tutorial/how-to-install-elastic-stack-on-centos-7/#step-install-and-configure-filebeat-on-the-centos-client
|
||||
[7]: https://www.howtoforge.com/tutorial/how-to-install-elastic-stack-on-centos-7/#step-install-and-configure-filebeat-on-the-ubuntu-client
|
||||
[8]: https://www.howtoforge.com/tutorial/how-to-install-elastic-stack-on-centos-7/#step-testing
|
||||
[9]: https://www.howtoforge.com/tutorial/how-to-install-elastic-stack-on-centos-7/#reference
|
||||
[10]: https://www.howtoforge.com/images/how-to-install-elastic-stack-on-centos-7/big/1.png
|
||||
[11]: https://www.howtoforge.com/images/how-to-install-elastic-stack-on-centos-7/big/2.png
|
||||
[12]: https://www.howtoforge.com/images/how-to-install-elastic-stack-on-centos-7/big/3.png
|
||||
[13]: https://www.howtoforge.com/images/how-to-install-elastic-stack-on-centos-7/big/4.png
|
||||
[14]: https://www.howtoforge.com/images/how-to-install-elastic-stack-on-centos-7/big/5.png
|
||||
[15]: https://www.howtoforge.com/images/how-to-install-elastic-stack-on-centos-7/big/6.png
|
||||
[16]: https://www.howtoforge.com/images/how-to-install-elastic-stack-on-centos-7/big/12.png
|
||||
[17]: https://www.howtoforge.com/images/how-to-install-elastic-stack-on-centos-7/big/7.png
|
||||
[18]: https://www.howtoforge.com/images/how-to-install-elastic-stack-on-centos-7/big/8.png
|
||||
[19]: https://www.howtoforge.com/images/how-to-install-elastic-stack-on-centos-7/big/9.png
|
||||
[20]: https://www.howtoforge.com/images/how-to-install-elastic-stack-on-centos-7/big/10.png
|
||||
[21]: https://www.howtoforge.com/images/how-to-install-elastic-stack-on-centos-7/big/11.png
|
||||
@ -0,0 +1,82 @@
|
||||
让你的 Linux 远离黑客(三):问题回答
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
Mike Guthrie 最近在 Linux 基金会的网络研讨会上回答了一些安全相关的问题。随时观看免费的研讨会。[Creative Commons Zero][1]
|
||||
|
||||
这个系列的[第一篇][6]和[第二篇][7]文章覆盖了 5 个让你的 Linux 远离黑客的最简单方法,并且知道他们是否已经进入。这一次,我将回答一些我最近在 Linux 基金会网络研讨会上收到的很好的安全性问题。[随时观看免费网络研讨会][8]。
|
||||
|
||||
### 如果系统自动使用私钥认证,如何存储密钥密码?
|
||||
|
||||
这个很难。这是我们一直在斗争的事情,特别是我们在做 “Red Team” 的时候,因为我们有些需要自动调用的东西。我使用 Expect,但我倾向于在这上面使用老方法。你需要编写脚本,是的,将密码存储在系统上不是那么简单的一件事,当你这么做时你需要加密它。
|
||||
|
||||
我的 Expect 脚本加密了存储的密码,然后解密,发送密码,并在完成后重新加密。我知道到这有一些缺陷,但它比使用无密码的密钥更好。
|
||||
|
||||
如果你有一个无密码的密钥,并且你确实需要使用它。我建议你尽量限制需要用它的用户。例如,如果你正在进行一些自动日志传输或自动化软件安装,则只给那些需要执行这些功能的程序权限。
|
||||
|
||||
你可以通过 SSH 运行命令,所以不要给它们一个 shell,使它只能运行那个命令就行,这样就能防止某人窃取了这个密钥并做其他事情。
|
||||
|
||||
### 你对密码管理器如 KeePass2 怎么看?
|
||||
|
||||
对我而言,密码管理器是一个非常好的目标。随着 GPU 破解的出现和 EC2 的一些破解能力,这些东西很容易就变成过去时。我一直在窃取这些密码库。
|
||||
|
||||
现在,我们在破解这些库的成功率是另外一件事。我们差不多有 10% 左右的破解成功率。如果人们不能为他们的密码库用一个安全的密码,那么我们就会进入并会获得丰硕成果。比不用要强,但是你仍需要保护好这些资产。如你保护其他密码一样保护好密码库。
|
||||
|
||||
### 你认为从安全的角度来看,除了创建具有更高密钥长度的主机密钥之外,创建一个新的 “Diffie-Hellman” 模数并限制 2048 位或更高值得么?
|
||||
|
||||
值得的。以前在 SSH 产品中存在弱点,你可以做到解密数据包流。有了它,你可以传递各种数据。作为一种加密机制,人们不假思索使用这种方式来传输文件和密码。使用健壮的加密并且改变你的密钥是很重要的。 我会轮换我的 SSH 密钥 - 这不像我的密码那么频繁,但是我每年会轮换一次。是的,这是一个麻烦,但它让我安心。我建议尽可能地使你的加密技术健壮。
|
||||
|
||||
### 使用完全随机的英语单词(大概 10 万个)作为密码合适么?
|
||||
|
||||
当然。我的密码实际上是一个完整的短语。它是带标点符号和大小写一句话。除此以外,我不再使用其他任何东西。
|
||||
|
||||
我是一个“你可以记住而不用写下来或者放在密码库的密码”的大大的支持者。一个你可以记住不必写下来的密码比你需要写下来的密码更安全。
|
||||
|
||||
使用短语或使用你可以记住的四个随机单词比那些需要经过几次转换的一串数字和字符的字符串更安全。我目前的密码长度大约是 200 个字符。这是我可以快速打出来并且记住的。
|
||||
|
||||
### 在物联网情景下对保护基于 Linux 的嵌入式系统有什么建议么?
|
||||
|
||||
物联网是一个新的领域,它是系统和安全的前沿,日新月异。现在,我尽量都保持离线。我不喜欢人们把我的灯光和冰箱搞乱。我故意不去购买支持联网的冰箱,因为我有朋友是黑客,我可不想我每天早上醒来都会看到那些不雅图片。封住它,锁住它,隔离它。
|
||||
|
||||
目前物联网设备的恶意软件取决于默认密码和后门,所以只需要对你所使用的设备进行一些研究,并确保没有其他人可以默认访问。然后确保这些设备的管理接口受到防火墙或其他此类设备的良好保护。
|
||||
|
||||
### 你可以提一个可以在 SMB 和大型环境中使用的防火墙/UTM(OS 或应用程序)么?
|
||||
|
||||
我使用 pfSense,它是 BSD 的衍生产品。我很喜欢它。它有很多模块,实际上现在它有商业支持,这对于小企业来说这是非常棒的。对于更大的设备、更大的环境,这取决于你有哪些管理员。
|
||||
|
||||
我一直都是 CheckPoint 管理员,但是 Palo Alto 也越来越受欢迎了。这些设备与小型企业或家庭使用很不同。我在各种小型网络中都使用 pfSense。
|
||||
|
||||
### 云服务有什么内在问题么?
|
||||
|
||||
并没有云,那只不过是其他人的电脑而已。云服务存在内在的问题。只知道谁访问了你的数据,你在上面放了什么。要知道当你向 Amazon 或 Google 或 Microsoft 上传某些东西时,你将不再完全控制它,并且该数据的隐私是有问题的。
|
||||
|
||||
### 要获得 OSCP 你建议需要准备些什么?
|
||||
|
||||
我现在准备通过这个认证。我的整个团队是这样。阅读他们的材料。记住, OSCP 将成为令人反感的安全基准。你一切都要使用 Kali。如果不这样做 - 如果你决定不使用 Kali,请确保仿照 Kali 实例安装所有的工具。
|
||||
|
||||
这将是一个基于工具的重要认证。这是一个很好的方式。看看一些名为“渗透测试框架”的内容,因为这将为你提供一个很好的测试流程,他们的实验室似乎是很棒的。这与我家里的实验室非常相似。
|
||||
|
||||
_[随时免费观看完整的网络研讨会][3]。查看这个系列的[第一篇][4]和[第二篇][5]文章获得 5 个简单的贴士来让你的 Linux 机器安全。_
|
||||
|
||||
_Mike Guthrie 为能源部工作,负责 “Red Team” 的工作和渗透测试。_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/webinar/2017/how-keep-hackers-out-your-linux-machine-part-3-your-questions-answered
|
||||
|
||||
作者:[MIKE GUTHRIE][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/anch
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]:https://www.linux.com/files/images/keep-hackers-outjpg
|
||||
[3]:http://portal.on24.com/view/channel/index.html?showId=1101876&showCode=linux&partnerref=linco
|
||||
[4]:https://www.linux.com/news/webinar/2017/how-keep-hackers-out-your-linux-machine-part-1-top-two-security-tips
|
||||
[5]:https://www.linux.com/news/webinar/2017/how-keep-hackers-out-your-linux-machine-part-2-three-more-easy-security-tips
|
||||
[6]:https://linux.cn/article-8189-1.html
|
||||
[7]:https://linux.cn/article-8338-1.html
|
||||
[8]:http://portal.on24.com/view/channel/index.html?showId=1101876&showCode=linux&partnerref=linco
|
||||
@ -0,0 +1,140 @@
|
||||
在 Linux 上使用 Meld 比较文件夹
|
||||
============================================================
|
||||
|
||||
我们已经从一个新手的角度[了解][15]了 Meld (包括 Meld 的安装),我们也提及了一些 Meld 中级用户常用的小技巧。如果你有印象,在新手教程中,我们说过 Meld 可以比较文件和文件夹。已经讨论过怎么比较文件,今天,我们来看看 Meld 怎么比较文件夹。
|
||||
|
||||
**需要指出的是,本教程中的所有命令和例子都是在 Ubuntu 14.04 上测试的,使用的 Meld 版本为 3.14.2。**
|
||||
|
||||
### 用 Meld 比较文件夹
|
||||
|
||||
打开 Meld 工具,然后选择 <ruby>比较文件夹<rt>Directory comparison</rt></ruby> 选项来比较两个文件夹。
|
||||
|
||||
[
|
||||
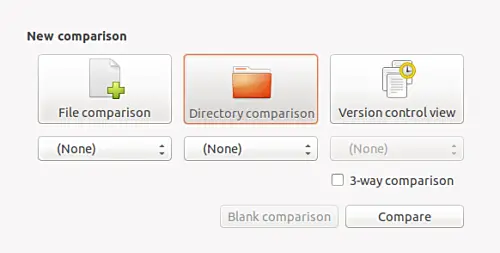
|
||||
][5]
|
||||
|
||||
选择你要比较的文件夹:
|
||||
|
||||
[
|
||||
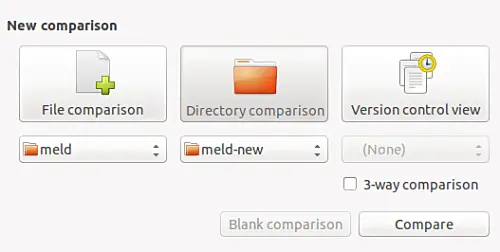
|
||||
][6]
|
||||
|
||||
然后单击<ruby>比较<rt>Compare </rt></ruby>按钮,你会看到 Meld 像图中这样分成两栏比较目录,就像文件比较一样。
|
||||
|
||||
[
|
||||
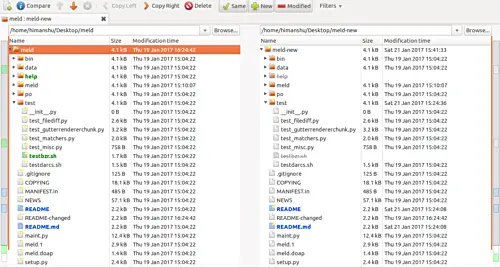
|
||||
][7]
|
||||
|
||||
分栏会树形显示这些文件夹。你可以在上图中看到 —— 区别之处,不论是新建的还是被修改过的文件 —— 都会以不同的颜色高亮显示。
|
||||
|
||||
根据 Meld 的官方文档可以知道,在窗口中看到的每个不同的文件或文件夹都会被突出显示。这样就很容易看出这个文件/文件夹与另一个分栏中对应位置的文件/文件夹的区别。
|
||||
|
||||
下表是 Meld 网站上列出的在比较文件夹时突出显示的不同字体大小/颜色/背景等代表的含义。
|
||||
|
||||
|**状态** | **表现** | **含义** |
|
||||
| --- | --- | --- |
|
||||
| 相同 | 正常字体 | 比较的文件夹中所有文件/文件夹相同。|
|
||||
| 过滤后相同 | 斜体 | 文件夹中文件不同,但使用文本过滤器的话,文件是相同的。|
|
||||
| 修改过 | 蓝色粗体 | 比较的文件夹中这些文件不同。 |
|
||||
| 新建 | 绿色粗体 | 该文件/文件夹在这个目录中存在,但其它目录中没有。|
|
||||
| 缺失 | 置灰文本,删除线 | 该文件/文件夹在这个目录中不存在,在在其它某个目录中存在。 |
|
||||
| 错误 | 黄色背景的红色粗体 | 比较文件时发生错误,最常见错误原因是文件权限(例如,Meld 无法打开该文件)和文件名编码错误。 |
|
||||
|
||||
Meld 默认会列出比较文件夹中的所有内容,即使这些内容没有任何不同。当然,你也可以在工具栏中单击<ruby>相同<rt>Same</rt></ruby>按钮设置 Meld 不显示这些相同的文件/文件夹 —— 单击这个按钮使其不可用。
|
||||
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
下面是单击 <ruby>相同<rt>Same</rt></ruby> 按钮使其不可用的截图:
|
||||
|
||||
[
|
||||
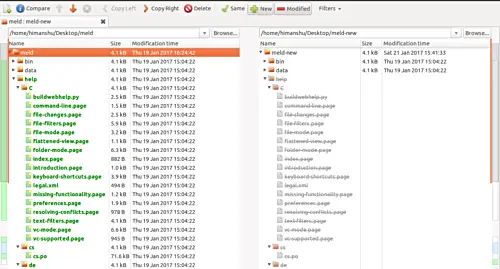
|
||||
][9]
|
||||
|
||||
这样你会看到只显示了两个文件夹中不同的文件(新建的和修改过的)。同样,如果你单击 <ruby>新建<rt>New</rt></ruby> 按钮使其不可用,那么 Meld 就只会列出修改过的文件。所以,在比较文件夹时可以通过这些按钮自定义要显示的内容。
|
||||
|
||||
你可以使用工具窗口显示区的上下箭头来切换选择是显示新建的文件还是修改过的文件。要打开两个文件进行分栏比较,可以双击文件,或者单击箭头旁边的 <ruby>比较<rt>Compare</rt></ruby>按钮。
|
||||
|
||||
[
|
||||
|
||||
][10]
|
||||
|
||||
**提示 1**:如果你仔细观察,就会看到 Meld 窗口的左边和右边有一些小条。这些条的目的是提供“简单的用颜色区分的比较结果”。对每个不同的文件/文件夹,条上就有一个小的颜色块。你可以单击每一个这样的小块跳到它对应的文件/文件夹。
|
||||
|
||||
**提示 2**:你总可以分栏比较文件,然后以你的方式合并不同的文件,假如你想要合并所有不同的文件/文件夹(就是说你想要一个特定的文件/文件夹与另一个完全相同),那么你可以用 <ruby>复制到左边<rt>Copy Left</rt></ruby>和 <ruby>复制到右边<rt>Copy Right</rt></ruby> 按钮:
|
||||
|
||||
[
|
||||

|
||||
][11]
|
||||
|
||||
比如,你可以在左边的分栏中选择一个文件或文件夹,然后单击 <ruby>复制到右边<rt>Copy Right</rt></ruby> 按钮,使右边对应条目完全一样。
|
||||
|
||||
现在,在窗口的下拉菜单中找到 <ruby>过滤<rt>Filters </rt></ruby> 按钮,它就在 <ruby>相同<rt>Same</rt></ruby>、<ruby>新建<rt>New</rt></ruby> 和 <ruby>修改的<rt>Modified</rt></ruby> 这三个按钮下面。这里你可以选择或取消文件的类型,告知 Meld 在比较文件夹时是否显示这种类型的文件/文件夹。官方文档解释说菜单中的这个条目表示“执行文件夹比较时该类文件名不会被查看。”
|
||||
|
||||
该列表中条目包括备份文件,操作系统元数据,版本控制文件、二进制文件和多媒体文件。
|
||||
|
||||
[
|
||||
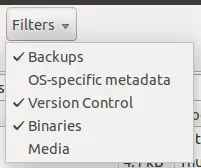
|
||||
][12]
|
||||
|
||||
前面提到的条目也可以通过这样的方式找到:_浏览->文件过滤_。你可以通过 _编辑->首选项->文件过滤_ 为这个条目增加新元素(也可以删除已经存在的元素)。
|
||||
|
||||
[
|
||||
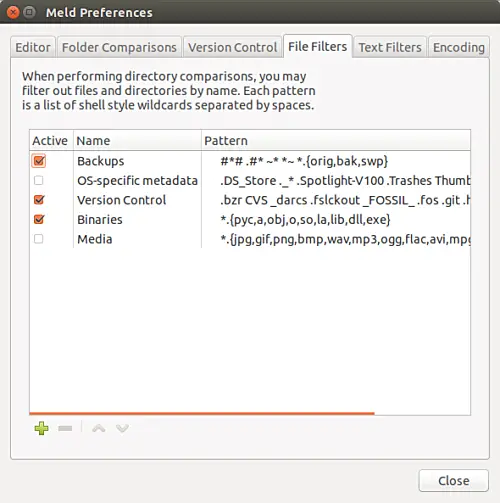
|
||||
][13]
|
||||
|
||||
要新建一个过滤条件,你需要使用一组 shell 符号,下表列出了 Meld 支持的 shell 符号:
|
||||
|
||||
| **通配符** | **匹配** |
|
||||
| --- | --- |
|
||||
| * | 任何字符 (例如,零个或多个字符) |
|
||||
| ? | 一个字符 |
|
||||
| [abc] | 所列字符中的任何一个 |
|
||||
| [!abc] | 不在所列字符中的任何一个 |
|
||||
| {cat,dog} | “cat” 或 “dog” 中的一个 |
|
||||
|
||||
最重要的一点是 Meld 的文件名默认大小写敏感。也就是说,Meld 认为 readme 和 ReadMe 与 README 是不一样的文件。
|
||||
|
||||
幸运的是,你可以关掉 Meld 的大小写敏感。只需要打开 _浏览_ 菜单然后选择 <ruby>忽略文件名大小写<rt> Ignore Filename Case </rt></ruby> 选项。
|
||||
[
|
||||
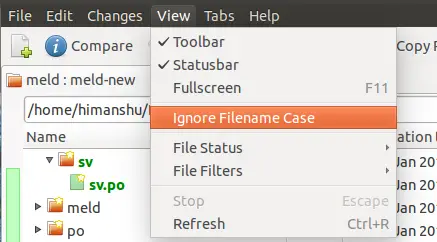
|
||||
][14]
|
||||
|
||||
### 结论
|
||||
|
||||
你是否觉得使用 Meld 比较文件夹很容易呢 —— 事实上,我认为它相当容易。只有新建一个文件过滤器会花点时间,但是这不意味着你没必要学习创建过滤器。显然,这取决于你的需求。
|
||||
|
||||
另外,你甚至可以用 Meld 比较三个文件夹。想要比较三个文件夹时,你可以通过单击 <ruby>三向比较<rt>3-way comparison</rt></ruby> 复选框。今天,我们不介绍怎么比较三个文件夹,但它肯定会出现在后续的教程中。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-perform-directory-comparison-using-meld/
|
||||
|
||||
作者:[Ansh][a]
|
||||
译者:[vim-kakali](https://github.com/vim-kakali)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/how-to-perform-directory-comparison-using-meld/
|
||||
[1]:https://www.howtoforge.com/tutorial/how-to-perform-directory-comparison-using-meld/#compare-directories-using-meld
|
||||
[2]:https://www.howtoforge.com/tutorial/how-to-perform-directory-comparison-using-meld/#conclusion
|
||||
[3]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-3/big/meld-same-button.png
|
||||
[4]:https://www.howtoforge.com/tutorial/beginners-guide-to-visual-merge-tool-meld-on-linux/
|
||||
[5]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-3/big/meld-dir-comp-1.png
|
||||
[6]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-3/big/meld-sel-dir-2.png
|
||||
[7]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-3/big/meld-dircomp-begins-3.png
|
||||
[8]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-3/big/meld-same-disabled.png
|
||||
[9]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-3/big/meld-only-diff.png
|
||||
[10]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-3/big/meld-compare-arrows.png
|
||||
[11]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-3/big/meld-copy-right-left.png
|
||||
[12]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-3/big/meld-filters.png
|
||||
[13]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-3/big/meld-edit-filters-menu.png
|
||||
[14]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-3/big/meld-ignore-case.png
|
||||
[15]:https://linux.cn/article-8402-1.html
|
||||
@ -2,17 +2,18 @@
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
>Image by : [Pixabay][2]. Modified by Opensource.com. [CC BY-SA 4.0][3]
|
||||
|
||||
我认识的大部分人为了他们的日历、电子邮件、文件存储等,都会使用一些基于 Web 的应用。但是,如果像我这样,对隐私感到担忧、或者只是希望将你自己的数字生活简单化为一个你所控制的地方呢? [Cozy][4] 就是一个朝着健壮的自主云平台方向发展的项目。你可以从 [GitHub][5] 上获取 Cozy 的源代码,它采用 AGPL 3.0 协议。
|
||||
|
||||
### 安装
|
||||
|
||||
安装 Cozy 非常快捷简单,这里有多种平台的 [简单易懂安装指令][6]。在我的测试中,我使用 64 位的 Debian 8 系统。安装需要几分钟时间,然后你只需要到服务器的 IP 地址注册一个账号,就会加载并准备好默认的应用程序集。
|
||||
安装 Cozy 非常快捷简单,这里有多种平台的 [简单易懂的安装指令][6]。在我的测试中,我使用 64 位的 Debian 8 系统。安装需要几分钟时间,然后你只需要到服务器的 IP 地址注册一个账号,就会加载并准备好默认的应用程序集。
|
||||
|
||||
要注意的一点 - 安装假设没有正在运行任何其它 Web 服务,而且它会尝试安装 [Nginx web 服务器][7]。如果你的服务器已经有网站正在运行,配置可能就比较麻烦。我是在一个全新的 VPS(Virtual Private Server,虚拟个人服务器)上安装,因此比较简单。运行安装程序、启动 Nginx,然后你就可以访问云了。
|
||||
|
||||
Cozy 还有一个 [应用商店][8],你可以从中下载额外的应用程序。有一些看起来非常有趣,例如 [Ghost 博客平台][9] 以及开源维基 [TiddlyWiki][10]。其中的目标,显然是允许把其它很多好的应用程序集成到这个平台。我认为你要看到很多其它流行的开源应用程序提供集成功能只是时间问题。此刻,已经支持 [Node.js][11],但是如何也支持其它应用层,你就可以看到很多其它很好的应用程序。
|
||||
Cozy 还有一个 [应用商店][8],你可以从中下载额外的应用程序。有一些看起来非常有趣,例如 [Ghost 博客平台][9] 以及开源维基 [TiddlyWiki][10]。其目的,显然是允许把其它很多好的应用程序集成到这个平台。我认为你要看到很多其它流行的开源应用程序提供集成功能只是时间问题。此刻,已经支持 [Node.js][11],但是如果也支持其它应用层,你就可以看到很多其它很好的应用程序。
|
||||
|
||||
其中可能的一个功能是从安卓设备中使用免费的安卓应用程序访问你的信息。当前还没有 iOS 应用,但有计划要解决这个问题。
|
||||
|
||||
@ -20,27 +21,27 @@ Cozy 还有一个 [应用商店][8],你可以从中下载额外的应用程序
|
||||
|
||||

|
||||
|
||||
主要 Cozy 界面
|
||||
*主要 Cozy 界面*
|
||||
|
||||
### 文件
|
||||
|
||||
和很多分支一样,我使用 [Dropbox][12] 进行文件存储。事实上,由于我有很多东西需要存储,我需要花钱买 DropBox Pro。对我来说,如果它有我想要的功能,那么把我的文件移动到 Cozy 能为我节省很多开销。
|
||||
|
||||
我希望我能说这是真的,我确实做到了。我被 Cozy 应用程序内建的基于 web 的文件上传和文件管理工具所惊讶。拖拽功能正如你期望的那样,界面也很干净整洁。我在上传事例文件和目录、随处跳转、移动、删除以及重命名文件时都没有遇到问题。
|
||||
我希望如此,而它真的可以。我被 Cozy 应用程序内建的基于 web 的文件上传和文件管理工具所惊讶。拖拽功能正如你期望的那样,界面也很干净整洁。我在上传事例文件和目录、随处跳转、移动、删除以及重命名文件时都没有遇到问题。
|
||||
|
||||
如果你想要的就是基于 web 的云文件存储,那么你做到了。对我来说,它缺失的是 DropBox 具有的选择性文件目录同步功能。在 DropBox 中,如果你拖拽一个文件到目录中,它就会被拷贝到云,几分钟后该文件在你所有同步设备中都可以看到。实际上,[Cozy 正在研发该功能][13],但此时它还处于 beta 版,而且只支持 Linux 客户端。另外,我有一个称为 [Download to Dropbox][15] 的 [Chrome][14] 扩展,我时不时用它抓取图片和其它内容,但当前 Cozy 中还没有类似的工具。
|
||||
如果你想要的就是基于 web 的云文件存储,那么你已经有了。对我来说,它缺失的是 DropBox 具有的选择性的文件目录同步功能。在 DropBox 中,如果你拖拽一个文件到目录中,它就会被拷贝到云,几分钟后该文件在你所有同步设备中都可以看到。实际上,[Cozy 正在研发该功能][13],但此时它还处于 beta 版,而且只支持 Linux 客户端。另外,我有一个称为 [Download to Dropbox][15] 的 [Chrome][14] 扩展,我时不时用它抓取图片和其它内容,但当前 Cozy 中还没有类似的工具。
|
||||
|
||||

|
||||
|
||||
文件管理界面
|
||||
*文件管理界面*
|
||||
|
||||
### 从 Google 导入数据
|
||||
|
||||
如果你正在使用 Google 日历和联系人,使用 Cozy 安装的应用程序很轻易的就可以导入它们。当你授权访问 Google 时,会给你一个 API 密钥,把它粘贴到 Cozy,它就会迅速高效地进行复制。两种情况下,内容都会被打上“从 Google 导入”的标签。对于我混乱的联系人,这可能是件好事情,因为它使得我有机会重新整理,把它们重新标记为更有意义的类别。“Google Calendar” 中所有的事件都导入了,但是我注意到其中一些事件的时间不对,可能是由于两端时区设置的影响。
|
||||
如果你正在使用 Google 日历和联系人,使用 Cozy 安装的应用程序很轻易的就可以导入它们。当你授权对 Google 的访问时,会给你一个 API 密钥,把它粘贴到 Cozy,它就会迅速高效地进行复制。两种情况下,内容都会被打上“从 Google 导入”的标签。对于我混乱的联系人,这可能是件好事情,因为它使得我有机会重新整理,把它们重新标记为更有意义的类别。“Google Calendar” 中所有的事件都导入了,但是我注意到其中一些事件的时间不对,可能是由于两端时区设置的影响。
|
||||
|
||||
### 联系人
|
||||
|
||||
联系人正如你期望的那样,界面也很像 Google 联系人。尽管如此,还是有一些不好的地方。和你(例如)智能手机的同步通过 [CardDAV][16] 完成,这是用于共享联系人数据的标准协议,但安卓手机并不原生支持该技术。为了把你的联系人同步到安卓设备,你需要在你的手机上安装一个应用。这对我来说是个很大的打击,因为我已经有很多类似这样的旧应用程序了(例如 work mail、Gmail以及其它 mail,我的天),我并不想安装一个不能和我智能手机原生联系人应用程序同步的软件。如果你正在使用 iPhone,你直接就能使用 CradDAV。
|
||||
联系人功能正如你期望的那样,界面也很像 Google 联系人。尽管如此,还是有一些不好的地方。例如,和你的智能手机的同步是通过 [CardDAV][16] 完成的,这是用于共享联系人数据的标准协议,但安卓手机并不原生支持该技术。为了把你的联系人同步到安卓设备,你需要在你的手机上安装一个应用。这对我来说是个很大的打击,因为我已经有很多类似这样的古怪应用程序了(例如 工作的邮件、Gmail 以及其它邮件,我的天),我并不想安装一个不能和我智能手机原生联系人应用程序同步的软件。如果你正在使用 iPhone,你直接就能使用 CradDAV。
|
||||
|
||||
### 日历
|
||||
|
||||
@ -48,15 +49,15 @@ Cozy 还有一个 [应用商店][8],你可以从中下载额外的应用程序
|
||||
|
||||
### 照片
|
||||
|
||||
照片应用让我印象深刻,它从文件应用程序借鉴了很多东西。你甚至可以把一个其它应用程序的照片文件添加到相册,或者直接通过拖拽上传。不幸的是,一旦上传后,我没有找到任何重拍和编辑照片的方法。你只能把它们从相册中删除。应用有一个通过令牌链接进行分享的工具,而且你可以指定一个或多个联系人。系统会给这些联系人发送邀请他们查看相册的电子邮件。当然还有很多比这个有更丰富功能的相册应用,但在 Cozy 平台中这算是一个好的起点。
|
||||
照片应用让我印象深刻,它从文件应用程序借鉴了很多东西。你甚至可以把一个其它应用程序的照片文件添加到相册,或者直接通过拖拽上传。不幸的是,一旦上传后,我没有找到任何重新排序和编辑照片的方法。你只能把它们从相册中删除。应用有一个通过令牌链接进行分享的工具,而且你可以指定一个或多个联系人。系统会给这些联系人发送邀请他们查看相册的电子邮件。当然还有很多比这个有更丰富功能的相册应用,但在 Cozy 平台中这算是一个好的起点。
|
||||
|
||||

|
||||
|
||||
Photos 界面
|
||||
*Photos 界面*
|
||||
|
||||
### 总结
|
||||
|
||||
Cozy 目标远大。他们尝试搭建你能部署任意你想要的基于云的服务的平台。它已经到了黄金时段吗?我并不认为。对于一些重度用户来说我之前提到的一些问题很严重,而且还没有 iOS 应用,这可能阻碍用户使用它。不管怎样,继续关注吧 - 随着研发的继续,Cozy 有一家代替很多应用程序的潜能。
|
||||
Cozy 目标远大。他们尝试搭建一个你能部署任意你想要的基于云服务的平台。它已经到了成熟期吗?我并不认为。对于一些重度用户来说我之前提到的一些问题很严重,而且还没有 iOS 应用,这可能阻碍用户使用它。不管怎样,继续关注吧 - 随着研发的继续,Cozy 有一家代替很多应用程序的潜能。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -70,7 +71,7 @@ via: https://opensource.com/article/17/2/cozy-personal-cloud
|
||||
|
||||
作者:[D Ruth Bavousett][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,57 @@
|
||||
OpenContrail:一个 OpenStack 生态中的重要工具
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
|
||||
*OpenContrail 是用于 OpenStack 云计算平台的 SDN 平台,它正在成为管理员需要具备的技能的重要工具。*
|
||||
|
||||
[Creative Commons Zero] [1] Pixabay
|
||||
|
||||
整个 2016 年,软件定义网络(SDN)迅速发展,开源和云计算领域的众多参与者正帮助其获得增长。结合这一趋势,用在 OpenStack 云计算平台上的流行的 SDN 平台 [OpenContrail][3] 正成为许多管理员需要具备的技能的重要工具。
|
||||
|
||||
正如管理员和开发人员在 OpenStack 生态系统中围绕着诸如 Ceph 等重要工具提升技能一样,他们将需要拥抱 OpenContrail,它是由 Apache 软件基金会全面开源并管理的软件。
|
||||
|
||||
考虑到这些,OpenStack 领域中最活跃的公司之一 Mirantis 已经[宣布][4]对 OpenContrail 的提供商业支持和贡献。该公司提到:“添加了 OpenContrail 后,Mirantis 将会为与 OpenStack 一起使用的开源技术,包括用于存储的 Ceph、用于计算的 OpenStack/KVM、用于 SDN 的 OpenContrail 或 Neutron 提供一站式的支持。”
|
||||
|
||||
根据 Mirantis 公告,“OpenContrail 是一个使用基于标准协议构建的 Apache 2.0 许可项目,为网络虚拟化提供了所有必要的组件 - SDN 控制器、虚拟路由器、分析引擎和已发布的上层 API,它有一个可扩展 REST API 用于配置以及从系统收集操作和分析数据。作为规模化构建,OpenContrail 可以作为云基础设施的基础网络平台。”
|
||||
|
||||
有消息称 Mirantis [收购了 TCP Cloud][5],这是一家专门从事 OpenStack、OpenContrail 和 Kubernetes 管理服务的公司。Mirantis 将使用 TCP Cloud 的云架构持续交付技术来管理将在 Docker 容器中运行的 OpenContrail 控制面板。作为这项工作的一部分,Mirantis 也会一直致力于 OpenContrail。
|
||||
|
||||
OpenContrail 的许多贡献者正在与 Mirantis 紧密合作,他们特别注意了 Mirantis 将提供的支持计划。
|
||||
|
||||
“OpenContrail 是 OpenStack 社区中一个重要的项目,而 Mirantis 很好地容器化并提供商业支持。我们团队正在做的工作使 OpenContrail 能轻松地扩展并更新,并与 Mirantis OpenStack 的其余部分进行无缝滚动升级。 ” Mirantis 的工程师总监和 OpenContrail 咨询委员会主任 Jakub Pavlik 说:“商业支持也将使 Mirantis 能够使该项目与各种交换机兼容,从而为客户提供更多的硬件和软件选择。”
|
||||
|
||||
除了 OpenContrail 的商业支持外,我们很可能还会看到 Mirantis 为那些想要学习如何利用它的云管理员和开发人员提供的教育服务。Mirantis 已经以其 [OpenStack 培训][6]课程而闻名,并将 Ceph 纳入了培训课程中。
|
||||
|
||||
在 2016 年,SDN 种类快速演变,并且对许多部署 OpenStack 的组织也有意义。IDC 最近发布了 SDN 市场的[一项研究][7],预计从 2014 年到 2020 年 SDN 市场的年均复合增长率为 53.9%,届时市场价值将达到 125 亿美元。此外,“Technology Trends 2016” 报告将 SDN 列为组织最佳的技术投资之一。
|
||||
|
||||
IDC 网络基础设施总裁 [Rohit Mehra][8] 说:“云计算和第三方平台推动了 SDN 的需求,它将在 2020 年代表一个价值超过 125 亿美元的市场。丝毫不用奇怪的是 SDN 的价值将越来越多地渗透到网络虚拟化软件和 SDN 应用中,包括虚拟化网络和安全服务。大型企业在数据中心中实现 SDN 的价值,但它们最终将会认识到其在横跨分支机构和校园网络的广域网中的广泛应用。”
|
||||
|
||||
同时,Linux 基金会最近[宣布][9]发布了其 2016 年度报告[“开放云指导:当前趋势和开源项目”][10]。第三份年度报告全面介绍了开放云计算,并包含一个关于 SDN 的部分。
|
||||
|
||||
Linux 基金会还提供了[软件定义网络基础知识][11](LFS265),这是一个自定进度的 SDN 在线课程,另外作为 [Open Daylight][12] 项目的领导者,另一个重要的开源 SDN 平台正在迅速成长。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/event/open-networking-summit/2017/2/opencontrail-essential-tool-openstack-ecosystem
|
||||
|
||||
作者:[SAM DEAN][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/sam-dean
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]:https://www.linux.com/files/images/contrails-cloudjpg
|
||||
[3]:https://www.globenewswire.com/Tracker?data=brZ3aJVRyVHeFOyzJ1Dl4DMY3CsSV7XcYkwRyOcrw4rDHplSItUqHxXtWfs18mLsa8_bPzeN2EgZXWcQU8vchg==
|
||||
[4]:http://www.econotimes.com/Mirantis-Becomes-First-Vendor-to-Offer-Support-and-Managed-Services-for-OpenContrail-SDN-486228
|
||||
[5]:https://www.globenewswire.com/Tracker?data=Lv6LkvREFzGWgujrf1n6r_qmjSdu67-zdRAYt2itKQ6Fytomhfphuk5EbDNjNYtfgAsbnqI8H1dn_5kB5uOSmmSYY9XP2ibkrPw_wKi5JtnAyV43AjuR_epMmOUkZZ8QtFdkR33lTGDmN6O5B4xkwv7fENcDpm30nI2Og_YrYf0b4th8Yy4S47lKgITa7dz2bJpwpbCIzd7muk0BZ17vsEp0S3j4kQJnmYYYk5udOMA=
|
||||
[6]:https://training.mirantis.com/
|
||||
[7]:https://www.idc.com/getdoc.jsp?containerId=prUS41005016
|
||||
[8]:http://www.idc.com/getdoc.jsp?containerId=PRF003513
|
||||
[9]:https://www.linux.com/blog/linux-foundation-issues-2016-guide-open-source-cloud-projects
|
||||
[10]:http://ctt.marketwire.com/?release=11G120876-001&id=10172077&type=0&url=http%3A%2F%2Fgo.linuxfoundation.org%2Frd-open-cloud-report-2016-pr
|
||||
[11]:https://training.linuxfoundation.org/linux-courses/system-administration-training/software-defined-networking-fundamentals
|
||||
[12]:https://www.opendaylight.org/
|
||||
@ -0,0 +1,198 @@
|
||||
lnav:Linux 下一个基于控制台的高级日志文件查看器
|
||||
============================================================
|
||||
|
||||
[LNAV][3](Log file Navigator)是 Linux 下一个基于控制台的高级日志文件查看器。它和其它文件查看器,例如 cat、more、tail 等,完成相同的任务,但有很多普通文件查看器没有的增强功能(尤其是它自带多种颜色和易于阅读的格式)。
|
||||
|
||||
它能在解压多个压缩日志文件(zip、gzip、bzip)的同时把它们合并到一起进行导航。基于消息的时间戳,`lnav` 能把多个日志文件合并到一个视图(Single Log Review),从而避免打开多个窗口。左边的颜色栏帮助显示消息所属的文件。
|
||||
|
||||
警告和错误的数量以(黄色和红色)高亮显示,因此我们能够很轻易地看到问题出现在哪里。它会自动加载新的日志行。
|
||||
|
||||
它按照消息时间戳排序显示所有文件的日志消息。顶部和底部的状态栏会告诉你位于哪个日志文件。如果你想按特定的模式查找,只需要在搜索弹窗中输入就会即时显示。
|
||||
|
||||
内建的日志消息解析器会自动从每一行中发现和提取详细信息。
|
||||
|
||||
服务器日志是一个由服务器创建并经常更新、用于抓取特定服务和应用的所有活动信息的日志文件。当你的应用或者服务出现问题时这个文件就会非常有用。从日志文件中你可以获取所有关于该问题的信息,例如基于警告或者错误信息它什么时候开始表现不正常。
|
||||
|
||||
当你用一个普通文件查看器打开一个日志文件时,它会用纯文本格式显示所有信息(如果用更直白的话说的话:纯白——黑底白字),这样很难去发现和理解哪里有警告或错误信息。为了克服这种情况,快速找到警告和错误信息来解决问题, lnav 是一个入手可用的更好的解决方案。
|
||||
|
||||
大部分常见的 Linux 日志文件都放在 `/var/log/`。
|
||||
|
||||
**lnav 自动检测以下日志格式**
|
||||
|
||||
* Common Web Access Log format(普通 web 访问日志格式)
|
||||
* CUPS page_log
|
||||
* Syslog
|
||||
* Glog
|
||||
* VMware ESXi/vCenter 日志
|
||||
* dpkg.log
|
||||
* uwsgi
|
||||
* “Generic” – 以时间戳开始的任何消息
|
||||
* Strace
|
||||
* sudo
|
||||
* gzib & bizp
|
||||
|
||||
**lnav 高级功能**
|
||||
|
||||
* 单一日志视图 - 基于消息时间戳,所有日志文件内容都会被合并到一个单一视图
|
||||
* 自动日志格式检测 - `lnav` 支持大部分日志格式
|
||||
* 过滤器 - 能进行基于正则表达式的过滤
|
||||
* 时间线视图
|
||||
* 适宜打印视图(Pretty-Print)
|
||||
* 使用 SQL 查询日志
|
||||
* 自动数据抽取
|
||||
* 实时操作
|
||||
* 语法高亮
|
||||
* Tab 补全
|
||||
* 当你查看相同文件集时可以自动保存和恢复会话信息。
|
||||
* Headless 模式
|
||||
|
||||
### 如何在 Linux 中安装 lnav
|
||||
|
||||
大部分发行版(Debian、Ubuntu、Mint、Fedora、suse、openSUSE、Arch Linux、Manjaro、Mageia 等等)默认都有 `lnav` 软件包,在软件包管理器的帮助下,我们可以很轻易地从发行版官方仓库中安装它。对于 CentOS/RHEL 我们需要启用 **[EPEL 仓库][1]**。
|
||||
|
||||
```
|
||||
[在 Debian/Ubuntu/LinuxMint 上安装 lnav]
|
||||
$ sudo apt-get install lnav
|
||||
|
||||
[在 RHEL/CentOS 上安装 lnav]
|
||||
$ sudo yum install lnav
|
||||
|
||||
[在 Fedora 上安装 lnav]
|
||||
$ sudo dnf install lnav
|
||||
|
||||
[在 openSUSE 上安装 lnav]
|
||||
$ sudo zypper install lnav
|
||||
|
||||
[在 Mageia 上安装 lnav]
|
||||
$ sudo urpmi lnav
|
||||
|
||||
[在基于 Arch Linux 的系统上安装 lnav]
|
||||
$ yaourt -S lnav
|
||||
```
|
||||
|
||||
如果你的发行版没有 `lnav` 软件包,别担心,开发者提供了 `.rpm` 和 `.deb` 安装包,因此我们可以轻易安装。确保你从 [开发者 github 页面][4] 下载最新版本的安装包。
|
||||
|
||||
```
|
||||
[在 Debian/Ubuntu/LinuxMint 上安装 lnav]
|
||||
$ sudo wget https://github.com/tstack/lnav/releases/download/v0.8.1/lnav_0.8.1_amd64.deb
|
||||
$ sudo dpkg -i lnav_0.8.1_amd64.deb
|
||||
|
||||
[在 RHEL/CentOS 上安装 lnav]
|
||||
$ sudo yum install https://github.com/tstack/lnav/releases/download/v0.8.1/lnav-0.8.1-1.x86_64.rpm
|
||||
|
||||
[在 Fedora 上安装 lnav]
|
||||
$ sudo dnf install https://github.com/tstack/lnav/releases/download/v0.8.1/lnav-0.8.1-1.x86_64.rpm
|
||||
|
||||
[在 openSUSE 上安装 lnav]
|
||||
$ sudo zypper install https://github.com/tstack/lnav/releases/download/v0.8.1/lnav-0.8.1-1.x86_64.rpm
|
||||
|
||||
[在 Mageia 上安装 lnav]
|
||||
$ sudo rpm -ivh https://github.com/tstack/lnav/releases/download/v0.8.1/lnav-0.8.1-1.x86_64.rpm
|
||||
```
|
||||
|
||||
### 不带参数运行 lnav
|
||||
|
||||
默认情况下你不带参数运行 `lnav` 时它会打开 `syslog` 文件。
|
||||
|
||||
```
|
||||
# lnav
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
### 使用 lnav 查看特定日志文件
|
||||
|
||||
要用 `lnav` 查看特定的日志文件,在 `lnav` 命令后面添加日志文件路径。例如我们想看 `/var/log/dpkg.log` 日志文件。
|
||||
|
||||
```
|
||||
# lnav /var/log/dpkg.log
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
### 用 lnav 查看多个日志文件
|
||||
|
||||
要用 `lnav` 查看多个日志文件,在 lnav 命令后面逐个添加日志文件路径,用一个空格隔开。例如我们想查看 `/var/log/dpkg.log` 和 `/var/log/kern.log` 日志文件。
|
||||
|
||||
左边的颜色栏帮助显示消息所属的文件。另外顶部状态栏还会显示当前日志文件的名称。为了显示多个日志文件,大部分应用经常会打开多个窗口、或者在窗口中水平或竖直切分,但 `lnav` 使用不同的方式(它基于日期组合在同一个窗口显示多个日志文件)。
|
||||
|
||||
```
|
||||
# lnav /var/log/dpkg.log /var/log/kern.log
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
### 使用 lnav 查看压缩的日志文件
|
||||
|
||||
要查看并同时解压被压缩的日志文件(zip、gzip、bzip),在 `lnav` 命令后面添加 `-r` 选项。
|
||||
|
||||
```
|
||||
# lnav -r /var/log/Xorg.0.log.old.gz
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
### 直方图视图
|
||||
|
||||
首先运行 `lnav` 然后按 `i` 键切换到/出直方图视图。
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
### 查看日志解析器结果
|
||||
|
||||
首先运行 `lnav` 然后按 `p` 键打开显示日志解析器结果。
|
||||
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
### 语法高亮
|
||||
|
||||
你可以搜索任何给定的字符串,它会在屏幕上高亮显示。首先运行 `lnav` 然后按 `/` 键并输入你想查找的字符串。为了测试,我搜索字符串 `Default`,看下面的截图。
|
||||
|
||||
[
|
||||

|
||||
][11]
|
||||
|
||||
### Tab 补全
|
||||
|
||||
命令窗口支持大部分操作的 tab 补全。例如,在进行搜索时,你可以使用 tab 补全屏幕上显示的单词,而不需要复制粘贴。为了测试,我搜索字符串 `/var/log/Xorg`,看下面的截图。
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.2daygeek.com/install-and-use-advanced-log-file-viewer-navigator-lnav-in-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.2daygeek.com/author/magesh/
|
||||
[1]:http://www.2daygeek.com/install-enable-epel-repository-on-rhel-centos-scientific-linux-oracle-linux/
|
||||
[2]:http://www.2daygeek.com/author/magesh/
|
||||
[3]:http://lnav.org/
|
||||
[4]:https://github.com/tstack/lnav/releases
|
||||
[5]:http://www.2daygeek.com/wp-content/uploads/2017/01/lnav-advanced-log-file-viewer-1.png
|
||||
[6]:http://www.2daygeek.com/wp-content/uploads/2017/01/lnav-advanced-log-file-viewer-2.png
|
||||
[7]:http://www.2daygeek.com/wp-content/uploads/2017/01/lnav-advanced-log-file-viewer-3.png
|
||||
[8]:http://www.2daygeek.com/wp-content/uploads/2017/01/lnav-advanced-log-file-viewer-6.png
|
||||
[9]:http://www.2daygeek.com/wp-content/uploads/2017/01/lnav-advanced-log-file-viewer-4.png
|
||||
[10]:http://www.2daygeek.com/wp-content/uploads/2017/01/lnav-advanced-log-file-viewer-5.png
|
||||
[11]:http://www.2daygeek.com/wp-content/uploads/2017/01/lnav-advanced-log-file-viewer-7.png
|
||||
[12]:http://www.2daygeek.com/wp-content/uploads/2017/01/lnav-advanced-log-file-viewer-8.png
|
||||
@ -0,0 +1,292 @@
|
||||
史上最全的使用 gnome-screenshot 获取屏幕快照指南
|
||||
============================================================
|
||||
|
||||
在应用市场中有好几种屏幕截图工具,但其中大多数都是基于 GUI 的。如果你花时间在 linux 命令行上工作,而且正在寻找一款优秀的功能丰富的基于命令行的屏幕截图工具,你可能会想尝试 [gnome-screenshot][17]。在本教程中,我将使用易于理解的例子来解释这个实用程序。
|
||||
|
||||
请注意,本教程中提到的所有例子已经在 Ubuntu 16.04 LTS 上测试过,测试所使用的 gonme-screenshot 版本是 3.18.0。
|
||||
|
||||
### 关于 Gnome-screenshot
|
||||
|
||||
Gnome-screenshot 是一款 GNOME 工具,顾名思义,它是一款用来对整个屏幕、一个特定的窗口或者用户所定义一些其他区域进行捕获的工具。该工具提供了几个其他的功能,包括对所捕获的截图的边界进行美化的功能。
|
||||
|
||||
### Gnome-screenshot 安装
|
||||
|
||||
Ubuntu 系统上已经预安装了 gnome-screeshot 工具,但是如果你出于某些原因需要重新安装这款软件程序,你可以使用下面的命令来进行安装:
|
||||
|
||||
```
|
||||
sudo apt-get install gnome-screeshot
|
||||
```
|
||||
|
||||
一旦软件安装完成后,你可以使用下面的命令来启动它:
|
||||
|
||||
```
|
||||
gnome-screenshot
|
||||
```
|
||||
|
||||
### Gnome-screenshot 用法/特点
|
||||
|
||||
在这部分,我们将讨论如何使用 gnome-screenshot ,以及它提供的所有功能。
|
||||
|
||||
默认情况下,使用该工具且不带任何命令行选项时,就会抓取整个屏幕。
|
||||
|
||||
[
|
||||
|
||||
][18]
|
||||
|
||||
#### 捕获当前活动窗口
|
||||
|
||||
如何你需要的话,你可以使用 `-w` 选项限制到只对当前活动窗口截图。
|
||||
|
||||
```
|
||||
gnome-screenshot -w
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][19]
|
||||
|
||||
#### 窗口边框
|
||||
|
||||
默认情况下,这个程序会将它捕获的窗口的边框包含在内,尽管还有一个明确的命令行选项 `-b` 可以启用此功能(以防你在某处想使用它)。以下是如何使用这个程序的:
|
||||
|
||||
```
|
||||
gnome-screenshot -wb
|
||||
```
|
||||
|
||||
当然,你需要同时使用 `-w` 选项和 `-b` 选项,以便捕获的是当前活动的窗口(否则,`-b` 将没有作用)。
|
||||
|
||||
更重要的是,如果你需要的话,你也可以移除窗口的边框。可以使用 `-B` 选项来完成。下面是你可以如何使用这个选项的一个例子:
|
||||
|
||||
```
|
||||
gnome-screenshot -wB
|
||||
```
|
||||
|
||||
下面是例子的截图:
|
||||
|
||||
[
|
||||
|
||||
][20]
|
||||
|
||||
#### 添加效果到窗口边框
|
||||
|
||||
在 gnome-screenshot 工具的帮助下,您还可以向窗口边框添加各种效果。这可以使用 `--border-effect` 选项来做到。
|
||||
|
||||
你可以添加这款程序所提供的任何效果,比如 `shadow` 效果(在窗口添加阴影)、`bordor` 效果(在屏幕截图周围添加矩形区域)和 `vintage` 效果(使截图略微淡化,着色并在其周围添加矩形区域)。
|
||||
|
||||
```
|
||||
gnome-screenshot --border-effect=[EFFECT]
|
||||
```
|
||||
|
||||
例如,运行下面的命令添加 shadow 效果:
|
||||
|
||||
```
|
||||
gnome-screenshot –border-effect=shadow
|
||||
```
|
||||
|
||||
以下是 shadow 效果的示例快照:
|
||||
|
||||
[
|
||||

|
||||
][21]
|
||||
|
||||
请注意,上述屏幕截图主要集中在终端的一个角落,以便您清楚地看到阴影效果。
|
||||
|
||||
#### 对特定区域的截图
|
||||
|
||||
如何你需要,你还可以使用 gnome-screenshot 程序对你电脑屏幕的某一特定区域进行截图。这可以通过使用 `-a` 选项来完成。
|
||||
|
||||
```
|
||||
gnome-screenshot -a
|
||||
```
|
||||
|
||||
当上面的命令被运行后,你的鼠标指针将会变成 '+' 这个符号。在这种模式下,你可以按住鼠标左键移动鼠标来对某个特定区域截图。
|
||||
|
||||
这是一个示例截图,裁剪了我的终端窗口的一小部分。
|
||||
|
||||
[
|
||||
|
||||
][22]
|
||||
|
||||
#### 在截图中包含鼠标指针
|
||||
|
||||
默认情况下,每当你使用这个工具截图的时候,截的图中并不会包含鼠标指针。然而,这个程序是可以让你把指针包括进去的,你可以使用 `-p` 命令行选项做到。
|
||||
|
||||
```
|
||||
gnome-screenshot -p
|
||||
```
|
||||
|
||||
这是一个示例截图:
|
||||
|
||||
[
|
||||
|
||||
][23]
|
||||
|
||||
#### 延时截图
|
||||
|
||||
截图时你还可以引入时间延迟。要做到这,你不需要给 `--delay` 选项赋予一个以秒为单位的值。
|
||||
|
||||
```
|
||||
gnome-screenshot –delay=[SECONDS]
|
||||
```
|
||||
|
||||
例如:
|
||||
|
||||
```
|
||||
gnome-screenshot --delay=5
|
||||
```
|
||||
|
||||
示例截图如下:
|
||||
|
||||
[
|
||||
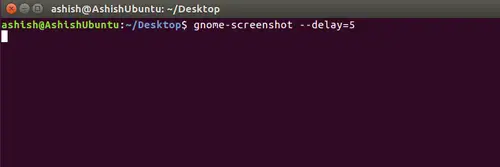
|
||||
][24]
|
||||
|
||||
#### 以交互模式运行这个工具
|
||||
|
||||
这个工具还允许你使用一个单独的 `-i` 选项来访问其所有功能。使用这个命令行选项,用户可以在运行这个命令时使用这个工具的一个或多个功能。
|
||||
|
||||
```
|
||||
gnome-screenshot -i
|
||||
```
|
||||
|
||||
示例截图如下:
|
||||
|
||||
[
|
||||
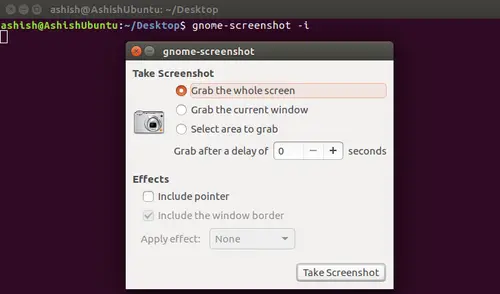
|
||||
][25]
|
||||
|
||||
你可以从上面的截图中看到,`-i` 选项提供了对很多功能的访问,比如截取整个屏幕、截取当前窗口、选择一个区域进行截图、延时选项和特效选项等都在交互模式里。
|
||||
|
||||
#### 直接保存你的截图
|
||||
|
||||
如果你需要的话,你可以直接将你截的图片从终端中保存到你当前的工作目录,这意味着,在这个程序运行后,它并不要求你为截取的图片输入一个文件名。这个功能可以使用 `--file` 命令行选项来获取,很明显,需要给它传递一个文件名。
|
||||
|
||||
```
|
||||
gnome-screenshot –file=[FILENAME]
|
||||
```
|
||||
|
||||
例如:
|
||||
|
||||
```
|
||||
gnome-screenshot --file=ashish
|
||||
```
|
||||
|
||||
示例截图如下:
|
||||
|
||||
[
|
||||
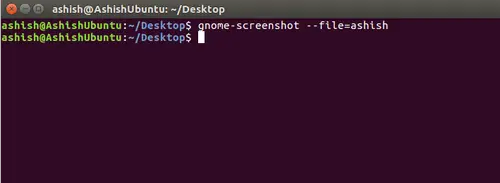
|
||||
][26]
|
||||
|
||||
#### 复制到剪切板
|
||||
|
||||
gnome-screenshot 也允许你把你截的图复制到剪切板。这可以通过使用 `-c` 命令行选项做到。
|
||||
|
||||
```
|
||||
gnome-screenshot -c
|
||||
```
|
||||
|
||||
[
|
||||
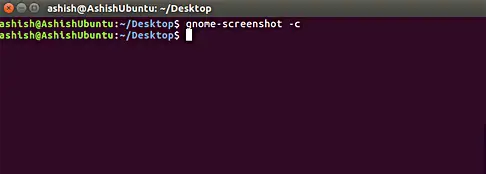
|
||||
][27]
|
||||
|
||||
在这个模式下,例如,你可以把复制的图直接粘贴到你的任何一个图片编辑器中(比如 GIMP)。
|
||||
|
||||
#### 多显示器情形下的截图
|
||||
|
||||
如果有多个显示器连接到你的系统,你想对某一个进行截图,那么你可以使用 `--then` 命令行选项。需要给这个选项一个显示器设备 ID 的值(需要被截图的显示器的 ID)。
|
||||
|
||||
```
|
||||
gnome-screenshot --display=[DISPLAY]
|
||||
```
|
||||
例如:
|
||||
|
||||
```
|
||||
gnome-screenshot --display=VGA-0
|
||||
```
|
||||
|
||||
在上面的例子中,VAG-0 是我正试图对其进行截图的显示器的 ID。为了找到你想对其进行截图的显示器的 ID,你可以使用下面的命令:
|
||||
|
||||
```
|
||||
xrandr --query
|
||||
```
|
||||
|
||||
为了让你明白一些,在我的例子中这个命令产生了下面的输出:
|
||||
|
||||
```
|
||||
$ xrandr --query
|
||||
Screen 0: minimum 320 x 200, current 1366 x 768, maximum 8192 x 8192
|
||||
VGA-0 connected primary 1366x768+0+0 (normal left inverted right x axis y axis) 344mm x 194mm
|
||||
1366x768 59.8*+
|
||||
1024x768 75.1 75.0 60.0
|
||||
832x624 74.6
|
||||
800x600 75.0 60.3 56.2
|
||||
640x480 75.0 60.0
|
||||
720x400 70.1
|
||||
HDMI-0 disconnected (normal left inverted right x axis y axis)
|
||||
```
|
||||
|
||||
#### 自动化屏幕截图过程
|
||||
|
||||
正如我们之前讨论的,`-a` 命令行选项可以帮助我们对屏幕的某一个特定区域进行截图。然而,我们需要用鼠标手动选取这个区域。如果你想的话,你可以使用 gnome-screenshot 来自动化完成这个过程,但是在那种情形下,你将需要使用一个名为 `xdotol` 的工具,它可以模仿敲打键盘甚至是点击鼠标这些事件。
|
||||
|
||||
例如:
|
||||
|
||||
```
|
||||
(gnome-screenshot -a &); sleep 0.1 && xdotool mousemove 100 100 mousedown 1 mousemove 400 400 mouseup 1
|
||||
```
|
||||
|
||||
`mousemove` 子命令自动把鼠标指针定位到明确的 `X` 坐标和 `Y` 坐标的位置(上面例子中是 100 和 100)。`mousedown` 子命令触发一个与点击执行相同操作的事件(因为我们想左击,所以我们使用了参数 1),然而 `mouseup` 子命令触发一个执行用户释放鼠标按钮的任务的事件。
|
||||
|
||||
所以总而言之,上面所示的 `xdotool` 命令做了一项本来需要使用鼠标手动执行对同一区域进行截图的工作。特别说明,该命令把鼠标指针定位到屏幕上坐标为 `100,100` 的位置并选择封闭区域,直到指针到达屏幕上坐标为 `400,400` 的位置。所选择的区域随之被 gnome-screenshot 捕获。
|
||||
|
||||
这是上述命令的截图:
|
||||
|
||||
[
|
||||
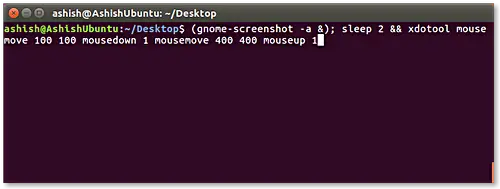
|
||||
][28]
|
||||
|
||||
这是输出的结果:
|
||||
|
||||
[
|
||||
|
||||
][29]
|
||||
|
||||
想获取更多关于 `xdotool` 的信息,[请到这来][30]。
|
||||
|
||||
#### 获取帮助
|
||||
|
||||
如果你有疑问或者你正面临一个与该命令行的其中某个选项有关的问题,那么你可以使用 --help、-? 或者 -h 选项来获取相关信息。
|
||||
|
||||
```
|
||||
gnome-screenshot -h
|
||||
```
|
||||
|
||||
### 总结
|
||||
|
||||
我推荐你至少使用一次这个程序,因为它不仅对初学者来说比较简单,而且还提供功能丰富的高级用法体验。动起手来,尝试一下吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/taking-screenshots-in-linux-using-gnome-screenshot/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[zhousiyu325](https://github.com/zhousiyu325)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/taking-screenshots-in-linux-using-gnome-screenshot/
|
||||
[17]:https://linux.die.net/man/1/gnome-screenshot
|
||||
[18]:https://www.howtoforge.com/images/taking-screenshots-in-linux-using-gnome-screenshot/big/gnome-default.png
|
||||
[19]:https://www.howtoforge.com/images/taking-screenshots-in-linux-using-gnome-screenshot/big/activewindow.png
|
||||
[20]:https://www.howtoforge.com/images/taking-screenshots-in-linux-using-gnome-screenshot/big/removeborder.png
|
||||
[21]:https://www.howtoforge.com/images/taking-screenshots-in-linux-using-gnome-screenshot/big/shadoweffect-new.png
|
||||
[22]:https://www.howtoforge.com/images/taking-screenshots-in-linux-using-gnome-screenshot/big/area.png
|
||||
[23]:https://www.howtoforge.com/images/taking-screenshots-in-linux-using-gnome-screenshot/big/includecursor.png
|
||||
[24]:https://www.howtoforge.com/images/taking-screenshots-in-linux-using-gnome-screenshot/big/delay.png
|
||||
[25]:https://www.howtoforge.com/images/taking-screenshots-in-linux-using-gnome-screenshot/big/interactive.png
|
||||
[26]:https://www.howtoforge.com/images/taking-screenshots-in-linux-using-gnome-screenshot/big/ashish.png
|
||||
[27]:https://www.howtoforge.com/images/taking-screenshots-in-linux-using-gnome-screenshot/big/copy.png
|
||||
[28]:https://www.howtoforge.com/images/taking-screenshots-in-linux-using-gnome-screenshot/big/automatedcommand.png
|
||||
[29]:https://www.howtoforge.com/images/taking-screenshots-in-linux-using-gnome-screenshot/big/outputxdo.png
|
||||
[30]:http://manpages.ubuntu.com/manpages/trusty/man1/xdotool.1.html
|
||||
@ -1,118 +1,119 @@
|
||||
OpenVAS - Vulnerability Assessment install on Kali Linux
|
||||
OpenVAS:Kali Linux 中的漏洞评估工具
|
||||
============================================================
|
||||
|
||||
### On this page
|
||||
本教程将介绍在 Kali Linux 中安装 OpenVAS 8.0 的过程。 OpenVAS 是一个可以自动执行网络安全审核和漏洞评估的开源[漏洞评估][6]程序。请注意,漏洞评估(Vulnerability Assessment)也称为 VA 并不是渗透测试(penetration test),渗透测试会进一步验证是否存在发现的漏洞,请参阅[什么是渗透测试][7]来对渗透测试的构成以及不同类型的安全测试有一个了解。
|
||||
|
||||
1. [What is Kali Linux?][1]
|
||||
2. [Updating Kali Linux][2]
|
||||
3. [Installing OpenVAS 8][3]
|
||||
4. [Start OpenVAS on Kali][4]
|
||||
### 什么是 Kali Linux?
|
||||
|
||||
This tutorial documents the process of installing OpenVAS 8.0 on Kali Linux rolling. OpenVAS is open source [vulnerability assessment][6] application that automates the process of performing network security audits and vulnerability assessments. Note, a vulnerability assessment also known as VA is not a penetration test, a penetration test goes a step further and validates the existence of a discovered vulnerability, see [what is penetration testing][7] for an overview of what pen testing consists of and the different types of security testing.
|
||||
Kali Linux 是 Linux 渗透测试分发版。它基于 Debian,并且预安装了许多常用的渗透测试工具,例如 Metasploit Framework (MSF)和其他通常在安全评估期间由渗透测试人员使用的命令行工具。
|
||||
|
||||
### What is Kali Linux?
|
||||
在大多数使用情况下,Kali 运行在虚拟机中,你可以在这里获取最新的 VMWare 或 Vbox 镜像:[https://www.offensive-security.com/kali-linux-vmware-virtualbox-image-download/][8] 。
|
||||
|
||||
Kali Linux is a Linux penetration testing distribution. It's Debian based and comes pre-installed with many commonly used penetration testing tools such as Metasploit Framework and other command line tools typically used by penetration testers during a security assessment.
|
||||
除非你有特殊的原因想要一个更小的虚拟机占用空间,否则请下载完整版本而不是 Kali light。 下载完成后,你需要解压文件并打开 vbox 或者 VMWare .vmx 文件,虚拟机启动后,默认帐号是 `root`/`toor`。请将 root 密码更改为安全的密码。
|
||||
|
||||
For most use cases Kali runs in a VM, you can grab the latest VMWare or Vbox image of Kali from here: [https://www.offensive-security.com/kali-linux-vmware-virtualbox-image-download/][8]
|
||||
或者,你可以下载 ISO 版本,并在裸机上执行 Kali 的安装。
|
||||
|
||||
Download the full version not Kali light, unless you have a specific reason for wanting a smaller virtual machine footprint. After the download finishes you will need to extract the contents and open the vbox or VMWare .vmx file, when the machine boots the default credentials are root / toor. Change the root password to a secure password.
|
||||
### 升级 Kali Linux
|
||||
|
||||
Alternatively, you can download the ISO version and perform an installation of Kali on the bare metal.
|
||||
完成安装后,为 Kail Linux 执行一次完整的升级。
|
||||
|
||||
### Updating Kali Linux
|
||||
|
||||
After installation, perform a full update of Kali Linux.
|
||||
|
||||
Updating Kali:
|
||||
升级 Kali:
|
||||
|
||||
```
|
||||
apt-get update && apt-get dist-upgrade -y
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][9]
|
||||
|
||||
The update process might take some time to complete. Kali is now a rolling release meaning you can update to the current version from any version of Kali rolling. However, there are release numbers but these are point in time versions of Kali rolling for VMWare snapshots. You can update to the current stable release from any of the VMWare images.
|
||||
更新过程可能需要一些时间才能完成。Kali 目前是滚动更新,这意味着你可以从任何版本的 Kali 滚动更新到当前版本。然而它仍有发布号,但这些是针对特定 Kali 时间点版本的 VMWare 快照。你可以从任何 VMWare 镜像更新到当前的稳定版本。
|
||||
|
||||
After updating perform a reboot.
|
||||
更新完成后重新启动。
|
||||
|
||||
### Installing OpenVAS 8
|
||||
### 安装 OpenVAS 8
|
||||
|
||||
[
|
||||
|
||||
][10]
|
||||
|
||||
```
|
||||
apt-get install openvas
|
||||
|
||||
openvas-setup
|
||||
```
|
||||
|
||||
During installation you'll be prompted about redis, select the default option to run as a UNIX socket.
|
||||
在安装中,你会被询问关于 redis 的问题,选择默认选项来以 UNIX 套接字运行。
|
||||
|
||||
[
|
||||
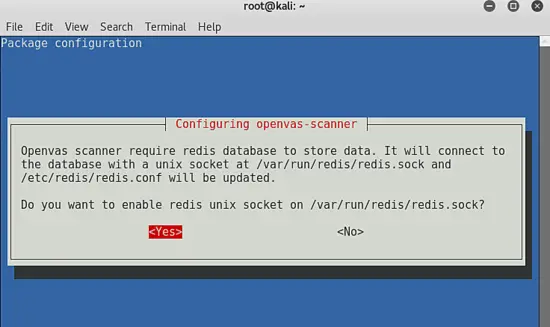
|
||||
][11]
|
||||
|
||||
Even on a fast connection openvas-setup takes a long time to download and update all the required CVE, SCAP definitions.
|
||||
即使是有快速的网络连接,openvas-setup 仍需要很长时间来下载和更新所有所需的 CVE、SCAP 定义。
|
||||
|
||||
[
|
||||
|
||||
][12]
|
||||
|
||||
Pay attention to the command output during openvas-setup, the password is generated during installation and printed to console near the end of the setup.
|
||||
请注意 openvas-setup 的命令输出,密码会在安装过程中生成,并在安装的最后在控制台中打印出来。
|
||||
|
||||
[
|
||||
|
||||
][13]
|
||||
|
||||
Verify openvas is running:
|
||||
验证 openvas 正在运行:
|
||||
|
||||
```
|
||||
netstat -tulpn
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][14]
|
||||
|
||||
### Start OpenVAS on Kali
|
||||
### 在 Kali 中运行 OpenVAS
|
||||
|
||||
To start the OpenVAS service on Kali run:
|
||||
要在 Kali 中启动 OpenVAS:
|
||||
|
||||
```
|
||||
openvas-start
|
||||
```
|
||||
|
||||
After installation, you should be able to access the OpenVAS web application at **https://127.0.0.1:9392**
|
||||
安装后,你应该可以通过 `https://127.0.0.1:9392` 访问 OpenVAS 的 web 程序了。
|
||||
|
||||
**[
|
||||
[
|
||||
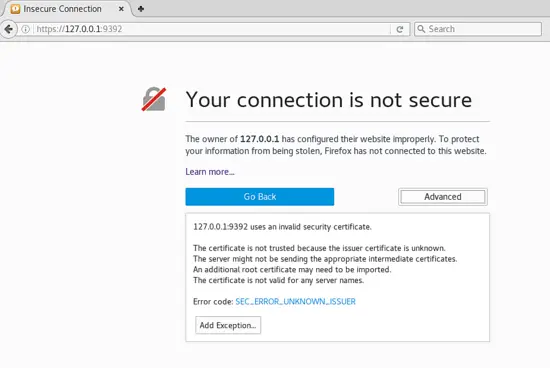
|
||||
][5]**
|
||||
][5]
|
||||
|
||||
Accept the self-signed certificate and login to the application using the credentials admin and the password displayed during openvas-setup.
|
||||
接受自签名证书,并使用 openvas-setup 输出的 admin 凭证和密码登录程序。
|
||||
|
||||
[
|
||||
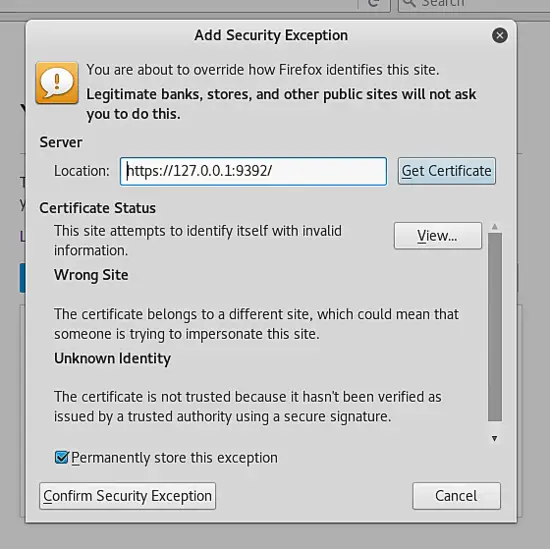
|
||||
][15]
|
||||
|
||||
After accepting the self-signed certificate, you should be presented with the login screen:
|
||||
接受自签名证书后,你应该可以看到登录界面了。
|
||||
|
||||
[
|
||||
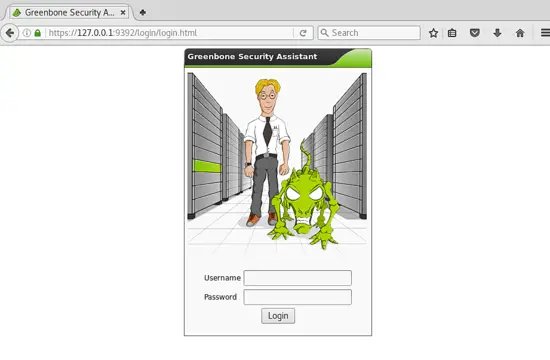
|
||||
][16]
|
||||
|
||||
After logging in you should be presented with the following screen:
|
||||
登录后,你应该可以看到下面的页面:
|
||||
|
||||
[
|
||||
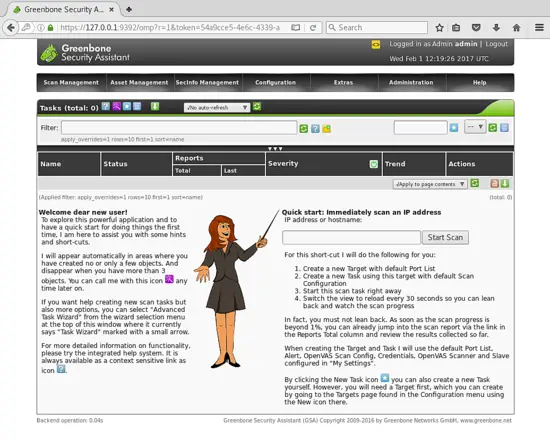
|
||||
][17]
|
||||
|
||||
From this point you should be able to configure your own vulnerability scans using the wizard.
|
||||
从此,你应该可以使用向导配置自己的漏洞扫描了。
|
||||
|
||||
It's recommended to read the documentation. Be aware of what a vulnerability assessment conductions (depending on configuration OpenVAS could attempt exploitation) and the traffic it will generate on a network as well as the DOS effect it can have on services / servers and hosts / devices on a network.
|
||||
我建议阅读文档。请注意漏洞评估导向(取决于 OpenVAS 可能尝试利用的配置)及其在网络上生成的流量以及网络上可能对服务/服务器和主机/设备产生的 DOS 影响。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/openvas-vulnerability-assessment-install-on-kali-linux/
|
||||
|
||||
作者:[KJS ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
作者:[KJS][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,114 @@
|
||||
在 PC 上尝试树莓派的 PIXEL OS
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
图片版权:树莓派基金会, CC BY-SA
|
||||
|
||||
在过去四年中,树莓派基金会非常努力地针对树莓派的硬件优化了 Debian 的移植版 Raspbian,包括创建新的教育软件、编程工具和更美观的桌面。
|
||||
|
||||
在(去年) 9 月份,我们发布了一个更新,介绍了树莓派新的桌面环境 PIXEL(Pi Improved Xwindows Environment,轻量级)。在圣诞节之前,我们[发布](https://linux.cn/article-8064-1.html)了一个在 x86 PC 上运行的操作系统版本,所以现在可以将它安装在 PC、Mac 或笔记本电脑上。
|
||||
|
||||

|
||||
|
||||
当然,像许多支持良好的 Linux 发行版一样,操作系统在旧的硬件上也能正常运行。 Raspbian 是让你几年前就丢弃的旧式 Windows 机器焕发新生的好方法。
|
||||
|
||||
[PIXEL ISO][13] 可从树莓派网站上下载,在 “[MagPi][14]” 杂志封面上也有赠送可启动的 Live DVD 。
|
||||
|
||||

|
||||
|
||||
为了消除想要学习计算机的人们的入门障碍,我们发布了树莓派的个人电脑操作系统。它比购买一块树莓派更便宜,因为它是免费的,你可以在现有的计算机上使用它。PIXEL 是我们一直想要的 Linux 桌面,我们希望它可供所有人使用。
|
||||
|
||||
### 由 Debian 提供支持
|
||||
|
||||
不构建在 Debian 之上的话,Raspbian 或 x86 PIXEL 发行版就都不会存在。 Debian 拥有庞大的可以从一个 apt 仓库中获得的免费开源软件、程序、游戏和其他工具。在树莓派中,你仅限运行为 [ARM][15] 芯片编译的软件包。然而,在 PC 镜像中,你可以在机器上运行的软件包的范围更广,因为 PC 中的 Intel 芯片有更多的支持。
|
||||
|
||||
 repository")
|
||||
|
||||
### PIXEL 包含什么
|
||||
|
||||
带有 PIXEL 的 Raspbian 和带有 PIXEL 的 Debian 都捆绑了大量的软件。Raspbian 自带:
|
||||
|
||||
* Python、Java、Scratch、Sonic Pi、Mathematica*、Node-RED 和 Sense HAT 仿真器的编程环境
|
||||
* LibreOffice 办公套件
|
||||
* Chromium(包含 Flash)和 Epiphany 网络浏览器
|
||||
* Minecraft:树莓派版(包括 Python API)*
|
||||
* 各种工具和实用程序
|
||||
|
||||
*由于许可证限制,本列表中唯一没有包含在 x86 版本中的程序是 Mathematica 和 Minecraft。
|
||||
|
||||

|
||||
|
||||
### 创建一个 PIXEL Live 盘
|
||||
|
||||
你可以下载 PIXEL ISO 并将其写入空白 DVD 或 USB 记忆棒中。 然后,你就可以从盘中启动你的电脑,这样你可以立刻看到 PIXEL 桌面。你可以浏览网页、打开编程环境或使用办公套件,而无需在计算机上安装任何内容。完成后,只需拿出 DVD 或 USB 驱动器,关闭计算机,再次重新启动计算机时,将会像以前一样重新启动到你平常的操作系统。
|
||||
|
||||
### 在虚拟机中运行 PIXEL
|
||||
|
||||
另外一种尝试 PIXEL 的方法是在像 VirtualBox 这样的虚拟机中安装它。
|
||||
|
||||

|
||||
|
||||
这允许你体验镜像而不用安装它,也可以在主操作系统里面的窗口中运行它,并访问 PIXEL 中的软件和工具。这也意味着你的会话会一直存在,而不是每次重新启动时从头开始,就像使用 Live 盘一样。
|
||||
|
||||
### 在 PC 中安装 PIXEL
|
||||
|
||||
如果你真的准备开始,你可以擦除旧的操作系统并将 PIXEL 安装在硬盘上。如果你想使用旧的闲置的笔记本电脑,这可能是个好主意。
|
||||
|
||||
### 用于教育的 PIXEL
|
||||
|
||||
许多学校在所有电脑上使用 Windows,并且对它们可以安装的软件进行严格的控制。这使得教师难以使用必要的软件工具和 IDE(集成开发环境)来教授编程技能。即使在线编程计划(如 Scratch 2)也可能被过于谨慎的网络过滤器阻止。在某些情况下,安装像 Python 这样的东西根本是不可能的。树莓派硬件通过提供包含教育软件的 SD 卡引导的小型廉价计算机来解决这个问题,学生可以连接到现有 PC 的显示器、鼠标和键盘上。
|
||||
|
||||
然而,PIXEL Live 光盘允许教师引导到装有能立即使用的编程语言和工具的系统中,所有这些都不需要安装权限。在课程结束时,他们可以安全关闭,使计算机恢复原状。这也是 Code Clubs、CoderDojos、青年俱乐部、Raspberry Jams 等等的一个方便的解决方案。
|
||||
|
||||
### 远程 GPIO
|
||||
|
||||
树莓派与传统台式 PC 区别的功能之一是 GPIO 引脚(通用输入/输出)引脚的存在,它允许你将现实世界中的电子元件和附加板连接设备上,这将开放一个新的世界,如业余项目、家庭自动化、连接的设备和物联网。
|
||||
|
||||
[GPIO Zero][16] Python 库的一个很棒的功能是通过在 PC 上写入一些简单的代码,然后在网络上控制树莓派的 GPIO 引脚。
|
||||
|
||||
远程 GPIO 可以从一台树莓派连接到另一台树莓派,或者从运行任何系统的 OS 的 PC 连接到树莓派上,但是,使用 PIXEL x86 的话所有需要的软件都是开箱即用的。参见 Josh 的[博文][17],并参考我的 [gist][18] 了解更多信息。
|
||||
|
||||
### 更多指南
|
||||
|
||||
[MagPi 的第 53 期][19]提供了一些试用和安装 PIXEL 的指南,包括使用带持久驱动的 Live 光盘来维护你的文件和应用程序。你可以购买一份,或免费下载 PDF 来了解更多。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Ben Nuttall - Ben Nuttall 是一名树莓派社区管理员。他除了为树莓派基金会工作外,他还对自由软件、数学、皮划艇、GitHub、Adventure Time 和 Futurama 等感兴趣。在 Twitter @ben_nuttall 上关注 Ben。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/1/try-raspberry-pis-pixel-os-your-pc
|
||||
|
||||
作者:[Ben Nuttall][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/bennuttall
|
||||
[1]:https://twitter.com/ben_nuttall
|
||||
[2]:https://twitter.com/intent/tweet?in_reply_to=811511740907261952
|
||||
[3]:https://twitter.com/intent/retweet?tweet_id=811511740907261952
|
||||
[4]:https://twitter.com/intent/like?tweet_id=811511740907261952
|
||||
[5]:https://twitter.com/ben_nuttall
|
||||
[6]:https://twitter.com/ben_nuttall/status/811511740907261952
|
||||
[7]:https://twitter.com/search?q=place%3A3bc1b6cfd27ef7f6
|
||||
[8]:https://twitter.com/ben_nuttall/status/811511740907261952/photo/1
|
||||
[9]:https://twitter.com/ben_nuttall/status/811511740907261952/photo/1
|
||||
[10]:https://twitter.com/ben_nuttall/status/811511740907261952/photo/1
|
||||
[11]:https://twitter.com/ben_nuttall/status/811511740907261952/photo/1
|
||||
[12]:https://opensource.com/article/17/1/try-raspberry-pis-pixel-os-your-pc?rate=iqVrGV3EhwRuqh68sf6Zye6Y7VSpXRCUQoZV3sg-QJM
|
||||
[13]:http://downloads.raspberrypi.org/pixel_x86/images/pixel_x86-2016-12-13/
|
||||
[14]:https://www.raspberrypi.org/magpi/issues/53/
|
||||
[15]:https://en.wikipedia.org/wiki/ARM_Holdings
|
||||
[16]:http://gpiozero.readthedocs.io/
|
||||
[17]:http://www.allaboutcode.co.uk/single-post/2016/12/21/GPIOZero-Remote-GPIO-with-PIXEL-x86
|
||||
[18]:https://gist.github.com/bennuttall/572789b0aa5fc2e7c05c7ada1bdc813e
|
||||
[19]:https://www.raspberrypi.org/magpi/issues/53/
|
||||
[20]:https://opensource.com/user/26767/feed
|
||||
[21]:https://opensource.com/article/17/1/try-raspberry-pis-pixel-os-your-pc#comments
|
||||
[22]:https://opensource.com/users/bennuttall
|
||||
@ -0,0 +1,233 @@
|
||||
使用 badIPs.com 保护你的服务器,并通过 Fail2ban 报告恶意 IP
|
||||
============================================================
|
||||
|
||||
这篇指南向你介绍使用 badips 滥用追踪器(abuse tracker) 和 Fail2ban 保护你的服务器或计算机的步骤。我已经在 Debian 8 Jessie 和 Debian 7 Wheezy 系统上进行了测试。
|
||||
|
||||
**什么是 badIPs?**
|
||||
|
||||
BadIps 是通过 [fail2ban][8] 报告为不良 IP 的列表。
|
||||
|
||||
这个指南包括两个部分,第一部分介绍列表的使用,第二部分介绍数据注入。
|
||||
|
||||
### 使用 badIPs 列表
|
||||
|
||||
#### 定义安全等级和类别
|
||||
|
||||
你可以通过使用 REST API 获取 IP 地址列表。
|
||||
|
||||
* 当你使用 GET 请求获取 URL:[https://www.badips.com/get/categories][9] 后,你就可以看到服务中现有的所有不同类别。
|
||||
* 第二步,决定适合你的等级。 参考 badips 应该有所帮助(我个人使用 `scope = 3`):
|
||||
* 如果你想要编译一个统计信息模块或者将数据用于实验目的,那么你应该用等级 0 开始。
|
||||
* 如果你想用防火墙保护你的服务器或者网站,使用等级 2。可能也要和你的结果相结合,尽管它们可能没有超过 0 或 1 的情况。
|
||||
* 如果你想保护一个网络商店、或高流量、赚钱的电子商务服务器,我推荐你使用值 3 或 4。当然还是要和你的结果相结合。
|
||||
* 如果你是偏执狂,那就使用 5。
|
||||
|
||||
现在你已经有了两个变量,通过把它们两者连接起来获取你的链接。
|
||||
|
||||
```
|
||||
http://www.badips.com/get/list/{{SERVICE}}/{{LEVEL}}
|
||||
```
|
||||
|
||||
注意:像我一样,你可以获取所有服务。在这种情况下把服务的名称改为 `any`。
|
||||
|
||||
最终的 URL 就是:
|
||||
|
||||
```
|
||||
https://www.badips.com/get/list/any/3
|
||||
```
|
||||
|
||||
### 创建脚本
|
||||
|
||||
所有都完成了之后,我们就会创建一个简单的脚本。
|
||||
|
||||
1、 把你的列表放到一个临时文件。
|
||||
|
||||
2、 在 iptables 中创建一个链(chain)(只需要创建一次)。(LCTT 译注:iptables 可能包括多个表(tables),表可能包括多个链(chains),链可能包括多个规则(rules))
|
||||
|
||||
3、 把所有链接到该链的数据(旧条目)刷掉。
|
||||
|
||||
4、 把每个 IP 链接到这个新的链。
|
||||
|
||||
5、 完成后,阻塞所有链接到该链的 INPUT / OUTPUT /FORWARD 请求。
|
||||
|
||||
6、 删除我们的临时文件。
|
||||
|
||||
为此,我们创建脚本:
|
||||
|
||||
```
|
||||
cd /home/<user>/
|
||||
vi myBlacklist.sh
|
||||
```
|
||||
|
||||
把以下内容输入到文件。
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
### based on this version http://www.timokorthals.de/?p=334
|
||||
### adapted by Stéphane T.
|
||||
|
||||
_ipt=/sbin/iptables ### iptables 路径(应该是这个)
|
||||
_input=badips.db ### 数据库的名称(会用这个名称下载)
|
||||
_pub_if=eth0 ### 连接到互联网的设备(执行 $ifconfig 获取)
|
||||
_droplist=droplist ### iptables 中链的名称(如果你已经有这么一个名称的链,你就换另外一个)
|
||||
_level=3 ### Blog(LCTT 译注:Bad log)等级:不怎么坏(0)、确认坏(3)、相当坏(5)(从 www.badips.com 获取详情)
|
||||
_service=any ### 记录日志的服务(从 www.badips.com 获取详情)
|
||||
|
||||
# 获取不良 IPs
|
||||
wget -qO- http://www.badips.com/get/list/${_service}/$_level > $_input || { echo "$0: Unable to download ip list."; exit 1; }
|
||||
|
||||
### 设置我们的黑名单 ###
|
||||
### 首先清除该链
|
||||
$_ipt --flush $_droplist
|
||||
|
||||
### 创建新的链
|
||||
### 首次运行时取消下面一行的注释
|
||||
# $_ipt -N $_droplist
|
||||
|
||||
### 过滤掉注释和空行
|
||||
### 保存每个 ip 到 $ip
|
||||
for ip in `cat $_input`
|
||||
do
|
||||
### 添加到 $_droplist
|
||||
$_ipt -A $_droplist -i ${_pub_if} -s $ip -j LOG --log-prefix "Drop Bad IP List "
|
||||
$_ipt -A $_droplist -i ${_pub_if} -s $ip -j DROP
|
||||
done
|
||||
|
||||
### 最后,插入或者追加到我们的黑名单列表
|
||||
$_ipt -I INPUT -j $_droplist
|
||||
$_ipt -I OUTPUT -j $_droplist
|
||||
$_ipt -I FORWARD -j $_droplist
|
||||
|
||||
### 删除你的临时文件
|
||||
rm $_input
|
||||
exit 0
|
||||
```
|
||||
|
||||
完成这些后,你应该创建一个定时任务定期更新我们的黑名单。
|
||||
|
||||
为此,我使用 crontab 在每天晚上 11:30(在我的延迟备份之前) 运行脚本。
|
||||
|
||||
```
|
||||
crontab -e
|
||||
```
|
||||
```
|
||||
23 30 * * * /home/<user>/myBlacklist.sh #Block BAD IPS
|
||||
```
|
||||
|
||||
别忘了更改脚本的权限:
|
||||
|
||||
````
|
||||
chmod + x myBlacklist.sh
|
||||
```
|
||||
|
||||
现在终于完成了,你的服务器/计算机应该更安全了。
|
||||
|
||||
你也可以像下面这样手动运行脚本:
|
||||
|
||||
```
|
||||
cd /home/<user>/
|
||||
./myBlacklist.sh
|
||||
```
|
||||
|
||||
它可能要花费一些时间,因此期间别中断脚本。事实上,耗时取决于该脚本的最后一行。
|
||||
|
||||
### 使用 Fail2ban 向 badIPs 报告 IP 地址
|
||||
|
||||
在本篇指南的第二部分,我会向你展示如何通过使用 Fail2ban 向 badips.com 网站报告不良 IP 地址。
|
||||
|
||||
#### Fail2ban >= 0.8.12
|
||||
|
||||
通过 Fail2ban 完成报告。取决于你 Fail2ban 的版本,你要使用本章的第一或第二节。
|
||||
|
||||
如果你 fail2ban 的版本是 0.8.12 或更新版本。
|
||||
|
||||
```
|
||||
fail2ban-server --version
|
||||
```
|
||||
|
||||
在每个你要报告的类别中,添加一个 action。
|
||||
|
||||
```
|
||||
[ssh]
|
||||
enabled = true
|
||||
action = iptables-multiport
|
||||
badips[category=ssh]
|
||||
port = ssh
|
||||
filter = sshd
|
||||
logpath = /var/log/auth.log
|
||||
maxretry= 6
|
||||
```
|
||||
|
||||
正如你看到的,类别是 SSH,从 ([https://www.badips.com/get/categories][11]) 查找正确类别。
|
||||
|
||||
#### Fail2ban < 0.8.12
|
||||
|
||||
如果版本是 0.8.12 之前,你需要新建一个 action。你可以从 [https://www.badips.com/asset/fail2ban/badips.conf][12] 下载。
|
||||
|
||||
```
|
||||
wget https://www.badips.com/asset/fail2ban/badips.conf -O /etc/fail2ban/action.d/badips.conf
|
||||
```
|
||||
|
||||
在上面的 badips.conf 中,你可以像前面那样激活每个类别,也可以全局启用它:
|
||||
|
||||
```
|
||||
cd /etc/fail2ban/
|
||||
vi jail.conf
|
||||
```
|
||||
|
||||
```
|
||||
[DEFAULT]
|
||||
...
|
||||
|
||||
banaction = iptables-multiport
|
||||
badips
|
||||
```
|
||||
|
||||
现在重启 fail2ban - 从现在开始它就应该开始报告了。
|
||||
|
||||
service fail2ban restart
|
||||
|
||||
### 你的 IP 报告统计信息
|
||||
|
||||
最后一步 - 没那么有用。你可以创建一个密钥。 但如果你想看你的数据,这一步就很有帮助。
|
||||
|
||||
复制/粘贴下面的命令,你的控制台中就会出现一个 JSON 响应。
|
||||
|
||||
```
|
||||
wget https://www.badips.com/get/key -qO -
|
||||
|
||||
{
|
||||
"err":"",
|
||||
"suc":"new key 5f72253b673eb49fc64dd34439531b5cca05327f has been set.",
|
||||
"key":"5f72253b673eb49fc64dd34439531b5cca05327f"
|
||||
}
|
||||
```
|
||||
|
||||
到 [badips][13] 网站,输入你的 “key” 并点击 “statistics”。
|
||||
|
||||
现在你就可以看到不同类别的统计信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/
|
||||
|
||||
作者:[Stephane T][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/
|
||||
[1]:https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/#define-your-security-level-and-category
|
||||
[2]:https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/#failban-gt-
|
||||
[3]:https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/#failban-ltnbsp
|
||||
[4]:https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/#use-the-badips-list
|
||||
[5]:https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/#lets-create-the-script
|
||||
[6]:https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/#report-ip-addresses-to-badips-with-failban
|
||||
[7]:https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/#statistics-of-your-ip-reporting
|
||||
[8]:http://www.fail2ban.org/
|
||||
[9]:https://www.badips.com/get/categories
|
||||
[10]:http://www.timokorthals.de/?p=334
|
||||
[11]:https://www.badips.com/get/categories
|
||||
[12]:https://www.badips.com/asset/fail2ban/badips.conf
|
||||
[13]:https://www.badips.com/
|
||||
@ -1,42 +1,39 @@
|
||||
Windows Trojan hacks into embedded devices to install Mirai
|
||||
Windows 木马攻破嵌入式设备来安装 Mirai 恶意软件
|
||||
============================================================
|
||||
|
||||
> The Trojan tries to authenticate over different protocols with factory default credentials and, if successful, deploys the Mirai bot
|
||||
|
||||
> 木马尝试使用出厂默认凭证对不同协议进行身份验证,如果成功则会部署 Mirai 僵尸程序。
|
||||
|
||||

|
||||
|
||||
*图片来源: Gerd Altmann / Pixabay*
|
||||
|
||||
Attackers have started to use Windows and Android malware to hack into embedded devices, dispelling the widely held belief that if such devices are not directly exposed to the Internet they're less vulnerable.
|
||||
攻击者已经开始使用 Windows 和 Android 恶意软件入侵嵌入式设备,这消除了人们广泛持有的想法,认为如果设备不直接暴露在互联网上,那么它们就不那么脆弱。
|
||||
|
||||
Researchers from Russian antivirus vendor Doctor Web have recently [come across a Windows Trojan program][21] that was designed to gain access to embedded devices using brute-force methods and to install the Mirai malware on them.
|
||||
来自俄罗斯防病毒供应商 Doctor Web 的研究人员最近[遇到了一个 Windows 木马程序][21],它使用暴力方法访问嵌入式设备,并在其上安装 Mirai 恶意软件。
|
||||
|
||||
Mirai is a malware program for Linux-based internet-of-things devices, such as routers, IP cameras, digital video recorders and others. It's used primarily to launch distributed denial-of-service (DDoS) attacks and spreads over Telnet by using factory device credentials.
|
||||
Mirai 是一种用在基于 Linux 的物联网设备的恶意程序,例如路由器、IP 摄像机、数字录像机等。它主要通过使用出厂设备凭据来发动分布式拒绝服务 (DDoS) 攻击并通过 Telnet 传播。
|
||||
|
||||
The Mirai botnet has been used to launch some of the largest DDoS attacks over the past six months. After [its source code was leaked][22], the malware was used to infect more than 500,000 devices.
|
||||
Mirai 的僵尸网络在过去六个月里一直被用来发起最大型的 DDoS 攻击。[它的源代码泄漏][22]之后,恶意软件被用来感染超过 50 万台设备。
|
||||
|
||||
Once installed on a Windows computer, the new Trojan discovered by Doctor Web downloads a configuration file from a command-and-control server. That file contains a range of IP addresses to attempt authentication over several ports including 22 (SSH) and 23 (Telnet).
|
||||
Doctor Web 发现,一旦在一台 Windows 上安装之后,该新木马会从命令控制服务器下载配置文件。该文件包含一系列 IP 地址,通过多个端口,包括 22(SSH)和 23(Telnet),尝试进行身份验证。
|
||||
|
||||
#### [■ GET YOUR DAILY SECURITY NEWS: Sign up for CSO's security newsletters][11]
|
||||
如果身份验证成功,恶意软件将会根据受害系统的类型。执行配置文件中指定的某些命令。在通过 Telnet 访问的 Linux 系统中,木马会下载并执行一个二进制包,然后安装 Mirai 僵尸程序。
|
||||
|
||||
如果按照设计或配置,受影响的设备不会从 Internet 直接访问,那么许多物联网供应商会降低漏洞的严重性。这种思维方式假定局域网是信任和安全的环境。
|
||||
|
||||
If authentication is successful, the malware executes certain commands specified in the configuration file, depending on the type of compromised system. In the case of Linux systems accessed via Telnet, the Trojan downloads and executes a binary package that then installs the Mirai bot.
|
||||
然而事实并非如此,其他威胁如跨站点请求伪造已经出现了多年。但 Doctor Web 发现的新木马似乎是第一个专门设计用于劫持嵌入式或物联网设备的 Windows 恶意软件。
|
||||
|
||||
Many IoT vendors downplay the severity of vulnerabilities if the affected devices are not intended or configured for direct access from the Internet. This way of thinking assumes that LANs are trusted and secure environments.
|
||||
Doctor Web 发现的新木马被称为 [Trojan.Mirai.1][23],从它可以看到,攻击者还可以使用受害的计算机来攻击不能从互联网直接访问的物联网设备。
|
||||
|
||||
This was never really the case, with other threats like cross-site request forgery attacks going around for years. But the new Trojan that Doctor Web discovered appears to be the first Windows malware specifically designed to hijack embedded or IoT devices.
|
||||
|
||||
This new Trojan found by Doctor Web, dubbed [Trojan.Mirai.1][23], shows that attackers can also use compromised computers to target IoT devices that are not directly accessible from the internet.
|
||||
|
||||
Infected smartphones can be used in a similar way. Researchers from Kaspersky Lab have already [found an Android app][24] designed to perform brute-force password guessing attacks against routers over the local network.
|
||||
受感染的智能手机可以以类似的方式使用。卡巴斯基实验室的研究人员已经[发现了一个 Android 程序][24],通过本地网络对路由器执行暴力密码猜测攻击。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.csoonline.com/article/3168357/security/windows-trojan-hacks-into-embedded-devices-to-install-mirai.html
|
||||
|
||||
作者:[ Lucian Constantin][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
作者:[Lucian Constantin][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -51,7 +48,6 @@ via: http://www.csoonline.com/article/3168357/security/windows-trojan-hacks-into
|
||||
[8]:http://www.csoonline.com/article/3144197/security/upgraded-mirai-botnet-disrupts-deutsche-telekom-by-infecting-routers.html
|
||||
[9]:http://www.csoonline.com/video/73795/security-sessions-the-csos-role-in-active-shooter-planning
|
||||
[10]:http://www.csoonline.com/video/73795/security-sessions-the-csos-role-in-active-shooter-planning
|
||||
[11]:http://csoonline.com/newsletters/signup.html#tk.cso-infsb
|
||||
[12]:http://www.csoonline.com/author/Lucian-Constantin/
|
||||
[13]:https://twitter.com/intent/tweet?url=http%3A%2F%2Fwww.csoonline.com%2Farticle%2F3168357%2Fsecurity%2Fwindows-trojan-hacks-into-embedded-devices-to-install-mirai.html&via=csoonline&text=Windows+Trojan+hacks+into+embedded+devices+to+install+Mirai
|
||||
[14]:https://www.facebook.com/sharer/sharer.php?u=http%3A%2F%2Fwww.csoonline.com%2Farticle%2F3168357%2Fsecurity%2Fwindows-trojan-hacks-into-embedded-devices-to-install-mirai.html
|
||||
@ -0,0 +1,129 @@
|
||||
使用 tmux 打造更强大的终端
|
||||
============================
|
||||
|
||||

|
||||
|
||||
一些 Fedora 用户把大部分甚至是所有时间花费在了[命令行][4]终端上。 终端可让您访问整个系统,以及数以千计的强大的实用程序。 但是,它默认情况下一次只显示一个命令行会话。 即使有一个大的终端窗口,整个窗口也只会显示一个会话。 这浪费了空间,特别是在大型显示器和高分辨率的笔记本电脑屏幕上。 但是,如果你可以将终端分成多个会话呢? 这正是 tmux 最方便的地方,或者说不可或缺的。
|
||||
|
||||
### 安装并启动 tmux
|
||||
|
||||
tmux 应用程序的名称来源于终端(terminal)复用器(muxer)或多路复用器(multiplexer)。 换句话说,它可以将您的单终端会话分成多个会话。 它管理窗口和窗格:
|
||||
|
||||
- 窗口(window)是一个单一的视图 - 也就是终端中显示的各种东西。
|
||||
- 窗格(pane) 是该视图的一部分,通常是一个终端会话。
|
||||
|
||||
开始前,请在系统上安装 `tmux` 应用程序。 你需要为您的用户帐户设置 `sudo` 权限(如果需要,请[查看本文][5]获取相关说明)。
|
||||
|
||||
```
|
||||
sudo dnf -y install tmux
|
||||
```
|
||||
|
||||
运行 `tmux`程序:
|
||||
|
||||
```
|
||||
tmux
|
||||
```
|
||||
|
||||
### 状态栏
|
||||
|
||||
首先,似乎什么也没有发生,除了出现在终端的底部的状态栏:
|
||||
|
||||
|
||||
|
||||
底部栏显示:
|
||||
|
||||
* `[0]` – 这是 `tmux` 服务器创建的第一个会话。编号从 0 开始。`tmux` 服务器会跟踪所有的会话确认其是否存活。
|
||||
* `0:testuser@scarlett:~` – 有关该会话的第一个窗口的信息。编号从 0 开始。这表示窗口的活动窗格中的终端归主机名 `scarlett` 中 `testuser` 用户所有。当前目录是 `~` (家目录)。
|
||||
* `*` – 显示你目前在此窗口中。
|
||||
* `“scarlett.internal.fri”` – 你正在使用的 `tmux` 服务器的主机名。
|
||||
* 此外,还会显示该特定主机上的日期和时间。
|
||||
|
||||
当你向会话中添加更多窗口和窗格时,信息栏将随之改变。
|
||||
|
||||
### tmux 基础知识
|
||||
|
||||
把你的终端窗口拉伸到最大。现在让我们尝试一些简单的命令来创建更多的窗格。默认情况下,所有的命令都以 `Ctrl+b` 开头。
|
||||
|
||||
* 敲 `Ctrl+b, "` 水平分割当前单个窗格。 现在窗口中有两个命令行窗格,一个在顶部,一个在底部。请注意,底部的新窗格是活动窗格。
|
||||
* 敲 `Ctrl+b, %` 垂直分割当前单个窗格。 现在你的窗口中有三个命令行窗格,右下角的窗格是活动窗格。
|
||||
|
||||
|
||||
|
||||
注意当前窗格周围高亮显示的边框。要浏览所有的窗格,请做以下操作:
|
||||
|
||||
* 敲 `Ctrl+b`,然后点箭头键
|
||||
* 敲 `Ctrl+b, q`,数字会短暂的出现在窗格上。在这期间,你可以你想要浏览的窗格上对应的数字。
|
||||
|
||||
现在,尝试使用不同的窗格运行不同的命令。例如以下这样的:
|
||||
|
||||
* 在顶部窗格中使用 `ls` 命令显示目录内容。
|
||||
* 在左下角的窗格中使用 `vi` 命令,编辑一个文本文件。
|
||||
* 在右下角的窗格中运行 `top` 命令监控系统进程。
|
||||
|
||||
屏幕将会如下显示:
|
||||
|
||||
|
||||
|
||||
到目前为止,这个示例中只是用了一个带多个窗格的窗口。你也可以在会话中运行多个窗口。
|
||||
|
||||
* 为了创建一个新的窗口,请敲`Ctrl+b, c` 。请注意,状态栏显示当前有两个窗口正在运行。(敏锐的读者会看到上面的截图。)
|
||||
* 要移动到上一个窗口,请敲 `Ctrl+b, p` 。
|
||||
* 要移动到下一个窗口,请敲 `Ctrl+b, n` 。
|
||||
* 要立即移动到特定的窗口,请敲 `Ctrl+b` 然后跟上窗口编号。
|
||||
|
||||
如果你想知道如何关闭窗格,只需要使用 `exit` 、`logout`,或者 `Ctrl+d` 来退出特定的命令行 shell。一旦你关闭了窗口中的所有窗格,那么该窗口也会消失。
|
||||
|
||||
### 脱离和附加
|
||||
|
||||
`tmux` 最强大的功能之一是能够脱离和重新附加到会话。 当你脱离的时候,你可以离开你的窗口和窗格独立运行。 此外,您甚至可以完全注销系统。 然后,您可以登录到同一个系统,重新附加到 `tmux` 会话,查看您离开时的所有窗口和窗格。 脱离的时候你运行的命令一直保持运行状态。
|
||||
|
||||
为了脱离一个会话,请敲 `Ctrl+b, d`。然后会话消失,你重新返回到一个标准的单一 shell。如果要重新附加到会话中,使用一下命令:
|
||||
|
||||
```
|
||||
tmux attach-session
|
||||
```
|
||||
|
||||
当你连接到主机的网络不稳定时,这个功能就像救生员一样有用。如果连接失败,会话中的所有的进程都会继续运行。只要连接恢复了,你就可以恢复正常,就好像什么事情也没有发生一样。
|
||||
|
||||
如果这些功能还不够,在每个会话的顶层窗口和窗格中,你可以运行多个会话。你可以列举出这些窗口和窗格,然后通过编号或者名称把他们附加到正确的会话中:
|
||||
|
||||
```
|
||||
tmux list-sessions
|
||||
```
|
||||
|
||||
### 延伸阅读
|
||||
|
||||
本文只触及的 `tmux` 的表面功能。你可以通过其他方式操作会话:
|
||||
|
||||
* 将一个窗格和另一个窗格交换
|
||||
* 将窗格移动到另一个窗口中(可以在同一个会话中也可以在不同的会话中)
|
||||
* 设定快捷键自动执行你喜欢的命令
|
||||
* 在 `~/.tmux.conf` 文件中配置你最喜欢的配置项,这样每一个会话都会按照你喜欢的方式呈现
|
||||
|
||||
有关所有命令的完整说明,请查看以下参考:
|
||||
|
||||
* 官方[手册页][1]
|
||||
* `tmux` [电子书][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Paul W. Frields 自 1997 年以来一直是 Linux 用户和爱好者,并于 2003 年加入 Fedora 项目,这个项目刚推出不久。他是 Fedora 项目委员会的创始成员,在文档,网站发布,宣传,工具链开发和维护软件方面都有贡献。他于2008 年 2 月至 2010 年 7 月加入 Red Hat,担任 Fedora 项目负责人,并担任 Red Hat 的工程经理。目前他和妻子以及两个孩子居住在弗吉尼亚。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/use-tmux-more-powerful-terminal/
|
||||
|
||||
作者:[Paul W. Frields][a]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/pfrields/
|
||||
[1]: http://man.openbsd.org/OpenBSD-current/man1/tmux.1
|
||||
[2]: https://pragprog.com/book/bhtmux2/tmux-2
|
||||
[3]: https://fedoramagazine.org/use-tmux-more-powerful-terminal/
|
||||
[4]: http://www.cryptonomicon.com/beginning.html
|
||||
[5]: https://fedoramagazine.org/howto-use-sudo/
|
||||
@ -0,0 +1,110 @@
|
||||
Linux 下网络协议分析器 Wireshark 使用基础
|
||||
=================
|
||||
|
||||
Wireshark 是 Kali 中预置的众多有价值工具中的一种。与其它工具一样,它可以被用于正面用途,同样也可以被用于不良目的。当然,本文将会介绍如何追踪你自己的网络流量来发现潜在的非正常活动。
|
||||
|
||||
Wireshark 相当的强大,当你第一次见到它的时候可能会被它吓到,但是它的目的始终就只有一个,那就是追踪网络流量,并且它所实现的所有选项都只为了加强它追踪流量的能力。
|
||||
|
||||
### 安装
|
||||
|
||||
Kali 中预置了 Wireshark 。不过,`wireshark-gtk` 包提供了一个更好的界面使你在使用 Wireshark 的时候会有更友好的体验。因此,在使用 Wireshark 前的第一步是安装 `wireshark-gtk` 这个包。
|
||||
|
||||
```
|
||||
# apt install wireshark-gtk
|
||||
```
|
||||
|
||||
如果你的 Kali 是从 live 介质上运行的也不需要担心,依然有效。
|
||||
|
||||
|
||||
### 基础配置
|
||||
|
||||
在你使用 Wireshark 之前,将它设置成你使用起来最舒适的状态可能是最好的。Wireshark 提供了许多不同的布局方案和选项来配置程序的行为。尽管数量很多,但是使用起来是相当直接明确的。
|
||||
|
||||
从启动 Wireshark-gtk 开始。需要确定启动的是 GTK 版本的。在 Kali 中它们是被分别列出的。
|
||||
|
||||

|
||||
|
||||
### 布局
|
||||
|
||||
默认情况下,Wireshark 的信息展示分为三块内容,每一块都叠在另一块上方。(LCTT 译注:这里的三部分指的是展示抓包信息的时候的那三块内容,本段配图没有展示,配图 4、5、6 的设置不是默认设置,与这里的描述不符)最上方的一块是所抓包的列表。中间的一块是包的详细信息。最下面那块中包含的是包的原始字节信息。通常来说,上面的两块中的信息比最下面的那块有用的多,但是对于资深用户来说这块内容仍然是重要信息。
|
||||
|
||||
每一块都是可以缩放的,可并不是每一个人都必须使用这样叠起来的布局方式。你可以在 Wireshark 的“选项(Preferences)”菜单中进行更改。点击“编辑(Edit)”菜单,最下方就是的“选项”菜单。这个选项会打开一个有更多选项的新窗口。单击侧边菜单中“用户界面(User Interface)”下的“布局(Layout)”选项。
|
||||
|
||||

|
||||
|
||||
你将会看到一些不同的布局方案。上方的图示可以让你选择不同的面板位置布局方案,下面的单选框可以让你选择不同面板中的数据内容。
|
||||
|
||||
下面那个标记为“列(Columns)”的标签可以让你选择展示所抓取包的哪些信息。选择那些你需要的数据信息,或者全部展示。
|
||||
|
||||
### 工具条
|
||||
|
||||
对于 Wireshark 的工具条能做的设置不是太多,但是如果你想设置的话,你依然在前文中提到的“布局”菜单中的窗口管理工具下方找到一些有用的设置选项。那些能让你配置工具条和工具条中条目的选项就在窗口选项下方。
|
||||
|
||||
你还可以在“视图(View)”菜单下勾选来配置工具条的显示内容。
|
||||
|
||||
### 功能
|
||||
|
||||
主要的用来控制 Wireshark 抓包的控制选项基本都集中在“捕捉(Capture)”菜单下的“选项(Options)”选项中。
|
||||
|
||||
在开启的窗口中最上方的“捕捉(Capture)”部分可以让你选择 Wireshark 要监控的某个具体的网络接口。这部分可能会由于你系统的配置不同而会有相当大的不同。要记得勾选正确的选择框才能获得正确的数据。虚拟机和伴随它们一起的网络接口也同样会在这个列表里显示。同样也会有多种不同的选项对应这多种不同的网络接口。
|
||||
|
||||

|
||||
|
||||
在网络接口列表的下方是两个选项。其中一个选项是全选所有的接口。另一个选项用来选择是否开启混杂模式。这个选项可以使你的计算机监控到所选网络上的所有的计算机。(LCTT 译注:混杂模式可以在 HUB 中或监听模式的交换机接口上捕获那些由于 MAC 地址非本机而会被自动丢弃的数据包)如果你想监控你所在的整个网络,这个选项是你所需要的。
|
||||
|
||||
**注意:** 在一个不属于你或者不拥有权限的网络上使用混杂模式来监控是非法的!
|
||||
|
||||
在窗口下方的右侧是“显示选项(Display Options)”和“名称解析(Name Resolution)”选项块。对于“显示选项(Display Options)”来说,三个选项全选可能就是一个很好的选择了。当然你也可以取消选择,但是最好还是保留选择“实时更新抓包列表”。
|
||||
|
||||
在“名称解析(Name Resolution)”中你也可以设置你的偏好。这里的选项会产生附加的请求因此选得越多就会有越多的请求产生使你的抓取的包列表显得杂乱。把 MAC 解析选项选上是个好主意,那样就可以知道所使用的网络硬件的品牌了。这可以帮助你来确定你是在与哪台设备上的哪个接口进行交互。
|
||||
|
||||
### 抓包
|
||||
|
||||
抓包是 Wireshark 的核心功能。监控和记录特定网络上的流量就是它最初产生的目的。使用它最基本的方式来作这个抓包的工作是相当简单方便的。当然,越多的配置和选项就越可以充分利用 Wireshark 的力量。这里的介绍的关注点依然还是它最基本的记录方式。
|
||||
|
||||
按下那个看起来像蓝色鲨鱼鳍的新建实时抓包按钮就可以开始抓包了。(LCTT 译注:在我的 Debian 上它是绿色的)
|
||||
|
||||
|
||||

|
||||
|
||||
在抓包的过程中,Wireshark 会收集所有它能收集到的包的数据并且记录下来。如果没有更改过相关设置的话,在抓包的过程中你会看见不断的有新的包进入到“包列表”面板中。你可以实时的查看你认为有趣的包,或者就让 Wireshark 运行着,同时你可以做一些其它的事情。
|
||||
|
||||
当你完成了,按下红色的正方形“停止”按钮就可以了。现在,你可以选择是否要保存这些所抓取的数据了。要保存的话,你可以使用“文件”菜单下的“保存”或者是“另存为”选项。
|
||||
|
||||
### 读取数据
|
||||
|
||||
Wireshark 的目标是向你提供你所需要的所有数据。这样做时,它会在它监控的网络上收集大量的与网络包相关的数据。它使用可折叠的标签来展示这些数据使得这些数据看起来没有那么吓人。每一个标签都对应于网络包中一部分的请求数据。
|
||||
|
||||
这些标签是按照从最底层到最高层一层层堆起来的。顶部标签总是包含数据包中包含的字节数据。最下方的标签可能会是多种多样的。在下图的例子中是一个 HTTP 请求,它会包含 HTTP 的信息。您遇到的大多数数据包将是 TCP 数据,它将展示在底层的标签中。
|
||||
|
||||

|
||||
|
||||
每一个标签页都包含了抓取包中对应部分的相关数据。一个 HTTP 包可能会包含与请求类型相关的信息,如所使用的网络浏览器,服务器的 IP 地址,语言,编码方式等的数据。一个 TCP 包会包含服务器与客户端使用的端口信息和 TCP 三次握手过程中的标志位信息。
|
||||
|
||||

|
||||
|
||||
在上方的其它标签中包含了一些大多数用户都感兴趣的少量信息。其中一个标签中包含了数据包是否是通过 IPv4 或者 IPv6 传输的,以及客户端和服务器端的 IP 地址。另一个标签中包含了客户端和接入因特网的路由器或网关的设备的 MAC 地址信息。
|
||||
|
||||
### 结语
|
||||
|
||||
即使只使用这些基础选项与配置,你依然可以发现 Wireshark 会是一个多么强大的工具。监控你的网络流量可以帮助你识别、终止网络攻击或者提升连接速度。它也可以帮你找到问题应用。下一篇 Wireshark 指南我们将会一起探索 Wireshark 的包过滤选项。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxconfig.org/basic-of-network-protocol-analyzer-wireshark-on-linux
|
||||
|
||||
作者:[Nick Congleton][a]
|
||||
译者:[wcnnbdk1](https://github.com/wcnnbdk1)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linuxconfig.org/basic-of-network-protocol-analyzer-wireshark-on-linux
|
||||
[1]:https://linuxconfig.org/basic-of-network-protocol-analyzer-wireshark-on-linux#h2-1-layout
|
||||
[2]:https://linuxconfig.org/basic-of-network-protocol-analyzer-wireshark-on-linux#h2-2-toolbars
|
||||
[3]:https://linuxconfig.org/basic-of-network-protocol-analyzer-wireshark-on-linux#h2-3-functionality
|
||||
[4]:https://linuxconfig.org/basic-of-network-protocol-analyzer-wireshark-on-linux#h1-installation
|
||||
[5]:https://linuxconfig.org/basic-of-network-protocol-analyzer-wireshark-on-linux#h2-basic-configuration
|
||||
[6]:https://linuxconfig.org/basic-of-network-protocol-analyzer-wireshark-on-linux#h3-capture
|
||||
[7]:https://linuxconfig.org/basic-of-network-protocol-analyzer-wireshark-on-linux#h4-reading-data
|
||||
[8]:https://linuxconfig.org/basic-of-network-protocol-analyzer-wireshark-on-linux#h5-closing-thoughts
|
||||
@ -1,30 +1,31 @@
|
||||
在 RHEL,CentOS 及 Fedora 上安装 Drupal 8
|
||||
在 RHEL、CentOS 及 Fedora 上安装 Drupal 8
|
||||
============================================================
|
||||
|
||||
**Drupal** 是一个开源,灵活,高度可拓展和安全的<ruby>内容管理系统<rt>Content Management System</rt></ruby>(CMS),使用户轻松的创建网站。
|
||||
|
||||
它可以使用模块拓展,使用户将内容管理转换为强大的数字解决方案。
|
||||
|
||||
**Drupal** 运行在诸如 **Apache,IIS,Lighttpd,Cherokee,Nginx** 的 Web 服务器上,后端数据库可以使用 **Mysql,MongoDB,MariaDB,PostgreSQL,MSSQL Server**。
|
||||
**Drupal** 运行在诸如 Apache、IIS、Lighttpd、Cherokee、Nginx 的 Web 服务器上,后端数据库可以使用 MySQL、MongoDB、MariaDB、PostgreSQL、MSSQL Server。
|
||||
|
||||
在这篇文章中, 我们会展示在 RHEL 7/6,CentOS 7/6 和 Fedora 20-25 发行版本使用 LAMP,如何手动安装和配置 Drupal 8。
|
||||
在这篇文章中, 我们会展示在 RHEL 7/6、CentOS 7/6 和 Fedora 20-25 发行版上使用 LAMP 架构,如何手动安装和配置 Drupal 8。
|
||||
|
||||
#### Drupal 需求:
|
||||
#### Drupal 需求:
|
||||
|
||||
1. **Apache 2.x** (推荐)
|
||||
2. **PHP 5.5.9** 或 更高 (推荐 PHP 5.5)
|
||||
3. **MYSQL 5.5.3** 或 **MariaDB 5.5.20** 与 PHP 数据对象(PDO)
|
||||
1. **Apache 2.x** (推荐)
|
||||
2. **PHP 5.5.9** 或 更高 (推荐 PHP 5.5)
|
||||
3. **MySQL 5.5.3** 或 **MariaDB 5.5.20** 与 PHP 数据对象(PDO) 支持
|
||||
|
||||
安装过程中,我使用 `drupal.tecmint.com` 作为网站主机名,IP 地址为 `192.168.0.104`。你的环境也许与这些设置不同,因此请适当做出更改。
|
||||
|
||||
### 步骤 1: 安装 Apache Web 服务器
|
||||
### 步骤 1:安装 Apache Web 服务器
|
||||
|
||||
1. 首先我们从官方仓库开始安装 Apache Web 服务器。
|
||||
1、 首先我们从官方仓库开始安装 Apache Web 服务器。
|
||||
|
||||
```
|
||||
# yum install httpd
|
||||
```
|
||||
|
||||
2. 安装完成后,服务将会被被禁用,因此我们需要手动启动它,同时让它下次系统启动时自动启动,如下:
|
||||
2、 安装完成后,服务开始是被禁用的,因此我们需要手动启动它,同时让它下次系统启动时自动启动,如下:
|
||||
|
||||
```
|
||||
------------- 通过 SystemD - CentOS/RHEL 7 和 Fedora 22+ -------------------
|
||||
@ -36,7 +37,7 @@
|
||||
# chkconfig --level 35 httpd on
|
||||
```
|
||||
|
||||
3. 接下来,为了允许通过 **HTTP** 和 **HTTPS** 访问 Apache 服务,我们必须打开 **HTTPD** 守护进程正在监听的 **80** 和 **443** 端口,如下所示:
|
||||
3、 接下来,为了允许通过 **HTTP** 和 **HTTPS** 访问 Apache 服务,我们必须打开 **HTTPD** 守护进程正在监听的 **80** 和 **443** 端口,如下所示:
|
||||
|
||||
```
|
||||
------------ 通过 Firewalld - CentOS/RHEL 7 and Fedora 22+ -------------
|
||||
@ -51,7 +52,7 @@
|
||||
# service iptables restart
|
||||
```
|
||||
|
||||
4. 现在验证 Apache 是否正常工作, 打开浏览器在地址栏中输入 http://server_IP, 输入你的服务器 IP 地址, 默认 Apache2 页面应出现,如下面截图所示:
|
||||
4、 现在验证 Apache 是否正常工作, 打开浏览器在地址栏中输入 `http://server_IP`, 输入你的服务器 IP 地址, 默认 Apache2 页面应出现,如下面截图所示:
|
||||
|
||||
[
|
||||

|
||||
@ -59,15 +60,15 @@
|
||||
|
||||
*Apache 默认页面*
|
||||
|
||||
### 步骤 2: 安装 Apache PHP 支持
|
||||
### 步骤 2: 安装 Apache PHP 支持
|
||||
|
||||
5. 接下来,安装 PHP 和 PHP 所需模块.
|
||||
5、 接下来,安装 PHP 和 PHP 所需模块。
|
||||
|
||||
```
|
||||
# yum install php php-mbstring php-gd php-xml php-pear php-fpm php-mysql php-pdo php-opcache
|
||||
```
|
||||
|
||||
**重要**: 假如你想要安装 **PHP7**, 你需要增加以下仓库:**EPEL** 和 **Webtactic** 才可以使用 yum 安装 PHP7.0:
|
||||
**重要**: 假如你想要安装 **PHP7**, 你需要增加以下仓库:**EPEL** 和 **Webtactic** 才可以使用 yum 安装 PHP7.0:
|
||||
|
||||
```
|
||||
------------- Install PHP 7 in CentOS/RHEL and Fedora -------------
|
||||
@ -76,7 +77,7 @@
|
||||
# yum install php70w php70w-opcache php70w-mbstring php70w-gd php70w-xml php70w-pear php70w-fpm php70w-mysql php70w-pdo
|
||||
```
|
||||
|
||||
6. 接下来,要从浏览器得到关于 PHP 安装和配置完整信息,使用下面命令在 Apache 文档根目录 (/var/www/html) 创建一个 `info.php` 文件。
|
||||
6、 接下来,要从浏览器得到关于 PHP 安装和配置完整信息,使用下面命令在 Apache 文档根目录 (`/var/www/html`) 创建一个 `info.php` 文件。
|
||||
|
||||
```
|
||||
# echo "<?php phpinfo(); ?>" > /var/www/html/info.php
|
||||
@ -98,7 +99,7 @@
|
||||
|
||||
### 步骤 3: 安装和配置 MariaDB 数据库
|
||||
|
||||
7. 请了解, **Red Hat Enterprise Linux/CentOS 7.0** 从支持 **MYSQL** 转为了 **MariaDB** 作为默认数据库管理系统。
|
||||
7、 请知晓, **Red Hat Enterprise Linux/CentOS 7.0** 从支持 **MySQL** 转为了 **MariaDB** 作为默认数据库管理系统。
|
||||
|
||||
要安装 **MariaDB** 数据库, 你需要添加 [官方 MariaDB 库][3] 到 `/etc/yum.repos.d/MariaDB.repo` 中,如下所示。
|
||||
|
||||
@ -110,13 +111,13 @@ gpgkey=https://yum.mariadb.org/RPM-GPG-KEY-MariaDB
|
||||
gpgcheck=1
|
||||
```
|
||||
|
||||
当仓库文件准备好后,你可以像这样安装 MariaDB :
|
||||
当仓库文件准备好后,你可以像这样安装 MariaDB:
|
||||
|
||||
```
|
||||
# yum install mariadb-server mariadb
|
||||
```
|
||||
|
||||
8. 当 MariaDB 数据库安装完成,启动数据库的守护进程,同时使它能够在下次启动后自动启动。
|
||||
8、 当 MariaDB 数据库安装完成,启动数据库的守护进程,同时使它能够在下次启动后自动启动。
|
||||
|
||||
```
|
||||
------------- 通过 SystemD - CentOS/RHEL 7 and Fedora 22+ -------------
|
||||
@ -127,7 +128,7 @@ gpgcheck=1
|
||||
# chkconfig --level 35 mysqld on
|
||||
```
|
||||
|
||||
9. 然后运行 `mysql_secure_installation` 脚本去保护数据库(设置 root 密码, 禁用远程登录,移除测试数据库并移除匿名用户),如下所示:
|
||||
9、 然后运行 `mysql_secure_installation` 脚本去保护数据库(设置 root 密码, 禁用远程登录,移除测试数据库并移除匿名用户),如下所示:
|
||||
|
||||
```
|
||||
# mysql_secure_installation
|
||||
@ -136,25 +137,25 @@ gpgcheck=1
|
||||

|
||||
][4]
|
||||
|
||||
*Mysql 安全安装*
|
||||
*MySQL 安全安装*
|
||||
|
||||
### 步骤 4: 在 CentOS 中安装和配置 Drupal 8
|
||||
### 步骤 4: 在 CentOS 中安装和配置 Drupal 8
|
||||
|
||||
10. 这里我们使用 [wget 命令][6] [下载最新版本 Drupal][5](例如 8.2.6),如果你没有安装 wget 和 gzip 包 ,请使用下面命令安装它们:
|
||||
10、 这里我们使用 [wget 命令][6] [下载最新版本 Drupal][5](例如 8.2.6),如果你没有安装 wget 和 gzip 包 ,请使用下面命令安装它们:
|
||||
|
||||
```
|
||||
# yum install wget gzip
|
||||
# wget -c https://ftp.drupal.org/files/projects/drupal-8.2.6.tar.gz
|
||||
```
|
||||
|
||||
11. 之后,[解压 tar 文件][7] 并移动 Drupal 目录到 Apache 文档根目录(`/var/www/html`).
|
||||
11、 之后,[解压 tar 文件][7] 并移动 Drupal 目录到 Apache 文档根目录(`/var/www/html`)。
|
||||
|
||||
```
|
||||
# tar -zxvf drupal-8.2.6.tar.gz
|
||||
# mv drupal-8.2.6 /var/www/html/drupal
|
||||
```
|
||||
|
||||
12. 然后,依据 `/var/www/html/drupal/sites/default` 目录下的示例设置文件 default.settings.php,创建设置文件 `settings.php`,然后给 Drupal 站点目录设置适当权限,包括子目录和文件,如下所示:
|
||||
12、 然后,依据 `/var/www/html/drupal/sites/default` 目录下的示例设置文件 `default.settings.php`,创建设置文件 `settings.php`,然后给 Drupal 站点目录设置适当权限,包括子目录和文件,如下所示:
|
||||
|
||||
```
|
||||
# cd /var/www/html/drupal/sites/default/
|
||||
@ -162,13 +163,13 @@ gpgcheck=1
|
||||
# chown -R apache:apache /var/www/html/drupal/
|
||||
```
|
||||
|
||||
13. 更重要的是在 `/var/www/html/drupal/sites/` 目录设置 **SElinux** 规则,如下:
|
||||
13、 更重要的是在 `/var/www/html/drupal/sites/` 目录设置 **SElinux** 规则,如下:
|
||||
|
||||
```
|
||||
# chcon -R -t httpd_sys_content_rw_t /var/www/html/drupal/sites/
|
||||
```
|
||||
|
||||
14. 现在我们必须为 Drupal 站点去创建一个数据库和用户来管理。
|
||||
14、 现在我们必须为 Drupal 站点去创建一个用于管理的数据库和用户。
|
||||
|
||||
```
|
||||
# mysql -u root -p
|
||||
@ -191,7 +192,7 @@ Query OK, 0 rows affected (0.00 sec)
|
||||
Bye
|
||||
```
|
||||
|
||||
15. 最后,打开地址: `http://server_IP/drupal/` 开始网站的安装,选择你首选的安装语言然后点击保存以继续。
|
||||
15、 最后,打开地址: `http://server_IP/drupal/` 开始网站的安装,选择你首选的安装语言然后点击保存以继续。
|
||||
|
||||
[
|
||||
|
||||
@ -199,7 +200,7 @@ Bye
|
||||
|
||||
*Drupal 安装语言*
|
||||
|
||||
16. 下一步,选择安装配置文件,选择 Standard(标准),点击保存继续。
|
||||
16、 下一步,选择安装配置文件,选择 Standard(标准),点击保存继续。
|
||||
|
||||
[
|
||||

|
||||
@ -207,7 +208,7 @@ Bye
|
||||
|
||||
*Drupal 安装配置文件*
|
||||
|
||||
17. 在进行下一步之前查看并通过需求审查并启用 `Clean URL`。
|
||||
17、 在进行下一步之前查看并通过需求审查并启用 `Clean URL`。
|
||||
|
||||
[
|
||||
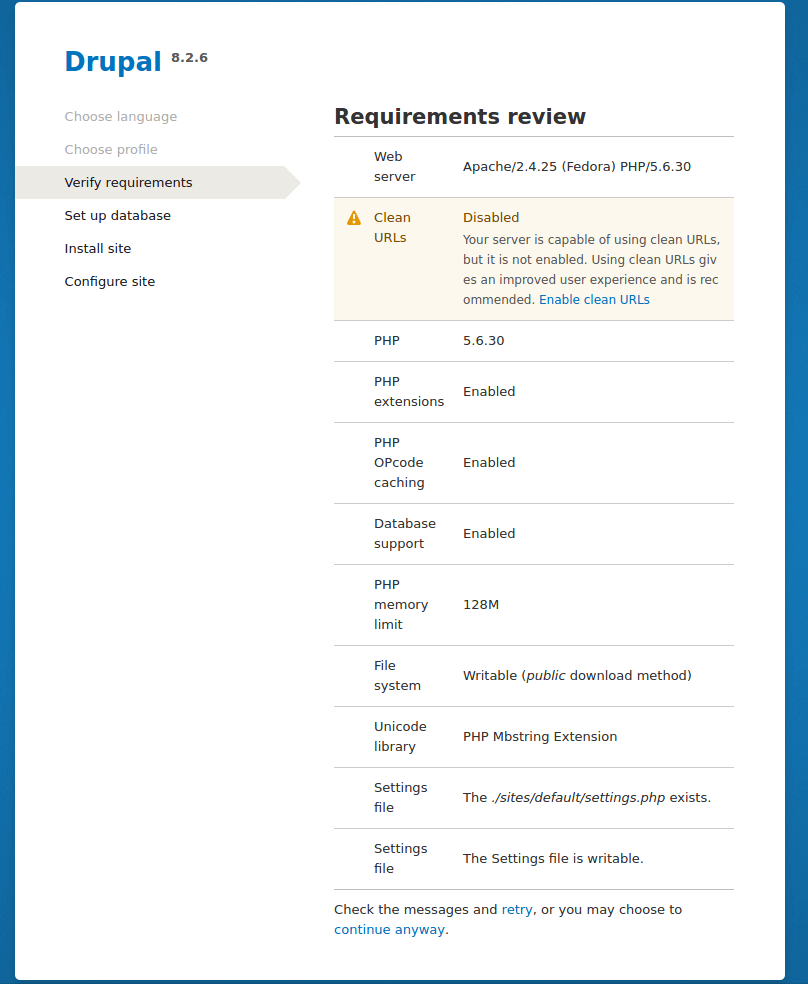
|
||||
@ -215,13 +216,13 @@ Bye
|
||||
|
||||
*验证 Drupal 需求*
|
||||
|
||||
现在在你的 Apache 配置下启用 Clean URL Drupal。
|
||||
现在在你的 Apache 配置下启用 Clean URL 的 Drupal。
|
||||
|
||||
```
|
||||
# vi /etc/httpd/conf/httpd.conf
|
||||
```
|
||||
|
||||
确保为默认根文档目录 **/var/www/html** 设置 **AllowOverride All**,如下图所示:
|
||||
确保为默认根文档目录 `/var/www/html` 设置 `AllowOverride All`,如下图所示:
|
||||
|
||||
[
|
||||
|
||||
@ -229,7 +230,7 @@ Bye
|
||||
|
||||
*在 Drupal 中启用 Clean URL*
|
||||
|
||||
18. 当你为 Drupal 启用 `Clean URL`,刷新页面从下面界面执行数据库配置,输入 Drupal 站点数据库名,数据库用户和数据库密码。
|
||||
18、 当你为 Drupal 启用 Clean URL,刷新页面从下面界面执行数据库配置,输入 Drupal 站点数据库名,数据库用户和数据库密码。
|
||||
|
||||
当填写完所有信息点击**保存并继续**。
|
||||
|
||||
@ -247,15 +248,15 @@ Bye
|
||||
|
||||
*Drupal 安装*
|
||||
|
||||
19. 接下来配置站点为下面的设置(使用适用你的情况的值):
|
||||
19、 接下来配置站点为下面的设置(使用适用你的情况的值):
|
||||
|
||||
- **站点名称** – TecMint Drupal Site
|
||||
- **站点邮箱地址** – admin@tecmint.com
|
||||
- **用户名** – admin
|
||||
- **密码** – ##########
|
||||
- **用户的邮箱地址** – admin@tecmint.com
|
||||
- **默认国家** – India
|
||||
- **默认时区** – UTC
|
||||
- **站点名称** – TecMint Drupal Site
|
||||
- **站点邮箱地址** – admin@tecmint.com
|
||||
- **用户名** – admin
|
||||
- **密码** – ##########
|
||||
- **用户的邮箱地址** – admin@tecmint.com
|
||||
- **默认国家** – India
|
||||
- **默认时区** – UTC
|
||||
|
||||
设置适当的值后,点击**保存并继续**完成站点安装过程。
|
||||
|
||||
@ -275,7 +276,7 @@ Bye
|
||||
|
||||
现在你可以点击**增加内容**,创建示例网页内容。
|
||||
|
||||
选项: 有些人[使用 MYSQL 命令行管理数据库][16]不舒服,可以从浏览器界面 [安装 PHPMYAdmin 管理数据库][17]
|
||||
选项: 有些人[使用 MySQL 命令行管理数据库][16]不舒服,可以从浏览器界面 [安装 PHPMYAdmin 管理数据库][17]
|
||||
|
||||
浏览 Drupal 文档 : [https://www.drupal.org/docs/8][18]
|
||||
|
||||
@ -1,18 +1,15 @@
|
||||
vim-kakali translating
|
||||
|
||||
Inxi – A Powerful Feature-Rich Commandline System Information Tool for Linux
|
||||
inxi:一个功能强大的获取 Linux 系统信息的命令行工具
|
||||
============================================================
|
||||
|
||||
Inxi 最初是为控制台和 IRC(网络中继聊天)开发的一个强大且优秀的命令行系统信息脚本。可以使用它获取用户的硬件和系统信息,它也用于调试或者社区技术支持工具。
|
||||
|
||||
Inxi is a powerful and remarkable command line-system information script designed for both console and IRC (Internet Relay Chat). It can be employed to instantly deduce user system configuration and hardware information, and also functions as a debugging, and forum technical support tool.
|
||||
使用 Inxi 可以很容易的获取所有的硬件信息:硬盘、声卡、显卡、网卡、CPU 和 RAM 等。同时也能够获取大量的操作系统信息,比如硬件驱动、Xorg 、桌面环境、内核、GCC 版本,进程,开机时间和内存等信息。
|
||||
|
||||
It displays handy information concerning system hardware (hard disk, sound cards, graphic card, network cards, CPU, RAM, and more), together with system information about drivers, Xorg, desktop environment, kernel, GCC version(s), processes, uptime, memory, and a wide array of other useful information.
|
||||
运行在命令行和 IRC 上的 Inxi 输出略有不同,IRC 上会有一些可供用户使用的默认过滤器和颜色选项。支持的 IRC 客户端有:BitchX、Gaim/Pidgin、ircII、Irssi、 Konversation、 Kopete、 KSirc、 KVIrc、 Weechat 和 Xchat 以及其它的一些客户端,它们具有展示内置或外部 Inxi 输出的能力。
|
||||
|
||||
However, it’s output slightly differs between the command line and IRC, with a few default filters and color options applicable to IRC usage. The supported IRC clients include: BitchX, Gaim/Pidgin, ircII, Irssi, Konversation, Kopete, KSirc, KVIrc, Weechat, and Xchat plus any others that are capable of showing either built in or external Inxi output.
|
||||
### 在 Linux 系统上安装 Inxi
|
||||
|
||||
### How to Install Inxi in Linux System
|
||||
|
||||
Inix is available in most mainstream Linux distribution repositories, and runs on BSDs as well.
|
||||
大多数主流 Linux 发行版的仓库中都有 Inxi ,包括大多数 BSD 系统。
|
||||
|
||||
```
|
||||
$ sudo apt-get install inxi [On Debian/Ubuntu/Linux Mint]
|
||||
@ -20,12 +17,15 @@ $ sudo yum install inxi [On CentOs/RHEL/Fedora]
|
||||
$ sudo dnf install inxi [On Fedora 22+]
|
||||
```
|
||||
|
||||
Before we start using it, we can run the command that follows to check all application dependencies plus recommends, and various directories, and display what package(s) we need to install to add support for a given feature.
|
||||
在使用 Inxi 之前,用下面的命令查看 Inxi 所有依赖和推荐的应用,以及各种目录,并显示需要安装哪些包来支持给定的功能。
|
||||
|
||||
|
||||
```
|
||||
$ inxi --recommends
|
||||
```
|
||||
Inxi Checking
|
||||
|
||||
Inxi 的输出:
|
||||
|
||||
```
|
||||
inxi will now begin checking for the programs it needs to operate. First a check of the main languages and tools
|
||||
inxi uses. Python is only for debugging data collection.
|
||||
@ -120,22 +120,22 @@ File: /var/run/dmesg.boot
|
||||
All tests completed.
|
||||
```
|
||||
|
||||
### Basic Usage of Inxi Tool in Linux
|
||||
### Inxi 工具的基本用法
|
||||
|
||||
Below are some basic Inxi options we can use to collect machine plus system information.
|
||||
用下面的基本用法获取系统和硬件的详细信息。
|
||||
|
||||
#### Show Linux System Information
|
||||
#### 获取 Linux 系统信息
|
||||
|
||||
When run without any flags, Inxi will produce output to do with system CPU, kernel, uptime, memory size, hard disk size, number of processes, client used and inxi version:
|
||||
Inix 不加任何选项就能输出下面的信息:CPU 、内核、开机时长、内存大小、硬盘大小、进程数、登录终端以及 Inxi 版本。
|
||||
|
||||
```
|
||||
$ inxi
|
||||
CPU~Dual core Intel Core i5-4210U (-HT-MCP-) speed/max~2164/2700 MHz Kernel~4.4.0-21-generic x86_64 Up~3:15 Mem~3122.0/7879.9MB HDD~1000.2GB(20.0% used) Procs~234 Client~Shell inxi~2.2.35
|
||||
```
|
||||
|
||||
#### Show Linux Kernel and Distribution Info
|
||||
#### 获取内核和发行版本信息
|
||||
|
||||
The command below will show sample system info (hostname, kernel info, desktop environment and disto) using the `-S` flag:
|
||||
使用 Inxi 的 `-S` 选项查看本机系统信息(主机名、内核信息、桌面环境和发行版):
|
||||
|
||||
```
|
||||
$ inxi -S
|
||||
@ -143,9 +143,10 @@ System: Host: TecMint Kernel: 4.4.0-21-generic x86_64 (64 bit) Desktop: Cinnamon
|
||||
Distro: Linux Mint 18 Sarah
|
||||
```
|
||||
|
||||
#### Find Linux Laptop or PC Model Information
|
||||
### 获取电脑机型
|
||||
|
||||
使用 `-M` 选项查看机型(笔记本/台式机)、产品 ID 、机器版本、主板、制造商和 BIOS 等信息:
|
||||
|
||||
To print machine data-same as product details (system, product id, version, Mobo, model, BIOS etc), we can use the option `-M` as follows:
|
||||
|
||||
```
|
||||
$ inxi -M
|
||||
@ -153,9 +154,9 @@ Machine: System: LENOVO (portable) product: 20354 v: Lenovo Z50-70
|
||||
Mobo: LENOVO model: Lancer 5A5 v: 31900059WIN Bios: LENOVO v: 9BCN26WW date: 07/31/2014
|
||||
```
|
||||
|
||||
#### Find Linux CPU and CPU Speed Information
|
||||
### 获取 CPU 及主频信息
|
||||
|
||||
We can display complete CPU information, including per CPU clock-speed and CPU max speed (if available) with the `-C` flag as follows:
|
||||
使用 `-C` 选项查看完整的 CPU 信息,包括每核 CPU 的频率及可用的最大主频。
|
||||
|
||||
```
|
||||
$ inxi -C
|
||||
@ -163,9 +164,9 @@ CPU: Dual core Intel Core i5-4210U (-HT-MCP-) cache: 3072 KB
|
||||
clock speeds: max: 2700 MHz 1: 1942 MHz 2: 1968 MHz 3: 1734 MHz 4: 1710 MHz
|
||||
```
|
||||
|
||||
#### Find Graphic Card Information in Linux
|
||||
#### 获取显卡信息
|
||||
|
||||
The option `-G` can be used to show graphics card info (card type, display server, resolution, GLX renderer and GLX version) like so:
|
||||
使用 `-G` 选项查看显卡信息,包括显卡类型、显示服务器、系统分辨率、GLX 渲染器和 GLX 版本等等(LCTT 译注: GLX 是一个 X 窗口系统的 OpenGL 扩展)。
|
||||
|
||||
```
|
||||
$ inxi -G
|
||||
@ -175,9 +176,9 @@ Display Server: X.Org 1.18.4 drivers: intel (unloaded: fbdev,vesa) Resolution: 1
|
||||
GLX Renderer: Mesa DRI Intel Haswell Mobile GLX Version: 3.0 Mesa 11.2.0
|
||||
```
|
||||
|
||||
#### Find Audio/Sound Card Information in Linux
|
||||
#### 获取声卡信息
|
||||
|
||||
To get info about system audio/sound card, we use the `-A` flag:
|
||||
使用 `-A` 选项查看声卡信息:
|
||||
|
||||
```
|
||||
$ inxi -A
|
||||
@ -185,9 +186,9 @@ Audio: Card-1 Intel 8 Series HD Audio Controller driver: snd_hda_intel Sound
|
||||
Card-2 Intel Haswell-ULT HD Audio Controller driver: snd_hda_intel
|
||||
```
|
||||
|
||||
#### Find Linux Network Card Information
|
||||
#### 获取网卡信息
|
||||
|
||||
To display network card info, we can make use of `-N` flag:
|
||||
使用 `-N` 选项查看网卡信息:
|
||||
|
||||
```
|
||||
$ inxi -N
|
||||
@ -195,18 +196,17 @@ Network: Card-1: Realtek RTL8111/8168/8411 PCI Express Gigabit Ethernet Contro
|
||||
Card-2: Realtek RTL8723BE PCIe Wireless Network Adapter driver: rtl8723be
|
||||
```
|
||||
|
||||
#### Find Linux Hard Disk Information
|
||||
#### 获取硬盘信息
|
||||
|
||||
To view full hard disk information,(size, id, model) we can use the flag `-D`:
|
||||
使用 `-D` 选项查看硬盘信息(大小、ID、型号):
|
||||
|
||||
```
|
||||
$ inxi -D
|
||||
Drives: HDD Total Size: 1000.2GB (20.0% used) ID-1: /dev/sda model: ST1000LM024_HN size: 1000.2GB
|
||||
```
|
||||
#### 获取简要的系统信息
|
||||
|
||||
#### Summarize Full Linux System Information Together
|
||||
|
||||
To show a summarized system information; combining all the information above, we need to use the `-b` flag as below:
|
||||
使用 `-b` 选项显示上述信息的简要系统信息:
|
||||
|
||||
```
|
||||
$ inxi -b
|
||||
@ -225,19 +225,18 @@ Drives: HDD Total Size: 1000.2GB (20.0% used)
|
||||
Info: Processes: 233 Uptime: 3:23 Memory: 3137.5/7879.9MB Client: Shell (bash) inxi: 2.2.35
|
||||
```
|
||||
|
||||
#### Find Linux Hard Disk Partition Details
|
||||
#### 获取硬盘分区信息
|
||||
|
||||
The next command will enable us view complete list of hard disk partitions in relation to size, used and available space, filesystem as well as filesystem type on each partition with the `-p` flag:
|
||||
使用 `-p` 选项输出完整的硬盘分区信息,包括每个分区的分区大小、已用空间、可用空间、文件系统以及文件系统类型。
|
||||
|
||||
```
|
||||
$ inxi -p
|
||||
Partition: ID-1: / size: 324G used: 183G (60%) fs: ext4 dev: /dev/sda10
|
||||
ID-2: swap-1 size: 4.00GB used: 0.00GB (0%) fs: swap dev: /dev/sda9
|
||||
```
|
||||
#### 获取完整的 Linux 系统信息
|
||||
|
||||
#### Shows Full Linux System Information
|
||||
|
||||
In order to show complete Inxi output, we use the `-F` flag as below (note that certain data is filtered for security reasons such as WAN IP):
|
||||
使用 `-F` 选项查看可以完整的 Inxi 输出(安全起见比如网络 IP 地址信息没有显示,下面的示例只显示部分输出信息):
|
||||
|
||||
```
|
||||
$ inxi -F
|
||||
@ -266,22 +265,22 @@ Fan Speeds (in rpm): cpu: N/A
|
||||
Info: Processes: 234 Uptime: 3:26 Memory: 3188.9/7879.9MB Client: Shell (bash) inxi: 2.2.35
|
||||
```
|
||||
|
||||
### Linux System Monitoring with Inxi Tool
|
||||
### 使用 Inxi 工具监控 Linux 系统
|
||||
|
||||
Following are few options used to monitor Linux system processes, uptime, memory etc.
|
||||
下面是监控 Linux 系统进程、开机时间和内存的几个选项的使用方法。
|
||||
|
||||
#### Monitor Linux Processes Memory Usage
|
||||
#### 监控 Linux 进程的内存使用
|
||||
|
||||
Get summarized system info in relation to total number of processes, uptime and memory usage:
|
||||
使用下面的命令查看进程数、开机时间和内存使用情况:
|
||||
|
||||
```
|
||||
$ inxi -I
|
||||
Info: Processes: 232 Uptime: 3:35 Memory: 3256.3/7879.9MB Client: Shell (bash) inxi: 2.2.35
|
||||
```
|
||||
|
||||
#### Monitoring Processes by CPU and Memory Usage
|
||||
#### 监控进程占用的 CPU 和内存资源
|
||||
|
||||
By default, it can help us determine the [top 5 processes consuming CPU or memory][1]. The `-t` option used together with `c` (CPU) and/or `m` (memory) options lists the top 5 most active processes eating up CPU and/or memory as shown below:
|
||||
Inxi 默认显示 [前 5 个最消耗 CPU 和内存的进程][1]。 `-t` 选项和 `c` 选项一起使用查看前 5 个最消耗 CPU 资源的进程,查看最消耗内存的进程使用 `-t` 选项和 `m` 选项; `-t`选项 和 `cm` 选项一起使用显示前 5 个最消耗 CPU 和内存资源的进程。
|
||||
|
||||
```
|
||||
----------------- Linux CPU Usage -----------------
|
||||
@ -322,7 +321,7 @@ Memory: MB / % used - Used/Total: 3223.6/7879.9MB - top 5 active
|
||||
5: mem: 211.68MB (2.6%) command: chrome pid: 6146
|
||||
```
|
||||
|
||||
We can use `cm` number (number can be 1-20) to specify a number other than 5, the command below will show us the [top 10 most active processes][2] eating up CPU and memory.
|
||||
可以在选项 `cm` 后跟一个整数(在 1-20 之间)设置显示多少个进程,下面的命令显示了前 10 个最消耗 CPU 和内存的进程:
|
||||
|
||||
```
|
||||
$ inxi -t cm10
|
||||
@ -350,9 +349,9 @@ Memory: MB / % used - Used/Total: 3163.1/7879.9MB - top 10 active
|
||||
10: mem: 151.83MB (1.9%) command: mysqld pid: 1259
|
||||
```
|
||||
|
||||
#### Monitor Linux Network Interfaces
|
||||
#### 监控网络设备
|
||||
|
||||
The command that follows will show us advanced network card information including interface, speed, mac id, state, IPs, etc:
|
||||
下面的命令会列出网卡信息,包括接口信息、网络频率、mac 地址、网卡状态和网络 IP 等信息。
|
||||
|
||||
```
|
||||
$ inxi -Nni
|
||||
@ -364,9 +363,9 @@ WAN IP: 111.91.115.195 IF: wlp2s0 ip-v4: N/A
|
||||
IF: enp1s0 ip-v4: 192.168.0.103
|
||||
```
|
||||
|
||||
#### Monitor Linux CPU Temperature and Fan Speed
|
||||
#### 监控 CPU 温度和电脑风扇转速
|
||||
|
||||
We can keep track of the [hardware installed/configured sensors][3] output by using the -s option:
|
||||
可以使用 `-s` 选项监控 [配置了传感器的机器][2] 获取温度和风扇转速:
|
||||
|
||||
```
|
||||
$ inxi -s
|
||||
@ -374,9 +373,9 @@ Sensors: System Temperatures: cpu: 53.0C mobo: N/A
|
||||
Fan Speeds (in rpm): cpu: N/A
|
||||
```
|
||||
|
||||
#### Find Weather Report in Linux
|
||||
#### 用 Linux 查看天气预报
|
||||
|
||||
We can also view whether info (though API used is unreliable) for the current location with the `-w` or `-W``<different_location>` to set a different location.
|
||||
使用 `-w` 选项查看本地区的天气情况(虽然使用的 API 可能不是很可靠),使用 `-W <different_location>` 设置另外的地区。
|
||||
|
||||
```
|
||||
$ inxi -w
|
||||
@ -387,9 +386,9 @@ $ inxi -W Nairobi,Kenya
|
||||
Weather: Conditions: 70 F (21 C) - Mostly Cloudy Time: February 20, 11:08 AM EAT
|
||||
```
|
||||
|
||||
#### Find All Linux Repsitory Information
|
||||
#### 查看所有的 Linux 仓库信息
|
||||
|
||||
We can additionally view a distro repository data with the `-r` flag:
|
||||
另外,可以使用 `-r` 选项查看一个 Linux 发行版的仓库信息:
|
||||
|
||||
```
|
||||
$ inxi -r
|
||||
@ -423,34 +422,36 @@ deb http://ppa.launchpad.net/ubuntu-mozilla-security/ppa/ubuntu xenial main
|
||||
deb-src http://ppa.launchpad.net/ubuntu-mozilla-security/ppa/ubuntu xenial main
|
||||
```
|
||||
|
||||
To view it’s current installed version, a quick help, and open the man page for a full list of options and detailed usage info plus lots more, type:
|
||||
下面是查看 Inxi 的安装版本、快速帮助和打开 man 主页的方法,以及更多的 Inxi 使用细节。
|
||||
|
||||
```
|
||||
$ inxi -v #show version
|
||||
$ inxi -h #quick help
|
||||
$ man inxi #open man page
|
||||
$ inxi -v #显示版本信息
|
||||
$ inxi -h #快速帮助
|
||||
$ man inxi #打开 man 主页
|
||||
```
|
||||
|
||||
For more information, visit official GitHub Repository: [https://github.com/smxi/inxi][4]
|
||||
浏览 Inxi 的官方 GitHub 主页 [https://github.com/smxi/inxi][4] 查看更多的信息。
|
||||
|
||||
That’s all for now! In this article, we reviewed Inxi, a full featured and remarkable command line tool for collecting machine hardware and system info. This is one of the best CLI based [hardware/system information collection tools][5] for Linux, I have ever used.
|
||||
Inxi 是一个功能强大的获取硬件和系统信息的命令行工具。这也是我使用过的最好的 [获取硬件和系统信息的命令行工具][5] 之一。
|
||||
|
||||
写下你的评论。如果你知道其他的像 Inxi 这样的工具,我们很高兴和你一起讨论。
|
||||
|
||||
To share your thoughts about it, use the comment form below. Lastly, in case you know of other, such useful tools as Inxi out there, you can inform us and we will be delighted to review them as well.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||
Aaron Kili 是一个 Linux 和 F.O.S.S 的狂热爱好者,即任的 Linux 系统管理员,web 开发者,TecMint 网站的专栏作者,他喜欢使用计算机工作,并且乐于分享计算机技术。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/inxi-command-to-find-linux-system-information/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[vim-kakali](https://github.com/vim-kakali)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
99
published/201704/20170309 8 reasons to use LXDE.md
Normal file
99
published/201704/20170309 8 reasons to use LXDE.md
Normal file
@ -0,0 +1,99 @@
|
||||
使用 LXDE 的 8 个理由
|
||||
============================================================
|
||||
|
||||
> 考虑使用轻量级桌面环境 LXDE 作为你 Linux 桌面的理由
|
||||
|
||||

|
||||
|
||||
>Image by : opensource.com
|
||||
|
||||
去年年底,升级到 Fedora 25 所装的新版本 [KDE][7] Plasma 给我带来了严重问题,让我难以完成任何工作。出于两个原因我决定尝试其它 Linux 桌面环境。第一,我需要完成我的工作。第二,一心使用 KDE 已经有很多年,我认为是时候尝试一些不同的桌面了。
|
||||
|
||||
我第一个尝试了几周的替代桌面是 [Cinnamon][8],我在 1 月份介绍过它。这次我已经使用了 LXDE(轻量级 X11 桌面环境(Lightweight X11 Desktop Environment))大概 6 周,我发现它有很多我喜欢的东西。这是我使用 LXDE 的 8 个理由。
|
||||
|
||||
更多 Linux 相关资源
|
||||
|
||||
* [Linux 是什么?][1]
|
||||
* [Linux 容器是什么?][2]
|
||||
* [在 Linux 中管理设备][3]
|
||||
* [马上下载:Linux 命令速查表][4]
|
||||
* [我们最新的 Linux 文章][5]
|
||||
|
||||
### 1、 LXDE 支持多个面板
|
||||
|
||||
和 KDE 以及 Cinnamon 一样,LXDE 支持包括系统菜单、应用启动器的面板,以及显示正在运行应用图标的任务栏。我第一次登录到 LXDE 时,面板的配置看起来异常熟悉。LDXE 看起来已经根据我的 KDE 配置情况为我准备好了喜欢的顶部和底部面板,并包括了系统托盘设置。顶部面板上的应用程序启动器看似来自 Cinnamon 。面板上的东西使得启动和管理程序变得容易。默认情况下,只在桌面底部有一个面板。
|
||||
|
||||

|
||||
|
||||
*打开了 Openbox 配置管理器的 LXDE 桌面。这个桌面还没有更改过,因此它使用了默认的颜色和图标主题。*
|
||||
|
||||
### 2、 Openbox 配置管理器提供了一个用于管理和体验桌面外观的简单工具。
|
||||
|
||||
它为主题、窗口修饰、多个显示器的窗口行为、移动和调整窗口大小、鼠标控制、多桌面等提供了选项。虽然这看起来似乎很多,但它远不如配置 KDE 桌面那么复杂,尽管如此 Openbox 仍然提供了绝佳的效果。
|
||||
|
||||
### 3、 LXDE 有一个强大的菜单工具
|
||||
|
||||
在桌面偏好(Desktop Preference)菜单的高级(Advanced)标签页有个有趣的选项。这个选项的名称是 “点击桌面时显示窗口管理器提供的菜单(Show menus provided by window managers when desktop is clicked)”。选中这个复选框,当你右击桌面时,会显示 Openbox 桌面菜单,而不是标准的 LXDE 桌面菜单。
|
||||
|
||||
Openbox 桌面菜单包括了几乎每个你可能想要的菜单选项,所有都可从桌面便捷访问。它包括了所有的应用程序菜单、系统管理、以及首选项。它甚至有一个菜单包括了所有已安装的终端模拟器应用程序的列表,因此系统管理员可以轻易地启动他们喜欢的终端。
|
||||
|
||||
### 4、 LXDE 桌面的设计干净简单
|
||||
|
||||
它没有任何会妨碍你完成工作的东西。尽管你可以添加一些文件、目录、应用程序的链接到桌面,但是没有可以添加到桌面的小部件。在我的 KDE 和 Cinnamon 桌面上我确实喜欢一些小部件,但它们很容易被覆盖住,然后我就需要移动或者最小化窗口,或者使用 “显示桌面(Show Desktop)” 按钮清空整个桌面才能看到它们。 LXDE 确实有一个 “图标化所有窗口(Iconify all windows)” 按钮,但我很少需要使用它,除非我想看我的壁纸。
|
||||
|
||||
### 5、 LXDE 有一个强大的文件管理器
|
||||
|
||||
LXDE 默认的文件管理器是 PCManFM,因此在我使用 LXDE 的时候它成为了我的文件管理器。PCManFM 非常灵活、可以配置为适用于大部分人和场景。它看起来没有我常用的文件管理器 Krusader 那么可配置,但我确实喜欢 Krusader 所没有的 PCManFM 侧边栏。
|
||||
|
||||
PCManFM 允许打开多个标签页,可以通过右击侧边栏的任何条目或者单击图标栏的新标签图标打开。PCManFM 窗口左边的位置(Places)面板显示了应用程序菜单,你可以从 PCManFM 启动应用程序。位置(Places)面板上面也显示了一个设备图标,可以用于查看你的物理存储设备,一系列带按钮的可移除设备允许你挂载和卸载它们,还有可以便捷访问的主目录、桌面、回收站。位置(Places)面板的底部包括一些默认目录的快捷方式,例如 Documents、Music、Pictures、Videos 以及 Downloads。你也可以拖拽其它目录到位置(Places)面板的快捷方式部分。位置(Places) 面板可以换为正常的目录树。
|
||||
|
||||
### 6、 如果在现有窗口后面打开,新窗口的标题栏会闪烁
|
||||
|
||||
这是一个在大量现有窗口中定位新窗口的好方法。
|
||||
|
||||
### 7、 大部分现代桌面环境允许多个桌面,LXDE 也不例外
|
||||
|
||||
我喜欢使用一个桌面用于我的开发、测试以及编辑工作,另一个桌面用于普通任务,例如电子邮件和网页浏览。LXDE 默认提供两个桌面,但你可以配置为只有一个或者多个。右击桌面切换器(Desktop Pager)配置它。
|
||||
|
||||
通过一些有害但不是破坏性的测试,我发现最大允许桌面数目是 100。我还发现当我把桌面数目减少到低于我实际已经在使用的 3 个时,不活动桌面上的窗口会被移动到桌面 1。多么有趣的发现!
|
||||
|
||||
### 8、 Xfce 电源管理器是一个小巧但强大的应用程序,它允许你配置电源管理如何工作
|
||||
|
||||
它提供了一个标签页用于通用配置,以及用于系统、显示和设备的标签页。设备标签页显示了我系统上已有设备的表格,例如电池供电的鼠标、键盘,甚至我的 UPS(不间断电源)。它显示了每个设备的详细信息,包括厂商和系列号,如果可用的话,还有电池充电状态。当我写这篇博客的时候,我 UPS 的电量是 100%,而我罗技鼠标的电量是 75%。 Xfce 电源管理器还在系统托盘显示了一个图标,因此你可以从那里快速了解你设备的电池状态。
|
||||
|
||||
关于 LXDE 桌面还有很多喜欢的东西,但这些就是抓住了我的注意力,它们也是对我使用现代图形用户界面工作非常重要、不可或缺的东西。
|
||||
|
||||
我注意到奇怪的一点是,我一直没有弄明白桌面(Openbox)菜单的 “重新配置(Reconfigure)” 选项是干什么的。我点击了几次,从没有注意到有任何类型的任何活动表明该选项实际起了作用。
|
||||
|
||||
我发现 LXDE 是一个简单但强大的桌面。我享受使用它写这篇文章的几周时间。通过允许我访问我想要的应用程序和文件,同时在其余时间保持不会让我分神,LXDE 使我得以高效地工作。我也没有遇到任何妨碍我完成工作的问题——当然,除了我用于探索这个好桌面所花的时间。我非常推荐 LXDE 桌面。
|
||||
|
||||
我现在正在试用 GNOME 3 和 GNOME Shell,并将在下一期中报告。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
David Both 是一个 Linux 和开源倡导者,他居住在北卡罗莱纳州的 Raleigh。他在 IT 行业已经超过 40 年,在他工作的 IBM 公司教授 OS/2 超过 20 年,他在 1981 年为最早的 IBM PC 写了第一个培训课程。他教过 Red Hat 的 RHCE 课程,在 MCI Worldcom、 Cisco 和北卡罗莱纳州 工作过。他一直在使用 Linux 和开源软件近 20 年。
|
||||
|
||||
--------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/3/8-reasons-use-lxde
|
||||
|
||||
作者:[David Both][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dboth
|
||||
[1]:https://opensource.com/resources/what-is-linux?src=linux_resource_menu
|
||||
[2]:https://opensource.com/resources/what-are-linux-containers?src=linux_resource_menu
|
||||
[3]:https://opensource.com/article/16/11/managing-devices-linux?src=linux_resource_menu
|
||||
[4]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=7016000000127cYAAQ
|
||||
[5]:https://opensource.com/tags/linux?src=linux_resource_menu
|
||||
[6]:https://opensource.com/article/17/3/8-reasons-use-lxde?rate=QigvkBy_9zLvktdsL-QaIWedjIqjtlwwJIVFQDQzsSY
|
||||
[7]:https://opensource.com/life/15/4/9-reasons-to-use-kde
|
||||
[8]:https://opensource.com/article/17/1/cinnamon-desktop-environment
|
||||
[9]:https://opensource.com/user/14106/feed
|
||||
[10]:https://opensource.com/article/17/3/8-reasons-use-lxde#comments
|
||||
[11]:https://opensource.com/users/dboth
|
||||
@ -1,4 +1,4 @@
|
||||
如何在 AWS EC2 的 Linux 服务器上打开端口
|
||||
如何在 AWS EC2 的 Linux 服务器上开放一个端口
|
||||
============================================================
|
||||
|
||||
_这是一篇用屏幕截图解释如何在 AWS EC2 Linux 服务器上打开端口的教程。它能帮助你管理 EC2 服务器上特定端口的服务。_
|
||||
@ -9,13 +9,13 @@ AWS(即 Amazon Web Services)不是 IT 世界中的新术语了。它是亚
|
||||
|
||||
AWS 提供服务器计算作为他们的服务之一,他们称之为 EC(弹性计算)。使用它可以构建我们的 Linux 服务器。我们已经看到了[如何在 AWS 上设置免费的 Linux 服务器][11]了。
|
||||
|
||||
默认情况下,所有基于 EC2 的 Linux 服务器都只打开 22 端口,即 SSH 服务端口(所有 IP 的入站)。因此,如果你托管了任何特定端口的服务,则要为你的服务器在 AWS 防火墙上打开相应端口。
|
||||
默认情况下,所有基于 EC2 的 Linux 服务器都只打开 22 端口,即 SSH 服务端口(允许所有 IP 的入站连接)。因此,如果你托管了任何特定端口的服务,则要为你的服务器在 AWS 防火墙上打开相应端口。
|
||||
|
||||
同样它的 1 到 65535 的端口是打开的(所有出站流量)。如果你想改变这个,你可以使用下面的方法编辑出站规则。
|
||||
同样它的 1 到 65535 的端口是打开的(对于所有出站流量)。如果你想改变这个,你可以使用下面的方法编辑出站规则。
|
||||
|
||||
在 AWS 上为你的服务器设置防火墙规则很容易。你能够在几秒钟内为你的服务器打开端口。我将用截图指导你如何打开 EC2 服务器的端口。
|
||||
|
||||
_步骤 1 :_
|
||||
### 步骤 1 :
|
||||
|
||||
登录 AWS 帐户并进入 **EC2 管理控制台**。进入<ruby>“网络及安全”<rt>Network & Security </rt></ruby>菜单下的<ruby>**安全组**<rt>Security Groups</rt></ruby>,如下高亮显示:
|
||||
|
||||
@ -23,9 +23,7 @@ AWS 提供服务器计算作为他们的服务之一,他们称之为 EC(弹
|
||||
|
||||
*AWS EC2 管理控制台*
|
||||
|
||||
* * *
|
||||
|
||||
_步骤 2 :_
|
||||
### 步骤 2 :
|
||||
|
||||
在<ruby>安全组<rt>Security Groups</rt></ruby>中选择你的 EC2 服务器,并在 <ruby>**行动**<rt>Actions</rt></ruby> 菜单下选择 <ruby>**编辑入站规则**<rt>Edit inbound rules</rt></ruby>。
|
||||
|
||||
@ -33,7 +31,7 @@ AWS 提供服务器计算作为他们的服务之一,他们称之为 EC(弹
|
||||
|
||||
*AWS 入站规则菜单*
|
||||
|
||||
_步骤 3:_
|
||||
### 步骤 3:
|
||||
|
||||
现在你会看到入站规则窗口。你可以在此处添加/编辑/删除入站规则。这有几个如 http、nfs 等列在下拉菜单中,它们可以为你自动填充端口。如果你有自定义服务和端口,你也可以定义它。
|
||||
|
||||
@ -46,15 +44,13 @@ AWS 提供服务器计算作为他们的服务之一,他们称之为 EC(弹
|
||||
* 类型:http
|
||||
* 协议:TCP
|
||||
* 端口范围:80
|
||||
* 源:任何来源(打开 80 端口接受来自任何IP(0.0.0.0/0)的请求),我的 IP:那么它会自动填充你当前的公共互联网 IP
|
||||
* 源:任何来源:打开 80 端口接受来自“任何IP(0.0.0.0/0)”的请求;我的 IP:那么它会自动填充你当前的公共互联网 IP
|
||||
|
||||
* * *
|
||||
|
||||
_步骤 4:_
|
||||
### 步骤 4:
|
||||
|
||||
就是这样了。保存完毕后,你的服务器入站 80 端口将会打开!你可以通过 telnet 到 EC2 服务器公共域名的 80 端口来检验(可以在 EC2 服务器详细信息中找到)。
|
||||
|
||||
|
||||
你也可以在 [ping.eu][12] 等网站上检验。
|
||||
|
||||
* * *
|
||||
@ -65,7 +61,7 @@ AWS 提供服务器计算作为他们的服务之一,他们称之为 EC(弹
|
||||
|
||||
via: http://kerneltalks.com/virtualization/how-to-open-port-on-aws-ec2-linux-server/
|
||||
|
||||
作者:[Shrikant Lavhate ][a]
|
||||
作者:[Shrikant Lavhate][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
@ -0,0 +1,128 @@
|
||||
如何在树莓派上安装 Fedora 25
|
||||
============================================================
|
||||
|
||||
> 了解 Fedora 第一个官方支持树莓派的版本
|
||||
|
||||

|
||||
|
||||
>图片提供 opensource.com
|
||||
|
||||
2016 年 10 月,Fedora 25 Beta 发布了,随之而来的还有对 [树莓派 2 和 3 的初步支持][6]。Fedora 25 的最终“通用”版在一个月后发布,从那时起,我一直在树莓派上尝试不同的 Fedora spins。
|
||||
|
||||
这篇文章不仅是一篇<ruby>树莓派<rt>Raspberry Pi</rt></ruby> 3 上的 Fedora 25 的点评,还集合了技巧、截图以及我对 Fedora 第一个官方支持 Pi 的这个版本的一些个人看法。
|
||||
|
||||
在我开始之前,需要说一下的是,为写这篇文章所做的所有工作都是在我的运行 Fedora 25 的个人笔记本电脑上完成的。我使用一张 microSD 插到 SD 适配器中,复制和编辑所有的 Fedora 镜像到 32GB 的 microSD 卡中,然后用它在一台三星电视上启动了树莓派 3。 因为 Fedora 25 尚不支持内置 Wi-Fi,所以树莓派 3 使用了以太网线缆进行网络连接。最后,我使用了 Logitech K410 无线键盘和触摸板进行输入。
|
||||
|
||||
如果你没有条件使用以太网线连接在你的树莓派上玩 Fedora 25,我曾经用过一个 Edimax Wi-Fi USB 适配器,它也可以在 Fedora 25 上工作,但在本文中,我只使用了以太网连接。
|
||||
|
||||
### 在树莓派上安装 Fedora 25 之前
|
||||
|
||||
阅读 Fedora 项目 wiki 上的[树莓派支持文档][7]。你可以从 wiki 下载 Fedora 25 安装所需的镜像,那里还列出了所有支持和不支持的内容。
|
||||
|
||||
此外,请注意,这是初始支持版本,还有许多新的工作和支持将随着 Fedora 26 的发布而出现,所以请随时报告 bug,并通过 [Bugzilla][8]、Fedora 的 [ARM 邮件列表][9]、或者 Freenode IRC 频道#fedora-arm,分享你在树莓派上使用 Fedora 25 的体验反馈。
|
||||
|
||||
### 安装
|
||||
|
||||
我下载并安装了五个不同的 Fedora 25 spin:GNOME(默认工作站)、KDE、Minimal、LXDE 和 Xfce。在多数情况下,它们都有一致和易于遵循的步骤,以确保我的树莓派 3 上启动正常。有的 spin 有已知 bug 的正在解决之中,而有的按照 Fedora wik 遵循标准操作程序即可。
|
||||
|
||||

|
||||
|
||||
*树莓派 3 上的 Fedora 25 workstation、 GNOME 版本*
|
||||
|
||||
### 安装步骤
|
||||
|
||||
1、 在你的笔记本上,从支持文档页面的链接下载一个树莓派的 Fedora 25 镜像。
|
||||
|
||||
2、 在笔记本上,使用 `fedora-arm-installer` 或下述命令行将镜像复制到 microSD:
|
||||
|
||||
```
|
||||
xzcat Fedora-Workstation-armhfp-25-1.3-sda.raw.xz | dd bs=4M status=progress of=/dev/mmcblk0
|
||||
```
|
||||
|
||||
注意:`/dev/mmclk0` 是我的 microSD 插到 SD 适配器后,在我的笔记本电脑上挂载的设备名。虽然我在笔记本上使用 Fedora,可以使用 `fedora-arm-installer`,但我还是喜欢命令行。
|
||||
|
||||
3、 复制完镜像后,_先不要启动你的系统_。我知道你很想这么做,但你仍然需要进行几个调整。
|
||||
|
||||
4、 为了使镜像文件尽可能小以便下载,镜像上的根文件系统是很小的,因此你必须增加根文件系统的大小。如果你不这么做,你仍然可以启动你的派,但如果你一旦运行 `dnf update` 来升级你的系统,它就会填满文件系统,导致糟糕的事情发生,所以趁着 microSD 还在你的笔记本上进行分区:
|
||||
|
||||
```
|
||||
growpart /dev/mmcblk0 4
|
||||
resize2fs /dev/mmcblk0p4
|
||||
```
|
||||
|
||||
注意:在 Fedora 中,`growpart` 命令由 `cloud-utils-growpart.noarch` 这个 RPM 提供的。
|
||||
|
||||
5、文件系统更新后,您需要将 `vc4` 模块列入黑名单。[更多有关此 bug 的信息在此。][10]
|
||||
|
||||
我建议在启动树莓派之前这样做,因为不同的 spin 有不同表现方式。例如,(至少对我来说)在没有黑名单 `vc4` 的情况下,GNOME 在我启动后首先出现,但在系统更新后,它不再出现。 KDE spin 则在第一次启动时根本不会出现 KDE。因此我们可能需要在我们的第一次启动之前将 `vc4` 加入黑名单,直到这个错误以后解决了。
|
||||
|
||||
黑名单应该出现在两个不同的地方。首先,在你的 microSD 根分区上,在 `etc/modprode.d/` 下创建一个 `vc4.conf`,内容是:`blacklist vc4`。第二,在你的 microSD 启动分区,添加 `rd.driver.blacklist=vc4` 到 `extlinux/extlinux.conf` 文件的末尾。
|
||||
|
||||
6、 现在,你可以启动你的树莓派了。
|
||||
|
||||
### 启动
|
||||
|
||||
你要有耐心,特别是对于 GNOME 和 KDE 发行版来说。在 SSD(固态驱动器)几乎即时启动的时代,你很容易就对派的启动速度感到不耐烦,特别是第一次启动时。在第一次启动 Window Manager 之前,会先弹出一个初始配置页面,可以配置 root 密码、常规用户、时区和网络。配置完毕后,你就应该能够 SSH 到你的树莓派上,方便地调试显示问题了。
|
||||
|
||||
### 系统更新
|
||||
|
||||
在树莓派上运行 Fedora 25 后,你最终(或立即)会想要更新系统。
|
||||
|
||||
首先,进行内核升级时,先熟悉你的 `/boot/extlinux/extlinux.conf` 文件。如果升级内核,下次启动时,除非手动选择正确的内核,否则很可能会启动进入救援( Rescue )模式。避免这种情况发生最好的方法是,在你的 `extlinux.conf` 中将定义 Rescue 镜像的那五行移动到文件的底部,这样最新的内核将在下次自动启动。你可以直接在派上或通过在笔记本挂载来编辑 `/boot/extlinux/extlinux.conf`:
|
||||
```
|
||||
label Fedora 25 Rescue fdcb76d0032447209f782a184f35eebc (4.9.9-200.fc25.armv7hl)
|
||||
kernel /vmlinuz-0-rescue-fdcb76d0032447209f782a184f35eebc
|
||||
append ro root=UUID=c19816a7-cbb8-4cbb-8608-7fec6d4994d0 rd.driver.blacklist=vc4
|
||||
fdtdir /dtb-4.9.9-200.fc25.armv7hl/
|
||||
initrd /initramfs-0-rescue-fdcb76d0032447209f782a184f35eebc.img
|
||||
```
|
||||
|
||||
第二点,如果无论什么原因,如果你的显示器在升级后再次变暗,并且你确定已经将 `vc4` 加入黑名单,请运行 `lsmod | grep vc4`。你可以先启动到多用户模式而不是图形模式,并从命令行中运行 `startx`。 请阅读 `/etc/inittab` 中的内容,了解如何切换 target 的说明。
|
||||
|
||||

|
||||
|
||||
*树莓派 3 上的 Fedora 25 workstation、 KDE 版本*
|
||||
|
||||
### Fedora Spin
|
||||
|
||||
在我尝试过的所有 Fedora Spin 中,唯一有问题的是 XFCE spin,我相信这是由于这个[已知的 bug][11] 导致的。
|
||||
|
||||
按照我在这里分享的步骤操作,GNOME、KDE、LXDE 和 minimal 都运行得很好。考虑到 KDE 和 GNOME 会占用更多资源,我会推荐想要在树莓派上使用 Fedora 25 的人使用 LXDE 和 Minimal。如果你是一位系统管理员,想要一台廉价的 SELinux 支持的服务器来满足你的安全考虑,而且只是想要使用树莓派作为你的服务器,开放 22 端口以及 vi 可用,那就用 Minimal 版本。对于开发人员或刚开始学习 Linux 的人来说,LXDE 可能是更好的方式,因为它可以快速方便地访问所有基于 GUI 的工具,如浏览器、IDE 和你可能需要的客户端。
|
||||
|
||||

|
||||
|
||||
*树莓派 3 上的 Fedora 25 workstation、LXDE。*
|
||||
|
||||
看到越来越多的 Linux 发行版在基于 ARM 的树莓派上可用,那真是太棒了。对于其第一个支持的版本,Fedora 团队为日常 Linux 用户提供了更好的体验。我很期待 Fedora 26 的改进和 bug 修复。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Anderson Silva - Anderson 于 1996 年开始使用 Linux。更精确地说是 Red Hat Linux。 2007 年,他作为 IT 部门的发布工程师时加入红帽,他的职业梦想成为了现实。此后,他在红帽担任过多个不同角色,从发布工程师到系统管理员、高级经理和信息系统工程师。他是一名 RHCE 和 RHCA 以及一名活跃的 Fedora 包维护者。
|
||||
|
||||
----------------
|
||||
|
||||
via: https://opensource.com/article/17/3/how-install-fedora-on-raspberry-pi
|
||||
|
||||
作者:[Anderson Silva][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ansilva
|
||||
[1]:https://opensource.com/tags/raspberry-pi?src=raspberry_pi_resource_menu
|
||||
[2]:https://opensource.com/resources/what-raspberry-pi?src=raspberry_pi_resource_menu
|
||||
[3]:https://opensource.com/article/16/12/getting-started-raspberry-pi?src=raspberry_pi_resource_menu
|
||||
[4]:https://opensource.com/article/17/2/raspberry-pi-submit-your-article?src=raspberry_pi_resource_menu
|
||||
[5]:https://opensource.com/article/17/3/how-install-fedora-on-raspberry-pi?rate=gIIRltTrnOlwo4h81uDvdAjAE3V2rnwoqH0s_Dx44mE
|
||||
[6]:https://fedoramagazine.org/raspberry-pi-support-fedora-25-beta/
|
||||
[7]:https://fedoraproject.org/wiki/Raspberry_Pi
|
||||
[8]:https://bugzilla.redhat.com/show_bug.cgi?id=245418
|
||||
[9]:https://lists.fedoraproject.org/admin/lists/arm%40lists.fedoraproject.org/
|
||||
[10]:https://bugzilla.redhat.com/show_bug.cgi?id=1387733
|
||||
[11]:https://bugzilla.redhat.com/show_bug.cgi?id=1389163
|
||||
[12]:https://opensource.com/user/26502/feed
|
||||
[13]:https://opensource.com/article/17/3/how-install-fedora-on-raspberry-pi#comments
|
||||
[14]:https://opensource.com/users/ansilva
|
||||
@ -1,20 +1,19 @@
|
||||
如何在现有的 Linux 系统上添加新的磁盘
|
||||
============================================================
|
||||
|
||||
作为一个系统管理员,我们会有这样的一些需求:作为升级服务器容量的一部分,或者有时出现磁盘故障时更换磁盘,我们需要将新的硬盘配置到现有服务器。
|
||||
|
||||
作为一个系统管理员,我们会有这样的一些需求:作为升级服务器容量的一部分、或者有时出现磁盘故障时更换磁盘,我们需要将新的硬盘配置到现有服务器。
|
||||
在这篇文章中,我会向你逐步介绍添加新硬盘到现有 **RHEL/CentOS** 或者 **Debian/Ubuntu Linux** 系统的步骤。
|
||||
|
||||
在这篇文章中,我会向你逐步介绍添加新硬盘到现有 RHEL/CentOS 或者 Debian/Ubuntu Linux 系统的步骤。
|
||||
|
||||
**推荐阅读:** [如何将超过 2TB 的新硬盘添加到现有 Linux][1]
|
||||
**推荐阅读:** [如何将超过 2TB 的新硬盘添加到现有 Linux][1]。
|
||||
|
||||
重要:请注意这篇文章的目的只是告诉你如何创建新的分区,而不包括分区扩展或者其它选项。
|
||||
|
||||
我使用 [fdisk 工具][2] 完成这些配置。
|
||||
|
||||
我已经添加了一块 20GB 容量的硬盘,挂载到了 `/data` 分区。
|
||||
我已经添加了一块 **20GB** 容量的硬盘,挂载到了 `/data` 分区。
|
||||
|
||||
fdisk 是一个在 Linux 系统上用于显示和管理硬盘和分区命令行工具。
|
||||
`fdisk` 是一个在 Linux 系统上用于显示和管理硬盘和分区命令行工具。
|
||||
|
||||
```
|
||||
# fdisk -l
|
||||
@ -26,7 +25,7 @@ fdisk 是一个在 Linux 系统上用于显示和管理硬盘和分区命令行
|
||||

|
||||
][3]
|
||||
|
||||
查看 Linux 分区详情
|
||||
*查看 Linux 分区详情*
|
||||
|
||||
添加了 20GB 容量的硬盘后,`fdisk -l` 的输出像下面这样。
|
||||
|
||||
@ -37,9 +36,9 @@ fdisk 是一个在 Linux 系统上用于显示和管理硬盘和分区命令行
|
||||
|
||||
][4]
|
||||
|
||||
查看新分区详情
|
||||
*查看新分区详情*
|
||||
|
||||
新添加的磁盘显示为 `/dev/xvdc`。如果我们添加的是物理磁盘,基于磁盘类型它会显示类似 `/dev/sda`。这里我使用的是虚拟磁盘。
|
||||
新添加的磁盘显示为 `/dev/xvdc`。如果我们添加的是物理磁盘,基于磁盘类型它会显示为类似 `/dev/sda`。这里我使用的是虚拟磁盘。
|
||||
|
||||
要在特定硬盘上分区,例如 `/dev/xvdc`。
|
||||
|
||||
@ -47,7 +46,7 @@ fdisk 是一个在 Linux 系统上用于显示和管理硬盘和分区命令行
|
||||
# fdisk /dev/xvdc
|
||||
```
|
||||
|
||||
常用 fdisk 命令。
|
||||
常用的 fdisk 命令。
|
||||
|
||||
* `n` - 创建分区
|
||||
* `p` - 打印分区表
|
||||
@ -61,7 +60,7 @@ fdisk 是一个在 Linux 系统上用于显示和管理硬盘和分区命令行
|
||||
|
||||
][5]
|
||||
|
||||
在 Linux上创建新分区
|
||||
*在 Linux 上创建新分区*
|
||||
|
||||
创建主分区或者扩展分区。默认情况下我们最多可以有 4 个主分区。
|
||||
|
||||
@ -69,7 +68,7 @@ fdisk 是一个在 Linux 系统上用于显示和管理硬盘和分区命令行
|
||||
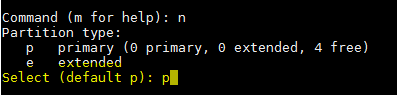
|
||||
][6]
|
||||
|
||||
创建主分区
|
||||
*创建主分区*
|
||||
|
||||
按需求输入分区编号。推荐使用默认的值 `1`。
|
||||
|
||||
@ -77,7 +76,7 @@ fdisk 是一个在 Linux 系统上用于显示和管理硬盘和分区命令行
|
||||
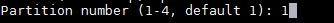
|
||||
][7]
|
||||
|
||||
分配分区编号
|
||||
*分配分区编号*
|
||||
|
||||
输入第一个扇区的大小。如果是一个新的磁盘,通常选择默认值。如果你是在同一个磁盘上创建第二个分区,我们需要在前一个分区的最后一个扇区的基础上加 `1`。
|
||||
|
||||
@ -85,7 +84,7 @@ fdisk 是一个在 Linux 系统上用于显示和管理硬盘和分区命令行
|
||||
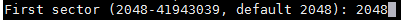
|
||||
][8]
|
||||
|
||||
为分区分配扇区
|
||||
*为分区分配扇区*
|
||||
|
||||
输入最后一个扇区或者分区大小的值。通常推荐输入分区的大小。总是添加前缀 `+` 以防止值超出范围错误。
|
||||
|
||||
@ -93,7 +92,7 @@ fdisk 是一个在 Linux 系统上用于显示和管理硬盘和分区命令行
|
||||
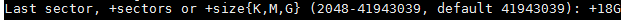
|
||||
][9]
|
||||
|
||||
分配分区大小
|
||||
*分配分区大小*
|
||||
|
||||
保存更改并退出。
|
||||
|
||||
@ -101,9 +100,9 @@ fdisk 是一个在 Linux 系统上用于显示和管理硬盘和分区命令行
|
||||
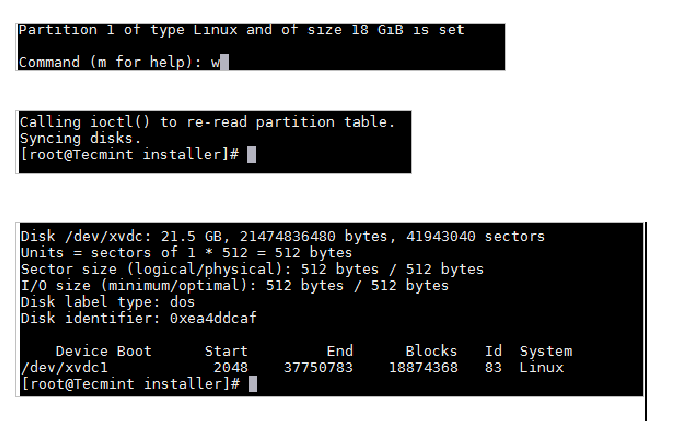
|
||||
][10]
|
||||
|
||||
保存分区更改
|
||||
*保存分区更改*
|
||||
|
||||
现在使用 mkfs 命令格式化磁盘。
|
||||
现在使用 **mkfs** 命令格式化磁盘。
|
||||
|
||||
```
|
||||
# mkfs.ext4 /dev/xvdc1
|
||||
@ -112,7 +111,7 @@ fdisk 是一个在 Linux 系统上用于显示和管理硬盘和分区命令行
|
||||
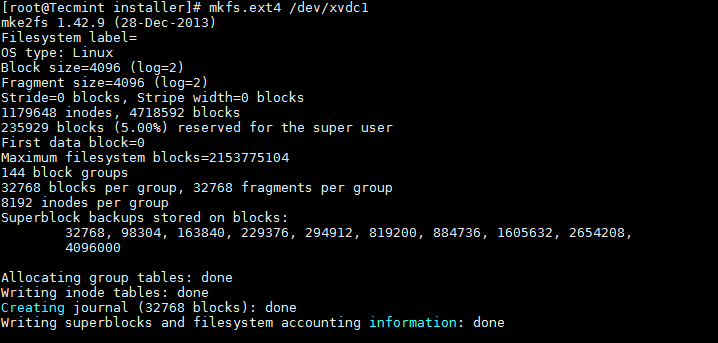
|
||||
][11]
|
||||
|
||||
格式化新分区
|
||||
*格式化新分区*
|
||||
|
||||
格式化完成后,按照下面的命令挂载分区。
|
||||
|
||||
@ -130,7 +129,7 @@ fdisk 是一个在 Linux 系统上用于显示和管理硬盘和分区命令行
|
||||
|
||||
现在你知道如何使用 [fdisk 命令][12] 在新磁盘上创建分区并挂载了。
|
||||
|
||||
当处理分区、尤其是编辑已配置磁盘的时候我们需要格外的小心。请分享你的反馈和建议吧。
|
||||
当处理分区、尤其是编辑已配置磁盘的时候,我们需要格外的小心。请分享你的反馈和建议吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -144,12 +143,12 @@ via: http://www.tecmint.com/add-new-disk-to-an-existing-linux/
|
||||
|
||||
作者:[Lakshmi Dhandapani][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/lakshmi/
|
||||
[1]:http://www.tecmint.com/add-disk-larger-than-2tb-to-an-existing-linux/
|
||||
[1]:https://linux.cn/article-8398-1.html
|
||||
[2]:http://www.tecmint.com/fdisk-commands-to-manage-linux-disk-partitions/
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2017/03/Find-Linux-Partition-Details.png
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2017/03/Find-New-Partition-Details.png
|
||||
@ -0,0 +1,366 @@
|
||||
关于 Linux 进程你所需要知道的一切
|
||||
============================================================
|
||||
|
||||
在这篇指南中,我们会逐步对进程做基本的了解,然后简要看看如何用特定命令[管理 Linux 进程][9]。
|
||||
|
||||
进程(process)是指正在执行的程序;是程序正在运行的一个实例。它由程序指令,和从文件、其它程序中读取的数据或系统用户的输入组成。
|
||||
|
||||
### 进程的类型
|
||||
|
||||
在 Linux 中主要有两种类型的进程:
|
||||
|
||||
* 前台进程(也称为交互式进程) - 这些进程由终端会话初始化和控制。换句话说,需要有一个连接到系统中的用户来启动这样的进程;它们不是作为系统功能/服务的一部分自动启动。
|
||||
* 后台进程(也称为非交互式/自动进程) - 这些进程没有连接到终端;它们不需要任何用户输入。
|
||||
|
||||
#### 什么是守护进程(daemon)
|
||||
|
||||
这是后台进程的特殊类型,它们在系统启动时启动,并作为服务一直运行;它们不会死亡。它们自发地作为系统任务启动(作为服务运行)。但是,它们能被用户通过 init 进程控制。
|
||||
|
||||
[
|
||||
|
||||
][10]
|
||||
|
||||
*Linux 进程状态*
|
||||
|
||||
### 在 Linux 中创建进程
|
||||
|
||||
(LCTT 译注:此节原文不确,根据译者理解重新提供)
|
||||
|
||||
在 Linux 中创建进程有三种方式:
|
||||
|
||||
#### fork() 方式
|
||||
|
||||
使用 fork() 函数以父进程为蓝本复制一个进程,其 PID号与父进程 PID 号不同。在 Linux 环境下,fork() 是以写复制实现的,新的子进程的环境和父进程一样,只有内存与父进程不同,其他与父进程共享,只有在父进程或者子进程进行了修改后,才重新生成一份。
|
||||
|
||||
#### system() 方式
|
||||
|
||||
system() 函数会调用 `/bin/sh –c command` 来执行特定的命令,并且阻塞当前进程的执行,直到 command 命令执行完毕。新的子进程会有新的 PID。
|
||||
|
||||
#### exec() 方式
|
||||
|
||||
exec() 方式有若干种不同的函数,与之前的 fork() 和 system() 函数不同,exec() 方式会用新进程代替原有的进程,系统会从新的进程运行,新的进程的 PID 值会与原来的进程的 PID 值相同。
|
||||
|
||||
### Linux 如何识别进程?
|
||||
|
||||
由于 Linux 是一个多用户系统,意味着不同的用户可以在系统上运行各种各样的程序,内核必须唯一标识程序运行的每个实例。
|
||||
|
||||
程序由它的进程 ID(PID)和它父进程的进程 ID(PPID)识别,因此进程可以被分类为:
|
||||
|
||||
* 父进程 - 这些是在运行时创建其它进程的进程。
|
||||
* 子进程 - 这些是在运行时由其它进程创建的进程。
|
||||
|
||||
#### init 进程
|
||||
|
||||
init 进程是系统中所有进程的父进程,它是[启动 Linux 系统][11]后第一个运行的程序;它管理着系统上的所有其它进程。它由内核自身启动,因此理论上说它没有父进程。
|
||||
|
||||
init 进程的进程 ID 总是为 1。它是所有孤儿进程的收养父母。(它会收养所有孤儿进程)。
|
||||
|
||||
#### 查找进程 ID
|
||||
|
||||
你可以用 pidof 命令查找某个进程的进程 ID:
|
||||
|
||||
```
|
||||
# pidof systemd
|
||||
# pidof top
|
||||
# pidof httpd
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][12]
|
||||
|
||||
*查找 Linux 进程 ID*
|
||||
|
||||
要查找当前 shell 的进程 ID 以及它父进程的进程 ID,可以运行:
|
||||
|
||||
```
|
||||
$ echo $$
|
||||
$ echo $PPID
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][13]
|
||||
|
||||
*查找 Linux 父进程 ID*
|
||||
|
||||
### 在 Linux 中启动进程
|
||||
|
||||
每次你运行一个命令或程序(例如 cloudcmd - CloudCommander),它就会在系统中启动一个进程。你可以按照下面的方式启动一个前台(交互式)进程,它会被连接到终端,用户可以发送输入给它:
|
||||
|
||||
```
|
||||
# cloudcmd
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][14]
|
||||
|
||||
*启动 Linux 交互进程*
|
||||
|
||||
#### Linux 后台任务
|
||||
|
||||
要在后台(非交互式)启动一个进程,使用 `&` 符号,此时,该进程不会从用户中读取输入,直到它被移到前台。
|
||||
|
||||
```
|
||||
# cloudcmd &
|
||||
# jobs
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][15]
|
||||
|
||||
*在后台启动 Linux 进程*
|
||||
|
||||
你也可以使用 `[Ctrl + Z]` 暂停执行一个程序并把它发送到后台,它会给进程发送 SIGSTOP 信号,从而暂停它的执行;它就会变为空闲:
|
||||
|
||||
```
|
||||
# tar -cf backup.tar /backups/* #press Ctrl+Z
|
||||
# jobs
|
||||
```
|
||||
|
||||
要在后台继续运行上面被暂停的命令,使用 `bg` 命令:
|
||||
|
||||
```
|
||||
# bg
|
||||
```
|
||||
|
||||
要把后台进程发送到前台,使用 `fg` 命令以及任务的 ID,类似:
|
||||
|
||||
```
|
||||
# jobs
|
||||
# fg %1
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][16]
|
||||
|
||||
*Linux 后台进程任务*
|
||||
|
||||
你也可能想要阅读:[如何在后台启动 Linux 命令以及在终端分离(Detach)进程][17]
|
||||
|
||||
### Linux 中进程的状态
|
||||
|
||||
在执行过程中,取决于它的环境一个进程会从一个状态转变到另一个状态。在 Linux 中,一个进程有下面的可能状态:
|
||||
|
||||
* Running - 此时它正在运行(它是系统中的当前进程)或准备运行(它正在等待分配 CPU 单元)。
|
||||
* Waiting - 在这个状态,进程正在等待某个事件的发生或者系统资源。另外,内核也会区分两种不同类型的等待进程;可中断等待进程(interruptible waiting processes) - 可以被信号中断,以及不可中断等待进程(uninterruptible waiting processes)- 正在等待硬件条件,不能被任何事件/信号中断。
|
||||
* Stopped - 在这个状态,进程已经被停止了,通常是由于收到了一个信号。例如,正在被调试的进程。
|
||||
* Zombie - 该进程已经死亡,它已经停止了但是进程表(process table)中仍然有它的条目。
|
||||
|
||||
### 如何在 Linux 中查看活跃进程
|
||||
|
||||
有很多 Linux 工具可以用于查看/列出系统中正在运行的进程,两个传统众所周知的是 [ps][18] 和 [top][19] 命令:
|
||||
|
||||
#### 1. ps 命令
|
||||
|
||||
它显示被选中的系统中活跃进程的信息,如下图所示:
|
||||
|
||||
```
|
||||
# ps
|
||||
# ps -e | head
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][20]
|
||||
|
||||
*列出 Linux 活跃进程*
|
||||
|
||||
#### 2. top - 系统监控工具
|
||||
|
||||
[top 是一个强大的工具][21],它能给你提供 [运行系统的动态实时视图][22],如下面截图所示:
|
||||
|
||||
```
|
||||
# top
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][23]
|
||||
|
||||
*列出 Linux 正在运行的程序*
|
||||
|
||||
阅读这篇文章获取更多 top 使用事例:[Linux 中 12 个 top 命令事例][24]
|
||||
|
||||
#### 3. glances - 系统监控工具
|
||||
|
||||
glances 是一个相对比较新的系统监控工具,它有一些比较高级的功能:
|
||||
|
||||
```
|
||||
# glances
|
||||
```
|
||||
|
||||
[
|
||||
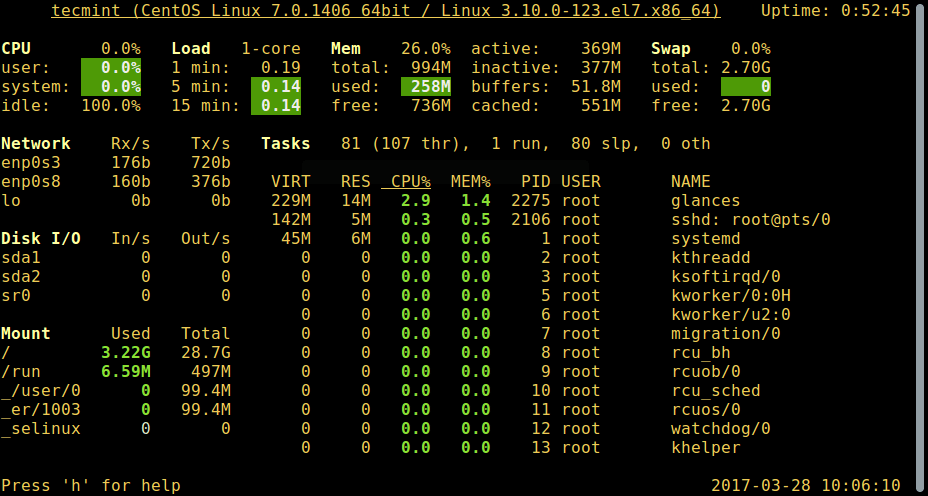
|
||||
][25]
|
||||
|
||||
*Glances – Linux 进程监控*
|
||||
|
||||
要获取完整使用指南,请阅读:[Glances - Linux 的一个高级实时系统监控工具][26]
|
||||
|
||||
还有很多你可以用来列出活跃进程的其它有用的 Linux 系统监视工具,打开下面的链接了解更多关于它们的信息:
|
||||
|
||||
1. [监控 Linux 性能的 20 个命令行工具][1]
|
||||
2. [13 个有用的 Linux 监控工具][2]
|
||||
|
||||
### 如何在 Linux 中控制进程
|
||||
|
||||
Linux 也有一些命令用于控制进程,例如 `kill`、`pkill`、`pgrep` 和 `killall`,下面是一些如何使用它们的基本事例:
|
||||
|
||||
````
|
||||
$ pgrep -u tecmint top
|
||||
$ kill 2308
|
||||
$ pgrep -u tecmint top
|
||||
$ pgrep -u tecmint glances
|
||||
$ pkill glances
|
||||
$ pgrep -u tecmint glances
|
||||
```
|
||||
|
||||
[
|
||||
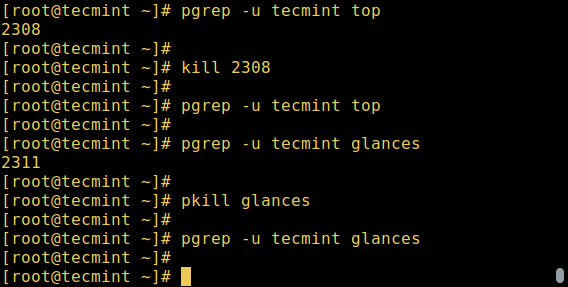
|
||||
][27]
|
||||
|
||||
*控制 Linux 进程*
|
||||
|
||||
想要深入了解如何使用这些命令,在 Linux 中杀死/终止活跃进程,可以点击下面的链接:
|
||||
|
||||
1. [终止 Linux 进程的 Kill、Pkill 和 Killall 命令指南][3]
|
||||
2. [如何在 Linux 中查找并杀死进程][4]
|
||||
|
||||
注意当你系统僵死(freeze)时你可以使用它们杀死 [Linux 中的不响应程序][28]。
|
||||
|
||||
#### 给进程发送信号
|
||||
|
||||
Linux 中控制进程的基本方法是给它们发送信号。你可以发送很多信号给一个进程,运行下面的命令可以查看所有信号:
|
||||
|
||||
```
|
||||
$ kill -l
|
||||
```
|
||||
[
|
||||

|
||||
][29]
|
||||
|
||||
*列出所有 Linux 信号*
|
||||
|
||||
要给一个进程发送信号,可以使用我们之前提到的 `kill`、`pkill` 或 `pgrep` 命令。但只有被编程为能识别这些信号时程序才能响应这些信号。
|
||||
|
||||
大部分信号都是系统内部使用,或者给程序员编写代码时使用。下面是一些对系统用户非常有用的信号:
|
||||
|
||||
* SIGHUP 1 - 当控制它的终端被被关闭时给进程发送该信号。
|
||||
* SIGINT 2 - 当用户使用 `[Ctrl+C]` 中断进程时控制它的终端给进程发送这个信号。
|
||||
* SIGQUIT 3 - 当用户发送退出信号 `[Ctrl+D]` 时给进程发送该信号。
|
||||
* SIGKILL 9 - 这个信号会马上中断(杀死)进程,进程不会进行清理操作。
|
||||
* SIGTERM 15 - 这是一个程序终止信号(kill 默认发送这个信号)。
|
||||
* SIGTSTP 20 - 它的控制终端发送这个信号给进程要求它停止(终端停止);通过用户按 `[Ctrl+Z]` 触发。
|
||||
|
||||
下面是当 Firefox 应用程序僵死时通过它的 PID 杀死它的 kill 命令事例:
|
||||
|
||||
```
|
||||
$ pidof firefox
|
||||
$ kill 9 2687
|
||||
或
|
||||
$ kill -KILL 2687
|
||||
或
|
||||
$ kill -SIGKILL 2687
|
||||
```
|
||||
|
||||
使用它的名称杀死应用,可以像下面这样使用 pkill 或 killall:
|
||||
|
||||
```
|
||||
$ pkill firefox
|
||||
$ killall firefox
|
||||
```
|
||||
|
||||
#### 更改 Linux 进程优先级
|
||||
|
||||
在 Linux 系统中,所有活跃进程都有一个优先级以及 nice 值。有比点优先级进程有更高优先级的进程一般会获得更多的 CPU 时间。
|
||||
|
||||
但是,有 root 权限的系统用户可以使用 `nice` 和 `renice` 命令影响(更改)优先级。
|
||||
|
||||
在 top 命令的输出中, NI 显示了进程的 nice 值:
|
||||
|
||||
```
|
||||
$ top
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][30]
|
||||
|
||||
*列出 Linux 正在运行的进程*
|
||||
|
||||
使用 `nice` 命令为一个进程设置 nice 值。记住一个普通用户可以给他拥有的进程设置 0 到 20 的 nice 值。
|
||||
|
||||
只有 root 用户可以使用负的 nice 值。
|
||||
|
||||
要重新设置一个进程的优先级,像下面这样使用 `renice` 命令:
|
||||
|
||||
```
|
||||
$ renice +8 2687
|
||||
$ renice +8 2103
|
||||
```
|
||||
|
||||
阅读我们其它如何管理和控制 Linux 进程的有用文章。
|
||||
|
||||
1. [Linux 进程管理:启动、停止以及中间过程][5]
|
||||
2. [使用 ‘top’ 命令 Batch 模式查找内存使用最高的 15 个进程][6]
|
||||
3. [在 Linux 中查找内存和 CPU 使用率最高的进程][7]
|
||||
4. [在 Linux 中如何使用进程 ID 查找进程名称][8]
|
||||
|
||||
就是这些!如果你有任何问题或者想法,通过下面的反馈框和我们分享吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili 是一个 Linux 和 F.O.S.S(Free and Open-Source Software) 爱好者,一个 Linux 系统管理员、web 开发员,现在也是 TecMint 的内容创建者,他喜欢和电脑一起工作,他相信知识共享。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-process-management/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
|
||||
[1]:http://www.tecmint.com/command-line-tools-to-monitor-linux-performance/
|
||||
[2]:http://www.tecmint.com/linux-performance-monitoring-tools/
|
||||
[3]:http://www.tecmint.com/how-to-kill-a-process-in-linux/
|
||||
[4]:http://www.tecmint.com/find-and-kill-running-processes-pid-in-linux/
|
||||
[5]:http://www.tecmint.com/rhcsa-exam-boot-process-and-process-management/
|
||||
[6]:http://www.tecmint.com/find-processes-by-memory-usage-top-batch-mode/
|
||||
[7]:http://www.tecmint.com/find-linux-processes-memory-ram-cpu-usage/
|
||||
[8]:http://www.tecmint.com/find-process-name-pid-number-linux/
|
||||
[9]:http://www.tecmint.com/dstat-monitor-linux-server-performance-process-memory-network/
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2017/03/ProcessState.png
|
||||
[11]:http://www.tecmint.com/linux-boot-process/
|
||||
[12]:http://www.tecmint.com/wp-content/uploads/2017/03/Find-Linux-Process-ID.png
|
||||
[13]:http://www.tecmint.com/wp-content/uploads/2017/03/Find-Linux-Parent-Process-ID.png
|
||||
[14]:http://www.tecmint.com/wp-content/uploads/2017/03/Start-Linux-Interactive-Process.png
|
||||
[15]:http://www.tecmint.com/wp-content/uploads/2017/03/Start-Linux-Process-in-Background.png
|
||||
[16]:http://www.tecmint.com/wp-content/uploads/2017/03/Linux-Background-Process-Jobs.png
|
||||
[17]:http://www.tecmint.com/run-linux-command-process-in-background-detach-process/
|
||||
[18]:http://www.tecmint.com/linux-boot-process-and-manage-services/
|
||||
[19]:http://www.tecmint.com/12-top-command-examples-in-linux/
|
||||
[20]:http://www.tecmint.com/wp-content/uploads/2017/03/ps-command.png
|
||||
[21]:http://www.tecmint.com/12-top-command-examples-in-linux/
|
||||
[22]:http://www.tecmint.com/bcc-best-linux-performance-monitoring-tools/
|
||||
[23]:http://www.tecmint.com/wp-content/uploads/2017/03/top-command.png
|
||||
[24]:http://www.tecmint.com/12-top-command-examples-in-linux/
|
||||
[25]:http://www.tecmint.com/wp-content/uploads/2017/03/glances.png
|
||||
[26]:http://www.tecmint.com/glances-an-advanced-real-time-system-monitoring-tool-for-linux/
|
||||
[27]:http://www.tecmint.com/wp-content/uploads/2017/03/Control-Linux-Processes.png
|
||||
[28]:http://www.tecmint.com/kill-processes-unresponsive-programs-in-ubuntu/
|
||||
[29]:http://www.tecmint.com/wp-content/uploads/2017/03/list-all-signals.png
|
||||
[30]:http://www.tecmint.com/wp-content/uploads/2017/03/top-command.png
|
||||
[31]:http://www.tecmint.com/author/aaronkili/
|
||||
[32]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[33]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
172
published/201704/20170403 Yes Python is Slow and I Dont Care.md
Normal file
172
published/201704/20170403 Yes Python is Slow and I Dont Care.md
Normal file
@ -0,0 +1,172 @@
|
||||
Python 是慢,但我无所谓
|
||||
=====================================
|
||||
|
||||
> 为牺牲性能追求生产率而呐喊
|
||||
|
||||

|
||||
|
||||
让我从关于 Python 中的 asyncio 这个标准库的讨论中休息一会,谈谈我最近正在思考的一些东西:Python 的速度。对不了解我的人说明一下,我是一个 Python 的粉丝,而且我在我能想到的所有地方都积极地使用 Python。人们对 Python 最大的抱怨之一就是它的速度比较慢,有些人甚至拒绝尝试使用 Python,因为它比其他语言速度慢。这里说说为什么我认为应该尝试使用 Python,尽管它是有点慢。
|
||||
|
||||
### 速度不再重要
|
||||
|
||||
过去的情形是,程序需要花费很长的时间来运行,CPU 比较贵,内存也很贵。程序的运行时间是一个很重要的指标。计算机非常的昂贵,计算机运行所需要的电也是相当贵的。对这些资源进行优化是因为一个永恒的商业法则:
|
||||
|
||||
> 优化你最贵的资源。
|
||||
|
||||
在过去,最贵的资源是计算机的运行时间。这就是导致计算机科学致力于研究不同算法的效率的原因。然而,这已经不再是正确的,因为现在硅芯片很便宜,确实很便宜。运行时间不再是你最贵的资源。公司最贵的资源现在是它的员工时间。或者换句话说,就是你。把事情做完比把它变快更加重要。实际上,这是相当的重要,我将把它再次放在这里,仿佛它是一个引文一样(给那些只是粗略浏览的人):
|
||||
|
||||
> 把事情做完比快速地做事更加重要。
|
||||
|
||||
你可能会说:“我的公司在意速度,我开发一个 web 应用程序,那么所有的响应时间必须少于 x 毫秒。”或者,“我们失去了客户,因为他们认为我们的 app 运行太慢了。”我并不是想说速度一点也不重要,我只是想说速度不再是最重要的东西;它不再是你最贵的资源。
|
||||
|
||||

|
||||
|
||||
### 速度是唯一重要的东西
|
||||
|
||||
当你在编程的背景下说 _速度_ 时,你通常是说性能,也就是 CPU 周期。当你的 CEO 在编程的背景下说 _速度_ 时,他指的是业务速度,最重要的指标是产品上市的时间。基本上,你的产品/web 程序是多么的快并不重要。它是用什么语言写的也不重要。甚至它需要花费多少钱也不重要。在一天结束时,让你的公司存活下来或者死去的唯一事物就是产品上市时间。我不只是说创业公司的想法 -- 你开始赚钱需要花费多久,更多的是“从想法到客户手中”的时间期限。企业能够存活下来的唯一方法就是比你的竞争对手更快地创新。如果在你的产品上市之前,你的竞争对手已经提前上市了,那么你想出了多少好的主意也将不再重要。你必须第一个上市,或者至少能跟上。一但你放慢了脚步,你就输了。
|
||||
|
||||
> 企业能够存活下来的唯一方法就是比你的竞争对手更快地创新。
|
||||
|
||||
#### 一个微服务的案例
|
||||
|
||||
像 Amazon、Google 和 Netflix 这样的公司明白快速前进的重要性。他们创建了一个业务系统,可以使用这个系统迅速地前进和快速的创新。微服务是针对他们的问题的解决方案。这篇文章不谈你是否应该使用微服务,但是至少要理解为什么 Amazon 和 Google 认为他们应该使用微服务。
|
||||
|
||||

|
||||
|
||||
微服务本来就很慢。微服务的主要概念是用网络调用来打破边界。这意味着你正在把使用的函数调用(几个 cpu 周期)转变为一个网络调用。没有什么比这更影响性能了。和 CPU 相比较,网络调用真的很慢。但是这些大公司仍然选择使用微服务。我所知道的架构里面没有比微服务还要慢的了。微服务最大的弊端就是它的性能,但是最大的长处就是上市的时间。通过在较小的项目和代码库上建立团队,一个公司能够以更快的速度进行迭代和创新。这恰恰表明了,非常大的公司也很在意上市时间,而不仅仅只是只有创业公司。
|
||||
|
||||
#### CPU 不是你的瓶颈
|
||||
|
||||

|
||||
|
||||
如果你在写一个网络应用程序,如 web 服务器,很有可能的情况会是,CPU 时间并不是你的程序的瓶颈。当你的 web 服务器处理一个请求时,可能会进行几次网络调用,例如到数据库,或者像 Redis 这样的缓存服务器。虽然这些服务本身可能比较快速,但是对它们的网络调用却很慢。[这里有一篇很好的关于特定操作的速度差异的博客文章][1]。在这篇文章里,作者把 CPU 周期时间缩放到更容易理解的人类时间。如果一个单独的 CPU 周期等同于 **1 秒**,那么一个从 California 到 New York 的网络调用将相当于 **4 年**。那就说明了网络调用是多少的慢。按一些粗略估计,我们可以假设在同一数据中心内的普通网络调用大约需要 3 毫秒。这相当于我们“人类比例” **3 个月**。现在假设你的程序是高 CPU 密集型,这需要 100000 个 CPU 周期来对单一调用进行响应。这相当于刚刚超过 **1 天**。现在让我们假设你使用的是一种要慢 5 倍的语言,这将需要大约 **5 天**。很好,将那与我们 3 个月的网络调用时间相比,4 天的差异就显得并不是很重要了。如果有人为了一个包裹不得不至少等待 3 个月,我不认为额外的 4 天对他们来说真的很重要。
|
||||
|
||||
上面所说的终极意思是,尽管 Python 速度慢,但是这并不重要。语言的速度(或者 CPU 时间)几乎从来不是问题。实际上谷歌曾经就这一概念做过一个研究,[并且他们就此发表过一篇论文][2]。那篇论文论述了设计高吞吐量的系统。在结论里,他们说到:
|
||||
|
||||
> 在高吞吐量的环境中使用解释性语言似乎是矛盾的,但是我们已经发现 CPU 时间几乎不是限制因素;语言的表达性是指,大多数程序是源程序,同时它们的大多数时间花费在 I/O 读写和本机的运行时代码上。而且,解释性语言无论是在语言层面的轻松实验还是在允许我们在很多机器上探索分布计算的方法都是很有帮助的,
|
||||
|
||||
再次强调:
|
||||
|
||||
> CPU 时间几乎不是限制因素。
|
||||
|
||||
### 如果 CPU 时间是一个问题怎么办?
|
||||
|
||||
你可能会说,“前面说的情况真是太好了,但是我们确实有过一些问题,这些问题中 CPU 成为了我们的瓶颈,并造成了我们的 web 应用的速度十分缓慢”,或者“在服务器上 X 语言比 Y 语言需要更少的硬件资源来运行。”这些都可能是对的。关于 web 服务器有这样的美妙的事情:你可以几乎无限地负载均衡它们。换句话说,可以在 web 服务器上投入更多的硬件。当然,Python 可能会比其他语言要求更好的硬件资源,比如 c 语言。只是把硬件投入在 CPU 问题上。相比于你的时间,硬件就显得非常的便宜了。如果你在一年内节省了两周的生产力时间,那将远远多于所增加的硬件开销的回报。
|
||||
|
||||

|
||||
|
||||
### 那么,Python 更快一些吗?
|
||||
|
||||
这一篇文章里面,我一直在谈论最重要的是开发时间。所以问题依然存在:当就开发时间而言,Python 要比其他语言更快吗?按常规惯例来看,我、[google][3] [还有][4][其他][5][几个人][6]可以告诉你 Python 是多么的[高效][7]。它为你抽象出很多东西,帮助你关注那些你真正应该编写代码的地方,而不会被困在琐碎事情的杂草里,比如你是否应该使用一个向量或者一个数组。但你可能不喜欢只是听别人说的这些话,所以让我们来看一些更多的经验数据。
|
||||
|
||||
在大多数情况下,关于 python 是否是更高效语言的争论可以归结为脚本语言(或动态语言)与静态类型语言两者的争论。我认为人们普遍接受的是静态类型语言的生产力较低,但是,[这有一篇优秀的论文][8]解释了为什么不是这样。就 Python 而言,这里有一项[研究][9],它调查了不同语言编写字符串处理的代码所需要花费的时间,供参考。
|
||||
|
||||
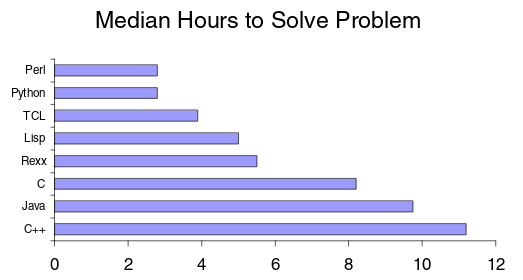
|
||||
|
||||
在上述研究中,Python 的效率比 Java 高出 2 倍。有一些其他研究也显示相似的东西。 Rosetta Code 对编程语言的差异进行了[深入的研究][10]。在论文中,他们把 python 与其他脚本语言/解释性语言相比较,得出结论:
|
||||
|
||||
> Python 更简洁,即使与函数式语言相比较(平均要短 1.2 到 1.6 倍)
|
||||
|
||||
普遍的趋势似乎是 Python 中的代码行总是更少。代码行听起来可能像一个可怕的指标,但是包括上面已经提到的两项研究在内的[多项研究][11]表明,每种语言中每行代码所需要花费的时间大约是一样的。因此,限制代码行数就可以提高生产效率。甚至 codinghorror(一名 C# 程序员)本人[写了一篇关于 Python 是如何更有效率的文章][12]。
|
||||
|
||||
我认为说 Python 比其他的很多语言更加的有效率是公正的。这主要是由于 Python 有大量的自带以及第三方库。[这里是一篇讨论 Python 和其他语言间的差异的简单的文章][13]。如果你不知道为何 Python 是如此的小巧和高效,我邀请你借此机会学习一点 python,自己多实践。这儿是你的第一个程序:
|
||||
|
||||
```
|
||||
import __hello__
|
||||
```
|
||||
|
||||
### 但是如果速度真的重要呢?
|
||||
|
||||

|
||||
|
||||
上述论点的语气可能会让人觉得优化与速度一点也不重要。但事实是,很多时候运行时性能真的很重要。一个例子是,你有一个 web 应用程序,其中有一个特定的端点需要用很长的时间来响应。你知道这个程序需要多快,并且知道程序需要改进多少。
|
||||
|
||||
在我们的例子中,发生了两件事:
|
||||
|
||||
1. 我们注意到有一个端点执行缓慢。
|
||||
2. 我们承认它是缓慢,因为我们有一个可以衡量是否足够快的标准,而它没达到那个标准。
|
||||
|
||||
我们不必在应用程序中微调优化所有内容,只需要让其中每一个都“足够快”。如果一个端点花费了几秒钟来响应,你的用户可能会注意到,但是,他们并不会注意到你将响应时间由 35 毫秒降低到 25 毫秒。“足够好”就是你需要做到的所有事情。_免责声明: 我应该说有**一些**应用程序,如实时投标程序,**确实**需要细微优化,每一毫秒都相当重要。但那只是例外,而不是规则。_
|
||||
|
||||
为了明白如何对端点进行优化,你的第一步将是配置代码,并尝试找出瓶颈在哪。毕竟:
|
||||
|
||||
> <ruby>任何除了瓶颈之外的改进都是错觉。<rt>Any improvements made anywhere besides the bottleneck are an illusion.</rt></ruby> -- Gene Kim
|
||||
|
||||
如果你的优化没有触及到瓶颈,你只是浪费你的时间,并没有解决实际问题。在你优化瓶颈之前,你不会得到任何重要的改进。如果你在不知道瓶颈是什么前就尝试优化,那么你最终只会在部分代码中玩耍。在测量和确定瓶颈之前优化代码被称为“过早优化”。人们常提及 Donald Knuth 说的话,但他声称这句话实际上是他从别人那里听来的:
|
||||
|
||||
> <ruby>过早优化是万恶之源<rt>Premature optimization is the root of all evil</rt></ruby>。
|
||||
|
||||
在谈到维护代码库时,来自 Donald Knuth 的更完整的引文是:
|
||||
|
||||
> 在 97% 的时间里,我们应该忘记微不足道的效率:**过早的优化是万恶之源**。然而在关
|
||||
> 键的 3%,我们不应该错过优化的机会。 —— Donald Knuth
|
||||
|
||||
换句话说,他所说的是,在大多数时间你应该忘记对你的代码进行优化。它几乎总是足够好。在不是足够好的情况下,我们通常只需要触及 3% 的代码路径。比如因为你使用了 if 语句而不是函数,你的端点快了几纳秒,但这并不会使你赢得任何奖项。
|
||||
|
||||
过早的优化包括调用某些更快的函数,或者甚至使用特定的数据结构,因为它通常更快。计算机科学认为,如果一个方法或者算法与另一个具有相同的渐近增长(或称为 Big-O),那么它们是等价的,即使在实践中要慢两倍。计算机是如此之快,算法随着数据/使用增加而造成的计算增长远远超过实际速度本身。换句话说,如果你有两个 O(log n) 的函数,但是一个要慢两倍,这实际上并不重要。随着数据规模的增大,它们都以同样的速度“慢下来”。这就是过早优化是万恶之源的原因;它浪费了我们的时间,几乎从来没有真正有助于我们的性能改进。
|
||||
|
||||
就 Big-O 而言,你可以认为对你的程序而言,所有的语言都是 O(n),其中 n 是代码或者指令的行数。对于同样的指令,它们以同样的速率增长。对于渐进增长,一种语言的速度快慢并不重要,所有语言都是相同的。在这个逻辑下,你可以说,为你的应用程序选择一种语言仅仅是因为它的“快速”是过早优化的最终形式。你选择某些预期快速的东西,却没有测量,也不理解瓶颈将在哪里。
|
||||
|
||||
> 为您的应用选择语言只是因为它的“快速”,是过早优化的最终形式。
|
||||
|
||||
|
||||

|
||||
|
||||
### 优化 Python
|
||||
|
||||
我最喜欢 Python 的一点是,它可以让你一次优化一点点代码。假设你有一个 Python 的方法,你发现它是你的瓶颈。你对它优化过几次,可能遵循[这里][14]和[那里][15]的一些指导,现在,你很肯定 Python 本身就是你的瓶颈。Python 有调用 C 代码的能力,这意味着,你可以用 C 重写这个方法来减少性能问题。你可以一次重写一个这样的方法。这个过程允许你用任何可以编译为 C 兼容汇编程序的语言,编写良好优化后的瓶颈方法。这让你能够在大多数时间使用 Python 编写,只在必要的时候都才用较低级的语言来写代码。
|
||||
|
||||
有一种叫做 Cython 的编程语言,它是 Python 的超集。它几乎是 Python 和 C 的合并,是一种渐进类型的语言。任何 Python 代码都是有效的 Cython 代码,Cython 代码可以编译成 C 代码。使用 Cython,你可以编写一个模块或者一个方法,并逐渐进步到越来越多的 C 类型和性能。你可以将 C 类型和 Python 的鸭子类型混在一起。使用 Cython,你可以获得混合后的完美组合,只在瓶颈处进行优化,同时在其他所有地方不失去 Python 的美丽。
|
||||
|
||||

|
||||
|
||||
*星战前夜的一幅截图:这是用 Python 编写的 space MMO 游戏。*
|
||||
|
||||
当您最终遇到 Python 的性能问题阻碍时,你不需要把你的整个代码库用另一种不同的语言来编写。你只需要用 Cython 重写几个函数,几乎就能得到你所需要的性能。这就是[星战前夜][16]采取的策略。这是一个大型多玩家的电脑游戏,在整个架构中使用 Python 和 Cython。它们通过优化 C/Cython 中的瓶颈来实现游戏级别的性能。如果这个策略对他们有用,那么它应该对任何人都有帮助。或者,还有其他方法来优化你的 Python。例如,[PyPy][17] 是一个 Python 的 JIT 实现,它通过使用 PyPy 替掉 CPython(这是 Python 的默认实现),为长时间运行的应用程序提供重要的运行时改进(如 web 服务器)。
|
||||
|
||||

|
||||
|
||||
让我们回顾一下要点:
|
||||
|
||||
* 优化你最贵的资源。那就是你,而不是计算机。
|
||||
* 选择一种语言/框架/架构来帮助你快速开发(比如 Python)。不要仅仅因为某些技术的快而选择它们。
|
||||
* 当你遇到性能问题时,请找到瓶颈所在。
|
||||
* 你的瓶颈很可能不是 CPU 或者 Python 本身。
|
||||
* 如果 Python 成为你的瓶颈(你已经优化过你的算法),那么可以转向热门的 Cython 或者 C。
|
||||
* 尽情享受可以快速做完事情的乐趣。
|
||||
|
||||
我希望你喜欢阅读这篇文章,就像我喜欢写这篇文章一样。如果你想说谢谢,请为我点下赞。另外,如果某个时候你想和我讨论 Python,你可以在 twitter 上艾特我(@nhumrich),或者你可以在 [Python slack channel][18] 找到我。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Nick Humrich -- 坚持采用持续交付的方法,并为之写了很多工具。同是还是一名 Python 黑客与技术狂热者,目前是一名 DevOps 工程师。
|
||||
|
||||
via: https://medium.com/hacker-daily/yes-python-is-slow-and-i-dont-care-13763980b5a1
|
||||
|
||||
作者:[Nick Humrich][a]
|
||||
译者:[zhousiyu325](https://github.com/zhousiyu325)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://hackernoon.com/@nhumrich
|
||||
[1]:https://blog.codinghorror.com/the-infinite-space-between-words/
|
||||
[2]:https://static.googleusercontent.com/media/research.google.com/en//archive/sawzall-sciprog.pdf
|
||||
[3]:https://www.codefellows.org/blog/5-reasons-why-python-is-powerful-enough-for-google/
|
||||
[4]:https://www.lynda.com/Python-tutorials/Python-Programming-Efficiently/534425-2.html
|
||||
[5]:https://www.linuxjournal.com/article/3882
|
||||
[6]:https://www.codeschool.com/blog/2016/01/27/why-python/
|
||||
[7]:http://pythoncard.sourceforge.net/what_is_python.html
|
||||
[8]:http://www.tcl.tk/doc/scripting.html
|
||||
[9]:http://www.connellybarnes.com/documents/language_productivity.pdf
|
||||
[10]:https://arxiv.org/pdf/1409.0252.pdf
|
||||
[11]:http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.113.1831&rep=rep1&type=pdf
|
||||
[12]:https://blog.codinghorror.com/are-all-programming-languages-the-same/
|
||||
[13]:https://www.python.org/doc/essays/comparisons/
|
||||
[14]:https://wiki.python.org/moin/PythonSpeed
|
||||
[15]:https://wiki.python.org/moin/PythonSpeed/PerformanceTips
|
||||
[16]:https://www.eveonline.com/
|
||||
[17]:http://pypy.org/
|
||||
[18]:http://pythondevelopers.herokuapp.com/
|
||||
@ -1,16 +1,15 @@
|
||||
pyDash — 一个基于 web 的 Linux 性能监测工具
|
||||
pyDash:一个基于 web 的 Linux 性能监测工具
|
||||
============================================================
|
||||
|
||||
pyDash 是一个轻量且[基于 web 的 Linux 性能监测工具][1],它是用 Python 和 [Django][2] 加上 Chart.js 来写的。经测试,在下面这些主流 Linux 发行版上可运行:CentOS、Fedora、Ubuntu、Debian、Raspbian 以及 Pidora 。
|
||||
`pyDash` 是一个轻量且[基于 web 的 Linux 性能监测工具][1],它是用 Python 和 [Django][2] 加上 Chart.js 来写的。经测试,在下面这些主流 Linux 发行版上可运行:CentOS、Fedora、Ubuntu、Debian、Raspbian 以及 Pidora 。
|
||||
|
||||
你可以使用这个工具来监视你的 Linux 个人电脑/服务器资源,比如 CPU、内存
|
||||
、网络统计,包括在线用户以及更多的进程。仪表盘是完全使用主要的 Python 版本提供的 Python 库开发的,因此它的依赖关系很少,你不需要安装许多包或库来运行它。
|
||||
你可以使用这个工具来监视你的 Linux 个人电脑/服务器资源,比如 CPU、内存、网络统计,包括在线用户的进程以及更多。仪表盘完全由主要的 Python 发行版本所提供的 Python 库开发,因此它的依赖关系很少,你不需要安装许多包或库来运行它。
|
||||
|
||||
在这篇文章中,我将展示如果安装 pyDash 来监测 Linux 服务器性能。
|
||||
在这篇文章中,我将展示如何安装 `pyDash` 来监测 Linux 服务器性能。
|
||||
|
||||
#### 如何在 Linux 系统下安装 pyDash
|
||||
### 如何在 Linux 系统下安装 pyDash
|
||||
|
||||
1、首先,像下面这样安装需要的软件包 git 和 Python pip:
|
||||
1、首先,像下面这样安装需要的软件包 `git` 和 `Python pip`:
|
||||
|
||||
```
|
||||
-------------- 在 Debian/Ubuntu 上 --------------
|
||||
@ -22,7 +21,7 @@ $ sudo apt-get install git python-pip
|
||||
# dnf install git python-pip
|
||||
```
|
||||
|
||||
2、如果安装好了 git 和 Python pip,那么接下来,像下面这样安装 virtualenv,它有助于处理针对 Python 项目的依赖关系:
|
||||
2、如果安装好了 git 和 Python pip,那么接下来,像下面这样安装 `virtualenv`,它有助于处理针对 Python 项目的依赖关系:
|
||||
|
||||
```
|
||||
# pip install virtualenv
|
||||
@ -30,14 +29,14 @@ $ sudo apt-get install git python-pip
|
||||
$ sudo pip install virtualenv
|
||||
```
|
||||
|
||||
3、现在,像下面这样使用 git 命令,把 pyDash 仓库克隆到 home 目录中:
|
||||
3、现在,像下面这样使用 `git` 命令,把 pyDash 仓库克隆到 home 目录中:
|
||||
|
||||
```
|
||||
# git clone https://github.com/k3oni/pydash.git
|
||||
# cd pydash
|
||||
```
|
||||
|
||||
4、下一步,使用下面的 virtualenv 命令为项目创建一个叫做 pydashtest 虚拟环境:
|
||||
4、下一步,使用下面的 `virtualenv` 命令为项目创建一个叫做 `pydashtest` 虚拟环境:
|
||||
|
||||
```
|
||||
$ virtualenv pydashtest #give a name for your virtual environment like pydashtest
|
||||
@ -48,9 +47,9 @@ $ virtualenv pydashtest #give a name for your virtual environment like pydashtes
|
||||
|
||||
*创建虚拟环境*
|
||||
|
||||
重点:请注意,上面的屏幕截图中,虚拟环境的 bin 目录被高亮显示,你的可能和这不一样,取决于你把 pyDash 目录克隆到什么位置。
|
||||
重要:请注意,上面的屏幕截图中,虚拟环境的 `bin` 目录被高亮显示,你的可能和这不一样,取决于你把 pyDash 目录克隆到什么位置。
|
||||
|
||||
5、创建好虚拟环境(pydashtest)以后,你需要在使用前像下面这样激活它:
|
||||
5、创建好虚拟环境(`pydashtest`)以后,你需要在使用前像下面这样激活它:
|
||||
|
||||
```
|
||||
$ source /home/aaronkilik/pydash/pydashtest/bin/activate
|
||||
@ -61,16 +60,16 @@ $ source /home/aaronkilik/pydash/pydashtest/bin/activate
|
||||
|
||||
*激活虚拟环境*
|
||||
|
||||
从上面的屏幕截图中,你可以注意到,提示字符串 1(PS1)已经发生改变,这表明虚拟环境已经被激活,而且可以开始使用。
|
||||
从上面的屏幕截图中,你可以注意到,提示字符串 1(`PS1`)已经发生改变,这表明虚拟环境已经被激活,而且可以开始使用。
|
||||
|
||||
6、现在,安装 pydash 项目 requirements;如何你是一个细心的人,那么可以使用 [cat 命令][5]查看 requirements.txt 的内容,然后像下面展示这样进行安装:
|
||||
6、现在,安装 pydash 项目 requirements;如何你好奇的话,可以使用 [cat 命令][5]查看 `requirements.txt` 的内容,然后像下面所示那样进行安装:
|
||||
|
||||
```
|
||||
$ cat requirements.txt
|
||||
$ pip install -r requirements.txt
|
||||
```
|
||||
|
||||
7、现在,进入 `pydash` 目录,里面包含一个名为 `settings.py` 的文件,也可直接运行下面的命令打开这个文件,然后把 `SECRET_KEY` 改为一个特定值:
|
||||
7、现在,进入 `pydash` 目录,里面包含一个名为 `settings.py` 的文件,也可直接运行下面的命令打开这个文件,然后把 `SECRET_KEY` 改为一个特定值:
|
||||
|
||||
```
|
||||
$ vi pydash/settings.py
|
||||
@ -83,7 +82,7 @@ $ vi pydash/settings.py
|
||||
|
||||
保存文件然后退出。
|
||||
|
||||
8、之后,运行下面的命令来创建一个项目数据库和安装 Django 的身份验证系统,并创建一个项目的超级用户:
|
||||
8、之后,运行下面的命令来创建一个项目数据库和安装 Django 的身份验证系统,并创建一个项目的超级用户:
|
||||
|
||||
```
|
||||
$ python manage.py syncdb
|
||||
@ -104,13 +103,13 @@ Password (again): ############
|
||||
|
||||
*创建项目数据库*
|
||||
|
||||
9、这个时候,一切都设置好了,然后,运行下面的命令来启用 Django 开发服务器:
|
||||
9、这个时候,一切都设置好了,然后,运行下面的命令来启用 Django 开发服务器:
|
||||
|
||||
```
|
||||
$ python manage.py runserver
|
||||
```
|
||||
|
||||
10、接下来,打开你的 web 浏览器,输入网址:http://127.0.0.1:8000/ 进入 web 控制台登录界面,输入你在第 8 步中创建数据库和安装 Django 身份验证系统时创建的超级用户名和密码,然后点击登录。
|
||||
10、接下来,打开你的 web 浏览器,输入网址:`http://127.0.0.1:8000/` 进入 web 控制台登录界面,输入你在第 8 步中创建数据库和安装 Django 身份验证系统时创建的超级用户名和密码,然后点击登录。
|
||||
|
||||
[
|
||||
|
||||
@ -118,7 +117,7 @@ $ python manage.py runserver
|
||||
|
||||
*pyDash 登录界面*
|
||||
|
||||
11、登录到 pydash 主页面以后,你将会得到一段监测系统的基本信息,包括 CPU、内存和硬盘使用量以及系统平均负载。
|
||||
11、登录到 pydash 主页面以后,你将会可以看到监测系统的基本信息,包括 CPU、内存和硬盘使用量以及系统平均负载。
|
||||
|
||||
向下滚动便可查看更多部分的信息。
|
||||
|
||||
@ -128,7 +127,7 @@ $ python manage.py runserver
|
||||
|
||||
*pydash 服务器性能概述*
|
||||
|
||||
12、下一个屏幕截图显示的是一段 pydash 的跟踪界面,包括 IP 地址、互联网流量、硬盘读/写、在线用户以及 netstats 。
|
||||
12、下一个屏幕截图显示的是一段 pydash 的跟踪界面,包括 IP 地址、互联网流量、硬盘读/写、在线用户以及 netstats 。
|
||||
|
||||
[
|
||||

|
||||
@ -136,7 +135,7 @@ $ python manage.py runserver
|
||||
|
||||
*pyDash 网络概述*
|
||||
|
||||
13、下一个 pydash 主页面的截图显示了一部分系统中被监视的活跃进程。
|
||||
13、下一个 pydash 主页面的截图显示了一部分系统中被监视的活跃进程。
|
||||
|
||||
|
||||
[
|
||||
@ -154,16 +153,16 @@ $ python manage.py runserver
|
||||
|
||||
作者简介:
|
||||
|
||||
我叫 Ravi Saive,是 TecMint 的创建者,是一个喜欢在网上分享技巧和知识的计算机极客和 Linux Guru 。我的大多数服务器都运行在叫做 Linux 的开源平台上。请关注我:[Twitter][10]、[Facebook][01] 以及 [Google+][02] 。
|
||||
我叫 Ravi Saive,是 TecMint 的原创作者,是一个喜欢在网上分享技巧和知识的计算机极客和 Linux Guru。我的大多数服务器都运行在 Linux 开源平台上。请关注我:[Twitter][10]、[Facebook][01] 以及 [Google+][02] 。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
via: http://www.tecmint.com/pydash-a-web-based-linux-performance-monitoring-tool/
|
||||
|
||||
作者:[Ravi Saive ][a]
|
||||
作者:[Ravi Saive][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,10 +1,11 @@
|
||||
# Anbox
|
||||
Anbox:容器中的 Android
|
||||
===============
|
||||
|
||||
Anbox 是一个基于容器的方式,在像 Ubuntu 这样的常规的 GNU Linux 系统上启动一个完整的 Android 系统。
|
||||
Anbox 以基于容器的方式,在像 Ubuntu 这样的常规的 GNU Linux 系统上启动一个完整的 Android 系统。
|
||||
|
||||
## 概述
|
||||
### 概述
|
||||
|
||||
Anbox 使用 Linux 命名空间(user、pid、uts、net、mount、ipc)来在容器中运行完整的 Android 系统,并提供任何基于 GNU Linux 平台的 Android 程序。
|
||||
Anbox 使用 Linux 命名空间(user、pid、uts、net、mount、ipc)来在容器中运行完整的 Android 系统,并在任何基于 GNU Linux 平台上提供 Android 应用。
|
||||
|
||||
容器内的 Android 无法直接访问任何硬件。所有硬件访问都通过主机上的 anbox 守护进程进行。我们重用基于 QEMU 的模拟器实现的 Android 中的 GL、ES 加速渲染。容器内的 Android 系统使用不同的管道与主机系统通信,并通过它发送所有硬件访问命令。
|
||||
|
||||
@ -15,19 +16,19 @@ Anbox 使用 Linux 命名空间(user、pid、uts、net、mount、ipc)来在
|
||||
* [Android 的 “qemud” 复用守护进程](https://android.googlesource.com/platform/external/qemu/+/emu-master-dev/android/docs/ANDROID-QEMUD.TXT)
|
||||
* [Android qemud 服务](https://android.googlesource.com/platform/external/qemu/+/emu-master-dev/android/docs/ANDROID-QEMUD-SERVICES.TXT)
|
||||
|
||||
Anbox 目前适合桌面使用,但也可使用移动操作系统,如 Ubuntu Touch、Sailfish OS 或 Lune OS。然而,由于 Android 程序映射目前只针对桌面环境,因此还需要额外的工作来支持其他的用户界面。
|
||||
Anbox 目前适合桌面使用,但也用在移动操作系统上,如 Ubuntu Touch、Sailfish OS 或 Lune OS。然而,由于 Android 程序的映射目前只针对桌面环境,因此还需要额外的工作来支持其他的用户界面。
|
||||
|
||||
Android 运行时环境带有一个基于[ Android 开源项目](https://source.android.com/)镜像的最小自定义 Android 系统。所使用的镜像目前基于 Android 7.1.1。
|
||||
Android 运行时环境带有一个基于 [Android 开源项目](https://source.android.com/)镜像的最小自定义 Android 系统。所使用的镜像目前基于 Android 7.1.1。
|
||||
|
||||
## 安装
|
||||
### 安装
|
||||
|
||||
目前,安装过程包括一些添加额外组件到系统的步骤。包括:
|
||||
|
||||
* 没有分发版内核同时启用的 binder 和 ashmen 原始内核模块。
|
||||
* 使用 udev 规则为 /dev/binder 和 /dev/ashmem 设置正确权限。
|
||||
* 能够启动 Anbox 会话管理器作为用户会话的一个启动任务。
|
||||
* 启用用于 binder 和 ashmen 的非发行的树外内核模块。
|
||||
* 使用 udev 规则为 /dev/binder 和 /dev/ashmem 设置正确权限。
|
||||
* 能够启动 Anbox 会话管理器作为用户会话的一个启动任务。
|
||||
|
||||
为了使这个过程尽可能简单,我们将必要的步骤绑定在一个 snap(见 https://snapcraft.io) 中,称为“anbox-installer”。这个安装程序会执行所有必要的步骤。你可以在所有支持 snap 的系统运行下面的命令安装它。
|
||||
为了使这个过程尽可能简单,我们将必要的步骤绑定在一个 snap(见 https://snapcraft.io) 中,称之为 “anbox-installer”。这个安装程序会执行所有必要的步骤。你可以在所有支持 snap 的系统运行下面的命令安装它。
|
||||
|
||||
```
|
||||
$ snap install --classic anbox-installer
|
||||
@ -49,11 +50,11 @@ $ anbox-installer
|
||||
|
||||
它会引导你完成安装过程。
|
||||
|
||||
**注意:** Anbox 目前处于** pre-alpha 开发状态**。不要指望它具有生产环境你需要的所有功能。你肯定会遇到错误和崩溃。如果你遇到了,请不要犹豫并报告它们!
|
||||
**注意:** Anbox 目前处于 **pre-alpha 开发状态**。不要指望它具有生产环境你需要的所有功能。你肯定会遇到错误和崩溃。如果你遇到了,请不要犹豫并报告它们!
|
||||
|
||||
**注意:** Anbox snap 目前 **完全没有约束**,因此它只能从边缘渠道获取。正确的约束是我们想要在未来实现的,但由于 Anbox 的性质和复杂性,这不是一个简单的任务。
|
||||
|
||||
## 已支持的 Linux 发行版
|
||||
### 已支持的 Linux 发行版
|
||||
|
||||
目前我们官方支持下面的 Linux 发行版:
|
||||
|
||||
@ -65,9 +66,9 @@ $ anbox-installer
|
||||
* Ubuntu 16.10 (yakkety)
|
||||
* Ubuntu 17.04 (zesty)
|
||||
|
||||
## 安装并运行 Android 程序
|
||||
### 安装并运行 Android 程序
|
||||
|
||||
## 从源码构建
|
||||
#### 从源码构建
|
||||
|
||||
要构建 Anbox 运行时不需要特别了解什么,我们使用 cmake 作为构建系统。你的主机系统中应已有下面这些构建依赖:
|
||||
|
||||
@ -132,11 +133,11 @@ $ snapcraft
|
||||
$ snap install --dangerous --devmode anbox_1_amd64.snap
|
||||
```
|
||||
|
||||
## 运行 Anbox
|
||||
#### 运行 Anbox
|
||||
|
||||
要从本地构建运行 Anbox ,你需要了解更多一点。请参考[“运行时步骤”](docs/runtime-setup.md)文档。
|
||||
|
||||
## 文档
|
||||
### 文档
|
||||
|
||||
在项目源代码的子目录下,你可以找到额外的关于 Anbox 的文档。
|
||||
|
||||
@ -145,15 +146,15 @@ $ snap install --dangerous --devmode anbox_1_amd64.snap
|
||||
* [运行时步骤](docs/runtime-setup.md)
|
||||
* [构建 Android 镜像](docs/build-android.md)
|
||||
|
||||
## 报告 bug
|
||||
### 报告 bug
|
||||
|
||||
如果你发现了一个 Anbox 问题,请[提交一个 bug](https://github.com/anbox/anbox/issues/new)。
|
||||
如果你发现了一个 Anbox 问题,请[提交 bug](https://github.com/anbox/anbox/issues/new)。
|
||||
|
||||
## 取得联系
|
||||
### 取得联系
|
||||
|
||||
如果你想要与开发者联系,你可以在 [FreeNode](https://freenode.net/) 中加入 *#anbox* 的 IRC 频道。
|
||||
|
||||
## 版权与许可
|
||||
### 版权与许可
|
||||
|
||||
Anbox 重用了像 Android QEMU 模拟器这样的其他项目的代码。这些项目可在外部/带有许可声明的子目录中得到。
|
||||
|
||||
@ -163,7 +164,7 @@ anbox 源码本身,如果没有在相关源码中声明其他的许可,默
|
||||
|
||||
via: https://github.com/anbox/anbox/blob/master/README.md
|
||||
|
||||
作者:[ Anbox][a]
|
||||
作者:[Anbox][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
@ -0,0 +1,238 @@
|
||||
GoTTY:把你的 Linux 终端放到浏览器里面
|
||||
============================================================
|
||||
|
||||
GoTTY 是一个简单的基于 Go 语言的命令行工具,它可以将你的终端(TTY)作为 web 程序共享。它会将命令行工具转换为 web 程序。
|
||||
|
||||
它使用 Chrome OS 的终端仿真器(hterm)来在 Web 浏览器上执行基于 JavaScript 的终端。重要的是,GoTTY 运行了一个 Web 套接字服务器,它基本上是将 TTY 的输出传输给客户端,并从客户端接收输入(即允许客户端的输入),并将其转发给 TTY。
|
||||
|
||||
它的架构(hterm + web socket 的想法)灵感来自 [Wetty 项目][1],它使终端能够通过 HTTP 和 HTTPS 使用。
|
||||
|
||||
### 先决条件
|
||||
|
||||
你需要在 Linux 中安装 [GoLang (Go 编程语言)][2] 环境来运行 GoTTY。
|
||||
|
||||
### 如何在 Linux 中安装 GoTTY
|
||||
|
||||
如果你已经有一个[可以工作的 Go 语言环境][3],运行下面的 `go get` 命令来安装它:
|
||||
|
||||
```
|
||||
# go get github.com/yudai/gotty
|
||||
```
|
||||
|
||||
上面的命令会在你的 `GOBIN` 环境变量中安装 GOTTY 的二进制,尝试检查下是否如此:
|
||||
|
||||
```
|
||||
# $GOPATH/bin/
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
*检查 GOBIN 环境*
|
||||
|
||||
### 如何在 Linux 中使用 GoTTY
|
||||
|
||||
要运行它,你可以使用 GOBIN 环境变量并用命令补全:
|
||||
|
||||
```
|
||||
# $GOBIN/gotty
|
||||
```
|
||||
|
||||
另外,要不带完整命令路径运行 GoTTY 或其他 Go 程序,使用 `export` 命令将 `GOBIN` 变量添加到 `~/.profile` 文件中的 `PATH` 环境变量中。
|
||||
|
||||
```
|
||||
export PATH="$PATH:$GOBIN"
|
||||
```
|
||||
|
||||
保存文件并关闭。接着运行 `source` 来使更改生效:
|
||||
|
||||
```
|
||||
# source ~/.profile
|
||||
```
|
||||
|
||||
运行 GoTTY 命令的常规语法是:
|
||||
|
||||
```
|
||||
Usage: gotty [options] <Linux command here> [<arguments...>]
|
||||
```
|
||||
|
||||
现在用 GoTTY 运行任意命令,如 [df][5] 来从 Web 浏览器中查看系统分区空间及使用率。
|
||||
|
||||
```
|
||||
# gotty df -h
|
||||
```
|
||||
|
||||
GoTTY 默认会在 8080 启动一个 Web 服务器。在浏览器中打开 URL:`http://127.0.0.1:8080/`,你会看到运行的命令仿佛运行在终端中一样:
|
||||
|
||||
[
|
||||
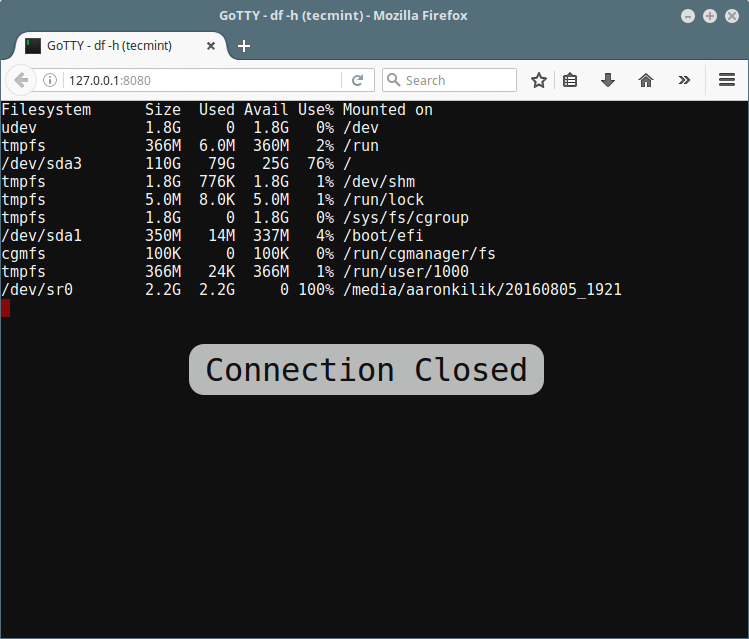
|
||||
][6]
|
||||
|
||||
*Gotty 查看 Linux 磁盘使用率*
|
||||
|
||||
### 如何在 Linux 中自定义 GoTTY
|
||||
|
||||
你可以在 `~/.gotty` 配置文件中修改默认选项以及终端,如果该文件存在,它会在每次启动时加载这个文件。
|
||||
|
||||
这是由 getty 命令读取的主要自定义文件,因此,按如下方式创建:
|
||||
|
||||
```
|
||||
# touch ~/.gotty
|
||||
```
|
||||
|
||||
并为配置选项设置你自己的有效值(在此处查找所有配置选项)以自定义 GoTTY,例如:
|
||||
|
||||
```
|
||||
// Listen at port 9000 by default
|
||||
port = "9000"
|
||||
// Enable TSL/SSL by default
|
||||
enable_tls = true
|
||||
// hterm preferences
|
||||
// Smaller font and a little bit bluer background color
|
||||
preferences {
|
||||
font_size = 5,
|
||||
background_color = "rgb(16, 16, 32)"
|
||||
}
|
||||
```
|
||||
|
||||
你可以使用命令行中的 `--html` 选项设置你自己的 `index.html` 文件:
|
||||
|
||||
```
|
||||
# gotty --index /path/to/index.html uptime
|
||||
```
|
||||
|
||||
### 如何在 GoTTY 中使用安全功能
|
||||
|
||||
由于 GoTTY 默认不提供可靠的安全保障,你需要手动使用下面说明的某些安全功能。
|
||||
|
||||
#### 允许客户端在终端中运行命令
|
||||
|
||||
请注意,默认情况下,GoTTY 不允许客户端输入到TTY中,它只支持窗口缩放。
|
||||
|
||||
但是,你可以使用 `-w` 或 `--permit-write` 选项来允许客户端写入 TTY,但是并不推荐这么做因为会有安全威胁。
|
||||
|
||||
以下命令会使用 [vi 命令行编辑器][7]在 Web 浏览器中打开文件 `fossmint.txt` 进行编辑:
|
||||
|
||||
```
|
||||
# gotty -w vi fossmint.txt
|
||||
```
|
||||
|
||||
以下是从 Web 浏览器看到的 vi 界面(像平常一样使用 vi 命令):
|
||||
|
||||
[
|
||||
|
||||
][8]
|
||||
|
||||
*Gotty Web Vi 编辑器*
|
||||
|
||||
#### 使用基本(用户名和密码)验证运行 GoTTY
|
||||
|
||||
尝试激活基本身份验证机制,这样客户端将需要输入指定的用户名和密码才能连接到 GoTTY 服务器。
|
||||
|
||||
以下命令使用 `-c` 选项限制客户端访问,以向用户询问指定的凭据(用户名:`test` 密码:`@67890`):
|
||||
|
||||
```
|
||||
# gotty -w -p "9000" -c "test@67890" glances
|
||||
```
|
||||
[
|
||||
|
||||
][9]
|
||||
|
||||
*使用基本验证运行 GoTTY*
|
||||
|
||||
#### Gotty 生成随机 URL
|
||||
|
||||
限制访问服务器的另一种方法是使用 `-r` 选项。GoTTY 会生成一个随机 URL,这样只有知道该 URL 的用户才可以访问该服务器。
|
||||
|
||||
还可以使用 `-title-format "GoTTY – {{ .Command }} ({{ .Hostname }})"` 选项来定义浏览器标题。[glances][10] 用于显示系统监控统计信息:
|
||||
|
||||
```
|
||||
# gotty -r --title-format "GoTTY - {{ .Command }} ({{ .Hostname }})" glances
|
||||
```
|
||||
|
||||
以下是从浏览器中看到的上面的命令的结果:
|
||||
|
||||
[
|
||||

|
||||
][11]
|
||||
|
||||
*使用 Gotty 随机 URL 用于 Glances 系统监控*
|
||||
|
||||
#### 带有 SSL/TLS 使用 GoTTY
|
||||
|
||||
因为默认情况下服务器和客户端之间的所有连接都不加密,当你通过 GoTTY 发送秘密信息(如用户凭据或任何其他信息)时,你需要使用 `-t` 或 `--tls` 选项才能在会话中启用 TLS/SSL:
|
||||
|
||||
默认情况下,GoTTY 会读取证书文件 `~/.gotty.crt` 和密钥文件 `~/.gotty.key`,因此,首先使用下面的 `openssl` 命令创建一个自签名的证书以及密钥( 回答问题以生成证书和密钥文件):
|
||||
|
||||
```
|
||||
# openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout ~/.gotty.key -out ~/.gotty.crt
|
||||
```
|
||||
|
||||
按如下所示,通过启用 SSL/TLS,以安全方式使用 GoTTY:
|
||||
|
||||
```
|
||||
# gotty -tr --title-format "GoTTY - {{ .Command }} ({{ .Hostname }})" glances
|
||||
```
|
||||
|
||||
#### 与多个客户端分享你的终端
|
||||
|
||||
你可以使用[终端复用程序][12]来与多个客户端共享一个进程,以下命令会启动一个名为 gotty 的新 [tmux 会话][13]来运行 [glances][14](确保你安装了 tmux):
|
||||
|
||||
```
|
||||
# gotty tmux new -A -s gotty glances
|
||||
```
|
||||
|
||||
要读取不同的配置文件,像下面那样使用 `–config "/path/to/file"` 选项:
|
||||
|
||||
```
|
||||
# gotty -tr --config "~/gotty_new_config" --title-format "GoTTY - {{ .Command }} ({{ .Hostname }})" glances
|
||||
```
|
||||
|
||||
要显示 GoTTY 版本,运行命令:
|
||||
|
||||
```
|
||||
# gotty -v
|
||||
```
|
||||
|
||||
访问 GoTTY GitHub 仓库以查找更多使用示例:[https://github.com/yudai/gotty][15] 。
|
||||
|
||||
就这样了!你有尝试过了吗?如何知道 GoTTY 的?通过下面的反馈栏与我们分享你的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili 是 Linux 和 F.O.S.S 爱好者,即将成为 Linux SysAdmin 和网络开发人员,目前是 TecMint 的内容创作者,他喜欢在电脑上工作,并坚信分享知识。
|
||||
|
||||
|
||||
----------
|
||||
|
||||
|
||||
via: http://www.tecmint.com/gotty-share-linux-terminal-in-web-browser/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/access-linux-server-terminal-in-web-browser-using-wetty/
|
||||
[2]:http://www.tecmint.com/install-go-in-linux/
|
||||
[3]:http://www.tecmint.com/install-go-in-linux/
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2017/03/Check-Go-Environment.png
|
||||
[5]:http://www.tecmint.com/how-to-check-disk-space-in-linux/
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2017/03/Gotty-Linux-Disk-Usage.png
|
||||
[7]:http://www.tecmint.com/vi-editor-usage/
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2017/03/Gotty-Web-Vi-Editor.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2017/03/Gotty-use-basic-authentication.png
|
||||
[10]:http://www.tecmint.com/glances-an-advanced-real-time-system-monitoring-tool-for-linux/
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2017/03/Gotty-Random-URL-for-Glances-Linux-Monitoring.png
|
||||
[12]:http://www.tecmint.com/tmux-to-access-multiple-linux-terminals-inside-a-single-console/
|
||||
[13]:http://www.tecmint.com/tmux-to-access-multiple-linux-terminals-inside-a-single-console/
|
||||
[14]:http://www.tecmint.com/glances-an-advanced-real-time-system-monitoring-tool-for-linux/
|
||||
[15]:https://github.com/yudai/gotty
|
||||
[16]:http://www.tecmint.com/author/aaronkili/
|
||||
[17]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[18]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -0,0 +1,453 @@
|
||||
调试器工作原理(二):断点
|
||||
============================================================
|
||||
|
||||
这是调试器工作原理系列文章的第二部分,阅读本文前,请确保你已经读过[第一部分][27]。
|
||||
|
||||
### 关于本文
|
||||
|
||||
我将会演示如何在调试器中实现断点。断点是调试的两大利器之一,另一个是可以在被调试进程的内存中检查变量值。我们在系列的第一部分已经了解过值检查,但是断点对我们来说依然神秘。不过本文过后,它们就不再如此了。
|
||||
|
||||
### 软件中断
|
||||
|
||||
为了在 x86 架构机器上实现断点,软件中断(也被称作“陷阱”)被会派上用场。在我们深入细节之前,我想先大致解释一下中断和陷阱的概念。
|
||||
|
||||
CPU 有一条单独的执行流,一条指令接一条的执行(在更高的层面看是这样的,但是在底层的细节上来说,现在的许多 CPU 都会并行执行多个指令,这其中的一些指令就不是按照原本的顺序执行的)。为了能够处理异步的事件,如 IO 和 硬件定时器,CPU 使用了中断。硬件中断通常是一个特定的电子信号,并附加了一个特别的”响应电路”。该电路通知中断激活,并让 CPU 停止当前执行,保存状态,然后跳转到一个预定义的地址,也就是中断处理程序的位置。当处理程序完成其工作后,CPU 又从之前停止的地方重新恢复运行。
|
||||
|
||||
软件中断在规则上与硬件相似,但实际操作中有些不同。CPU 支持一些特殊的指令,来允许软件模拟出一个中断。当这样的一个指令被执行时,CPU 像对待一个硬件中断那样 —— 停止正常的执行流,保存状态,然后跳转到一个处理程序。这种“中断”使得许多现代 OS 的惊叹设计得以高效地实现(如任务调度,虚拟内存,内存保护,调试)。
|
||||
|
||||
许多编程错误(如被 0 除)也被 CPU 当做中断对待,常常也叫做“异常”, 这时候硬件和软件中断之间的界限就模糊了,很难说这种异常到底是硬件中断还是软件中断。但我已经偏离今天主题太远了,所以现在让我们回到断点上来。
|
||||
|
||||
### int 3 理论
|
||||
|
||||
前面说了很多,现在简单来说断点就是一个部署在 CPU 上的特殊中断,叫 `int 3`。`int` 是一个 “中断指令”的 x86 术语,该指令是对一个预定义中断处理的调用。x86 支持 8 位的 int 指令操作数,这决定了中断的数量,所以理论上可以支持 256 个中断。前 32 个中断为 CPU 自己保留,而 int 3 就是本文关注的 —— 它被叫做 “调试器专用中断”。
|
||||
|
||||
避免更深的解释,我将引用“圣经”里一段话(这里说的“圣经”,当然指的是英特尔的体系结构软件开发者手册, 卷 2A)。
|
||||
|
||||
> INT 3 指令生成一个以字节操作码(CC),用于调用该调试异常处理程序。(这个一字节格式是非常有用的,因为它可以用于使用断点来替换任意指令的第一个字节 ,包括哪些一字节指令,而不会覆写其它代码)
|
||||
|
||||
上述引用非常重要,但是目前去解释它还是为时过早。本文后面我们会回过头再看。
|
||||
|
||||
### int 3 实践
|
||||
|
||||
没错,知道事物背后的理论非常不错,不过,这些理论到底意思是啥?我们怎样使用 `int 3` 部署断点?或者怎么翻译成通用的编程术语 —— _请给我看代码!_
|
||||
|
||||
实际上,实现非常简单。一旦你的程序执行了 `int 3` 指令, OS 就会停止程序( OS 是怎么做到像这样停止进程的? OS 注册其 int 3 的控制程序到 CPU 即可,就这么简单)。在 Linux(这也是本文比较关心的地方) 上, OS 会发送给进程一个信号 —— `SIGTRAP`。
|
||||
|
||||
就是这样,真的。现在回想一下本系列的第一部分, 追踪进程(调试程序) 会得到其子进程(或它所连接的被调试进程)所得到的所有信号的通知,接下来你就知道了。
|
||||
|
||||
就这样, 没有更多的电脑架构基础术语了。该是例子和代码的时候了。
|
||||
|
||||
### 手动设置断点
|
||||
|
||||
现在我要演示在程序里设置断点的代码。我要使用的程序如下:
|
||||
|
||||
```
|
||||
section .text
|
||||
; The _start symbol must be declared for the linker (ld)
|
||||
global _start
|
||||
|
||||
_start:
|
||||
|
||||
; Prepare arguments for the sys_write system call:
|
||||
; - eax: system call number (sys_write)
|
||||
; - ebx: file descriptor (stdout)
|
||||
; - ecx: pointer to string
|
||||
; - edx: string length
|
||||
mov edx, len1
|
||||
mov ecx, msg1
|
||||
mov ebx, 1
|
||||
mov eax, 4
|
||||
|
||||
; Execute the sys_write system call
|
||||
int 0x80
|
||||
|
||||
; Now print the other message
|
||||
mov edx, len2
|
||||
mov ecx, msg2
|
||||
mov ebx, 1
|
||||
mov eax, 4
|
||||
int 0x80
|
||||
|
||||
; Execute sys_exit
|
||||
mov eax, 1
|
||||
int 0x80
|
||||
|
||||
section .data
|
||||
|
||||
msg1 db 'Hello,', 0xa
|
||||
len1 equ $ - msg1
|
||||
msg2 db 'world!', 0xa
|
||||
len2 equ $ - msg2
|
||||
```
|
||||
|
||||
我现在在使用汇编语言,是为了当我们面对 C 代码的时候,能清楚一些编译细节。上面代码做的事情非常简单,就是在一行打印出 “hello,”,然后在下一行打印出 “world!”。这与之前文章中的程序非常类似。
|
||||
|
||||
现在我想在第一次打印和第二次打印之间设置一个断点。我们看到在第一条 `int 0x80` ,其后指令是 `mov edx, len2`。(等等,再次 int?是的,Linux 使用 `int 0x80` 来实现用户进程到系统内核的系统调用。用户将系统调用的号码及其参数放到寄存器,并执行 `int 0x80`。然后 CPU 会跳到相应的中断处理程序,其中, OS 注册了一个过程,该过程查看寄存器并决定要执行的系统调用。)首先,我们需要知道该指令所映射的地址。运行 `objdump -d`:
|
||||
|
||||
```
|
||||
traced_printer2: file format elf32-i386
|
||||
|
||||
Sections:
|
||||
Idx Name Size VMA LMA File off Algn
|
||||
0 .text 00000033 08048080 08048080 00000080 2**4
|
||||
CONTENTS, ALLOC, LOAD, READONLY, CODE
|
||||
1 .data 0000000e 080490b4 080490b4 000000b4 2**2
|
||||
CONTENTS, ALLOC, LOAD, DATA
|
||||
|
||||
Disassembly of section .text:
|
||||
|
||||
08048080 <.text>:
|
||||
8048080: ba 07 00 00 00 mov $0x7,%edx
|
||||
8048085: b9 b4 90 04 08 mov $0x80490b4,%ecx
|
||||
804808a: bb 01 00 00 00 mov $0x1,%ebx
|
||||
804808f: b8 04 00 00 00 mov $0x4,%eax
|
||||
8048094: cd 80 int $0x80
|
||||
8048096: ba 07 00 00 00 mov $0x7,%edx
|
||||
804809b: b9 bb 90 04 08 mov $0x80490bb,%ecx
|
||||
80480a0: bb 01 00 00 00 mov $0x1,%ebx
|
||||
80480a5: b8 04 00 00 00 mov $0x4,%eax
|
||||
80480aa: cd 80 int $0x80
|
||||
80480ac: b8 01 00 00 00 mov $0x1,%eax
|
||||
80480b1: cd 80 int $0x80
|
||||
```
|
||||
|
||||
所以,我们要设置断点的地址是 `0x8048096`。等等,这不是调试器工作的真实姿势,对吧?真正的调试器是在代码行和函数上设置断点,而不是赤裸裸的内存地址?完全正确,但是目前我们仍然还没到那一步,为了更像_真正的_调试器一样设置断点,我们仍不得不首先理解一些符号和调试信息。所以现在,我们就得面对内存地址。
|
||||
|
||||
在这点上,我真想又偏离一下主题。所以现在你有两个选择,如果你真的感兴趣想知道_为什么_那个地址应该是 `0x8048096`,它代表着什么,那就看下面的部分。否则你只是想了解断点,你可以跳过这部分。
|
||||
|
||||
### 题外话 —— 程序地址和入口
|
||||
|
||||
坦白说,`0x8048096` 本身没多大意义,仅仅是可执行程序的 text 部分开端偏移的一些字节。如果你看上面导出来的列表,你会看到 text 部分从地址 `0x08048080` 开始。这告诉 OS 在分配给进程的虚拟地址空间里,将该地址映射到 text 部分开始的地方。在 Linux 上面,这些地址可以是绝对地址(例如,当可执行程序加载到内存中时它不做重定位),因为通过虚拟地址系统,每个进程获得自己的一块内存,并且将整个 32 位地址空间看做自己的(称为 “线性” 地址)。
|
||||
|
||||
如果我们使用 `readelf` 命令检查 ELF 文件头部(ELF,可执行和可链接格式,是 Linux 上用于对象文件、共享库和可执行程序的文件格式),我们会看到:
|
||||
|
||||
```
|
||||
$ readelf -h traced_printer2
|
||||
ELF Header:
|
||||
Magic: 7f 45 4c 46 01 01 01 00 00 00 00 00 00 00 00 00
|
||||
Class: ELF32
|
||||
Data: 2's complement, little endian
|
||||
Version: 1 (current)
|
||||
OS/ABI: UNIX - System V
|
||||
ABI Version: 0
|
||||
Type: EXEC (Executable file)
|
||||
Machine: Intel 80386
|
||||
Version: 0x1
|
||||
Entry point address: 0x8048080
|
||||
Start of program headers: 52 (bytes into file)
|
||||
Start of section headers: 220 (bytes into file)
|
||||
Flags: 0x0
|
||||
Size of this header: 52 (bytes)
|
||||
Size of program headers: 32 (bytes)
|
||||
Number of program headers: 2
|
||||
Size of section headers: 40 (bytes)
|
||||
Number of section headers: 4
|
||||
Section header string table index: 3
|
||||
```
|
||||
|
||||
注意头部里的 `Entry point address`,它同样指向 `0x8048080`。所以我们在系统层面解释该 elf 文件的编码信息,它意思是:
|
||||
|
||||
1. 映射 text 部分(包含所给的内容)到地址 `0x8048080`
|
||||
2. 从入口 —— 地址 `0x8048080` 处开始执行
|
||||
|
||||
但是,为什么是 `0x8048080` 呢?事实证明是一些历史原因。一些 Google 的结果把我引向源头,宣传每个进程的地址空间的前 128M 是保留在栈里的。128M 对应为 `0x8000000`,该地址是可执行程序其他部分可以开始的地方。而 `0x8048080`,比较特别,是 Linux `ld` 链接器使用的默认入口地址。该入口可以通过给 `ld` 传递 `-Ttext` 参数改变。
|
||||
|
||||
总结一下,这地址没啥特别的,我们可以随意修改它。只要 ELF 可执行文件被合理的组织,并且头部里的入口地址与真正的程序代码(text 部分)开始的地址匹配,一切都没问题。
|
||||
|
||||
### 用 int 3 在调试器中设置断点
|
||||
|
||||
为了在被追踪进程的某些目标地址设置一个断点,调试器会做如下工作:
|
||||
|
||||
1. 记住存储在目标地址的数据
|
||||
2. 用 int 指令替换掉目标地址的第一个字节
|
||||
|
||||
然后,当调试器要求 OS 运行该进程的时候(通过上一篇文章中提过的 `PTRACE_CONT`),进程就会运行起来直到遇到 `int 3`,此处进程会停止运行,并且 OS 会发送一个信号给调试器。调试器会收到一个信号表明其子进程(或者说被追踪进程)停止了。调试器可以做以下工作:
|
||||
|
||||
1. 在目标地址,用原来的正常执行指令替换掉 int 3 指令
|
||||
2. 将被追踪进程的指令指针回退一步。这是因为现在指令指针位于刚刚执行过的 int 3 之后。
|
||||
3. 允许用户以某些方式与进程交互,因为该进程仍然停止在特定的目标地址。这里你的调试器可以让你取得变量值,调用栈等等。
|
||||
4. 当用户想继续运行,调试器会小心地把断点放回目标地址去(因为它在第 1 步时被移走了),除非用户要求取消该断点。
|
||||
|
||||
让我们来看看,这些步骤是如何翻译成具体代码的。我们会用到第一篇里的调试器 “模板”(fork 一个子进程并追踪它)。无论如何,文末会有一个完整样例源代码的链接
|
||||
|
||||
```
|
||||
/* Obtain and show child's instruction pointer */
|
||||
ptrace(PTRACE_GETREGS, child_pid, 0, ®s);
|
||||
procmsg("Child started. EIP = 0x%08x\n", regs.eip);
|
||||
|
||||
/* Look at the word at the address we're interested in */
|
||||
unsigned addr = 0x8048096;
|
||||
unsigned data = ptrace(PTRACE_PEEKTEXT, child_pid, (void*)addr, 0);
|
||||
procmsg("Original data at 0x%08x: 0x%08x\n", addr, data);
|
||||
```
|
||||
|
||||
这里调试器从被追踪的进程中取回了指令指针,也检查了在 `0x8048096` 的字。当开始追踪运行文章开头的汇编代码,将会打印出:
|
||||
|
||||
```
|
||||
[13028] Child started. EIP = 0x08048080
|
||||
[13028] Original data at 0x08048096: 0x000007ba
|
||||
```
|
||||
|
||||
目前为止都看起来不错。接下来:
|
||||
|
||||
```
|
||||
/* Write the trap instruction 'int 3' into the address */
|
||||
unsigned data_with_trap = (data & 0xFFFFFF00) | 0xCC;
|
||||
ptrace(PTRACE_POKETEXT, child_pid, (void*)addr, (void*)data_with_trap);
|
||||
|
||||
/* See what's there again... */
|
||||
unsigned readback_data = ptrace(PTRACE_PEEKTEXT, child_pid, (void*)addr, 0);
|
||||
procmsg("After trap, data at 0x%08x: 0x%08x\n", addr, readback_data);
|
||||
```
|
||||
|
||||
注意到 `int 3` 是如何被插入到目标地址的。此处打印:
|
||||
|
||||
```
|
||||
[13028] After trap, data at 0x08048096: 0x000007cc
|
||||
```
|
||||
|
||||
正如预料的那样 —— `0xba` 被 `0xcc` 替换掉了。现在调试器运行子进程并等待它在断点处停止:
|
||||
|
||||
```
|
||||
/* Let the child run to the breakpoint and wait for it to
|
||||
** reach it
|
||||
*/
|
||||
ptrace(PTRACE_CONT, child_pid, 0, 0);
|
||||
|
||||
wait(&wait_status);
|
||||
if (WIFSTOPPED(wait_status)) {
|
||||
procmsg("Child got a signal: %s\n", strsignal(WSTOPSIG(wait_status)));
|
||||
}
|
||||
else {
|
||||
perror("wait");
|
||||
return;
|
||||
}
|
||||
|
||||
/* See where the child is now */
|
||||
ptrace(PTRACE_GETREGS, child_pid, 0, ®s);
|
||||
procmsg("Child stopped at EIP = 0x%08x\n", regs.eip);
|
||||
```
|
||||
|
||||
这里打印出:
|
||||
|
||||
```
|
||||
Hello,
|
||||
[13028] Child got a signal: Trace/breakpoint trap
|
||||
[13028] Child stopped at EIP = 0x08048097
|
||||
```
|
||||
|
||||
注意到 “Hello,” 在断点前打印出来了 —— 完全如我们计划的那样。同时注意到子进程停止的地方 —— 刚好就是单字节中断指令后面。
|
||||
|
||||
最后,如早先诠释的那样,为了让子进程继续运行,我们得做一些工作。我们用原来的指令替换掉中断指令,并且让进程从这里继续之前的运行。
|
||||
|
||||
```
|
||||
/* Remove the breakpoint by restoring the previous data
|
||||
** at the target address, and unwind the EIP back by 1 to
|
||||
** let the CPU execute the original instruction that was
|
||||
** there.
|
||||
*/
|
||||
ptrace(PTRACE_POKETEXT, child_pid, (void*)addr, (void*)data);
|
||||
regs.eip -= 1;
|
||||
ptrace(PTRACE_SETREGS, child_pid, 0, ®s);
|
||||
|
||||
/* The child can continue running now */
|
||||
ptrace(PTRACE_CONT, child_pid, 0, 0);
|
||||
```
|
||||
|
||||
这会使子进程继续打印出 “world!”,然后退出。
|
||||
|
||||
注意,我们在这里没有恢复断点。通过在单步调试模式下,运行原来的指令,然后将中断放回去,并且只在运行 PTRACE_CONT 时做到恢复断点。文章稍后会展示 debuglib 如何做到这点。
|
||||
|
||||
### 更多关于 int 3
|
||||
|
||||
现在可以回过头去看看 `int 3` 和因特尔手册里那个神秘的说明,原文如下:
|
||||
|
||||
|
||||
> 这个一字节格式是非常有用的,因为它可以用于使用断点来替换任意指令的第一个字节 ,包括哪些一字节指令,而不会覆写其它代码
|
||||
|
||||
int 指令在 x86 机器上占两个字节 —— `0xcd` 紧跟着中断数(细心的读者可以在上面列出的转储中发现 `int 0x80` 翻译成了 `cd 80`)。`int 3` 被编码为 `cd 03`,但是为其还保留了一个单字节指令 —— `0xcc`。
|
||||
|
||||
为什么这样呢?因为这可以允许我们插入一个断点,而不需要重写多余的指令。这非常重要,考虑下面的代码:
|
||||
|
||||
```
|
||||
.. some code ..
|
||||
jz foo
|
||||
dec eax
|
||||
foo:
|
||||
call bar
|
||||
.. some code ..
|
||||
```
|
||||
|
||||
假设你想在 `dec eax` 这里放置一个断点。这对应一个单字节指令(操作码为 `0x48`)。由于替换断点的指令长于一个字节,我们不得不强制覆盖掉下个指令(`call`)的一部分,这就会篡改 `call` 指令,并很可能导致一些完全不合理的事情发生。这样一来跳转到 `foo` 分支的 `jz foo` 指令会导致什么?就会不在 dec eax 这里停止,CPU 径直去执行后面一些无效的指令了。
|
||||
|
||||
而有了单字节的 `int 3` 指令,这个问题就解决了。 1 字节是在 x86 上面所能找到的最短指令,这样我们可以保证仅改变我们想中断的指令。
|
||||
|
||||
### 封装一些晦涩的细节
|
||||
|
||||
很多上述章节样例代码的底层细节,都可以很容易封装在方便使用的 API 里。我已经做了很多封装的工作,将它们都放在一个叫做 debuglib 的通用库里 —— 文末可以去下载。这里我仅仅是想展示它的用法示例,但是绕了一圈。下面我们将追踪一个用 C 写的程序。
|
||||
|
||||
### 追踪一个 C 程序地址和入口
|
||||
|
||||
目前为止,为了简单,我把注意力放在了目标汇编代码。现在是时候往上一个层次,去看看我们如何追踪一个 C 程序。
|
||||
|
||||
事实证明并不是非常难 —— 找到放置断点位置有一点难罢了。考虑下面样例程序:
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
|
||||
void do_stuff()
|
||||
{
|
||||
printf("Hello, ");
|
||||
}
|
||||
|
||||
int main()
|
||||
{
|
||||
for (int i = 0; i < 4; ++i)
|
||||
do_stuff();
|
||||
printf("world!\n");
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
假设我想在 `do_stuff` 入口处放置一个断点。我会先使用 `objdump` 反汇编一下可执行文件,但是打印出的东西太多。尤其看到很多无用,也不感兴趣的 C 程序运行时的初始化代码。所以我们仅看一下 `do_stuff` 部分:
|
||||
|
||||
```
|
||||
080483e4 <do_stuff>:
|
||||
80483e4: 55 push %ebp
|
||||
80483e5: 89 e5 mov %esp,%ebp
|
||||
80483e7: 83 ec 18 sub $0x18,%esp
|
||||
80483ea: c7 04 24 f0 84 04 08 movl $0x80484f0,(%esp)
|
||||
80483f1: e8 22 ff ff ff call 8048318 <puts@plt>
|
||||
80483f6: c9 leave
|
||||
80483f7: c3 ret
|
||||
```
|
||||
|
||||
那么,我们将会把断点放在 `0x080483e4`,这是 `do_stuff` 第一条指令执行的地方。而且,该函数是在循环里面调用的,我们想要在断点处一直停止执行直到循环结束。我们将会使用 debuglib 来简化该流程,下面是完整的调试函数:
|
||||
|
||||
```
|
||||
void run_debugger(pid_t child_pid)
|
||||
{
|
||||
procmsg("debugger started\n");
|
||||
|
||||
/* Wait for child to stop on its first instruction */
|
||||
wait(0);
|
||||
procmsg("child now at EIP = 0x%08x\n", get_child_eip(child_pid));
|
||||
|
||||
/* Create breakpoint and run to it*/
|
||||
debug_breakpoint* bp = create_breakpoint(child_pid, (void*)0x080483e4);
|
||||
procmsg("breakpoint created\n");
|
||||
ptrace(PTRACE_CONT, child_pid, 0, 0);
|
||||
wait(0);
|
||||
|
||||
/* Loop as long as the child didn't exit */
|
||||
while (1) {
|
||||
/* The child is stopped at a breakpoint here. Resume its
|
||||
** execution until it either exits or hits the
|
||||
** breakpoint again.
|
||||
*/
|
||||
procmsg("child stopped at breakpoint. EIP = 0x%08X\n", get_child_eip(child_pid));
|
||||
procmsg("resuming\n");
|
||||
int rc = resume_from_breakpoint(child_pid, bp);
|
||||
|
||||
if (rc == 0) {
|
||||
procmsg("child exited\n");
|
||||
break;
|
||||
}
|
||||
else if (rc == 1) {
|
||||
continue;
|
||||
}
|
||||
else {
|
||||
procmsg("unexpected: %d\n", rc);
|
||||
break;
|
||||
}
|
||||
}
|
||||
|
||||
cleanup_breakpoint(bp);
|
||||
}
|
||||
```
|
||||
|
||||
为了避免修改 EIP 标志位和目的进程的内存空间的麻烦,我们仅需要调用 `create_breakpoint`,`resume_from_breakpoint` 和 `cleanup_breakpoint`。让我们来看看追踪上面的 C 代码样例会输出什么:
|
||||
|
||||
```
|
||||
$ bp_use_lib traced_c_loop
|
||||
[13363] debugger started
|
||||
[13364] target started. will run 'traced_c_loop'
|
||||
[13363] child now at EIP = 0x00a37850
|
||||
[13363] breakpoint created
|
||||
[13363] child stopped at breakpoint. EIP = 0x080483E5
|
||||
[13363] resuming
|
||||
Hello,
|
||||
[13363] child stopped at breakpoint. EIP = 0x080483E5
|
||||
[13363] resuming
|
||||
Hello,
|
||||
[13363] child stopped at breakpoint. EIP = 0x080483E5
|
||||
[13363] resuming
|
||||
Hello,
|
||||
[13363] child stopped at breakpoint. EIP = 0x080483E5
|
||||
[13363] resuming
|
||||
Hello,
|
||||
world!
|
||||
[13363] child exited
|
||||
```
|
||||
|
||||
如预期一样!
|
||||
|
||||
### 样例代码
|
||||
|
||||
[这里是][25]本文用到的完整源代码文件。在归档中你可以找到:
|
||||
|
||||
* debuglib.h 和 debuglib.c - 封装了调试器的一些内部工作的示例库
|
||||
* bp_manual.c - 这篇文章开始部分介绍的“手动”设置断点的方法。一些样板代码使用了 debuglib 库。
|
||||
* bp_use_lib.c - 大部分代码使用了 debuglib 库,用于在第二个代码范例中演示在 C 程序的循环中追踪。
|
||||
|
||||
### 引文
|
||||
|
||||
在准备本文的时候,我搜集了如下的资源和文章:
|
||||
|
||||
* [How debugger works][12]
|
||||
* [Understanding ELF using readelf and objdump][13]
|
||||
* [Implementing breakpoints on x86 Linux][14]
|
||||
* [NASM manual][15]
|
||||
* [SO discussion of the ELF entry point][16]
|
||||
* [This Hacker News discussion][17] of the first part of the series
|
||||
* [GDB Internals][18]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints
|
||||
|
||||
作者:[Eli Bendersky][a]
|
||||
译者:[wi-cuckoo](https://github.com/wi-cuckoo)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://eli.thegreenplace.net/
|
||||
[1]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id1
|
||||
[2]:http://en.wikipedia.org/wiki/Out-of-order_execution
|
||||
[3]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id2
|
||||
[4]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id3
|
||||
[5]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id4
|
||||
[6]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id5
|
||||
[7]:http://en.wikipedia.org/wiki/Executable_and_Linkable_Format
|
||||
[8]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id6
|
||||
[9]:http://eli.thegreenplace.net/tag/articles
|
||||
[10]:http://eli.thegreenplace.net/tag/debuggers
|
||||
[11]:http://eli.thegreenplace.net/tag/programming
|
||||
[12]:http://www.alexonlinux.com/how-debugger-works
|
||||
[13]:http://www.linuxforums.org/articles/understanding-elf-using-readelf-and-objdump_125.html
|
||||
[14]:http://mainisusuallyafunction.blogspot.com/2011/01/implementing-breakpoints-on-x86-linux.html
|
||||
[15]:http://www.nasm.us/xdoc/2.09.04/html/nasmdoc0.html
|
||||
[16]:http://stackoverflow.com/questions/2187484/elf-binary-entry-point
|
||||
[17]:http://news.ycombinator.net/item?id=2131894
|
||||
[18]:http://www.deansys.com/doc/gdbInternals/gdbint_toc.html
|
||||
[19]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id7
|
||||
[20]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id8
|
||||
[21]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id9
|
||||
[22]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id10
|
||||
[23]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id11
|
||||
[24]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id12
|
||||
[25]:https://github.com/eliben/code-for-blog/tree/master/2011/debuggers_part2_code
|
||||
[26]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints
|
||||
[27]:https://linux.cn/article-8418-1.html
|
||||
@ -0,0 +1,218 @@
|
||||
详解 UEFI 模式下安装 Linux
|
||||
============================================================
|
||||
|
||||
> 此页面是免费浏览的,没有烦人的外部广告;然而,我的确花了时间准备,网站托管也花了钱。如果您发现此页面帮到了您,请考虑进行小额[捐款](http://www.rodsbooks.com/linux-uefi/),以帮助保持网站的运行。谢谢!
|
||||
> 原著于 2013/10/19;最后修改于 2015/3/16
|
||||
|
||||
### 引言
|
||||
|
||||
几年来,一种新的固件技术悄然出现,而大多数普通用户对此并无所知。该技术被称为 [ <ruby>可扩展固件接口<rt>Extensible Firmware Interface</rt></ruby>][29](EFI), 或更新一些的统一可扩展固件接口(Unified EFI,UEFI,本质上是 EFI 2.x),它已经开始替代古老的[<ruby>基本输入/输出系统<rt>Basic Input/Output System</rt></ruby>][30](BIOS)固件技术,有经验的计算机用户或多或少都有些熟悉 BIOS。
|
||||
|
||||
本页面是给 Linux 用户使用 EFI 技术的一个快速介绍,其中包括有关开始将 Linux 安装到此类计算机上的建议。不幸的是,EFI 是一个庞杂的话题;EFI 软件本身是复杂的,许多实现有系统特定的怪异行为甚至是缺陷。因此,我无法在一个页面上描述在 EFI 计算机上安装和使用 Linux 的一切知识。我希望你能将本页面作为一个有用的起点,不管怎么说,每个部分以及末尾[参考文献][31]部分的链接可以指引你找到更多的文档。
|
||||
|
||||
### 你的计算机是否使用 EFI 技术?
|
||||
|
||||
EFI 是一种_固件_,意味着它是内置于计算机中处理低级任务的软件。最重要的是,固件控制着计算机的引导过程,反过来说这代表着基于 EFI 的计算机与基于 BIOS 的计算机的引导过程不同。(有关此规律的例外之处稍后再说。)这种差异可能使操作系统安装介质的设计超级复杂化,但是一旦安装好并运行之后,它对计算机的日常操作几乎没有影响。请注意,大多数制造商使用术语 “BIOS” 来表示他们的 EFI。我认为这种用法很混乱,所以我避免了;在我看来,EFI 和 BIOS 是两种不同类型的固件。
|
||||
|
||||
> **注意:**苹果公司的 Mac 使用的 EFI 在许多方面是不同寻常的。尽管本页面的大部分内容同样适用于 Mac,但有些细节上的出入,特别是在设置 EFI 引导加载程序的时候。这个任务最好在 OS X 上进行,使用 Mac 的 [bless utility][49]工具,我不在此做过多描述。
|
||||
|
||||
自从 2006 年第一次推出以来,EFI 已被用于基于英特尔的 Mac 上。从 2012 年底开始,大多数安装 Windows 8 或更高版本系统的计算机就已经默认使用 UEFI 启动,实际上大多数 PC 从 2011 年中期就开始使用 UEFI,虽然默认情况下它们可能无法以 EFI 模式启动。2011 年前销出的 PC 也有一些支持 EFI,尽管它们大都默认使用 BIOS 模式启动。
|
||||
|
||||
如果你不确定你的计算机是否支持 EFI,则应查看固件设置实用程序和参考用户手册关于 _EFI_、_UEFI_ 以及 _legacy booting_ 的部分。(可以通过搜索用户手册的 PDF 文件来快速了解。)如果你没有找到类似的参考,你的计算机可能使用老式的(“legacy”) BIOS 引导;但如果你找到了这些术语的参考,几乎可以肯定它使用了 EFI 技术。你还可以尝试_只_有 EFI 模式的引导加载器的安装介质。使用 [rEFInd][50] 制作的 USB 闪存驱动器或 CD-R 镜像是用来测试不错的选择。
|
||||
|
||||
在继续之前,你应当了解大多数 x86 和 x86-64 架构的计算机上的 EFI 都包含一个叫做<ruby>兼容支持模块<rt>Compatibility Support Module</rt></ruby>(CSM)的组件,这使得 EFI 能够使用旧的 BIOS 风格的引导机制来引导操作系统。这会非常方便,因为它向后兼容;但是这样也导致一些意外情况的发生,因为计算机不论以 EFI 模式引导还是以 BIOS (也称为 CSM 或 legacy)模式引导,在控制时没有标准的使用规范和用户界面。特别地,你的 Linux 安装介质非常容易意外的以 BIOS/CSM/legacy 模式启动,这会导致 Linux 以 BIOS/CSM/legacy 模式安装。如果 Linux 是唯一的操作系统,也可以正常工作,但是如果与在 EFI 模式下的 Windows 组成双启动的话,就会非常复杂。(反过来问题也可能发生。)以下部分将帮助你以正确模式引导安装程序。如果你在阅读这篇文章之前就已经以 BIOS 模式安装了 Linux,并且希望切换引导模式,请阅读后续章节,[哎呀:将传统模式下安装的引导转为 EFI 模式下的引导][51]。
|
||||
|
||||
UEFI 的一个附加功能值得一提:<ruby>安全启动<rt>Secure Boot</rt></ruby>。此特性旨在最大限度的降低计算机受到 _boot kit_ 病毒感染的风险,这是一种感染计算机引导加载程序的恶意软件。Boot kits 很难检测和删除,阻止它们的运行刻不容缓。微软公司要求所有带有支持 Windows 8 标志的台式机和笔记本电脑启用 安全启动。这一配置使 Linux 的安装变得复杂,尽管有些发行版可以较好的处理这个问题。不要将安全启动和 EFI 或 UEFI 混淆;支持 EFI 的计算机不一定支持 安全启动,而且支持 EFI 的 x86-64 的计算机也可以禁用 安全启动。微软同意用户在 Windows 8 认证的 x86 和 x86-64 计算机上禁用安全启动功能;然而对装有 Windows 8 的 ARM 计算机而言却相反,它们必须**不允许**用户禁用 安全启动。幸运的是,基于 ARM 的 Windows 8 计算机目前很少见。我建议避免使用它们。
|
||||
|
||||
### 你的发行版是否支持 EFI 技术?
|
||||
|
||||
大多数 Linux 发行版已经支持 EFI 好多年了。然而,不同的发行版对 EFI 的支持程度不同。大多数主流发行版(Fedora,OpenSUSE,Ubuntu 等)都能很好的支持 EFI,包括对安全启动的支持。另外一些“自行打造”的发行版,比如 Gentoo,对 EFI 的支持较弱,但它们的性质使其很容易添加 EFI 支持。事实上,可以向_任意_ Linux 发行版添加 EFI 支持:你需要安装 Linux(即使在 BIOS 模式下),然后在计算机上安装 EFI 引导加载程序。有关如何执行此操作的信息,请参阅[哎呀:将传统模式下安装的引导转为 EFI 模式下的引导][52]部分。
|
||||
|
||||
你应当查看发行版的功能列表,来确定它是否支持 EFI。你还应当注意你的发行版对安全启动的支持情况,特别是如果你打算和 Windows 8 组成双启动。请注意,即使正式支持安全启动的发行版也可能要求禁用此功能,因为 Linux 对安全启动的支持通常很差劲,或者导致意外情况的发生。
|
||||
|
||||
### 准备安装 Linux
|
||||
|
||||
下面几个准备步骤有助于在 EFI 计算机上 Linux 的安装,使其更加顺利:
|
||||
|
||||
#### 1、 升级固件
|
||||
|
||||
有些 EFI 是有问题的,不过硬件制造商偶尔会发布其固件的更新。因此我建议你将固件升级到最新可用的版本。如果你从论坛的帖子知道自己计算机的 EFI 有问题,你应当在安装 Linux 之前更新它,因为如果安装 Linux 之后更新固件,会有些问题需要额外的操作才能解决。另一方面,升级固件是有一定风险的,所以如果制造商提供了 EFI 支持,最好的办法就是按它们提供的方式进行升级。
|
||||
|
||||
#### 2、 了解如何使用固件
|
||||
|
||||
通常你可以通过在引导过程之初按 Del 键或功能键进入固件设置实用程序。按下开机键后尽快查看相关的提示信息,或者尝试每个功能键。类似的,ESC 键或功能键通常可以进入固件的内置引导管理器,可以选择要进入的操作系统或外部设备。一些制造商把这些设置隐藏的很深。在某些情况下,如[此页面][32]所述,你可以在 Windows 8 内做到这些。
|
||||
|
||||
#### 3、调整以下固件设置
|
||||
|
||||
* **快速启动** — 此功能可以通过在硬件初始化时使用快捷方式来加快引导过程。这很好用,但有时候会使 USB 设备不能初始化,导致计算机无法从 USB 闪存驱动器或类似的设备启动。因此禁用快速启动_可能_有一定的帮助,甚至是必须的;你可以让它保持激活,而只在 Linux 安装程序启动遇到问题时将其停用。请注意,此功能有时可能会以其它名字出现。在某些情况下,你必须_启用_ USB 支持,而不是_禁用_快速启动功能。
|
||||
* **安全启动** — Fedora,OpenSUSE,Ubuntu 以及其它的发行版官方就支持安全启动;但是如果在启动引导加载程序或内核时遇到问题,可能需要禁用此功能。不幸的是,没办法具体描述怎么禁用,因为不同计算机的设置方法也不同。请参阅[我的安全启动页面][1]获取更多关于此话题的信息。
|
||||
|
||||
> **注意:** 一些教程说安装 Linux 时需要启用 BIOS/CSM/legacy 支持。通常情况下,这样做是错的。启用这些支持可以解决启动安装程序涉及的问题,但也会带来新的问题。以这种方式安装的教程通常可以通过“引导修复”来解决这些问题,但最好从一开始就做对。本页面提供了帮助你以 EFI 模式启动 Linux 安装程序的提示,从而避免以后的问题。
|
||||
* **CSM/legacy 选项** — 如果你想以 EFI 模式安装,请_关闭_这些选项。一些教程推荐启用这些选项,有时这是必须的 —— 比如,有些附加视频卡需要在固件中启用 BIOS 模式。尽管如此,大多数情况下启用 CSM/legacy 支持只会无意中增加以 BIOS 模式启动 Linux 的风险,但你并_不想_这样。请注意,安全启动和 CSM/legacy 选项有时会交织在一起,因此更改任一选项之后务必检查另一个。
|
||||
|
||||
#### 4、 禁用 Windows 的快速启动功能
|
||||
|
||||
[这个页面][33]描述了如何禁用此功能,不禁用的话会导致文件系统损坏。请注意此功能与固件的快速启动不同。
|
||||
|
||||
#### 5、 检查分区表
|
||||
|
||||
使用 [GPT fdisk][34]、parted 或其它任意分区工具检查磁盘分区。理想情况下,你应该创建一个包含每个分区确切起点和终点(以扇区为单位)的纸面记录。这会是很有用的参考,特别是在安装时进行手动分区的时候。如果已经安装了 Windows,确定可以识别你的 [EFI 系统分区(ESP)][35],它是一个 FAT 分区,设置了“启动标记”(在 parted 或 Gparted 中)或在 gdisk 中的类型码为 EF00。
|
||||
|
||||
### 安装 Linux
|
||||
|
||||
大部分 Linux 发行版都提供了足够的安装说明;然而我注意到了在 EFI 模式安装中的几个常见的绊脚石:
|
||||
|
||||
* **确保使用正确位深的发行版** — EFI 启动加载器和 EFI 自身的位深相同。现代计算机通常是 64 位,尽管最初几代基于 Intel 的 Mac、一些现代的平板电脑和变形本、以及一些鲜为人知的电脑使用 32 位 EFI。虽然可以将 32 位 EFI 引导加载程序添加至 32 位发行版,但我还没有遇到过正式支持 32 位 EFI 的 Linux 发行版。(我的 《[在 Linux 上管理 EFI 引导加载程序][36]》 一文概述了引导加载程序,而且理解了这些原则你就可以修改 32 位发行版的安装程序,尽管这不是一个初学者该做的。)在 64 位 EFI 的计算机上安装 32 位发行版最让人头疼,我不准备在这里描述这一过程;在具有 64 位 EFI 的计算机上,你应当使用 64 位的发行版。
|
||||
* **正确准备引导介质** — 将 .iso 镜像传输到 USB 闪存驱动器的第三方工具,比如 unetbootin,在创建正确的 EFI 模式引导项时经常失败。我建议按照发行版维护者的建议来创建 USB 闪存驱动器。如果没有类似的建议,使用 Linux 的 dd 工具,通过执行 `dd if=image.iso of=/dev/sdc` 在识别为 `/dev/sdc` 的 USB 闪存驱动器上创建一个镜像。至于 Windows,有 [WinDD][37] 和 [dd for windows][38],但我从没测试过它们。请注意,使用不兼容 EFI 的工具创建安装介质是错误的,这会导致人们进入在 BIOS 模式下安装然后再纠正它们的误区,所以不要忽视这一点!
|
||||
* **备份 ESP 分区** — 如果计算机已经存在 Windows 或者其它的操作系统,我建议在安装 Linux 之前备份你的 ESP 分区。尽管 Linux _不应该_ 损坏 ESP 分区已有的文件,但似乎这时不时发生。发生这种事情时备份会有很大用处。只需简单的文件级的备份(使用 cp,tar,或者 zip 类似的工具)就足够了。
|
||||
* **以 EFI 模式启动** — 以 BIOS/CSM/legacy 模式引导 Linux 安装程序的意外非常容易发生,特别是当固件启用 CSM/legacy 选项时。下面一些提示可以帮助你避免此问题:
|
||||
* 进入 Linux shell 环境执行 `ls /sys/firmware/efi` 验证当前是否处于 EFI 引导模式。如果你看到一系列文件和目录,表明你已经以 EFI 模式启动,而且可以忽略以下多余的提示;如果没有,表明你是以 BIOS 模式启动的,应当重新检查你的设置。
|
||||
* 使用固件内置的引导管理器(你应该已经知道在哪;请参阅[了解如何使用固件][26])使之以 EFI 模式启动。一般你会看到 CD-R 或 USB 闪存驱动器两个选项,其中一个选项包括 _EFI_ 或 _UEFI_ 字样的描述,另一个不包括。使用 EFI/UEFI 选项来启动介质。
|
||||
* 禁用安全启动 - 即使你使用的发行版官方支持安全启动,有时它们也不能生效。在这种情况下,计算机会静默的转到下一个引导加载程序,它可能是启动介质的 BIOS 模式的引导加载程序,导致你以 BIOS 模式启动。请参阅我的[安全启动的相关文章][27]以得到禁用安全启动的相关提示。
|
||||
* 如果 Linux 安装程序总是无法以 EFI 模式启动,试试用我的 [rEFInd 引导管理器][28] 制作的 USB 闪存驱动器或 CD-R。如果 rEFInd 启动成功,那它保证是以 EFI 模式运行的,而且在基于 UEFI 的 PC 上,它只显示 EFI 模式的引导项,因此若您启动到 Linux 安装程序,则应处于 EFI 模式。(但是在 Mac 上,除了 EFI 模式选项之外,rEFInd 还显示 BIOS 模式的引导项。)
|
||||
* **准备 ESP 分区** — 除了 Mac,EFI 使用 ESP 分区来保存引导加载程序。如果你的计算机已经预装了 Windows,那么 ESP 分区就已存在,可以在 Linux 上直接使用。如果不是这样,那么我建议创建一个大小为 550 MB 的 ESP 分区。(如果你已有的 ESP 分区比这小,别担心,直接用就行。)在此分区上创建一个 FAT32 文件系统。如果你使用 Gparted 或者 parted 准备 ESP 分区,记得给它一个“启动标记”。如果你使用 GPT fdisk(gdisk,cgdisk 或 sgdisk)准备 ESP 分区,记得给它一个名为 EF00 的类型码。有些安装程序会创建一个较小的 ESP 分区,并且设置为 FAT16 文件系统。尽管这样能正常工作,但如果你之后需要重装 Windows,安装程序会无法识别 FAT16 文件系统的 ESP 分区,所以你需要将其备份后转为 FAT32 文件系统。
|
||||
* **使用 ESP 分区** — 不同发行版的安装程序以不同的方式辨识 ESP 分区。比如,Debian 和 Ubuntu 的某些版本把 ESP 分区称为“EFI boot partition”,而且不会明确显示它的挂载点(尽管它会在后台挂载);但是有些发行版,像 Arch 或 Gentoo,需要你去手动挂载。尽管将 ESP 分区挂载到 /boot 进行相应配置后可以正常工作,特别是当你想使用 gummiboot 或 ELILO(译者注:gummiboot 和 ELILO 都是 EFI 引导工具)时,但是在 Linux 中最标准的 ESP 分区挂载点是 /boot/efi。某些发行版的 /boot 不能用 FAT 分区。因此,当你设置 ESP 分区挂载点时,请将其设置为 /boot/efi。除非 ESP 分区没有,否则_不要_为其新建文件系统 — 如果已经安装 Windows 或其它操作系统,它们的引导文件都在 ESP 分区里,新建文件系统会销毁这些文件。
|
||||
* **设置引导程序的位置** — 某些发行版会询问将引导程序(GRUB)装到何处。如果 ESP 分区按上述内容正确标记,不必理会此问题,但有些发行版仍会询问。请尝试使用 ESP 分区。
|
||||
* **其它分区** — 除了 ESP 分区,不再需要其它的特殊分区;你可以设置 根(/)分区,swap 分区,/home 分区,或者其它分区,就像你在 BIOS 模式下安装时一样。请注意 EFI 模式下_不需要设置_[BIOS 启动分区][39],所以如果安装程序提示你需要它,意味着你可能意外的进入了 BIOS 模式。另一方面,如果你创建了 BIOS 启动分区,会更灵活,因为你可以安装 BIOS 模式下的 GRUB,然后以任意模式(EFI 模式 或 BIOS 模式)引导。
|
||||
* **解决无显示问题** — 2013 年,许多人在 EFI 模式下经常遇到(之后出现的频率逐渐降低)无显示的问题。有时可以在命令行下通过给内核添加 `nomodeset` 参数解决这一问题。在 GRUB 界面按 `e` 键会打开一个简易文本编辑器。大多数情况下你需要搜索有关此问题的更多信息,因为此问题更多是由特定硬件引起的。
|
||||
|
||||
在某些情况下,你可能不得不以 BIOS 模式安装 Linux。但你可以手动安装 EFI 引导程序让 Linux 以 EFI 模式启动。请参阅《 [在 Linux 上管理 EFI 引导加载程序][53]》 页面获取更多有关它们以及如何安装的可用信息。
|
||||
|
||||
### 解决安装后的问题
|
||||
|
||||
如果 Linux 无法在 EFI 模式下工作,但在 BIOS 模式下成功了,那么你可以完全放弃 EFI 模式。在只有 Linux 的计算机上这非常简单;安装 BIOS 引导程序即可(如果你是在 BIOS 模式下安装的,引导程序也应随之装好)。如果是和 EFI 下的 Windows 组成双系统,最简单的方法是安装我的 [rEFInd 引导管理器][54]。在 Windows 上安装它,然后编辑 `refind.conf` 文件:取消注释 `scanfor` 一行,并确保拥有 `hdbios` 选项。这样 rEFInd 在引导时会重定向到 BIOS 模式的引导项。
|
||||
|
||||
如果重启后计算机直接进入了 Windows,很可能是 Linux 的引导程序或管理器安装不正确。(但是应当首先尝试禁用安全启动;之前提到过,它经常引发各种问题。)下面是关于此问题的几种可能的解决方案:
|
||||
|
||||
* **使用 efibootmgr** — 你可以以 _EFI 模式_引导一个 Linux 急救盘,使用 efibootmgr 实用工具尝试重新注册你的 Linux 引导程序,如[这里][40]所述。
|
||||
* **使用 Windows 上的 bcdedit** — 在 Windows 管理员命令提示符窗口中,输入 `bcdedit /set {bootmgr}path \EFI\fedora\grubx64.efi` 会用 ESP 分区的 `EFI/fedora/grubx64.efi` 文件作为默认的引导加载程序。根据需要更改此路径,指向你想设置的引导文件。如果你启用了安全启动,需要设置 `shim.efi`,`shimx64.efi` 或者 `PreLoader.efi`(不管有哪个)为引导而不是 `grubx64.efi`。
|
||||
* **安装 rEFInd** — 有时候 rEFInd 可以解决这个问题。我推荐使用 [CD-R 或者 USB 闪存驱动器][41]进行测试。如果 Linux 可以启动,就安装 Debian 软件包、RPM 程序,或者 .zip 文件包。(请注意,你需要在一个高亮的 Linux vmlinuz* 选项按两次 `F2` 或 `Insert` 修改启动选项。如果你的启动分区是单独的,这就更有必要了,因为这种情况下,rEFInd 无法找到根(/)分区,也就无法传递参数给内核。)
|
||||
* **使用修复引导程序** — Ubuntu 的[引导修复实用工具][42]可以自动修复一些问题;然而,我建议只在 Ubuntu 和 密切相关的发行版上使用,比如 Mint。有时候,有必要通过高级选项备份并替换 Windows 的引导。
|
||||
* **劫持 Windows 引导程序** — 有些不完整的 EFI 引导只能引导 Windows,就是 ESP 分区上的 `EFI/Microsoft/Boot/bootmgfw.efi` 文件。因此,你可能需要将引导程序改名(我建议将其移动到上级目录 `EFI/Microsoft/bootmgfw.efi`),然后将首选引导程序复制到这里。(大多数发行版会在 EFI 的子目录放置 GRUB 的副本,例如 Ubuntu 的 EFI/ubuntu,Fedora 的 EFI/fedora。)请注意此方法是个丑陋的解决方法,有用户反映 Windows 会替换引导程序,所以这个办法不是 100% 有效。然而,这是在不完整的 EFI 上生效的唯一办法。在尝试之前,我建议你升级固件并重新注册自己的引导程序,Linux 上用 efibootmgr,Windows 上用 bcdedit。
|
||||
|
||||
有关引导程序的其它类型的问题 - 如果 GRUB(或者你的发行版默认的其它引导程序或引导管理器)没有引导操作系统,你必须修复这个问题。因为 GRUB 2 引导 Windows 时非常挑剔,所以 Windows 经常启动失败。在某些情况下,安全启动会加剧这个问题。请参阅[我的关于 GRUB 2 的页面][55]获取一个引导 Windows 的 GRUB 2 示例。还会有很多原因导致 Linux 引导出现问题,类似于 BIOS 模式下的情况,所以我没有全部写出来。
|
||||
|
||||
尽管 GRUB 2 使用很普遍,但我对它的评价却不高 - 它很复杂,而且难以配置和使用。因此,如果你在使用 GRUB 的时候遇到了问题,我的第一反应就是用别的东西代替。[我的用于 Linux 的 EFI 引导程序页面][56]有其它的选择。其中包括我的 [rEFInd 引导管理器][57],它除了能够让许多发行版上的 GRUB 2 工作,也更容易安装和维护 - 但是它还不能完全代替 GRUB 2。
|
||||
|
||||
除此之外,EFI 引导的问题可能很奇怪,所以你需要去论坛发帖求助。尽量将问题描述完整。[Boot Info Script][58] 可帮助你提供有用的信息 - 运行此脚本,将生成的名为 RESULTS.txt 的文件粘贴到论坛的帖子上。一定要将文本粘贴到 `[code]` 和 `[/code]` 之间;不然会遭人埋怨。或者将 RESULTS.txt 文件上传到 pastebin 网站上,比如 [pastebin.com][59],然后将网站给你的 URL 地址发布到论坛。
|
||||
|
||||
### 哎呀:将传统模式下安装的系统转为 EFI 模式下引导
|
||||
|
||||
**警告:**这些指南主要用于基于 UEFI 的 PC。如果你的 Mac 已经安装了 BIOS 模式下的 Linux,但想以 EFI 模式启动 Linux,可以_在 OS X_ 中安装引导程序。rEFInd(或者旧式的 rEFIt)是 Mac 上的常用选择,但 GRUB 可以做的更多。
|
||||
|
||||
论坛上有很多人看了错误的教程,在已经存在 EFI 模式的 Windows 的情况下,安装了 BIOS 引导的 Linux,这一问题在 2015 年初很普遍。这样配置效果很不好,因为大多数 EFI 很难在两种模式之间切换,而且 GRUB 也无法胜任这项工作。你可能会遇到不完善的 EFI 无法启动外部介质的情况,也可能遇到 EFI 模式下的显示问题,或者其它问题。
|
||||
|
||||
如前所述,在[解决安装后的问题][60]部分,解决办法之一就是_在 Windows_ 上安装 rEFInd,将其配置为支持 BIOS 模式引导。然后可以引导 rEFInd 并链式引导到你的 BIOS 模式的 GRUB。在 Linux 上遇到 EFI 特定的问题时,例如无法使用显卡,我建议你使用这个办法修复。如果你没有这样的 EFI 特定的问题,在 Windows 中安装 rEFInd 和合适的 EFI 文件系统驱动可以让 Linux 直接以 EFI 模式启动。这个解决方案很完美,它和我下面描述的内容等同。
|
||||
|
||||
大多数情况下,最好将 Linux 配置为以 EFI 模式启动。有很多办法可以做到,但最好的是使用 Linux 的 EFI 引导模式(或者,可以想到,Windows,或者一个 EFI shell)注册到你首选的引导管理器。实现这一目标的方法如下:
|
||||
|
||||
1. 下载适用于 USB 闪存驱动器或 CD-R 的 [rEFInd 引导管理器][43]。
|
||||
2. 从下载的镜像文件生成安装介质。可以在任何计算机上准备,不管是 EFI 还是 BIOS 的计算机都可以(或者在其它平台上使用其它方法)。
|
||||
3. 如果你还没有这样做,[请禁用安全启动][44]。因为 rEFInd CD-R 和 USB 镜像不支持安全启动,所以这很必要,你可以在以后重新启用它。
|
||||
4. 在目标计算机上启动 rEFInd。如前所述,你可能需要调整固件设置,并使用内置引导管理器选择要引导的介质。你选择的那一项也许在其描述中包含 _UEFI_ 这样的字符串。
|
||||
5. 在 rEFInd 上测试引导项。你应该至少看到一个启动 Linux 内核的选项(名字含有 vmlinuz 这样的字符串)。有两种方法可以启动它:
|
||||
* 如果你_没有_独立的 `/boot` 分区,只需简单的选择内核并按回车键。Linux 就会启动。
|
||||
* 如果你_确定有_一个独立的 `/boot` 分区,按两次 `Insert` 或 `F2` 键。这样会打开一个行编辑器,你可以用它来编辑内核选项。增加一个 `root=` 格式以标识根(/)文件系统,如果根(/)分区在 `/dev/sda5` 上,就添加 `root=/dev/sda5`。如果不知道根文件系统在哪里,那你需要重启并尽可能想到办法。
|
||||
|
||||
在一些罕见的情况下,你可能需要添加其它内核选项来代替或补充 `root=` 选项。比如配置了 LVM(LCTT 译注:Logical Volume Manager,逻辑卷管理)的 Gentoo 就需要 `dolvm` 选项。
|
||||
6. Linux 一旦启动,安装你想要的引导程序。rEFInd 的安装很简单,可以通过 RPM、Debian 软件包、PPA,或从[rEFInd 下载页面][45]下载的二进制 .zip 文件进行安装。在 Ubuntu 和相关的发行版上,引导修改程序可以相对简单地修复你的 GRUB 设置,但你要对它有信心可以正常工作。(它通常工作良好,但有时候会把事情搞得一团糟。)另外一些选项都在我的 《[在 Linux 上管理 EFI 引导加载程序][46]》 页面上。
|
||||
7. 如果你想在安全启动激活的情况下引导,只需重启并启用它。但是,请注意,可能需要额外的安装步骤才能将引导程序设置为使用安全启动。有关详细信息,请参阅[我关于这个主题的页面][47]或你的引导程序有关安全启动的文档资料。
|
||||
|
||||
重启时,你可以看到刚才安装的引导程序。如果计算机进入了 BIOS 模式下的 GRUB,你应当进入固件禁用 BIOS/CSM/legacy 支持,或调整引导顺序。如果计算机直接进入了 Windows,那么你应当阅读前一部分,[解决安装后的问题][61]。
|
||||
|
||||
你可能想或需要调整你的配置。通常是为了看到额外的引导选项,或者隐藏某些选项。请参阅引导程序的文档资料,以了解如何进行这些更改。
|
||||
|
||||
### 参考和附加信息
|
||||
|
||||
* **信息网页**
|
||||
* 我的 《[在 Linux 上管理 EFI 引导加载程序][2]》 页面含有可用的 EFI 引导程序和引导管理器。
|
||||
* [OS X's bless tool 的手册页][3] 页面在设置 OS X 平台上的引导程序或引导管理器时可能会很有用。
|
||||
* [EFI 启动过程][4] 描述了 EFI 启动时的大致框架。
|
||||
* [Arch Linux UEFI wiki page][5] 有大量关于 UEFI 和 Linux 的详细信息。
|
||||
* 亚当·威廉姆森写的一篇不错的 《[什么是 EFI,它是怎么工作的][6]》。
|
||||
* [这个页面][7] 描述了如何从 Windows 8 调整 EFI 的固件设置。
|
||||
* 马修·J·加勒特是 Shim 引导程序的开发者,此程序支持安全启动,他维护的[博客][8]经常更新有关 EFI 的问题。
|
||||
* 如果你对 EFI 软件的开发感兴趣,我的 《[EFI 编程][9]》 页面可以为你起步助力。
|
||||
* **附加程序**
|
||||
* [rEFInd 官网][10]
|
||||
* [gummiboot 官网][11]
|
||||
* [ELILO 官网][12]
|
||||
* [GRUB 官网][13]
|
||||
* [GPT fdisk 分区软件官网][14]
|
||||
* Ubuntu 的 [引导修复实用工具][15]可帮助解决一些引启动问题
|
||||
* **交流**
|
||||
* [Sourceforge 上的 rEFInd 交流论坛][16]是 rEFInd 用户互相交流或与我联系的一种方法。
|
||||
* Pastebin 网站,比如 [http://pastebin.com][17], 是在 Web 论坛上与其他用户交换大量文本的一种便捷的方法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.rodsbooks.com/linux-uefi/
|
||||
|
||||
作者:[Roderick W. Smith][a]
|
||||
译者:[fuowang](https://github.com/fuowang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:rodsmith@rodsbooks.com
|
||||
[1]:http://www.rodsbooks.com/efi-bootloaders/secureboot.html#disable
|
||||
[2]:http://www.rodsbooks.com/efi-bootloaders/
|
||||
[3]:http://ss64.com/osx/bless.html
|
||||
[4]:http://homepage.ntlworld.com/jonathan.deboynepollard/FGA/efi-boot-process.html
|
||||
[5]:https://wiki.archlinux.org/index.php/Unified_Extensible_Firmware_Interface
|
||||
[6]:https://www.happyassassin.net/2014/01/25/uefi-boot-how-does-that-actually-work-then/
|
||||
[7]:http://www.eightforums.com/tutorials/20256-uefi-firmware-settings-boot-inside-windows-8-a.html
|
||||
[8]:http://mjg59.dreamwidth.org/
|
||||
[9]:http://www.rodsbooks.com/efi-programming/
|
||||
[10]:http://www.rodsbooks.com/refind/
|
||||
[11]:http://freedesktop.org/wiki/Software/gummiboot
|
||||
[12]:http://elilo.sourceforge.net/
|
||||
[13]:http://www.gnu.org/software/grub/
|
||||
[14]:http://www.rodsbooks.com/gdisk/
|
||||
[15]:https://help.ubuntu.com/community/Boot-Repair
|
||||
[16]:https://sourceforge.net/p/refind/discussion/
|
||||
[17]:http://pastebin.com/
|
||||
[18]:http://www.rodsbooks.com/linux-uefi/#intro
|
||||
[19]:http://www.rodsbooks.com/linux-uefi/#isitefi
|
||||
[20]:http://www.rodsbooks.com/linux-uefi/#distributions
|
||||
[21]:http://www.rodsbooks.com/linux-uefi/#preparing
|
||||
[22]:http://www.rodsbooks.com/linux-uefi/#installing
|
||||
[23]:http://www.rodsbooks.com/linux-uefi/#troubleshooting
|
||||
[24]:http://www.rodsbooks.com/linux-uefi/#oops
|
||||
[25]:http://www.rodsbooks.com/linux-uefi/#references
|
||||
[26]:http://www.rodsbooks.com/linux-uefi/#using_firmware
|
||||
[27]:http://www.rodsbooks.com/efi-bootloaders/secureboot.html#disable
|
||||
[28]:http://www.rodsbooks.com/refind/getting.html
|
||||
[29]:https://en.wikipedia.org/wiki/Uefi
|
||||
[30]:https://en.wikipedia.org/wiki/BIOS
|
||||
[31]:http://www.rodsbooks.com/linux-uefi/#references
|
||||
[32]:http://www.eightforums.com/tutorials/20256-uefi-firmware-settings-boot-inside-windows-8-a.html
|
||||
[33]:http://www.eightforums.com/tutorials/6320-fast-startup-turn-off-windows-8-a.html
|
||||
[34]:http://www.rodsbooks.com/gdisk/
|
||||
[35]:http://en.wikipedia.org/wiki/EFI_System_partition
|
||||
[36]:http://www.rodsbooks.com/efi-bootloaders
|
||||
[37]:https://sourceforge.net/projects/windd/
|
||||
[38]:http://www.chrysocome.net/dd
|
||||
[39]:https://en.wikipedia.org/wiki/BIOS_Boot_partition
|
||||
[40]:http://www.rodsbooks.com/efi-bootloaders/installation.html
|
||||
[41]:http://www.rodsbooks.com/refind/getting.html
|
||||
[42]:https://help.ubuntu.com/community/Boot-Repair
|
||||
[43]:http://www.rodsbooks.com/refind/getting.html
|
||||
[44]:http://www.rodsbooks.com/efi-bootloaders/secureboot.html#disable
|
||||
[45]:http://www.rodsbooks.com/refind/getting.html
|
||||
[46]:http://www.rodsbooks.com/efi-bootloaders/
|
||||
[47]:http://www.rodsbooks.com/efi-bootloaders/secureboot.html
|
||||
[48]:mailto:rodsmith@rodsbooks.com
|
||||
[49]:http://ss64.com/osx/bless.html
|
||||
[50]:http://www.rodsbooks.com/refind/getting.html
|
||||
[51]:http://www.rodsbooks.com/linux-uefi/#oops
|
||||
[52]:http://www.rodsbooks.com/linux-uefi/#oops
|
||||
[53]:http://www.rodsbooks.com/efi-bootloaders/
|
||||
[54]:http://www.rodsbooks.com/refind/
|
||||
[55]:http://www.rodsbooks.com/efi-bootloaders/grub2.html
|
||||
[56]:http://www.rodsbooks.com/efi-bootloaders
|
||||
[57]:http://www.rodsbooks.com/refind/
|
||||
[58]:http://sourceforge.net/projects/bootinfoscript/
|
||||
[59]:http://pastebin.com/
|
||||
[60]:http://www.rodsbooks.com/linux-uefi/#troubleshooting
|
||||
[61]:http://www.rodsbooks.com/linux-uefi/#troubleshooting
|
||||
@ -1,46 +1,44 @@
|
||||
|
||||
微流冷却技术可能让摩尔定律起死回生
|
||||
============================================================
|
||||
|
||||

|
||||
>Image: iStock/agsandrew
|
||||
|
||||
*Image: iStock/agsandrew*
|
||||
|
||||
现有的技术无法对微芯片进行有效的冷却,这正快速成为摩尔定律消亡的第一原因。
|
||||
|
||||
随着对数字计算速度的需求,科学家和工程师正努力地将更多的晶体管和支撑电路放在已经很拥挤的硅片上。的确,它非常地复杂,然而,和复杂性相比,热量聚积引起的问题更严重。
|
||||
|
||||
洛克希德马丁公司首席研究员John Ditri在新闻稿中说到:当前,我们可以放入微芯片的功能是有限的,最主要的原因之一是发热的管理。如果你能管理好发热,你可以用较少的芯片,较少的材料,那样就可以节约成本,并能减少系统的大小和重量。如果你能管理好发热,用相同数量的芯片将能获得更好的系统性能。
|
||||
洛克希德马丁公司首席研究员 John Ditri 在新闻稿中说到:当前,我们可以放入微芯片的功能是有限的,最主要的原因之一是发热的管理。如果你能管理好发热,你可以用较少的芯片,也就是说较少的材料,那样就可以节约成本,并能减少系统的大小和重量。如果你能管理好发热,用相同数量的芯片将能获得更好的系统性能。
|
||||
|
||||
硅对电子流动的阻力产生了热量,在如此小的空间封装如此多的晶体管累积了足以毁坏元器件的热量。一种消除热累积的方法是在芯片层用光子学技术减少电子的流动,然而光子学技术有它的一系列问题。
|
||||
|
||||
SEE:2015年硅光子将引起数据中心的革命 [Silicon photonics will revolutionize data centers in 2015][5]
|
||||
参见: [2015 年硅光子将引起数据中心的革命][5]
|
||||
|
||||
### 微流冷却技术可能是问题的解决之道
|
||||
|
||||
为了寻找其他解决办法,国防高级研究计划局DARPA发起了一个关于ICECool应用[ICECool Applications][6] (片内/片间增强冷却技术)的项目。GSA网站 [GSA website FedBizOpps.gov][7] 报道:ICECool正在探索革命性的热技术,其将减轻热耗对军用电子系统的限制,同时能显著减小军用电子系统的尺寸,重量和功耗。
|
||||
为了寻找其他解决办法,美国国防高级研究计划局 DARPA 发起了一个关于 [ICECool 应用][6] (片内/片间增强冷却技术)的项目。 [GSA 的网站 FedBizOpps.gov][7] 报道:ICECool 正在探索革命性的热技术,其将减轻热耗对军用电子系统的限制,同时能显著减小军用电子系统的尺寸,重量和功耗。
|
||||
|
||||
微流冷却方法的独特之处在于组合使用片内和(或)片间微流冷却技术和片上热互连技术。
|
||||
|
||||

|
||||
>MicroCooling 1 Image: DARPA
|
||||
|
||||
DARPA ICECool应用项目 [DARPA ICECool Application announcement][8] 指出, 这种微型片内和(或)片间通道可采用轴向微通道,径向通道和(或)横流通道,采用微孔和歧管结构及局部液体喷射形式来疏散和重新引导微流,从而以最有利的方式来满足指定的散热指标。
|
||||
*MicroCooling 1 Image: DARPA*
|
||||
|
||||
通过上面的技术,洛克希德马丁的工程师已经实验性地证明了片上冷却是如何得到显著改善的。洛克希德马丁新闻报道:ICECool项目的第一阶段发现,当冷却具有多个局部30kW/cm2热点,发热为1kw/cm2的芯片时热阻减少了4倍,进而验证了洛克希德的嵌入式微流冷却方法的有效性。
|
||||
[DARPA ICECool 应用发布的公告][8] 指出,这种微型片内和(或)片间通道可采用轴向微通道、径向通道和(或)横流通道,采用微孔和歧管结构及局部液体喷射形式来疏散和重新引导微流,从而以最有利的方式来满足指定的散热指标。
|
||||
|
||||
第二阶段,洛克希德马丁的工程师聚焦于RF放大器。通过ICECool的技术,团队演示了RF的输出功率可以得到6倍的增长,而放大器仍然比其常规冷却的更凉。
|
||||
通过上面的技术,洛克希德马丁的工程师已经实验性地证明了片上冷却是如何得到显著改善的。洛克希德马丁新闻报道:ICECool 项目的第一阶段发现,当冷却具有多个局部 30kW/cm2 热点,发热为 1kw/cm2 的芯片时热阻减少了 4 倍,进而验证了洛克希德的嵌入式微流冷却方法的有效性。
|
||||
|
||||
第二阶段,洛克希德马丁的工程师聚焦于 RF 放大器。通过 ICECool 的技术,团队演示了 RF 的输出功率可以得到 6 倍的增长,而放大器仍然比其常规冷却的更凉。
|
||||
|
||||
### 投产
|
||||
|
||||
出于对技术的信心,洛克希德马丁已经在设计和制造实用的微流冷却发射天线。 Lockheed Martin还与Qorvo合作,将其热解决方案与Qorvo的高性能GaN工艺 [GaN process][9] 集成.
|
||||
出于对技术的信心,洛克希德马丁已经在设计和制造实用的微流冷却发射天线。 洛克希德马丁还与 Qorvo 合作,将其热解决方案与 Qorvo 的高性能 [ GaN 工艺][9] 相集成。
|
||||
|
||||
研究论文 [DARPA's Intra/Interchip Enhanced Cooling (ICECool) Program][10] 的作者认为ICECool将使电子系统的热管理模式发生改变。ICECool应用的执行者将根据应用来定制片内和片间的热管理方法,这个方法需要兼顾应用的材料,制造工艺和工作环境。
|
||||
研究论文 [DARPA 的片间/片内增强冷却技术(ICECool)流程][10] 的作者认为 ICECool 将使电子系统的热管理模式发生改变。ICECool 应用的执行者将根据应用来定制片内和片间的热管理方法,这个方法需要兼顾应用的材料,制造工艺和工作环境。
|
||||
|
||||
如果微流冷却能像科学家和工程师所说的成功的话,似乎摩尔定律会起死回生。
|
||||
|
||||
更多的关于网络的信息,请订阅Data Centers newsletter。
|
||||
|
||||
[SUBSCRIBE](https://secure.techrepublic.com/user/login/?regSource=newsletter-button&position=newsletter-button&appId=true&redirectUrl=http%3A%2F%2Fwww.techrepublic.com%2Farticle%2Fmicrofluidic-cooling-may-prevent-the-demise-of-moores-law%2F&)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -48,7 +46,7 @@ via: http://www.techrepublic.com/article/microfluidic-cooling-may-prevent-the-de
|
||||
|
||||
作者:[Michael Kassner][a]
|
||||
译者:[messon007](https://github.com/messon007)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,384 @@
|
||||
大数据初步:在树莓派上通过 Apache Spark on YARN 搭建 Hadoop 集群
|
||||
===
|
||||
|
||||
有些时候我们想从 DQYDJ 网站的数据中分析点有用的东西出来,在过去,我们要[用 R 语言提取固定宽度的数据](https://dqydj.com/how-to-import-fixed-width-data-into-a-spreadsheet-via-r-playing-with-ipums-cps-data/),然后通过数学建模来分析[美国的最低收入补贴](http://dqydj.com/negative-income-tax-cost-calculator-united-states/),当然也包括其他优秀的方法。
|
||||
|
||||
今天我将向你展示对大数据的一点探索,不过有点变化,使用的是全世界最流行的微型电脑————[树莓派](https://www.raspberrypi.org/),如果手头没有,那就看下一篇吧(可能是已经处理好的数据),对于其他用户,请继续阅读吧,今天我们要建立一个树莓派 Hadoop集群!
|
||||
|
||||
### I. 为什么要建立一个树莓派的 Hadoop 集群?
|
||||
|
||||

|
||||
|
||||
*由三个树莓派节点组成的 Hadoop 集群*
|
||||
|
||||
我们对 DQYDJ 的数据做了[大量的处理工作](https://dqydj.com/finance-calculators-investment-calculators-and-visualizations/),但这些还不能称得上是大数据。
|
||||
|
||||
和许许多多有争议的话题一样,数据的大小之别被解释成这样一个笑话:
|
||||
|
||||
> 如果能被内存所存储,那么它就不是大数据。 ————佚名
|
||||
|
||||
似乎这儿有两种解决问题的方法:
|
||||
|
||||
1. 我们可以找到一个足够大的数据集合,任何家用电脑的物理或虚拟内存都存不下。
|
||||
2. 我们可以买一些不用特别定制,我们现有数据就能淹没它的电脑:
|
||||
|
||||
—— 上手树莓派 2B
|
||||
|
||||
这个由设计师和工程师制作出来的精致小玩意儿拥有 1GB 的内存, MicroSD 卡充当它的硬盘,此外,每一台的价格都低于 50 美元,这意味着你可以花不到 250 美元的价格搭建一个 Hadoop 集群。
|
||||
|
||||
或许天下没有比这更便宜的入场券来带你进入大数据的大门。
|
||||
|
||||
### II. 制作一个树莓派集群
|
||||
|
||||
我最喜欢制作的原材料。
|
||||
|
||||
这里我将给出我原来为了制作树莓派集群购买原材料的链接,如果以后要在亚马逊购买的话你可先这些链接收藏起来,也是对本站的一点支持。(谢谢)
|
||||
|
||||
- [树莓派 2B 3 块](http://amzn.to/2bEFTVh)
|
||||
- [4 层亚克力支架](http://amzn.to/2bTo1br)
|
||||
- [6 口 USB 转接器](http://amzn.to/2bEGO8g),我选了白色 RAVPower 50W 10A 6 口 USB 转接器
|
||||
- [MicroSD 卡](http://amzn.to/2cguV9I),这个五件套 32GB 卡非常棒
|
||||
- [短的 MicroUSB 数据线](http://amzn.to/2bX2mwm),用于给树莓派供电
|
||||
- [短网线](http://amzn.to/2bDACQJ)
|
||||
- 双面胶,我有一些 3M 的,很好用
|
||||
|
||||
#### 开始制作
|
||||
|
||||
1. 首先,装好三个树莓派,每一个用螺丝钉固定在亚克力面板上。(看下图)
|
||||
2. 接下来,安装以太网交换机,用双面胶贴在其中一个在亚克力面板上。
|
||||
3. 用双面胶贴将 USB 转接器贴在一个在亚克力面板使之成为最顶层。
|
||||
4. 接着就是一层一层都拼好——这里我选择将树莓派放在交换机和USB转接器的底下(可以看看完整安装好的两张截图)
|
||||
|
||||
想办法把线路放在需要的地方——如果你和我一样购买力 USB 线和网线,我可以将它们卷起来放在亚克力板子的每一层
|
||||
|
||||
现在不要急着上电,需要将系统烧录到 SD 卡上才能继续。
|
||||
|
||||
#### 烧录 Raspbian
|
||||
|
||||
按照[这个教程](https://www.raspberrypi.org/downloads/raspbian/)将 Raspbian 烧录到三张 SD 卡上,我使用的是 Win7 下的 [Win32DiskImager][2]。
|
||||
|
||||
将其中一张烧录好的 SD 卡插在你想作为主节点的树莓派上,连接 USB 线并启动它。
|
||||
|
||||
#### 启动主节点
|
||||
|
||||
这里有[一篇非常棒的“Because We Can Geek”的教程](http://www.becausewecangeek.com/building-a-raspberry-pi-hadoop-cluster-part-1/),讲如何安装 Hadoop 2.7.1,此处就不再熬述。
|
||||
|
||||
在启动过程中有一些要注意的地方,我将带着你一起设置直到最后一步,记住我现在使用的 IP 段为 192.168.1.50 – 192.168.1.52,主节点是 .50,从节点是 .51 和 .52,你的网络可能会有所不同,如果你想设置静态 IP 的话可以在评论区看看或讨论。
|
||||
|
||||
一旦你完成了这些步骤,接下来要做的就是启用交换文件,Spark on YARN 将分割出一块非常接近内存大小的交换文件,当你内存快用完时便会使用这个交换分区。
|
||||
|
||||
(如果你以前没有做过有关交换分区的操作的话,可以看看[这篇教程](https://www.digitalocean.com/community/tutorials/how-to-add-swap-on-ubuntu-14-04),让 `swappiness` 保持较低水准,因为 MicroSD 卡的性能扛不住)
|
||||
|
||||
现在我准备介绍有关我的和“Because We Can Geek”关于启动设置一些微妙的区别。
|
||||
|
||||
对于初学者,确保你给你的树莓派起了一个正式的名字——在 `/etc/hostname` 设置,我的主节点设置为 ‘RaspberryPiHadoopMaster’ ,从节点设置为 ‘RaspberryPiHadoopSlave#’
|
||||
|
||||
主节点的 `/etc/hosts` 配置如下:
|
||||
|
||||
```
|
||||
#/etc/hosts
|
||||
127.0.0.1 localhost
|
||||
::1 localhost ip6-localhost ip6-loopback
|
||||
ff02::1 ip6-allnodes
|
||||
ff02::2 ip6-allrouters
|
||||
|
||||
192.168.1.50 RaspberryPiHadoopMaster
|
||||
192.168.1.51 RaspberryPiHadoopSlave1
|
||||
192.168.1.52 RaspberryPiHadoopSlave2
|
||||
```
|
||||
|
||||
如果你想让 Hadoop、YARN 和 Spark 运行正常的话,你也需要修改这些配置文件(不妨现在就编辑)。
|
||||
|
||||
这是 `hdfs-site.xml`:
|
||||
|
||||
```
|
||||
<?xml version="1.0" encoding="UTF-8"?>
|
||||
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
|
||||
<configuration>
|
||||
<property>
|
||||
<name>fs.default.name</name>
|
||||
<value>hdfs://RaspberryPiHadoopMaster:54310</value>
|
||||
</property>
|
||||
<property>
|
||||
<name>hadoop.tmp.dir</name>
|
||||
<value>/hdfs/tmp</value>
|
||||
</property>
|
||||
</configuration>
|
||||
```
|
||||
|
||||
这是 `yarn-site.xml` (注意内存方面的改变):
|
||||
|
||||
```
|
||||
<?xml version="1.0"?>
|
||||
<configuration>
|
||||
|
||||
<!-- Site specific YARN configuration properties -->
|
||||
<property>
|
||||
<name>yarn.nodemanager.aux-services</name>
|
||||
<value>mapreduce_shuffle</value>
|
||||
</property>
|
||||
<property>
|
||||
<name>yarn.nodemanager.resource.cpu-vcores</name>
|
||||
<value>4</value>
|
||||
</property>
|
||||
<property>
|
||||
<name>yarn.nodemanager.resource.memory-mb</name>
|
||||
<value>1024</value>
|
||||
</property>
|
||||
<property>
|
||||
<name>yarn.scheduler.minimum-allocation-mb</name>
|
||||
<value>128</value>
|
||||
</property>
|
||||
<property>
|
||||
<name>yarn.scheduler.maximum-allocation-mb</name>
|
||||
<value>1024</value>
|
||||
</property>
|
||||
<property>
|
||||
<name>yarn.scheduler.minimum-allocation-vcores</name>
|
||||
<value>1</value>
|
||||
</property>
|
||||
<property>
|
||||
<name>yarn.scheduler.maximum-allocation-vcores</name>
|
||||
<value>4</value>
|
||||
</property>
|
||||
<property>
|
||||
<name>yarn.nodemanager.vmem-check-enabled</name>
|
||||
<value>false</value>
|
||||
<description>Whether virtual memory limits will be enforced for containers</description>
|
||||
</property>
|
||||
<property>
|
||||
<name>yarn.nodemanager.vmem-pmem-ratio</name>
|
||||
<value>4</value>
|
||||
<description>Ratio between virtual memory to physical memory when setting memory limits for containers</description>
|
||||
</property>
|
||||
<property>
|
||||
<name>yarn.resourcemanager.resource-tracker.address</name>
|
||||
<value>RaspberryPiHadoopMaster:8025</value>
|
||||
</property>
|
||||
<property>
|
||||
<name>yarn.resourcemanager.scheduler.address</name>
|
||||
<value>RaspberryPiHadoopMaster:8030</value>
|
||||
</property>
|
||||
<property>
|
||||
<name>yarn.resourcemanager.address</name>
|
||||
<value>RaspberryPiHadoopMaster:8040</value>
|
||||
</property>
|
||||
</configuration>
|
||||
```
|
||||
|
||||
`slaves`:
|
||||
|
||||
```
|
||||
RaspberryPiHadoopMaster
|
||||
RaspberryPiHadoopSlave1
|
||||
RaspberryPiHadoopSlave2
|
||||
```
|
||||
|
||||
`core-site.xml`:
|
||||
|
||||
```
|
||||
<?xml version="1.0" encoding="UTF-8"?>
|
||||
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
|
||||
<configuration>
|
||||
<property>
|
||||
<name>fs.default.name</name>
|
||||
<value>hdfs://RaspberryPiHadoopMaster:54310</value>
|
||||
</property>
|
||||
<property>
|
||||
<name>hadoop.tmp.dir</name>
|
||||
<value>/hdfs/tmp</value>
|
||||
</property>
|
||||
</configuration>
|
||||
```
|
||||
|
||||
#### 设置两个从节点:
|
||||
|
||||
接下来[按照 “Because We Can Geek”上的教程](http://www.becausewecangeek.com/building-a-raspberry-pi-hadoop-cluster-part-2/),你需要对上面的文件作出小小的改动。 在 `yarn-site.xml` 中主节点没有改变,所以从节点中不必含有这个 `slaves` 文件。
|
||||
|
||||
### III. 在我们的树莓派集群中测试 YARN
|
||||
|
||||
如果所有设备都正常工作,在主节点上你应该执行如下命令:
|
||||
|
||||
```
|
||||
start-dfs.sh
|
||||
start-yarn.sh
|
||||
```
|
||||
|
||||
当设备启动后,以 Hadoop 用户执行,如果你遵循教程,用户应该是 `hduser`。
|
||||
|
||||
接下来执行 `hdfs dfsadmin -report` 查看三个节点是否都正确启动,确认你看到一行粗体文字 ‘Live datanodes (3)’:
|
||||
|
||||
```
|
||||
Configured Capacity: 93855559680 (87.41 GB)
|
||||
Raspberry Pi Hadoop Cluster picture Straight On
|
||||
Present Capacity: 65321992192 (60.84 GB)
|
||||
DFS Remaining: 62206627840 (57.93 GB)
|
||||
DFS Used: 3115364352 (2.90 GB)
|
||||
DFS Used%: 4.77%
|
||||
Under replicated blocks: 0
|
||||
Blocks with corrupt replicas: 0
|
||||
Missing blocks: 0
|
||||
Missing blocks (with replication factor 1): 0
|
||||
————————————————-
|
||||
Live datanodes (3):
|
||||
Name: 192.168.1.51:50010 (RaspberryPiHadoopSlave1)
|
||||
Hostname: RaspberryPiHadoopSlave1
|
||||
Decommission Status : Normal
|
||||
```
|
||||
|
||||
你现在可以做一些简单的诸如 ‘Hello, World!’ 的测试,或者直接进行下一步。
|
||||
|
||||
### IV. 安装 SPARK ON YARN
|
||||
|
||||
YARN 的意思是另一种非常好用的资源调度器(Yet Another Resource Negotiator),已经作为一个易用的资源管理器集成在 Hadoop 基础安装包中。
|
||||
|
||||
[Apache Spark](https://spark.apache.org/) 是 Hadoop 生态圈中的另一款软件包,它是一个毁誉参半的执行引擎和[捆绑的 MapReduce](https://hadoop.apache.org/docs/r1.2.1/mapred_tutorial.html)。在一般情况下,相对于基于磁盘存储的 MapReduce,Spark 更适合基于内存的存储,某些运行任务能够得到 10-100 倍提升——安装完成集群后你可以试试 Spark 和 MapReduce 有什么不同。
|
||||
|
||||
我个人对 Spark 还是留下非常深刻的印象,因为它提供了两种数据工程师和科学家都比较擅长的语言—— Python 和 R。
|
||||
|
||||
安装 Apache Spark 非常简单,在你家目录下,`wget "为 Hadoop 2.7 构建的 Apache Spark”`([来自这个页面](https://spark.apache.org/downloads.html)),然后运行 `tar -xzf “tgz 文件”`,最后把解压出来的文件移动至 `/opt`,并清除刚才下载的文件,以上这些就是安装步骤。
|
||||
|
||||
我又创建了只有两行的文件 `spark-env.sh`,其中包含 Spark 的配置文件目录。
|
||||
|
||||
```
|
||||
SPARK_MASTER_IP=192.168.1.50
|
||||
SPARK_WORKER_MEMORY=512m
|
||||
```
|
||||
|
||||
(在 YARN 跑起来之前我不确定这些是否有必要。)
|
||||
|
||||
### V. 你好,世界! 为 Apache Spark 寻找有趣的数据集!
|
||||
|
||||
在 Hadoop 世界里面的 ‘Hello, World!’ 就是做单词计数。
|
||||
|
||||
我决定让我们的作品做一些内省式……为什么不统计本站最常用的单词呢?也许统计一些关于本站的大数据会更有用。
|
||||
|
||||
如果你有一个正在运行的 WordPress 博客,可以通过简单的两步来导出和净化。
|
||||
|
||||
1. 我使用 [Export to Text](https://wordpress.org/support/plugin/export-to-text) 插件导出文章的内容到纯文本文件中
|
||||
2. 我使用一些[压缩库](https://pypi.python.org/pypi/bleach)编写了一个 Python 脚本来剔除 HTML
|
||||
|
||||
```
|
||||
import bleach
|
||||
|
||||
# Change this next line to your 'import' filename, whatever you would like to strip
|
||||
# HTML tags from.
|
||||
ascii_string = open('dqydj_with_tags.txt', 'r').read()
|
||||
|
||||
|
||||
new_string = bleach.clean(ascii_string, tags=[], attributes={}, styles=[], strip=True)
|
||||
new_string = new_string.encode('utf-8').strip()
|
||||
|
||||
# Change this next line to your 'export' filename
|
||||
f = open('dqydj_stripped.txt', 'w')
|
||||
f.write(new_string)
|
||||
f.close()
|
||||
```
|
||||
|
||||
现在我们有了一个更小的、适合复制到树莓派所搭建的 HDFS 集群上的文件。
|
||||
|
||||
如果你不能树莓派主节点上完成上面的操作,找个办法将它传输上去(scp、 rsync 等等),然后用下列命令行复制到 HDFS 上。
|
||||
|
||||
```
|
||||
hdfs dfs -copyFromLocal dqydj_stripped.txt /dqydj_stripped.txt
|
||||
```
|
||||
|
||||
现在准备进行最后一步 - 向 Apache Spark 写入一些代码。
|
||||
|
||||
### VI. 点亮 Apache Spark
|
||||
|
||||
Cloudera 有个极棒的程序可以作为我们的超级单词计数程序的基础,[你可以在这里找到](https://www.cloudera.com/documentation/enterprise/5-6-x/topics/spark_develop_run.html)。我们接下来为我们的内省式单词计数程序修改它。
|
||||
|
||||
在主节点上[安装‘stop-words’](https://pypi.python.org/pypi/stop-words)这个 python 第三方包,虽然有趣(我在 DQYDJ 上使用了 23,295 次 the 这个单词),你可能不想看到这些语法单词占据着单词计数的前列,另外,在下列代码用你自己的数据集替换所有有关指向 dqydj 文件的地方。
|
||||
|
||||
```
|
||||
import sys
|
||||
|
||||
from stop_words import get_stop_words
|
||||
from pyspark import SparkContext, SparkConf
|
||||
|
||||
if __name__ == "__main__":
|
||||
|
||||
# create Spark context with Spark configuration
|
||||
conf = SparkConf().setAppName("Spark Count")
|
||||
sc = SparkContext(conf=conf)
|
||||
|
||||
# get threshold
|
||||
try:
|
||||
threshold = int(sys.argv[2])
|
||||
except:
|
||||
threshold = 5
|
||||
|
||||
# read in text file and split each document into words
|
||||
tokenized = sc.textFile(sys.argv[1]).flatMap(lambda line: line.split(" "))
|
||||
|
||||
# count the occurrence of each word
|
||||
wordCounts = tokenized.map(lambda word: (word.lower().strip(), 1)).reduceByKey(lambda v1,v2:v1 +v2)
|
||||
|
||||
# filter out words with fewer than threshold occurrences
|
||||
filtered = wordCounts.filter(lambda pair:pair[1] >= threshold)
|
||||
|
||||
print "*" * 80
|
||||
print "Printing top words used"
|
||||
print "-" * 80
|
||||
filtered_sorted = sorted(filtered.collect(), key=lambda x: x[1], reverse = True)
|
||||
for (word, count) in filtered_sorted: print "%s : %d" % (word.encode('utf-8').strip(), count)
|
||||
|
||||
|
||||
# Remove stop words
|
||||
print "\n\n"
|
||||
print "*" * 80
|
||||
print "Printing top non-stop words used"
|
||||
print "-" * 80
|
||||
# Change this to your language code (see the stop-words documentation)
|
||||
stop_words = set(get_stop_words('en'))
|
||||
no_stop_words = filter(lambda x: x[0] not in stop_words, filtered_sorted)
|
||||
for (word, count) in no_stop_words: print "%s : %d" % (word.encode('utf-8').strip(), count)
|
||||
```
|
||||
|
||||
保存好 wordCount.py,确保上面的路径都是正确无误的。
|
||||
|
||||
现在,准备念出咒语,让运行在 YARN 上的 Spark 跑起来,你可以看到我在 DQYDJ 使用最多的单词是哪一个。
|
||||
|
||||
```
|
||||
/opt/spark-2.0.0-bin-hadoop2.7/bin/spark-submit –master yarn –executor-memory 512m –name wordcount –executor-cores 8 wordCount.py /dqydj_stripped.txt
|
||||
```
|
||||
|
||||
### VII. 我在 DQYDJ 使用最多的单词
|
||||
|
||||
可能入列的单词有哪一些呢?“can, will, it’s, one, even, like, people, money, don’t, also“.
|
||||
|
||||
嘿,不错,“money”悄悄挤进了前十。在一个致力于金融、投资和经济的网站上谈论这似乎是件好事,对吧?
|
||||
|
||||
下面是的前 50 个最常用的词汇,请用它们刻画出有关我的文章的水平的结论。
|
||||
|
||||
|
||||
|
||||
我希望你能喜欢这篇关于 Hadoop、YARN 和 Apache Spark 的教程,现在你可以在 Spark 运行和编写其他的应用了。
|
||||
|
||||
你的下一步是任务是开始[阅读 pyspark 文档](https://spark.apache.org/docs/2.0.0/api/python/index.html)(以及用于其他语言的该库),去学习一些可用的功能。根据你的兴趣和你实际存储的数据,你将会深入学习到更多——有流数据、SQL,甚至机器学习的软件包!
|
||||
|
||||
你怎么看?你要建立一个树莓派 Hadoop 集群吗?想要在其中挖掘一些什么吗?你在上面看到最令你惊奇的单词是什么?为什么 'S&P' 也能上榜?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://dqydj.com/raspberry-pi-hadoop-cluster-apache-spark-yarn/
|
||||
|
||||
作者:[PK][a]
|
||||
译者:[popy32](https://github.com/sfantree)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://dqydj.com/about/#contact_us
|
||||
[1]: https://www.raspberrypi.org/downloads/raspbian/
|
||||
[2]: https://sourceforge.net/projects/win32diskimager/
|
||||
[3]: http://www.becausewecangeek.com/building-a-raspberry-pi-hadoop-cluster-part-1/
|
||||
[4]: https://www.digitalocean.com/community/tutorials/how-to-add-swap-on-ubuntu-14-04
|
||||
[5]: http://www.becausewecangeek.com/building-a-raspberry-pi-hadoop-cluster-part-2/
|
||||
[6]: https://spark.apache.org/
|
||||
[7]: https://hadoop.apache.org/docs/r1.2.1/mapred_tutorial.html
|
||||
[8]: https://spark.apache.org/downloads.html
|
||||
[9]: https://wordpress.org/support/plugin/export-to-text
|
||||
[10]: https://pypi.python.org/pypi/bleach
|
||||
|
||||
@ -0,0 +1,69 @@
|
||||
Rowhammer:针对物理内存的攻击可以取得 Android 设备的 root 权限
|
||||
===
|
||||
|
||||
> 攻击者确实可以在物理存储单元中实现位翻转来达到侵入移动设备与计算机的目的
|
||||
|
||||

|
||||
|
||||
|
||||
研究者们发现了一种新的在不利用任何软件漏洞情况下,利用内存芯片物理设计上的弱点来侵入 Android 设备的方式。这种攻击技术同样可以影响到其它如 ARM 和 X86 架构的设备与计算机。
|
||||
|
||||
这种称之为“Rowhammer”的攻击起源于过去十多年中将更多的 DRAM(动态随机存取存储器)容量封装进越来越小的芯片中,这将导致在特定情况下存储单元电子可以从相邻两<ruby>行<rt>row</rt></ruby>的一边泄漏到另一边。(LCTT 译注:参见 https://en.wikipedia.org/wiki/Row_hammer)
|
||||
|
||||
例如,反复且快速的访问相同的物理储存位置,这种被称为 “<ruby>锤击<rt>hammering</rt></ruby>” 的行为可以导致相邻位置的位值从 0 反转成 1,或者相反。
|
||||
|
||||
虽然这样的电子干扰已经被生产商知晓并且从可靠性角度研究了一段时间了,因为内存错误能够导致系统崩溃。而研究者们现在展示了在可控方式的触发下它所存在的严重安全隐患。
|
||||
|
||||
在 2015 年 4 月,来自谷歌 Project Zero 项目的研究者公布了两份基于内存 “Rowhammer”漏洞对于 x86-64 CPU 架构的 [提权利用][7]。其中一份利用可以使代码从谷歌的 Chrome 浏览器沙盒里逃逸并且直接在系统上执行,另一份可以在 Linux 机器上获取内核级权限。
|
||||
|
||||
此后,其他的研究者进行了更深入的调查并且展示了[通过网站中 JaveScript 脚本进行利用的方式][6]甚至能够影响运行在云环境下的[虚拟服务器][5]。然而,对于这项技术是否可以应用在智能手机和移动设备大量使用的 ARM 架构中还是有疑问的。
|
||||
|
||||
现在,一队成员来自荷兰阿姆斯特丹自由大学、奥地利格拉茨技术大学和加州大学圣塔芭芭拉分校的 VUSec 小组,已经证明了 Rowhammer 不仅仅可以应用在 ARM 架构上并且甚至比在 x86 架构上更容易。
|
||||
|
||||
研究者们将他们的新攻击命名为 Drammer,代表了 Rowhammer 确实存在,并且计划于周三在维也纳举办的第 23 届 ACM 计算机与通信安全大会上展示。这种攻击建立在之前就被发现与实现的 Rowhammer 技术之上。
|
||||
|
||||
VUSec 小组的研究者已经制造了一个适用于 Android 设备的恶意应用,当它被执行的时候利用不易察觉的内存位反转在不需要任何权限的情况下就可以获取设备根权限。
|
||||
|
||||
研究者们测试了来自不同制造商的 27 款 Android 设备,21 款使用 ARMv7(32-bit)指令集架构,其它 6 款使用 ARMv8(64-bit)指令集架构。他们成功的在 17 款 ARMv7 设备和 1 款 ARMv8 设备上实现了为反转,表明了这些设备是易受攻击的。
|
||||
|
||||
此外,Drammer 能够与其它的 Android 漏洞组合使用,例如 [Stagefright][4] 或者 [BAndroid][3] 来实现无需用户手动下载恶意应用的远程攻击。
|
||||
|
||||
谷歌已经注意到了这一类型的攻击。“在研究者向谷歌漏洞奖励计划报告了这个问题之后,我们与他们进行了密切的沟通来深入理解这个问题以便我们更好的保护用户,”一位谷歌的代表在一份邮件申明中这样说到。“我们已经开发了一个缓解方案,将会包含在十一月的安全更新中。”(LCTT 译注:缓解方案,参见 https://en.wikipedia.org/wiki/Vulnerability_management)
|
||||
|
||||
VUSec 的研究者认为,谷歌的缓解方案将会使得攻击过程更为复杂,但是它不能修复潜在的问题。
|
||||
|
||||
事实上,从软件上去修复一个由硬件导致的问题是不现实的。硬件供应商正在研究相关问题并且有可能在将来的内存芯片中被修复,但是在现有设备的芯片中风险依然存在。
|
||||
|
||||
更糟的是,研究者们说,由于有许多因素会影响到攻击的成功与否并且这些因素尚未被研究透彻,因此很难去说有哪些设备会被影响到。例如,内存控制器可能会在不同的电量的情况下展现不同的行为,因此一个设备可能在满电的情况下没有风险,当它处于低电量的情况下就是有风险的。
|
||||
|
||||
同样的,在网络安全中有这样一句俗语:<ruby>攻击将变本加厉,如火如荼<rt>Attacks always get getter, they never get worse</rt></ruby>。Rowhammer 攻击已经从理论变成了现实可能,同样的,它也可能会从现在的现实可能变成确确实实的存在。这意味着今天某个设备是不被影响的,在明天就有可能被改进后的 Rowhammer 技术证明它是存在风险的。
|
||||
|
||||
Drammer 在 Android 上实现是因为研究者期望研究基于 ARM 设备的影响,但是潜在的技术可以被使用在所有的架构与操作系统上。新的攻击相较于之前建立在运气与特殊特性与特定平台之上并且十分容易失效的技术已经是一个巨大的进步了。
|
||||
|
||||
Drammer 攻击的实现依靠于被包括图形、网络、声音等大量硬件子系统所使用的 DMA(直接存储访问)缓存。Drammer 的实现采用了所有操作系统上都有的 Android 的 ION 内存分配器、接口与方法,这给我们带来的警示是该论文的主要贡献之一。
|
||||
|
||||
“破天荒的,我们成功地展示了我们可以做到,在不依赖任何特定的特性情况下完全可靠的证明了 Rowhammer”, VUSec 小组中的其中一位研究者 Cristiano Giuffrida 这样说道。“攻击所利用的内存位置并非是 Android 独有的。攻击在任何的 Linux 平台上都能工作 -- 我们甚至怀疑其它操作系统也可以 -- 因为它利用的是操作系统内核内存管理中固有的特性。”
|
||||
|
||||
“我期待我们可以看到更多针对其它平台的攻击的变种,”阿姆斯特丹自由大学的教授兼 VUSec 系统安全研究小组的领导者 Herbert Bos 补充道。
|
||||
|
||||
在他们的[论文][2]之外,研究者们也释出了一个 Android 应用来测试 Android 设备在当前所知的技术条件下受到 Rowhammer 攻击时是否会有风险。应用还没有传上谷歌应用商店,可以从 [VUSec Drammer 网站][1] 下载来手动安装。一个开源的 Rowhammer 模拟器同样能够帮助其他的研究者来更深入的研究这个问题。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:http://www.csoonline.com/article/3134726/security/physical-ram-attack-can-root-android-and-possibly-other-devices.html
|
||||
|
||||
作者:[Lucian Constantin][a]
|
||||
译者:[wcnnbdk1](https://github.com/wcnnbdk1)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.csoonline.com/author/Lucian-Constantin/
|
||||
[1]:https://www.vusec.net/projects/drammer/
|
||||
[2]:https://vvdveen.com/publications/drammer.pdf
|
||||
[3]:https://www.vusec.net/projects/bandroid/
|
||||
[4]:http://www.csoonline.com/article/3045836/security/new-stagefright-exploit-puts-millions-of-android-devices-at-risk.html
|
||||
[5]:http://www.infoworld.com/article/3105889/security/flip-feng-shui-attack-on-cloud-vms-exploits-hardware-weaknesses.html
|
||||
[6]:http://www.computerworld.com/article/2954582/security/researchers-develop-astonishing-webbased-attack-on-a-computers-dram.html
|
||||
[7]:http://www.computerworld.com/article/2895898/google-researchers-hack-computers-using-dram-electrical-leaks.html
|
||||
[8]:http://csoonline.com/newsletters/signup.html
|
||||
466
published/201705/20161025 GitLab Workflow An Overview.md
Normal file
466
published/201705/20161025 GitLab Workflow An Overview.md
Normal file
@ -0,0 +1,466 @@
|
||||
GitLab 工作流概览
|
||||
======
|
||||
|
||||
GitLab 是一个基于 git 的仓库管理程序,也是一个方便软件开发的强大完整应用。
|
||||
|
||||
GitLab 拥有一个“用户新人友好”的界面,通过图形界面和命令行界面,使你的工作更加具有效率。GitLab 不仅仅对开发者是一个有用的工具,它甚至可以被集成到你的整个团队中,使得每一个人获得一个独自唯一的平台。
|
||||
|
||||
GitLab 工作流逻辑符合使用者思维,使得整个平台变得更加易用。相信我,使用一次,你就离不开它了!
|
||||
|
||||
### GitLab 工作流
|
||||
|
||||
**GitLab 工作流** 是在软件开发过程中,在使用 GitLab 作为代码托管平台时,可以采取的动作的一个逻辑序列。
|
||||
|
||||
GitLab 工作流遵循了 [GitLab Flow][97] 策略,这是由一系列由**基于 Git** 的方法和策略组成的,这些方法为版本的管理,例如**分支策略**、**Git最佳实践**等等提供了保障。
|
||||
|
||||
通过 GitLab 工作流,可以很方便的[提升](https://about.gitlab.com/2016/09/13/gitlab-master-plan/)团队的工作效率以及凝聚力。这种提升,从引入一个新的项目开始,一直到发布这个项目,成为一个产品都有所体现。这就是我们所说的“如何通过最快的速度把一个点子在 10 步之内变成一个产品”。
|
||||
|
||||

|
||||
|
||||
#### 软件开发阶段
|
||||
|
||||
一般情况下,软件开发经过 10 个主要阶段;GitLab 为这 10 个阶段依次提供了解决方案:
|
||||
|
||||
1. **IDEA**: 每一个从点子开始的项目,通常来源于一次闲聊。在这个阶段,GitLab 集成了 [Mattermost][44]。
|
||||
2. **ISSUE**: 最有效的讨论一个点子的方法,就是为这个点子建立一个工单讨论。你的团队和你的合作伙伴可以在 <ruby>工单追踪器<rt>issue tracker</rt></ruby> 中帮助你去提升这个点子
|
||||
3. **PLAN**: 一旦讨论得到一致的同意,就是开始编码的时候了。但是等等!首先,我们需要优先考虑组织我们的工作流。对于此,我们可以使用 <ruby>工单看板<rt>Issue Board</rt></ruby>。
|
||||
4. **CODE**: 现在,当一切准备就绪,我们可以开始写代码了。
|
||||
5. **COMMIT**: 当我们为我们的初步成果欢呼的时候,我们就可以在版本控制下,提交代码到功能分支了。
|
||||
6. **TEST**: 通过 [GitLab CI][41],我们可以运行脚本来构建和测试我们的应用。
|
||||
7. **REVIEW**: 一旦脚本成功运行,我们测试和构建成功,我们就可以进行 <ruby>代码复审<rt>code review</rt></ruby> 以及批准。
|
||||
8. **STAGING:**: 现在是时候[将我们的代码部署到演示环境][39]来检查一下,看看是否一切就像我们预估的那样顺畅——或者我们可能仍然需要修改。
|
||||
9. **PRODUCTION**: 当一切都如预期,就是[部署到生产环境][38]的时候了!
|
||||
10. **FEEDBACK**: 现在是时候返回去看我们项目中需要提升的部分了。我们使用[<ruby>周期分析<rt> Cycle Analytics</rt></ruby>][37]来对当前项目中关键的部分进行的反馈。
|
||||
|
||||
简单浏览这些步骤,我们可以发现,提供强大的工具来支持这些步骤是十分重要的。在接下来的部分,我们为 GitLab 的可用工具提供一个简单的概览。
|
||||
|
||||
### GitLab 工单追踪器
|
||||
|
||||
GitLab 有一个强大的工单追溯系统,在使用过程中,允许你和你的团队,以及你的合作者分享和讨论建议。
|
||||
|
||||
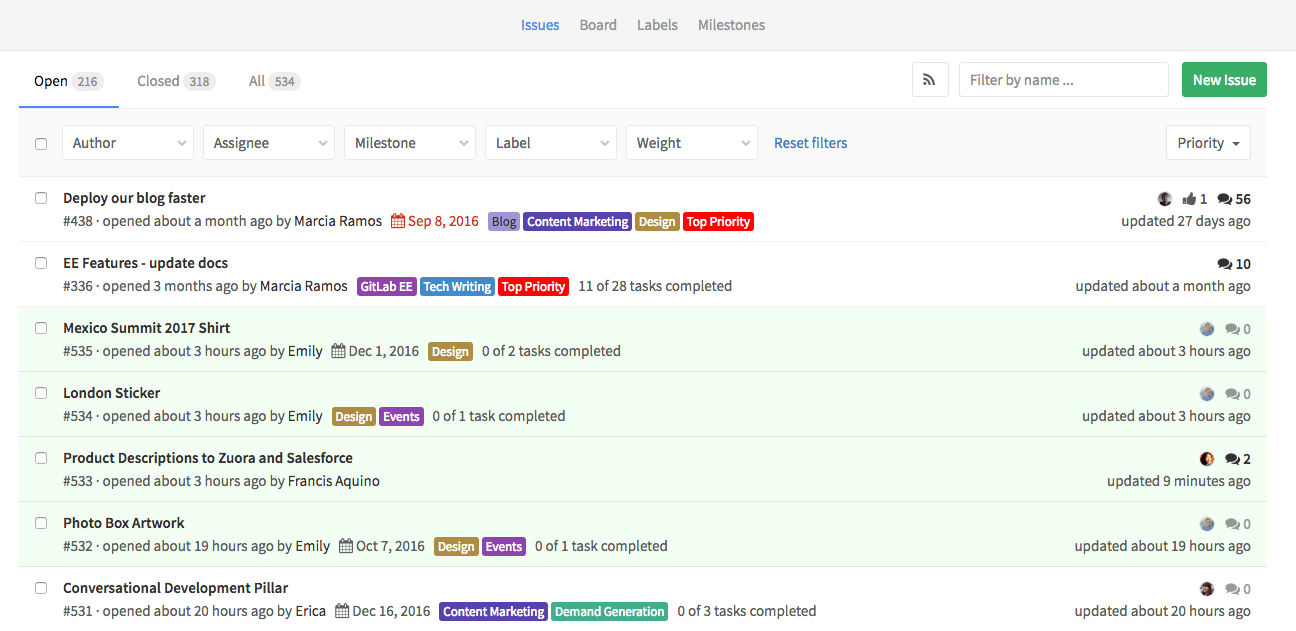
|
||||
|
||||
工单是 GitLab 工作流的第一个重要重要特性。[以工单的讨论为开始][95]; 跟踪新点子的改变是一个最好的方式。
|
||||
|
||||
这十分有利于:
|
||||
|
||||
* 讨论点子
|
||||
* 提交功能建议
|
||||
* 提问题
|
||||
* 提交错误和故障
|
||||
* 获取支持
|
||||
* 精细化新代码的引入
|
||||
|
||||
每一个在 GitLab 上部署的项目都有一个工单追踪器。找到你的项目中的 **Issues** > **New issue** 来创建一个新的工单。建立一个标题来总结要被讨论的主题,并且使用 [Markdown][94] 来形容它。看看下面的“专业技巧”来加强你的工单描述。
|
||||
|
||||
GitLab 工单追踪器提供了一个额外的实用功能,使得步骤变得更佳易于管理和考虑。下面的部分仔细描述了它。
|
||||
|
||||
|
||||
|
||||
#### 秘密工单
|
||||
|
||||
无论何时,如果你仅仅想要在团队中讨论这个工单,你可以使[该工单成为秘密的][92]。即使你的项目是公开的,你的工单也会被保密起来。当一个不是本项目成员的人,就算是 [报告人级别][01],想要访问工单的地址时,浏览器也会返回一个 404 错误。
|
||||
|
||||
#### 截止日期
|
||||
|
||||
每一个工单允许你填写一个[截止日期][90]。有些团队工作时间表安排紧凑,以某种方式去设置一个截止日期来解决问题,是有必要的。这些都可以通过截止日期这一功能实现。
|
||||
|
||||
当你对一个多任务项目有截止日期的时候——比如说,一个新的发布活动、项目的启动,或者按阶段追踪任务——你可以使用[里程碑][89]。
|
||||
|
||||
#### 受托者
|
||||
|
||||
要让某人处理某个工单,可以将其分配给他。你可以任意修改被分配者,直到满足你的需求。这个功能的想法是,一个受托者本身对这个工单负责,直到其将这个工单重新赋予其他人。
|
||||
|
||||
这也可以用于按受托者筛选工单。
|
||||
|
||||
#### 标签
|
||||
|
||||
GitLab 标签也是 GitLab 流的一个重要组成部分。你可以使用它们来分类你的工单,在工作流中定位,以及通过[优先级标签][88]来安装优先级组织它们。
|
||||
|
||||
标签使得你与[GitLab 工单看板][87]协同工作,加快工程进度以及组织你的工作流。
|
||||
|
||||
**新功能:** 你可以创建[组标签][86]。它可以使得在每一个项目组中使用相同的标签。
|
||||
|
||||
#### 工单权重
|
||||
|
||||
你可以添加个[工单权重][85]使得一个工单重要性表现的更为清晰。01 - 03 表示工单不是特别重要,07 - 09 表示十分重要,04 - 06 表示程度适中。此外,你可以与你的团队自行定义工单重要性的指标。
|
||||
|
||||
注:该功能仅可用于 GitLab 企业版和 GitLab.com 上。
|
||||
|
||||
#### GitLab 工单看板
|
||||
|
||||
在项目中,[GitLab 工单看板][84]是一个用于计划以及组织你的工单,使之符合你的项目工作流的工具。
|
||||
|
||||
看板包含了与其相关的相应标签,每一个列表包含了相关的被标记的工单,并且以卡片的形式展示出来。
|
||||
|
||||
这些卡片可以在列表之间移动,被移动的卡片,其标签将会依据你移动的位置相应更新到列表上。
|
||||
|
||||
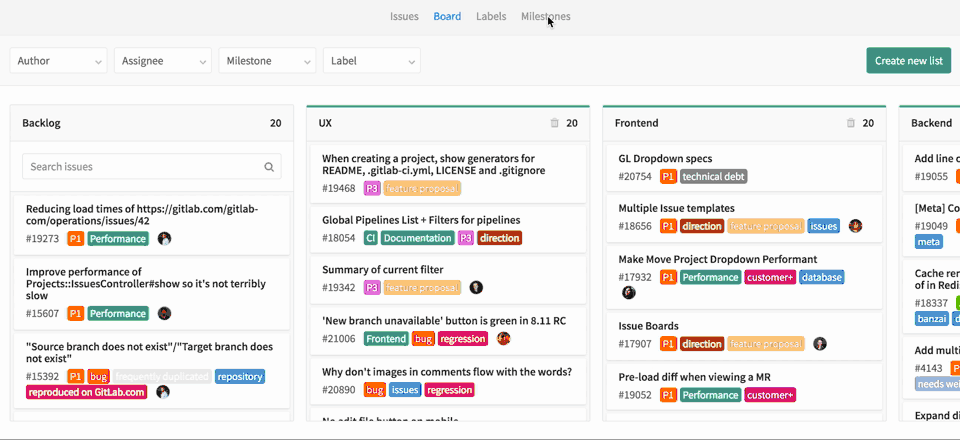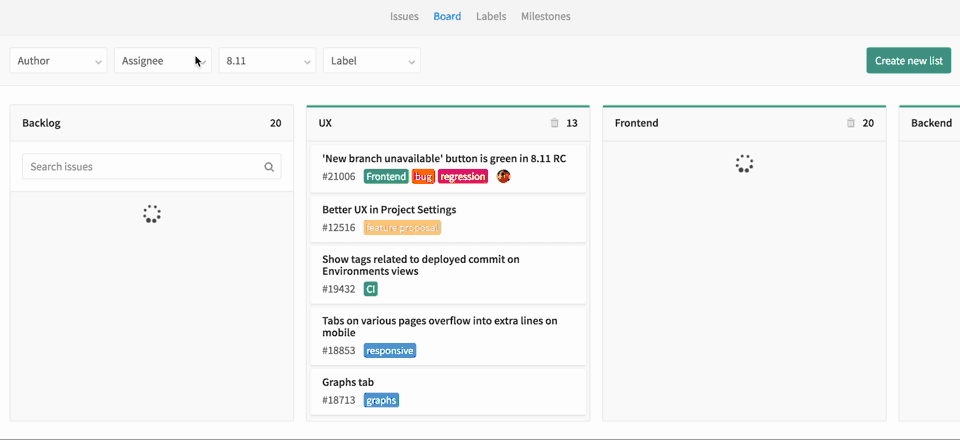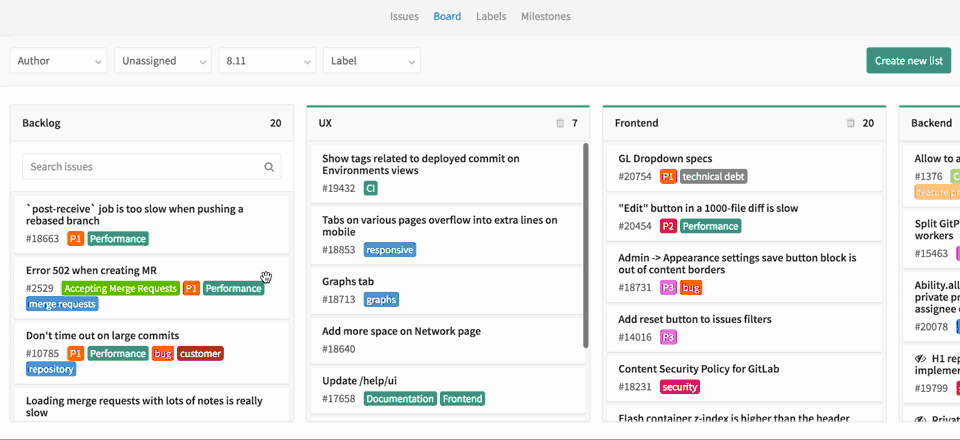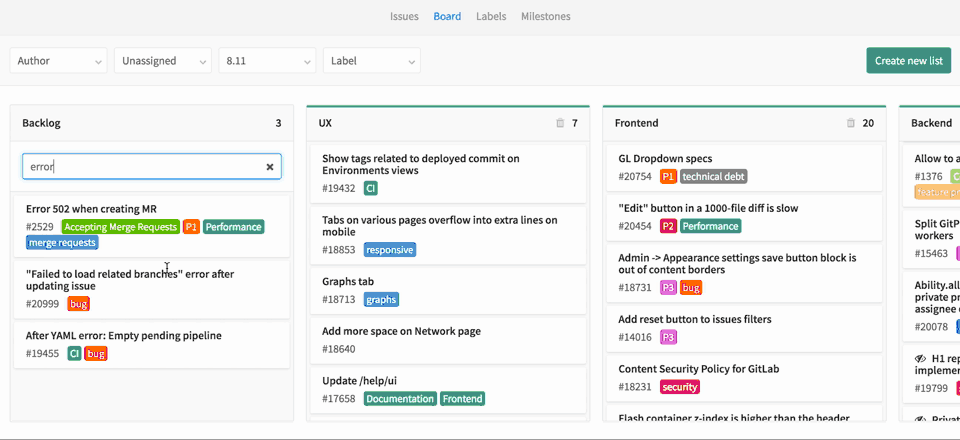
|
||||
|
||||
**新功能:** 你也可以通过点击列表上方的“+”按钮在看板右边创建工单。当你这么做的时候,这个工单将会自动添加与列表相关的标签。
|
||||
|
||||
**新功能:** 我们[最近推出了][83] 每一个 GitLab 项目拥有**多个工单看板**的功能(仅存在于 [GitLab 企业版][82]);这是为不同的工作流组织你的工单的好方法。
|
||||
|
||||
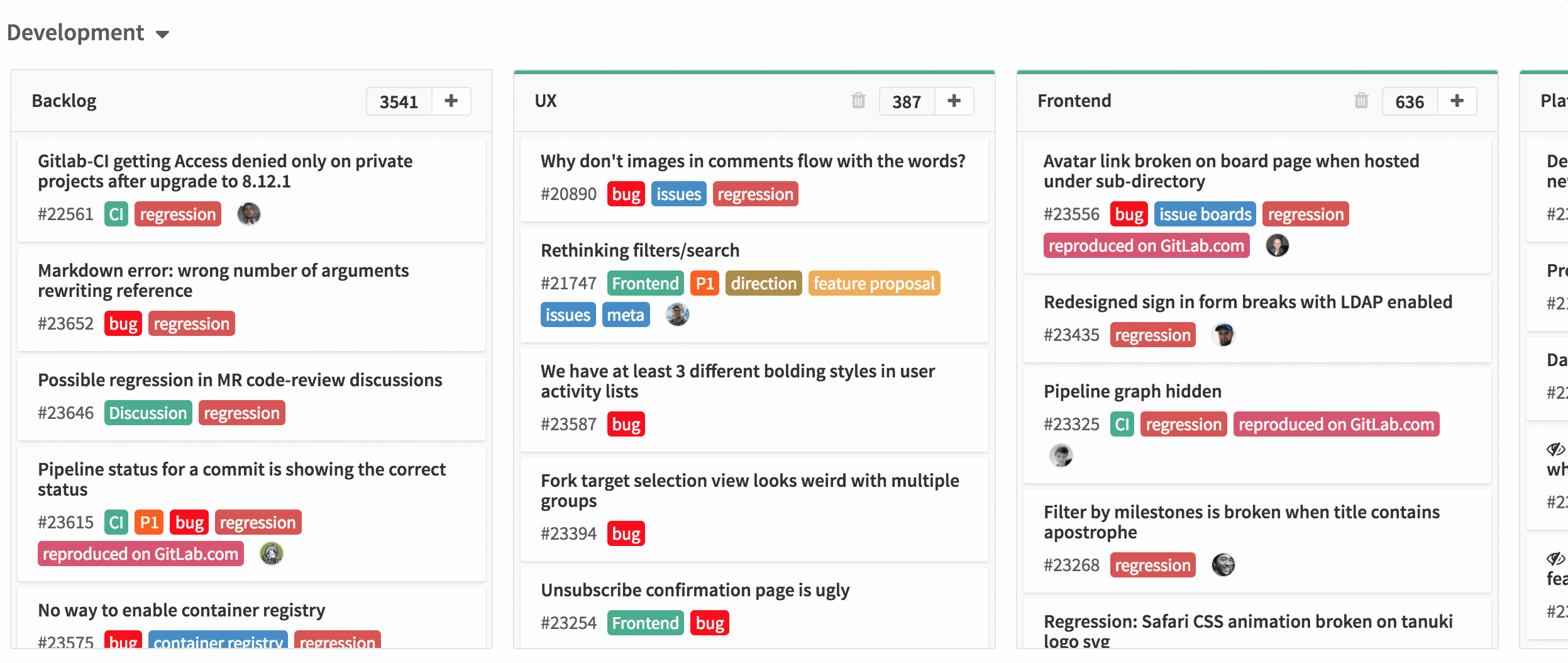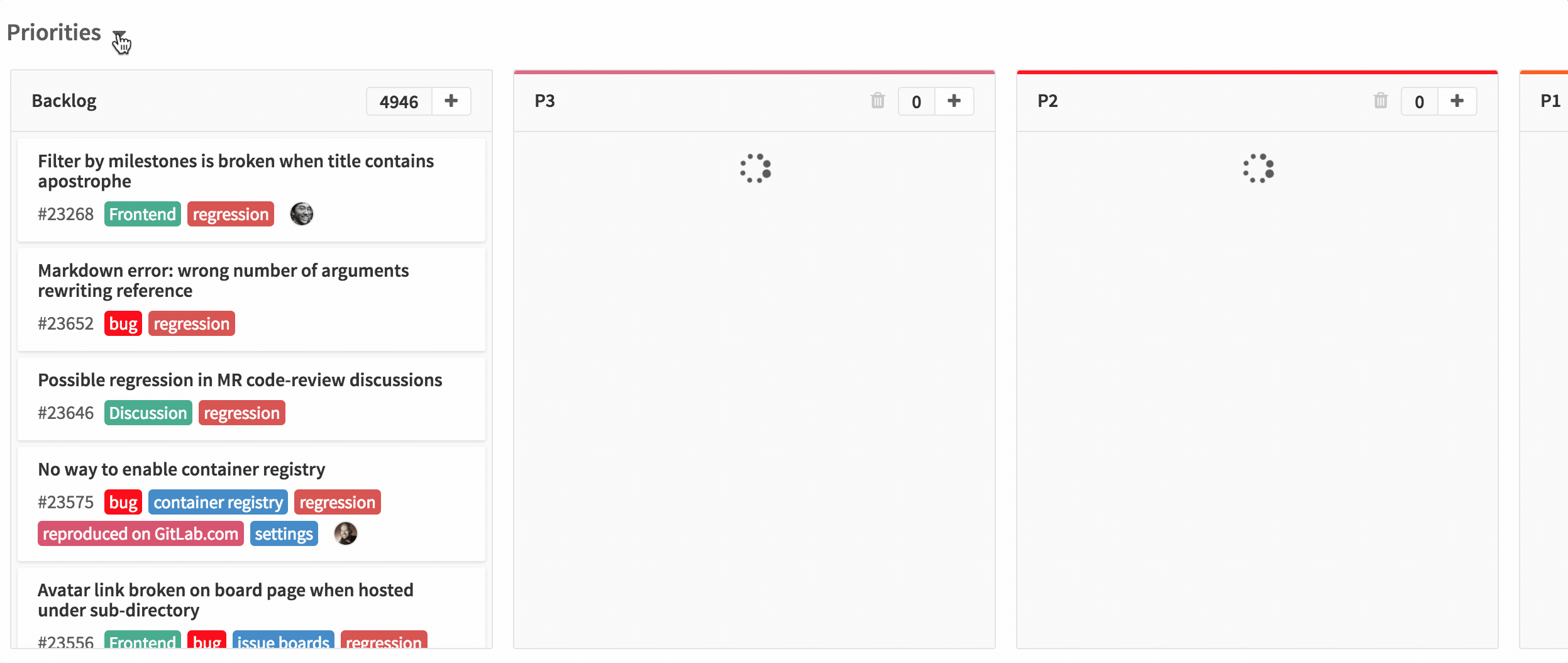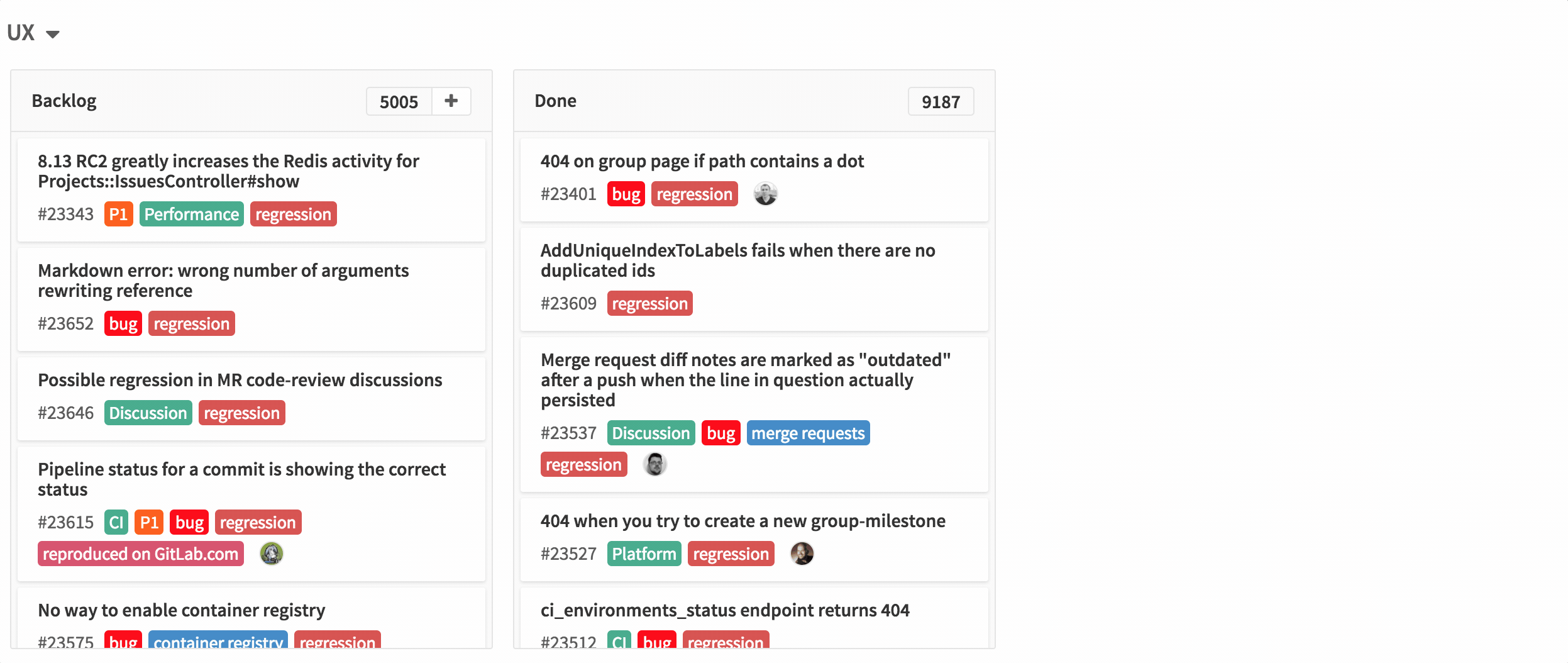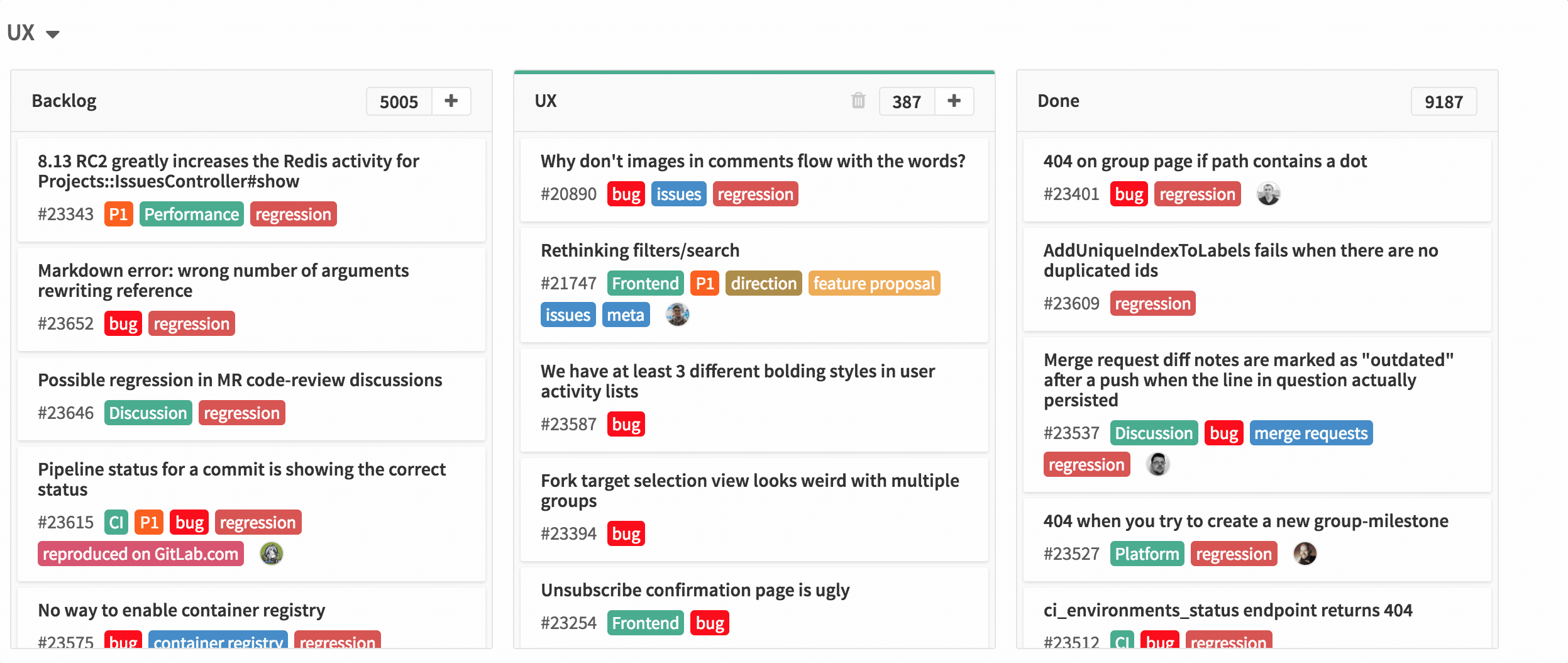
|
||||
|
||||
### 通过 GitLab 进行代码复审
|
||||
|
||||
在工单追踪器中,讨论了新的提议之后,就是在代码上做工作的时候了。你在本地书写代码,一旦你完成了你的第一个版本,提交你的代码并且推送到你的 GitLab 仓库。你基于 Git 的管理策略可以在 [GitLab 流][81]中被提升。
|
||||
|
||||
#### 第一次提交
|
||||
|
||||
在你的第一次提交信息中,你可以添加涉及到工单号在其中。通过这样做你可以将两个阶段的开发工作流链接起来:工单本身以及关于这个工单的第一次提交。
|
||||
|
||||
这样做,如果你提交的代码和工单属于同一个项目,你可以简单的添加 `#xxx` 到提交信息中(LCTT 译注:`git commit message`),`xxx`是一个工单号。如果它们不在一个项目中,你可以添加整个工单的整个URL(`https://gitlab.com/<username>/<projectname>/issues/<xxx>`)。
|
||||
|
||||
```
|
||||
git commit -m "this is my commit message. Ref #xxx"
|
||||
```
|
||||
|
||||
或者
|
||||
|
||||
```
|
||||
git commit -m "this is my commit message. Related to https://gitlab.com/<username>/<projectname>/issues/<xxx>"
|
||||
```
|
||||
|
||||
当然,你也可以替换 `gitlab.com`,以你自己的 GitLab 实例来替换这个 URL。
|
||||
|
||||
**注:** 链接工单和你的第一次提交是为了通过 [GitLab 周期分析][80]追踪你的进展。这将会衡量计划执行该工单所采取的时间,即创建工单与第一次提交的间隔时间。
|
||||
|
||||
#### 合并请求
|
||||
|
||||
一旦将你的改动提交到功能分支,GitLab 将识别该修改,并且建议你提交一次<ruby>合并请求<rt>Merge Request</rt></ruby>(MR)。
|
||||
|
||||
每一次 MR 都会有一个标题(这个标题总结了这次的改动)并且一个用 [Markdown][79] 书写的描述。在描述中,你可以简单的描述该 MR 做了什么,提及任何工单以及 MR(在它们之间创建联系),并且,你也可以添加个[关闭工单模式][78],当该 MR 被**合并**的时候,相关联的工单就会被关闭。
|
||||
|
||||
例如:
|
||||
|
||||
```
|
||||
## 增加一个新页面
|
||||
|
||||
这个 MR 将会为这个项目创建一个包含该 app 概览的 `readme.md`。
|
||||
|
||||
Closes #xxx and https://gitlab.com/<username>/<projectname>/issues/<xxx>
|
||||
|
||||
预览:
|
||||
|
||||

|
||||
|
||||
cc/ @Mary @Jane @John
|
||||
```
|
||||
|
||||
当你创建一个如上的带有描述的 MR,它将会:
|
||||
|
||||
* 当合并时,关闭包括工单 `#xxx` 以及 `https://gitlab.com/<username>/<projectname>/issues/<xxx>`
|
||||
* 展示一张图片
|
||||
* 通过邮件提醒用户 `@Mary`、`@Jane`,以及给 `@John`
|
||||
|
||||
你可以分配这个 MR 给你自己,直到你完成你的工作,然后把它分配给其他人来做一次代码复审。如果有必要的话,这个 MR 可以被重新分配多次,直到你覆盖你所需要的所有复审。
|
||||
|
||||
它也可以被标记,并且添加一个[里程碑][77]来促进管理。
|
||||
|
||||
当你从图形界面而不是命令行添加或者修改一个文件并且提交一个新的分支时,也很容易创建一个新的 MR,仅仅需要标记一下复选框,“以这些改变开始一个新的合并请求”,然后,一旦你提交你的改动,GitLab 将会自动创建一个新的 MR。
|
||||
|
||||
|
||||
|
||||
**注:** 添加[关闭工单样式][76]到你的 MR 以便可以使用 [GitLab 周期分析][75]追踪你的项目进展,是十分重要的。它将会追踪“CODE”阶段,衡量第一次提交及创建一个相关的合并请求所间隔的时间。
|
||||
|
||||
**新功能:** 我们已经开发了[审查应用][74],这是一个可以让你部署你的应用到一个动态的环境中的新功能,在此你可以按分支名字、每个合并请求来预览改变。参看这里的[可用示例][73]。
|
||||
|
||||
#### WIP MR
|
||||
|
||||
WIP MR 含义是 **在工作过程中的合并请求**,是一个我们在 GitLab 中避免 MR 在准备就绪前被合并的技术。只需要添加 `WIP:` 在 MR 的标题开头,它将不会被合并,除非你把 `WIP:` 删除。
|
||||
|
||||
当你改动已经准备好被合并,编辑工单来手动删除 `WIP:` ,或者使用就像如下 MR 描述下方的快捷方式。
|
||||
|
||||

|
||||
|
||||
**新功能:** `WIP` 模式可以通过[斜线命令][71] `/wip` [快速添加到合并请求中][72]。只需要在评论或者 MR 描述中输入它并提交即可。
|
||||
|
||||
#### 复审
|
||||
|
||||
一旦你创建一个合并请求,就是你开始从你的团队以及合作方收取反馈的时候了。使用图形界面中的差异比较功能,你可以简单的添加行内注释,以及回复或者解决它们。
|
||||
|
||||
你也可以通过点击行号获取每一行代码的链接。
|
||||
|
||||
在图形界面中可以看到提交历史,通过提交历史,你可以追踪文件的每一次改变。你可以以行内差异或左右对比的方式浏览它们。
|
||||
|
||||

|
||||
|
||||
**新功能:** 如果你遇到合并冲突,可以快速地[通过图形界面来解决][70],或者依据你的需要修改文件来修复冲突。
|
||||
|
||||
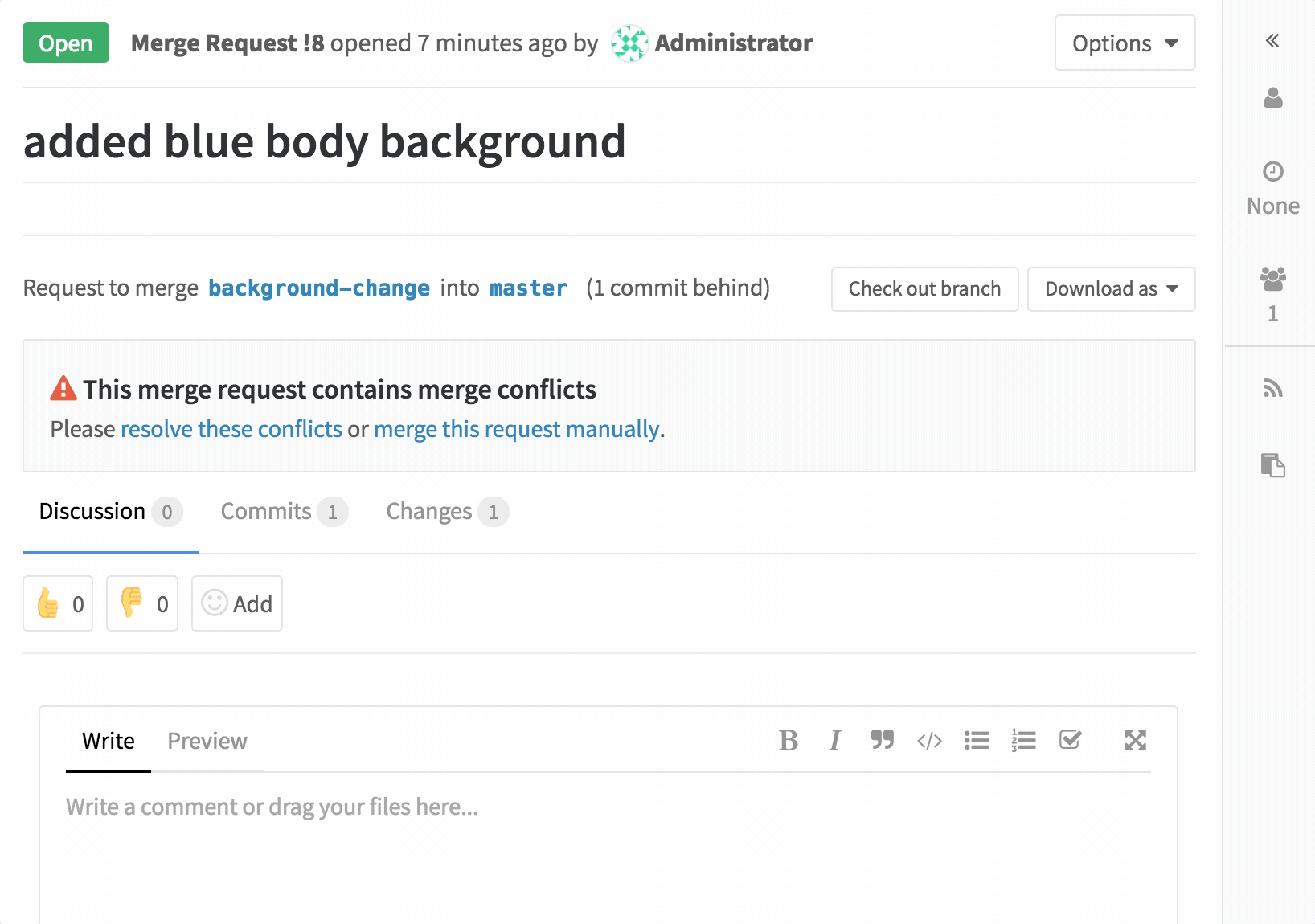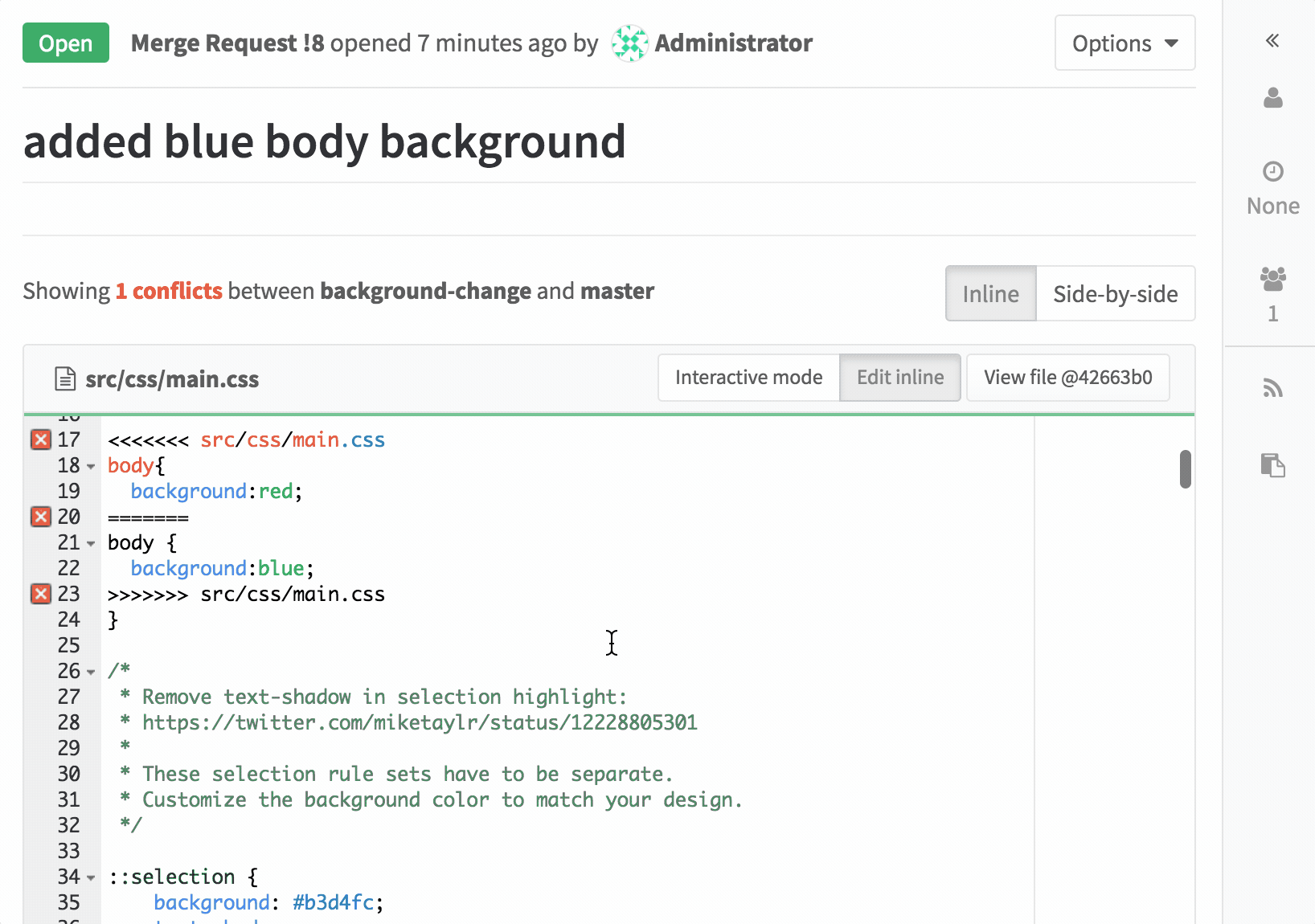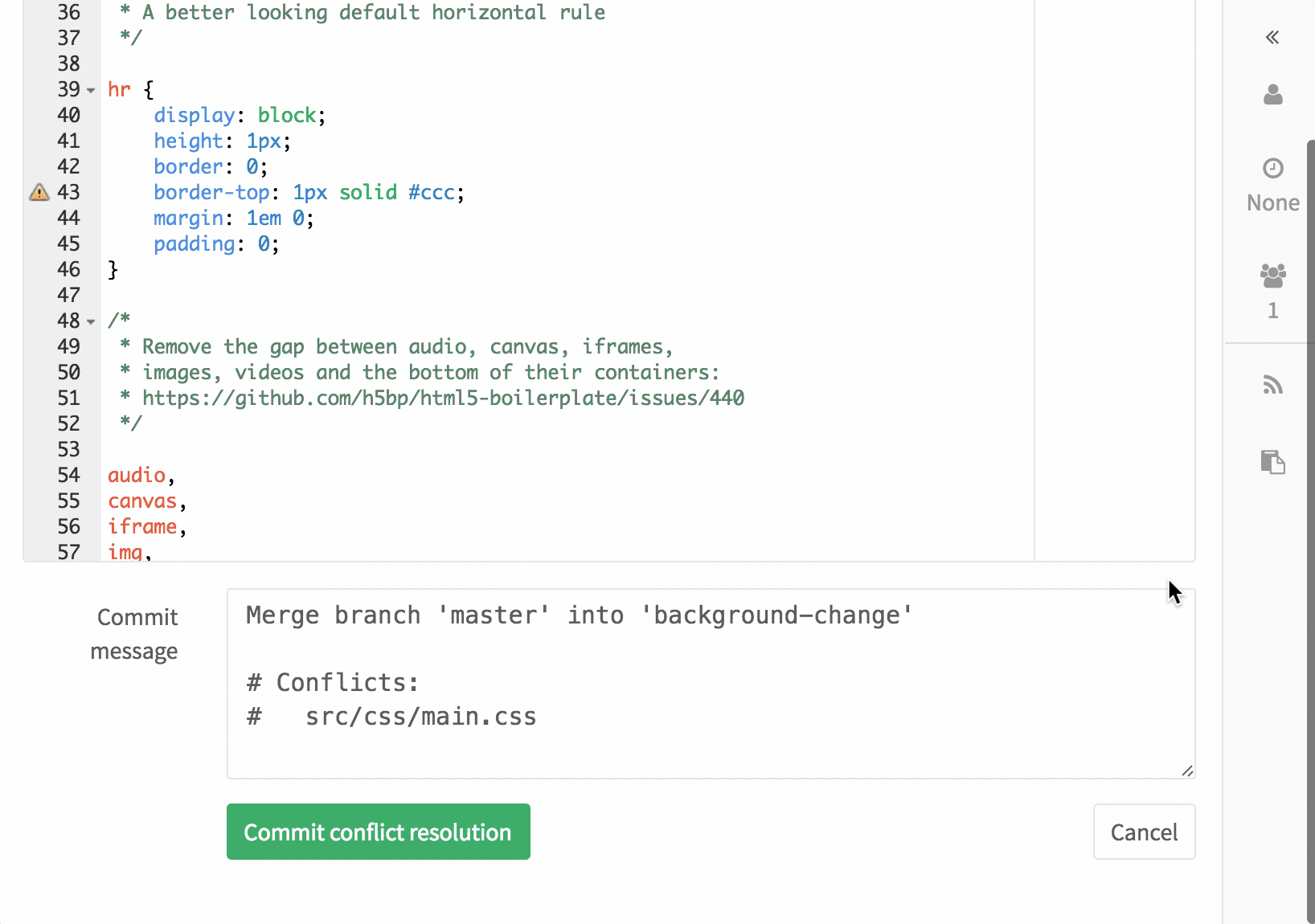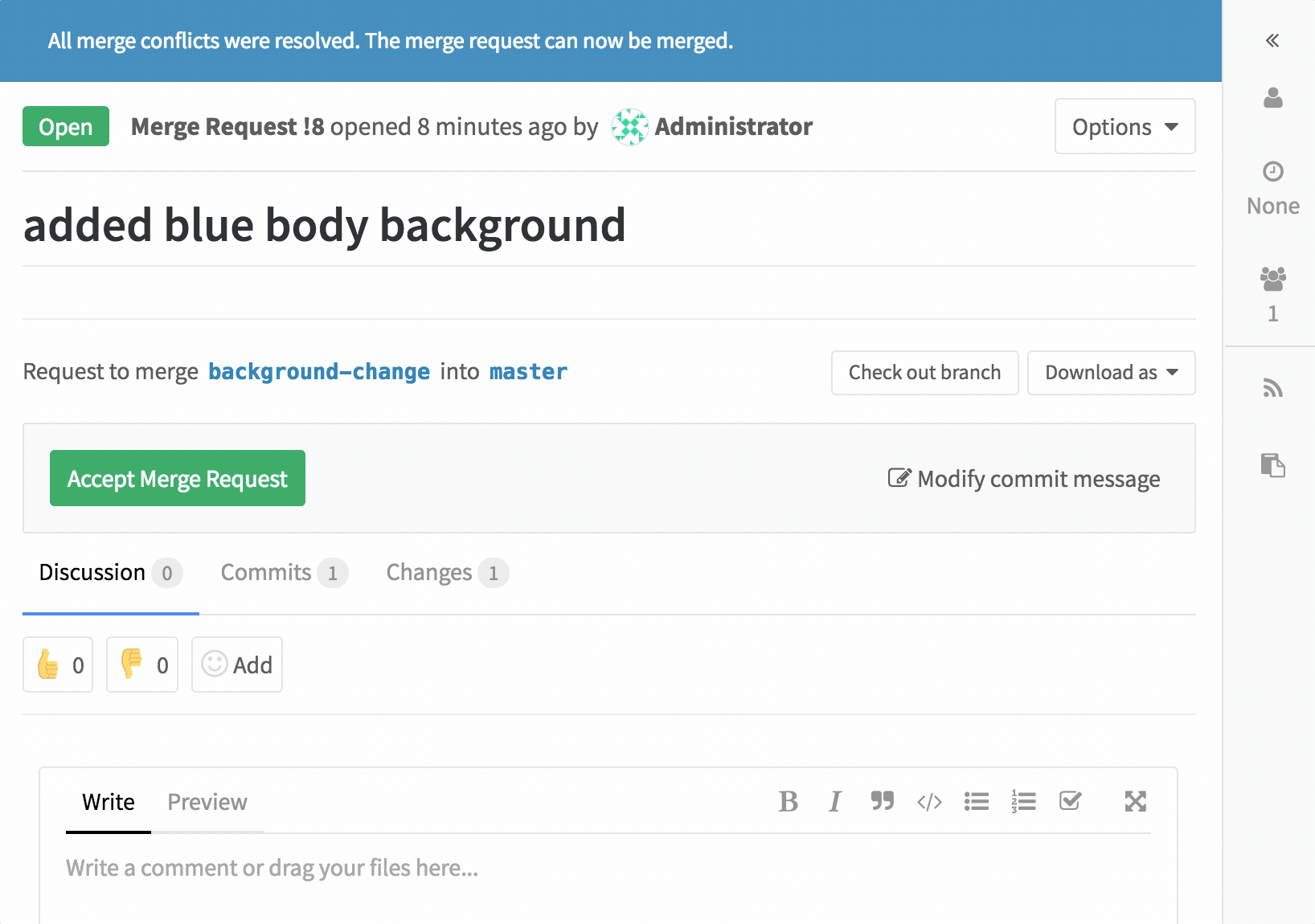
|
||||
|
||||
### 构建、测试以及发布
|
||||
|
||||
[GitLab CI][69] 是一个强大的内建工具,其作用是[持续集成、持续发布以及持续分发][58],它可以按照你希望的运行一些脚本。它的可能性是无止尽的:你可以把它看做是自己运行的命令行。
|
||||
|
||||
它完全是通过一个名为 `.gitlab-ci.yml` 的 YAML 文件设置的,其放置在你的项目仓库中。使用 Web 界面简单的添加一个文件,命名为 `.gitlab-ci.yml` 来触发一个下拉菜单,为不同的应用选择各种 CI 模版。
|
||||
|
||||
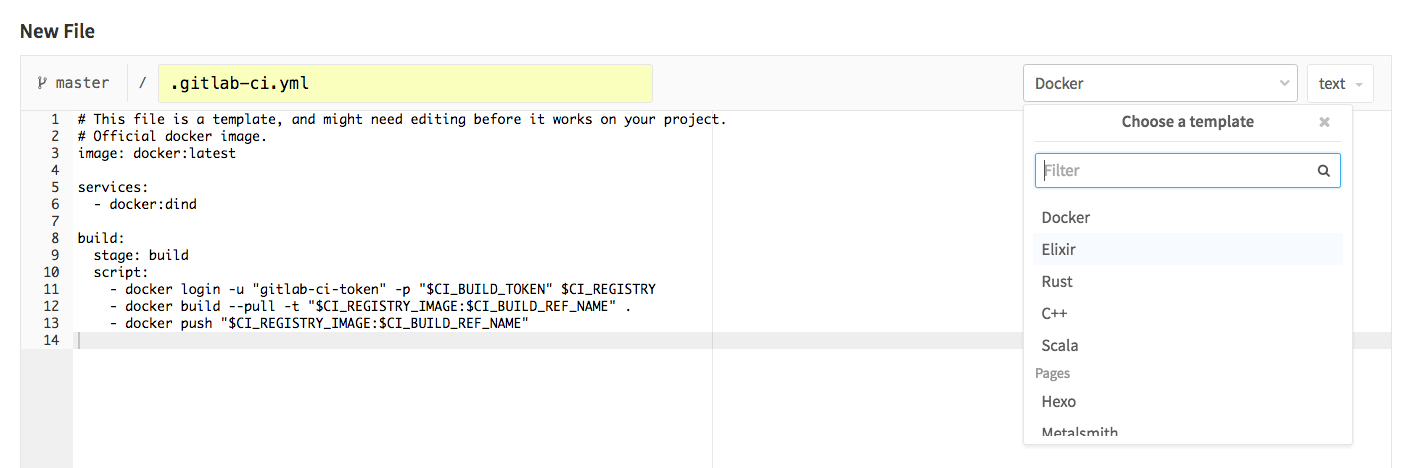
|
||||
|
||||
#### Koding
|
||||
|
||||
Use GitLab's [Koding integration][67] to run your entire development environment in the cloud. This means that you can check out a project or just a merge request in a full-fledged IDE with the press of a button.
|
||||
|
||||
可以使用 GitLab 的 [Koding 集成][67]功能在云端运行你的整个云端开发环境。这意味着你可以轻轻一键即可在一个完整的 IDE 中检出以个项目,或者合并一个请求。
|
||||
|
||||
#### 使用案例
|
||||
|
||||
GitLab CI 的使用案例:
|
||||
|
||||
* 用它来[构建][36]任何[静态网站生成器][35],并且通过 [GitLab Pages][34] 发布你的网站。
|
||||
* 用它来[发布你的网站][33] 到 `staging` 以及 `production` [环境][32]。
|
||||
* 用它来[构建一个 iOS 应用][31]。
|
||||
* 用它来[构建和发布你的 Docker 镜像][30]到 [GitLab 容器注册库][29]。
|
||||
|
||||
我们已经准备一大堆 [GitLab CI 样例工程][66]作为您的指南。看看它们吧!
|
||||
|
||||
### 反馈:周期分析
|
||||
|
||||
当你遵循 GitLab 工作流进行工作,你的团队从点子到产品,在每一个[过程的关键部分][64],你将会在下列时间获得一个 [GitLab 周期分析][65]的反馈:
|
||||
|
||||
* **Issue**: 从创建一个工单,到分配这个工单给一个里程碑或者添加工单到你的工单看板的时间。
|
||||
* **Plan**: 从给工单分配一个里程碑或者把它添加到工单看板,到推送第一次提交的时间。
|
||||
* **Code**: 从第一次提交到提出该合并请求的时间。
|
||||
* **Test**: CI 为了相关合并请求而运行整个过程的时间。
|
||||
* **Review**: 从创建一个合并请求到合并它的时间。
|
||||
* **Staging**: 从合并到发布成为产品的时间。
|
||||
* **Production(Total)**: 从创建工单到把代码发布成[产品][28]的时间。
|
||||
|
||||
### 加强
|
||||
|
||||
#### 工单以及合并请求模版
|
||||
|
||||
[工单以及合并请求模版][63]允许你为你的项目去定义一个特定内容的工单模版和合并请求的描述字段。
|
||||
|
||||
你可以以 [Markdown][62] 形式书写它们,并且把它们加入仓库的默认分支。当创建工单或者合并请求时,可以通过下拉菜单访问它们。
|
||||
|
||||
它们节省了您在描述工单和合并请求的时间,并标准化了需要持续跟踪的重要信息。它确保了你需要的一切都在你的掌控之中。
|
||||
|
||||
你可以创建许多模版,用于不同的用途。例如,你可以有一个提供功能建议的工单模版,或者一个 bug 汇报的工单模版。在 [GitLab CE project][61] 中寻找真实的例子吧!
|
||||
|
||||
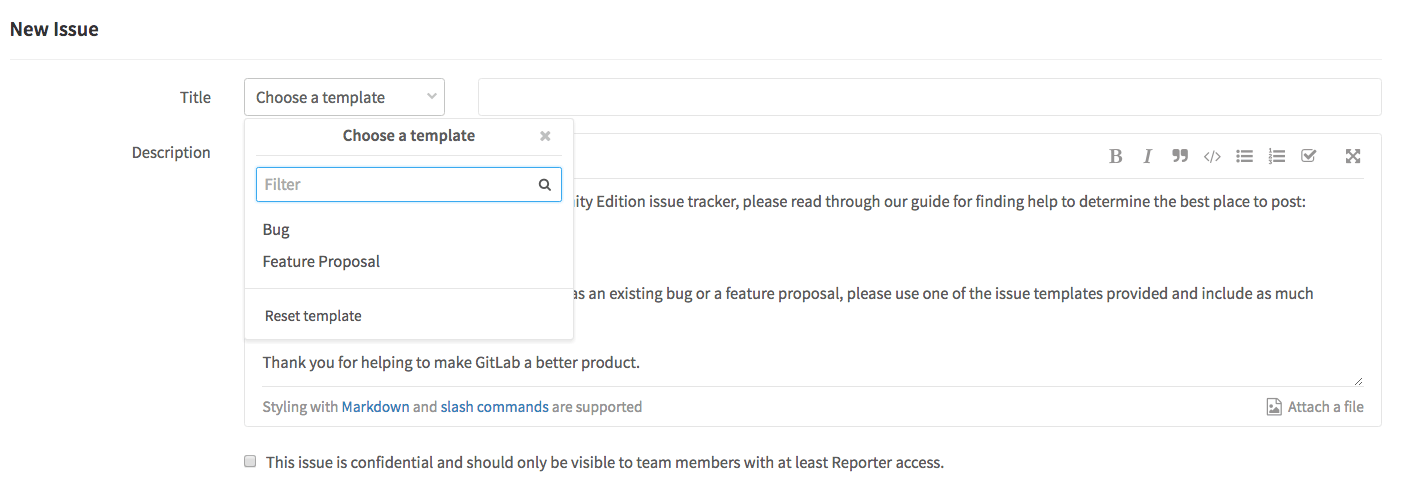
|
||||
|
||||
#### 里程碑
|
||||
|
||||
[里程碑][60] 是 GitLab 中基于共同的目标、详细的日期追踪你队伍工作的最好工具。
|
||||
|
||||
不同情况下的目的是不同的,但是大致是相同的:你有为了达到特定的目标的工单的集合以及正在编码的合并请求。
|
||||
|
||||
这个目标基本上可以是任何东西——用来结合团队的工作,在一个截止日期前完成一些事情。例如,发布一个新的版本,启动一个新的产品,在某个日期前完成,或者按季度收尾一些项目。
|
||||
|
||||
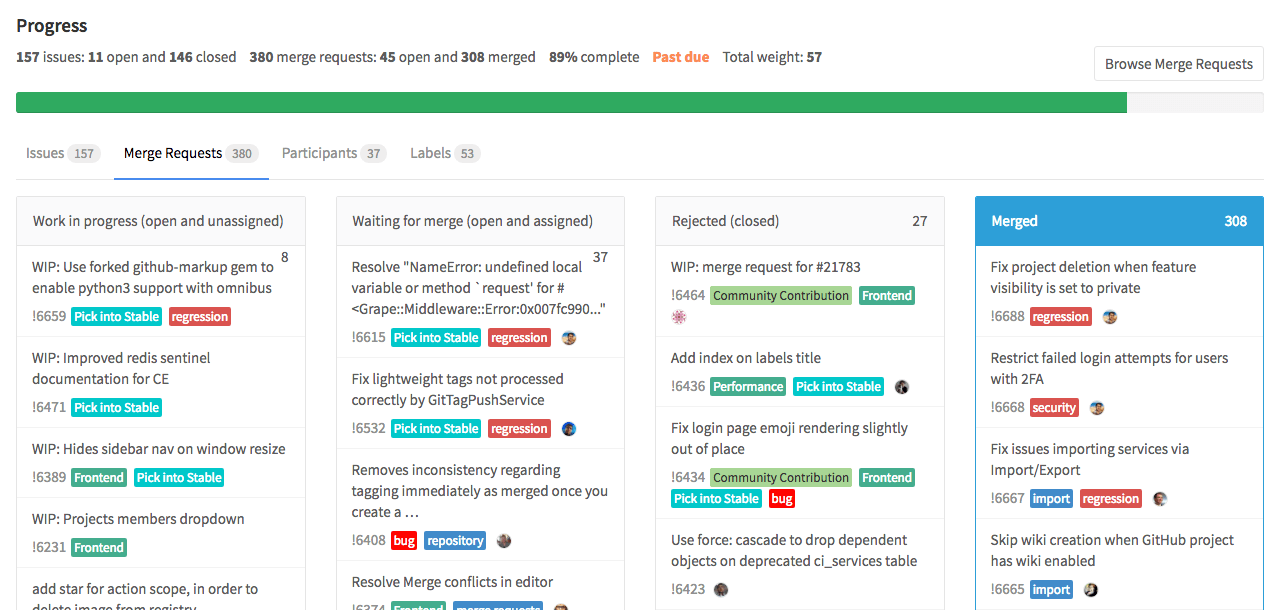
|
||||
|
||||
### 专业技巧
|
||||
|
||||
#### 工单和 MR
|
||||
|
||||
* 在工单和 MR 的描述中:
|
||||
* 输入 `#` 来触发一个已有工单的下拉列表
|
||||
* 输入 `!` 来触发一个已有 MR 的下拉列表
|
||||
* 输入 `/` 来触发[斜线命令][4]
|
||||
* 输入 `:` 来出发 emoji 表情 (也支持行中评论)
|
||||
* 通过按钮“附加文件”来添加图片(jpg、png、gif) 和视频到行内评论
|
||||
* 通过 [GitLab Webhooks][26] [自动应用标签][27]
|
||||
* [构成引用][24]: 使用语法 `>>>` 来开始或者结束一个引用
|
||||
|
||||
```
|
||||
>>>
|
||||
Quoted text
|
||||
|
||||
Another paragraph
|
||||
>>>
|
||||
```
|
||||
* 创建[任务列表][23]:
|
||||
|
||||
```
|
||||
- [ ] Task 1
|
||||
- [ ] Task 2
|
||||
- [ ] Task 3
|
||||
```
|
||||
|
||||
##### 订阅
|
||||
|
||||
你是否发现你有一个工单或者 MR 想要追踪?展开你的右边的导航,点击[订阅][59],你就可以在随时收到一个评论的提醒。要是你想要一次订阅多个工单和 MR?使用[批量订阅][58]。
|
||||
|
||||
##### 添加代办
|
||||
|
||||
除了一直留意工单和 MR,如果你想要对它预先做点什么,或者不管什么时候你想要在 GitLab 代办列表中添加点什么,点击你右边的导航,并且[点击**添加代办**][57]。
|
||||
|
||||
##### 寻找你的工单和 MR
|
||||
|
||||
当你寻找一个在很久以前由你开启的工单或 MR——它们可能数以十计、百计、甚至千计——所以你很难找到它们。打开你左边的导航,并且点击**工单**或者**合并请求**,你就会看到那些分配给你的。同时,在那里或者任何工单追踪器里,你可以通过作者、分配者、里程碑、标签以及重要性来过滤工单,也可以通过搜索所有不同状态的工单,例如开启的、合并的,关闭的等等。
|
||||
|
||||
#### 移动工单
|
||||
|
||||
一个工单在一个错误的项目中结束了?不用担心,点击**Edit**,然后[移动工单][56]到正确的项目。
|
||||
|
||||
#### 代码片段
|
||||
|
||||
你经常在不同的项目以及文件中使用一些相同的代码段和模版吗?创建一个代码段并且使它在你需要的时候可用。打开左边导航栏,点击**[Snipptes][25]**。所有你的片段都会在那里。你可以把它们设置成公开的,内部的(仅为 GitLab 注册用户提供),或者私有的。
|
||||
|
||||
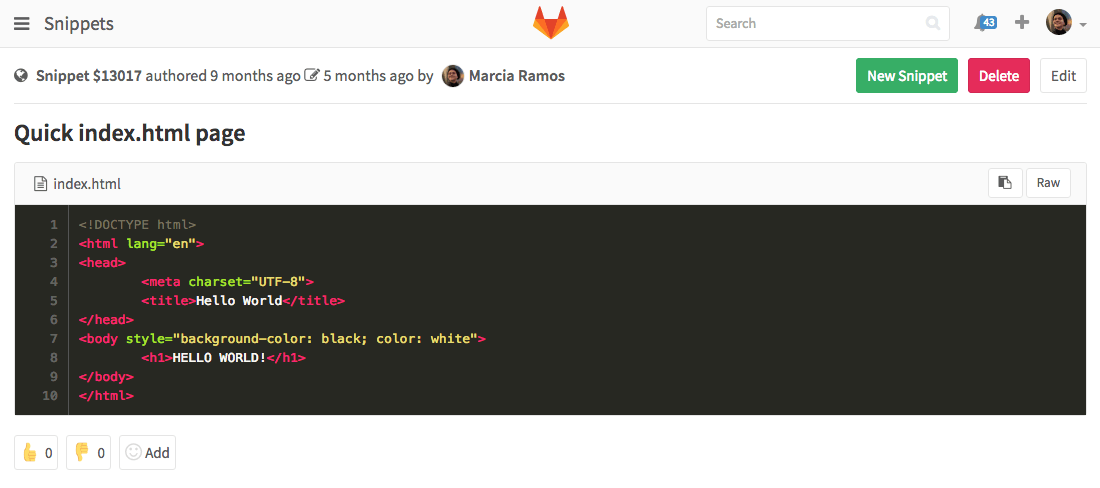
|
||||
|
||||
### GitLab 工作流用户案例概要
|
||||
|
||||
作为总结,让我们把所有东西聚在一起理顺一下。不必担心,这十分简单。
|
||||
|
||||
让我们假设:你工作于一个专注于软件开发的公司。你创建了一个新的工单,这个工单是为了开发一个新功能,实施于你的一个应用中。
|
||||
|
||||
**标签策略**
|
||||
|
||||
为了这个应用,你已经创建了几个标签,“讨论”、“后端”、“前端”、“正在进行”、“展示”、“就绪”、“文档”、“营销”以及“产品”。所有都已经在工单看板有它们自己的列表。你的当前的工单已经有了标签“讨论”。
|
||||
|
||||
在工单追踪器中的讨论达成一致之后,你的后端团队开始在工单上工作,所以他们把这个工单的标签从“讨论”移动到“后端”。第一个开发者开始写代码,并且把这个工单分配给自己,增加标签“正在进行”。
|
||||
|
||||
**编码 & 提交**
|
||||
|
||||
在他的第一次提交的信息中,他提及了他的工单编号。在工作后,他把他的提交推送到一个功能分支,并且创建一个新的合并请求,在 MR 描述中,包含工单关闭模式。他的团队复审了他的代码并且保证所有的测试和建立都已经通过。
|
||||
|
||||
**使用工单看板**
|
||||
|
||||
一旦后端团队完成了他们的工作,他们就删除“正在进行”标签,并且把工单从“后端”移动到“前端”看板。所以,前端团队接到通知,这个工单已经为他们准备好了。
|
||||
|
||||
**发布到演示**
|
||||
|
||||
当一个前端开发者开始在该工单上工作,他(她)增加一个标签“正在进行”,并且把这个工单重新分配给自己。当工作完成,该实现将会被发布到一个**演示**环境。标签“正在进行”就会被删除,然后在工单看板里,工单卡被移动到“演示”列表中。
|
||||
|
||||
**团队合作**
|
||||
|
||||
最后,当新功能成功实现,你的团队把它移动到“就绪”列表。
|
||||
|
||||
然后,就是你的技术文档编写团队的时间了,他们为新功能书写文档。一旦某个人完成书写,他添加标签“文档”。同时,你的市场团队开始启动并推荐该功能,所以某个人添加“市场”。当技术文档书写完毕,书写者删除标签“文档”。一旦市场团队完成他们的工作,他们将工单从“市场”移动到“生产”。
|
||||
|
||||
**部署到生产环境**
|
||||
|
||||
最后,你将会成为那个为新版本负责的人,合并“合并请求”并且将新功能部署到**生产**环境,然后工单的状态转变为**关闭**。
|
||||
|
||||
**反馈**
|
||||
|
||||
通过[周期分析][55],你和你的团队节省了如何从点子到产品的时间,并且开启另一个工单,来讨论如何将这个过程进一步提升。
|
||||
|
||||
### 总结
|
||||
|
||||
GitLab 工作流通过一个单一平台帮助你的团队加速从点子到生产的改变:
|
||||
|
||||
* 它是**有效的**:因为你可以获取你想要的结果
|
||||
* 它是**高效的**:因为你可以用最小的努力和成本达到最大的生产力
|
||||
* 它是**高产的**:因为你可以非常有效的计划和行动
|
||||
* 它是**简单的**:因为你不需要安装不同的工具去完成你的目的,仅仅需要 GitLab
|
||||
* 它是**快速的**:因为你不需要在多个平台间跳转来完成你的工作
|
||||
|
||||
每一个月的 22 号都会有一个新的 GitLab 版本释出,让它在集成软件开发解决方案上变得越来越好,让团队可以在一个单一的、唯一的界面下一起工作。
|
||||
|
||||
在 GitLab,每个人都可以奉献!多亏了我们强大的社区,我们获得了我们想要的。并且多亏了他们,我们才能一直为你提供更好的产品。
|
||||
|
||||
还有什么问题和反馈吗?请留言,或者在推特上@我们[@GitLab][54]!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/
|
||||
|
||||
作者:[Marcia Ramos][a]
|
||||
译者:[svtter](https://github.com/svtter)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://twitter.com/XMDRamos
|
||||
[1]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#search-for-your-issues-and-mrs
|
||||
[2]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#add-to-do
|
||||
[3]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#subscribe
|
||||
[4]:https://docs.gitlab.com/ce/user/project/slash_commands.html
|
||||
[5]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#code-snippets
|
||||
[6]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#moving-issues
|
||||
[7]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#for-both-issues-and-mrs
|
||||
[8]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#milestones
|
||||
[9]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#issue-and-mr-templates
|
||||
[10]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#use-cases
|
||||
[11]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#koding
|
||||
[12]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#review
|
||||
[13]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#wip-mr
|
||||
[14]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#merge-request
|
||||
[15]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#first-commit
|
||||
[16]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#gitlab-issue-board
|
||||
[17]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#issue-weight
|
||||
[18]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#labels
|
||||
[19]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#assignee
|
||||
[20]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#due-dates
|
||||
[21]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#confidential-issues
|
||||
[22]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#stages-of-software-development
|
||||
[23]:https://docs.gitlab.com/ee/user/markdown.html#task-lists
|
||||
[24]:https://about.gitlab.com/2016/07/22/gitlab-8-10-released/#blockquote-fence-syntax
|
||||
[25]:https://gitlab.com/dashboard/snippets
|
||||
[26]:https://docs.gitlab.com/ce/web_hooks/web_hooks.html
|
||||
[27]:https://about.gitlab.com/2016/08/19/applying-gitlab-labels-automatically/
|
||||
[28]:https://docs.gitlab.com/ce/ci/yaml/README.html#environment
|
||||
[29]:https://about.gitlab.com/2016/05/23/gitlab-container-registry/
|
||||
[30]:https://about.gitlab.com/2016/08/11/building-an-elixir-release-into-docker-image-using-gitlab-ci-part-1/
|
||||
[31]:https://about.gitlab.com/2016/03/10/setting-up-gitlab-ci-for-ios-projects/
|
||||
[32]:https://docs.gitlab.com/ce/ci/yaml/README.html#environment
|
||||
[33]:https://about.gitlab.com/2016/08/26/ci-deployment-and-environments/
|
||||
[34]:https://pages.gitlab.io/
|
||||
[35]:https://about.gitlab.com/2016/06/17/ssg-overview-gitlab-pages-part-3-examples-ci/
|
||||
[36]:https://about.gitlab.com/2016/04/07/gitlab-pages-setup/
|
||||
[37]:https://about.gitlab.com/solutions/cycle-analytics/
|
||||
[38]:https://about.gitlab.com/2016/08/05/continuous-integration-delivery-and-deployment-with-gitlab/
|
||||
[39]:https://about.gitlab.com/2016/08/05/continuous-integration-delivery-and-deployment-with-gitlab/
|
||||
[40]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#gitlab-code-review
|
||||
[41]:https://about.gitlab.com/gitlab-ci/
|
||||
[42]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#gitlab-issue-board
|
||||
[43]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#gitlab-issue-tracker
|
||||
[44]:https://about.gitlab.com/2015/08/18/gitlab-loves-mattermost/
|
||||
[45]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#conclusions
|
||||
[46]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#gitlab-workflow-use-case-scenario
|
||||
[47]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#pro-tips
|
||||
[48]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#enhance
|
||||
[49]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#feedback
|
||||
[50]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#build-test-and-deploy
|
||||
[51]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#code-review-with-gitlab
|
||||
[52]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#gitlab-issue-tracker
|
||||
[53]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#gitlab-workflow
|
||||
[54]:https://twitter.com/gitlab
|
||||
[55]:https://about.gitlab.com/solutions/cycle-analytics/
|
||||
[56]:https://about.gitlab.com/2016/03/22/gitlab-8-6-released/#move-issues-to-other-projects
|
||||
[57]:https://about.gitlab.com/2016/06/22/gitlab-8-9-released/#manually-add-todos
|
||||
[58]:https://about.gitlab.com/2016/07/22/gitlab-8-10-released/#bulk-subscribe-to-issues
|
||||
[59]:https://about.gitlab.com/2016/03/22/gitlab-8-6-released/#subscribe-to-a-label
|
||||
[60]:https://about.gitlab.com/2016/08/05/feature-highlight-set-dates-for-issues/#milestones
|
||||
[61]:https://gitlab.com/gitlab-org/gitlab-ce/issues/new
|
||||
[62]:https://docs.gitlab.com/ee/user/markdown.html
|
||||
[63]:https://docs.gitlab.com/ce/user/project/description_templates.html
|
||||
[64]:https://about.gitlab.com/2016/09/21/cycle-analytics-feature-highlight/
|
||||
[65]:https://about.gitlab.com/solutions/cycle-analytics/
|
||||
[66]:https://docs.gitlab.com/ee/ci/examples/README.html
|
||||
[67]:https://about.gitlab.com/2016/08/22/gitlab-8-11-released/#koding-integration
|
||||
[68]:https://about.gitlab.com/2016/08/05/continuous-integration-delivery-and-deployment-with-gitlab/
|
||||
[69]:https://about.gitlab.com/gitlab-ci/
|
||||
[70]:https://about.gitlab.com/2016/08/22/gitlab-8-11-released/#merge-conflict-resolution
|
||||
[71]:https://docs.gitlab.com/ce/user/project/slash_commands.html
|
||||
[72]:https://about.gitlab.com/2016/10/22/gitlab-8-13-released/#wip-slash-command
|
||||
[73]:https://gitlab.com/gitlab-examples/review-apps-nginx/
|
||||
[74]:https://about.gitlab.com/2016/10/22/gitlab-8-13-released/#ability-to-stop-review-apps
|
||||
[75]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#feedback
|
||||
[76]:https://docs.gitlab.com/ce/administration/issue_closing_pattern.html
|
||||
[77]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#milestones
|
||||
[78]:https://docs.gitlab.com/ce/administration/issue_closing_pattern.html
|
||||
[79]:https://docs.gitlab.com/ee/user/markdown.html
|
||||
[80]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#feedback
|
||||
[81]:https://about.gitlab.com/2014/09/29/gitlab-flow/
|
||||
[82]:https://about.gitlab.com/free-trial/
|
||||
[83]:https://about.gitlab.com/2016/10/22/gitlab-8-13-released/#multiple-issue-boards-ee
|
||||
[84]:https://about.gitlab.com/solutions/issueboard
|
||||
[85]:https://docs.gitlab.com/ee/workflow/issue_weight.html
|
||||
[86]:https://about.gitlab.com/2016/10/22/gitlab-8-13-released/#group-labels
|
||||
[87]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#gitlab-issue-board
|
||||
[88]:https://docs.gitlab.com/ee/user/project/labels.html#prioritize-labels
|
||||
[89]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#milestones
|
||||
[90]:https://about.gitlab.com/2016/08/05/feature-highlight-set-dates-for-issues/#due-dates-for-issues
|
||||
[91]:https://docs.gitlab.com/ce/user/permissions.html
|
||||
[92]:https://about.gitlab.com/2016/03/31/feature-highlihght-confidential-issues/
|
||||
[93]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#pro-tips
|
||||
[94]:https://docs.gitlab.com/ee/user/markdown.html
|
||||
[95]:https://about.gitlab.com/2016/03/03/start-with-an-issue/
|
||||
[96]:https://about.gitlab.com/2016/09/13/gitlab-master-plan/
|
||||
[97]:https://about.gitlab.com/2014/09/29/gitlab-flow/
|
||||
@ -0,0 +1,138 @@
|
||||
向 Linus Torvalds 学习让编出的代码具有 “good taste”
|
||||
========
|
||||
|
||||
在[最近关于 Linus Torvalds 的一个采访中][1],这位 Linux 的创始人,在采访过程中大约 14:20 的时候,提及了关于代码的 “good taste”。good taste?采访者请他展示更多的细节,于是,Linus Torvalds 展示了一张提前准备好的插图。
|
||||
|
||||
他展示的是一个代码片段。但这段代码并没有 “good taste”。这是一个具有 “poor taste” 的代码片段,把它作为例子,以提供一些初步的比较。
|
||||
|
||||

|
||||
|
||||
这是一个用 C 写的函数,作用是删除链表中的一个对象,它包含有 10 行代码。
|
||||
|
||||
他把注意力集中在底部的 `if` 语句。正是这个 `if` 语句受到他的批判。
|
||||
|
||||
我暂停了这段视频,开始研究幻灯片。我发现我最近有写过和这很像的代码。Linus 不就是在说我的代码品味很差吗?我放下自傲,继续观看视频。
|
||||
|
||||
随后, Linus 向观众解释,正如我们所知道的,当从链表中删除一个对象时,需要考虑两种可能的情况。当所需删除的对象位于链表的表头时,删除过程和位于链表中间的情况不同。这就是这个 `if` 语句具有 “poor taste” 的原因。
|
||||
|
||||
但既然他承认考虑这两种不同的情况是必要的,那为什么像上面那样写如此糟糕呢?
|
||||
|
||||
接下来,他又向观众展示了第二张幻灯片。这个幻灯片展示的是实现同样功能的一个函数,但这段代码具有 “goog taste” 。
|
||||
|
||||

|
||||
|
||||
原先的 10 行代码现在减少为 4 行。
|
||||
|
||||
但代码的行数并不重要,关键是 `if` 语句,它不见了,因为不再需要了。代码已经被重构,所以,不用管对象在列表中的位置,都可以运用同样的操作把它删除。
|
||||
|
||||
Linus 解释了一下新的代码,它消除了边缘情况,就是这样。然后采访转入了下一个话题。
|
||||
|
||||
我琢磨了一会这段代码。 Linus 是对的,的确,第二个函数更好。如果这是一个确定代码具有 “good taste” 还是 “bad taste” 的测试,那么很遗憾,我失败了。我从未想到过有可能能够去除条件语句。我写过不止一次这样的 `if` 语句,因为我经常使用链表。
|
||||
|
||||
这个例子的意义,不仅仅是教给了我们一个从链表中删除对象的更好方法,而是启发了我们去思考自己写的代码。你通过程序实现的一个简单算法,可能还有改进的空间,只是你从来没有考虑过。
|
||||
|
||||
以这种方式,我回去审查最近正在做的项目的代码。也许是一个巧合,刚好也是用 C 写的。
|
||||
|
||||
我尽最大的能力去审查代码,“good taste” 的一个基本要求是关于边缘情况的消除方法,通常我们会使用条件语句来消除边缘情况。你的测试使用的条件语句越少,你的代码就会有更好的 “taste” 。
|
||||
|
||||
下面,我将分享一个通过审查代码进行了改进的一个特殊例子。
|
||||
|
||||
这是一个关于初始化网格边缘的算法。
|
||||
|
||||
下面所写的是一个用来初始化网格边缘的算法,网格 grid 以一个二维数组表示:grid[行][列] 。
|
||||
|
||||
再次说明,这段代码的目的只是用来初始化位于 grid 边缘的点的值,所以,只需要给最上方一行、最下方一行、最左边一列以及最右边一列赋值即可。
|
||||
|
||||
为了完成这件事,我通过循环遍历 grid 中的每一个点,然后使用条件语句来测试该点是否位于边缘。代码看起来就是下面这样:
|
||||
|
||||
```Tr
|
||||
for (r = 0; r < GRID_SIZE; ++r) {
|
||||
for (c = 0; c < GRID_SIZE; ++c) {
|
||||
// Top Edge
|
||||
if (r == 0)
|
||||
grid[r][c] = 0;
|
||||
// Left Edge
|
||||
if (c == 0)
|
||||
grid[r][c] = 0;
|
||||
// Right Edge
|
||||
if (c == GRID_SIZE - 1)
|
||||
grid[r][c] = 0;
|
||||
// Bottom Edge
|
||||
if (r == GRID_SIZE - 1)
|
||||
grid[r][c] = 0;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
虽然这样做是对的,但回过头来看,这个结构存在一些问题。
|
||||
|
||||
1. 复杂性 — 在双层循环里面使用 4 个条件语句似乎过于复杂。
|
||||
2. 高效性 — 假设 `GRID_SIZE` 的值为 64,那么这个循环需要执行 4096 次,但需要进行赋值的只有位于边缘的 256 个点。
|
||||
|
||||
用 Linus 的眼光来看,将会认为这段代码没有 “good taste” 。
|
||||
|
||||
所以,我对上面的问题进行了一下思考。经过一番思考,我把复杂度减少为包含四个条件语句的单层 `for` 循环。虽然只是稍微改进了一下复杂性,但在性能上也有了极大的提高,因为它只是沿着边缘的点进行了 256 次循环。
|
||||
|
||||
```
|
||||
for (i = 0; i < GRID_SIZE * 4; ++i) {
|
||||
// Top Edge
|
||||
if (i < GRID_SIZE)
|
||||
grid[0][i] = 0;
|
||||
// Right Edge
|
||||
else if (i < GRID_SIZE * 2)
|
||||
grid[i - GRID_SIZE][GRID_SIZE - 1] = 0;
|
||||
// Left Edge
|
||||
else if (i < GRID_SIZE * 3)
|
||||
grid[i - (GRID_SIZE * 2)][0] = 0;
|
||||
// Bottom Edge
|
||||
else
|
||||
grid[GRID_SIZE - 1][i - (GRID_SIZE * 3)] = 0;
|
||||
}
|
||||
```
|
||||
|
||||
的确是一个很大的提高。但是它看起来很丑,并不是易于阅读理解的代码。基于这一点,我并不满意。
|
||||
|
||||
我继续思考,是否可以进一步改进呢?事实上,答案是 YES!最后,我想出了一个非常简单且优雅的算法,老实说,我不敢相信我会花了那么长时间才发现这个算法。
|
||||
|
||||
下面是这段代码的最后版本。它只有一层 `for` 循环并且没有条件语句。另外。循环只执行了 64 次迭代,极大的改善了复杂性和高效性。
|
||||
|
||||
```
|
||||
for (i = 0; i < GRID_SIZE; ++i) {
|
||||
// Top Edge
|
||||
grid[0][i] = 0;
|
||||
|
||||
// Bottom Edge
|
||||
grid[GRID_SIZE - 1][i] = 0;
|
||||
// Left Edge
|
||||
grid[i][0] = 0;
|
||||
// Right Edge
|
||||
grid[i][GRID_SIZE - 1] = 0;
|
||||
}
|
||||
```
|
||||
|
||||
这段代码通过每次循环迭代来初始化四条边缘上的点。它并不复杂,而且非常高效,易于阅读。和原始的版本,甚至是第二个版本相比,都有天壤之别。
|
||||
|
||||
至此,我已经非常满意了。
|
||||
|
||||
那么,我是一个有 “good taste” 的开发者么?
|
||||
|
||||
我觉得我是,但是这并不是因为我上面提供的这个例子,也不是因为我在这篇文章中没有提到的其它代码……而是因为具有 “good taste” 的编码工作远非一段代码所能代表。Linus 自己也说他所提供的这段代码不足以表达他的观点。
|
||||
|
||||
我明白 Linus 的意思,也明白那些具有 “good taste” 的程序员虽各有不同,但是他们都是会将他们之前开发的代码花费时间重构的人。他们明确界定了所开发的组件的边界,以及是如何与其它组件之间的交互。他们试着确保每一样工作都完美、优雅。
|
||||
|
||||
其结果就是类似于 Linus 的 “good taste” 的例子,或者像我的例子一样,不过是千千万万个 “good taste”。
|
||||
|
||||
你会让你的下个项目也具有这种 “good taste” 吗?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.com/@bartobri/applying-the-linus-tarvolds-good-taste-coding-requirement-99749f37684a
|
||||
|
||||
作者:[Brian Barto][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.com/@bartobri?source=post_header_lockup
|
||||
[1]:https://www.ted.com/talks/linus_torvalds_the_mind_behind_linux
|
||||
@ -0,0 +1,165 @@
|
||||
Linux 容器能否弥补 IoT 的安全短板?
|
||||
========
|
||||
|
||||

|
||||
|
||||
> 在这个最后的物联网系列文章中,Canonical 和 Resin.io 向以 Linux 容器技术作为解决方案向物联网安全性和互操作性发起挑战。
|
||||
|
||||

|
||||
|
||||
*Artik 7*
|
||||
|
||||
尽管受到日益增长的安全威胁,但对物联网(IoT)的炒作没有显示减弱的迹象。为了刷存在感,公司们正忙于重新规划它们的物联网方面的路线图。物联网大潮迅猛异常,比移动互联网革命渗透的更加深入和广泛。IoT 像黑洞一样,吞噬一切,包括智能手机,它通常是我们通向物联网世界的窗口,有时也作为我们的汇聚点或终端。
|
||||
|
||||
新的针对物联网的处理器和嵌入式主板继续重塑其技术版图。自从 9 月份推出 [面向物联网的 Linux 和开源硬件][5] 系列文章之后,我们看到了面向物联网网关的 “Apollo Lake]” SoC 芯片 [Intel Atom E3900][6] 以及[三星 新的 Artik 模块][7],包括用于网关并由 Linux 驱动的 64 位 Artik 7 COM 及自带 RTOS 的 Cortex-M4 Artik。 ARM 为具有 ARMv8-M 和 TrustZone 安全性的 IoT 终端发布了 [Cortex-M23 和 Cortex-M33][8] 芯片。
|
||||
|
||||
讲道理,安全是这些产品的卖点。最近攻击 Dyn 服务并在一天内摧毁了美国大部分互联网的 Mirai 僵尸网络将基于 Linux 的物联网推到台前 - 当然这种方式似乎不太体面。就像 IoT 设备可以成为 DDoS 的帮凶一样,设备及其所有者同样可能直接遭受恶意攻击。
|
||||
|
||||

|
||||
|
||||
*Cortex-M33 和 -M23*
|
||||
|
||||
Dyn 攻击更加证明了这种观点,即物联网将更加蓬勃地在受控制和受保护的工业环境发展,而不是家用环境中。这不是因为没有消费级[物联网安全技术][9],但除非产品设计之初就以安全为目标,否则如我们的[智能家居集线器系列][10]中的许多解决方案一样,后期再考虑安全就会增加成本和复杂性。
|
||||
|
||||
在物联网系列的最后这个未来展望的部分,我们将探讨两种基于 Linux 的面向 Docker 的容器技术,这些技术被提出作为物联网安全解决方案。容器还可以帮助解决我们在[物联网框架][11]中探讨的开发复杂性和互操作性障碍的问题。
|
||||
|
||||
我们与 Canonical 的 Ubuntu 客户平台工程副总裁 Oliver Ries 讨论了 Ubuntu Core 和适用于 Docker 的容器式 Snaps 包管理技术。我们还就新的基于 Docker 的物联网方案 ResinOS 采访了 Resin.io 首席执行官和联合创始人 Alexandros Marinos。
|
||||
|
||||
### Ubuntu Core Snaps
|
||||
|
||||
Canonical 面向物联网的 [Snappy Ubuntu Core][12] 版本的 Ubuntu 是围绕一个类似容器的快照包管理机制而构建的,并提供应用商店支持。 snaps 技术最近[自行发布了][13]用于其他 Linux 发行版的版本。去年 11 月 3 日,Canonical 发布了 [Ubuntu Core 16] [14],该版本改进了白标应用商店和更新控制服务。
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
*传统 Ubuntu(左)架构 与 Ubuntu Core 16*
|
||||
|
||||
快照机制提供自动更新,并有助于阻止未经授权的更新。 使用事务系统管理,快照可确保更新按预期部署或根本不部署。 在 Ubuntu Core 中,使用 AppArmor 进一步加强了安全性,并且所有应用程序文件都是只读的且保存在隔离的孤岛中。
|
||||
|
||||

|
||||
|
||||
*LimeSDR*
|
||||
|
||||
Ubuntu Core 是我们最近展开的[开源物联网操作系统调查][16]的一部分,现在运行于 Gumstix 主板、Erle 机器人无人机、Dell Edge 网关、[Nextcloud Box][17]、LimeSDR、Mycroft 家庭集线器、英特尔的 Joule 和符合 Linaro 的 96Boards 规范的 SBC(单板计算机) 上。 Canonical 公司还与 Linaro 物联网和嵌入式(LITE)部门集团在其 [96Boards 物联网版(IE)][18] 上达成合作。最初,96Boards IE 专注于 Zephyr 驱动的 Cortex-M4 板卡,如 Seeed 的 [BLE Carbon] [19],不过它将扩展到可以运行 Ubuntu Core 的网关板卡上。
|
||||
|
||||
“Ubuntu Core 和 snaps 具有从边缘到网关到云的相关性,”Canonical 的 Ries 说。 “能够在任何主要发行版(包括 Ubuntu Server 和 Ubuntu for Cloud)上运行快照包,使我们能够提供一致的体验。 snaps 可以使用事务更新以免故障方式升级,可用于安全性更新、错误修复或新功能的持续更新,这在物联网环境中非常重要。”
|
||||
|
||||

|
||||
|
||||
*Nextcloud盒子*
|
||||
|
||||
安全性和可靠性是关注的重点,Ries 说。 “snaps 应用可以完全独立于彼此和操作系统而运行,使得两个应用程序可以安全地在单个网关上运行,”他说。 “snaps 是只读的和经过认证的,可以保证代码的完整性。
|
||||
|
||||
Ries 还说这种技术减少开发时间。 “snap 软件包允许开发人员向支持它的任何平台提供相同的二进制包,从而降低开发和测试成本,减少部署时间和提高更新速度。 “使用 snap 软件包,开发人员完可以全控制开发生命周期,并可以立即更新。 snap 包提供了所有必需的依赖项,因此开发人员可以选择定制他们使用的组件。”
|
||||
|
||||
### ResinOS: 为 IoT 而生的 Docker
|
||||
|
||||
Resin.io 公司,与其商用的 IoT 框架同名,最近剥离了该框架的基于 Yocto Linux 的 [ResinOS 2.0][20],ResinOS 2.0 将作为一个独立的开源项目运营。 Ubuntu Core 在 snap 包中运行 Docker 容器引擎,ResinOS 在主机上运行 Docker。 极致简约的 ResinOS 抽离了使用 Yocto 代码的复杂性,使开发人员能够快速部署 Docker 容器。
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
*ResinOS 2.0 架构*
|
||||
|
||||
与基于 Linux 的 CoreOS 一样,ResinOS 集成了 systemd 控制服务和网络协议栈,可通过异构网络安全地部署更新的应用程序。 但是,它是为在资源受限的设备(如 ARM 黑客板)上运行而设计的,与之相反,CoreOS 和其他基于 Docker 的操作系统(例如基于 Red Hat 的 Project Atomic)目前仅能运行在 x86 上,并且更喜欢资源丰富的服务器平台。 ResinOS 可以在 20 中 Linux 设备上运行,并不断增长,包括 Raspberry Pi,BeagleBone 和Odroid-C1 等。
|
||||
|
||||
“我们认为 Linux 容器对嵌入式系统比对于云更重要,”Resin.io 的 Marinos 说。 “在云中,容器代表了对之前的进程的优化,但在嵌入式中,它们代表了姗姗来迟的通用虚拟化“
|
||||
|
||||

|
||||
|
||||
*BeagleBone Black*
|
||||
|
||||
当应用于物联网时,完整的企业级虚拟机有直接访问硬件的限制的性能缺陷,Marinos 说。像 OSGi 和 Android 的Dalvik 这样的移动设备虚拟机可以用于 IoT,但是它们依赖 Java 并有其他限制。
|
||||
|
||||
对于企业开发人员来说,使用 Docker 似乎很自然,但是你如何说服嵌入式黑客转向全新的范式呢? “Marinos 解释说,”ResinOS 不是把云技术的实践经验照单全收,而是针对嵌入式进行了优化。”此外,他说,容器比典型的物联网技术更好地包容故障。 “如果有软件缺陷,主机操作系统可以继续正常工作,甚至保持连接。要恢复,您可以重新启动容器或推送更新。更新设备而不重新启动它的能力进一步消除了故障引发问题的机率。”
|
||||
|
||||
据 Marinos 所说,其他好处源自与云技术的一致性,例如拥有更广泛的开发人员。容器提供了“跨数据中心和边缘的统一范式,以及一种方便地将技术、工作流、基础设施,甚至应用程序转移到边缘(终端)的方式。”
|
||||
|
||||
Marinos 说,容器中的固有安全性优势正在被其他技术增强。 “随着 Docker 社区推动实现镜像签名和鉴证,这些自然会转移并应用到 ResinOS,”他说。 “当 Linux 内核被强化以提高容器安全性时,或者获得更好地管理容器所消耗的资源的能力时,会产生类似的好处。
|
||||
|
||||
容器也适合开源 IoT 框架,Marinos 说。 “Linux 容器很容易与几乎各种协议、应用程序、语言和库结合使用,”Marinos 说。 “Resin.io 参加了 AllSeen 联盟,我们与使用 IoTivity 和 Thread的 伙伴一起合作。”
|
||||
|
||||
### IoT的未来:智能网关与智能终端
|
||||
|
||||
Marinos 和 Canonical 的 Ries 对未来物联网的几个发展趋势具有一致的看法。 首先,物联网的最初概念(其中基于 MCU 的端点直接与云进行通信以进行处理)正在迅速被雾化计算架构所取代。 这需要更智能的网关,也需要比仅仅在 ZigBee 和 WiFi 之间聚合和转换数据更多的功能。
|
||||
|
||||
其次,网关和智能边缘设备越来越多地运行多个应用程序。 第三,许多这些设备将提供板载分析,这些在最新的[智能家居集线器][22]上都有体现。 最后,富媒体将很快成为物联网组合的一部分。
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
*最新设备网关: Eurotech 的 [ReliaGate 20-26][1]*
|
||||
|
||||

|
||||
|
||||
|
||||
*最新设备网关: Advantech 的 [UBC-221][2]*
|
||||
|
||||
“智能网关正在接管最初为云服务设计的许多处理和控制功能,”Marinos 说。 “因此,我们看到对容器化的推动力在增加,可以在 IoT 设备中使用类似云工作流程来部署与功能和安全相关的优化。去中心化是由移动数据紧缩、不断发展的法律框架和各种物理限制等因素驱动的。”
|
||||
|
||||
Ubuntu Core 等平台正在使“可用于网关的软件爆炸式增长”,Canonical 的 Ries 说。 “在单个设备上运行多个应用程序的能力吸引了众多单一功能设备的用户,以及现在可以产生持续的软件收入的设备所有者。”
|
||||
|
||||

|
||||
|
||||
*两种 IoT 网关: [MyOmega MYNXG IC2 Controller][3]*
|
||||
|
||||

|
||||
|
||||
*两种 IoT 网关: TechNexion 的 [LS1021A-IoT Gateway][4]*
|
||||
|
||||
不仅是网关 - 终端也变得更聪明。 “阅读大量的物联网新闻报道,你得到的印象是所有终端都运行在微控制器上,”Marinos 说。 “但是我们对大量的 Linux 终端,如数字标牌,无人机和工业机械等直接执行任务,而不是作为操作中介(数据转发)感到惊讶。我们称之为影子 IoT。”
|
||||
|
||||
Canonical 的 Ries 同意,对简约技术的专注使他们忽视了新兴物联网领域。 “轻量化的概念在一个发展速度与物联网一样快的行业中初现端倪,”Ries 说。 “今天的高级消费硬件可以持续为终端供电数月。”
|
||||
|
||||
虽然大多数物联网设备将保持轻量和“无头”(一种配置方式,比如物联网设备缺少显示器,键盘等),它们装备有如加速度计和温度传感器这样的传感器并通过低速率的数据流通信,但是许多较新的物联网应用已经使用富媒体。 “媒体输入/输出只是另一种类型的外设,”Marinos 说。 “总是存在多个容器竞争有限资源的问题,但它与传感器或蓝牙竞争天线资源没有太大区别。”
|
||||
|
||||
Ries 看到了工业和家庭网关中“提高边缘智能”的趋势。 “我们看到人工智能、机器学习、计算机视觉和上下文意识的大幅上升,”Ries 说。 “为什么要在云中运行面部检测软件,如果相同的软件可以在边缘设备运行而又没有网络延迟和带宽及计算成本呢?“
|
||||
|
||||
当我们在这个物联网系列的[开篇故事][27]中探索时,我们发现存在与安全相关的物联网问题,例如隐私丧失和生活在监视文化中的权衡。还有一些问题如把个人决策交给可能由他人操控的 AI 裁定。这些不会被容器,快照或任何其他技术完全解决。
|
||||
|
||||
如果 AWS Alexa 可以处理生活琐事,而我们专注在要事上,也许我们会更快乐。或许有一个方法来平衡隐私和效用,现在,我们仍在探索,如此甚好。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://hackerboards.com/can-linux-containers-save-iot-from-a-security-meltdown/
|
||||
|
||||
作者:[Eric Brown][a]
|
||||
译者:[firstadream](https://github.com/firstadream)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://hackerboards.com/can-linux-containers-save-iot-from-a-security-meltdown/
|
||||
[1]:http://hackerboards.com/atom-based-gateway-taps-new-open-source-iot-cloud-platform/
|
||||
[2]:http://hackerboards.com/compact-iot-gateway-runs-yocto-linux-on-quark/
|
||||
[3]:http://hackerboards.com/wireless-crazed-customizable-iot-gateway-uses-arm-or-x86-coms/
|
||||
[4]:http://hackerboards.com/iot-gateway-runs-linux-on-qoriq-accepts-arduino-shields/
|
||||
[5]:http://hackerboards.com/linux-and-open-source-hardware-for-building-iot-devices/
|
||||
[6]:http://hackerboards.com/intel-launches-14nm-atom-e3900-and-spins-an-automotive-version/
|
||||
[7]:http://hackerboards.com/samsung-adds-first-64-bit-and-cortex-m4-based-artik-modules/
|
||||
[8]:http://hackerboards.com/new-cortex-m-chips-add-armv8-and-trustzone/
|
||||
[9]:http://hackerboards.com/exploring-security-challenges-in-linux-based-iot-devices/
|
||||
[10]:http://hackerboards.com/linux-based-smart-home-hubs-advance-into-ai/
|
||||
[11]:http://hackerboards.com/open-source-projects-for-the-internet-of-things-from-a-to-z/
|
||||
[12]:http://hackerboards.com/lightweight-snappy-ubuntu-core-os-targets-iot/
|
||||
[13]:http://hackerboards.com/canonical-pushes-snap-as-a-universal-linux-package-format/
|
||||
[14]:http://hackerboards.com/ubuntu-core-16-gets-smaller-goes-all-snaps/
|
||||
[15]:http://hackerboards.com/files/canonical_ubuntucore16_diagram.jpg
|
||||
[16]:http://hackerboards.com/open-source-oses-for-the-internet-of-things/
|
||||
[17]:http://hackerboards.com/private-cloud-server-and-iot-gateway-runs-ubuntu-snappy-on-rpi/
|
||||
[18]:http://hackerboards.com/linaro-beams-lite-at-internet-of-things-devices/
|
||||
[19]:http://hackerboards.com/96boards-goes-cortex-m4-with-iot-edition-and-carbon-sbc/
|
||||
[20]:http://hackerboards.com/can-linux-containers-save-iot-from-a-security-meltdown/%3Ca%20href=
|
||||
[21]:http://hackerboards.com/files/resinio_resinos_arch.jpg
|
||||
[22]:http://hackerboards.com/linux-based-smart-home-hubs-advance-into-ai/
|
||||
[23]:http://hackerboards.com/files/eurotech_reliagate2026.jpg
|
||||
[24]:http://hackerboards.com/files/advantech_ubc221.jpg
|
||||
[25]:http://hackerboards.com/files/myomega_mynxg.jpg
|
||||
[26]:http://hackerboards.com/files/technexion_ls1021aiot_front.jpg
|
||||
[27]:http://hackerboards.com/an-open-source-perspective-on-the-internet-of-things-part-1/
|
||||
[28]:http://hackerboards.com/can-linux-containers-save-iot-from-a-security-meltdown/
|
||||
@ -1,8 +1,7 @@
|
||||
如何在 Ubuntu16.04 中用 Apache 部署 Jenkins 自动化服务器
|
||||
============================================================
|
||||
|
||||
|
||||
Jenkins 是从 Hudson 项目衍生出来的自动化服务器。Jenkins 是一个基于服务器的应用程序,运行在 Java servlet 容器中,它支持包括 Git、SVN 以及 Mercurial 在内的多种 SCM(Source Control Management,源码控制工具)。Jenkins 提供了上百种插件帮助你的项目实现自动化。Jenkins 由 Kohsuke Kawaguchi 开发,在 2011 年使用 MIT 协议发布了第一个发行版,它是个免费软件。
|
||||
Jenkins 是从 Hudson 项目衍生出来的自动化服务器。Jenkins 是一个基于服务器的应用程序,运行在 Java servlet 容器中,它支持包括 Git、SVN 以及 Mercurial 在内的多种 SCM(Source Control Management,源码控制工具)。Jenkins 提供了上百种插件帮助你的项目实现自动化。Jenkins 由 Kohsuke Kawaguchi 开发,在 2011 年使用 MIT 协议发布了第一个发行版,它是个自由软件。
|
||||
|
||||
在这篇指南中,我会向你介绍如何在 Ubuntu 16.04 中安装最新版本的 Jenkins。我们会用自己的域名运行 Jenkins,在 apache web 服务器中安装和配置 Jenkins,而且支持反向代理。
|
||||
|
||||
@ -17,22 +16,28 @@ Jenkins 基于 Java,因此我们需要在服务器上安装 Java OpenJDK 7。
|
||||
|
||||
默认情况下,Ubuntu 16.04 没有安装用于管理 PPA 仓库的 python-software-properties 软件包,因此我们首先需要安装这个软件。使用 apt 命令安装 python-software-properties。
|
||||
|
||||
`apt-get install python-software-properties`
|
||||
```
|
||||
apt-get install python-software-properties
|
||||
```
|
||||
|
||||
下一步,添加 Java PPA 仓库到服务器中。
|
||||
|
||||
`add-apt-repository ppa:openjdk-r/ppa`
|
||||
```
|
||||
add-apt-repository ppa:openjdk-r/ppa
|
||||
```
|
||||
|
||||
输入回车键
|
||||
用 apt 命令更新 Ubuntu 仓库并安装 Java OpenJDK。
|
||||
|
||||
用 apt 命令更新 Ubuntu 仓库并安装 Java OpenJDK。`
|
||||
|
||||
`apt-get update`
|
||||
`apt-get install openjdk-7-jdk`
|
||||
```
|
||||
apt-get update
|
||||
apt-get install openjdk-7-jdk
|
||||
```
|
||||
|
||||
输入下面的命令验证安装:
|
||||
|
||||
`java -version`
|
||||
```
|
||||
java -version
|
||||
```
|
||||
|
||||
你会看到安装到服务器上的 Java 版本。
|
||||
|
||||
@ -46,21 +51,29 @@ Jenkins 给软件安装包提供了一个 Ubuntu 仓库,我们会从这个仓
|
||||
|
||||
用下面的命令添加 Jenkins 密钥和仓库到系统中。
|
||||
|
||||
`wget -q -O - https://pkg.jenkins.io/debian-stable/jenkins.io.key | sudo apt-key add -`
|
||||
`echo 'deb https://pkg.jenkins.io/debian-stable binary/' | tee -a /etc/apt/sources.list`
|
||||
```
|
||||
wget -q -O - https://pkg.jenkins.io/debian-stable/jenkins.io.key | sudo apt-key add -
|
||||
echo 'deb https://pkg.jenkins.io/debian-stable binary/' | tee -a /etc/apt/sources.list
|
||||
```
|
||||
|
||||
更新仓库并安装 Jenkins。
|
||||
|
||||
`apt-get update`
|
||||
`apt-get install jenkins`
|
||||
```
|
||||
apt-get update
|
||||
apt-get install jenkins
|
||||
```
|
||||
|
||||
安装完成后,用下面的命令启动 Jenkins。
|
||||
|
||||
`systemctl start jenkins`
|
||||
```
|
||||
systemctl start jenkins
|
||||
```
|
||||
|
||||
通过检查 Jenkins 默认使用的端口(端口 8080)验证 Jenkins 正在运行。我会像下面这样用 netstat 命令检测:
|
||||
通过检查 Jenkins 默认使用的端口(端口 8080)验证 Jenkins 正在运行。我会像下面这样用 `netstat` 命令检测:
|
||||
|
||||
`netstat -plntu`
|
||||
```
|
||||
netstat -plntu
|
||||
```
|
||||
|
||||
Jenkins 已经安装好了并运行在 8080 端口。
|
||||
|
||||
@ -70,23 +83,29 @@ Jenkins 已经安装好了并运行在 8080 端口。
|
||||
|
||||
### 第三步 - 为 Jenkins 安装和配置 Apache 作为反向代理
|
||||
|
||||
在这篇指南中,我们会在一个 apache web 服务器中运行 Jenkins,我们会为 Jenkins 配置 apache 作为反向代理。首先我会安装 apache 并启用一些需要的模块,然后我会为 Jenkins 用域名 my.jenkins.id 创建虚拟 host 文件。请在这里使用你自己的域名并在所有配置文件中出现的地方替换。
|
||||
在这篇指南中,我们会在一个 Apache web 服务器中运行 Jenkins,我们会为 Jenkins 配置 apache 作为反向代理。首先我会安装 apache 并启用一些需要的模块,然后我会为 Jenkins 用域名 my.jenkins.id 创建虚拟主机文件。请在这里使用你自己的域名并在所有配置文件中出现的地方替换。
|
||||
|
||||
从 Ubuntu 仓库安装 apache2 web 服务器。
|
||||
|
||||
`apt-get install apache2`
|
||||
```
|
||||
apt-get install apache2
|
||||
```
|
||||
|
||||
安装完成后,启用 proxy 和 proxy_http 模块以便将 apache 配置为 Jenkins 的前端服务器/反向代理。
|
||||
|
||||
`a2enmod proxy`
|
||||
`a2enmod proxy_http`
|
||||
```
|
||||
a2enmod proxy
|
||||
a2enmod proxy_http
|
||||
```
|
||||
|
||||
下一步,在 sites-available 目录创建新的虚拟 host 文件。
|
||||
下一步,在 `sites-available` 目录创建新的虚拟主机文件。
|
||||
|
||||
`cd /etc/apache2/sites-available/`
|
||||
`vim jenkins.conf`
|
||||
```
|
||||
cd /etc/apache2/sites-available/
|
||||
vim jenkins.conf
|
||||
```
|
||||
|
||||
粘贴下面的虚拟 host 配置。
|
||||
粘贴下面的虚拟主机配置。
|
||||
|
||||
```
|
||||
<Virtualhost *:80>
|
||||
@ -106,18 +125,24 @@ Jenkins 已经安装好了并运行在 8080 端口。
|
||||
</Virtualhost>
|
||||
```
|
||||
|
||||
保存文件。然后用 a2ensite 命令激活 Jenkins 虚拟 host。
|
||||
保存文件。然后用 `a2ensite` 命令激活 Jenkins 虚拟主机。
|
||||
|
||||
`a2ensite jenkins`
|
||||
```
|
||||
a2ensite jenkins
|
||||
```
|
||||
|
||||
重启 Apache 和 Jenkins。
|
||||
|
||||
`systemctl restart apache2`
|
||||
`systemctl restart jenkins`
|
||||
```
|
||||
systemctl restart apache2
|
||||
systemctl restart jenkins
|
||||
```
|
||||
|
||||
检查 Jenkins 和 Apache 正在使用 80 和 8080 端口。
|
||||
|
||||
`netstat -plntu`
|
||||
```
|
||||
netstat -plntu
|
||||
```
|
||||
|
||||
[
|
||||
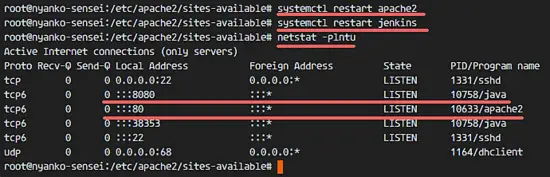
|
||||
@ -127,29 +152,30 @@ Jenkins 已经安装好了并运行在 8080 端口。
|
||||
|
||||
Jenkins 用域名 'my.jenkins.id' 运行。打开你的 web 浏览器然后输入 URL。你会看到要求你输入初始管理员密码的页面。Jenkins 已经生成了一个密码,因此我们只需要显示并把结果复制到密码框。
|
||||
|
||||
用 cat 命令显示 Jenkins 初始管理员密码。
|
||||
|
||||
`cat /var/lib/jenkins/secrets/initialAdminPassword`
|
||||
用 `cat` 命令显示 Jenkins 初始管理员密码。
|
||||
|
||||
```
|
||||
cat /var/lib/jenkins/secrets/initialAdminPassword
|
||||
a1789d1561bf413c938122c599cf65c9
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
将结果粘贴到密码框然后点击 ‘**Continue**’。
|
||||
将结果粘贴到密码框然后点击 Continue。
|
||||
|
||||
[
|
||||
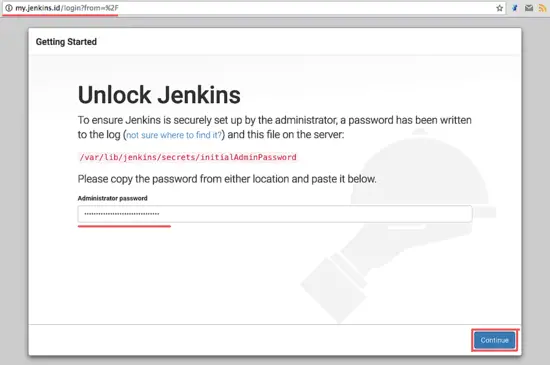
|
||||
][13]
|
||||
|
||||
现在为了后面能比较好的使用,我们需要在 Jenkins 中安装一些插件。选择 ‘**Install Suggested Plugin**’,点击它。
|
||||
现在为了后面能比较好的使用,我们需要在 Jenkins 中安装一些插件。选择 Install Suggested Plugin,点击它。
|
||||
|
||||
[
|
||||
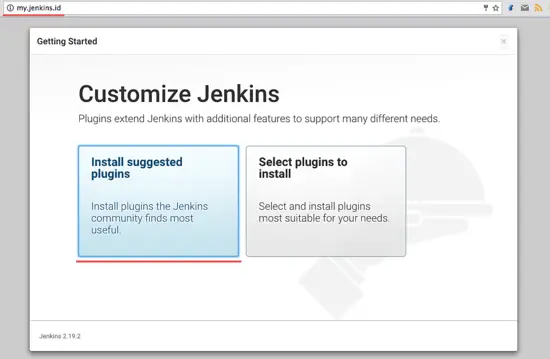
|
||||
][14]
|
||||
|
||||
Jenkins 插件安装过程
|
||||
Jenkins 插件安装过程:
|
||||
|
||||
[
|
||||
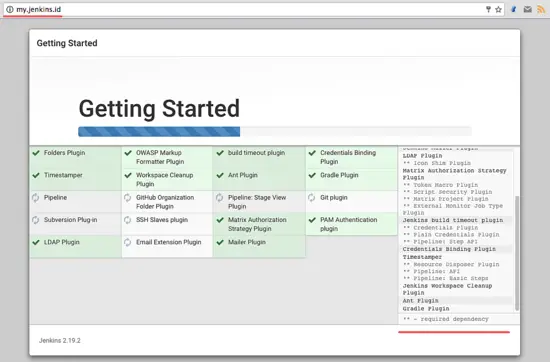
|
||||
@ -199,27 +225,29 @@ Jenkins 在 ‘**Access Control**’ 部分提供了多种认证方法。为了
|
||||
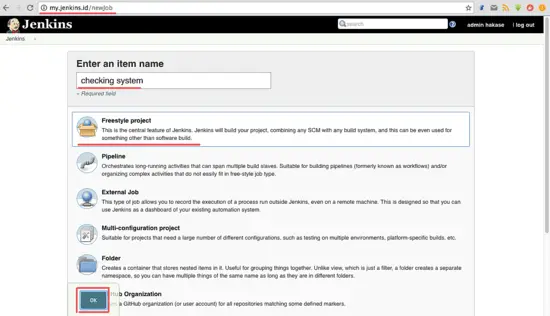
|
||||
][21]
|
||||
|
||||
输入任务的名称,在这里我用 ‘Checking System’,选择 ‘**Freestyle Project**’ 然后点击 ‘**OK**’。
|
||||
输入任务的名称,在这里我输入 ‘Checking System’,选择 Freestyle Project 然后点击 OK。
|
||||
|
||||
[
|
||||
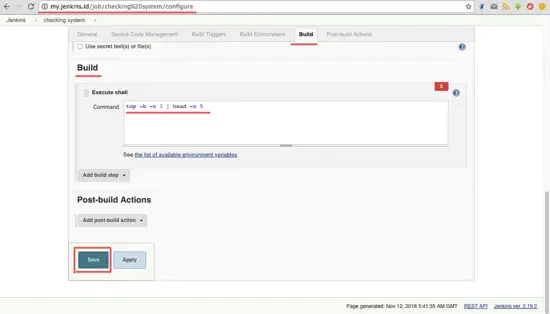
|
||||
][22]
|
||||
|
||||
进入 ‘**Build**’ 标签页。在 ‘**Add build step**’,选择选项 ‘**Execute shell**’。
|
||||
进入 Build 标签页。在 Add build step,选择选项 Execute shell。
|
||||
|
||||
在输入框输入下面的命令。
|
||||
|
||||
`top -b -n 1 | head -n 5`
|
||||
```
|
||||
top -b -n 1 | head -n 5
|
||||
```
|
||||
|
||||
点击 ‘**Save**’。
|
||||
点击 Save。
|
||||
|
||||
[
|
||||
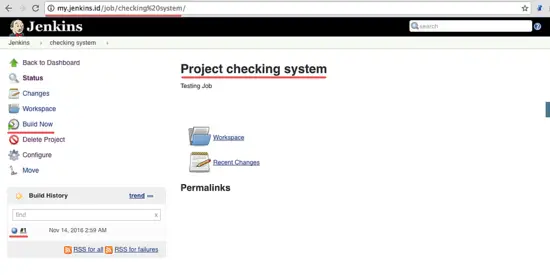
|
||||
][23]
|
||||
|
||||
现在你是在任务 ‘Project checking system’的任务页。点击 ‘**Build Now**’ 执行任务 ‘checking system’。
|
||||
现在你是在任务 ‘Project checking system’ 的任务页。点击 Build Now 执行任务 ‘checking system’。
|
||||
|
||||
任务执行完成后,你会看到 ‘**Build History**’,点击第一个任务查看结果。
|
||||
任务执行完成后,你会看到 Build History,点击第一个任务查看结果。
|
||||
|
||||
下面是 Jenkins 任务执行的结果。
|
||||
|
||||
@ -233,9 +261,9 @@ Jenkins 在 ‘**Access Control**’ 部分提供了多种认证方法。为了
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-install-jenkins-with-apache-on-ubuntu-16-04/
|
||||
|
||||
作者:[Muhammad Arul ][a]
|
||||
作者:[Muhammad Arul][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,68 +1,67 @@
|
||||
该死,原生移动应用的开发成本太高了!
|
||||
============================================================
|
||||
|
||||
### 一个有价值的命题
|
||||
> 一个有价值的命题
|
||||
|
||||
我们遇到了一个临界点。除去几个比较好的用例之外,使用原生框架和原生应用开发团队构建、维护移动应用再也没有意义了。
|
||||
我们遇到了一个临界点。除去少数几个特别的的用例之外,使用原生框架和原生应用开发团队构建、维护移动应用再也没有意义了。
|
||||
|
||||
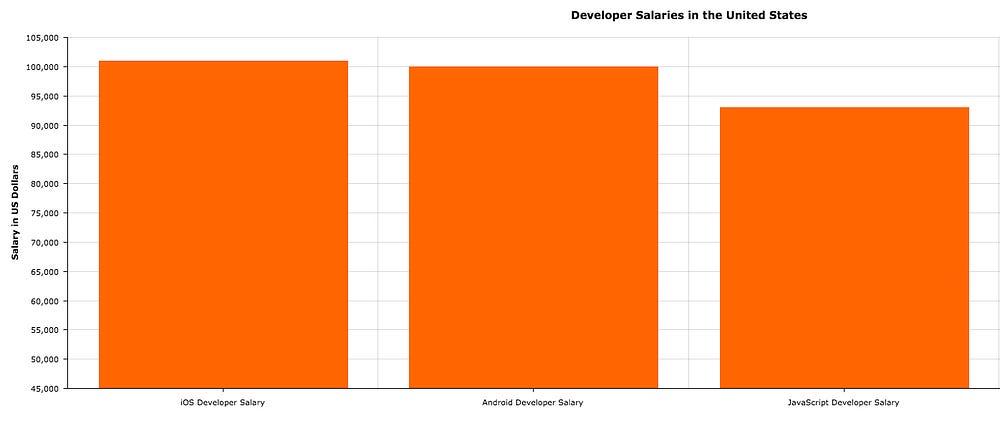
|
||||
|
||||
在美国,雇佣 iOS,Android,JavaScript 开发人员的平均花费([http://www.indeed.com/salary][1],[http://www.payscale.com/research/US/Skill=JavaScript/Salary][2])
|
||||
*在美国,雇佣 [iOS,Android][1],[JavaScript][2] 开发人员的平均花费*
|
||||
|
||||
在过去的几年,原生移动应用开发的费用螺旋式上升,无法控制。对没有大量资金的新创业者来说,创建原生应用、MVP 设计架构和原型的难度大大增加。现有的公司需要抓住人才,以便在现有应用上进行迭代开发或者构建一个新的应用。要尽一切努力留住最好的人才,与 [世界各地的公司][9] 拼尽全力 [争][6] 个 [高][7] [下][8]。
|
||||
在过去的几年,原生移动应用开发的费用螺旋式上升,无法控制。对没有大量资金的新创业者来说,创建原生应用、MVP 设计架构和原型的难度大大增加。现有的公司需要抓住人才,以便在现有应用上进行迭代开发或者构建一个新的应用。要尽一切努力才能留住最好的人才,与 [世界各地的公司][9] 拼尽全力[争个][6][高][7][下][8]。
|
||||
|
||||
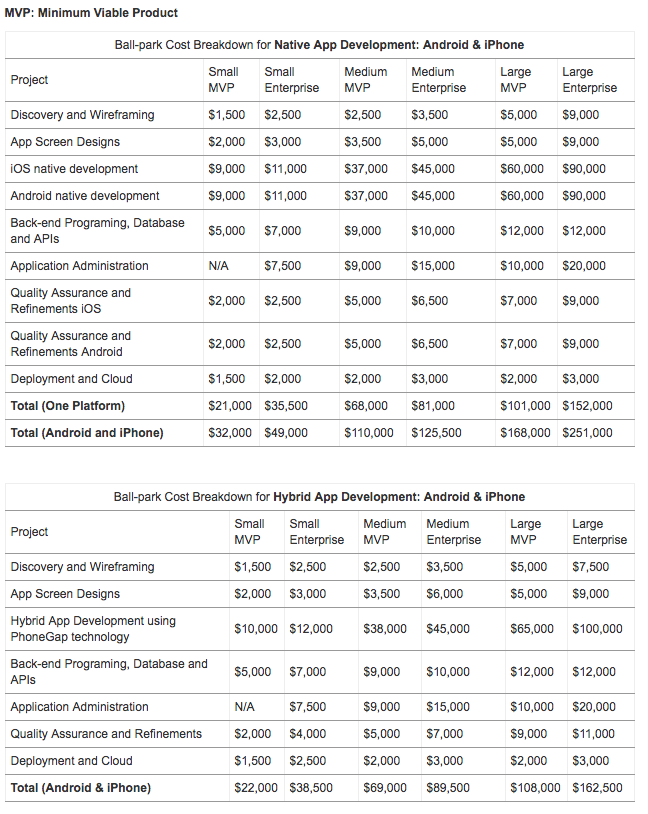
|
||||
|
||||
2015年初,原生方式和混合方式开发 MVP 设计架构的费用对比([Comomentum.com][3])
|
||||
*2015 年初,原生方式和混合方式开发 MVP 设计架构的费用[对比][3]*
|
||||
|
||||
### 这一切对于我们意味着什么?
|
||||
|
||||
如果你的公司很大或者有足够多的现金,旧思维是只要你在原生应用开发方面投入足够多的资金,就高枕无忧。但事实不再如此。
|
||||
|
||||
Facebook 是你最不会想到的在人才战中失败的公司(因为他们没有失败),它也遇到了原生应用方面金钱无法解决的问题。他们的移动应用庞大而又复杂,[可以看到编译它竟然需要15分钟][10]。这意味着哪怕是极小的用户界面改动,比如移动几个点,测试起来都要花费几个小时(甚至几天)。
|
||||
Facebook 是你最不会想到的在人才战中失败的公司(因为他们没有失败),它也遇到了原生应用方面金钱无法解决的问题。他们的移动应用庞大而又复杂,[他们发现编译它竟然需要 15 分钟][10]。这意味着哪怕是极小的用户界面改动,比如移动几个点,测试起来都要花费几个小时(甚至几天)。
|
||||
|
||||
除了冗长的编译时间,应用的每一个小改动在测试时都需要在两个完全不同的环境(IOS 和 Android)实施,开发团队需要使用两种语言和框架工作,这趟水更浑了。
|
||||
|
||||
Facebook 对这个问题的解决方案是 [React Native][11]。
|
||||
|
||||
### 能不能抛弃移动应用,仅面向Web呢?
|
||||
### 能不能抛弃移动应用,仅面向 Web 呢?
|
||||
|
||||
[一些人认为移动应用的末日已到。][12] 尽管我很欣赏、尊重 [Eric Elliott][13] 和他的工作,但我们还是通过考察一些近期的数据,进而讨论一下某些相反的观点:
|
||||
[一些人认为移动应用的末日已到][12]。尽管我很欣赏、尊重 [Eric Elliott][13] 和他的工作,但我们还是通过考察一些近期的数据,进而讨论一下某些相反的观点:
|
||||
|
||||
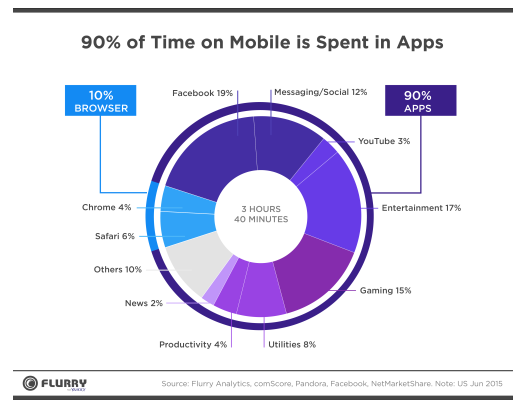
|
||||
|
||||

|
||||
|
||||
人们在移动应用上花费的时间(2016年4月,[smartinsights.com][4])
|
||||
*人们在移动应用上花费的[时间][4](2016年4月)*
|
||||
|
||||
> 人们使用 APP 的时间占使用手机总时长的 90%
|
||||
|
||||
目前世界上有 25 亿人在使用移动手机。[这个数字增长到 50 亿的速度会比我们想象的还要快。][14] 在正常情况下,丢掉 45 亿人的生意,或者抛弃有 45 亿人使用的应用程序是绝对荒唐且行不通的。
|
||||
|
||||
老问题是原生移动应用的开发成本对大多数公司来说太高了。尽管这个问题确实存在,但面向 web 的开发成本也在增加。[在美国,JavaScript 开发者的平均工资已达到 $97,000.00。][15]
|
||||
老问题是原生移动应用的开发成本对大多数公司来说太高了。然而,面向 web 的开发成本也在增加。[在美国,JavaScript 开发者的平均工资已达到 $97,000.00][15]。
|
||||
|
||||
伴随着复杂性的增加以及暴涨的高质量 web 开发需求,雇佣一个JavaScript 开发者的平均价格直逼原生应用开发者。论证 web 开发更便宜已经没用了。
|
||||
伴随着复杂性的增加以及对高质量 web 开发的需求暴涨,雇佣一个 JavaScript 开发者的平均价格直逼原生应用开发者。论证 web 开发更便宜已经没用了。
|
||||
|
||||
### 那混合开发呢?
|
||||
|
||||
混合应用是将 HTML5 应用内嵌在原生应用的容器里,并且提供实现原生平台特性所需的权限。Cordova 和 PhoneGap 就是典型的例子。
|
||||
|
||||
如果你想构建一个 MVP 设计架构、一个产品原型,或者不担心模仿原生应用的用户体验,那么混合应用会很适合你。谨记如果你最后想把它转为原生应用,整个项目都得重写。
|
||||
如果你想构建一个 MVP 设计架构、一个产品原型,或者不担心对原生应用的模仿的用户体验,那么混合应用会很适合你。但谨记如果你最后想把它转为原生应用,整个项目都得重写。
|
||||
|
||||
此领域有很多创新的东西,我最喜欢的当属 [Ionic Framework][16]。混合开发正变得越来越好,但还不如原生开发那么流畅自然。
|
||||
|
||||
有很多公司,包括最严峻的初创公司,也包括大中规模的公司,混合应用在质量上的表现似乎没有满足客户的要求,给人的感觉是活糙、不够专业。
|
||||
|
||||
[听说应用商店里的前 100 名都不是混合应用,][17]我没有证据支持这一观点。如果说有百分之零到百分之五是混合应用,我就不怀疑了。
|
||||
[听说应用商店里的前 100 名都不是混合应用][17],我没有证据支持这一观点。如果说有百分之零到百分之五是混合应用,我就不怀疑了。
|
||||
|
||||
> [我们最大的错误是在 HTML5 身上下了太多的赌注][18] — 马克 扎克伯格
|
||||
> [我们最大的错误是在 HTML5 身上下了太多的赌注][18] — 马克·扎克伯格
|
||||
|
||||
### 解决方案
|
||||
|
||||
如果你紧跟移动开发动向,那么你绝对听说过像 [NativeScript][19] 和 [React Native][20] 这样的项目。
|
||||
|
||||
通过这些项目,使用用 JavaScript 写成的基本 UI 组成块,像常规 iOS 和 Android 应用那样,就可以构建出高质量的原生移动应用。
|
||||
通过这些项目,使用由 JavaScript 写成的基本 UI 组成块,像常规 iOS 和 Android 应用那样,就可以构建出高质量的原生移动应用。
|
||||
|
||||
你可以仅用一位工程师,也可以用一个专业的工程师团队,通过 React Native 使用 [现有代码库][22] 或者 [底层技术][23] 进行跨平台移动应用开发,[原生桌面开发][21], 甚至还有 web 开发。把你的应用发布到 APP Store上, Play Store上,还有 Web 上。如此可以在保证不丧失原生应用性能和质量的同时,使成本仅占传统开发的一小部分。
|
||||
你可以仅用一位工程师,也可以用一个专业的工程师团队,通过 React Native 使用 [现有代码库][22] 或者 [底层技术][23] 进行跨平台移动应用开发、[原生桌面开发][21],甚至还有 web 开发。把你的应用发布到 APP Store 上、 Play Store 上,还有 Web 上。如此可以在保证不丧失原生应用性能和质量的同时,使成本仅占传统开发的一小部分。
|
||||
|
||||
通过 React Native 进行跨平台开发时重复使用其中 90% 的代码也不是没有的事,这个范围通常是 80% 到 90%。
|
||||
|
||||
@ -72,7 +71,7 @@ Facebook 对这个问题的解决方案是 [React Native][11]。
|
||||
|
||||
React Native 还可以使用 [Code Push][24] 和 [AppHub][25] 这样的工具来远程更新你的 JavaScript 代码。这意味着你可以向用户实时推送更新、新特性,快速修复 bug,绕过打包、发布这些工作,绕过 App Store、Google Play Store 的审核,省去了耗时 2 到 7 天的过程(App Store 一直是整个过程的痛点)。混合应用的这些优势原生应用不可能比得上。
|
||||
|
||||
如果这个领域的创新力能像刚发行时那样保持,将来你甚至可以为 [Apple Watch ][26],[Apple TV][27],和 [Tizen][28] 这样的平台开发应用。
|
||||
如果这个领域的创新力能像刚发行时那样保持,将来你甚至可以为 [Apple Watch][26]、[Apple TV][27],和 [Tizen][28] 这样的平台开发应用。
|
||||
|
||||
> NativeScript 依然是个相当年轻的框架驱动,Angular 版本 2,[上个月刚刚发布测试版][29]。但只要它保持良好的市场份额,未来就很有前途。
|
||||
|
||||
@ -84,49 +83,57 @@ React Native 还可以使用 [Code Push][24] 和 [AppHub][25] 这样的工具
|
||||
|
||||
看下面的例子,[这是一个使用 React Native 技术的著名应用列表][31]。
|
||||
|
||||
### Facebook
|
||||
#### Facebook
|
||||
|
||||

|
||||
|
||||
Facebook 公司的 React Native 应用
|
||||
*Facebook 公司的 React Native 应用*
|
||||
|
||||
Facebook 的两款应用 [Ads Manager][32] 和 [Facebook Groups][33]都在使用 React Native 技术,并且[将会应用到实现动态消息的框架上][34]。
|
||||
Facebook 的两款应用 [Ads Manager][32] 和 [Facebook Groups][33] 都在使用 React Native 技术,并且[将会应用到实现动态消息的框架上][34]。
|
||||
|
||||
Facebook 也会投入大量的资金创立和维护像 React Native 这样的开源项目,而且开源项目的开发者最近已经创建很多了不起的项目,这是很了不起的工作,像我以及全世界的业务每天都从中享受诸多好处。
|
||||
|
||||
### Instagram
|
||||
#### Instagram
|
||||
|
||||

|
||||
|
||||
Instagram
|
||||
*Instagram*
|
||||
|
||||
Instagram 应用的一部分已经使用了 React Native 技术。
|
||||
|
||||
### Airbnb
|
||||
#### Airbnb
|
||||
|
||||

|
||||
|
||||
Airbnb
|
||||
*Airbnb*
|
||||
|
||||
Airbnb 的很多东西正用 React Native 重写。(来自 [Leland Richardson][36])
|
||||
|
||||
超过 90% 的 Airbnb 旅行平台都是用 React Native 写的。(来自 [spikebrehm][37])
|
||||
|
||||
### Vogue
|
||||
#### Vogue
|
||||
|
||||

|
||||
|
||||
Vogue 是 2016 年度十佳应用之一
|
||||
*Vogue 是 2016 年度十佳应用之一*
|
||||
|
||||
Vogue 这么突出不仅仅因为它也用 React Native 写成,而是[因为它被苹果公司评为年度十佳应用之一][38]。
|
||||
|
||||
|
||||
|
||||
微软
|
||||
#### 沃尔玛
|
||||
|
||||
微软在 React Native 身上下的赌注很大
|
||||

|
||||
|
||||
它早已发布多个开源工具,包括 [Code Push][39],[React Native VS Code][40],以及 [React Native Windows][41],旨在帮助开发者向 React Native 领域转移。
|
||||
*Walmart Labs*
|
||||
|
||||
查看这篇 [Keerti](https://medium.com/@Keerti) 的[文章](https://medium.com/walmartlabs/react-native-at-walmartlabs-cdd140589560#.azpn97g8t)来了解沃尔玛是怎样看待 React Native 的优势的。
|
||||
|
||||
#### 微软
|
||||
|
||||
微软在 React Native 身上下的赌注很大。
|
||||
|
||||
它早已发布多个开源工具,包括 [Code Push][39]、[React Native VS Code][40],以及 [React Native Windows][41],旨在帮助开发者向 React Native 领域转移。
|
||||
|
||||
微软考虑的是那些已经使用 React Native 为 iOS 和 Android 开发应用的开发者,他们可以重用高达 90% 的代码,不用花费太多额外的时间和成本就可将应用发布到 Windows 上。
|
||||
|
||||
@ -136,11 +143,11 @@ Vogue 这么突出不仅仅因为它也用 React Native 写成,而是[因为
|
||||
|
||||
移动应用界面设计和移动应用开发要进行范式转变,下一步就是 React Native 以及与其相似的技术。
|
||||
|
||||
公司
|
||||
#### 公司
|
||||
|
||||
如果你的公司正想着削减成本、加快开发速度,而又不想在应用质量和性能上妥协,这是最适合使用 React Native 的时候,它能提高你的净利润。
|
||||
|
||||
开发者
|
||||
#### 开发者
|
||||
|
||||
如果你是一个开发者,想进入一个将来会快速发展的领域,我强烈推荐你把 React Native 列入你的学习清单。
|
||||
|
||||
@ -166,7 +173,7 @@ via: https://hackernoon.com/the-cost-of-native-mobile-app-development-is-too-dam
|
||||
|
||||
作者:[Nader Dabit][a]
|
||||
译者:[fuowang](https://github.com/fuowang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
237
published/201705/20161221 Living Android without Kotlin.md
Normal file
237
published/201705/20161221 Living Android without Kotlin.md
Normal file
@ -0,0 +1,237 @@
|
||||
在没有 Kotlin 的世界与 Android 共舞
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
> 开始投入一件事比远离它更容易。 — Donald Rumsfeld
|
||||
|
||||
没有 Kotlin 的生活就像在触摸板上玩魔兽争霸 3。购买鼠标很简单,但如果你的新雇主不想让你在生产中使用 Kotlin,你该怎么办?
|
||||
|
||||
下面有一些选择。
|
||||
* 与你的产品负责人争取获得使用 Kotlin 的权利。
|
||||
* 使用 Kotlin 并且不告诉其他人因为你知道最好的东西是只适合你的。
|
||||
* 擦掉你的眼泪,自豪地使用 Java。
|
||||
|
||||
想象一下,你在和产品负责人的斗争中失败,作为一个专业的工程师,你不能在没有同意的情况下私自去使用那些时髦的技术。我知道这听起来非常恐怖,特别当你已经品尝到 Kotlin 的好处时,不过不要失去生活的信念。
|
||||
|
||||
在文章接下来的部分,我想简短地描述一些 Kotlin 的特征,使你通过一些知名的工具和库,可以应用到你的 Android 里的 Java 代码中去。对于 Kotlin 和 Java 的基本认识是需要的。
|
||||
|
||||
### 数据类
|
||||
|
||||
我想你肯定已经喜欢上 Kotlin 的数据类。对于你来说,得到 `equals()`、 `hashCode()`、 `toString()` 和 `copy()` 这些是很容易的。具体来说,`data` 关键字还可以按照声明顺序生成对应于属性的 `componentN()` 函数。 它们用于解构声明。
|
||||
|
||||
```
|
||||
data class Person(val name: String)
|
||||
val (riddle) = Person("Peter")
|
||||
println(riddle)
|
||||
```
|
||||
|
||||
你知道什么会被打印出来吗?确实,它不会是从 `Person` 类的 `toString()` 返回的值。这是解构声明的作用,它赋值从 `name` 到 `riddle`。使用园括号 `(riddle)` 编译器知道它必须使用解构声明机制。
|
||||
|
||||
```
|
||||
val (riddle): String = Person("Peter").component1()
|
||||
println(riddle) // prints Peter)
|
||||
```
|
||||
|
||||
> 这个代码没编译。它就是展示了构造声明怎么工作的。
|
||||
|
||||
正如你可以看到 `data` 关键字是一个超级有用的语言特性,所以你能做什么把它带到你的 Java 世界? 使用注释处理器并修改抽象语法树(Abstract Syntax Tree)。 如果你想更深入,请阅读文章末尾列出的文章(Project Lombok— Trick Explained)。
|
||||
|
||||
使用项目 Lombok 你可以实现 `data`关键字所提供的几乎相同的功能。 不幸的是,没有办法进行解构声明。
|
||||
|
||||
```
|
||||
import lombok.Data;
|
||||
|
||||
@Data class Person {
|
||||
final String name;
|
||||
}
|
||||
```
|
||||
|
||||
`@Data` 注解生成 `equals()`、`hashCode()` 和 `toString()`。 此外,它为所有字段创建 getter,为所有非最终字段创建setter,并为所有必填字段(final)创建构造函数。 值得注意的是,Lombok 仅用于编译,因此库代码不会添加到您的最终的 .apk。
|
||||
|
||||
### Lambda 表达式
|
||||
|
||||
Android 工程师有一个非常艰难的生活,因为 Android 中缺乏 Java 8 的特性,而且其中之一是 lambda 表达式。 Lambda 是很棒的,因为它们为你减少了成吨的样板。 你可以在回调和流中使用它们。 在 Kotlin 中,lambda 表达式是内置的,它们看起来比它们在 Java 中看起来好多了。 此外,lambda 的字节码可以直接插入到调用方法的字节码中,因此方法计数不会增加。 它可以使用内联函数。
|
||||
|
||||
```
|
||||
button.setOnClickListener { println("Hello World") }
|
||||
```
|
||||
|
||||
最近 Google 宣布在 Android 中支持 Java 8 的特性,由于 Jack 编译器,你可以在你的代码中使用 lambda。还要提及的是,它们在 API 23 或者更低的级别都可用。
|
||||
|
||||
```
|
||||
button.setOnClickListener(view -> System.out.println("Hello World!"));
|
||||
```
|
||||
|
||||
怎样使用它们?就只用添加下面几行到你的 `build.gradle` 文件中。
|
||||
|
||||
```
|
||||
defaultConfig {
|
||||
jackOptions {
|
||||
enabled true
|
||||
}
|
||||
}
|
||||
|
||||
compileOptions {
|
||||
sourceCompatibility JavaVersion.VERSION_1_8
|
||||
targetCompatibility JavaVersion.VERSION_1_8
|
||||
}
|
||||
```
|
||||
|
||||
如果你不喜欢用 Jack 编译器,或者你由于一些原因不能使用它,这里有一个不同的解决方案提供给你。Retrolambda 项目允许你在 Java 7,6 或者 5 上运行带有 lambda 表达式的 Java 8 代码,下面是设置过程。
|
||||
|
||||
```
|
||||
dependencies {
|
||||
classpath 'me.tatarka:gradle-retrolambda:3.4.0'
|
||||
}
|
||||
|
||||
apply plugin: 'me.tatarka.retrolambda'
|
||||
|
||||
compileOptions {
|
||||
sourceCompatibility JavaVersion.VERSION_1_8
|
||||
targetCompatibility JavaVersion.VERSION_1_8
|
||||
}
|
||||
```
|
||||
|
||||
正如我前面提到的,在 Kotlin 下的 lambda 内联函数不增加方法计数,但是如何在 Jack 或者 Retrolambda 下使用它们呢? 显然,它们不是没成本的,隐藏的成本如下。
|
||||
|
||||
|
||||
|
||||
*该表展示了使用不同版本的 Retrolambda 和 Jack 编译器生成的方法数量。该比较结果来自 Jake Wharton 的“[探索 Java 的隐藏成本](http://jakewharton.com/exploring-java-hidden-costs/)” 技术讨论之中。*
|
||||
|
||||
### 数据操作
|
||||
|
||||
Kotlin 引入了高阶函数作为流的替代。 当您必须将一组数据转换为另一组数据或过滤集合时,它们非常有用。
|
||||
|
||||
```
|
||||
fun foo(persons: MutableList<Person>) {
|
||||
persons.filter { it.age >= 21 }
|
||||
.filter { it.name.startsWith("P") }
|
||||
.map { it.name }
|
||||
.sorted()
|
||||
.forEach(::println)
|
||||
}
|
||||
|
||||
data class Person(val name: String, val age: Int)
|
||||
```
|
||||
|
||||
流也由 Google 通过 Jack 编译器提供。 不幸的是,Jack 不使用 Lombok,因为它在编译代码时跳过生成中间的 `.class` 文件,而 Lombok 却依赖于这些文件。
|
||||
|
||||
```
|
||||
void foo(List<Person> persons) {
|
||||
persons.stream()
|
||||
.filter(it -> it.getAge() >= 21)
|
||||
.filter(it -> it.getName().startsWith("P"))
|
||||
.map(Person::getName)
|
||||
.sorted()
|
||||
.forEach(System.out::println);
|
||||
}
|
||||
|
||||
class Person {
|
||||
final private String name;
|
||||
final private int age;
|
||||
|
||||
public Person(String name, int age) {
|
||||
this.name = name;
|
||||
this.age = age;
|
||||
}
|
||||
|
||||
String getName() { return name; }
|
||||
int getAge() { return age; }
|
||||
}
|
||||
```
|
||||
|
||||
这简直太好了,所以 catch 在哪里? 令人悲伤的是,流从 API 24 才可用。谷歌做了好事,但哪个应用程序有用 `minSdkVersion = 24`?
|
||||
|
||||
幸运的是,Android 平台有一个很好的提供许多很棒的库的开源社区。Lightweight-Stream-API 就是其中的一个,它包含了 Java 7 及以下版本的基于迭代器的流实现。
|
||||
|
||||
```
|
||||
import lombok.Data;
|
||||
import com.annimon.stream.Stream;
|
||||
|
||||
void foo(List<Person> persons) {
|
||||
Stream.of(persons)
|
||||
.filter(it -> it.getAge() >= 21)
|
||||
.filter(it -> it.getName().startsWith("P"))
|
||||
.map(Person::getName)
|
||||
.sorted()
|
||||
.forEach(System.out::println);
|
||||
}
|
||||
|
||||
@Data class Person {
|
||||
final String name;
|
||||
final int age;
|
||||
}
|
||||
```
|
||||
|
||||
上面的例子结合了 Lombok、Retrolambda 和 Lightweight-Stream-API,它看起来几乎和 Kotlin 一样棒。使用静态工厂方法允许您将任何 Iterable 转换为流,并对其应用 lambda,就像 Java 8 流一样。 将静态调用 `Stream.of(persons)` 包装为 Iterable 类型的扩展函数是完美的,但是 Java 不支持它。
|
||||
|
||||
### 扩展函数
|
||||
|
||||
扩展机制提供了向类添加功能而无需继承它的能力。 这个众所周知的概念非常适合 Android 世界,这就是 Kotlin 在该社区很受欢迎的原因。
|
||||
|
||||
有没有技术或魔术将扩展功能添加到你的 Java 工具箱? 因 Lombok,你可以使用它们作为一个实验功能。 根据 Lombok 文档的说明,他们想把它从实验状态移出,基本上没有什么变化的话很快。 让我们重构最后一个例子,并将 `Stream.of(persons)` 包装成扩展函数。
|
||||
|
||||
```
|
||||
import lombok.Data;
|
||||
import lombok.experimental.ExtensionMethod;
|
||||
|
||||
@ExtensionMethod(Streams.class)
|
||||
public class Foo {
|
||||
void foo(List<Person> persons) {
|
||||
persons.toStream()
|
||||
.filter(it -> it.getAge() >= 21)
|
||||
.filter(it -> it.getName().startsWith("P"))
|
||||
.map(Person::getName)
|
||||
.sorted()
|
||||
.forEach(System.out::println);
|
||||
}
|
||||
}
|
||||
|
||||
@Data class Person {
|
||||
final String name;
|
||||
final int age;
|
||||
}
|
||||
|
||||
class Streams {
|
||||
static <T> Stream<T> toStream(List<T> list) {
|
||||
return Stream.of(list);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
所有的方法是 `public`、`static` 的,并且至少有一个参数的类型不是原始的,因而是扩展方法。 `@ExtensionMethod` 注解允许你指定一个包含你的扩展函数的类。 你也可以传递数组,而不是使用一个 `.class` 对象。
|
||||
|
||||
* * *
|
||||
|
||||
我完全知道我的一些想法是非常有争议的,特别是 Lombok,我也知道,有很多的库,可以使你的生活更轻松。请不要犹豫在评论里分享你的经验。干杯!
|
||||
|
||||

|
||||
|
||||
---------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Coder and professional dreamer @ Grid Dynamics
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.com/proandroiddev/living-android-without-kotlin-db7391a2b170
|
||||
|
||||
作者:[Piotr Ślesarew][a]
|
||||
译者:[DockerChen](https://github.com/DockerChen)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://hackernoon.com/@piotr.slesarew?source=post_header_lockup
|
||||
[1]:http://jakewharton.com/exploring-java-hidden-costs/
|
||||
[2]:https://medium.com/u/8ddd94878165
|
||||
[3]:https://projectlombok.org/index.html
|
||||
[4]:https://github.com/aNNiMON/Lightweight-Stream-API
|
||||
[5]:https://github.com/orfjackal/retrolambda
|
||||
[6]:http://notatube.blogspot.com/2010/11/project-lombok-trick-explained.html
|
||||
[7]:http://notatube.blogspot.com/2010/11/project-lombok-trick-explained.html
|
||||
[8]:https://twitter.com/SliskiCode
|
||||
@ -0,0 +1,405 @@
|
||||
GraphQL 用例:使用 Golang 和 PostgreSQL 构建一个博客引擎 API
|
||||
============================================================
|
||||
|
||||
### 摘要
|
||||
|
||||
GraphQL 在生产环境中似乎难以使用:虽然对于建模功能来说图接口非常灵活,但是并不适用于关系型存储,不管是在实现还是性能方面。
|
||||
|
||||
在这篇博客中,我们会设计并实现一个简单的博客引擎 API,它支持以下功能:
|
||||
|
||||
* 三种类型的资源(用户、博文以及评论)支持多种功能(创建用户、创建博文、给博文添加评论、关注其它用户的博文和评论,等等。)
|
||||
* 使用 PostgreSQL 作为后端数据存储(选择它因为它是一个流行的关系型数据库)。
|
||||
* 使用 Golang(开发 API 的一个流行语言)实现 API。
|
||||
|
||||
我们会比较简单的 GraphQL 实现和纯 REST 替代方案,在一种普通场景(呈现博客文章页面)下对比它们的实现复杂性和效率。
|
||||
|
||||
### 介绍
|
||||
|
||||
GraphQL 是一种 IDL(Interface Definition Language,接口定义语言),设计者定义数据类型和并把数据建模为一个图(graph)。每个顶点都是一种数据类型的一个实例,边代表了节点之间的关系。这种方式非常灵活,能适应任何业务领域。然而,问题是设计过程更加复杂,而且传统的数据存储不能很好地映射到图模型。阅读_附录1_了解更多关于这个问题的详细信息。
|
||||
|
||||
GraphQL 在 2014 年由 Facebook 的工程师团队首次提出。尽管它的优点和功能非常有趣而且引人注目,但它并没有得到大规模应用。开发者需要权衡 REST 的设计简单性、熟悉性、丰富的工具和 GraphQL 不会受限于 CRUD(LCTT 译注:Create、Read、Update、Delete) 以及网络性能(它优化了往返服务器的网络)的灵活性。
|
||||
|
||||
大部分关于 GraphQL 的教程和指南都跳过了从数据存储获取数据以便解决查询的问题。也就是,如何使用通用目的、流行存储方案(例如关系型数据库)为 GraphQL API 设计一个支持高效数据提取的数据库。
|
||||
|
||||
这篇博客介绍构建一个博客引擎 GraphQL API 的流程。它的功能相当复杂。为了和基于 REST 的方法进行比较,它的范围被限制为一个熟悉的业务领域。
|
||||
|
||||
这篇博客的文章结构如下:
|
||||
|
||||
* 第一部分我们会设计一个 GraphQL 模式并介绍所使用语言的一些功能。
|
||||
* 第二部分是 PostgreSQL 数据库的设计。
|
||||
* 第三部分介绍了使用 Golang 实现第一部分设计的 GraphQL 模式。
|
||||
* 第四部分我们以从后端获取所需数据的角度来比较呈现博客文章页面的任务。
|
||||
|
||||
### 相关阅读
|
||||
|
||||
* 很棒的 [GraphQL 介绍文档][1]。
|
||||
* 该项目的完整实现代码在 [github.com/topliceanu/graphql-go-example][2]。
|
||||
|
||||
### 在 GraphQL 中建模一个博客引擎
|
||||
|
||||
下述_列表1_包括了博客引擎 API 的全部模式。它显示了组成图的顶点的数据类型。顶点之间的关系,也就是边,被建模为指定类型的属性。
|
||||
|
||||
```
|
||||
type User {
|
||||
id: ID
|
||||
email: String!
|
||||
post(id: ID!): Post
|
||||
posts: [Post!]!
|
||||
follower(id: ID!): User
|
||||
followers: [User!]!
|
||||
followee(id: ID!): User
|
||||
followees: [User!]!
|
||||
}
|
||||
|
||||
type Post {
|
||||
id: ID
|
||||
user: User!
|
||||
title: String!
|
||||
body: String!
|
||||
comment(id: ID!): Comment
|
||||
comments: [Comment!]!
|
||||
}
|
||||
|
||||
type Comment {
|
||||
id: ID
|
||||
user: User!
|
||||
post: Post!
|
||||
title: String
|
||||
body: String!
|
||||
}
|
||||
|
||||
type Query {
|
||||
user(id: ID!): User
|
||||
}
|
||||
|
||||
type Mutation {
|
||||
createUser(email: String!): User
|
||||
removeUser(id: ID!): Boolean
|
||||
follow(follower: ID!, followee: ID!): Boolean
|
||||
unfollow(follower: ID!, followee: ID!): Boolean
|
||||
createPost(user: ID!, title: String!, body: String!): Post
|
||||
removePost(id: ID!): Boolean
|
||||
createComment(user: ID!, post: ID!, title: String!, body: String!): Comment
|
||||
removeComment(id: ID!): Boolean
|
||||
}
|
||||
```
|
||||
|
||||
_列表1_
|
||||
|
||||
模式使用 GraphQL DSL 编写,它用于定义自定义数据类型,例如 `User`、`Post` 和 `Comment`。该语言也提供了一系列原始数据类型,例如 `String`、`Boolean` 和 `ID`(它是`String` 的别名,但是有顶点唯一标识符的额外语义)。
|
||||
|
||||
`Query` 和 `Mutation` 是语法解析器能识别并用于查询图的可选类型。从 GraphQL API 读取数据等同于遍历图。需要提供这样一个起始顶点;该角色通过 `Query` 类型来实现。在这种情况中,所有图的查询都要从一个由 id `user(id:ID!)` 指定的用户开始。对于写数据,定义了 `Mutation` 顶点。它提供了一系列操作,建模为能遍历(并返回)新创建顶点类型的参数化属性。_列表2_是这些查询的一些例子。
|
||||
|
||||
顶点属性能被参数化,也就是能接受参数。在图遍历场景中,如果一个博文顶点有多个评论顶点,你可以通过指定 `comment(id: ID)` 只遍历其中的一个。所有这些都取决于设计,设计者可以选择不提供到每个独立顶点的直接路径。
|
||||
|
||||
`!` 字符是一个类型后缀,适用于原始类型和用户定义类型,它有两种语义:
|
||||
|
||||
* 当被用于参数化属性的参数类型时,表示这个参数是必须的。
|
||||
* 当被用于一个属性的返回类型时,表示当顶点被获取时该属性不会为空。
|
||||
* 也可以把它们组合起来,例如 `[Comment!]!` 表示一个非空 Comment 顶点链表,其中 `[]`、`[Comment]` 是有效的,但 `null, [null], [Comment, null]` 就不是。
|
||||
|
||||
|
||||
_列表2_ 包括一系列用于博客 API 的 `curl` 命令,它们会使用 mutation 填充图然后查询图以便获取数据。要运行它们,按照 [topliceanu/graphql-go-example][3] 仓库中的指令编译并运行服务。
|
||||
|
||||
```
|
||||
# 创建用户 1、2 和 3 的更改。更改和查询类似,在该情景中我们检索新创建用户的 id 和 email。
|
||||
curl -XPOST http://vm:8080/graphql -d 'mutation {createUser(email:"user1@x.co"){id, email}}'
|
||||
curl -XPOST http://vm:8080/graphql -d 'mutation {createUser(email:"user2@x.co"){id, email}}'
|
||||
curl -XPOST http://vm:8080/graphql -d 'mutation {createUser(email:"user3@x.co"){id, email}}'
|
||||
# 为用户添加博文的更改。为了和模式匹配我们需要检索他们的 id,否则会出现错误。
|
||||
curl -XPOST http://vm:8080/graphql -d 'mutation {createPost(user:1,title:"post1",body:"body1"){id}}'
|
||||
curl -XPOST http://vm:8080/graphql -d 'mutation {createPost(user:1,title:"post2",body:"body2"){id}}'
|
||||
curl -XPOST http://vm:8080/graphql -d 'mutation {createPost(user:2,title:"post3",body:"body3"){id}}'
|
||||
# 博文所有评论的更改。`createComment` 需要用户 id,标题和正文。看列表 1 的模式。
|
||||
curl -XPOST http://vm:8080/graphql -d 'mutation {createComment(user:2,post:1,title:"comment1",body:"comment1"){id}}'
|
||||
curl -XPOST http://vm:8080/graphql -d 'mutation {createComment(user:1,post:3,title:"comment2",body:"comment2"){id}}'
|
||||
curl -XPOST http://vm:8080/graphql -d 'mutation {createComment(user:3,post:3,title:"comment3",body:"comment3"){id}}'
|
||||
# 让用户 3 关注用户 1 和用户 2 的更改。注意 `follow` 更改只返回一个布尔值而不需要指定。
|
||||
curl -XPOST http://vm:8080/graphql -d 'mutation {follow(follower:3, followee:1)}'
|
||||
curl -XPOST http://vm:8080/graphql -d 'mutation {follow(follower:3, followee:2)}'
|
||||
|
||||
# 用户获取用户 1 所有数据的查询。
|
||||
curl -XPOST http://vm:8080/graphql -d '{user(id:1)}'
|
||||
# 用户获取用户 2 和用户 1 的关注者的查询。
|
||||
curl -XPOST http://vm:8080/graphql -d '{user(id:2){followers{id, email}}}'
|
||||
curl -XPOST http://vm:8080/graphql -d '{user(id:1){followers{id, email}}}'
|
||||
# 检测用户 2 是否被用户 1 关注的查询。如果是,检索用户 1 的 email,否则返回空。
|
||||
curl -XPOST http://vm:8080/graphql -d '{user(id:2){follower(id:1){email}}}'
|
||||
# 返回用户 3 关注的所有用户 id 和 email 的查询。
|
||||
curl -XPOST http://vm:8080/graphql -d '{user(id:3){followees{id, email}}}'
|
||||
# 如果用户 3 被用户 1 关注,就获取用户 3 email 的查询。
|
||||
curl -XPOST http://vm:8080/graphql -d '{user(id:1){followee(id:3){email}}}'
|
||||
# 获取用户 1 的第二篇博文的查询,检索它的标题和正文。如果博文 2 不是由用户 1 创建的,就会返回空。
|
||||
curl -XPOST http://vm:8080/graphql -d '{user(id:1){post(id:2){title,body}}}'
|
||||
# 获取用户 1 的所有博文的所有数据的查询。
|
||||
curl -XPOST http://vm:8080/graphql -d '{user(id:1){posts{id,title,body}}}'
|
||||
# 获取写博文 2 用户的查询,如果博文 2 是由 用户 1 撰写;一个现实语言灵活性的例证。
|
||||
curl -XPOST http://vm:8080/graphql -d '{user(id:1){post(id:2){user{id,email}}}}'
|
||||
```
|
||||
|
||||
_列表2_
|
||||
|
||||
通过仔细设计 mutation 和类型属性,可以实现强大而富有表达力的查询。
|
||||
|
||||
### 设计 PostgreSQL 数据库
|
||||
|
||||
关系型数据库的设计,一如以往,由避免数据冗余的需求驱动。选择该方式有两个原因:
|
||||
|
||||
1. 表明实现 GraphQL API 不需要定制化的数据库技术或者学习和使用新的设计技巧。
|
||||
2. 表明 GraphQL API 能在现有的数据库之上创建,更具体地说,最初设计用于 REST 后端甚至传统的呈现 HTML 站点的服务器端数据库。
|
||||
|
||||
阅读 _附录1_ 了解关于关系型和图数据库在构建 GraphQL API 方面的区别。_列表3_ 显示了用于创建新数据库的 SQL 命令。数据库模式和 GraphQL 模式相对应。为了支持 `follow/unfollow` 更改,需要添加 `followers` 关系。
|
||||
|
||||
```
|
||||
CREATE TABLE IF NOT EXISTS users (
|
||||
id SERIAL PRIMARY KEY,
|
||||
email VARCHAR(100) NOT NULL
|
||||
);
|
||||
CREATE TABLE IF NOT EXISTS posts (
|
||||
id SERIAL PRIMARY KEY,
|
||||
user_id INTEGER NOT NULL REFERENCES users(id) ON DELETE CASCADE,
|
||||
title VARCHAR(200) NOT NULL,
|
||||
body TEXT NOT NULL
|
||||
);
|
||||
CREATE TABLE IF NOT EXISTS comments (
|
||||
id SERIAL PRIMARY KEY,
|
||||
user_id INTEGER NOT NULL REFERENCES users(id) ON DELETE CASCADE,
|
||||
post_id INTEGER NOT NULL REFERENCES posts(id) ON DELETE CASCADE,
|
||||
title VARCHAR(200) NOT NULL,
|
||||
body TEXT NOT NULL
|
||||
);
|
||||
CREATE TABLE IF NOT EXISTS followers (
|
||||
follower_id INTEGER NOT NULL REFERENCES users(id) ON DELETE CASCADE,
|
||||
followee_id INTEGER NOT NULL REFERENCES users(id) ON DELETE CASCADE,
|
||||
PRIMARY KEY(follower_id, followee_id)
|
||||
);
|
||||
```
|
||||
|
||||
_列表3_
|
||||
|
||||
### Golang API 实现
|
||||
|
||||
本项目使用的用 Go 实现的 GraphQL 语法解析器是 `github.com/graphql-go/graphql`。它包括一个查询解析器,但不包括模式解析器。这要求开发者利用库提供的结构使用 Go 构建 GraphQL 模式。这和 [nodejs 实现][3] 不同,后者提供了一个模式解析器并为数据获取暴露了钩子。因此 _列表1_ 中的模式只是作为指导使用,需要转化为 Golang 代码。然而,这个_“限制”_提供了与抽象级别对等的机会,并且了解模式如何和用于检索数据的图遍历模型相关。_列表4_ 显示了 `Comment` 顶点类型的实现:
|
||||
|
||||
```
|
||||
var CommentType = graphql.NewObject(graphql.ObjectConfig{
|
||||
Name: "Comment",
|
||||
Fields: graphql.Fields{
|
||||
"id": &graphql.Field{
|
||||
Type: graphql.NewNonNull(graphql.ID),
|
||||
Resolve: func(p graphql.ResolveParams) (interface{}, error) {
|
||||
if comment, ok := p.Source.(*Comment); ok == true {
|
||||
return comment.ID, nil
|
||||
}
|
||||
return nil, nil
|
||||
},
|
||||
},
|
||||
"title": &graphql.Field{
|
||||
Type: graphql.NewNonNull(graphql.String),
|
||||
Resolve: func(p graphql.ResolveParams) (interface{}, error) {
|
||||
if comment, ok := p.Source.(*Comment); ok == true {
|
||||
return comment.Title, nil
|
||||
}
|
||||
return nil, nil
|
||||
},
|
||||
},
|
||||
"body": &graphql.Field{
|
||||
Type: graphql.NewNonNull(graphql.ID),
|
||||
Resolve: func(p graphql.ResolveParams) (interface{}, error) {
|
||||
if comment, ok := p.Source.(*Comment); ok == true {
|
||||
return comment.Body, nil
|
||||
}
|
||||
return nil, nil
|
||||
},
|
||||
},
|
||||
},
|
||||
})
|
||||
func init() {
|
||||
CommentType.AddFieldConfig("user", &graphql.Field{
|
||||
Type: UserType,
|
||||
Resolve: func(p graphql.ResolveParams) (interface{}, error) {
|
||||
if comment, ok := p.Source.(*Comment); ok == true {
|
||||
return GetUserByID(comment.UserID)
|
||||
}
|
||||
return nil, nil
|
||||
},
|
||||
})
|
||||
CommentType.AddFieldConfig("post", &graphql.Field{
|
||||
Type: PostType,
|
||||
Args: graphql.FieldConfigArgument{
|
||||
"id": &graphql.ArgumentConfig{
|
||||
Description: "Post ID",
|
||||
Type: graphql.NewNonNull(graphql.ID),
|
||||
},
|
||||
},
|
||||
Resolve: func(p graphql.ResolveParams) (interface{}, error) {
|
||||
i := p.Args["id"].(string)
|
||||
id, err := strconv.Atoi(i)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
return GetPostByID(id)
|
||||
},
|
||||
})
|
||||
}
|
||||
```
|
||||
|
||||
_列表4_
|
||||
|
||||
正如 _列表1_ 中的模式,`Comment` 类型是静态定义的一个有三个属性的结构体:`id`、`title` 和 `body`。为了避免循环依赖,动态定义了 `user` 和 `post` 两个其它属性。
|
||||
|
||||
Go 并不适用于这种动态建模,它只支持一些类型检查,代码中大部分变量都是 `interface{}` 类型,在使用之前都需要进行类型断言。`CommentType` 是一个 `graphql.Object` 类型的变量,它的属性是 `graphql.Field` 类型。因此,GraphQL DSL 和 Go 中使用的数据结构并没有直接的转换。
|
||||
|
||||
每个字段的 `resolve` 函数暴露了 `Source` 参数,它是表示遍历时前一个节点的数据类型顶点。`Comment` 的所有属性都有作为 source 的当前 `CommentType` 顶点。检索`id`、`title` 和 `body` 是一个直接属性访问,而检索 `user` 和 `post` 要求图遍历,也需要数据库查询。由于它们非常简单,这篇文章并没有介绍这些 SQL 查询,但在_参考文献_部分列出的 github 仓库中有。
|
||||
|
||||
### 普通场景下和 REST 的对比
|
||||
|
||||
在这一部分,我们会展示一个普通的博客文章呈现场景,并比较 REST 和 GraphQL 的实现。关注重点会放在入站/出站请求数量,因为这些是造成页面呈现延迟的最主要原因。
|
||||
|
||||
场景:呈现一个博客文章页面。它应该包含关于作者(email)、博客文章(标题、正文)、所有评论(标题、正文)以及评论人是否关注博客文章作者的信息。_图1_ 和 _图2_ 显示了客户端 SPA、API 服务器以及数据库之间的交互,一个是 REST API、另一个对应是 GraphQL API。
|
||||
|
||||
```
|
||||
+------+ +------+ +--------+
|
||||
|client| |server| |database|
|
||||
+--+---+ +--+---+ +----+---+
|
||||
| GET /blogs/:id | |
|
||||
1\. +-------------------------> SELECT * FROM blogs... |
|
||||
| +--------------------------->
|
||||
| <---------------------------+
|
||||
<-------------------------+ |
|
||||
| | |
|
||||
| GET /users/:id | |
|
||||
2\. +-------------------------> SELECT * FROM users... |
|
||||
| +--------------------------->
|
||||
| <---------------------------+
|
||||
<-------------------------+ |
|
||||
| | |
|
||||
| GET /blogs/:id/comments | |
|
||||
3\. +-------------------------> SELECT * FROM comments... |
|
||||
| +--------------------------->
|
||||
| <---------------------------+
|
||||
<-------------------------+ |
|
||||
| | |
|
||||
| GET /users/:id/followers| |
|
||||
4\. +-------------------------> SELECT * FROM followers.. |
|
||||
| +--------------------------->
|
||||
| <---------------------------+
|
||||
<-------------------------+ |
|
||||
| | |
|
||||
+ + +
|
||||
```
|
||||
|
||||
_图1_
|
||||
|
||||
```
|
||||
+------+ +------+ +--------+
|
||||
|client| |server| |database|
|
||||
+--+---+ +--+---+ +----+---+
|
||||
| GET /graphql | |
|
||||
1\. +-------------------------> SELECT * FROM blogs... |
|
||||
| +--------------------------->
|
||||
| <---------------------------+
|
||||
| | |
|
||||
| | |
|
||||
| | |
|
||||
2\. | | SELECT * FROM users... |
|
||||
| +--------------------------->
|
||||
| <---------------------------+
|
||||
| | |
|
||||
| | |
|
||||
| | |
|
||||
3\. | | SELECT * FROM comments... |
|
||||
| +--------------------------->
|
||||
| <---------------------------+
|
||||
| | |
|
||||
| | |
|
||||
| | |
|
||||
4\. | | SELECT * FROM followers.. |
|
||||
| +--------------------------->
|
||||
| <---------------------------+
|
||||
<-------------------------+ |
|
||||
| | |
|
||||
+ + +
|
||||
```
|
||||
|
||||
_图2_
|
||||
|
||||
_列表5_ 是一条用于获取所有呈现博文所需数据的简单 GraphQL 查询。
|
||||
|
||||
```
|
||||
{
|
||||
user(id: 1) {
|
||||
email
|
||||
followers
|
||||
post(id: 1) {
|
||||
title
|
||||
body
|
||||
comments {
|
||||
id
|
||||
title
|
||||
user {
|
||||
id
|
||||
email
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
_列表5_
|
||||
|
||||
对于这种情况,对数据库的查询次数是故意相同的,但是到 API 服务器的 HTTP 请求已经减少到只有一个。我们认为在这种类型的应用程序中通过互联网的 HTTP 请求是最昂贵的。
|
||||
|
||||
为了利用 GraphQL 的优势,后端并不需要进行特别设计,从 REST 到 GraphQL 的转换可以逐步完成。这使得可以测量性能提升和优化。从这一点,API 设计者可以开始优化(潜在的合并) SQL 查询从而提高性能。缓存的机会在数据库和 API 级别都大大增加。
|
||||
|
||||
SQL 之上的抽象(例如 ORM 层)通常会和 `n+1` 问题相抵触。在 REST 示例的步骤 4 中,客户端可能不得不在单独的请求中为每个评论的作者请求关注状态。这是因为在 REST 中没有标准的方式来表达两个以上资源之间的关系,而 GraphQL 旨在通过使用嵌套查询来防止这类问题。这里我们通过获取用户的所有关注者来作弊。我们向客户提出了如何确定评论并关注了作者的用户的逻辑。
|
||||
|
||||
另一个区别是获取比客户端所需更多的数据,以免破坏 REST 资源抽象。这对于用于解析和存储不需要数据的带宽消耗和电池寿命非常重要。
|
||||
|
||||
### 总结
|
||||
|
||||
GraphQL 是 REST 的一个可用替代方案,因为:
|
||||
|
||||
* 尽管设计 API 更加困难,但该过程可以逐步完成。也是由于这个原因,从 REST 转换到 GraphQL 非常容易,两个流程可以没有任何问题地共存。
|
||||
* 在网络请求方面更加高效,即使是类似本博客中的简单实现。它还提供了更多查询优化和结果缓存的机会。
|
||||
* 在用于解析结果的带宽消耗和 CPU 周期方面它更加高效,因为它只返回呈现页面所需的数据。
|
||||
|
||||
REST 仍然非常有用,如果:
|
||||
|
||||
* 你的 API 非常简单,只有少量的资源或者资源之间关系简单。
|
||||
* 在你的组织中已经在使用 REST API,而且你已经配置好了所有工具,或者你的客户希望获取 REST API。
|
||||
* 你有复杂的 ACL(LCTT 译注:Access Control List) 策略。在博客例子中,可能的功能是允许用户良好地控制谁能查看他们的电子邮箱、博客、特定博客的评论、他们关注了谁,等等。优化数据获取同时检查复杂的业务规则可能会更加困难。
|
||||
|
||||
### 附录1:图数据库和高效数据存储
|
||||
|
||||
尽管将其应用领域数据想象为一个图非常直观,正如这篇博文介绍的那样,但是支持这种接口的高效数据存储问题仍然没有解决。
|
||||
|
||||
近年来图数据库变得越来越流行。通过将 GraphQL 查询转换为特定的图数据库查询语言从而延迟解决请求的复杂性似乎是一种可行的方案。
|
||||
|
||||
问题是和关系型数据库相比,图并不是一种高效的数据结构。图中一个顶点可能有到任何其它顶点的连接,访问模式比较难以预测因此提供了较少的优化机会。
|
||||
|
||||
例如缓存的问题,为了快速访问需要将哪些顶点保存在内存中?通用缓存算法在图遍历场景中可能没那么高效。
|
||||
|
||||
数据库分片问题:把数据库切分为更小、没有交叉的数据库并保存到独立的硬件。在学术上,最小切割的图划分问题已经得到了很好的理解,但可能是次优的,而且由于病态的最坏情况可能导致高度不平衡切割。
|
||||
|
||||
在关系型数据库中,数据被建模为记录(行或者元组)和列,表和数据库名称都只是简单的命名空间。大部分数据库都是面向行的,意味着每个记录都是一个连续的内存块,一个表中的所有记录在磁盘上一个接一个地整齐地打包(通常按照某个关键列排序)。这非常高效,因为这是物理存储最优的工作方式。HDD 最昂贵的操作是将磁头移动到磁盘上的另一个扇区,因此最小化此类访问非常重要。
|
||||
|
||||
很有可能如果应用程序对一条特定记录感兴趣,它需要获取整条记录,而不仅仅是记录中的其中一列。也很有可能如果应用程序对一条记录感兴趣,它也会对该记录周围的记录感兴趣,例如全表扫描。这两点使得关系型数据库相当高效。然而,也是因为这个原因,关系型数据库的最差使用场景就是总是随机访问所有数据。图数据库正是如此。
|
||||
|
||||
随着支持更快随机访问的 SSD 驱动器的出现,更便宜的内存使得缓存大部分图数据库成为可能,更好的优化图缓存和分区的技术,图数据库开始成为可选的存储解决方案。大部分大公司也使用它:Facebook 有 Social Graph,Google 有 Knowledge Graph。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://alexandrutopliceanu.ro/post/graphql-with-go-and-postgresql
|
||||
|
||||
作者:[Alexandru Topliceanu][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://github.com/topliceanu
|
||||
[1]:http://graphql.org/learn/
|
||||
[2]:https://github.com/topliceanu/graphql-go-example
|
||||
[3]:https://github.com/graphql/graphql-js
|
||||
@ -0,0 +1,67 @@
|
||||
为何我们需要一个开放模型来设计评估公共政策
|
||||
============================================================
|
||||
|
||||
> 想象一个 app 可以让市民来试车提出的政策。
|
||||
|
||||

|
||||
|
||||
图片提供:opensource.com
|
||||
|
||||
在政治选举之前的几个月中,公众辩论会加剧,并且公民面临大量的各种政策选择的信息。在数据驱动的社会中,新的见解一直在为决策提供信息,对这些信息的深入了解从未如此重要,但公众仍然没有意识到为公共政策建模的全部潜力。
|
||||
|
||||
在“<ruby>开放政府<rt>open government</rt></ruby>”的概念不断演变以跟上新技术进步的时代,政府的政策模型和分析可能是新一代的开放知识。
|
||||
|
||||
政府开源模型 (GOSM) 是指政府开发的模型,其目的是设计和评估政策,免费提供给所有人使用、分发、不受限制地修改。社区可以提高政策建模的质量、可靠性和准确性,创造有利于公众的新的数据驱动程序。
|
||||
|
||||
今天的这一代人与技术相互作用,这俨然成为了它的第二种本质,自然而然地吸收了大量的信息。如果我们可以在使用 GOSM 在虚拟、沉浸式环境中与不同的公共政策进行互动那会如何?
|
||||
|
||||
想象一下如果有一个程序,允许公民试车提出的政策来确定他们想要生活的未来。他们会本能地学习关键的驱动因素和所需要的东西。不久之后,公众将更深入地了解公共政策的影响,并更加精明地引导有争议性的公众辩论。
|
||||
|
||||
为什么我们以前没有更好的使用这些模型?原因在于公共政策建模的神秘面纱。
|
||||
|
||||
在一个如我们所生活的复杂的社会中,量化政策影响是一项艰巨的任务,并被被描述为一种“美好艺术”。此外,大多数政府政策模型都是基于行政和其他私人持有的数据。然而,政策分析师为了指导政策设计而勇于追求,多次以大量武力而赢得政治斗争的胜利。
|
||||
|
||||
数字是很有说服力的。它们构建可信度,并常常被用作引入新政策的理由。公共政策模型的发展赋予政治家和官僚权力,这些政治家和官僚们可能不愿意破坏现状。给予这一点可能并不容易,但 GOSM 为前所未有的公共政策改革提供了机会。
|
||||
|
||||
GOSM 将所有人的竞争环境均衡化:政治家、媒体、游说团体、利益相关者和公众。通过向社区开放政策评估的大门, 政府可以在公共领域为创造、创新和效率引入新的和未发现的能力。但在公共政策设计中,利益相关者和政府之间战略互动有哪些实际影响?
|
||||
|
||||
GOSM 是独一无二的,因为它们主要是设计公共政策的工具,而不一定需要重新分配私人收益。利益相关者和游说团体可能会将 GOSM 与其私人信息一起使用,以获得对经济参与者私人利益的政策环境运作的新见解。
|
||||
|
||||
GOSM 可以成为利益相关者在公共辩论中保持权力平衡的武器,并为战略争取最佳利益么?
|
||||
|
||||
作为一个可变的公共资源,GOSM 在概念上由纳税人资助,并属于国家。私有实体在不向社会带来利益的情况下从 GOSM 中获得资源是合乎道德的吗?与可能用于更有效的服务提供的那些程序不同,替代政策建议更有可能由咨询机构使用,并有助于公众辩论。
|
||||
|
||||
开源社区经常使用 “copyleft 许可证” 来确保代码和在此许可证下的任何衍生作品对所有人都开放。当产品价值是代码本身,这需要重新分配才能获得最大利益,它需要重新分发来获得最大的利益。但是,如果代码或 GOSM 重新分发是主要产品附带的,那它会是对现有政策环境的新战略洞察么?
|
||||
|
||||
在私人收集的数据变得越来越多的时候,GOSM 背后的真正价值可能是底层数据,它可以用来改进模型本身。最终,政府是唯一有权实施政策的消费者,利益相关者可以选择在谈判中分享修改后的 GOSM。
|
||||
|
||||
政府在公开发布政策模型时面临的巨大挑战是提高透明度的同时保护隐私。理想情况下,发布 GOSM 将需要以保护建模关键特征的方式保护封闭的数据。
|
||||
|
||||
公开发布 GOSM 通过促进市民对民主的更多了解和参与,使公民获得权力,从而改善政策成果和提高公众满意度。在开放的政府乌托邦中,开放的公共政策发展将是政府和社区之间的合作性努力,这里知识、数据和分析可供大家免费使用。
|
||||
|
||||
_在霍巴特举行的 linux.conf.au 2017([#lca2017][1])了解更多 Audrey Lobo-Pulo 的讲话:[公开发布的政府模型][2]。_
|
||||
|
||||
_声明:本文中提出的观点属于 Audrey Lobo-Pulo,不一定是澳大利亚政府的观点。_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Audrey Lobo-Pulo - Audrey Lobo-Pulo 博士是 Phoensight 的联合创始人,并且开放政府以及政府建模开源软件的倡导者。一位物理学家,在加入澳大利亚公共服务部后,她转而从事经济政策建模工作。Audrey 参与了各种经济政策选择的建模,目前对政府开放数据和开放式政策建模感兴趣。 Audrey 对政府的愿景是将数据科学纳入公共政策分析。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/1/government-open-source-models
|
||||
|
||||
作者:[Audrey Lobo-Pulo][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/audrey-lobo-pulo
|
||||
[1]:https://twitter.com/search?q=%23lca2017&src=typd
|
||||
[2]:https://linux.conf.au/schedule/presentation/31/
|
||||
[3]:https://opensource.com/article/17/1/government-open-source-models?rate=p9P_dJ3xMrvye9a6xiz6K_Hc8pdKmRvMypzCNgYthA0
|
||||
@ -0,0 +1,59 @@
|
||||
一位老极客的眼中的开发和部署
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
图片提供 : opensource.com
|
||||
|
||||
多年前,我曾是一名 Smalltalk 程序员,这种经验让我以一种不同的视角来观察编程的世界,例如,需要花时间来适应源代码应该存储在文本文件中的这种做法。
|
||||
|
||||
我们作为程序员通常会区分“开发”和“部署”,特别是我们在开发的地方所使用的工具不同于我们在之后部署软件时的地点和工具时。而在 Smalltalk 世界里,没有这样的区别。
|
||||
|
||||
Smalltalk 构建于虚拟机包含了你的开发环境(IDE、调试器、文本编辑器、版本控制等)的思路之上,如果你需要修改任何一处代码,你得修改内存中运行副本。如果需要的话,你可以为运行中的机器做个快照;如果你想分发你的代码,你可以发送一个运行中的机器的镜像副本(包括 IDE、调试器、文本编辑器、版本控制等)给用户。这就是上世纪 90 年代软件开发的方式(对我们中的一些人来说)。
|
||||
|
||||
如今,部署环境与开发环境有了很大的不同。起初,你不要期望那里(指部署环境)有任何开发工具。一旦部署,就没有版本控制、没有调试、没有开发环境。有的是记录和监视,这些在我们的开发环境中都没有,而有一个“构建管道”,它将我们的软件从开发形式转换为部署形式。作为一个例证,Docker 容器则试图重新找回上世纪 90 年代 Smalltalk 程序员部署体验的那种简单性,而避免同样的开发体验。
|
||||
|
||||
我想如果 Smalltalk 世界是我唯一的编程方面的体验,让我无法区分开发和部署环境,我可能会偶尔回顾一下它。但是在我成为一名 Smalltalk 程序员之前,我还是一位 APL 程序员,这也是一个可修改的虚拟机镜像的世界,其中开发和部署是无法区分的。因此,我相信,在当前的时代,人们编辑单独的源代码文件,然后运行构建管道以创建在编辑代码时尚不存在的部署作品,然后将这些作品部署给用户。我们已经以某种方式将这种反模式的软件开发制度化,而不断发展的软件环境的需求正在迫使我们找回到上世纪 90 年代的更有效的技术方法。因此才会有 Docker 的成功,所以,我需要提出我的建议。
|
||||
|
||||
我有两个建议:我们在运行时系统中实现(并使用)版本控制,以及,我们通过更改运行中的系统来开发软件,而不是用新的运行系统替换它们。这两个想法是相关的。为了安全地更改正在运行的系统,我们需要一些版本控制功能来支持“撤消”功能。也许公平地说,我只提出了一个建议。让我举例来说明。
|
||||
|
||||
让我们开始假设一个静态网站。你要修改一些 HTML 文件。你应该如何工作?如果你像大多数开发者一样,你会有两个,也许三个网站 - 一个用于开发,一个用于 QA(或者预发布),一个用于生产。你将直接编辑开发实例中的文件。准备就绪后,你将把你的修改“部署”到预发布实例。在用户验收测试之后,你将再次部署,这次是生产环境。
|
||||
|
||||
使用 Occam 的 Razor,让我们可以避免不必要地创建实例。我们需要多少台机器?我们可以使用一台电脑。我们需要多少台 web 服务器?我们可以使用具有多个虚拟主机的单台 web 服务器。如果不使用多个虚拟主机的话,我们可以只使用单个虚拟主机吗?那么我们就需要多个目录,并需要使用 URL 的顶级路径来区分不同的版本,而不是虚拟主机名。但是为什么我们需要多个目录?因为 web 服务器将从文件系统中提供静态文件。我们的问题是,目录有三个不同的版本,我们的解决方案是创建目录的三个不同的副本。这不是正是 Subversion 和 Git 这样的版本控制系统解决的问题吗?制作目录的多个副本以存储多个版本的策略回到了版本控制 CVS 之前的日子。为什么不使用比如说一个空的的 Git 仓库来存储文件呢?要这样做,web 服务器将需要能够从 git 仓库读取文件(参见 [mod_git] [3])。
|
||||
|
||||
这将是一个支持版本控制的运行时系统。
|
||||
|
||||
使用这样的 web 服务器,使用的版本可以由 cookie 来标识。这样,任何人都可以推送到仓库,用户将继续看到他们发起会话时所分配的版本。版本控制系统有不可改变的提交; 一旦会话开始,开发人员可以在不影响正在运行的用户的情况下快速推送更改。开发人员可以重置其会话以跟踪他们的新提交,因此开发人员或测试人员就可能如普通用户一样查看在同台服务器上同一个 URL 上正在开发或正在测试的版本。作为偶然的副作用,A/B 测试仅仅是将不同的用户分配给不同的提交的情况。所有用于管理多个版本的 git 设施都可以在运行环境中发挥作用。当然,git reset 为我们提供了前面提到的“撤销”功能。
|
||||
|
||||
为什么不是每个人都这样做?
|
||||
|
||||
一种可能性是,诸如版本控制系统的工具没有被设计为在生产环境中使用。例如,给某人推送到测试分支而不是生产分支的许可是不可能的。对这个方案最常见的反对是,如果发现了一个漏洞,你会想要将某些提交标记为不可访问。这将是另一种更细粒度的权限的情况;开发人员将具有对所有提交的读取权限,但外部用户不会。我们可能需要对现有工具进行一些额外的改造以支持这种模式,但是这些功能很容易理解,并已被设计到其他软件中。例如,Linux (或 PostgreSQL)实现了对不同用户的细粒度权限的想法。
|
||||
|
||||
随着云环境变得越来越普及,这些想法变得更加相关:云总是在运行。例如,我们可以看到,AWS 中等价的 “文件系统”(S3)实现了版本控制,所以你可能有一个不同的想法,使用一台 web 服务器提供来自 S3 的资源文件,并根据会话信息选择不同版本的资源文件。重要的并不是哪个实现是最好的,而是支持这种运行时版本控制的愿景。
|
||||
|
||||
部署的软件环境应该是“版本感知”的原则,应该扩展到除了服务静态文件的 web 服务器之外的其他工具。在将来的文章中,我将介绍版本库,数据库和应用程序服务器的方法。
|
||||
|
||||
_在 linux.conf.au 中了解更多 Robert Lefkowitz 2017 年 ([#lca2017][1])在 Hobart:[保持 Linux 伟大][2]的主题。_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Robert M. Lefkowitz - Robert(即 r0ml)是一个喜欢复杂编程语言的编程语言爱好者。 他是一个提高清晰度、提高可靠性和最大限度地简化的编程技术收藏家。他通过让计算机更加容易获得来使它普及化。他经常演讲中世纪晚期和早期文艺复兴对编程艺术的影响。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/1/difference-between-development-deployment
|
||||
|
||||
作者:[Robert M. Lefkowitz][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[Bestony](https://github.com/Bestony)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/r0ml
|
||||
[1]:https://twitter.com/search?q=%23lca2017&src=typd
|
||||
[2]:https://www.linux.conf.au/schedule/presentation/107/
|
||||
[3]:https://github.com/r0ml/mod_git
|
||||
160
published/201705/20170112 Partition Backup.md
Normal file
160
published/201705/20170112 Partition Backup.md
Normal file
@ -0,0 +1,160 @@
|
||||
如何备份一个磁盘分区
|
||||
============
|
||||
|
||||
通常你可能会把数据放在一个分区上,有时候可能需要对该设备或者上面的一个分区进行备份。树莓派用户为了可引导 SD 卡当然有这个需求。其它小体积计算机的用户也会发现这非常有用。有时候设备看起来要出现故障时最好快速做个备份。
|
||||
|
||||
进行本文中的实验你需要一个叫 `dcfldd` 的工具。
|
||||
|
||||
### dcfldd 工具
|
||||
|
||||
该工具是 coreutils 软件包中 `dd` 工具的增强版。`dcfldd` 是 Nicholas Harbour 在美国国防部计算机取证实验室(DCFL)工作期间研发的。该工具的名字也基于他工作的地方 - `dcfldd`。
|
||||
|
||||
对于仍然在使用 CoreUtils 8.23 或更低版本的系统,并没有一个可以轻松查看正在创建副本的进度的选项。有时候看起来就像什么都没有发生,以至于你就想取消掉备份。
|
||||
|
||||
**注意:**如果你使用 8.24 或更新版本的 `dd` 工具,你就不需要使用 `dcfldd`,只需要用 `dd` 替换 `dcfldd` 即可。所有其它参数仍然适用。
|
||||
|
||||
在 Debian 系统上你只需要在 Package Manager 中搜索 `dcfldd`。你也可以打开一个终端然后输入下面的命令:
|
||||
|
||||
```
|
||||
sudo apt-get install dcfldd
|
||||
```
|
||||
|
||||
对于 Red Hat 系统,可以用下面的命令:
|
||||
|
||||
```
|
||||
cd /tmp
|
||||
wget dl.fedoraproject.org/pub/epel/6/i386/dcfldd-1.3.4.1-4.el6.i686.rpm
|
||||
sudo yum install dcfldd-1.3.4.1-4.el6.i686.rpm
|
||||
dcfldd --version
|
||||
```
|
||||
|
||||
**注意:** 上面的命令安装的是 32 位版本。对于 64 位版本,使用下面的命令:
|
||||
|
||||
````
|
||||
cd /tmp
|
||||
wget dl.fedoraproject.org/pub/epel/6/x86_64/dcfldd-1.3.4.1-4.el6.x86_64.rpm
|
||||
sudo yum install dcfldd-1.3.4.1-4.el6.x86_64.rpm
|
||||
dcfldd --version
|
||||
```
|
||||
|
||||
每组命令中的最后一个语句会列出 `dcfldd` 的版本并显示该命令文件已经被加载。
|
||||
|
||||
**注意:**确保你以 root 用户执行 `dd` 或者 `dcfldd` 命令。
|
||||
|
||||
安装完该工具后你就可以继续使用它备份和恢复分区。
|
||||
|
||||
### 备份分区
|
||||
|
||||
备份设备的时候可以备份整个设备也可以只是其中的一个分区。如果设备有多个分区,我们可以分别备份每个分区。
|
||||
|
||||
在进行备份之前,先让我们来看一下设备和分区的区别。假设我们有一个已经被格式化为一个大磁盘的 SD 卡。这个 SD 卡只有一个分区。如果空间被切分使得 SD 卡看起来是两个设备,那么它就有两个分区。
|
||||
|
||||
假设我们有一个树莓派中的 SD 卡。SD 卡容量为 8 GB,有两个分区。第一个分区存放 BerryBoot 启动引导器。第二个分区存放 Kali(LCTT 译注:Kali Linux 是一个 Debian 派生的 Linux 发行版)。现在已经没有可用的空间用来安装第二个操作系统。我们使用大小为 16 GB 的第二个 SD 卡,但拷贝到第二个 SD 卡之前,第一个 SD 卡必须先备份。
|
||||
|
||||
要备份第一个 SD 卡我们需要备份设备 `/dev/sdc`。进行备份的命令如下所示:
|
||||
|
||||
```
|
||||
dcfldd if=/dev/sdc of=/tmp/SD-Card-Backup.img
|
||||
```
|
||||
|
||||
备份包括输入文件(`if`)以及被设置为 `/tmp` 目录下名为 `SD-Card-Backup.img` 的输出文件(`of`)。
|
||||
|
||||
`dd` 和 `dcfldd` 默认都是每次读写文件中的一个块。通过上述命令,它可以一次默认读写 512 个字节。记住,该复制是一个精准的拷贝 - 逐位逐字节。
|
||||
|
||||
默认的 512 个字节可以通过块大小参数 - `bs=` 更改。例如,要每次读写 1 兆字节,参数为 `bs=1M`。使用以下所用的缩写可以设置不同大小:
|
||||
|
||||
* b – 512 字节
|
||||
* KB – 1000 字节
|
||||
* K – 1024 字节
|
||||
* MB – 1000x1000 字节
|
||||
* M – 1024x1024 字节
|
||||
* GB – 1000x1000x1000 字节
|
||||
* G – 1024x1024x1024 字节
|
||||
|
||||
你也可以单独指定读和写的块大小。要指定读块的大小使用 `ibs=`。要指定写块的大小使用 `obs=`。
|
||||
|
||||
我使用三种不同的块大小做了一个 120 MB 分区的备份测试。第一次使用默认的 512 字节,它用了 7 秒钟。第二次块大小为 1024 K,它用时 2 秒。第三次块大小是 2048 K,它用时 3 秒。用时会随系统以及其它硬件实现的不同而变化,但通常来说更大的块大小会比默认的稍微快一点。
|
||||
|
||||
完成备份后,你还需要知道如何把数据恢复到设备中。
|
||||
|
||||
### 恢复分区
|
||||
|
||||
现在我们已经有了一个备份点,假设数据可能被损毁了或者由于某些原因需要进行恢复。
|
||||
|
||||
命令和备份时相同,只是源和目标相反。对于上面的例子,命令会变为:
|
||||
|
||||
```
|
||||
dcfldd of=/dev/sdc if=/tmp/SD-Card-Backup.img
|
||||
```
|
||||
|
||||
这里,镜像文件被用作输入文件(`if`)而设备(sdc)被用作输出文件(`of`)。
|
||||
|
||||
**注意:** 要记住输出设备会被重写,它上面的所有数据都会丢失。通常来说在恢复数据之前最好用 GParted 删除 SD 卡上的所有分区。
|
||||
|
||||
假如你在使用多个 SD 卡,例如多个树莓派主板,你可以一次性写多块 SD 卡。为了做到这点,你需要知道系统中卡的 ID。例如,假设我们想把镜像 `BerryBoot.img` 拷贝到两个 SD 卡。SD 卡分别是 `/dev/sdc` 和 `/dev/sdd`。下面的命令在显示进度时每次读写 1 MB 的块。命令如下:
|
||||
|
||||
```
|
||||
dcfldd if=BerryBoot.img bs=1M status=progress | tee >(dcfldd of=/dev/sdc) | dcfldd of=/dev/sdd
|
||||
```
|
||||
|
||||
在这个命令中,第一个 `dcfldd` 指定输入文件并把块大小设置为 1 MB。`status` 参数被设置为显示进度。然后输入通过管道 `|`传输给命令 `tee`。`tee` 用于将输入分发到多个地方。第一个输出是到命令 `dcfldd of=/dev/sdc`。命令被放到小括号内被作为一个命令执行。我们还需要最后一个管道 `|`,否则命令 `tee` 会把信息发送到 `stdout` (屏幕)。因此,最后的输出是被发送到命令 `dcfldd of=/dev/sdd`。如果你有第三个 SD 卡,甚至更多,只需要添加另外的重定向和命令,类似 `>(dcfldd of=/dev/sde`。
|
||||
|
||||
**注意:**记住最后一个命令必须在管道 `|` 后面。
|
||||
|
||||
必须验证写的数据确保数据是正确的。
|
||||
|
||||
### 验证数据
|
||||
|
||||
一旦创建了一个镜像或者恢复了一个备份,你可以验证这些写入的数据。要验证数据,你会使用名为 `diff` 的另一个不同程序。
|
||||
|
||||
使用 `diff` ,你需要指定镜像文件的位置以及系统中拷贝自或写入的物理媒介。你可以在创建备份或者恢复了一个镜像之后使用 `diff` 命令。
|
||||
|
||||
该命令有两个参数。第一个是物理媒介,第二个是镜像文件名称。
|
||||
|
||||
对于例子 `dcfldd of=/dev/sdc if=/tmp/SD-Card-Backup.img`,对应的 `diff` 命令是:
|
||||
|
||||
```
|
||||
diff /dev/sdc /tmp/SD-Card-Backup.img
|
||||
```
|
||||
|
||||
如果镜像和物理设备有任何的不同,你会被告知。如果没有显示任何信息,那么数据就验证为完全相同。
|
||||
|
||||
确保数据完全一致是验证备份和恢复完整性的关键。进行备份时需要注意的一个主要问题是镜像大小。
|
||||
|
||||
### 分割镜像
|
||||
|
||||
假设你想要备份一个 16GB 的 SD 卡。镜像文件大小会大概相同。如果你只能把它备份到 FAT32 分区会怎样呢?FAT32 最大文件大小限制是 4 GB。
|
||||
|
||||
必须做的是文件必须被切分为 4 GB 的分片。通过管道 `|` 将数据传输给 `split` 命令可以切分正在被写的镜像文件。
|
||||
|
||||
创建备份的方法相同,但命令会包括管道和切分命令。示例备份命令为 `dcfldd if=/dev/sdc of=/tmp/SD-Card-Backup.img` ,其切分文件的新命令如下:
|
||||
|
||||
```
|
||||
dcfldd if=/dev/sdc | split -b 4000MB - /tmp/SD-Card-Backup.img
|
||||
```
|
||||
|
||||
**注意:** 大小后缀和对 `dd` 及 `dcfldd` 命令的意义相同。 `split` 命令中的破折号用于将通过管道从 `dcfldd` 命令传输过来的数据填充到输入文件。
|
||||
|
||||
文件会被保存为 `SD-Card-Backup.imgaa` 和 `SD-Card-Backup.imgab`,如此类推。如果你担心文件大小太接近 4 GB 的限制,可以试着用 3500MB。
|
||||
|
||||
将文件恢复到设备也很简单。你使用 `cat` 命令将它们连接起来然后像下面这样用 `dcfldd` 写输出:
|
||||
|
||||
```
|
||||
cat /tmp/SD-Card-Backup.img* | dcfldd of=/dev/sdc
|
||||
```
|
||||
|
||||
你可以在命令中 `dcfldd` 部分包含任何需要的参数。
|
||||
|
||||
我希望你了解并能执行任何需要的数据备份和恢复,正如 SD 卡和类似设备所需的那样。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxforum.com/threads/partition-backup.3638/
|
||||
|
||||
作者:[Jarret][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxforum.com/members/jarret.268/
|
||||
@ -0,0 +1,67 @@
|
||||
六个开源软件开发的“潜规则”
|
||||
============================================================
|
||||
|
||||
> 你想成为开源项目中得意满满、功成名就的那个人吗,那就要遵守下面的“潜规则”。
|
||||
|
||||

|
||||
|
||||
正如体育界不成文的规定一样,这些规则基本上不会出现在官方文档和正式记录上。比如说,在棒球运动中,从比分领先时不要盗垒,到跑垒员跑了第一时也不要放弃四坏球保送。对于圈外人来讲,这些东西很难懂,甚至觉得没什么意义。但是对于那些想成为 MVP 的队员来说,这些都是理所当然的。
|
||||
|
||||
软件开发,特别是开源软件开发中,也有一套不成文的规定。和其它的团队运动一样,这些规定很大程度上决定了开源社区如何看待一名开发者,特别是新加入社区的开发者。
|
||||
|
||||
### 运行之前先调试
|
||||
|
||||
在参与社区之前,比如开放源代码或者其它什么的,你需要做一些基本工作。对于有眼界的开源贡献者,这意味这你需要理解社区的目标,并学习应该从哪里起步。人人都想贡献源代码,但是只有少量的人做过准备,并且乐意、同时也有能力完成这项艰苦卓绝的工作:测试补丁、复审代码、撰写文档、修正错误。所有的这些不受待见的任务在一个健康的社区中都是必要的。
|
||||
|
||||
为什么要在优雅地写代码前做这些呢?这是一种信任,更重要的是,不要只关注自己开发的功能,而是要关注整个社区的动向。
|
||||
|
||||
### 填坑而不是挖坑
|
||||
|
||||
当你在某个社区中建立起自己的声望,那么很有必要全面了解该项目和代码。不要停留于任务状态上,而是要去钻研项目本身,理解那些超出你擅长范围之外的知识。不要只把自己的理解局限于开发者,这样会让你着眼于让你的代码有更大的影响,而不只是你那一亩三分地。
|
||||
|
||||
打个比方,你已经完成了一个网络模块的测试版本。你测试了一下,觉得不错。然后你把它开放到社区,想要更多的人测试。结果发现,当它以特定的方式部署时,有可能会破坏安全设置,还可能导致主存储泄露。如果你将代码视为一个整体时问题就可以迎刃而解,而不是孤立地看待问题。这表明,你要对项目各个部分如何与其他人协作交互有比较深入的理解。让你的补丁填坑而不是挖坑。这样你朝成为社区精英的目标上又前进了一大步。
|
||||
|
||||
### 不投放代码炸弹
|
||||
|
||||
代码提交完毕后你的工作还没结束。如果代码被接受,还会有一些关于这些更改的讨论和常见的问答,还要做测试。你要确保你可以准时提交,努力去理解如何在不影响社区其他成员的情况下,改进代码和补丁。
|
||||
|
||||
### 助己之前先助人
|
||||
|
||||
开源社区不是自相残杀的丛林世界,我们更看重项目的价值而非个体的贡献和成功。如果你想给自己加分,让自己成为更重要的社区成员、让社区接纳你的代码,那就努力帮助别人。如果你熟悉网络部分,那就去复审网络部分,用你的专业技能让整个代码更加优雅。道理很简单,顶级的审查者经常和顶级的贡献者打交道。你帮助的人越多,你就越有价值。
|
||||
|
||||
### 打磨抛光才算完
|
||||
|
||||
作为一个开发者,你很可能希望为开源项目解决一个特定的痛点。或许你想要运行在一个目前还不支持的系统上,抑或你很希望改革社区目前使用的安全技术。想要引进新技术,特别是比较有争议的技术,最好的办法就是让人无法拒绝它。你需要透彻地了解底层代码,考虑每个极端情况。在不影响已实现功能的前提下增加新功能。不仅仅是完成就行,还要在特性的完善上下功夫。
|
||||
|
||||
### 不离不弃方始终
|
||||
|
||||
开源社区也有许多玩玩就算的人,但是承诺了就不要轻易失信。不要就因为提交被拒就离开社区。找出原因,修正错误,然后再试一试。当你开发时候,要和整个代码库保持一致,确保即使项目发生变化而你的补丁仍然可用。不要把你的代码留给别人修复,要自己修复。这样可以在社区形成良好的风气,每个人都自己改。
|
||||
|
||||
---
|
||||
|
||||
这些“潜规则”看上去很简单,但是还是有许多开源项目的贡献者并没有遵守。这样做的开发者不仅可以为成功地推动他们自己的项目,而且也有助于开源社区。
|
||||
|
||||
作者简介:
|
||||
|
||||
Matt Hicks 是 Red Hat 软件工程的副主席,也是 Red Hat 开源合作团队的奠基成员之一。他历时十五年,在软件工程中担任多种职务:开发,运行,架构,管理。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoworld.com/article/3156776/open-source-tools/the-6-unwritten-rules-of-open-source-development.html
|
||||
|
||||
作者:[Matt Hicks][a]
|
||||
译者:[Taylor1024](https://github.com/Taylor1024)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.infoworld.com/blog/new-tech-forum/
|
||||
[1]:https://twitter.com/intent/tweet?url=http%3A%2F%2Fwww.infoworld.com%2Farticle%2F3156776%2Fopen-source-tools%2Fthe-6-unwritten-rules-of-open-source-development.html&via=infoworld&text=The+6+unwritten+rules+of+open+source+development
|
||||
[2]:https://www.facebook.com/sharer/sharer.php?u=http%3A%2F%2Fwww.infoworld.com%2Farticle%2F3156776%2Fopen-source-tools%2Fthe-6-unwritten-rules-of-open-source-development.html
|
||||
[3]:http://www.linkedin.com/shareArticle?url=http%3A%2F%2Fwww.infoworld.com%2Farticle%2F3156776%2Fopen-source-tools%2Fthe-6-unwritten-rules-of-open-source-development.html&title=The+6+unwritten+rules+of+open+source+development
|
||||
[4]:https://plus.google.com/share?url=http%3A%2F%2Fwww.infoworld.com%2Farticle%2F3156776%2Fopen-source-tools%2Fthe-6-unwritten-rules-of-open-source-development.html
|
||||
[5]:http://reddit.com/submit?url=http%3A%2F%2Fwww.infoworld.com%2Farticle%2F3156776%2Fopen-source-tools%2Fthe-6-unwritten-rules-of-open-source-development.html&title=The+6+unwritten+rules+of+open+source+development
|
||||
[6]:http://www.stumbleupon.com/submit?url=http%3A%2F%2Fwww.infoworld.com%2Farticle%2F3156776%2Fopen-source-tools%2Fthe-6-unwritten-rules-of-open-source-development.html
|
||||
[7]:http://www.infoworld.com/article/3156776/open-source-tools/the-6-unwritten-rules-of-open-source-development.html#email
|
||||
[8]:http://www.infoworld.com/article/3152565/linux/5-rock-solid-linux-distros-for-developers.html#tk.ifw-infsb
|
||||
[9]:http://www.infoworld.com/newsletters/signup.html#tk.ifw-infsb
|
||||
@ -0,0 +1,74 @@
|
||||
5 个提升你开源项目贡献者基数的方法
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
图片提供:opensource.com
|
||||
|
||||
许多自由和开源软件项目因解决问题而出现,人们开始为它们做贡献,是因为他们也想修复遇到的问题。当项目的最终用户发现它对他们的需求有用,该项目就开始增长。并且出于分享的目的把人们吸引到同一个项目社区。
|
||||
|
||||
就像任何事物都是有寿命的,增长既是项目成功的标志也是来源。那么项目领导者和维护者如何激励贡献者基数的增长?这里有五种方法。
|
||||
|
||||
### 1、 提供好的文档
|
||||
|
||||
人们经常低估项目[文档][2]的重要性。它是项目贡献者的主要信息来源,它会激励他们努力。信息必须是正确和最新的。它应该包括如何构建该软件、如何提交补丁、编码风格指南等步骤。
|
||||
|
||||
查看经验丰富的科技作家、编辑 Bob Reselman 的 [7 个创建世界级文档的规则][3]。
|
||||
|
||||
开发人员文档的一个很好的例子是 [Python 开发人员指南][4]。它包括清晰简洁的步骤,涵盖 Python 开发的各个方面。
|
||||
|
||||
### 2、 降低进入门槛
|
||||
|
||||
如果你的项目有[工单或 bug 追踪工具][5],请确保将初级任务标记为一个“小 bug” 或“起点”。新的贡献者可以很容易地通过解决这些问题进入项目。追踪工具也是标记非编程任务(如平面设计、图稿和文档改进)的地方。有许多项目成员不是每天都编码,但是却通过这种方式成为推动力。
|
||||
|
||||
Fedora 项目维护着一个这样的[易修复和入门级问题的追踪工具][6]。
|
||||
|
||||
### 3、 为补丁提供常规反馈
|
||||
|
||||
确认每个补丁,即使它只有一行代码,并给作者反馈。提供反馈有助于吸引潜在的候选人,并指导他们熟悉项目。所有项目都应有一个邮件列表和[聊天功能][7]进行通信。问答可在这些媒介中发生。大多数项目不会在一夜之间成功,但那些繁荣的列表和沟通渠道为增长创造了环境。
|
||||
|
||||
### 4、 推广你的项目
|
||||
|
||||
始于解决问题的项目实际上可能对其他开发人员也有用。作为项目的主要贡献者,你的责任是为你的的项目建立文档并推广它。写博客文章,并在社交媒体上分享项目的进展。你可以从简要描述如何成为项目的贡献者开始,并在该描述中提供主要开发者文档的参考连接。此外,请务必提供有关路线图和未来版本的信息。
|
||||
|
||||
为了你的听众,看看由 Opensource.com 的社区经理 Rikki Endsley 写的[写作提示][8]。
|
||||
|
||||
### 5、 保持友好
|
||||
|
||||
友好的对话语调和迅速的回复将加强人们对你的项目的兴趣。最初,这些问题只是为了寻求帮助,但在未来,新的贡献者也可能会提出想法或建议。让他们有信心他们可以成为项目的贡献者。
|
||||
|
||||
记住你一直在被人评头论足!人们会观察项目开发者是如何在邮件列表或聊天上交谈。这些意味着对新贡献者的欢迎和开放程度。当使用技术时,我们有时会忘记人文关怀,但这对于任何项目的生态系统都很重要。考虑一个情况,项目是很好的,但项目维护者不是很受欢迎。这样的管理员可能会驱使用户远离项目。对于有大量用户基数的项目而言,不被支持的环境可能导致分裂,一部分用户可能决定复刻项目并启动新项目。在开源世界中有这样的先例。
|
||||
|
||||
另外,拥有不同背景的人对于开源项目的持续增长和源源不断的点子是很重要的。
|
||||
|
||||
最后,项目负责人有责任维持和帮助项目成长。指导新的贡献者是项目的关键,他们将成为项目和社区未来的领导者。
|
||||
|
||||
阅读:由红帽的内容战略家 Nicole Engard 写的 [7 种让新的贡献者感到受欢迎的方式][1]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Kushal Das - Kushal Das 是 Python 软件基金会的一名 CPython 核心开发人员和主管。他是一名长期的 FOSS 贡献者和导师,他帮助新人进入贡献世界。他目前在 Red Hat 担任 Fedora 云工程师。他的博客在 https://kushaldas.in 。你也可以在 Twitter @kushaldas 上找到他
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/1/expand-project-contributor-base
|
||||
|
||||
作者:[Kushal Das][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[Bestony](https://github.com/bestony)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/kushaldas
|
||||
[1]:https://opensource.com/life/16/5/sumana-harihareswara-maria-naggaga-oscon
|
||||
[2]:https://opensource.com/tags/documentation
|
||||
[3]:https://opensource.com/business/16/1/scale-14x-interview-bob-reselman
|
||||
[4]:https://docs.python.org/devguide/
|
||||
[5]:https://opensource.com/tags/bugs-and-issues
|
||||
[6]:https://fedoraproject.org/easyfix/
|
||||
[7]:https://opensource.com/alternatives/slack
|
||||
[8]:https://opensource.com/business/15/10/what-stephen-king-can-teach-tech-writers
|
||||
@ -0,0 +1,101 @@
|
||||
如何在 Linux 中捕获并流式传输你的游戏过程
|
||||
============================================================
|
||||
|
||||
也许没有那么多铁杆的游戏玩家使用 Linux,但肯定有很多 Linux 用户喜欢玩游戏。如果你是其中之一,并希望向世界展示 Linux 游戏不再是一个笑话,那么你会喜欢下面这个关于如何捕捉并且/或者以流式播放游戏的快速教程。我在这将用一个名为 “[Open Broadcaster Software Studio][5]” 的软件,这可能是我们所能找到最好的一种。
|
||||
|
||||
### 捕获设置
|
||||
|
||||
在顶层菜单中,我们选择 “File” → “Settings”,然后我们选择 “Output” 来设置要生成的文件的选项。这里我们可以设置想要的音频和视频的比特率、新创建的文件的目标路径和文件格式。这上面还提供了粗略的质量设置。
|
||||
|
||||
[
|
||||
|
||||
][6]
|
||||
|
||||
如果我们将顶部的输出模式从 “Simple” 更改为 “Advanced”,我们就能够设置 CPU 负载,以控制 OBS 对系统的影响。根据所选的质量、CPU 能力和捕获的游戏,可以设置一个不会导致丢帧的 CPU 负载设置。你可能需要做一些试验才能找到最佳设置,但如果将质量设置为低,则不用太多设置。
|
||||
|
||||
[
|
||||
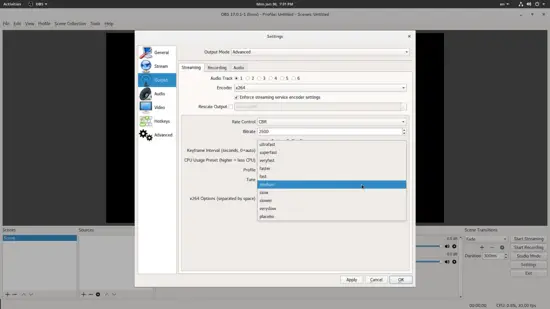
|
||||
][7]
|
||||
|
||||
接下来,我们转到设置的 “Video” 部分,我们可以设置我们想要的输出视频分辨率。注意缩小过滤(downscaling filtering )方式,因为它使最终的质量有所不同。
|
||||
|
||||
[
|
||||
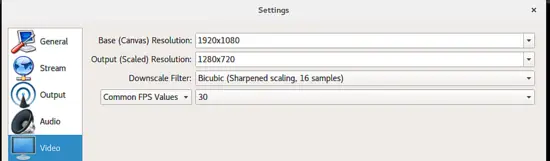
|
||||
][8]
|
||||
|
||||
你可能还需要绑定热键以启动、暂停和停止录制。这特别有用,这样你就可以在录制时看到游戏的屏幕。为此,请在设置中选择 “Hotkeys” 部分,并在相应的框中分配所需的按键。当然,你不必每个框都填写,你只需要填写所需的。
|
||||
|
||||
[
|
||||
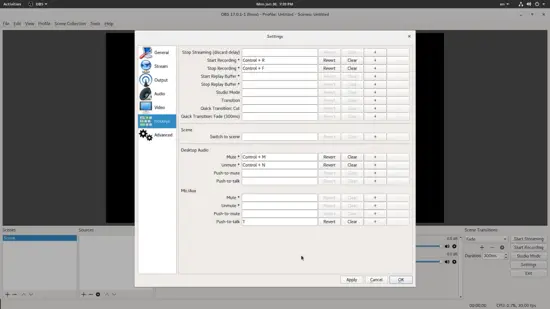
|
||||
][9]
|
||||
|
||||
如果你对流式传输感兴趣,而不仅仅是录制,请选择 “Stream” 分类的设置,然后你可以选择支持的 30 种流媒体服务,包括 Twitch、Facebook Live 和 Youtube,然后选择服务器并输入 流密钥。
|
||||
|
||||
[
|
||||
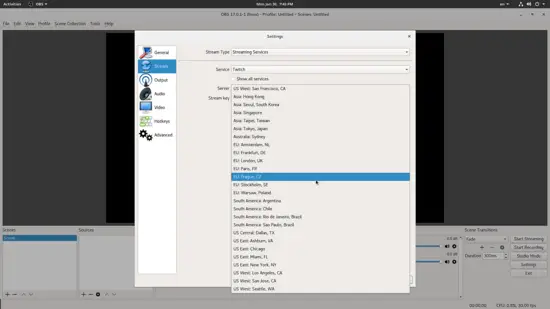
|
||||
][10]
|
||||
|
||||
### 设置源
|
||||
|
||||
在左下方,你会发现一个名为 “Sources” 的框。我们按下加号来添加一个新的源,它本质上就是我们录制的媒体源。在这你可以设置音频和视频源,但是图像甚至文本也是可以的。
|
||||
|
||||
[
|
||||
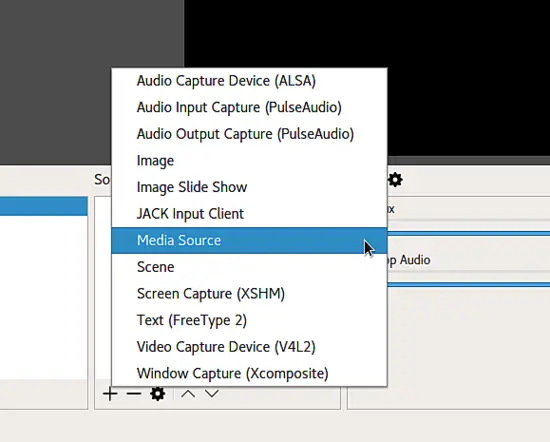
|
||||
][11]
|
||||
|
||||
前三个是关于音频源,接下来的两个是图像,JACK 选项用于从乐器捕获的实时音频, Media Source 用于添加文件等。这里我们感兴趣的是 “Screen Capture (XSHM)”、“Video Capture Device (V4L2)” 和 “Window Capture (Xcomposite)” 选项。
|
||||
|
||||
屏幕捕获选项让你选择要捕获的屏幕(包括活动屏幕),以便记录所有内容。如工作区更改、窗口最小化等。对于标准批量录制来说,这是一个适合的选项,它可在发布之前进行编辑。
|
||||
|
||||
我们来探讨另外两个。Window Capture 将让我们选择一个活动窗口并将其放入捕获监视器。为了将我们的脸放在一个角落,视频捕获设备用于人们可以在我们说话时可以看到我们。当然,每个添加的源都提供了一组选项来供我们实现我们最后要的效果。
|
||||
|
||||
[
|
||||
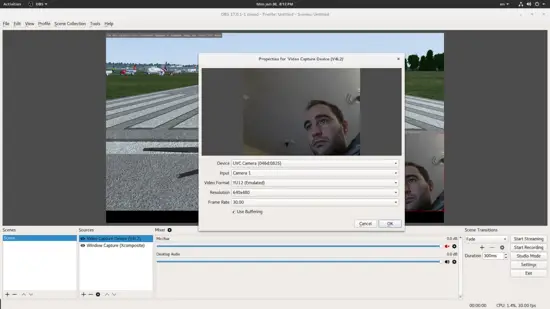
|
||||
][12]
|
||||
|
||||
添加的来源是可以调整大小的,也可以沿着录制帧的平面移动,因此你可以添加多个来源,并根据需要进行排列,最后通过右键单击执行基本的编辑任务。
|
||||
|
||||
[
|
||||
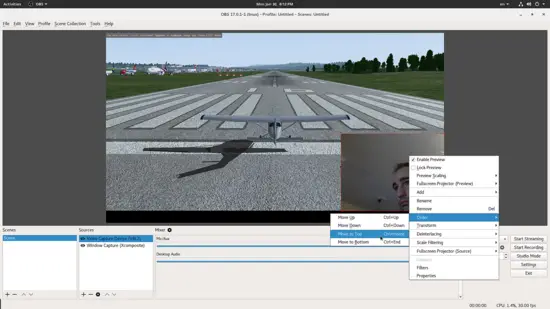
|
||||
][13]
|
||||
|
||||
### 过渡
|
||||
|
||||
最后,如果你正在流式传输游戏会话时希望能够在游戏视图和自己(或任何其他来源)之间切换。为此,请从右下角切换为“Studio Mode”,并添加一个分配给另一个源的场景。你还可以通过取消选中 “Duplicate scene” 并检查 “Transitions” 旁边的齿轮图标上的 “Duplicate sources” 来切换。 当你想在简短评论中显示你的脸部时,这很有帮助。
|
||||
|
||||
[
|
||||
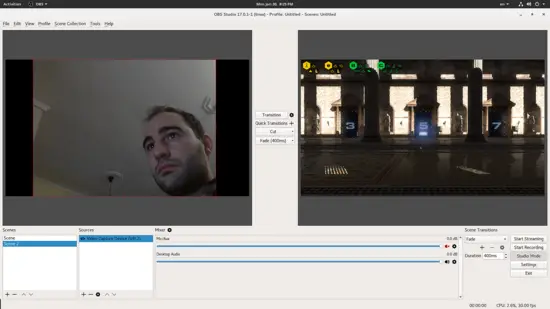
|
||||
][14]
|
||||
|
||||
这个软件有许多过渡效果,你可以按中心的 “Quick Transitions” 旁边的加号图标添加更多。当你添加它们时,还将会提示你进行设置。
|
||||
|
||||
### 总结
|
||||
|
||||
OBS Studio 是一个功能强大的免费软件,它工作稳定,使用起来相当简单直接,并且拥有越来越多的扩展其功能的[附加插件][15]。如果你需要在 Linux 上记录并且/或者流式传输游戏会话,除了使用 OBS 之外,我无法想到其他更好的解决方案。你有其他类似工具的经验么? 请在评论中分享也欢迎包含一个展示你技能的视频链接。:)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-capture-and-stream-your-gaming-session-on-linux/
|
||||
|
||||
作者:[Bill Toulas][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/how-to-capture-and-stream-your-gaming-session-on-linux/
|
||||
[1]:https://www.howtoforge.com/tutorial/how-to-capture-and-stream-your-gaming-session-on-linux/#capture-settings
|
||||
[2]:https://www.howtoforge.com/tutorial/how-to-capture-and-stream-your-gaming-session-on-linux/#setting-up-the-sources
|
||||
[3]:https://www.howtoforge.com/tutorial/how-to-capture-and-stream-your-gaming-session-on-linux/#transitioning
|
||||
[4]:https://www.howtoforge.com/tutorial/how-to-capture-and-stream-your-gaming-session-on-linux/#conclusion
|
||||
[5]:https://obsproject.com/download
|
||||
[6]:https://www.howtoforge.com/images/how-to-capture-and-stream-your-gaming-session-on-linux/big/pic_1.png
|
||||
[7]:https://www.howtoforge.com/images/how-to-capture-and-stream-your-gaming-session-on-linux/big/pic_2.png
|
||||
[8]:https://www.howtoforge.com/images/how-to-capture-and-stream-your-gaming-session-on-linux/big/pic_3.png
|
||||
[9]:https://www.howtoforge.com/images/how-to-capture-and-stream-your-gaming-session-on-linux/big/pic_4.png
|
||||
[10]:https://www.howtoforge.com/images/how-to-capture-and-stream-your-gaming-session-on-linux/big/pic_5.png
|
||||
[11]:https://www.howtoforge.com/images/how-to-capture-and-stream-your-gaming-session-on-linux/big/pic_6.png
|
||||
[12]:https://www.howtoforge.com/images/how-to-capture-and-stream-your-gaming-session-on-linux/big/pic_7.png
|
||||
[13]:https://www.howtoforge.com/images/how-to-capture-and-stream-your-gaming-session-on-linux/big/pic_8.png
|
||||
[14]:https://www.howtoforge.com/images/how-to-capture-and-stream-your-gaming-session-on-linux/big/pic_9.png
|
||||
[15]:https://obsproject.com/forum/resources/categories/obs-studio-plugins.6/
|
||||
@ -0,0 +1,117 @@
|
||||
如何在 Vim 中使用模式行进行文件特定的设置
|
||||
============================================================
|
||||
|
||||
虽然[插件][4]毫无疑问是 Vim 最大的优势,然而,还有其它一些功能,使得它成为当今 Linux 用户中最强大、功能最丰富的文本编辑器/IDE 之一。其中一个功能就是可以根据文件做特定的设置。我们可以使用该编辑器的模式行(Modeline)特性来实现该功能。
|
||||
|
||||
在这篇文章中,我将讨论如何使用 Vim 的[模式行(Modeline)][5]特性来简单的理解一些例子。
|
||||
|
||||
在开始之前,值得提醒一下,这篇教程中提及的所有例子、命令和指令都已经在 Ubuntu 16.04 中使用 Vim 7.4 版本测试过。
|
||||
|
||||
### VIM 模式行
|
||||
|
||||
#### 用法
|
||||
|
||||
正如上面已经提到的, Vim 的模式行特性让你能够进行特定于文件的更改。比如,假设你想把项目中的一个特定文件中的所有制表符用空格替换,并且确保这个更改不会影响到其它所有文件。这是模式行帮助你完成你想做的事情的一个理想情况。
|
||||
|
||||
因此,你可以考虑将下面这一行加入文件的开头或结尾来完成这件事。
|
||||
|
||||
```
|
||||
# vim: set expandtab:
|
||||
```
|
||||
|
||||
(LCTT 译注:模式行就是一行以注释符,如 `#`、`//`、`/*` 开头,间隔一个空格,以 `vim:` 关键字触发的设置命令。可参看:http://vim.wikia.com/wiki/Modeline_magic )
|
||||
|
||||
如果你是在 Linux 系统上尝试上面的练习来测试用例,很有可能它将不会像你所期望的那样工作。如果是这样,也不必担心,因为某些情况下,模式行特性需要先激活才能起作用(出于安全原因,在一些系统比如 Debian、Ubuntu、GGentoo 和 OSX 上默认情况下禁用)。
|
||||
|
||||
为了启用该特性,打开 `.vimrc` 文件(位于 `home` 目录),然后加入下面一行内容:
|
||||
|
||||
```
|
||||
set modeline
|
||||
```
|
||||
|
||||
现在,无论何时你在该文件输入一个制表符然后保存时(文件中已输入 `expandtab` 模式行命令的前提下),都会被自动转换为空格。
|
||||
|
||||
让我们考虑另一个用例。假设在 Vim 中, 制表符默认设置为 4 个空格,但对于某个特殊的文件,你想把它增加到 8 个。对于这种情况,你需要在文件的开头或末尾加上下面这行内容:
|
||||
|
||||
```
|
||||
// vim: noai:ts=8:
|
||||
```
|
||||
|
||||
现在,输入一个制表符,你会看到,空格的数量为 8 个。
|
||||
|
||||
你可能已经注意到我刚才说的,这些模式行命令需要加在靠近文件的顶部或底部。如果你好奇为什么是这样,那么理由是该特性以这种方式设计的。下面这一行(来自 Vim 官方文件)将会解释清楚:
|
||||
|
||||
> “模式行不能随意放在文件中的任何位置:它需要放在文件中的前几行或最后几行。`modelines` 变量控制 Vim 检查模式行在文件中的确切位置。请查看 `:help modelines` 。默认情况下,设置为 5 行。”
|
||||
|
||||
下面是 `:help modelines` 命令(上面提到的)输出的内容:
|
||||
|
||||
> 如果 `modeline` 已启用并且 `modelines` 给出了行数,那么便在相应位置查找 `set` 命令。如果 `modeline` 禁用或 `modelines` 设置的行数为 0 则不查找。
|
||||
|
||||
尝试把模式行命令置于超出 5 行的范围(距离文件底部和顶部的距离均超过 5 行),你会发现, 制表符将会恢复为 Vim 默认数目的空格 — 在我的情况里是 4 个空格。
|
||||
|
||||
然而,你可以按照自己的意愿改变默认行数,只需在你的 `.vimrc` 文件中加入下面一行命令
|
||||
|
||||
```
|
||||
set modelines=[新值]
|
||||
```
|
||||
|
||||
比如,我把值从 5 增加到了 10 。
|
||||
|
||||
```
|
||||
set modelines=10
|
||||
```
|
||||
|
||||
这意味着,现在我可以把模式行命令置于文件前 10 行或最后 10 行的任意位置。
|
||||
|
||||
继续,无论何时,当你在编辑一个文件的时候,你可以输入下面的命令(在 Vim 编辑器的命令模式下输入)来查看当前与命令行相关的设置以及它们最新的设置。
|
||||
|
||||
```
|
||||
:verbose set modeline? modelines?
|
||||
```
|
||||
|
||||
比如,在我的例子中,上面的命令产生了如下所示的输出:
|
||||
|
||||
```
|
||||
modeline
|
||||
Last set from ~/.vimrc
|
||||
modelines=10
|
||||
Last set from ~/.vimrc
|
||||
```
|
||||
|
||||
关于 Vim 的模式行特性,你还需要知道一些重要的点:
|
||||
|
||||
* 默认情况下,当 Vim 以非兼容(`nocompatible`)模式运行时该特性是启用的,但需要注意的是,在一些发行版中,出于安全考虑,系统的 `vimrc` 文件禁用了该选项。
|
||||
* 默认情况下,当以 root 权限编辑文件时,该特性被禁用(如果你是使用 `sudo` 方式打开该文件,那么该特性依旧能够正常工作)。
|
||||
* 通过 `set` 来设置模式行,其结束于第一个冒号,而非反斜杠。不使用 `set`,则后面的文本都是选项。比如,`/* vim: noai:ts=4:sw=4 */` 是一个无效的模式行。
|
||||
|
||||
(LCTT 译注:关于模式行中的 `set`,上述描述指的是:如果用 `set` 来设置,那么当发现第一个 `:` 时,表明选项结束,后面的 `*/` 之类的为了闭合注释而出现的文本均无关;而如果不用 `set` 来设置,那么以 `vim:` 起头的该行所有内容均视作选项。 )
|
||||
|
||||
#### 安全考虑
|
||||
|
||||
令人沮丧的是, Vim 的模式行特性可能会造成安全性问题。事实上,在过去,已经报道过多个和模式行相关的问题,包括 [shell 命令注入][6],[任意命令执行][7]和[无授权访问][8]等。我知道,这些问题发生在很早的一些时候,现在应该已经修复好了,但是,这提醒了我们,模式行特性有可能会被黑客滥用。
|
||||
|
||||
### 结论
|
||||
|
||||
模式行可能是 Vim 编辑器的一个高级命令,但是它并不难理解。毫无疑问,它的学习曲线会有一些复杂,但是不需多问也知道,该特性是多么的有用。当然,出于安全考虑,在启用并使用该选项前,你需要对自己的选择进行权衡。
|
||||
|
||||
你有使用过模式行特性吗?你的体验是什么样的?记得在下面的评论中分享给我们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/vim-modeline-settings/
|
||||
|
||||
作者:[Ansh][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/vim-modeline-settings/
|
||||
[1]:https://www.howtoforge.com/tutorial/vim-modeline-settings/#usage
|
||||
[2]:https://www.howtoforge.com/tutorial/vim-modeline-settings/#vim-modeline
|
||||
[3]:https://www.howtoforge.com/tutorial/vim-modeline-settings/#conclusion
|
||||
[4]:https://linux.cn/article-7901-1.html
|
||||
[5]:http://vim.wikia.com/wiki/Modeline_magic
|
||||
[6]:https://tools.cisco.com/security/center/viewAlert.x?alertId=13223
|
||||
[7]:http://usevim.com/2012/03/28/modelines/
|
||||
[8]:https://tools.cisco.com/security/center/viewAlert.x?alertId=5169
|
||||
@ -0,0 +1,287 @@
|
||||
如何在 Linux 中使用 Asciinema 进行录制和回放终端会话
|
||||
===========
|
||||
|
||||

|
||||
|
||||
|
||||
### 简介
|
||||
|
||||
Asciinema 是一个轻量并且非常高效的终端会话录制器。使用它可以录制、回放和分享 JSON 格式的终端会话记录。与一些桌面录制器,比如 Recordmydesktop、Simplescreenrecorder、Vokoscreen 或 Kazam 相比,Asciinema 最主要的优点是,它能够以通过 ASCII 文本以及 ANSI 转义码编码来录制所有的标准终端输入、输出和错误信息。
|
||||
|
||||
事实上,即使是很长的终端会话,录制出的 JSON 格式文件也非常小。另外,JSON 格式使得用户可以利用简单的文件转化器,将输出的 JSON 格式文件嵌入到 HTML 代码中,然后分享到公共网站或者使用 asciinema 账户分享到 Asciinema.org 。最后,如果你的终端会话中有一些错误,并且你还懂一些 ASCI 转义码语法,那么你可以使用任何编辑器来修改你的已录制终端会话。
|
||||
|
||||
**难易程度:**
|
||||
|
||||
很简单!
|
||||
|
||||
**标准终端:**
|
||||
|
||||
* **#** - 给定命令需要以 root 用户权限运行或者使用 `sudo` 命令
|
||||
* **$** - 给定命令以常规权限用户运行
|
||||
|
||||
### 从软件库安装
|
||||
|
||||
通常, asciinema 可以使用你的发行版的软件库进行安装。但是,如果不可以使用系统的软件库进行安装或者你想安装最新的版本,那么,你可以像下面的“从源代码安装”部分所描述的那样,使用 Linuxbrew 包管理器来执行 Asciinema 安装。
|
||||
|
||||
**在 Arch Linux 上安装:**
|
||||
|
||||
```
|
||||
# pacman -S asciinema
|
||||
```
|
||||
|
||||
**在 Debian 上安装:**
|
||||
|
||||
```
|
||||
# apt install asciinema
|
||||
```
|
||||
|
||||
**在 Ubuntu 上安装:**
|
||||
|
||||
```
|
||||
$ sudo apt install asciinema
|
||||
```
|
||||
|
||||
**在 Fedora 上安装:**
|
||||
|
||||
```
|
||||
$ sudo dnf install asciinema
|
||||
```
|
||||
|
||||
### 从源代码安装
|
||||
|
||||
最简单并且值得推荐的方式是使用 Linuxbrew 包管理器,从源代码安装最新版本的 Asciinema 。
|
||||
|
||||
#### 前提条件
|
||||
|
||||
下面列出的前提条件是安装 Linuxbrew 和 Asciinema 需要满足的依赖关系:
|
||||
|
||||
* git
|
||||
* gcc
|
||||
* make
|
||||
* ruby
|
||||
|
||||
在安装 Linuxbrew 之前,请确保上面的这些包都已经安装在了你的 Linux 系统中。
|
||||
|
||||
**在 Arch Linux 上安装 ruby:**
|
||||
|
||||
```
|
||||
# pacman -S git gcc make ruby
|
||||
```
|
||||
|
||||
**在 Debian 上安装 ruby:**
|
||||
|
||||
```
|
||||
# apt install git gcc make ruby
|
||||
```
|
||||
|
||||
**在 Ubuntu 上安装 ruby:**
|
||||
|
||||
```
|
||||
$ sudo apt install git gcc make ruby
|
||||
```
|
||||
|
||||
**在 Fedora 上安装 ruby:**
|
||||
|
||||
```
|
||||
$ sudo dnf install git gcc make ruby
|
||||
```
|
||||
|
||||
**在 CentOS 上安装 ruby:**
|
||||
|
||||
```
|
||||
# yum install git gcc make ruby
|
||||
```
|
||||
|
||||
#### 安装 Linuxbrew
|
||||
|
||||
Linuxbrew 包管理器是苹果的 MacOS 操作系统很受欢迎的 Homebrew 包管理器的一个复刻版本。还没发布多久,Homebrew 就以容易使用而著称。如果你想使用 Linuxbrew 来安装 Asciinema,那么,请运行下面命令在你的 Linux 版本上安装 Linuxbrew:
|
||||
|
||||
```
|
||||
$ ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Linuxbrew/install/master/install)"
|
||||
```
|
||||
|
||||
现在,Linuxbrew 已经安装到了目录 `$HOME/.linuxbrew/` 下。剩下需要做的就是使它成为可执行 `PATH` 环境变量的一部分。
|
||||
|
||||
```
|
||||
$ echo 'export PATH="$HOME/.linuxbrew/bin:$PATH"' >>~/.bash_profile
|
||||
$ . ~/.bash_profile
|
||||
```
|
||||
|
||||
为了确认 Linuxbrew 是否已经安装好,你可以使用 `brew` 命令来查看它的版本:
|
||||
|
||||
```
|
||||
$ brew --version
|
||||
Homebrew 1.1.7
|
||||
Homebrew/homebrew-core (git revision 5229; last commit 2017-02-02)
|
||||
```
|
||||
|
||||
#### 安装 Asciinema
|
||||
|
||||
安装好 Linuxbrew 以后,安装 Asciinema 就变得无比容易了:
|
||||
|
||||
```
|
||||
$ brew install asciinema
|
||||
```
|
||||
|
||||
检查 Asciinema 是否安装正确:
|
||||
|
||||
```
|
||||
$ asciinema --version
|
||||
asciinema 1.3.0
|
||||
```
|
||||
|
||||
### 录制终端会话
|
||||
|
||||
经过一番辛苦的安装工作以后,是时候来干一些有趣的事情了。Asciinema 是一个非常容易使用的软件。事实上,目前的 1.3 版本只有很少的几个可用命令行选项,其中一个是 `--help` 。
|
||||
|
||||
我们首先使用 `rec` 选项来录制终端会话。下面的命令将会开始录制终端会话,之后,你将会有一个选项来丢弃已录制记录或者把它上传到 asciinema.org 网站以便将来参考。
|
||||
|
||||
```
|
||||
$ asciinema rec
|
||||
```
|
||||
|
||||
运行上面的命令以后,你会注意到, Asciinema 已经开始录制终端会话了,你可以按下 `CTRL+D` 快捷键或执行 `exit` 命令来停止录制。如果你使用的是 Debian/Ubuntu/Mint Linux 系统,你可以像下面这样尝试进行第一次 asciinema 录制:
|
||||
|
||||
```
|
||||
$ su
|
||||
Password:
|
||||
# apt install sl
|
||||
# exit
|
||||
$ sl
|
||||
```
|
||||
|
||||
一旦输入最后一个 `exit` 命令以后,将会询问你:
|
||||
|
||||
```
|
||||
$ exit
|
||||
~ Asciicast recording finished.
|
||||
~ Press <Enter> to upload, <Ctrl-C> to cancel.
|
||||
|
||||
https://asciinema.org/a/7lw94ys68gsgr1yzdtzwijxm4
|
||||
```
|
||||
|
||||
如果你不想上传你的私密命令行技巧到 asciinema.org 网站,那么有一个选项可以把 Asciinema 记录以 JSON 格式保存为本地文件。比如,下面的 asciinema 记录将被存为 `/tmp/my_rec.json`:
|
||||
|
||||
```
|
||||
$ asciinema rec /tmp/my_rec.json
|
||||
```
|
||||
|
||||
另一个非常有用的 asciinema 特性是时间微调。如果你的键盘输入速度很慢,或者你在进行多任务,输入命令和执行命令之间的时间会比较长。Asciinema 会记录你的实时按键时间,这意味着每一个停顿都将反映在最终视频的长度上。可以使用 `-w` 选项来缩短按键的时间间隔。比如,下面的命令将按键的时间间隔缩短为 0.2 秒:
|
||||
|
||||
```
|
||||
$ asciinema rec -w 0.2
|
||||
```
|
||||
|
||||
### 回放已录制终端会话
|
||||
|
||||
有两种方式可以来回放已录制会话。第一种方式是直接从 asciinema.org 网站上播放终端会话。这意味着,你之前已经把录制会话上传到了 asciinema.org 网站,并且需要提供有效链接:
|
||||
|
||||
```
|
||||
$ asciinema play https://asciinema.org/a/7lw94ys68gsgr1yzdtzwijxm4
|
||||
```
|
||||
|
||||
另外,你也可以使用本地存储的 JSON 文件:
|
||||
|
||||
```
|
||||
$ asciinema play /tmp/my_rec.json
|
||||
```
|
||||
|
||||
如果要使用 `wget` 命令来下载之前的上传记录,只需在链接的后面加上 `.json`:
|
||||
|
||||
```
|
||||
$ wget -q -O steam_locomotive.json https://asciinema.org/a/7lw94ys68gsgr1yzdtzwijxm4.json
|
||||
$ asciinema play steam_locomotive.json
|
||||
```
|
||||
|
||||
### 将视频嵌入 HTML
|
||||
|
||||
最后,asciinema 还带有一个独立的 JavaScript 播放器。这意味者你可以很容易的在你的网站上分享终端会话记录。下面,使用一段简单的 `index.html` 代码来说明这个方法。首先,下载所有必要的东西:
|
||||
|
||||
```
|
||||
$ cd /tmp/
|
||||
$ mkdir steam_locomotive
|
||||
$ cd steam_locomotive/
|
||||
$ wget -q -O steam_locomotive.json https://asciinema.org/a/7lw94ys68gsgr1yzdtzwijxm4.json
|
||||
$ wget -q https://github.com/asciinema/asciinema-player/releases/download/v2.4.0/asciinema-player.css
|
||||
$ wget -q https://github.com/asciinema/asciinema-player/releases/download/v2.4.0/asciinema-player.js
|
||||
```
|
||||
之后,创建一个新的包含下面这些内容的 `/tmp/steam_locomotive/index.html` 文件:
|
||||
|
||||
```
|
||||
<html>
|
||||
<head>
|
||||
<link rel="stylesheet" type="text/css" href="./asciinema-player.css" />
|
||||
</head>
|
||||
<body>
|
||||
<asciinema-player src="./steam_locomotive.json" cols="80" rows="24"></asciinema-player>
|
||||
<script src="./asciinema-player.js"></script>
|
||||
</body>
|
||||
</html>
|
||||
```
|
||||
|
||||
完成以后,打开你的网页浏览器,按下 `CTRL+O` 来打开新创建的 `/tmp/steam_locomotive/index.html` 文件。
|
||||
|
||||
### 结论
|
||||
|
||||
正如前面所说的,使用 asciinema 录制器来录制终端会话最主要的优点是它的输出文件非常小,这使得你的视频很容易分享出去。上面的例子产生了一个包含 58472 个字符的文件,它是一个只有 58 KB 大 小的 22 秒终端会话视频。如果我们查看输出的 JSON 文件,会发现甚至这个数字已经非常大了,这主要是因为一个 “蒸汽机车” 已经跑过了终端。这个长度的正常终端会话一般会产生一个更小的输出文件。
|
||||
|
||||
下次,当你想要在一个论坛上询问关于 Linux 配置的问题,并且很难描述你的问题的时候,只需运行下面的命令:
|
||||
|
||||
```
|
||||
$ asciinema rec
|
||||
```
|
||||
|
||||
然后把最后的链接贴到论坛的帖子里。
|
||||
|
||||
### 故障排除
|
||||
|
||||
#### 在 UTF-8 环境下运行 asciinema
|
||||
|
||||
错误信息:
|
||||
|
||||
```
|
||||
asciinema needs a UTF-8 native locale to run. Check the output of `locale` command.
|
||||
```
|
||||
|
||||
解决方法:
|
||||
生成并导出 UTF-8 语言环境。例如:
|
||||
|
||||
```
|
||||
$ localedef -c -f UTF-8 -i en_US en_US.UTF-8
|
||||
$ export LC_ALL=en_US.UTF-8
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux
|
||||
|
||||
作者:[Lubos Rendek][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux
|
||||
[1]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h4-1-arch-linux
|
||||
[2]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h4-2-debian
|
||||
[3]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h4-3-ubuntu
|
||||
[4]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h4-4-fedora
|
||||
[5]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h6-1-arch-linux
|
||||
[6]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h6-2-debian
|
||||
[7]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h6-3-ubuntu
|
||||
[8]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h6-4-fedora
|
||||
[9]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h6-5-centos
|
||||
[10]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h13-1-asciinema-needs-a-utf-8
|
||||
[11]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h1-introduction
|
||||
[12]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h2-difficulty
|
||||
[13]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h3-conventions
|
||||
[14]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h4-standard-repository-installation
|
||||
[15]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h5-installation-from-source
|
||||
[16]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h6-prerequisites
|
||||
[17]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h7-linuxbrew-installation
|
||||
[18]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h8-asciinema-installation
|
||||
[19]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h9-recording-terminal-session
|
||||
[20]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h10-replay-recorded-terminal-session
|
||||
[21]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h11-embedding-video-as-html
|
||||
[22]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h12-conclusion
|
||||
[23]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h13-troubleshooting
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user