mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-19 00:30:12 +08:00
commit
1fb55e0b02
@ -0,0 +1,128 @@
|
||||
如何在树莓派上安装 Fedora 25
|
||||
============================================================
|
||||
|
||||
> 了解 Fedora 第一个官方支持树莓派的版本
|
||||
|
||||

|
||||
|
||||
>图片提供 opensource.com
|
||||
|
||||
2016 年 10 月,Fedora 25 Beta 发布了,随之而来的还有对 [树莓派 2 和 3 的初步支持][6]。Fedora 25 的最终“通用”版在一个月后发布,从那时起,我一直在树莓派上尝试不同的 Fedora spins。
|
||||
|
||||
这篇文章不仅是一篇<ruby>树莓派<rt>Raspberry Pi</rt></ruby> 3 上的 Fedora 25 的点评,还集合了技巧、截图以及我对 Fedora 第一个官方支持 Pi 的这个版本的一些个人看法。
|
||||
|
||||
在我开始之前,需要说一下的是,为写这篇文章所做的所有工作都是在我的运行 Fedora 25 的个人笔记本电脑上完成的。我使用一张 microSD 插到 SD 适配器中,复制和编辑所有的 Fedora 镜像到 32GB 的 microSD 卡中,然后用它在一台三星电视上启动了树莓派 3。 因为 Fedora 25 尚不支持内置 Wi-Fi,所以树莓派 3 使用了以太网线缆进行网络连接。最后,我使用了 Logitech K410 无线键盘和触摸板进行输入。
|
||||
|
||||
如果你没有条件使用以太网线连接在你的树莓派上玩 Fedora 25,我曾经用过一个 Edimax Wi-Fi USB 适配器,它也可以在 Fedora 25 上工作,但在本文中,我只使用了以太网连接。
|
||||
|
||||
### 在树莓派上安装 Fedora 25 之前
|
||||
|
||||
阅读 Fedora 项目 wiki 上的[树莓派支持文档][7]。你可以从 wiki 下载 Fedora 25 安装所需的镜像,那里还列出了所有支持和不支持的内容。
|
||||
|
||||
此外,请注意,这是初始支持版本,还有许多新的工作和支持将随着 Fedora 26 的发布而出现,所以请随时报告 bug,并通过 [Bugzilla][8]、Fedora 的 [ARM 邮件列表][9]、或者 Freenode IRC 频道#fedora-arm,分享你在树莓派上使用 Fedora 25 的体验反馈。
|
||||
|
||||
### 安装
|
||||
|
||||
我下载并安装了五个不同的 Fedora 25 spin:GNOME(默认工作站)、KDE、Minimal、LXDE 和 Xfce。在多数情况下,它们都有一致和易于遵循的步骤,以确保我的树莓派 3 上启动正常。有的 spin 有已知 bug 的正在解决之中,而有的按照 Fedora wik 遵循标准操作程序即可。
|
||||
|
||||

|
||||
|
||||
*树莓派 3 上的 Fedora 25 workstation、 GNOME 版本*
|
||||
|
||||
### 安装步骤
|
||||
|
||||
1、 在你的笔记本上,从支持文档页面的链接下载一个树莓派的 Fedora 25 镜像。
|
||||
|
||||
2、 在笔记本上,使用 `fedora-arm-installer` 或下述命令行将镜像复制到 microSD:
|
||||
|
||||
```
|
||||
xzcat Fedora-Workstation-armhfp-25-1.3-sda.raw.xz | dd bs=4M status=progress of=/dev/mmcblk0
|
||||
```
|
||||
|
||||
注意:`/dev/mmclk0` 是我的 microSD 插到 SD 适配器后,在我的笔记本电脑上挂载的设备名。虽然我在笔记本上使用 Fedora,可以使用 `fedora-arm-installer`,但我还是喜欢命令行。
|
||||
|
||||
3、 复制完镜像后,_先不要启动你的系统_。我知道你很想这么做,但你仍然需要进行几个调整。
|
||||
|
||||
4、 为了使镜像文件尽可能小以便下载,镜像上的根文件系统是很小的,因此你必须增加根文件系统的大小。如果你不这么做,你仍然可以启动你的派,但如果你一旦运行 `dnf update` 来升级你的系统,它就会填满文件系统,导致糟糕的事情发生,所以趁着 microSD 还在你的笔记本上进行分区:
|
||||
|
||||
```
|
||||
growpart /dev/mmcblk0 4
|
||||
resize2fs /dev/mmcblk0p4
|
||||
```
|
||||
|
||||
注意:在 Fedora 中,`growpart` 命令由 `cloud-utils-growpart.noarch` 这个 RPM 提供的。
|
||||
|
||||
5、文件系统更新后,您需要将 `vc4` 模块列入黑名单。[更多有关此 bug 的信息在此。][10]
|
||||
|
||||
我建议在启动树莓派之前这样做,因为不同的 spin 有不同表现方式。例如,(至少对我来说)在没有黑名单 `vc4` 的情况下,GNOME 在我启动后首先出现,但在系统更新后,它不再出现。 KDE spin 则在第一次启动时根本不会出现 KDE。因此我们可能需要在我们的第一次启动之前将 `vc4` 加入黑名单,直到这个错误以后解决了。
|
||||
|
||||
黑名单应该出现在两个不同的地方。首先,在你的 microSD 根分区上,在 `etc/modprode.d/` 下创建一个 `vc4.conf`,内容是:`blacklist vc4`。第二,在你的 microSD 启动分区,添加 `rd.driver.blacklist=vc4` 到 `extlinux/extlinux.conf` 文件的末尾。
|
||||
|
||||
6、 现在,你可以启动你的树莓派了。
|
||||
|
||||
### 启动
|
||||
|
||||
你要有耐心,特别是对于 GNOME 和 KDE 发行版来说。在 SSD(固态驱动器)几乎即时启动的时代,你很容易就对派的启动速度感到不耐烦,特别是第一次启动时。在第一次启动 Window Manager 之前,会先弹出一个初始配置页面,可以配置 root 密码、常规用户、时区和网络。配置完毕后,你就应该能够 SSH 到你的树莓派上,方便地调试显示问题了。
|
||||
|
||||
### 系统更新
|
||||
|
||||
在树莓派上运行 Fedora 25 后,你最终(或立即)会想要更新系统。
|
||||
|
||||
首先,进行内核升级时,先熟悉你的 `/boot/extlinux/extlinux.conf` 文件。如果升级内核,下次启动时,除非手动选择正确的内核,否则很可能会启动进入救援( Rescue )模式。避免这种情况发生最好的方法是,在你的 `extlinux.conf` 中将定义 Rescue 镜像的那五行移动到文件的底部,这样最新的内核将在下次自动启动。你可以直接在派上或通过在笔记本挂载来编辑 `/boot/extlinux/extlinux.conf`:
|
||||
```
|
||||
label Fedora 25 Rescue fdcb76d0032447209f782a184f35eebc (4.9.9-200.fc25.armv7hl)
|
||||
kernel /vmlinuz-0-rescue-fdcb76d0032447209f782a184f35eebc
|
||||
append ro root=UUID=c19816a7-cbb8-4cbb-8608-7fec6d4994d0 rd.driver.blacklist=vc4
|
||||
fdtdir /dtb-4.9.9-200.fc25.armv7hl/
|
||||
initrd /initramfs-0-rescue-fdcb76d0032447209f782a184f35eebc.img
|
||||
```
|
||||
|
||||
第二点,如果无论什么原因,如果你的显示器在升级后再次变暗,并且你确定已经将 `vc4` 加入黑名单,请运行 `lsmod | grep vc4`。你可以先启动到多用户模式而不是图形模式,并从命令行中运行 `startx`。 请阅读 `/etc/inittab` 中的内容,了解如何切换 target 的说明。
|
||||
|
||||

|
||||
|
||||
*树莓派 3 上的 Fedora 25 workstation、 KDE 版本*
|
||||
|
||||
### Fedora Spin
|
||||
|
||||
在我尝试过的所有 Fedora Spin 中,唯一有问题的是 XFCE spin,我相信这是由于这个[已知的 bug][11] 导致的。
|
||||
|
||||
按照我在这里分享的步骤操作,GNOME、KDE、LXDE 和 minimal 都运行得很好。考虑到 KDE 和 GNOME 会占用更多资源,我会推荐想要在树莓派上使用 Fedora 25 的人使用 LXDE 和 Minimal。如果你是一位系统管理员,想要一台廉价的 SELinux 支持的服务器来满足你的安全考虑,而且只是想要使用树莓派作为你的服务器,开放 22 端口以及 vi 可用,那就用 Minimal 版本。对于开发人员或刚开始学习 Linux 的人来说,LXDE 可能是更好的方式,因为它可以快速方便地访问所有基于 GUI 的工具,如浏览器、IDE 和你可能需要的客户端。
|
||||
|
||||

|
||||
|
||||
*树莓派 3 上的 Fedora 25 workstation、LXDE。*
|
||||
|
||||
看到越来越多的 Linux 发行版在基于 ARM 的树莓派上可用,那真是太棒了。对于其第一个支持的版本,Fedora 团队为日常 Linux 用户提供了更好的体验。我很期待 Fedora 26 的改进和 bug 修复。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Anderson Silva - Anderson 于 1996 年开始使用 Linux。更精确地说是 Red Hat Linux。 2007 年,他作为 IT 部门的发布工程师时加入红帽,他的职业梦想成为了现实。此后,他在红帽担任过多个不同角色,从发布工程师到系统管理员、高级经理和信息系统工程师。他是一名 RHCE 和 RHCA 以及一名活跃的 Fedora 包维护者。
|
||||
|
||||
----------------
|
||||
|
||||
via: https://opensource.com/article/17/3/how-install-fedora-on-raspberry-pi
|
||||
|
||||
作者:[Anderson Silva][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ansilva
|
||||
[1]:https://opensource.com/tags/raspberry-pi?src=raspberry_pi_resource_menu
|
||||
[2]:https://opensource.com/resources/what-raspberry-pi?src=raspberry_pi_resource_menu
|
||||
[3]:https://opensource.com/article/16/12/getting-started-raspberry-pi?src=raspberry_pi_resource_menu
|
||||
[4]:https://opensource.com/article/17/2/raspberry-pi-submit-your-article?src=raspberry_pi_resource_menu
|
||||
[5]:https://opensource.com/article/17/3/how-install-fedora-on-raspberry-pi?rate=gIIRltTrnOlwo4h81uDvdAjAE3V2rnwoqH0s_Dx44mE
|
||||
[6]:https://fedoramagazine.org/raspberry-pi-support-fedora-25-beta/
|
||||
[7]:https://fedoraproject.org/wiki/Raspberry_Pi
|
||||
[8]:https://bugzilla.redhat.com/show_bug.cgi?id=245418
|
||||
[9]:https://lists.fedoraproject.org/admin/lists/arm%40lists.fedoraproject.org/
|
||||
[10]:https://bugzilla.redhat.com/show_bug.cgi?id=1387733
|
||||
[11]:https://bugzilla.redhat.com/show_bug.cgi?id=1389163
|
||||
[12]:https://opensource.com/user/26502/feed
|
||||
[13]:https://opensource.com/article/17/3/how-install-fedora-on-raspberry-pi#comments
|
||||
[14]:https://opensource.com/users/ansilva
|
||||
152
sources/tech/ 20170422 FEWER MALLOCS IN CURL.md
Normal file
152
sources/tech/ 20170422 FEWER MALLOCS IN CURL.md
Normal file
@ -0,0 +1,152 @@
|
||||
FEWER MALLOCS IN CURL
|
||||
===========================================================
|
||||
|
||||

|
||||
|
||||
Today I landed yet [another small change][4] to libcurl internals that further reduces the number of small mallocs we do. This time the generic linked list functions got converted to become malloc-less (the way linked list functions should behave, really).
|
||||
|
||||
### Instrument mallocs
|
||||
|
||||
I started out my quest a few weeks ago by instrumenting our memory allocations. This is easy since we have our own memory debug and logging system in curl since many years. Using a debug build of curl I run this script in my build dir:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
export CURL_MEMDEBUG=$HOME/tmp/curlmem.log
|
||||
./src/curl http://localhost
|
||||
./tests/memanalyze.pl -v $HOME/tmp/curlmem.log
|
||||
```
|
||||
|
||||
For curl 7.53.1, this counted about 115 memory allocations. Is that many or a few?
|
||||
|
||||
The memory log is very basic. To give you an idea what it looks like, here’s an example snippet:
|
||||
|
||||
```
|
||||
MEM getinfo.c:70 free((nil))
|
||||
MEM getinfo.c:73 free((nil))
|
||||
MEM url.c:294 free((nil))
|
||||
MEM url.c:297 strdup(0x559e7150d616) (24) = 0x559e73760f98
|
||||
MEM url.c:294 free((nil))
|
||||
MEM url.c:297 strdup(0x559e7150d62e) (22) = 0x559e73760fc8
|
||||
MEM multi.c:302 calloc(1,480) = 0x559e73760ff8
|
||||
MEM hash.c:75 malloc(224) = 0x559e737611f8
|
||||
MEM hash.c:75 malloc(29152) = 0x559e737a2bc8
|
||||
MEM hash.c:75 malloc(3104) = 0x559e737a9dc8
|
||||
```
|
||||
|
||||
### Check the log
|
||||
|
||||
I then studied the log closer and I realized that there were many small memory allocations done from the same code lines. We clearly had some rather silly code patterns where we would allocate a struct and then add that struct to a linked list or a hash and that code would then subsequently add yet another small struct and similar – and then often do that in a loop. (I say _we_ here to avoid blaming anyone, but of course I myself am to blame for most of this…)
|
||||
|
||||
Those two allocations would always happen in pairs and they would be freed at the same time. I decided to address those. Doing very small (less than say 32 bytes) allocations is also wasteful just due to the very large amount of data in proportion that will be used just to keep track of that tiny little memory area (within the malloc system). Not to mention fragmentation of the heap.
|
||||
|
||||
So, fixing the hash code and the linked list code to not use mallocs were immediate and easy ways to remove over 20% of the mallocs for a plain and simple ‘curl http://localhost’ transfer.
|
||||
|
||||
At this point I sorted all allocations based on size and checked all the smallest ones. One that stood out was one we made in _curl_multi_wait(),_ a function that is called over and over in a typical curl transfer main loop. I converted it over to [use the stack][5] for most typical use cases. Avoiding mallocs in very repeatedly called functions is a good thing.
|
||||
|
||||
### Recount
|
||||
|
||||
Today, the script from above shows that the same “curl localhost” command is down to 80 allocations from the 115 curl 7.53.1 used. Without sacrificing anything really. An easy 26% improvement. Not bad at all!
|
||||
|
||||
But okay, since I modified curl_multi_wait() I wanted to also see how it actually improves things for a slightly more advanced transfer. I took the [multi-double.c][6] example code, added the call to initiate the memory logging, made it uses curl_multi_wait() and had it download these two URLs in parallel:
|
||||
|
||||
```
|
||||
http://www.example.com/
|
||||
http://localhost/512M
|
||||
```
|
||||
|
||||
The second one being just 512 megabytes of zeroes and the first being a 600 bytes something public html page. Here’s the [count-malloc.c code][7].
|
||||
|
||||
First, I brought out 7.53.1 and built the example against that and had the memanalyze script check it:
|
||||
|
||||
```
|
||||
Mallocs: 33901
|
||||
Reallocs: 5
|
||||
Callocs: 24
|
||||
Strdups: 31
|
||||
Wcsdups: 0
|
||||
Frees: 33956
|
||||
Allocations: 33961
|
||||
Maximum allocated: 160385
|
||||
```
|
||||
|
||||
Okay, so it used 160KB of memory totally and it did over 33,900 allocations. But ok, it downloaded over 512 megabytes of data so it makes one malloc per 15KB of data. Good or bad?
|
||||
|
||||
Back to git master, the version we call 7.54.1-DEV right now – since we’re not quite sure which version number it’ll become when we release the next release. It can become 7.54.1 or 7.55.0, it has not been determined yet. But I digress, I ran the same modified multi-double.c example again, ran memanalyze on the memory log again and it now reported…
|
||||
|
||||
```
|
||||
Mallocs: 69
|
||||
Reallocs: 5
|
||||
Callocs: 24
|
||||
Strdups: 31
|
||||
Wcsdups: 0
|
||||
Frees: 124
|
||||
Allocations: 129
|
||||
Maximum allocated: 153247
|
||||
```
|
||||
|
||||
I had to look twice. Did I do something wrong? I better run it again just to double-check. The results are the same no matter how many times I run it…
|
||||
|
||||
### 33,961 vs 129
|
||||
|
||||
curl_multi_wait() is called a lot of times in a typical transfer, and it had at least one of the memory allocations we normally did during a transfer so removing that single tiny allocation had a pretty dramatic impact on the counter. A normal transfer also moves things in and out of linked lists and hashes a bit, but they too are mostly malloc-less now. Simply put: the remaining allocations are not done in the transfer loop so they’re way less important.
|
||||
|
||||
The old curl did 263 times the number of allocations the current does for this example. Or the other way around: the new one does 0.37% the number of allocations the old one did…
|
||||
|
||||
As an added bonus, the new one also allocates less memory in total as it decreased that amount by 7KB (4.3%).
|
||||
|
||||
### Are mallocs important?
|
||||
|
||||
In the day and age with many gigabytes of RAM and all, does a few mallocs in a transfer really make a notable difference for mere mortals? What is the impact of 33,832 extra mallocs done for 512MB of data?
|
||||
|
||||
To measure what impact these changes have, I decided to compare HTTP transfers from localhost and see if we can see any speed difference. localhost is fine for this test since there’s no network speed limit, but the faster curl is the faster the download will be. The server side will be equally fast/slow since I’ll use the same set for both tests.
|
||||
|
||||
I built curl 7.53.1 and curl 7.54.1-DEV identically and ran this command line:
|
||||
|
||||
```
|
||||
curl http://localhost/80GB -o /dev/null
|
||||
```
|
||||
|
||||
80 gigabytes downloaded as fast as possible written into the void.
|
||||
|
||||
The exact numbers I got for this may not be totally interesting, as it will depend on CPU in the machine, which HTTP server that serves the file and optimization level when I build curl etc. But the relative numbers should still be highly relevant. The old code vs the new.
|
||||
|
||||
7.54.1-DEV repeatedly performed 30% faster! The 2200MB/sec in my build of the earlier release increased to over 2900 MB/sec with the current version.
|
||||
|
||||
The point here is of course not that it easily can transfer HTTP over 20GB/sec using a single core on my machine – since there are very few users who actually do that speedy transfers with curl. The point is rather that curl now uses less CPU per byte transferred, which leaves more CPU over to the rest of the system to perform whatever it needs to do. Or to save battery if the device is a portable one.
|
||||
|
||||
On the cost of malloc: The 512MB test I did resulted in 33832 more allocations using the old code. The old code transferred HTTP at a rate of about 2200MB/sec. That equals 145,827 mallocs/second – that are now removed! A 600 MB/sec improvement means that curl managed to transfer 4300 bytes extra for each malloc it didn’t do, each second.
|
||||
|
||||
### Was removing these mallocs hard?
|
||||
|
||||
Not at all, it was all straight forward. It is however interesting that there’s still room for changes like this in a project this old. I’ve had this idea for some years and I’m glad I finally took the time to make it happen. Thanks to our test suite I could do this level of “drastic” internal change with a fairly high degree of confidence that I don’t introduce too terrible regressions. Thanks to our APIs being good at hiding internals, this change could be done completely without changing anything for old or new applications.
|
||||
|
||||
(Yeah I haven’t shipped the entire change in a release yet so there’s of course a risk that I’ll have to regret my “this was easy” statement…)
|
||||
|
||||
### Caveats on the numbers
|
||||
|
||||
There have been 213 commits in the curl git repo from 7.53.1 till today. There’s a chance one or more other commits than just the pure alloc changes have made a performance impact, even if I can’t think of any.
|
||||
|
||||
### More?
|
||||
|
||||
Are there more “low hanging fruits” to pick here in the similar vein?
|
||||
|
||||
Perhaps. We don’t do a lot of performance measurements or comparisons so who knows, we might do more silly things that we could stop doing and do even better. One thing I’ve always wanted to do, but never got around to, was to add daily “monitoring” of memory/mallocs used and how fast curl performs in order to better track when we unknowingly regress in these areas.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://daniel.haxx.se/blog/2017/04/22/fewer-mallocs-in-curl/
|
||||
|
||||
作者:[DANIEL STENBERG ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://daniel.haxx.se/blog/author/daniel/
|
||||
[1]:https://daniel.haxx.se/blog/author/daniel/
|
||||
[2]:https://daniel.haxx.se/blog/2017/04/22/fewer-mallocs-in-curl/
|
||||
[3]:https://daniel.haxx.se/blog/2017/04/22/fewer-mallocs-in-curl/#comments
|
||||
[4]:https://github.com/curl/curl/commit/cbae73e1dd95946597ea74ccb580c30f78e3fa73
|
||||
[5]:https://github.com/curl/curl/commit/5f1163517e1597339d
|
||||
[6]:https://github.com/curl/curl/commit/5f1163517e1597339d
|
||||
[7]:https://gist.github.com/bagder/dc4a42cb561e791e470362da7ef731d3
|
||||
@ -1,3 +1,4 @@
|
||||
ictlyh Translating
|
||||
GraphQL In Use: Building a Blogging Engine API with Golang and PostgreSQL
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
geekrainy translating
|
||||
A look at 6 iconic open source brands
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,226 +0,0 @@
|
||||
How to protect your server with badIPs.com and report IPs with Fail2ban on Debian
|
||||
============================================================
|
||||
|
||||
### On this page
|
||||
|
||||
1. [Use the badIPs list][4]
|
||||
1. [Define your security level and category][1]
|
||||
2. [Let's create the script][5]
|
||||
3. [Report IP addresses to badIPs with Fail2ban][6]
|
||||
1. [Fail2ban >= 0.8.12][2]
|
||||
2. [Fail2ban < 0.8.12][3]
|
||||
4. [Statistics of your IP reporting][7]
|
||||
|
||||
This tutorial documents the process of using the badips abuse tracker in conjunction with Fail2ban to protect your server or computer. I've tested it on a Debian 8 Jessie and Debian 7 Wheezy system.
|
||||
|
||||
**What is badIPs?**
|
||||
|
||||
BadIps is a listing of IP that are reported as bad in combinaison with [fail2ban][8].
|
||||
|
||||
This tutorial contains two parts, the first one will deal with the use of the list and the second will deal with the injection of data.
|
||||
|
||||
###
|
||||
Use the badIPs list
|
||||
|
||||
### Define your security level and category
|
||||
|
||||
You can get the IP address list by simply using the REST API.
|
||||
|
||||
When you GET this URL : [https://www.badips.com/get/categories][9]
|
||||
You’ll see all the different categories that are present on the service.
|
||||
|
||||
* Second step, determine witch score is made for you.
|
||||
Here a quote from badips that should help (personnaly I took score = 3):
|
||||
* If you'd like to compile a statistic or use the data for some experiment etc. you may start with score 0.
|
||||
* If you'd like to firewall your private server or website, go with scores from 2\. Maybe combined with your own results, even if they do not have a score above 0 or 1.
|
||||
* If you're about to protect a webshop or high traffic, money-earning e-commerce server, we recommend to use values from 3 or 4\. Maybe as well combined with your own results (key / sync).
|
||||
* If you're paranoid, take 5.
|
||||
|
||||
So now that you get your two variables, let's make your link by concatening them and grab your link.
|
||||
|
||||
http://www.badips.com/get/list/{{SERVICE}}/{{LEVEL}}
|
||||
|
||||
Note: Like me, you can take all the services. Change the name of the service to "any" in this case.
|
||||
|
||||
The resulting URL is:
|
||||
|
||||
https://www.badips.com/get/list/any/3
|
||||
|
||||
### Let's create the script
|
||||
|
||||
Alright, when that’s done, we’ll create a simple script.
|
||||
|
||||
1. Put our list in a tempory file.
|
||||
2. (only once) create a chain in iptables.
|
||||
3. Flush all the data linked to our chain (old entries).
|
||||
4. We’ll link each IP to our new chain.
|
||||
5. When it’s done, block all INPUT / OUTPUT / FORWARD that’s linked to our chain.
|
||||
6. Remove our temp file.
|
||||
|
||||
Nowe we'll create the script for that:
|
||||
|
||||
cd /home/<user>/
|
||||
vi myBlacklist.sh
|
||||
|
||||
Enter the following content into that file.
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
# based on this version http://www.timokorthals.de/?p=334
|
||||
# adapted by Stéphane T.
|
||||
|
||||
_ipt=/sbin/iptables # Location of iptables (might be correct)
|
||||
_input=badips.db # Name of database (will be downloaded with this name)
|
||||
_pub_if=eth0 # Device which is connected to the internet (ex. $ifconfig for that)
|
||||
_droplist=droplist # Name of chain in iptables (Only change this if you have already a chain with this name)
|
||||
_level=3 # Blog level: not so bad/false report (0) over confirmed bad (3) to quite aggressive (5) (see www.badips.com for that)
|
||||
_service=any # Logged service (see www.badips.com for that)
|
||||
|
||||
# Get the bad IPs
|
||||
wget -qO- http://www.badips.com/get/list/${_service}/$_level > $_input || { echo "$0: Unable to download ip list."; exit 1; }
|
||||
|
||||
### Setup our black list ###
|
||||
# First flush it
|
||||
$_ipt --flush $_droplist
|
||||
|
||||
# Create a new chain
|
||||
# Decomment the next line on the first run
|
||||
# $_ipt -N $_droplist
|
||||
|
||||
# Filter out comments and blank lines
|
||||
# store each ip in $ip
|
||||
for ip in `cat $_input`
|
||||
do
|
||||
# Append everything to $_droplist
|
||||
$_ipt -A $_droplist -i ${_pub_if} -s $ip -j LOG --log-prefix "Drop Bad IP List "
|
||||
$_ipt -A $_droplist -i ${_pub_if} -s $ip -j DROP
|
||||
done
|
||||
|
||||
# Finally, insert or append our black list
|
||||
$_ipt -I INPUT -j $_droplist
|
||||
$_ipt -I OUTPUT -j $_droplist
|
||||
$_ipt -I FORWARD -j $_droplist
|
||||
|
||||
# Delete your temp file
|
||||
rm $_input
|
||||
exit 0
|
||||
```
|
||||
|
||||
When that’s done, you should create a cronjob that will update our blacklist.
|
||||
|
||||
For this, I used crontab and I run the script every day on 11:30PM (just before my delayed backup).
|
||||
|
||||
crontab -e
|
||||
|
||||
```
|
||||
23 30 * * * /home/<user>/myBlacklist.sh #Block BAD IPS
|
||||
```
|
||||
|
||||
Don’t forget to chmod your script:
|
||||
|
||||
chmod + x myBlacklist.sh
|
||||
|
||||
Now that’s done, your server/computer should be a little bit safer.
|
||||
|
||||
You can also run the script manually like this:
|
||||
|
||||
cd /home/<user>/
|
||||
./myBlacklist.sh
|
||||
|
||||
It should take some time… so don’t break the script. In fact, the value of it lies in the last lines.
|
||||
|
||||
### Report IP addresses to badIPs with Fail2ban
|
||||
|
||||
In the second part of this tutorial, I will show you how to report bd IP addresses bach to the badips.com website by using Fail2ban.
|
||||
|
||||
### Fail2ban >= 0.8.12
|
||||
|
||||
The reporting is made with Fail2ban. Depending on your Fail2ban version you must use the first or second section of this chapter.If you have fail2ban in version 0.8.12.
|
||||
|
||||
If you have fail2ban version 0.8.12 or later.
|
||||
|
||||
fail2ban-server --version
|
||||
|
||||
In each category that you’ll report, simply add an action.
|
||||
|
||||
```
|
||||
[ssh]
|
||||
enabled = true
|
||||
action = iptables-multiport
|
||||
badips[category=ssh]
|
||||
port = ssh
|
||||
filter = sshd
|
||||
logpath = /var/log/auth.log
|
||||
maxretry= 6
|
||||
```
|
||||
|
||||
As you can see, the category is SSH, take a look here ([https://www.badips.com/get/categories][11]) to find the correct category.
|
||||
|
||||
### Fail2ban < 0.8.12
|
||||
|
||||
If the version is less recent than 0.8.12, you’ll have a to create an action. This can be downloaded here: [https://www.badips.com/asset/fail2ban/badips.conf][12].
|
||||
|
||||
wget https://www.badips.com/asset/fail2ban/badips.conf -O /etc/fail2ban/action.d/badips.conf
|
||||
|
||||
With the badips.conf from above, you can either activate per category as above or you can enable it globally:
|
||||
|
||||
cd /etc/fail2ban/
|
||||
vi jail.conf
|
||||
|
||||
```
|
||||
[DEFAULT]
|
||||
|
||||
...
|
||||
|
||||
banaction = iptables-multiport
|
||||
badips
|
||||
```
|
||||
|
||||
Now restart fail2ban - it should start reporting from now on.
|
||||
|
||||
service fail2ban restart
|
||||
|
||||
### Statistics of your IP reporting
|
||||
|
||||
Last step – not really useful… You can create a key.
|
||||
This one is usefull if you want to see your data.
|
||||
Just copy / paste this and a JSON response will appear on your console.
|
||||
|
||||
wget https://www.badips.com/get/key -qO -
|
||||
|
||||
```
|
||||
{
|
||||
"err":"",
|
||||
"suc":"new key 5f72253b673eb49fc64dd34439531b5cca05327f has been set.",
|
||||
"key":"5f72253b673eb49fc64dd34439531b5cca05327f"
|
||||
}
|
||||
```
|
||||
|
||||
Then go on [badips][13] website, enter your “key” and click “statistics”.
|
||||
|
||||
Here we go… all your stats by category.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/
|
||||
|
||||
作者:[Stephane T][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/
|
||||
[1]:https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/#define-your-security-level-and-category
|
||||
[2]:https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/#failban-gt-
|
||||
[3]:https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/#failban-ltnbsp
|
||||
[4]:https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/#use-the-badips-list
|
||||
[5]:https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/#lets-create-the-script
|
||||
[6]:https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/#report-ip-addresses-to-badips-with-failban
|
||||
[7]:https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/#statistics-of-your-ip-reporting
|
||||
[8]:http://www.fail2ban.org/
|
||||
[9]:https://www.badips.com/get/categories
|
||||
[10]:http://www.timokorthals.de/?p=334
|
||||
[11]:https://www.badips.com/get/categories
|
||||
[12]:https://www.badips.com/asset/fail2ban/badips.conf
|
||||
[13]:https://www.badips.com/
|
||||
@ -0,0 +1,438 @@
|
||||
Writing a Time Series Database from Scratch
|
||||
============================================================
|
||||
|
||||
|
||||
I work on monitoring. In particular on [Prometheus][2], a monitoring system that includes a custom time series database, and its integration with [Kubernetes][3].
|
||||
|
||||
In many ways Kubernetes represents all the things Prometheus was designed for. It makes continuous deployments, auto scaling, and other features of highly dynamic environments easily accessible. The query language and operational model, among many other conceptual decisions make Prometheus particularly well-suited for such environments. Yet, if monitored workloads become significantly more dynamic, this also puts new strains on monitoring system itself. With this in mind, rather than doubling back on problems Prometheus already solves well, we specifically aim to increase its performance in environments with highly dynamic, or transient services.
|
||||
|
||||
Prometheus's storage layer has historically shown outstanding performance, where a single server is able to ingest up to one million samples per second as several million time series, all while occupying a surprisingly small amount of disk space. While the current storage has served us well, I propose a newly designed storage subsystem that corrects for shortcomings of the existing solution and is equipped to handle the next order of scale.
|
||||
|
||||
> Note: I've no background in databases. What I say might be wrong and mislead. You can channel your criticism towards me (fabxc) in #prometheus on Freenode.
|
||||
|
||||
### Problems, Problems, Problem Space
|
||||
|
||||
First, a quick outline of what we are trying to accomplish and what key problems it raises. For each, we take a look at Prometheus' current approach, what it does well, and which problems we aim to address with the new design.
|
||||
|
||||
### Time series data
|
||||
|
||||
We have a system that collects data points over time.
|
||||
|
||||
```
|
||||
identifier -> (t0, v0), (t1, v1), (t2, v2), (t3, v3), ....
|
||||
```
|
||||
|
||||
Each data point is a tuple of a timestamp and a value. For the purpose of monitoring, the timestamp is an integer and the value any number. A 64 bit float turns out to be a good representation for counter as well as gauge values, so we go with that. A sequence of data points with strictly monotonically increasing timestamps is a series, which is addressed by an identifier. Our identifier is a metric name with a dictionary of _label dimensions_ . Label dimensions partition the measurement space of a single metric. Each metric name plus a unique set of labels is its own _time series_ that has a value stream associated with it.
|
||||
|
||||
This is a typical set of series identifiers that are part of metric counting requests:
|
||||
|
||||
```
|
||||
requests_total{path="/status", method="GET", instance=”10.0.0.1:80”}
|
||||
requests_total{path="/status", method="POST", instance=”10.0.0.3:80”}
|
||||
requests_total{path="/", method="GET", instance=”10.0.0.2:80”}
|
||||
```
|
||||
|
||||
Let's simplify this representation right away: A metric name can be treated as just another label dimension — `__name__` in our case. At the query level, it might be be treated specially but that doesn't concern our way of storing it, as we will see later.
|
||||
|
||||
```
|
||||
{__name__="requests_total", path="/status", method="GET", instance=”10.0.0.1:80”}
|
||||
{__name__="requests_total", path="/status", method="POST", instance=”10.0.0.3:80”}
|
||||
{__name__="requests_total", path="/", method="GET", instance=”10.0.0.2:80”}
|
||||
```
|
||||
|
||||
When querying time series data, we want to do so by selecting series by their labels. In the simplest case `{__name__="requests_total"}` selects all series belonging to the `requests_total` metric. For all selected series, we retrieve data points within a specified time window.
|
||||
In more complex queries, we may wish to select series satisfying several label selectors at once and also represent more complex conditions than equality. For example, negative (`method!="GET"`) or regular expression matching (`method=~"PUT|POST"`).
|
||||
|
||||
This largely defines the stored data and how it is recalled.
|
||||
|
||||
### Vertical and Horizontal
|
||||
|
||||
In a simplified view, all data points can be laid out on a two-dimensional plane. The _horizontal_ dimension represents the time and the series identifier space spreads across the _vertical_ dimension.
|
||||
|
||||
```
|
||||
series
|
||||
^
|
||||
│ . . . . . . . . . . . . . . . . . . . . . . {__name__="request_total", method="GET"}
|
||||
│ . . . . . . . . . . . . . . . . . . . . . . {__name__="request_total", method="POST"}
|
||||
│ . . . . . . .
|
||||
│ . . . . . . . . . . . . . . . . . . . ...
|
||||
│ . . . . . . . . . . . . . . . . . . . . .
|
||||
│ . . . . . . . . . . . . . . . . . . . . . {__name__="errors_total", method="POST"}
|
||||
│ . . . . . . . . . . . . . . . . . {__name__="errors_total", method="GET"}
|
||||
│ . . . . . . . . . . . . . .
|
||||
│ . . . . . . . . . . . . . . . . . . . ...
|
||||
│ . . . . . . . . . . . . . . . . . . . .
|
||||
v
|
||||
<-------------------- time --------------------->
|
||||
```
|
||||
|
||||
Prometheus retrieves data points by periodically scraping the current values for a set of time series. The entity from which we retrieve such a batch is called a _target_ . Thereby, the write pattern is completely vertical and highly concurrent as samples from each target are ingested independently.
|
||||
To provide some measurement of scale: A single Prometheus instance collects data points from tens of thousands of _targets_ , which expose hundreds to thousands of different time series each.
|
||||
|
||||
At the scale of collecting millions of data points per second, batching writes is a non-negotiable performance requirement. Writing single data points scattered across our disk would be painfully slow. Thus, we want to write larger chunks of data in sequence.
|
||||
This is an unsurprising fact for spinning disks, as their head would have to physically move to different sections all the time. While SSDs are known for fast random writes, they actually can't modify individual bytes but only write in _pages_ of 4KiB or more. This means writing a 16 byte sample is equivalent to writing a full 4KiB page. This behavior is part of what is known as [ _write amplification_ ][4], which as a bonus causes your SSD to wear out – so it wouldn't just be slow, but literally destroy your hardware within a few days or weeks.
|
||||
For more in-depth information on the problem, the blog series ["Coding for SSDs" series][5] is a an excellent resource. Let's just consider the main take away: sequential and batched writes are the ideal write pattern for spinning disks and SSDs alike. A simple rule to stick to.
|
||||
|
||||
The querying pattern is significantly more differentiated than the write the pattern. We can query a single datapoint for a single series, a single datapoint for 10000 series, weeks of data points for a single series, weeks of data points for 10000 series, etc. So on our two-dimensional plane, queries are neither fully vertical or horizontal, but a rectangular combination of the two.
|
||||
[Recording rules][6] mitigate the problem for known queries but are not a general solution for ad-hoc queries, which still have to perform reasonably well.
|
||||
|
||||
We know that we want to write in batches, but the only batches we get are vertical sets of data points across series. When querying data points for a series over a time window, not only would it be hard to figure out where the individual points can be found, we'd also have to read from a lot of random places on disk. With possibly millions of touched samples per query, this is slow even on the fastest SSDs. Reads will also retrieve more data from our disk than the requested 16 byte sample. SSDs will load a full page, HDDs will at least read an entire sector. Either way, we are wasting precious read throughput.
|
||||
So ideally, samples for the same series would be stored sequentially so we can just scan through them with as few reads as possible. On top, we only need to know where this sequence starts to access all data points.
|
||||
|
||||
There's obviously a strong tension between the ideal pattern for writing collected data to disk and the layout that would be significantly more efficient for serving queries. It is _the_ fundamental problem our TSDB has to solve.
|
||||
|
||||
#### Current solution
|
||||
|
||||
Time to take a look at how Prometheus's current storage, let's call it "V2", addresses this problem.
|
||||
We create one file per time series that contains all of its samples in sequential order. As appending single samples to all those files every few seconds is expensive, we batch up 1KiB chunks of samples for a series in memory and append those chunks to the individual files, once they are full. This approach solves a large part of the problem. Writes are now batched, samples are stored sequentially. It also enables incredibly efficient compression formats, based on the property that a given sample changes only very little with respect to the previous sample in the same series. Facebook's paper on their Gorilla TSDB describes a similar chunk-based approach and [introduces a compression format][7] that reduces 16 byte samples to an average of 1.37 bytes. The V2 storage uses various compression formats including a variation of Gorilla’s.
|
||||
|
||||
```
|
||||
┌──────────┬─────────┬─────────┬─────────┬─────────┐ series A
|
||||
└──────────┴─────────┴─────────┴─────────┴─────────┘
|
||||
┌──────────┬─────────┬─────────┬─────────┬─────────┐ series B
|
||||
└──────────┴─────────┴─────────┴─────────┴─────────┘
|
||||
. . .
|
||||
┌──────────┬─────────┬─────────┬─────────┬─────────┬─────────┐ series XYZ
|
||||
└──────────┴─────────┴─────────┴─────────┴─────────┴─────────┘
|
||||
chunk 1 chunk 2 chunk 3 ...
|
||||
```
|
||||
|
||||
While the chunk-based approach is great, keeping a separate file for each series is troubling the V2 storage for various reasons:
|
||||
|
||||
* We actually need a lot more files than the number of time series we are currently collecting data for. More on that in the section on "Series Churn". With several million files, sooner or later way may run out of [inodes][1] on our filesystem. This is a condition we can only recover from by reformatting our disks, which is as invasive and disruptive as it could be. We generally want to avoid formatting disks specifically to fit a single application.
|
||||
* Even when chunked, several thousands of chunks per second are completed and ready to be persisted. This still requires thousands of individual disk writes every second. While it is alleviated by also batching up several completed chunks for a series, this in return increases the total memory footprint of data which is waiting to be persisted.
|
||||
* It's infeasible to keep all files open for reads and writes. In particular because ~99% of data is never queried again after 24 hours. If it is queried though though, we have to open up to thousands of files, find and read relevant data points into memory, and close them again. As this would result in high query latencies, data chunks are cached rather aggressively leading to problems outlined further in the section on "Resource Consumption".
|
||||
* Eventually, old data has to be deleted and data needs to be removed from the front of millions of files. This means that deletions are actually write intensive operations. Additionally, cycling through millions of files and analyzing them makes this a process that often takes hours. By the time it completes, it might have to start over again. Oh yea, and deleting the old files will cause further write amplification for your SSD!
|
||||
* Chunks that are currently accumulating are only held in memory. If the application crashes, data will be lost. To avoid this, the memory state is periodically checkpointed to disk, which may take significantly longer than the window of data loss we are willing to accept. Restoring the checkpoint may also take several minutes, causing painfully long restart cycles.
|
||||
|
||||
The key take away from the existing design is the concept of chunks, which we most certainly want to keep. The most recent chunks always being held in memory is also generally good. After all, the most recent data is queried the most by a large margin.
|
||||
Having one file per time series is a concept we would like to find an alternative to.
|
||||
|
||||
### Series Churn
|
||||
|
||||
In the Prometheus context, we use the term _series churn_ to describe that a set of time series becomes inactive, i.e. receives no more data points, and a new set of active series appears instead.
|
||||
For example, all series exposed by a given microservice instance have a respective “instance” label attached that identifies its origin. If we perform a rolling update of our microservice and swap out every instance with a newer version, series churn occurs. In more dynamic environments those events may happen on an hourly basis. Cluster orchestration systems like Kubernetes allow continuous auto-scaling and frequent rolling updates of applications, potentially creating tens of thousands of new application instances, and with them completely new sets of time series, every day.
|
||||
|
||||
```
|
||||
series
|
||||
^
|
||||
│ . . . . . .
|
||||
│ . . . . . .
|
||||
│ . . . . . .
|
||||
│ . . . . . . .
|
||||
│ . . . . . . .
|
||||
│ . . . . . . .
|
||||
│ . . . . . .
|
||||
│ . . . . . .
|
||||
│ . . . . .
|
||||
│ . . . . .
|
||||
│ . . . . .
|
||||
v
|
||||
<-------------------- time --------------------->
|
||||
```
|
||||
|
||||
So even if the entire infrastructure roughly remains constant in size, over time there's a linear growth of time series in our database. While a Prometheus server will happily collect data for 10 million time series, query performance is significantly impacted if data has to be found among a billion series.
|
||||
|
||||
#### Current solution
|
||||
|
||||
The current V2 storage of Prometheus has an index based on LevelDB for all series that are currently stored. It allows querying series containing a given label pair, but lacks a scalable way to combine results from different label selections.
|
||||
For example, selecting all series with label `__name__="requests_total"` works efficiently, but selecting all series with `instance="A" AND __name__="requests_total"` has scalability problems. We will later revisit what causes this and which tweaks are necessary to improve lookup latencies.
|
||||
|
||||
This problem is in fact what spawned the initial hunt for a better storage system. Prometheus needed an improved indexing approach for quickly searching hundreds of millions of time series.
|
||||
|
||||
### Resource consumption
|
||||
|
||||
Resource consumption is one of the consistent topics when trying to scale Prometheus (or anything, really). But it's not actually the absolute resource hunger that is troubling users. In fact, Prometheus manages an incredible throughput given its requirements. The problem is rather its relative unpredictability and instability in face of changes. By its architecture the V2 storage slowly builds up chunks of sample data, which causes the memory consumption to ramp up over time. As chunks get completed, they are written to disk and can be evicted from memory. Eventually, Prometheus's memory usage reaches a steady state. That is until the monitored environment changes — _series churn_ increases the usage of memory, CPU, and disk IO every time we scale an application or do a rolling update.
|
||||
If the change is ongoing, it will yet again reach a steady state eventually but it will be significantly higher than in a more static environment. Transition periods are often multiple hours long and it is hard to determine what the maximum resource usage will be.
|
||||
|
||||
The approach of having a single file per time series also makes it way too easy for a single query to knock out the Prometheus process. When querying data that is not cached in memory, the files for queried series are opened and the chunks containing relevant data points are read into memory. If the amount of data exceeds the memory available, Prometheus quits rather ungracefully by getting OOM-killed.
|
||||
After the query is completed the loaded data can be released again but it is generally cached much longer to serve subsequent queries on the same data faster. The latter is a good thing obviously.
|
||||
|
||||
Lastly, we looked at write amplification in the context of SSDs and how Prometheus addresses it by batching up writes to mitigate it. Nonetheless, in several places it still causes write amplification by having too small batches and not aligning data precisely on page boundaries. For larger Prometheus servers, a reduced hardware lifetime was observed in the real world. Chances are that this is still rather normal for database applications with high write throughput, but we should keep an eye on whether we can mitigate it.
|
||||
|
||||
### Starting Over
|
||||
|
||||
By now we have a good idea of our problem domain, how the V2 storage solves it, and where its design has issues. We also saw some great concepts that we want to adapt more or less seamlessly. A fair amount of V2's problems can be addressed with improvements and partial redesigns, but to keep things fun (and after carefully evaluating my options, of course), I decided to take a stab at writing an entire time series database — from scratch, i.e. writing bytes to the file system.
|
||||
|
||||
The critical concerns of performance and resource usage are a direct consequence of the chosen storage format. We have to find the right set of algorithms and disk layout for our data to implement a well-performing storage layer.
|
||||
|
||||
This is where I take the shortcut and drive straight to the solution — skip the headache, failed ideas, endless sketching, tears, and despair.
|
||||
|
||||
### V3 — Macro Design
|
||||
|
||||
What's the macro layout of our storage? In short, everything that is revealed when running `tree` on our data directory. Just looking at that gives us a surprisingly good picture of what is going on.
|
||||
|
||||
```
|
||||
$ tree ./data
|
||||
./data
|
||||
├── b-000001
|
||||
│ ├── chunks
|
||||
│ │ ├── 000001
|
||||
│ │ ├── 000002
|
||||
│ │ └── 000003
|
||||
│ ├── index
|
||||
│ └── meta.json
|
||||
├── b-000004
|
||||
│ ├── chunks
|
||||
│ │ └── 000001
|
||||
│ ├── index
|
||||
│ └── meta.json
|
||||
├── b-000005
|
||||
│ ├── chunks
|
||||
│ │ └── 000001
|
||||
│ ├── index
|
||||
│ └── meta.json
|
||||
└── b-000006
|
||||
├── meta.json
|
||||
└── wal
|
||||
├── 000001
|
||||
├── 000002
|
||||
└── 000003
|
||||
```
|
||||
|
||||
At the top level, we have a sequence of numbered blocks, prefixed with `b-`. Each block obviously holds a file containing an index and a "chunk" directory holding more numbered files. The “chunks” directory contains nothing but raw chunks of data points for various series. Just as for V2, this makes reading series data over a time windows very cheap and allows us to apply the same efficient compression algorithms. The concept has proven to work well and we stick with it. Obviously, there is no longer a single file per series but instead a handful of files holds chunks for many of them.
|
||||
The existence of an “index” file should not be surprising. Let's just assume it contains a lot of black magic allowing us to find labels, their possible values, entire time series and the chunks holding their data points.
|
||||
|
||||
But why are there several directories containing the layout of index and chunk files? And why does the last one contain a "wal" directory instead? Understanding those two questions, solves about 90% of our problems.
|
||||
|
||||
#### Many Little Databases
|
||||
|
||||
We partition our _horizontal_ dimension, i.e. the time space, into non-overlapping blocks. Each block acts as a fully independent database containing all time series data for its time window. Hence, it has its own index and set of chunk files.
|
||||
|
||||
```
|
||||
|
||||
t0 t1 t2 t3 now
|
||||
┌───────────┐ ┌───────────┐ ┌───────────┐ ┌───────────┐
|
||||
│ │ │ │ │ │ │ │ ┌────────────┐
|
||||
│ │ │ │ │ │ │ mutable │ <─── write ──── ┤ Prometheus │
|
||||
│ │ │ │ │ │ │ │ └────────────┘
|
||||
└───────────┘ └───────────┘ └───────────┘ └───────────┘ ^
|
||||
└──────────────┴───────┬──────┴──────────────┘ │
|
||||
│ query
|
||||
│ │
|
||||
merge ─────────────────────────────────────────────────┘
|
||||
```
|
||||
|
||||
Every block of data is immutable. Of course, we must be able to add new series and samples to the most recent block as we collect new data. For this block, all new data is written to an in-memory database that provides the same lookup properties as our persistent blocks. The in-memory data structures can be updated efficiently. To prevent data loss, all incoming data is also written to a temporary _write ahead log_ , which is the set of files in our “wal” directory, from which we can re-populate the in-memory database on restart.
|
||||
All these files come with their own serialization format, which comes with all the things one would expect: lots of flags, offsets, varints, and CRC32 checksums. Good fun to come up with, rather boring to read about.
|
||||
|
||||
This layout allows us to fan out queries to all blocks relevant to the queried time range. The partial results from each block are merged back together to form the overall result.
|
||||
|
||||
This horizontal partitioning adds a few great capabilities:
|
||||
|
||||
* When querying a time range, we can easily ignore all data blocks outside of this range. It trivially addresses the problem of _series churn_ by reducing the set of inspected data to begin with.
|
||||
* When completing a block, we can persist the data from our in-memory database by sequentially writing just a handful of larger files. We avoid any write-amplification and serve SSDs and HDDs equally well.
|
||||
* We keep the good property of V2 that recent chunks, which are queried most, are always hot in memory.
|
||||
* Nicely enough, we are also no longer bound to the fixed 1KiB chunk size to better align data on disk. We can pick any size that makes the most sense for the individual data points and chosen compression format.
|
||||
* Deleting old data becomes extremely cheap and instantaneous. We merely have to delete a single directory. Remember, in the old storage we had to analyze and re-write up to hundreds of millions of files, which could take hours to converge.
|
||||
|
||||
Each block also contains a `meta.json` file. It simply holds human-readable information about the block to easily understand the state of our storage and the data it contains.
|
||||
|
||||
##### mmap
|
||||
|
||||
Moving from millions of small files to a handful of larger allows us to keep all files open with little overhead. This unblocks the usage of [`mmap(2)`][8], a system call that allows us to transparently back a virtual memory region by file contents. For simplicity, you might want to think of it like swap space, just that all our data is on disk already and no writes occur when swapping data out of memory.
|
||||
|
||||
This means we can treat all contents of our database as if they were in memory without occupying any physical RAM. Only if we access certain byte ranges in our database files, the operating system lazily loads pages from disk. This puts the operating system in charge of all memory management related to our persisted data. Generally, it is more qualified to make such decisions, as it has the full view on the entire machine and all its processes. Queried data can be rather aggressively cached in memory, yet under memory pressure the pages will be evicted. If the machine has unused memory, Prometheus will now happily cache the entire database, yet will immediately return it once another application needs it.
|
||||
Therefore, queries can longer easily OOM our process by querying more persisted data than fits into RAM. The memory cache size becomes fully adaptive and data is only loaded once the query actually needs it.
|
||||
|
||||
From my understanding, this is how a lot of databases work today and an ideal way to do it if the disk format allows — unless one is confident to outsmart the OS from within the process. We certainly get a lot of capabilities with little work from our side.
|
||||
|
||||
#### Compaction
|
||||
|
||||
The storage has to periodically "cut" a new block and write the previous one, which is now completed, onto disk. Only after the block was successfully persisted, the write ahead log files, which are used to restore in-memory blocks, are deleted.
|
||||
We are interested in keeping each block reasonably short (about two hours for a typical setup) to avoid accumulating too much data in memory. When querying multiple blocks, we have to merge their results into an overall result. This merge procedure obviously comes with a cost and a week-long query should not have to merge 80+ partial results.
|
||||
|
||||
To achieve both, we introduce _compaction_ . Compaction describes the process of taking one or more blocks of data and writing them into a, potentially larger, block. It can also modify existing data along the way, e.g. dropping deleted data, or restructuring our sample chunks for improved query performance.
|
||||
|
||||
```
|
||||
|
||||
t0 t1 t2 t3 t4 now
|
||||
┌────────────┐ ┌──────────┐ ┌───────────┐ ┌───────────┐ ┌───────────┐
|
||||
│ 1 │ │ 2 │ │ 3 │ │ 4 │ │ 5 mutable │ before
|
||||
└────────────┘ └──────────┘ └───────────┘ └───────────┘ └───────────┘
|
||||
┌─────────────────────────────────────────┐ ┌───────────┐ ┌───────────┐
|
||||
│ 1 compacted │ │ 4 │ │ 5 mutable │ after (option A)
|
||||
└─────────────────────────────────────────┘ └───────────┘ └───────────┘
|
||||
┌──────────────────────────┐ ┌──────────────────────────┐ ┌───────────┐
|
||||
│ 1 compacted │ │ 3 compacted │ │ 5 mutable │ after (option B)
|
||||
└──────────────────────────┘ └──────────────────────────┘ └───────────┘
|
||||
```
|
||||
|
||||
In this example we have the sequential blocks `[1, 2, 3, 4]`. Blocks 1, 2, and 3 can be compacted together and the new layout is `[1, 4]`. Alternatively, compact them in pairs of two into `[1, 3]`. All time series data still exist but now in fewer blocks overall. This significantly reduces the merging cost at query time as fewer partial query results have to be merged.
|
||||
|
||||
#### Retention
|
||||
|
||||
We saw that deleting old data was a slow process in the V2 storage and put a toll on CPU, memory, and disk alike. How can we drop old data in our block based design? Quite simply, by just deleting the directory of a block that has no data within our configured retention window. In the example below, block 1 can safely be deleted, whereas 2 has to stick around until it falls fully behind the boundary.
|
||||
|
||||
```
|
||||
|
|
||||
┌────────────┐ ┌────┼─────┐ ┌───────────┐ ┌───────────┐ ┌───────────┐
|
||||
│ 1 │ │ 2 | │ │ 3 │ │ 4 │ │ 5 │ . . .
|
||||
└────────────┘ └────┼─────┘ └───────────┘ └───────────┘ └───────────┘
|
||||
|
|
||||
|
|
||||
retention boundary
|
||||
```
|
||||
|
||||
The older data gets, the larger the blocks may become as we keep compacting previously compacted blocks. An upper limit has to be applied so blocks don’t grow to span the entire database and thus diminish the original benefits of our design.
|
||||
Conveniently, this also limits the total disk overhead of blocks that are partially inside and partially outside of the retention window, i.e. block 2 in the example above. When setting the maximum block size at 10% of the total retention window, our total overhead of keeping block 2 around is also bound by 10%.
|
||||
|
||||
Summed up, retention deletion goes from very expensive, to practically free.
|
||||
|
||||
> _If you've come this far and have some background in databases, you might be asking one thing by now: Is any of this new? — Not really; and probably for the better._
|
||||
>
|
||||
> _The pattern of batching data up in memory, tracked in a write ahead log, and periodically flushed to disk is ubiquitous today._
|
||||
> _The benefits we have seen apply almost universally regardless of the data's domain specifics. Prominent open source examples following this approach are LevelDB, Cassandra, InfluxDB, or HBase. The key takeaway is to avoid reinventing an inferior wheel, researching proven methods, and applying them with the right twist._
|
||||
> _Running out of places to add your own magic dust later is an unlikely scenario._
|
||||
|
||||
### The Index
|
||||
|
||||
The initial motivation to investigate storage improvements were the problems brought by _series churn_ . The block-based layout reduces the total number of series that have to be considered for serving a query. So assuming our index lookup was of complexity _O(n^2)_ , we managed to reduce the _n_ a fair amount and now have an improved complexity of _O(n^2)_ — uhm, wait... damnit.
|
||||
A quick flashback to "Algorithms 101" reminds us that this, in theory, did not buy us anything. If things were bad before, they are just as bad now. Theory can be depressing.
|
||||
|
||||
In practice, most of our queries will already be answered significantly faster. Yet, queries spanning the full time range remain slow even if they just need to find a handful of series. My original idea, dating back way before all this work was started, was a solution to exactly this problem: we need a more capable [ _inverted index_ ][9].
|
||||
An inverted index provides a fast lookup of data items based on a subset of their contents. Simply put, I can look up all series that have a label `app=”nginx"` without having to walk through every single series and check whether it contains that label.
|
||||
|
||||
For that, each series is assigned a unique ID by which it can be retrieved in constant time, i.e. O(1). In this case the ID is our _forward index_ .
|
||||
|
||||
> Example: If the series with IDs 10, 29, and 9 contain the label `app="nginx"`, the inverted index for the label "nginx" is the simple list `[10, 29, 9]`, which can be used to quickly retrieve all series containing the label. Even if there were 20 billion further series, it would not affect the speed of this lookup.
|
||||
|
||||
In short, if _n_ is our total number of series, and _m_ is the result size for a given query, the complexity of our query using the index is now _O(m)_ . Queries scaling along the amount of data they retrieve ( _m_ ) instead of the data body being searched ( _n_ ) is a great property as _m_ is generally significantly smaller.
|
||||
For brevity, let’s assume we can retrieve the inverted index list itself in constant time.
|
||||
|
||||
Actually, this is almost exactly the kind of inverted index V2 has and a minimum requirement to serve performant queries across millions of series. The keen observer will have noticed, that in the worst case, a label exists in all series and thus _m_ is, again, in _O(n)_ . This is expected and perfectly fine. If you query all data, it naturally takes longer. Things become problematic once we get involved with more complex queries.
|
||||
|
||||
#### Combining Labels
|
||||
|
||||
Labels associated with millions of series are common. Suppose a horizontally scaling “foo” microservice with hundreds of instances with thousands of series each. Every single series will have the label `app="foo"`. Of course, one generally won't query all series but restrict the query by further labels, e.g. I want to know how many requests my service instances received and query `__name__="requests_total" AND app="foo"`.
|
||||
|
||||
To find all series satisfying both label selectors, we take the inverted index list for each and intersect them. The resulting set will typically be orders of magnitude smaller than each input list individually. As each input list has the worst case size O(n), the brute force solution of nested iteration over both lists, has a runtime of O(n^2). The same cost applies for other set operations, such as the union (`app="foo" OR app="bar"`). When adding further label selectors to the query, the exponent increases for each to O(n^3), O(n^4), O(n^5), ... O(n^k). A lot of tricks can be played to minimize the effective runtime by changing the execution order. The more sophisticated, the more knowledge about the shape of the data and the relationships between labels is needed. This introduces a lot of complexity, yet does not decrease our algorithmic worst case runtime.
|
||||
|
||||
This is essentially the approach in the V2 storage and luckily a seemingly slight modification is enough gain significant improvements. What happens if we assume that the IDs in our inverted indices are sorted?
|
||||
|
||||
Suppose this example of lists for our initial query:
|
||||
|
||||
```
|
||||
__name__="requests_total" -> [ 9999, 1000, 1001, 2000000, 2000001, 2000002, 2000003 ]
|
||||
app="foo" -> [ 1, 3, 10, 11, 12, 100, 311, 320, 1000, 1001, 10002 ]
|
||||
|
||||
intersection => [ 1000, 1001 ]
|
||||
```
|
||||
|
||||
The intersection is fairly small. We can find it by setting a cursor at the beginning of each list and always advancing the one at the smaller number. When both numbers are equal, we add the number to our result and advance both cursors. Overall, we scan both lists in this zig-zag pattern and thus have a total cost of _O(2n) = O(n)_ as we only ever move forward in either list.
|
||||
|
||||
The procedure for more than two lists of different set operations works similarly. So the number of _k_ set operations merely modifies the factor ( _O(k*n)_ ) instead of the exponent ( _O(n^k)_ ) of our worst-case lookup runtime. A great improvement.
|
||||
What I described here is a simplified version of the canonical search index used by practically any [full text search engine][10] out there. Every series descriptor is treated as a short "document", and every label (name + fixed value) as a "word" inside of it. We can ignore a lot of additional data typically encountered in search engine indices, such as word position and frequency data.
|
||||
Seemingly endless research exists on approaches improving the practical runtime, often making some assumptions about the input data. Unsurprisingly, there are also plenty of techniques to compress inverted indices that come with their own benefits and drawbacks. As our "documents" are tiny and the “words” are hugely repetitive across all series, compression becomes almost irrelevant. For example, a real-world dataset of ~4.4 million series with about 12 labels each has less than 5,000 unique labels. For our initial storage version, we stick to the basic approach without compression, and just a few simple tweaks added to skip over large ranges of non-intersecting IDs.
|
||||
|
||||
While keeping the IDs sorted may sound simple, it is not always a trivial invariant to keep up. For instance, the V2 storage assigns hashes as IDs to new series and we cannot efficiently build up sorted inverted indices.
|
||||
Another daunting task is modifying the indices on disk as data gets deleted or updated. Typically, the easiest approach is to simply recompute and rewrite them but doing so while keeping the database queryable and consistent. The V3 storage does exactly this by having a separate immutable index per block that is only modified via rewrite on compaction. Only the indices for the mutable blocks, which are held entirely in memory, need to be updated.
|
||||
|
||||
### Benchmarking
|
||||
|
||||
I started initial development of the storage with a benchmark based on ~4.4 million series descriptors extracted from a real world data set and generated synthetic data points to feed into those series. This iteration just tested the stand-alone storage and was crucial to quickly identify performance bottlenecks and trigger deadlocks only experienced under highly concurrent load.
|
||||
|
||||
After the conceptual implementation was done, the benchmark could sustain a write throughput of 20 million data points per second on my Macbook Pro — all while a dozen Chrome tabs and Slack were running. So while this sounded all great it also indicated that there's no further point in pushing this benchmark (or running it in a less random environment for that matter). After all, it is synthetic and thus not worth much beyond a good first impression. Starting out about 20x above the initial design target, it was time to embed this into an actual Prometheus server, adding all the practical overhead and flakes only experienced in more realistic environments.
|
||||
|
||||
We actually had no reproducible benchmarking setup for Prometheus, in particular none that allowed A/B testing of different versions. Concerning in hindsight, but [now we have one][11]!
|
||||
|
||||
Our tool allows us to declaratively define a benchmarking scenario, which is then deployed to a Kubernetes cluster on AWS. While this is not the best environment for all-out benchmarking, it certainly reflects our user base better than dedicated bare metal servers with 64 cores and 128GB of memory.
|
||||
We deploy two Prometheus 1.5.2 servers (V2 storage) and two Prometheus servers from the 2.0 development branch (V3 storage). Each Prometheus server runs on a dedicated machine with an SSD. A horizontally scaled application exposing typical microservice metrics is deployed to worker nodes. Additionally, the Kubernetes cluster itself and the nodes are being monitored. The whole setup is supervised by yet another Meta-Prometheus, monitoring each Prometheus server for health and performance.
|
||||
To simulate series churn, the microservice is periodically scaled up and down to remove old pods and spawn new pods, exposing new series. Query load is simulated by a selection of "typical" queries, run against one server of each Prometheus version.
|
||||
|
||||
Overall the scaling and querying load as well as the sampling frequency significantly exceed today's production deployments of Prometheus. For instance, we swap out 60% of our microservice instances every 15 minutes to produce series churn. This would likely only happen 1-5 times a day in a modern infrastructure. This ensures that our V3 design is capable of handling the workloads of the years ahead. As a result, the performance differences between Prometheus 1.5.2 and 2.0 are larger than in a more moderate environment.
|
||||
In total, we are collecting about 110,000 samples per second from 850 targets exposing half a million series at a time.
|
||||
|
||||
After leaving this setup running for a while, we can take a look at the numbers. We evaluate several metrics over the first 12 hours within both versiones reached a steady state.
|
||||
|
||||
> Be aware of the slightly truncated Y axis in screen shots from the Prometheus graph UI.
|
||||
|
||||

|
||||
> _Heap memory usage in GB_
|
||||
|
||||
Memory usage is the most troubling resource for users today as it is relatively unpredictable and it may cause the process to crash.
|
||||
Obviously, the queried servers are consuming more memory, which can largely be attributed to overhead of the query engine, which will be subject to future optimizations. Overall, Prometheus 2.0's memory consumption is reduced by 3-4x. After about six hours, there is a clear spike in Prometheus 1.5, which aligns with the our retention boundary at six hours. As deletions are quite costly, resource consumption ramps up. This will become visible throughout various other graphs below.
|
||||
|
||||

|
||||
> _CPU usage in cores/second_
|
||||
|
||||
A similar pattern shows for CPU usage, but the delta between queried and non-queried servers is more significant. Averaging at about 0.5 cores/sec while ingesting about 110,000 samples/second, our new storage becomes almost negligible compared to the cycles spent on query evaluation. In total the new storage needs 3-10 times fewer CPU resources.
|
||||
|
||||

|
||||
>_Disk writes in MB/second_
|
||||
|
||||
The by far most dramatic and unexpected improvement shows in write utilization of our disk. It clearly shows why Prometheus 1.5 is prone to wear out SSDs. We see an initial ramp-up as soon as the first chunks are persisted into the series files and a second ramp-up once deletion starts rewriting them. Surprisingly, the queried and non-queried server show a very different utilization.
|
||||
Prometheus 2.0 on the other hand, merely writes about a single Megabyte per second to its write ahead log. Writes periodically spike when blocks are compacted to disk. Overall savings: staggering 97-99%.
|
||||
|
||||

|
||||
> _Disk size in GB_
|
||||
|
||||
Closely related to disk writes is the total amount of occupied disk space. As we are using almost the same compression algorithm for samples, which is the bulk of our data, they should be about the same. In a more stable setup that would largely be true, but as we are dealing with high _series churn_ , there's also the per-series overhead to consider.
|
||||
As we can see, Prometheus 1.5 ramps up storage space a lot faster before both versions reach a steady state as the retention kicks in. Prometheus 2.0 seems to have a significantly lower overhead per individual series. We can nicely see how space is linearly filled up by the write ahead log and instantaneously drops as its gets compacted. The fact that the lines for both Prometheus 2.0 servers do not exactly match is a fact that needs further investigation.
|
||||
|
||||
This all looks quite promising. The important piece left is query latency. The new index should have improved our lookup complexity. What has not substantially changed is processing of this data, e.g. in `rate()` functions or aggregations. Those aspects are part of the query engine.
|
||||
|
||||

|
||||
>_99th percentile query latency in seconds_
|
||||
|
||||
Expectations are completely met by the data. In Prometheus 1.5 the query latency increases over time as more series are stored. It only levels off once retention starts and old series are deleted. In contrast, Prometheus 2.0 stays in place right from the beginning.
|
||||
Some caution must be taken on how this data was collected. The queries fired against the servers were chosen by estimating a good mix of range and instant queries, doing heavier and more lightweight computations, and touching few or many series. It does not necessarily represent a real-world distribution of queries. It is also not representative for queries hitting cold data and we can assume that all sample data is practically always hot in memory in either storage.
|
||||
Nonetheless, we can say with good confidence, that the overall query performance became very resilient to series churn and improved by up to 4x in our straining benchmarking scenario. In a more static environment, we can assume query time to be mostly spent in the query engine itself and the improvement to be notably lower.
|
||||
|
||||

|
||||
>_Ingested samples/second_
|
||||
|
||||
Lastly, a quick look into our ingestion rates of the different Prometheus servers. We can see that both servers with the V3 storage have the same ingestion rate. After a few hours it becomes unstable, which is caused by various nodes of the benchmarking cluster becoming unresponsive due to high load rather than the Prometheus instances. (The fact that both 2.0 lines exactly match is hopefully convincing enough.)
|
||||
Both Prometheus 1.5.2 servers start suffering from significant drops in ingestion rate even though more CPU and memory resources are available. The high stress of series churn causes a larger amount of data to not be collected.
|
||||
|
||||
But what's the _absolute maximum_ number of samples per second you could ingest now?
|
||||
|
||||
I don't know — and deliberately don't care.
|
||||
|
||||
There are a lot of factors that shape the data flowing into Prometheus and there is no single number capable of capturing quality. Maximum ingestion rate has historically been a metric leading to skewed benchmarks and neglect of more important aspects such as query performance and resilience to series churn. The rough assumption that resource usage increases linearly was confirmed by some basic testing. It is easy to extrapolate what could be possible.
|
||||
|
||||
Our benchmarking setup simulates a highly dynamic environment stressing Prometheus more than most real-world setups today. The results show we went way above our initial design goal, while running on non-optimal cloud servers. Ultimately, success will be determined by user feedback rather than benchmarking numbers.
|
||||
|
||||
> Note: _At time of writing this, Prometheus 1.6 is in development, which will allow configuring the maximum memory usage more reliably and may notably reduce overall consumption in favor of slightly increased CPU utilization. I did not repeat the tests against this as the overall results still hold, especially when facing high series churn._
|
||||
|
||||
### Conclusion
|
||||
|
||||
Prometheus sets out to handle high cardinality of series and throughput of individual samples. It remains a challenging task, but the new storage seems to position us well for the hyper-scale, hyper-convergent, GIFEE infrastructure of the futu... well, it seems to work pretty well.
|
||||
|
||||
A [first alpha release of Prometheus 2.0][12] with the new V3 storage is available for testing. Expect crashes, deadlocks, and other bugs at this early stage.
|
||||
|
||||
The code for the storage itself can be found [in a separate project][13]. It's surprisingly agnostic to Prometheus itself and could be widely useful for a wider range of applications looking for an efficient local storage time series database.
|
||||
|
||||
> _There's a long list of people to thank for their contributions to this work. Here they go in no particular order:_
|
||||
>
|
||||
> _The groundlaying work by Bjoern Rabenstein and Julius Volz on the V2 storage engine and their feedback on V3 was fundamental to everything seen in this new generation._
|
||||
>
|
||||
> _Wilhelm Bierbaum's ongoing advice and insight contributed significantly to the new design. Brian Brazil's continous feedback ensured that we ended up with a semantically sound approach. Insightful discussions with Peter Bourgon validated the design and shaped this write-up._
|
||||
>
|
||||
> _Not to forget my entire team at CoreOS and the company itself for supporting and sponsoring this work. Thanks to everyone who listened to my ramblings about SSDs, floats, and serialization formats again and again._
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fabxc.org/blog/2017-04-10-writing-a-tsdb/
|
||||
|
||||
作者:[Fabian Reinartz ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://twitter.com/fabxc
|
||||
[1]:https://en.wikipedia.org/wiki/Inode
|
||||
[2]:https://prometheus.io/
|
||||
[3]:https://kubernetes.io/
|
||||
[4]:https://en.wikipedia.org/wiki/Write_amplification
|
||||
[5]:http://codecapsule.com/2014/02/12/coding-for-ssds-part-1-introduction-and-table-of-contents/
|
||||
[6]:https://prometheus.io/docs/practices/rules/
|
||||
[7]:http://www.vldb.org/pvldb/vol8/p1816-teller.pdf
|
||||
[8]:https://en.wikipedia.org/wiki/Mmap
|
||||
[9]:https://en.wikipedia.org/wiki/Inverted_index
|
||||
[10]:https://en.wikipedia.org/wiki/Search_engine_indexing#Inverted_indices
|
||||
[11]:https://github.com/prometheus/prombench
|
||||
[12]:https://prometheus.io/blog/2017/04/10/promehteus-20-sneak-peak/
|
||||
[13]:https://github.com/prometheus/tsdb
|
||||
@ -1,239 +0,0 @@
|
||||
GoTTY – Share Your Linux Terminal (TTY) as a Web Application
|
||||
============================================================
|
||||
|
||||
|
||||
GoTTY is a simple GoLang based command line tool that enables you to share your terminal(TTY) as a web application. It turns command line tools into web applications.
|
||||
|
||||
It employs Chrome OS’ terminal emulator (hterm) to execute a JavaScript based terminal on a web browsers. And importantly, GoTTY runs a web socket server that basically transfers output from the TTYto clients and receives input from clients (that is if input from clients is permitted) and forwards it to the TTY.
|
||||
|
||||
Its architecture (hterm + web socket idea) was inspired by [Wetty program][1] which enables terminal over HTTP and HTTPS.
|
||||
|
||||
#### Prerequisites:
|
||||
|
||||
You should have [GoLang (Go Programming Language)][2] environment installed in Linux to run GoTTY.
|
||||
|
||||
### How To Install GoTTY in Linux Systems
|
||||
|
||||
If you already have a [working GoLang environment][3], run the go get command below to install it:
|
||||
|
||||
```
|
||||
# go get github.com/yudai/gotty
|
||||
```
|
||||
|
||||
The command above will install the GoTTY binary in your GOBIN environment variable, try to check if that is the case:
|
||||
|
||||
```
|
||||
# $GOPATH/bin/
|
||||
```
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
Check GOBIN Environment
|
||||
|
||||
### How To Use GoTTY in Linux
|
||||
|
||||
To run it, you can use the GOBIN env variable and command auto-completion feature as follows:
|
||||
|
||||
```
|
||||
# $GOBIN/gotty
|
||||
```
|
||||
|
||||
Else, run GoTTY or any other Go program without typing the full path to the binary, add your GOBIN variable to PATH in the `~/.profile` file using the export command below:
|
||||
|
||||
```
|
||||
export PATH="$PATH:$GOBIN"
|
||||
```
|
||||
|
||||
Save the file and close it. Then source the file to effect the changes above:
|
||||
|
||||
```
|
||||
# source ~/.profile
|
||||
```
|
||||
|
||||
The general syntax for running GoTTY commands is:
|
||||
|
||||
```
|
||||
Usage: gotty [options] <Linux command here> [<arguments...>]
|
||||
```
|
||||
|
||||
Now run GoTTY with any command such as the [df command][5] to view system disk partitions space and usage from the web browser:
|
||||
|
||||
```
|
||||
# gotty df -h
|
||||
```
|
||||
|
||||
GoTTY will start a web server at port 8080 by default. Then open the URL: `http://127.0.0.1:8080/`on your web browser and you will see the running command as if it were running on your terminal:
|
||||
|
||||
[
|
||||
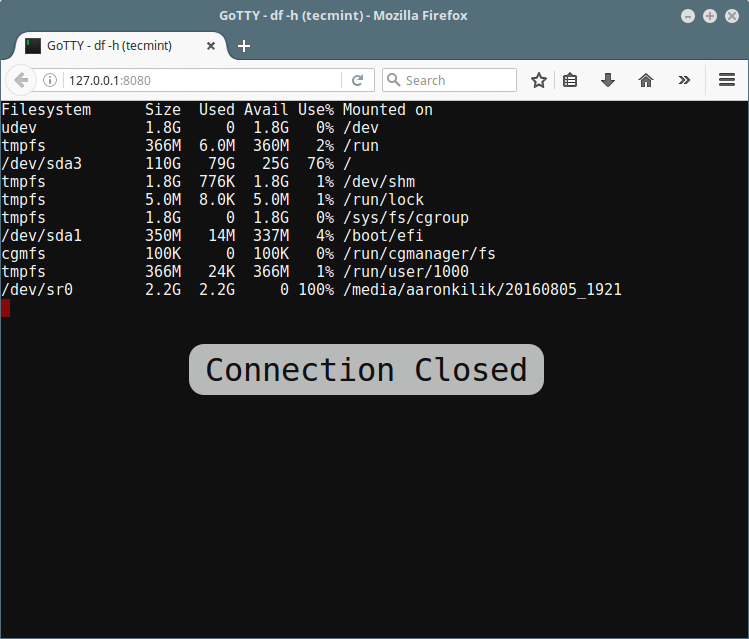
|
||||
][6]
|
||||
|
||||
Gotty Linux Disk Usage
|
||||
|
||||
### How To Customize GoTTY in Linux
|
||||
|
||||
You can alter default options and your terminal (hterm) in the profile file `~/.gotty`, it will load this file by default in case it exists.
|
||||
|
||||
This is the main customization file read by gotty commands, so, create it as follows:
|
||||
|
||||
```
|
||||
# touch ~/.gotty
|
||||
```
|
||||
|
||||
And set your own valid values for the config options (find all config options here) to customize GoTTY for example:
|
||||
|
||||
```
|
||||
// Listen at port 9000 by default
|
||||
port = "9000"
|
||||
// Enable TSL/SSL by default
|
||||
enable_tls = true
|
||||
// hterm preferences
|
||||
// Smaller font and a little bit bluer background color
|
||||
preferences {
|
||||
font_size = 5,
|
||||
background_color = "rgb(16, 16, 32)"
|
||||
}
|
||||
```
|
||||
|
||||
You can set your own index.html file using the `--html` option from the command line:
|
||||
|
||||
```
|
||||
# gotty --index /path/to/index.html uptime
|
||||
```
|
||||
|
||||
### How to Use Security Features in GoTTY
|
||||
|
||||
Because GoTTY doesn’t offer reliable security by default, you need to manually use certain security features explained below.
|
||||
|
||||
#### Permit Clients to Run Commands/Type Input in Terminal
|
||||
|
||||
Note that, by default, GoTTY doesn’t permit clients to type input into the TTY, it only enables window resizing.
|
||||
|
||||
However, you can use the `-w` or `--permit-write` option to allow clients to write to the TTY, which is not recommended due to security threats to the server.
|
||||
|
||||
The following command will use [vi command line editor][7] to open the file fossmint.txt for editing in the web browser:
|
||||
|
||||
```
|
||||
# gotty -w vi fossmint.txt
|
||||
```
|
||||
|
||||
Below is the vi interface as seen from the web browser (use vi commands here as usual):
|
||||
|
||||
[
|
||||
|
||||
][8]
|
||||
|
||||
Gotty Web Vi Editor
|
||||
|
||||
#### Use GoTTY with Basic (Username and Password) Authentication
|
||||
|
||||
Try to activate a basic authentication mechanism, where clients will be required to input the specified username and password to connect to the GoTTY server.
|
||||
|
||||
The command below will restrict client access using the `-c` option to ask users for specified credentials (username: test and password: @67890):
|
||||
|
||||
```
|
||||
# gotty -w -p "9000" -c "test@67890" glances
|
||||
```
|
||||
[
|
||||
|
||||
][9]
|
||||
|
||||
Gotty with Basic Authentication
|
||||
|
||||
#### Gotty Generate Random URL
|
||||
|
||||
Another way of restricting access to the server is by using the `-r` option. Here, GoTTY will generate a random URL so that only users who know the URL can get access to the server.
|
||||
|
||||
Also use the –title-format “GoTTY – {{ .Command }} ({{ .Hostname }})” option to define the web browsers interface title and [glances command][10] is used to show system monitoring stats:
|
||||
|
||||
```
|
||||
# gotty -r --title-format "GoTTY - {{ .Command }} ({{ .Hostname }})" glances
|
||||
```
|
||||
|
||||
The following is result of the command above as seen from the web browser interface:
|
||||
|
||||
[
|
||||

|
||||
][11]
|
||||
|
||||
Gotty Random URL for Glances Linux Monitoring
|
||||
|
||||
#### Use GoTTY with SSL/TLS
|
||||
|
||||
Because by default, all connections between the server and clients are not encrypted, when you send secret information through GoTTY such as user credentials or any other info, you have to use the `-t` or `--tls` option which enables TLS/SSL on the session:
|
||||
|
||||
GoTTY will by default read the certificate file `~/.gotty.crt` and key file `~/.gotty.key`, therefore, start by creating a self-signed certification as well as the key file using the openssl command below (answer the question asked in order to generate the cert and key files):
|
||||
|
||||
```
|
||||
# openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout ~/.gotty.key -out ~/.gotty.crt
|
||||
```
|
||||
|
||||
Then use GoTTY in a secure way with SSL/TLS enabled as follows:
|
||||
|
||||
```
|
||||
# gotty -tr --title-format "GoTTY - {{ .Command }} ({{ .Hostname }})" glances
|
||||
```
|
||||
|
||||
#### Share Your Terminal With Multiple Clients
|
||||
|
||||
You can make use of [terminal multiplexers][12] for sharing a single process with multiple clients, the following command will start a new [tmux session][13] named gotty with [glances command][14] (make sure you have tmux installed):
|
||||
|
||||
```
|
||||
# gotty tmux new -A -s gotty glances
|
||||
```
|
||||
|
||||
To read a different config file, use the –config “/path/to/file” option like so:
|
||||
|
||||
```
|
||||
# gotty -tr --config "~/gotty_new_config" --title-format "GoTTY - {{ .Command }} ({{ .Hostname }})" glances
|
||||
```
|
||||
|
||||
To display the GoTTY version, run the command:
|
||||
|
||||
```
|
||||
# gotty -v
|
||||
```
|
||||
|
||||
Visit the GoTTY GitHub repository to find more usage examples: [https://github.com/yudai/gotty][15]
|
||||
|
||||
That’s all! Have you tried it out? How do you find GoTTY? Share your thoughts with us via the feedback form below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||
|
||||
|
||||
|
||||
----------
|
||||
|
||||
|
||||
via: http://www.tecmint.com/gotty-share-linux-terminal-in-web-browser/
|
||||
|
||||
作者:[ Aaron Kili][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/access-linux-server-terminal-in-web-browser-using-wetty/
|
||||
[2]:http://www.tecmint.com/install-go-in-linux/
|
||||
[3]:http://www.tecmint.com/install-go-in-linux/
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2017/03/Check-Go-Environment.png
|
||||
[5]:http://www.tecmint.com/how-to-check-disk-space-in-linux/
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2017/03/Gotty-Linux-Disk-Usage.png
|
||||
[7]:http://www.tecmint.com/vi-editor-usage/
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2017/03/Gotty-Web-Vi-Editor.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2017/03/Gotty-use-basic-authentication.png
|
||||
[10]:http://www.tecmint.com/glances-an-advanced-real-time-system-monitoring-tool-for-linux/
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2017/03/Gotty-Random-URL-for-Glances-Linux-Monitoring.png
|
||||
[12]:http://www.tecmint.com/tmux-to-access-multiple-linux-terminals-inside-a-single-console/
|
||||
[13]:http://www.tecmint.com/tmux-to-access-multiple-linux-terminals-inside-a-single-console/
|
||||
[14]:http://www.tecmint.com/glances-an-advanced-real-time-system-monitoring-tool-for-linux/
|
||||
[15]:https://github.com/yudai/gotty
|
||||
[16]:http://www.tecmint.com/author/aaronkili/
|
||||
[17]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[18]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
66
sources/tech/20170422 The root of all eval.md
Normal file
66
sources/tech/20170422 The root of all eval.md
Normal file
@ -0,0 +1,66 @@
|
||||
[The root of all eval][1]
|
||||
============================================================
|
||||
|
||||
Ah, the `eval` function. Loved, hated. Mostly the latter.
|
||||
|
||||
```
|
||||
$ perl -E'my $program = q[say "OH HAI"]; eval $program'
|
||||
OH HAI
|
||||
```
|
||||
|
||||
I was a bit stunned when the `eval` function was renamed to `EVAL` in Perl 6 (back in 2013, after spec discussion [here][2]). I've never felt really comfortable with the rationale for doing so. I seem to be more or less alone in this opinion, though, which is fine.
|
||||
|
||||
The rationale was "the function does something really weird, so we should flag it with upper case". Like we do with `BEGIN` and the other phasers, for example. With `BEGIN` and others, the upper-casing is motivated, I agree. A phaser takes you "outside of the normal control flow". The `eval` function doesn't.
|
||||
|
||||
Other things that we upper-case are things like `.WHAT`, which look like attributes but are really specially code-generated at compile-time into something completely different. So even there the upper-casing is motivated because something outside of the normal is happening.
|
||||
|
||||
`eval` in the end is just another function. Yes, it's a function with potentially quite wide-ranging side effects, that's true. But a lot of fairly standard functions have wide-ranging side effects. (To name a few: `shell`, `die`, `exit`.) You don't see anyone clamoring to upper-case those.
|
||||
|
||||
I guess it could be argued that `eval` is very special because it hooks into the compiler and runtime in ways that normal functions don't, and maybe can't. (This is also how TimToady explained it in [the commit message][3] of the renaming commit.) But that's an argument from implementation details, which doesn't feel satisfactory. It applies with equal force to the lower-cased functions just mentioned.
|
||||
|
||||
To add insult to injury, the renamed `EVAL` is also made deliberately harder to use:
|
||||
|
||||
```
|
||||
$ perl6 -e'my $program = q[say "OH HAI"]; EVAL $program'
|
||||
===SORRY!=== Error while compiling -e
|
||||
EVAL is a very dangerous function!!! (use the MONKEY-SEE-NO-EVAL pragma to override this error,
|
||||
but only if you're VERY sure your data contains no injection attacks)
|
||||
at -e:1
|
||||
------> program = q[say "OH HAI"]; EVAL $program⏏<EOL>
|
||||
|
||||
$ perl6 -e'use MONKEY-SEE-NO-EVAL; my $program = q[say "OH HAI"]; EVAL $program'
|
||||
OH HAI
|
||||
```
|
||||
|
||||
Firstly, injection attacks are a real issue, and no laughing matter. We should educate each other and newcomers about them.
|
||||
|
||||
Secondly, that error message (`"EVAL is a very dangerous function!!!"`) is completely over-the-top in a way that damages rather than helps. I believe when we explain the dangers of code injection to people, we need to do it calmly and matter-of-factly. Not with three exclamation marks. The error message makes sense to [someone who already knows about injection attacks][4]; it provides no hints or clues for people who are unaware of the risks.
|
||||
|
||||
(The Perl 6 community is not unique in `eval`-hysteria. Yesterday I stumbled across a StackOverflow thread about how to turn a string with a type name into the corresponding constructor in JavaScript. Some unlucky soul suggested `eval`, and everybody else immediately piled on to point out how irresponsible that was. Solely as a knee-jerk reaction "because eval is bad".)
|
||||
|
||||
Thirdly, `MOKNEY-SEE-NO-EVAL`. Please, can we just... not. 😓 Random reference to monkies and the weird attempt at levity while switching on a nuclear-chainsaw function aside, I find it odd that a function that _enables_ `EVAL` is called something with `NO-EVAL`. That's not Least Surprise.
|
||||
|
||||
Anyway, the other day I realized how I can get around both the problem of the all-caps name and the problem of the necessary pragma:
|
||||
|
||||
```
|
||||
$ perl6 -e'my &eval = &EVAL; my $program = q[say "OH HAI"]; eval $program'
|
||||
OH HAI
|
||||
```
|
||||
|
||||
I was so happy to realize this that I thought I'd blog about it. Apparently the very dangerous function (`!!!`) is fine again if we just give it back its old name. 😜
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://strangelyconsistent.org/blog/the-root-of-all-eval
|
||||
|
||||
作者:[Carl Mäsak ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://strangelyconsistent.org/about
|
||||
[1]:http://strangelyconsistent.org/blog/the-root-of-all-eval
|
||||
[2]:https://github.com/perl6/specs/issues/50
|
||||
[3]:https://github.com/perl6/specs/commit/0b7df09ecc096eed5dc30f3dbdf568bbfd9de8f6
|
||||
[4]:http://bobby-tables.com/
|
||||
157
sources/tech/20170423 THE STORY OF GETTING SSH PORT 22.md
Normal file
157
sources/tech/20170423 THE STORY OF GETTING SSH PORT 22.md
Normal file
@ -0,0 +1,157 @@
|
||||
SSH PORT
|
||||
============================================================
|
||||
|
||||
The [SSH][4] (Secure Shell) port is 22\. It is not a co-incidence. This is a story I (Tatu Ylonen) haven't told before.
|
||||
|
||||
### THE STORY OF GETTING SSH PORT 22
|
||||
|
||||
I wrote the initial version of SSH in Spring 1995\. It was a time when [telnet][5] and [FTP][6] were widely used.
|
||||
|
||||
Anyway, I designed SSH to replace both `telnet` (port 23) and `ftp` (port 21). Port 22 was free. It was conveniently between the ports for `telnet` and `ftp`. I figured having that port number might be one of those small things that would give some aura of credibility. But how could I get that port number? I had never allocated one, but I knew somebody who had allocated a port.
|
||||
|
||||
The basic process for port allocation was fairly simple at that time. Internet was smaller and we were in very early stages of the Internet boom. Port numbers were allocated by IANA (Internet Assigned Numbers Authority). At the time, that meant an esteemed Internet pioneer called [Jon Postel][7] and [Joyce K. Reynolds][8]. Among other things, Jon had been the editor of such minor protocol standards as IP (RFC 791), ICMP (RFC 792), and TCP (RFC 793). Some of you may have heard of them.
|
||||
|
||||
To me Jon felt outright scary, having authored all the main Internet RFCs!
|
||||
|
||||
Anyway, just before announcing `ssh-1.0` in July 1995, I sent this e-mail to IANA:
|
||||
|
||||
```
|
||||
From ylo Mon Jul 10 11:45:48 +0300 1995
|
||||
From: Tatu Ylonen <ylo@cs.hut.fi>
|
||||
To: Internet Assigned Numbers Authority <iana@isi.edu>
|
||||
Subject: request for port number
|
||||
Organization: Helsinki University of Technology, Finland
|
||||
|
||||
Dear Sir,
|
||||
|
||||
I have written a program to securely log from one machine into another
|
||||
over an insecure network. It provides major improvements in security
|
||||
and functionality over existing telnet and rlogin protocols and
|
||||
implementations. In particular, it prevents IP, DNS and routing
|
||||
spoofing. My plan is to distribute the software freely on the
|
||||
Internet and to get it into as wide use as possible.
|
||||
|
||||
I would like to get a registered privileged port number for the
|
||||
software. The number should preferably be in the range 1-255 so that
|
||||
it can be used in the WKS field in name servers.
|
||||
|
||||
I'll enclose the draft RFC for the protocol below. The software has
|
||||
been in local use for several months, and is ready for publication
|
||||
except for the port number. If the port number assignment can be
|
||||
arranged in time, I'd like to publish the software already this week.
|
||||
I am currently using port number 22 in the beta test. It would be
|
||||
great if this number could be used (it is currently shown as
|
||||
Unassigned in the lists).
|
||||
|
||||
The service name for the software is "ssh" (for Secure Shell).
|
||||
|
||||
Yours sincerely,
|
||||
|
||||
Tatu Ylonen <ylo@cs.hut.fi>
|
||||
|
||||
... followed by protocol specification for ssh-1.0
|
||||
```
|
||||
|
||||
The next day, I had an e-mail from Joyce waiting in my mailbox:
|
||||
|
||||
```
|
||||
Date: Mon, 10 Jul 1995 15:35:33 -0700
|
||||
From: jkrey@ISI.EDU
|
||||
To: ylo@cs.hut.fi
|
||||
Subject: Re: request for port number
|
||||
Cc: iana@ISI.EDU
|
||||
|
||||
Tatu,
|
||||
|
||||
We have assigned port number 22 to ssh, with you as the point of
|
||||
contact.
|
||||
|
||||
Joyce
|
||||
```
|
||||
|
||||
There we were! SSH port was 22!!!
|
||||
|
||||
On July 12, 1995, at 2:32am, I announced a final beta version to my beta testers at Helsinki University of Technology. At 5:23pm I announced ssh-1.0.0 packages to my beta testers. At 5:51pm on July 12, 1995, I sent an announcement about SSH (Secure Shell) to the `cypherpunks@toad.com` mailing list. I also posted it in a few newsgroups, mailing lists, and directly to selected people who had discussed related topics on the Internet.
|
||||
|
||||
### CHANGING THE SSH PORT IN THE SERVER
|
||||
|
||||
By default, the SSH server still runs in port 22\. However, there are occasions when it is run in a different port. Testing use is one reason. Running multiple configurations on the same host is another. Rarely, it may also be run without root privileges, in which case it must be run in a non-privileged port (i.e., port number >= 1024).
|
||||
|
||||
The port number can be configured by changing the `Port 22` directive in [/etc/ssh/sshd_config][9]. It can also be specified using the `-p <port>` option to [sshd][10]. The SSH client and [sftp][11] programs also support the `-p <port>` option.
|
||||
|
||||
### CONFIGURING SSH THROUGH FIREWALLS
|
||||
|
||||
SSH is one of the few protocols that are frequently permitted through firewalls. Unrestricted outbound SSH is very common, especially in smaller and more technical organizations. Inbound SSH is usually restricted to one or very few servers.
|
||||
|
||||
### OUTBOUND SSH
|
||||
|
||||
Configuring outbound SSH in a firewall is very easy. If there are restrictions on outgoing traffic at all, just create a rule that allows TCP port 22 to go out. That is all. If you want to restrict the destination addresses, you can also limit the rule to only permit access to your organization's external servers in the cloud, or to a [jump server][12] that guards cloud access.
|
||||
|
||||
### BACK-TUNNELING IS A RISK
|
||||
|
||||
Unrestricted outbound SSH can, however, be risky. The SSH protocol supports [tunneling][13]. The basic idea is that it is possible to have the SSH server on an external server listen to connections from anywhere, forward those back into the organization, and then make a connection to some Internal server.
|
||||
|
||||
This can be very convenient in some environments. Developers and system administrators frequently use it to open a tunnel that they can use to gain remote access from their home or from their laptop when they are travelling.
|
||||
|
||||
However, it generally violates policy, takes control away from firewall administrators and the security team, and it violates policy. It can, for example, violate [PCI][14], [HIPAA][15], or [NIST SP 800-53][16]. It can be used by hackers and foreign intelligence agencies to leave backdoors into organizations.
|
||||
|
||||
[CryptoAuditor][17] is a product that can control tunneling at a firewall or at the entry point to a group of cloud servers. It works together with [Universal SSH Key Manager][18] to gain access to [host keys][19] and is able to use them to decrypt the SSH sessions at a firewall and block unauthorized forwarding.
|
||||
|
||||
### INBOUND SSH ACCESS
|
||||
|
||||
For inbound access, there are a few practical alternatives:
|
||||
|
||||
* Configure firewall to forward all connections to port 22 to a particular IP address on the internal network or [DMZ][1]. Run [CryptoAuditor][2] or a jump server at that IP address to control and audit further access into the organization.
|
||||
* Use different ports on the firewall to access different servers.
|
||||
* Only allow SSH access after you have logged in using a VPN (Virtual Private Network), typically using the [IPsec][3] protocol.
|
||||
|
||||
### ENABLING SSH ACCESS VIA IPTABLES
|
||||
|
||||
[Iptables][20] is a host firewall built into the Linux kernel. It is typically configured to protect the server by preventing access to any ports that have not been expressly opened.
|
||||
|
||||
If `iptables` is enabled on the server, the following commands can be used to permit incoming SSH access. They must be run as root.
|
||||
|
||||
```
|
||||
iptables -A INPUT -p tcp --dport 22 -m conntrack --ctstate NEW,ESTABLISHED -j ACCEPT
|
||||
iptables -A OUTPUT -p tcp --sport 22 -m conntrack --ctstate ESTABLISHED -j ACCEPT
|
||||
```
|
||||
|
||||
If you want to save the rules permanently, on some systems that can be done with the command:
|
||||
|
||||
```
|
||||
service iptables save
|
||||
```
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ssh.com/ssh/port
|
||||
|
||||
作者:[Tatu Ylonen ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ssh.com/ssh/port
|
||||
[1]:https://en.wikipedia.org/wiki/DMZ_(computing)
|
||||
[2]:https://www.ssh.com/products/cryptoauditor/
|
||||
[3]:https://www.ssh.com/network/ipsec/
|
||||
[4]:https://www.ssh.com/ssh/
|
||||
[5]:https://www.ssh.com/ssh/telnet
|
||||
[6]:https://www.ssh.com/ssh/ftp/
|
||||
[7]:https://en.wikipedia.org/wiki/Jon_Postel
|
||||
[8]:https://en.wikipedia.org/wiki/Joyce_K._Reynolds
|
||||
[9]:https://www.ssh.com/ssh/sshd_config/
|
||||
[10]:https://www.ssh.com/ssh/sshd/
|
||||
[11]:https://www.ssh.com/ssh/sftp/
|
||||
[12]:https://www.ssh.com/iam/jump-server
|
||||
[13]:https://www.ssh.com/ssh/tunneling/
|
||||
[14]:https://www.ssh.com/compliance/pci/
|
||||
[15]:https://www.ssh.com/compliance/hipaa/security-rule
|
||||
[16]:https://www.ssh.com/compliance/nist-800-53/
|
||||
[17]:https://www.ssh.com/products/cryptoauditor/
|
||||
[18]:https://www.ssh.com/products/universal-ssh-key-manager/
|
||||
[19]:https://www.ssh.com/ssh/host-key
|
||||
[20]:https://en.wikipedia.org/wiki/Iptables
|
||||
@ -3,24 +3,28 @@
|
||||
|
||||
我们已经从一个新手的角度了解了 Meld (包括 Meld 的安装),我们也提及了一些 Meld 中级用户常用的小技巧。如果你有印象,在新手教程中,我们说过 Meld 可以比较文件和文件夹。已经讨论过怎么比较文件,今天,我们来看看 Meld 怎么比较文件夹。
|
||||
|
||||
*需要指出的是,本教程中的所有命令和例子都是在 Ubuntu 14.04 上测试的,使用的 Meld 版本为 3.14.2。 *
|
||||
**需要指出的是,本教程中的所有命令和例子都是在 Ubuntu 14.04 上测试的,使用的 Meld 版本为 3.14.2。**
|
||||
|
||||
### 用 Meld 比较文件夹
|
||||
|
||||
打开 Meld 工具,然后选择 <ruby>比较文件夹<rt>Directory comparison</rt></ruby> 选项来比较两个文件夹。
|
||||
|
||||
[
|
||||
|
||||
][5]
|
||||
|
||||
选择你要比较的文件夹:
|
||||
|
||||
[
|
||||
|
||||
][6]
|
||||
|
||||
然后单击<ruby>比较<rt>Compare </rt></ruby>按钮,你会看到 Meld 像图中这样分成两栏比较目录,就像文件比较一样。
|
||||
|
||||
[
|
||||
|
||||
][7]
|
||||
|
||||
分栏会树形显示这些文件夹。你可以在上图中看到 —— 区别之处,不论是新建的还是被修改过的文件 —— 都会以不同的颜色高亮显示。
|
||||
|
||||
根据 Meld 的官方文档可以知道,在窗口中看到的每个不同的文件或文件夹都会被突出显示。这样就很容易看出这个文件/文件夹与另一个分栏中对应位置的文件/文件夹的区别。
|
||||
@ -28,16 +32,17 @@
|
||||
下表是 Meld 网站上列出的在比较文件夹时突出显示的不同字体大小/颜色/背景等代表的含义。
|
||||
|
||||
|
||||
|**State** | **Appearance** | **Meaning** |
|
||||
|**状态** | **Appearance** | **含义** |
|
||||
| --- | --- | --- |
|
||||
| Same | Normal font | The file/folder is the same across all compared folders. |
|
||||
| Same when filtered | Italics | These files are different across folders, but once text filters are applied, these files become identical. |
|
||||
| Modified | Blue and bold | These files differ between the folders being compared. |
|
||||
| New | Green and bold | This file/folder exists in this folder, but not in the others. |
|
||||
| Missing | Greyed out text with a line through the middle | This file/folder doesn't exist in this folder, but does in one of the others. |
|
||||
| Error | Bright red with a yellow background and bold | When comparing this file, an error occurred. The most common error causes are file permissions (i.e., Meld was not allowed to open the file) and filename encoding errors. |
|
||||
| 相同 | 正常字体 | 比较的文件夹中所有文件/文件夹相同。|
|
||||
| 过滤后相同 | 斜体 | 文件夹中文件不同,但使用文本过滤器的话,文件是相同的。|
|
||||
| 修改过 | 蓝色粗体 | 比较的文件夹中这些文件不同。 |
|
||||
| 新建 | 绿色粗体 | 该文件/文件夹在这个目录中存在,但其它目录中没有。|
|
||||
| 缺失 | 置灰文本,中间一条线 | 该文件/文件夹在这个目录中不存在,在在其它某个目录中存在。 |
|
||||
| 错误 | 黄色背景的红色粗体 | 比较文件时发生错误,最常见错误原因是文件权限(例如,Meld 无法打开该文件)和文件名编码错误。 |
|
||||
|
||||
Meld 默认会列出比较文件夹中的所有内容,即使这些内容没有任何不同。当然,你也可以在工具栏中单击<ruby>相同<rt>Same</rt></ruby>按钮设置 Meld 不显示这些相同的文件/文件夹 —— 单击这个按钮使其不可用。
|
||||
|
||||
[
|
||||

|
||||
][3]
|
||||
@ -45,60 +50,67 @@ Meld 默认会列出比较文件夹中的所有内容,即使这些内容没有
|
||||
[
|
||||

|
||||
][8]
|
||||
下面是单击_同样的_按钮使其不可用的截图:
|
||||
|
||||
下面是单击 _Same_ 按钮使其不可用的截图:
|
||||
|
||||
[
|
||||
|
||||
][9]
|
||||
这样你会看到只显示了两个文件夹中不同的文件(新建的和修改过的)。同样,如果你单击_新建的_按钮使其不可用,那么 Meld 就只会列出修改过的文件。所以,在比较文件夹时可以通过这些按钮自定义要显示的内容。
|
||||
|
||||
你可以使用上下箭头来切换选择是显示新建的文件还是修改过的文件,然后打开两个文件进行分栏比较。双击文件或者单击箭头旁边的_比较_按钮都可以进行分栏比较。。
|
||||
这样你会看到只显示了两个文件夹中不同的文件(新建的和修改过的)。同样,如果你单击 <ruby>新建<rt>New</rt></ruby> 按钮使其不可用,那么 Meld 就只会列出修改过的文件。所以,在比较文件夹时可以通过这些按钮自定义要显示的内容。
|
||||
|
||||
你可以使用工具窗口显示区的上下箭头来切换选择是显示新建的文件还是修改过的文件。要打开两个文件进行分栏比较,可以双击文件,或者单击箭头旁边的 <ruby>比较<rt>Compare</rt></ruby>按钮。
|
||||
|
||||
[
|
||||
|
||||
][10]
|
||||
|
||||
**提示 1**:如果你仔细观察,就会看到 Meld 窗口的左边和右边有一些小进度块。这些进度块就像是“用颜色区分的包含不同文件/文件夹的数个区段”。每个区段都由很多的小进度块组成,而一个个小小的有颜色的进度块就表示此处有不同的文件/文件夹。你可以单击每一个这样的小小进度块跳到它对应的文件/文件夹。
|
||||
**提示 1**:如果你仔细观察,就会看到 Meld 窗口的左边和右边有一些小条。这些条的目的是提供“简单的用颜色区分的比较结果”。对每个不同的文件/文件夹,条上就有一个小的颜色块。你可以单击每一个这样的小块跳到它对应的文件/文件夹。
|
||||
|
||||
**提示 2**:你总可以分栏比较文件,然后以你的方式合并不同的文件,假如你想要合并所有不同的文件/文件夹(就是说你想要一个特定的文件/文件夹与另一个完全相同),那么你可以用 <ruby>复制到左边<rt>Copy Left</rt></ruby>和 <ruby>复制到右边<rt> Copy Right</rt></ruby> 按钮:
|
||||
|
||||
**提示 2**:尽管你经常分栏比较文件然后以你的方式合并不同的文件,假如你想要合并所有不同的文件/文件夹(就是说你想要把一个文件夹中特有的文件/文件夹添加到另一个文件夹中),那么你可以用_复制到左边_和_复制到右边_按钮:
|
||||
[
|
||||

|
||||
][11]
|
||||
比如,你可以在左边的分栏中选择一个文件或文件夹,然后单击_复制到右边_按钮在右边的文件夹中对应的位置新建完全一样的文件或文件夹。
|
||||
|
||||
现在,在窗口的下栏菜单中找到_过滤_按钮,它就在_同样的_、_新建的_和_修改过的_ 这三个按钮下面。这里你可以选择或取消文件的类型来让 Meld 在比较文件夹时决定是否显示这种类型的文件/文件夹。官方文档解释说菜单中的这个条目表示“被匹配到的文件不会显示。”
|
||||
比如,你可以在左边的分栏中选择一个文件或文件夹,然后单击 _复制到右边_ 按钮,使右边对应条目完全一样。
|
||||
|
||||
这个条目包括备份文件,操作系统元数据,版本控制文件、二进制文件和多媒体文件。
|
||||
现在,在窗口的下拉菜单中找到 <ruby>过滤<rt>Filters </rt></ruby> 按钮,它就在 _Same_、_New_ 和 _Modified_ 这三个按钮下面。这里你可以选择或取消文件的类型,告知 Meld 在比较文件夹时是否显示这种类型的文件/文件夹。官方文档解释说菜单中的这个条目表示“执行文件夹比较时该类文件名不会被查看。”
|
||||
|
||||
该列表中条目包括备份文件,操作系统元数据,版本控制文件、二进制文件和多媒体文件。
|
||||
|
||||
[
|
||||
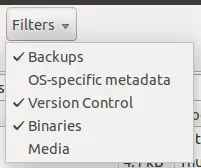
|
||||
][12]
|
||||
前面提到的条目也可以通过这样的方式找到:_浏览->文件过滤_。你可以同过 _编辑->首选项->文件过滤_ 为这个条目增加新元素(也可以删除已经存在的元素)。
|
||||
|
||||
前面提到的条目也可以通过这样的方式找到:_浏览->文件过滤_。你可以通过 _编辑->首选项->文件过滤_ 为这个条目增加新元素(也可以删除已经存在的元素)。
|
||||
|
||||
[
|
||||
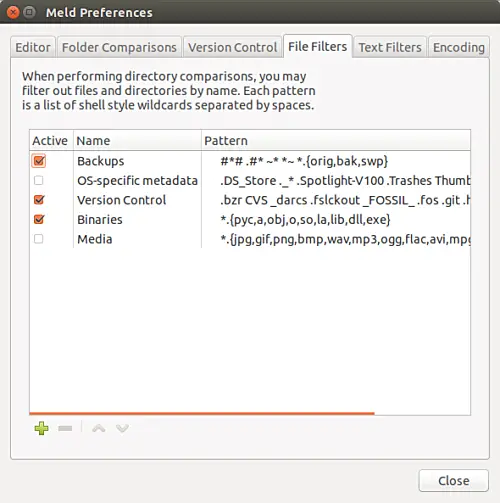
|
||||
][13]
|
||||
|
||||
要新建一个过滤条件,你需要使用一组 shell 符号,下表列出了 Meld 支持的 shell 符号:
|
||||
|
||||
|
||||
| **Wildcard** | **Matches** |
|
||||
| **通配符** | **匹配** |
|
||||
| --- | --- |
|
||||
| * | anything (i.e., zero or more characters) |
|
||||
| ? | exactly one character |
|
||||
| [abc] | any one of the listed characters |
|
||||
| [!abc] | anything except one of the listed characters |
|
||||
| {cat,dog} | either "cat" or "dog" |
|
||||
| * | 任何字符 (例如,零个或多个字符) |
|
||||
| ? | 一个字符 |
|
||||
| [abc] | 所列字符中的任何一个 |
|
||||
| [!abc] | 不在所列字符中的任何一个 |
|
||||
| {cat,dog} | “cat” 或 “dog” 中的一个 |
|
||||
|
||||
最重要的一点是 Meld 的文件名默认大小写敏感。也就是说,Meld 认为 readme 和 ReadMe 与 README 是不一样的文件。
|
||||
|
||||
幸运的是,你可以关掉 Meld 的大小写敏感。只需要打开_浏览_菜单然后选择_忽略文件名大小写_选项。
|
||||
幸运的是,你可以关掉 Meld 的大小写敏感。只需要打开 _浏览_ 菜单然后选择 <ruby>忽略文件名大小写<rt> Ignore Filename Case </rt></ruby> 选项。
|
||||
[
|
||||
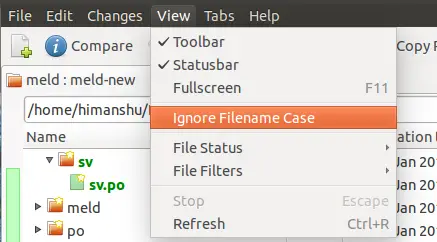
|
||||
][14]
|
||||
|
||||
### 结论
|
||||
你是否觉得使用 Meld 比较文件夹很容易呢——事实上,我认为它相当容易。只有新建一个过滤器会花点时间,但是这不意味着你没必要学习创建过滤器。显然,这取决于你要过滤的内容。
|
||||
|
||||
真的很棒,你甚至可以用 Meld 比较三个文件夹。想要比较三个文件夹时你可以通过_单击 3 个比较_ 复选框。今天,我们不介绍怎么比较三个文件夹,但它肯定会出现在后续的教程中。
|
||||
你是否觉得使用 Meld 比较文件夹很容易呢 —— 事实上,我认为它相当容易。只有新建一个过滤器会花点时间,但是这不意味着你没必要学习创建过滤器。显然,这取决于你的需求。
|
||||
|
||||
另外,你甚至可以用 Meld 比较三个文件夹。想要比较三个文件夹时,你可以通过单击 <ruby>三向比较<rt>3-way comparison</rt></ruby> 复选框。今天,我们不介绍怎么比较三个文件夹,但它肯定会出现在后续的教程中。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -0,0 +1,224 @@
|
||||
如何在 Debian 中使用 badIPs.com 保护你的服务器并通过 Fail2ban 报告 IP
|
||||
============================================================
|
||||
|
||||
### 文章导航
|
||||
|
||||
1. [使用 badIPs 列表][4]
|
||||
1. [定义安全等级和类别][1]
|
||||
2. [创建脚本][5]
|
||||
3. [使用 Fail2ban 向 badIPs 报告 IP][6]
|
||||
1. [Fail2ban >= 0.8.12][2]
|
||||
2. [Fail2ban < 0.8.12][3]
|
||||
4. [你的 IP 报告统计信息][7]
|
||||
|
||||
这篇指南向你介绍使用 badips 滥用追踪器(abuse tracker) 和 Fail2ban 保护你的服务器或计算机的步骤。我已经在 Debian 8 Jessie 和 Debian 7 Wheezy 系统上进行了测试。
|
||||
|
||||
**什么是 badIPs?**
|
||||
|
||||
BadIps 是通过 [fail2ban][8] 报告为不良 IP 的列表。
|
||||
|
||||
这个指南包括两个部分,第一部分介绍列表的使用,第二部分介绍数据注入。
|
||||
|
||||
### 使用 badIPs 列表
|
||||
|
||||
### 定义安全等级和类别
|
||||
|
||||
你可以通过使用 REST API 获取 IP 地址列表。
|
||||
|
||||
当你使用 GET 请求获取 URL:[https://www.badips.com/get/categories][9] 后,你就可以看到服务中现有的所有不同类别。
|
||||
|
||||
* 第二步,决定适合你的等级。
|
||||
参考 badips 应该有所帮助(我个人使用 scope=3):
|
||||
* 如果你想要编译统计信息或者将数据用于实验目的,那么你应该用等级 0 开始。
|
||||
* 如果你想用防火墙保护你的服务器或者网站,使用等级 2。可能也要和你的结果相结合,尽管它们可能没有超过 0 或 1 的等级。
|
||||
* 如果你想保护一个网络商店、或高流量、赚钱的电子商务服务器,我推荐你使用值 3 或 4。当然还是要和你的结果相结合。
|
||||
* 如果你是偏执狂,那就使用 5。
|
||||
|
||||
现在你已经有了两个变量,通过把它们两者连接起来获取你的链接。
|
||||
|
||||
http://www.badips.com/get/list/{{SERVICE}}/{{LEVEL}}
|
||||
|
||||
注意:像我一样,你可以要求所有服务。在这种情况下把服务的名称改为 “any”。
|
||||
|
||||
最终的 URL 就是:
|
||||
|
||||
https://www.badips.com/get/list/any/3
|
||||
|
||||
### 创建脚本
|
||||
|
||||
所有都完成了之后,我们就会创建一个简单的脚本。
|
||||
|
||||
1. 把你的列表放到一个临时文件。
|
||||
2. 在 iptables 中创建一个 chain(只需要一次)。(译者注:iptables 可能包括多个表(tables),表可能包括多个链(chains),链可能包括多个规则(rules))
|
||||
3. 把所有链接的数据(旧条目)刷到 chain。
|
||||
4. 把每个 IP 连接到新的 chain。
|
||||
5. 完成后,阻塞所有链接到 chain 的 INPUT / OUTPUT /FORWARD。
|
||||
6. 删除我们的临时文件。
|
||||
|
||||
为此,我们创建脚本:
|
||||
|
||||
cd /home/<user>/
|
||||
vi myBlacklist.sh
|
||||
|
||||
把以下内容输入到文件。
|
||||
|
||||
|
||||
#!/bin/sh
|
||||
# based on this version http://www.timokorthals.de/?p=334
|
||||
# adapted by Stéphane T.
|
||||
|
||||
_ipt=/sbin/iptables # iptables 路径(应该是对的)
|
||||
_input=badips.db # 数据库的名称(会用这个名称下载)Name of database (will be downloaded with this name)
|
||||
_pub_if=eth0 # 连接到网络的设备(执行 $ifconfig 获取)Device which is connected to the internet (ex. $ifconfig for that)
|
||||
_droplist=droplist # iptables 中 chain 的名称(只有当你已经有这么一个名称的 chain 时才修改它)Name of chain in iptables (Only change this if you have already a chain with this name)
|
||||
_level=3 # Blog(译者注:Bad log)等级:不怎么坏(0)、确认坏(3)、相当坏(5)(从 www.badips.com 获取详情)Blog level: not so bad/false report (0) over confirmed bad (3) to quite aggressive (5) (see www.badips.com for that)
|
||||
_service=any # 记录日志的服务(从 www.badips.com 获取详情)Logged service (see www.badips.com for that)
|
||||
|
||||
# 获取不良 IPs
|
||||
wget -qO- http://www.badips.com/get/list/${_service}/$_level > $_input || { echo "$0: Unable to download ip list."; exit 1; }
|
||||
|
||||
### 设置我们的黑名单 ###
|
||||
# 首先刷盘
|
||||
$_ipt --flush $_droplist
|
||||
|
||||
# 创建新的 chain
|
||||
# 首次运行时取消下面一行的注释
|
||||
# $_ipt -N $_droplist
|
||||
|
||||
# 过滤掉注释和空行
|
||||
# 保存每个 ip 到 $ip
|
||||
for ip in `cat $_input`
|
||||
do
|
||||
# 添加到 $_droplist
|
||||
$_ipt -A $_droplist -i ${_pub_if} -s $ip -j LOG --log-prefix "Drop Bad IP List "
|
||||
$_ipt -A $_droplist -i ${_pub_if} -s $ip -j DROP
|
||||
done
|
||||
|
||||
# 最后,插入或者追加我们的黑名单列表
|
||||
$_ipt -I INPUT -j $_droplist
|
||||
$_ipt -I OUTPUT -j $_droplist
|
||||
$_ipt -I FORWARD -j $_droplist
|
||||
|
||||
# 删除你的临时文件
|
||||
rm $_input
|
||||
exit 0
|
||||
|
||||
|
||||
完成这些后,你应该创建一个 cronjob 定期更新我们的黑名单。
|
||||
|
||||
为此,我使用 crontab 在每天晚上 11:30(在我的延迟备份之前) 运行脚本。
|
||||
|
||||
crontab -e
|
||||
|
||||
|
||||
23 30 * * * /home/<user>/myBlacklist.sh #Block BAD IPS
|
||||
|
||||
|
||||
别忘了更改脚本的权限:
|
||||
|
||||
chmod + x myBlacklist.sh
|
||||
|
||||
现在终于完成了,你的服务器/计算机应该更安全了。
|
||||
|
||||
你也可以像下面这样手动运行脚本:
|
||||
|
||||
cd /home/<user>/
|
||||
./myBlacklist.sh
|
||||
|
||||
它可能要花费一些时间,因此期间别中断脚本。事实上,耗时取决于最后一行。
|
||||
|
||||
### 使用 Fail2ban 向 badIPs 报告 IP 地址
|
||||
|
||||
在本篇指南的第二部分,我会向你展示如何通过使用 Fail2ban 向 badips.com 网站报告不良 IP 地址。
|
||||
|
||||
### Fail2ban >= 0.8.12
|
||||
|
||||
通过 Fail2ban 完成报告。取决于你 Fail2ban 的版本,你要使用本章的第一或第二节。
|
||||
|
||||
如果你 fail2ban 的版本是 0.8.12 或更新版本。
|
||||
|
||||
fail2ban-server --version
|
||||
|
||||
在每个你要报告的类别中,添加一个action。
|
||||
|
||||
|
||||
[ssh]
|
||||
enabled = true
|
||||
action = iptables-multiport
|
||||
badips[category=ssh]
|
||||
port = ssh
|
||||
filter = sshd
|
||||
logpath = /var/log/auth.log
|
||||
maxretry= 6
|
||||
|
||||
|
||||
正如你看到的,类别是 SSH,从 ([https://www.badips.com/get/categories][11]) 查找正确类别。
|
||||
|
||||
### Fail2ban < 0.8.12
|
||||
|
||||
如果版本是 0.8.12 之前,你需要新建一个 action。你可以从 [https://www.badips.com/asset/fail2ban/badips.conf][12] 下载。
|
||||
|
||||
wget https://www.badips.com/asset/fail2ban/badips.conf -O /etc/fail2ban/action.d/badips.conf
|
||||
|
||||
在上面的 badips.conf 中,你可以像前面那样激活每个类别,也可以全局启用它:
|
||||
|
||||
cd /etc/fail2ban/
|
||||
vi jail.conf
|
||||
|
||||
|
||||
[DEFAULT]
|
||||
|
||||
...
|
||||
|
||||
banaction = iptables-multiport
|
||||
badips
|
||||
|
||||
|
||||
现在重启 fail2ban - 从现在开始它就应该开始报告了。
|
||||
|
||||
service fail2ban restart
|
||||
|
||||
### 你的 IP 报告统计信息
|
||||
|
||||
最后一步 - 没那么有用。你可以创建一个密钥。
|
||||
如果你想看你的数据,这一步就很有帮助。
|
||||
复制/粘贴下面的命令,你的控制台中就会出现一个 JSON 响应。
|
||||
|
||||
wget https://www.badips.com/get/key -qO -
|
||||
|
||||
|
||||
{
|
||||
"err":"",
|
||||
"suc":"new key 5f72253b673eb49fc64dd34439531b5cca05327f has been set.",
|
||||
"key":"5f72253b673eb49fc64dd34439531b5cca05327f"
|
||||
}
|
||||
|
||||
|
||||
到[badips][13] 网站,输入你的 “key” 并点击 “statistics”。
|
||||
|
||||
现在你就可以看到不同类别的统计信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/
|
||||
|
||||
作者:[Stephane T][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/
|
||||
[1]:https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/#define-your-security-level-and-category
|
||||
[2]:https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/#failban-gt-
|
||||
[3]:https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/#failban-ltnbsp
|
||||
[4]:https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/#use-the-badips-list
|
||||
[5]:https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/#lets-create-the-script
|
||||
[6]:https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/#report-ip-addresses-to-badips-with-failban
|
||||
[7]:https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/#statistics-of-your-ip-reporting
|
||||
[8]:http://www.fail2ban.org/
|
||||
[9]:https://www.badips.com/get/categories
|
||||
[10]:http://www.timokorthals.de/?p=334
|
||||
[11]:https://www.badips.com/get/categories
|
||||
[12]:https://www.badips.com/asset/fail2ban/badips.conf
|
||||
[13]:https://www.badips.com/
|
||||
@ -34,7 +34,7 @@ via: http://www.csoonline.com/article/3168357/security/windows-trojan-hacks-into
|
||||
|
||||
作者:[ Lucian Constantin][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -1,122 +0,0 @@
|
||||
如何在树莓派上安装 Fedora 25
|
||||
============================================================
|
||||
|
||||
### 继续阅读,了解 Fedora 第一个官方支持 Pi 的版本。
|
||||
|
||||

|
||||
>图片提供 opensource.com
|
||||
|
||||
2016 年 10 月,Fedora 25 Beta 发布了,随之而来的还有对[ Raspberry Pi 2 和 3 的初步支持][6]。Fedora 25 的最终“通用”版在一个月后发布,从那时起,我一直在树莓派上尝试不同的 Fedora spins。
|
||||
|
||||
这篇文章不仅是一篇 Raspberry Pi 3 上的 Fedora 25 的评论,还集合了提示、截图以及我对 Fedora 第一个官方支持 Pi 的这个版本的一些个人想法。
|
||||
|
||||
在我开始之前,需要说一下的是,为写这篇文章所做的所有工作都是在我的运行 Fedora 25 的个人笔记本电脑上完成的。我使用一张 microSD 插到 SD 适配器中,复制和编辑所有的 Fedora 镜像到 32GB 的 microSD 卡中,然后用它在一台三星电视上启动了 Raspberry Pi 3。 因为 Fedora 25 尚不支持内置 Wi-Fi,所以 Raspberry Pi 3 还使用以太网线缆进行网络连接。最后,我使用了 Logitech K410 无线键盘和触摸板进行输入。
|
||||
|
||||
如果你没有机会使用以太网线连接,在你的树莓派上玩 Fedora 25,我曾经有一个 Edimax Wi-Fi USB 适配器,它也可以在 Fedora 25 上工作,但在本文中,我只使用了以太网连接。
|
||||
|
||||
## 在树莓派上安装 Fedora 25 之前
|
||||
|
||||
阅读 Fedora 项目 wiki 上 的[树莓派支持文档][7]。你可以从 wiki 下载 Fedora 25 安装所需的镜像,那里还列出了所有支持和不支持的内容。
|
||||
|
||||
此外,请注意,这是初始支持版本,还有许多新的工作和支持将随着 Fedora 26 的发布而出现,所以请随时报告 bug,并通过 [Bugzilla][8]、Fedora 的[ ARM 邮件列表][9]、或者 Freenode IRC 频道#fedora-arm,分享你在树莓派上使用 Fedora 25 的体验反馈。
|
||||
|
||||
### 安装
|
||||
|
||||
我下载并安装了五个不同的 Fedora 25 spin:GNOME(工作站默认)、KDE、Minimal、LXDE 和 Xfce。在多数情况下,它们都有一致和易于遵循的步骤,以确保我的 Raspberry Pi 3 上启动正常。有的 spin 有人们正在解决的已知 bug,有的通过 Fedora wik 遵循标准操作程序。
|
||||
|
||||

|
||||
|
||||
*Raspberry Pi 3 上的 Fedora 25 workstation、 GNOME 版本*
|
||||
|
||||
### 安装步骤
|
||||
|
||||
1\. 在你的笔记本上,从支持文档页面的链接下载树莓派的 Fedora 25 镜像。
|
||||
|
||||
2\. 在笔记本上,使用 **fedora-arm-installer** 或命令行将镜像复制到 microSD:
|
||||
|
||||
**xzcat Fedora-Workstation-armhfp-25-1.3-sda.raw.xz | dd bs=4M status=progress of=/dev/mmcblk0**
|
||||
|
||||
注意:**/dev/mmclk0** 是我的 microSD 插到 SD 适配器后,在我的笔记本电脑上挂载的设备。虽然我在笔记本上使用 Fedora,可以使用 **fedora-arm-installer**,但我还是喜欢命令行。
|
||||
|
||||
3\. 复制完镜像后,_先不要启动你的系统_。我知道你很想这么做,但你仍然需要进行几个调整。
|
||||
|
||||
4\. 为了使镜像文件尽可能小以便下载,镜像上的根文件系统是很小的,因此你必须增加根文件系统的大小。如果你不这么做,你仍然可以启动你的派,但如果你一旦运行 **dnf update** 来升级你的系统,它就会填满文件系统,导致糟糕的事情发生,所以趁着 microSD 还在你的笔记本上进行分区:
|
||||
|
||||
**growpart /dev/mmcblk0 4
|
||||
resize2fs /dev/mmcblk0p4**
|
||||
|
||||
注意:在 Fedora 中,**growpart** 命令由 **cloud-utils-growpart.noarch** 这个 RPM 提供。
|
||||
|
||||
5\.文件系统更新后,您需要将 **vc4** 模块列入黑名单。[更多有关此 bug 的信息。][10]
|
||||
|
||||
我建议在启动树莓派之前这样做,因为不同的 spin 将以不同的方式表现。例如,(至少对我来说)在没有黑名单 **vc4** 的情况下,GNOME 在我启动后首先出现,但在系统更新后,它不再出现。 KDE spin 在第一次启动时根本不会出现。因此我们可能需要在我们的第一次启动之前将 **vc4** 加入黑名单,直到错误解决。
|
||||
|
||||
黑名单应该出现在两个不同的地方。首先,在你的 microSD 根分区上,在 **etc/modprode.d/** 下创建一个 **vc4.conf**,内容是:**blacklist vc4**。第二,在你的 microSD 启动分区,添加 **rd.driver.blacklist=vc4** 到 **extlinux/extlinux.conf** 的末尾。
|
||||
|
||||
6\. 现在,你可以启动你的树莓派了。
|
||||
|
||||
### 启动
|
||||
|
||||
你要有耐心,特别是对于 GNOME 和 KDE 发行版来说。在 SSD(固态驱动器)和几乎即时启动的时代,你很容易就对派的启动速度感到不耐烦,特别是第一次启动时。在第一次启动 Window Manager 之前,会先弹出一个初始配置页面,可以配置 root 密码、常规用户、时区和网络。配置完毕后,你就应该能够 SSH 到你的树莓派上,方便地调试显示问题了。
|
||||
|
||||
### 系统更新
|
||||
|
||||
在树莓派上运行 Fedora 25 后,你最终(或立即)会想要更新系统。
|
||||
|
||||
首先,进行内核升级时,先熟悉你的 **/boot/extlinux/extlinux.conf** 文件。如果升级内核,下次启动时,除非手动选择正确的内核,否则很可能会启动进入 Rescue 模式。避免这种情况发生最好的方法是,在你的 **extlinux.conf** 中将定义 Rescue 镜像的那五行移动到文件的底部,这样最新的内核将在下次自动启动。你可以直接在派上或通过在笔记本挂载来编辑 **/boot/extlinux/extlinux.conf**:
|
||||
|
||||
**label Fedora 25 Rescue fdcb76d0032447209f782a184f35eebc (4.9.9-200.fc25.armv7hl)
|
||||
kernel /vmlinuz-0-rescue-fdcb76d0032447209f782a184f35eebc
|
||||
append ro root=UUID=c19816a7-cbb8-4cbb-8608-7fec6d4994d0 rd.driver.blacklist=vc4
|
||||
fdtdir /dtb-4.9.9-200.fc25.armv7hl/
|
||||
initrd /initramfs-0-rescue-fdcb76d0032447209f782a184f35eebc.img**
|
||||
|
||||
第二点,如果无论什么原因,如果你的显示器在升级后再次变暗,并且你确定已经将 **vc4** 加入黑名单,请运行 **lsmod | grep vc4**。你可以先启动到多用户模式而不是图形模式,并从命令行中运行 **startx**。 请阅读 **/etc/inittab** 中的内容,了解如何切换目标的说明。
|
||||
|
||||

|
||||
|
||||
*Raspberry Pi 3 上的 Fedora 25 workstation、 KDE 版本*
|
||||
|
||||
### Fedora Spins
|
||||
|
||||
在我尝试过的所有 Fedora Spin 中,唯一有问题的是 XFCE spin,我相信这是由于这个[已知的 bug][11]。
|
||||
|
||||
按照我在这里分享的步骤操作,GNOME、KDE、LXDE 和 minimal 都运行得很好。考虑到 KDE 和 GNOME 会占用更多资源,我会推荐想要在树莓派上使用 Fedora 25 的人 使用 LXDE 和 Minimal。如果你是一位系统管理员,想要一台廉价的 SELinux 支持的服务器来满足你的安全考虑,而且只是想要使用树莓派作为你的服务器,开放 22 端口以及 vi 可用,那就用 Minimal 版本。对于开发人员或刚开始学习 Linux 的人来说,LXDE 可能是更好的方式,因为它可以快速方便地访问所有基于 GUI 的工具,如浏览器、IDE 和你可能需要的客户端。
|
||||
|
||||

|
||||
|
||||
*Raspberry Pi 3 上的 Fedora 25 workstation、LXDE。*
|
||||
|
||||
看到越来越多的 Linux 发行版在基于 ARM 的树莓派上可用,那真是太棒了。对于其第一个支持的版本,Fedora 团队为日常 Linux 用户提供了更好的体验。我很期待 Fedora 26 的改进和 bug 修复。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Anderson Silva - Anderson 于 1996 年开始使用 Linux。更精确地说是 Red Hat Linux。 2007 年,他作为 IT 部门的发布工程师时加入红帽,他的职业梦想成为了现实。此后,他在红帽担任过多个不同角色,从发布工程师到系统管理员、高级经理和信息系统工程师。他是一名 RHCE 和 RHCA 以及一名活跃的 Fedora 包维护者。
|
||||
|
||||
----------------
|
||||
|
||||
via: https://opensource.com/article/17/3/how-install-fedora-on-raspberry-pi
|
||||
|
||||
作者:[Anderson Silva][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ansilva
|
||||
[1]:https://opensource.com/tags/raspberry-pi?src=raspberry_pi_resource_menu
|
||||
[2]:https://opensource.com/resources/what-raspberry-pi?src=raspberry_pi_resource_menu
|
||||
[3]:https://opensource.com/article/16/12/getting-started-raspberry-pi?src=raspberry_pi_resource_menu
|
||||
[4]:https://opensource.com/article/17/2/raspberry-pi-submit-your-article?src=raspberry_pi_resource_menu
|
||||
[5]:https://opensource.com/article/17/3/how-install-fedora-on-raspberry-pi?rate=gIIRltTrnOlwo4h81uDvdAjAE3V2rnwoqH0s_Dx44mE
|
||||
[6]:https://fedoramagazine.org/raspberry-pi-support-fedora-25-beta/
|
||||
[7]:https://fedoraproject.org/wiki/Raspberry_Pi
|
||||
[8]:https://bugzilla.redhat.com/show_bug.cgi?id=245418
|
||||
[9]:https://lists.fedoraproject.org/admin/lists/arm%40lists.fedoraproject.org/
|
||||
[10]:https://bugzilla.redhat.com/show_bug.cgi?id=1387733
|
||||
[11]:https://bugzilla.redhat.com/show_bug.cgi?id=1389163
|
||||
[12]:https://opensource.com/user/26502/feed
|
||||
[13]:https://opensource.com/article/17/3/how-install-fedora-on-raspberry-pi#comments
|
||||
[14]:https://opensource.com/users/ansilva
|
||||
@ -0,0 +1,238 @@
|
||||
GoTTY - 在 web 中共享你的 Linux 终端(TTY)
|
||||
============================================================
|
||||
|
||||
|
||||
GoTTY 是一个简单的基于 Go 语言的命令行工具,它可以将你的终端 (TTY) 作为 web 程序共享。它会将命令行工具转换为 web 程序。
|
||||
|
||||
它使用 Chrome OS 的终端仿真器(hterm)来在 Web 浏览器上执行基于 JavaScript 的终端。重要的是,GoTTY 运行了一个 Web 套接字服务器,它基本上是将 TTY 的输出传输给客户端,并从客户端接收输入(即允许客户端的输入),并将其转发给 TTY。
|
||||
|
||||
它的架构(hterm + web socket 的想法)灵感来自[ Wetty 项目][1],它使终端能够通过 HTTP 和 HTTPS 使用。
|
||||
|
||||
#### 先决条件:
|
||||
|
||||
你需要在 Linux 中安装 [ GoLang (Go 编程语言)][2] 环境来运行 GoTTY。
|
||||
|
||||
### 如何在 Linux 中安装 GoTTY
|
||||
|
||||
I如果你已经有一个[工作的 Go 语言环境][3],运行下面的 go get 命令来安装它:
|
||||
|
||||
```
|
||||
# go get github.com/yudai/gotty
|
||||
```
|
||||
|
||||
上面的命令会在你的 GOBIN 环境变量中安装 GOTTY 的二进制,尝试检查下是否如此:
|
||||
|
||||
```
|
||||
# $GOPATH/bin/
|
||||
```
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
检查 GOBIN 环境
|
||||
|
||||
### 如何在 Linux 中使用 GoTTY
|
||||
|
||||
要运行它,你可以使用 GOBIN 环境变量并用命令补全:
|
||||
|
||||
```
|
||||
# $GOBIN/gotty
|
||||
```
|
||||
|
||||
另外,要不带完整命令路径运行 GoTTY 或其他 Go 程序,使用 export 命令将 GOBIN 变量添加到 `~/.profile` 文件中的 PATH 中。
|
||||
|
||||
```
|
||||
export PATH="$PATH:$GOBIN"
|
||||
```
|
||||
|
||||
保存文件并关闭。接着运行 source 来使更改生效:
|
||||
|
||||
```
|
||||
# source ~/.profile
|
||||
```
|
||||
|
||||
运行 GoTTY 命令的常规语法是:
|
||||
|
||||
```
|
||||
Usage: gotty [options] <Linux command here> [<arguments...>]
|
||||
```
|
||||
|
||||
现在用 GoTTY 运行任意命令,如 [df][5] 来从 Web 浏览器中查看系统分区空间及使用率。
|
||||
|
||||
```
|
||||
# gotty df -h
|
||||
```
|
||||
|
||||
GoTTY 默认会在 8080 启动一个 Web 服务器。在浏览器中打开 URL:`http://127.0.0.1:8080/`,你会看到运行的命令仿佛运行在终端中一样:
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
Gotty Linux 磁盘使用率
|
||||
|
||||
### 如何在 Linux 中自定义 GoTTY
|
||||
|
||||
你可以在 `~/.gotty` 配置文件中修改默认选项以及终端,如果存在,它会在每次启动时加载这个文件。
|
||||
|
||||
这是由 getty 命令读取的主自定义文件,因此,按如下方式创建:
|
||||
|
||||
```
|
||||
# touch ~/.gotty
|
||||
```
|
||||
|
||||
并为配置选项设置你自己的有效值(在此处查找所有配置选项)以自定义 GoTTY,例如:
|
||||
|
||||
```
|
||||
// Listen at port 9000 by default
|
||||
port = "9000"
|
||||
// Enable TSL/SSL by default
|
||||
enable_tls = true
|
||||
// hterm preferences
|
||||
// Smaller font and a little bit bluer background color
|
||||
preferences {
|
||||
font_size = 5,
|
||||
background_color = "rgb(16, 16, 32)"
|
||||
}
|
||||
```
|
||||
|
||||
你可以使用命令行中的 “--html” 选项设置你自己的 index.html 文件:
|
||||
|
||||
```
|
||||
# gotty --index /path/to/index.html uptime
|
||||
```
|
||||
|
||||
### 如何在 GoTTY 中使用安全功能
|
||||
|
||||
由于 GoTTY 默认不提供可靠的安全,你需要手动使用下面说明的某些安全功能。
|
||||
|
||||
#### 允许客户端在终端中运行命令
|
||||
|
||||
请注意,默认情况下,GoTTY 不允许客户端输入到TTY中,它只能启用窗口调整。
|
||||
|
||||
但是,你可以使用 `-w` 或 `--permit-write` 选项来允许客户端写入 TTY,但是并不推荐这么做因为会有安全威胁。
|
||||
|
||||
以下命令会使用[ vi 命令行编辑器][7]在 Web 浏览器中打开文件 fossmint.txt 进行编辑:
|
||||
|
||||
```
|
||||
# gotty -w vi fossmint.txt
|
||||
```
|
||||
|
||||
以下是从 Web 浏览器看到的 vi 界面(像平常一样使用 vi 命令):
|
||||
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
Gotty Web Vi 编辑器
|
||||
|
||||
#### 使用基本(用户名和密码)验证运行 GoTTY
|
||||
|
||||
尝试激活基本身份验证机制,这样客户端将需要输入指定的用户名和密码才能连接到 GoTTY 服务器。
|
||||
|
||||
以下命令使用 `-c` 选项限制客户端访问,以向用户询问指定的凭据(用户名:test 密码:@67890):
|
||||
|
||||
```
|
||||
# gotty -w -p "9000" -c "test@67890" glances
|
||||
```
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
使用基本验证运行 GoTTY
|
||||
|
||||
#### Gotty 生成随机 URL
|
||||
|
||||
限制访问服务器的另一种方法是使用 `-r` 选项。GoTTY 会生成一个随机 URL,这样只有知道该 URL 的用户才可以访问该服务器。
|
||||
|
||||
还可以使用 -title-format “GoTTY – {{ .Command }} ({{ .Hostname }})” 选项来定义浏览器标题,[glances][10] 用于显示系统监控统计信息:
|
||||
|
||||
```
|
||||
# gotty -r --title-format "GoTTY - {{ .Command }} ({{ .Hostname }})" glances
|
||||
```
|
||||
|
||||
以下是从浏览器中看到的上面的命令的结果:
|
||||
|
||||
[
|
||||

|
||||
][11]
|
||||
|
||||
使用 Gotty 随机 URL 用于 Glances 系统监控
|
||||
|
||||
#### 带有 SSL/TLS 使用 GoTTY
|
||||
|
||||
因为默认情况下服务器和客户端之间的所有连接都不加密,当你通过 GoTTY 发送秘密信息(如用户凭据或任何其他信息)时,你需要使用 “-t” 或 “--tls” 选项才能在会话中启用 TLS/SSL:
|
||||
|
||||
默认情况下,GoTTY 会读取证书文件 `~/.gotty.crt` 和密钥文件 `~/.gotty.key`,因此,首先使用下面的 openssl 命令创建一个自签名的证书以及密钥( 回答问题以生成证书和密钥文件):
|
||||
|
||||
```
|
||||
# openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout ~/.gotty.key -out ~/.gotty.crt
|
||||
```
|
||||
|
||||
按如下所示,通过启用 SSL/TLS,以安全方式使用GoTTY:
|
||||
|
||||
```
|
||||
# gotty -tr --title-format "GoTTY - {{ .Command }} ({{ .Hostname }})" glances
|
||||
```
|
||||
|
||||
#### 与多个客户端分享你的终端
|
||||
|
||||
你可以使用[终端复用程序][12]来与多个客户端共享一个进程,以下命令会启动一个名为 gotty 的新[ tmux 会话][13]来运行 [glances][14](确保你安装了 tmux):
|
||||
|
||||
```
|
||||
# gotty tmux new -A -s gotty glances
|
||||
```
|
||||
|
||||
要读取不同的配置文件,像下面那样使用 –config “/path/to/file” 选项:
|
||||
|
||||
```
|
||||
# gotty -tr --config "~/gotty_new_config" --title-format "GoTTY - {{ .Command }} ({{ .Hostname }})" glances
|
||||
```
|
||||
|
||||
要显示 GoTTY 版本,运行命令:
|
||||
|
||||
```
|
||||
# gotty -v
|
||||
```
|
||||
|
||||
访问 GoTTY GitHub 仓库以查找更多使用示例:[https://github.com/yudai/gotty][15]
|
||||
|
||||
就这样了!你有尝试过了吗?如何找到GoTTY?通过下面的反馈栏与我们分享你的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili 是 Linux 和 F.O.S.S 爱好者,即将成为 Linux SysAdmin 和网络开发人员,目前是 TecMint 的内容创作者,他喜欢在电脑上工作,并坚信分享知识。
|
||||
|
||||
|
||||
----------
|
||||
|
||||
|
||||
via: http://www.tecmint.com/gotty-share-linux-terminal-in-web-browser/
|
||||
|
||||
作者:[ Aaron Kili][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/access-linux-server-terminal-in-web-browser-using-wetty/
|
||||
[2]:http://www.tecmint.com/install-go-in-linux/
|
||||
[3]:http://www.tecmint.com/install-go-in-linux/
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2017/03/Check-Go-Environment.png
|
||||
[5]:http://www.tecmint.com/how-to-check-disk-space-in-linux/
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2017/03/Gotty-Linux-Disk-Usage.png
|
||||
[7]:http://www.tecmint.com/vi-editor-usage/
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2017/03/Gotty-Web-Vi-Editor.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2017/03/Gotty-use-basic-authentication.png
|
||||
[10]:http://www.tecmint.com/glances-an-advanced-real-time-system-monitoring-tool-for-linux/
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2017/03/Gotty-Random-URL-for-Glances-Linux-Monitoring.png
|
||||
[12]:http://www.tecmint.com/tmux-to-access-multiple-linux-terminals-inside-a-single-console/
|
||||
[13]:http://www.tecmint.com/tmux-to-access-multiple-linux-terminals-inside-a-single-console/
|
||||
[14]:http://www.tecmint.com/glances-an-advanced-real-time-system-monitoring-tool-for-linux/
|
||||
[15]:https://github.com/yudai/gotty
|
||||
[16]:http://www.tecmint.com/author/aaronkili/
|
||||
[17]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[18]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
Loading…
Reference in New Issue
Block a user