diff --git a/sources/talk/20180826 How to Install and Use FreeDOS on VirtualBox.md b/sources/talk/20180826 How to Install and Use FreeDOS on VirtualBox.md
new file mode 100644
index 0000000000..8ba7db5139
--- /dev/null
+++ b/sources/talk/20180826 How to Install and Use FreeDOS on VirtualBox.md
@@ -0,0 +1,154 @@
+How to Install and Use FreeDOS on VirtualBox
+======
+This step-by-step guide shows you how to install FreeDOS on VirtualBox in Linux.
+
+### Installing FreeDOS on VirtualBox in Linux
+
+
+
+In November of 2017, I [interviewed Jim Hall][1] about the history behind the [FreeDOS project][2]. Today, I’m going to tell you how to install and use FreeDOS. Please note: I will be using [VirtualBox][3] 5.2.14 on [Solus][4].
+
+Note: I used Solus as the host operating system for this tutorial because it is very easy to setup. One thing you should keep in mind is that Solus’ Software Center contains two versions of VirtualBox: `virtualbox` and `virtualbox-current`. Solus gives you the option to use the linux-lts kernel and the linux-current kernel. `virtualbox`is modified for linux-lts and `virtualbox-current` is for linux-current.
+
+#### Step 1 – Create New Virtual Machine
+
+![][5]
+
+Once you open VirtualBox, press the “New” button to create a new virtual machine. You can name it whatever you want, I just use “FreeDOS”. You can use the label to specify what version of FreeDOS you are installing. You also need to select the type and version of the operating system you will be installing. Select “Other” and “DOS”.
+
+#### Step 2 – Select Memory Size
+
+![][6]
+
+The next dialog box will ask you how much of the host computer’s memory you want to make available to FreeDOS. The default is 32MB. Don’t change it. Back in the day, this would be a huge amount of RAM for a DOS machine. If you need to, you can increase it later by right-clicking on the virtual machine you created for FreeDOS and selecting Settings -> System.
+
+![][7]
+
+#### Step 3 – Create Virtual Hard Disk
+
+![][8]
+
+Next, you will be asked to create a virtual hard drive where FreeDOS and its files will be stored. Since you haven’t created one yet, just click “Create”.
+
+The next dialog box will ask you what hard disk file type you want to use. This default (VirtualBox Disk Image) works just fine. Click “Next”.
+
+The next question you will encounter is how you want the virtual disk to act. Do you want it to start small and gradually grow to its full size as you create files and install programs? Then choose dynamically allocated. If you prefer that the virtual hard drive (vhd) is created at full size, then choose fixed size. Dynamically allocated is nice if you don’t plan to use the whole vhd or if you don’t have very much free space on your hard drive. (Keep in mind that while the size of a dynamically allocated vhd increases as you add files, it will not drop when you remove files.) I prefer dynamically allocated, but you can choose the option that serves your needs best and click “Next”.
+
+![][9]
+
+Now, you can choose the size and location of the vhd. 500 MB should be plenty of space. Remember most of the programs you will be using will be text-based, thus fairly small. Once you make your adjustments, click Create,
+
+#### Step 4 – Attach .iso file
+
+Before we continue, you will need to [download][10] the FreeDOS .iso file. You will need to choose the CDROM “standard” installer.
+
+![][11]
+
+Once the file has been downloaded, return to VirtualBox. Select your virtual machine and open the settings. You can do this by either right-clicking on the virtual machine and selecting “Settings” or highlight the virtual machine and click the “Settings” button.
+
+Now, click the “Storage” tab. Under “Storage Devices”, select the CD icon. (It should say “Empty” next to it.) In the “Attributes” panel on the right, click on the CD icon and select the location of the .iso file you just downloaded.
+
+Note: Typically, after you install an operating system on VirtualBox you can delete the original .iso file. Not with FreeDOS. You need the .iso file if you want to install applications via the FreeDOS package manager. I generally keep the ,iso file attached the virtual machine in case I want to install something. If you do that, you have to make sure that you tell FreeDOS you want to boot from the hard drive each time you boot it up because it defaults to the attached CD/iso. If you forget to attach the .iso, don’t worry. You can do so by selecting “Devices” on the top of your FreeDOS virtual machine window. The .iso files are listed under “Optical Drives”.
+
+#### Step 5 – Install FreeDOS
+
+![][12]
+
+Now that we’ve completed all of the preparations, let’s install FreeDOS.
+
+First, you need to be aware of a bug in the most recent version of VirtualBox. If you start the virtual machine that we just created and select “Install to harddisk” when the FreeDOS welcome screen appears, you will see an unending, scrolling mass of machine code. I’ve only run into this issue recently and it affects both the Linux and Windows versions of VirtualBox. (I know first hand.)
+
+To get around this, you need to make a simple edit. When you see the FreeDOS welcome screen, press Tab. (Make sure that the “Install to harddrive” option is selected.) Type the word `raw` after “fdboot.img” and hit Enter. The FreeDOS installer will then start.
+
+![][13]
+
+The first part of the installer will handle formatting your virtual drive. Once formatting is completed, the installer will reboot. When the FreeDOS welcome screen appears again, you will have to re-enter the `raw` comment you used earlier.
+
+Make sure that you select “Yes” on all of the questions in the installer. One important question that doesn’t have a “Yes” or “No” answer is: “What FreeDOS packages do you want to install?. The two options are “Base packages” or “Full installation”. Base packages are for those who want a DOS experience most like the original MS-DOS. The Full installation includes a bunch of tools and utilities to improve DOS.
+
+At the end of the installation, you will be given the option to reboot or stay on DOS. Select “reboot”.
+
+#### Step 6 – Setup Networking
+
+Unlike the original DOS, FreeDOS can access the internet. You can install new packages and update the ones already you have installed. In order to use networking, you need to install several applications in FreeDOS.
+
+![][14]
+
+First, boot into your newly created FreeDOS virtual machine. At the FreeDOS selection screen, select “Boot from System harddrive”.
+
+![][15]
+
+Now, to access the FreeDOS package manager, type `fdimples`. You can navigate around the package manager with the arrow keys and select categories or packages with the space bar. From the “Networking” category, you need to select `fdnet`. The FreeDOS Project also recommends installing `mtcp` and `wget`. Hit “Tab” several times until “OK” is selected and press “Enter”. Once the installation is complete, type `reboot` and hit enter. After the system reboots, boot to your system drive. If the network installation was successful, you will see several new messages at the terminal listing your network information.
+
+![][16]
+
+##### Note
+
+Sometimes the default VirtualBox setup doesn’t work. If that happens, close your FreeDOS VirtualBox window. Right-click your virtual machine from the main VirtualBox screen and select “Settings”. The default VirtualBox network setting is “NAT”. Change it to “Bridged Adapter” and retry installing the FreeDOS packages. It should work now.
+
+#### Step 7 – Basic Usage of FreeDOS
+
+##### Commons Commands
+
+Now that you have installed FreeDOS, let’s look at a few basic commands. If you have ever used the Command Prompt on Windows, you will be familiar with some of these commands.
+
+ * `DIR`– display the contents of the current directory
+ * `CD` – change the directory you are currently in
+ * `COPY OLD.TXT NEW.TXT`– copy files
+ * `TYPE TEST.TXT` – display content of file
+ * `DEL TEST.TXT` – delete file
+ * `XCOPY DIR NEWDIR` – copy directory and all of its contents
+ * `EDIT TEST.TXT`– edit a file
+ * `MKDIR NEWDIR` – create a new directory
+ * `CLS` – clear the screen
+
+
+
+You can find more basic DOS commands on the web or the [handy cheat sheet][17] created by Jim Hall.
+
+##### Running a Program
+
+Running program on FreeDos is fairly easy. When you install an application with the `fdimples` package manager, be sure to note where the .EXE file of the application is located. This is shown in the application’s details. To run the application, you generally need to navigate to the application folder and type the application’s name.
+
+For example, FreeDOS has an editor named `FED` that you can install. After installing it, all you need to do is navigate to `C:\FED` and type `FED`.
+
+Sometimes a program, such as Pico, is stored in the `\bin` folder. These programs can be called up from any folder.
+
+Games usually have an .EXE program or two that you have to run before you can play the game. These setup file usually fix sound, video, or control issues.
+
+If you run into problems that this tutorial didn’t cover, don’t forget to visit the [home of FreeDOS][2]. They have a wiki and several other support options.
+
+Have you ever used FreeDOS? What tutorials would you like to see in the future? Please let us know in the comments below.
+
+If you found this article interesting, please take a minute to share it on social media, Hacker News or [Reddit][18].
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/install-freedos/
+
+作者:[John Paul][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/john/
+[1]:https://itsfoss.com/interview-freedos-jim-hall/
+[2]:http://www.freedos.org/
+[3]:https://www.virtualbox.org/
+[4]:https://solus-project.com/home/
+[5]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/freedos-tutorial-1.jpg
+[6]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/freedos-tutorial-2.jpg
+[7]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/freedos-tutorial-3.jpg
+[8]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/freedos-tutorial-4.jpg
+[9]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/freedos-tutorial-6.jpg
+[10]:http://www.freedos.org/download/
+[11]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/freedos-tutorial-7.jpg
+[12]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/freedos-tutorial-8.png
+[13]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/freedos-tutorial-9.png
+[14]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/freedos-tutorial-10.png
+[15]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/freedos-tutorial-11.png
+[16]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/freedos-tutorial-12.png
+[17]:https://opensource.com/article/18/6/freedos-commands-cheat-sheet
+[18]:http://reddit.com/r/linuxusersgroup
diff --git a/sources/tech/20180730 How to use VS Code for your Python projects.md b/sources/tech/20180730 How to use VS Code for your Python projects.md
deleted file mode 100644
index 79cc8216f5..0000000000
--- a/sources/tech/20180730 How to use VS Code for your Python projects.md
+++ /dev/null
@@ -1,162 +0,0 @@
-idea2act translating
-
-How to use VS Code for your Python projects
-======
-
-
-Visual Studio Code, or VS Code, is an open source code editor that also includes tools for building and debugging an application. With the Python extension enabled, vscode becomes a great working environment for any Python developer. This article shows you which extensions are useful, and how to configure VS Code to get the most out of it.
-
-If you don’t have it installed, check out our previous article, [Using Visual Studio Code on Fedora][1]:
-
-[Using Visual Studio Code on Fedora ](https://fedoramagazine.org/using-visual-studio-code-fedora/)
-
-### Install the VS Code Python extension
-
-First, to make VS Code Python friendly, install the Python extension from the marketplace.
-
-![][2]
-
-Once the Python extension installed, you can now configure the Python extension.
-
-VS Code manages its configuration inside JSON files. Two files are used:
-
- * One for the global settings that applies to all projects
- * One for project specific settings
-
-
-
-Press **Ctrl+,** (comma) to open the global settings.
-
-#### Setup the Python Path
-
-You can configure VS Code to automatically select the best Python interpreter for each of your projects. To do this, configure the python.pythonPath key in the global settings.
-```
-// Place your settings in this file to overwrite default and user settings.
-{
- "python.pythonPath":"${workspaceRoot}/.venv/bin/python",
-}
-
-```
-
-This sets VS Code to use the Python interpreter located in the project root directory under the .venv virtual environment directory.
-
-#### Use environment variables
-
-By default, VS Code uses environment variables defined in the project root directory in a .env file. This is useful to set environment variables like:
-```
-PYTHONWARNINGS="once"
-
-```
-
-That setting ensures that warnings are displayed when your program is running.
-
-To change this default, set the python.envFile configuration key as follows:
-```
-"python.envFile": "${workspaceFolder}/.env",
-
-```
-
-### Code Linting
-
-The Python extension also supports different code linters (pep8, flake8, pylint). To enable your favorite linter, or the one used by the project you’re working on, you need to set a few configuration items.
-
-By default pylint is enabled. But for this example, configure flake8:
-```
-"python.linting.pylintEnabled": false,
-"python.linting.flake8Path": "${workspaceRoot}/.venv/bin/flake8",
-"python.linting.flake8Enabled": true,
-"python.linting.flake8Args": ["--max-line-length=90"],
-
-```
-
-After enabling the linter, your code is underlined to show where it doesn’t meet criteria enforced by the linter. Note that for this example to work, you need to install flake8 in the virtual environment of the project.
-
-![][3]
-
-### Code Formatting
-
-VS Code also lets you configure automatic code formatting. The extension currently supports autopep8, black and yapf. Here’s how to configure black.
-```
-"python.formatting.provider": "black",
-"python.formatting.blackPath": "${workspaceRoot}/.venv/bin/black"
-"python.formatting.blackArgs": ["--line-length=90"],
-"editor.formatOnSave": true,
-
-```
-
-If you don’t want the editor to format your file on save, set the option to false and use **Ctrl+Shift+I** to format the current document. Note that for this example to work, you need to install black in the virtual environment of the project.
-
-### Running Tasks
-
-Another great feature of VS Code is that it can run tasks. These tasks are also defined in a JSON file saved in the project root directory.
-
-#### Run a development flask server
-
-In this example, you’ll create a task to run a Flask development server. Create a new Build using the basic template that can run an external command:
-
-![][4]
-
-Edit the tasks.json file as follows to create a new task that runs the Flask development server:
-```
-{
- // See https://go.microsoft.com/fwlink/?LinkId=733558
- // for the documentation about the tasks.json format
- "version": "2.0.0",
- "tasks": [
- {
-
- "label": "Run Debug Server",
- "type": "shell",
- "command": "${workspaceRoot}/.venv/bin/flask run -h 0.0.0.0 -p 5000",
- "group": {
- "kind": "build",
- "isDefault": true
- }
- }
- ]
-}
-
-```
-
-The Flask development server uses an environment variable to get the entrypoint of the application. Use the .env file to declare these variables. For example:
-```
-FLASK_APP=wsgi.py
-FLASK_DEBUG=True
-
-```
-
-Now you can execute the task using **Ctrl+Shift+B**.
-
-### Unit tests
-
-VS Code also has the unit test runners pytest, unittest, and nosetest integrated out of the box. After you enable a test runner, VS Code discovers the unit tests and letsyou to run them individually, by test suite, or simply all the tests.
-
-For example, to enable pytest:
-```
-"python.unitTest.pyTestEnabled": true,
-"python.unitTest.pyTestPath": "${workspaceRoot}/.venv/bin/pytest",
-
-```
-
-Note that for this example to work, you need to install pytest in the virtual environment of the project.
-
-![][5]
-
-
---------------------------------------------------------------------------------
-
-via: https://fedoramagazine.org/vscode-python-howto/
-
-作者:[Clément Verna][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://fedoramagazine.org
-[1]:https://fedoramagazine.org/using-visual-studio-code-fedora/
-[2]:https://fedoramagazine.org/wp-content/uploads/2018/07/Peek-2018-07-27-09-44.gif
-[3]:https://fedoramagazine.org/wp-content/uploads/2018/07/Peek-2018-07-27-12-05.gif
-[4]:https://fedoramagazine.org/wp-content/uploads/2018/07/Peek-2018-07-27-13-26.gif
-[5]:https://fedoramagazine.org/wp-content/uploads/2018/07/Peek-2018-07-27-15-33.gif
diff --git a/sources/tech/20180808 5 applications to manage your to-do list on Fedora.md b/sources/tech/20180808 5 applications to manage your to-do list on Fedora.md
index 58b01c56c4..aac9ce192f 100644
--- a/sources/tech/20180808 5 applications to manage your to-do list on Fedora.md
+++ b/sources/tech/20180808 5 applications to manage your to-do list on Fedora.md
@@ -1,3 +1,5 @@
+translating---geekpi
+
5 applications to manage your to-do list on Fedora
======
diff --git a/sources/tech/20180813 MPV Player- A Minimalist Video Player for Linux.md b/sources/tech/20180813 MPV Player- A Minimalist Video Player for Linux.md
deleted file mode 100644
index 93724445b9..0000000000
--- a/sources/tech/20180813 MPV Player- A Minimalist Video Player for Linux.md
+++ /dev/null
@@ -1,112 +0,0 @@
-MPV Player: A Minimalist Video Player for Linux
-======
-MPV is an open source, cross platform video player that comes with a minimalist GUI and feature rich command line version.
-
-VLC is probably the best video player for Linux or any other operating system. I have been using VLC for years and it is still my favorite.
-
-However, lately, I am more inclined towards minimalist applications with a clean UI. This is how came across MPV. I loved it so much that I added it in the list of [best Ubuntu applications][1].
-
-[MPV][2] is an open source video player available for Linux, Windows, macOS, BSD and Android. It is actually a fork of [MPlayer][3].
-
-The graphical user interface is sleek and minimalist.
-
-![MPV Player Interface in Linux][4]
-MPV Player
-
-### MPV Features
-
-MPV has all the features required from a standard video player. You can play a variety of videos and control the playback with usual shortcuts.
-
- * Minimalist GUI with only the necessary controls.
- * Video codecs support.
- * High quality video output and GPU video decoding.
- * Supports subtitles.
- * Can play YouTube and other streaming videos through the command line.
- * CLI version of MPV can be embedded in web and other applications.
-
-
-
-Though MPV player has a minimal UI with limited options, don’t underestimate its capabilities. Its main power lies in the command line version.
-
-Just type the command mpv –list-options and you’ll see that it provides 447 different kind of options. But this article is not about utilizing the advanced settings of MPV. Let’s see how good it is as a regular desktop video player.
-
-### Installing MPV in Linux
-
-MPV is a popular application and it should be found in the default repositories of most Linux distributions. Just look for it in the Software Center application.
-
-I can confirm that it is available in Ubuntu’s Software Center. You can install it from there or simply use the following command:
-```
-sudo apt install mpv
-
-```
-
-You can find installation instructions for other platforms on [MPV website][5].
-
-### Using MPV Video Player
-
-Once installed, you can open a video file with MPV by right-clicking and choosing MPV.
-
-![MPV Player Interface][6]
-MPV Player Interface
-
-The interface has only a control panel that is only visible when you hover your mouse on the player. As you can see, the control panel provides you the option to pause/play, change track, change audio track, subtitles and switch to full screen.
-
-MPV’s default size depends upon the quality of video you are playing. For a 240p video, the application video will be small while as 1080p video will result in almost full screen app window size on a Full-HD screen. You can always double click on the player to make it full screen irrespective of the video size.
-
-#### The subtitle struggle
-
-If your video has a subtitle file, MPV will [automatically play subtitles][7] and you can choose to disable it. However, if you want to use an external subtitle file, it’s not that available directly from the player.
-
-You can rename the additional subtitle file exactly the same as the name of the video file and keep it in the same folder as the video file. MPV should now play your subtitles.
-
-An easier option to play external subtitles is to simply drag and drop into the player.
-
-#### Playing YouTube and other online video content
-
-To play online videos, you’ll have to use the command line version of MPV.
-
-Open a terminal and use it in the following fashion:
-```
-mpv
-
-```
-
-![Playing YouTube videos on Linux desktop using MPV][8]
-Playing YouTube videos with MPV
-
-I didn’t find playing YouTube videos in MPV player a pleasant experience. It kept on buffering and that was utter frustrating.
-
-#### Should you use MPV player?
-
-That depends on you. If you like to experiment with applications, you should give MPV a go. Otherwise, the default video player and VLC are always good enough.
-
-Earlier when I wrote about [Sayonara][9], I wasn’t sure if people would like an obscure music player over the popular ones but it was loved by It’s FOSS readers.
-
-Try MPV and see if it is something you would like to use as your default video player.
-
-If you liked MPV but want slightly more features on the graphical interface, I suggest using [GNOME MPV Player][10].
-
-Have you used MPV video player? How was your experience with it? What you liked or disliked about it? Do share your views in the comments below.
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/mpv-video-player/
-
-作者:[Abhishek Prakash][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://itsfoss.com/author/abhishek/
-[1]:https://itsfoss.com/best-ubuntu-apps/
-[2]:https://mpv.io/
-[3]:http://www.mplayerhq.hu/design7/news.html
-[4]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/mpv-player.jpg
-[5]:https://mpv.io/installation/
-[6]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/mpv-player-interface.png
-[7]:https://itsfoss.com/how-to-play-movie-with-subtitles-on-samsung-tv-via-usb/
-[8]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/play-youtube-videos-on-mpv-player.jpeg
-[9]:https://itsfoss.com/sayonara-music-player/
-[10]:https://gnome-mpv.github.io/
diff --git a/sources/tech/20180821 How I recorded user behaviour on my competitor-s websites.md b/sources/tech/20180821 How I recorded user behaviour on my competitor-s websites.md
new file mode 100644
index 0000000000..b4729d730e
--- /dev/null
+++ b/sources/tech/20180821 How I recorded user behaviour on my competitor-s websites.md
@@ -0,0 +1,117 @@
+How I recorded user behaviour on my competitor’s websites
+======
+
+### Update
+
+Google’s team has tracked down my test site, most likely using the source code I shared and de-indexed the whole domain.
+
+Last time [I publicly exposed a flaw][1], Google issued a [manual penalty][2] and devalued a single offending page. This time, there is no notice in Search Console. The site is completely removed from their index without any notification.
+
+I’ve received a lot of criticism in the way I’ve handled this. Many are suggesting the right way is to approach Google directly with security flaws like this instead of writing about it publicly. Others are suggesting I acted unethically, or even illegally by running this test. I think it should be obvious that if I intended to exploit this method I wouldn’t write about it. With so much risk and so little gain, is this even worth doing in practice? Of course not. I’d be more concerned about those who do unethical things and don’t write about it.
+
+### My wish list:
+
+a) Manipulating the back button in Chrome shouldn’t be possible in 2018
+b) Websites that employ this tactic should be detected and penalised by Google’s algorithms
+c) If still found in Google’s results, such pages should be labelled with “this page may be harmful” notice.
+
+### Here’s what I did:
+
+ 1. User lands on my page (referrer: google)
+ 2. When they hit “back” button in Chrome, JS sends them to my copy of SERP
+ 3. Click on any competitor takes them to my mirror of competitor’s site (noindex)
+ 4. Now I generate heatmaps, scrollmaps, records screen interactions and typing.
+
+![][3]
+
+![script][4]
+![][5]
+![][6]
+
+Interestingly, only about 50% of users found anything suspicious, partly due to the fact that I used https on all my pages, which is one of the main [trust factors on the web][7].
+
+Many users are just happy to see the “padlock” in their browser.
+
+At this point I was able to:
+
+ * Generate heatmaps (clicks, moves, scroll depth)
+ * Record actual sessions (mouse movement, clicks, typing)
+
+
+
+I gasped when I realised I can actually **capture all form submissions and send them to my own email**.
+
+Note: I never actually tried that.
+
+Yikes!
+
+### Wouldn’t a website doing this be penalised?
+
+You would think so.
+
+I had this implemented for a **very brief period of time** (and for ethical reasons took it down almost immediately, realising that this may cause trouble). After that I changed the topic of the page completely and moved the test to one of my disposable domains where **remained** for five years and ranked really well, though for completely different search terms with rather low search volumes. Its new purpose was to mess with conspiracy theory people.
+
+### Alternative Technique
+
+You don’t have to spoof Google SERPs to generate competitor’s heatmaps, you can simply A/B test your landing page VS your clone of theirs through paid traffic (e.g. social media). Is the A/B testing version of this ethically OK? I don’t know, but it may get you in legal trouble depending on where you live.
+
+### What did I learn?
+
+Users seldom read home page “fluff” and often look for things like testimonials, case studies, pricing levels and staff profiles / company information in search for credibility and trust. One of my upcoming tests will be to combine home page with “about us”, “testimonials”, “case studies” and “packages”. This would give users all they really want on a single page.
+
+### Reader Suggestions
+
+“I would’ve thrown in an exit pop-up to let users know what they’d just been subjected to.”
+
+
+### From Hacker News
+
+> Howdy, former Matasano pentester here.
+> FWIW, I would probably have done something similar to them before I’d worked in the security industry. It’s an easy mistake to make, because it’s one you make by default: intellectual curiosity doesn’t absolve you from legal judgement, and people on the internet tend to flip out if you do something illegal and say anything but “You’re right, I was mistaken. I’ve learned my lesson.”
+>
+> To the author: The reason you pattern-matched into the blackhat category instead of whitehat/grayhat (grayhat?) category is that in the security industry, whenever we discover a vuln, we PoC it and then write it up in the report and tell them immediately. The report typically includes background info, reproduction steps, and recommended actions. The whole thing is typically clinical and detached.
+>
+> Most notably, the PoC is usually as simple as possible. alert(1) suffices to demonstrate XSS, for example, rather than implementing a fully-working cookie swipe. The latter is more fun, but the former is more impactful.
+>
+> One interesting idea would’ve been to create a fake competitor — e.g. “VirtualBagel: Just download your bagels and enjoy.” Once it’s ranking on Google, run this same experiment and see if you could rank higher.
+>
+> That experiment would demonstrate two things: (1) the history vulnerability exists, and (2) it’s possible for someone to clone a competitor and outrank them with this vulnerability, thereby raising it from sev:low to sev:hi.
+>
+> So to be clear, the crux of the issue was running the exploit on a live site without their blessing.
+>
+> But again, don’t worry too much. I would have made similar errors without formal training. It’s easy for everyone to say “Oh well it’s obvious,” but when you feel like you have good intent, it’s not obvious at all.
+>
+> I remind everyone that RTM once ran afoul of the law due to similar intellectual curiosity. (In fairness, his experiment exploded half the internet, but still.)
+
+Source:
+
+
+### About the author
+
+[Dan Petrovic][9]
+
+Dan Petrovic, the managing director of DEJAN, is Australia’s best-known name in the field of search engine optimisation. Dan is a web author, innovator and a highly regarded search industry event speaker.
+
+
+--------------------------------------------------------------------------------
+
+via: https://dejanseo.com.au/competitor-hack/
+
+作者:[Dan Petrovic][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://dejanseo.com.au/dan-petrovic/
+[1]:https://dejanseo.com.au/hijack/
+[2]:https://dejanseo.com.au/google-against-content-scrapers/
+[3]:https://dejanseo.com.au/wp-content/uploads/2018/08/step-1.png
+[4]:https://dejanseo.com.au/wp-content/uploads/2018/08/script.gif
+[5]:https://dejanseo.com.au/wp-content/uploads/2018/08/step-2.png
+[6]:https://dejanseo.com.au/wp-content/uploads/2018/08/step-3.png
+[7]:https://dejanseo.com.au/trust/
+[8]:https://secure.gravatar.com/avatar/9068275e6d3863b7dc11f7dff0974ced?s=100&d=mm&r=g
+[9]:https://dejanseo.com.au/dan-petrovic/ (Dan Petrovic)
+[10]:https://dejanseo.com.au/author/admin/ (More posts by Dan Petrovic)
diff --git a/sources/tech/20180822 What is a Makefile and how does it work.md b/sources/tech/20180822 What is a Makefile and how does it work.md
new file mode 100644
index 0000000000..cf168cc44d
--- /dev/null
+++ b/sources/tech/20180822 What is a Makefile and how does it work.md
@@ -0,0 +1,322 @@
+What is a Makefile and how does it work?
+======
+
+
+If you want to run or update a task when certain files are updated, the `make` utility can come in handy. The `make` utility requires a file, `Makefile` (or `makefile`), which defines set of tasks to be executed. You may have used `make` to compile a program from source code. Most open source projects use `make` to compile a final executable binary, which can then be installed using `make install`.
+
+In this article, we'll explore `make` and `Makefile` using basic and advanced examples. Before you start, ensure that `make` is installed in your system.
+
+### Basic examples
+
+Let's start by printing the classic "Hello World" on the terminal. Create a empty directory `myproject` containing a file `Makefile` with this content:
+```
+say_hello:
+
+ echo "Hello World"
+
+```
+
+Now run the file by typing `make` inside the directory `myproject`. The output will be:
+```
+$ make
+
+echo "Hello World"
+
+Hello World
+
+```
+
+In the example above, `say_hello` behaves like a function name, as in any programming language. This is called the target. The prerequisites or dependencies follow the target. For the sake of simplicity, we have not defined any prerequisites in this example. The command `echo "Hello World"` is called the recipe. The recipe uses prerequisites to make a target. The target, prerequisites, and recipes together make a rule.
+
+To summarize, below is the syntax of a typical rule:
+```
+target: prerequisites
+
+ recipe
+
+```
+
+As an example, a target might be a binary file that depends on prerequisites (source files). On the other hand, a prerequisite can also be a target that depends on other dependencies:
+```
+final_target: sub_target final_target.c
+
+ Recipe_to_create_final_target
+
+
+
+sub_target: sub_target.c
+
+ Recipe_to_create_sub_target
+
+```
+
+It is not necessary for the target to be a file; it could be just a name for the recipe, as in our example. We call these "phony targets."
+
+Going back to the example above, when `make` was executed, the entire command `echo "Hello World"` was displayed, followed by actual command output. We often don't want that. To suppress echoing the actual command, we need to start `echo` with `@`:
+```
+say_hello:
+
+ @echo "Hello World"
+
+```
+
+Now try to run `make` again. The output should display only this:
+```
+$ make
+
+Hello World
+
+```
+
+Let's add a few more phony targets: `generate` and `clean` to the `Makefile`:
+```
+say_hello:
+ @echo "Hello World"
+
+generate:
+ @echo "Creating empty text files..."
+ touch file-{1..10}.txt
+
+clean:
+ @echo "Cleaning up..."
+ rm *.txt
+```
+
+If we try to run `make` after the changes, only the target `say_hello` will be executed. That's because only the first target in the makefile is the default target. Often called the default goal, this is the reason you will see `all` as the first target in most projects. It is the responsibility of `all` to call other targets. We can override this behavior using a special phony target called `.DEFAULT_GOAL`.
+
+Let's include that at the beginning of our makefile:
+```
+.DEFAULT_GOAL := generate
+```
+
+This will run the target `generate` as the default:
+```
+$ make
+Creating empty text files...
+touch file-{1..10}.txt
+```
+
+As the name suggests, the phony target `.DEFAULT_GOAL` can run only one target at a time. This is why most makefiles include `all` as a target that can call as many targets as needed.
+
+Let's include the phony target `all` and remove `.DEFAULT_GOAL`:
+```
+all: say_hello generate
+
+say_hello:
+ @echo "Hello World"
+
+generate:
+ @echo "Creating empty text files..."
+ touch file-{1..10}.txt
+
+clean:
+ @echo "Cleaning up..."
+ rm *.txt
+```
+
+Before running `make`, let's include another special phony target, `.PHONY`, where we define all the targets that are not files. `make` will run its recipe regardless of whether a file with that name exists or what its last modification time is. Here is the complete makefile:
+```
+.PHONY: all say_hello generate clean
+
+all: say_hello generate
+
+say_hello:
+ @echo "Hello World"
+
+generate:
+ @echo "Creating empty text files..."
+ touch file-{1..10}.txt
+
+clean:
+ @echo "Cleaning up..."
+ rm *.txt
+```
+
+The `make` should call `say_hello` and `generate`:
+```
+$ make
+Hello World
+Creating empty text files...
+touch file-{1..10}.txt
+```
+
+It is a good practice not to call `clean` in `all` or put it as the first target. `clean` should be called manually when cleaning is needed as a first argument to `make`:
+```
+$ make clean
+Cleaning up...
+rm *.txt
+```
+
+Now that you have an idea of how a basic makefile works and how to write a simple makefile, let's look at some more advanced examples.
+
+### Advanced examples
+
+#### Variables
+
+In the above example, most target and prerequisite values are hard-coded, but in real projects, these are replaced with variables and patterns.
+
+The simplest way to define a variable in a makefile is to use the `=` operator. For example, to assign the command `gcc` to a variable `CC`:
+```
+CC = gcc
+```
+
+This is also called a recursive expanded variable, and it is used in a rule as shown below:
+```
+hello: hello.c
+ ${CC} hello.c -o hello
+```
+
+As you may have guessed, the recipe expands as below when it is passed to the terminal:
+```
+gcc hello.c -o hello
+```
+
+Both `${CC}` and `$(CC)` are valid references to call `gcc`. But if one tries to reassign a variable to itself, it will cause an infinite loop. Let's verify this:
+```
+CC = gcc
+CC = ${CC}
+
+all:
+ @echo ${CC}
+```
+
+Running `make` will result in:
+```
+$ make
+Makefile:8: *** Recursive variable 'CC' references itself (eventually). Stop.
+```
+
+To avoid this scenario, we can use the `:=` operator (this is also called the simply expanded variable). We should have no problem running the makefile below:
+```
+CC := gcc
+CC := ${CC}
+
+all:
+ @echo ${CC}
+```
+
+#### Patterns and functions
+
+The following makefile can compile all C programs by using variables, patterns, and functions. Let's explore it line by line:
+```
+# Usage:
+# make # compile all binary
+# make clean # remove ALL binaries and objects
+
+.PHONY = all clean
+
+CC = gcc # compiler to use
+
+LINKERFLAG = -lm
+
+SRCS := $(wildcard *.c)
+BINS := $(SRCS:%.c=%)
+
+all: ${BINS}
+
+%: %.o
+ @echo "Checking.."
+ ${CC} ${LINKERFLAG} $< -o $@
+
+%.o: %.c
+ @echo "Creating object.."
+ ${CC} -c $<
+
+clean:
+ @echo "Cleaning up..."
+ rm -rvf *.o ${BINS}
+```
+
+ * Lines starting with `#` are comments.
+
+ * Line `.PHONY = all clean` defines phony targets `all` and `clean`.
+
+ * Variable `LINKERFLAG` defines flags to be used with `gcc` in a recipe.
+
+ * `SRCS := $(wildcard *.c)`: `$(wildcard pattern)` is one of the functions for filenames. In this case, all files with the `.c` extension will be stored in a variable `SRCS`.
+
+ * `BINS := $(SRCS:%.c=%)`: This is called as substitution reference. In this case, if `SRCS` has values `'foo.c bar.c'`, `BINS` will have `'foo bar'`.
+
+ * Line `all: ${BINS}`: The phony target `all` calls values in`${BINS}` as individual targets.
+
+ * Rule:
+```
+%: %.o
+ @echo "Checking.."
+ ${CC} ${LINKERFLAG} $< -o $@
+```
+
+Let's look at an example to understand this rule. Suppose `foo` is one of the values in `${BINS}`. Then `%` will match `foo`(`%` can match any target name). Below is the rule in its expanded form:
+```
+foo: foo.o
+ @echo "Checking.."
+ gcc -lm foo.o -o foo
+
+```
+
+As shown, `%` is replaced by `foo`. `$<` is replaced by `foo.o`. `$<` is patterned to match prerequisites and `$@` matches the target. This rule will be called for every value in `${BINS}`
+
+ * Rule:
+```
+%.o: %.c
+ @echo "Creating object.."
+ ${CC} -c $<
+```
+
+Every prerequisite in the previous rule is considered a target for this rule. Below is the rule in its expanded form:
+```
+foo.o: foo.c
+ @echo "Creating object.."
+ gcc -c foo.c
+```
+
+ * Finally, we remove all binaries and object files in target `clean`.
+
+
+
+
+Below is the rewrite of the above makefile, assuming it is placed in the directory having a single file `foo.c:`
+```
+# Usage:
+# make # compile all binary
+# make clean # remove ALL binaries and objects
+
+.PHONY = all clean
+
+CC = gcc # compiler to use
+
+LINKERFLAG = -lm
+
+SRCS := foo.c
+BINS := foo
+
+all: foo
+
+foo: foo.o
+ @echo "Checking.."
+ gcc -lm foo.o -o foo
+
+foo.o: foo.c
+ @echo "Creating object.."
+ gcc -c foo.c
+
+clean:
+ @echo "Cleaning up..."
+ rm -rvf foo.o foo
+```
+
+For more on makefiles, refer to the [GNU Make manual][1], which offers a complete reference and examples.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/8/what-how-makefile
+
+作者:[Sachin Patil][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/psachin
+[1]:https://www.gnu.org/software/make/manual/make.pdf
diff --git a/sources/tech/20180823 An introduction to pipes and named pipes in Linux.md b/sources/tech/20180823 An introduction to pipes and named pipes in Linux.md
new file mode 100644
index 0000000000..0f52ed2da3
--- /dev/null
+++ b/sources/tech/20180823 An introduction to pipes and named pipes in Linux.md
@@ -0,0 +1,58 @@
+An introduction to pipes and named pipes in Linux
+======
+
+
+
+In Linux, the `pipe` command lets you sends the output of one command to another. Piping, as the term suggests, can redirect the standard output, input, or error of one process to another for further processing.
+
+The syntax for the `pipe` or `unnamed pipe` command is the `|` character between any two commands:
+
+`Command-1 | Command-2 | …| Command-N`
+
+Here, the pipe cannot be accessed via another session; it is created temporarily to accommodate the execution of `Command-1` and redirect the standard output. It is deleted after successful execution.
+
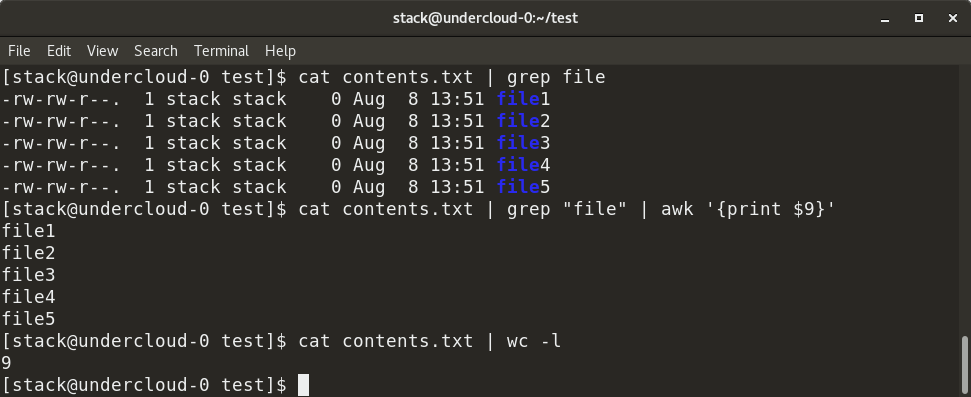
+
+
+In the example above, contents.txt contains a list of all files in a particular directory—specifically, the output of the ls -al command. We first grep the filenames with the "file" keyword from contents.txt by piping (as shown), so the output of the cat command is provided as the input for the grep command. Next, we add piping to execute the awk command, which displays the 9th column from the filtered output from the grep command. We can also count the number of rows in contents.txt using the wc -l command.
+
+A named pipe can last until as long as the system is up and running or until it is deleted. It is a special file that follows the [FIFO][1] (first in, first out) mechanism. It can be used just like a normal file; i.e., you can write to it, read from it, and open or close it. To create a named pipe, the command is:
+```
+mkfifo
+
+```
+
+This creates a named pipe file that can be used even over multiple shell sessions.
+
+Another way to create a FIFO named pipe is to use this command:
+```
+mknod p
+
+```
+
+To redirect a standard output of any command to another process, use the `>` symbol. To redirect a standard input of any command, use the `<` symbol.
+
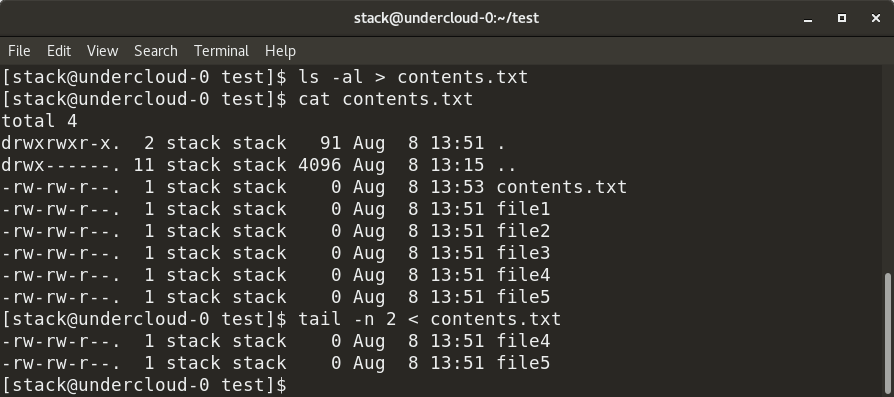
+
+
+As shown above, the output of the `ls -al` command is redirected to `contents.txt` and inserted in the file. Similarly, the input for the `tail` command is provided as `contents.txt` via the `<` symbol.
+
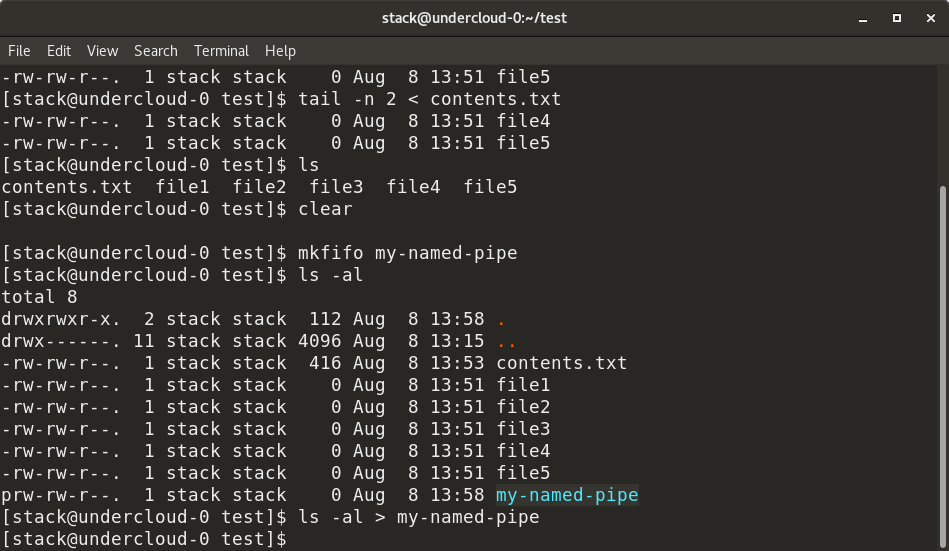
+
+
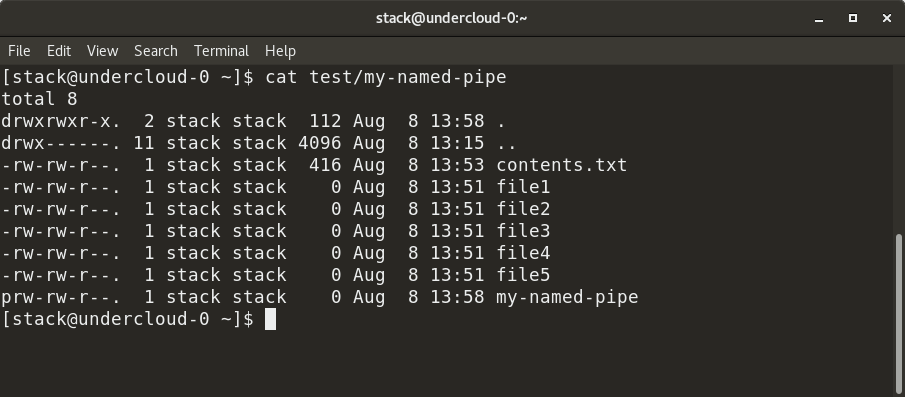
+
+
+Here, we have created a named pipe, `my-named-pipe`, and redirected the output of the `ls -al` command into the named pipe. We can the open a new shell session and `cat` the contents of the named pipe, which shows the output of the `ls -al` command, as previously supplied. Notice the size of the named pipe is zero and it has a designation of "p".
+
+So, next time you're working with commands at the Linux terminal and find yourself moving data between commands, hopefully a pipe will make the process quick and easy.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/8/introduction-pipes-linux
+
+作者:[Archit Modi][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/architmodi
+[1]:https://en.wikipedia.org/wiki/FIFO_(computing_and_electronics)
diff --git a/sources/tech/20180823 Getting started with Sensu monitoring.md b/sources/tech/20180823 Getting started with Sensu monitoring.md
new file mode 100644
index 0000000000..7d0a65e306
--- /dev/null
+++ b/sources/tech/20180823 Getting started with Sensu monitoring.md
@@ -0,0 +1,290 @@
+Getting started with Sensu monitoring
+======
+
+
+Sensu is an open source infrastructure and application monitoring solution that monitors servers, services, and application health, and sends alerts and notifications with third-party integration. Written in Ruby, Sensu can use either [RabbitMQ][1] or [Redis][2] to handle messages. It uses Redis to store data.
+
+If you want to monitor your cloud infrastructure in a simple and efficient manner, Sensu is a good option. It can be integrated with many of the modern DevOps stacks your organization may already be using, such as [Slack][3], [HipChat][4], or [IRC][5], and it can even send mobile/pager alerts with [PagerDuty][6].
+
+Sensu's [modular architecture][7] means every component can be installed on the same server or on completely separate machines.
+
+### Architecture
+
+Sensu's main communication mechanism is the Transport. Every Sensu component must connect to the Transport in order to send messages to each other. Transport can use either RabbitMQ (recommended in production) or Redis.
+
+Sensu Server processes event data and takes action. It registers clients and processes check results and monitoring events using filters, mutators, and handlers. The server publishes check definitions to the clients and the Sensu API provides a RESTful API, providing access to monitoring data and core functionality.
+
+[Sensu Client][8] executes checks either scheduled by Sensu Server or local checks definitions. Sensu uses a data store (Redis) to keep all the persistent data. Finally, [Uchiwa][9] is the web interface to communicate with Sensu API.
+
+![sensu_system.png][11]
+
+### Installing Sensu
+
+#### Prerequisites
+
+ * One Linux installation to act as the server node (I used CentOS 7 for this article)
+
+ * One or more Linux machines to monitor (clients)
+
+
+
+
+#### Server side
+
+Sensu requires Redis to be installed. To install Redis, enable the EPEL repository:
+```
+$ sudo yum install epel-release -y
+
+```
+
+Then install Redis:
+```
+$ sudo yum install redis -y
+
+```
+
+Modify `/etc/redis.conf` to disable protected mode, listen on every interface, and set a password:
+```
+$ sudo sed -i 's/^protected-mode yes/protected-mode no/g' /etc/redis.conf
+
+$ sudo sed -i 's/^bind 127.0.0.1/bind 0.0.0.0/g' /etc/redis.conf
+
+$ sudo sed -i 's/^# requirepass foobared/requirepass password123/g' /etc/redis.conf
+
+```
+
+Enable and start Redis service:
+```
+$ sudo systemctl enable redis
+$ sudo systemctl start redis
+```
+
+Redis is now installed and ready to be used by Sensu.
+
+Now let’s install Sensu.
+
+First, configure the Sensu repository and install the packages:
+```
+$ sudo tee /etc/yum.repos.d/sensu.repo << EOF
+[sensu]
+name=sensu
+baseurl=https://sensu.global.ssl.fastly.net/yum/\$releasever/\$basearch/
+gpgcheck=0
+enabled=1
+EOF
+
+$ sudo yum install sensu uchiwa -y
+```
+
+Let’s create the bare minimum configuration files for Sensu:
+```
+$ sudo tee /etc/sensu/conf.d/api.json << EOF
+{
+ "api": {
+ "host": "127.0.0.1",
+ "port": 4567
+ }
+}
+EOF
+```
+
+Next, configure `sensu-api` to listen on localhost, with Port 4567:
+```
+$ sudo tee /etc/sensu/conf.d/redis.json << EOF
+{
+ "redis": {
+ "host": "",
+ "port": 6379,
+ "password": "password123"
+ }
+}
+EOF
+
+
+$ sudo tee /etc/sensu/conf.d/transport.json << EOF
+{
+ "transport": {
+ "name": "redis"
+ }
+}
+EOF
+```
+
+In these two files, we configure Sensu to use Redis as the transport mechanism and the address where Redis will listen. Clients need to connect directly to the transport mechanism. These two files will be required on each client machine.
+```
+$ sudo tee /etc/sensu/uchiwa.json << EOF
+{
+ "sensu": [
+ {
+ "name": "sensu",
+ "host": "127.0.0.1",
+ "port": 4567
+ }
+ ],
+ "uchiwa": {
+ "host": "0.0.0.0",
+ "port": 3000
+ }
+}
+EOF
+```
+
+In this file, we configure Uchiwa to listen on every interface (0.0.0.0) on Port 3000. We also configure Uchiwa to use `sensu-api` (already configured).
+
+For security reasons, change the owner of the configuration files you just created:
+```
+$ sudo chown -R sensu:sensu /etc/sensu
+```
+
+Enable and start the Sensu services:
+```
+$ sudo systemctl enable sensu-server sensu-api sensu-client
+$ sudo systemctl start sensu-server sensu-api sensu-client
+$ sudo systemctl enable uchiwa
+$ sudo systemctl start uchiwa
+```
+
+Try accessing the Uchiwa website: http://:3000
+
+For production environments, it’s recommended to run a cluster of RabbitMQ as the Transport instead of Redis (a Redis cluster can be used in production too), and to run more than one instance of Sensu Server and API for load balancing and high availability.
+
+Sensu is now installed. Now let’s configure the clients.
+
+#### Client side
+
+To add a new client, you will need to enable Sensu repository on the client machines by creating the file `/etc/yum.repos.d/sensu.repo`.
+```
+$ sudo tee /etc/yum.repos.d/sensu.repo << EOF
+[sensu]
+name=sensu
+baseurl=https://sensu.global.ssl.fastly.net/yum/\$releasever/\$basearch/
+gpgcheck=0
+enabled=1
+EOF
+```
+
+With the repository enabled, install the package Sensu:
+```
+$ sudo yum install sensu -y
+```
+
+To configure `sensu-client`, create the same `redis.json` and `transport.json` created in the server machine, as well as the `client.json` configuration file:
+```
+$ sudo tee /etc/sensu/conf.d/client.json << EOF
+{
+ "client": {
+ "name": "rhel-client",
+ "environment": "development",
+ "subscriptions": [
+ "frontend"
+ ]
+ }
+}
+EOF
+```
+
+In the name field, specify a name to identify this client (typically the hostname). The environment field can help you filter, and subscription defines which monitoring checks will be executed by the client.
+
+Finally, enable and start the services and check in Uchiwa, as the new client will register automatically:
+```
+$ sudo systemctl enable sensu-client
+$ sudo systemctl start sensu-client
+```
+
+### Sensu checks
+
+Sensu checks have two components: a plugin and a definition.
+
+Sensu is compatible with the [Nagios check plugin specification][12], so any check for Nagios can be used without modification. Checks are executable files and are run by the Sensu client.
+
+Check definitions let Sensu know how, where, and when to run the plugin.
+
+#### Client side
+
+Let’s install one check plugin on the client machine. Remember, this plugin will be executed on the clients.
+
+Enable EPEL and install `nagios-plugins-http` :
+```
+$ sudo yum install -y epel-release
+$ sudo yum install -y nagios-plugins-http
+```
+
+Now let’s explore the plugin by executing it manually. Try checking the status of a web server running on the client machine. It should fail as we don’t have a web server running:
+```
+$ /usr/lib64/nagios/plugins/check_http -I 127.0.0.1
+connect to address 127.0.0.1 and port 80: Connection refused
+HTTP CRITICAL - Unable to open TCP socket
+```
+
+It failed, as expected. Check the return code of the execution:
+```
+$ echo $?
+2
+
+```
+
+The Nagios check plugin specification defines four return codes for the plugin execution:
+
+| **Plugin return code** | **State** |
+|------------------------|-----------|
+| 0 | OK |
+| 1 | WARNING |
+| 2 | CRITICAL |
+| 3 | UNKNOWN |
+
+With this information, we can now create the check definition on the server.
+
+#### Server side
+
+On the server machine, create the file `/etc/sensu/conf.d/check_http.json`:
+```
+{
+ "checks": {
+ "check_http": {
+ "command": "/usr/lib64/nagios/plugins/check_http -I 127.0.0.1",
+ "interval": 10,
+ "subscribers": [
+ "frontend"
+ ]
+ }
+ }
+}
+```
+
+In the command field, use the command we tested before. `Interval` will tell Sensu how frequently, in seconds, this check should be executed. Finally, `subscribers` will define the clients where the check will be executed.
+
+Restart both sensu-api and sensu-server and confirm that the new check is available in Uchiwa.
+```
+$ sudo systemctl restart sensu-api sensu-server
+```
+
+### What’s next?
+
+Sensu is a powerful tool, and this article covers just a glimpse of what it can do. See the [documentation][13] to learn more, and visit the Sensu site to learn more about the [Sensu community][14].
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/8/getting-started-sensu-monitoring-solution
+
+作者:[Michael Zamot][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/mzamot
+[1]:https://www.rabbitmq.com/
+[2]:https://redis.io/topics/config
+[3]:https://slack.com/
+[4]:https://en.wikipedia.org/wiki/HipChat
+[5]:http://www.irc.org/
+[6]:https://www.pagerduty.com/
+[7]:https://docs.sensu.io/sensu-core/1.4/overview/architecture/
+[8]:https://docs.sensu.io/sensu-core/1.4/installation/install-sensu-client/
+[9]:https://uchiwa.io/#/
+[10]:/file/406576
+[11]:https://opensource.com/sites/default/files/uploads/sensu_system.png (sensu_system.png)
+[12]:https://assets.nagios.com/downloads/nagioscore/docs/nagioscore/4/en/pluginapi.html
+[13]:https://docs.sensu.io/
+[14]:https://sensu.io/community
diff --git a/sources/tech/20180823 How To Easily And Safely Manage Cron Jobs In Linux.md b/sources/tech/20180823 How To Easily And Safely Manage Cron Jobs In Linux.md
new file mode 100644
index 0000000000..aa4ec0a655
--- /dev/null
+++ b/sources/tech/20180823 How To Easily And Safely Manage Cron Jobs In Linux.md
@@ -0,0 +1,131 @@
+How To Easily And Safely Manage Cron Jobs In Linux
+======
+
+
+
+When it comes to schedule tasks in Linux, which utility comes to your mind first? Yeah, you guessed it right. **Cron!** The cron utility helps you to schedule commands/tasks at specific time in Unix-like operating systems. We already published a [**beginners guides to Cron jobs**][1]. I have a few years experience in Linux, so setting up cron jobs is no big deal for me. But, it is not piece of cake for newbies. The noobs may unknowingly do small mistakes while editing plain text crontab and bring down all cron jobs. Just in case, if you think you might mess up with your cron jobs, there is a good alternative way. Say hello to **Crontab UI** , a web-based tool to easily and safely manage cron jobs in Unix-like operating systems.
+
+You don’t need to manually edit the crontab file to create, delete and manage cron jobs. Everything can be done via a web browser with a couple mouse clicks. Crontab UI allows you to easily create, edit, pause, delete, backup cron jobs, and even import, export and deploy jobs on other machines without much hassle. Error log, mailing and hooks support also possible. It is free, open source and written using NodeJS.
+
+### Installing Crontab UI
+
+Installing Crontab UI is just a one-liner command. Make sure you have installed NPM. If you haven’t install npm yet, refer the following link.
+
+Next, run the following command to install Crontab UI.
+```
+$ npm install -g crontab-ui
+
+```
+
+It’s that simple. Let us go ahead and see how to manage cron jobs using Crontab UI.
+
+### Easily And Safely Manage Cron Jobs In Linux
+
+To launch Crontab UI, simply run:
+```
+$ crontab-ui
+
+```
+
+You will see the following output:
+```
+Node version: 10.8.0
+Crontab UI is running at http://127.0.0.1:8000
+
+```
+
+Now, open your web browser and navigate to ****. Make sure the port no 8000 is allowed in your firewall/router.
+
+Please note that you can only access Crontab UI web dashboard within the local system itself.
+
+If you want to run Crontab UI with your system’s IP and custom port (so you can access it from any remote system in the network), use the following command instead:
+```
+$ HOST=0.0.0.0 PORT=9000 crontab-ui
+Node version: 10.8.0
+Crontab UI is running at http://0.0.0.0:9000
+
+```
+
+Now, Crontab UI can be accessed from the any system in the nework using URL – **http:// :9000**.
+
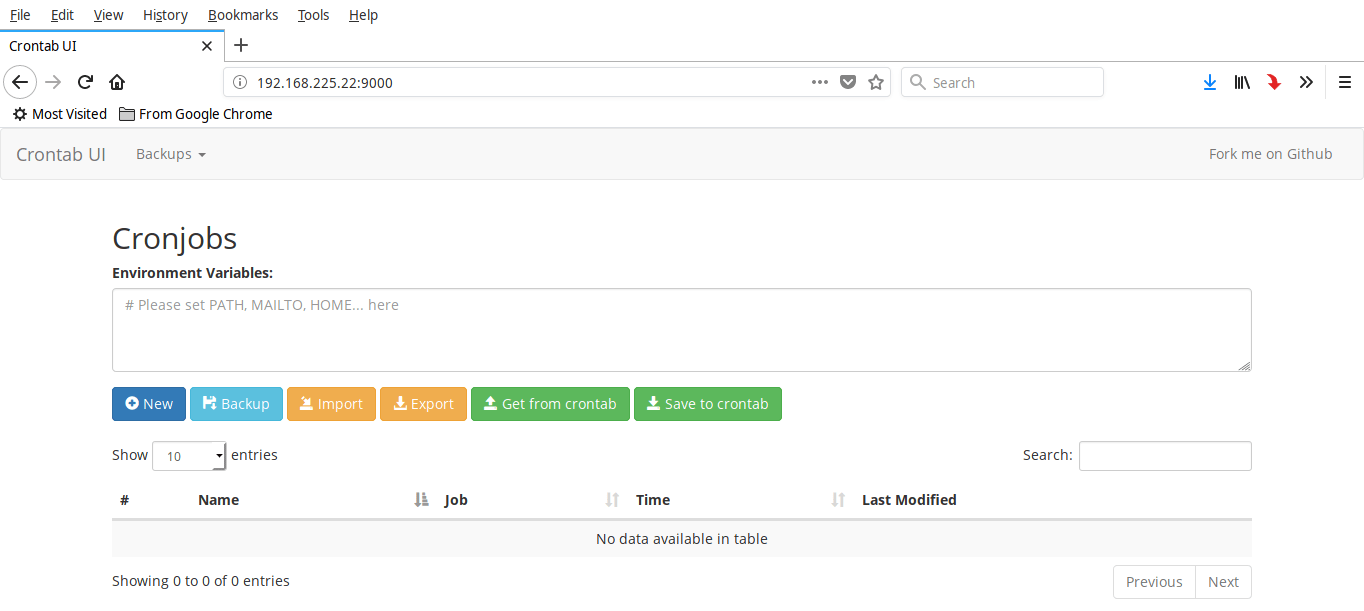
+This is how Crontab UI dashboard looks like.
+
+
+
+As you can see in the above screenshot, Crontab UI dashbaord is very simply. All options are self-explanatory.
+
+To exit Crontab UI, press **CTRL+C**.
+
+**Create, edit, run, stop, delete a cron job**
+
+To create a new cron job, click on “New” button. Enter your cron job details and click Save.
+
+ 1. Name the cron job. It is optional.
+ 2. The full command you want to run.
+ 3. Choose schedule time. You can either choose the quick schedule time, (such as Startup, Hourly, Daily, Weekly, Monthly, Yearly) or set the exact time to run the command. After you choosing the schedule time, the syntax of the cron job will be shown in **Jobs** field.
+ 4. Choose whether you want to enable error logging for the particular job.
+
+
+
+Here is my sample cron job.
+
+
+
+As you can see, I have setup a cron job to clear pacman cache at every month.
+
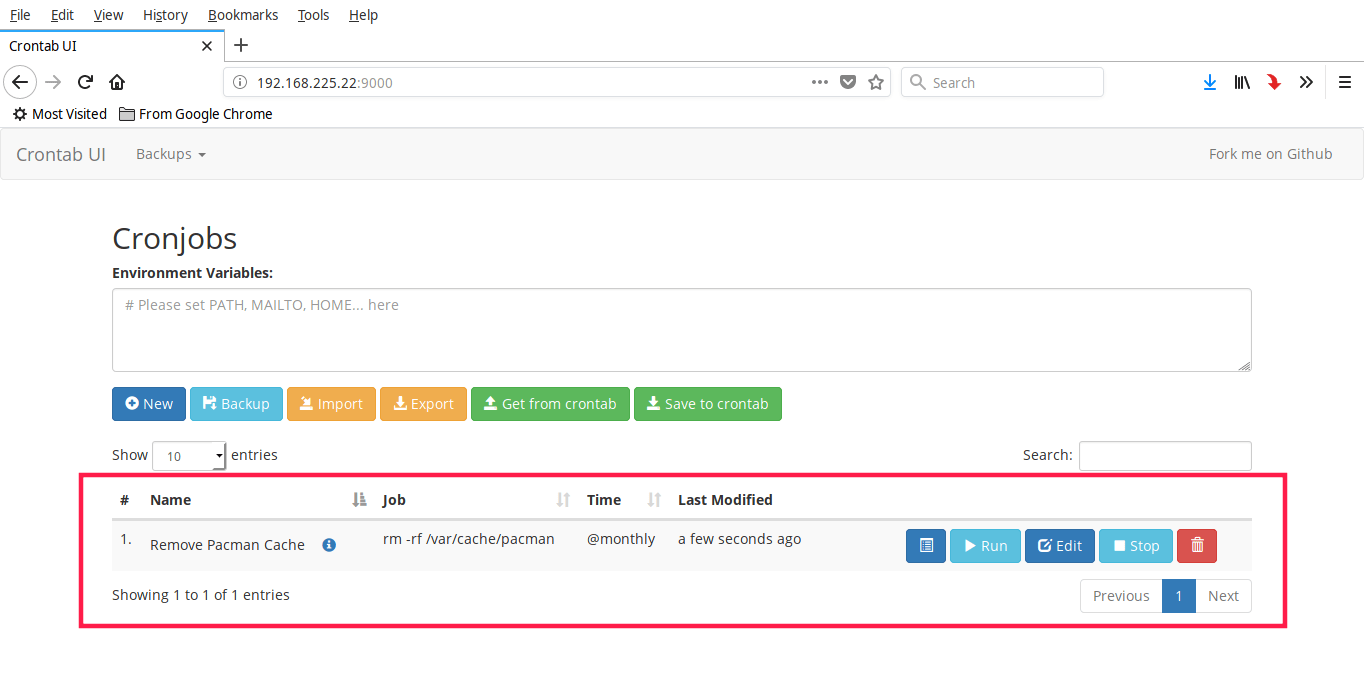
+Similarly, you can create any number of jobs as you want. You will see all cron jobs in the dashboard.
+
+
+
+If you wanted to change any parameter in a cron job, just click on the **Edit** button below the job and modify the parameters as you wish. To run a job immediately, click on the button that says **Run**. To stop a job, click **Stop** button. You can view the log details of any job by clicking on the **Log** button. If the job is no longer required, simply press **Delete** button.
+
+**Backup cron jobs**
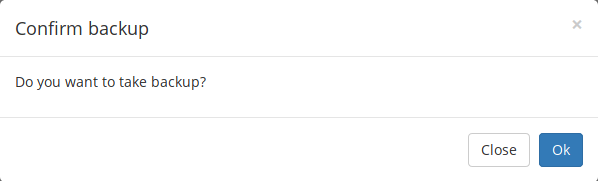
+
+To backup all cron jobs, press the Backup from main dashboard and choose OK to confirm the backup.
+
+
+
+You can use this backup in case you messed with the contents of the crontab file.
+
+**Import/Export cron jobs to other systems**
+
+Another notable feature of Crontab UI is you can import, export and deploy cron jobs to other systems. If you have multiple systems on your network that requires the same cron jobs, just press **Export** button and choose the location to save the file. All contents of crontab file will be saved in a file named **crontab.db**.
+
+Here is the contents of the crontab.db file.
+```
+$ cat Downloads/crontab.db
+{"name":"Remove Pacman Cache","command":"rm -rf /var/cache/pacman","schedule":"@monthly","stopped":false,"timestamp":"Thu Aug 23 2018 10:34:19 GMT+0000 (Coordinated Universal Time)","logging":"true","mailing":{},"created":1535020459093,"_id":"lcVc1nSdaceqS1ut"}
+
+```
+
+Then you can transfer the entire crontab.db file to some other system and import its to the new system. You don’t need to manually create cron jobs in all systems. Just create them in one system and export and import all of them to every system on the network.
+
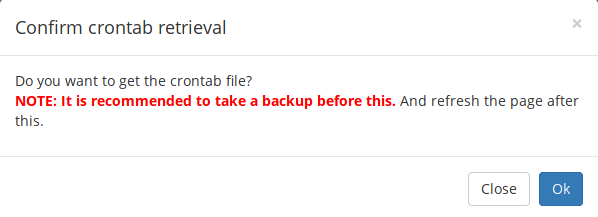
+**Get the contents from or save to existing crontab file**
+
+There are chances that you might have already created some cron jobs using **crontab** command. If so, you can retrieve contents of the existing crontab file by click on the **“Get from crontab”** button in main dashboard.
+
+
+
+Similarly, you can save the newly created jobs using Crontab UI utility to existing crontab file in your system. To do so, just click **Save to crontab** option in the dashboard.
+
+See? Managing cron jobs is not that complicated. Any newbie user can easily maintain any number of jobs without much hassle using Crontab UI. Give it a try and let us know what do you think about this tool. I am all ears!
+
+And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
+
+Cheers!
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/how-to-easily-and-safely-manage-cron-jobs-in-linux/
+
+作者:[SK][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.ostechnix.com/author/sk/
+[1]:https://www.ostechnix.com/a-beginners-guide-to-cron-jobs/
diff --git a/sources/tech/20180823 How to publish a WordPress blog to a static GitLab Pages site.md b/sources/tech/20180823 How to publish a WordPress blog to a static GitLab Pages site.md
new file mode 100644
index 0000000000..5e91bf0708
--- /dev/null
+++ b/sources/tech/20180823 How to publish a WordPress blog to a static GitLab Pages site.md
@@ -0,0 +1,90 @@
+How to publish a WordPress blog to a static GitLab Pages site
+======
+
+
+
+A long time ago, I set up a WordPress blog for a family member. There are lots of options these days, but back then there were few decent choices if you needed a web-based CMS with a WYSIWYG editor. An unfortunate side effect of things working well is that the blog has generated a lot of content over time. That means I was also regularly updating WordPress to protect against the exploits that are constantly popping up.
+
+So I decided to convince the family member that switching to [Hugo][1] would be relatively easy, and the blog could then be hosted on [GitLab][2]. But trying to extract all that content and convert it to [Markdown][3] turned into a huge hassle. There were automated scripts that got me 95% there, but nothing worked perfectly. Manually updating all the posts was not something I wanted to do, so eventually, I gave up trying to move the blog.
+
+Recently, I started thinking about this again and realized there was a solution I hadn't considered: I could continue maintaining the WordPress server but set it up to publish a static mirror and serve that with [GitLab Pages][4] (or [GitHub Pages][5] if you like). This would allow me to automate [Let's Encrypt][6] certificate renewals as well as eliminate the security concerns associated with hosting a WordPress site. This would, however, mean comments would stop working, but that feels like a minor loss in this case because the blog did not garner many comments.
+
+Here's the solution I came up with, which so far seems to be working well:
+
+ * Host WordPress site at URL that is not linked to or from anywhere else to reduce the odds of it being exploited. In this example, we'll use (even though this site is actually built with Pelican).
+ * [Set up hosting on GitLab Pages][7] for the public URL .
+ * Add a [cron job][8] that determines when the last-built date differs between the two URLs; if the build dates differ, mirror the WordPress version.
+ * After mirroring with `wget`, update all links from "private" version to "public" version.
+ * Do a `git push` to publish the new content.
+
+
+
+These are the two scripts I use:
+
+`check-diff.sh` (called by cron every 15 minutes)
+```
+#!/bin/bash
+
+ORIGINDATE="$(curl -v --silent http://private.localconspiracy.com/feed/ 2>&1|grep lastBuildDate)"
+PUBDATE="$(curl -v --silent https://www.localconspiracy.com/feed/ 2>&1|grep lastBuildDate)"
+
+if [ "$ORIGINDATE" != "$PUBDATE" ]
+then
+ /home/doc/repos/localconspiracy/mirror.sh
+fi
+```
+
+`mirror.sh:`
+```
+#!/bin/sh
+
+cd /home/doc/repos/localconspiracy
+
+wget \
+--mirror \
+--convert-links \
+--adjust-extension \
+--page-requisites \
+--retry-connrefused \
+--exclude-directories=comments \
+--execute robots=off \
+http://private.localconspiracy.com
+
+git rm -rf public/*
+mv private.localconspiracy.com/* public/.
+rmdir private.localconspiracy.com
+find ./public/ -type f -exec sed -i -e 's|http://private.localconspiracy|https://www.localconspiracy|g' {} \;
+find ./public/ -type f -exec sed -i -e 's|http://www.localconspiracy|https://www.localconspiracy|g' {} \;
+git add public/*
+git commit -m "new snapshot"
+git push origin master
+```
+
+That's it! Now, when the blog is changed, within 15 minutes the site is mirrored to a static version and pushed up to the repo where it will be reflected in GitLab pages.
+
+This concept could be extended a little further if you wanted to [run WordPress locally][9]. In that case, you would not need a server to host your WordPress blog; you could just run it on your local machine. In that scenario, there's no chance of your blog getting exploited. As long as you can run `wget` against it locally, you could use the approach outlined above to have a WordPress site hosted on GitLab Pages.
+
+_This article was originally posted at[Local Conspiracy][10]. Reposted with permission._
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/8/publish-wordpress-static-gitlab-pages-site
+
+作者:[Christopher Aedo][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/docaedo
+[1]:https://gohugo.io/
+[2]:https://gitlab.com/
+[3]:https://en.wikipedia.org/wiki/Markdown
+[4]:https://docs.gitlab.com/ee/user/project/pages/
+[5]:https://pages.github.com/
+[6]:https://letsencrypt.org/
+[7]:https://about.gitlab.com/2016/04/07/gitlab-pages-setup/
+[8]:https://en.wikipedia.org/wiki/Cron
+[9]:https://codex.wordpress.org/Installing_WordPress_Locally_on_Your_Mac_With_MAMP
+[10]:https://localconspiracy.com/2018/08/wp-on-gitlab.html
diff --git a/sources/tech/20180824 5 cool music player apps.md b/sources/tech/20180824 5 cool music player apps.md
new file mode 100644
index 0000000000..3a8d90400c
--- /dev/null
+++ b/sources/tech/20180824 5 cool music player apps.md
@@ -0,0 +1,108 @@
+5 cool music player apps
+======
+
+
+Do you like music? Then Fedora may have just what you’re looking for. This article introduces different music player apps that run on Fedora. You’re covered whether you have an extensive music library, a small one, or none at all. Here are four graphical application and one terminal-based music player that will have you jamming.
+
+### Quod Libet
+
+Quod Libet is a complete manager for your large audio library. If you have an extensive audio library that you would like not just listen to, but also manage, Quod Libet might a be a good choice for you.
+
+![][1]
+
+Quod Libet can import music from multiple locations on your disk, and allows you to edit tags of the audio files — so everything is under your control. As a bonus, there are various plugins available for anything from a simple equalizer to a [last.fm][2] sync. You can also search and play music directly from [Soundcloud][3].
+
+Quod Libet works great on HiDPI screens, and is available as an RPM in Fedora or on [Flathub][4] in case you run [Silverblue][5]. Install it using Gnome Software or the command line:
+```
+$ sudo dnf install quodlibet
+
+```
+
+### Audacious
+
+If you like a simple music player that could even look like the legendary Winamp, Audacious might be a good choice for you.
+
+![][6]
+
+Audacious probably won’t manage all your music at once, but it works great if you like to organize your music as files. You can also export and import playlists without reorganizing the music files themselves.
+
+As a bonus, you can make it look likeWinamp. To make it look the same as on the screenshot above, go to Settings / Appearance, select Winamp Classic Interface at the top, and choose the Refugee skin right below. And Bob’s your uncle!
+
+Audacious is available as an RPM in Fedora, and can be installed using the Gnome Software app or the following command on the terminal:
+```
+$ sudo dnf install audacious
+
+```
+
+### Lollypop
+
+Lollypop is a music player that provides great integration with GNOME. If you enjoy how GNOME looks, and would like a music player that’s nicely integrated, Lollypop could be for you.
+
+![][7]
+
+Apart from nice visual integration with the GNOME Shell, it woks nicely on HiDPI screens, and supports a dark theme.
+
+As a bonus, Lollypop has an integrated cover art downloader, and a so-called Party Mode (the note button at the top-right corner) that selects and plays music automatically for you. It also integrates with online services such as [last.fm][2] or [libre.fm][8].
+
+Available as both an RPM in Fedora or a [Flathub][4] for your [Silverblue][5] workstation, install it using the Gnome Software app or using the terminal:
+```
+$ sudo dnf install lollypop
+
+```
+
+### Gradio
+
+What if you don’t own any music, but still like to listen to it? Or you just simply love radio? Then Gradio is here for you.
+
+![][9]
+
+Gradio is a simple radio player that allows you to search and play internet radio stations. You can find them by country, language, or simply using search. As a bonus, it’s visually integrated into GNOME Shell, works great with HiDPI screens, and has an option for a dark theme.
+
+Gradio is available on [Flathub][4] which works with both Fedora Workstation and [Silverblue][5]. Install it using the Gnome Software app.
+
+### sox
+
+Do you like using the terminal instead, and listening to some music while you work? You don’t have to leave the terminal thanks to sox.
+
+![][10]
+
+sox is a very simple, terminal-based music player. All you need to do is to run a command such as:
+```
+$ play file.mp3
+
+```
+
+…and sox will play it for you. Apart from individual audio files, sox also supports playlists in the m3u format.
+
+As a bonus, because sox is a terminal-based application, you can run it over ssh. Do you have a home server with speakers attached to it? Or do you want to play music from a different computer? Try using it together with [tmux][11], so you can keep listening even when the session closes.
+
+sox is available in Fedora as an RPM. Install it by running:
+```
+$ sudo dnf install sox
+
+```
+
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/5-cool-music-player-apps/
+
+作者:[Adam Šamalík][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://fedoramagazine.org/author/asamalik/
+[1]:https://fedoramagazine.org/wp-content/uploads/2018/08/qodlibet-300x217.png
+[2]:https://last.fm
+[3]:https://soundcloud.com/
+[4]:https://flathub.org/home
+[5]:https://teamsilverblue.org/
+[6]:https://fedoramagazine.org/wp-content/uploads/2018/08/audacious-300x136.png
+[7]:https://fedoramagazine.org/wp-content/uploads/2018/08/lollypop-300x172.png
+[8]:https://libre.fm
+[9]:https://fedoramagazine.org/wp-content/uploads/2018/08/gradio.png
+[10]:https://fedoramagazine.org/wp-content/uploads/2018/08/sox-300x179.png
+[11]:https://fedoramagazine.org/use-tmux-more-powerful-terminal/
diff --git a/sources/tech/20180824 Add free books to your eReader- Formatting tips.md b/sources/tech/20180824 Add free books to your eReader- Formatting tips.md
new file mode 100644
index 0000000000..bbafc0023d
--- /dev/null
+++ b/sources/tech/20180824 Add free books to your eReader- Formatting tips.md
@@ -0,0 +1,183 @@
+Add free books to your eReader: Formatting tips
+======
+
+
+
+In my recent article, [A handy way to add free books to your eReader][1], I explained how to convert the plaintext indexes at [Project Gutenberg][2] to HTML and then EPUBs. But as one commenter noted, there is a problem in older indexes, where individual books are not always separated by an extra newline character.
+
+I saw quite vividly the extent of the problem when I was working on the index for 2007, where you see things like this:
+```
+Audio: The General Epistle of James 22931
+Audio: The Epistle to the Hebrews 22930
+Audio: The Epistle of Philemon 22929
+
+Sacrifice, by Stephen French Whitman 22928
+The Atlantic Monthly, Volume 18, No. 105, July 1866, by Various 22927
+The Continental Monthly, Vol. 6, No 3, September 1864, by Various 22926
+
+The Story of Young Abraham Lincoln, by Wayne Whipple 22925
+Pathfinder, by Alan Douglas 22924
+ [Subtitle: or, The Missing Tenderfoot]
+Pieni helmivyo, by Various 22923
+ [Subtitle: Suomen runoja koulunuorisolle]
+ [Editor: J. Waananen] [Language: Finnish]
+The Posy Ring, by Various 22922
+```
+
+My first reaction was, "Well, how bad can it be to just add newlines where needed?" The answer: "Really bad." After days of working this way and stopping only when the cramps in my hand became too annoying, I decided to revisit the problem. I thought I might need to do multiple Find-Replace passes, maybe keyed on things like `[Language: Finnish] `or maybe just the `]` bracket, but this seemed almost as laborious as the manual method.
+
+Then I noticed a particular feature: For most instances where a newline was needed, a newline character was immediately followed by the capital letter of the next title. For lines where there was still more information about the book, the newline was followed by spaces. So I tried this: In the Find text box in [KWrite][3] (remember, we’re using regex), I put:
+```
+(\n[A-Z])
+
+```
+
+and in Replace, I put:
+```
+\n\1
+
+```
+
+For every match inside the parentheses, I added a preceding newline, retaining whatever the capital letter was. This worked extremely well. The few instances where it failed involved book titles beginning with a number or with quotes. I fixed these manually, but I could have put this:
+```
+(\n[0-9])
+
+```
+
+In Find and run Replace All again. Later, I also tried it with the quotes—this requires a backslash, like this:
+```
+(\n\”) and (\n\’)
+
+```
+
+One side effect is that a number of the listings were separated by three newline characters. Not an issue for XHTML, but easily fixed by putting in Find:
+```
+\n\n\n
+
+```
+
+and in Replace:
+```
+\n\n
+
+```
+
+To review the process with the new features:
+
+ 1. Remove the preamble and other text you don’t want
+ 2. Add extra newlines with the method shown above
+ 3. Convert three consecutive newlines to two (optional)
+ 4. Add the appropriate HTML tags at the beginning and end
+ 5. Create the links based on finding `(\d\d\d\d\d)`, replacing with `\1`
+ 6. Add paragraph tags by finding `\n\n` and replacing with `\n\n`
+ 7. Add a `
` just before the `
+GutIndexes
+
+
+
+ ` tag at the end
+ 8. Fix the headers, preceding each with `