mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-21 02:10:11 +08:00
Delete 20180221 Getting started with SQL.md
This commit is contained in:
parent
9af5705ccc
commit
1f602dac14
@ -1,252 +0,0 @@
|
||||
Translating by MjSeven
|
||||
|
||||
Getting started with SQL
|
||||
======
|
||||
|
||||

|
||||
|
||||
Building a database using SQL is simpler than most people think. In fact, you don't even need to be an experienced programmer to use SQL to create a database. In this article, I'll explain how to create a simple relational database management system (RDMS) using MySQL 5.6. Before I get started, I want to quickly thank [SQL Fiddle][1], which I used to run my script. It provides a useful sandbox for testing simple scripts.
|
||||
|
||||
|
||||
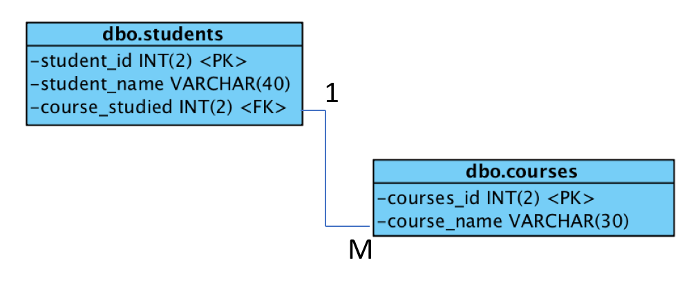
In this tutorial, I'll build a database that uses the simple schema shown in the entity relationship diagram (ERD) below. The database lists students and the course each is studying. I used two entities (i.e., tables) to keep things simple, with only a single relationship and dependency. The entities are called `dbo_students` and `dbo_courses`.
|
||||
|
||||
|
||||
|
||||
The multiplicity of the database is 1-to-many, as each course can contain many students, but each student can study only one course.
|
||||
|
||||
A quick note on terminology:
|
||||
|
||||
1. A table is called an entity.
|
||||
2. A field is called an attribute.
|
||||
3. A record is called a tuple.
|
||||
4. The script used to construct the database is called a schema.
|
||||
|
||||
|
||||
|
||||
### Constructing the schema
|
||||
|
||||
To construct the database, use the `CREATE TABLE <table name>` command, then define each field name and data type. This database uses `VARCHAR(n)` (string) and `INT(n)` (integer), where n refers to the number of values that can be stored. For example `INT(2)` could be 01.
|
||||
|
||||
This is the code used to create the two tables:
|
||||
```
|
||||
CREATE TABLE dbo_students
|
||||
|
||||
(
|
||||
|
||||
student_id INT(2) AUTO_INCREMENT NOT NULL,
|
||||
|
||||
student_name VARCHAR(50),
|
||||
|
||||
course_studied INT(2),
|
||||
|
||||
PRIMARY KEY (student_id)
|
||||
|
||||
);
|
||||
|
||||
|
||||
|
||||
CREATE TABLE dbo_courses
|
||||
|
||||
(
|
||||
|
||||
course_id INT(2) AUTO_INCREMENT NOT NULL,
|
||||
|
||||
course_name VARCHAR(30),
|
||||
|
||||
PRIMARY KEY (course_id)
|
||||
|
||||
);
|
||||
|
||||
```
|
||||
|
||||
`NOT NULL` means that the field cannot be empty, and `AUTO_INCREMENT` means that when a new tuple is added, the ID number will be auto-generated with 1 added to the previously stored ID number in order to enforce referential integrity across entities. `PRIMARY KEY` is the unique identifier attribute for each table. This means each tuple has its own distinct identity.
|
||||
|
||||
### Relationships as a constraint
|
||||
|
||||
As it stands, the two tables exist on their own with no connections or relationships. To connect them, a foreign key must be identified. In `dbo_students`, the foreign key is `course_studied`, the source of which is within `dbo_courses`, meaning that the field is referenced. The specific command within SQL is called a `CONSTRAINT`, and this relationship will be added using another command called `ALTER TABLE`, which allows tables to be edited even after the schema has been constructed.
|
||||
|
||||
The following code adds the relationship to the database construction script:
|
||||
```
|
||||
ALTER TABLE dbo_students
|
||||
|
||||
ADD CONSTRAINT FK_course_studied
|
||||
|
||||
FOREIGN KEY (course_studied) REFERENCES dbo_courses(course_id);
|
||||
|
||||
```
|
||||
|
||||
Using the `CONSTRAINT` command is not actually necessary, but it's good practice because it means the constraint can be named and it makes maintenance easier. Now that the database is complete, it's time to add some data.
|
||||
|
||||
### Adding data to the database
|
||||
|
||||
`INSERT INTO <table name>` is the command used to directly choose which attributes (i.e., fields) data is added to. The entity name is defined first, then the attributes. Underneath this command is the data that will be added to that entity, creating a tuple. If `NOT NULL` has been specified, it means that the attribute cannot be left blank. The following code shows how to add records to the table:
|
||||
```
|
||||
INSERT INTO dbo_courses(course_id,course_name)
|
||||
|
||||
VALUES(001,'Software Engineering');
|
||||
|
||||
INSERT INTO dbo_courses(course_id,course_name)
|
||||
|
||||
VALUES(002,'Computer Science');
|
||||
|
||||
INSERT INTO dbo_courses(course_id,course_name)
|
||||
|
||||
VALUES(003,'Computing');
|
||||
|
||||
|
||||
|
||||
INSERT INTO dbo_students(student_id,student_name,course_studied)
|
||||
|
||||
VALUES(001,'student1',001);
|
||||
|
||||
INSERT INTO dbo_students(student_id,student_name,course_studied)
|
||||
|
||||
VALUES(002,'student2',002);
|
||||
|
||||
INSERT INTO dbo_students(student_id,student_name,course_studied)
|
||||
|
||||
VALUES(003,'student3',002);
|
||||
|
||||
INSERT INTO dbo_students(student_id,student_name,course_studied)
|
||||
|
||||
VALUES(004,'student4',003);
|
||||
|
||||
```
|
||||
|
||||
Now that the database schema is complete and data is added, it's time to run queries on the database.
|
||||
|
||||
### Queries
|
||||
|
||||
Queries follow a set structure using these commands:
|
||||
```
|
||||
SELECT <attributes>
|
||||
|
||||
FROM <entity>
|
||||
|
||||
WHERE <condition>
|
||||
|
||||
```
|
||||
|
||||
To display all records within the `dbo_courses` entity and display the course code and course name, use an asterisk. This is a wildcard that eliminates the need to type all attribute names. (Its use is not recommended in production databases.) The code for this query is:
|
||||
```
|
||||
SELECT *
|
||||
|
||||
FROM dbo_courses
|
||||
|
||||
```
|
||||
|
||||
The output of this query shows all tuples in the table, so all available courses can be displayed:
|
||||
```
|
||||
| course_id | course_name |
|
||||
|
||||
|-----------|----------------------|
|
||||
|
||||
| 1 | Software Engineering |
|
||||
|
||||
| 2 | Computer Science |
|
||||
|
||||
| 3 | Computing |
|
||||
|
||||
```
|
||||
|
||||
In a future article, I'll explain more complicated queries using one of the three types of joins: Inner, Outer, or Cross.
|
||||
|
||||
Here is the completed script:
|
||||
```
|
||||
CREATE TABLE dbo_students
|
||||
|
||||
(
|
||||
|
||||
student_id INT(2) AUTO_INCREMENT NOT NULL,
|
||||
|
||||
student_name VARCHAR(50),
|
||||
|
||||
course_studied INT(2),
|
||||
|
||||
PRIMARY KEY (student_id)
|
||||
|
||||
);
|
||||
|
||||
|
||||
|
||||
CREATE TABLE dbo_courses
|
||||
|
||||
(
|
||||
|
||||
course_id INT(2) AUTO_INCREMENT NOT NULL,
|
||||
|
||||
course_name VARCHAR(30),
|
||||
|
||||
PRIMARY KEY (course_id)
|
||||
|
||||
);
|
||||
|
||||
|
||||
|
||||
ALTER TABLE dbo_students
|
||||
|
||||
ADD CONSTRAINT FK_course_studied
|
||||
|
||||
FOREIGN KEY (course_studied) REFERENCES dbo_courses(course_id);
|
||||
|
||||
|
||||
|
||||
INSERT INTO dbo_courses(course_id,course_name)
|
||||
|
||||
VALUES(001,'Software Engineering');
|
||||
|
||||
INSERT INTO dbo_courses(course_id,course_name)
|
||||
|
||||
VALUES(002,'Computer Science');
|
||||
|
||||
INSERT INTO dbo_courses(course_id,course_name)
|
||||
|
||||
VALUES(003,'Computing');
|
||||
|
||||
|
||||
|
||||
INSERT INTO dbo_students(student_id,student_name,course_studied)
|
||||
|
||||
VALUES(001,'student1',001);
|
||||
|
||||
INSERT INTO dbo_students(student_id,student_name,course_studied)
|
||||
|
||||
VALUES(002,'student2',002);
|
||||
|
||||
INSERT INTO dbo_students(student_id,student_name,course_studied)
|
||||
|
||||
VALUES(003,'student3',002);
|
||||
|
||||
INSERT INTO dbo_students(student_id,student_name,course_studied)
|
||||
|
||||
VALUES(004,'student4',003);
|
||||
|
||||
|
||||
|
||||
SELECT *
|
||||
|
||||
FROM dbo_courses
|
||||
|
||||
```
|
||||
|
||||
### Learning more
|
||||
|
||||
SQL isn't difficult; I think it is simpler than programming, and the language is universal to different database systems. Note that `dbo.<entity>` is not a required entity-naming convention; I used it simply because it is the standard in Microsoft SQL Server.
|
||||
|
||||
If you'd like to learn more, the best guide this side of the internet is [W3Schools.com][2]'s comprehensive guide to SQL for all database platforms.
|
||||
|
||||
Please feel free to play around with my database. Also, if you have suggestions or questions, please respond in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/getting-started-sql
|
||||
|
||||
作者:[Aaron Cocker][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/aaroncocker
|
||||
[1]:http://sqlfiddle.com
|
||||
[2]:https://www.w3schools.com/sql/default.asp
|
||||
Loading…
Reference in New Issue
Block a user