mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-03 23:40:14 +08:00
Merge branch 'master' of github.com:LCTT/TranslateProject into 99ff4949-13ae-4e4e-8efc-1927b1f6153b
This commit is contained in:
commit
1f5fe05dbd
102
published/20090203 How the Kernel Manages Your Memory.md
Normal file
102
published/20090203 How the Kernel Manages Your Memory.md
Normal file
@ -0,0 +1,102 @@
|
||||
内核如何管理内存
|
||||
============================================================
|
||||
|
||||
在学习了进程的 [虚拟地址布局][1] 之后,让我们回到内核,来学习它管理用户内存的机制。这里再次使用 Gonzo:
|
||||
|
||||
|
||||
|
||||
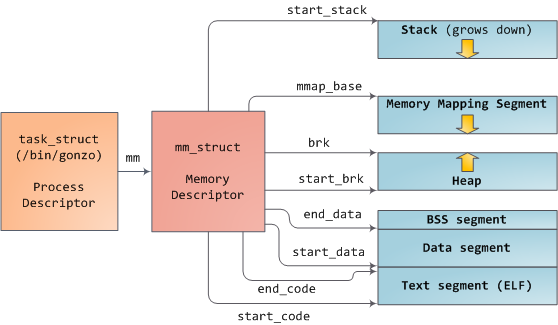
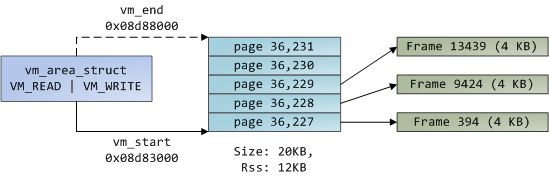
Linux 进程在内核中是作为进程描述符 [task_struct][2] (LCTT 译注:它是在 Linux 中描述进程完整信息的一种数据结构)的实例来实现的。在 task_struct 中的 [mm][3] 域指向到**内存描述符**,[mm_struct][4] 是一个程序在内存中的执行摘要。如上图所示,它保存了起始和结束内存段,进程使用的物理内存页面的 [数量][5](RSS <ruby>常驻内存大小<rt>Resident Set Size</rt></ruby> )、虚拟地址空间使用的 [总数量][6]、以及其它片断。 在内存描述符中,我们可以获悉它有两种管理内存的方式:**虚拟内存区域**集和**页面表**。Gonzo 的内存区域如下所示:
|
||||
|
||||
|
||||
|
||||
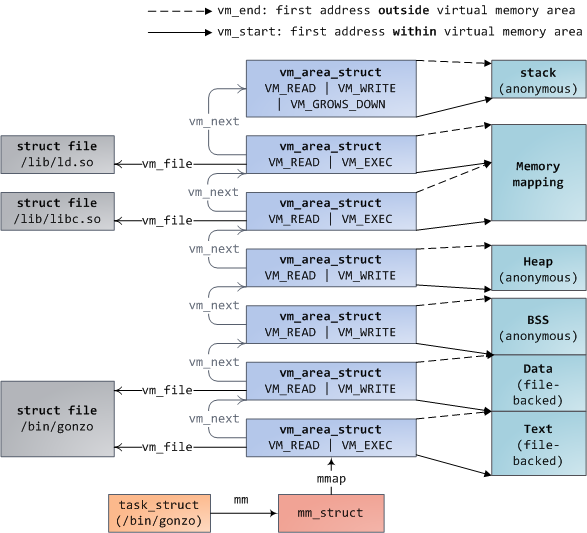
每个虚拟内存区域(VMA)是一个连续的虚拟地址范围;这些区域绝对不会重叠。一个 [vm_area_struct][7] 的实例完整地描述了一个内存区域,包括它的起始和结束地址,[flags][8] 决定了访问权限和行为,并且 [vm_file][9] 域指定了映射到这个区域的文件(如果有的话)。(除了内存映射段的例外情况之外,)一个 VMA 是不能**匿名**映射文件的。上面的每个内存段(比如,堆、栈)都对应一个单个的 VMA。虽然它通常都使用在 x86 的机器上,但它并不是必需的。VMA 也不关心它们在哪个段中。
|
||||
|
||||
一个程序的 VMA 在内存描述符中是作为 [mmap][10] 域的一个链接列表保存的,以起始虚拟地址为序进行排列,并且在 [mm_rb][12] 域中作为一个 [红黑树][11] 的根。红黑树允许内核通过给定的虚拟地址去快速搜索内存区域。在你读取文件 `/proc/pid_of_process/maps` 时,内核只是简单地读取每个进程的 VMA 的链接列表并[显示它们][13]。
|
||||
|
||||
在 Windows 中,[EPROCESS][14] 块大致类似于一个 task_struct 和 mm_struct 的结合。在 Windows 中模拟一个 VMA 的是虚拟地址描述符,或称为 [VAD][15];它保存在一个 [AVL 树][16] 中。你知道关于 Windows 和 Linux 之间最有趣的事情是什么吗?其实它们只有一点小差别。
|
||||
|
||||
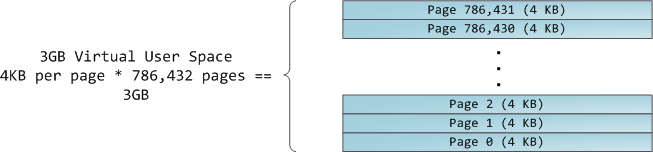
4GB 虚拟地址空间被分配到**页面**中。在 32 位模式中的 x86 处理器中支持 4KB、2MB、以及 4MB 大小的页面。Linux 和 Windows 都使用大小为 4KB 的页面去映射用户的一部分虚拟地址空间。字节 0-4095 在页面 0 中,字节 4096-8191 在页面 1 中,依次类推。VMA 的大小 _必须是页面大小的倍数_ 。下图是使用 4KB 大小页面的总数量为 3GB 的用户空间:
|
||||
|
||||
|
||||
|
||||
处理器通过查看**页面表**去转换一个虚拟内存地址到一个真实的物理内存地址。每个进程都有它自己的一组页面表;每当发生进程切换时,用户空间的页面表也同时切换。Linux 在内存描述符的 [pgd][17] 域中保存了一个指向进程的页面表的指针。对于每个虚拟页面,页面表中都有一个相应的**页面表条目**(PTE),在常规的 x86 页面表中,它是一个简单的如下所示的大小为 4 字节的记录:
|
||||
|
||||

|
||||
|
||||
Linux 通过函数去 [读取][18] 和 [设置][19] PTE 条目中的每个标志位。标志位 P 告诉处理器这个虚拟页面是否**在**物理内存中。如果该位被清除(设置为 0),访问这个页面将触发一个页面故障。请记住,当这个标志位为 0 时,内核可以在剩余的域上**做任何想做的事**。R/W 标志位是读/写标志;如果被清除,这个页面将变成只读的。U/S 标志位表示用户/超级用户;如果被清除,这个页面将仅被内核访问。这些标志都是用于实现我们在前面看到的只读内存和内核空间保护。
|
||||
|
||||
标志位 D 和 A 用于标识页面是否是“**脏的**”或者是已**被访问过**。一个脏页面表示已经被写入,而一个被访问过的页面则表示有一个写入或者读取发生过。这两个标志位都是粘滞位:处理器只能设置它们,而清除则是由内核来完成的。最终,PTE 保存了这个页面相应的起始物理地址,它们按 4KB 进行整齐排列。这个看起来不起眼的域是一些痛苦的根源,因为它限制了物理内存最大为 [4 GB][20]。其它的 PTE 域留到下次再讲,因为它是涉及了物理地址扩展的知识。
|
||||
|
||||
由于在一个虚拟页面上的所有字节都共享一个 U/S 和 R/W 标志位,所以内存保护的最小单元是一个虚拟页面。但是,同一个物理内存可能被映射到不同的虚拟页面,这样就有可能会出现相同的物理内存出现不同的保护标志位的情况。请注意,在 PTE 中是看不到运行权限的。这就是为什么经典的 x86 页面上允许代码在栈上被执行的原因,这样会很容易导致挖掘出栈缓冲溢出漏洞(可能会通过使用 [return-to-libc][21] 和其它技术来找出非可执行栈)。由于 PTE 缺少禁止运行标志位说明了一个更广泛的事实:在 VMA 中的权限标志位有可能或可能不完全转换为硬件保护。内核只能做它能做到的,但是,最终的架构限制了它能做的事情。
|
||||
|
||||
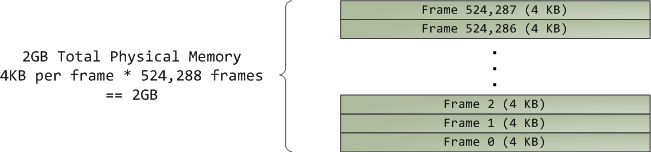
虚拟内存不保存任何东西,它只是简单地 _映射_ 一个程序的地址空间到底层的物理内存上。物理内存被当作一个称之为**物理地址空间**的巨大块而由处理器访问。虽然内存的操作[涉及到某些][22]总线,我们在这里先忽略它,并假设物理地址范围从 0 到可用的最大值按字节递增。物理地址空间被内核进一步分解为**页面帧**。处理器并不会关心帧的具体情况,这一点对内核也是至关重要的,因为,**页面帧是物理内存管理的最小单元**。Linux 和 Windows 在 32 位模式下都使用 4KB 大小的页面帧;下图是一个有 2 GB 内存的机器的例子:
|
||||
|
||||
|
||||
|
||||
在 Linux 上每个页面帧是被一个 [描述符][23] 和 [几个标志][24] 来跟踪的。通过这些描述符和标志,实现了对机器上整个物理内存的跟踪;每个页面帧的具体状态是公开的。物理内存是通过使用 [Buddy 内存分配][25] (LCTT 译注:一种内存分配算法)技术来管理的,因此,如果一个页面帧可以通过 Buddy 系统分配,那么它是**未分配的**(free)。一个被分配的页面帧可以是**匿名的**、持有程序数据的、或者它可能处于页面缓存中、持有数据保存在一个文件或者块设备中。还有其它的异形页面帧,但是这些异形页面帧现在已经不怎么使用了。Windows 有一个类似的页面帧号(Page Frame Number (PFN))数据库去跟踪物理内存。
|
||||
|
||||
我们把虚拟内存区域(VMA)、页面表条目(PTE),以及页面帧放在一起来理解它们是如何工作的。下面是一个用户堆的示例:
|
||||
|
||||
|
||||
|
||||
蓝色的矩形框表示在 VMA 范围内的页面,而箭头表示页面表条目映射页面到页面帧。一些缺少箭头的虚拟页面,表示它们对应的 PTE 的当前标志位被清除(置为 0)。这可能是因为这个页面从来没有被使用过,或者是它的内容已经被交换出去了。在这两种情况下,即便这些页面在 VMA 中,访问它们也将导致产生一个页面故障。对于这种 VMA 和页面表的不一致的情况,看上去似乎很奇怪,但是这种情况却经常发生。
|
||||
|
||||
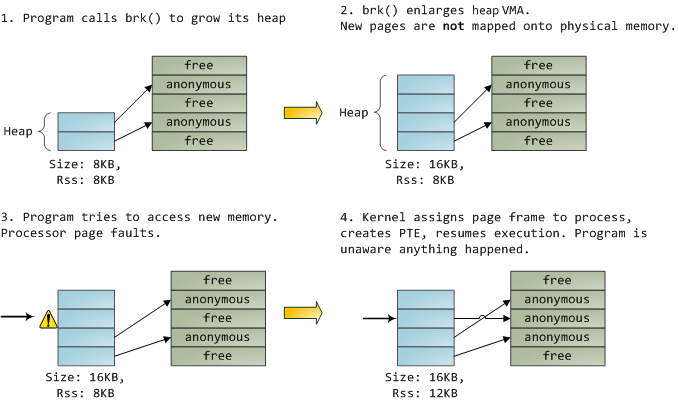
一个 VMA 像一个在你的程序和内核之间的合约。你请求它做一些事情(分配内存、文件映射、等等),内核会回应“收到”,然后去创建或者更新相应的 VMA。 但是,它 _并不立刻_ 去“兑现”对你的承诺,而是它会等待到发生一个页面故障时才去 _真正_ 做这个工作。内核是个“懒惰的家伙”、“不诚实的人渣”;这就是虚拟内存的基本原理。它适用于大多数的情况,有一些类似情况和有一些意外的情况,但是,它是规则是,VMA 记录 _约定的_ 内容,而 PTE 才反映这个“懒惰的内核” _真正做了什么_。通过这两种数据结构共同来管理程序的内存;它们共同来完成解决页面故障、释放内存、从内存中交换出数据、等等。下图是内存分配的一个简单案例:
|
||||
|
||||
|
||||
|
||||
当程序通过 [brk()][26] 系统调用来请求一些内存时,内核只是简单地 [更新][27] 堆的 VMA 并给程序回复“已搞定”。而在这个时候并没有真正地分配页面帧,并且新的页面也没有映射到物理内存上。一旦程序尝试去访问这个页面时,处理器将发生页面故障,然后调用 [do_page_fault()][28]。这个函数将使用 [find_vma()][30] 去 [搜索][29] 发生页面故障的 VMA。如果找到了,然后在 VMA 上进行权限检查以防范恶意访问(读取或者写入)。如果没有合适的 VMA,也没有所尝试访问的内存的“合约”,将会给进程返回段故障。
|
||||
|
||||
当[找到][31]了一个合适的 VMA,内核必须通过查找 PTE 的内容和 VMA 的类型去[处理][32]故障。在我们的案例中,PTE 显示这个页面是 [不存在的][33]。事实上,我们的 PTE 是全部空白的(全部都是 0),在 Linux 中这表示虚拟内存还没有被映射。由于这是匿名 VMA,我们有一个完全的 RAM 事务,它必须被 [do_anonymous_page()][34] 来处理,它分配页面帧,并且用一个 PTE 去映射故障虚拟页面到一个新分配的帧。
|
||||
|
||||
有时候,事情可能会有所不同。例如,对于被交换出内存的页面的 PTE,在当前(Present)标志位上是 0,但它并不是空白的。而是在交换位置仍有页面内容,它必须从磁盘上读取并且通过 [do_swap_page()][35] 来加载到一个被称为 [major fault][36] 的页面帧上。
|
||||
|
||||
这是我们通过探查内核的用户内存管理得出的前半部分的结论。在下一篇文章中,我们通过将文件加载到内存中,来构建一个完整的内存框架图,以及对性能的影响。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://duartes.org/gustavo/blog/post/how-the-kernel-manages-your-memory/
|
||||
|
||||
作者:[Gustavo Duarte][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://duartes.org/gustavo/blog/about/
|
||||
[1]:https://linux.cn/article-9255-1.html
|
||||
[2]:http://lxr.linux.no/linux+v2.6.28.1/include/linux/sched.h#L1075
|
||||
[3]:http://lxr.linux.no/linux+v2.6.28.1/include/linux/sched.h#L1129
|
||||
[4]:http://lxr.linux.no/linux+v2.6.28.1/include/linux/mm_types.h#L173
|
||||
[5]:http://lxr.linux.no/linux+v2.6.28.1/include/linux/mm_types.h#L197
|
||||
[6]:http://lxr.linux.no/linux+v2.6.28.1/include/linux/mm_types.h#L206
|
||||
[7]:http://lxr.linux.no/linux+v2.6.28.1/include/linux/mm_types.h#L99
|
||||
[8]:http://lxr.linux.no/linux+v2.6.28/include/linux/mm.h#L76
|
||||
[9]:http://lxr.linux.no/linux+v2.6.28.1/include/linux/mm_types.h#L150
|
||||
[10]:http://lxr.linux.no/linux+v2.6.28.1/include/linux/mm_types.h#L174
|
||||
[11]:http://en.wikipedia.org/wiki/Red_black_tree
|
||||
[12]:http://lxr.linux.no/linux+v2.6.28.1/include/linux/mm_types.h#L175
|
||||
[13]:http://lxr.linux.no/linux+v2.6.28.1/fs/proc/task_mmu.c#L201
|
||||
[14]:http://www.nirsoft.net/kernel_struct/vista/EPROCESS.html
|
||||
[15]:http://www.nirsoft.net/kernel_struct/vista/MMVAD.html
|
||||
[16]:http://en.wikipedia.org/wiki/AVL_tree
|
||||
[17]:http://lxr.linux.no/linux+v2.6.28.1/include/linux/mm_types.h#L185
|
||||
[18]:http://lxr.linux.no/linux+v2.6.28.1/arch/x86/include/asm/pgtable.h#L173
|
||||
[19]:http://lxr.linux.no/linux+v2.6.28.1/arch/x86/include/asm/pgtable.h#L230
|
||||
[20]:http://www.google.com/search?hl=en&amp;amp;amp;amp;q=2^20+*+2^12+bytes+in+GB
|
||||
[21]:http://en.wikipedia.org/wiki/Return-to-libc_attack
|
||||
[22]:http://duartes.org/gustavo/blog/post/getting-physical-with-memory
|
||||
[23]:http://lxr.linux.no/linux+v2.6.28/include/linux/mm_types.h#L32
|
||||
[24]:http://lxr.linux.no/linux+v2.6.28/include/linux/page-flags.h#L14
|
||||
[25]:http://en.wikipedia.org/wiki/Buddy_memory_allocation
|
||||
[26]:http://www.kernel.org/doc/man-pages/online/pages/man2/brk.2.html
|
||||
[27]:http://lxr.linux.no/linux+v2.6.28.1/mm/mmap.c#L2050
|
||||
[28]:http://lxr.linux.no/linux+v2.6.28/arch/x86/mm/fault.c#L583
|
||||
[29]:http://lxr.linux.no/linux+v2.6.28/arch/x86/mm/fault.c#L692
|
||||
[30]:http://lxr.linux.no/linux+v2.6.28/mm/mmap.c#L1466
|
||||
[31]:http://lxr.linux.no/linux+v2.6.28/arch/x86/mm/fault.c#L711
|
||||
[32]:http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2653
|
||||
[33]:http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2674
|
||||
[34]:http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2681
|
||||
[35]:http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2280
|
||||
[36]:http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2316
|
||||
@ -0,0 +1,435 @@
|
||||
使用 sar 和 kSar 来发现 Linux 性能瓶颈
|
||||
======
|
||||
|
||||
`sar` 命令用用收集、报告、或者保存 UNIX / Linux 系统的活动信息。它保存选择的计数器到操作系统的 `/var/log/sa/sadd` 文件中。从收集的数据中,你可以得到许多关于你的服务器的信息:
|
||||
|
||||
1. CPU 使用率
|
||||
2. 内存页面和使用率
|
||||
3. 网络 I/O 和传输统计
|
||||
4. 进程创建活动
|
||||
5. 所有的块设备活动
|
||||
6. 每秒中断数等等
|
||||
|
||||
`sar` 命令的输出能够用于识别服务器瓶颈。但是,分析 `sar` 命令提供的信息可能比较困难,所以要使用 kSar 工具。kSar 工具可以将 `sar` 命令的输出绘制成基于时间周期的、易于理解的图表。
|
||||
|
||||
### sysstat 包
|
||||
|
||||
`sar`、`sa1`、和 `sa2` 命令都是 sysstat 包的一部分。它是 Linux 包含的性能监视工具集合。
|
||||
|
||||
1. `sar`:显示数据
|
||||
2. `sa1` 和 `sa2`:收集和保存数据用于以后分析。`sa2` shell 脚本在 `/var/log/sa` 目录中每日写入一个报告。`sa1` shell 脚本将每日的系统活动信息以二进制数据的形式写入到文件中。
|
||||
3. sadc —— 系统活动数据收集器。你可以通过修改 `sa1` 和 `sa2` 脚本去配置各种选项。它们位于以下的目录:
|
||||
* `/usr/lib64/sa/sa1` (64 位)或者 `/usr/lib/sa/sa1` (32 位) —— 它调用 `sadc` 去记录报告到 `/var/log/sa/sadX` 格式。
|
||||
* `/usr/lib64/sa/sa2` (64 位)或者 `/usr/lib/sa/sa2` (32 位) —— 它调用 `sar` 去记录报告到 `/var/log/sa/sarX` 格式。
|
||||
|
||||
#### 如何在我的系统上安装 sar?
|
||||
|
||||
在一个基于 CentOS/RHEL 的系统上,输入如下的 [yum 命令][1] 去安装 sysstat:
|
||||
|
||||
```
|
||||
# yum install sysstat
|
||||
```
|
||||
|
||||
示例输出如下:
|
||||
|
||||
```
|
||||
Loaded plugins: downloadonly, fastestmirror, priorities,
|
||||
: protectbase, security
|
||||
Loading mirror speeds from cached hostfile
|
||||
* addons: mirror.cs.vt.edu
|
||||
* base: mirror.ash.fastserv.com
|
||||
* epel: serverbeach1.fedoraproject.org
|
||||
* extras: mirror.cogentco.com
|
||||
* updates: centos.mirror.nac.net
|
||||
0 packages excluded due to repository protections
|
||||
Setting up Install Process
|
||||
Resolving Dependencies
|
||||
--> Running transaction check
|
||||
---> Package sysstat.x86_64 0:7.0.2-3.el5 set to be updated
|
||||
--> Finished Dependency Resolution
|
||||
|
||||
Dependencies Resolved
|
||||
|
||||
====================================================================
|
||||
Package Arch Version Repository Size
|
||||
====================================================================
|
||||
Installing:
|
||||
sysstat x86_64 7.0.2-3.el5 base 173 k
|
||||
|
||||
Transaction Summary
|
||||
====================================================================
|
||||
Install 1 Package(s)
|
||||
Update 0 Package(s)
|
||||
Remove 0 Package(s)
|
||||
|
||||
Total download size: 173 k
|
||||
Is this ok [y/N]: y
|
||||
Downloading Packages:
|
||||
sysstat-7.0.2-3.el5.x86_64.rpm | 173 kB 00:00
|
||||
Running rpm_check_debug
|
||||
Running Transaction Test
|
||||
Finished Transaction Test
|
||||
Transaction Test Succeeded
|
||||
Running Transaction
|
||||
Installing : sysstat 1/1
|
||||
|
||||
Installed:
|
||||
sysstat.x86_64 0:7.0.2-3.el5
|
||||
|
||||
Complete!
|
||||
```
|
||||
|
||||
#### 为 sysstat 配置文件
|
||||
|
||||
编辑 `/etc/sysconfig/sysstat` 文件去指定日志文件保存多少天(最长为一个月):
|
||||
|
||||
```
|
||||
# vi /etc/sysconfig/sysstat
|
||||
```
|
||||
|
||||
示例输出如下 :
|
||||
|
||||
```
|
||||
# keep log for 28 days
|
||||
# the default is 7
|
||||
HISTORY=28
|
||||
```
|
||||
|
||||
保存并关闭这个文件。
|
||||
|
||||
### 找到 sar 默认的 cron 作业
|
||||
|
||||
[默认的 cron 作业位于][2] `/etc/cron.d/sysstat`:
|
||||
|
||||
```
|
||||
# cat /etc/cron.d/sysstat
|
||||
```
|
||||
|
||||
示例输出如下:
|
||||
|
||||
```
|
||||
# run system activity accounting tool every 10 minutes
|
||||
*/10 * * * * root /usr/lib64/sa/sa1 1 1
|
||||
# generate a daily summary of process accounting at 23:53
|
||||
53 23 * * * root /usr/lib64/sa/sa2 -A
|
||||
```
|
||||
|
||||
#### 告诉 sadc 去报告磁盘的统计数据
|
||||
|
||||
使用一个文本编辑器去编辑 `/etc/cron.d/sysstat` 文件,比如使用 `vim` 命令,输入如下:
|
||||
|
||||
```
|
||||
# vi /etc/cron.d/sysstat
|
||||
```
|
||||
|
||||
像下面的示例那样更新这个文件,以记录所有的硬盘统计数据(`-d` 选项强制记录每个块设备的统计数据,而 `-I` 选项强制记录所有系统中断的统计数据):
|
||||
|
||||
```
|
||||
# run system activity accounting tool every 10 minutes
|
||||
*/10 * * * * root /usr/lib64/sa/sa1 -I -d 1 1
|
||||
# generate a daily summary of process accounting at 23:53
|
||||
53 23 * * * root /usr/lib64/sa/sa2 -A
|
||||
```
|
||||
|
||||
在 CentOS/RHEL 7.x 系统上你需要传递 `-S DISK` 选项去收集块设备的数据。传递 `-S XALL` 选项去采集如下所列的数据:
|
||||
|
||||
1. 磁盘
|
||||
2. 分区
|
||||
3. 系统中断
|
||||
4. SNMP
|
||||
5. IPv6
|
||||
|
||||
```
|
||||
# Run system activity accounting tool every 10 minutes
|
||||
*/10 * * * * root /usr/lib64/sa/sa1 -S DISK 1 1
|
||||
# 0 * * * * root /usr/lib64/sa/sa1 600 6 &
|
||||
# Generate a daily summary of process accounting at 23:53
|
||||
53 23 * * * root /usr/lib64/sa/sa2 -A
|
||||
# Run system activity accounting tool every 10 minutes
|
||||
```
|
||||
|
||||
保存并关闭这个文件。
|
||||
|
||||
#### 打开 CentOS/RHEL 版本 5.x/6.x 的服务
|
||||
|
||||
输入如下命令:
|
||||
|
||||
```
|
||||
chkconfig sysstat on
|
||||
service sysstat start
|
||||
```
|
||||
|
||||
示例输出如下:
|
||||
|
||||
```
|
||||
Calling the system activity data collector (sadc):
|
||||
```
|
||||
|
||||
对于 CentOS/RHEL 7.x,运行如下的命令:
|
||||
|
||||
```
|
||||
# systemctl enable sysstat
|
||||
# systemctl start sysstat.service
|
||||
# systemctl status sysstat.service
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
● sysstat.service - Resets System Activity Logs
|
||||
Loaded: loaded (/usr/lib/systemd/system/sysstat.service; enabled; vendor preset: enabled)
|
||||
Active: active (exited) since Sat 2018-01-06 16:33:19 IST; 3s ago
|
||||
Process: 28297 ExecStart=/usr/lib64/sa/sa1 --boot (code=exited, status=0/SUCCESS)
|
||||
Main PID: 28297 (code=exited, status=0/SUCCESS)
|
||||
|
||||
Jan 06 16:33:19 centos7-box systemd[1]: Starting Resets System Activity Logs...
|
||||
Jan 06 16:33:19 centos7-box systemd[1]: Started Resets System Activity Logs.
|
||||
```
|
||||
|
||||
### 如何使用 sar?如何查看统计数据?
|
||||
|
||||
使用 `sar` 命令去显示操作系统中选定的累积活动计数器输出。在这个示例中,运行 `sar` 命令行,去实时获得 CPU 使用率的报告:
|
||||
|
||||
```
|
||||
# sar -u 3 10
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
Linux 2.6.18-164.2.1.el5 (www-03.nixcraft.in) 12/14/2009
|
||||
|
||||
09:49:47 PM CPU %user %nice %system %iowait %steal %idle
|
||||
09:49:50 PM all 5.66 0.00 1.22 0.04 0.00 93.08
|
||||
09:49:53 PM all 12.29 0.00 1.93 0.04 0.00 85.74
|
||||
09:49:56 PM all 9.30 0.00 1.61 0.00 0.00 89.10
|
||||
09:49:59 PM all 10.86 0.00 1.51 0.04 0.00 87.58
|
||||
09:50:02 PM all 14.21 0.00 3.27 0.04 0.00 82.47
|
||||
09:50:05 PM all 13.98 0.00 4.04 0.04 0.00 81.93
|
||||
09:50:08 PM all 6.60 6.89 1.26 0.00 0.00 85.25
|
||||
09:50:11 PM all 7.25 0.00 1.55 0.04 0.00 91.15
|
||||
09:50:14 PM all 6.61 0.00 1.09 0.00 0.00 92.31
|
||||
09:50:17 PM all 5.71 0.00 0.96 0.00 0.00 93.33
|
||||
Average: all 9.24 0.69 1.84 0.03 0.00 88.20
|
||||
```
|
||||
|
||||
其中:
|
||||
|
||||
* 3 表示间隔时间
|
||||
* 10 表示次数
|
||||
|
||||
查看进程创建的统计数据,输入:
|
||||
|
||||
```
|
||||
# sar -c 3 10
|
||||
```
|
||||
|
||||
查看 I/O 和传输率统计数据,输入:
|
||||
|
||||
```
|
||||
# sar -b 3 10
|
||||
```
|
||||
|
||||
查看内存页面统计数据,输入:
|
||||
|
||||
```
|
||||
# sar -B 3 10
|
||||
```
|
||||
|
||||
查看块设备统计数据,输入:
|
||||
|
||||
```
|
||||
# sar -d 3 10
|
||||
```
|
||||
|
||||
查看所有中断的统计数据,输入:
|
||||
|
||||
```
|
||||
# sar -I XALL 3 10
|
||||
```
|
||||
|
||||
查看网络设备特定的统计数据,输入:
|
||||
|
||||
```
|
||||
# sar -n DEV 3 10
|
||||
# sar -n EDEV 3 10
|
||||
```
|
||||
|
||||
查看 CPU 特定的统计数据,输入:
|
||||
|
||||
```
|
||||
# sar -P ALL
|
||||
# Only 1st CPU stats
|
||||
# sar -P 1 3 10
|
||||
```
|
||||
|
||||
查看队列长度和平均负载的统计数据,输入:
|
||||
|
||||
```
|
||||
# sar -q 3 10
|
||||
```
|
||||
|
||||
查看内存和交换空间的使用统计数据,输入:
|
||||
|
||||
```
|
||||
# sar -r 3 10
|
||||
# sar -R 3 10
|
||||
```
|
||||
|
||||
查看 inode、文件、和其它内核表统计数据状态,输入:
|
||||
|
||||
```
|
||||
# sar -v 3 10
|
||||
```
|
||||
|
||||
查看系统切换活动统计数据,输入:
|
||||
|
||||
```
|
||||
# sar -w 3 10
|
||||
```
|
||||
|
||||
查看交换统计数据,输入:
|
||||
|
||||
```
|
||||
# sar -W 3 10
|
||||
```
|
||||
|
||||
查看一个 PID 为 3256 的 Apache 进程,输入:
|
||||
|
||||
```
|
||||
# sar -x 3256 3 10
|
||||
```
|
||||
|
||||
### kSar 介绍
|
||||
|
||||
`sar` 和 `sadf` 提供了基于命令行界面的输出。这种输出可能会使新手用户/系统管理员感到无从下手。因此,你需要使用 kSar,它是一个图形化显示你的 `sar` 数据的 Java 应用程序。它也允许你以 PDF/JPG/PNG/CSV 格式导出数据。你可以用三种方式去加载数据:本地文件、运行本地命令、以及通过 SSH 远程运行的命令。kSar 可以处理下列操作系统的 `sar` 输出:
|
||||
|
||||
1. Solaris 8, 9 和 10
|
||||
2. Mac OS/X 10.4+
|
||||
3. Linux (Systat Version >= 5.0.5)
|
||||
4. AIX (4.3 & 5.3)
|
||||
5. HPUX 11.00+
|
||||
|
||||
#### 下载和安装 kSar
|
||||
|
||||
访问 [官方][3] 网站去获得最新版本的源代码。使用 [wget][4] 去下载源代码,输入:
|
||||
|
||||
```
|
||||
$ wget https://github.com/vlsi/ksar/releases/download/v5.2.4-snapshot-652bf16/ksar-5.2.4-SNAPSHOT-all.jar
|
||||
```
|
||||
|
||||
#### 如何运行 kSar?
|
||||
|
||||
首先要确保你的机器上 [JAVA jdk][5] 已安装并能够正常工作。输入下列命令去启动 kSar:
|
||||
|
||||
```
|
||||
$ java -jar ksar-5.2.4-SNAPSHOT-all.jar
|
||||
```
|
||||
|
||||
![Fig.01: kSar welcome screen][6]
|
||||
|
||||
接下来你将看到 kSar 的主窗口,和有两个菜单的面板。
|
||||
|
||||
![Fig.02: kSar - the main window][7]
|
||||
|
||||
左侧有一个列表,是 kSar 根据数据已经解析出的可用图表的列表。右侧窗口将展示你选定的图表。
|
||||
|
||||
#### 如何使用 kSar 去生成 sar 图表?
|
||||
|
||||
首先,你需要从命名为 server1 的服务器上采集 `sar` 命令的统计数据。输入如下的命令:
|
||||
|
||||
```
|
||||
[ server1 ]# LC_ALL=C sar -A > /tmp/sar.data.txt
|
||||
```
|
||||
|
||||
接下来,使用 `scp` 命令从本地桌面拷贝到远程电脑上:
|
||||
|
||||
```
|
||||
[ desktop ]$ scp user@server1.nixcraft.com:/tmp/sar.data.txt /tmp/
|
||||
```
|
||||
|
||||
切换到 kSar 窗口,点击 “Data” > “Load data from text file” > 从 `/tmp/` 中选择 `sar.data.txt` > 点击 “Open” 按钮。
|
||||
|
||||
现在,图表类型树已经出现在左侧面板中并选定了一个图形:
|
||||
|
||||
![Fig.03: Processes for server1][8]
|
||||
|
||||
![Fig.03: Disk stats (blok device) stats for server1][9]
|
||||
|
||||
![Fig.05: Memory stats for server1][10]
|
||||
|
||||
##### 放大和缩小
|
||||
|
||||
通过移动你可以交互式缩放图像的一部分。在要缩放的图像的左上角点击并按下鼠标,移动到要缩放区域的右下角,可以选定要缩放的区域。返回到未缩放状态,点击并拖动鼠标到除了右下角外的任意位置,你也可以点击并选择 zoom 选项。
|
||||
|
||||
##### 了解 kSar 图像和 sar 数据
|
||||
|
||||
我强烈建议你去阅读 `sar` 和 `sadf` 命令的 man 页面:
|
||||
|
||||
```
|
||||
$ man sar
|
||||
$ man sadf
|
||||
```
|
||||
|
||||
### 案例学习:识别 Linux 服务器的 CPU 瓶颈
|
||||
|
||||
使用 `sar` 命令和 kSar 工具,可以得到内存、CPU、以及其它子系统的详细快照。例如,如果 CPU 使用率在一个很长的时间内持续高于 80%,有可能就是出现了一个 CPU 瓶颈。使用 `sar -x ALL` 你可以找到大量消耗 CPU 的进程。
|
||||
|
||||
[mpstat 命令][11] 的输出(sysstat 包的一部分)也会帮你去了解 CPU 的使用率。但你可以使用 kSar 很容易地去分析这些信息。
|
||||
|
||||
#### 找出 CPU 瓶颈后 …
|
||||
|
||||
对 CPU 执行如下的调整:
|
||||
|
||||
1. 确保没有不需要的进程在后台运行。关闭 [Linux 上所有不需要的服务][12]。
|
||||
2. 使用 [cron][13] 在一个非高峰时刻运行任务(比如,备份)。
|
||||
3. 使用 [top 和 ps 命令][14] 去找出所有非关键的后台作业/服务。使用 [renice 命令][15] 去调整低优先级作业。
|
||||
4. 使用 [taskset 命令去设置进程使用的 CPU ][16] (卸载所使用的 CPU),即,绑定进程到不同的 CPU 上。例如,在 2# CPU 上运行 MySQL 数据库,而在 3# CPU 上运行 Apache。
|
||||
5. 确保你的系统使用了最新的驱动程序和固件。
|
||||
6. 如有可能在系统上增加额外的 CPU。
|
||||
7. 为单线程应用程序使用更快的 CPU(比如,Lighttpd web 服务器应用程序)。
|
||||
8. 为多线程应用程序使用多个 CPU(比如,MySQL 数据库服务器应用程序)。
|
||||
9. 为一个 web 应用程序使用多个计算节点并设置一个 [负载均衡器][17]。
|
||||
|
||||
### isag —— 交互式系统活动记录器(替代工具)
|
||||
|
||||
`isag` 命令图形化显示了以前运行 `sar` 命令时存储在二进制文件中的系统活动数据。`isag` 命令引用 `sar` 并提取出它的数据来绘制图形。与 kSar 相比,`isag` 的选项比较少。
|
||||
|
||||
![Fig.06: isag CPU utilization graphs][18]
|
||||
|
||||
### 关于作者
|
||||
|
||||
本文作者是 nixCraft 的创始人和一位经验丰富的 Linux 操作系统/Unix shell 脚本培训师。他与包括 IT、教育、国防和空间研究、以及非营利组织等全球各行业客户一起合作。可以在 [Twitter][19]、[Facebook][20]、[Google+][21] 上关注他。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/tips/identifying-linux-bottlenecks-sar-graphs-with-ksar.html
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/ "See Linux/Unix yum command examples for more info"
|
||||
[2]:https://www.cyberciti.biz/faq/how-do-i-add-jobs-to-cron-under-linux-or-unix-oses/
|
||||
[3]:https://github.com/vlsi/ksar
|
||||
[4]:https://www.cyberciti.biz/tips/linux-wget-your-ultimate-command-line-downloader.html
|
||||
[5]:https://www.cyberciti.biz/faq/howto-ubuntu-linux-install-configure-jdk-jre/
|
||||
[6]:https://www.cyberciti.biz/media/new/tips/2009/12/sar-welcome.png "kSar welcome screen"
|
||||
[7]:https://www.cyberciti.biz/media/new/tips/2009/12/screenshot-kSar-a-sar-grapher-01.png "kSar - the main window"
|
||||
[8]:https://www.cyberciti.biz/media/new/tips/2009/12/cpu-ksar.png "Linux kSar Processes for server1 "
|
||||
[9]:https://www.cyberciti.biz/media/new/tips/2009/12/disk-stats-ksar.png "Linux Disk I/O Stats Using kSar"
|
||||
[10]:https://www.cyberciti.biz/media/new/tips/2009/12/memory-ksar.png "Linux Memory paging and its utilization stats"
|
||||
[11]:https://www.cyberciti.biz/tips/how-do-i-find-out-linux-cpu-utilization.html
|
||||
[12]:https://www.cyberciti.biz/faq/check-running-services-in-rhel-redhat-fedora-centoslinux/
|
||||
[13]:https://www.cyberciti.biz/faq/how-do-i-add-jobs-to-cron-under-linux-or-unix-oses/
|
||||
[14]:https://www.cyberciti.biz/faq/show-all-running-processes-in-linux/
|
||||
[15]:https://www.cyberciti.biz/faq/howto-change-unix-linux-process-priority/
|
||||
[16]:https://www.cyberciti.biz/faq/taskset-cpu-affinity-command/
|
||||
[17]:https://www.cyberciti.biz/tips/load-balancer-open-source-software.html
|
||||
[18]:https://www.cyberciti.biz/media/new/tips/2009/12/isag.cpu_.png "Fig.06: isag CPU utilization graphs"
|
||||
[19]:https://twitter.com/nixcraft
|
||||
[20]:https://facebook.com/nixcraft
|
||||
[21]:https://plus.google.com/+CybercitiBiz
|
||||
@ -1,26 +1,27 @@
|
||||
让我们做个简单的解释器(1)
|
||||
让我们做个简单的解释器(一)
|
||||
======
|
||||
|
||||
> “如果你不知道编译器是怎么工作的,那你就不知道电脑是怎么工作的。如果你不能百分百确定,那就是不知道它们是如何工作的。” --Steve Yegge
|
||||
|
||||
> **" If you don't know how compilers work, then you don't know how computers work. If you're not 100% sure whether you know how compilers work, then you don't know how they work."** -- Steve Yegge
|
||||
> **“如果你不知道编译器是怎么工作的,那你就不知道电脑是怎么工作的。如果你不能百分百确定,那就是不知道他们是如何工作的。”** --Steve Yegge
|
||||
就是这样。想一想。你是萌新还是一个资深的软件开发者实际上都无关紧要:如果你不知道<ruby>编译器<rt>compiler</rt></ruby>和<ruby>解释器<rt>interpreter</rt></ruby>是怎么工作的,那么你就不知道电脑是怎么工作的。就这么简单。
|
||||
|
||||
就是这样。想一想。你是萌新还是一个资深的软件开发者实际上都无关紧要:如果你不知道编译器和解释器是怎么工作的,那么你就不知道电脑是怎么工作的。就这么简单。
|
||||
所以,你知道编译器和解释器是怎么工作的吗?我是说,你百分百确定自己知道他们怎么工作吗?如果不知道。
|
||||
|
||||
所以,你知道编译器和解释器是怎么工作的吗?我是说,你百分百确定自己知道他们怎么工作吗?如果不知道。![][1]
|
||||
![][1]
|
||||
|
||||
或者如果你不知道但你非常想要了解它。 ![][2]
|
||||
或者如果你不知道但你非常想要了解它。
|
||||
|
||||
不用担心。如果你能坚持跟着这个系列做下去,和我一起构建一个解释器和编译器,最后你将会知道他们是怎么工作的。并且你会变成一个自信满满的快乐的人。至少我希望如此。![][3]。
|
||||
![][2]
|
||||
|
||||
不用担心。如果你能坚持跟着这个系列做下去,和我一起构建一个解释器和编译器,最后你将会知道他们是怎么工作的。并且你会变成一个自信满满的快乐的人。至少我希望如此。
|
||||
|
||||
![][3]
|
||||
|
||||
为什么要学习编译器和解释器?有三点理由。
|
||||
|
||||
1. 要写出一个解释器或编译器,你需要有很多的专业知识,并能融会贯通。写一个解释器或编译器能帮你加强这些能力,成为一个更厉害的软件开发者。而且,你要学的技能对写软件非常有用,而不是仅仅局限于解释器或编译器。
|
||||
2. 你确实想要了解电脑是怎么工作的。一般解释器和编译器看上去很魔幻。你或许不习惯这种魔力。你会想去揭开构建解释器和编译器那层神秘的面纱,了解他们的原理,把事情做好。
|
||||
3. 你想要创建自己的编程语言或者特定领域的语言。如果你创建了一个,你还要为它创建一个解释器或者编译器。最近,兴起了对新的编程语言的兴趣。你能看到几乎每天都有一门新的编程语言横空出世:Elixir,Go,Rust,还有很多。
|
||||
|
||||
|
||||
|
||||
1. 要写出一个解释器或编译器,你需要有很多的专业知识,并能融会贯通。写一个解释器或编译器能帮你加强这些能力,成为一个更厉害的软件开发者。而且,你要学的技能对编写软件非常有用,而不是仅仅局限于解释器或编译器。
|
||||
2. 你确实想要了解电脑是怎么工作的。通常解释器和编译器看上去很魔幻。你或许不习惯这种魔力。你会想去揭开构建解释器和编译器那层神秘的面纱,了解它们的原理,把事情做好。
|
||||
3. 你想要创建自己的编程语言或者特定领域的语言。如果你创建了一个,你还要为它创建一个解释器或者编译器。最近,兴起了对新的编程语言的兴趣。你能看到几乎每天都有一门新的编程语言横空出世:Elixir,Go,Rust,还有很多。
|
||||
|
||||
好,但什么是解释器和编译器?
|
||||
|
||||
@ -32,11 +33,12 @@
|
||||
|
||||
我希望你现在确信你很想学习构建一个编译器和解释器。你期望在这个教程里学习解释器的哪些知识呢?
|
||||
|
||||
你看这样如何。你和我一起做一个简单的解释器当作 [Pascal][5] 语言的子集。在这个系列结束的时候你能做出一个可以运行的 Pascal 解释器和一个像 Python 的 [pdb][6] 那样的源代码级别的调试器。
|
||||
你看这样如何。你和我一起为 [Pascal][5] 语言的一个大子集做一个简单的解释器。在这个系列结束的时候你能做出一个可以运行的 Pascal 解释器和一个像 Python 的 [pdb][6] 那样的源代码级别的调试器。
|
||||
|
||||
你或许会问,为什么是 Pascal?有一点,它不是我为了这个系列而提出的一个虚构的语言:它是真实存在的一门编程语言,有很多重要的语言结构。有些陈旧但有用的计算机书籍使用 Pascal 编程语言作为示例(我知道对于选择一门语言来构建解释器,这个理由并不令人信服,但我认为学一门非主流的语言也不错:)。
|
||||
你或许会问,为什么是 Pascal?一方面,它不是我为了这个系列而提出的一个虚构的语言:它是真实存在的一门编程语言,有很多重要的语言结构。有些陈旧但有用的计算机书籍使用 Pascal 编程语言作为示例(我知道对于选择一门语言来构建解释器,这个理由并不令人信服,但我认为学一门非主流的语言也不错 :))。
|
||||
|
||||
这有个 Pascal 中的阶乘函数示例,你将能用自己的解释器解释代码,还能够用可交互的源码级调试器进行调试,你可以这样创造:
|
||||
|
||||
这有个 Pascal 中的阶乘函数示例,你能用自己的解释器解释代码,还能够用可交互的源码级调试器进行调试,你可以这样创造:
|
||||
```
|
||||
program factorial;
|
||||
|
||||
@ -57,15 +59,14 @@ begin
|
||||
end.
|
||||
```
|
||||
|
||||
这个 Pascal 解释器的实现语言会用 Python,但你也可以用其他任何语言,因为这里展示的思想不依赖任何特殊的实现语言。好,让我们开始干活。准备好了,出发!
|
||||
|
||||
你会从编写一个简单的算术表达式解析器,也就是常说的计算器,开始学习解释器和编译器。今天的目标非常简单:让你的计算器能处理两个个位数相加,比如 **3+5**。这是你的计算器的源代码,不好意思,是解释器:
|
||||
这个 Pascal 解释器的实现语言会使用 Python,但你也可以用其他任何语言,因为这里展示的思想不依赖任何特殊的实现语言。好,让我们开始干活。准备好了,出发!
|
||||
|
||||
你会从编写一个简单的算术表达式解析器,也就是常说的计算器,开始学习解释器和编译器。今天的目标非常简单:让你的计算器能处理两个个位数相加,比如 `3+5`。下面是你的计算器的源代码——不好意思,是解释器:
|
||||
|
||||
```
|
||||
# 标记类型
|
||||
#
|
||||
# EOF (end-of-file 文件末尾) 标记是用来表示所有输入都解析完成
|
||||
# EOF (end-of-file 文件末尾)标记是用来表示所有输入都解析完成
|
||||
INTEGER, PLUS, EOF = 'INTEGER', 'PLUS', 'EOF'
|
||||
|
||||
|
||||
@ -73,7 +74,7 @@ class Token(object):
|
||||
def __init__(self, type, value):
|
||||
# token 类型: INTEGER, PLUS, MINUS, or EOF
|
||||
self.type = type
|
||||
# token 值: 0, 1, 2. 3, 4, 5, 6, 7, 8, 9, '+', 或 None
|
||||
# token 值: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, '+', 或 None
|
||||
self.value = value
|
||||
|
||||
def __str__(self):
|
||||
@ -187,7 +188,8 @@ if __name__ == '__main__':
|
||||
```
|
||||
|
||||
|
||||
把上面的代码保存到 calc1.py 文件,或者直接从 [GitHub][7] 上下载。在你深入研究代码前,在命令行里面运行它看看效果。试一试!这是我笔记本上的示例会话(如果你想在 Python3 下运行,你要把 raw_input 换成 input):
|
||||
把上面的代码保存到 `calc1.py` 文件,或者直接从 [GitHub][7] 上下载。在你深入研究代码前,在命令行里面运行它看看效果。试一试!这是我笔记本上的示例会话(如果你想在 Python3 下运行,你要把 `raw_input` 换成 `input`):
|
||||
|
||||
```
|
||||
$ python calc1.py
|
||||
calc> 3+4
|
||||
@ -205,31 +207,32 @@ calc>
|
||||
* 此时支持的唯一一个运算符是加法
|
||||
* 输入中不允许有任何的空格符号
|
||||
|
||||
|
||||
|
||||
要让计算器变得简单,这些限制非常必要。不用担心,你很快就会让它变得很复杂。
|
||||
|
||||
好,现在让我们深入它,看看解释器是怎么工作,它是怎么评估出算术表达式的。
|
||||
|
||||
当你在命令行中输入一个表达式 3+5,解释器就获得了字符串 “3+5”。为了让解释器能够真正理解要用这个字符串做什么,它首先要把输入 “3+5” 分到叫做 **token(标记)** 的容器里。**标记** 是一个拥有类型和值的对象。比如说,对字符 “3” 而言,标记的类型是 INTEGER 整数,对应的值是 3。
|
||||
当你在命令行中输入一个表达式 `3+5`,解释器就获得了字符串 “3+5”。为了让解释器能够真正理解要用这个字符串做什么,它首先要把输入 “3+5” 分到叫做 `token`(标记)的容器里。<ruby>标记<rt>token</rt></ruby> 是一个拥有类型和值的对象。比如说,对字符 “3” 而言,标记的类型是 INTEGER 整数,对应的值是 3。
|
||||
|
||||
把输入字符串分成标记的过程叫 **词法分析**。因此解释器的需要做的第一步是读取输入字符,并将其转换成标记流。解释器中的这一部分叫做 **词法分析器**,或者简短点叫 **lexer**。你也可以给它起别的名字,诸如 **扫描器** 或者 **标记器**。他们指的都是同一个东西:解释器或编译器中将输入字符转换成标记流的那部分。
|
||||
把输入字符串分成标记的过程叫<ruby>词法分析<rt>lexical analysis</rt></ruby>。因此解释器的需要做的第一步是读取输入字符,并将其转换成标记流。解释器中的这一部分叫做<ruby>词法分析器<rt>lexical analyzer</rt></ruby>,或者简短点叫 **lexer**。你也可以给它起别的名字,诸如<ruby>扫描器<rt>scanner</rt></ruby>或者<ruby>标记器<rt>tokenizer</rt></ruby>。它们指的都是同一个东西:解释器或编译器中将输入字符转换成标记流的那部分。
|
||||
|
||||
Interpreter 类中的 get_next_token 方法就是词法分析器。每次调用它的时候,你都能从传入解释器的输入字符中获得创建的下一个标记。仔细看看这个方法,看看它是如何完成把字符转换成标记的任务的。输入被存在可变文本中,它保存了输入的字符串和关于该字符串的索引(把字符串想象成字符数组)。pos 开始时设为 0,指向 ‘3’.这个方法一开始检查字符是不是数字,如果是,就将 pos 加 1,并返回一个 INTEGER 类型的标记实例,并把字符 ‘3’ 的值设为整数,也就是整数 3:
|
||||
`Interpreter` 类中的 `get_next_token` 方法就是词法分析器。每次调用它的时候,你都能从传入解释器的输入字符中获得创建的下一个标记。仔细看看这个方法,看看它是如何完成把字符转换成标记的任务的。输入被存在可变文本中,它保存了输入的字符串和关于该字符串的索引(把字符串想象成字符数组)。`pos` 开始时设为 0,指向字符 ‘3’。这个方法一开始检查字符是不是数字,如果是,就将 `pos` 加 1,并返回一个 INTEGER 类型的标记实例,并把字符 ‘3’ 的值设为整数,也就是整数 3:
|
||||
|
||||
![][8]
|
||||
|
||||
现在 pos 指向文本中的 ‘+’ 号。下次调用这个方法的时候,它会测试 pos 位置的字符是不是个数字,然后检测下一个字符是不是个加号,就是这样。结果这个方法把 pos 加一,返回一个新创建的标记,类型是 PLUS,值为 ‘+’。
|
||||
现在 `pos` 指向文本中的 ‘+’ 号。下次调用这个方法的时候,它会测试 `pos` 位置的字符是不是个数字,然后检测下一个字符是不是个加号,就是这样。结果这个方法把 `pos` 加 1,返回一个新创建的标记,类型是 PLUS,值为 ‘+’。
|
||||
|
||||
![][9]
|
||||
|
||||
pos 现在指向字符 ‘5’。当你再调用 get_next_token 方法时,该方法会检查这是不是个数字,就是这样,然后它把 pos 加一,返回一个新的 INTEGER 标记,该标记的值被设为 5:
|
||||
`pos` 现在指向字符 ‘5’。当你再调用 `get_next_token` 方法时,该方法会检查这是不是个数字,就是这样,然后它把 `pos` 加 1,返回一个新的 INTEGER 标记,该标记的值被设为整数 5:
|
||||
|
||||
![][10]
|
||||
|
||||
因为 pos 索引现在到了字符串 “3+5” 的末尾,你每次调用 get_next_token 方法时,它将会返回 EOF 标记:
|
||||
因为 `pos` 索引现在到了字符串 “3+5” 的末尾,你每次调用 `get_next_token` 方法时,它将会返回 EOF 标记:
|
||||
|
||||
![][11]
|
||||
|
||||
自己试一试,看看计算器里的词法分析器的运行:
|
||||
|
||||
```
|
||||
>>> from calc1 import Interpreter
|
||||
>>>
|
||||
@ -248,17 +251,16 @@ Token(EOF, None)
|
||||
>>>
|
||||
```
|
||||
|
||||
既然你的解释器能够从输入字符中获取标记流,解释器需要做点什么:它需要在词法分析器 get_next_token 中获取的标记流中找出相应的结构。你的解释器应该能够找到流中的结构:INTEGER -> PLUS -> INTEGER。就是这样,它尝试找出标记的序列:整数后面要跟着加号,加号后面要跟着整数。
|
||||
既然你的解释器能够从输入字符中获取标记流,解释器需要对它做点什么:它需要在词法分析器 `get_next_token` 中获取的标记流中找出相应的结构。你的解释器应该能够找到流中的结构:INTEGER -> PLUS -> INTEGER。就是这样,它尝试找出标记的序列:整数后面要跟着加号,加号后面要跟着整数。
|
||||
|
||||
负责找出并解释结构的方法就是 expr。该方法检验标记序列确实与期望的标记序列是对应的,比如 INTEGER -> PLUS -> INTEGER。成功确认了这个结构后,就会生成加号左右两边的标记的值相加的结果,这样就成功解释你输入到解释器中的算术表达式了。
|
||||
负责找出并解释结构的方法就是 `expr`。该方法检验标记序列确实与期望的标记序列是对应的,比如 INTEGER -> PLUS -> INTEGER。成功确认了这个结构后,就会生成加号左右两边的标记的值相加的结果,这样就成功解释你输入到解释器中的算术表达式了。
|
||||
|
||||
expr 方法用了一个助手方法 eat 来检验传入的标记类型是否与当前的标记类型相匹配。在匹配到传入的标记类型后,eat 方法获取下一个标记,并将其赋给 current_token 变量,然后高效地 “吃掉” 当前匹配的标记,并将标记流的虚拟指针向后移动。如果标记流的结构与期望的 INTEGER PLUS INTEGER 标记序列不对应,eat 方法就抛出一个异常。
|
||||
`expr` 方法用了一个助手方法 `eat` 来检验传入的标记类型是否与当前的标记类型相匹配。在匹配到传入的标记类型后,`eat` 方法会获取下一个标记,并将其赋给 `current_token` 变量,然后高效地 “吃掉” 当前匹配的标记,并将标记流的虚拟指针向后移动。如果标记流的结构与期望的 INTEGER -> PLUS -> INTEGER 标记序列不对应,`eat` 方法就抛出一个异常。
|
||||
|
||||
让我们回顾下解释器做了什么来对算术表达式进行评估的:
|
||||
|
||||
* 解释器接受输入字符串,就把它当作 “3+5”
|
||||
* 解释器调用 expr 方法,在词法分析器 get_next_token 返回的标记流中找出结构。这个结构就是 INTEGER PLUS INTEGER 这样的格式。在确认了格式后,它就通过把两个整型标记相加解释输入,因为此时对于解释器来说很清楚,他要做的就是把两个整数 3 和 5 进行相加。
|
||||
|
||||
* 解释器接受输入字符串,比如说 “3+5”
|
||||
* 解释器调用 `expr` 方法,在词法分析器 `get_next_token` 返回的标记流中找出结构。这个结构就是 INTEGER -> PLUS -> INTEGER 这样的格式。在确认了格式后,它就通过把两个整型标记相加来解释输入,因为此时对于解释器来说很清楚,它要做的就是把两个整数 3 和 5 进行相加。
|
||||
|
||||
恭喜。你刚刚学习了怎么构建自己的第一个解释器!
|
||||
|
||||
@ -268,42 +270,38 @@ expr 方法用了一个助手方法 eat 来检验传入的标记类型是否与
|
||||
|
||||
看了这篇文章,你肯定觉得不够,是吗?好,准备好做这些练习:
|
||||
|
||||
1. 修改代码,允许输入多位数,比如 “12+3”
|
||||
2. 添加一个方法忽略空格符,让你的计算器能够处理带有空白的输入,比如“12 + 3”
|
||||
3. 修改代码,用 ‘-’ 号而非 ‘+’ 号去执行减法比如 “7-5”
|
||||
|
||||
1. 修改代码,允许输入多位数,比如 “12+3”
|
||||
2. 添加一个方法忽略空格符,让你的计算器能够处理带有空白的输入,比如 “12 + 3”
|
||||
3. 修改代码,用 ‘-’ 号而非 ‘+’ 号去执行减法比如 “7-5”
|
||||
|
||||
**检验你的理解**
|
||||
|
||||
1. 什么是解释器?
|
||||
2. 什么是编译器
|
||||
3. 解释器和编译器有什么差别?
|
||||
4. 什么是标记?
|
||||
5. 将输入分隔成若干个标记的过程叫什么?
|
||||
6. 解释器中进行词法分析的部分叫什么?
|
||||
7. 解释器或编译器中进行词法分析的部分有哪些其他的常见名字?
|
||||
|
||||
|
||||
1. 什么是解释器?
|
||||
2. 什么是编译器
|
||||
3. 解释器和编译器有什么差别?
|
||||
4. 什么是标记?
|
||||
5. 将输入分隔成若干个标记的过程叫什么?
|
||||
6. 解释器中进行词法分析的部分叫什么?
|
||||
7. 解释器或编译器中进行词法分析的部分有哪些其他的常见名字?
|
||||
|
||||
在结束本文前,我衷心希望你能留下学习解释器和编译器的承诺。并且现在就开始做。不要把它留到以后。不要拖延。如果你已经看完了本文,就开始吧。如果已经仔细看完了但是还没做什么练习 —— 现在就开始做吧。如果已经开始做练习了,那就把剩下的做完。你懂得。而且你知道吗?签下承诺书,今天就开始学习解释器和编译器!
|
||||
|
||||
> 本人, ______,身体健全,思想正常,在此承诺从今天开始学习解释器和编译器,直到我百分百了解它们是怎么工作的!
|
||||
|
||||
_本人, ______,身体健全,思想正常,在此承诺从今天开始学习解释器和编译器,直到我百分百了解它们是怎么工作的!_
|
||||
>
|
||||
|
||||
签字人:
|
||||
> 签字人:
|
||||
|
||||
日期:
|
||||
> 日期:
|
||||
|
||||
![][13]
|
||||
|
||||
签字,写上日期,把它放在你每天都能看到的地方,确保你能坚守承诺。谨记你的承诺:
|
||||
|
||||
> "Commitment is doing the thing you said you were going to do long after the mood you said it in has left you." -- Darren Hardy
|
||||
> “承诺就是,你说自己会去做的事,在你说完就一直陪着你的东西。” —— Darren Hardy
|
||||
|
||||
好,今天的就结束了。这个系列的下一篇文章里,你将会扩展自己的计算器,让它能够处理更复杂的算术表达式。敬请期待。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://ruslanspivak.com/lsbasi-part1/
|
||||
@ -311,7 +309,7 @@ via: https://ruslanspivak.com/lsbasi-part1/
|
||||
|
||||
作者:[Ruslan Spivak][a]
|
||||
译者:[BriFuture](https://github.com/BriFuture)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
189
published/20150708 Choosing a Linux Tracer (2015).md
Normal file
189
published/20150708 Choosing a Linux Tracer (2015).md
Normal file
@ -0,0 +1,189 @@
|
||||
Linux 跟踪器之选
|
||||
======
|
||||
|
||||
[![][1]][2]
|
||||
|
||||
> Linux 跟踪很神奇!
|
||||
|
||||
<ruby>跟踪器<rt>tracer</rt></ruby>是一个高级的性能分析和调试工具,如果你使用过 `strace(1)` 或者 `tcpdump(8)`,你不应该被它吓到 ... 你使用的就是跟踪器。系统跟踪器能让你看到很多的东西,而不仅是系统调用或者数据包,因为常见的跟踪器都可以跟踪内核或者应用程序的任何东西。
|
||||
|
||||
有大量的 Linux 跟踪器可供你选择。由于它们中的每个都有一个官方的(或者非官方的)的吉祥物,我们有足够多的选择给孩子们展示。
|
||||
|
||||
你喜欢使用哪一个呢?
|
||||
|
||||
我从两类读者的角度来回答这个问题:大多数人和性能/内核工程师。当然,随着时间的推移,这也可能会发生变化,因此,我需要及时去更新本文内容,或许是每年一次,或者更频繁。(LCTT 译注:本文最后更新于 2015 年)
|
||||
|
||||
### 对于大多数人
|
||||
|
||||
大多数人(开发者、系统管理员、运维人员、网络可靠性工程师(SRE)…)是不需要去学习系统跟踪器的底层细节的。以下是你需要去了解和做的事情:
|
||||
|
||||
#### 1. 使用 perf_events 进行 CPU 剖析
|
||||
|
||||
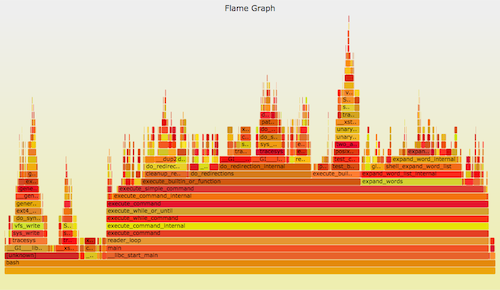
可以使用 perf_events 进行 CPU <ruby>剖析<rt>profiling</rt></ruby>。它可以用一个 [火焰图][3] 来形象地表示。比如:
|
||||
|
||||
```
|
||||
git clone --depth 1 https://github.com/brendangregg/FlameGraph
|
||||
perf record -F 99 -a -g -- sleep 30
|
||||
perf script | ./FlameGraph/stackcollapse-perf.pl | ./FlameGraph/flamegraph.pl > perf.svg
|
||||
```
|
||||
|
||||
|
||||
|
||||
Linux 的 perf_events(即 `perf`,后者是它的命令)是官方为 Linux 用户准备的跟踪器/分析器。它位于内核源码中,并且维护的非常好(而且现在它的功能还在快速变强)。它一般是通过 linux-tools-common 这个包来添加的。
|
||||
|
||||
`perf` 可以做的事情很多,但是,如果我只能建议你学习其中的一个功能的话,那就是 CPU 剖析。虽然从技术角度来说,这并不是事件“跟踪”,而是<ruby>采样<rt>sampling</rt></ruby>。最难的部分是获得完整的栈和符号,这部分在我的 [Linux Profiling at Netflix][4] 中针对 Java 和 Node.js 讨论过。
|
||||
|
||||
#### 2. 知道它能干什么
|
||||
|
||||
正如一位朋友所说的:“你不需要知道 X 光机是如何工作的,但你需要明白的是,如果你吞下了一个硬币,X 光机是你的一个选择!”你需要知道使用跟踪器能够做什么,因此,如果你在业务上确实需要它,你可以以后再去学习它,或者请会使用它的人来做。
|
||||
|
||||
简单地说:几乎任何事情都可以通过跟踪来了解它。内部文件系统、TCP/IP 处理过程、设备驱动、应用程序内部情况。阅读我在 lwn.net 上的 [ftrace][5] 的文章,也可以去浏览 [perf_events 页面][6],那里有一些跟踪(和剖析)能力的示例。
|
||||
|
||||
#### 3. 需要一个前端工具
|
||||
|
||||
如果你要购买一个性能分析工具(有许多公司销售这类产品),并要求支持 Linux 跟踪。想要一个直观的“点击”界面去探查内核的内部,以及包含一个在不同堆栈位置的延迟热力图。就像我在 [Monitorama 演讲][7] 中描述的那样。
|
||||
|
||||
我创建并开源了我自己的一些前端工具,虽然它是基于 CLI 的(不是图形界面的)。这样可以使其它人使用跟踪器更快更容易。比如,我的 [perf-tools][8],跟踪新进程是这样的:
|
||||
|
||||
```
|
||||
# ./execsnoop
|
||||
Tracing exec()s. Ctrl-C to end.
|
||||
PID PPID ARGS
|
||||
22898 22004 man ls
|
||||
22905 22898 preconv -e UTF-8
|
||||
22908 22898 pager -s
|
||||
22907 22898 nroff -mandoc -rLL=164n -rLT=164n -Tutf8
|
||||
[...]
|
||||
```
|
||||
|
||||
在 Netflix 公司,我正在开发 [Vector][9],它是一个实例分析工具,实际上它也是一个 Linux 跟踪器的前端。
|
||||
|
||||
### 对于性能或者内核工程师
|
||||
|
||||
一般来说,我们的工作都非常难,因为大多数人或许要求我们去搞清楚如何去跟踪某个事件,以及因此需要选择使用哪个跟踪器。为完全理解一个跟踪器,你通常需要花至少一百多个小时去使用它。理解所有的 Linux 跟踪器并能在它们之间做出正确的选择是件很难的事情。(我或许是唯一接近完成这件事的人)
|
||||
|
||||
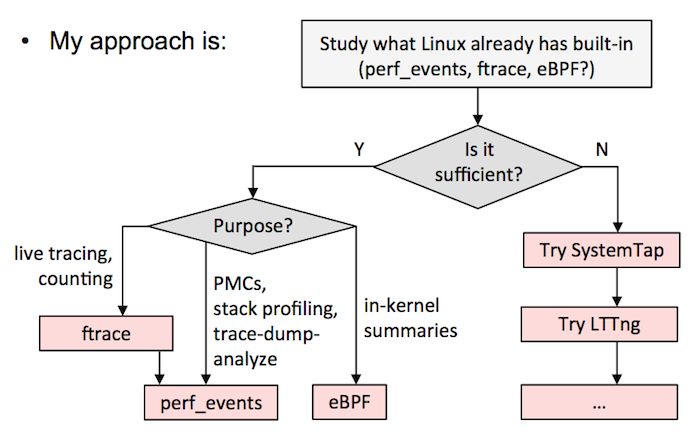
在这里我建议选择如下,要么:
|
||||
|
||||
A)选择一个全能的跟踪器,并以它为标准。这需要在一个测试环境中花大量的时间来搞清楚它的细微差别和安全性。我现在的建议是 SystemTap 的最新版本(例如,从 [源代码][10] 构建)。我知道有的公司选择的是 LTTng ,尽管它并不是很强大(但是它很安全),但他们也用的很好。如果在 `sysdig` 中添加了跟踪点或者是 kprobes,它也是另外的一个候选者。
|
||||
|
||||
B)按我的 [Velocity 教程中][11] 的流程图。这意味着尽可能使用 ftrace 或者 perf_events,eBPF 已经集成到内核中了,然后用其它的跟踪器,如 SystemTap/LTTng 作为对 eBPF 的补充。我目前在 Netflix 的工作中就是这么做的。
|
||||
|
||||
|
||||
|
||||
以下是我对各个跟踪器的评价:
|
||||
|
||||
#### 1. ftrace
|
||||
|
||||
我爱 [ftrace][12],它是内核黑客最好的朋友。它被构建进内核中,它能够利用跟踪点、kprobes、以及 uprobes,以提供一些功能:使用可选的过滤器和参数进行事件跟踪;事件计数和计时,内核概览;<ruby>函数流步进<rt>function-flow walking</rt></ruby>。关于它的示例可以查看内核源代码树中的 [ftrace.txt][13]。它通过 `/sys` 来管理,是面向单一的 root 用户的(虽然你可以使用缓冲实例以让其支持多用户),它的界面有时很繁琐,但是它比较容易<ruby>调校<rt>hackable</rt></ruby>,并且有个前端:ftrace 的主要创建者 Steven Rostedt 设计了一个 trace-cmd,而且我也创建了 perf-tools 集合。我最诟病的就是它不是<ruby>可编程的<rt>programmable</rt></ruby>,因此,举个例子说,你不能保存和获取时间戳、计算延迟,以及将其保存为直方图。你需要转储事件到用户级以便于进行后期处理,这需要花费一些成本。它也许可以通过 eBPF 实现可编程。
|
||||
|
||||
#### 2. perf_events
|
||||
|
||||
[perf_events][14] 是 Linux 用户的主要跟踪工具,它的源代码位于 Linux 内核中,一般是通过 linux-tools-common 包来添加的。它又称为 `perf`,后者指的是它的前端,它相当高效(动态缓存),一般用于跟踪并转储到一个文件中(perf.data),然后可以在之后进行后期处理。它可以做大部分 ftrace 能做的事情。它不能进行函数流步进,并且不太容易调校(而它的安全/错误检查做的更好一些)。但它可以做剖析(采样)、CPU 性能计数、用户级的栈转换、以及使用本地变量利用<ruby>调试信息<rt>debuginfo</rt></ruby>进行<ruby>行级跟踪<rt>line tracing</rt></ruby>。它也支持多个并发用户。与 ftrace 一样,它也不是内核可编程的,除非 eBPF 支持(补丁已经在计划中)。如果只学习一个跟踪器,我建议大家去学习 perf,它可以解决大量的问题,并且它也相当安全。
|
||||
|
||||
#### 3. eBPF
|
||||
|
||||
<ruby>扩展的伯克利包过滤器<rt>extended Berkeley Packet Filter</rt></ruby>(eBPF)是一个<ruby>内核内<rt>in-kernel</rt></ruby>的虚拟机,可以在事件上运行程序,它非常高效(JIT)。它可能最终为 ftrace 和 perf_events 提供<ruby>内核内编程<rt>in-kernel programming</rt></ruby>,并可以去增强其它跟踪器。它现在是由 Alexei Starovoitov 开发的,还没有实现完全的整合,但是对于一些令人印象深刻的工具,有些内核版本(比如,4.1)已经支持了:比如,块设备 I/O 的<ruby>延迟热力图<rt>latency heat map</rt></ruby>。更多参考资料,请查阅 Alexei 的 [BPF 演示][15],和它的 [eBPF 示例][16]。
|
||||
|
||||
#### 4. SystemTap
|
||||
|
||||
[SystemTap][17] 是一个非常强大的跟踪器。它可以做任何事情:剖析、跟踪点、kprobes、uprobes(它就来自 SystemTap)、USDT、内核内编程等等。它将程序编译成内核模块并加载它们 —— 这是一种很难保证安全的方法。它开发是在内核代码树之外进行的,并且在过去出现过很多问题(内核崩溃或冻结)。许多并不是 SystemTap 的过错 —— 它通常是首次对内核使用某些跟踪功能,并率先遇到 bug。最新版本的 SystemTap 是非常好的(你需要从它的源代码编译),但是,许多人仍然没有从早期版本的问题阴影中走出来。如果你想去使用它,花一些时间去测试环境,然后,在 irc.freenode.net 的 #systemtap 频道与开发者进行讨论。(Netflix 有一个容错架构,我们使用了 SystemTap,但是我们或许比起你来说,更少担心它的安全性)我最诟病的事情是,它似乎假设你有办法得到内核调试信息,而我并没有这些信息。没有它我实际上可以做很多事情,但是缺少相关的文档和示例(我现在自己开始帮着做这些了)。
|
||||
|
||||
#### 5. LTTng
|
||||
|
||||
[LTTng][18] 对事件收集进行了优化,性能要好于其它的跟踪器,也支持许多的事件类型,包括 USDT。它的开发是在内核代码树之外进行的。它的核心部分非常简单:通过一个很小的固定指令集写入事件到跟踪缓冲区。这样让它既安全又快速。缺点是做内核内编程不太容易。我觉得那不是个大问题,由于它优化的很好,可以充分的扩展,尽管需要后期处理。它也探索了一种不同的分析技术。很多的“黑匣子”记录了所有感兴趣的事件,以便可以在 GUI 中以后分析它。我担心该记录会错失之前没有预料的事件,我真的需要花一些时间去看看它在实践中是如何工作的。这个跟踪器上我花的时间最少(没有特别的原因)。
|
||||
|
||||
#### 6. ktap
|
||||
|
||||
[ktap][19] 是一个很有前途的跟踪器,它在内核中使用了一个 lua 虚拟机,不需要调试信息和在嵌入时设备上可以工作的很好。这使得它进入了人们的视野,在某个时候似乎要成为 Linux 上最好的跟踪器。然而,由于 eBPF 开始集成到了内核,而 ktap 的集成工作被推迟了,直到它能够使用 eBPF 而不是它自己的虚拟机。由于 eBPF 在几个月过去之后仍然在集成过程中,ktap 的开发者已经等待了很长的时间。我希望在今年的晚些时间它能够重启开发。
|
||||
|
||||
#### 7. dtrace4linux
|
||||
|
||||
[dtrace4linux][20] 主要由一个人(Paul Fox)利用业务时间将 Sun DTrace 移植到 Linux 中的。它令人印象深刻,一些<ruby>供应器<rt>provider</rt></ruby>可以工作,还不是很完美,它最多应该算是实验性的工具(不安全)。我认为对于许可证的担心,使人们对它保持谨慎:它可能永远也进入不了 Linux 内核,因为 Sun 是基于 CDDL 许可证发布的 DTrace;Paul 的方法是将它作为一个插件。我非常希望看到 Linux 上的 DTrace,并且希望这个项目能够完成,我想我加入 Netflix 时将花一些时间来帮它完成。但是,我一直在使用内置的跟踪器 ftrace 和 perf_events。
|
||||
|
||||
#### 8. OL DTrace
|
||||
|
||||
[Oracle Linux DTrace][21] 是将 DTrace 移植到 Linux (尤其是 Oracle Linux)的重大努力。过去这些年的许多发布版本都一直稳定的进步,开发者甚至谈到了改善 DTrace 测试套件,这显示出这个项目很有前途。许多有用的功能已经完成:系统调用、剖析、sdt、proc、sched、以及 USDT。我一直在等待着 fbt(函数边界跟踪,对内核的动态跟踪),它将成为 Linux 内核上非常强大的功能。它最终能否成功取决于能否吸引足够多的人去使用 Oracle Linux(并为支持付费)。另一个羁绊是它并非完全开源的:内核组件是开源的,但用户级代码我没有看到。
|
||||
|
||||
#### 9. sysdig
|
||||
|
||||
[sysdig][22] 是一个很新的跟踪器,它可以使用类似 `tcpdump` 的语法来处理<ruby>系统调用<rt>syscall</rt></ruby>事件,并用 lua 做后期处理。它也是令人印象深刻的,并且很高兴能看到在系统跟踪领域的创新。它的局限性是,它的系统调用只能是在当时,并且,它转储所有事件到用户级进行后期处理。你可以使用系统调用来做许多事情,虽然我希望能看到它去支持跟踪点、kprobes、以及 uprobes。我也希望看到它支持 eBPF 以查看内核内概览。sysdig 的开发者现在正在增加对容器的支持。可以关注它的进一步发展。
|
||||
|
||||
### 深入阅读
|
||||
|
||||
我自己的工作中使用到的跟踪器包括:
|
||||
|
||||
- **ftrace** : 我的 [perf-tools][8] 集合(查看示例目录);我的 lwn.net 的 [ftrace 跟踪器的文章][5]; 一个 [LISA14][8] 演讲;以及帖子: [函数计数][23]、 [iosnoop][24]、 [opensnoop][25]、 [execsnoop][26]、 [TCP retransmits][27]、 [uprobes][28] 和 [USDT][29]。
|
||||
- **perf_events** : 我的 [perf_events 示例][6] 页面;在 SCALE 的一个 [Linux Profiling at Netflix][4] 演讲;和帖子:[CPU 采样][30]、[静态跟踪点][31]、[热力图][32]、[计数][33]、[内核行级跟踪][34]、[off-CPU 时间火焰图][35]。
|
||||
- **eBPF** : 帖子 [eBPF:一个小的进步][36],和一些 [BPF-tools][37] (我需要发布更多)。
|
||||
- **SystemTap** : 很久以前,我写了一篇 [使用 SystemTap][38] 的文章,它有点过时了。最近我发布了一些 [systemtap-lwtools][39],展示了在没有内核调试信息的情况下,SystemTap 是如何使用的。
|
||||
- **LTTng** : 我使用它的时间很短,不足以发布什么文章。
|
||||
- **ktap** : 我的 [ktap 示例][40] 页面包括一行程序和脚本,虽然它是早期的版本。
|
||||
- **dtrace4linux** : 在我的 [系统性能][41] 书中包含了一些示例,并且在过去我为了某些事情开发了一些小的修补,比如, [timestamps][42]。
|
||||
- **OL DTrace** : 因为它是对 DTrace 的直接移植,我早期 DTrace 的工作大多与之相关(链接太多了,可以去 [我的主页][43] 上搜索)。一旦它更加完美,我可以开发很多专用工具。
|
||||
- **sysdig** : 我贡献了 [fileslower][44] 和 [subsecond offset spectrogram][45] 的 chisel。
|
||||
- **其它** : 关于 [strace][46],我写了一些告诫文章。
|
||||
|
||||
不好意思,没有更多的跟踪器了! … 如果你想知道为什么 Linux 中的跟踪器不止一个,或者关于 DTrace 的内容,在我的 [从 DTrace 到 Linux][47] 的演讲中有答案,从 [第 28 张幻灯片][48] 开始。
|
||||
|
||||
感谢 [Deirdre Straughan][49] 的编辑,以及跟踪小马的创建(General Zoi 是小马的创建者)。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.brendangregg.com/blog/2015-07-08/choosing-a-linux-tracer.html
|
||||
|
||||
作者:[Brendan Gregg][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.brendangregg.com
|
||||
[1]:http://www.brendangregg.com/blog/images/2015/tracing_ponies.png
|
||||
[2]:http://www.slideshare.net/brendangregg/velocity-2015-linux-perf-tools/105
|
||||
[3]:http://www.brendangregg.com/FlameGraphs/cpuflamegraphs.html
|
||||
[4]:http://www.brendangregg.com/blog/2015-02-27/linux-profiling-at-netflix.html
|
||||
[5]:http://lwn.net/Articles/608497/
|
||||
[6]:http://www.brendangregg.com/perf.html
|
||||
[7]:http://www.brendangregg.com/blog/2015-06-23/netflix-instance-analysis-requirements.html
|
||||
[8]:http://www.brendangregg.com/blog/2015-03-17/linux-performance-analysis-perf-tools.html
|
||||
[9]:http://techblog.netflix.com/2015/04/introducing-vector-netflixs-on-host.html
|
||||
[10]:https://sourceware.org/git/?p=systemtap.git;a=blob_plain;f=README;hb=HEAD
|
||||
[11]:http://www.slideshare.net/brendangregg/velocity-2015-linux-perf-tools
|
||||
[12]:http://lwn.net/Articles/370423/
|
||||
[13]:https://www.kernel.org/doc/Documentation/trace/ftrace.txt
|
||||
[14]:https://perf.wiki.kernel.org/index.php/Main_Page
|
||||
[15]:http://www.phoronix.com/scan.php?page=news_item&px=BPF-Understanding-Kernel-VM
|
||||
[16]:https://github.com/torvalds/linux/tree/master/samples/bpf
|
||||
[17]:https://sourceware.org/systemtap/wiki
|
||||
[18]:http://lttng.org/
|
||||
[19]:http://ktap.org/
|
||||
[20]:https://github.com/dtrace4linux/linux
|
||||
[21]:http://docs.oracle.com/cd/E37670_01/E38608/html/index.html
|
||||
[22]:http://www.sysdig.org/
|
||||
[23]:http://www.brendangregg.com/blog/2014-07-13/linux-ftrace-function-counting.html
|
||||
[24]:http://www.brendangregg.com/blog/2014-07-16/iosnoop-for-linux.html
|
||||
[25]:http://www.brendangregg.com/blog/2014-07-25/opensnoop-for-linux.html
|
||||
[26]:http://www.brendangregg.com/blog/2014-07-28/execsnoop-for-linux.html
|
||||
[27]:http://www.brendangregg.com/blog/2014-09-06/linux-ftrace-tcp-retransmit-tracing.html
|
||||
[28]:http://www.brendangregg.com/blog/2015-06-28/linux-ftrace-uprobe.html
|
||||
[29]:http://www.brendangregg.com/blog/2015-07-03/hacking-linux-usdt-ftrace.html
|
||||
[30]:http://www.brendangregg.com/blog/2014-06-22/perf-cpu-sample.html
|
||||
[31]:http://www.brendangregg.com/blog/2014-06-29/perf-static-tracepoints.html
|
||||
[32]:http://www.brendangregg.com/blog/2014-07-01/perf-heat-maps.html
|
||||
[33]:http://www.brendangregg.com/blog/2014-07-03/perf-counting.html
|
||||
[34]:http://www.brendangregg.com/blog/2014-09-11/perf-kernel-line-tracing.html
|
||||
[35]:http://www.brendangregg.com/blog/2015-02-26/linux-perf-off-cpu-flame-graph.html
|
||||
[36]:http://www.brendangregg.com/blog/2015-05-15/ebpf-one-small-step.html
|
||||
[37]:https://github.com/brendangregg/BPF-tools
|
||||
[38]:http://dtrace.org/blogs/brendan/2011/10/15/using-systemtap/
|
||||
[39]:https://github.com/brendangregg/systemtap-lwtools
|
||||
[40]:http://www.brendangregg.com/ktap.html
|
||||
[41]:http://www.brendangregg.com/sysperfbook.html
|
||||
[42]:https://github.com/dtrace4linux/linux/issues/55
|
||||
[43]:http://www.brendangregg.com
|
||||
[44]:https://github.com/brendangregg/sysdig/commit/d0eeac1a32d6749dab24d1dc3fffb2ef0f9d7151
|
||||
[45]:https://github.com/brendangregg/sysdig/commit/2f21604dce0b561407accb9dba869aa19c365952
|
||||
[46]:http://www.brendangregg.com/blog/2014-05-11/strace-wow-much-syscall.html
|
||||
[47]:http://www.brendangregg.com/blog/2015-02-28/from-dtrace-to-linux.html
|
||||
[48]:http://www.slideshare.net/brendangregg/from-dtrace-to-linux/28
|
||||
[49]:http://www.beginningwithi.com/
|
||||
@ -0,0 +1,210 @@
|
||||
9 个提高系统运行速度的轻量级 Linux 应用
|
||||
======
|
||||
|
||||
**简介:** [加速 Ubuntu 系统][1]有很多方法,办法之一是使用轻量级应用来替代一些常用应用程序。我们之前之前发布过一篇 [Linux 必备的应用程序][2],如今将分享这些应用程序在 Ubuntu 或其他 Linux 发行版的轻量级替代方案。
|
||||
|
||||
![在 ubunt 使用轻量级应用程序替代方案][4]
|
||||
|
||||
### 9 个常用 Linux 应用程序的轻量级替代方案
|
||||
|
||||
你的 Linux 系统很慢吗?应用程序是不是很久才能打开?你最好的选择是使用[轻量级的 Linux 系统][5]。但是重装系统并非总是可行,不是吗?
|
||||
|
||||
所以如果你想坚持使用你现在用的 Linux 发行版,但是想要提高性能,你应该使用更轻量级应用来替代你一些常用的应用。这篇文章会列出各种 Linux 应用程序的轻量级替代方案。
|
||||
|
||||
由于我使用的是 Ubuntu,因此我只提供了基于 Ubuntu 的 Linux 发行版的安装说明。但是这些应用程序可以用于几乎所有其他 Linux 发行版。你只需去找这些轻量级应用在你的 Linux 发行版中的安装方法就可以了。
|
||||
|
||||
### 1. Midori: Web 浏览器
|
||||
|
||||
[Midori][8] 是与现代互联网环境具有良好兼容性的最轻量级网页浏览器之一。它是开源的,使用与 Google Chrome 最初所基于的相同的渲染引擎 —— WebKit。并且超快速,最小化但高度可定制。
|
||||
|
||||
![Midori Browser][6]
|
||||
|
||||
Midori 浏览器有很多可以定制的扩展和选项。如果你有最高权限,使用这个浏览器也是一个不错的选择。如果在浏览网页的时候遇到了某些问题,请查看其网站上[常见问题][7]部分 -- 这包含了你可能遇到的常见问题及其解决方案。
|
||||
|
||||
|
||||
#### 在基于 Ubuntu 的发行版上安装 Midori
|
||||
|
||||
在 Ubuntu 上,可通过官方源找到 Midori 。运行以下指令即可安装它:
|
||||
|
||||
```
|
||||
sudo apt install midori
|
||||
```
|
||||
|
||||
### 2. Trojita:电子邮件客户端
|
||||
|
||||
[Trojita][11] 是一款开源强大的 IMAP 电子邮件客户端。它速度快,资源利用率高。我可以肯定地称它是 [Linux 最好的电子邮件客户端之一][9]。如果你只需电子邮件客户端提供 IMAP 支持,那么也许你不用再进一步考虑了。
|
||||
|
||||
![Trojitá][10]
|
||||
|
||||
Trojita 使用各种技术 —— 按需电子邮件加载、离线缓存、带宽节省模式等 —— 以实现其令人印象深刻的性能。
|
||||
|
||||
#### 在基于 Ubuntu 的发行版上安装 Trojita
|
||||
|
||||
Trojita 目前没有针对 Ubuntu 的官方 PPA 。但这应该不成问题。您可以使用以下命令轻松安装它:
|
||||
|
||||
```
|
||||
sudo sh -c "echo 'deb http://download.opensuse.org/repositories/home:/jkt-gentoo:/trojita/xUbuntu_16.04/ /' > /etc/apt/sources.list.d/trojita.list"
|
||||
wget http://download.opensuse.org/repositories/home:jkt-gentoo:trojita/xUbuntu_16.04/Release.key
|
||||
sudo apt-key add - < Release.key
|
||||
sudo apt update
|
||||
sudo apt install trojita
|
||||
```
|
||||
|
||||
### 3. GDebi:包安装程序
|
||||
|
||||
有时您需要快速安装 DEB 软件包。Ubuntu 软件中心是一个消耗资源严重的应用程序,仅用于安装 .deb 文件并不明智。
|
||||
|
||||
Gdebi 无疑是一款可以完成同样目的的漂亮工具,而它只有个极简的图形界面。
|
||||
|
||||
![GDebi][12]
|
||||
|
||||
GDebi 是完全轻量级的,完美无缺地完成了它的工作。你甚至应该[让 Gdebi 成为 DEB 文件的默认安装程序][13]。
|
||||
|
||||
#### 在基于 Ubuntu 的发行版上安装 GDebi
|
||||
|
||||
只需一行指令,你便可以在 Ubuntu 上安装 GDebi:
|
||||
|
||||
```
|
||||
sudo apt install gdebi
|
||||
```
|
||||
|
||||
### 4. App Grid:软件中心
|
||||
|
||||
如果您经常在 Ubuntu 上使用软件中心搜索、安装和管理应用程序,则 [App Grid][15] 是必备的应用程序。它是默认的 Ubuntu 软件中心最具视觉吸引力且速度最快的替代方案。
|
||||
|
||||
![App Grid][14]
|
||||
|
||||
App Grid 支持应用程序的评分、评论和屏幕截图。
|
||||
|
||||
#### 在基于 Ubuntu 的发行版上安装 App Grid
|
||||
|
||||
App Grid 拥有 Ubuntu 的官方 PPA。使用以下指令安装 App Grid:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:appgrid/stable
|
||||
sudo apt update
|
||||
sudo apt install appgrid
|
||||
```
|
||||
|
||||
### 5. Yarock:音乐播放器
|
||||
|
||||
[Yarock][17] 是一个优雅的音乐播放器,拥有现代而最轻量级的用户界面。尽管在设计上是轻量级的,但 Yarock 有一个全面的高级功能列表。
|
||||
|
||||
![Yarock][16]
|
||||
|
||||
Yarock 的主要功能包括多种音乐收藏、评级、智能播放列表、多种后端选项、桌面通知、音乐剪辑、上下文获取等。
|
||||
|
||||
### 在基于 Ubuntu 的发行版上安装 Yarock
|
||||
|
||||
您得通过 PPA 使用以下指令在 Ubuntu 上安装 Yarock:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:nilarimogard/webupd8
|
||||
sudo apt update
|
||||
sudo apt install yarock
|
||||
```
|
||||
|
||||
### 6. VLC:视频播放器
|
||||
|
||||
谁不需要视频播放器?谁还从未听说过 [VLC][19]?我想并不需要对它做任何介绍。
|
||||
|
||||
![VLC][18]
|
||||
|
||||
VLC 能满足你在 Ubuntu 上播放各种媒体文件的全部需求,而且它非常轻便。它甚至可以在非常旧的 PC 上完美运行。
|
||||
|
||||
#### 在基于 Ubuntu 的发行版上安装 VLC
|
||||
|
||||
VLC 为 Ubuntu 提供官方 PPA。可以输入以下命令来安装它:
|
||||
|
||||
```
|
||||
sudo apt install vlc
|
||||
```
|
||||
|
||||
### 7. PCManFM:文件管理器
|
||||
|
||||
PCManFM 是 LXDE 的标准文件管理器。与 LXDE 的其他应用程序一样,它也是轻量级的。如果您正在为文件管理器寻找更轻量级的替代品,可以尝试使用这个应用。
|
||||
|
||||
![PCManFM][20]
|
||||
|
||||
尽管来自 LXDE,PCManFM 也同样适用于其他桌面环境。
|
||||
|
||||
#### 在基于 Ubuntu 的发行版上安装 PCManFM
|
||||
|
||||
在 Ubuntu 上安装 PCManFM 只需要一条简单的指令:
|
||||
|
||||
```
|
||||
sudo apt install pcmanfm
|
||||
```
|
||||
|
||||
### 8. Mousepad:文本编辑器
|
||||
|
||||
在轻量级方面,没有什么可以击败像 nano、vim 等命令行文本编辑器。但是,如果你想要一个图形界面,你可以尝试一下 Mousepad -- 一个最轻量级的文本编辑器。它非常轻巧,速度非常快。带有简单的可定制的用户界面和多个主题。
|
||||
|
||||
![Mousepad][21]
|
||||
|
||||
Mousepad 支持语法高亮显示。所以,你也可以使用它作为基础的代码编辑器。
|
||||
|
||||
#### 在基于 Ubuntu 的发行版上安装 Mousepad
|
||||
|
||||
想要安装 Mousepad ,可以使用以下指令:
|
||||
|
||||
```
|
||||
sudo apt install mousepad
|
||||
```
|
||||
|
||||
### 9. GNOME Office:办公软件
|
||||
|
||||
许多人需要经常使用办公应用程序。通常,大多数办公应用程序体积庞大且很耗资源。Gnome Office 在这方面非常轻便。Gnome Office 在技术上不是一个完整的办公套件。它由不同的独立应用程序组成,在这之中 AbiWord&Gnumeric 脱颖而出。
|
||||
|
||||
**AbiWord** 是文字处理器。它比其他替代品轻巧并且快得多。但是这样做是有代价的 —— 你可能会失去宏、语法检查等一些功能。AdiWord 并不完美,但它可以满足你基本的需求。
|
||||
|
||||
![AbiWord][22]
|
||||
|
||||
**Gnumeric** 是电子表格编辑器。就像 AbiWord 一样,Gnumeric 也非常快速,提供了精确的计算功能。如果你正在寻找一个简单轻便的电子表格编辑器,Gnumeric 已经能满足你的需求了。
|
||||
|
||||
![Gnumeric][23]
|
||||
|
||||
在 [Gnome Office][24] 下面还有一些其它应用程序。你可以在官方页面找到它们。
|
||||
|
||||
#### 在基于 Ubuntu 的发行版上安装 AbiWord&Gnumeric
|
||||
|
||||
要安装 AbiWord&Gnumeric,只需在终端中输入以下指令:
|
||||
|
||||
```
|
||||
sudo apt install abiword gnumeric
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/lightweight-alternative-applications-ubuntu/
|
||||
|
||||
作者:[Munif Tanjim][a]
|
||||
译者:[imquanquan](https://github.com/imquanquan)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/munif/
|
||||
[1]:https://itsfoss.com/speed-up-ubuntu-1310/
|
||||
[2]:https://itsfoss.com/essential-linux-applications/
|
||||
[4]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Lightweight-alternative-applications-for-Linux-800x450.jpg
|
||||
[5]:https://itsfoss.com/lightweight-linux-beginners/
|
||||
[6]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Midori-800x497.png
|
||||
[7]:http://midori-browser.org/faqs/
|
||||
[8]:http://midori-browser.org/
|
||||
[9]:https://itsfoss.com/best-email-clients-linux/
|
||||
[10]:http://trojita.flaska.net/img/2016-03-22-trojita-home.png
|
||||
[11]:http://trojita.flaska.net/
|
||||
[12]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/GDebi.png
|
||||
[13]:https://itsfoss.com/gdebi-default-ubuntu-software-center/
|
||||
[14]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/AppGrid-800x553.png
|
||||
[15]:http://www.appgrid.org/
|
||||
[16]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Yarock-800x529.png
|
||||
[17]:https://seb-apps.github.io/yarock/
|
||||
[18]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/VLC-800x526.png
|
||||
[19]:http://www.videolan.org/index.html
|
||||
[20]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/PCManFM.png
|
||||
[21]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Mousepad.png
|
||||
[22]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/AbiWord-800x626.png
|
||||
[23]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Gnumeric-800x470.png
|
||||
[24]:https://gnome.org/gnome-office/
|
||||
@ -1,28 +1,21 @@
|
||||
|
||||
如何提供有帮助的回答
|
||||
=============================
|
||||
|
||||
如果你的同事问你一个不太清晰的问题,你会怎么回答?我认为提问题是一种技巧(可以看 [如何提出有意义的问题][1]) 同时,合理地回答问题也是一种技巧。他们都是非常实用的。
|
||||
如果你的同事问你一个不太清晰的问题,你会怎么回答?我认为提问题是一种技巧(可以看 [如何提出有意义的问题][1]) 同时,合理地回答问题也是一种技巧,它们都是非常实用的。
|
||||
|
||||
一开始 - 有时向你提问的人不尊重你的时间,这很糟糕。
|
||||
|
||||
理想情况下,我们假设问你问题的人是一个理性的人并且正在尽力解决问题而你想帮助他们。和我一起工作的人是这样,我所生活的世界也是这样。当然,现实生活并不是这样。
|
||||
一开始 —— 有时向你提问的人不尊重你的时间,这很糟糕。理想情况下,我们假设问你问题的人是一个理性的人并且正在尽力解决问题,而你想帮助他们。和我一起工作的人是这样,我所生活的世界也是这样。当然,现实生活并不是这样。
|
||||
|
||||
下面是有助于回答问题的一些方法!
|
||||
|
||||
|
||||
### 如果他们提问不清楚,帮他们澄清
|
||||
### 如果他们的提问不清楚,帮他们澄清
|
||||
|
||||
通常初学者不会提出很清晰的问题,或者问一些对回答问题没有必要信息的问题。你可以尝试以下方法 澄清问题:
|
||||
|
||||
* ** 重述为一个更明确的问题 ** 来回复他们(”你是想问 X 吗?“)
|
||||
|
||||
* ** 向他们了解更具体的他们并没有提供的信息 ** (”你使用 IPv6 ?”)
|
||||
|
||||
* ** 问是什么导致了他们的问题 ** 例如,有时有些人会进入我的团队频道,询问我们的服务发现(service discovery )如何工作的。这通常是因为他们试图设置/重新配置服务。在这种情况下,如果问“你正在使用哪种服务?可以给我看看你正在处理的 pull requests 吗?”是有帮助的。
|
||||
|
||||
这些方法很多来自 [如何提出有意义的问题][2]中的要点。(尽管我永远不会对某人说“噢,你得先看完 “如何提出有意义的问题”这篇文章后再来像我提问)
|
||||
* **重述为一个更明确的问题**来回复他们(“你是想问 X 吗?”)
|
||||
* **向他们了解更具体的他们并没有提供的信息** (“你使用 IPv6 ?”)
|
||||
* **问是什么导致了他们的问题**。例如,有时有些人会进入我的团队频道,询问我们的<ruby>服务发现<rt>service discovery</rt></ruby>如何工作的。这通常是因为他们试图设置/重新配置服务。在这种情况下,如果问“你正在使用哪种服务?可以给我看看你正在处理的‘拉取请求’吗?”是有帮助的。
|
||||
|
||||
这些方法很多来自[如何提出有意义的问题][2]中的要点。(尽管我永远不会对某人说“噢,你得先看完《如何提出有意义的问题》这篇文章后再来向我提问)
|
||||
|
||||
### 弄清楚他们已经知道了什么
|
||||
|
||||
@ -30,66 +23,54 @@
|
||||
|
||||
Harold Treen 给了我一个很好的例子:
|
||||
|
||||
> 前几天,有人请我解释“ Redux-Sagas ”。与其深入解释不如说“ 他们就像 worker threads 监听行为(actions),让你更新 Redux store 。
|
||||
> 前几天,有人请我解释 “Redux-Sagas”。与其深入解释,不如说 “它们就像监听 action 的工人线程,并可以让你更新 Redux store。
|
||||
|
||||
> 我开始搞清楚他们对 Redux 、行为(actions)、store 以及其他基本概念了解多少。将这些概念都联系在一起再来解释会容易得多。
|
||||
> 我开始搞清楚他们对 Redux、action、store 以及其他基本概念了解多少。将这些概念都联系在一起再来解释会容易得多。
|
||||
|
||||
弄清楚问你问题的人已经知道什么是非常重要的。因为有时他们可能会对基础概念感到疑惑(“ Redux 是什么?“),或者他们可能是专家但是恰巧遇到了微妙的极端情况(corner case)。如果答案建立在他们不知道的概念上会令他们困惑,但如果重述他们已经知道的的又会是乏味的。
|
||||
弄清楚问你问题的人已经知道什么是非常重要的。因为有时他们可能会对基础概念感到疑惑(“Redux 是什么?”),或者他们可能是专家,但是恰巧遇到了微妙的<ruby>极端情况<rt>corner case</rt></ruby>。如果答案建立在他们不知道的概念上会令他们困惑,但如果重述他们已经知道的的又会是乏味的。
|
||||
|
||||
这里有一个很实用的技巧来了解他们已经知道什么 - 比如可以尝试用“你对 X 了解多少?”而不是问“你知道 X 吗?”。
|
||||
|
||||
|
||||
### 给他们一个文档
|
||||
|
||||
“RTFM” (“去读那些他妈的手册”(Read The Fucking Manual))是一个典型的无用的回答,但事实上如果向他们指明一个特定的文档会是非常有用的!当我提问题的时候,我当然很乐意翻看那些能实际解决我的问题的文档,因为它也可能解决其他我想问的问题。
|
||||
“RTFM” (<ruby>“去读那些他妈的手册”<rt>Read The Fucking Manual</rt></ruby>)是一个典型的无用的回答,但事实上如果向他们指明一个特定的文档会是非常有用的!当我提问题的时候,我当然很乐意翻看那些能实际解决我的问题的文档,因为它也可能解决其他我想问的问题。
|
||||
|
||||
我认为明确你所给的文档的确能够解决问题是非常重要的,或者至少经过查阅后确认它对解决问题有帮助。否则,你可能将以下面这种情形结束对话(非常常见):
|
||||
|
||||
* Ali:我应该如何处理 X ?
|
||||
* Jada:\<文档链接>
|
||||
* Ali: 这个没有实际解释如何处理 X ,它仅仅解释了如何处理 Y !
|
||||
|
||||
* Jada:<文档链接>
|
||||
|
||||
* Ali: 这个并有实际解释如何处理 X ,它仅仅解释了如何处理 Y !
|
||||
|
||||
如果我所给的文档特别长,我会指明文档中那个我将会谈及的特定部分。[bash 手册][3] 有44000个字(真的!),所以如果只说“它在 bash 手册中有说明”是没有帮助的:)
|
||||
|
||||
如果我所给的文档特别长,我会指明文档中那个我将会谈及的特定部分。[bash 手册][3] 有 44000 个字(真的!),所以如果只说“它在 bash 手册中有说明”是没有帮助的 :)
|
||||
|
||||
### 告诉他们一个有用的搜索
|
||||
|
||||
在工作中,我经常发现我可以利用我所知道的关键字进行搜索找到能够解决我的问题的答案。对于初学者来说,这些关键字往往不是那么明显。所以说“这是我用来寻找这个答案的搜索”可能有用些。再次说明,回答时请经检查后以确保搜索能够得到他们所需要的答案:)
|
||||
|
||||
在工作中,我经常发现我可以利用我所知道的关键字进行搜索来找到能够解决我的问题的答案。对于初学者来说,这些关键字往往不是那么明显。所以说“这是我用来寻找这个答案的搜索”可能有用些。再次说明,回答时请经检查后以确保搜索能够得到他们所需要的答案 :)
|
||||
|
||||
### 写新文档
|
||||
|
||||
人们经常一次又一次地问我的团队同样的问题。很显然这并不是他们的错(他们怎么能够知道在他们之前已经有10个人问了这个问题,且知道答案是什么呢?)因此,我们会尝试写新文档,而不是直接回答回答问题。
|
||||
人们经常一次又一次地问我的团队同样的问题。很显然这并不是他们的错(他们怎么能够知道在他们之前已经有 10 个人问了这个问题,且知道答案是什么呢?)因此,我们会尝试写新文档,而不是直接回答回答问题。
|
||||
|
||||
1. 马上写新文档
|
||||
|
||||
2. 给他们我们刚刚写好的新文档
|
||||
|
||||
3. 公示
|
||||
|
||||
写文档有时往往比回答问题需要花很多时间,但这是值得的。写文档尤其重要,如果:
|
||||
|
||||
a. 这个问题被问了一遍又一遍
|
||||
|
||||
b. 随着时间的推移,这个答案不会变化太大(如果这个答案每一个星期或者一个月就会变化,文档就会过时并且令人受挫)
|
||||
|
||||
|
||||
### 解释你做了什么
|
||||
|
||||
对于一个话题,作为初学者来说,这样的交流会真让人沮丧:
|
||||
|
||||
* 新人:“嗨!你如何处理 X ?”
|
||||
|
||||
* 有经验的人:“我已经处理过了,而且它已经完美解决了”
|
||||
|
||||
* 新人:”...... 但是你做了什么?!“
|
||||
|
||||
如果问你问题的人想知道事情是如何进行的,这样是有帮助的:
|
||||
|
||||
* 让他们去完成任务而不是自己做
|
||||
|
||||
* 告诉他们你是如何得到你给他们的答案的。
|
||||
|
||||
这可能比你自己做的时间还要长,但对于被问的人来说这是一个学习机会,因为那样做使得他们将来能够更好地解决问题。
|
||||
@ -97,88 +78,74 @@ b. 随着时间的推移,这个答案不会变化太大(如果这个答案
|
||||
这样,你可以进行更好的交流,像这:
|
||||
|
||||
* 新人:“这个网站出现了错误,发生了什么?”
|
||||
|
||||
* 有经验的人:(2分钟后)”oh 这是因为发生了数据库故障转移“
|
||||
|
||||
* 新人: ”你是怎么知道的??!?!?“
|
||||
|
||||
* 有经验的人:“以下是我所做的!“:
|
||||
|
||||
* 有经验的人:(2分钟后)“oh 这是因为发生了数据库故障转移”
|
||||
* 新人: “你是怎么知道的??!?!?”
|
||||
* 有经验的人:“以下是我所做的!”:
|
||||
1. 通常这些错误是因为服务器 Y 被关闭了。我查看了一下 `$PLACE` 但它表明服务器 Y 开着。所以,并不是这个原因导致的。
|
||||
|
||||
2. 然后我查看 X 的仪表盘 ,仪表盘的这个部分显示这里发生了数据库故障转移。
|
||||
|
||||
3. 然后我在日志中找到了相应服务器,并且它显示连接数据库错误,看起来错误就是这里。
|
||||
|
||||
如果你正在解释你是如何调试一个问题,解释你是如何发现问题,以及如何找出问题的。尽管看起来你好像已经得到正确答案,但感觉更好的是能够帮助他们提高学习和诊断能力,并了解可用的资源。
|
||||
|
||||
|
||||
### 解决根本问题
|
||||
|
||||
这一点有点棘手。有时候人们认为他们依旧找到了解决问题的正确途径,且他们只再多一点信息就可以解决问题。但他们可能并不是走在正确的道路上!比如:
|
||||
这一点有点棘手。有时候人们认为他们依旧找到了解决问题的正确途径,且他们只要再多一点信息就可以解决问题。但他们可能并不是走在正确的道路上!比如:
|
||||
|
||||
* George:”我在处理 X 的时候遇到了错误,我该如何修复它?“
|
||||
|
||||
* Jasminda:”你是正在尝试解决 Y 吗?如果是这样,你不应该处理 X ,反而你应该处理 Z 。“
|
||||
|
||||
* George:“噢,你是对的!!!谢谢你!我回反过来处理 Z 的。“
|
||||
* George:“我在处理 X 的时候遇到了错误,我该如何修复它?”
|
||||
* Jasminda:“你是正在尝试解决 Y 吗?如果是这样,你不应该处理 X ,反而你应该处理 Z 。”
|
||||
* George:“噢,你是对的!!!谢谢你!我回反过来处理 Z 的。”
|
||||
|
||||
Jasminda 一点都没有回答 George 的问题!反而,她猜测 George 并不想处理 X ,并且她是猜对了。这是非常有用的!
|
||||
|
||||
如果你这样做可能会产生高高在上的感觉:
|
||||
|
||||
* George:”我在处理 X 的时候遇到了错误,我该如何修复它?“
|
||||
* George:“我在处理 X 的时候遇到了错误,我该如何修复它?”
|
||||
* Jasminda:“不要这样做,如果你想处理 Y ,你应该反过来完成 Z 。”
|
||||
* George:“好吧,我并不是想处理 Y 。实际上我想处理 X 因为某些原因(REASONS)。所以我该如何处理 X 。”
|
||||
|
||||
* Jasminda:不要这样做,如果你想处理 Y ,你应该反过来完成 Z 。
|
||||
|
||||
* George:“好吧,我并不是想处理 Y 。实际上我想处理 X 因为某些原因(REASONS)。所以我该如何处理 X 。
|
||||
|
||||
所以不要高高在上,且要记住有时有些提问者可能已经偏离根本问题很远了。同时回答提问者提出的问题以及他们本该提出的问题都是合理的:“嗯,如果你想处理 X ,那么你可能需要这么做,但如果你想用这个解决 Y 问题,可能通过处理其他事情你可以更好地解决这个问题,这就是为什么可以做得更好的原因。
|
||||
所以不要高高在上,且要记住有时有些提问者可能已经偏离根本问题很远了。同时回答提问者提出的问题以及他们本该提出的问题都是合理的:“嗯,如果你想处理 X ,那么你可能需要这么做,但如果你想用这个解决 Y 问题,可能通过处理其他事情你可以更好地解决这个问题,这就是为什么可以做得更好的原因。”
|
||||
|
||||
|
||||
### 询问”那个回答可以解决您的问题吗?”
|
||||
### 询问“那个回答可以解决您的问题吗?”
|
||||
|
||||
我总是喜欢在我回答了问题之后核实是否真的已经解决了问题:”这个回答解决了您的问题吗?您还有其他问题吗?“在问完这个之后最好等待一会,因为人们通常需要一两分钟来知道他们是否已经找到了答案。
|
||||
我总是喜欢在我回答了问题之后核实是否真的已经解决了问题:“这个回答解决了您的问题吗?您还有其他问题吗?”在问完这个之后最好等待一会,因为人们通常需要一两分钟来知道他们是否已经找到了答案。
|
||||
|
||||
我发现尤其是问“这个回答解决了您的问题吗”这个额外的步骤在写完文档后是非常有用的。通常,在写关于我熟悉的东西的文档时,我会忽略掉重要的东西而不会意识到它。
|
||||
|
||||
|
||||
### 结对编程和面对面交谈
|
||||
|
||||
我是远程工作的,所以我的很多对话都是基于文本的。我认为这是沟通的默认方式。
|
||||
|
||||
今天,我们生活在一个方便进行小视频会议和屏幕共享的世界!在工作时候,在任何时间我都可以点击一个按钮并快速加入与他人的视频对话或者屏幕共享的对话中!
|
||||
|
||||
例如,最近有人问如何自动调节他们的服务容量规划。我告诉他们我们有几样东西需要清理,但我还不太确定他们要清理的是什么。然后我们进行了一个简短的视屏会话并在5分钟后,我们解决了他们问题。
|
||||
例如,最近有人问如何自动调节他们的服务容量规划。我告诉他们我们有几样东西需要清理,但我还不太确定他们要清理的是什么。然后我们进行了一个简短的视频会话并在 5 分钟后,我们解决了他们问题。
|
||||
|
||||
我认为,特别是如果有人真的被困在该如何开始一项任务时,开启视频进行结对编程几分钟真的比电子邮件或者一些即时通信更有效。
|
||||
|
||||
|
||||
### 不要表现得过于惊讶
|
||||
|
||||
这是源自 Recurse Center 的一则法则:[不要故作惊讶][4]。这里有一个常见的情景:
|
||||
|
||||
* 某人1:“什么是 Linux 内核”
|
||||
* 某甲:“什么是 Linux 内核”
|
||||
* 某乙:“你竟然不知道什么是 Linux 内核?!!!!?!!!????”
|
||||
|
||||
* 某人2:“你竟然不知道什么是 Linux 内核(LINUX KERNEL)?!!!!?!!!????”
|
||||
某乙的表现(无论他们是否真的如此惊讶)是没有帮助的。这大部分只会让某甲不好受,因为他们确实不知道什么是 Linux 内核。
|
||||
|
||||
某人2表现(无论他们是否真的如此惊讶)是没有帮助的。这大部分只会让某人1不好受,因为他们确实不知道什么是 Linux 内核。
|
||||
我一直在假装不惊讶,即使我事实上确实有点惊讶那个人不知道这种东西。
|
||||
|
||||
我一直在假装不惊讶即使我事实上确实有点惊讶那个人不知道这种东西但它是令人敬畏的。
|
||||
|
||||
### 回答问题是令人敬畏的
|
||||
### 回答问题真的很棒
|
||||
|
||||
显然并不是所有方法都是合适的,但希望你能够发现这里有些是有帮助的!我发现花时间去回答问题并教导人们是其实是很有收获的。
|
||||
|
||||
特别感谢 Josh Triplett 的一些建议并做了很多有益的补充,以及感谢 Harold Treen、Vaibhav Sagar、Peter Bhat Hatkins、Wesley Aptekar Cassels 和 Paul Gowder的阅读或评论。
|
||||
特别感谢 Josh Triplett 的一些建议并做了很多有益的补充,以及感谢 Harold Treen、Vaibhav Sagar、Peter Bhat Hatkins、Wesley Aptekar Cassels 和 Paul Gowder 的阅读或评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/answer-questions-well/
|
||||
|
||||
作者:[ Julia Evans][a]
|
||||
作者:[Julia Evans][a]
|
||||
译者:[HardworkFish](https://github.com/HardworkFish)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,23 +1,34 @@
|
||||
绕过 Linux/Unix 命令别名
|
||||
4 种绕过 Linux/Unix 命令别名的方法
|
||||
======
|
||||
|
||||
我在我的 Linux 系统上定义了如下 mount 别名:
|
||||
|
||||
```
|
||||
alias mount='mount | column -t'
|
||||
```
|
||||
但是我需要在挂载文件系统和其他用途时绕过 bash 别名。我如何在 Linux、\*BSD、macOS 或者类 Unix 系统上临时禁用或者绕过 bash shell 呢?
|
||||
|
||||
但是我需要在挂载文件系统和其他用途时绕过这个 bash 别名。我如何在 Linux、*BSD、macOS 或者类 Unix 系统上临时禁用或者绕过 bash shell 呢?
|
||||
|
||||
你可以使用 `alias` 命令定义或显示 bash shell 别名。一旦创建了 bash shell 别名,它们将优先于外部或内部命令。本文将展示如何暂时绕过 bash 别名,以便你可以运行实际的内部或外部命令。
|
||||
|
||||
你可以使用 alias 命令定义或显示 bash shell 别名。一旦创建了 bash shell 别名,它们将优先于外部或内部命令。本文将展示如何暂时绕过 bash 别名,以便你可以运行实际的内部或外部命令。
|
||||
[![Bash Bypass Alias Linux BSD macOS Unix Command][1]][1]
|
||||
|
||||
## 4 种绕过 bash 别名的方法
|
||||
|
||||
### 4 种绕过 bash 别名的方法
|
||||
|
||||
尝试以下任意一种方法来运行被 bash shell 别名绕过的命令。让我们[如下定义一个别名][2]:
|
||||
`alias mount='mount | column -t'`
|
||||
|
||||
```
|
||||
alias mount='mount | column -t'
|
||||
```
|
||||
|
||||
运行如下:
|
||||
`mount `
|
||||
|
||||
```
|
||||
mount
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
sysfs on /sys type sysfs (rw,nosuid,nodev,noexec,relatime)
|
||||
proc on /proc type proc (rw,nosuid,nodev,noexec,relatime)
|
||||
@ -30,45 +41,83 @@ binfmt_misc on /proc/sys/fs/binfmt_misc type binfmt_m
|
||||
lxcfs on /var/lib/lxcfs type fuse.lxcfs (rw,nosuid,nodev,relatime,user_id=0,group_id=0,allow_other)
|
||||
```
|
||||
|
||||
### 方法1 - 使用 \command
|
||||
#### 方法 1 - 使用 `\command`
|
||||
|
||||
输入以下命令暂时绕过名为 mount 的 bash 别名:
|
||||
`\mount`
|
||||
输入以下命令暂时绕过名为 `mount` 的 bash 别名:
|
||||
|
||||
### 方法2 - 使用 "command" 或 'command'
|
||||
```
|
||||
\mount
|
||||
```
|
||||
|
||||
#### 方法 2 - 使用 `"command"` 或 `'command'`
|
||||
|
||||
如下引用 `mount` 命令调用实际的 `/bin/mount`:
|
||||
|
||||
```
|
||||
"mount"
|
||||
```
|
||||
|
||||
如下引用 mount 命令调用实际的 /bin/mount:
|
||||
`"mount"`
|
||||
或者
|
||||
`'mount'`
|
||||
|
||||
### Method 3 - Use full command path
|
||||
```
|
||||
'mount'
|
||||
```
|
||||
|
||||
Use full binary path such as /bin/mount:
|
||||
`/bin/mount
|
||||
/bin/mount /dev/sda1 /mnt/sda`
|
||||
#### 方法 3 - 使用命令的完全路径
|
||||
|
||||
### 方法3 - 使用完整的命令路径
|
||||
使用完整的二进制路径,如 `/bin/mount`:
|
||||
|
||||
```
|
||||
/bin/mount
|
||||
/bin/mount /dev/sda1 /mnt/sda
|
||||
```
|
||||
|
||||
#### 方法 4 - 使用内部命令 `command`
|
||||
|
||||
语法是:
|
||||
`command cmd
|
||||
command cmd arg1 arg2`
|
||||
要覆盖 .bash_aliases 中设置的别名,例如 mount:
|
||||
`command mount
|
||||
command mount /dev/sdc /mnt/pendrive/`
|
||||
[”command“ 运行命令或显示][3]关于命令的信息。它带参数运行命令会抑制 shell 函数查询或者别名,或者显示有关给定命令的信息。
|
||||
|
||||
## 关于 unalias 命令的说明
|
||||
```
|
||||
command cmd
|
||||
command cmd arg1 arg2
|
||||
```
|
||||
|
||||
要覆盖 `.bash_aliases` 中设置的别名,例如 `mount`:
|
||||
|
||||
```
|
||||
command mount
|
||||
command mount /dev/sdc /mnt/pendrive/
|
||||
```
|
||||
|
||||
[“command” 直接运行命令或显示][3]关于命令的信息。它带参数运行命令会抑制 shell 函数查询或者别名,或者显示有关给定命令的信息。
|
||||
|
||||
### 关于 unalias 命令的说明
|
||||
|
||||
要从当前会话的已定义别名列表中移除别名,请使用 `unalias` 命令:
|
||||
|
||||
```
|
||||
unalias mount
|
||||
```
|
||||
|
||||
要从当前会话的已定义别名列表中移除别名,请使用 unalias 命令:
|
||||
`unalias mount`
|
||||
要从当前 bash 会话中删除所有别名定义:
|
||||
`unalias -a`
|
||||
确保你更新你的 ~/.bashrc 或 $HOME/.bash_aliases。如果要永久删除定义的别名,则必须删除定义的别名:
|
||||
`vi ~/.bashrc`
|
||||
|
||||
```
|
||||
unalias -a
|
||||
```
|
||||
|
||||
确保你更新你的 `~/.bashrc` 或 `$HOME/.bash_aliases`。如果要永久删除定义的别名,则必须删除定义的别名:
|
||||
|
||||
```
|
||||
vi ~/.bashrc
|
||||
```
|
||||
|
||||
或者
|
||||
`joe $HOME/.bash_aliases`
|
||||
|
||||
```
|
||||
joe $HOME/.bash_aliases
|
||||
```
|
||||
|
||||
想了解更多信息,参考[这里][4]的在线手册,或者输入下面的命令查看:
|
||||
|
||||
```
|
||||
man bash
|
||||
help command
|
||||
@ -76,14 +125,13 @@ help unalias
|
||||
help alias
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/bash-bypass-alias-command-on-linux-macos-unix/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,129 @@
|
||||
Linux 容器安全的 10 个层面
|
||||
======
|
||||
|
||||
> 应用这些策略来保护容器解决方案的各个层面和容器生命周期的各个阶段的安全。
|
||||
|
||||

|
||||
|
||||
容器提供了打包应用程序的一种简单方法,它实现了从开发到测试到投入生产系统的无缝传递。它也有助于确保跨不同环境的连贯性,包括物理服务器、虚拟机、以及公有云或私有云。这些好处使得一些组织为了更方便地部署和管理为他们提升业务价值的应用程序,而快速地采用了容器技术。
|
||||
|
||||

|
||||
|
||||
企业需要高度安全,在容器中运行核心服务的任何人都会问,“容器安全吗?”以及“我们能信任运行在容器中的应用程序吗?”
|
||||
|
||||
对容器进行安全保护就像是对运行中的进程进行安全保护一样。在你部署和运行你的容器之前,你需要去考虑整个解决方案各个层面的安全。你也需要去考虑贯穿了应用程序和容器整个生命周期的安全。
|
||||
|
||||
请尝试从这十个关键的因素去确保容器解决方案栈不同层面、以及容器生命周期的不同阶段的安全。
|
||||
|
||||
### 1. 容器宿主机操作系统和多租户环境
|
||||
|
||||
由于容器将应用程序和它的依赖作为一个单元来处理,使得开发者构建和升级应用程序变得更加容易,并且,容器可以启用多租户技术将许多应用程序和服务部署到一台共享主机上。在一台单独的主机上以容器方式部署多个应用程序、按需启动和关闭单个容器都是很容易的。为完全实现这种打包和部署技术的优势,运营团队需要运行容器的合适环境。运营者需要一个安全的操作系统,它能够在边界上保护容器安全、从容器中保护主机内核,以及保护容器彼此之间的安全。
|
||||
|
||||
容器是隔离而资源受限的 Linux 进程,允许你在一个共享的宿主机内核上运行沙盒化的应用程序。保护容器的方法与保护你的 Linux 中运行的任何进程的方法是一样的。降低权限是非常重要的,也是保护容器安全的最佳实践。最好使用尽可能小的权限去创建容器。容器应该以一个普通用户的权限来运行,而不是 root 权限的用户。在 Linux 中可以使用多个层面的安全加固手段,Linux 命名空间、安全强化 Linux([SELinux][1])、[cgroups][2] 、capabilities(LCTT 译注:Linux 内核的一个安全特性,它打破了传统的普通用户与 root 用户的概念,在进程级提供更好的安全控制)、以及安全计算模式( [seccomp][3] ),这五种 Linux 的安全特性可以用于保护容器的安全。
|
||||
|
||||
### 2. 容器内容(使用可信来源)
|
||||
|
||||
在谈到安全时,首先要考虑你的容器里面有什么?例如 ,有些时候,应用程序和基础设施是由很多可用组件所构成的。它们中的一些是开源的软件包,比如,Linux 操作系统、Apache Web 服务器、Red Hat JBoss 企业应用平台、PostgreSQL,以及 Node.js。这些软件包的容器化版本已经可以使用了,因此,你没有必要自己去构建它们。但是,对于你从一些外部来源下载的任何代码,你需要知道这些软件包的原始来源,是谁构建的它,以及这些包里面是否包含恶意代码。
|
||||
|
||||
### 3. 容器注册(安全访问容器镜像)
|
||||
|
||||
你的团队的容器构建于下载的公共容器镜像,因此,访问和升级这些下载的容器镜像以及内部构建镜像,与管理和下载其它类型的二进制文件的方式是相同的,这一点至关重要。许多私有的注册库支持容器镜像的存储。选择一个私有的注册库,可以帮你将存储在它的注册中的容器镜像实现策略自动化。
|
||||
|
||||
### 4. 安全性与构建过程
|
||||
|
||||
在一个容器化环境中,软件构建过程是软件生命周期的一个阶段,它将所需的运行时库和应用程序代码集成到一起。管理这个构建过程对于保护软件栈安全来说是很关键的。遵守“一次构建,到处部署”的原则,可以确保构建过程的结果正是生产系统中需要的。保持容器的恒定不变也很重要 — 换句话说就是,不要对正在运行的容器打补丁,而是,重新构建和部署它们。
|
||||
|
||||
不论是因为你处于一个高强度监管的行业中,还是只希望简单地优化你的团队的成果,设计你的容器镜像管理以及构建过程,可以使用容器层的优势来实现控制分离,因此,你应该去这么做:
|
||||
|
||||
* 运营团队管理基础镜像
|
||||
* 架构师管理中间件、运行时、数据库,以及其它解决方案
|
||||
* 开发者专注于应用程序层面,并且只写代码
|
||||
|
||||
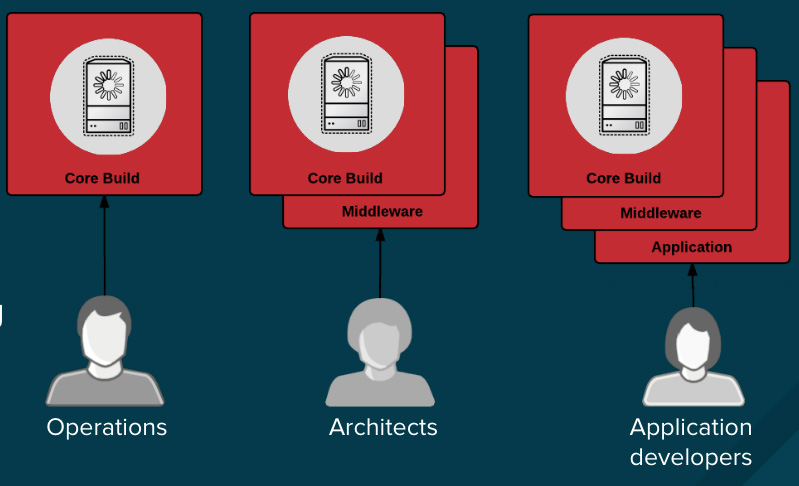
|
||||
|
||||
最后,标记好你的定制构建容器,这样可以确保在构建和部署时不会搞混乱。
|
||||
|
||||
### 5. 控制好在同一个集群内部署应用
|
||||
|
||||
如果是在构建过程中出现的任何问题,或者在镜像被部署之后发现的任何漏洞,那么,请在基于策略的、自动化工具上添加另外的安全层。
|
||||
|
||||
我们来看一下,一个应用程序的构建使用了三个容器镜像层:内核、中间件,以及应用程序。如果在内核镜像中发现了问题,那么只能重新构建镜像。一旦构建完成,镜像就会被发布到容器平台注册库中。这个平台可以自动检测到发生变化的镜像。对于基于这个镜像的其它构建将被触发一个预定义的动作,平台将自己重新构建应用镜像,合并该修复的库。
|
||||
|
||||
一旦构建完成,镜像将被发布到容器平台的内部注册库中。在它的内部注册库中,会立即检测到镜像发生变化,应用程序在这里将会被触发一个预定义的动作,自动部署更新镜像,确保运行在生产系统中的代码总是使用更新后的最新的镜像。所有的这些功能协同工作,将安全功能集成到你的持续集成和持续部署(CI/CD)过程和管道中。
|
||||
|
||||
### 6. 容器编配:保护容器平台安全
|
||||
|
||||
当然了,应用程序很少会以单一容器分发。甚至,简单的应用程序一般情况下都会有一个前端、一个后端、以及一个数据库。而在容器中以微服务模式部署的应用程序,意味着应用程序将部署在多个容器中,有时它们在同一台宿主机上,有时它们是分布在多个宿主机或者节点上,如下面的图所示:
|
||||
|
||||
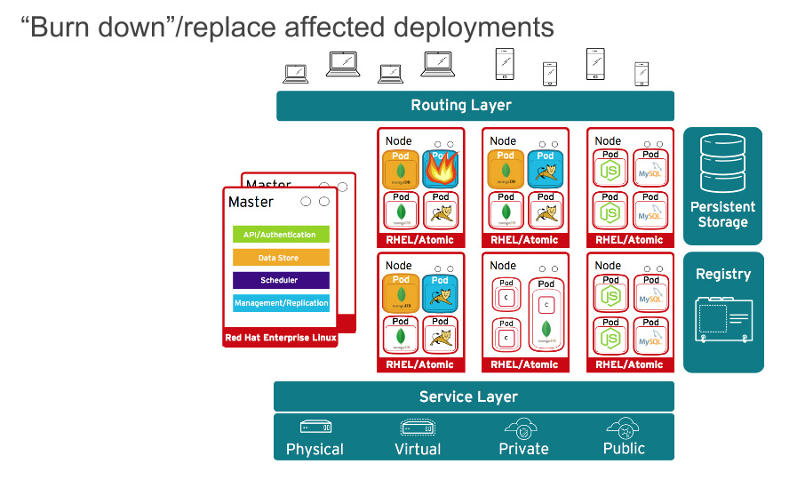
|
||||
|
||||
在大规模的容器部署时,你应该考虑:
|
||||
|
||||
* 哪个容器应该被部署在哪个宿主机上?
|
||||
* 那个宿主机应该有什么样的性能?
|
||||
* 哪个容器需要访问其它容器?它们之间如何发现彼此?
|
||||
* 你如何控制和管理对共享资源的访问,像网络和存储?
|
||||
* 如何监视容器健康状况?
|
||||
* 如何去自动扩展性能以满足应用程序的需要?
|
||||
* 如何在满足安全需求的同时启用开发者的自助服务?
|
||||
|
||||
考虑到开发者和运营者的能力,提供基于角色的访问控制是容器平台的关键要素。例如,编配管理服务器是中心访问点,应该接受最高级别的安全检查。API 是规模化的自动容器平台管理的关键,可以用于为 pod、服务,以及复制控制器验证和配置数据;在入站请求上执行项目验证;以及调用其它主要系统组件上的触发器。
|
||||
|
||||
### 7. 网络隔离
|
||||
|
||||
在容器中部署现代微服务应用,经常意味着跨多个节点在多个容器上部署。考虑到网络防御,你需要一种在一个集群中的应用之间的相互隔离的方法。一个典型的公有云容器服务,像 Google 容器引擎(GKE)、Azure 容器服务,或者 Amazon Web 服务(AWS)容器服务,是单租户服务。他们让你在你初始化建立的虚拟机集群上运行你的容器。对于多租户容器的安全,你需要容器平台为你启用一个单一集群,并且分割流量以隔离不同的用户、团队、应用、以及在这个集群中的环境。
|
||||
|
||||
使用网络命名空间,容器内的每个集合(即大家熟知的 “pod”)都会得到它自己的 IP 和绑定的端口范围,以此来从一个节点上隔离每个 pod 网络。除使用下面所述的方式之外,默认情况下,来自不同命名空间(项目)的 pod 并不能发送或者接收其它 pod 上的包和不同项目的服务。你可以使用这些特性在同一个集群内隔离开发者环境、测试环境,以及生产环境。但是,这样会导致 IP 地址和端口数量的激增,使得网络管理更加复杂。另外,容器是被设计为反复使用的,你应该在处理这种复杂性的工具上进行投入。在容器平台上比较受欢迎的工具是使用 [软件定义网络][4] (SDN) 提供一个定义的网络集群,它允许跨不同集群的容器进行通讯。
|
||||
|
||||
### 8. 存储
|
||||
|
||||
容器即可被用于无状态应用,也可被用于有状态应用。保护外加的存储是保护有状态服务的一个关键要素。容器平台对多种受欢迎的存储提供了插件,包括网络文件系统(NFS)、AWS 弹性块存储(EBS)、GCE 持久磁盘、GlusterFS、iSCSI、 RADOS(Ceph)、Cinder 等等。
|
||||
|
||||
一个持久卷(PV)可以通过资源提供者支持的任何方式装载到一个主机上。提供者有不同的性能,而每个 PV 的访问模式被设置为特定的卷支持的特定模式。例如,NFS 能够支持多路客户端同时读/写,但是,一个特定的 NFS 的 PV 可以在服务器上被发布为只读模式。每个 PV 有它自己的一组反应特定 PV 性能的访问模式的描述,比如,ReadWriteOnce、ReadOnlyMany、以及 ReadWriteMany。
|
||||
|
||||
### 9. API 管理、终端安全、以及单点登录(SSO)
|
||||
|
||||
保护你的应用安全,包括管理应用、以及 API 的认证和授权。
|
||||
|
||||
Web SSO 能力是现代应用程序的一个关键部分。在构建它们的应用时,容器平台带来了开发者可以使用的多种容器化服务。
|
||||
|
||||
API 是微服务构成的应用程序的关键所在。这些应用程序有多个独立的 API 服务,这导致了终端服务数量的激增,它就需要额外的管理工具。推荐使用 API 管理工具。所有的 API 平台应该提供多种 API 认证和安全所需要的标准选项,这些选项既可以单独使用,也可以组合使用,以用于发布证书或者控制访问。
|
||||
|
||||
这些选项包括标准的 API key、应用 ID 和密钥对,以及 OAuth 2.0。
|
||||
|
||||
### 10. 在一个联合集群中的角色和访问管理
|
||||
|
||||
在 2016 年 7 月份,Kubernetes 1.3 引入了 [Kubernetes 联合集群][5]。这是一个令人兴奋的新特性之一,它是在 Kubernetes 上游、当前的 Kubernetes 1.6 beta 中引用的。联合是用于部署和访问跨多集群运行在公有云或企业数据中心的应用程序服务的。多个集群能够用于去实现应用程序的高可用性,应用程序可以跨多个可用区域,或者去启用部署公共管理,或者跨不同的供应商进行迁移,比如,AWS、Google Cloud、以及 Azure。
|
||||
|
||||
当管理联合集群时,你必须确保你的编配工具能够提供你所需要的跨不同部署平台的实例的安全性。一般来说,认证和授权是很关键的 —— 不论你的应用程序运行在什么地方,将数据安全可靠地传递给它们,以及管理跨集群的多租户应用程序。Kubernetes 扩展了联合集群,包括对联合的秘密数据、联合的命名空间、以及 Ingress objects 的支持。
|
||||
|
||||
### 选择一个容器平台
|
||||
|
||||
当然,它并不仅关乎安全。你需要提供一个你的开发者团队和运营团队有相关经验的容器平台。他们需要一个安全的、企业级的基于容器的应用平台,它能够同时满足开发者和运营者的需要,而且还能够提高操作效率和基础设施利用率。
|
||||
|
||||
想从 Daniel 在 [欧盟开源峰会][7] 上的 [容器安全的十个层面][6] 的演讲中学习更多知识吗?这个峰会已于 10 月 23 - 26 日在 Prague 举行。
|
||||
|
||||
### 关于作者
|
||||
|
||||
Daniel Oh;Microservives;Agile;Devops;Java Ee;Container;Openshift;Jboss;Evangelism
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/10/10-layers-container-security
|
||||
|
||||
作者:[Daniel Oh][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/daniel-oh
|
||||
[1]:https://en.wikipedia.org/wiki/Security-Enhanced_Linux
|
||||
[2]:https://en.wikipedia.org/wiki/Cgroups
|
||||
[3]:https://en.wikipedia.org/wiki/Seccomp
|
||||
[4]:https://en.wikipedia.org/wiki/Software-defined_networking
|
||||
[5]:https://kubernetes.io/docs/concepts/cluster-administration/federation/
|
||||
[6]:https://osseu17.sched.com/mobile/#session:f2deeabfc1640d002c1d55101ce81223
|
||||
[7]:http://events.linuxfoundation.org/events/open-source-summit-europe
|
||||
@ -0,0 +1,91 @@
|
||||
给 “rm” 命令添加个“垃圾桶”
|
||||
============
|
||||
|
||||
人类犯错误是因为我们不是一个可编程设备,所以,在使用 `rm` 命令时要额外注意,不要在任何时候使用 `rm -rf *`。当你使用 `rm` 命令时,它会永久删除文件,不会像文件管理器那样将这些文件移动到 “垃圾箱”。
|
||||
|
||||
有时我们会将不应该删除的文件删除掉,所以当错误地删除了文件时该怎么办? 你必须看看恢复工具(Linux 中有很多数据恢复工具),但我们不知道是否能将它百分之百恢复,所以要如何解决这个问题?
|
||||
|
||||
我们最近发表了一篇关于 [Trash-Cli][1] 的文章,在评论部分,我们从用户 Eemil Lgz 那里获得了一个关于 [saferm.sh][2] 脚本的更新,它可以帮助我们将文件移动到“垃圾箱”而不是永久删除它们。
|
||||
|
||||
将文件移动到“垃圾桶”是一个好主意,当你无意中运行 `rm` 命令时,可以拯救你;但是很少有人会说这是一个坏习惯,如果你不注意“垃圾桶”,它可能会在一定的时间内被文件和文件夹堆积起来。在这种情况下,我建议你按照你的意愿去做一个定时任务。
|
||||
|
||||
这适用于服务器和桌面两种环境。 如果脚本检测到 GNOME 、KDE、Unity 或 LXDE 桌面环境(DE),则它将文件或文件夹安全地移动到默认垃圾箱 `$HOME/.local/share/Trash/files`,否则会在您的主目录中创建垃圾箱文件夹 `$HOME/Trash`。
|
||||
|
||||
`saferm.sh` 脚本托管在 Github 中,可以从仓库中克隆,也可以创建一个名为 `saferm.sh` 的文件并复制其上的代码。
|
||||
|
||||
```
|
||||
$ git clone https://github.com/lagerspetz/linux-stuff
|
||||
$ sudo mv linux-stuff/scripts/saferm.sh /bin
|
||||
$ rm -Rf linux-stuff
|
||||
```
|
||||
|
||||
在 `.bashrc` 文件中设置别名,
|
||||
|
||||
```
|
||||
alias rm=saferm.sh
|
||||
```
|
||||
|
||||
执行下面的命令使其生效,
|
||||
|
||||
```
|
||||
$ source ~/.bashrc
|
||||
```
|
||||
|
||||
一切就绪,现在你可以执行 `rm` 命令,自动将文件移动到”垃圾桶”,而不是永久删除它们。
|
||||
|
||||
测试一下,我们将删除一个名为 `magi.txt` 的文件,命令行明确的提醒了 `Moving magi.txt to $HOME/.local/share/Trash/file`。
|
||||
|
||||
|
||||
```
|
||||
$ rm -rf magi.txt
|
||||
Moving magi.txt to /home/magi/.local/share/Trash/files
|
||||
```
|
||||
|
||||
也可以通过 `ls` 命令或 `trash-cli` 进行验证。
|
||||
|
||||
```
|
||||
$ ls -lh /home/magi/.local/share/Trash/files
|
||||
Permissions Size User Date Modified Name
|
||||
.rw-r--r-- 32 magi 11 Oct 16:24 magi.txt
|
||||
```
|
||||
|
||||
或者我们可以通过文件管理器界面中查看相同的内容。
|
||||
|
||||
![![][3]][4]
|
||||
|
||||
(LCTT 译注:原文此处混淆了部分 trash-cli 的内容,考虑到文章衔接和逻辑,此处略。)
|
||||
|
||||
要了解 `saferm.sh` 的其他选项,请查看帮助。
|
||||
|
||||
```
|
||||
$ saferm.sh -h
|
||||
This is saferm.sh 1.16. LXDE and Gnome3 detection.
|
||||
Will ask to unsafe-delete instead of cross-fs move. Allows unsafe (regular rm) delete (ignores trashinfo).
|
||||
Creates trash and trashinfo directories if they do not exist. Handles symbolic link deletion.
|
||||
Does not complain about different user any more.
|
||||
|
||||
Usage: /path/to/saferm.sh [OPTIONS] [--] files and dirs to safely remove
|
||||
OPTIONS:
|
||||
-r allows recursively removing directories.
|
||||
-f Allow deleting special files (devices, ...).
|
||||
-u Unsafe mode, bypass trash and delete files permanently.
|
||||
-v Verbose, prints more messages. Default in this version.
|
||||
-q Quiet mode. Opposite of verbose.
|
||||
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/rm-command-to-move-files-to-trash-can-rm-alias/
|
||||
|
||||
作者:[2DAYGEEK][a]
|
||||
译者:[amwps290](https://github.com/amwps290)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/2daygeek/
|
||||
[1]:https://www.2daygeek.com/trash-cli-command-line-trashcan-linux-system/
|
||||
[2]:https://github.com/lagerspetz/linux-stuff/blob/master/scripts/saferm.sh
|
||||
[3]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[4]:https://www.2daygeek.com/wp-content/uploads/2017/10/rm-command-to-move-files-to-trash-can-rm-alias-1.png
|
||||
@ -0,0 +1,59 @@
|
||||
我的 Linux 主目录中的隐藏文件是干什么用的?
|
||||
======
|
||||
|
||||

|
||||
|
||||
在 Linux 系统中,你可能会在主目录中存储了大量文件和文件夹。但在这些文件之外,你知道你的主目录还附带了很多隐藏的文件和文件夹吗?如果你在主目录中运行 `ls -a`,你会发现一堆带有点前缀的隐藏文件和目录。这些隐藏的文件到底做了什么?
|
||||
|
||||
### 在主目录中隐藏的文件是干什么用的?
|
||||
|
||||
![hidden-files-liunux-2][1]
|
||||
|
||||
通常,主目录中的隐藏文件和目录包含该用户程序访问的设置或数据。它们不打算让用户编辑,只需要应用程序进行编辑。这就是为什么它们被隐藏在用户的正常视图之外。
|
||||
|
||||
通常,删除和修改自己主目录中的文件不会损坏操作系统。然而,依赖这些隐藏文件的应用程序可能不那么灵活。从主目录中删除隐藏文件时,通常会丢失与其关联的应用程序的设置。
|
||||
|
||||
依赖该隐藏文件的程序通常会重新创建它。 但是,你将从“开箱即用”设置开始,如全新用户一般。如果你在使用应用程序时遇到问题,那实际上可能是一个巨大的帮助。它可以让你删除可能造成麻烦的自定义设置。但如果你不这样做,这意味着你需要把所有的东西都设置成原来的样子。
|
||||
|
||||
### 主目录中某些隐藏文件的特定用途是什么?
|
||||
|
||||
![hidden-files-linux-3][2]
|
||||
|
||||
每个人在他们的主目录中都会有不同的隐藏文件。每个人都有一些。但是,无论应用程序如何,这些文件都有类似的用途。
|
||||
|
||||
#### 系统设置
|
||||
|
||||
系统设置包括桌面环境和 shell 的配置。
|
||||
|
||||
* shell 和命令行程序的**配置文件**:根据你使用的特定 shell 和类似命令的应用程序,特定的文件名称会变化。你会看到 `.bashrc`、`.vimrc` 和 `.zshrc`。这些文件包含你已经更改的有关 shell 的操作环境的任何设置,或者对 `vim` 等命令行实用工具的设置进行的调整。删除这些文件将使关联的应用程序返回到其默认状态。考虑到许多 Linux 用户多年来建立了一系列微妙的调整和设置,删除这个文件可能是一个非常头疼的问题。
|
||||
* **用户配置文件**:像上面的配置文件一样,这些文件(通常是 `.profile` 或 `.bash_profile`)保存 shell 的用户设置。该文件通常包含你的 `PATH` 环境变量。它还包含你设置的[别名][3]。用户也可以在 `.bashrc` 或其他位置放置别名。`PATH` 环境变量控制着 shell 寻找可执行命令的位置。通过添加或修改 `PATH`,可以更改 shell 的命令查找位置。别名更改了原有命令的名称。例如:一个别名可能将 `ls -l` 设置为 `ll`。这为经常使用的命令提供基于文本的快捷方式。如果删除 `.profile` 文件,通常可以在 `/etc/skel` 目录中找到默认版本。
|
||||
* **桌面环境设置**:这里保存你的桌面环境的任何定制。其中包括桌面背景、屏幕保护程序、快捷键、菜单栏和任务栏图标以及用户针对其桌面环境设置的其他任何内容。当你删除这个文件时,用户的环境会在下一次登录时恢复到新的用户环境。
|
||||
|
||||
#### 应用配置文件
|
||||
|
||||
你会在 Ubuntu 的 `.config` 文件夹中找到它们。 这些是针对特定应用程序的设置。 它们将包含喜好列表和设置等内容。
|
||||
|
||||
* **应用程序的配置文件**:这包括应用程序首选项菜单中的设置、工作区配置等。 你在这里找到的具体取决于应用程序。
|
||||
* **Web 浏览器数据**:这可能包括书签和浏览历史记录等内容。这些文件大部分是缓存。这是 Web 浏览器临时存储下载文件(如图片)的地方。删除这些内容可能会降低你首次访问某些媒体网站的速度。
|
||||
* **缓存**:如果用户应用程序缓存仅与该用户相关的数据(如 [Spotify 应用程序存储播放列表的缓存][4]),则主目录是存储该目录的默认地点。 这些缓存可能包含大量数据或仅包含几行代码:这取决于应用程序需要什么。 如果你删除这些文件,则应用程序会根据需要重新创建它们。
|
||||
* **日志**:一些用户应用程序也可能在这里存储日志。根据开发人员设置应用程序的方式,你可能会发现存储在你的主目录中的日志文件。然而,这不是一个常见的选择。
|
||||
|
||||
### 结论
|
||||
|
||||
在大多数情况下,你的 Linux 主目录中的隐藏文件用于存储用户设置。 这包括命令行程序以及基于 GUI 的应用程序的设置。删除它们将删除用户设置。 通常情况下,它不会导致程序被破坏。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/hidden-files-linux-home-directory/
|
||||
|
||||
作者:[Alexander Fox][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/alexfox/
|
||||
[1]:https://www.maketecheasier.com/assets/uploads/2017/06/hidden-files-liunux-2.png (hidden-files-liunux-2)
|
||||
[2]:https://www.maketecheasier.com/assets/uploads/2017/06/hidden-files-linux-3.png (hidden-files-linux-3)
|
||||
[3]:https://www.maketecheasier.com/making-the-linux-command-line-a-little-friendlier/#aliases
|
||||
[4]:https://www.maketecheasier.com/clear-spotify-cache/
|
||||
@ -12,17 +12,17 @@
|
||||
|
||||
### 使用 libuv 抽象出事件驱动循环
|
||||
|
||||
在 [第三节][11] 中,我们看到了基于 `select` 和 `epoll` 的服务器的相似之处,并且,我说过,在它们之间抽象出细微的差别是件很有吸引力的事。许多库已经做到了这些,所以在这一部分中我将去选一个并使用它。我选的这个库是 [libuv][12],它最初设计用于 Node.js 底层的可移植平台层,并且,后来发现在其它的项目中已有使用。libuv 是用 C 写的,因此,它具有很高的可移植性,非常适用嵌入到像 JavaScript 和 Python 这样的高级语言中。
|
||||
在 [第三节][11] 中,我们看到了基于 `select` 和 `epoll` 的服务器的相似之处,并且,我说过,在它们之间抽象出细微的差别是件很有吸引力的事。许多库已经做到了这些,所以在这一部分中我将去选一个并使用它。我选的这个库是 [libuv][12],它最初设计用于 Node.js 底层的可移植平台层,并且,后来发现在其它的项目中也有使用。libuv 是用 C 写的,因此,它具有很高的可移植性,非常适用嵌入到像 JavaScript 和 Python 这样的高级语言中。
|
||||
|
||||
虽然 libuv 为抽象出底层平台细节已经变成了一个相当大的框架,但它仍然是以 _事件循环_ 思想为中心的。在我们第三部分的事件驱动服务器中,事件循环在 `main` 函数中是很明确的;当使用 libuv 时,该循环通常隐藏在库自身中,而用户代码仅需要注册事件句柄(作为一个回调函数)和运行这个循环。此外,libuv 会在给定的平台上使用更快的事件循环实现,对于 Linux 它是 epoll,等等。
|
||||
虽然 libuv 为了抽象出底层平台细节已经变成了一个相当大的框架,但它仍然是以 _事件循环_ 思想为中心的。在我们第三部分的事件驱动服务器中,事件循环是显式定义在 `main` 函数中的;当使用 libuv 时,该循环通常隐藏在库自身中,而用户代码仅需要注册事件句柄(作为一个回调函数)和运行这个循环。此外,libuv 会在给定的平台上使用更快的事件循环实现,对于 Linux 它是 `epoll`,等等。
|
||||
|
||||

|
||||
|
||||
libuv 支持多路事件循环,并且,因此事件循环在库中是非常重要的;它有一个句柄 —— `uv_loop_t`,和创建/杀死/启动/停止循环的函数。也就是说,在这篇文章中,我将仅需要使用 “默认的” 循环,libuv 可通过 `uv_default_loop()` 提供它;多路循环大多用于多线程事件驱动的服务器,这是一个更高级别的话题,我将留在这一系列文章的以后部分。
|
||||
libuv 支持多路事件循环,因此事件循环在库中是非常重要的;它有一个句柄 —— `uv_loop_t`,以及创建/杀死/启动/停止循环的函数。也就是说,在这篇文章中,我将仅需要使用 “默认的” 循环,libuv 可通过 `uv_default_loop()` 提供它;多路循环大多用于多线程事件驱动的服务器,这是一个更高级别的话题,我将留在这一系列文章的以后部分。
|
||||
|
||||
### 使用 libuv 的并发服务器
|
||||
|
||||
为了对 libuv 有一个更深的印象,让我们跳转到我们的可靠协议的服务器,它通过我们的这个系列已经有了一个强大的重新实现。这个服务器的结构与第三部分中的基于 select 和 epoll 的服务器有一些相似之处,因为,它也依赖回调。完整的 [示例代码在这里][13];我们开始设置这个服务器的套接字绑定到一个本地端口:
|
||||
为了对 libuv 有一个更深的印象,让我们跳转到我们的可靠协议的服务器,它通过我们的这个系列已经有了一个强大的重新实现。这个服务器的结构与第三部分中的基于 `select` 和 `epoll` 的服务器有一些相似之处,因为,它也依赖回调。完整的 [示例代码在这里][13];我们开始设置这个服务器的套接字绑定到一个本地端口:
|
||||
|
||||
```
|
||||
int portnum = 9090;
|
||||
@ -47,9 +47,9 @@ if ((rc = uv_tcp_bind(&server_stream, (const struct sockaddr*)&server_address, 0
|
||||
}
|
||||
```
|
||||
|
||||
除了它被封装进 libuv API 中之外,你看到的是一个相当标准的套接字。在它的返回中,我们取得一个可工作于任何 libuv 支持的平台上的可移植接口。
|
||||
除了它被封装进 libuv API 中之外,你看到的是一个相当标准的套接字。在它的返回中,我们取得了一个可工作于任何 libuv 支持的平台上的可移植接口。
|
||||
|
||||
这些代码也展示了很认真负责的错误处理;多数的 libuv 函数返回一个整数状态,返回一个负数意味着出现了一个错误。在我们的服务器中,我们把这些错误看做致命问题进行处理,但也可以设想为一个更优雅的错误恢复。
|
||||
这些代码也展示了很认真负责的错误处理;多数的 libuv 函数返回一个整数状态,返回一个负数意味着出现了一个错误。在我们的服务器中,我们把这些错误看做致命问题进行处理,但也可以设想一个更优雅的错误恢复。
|
||||
|
||||
现在,那个套接字已经绑定,是时候去监听它了。这里我们运行首个回调注册:
|
||||
|
||||
@ -73,7 +73,7 @@ uv_run(uv_default_loop(), UV_RUN_DEFAULT);
|
||||
return uv_loop_close(uv_default_loop());
|
||||
```
|
||||
|
||||
注意,在运行事件循环之前,只有一个回调是通过 main 注册的;我们稍后将看到怎么去添加更多的回调。在事件循环的整个运行过程中,添加和删除回调并不是一个问题 —— 事实上,大多数服务器就是这么写的。
|
||||
注意,在运行事件循环之前,只有一个回调是通过 `main` 注册的;我们稍后将看到怎么去添加更多的回调。在事件循环的整个运行过程中,添加和删除回调并不是一个问题 —— 事实上,大多数服务器就是这么写的。
|
||||
|
||||
这是一个 `on_peer_connected`,它处理到服务器的新的客户端连接:
|
||||
|
||||
@ -132,8 +132,8 @@ void on_peer_connected(uv_stream_t* server_stream, int status) {
|
||||
|
||||
这些代码都有很好的注释,但是,这里有一些重要的 libuv 语法我想去强调一下:
|
||||
|
||||
* 传入自定义数据到回调中:因为 C 还没有闭包,这可能是个挑战,libuv 在它的所有的处理类型中有一个 `void* data` 字段;这些字段可以被用于传递用户数据。例如,注意 `client->data` 是如何指向到一个 `peer_state_t` 结构上,以便于 `uv_write` 和 `uv_read_start` 注册的回调可以知道它们正在处理的是哪个客户端的数据。
|
||||
* 内存管理:在带有垃圾回收的语言中进行事件驱动编程是非常容易的,因为,回调通常运行在一个它们注册的完全不同的栈帧中,使得基于栈的内存管理很困难。它总是需要传递堆分配的数据到 libuv 回调中(当所有回调运行时,除了 main,其它的都运行在栈上),并且,为了避免泄漏,许多情况下都要求这些数据去安全释放。这些都是些需要实践的内容 [[1]][6]。
|
||||
* 传入自定义数据到回调中:因为 C 语言还没有闭包,这可能是个挑战,libuv 在它的所有的处理类型中有一个 `void* data` 字段;这些字段可以被用于传递用户数据。例如,注意 `client->data` 是如何指向到一个 `peer_state_t` 结构上,以便于 `uv_write` 和 `uv_read_start` 注册的回调可以知道它们正在处理的是哪个客户端的数据。
|
||||
* 内存管理:在带有垃圾回收的语言中进行事件驱动编程是非常容易的,因为,回调通常运行在一个与它们注册的地方完全不同的栈帧中,使得基于栈的内存管理很困难。它总是需要传递堆分配的数据到 libuv 回调中(当所有回调运行时,除了 `main`,其它的都运行在栈上),并且,为了避免泄漏,许多情况下都要求这些数据去安全释放(`free()`)。这些都是些需要实践的内容 ^注1 。
|
||||
|
||||
这个服务器上对端的状态如下:
|
||||
|
||||
@ -146,7 +146,7 @@ typedef struct {
|
||||
} peer_state_t;
|
||||
```
|
||||
|
||||
它与第三部分中的状态非常类似;我们不再需要 sendptr,因为,在调用 "done writing" 回调之前,`uv_write` 将确保去发送它提供的整个缓冲。我们也为其它的回调使用保持了一个到客户端的指针。这里是 `on_wrote_init_ack`:
|
||||
它与第三部分中的状态非常类似;我们不再需要 `sendptr`,因为,在调用 “done writing” 回调之前,`uv_write` 将确保发送它提供的整个缓冲。我们也为其它的回调使用保持了一个到客户端的指针。这里是 `on_wrote_init_ack`:
|
||||
|
||||
```
|
||||
void on_wrote_init_ack(uv_write_t* req, int status) {
|
||||
@ -171,7 +171,7 @@ void on_wrote_init_ack(uv_write_t* req, int status) {
|
||||
}
|
||||
```
|
||||
|
||||
然后,我们确信知道了这个初始的 '*' 已经被发送到对端,我们通过调用 `uv_read_start` 去监听从这个对端来的入站数据,它注册一个回调(`on_peer_read`)去被调用,不论什么时候,事件循环都在套接字上接收来自客户端的调用:
|
||||
然后,我们确信知道了这个初始的 `'*'` 已经被发送到对端,我们通过调用 `uv_read_start` 去监听从这个对端来的入站数据,它注册一个将被事件循环调用的回调(`on_peer_read`),不论什么时候,事件循环都在套接字上接收来自客户端的调用:
|
||||
|
||||
```
|
||||
void on_peer_read(uv_stream_t* client, ssize_t nread, const uv_buf_t* buf) {
|
||||
@ -236,11 +236,11 @@ void on_peer_read(uv_stream_t* client, ssize_t nread, const uv_buf_t* buf) {
|
||||
}
|
||||
```
|
||||
|
||||
这个服务器的运行时行为非常类似于第三部分的事件驱动服务器:所有的客户端都在一个单个的线程中并发处理。并且一些行为被维护在服务器代码中:服务器的逻辑实现为一个集成的回调,并且长周期运行是禁止的,因为它会阻塞事件循环。这一点也很类似。让我们进一步探索这个问题。
|
||||
这个服务器的运行时行为非常类似于第三部分的事件驱动服务器:所有的客户端都在一个单个的线程中并发处理。并且类似的,一些特定的行为必须在服务器代码中维护:服务器的逻辑实现为一个集成的回调,并且长周期运行是禁止的,因为它会阻塞事件循环。这一点也很类似。让我们进一步探索这个问题。
|
||||
|
||||
### 在事件驱动循环中的长周期运行的操作
|
||||
|
||||
单线程的事件驱动代码使它先天地对一些常见问题非常敏感:整个循环中的长周期运行的代码块。参见如下的程序:
|
||||
单线程的事件驱动代码使它先天就容易受到一些常见问题的影响:长周期运行的代码会阻塞整个循环。参见如下的程序:
|
||||
|
||||
```
|
||||
void on_timer(uv_timer_t* timer) {
|
||||
@ -280,23 +280,21 @@ on_timer [18850 ms]
|
||||
...
|
||||
```
|
||||
|
||||
`on_timer` 忠实地每秒执行一次,直到随机出现的睡眠为止。在那个时间点,`on_timer` 不再被调用,直到睡眠时间结束;事实上,_没有其它的回调_ 在这个时间帧中被调用。这个睡眠调用阻塞当前线程,它正是被调用的线程,并且也是事件循环使用的线程。当这个线程被阻塞后,事件循环也被阻塞。
|
||||
`on_timer` 忠实地每秒执行一次,直到随机出现的睡眠为止。在那个时间点,`on_timer` 不再被调用,直到睡眠时间结束;事实上,_没有其它的回调_ 会在这个时间帧中被调用。这个睡眠调用阻塞了当前线程,它正是被调用的线程,并且也是事件循环使用的线程。当这个线程被阻塞后,事件循环也被阻塞。
|
||||
|
||||
这个示例演示了在事件驱动的调用中为什么回调不能被阻塞是多少的重要。并且,同样适用于 Node.js 服务器、客户端侧的 Javascript、大多数的 GUI 编程框架、以及许多其它的异步编程模型。
|
||||
|
||||
但是,有时候运行耗时的任务是不可避免的。并不是所有任务都有一个异步 APIs;例如,我们可能使用一些仅有同步 API 的库去处理,或者,正在执行一个可能的长周期计算。我们如何用事件驱动编程去结合这些代码?线程可以帮到你!
|
||||
但是,有时候运行耗时的任务是不可避免的。并不是所有任务都有一个异步 API;例如,我们可能使用一些仅有同步 API 的库去处理,或者,正在执行一个可能的长周期计算。我们如何用事件驱动编程去结合这些代码?线程可以帮到你!
|
||||
|
||||
### “转换” 阻塞调用到异步调用的线程
|
||||
### “转换” 阻塞调用为异步调用的线程
|
||||
|
||||
一个线程池可以被用于去转换阻塞调用到异步调用,通过与事件循环并行运行,并且当任务完成时去由它去公布事件。一个给定的阻塞函数 `do_work()`,这里介绍了它是怎么运行的:
|
||||
一个线程池可以用于转换阻塞调用为异步调用,通过与事件循环并行运行,并且当任务完成时去由它去公布事件。以阻塞函数 `do_work()` 为例,这里介绍了它是怎么运行的:
|
||||
|
||||
1. 在一个回调中,用 `do_work()` 代表直接调用,我们将它打包进一个 “任务”,并且请求线程池去运行这个任务。当任务完成时,我们也为循环去调用它注册一个回调;我们称它为 `on_work_done()`。
|
||||
1. 不在一个回调中直接调用 `do_work()` ,而是将它打包进一个 “任务”,让线程池去运行这个任务。当任务完成时,我们也为循环去调用它注册一个回调;我们称它为 `on_work_done()`。
|
||||
2. 在这个时间点,我们的回调就可以返回了,而事件循环保持运行;在同一时间点,线程池中的有一个线程运行这个任务。
|
||||
3. 一旦任务运行完成,通知主线程(指正在运行事件循环的线程),并且事件循环调用 `on_work_done()`。
|
||||
|
||||
2. 在这个时间点,我们的回调可以返回并且事件循环保持运行;在同一时间点,线程池中的一个线程运行这个任务。
|
||||
|
||||
3. 一旦任务运行完成,通知主线程(指正在运行事件循环的线程),并且,通过事件循环调用 `on_work_done()`。
|
||||
|
||||
让我们看一下,使用 libuv 的工作调度 API,是怎么去解决我们前面的 timer/sleep 示例中展示的问题的:
|
||||
让我们看一下,使用 libuv 的工作调度 API,是怎么去解决我们前面的计时器/睡眠示例中展示的问题的:
|
||||
|
||||
```
|
||||
void on_after_work(uv_work_t* req, int status) {
|
||||
@ -327,7 +325,7 @@ int main(int argc, const char** argv) {
|
||||
}
|
||||
```
|
||||
|
||||
通过一个 work_req [[2]][14] 类型的句柄,我们进入一个任务队列,代替在 `on_timer` 上直接调用 sleep,这个函数在任务中(`on_work`)运行,并且,一旦任务完成(`on_after_work`),这个函数被调用一次。`on_work` 在这里是指发生的 “work”(阻塞中的/耗时的操作)。在这两个回调传递到 `uv_queue_work` 时,注意一个关键的区别:`on_work` 运行在线程池中,而 `on_after_work` 运行在事件循环中的主线程上 - 就好像是其它的回调一样。
|
||||
通过一个 `work_req` ^注2 类型的句柄,我们进入一个任务队列,代替在 `on_timer` 上直接调用 sleep,这个函数在任务中(`on_work`)运行,并且,一旦任务完成(`on_after_work`),这个函数被调用一次。`on_work` 是指 “work”(阻塞中的/耗时的操作)进行的地方。注意在这两个回调传递到 `uv_queue_work` 时的一个关键区别:`on_work` 运行在线程池中,而 `on_after_work` 运行在事件循环中的主线程上 —— 就好像是其它的回调一样。
|
||||
|
||||
让我们看一下这种方式的运行:
|
||||
|
||||
@ -347,25 +345,25 @@ on_timer [97578 ms]
|
||||
...
|
||||
```
|
||||
|
||||
即便在 sleep 函数被调用时,定时器也每秒钟滴答一下,睡眠(sleeping)现在运行在一个单独的线程中,并且不会阻塞事件循环。
|
||||
即便在 sleep 函数被调用时,定时器也每秒钟滴答一下,睡眠现在运行在一个单独的线程中,并且不会阻塞事件循环。
|
||||
|
||||
### 一个用于练习的素数测试服务器
|
||||
|
||||
因为通过睡眼去模拟工作并不是件让人兴奋的事,我有一个事先准备好的更综合的一个示例 - 一个基于套接字接受来自客户端的数字的服务器,检查这个数字是否是素数,然后去返回一个 “prime" 或者 “composite”。完整的 [服务器代码在这里][15] - 我不在这里粘贴了,因为它太长了,更希望读者在一些自己的练习中去体会它。
|
||||
因为通过睡眠去模拟工作并不是件让人兴奋的事,我有一个事先准备好的更综合的一个示例 —— 一个基于套接字接受来自客户端的数字的服务器,检查这个数字是否是素数,然后去返回一个 “prime" 或者 “composite”。完整的 [服务器代码在这里][15] —— 我不在这里粘贴了,因为它太长了,更希望读者在一些自己的练习中去体会它。
|
||||
|
||||
这个服务器使用了一个原生的素数测试算法,因此,对于大的素数可能花很长时间才返回一个回答。在我的机器中,对于 2305843009213693951,它花了 ~5 秒钟去计算,但是,你的方法可能不同。
|
||||
|
||||
练习 1:服务器有一个设置(通过一个名为 MODE 的环境变量)要么去在套接字回调(意味着在主线程上)中运行素数测试,要么在 libuv 工作队列中。当多个客户端同时连接时,使用这个设置来观察服务器的行为。当它计算一个大的任务时,在阻塞模式中,服务器将不回复其它客户端,而在非阻塞模式中,它会回复。
|
||||
练习 1:服务器有一个设置(通过一个名为 `MODE` 的环境变量)要么在套接字回调(意味着在主线程上)中运行素数测试,要么在 libuv 工作队列中。当多个客户端同时连接时,使用这个设置来观察服务器的行为。当它计算一个大的任务时,在阻塞模式中,服务器将不回复其它客户端,而在非阻塞模式中,它会回复。
|
||||
|
||||
练习 2;libuv 有一个缺省大小的线程池,并且线程池的大小可以通过环境变量配置。你可以通过使用多个客户端去实验找出它的缺省值是多少?找到线程池缺省值后,使用不同的设置去看一下,在重负载下怎么去影响服务器的响应能力。
|
||||
练习 2:libuv 有一个缺省大小的线程池,并且线程池的大小可以通过环境变量配置。你可以通过使用多个客户端去实验找出它的缺省值是多少?找到线程池缺省值后,使用不同的设置去看一下,在重负载下怎么去影响服务器的响应能力。
|
||||
|
||||
### 在非阻塞文件系统中使用工作队列
|
||||
|
||||
对于仅傻傻的演示和 CPU 密集型的计算来说,将可能的阻塞操作委托给一个线程池并不是明智的;libuv 在它的文件系统 APIs 中本身就大量使用了这种性能。通过这种方式,libuv 使用一个异步 API,在一个轻便的方式中,显示出它强大的文件系统的处理能力。
|
||||
对于只是呆板的演示和 CPU 密集型的计算来说,将可能的阻塞操作委托给一个线程池并不是明智的;libuv 在它的文件系统 API 中本身就大量使用了这种能力。通过这种方式,libuv 使用一个异步 API,以一个轻便的方式显示出它强大的文件系统的处理能力。
|
||||
|
||||
让我们使用 `uv_fs_read()`,例如,这个函数从一个文件中(以一个 `uv_fs_t` 句柄为代表)读取一个文件到一个缓冲中 [[3]][16],并且当读取完成后调用一个回调。换句话说,`uv_fs_read()` 总是立即返回,甚至如果文件在一个类似 NFS 的系统上,并且,数据到达缓冲区可能需要一些时间。换句话说,这个 API 与这种方式中其它的 libuv APIs 是异步的。这是怎么工作的呢?
|
||||
让我们使用 `uv_fs_read()`,例如,这个函数从一个文件中(表示为一个 `uv_fs_t` 句柄)读取一个文件到一个缓冲中 ^注3,并且当读取完成后调用一个回调。换句话说,`uv_fs_read()` 总是立即返回,即使是文件在一个类似 NFS 的系统上,而数据到达缓冲区可能需要一些时间。换句话说,这个 API 与这种方式中其它的 libuv API 是异步的。这是怎么工作的呢?
|
||||
|
||||
在这一点上,我们看一下 libuv 的底层;内部实际上非常简单,并且它是一个很好的练习。作为一个便携的库,libuv 对于 Windows 和 Unix 系统在它的许多函数上有不同的实现。我们去看一下在 libuv 源树中的 src/unix/fs.c。
|
||||
在这一点上,我们看一下 libuv 的底层;内部实际上非常简单,并且它是一个很好的练习。作为一个可移植的库,libuv 对于 Windows 和 Unix 系统在它的许多函数上有不同的实现。我们去看一下在 libuv 源树中的 `src/unix/fs.c`。
|
||||
|
||||
这是 `uv_fs_read` 的代码:
|
||||
|
||||
@ -400,9 +398,9 @@ int uv_fs_read(uv_loop_t* loop, uv_fs_t* req,
|
||||
}
|
||||
```
|
||||
|
||||
第一次看可能觉得很困难,因为它延缓真实的工作到 INIT 和 POST 宏中,在 POST 中与一些本地变量一起设置。这样做可以避免了文件中的许多重复代码。
|
||||
第一次看可能觉得很困难,因为它延缓真实的工作到 `INIT` 和 `POST` 宏中,以及为 `POST` 设置了一些本地变量。这样做可以避免了文件中的许多重复代码。
|
||||
|
||||
这是 INIT 宏:
|
||||
这是 `INIT` 宏:
|
||||
|
||||
```
|
||||
#define INIT(subtype) \
|
||||
@ -421,9 +419,9 @@ int uv_fs_read(uv_loop_t* loop, uv_fs_t* req,
|
||||
while (0)
|
||||
```
|
||||
|
||||
它设置了请求,并且更重要的是,设置 `req->fs_type` 域为真实的 FS 请求类型。因为 `uv_fs_read` 调用 invokes INIT(READ),它意味着 `req->fs_type` 被分配一个常数 `UV_FS_READ`。
|
||||
它设置了请求,并且更重要的是,设置 `req->fs_type` 域为真实的 FS 请求类型。因为 `uv_fs_read` 调用 `INIT(READ)`,它意味着 `req->fs_type` 被分配一个常数 `UV_FS_READ`。
|
||||
|
||||
这是 POST 宏:
|
||||
这是 `POST` 宏:
|
||||
|
||||
```
|
||||
#define POST \
|
||||
@ -440,31 +438,25 @@ int uv_fs_read(uv_loop_t* loop, uv_fs_t* req,
|
||||
while (0)
|
||||
```
|
||||
|
||||
它做什么取决于回调是否为 NULL。在 libuv 文件系统 APIs 中,一个 NULL 回调意味着我们真实地希望去执行一个 _同步_ 操作。在这种情况下,POST 直接调用 `uv__fs_work`(我们需要了解一下这个函数的功能),而对于一个 non-NULL 回调,它提交 `uv__fs_work` 作为一个工作事项到工作队列(指的是线程池),然后,注册 `uv__fs_done` 作为回调;该函数执行一些登记并调用用户提供的回调。
|
||||
它做什么取决于回调是否为 `NULL`。在 libuv 文件系统 API 中,一个 `NULL` 回调意味着我们真实地希望去执行一个 _同步_ 操作。在这种情况下,`POST` 直接调用 `uv__fs_work`(我们需要了解一下这个函数的功能),而对于一个非 `NULL` 回调,它把 `uv__fs_work` 作为一个工作项提交到工作队列(指的是线程池),然后,注册 `uv__fs_done` 作为回调;该函数执行一些登记并调用用户提供的回调。
|
||||
|
||||
如果我们去看 `uv__fs_work` 的代码,我们将看到它使用很多宏去按需路由工作到真实的文件系统调用。在我们的案例中,对于 `UV_FS_READ` 这个调用将被 `uv__fs_read` 生成,它(最终)使用普通的 POSIX APIs 去读取。这个函数可以在一个 _阻塞_ 方式中很安全地实现。因为,它通过异步 API 调用时被置于一个线程池中。
|
||||
如果我们去看 `uv__fs_work` 的代码,我们将看到它使用很多宏按照需求将工作分发到实际的文件系统调用。在我们的案例中,对于 `UV_FS_READ` 这个调用将被 `uv__fs_read` 生成,它(最终)使用普通的 POSIX API 去读取。这个函数可以在一个 _阻塞_ 方式中很安全地实现。因为,它通过异步 API 调用时被置于一个线程池中。
|
||||
|
||||
在 Node.js 中,fs.readFile 函数是映射到 `uv_fs_read` 上。因此,可以在一个非阻塞模式中读取文件,甚至是当底层文件系统 API 是阻塞方式时。
|
||||
在 Node.js 中,`fs.readFile` 函数是映射到 `uv_fs_read` 上。因此,可以在一个非阻塞模式中读取文件,甚至是当底层文件系统 API 是阻塞方式时。
|
||||
|
||||
* * *
|
||||
|
||||
|
||||
[[1]][1] 为确保服务器不泄露内存,我在一个启用泄露检查的 Valgrind 中运行它。因为服务器经常是被设计为永久运行,这是一个挑战;为克服这个问题,我在服务器上添加了一个 “kill 开关” - 一个从客户端接收的特定序列,以使它可以停止事件循环并退出。这个代码在 `theon_wrote_buf` 句柄中。
|
||||
|
||||
|
||||
[[2]][2] 在这里我们不过多地使用 `work_req`;讨论的素数测试服务器接下来将展示怎么被用于去传递上下文信息到回调中。
|
||||
|
||||
|
||||
[[3]][3] `uv_fs_read()` 提供了一个类似于 preadv Linux 系统调用的通用 API:它使用多缓冲区用于排序,并且支持一个到文件中的偏移。基于我们讨论的目的可以忽略这些特性。
|
||||
|
||||
- 注1: 为确保服务器不泄露内存,我在一个启用泄露检查的 Valgrind 中运行它。因为服务器经常是被设计为永久运行,这是一个挑战;为克服这个问题,我在服务器上添加了一个 “kill 开关” —— 一个从客户端接收的特定序列,以使它可以停止事件循环并退出。这个代码在 `theon_wrote_buf` 句柄中。
|
||||
- 注2: 在这里我们不过多地使用 `work_req`;讨论的素数测试服务器接下来将展示怎么被用于去传递上下文信息到回调中。
|
||||
- 注3: `uv_fs_read()` 提供了一个类似于 `preadv` Linux 系统调用的通用 API:它使用多缓冲区用于排序,并且支持一个到文件中的偏移。基于我们讨论的目的可以忽略这些特性。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://eli.thegreenplace.net/2017/concurrent-servers-part-4-libuv/
|
||||
|
||||
作者:[Eli Bendersky ][a]
|
||||
作者:[Eli Bendersky][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,94 @@
|
||||
如何在 Linux 中配置 ssh 登录导语
|
||||
======
|
||||
|
||||
> 了解如何在 Linux 中创建登录导语,来向要登录或登录后的用户显示不同的警告或消息。
|
||||
|
||||
![Login banners in Linux][1]
|
||||
|
||||
无论何时登录公司的某些生产系统,你都会看到一些登录消息、警告或关于你将登录或已登录的服务器的信息,如下所示。这些是<ruby>登录导语<rt>login banner</rt></ruby>。
|
||||
|
||||
![Login welcome messages in Linux][2]
|
||||
|
||||
在本文中,我们将引导你配置它们。
|
||||
|
||||
你可以配置两种类型的导语。
|
||||
|
||||
1. 用户登录前显示的导语信息(在你选择的文件中配置,例如 `/etc/login.warn`)
|
||||
2. 用户成功登录后显示的导语信息(在 `/etc/motd` 中配置)
|
||||
|
||||
### 如何在用户登录前连接系统时显示消息
|
||||
|
||||
当用户连接到服务器并且在登录之前,这个消息将被显示给他。意味着当他输入用户名时,该消息将在密码提示之前显示。
|
||||
|
||||
你可以使用任何文件名并在其中输入信息。在这里我们使用 `/etc/login.warn` 并且把我们的消息放在里面。
|
||||
|
||||
```
|
||||
# cat /etc/login.warn
|
||||
!!!! Welcome to KernelTalks test server !!!!
|
||||
This server is meant for testing Linux commands and tools. If you are
|
||||
not associated with kerneltalks.com and not authorized please dis-connect
|
||||
immediately.
|
||||
```
|
||||
|
||||
现在,需要将此文件和路径告诉 `sshd` 守护进程,以便它可以为每个用户登录请求获取此标语。对于此,打开 `/etc/sshd/sshd_config` 文件并搜索 `#Banner none`。
|
||||
|
||||
这里你需要编辑该配置文件,并写下你的文件名并删除注释标记(`#`)。它应该看起来像:`Banner /etc/login.warn`。
|
||||
|
||||
保存文件并重启 `sshd` 守护进程。为避免断开现有的连接用户,请使用 HUP 信号重启 sshd。
|
||||
|
||||
```
|
||||
root@kerneltalks # ps -ef | grep -i sshd
|
||||
root 14255 1 0 18:42 ? 00:00:00 /usr/sbin/sshd -D
|
||||
root 19074 14255 0 18:46 ? 00:00:00 sshd: ec2-user [priv]
|
||||
root 19177 19127 0 18:54 pts/0 00:00:00 grep -i sshd
|
||||
|
||||
root@kerneltalks # kill -HUP 14255
|
||||
```
|
||||
|
||||
就是这样了!打开新的会话并尝试登录。你将看待你在上述步骤中配置的消息。
|
||||
|
||||
![Login banner in Linux][3]
|
||||
|
||||
你可以在用户输入密码登录系统之前看到此消息。
|
||||
|
||||
### 如何在用户登录后显示消息
|
||||
|
||||
消息用户在成功登录系统后看到的<ruby>当天消息<rt>Message Of The Day</rt></ruby>(MOTD)由 `/etc/motd` 控制。编辑这个文件并输入当成功登录后欢迎用户的消息。
|
||||
|
||||
```
|
||||
root@kerneltalks # cat /etc/motd
|
||||
W E L C O M E
|
||||
Welcome to the testing environment of kerneltalks.
|
||||
Feel free to use this system for testing your Linux
|
||||
skills. In case of any issues reach out to admin at
|
||||
info@kerneltalks.com. Thank you.
|
||||
|
||||
```
|
||||
|
||||
你不需要重启 `sshd` 守护进程来使更改生效。只要保存该文件,`sshd` 守护进程就会下一次登录请求时读取和显示。
|
||||
|
||||
![motd in linux][4]
|
||||
|
||||
你可以在上面的截图中看到:黄色框是由 `/etc/motd` 控制的 MOTD,绿色框就是我们之前看到的登录导语。
|
||||
|
||||
你可以使用 [cowsay][5]、[banner][6]、[figlet][7]、[lolcat][8] 等工具创建出色的引人注目的登录消息。此方法适用于几乎所有 Linux 发行版,如 RedHat、CentOs、Ubuntu、Fedora 等。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://kerneltalks.com/tips-tricks/how-to-configure-login-banners-in-linux/
|
||||
|
||||
作者:[kerneltalks][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://kerneltalks.com
|
||||
[1]:https://a3.kerneltalks.com/wp-content/uploads/2017/11/login-banner-message-in-linux.png
|
||||
[2]:https://a3.kerneltalks.com/wp-content/uploads/2017/11/Login-message-in-linux.png
|
||||
[3]:https://a1.kerneltalks.com/wp-content/uploads/2017/11/login-banner.png
|
||||
[4]:https://a3.kerneltalks.com/wp-content/uploads/2017/11/motd-message-in-linux.png
|
||||
[5]:https://kerneltalks.com/tips-tricks/cowsay-fun-in-linux-terminal/
|
||||
[6]:https://kerneltalks.com/howto/create-nice-text-banner-hpux/
|
||||
[7]:https://kerneltalks.com/tips-tricks/create-beautiful-ascii-text-banners-linux/
|
||||
[8]:https://kerneltalks.com/linux/lolcat-tool-to-rainbow-color-linux-terminal/
|
||||
@ -0,0 +1,78 @@
|
||||
使用 Showterm 录制和分享终端会话
|
||||
======
|
||||
|
||||

|
||||
|
||||
你可以使用几乎所有的屏幕录制程序轻松录制终端会话。但是,你很可能会得到超大的视频文件。Linux 中有几种终端录制程序,每种录制程序都有自己的优点和缺点。Showterm 是一个可以非常容易地记录终端会话、上传、分享,并将它们嵌入到任何网页中的工具。一个优点是,你不会有巨大的文件来处理。
|
||||
|
||||
Showterm 是开源的,该项目可以在这个 [GitHub 页面][1]上找到。
|
||||
|
||||
**相关**:[2 个简单的将你的终端会话录制为视频的 Linux 程序][2]
|
||||
|
||||
### 在 Linux 中安装 Showterm
|
||||
|
||||
Showterm 要求你在计算机上安装了 Ruby。以下是如何安装该程序。
|
||||
|
||||
```
|
||||
gem install showterm
|
||||
```
|
||||
|
||||
如果你没有在 Linux 上安装 Ruby,可以这样:
|
||||
|
||||
```
|
||||
sudo curl showterm.io/showterm > ~/bin/showterm
|
||||
sudo chmod +x ~/bin/showterm
|
||||
```
|
||||
|
||||
如果你只是想运行程序而不是安装:
|
||||
|
||||
```
|
||||
bash <(curl record.showterm.io)
|
||||
```
|
||||
|
||||
你可以在终端输入 `showterm --help` 得到帮助页面。如果没有出现帮助页面,那么可能是未安装 `showterm`。现在你已安装了 Showterm(或正在运行独立版本),让我们开始使用该工具进行录制。
|
||||
|
||||
**相关**:[如何在 Ubuntu 中录制终端会话][3]
|
||||
|
||||
### 录制终端会话
|
||||
|
||||
![showterm terminal][4]
|
||||
|
||||
录制终端会话非常简单。从命令行运行 `showterm`。这会在后台启动终端录制。所有从命令行输入的命令都由 Showterm 记录。完成录制后,请按 `Ctrl + D` 或在命令行中输入`exit` 停止录制。
|
||||
|
||||
Showterm 会上传你的视频并输出一个看起来像 `http://showterm.io/<一长串字符>` 的链接的视频。不幸的是,终端会话会立即上传,而没有任何提示。请不要惊慌!你可以通过输入 `showterm --delete <recording URL>` 删除任何已上传的视频。在上传视频之前,你可以通过在 `showterm` 命令中添加 `-e` 选项来改变计时。如果视频无法上传,你可以使用 `showterm --retry <script> <times>` 强制重试。
|
||||
|
||||
在查看录制内容时,还可以通过在 URL 中添加 `#slow`、`#fast` 或 `#stop` 来控制视频的计时。`#slow` 让视频以正常速度播放、`#fast` 是速度加倍、`#stop`,如名称所示,停止播放视频。
|
||||
|
||||
Showterm 终端录制视频可以通过 iframe 轻松嵌入到网页中。这可以通过将 iframe 源添加到 showterm 视频地址来实现,如下所示。
|
||||
|
||||
![showtermio][5]
|
||||
|
||||
作为开源工具,Showterm 允许进一步定制。例如,要运行你自己的 Showterm 服务器,你需要运行以下命令:
|
||||
|
||||
```
|
||||
export SHOWTERM_SERVER=https://showterm.myorg.local/
|
||||
```
|
||||
|
||||
这样你的客户端可以和它通信。还有额外的功能只需很少的编程知识就可添加。Showterm 服务器项目可在此 [GitHub 页面][1]获得。
|
||||
|
||||
### 结论
|
||||
|
||||
如果你想与同事分享一些命令行教程,请务必记得 Showterm。Showterm 是基于文本的。因此,与其他屏幕录制机相比,它将产生相对较小的视频。该工具本身尺寸相当小 —— 只有几千字节。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/record-terminal-session-showterm/
|
||||
|
||||
作者:[Bruno Edoh][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/brunoedoh/
|
||||
[1]:https://github.com/ConradIrwin/showterm
|
||||
[2]:https://www.maketecheasier.com/record-terminal-session-as-video/ (2 Simple Applications That Record Your Terminal Session as Video [Linux])
|
||||
[3]:https://www.maketecheasier.com/record-terminal-session-in-ubuntu/ (How to Record Terminal Session in Ubuntu)
|
||||
[4]:https://www.maketecheasier.com/assets/uploads/2017/11/showterm-interface.png (showterm terminal)
|
||||
[5]:https://www.maketecheasier.com/assets/uploads/2017/11/showterm-site.png (showtermio)
|
||||
@ -3,11 +3,11 @@
|
||||
|
||||
### 目标
|
||||
|
||||
学习在 Linux 上使用 "pass" 密码管理器来管理你的密码
|
||||
学习在 Linux 上使用 pass 密码管理器来管理你的密码
|
||||
|
||||
### 条件
|
||||
|
||||
* 需要 root 权限来安装需要的包
|
||||
* 需要 root 权限来安装需要的包
|
||||
|
||||
### 难度
|
||||
|
||||
@ -15,75 +15,81 @@
|
||||
|
||||
### 约定
|
||||
|
||||
* **#** - 执行指定命令需要 root 权限,可以是直接使用 root 用户来执行或者使用 `sudo` 命令来执行
|
||||
* **$** - 使用普通的非特权用户执行指定命令
|
||||
* `#` - 执行指定命令需要 root 权限,可以是直接使用 root 用户来执行或者使用 `sudo` 命令来执行
|
||||
* `$` - 使用普通的非特权用户执行指定命令
|
||||
|
||||
### 介绍
|
||||
|
||||
如果你有根据不同的意图设置不同密码的好习惯,你可能已经感受到需要一个密码管理器的必要性了。在 Linux 上有很多选择,可以是专利软件(如果你敢的话)也可以是开源软件。如果你跟我一样喜欢简洁的话,你可能会对 `pass` 感兴趣。
|
||||
如果你有根据不同的意图设置不同密码的好习惯,你可能已经感受到需要一个密码管理器的必要性了。在 Linux 上有很多选择,可以是专有软件(如果你敢用的话)也可以是开源软件。如果你跟我一样喜欢简洁的话,你可能会对 `pass` 感兴趣。
|
||||
|
||||
### First steps
|
||||
### 第一步
|
||||
|
||||
Pass 作为一个密码管理器,其实际上是一些你可能早已每天使用的、可信赖且实用的工具的一种封装,比如 `gpg` 和 `git` 。虽然它也有图形界面,但它专门设计能成在命令行下工作的:因此它也可以在 headless machines 上工作 (LCTT 注:根据 wikipedia 的说法,所谓 headless machines 是指没有显示器、键盘和鼠标的机器,一般通过网络链接来控制)。
|
||||
pass 作为一个密码管理器,其实际上是一些你可能早已每天使用的、可信赖且实用的工具的一种封装,比如 `gpg` 和 `git` 。虽然它也有图形界面,但它专门设计能成在命令行下工作的:因此它也可以在 headless 机器上工作(LCTT 译注:根据 wikipedia 的说法,所谓 headless 是指没有显示器、键盘和鼠标的机器,一般通过网络链接来控制)。
|
||||
|
||||
### 步骤 1 - 安装
|
||||
### 安装
|
||||
|
||||
Pass 在主流的 linux 发行版中都是可用的,你可以通过包管理器安装:
|
||||
pass 在主流的 Linux 发行版中都是可用的,你可以通过包管理器安装:
|
||||
|
||||
#### Fedora
|
||||
|
||||
```
|
||||
# dnf install pass
|
||||
```
|
||||
|
||||
#### RHEL and CentOS
|
||||
#### RHEL 和 CentOS
|
||||
|
||||
pass 不在官方仓库中,但你可以从 `epel` 中获取道它。要在 CentOS7 上启用后面这个源,只需要执行:
|
||||
|
||||
Pass 不在官方仓库中,但你可以从 `epel` 中获取道它。要在 CentOS7 上启用后面这个源,只需要执行:
|
||||
```
|
||||
# yum install epel-release
|
||||
```
|
||||
|
||||
然而在 Red Hat 企业版的 Linux 上,这个额外的源是不可用的;你需要从 EPEL 官方网站上下载它。
|
||||
然而在 Red Hat 企业版的 Linux 上,这个额外的源是不可用的;你需要从 EPEL 官方网站上下载它。
|
||||
|
||||
#### Debian 和 Ubuntu
|
||||
|
||||
#### Debian and Ubuntu
|
||||
```
|
||||
# apt-get install pass
|
||||
```
|
||||
|
||||
#### Arch Linux
|
||||
|
||||
```
|
||||
# pacman -S pass
|
||||
```
|
||||
|
||||
### 初始化密码仓库
|
||||
|
||||
安装好 `pass` 后,就可以开始使用和配置它了。首先,由于 pass 依赖 `gpg` 来对我们的密码进行加密并以安全的方式进行存储,我们必须准备好一个 `gpg 密钥对`。
|
||||
安装好 `pass` 后,就可以开始使用和配置它了。首先,由于 `pass` 依赖于 `gpg` 来对我们的密码进行加密并以安全的方式进行存储,我们必须准备好一个 gpg 密钥对。
|
||||
|
||||
首先我们要初始化密码仓库:这就是一个用来存放 gpg 加密后的密码的目录。默认情况下它会在你的 `$HOME` 创建一个隐藏目录,不过你也可以通过使用 `PASSWORD_STORE_DIR` 这一环境变量来指定另一个路径。让我们运行:
|
||||
|
||||
首先我们要初始化 `密码仓库`:这就是一个用来存放 gpg 加密后的密码的目录。默认情况下它会在你的 `$HOME` 创建一个隐藏目录,不过你也可以通过使用 `PASSWORD_STORE_DIR` 这一环境变量来指定另一个路径。让我们运行:
|
||||
```
|
||||
$ pass init
|
||||
```
|
||||
|
||||
然后`密码仓库`目录就创建好了。现在,让我们来存储我们第一个密码:
|
||||
然后 `password-store` 目录就创建好了。现在,让我们来存储我们第一个密码:
|
||||
|
||||
```
|
||||
$ pass edit mysite
|
||||
```
|
||||
|
||||
这会打开默认文本编辑器,我么只需要输入密码就可以了。输入的内容会用 gpg 加密并存储为密码仓库目录中的 `mysite.gpg` 文件。
|
||||
|
||||
Pass 以目录树的形式存储加密后的文件,也就是说我们可以在逻辑上将多个文件放在子目录中以实现更好的组织形式,我们只需要在创建文件时指定存在哪个目录下就行了,像这样:
|
||||
`pass` 以目录树的形式存储加密后的文件,也就是说我们可以在逻辑上将多个文件放在子目录中以实现更好的组织形式,我们只需要在创建文件时指定存在哪个目录下就行了,像这样:
|
||||
|
||||
```
|
||||
$ pass edit foo/bar
|
||||
```
|
||||
|
||||
跟上面的命令一样,它也会让你输入密码,但是创建的文件是放在密码仓库目录下的 `foo` 子目录中的。要查看文件组织结构,只需要不带任何参数运行 `pass` 命令即可:
|
||||
```
|
||||
|
||||
```
|
||||
$ pass
|
||||
Password Store
|
||||
├── foo
|
||||
│ └── bar
|
||||
└── mysite
|
||||
|
||||
```
|
||||
|
||||
若想修改密码,只需要重复创建密码的操作就行了。
|
||||
@ -91,11 +97,13 @@ Password Store
|
||||
### 获取密码
|
||||
|
||||
有两种方法可以获取密码:第一种会显示密码到终端上,方法是运行:
|
||||
|
||||
```
|
||||
pass mysite
|
||||
```
|
||||
|
||||
然而更好的方法是使用 `-c` 选项让 pass 将密码直接拷贝到剪切板上:
|
||||
然而更好的方法是使用 `-c` 选项让 `pass` 将密码直接拷贝到剪切板上:
|
||||
|
||||
```
|
||||
pass -c mysite
|
||||
```
|
||||
@ -104,29 +112,32 @@ pass -c mysite
|
||||
|
||||
### 生成密码
|
||||
|
||||
Pass 也可以为我们自动生成(并自动存储)安全密码。假设我们想要生成一个由 15 个字符组成的密码:包含字母,数字和特殊符号,其命令如下:
|
||||
`pass` 也可以为我们自动生成(并自动存储)安全密码。假设我们想要生成一个由 15 个字符组成的密码:包含字母,数字和特殊符号,其命令如下:
|
||||
|
||||
```
|
||||
pass generate mysite 15
|
||||
```
|
||||
|
||||
若希望密码只包含字母和数字则可以是使用 `--no-symbols` 选项。生成的密码会显示在屏幕上。也可以通过 `--clip` 或 `-c` 选项让 pass 把密码直接拷贝到剪切板中。通过使用 `-q` 或 `--qrcode` 选项来生成二维码:
|
||||
若希望密码只包含字母和数字则可以是使用 `--no-symbols` 选项。生成的密码会显示在屏幕上。也可以通过 `--clip` 或 `-c` 选项让 `pass` 把密码直接拷贝到剪切板中。通过使用 `-q` 或 `--qrcode` 选项来生成二维码:
|
||||
|
||||
![qrcode][1]
|
||||
|
||||
从上面的截屏中尅看出,生成了一个二维码,不过由于 `mysite` 的密码已经存在了,pass 会提示我们确认是否要覆盖原密码。
|
||||
从上面的截屏中可看出,生成了一个二维码,不过由于运行该命令时 `mysite` 的密码已经存在了,`pass` 会提示我们确认是否要覆盖原密码。
|
||||
|
||||
Pass 使用 `/dev/urandom` 设备作为(伪)随机数据生成器来生成密码,同时它使用 `xclip` 工具来将密码拷贝到粘帖板中,同时使用 `qrencode` 来将密码以二维码的形式显示出来。在我看来,这种模块化的设计正是它最大的优势:它并不重复造轮子,而只是将常用的工具包装起来完成任务。
|
||||
`pass` 使用 `/dev/urandom` 设备作为(伪)随机数据生成器来生成密码,同时它使用 `xclip` 工具来将密码拷贝到粘帖板中,而使用 `qrencode` 来将密码以二维码的形式显示出来。在我看来,这种模块化的设计正是它最大的优势:它并不重复造轮子,而只是将常用的工具包装起来完成任务。
|
||||
|
||||
你也可以使用 `pass mv`,`pass cp`,和 `pass rm` 来重命名,拷贝和删除密码仓库中的文件。
|
||||
你也可以使用 `pass mv`、`pass cp` 和 `pass rm` 来重命名、拷贝和删除密码仓库中的文件。
|
||||
|
||||
### 将密码仓库变成 git 仓库
|
||||
|
||||
`pass` 另一个很棒的功能就是可以将密码仓库当成 git 仓库来用:通过版本管理系统能让我们管理密码更方便。
|
||||
|
||||
```
|
||||
pass git init
|
||||
```
|
||||
|
||||
这会创建 git 仓库,并自动提交所有已存在的文件。下一步就是指定跟踪的远程仓库了:
|
||||
|
||||
```
|
||||
pass git remote add <name> <url>
|
||||
```
|
||||
@ -135,7 +146,6 @@ pass git remote add <name> <url>
|
||||
|
||||
`pass` 有一个叫做 `qtpass` 的图形界面,而且也支持 Windows 和 MacOs。通过使用 `PassFF` 插件,它还能获取 firefox 中存储的密码。在它的项目网站上可以查看更多详细信息。试一下 `pass` 吧,你不会失望的!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxconfig.org/how-to-organize-your-passwords-using-pass-password-manager
|
||||
@ -147,4 +157,4 @@ via: https://linuxconfig.org/how-to-organize-your-passwords-using-pass-password-
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linuxconfig.org
|
||||
[1]:/https://linuxconfig.org/images/pass-manager-qrcode.png
|
||||
[1]:https://linuxconfig.org/images/pass-manager-qrcode.png
|
||||
@ -1,25 +1,25 @@
|
||||
Torrents - 你需要知道的一切事情
|
||||
Torrents(种子):你需要知道的一切事情
|
||||
======
|
||||
|
||||

|
||||
|
||||
**Torrents** — 每次听到这个词时,在我的脑海里想到的唯一的事情就是免费的电影、游戏、和被破解的软件。但是我们并不知道它们是如何工作的,在 Torrents 中涉及到各种概念。因此,通过这篇文章我们从技术的角度来了解 **torrenting** 是什么。
|
||||
**Torrents(种子)** — 每次听到这个词时,在我的脑海里想到的唯一的事情就是免费的电影、游戏、和被破解的软件。但是我们并不知道它们是如何工作的,在“种子”中涉及到各种概念。因此,通过这篇文章我们从技术的角度来了解**种子下载**是什么。
|
||||
|
||||
### Torrents 是什么?
|
||||
### “种子”是什么?
|
||||
|
||||
Torrents 是一个到因特网上文件位置的链接。它们不是一个文件,它们仅仅是动态指向到你想去下载的原始文件上。
|
||||
“种子”是一个到因特网上文件位置的链接。它们不是一个文件,它们仅仅是动态指向到你想去下载的原始文件上。
|
||||
|
||||
例如:如果你点击 [Google Chrome][1],你可以从谷歌的服务器上下载 Google Chrome 浏览器。
|
||||
|
||||
如果你明天、或者下周、或者下个月再去点击那个链接,这个文件仍然可以从谷歌服务器上去下载。
|
||||
|
||||
但是当我们使用 torrents 下载时,它并没有固定的服务器。文件是从以前使用 torrents 下载的其它人的个人电脑上下载的。
|
||||
但是当我们使用“种子”下载时,它并没有固定的服务器。文件是从以前使用“种子”下载的其它人的个人电脑上下载的。
|
||||
|
||||
### Torrents 是如何工作的?
|
||||
|
||||
[][2]
|
||||
|
||||
假设 ‘A’ 上有一些视频,它希望以 torrent 方式去下载。因此,他创建了一个 torrent,并将这个链接发送给 ‘B’,这个链接包含了那个视频在因特网上的准确 IP 地址的信息。因此,当 ‘B’ 开始下载那个文件的时候,‘B’ 连接到 ‘A’ 的计算机。在 ‘B’ 下载完成这个视频之后,‘B’ 将开始做为种子,也就是 ‘B’ 将允许其它的 ‘C’ 或者 ‘D’ 从 ‘B’ 的计算机上下载它。
|
||||
假设 ‘A’ 上有一些视频,它希望以“种子”方式去下载。因此,他创建了一个“种子”,并将这个链接发送给 ‘B’,这个链接包含了那个视频在因特网上的准确 IP 地址的信息。因此,当 ‘B’ 开始下载那个文件的时候,‘B’ 连接到 ‘A’ 的计算机。在 ‘B’ 下载完成这个视频之后,‘B’ 将开始做为种子,也就是 ‘B’ 将允许其它的 ‘C’ 或者 ‘D’ 从 ‘B’ 的计算机上下载它。
|
||||
|
||||
因此每个人先下载文件然后会上传,下载的人越多,下载的速度也越快。并且在任何情况下,如果想停止上传,也没有问题,随时可以。这样做并不会成为什么问题,除非很多的人下载而上传的人很少。
|
||||
|
||||
@ -35,7 +35,7 @@ Torrents 是一个到因特网上文件位置的链接。它们不是一个文
|
||||
|
||||
[][4]
|
||||
|
||||
所有的 torrent 文件都独立分割成固定大小的数据包,因此,它们可以非线性顺序和随机顺序下载。每个块都有唯一的标识,因此,一旦所有的块下载完成之后,它们会被拼接出原始文件。
|
||||
所有的“种子”文件都独立分割成固定大小的数据包,因此,它们可以非线性顺序和随机顺序下载。每个块都有唯一的标识,因此,一旦所有的块下载完成之后,它们会被拼接出原始文件。
|
||||
|
||||
正是因为这种机制,如果你正在从某人处下载一个文件,假如这个时候因某些原因他停止了上传,你可以继续从其它的播种者处继续下载,而不需要从头开始重新下载。
|
||||
|
||||
@ -49,23 +49,23 @@ Torrents 是一个到因特网上文件位置的链接。它们不是一个文
|
||||
|
||||
### 最佳实践
|
||||
|
||||
当你下载一个 torrent 时,总是选择最大的播种者。这就是最佳经验。
|
||||
当你下载一个“种子”时,总是选择最大的播种者。这就是最佳经验。
|
||||
|
||||
这里并没有最小的标准,但是只要确保你选择的是最大的那一个播种者就可以了。
|
||||
|
||||
### Torrent 相关的法律
|
||||
### “种子”相关的法律
|
||||
|
||||
[][5]
|
||||
|
||||
Torrent 相关的法律和其它的法律并没有什么区别,对受版权保护的其它任何东西一样,侵权行为会受到法律的制裁。大多数的政府都拦截 torrent 站点和协议,但是 torrenting 本身并不是有害的东西。
|
||||
“种子”相关的法律和其它的法律并没有什么区别,对受版权保护的其它任何东西一样,侵权行为会受到法律的制裁。大多数的政府都拦截“种子”站点和协议,但是“种子”下载本身并不是有害的东西。
|
||||
|
||||
Torrents 对快速分享文件是非常有用的,并且它们被用来共享开源社区的软件,因为它们能节约大量的服务器资源。但是,许多人却因为盗版而使用它们。
|
||||
“种子”对快速分享文件是非常有用的,并且它们被用来共享开源社区的软件,因为它们能节约大量的服务器资源。但是,许多人却因为盗版而使用它们。
|
||||
|
||||
### 结束语
|
||||
|
||||
Torrenting 是降低服务器上负载的一个非常完美的技术。Torrenting 可以使我们将下载速度提升到网卡的极限,这是非常好的。但是,在这种非中心化的服务器上,盗版成为一种必然发生的事。限制我们分享的内容,从不去下载盗版的东西,这是我们的道德责任。
|
||||
Torrenting 是降低服务器上负载的一个非常完美的技术。“种子”下载可以使我们将下载速度提升到网卡的极限,这是非常好的。但是,在这种非中心化的服务器上,盗版成为一种必然发生的事。限制我们分享的内容,从不去下载盗版的东西,这是我们的道德责任。
|
||||
|
||||
请在下面的评论中分享你使用 torrents 的心得,分享你喜欢的、法律许可下载的 torrent 网站。
|
||||
请在下面的评论中分享你使用“种子”的心得,分享你喜欢的、法律许可下载的“种子”网站。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -73,7 +73,7 @@ via: http://www.linuxandubuntu.com/home/torrents-everything-you-need-to-know
|
||||
|
||||
作者:[LINUXANDUBUNTU][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,32 +1,31 @@
|
||||
在你下一次技术面试的时候要提的 3 个基本问题
|
||||
下一次技术面试时要问的 3 个重要问题
|
||||
======
|
||||
|
||||

|
||||
|
||||
面试可能会有压力,但 58% 的公司告诉 Dice 和 Linux 基金会,他们需要在未来几个月内聘请开源人才。学习如何提出正确的问题。
|
||||
|
||||
Linux 基金会
|
||||
> 面试可能会有压力,但 58% 的公司告诉 Dice 和 Linux 基金会,他们需要在未来几个月内聘请开源人才。学习如何提出正确的问题。
|
||||
|
||||
Dice 和 Linux 基金会的年度[开源工作报告][1]揭示了开源专业人士的前景以及未来一年的招聘活动。在今年的报告中,86% 的科技专业人士表示,了解开源推动了他们的职业生涯。然而,当在他们自己的组织内推进或在别处申请新职位的时候,有这些经历会发生什么呢?
|
||||
|
||||
面试新工作绝非易事。除了在准备新职位时还要应付复杂的工作,当面试官问“你对我有什么问题吗?”时适当的回答更增添了压力。
|
||||
面试新工作绝非易事。除了在准备新职位时还要应付复杂的工作,当面试官问“你有什么问题要问吗?”时,适当的回答更增添了压力。
|
||||
|
||||
在 Dice,我们从事职业、建议,并将技术专家与雇主连接起来。但是我们也在公司雇佣技术人才来开发开源项目。实际上,Dice 平台基于许多 Linux 发行版,我们利用开源数据库作为我们搜索功能的基础。总之,如果没有开源软件,我们就无法运行 Dice,因此聘请了解和热爱开源软件的专业人士至关重要。
|
||||
在 Dice,我们从事职业、建议,并将技术专家与雇主连接起来。但是我们也在公司里雇佣技术人才来开发开源项目。实际上,Dice 平台基于许多 Linux 发行版,我们利用开源数据库作为我们搜索功能的基础。总之,如果没有开源软件,我们就无法运行 Dice,因此聘请了解和热爱开源软件的专业人士至关重要。
|
||||
|
||||
多年来,我在面试中了解到提出好问题的重要性。这是一个了解你的潜在新雇主的机会,以及更好地了解他们是否与你的技能相匹配。
|
||||
|
||||
这里有三个重要的问题需要以及其重要的原因:
|
||||
这里有三个要问的重要问题,以及其重要的原因:
|
||||
|
||||
**1\. 公司对员工在空闲时间致力于开源项目或编写代码的立场是什么?**
|
||||
### 1、 公司对员工在空闲时间致力于开源项目或编写代码的立场是什么?
|
||||
|
||||
这个问题的答案会告诉正在面试的公司的很多信息。一般来说,只要它与你在该公司所从事的工作没有冲突,公司会希望技术专家为网站或项目做出贡献。在公司之外允许这种情况,也会在技术组织中培养出一种创业精神,并教授技术技能,否则在正常的日常工作中你可能无法获得这些技能。
|
||||
|
||||
**2\. 项目在这如何分优先级?**
|
||||
### 2、 项目如何区分优先级?
|
||||
|
||||
由于所有的公司都成为了科技公司,所以在创新的客户面对技术项目与改进平台本身之间往往存在着分歧。你会努力保持现有的平台最新么?或者致力于公众开发新产品?根据你的兴趣,答案可以决定公司是否适合你。
|
||||
|
||||
**3\. 谁主要决定新产品,开发者在决策过程中有多少投入?**
|
||||
### 3、 谁主要决定新产品,开发者在决策过程中有多少投入?
|
||||
|
||||
这个问题是了解谁负责公司创新(以及与他/她有多少联系),还有一个是了解你在公司的职业道路。在开发新产品之前,一个好的公司会和开发人员和开源人才交流。这看起来没有困难,但有时会错过这步,意味着在新产品发布之前是协作环境或者混乱的过程。
|
||||
这个问题是了解谁负责公司创新(以及与他/她有多少联系),还有一个是了解你在公司的职业道路。在开发新产品之前,一个好的公司会和开发人员和开源人才交流。这看起来不用多想,但有时会错过这步,意味着在新产品发布之前协作环境的不同或者混乱的过程。
|
||||
|
||||
面试可能会有压力,但是 58% 的公司告诉 Dice 和 Linux 基金会他们需要在未来几个月内聘用开源人才,所以记住高需求会让像你这样的专业人士成为雇员。以你想要的方向引导你的事业。
|
||||
|
||||
@ -38,7 +37,7 @@ via: https://www.linux.com/blog/os-jobs/2017/12/3-essential-questions-ask-your-n
|
||||
|
||||
作者:[Brian Hostetter][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,109 @@
|
||||
并发服务器(五):Redis 案例研究
|
||||
======
|
||||
|
||||
这是我写的并发网络服务器系列文章的第五部分。在前四部分中我们讨论了并发服务器的结构,这篇文章我们将去研究一个在生产系统中大量使用的服务器的案例—— [Redis][10]。
|
||||
|
||||

|
||||
|
||||
Redis 是一个非常有魅力的项目,我关注它很久了。它最让我着迷的一点就是它的 C 源代码非常清晰。它也是一个高性能、大并发的内存数据库服务器的非常好的例子,它是研究网络并发服务器的一个非常好的案例,因此,我们不能错过这个好机会。
|
||||
|
||||
我们来看看前四部分讨论的概念在真实世界中的应用程序。
|
||||
|
||||
本系列的所有文章有:
|
||||
|
||||
* [第一节 - 简介][3]
|
||||
* [第二节 - 线程][4]
|
||||
* [第三节 - 事件驱动][5]
|
||||
* [第四节 - libuv][6]
|
||||
* [第五节 - Redis 案例研究][7]
|
||||
|
||||
### 事件处理库
|
||||
|
||||
Redis 最初发布于 2009 年,它最牛逼的一件事情大概就是它的速度 —— 它能够处理大量的并发客户端连接。需要特别指出的是,它是用*一个单线程*来完成的,而且还不对保存在内存中的数据使用任何复杂的锁或者同步机制。
|
||||
|
||||
Redis 之所以如此牛逼是因为,它在给定的系统上使用了其可用的最快的事件循环,并将它们封装成由它实现的事件循环库(在 Linux 上是 epoll,在 BSD 上是 kqueue,等等)。这个库的名字叫做 [ae][11]。ae 使得编写一个快速服务器变得很容易,只要在它内部没有阻塞即可,而 Redis 则保证 ^注1 了这一点。
|
||||
|
||||
在这里,我们的兴趣点主要是它对*文件事件*的支持 —— 当文件描述符(如网络套接字)有一些有趣的未决事情时将调用注册的回调函数。与 libuv 类似,ae 支持多路事件循环(参阅本系列的[第三节][5]和[第四节][6])和不应该感到意外的 `aeCreateFileEvent` 信号:
|
||||
|
||||
```
|
||||
int aeCreateFileEvent(aeEventLoop *eventLoop, int fd, int mask,
|
||||
aeFileProc *proc, void *clientData);
|
||||
```
|
||||
|
||||
它在 `fd` 上使用一个给定的事件循环,为新的文件事件注册一个回调(`proc`)函数。当使用的是 epoll 时,它将调用 `epoll_ctl` 在文件描述符上添加一个事件(可能是 `EPOLLIN`、`EPOLLOUT`、也或许两者都有,取决于 `mask` 参数)。ae 的 `aeProcessEvents` 功能是 “运行事件循环和发送回调函数”,它在底层调用了 `epoll_wait`。
|
||||
|
||||
### 处理客户端请求
|
||||
|
||||
我们通过跟踪 Redis 服务器代码来看一下,ae 如何为客户端事件注册回调函数的。`initServer` 启动时,通过注册一个回调函数来读取正在监听的套接字上的事件,通过使用回调函数 `acceptTcpHandler` 来调用 `aeCreateFileEvent`。当新的连接可用时,这个回调函数被调用。它调用 `accept` ^注2 ,接下来是 `acceptCommonHandler`,它转而去调用 `createClient` 以初始化新客户端连接所需要的数据结构。
|
||||
|
||||
`createClient` 的工作是去监听来自客户端的入站数据。它将套接字设置为非阻塞模式(一个异步事件循环中的关键因素)并使用 `aeCreateFileEvent` 去注册另外一个文件事件回调函数以读取事件 —— `readQueryFromClient`。每当客户端发送数据,这个函数将被事件循环调用。
|
||||
|
||||
`readQueryFromClient` 就让我们期望的那样 —— 解析客户端命令和动作,并通过查询和/或操作数据来回复。因为客户端套接字是非阻塞的,所以这个函数必须能够处理 `EAGAIN`,以及部分数据;从客户端中读取的数据是累积在客户端专用的缓冲区中,而完整的查询可能被分割在回调函数的多个调用当中。
|
||||
|
||||
### 将数据发送回客户端
|
||||
|
||||
在前面的内容中,我说到了 `readQueryFromClient` 结束了发送给客户端的回复。这在逻辑上是正确的,因为 `readQueryFromClient` *准备*要发送回复,但它不真正去做实质的发送 —— 因为这里并不能保证客户端套接字已经准备好写入/发送数据。我们必须为此使用事件循环机制。
|
||||
|
||||
Redis 是这样做的,它注册一个 `beforeSleep` 函数,每次事件循环即将进入休眠时,调用它去等待套接字变得可以读取/写入。`beforeSleep` 做的其中一件事情就是调用 `handleClientsWithPendingWrites`。它的作用是通过调用 `writeToClient` 去尝试立即发送所有可用的回复;如果一些套接字不可用时,那么*当*套接字可用时,它将注册一个事件循环去调用 `sendReplyToClient`。这可以被看作为一种优化 —— 如果套接字可用于立即发送数据(一般是 TCP 套接字),这时并不需要注册事件 ——直接发送数据。因为套接字是非阻塞的,它从不会去阻塞循环。
|
||||
|
||||
### 为什么 Redis 要实现它自己的事件库?
|
||||
|
||||
在 [第四节][14] 中我们讨论了使用 libuv 来构建一个异步并发服务器。需要注意的是,Redis 并没有使用 libuv,或者任何类似的事件库,而是它去实现自己的事件库 —— ae,用 ae 来封装 epoll、kqueue 和 select。事实上,Antirez(Redis 的创建者)恰好在 [2011 年的一篇文章][15] 中回答了这个问题。他的回答的要点是:ae 只有大约 770 行他理解的非常透彻的代码;而 libuv 代码量非常巨大,也没有提供 Redis 所需的额外功能。
|
||||
|
||||
现在,ae 的代码大约增长到 1300 多行,比起 libuv 的 26000 行(这是在没有 Windows、测试、示例、文档的情况下的数据)来说那是小巫见大巫了。libuv 是一个非常综合的库,这使它更复杂,并且很难去适应其它项目的特殊需求;另一方面,ae 是专门为 Redis 设计的,与 Redis 共同演进,只包含 Redis 所需要的东西。
|
||||
|
||||
这是我 [前些年在一篇文章中][16] 提到的软件项目依赖关系的另一个很好的示例:
|
||||
|
||||
> 依赖的优势与在软件项目上花费的工作量成反比。
|
||||
|
||||
在某种程度上,Antirez 在他的文章中也提到了这一点。他提到,提供大量附加价值(在我的文章中的“基础” 依赖)的依赖比像 libuv 这样的依赖更有意义(它的例子是 jemalloc 和 Lua),对于 Redis 特定需求,其功能的实现相当容易。
|
||||
|
||||
### Redis 中的多线程
|
||||
|
||||
[在 Redis 的绝大多数历史中][17],它都是一个不折不扣的单线程的东西。一些人觉得这太不可思议了,有这种想法完全可以理解。Redis 本质上是受网络束缚的 —— 只要数据库大小合理,对于任何给定的客户端请求,其大部分延时都是浪费在网络等待上,而不是在 Redis 的数据结构上。
|
||||
|
||||
然而,现在事情已经不再那么简单了。Redis 现在有几个新功能都用到了线程:
|
||||
|
||||
1. “惰性” [内存释放][8]。
|
||||
2. 在后台线程中使用 fsync 调用写一个 [持久化日志][9]。
|
||||
3. 运行需要执行一个长周期运行的操作的用户定义模块。
|
||||
|
||||
对于前两个特性,Redis 使用它自己的一个简单的 bio(它是 “Background I/O" 的首字母缩写)库。这个库是根据 Redis 的需要进行了硬编码,它不能用到其它的地方 —— 它运行预设数量的线程,每个 Redis 后台作业类型需要一个线程。
|
||||
|
||||
而对于第三个特性,[Redis 模块][18] 可以定义新的 Redis 命令,并且遵循与普通 Redis 命令相同的标准,包括不阻塞主线程。如果在模块中自定义的一个 Redis 命令,希望去执行一个长周期运行的操作,这将创建一个线程在后台去运行它。在 Redis 源码树中的 `src/modules/helloblock.c` 提供了这样的一个示例。
|
||||
|
||||
有了这些特性,Redis 使用线程将一个事件循环结合起来,在一般的案例中,Redis 具有了更快的速度和弹性,这有点类似于在本系统文章中 [第四节][19] 讨论的工作队列。
|
||||
|
||||
- 注1: Redis 的一个核心部分是:它是一个 _内存中_ 数据库;因此,查询从不会运行太长的时间。当然了,这将会带来各种各样的其它问题。在使用分区的情况下,服务器可能最终路由一个请求到另一个实例上;在这种情况下,将使用异步 I/O 来避免阻塞其它客户端。
|
||||
- 注2: 使用 `anetAccept`;`anet` 是 Redis 对 TCP 套接字代码的封装。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/
|
||||
|
||||
作者:[Eli Bendersky][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://eli.thegreenplace.net/pages/about
|
||||
[1]:https://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/#id1
|
||||
[2]:https://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/#id2
|
||||
[3]:https://linux.cn/article-8993-1.html
|
||||
[4]:https://linux.cn/article-9002-1.html
|
||||
[5]:https://linux.cn/article-9117-1.html
|
||||
[6]:https://linux.cn/article-9397-1.html
|
||||
[7]:http://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/
|
||||
[8]:http://antirez.com/news/93
|
||||
[9]:https://redis.io/topics/persistence
|
||||
[10]:https://redis.io/
|
||||
[11]:https://redis.io/topics/internals-rediseventlib
|
||||
[12]:https://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/#id4
|
||||
[13]:https://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/#id5
|
||||
[14]:https://linux.cn/article-9397-1.html
|
||||
[15]:http://oldblog.antirez.com/post/redis-win32-msft-patch.html
|
||||
[16]:http://eli.thegreenplace.net/2017/benefits-of-dependencies-in-software-projects-as-a-function-of-effort/
|
||||
[17]:http://antirez.com/news/93
|
||||
[18]:https://redis.io/topics/modules-intro
|
||||
[19]:https://linux.cn/article-9397-1.html
|
||||
115
published/20171214 6 open source home automation tools.md
Normal file
115
published/20171214 6 open source home automation tools.md
Normal file
@ -0,0 +1,115 @@
|
||||
6 个开源的家庭自动化工具
|
||||
======
|
||||
|
||||
> 用这些开源软件解决方案构建一个更智能的家庭。
|
||||
|
||||

|
||||
|
||||
[物联网][13] 不仅是一个时髦词,在现实中,自 2016 年我们发布了一篇关于家庭自动化工具的评论文章以来,它也在迅速占领着我们的生活。在 2017,[26.5% 的美国家庭][14] 已经使用了一些智能家居技术;预计五年内,这一数字还将翻倍。
|
||||
|
||||
随着这些数量持续增加的各种设备的使用,可以帮助你实现对家庭的自动化管理、安保、和监视,在家庭自动化方面,从来没有像现在这样容易和更加吸引人过。不论你是要远程控制你的 HVAC 系统,集成一个家庭影院,保护你的家免受盗窃、火灾、或是其它威胁,还是节省能源或只是控制几盏灯,现在都有无数的设备可以帮到你。
|
||||
|
||||
但同时,还有许多用户担心安装在他们家庭中的新设备带来的安全和隐私问题 —— 这是一个很现实也很 [严肃的问题][15]。他们想要去控制有谁可以接触到这个重要的系统,这个系统管理着他们的应用程序,记录了他们生活中的点点滴滴。这种想法是可以理解的:毕竟在一个连你的冰箱都是智能设备的今天,你不想要一个基本的保证吗?甚至是如果你授权了设备可以与外界通讯,它是否是仅被授权的人访问它呢?
|
||||
|
||||
[对安全的担心][16] 是为什么开源对我们将来使用的互联设备至关重要的众多理由之一。由于源代码运行在他们自己的设备上,完全可以去搞明白控制你的家庭的程序,也就是说你可以查看它的代码,如果必要的话甚至可以去修改它。
|
||||
|
||||
虽然联网设备通常都包含它们专有的组件,但是将开源引入家庭自动化的第一步是确保你的设备和这些设备可以共同工作 —— 它们为你提供一个接口 —— 并且是开源的。幸运的是,现在有许多解决方案可供选择,从 PC 到树莓派,你可以在它们上做任何事情。
|
||||
|
||||
这里有几个我比较喜欢的。
|
||||
|
||||
### Calaos
|
||||
|
||||
[Calaos][17] 是一个设计为全栈的家庭自动化平台,包含一个服务器应用程序、触摸屏界面、Web 应用程序、支持 iOS 和 Android 的原生移动应用、以及一个运行在底层的预配置好的 Linux 操作系统。Calaos 项目出自一个法国公司,因此它的支持论坛以法语为主,不过大量的介绍资料和文档都已经翻译为英语了。
|
||||
|
||||
Calaos 使用的是 [GPL][18] v3 的许可证,你可以在 [GitHub][19] 上查看它的源代码。
|
||||
|
||||
### Domoticz
|
||||
|
||||
[Domoticz][20] 是一个有大量设备库支持的家庭自动化系统,在它的项目网站上有大量的文档,从气象站到远程控制的烟雾探测器,以及大量的第三方 [集成软件][21] 。它使用一个 HTML5 前端,可以从桌面浏览器或者大多数现代的智能手机上访问它,它是一个轻量级的应用,可以运行在像树莓派这样的低功耗设备上。
|
||||
|
||||
Domoticz 是用 C++ 写的,使用 [GPLv3][22] 许可证。它的 [源代码][23] 在 GitHub 上。
|
||||
|
||||
### Home Assistant
|
||||
|
||||
[Home Assistant][24] 是一个开源的家庭自动化平台,它可以轻松部署在任何能运行 Python 3 的机器上,从树莓派到网络存储(NAS),甚至可以使用 Docker 容器轻松地部署到其它系统上。它集成了大量的开源和商业的产品,允许你去连接它们,比如,IFTTT、天气信息、或者你的 Amazon Echo 设备,去控制从锁到灯的各种硬件。
|
||||
|
||||
Home Assistant 以 [MIT 许可证][25] 发布,它的源代码可以从 [GitHub][26] 上下载。
|
||||
|
||||
### MisterHouse
|
||||
|
||||
从 2016 年起,[MisterHouse][27] 取得了很多的进展,我们把它作为一个“可以考虑的另外选择”列在这个清单上。它使用 Perl 脚本去监视任何东西,它可以通过一台计算机来查询或者控制任何可以远程控制的东西。它可以响应语音命令,查询当前时间、天气、位置、以及其它事件,比如去打开灯、唤醒你、记下你喜欢的电视节目、通报呼入的来电、开门报警、记录你儿子上了多长时间的网、如果你女儿汽车超速它也可以告诉你等等。它可以运行在 Linux、macOS、以及 Windows 计算机上,它可以读/写很多的设备,包括安全系统、气象站、来电显示、路由器、机动车位置系统等等。
|
||||
|
||||
MisterHouse 使用 [GPLv2][28] 许可证,你可以在 [GitHub][29] 上查看它的源代码。
|
||||
|
||||
### OpenHAB
|
||||
|
||||
[OpenHAB][30](开放家庭自动化总线的简称)是在开源爱好者中所熟知的家庭自动化工具,它拥有大量用户的社区以及支持和集成了大量的设备。它是用 Java 写的,OpenHAB 非常轻便,可以跨大多数主流操作系统使用,它甚至在树莓派上也运行的很好。支持成百上千的设备,OpenHAB 被设计为与设备无关的,这使开发者在系统中添加他们的设备或者插件很容易。OpenHAB 也支持通过 iOS 和 Android 应用来控制设备以及设计工具,因此,你可以为你的家庭系统创建你自己的 UI。
|
||||
|
||||
你可以在 GitHub 上找到 OpenHAB 的 [源代码][31],它使用 [Eclipse 公共许可证][32]。
|
||||
|
||||
### OpenMotics
|
||||
|
||||
[OpenMotics][33] 是一个开源的硬件和软件家庭自动化系统。它的设计目标是为控制设备提供一个综合的系统,而不是从不同的供应商处将各种设备拼接在一起。不像其它的系统主要是为了方便改装而设计的,OpenMotics 专注于硬件解决方案。更多资料请查阅来自 OpenMotics 的后端开发者 Frederick Ryckbosch的 [完整文章][34] 。
|
||||
|
||||
OpenMotics 使用 [GPLv2][35] 许可证,它的源代码可以从 [GitHub][36] 上下载。
|
||||
|
||||
当然了,我们的选择不仅有这些。许多家庭自动化爱好者使用不同的解决方案,甚至是他们自己动手做。其它用户选择使用单独的智能家庭设备而无需集成它们到一个单一的综合系统中。
|
||||
|
||||
如果上面的解决方案并不能满足你的需求,下面还有一些潜在的替代者可以去考虑:
|
||||
|
||||
* [EventGhost][1] 是一个开源的([GPL v2][2])家庭影院自动化工具,它只能运行在 Microsoft Windows PC 上。它允许用户去控制多媒体电脑和连接的硬件,它通过触发宏指令的插件或者定制的 Python 脚本来使用。
|
||||
* [ioBroker][3] 是一个基于 JavaScript 的物联网平台,它能够控制灯、锁、空调、多媒体、网络摄像头等等。它可以运行在任何可以运行 Node.js 的硬件上,包括 Windows、Linux、以及 macOS,它使用 [MIT 许可证][4]。
|
||||
* [Jeedom][5] 是一个由开源软件([GPL v2][6])构成的家庭自动化平台,它可以控制灯、锁、多媒体等等。它包含一个移动应用程序(Android 和 iOS),并且可以运行在 Linux PC 上;该公司也销售 hub,它为配置家庭自动化提供一个现成的解决方案。
|
||||
* [LinuxMCE][7] 标称它是你的多媒体与电子设备之间的“数字粘合剂”。它运行在 Linux(包括树莓派)上,它基于 Pluto 开源 [许可证][8] 发布,它可以用于家庭安全、电话(VoIP 和语音信箱)、A/V 设备、家庭自动化、以及玩视频游戏。
|
||||
* [OpenNetHome][9],和这一类中的其它解决方案一样,是一个控制灯、报警、应用程序等等的一个开源软件。它基于 Java 和 Apache Maven,可以运行在 Windows、macOS、以及 Linux —— 包括树莓派,它以 [GPLv3][10] 许可证发布。
|
||||
* [Smarthomatic][11] 是一个专注于硬件设备和软件的开源家庭自动化框架,而不仅是用户界面。它基于 [GPLv3][12] 许可证,它可用于控制灯、电器、以及空调、检测温度、提醒给植物浇水。
|
||||
|
||||
现在该轮到你了:你已经准备好家庭自动化系统了吗?或者正在研究去设计一个。你对家庭自动化的新手有什么建议,你会推荐什么样的系统?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/17/12/home-automation-tools
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jason-baker
|
||||
[1]:http://www.eventghost.net/
|
||||
[2]:http://www.gnu.org/licenses/old-licenses/gpl-2.0.html
|
||||
[3]:http://iobroker.net/
|
||||
[4]:https://github.com/ioBroker/ioBroker#license
|
||||
[5]:https://www.jeedom.com/site/en/index.html
|
||||
[6]:http://www.gnu.org/licenses/old-licenses/gpl-2.0.html
|
||||
[7]:http://www.linuxmce.com/
|
||||
[8]:http://wiki.linuxmce.org/index.php/License
|
||||
[9]:http://opennethome.org/
|
||||
[10]:https://github.com/NetHome/NetHomeServer/blob/master/LICENSE
|
||||
[11]:https://www.smarthomatic.org/
|
||||
[12]:https://github.com/breaker27/smarthomatic/blob/develop/GPL3.txt
|
||||
[13]:https://opensource.com/resources/internet-of-things
|
||||
[14]:https://www.statista.com/outlook/279/109/smart-home/united-states
|
||||
[15]:http://www.crn.com/slide-shows/internet-of-things/300089496/black-hat-2017-9-iot-security-threats-to-watch.htm
|
||||
[16]:https://opensource.com/business/15/5/why-open-source-means-stronger-security
|
||||
[17]:https://calaos.fr/en/
|
||||
[18]:https://github.com/calaos/calaos-os/blob/master/LICENSE
|
||||
[19]:https://github.com/calaos
|
||||
[20]:https://domoticz.com/
|
||||
[21]:https://www.domoticz.com/wiki/Integrations_and_Protocols
|
||||
[22]:https://github.com/domoticz/domoticz/blob/master/License.txt
|
||||
[23]:https://github.com/domoticz/domoticz
|
||||
[24]:https://home-assistant.io/
|
||||
[25]:https://github.com/home-assistant/home-assistant/blob/dev/LICENSE.md
|
||||
[26]:https://github.com/balloob/home-assistant
|
||||
[27]:http://misterhouse.sourceforge.net/
|
||||
[28]:http://www.gnu.org/licenses/old-licenses/gpl-2.0.en.html
|
||||
[29]:https://github.com/hollie/misterhouse
|
||||
[30]:http://www.openhab.org/
|
||||
[31]:https://github.com/openhab/openhab
|
||||
[32]:https://github.com/openhab/openhab/blob/master/LICENSE.TXT
|
||||
[33]:https://www.openmotics.com/
|
||||
[34]:https://opensource.com/life/14/12/open-source-home-automation-system-opemmotics
|
||||
[35]:http://www.gnu.org/licenses/old-licenses/gpl-2.0.en.html
|
||||
[36]:https://github.com/openmotics
|
||||
110
published/20171214 IPv6 Auto-Configuration in Linux.md
Normal file
110
published/20171214 IPv6 Auto-Configuration in Linux.md
Normal file
@ -0,0 +1,110 @@
|
||||
在 Linux 中自动配置 IPv6 地址
|
||||
======
|
||||
|
||||

|
||||
|
||||
在 [KVM 中测试 IPv6 网络:第 1 部分][1] 一文中,我们学习了关于<ruby>唯一本地地址<rt>unique local addresses</rt></ruby>(ULA)的相关内容。在本文中,我们将学习如何为 ULA 自动配置 IP 地址。
|
||||
|
||||
### 何时使用唯一本地地址
|
||||
|
||||
<ruby>唯一本地地址<rt>unique local addresses</rt></ruby>(ULA)使用 `fd00::/8` 地址块,它类似于我们常用的 IPv4 的私有地址:`10.0.0.0/8`、`172.16.0.0/12`、以及 `192.168.0.0/16`。但它们并不能直接替换。IPv4 的私有地址分类和网络地址转换(NAT)功能是为了缓解 IPv4 地址短缺的问题,这是个明智的解决方案,它延缓了本该被替换的 IPv4 的生命周期。IPv6 也支持 NAT,但是我想不出使用它的理由。IPv6 的地址数量远远大于 IPv4;它是不一样的,因此需要做不一样的事情。
|
||||
|
||||
那么,ULA 存在的意义是什么呢?尤其是在我们已经有了<ruby>本地链路地址<rt>link-local addresses</rt></ruby>(`fe80::/10`)时,到底需不需要我们去配置它们呢?它们之间(LCTT 译注:指的是唯一本地地址和本地链路地址)有两个重要的区别。一是,本地链路地址是不可路由的,因此,你不能跨子网使用它。二是,ULA 是你自己管理的;你可以自己选择它用于子网的地址范围,并且它们是可路由的。
|
||||
|
||||
使用 ULA 的另一个好处是,如果你只是在局域网中“混日子”的话,你不需要为它们分配全局单播 IPv6 地址。当然了,如果你的 ISP 已经为你分配了 IPv6 的<ruby>全局单播地址<rt>global unicast addresses</rt></ruby>,就不需要使用 ULA 了。你也可以在同一个网络中混合使用全局单播地址和 ULA,但是,我想不出这样使用的一个好理由,并且要一定确保你不使用网络地址转换(NAT)以使 ULA 可公共访问。在我看来,这是很愚蠢的行为。
|
||||
|
||||
ULA 是仅为私有网络使用的,并且应该阻止其流出你的网络,不允许进入因特网。这很简单,在你的边界设备上只要阻止整个 `fd00::/8` 范围的 IPv6 地址即可实现。
|
||||
|
||||
### 地址自动配置
|
||||
|
||||
ULA 不像本地链路地址那样自动配置的,但是使用 radvd 设置自动配置是非常容易的,radva 是路由器公告守护程序。在你开始之前,运行 `ifconfig` 或者 `ip addr show` 去查看你现有的 IP 地址。
|
||||
|
||||
在生产系统上使用时,你应该将 radvd 安装在一台单独的路由器上,如果只是测试使用,你可以将它安装在你的网络中的任意 Linux PC 上。在我的小型 KVM 测试实验室中,我使用 `apt-get install radvd` 命令把它安装在 Ubuntu 上。安装完成之后,我先不启动它,因为它还没有配置文件:
|
||||
|
||||
```
|
||||
$ sudo systemctl status radvd
|
||||
● radvd.service - LSB: Router Advertising Daemon
|
||||
Loaded: loaded (/etc/init.d/radvd; bad; vendor preset: enabled)
|
||||
Active: active (exited) since Mon 2017-12-11 20:08:25 PST; 4min 59s ago
|
||||
Docs: man:systemd-sysv-generator(8)
|
||||
|
||||
Dec 11 20:08:25 ubunut1 systemd[1]: Starting LSB: Router Advertising Daemon...
|
||||
Dec 11 20:08:25 ubunut1 radvd[3541]: Starting radvd:
|
||||
Dec 11 20:08:25 ubunut1 radvd[3541]: * /etc/radvd.conf does not exist or is empty.
|
||||
Dec 11 20:08:25 ubunut1 radvd[3541]: * See /usr/share/doc/radvd/README.Debian
|
||||
Dec 11 20:08:25 ubunut1 radvd[3541]: * radvd will *not* be started.
|
||||
Dec 11 20:08:25 ubunut1 systemd[1]: Started LSB: Router Advertising Daemon.
|
||||
```
|
||||
|
||||
这些所有的消息有点让人困惑,实际上 radvd 并没有运行,你可以使用经典命令 `ps | grep radvd` 来验证这一点。因此,我们现在需要去创建 `/etc/radvd.conf` 文件。拷贝这个示例,将第一行的网络接口名替换成你自己的接口名字:
|
||||
|
||||
```
|
||||
interface ens7 {
|
||||
AdvSendAdvert on;
|
||||
MinRtrAdvInterval 3;
|
||||
MaxRtrAdvInterval 10;
|
||||
prefix fd7d:844d:3e17:f3ae::/64
|
||||
{
|
||||
AdvOnLink on;
|
||||
AdvAutonomous on;
|
||||
};
|
||||
|
||||
};
|
||||
```
|
||||
|
||||
前缀(`prefix`)定义了你的网络地址,它是地址的前 64 位。前两个字符必须是 `fd`,前缀接下来的剩余部分你自己定义它,最后的 64 位留空,因为 radvd 将去分配最后的 64 位。前缀后面的 16 位用来定义子网,剩余的地址定义为主机地址。你的子网必须总是 `/64`。RFC 4193 要求地址必须随机生成;查看 [在 KVM 中测试 IPv6 Networking:第 1 部分][1] 学习创建和管理 ULAs 的更多知识。
|
||||
|
||||
### IPv6 转发
|
||||
|
||||
IPv6 转发必须要启用。下面的命令去启用它,重启后生效:
|
||||
|
||||
```
|
||||
$ sudo sysctl -w net.ipv6.conf.all.forwarding=1
|
||||
```
|
||||
|
||||
取消注释或者添加如下的行到 `/etc/sysctl.conf` 文件中,以使它永久生效:
|
||||
|
||||
```
|
||||
net.ipv6.conf.all.forwarding = 1
|
||||
```
|
||||
|
||||
启动 radvd 守护程序:
|
||||
|
||||
```
|
||||
$ sudo systemctl stop radvd
|
||||
$ sudo systemctl start radvd
|
||||
```
|
||||
|
||||
这个示例在我的 Ubuntu 测试系统中遇到了一个怪事;radvd 总是停止,我查看它的状态却没有任何问题,做任何改变之后都需要重新启动 radvd。
|
||||
|
||||
启动成功后没有任何输出,并且失败也是如此,因此,需要运行 `sudo systemctl status radvd` 去查看它的运行状态。如果有错误,`systemctl` 会告诉你。一般常见的错误都是 `/etc/radvd.conf` 中的语法错误。
|
||||
|
||||
在 Twitter 上抱怨了上述问题之后,我学到了一件很酷的技巧:当你运行 ` journalctl -xe --no-pager` 去调试 `systemctl` 错误时,你的输出会被换行,然后,你就可以看到错误信息。
|
||||
|
||||
现在检查你的主机,查看它们自动分配的新地址:
|
||||
|
||||
```
|
||||
$ ifconfig
|
||||
ens7 Link encap:Ethernet HWaddr 52:54:00:57:71:50
|
||||
[...]
|
||||
inet6 addr: fd7d:844d:3e17:f3ae:9808:98d5:bea9:14d9/64 Scope:Global
|
||||
[...]
|
||||
```
|
||||
|
||||
本文到此为止,下周继续学习如何为 ULA 管理 DNS,这样你就可以使用一个合适的主机名来代替这些长长的 IPv6 地址。
|
||||
|
||||
通过来自 Linux 基金会和 edX 的 [“Linux 入门”][2] 免费课程学习更多 Linux 的知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/12/ipv6-auto-configuration-linux
|
||||
|
||||
作者:[Carla Schroder][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/learn/intro-to-linux/2017/11/testing-ipv6-networking-kvm-part-1
|
||||
[2]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,47 +1,47 @@
|
||||
什么是 CGManager?[][1]
|
||||
什么是 CGManager?
|
||||
============================================================
|
||||
|
||||
CGManager 是一个核心的特权守护进程,通过一个简单的 D-Bus API 管理你所有的 cgroup。它被设计用来处理嵌套的 LXC 容器以及接受无特权的请求,包括解析用户名称空间的 UID/GID。
|
||||
|
||||
# 组件[][2]
|
||||
### 组件
|
||||
|
||||
### cgmanager[][3]
|
||||
#### cgmanager
|
||||
|
||||
这个守护进程在主机上运行,将 cgroupfs 挂载到一个独立的挂载名称空间(所以它不能从主机上看到),绑定 /sys/fs/cgroup/cgmanager/sock 用于传入的 D-Bus 查询,并通常处理主机上直接运行的所有客户端。
|
||||
这个守护进程在宿主机上运行,将 cgroupfs 挂载到一个独立的挂载名称空间(所以它不能从宿主机上看到),绑定 `/sys/fs/cgroup/cgmanager/sock` 用于传入的 D-Bus 查询,并通常处理宿主机上直接运行的所有客户端。
|
||||
|
||||
cgmanager 同时接受使用 D-Bus + SCM 凭证的身份验证请求,用于在命名空间之间转换 uid、gid 和 pid,或者使用简单的 “unauthenticated”(只是初始的 ucred)D-Bus 来查询来自主机级别的查询。
|
||||
cgmanager 既接受使用 D-Bus + SCM 凭证的身份验证请求,用于在命名空间之间转换 uid、gid 和 pid,也可以使用简单的 “unauthenticated”(只是初始的 ucred)D-Bus 来查询来自宿主机级别的查询。
|
||||
|
||||
### cgproxy[][4]
|
||||
#### cgproxy
|
||||
|
||||
你可能会在两种情况下看到这个守护进程运行。在主机上,如果你的内核小于 3.8(没有 pidns 连接支持)或在容器中(只有 cgproxy 运行)。
|
||||
你可能会在两种情况下看到这个守护进程运行。在宿主机上,如果你的内核老于 3.8(没有 pidns 连接支持)或处于容器中(只有 cgproxy 运行)。
|
||||
|
||||
cgproxy 本身并不做任何 cgroup 配置更改,而是如其名称所示,代理请求给主 cgmanager 进程。
|
||||
|
||||
这是必要的,所以一个进程可以直接使用 D-Bus(例如使用 dbus-send)与 /sys/fs/cgroup/cgmanager/sock 进行通信。
|
||||
这是必要的,所以一个进程可以直接使用 D-Bus(例如使用 dbus-send)与 `/sys/fs/cgroup/cgmanager/sock` 进行通信。
|
||||
|
||||
之后 cgproxy 将从该查询中得到 ucred,并对真正的 cgmanager 套接字进行经过身份验证的 SCM 查询,并通过 ucred 结构体传递参数,使它们能够正确地转换为 cgmanager 可以理解的主机命名空间 。
|
||||
之后 cgproxy 将从该查询中得到 ucred,并对真正的 cgmanager 套接字进行身份验证的 SCM 查询,并通过 ucred 结构体传递参数,使它们能够正确地转换为 cgmanager 可以理解的宿主机命名空间 。
|
||||
|
||||
### cgm[][5]
|
||||
#### cgm
|
||||
|
||||
一个简单的命令行工具,与 D-Bus 服务通信,并允许你从命令行执行所有常见的 cgroup 操作。
|
||||
|
||||
# 通信协议[][6]
|
||||
### 通信协议
|
||||
|
||||
如上所述,cgmanager 和 cgproxy 使用 D-Bus。建议外部客户端(所以不要是 cgproxy)使用标准的 D-Bus API,不要试图实现 SCM creds 协议,因为它是不必要的,并且容易出错。
|
||||
|
||||
相反,只要简单假设与 /sys/fs/cgroup/cgmanager/sock 的通信总是正确的。
|
||||
相反,只要简单假设与 `/sys/fs/cgroup/cgmanager/sock` 的通信总是正确的。
|
||||
|
||||
cgmanager API 仅在独立的 D-Bus 套接字上可用,cgmanager 本身不连接到系统总线,所以 cgmanager/cgproxy 不要求有运行中的 dbus 守护进程。
|
||||
|
||||
你可以在[这里][7]阅读更多关于 D-Bus API。
|
||||
|
||||
# Licensing[][8]
|
||||
### 许可证
|
||||
|
||||
CGManager 是免费软件,大部分代码是根据 GNU LGPLv2.1+ 许可条款发布的,一些二进制文件是在 GNU GPLv2 许可下发布的。
|
||||
|
||||
该项目的默认许可证是 GNU LGPLv2.1+
|
||||
|
||||
# Support[][9]
|
||||
### 支持
|
||||
|
||||
CGManager 的稳定版本支持依赖于 Linux 发行版以及它们自己承诺推出稳定修复和安全更新。
|
||||
|
||||
@ -51,9 +51,9 @@ CGManager 的稳定版本支持依赖于 Linux 发行版以及它们自己承诺
|
||||
|
||||
via: https://linuxcontainers.org/cgmanager/introduction/
|
||||
|
||||
作者:[Canonical Ltd. ][a]
|
||||
作者:[Canonical Ltd.][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
176
published/20180102 HTTP errors in WordPress.md
Normal file
176
published/20180102 HTTP errors in WordPress.md
Normal file
@ -0,0 +1,176 @@
|
||||
如何修复 WordPress 中的 HTTP 错误
|
||||
======
|
||||
|
||||
![http error wordpress][1]
|
||||
|
||||
我们会向你介绍,如何在 Linux VPS 上修复 WordPress 中的 HTTP 错误。 下面列出了 WordPress 用户遇到的最常见的 HTTP 错误,我们的建议侧重于如何发现错误原因以及解决方法。
|
||||
|
||||
|
||||
### 1、 修复在上传图像时出现的 HTTP 错误
|
||||
|
||||
如果你在基于 WordPress 的网页中上传图像时出现错误,这也许是因为服务器上 PHP 的配置,例如存储空间不足或者其他配置问题造成的。
|
||||
|
||||
用如下命令查找 php 配置文件:
|
||||
|
||||
```
|
||||
php -i | grep php.ini
|
||||
Configuration File (php.ini) Path => /etc
|
||||
Loaded Configuration File => /etc/php.ini
|
||||
```
|
||||
|
||||
根据输出结果,php 配置文件位于 `/etc` 文件夹下。编辑 `/etc/php.ini` 文件,找出下列行,并按照下面的例子修改其中相对应的值:
|
||||
|
||||
```
|
||||
vi /etc/php.ini
|
||||
```
|
||||
|
||||
```
|
||||
upload_max_filesize = 64M
|
||||
post_max_size = 32M
|
||||
max_execution_time = 300
|
||||
max_input_time 300
|
||||
memory_limit = 128M
|
||||
```
|
||||
|
||||
当然,如果你不习惯使用 vi 文本编辑器,你可以选用自己喜欢的。
|
||||
|
||||
不要忘记重启你的网页服务器来让改动生效。
|
||||
|
||||
如果你安装的网页服务器是 Apache,你也可以使用 `.htaccess` 文件。首先,找到 `.htaccess` 文件。它位于 WordPress 安装路径的根文件夹下。如果没有找到 `.htaccess` 文件,需要自己手动创建一个,然后加入如下内容:
|
||||
|
||||
|
||||
```
|
||||
vi /www/html/path_to_wordpress/.htaccess
|
||||
```
|
||||
|
||||
```
|
||||
php_value upload_max_filesize 64M
|
||||
php_value post_max_size 32M
|
||||
php_value max_execution_time 180
|
||||
php_value max_input_time 180
|
||||
|
||||
# BEGIN WordPress
|
||||
<IfModule mod_rewrite.c>
|
||||
RewriteEngine On
|
||||
RewriteBase /
|
||||
RewriteRule ^index\.php$ - [L]
|
||||
RewriteCond %{REQUEST_FILENAME} !-f
|
||||
RewriteCond %{REQUEST_FILENAME} !-d
|
||||
RewriteRule . /index.php [L]
|
||||
</IfModule>
|
||||
# END WordPress
|
||||
```
|
||||
|
||||
如果你使用的网页服务器是 nginx,在 nginx 的 `server` 配置块中配置你的 WordPress 实例。详细配置和下面的例子相似:
|
||||
|
||||
```
|
||||
server {
|
||||
|
||||
listen 80;
|
||||
client_max_body_size 128m;
|
||||
client_body_timeout 300;
|
||||
|
||||
server_name your-domain.com www.your-domain.com;
|
||||
|
||||
root /var/www/html/wordpress;
|
||||
index index.php;
|
||||
|
||||
location = /favicon.ico {
|
||||
log_not_found off;
|
||||
access_log off;
|
||||
}
|
||||
|
||||
location = /robots.txt {
|
||||
allow all;
|
||||
log_not_found off;
|
||||
access_log off;
|
||||
}
|
||||
|
||||
location / {
|
||||
try_files $uri $uri/ /index.php?$args;
|
||||
}
|
||||
|
||||
location ~ \.php$ {
|
||||
include fastcgi_params;
|
||||
fastcgi_pass 127.0.0.1:9000;
|
||||
fastcgi_index index.php;
|
||||
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
|
||||
}
|
||||
|
||||
location ~* \.(js|css|png|jpg|jpeg|gif|ico)$ {
|
||||
expires max;
|
||||
log_not_found off;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
根据自己的 PHP 配置,你需要将 `fastcgi_pass 127.0.0.1:9000;` 用类似于 `fastcgi_pass unix:/var/run/php7-fpm.sock;` 替换掉(依照实际连接方式)
|
||||
|
||||
重启 nginx 服务来使改动生效。
|
||||
|
||||
### 2、 修复因为不恰当的文件权限而产生的 HTTP 错误
|
||||
|
||||
如果你在 WordPress 中出现一个意外错误,也许是因为不恰当的文件权限导致的,所以需要给 WordPress 文件和文件夹设置一个正确的权限:
|
||||
|
||||
```
|
||||
chown www-data:www-data -R /var/www/html/path_to_wordpress/
|
||||
```
|
||||
|
||||
将 `www-data` 替换成实际的网页服务器用户,将 `/var/www/html/path_to_wordpress` 换成 WordPress 的实际安装路径。
|
||||
|
||||
### 3、 修复因为内存不足而产生的 HTTP 错误
|
||||
|
||||
你可以通过在 `wp-config.php` 中添加如下内容来设置 PHP 的最大内存限制:
|
||||
|
||||
```
|
||||
define('WP_MEMORY_LIMIT', '128MB');
|
||||
```
|
||||
|
||||
### 4、 修复因为 php.ini 文件错误配置而产生的 HTTP 错误
|
||||
|
||||
编辑 PHP 配置主文件,然后找到 `cgi.fix_pathinfo` 这一行。 这一行内容默认情况下是被注释掉的,默认值为 `1`。取消这一行的注释(删掉这一行最前面的分号),然后将 `1` 改为 `0` 。同时需要修改 `date.timezone` 这一 PHP 设置,再次编辑 PHP 配置文件并将这一选项改成 `date.timezone = Asia/Shanghai` (或者将等号后内容改为你所在的时区)。
|
||||
|
||||
```
|
||||
vi /etc/php.ini
|
||||
```
|
||||
```
|
||||
cgi.fix_pathinfo=0
|
||||
date.timezone = Asia/Shanghai
|
||||
```
|
||||
|
||||
### 5、 修复因为 Apache mod_security 模块而产生的 HTTP 错误
|
||||
|
||||
如果你在使用 Apache mod_security 模块,这可能也会引起问题。试着禁用这一模块,确认是否因为在 `.htaccess` 文件中加入如下内容而引起了问题:
|
||||
|
||||
```
|
||||
<IfModule mod_security.c>
|
||||
SecFilterEngine Off
|
||||
SecFilterScanPOST Off
|
||||
</IfModule>
|
||||
```
|
||||
|
||||
### 6、 修复因为有问题的插件/主题而产生的 HTTP 错误
|
||||
|
||||
一些插件或主题也会导致 HTTP 错误以及其他问题。你可以首先禁用有问题的插件/主题,或暂时禁用所有 WordPress 插件。如果你有 phpMyAdmin,使用它来禁用所有插件:在其中找到 `wp_options` 数据表,在 `option_name` 这一列中找到 `active_plugins` 这一记录,然后将 `option_value` 改为 :`a:0:{}`。
|
||||
|
||||
或者用以下命令通过SSH重命名插件所在文件夹:
|
||||
|
||||
```
|
||||
mv /www/html/path_to_wordpress/wp-content/plugins /www/html/path_to_wordpress/wp-content/plugins.old
|
||||
```
|
||||
|
||||
通常情况下,HTTP 错误会被记录在网页服务器的日志文件中,所以寻找错误时一个很好的切入点就是查看服务器日志。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.rosehosting.com/blog/http-error-wordpress/
|
||||
|
||||
作者:[rosehosting][a]
|
||||
译者:[wenwensnow](https://github.com/wenwensnow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.rosehosting.com
|
||||
[1]:https://www.rosehosting.com/blog/wp-content/uploads/2018/01/http-error-wordpress.jpg
|
||||
[2]:https://www.rosehosting.com/wordpress-hosting.html
|
||||
@ -0,0 +1,110 @@
|
||||
如何使用 syslog-ng 从远程 Linux 机器上收集日志
|
||||
======
|
||||
|
||||
![linuxhero.jpg][1]
|
||||
|
||||
如果你的数据中心全是 Linux 服务器,而你就是系统管理员。那么你的其中一项工作内容就是查看服务器的日志文件。但是,如果你在大量的机器上去查看日志文件,那么意味着你需要挨个去登入到机器中来阅读日志文件。如果你管理的机器很多,仅这项工作就可以花费你一天的时间。
|
||||
|
||||
另外的选择是,你可以配置一台单独的 Linux 机器去收集这些日志。这将使你的每日工作更加高效。要实现这个目的,有很多的不同系统可供你选择,而 syslog-ng 就是其中之一。
|
||||
|
||||
syslog-ng 的不足是文档并不容易梳理。但是,我已经解决了这个问题,我可以通过这种方法马上进行安装和配置 syslog-ng。下面我将在 Ubuntu Server 16.04 上示范这两种方法:
|
||||
|
||||
* UBUNTUSERVERVM 的 IP 地址是 192.168.1.118 ,将配置为日志收集器
|
||||
* UBUNTUSERVERVM2 将配置为一个客户端,发送日志文件到收集器
|
||||
|
||||
现在我们来开始安装和配置。
|
||||
|
||||
### 安装
|
||||
|
||||
安装很简单。为了尽可能容易,我将从标准仓库安装。打开一个终端窗口,运行如下命令:
|
||||
|
||||
```
|
||||
sudo apt install syslog-ng
|
||||
```
|
||||
|
||||
你必须在收集器和客户端的机器上都要运行上面的命令。安装完成之后,你将开始配置。
|
||||
|
||||
### 配置收集器
|
||||
|
||||
现在,我们开始日志收集器的配置。它的配置文件是 `/etc/syslog-ng/syslog-ng.conf`。syslog-ng 安装完成时就已经包含了一个配置文件。我们不使用这个默认的配置文件,可以使用 `mv /etc/syslog-ng/syslog-ng.conf /etc/syslog-ng/syslog-ng.conf.BAK` 将这个自带的默认配置文件重命名。现在使用 `sudo nano /etc/syslog/syslog-ng.conf` 命令创建一个新的配置文件。在这个文件中添加如下的行:
|
||||
|
||||
```
|
||||
@version: 3.5
|
||||
@include "scl.conf"
|
||||
@include "`scl-root`/system/tty10.conf"
|
||||
options {
|
||||
time-reap(30);
|
||||
mark-freq(10);
|
||||
keep-hostname(yes);
|
||||
};
|
||||
source s_local { system(); internal(); };
|
||||
source s_network {
|
||||
syslog(transport(tcp) port(514));
|
||||
};
|
||||
destination d_local {
|
||||
file("/var/log/syslog-ng/messages_${HOST}"); };
|
||||
destination d_logs {
|
||||
file(
|
||||
"/var/log/syslog-ng/logs.txt"
|
||||
owner("root")
|
||||
group("root")
|
||||
perm(0777)
|
||||
); };
|
||||
log { source(s_local); source(s_network); destination(d_logs); };
|
||||
```
|
||||
|
||||
需要注意的是,syslog-ng 使用 514 端口,你需要确保在你的网络上它可以被访问。
|
||||
|
||||
保存并关闭这个文件。上面的配置将转存期望的日志文件(由 `system()` 和 `internal()` 指出)到 `/var/log/syslog-ng/logs.txt` 中。因此,你需要使用如下的命令去创建所需的目录和文件:
|
||||
|
||||
```
|
||||
sudo mkdir /var/log/syslog-ng
|
||||
sudo touch /var/log/syslog-ng/logs.txt
|
||||
```
|
||||
|
||||
使用如下的命令启动和启用 syslog-ng:
|
||||
|
||||
```
|
||||
sudo systemctl start syslog-ng
|
||||
sudo systemctl enable syslog-ng
|
||||
```
|
||||
|
||||
### 配置客户端
|
||||
|
||||
我们将在客户端上做同样的事情(移动默认配置文件并创建新配置文件)。拷贝下列文本到新的客户端配置文件中:
|
||||
|
||||
```
|
||||
@version: 3.5
|
||||
@include "scl.conf"
|
||||
@include "`scl-root`/system/tty10.conf"
|
||||
source s_local { system(); internal(); };
|
||||
destination d_syslog_tcp {
|
||||
syslog("192.168.1.118" transport("tcp") port(514)); };
|
||||
log { source(s_local);destination(d_syslog_tcp); };
|
||||
```
|
||||
|
||||
请注意:请将 IP 地址修改为收集器的 IP 地址。
|
||||
|
||||
保存和关闭这个文件。与在配置为收集器的机器上一样的方法启动和启用 syslog-ng。
|
||||
|
||||
## 查看日志文件
|
||||
|
||||
回到你的配置为收集器的服务器上,运行这个命令 `sudo tail -f /var/log/syslog-ng/logs.txt`。你将看到包含了收集器和客户端的日志条目的输出(图 A)。
|
||||
|
||||
![图 A][3]
|
||||
|
||||
恭喜你!syslog-ng 已经正常工作了。你现在可以登入到你的收集器上查看本地机器和远程客户端的日志了。如果你的数据中心有很多 Linux 服务器,在每台服务器上都安装上 syslog-ng 并配置它们作为客户端发送日志到收集器,这样你就不需要登入到每个机器去查看它们的日志了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.techrepublic.com/article/how-to-use-syslog-ng-to-collect-logs-from-remote-linux-machines/
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[1]:https://tr1.cbsistatic.com/hub/i/r/2017/01/11/51204409-68e0-49b8-a637-01af26be85f6/resize/770x/688dfedad4ed30ec4baf548c2adb8cd4/linuxhero.jpg
|
||||
[3]:https://tr4.cbsistatic.com/hub/i/2018/01/09/6a24e5c0-6a29-46d3-8a66-bc72747b5beb/6f94d3e6c6c2121fab6223ed9d8c6aa6/syslognga.jpg
|
||||
@ -0,0 +1,138 @@
|
||||
Linux 下最好的图片截取和视频截录工具
|
||||
======
|
||||
|
||||

|
||||
|
||||
可能有一个困扰你多时的问题,当你想要获取一张屏幕截图向开发者反馈问题,或是在 Stack Overflow 寻求帮助时,你可能缺乏一个可靠的屏幕截图工具去保存和发送截图。在 GNOME 中有一些这种类型的程序和 shell 拓展工具。这里介绍的是 Linux 最好的屏幕截图工具,可以供你截取图片或截录视频。
|
||||
|
||||
### 1. Shutter
|
||||
|
||||
[][2]
|
||||
|
||||
[Shutter][3] 可以截取任意你想截取的屏幕,是 Linux 最好的截屏工具之一。得到截屏之后,它还可以在保存截屏之前预览图片。它也有一个扩展菜单,展示在 GNOME 顶部面板,使得用户进入软件变得更人性化,非常方便使用。
|
||||
|
||||
你可以截取选区、窗口、桌面、当前光标下的窗口、区域、菜单、提示框或网页。Shutter 允许用户直接上传屏幕截图到设置内首选的云服务商。它同样允许用户在保存截图之前编辑器图片;同时提供了一些可自由添加或移除的插件。
|
||||
|
||||
终端内键入下列命令安装此工具:
|
||||
|
||||
```
|
||||
sudo add-apt-repository -y ppa:shutter/ppa
|
||||
sudo apt-get update && sudo apt-get install shutter
|
||||
```
|
||||
|
||||
### 2. Vokoscreen
|
||||
|
||||
[][4]
|
||||
|
||||
[Vokoscreen][5] 是一款允许你记录和叙述屏幕活动的一款软件。它易于使用,有一个简洁的界面和顶部面板的菜单,方便用户录制视频。
|
||||
|
||||
你可以选择记录整个屏幕,或是记录一个窗口,抑或是记录一个选区。自定义记录可以让你轻松得到所需的保存类型,你甚至可以将屏幕录制记录保存为 gif 文件。当然,你也可以使用网络摄像头记录自己的情况,用于你写作教程吸引学习者。记录完成后,你还可以在该应用程序中回放视频记录,这样就不必到处去找你记录的内容。
|
||||
|
||||
[][6]
|
||||
|
||||
你可以从你的发行版仓库安装 Vocoscreen,或者你也可以在 [pkgs.org][7] 选择下载你需要的版本。
|
||||
|
||||
```
|
||||
sudo dpkg -i vokoscreen_2.5.0-1_amd64.deb
|
||||
```
|
||||
|
||||
### 3. OBS
|
||||
|
||||
[][8]
|
||||
|
||||
[OBS][9] 可以用来录制自己的屏幕亦可用来录制互联网上的流媒体。它允许你看到自己所录制的内容或你叙述的屏幕录制。它允许你根据喜好选择录制视频的品质;它也允许你选择文件的保存类型。除了视频录制功能之外,你还可以切换到 Studio 模式,不借助其他软件进行视频编辑。要在你的 Linux 系统中安装 OBS,你必须确保你的电脑已安装 FFmpeg。ubuntu 14.04 或更早的版本安装 FFmpeg 可以使用如下命令:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:kirillshkrogalev/ffmpeg-next
|
||||
|
||||
sudo apt-get update && sudo apt-get install ffmpeg
|
||||
```
|
||||
|
||||
ubuntu 15.04 以及之后的版本,你可以在终端中键入如下命令安装 FFmpeg:
|
||||
|
||||
```
|
||||
sudo apt-get install ffmpeg
|
||||
```
|
||||
|
||||
如果 FFmpeg 安装完成,在终端中键入如下安装 OBS:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:obsproject/obs-studio
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
sudo apt-get install obs-studio
|
||||
```
|
||||
|
||||
### 4. Green Recorder
|
||||
|
||||
[][10]
|
||||
|
||||
[Green recorder][11] 是一款界面简单的程序,它可以让你记录屏幕。你可以选择包括视频和单纯的音频在内的录制内容,也可以显示鼠标指针,甚至可以跟随鼠标录制视频。同样,你可以选择记录窗口或是屏幕上的选区,以便于只在自己的记录中保留需要的内容;你还可以自定义最终保存的视频的帧数。如果你想要延迟录制,它提供给你一个选项可以设置出你想要的延迟时间。它还提供一个录制结束后的命令运行选项,这样,就可以在视频录制结束后立即运行。
|
||||
|
||||
在终端中键入如下命令来安装 green recorder:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:fossproject/ppa
|
||||
|
||||
sudo apt update && sudo apt install green-recorder
|
||||
```
|
||||
|
||||
### 5. Kazam
|
||||
|
||||
[][12]
|
||||
|
||||
[Kazam][13] 在几乎所有使用截图工具的 Linux 用户中都十分流行。这是一款简单直观的软件,它可以让你做一个屏幕截图或是视频录制,也同样允许在屏幕截图或屏幕录制之前设置延时。它可以让你选择录制区域,窗口或是你想要抓取的整个屏幕。Kazam 的界面接口安排的非常好,和其它软件相比毫无复杂感。它的特点,就是让你优雅的截图。Kazam 在系统托盘和菜单中都有图标,无需打开应用本身,你就可以开始屏幕截图。
|
||||
|
||||
终端中键入如下命令来安装 Kazam:
|
||||
|
||||
```
|
||||
sudo apt-get install kazam
|
||||
```
|
||||
|
||||
如果没有找到该 PPA,你需要使用下面的命令安装它:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:kazam-team/stable-series
|
||||
|
||||
sudo apt-get update && sudo apt-get install kazam
|
||||
```
|
||||
|
||||
### 6. GNOME 扩展截屏工具
|
||||
|
||||
[][1]
|
||||
|
||||
GNOME 的一个扩展软件就叫做 screenshot tool,它常驻系统面板,如果你没有设置禁用它的话。由于它是常驻系统面板的软件,所以它会一直等待你的调用,获取截图,方便和容易获取是它最主要的特点,除非你在调整工具中禁用,否则它将一直在你的系统面板中。这个工具也有用来设置首选项的选项窗口。在 extensions.gnome.org 中搜索 “_Screenshot Tool_”,在你的 GNOME 中安装它。
|
||||
|
||||
你需要安装 gnome 扩展的 chrome 扩展组件和 GNOME 调整工具才能使用这个工具。
|
||||
|
||||
[][14]
|
||||
|
||||
当你碰到一个问题,不知道怎么处理,想要在 [Linux 社区][15] 或者其他开发社区分享、寻求帮助的的时候, **Linux 截图工具** 尤其合适。学习开发、程序或者其他任何事物都会发现这些工具在分享截图的时候真的很实用。Youtube 用户和教程制作爱好者会发现视频截录工具真的很适合录制可以发表的教程。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/best-linux-screenshot-screencasting-tools
|
||||
|
||||
作者:[linuxandubuntu][a]
|
||||
译者:[CYLeft](https://github.com/CYLeft)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com
|
||||
[1]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/gnome-screenshot-extension-compressed_orig.jpg
|
||||
[2]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/shutter-linux-screenshot-taking-tools_orig.jpg
|
||||
[3]:http://shutter-project.org/
|
||||
[4]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/vokoscreen-screencasting-tool-for-linux_orig.jpg
|
||||
[5]:https://github.com/vkohaupt/vokoscreen
|
||||
[6]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/vokoscreen-preferences_orig.jpg
|
||||
[7]:https://pkgs.org/download/vokoscreen
|
||||
[8]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/obs-linux-screencasting-tool_orig.jpg
|
||||
[9]:https://obsproject.com/
|
||||
[10]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/green-recording-linux-tool_orig.jpg
|
||||
[11]:https://github.com/foss-project/green-recorder
|
||||
[12]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/kazam-screencasting-tool-for-linux_orig.jpg
|
||||
[13]:https://launchpad.net/kazam
|
||||
[14]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/gnome-screenshot-extension-preferences_orig.jpg
|
||||
[15]:http://www.linuxandubuntu.com/home/top-10-communities-to-help-you-learn-linux
|
||||
@ -1,56 +1,56 @@
|
||||
如何在 Linux 上安装/更新 Intel 微码固件
|
||||
======
|
||||
|
||||
如果你是一个 Linux 系统管理方面的新手,如何在 Linux 上使用命令行方式去安装或者更新 Intel/AMD CPU 的微码固件呢?
|
||||
|
||||
如果你是一个 Linux 系统管理方面的新手,如何在 Linux 上使用命令行选项去安装或者更新 Intel/AMD CPU 的微码固件?
|
||||
|
||||
|
||||
微码只是由 Intel/AMD 提供的 CPU 固件而已。Linux 的内核可以在系统引导时不需要升级 BIOS 的情况下更新 CPU 的固件。处理器微码保存在内存中,在每次启动系统时,内核可以更新这个微码。这些来自 Intel/AMD 的升级微码可以去修复 bug 或者使用补丁来防范 bugs。这篇文章演示了如何使用包管理器去安装 AMD 或者 Intel 微码更新,或者由 lntel 提供的 Linux 上的处理器微码更新。
|
||||
|
||||
## 如何查看当前的微码状态
|
||||
<ruby>微码<rt>microcode</rt></ruby>就是由 Intel/AMD 提供的 CPU 固件。Linux 的内核可以在引导时更新 CPU 固件,而无需 BIOS 更新。处理器的微码保存在内存中,在每次启动系统时,内核可以更新这个微码。这些来自 Intel/AMD 的微码的更新可以去修复 bug 或者使用补丁来防范 bug。这篇文章演示了如何使用包管理器或由 lntel 提供的 Linux 处理器微码更新来安装 AMD 或 Intel 的微码更新。
|
||||
|
||||
### 如何查看当前的微码状态
|
||||
|
||||
以 root 用户运行下列命令:
|
||||
`# dmesg | grep microcode`
|
||||
|
||||
```
|
||||
# dmesg | grep microcode
|
||||
```
|
||||
|
||||
输出如下:
|
||||
|
||||
[![Verify microcode update on a CentOS RHEL Fedora Ubuntu Debian Linux][1]][1]
|
||||
|
||||
请注意,你的 CPU 在这里完全有可能出现没有可用的微码更新的情况。如果是这种情况,它的输出可能是如下图这样的:
|
||||
请注意,你的 CPU 在这里完全有可能出现没有可用的微码更新的情况。如果是这种情况,它的输出可能是如下这样的:
|
||||
|
||||
```
|
||||
[ 0.952699] microcode: sig=0x306a9, pf=0x10, revision=0x1c
|
||||
[ 0.952773] microcode: Microcode Update Driver: v2.2.
|
||||
|
||||
```
|
||||
|
||||
## 如何在 Linux 上使用包管理器去安装微码固件更新
|
||||
|
||||
对于运行在 Linux 系统的 x86/amd64 架构的 CPU 上,Linux 自带了工具去更改或者部署微码固件。在 Linux 上安装 AMD 或者 Intel 的微码固件的过程如下:
|
||||
|
||||
1. 打开终端应用程序
|
||||
2. Debian/Ubuntu Linux 用户推输入:**sudo apt install intel-microcode**
|
||||
3. CentOS/RHEL Linux 用户输入:**sudo yum install microcode_ctl**
|
||||
### 如何在 Linux 上使用包管理器去安装微码固件更新
|
||||
|
||||
对于运行在 x86/amd64 架构的 CPU 上的 Linux 系统,Linux 自带了工具去更改或者部署微码固件。在 Linux 上安装 AMD 或者 Intel 的微码固件的过程如下:
|
||||
|
||||
1. 打开终端应用程序
|
||||
2. Debian/Ubuntu Linux 用户推输入:`sudo apt install intel-microcode`
|
||||
3. CentOS/RHEL Linux 用户输入:`sudo yum install microcode_ctl`
|
||||
|
||||
对于流行的 Linux 发行版,这个包的名字一般如下 :
|
||||
|
||||
* microcode_ctl 和 linux-firmware —— CentOS/RHEL 微码更新包
|
||||
* intel-microcode —— Debian/Ubuntu 和 clones 发行版适用于 Intel CPU 的微码更新包
|
||||
* amd64-microcode —— Debian/Ubuntu 和 clones 发行版适用于 AMD CPU 的微码固件
|
||||
* linux-firmware —— 适用于 AMD CPU 的 Arch Linux 发行版微码固件(你不用做任何操作,它是默认安装的)
|
||||
* intel-ucode —— 适用于 Intel CPU 的 Arch Linux 发行版微码固件
|
||||
* microcode_ctl 和 ucode-intel —— Suse/OpenSUSE Linux 微码更新包
|
||||
* `microcode_ctl` 和 `linux-firmware` —— CentOS/RHEL 微码更新包
|
||||
* `intel-microcode` —— Debian/Ubuntu 和衍生发行版的适用于 Intel CPU 的微码更新包
|
||||
* `amd64-microcode` —— Debian/Ubuntu 和衍生发行版的适用于 AMD CPU 的微码固件
|
||||
* `linux-firmware` —— 适用于 AMD CPU 的 Arch Linux 发行版的微码固件(你不用做任何操作,它是默认安装的)
|
||||
* `intel-ucode` —— 适用于 Intel CPU 的 Arch Linux 发行版微码固件
|
||||
* `microcode_ctl` 、`linux-firmware` 和 `ucode-intel` —— Suse/OpenSUSE Linux 微码更新包
|
||||
|
||||
**警告 :在某些情况下,微码更新可能会导致引导问题,比如,服务器在引导时被挂起或者自动重置。以下的步骤是在我的机器上运行过的,并且我是一个经验丰富的系统管理员。对于由此引发的任何硬件故障,我不承担任何责任。在做固件更新之前,请充分评估操作风险!**
|
||||
|
||||
|
||||
**警告 :在某些情况下,更新微码可能会导致引导问题,比如,服务器在引导时被挂起或者自动重置。以下的步骤是在我的机器上运行过的,并且我是一个经验丰富的系统管理员。对于由此引发的任何硬件故障,我不承担任何责任。在做固件更新之前,请充分评估操作风险!**
|
||||
|
||||
### 示例
|
||||
#### 示例
|
||||
|
||||
在使用 Intel CPU 的 Debian/Ubuntu Linux 系统上,输入如下的 [apt 命令][2]/[apt-get 命令][3]:
|
||||
|
||||
`$ sudo apt-get install intel-microcode`
|
||||
```
|
||||
$ sudo apt-get install intel-microcode
|
||||
```
|
||||
|
||||
示例输出如下:
|
||||
|
||||
@ -58,11 +58,15 @@
|
||||
|
||||
你 [必须重启服务器以激活微码][5] 更新:
|
||||
|
||||
`$ sudo reboot`
|
||||
```
|
||||
$ sudo reboot
|
||||
```
|
||||
|
||||
重启后检查微码状态:
|
||||
|
||||
`# dmesg | grep 'microcode'`
|
||||
```
|
||||
# dmesg | grep 'microcode'
|
||||
```
|
||||
|
||||
示例输出如下:
|
||||
|
||||
@ -70,7 +74,6 @@
|
||||
[ 0.000000] microcode: microcode updated early to revision 0x1c, date = 2015-02-26
|
||||
[ 1.604672] microcode: sig=0x306a9, pf=0x10, revision=0x1c
|
||||
[ 1.604976] microcode: Microcode Update Driver: v2.01 <tigran@aivazian.fsnet.co.uk>, Peter Oruba
|
||||
|
||||
```
|
||||
|
||||
如果你使用的是 RHEL/CentOS 系统,使用 [yum 命令][6] 尝试去安装或者更新以下两个包:
|
||||
@ -81,13 +84,14 @@ $ sudo reboot
|
||||
$ sudo dmesg | grep 'microcode'
|
||||
```
|
||||
|
||||
## 如何去更新/安装从 Intel 网站上下载的微码
|
||||
### 如何更新/安装从 Intel 网站上下载的微码
|
||||
|
||||
仅当你的 CPU 制造商建议这么做的时候,才可以使用下列的方法去更新/安装微码,除此之外,都应该使用上面的方法去更新。大多数 Linux 发行版都可以通过包管理器来维护更新微码。使用包管理器的方法是经过测试的,对大多数用户来说是最安全的方式。
|
||||
只有在你的 CPU 制造商建议这么做的时候,才可以使用下列的方法去更新/安装微码,除此之外,都应该使用上面的方法去更新。大多数 Linux 发行版都可以通过包管理器来维护、更新微码。使用包管理器的方法是经过测试的,对大多数用户来说是最安全的方式。
|
||||
|
||||
### 如何为 Linux 安装 Intel 处理器微码块(20180108 发布)
|
||||
#### 如何为 Linux 安装 Intel 处理器微码块(20180108 发布)
|
||||
|
||||
首先通过 AMD 或 [Intel 网站][7] 去获取最新的微码固件。在本示例中,我有一个名称为 `~/Downloads/microcode-20180108.tgz` 的文件(不要忘了去验证它的检验和),它的用途是去防范 `meltdown/Spectre` bug。先使用 `tar` 命令去提取它:
|
||||
|
||||
首先通过 AMD 或 [Intel 网站][7] 去获取最新的微码固件。在本示例中,我有一个名称为 ~/Downloads/microcode-20180108.tgz(不要忘了去验证它的检验和),它的用途是去防范 meltdown/Spectre bugs。先使用 tar 命令去提取它:
|
||||
```
|
||||
$ mkdir firmware
|
||||
$ cd firmware
|
||||
@ -101,33 +105,44 @@ $ ls -l
|
||||
drwxr-xr-x 2 vivek vivek 4096 Jan 8 12:41 intel-ucode
|
||||
-rw-r--r-- 1 vivek vivek 4847056 Jan 8 12:39 microcode.dat
|
||||
-rw-r--r-- 1 vivek vivek 1907 Jan 9 07:03 releasenote
|
||||
|
||||
```
|
||||
|
||||
检查一下,确保存在 /sys/devices/system/cpu/microcode/reload 目录:
|
||||
> 我只在 CentOS 7.x/RHEL、 7.x/Debian 9.x 和 Ubuntu 17.10 上测试了如下操作。如果你没有找到 `/sys/devices/system/cpu/microcode/reload` 文件的话,更老的发行版所带的更老的内核也许不能使用此方法。参见下面的讨论。请注意,在应用了固件更新之后,有一些客户遇到了系统重启现象。特别是对于[那些运行 Intel Broadwell 和 Haswell CPU][12] 的用于客户机和数据中心服务器上的系统。不要在 Intel Broadwell 和 Haswell CPU 上应用 20180108 版本。尽可能使用软件包管理器方式。
|
||||
|
||||
`$ ls -l /sys/devices/system/cpu/microcode/reload`
|
||||
检查一下,确保存在 `/sys/devices/system/cpu/microcode/reload`:
|
||||
|
||||
你必须使用 [cp 命令][8] 拷贝 intel-ucode 目录下的所有文件到 /lib/firmware/intel-ucode/ 下面:
|
||||
```
|
||||
$ ls -l /sys/devices/system/cpu/microcode/reload
|
||||
```
|
||||
|
||||
`$ sudo cp -v intel-ucode/* /lib/firmware/intel-ucode/`
|
||||
你必须使用 [cp 命令][8] 拷贝 `intel-ucode` 目录下的所有文件到 `/lib/firmware/intel-ucode/` 下面:
|
||||
|
||||
你只需要将 intel-ucode 这个目录整个拷贝到 /lib/firmware/ 目录下即可。然后在重新加载接口中写入 1 去重新加载微码文件:
|
||||
```
|
||||
$ sudo cp -v intel-ucode/* /lib/firmware/intel-ucode/
|
||||
```
|
||||
|
||||
`# echo 1 > /sys/devices/system/cpu/microcode/reload`
|
||||
你只需要将 `intel-ucode` 这个目录整个拷贝到 `/lib/firmware/` 目录下即可。然后在重新加载接口中写入 `1` 去重新加载微码文件:
|
||||
|
||||
更新现有的 initramfs,以便于下次启动时通过内核来加载:
|
||||
```
|
||||
# echo 1 > /sys/devices/system/cpu/microcode/reload
|
||||
```
|
||||
|
||||
更新现有的 initramfs,以便于下次启动时它能通过内核来加载:
|
||||
|
||||
```
|
||||
$ sudo update-initramfs -u
|
||||
$ sudo reboot
|
||||
```
|
||||
|
||||
重启后通过以下的命令验证微码是否已经更新:
|
||||
`# dmesg | grep microcode`
|
||||
|
||||
```
|
||||
# dmesg | grep microcode
|
||||
```
|
||||
|
||||
到此为止,就是更新处理器微码的全部步骤。如果一切顺利的话,你的 Intel CPU 的固件将已经是最新的版本了。
|
||||
|
||||
## 关于作者
|
||||
### 关于作者
|
||||
|
||||
作者是 nixCraft 的创始人、一位经验丰富的系统管理员、Linux/Unix 操作系统 shell 脚本培训师。他与全球的包括 IT、教育、国防和空间研究、以及非盈利组织等各行业的客户一起工作。可以在 [Twitter][9]、[Facebook][10]、[Google+][11] 上关注他。
|
||||
|
||||
@ -137,7 +152,7 @@ via: https://www.cyberciti.biz/faq/install-update-intel-microcode-firmware-linux
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -153,3 +168,4 @@ via: https://www.cyberciti.biz/faq/install-update-intel-microcode-firmware-linux
|
||||
[9]:https://twitter.com/nixcraft
|
||||
[10]:https://facebook.com/nixcraft
|
||||
[11]:https://plus.google.com/+CybercitiBiz
|
||||
[12]:https://newsroom.intel.com/news/intel-security-issue-update-addressing-reboot-issues/
|
||||
@ -0,0 +1,119 @@
|
||||
fold 命令入门示例教程
|
||||
======
|
||||
|
||||

|
||||
|
||||
你有没有发现自己在某种情况下想要折叠或中断命令的输出,以适应特定的宽度?在运行虚拟机的时候,我遇到了几次这种的情况,特别是没有 GUI 的服务器。 以防万一,如果你想限制一个命令的输出为一个特定的宽度,现在看看这里! `fold` 命令在这里就能派的上用场了! `fold` 命令会以适合指定的宽度调整输入文件中的每一行,并将其打印到标准输出。
|
||||
|
||||
在这个简短的教程中,我们将看到 `fold` 命令的用法,带有实例。
|
||||
|
||||
### fold 命令示例教程
|
||||
|
||||
`fold` 命令是 GNU coreutils 包的一部分,所以我们不用为安装的事情烦恼。
|
||||
|
||||
`fold` 命令的典型语法:
|
||||
|
||||
```
|
||||
fold [OPTION]... [FILE]...
|
||||
```
|
||||
|
||||
请允许我向您展示一些示例,以便您更好地了解 `fold` 命令。 我有一个名为 `linux.txt` 文件,内容是随机的。
|
||||
|
||||
|
||||
![][2]
|
||||
|
||||
要将上述文件中的每一行换行为默认宽度,请运行:
|
||||
|
||||
```
|
||||
fold linux.txt
|
||||
```
|
||||
|
||||
每行 80 列是默认的宽度。 这里是上述命令的输出:
|
||||
|
||||
![][3]
|
||||
|
||||
正如你在上面的输出中看到的,`fold` 命令已经将输出限制为 80 个字符的宽度。
|
||||
|
||||
当然,我们可以指定您的首选宽度,例如 50,如下所示:
|
||||
|
||||
```
|
||||
fold -w50 linux.txt
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
![][4]
|
||||
|
||||
我们也可以将输出写入一个新的文件,如下所示:
|
||||
|
||||
```
|
||||
fold -w50 linux.txt > linux1.txt
|
||||
```
|
||||
|
||||
以上命令将把 `linux.txt` 的行宽度改为 50 个字符,并将输出写入到名为 `linux1.txt` 的新文件中。
|
||||
|
||||
让我们检查一下新文件的内容:
|
||||
|
||||
```
|
||||
cat linux1.txt
|
||||
```
|
||||
|
||||
![][5]
|
||||
|
||||
你有没有注意到前面的命令的输出? 有些词在行之间被中断。 为了解决这个问题,我们可以使用 `-s` 标志来在空格处换行。
|
||||
|
||||
以下命令将给定文件中的每行调整为宽度 50,并在空格处换到新行:
|
||||
|
||||
```
|
||||
fold -w50 -s linux.txt
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
![][6]
|
||||
|
||||
看清楚了吗? 现在,输出很清楚。 换到新行中的单词都是用空格隔开的,所在行单词的长度大于 50 的时候就会被调整到下一行。
|
||||
|
||||
在所有上面的例子中,我们用列来限制输出宽度。 但是,我们可以使用 `-b` 选项将输出的宽度强制为指定的字节数。 以下命令以 20 个字节中断输出。
|
||||
|
||||
```
|
||||
fold -b20 linux.txt
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
![][7]
|
||||
|
||||
另请阅读:
|
||||
|
||||
- [Uniq 命令入门级示例教程][8]
|
||||
|
||||
有关更多详细信息,请参阅 man 手册页。
|
||||
|
||||
```
|
||||
man fold
|
||||
```
|
||||
|
||||
这些就是所有的内容了。 您现在知道如何使用 `fold` 命令以适应特定的宽度来限制命令的输出。 我希望这是有用的。 我们将每天发布更多有用的指南。 敬请关注!
|
||||
|
||||
干杯!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/fold-command-tutorial-examples-beginners/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/01/fold-command-1.png
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/01/fold-command-2.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2018/01/fold-command-3-1.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/01/fold-command-4.png
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2018/01/fold-command-5-1.png
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2018/01/fold-command-6-1.png
|
||||
[8]:https://www.ostechnix.com/uniq-command-tutorial-examples-beginners/
|
||||
@ -0,0 +1,95 @@
|
||||
Partclone:多功能的分区和克隆的自由软件
|
||||
======
|
||||
|
||||
|
||||
|
||||
[Partclone][1] 是由 Clonezilla 的开发者们开发的用于创建和克隆分区镜像的自由开源软件。实际上,Partclone 是 Clonezilla 所基于的工具之一。
|
||||
|
||||
它为用户提供了备份与恢复已用分区的工具,并与多个文件系统高度兼容,这要归功于它能够使用像 e2fslibs 这样的现有库来读取和写入分区,例如 ext2。
|
||||
|
||||
它最大的优点是支持各种格式,包括 ext2、ext3、ext4、hfs+、reiserfs、reiser4、btrfs、vmfs3、vmfs5、xfs、jfs、ufs、ntfs、fat(12/16/32)、exfat、f2fs 和 nilfs。
|
||||
|
||||
它还有许多的程序,包括 partclone.ext2(ext3&ext4)、partclone.ntfs、partclone.exfat、partclone.hfsp 和 partclone.vmfs(v3和v5) 等等。
|
||||
|
||||
### Partclone中的功能
|
||||
|
||||
* 免费软件: Partclone 免费供所有人下载和使用。
|
||||
* 开源: Partclone 是在 GNU GPL 许可下发布的,并在 [GitHub][2] 上公开。
|
||||
* 跨平台:适用于 Linux、Windows、MAC、ESX 文件系统备份/恢复和 FreeBSD。
|
||||
* 一个在线的[文档页面][3],你可以从中查看帮助文档并跟踪其 GitHub 问题。
|
||||
* 为初学者和专业人士提供的在线[用户手册][4]。
|
||||
* 支持救援。
|
||||
* 克隆分区成镜像文件。
|
||||
* 将镜像文件恢复到分区。
|
||||
* 快速复制分区。
|
||||
* 支持 raw 克隆。
|
||||
* 显示传输速率和持续时间。
|
||||
* 支持管道。
|
||||
* 支持 crc32 校验。
|
||||
* 支持 ESX vmware server 的 vmfs 和 FreeBSD 的文件系统 ufs。
|
||||
|
||||
Partclone 中还捆绑了更多功能,你可以在[这里][5]查看其余的功能。
|
||||
|
||||
- [下载 Linux 中的 Partclone][6]
|
||||
|
||||
### 如何安装和使用 Partclone
|
||||
|
||||
在 Linux 上安装 Partclone。
|
||||
|
||||
```
|
||||
$ sudo apt install partclone [On Debian/Ubuntu]
|
||||
$ sudo yum install partclone [On CentOS/RHEL/Fedora]
|
||||
```
|
||||
|
||||
克隆分区为镜像。
|
||||
|
||||
```
|
||||
# partclone.ext4 -d -c -s /dev/sda1 -o sda1.img
|
||||
```
|
||||
|
||||
将镜像恢复到分区。
|
||||
|
||||
```
|
||||
# partclone.ext4 -d -r -s sda1.img -o /dev/sda1
|
||||
```
|
||||
|
||||
分区到分区克隆。
|
||||
|
||||
```
|
||||
# partclone.ext4 -d -b -s /dev/sda1 -o /dev/sdb1
|
||||
```
|
||||
|
||||
显示镜像信息。
|
||||
|
||||
```
|
||||
# partclone.info -s sda1.img
|
||||
```
|
||||
|
||||
检查镜像。
|
||||
|
||||
```
|
||||
# partclone.chkimg -s sda1.img
|
||||
```
|
||||
|
||||
你是 Partclone 的用户吗?我最近在 [Deepin Clone][7] 上写了一篇文章,显然,Partclone 有擅长处理的任务。你使用其他备份和恢复工具的经验是什么?
|
||||
|
||||
请在下面的评论区与我们分享你的想法和建议。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.fossmint.com/partclone-linux-backup-clone-tool/
|
||||
|
||||
作者:[Martins D. Okoi][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.fossmint.com/author/dillivine/
|
||||
[1]:https://partclone.org/
|
||||
[2]:https://github.com/Thomas-Tsai/partclone
|
||||
[3]:https://partclone.org/help/
|
||||
[4]:https://partclone.org/usage/
|
||||
[5]:https://partclone.org/features/
|
||||
[6]:https://partclone.org/download/
|
||||
[7]:https://www.fossmint.com/deepin-clone-system-backup-restore-for-deepin-users/
|
||||
@ -0,0 +1,100 @@
|
||||
SPARTA:用于网络渗透测试的 GUI 工具套件
|
||||
======
|
||||
|
||||

|
||||
|
||||
SPARTA 是使用 Python 开发的 GUI 应用程序,它是 Kali Linux 内置的网络渗透测试工具。它简化了扫描和枚举阶段,并更快速的得到结果。
|
||||
|
||||
SPARTA GUI 工具套件最擅长的事情是扫描和发现目标端口和运行的服务。
|
||||
|
||||
此外,作为枚举阶段的一部分功能,它提供对开放端口和服务的暴力攻击。
|
||||
|
||||
延伸阅读:[网络渗透检查清单][1]
|
||||
|
||||
### 安装
|
||||
|
||||
请从 GitHub 上克隆最新版本的 SPARTA:
|
||||
|
||||
```
|
||||
git clone https://github.com/secforce/sparta.git
|
||||
```
|
||||
|
||||
或者,从 [这里][2] 下载最新版本的 Zip 文件。
|
||||
|
||||
```
|
||||
cd /usr/share/
|
||||
git clone https://github.com/secforce/sparta.git
|
||||
```
|
||||
|
||||
将 `sparta` 文件放到 `/usr/bin/` 目录下并赋于可运行权限。
|
||||
|
||||
在任意终端中输入 'sparta' 来启动应用程序。
|
||||
|
||||
### 网络渗透测试的范围
|
||||
|
||||
添加一个目标主机或者目标主机的列表到测试范围中,来发现一个组织的网络基础设备在安全方面的薄弱环节。
|
||||
|
||||
选择菜单条 - “File” -> “Add host(s) to scope”
|
||||
|
||||
[![Network Penetration Testing][3]][4]
|
||||
|
||||
[![Network Penetration Testing][5]][6]
|
||||
|
||||
上图展示了在扫描范围中添加 IP 地址。根据你网络的具体情况,你可以添加一个 IP 地址的范围去扫描。
|
||||
扫描范围添加之后,Nmap 将开始扫描,并很快得到结果,扫描阶段结束。
|
||||
|
||||
### 打开的端口及服务
|
||||
|
||||
Nmap 扫描结果提供了目标上开放的端口和服务。
|
||||
|
||||
[![Network Penetration Testing][7]][8]
|
||||
|
||||
上图展示了扫描发现的目标操作系统、开发的端口和服务。
|
||||
|
||||
### 在开放端口上实施暴力攻击
|
||||
|
||||
我们来通过 445 端口的服务器消息块(SMB)协议来暴力获取用户列表和它们的有效密码。
|
||||
|
||||
[![Network Penetration Testing][9]][10]
|
||||
|
||||
右键并选择 “Send to Brute” 选项。也可以选择发现的目标上的开放端口和服务。
|
||||
|
||||
浏览和在用户名密码框中添加字典文件。
|
||||
|
||||
[![Network Penetration Testing][11]][12]
|
||||
|
||||
点击 “Run” 去启动对目标的暴力攻击。上图展示了对目标 IP 地址进行的暴力攻击取得成功,找到了有效的密码。
|
||||
|
||||
在 Windows 中失败的登陆尝试总是被记录到事件日志中。
|
||||
|
||||
密码每 15 到 30 天改变一次的策略是非常好的一个实践经验。
|
||||
|
||||
强烈建议使用强密码策略。密码锁定策略是阻止这种暴力攻击的最佳方法之一( 5 次失败的登录尝试之后将锁定帐户)。
|
||||
|
||||
将关键业务资产整合到 SIEM( 安全冲突 & 事件管理)中将尽可能快地检测到这类攻击行为。
|
||||
|
||||
SPARTA 对渗透测试的扫描和枚举阶段来说是一个非常省时的 GUI 工具套件。SPARTA 可以扫描和暴力破解各种协议。它有许多的功能!祝你测试顺利!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://gbhackers.com/sparta-network-penetration-testing-gui-toolkit/
|
||||
|
||||
作者:[Balaganesh][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://gbhackers.com/author/balaganesh/
|
||||
[1]:https://gbhackers.com/network-penetration-testing-checklist-examples/
|
||||
[2]:https://github.com/SECFORCE/sparta/archive/master.zip
|
||||
[3]:https://i0.wp.com/gbhackers.com/wp-content/uploads/2018/01/Screenshot-526.png?resize=696%2C495&ssl=1
|
||||
[4]:https://i0.wp.com/gbhackers.com/wp-content/uploads/2018/01/Screenshot-526.png?ssl=1
|
||||
[5]:https://i2.wp.com/gbhackers.com/wp-content/uploads/2018/01/Screenshot-527.png?resize=696%2C516&ssl=1
|
||||
[6]:https://i2.wp.com/gbhackers.com/wp-content/uploads/2018/01/Screenshot-527.png?ssl=1
|
||||
[7]:https://i2.wp.com/gbhackers.com/wp-content/uploads/2018/01/Screenshot-528.png?resize=696%2C519&ssl=1
|
||||
[8]:https://i2.wp.com/gbhackers.com/wp-content/uploads/2018/01/Screenshot-528.png?ssl=1
|
||||
[9]:https://i1.wp.com/gbhackers.com/wp-content/uploads/2018/01/Screenshot-529.png?resize=696%2C525&ssl=1
|
||||
[10]:https://i1.wp.com/gbhackers.com/wp-content/uploads/2018/01/Screenshot-529.png?ssl=1
|
||||
[11]:https://i2.wp.com/gbhackers.com/wp-content/uploads/2018/01/Screenshot-531.png?resize=696%2C523&ssl=1
|
||||
[12]:https://i2.wp.com/gbhackers.com/wp-content/uploads/2018/01/Screenshot-531.png?ssl=1
|
||||
@ -1,35 +1,38 @@
|
||||
如何在 Linux 上使用 Vundle 管理 Vim 插件
|
||||
======
|
||||
|
||||
|
||||
|
||||
毋庸置疑,**Vim** 是一款强大的文本文件处理的通用工具,能够管理系统配置文件,编写代码。通过插件,vim 可以被拓展出不同层次的功能。通常,所有的插件和附属的配置文件都会存放在 **~/.vim** 目录中。由于所有的插件文件都被存储在同一个目录下,所以当你安装更多插件时,不同的插件文件之间相互混淆。因而,跟踪和管理它们将是一个恐怖的任务。然而,这正是 Vundle 所能处理的。Vundle,分别是 **V** im 和 B **undle** 的缩写,它是一款能够管理 Vim 插件的极其实用的工具。
|
||||
毋庸置疑,Vim 是一款强大的文本文件处理的通用工具,能够管理系统配置文件和编写代码。通过插件,Vim 可以被拓展出不同层次的功能。通常,所有的插件和附属的配置文件都会存放在 `~/.vim` 目录中。由于所有的插件文件都被存储在同一个目录下,所以当你安装更多插件时,不同的插件文件之间相互混淆。因而,跟踪和管理它们将是一个恐怖的任务。然而,这正是 Vundle 所能处理的。Vundle,分别是 **V** im 和 B **undle** 的缩写,它是一款能够管理 Vim 插件的极其实用的工具。
|
||||
|
||||
Vundle 为每一个你安装和存储的拓展配置文件创建各自独立的目录树。因此,相互之间没有混淆的文件。简言之,Vundle 允许你安装新的插件、配置已存在的插件、更新插件配置、搜索安装插件和清理不使用的插件。所有的操作都可以在单一按键的交互模式下完成。在这个简易的教程中,让我告诉你如何安装 Vundle,如何在 GNU/Linux 中使用它来管理 Vim 插件。
|
||||
Vundle 为每一个你安装的插件创建一个独立的目录树,并在相应的插件目录中存储附加的配置文件。因此,相互之间没有混淆的文件。简言之,Vundle 允许你安装新的插件、配置已有的插件、更新插件配置、搜索安装的插件和清理不使用的插件。所有的操作都可以在一键交互模式下完成。在这个简易的教程中,让我告诉你如何安装 Vundle,如何在 GNU/Linux 中使用它来管理 Vim 插件。
|
||||
|
||||
### Vundle 安装
|
||||
|
||||
如果你需要 Vundle,那我就当作你的系统中,已将安装好了 **vim**。如果没有,安装 vim,尽情 **git**(下载 vundle)去吧。在大部分 GNU/Linux 发行版中的官方仓库中都可以获取到这两个包。比如,在 Debian 系列系统中,你可以使用下面的命令安装这两个包。
|
||||
如果你需要 Vundle,那我就当作你的系统中,已将安装好了 Vim。如果没有,请安装 Vim 和 git(以下载 Vundle)。在大部分 GNU/Linux 发行版中的官方仓库中都可以获取到这两个包。比如,在 Debian 系列系统中,你可以使用下面的命令安装这两个包。
|
||||
|
||||
```
|
||||
sudo apt-get install vim git
|
||||
```
|
||||
|
||||
**下载 Vundle**
|
||||
#### 下载 Vundle
|
||||
|
||||
复制 Vundle 的 GitHub 仓库地址:
|
||||
|
||||
```
|
||||
git clone https://github.com/VundleVim/Vundle.vim.git ~/.vim/bundle/Vundle.vim
|
||||
```
|
||||
|
||||
**配置 Vundle**
|
||||
#### 配置 Vundle
|
||||
|
||||
创建 **~/.vimrc** 文件,通知 vim 使用新的插件管理器。这个文件获得有安装、更新、配置和移除插件的权限。
|
||||
创建 `~/.vimrc` 文件,以通知 Vim 使用新的插件管理器。安装、更新、配置和移除插件需要这个文件。
|
||||
|
||||
```
|
||||
vim ~/.vimrc
|
||||
```
|
||||
|
||||
在此文件顶部,加入如下若干行内容:
|
||||
|
||||
```
|
||||
set nocompatible " be iMproved, required
|
||||
filetype off " required
|
||||
@ -76,35 +79,39 @@ filetype plugin indent on " required
|
||||
" Put your non-Plugin stuff after this line
|
||||
```
|
||||
|
||||
被标记的行中,是 Vundle 的请求项。其余行仅是一些例子。如果你不想安装那些特定的插件,可以移除它们。一旦你安装过,键入 **:wq** 保存退出。
|
||||
被标记为 “required” 的行是 Vundle 的所需配置。其余行仅是一些例子。如果你不想安装那些特定的插件,可以移除它们。完成后,键入 `:wq` 保存退出。
|
||||
|
||||
最后,打开 Vim:
|
||||
|
||||
最后,打开 vim
|
||||
```
|
||||
vim
|
||||
```
|
||||
|
||||
然后键入下列命令安装插件。
|
||||
然后键入下列命令安装插件:
|
||||
|
||||
```
|
||||
:PluginInstall
|
||||
```
|
||||
|
||||
[![][1]][2]
|
||||
![][2]
|
||||
|
||||
将会弹出一个新的分窗口,.vimrc 中陈列的项目都会自动安装。
|
||||
将会弹出一个新的分窗口,我们加在 `.vimrc` 文件中的所有插件都会自动安装。
|
||||
|
||||
[![][1]][3]
|
||||
![][3]
|
||||
|
||||
安装完毕之后,键入下列命令,可以删除高速缓存区缓存并关闭窗口:
|
||||
|
||||
安装完毕之后,键入下列命令,可以删除高速缓存区缓存并关闭窗口。
|
||||
```
|
||||
:bdelete
|
||||
```
|
||||
|
||||
在终端上使用下面命令,规避使用 vim 安装插件
|
||||
你也可以在终端上使用下面命令安装插件,而不用打开 Vim:
|
||||
|
||||
```
|
||||
vim +PluginInstall +qall
|
||||
```
|
||||
|
||||
使用 [**fish shell**][4] 的朋友,添加下面这行到你的 **.vimrc** 文件中。
|
||||
使用 [fish shell][4] 的朋友,添加下面这行到你的 `.vimrc` 文件中。
|
||||
|
||||
```
|
||||
set shell=/bin/bash
|
||||
@ -112,123 +119,138 @@ set shell=/bin/bash
|
||||
|
||||
### 使用 Vundle 管理 Vim 插件
|
||||
|
||||
**添加新的插件**
|
||||
#### 添加新的插件
|
||||
|
||||
首先,使用下面的命令搜索可以使用的插件:
|
||||
|
||||
首先,使用下面的命令搜索可以使用的插件。
|
||||
```
|
||||
:PluginSearch
|
||||
```
|
||||
|
||||
命令之后添加 **"! "**,刷新 vimscripts 网站内容到本地。
|
||||
要从 vimscripts 网站刷新本地的列表,请在命令之后添加 `!`。
|
||||
|
||||
```
|
||||
:PluginSearch!
|
||||
```
|
||||
|
||||
一个陈列可用插件列表的新分窗口将会被弹出。
|
||||
会弹出一个列出可用插件列表的新分窗口:
|
||||
|
||||
[![][1]][5]
|
||||
![][5]
|
||||
|
||||
你还可以通过直接指定插件名的方式,缩小搜索范围。
|
||||
|
||||
```
|
||||
:PluginSearch vim
|
||||
```
|
||||
|
||||
这样将会列出包含关键词“vim”的插件。
|
||||
这样将会列出包含关键词 “vim” 的插件。
|
||||
|
||||
当然你也可以指定确切的插件名,比如:
|
||||
|
||||
```
|
||||
:PluginSearch vim-dasm
|
||||
```
|
||||
|
||||
移动焦点到正确的一行上,点击 **" i"** 来安装插件。现在,被选择的插件将会被安装。
|
||||
移动焦点到正确的一行上,按下 `i` 键来安装插件。现在,被选择的插件将会被安装。
|
||||
|
||||
[![][1]][6]
|
||||
![][6]
|
||||
|
||||
类似的,在你的系统中安装所有想要的插件。一旦安装成功,使用下列命令删除 Vundle 缓存:
|
||||
|
||||
在你的系统中,所有想要的的插件都以类似的方式安装。一旦安装成功,使用下列命令删除 Vundle 缓存:
|
||||
```
|
||||
:bdelete
|
||||
```
|
||||
|
||||
现在,插件已经安装完成。在 .vimrc 文件中添加安装好的插件名,让插件正确加载。
|
||||
现在,插件已经安装完成。为了让插件正确的自动加载,我们需要在 `.vimrc` 文件中添加安装好的插件名。
|
||||
|
||||
这样做:
|
||||
|
||||
```
|
||||
:e ~/.vimrc
|
||||
```
|
||||
|
||||
添加这一行:
|
||||
|
||||
```
|
||||
[...]
|
||||
Plugin 'vim-dasm'
|
||||
[...]
|
||||
```
|
||||
|
||||
用自己的插件名替换 vim-dasm。然后,敲击 ESC,键入 **:wq** 保存退出。
|
||||
用自己的插件名替换 vim-dasm。然后,敲击 `ESC`,键入 `:wq` 保存退出。
|
||||
|
||||
请注意,所有插件都必须在 `.vimrc` 文件中追加如下内容。
|
||||
|
||||
请注意,所有插件都必须在 .vimrc 文件中追加如下内容。
|
||||
```
|
||||
[...]
|
||||
filetype plugin indent on
|
||||
```
|
||||
|
||||
**列出已安装的插件**
|
||||
#### 列出已安装的插件
|
||||
|
||||
键入下面命令列出所有已安装的插件:
|
||||
|
||||
```
|
||||
:PluginList
|
||||
```
|
||||
|
||||
[![][1]][7]
|
||||
![][7]
|
||||
|
||||
**更新插件**
|
||||
#### 更新插件
|
||||
|
||||
键入下列命令更新插件:
|
||||
|
||||
```
|
||||
:PluginUpdate
|
||||
```
|
||||
|
||||
键入下列命令重新安装所有插件
|
||||
键入下列命令重新安装所有插件:
|
||||
|
||||
```
|
||||
:PluginInstall!
|
||||
```
|
||||
|
||||
**卸载插件**
|
||||
#### 卸载插件
|
||||
|
||||
首先,列出所有已安装的插件:
|
||||
|
||||
```
|
||||
:PluginList
|
||||
```
|
||||
|
||||
之后将焦点置于正确的一行上,敲 **" SHITF+d"** 组合键。
|
||||
之后将焦点置于正确的一行上,按下 `SHITF+d` 组合键。
|
||||
|
||||
[![][1]][8]
|
||||
![][8]
|
||||
|
||||
然后编辑你的 `.vimrc` 文件:
|
||||
|
||||
然后编辑你的 .vimrc 文件:
|
||||
```
|
||||
:e ~/.vimrc
|
||||
```
|
||||
|
||||
再然后删除插件入口。最后,键入 **:wq** 保存退出。
|
||||
删除插件入口。最后,键入 `:wq` 保存退出。
|
||||
|
||||
或者,你可以通过移除插件所在 `.vimrc` 文件行,并且执行下列命令,卸载插件:
|
||||
|
||||
或者,你可以通过移除插件所在 .vimrc 文件行,并且执行下列命令,卸载插件:
|
||||
```
|
||||
:PluginClean
|
||||
```
|
||||
|
||||
这个命令将会移除所有不在你的 .vimrc 文件中但是存在于 bundle 目录中的插件。
|
||||
这个命令将会移除所有不在你的 `.vimrc` 文件中但是存在于 bundle 目录中的插件。
|
||||
|
||||
你应该已经掌握了 Vundle 管理插件的基本方法了。在 Vim 中使用下列命令,查询帮助文档,获取更多细节。
|
||||
|
||||
你应该已经掌握了 Vundle 管理插件的基本方法了。在 vim 中使用下列命令,查询帮助文档,获取更多细节。
|
||||
```
|
||||
:h vundle
|
||||
```
|
||||
|
||||
**捎带看看:**
|
||||
|
||||
现在我已经把所有内容都告诉你了。很快,我就会出下一篇教程。保持关注 OSTechNix!
|
||||
现在我已经把所有内容都告诉你了。很快,我就会出下一篇教程。保持关注!
|
||||
|
||||
干杯!
|
||||
|
||||
**来源:**
|
||||
### 资源
|
||||
|
||||
[Vundle GitHub 仓库][9]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -236,16 +258,17 @@ via: https://www.ostechnix.com/manage-vim-plugins-using-vundle-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[CYLeft](https://github.com/CYLeft)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-1.png ()
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-2.png ()
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-1.png
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-2.png
|
||||
[4]:https://www.ostechnix.com/install-fish-friendly-interactive-shell-linux/
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-3.png ()
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-4-2.png ()
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-5-1.png ()
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-6.png ()
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-3.png
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-4-2.png
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-5-1.png
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-6.png
|
||||
[9]:https://github.com/VundleVim/Vundle.vim
|
||||
@ -1,28 +1,28 @@
|
||||
为初学者介绍的 Linux tee 命令(6 个例子)
|
||||
======
|
||||
|
||||
有时候,你会想手动跟踪命令的输出内容,同时又想将输出的内容写入文件,确保之后可以用来参考。如果你想寻找这相关的工具,那么恭喜你,Linux 已经有了一个叫做 **tee** 的命令可以帮助你。
|
||||
有时候,你会想手动跟踪命令的输出内容,同时又想将输出的内容写入文件,确保之后可以用来参考。如果你想寻找这相关的工具,那么恭喜你,Linux 已经有了一个叫做 `tee` 的命令可以帮助你。
|
||||
|
||||
本教程中,我们将基于 tee 命令,用一些简单的例子开始讨论。但是在此之前,值得一提的是,本文我们所有的测试实例都基于 Ubuntu 16.04 LTS。
|
||||
本教程中,我们将基于 `tee` 命令,用一些简单的例子开始讨论。但是在此之前,值得一提的是,本文我们所有的测试实例都基于 Ubuntu 16.04 LTS。
|
||||
|
||||
### Linux tee 命令
|
||||
|
||||
tee 命令基于标准输入读取数据,标准输出或文件写入数据。感受下这个命令的语法:
|
||||
`tee` 命令基于标准输入读取数据,标准输出或文件写入数据。感受下这个命令的语法:
|
||||
|
||||
```
|
||||
tee [OPTION]... [FILE]...
|
||||
```
|
||||
|
||||
这里是帮助文档的说明:
|
||||
```
|
||||
从标准输入中复制到每一个文件,并输出到标准输出。
|
||||
```
|
||||
|
||||
> 从标准输入中复制到每一个文件,并输出到标准输出。
|
||||
|
||||
|
||||
让 Q&A(问&答)风格的实例给我们带来更多灵感,深入了解这个命令。
|
||||
|
||||
### Q1. 如何在 Linux 上使用这个命令?
|
||||
### Q1、 如何在 Linux 上使用这个命令?
|
||||
|
||||
假设因为某些原因,你正在使用 ping 命令。
|
||||
假设因为某些原因,你正在使用 `ping` 命令。
|
||||
|
||||
```
|
||||
ping google.com
|
||||
@ -30,29 +30,29 @@ ping google.com
|
||||
|
||||
[![如何在 Linux 上使用 tee 命令][1]][2]
|
||||
|
||||
然后同时,你想要输出的信息也同时能写入文件。这个时候,tee 命令就有其用武之地了。
|
||||
然后同时,你想要输出的信息也同时能写入文件。这个时候,`tee` 命令就有其用武之地了。
|
||||
|
||||
```
|
||||
ping google.com | tee output.txt
|
||||
```
|
||||
|
||||
下面的截图展示了这个输出内容不仅被写入 ‘output.txt’ 文件,也被显示在标准输出中。
|
||||
下面的截图展示了这个输出内容不仅被写入 `output.txt` 文件,也被显示在标准输出中。
|
||||
|
||||
[![tee command 输出][3]][4]
|
||||
|
||||
如此应当明确了 tee 的基础用法。
|
||||
如此应当明白了 `tee` 的基础用法。
|
||||
|
||||
### Q2. 如何确保 tee 命令追加信息到文件中?
|
||||
### Q2、 如何确保 tee 命令追加信息到文件中?
|
||||
|
||||
默认情况下,在同一个文件下再次使用 tee 命令会覆盖之前的信息。如果你想的话,可以通过 -a 命令选项改变默认设置。
|
||||
默认情况下,在同一个文件下再次使用 `tee` 命令会覆盖之前的信息。如果你想的话,可以通过 `-a` 命令选项改变默认设置。
|
||||
|
||||
```
|
||||
[command] | tee -a [file]
|
||||
```
|
||||
|
||||
基本上,-a 选项强制 tee 命令追加信息到文件。
|
||||
基本上,`-a` 选项强制 `tee` 命令追加信息到文件。
|
||||
|
||||
### Q3. 如何让 tee 写入多个文件?
|
||||
### Q3、 如何让 tee 写入多个文件?
|
||||
|
||||
这非常之简单。你仅仅只需要写明文件名即可。
|
||||
|
||||
@ -70,7 +70,7 @@ ping google.com | tee output1.txt output2.txt output3.txt
|
||||
|
||||
### Q4. 如何让 tee 命令的输出内容直接作为另一个命令的输入内容?
|
||||
|
||||
使用 tee 命令,你不仅可以将输出内容写入文件,还可以把输出内容作为另一个命令的输入内容。比如说,下面的命令不仅会将文件名存入‘output.txt’文件中,还会通过 wc 命令让你知道输入到 output.txt 中的文件数目。
|
||||
使用 `tee` 命令,你不仅可以将输出内容写入文件,还可以把输出内容作为另一个命令的输入内容。比如说,下面的命令不仅会将文件名存入 `output.txt` 文件中,还会通过 `wc` 命令让你知道输入到 `output.txt` 中的文件数目。
|
||||
|
||||
```
|
||||
ls file* | tee output.txt | wc -l
|
||||
@ -80,11 +80,11 @@ ls file* | tee output.txt | wc -l
|
||||
|
||||
### Q5. 如何使用 tee 命令提升文件写入权限?
|
||||
|
||||
假如你使用 [Vim editor][9] 打开文件,并且做了很多更改,然后当你尝试保存修改时,你得到一个报错,让你意识到那是一个 root 所拥有的文件,这意味着你需要使用 sudo 权限保存修改。
|
||||
假如你使用 [Vim 编辑器][9] 打开文件,并且做了很多更改,然后当你尝试保存修改时,你得到一个报错,让你意识到那是一个 root 所拥有的文件,这意味着你需要使用 `sudo` 权限保存修改。
|
||||
|
||||
[![如何使用 tee 命令提升文件写入权限][10]][11]
|
||||
|
||||
如此情况下,你可以使用 tee 命令来提高权限。
|
||||
如此情况下,你可以(在 Vim 内)使用 `tee` 命令来提高权限。
|
||||
|
||||
```
|
||||
:w !sudo tee %
|
||||
@ -94,17 +94,17 @@ ls file* | tee output.txt | wc -l
|
||||
|
||||
### Q6. 如何让 tee 命令忽视中断?
|
||||
|
||||
-i 命令行选项使 tee 命令忽视通常由 crl+c 组合键发起的中断信号(`SIGINT`)。
|
||||
`-i` 命令行选项使 `tee` 命令忽视通常由 `ctrl+c` 组合键发起的中断信号(`SIGINT`)。
|
||||
|
||||
```
|
||||
[command] | tee -i [file]
|
||||
```
|
||||
|
||||
当你想要使用 crl+c 中断命令的同时,让 tee 命令优雅的退出,这个选项尤为实用。
|
||||
当你想要使用 `ctrl+c` 中断该命令,同时让 `tee` 命令优雅的退出,这个选项尤为实用。
|
||||
|
||||
### 总结
|
||||
|
||||
现在你可能已经认同 tee 是一个非常实用的命令。基于 tee 命令的用法,我们已经介绍了其绝大多数的命令行选项。这个工具并没有什么陡峭的学习曲线,所以,只需跟随这几个例子练习,你就可以运用自如了。更多信息,请查看 [帮助文档][12].
|
||||
现在你可能已经认同 `tee` 是一个非常实用的命令。基于 `tee` 命令的用法,我们已经介绍了其绝大多数的命令行选项。这个工具并没有什么陡峭的学习曲线,所以,只需跟随这几个例子练习,你就可以运用自如了。更多信息,请查看 [帮助文档][12].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -113,7 +113,7 @@ via: https://www.howtoforge.com/linux-tee-command/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[CYLeft](https://github.com/CYLeft)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,73 @@
|
||||
5 个在视觉上最轻松的黑暗主题
|
||||
======
|
||||
|
||||

|
||||
|
||||
人们在电脑上选择黑暗主题有几个原因。有些人觉得对于眼睛轻松,而另一些人因为他们的医学条件选择黑色。特别地,程序员喜欢黑暗的主题,因为可以减少眼睛的眩光。
|
||||
|
||||
如果你是一位 Linux 用户和黑暗主题爱好者,那么你很幸运。这里有五个最好的 Linux 黑暗主题。去看一下!
|
||||
|
||||
### 1. OSX-Arc-Shadow
|
||||
|
||||
![OSX-Arc-Shadow Theme][1]
|
||||
|
||||
顾名思义,这个主题受 OS X 的启发,它是基于 Arc 的平面主题。该主题支持 GTK 3 和 GTK 2 桌面环境,因此 Gnome、Cinnamon、Unity、Manjaro、Mate 和 XFCE 用户可以安装和使用该主题。[OSX-Arc-Shadow][2] 是 OSX-Arc 主题集合的一部分。该集合还包括其他几个主题(黑暗和明亮)。你可以下载整个系列并使用黑色主题。
|
||||
|
||||
基于 Debian 和 Ubuntu 的发行版用户可以选择使用此[页面][3]中找到的 .deb 文件来安装稳定版本。压缩的源文件也位于同一页面上。Arch Linux 用户,请查看此 [AUR 链接][4]。最后,要手动安装主题,请将 zip 解压到 `~/.themes` ,并将其设置为当前主题、控件和窗口边框。
|
||||
|
||||
### 2. Kiss-Kool-Red version 2
|
||||
|
||||
![Kiss-Kool-Red version 2 ][5]
|
||||
|
||||
该主题发布不久。与 OSX-Arc-Shadow 相比它有更黑的外观和红色选择框。对于那些希望电脑屏幕上有更强对比度和更少眩光的人尤其有吸引力。因此,它可以减少在夜间使用或在光线较暗的地方使用时的注意力分散。它支持 GTK 3 和 GTK2。
|
||||
|
||||
前往 [gnome-looks][6],在“文件”菜单下下载主题。安装过程很简单:将主题解压到 `~/.themes` 中,并将其设置为当前主题、控件和窗口边框。
|
||||
|
||||
### 3. Equilux
|
||||
|
||||
![Equilux][7]
|
||||
|
||||
Equilux 是另一个基于 Materia 主题的简单的黑暗主题。它有一个中性的深色调,并不过分花哨。选择框之间的对比度也很小,并且没有 Kiss-Kool-Red 中红色的锐利。这个主题的确是为减轻眼睛疲劳而做的。
|
||||
|
||||
[下载压缩文件][8]并将其解压缩到你的 `~/.themes` 中。然后,你可以将其设置为你的主题。你可以查看[它的 GitHub 页面][9]了解最新的增加内容。
|
||||
|
||||
### 4. Deepin Dark
|
||||
|
||||
![Deepin Dark][10]
|
||||
|
||||
Deepin Dark 是一个完全黑暗的主题。对于那些喜欢更黑暗的人来说,这个主题绝对是值得考虑的。此外,它还可以减少电脑屏幕的眩光量。另外,它支持 Unity。[在这里下载 Deepin Dark][11]。
|
||||
|
||||
### 5. Ambiance DS BlueSB12
|
||||
|
||||
![Ambiance DS BlueSB12 ][12]
|
||||
|
||||
Ambiance DS BlueSB12 是一个简单的黑暗主题,它使得重要细节突出。它有助于专注,不花哨。它与 Deepin Dark 非常相似。特别是对于 Ubuntu 用户,它与 Ubuntu 17.04 兼容。你可以从[这里][13]下载并尝试。
|
||||
|
||||
### 总结
|
||||
|
||||
如果你长时间使用电脑,黑暗主题是减轻眼睛疲劳的好方法。即使你不这样做,黑暗主题也可以在其他方面帮助你,例如提高专注。让我们知道你最喜欢哪一个。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/best-linux-dark-themes/
|
||||
|
||||
作者:[Bruno Edoh][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com
|
||||
[1]:https://www.maketecheasier.com/assets/uploads/2017/12/osx-arc-shadow.png (OSX-Arc-Shadow Theme)
|
||||
[2]:https://github.com/LinxGem33/OSX-Arc-Shadow/
|
||||
[3]:https://github.com/LinxGem33/OSX-Arc-Shadow/releases
|
||||
[4]:https://aur.archlinux.org/packages/osx-arc-shadow/
|
||||
[5]:https://www.maketecheasier.com/assets/uploads/2017/12/Kiss-Kool-Red.png (Kiss-Kool-Red version 2 )
|
||||
[6]:https://www.gnome-look.org/p/1207964/
|
||||
[7]:https://www.maketecheasier.com/assets/uploads/2017/12/equilux.png (Equilux)
|
||||
[8]:https://www.gnome-look.org/p/1182169/
|
||||
[9]:https://github.com/ddnexus/equilux-theme
|
||||
[10]:https://www.maketecheasier.com/assets/uploads/2017/12/deepin-dark.png (Deepin Dark )
|
||||
[11]:https://www.gnome-look.org/p/1190867/
|
||||
[12]:https://www.maketecheasier.com/assets/uploads/2017/12/ambience.png (Ambiance DS BlueSB12 )
|
||||
[13]:https://www.gnome-look.org/p/1013664/
|
||||
@ -1,9 +1,9 @@
|
||||
如何在 Linux 上安装 Spotify
|
||||
如何在 Linux 上使用 snap 安装 Spotify(声破天)
|
||||
======
|
||||
|
||||
如何在 Ubuntu Linux 桌面上安装 Spotify 来在线听音乐?
|
||||
如何在 Ubuntu Linux 桌面上安装 spotify 来在线听音乐?
|
||||
|
||||
Spotify 是一个可让你访问大量歌曲的数字音乐流服务。你可以免费收听或者购买订阅。可以创建播放列表。订阅用户可以免广告收听音乐。你会得到更好的音质。本教程**展示如何使用在 Ubuntu、Mint、Debian、Fedora、Arch 和其他更多发行版**上的 snap 包管理器安装 Spotify。
|
||||
Spotify 是一个可让你访问大量歌曲的数字音乐流服务。你可以免费收听或者购买订阅,可以创建播放列表。订阅用户可以免广告收听音乐,你会得到更好的音质。本教程展示如何使用在 Ubuntu、Mint、Debian、Fedora、Arch 和其他更多发行版上的 snap 包管理器安装 Spotify。
|
||||
|
||||
### 在 Linux 上安装 spotify
|
||||
|
||||
@ -11,33 +11,28 @@ Spotify 是一个可让你访问大量歌曲的数字音乐流服务。你可以
|
||||
|
||||
1. 安装 snapd
|
||||
2. 打开 snapd
|
||||
3. 找到 Spotify snap:
|
||||
```
|
||||
snap find spotify
|
||||
```
|
||||
4. 安装 spotify:
|
||||
```
|
||||
do snap install spotify
|
||||
```
|
||||
5. 运行:
|
||||
```
|
||||
spotify &
|
||||
```
|
||||
3. 找到 Spotify snap:`snap find spotify`
|
||||
4. 安装 spotify:`sudo snap install spotify`
|
||||
5. 运行:`spotify &`
|
||||
|
||||
让我们详细看看所有的步骤和例子。
|
||||
|
||||
### 步骤 1 - 安装 Snapd
|
||||
### 步骤 1 - 安装 snapd
|
||||
|
||||
你需要安装 snapd 包。它是一个守护进程(服务),并能在 Linux 系统上启用 snap 包管理。
|
||||
|
||||
#### Debian/Ubuntu/Mint Linux 上的 Snapd
|
||||
#### Debian/Ubuntu/Mint Linux 上的 snapd
|
||||
|
||||
输入以下[ apt 命令][1]/ [apt-get 命令][2]:
|
||||
`$ sudo apt install snapd`
|
||||
输入以下 [apt 命令][1]/ [apt-get 命令][2]:
|
||||
|
||||
```
|
||||
$ sudo apt install snapd
|
||||
```
|
||||
|
||||
#### 在 Arch Linux 上安装 snapd
|
||||
|
||||
snapd 只包含在 Arch User Repository(AUR)中。运行 yaourt 命令(参见[如何在 Archlinux 上安装 yaourt][3]):
|
||||
snapd 只包含在 Arch User Repository(AUR)中。运行 `yaourt` 命令(参见[如何在 Archlinux 上安装 yaourt][3]):
|
||||
|
||||
```
|
||||
$ sudo yaourt -S snapd
|
||||
$ sudo systemctl enable --now snapd.socket
|
||||
@ -45,7 +40,8 @@ $ sudo systemctl enable --now snapd.socket
|
||||
|
||||
#### 在 Fedora 上获取 snapd
|
||||
|
||||
运行 snapd 命令
|
||||
运行 snapd 命令:
|
||||
|
||||
```
|
||||
sudo dnf install snapd
|
||||
sudo ln -s /var/lib/snapd/snap /snap
|
||||
@ -53,26 +49,67 @@ sudo ln -s /var/lib/snapd/snap /snap
|
||||
|
||||
#### OpenSUSE 安装 snapd
|
||||
|
||||
执行如下的 `zypper` 命令:
|
||||
|
||||
```
|
||||
### Tumbleweed verson ###
|
||||
$ sudo zypper addrepo http://download.opensuse.org/repositories/system:/snappy/openSUSE_Tumbleweed/ snappy
|
||||
### Leap version ##
|
||||
$ sudo zypper addrepo http://download.opensuse.org/repositories/system:/snappy/openSUSE_Leap_42.3/ snappy
|
||||
```
|
||||
|
||||
安装:
|
||||
|
||||
```
|
||||
$ sudo zypper install snapd
|
||||
$ sudo systemctl enable --now snapd.socket
|
||||
```
|
||||
|
||||
### 步骤 2 - 在 Linux 上使用 snap 安装 spofity
|
||||
|
||||
执行 snap 命令:
|
||||
`$ snap find spotify`
|
||||
|
||||
```
|
||||
$ snap find spotify
|
||||
```
|
||||
|
||||
[![snap search for spotify app command][4]][4]
|
||||
|
||||
安装它:
|
||||
`$ sudo snap install spotify`
|
||||
|
||||
```
|
||||
$ sudo snap install spotify
|
||||
```
|
||||
|
||||
[![How to install Spotify application on Linux using snap command][5]][5]
|
||||
|
||||
### 步骤 3 - 运行 spotify 并享受它(译注:原博客中就是这么直接跳到 step3 的)
|
||||
### 步骤 3 - 运行 spotify 并享受它
|
||||
|
||||
从 GUI 运行它,或者只需输入:
|
||||
`$ spotify`
|
||||
|
||||
```
|
||||
$ spotify
|
||||
```
|
||||
|
||||
在启动时自动登录你的帐户:
|
||||
|
||||
```
|
||||
$ spotify --username vivek@nixcraft.com
|
||||
$ spotify --username vivek@nixcraft.com --password 'myPasswordHere'
|
||||
```
|
||||
|
||||
在初始化时使用给定的 URI 启动 Spotify 客户端:
|
||||
`$ spotify--uri=<uri>`
|
||||
|
||||
```
|
||||
$ spotify --uri=<uri>
|
||||
```
|
||||
|
||||
以指定的网址启动:
|
||||
`$ spotify--url=<url>`
|
||||
|
||||
```
|
||||
$ spotify --url=<url>
|
||||
```
|
||||
|
||||
[![Spotify client app running on my Ubuntu Linux desktop][6]][6]
|
||||
|
||||
### 关于作者
|
||||
@ -85,7 +122,7 @@ via: https://www.cyberciti.biz/faq/how-to-install-spotify-application-on-linux/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,113 @@
|
||||
搭建私有云:OwnCloud
|
||||
======
|
||||
|
||||
所有人都在讨论云。尽管市面上有很多为我们提供云存储和其他云服务的主要服务商,但是我们还是可以为自己搭建一个私有云。
|
||||
|
||||
在本教程中,我们将讨论如何利用 OwnCloud 搭建私有云。OwnCloud 是一个可以安装在我们 Linux 设备上的 web 应用程序,能够存储和用我们的数据提供服务。OwnCloud 可以分享日历、联系人和书签,共享音/视频流等等。
|
||||
|
||||
本教程中,我们使用的是 CentOS 7 系统,但是本教程同样适用于其他 Linux 发行版中安装 OwnCloud。让我们开始安装 OwnCloud 并且做一些准备工作,
|
||||
|
||||
- 推荐阅读:[如何在 CentOS & RHEL 上使用 Apache 作为反向代理服务器][1]
|
||||
- 同时推荐:[实时 Linux 服务器监测和 GLANCES 监测工具][2]
|
||||
|
||||
### 预备
|
||||
|
||||
* 我们需要在机器上配置 LAMP。参照阅读我们的文章《[在 CentOS/RHEL 上配置 LAMP 服务器最简单的教程][3]》 & 《[在 Ubuntu 搭建 LAMP][4]》。
|
||||
* 我们需要在自己的设备里安装这些包,`php-mysql`、 `php-json`、 `php-xml`、 `php-mbstring`、 `php-zip`、 `php-gd`、 `curl、 `php-curl` 、`php-pdo`。使用包管理器安装它们。
|
||||
|
||||
```
|
||||
$ sudo yum install php-mysql php-json php-xml php-mbstring php-zip php-gd curl php-curl php-pdo
|
||||
```
|
||||
|
||||
### 安装
|
||||
|
||||
安装 OwnCloud,我们现在需要在服务器上下载 OwnCloud 安装包。使用下面的命令从官方网站下载最新的安装包(10.0.4-1):
|
||||
|
||||
```
|
||||
$ wget https://download.owncloud.org/community/owncloud-10.0.4.tar.bz2
|
||||
```
|
||||
|
||||
使用下面的命令解压:
|
||||
|
||||
```
|
||||
$ tar -xvf owncloud-10.0.4.tar.bz2
|
||||
```
|
||||
|
||||
现在,将所有解压后的文件移动至 `/var/www/html`:
|
||||
|
||||
```
|
||||
$ mv owncloud/* /var/www/html
|
||||
```
|
||||
|
||||
下一步,我们需要在 Apache 的配置文件 `httpd.conf` 上做些修改:
|
||||
|
||||
```
|
||||
$ sudo vim /etc/httpd/conf/httpd.conf
|
||||
```
|
||||
|
||||
更改下面的选项:
|
||||
|
||||
```
|
||||
AllowOverride All
|
||||
```
|
||||
|
||||
保存该文件,并修改 OwnCloud 文件夹的文件权限:
|
||||
|
||||
```
|
||||
$ sudo chown -R apache:apache /var/www/html/
|
||||
$ sudo chmod 777 /var/www/html/config/
|
||||
```
|
||||
|
||||
然后重启 Apache 服务器执行修改:
|
||||
|
||||
```
|
||||
$ sudo systemctl restart httpd
|
||||
```
|
||||
|
||||
现在,我们需要在 MariaDB 上创建一个数据库,保存来自 OwnCloud 的数据。使用下面的命令创建数据库和数据库用户:
|
||||
|
||||
```
|
||||
$ mysql -u root -p
|
||||
MariaDB [(none)] > create database owncloud;
|
||||
MariaDB [(none)] > GRANT ALL ON owncloud.* TO ocuser@localhost IDENTIFIED BY 'owncloud';
|
||||
MariaDB [(none)] > flush privileges;
|
||||
MariaDB [(none)] > exit
|
||||
```
|
||||
|
||||
服务器配置部分完成后,现在我们可以在网页浏览器上访问 OwnCloud。打开浏览器,输入您的服务器 IP 地址,我这边的服务器是 10.20.30.100:
|
||||
|
||||
![安装 owncloud][7]
|
||||
|
||||
一旦 URL 加载完毕,我们将呈现上述页面。这里,我们将创建管理员用户同时提供数据库信息。当所有信息提供完毕,点击“Finish setup”。
|
||||
|
||||
我们将被重定向到登录页面,在这里,我们需要输入先前创建的凭据:
|
||||
|
||||
![安装 owncloud][9]
|
||||
|
||||
认证成功之后,我们将进入 OwnCloud 面板:
|
||||
|
||||
![安装 owncloud][11]
|
||||
|
||||
我们可以使用手机应用程序,同样也可以使用网页界面更新我们的数据。现在,我们已经有自己的私有云了,同时,关于如何安装 OwnCloud 创建私有云的教程也进入尾声。请在评论区留下自己的问题或建议。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/create-personal-cloud-install-owncloud/
|
||||
|
||||
作者:[SHUSAIN][a]
|
||||
译者:[CYLeft](https://github.com/CYLeft)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:http://linuxtechlab.com/apache-as-reverse-proxy-centos-rhel/
|
||||
[2]:http://linuxtechlab.com/linux-server-glances-monitoring-tool/
|
||||
[3]:http://linuxtechlab.com/easiest-guide-creating-lamp-server/
|
||||
[4]:http://linuxtechlab.com/install-lamp-stack-on-ubuntu/
|
||||
[6]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=400%2C647
|
||||
[7]:https://i1.wp.com/linuxtechlab.com/wp-content/uploads/2018/01/owncloud1-compressor.jpg?resize=400%2C647
|
||||
[8]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=876%2C541
|
||||
[9]:https://i1.wp.com/linuxtechlab.com/wp-content/uploads/2018/01/owncloud2-compressor1.jpg?resize=876%2C541
|
||||
[10]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=981%2C474
|
||||
[11]:https://i0.wp.com/linuxtechlab.com/wp-content/uploads/2018/01/owncloud3-compressor1.jpg?resize=981%2C474
|
||||
@ -1,42 +1,41 @@
|
||||
How programmers learn to code
|
||||
程序员如何学习编码
|
||||
============================================================
|
||||
|
||||
[][8]
|
||||
|
||||
HackerRank 最近公布了 2018 年开发者技能报告的结果,其中向程序员询问了他们何时开始编码。
|
||||
|
||||
HackerRank recently published the results of its 2018 Developer Skills Report, in which it asked programmers when they started coding.
|
||||
39,441 名专业人员和学生开发者于 2016 年 10 月 16 日至 11 月 1 日完成了在线调查,超过 25% 的被调查的开发者在 16 岁前编写了他们的第一段代码。(LCTT 译注:日期恐有误)
|
||||
|
||||
39,441 professional and student developers completed the online survey from 16 October to 1 November 2016, with over 25% of the developers surveyed writing their first piece of code before they were 16 years old.
|
||||
### 程序员是如何学习的
|
||||
|
||||
### How programmers learn
|
||||
报告称,就程序员如何学习编码而言,自学是所有年龄段开发者的常态。
|
||||
|
||||
In terms of how programmers learnt to code, self-teaching is the norm for developers of all ages, stated the report.
|
||||
“尽管 67% 的开发者拥有计算机科学学位,但大约 74% 的人表示他们至少一部分是自学的。”
|
||||
|
||||
“Even though 67% of developers have computer science degrees, roughly 74% said they were at least partially self-taught.”
|
||||
开发者平均了解四种语言,但他们想学习更多语言。
|
||||
|
||||
On average, developers know four languages, but they want to learn four more.
|
||||
|
||||
The thirst for learning varies by generations – developers between 18 and 24 plan to learn six languages, whereas developers older than 35 only plan to learn three.
|
||||
对学习的渴望因人而异 —— 18 至 24 岁的开发者计划学习 6 种语言,而 35 岁以上的开发者只计划学习 3 种语言。
|
||||
|
||||
[][5]
|
||||
|
||||
### What programmers want
|
||||
### 程序员想要什么
|
||||
|
||||
HackerRank also looked at what developers want most from an employer.
|
||||
HackerRank 还研究了开发者最想从雇主那里得到什么。
|
||||
|
||||
On average, a good work-life balance, closely followed by professional growth and learning, was the most desired requirement.
|
||||
平均而言,良好的工作与生活平衡,紧随其后的是专业成长与学习,是最理想的要求。
|
||||
|
||||
Segmenting the data by region revealed that Americans crave work-life balance more than developers Asia and Europe.
|
||||
按地区划分的数据显示,美国人比亚洲和欧洲的开发者更渴望工作与生活的平衡。
|
||||
|
||||
Students tend to rank growth and learning over work-life balance, while professionals rate compensation more highly than students do.
|
||||
学生倾向于将成长和学习列在工作与生活的平衡之上,而专业人员对薪酬的排名比学生高得多。
|
||||
|
||||
People who work in smaller companies tended to rank work-life balance lower, but it was still in their top three.
|
||||
在小公司工作的人倾向于降低工作与生活的平衡,但仍处于前三名。
|
||||
|
||||
Age also made a difference, with developers 25 and older rating work-life balance as most important, while those between 18 and 24 rate it as less important.
|
||||
年龄也制造了不同,25 岁以上的开发者将工作与生活的平衡评为最重要的,而 18 岁至 24 岁的人们则认为其重要性较低。
|
||||
|
||||
“In some ways, we’ve discovered a slight contradiction here. Developers want work-life balance, but they also have an insatiable thirst and need for learning,” said HackerRank.
|
||||
HackerRank 说:“在某些方面,我们发现了一个小矛盾。开发人员需要工作与生活的平衡,但他们也渴望学习“。
|
||||
|
||||
It advised that focusing on doing what you enjoy, as opposed to trying to learning everything, can help strike a better work-life balance.
|
||||
它建议,专注于做你喜欢的事情,而不是试图学习一切,这可以帮助实现更好的工作与生活的平衡。
|
||||
|
||||
[][6]
|
||||
|
||||
@ -46,9 +45,9 @@ It advised that focusing on doing what you enjoy, as opposed to trying to learni
|
||||
|
||||
via: https://mybroadband.co.za/news/smartphones/246583-how-programmers-learn-to-code.html
|
||||
|
||||
作者:[Staff Writer ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
作者:[Staff Writer][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,89 @@
|
||||
如何使用 lftp 来加速 Linux/UNIX 上的 ftp/https 下载速度
|
||||
======
|
||||
|
||||
`lftp` 是一个文件传输程序。它可以用于复杂的 FTP、 HTTP/HTTPS 和其他连接。如果指定了站点 URL,那么 `lftp` 将连接到该站点,否则会使用 `open` 命令建立连接。它是所有 Linux/Unix 命令行用户的必备工具。我目前写了一些关于 [Linux 下超快命令行下载加速器][1],比如 Axel 和 prozilla。`lftp` 是另一个能做相同的事,但有更多功能的工具。`lftp` 可以处理七种文件访问方式:
|
||||
|
||||
1. ftp
|
||||
2. ftps
|
||||
3. http
|
||||
4. https
|
||||
5. hftp
|
||||
6. fish
|
||||
7. sftp
|
||||
8. file
|
||||
|
||||
### 那么 lftp 的独特之处是什么?
|
||||
|
||||
* `lftp` 中的每个操作都是可靠的,即任何非致命错误都被忽略,并且重复进行操作。所以如果下载中断,它会自动重新启动。即使 FTP 服务器不支持 `REST` 命令,lftp 也会尝试从开头检索文件,直到文件传输完成。
|
||||
* `lftp` 具有类似 shell 的命令语法,允许你在后台并行启动多个命令。
|
||||
* `lftp` 有一个内置的镜像功能,可以下载或更新整个目录树。还有一个反向镜像功能(`mirror -R`),它可以上传或更新服务器上的目录树。镜像也可以在两个远程服务器之间同步目录,如果可用的话会使用 FXP。
|
||||
|
||||
### 如何使用 lftp 作为下载加速器
|
||||
|
||||
`lftp` 有 `pget` 命令。它能让你并行下载。语法是:
|
||||
|
||||
```
|
||||
lftp -e 'pget -n NUM -c url; exit'
|
||||
```
|
||||
|
||||
例如,使用 `pget` 分 5个部分下载 <http://kernel.org/pub/linux/kernel/v2.6/linux-2.6.22.2.tar.bz2>:
|
||||
|
||||
```
|
||||
$ cd /tmp
|
||||
$ lftp -e 'pget -n 5 -c http://kernel.org/pub/linux/kernel/v2.6/linux-2.6.22.2.tar.bz2'
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
45108964 bytes transferred in 57 seconds (775.3K/s)
|
||||
lftp :~>quit
|
||||
```
|
||||
|
||||
这里:
|
||||
|
||||
1. `pget` - 并行下载文件
|
||||
2. `-n 5` - 将最大连接数设置为 5
|
||||
3. `-c` - 如果当前目录存在 `lfile.lftp-pget-status`,则继续中断的传输
|
||||
|
||||
### 如何在 Linux/Unix 中使用 lftp 来加速 ftp/https下载
|
||||
|
||||
再尝试添加 `exit` 命令:
|
||||
|
||||
```
|
||||
$ lftp -e 'pget -n 10 -c https://cdn.kernel.org/pub/linux/kernel/v4.x/linux-4.15.tar.xz; exit'
|
||||
```
|
||||
|
||||
[Linux-lftp-command-demo](https://www.cyberciti.biz/tips/wp-content/uploads/2007/08/Linux-lftp-command-demo.mp4)
|
||||
|
||||
### 关于并行下载的说明
|
||||
|
||||
请注意,通过使用下载加速器,你将增加远程服务器负载。另请注意,`lftp` 可能无法在不支持多点下载的站点上工作,或者防火墙阻止了此类请求。
|
||||
|
||||
其它的命令提供了更多功能。有关更多信息,请参考 [lftp][2] 的 man 页面:
|
||||
|
||||
```
|
||||
man lftp
|
||||
```
|
||||
|
||||
### 关于作者
|
||||
|
||||
作者是 nixCraft 的创建者,经验丰富的系统管理员,也是 Linux 操作系统/Unix shell 脚本的培训师。他曾与全球客户以及IT、教育、国防和太空研究以及非营利部门等多个行业合作。在 [Twitter][9]、[Facebook][10]、[Google +][11] 上关注他。通过 [RSS/XML 订阅][5]获取最新的系统管理、Linux/Unix 以及开源主题教程。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/tips/linux-unix-download-accelerator.html
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/tips/download-accelerator-for-linux-command-line-tools.html
|
||||
[2]:https://lftp.yar.ru/
|
||||
[3]:https://twitter.com/nixcraft
|
||||
[4]:https://facebook.com/nixcraft
|
||||
[5]:https://plus.google.com/+CybercitiBiz
|
||||
[6]:https://www.cyberciti.biz/atom/atom.xml
|
||||
@ -0,0 +1,557 @@
|
||||
20 个 OpenSSH 最佳安全实践
|
||||
======
|
||||
|
||||
![OpenSSH 安全提示][1]
|
||||
|
||||
OpenSSH 是 SSH 协议的一个实现。一般通过 `scp` 或 `sftp` 用于远程登录、备份、远程文件传输等功能。SSH能够完美保障两个网络或系统间数据传输的保密性和完整性。尽管如此,它最大的优势是使用公匙加密来进行服务器验证。时不时会出现关于 OpenSSH 零日漏洞的[传言][2]。本文将描述如何设置你的 Linux 或类 Unix 系统以提高 sshd 的安全性。
|
||||
|
||||
|
||||
### OpenSSH 默认设置
|
||||
|
||||
* TCP 端口 - 22
|
||||
* OpenSSH 服务配置文件 - `sshd_config` (位于 `/etc/ssh/`)
|
||||
|
||||
### 1、 基于公匙的登录
|
||||
|
||||
OpenSSH 服务支持各种验证方式。推荐使用公匙加密验证。首先,使用以下 `ssh-keygen` 命令在本地电脑上创建密匙对:
|
||||
|
||||
> 1024 位或低于它的 DSA 和 RSA 加密是很弱的,请不要使用。当考虑 ssh 客户端向后兼容性的时候,请使用 RSA密匙代替 ECDSA 密匙。所有的 ssh 密钥要么使用 ED25519 ,要么使用 RSA,不要使用其它类型。
|
||||
|
||||
```
|
||||
$ ssh-keygen -t key_type -b bits -C "comment"
|
||||
```
|
||||
|
||||
示例:
|
||||
|
||||
```
|
||||
$ ssh-keygen -t ed25519 -C "Login to production cluster at xyz corp"
|
||||
或
|
||||
$ ssh-keygen -t rsa -b 4096 -f ~/.ssh/id_rsa_aws_$(date +%Y-%m-%d) -C "AWS key for abc corp clients"
|
||||
```
|
||||
|
||||
下一步,使用 `ssh-copy-id` 命令安装公匙:
|
||||
|
||||
```
|
||||
$ ssh-copy-id -i /path/to/public-key-file user@host
|
||||
或
|
||||
$ ssh-copy-id user@remote-server-ip-or-dns-name
|
||||
```
|
||||
|
||||
示例:
|
||||
|
||||
```
|
||||
$ ssh-copy-id vivek@rhel7-aws-server
|
||||
```
|
||||
|
||||
提示输入用户名和密码的时候,确认基于 ssh 公匙的登录是否工作:
|
||||
|
||||
```
|
||||
$ ssh vivek@rhel7-aws-server
|
||||
```
|
||||
|
||||
[![OpenSSH 服务安全最佳实践][3]][3]
|
||||
|
||||
更多有关 ssh 公匙的信息,参照以下文章:
|
||||
|
||||
* [为备份脚本设置无密码安全登录][48]
|
||||
* [sshpass:使用脚本密码登录 SSH 服务器][49]
|
||||
* [如何为一个 Linux/类 Unix 系统设置 SSH 登录密匙][50]
|
||||
* [如何使用 Ansible 工具上传 ssh 登录授权公匙][51]
|
||||
|
||||
|
||||
### 2、 禁用 root 用户登录
|
||||
|
||||
禁用 root 用户登录前,确认普通用户可以以 root 身份登录。例如,允许用户 vivek 使用 `sudo` 命令以 root 身份登录。
|
||||
|
||||
#### 在 Debian/Ubuntu 系统中如何将用户 vivek 添加到 sudo 组中
|
||||
|
||||
允许 sudo 组中的用户执行任何命令。 [将用户 vivek 添加到 sudo 组中][4]:
|
||||
|
||||
```
|
||||
$ sudo adduser vivek sudo
|
||||
```
|
||||
|
||||
使用 [id 命令][5] 验证用户组。
|
||||
|
||||
```
|
||||
$ id vivek
|
||||
```
|
||||
|
||||
#### 在 CentOS/RHEL 系统中如何将用户 vivek 添加到 sudo 组中
|
||||
|
||||
在 CentOS/RHEL 和 Fedora 系统中允许 wheel 组中的用户执行所有的命令。使用 `usermod` 命令将用户 vivek 添加到 wheel 组中:
|
||||
|
||||
```
|
||||
$ sudo usermod -aG wheel vivek
|
||||
$ id vivek
|
||||
```
|
||||
|
||||
#### 测试 sudo 权限并禁用 ssh root 登录
|
||||
|
||||
测试并确保用户 vivek 可以以 root 身份登录执行以下命令:
|
||||
|
||||
```
|
||||
$ sudo -i
|
||||
$ sudo /etc/init.d/sshd status
|
||||
$ sudo systemctl status httpd
|
||||
```
|
||||
|
||||
添加以下内容到 `sshd_config` 文件中来禁用 root 登录:
|
||||
|
||||
```
|
||||
PermitRootLogin no
|
||||
ChallengeResponseAuthentication no
|
||||
PasswordAuthentication no
|
||||
UsePAM no
|
||||
```
|
||||
|
||||
更多信息参见“[如何通过禁用 Linux 的 ssh 密码登录来增强系统安全][6]” 。
|
||||
|
||||
### 3、 禁用密码登录
|
||||
|
||||
所有的密码登录都应该禁用,仅留下公匙登录。添加以下内容到 `sshd_config` 文件中:
|
||||
|
||||
```
|
||||
AuthenticationMethods publickey
|
||||
PubkeyAuthentication yes
|
||||
```
|
||||
|
||||
CentOS 6.x/RHEL 6.x 系统中老版本的 sshd 用户可以使用以下设置:
|
||||
|
||||
```
|
||||
PubkeyAuthentication yes
|
||||
```
|
||||
|
||||
### 4、 限制用户的 ssh 访问
|
||||
|
||||
默认状态下,所有的系统用户都可以使用密码或公匙登录。但是有些时候需要为 FTP 或者 email 服务创建 UNIX/Linux 用户。然而,这些用户也可以使用 ssh 登录系统。他们将获得访问系统工具的完整权限,包括编译器和诸如 Perl、Python(可以打开网络端口干很多疯狂的事情)等的脚本语言。通过添加以下内容到 `sshd_config` 文件中来仅允许用户 root、vivek 和 jerry 通过 SSH 登录系统:
|
||||
|
||||
```
|
||||
AllowUsers vivek jerry
|
||||
```
|
||||
|
||||
当然,你也可以添加以下内容到 `sshd_config` 文件中来达到仅拒绝一部分用户通过 SSH 登录系统的效果。
|
||||
|
||||
```
|
||||
DenyUsers root saroj anjali foo
|
||||
```
|
||||
|
||||
你也可以通过[配置 Linux PAM][7] 来禁用或允许用户通过 sshd 登录。也可以允许或禁止一个[用户组列表][8]通过 ssh 登录系统。
|
||||
|
||||
### 5、 禁用空密码
|
||||
|
||||
你需要明确禁止空密码账户远程登录系统,更新 `sshd_config` 文件的以下内容:
|
||||
|
||||
```
|
||||
PermitEmptyPasswords no
|
||||
```
|
||||
|
||||
### 6、 为 ssh 用户或者密匙使用强密码
|
||||
|
||||
为密匙使用强密码和短语的重要性再怎么强调都不过分。暴力破解可以起作用就是因为用户使用了基于字典的密码。你可以强制用户避开[字典密码][9]并使用[约翰的开膛手工具][10]来检测弱密码。以下是一个随机密码生成器(放到你的 `~/.bashrc` 下):
|
||||
|
||||
```
|
||||
genpasswd() {
|
||||
local l=$1
|
||||
[ "$l" == "" ] && l=20
|
||||
tr -dc A-Za-z0-9_ < /dev/urandom | head -c ${l} | xargs
|
||||
}
|
||||
```
|
||||
|
||||
运行:
|
||||
|
||||
```
|
||||
genpasswd 16
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
```
|
||||
uw8CnDVMwC6vOKgW
|
||||
```
|
||||
|
||||
* [使用 mkpasswd / makepasswd / pwgen 生成随机密码][52]
|
||||
* [Linux / UNIX: 生成密码][53]
|
||||
* [Linux 随机密码生成命令][54]
|
||||
|
||||
### 7、 为 SSH 的 22端口配置防火墙
|
||||
|
||||
你需要更新 `iptables`/`ufw`/`firewall-cmd` 或 pf 防火墙配置来为 ssh 的 TCP 端口 22 配置防火墙。一般来说,OpenSSH 服务应该仅允许本地或者其他的远端地址访问。
|
||||
|
||||
#### Netfilter(Iptables) 配置
|
||||
|
||||
更新 [/etc/sysconfig/iptables (Redhat 和其派生系统特有文件) ][11] 实现仅接受来自于 192.168.1.0/24 和 202.54.1.5/29 的连接,输入:
|
||||
|
||||
```
|
||||
-A RH-Firewall-1-INPUT -s 192.168.1.0/24 -m state --state NEW -p tcp --dport 22 -j ACCEPT
|
||||
-A RH-Firewall-1-INPUT -s 202.54.1.5/29 -m state --state NEW -p tcp --dport 22 -j ACCEPT
|
||||
```
|
||||
|
||||
如果同时使用 IPv6 的话,可以编辑 `/etc/sysconfig/ip6tables` (Redhat 和其派生系统特有文件),输入:
|
||||
|
||||
```
|
||||
-A RH-Firewall-1-INPUT -s ipv6network::/ipv6mask -m tcp -p tcp --dport 22 -j ACCEPT
|
||||
```
|
||||
|
||||
将 `ipv6network::/ipv6mask` 替换为实际的 IPv6 网段。
|
||||
|
||||
#### Debian/Ubuntu Linux 下的 UFW
|
||||
|
||||
[UFW 是 Uncomplicated FireWall 的首字母缩写,主要用来管理 Linux 防火墙][12],目的是提供一种用户友好的界面。输入[以下命令使得系统仅允许网段 202.54.1.5/29 接入端口 22][13]:
|
||||
|
||||
```
|
||||
$ sudo ufw allow from 202.54.1.5/29 to any port 22
|
||||
```
|
||||
|
||||
更多信息请参见 “[Linux:菜鸟管理员的 25 个 Iptables Netfilter 命令][14]”。
|
||||
|
||||
#### *BSD PF 防火墙配置
|
||||
|
||||
如果使用 PF 防火墙 [/etc/pf.conf][15] 配置如下:
|
||||
|
||||
```
|
||||
pass in on $ext_if inet proto tcp from {192.168.1.0/24, 202.54.1.5/29} to $ssh_server_ip port ssh flags S/SA synproxy state
|
||||
```
|
||||
|
||||
### 8、 修改 SSH 端口和绑定 IP
|
||||
|
||||
ssh 默认监听系统中所有可用的网卡。修改并绑定 ssh 端口有助于避免暴力脚本的连接(许多暴力脚本只尝试端口 22)。更新文件 `sshd_config` 的以下内容来绑定端口 300 到 IP 192.168.1.5 和 202.54.1.5:
|
||||
|
||||
```
|
||||
Port 300
|
||||
ListenAddress 192.168.1.5
|
||||
ListenAddress 202.54.1.5
|
||||
```
|
||||
|
||||
当需要接受动态广域网地址的连接时,使用主动脚本是个不错的选择,比如 fail2ban 或 denyhosts。
|
||||
|
||||
### 9、 使用 TCP wrappers (可选的)
|
||||
|
||||
TCP wrapper 是一个基于主机的访问控制系统,用来过滤来自互联网的网络访问。OpenSSH 支持 TCP wrappers。只需要更新文件 `/etc/hosts.allow` 中的以下内容就可以使得 SSH 只接受来自于 192.168.1.2 和 172.16.23.12 的连接:
|
||||
|
||||
```
|
||||
sshd : 192.168.1.2 172.16.23.12
|
||||
```
|
||||
|
||||
在 Linux/Mac OS X 和类 UNIX 系统中参见 [TCP wrappers 设置和使用的常见问题][16]。
|
||||
|
||||
### 10、 阻止 SSH 破解或暴力攻击
|
||||
|
||||
暴力破解是一种在单一或者分布式网络中使用大量(用户名和密码的)组合来尝试连接一个加密系统的方法。可以使用以下软件来应对暴力攻击:
|
||||
|
||||
* [DenyHosts][17] 是一个基于 Python SSH 安全工具。该工具通过监控授权日志中的非法登录日志并封禁原始 IP 的方式来应对暴力攻击。
|
||||
* RHEL / Fedora 和 CentOS Linux 下如何设置 [DenyHosts][18]。
|
||||
* [Fail2ban][19] 是另一个类似的用来预防针对 SSH 攻击的工具。
|
||||
* [sshguard][20] 是一个使用 pf 来预防针对 SSH 和其他服务攻击的工具。
|
||||
* [security/sshblock][21] 阻止滥用 SSH 尝试登录。
|
||||
* [IPQ BDB filter][22] 可以看做是 fail2ban 的一个简化版。
|
||||
|
||||
### 11、 限制 TCP 端口 22 的传入速率(可选的)
|
||||
|
||||
netfilter 和 pf 都提供速率限制选项可以对端口 22 的传入速率进行简单的限制。
|
||||
|
||||
#### Iptables 示例
|
||||
|
||||
以下脚本将会阻止 60 秒内尝试登录 5 次以上的客户端的连入。
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
inet_if=eth1
|
||||
ssh_port=22
|
||||
$IPT -I INPUT -p tcp --dport ${ssh_port} -i ${inet_if} -m state --state NEW -m recent --set
|
||||
$IPT -I INPUT -p tcp --dport ${ssh_port} -i ${inet_if} -m state --state NEW -m recent --update --seconds 60 --hitcount 5
|
||||
```
|
||||
|
||||
在你的 iptables 脚本中调用以上脚本。其他配置选项:
|
||||
|
||||
```
|
||||
$IPT -A INPUT -i ${inet_if} -p tcp --dport ${ssh_port} -m state --state NEW -m limit --limit 3/min --limit-burst 3 -j ACCEPT
|
||||
$IPT -A INPUT -i ${inet_if} -p tcp --dport ${ssh_port} -m state --state ESTABLISHED -j ACCEPT
|
||||
$IPT -A OUTPUT -o ${inet_if} -p tcp --sport ${ssh_port} -m state --state ESTABLISHED -j ACCEPT
|
||||
# another one line example
|
||||
# $IPT -A INPUT -i ${inet_if} -m state --state NEW,ESTABLISHED,RELATED -p tcp --dport 22 -m limit --limit 5/minute --limit-burst 5-j ACCEPT
|
||||
```
|
||||
|
||||
其他细节参见 iptables 用户手册。
|
||||
|
||||
#### *BSD PF 示例
|
||||
|
||||
以下脚本将限制每个客户端的连入数量为 20,并且 5 秒内的连接不超过 15 个。如果客户端触发此规则,则将其加入 abusive_ips 表并限制该客户端连入。最后 flush 关键词杀死所有触发规则的客户端的连接。
|
||||
|
||||
```
|
||||
sshd_server_ip = "202.54.1.5"
|
||||
table <abusive_ips> persist
|
||||
block in quick from <abusive_ips>
|
||||
pass in on $ext_if proto tcp to $sshd_server_ip port ssh flags S/SA keep state (max-src-conn 20, max-src-conn-rate 15/5, overload <abusive_ips> flush)
|
||||
```
|
||||
|
||||
### 12、 使用端口敲门(可选的)
|
||||
|
||||
[端口敲门][23]是通过在一组预先指定的封闭端口上生成连接尝试,以便从外部打开防火墙上的端口的方法。一旦指定的端口连接顺序被触发,防火墙规则就被动态修改以允许发送连接的主机连入指定的端口。以下是一个使用 iptables 实现的端口敲门的示例:
|
||||
|
||||
```
|
||||
$IPT -N stage1
|
||||
$IPT -A stage1 -m recent --remove --name knock
|
||||
$IPT -A stage1 -p tcp --dport 3456 -m recent --set --name knock2
|
||||
|
||||
$IPT -N stage2
|
||||
$IPT -A stage2 -m recent --remove --name knock2
|
||||
$IPT -A stage2 -p tcp --dport 2345 -m recent --set --name heaven
|
||||
|
||||
$IPT -N door
|
||||
$IPT -A door -m recent --rcheck --seconds 5 --name knock2 -j stage2
|
||||
$IPT -A door -m recent --rcheck --seconds 5 --name knock -j stage1
|
||||
$IPT -A door -p tcp --dport 1234 -m recent --set --name knock
|
||||
|
||||
$IPT -A INPUT -m --state ESTABLISHED,RELATED -j ACCEPT
|
||||
$IPT -A INPUT -p tcp --dport 22 -m recent --rcheck --seconds 5 --name heaven -j ACCEPT
|
||||
$IPT -A INPUT -p tcp --syn -j door
|
||||
```
|
||||
|
||||
更多信息请参见:
|
||||
|
||||
[Debian / Ubuntu: 使用 Knockd and Iptables 设置端口敲门][55]
|
||||
|
||||
### 13、 配置空闲超时注销时长
|
||||
|
||||
用户可以通过 ssh 连入服务器,可以配置一个超时时间间隔来避免无人值守的 ssh 会话。 打开 `sshd_config` 并确保配置以下值:
|
||||
|
||||
```
|
||||
ClientAliveInterval 300
|
||||
ClientAliveCountMax 0
|
||||
```
|
||||
|
||||
以秒为单位设置一个空闲超时时间(300秒 = 5分钟)。一旦空闲时间超过这个值,空闲用户就会被踢出会话。更多细节参见[如何自动注销空闲超时的 BASH / TCSH / SSH 用户][24]。
|
||||
|
||||
### 14、 为 ssh 用户启用警示标语
|
||||
|
||||
更新 `sshd_config` 文件如下行来设置用户的警示标语:
|
||||
|
||||
```
|
||||
Banner /etc/issue
|
||||
```
|
||||
|
||||
`/etc/issue 示例文件:
|
||||
|
||||
```
|
||||
----------------------------------------------------------------------------------------------
|
||||
You are accessing a XYZ Government (XYZG) Information System (IS) that is provided for authorized use only.
|
||||
By using this IS (which includes any device attached to this IS), you consent to the following conditions:
|
||||
|
||||
+ The XYZG routinely intercepts and monitors communications on this IS for purposes including, but not limited to,
|
||||
penetration testing, COMSEC monitoring, network operations and defense, personnel misconduct (PM),
|
||||
law enforcement (LE), and counterintelligence (CI) investigations.
|
||||
|
||||
+ At any time, the XYZG may inspect and seize data stored on this IS.
|
||||
|
||||
+ Communications using, or data stored on, this IS are not private, are subject to routine monitoring,
|
||||
interception, and search, and may be disclosed or used for any XYZG authorized purpose.
|
||||
|
||||
+ This IS includes security measures (e.g., authentication and access controls) to protect XYZG interests--not
|
||||
for your personal benefit or privacy.
|
||||
|
||||
+ Notwithstanding the above, using this IS does not constitute consent to PM, LE or CI investigative searching
|
||||
or monitoring of the content of privileged communications, or work product, related to personal representation
|
||||
or services by attorneys, psychotherapists, or clergy, and their assistants. Such communications and work
|
||||
product are private and confidential. See User Agreement for details.
|
||||
----------------------------------------------------------------------------------------------
|
||||
```
|
||||
|
||||
以上是一个标准的示例,更多的用户协议和法律细节请咨询你的律师团队。
|
||||
|
||||
### 15、 禁用 .rhosts 文件(需核实)
|
||||
|
||||
禁止读取用户的 `~/.rhosts` 和 `~/.shosts` 文件。更新 `sshd_config` 文件中的以下内容:
|
||||
|
||||
```
|
||||
IgnoreRhosts yes
|
||||
```
|
||||
|
||||
SSH 可以模拟过时的 rsh 命令,所以应该禁用不安全的 RSH 连接。
|
||||
|
||||
### 16、 禁用基于主机的授权(需核实)
|
||||
|
||||
禁用基于主机的授权,更新 `sshd_config` 文件的以下选项:
|
||||
|
||||
```
|
||||
HostbasedAuthentication no
|
||||
```
|
||||
|
||||
### 17、 为 OpenSSH 和操作系统打补丁
|
||||
|
||||
推荐你使用类似 [yum][25]、[apt-get][26] 和 [freebsd-update][27] 等工具保持系统安装了最新的安全补丁。
|
||||
|
||||
### 18、 Chroot OpenSSH (将用户锁定在主目录)
|
||||
|
||||
默认设置下用户可以浏览诸如 `/etc`、`/bin` 等目录。可以使用 chroot 或者其他专有工具如 [rssh][28] 来保护 ssh 连接。从版本 4.8p1 或 4.9p1 起,OpenSSH 不再需要依赖诸如 rssh 或复杂的 chroot(1) 等第三方工具来将用户锁定在主目录中。可以使用新的 `ChrootDirectory` 指令将用户锁定在其主目录,参见[这篇博文][29]。
|
||||
|
||||
### 19. 禁用客户端的 OpenSSH 服务
|
||||
|
||||
工作站和笔记本不需要 OpenSSH 服务。如果不需要提供 ssh 远程登录和文件传输功能的话,可以禁用 sshd 服务。CentOS / RHEL 用户可以使用 [yum 命令][30] 禁用或删除 openssh-server:
|
||||
|
||||
```
|
||||
$ sudo yum erase openssh-server
|
||||
```
|
||||
|
||||
Debian / Ubuntu 用户可以使用 [apt 命令][31]/[apt-get 命令][32] 删除 openssh-server:
|
||||
|
||||
```
|
||||
$ sudo apt-get remove openssh-server
|
||||
```
|
||||
|
||||
有可能需要更新 iptables 脚本来移除 ssh 的例外规则。CentOS / RHEL / Fedora 系统可以编辑文件 `/etc/sysconfig/iptables` 和 `/etc/sysconfig/ip6tables`。最后[重启 iptables][33] 服务:
|
||||
|
||||
```
|
||||
# service iptables restart
|
||||
# service ip6tables restart
|
||||
```
|
||||
|
||||
### 20. 来自 Mozilla 的额外提示
|
||||
|
||||
如果使用 6.7+ 版本的 OpenSSH,可以尝试下[以下设置][34]:
|
||||
|
||||
```
|
||||
#################[ WARNING ]########################
|
||||
# Do not use any setting blindly. Read sshd_config #
|
||||
# man page. You must understand cryptography to #
|
||||
# tweak following settings. Otherwise use defaults #
|
||||
####################################################
|
||||
|
||||
# Supported HostKey algorithms by order of preference.
|
||||
HostKey /etc/ssh/ssh_host_ed25519_key
|
||||
HostKey /etc/ssh/ssh_host_rsa_key
|
||||
HostKey /etc/ssh/ssh_host_ecdsa_key
|
||||
|
||||
# Specifies the available KEX (Key Exchange) algorithms.
|
||||
KexAlgorithms curve25519-sha256@libssh.org,ecdh-sha2-nistp521,ecdh-sha2-nistp384,ecdh-sha2-nistp256,diffie-hellman-group-exchange-sha256
|
||||
|
||||
# Specifies the ciphers allowed
|
||||
Ciphers chacha20-poly1305@openssh.com,aes256-gcm@openssh.com,aes128-gcm@openssh.com,aes256-ctr,aes192-ctr,aes128-ctr
|
||||
|
||||
#Specifies the available MAC (message authentication code) algorithms
|
||||
MACs hmac-sha2-512-etm@openssh.com,hmac-sha2-256-etm@openssh.com,umac-128-etm@openssh.com,hmac-sha2-512,hmac-sha2-256,umac-128@openssh.com
|
||||
|
||||
# LogLevel VERBOSE logs user's key fingerprint on login. Needed to have a clear audit track of which key was using to log in.
|
||||
LogLevel VERBOSE
|
||||
|
||||
# Log sftp level file access (read/write/etc.) that would not be easily logged otherwise.
|
||||
Subsystem sftp /usr/lib/ssh/sftp-server -f AUTHPRIV -l INFO
|
||||
```
|
||||
|
||||
使用以下命令获取 OpenSSH 支持的加密方法:
|
||||
|
||||
```
|
||||
$ ssh -Q cipher
|
||||
$ ssh -Q cipher-auth
|
||||
$ ssh -Q mac
|
||||
$ ssh -Q kex
|
||||
$ ssh -Q key
|
||||
```
|
||||
|
||||
[![OpenSSH安全教程查询密码和算法选择][35]][35]
|
||||
|
||||
### 如何测试 sshd_config 文件并重启/重新加载 SSH 服务?
|
||||
|
||||
在重启 sshd 前检查配置文件的有效性和密匙的完整性,运行:
|
||||
|
||||
```
|
||||
$ sudo sshd -t
|
||||
```
|
||||
|
||||
扩展测试模式:
|
||||
|
||||
```
|
||||
$ sudo sshd -T
|
||||
```
|
||||
|
||||
最后,根据系统的的版本[重启 Linux 或类 Unix 系统中的 sshd 服务][37]:
|
||||
|
||||
```
|
||||
$ [sudo systemctl start ssh][38] ## Debian/Ubunt Linux##
|
||||
$ [sudo systemctl restart sshd.service][39] ## CentOS/RHEL/Fedora Linux##
|
||||
$ doas /etc/rc.d/sshd restart ## OpenBSD##
|
||||
$ sudo service sshd restart ## FreeBSD##
|
||||
```
|
||||
|
||||
### 其他建议
|
||||
|
||||
1. [使用 2FA 加强 SSH 的安全性][40] - 可以使用 [OATH Toolkit][41] 或 [DuoSecurity][42] 启用多重身份验证。
|
||||
2. [基于密匙链的身份验证][43] - 密匙链是一个 bash 脚本,可以使得基于密匙的验证非常的灵活方便。相对于无密码密匙,它提供更好的安全性。
|
||||
|
||||
### 更多信息:
|
||||
|
||||
* [OpenSSH 官方][44] 项目。
|
||||
* 用户手册: sshd(8)、ssh(1)、ssh-add(1)、ssh-agent(1)。
|
||||
|
||||
如果知道这里没用提及的方便的软件或者技术,请在下面的评论中分享,以帮助读者保持 OpenSSH 的安全。
|
||||
|
||||
### 关于作者
|
||||
|
||||
作者是 nixCraft 的创始人,一个经验丰富的系统管理员和 Linux/Unix 脚本培训师。他曾与全球客户合作,领域涉及 IT,教育,国防和空间研究以及非营利部门等多个行业。请在 [Twitter][45]、[Facebook][46]、[Google+][47] 上关注他。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/tips/linux-unix-bsd-openssh-server-best-practices.html
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[shipsw](https://github.com/shipsw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/media/new/tips/2009/07/openSSH_logo.png
|
||||
[2]:https://isc.sans.edu/diary/OpenSSH+Rumors/6742
|
||||
[3]:https://www.cyberciti.biz/tips/wp-content/uploads/2009/07/OpenSSH-server-security-best-practices.png
|
||||
[4]:https://www.cyberciti.biz/faq/how-to-create-a-sudo-user-on-ubuntu-linux-server/
|
||||
[5]:https://www.cyberciti.biz/faq/unix-linux-id-command-examples-usage-syntax/ (See Linux/Unix id command examples for more info)
|
||||
[6]:https://www.cyberciti.biz/faq/how-to-disable-ssh-password-login-on-linux/
|
||||
[7]:https://www.cyberciti.biz/tips/linux-pam-configuration-that-allows-or-deny-login-via-the-sshd-server.html
|
||||
[8]:https://www.cyberciti.biz/tips/openssh-deny-or-restrict-access-to-users-and-groups.html
|
||||
[9]:https://www.cyberciti.biz/tips/linux-check-passwords-against-a-dictionary-attack.html
|
||||
[10]:https://www.cyberciti.biz/faq/unix-linux-password-cracking-john-the-ripper/
|
||||
[11]:https://www.cyberciti.biz/faq/rhel-fedorta-linux-iptables-firewall-configuration-tutorial/
|
||||
[12]:https://www.cyberciti.biz/faq/howto-configure-setup-firewall-with-ufw-on-ubuntu-linux/
|
||||
[13]:https://www.cyberciti.biz/faq/ufw-allow-incoming-ssh-connections-from-a-specific-ip-address-subnet-on-ubuntu-debian/
|
||||
[14]:https://www.cyberciti.biz/tips/linux-iptables-examples.html
|
||||
[15]:https://bash.cyberciti.biz/firewall/pf-firewall-script/
|
||||
[16]:https://www.cyberciti.biz/faq/tcp-wrappers-hosts-allow-deny-tutorial/
|
||||
[17]:https://www.cyberciti.biz/faq/block-ssh-attacks-with-denyhosts/
|
||||
[18]:https://www.cyberciti.biz/faq/rhel-linux-block-ssh-dictionary-brute-force-attacks/
|
||||
[19]:https://www.fail2ban.org
|
||||
[20]:https://sshguard.sourceforge.net/
|
||||
[21]:http://www.bsdconsulting.no/tools/
|
||||
[22]:https://savannah.nongnu.org/projects/ipqbdb/
|
||||
[23]:https://en.wikipedia.org/wiki/Port_knocking
|
||||
[24]:https://www.cyberciti.biz/faq/linux-unix-login-bash-shell-force-time-outs/
|
||||
[25]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/
|
||||
[26]:https://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html
|
||||
[27]:https://www.cyberciti.biz/tips/howto-keep-freebsd-system-upto-date.html
|
||||
[28]:https://www.cyberciti.biz/tips/rhel-centos-linux-install-configure-rssh-shell.html
|
||||
[29]:https://www.debian-administration.org/articles/590
|
||||
[30]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/ (See Linux/Unix yum command examples for more info)
|
||||
[31]:https://www.cyberciti.biz/faq/ubuntu-lts-debian-linux-apt-command-examples/ (See Linux/Unix apt command examples for more info)
|
||||
[32]:https://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html (See Linux/Unix apt-get command examples for more info)
|
||||
[33]:https://www.cyberciti.biz/faq/howto-rhel-linux-open-port-using-iptables/
|
||||
[34]:https://wiki.mozilla.org/Security/Guidelines/OpenSSH
|
||||
[35]:https://www.cyberciti.biz/tips/wp-content/uploads/2009/07/OpenSSH-Security-Tutorial-Query-Ciphers-and-algorithms-choice.jpg
|
||||
[36]:https://www.cyberciti.biz/tips/checking-openssh-sshd-configuration-syntax-errors.html
|
||||
[37]:https://www.cyberciti.biz/faq/howto-restart-ssh/
|
||||
[38]:https://www.cyberciti.biz/faq/howto-start-stop-ssh-server/ (Restart sshd on a Debian/Ubuntu Linux)
|
||||
[39]:https://www.cyberciti.biz/faq/centos-stop-start-restart-sshd-command/ (Restart sshd on a CentOS/RHEL/Fedora Linux)
|
||||
[40]:https://www.cyberciti.biz/open-source/howto-protect-linux-ssh-login-with-google-authenticator/
|
||||
[41]:http://www.nongnu.org/oath-toolkit/
|
||||
[42]:https://duo.com
|
||||
[43]:https://www.cyberciti.biz/faq/ssh-passwordless-login-with-keychain-for-scripts/
|
||||
[44]:https://www.openssh.com/
|
||||
[45]:https://twitter.com/nixcraft
|
||||
[46]:https://facebook.com/nixcraft
|
||||
[47]:https://plus.google.com/+CybercitiBiz
|
||||
[48]:https://www.cyberciti.biz/faq/ssh-passwordless-login-with-keychain-for-scripts/
|
||||
[49]:https://linux.cn/article-8086-1.html
|
||||
[50]:https://www.cyberciti.biz/faq/how-to-set-up-ssh-keys-on-linux-unix/
|
||||
[51]:https://www.cyberciti.biz/faq/how-to-upload-ssh-public-key-to-as-authorized_key-using-ansible/
|
||||
[52]:https://www.cyberciti.biz/faq/generating-random-password/
|
||||
[53]:https://www.cyberciti.biz/faq/linux-unix-generating-passwords-command/
|
||||
[54]:https://www.cyberciti.biz/faq/linux-random-password-generator/
|
||||
[55]:https://www.cyberciti.biz/faq/debian-ubuntu-linux-iptables-knockd-port-knocking-tutorial/
|
||||
@ -1,12 +1,13 @@
|
||||
# Liunx 平台 6 个最好的替代 Microsoft Office 的开源办公软件
|
||||
6 个 Liunx 平台下最好的替代 Microsoft Office 的开源办公软件
|
||||
===========
|
||||
|
||||
**概要:还在 Linux 中寻找 Microsoft Office ? 这里有一些最好的在 Linux 平台替代 Microsoft Office 的开源软件。**
|
||||
> 概要:还在 Linux 中寻找 Microsoft Office 吗? 这里有一些最好的在 Linux 平台下替代 Microsoft Office 的开源软件。
|
||||
|
||||
办公套件是任何操作系统的必备品。很难想象没有Office 软件的桌面操作系统。虽然 Windows 有 MS Office 套件,Mac OS X 也有它自己的 iWork,但其他很多办公套件都是专门针对这些操作系统的,Linux 也有自己的办公套件。
|
||||
办公套件是任何操作系统的必备品。很难想象没有 Office 软件的桌面操作系统。虽然 Windows 有 MS Office 套件,Mac OS X 也有它自己的 iWork,但其他很多办公套件都是专门针对这些操作系统的,Linux 也有自己的办公套件。
|
||||
|
||||
在本文中,我会列举一些在 Linux 平台替代 Microsoft Office 的办公软件。
|
||||
|
||||
## Linux 最好的 MS Office 开源替代软件
|
||||
### Linux 最好的 MS Office 开源替代软件
|
||||
|
||||
![Best Microsoft office alternatives for Linux][1]
|
||||
|
||||
@ -16,62 +17,61 @@
|
||||
* 电子表格
|
||||
* 演示功能
|
||||
|
||||
|
||||
我知道 Microsoft Office 提供了比上述三种工具更多的工具,但事实上, 您主要使用这三个工具。 开源办公套件并不限于只有这三种产品。 其中有一些套件提供了一些额外的工具,但我们的重点将放在上述工具上。
|
||||
我知道 Microsoft Office 提供了比上述三种工具更多的工具,但事实上,您主要使用这三个工具。开源办公套件并不限于只有这三种产品。其中有一些套件提供了一些额外的工具,但我们的重点将放在上述工具上。
|
||||
|
||||
让我们看看在 Linux 上有什么办公套件:
|
||||
|
||||
### 6. Apache OpenOffice
|
||||
#### 6. Apache OpenOffice
|
||||
|
||||
![OpenOffice Logo][2]
|
||||
|
||||
[Apache OpenOffice][3] 或简单的称为 OpenOffice 有一段名称/所有者变更的历史。 它于1999年由 Sun Microsystems 公司开发,后来改名为 OpenOffice ,将它作为一个与 MS Office 对抗的免费的开源替代软件。 当Oracle 在 2010 年收购 Sun 公司后,一年之后便停止开发 OpenOffice。 最后是 Apache 支持它,现在被称为Apache OpenOffice。
|
||||
[Apache OpenOffice][3] 或简单的称为 OpenOffice 有一段名称/所有者变更的历史。 它于 1999 年由 Sun Microsystems 公司开发,后来改名为 OpenOffice,将它作为一个与 MS Office 对抗的自由开源的替代软件。 当 Oracle 在 2010 年收购 Sun 公司后,一年之后便停止开发 OpenOffice。 最后是 Apache 支持它,现在被称为 Apache OpenOffice。
|
||||
|
||||
Apache OpenOffice 可用于多种平台,包括 Linux,Windows,Mac OS X,Unix,BSD。 除了 OpenDocument 格式外,它还支持 MS Office 文件。 办公套件包含以下应用程序:Writer,Calc,Impress,Base,Draw,Math。
|
||||
Apache OpenOffice 可用于多种平台,包括 Linux、Windows、Mac OS X、Unix、BSD。 除了 OpenDocument 格式外,它还支持 MS Office 文件。 办公套件包含以下应用程序:Writer、Calc、Impress、Base、Draw、Math。
|
||||
|
||||
安装 OpenOffice 是一件痛苦的事,因为它没有提供一个友好的安装程序。 另外,有传言说 OpenOffice 开发可能已经停滞。 这两个是我不推荐的主要原因。 为了历史目的,我在这里列出它。
|
||||
安装 OpenOffice 是一件痛苦的事,因为它没有提供一个友好的安装程序。另外,有传言说 OpenOffice 开发可能已经停滞。 这是我不推荐的两个主要原因。 出于历史目的,我在这里列出它。
|
||||
|
||||
### 5. Feng Office
|
||||
#### 5. Feng Office
|
||||
|
||||
![Feng Office logo][6]
|
||||
|
||||
[Feng Office][7] 以前被称为 OpenGoo。 这不是一个常规的办公套件。 它完全专注于在线办公,如 Google 文档。 换句话说,这是一个开源[协作平台][8]。
|
||||
[Feng Office][7] 以前被称为 OpenGoo。 这不是一个常规的办公套件。 它完全专注于在线办公,如 Google 文档一样。 换句话说,这是一个开源[协作平台][8]。
|
||||
|
||||
Feng Office 不支持桌面使用,因此如果您想在单个Linux 桌面上使用它,这个可能无法实现。 另一方面,如果你有一个小企业,一个机构或其他组织,你可以尝试将其部署在本地服务器上。
|
||||
Feng Office 不支持桌面使用,因此如果您想在单个 Linux 桌面上使用它,这个可能无法实现。 另一方面,如果你有一个小企业、一个机构或其他组织,你可以尝试将其部署在本地服务器上。
|
||||
|
||||
### 4. Siag Office
|
||||
#### 4. Siag Office
|
||||
|
||||
![SIAG Office logo][9]
|
||||
|
||||
[Siag][10] 是一个非常轻量级的办公套件,适用于类 Unix 系统,可以在 16 MB 系统上运行。 由于它非常轻便,因此缺少标准办公套件中的许多功能。 但小即是美丽的,不是吗? 它具有办公套件的所有必要功能,可以在[轻量级 Linux 发行版][11]上“正常工作”。它是 [Damn Small Linux][12] 默认安装软件。(译者注: 根据官网,现已不是默认安装软件)
|
||||
[Siag][10] 是一个非常轻量级的办公套件,适用于类 Unix 系统,可以在 16MB 的系统上运行。 由于它非常轻便,因此缺少标准办公套件中的许多功能。 但小即是丽,不是吗? 它具有办公套件的所有必要功能,可以在[轻量级 Linux 发行版][11]上“正常工作”。它是 [Damn Small Linux][12] 默认安装软件。(LCTT 译注:根据官网,现已不是默认安装软件)
|
||||
|
||||
### 3. Calligra Suite
|
||||
#### 3. Calligra Suite
|
||||
|
||||
![Calligra free and Open Source office logo][13]
|
||||
|
||||
[Calligra][14],以前被称为 KOffice,是 KDE 中默认的 Office 套件。 它支持 Mac OS X,Windows,Linux,FreeBSD系统。 它也曾经推出 Android 版本。 但不幸的是,后续没有继续支持 Android。 它拥有办公套件所需的必要应用程序以及一些额外的应用程序,如用于绘制流程图的 Flow 和用于项目管理的 Plane。
|
||||
[Calligra][14],以前被称为 KOffice,是 KDE 中默认的 Office 套件。 它支持 Mac OS X、Windows、Linux、FreeBSD 系统。 它也曾经推出 Android 版本。 但不幸的是,后续没有继续支持 Android。 它拥有办公套件所需的必要应用程序以及一些额外的应用程序,如用于绘制流程图的 Flow 和用于项目管理的 Plane。
|
||||
|
||||
Calligra 最近的发展产生了相当大的影响,很有可能成为 [LibreOffice 的替代品][16]。
|
||||
|
||||
### 2. ONLYOFFICE
|
||||
#### 2. ONLYOFFICE
|
||||
|
||||
![ONLYOFFICE is Linux alternative to Microsoft Office][17]
|
||||
|
||||
[ONLYOFFICE][18] 是办公套件市场上的新玩家,它更专注于协作部分。 企业(甚至个人)可以将其部署到自己的服务器上,以获得类似 Google Docs 之类的协作办公套件。
|
||||
|
||||
别担心。 您不必必须将其安装在服务器上。 有一个免费的开源[桌面版本][19] ONLYOFFICE。 您甚至可以获取 .deb 和 .rpm 二进制文件,以便将其安装在 Linux 桌面系统上。
|
||||
别担心,您不是必须将其安装在服务器上。有一个免费的开源[桌面版本][19] ONLYOFFICE。 您甚至可以获取 .deb 和 .rpm 二进制文件,以便将其安装在 Linux 桌面系统上。
|
||||
|
||||
### 1. LibreOffice
|
||||
#### 1. LibreOffice
|
||||
|
||||
![LibreOffice logo][20]
|
||||
|
||||
当 Oracle 决定停止 OpenOffice 的开发时,是[文档基金会][21]将其复制分发,这就是我们所熟知的 [Libre-Office][22] 。从那时起,许多 Linux 发行版都将 OpenOffice 替换为 LibreOffice 作为它们的默认办公应用程序。
|
||||
当 Oracle 决定停止 OpenOffice 的开发时,是[文档基金会][21]将其复制分发,这就是我们所熟知的 [Libre-Office][22]。从那时起,许多 Linux 发行版都将 OpenOffice 替换为 LibreOffice 作为它们的默认办公应用程序。
|
||||
|
||||
它适用于 Linux,Windows 和 Mac OS X,这使得在跨平台环境中易于使用。 和 Apache OpenOffice 一样,这也包括了除了 OpenDocument 格式以外的对 MS Office 文件的支持。 它还包含与 Apache OpenOffice 相同的应用程序。
|
||||
|
||||
您还可以使用 LibreOffice 作为 [Collabora Online][23] 的协作平台。 基本上,LibreOffice 是一个完整的软件包,无疑是 Linux,Windows 和 MacOS 的**最佳 Microsoft Office 替代品**。
|
||||
您还可以使用 LibreOffice 作为 [Collabora Online][23] 的协作平台。 基本上,LibreOffice 是一个完整的软件包,无疑是 Linux、Windows 和 MacOS 的**最佳 Microsoft Office 替代品**。
|
||||
|
||||
## 你认为呢?
|
||||
### 你认为呢?
|
||||
|
||||
我希望 Microsoft Office 的这些开源替代软件可以节省您的资金。 您会使用哪种开源生产力办公套件?
|
||||
|
||||
@ -81,7 +81,7 @@ via: https://itsfoss.com/best-free-open-source-alternatives-microsoft-office/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
译者:[amwps290](https://github.com/amwps290)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,15 +1,15 @@
|
||||
学习你的工具:驾驭你的 Git 历史
|
||||
学习用工具来驾驭 Git 历史
|
||||
============================================================
|
||||
|
||||
在你的日常工作中,不可能每天都从头开始去开发一个新的应用程序。而真实的情况是,在日常工作中,我们大多数时候所面对的都是遗留下来的一个代码库,我们能够去修改一些特性的内容或者现存的一些代码行,是我们在日常工作中很重要的一部分。而这也就是分布式版本控制系统 `git` 的价值所在。现在,我们来深入了解怎么去使用 `git` 的历史以及如何很轻松地去浏览它的历史。
|
||||
在你的日常工作中,不可能每天都从头开始去开发一个新的应用程序。而真实的情况是,在日常工作中,我们大多数时候所面对的都是遗留下来的一个代码库,去修改一些特性的内容或者现存的一些代码行,这是我们在日常工作中很重要的一部分。而这也就是分布式版本控制系统 `git` 的价值所在。现在,我们来深入了解怎么去使用 `git` 的历史以及如何很轻松地去浏览它的历史。
|
||||
|
||||
### Git 历史
|
||||
|
||||
首先和最重要的事是,什么是 `git` 历史?正如其名字一样,它是一个 `git` 仓库的提交历史。它包含一堆提交信息,其中有它们的作者的名字、提交的哈希值以及提交日期。查看一个 `git` 仓库历史的方法很简单,就是一个 `git log` 命令。
|
||||
首先和最重要的事是,什么是 `git` 历史?正如其名字一样,它是一个 `git` 仓库的提交历史。它包含一堆提交信息,其中有它们的作者的名字、该提交的哈希值以及提交日期。查看一个 `git` 仓库历史的方法很简单,就是一个 `git log` 命令。
|
||||
|
||||
> _*旁注:**为便于本文的演示,我们使用 Ruby 在 Rails 仓库的 `master` 分支。之所以选择它的理由是因为,Rails 有很好的 `git` 历史,有很好的提交信息、引用以及每个变更的解释。如果考虑到代码库的大小、维护者的年龄和数据,Rails 肯定是我见过的最好的仓库。当然了,我并不是说其它 `git` 仓库做的不好,它只是我见过的比较好的一个仓库。_
|
||||
> _旁注:为便于本文的演示,我们使用 Ruby on Rails 的仓库的 `master` 分支。之所以选择它的理由是因为,Rails 有良好的 `git` 历史,漂亮的提交信息、引用以及对每个变更的解释。如果考虑到代码库的大小、维护者的年龄和数量,Rails 肯定是我见过的最好的仓库。当然了,我并不是说其它的 `git` 仓库做的不好,它只是我见过的比较好的一个仓库。_
|
||||
|
||||
因此,回到 Rails 仓库。如果你在 Ralis 仓库上运行 `git log`。你将看到如下所示的输出:
|
||||
那么,回到 Rails 仓库。如果你在 Ralis 仓库上运行 `git log`。你将看到如下所示的输出:
|
||||
|
||||
```
|
||||
commit 66ebbc4952f6cfb37d719f63036441ef98149418
|
||||
@ -72,7 +72,7 @@ Date: Thu Jun 2 21:26:53 2016 -0500
|
||||
[skip ci] Make header bullets consistent in engines.md
|
||||
```
|
||||
|
||||
正如你所见,`git log` 展示了提交哈希、作者和他的 email 以及提交日期。当然,`git` 输出的可定制性很强大,它允许你去定制 `git log` 命令的输出格式。比如说,我们希望看到提交的信息显示在一行上,我们可以运行 `git log --oneline`,它将输出一个更紧凑的日志:
|
||||
正如你所见,`git log` 展示了提交的哈希、作者及其 email 以及该提交创建的日期。当然,`git` 输出的可定制性很强大,它允许你去定制 `git log` 命令的输出格式。比如说,我们只想看提交信息的第一行,我们可以运行 `git log --oneline`,它将输出一个更紧凑的日志:
|
||||
|
||||
```
|
||||
66ebbc4 Dont re-define class SQLite3Adapter on test
|
||||
@ -89,15 +89,15 @@ e98caf8 [skip ci] Make header bullets consistent in engines.md
|
||||
|
||||
如果你想看 `git log` 的全部选项,我建议你去查阅 `git log` 的 man 页面,你可以在一个终端中输入 `man git-log` 或者 `git help log` 来获得。
|
||||
|
||||
> _**小提示:**如果你觉得 `git log` 看起来太恐怖或者过于复杂,或者你觉得看它太无聊了,我建议你去寻找一些 `git` GUI 命令行工具。在以前的文章中,我使用过 [GitX][1] ,我觉得它很不错,但是,由于我看命令行更“亲切”一些,在我尝试了 [tig][2] 之后,就再也没有去用过它。_
|
||||
> _小提示:如果你觉得 `git log` 看起来太恐怖或者过于复杂,或者你觉得看它太无聊了,我建议你去寻找一些 `git` 的 GUI 或命令行工具。在之前,我使用过 [GitX][1] ,我觉得它很不错,但是,由于我看命令行更“亲切”一些,在我尝试了 [tig][2] 之后,就再也没有去用过它。_
|
||||
|
||||
### 查找尼莫
|
||||
### 寻找尼莫
|
||||
|
||||
现在,我们已经知道了关于 `git log` 命令一些很基础的知识之后,我们来看一下,在我们的日常工作中如何使用它更加高效地浏览历史。
|
||||
现在,我们已经知道了关于 `git log` 命令的一些很基础的知识之后,我们来看一下,在我们的日常工作中如何使用它更加高效地浏览历史。
|
||||
|
||||
假如,我们怀疑在 `String#classify` 方法中有一个预期之外的行为,我们希望能够找出原因,并且定位出实现它的代码行。
|
||||
|
||||
为达到上述目的,你可以使用的第一个命令是 `git grep`,通过它可以找到这个方法定义在什么地方。简单来说,这个命令输出了给定的某些“样品”的匹配行。现在,我们来找出定义它的方法,它非常简单 —— 我们对 `def classify` 运行 grep,然后看到的输出如下:
|
||||
为达到上述目的,你可以使用的第一个命令是 `git grep`,通过它可以找到这个方法定义在什么地方。简单来说,这个命令输出了匹配特定模式的那些行。现在,我们来找出定义它的方法,它非常简单 —— 我们对 `def classify` 运行 grep,然后看到的输出如下:
|
||||
|
||||
```
|
||||
➜ git grep 'def classify'
|
||||
@ -113,7 +113,7 @@ activesupport/lib/active_support/core_ext/string/inflections.rb: def classifyact
|
||||
activesupport/lib/active_support/core_ext/string/inflections.rb:205: def classifyactivesupport/lib/active_support/inflector/methods.rb:186: def classify(table_name)tools/profile:112: def classify
|
||||
```
|
||||
|
||||
更好看了,是吧?考虑到上下文,我们可以很轻松地找到,这个方法在`activesupport/lib/active_support/core_ext/string/inflections.rb` 的第 205 行的 `classify` 方法,它看起来像这样,是不是很容易?
|
||||
更好看了,是吧?考虑到上下文,我们可以很轻松地找到,这个方法在 `activesupport/lib/active_support/core_ext/string/inflections.rb` 的第 205 行的 `classify` 方法,它看起来像这样,是不是很容易?
|
||||
|
||||
```
|
||||
# Creates a class name from a plural table name like Rails does for table names to models.
|
||||
@ -127,7 +127,7 @@ activesupport/lib/active_support/core_ext/string/inflections.rb:205: def classi
|
||||
end
|
||||
```
|
||||
|
||||
尽管这个方法我们找到的是在 `String` 上的一个常见的调用,它涉及到`ActiveSupport::Inflector` 上的另一个方法,使用了相同的名字。获得了 `git grep` 的结果,我们可以很轻松地导航到这里,因此,我们看到了结果的第二行, `activesupport/lib/active_support/inflector/methods.rb` 在 186 行上。我们正在寻找的方法是:
|
||||
尽管我们找到的这个方法是在 `String` 上的一个常见的调用,它调用了 `ActiveSupport::Inflector` 上的另一个同名的方法。根据之前的 `git grep` 的结果,我们可以很轻松地发现结果的第二行, `activesupport/lib/active_support/inflector/methods.rb` 在 186 行上。我们正在寻找的方法是这样的:
|
||||
|
||||
```
|
||||
# Creates a class name from a plural table name like Rails does for table
|
||||
@ -146,17 +146,17 @@ def classify(table_name)
|
||||
end
|
||||
```
|
||||
|
||||
酷!考虑到 Rails 仓库的大小,我们借助 `git grep` 找到它,用时没有超越 30 秒。
|
||||
酷!考虑到 Rails 仓库的大小,我们借助 `git grep` 找到它,用时都没有超越 30 秒。
|
||||
|
||||
### 那么,最后的变更是什么?
|
||||
|
||||
我们已经掌握了有用的方法,现在,我们需要搞清楚这个文件所经历的变更。由于我们已经知道了正确的文件名和行数,我们可以使用 `git blame`。这个命令展示了一个文件中每一行的最后修订者和修订的内容。我们来看一下这个文件最后的修订都做了什么:
|
||||
现在,我们已经找到了所要找的方法,现在,我们需要搞清楚这个文件所经历的变更。由于我们已经知道了正确的文件名和行数,我们可以使用 `git blame`。这个命令展示了一个文件中每一行的最后修订者和修订的内容。我们来看一下这个文件最后的修订都做了什么:
|
||||
|
||||
```
|
||||
git blame activesupport/lib/active_support/inflector/methods.rb
|
||||
```
|
||||
|
||||
虽然我们得到了这个文件每一行的最后的变更,但是,我们更感兴趣的是对指定的方法(176 到 189 行)的最后变更。让我们在 `git blame` 命令上增加一个选项,它将只显示那些行。此外,我们将在命令上增加一个 `-s` (阻止) 选项,去跳过那一行变更时的作者名字和修订(提交)的时间戳:
|
||||
虽然我们得到了这个文件每一行的最后的变更,但是,我们更感兴趣的是对特定方法(176 到 189 行)的最后变更。让我们在 `git blame` 命令上增加一个选项,让它只显示那些行的变化。此外,我们将在命令上增加一个 `-s` (忽略)选项,去跳过那一行变更时的作者名字和修订(提交)的时间戳:
|
||||
|
||||
```
|
||||
git blame -L 176,189 -s activesupport/lib/active_support/inflector/methods.rb
|
||||
@ -183,13 +183,13 @@ git blame -L 176,189 -s activesupport/lib/active_support/inflector/methods.rb
|
||||
git show 5bb1d4d2
|
||||
```
|
||||
|
||||
你亲自做实验了吗?如果没有做,我直接告诉你结果,这个令人惊叹的 [提交][3] 是由 [Schneems][4] 做的,他通过使用 frozen 字符串做了一个非常有趣的性能优化,这在我们当前的上下文中是非常有意义的。但是,由于我们在这个假设的调试会话中,这样做并不能告诉我们当前问题所在。因此,我们怎么样才能够通过研究来发现,我们选定的方法经过了哪些变更?
|
||||
你亲自做实验了吗?如果没有做,我直接告诉你结果,这个令人惊叹的 [提交][3] 是由 [Schneems][4] 完成的,他通过使用 frozen 字符串做了一个非常有趣的性能优化,这在我们当前的场景中是非常有意义的。但是,由于我们在这个假设的调试会话中,这样做并不能告诉我们当前问题所在。因此,我们怎么样才能够通过研究来发现,我们选定的方法经过了哪些变更?
|
||||
|
||||
### 搜索日志
|
||||
|
||||
现在,我们回到 `git` 日志,现在的问题是,怎么能够看到 `classify` 方法经历了哪些修订?
|
||||
|
||||
`git log` 命令非常强大,因此它提供了非常多的列表选项。我们尝试去看一下保存了这个文件的 `git` 日志内容。使用 `-p` 选项,它的意思是在 `git` 日志中显示这个文件的完整补丁:
|
||||
`git log` 命令非常强大,因此它提供了非常多的列表选项。我们尝试使用 `-p` 选项去看一下保存了这个文件的 `git` 日志内容,这个选项的意思是在 `git` 日志中显示这个文件的完整补丁:
|
||||
|
||||
```
|
||||
git log -p activesupport/lib/active_support/inflector/methods.rb
|
||||
@ -201,13 +201,13 @@ git log -p activesupport/lib/active_support/inflector/methods.rb
|
||||
git log -L 176,189:activesupport/lib/active_support/inflector/methods.rb
|
||||
```
|
||||
|
||||
`git log` 命令接受了 `-L` 选项,它有一个行的范围和文件名做为参数。它的格式可能有点奇怪,格式解释如下:
|
||||
`git log` 命令接受 `-L` 选项,它用一个行的范围和文件名做为参数。它的格式可能有点奇怪,格式解释如下:
|
||||
|
||||
```
|
||||
git log -L <start-line>,<end-line>:<path-to-file>
|
||||
```
|
||||
|
||||
当我们去运行这个命令之后,我们可以看到对这些行的一个修订列表,它将带我们找到创建这个方法的第一个修订:
|
||||
当我们运行这个命令之后,我们可以看到对这些行的一个修订列表,它将带我们找到创建这个方法的第一个修订:
|
||||
|
||||
```
|
||||
commit 51xd6bb829c418c5fbf75de1dfbb177233b1b154
|
||||
@ -238,11 +238,11 @@ diff--git a/activesupport/lib/active_support/inflector/methods.rb b/activesuppor
|
||||
|
||||
现在,我们再来看一下 —— 它是在 2011 年提交的。`git` 可以让我们重回到这个时间。这是一个很好的例子,它充分说明了足够的提交信息对于重新了解当时的上下文环境是多么的重要,因为从这个提交信息中,我们并不能获得足够的信息来重新理解当时的创建这个方法的上下文环境,但是,话说回来,你**不应该**对此感到恼怒,因为,你看到的这些项目,它们的作者都是无偿提供他们的工作时间和精力来做开源工作的。(向开源项目贡献者致敬!)
|
||||
|
||||
回到我们的正题,我们并不能确认 `classify` 方法最初实现是怎么回事,考虑到这个第一次的提交只是一个重构。现在,如果你认为,“或许、有可能、这个方法不在 176 行到 189 行的范围之内,那么就你应该在这个文件中扩大搜索范围”,这样想是对的。我们看到在它的修订提交的信息中提到了“重构”这个词,它意味着这个方法可能在那个文件中是真实存在的,只是在重构之后它才存在于那个行的范围内。
|
||||
回到我们的正题,我们并不能确认 `classify` 方法最初实现是怎么回事,考虑到这个第一次的提交只是一个重构。现在,如果你认为,“或许、有可能、这个方法不在 176 行到 189 行的范围之内,那么就你应该在这个文件中扩大搜索范围”,这样想是对的。我们看到在它的修订提交的信息中提到了“重构”这个词,它意味着这个方法可能在那个文件中是真实存在的,而且是在重构之后它才存在于那个行的范围内。
|
||||
|
||||
但是,我们如何去确认这一点呢?不管你信不信,`git` 可以再次帮助你。`git log` 命令有一个 `-S` 选项,它可以传递一个特定的字符串作为参数,然后去查找代码变更(添加或者删除)。也就是说,如果我们执行 `git log -S classify` 这样的命令,我们可以看到所有包含 `classify` 字符串的变更行的提交。
|
||||
|
||||
如果你在 Ralis 仓库上运行上述命令,首先你会发现这个命令运行有点慢。但是,你应该会发现 `git` 真的解析了在那个仓库中的所有修订来匹配这个字符串,因为仓库非常大,实际上它的运行速度是非常快的。在你的指尖下 `git` 再次展示了它的强大之处。因此,如果去找关于 `classify` 方法的第一个修订,我们可以运行如下的命令:
|
||||
如果你在 Ralis 仓库上运行上述命令,首先你会发现这个命令运行有点慢。但是,你应该会发现 `git` 实际上解析了在那个仓库中的所有修订来匹配这个字符串,其实它的运行速度是非常快的。在你的指尖下 `git` 再次展示了它的强大之处。因此,如果去找关于 `classify` 方法的第一个修订,我们可以运行如下的命令:
|
||||
|
||||
```
|
||||
git log -S 'def classify'
|
||||
@ -258,7 +258,7 @@ Date: Wed Nov 24 01:04:44 2004 +0000
|
||||
git-svn-id: http://svn-commit.rubyonrails.org/rails/trunk@4 5ecf4fe2-1ee6-0310-87b1-e25e094e27de
|
||||
```
|
||||
|
||||
很酷!是吧?它初次被提交到 Rails,是由 DHHD 在一个 `svn` 仓库上做的!这意味着 `classify` 提交到 Rails 仓库的大概时间。现在,我们去看一下这个提交的所有变更信息,我们运行如下的命令:
|
||||
很酷!是吧?它初次被提交到 Rails,是由 DHH 在一个 `svn` 仓库上做的!这意味着 `classify` 大概在一开始就被提交到了 Rails 仓库。现在,我们去看一下这个提交的所有变更信息,我们运行如下的命令:
|
||||
|
||||
```
|
||||
git show db045dbbf60b53dbe013ef25554fd013baf88134
|
||||
@ -268,7 +268,7 @@ git show db045dbbf60b53dbe013ef25554fd013baf88134
|
||||
|
||||
### 下次见
|
||||
|
||||
当然,我们并不会真的去修改任何 bug,因为我们只是去尝试使用一些 `git` 命令,来演示如何查看 `classify` 方法的演变历史。但是不管怎样,`git` 是一个非常强大的工具,我们必须学好它、用好它。我希望这篇文章可以帮助你掌握更多的关于如何使用 `git` 的知识。
|
||||
当然,我们并没有真的去修改任何 bug,因为我们只是去尝试使用一些 `git` 命令,来演示如何查看 `classify` 方法的演变历史。但是不管怎样,`git` 是一个非常强大的工具,我们必须学好它、用好它。我希望这篇文章可以帮助你掌握更多的关于如何使用 `git` 的知识。
|
||||
|
||||
你喜欢这些内容吗?
|
||||
|
||||
@ -284,9 +284,9 @@ git show db045dbbf60b53dbe013ef25554fd013baf88134
|
||||
|
||||
via: https://ieftimov.com/learn-your-tools-navigating-git-history
|
||||
|
||||
作者:[Ilija Eftimov ][a]
|
||||
作者:[Ilija Eftimov][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,124 @@
|
||||
在 Linux 上安装必应桌面墙纸更换器
|
||||
======
|
||||
|
||||
你是否厌倦了 Linux 桌面背景,想要设置好看的壁纸,但是不知道在哪里可以找到?别担心,我们在这里会帮助你。
|
||||
|
||||
我们都知道必应搜索引擎,但是由于一些原因很少有人使用它,每个人都喜欢必应网站的背景壁纸,它是非常漂亮和惊人的高分辨率图像。
|
||||
|
||||
如果你想使用这些图片作为你的桌面壁纸,你可以手动下载它,但是很难去每天下载一个新的图片,然后把它设置为壁纸。这就是自动壁纸改变的地方。
|
||||
|
||||
[必应桌面墙纸更换器][1]会自动下载并将桌面壁纸更改为当天的必应照片。所有的壁纸都储存在 `/home/[user]/Pictures/BingWallpapers/`。
|
||||
|
||||
### 方法 1: 使用 Utkarsh Gupta Shell 脚本
|
||||
|
||||
这个小型 Python 脚本会自动下载并将桌面壁纸更改为当天的必应照片。该脚本在机器启动时自动运行,并工作于 GNU/Linux 上的 Gnome 或 Cinnamon 环境。它不需要手动工作,安装程序会为你做所有事情。
|
||||
|
||||
从 2.0+ 版本开始,该脚本的安装程序就可以像普通的 Linux 二进制命令一样工作,它会为某些任务请求 sudo 权限。
|
||||
|
||||
只需克隆仓库并切换到项目目录,然后运行 shell 脚本即可安装必应桌面墙纸更换器。
|
||||
|
||||
```
|
||||
$ https://github.com/UtkarshGpta/bing-desktop-wallpaper-changer/archive/master.zip
|
||||
$ unzip master
|
||||
$ cd bing-desktop-wallpaper-changer-master
|
||||
```
|
||||
|
||||
运行 `installer.sh` 使用 `--install` 选项来安装必应桌面墙纸更换器。它会下载并设置必应照片为你的 Linux 桌面。
|
||||
|
||||
```
|
||||
$ ./installer.sh --install
|
||||
|
||||
Bing-Desktop-Wallpaper-Changer
|
||||
BDWC Installer v3_beta2
|
||||
|
||||
GitHub:
|
||||
Contributors:
|
||||
.
|
||||
.
|
||||
[sudo] password for daygeek: ******
|
||||
.
|
||||
Where do you want to install Bing-Desktop-Wallpaper-Changer?
|
||||
Entering 'opt' or leaving input blank will install in /opt/bing-desktop-wallpaper-changer
|
||||
Entering 'home' will install in /home/daygeek/bing-desktop-wallpaper-changer
|
||||
Install Bing-Desktop-Wallpaper-Changer in (opt/home)? :Press Enter
|
||||
|
||||
Should we create bing-desktop-wallpaper-changer symlink to /usr/bin/bingwallpaper so you could easily execute it?
|
||||
Create symlink for easy execution, e.g. in Terminal (y/n)? : y
|
||||
|
||||
Should bing-desktop-wallpaper-changer needs to autostart when you log in? (Add in Startup Application)
|
||||
Add in Startup Application (y/n)? : y
|
||||
.
|
||||
.
|
||||
Executing bing-desktop-wallpaper-changer...
|
||||
|
||||
|
||||
Finished!!
|
||||
```
|
||||
|
||||
![][3]
|
||||
|
||||
要卸载该脚本:
|
||||
|
||||
```
|
||||
$ ./installer.sh --uninstall
|
||||
```
|
||||
|
||||
使用帮助页面了解更多关于此脚本的选项。
|
||||
|
||||
```
|
||||
$ ./installer.sh --help
|
||||
```
|
||||
|
||||
### 方法 2: 使用 GNOME Shell 扩展
|
||||
|
||||
这个轻量级 [GNOME shell 扩展][4],可将你的壁纸每天更改为微软必应的壁纸。它还会显示一个包含图像标题和解释的通知。
|
||||
|
||||
该扩展大部分基于 Elinvention 的 NASA APOD 扩展,受到了 Utkarsh Gupta 的 Bing Desktop WallpaperChanger 启发。
|
||||
|
||||
#### 特点
|
||||
|
||||
- 获取当天的必应壁纸并设置为锁屏和桌面墙纸(这两者都是用户可选的)
|
||||
- 可强制选择某个特定区域(即地区)
|
||||
- 为多个显示器自动选择最高分辨率(和最合适的墙纸)
|
||||
- 可以选择在 1 到 7 天之后清理墙纸目录(删除最旧的)
|
||||
- 只有当它们被更新时,才会尝试下载壁纸
|
||||
- 不会持续进行更新 - 每天只进行一次,启动时也要进行一次(更新是在必应更新时进行的)
|
||||
|
||||
#### 如何安装
|
||||
|
||||
访问 [extenisons.gnome.org][5] 网站并将切换按钮拖到 “ON”,然后点击 “Install” 按钮安装必应壁纸 GNOME 扩展。(LCTT 译注:页面上并没有发现 ON 按钮,但是有 Download 按钮)
|
||||
|
||||
![][6]
|
||||
|
||||
安装必应壁纸 GNOME 扩展后,它会自动下载并为你的 Linux 桌面设置当天的必应照片,并显示关于壁纸的通知。
|
||||
|
||||
![][7]
|
||||
|
||||
托盘指示器将帮助你执行少量操作,也可以打开设置。
|
||||
|
||||
![][8]
|
||||
|
||||
根据你的要求自定义设置。
|
||||
|
||||
![][9]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/bing-desktop-wallpaper-changer-linux-bing-photo-of-the-day/
|
||||
|
||||
作者:[2daygeek][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/2daygeek/
|
||||
[1]:https://github.com/UtkarshGpta/bing-desktop-wallpaper-changer
|
||||
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]:https://www.2daygeek.com/wp-content/uploads/2017/09/bing-wallpaper-changer-linux-5.png
|
||||
[4]:https://github.com/neffo/bing-wallpaper-gnome-extension
|
||||
[5]:https://extensions.gnome.org/extension/1262/bing-wallpaper-changer/
|
||||
[6]:https://www.2daygeek.com/wp-content/uploads/2017/09/bing-wallpaper-changer-for-linux-1.png
|
||||
[7]:https://www.2daygeek.com/wp-content/uploads/2017/09/bing-wallpaper-changer-for-linux-2.png
|
||||
[8]:https://www.2daygeek.com/wp-content/uploads/2017/09/bing-wallpaper-changer-for-linux-3.png
|
||||
[9]:https://www.2daygeek.com/wp-content/uploads/2017/09/bing-wallpaper-changer-for-linux-4.png
|
||||
@ -0,0 +1,107 @@
|
||||
关于处理器你所需要知道的一切
|
||||
============
|
||||
|
||||
[![][b]][b]
|
||||
|
||||
我们的手机、主机以及笔记本电脑这样的数字设备已经变得如此成熟,以至于它们进化成为我们的一部分,而不只是一种设备。
|
||||
|
||||
在应用和软件的帮助下,处理器执行许多任务。我们是否曾经想过是什么给了这些软件这样的能力?它们是如何执行它们的逻辑的?它们的大脑在哪?
|
||||
|
||||
我们知道 CPU (或称处理器)是那些需要处理数据和执行逻辑任务的设备的大脑。
|
||||
|
||||
[![cpu image][1]][1]
|
||||
|
||||
在处理器的深处有那些不一样的概念呢?它们是如何演化的?一些处理器是如何做到比其它处理器更快的?让我们来看看关于处理器的主要术语,以及它们是如何影响处速度的。
|
||||
|
||||
### 架构
|
||||
|
||||
处理器有不同的架构,你一定遇到过不同类型的程序说它们是 64 位或 32 位的,这其中的意思就是程序支持特定的处理器架构。
|
||||
|
||||
如果一颗处理器是 32 位的架构,这意味着这颗处理器能够在一个处理周期内处理一个 32 位的数据。
|
||||
|
||||
同理可得,64 位的处理器能够在一个周期内处理一个 64 位的数据。
|
||||
|
||||
同时,你可以使用的内存大小决定于处理器的架构,你可以使用的内存总量为 2 的处理器架构的幂次方(如:`2^64`)。
|
||||
|
||||
16 位架构的处理器,仅仅有 64 kb 的内存使用。32 位架构的处理器,最大可使用的 RAM 是 4 GB,64 位架构的处理器的可用内存是 16 EB。
|
||||
|
||||
### 核心
|
||||
|
||||
在电脑上,核心是基本的处理单元。核心接收指令并且执行它。越多的核心带来越快的速度。把核心比作工厂里的工人,越多的工人使工作能够越快的完成。另一方面,工人越多,你所付出的薪水也就越多,工厂也会越拥挤;相对于核心来说,越多的核心消耗更多的能量,比核心少的 CPU 更容易发热。
|
||||
|
||||
### 时钟速度
|
||||
|
||||
[![CPU CLOCK SPEED][2]][2]
|
||||
|
||||
GHz 是 GigaHertz 的简写,Giga 意思是 10 亿次,Hertz (赫兹)意思是一秒有几个周期,2 GHz 的处理器意味着处理器一秒能够执行 20 亿个周期 。
|
||||
|
||||
它也以“频率”或者“时钟速度”而熟知。这项数值越高,CPU 的性能越好。
|
||||
|
||||
### CPU 缓存
|
||||
|
||||
CPU 缓存是处理器内部的一块小的存储单元,用来存储一些内存。不管如何,我们需要执行一些任务时,数据需要从内存传递到 CPU,CPU 的工作速度远快于内存,CPU 在大多数时间是在等待从内存传递过来的数据,而此时 CPU 是处于空闲状态的。为了解决这个问题,内存持续的向 CPU 缓存发送数据。
|
||||
|
||||
一般的处理器会有 2 ~ 3 Mb 的 CPU 缓存。高端的处理器会有 6 Mb 的 CPU 缓存,越大的缓存,意味着处理器更好。
|
||||
|
||||
### 印刷工艺
|
||||
|
||||
晶体管的大小就是处理器平板印刷的大小,尺寸通常是纳米,更小的尺寸意味者更紧凑。这可以让你有更多的核心,更小的面积,更小的能量消耗。
|
||||
|
||||
最新的 Intel 处理器有 14 nm 的印刷工艺。
|
||||
|
||||
### 热功耗设计(TDP)
|
||||
|
||||
代表着平均功耗,单位是瓦特,是在全核心激活以基础频率来处理 Intel 定义的高复杂度的负载时,处理器所散失的功耗。
|
||||
|
||||
所以,越低的热功耗设计对你越好。一个低的热功耗设计不仅可以更好的利用能量,而且产生更少的热量。
|
||||
|
||||
[![battery][3]][3]
|
||||
|
||||
桌面版的处理器通常消耗更多的能量,热功耗消耗的能量能在 40% 以上,相对应的移动版本只有不到桌面版本的 1/3。
|
||||
|
||||
### 内存支持
|
||||
|
||||
我们已经提到了处理器的架构是如何影响到我们能够使用的内存总量,但这只是理论上而已。在实际的应用中,我们所能够使用的内存的总量对于处理器的规格来说是足够的,它通常是由处理器规格详细规定的。
|
||||
|
||||
[![RAM][4]][4]
|
||||
|
||||
它也指出了内存所支持的 DDR 的版本号。
|
||||
|
||||
### 超频
|
||||
|
||||
前面我们讲过时钟频率,超频是程序强迫 CPU 执行更多的周期。游戏玩家经常会使他们的处理器超频,以此来获得更好的性能。这样确实会增加速度,但也会增加消耗的能量,产生更多的热量。
|
||||
|
||||
一些高端的处理器允许超频,如果我们想让一个不支持超频的处理器超频,我们需要在主板上安装一个新的 BIOS 。
|
||||
这样通常会成功,但这种情况是不安全的,也是不建议的。
|
||||
|
||||
### 超线程(HT)
|
||||
|
||||
如果不能添加核心以满足特定的处理需要,那么超线程是建立一个虚拟核心的方式。
|
||||
|
||||
如果一个双核处理器有超线程,那么这个双核处理器就有两个物理核心和两个虚拟核心,在技术上讲,一个双核处理器拥有四个核心。
|
||||
|
||||
### 结论
|
||||
|
||||
处理器有许多相关的数据,这些对数字设备来说是最重要的部分。我们在选择设备时,我们应该在脑海中仔细的检查处理器在上面提到的数据。
|
||||
|
||||
时钟速度、核心数、CPU 缓存,以及架构是最重要的数据。印刷尺寸以及热功耗设计重要性差一些 。
|
||||
|
||||
仍然有疑惑? 欢迎评论,我会尽快回复的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.theitstuff.com/processors-everything-need-know
|
||||
|
||||
作者:[Rishabh Kandari][a]
|
||||
译者:[singledo](https://github.com/singledo)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.theitstuff.com/author/reevkandari
|
||||
[b]:http://www.theitstuff.com/wp-content/uploads/2017/10/processors-all-you-need-to-know.jpg
|
||||
[1]:http://www.theitstuff.com/wp-content/uploads/2017/10/download.jpg
|
||||
[2]:http://www.theitstuff.com/wp-content/uploads/2017/10/download-1.jpg
|
||||
[3]:http://www.theitstuff.com/wp-content/uploads/2017/10/download-2.jpg
|
||||
[4]:http://www.theitstuff.com/wp-content/uploads/2017/10/images.jpg
|
||||
[5]:http://www.theitstuff.com/wp-content/uploads/2017/10/processors-all-you-need-to-know.jpg
|
||||
@ -1,23 +1,22 @@
|
||||
Torrent 提速 - 为什么总是无济于事
|
||||
Torrent 提速为什么总是无济于事
|
||||
======
|
||||
|
||||

|
||||

|
||||
|
||||
是不是总是想要 **更快的 torrent 速度**?不管现在的速度有多块,但总是无法对此满足。我们对 torrent 速度的痴迷使我们经常从包括 YouTube 视频在内的许多网站上寻找并应用各种所谓的技巧。但是相信我,从小到大我就没发现哪个技巧有用过。因此本文我们就就来看看,为什么尝试提高 torrent 速度是行不通的。
|
||||
|
||||
## 影响速度的因素
|
||||
### 影响速度的因素
|
||||
|
||||
### 本地因素
|
||||
#### 本地因素
|
||||
|
||||
从下图中可以看到 3 台电脑分别对应的 A,B,C 三个用户。A 和 B 本地相连,而 C 的位置则比较远,它与本地之间有 1,2,3 三个连接点。
|
||||
从下图中可以看到 3 台电脑分别对应的 A、B、C 三个用户。A 和 B 本地相连,而 C 的位置则比较远,它与本地之间有 1、2、3 三个连接点。
|
||||
|
||||
[![][1]][2]
|
||||
|
||||
若用户 A 和用户 B 之间要分享文件,他们之间直接分享就能达到最大速度了而无需使用 torrent。这个速度跟互联网什么的都没有关系。
|
||||
|
||||
+ 网线的性能
|
||||
|
||||
+ 网卡的性能
|
||||
|
||||
+ 路由器的性能
|
||||
|
||||
当谈到 torrent 的时候,人们都是在说一些很复杂的东西,但是却总是不得要点。
|
||||
@ -30,7 +29,7 @@ Torrent 提速 - 为什么总是无济于事
|
||||
|
||||
即使你把目标降到 30 Megabytes,然而你连接到路由器的电缆/网线的性能最多只有 100 megabits 也就是 10 MegaBytes。这是一个纯粹的瓶颈问题,由一个薄弱的环节影响到了其他强健部分,也就是说这个传输速率只能达到 10 Megabytes,即电缆的极限速度。现在想象有一个 torrent 即使能够用最大速度进行下载,那也会由于你的硬件不够强大而导致瓶颈。
|
||||
|
||||
### 外部因素
|
||||
#### 外部因素
|
||||
|
||||
现在再来看一下这幅图。用户 C 在很遥远的某个地方。甚至可能在另一个国家。
|
||||
|
||||
@ -40,24 +39,23 @@ Torrent 提速 - 为什么总是无济于事
|
||||
|
||||
第二,由于 C 与本地之间多个有连接点,其中一个点就有可能成为瓶颈所在,可能由于繁重的流量和相对薄弱的硬件导致了缓慢的速度。
|
||||
|
||||
### Seeders( 译者注:做种者) 与 Leechers( 译者注:只下载不做种的人)
|
||||
#### 做种者与吸血者
|
||||
|
||||
关于此已经有了太多的讨论,总的想法就是搜索更多的种子,但要注意上面的那些因素,一个很好的种子提供者但是跟我之间的连接不好的话那也是无济于事的。通常,这不可能发生,因为我们也不是唯一下载这个资源的人,一般都会有一些在本地的人已经下载好了这个文件并已经在做种了。
|
||||
关于此已经有了太多的讨论,总的想法就是搜索更多的种子,但要注意上面的那些因素,有一个很好的种子提供者,但是跟我之间的连接不好的话那也是无济于事的。通常,这不可能发生,因为我们也不是唯一下载这个资源的人,一般都会有一些在本地的人已经下载好了这个文件并已经在做种了。
|
||||
|
||||
## 结论
|
||||
### 结论
|
||||
|
||||
我们尝试搞清楚哪些因素影响了 torrent 速度的好坏。不管我们如何用软件进行优化,大多数时候是这是由于物理瓶颈导致的。我从来不关心那些软件,使用默认配置对我来说就够了。
|
||||
|
||||
希望你会喜欢这篇文章,有什么想法敬请留言。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.theitstuff.com/increase-torrent-speed-will-never-work
|
||||
|
||||
作者:[Rishabh Kandari][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,125 @@
|
||||
如何在 Ubuntu 16.04 上安装和使用 Encryptpad
|
||||
==============
|
||||
|
||||
EncryptPad 是一个自由开源软件,它通过简单方便的图形界面和命令行接口来查看和修改加密的文本,它使用 OpenPGP RFC 4880 文件格式。通过 EncryptPad,你可以很容易的加密或者解密文件。你能够像保存密码、信用卡信息等私人信息,并使用密码或者密钥文件来访问。
|
||||
|
||||
### 特性
|
||||
|
||||
- 支持 windows、Linux 和 Max OS。
|
||||
- 可定制的密码生成器,可生成健壮的密码。
|
||||
- 随机的密钥文件和密码生成器。
|
||||
- 支持 GPG 和 EPD 文件格式。
|
||||
- 能够通过 CURL 自动从远程远程仓库下载密钥。
|
||||
- 密钥文件的路径能够存储在加密的文件中。如果这样做的话,你不需要每次打开文件都指定密钥文件。
|
||||
- 提供只读模式来防止文件被修改。
|
||||
- 可加密二进制文件,例如图片、视频、归档等。
|
||||
|
||||
|
||||
在这份教程中,我们将学习如何在 Ubuntu 16.04 中安装和使用 EncryptPad。
|
||||
|
||||
### 环境要求
|
||||
|
||||
- 在系统上安装了 Ubuntu 16.04 桌面版本。
|
||||
- 在系统上有 `sudo` 的权限的普通用户。
|
||||
|
||||
### 安装 EncryptPad
|
||||
|
||||
在默认情况下,EncryPad 在 Ubuntu 16.04 的默认仓库是不存在的。你需要安装一个额外的仓库。你能够通过下面的命令来添加它 :
|
||||
|
||||
```
|
||||
sudo apt-add-repository ppa:nilaimogard/webupd8
|
||||
```
|
||||
|
||||
下一步,用下面的命令来更新仓库:
|
||||
|
||||
```
|
||||
sudo apt-get update -y
|
||||
```
|
||||
|
||||
最后一步,通过下面命令安装 EncryptPad:
|
||||
|
||||
```
|
||||
sudo apt-get install encryptpad encryptcli -y
|
||||
```
|
||||
|
||||
当 EncryptPad 安装完成后,你可以在 Ubuntu 的 Dash 上找到它。
|
||||
|
||||
### 使用 EncryptPad 生成密钥和密码
|
||||
|
||||
现在,在 Ubunntu Dash 上输入 `encryptpad`,你能够在你的屏幕上看到下面的图片 :
|
||||
|
||||
[![Ubuntu DeskTop][1]][2]
|
||||
|
||||
下一步,点击 EncryptPad 的图标。你能够看到 EncryptPad 的界面,它是一个简单的文本编辑器,带有顶部菜单栏。
|
||||
|
||||
[![EncryptPad screen][3]][4]
|
||||
|
||||
首先,你需要生成一个密钥文件和密码用于加密/解密任务。点击顶部菜单栏中的 “Encryption->Generate Key”,你会看见下面的界面:
|
||||
|
||||
[![Generate key][5]][6]
|
||||
|
||||
选择文件保存的路径,点击 “OK” 按钮,你将看到下面的界面:
|
||||
|
||||
[![select path][7]][8]
|
||||
|
||||
输入密钥文件的密码,点击 “OK” 按钮 ,你将看到下面的界面:
|
||||
|
||||
[![last step][9]][10]
|
||||
|
||||
点击 “yes” 按钮来完成该过程。
|
||||
|
||||
### 加密和解密文件
|
||||
|
||||
现在,密钥文件和密码都已经生成了。可以执行加密和解密操作了。在这个文件编辑器中打开一个文件文件,点击 “encryption” 图标 ,你会看见下面的界面:
|
||||
|
||||
[![Encry operation][11]][12]
|
||||
|
||||
提供需要加密的文件和指定输出的文件,提供密码和前面产生的密钥文件。点击 “Start” 按钮来开始加密的进程。当文件被成功的加密,会出现下面的界面:
|
||||
|
||||
[![Success Encrypt][13]][14]
|
||||
|
||||
文件已经被该密码和密钥文件加密了。
|
||||
|
||||
如果你想解密被加密后的文件,打开 EncryptPad ,点击 “File Encryption” ,选择 “Decryption” 操作,提供加密文件的位置和你要保存输出的解密文件的位置,然后提供密钥文件地址,点击 “Start” 按钮,它将要求你输入密码,输入你先前加密使用的密码,点击 “OK” 按钮开始解密过程。当该过程成功完成,你会看到 “File has been decrypted successfully” 的消息 。
|
||||
|
||||
|
||||
[![decrypt ][16]][17]
|
||||
[![][18]][18]
|
||||
[![][13]]
|
||||
|
||||
|
||||
**注意:**
|
||||
|
||||
如果你遗忘了你的密码或者丢失了密钥文件,就没有其他的方法可以打开你的加密信息了。对于 EncrypePad 所支持的格式是没有后门的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
via: https://www.howtoforge.com/tutorial/how-to-install-and-use-encryptpad-on-ubuntu-1604/
|
||||
|
||||
作者:[Hitesh Jethva][a]
|
||||
译者:[singledo](https://github.com/singledo)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-dash.png
|
||||
[2]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-dash.png
|
||||
[3]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-dashboard.png
|
||||
[4]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-dashboard.png
|
||||
[5]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-generate-key.png
|
||||
[6]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-generate-key.png
|
||||
[7]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-generate-passphrase.png
|
||||
[8]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-generate-passphrase.png
|
||||
[9]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-use-key-file.png
|
||||
[10]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-use-key-file.png
|
||||
[11]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-start-encryption.png
|
||||
[12]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-start-encryption.png
|
||||
[13]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-file-encrypted-successfully.png
|
||||
[14]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-file-encrypted-successfully.png
|
||||
[15]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-decryption-page.png
|
||||
[16]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-decryption-page.png
|
||||
[17]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-decryption-passphrase.png
|
||||
[18]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-decryption-passphrase.png
|
||||
[19]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-decryption-successfully.png
|
||||
[20]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-decryption-successfully.png
|
||||
@ -0,0 +1,87 @@
|
||||
Opensource.com 的 2017 年最佳开源教程
|
||||
======
|
||||
|
||||
2017 年,Opensource.com 发布了一系列用于帮助从初学者到专家的教程。让我们看看哪些最好。
|
||||
|
||||

|
||||
|
||||
精心编写的教程对于任何软件的官方文档来说都是一个很好的补充。如果官方文件写得不好,不完整或根本没有,那么这些教程也可以是个有效的替代品。
|
||||
|
||||
2017 年,Opensource.com 发布一些有关各种主题的优秀教程。这些教程不只是针对专家们的,它们是针对各种技能水平和经验的用户的。
|
||||
|
||||
让我们来看看其中最好的教程。
|
||||
|
||||
### 关于代码
|
||||
|
||||
对许多人来说,他们第一次涉足开源是为一个项目或另一个项目贡献代码。你在哪里学习编码或编程的?以下两篇文章是很好的起点。
|
||||
|
||||
严格来说,VM Brasseur 的[如何开始学习编程][1]是新手程序员的一个很好的起点,而不是一个教程。它不仅指出了一些有助于你开始学习的优秀资源,而且还提供了了解你的学习方式和如何选择语言的重要建议。
|
||||
|
||||
如果您已经在一个 [IDE][2] 或文本编辑器中敲击了几个小时,那么您可能需要学习更多关于编码的不同方法。Fraser Tweedale 的[函数式编程简介][3]很好地介绍了可以应用到许多广泛使用的编程语言的范式。
|
||||
|
||||
### 踏足 Linux
|
||||
|
||||
Linux 是开源的典范。它运行了大量的 Web 站点,为世界顶级的超级计算机提供了动力。它让任何人都可以替代台式机上的专有操作系统。
|
||||
|
||||
如果你有兴趣深入 Linux,这里有三个教程供你参考。
|
||||
|
||||
Jason Baker 告诉你[设置 Linux $PATH 变量][4]。他引导你掌握这一“任何 Linux 初学者的重要技巧”,使您能够告知系统包含了程序和脚本的目录。
|
||||
|
||||
感谢 David Both 的[建立一个 DNS 域名服务器][5]指南。他详细地记录了如何设置和运行服务器,包括要编辑的配置文件以及如何编辑它们。
|
||||
|
||||
想在你的电脑上更复古一点吗?Jim Hall 告诉你如何使用 [FreeDOS][7]和 [qemu][8] [在 Linux 下运行 DOS 程序][6]。Hall 的文章着重于运行 DOS 生产力工具,但并不全是严肃的——他也谈到了运行他最喜欢的 DOS 游戏。
|
||||
|
||||
### 3 片(篇)树莓派
|
||||
|
||||
廉价的单板计算机使硬件再次变得有趣,这并不是秘密。不仅如此,它们使更多的人更容易接近,无论他们的年龄或技术水平如何。
|
||||
|
||||
其中,[树莓派][9]可能是最广泛使用的单板计算机。Ben Nuttall 带我们一起[在树莓派上安装和设置 Postgres 数据库][10]。这样,你可以在任何你想要的项目中使用它。
|
||||
|
||||
如果你的品味包括文学和技术,你可能会对 Don Watkins 的[如何将树莓派变成电子书服务器][11]感兴趣。稍微付出一点努力和一份 [Calibre 电子书管理软件][12]副本,你就可以得到你最喜欢的电子书,无论你在哪里。
|
||||
|
||||
树莓派并不是其中唯一有特点的。还有 [Orange Pi Pc Plus][13],这是一种开源的单板机。David Egts 告诉你[如何开始使用这个可编程的迷你电脑][14]。
|
||||
|
||||
### 日常的计算机使用
|
||||
|
||||
开源并不仅针对技术专家,更多的普通人用它来做日常工作,而且更加效率。这里有三篇文章,可以使我们这些笨手笨脚的人(你可能不是)做任何事情变得优雅。
|
||||
|
||||
当你想到微博客的时候,你可能会想到 Twitter。但是 Twitter 的问题很多。[Mastodon][15] 是 Twitter 的开放的替代方案,它在 2016 年首次亮相。从此, Mastodon 就获得相当大的用户基数。Seth Kenlon 说明[如何加入和使用 Mastodon][16],甚至告诉你如何在 Mastodon 和 Twitter 间交替使用。
|
||||
|
||||
你需要一点帮助来维持开支吗?你所需要的只是一个电子表格和正确的模板。我关于[要控制你的财政状况][17]的文章,向你展示了如何用 [LibreOffice Calc][18] (或任何其他电子表格编辑器)创建一个简单而有吸引力的财务跟踪。
|
||||
|
||||
ImageMagick 是强大的图形处理工具。但是,很多人不经常使用。这意味着他们在最需要它们时忘记了命令。如果你也是这样,Greg Pittman 的 [ImageMagick 入门教程][19]能在你需要一些帮助时候能派上用场。
|
||||
|
||||
你有最喜欢的 2017 Opensource.com 发布的教程吗?请随意留言与社区分享。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/best-tutorials
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
译者:[zjon](https://github.com/zjon)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:https://linux.cn/article-8694-1.html
|
||||
[2]:https://en.wikipedia.org/wiki/Integrated_development_environment
|
||||
[3]:https://linux.cn/article-8869-1.html
|
||||
[4]:https://opensource.com/article/17/6/set-path-linux
|
||||
[5]:https://opensource.com/article/17/4/build-your-own-name-server
|
||||
[6]:https://linux.cn/article-9014-1.html
|
||||
[7]:http://www.freedos.org/
|
||||
[8]:https://www.qemu.org
|
||||
[9]:https://en.wikipedia.org/wiki/Raspberry_Pi
|
||||
[10]:https://linux.cn/article-9056-1.html
|
||||
[11]:https://linux.cn/article-8684-1.html
|
||||
[12]:https://calibre-ebook.com/
|
||||
[13]:http://www.orangepi.org/
|
||||
[14]:https://linux.cn/article-8308-1.html
|
||||
[15]:https://joinmastodon.org/
|
||||
[16]:https://opensource.com/article/17/4/guide-to-mastodon
|
||||
[17]:https://linux.cn/article-8831-1.html
|
||||
[18]:https://www.libreoffice.org/discover/calc/
|
||||
[19]:https://linux.cn/article-8851-1.html
|
||||
|
||||
|
||||
@ -1,12 +1,15 @@
|
||||
如何使用cloud-init来预配置LXD容器
|
||||
如何使用 cloud-init 来预配置 LXD 容器
|
||||
======
|
||||
当你正在创建LXD容器的时候,你希望它们能被预先配置好。例如在容器一启动就自动执行 **apt update**来安装一些软件包,或者运行一些命令。
|
||||
这篇文章将讲述如何用[**cloud-init**][1]来对[LXD容器进行进行早期初始化][2]。
|
||||
|
||||
当你正在创建 LXD 容器的时候,你希望它们能被预先配置好。例如在容器一启动就自动执行 `apt update`来安装一些软件包,或者运行一些命令。
|
||||
|
||||
这篇文章将讲述如何用 [cloud-init][1] 来对 [LXD 容器进行进行早期初始化][2]。
|
||||
|
||||
接下来,我们将创建一个包含cloud-init指令的LXD profile,然后启动一个新的容器来使用这个profile。
|
||||
|
||||
### 如何创建一个新的LXD profile
|
||||
### 如何创建一个新的 LXD profile
|
||||
|
||||
查看已经存在的profile:
|
||||
查看已经存在的 profile:
|
||||
|
||||
```shell
|
||||
$ lxc profile list
|
||||
@ -17,7 +20,7 @@ $ lxc profile list
|
||||
+---------|---------+
|
||||
```
|
||||
|
||||
我们把名叫default的profile复制一份,然后在其内添加新的指令:
|
||||
我们把名叫 `default` 的 profile 复制一份,然后在其内添加新的指令:
|
||||
|
||||
```shell
|
||||
$ lxc profile copy default devprofile
|
||||
@ -32,7 +35,7 @@ $ lxc profile list
|
||||
+------------|---------+
|
||||
```
|
||||
|
||||
我们就得到了一个新的profile: **devprofile**。下面是它的详情:
|
||||
我们就得到了一个新的 profile: `devprofile`。下面是它的详情:
|
||||
|
||||
```yaml
|
||||
$ lxc profile show devprofile
|
||||
@ -52,11 +55,12 @@ name: devprofile
|
||||
used_by: []
|
||||
```
|
||||
|
||||
注意这几个部分: **config:** , **description:** , **devices:** , **name:** 和 **used_by:**,当你修改这些内容的时候注意不要搞错缩进。(译者注:因为这些内容是YAML格式的,缩进是语法的一部分)
|
||||
注意这几个部分: `config:` 、 `description:` 、 `devices:` 、 `name:` 和 `used_by:`,当你修改这些内容的时候注意不要搞错缩进。(LCTT 译注:因为这些内容是 YAML 格式的,缩进是语法的一部分)
|
||||
|
||||
### 如何把cloud-init添加到LXD profile里
|
||||
### 如何把 cloud-init 添加到 LXD profile 里
|
||||
|
||||
[cloud-init][1] 可以添加到 LXD profile 的 `config` 里。当这些指令将被传递给容器后,会在容器第一次启动的时候执行。
|
||||
|
||||
[cloud-init][1]可以添加到LXD profile的 **config** 里。当这些指令将被传递给容器后,会在容器第一次启动的时候执行。
|
||||
下面是用在示例中的指令:
|
||||
|
||||
```yaml
|
||||
@ -69,11 +73,9 @@ used_by: []
|
||||
- [touch, /tmp/simos_was_here]
|
||||
```
|
||||
|
||||
**package_upgrade: true** 是指当容器第一次被启动时,我们想要**cloud-init** 运行 **sudo apt upgrade**。
|
||||
**packages:** 列出了我们想要自动安装的软件。然后我们设置了**locale** and **timezone**。在Ubuntu容器的镜像里,root用户默认的 locale 是**C.UTF-8**,而**ubuntu** 用户则是 **en_US.UTF-8**。此外,我们把时区设置为**Etc/UTC**。
|
||||
最后,我们展示了[如何使用**runcmd**来运行一个Unix命令][3]。
|
||||
`package_upgrade: true` 是指当容器第一次被启动时,我们想要 `cloud-init` 运行 `sudo apt upgrade`。`packages:` 列出了我们想要自动安装的软件。然后我们设置了 `locale` 和 `timezone`。在 Ubuntu 容器的镜像里,root 用户默认的 `locale` 是 `C.UTF-8`,而 `ubuntu` 用户则是 `en_US.UTF-8`。此外,我们把时区设置为 `Etc/UTC`。最后,我们展示了[如何使用 runcmd 来运行一个 Unix 命令][3]。
|
||||
|
||||
我们需要关注如何将**cloud-init**指令插入LXD profile。
|
||||
我们需要关注如何将 `cloud-init` 指令插入 LXD profile。
|
||||
|
||||
我首选的方法是:
|
||||
|
||||
@ -110,15 +112,15 @@ name: devprofile
|
||||
used_by: []
|
||||
```
|
||||
|
||||
### 如何使用LXD profile启动一个容器
|
||||
### 如何使用 LXD profile 启动一个容器
|
||||
|
||||
使用profile **devprofile**来启动一个新容器:
|
||||
使用 profile `devprofile` 来启动一个新容器:
|
||||
|
||||
```
|
||||
$ lxc launch --profile devprofile ubuntu:x mydev
|
||||
```
|
||||
|
||||
然后访问该容器来查看我们的的指令是否生效:
|
||||
然后访问该容器来查看我们的指令是否生效:
|
||||
|
||||
```shell
|
||||
$ lxc exec mydev bash
|
||||
@ -139,7 +141,7 @@ root@mydev:~# ps ax
|
||||
root@mydev:~#
|
||||
```
|
||||
|
||||
如果我们连接得够快,通过**ps ax**将能够看到系统正在更新软件。我们可以从/var/log/cloud-init-output.log看到完整的日志:
|
||||
如果我们连接得够快,通过 `ps ax` 将能够看到系统正在更新软件。我们可以从 `/var/log/cloud-init-output.log` 看到完整的日志:
|
||||
|
||||
```
|
||||
Generating locales (this might take a while)...
|
||||
@ -147,7 +149,7 @@ Generating locales (this might take a while)...
|
||||
Generation complete.
|
||||
```
|
||||
|
||||
以上可以看出locale已经被更改了。root 用户还是保持默认的**C.UTF-8**,只有非root用户**ubuntu**使用了新的locale。
|
||||
以上可以看出 `locale` 已经被更改了。root 用户还是保持默认的 `C.UTF-8`,只有非 root 用户 `ubuntu` 使用了新的`locale` 设置。
|
||||
|
||||
```
|
||||
Hit:1 http://archive.ubuntu.com/ubuntu xenial InRelease
|
||||
@ -155,7 +157,7 @@ Get:2 http://archive.ubuntu.com/ubuntu xenial-updates InRelease [102 kB]
|
||||
Get:3 http://security.ubuntu.com/ubuntu xenial-security InRelease [102 kB]
|
||||
```
|
||||
|
||||
以上是安装软件包之前执行的**apt update**。
|
||||
以上是安装软件包之前执行的 `apt update`。
|
||||
|
||||
```
|
||||
The following packages will be upgraded:
|
||||
@ -163,16 +165,18 @@ The following packages will be upgraded:
|
||||
4 upgraded, 1 newly installed, 0 to remove and 0 not upgraded.
|
||||
Need to get 211 kB of archives.
|
||||
```
|
||||
以上是在执行**package_upgrade: true**和安装软件包。
|
||||
|
||||
以上是在执行 `package_upgrade: true` 和安装软件包。
|
||||
|
||||
```
|
||||
The following NEW packages will be installed:
|
||||
binutils build-essential cpp cpp-5 dpkg-dev fakeroot g++ g++-5 gcc gcc-5
|
||||
libalgorithm-diff-perl libalgorithm-diff-xs-perl libalgorithm-merge-perl
|
||||
```
|
||||
以上是我们安装**build-essential**软件包的指令。
|
||||
|
||||
**runcmd** 执行的结果如何?
|
||||
以上是我们安装 `build-essential` 软件包的指令。
|
||||
|
||||
`runcmd` 执行的结果如何?
|
||||
|
||||
```
|
||||
root@mydev:~# ls -l /tmp/
|
||||
@ -185,7 +189,7 @@ root@mydev:~#
|
||||
|
||||
### 结论
|
||||
|
||||
当我们启动LXD容器的时候,我们常常需要默认启用一些配置,并且希望能够避免重复工作。通常解决这个问题的方法是创建LXD profile,然后把需要的配置添加进去。最后,当我们启动新的容器时,只需要应用该LXD profile即可。
|
||||
当我们启动 LXD 容器的时候,我们常常需要默认启用一些配置,并且希望能够避免重复工作。通常解决这个问题的方法是创建 LXD profile,然后把需要的配置添加进去。最后,当我们启动新的容器时,只需要应用该 LXD profile 即可。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -193,7 +197,7 @@ via: https://blog.simos.info/how-to-preconfigure-lxd-containers-with-cloud-init/
|
||||
|
||||
作者:[Simos Xenitellis][a]
|
||||
译者:[kaneg](https://github.com/kaneg)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,73 +1,71 @@
|
||||
Intel 设计缺陷背后的原因是什么?
|
||||
============================================================
|
||||
|
||||
### 我们知道有问题,但是并不知道问题的详细情况。
|
||||
|
||||
> 我们知道有问题,但是并不知道问题的详细情况。
|
||||
|
||||

|
||||
|
||||
(本文发表于 1 月份)最近 Windows 和 Linux 都发送了重大安全更新,为防范这个尚未完全公开的问题,在最坏的情况下,它可能会导致性能下降多达一半。
|
||||
|
||||
最近 Windows 和 Linux 都发送了重大安全更新,为防范这个尚未完全公开的问题,在最坏的情况下,它可能会导致性能下降多达一半。
|
||||
在过去的几周,Linux 内核陆续打了几个补丁。Microsoft [自 11 月份开始也内部测试了 Windows 更新][3],并且它预计在下周二的例行补丁中将这个改进推送到主流 Windows 构建版中。Microsoft 的 Azure 也在下周的维护窗口中做好了安排,而 Amazon 的 AWS 也安排在周五对相关的设施进行维护。
|
||||
|
||||
在过去的几周,Linux 内核陆续打了几个补丁。Microsoft [自 11 月份开始也内部测试了 Windows 更新][3],并且它预计在下周二的例行补丁中将这个改进推送到主流 Windows 构建版中。Microsoft 的 Azure 也在下周的维护窗口中做好了安排,而 Amazon 的 AWS 也安排在周五对相关的设施进行维护。
|
||||
|
||||
自从 Linux 第一个补丁 [KPTI:内核页表隔离的当前的发展][4] ,明确描绘了出现的错误以后。虽然 Linux 和 Windows 基于不同的考虑,对此持有不同的看法,但是这两个操作系统 — 当然还有其它的 x86 操作系统,比如 FreeBSD 和 [macOS][5] — 对系统内存的处理采用了相同的方式,因为对于操作系统在这一部分特性是与底层的处理器高度耦合的。
|
||||
自从 Linux 第一个补丁 (参见 [KPTI:内核页表隔离的当前的发展][4]) 明确描绘了出现的错误以后。虽然 Linux 和 Windows 基于不同的考虑,对此持有不同的看法,但是这两个操作系统 —— 当然还有其它的 x86 操作系统,比如 FreeBSD 和 [macOS][5] — 对系统内存的处理采用了相同的方式,因为对于操作系统在这一部分特性是与底层的处理器高度耦合的。
|
||||
|
||||
### 保持地址跟踪
|
||||
|
||||
在一个系统中的每个内存字节都是隐性编码的,这些数字是每个字节的地址。早期的操作系统使用物理内存地址,但是,物理内存地址由于各种原因,它并不很合适。例如,在地址中经常会有空隙,并且(尤其是 32 位的系统上)物理地址很难操作,需要 36 位的数字,甚至更多。
|
||||
在一个系统中的每个内存字节都是隐性编码的,这些编码数字是每个字节的地址。早期的操作系统使用物理内存地址,但是,物理内存地址由于各种原因,它并不很合适。例如,在地址中经常会有空隙,并且(尤其是 32 位的系统上)物理地址很难操作,需要 36 位数字,甚至更多。
|
||||
|
||||
因此,现在操作系统完全依赖一个叫虚拟内存的概念。虚拟内存系统允许程序和内核一起在一个简单、清晰、统一的环境中各自去操作。而不是使用空隙和其它奇怪的东西的物理内存,每个程序和内核自身都使用虚拟地址去访问内存。这些虚拟地址是连续的 — 不用担心有空隙 — 并且合适的大小也更便于操作。32 位的程序仅可以看到 32 位的地址,而不用管物理地址是 36 位还是更多位。
|
||||
因此,现在操作系统完全依赖一个叫虚拟内存的概念。虚拟内存系统允许程序和内核一起在一个简单、清晰、统一的环境中各自去操作。而不是使用空隙和其它奇怪的东西的物理内存,每个程序和内核自身都使用虚拟地址去访问内存。这些虚拟地址是连续的 —— 不用担心有空隙 —— 并且合适的大小也更便于操作。32 位的程序仅可以看到 32 位的地址,而不用管物理地址是 36 位还是更多位。
|
||||
|
||||
虽然虚拟地址对每个软件几乎是透明的,但是,处理器最终还是需要知道虚拟地址引用的物理地址是哪个。因此,有一个虚拟地址到物理地址的映射,它保存在一个被称为页面表的数据结构中。操作系统构建页面表,使用一个由处理器决定的布局,并且处理器和操作系统在虚拟地址和物理地址之间进行转换时就需要用到页面表。
|
||||
|
||||
这个映射过程是非常重要的,它也是现代操作系统和处理器的重要基础,处理器有专用的缓存 — translation lookaside buffer(简称 TLB)— 它保存了一定数量的虚拟地址到物理地址的映射,这样就不需要每次都使用全部页面。
|
||||
这个映射过程是非常重要的,它也是现代操作系统和处理器的重要基础,处理器有专用的缓存 — Translation Lookaside Buffer(简称 TLB)—— 它保存了一定数量的虚拟地址到物理地址的映射,这样就不需要每次都使用全部页面。
|
||||
|
||||
虚拟内存的使用为我们提供了很多除了简单寻址之外的有用的特性。其中最主要的是,每个程序都有了自己独立的一组虚拟地址,有了它自己的一组虚拟地址到物理地址的映射。这就是用于提供“内存保护”的关键技术,一个程序不能破坏或者篡改其它程序使用的内存,因为其它程序的内存并不在它的地址映射范围之内。
|
||||
|
||||
由于每个进程使用一个单独的映射,因此每个程序也就有了一个额外的页面表,这就使得 TLB 缓存很拥挤。TLB 并不大 — 一般情况下总共可以容纳几百个映射 — 而系统使用的页面表越多,TLB 能够包含的任何特定的虚拟地址到物理地址的映射就越少。
|
||||
由于每个进程使用一个单独的映射,因此每个程序也就有了一个额外的页面表,这就使得 TLB 缓存很拥挤。TLB 并不大 —— 一般情况下总共可以容纳几百个映射 —— 而系统使用的页面表越多,TLB 能够包含的任何特定的虚拟地址到物理地址的映射就越少。
|
||||
|
||||
### 一半一半
|
||||
|
||||
为了更好地使用 TLB,每个主流的操作系统都将虚拟地址范围一分为二。一半用于程序;另一半用于内核。当进程切换时,仅有一半的页面表条目发生变化 — 仅属于程序的那一半。内核的那一半是每个程序公用的(因为只有一个内核)并且因此它可以为每个进程使用相同的页面表映射。这对 TLB 的帮助非常大;虽然它仍然会丢弃属于进程的那一半内存地址映射;但是它还保持着另一半属于内核的映射。
|
||||
为了更好地使用 TLB,每个主流的操作系统都将虚拟地址范围一分为二。一半用于程序;另一半用于内核。当进程切换时,仅有一半的页面表条目发生变化 —— 仅属于程序的那一半。内核的那一半是每个程序公用的(因为只有一个内核)并且因此它可以为每个进程使用相同的页面表映射。这对 TLB 的帮助非常大;虽然它仍然会丢弃属于进程的那一半内存地址映射;但是它还保持着另一半属于内核的映射。
|
||||
|
||||
这种设计并不是一成不变的。在 Linux 上做了一项工作,使它可以为一个 32 位的进程提供整个地址范围,而不用在内核页面表和每个进程之间共享。虽然这样为程序提供了更多的地址空间,但这是以牺牲性能为代价的,因为每次内核代码需要运行时,TLB 重新加载内核的页面表条目。因此,这种方法并没有广泛应用到 x86 的系统上。
|
||||
|
||||
在内核和每个程序之间分割虚拟地址的这种做法的一个负面影响是,内存保护被削弱了。如果内核有它自己的一组页面表和虚拟地址,它将在不同的程序之间提供相同的保护;内核内存将是简单的不可见。但是使用地址分割之后,用户程序和内核使用了相同的地址范围,并且从原理上来说,一个用户程序有可能去读写内核内存。
|
||||
|
||||
为避免这种明显不好的情况,处理器和虚拟地址系统有一个 “Ring" 或者 ”模式“的概念。x86 处理器有许多 rings,但是对于这个问题,仅有两个是相关的:"user" (ring 3)和 "supervisor"(ring 0)。当运行普通的用户程序时,处理器将置为用户模式 (ring 3)。当运行内核代码时,处理器将处于 ring 0 —— supervisor 模式,也称为内核模式。
|
||||
为避免这种明显不好的情况,处理器和虚拟地址系统有一个 “Ring” 或者 “模式”的概念。x86 处理器有许多 Ring,但是对于这个问题,仅有两个是相关的:“user” (Ring 3)和 “supervisor”(ring 0)。当运行普通的用户程序时,处理器将置为用户模式 (Ring 3)。当运行内核代码时,处理器将处于 Ring 0 —— supervisor 模式,也称为内核模式。
|
||||
|
||||
这些 rings 也用于从用户程序中保护内核内存。页面表并不仅仅有虚拟地址到物理地址的映射;它也包含关于这些地址的元数据,包含哪个 rings 可能访问哪个地址的信息。内核页面表条目被标记为仅 ring 0 可以访问;程序的条目被标记为任何 ring 都可以访问。如果一个处于 ring 3 中的进程去尝试访问标记为 ring 0 的内存,处理器将阻止这个访问并生成一个意外错误信息。运行在 ring 3 中的用户程序不能得到内核以及运行在 ring 0 内存中的任何东西。
|
||||
这些 Ring 也用于从用户程序中保护内核内存。页面表并不仅仅有虚拟地址到物理地址的映射;它也包含关于这些地址的元数据,包含哪个 Ring 可能访问哪个地址的信息。内核页面表条目被标记为仅有 Ring 0 可以访问;程序的条目被标记为任何 Ring 都可以访问。如果一个处于 Ring 3 中的进程去尝试访问标记为 Ring 0 的内存,处理器将阻止这个访问并生成一个意外错误信息。运行在 Ring 3 中的用户程序不能得到内核以及运行在 Ring 0 内存中的任何东西。
|
||||
|
||||
至少理论上是这样的。大量的补丁和更新表明,这个地方已经被突破了。这就是最大的谜团所在。
|
||||
|
||||
### Ring 间迁移
|
||||
|
||||
这就是我们所知道的。每个现代处理器都执行一定数量的推测运行。例如,给一些指令,让两个数加起来,然后将结果保存在内存中,在查明内存中的目标是否可访问和可写入之前,一个处理器可能已经推测性地做了加法。在一些常见案例中,在位置是可写入的地方,处理器节省了一些时间,因为它以并行方式计算出内存中的目标是什么。如果它发现目标位置不可写入 — 例如,一个程序尝试去写入到一个没有映射的地址以及压根就不存在的物理位置— 然后它将产生一个意外错误,而推测运行就白做了。
|
||||
这就是我们所知道的。每个现代处理器都执行一定数量的推测运行。例如,给一些指令,让两个数加起来,然后将结果保存在内存中,在查明内存中的目标是否可访问和可写入之前,一个处理器可能已经推测性地做了加法。在一些常见案例中,在地址可写入的地方,处理器节省了一些时间,因为它以并行方式计算出内存中的目标是什么。如果它发现目标位置不可写入 —— 例如,一个程序尝试去写入到一个没有映射的地址或压根就不存在的物理位置 —— 然后它将产生一个意外错误,而推测运行就白做了。
|
||||
|
||||
Intel 处理器,尤其是 — [虽然不是 AMD 的][6] — 但允许对 ring 3 代码进行推测运行并写入到 ring 0 内存中的处理器上。处理器并不完全阻止这种写入,但是推测运行轻微扰乱了处理器状态,因为,为了查明目标位置是否可写入,某些数据已经被加载到缓存和 TLB 中。这又意味着一些操作可能快几个周期,或者慢几个周期,这取决于它们所需要的数据是否仍然在缓存中。除此之外,Intel 的处理器还有一些特殊的功能,比如,在 Skylake 处理器上引入的软件保护扩展(SGX)指令,它改变了一点点访问内存的方式。同样的,处理器仍然是保护 ring 0 的内存不被来自 ring 3 的程序所访问,但是同样的,它的缓存和其它内部状态已经发生了变化,产生了可测量的差异。
|
||||
Intel 处理器,尤其是([虽然不是 AMD 的][6])允许对 Ring 3 代码进行推测运行并写入到 Ring 0 内存中的处理器上。处理器并不完全阻止这种写入,但是推测运行轻微扰乱了处理器状态,因为,为了查明目标位置是否可写入,某些数据已经被加载到缓存和 TLB 中。这又意味着一些操作可能快几个周期,或者慢几个周期,这取决于它们所需要的数据是否仍然在缓存中。除此之外,Intel 的处理器还有一些特殊的功能,比如,在 Skylake 处理器上引入的软件保护扩展(SGX)指令,它改变了一点点访问内存的方式。同样的,处理器仍然是保护 Ring 0 的内存不被来自 Ring 3 的程序所访问,但是同样的,它的缓存和其它内部状态已经发生了变化,产生了可测量的差异。
|
||||
|
||||
我们至今仍然并不知道具体的情况,到底有多少内核的内存信息泄露给了用户程序,或者信息泄露的情况有多容易发生。以及有哪些 Intel 处理器会受到影响?也或者并不完全清楚,但是,有迹象表明每个 Intel 芯片都使用了推测运行(是自 1995 年 Pentium Pro 以来的,所有主流处理器吗?),它们都可能会因此而泄露信息。
|
||||
我们至今仍然并不知道具体的情况,到底有多少内核的内存信息泄露给了用户程序,或者信息泄露的情况有多容易发生。以及有哪些 Intel 处理器会受到影响?也或者并不完全清楚,但是,有迹象表明每个 Intel 芯片都使用了推测运行(是自 1995 年 Pentium Pro 以来的所有主流处理器吗?),它们都可能会因此而泄露信息。
|
||||
|
||||
这个问题第一次被披露是由来自 [奥地利的 Graz Technical University][7] 的研究者。他们披露的信息表明这个问题已经足够破坏内核模式地址空间布局随机化(内核 ASLR,或称 KASLR)。ASLR 是防范 [缓冲区溢出][8] 漏洞利用的最后一道防线。启用 ASLR 之后,程序和它们的数据被置于随机的内存地址中,它将使一些安全漏洞利用更加困难。KASLR 将这种随机化应用到内核中,这样就使内核的数据(包括页面表)和代码也随机化分布。
|
||||
|
||||
Graz 的研究者开发了 [KAISER][9],一组防范这个问题的 Linux 内核补丁。
|
||||
|
||||
如果这个问题正好使 ASLR 的随机化被破坏了,这或许将成为一个巨大的灾难。ASLR 是一个非常强大的保护措施,但是它并不是完美的,这意味着对于黑客来说将是一个很大的障碍,一个无法逾越的障碍。整个行业对此的反应是 — Windows 和 Linux 都有一个非常重要的变化,秘密开发 — 这表明不仅是 ASLR 被破坏了,而且从内核泄露出信息的更普遍的技术被开发出来了。确实是这样的,研究者已经 [在 tweet 上发布信息][10],他们已经可以随意泄露和读取内核数据了。另一种可能是,漏洞可能被用于从虚拟机中”越狱“,并可能会危及 hypervisor。
|
||||
如果这个问题正好使 ASLR 的随机化被破坏了,这或许将成为一个巨大的灾难。ASLR 是一个非常强大的保护措施,但是它并不是完美的,这意味着对于黑客来说将是一个很大的障碍,一个无法逾越的障碍。整个行业对此的反应是 —— Windows 和 Linux 都有一个非常重要的变化,秘密开发 —— 这表明不仅是 ASLR 被破坏了,而且从内核泄露出信息的更普遍的技术被开发出来了。确实是这样的,研究者已经 [在 Twitter 上发布信息][10],他们已经可以随意泄露和读取内核数据了。另一种可能是,漏洞可能被用于从虚拟机中“越狱”,并可能会危及 hypervisor。
|
||||
|
||||
Windows 和 Linux 选择的解决方案是非常相似的,将 KAISER 分为两个区域:内核页面表的条目不再是由每个进程共享。在 Linux 中,这被称为内核页面表隔离(KPTI)。
|
||||
|
||||
应用补丁后,内存地址仍然被一分为二:这样使内核的那一半几乎是空的。当然它并不是非常的空,因为一些内核片断需要永久映射,不论进程是运行在 ring 3 还是 ring 0 中,它都几乎是空的。这意味着如果恶意用户程序尝试去探测内核内存以及泄露信息,它将会失败 — 因为那里几乎没有信息。而真正的内核页面中只有当内核自身运行的时刻它才能被用到。
|
||||
应用补丁后,内存地址仍然被一分为二:这样使内核的那一半几乎是空的。当然它并不是非常的空,因为一些内核片断需要永久映射,不论进程是运行在 Ring 3 还是 Ring 0 中,它都几乎是空的。这意味着如果恶意用户程序尝试去探测内核内存以及泄露信息,它将会失败 —— 因为那里几乎没有信息。而真正的内核页面中只有当内核自身运行的时刻它才能被用到。
|
||||
|
||||
这样做就破坏了最初将地址空间分割的理由。现在,每次切换到用户程序时,TLB 需要实时去清除与内核页面表相关的所有条目,这样就失去了启用分割带来的性能提升。
|
||||
|
||||
影响的具体大小取决于工作负载。每当一个程序被调入到内核 — 从磁盘读入、发送数据到网络、打开一个文件等等 — 这种调用的成本可能会增加一点点,因为它强制 TLB 清除了缓存并实时加载内核页面表。不使用内核的程序可能会观测到 2 - 3 个百分点的性能影响 — 这里仍然有一些开销,因为内核仍然是偶尔会运行去处理一些事情,比如多任务等等。
|
||||
影响的具体大小取决于工作负载。每当一个程序被调入到内核 —— 从磁盘读入、发送数据到网络、打开一个文件等等 —— 这种调用的成本可能会增加一点点,因为它强制 TLB 清除了缓存并实时加载内核页面表。不使用内核的程序可能会观测到 2 - 3 个百分点的性能影响 —— 这里仍然有一些开销,因为内核仍然是偶尔会运行去处理一些事情,比如多任务等等。
|
||||
|
||||
但是大量调用进入到内核的工作负载将观测到很大的性能损失。在一个基准测试中,一个除了调入到内核之外什么都不做的程序,观察到 [它的性能下降大约为 50%][11];换句话说就是,打补丁后每次对内核的调用的时间要比不打补丁调用内核的时间增加一倍。基准测试使用的 Linux 的网络回环(loopback)也观测到一个很大的影响,比如,在 Postgres 的基准测试中大约是 [17%][12]。真实的数据库负载使用了实时网络可能观测到的影响要低一些,因为使用实时网络时,内核调用的开销基本是使用真实网络的开销。
|
||||
|
||||
虽然对 Intel 系统的影响是众所周知的,但是它们可能并不是唯一受影响的。其它的一些平台,比如 SPARC 和 IBM 的 S390,是不受这个问题影响的,因为它们的处理器的内存管理并不需要分割地址空间和共享内核页面表;在这些平台上的操作系统一直就是将它们的内核页面表从用户模式中隔离出来的。但是其它的,比如 ARM,可能就没有这么幸运了;[适用于 ARM Linux 的类似补丁][13] 正在开发中。
|
||||
虽然对 Intel 系统的影响是众所周知的,但是它们可能并不是唯一受影响的。其它的一些平台,比如 SPARC 和 IBM 的 S390,是不受这个问题影响的,因为它们的处理器的内存管理并不需要分割地址空间和共享内核页面表;在这些平台上的操作系统一直就是将它们的内核页面表从用户模式中隔离出来的。但是其它的,比如 ARM,可能就没有这么幸运了;[适用于 ARM Linux 的类似补丁][13] 正在开发中。
|
||||
|
||||
<aside class="ad_native" id="ad_xrail_native" style="box-sizing: inherit;"></aside>
|
||||
---
|
||||
|
||||
[][15][PETER BRIGHT][14] 是 Ars 的一位技术编辑。他涉及微软、编程及软件开发、Web 技术和浏览器、以及安全方面。它居住在纽约的布鲁克林。
|
||||
|
||||
@ -75,9 +73,9 @@ Windows 和 Linux 选择的解决方案是非常相似的,将 KAISER 分为两
|
||||
|
||||
via: https://arstechnica.com/gadgets/2018/01/whats-behind-the-intel-design-flaw-forcing-numerous-patches/
|
||||
|
||||
作者:[ PETER BRIGHT ][a]
|
||||
作者:[PETER BRIGHT][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,17 +1,17 @@
|
||||
五个值得现在安装的火狐插件
|
||||
======
|
||||
|
||||
合适的插件能大大增强你浏览器的功能,但仔细挑选插件很重要。本文有五个值得一看的插件。
|
||||
> 合适的插件能大大增强你浏览器的功能,但仔细挑选插件很重要。本文有五个值得一看的插件。
|
||||
|
||||

|
||||
|
||||
对于很多用户来说,网页浏览器已经成为电脑使用体验的重要环节。现代浏览器已经发展成强大、可拓展的平台。作为平台的一部分,_插件_能添加或修改浏览器的功能。火狐插件的构建使用了 WebExtensions API ,一个跨浏览器的开发系统。
|
||||
对于很多用户来说,网页浏览器已经成为电脑使用体验的重要环节。现代浏览器已经发展成强大、可拓展的平台。作为平台的一部分,_插件_能添加或修改浏览器的功能。火狐插件的构建使用了 WebExtensions API ,这是一个跨浏览器的开发系统。
|
||||
|
||||
你得安装哪一个插件?一般而言,这个问题的答案取决于你如何使用你的浏览器、你对于隐私的看法、你信任插件开发者多少以及其他个人喜好。
|
||||
你应该安装哪一个插件?一般而言,这个问题的答案取决于你如何使用你的浏览器、你对于隐私的看法、你信任插件开发者多少以及其他个人喜好。
|
||||
|
||||
首先,我想指出浏览器插件通常需要读取和(或者)修改你浏览的网页上的每项内容。你应该_非常_仔细地考虑这件事的后果。如果一个插件有修改所有你访问过的网页的权限,那么它可能记录你的按键、拦截信用卡信息、在线跟踪你、插入广告,以及其他各种各样邪恶的行为。
|
||||
|
||||
并不是每个插件都偷偷摸摸地做这些事,但是在你安装任何插件之前,你要慎重考虑下插件安装来源、涉及的权限、你的风险数据和其他因素。记住,你可以从个人数据的角度来管理一个插件如何影响你的攻击面( LCTT 译者注:攻击面是指入侵者能尝试获取或提取数据的途径总和)——例如使用特定的配置、不使用插件来完成例如网上银行的操作。
|
||||
并不是每个插件都偷偷摸摸地做这些事,但是在你安装任何插件之前,你要慎重考虑下插件安装来源、涉及的权限、你的风险数据和其他因素。记住,你可以从个人数据的角度来管理一个插件如何影响你的攻击面( LCTT 译注:攻击面是指入侵者能尝试获取或提取数据的途径总和)——例如使用特定的配置、不使用插件来完成例如网上银行的操作。
|
||||
|
||||
考虑到这一点,这里有你或许想要考虑的五个火狐插件
|
||||
|
||||
@ -19,29 +19,29 @@
|
||||
|
||||
![ublock origin ad blocker screenshot][2]
|
||||
|
||||
ublock Origin 可以拦截广告和恶意网页,还允许用户定义自己的内容过滤器。
|
||||
*ublock Origin 可以拦截广告和恶意网页,还允许用户定义自己的内容过滤器。*
|
||||
|
||||
[uBlock Origin][3] 是一款快速、内存占用低、适用范围广的拦截器,它不仅能屏蔽广告,还能让你执行你自己的内容过滤。uBlock Origin 默认使用多份预定义好的过滤名单来拦截广告、跟踪器和恶意网页。它允许你任意地添加列表和规则,或者锁定在一个默认拒绝的模式。除了强大之外,这个插件已被证明是效率高、性能好。
|
||||
[uBlock Origin][3] 是一款快速、内存占用低、适用范围广的拦截器,它不仅能屏蔽广告,还能让你执行你自己定制的内容过滤。uBlock Origin 默认使用多份预定义好的过滤名单来拦截广告、跟踪器和恶意网页。它允许你任意地添加列表和规则,或者锁定在一个默认拒绝的模式。除了强大之外,这个插件已被证明是效率高、性能好。
|
||||
|
||||
### Privacy Badger
|
||||
|
||||
![privacy badger ad blocker][5]
|
||||
|
||||
Privacy Badger 运用了算法来无缝地屏蔽侵犯用户准则的广告和跟踪器。
|
||||
*Privacy Badger 运用了算法来无缝地屏蔽侵犯用户准则的广告和跟踪器。*
|
||||
|
||||
正如它名字所表明,[Privacy Badger][6] 是一款专注于隐私的插件,它屏蔽广告和第三方跟踪器。EFF (LCTT 译者注:EFF全称是电子前哨基金会(Electronic Frontier Foundation),旨在宣传互联网版权和监督执法机构 )说:“我们想要推荐一款能自动分析并屏蔽任何侵犯用户准则的跟踪器和广告,而 Privacy Badger 诞生于此目的;它不用任何设置、知识或者用户的配置,就能运行得很好;它是由一个明显为用户服务而不是为广告主服务的组织出品;它使用算法来绝定什么正在跟踪,什么没有在跟踪”
|
||||
正如它名字所表明,[Privacy Badger][6] 是一款专注于隐私的插件,它屏蔽广告和第三方跟踪器。EFF (LCTT 译注:EFF 全称是<ruby>电子前哨基金会<rt>Electronic Frontier Foundation</rt></ruby>,旨在宣传互联网版权和监督执法机构)说:“我们想要推荐一款能自动分析并屏蔽任何侵犯用户准则的跟踪器和广告,而 Privacy Badger 诞生于此目的;它不用任何设置、知识或者用户的配置,就能运行得很好;它是由一个明显为用户服务而不是为广告主服务的组织出品;它使用算法来确定正在跟踪什么,而没有跟踪什么。”
|
||||
|
||||
为什么 Privacy Badger 出现在这列表上的原因跟 uBlock Origin 如此相似?其中一个原因是Privacy Badger 从根本上跟 uBlock Origin 的工作不同。另一个原因是纵深防御的做法是个可以跟随的合理策略。
|
||||
为什么 Privacy Badger 出现在这列表上的原因跟 uBlock Origin 如此相似?其中一个原因是 Privacy Badger 从根本上跟 uBlock Origin 的工作不同。另一个原因是纵深防御的做法是个可以遵循的合理策略。
|
||||
|
||||
### LastPass
|
||||
|
||||
![lastpass password manager screenshot][8]
|
||||
|
||||
LastPass 是一款用户友好的密码管理插件,支持双重授权。
|
||||
*LastPass 是一款用户友好的密码管理插件,支持双因子认证。*
|
||||
|
||||
这个插件对于很多人来说是个有争议的补充。你是否应该使用密码管理器——如果你用了,你是否应该选择一个浏览器插件——这都是个热议的话题,而答案取决于你的风险资料。我想说大部分不关心的电脑用户应该用一个,因为这比起常见的选择:每一处使用相同的弱密码,都好太多了。
|
||||
|
||||
[LastPass][9] 对于用户很友好,支持双重授权,相当安全。这家公司过去出过点安全事故,但是都处理得当,而且资金充足。记住使用密码管理器不是非此即彼的命题。很多用户选择使用密码管理器管理绝大部分密码,但是保持了一点复杂性,为例如银行这样重要的网页精心设计了密码和使用多重认证。
|
||||
[LastPass][9] 对于用户很友好,支持双因子认证,相当安全。这家公司过去出过点安全事故,但是都处理得当,而且资金充足。记住使用密码管理器不是非此即彼的命题。很多用户选择使用密码管理器管理绝大部分密码,但是保持了一点复杂性,为例如银行这样重要的网页采用了精心设计的密码和多因子认证。
|
||||
|
||||
### Xmarks Sync
|
||||
|
||||
@ -51,11 +51,11 @@ LastPass 是一款用户友好的密码管理插件,支持双重授权。
|
||||
|
||||
[Awesome Screenshot Plus][11] 允许你很容易捕获任意网页的全部或部分区域,也能添加注释、评论、使敏感信息模糊等。你还能用一个可选的在线服务来分享图片。我发现这工具在网页调试时截图、讨论设计和分享信息上很棒。这是一款比你预期中发现自己使用得多的工具。
|
||||
|
||||
我发现这五款插件有用,我把它们推荐给其他人。这就是说,还有很多浏览器插件。我好奇其他的哪一款是 Opensource.com 社区用户正在使用并推荐的。让评论中让我知道。(LCTT 译者注:本文引用自 Opensource.com ,这两句话意在引导用户留言,推荐自己使用的插件)
|
||||
|
||||
![Awesome Screenshot Plus screenshot][13]
|
||||
|
||||
Awesome Screenshot Plus 允许你容易地截下任何网页的部分或全部内容。
|
||||
*Awesome Screenshot Plus 允许你容易地截下任何网页的部分或全部内容。*
|
||||
|
||||
我发现这五款插件有用,我把它们推荐给其他人。这就是说,还有很多浏览器插件。我很感兴趣社区用户们正在使用哪些插件,请在评论中让我知道。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -63,17 +63,17 @@ via: https://opensource.com/article/18/1/top-5-firefox-extensions
|
||||
|
||||
作者:[Jeremy Garcia][a]
|
||||
译者:[ypingcn](https://github.com/ypingcn)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jeremy-garcia
|
||||
[2]: https://opensource.com/sites/default/files/ublock.png "ublock origin ad blocker screenshot"
|
||||
[2]: https://opensource.com/sites/default/files/ublock.png
|
||||
[3]: https://addons.mozilla.org/en-US/firefox/addon/ublock-origin/
|
||||
[5]: https://opensource.com/sites/default/files/images/life-uploads/privacy_badger_1.0.1.png "privacy badger ad blocker screenshot"
|
||||
[5]: https://opensource.com/sites/default/files/images/life-uploads/privacy_badger_1.0.1.png
|
||||
[6]: https://www.eff.org/privacybadger
|
||||
[8]: https://opensource.com/sites/default/files/images/life-uploads/lastpass4.jpg "lastpass password manager screenshot"
|
||||
[8]: https://opensource.com/sites/default/files/images/life-uploads/lastpass4.jpg
|
||||
[9]: https://addons.mozilla.org/en-US/firefox/addon/lastpass-password-manager/
|
||||
[10]: https://addons.mozilla.org/en-US/firefox/addon/xmarks-sync/
|
||||
[11]: https://addons.mozilla.org/en-US/firefox/addon/screenshot-capture-annotate/
|
||||
[13]: https://opensource.com/sites/default/files/screenshot_from_2018-01-04_17-11-32.png "Awesome Screenshot Plus screenshot"
|
||||
[13]: https://opensource.com/sites/default/files/screenshot_from_2018-01-04_17-11-32.png
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user