mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-03 23:40:14 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
1f42ba1c65
@ -1,113 +1,113 @@
|
||||
Python 中的 Hello World 和字符串操作
|
||||
初识 Python:Hello World 和字符串操作
|
||||
======
|
||||
|
||||
|
||||
|
||||
开始之前,说一下本文中的[代码][1]和[视频][2]可以在我的 github 上找到。
|
||||
开始之前,说一下本文中的[代码][1]和[视频][2]可以在我的 GitHub 上找到。
|
||||
|
||||
那么,让我们开始吧!如果你糊涂了,我建议你在单独的选项卡中打开下面的[视频][3]。
|
||||
那么,让我们开始吧!如果你糊涂了,我建议你在单独的选项卡中打开下面的视频。
|
||||
|
||||
[Python 的 Hello World 和字符串操作视频][2]
|
||||
- [Python 的 Hello World 和字符串操作视频][2]
|
||||
|
||||
#### ** 开始 (先决条件)
|
||||
### 开始 (先决条件)
|
||||
|
||||
在你的操作系统上安装 Anaconda(Python)。你可以从[官方网站][4]下载 anaconda 并自行安装,或者你可以按照以下这些 anaconda 安装教程进行安装。
|
||||
首先在你的操作系统上安装 Anaconda (Python)。你可以从[官方网站][4]下载 anaconda 并自行安装,或者你可以按照以下这些 anaconda 安装教程进行安装。
|
||||
|
||||
在 Windows 上安装 Anaconda: [链接[5]
|
||||
- 在 Windows 上安装 Anaconda: [链接[5]
|
||||
- 在 Mac 上安装 Anaconda: [链接][6]
|
||||
- 在 Ubuntu (Linux) 上安装 Anaconda:[链接][7]
|
||||
|
||||
在 Mac 上安装 Anaconda: [链接][6]
|
||||
|
||||
在 Ubuntu (Linux) 上安装 Anaconda:[链接][7]
|
||||
|
||||
#### 打开一个 Jupyter Notebook
|
||||
### 打开一个 Jupyter Notebook
|
||||
|
||||
打开你的终端(Mac)或命令行,并输入以下内容([请参考视频中的 1:16 处][8])来打开 Jupyter Notebook:
|
||||
|
||||
```
|
||||
jupyter notebook
|
||||
|
||||
```
|
||||
|
||||
#### 打印语句/Hello World
|
||||
### 打印语句/Hello World
|
||||
|
||||
在 Jupyter 的单元格中输入以下内容并按下 `shift + 回车`来执行代码。
|
||||
|
||||
在 Jupyter 的单元格中输入以下内容并按下 **shift + 回车**来执行代码。
|
||||
```
|
||||
# This is a one line comment
|
||||
print('Hello World!')
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
打印输出 “Hello World!”
|
||||

|
||||
|
||||
#### 字符串和字符串操作
|
||||
*打印输出 “Hello World!”*
|
||||
|
||||
### 字符串和字符串操作
|
||||
|
||||
字符串是 Python 类的一种特殊类型。作为对象,在类中,你可以使用 `.methodName()` 来调用字符串对象的方法。字符串类在 Python 中默认是可用的,所以你不需要 `import` 语句来使用字符串对象接口。
|
||||
|
||||
字符串是 python 类的一种特殊类型。作为对象,在类中,你可以使用 .methodName() 来调用字符串对象的方法。字符串类在 python 中默认是可用的,所以你不需要 import 语句来使用字符串对象接口。
|
||||
```
|
||||
# Create a variable
|
||||
# Variables are used to store information to be referenced
|
||||
# and manipulated in a computer program.
|
||||
firstVariable = 'Hello World'
|
||||
print(firstVariable)
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
输出打印变量 firstVariable
|
||||
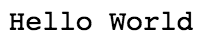
|
||||
|
||||
*输出打印变量 firstVariable*
|
||||
|
||||
```
|
||||
# Explore what various string methods
|
||||
print(firstVariable.lower())
|
||||
print(firstVariable.upper())
|
||||
print(firstVariable.title())
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
使用 .lower()、.upper() 和 title() 方法输出
|
||||

|
||||
|
||||
*使用 .lower()、.upper() 和 title() 方法输出*
|
||||
|
||||
```
|
||||
# Use the split method to convert your string into a list
|
||||
print(firstVariable.split(' '))
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
使用 split 方法输出(此例中以空格分隔)
|
||||
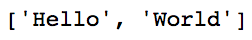
|
||||
|
||||
*使用 split 方法输出(此例中以空格分隔)*
|
||||
|
||||
```
|
||||
# You can add strings together.
|
||||
a = "Fizz" + "Buzz"
|
||||
print(a)
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
字符串连接
|
||||
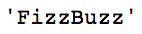
|
||||
|
||||
#### 查询方法的功能
|
||||
*字符串连接*
|
||||
|
||||
### 查询方法的功能
|
||||
|
||||
对于新程序员,他们经常问你如何知道每种方法的功能。Python 提供了两种方法来实现。
|
||||
|
||||
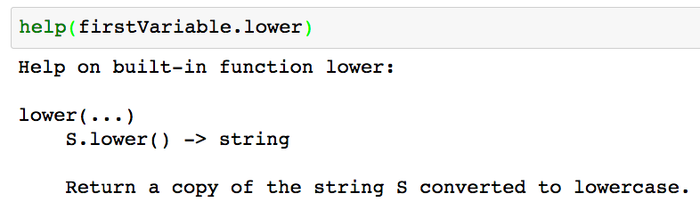
1.(在不在 Jupyter Notebook 中都可用)使用 **help** 查询每个方法的功能。
|
||||
1、(在不在 Jupyter Notebook 中都可用)使用 `help` 查询每个方法的功能。
|
||||
|
||||
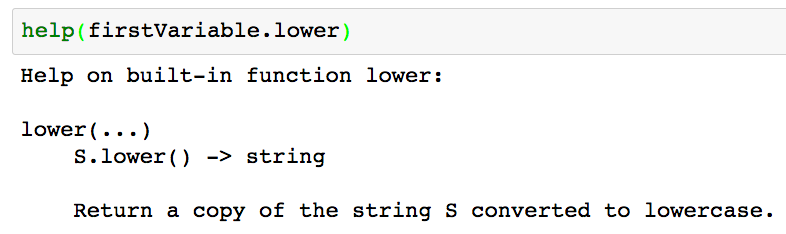
|
||||
|
||||
*查询每个方法的功能*
|
||||
|
||||
![][9]
|
||||
查询每个方法的功能
|
||||
|
||||
2. (Jupyter Notebook exclusive) You can also look up what a method does by having a question mark after a method.
|
||||
2.(Jupyter Notebook 专用)你也可以通过在方法之后添加问号来查找方法的功能。
|
||||
|
||||
2.(Jupyter Notebook 专用)你也可以通过在方法之后添加问号来查找方法的功能。
|
||||
|
||||
```
|
||||
# To look up what each method does in jupyter (doesnt work outside of jupyter)
|
||||
firstVariable.lower?
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
在 Jupyter 中查找每个方法的功能
|
||||
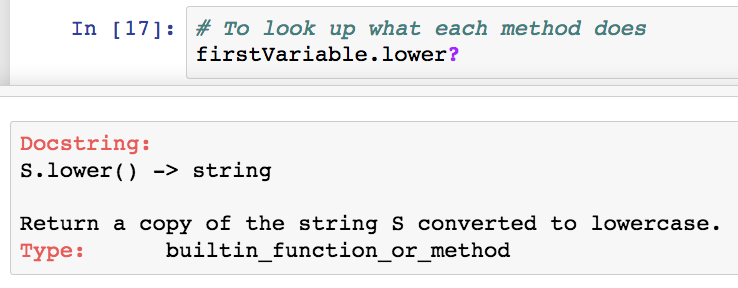
|
||||
|
||||
#### 结束语
|
||||
*在 Jupyter 中查找每个方法的功能*
|
||||
|
||||
如果你对本文或在[ YouTube 视频][2]的评论部分有任何疑问,请告诉我们。文章中的代码也可以在我的 [github][1] 上找到。本系列教程的第 2 部分是[简单的数学操作][10]。
|
||||
### 结束语
|
||||
|
||||
如果你对本文或在 [YouTube 视频][2]的评论部分有任何疑问,请告诉我们。文章中的代码也可以在我的 [GitHub][1] 上找到。本系列教程的第 2 部分是[简单的数学操作][10]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -115,7 +115,7 @@ via: https://www.codementor.io/mgalarny/python-hello-world-and-string-manipulati
|
||||
|
||||
作者:[Michael][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,113 @@
|
||||
使用 Zim 在你的 Linux 桌面上创建一个维基
|
||||
======
|
||||
|
||||
> 用强大而小巧的 Zim 在桌面上像维基一样管理信息。
|
||||
|
||||
|
||||
|
||||
不可否认<ruby>维基<rt>wiki</rt></ruby>的用处,即使对于一个极客来说也是如此。你可以用它做很多事——写笔记和手稿,协作项目,建立完整的网站。还有更多的事。
|
||||
|
||||
这些年来,我已经使用了几个维基,要么是为了我自己的工作,要么就是为了我接到的各种合同和全职工作。虽然传统的维基很好,但我真的喜欢[桌面版维基][1] 这个想法。它们体积小,易于安装和维护,甚至更容易使用。而且,正如你可能猜到的那样,有许多可以用在 Linux 中的桌面版维基。
|
||||
|
||||
让我们来看看更好的桌面版的 维基 之一: [Zim][2]。
|
||||
|
||||
### 开始吧
|
||||
|
||||
你可以从 Zim 的官网[下载][3]并安装 Zim,或者通过发行版的软件包管理器轻松地安装。
|
||||
|
||||
安装好了 Zim,就启动它。
|
||||
|
||||
在 Zim 中的一个关键概念是<ruby>笔记本<rt>notebook</rt></ruby>,它们就像某个单一主题的维基页面的集合。当你第一次启动 Zim 时,它要求你为你的笔记本指定一个文件夹和笔记本的名称。Zim 建议用 `Notes` 来表示文件夹的名称和指定文件夹为 `~/Notebooks/`。如果你愿意,你可以改变它。我是这么做的。
|
||||
|
||||
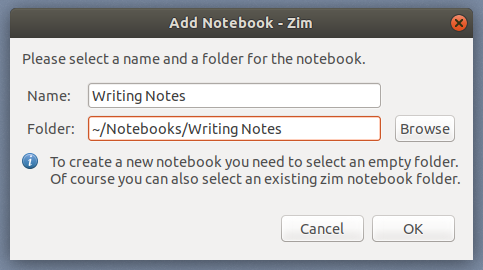
|
||||
|
||||
在为笔记本设置好名称和指定好文件夹后,单击 “OK” 。你得到的本质上是你的维基页面的容器。
|
||||
|
||||
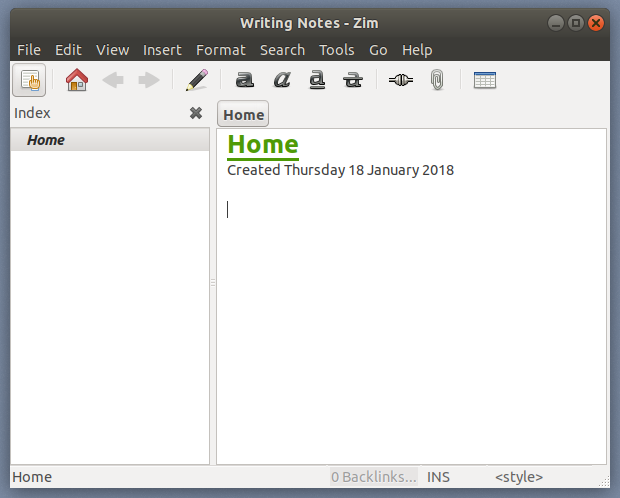
|
||||
|
||||
### 将页面添加到笔记本
|
||||
|
||||
所以你有了一个容器。那现在怎么办?你应该开始往里面添加页面。当然,为此,选择 “File > New Page”。
|
||||
|
||||
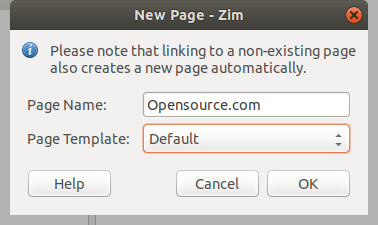
|
||||
|
||||
输入该页面的名称,然后单击 “OK”。从那里开始,你可以开始输入信息以向该页面添加信息。
|
||||
|
||||
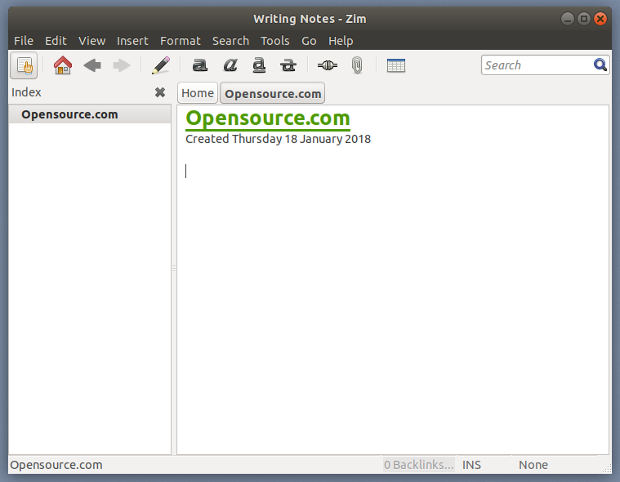
|
||||
|
||||
这一页可以是你想要的任何内容:你正在选修的课程的笔记、一本书或者一片文章或论文的大纲,或者是你的书的清单。这取决于你。
|
||||
|
||||
Zim 有一些格式化的选项,其中包括:
|
||||
|
||||
* 标题
|
||||
* 字符格式
|
||||
* 圆点和编号清单
|
||||
* 核对清单
|
||||
|
||||
你可以添加图片和附加文件到你的维基页面,甚至可以从文本文件中提取文本。
|
||||
|
||||
### Zim 的维基语法
|
||||
|
||||
你可以使用工具栏向一个页面添加格式。但这不是唯一的方法。如果你像我一样是个老派人士,你可以使用维基标记来进行格式化。
|
||||
|
||||
[Zim 的标记][4] 是基于在 [DokuWiki][5] 中使用的标记。它本质上是有一些小变化的 [WikiText][6] 。例如,要创建一个子弹列表,输入一个星号(`*`)。用两个星号包围一个单词或短语来使它加黑。
|
||||
|
||||
### 添加链接
|
||||
|
||||
如果你在笔记本上有一些页面,很容易将它们联系起来。有两种方法可以做到这一点。
|
||||
|
||||
第一种方法是使用 [驼峰命名法][7] 来命名这些页面。假设我有个叫做 “Course Notes” 的笔记本。我可以通过输入 “AnalysisCourse” 来重命名为我正在学习的数据分析课程。 当我想从笔记本的另一个页面链接到它时,我只需要输入 “AnalysisCourse” 然后按下空格键。即时超链接。
|
||||
|
||||
第二种方法是点击工具栏上的 “Insert link” 按钮。 在 “Link to” 中输入你想要链接到的页面的名称,从显示的列表中选择它,然后点击 “Link”。
|
||||
|
||||
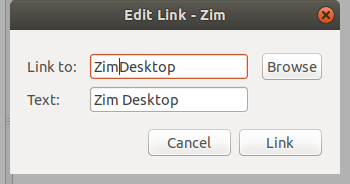
|
||||
|
||||
我只能在同一个笔记本中的页面之间进行链接。每当我试图连接到另一个笔记本中的一个页面时,这个文件(有 .txt 的后缀名)总是在文本编辑器中被打开。
|
||||
|
||||
### 输出你的维基页面
|
||||
|
||||
也许有一天你会想在别的地方使用笔记本上的信息 —— 比如,在一份文件或网页上。你可以将笔记本页面导出到以下格式中的任何一种。而不是复制和粘贴(和丢失格式):
|
||||
|
||||
* HTML
|
||||
* LaTeX
|
||||
* Markdown
|
||||
* ReStructuredText
|
||||
|
||||
为此,点击你想要导出的维基页面。然后,选择 “File > Export”。决定是要导出整个笔记本还是一个页面,然后点击 “Forward”。
|
||||
|
||||
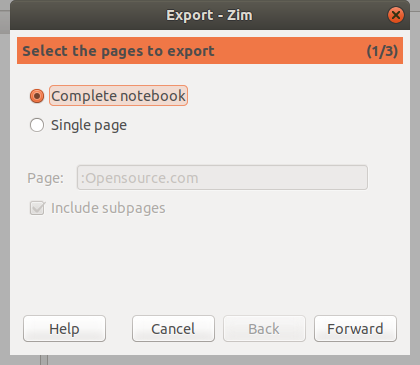
|
||||
|
||||
选择要用来保存页面或笔记本的文件格式。使用 HTML 和 LaTeX,你可以选择一个模板。 随便看看什么最适合你。 例如,如果你想把你的维基页面变成 HTML 演示幻灯片,你可以在 “Template” 中选择 “SlideShow s5”。 如果你想知道,这会产生由 [S5 幻灯片框架][8]驱动的幻灯片。
|
||||
|
||||
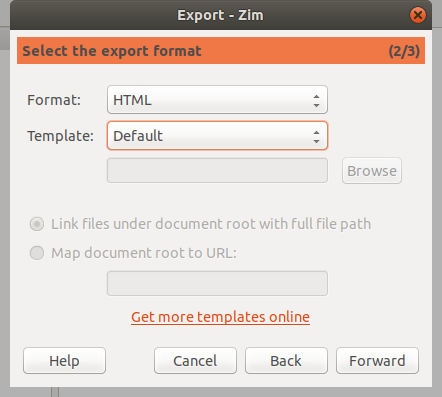
|
||||
|
||||
点击 “Forward”,如果你在导出一个笔记本,你可以选择将页面作为单个文件或一个文件导出。 你还可以指向要保存导出文件的文件夹。
|
||||
|
||||
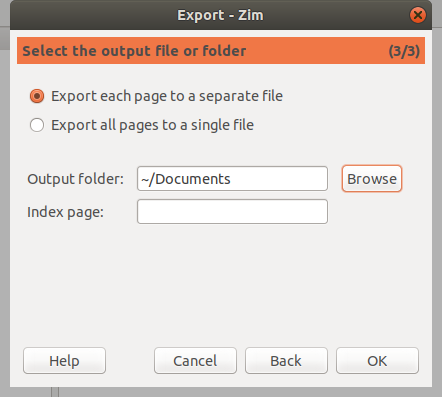
|
||||
|
||||
### Zim 能做的就这些吗?
|
||||
|
||||
远远不止这些,还有一些 [插件][9] 可以扩展它的功能。它甚至包含一个内置的 Web 服务器,可以让你将你的笔记本作为静态的 HTML 文件。这对于在内部网络上分享你的页面和笔记本是非常有用的。
|
||||
|
||||
总的来说,Zim 是一个用来管理你的信息的强大而又紧凑的工具。这是我使用过的最好的桌面版维基,而且我一直在使用它。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/create-wiki-your-linux-desktop-zim
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
译者:[Auk7F7](https://github.com/Auk7F7)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:https://opensource.com/article/17/2/3-desktop-wikis
|
||||
[2]:http://zim-wiki.org/
|
||||
[3]:http://zim-wiki.org/downloads.html
|
||||
[4]:http://zim-wiki.org/manual/Help/Wiki_Syntax.html
|
||||
[5]:https://www.dokuwiki.org/wiki:syntax
|
||||
[6]:http://en.wikipedia.org/wiki/Wikilink
|
||||
[7]:https://en.wikipedia.org/wiki/Camel_case
|
||||
[8]:https://meyerweb.com/eric/tools/s5/
|
||||
[9]:http://zim-wiki.org/manual/Plugins.html
|
||||
@ -1,104 +0,0 @@
|
||||
[fuzheng1998 tranlating]
|
||||
我是如何创造“开源”这个词的
|
||||
============================================================
|
||||
|
||||
### Christine Peterson 最终发布了对于二十年前那决定命运一天的陈述。
|
||||
|
||||

|
||||
图片来自: opensource.com
|
||||
|
||||
In a few days, on February 3, the 20th anniversary of the introduction of the term "[开源软件][6]" is upon us. As open source software grows in popularity and powers some of the most robust and important innovations of our time, we reflect on its rise to prominence.
|
||||
|
||||
I am the originator of the term "open source software" and came up with it while executive director at Foresight Institute. Not a software developer like the rest, I thank Linux programmer Todd Anderson for supporting the term and proposing it to the group.
|
||||
|
||||
This is my account of how I came up with it, how it was proposed, and the subsequent reactions. Of course, there are a number of accounts of the coining of the term, for example by Eric Raymond and Richard Stallman, yet this is mine, written on January 2, 2006.
|
||||
|
||||
直到今天,它才公诸于世。
|
||||
|
||||
* * *
|
||||
|
||||
The introduction of the term "open source software" was a deliberate effort to make this field of endeavor more understandable to newcomers and to business, which was viewed as necessary to its spread to a broader community of users. The problem with the main earlier label, "free software," was not its political connotations, but that—to newcomers—its seeming focus on price is distracting. A term was needed that focuses on the key issue of source code and that does not immediately confuse those new to the concept. The first term that came along at the right time and fulfilled these requirements was rapidly adopted: open source.
|
||||
|
||||
This term had long been used in an "intelligence" (i.e., spying) context, but to my knowledge, use of the term with respect to software prior to 1998 has not been confirmed. The account below describes how the term [open source software][7] caught on and became the name of both an industry and a movement.
|
||||
|
||||
### 计算机安全会议
|
||||
|
||||
In late 1997, weekly meetings were being held at Foresight Institute to discuss computer security. Foresight is a nonprofit think tank focused on nanotechnology and artificial intelligence, and software security is regarded as central to the reliability and security of both. We had identified free software as a promising approach to improving software security and reliability and were looking for ways to promote it. Interest in free software was starting to grow outside the programming community, and it was increasingly clear that an opportunity was coming to change the world. However, just how to do this was unclear, and we were groping for strategies.
|
||||
|
||||
At these meetings, we discussed the need for a new term due to the confusion factor. The argument was as follows: those new to the term "free software" assume it is referring to the price. Oldtimers must then launch into an explanation, usually given as follows: "We mean free as in freedom, not free as in beer." At this point, a discussion on software has turned into one about the price of an alcoholic beverage. The problem was not that explaining the meaning is impossible—the problem was that the name for an important idea should not be so confusing to newcomers. A clearer term was needed. No political issues were raised regarding the free software term; the issue was its lack of clarity to those new to the concept.
|
||||
|
||||
### 网景发布
|
||||
|
||||
On February 2, 1998, Eric Raymond arrived on a visit to work with Netscape on the plan to release the browser code under a free-software-style license. We held a meeting that night at Foresight's office in Los Altos to strategize and refine our message. In addition to Eric and me, active participants included Brian Behlendorf, Michael Tiemann, Todd Anderson, Mark S. Miller, and Ka-Ping Yee. But at that meeting, the field was still described as free software or, by Brian, "source code available" software.
|
||||
|
||||
While in town, Eric used Foresight as a base of operations. At one point during his visit, he was called to the phone to talk with a couple of Netscape legal and/or marketing staff. When he was finished, I asked to be put on the phone with them—one man and one woman, perhaps Mitchell Baker—so I could bring up the need for a new term. They agreed in principle immediately, but no specific term was agreed upon.
|
||||
|
||||
Between meetings that week, I was still focused on the need for a better name and came up with the term "open source software." While not ideal, it struck me as good enough. I ran it by at least four others: Eric Drexler, Mark Miller, and Todd Anderson liked it, while a friend in marketing and public relations felt the term "open" had been overused and abused and believed we could do better. He was right in theory; however, I didn't have a better idea, so I thought I would try to go ahead and introduce it. In hindsight, I should have simply proposed it to Eric Raymond, but I didn't know him well at the time, so I took an indirect strategy instead.
|
||||
|
||||
Todd had agreed strongly about the need for a new term and offered to assist in getting the term introduced. This was helpful because, as a non-programmer, my influence within the free software community was weak. My work in nanotechnology education at Foresight was a plus, but not enough for me to be taken very seriously on free software questions. As a Linux programmer, Todd would be listened to more closely.
|
||||
|
||||
### 关键的会议
|
||||
|
||||
Later that week, on February 5, 1998, a group was assembled at VA Research to brainstorm on strategy. Attending—in addition to Eric Raymond, Todd, and me—were Larry Augustin, Sam Ockman, and attending by phone, Jon "maddog" Hall.
|
||||
|
||||
The primary topic was promotion strategy, especially which companies to approach. I said little, but was looking for an opportunity to introduce the proposed term. I felt that it wouldn't work for me to just blurt out, "All you technical people should start using my new term." Most of those attending didn't know me, and for all I knew, they might not even agree that a new term was greatly needed, or even somewhat desirable.
|
||||
|
||||
Fortunately, Todd was on the ball. Instead of making an assertion that the community should use this specific new term, he did something less directive—a smart thing to do with this community of strong-willed individuals. He simply used the term in a sentence on another topic—just dropped it into the conversation to see what happened. I went on alert, hoping for a response, but there was none at first. The discussion continued on the original topic. It seemed only he and I had noticed the usage.
|
||||
|
||||
Not so—memetic evolution was in action. A few minutes later, one of the others used the term, evidently without noticing, still discussing a topic other than terminology. Todd and I looked at each other out of the corners of our eyes to check: yes, we had both noticed what happened. I was excited—it might work! But I kept quiet: I still had low status in this group. Probably some were wondering why Eric had invited me at all.
|
||||
|
||||
Toward the end of the meeting, the [question of terminology][8] was brought up explicitly, probably by Todd or Eric. Maddog mentioned "freely distributable" as an earlier term, and "cooperatively developed" as a newer term. Eric listed "free software," "open source," and "sourceware" as the main options. Todd advocated the "open source" model, and Eric endorsed this. I didn't say much, letting Todd and Eric pull the (loose, informal) consensus together around the open source name. It was clear that to most of those at the meeting, the name change was not the most important thing discussed there; a relatively minor issue. Only about 10% of my notes from this meeting are on the terminology question.
|
||||
|
||||
But I was elated. These were some key leaders in the community, and they liked the new name, or at least didn't object. This was a very good sign. There was probably not much more I could do to help; Eric Raymond was far better positioned to spread the new meme, and he did. Bruce Perens signed on to the effort immediately, helping set up [Opensource.org][9] and playing a key role in spreading the new term.
|
||||
|
||||
For the name to succeed, it was necessary, or at least highly desirable, that Tim O'Reilly agree and actively use it in his many projects on behalf of the community. Also helpful would be use of the term in the upcoming official release of the Netscape Navigator code. By late February, both O'Reilly & Associates and Netscape had started to use the term.
|
||||
|
||||
### 名字的诞生
|
||||
|
||||
After this, there was a period during which the term was promoted by Eric Raymond to the media, by Tim O'Reilly to business, and by both to the programming community. It seemed to spread very quickly.
|
||||
|
||||
On April 7, 1998, Tim O'Reilly held a meeting of key leaders in the field. Announced in advance as the first "[Freeware Summit][10]," by April 14 it was referred to as the first "[Open Source Summit][11]."
|
||||
|
||||
These months were extremely exciting for open source. Every week, it seemed, a new company announced plans to participate. Reading Slashdot became a necessity, even for those like me who were only peripherally involved. I strongly believe that the new term was helpful in enabling this rapid spread into business, which then enabled wider use by the public.
|
||||
|
||||
A quick Google search indicates that "open source" appears more often than "free software," but there still is substantial use of the free software term, which remains useful and should be included when communicating with audiences who prefer it.
|
||||
|
||||
### A happy twinge
|
||||
|
||||
When an [early account][12] of the terminology change written by Eric Raymond was posted on the Open Source Initiative website, I was listed as being at the VA brainstorming meeting, but not as the originator of the term. This was my own fault; I had neglected to tell Eric the details. My impulse was to let it pass and stay in the background, but Todd felt otherwise. He suggested to me that one day I would be glad to be known as the person who coined the name "open source software." He explained the situation to Eric, who promptly updated his site.
|
||||
|
||||
Coming up with a phrase is a small contribution, but I admit to being grateful to those who remember to credit me with it. Every time I hear it, which is very often now, it gives me a little happy twinge.
|
||||
|
||||
The big credit for persuading the community goes to Eric Raymond and Tim O'Reilly, who made it happen. Thanks to them for crediting me, and to Todd Anderson for his role throughout. The above is not a complete account of open source history; apologies to the many key players whose names do not appear. Those seeking a more complete account should refer to the links in this article and elsewhere on the net.
|
||||
|
||||
### 关于作者
|
||||
|
||||
[][13] Christine Peterson - Christine Peterson writes, lectures, and briefs the media on coming powerful technologies, especially nanotechnology, artificial intelligence, and longevity. She is Cofounder and Past President of Foresight Institute, the leading nanotech public interest group. Foresight educates the public, technical community, and policymakers on coming powerful technologies and how to guide their long-term impact. She serves on the Advisory Board of the [Machine Intelligence... ][2][more about Christine Peterson][3][More about me][4]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/coining-term-open-source-software
|
||||
|
||||
作者:[ Christine Peterson][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/christine-peterson
|
||||
[1]:https://opensource.com/article/18/2/coining-term-open-source-software?rate=HFz31Mwyy6f09l9uhm5T_OFJEmUuAwpI61FY-fSo3Gc
|
||||
[2]:http://intelligence.org/
|
||||
[3]:https://opensource.com/users/christine-peterson
|
||||
[4]:https://opensource.com/users/christine-peterson
|
||||
[5]:https://opensource.com/user/206091/feed
|
||||
[6]:https://opensource.com/resources/what-open-source
|
||||
[7]:https://opensource.org/osd
|
||||
[8]:https://wiki2.org/en/Alternative_terms_for_free_software
|
||||
[9]:https://opensource.org/
|
||||
[10]:http://www.oreilly.com/pub/pr/636
|
||||
[11]:http://www.oreilly.com/pub/pr/796
|
||||
[12]:https://ipfs.io/ipfs/QmXoypizjW3WknFiJnKLwHCnL72vedxjQkDDP1mXWo6uco/wiki/Alternative_terms_for_free_software.html
|
||||
[13]:https://opensource.com/users/christine-peterson
|
||||
[14]:https://opensource.com/users/christine-peterson
|
||||
[15]:https://opensource.com/users/christine-peterson
|
||||
[16]:https://opensource.com/article/18/2/coining-term-open-source-software#comments
|
||||
@ -0,0 +1,89 @@
|
||||
How to apply systems thinking in DevOps
|
||||
======
|
||||
|
||||

|
||||
For most organizations, adopting DevOps requires a mindset shift. Unless you understand the core of [DevOps][1], you might think it's hype or just another buzzword—or worse, you might believe you have already adopted DevOps because you are using the right tools.
|
||||
|
||||
Let’s dig deeper into what DevOps means, and explore how to apply systems thinking in your organization.
|
||||
|
||||
### What is systems thinking?
|
||||
|
||||
Systems thinking is a holistic approach to problem-solving. It's the opposite of analytical thinking, which separates a problem from the "bigger picture" to better understand it. Instead, systems thinking studies all the elements of a problem, along with the interactions between these elements.
|
||||
|
||||
Most people are not used to thinking this way. Since childhood, most of us were taught math, science, and every other subject separately, by different teachers. This approach to learning follows us throughout our lives, from school to university to the workplace. When we first join an organization, we typically work in only one department.
|
||||
|
||||
Unfortunately, the world is not that simple. Complexity, unpredictability, and sometimes chaos are unavoidable and require a broader way of thinking. Systems thinking helps us understand the systems we are part of, which in turn enables us to manage them rather than be controlled by them.
|
||||
|
||||
According to systems thinking, everything is a system: your body, your family, your neighborhood, your city, your company, and even the communities you belong to. These systems evolve organically; they are alive and fluid. The better you understand a system's behavior, the better you can manage and leverage it. You become their change agent and are accountable for them.
|
||||
|
||||
### Systems thinking and DevOps
|
||||
|
||||
All systems include properties that DevOps addresses through its practices and tools. Awareness of these properties helps us properly adapt to DevOps. Let's look at the properties of a system and how DevOps relates to each one.
|
||||
|
||||
### How systems work
|
||||
|
||||
The figure below represents a system. To reach a goal, the system requires input, which is processed and generates output. Feedback is essential for moving the system toward the goal. Without a purpose, the system dies.
|
||||
|
||||

|
||||
|
||||
If an organization is a system, its departments are subsystems. The flow of work moves through each department, starting with identifying a market need (the first input on the left) and moving toward releasing a solution that meets that need (the last output on the right). The output that each department generates serves as required input for the next department in the chain.
|
||||
|
||||
The more specialized teams an organization has, the more handoffs happen between departments. The process of generating value to clients is more likely to create bottlenecks and thus it takes longer to deliver value. Also, when work is passed between teams, the gap between the goal and what has been done widens.
|
||||
|
||||
DevOps aims to optimize the flow of work throughout the organization to deliver value to clients faster—in other words, DevOps reduces time to market. This is done in part by maximizing automation, but mainly by targeting the organization's goals. This empowers prioritization and reduces duplicated work and other inefficiencies that happen during the delivery process.
|
||||
|
||||
### System deterioration
|
||||
|
||||
All systems are affected by entropy. Nothing can prevent system degradation; that's irreversible. The tendency to decline shows the failure nature of systems. Moreover, systems are subject to threats of all types, and failure is a matter of time.
|
||||
|
||||
To mitigate entropy, systems require constant maintenance and improvements. The effects of entropy can be delayed only when new actions are taken or input is changed.
|
||||
|
||||
This pattern of deterioration and its opposite force, survival, can be observed in living organisms, social relationships, and other systems as well as in organizations. In fact, if an organization is not evolving, entropy is guaranteed to be increasing.
|
||||
|
||||
DevOps attempts to break the entropy process within an organization by fostering continuous learning and improvement. With DevOps, the organization becomes fault-tolerant because it recognizes the inevitability of failure. DevOps enables a blameless culture that offers the opportunity to learn from failure. The [postmortem][2] is an example of a DevOps practice used by organizations that embrace inherent failure.
|
||||
|
||||
The idea of intentionally embracing failure may sound counterintuitive, but that's exactly what happens in techniques like [Chaos Monkey][3]: Failure is intentionally introduced to improve availability and reliability in the system. DevOps suggests that putting some pressure into the system in a controlled way is not a bad thing. Like a muscle that gets stronger with exercise, the system benefits from the challenge.
|
||||
|
||||
### System complexity
|
||||
|
||||
The figure below shows how complex the systems can be. In most cases, one effect can have multiple causes, and one cause can generate multiple effects. The more elements and interactions a system has, the more complex the system.
|
||||
|
||||

|
||||
|
||||
In this scenario, we can't immediately identify the reason for a particular event. Likewise, we can't predict with 100% certainty what will happen if a specific action is taken. We are constantly making assumptions and dealing with hypotheses.
|
||||
|
||||
System complexity can be explained using the scientific method. In a recent study, for example, mice that were fed excess salt showed suppressed cerebral blood flow. This same experiment would have had different results if, say, the mice were fed sugar and salt. One variable can radically change results in complex systems.
|
||||
|
||||
DevOps handles complexity by encouraging experimentation—for example, using the scientific method—and reducing feedback cycles. Smaller changes inserted into the system can be tested and validated more quickly. With a "[fail-fast][4]" approach, organizations can pivot quickly and achieve resiliency. Reacting rapidly to changes makes organizations more adaptable.
|
||||
|
||||
DevOps also aims to minimize guesswork and maximize understanding by making the process of delivering value more tangible. By measuring processes, revealing flaws and advantages, and monitoring as much as possible, DevOps helps organizations discover the changes they need to make.
|
||||
|
||||
### System limitations
|
||||
|
||||
All systems have constraints that limit their performance; a system's overall capacity is delimited by its restrictions. Most of us have learned from experience that systems operating too long at full capacity can crash, and most systems work better when they function with some slack. Ignoring limitations puts systems at risk. For example, when we are under too much stress for a long time, we get sick. Similarly, overused vehicle engines can be damaged.
|
||||
|
||||
This principle also applies to organizations. Unfortunately, organizations can't put everything into a system at once. Although this limitation may sometimes lead to frustration, the quality of work usually improves when input is reduced.
|
||||
|
||||
Consider what happened when the speed limit on the main roads in São Paulo, Brazil was reduced from 90 km/h to 70 km/h. Studies showed that the number of accidents decreased by 38.5% and the average speed increased by 8.7%. In other words, the entire road system improved and more vehicles arrived safely at their destinations.
|
||||
|
||||
For organizations, DevOps suggests global rather than local improvements. It doesn't matter if some improvement is put after a constraint because there's no effect on the system at all. One constraint that DevOps addresses, for instance, is dependency on specialized teams. DevOps brings to organizations a more collaborative culture, knowledge sharing, and cross-functional teams.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Before adopting DevOps, understand what is involved and how you want to apply it to your organization. Systems thinking will help you accomplish that while also opening your mind to new possibilities. DevOps may be seen as a popular trend today, but in 10 or 20 years, it will be status quo.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/how-apply-systems-thinking-devops
|
||||
|
||||
作者:[Gustavo Muniz do Carmo][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/gustavomcarmo
|
||||
[1]:https://opensource.com/tags/devops
|
||||
[2]:https://landing.google.com/sre/book/chapters/postmortem-culture.html
|
||||
[3]:https://medium.com/netflix-techblog/the-netflix-simian-army-16e57fbab116
|
||||
[4]:https://en.wikipedia.org/wiki/Fail-fast
|
||||
@ -0,0 +1,63 @@
|
||||
Pi Day: 12 fun facts and ways to celebrate
|
||||
======
|
||||
|
||||

|
||||
Today, tech teams around the world will celebrate a number. March 14 (written 3/14 in the United States) is known as Pi Day, a holiday that people ring in with pie eating contests, pizza parties, and math puns. If the most important number in mathematics wasn’t enough of a reason to reach for a slice of pie, March 14 also happens to be Albert Einstein’s birthday, the release anniversary of Linux kernel 1.0.0, and the day Eli Whitney patented the cotton gin.
|
||||
|
||||
In honor of this special day, we’ve rounded up a dozen fun facts and interesting pi-related projects. Master you team’s Pi Day trivia, or borrow an idea or two for a team-building exercise. Do a project with a budding technologist. And let us know in the comments if you are doing anything unique to celebrate everyone’s favorite never-ending number.
|
||||
|
||||
### Pi Day celebrations:
|
||||
|
||||
* Today is the 30th anniversary of Pi Day. The first was held in 1988 in San Francisco at the Exploratorium by physicist Larry Shaw. “On [the first Pi Day][1], staff brought in fruit pies and a tea urn for the celebration. At 1:59 – the pi numbers that follow 3.14 – Shaw led a circular parade around the museum with his boombox blaring the digits of pi to the music of ‘Pomp and Circumstance.’” It wasn’t until 21 years later, March 2009, that Pi Day became an official national holiday in the U.S.
|
||||
* Although it started in San Francisco, one of the biggest Pi Day celebrations can be found in Princeton. The town holds a [number of events][2] over the course of five days, including an Einstein look-alike contest, a pie-throwing event, and a pi recitation competition. Some of the activities even offer a cash prize of $314.15 for the winner.
|
||||
* MIT Sloan School of Management (on Twitter as [@MITSloan][3]) is celebrating Pi Day with fun facts about pi – and pie. Follow along with the Twitter hashtag #PiVersusPie
|
||||
|
||||
|
||||
|
||||
### Pi-related projects and activities:
|
||||
|
||||
* If you want to keep your math skills sharpened, NASA Jet Propulsion Lab has posted a [new set of math problems][4] that illustrate how pi can be used to unlock the mysteries of space. This marks the fifth year of NASA’s Pi Day Challenge, geared toward students.
|
||||
* There's no better way to get into the spirit of Pi Day than to take on a [Raspberry Pi][5] project. Whether you are looking for a project to do with your kids or with your team, there’s no shortage of ideas out there. Since its launch in 2012, millions of the basic computer boards have been sold. In fact, it’s the [third best-selling general purpose computer][6] of all time. Here are a few Raspberry Pi projects and activities that caught our eye:
|
||||
* Grab an AIY (AI-Yourself) kit from Google. You can create a [voice-controlled digital assistant][7] or an [image-recognition device][8].
|
||||
* [Run Kubernetes][9] on a Raspberry Pi.
|
||||
* Save Princess Peach by building a [retro gaming system][10].
|
||||
* Host a [Raspberry Jam][11] with your team. The Raspberry Pi Foundation has released a [Guidebook][12] to make hosting easy. According to the website, Raspberry Jams provide, “a support network for people of all ages in digital making. All around the world, like-minded people meet up to discuss and share their latest projects, give workshops, and chat about all things Pi.”
|
||||
|
||||
|
||||
|
||||
### Other fun Pi facts:
|
||||
|
||||
* The current [world record holder][13] for reciting pi is Suresh Kumar Sharma, who in October 2015 recited 70,030 digits. It took him 17 hours and 14 minutes to do so. However, the [unofficial record][14] goes to Akira Haraguchi, who claims he can recite up to 111,700 digits.
|
||||
* And, there’s more to remember than ever before. In November 2016, R&D scientist Peter Trueb calculated 22,459,157,718,361 digits of pi – [9 trillion more digits][15] than the previous world record set in 2013. According to New Scientist, “The final file containing the 22 trillion digits of pi is nearly 9 terabytes in size. If printed out, it would fill a library of several million books containing a thousand pages each."
|
||||
|
||||
|
||||
|
||||
Happy Pi Day!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2018/3/pi-day-12-fun-facts-and-ways-celebrate
|
||||
|
||||
作者:[Carla Rudder][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://enterprisersproject.com/user/crudder
|
||||
[1]:https://www.exploratorium.edu/pi/pi-day-history
|
||||
[2]:https://princetontourcompany.com/activities/pi-day/
|
||||
[3]:https://twitter.com/MITSloan
|
||||
[4]:https://www.jpl.nasa.gov/news/news.php?feature=7074
|
||||
[5]:https://opensource.com/resources/raspberry-pi
|
||||
[6]:https://www.theverge.com/circuitbreaker/2017/3/17/14962170/raspberry-pi-sales-12-5-million-five-years-beats-commodore-64
|
||||
[7]:http://www.zdnet.com/article/raspberry-pi-this-google-kit-will-turn-your-pi-into-a-voice-controlled-digital-assistant/
|
||||
[8]:http://www.zdnet.com/article/google-offers-raspberry-pi-owners-this-new-ai-vision-kit-to-spot-cats-people-emotions/
|
||||
[9]:https://opensource.com/article/17/3/kubernetes-raspberry-pi
|
||||
[10]:https://opensource.com/article/18/1/retro-gaming
|
||||
[11]:https://opensource.com/article/17/5/how-run-raspberry-pi-meetup
|
||||
[12]:https://www.raspberrypi.org/blog/support-raspberry-jam-community/
|
||||
[13]:http://www.pi-world-ranking-list.com/index.php?page=lists&category=pi
|
||||
[14]:https://www.theguardian.com/science/alexs-adventures-in-numberland/2015/mar/13/pi-day-2015-memory-memorisation-world-record-japanese-akira-haraguchi
|
||||
[15]:https://www.newscientist.com/article/2124418-celebrate-pi-day-with-9-trillion-more-digits-than-ever-before/?utm_medium=Social&utm_campaign=Echobox&utm_source=Facebook&utm_term=Autofeed&cmpid=SOC%7CNSNS%7C2017-Echobox#link_time=1489480071
|
||||
@ -0,0 +1,111 @@
|
||||
6 ways a thriving community will help your project succeed
|
||||
======
|
||||
|
||||

|
||||
NethServer is an open source product that my company, [Nethesis][1], launched just a few years ago. [The product][2] wouldn't be [what it is today][3] without the vibrant community that surrounds and supports it.
|
||||
|
||||
In my previous article, I [discussed what organizations should expect to give][4] if they want to experience the benefits of thriving communities. In this article, I'll describe what organizations should expect to receive in return for their investments in the passionate people that make up their communities.
|
||||
|
||||
Let's review six benefits.
|
||||
|
||||
### 1\. Innovation
|
||||
|
||||
"Open innovation" occurs when a company sharing information also listens to the feedback and suggestions from outside the company. As a company, we don't just look at the crowd for ideas. We innovate in, with, and through communities.
|
||||
|
||||
You may know that "[the best way to have a good idea is to have a lot of ideas][5]." You can't always expect to have the right idea on your own, so having different point of views on your product is essential. How many truly disruptive ideas can a small company (like Nethesis) create? We're all young, caucasian, and European—while in our community, we can pick up a set of inspirations from a variety of people, with different genders, backgrounds, skills, and ethnicities.
|
||||
|
||||
So the ability to invite the entire world to continuously improve the product is now no longer a dream; it's happening before our eyes. Your community could be the idea factory for innovation. With the community, you can really leverage the power of the collective.
|
||||
|
||||
No matter who you are, most of the smartest people work for someone else. And community is the way to reach those smart people and work with them.
|
||||
|
||||
### 2\. Research
|
||||
|
||||
A community can be your strongest source of valuable product research.
|
||||
|
||||
First, it can help you avoid "ivory tower development." [As Stack Exchange co-founder Jeff Atwood has said][6], creating an environment where developers have no idea who the users are is dangerous. Isolated developers, who have worked for years in their high towers, often encounter bad results because they don't have any clue about how users actually use their software. Developing in an Ivory tower keeps you away from your users and can only lead to bad decisions. A community brings developers back to reality and helps them stay grounded. Gone are the days of developers working in isolation with limited resources. In this day and age, thanks to the advent of open source communities research department is opening up to the entire world.
|
||||
|
||||
No matter who you are, most of the smartest people work for someone else. And community is the way to reach those smart people and work with them.
|
||||
|
||||
Second, a community can be an obvious source of product feedback—always necessary as you're researching potential paths forward. If someone gives you feedback, it means that person cares about you. It's a big gift. The community is a good place to acquire such invaluable feedback. Receiving early feedback is super important, because it reduces the cost of developing something that doesn't work in your target market. You can safely fail early, fail fast, and fail often.
|
||||
|
||||
And third, communities help you generate comparisons with other projects. You can't know all the features, pros, and cons of your competitors' offerings. [The community, however, can.][7] Ask your community.
|
||||
|
||||
### 3\. Perspective
|
||||
|
||||
Communities enable companies to look at themselves and their products [from the outside][8], letting them catch strengths and weaknesses, and mostly realize who their products' audiences really are.
|
||||
|
||||
Let me offer an example. When we launched the NethServer, we chose a catchy tagline for it. We were all convinced the following sentence was perfect:
|
||||
|
||||
> [NethServer][9] is an operating system for Linux enthusiasts, designed for small offices and medium enterprises.
|
||||
|
||||
Two years have passed since then. And we've learned that sentence was an epic fail.
|
||||
|
||||
We failed to realize who our audience was. Now we know: NethServer is not just for Linux enthusiasts; actually, Windows users are the majority. It's not just for small offices and medium enterprises; actually, several home users install NethServer for personal use. Our community helps us to fully understand our product and look at it from our users' eyes.
|
||||
|
||||
### 4\. Development
|
||||
|
||||
In open source communities especially, communities can be a welcome source of product development.
|
||||
|
||||
They can, first of all, provide testing and bug reporting. In fact, if I ask my developers about the most important community benefit, they'd answer "testing and bug reporting." Definitely. But because your code is freely available to the whole world, practically anyone with a good working knowledge of it (even hobbyists and other companies) has the opportunity to play with it, tweak it, and constantly improve it (even develop additional modules, as in our case). People can do more than just report bugs; they can fix those bugs, too, if they have the time and knowledge.
|
||||
|
||||
But the community doesn't just create code. It can also generate resources like [how-to guides,][10] FAQs, support documents, and case studies. How much would it cost to fully translate your product in seven different languages? At NethServer, we got that for free—thanks to our community members.
|
||||
|
||||
### 5\. Marketing
|
||||
|
||||
Communities can help your company go global. Our small Italian company, for example, wasn't prepared for a global market. The community got us prepared. For example, we needed to study and improve our English so we could read and write correctly or speak in public without looking foolish for an audience. The community gently forced us to organize [our first NethServer Conference][11], too—only in English.
|
||||
|
||||
A strong community can also help your organization attain the holy grail of marketers everywhere: word of mouth marketing (or what Seth Godin calls "[tribal marketing][12]").
|
||||
|
||||
Communities ensure that your company's messaging travels not only from company to tribe but also "sideways," from tribe member to potential tribe member. The community will become your street team, spreading word of your organization and its projects to anyone who will listen.
|
||||
|
||||
In addition, communities help organizations satisfy one of the most fundamental members needs: the desire to belong, to be involved in something bigger than themselves, and to change the world together.
|
||||
|
||||
Never forget that working with communities is always a matter of giving and taking—striking a delicate balance between the company and the community.
|
||||
|
||||
### 6\. Loyalty
|
||||
|
||||
Attracting new users costs a business five times as much as keeping an existing one. So loyalty can have a huge impact on your bottom line. Quite simply, community helps us build brand loyalty. It's much more difficult to leave a group of people you're connected to than a faceless product or company. In a community, you're building connections with people, which is way more powerful than features or money (trust me!).
|
||||
|
||||
### Conclusion
|
||||
|
||||
Never forget that working with communities is always a matter of giving and taking—striking a delicate balance between the company and the community.
|
||||
|
||||
And I wouldn't be honest with you if I didn't admit that the approach has some drawbacks. Doing everything in the open means moderating, evaluating, and processing of all the data you're receiving. Supporting your members and leading the discussions definitely takes time and resources. But, if you look at what a community enables, you'll see that all this is totally worth the effort.
|
||||
|
||||
As my friend and mentor [David Spinks keeps saying over and over again][13], "Companies fail their communities when when they treat community as a tactic instead of making it a core part of their business philosophy." And [as I've said][4]: Communities aren't simply extensions of your marketing teams; "community" isn't an efficient short-term strategy. When community is a core part of your business philosophy, it can do so much more than give you short-term returns.
|
||||
|
||||
At Nethesis we experience that every single day. As a small company, we could never have achieved the results we have without our community. Never.
|
||||
|
||||
Community can completely set your business apart from every other company in the field. It can redefine markets. It can inspire millions of people, give them a sense of belonging, and make them feel an incredible bond with your company.
|
||||
|
||||
And it can make you a whole lot of money.
|
||||
|
||||
Community-driven companies will always win. Remember that.
|
||||
|
||||
[Subscribe to our weekly newsletter][14] to learn more about open organizations.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/18/3/why-build-community-3
|
||||
|
||||
作者:[Alessio Fattorini][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/alefattorini
|
||||
[1]:http://www.nethesis.it/
|
||||
[2]:https://www.nethserver.org/
|
||||
[3]:https://distrowatch.com/table.php?distribution=nethserver
|
||||
[4]:https://opensource.com/open-organization/18/2/why-build-community-2
|
||||
[5]:https://www.goodreads.com/author/quotes/52938.Linus_Pauling
|
||||
[6]:https://blog.codinghorror.com/ivory-tower-development/
|
||||
[7]:https://community.nethserver.org/tags/comparison
|
||||
[8]:https://community.nethserver.org/t/improve-our-communication/2569
|
||||
[9]:http://www.nethserver.org/
|
||||
[10]:https://community.nethserver.org/c/howto
|
||||
[11]:https://community.nethserver.org/t/nethserver-conference-in-italy-sept-29-30-2017/6404
|
||||
[12]:https://www.ted.com/talks/seth_godin_on_the_tribes_we_lead
|
||||
[13]:http://cmxhub.com/article/community-business-philosophy-tactic/
|
||||
[14]:https://opensource.com/open-organization/resources/newsletter
|
||||
@ -0,0 +1,40 @@
|
||||
Lessons Learned from Growing an Open Source Project Too Fast
|
||||
======
|
||||
![open source project][1]
|
||||
|
||||
Are you managing an open source project or considering launching one? If so, it may come as a surprise that one of the challenges you can face is rapid growth. Matt Butcher, Principal Software Development Engineer at Microsoft, addressed this issue in a presentation at Open Source Summit North America. His talk covered everything from teamwork to the importance of knowing your goals and sticking to them.
|
||||
|
||||
Butcher is no stranger to managing open source projects. As [Microsoft invests more deeply into open source][2], Butcher has been involved with many projects, including toolkits for Kubernetes and QueryPath, the jQuery-like library for PHP.
|
||||
|
||||
Butcher described a case study involving Kubernetes Helm, a package system for Kubernetes. Helm arose from a company team-building hackathon, with an original team of three people giving birth to it. Within 18 months, the project had hundreds of contributors and thousands of active users.
|
||||
|
||||
### Teamwork
|
||||
|
||||
“We were stretched to our limits as we learned to grow,” Butcher said. “When you’re trying to set up your team of core maintainers and they’re all trying to work together, you want to spend some actual time trying to optimize for a process that lets you be cooperative. You have to adjust some expectations regarding how you treat each other. When you’re working as a group of open source collaborators, the relationship is not employer/employee necessarily. It’s a collaborative effort.”
|
||||
|
||||
In addition to focusing on the right kinds of teamwork, Butcher and his collaborators learned that managing governance and standards is an ongoing challenge. “You want people to understand who makes decisions, how they make decisions and why they make the decisions that they make,” he said. “When we were a small project, there might have been two paragraphs in one of our documents on standards, but as a project grows and you get growing pains, these documented things gain a life of their own. They get their very own repositories, and they just keep getting bigger along with the project.”
|
||||
|
||||
Should all discussion surrounding a open source project go on in public, bathed in the hot lights of community scrutiny? Not necessarily, Butcher noted. “A minor thing can get blown into catastrophic proportions in a short time because of misunderstandings and because something that should have been done in private ended up being public,” he said. “Sometimes we actually make architectural recommendations as a closed group. The reason we do this is that we don’t want to miscue the community. The people who are your core maintainers are core maintainers because they’re experts, right? These are the people that have been selected from the community because they understand the project. They understand what people are trying to do with it. They understand the frustrations and concerns of users.”
|
||||
|
||||
### Acknowledge Contributions
|
||||
|
||||
Butcher added that it is essential to acknowledge people’s contributions to keep the environment surrounding a fast-growing project from becoming toxic. “We actually have an internal rule in our core maintainers guide that says, ‘Make sure that at least one comment that you leave on a code review, if you’re asking for changes, is a positive one,” he said. “It sounds really juvenile, right? But it serves a specific purpose. It lets somebody know, ‘I acknowledge that you just made a gift of your time and your resources.”
|
||||
|
||||
Want more tips on successfully launching and managing open source projects? Stay tuned for more insight from Matt Butcher’s talk, in which he provides specific project management issues faced by Kubernetes Helm.
|
||||
|
||||
For more information, be sure to check out [The Linux Foundation’s growing list of Open Source Guides for the Enterprise][3], covering topics such as starting an open source project, improving your open source impact, and participating in open source communities.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxfoundation.org/blog/lessons-learned-from-growing-an-open-source-project-too-fast/
|
||||
|
||||
作者:[Sam Dean][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxfoundation.org/author/sdean/
|
||||
[1]:https://www.linuxfoundation.org/wp-content/uploads/2018/03/huskies-2279627_1920.jpg
|
||||
[2]:https://thenewstack.io/microsoft-shifting-emphasis-open-source/
|
||||
[3]:https://www.linuxfoundation.org/resources/open-source-guides/
|
||||
@ -0,0 +1,119 @@
|
||||
How to avoid humiliating newcomers: A guide for advanced developers
|
||||
======
|
||||
|
||||

|
||||
Every year in New York City, a few thousand young men come to town, dress up like Santa Claus, and do a pub crawl. One year during this SantaCon event, I was walking on the sidewalk and minding my own business, when I saw an extraordinary scene. There was a man dressed up in a red hat and red jacket, and he was talking to a homeless man who was sitting in a wheelchair. The homeless man asked Santa Claus, "Can you spare some change?" Santa dug into his pocket and brought out a $5 bill. He hesitated, then gave it to the homeless man. The homeless man put the bill in his pocket.
|
||||
|
||||
In an instant, something went wrong. Santa yelled at the homeless man, "I gave you $5. I wanted to give you one dollar, but five is the smallest I had, so you oughtta be grateful. This is your lucky day, man. You should at least say thank you!"
|
||||
|
||||
This was a terrible scene to witness. First, the power difference was terrible: Santa was an able-bodied white man with money and a home, and the other man was black, homeless, and using a wheelchair. It was also terrible because Santa Claus was dressed like the very symbol of generosity! And he was behaving like Santa until, in an instant, something went wrong and he became cruel.
|
||||
|
||||
This is not merely a story about Drunk Santa, however; this is a story about technology communities. We, too, try to be generous when we answer new programmers' questions, and every day our generosity turns to rage. Why?
|
||||
|
||||
### My cruelty
|
||||
|
||||
I'm reminded of my own bad behavior in the past. I was hanging out on my company's Slack when a new colleague asked a question.
|
||||
|
||||
> **New Colleague:** Hey, does anyone know how to do such-and-such with MongoDB?
|
||||
> **Jesse:** That's going to be implemented in the next release.
|
||||
> **New Colleague:** What's the ticket number for that feature?
|
||||
> **Jesse:** I memorize all ticket numbers. It's #12345.
|
||||
> **New Colleague:** Are you sure? I can't find ticket 12345.
|
||||
|
||||
He had missed my sarcasm, and his mistake embarrassed him in front of his peers. I laughed to myself, and then I felt terrible. As one of the most senior programmers at MongoDB, I should not have been setting this example. And yet, such behavior is commonplace among programmers everywhere: We get sarcastic with newcomers, and we humiliate them.
|
||||
|
||||
### Why does it matter?
|
||||
|
||||
Perhaps you are not here to make friends; you are here to write code. If the code works, does it matter if we are nice to each other or not?
|
||||
|
||||
A few months ago on the Stack Overflow blog, David Robinson showed that [Python has been growing dramatically][1], and it is now the top language that people view questions about on Stack Overflow. Even in the most pessimistic forecast, it will far outgrow the other languages this year.
|
||||
|
||||
![Projections for programming language popularity][2]
|
||||
|
||||
If you are a Python expert, then the line surging up and to the right is good news for you. It does not represent competition, but confirmation. As more new programmers learn Python, our expertise becomes ever more valuable, and we will see that reflected in our salaries, our job opportunities, and our job security.
|
||||
|
||||
But there is a danger. There are soon to be more new Python programmers than ever before. To sustain this growth, we must welcome them, and we are not always a welcoming bunch.
|
||||
|
||||
### The trouble with Stack Overflow
|
||||
|
||||
I searched Stack Overflow for rude answers to beginners' questions, and they were not hard to find.
|
||||
|
||||
![An abusive answer on StackOverflow][3]
|
||||
|
||||
The message is plain: If you are asking a question this stupid, you are doomed. Get out.
|
||||
|
||||
I immediately found another example of bad behavior:
|
||||
|
||||
![Another abusive answer on Stack Overflow][4]
|
||||
|
||||
Who has never been confused by Unicode in Python? Yet the message is clear: You do not belong here. Get out.
|
||||
|
||||
Do you remember how it felt when you needed help and someone insulted you? It feels terrible. And it decimates the community. Some of our best experts leave every day because they see us treating each other this way. Maybe they still program Python, but they are no longer participating in conversations online. This cruelty drives away newcomers, too, particularly members of groups underrepresented in tech who might not be confident they belong. People who could have become the great Python programmers of the next generation, but if they ask a question and somebody is cruel to them, they leave.
|
||||
|
||||
This is not in our interest. It hurts our community, and it makes our skills less valuable because we drive people out. So, why do we act against our own interests?
|
||||
|
||||
### Why generosity turns to rage
|
||||
|
||||
There are a few scenarios that really push my buttons. One is when I act generously but don't get the acknowledgment I expect. (I am not the only person with this resentment: This is probably why Drunk Santa snapped when he gave a $5 bill to a homeless man and did not receive any thanks.)
|
||||
|
||||
Another is when answering requires more effort than I expect. An example is when my colleague asked a question on Slack and followed-up with, "What's the ticket number?" I had judged how long it would take to help him, and when he asked for more help, I lost my temper.
|
||||
|
||||
These scenarios boil down to one problem: I have expectations for how things are going to go, and when those expectations are violated, I get angry.
|
||||
|
||||
I've been studying Buddhism for years, so my understanding of this topic is based in Buddhism. I like to think that the Buddha discussed the problem of expectations in his first tech talk when, in his mid-30s, he experienced a breakthrough after years of meditation and convened a small conference to discuss his findings. He had not rented a venue, so he sat under a tree. The attendees were a handful of meditators the Buddha had met during his wanderings in northern India. The Buddha explained that he had discovered four truths:
|
||||
|
||||
* First, that to be alive is to be dissatisfied—to want things to be better than they are now.
|
||||
* Second, this dissatisfaction is caused by wants; specifically, by our expectation that if we acquire what we want and eliminate what we do not want, it will make us happy for a long time. This expectation is unrealistic: If I get a promotion or if I delete 10 emails, it is temporarily satisfying, but it does not make me happy over the long-term. We are dissatisfied because every material thing quickly disappoints us.
|
||||
* The third truth is that we can be liberated from this dissatisfaction by accepting our lives as they are.
|
||||
* The fourth truth is that the way to transform ourselves is to understand our minds and to live a generous and ethical life.
|
||||
|
||||
|
||||
|
||||
I still get angry at people on the internet. It happened to me recently, when someone posted a comment on [a video I published about Python co-routines][5]. It had taken me months of research and preparation to create this video, and then a newcomer commented, "I want to master python what should I do."
|
||||
|
||||
![Comment on YouTube][6]
|
||||
|
||||
This infuriated me. My first impulse was to be sarcastic, "For starters, maybe you could spell Python with a capital P and end a question with a question mark." Fortunately, I recognized my anger before I acted on it, and closed the tab instead. Sometimes liberation is just a Command+W away.
|
||||
|
||||
### What to do about it
|
||||
|
||||
If you joined a community with the intent to be helpful but on occasion find yourself flying into a rage, I have a method to prevent this. For me, it is the step when I ask myself, "Am I angry?" Knowing is most of the battle. Online, however, we can lose track of our emotions. It is well-established that one reason we are cruel on the internet is because, without seeing or hearing the other person, our natural empathy is not activated. But the other problem with the internet is that, when we use computers, we lose awareness of our bodies. I can be angry and type a sarcastic message without even knowing I am angry. I do not feel my heart pound and my neck grow tense. So, the most important step is to ask myself, "How do I feel?"
|
||||
|
||||
If I am too angry to answer, I can usually walk away. As [Thumper learned in Bambi][7], "If you can't say something nice, don't say nothing at all."
|
||||
|
||||
### The reward
|
||||
|
||||
Helping a newcomer is its own reward, whether you receive thanks or not. But it does not hurt to treat yourself to a glass of whiskey or a chocolate, or just a sigh of satisfaction after your good deed.
|
||||
|
||||
But besides our personal rewards, the payoff for the Python community is immense. We keep the line surging up and to the right. Python continues growing, and that makes our own skills more valuable. We welcome new members, people who might not be sure they belong with us, by reassuring them that there is no such thing as a stupid question. We use Python to create an inclusive and diverse community around writing code. And besides, it simply feels good to be part of a community where people treat each other with respect. It is the kind of community that I want to be a member of.
|
||||
|
||||
### The three-breath vow
|
||||
|
||||
There is one idea I hope you remember from this article: To control our behavior online, we must occasionally pause and notice our feelings. I invite you, if you so choose, to repeat the following vow out loud:
|
||||
|
||||
> I vow
|
||||
> to take three breaths
|
||||
> before I answer a question online.
|
||||
|
||||
This article is based on a talk, [Why Generosity Turns To Rage, and What To Do About It][8], that Jesse gave at PyTennessee in February. For more insight for Python developers, attend [PyCon 2018][9], May 9-17 in Cleveland, Ohio.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/avoid-humiliating-newcomers
|
||||
|
||||
作者:[A. Jesse][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/emptysquare
|
||||
[1]:https://stackoverflow.blog/2017/09/06/incredible-growth-python/
|
||||
[2]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/projections.png?itok=5QTeJ4oe (Projections for programming language popularity)
|
||||
[3]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/abusive-answer-1.jpg?itok=BIWW10Rl (An abusive answer on StackOverflow)
|
||||
[4]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/abusive-answer-2.jpg?itok=0L-n7T-k (Another abusive answer on Stack Overflow)
|
||||
[5]:https://www.youtube.com/watch?v=7sCu4gEjH5I
|
||||
[6]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/i-want-to-master-python.png?itok=Y-2u1XwA (Comment on YouTube)
|
||||
[7]:https://www.youtube.com/watch?v=nGt9jAkWie4
|
||||
[8]:https://www.pytennessee.org/schedule/presentation/175/
|
||||
[9]:https://us.pycon.org/2018/
|
||||
104
sources/tech/20140107 Caffeinated 6.828- Exercise- Shell.md
Normal file
104
sources/tech/20140107 Caffeinated 6.828- Exercise- Shell.md
Normal file
@ -0,0 +1,104 @@
|
||||
Caffeinated 6.828: Exercise: Shell
|
||||
======
|
||||
|
||||
This assignment will make you more familiar with the Unix system call interface and the shell by implementing several features in a small shell. You can do this assignment on any operating system that supports the Unix API (a Linux Athena machine, your laptop with Linux or Mac OS, etc.). Please submit your shell to the the [submission web site][1] at any time before the first lecture.
|
||||
|
||||
While you shouldn't be shy about emailing the [staff mailing list][2] if you get stuck or don't understand something in this exercise, we do expect you to be able to handle this level of C programming on your own for the rest of the class. If you're not very familiar with C, consider this a quick check to see how familiar you are. Again, do feel encouraged to ask us for help if you have any questions.
|
||||
|
||||
Download the [skeleton][3] of the xv6 shell, and look it over. The skeleton shell contains two main parts: parsing shell commands and implementing them. The parser recognizes only simple shell commands such as the following:
|
||||
```
|
||||
ls > y
|
||||
cat < y | sort | uniq | wc > y1
|
||||
cat y1
|
||||
rm y1
|
||||
ls | sort | uniq | wc
|
||||
rm y
|
||||
|
||||
```
|
||||
|
||||
Cut and paste these commands into a file `t.sh`
|
||||
|
||||
You can compile the skeleton shell as follows:
|
||||
```
|
||||
$ gcc sh.c
|
||||
|
||||
```
|
||||
|
||||
which produces a file named `a.out`, which you can run:
|
||||
```
|
||||
$ ./a.out < t.sh
|
||||
|
||||
```
|
||||
|
||||
This execution will panic because you have not implemented several features. In the rest of this assignment you will implement those features.
|
||||
|
||||
### Executing simple commands
|
||||
|
||||
Implement simple commands, such as:
|
||||
```
|
||||
$ ls
|
||||
|
||||
```
|
||||
|
||||
The parser already builds an `execcmd` for you, so the only code you have to write is for the ' ' case in `runcmd`. To test that you can run "ls". You might find it useful to look at the manual page for `exec`; type `man 3 exec`.
|
||||
|
||||
You do not have to implement quoting (i.e., treating the text between double-quotes as a single argument).
|
||||
|
||||
### I/O redirection
|
||||
|
||||
Implement I/O redirection commands so that you can run:
|
||||
```
|
||||
echo "6.828 is cool" > x.txt
|
||||
cat < x.txt
|
||||
|
||||
```
|
||||
|
||||
The parser already recognizes '>' and '<', and builds a `redircmd` for you, so your job is just filling out the missing code in `runcmd` for those symbols. Make sure your implementation runs correctly with the above test input. You might find the man pages for `open` (`man 2 open`) and `close` useful.
|
||||
|
||||
Note that this shell will not process quotes in the same way that `bash`, `tcsh`, `zsh` or other UNIX shells will, and your sample file `x.txt` is expected to contain the quotes.
|
||||
|
||||
### Implement pipes
|
||||
|
||||
Implement pipes so that you can run command pipelines such as:
|
||||
```
|
||||
$ ls | sort | uniq | wc
|
||||
|
||||
```
|
||||
|
||||
The parser already recognizes "|", and builds a `pipecmd` for you, so the only code you must write is for the '|' case in `runcmd`. Test that you can run the above pipeline. You might find the man pages for `pipe`, `fork`, `close`, and `dup` useful.
|
||||
|
||||
Now you should be able the following command correctly:
|
||||
```
|
||||
$ ./a.out < t.sh
|
||||
|
||||
```
|
||||
|
||||
Don't forget to submit your solution to the [submission web site][1], with or without challenge solutions.
|
||||
|
||||
### Challenge exercises
|
||||
|
||||
If you'd like to experiment more, you can add any feature of your choice to your shell. You might try one of the following suggestions:
|
||||
|
||||
* Implement lists of commands, separated by `;`
|
||||
* Implement subshells by implementing `(` and `)`
|
||||
* Implement running commands in the background by supporting `&` and `wait`
|
||||
* Implement quoting of arguments
|
||||
|
||||
|
||||
|
||||
All of these require making changing to the parser and the `runcmd` function.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://sipb.mit.edu/iap/6.828/lab/shell/
|
||||
|
||||
作者:[mit][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://sipb.mit.edu
|
||||
[1]:https://exokernel.scripts.mit.edu/submit/
|
||||
[2]:mailto:sipb-iap-6.828@mit.edu
|
||||
[3]:https://sipb.mit.edu/iap/6.828/files/sh.c
|
||||
624
sources/tech/20140110 Caffeinated 6.828- Lab 1- Booting a PC.md
Normal file
624
sources/tech/20140110 Caffeinated 6.828- Lab 1- Booting a PC.md
Normal file
@ -0,0 +1,624 @@
|
||||
Caffeinated 6.828: Lab 1: Booting a PC
|
||||
======
|
||||
|
||||
### Introduction
|
||||
|
||||
This lab is split into three parts. The first part concentrates on getting familiarized with x86 assembly language, the QEMU x86 emulator, and the PC's power-on bootstrap procedure. The second part examines the boot loader for our 6.828 kernel, which resides in the `boot` directory of the `lab` tree. Finally, the third part delves into the initial template for our 6.828 kernel itself, named JOS, which resides in the `kernel` directory.
|
||||
|
||||
#### Software Setup
|
||||
|
||||
The files you will need for this and subsequent lab assignments in this course are distributed using the [Git][1] version control system. To learn more about Git, take a look at the [Git user's manual][2], or, if you are already familiar with other version control systems, you may find this [CS-oriented overview of Git][3] useful.
|
||||
|
||||
The URL for the course Git repository is `https://exokernel.scripts.mit.edu/joslab.git`. To install the files in your Athena account, you need to clone the course repository, by running the commands below. You can log into a public Athena host with `ssh -X athena.dialup.mit.edu`.
|
||||
```
|
||||
athena% mkdir ~/6.828
|
||||
athena% cd ~/6.828
|
||||
athena% add git
|
||||
athena% git clone https://exokernel.scripts.mit.edu/joslab.git lab
|
||||
Cloning into lab...
|
||||
athena% cd lab
|
||||
athena%
|
||||
|
||||
```
|
||||
|
||||
Git allows you to keep track of the changes you make to the code. For example, if you are finished with one of the exercises, and want to checkpoint your progress, you can commit your changes by running:
|
||||
```
|
||||
athena% git commit -am 'my solution for lab1 exercise 9'
|
||||
Created commit 60d2135: my solution for lab1 exercise 9
|
||||
1 files changed, 1 insertions(+), 0 deletions(-)
|
||||
athena%
|
||||
|
||||
```
|
||||
|
||||
You can keep track of your changes by using the `git diff` command. Running `git diff` will display the changes to your code since your last commit, and `git diff origin/lab1` will display the changes relative to the initial code supplied for this lab. Here, `origin/lab1` is the name of the git branch with the initial code you downloaded from our server for this assignment.
|
||||
|
||||
We have set up the appropriate compilers and simulators for you on Athena. To use them, run `add exokernel`. You must run this command every time you log in (or add it to your `~/.environment` file). If you get obscure errors while compiling or running `qemu`, double check that you added the course locker.
|
||||
|
||||
If you are working on a non-Athena machine, you'll need to install `qemu` and possibly `gcc` following the directions on the [tools page][4]. We've made several useful debugging changes to `qemu` and some of the later labs depend on these patches, so you must build your own. If your machine uses a native ELF toolchain (such as Linux and most BSD's, but notably not OS X), you can simply install `gcc` from your package manager. Otherwise, follow the directions on the tools page.
|
||||
|
||||
#### Hand-In Procedure
|
||||
|
||||
We use different Git repositories for you to hand in your lab. The hand-in repositories reside behind an SSH server. You will get your own hand-in repository, which is inaccessible by any other students. To authenticate yourself with the SSH server, you should have an RSA key pair, and let the server know your public key.
|
||||
|
||||
The lab code comes with a script that helps you to set up access to your hand-in repository. Before running the script, you must have an account at our [submission web interface][5]. On the login page, type in your Athena user name and click on "Mail me my password". You will receive your `6.828` password in your mailbox shortly. Note that every time you click the button, the system will assign you a new random password.
|
||||
|
||||
Now that you have your `6.828` password, in the `lab` directory, set up the hand-in repository by running:
|
||||
```
|
||||
athena% make handin-prep
|
||||
Using public key from ~/.ssh/id_rsa:
|
||||
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQD0lnnkoHSi4JDFA ...
|
||||
Continue? [Y/n] Y
|
||||
|
||||
Login to 6.828 submission website.
|
||||
If you do not have an account yet, sign up at https://exokernel.scripts.mit.edu/submit/
|
||||
before continuing.
|
||||
Username: <your Athena username>
|
||||
Password: <your 6.828 password>
|
||||
Your public key has been successfully updated.
|
||||
Setting up hand-in Git repository...
|
||||
Adding remote repository ssh://josgit@exokernel.mit.edu/joslab.git as 'handin'.
|
||||
Done! Use 'make handin' to submit your lab code.
|
||||
athena%
|
||||
|
||||
```
|
||||
|
||||
The script may also ask you to generate a new key pair if you did not have one:
|
||||
```
|
||||
athena% make handin-prep
|
||||
SSH key file ~/.ssh/id_rsa does not exists, generate one? [Y/n] Y
|
||||
Generating public/private rsa key pair.
|
||||
Your identification has been saved in ~/.ssh/id_rsa.
|
||||
Your public key has been saved in ~/.ssh/id_rsa.pub.
|
||||
The key fingerprint is:
|
||||
xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx
|
||||
The keyʼs randomart image is:
|
||||
+--[ RSA 2048]----+
|
||||
| ........ |
|
||||
| ........ |
|
||||
+-----------------+
|
||||
Using public key from ~/.ssh/id_rsa:
|
||||
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQD0lnnkoHSi4JDFA ...
|
||||
Continue? [Y/n] Y
|
||||
.....
|
||||
athena%
|
||||
|
||||
```
|
||||
|
||||
When you are ready to hand in your lab, first commit your changes with git commit, and then type make handin in the `lab` directory. The latter will run git push handin HEAD, which pushes the current branch to the same name on the remote `handin` repository.
|
||||
```
|
||||
athena% git commit -am "ready to submit my lab"
|
||||
[lab1 c2e3c8b] ready to submit my lab
|
||||
2 files changed, 18 insertions(+), 2 deletions(-)
|
||||
|
||||
athena% make handin
|
||||
Handin to remote repository using 'git push handin HEAD' ...
|
||||
Counting objects: 59, done.
|
||||
Delta compression using up to 4 threads.
|
||||
Compressing objects: 100% (55/55), done.
|
||||
Writing objects: 100% (59/59), 49.75 KiB, done.
|
||||
Total 59 (delta 3), reused 0 (delta 0)
|
||||
To ssh://josgit@am.csail.mit.edu/joslab.git
|
||||
* [new branch] HEAD -> lab1
|
||||
athena%
|
||||
|
||||
```
|
||||
|
||||
If you have made changes to your hand-in repository, an email receipt will be sent to you to confirm the submission. You can run make handin (or git push handin) as many times as you want. The late hours of your submission for a specific lab is based on the latest hand-in (push) time of the corresponding branch.
|
||||
|
||||
In the case that make handin does not work properly, try fixing the problem with Git commands. Or you can run make tarball. This will make a tar file for you, which you can then upload via our [web interface][5]. `make handin` provides more specific directions.
|
||||
|
||||
For Lab 1, you do not need to turn in answers to any of the questions below. (Do answer them for yourself though! They will help with the rest of the lab.)
|
||||
|
||||
We will be grading your solutions with a grading program. You can run make grade to test your solutions with the grading program.
|
||||
|
||||
### Part 1: PC Bootstrap
|
||||
|
||||
The purpose of the first exercise is to introduce you to x86 assembly language and the PC bootstrap process, and to get you started with QEMU and QEMU/GDB debugging. You will not have to write any code for this part of the lab, but you should go through it anyway for your own understanding and be prepared to answer the questions posed below.
|
||||
|
||||
#### Getting Started with x86 assembly
|
||||
|
||||
If you are not already familiar with x86 assembly language, you will quickly become familiar with it during this course! The [PC Assembly Language Book][6] is an excellent place to start. Hopefully, the book contains mixture of new and old material for you.
|
||||
|
||||
Warning: Unfortunately the examples in the book are written for the NASM assembler, whereas we will be using the GNU assembler. NASM uses the so-called Intel syntax while GNU uses the AT&T syntax. While semantically equivalent, an assembly file will differ quite a lot, at least superficially, depending on which syntax is used. Luckily the conversion between the two is pretty simple, and is covered in [Brennan's Guide to Inline Assembly][7].
|
||||
|
||||
> **Exercise 1**
|
||||
>
|
||||
> Familiarize yourself with the assembly language materials available on [the 6.828 reference page][8]. You don't have to read them now, but you'll almost certainly want to refer to some of this material when reading and writing x86 assembly.
|
||||
|
||||
We do recommend reading the section "The Syntax" in [Brennan's Guide to Inline Assembly][7]. It gives a good (and quite brief) description of the AT&T assembly syntax we'll be using with the GNU assembler in JOS.
|
||||
|
||||
Certainly the definitive reference for x86 assembly language programming is Intel's instruction set architecture reference, which you can find on [the 6.828 reference page][8] in two flavors: an HTML edition of the old [80386 Programmer's Reference Manual][9], which is much shorter and easier to navigate than more recent manuals but describes all of the x86 processor features that we will make use of in 6.828; and the full, latest and greatest [IA-32 Intel Architecture Software Developer's Manuals][10] from Intel, covering all the features of the most recent processors that we won't need in class but you may be interested in learning about. An equivalent (and often friendlier) set of manuals is [available from AMD][11]. Save the Intel/AMD architecture manuals for later or use them for reference when you want to look up the definitive explanation of a particular processor feature or instruction.
|
||||
|
||||
#### Simulating the x86
|
||||
|
||||
Instead of developing the operating system on a real, physical personal computer (PC), we use a program that faithfully emulates a complete PC: the code you write for the emulator will boot on a real PC too. Using an emulator simplifies debugging; you can, for example, set break points inside of the emulated x86, which is difficult to do with the silicon version of an x86.
|
||||
|
||||
In 6.828 we will use the [QEMU Emulator][12], a modern and relatively fast emulator. While QEMU's built-in monitor provides only limited debugging support, QEMU can act as a remote debugging target for the [GNU debugger][13] (GDB), which we'll use in this lab to step through the early boot process.
|
||||
|
||||
To get started, extract the Lab 1 files into your own directory on Athena as described above in "Software Setup", then type make (or gmake on BSD systems) in the `lab` directory to build the minimal 6.828 boot loader and kernel you will start with. (It's a little generous to call the code we're running here a "kernel," but we'll flesh it out throughout the semester.)
|
||||
```
|
||||
athena% cd lab
|
||||
athena% make
|
||||
+ as kern/entry.S
|
||||
+ cc kern/init.c
|
||||
+ cc kern/console.c
|
||||
+ cc kern/monitor.c
|
||||
+ cc kern/printf.c
|
||||
+ cc lib/printfmt.c
|
||||
+ cc lib/readline.c
|
||||
+ cc lib/string.c
|
||||
+ ld obj/kern/kernel
|
||||
+ as boot/boot.S
|
||||
+ cc -Os boot/main.c
|
||||
+ ld boot/boot
|
||||
boot block is 414 bytes (max 510)
|
||||
+ mk obj/kern/kernel.img
|
||||
|
||||
```
|
||||
|
||||
(If you get errors like "undefined reference to `__udivdi3'", you probably don't have the 32-bit gcc multilib. If you're running Debian or Ubuntu, try installing the gcc-multilib package.)
|
||||
|
||||
Now you're ready to run QEMU, supplying the file `obj/kern/kernel.img`, created above, as the contents of the emulated PC's "virtual hard disk." This hard disk image contains both our boot loader (`obj/boot/boot`) and our kernel (`obj/kernel`).
|
||||
```
|
||||
athena% make qemu
|
||||
|
||||
```
|
||||
|
||||
This executes QEMU with the options required to set the hard disk and direct serial port output to the terminal. Some text should appear in the QEMU window:
|
||||
```
|
||||
Booting from Hard Disk...
|
||||
6828 decimal is XXX octal!
|
||||
entering test_backtrace 5
|
||||
entering test_backtrace 4
|
||||
entering test_backtrace 3
|
||||
entering test_backtrace 2
|
||||
entering test_backtrace 1
|
||||
entering test_backtrace 0
|
||||
leaving test_backtrace 0
|
||||
leaving test_backtrace 1
|
||||
leaving test_backtrace 2
|
||||
leaving test_backtrace 3
|
||||
leaving test_backtrace 4
|
||||
leaving test_backtrace 5
|
||||
Welcome to the JOS kernel monitor!
|
||||
Type 'help' for a list of commands.
|
||||
K>
|
||||
|
||||
```
|
||||
|
||||
Everything after '`Booting from Hard Disk...`' was printed by our skeletal JOS kernel; the `K>` is the prompt printed by the small monitor, or interactive control program, that we've included in the kernel. These lines printed by the kernel will also appear in the regular shell window from which you ran QEMU. This is because for testing and lab grading purposes we have set up the JOS kernel to write its console output not only to the virtual VGA display (as seen in the QEMU window), but also to the simulated PC's virtual serial port, which QEMU in turn outputs to its own standard output. Likewise, the JOS kernel will take input from both the keyboard and the serial port, so you can give it commands in either the VGA display window or the terminal running QEMU. Alternatively, you can use the serial console without the virtual VGA by running make qemu-nox. This may be convenient if you are SSH'd into an Athena dialup.
|
||||
|
||||
There are only two commands you can give to the kernel monitor, `help` and `kerninfo`.
|
||||
```
|
||||
K> help
|
||||
help - display this list of commands
|
||||
kerninfo - display information about the kernel
|
||||
K> kerninfo
|
||||
Special kernel symbols:
|
||||
entry f010000c (virt) 0010000c (phys)
|
||||
etext f0101a75 (virt) 00101a75 (phys)
|
||||
edata f0112300 (virt) 00112300 (phys)
|
||||
end f0112960 (virt) 00112960 (phys)
|
||||
Kernel executable memory footprint: 75KB
|
||||
K>
|
||||
|
||||
```
|
||||
|
||||
The `help` command is obvious, and we will shortly discuss the meaning of what the `kerninfo` command prints. Although simple, it's important to note that this kernel monitor is running "directly" on the "raw (virtual) hardware" of the simulated PC. This means that you should be able to copy the contents of `obj/kern/kernel.img` onto the first few sectors of a real hard disk, insert that hard disk into a real PC, turn it on, and see exactly the same thing on the PC's real screen as you did above in the QEMU window. (We don't recommend you do this on a real machine with useful information on its hard disk, though, because copying `kernel.img` onto the beginning of its hard disk will trash the master boot record and the beginning of the first partition, effectively causing everything previously on the hard disk to be lost!)
|
||||
|
||||
#### The PC's Physical Address Space
|
||||
|
||||
We will now dive into a bit more detail about how a PC starts up. A PC's physical address space is hard-wired to have the following general layout:
|
||||
```
|
||||
+------------------+ <- 0xFFFFFFFF (4GB)
|
||||
| 32-bit |
|
||||
| memory mapped |
|
||||
| devices |
|
||||
| |
|
||||
/\/\/\/\/\/\/\/\/\/\
|
||||
|
||||
/\/\/\/\/\/\/\/\/\/\
|
||||
| |
|
||||
| Unused |
|
||||
| |
|
||||
+------------------+ <- depends on amount of RAM
|
||||
| |
|
||||
| |
|
||||
| Extended Memory |
|
||||
| |
|
||||
| |
|
||||
+------------------+ <- 0x00100000 (1MB)
|
||||
| BIOS ROM |
|
||||
+------------------+ <- 0x000F0000 (960KB)
|
||||
| 16-bit devices, |
|
||||
| expansion ROMs |
|
||||
+------------------+ <- 0x000C0000 (768KB)
|
||||
| VGA Display |
|
||||
+------------------+ <- 0x000A0000 (640KB)
|
||||
| |
|
||||
| Low Memory |
|
||||
| |
|
||||
+------------------+ <- 0x00000000
|
||||
|
||||
```
|
||||
|
||||
The first PCs, which were based on the 16-bit Intel 8088 processor, were only capable of addressing 1MB of physical memory. The physical address space of an early PC would therefore start at `0x00000000` but end at `0x000FFFFF` instead of `0xFFFFFFFF`. The 640KB area marked "Low Memory" was the only random-access memory (RAM) that an early PC could use; in fact the very earliest PCs only could be configured with 16KB, 32KB, or 64KB of RAM!
|
||||
|
||||
The 384KB area from `0x000A0000` through `0x000FFFFF` was reserved by the hardware for special uses such as video display buffers and firmware held in non-volatile memory. The most important part of this reserved area is the Basic Input/Output System (BIOS), which occupies the 64KB region from `0x000F0000` through `0x000FFFFF`. In early PCs the BIOS was held in true read-only memory (ROM), but current PCs store the BIOS in updateable flash memory. The BIOS is responsible for performing basic system initialization such as activating the video card and checking the amount of memory installed. After performing this initialization, the BIOS loads the operating system from some appropriate location such as floppy disk, hard disk, CD-ROM, or the network, and passes control of the machine to the operating system.
|
||||
|
||||
When Intel finally "broke the one megabyte barrier" with the 80286 and 80386 processors, which supported 16MB and 4GB physical address spaces respectively, the PC architects nevertheless preserved the original layout for the low 1MB of physical address space in order to ensure backward compatibility with existing software. Modern PCs therefore have a "hole" in physical memory from `0x000A0000` to `0x00100000`, dividing RAM into "low" or "conventional memory" (the first 640KB) and "extended memory" (everything else). In addition, some space at the very top of the PC's 32-bit physical address space, above all physical RAM, is now commonly reserved by the BIOS for use by 32-bit PCI devices.
|
||||
|
||||
Recent x86 processors can support more than 4GB of physical RAM, so RAM can extend further above `0xFFFFFFFF`. In this case the BIOS must arrange to leave a second hole in the system's RAM at the top of the 32-bit addressable region, to leave room for these 32-bit devices to be mapped. Because of design limitations JOS will use only the first 256MB of a PC's physical memory anyway, so for now we will pretend that all PCs have "only" a 32-bit physical address space. But dealing with complicated physical address spaces and other aspects of hardware organization that evolved over many years is one of the important practical challenges of OS development.
|
||||
|
||||
#### The ROM BIOS
|
||||
|
||||
In this portion of the lab, you'll use QEMU's debugging facilities to investigate how an IA-32 compatible computer boots.
|
||||
|
||||
Open two terminal windows. In one, enter `make qemu-gdb` (or `make qemu-nox-gdb`). This starts up QEMU, but QEMU stops just before the processor executes the first instruction and waits for a debugging connection from GDB. In the second terminal, from the same directory you ran `make`, run `make gdb`. You should see something like this,
|
||||
```
|
||||
athena% make gdb
|
||||
GNU gdb (GDB) 6.8-debian
|
||||
Copyright (C) 2008 Free Software Foundation, Inc.
|
||||
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
|
||||
This is free software: you are free to change and redistribute it.
|
||||
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
|
||||
and "show warranty" for details.
|
||||
This GDB was configured as "i486-linux-gnu".
|
||||
+ target remote localhost:1234
|
||||
The target architecture is assumed to be i8086
|
||||
[f000:fff0] 0xffff0: ljmp $0xf000,$0xe05b
|
||||
0x0000fff0 in ?? ()
|
||||
+ symbol-file obj/kern/kernel
|
||||
(gdb)
|
||||
|
||||
```
|
||||
|
||||
The `make gdb` target runs a script called `.gdbrc`, which sets up GDB to debug the 16-bit code used during early boot and directs it to attach to the listening QEMU.
|
||||
|
||||
The following line:
|
||||
```
|
||||
[f000:fff0] 0xffff0: ljmp $0xf000,$0xe05b
|
||||
|
||||
```
|
||||
|
||||
is GDB's disassembly of the first instruction to be executed. From this output you can conclude a few things:
|
||||
|
||||
* The IBM PC starts executing at physical address `0x000ffff0`, which is at the very top of the 64KB area reserved for the ROM BIOS.
|
||||
* The PC starts executing with `CS = 0xf000` and `IP = 0xfff0`.
|
||||
* The first instruction to be executed is a `jmp` instruction, which jumps to the segmented address `CS = 0xf000` and `IP = 0xe05b`.
|
||||
|
||||
|
||||
|
||||
Why does QEMU start like this? This is how Intel designed the 8088 processor, which IBM used in their original PC. Because the BIOS in a PC is "hard-wired" to the physical address range `0x000f0000-0x000fffff`, this design ensures that the BIOS always gets control of the machine first after power-up or any system restart - which is crucial because on power-up there is no other software anywhere in the machine's RAM that the processor could execute. The QEMU emulator comes with its own BIOS, which it places at this location in the processor's simulated physical address space. On processor reset, the (simulated) processor enters real mode and sets CS to `0xf000` and the IP to `0xfff0`, so that execution begins at that (CS:IP) segment address. How does the segmented address 0xf000:fff0 turn into a physical address?
|
||||
|
||||
To answer that we need to know a bit about real mode addressing. In real mode (the mode that PC starts off in), address translation works according to the formula: physical address = 16 * segment + offset. So, when the PC sets CS to `0xf000` and IP to `0xfff0`, the physical address referenced is:
|
||||
```
|
||||
16 * 0xf000 + 0xfff0 # in hex multiplication by 16 is
|
||||
= 0xf0000 + 0xfff0 # easy--just append a 0.
|
||||
= 0xffff0
|
||||
|
||||
```
|
||||
|
||||
`0xffff0` is 16 bytes before the end of the BIOS (`0x100000`). Therefore we shouldn't be surprised that the first thing that the BIOS does is `jmp` backwards to an earlier location in the BIOS; after all how much could it accomplish in just 16 bytes?
|
||||
|
||||
> **Exercise 2**
|
||||
>
|
||||
> Use GDB's `si` (Step Instruction) command to trace into the ROM BIOS for a few more instructions, and try to guess what it might be doing. You might want to look at [Phil Storrs I/O Ports Description][14], as well as other materials on the [6.828 reference materials page][8]. No need to figure out all the details - just the general idea of what the BIOS is doing first.
|
||||
|
||||
When the BIOS runs, it sets up an interrupt descriptor table and initializes various devices such as the VGA display. This is where the "`Starting SeaBIOS`" message you see in the QEMU window comes from.
|
||||
|
||||
After initializing the PCI bus and all the important devices the BIOS knows about, it searches for a bootable device such as a floppy, hard drive, or CD-ROM. Eventually, when it finds a bootable disk, the BIOS reads the boot loader from the disk and transfers control to it.
|
||||
|
||||
### Part 2: The Boot Loader
|
||||
|
||||
Floppy and hard disks for PCs are divided into 512 byte regions called sectors. A sector is the disk's minimum transfer granularity: each read or write operation must be one or more sectors in size and aligned on a sector boundary. If the disk is bootable, the first sector is called the boot sector, since this is where the boot loader code resides. When the BIOS finds a bootable floppy or hard disk, it loads the 512-byte boot sector into memory at physical addresses 0x7c00 through `0x7dff`, and then uses a `jmp` instruction to set the CS:IP to `0000:7c00`, passing control to the boot loader. Like the BIOS load address, these addresses are fairly arbitrary - but they are fixed and standardized for PCs.
|
||||
|
||||
The ability to boot from a CD-ROM came much later during the evolution of the PC, and as a result the PC architects took the opportunity to rethink the boot process slightly. As a result, the way a modern BIOS boots from a CD-ROM is a bit more complicated (and more powerful). CD-ROMs use a sector size of 2048 bytes instead of 512, and the BIOS can load a much larger boot image from the disk into memory (not just one sector) before transferring control to it. For more information, see the ["El Torito" Bootable CD-ROM Format Specification][15].
|
||||
|
||||
For 6.828, however, we will use the conventional hard drive boot mechanism, which means that our boot loader must fit into a measly 512 bytes. The boot loader consists of one assembly language source file, `boot/boot.S`, and one C source file, `boot/main.c` Look through these source files carefully and make sure you understand what's going on. The boot loader must perform two main functions:
|
||||
|
||||
1. First, the boot loader switches the processor from real mode to 32-bit protected mode, because it is only in this mode that software can access all the memory above 1MB in the processor's physical address space. Protected mode is described briefly in sections 1.2.7 and 1.2.8 of [PC Assembly Language][6], and in great detail in the Intel architecture manuals. At this point you only have to understand that translation of segmented addresses (segment:offset pairs) into physical addresses happens differently in protected mode, and that after the transition offsets are 32 bits instead of 16.
|
||||
2. Second, the boot loader reads the kernel from the hard disk by directly accessing the IDE disk device registers via the x86's special I/O instructions. If you would like to understand better what the particular I/O instructions here mean, check out the "IDE hard drive controller" section on [the 6.828 reference page][8]. You will not need to learn much about programming specific devices in this class: writing device drivers is in practice a very important part of OS development, but from a conceptual or architectural viewpoint it is also one of the least interesting.
|
||||
|
||||
|
||||
|
||||
After you understand the boot loader source code, look at the file `obj/boot/boot.asm`. This file is a disassembly of the boot loader that our GNUmakefile creates after compiling the boot loader. This disassembly file makes it easy to see exactly where in physical memory all of the boot loader's code resides, and makes it easier to track what's happening while stepping through the boot loader in GDB. Likewise, `obj/kern/kernel.asm` contains a disassembly of the JOS kernel, which can often be useful for debugging.
|
||||
|
||||
You can set address breakpoints in GDB with the `b` command. For example, `b *0x7c00` sets a breakpoint at address `0x7C00`. Once at a breakpoint, you can continue execution using the `c` and `si` commands: `c` causes QEMU to continue execution until the next breakpoint (or until you press Ctrl-C in GDB), and `si N` steps through the instructions `N` at a time.
|
||||
|
||||
To examine instructions in memory (besides the immediate next one to be executed, which GDB prints automatically), you use the `x/i` command. This command has the syntax `x/Ni ADDR`, where `N` is the number of consecutive instructions to disassemble and `ADDR` is the memory address at which to start disassembling.
|
||||
|
||||
> **Exercise 3**
|
||||
>
|
||||
> Take a look at the [lab tools guide][16], especially the section on GDB commands. Even if you're familiar with GDB, this includes some esoteric GDB commands that are useful for OS work.
|
||||
|
||||
Set a breakpoint at address 0x7c00, which is where the boot sector will be loaded. Continue execution until that breakpoint. Trace through the code in `boot/boot.S`, using the source code and the disassembly file `obj/boot/boot.asm` to keep track of where you are. Also use the `x/i` command in GDB to disassemble sequences of instructions in the boot loader, and compare the original boot loader source code with both the disassembly in `obj/boot/boot.asm` and GDB.
|
||||
|
||||
Trace into `bootmain()` in `boot/main.c`, and then into `readsect()`. Identify the exact assembly instructions that correspond to each of the statements in `readsect()`. Trace through the rest of `readsect()` and back out into `bootmain()`, and identify the begin and end of the `for` loop that reads the remaining sectors of the kernel from the disk. Find out what code will run when the loop is finished, set a breakpoint there, and continue to that breakpoint. Then step through the remainder of the boot loader.
|
||||
|
||||
Be able to answer the following questions:
|
||||
|
||||
* At what point does the processor start executing 32-bit code? What exactly causes the switch from 16- to 32-bit mode?
|
||||
* What is the last instruction of the boot loader executed, and what is the first instruction of the kernel it just loaded?
|
||||
* Where is the first instruction of the kernel?
|
||||
* How does the boot loader decide how many sectors it must read in order to fetch the entire kernel from disk? Where does it find this information?
|
||||
|
||||
|
||||
|
||||
#### Loading the Kernel
|
||||
|
||||
We will now look in further detail at the C language portion of the boot loader, in `boot/main.c`. But before doing so, this is a good time to stop and review some of the basics of C programming.
|
||||
|
||||
> **Exercise 4**
|
||||
>
|
||||
> Download the code for [pointers.c][17], run it, and make sure you understand where all of the printed values come from. In particular, make sure you understand where the pointer addresses in lines 1 and 6 come from, how all the values in lines 2 through 4 get there, and why the values printed in line 5 are seemingly corrupted.
|
||||
>
|
||||
> If you're not familiar with pointers, The C Programming Language by Brian Kernighan and Dennis Ritchie (known as 'K&R') is a good reference. Students can purchase this book (here is an [Amazon Link][18]) or find one of [MIT's 7 copies][19]. 3 copies are also available for perusal in the [SIPB Office][20].
|
||||
>
|
||||
> [A tutorial by Ted Jensen][21] that cites K&R heavily is available in the course readings.
|
||||
>
|
||||
> Warning: Unless you are already thoroughly versed in C, do not skip or even skim this reading exercise. If you do not really understand pointers in C, you will suffer untold pain and misery in subsequent labs, and then eventually come to understand them the hard way. Trust us; you don't want to find out what "the hard way" is.
|
||||
|
||||
To make sense out of `boot/main.c` you'll need to know what an ELF binary is. When you compile and link a C program such as the JOS kernel, the compiler transforms each C source ('`.c`') file into an object ('`.o`') file containing assembly language instructions encoded in the binary format expected by the hardware. The linker then combines all of the compiled object files into a single binary image such as `obj/kern/kernel`, which in this case is a binary in the ELF format, which stands for "Executable and Linkable Format".
|
||||
|
||||
Full information about this format is available in [the ELF specification][22] on [our reference page][8], but you will not need to delve very deeply into the details of this format in this class. Although as a whole the format is quite powerful and complex, most of the complex parts are for supporting dynamic loading of shared libraries, which we will not do in this class.
|
||||
|
||||
For purposes of 6.828, you can consider an ELF executable to be a header with loading information, followed by several program sections, each of which is a contiguous chunk of code or data intended to be loaded into memory at a specified address. The boot loader does not modify the code or data; it loads it into memory and starts executing it.
|
||||
|
||||
An ELF binary starts with a fixed-length ELF header, followed by a variable-length program header listing each of the program sections to be loaded. The C definitions for these ELF headers are in `inc/elf.h`. The program sections we're interested in are:
|
||||
|
||||
* `.text`: The program's executable instructions.
|
||||
* `.rodata`: Read-only data, such as ASCII string constants produced by the C compiler. (We will not bother setting up the hardware to prohibit writing, however.)
|
||||
* `.data`: The data section holds the program's initialized data, such as global variables declared with initializers like `int x = 5;`.
|
||||
|
||||
|
||||
|
||||
When the linker computes the memory layout of a program, it reserves space for uninitialized global variables, such as `int x;`, in a section called `.bss` that immediately follows `.data` in memory. C requires that "uninitialized" global variables start with a value of zero. Thus there is no need to store contents for `.bss` in the ELF binary; instead, the linker records just the address and size of the `.bss` section. The loader or the program itself must arrange to zero the `.bss` section.
|
||||
|
||||
Examine the full list of the names, sizes, and link addresses of all the sections in the kernel executable by typing:
|
||||
```
|
||||
athena% i386-jos-elf-objdump -h obj/kern/kernel
|
||||
|
||||
```
|
||||
|
||||
You can substitute `objdump` for `i386-jos-elf-objdump` if your computer uses an ELF toolchain by default like most modern Linuxen and BSDs.
|
||||
|
||||
You will see many more sections than the ones we listed above, but the others are not important for our purposes. Most of the others are to hold debugging information, which is typically included in the program's executable file but not loaded into memory by the program loader.
|
||||
|
||||
Take particular note of the "VMA" (or link address) and the "LMA" (or load address) of the `.text` section. The load address of a section is the memory address at which that section should be loaded into memory. In the ELF object, this is stored in the `ph->p_pa` field (in this case, it really is a physical address, though the ELF specification is vague on the actual meaning of this field).
|
||||
|
||||
The link address of a section is the memory address from which the section expects to execute. The linker encodes the link address in the binary in various ways, such as when the code needs the address of a global variable, with the result that a binary usually won't work if it is executing from an address that it is not linked for. (It is possible to generate position-independent code that does not contain any such absolute addresses. This is used extensively by modern shared libraries, but it has performance and complexity costs, so we won't be using it in 6.828.)
|
||||
|
||||
Typically, the link and load addresses are the same. For example, look at the `.text` section of the boot loader:
|
||||
```
|
||||
athena% i386-jos-elf-objdump -h obj/boot/boot.out
|
||||
|
||||
```
|
||||
|
||||
The BIOS loads the boot sector into memory starting at address 0x7c00, so this is the boot sector's load address. This is also where the boot sector executes from, so this is also its link address. We set the link address by passing `-Ttext 0x7C00` to the linker in `boot/Makefrag`, so the linker will produce the correct memory addresses in the generated code.
|
||||
|
||||
> **Exercise 5**
|
||||
>
|
||||
> Trace through the first few instructions of the boot loader again and identify the first instruction that would "break" or otherwise do the wrong thing if you were to get the boot loader's link address wrong. Then change the link address in `boot/Makefrag` to something wrong, run make clean, recompile the lab with make, and trace into the boot loader again to see what happens. Don't forget to change the link address back and make clean again afterward!
|
||||
|
||||
Look back at the load and link addresses for the kernel. Unlike the boot loader, these two addresses aren't the same: the kernel is telling the boot loader to load it into memory at a low address (1 megabyte), but it expects to execute from a high address. We'll dig in to how we make this work in the next section.
|
||||
|
||||
Besides the section information, there is one more field in the ELF header that is important to us, named `e_entry`. This field holds the link address of the entry point in the program: the memory address in the program's text section at which the program should begin executing. You can see the entry point:
|
||||
```
|
||||
athena% i386-jos-elf-objdump -f obj/kern/kernel
|
||||
|
||||
```
|
||||
|
||||
You should now be able to understand the minimal ELF loader in `boot/main.c`. It reads each section of the kernel from disk into memory at the section's load address and then jumps to the kernel's entry point.
|
||||
|
||||
> **Exercise 6**
|
||||
>
|
||||
> We can examine memory using GDB's x command. The [GDB manual][23] has full details, but for now, it is enough to know that the command `x/Nx ADDR` prints `N` words of memory at `ADDR`. (Note that both `x`s in the command are lowercase.) Warning: The size of a word is not a universal standard. In GNU assembly, a word is two bytes (the 'w' in xorw, which stands for word, means 2 bytes).
|
||||
|
||||
Reset the machine (exit QEMU/GDB and start them again). Examine the 8 words of memory at `0x00100000` at the point the BIOS enters the boot loader, and then again at the point the boot loader enters the kernel. Why are they different? What is there at the second breakpoint? (You do not really need to use QEMU to answer this question. Just think.)
|
||||
|
||||
### Part 3: The Kernel
|
||||
|
||||
We will now start to examine the minimal JOS kernel in a bit more detail. (And you will finally get to write some code!). Like the boot loader, the kernel begins with some assembly language code that sets things up so that C language code can execute properly.
|
||||
|
||||
#### Using virtual memory to work around position dependence
|
||||
|
||||
When you inspected the boot loader's link and load addresses above, they matched perfectly, but there was a (rather large) disparity between the kernel's link address (as printed by objdump) and its load address. Go back and check both and make sure you can see what we're talking about. (Linking the kernel is more complicated than the boot loader, so the link and load addresses are at the top of `kern/kernel.ld`.)
|
||||
|
||||
Operating system kernels often like to be linked and run at very high virtual address, such as `0xf0100000`, in order to leave the lower part of the processor's virtual address space for user programs to use. The reason for this arrangement will become clearer in the next lab.
|
||||
|
||||
Many machines don't have any physical memory at address `0xf0100000`, so we can't count on being able to store the kernel there. Instead, we will use the processor's memory management hardware to map virtual address `0xf0100000` (the link address at which the kernel code expects to run) to physical address `0x00100000` (where the boot loader loaded the kernel into physical memory). This way, although the kernel's virtual address is high enough to leave plenty of address space for user processes, it will be loaded in physical memory at the 1MB point in the PC's RAM, just above the BIOS ROM. This approach requires that the PC have at least a few megabytes of physical memory (so that physical address `0x00100000` works), but this is likely to be true of any PC built after about 1990.
|
||||
|
||||
In fact, in the next lab, we will map the entire bottom 256MB of the PC's physical address space, from physical addresses `0x00000000` through `0x0fffffff`, to virtual addresses `0xf0000000` through `0xffffffff` respectively. You should now see why JOS can only use the first 256MB of physical memory.
|
||||
|
||||
For now, we'll just map the first 4MB of physical memory, which will be enough to get us up and running. We do this using the hand-written, statically-initialized page directory and page table in `kern/entrypgdir.c`. For now, you don't have to understand the details of how this works, just the effect that it accomplishes. Up until `kern/entry.S` sets the `CR0_PG` flag, memory references are treated as physical addresses (strictly speaking, they're linear addresses, but boot/boot.S set up an identity mapping from linear addresses to physical addresses and we're never going to change that). Once `CR0_PG` is set, memory references are virtual addresses that get translated by the virtual memory hardware to physical addresses. `entry_pgdir` translates virtual addresses in the range `0xf0000000` through `0xf0400000` to physical addresses `0x00000000` through `0x00400000`, as well as virtual addresses `0x00000000` through `0x00400000` to physical addresses `0x00000000` through `0x00400000`. Any virtual address that is not in one of these two ranges will cause a hardware exception which, since we haven't set up interrupt handling yet, will cause QEMU to dump the machine state and exit (or endlessly reboot if you aren't using the 6.828-patched version of QEMU).
|
||||
|
||||
> **Exercise 7**
|
||||
>
|
||||
> Use QEMU and GDB to trace into the JOS kernel and stop at the `movl %eax, %cr0`. Examine memory at `0x00100000` and at `0xf0100000`. Now, single step over that instruction using the `stepi` GDB command. Again, examine memory at `0x00100000` and at `0xf0100000`. Make sure you understand what just happened.
|
||||
|
||||
What is the first instruction after the new mapping is established that would fail to work properly if the mapping weren't in place? Comment out the `movl %eax, %cr0` in `kern/entry.S`, trace into it, and see if you were right.
|
||||
|
||||
#### Formatted Printing to the Console
|
||||
|
||||
Most people take functions like `printf()` for granted, sometimes even thinking of them as "primitives" of the C language. But in an OS kernel, we have to implement all I/O ourselves.
|
||||
|
||||
Read through `kern/printf.c`, `lib/printfmt.c`, and `kern/console.c`, and make sure you understand their relationship. It will become clear in later labs why `printfmt.c` is located in the separate `lib` directory.
|
||||
|
||||
> **Exercise 8**
|
||||
>
|
||||
> We have omitted a small fragment of code - the code necessary to print octal numbers using patterns of the form "%o". Find and fill in this code fragment.
|
||||
>
|
||||
> Be able to answer the following questions:
|
||||
>
|
||||
> 1. Explain the interface between `printf.c` and `console.c`. Specifically, what function does `console.c` export? How is this function used by `printf.c`?
|
||||
>
|
||||
> 2. Explain the following from `console.c`:
|
||||
[code] > if (crt_pos >= CRT_SIZE) {
|
||||
> int i;
|
||||
> memcpy(crt_buf, crt_buf + CRT_COLS, (CRT_SIZE - CRT_COLS) * sizeof(uint16_t));
|
||||
> for (i = CRT_SIZE - CRT_COLS; i < CRT_SIZE; i++)
|
||||
> crt_buf[i] = 0x0700 | ' ';
|
||||
> crt_pos -= CRT_COLS;
|
||||
> }
|
||||
>
|
||||
```
|
||||
>
|
||||
> 3. For the following questions you might wish to consult the notes for Lecture 1. These notes cover GCC's calling convention on the x86.
|
||||
>
|
||||
> Trace the execution of the following code step-by-step:
|
||||
[code] > int x = 1, y = 3, z = 4;
|
||||
> cprintf("x %d, y %x, z %d\n", x, y, z);
|
||||
>
|
||||
```
|
||||
>
|
||||
> 1. In the call to `cprintf()`, to what does `fmt` point? To what does `ap` point?
|
||||
> 2. List (in order of execution) each call to `cons_putc`, `va_arg`, and `vcprintf`. For `cons_putc`, list its argument as well. For `va_arg`, list what `ap` points to before and after the call. For `vcprintf` list the values of its two arguments.
|
||||
> 4. Run the following code.
|
||||
[code] > unsigned int i = 0x00646c72;
|
||||
> cprintf("H%x Wo%s", 57616, &i);
|
||||
>
|
||||
```
|
||||
>
|
||||
> What is the output? Explain how this output is arrived at in the step-by-step manner of the previous exercise. [Here's an ASCII table][24] that maps bytes to characters.
|
||||
>
|
||||
> The output depends on that fact that the x86 is little-endian. If the x86 were instead big-endian what would you set `i` to in order to yield the same output? Would you need to change `57616` to a different value?
|
||||
>
|
||||
> [Here's a description of little- and big-endian][25] and [a more whimsical description][26].
|
||||
>
|
||||
> 5. In the following code, what is going to be printed after `y=`? (note: the answer is not a specific value.) Why does this happen?
|
||||
[code] > cprintf("x=%d y=%d", 3);
|
||||
>
|
||||
```
|
||||
>
|
||||
> 6. Let's say that GCC changed its calling convention so that it pushed arguments on the stack in declaration order, so that the last argument is pushed last. How would you have to change `cprintf` or its interface so that it would still be possible to pass it a variable number of arguments?
|
||||
>
|
||||
>
|
||||
|
||||
|
||||
#### The Stack
|
||||
|
||||
In the final exercise of this lab, we will explore in more detail the way the C language uses the stack on the x86, and in the process write a useful new kernel monitor function that prints a backtrace of the stack: a list of the saved Instruction Pointer (IP) values from the nested `call` instructions that led to the current point of execution.
|
||||
|
||||
> **Exercise 9**
|
||||
>
|
||||
> Determine where the kernel initializes its stack, and exactly where in memory its stack is located. How does the kernel reserve space for its stack? And at which "end" of this reserved area is the stack pointer initialized to point to?
|
||||
|
||||
The x86 stack pointer (`esp` register) points to the lowest location on the stack that is currently in use. Everything below that location in the region reserved for the stack is free. Pushing a value onto the stack involves decreasing the stack pointer and then writing the value to the place the stack pointer points to. Popping a value from the stack involves reading the value the stack pointer points to and then increasing the stack pointer. In 32-bit mode, the stack can only hold 32-bit values, and esp is always divisible by four. Various x86 instructions, such as `call`, are "hard-wired" to use the stack pointer register.
|
||||
|
||||
The `ebp` (base pointer) register, in contrast, is associated with the stack primarily by software convention. On entry to a C function, the function's prologue code normally saves the previous function's base pointer by pushing it onto the stack, and then copies the current `esp` value into `ebp` for the duration of the function. If all the functions in a program obey this convention, then at any given point during the program's execution, it is possible to trace back through the stack by following the chain of saved `ebp` pointers and determining exactly what nested sequence of function calls caused this particular point in the program to be reached. This capability can be particularly useful, for example, when a particular function causes an `assert` failure or `panic` because bad arguments were passed to it, but you aren't sure who passed the bad arguments. A stack backtrace lets you find the offending function.
|
||||
|
||||
> **Exercise 10**
|
||||
>
|
||||
> To become familiar with the C calling conventions on the x86, find the address of the `test_backtrace` function in `obj/kern/kernel.asm`, set a breakpoint there, and examine what happens each time it gets called after the kernel starts. How many 32-bit words does each recursive nesting level of `test_backtrace` push on the stack, and what are those words?
|
||||
|
||||
The above exercise should give you the information you need to implement a stack backtrace function, which you should call `mon_backtrace()`. A prototype for this function is already waiting for you in `kern/monitor.c`. You can do it entirely in C, but you may find the `read_ebp()` function in `inc/x86.h` useful. You'll also have to hook this new function into the kernel monitor's command list so that it can be invoked interactively by the user.
|
||||
|
||||
The backtrace function should display a listing of function call frames in the following format:
|
||||
```
|
||||
Stack backtrace:
|
||||
ebp f0109e58 eip f0100a62 args 00000001 f0109e80 f0109e98 f0100ed2 00000031
|
||||
ebp f0109ed8 eip f01000d6 args 00000000 00000000 f0100058 f0109f28 00000061
|
||||
...
|
||||
|
||||
```
|
||||
|
||||
The first line printed reflects the currently executing function, namely `mon_backtrace` itself, the second line reflects the function that called `mon_backtrace`, the third line reflects the function that called that one, and so on. You should print all the outstanding stack frames. By studying `kern/entry.S` you'll find that there is an easy way to tell when to stop.
|
||||
|
||||
Within each line, the `ebp` value indicates the base pointer into the stack used by that function: i.e., the position of the stack pointer just after the function was entered and the function prologue code set up the base pointer. The listed `eip` value is the function's return instruction pointer: the instruction address to which control will return when the function returns. The return instruction pointer typically points to the instruction after the `call` instruction (why?). Finally, the five hex values listed after `args` are the first five arguments to the function in question, which would have been pushed on the stack just before the function was called. If the function was called with fewer than five arguments, of course, then not all five of these values will be useful. (Why can't the backtrace code detect how many arguments there actually are? How could this limitation be fixed?)
|
||||
|
||||
Here are a few specific points you read about in K&R Chapter 5 that are worth remembering for the following exercise and for future labs.
|
||||
|
||||
* If `int *p = (int*)100`, then `(int)p + 1` and `(int)(p + 1)` are different numbers: the first is `101` but the second is `104`. When adding an integer to a pointer, as in the second case, the integer is implicitly multiplied by the size of the object the pointer points to.
|
||||
* `p[i]` is defined to be the same as `*(p+i)`, referring to the i'th object in the memory pointed to by p. The above rule for addition helps this definition work when the objects are larger than one byte.
|
||||
* `&p[i]` is the same as `(p+i)`, yielding the address of the i'th object in the memory pointed to by p.
|
||||
|
||||
|
||||
|
||||
Although most C programs never need to cast between pointers and integers, operating systems frequently do. Whenever you see an addition involving a memory address, ask yourself whether it is an integer addition or pointer addition and make sure the value being added is appropriately multiplied or not.
|
||||
|
||||
> **Exercise 11**
|
||||
>
|
||||
> Implement the backtrace function as specified above. Use the same format as in the example, since otherwise the grading script will be confused. When you think you have it working right, run make grade to see if its output conforms to what our grading script expects, and fix it if it doesn't. After you have handed in your Lab 1 code, you are welcome to change the output format of the backtrace function any way you like.
|
||||
|
||||
At this point, your backtrace function should give you the addresses of the function callers on the stack that lead to `mon_backtrace()` being executed. However, in practice you often want to know the function names corresponding to those addresses. For instance, you may want to know which functions could contain a bug that's causing your kernel to crash.
|
||||
|
||||
To help you implement this functionality, we have provided the function `debuginfo_eip()`, which looks up `eip` in the symbol table and returns the debugging information for that address. This function is defined in `kern/kdebug.c`.
|
||||
|
||||
> **Exercise 12**
|
||||
>
|
||||
> Modify your stack backtrace function to display, for each `eip`, the function name, source file name, and line number corresponding to that `eip`.
|
||||
|
||||
In `debuginfo_eip`, where do `__STAB_*` come from? This question has a long answer; to help you to discover the answer, here are some things you might want to do:
|
||||
|
||||
* look in the file `kern/kernel.ld` for `__STAB_*`
|
||||
* run i386-jos-elf-objdump -h obj/kern/kernel
|
||||
* run i386-jos-elf-objdump -G obj/kern/kernel
|
||||
* run i386-jos-elf-gcc -pipe -nostdinc -O2 -fno-builtin -I. -MD -Wall -Wno-format -DJOS_KERNEL -gstabs -c -S kern/init.c, and look at init.s.
|
||||
* see if the bootloader loads the symbol table in memory as part of loading the kernel binary
|
||||
|
||||
|
||||
|
||||
Complete the implementation of `debuginfo_eip` by inserting the call to `stab_binsearch` to find the line number for an address.
|
||||
|
||||
Add a `backtrace` command to the kernel monitor, and extend your implementation of `mon_backtrace` to call `debuginfo_eip` and print a line for each stack frame of the form:
|
||||
```
|
||||
K> backtrace
|
||||
Stack backtrace:
|
||||
ebp f010ff78 eip f01008ae args 00000001 f010ff8c 00000000 f0110580 00000000
|
||||
kern/monitor.c:143: monitor+106
|
||||
ebp f010ffd8 eip f0100193 args 00000000 00001aac 00000660 00000000 00000000
|
||||
kern/init.c:49: i386_init+59
|
||||
ebp f010fff8 eip f010003d args 00000000 00000000 0000ffff 10cf9a00 0000ffff
|
||||
kern/entry.S:70: <unknown>+0
|
||||
K>
|
||||
|
||||
```
|
||||
|
||||
Each line gives the file name and line within that file of the stack frame's `eip`, followed by the name of the function and the offset of the `eip` from the first instruction of the function (e.g., `monitor+106` means the return `eip` is 106 bytes past the beginning of `monitor`).
|
||||
|
||||
Be sure to print the file and function names on a separate line, to avoid confusing the grading script.
|
||||
|
||||
Tip: printf format strings provide an easy, albeit obscure, way to print non-null-terminated strings like those in STABS tables. `printf("%.*s", length, string)` prints at most `length` characters of `string`. Take a look at the printf man page to find out why this works.
|
||||
|
||||
You may find that some functions are missing from the backtrace. For example, you will probably see a call to `monitor()` but not to `runcmd()`. This is because the compiler in-lines some function calls. Other optimizations may cause you to see unexpected line numbers. If you get rid of the `-O2` from `GNUMakefile`, the backtraces may make more sense (but your kernel will run more slowly).
|
||||
|
||||
**This completes the lab.** In the `lab` directory, commit your changes with `git commit` and type `make handin` to submit your code.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://sipb.mit.edu/iap/6.828/lab/lab1/
|
||||
|
||||
作者:[mit][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://sipb.mit.edu
|
||||
[1]:http://www.git-scm.com/
|
||||
[2]:http://www.kernel.org/pub/software/scm/git/docs/user-manual.html
|
||||
[3]:http://eagain.net/articles/git-for-computer-scientists/
|
||||
[4]:https://sipb.mit.edu/iap/6.828/tools
|
||||
[5]:https://exokernel.scripts.mit.edu/submit/
|
||||
[6]:https://sipb.mit.edu/iap/6.828/readings/pcasm-book.pdf
|
||||
[7]:http://www.delorie.com/djgpp/doc/brennan/brennan_att_inline_djgpp.html
|
||||
[8]:https://sipb.mit.edu/iap/6.828/reference
|
||||
[9]:https://sipb.mit.edu/iap/6.828/readings/i386/toc.htm
|
||||
[10]:http://www.intel.com/content/www/us/en/processors/architectures-software-developer-manuals.html
|
||||
[11]:http://developer.amd.com/documentation/guides/Pages/default.aspx#manuals
|
||||
[12]:http://www.qemu.org/
|
||||
[13]:http://www.gnu.org/software/gdb/
|
||||
[14]:http://web.archive.org/web/20040404164813/members.iweb.net.au/%7Epstorr/pcbook/book2/book2.htm
|
||||
[15]:https://sipb.mit.edu/iap/6.828/readings/boot-cdrom.pdf
|
||||
[16]:https://sipb.mit.edu/iap/6.828/labguide
|
||||
[17]:https://sipb.mit.edu/iap/6.828/files/pointers.c
|
||||
[18]:http://www.amazon.com/C-Programming-Language-2nd/dp/0131103628/sr=8-1/qid=1157812738/ref=pd_bbs_1/104-1502762-1803102?ie=UTF8&s=books
|
||||
[19]:http://library.mit.edu/F/AI9Y4SJ2L5ELEE2TAQUAAR44XV5RTTQHE47P9MKP5GQDLR9A8X-10422?func=item-global&doc_library=MIT01&doc_number=000355242&year=&volume=&sub_library=
|
||||
[20]:http://sipb.mit.edu/
|
||||
[21]:https://sipb.mit.edu/iap/6.828/readings/pointers.pdf
|
||||
[22]:https://sipb.mit.edu/iap/6.828/readings/elf.pdf
|
||||
[23]:http://sourceware.org/gdb/current/onlinedocs/gdb_9.html#SEC63
|
||||
[24]:http://web.cs.mun.ca/%7Emichael/c/ascii-table.html
|
||||
[25]:http://www.webopedia.com/TERM/b/big_endian.html
|
||||
[26]:http://www.networksorcery.com/enp/ien/ien137.txt
|
||||
@ -1,3 +1,4 @@
|
||||
transalting by wyxplus
|
||||
4 Tools for Network Snooping on Linux
|
||||
======
|
||||
Computer networking data has to be exposed, because packets can't travel blindfolded, so join us as we use `whois`, `dig`, `nmcli`, and `nmap` to snoop networks.
|
||||
|
||||
@ -1,94 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Tlog - A Tool to Record / Play Terminal IO and Sessions
|
||||
======
|
||||
Tlog is a terminal I/O recording and playback package for Linux Distros. It's suitable for implementing centralized user session recording. It logs everything that passes through as JSON messages. The primary purpose of logging in JSON format is to eventually deliver the recorded data to a storage service such as Elasticsearch, where it can be searched and queried, and from where it can be played back. At the same time, they retain all the passed data and timing.
|
||||
|
||||
Tlog contains three tools namely tlog-rec, tlog-rec-session and tlog-play.
|
||||
|
||||
* `Tlog-rec tool` is used for recording terminal input or output of programs or shells in general.
|
||||
* `Tlog-rec-session tool` is used for recording I/O of whole terminal sessions, with protection from recorded users.
|
||||
* `Tlog-play tool` for playing back the recordings.
|
||||
|
||||
|
||||
|
||||
In this article, I'll explain how to install Tlog on a CentOS 7.4 server.
|
||||
|
||||
### Installation
|
||||
|
||||
Before proceeding with the install, we need to ensure that our system meets all the software requirements for compiling and installing the application. On the first step, update your system repositories and software packages by using the below command.
|
||||
```
|
||||
#yum update
|
||||
```
|
||||
|
||||
We need to install the required dependencies for this software installation. I've installed all dependency packages with these commands prior to the installation.
|
||||
```
|
||||
#yum install wget gcc
|
||||
#yum install systemd-devel json-c-devel libcurl-devel m4
|
||||
```
|
||||
|
||||
After completing these installations, we can download the [source package][1] for this tool and extract it on your server as required:
|
||||
```
|
||||
#wget https://github.com/Scribery/tlog/releases/download/v3/tlog-3.tar.gz
|
||||
#tar -xvf tlog-3.tar.gz
|
||||
# cd tlog-3
|
||||
```
|
||||
|
||||
Now you can start building this tool using our usual configure and make approach.
|
||||
```
|
||||
#./configure --prefix=/usr --sysconfdir=/etc && make
|
||||
#make install
|
||||
#ldconfig
|
||||
```
|
||||
|
||||
Finally, you need to run `ldconfig`. It creates the necessary links and cache to the most recent shared libraries found in the directories specified on the command line, in the file /etc/ld.so.conf, and in the trusted directories (/lib and /usr/lib).
|
||||
|
||||
### Tlog workflow chart
|
||||
|
||||
![Tlog working process][2]
|
||||
|
||||
Firstly, a user authenticates to login via PAM. The Name Service Switch (NSS) provides the information as `tlog` is a shell to the user. This initiates the tlog section and it collects the information from the Env/config files about the actual shell and starts the actual shell in a PTY. Then it starts logging everything passing between the terminal and the PTY via syslog or sd-journal.
|
||||
|
||||
### Usage
|
||||
|
||||
You can test if session recording and playback work in general with a freshly installed tlog, by recording a session into a file with `tlog-rec` and then playing it back with `tlog-play`.
|
||||
|
||||
#### Recording to a file
|
||||
|
||||
To record a session into a file, execute `tlog-rec` on the command line as such:
|
||||
```
|
||||
tlog-rec --writer=file --file-path=tlog.log
|
||||
```
|
||||
|
||||
This command will record our terminal session to a file named tlog.log and save it in the path specified in the command.
|
||||
|
||||
#### Playing back from a file
|
||||
|
||||
You can playback the recorded session during or after recording using `tlog-play` command.
|
||||
```
|
||||
tlog-play --reader=file --file-path=tlog.log
|
||||
```
|
||||
|
||||
This command reads the previously recorded file tlog.log from the file path mentioned in the command line.
|
||||
|
||||
### Wrapping up
|
||||
|
||||
Tlog is an open-source package which can be used for implementing centralized user session recording. This is mainly intended to be used as part of a larger user session recording solution but is designed to be independent and reusable.This tool can be a great help for recording everything users do and store it somewhere on the server side safe for the future reference. You can get more details about this package usage in this [documentation][3]. I hope this article is useful to you. Please post your valuable suggestions and comments on this.
|
||||
|
||||
### About Saheetha Shameer(the author)
|
||||
I'm working as a Senior System Administrator. I'm a quick learner and have a slight inclination towards following the current and emerging trends in the industry. My hobbies include hearing music, playing strategy computer games, reading and gardening. I also have a high passion for experimenting with various culinary delights :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linoxide.com/linux-how-to/tlog-tool-record-play-terminal-io-sessions/
|
||||
|
||||
作者:[Saheetha Shameer][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linoxide.com/author/saheethas/
|
||||
[1]:https://github.com/Scribery/tlog/releases/download/v3/tlog-3.tar.gz
|
||||
[2]:https://linoxide.com/wp-content/uploads/2018/01/Tlog-working-process.png
|
||||
[3]:https://github.com/Scribery/tlog/blob/master/README.md
|
||||
@ -1,195 +0,0 @@
|
||||
How to Create a Docker Image
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
Learn the basic steps for creating Docker images in this tutorial.[Creative Commons Zero][1]Pixabay
|
||||
|
||||
In the previous [article][4], we learned about how to get started with Docker on Linux, macOS, and Windows. In this article, we will get a basic understanding of creating Docker images. There are prebuilt images available on DockerHub that you can use for your own project, and you can publish your own image there.
|
||||
|
||||
We are going to use prebuilt images to get the base Linux subsystem, as it’s a lot of work to build one from scratch. You can get Alpine (the official distro used by Docker Editions), Ubuntu, BusyBox, or scratch. In this example, I will use Ubuntu.
|
||||
|
||||
Before we start building our images, let’s “containerize” them! By this I just mean creating directories for all of your Docker images so that you can maintain different projects and stages isolated from each other.
|
||||
|
||||
```
|
||||
$ mkdir dockerprojects
|
||||
|
||||
cd dockerprojects
|
||||
```
|
||||
|
||||
Now create a _Dockerfile_ inside the _dockerprojects_ directory using your favorite text editor; I prefer nano, which is also easy for new users.
|
||||
|
||||
```
|
||||
$ nano Dockerfile
|
||||
```
|
||||
|
||||
And add this line:
|
||||
|
||||
```
|
||||
FROM Ubuntu
|
||||
```
|
||||
|
||||

|
||||
|
||||
Save it with Ctrl+Exit then Y.
|
||||
|
||||
Now create your new image and provide it with a name (run these commands within the same directory):
|
||||
|
||||
```
|
||||
$ docker build -t dockp .
|
||||
```
|
||||
|
||||
(Note the dot at the end of the command.) This should build successfully, so you'll see:
|
||||
|
||||
```
|
||||
Sending build context to Docker daemon 2.048kB
|
||||
|
||||
Step 1/1 : FROM ubuntu
|
||||
|
||||
---> 2a4cca5ac898
|
||||
|
||||
Successfully built 2a4cca5ac898
|
||||
|
||||
Successfully tagged dockp:latest
|
||||
```
|
||||
|
||||
It’s time to run and test your image:
|
||||
|
||||
```
|
||||
$ docker run -it Ubuntu
|
||||
```
|
||||
|
||||
You should see root prompt:
|
||||
|
||||
```
|
||||
root@c06fcd6af0e8:/#
|
||||
```
|
||||
|
||||
This means you are literally running bare minimal Ubuntu inside Linux, Windows, or macOS. You can run all native Ubuntu commands and CLI utilities.
|
||||
|
||||

|
||||
|
||||
Let’s check all the Docker images you have in your directory:
|
||||
|
||||
```
|
||||
$docker images
|
||||
|
||||
REPOSITORY TAG IMAGE ID CREATED SIZE
|
||||
|
||||
dockp latest 2a4cca5ac898 1 hour ago 111MB
|
||||
|
||||
ubuntu latest 2a4cca5ac898 1 hour ago 111MB
|
||||
|
||||
hello-world latest f2a91732366c 8 weeks ago 1.85kB
|
||||
```
|
||||
|
||||
You can see all three images: _dockp, Ubuntu_ _,_ and _hello-world_ , which I created a few weeks ago when working on the previous articles of this series. Building a whole LAMP stack can be challenging, so we are going create a simple Apache server image with Dockerfile.
|
||||
|
||||
Dockerfile is basically a set of instructions to install all the needed packages, configure, and copy files. In this case, it’s Apache and Nginx.
|
||||
|
||||
You may also want to create an account on DockerHub and log into your account before building images, in case you are pulling something from DockerHub. To log into DockerHub from the command line, just run:
|
||||
|
||||
```
|
||||
$ docker login
|
||||
```
|
||||
|
||||
Enter your username and password and you are logged in.
|
||||
|
||||
Next, create a directory for Apache inside the dockerproject:
|
||||
|
||||
```
|
||||
$ mkdir apache
|
||||
```
|
||||
|
||||
Create a Dockerfile inside Apache folder:
|
||||
|
||||
```
|
||||
$ nano Dockerfile
|
||||
```
|
||||
|
||||
And paste these lines:
|
||||
|
||||
```
|
||||
FROM ubuntu
|
||||
|
||||
MAINTAINER Kimbro Staken version: 0.1
|
||||
|
||||
RUN apt-get update && apt-get install -y apache2 && apt-get clean && rm -rf /var/lib/apt/lists/*
|
||||
|
||||
ENV APACHE_RUN_USER www-data
|
||||
|
||||
ENV APACHE_RUN_GROUP www-data
|
||||
|
||||
ENV APACHE_LOG_DIR /var/log/apache2
|
||||
|
||||
EXPOSE 80
|
||||
|
||||
CMD ["/usr/sbin/apache2", "-D", "FOREGROUND"]
|
||||
```
|
||||
|
||||
Then, build the image:
|
||||
|
||||
```
|
||||
docker build -t apache .
|
||||
```
|
||||
|
||||
(Note the dot after a space at the end.)
|
||||
|
||||
It will take some time, then you should see successful build like this:
|
||||
|
||||
```
|
||||
Successfully built e7083fd898c7
|
||||
|
||||
Successfully tagged ng:latest
|
||||
|
||||
Swapnil:apache swapnil$
|
||||
```
|
||||
|
||||
Now let’s run the server:
|
||||
|
||||
```
|
||||
$ docker run –d apache
|
||||
|
||||
a189a4db0f7c245dd6c934ef7164f3ddde09e1f3018b5b90350df8be85c8dc98
|
||||
```
|
||||
|
||||
Eureka. Your container image is running. Check all the running containers:
|
||||
|
||||
```
|
||||
$ docker ps
|
||||
|
||||
CONTAINER ID IMAGE COMMAND CREATED
|
||||
|
||||
a189a4db0f7 apache "/usr/sbin/apache2ctl" 10 seconds ago
|
||||
```
|
||||
|
||||
You can kill the container with the _docker kill_ command:
|
||||
|
||||
```
|
||||
$docker kill a189a4db0f7
|
||||
```
|
||||
|
||||
So, you see the “image” itself is persistent that stays in your directory, but the container runs and goes away. Now you can create as many images as you want and spin and nuke as many containers as you need from those images.
|
||||
|
||||
That’s how to create an image and run containers.
|
||||
|
||||
To learn more, you can open your web browser and check out the documentation about how to build more complicated Docker images like the whole LAMP stack. Here is a[ Dockerfile][5] file for you to play with. In the next article, I’ll show how to push images to DockerHub.
|
||||
|
||||
_Learn more about Linux through the free ["Introduction to Linux" ][3]course from The Linux Foundation and edX._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/intro-to-linux/2018/1/how-create-docker-image
|
||||
|
||||
作者:[SWAPNIL BHARTIYA][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/arnieswap
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]:https://www.linux.com/files/images/container-imagejpg-0
|
||||
[3]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
[4]:https://www.linux.com/blog/learn/intro-to-linux/how-install-docker-ce-your-desktop
|
||||
[5]:https://github.com/fauria/docker-lamp/blob/master/Dockerfile
|
||||
@ -1,77 +0,0 @@
|
||||
translating by wyxplus
|
||||
Become a Hollywood movie hacker with these three command line tools
|
||||
======
|
||||
|
||||

|
||||
|
||||
If you ever spent time growing up watching spy thrillers, action flicks, or crime movies, you developed a clear picture in your mind of what a hacker's computer screen looked like. Rows upon rows of rapidly moving code, streams of grouped hexadecimal numbers flying past like [raining code][1] in The Matrix.
|
||||
|
||||
Perhaps there's a world map with flashing points of light and a few rapidly updating charts thrown in there for good measure. And probably a 3D rotating geometric shape, because why not? If possible, this is all shown on a ridiculous number of monitors in an ergonomically uncomfortable configuration. I think Swordfish sported seven.
|
||||
|
||||
Of course, those of us who pursued technical careers quickly realized that this was all utter nonsense. While many of us have dual monitors (or more), a dashboard of blinky, flashing data is usually pretty antithetical to focusing on work. Writing code, managing projects, and administering systems is not the same thing as day trading. Most of the situations we encounter require a great deal of thinking about the problem we're trying to solve, a good bit of communicating with stakeholders, some researching and organizing information, and very, very little [rapid-fire typing][7].
|
||||
|
||||
That doesn't mean that we sometimes don't feel like we want to be inside of one of those movies. Or maybe, we're just trying to look like we're "being productive."
|
||||
|
||||
**Side note: Of course I mean this article in jest.** If you're actually being evaluated on how busy you look, whether that's at your desk or in meetings, you've got a huge cultural problem at your workplace that needs to be addressed. A culture of manufactured busyness is a toxic culture and one that's almost certainly helping neither the company nor its employees.
|
||||
|
||||
That said, let's have some fun and fill our screens with some panels of good old-fashioned meaningless data and code snippets. (Well, the data might have some meaning, but not without context.) While there are plenty of fancy GUIs for this (consider checking out [Hacker Typer][8] or [GEEKtyper.com][9] for a web-based version), why not just use your standard Linux terminal? For a more old-school look, consider using [Cool Retro Term][10], which is indeed what it sounds like: A cool retro terminal. I'll use Cool Retro Term for the screenshots below because it does indeed look 100% cooler.
|
||||
|
||||
### Genact
|
||||
|
||||
The first tool we'll look at is Genact. Genact simply plays back a sequence of your choosing, slowly and indefinitely, letting your code “compile” while you go out for a coffee break. The sequence it plays is up to you, but included by default are a cryptocurrency mining simulator, Composer PHP dependency manager, kernel compiler, downloader, memory dump, and more. My favorite, though, is the setting which displays SimCity loading messages. So as long as no one checks too closely, you can spend all afternoon waiting on your computer to finish reticulating splines.
|
||||
|
||||
Genact has [releases][11] available for Linux, OS X, and Windows, and the Rust [source code][12] is available on GitHub under an [MIT license][13].
|
||||
|
||||
|
||||
|
||||
### Hollywood
|
||||
|
||||
Hollywood takes a more straightforward approach. It essentially creates a random number and configuration of split screens in your terminal and launches busy looking applications like htop, directory trees, source code files, and others, and switch them out every few seconds. It's put together as a shell script, so it's fairly straightforward to modify as you wish.
|
||||
|
||||
The [source code][14] for Hollywood can be found on GitHub under an [Apache 2.0][15] license.
|
||||
|
||||
|
||||
|
||||
### Blessed-contrib
|
||||
|
||||
My personal favorite isn't actually an application designed for this purpose. Instead, it's the demo file for a Node.js-based terminal dashboard building library called Blessed-contrib. Unlike the other two, I actually have used Blessed-contrib's library for doing something that resembles actual work, as opposed to pretend-work, as it is a quite helpful library and set of widgets for displaying information at the command line. But it's also easy to fill with dummy data to fulfill your dream of simulating the computer from WarGames.
|
||||
|
||||
The [source code][16] for Blessed-contrib can be found on GitHub under an [MIT license][17].
|
||||
|
||||
|
||||
|
||||
Of course, while these tools make it easy, there are plenty of ways to fill up your screen with nonsense. One of the most common tools you'll see in movies is Nmap, an open source security scanner. In fact, it is so overused as the tool to demonstrate on-screen hacking in Hollywood that the makers have created a page listing some of the movies it has [appeared in][18], from The Matrix Reloaded to The Bourne Ultimatum, The Girl with the Dragon Tattoo, and even Die Hard 4.
|
||||
|
||||
You can create your own combination, of course, using a terminal multiplexer like screen or tmux to fire up whatever selection of data-spitting applications you wish.
|
||||
|
||||
What's your go-to screen for looking busy?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/command-line-tools-productivity
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jason-baker
|
||||
[1]:http://tvtropes.org/pmwiki/pmwiki.php/Main/MatrixRainingCode
|
||||
[2]:https://opensource.com/resources/what-is-linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[3]:https://opensource.com/resources/what-are-linux-containers?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[4]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[5]:https://developers.redhat.com/cheat-sheet/advanced-linux-commands-cheatsheet?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[6]:https://opensource.com/tags/linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[7]:http://tvtropes.org/pmwiki/pmwiki.php/Main/RapidFireTyping
|
||||
[8]:https://hackertyper.net/
|
||||
[9]:http://geektyper.com
|
||||
[10]:https://github.com/Swordfish90/cool-retro-term
|
||||
[11]:https://github.com/svenstaro/genact/releases
|
||||
[12]:https://github.com/svenstaro/genact
|
||||
[13]:https://github.com/svenstaro/genact/blob/master/LICENSE
|
||||
[14]:https://github.com/dustinkirkland/hollywood
|
||||
[15]:http://www.apache.org/licenses/LICENSE-2.0
|
||||
[16]:https://github.com/yaronn/blessed-contrib
|
||||
[17]:http://opensource.org/licenses/MIT
|
||||
[18]:https://nmap.org/movies/
|
||||
@ -1,126 +0,0 @@
|
||||
Translating by MjSeven
|
||||
|
||||
Test Your BASH Skills By Playing Command Line Games
|
||||
======
|
||||
|
||||

|
||||
We tend to learn and remember Linux commands more effectively if we use them regularly in a live scenario. You may forget the Linux commands over a period of time, unless you use them often. Whether you’re newbie, intermediate user, there are always some exciting methods to test your BASH skills. In this tutorial, I am going to explain how to test your BASH skills by playing command line games. Well, technically these are not actual games like Super TuxKart, NFS, or Counterstrike etc. These are just gamified versions of Linux command training lessons. You will be given a task to complete by follow certain instructions in the game itself.
|
||||
|
||||
Now, we will see few games that will help you to learn and practice Linux commands in real-time. These are not a time-passing or mind-boggling games. These games will help you to get a hands-on experience of terminal commands. Read on.
|
||||
|
||||
### Test BASH Skills with “Wargames”
|
||||
|
||||
It is an online game, so you must have an active Internet connection. These games helps you to learn and practice Linux commands in the form of fun-filled games. Wargames are collection of shell games and each game has many levels. You can access the next levels only by solving previous levels. Not to be worried! Each game provides clear and concise instructions about how to access the next levels.
|
||||
|
||||
To play the Wargames, go the following link:
|
||||
|
||||
![][2]
|
||||
|
||||
As you can see, there many shell games listed on the left side. Each shell game has its own SSH port. So, you will have to connect to the game via SSH from your local system. You can find the information about how to connect to each game using SSH in the top left corner of the Wargames website.
|
||||
|
||||
For instance, let us play the **Bandit** game. To do so, click on the Bandit link on the Wargames homepage. On the top left corner, you will see SSH information of the Bandit game.
|
||||
|
||||
![][3]
|
||||
|
||||
As you see in the above screenshot, there are many levels. To go to each level, click on the respective link on the left column. Also, there are instructions for the beginners on the right side. Read them if you have any questions about how to play this game.
|
||||
|
||||
Now, let us go to the level 0 by clicking on it. In the next screen, you will SSH information of this level.
|
||||
|
||||
![][4]
|
||||
|
||||
As you can see on the above screenshot, you need to connect is **bandit.labs.overthewire.org** , on port 2220 via SSH. The username is **bandit0** and the password is **bandit0**.
|
||||
|
||||
Let us connect to Bandit game level 0.
|
||||
|
||||
Enter the password i.e **bandit0**
|
||||
|
||||
Sample output will be:
|
||||
|
||||
![][5]
|
||||
|
||||
Once logged in, type **ls** command to see what’s in their or go to the **Level 1 page** to find out how to beat Level 1 and so on. The list of suggested command have been provided in every level. So, you can pick and use any suitable command to solve the each level.
|
||||
|
||||
I must admit that Wargames are addictive and really fun to solve each level. However some levels are really challenging, so you may need to google to know how to solve it. Give it a try, you will really like it.
|
||||
|
||||
### Test BASH Skills with “Terminus” game
|
||||
|
||||
This is a yet another browser-based online CLI game which can be used to improve or test your Linux command skills. To play this game, open up your web browser and navigate to the following URL.
|
||||
|
||||
Once you entered in the game, you see the instructions to learn how to play it. Unlike Wargames, you don’t need to connect to their game server to play the games. Terminus has a built-in CLI where you can find the instructions about how to play it.
|
||||
|
||||
You can look at your surroundings with the command **“ls”** , move to a new location with the command **“cd LOCATION”** , go back with the command **“cd ..”** , interact with things in the world with the command **“less ITEM”** and so on. To know your current location, just type **“pwd”**.
|
||||
|
||||
![][6]
|
||||
|
||||
### Test BASH Skills with “clmystery” game
|
||||
|
||||
Unlike the above games, you can play this game locally. You don’t need to be connected with any remote system. This is completely offline game.
|
||||
|
||||
Trust me, this is an interesting game folks. You are going to play a detective role to solve a mystery case by following the given instructions.
|
||||
|
||||
First, clone the repository:
|
||||
```
|
||||
$ git clone https://github.com/veltman/clmystery.git
|
||||
|
||||
```
|
||||
|
||||
Or, download it as a zip file from [**here**][7]. Extract it and go to the location where you have the files. Finally, solve the mystery case by reading the “instructions” file.
|
||||
```
|
||||
[sk@sk]: clmystery-master>$ ls
|
||||
cheatsheet.md cheatsheet.pdf encoded hint1 hint2 hint3 hint4 hint5 hint6 hint7 hint8 instructions LICENSE.md mystery README.md solution
|
||||
|
||||
```
|
||||
|
||||
Here is the instructions to play this game:
|
||||
|
||||
There’s been a murder in Terminal City, and TCPD needs your help. You need to help them to figure out who did the crime.
|
||||
|
||||
To find out who did it, you need to go to the **‘mystery’** subdirectory and start working from there. You might need to look into all clues at the crime scene (the **‘crimescene’** file). The officers on the scene are pretty meticulous, so they’ve written down EVERYTHING in their officer reports. Fortunately the sergeant went through and marked the real clues with the word “CLUE” in all caps.
|
||||
|
||||
If you get stuck at anywhere, open one of the hint files such as hint1, hint2 etc. You can open the hint files using cat command like below.
|
||||
```
|
||||
$ cat hint1
|
||||
|
||||
$ cat hint2
|
||||
|
||||
```
|
||||
|
||||
To check your answer or find out the solution, open the file ‘solution’ in the clmystery directory.
|
||||
```
|
||||
$ cat solution
|
||||
|
||||
```
|
||||
|
||||
To get started on how to use the command line, refer **cheatsheet.md** or **cheatsheet.pdf** (from the command line, you can type ‘nano cheatsheet.md’). Don’t use a text editor to view any files except these instructions, the cheatsheet, and hints.
|
||||
|
||||
For more details, refer the [**clmystery GitHub**][8] page.
|
||||
|
||||
**Recommended read:**
|
||||
|
||||
And, that’s all I can remember now. I will keep adding more games if I came across anything in future. Bookmark this link and do visit from time to time. If you know any other similar games, please let me know in the comment section below. I will test and update this guide.
|
||||
|
||||
More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/test-your-bash-skills-by-playing-command-line-games/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/03/Wargames-1.png
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/03/Bandit-game.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2018/03/Bandit-level-0.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/03/Bandit-level-0-ssh-1.png
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2018/03/Terminus.png
|
||||
[7]:https://github.com/veltman/clmystery/archive/master.zip
|
||||
[8]:https://github.com/veltman/clmystery
|
||||
60
sources/tech/20180312 Continuous integration in Fedora.md
Normal file
60
sources/tech/20180312 Continuous integration in Fedora.md
Normal file
@ -0,0 +1,60 @@
|
||||
translating---geekpi
|
||||
|
||||
Continuous integration in Fedora
|
||||
======
|
||||
|
||||

|
||||
Continuous Integration (CI) is the process of running tests for every change made to a project, integrated as if this were the new deliverable. If done consistently, it means that software is always ready to be released. CI is a very well established process across the entire IT industry as well as free and open source projects. Fedora has been a little behind on this, but we’re catching up. Read below to find out how.
|
||||
|
||||
### Why do we need this?
|
||||
|
||||
CI will improve Fedora all around. It provides a more stable and consistent operating system by revealing bugs as early as possible. It lets you add tests when you encounter an issue so it doesn’t happen again (avoid regressions). CI can run tests from the upstream project as well as Fedora-specific ones that test the integration of the application in the distribution.
|
||||
|
||||
Above all, consistent CI allows automation and reduced manual labor. It frees up our valuable volunteers and contributors to spend more time on new things for Fedora.
|
||||
|
||||
### How will it look?
|
||||
|
||||
For starters, we’ll run tests for every commit to git repositories of Fedora’s packages (dist-git). These tests are independent of the tests each of these packages run when built. However, they test the functionality of the package in an environment as close as possible to what Fedora’s users run. In addition to package-specific tests, Fedora also runs some distribution-wide tests, such as upgrade testing from F27 to F28 or rawhide.
|
||||
|
||||
Packages are “gated” based on test results: test failures prevent an update being pushed to users. However, sometimes tests fail for various reasons. Perhaps the tests themselves are wrong, or not up to date with the software. Or perhaps an infrastructure issue occurred and prevented the tests from running correctly. Maintainers will be able to re-trigger the tests or waive their results until the tests are updated.
|
||||
|
||||
Eventually, Fedora’s CI will run tests when a new pull-request is opened or updated on <https://src.fedoraproject.org>. This will give maintainers information about the impact of the proposed change on the stability of the package, and help them decide how to proceed.
|
||||
|
||||
### What do we have today?
|
||||
|
||||
Currently, a CI pipeline runs tests on packages that are part of Fedora Atomic Host. Other packages can have tests in dist-git, but they won’t be run automatically yet. Distribution specific tests already run on all of our packages. These test results are used to gate packages with failures.
|
||||
|
||||
### How do I get involved?
|
||||
|
||||
The best way to get started is to read the documentation about [Continuous Integration in Fedora][1]. You should get familiar with the [Standard Test Interface][2], which describes a lot of the terminology as well as how to write tests and use existing ones.
|
||||
|
||||
With this knowledge, if you’re a package maintainer you can start adding tests to your packages. You can run them on your local machine or in a virtual machine. (This latter is advisable for destructive tests!)
|
||||
|
||||
The Standard Test Interface makes testing consistent. As a result, you can easily add any tests to a package you like, and submit them to the maintainers in a pull-request on its [repository][3].
|
||||
|
||||
Reach out on #fedora-ci on irc.freenode.net with feedback, questions or for a general discussion on CI.
|
||||
|
||||
Photo by [Samuel Zeller][4] on [Unsplash][5]
|
||||
|
||||
#### Like this:
|
||||
|
||||
Like
|
||||
|
||||
Loading...
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/continuous-integration-fedora/
|
||||
|
||||
作者:[Pierre-Yves Chibon;Dominik Perpeet][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org
|
||||
[1]:http://fedoraproject.org/wiki/CI
|
||||
[2]:http://fedoraproject.org/wiki/CI/Standard_Test_Interface
|
||||
[3]:https://src.fedoraproject.org
|
||||
[4]:https://unsplash.com/photos/77oXlGwwOw0?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[5]:https://unsplash.com/search/photos/factory-line?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
87
sources/tech/20180313 Running DOS on the Raspberry Pi.md
Normal file
87
sources/tech/20180313 Running DOS on the Raspberry Pi.md
Normal file
@ -0,0 +1,87 @@
|
||||
hankchow translating
|
||||
|
||||
Running DOS on the Raspberry Pi
|
||||
======
|
||||
|
||||
|
||||
You may be familiar with [The FreeDOS Project][1]. FreeDOS is a complete, free, DOS-compatible operating system that you can use to play classic DOS games, run legacy business software, or develop embedded PC applications. Any program that works on MS-DOS should also run on FreeDOS.
|
||||
|
||||
As the founder and project coordinator of the FreeDOS Project, I'm often the go-to person when users ask questions. And one question I seem to get a lot lately is: "Can you run FreeDOS on the Raspberry Pi?"
|
||||
|
||||
This question isn't surprising. After all, Linux runs great on the Raspberry Pi, and FreeDOS is an older operating system that requires fewer resources than Linux, so why shouldn't FreeDOS run on the Raspberry Pi.
|
||||
|
||||
**[Enter our[Raspberry Pi week giveaway][2] for a chance at this arcade gaming kit.]**
|
||||
|
||||
The simple answer is that FreeDOS cannot run on a Raspberry Pi by itself because of the CPU architecture. Like any DOS, FreeDOS requires an Intel x86 CPU and a BIOS to provide basic runtime services. But the Raspberry Pi is a completely different architecture. The Raspberry Pi runs an ARM CPU, which is not binary compatible with the Intel CPU and does not include a BIOS. So FreeDOS cannot run on the Raspberry Pi at the "bare hardware" level.
|
||||
|
||||
Fortunately, it's possible to run FreeDOS on the Raspberry Pi through PC emulation. Maybe that's not as cool as running FreeDOS natively, but it's a great way to run DOS applications on the Raspberry Pi.
|
||||
|
||||
### What about DOSBox?
|
||||
|
||||
Some might ask, "Why not use DOSBox instead?" DOSBox is an open source x86 emulator that runs on a variety of systems, including Linux. It is a great system that provides a DOS-like environment, mostly aimed at running games. So if you just want to run a classic DOS game, DOSBox can do that for you. But if you run want to run DOS applications, DOSBox isn't the best platform. And if you ask the DOSBox forums, they'll tell you DOSBox is really meant for games.
|
||||
|
||||
For most users, it's a matter of preference. It shouldn't be a surprise that I prefer to install FreeDOS to run classic DOS games and other programs. I find the full DOS experience gives me greater flexibility and control than running DOSBox. I use DOSBox for a few games, but for most things I prefer to run a full FreeDOS instead.
|
||||
|
||||
### Installing FreeDOS on Raspberry Pi
|
||||
|
||||
[QEMU][3] (short for Quick EMUlator) is an open source virtual machine software system that can run DOS as a "guest" operating system on Linux. Most popular Linux systems include QEMU by default. QEMU is available for Raspbian, the Linux distribution I'm using on my Raspberry Pi. I took the QEMU screenshots in this article with my Raspberry Pi running [Raspbian GNU/Linux 9 (Stretch)][4].
|
||||
|
||||
Last year, I wrote an article about [how to run DOS programs in Linux][5] using QEMU. The steps to install and run FreeDOS using QEMU are basically the same on the Raspberry Pi as they were for my GNOME-based system.
|
||||
|
||||
In QEMU, you need to "build" your virtual system by instructing QEMU to add each component of the virtual machine. Let's start by defining a virtual disk image that we'll use to install and run DOS. The `qemu-img` command lets you create virtual disk images. For FreeDOS, we won't need much room, so I created my virtual disk with 200 megabytes:
|
||||
```
|
||||
qemu-img create freedos.img 200M
|
||||
|
||||
```
|
||||
|
||||
Unlike PC emulator systems like VMware or VirtualBox, you need to "build" your virtual system by instructing QEMU to add each component of the virtual machine. Although this may seem laborious, it's not that hard. I used these parameters to run QEMU to install FreeDOS on my Raspberry Pi:
|
||||
```
|
||||
qemu-system-i386 -m 16 -k en-us -rtc base=localtime -soundhw sb16,adlib -device cirrus-vga -hda freedos.img -cdrom FD12CD.iso -boot order=d
|
||||
|
||||
```
|
||||
|
||||
You can find the full description of that command line in my other [article][5]. In brief, the command line defines an Intel i386-compatible virtual machine with 16 megabytes of memory, a US/English keyboard, and a real-time clock based on my local system time. The command line also defines a classic Sound Blaster 16 sound card, Adlib digital music card, and standard Cirrus Logic VGA card. The file `freedos.img` is defined as the first hard drive (`C:`) and the `FD12CD.iso` image as the CD-ROM (`D:`) drive. QEMU is set to boot from that `D:` CD-ROM drive.
|
||||
|
||||
The FreeDOS 1.2 distribution is easy to install. Just follow the prompts.
|
||||
|
||||
However, it takes forever to install because of the heavy disk I/O when you install the operating system, and the microSD card isn't exactly fast.
|
||||
|
||||
### Running FreeDOS on Raspberry Pi
|
||||
|
||||
Your results may vary depending on the microSD card you use. I used a SanDisk Ultra 64GB microSDXC UHS-I U1A1 card. The U1 is designed to support 1080p video recording (such as you might use in a GoPro camera) at minimum serial write speeds of 10MB/s. By comparison, a V60 is aimed at cameras that do 4K video and has a minimum sequential write speed of 60MB/s. If your Pi has a V60 microSD card or even a V30 (30MB/s), you'll see noticeably better disk I/O performance than I did.
|
||||
|
||||
After installing FreeDOS, you may prefer to boot directly from the virtual `C:` drive. Modify your QEMU command line to change the boot order, using `-boot order=c`, like this:
|
||||
```
|
||||
qemu-system-i386 -m 16 -k en-us -rtc base=localtime -soundhw sb16,adlib -device cirrus-vga -hda freedos.img -cdrom FD12CD.iso -boot order=c
|
||||
|
||||
```
|
||||
|
||||
Once you have installed FreeDOS in QEMU on the Raspberry Pi, you shouldn't notice any performance issues. For example, games usually load maps, sprites, sounds, and other data when you start each level. While starting a new level in a game might take a while, I didn't notice any performance lag while playing DOS games in FreeDOS on the Raspberry Pi.
|
||||
|
||||
The FreeDOS 1.2 distribution includes many games and other applications that might interest you. You may need to run the `FDIMPLES` package manager program to install these extra packages. My favorite game in FreeDOS 1.2 is WING, a space-shooter game that's very reminiscent of the classic arcade game Galaga. (The name WING is a recursive acronym for Wing Is Not Galaga.)
|
||||
|
||||
One of my favorite DOS programs is the shareware As-Easy-As spreadsheet program. It was a popular spreadsheet application from the 1980s and 1990s, which does the same job Microsoft Excel and LibreOffice Calc fulfill today or that the DOS-based Lotus 1-2-3 spreadsheet did back in the day. As-Easy-As and Lotus 1-2-3 both saved data as WKS files, which newer versions of Microsoft Excel can't read, but LibreOffice Calc may still support, depending on compatibility. While the original version of As-Easy-As was shareware, TRIUS Software made the [activation code for As-Easy-As 5.7][6] available for free.
|
||||
|
||||
I'm also quite fond of the GNU Emacs editor, and FreeDOS includes a similar Emacs-like text editor called Freemacs. If you want a more powerful editor than the default FreeDOS Edit and desire an experience like GNU Emacs, then Freemacs is for you. You can install Freemacs using the `FDIMPLES` package manager in the FreeDOS 1.2 distribution.
|
||||
|
||||
### Yes, you can run DOS on the Raspberry Pi (sort of)
|
||||
|
||||
While you can't run DOS on "bare hardware" on the Raspberry Pi, it's nice to know that you can still run DOS on the Raspberry Pi via an emulator. Thanks to the QEMU PC emulator and FreeDOS, it's possible to play classic DOS games and run other DOS programs on the Raspberry Pi. Expect a slight performance hit when doing any disk I/O, especially if you're doing something intensive on the disk, like writing large amounts of data, but things will run fine after that. Once you've set up QEMU as the virtual machine emulator and installed FreeDOS, you are all set to enjoy your favorite classic DOS programs on the Raspberry Pi.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/can-you-run-dos-raspberry-pi
|
||||
|
||||
作者:[Jim Hall][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jim-hall
|
||||
[1]:http://www.freedos.org/
|
||||
[2]:https://opensource.com/article/18/3/raspberry-pi-week-giveaway
|
||||
[3]:https://www.qemu.org/
|
||||
[4]:https://www.raspberrypi.org/downloads/
|
||||
[5]:https://opensource.com/article/17/10/run-dos-applications-linux
|
||||
[6]:http://www.triusinc.com/forums/viewtopic.php?t=10
|
||||
@ -0,0 +1,80 @@
|
||||
The Type Command Tutorial With Examples For Beginners
|
||||
======
|
||||
|
||||

|
||||
|
||||
The **Type** command is used to find out the information about a Linux command. As the name implies, you can easily find whether the given command is an alias, shell built-in, file, function, or keyword using “type” command. Additionally, you can find the actual path of the command too. Why would anyone need to find the command type? For instance, if you happen to work on a shared computer often, some guys may intentionally or accidentally create an alias to a particular Linux command to perform an unwanted operation, for example **“alias ls = rm -rf /”**. So, it is always good idea to inspect them before something worse happen. This is where the type command comes in help.
|
||||
|
||||
Let me show you some examples.
|
||||
|
||||
Run the Type command without any flags.
|
||||
```
|
||||
$ type ls
|
||||
ls is aliased to `ls --color=auto'
|
||||
|
||||
```
|
||||
|
||||
As you can see in the above output, the “ls” command has been aliased to “ls –color-auto”. It is, however, harmless. But just think of if the **ls** command is aliased to something dangerous. You don’t want that, do you?
|
||||
|
||||
You can use **-t** flag to find only the type of a Linux command. For example:
|
||||
```
|
||||
$ type -t ls
|
||||
alias
|
||||
|
||||
$ type -t mkdir
|
||||
file
|
||||
|
||||
$ type -t pwd
|
||||
builtin
|
||||
|
||||
$ type -t if
|
||||
keyword
|
||||
|
||||
$ type -t rvm
|
||||
function
|
||||
|
||||
```
|
||||
|
||||
This command just displays the type of the command, i.e alias. It doesn’t display what is aliased to the given command. If a command is not found, you will see nothing in the terminal.
|
||||
|
||||
The another useful advantage of type command is we can easily find out the absolute path of a given Linux command. To do so, use **-p** flag as shown below.
|
||||
```
|
||||
$ type -p cal
|
||||
/usr/bin/cal
|
||||
|
||||
```
|
||||
|
||||
This is similar to ‘which ls’ command. If the given command is aliased, nothing will be printed.
|
||||
|
||||
To display all information of a command, use **-a** flag.
|
||||
```
|
||||
$ type -a ls
|
||||
ls is aliased to `ls --color=auto'
|
||||
ls is /usr/bin/ls
|
||||
ls is /bin/ls
|
||||
|
||||
```
|
||||
|
||||
As you see, -a flag displays the type of the given command and its absolute path. For more details, refer man pages.
|
||||
```
|
||||
$ man type
|
||||
|
||||
```
|
||||
|
||||
Hope this helps. More good stuffs to come. Keep visiting!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/the-type-command-tutorial-with-examples-for-beginners/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
@ -0,0 +1,193 @@
|
||||
How to measure particulate matter with a Raspberry Pi
|
||||
======
|
||||
|
||||

|
||||
We regularly measure particulate matter in the air at our school in Southeast Asia. The values here are very high, particularly between February and May, when weather conditions are very dry and hot, and many fields burn. These factors negatively affect the quality of the air. In this article, I will show you how to measure particulate matter using a Raspberry Pi.
|
||||
|
||||
### What is particulate matter?
|
||||
|
||||
Particulate matter is fine dust or very small particles in the air. A distinction is made between PM10 and PM2.5: PM10 refers to particles that are smaller than 10µm; PM2.5 refers to particles that are smaller than 2.5µm. The smaller the particles—i.e., anything smaller than 2.5µm—the more dangerous they are to one's health, as they can penetrate into the alveoli and impact the respiratory system.
|
||||
|
||||
The World Health Organization recommends [limiting particulate matter][1] to the following values:
|
||||
|
||||
* Annual average PM10 20 µg/m³
|
||||
* Annual average PM2,5 10 µg/m³ per year
|
||||
* Daily average PM10 50 µg/m³ without permitted days on which exceeding is possible.
|
||||
* Daily average PM2,5 25 µg/m³ without permitted days on which exceeding is possible.
|
||||
|
||||
|
||||
|
||||
These values are below the limits set in most countries. In the European Union, an annual average of 40 µg/m³ for PM10 is allowed.
|
||||
|
||||
### What is the Air Quality Index (AQI)?
|
||||
|
||||
The Air Quality Index indicates how “good” or “bad” air is based on its particulate measurement. Unfortunately, there is no uniform standard for AQI because not all countries calculate it the same way. The Wikipedia article on the [Air Quality Index][2] offers a helpful overview. At our school, we are guided by the classification established by the United States' [Environmental Protection Agency][3].
|
||||
|
||||
|
||||
![Air quality index][5]
|
||||
|
||||
Air quality index
|
||||
|
||||
### What do we need to measure particulate matter?
|
||||
|
||||
Measuring particulate matter requires only two things:
|
||||
|
||||
* A Raspberry Pi (every model works; a model with WiFi is best)
|
||||
* A particulates sensor SDS011
|
||||
|
||||
|
||||
|
||||
![Particulate sensor][7]
|
||||
|
||||
Particulate sensor
|
||||
|
||||
If you are using a Raspberry Pi Zero W, you will also need an adapter cable to a standard USB port because the Zero has only a Micro USB. These are available for about $20. The sensor comes with a USB adapter for the serial interface.
|
||||
|
||||
### Installation
|
||||
|
||||
For our Raspberry Pi we download the corresponding Raspbian Lite Image and [write it on the Micro SD card][8]. (I will not go into the details of setting up the WLAN connection; many tutorials are available online).
|
||||
|
||||
If you want to have SSH enabled after booting, you need to create an empty file named `ssh` in the boot partition. The IP of the Raspberry Pi can best be obtained via your own router/DHCP server. You can then log in via SSH (the default password is raspberry):
|
||||
```
|
||||
$ ssh pi@192.168.1.5
|
||||
|
||||
```
|
||||
|
||||
First we need to install some packages on the Pi:
|
||||
```
|
||||
$ sudo apt install git-core python-serial python-enum lighttpd
|
||||
|
||||
```
|
||||
|
||||
Before we can start, we need to know which serial port the USB adapter is connected to. `dmesg` helps us:
|
||||
```
|
||||
$ dmesg
|
||||
|
||||
[ 5.559802] usbcore: registered new interface driver usbserial
|
||||
|
||||
[ 5.559930] usbcore: registered new interface driver usbserial_generic
|
||||
|
||||
[ 5.560049] usbserial: USB Serial support registered for generic
|
||||
|
||||
[ 5.569938] usbcore: registered new interface driver ch341
|
||||
|
||||
[ 5.570079] usbserial: USB Serial support registered for ch341-uart
|
||||
|
||||
[ 5.570217] ch341 1–1.4:1.0: ch341-uart converter detected
|
||||
|
||||
[ 5.575686] usb 1–1.4: ch341-uart converter now attached to ttyUSB0
|
||||
|
||||
```
|
||||
|
||||
In the last line, you can see our interface: `ttyUSB0`. We now need a small Python script that reads the data and saves it in a JSON file, and then we will create a small HTML page that reads and displays the data.
|
||||
|
||||
### Reading data on the Raspberry Pi
|
||||
|
||||
We first create an instance of the sensor and then read the sensor every 5 minutes, for 30 seconds. These values can, of course, be adjusted. Between the measuring intervals, we put the sensor into a sleep mode to increase its lifespan (according to the manufacturer, the lifespan totals approximately 8000 hours).
|
||||
|
||||
We can download the script with this command:
|
||||
```
|
||||
$ wget -O /home/pi/aqi.py https://raw.githubusercontent.com/zefanja/aqi/master/python/aqi.py
|
||||
|
||||
```
|
||||
|
||||
For the script to run without errors, two small things are still needed:
|
||||
```
|
||||
$ sudo chown pi:pi /var/wwww/html/
|
||||
|
||||
$ echo[] > /var/wwww/html/aqi.json
|
||||
|
||||
```
|
||||
|
||||
Now you can start the script:
|
||||
```
|
||||
$ chmod +x aqi.py
|
||||
|
||||
$ ./aqi.py
|
||||
|
||||
PM2.5:55.3, PM10:47.5
|
||||
|
||||
PM2.5:55.5, PM10:47.7
|
||||
|
||||
PM2.5:55.7, PM10:47.8
|
||||
|
||||
PM2.5:53.9, PM10:47.6
|
||||
|
||||
PM2.5:53.6, PM10:47.4
|
||||
|
||||
PM2.5:54.2, PM10:47.3
|
||||
|
||||
…
|
||||
|
||||
```
|
||||
|
||||
### Run the script automatically
|
||||
|
||||
So that we don’t have to start the script manually every time, we can let it start with a cronjob, e.g., with every restart of the Raspberry Pi. To do this, open the crontab file:
|
||||
```
|
||||
$ crontab -e
|
||||
|
||||
```
|
||||
|
||||
and add the following line at the end:
|
||||
```
|
||||
@reboot cd /home/pi/ && ./aqi.py
|
||||
|
||||
```
|
||||
|
||||
Now our script starts automatically with every restart.
|
||||
|
||||
### HTML page for displaying measured values and AQI
|
||||
|
||||
We have already installed a lightweight webserver, `lighttpd`. So we need to save our HTML, JavaScript, and CSS files in the directory `/var/www/html/` so that we can access the data from another computer or smartphone. With the next three commands, we simply download the corresponding files:
|
||||
```
|
||||
$ wget -O /var/wwww/html/index.html https://raw.githubusercontent.com/zefanja/aqi/master/html/index.html
|
||||
|
||||
$ wget -O /var/wwww/html/aqi.js https://raw.githubusercontent.com/zefanja/aqi/master/html/aqi.js
|
||||
|
||||
$ wget -O /var/wwww/html/style.css https://raw.githubusercontent.com/zefanja/aqi/master/html/style.css
|
||||
|
||||
```
|
||||
|
||||
The main work is done in the JavaScript file, which opens our JSON file, takes the last value, and calculates the AQI based on this value. Then the background colors are adjusted according to the scale of the EPA.
|
||||
|
||||
Now you simply open the address of the Raspberry Pi in your browser and look at the current particulates values, e.g., [http://192.168.1.5:][9]
|
||||
|
||||
The page is very simple and can be extended, for example, with a chart showing the history of the last hours, etc. Pull requests are welcome.
|
||||
|
||||
The complete [source code is available on Github][10].
|
||||
|
||||
**[Enter our[Raspberry Pi week giveaway][11] for a chance at this arcade gaming kit.]**
|
||||
|
||||
### Wrapping up
|
||||
|
||||
For relatively little money, we can measure particulate matter with a Raspberry Pi. There are many possible applications, from a permanent outdoor installation to a mobile measuring device. At our school, we use both: There is a sensor that measures outdoor values day and night, and a mobile sensor that checks the effectiveness of the air conditioning filters in our classrooms.
|
||||
|
||||
[Luftdaten.info][12] offers guidance to build a similar sensor. The software is delivered ready to use, and the measuring device is even more compact because it does not use a Raspberry Pi. Great project!
|
||||
|
||||
Creating a particulates sensor is an excellent project to do with students in computer science classes or a workshop.
|
||||
|
||||
What do you use a [Raspberry Pi][13] for?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/how-measure-particulate-matter-raspberry-pi
|
||||
|
||||
作者:[Stephan Tetzel][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/stephan
|
||||
[1]:https://en.wikipedia.org/wiki/Particulates
|
||||
[2]:https://en.wikipedia.org/wiki/Air_quality_index
|
||||
[3]:https://en.wikipedia.org/wiki/United_States_Environmental_Protection_Agency
|
||||
[5]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/images/life-uploads/air_quality_index.png?itok=FwmGf1ZS (Air quality index)
|
||||
[7]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/images/life-uploads/particulate_sensor.jpg?itok=ddH3bBwO (Particulate sensor)
|
||||
[8]:https://www.raspberrypi.org/documentation/installation/installing-images/README.md
|
||||
[9]:http://192.168.1.5/
|
||||
[10]:https://github.com/zefanja/aqi
|
||||
[11]:https://opensource.com/article/18/3/raspberry-pi-week-giveaway
|
||||
[12]:http://luftdaten.info/
|
||||
[13]:https://openschoolsolutions.org/shutdown-servers-case-power-failure%e2%80%8a-%e2%80%8aups-nut-co/
|
||||
40
sources/tech/20180314 Playing with water.md
Normal file
40
sources/tech/20180314 Playing with water.md
Normal file
@ -0,0 +1,40 @@
|
||||
Playing with water
|
||||
======
|
||||
![H2o Flow gradient boosting job][1]
|
||||
|
||||
I'm currently taking a machine learning class and although it is an insane amount of work, I like it a lot. I initially had planned to use [R][2] to play around with the database I have, but the teacher recommended I use [H2o][3], a FOSS machine learning framework.
|
||||
|
||||
I was a bit sceptical at first since I'm already pretty good with R, but then I found out you could simply import H2o as an R library. H2o replaces most R functions by its own parallelized ones to cut down on processing time (no more `doParallel` calls) and uses an "external" server you have to run on the side instead of running R calls directly.
|
||||
|
||||
![H2o Flow gradient boosting model][4]
|
||||
|
||||
I was pretty happy with this situation, that is until I actually started using H2o in R. With the huge database I'm playing with, the library felt clunky and I had a hard time doing anything useful. Most of the time, I just ended up with long Java traceback calls. Much love.
|
||||
|
||||
I'm sure in the right hands using H2o as a library could have been incredibly powerful, but sadly it seems I haven't earned my black belt in R-fu yet.
|
||||
|
||||
![H2o Flow variable importance weights][5]
|
||||
|
||||
I was pissed for at least a whole day - not being able to achieve what I wanted to do - until I realised H2o comes with a WebUI called Flow. I'm normally not very fond of using web thingies to do important work like writing code, but Flow is simply incredible.
|
||||
|
||||
Automated graphing functions, integrated ETA when running resource intensive models, descriptions for each and every model parameters (the parameters are even divided in sections based on your familiarly with the statistical models in question), Flow seemingly has it all. In no time I was able to run 3 basic machine learning models and get actual interpretable results.
|
||||
|
||||
So yeah, if you've been itching to analyse very large databases using state of the art machine learning models, I would recommend using H2o. Try Flow at first instead of the Python or R hooks to see what it's capable of doing.
|
||||
|
||||
The only downside to all of this is that H2o is written in Java and depends on Java 1.7 to run... That, and be warned: it requires a metric fuckton of processing power and RAM. My poor server struggled quite a bit even with 10 available cores and 10Gb of RAM...
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://veronneau.org/playing-with-water.html
|
||||
|
||||
作者:[Louis-Philippe Véronneau][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://veronneau.org/
|
||||
[1]:https://veronneau.org/media/blog/2018-03-14/h2o_job.png (H2o Flow gradient boosting job)
|
||||
[2]:https://en.wikipedia.org/wiki/R_(programming_language)
|
||||
[3]:https://www.h2o.ai
|
||||
[4]:https://veronneau.org/media/blog/2018-03-14/h2o_model.png (H2o Flow gradient boosting model)
|
||||
[5]:https://veronneau.org/media/blog/2018-03-14/h2o_var_importance.png (H2o Flow variable importance weights)
|
||||
@ -0,0 +1,303 @@
|
||||
Protecting Code Integrity with PGP — Part 5: Moving Subkeys to a Hardware Device
|
||||
======
|
||||
|
||||

|
||||
|
||||
In this tutorial series, we're providing practical guidelines for using PGP. If you missed the previous article, you can catch up with the links below. But, in this article, we'll continue our discussion about securing your keys and look at some tips for moving your subkeys to a specialized hardware device.
|
||||
|
||||
[Part 1: Basic Concepts and Tools][1]
|
||||
|
||||
[Part 2: Generating Your Master Key][2]
|
||||
|
||||
[Part 3: Generating PGP Subkeys][3]
|
||||
|
||||
[Part 4: Moving Your Master Key to Offline Storage][4]
|
||||
|
||||
### Checklist
|
||||
|
||||
* Get a GnuPG-compatible hardware device (NICE)
|
||||
|
||||
* Configure the device to work with GnuPG (NICE)
|
||||
|
||||
* Set the user and admin PINs (NICE)
|
||||
|
||||
* Move your subkeys to the device (NICE)
|
||||
|
||||
|
||||
|
||||
|
||||
### Considerations
|
||||
|
||||
Even though the master key is now safe from being leaked or stolen, the subkeys are still in your home directory. Anyone who manages to get their hands on those will be able to decrypt your communication or fake your signatures (if they know the passphrase). Furthermore, each time a GnuPG operation is performed, the keys are loaded into system memory and can be stolen from there by sufficiently advanced malware (think Meltdown and Spectre).
|
||||
|
||||
The best way to completely protect your keys is to move them to a specialized hardware device that is capable of smartcard operations.
|
||||
|
||||
#### The benefits of smartcards
|
||||
|
||||
A smartcard contains a cryptographic chip that is capable of storing private keys and performing crypto operations directly on the card itself. Because the key contents never leave the smartcard, the operating system of the computer into which you plug in the hardware device is not able to retrieve the private keys themselves. This is very different from the encrypted USB storage device we used earlier for backup purposes -- while that USB device is plugged in and decrypted, the operating system is still able to access the private key contents. Using external encrypted USB media is not a substitute to having a smartcard-capable device.
|
||||
|
||||
Some other benefits of smartcards:
|
||||
|
||||
* They are relatively cheap and easy to obtain
|
||||
|
||||
* They are small and easy to carry with you
|
||||
|
||||
* They can be used with multiple devices
|
||||
|
||||
* Many of them are tamper-resistant (depends on manufacturer)
|
||||
|
||||
|
||||
|
||||
|
||||
#### Available smartcard devices
|
||||
|
||||
Smartcards started out embedded into actual wallet-sized cards, which earned them their name. You can still buy and use GnuPG-capable smartcards, and they remain one of the cheapest available devices you can get. However, actual smartcards have one important downside: they require a smartcard reader, and very few laptops come with one.
|
||||
|
||||
For this reason, manufacturers have started providing small USB devices, the size of a USB thumb drive or smaller, that either have the microsim-sized smartcard pre-inserted, or that simply implement the smartcard protocol features on the internal chip. Here are a few recommendations:
|
||||
|
||||
* [Nitrokey Start][5]: Open hardware and Free Software: one of the cheapest options for GnuPG use, but with fewest extra security features
|
||||
|
||||
* [Nitrokey Pro][6]: Similar to the Nitrokey Start, but is tamper-resistant and offers more security features (but not U2F, see the Fido U2F section of the guide)
|
||||
|
||||
* [Yubikey 4][7]: Proprietary hardware and software, but cheaper than Nitrokey Pro and comes available in the USB-C form that is more useful with newer laptops; also offers additional security features such as U2F
|
||||
|
||||
|
||||
|
||||
|
||||
Our recommendation is to pick a device that is capable of both smartcard functionality and U2F, which, at the time of writing, means a Yubikey 4.
|
||||
|
||||
#### Configuring your smartcard device
|
||||
|
||||
Your smartcard device should Just Work (TM) the moment you plug it into any modern Linux or Mac workstation. You can verify it by running:
|
||||
```
|
||||
$ gpg --card-status
|
||||
|
||||
```
|
||||
|
||||
If you didn't get an error, but a full listing of the card details, then you are good to go. Unfortunately, troubleshooting all possible reasons why things may not be working for you is way beyond the scope of this guide. If you are having trouble getting the card to work with GnuPG, please seek support via your operating system's usual support channels.
|
||||
|
||||
##### PINs don't have to be numbers
|
||||
|
||||
Note, that despite having the name "PIN" (and implying that it must be a "number"), neither the user PIN nor the admin PIN on the card need to be numbers.
|
||||
|
||||
Your device will probably have default user and admin PINs set up when it arrives. For Yubikeys, these are 123456 and 12345678, respectively. If those don't work for you, please check any accompanying documentation that came with your device.
|
||||
|
||||
##### Quick setup
|
||||
|
||||
To configure your smartcard, you will need to use the GnuPG menu system, as there are no convenient command-line switches:
|
||||
```
|
||||
$ gpg --card-edit
|
||||
[...omitted...]
|
||||
gpg/card> admin
|
||||
Admin commands are allowed
|
||||
gpg/card> passwd
|
||||
|
||||
```
|
||||
|
||||
You should set the user PIN (1), Admin PIN (3), and the Reset Code (4). Please make sure to record and store these in a safe place -- especially the Admin PIN and the Reset Code (which allows you to completely wipe the smartcard). You so rarely need to use the Admin PIN, that you will inevitably forget what it is if you do not record it.
|
||||
|
||||
Getting back to the main card menu, you can also set other values (such as name, sex, login data, etc), but it's not necessary and will additionally leak information about your smartcard should you lose it.
|
||||
|
||||
#### Moving the subkeys to your smartcard
|
||||
|
||||
Exit the card menu (using "q") and save all changes. Next, let's move your subkeys onto the smartcard. You will need both your PGP key passphrase and the admin PIN of the card for most operations. Remember, that [fpr] stands for the full 40-character fingerprint of your key.
|
||||
```
|
||||
$ gpg --edit-key [fpr]
|
||||
|
||||
Secret subkeys are available.
|
||||
|
||||
pub rsa4096/AAAABBBBCCCCDDDD
|
||||
created: 2017-12-07 expires: 2019-12-07 usage: C
|
||||
trust: ultimate validity: ultimate
|
||||
ssb rsa2048/1111222233334444
|
||||
created: 2017-12-07 expires: never usage: E
|
||||
ssb rsa2048/5555666677778888
|
||||
created: 2017-12-07 expires: never usage: S
|
||||
[ultimate] (1). Alice Engineer <alice@example.org>
|
||||
[ultimate] (2) Alice Engineer <allie@example.net>
|
||||
|
||||
gpg>
|
||||
|
||||
```
|
||||
|
||||
Using --edit-key puts us into the menu mode again, and you will notice that the key listing is a little different. From here on, all commands are done from inside this menu mode, as indicated by gpg>.
|
||||
|
||||
First, let's select the key we'll be putting onto the card -- you do this by typing key 1 (it's the first one in the listing, our [E] subkey):
|
||||
```
|
||||
gpg> key 1
|
||||
|
||||
```
|
||||
|
||||
The output should be subtly different:
|
||||
```
|
||||
pub rsa4096/AAAABBBBCCCCDDDD
|
||||
created: 2017-12-07 expires: 2019-12-07 usage: C
|
||||
trust: ultimate validity: ultimate
|
||||
ssb* rsa2048/1111222233334444
|
||||
created: 2017-12-07 expires: never usage: E
|
||||
ssb rsa2048/5555666677778888
|
||||
created: 2017-12-07 expires: never usage: S
|
||||
[ultimate] (1). Alice Engineer <alice@example.org>
|
||||
[ultimate] (2) Alice Engineer <allie@example.net>
|
||||
|
||||
```
|
||||
|
||||
Notice the * that is next to the ssb line corresponding to the key -- it indicates that the key is currently "selected." It works as a toggle, meaning that if you type key 1 again, the * will disappear and the key will not be selected any more.
|
||||
|
||||
Now, let's move that key onto the smartcard:
|
||||
```
|
||||
gpg> keytocard
|
||||
Please select where to store the key:
|
||||
(2) Encryption key
|
||||
Your selection? 2
|
||||
|
||||
```
|
||||
|
||||
Since it's our [E] key, it makes sense to put it into the Encryption slot. When you submit your selection, you will be prompted first for your PGP key passphrase, and then for the admin PIN. If the command returns without an error, your key has been moved.
|
||||
|
||||
**Important:** Now type key 1 again to unselect the first key, and key 2 to select the [S] key:
|
||||
```
|
||||
gpg> key 1
|
||||
gpg> key 2
|
||||
gpg> keytocard
|
||||
Please select where to store the key:
|
||||
(1) Signature key
|
||||
(3) Authentication key
|
||||
Your selection? 1
|
||||
|
||||
```
|
||||
|
||||
You can use the [S] key both for Signature and Authentication, but we want to make sure it's in the Signature slot, so choose (1). Once again, if your command returns without an error, then the operation was successful.
|
||||
|
||||
Finally, if you created an [A] key, you can move it to the card as well, making sure first to unselect key 2. Once you're done, choose "q":
|
||||
```
|
||||
gpg> q
|
||||
Save changes? (y/N) y
|
||||
|
||||
```
|
||||
|
||||
Saving the changes will delete the keys you moved to the card from your home directory (but it's okay, because we have them in our backups should we need to do this again for a replacement smartcard).
|
||||
|
||||
##### Verifying that the keys were moved
|
||||
|
||||
If you perform --list-secret-keys now, you will see a subtle difference in the output:
|
||||
```
|
||||
$ gpg --list-secret-keys
|
||||
sec# rsa4096 2017-12-06 [C] [expires: 2019-12-06]
|
||||
111122223333444455556666AAAABBBBCCCCDDDD
|
||||
uid [ultimate] Alice Engineer <alice@example.org>
|
||||
uid [ultimate] Alice Engineer <allie@example.net>
|
||||
ssb> rsa2048 2017-12-06 [E]
|
||||
ssb> rsa2048 2017-12-06 [S]
|
||||
|
||||
```
|
||||
|
||||
The > in the ssb> output indicates that the subkey is only available on the smartcard. If you go back into your secret keys directory and look at the contents there, you will notice that the .key files there have been replaced with stubs:
|
||||
```
|
||||
$ cd ~/.gnupg/private-keys-v1.d
|
||||
$ strings *.key
|
||||
|
||||
```
|
||||
|
||||
The output should contain shadowed-private-key to indicate that these files are only stubs and the actual content is on the smartcard.
|
||||
|
||||
#### Verifying that the smartcard is functioning
|
||||
|
||||
To verify that the smartcard is working as intended, you can create a signature:
|
||||
```
|
||||
$ echo "Hello world" | gpg --clearsign > /tmp/test.asc
|
||||
$ gpg --verify /tmp/test.asc
|
||||
|
||||
```
|
||||
|
||||
This should ask for your smartcard PIN on your first command, and then show "Good signature" after you run gpg --verify.
|
||||
|
||||
Congratulations, you have successfully made it extremely difficult to steal your digital developer identity!
|
||||
|
||||
### Other common GnuPG operations
|
||||
|
||||
Here is a quick reference for some common operations you'll need to do with your PGP key.
|
||||
|
||||
In all of the below commands, the [fpr] is your key fingerprint.
|
||||
|
||||
#### Mounting your master key offline storage
|
||||
|
||||
You will need your master key for any of the operations below, so you will first need to mount your backup offline storage and tell GnuPG to use it. First, find out where the media got mounted, for example, by looking at the output of the mount command. Then, locate the directory with the backup of your GnuPG directory and tell GnuPG to use that as its home:
|
||||
```
|
||||
$ export GNUPGHOME=/media/disk/name/gnupg-backup
|
||||
$ gpg --list-secret-keys
|
||||
|
||||
```
|
||||
|
||||
You want to make sure that you see sec and not sec# in the output (the # means the key is not available and you're still using your regular home directory location).
|
||||
|
||||
##### Updating your regular GnuPG working directory
|
||||
|
||||
After you make any changes to your key using the offline storage, you will want to import these changes back into your regular working directory:
|
||||
```
|
||||
$ gpg --export | gpg --homedir ~/.gnupg --import
|
||||
$ unset GNUPGHOME
|
||||
|
||||
```
|
||||
|
||||
#### Extending key expiration date
|
||||
|
||||
The master key we created has the default expiration date of 2 years from the date of creation. This is done both for security reasons and to make obsolete keys eventually disappear from keyservers.
|
||||
|
||||
To extend the expiration on your key by a year from current date, just run:
|
||||
```
|
||||
$ gpg --quick-set-expire [fpr] 1y
|
||||
|
||||
```
|
||||
|
||||
You can also use a specific date if that is easier to remember (e.g. your birthday, January 1st, or Canada Day):
|
||||
```
|
||||
$ gpg --quick-set-expire [fpr] 2020-07-01
|
||||
|
||||
```
|
||||
|
||||
Remember to send the updated key back to keyservers:
|
||||
```
|
||||
$ gpg --send-key [fpr]
|
||||
|
||||
```
|
||||
|
||||
#### Revoking identities
|
||||
|
||||
If you need to revoke an identity (e.g., you changed employers and your old email address is no longer valid), you can use a one-liner:
|
||||
```
|
||||
$ gpg --quick-revoke-uid [fpr] 'Alice Engineer <aengineer@example.net>'
|
||||
|
||||
```
|
||||
|
||||
You can also do the same with the menu mode using gpg --edit-key [fpr].
|
||||
|
||||
Once you are done, remember to send the updated key back to keyservers:
|
||||
```
|
||||
$ gpg --send-key [fpr]
|
||||
|
||||
```
|
||||
|
||||
Next time, we'll look at how Git supports multiple levels of integration with PGP.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][8]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/pgp/2018/3/protecting-code-integrity-pgp-part-5-moving-subkeys-hardware-device
|
||||
|
||||
作者:[KONSTANTIN RYABITSEV][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/mricon
|
||||
[1]:https://www.linux.com/blog/learn/2018/2/protecting-code-integrity-pgp-part-1-basic-pgp-concepts-and-tools
|
||||
[2]:https://www.linux.com/blog/learn/pgp/2018/2/protecting-code-integrity-pgp-part-2-generating-and-protecting-your-master-pgp-key
|
||||
[3]:https://www.linux.com/blog/learn/pgp/2018/2/protecting-code-integrity-pgp-part-3-generating-pgp-subkeys
|
||||
[4]:https://www.linux.com/blog/learn/pgp/2018/3/protecting-code-integrity-pgp-part-4-moving-your-master-key-offline-storage
|
||||
[5]:https://shop.nitrokey.com/shop/product/nitrokey-start-6
|
||||
[6]:https://shop.nitrokey.com/shop/product/nitrokey-pro-3
|
||||
[7]:https://www.yubico.com/product/yubikey-4-series/
|
||||
[8]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -0,0 +1,179 @@
|
||||
How to Encrypt Files From Within a File Manager
|
||||
======
|
||||
|
||||

|
||||
The Linux desktop and server enjoys a remarkable level of security. That doesn’t mean, however, you should simply rest easy. You should always consider that your data is always a quick hack away from being compromised. That being said, you might want to employ various tools for encryption, such as GnuPG, which lets you encrypt and decrypt files and much more. One problem with GnuPG is that some users don’t want to mess with the command line. If that’s the case, you can turn to a desktop file manager. Many Linux desktops include the ability to easily encrypt or decrypt files, and if that capability is not built in, it’s easy to add.
|
||||
|
||||
I will walk you through the process of encrypting and decrypting a file from within three popular Linux file managers:
|
||||
|
||||
* Nautilus (aka GNOME Files)
|
||||
|
||||
* Dolphin
|
||||
|
||||
* Thunar
|
||||
|
||||
|
||||
|
||||
|
||||
### Installing GnuPG
|
||||
|
||||
Before we get into the how to of this, we have to ensure your system includes the necessary base component… [GnuPG][1]. Most distributions ship with GnuPG included. On the off chance you use a distribution that doesn’t ship with GnuPG, here’s how to install it:
|
||||
|
||||
* Ubuntu-based distribution: sudo apt install gnupg
|
||||
|
||||
* Fedora-based distribution: sudo yum install gnupg
|
||||
|
||||
* openSUSE: sudo zypper in gnupg
|
||||
|
||||
* Arch-based distribution: sudo pacman -S gnupg
|
||||
|
||||
|
||||
|
||||
|
||||
Whether you’ve just now installed GnuPG or it was installed by default, you will have to create a GPG key for this to work. Each desktop uses a different GUI tool for this (or may not even include a GUI tool for the task), so let’s create that key from the command line. Open up your terminal window and issue the following command:
|
||||
```
|
||||
gpg --gen-key
|
||||
|
||||
```
|
||||
|
||||
You will then be asked to answer the following questions. Unless you have good reason, you can accept the defaults:
|
||||
|
||||
* What kind of key do you want?
|
||||
|
||||
* What key size do you want?
|
||||
|
||||
* Key is valid for?
|
||||
|
||||
|
||||
|
||||
|
||||
Once you’ve answered these questions, type y to indicate the answers are correct. Next you’ll need to supply the following information:
|
||||
|
||||
* Real name.
|
||||
|
||||
* Email address.
|
||||
|
||||
* Comment.
|
||||
|
||||
|
||||
|
||||
|
||||
Complete the above and then, when prompted, type O (for Okay). You will then be required to type a passphrase for the new key. Once the system has collected enough entropy (you’ll need to do some work on the desktop so this can happen), your key will have been created and you’re ready to go.
|
||||
|
||||
Let’s see how to encrypt/decrypt files from within the file managers.
|
||||
|
||||
### Nautilus
|
||||
|
||||
We start with the default GNOME file manager because it is the easiest. Nautilus requires no extra installation or extra work to encrypt/decrypt files from within it’s well-designed interface. Once you have your gpg key created, you can open up the file manager, navigate to the directory housing the file to be encrypted, right-click the file in question, and select Encrypt from the menu (Figure 1).
|
||||
|
||||
|
||||
![nautilus][3]
|
||||
|
||||
Figure 1: Encrypting a file from within Nautilus.
|
||||
|
||||
[Used with permission][4]
|
||||
|
||||
You will be asked to select a recipient (or list of recipients — Figure 2). NOTE: Recipients will be those users whose public keys you have imported. Select the necessary keys and then select your key (email address) from the Sign message as drop-down.
|
||||
|
||||
![nautilus][6]
|
||||
|
||||
Figure 2: Selecting recipients and a signer.
|
||||
|
||||
[Used with permission][4]
|
||||
|
||||
Notice you can also opt to encrypt the file with only a passphrase. This is important if the file will remain on your local machine (more on this later). Once you’ve set up the encryption, click OK and (when prompted) type the passphrase for your key. The file will be encrypted (now ending in .gpg) and saved in the working directory. You can now send that encrypted file to the recipients you selected during the encryption process.
|
||||
|
||||
Say someone (who has your public key) has sent you an encrypted file. Save that file, open the file manager, navigate to the directory housing that file, right-click the encrypted file, select Open With Decrypt File, give the file a new name (without the .gpg extension), and click Save. When prompted, type your gpg key passphrase and the file will be decrypted and ready to use.
|
||||
|
||||
### Dolphin
|
||||
|
||||
On the KDE front, there’s a package that must be installed in order to encrypt/decrypt from with the Dolphin file manager. Log into your KDE desktop, open the terminal window, and issue the following command (I’m demonstrating with Neon. If your distribution isn’t Ubuntu-based, you’ll have to alter the command accordingly):
|
||||
```
|
||||
sudo apt install kgpg
|
||||
|
||||
```
|
||||
|
||||
Once that installs, logout and log back into the KDE desktop. You can open up Dolphin and right-click a file to be encrypted. Since this is the first time you’ve used kgpg, you’ll have to walk through a quick setup wizard (which self-explanatory). When you’ve completed the wizard, you can go back to that file, right-click it (Figure 3), and select Encrypt File.
|
||||
|
||||
|
||||
![Dolphin][8]
|
||||
|
||||
Figure 3: Encrypting a file within Dolphin.
|
||||
|
||||
[Used with permission][4]
|
||||
|
||||
You’ll be prompted to select the key to use for encryption (Figure 4). Make your selection and click OK. The file will encrypt and you’re ready to send it to the recipient.
|
||||
|
||||
Note: With KDE’s Dolphin file manager, you cannot encrypt with a passphrase only.
|
||||
|
||||
|
||||
![Dolphin][10]
|
||||
|
||||
Figure 4: Selecting your recipients for encryption.
|
||||
|
||||
[Used with permission][4]
|
||||
|
||||
If you receive an encrypted file from a user who has your public key (or you have a file you’ve encrypted yourself), open up Dolphin, navigate to the file in question, double-click the file, give the file a new name, type the encryption passphrase, and click OK. You can now read your newly decrypted file. If you’ve encrypted the file with your own key, you won’t be prompted to type the passphrase (as it has already been stored).
|
||||
|
||||
### Thunar
|
||||
|
||||
The Thunar file manager is a bit trickier. There aren’t any extra packages to install; instead, you need to create new custom action for Encrypt. Once you’ve done this, you’ll have the ability to do this from within the file manager.
|
||||
|
||||
To create the custom actions, open up the Thunar file manager and click Edit > Configure Custom Actions. In the resulting window, click the + button (Figure 5) and enter the following for an Encrypt action:
|
||||
|
||||
Name: Encrypt
|
||||
|
||||
Description: File Encryption
|
||||
|
||||
Command: gnome-terminal -x gpg --encrypt --recipient %f
|
||||
|
||||
Click OK to save this action.
|
||||
|
||||
|
||||
![Thunar][12]
|
||||
|
||||
Figure 5: Creating an custom action within Thunar.
|
||||
|
||||
[Used with permission][4]
|
||||
|
||||
NOTE: If gnome-terminal isn’t your default terminal, substitute the command to open your default terminal in.
|
||||
|
||||
You can also create an action that encrypts with a passphrase only (not a key). To do this, the details for the action would be:
|
||||
|
||||
Name: Encrypt Passphrase
|
||||
|
||||
Description: Encrypt with Passphrase only
|
||||
|
||||
Command: gnome-terminal -x gpg -c %f
|
||||
|
||||
You don’t need to create a custom action for the decryption process, as Thunar already knows what to do with an encrypted file. To decrypt a file, simply right-click it (within Thunar), select Open With Decrypt File, give the decrypted file a name, and (when/if prompted) type the encryption passphrase. Viola, your encrypted file has been decrypted and is ready to use.
|
||||
|
||||
### One caveat
|
||||
|
||||
Do note: If you encrypt your own files, using your own keys, you won’t need to enter an encryption passphrase to decrypt them (because your public keys are stored). If, however, you receive files from others (who have your public key) you will be required to enter your passphrase. If you’re wanting to store your own encrypted files, instead of encrypting them with a key, encrypt them with a passphrase only. This is possible with Nautilus and Thunar (but not KDE). By opting for passphrase encryption (over key encryption), when you go to decrypt the file, it will always prompt you for the passphrase.
|
||||
|
||||
### Other file managers
|
||||
|
||||
There are plenty of other file managers out there, some of them can work with encryption, some cannot. Chances are, you’re using one of these three tools, so the ability to add encryption/decryption to the contextual menu is not only possible, it’s pretty easy. Give this a try and see if it doesn’t make the process of encryption and decryption much easier.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][13] course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/3/how-encrypt-files-within-file-manager
|
||||
|
||||
作者:[JACK WALLEN][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://www.gnupg.org/
|
||||
[3]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/nautilus.jpg?itok=ae7Gtj60 (nautilus)
|
||||
[4]:https://www.linux.com/licenses/category/used-permission
|
||||
[6]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/nautilus_2.jpg?itok=3ht7j63n (nautilus)
|
||||
[8]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/kde_0.jpg?itok=KSTctVw0 (Dolphin)
|
||||
[10]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/kde_2.jpg?itok=CeqWikNl (Dolphin)
|
||||
[12]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/thunar.jpg?itok=fXcHk08B (Thunar)
|
||||
[13]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -2,7 +2,7 @@
|
||||
======
|
||||
纵观现代计算机的历史,从与系统的交互方式方面,可以划分为数个进化阶段。而我更倾向于将之归类为以下几个阶段:
|
||||
|
||||
1. 数字系统
|
||||
1. 数字系统
|
||||
2. 专用应用系统
|
||||
3. 应用中心系统
|
||||
4. 信息中心系统
|
||||
@ -47,7 +47,7 @@
|
||||
|
||||
松散型应用中心系统(通过文件管理器来提取文件)应用而生。在这种系统下,当打开一个文件的时候,操作系统会自动启动与之相关的应用程序。这是一次小而精妙的用法转变。这种应用中心系统的用法模式一直是个人电脑的主要用法模式。
|
||||
|
||||
然而,这种模式有很多的缺点。例如,对于一个给定的项目,为了防止数据提取出现问题,需要维护一个包含所有相关文件的严格文件夹层次结构。不幸的是,人们并不总能这样做。当然,也有可能因为[ 文件数量规模还不是很大 ][8]。 桌面搜索引擎和高级数据组织工具(像[ tagstore ][9])可以起到一点改善作用。正如研究显示的那样,只有一少部分人正在使用那些高级文件提取工具。大多数的用户不使用替代提取工具或者辅助提取技术在文件系统中寻找文件。
|
||||
然而,这种模式有很多的缺点。例如,对于一个给定的项目,为了防止数据提取出现问题,需要维护一个包含所有相关文件的严格文件夹层次结构。不幸的是,人们并不总能这样做。更进一步说,[ 这种模式不能很好的扩展 ][8]。 桌面搜索引擎和高级数据组织工具(像[ tagstore ][9])可以起到一点改善作用。正如研究显示的那样,只有一少部分人正在使用那些高级文件提取工具。大多数的用户不使用替代提取工具或者辅助提取技术在文件系统中寻找文件。
|
||||
|
||||
### 信息中心系统
|
||||
|
||||
@ -70,7 +70,7 @@
|
||||
|
||||
我能想到这样一类操作系统,我称之为无应用系统。在下一步的发展中,系统将不需要单域应用程序,即使它们能和 Org-mode 一样出色。计算机直接提供一个处理信息和使用功能的友好用户接口,而不通过文件和程序。甚至连传统的操作系统也不需要。
|
||||
|
||||
无应用系统也可能和 [人工智能][21] 联系起来。把它想象成 [2001太空漫游][23] 中的 02[HAL 9000][22] 和星际迷航中的 [LCARS][24]一类的东西就可以了。
|
||||
无应用系统也可能和 [人工智能][21] 联系起来。把它想象成 [2001太空漫游][23] 中的 [HAL 9000][22] 和星际迷航中的 [LCARS][24]一类的东西就可以了。
|
||||
|
||||
从基于应用的,基于供应商的软件文化到无应用系统的转化让人很难相信。 或许,缓慢但却不断发展的开源环境,可以使一个由各种各样组织和人们贡献的真正无应用环境成型。
|
||||
|
||||
|
||||
104
translated/talk/20180201 How I coined the term open source.md
Normal file
104
translated/talk/20180201 How I coined the term open source.md
Normal file
@ -0,0 +1,104 @@
|
||||
[fuzheng1998 translating]
|
||||
我是如何创造“开源”这个词的
|
||||
============================================================
|
||||
|
||||
### Christine Peterson 最终公开讲述了二十年前那决定命运的一天。
|
||||
|
||||

|
||||
图片来自: opensource.com
|
||||
|
||||
几天后, 2 月 3 日, 术语“[开源软件][6]”创立 20 周年的纪念日即将到来。由于开源软件渐受欢迎并且为这个时代强有力的重要变革提供动力,我们仔细反思了它的初生到崛起。
|
||||
|
||||
我是 “开源软件” 这个词的始作俑者,它是我在前瞻技术协会(Foresight Institute)担任执行董事时想出的。并非向上面的一个程序开发者一样,我感谢 Linux 程序员 Todd Anderson 对这个术语的支持并将它提交小组讨论。
|
||||
|
||||
这是我对于它如何想到的,如何提出的,以及后续影响的记叙。当然,还有一些有关该术语的记叙,例如 Eric Raymond 和 Richard Stallman 写的,而我的,则写于 2006 年 1 月 2 日。
|
||||
|
||||
直到今天,它终于公诸于世。
|
||||
|
||||
* * *
|
||||
|
||||
推行术语“开源软件”是特地为了这个领域让新手和商业人士更加易懂,它的推广被认为对于更大的用户社区很有必要。早期称号的问题是,“自由软件” 并非有政治含义,但是那对于新手来说貌似对于价格的关注令人感到心烦意乱。一个术语需要聚焦于关键的源代码而且不会被立即把概念跟那些新东西混淆。一个恰好想出并且满足这些要求的第一个术语被快速接受:开源(open source)。
|
||||
|
||||
这个术语很长一段时间被用在“情报”(即间谍活动)的背景下,但据我所知,1998 年以前软件领域使用该术语尚未得到证实。下面这个就是讲述了术语“开源软件”如何流行起来并且变成了一项产业和一场运动名称的故事。
|
||||
|
||||
### 计算机安全会议
|
||||
|
||||
在 1997 年的晚些时候,为期一周的会议将被在前瞻技术协会(Foresight Insttitue) 举行来讨论计算机安全问题。这个协会是一个非盈利性智库,它专注于纳米技术和人工智能,并且认为软件安全是二者的安全性以及可靠性的核心。我们在那确定了自由软件是一个改进软件安全可靠性且具有发展前景的方法并将寻找推动它的方式。 对自由软件的兴趣开始在编程社区外开始增长,而且越来越清晰,一个改变世界的机会正在来临。然而,该怎么做我们并不清楚,因为我们当时正在摸索中。
|
||||
|
||||
在这些会议中,我们讨论了一些由于使人迷惑不解的因素而采用一个新术语的必要性。观点主要有以下:对于那些新接触“自由软件”的人把 "free" 当成了价格上的 “免费” 。老资格的成员们开始解释,通常像下面所说的:“我们的意思是自由的,而不是免费啤酒上的。"在这个点子上,一个软件方面的讨论变成了一个关于酒精价格的讨论。问题不在于解释不了含义——问题是重要概念的名称不应该使新手们感到困惑。所以需要一个更清晰的术语了。关于自由软件术语并没有政治上的问题;问题是缺乏对新概念的认识。
|
||||
|
||||
### 网景发布
|
||||
|
||||
1998 年 2 月 2 日,Eric Raymond 抵达访问网景并与它一起计划采用免费软件样式的许可证发布浏览器代码。我们那晚在前瞻位于罗斯阿尔托斯(Los Altos)的办公室制定了策略并改进了我们的要旨。除了 Eric 和我,活跃的参与者还有 Brian Behlendorf,Michael Tiemann,Todd Anderson,Mark S. Miller and Ka-Ping Yee。但在那次会议上,这个领域仍然被描述成“自由软件”,或者用 Brian 的话说, 叫“可获得源代码的” 软件。
|
||||
|
||||
在这个镇上,Eric 把前瞻协会(Foresight) 作为行动的大本营。他一开始访问行程,他就被几个网景法律和市场部门的员工通电话。当他挂电话后,我被要求带着电话跟他们——一男一女,可能是 Mitchell Baker——这样我才能谈论对于新术语的需求。他们原则上是立即同意了,但详细条款并未达成协议。
|
||||
|
||||
在那周的会议中,我仍然专注于起一个更好的名字并提出术语 “开源软件”。 虽然那不是完美的,但我觉得足够好了。我依靠至少另外四个人运营这个项目:Eric Drexler、Mark Miller,以及 Todd Anderson 和他这样的人,然而一个从事市场公关的朋友觉得术语 “open” 被滥用了并且相信我们能做更好再说。理论上它是对的,可我想不出更好的了,所以我想尝试并推广它。 事后一想我应该直接向 Eric Raymond 提案,但在那时我并不是很了解他,所以我采取了间接的策略。
|
||||
|
||||
Todd 强烈同意需要新的术语并提供协助推广它。这很有帮助,因为作为一个非编程人员,我在自由软件社区的影响力很弱。我从事的纳米技术是一个加分项,但不足以让我认真地接受自由软件问题的工作。作为一个Linux程序员,Todd 将会更仔细地聆听它。
|
||||
|
||||
### 关键的会议
|
||||
|
||||
那周之后,1998 年的 2 月 5 日,一伙人在 VA research 进行头脑风暴商量对策。与会者——除了 Eric Raymond,Todd和我之外,还有 Larry Augustin,Sam Ockman,还有 Jon“maddog”Hall 的电话。
|
||||
|
||||
会议的主要议题是推广策略,特别是要接洽的公司。 我几乎没说什么,而是在寻找机会推广已经提交讨论的术语。我觉得突然脱口而出那句话没什么用,“你们技术人员应当开始讨论我的新术语了。”他们大多数与会者不认识我,而且据我所知,他们可能甚至不同意对新术语的急切需求,或者是某种渴望。
|
||||
|
||||
幸运的是,Todd 是明智的。他没有主张社区应该用哪个特定的术语,而是间接地做了一些事——一件和社区里有强烈意愿的人做的明智之举。他简单地在其他话题中使用那个术语——把他放进对话里看看会发生什么。我警觉起来,希望得到一个答复,但是起初什么也没有。讨论继续进行原来的话题。似乎只有他和我注意了术语的使用。
|
||||
|
||||
不仅如此——模因演化(人类学术语)在起作用。几分钟后,另一个人明显地,没有提醒地,在仍然进行话题讨论而没说术语的情况下,用了这个术语。Todd 和我面面相觑对视:是的我们都注意到了发生的事。我很激动——它起作用了!但我保持了安静:我在小组中仍然地位不高。可能有些人都奇怪为什么 Eric 会最终邀请我。
|
||||
|
||||
临近会议尾声,可能是 Todd or Eric,[术语问题][8] 被明确提出。Maddog 提及了一个早期的术语“可自由分发的,和一个新的术语“合作开发的”。Eric 列出了“自由软件”、“开源软件”,并把 "自由软件源" 作为一个主要选项。Todd宣传 “开源” 模型,然后Eric 支持了他。我什么也没说,让 Todd 和 Eric 共同促进开源名字达成共识。对于大多数与会者,他们很清楚改名不是在这讨论的最重要议题;那只是一个次要的相关议题。 我在会议中只有大约10%的说明放在了术语问答中。
|
||||
|
||||
但是我很高兴。在那有许多社区的关键领导人,并且他们喜欢这新名字,或者至少没反对。这是一个好的信号信号。可能我帮不上什么忙; Eric Raymond 被相当好地放在了一个宣传模因的好位子上,而且他的确做到了。立即签约参加行动,帮助建立 [Opensource.org][9] 并在新术语的宣传中发挥重要作用。
|
||||
|
||||
对于这个成功的名字,那很必要,甚至是相当渴望, 因此 Tim O'Reilly 同意以社区的名义在公司积极使用它。在官方即将发布的 the Netscape Navigator(网景浏览器)代码中的术语使用也为此帮了忙。 到二月底, O'Reilly & Associates 还有网景公司(Netscape) 已经开始使用新术语。
|
||||
|
||||
### 名字的诞生
|
||||
|
||||
在那之后的一段时间,这条术语由 Eric Raymond 向媒体推广,由 Tim O'Reilly 向商业推广,并由二人向编程社区推广,那似乎传播的相当快。
|
||||
|
||||
1998 年 4 月 17 日, Tim O'Reilly 提前宣布首届 “[自由软件峰会][10]” ,在 4 月14 日之前,它以首届 “[开源峰会][11]” 被提及。
|
||||
|
||||
这几个月对于开源来说是相当激动人心的。似乎每周都有一个新公司宣布加入计划。读 Slashdot(科技资讯网站)已经成了一个必需操作, 甚至对于那些像我一样只能外围地参与者亦是如此。我坚信新术语能对快速传播到商业很有帮助,能被公众广泛使用。
|
||||
|
||||
尽管快捷的谷歌搜索表明“开源”比“自由软件”出现的更多,但后者仍然有大量的使用,特别是和偏爱它的人们沟通的时候。
|
||||
|
||||
### 一丝快感
|
||||
|
||||
当一个被 Eric Raymond 写的有关修改术语的早期的陈述被发布在了开放源代码促进会的网站上时,我上了 VA 头脑风暴会议的名单,但并不是作为一个术语的创始人。这是我自己的错,我没告诉 Eric 细节。我当时一时冲动只想让它表决通过然后我只是呆在后台,但是 Todd 不这样认为。他认为我总有一天将作为“开源软件”这个名词的创造者而感到高兴。他向 Eric 解释了这个情况,Eric 及时更新了它的网站。
|
||||
|
||||
想出这个短语只是一个小贡献,但是我得承认我十分感激那些把它归功于我的人。每次我听到它,它都给我些许激动的喜悦,到现在也时常感受到。
|
||||
|
||||
说服团队的大功劳归功于 Eric Raymond 和 Tim O'Reilly,这是他们搞定的。感谢他们对我的评价,并感谢 Todd Anderson 在整个过程中的角色。以上内容并非完整的开源历史记录,对很多没有无名人士表示歉意。那些寻求更完整讲述的人应该参考本文和网上其他地方的链接。
|
||||
|
||||
### 关于作者
|
||||
|
||||
[][13] Christine Peterson - Christine Peterson 撰写,举办讲座,并向媒体介绍未来强大的技术,特别是纳米技术,人工智能和长寿。她是著名的纳米科技公共利益集团的创始人和过去的前瞻技术协会主席。前瞻向公众、技术团体和政策制定者提供未来强大的技术的教育以及告诉它是如何引导他们的长期影响。她服务于 [机器智能 ][2]咨询委员会……[更多关于 Christine Peterson][3][关于我][4]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/coining-term-open-source-software
|
||||
|
||||
作者:[ Christine Peterson][a]
|
||||
译者:[fuzheng1998](https://github.com/fuzheng1998)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/christine-peterson
|
||||
[1]:https://opensource.com/article/18/2/coining-term-open-source-software?rate=HFz31Mwyy6f09l9uhm5T_OFJEmUuAwpI61FY-fSo3Gc
|
||||
[2]:http://intelligence.org/
|
||||
[3]:https://opensource.com/users/christine-peterson
|
||||
[4]:https://opensource.com/users/christine-peterson
|
||||
[5]:https://opensource.com/user/206091/feed
|
||||
[6]:https://opensource.com/resources/what-open-source
|
||||
[7]:https://opensource.org/osd
|
||||
[8]:https://wiki2.org/en/Alternative_terms_for_free_software
|
||||
[9]:https://opensource.org/
|
||||
[10]:http://www.oreilly.com/pub/pr/636
|
||||
[11]:http://www.oreilly.com/pub/pr/796
|
||||
[12]:https://ipfs.io/ipfs/QmXoypizjW3WknFiJnKLwHCnL72vedxjQkDDP1mXWo6uco/wiki/Alternative_terms_for_free_software.html
|
||||
[13]:https://opensource.com/users/christine-peterson
|
||||
[14]:https://opensource.com/users/christine-peterson
|
||||
[15]:https://opensource.com/users/christine-peterson
|
||||
[16]:https://opensource.com/article/18/2/coining-term-open-source-software#comments
|
||||
@ -0,0 +1,92 @@
|
||||
Tlog - 录制/播放终端 IO 和会话的工具
|
||||
======
|
||||
Tlog 是 Linux 中终端 I/O 录制和回放软件包。它用于实现集中式用户会话录制。它将所有经过的消息录制为 JSON 消息。录制为 JSON 格式的主要目的是将数据传送到 Elasticsearch 之类的存储服务,可以从中搜索和查询,以及回放。同时,他们保留所有通过的数据和时序。
|
||||
|
||||
Tlog 包含三个工具,分别是 tlog-rec、tlog-rec-session 和 tlog-play。
|
||||
|
||||
* `Tlog-rec tool` 一般用于录制终端、程序或 shell 的输入或输出。
|
||||
* `Tlog-rec-session tool` 用于录制整个终端会话的 I/O,并保护录制的用户。
|
||||
* `Tlog-rec-session tool` 用于回放录制。
|
||||
|
||||
|
||||
|
||||
在本文中,我将解释如何在 CentOS 7.4 服务器上安装 Tlog。
|
||||
|
||||
### 安装
|
||||
|
||||
在安装之前,我们需要确保我们的系统满足编译和安装程序的所有软件要求。在第一步中,使用以下命令更新系统仓库和软件包。
|
||||
```
|
||||
#yum update
|
||||
```
|
||||
|
||||
我们需要安装此软件安装所需的依赖项。在安装之前,我已经使用这些命令安装了所有依赖包。
|
||||
```
|
||||
#yum install wget gcc
|
||||
#yum install systemd-devel json-c-devel libcurl-devel m4
|
||||
```
|
||||
|
||||
完成这些安装后,我们可以下载该工具的[源码包][1]并根据需要将其解压到服务器上:
|
||||
```
|
||||
#wget https://github.com/Scribery/tlog/releases/download/v3/tlog-3.tar.gz
|
||||
#tar -xvf tlog-3.tar.gz
|
||||
# cd tlog-3
|
||||
```
|
||||
|
||||
现在,你可以使用我们通常的配置和制作方法开始构建此工具。
|
||||
```
|
||||
#./configure --prefix=/usr --sysconfdir=/etc && make
|
||||
#make install
|
||||
#ldconfig
|
||||
```
|
||||
|
||||
最后,你需要运行 `ldconfig`。它会创建必要的链接,并缓存命令行中指定目录中最近的共享库。( /etc/ld.so.conf 中的文件,以及信任的目录 (/lib and /usr/lib))
|
||||
|
||||
### Tlog 工作流程图
|
||||
|
||||
![Tlog working process][2]
|
||||
|
||||
首先,用户通过 PAM 进行身份验证登录。名称服务交换机(NSS)提供的 `tlog` 信息是用户的 shell。这初始化了 tlog 部分,并从环境变量/配置文件收集关于实际 shell 的信息,并以 PTY 的形式启动实际的 shell。然后通过 syslog 或 sd-journal 开始录制在终端和 PTY 之间传递的所有内容。
|
||||
|
||||
### 用法
|
||||
|
||||
你可以使用 `tlog-rec` 录制一个会话并使用 `tlog-play` 回放它来测试新安装的 tlog 是否能够正常录制和回放会话。
|
||||
|
||||
#### 录制到文件中
|
||||
|
||||
要将会话录制到文件中,请在命令行中执行 `tlog-rec`,如下所示:
|
||||
```
|
||||
tlog-rec --writer=file --file-path=tlog.log
|
||||
```
|
||||
|
||||
该命令会将我们的终端会话录制到名为 tlog.log 的文件中,并将其保存在命令中指定的路径中。
|
||||
|
||||
#### 从文件中回放
|
||||
|
||||
你可以在录制过程中或录制后使用 `tlog-play` 命令回放录制的会话。
|
||||
```
|
||||
tlog-play --reader=file --file-path=tlog.log
|
||||
```
|
||||
|
||||
该命令从指定的路径读取先前录制的文件 tlog.log。
|
||||
|
||||
### 总结
|
||||
|
||||
Tlog 是一个开源软件包,可用于实现集中式用户会话录制。它主要是作为一个更大的用户会话录制解决方案的一部分使用,但它被设计为独立且可重用的。该工具可以帮助录制用户所做的一切并将其存储在服务器的某个位置,以备将来参考。你可以从这个[文档][3]中获得关于这个软件包使用的更多细节。我希望这篇文章对你有用。请发表你的宝贵建议和意见。
|
||||
|
||||
### 关于 Saheetha Shameer (作者)
|
||||
我正在担任高级系统管理员。我是一名快速学习者,有轻微的倾向跟随行业中目前和正在出现的趋势。我的爱好包括听音乐、玩策略游戏、阅读和园艺。我对尝试各种美食也有很高的热情 :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linoxide.com/linux-how-to/tlog-tool-record-play-terminal-io-sessions/
|
||||
|
||||
作者:[Saheetha Shameer][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linoxide.com/author/saheethas/
|
||||
[1]:https://github.com/Scribery/tlog/releases/download/v3/tlog-3.tar.gz
|
||||
[2]:https://linoxide.com/wp-content/uploads/2018/01/Tlog-working-process.png
|
||||
[3]:https://github.com/Scribery/tlog/blob/master/README.md
|
||||
@ -0,0 +1,82 @@
|
||||
用这三个命令行工具成为好莱坞电影中的黑客
|
||||
======
|
||||
|
||||

|
||||
|
||||
如果在你成长过程中有看过谍战片、动作片或犯罪片,那么你就会清楚地了解黑客的电脑屏幕是什么样子。就像是在《黑客帝国》电影中,[代码雨][1] 一样的十六进制数字流,又或是一排排快速移动的代码 。
|
||||
|
||||
也许电影中出现一幅世界地图,其中布满了闪烁的光点除和一些快速更新的字符。 而且是3D旋转的几何图像,为什么不可能出现在现实中呢? 如果可能的话,那么就会出现数量多得不可思议的显示屏,以及不符合人体工学的电脑椅或其他配件。 在《剑鱼行动》电影中黑客就使用了七个显示屏。
|
||||
|
||||
当然,我们这些从事计算机行业的人一下子就明白这完全是胡说八道。虽然在我们中,许多人都有双显示器(或更多),但一个闪烁的数据仪表盘通常和专注工作是相互矛盾的。编写代码、项目管理和系统管理与日常工作不同。我们遇到的大多数情况,为了解决问题,都需要大量的思考,与客户沟通所得到一些研究和组织的资料,然后才是少许的 [敲代码][7]。
|
||||
|
||||
然而,这与我们想追求电影中的效果并不矛盾,也许,我们只是想要看起来“忙于工作”而已。
|
||||
|
||||
**注:当然,我仅仅是在此胡诌。**如果实际上您公司是根据您繁忙程度来评估您的工作时,无论您是蓝领还是白领,都需要亟待解决这样的工作文化。假装工作很忙是一种有毒的文化,对公司和员工都有害无益。
|
||||
|
||||
这就是说,让我们找些乐子,用一些老式的、毫无意义的数据和代码片段填充我们的屏幕。(当然,数据或许有意义,而不是没有上下文。)当然有许多有趣的图形界面,如 [hackertyper.net][8] 或是 [GEEKtyper.com][9] 网站(译者注:是在线模拟黑客网站),为什么不使用Linux终端程序呢?对于更老派的外观,可以考虑使用 [酷炫复古终端][10],这听起来确实如此:一个酷炫的复古终端程序。我将在下面的屏幕截图中使用酷炫复古终端,因为它看起来的确很酷。
|
||||
|
||||
|
||||
### Genact
|
||||
|
||||
我们来看下第一个工具——Genact。Genact的原理很简单,就是慢慢地循环播放您选择的一个序列,让您的代码在您外出休息时“编译”。由您来决定播放顺序,但是其中默认包含数字货币挖矿模拟器、PHP管理依赖关系工具、内核编译器、下载器、内存转储等工具。其中我最喜欢的是其中类似《模拟城市》加载显示。所以只要没有人仔细检查,你可以花一整个下午等待您的电脑完成进度条。
|
||||
|
||||
Genact[发行版][11]支持Linux、OS X和Windows。并且用Rust编写。[源代码][12] 在GitHub上开源(遵循[MIT许可证][13])
|
||||
|
||||

|
||||
|
||||
### Hollywood
|
||||
|
||||
|
||||
Hollywood采取更直接的方法。它本质上是在终端中创建一个随机数字和配置分屏,并启动跑个不停的应用程序,如htop,目录树,源代码文件等,并每隔几秒将其切换。它被放在一起作为一个shell脚本,所以可以非常容易地根据需求进行修改。
|
||||
|
||||
|
||||
Hollywood的 [源代码][14] 在GitHub上开源(遵循[Apache 2.0许可证][15])。
|
||||
|
||||

|
||||
|
||||
### Blessed-contrib
|
||||
|
||||
Blessed-contrib是我个人最喜欢的应用,实际上并不是为了表演而专门设计的应用。相反地,它是一个基于Node.js的后台终端构建库的演示文件。与其他两个不同,实际上我已经在工作中使用Blessed-contrib的库,而不是用于假装忙于工作。因为它是一个相当有用的库,并且可以使用一组在命令行显示信息的小部件。与此同时填充虚拟数据也很容易,所以可以很容易实现模拟《战争游戏》的想法。
|
||||
|
||||
|
||||
Blessed-contrib的[源代码][16]在GitHub上(遵循[MIT许可证][17])。
|
||||
|
||||
|
||||

|
||||
|
||||
当然,尽管这些工具很容易使用,但也有很多其他的方式使你的屏幕丰富。在你看到电影中最常用的工具之一就是Nmap,一个开源的网络安全扫描工具。实际上,它被广泛用作展示好莱坞电影中,黑客电脑屏幕上的工具。因此Nmap的开发者创建了一个 [页面][18],列出了它出现在其中的一些电影,从《黑客帝国2:重装上阵》到《谍影重重3》、《龙纹身的女孩》,甚至《虎胆龙威4》。
|
||||
|
||||
当然,您可以创建自己的组合,使用终端多路复用器(如屏幕或tmux)启动您希望的任何数据分散应用程序。
|
||||
|
||||
|
||||
那么,您是如何使用您的屏幕的呢?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/command-line-tools-productivity
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
译者:[wyxplus](https://github.com/wyxplus)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jason-baker
|
||||
[1]:http://tvtropes.org/pmwiki/pmwiki.php/Main/MatrixRainingCode
|
||||
[2]:https://opensource.com/resources/what-is-linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[3]:https://opensource.com/resources/what-are-linux-containers?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[4]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[5]:https://developers.redhat.com/cheat-sheet/advanced-linux-commands-cheatsheet?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[6]:https://opensource.com/tags/linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[7]:http://tvtropes.org/pmwiki/pmwiki.php/Main/RapidFireTyping
|
||||
[8]:https://hackertyper.net/
|
||||
[9]:http://geektyper.com
|
||||
[10]:https://github.com/Swordfish90/cool-retro-term
|
||||
[11]:https://github.com/svenstaro/genact/releases
|
||||
[12]:https://github.com/svenstaro/genact
|
||||
[13]:https://github.com/svenstaro/genact/blob/master/LICENSE
|
||||
[14]:https://github.com/dustinkirkland/hollywood
|
||||
[15]:http://www.apache.org/licenses/LICENSE-2.0
|
||||
[16]:https://github.com/yaronn/blessed-contrib
|
||||
[17]:http://opensource.org/licenses/MIT
|
||||
[18]:https://nmap.org/movies/
|
||||
@ -1,116 +0,0 @@
|
||||
|
||||
使用 Zim 在你的 Linux 桌面上创建一个 wiki
|
||||
======
|
||||
|
||||

|
||||
|
||||
不可否认 wiki 的用处,即使对于一个极客来说也是如此。你可以用它做很多事——写笔记和手稿,协作项目,建立完整的网站。还有更多的事。
|
||||
|
||||
这些年来,我已经使用了超过几条维基百科,要么是为了我自己的工作,要么就是为了我所持有的各种合约和全职工作。虽然传统的维基很好,但我真的喜欢[桌面版 wiki][1] 这个想法。它们体积小,易于安装和维护,甚至更容易使用。而且,正如你可能猜到的那样,Linux 中有许多可用的桌面版 wiki。
|
||||
|
||||
让我们来看看更好的桌面版的 wiki 之一: [Zim][2]。
|
||||
|
||||
### 开始吧
|
||||
|
||||
你可以从 Zim 的官网[下载][3]并安装 Zim,或者通过发行版的软件包管理器轻松地安装。
|
||||
|
||||
一旦安装了 Zim,就启动它。
|
||||
|
||||
在 Zim 中的一个关键概念是笔记本,它们就像一个主题上的 wiki 页面的集合。当你第一次启动 Zim 时,它要求你为你的笔记本指定一个文件夹和笔记本的名称。Zim 建议用 "Notes" 来表示文件夹的名称和指定文件夹为`~/Notebooks/`。如果你愿意,你可以改变它。我是这么做的。
|
||||
|
||||

|
||||
|
||||
在为笔记本设置好名称和指定好文件夹后,单击 **OK** 。你得到的本质上是你的 wiki 页面的容器。
|
||||
|
||||

|
||||
|
||||
### 将页面添加到笔记本
|
||||
|
||||
所以你有了一个容器。那现在怎么办?你应该开始往里面添加页面。当然,为此,选择 **File > New Page**。
|
||||
|
||||

|
||||
|
||||
输入该页面的名称,然后单击 **OK**。从那里开始,你可以开始输入信息以向该页面添加信息。
|
||||
|
||||

|
||||
|
||||
这一页可以是你想要的任何内容:你正在选修的课程的笔记,一本书或者一片文章或论文的大纲,或者是你的书的清单。这取决于你。
|
||||
|
||||
Zim 有一些格式化的选项,其中包括:
|
||||
|
||||
* 标题
|
||||
* 字符格式
|
||||
* 子弹和编号清单
|
||||
* 核对清单
|
||||
|
||||
|
||||
|
||||
你可以添加图片和附加文件到你的 wiki 页面,甚至可以从文本文件中提取文本。
|
||||
|
||||
### Zim 的 wiki 语法
|
||||
|
||||
你可以使用工具栏向一个页面添加格式。但这不是唯一的方法。如果你像我一样是个老派人士,你可以使用 wiki 标记来进行格式化。
|
||||
|
||||
[Zim 的标记][4] 是基于在 [DokuWiki][5] 中使用的标记。它本质上是有一些小变化的 [WikiText][6] 。例如,要创建一个子弹列表,输入一个星号(*)。用两个星号包围一个单词或短语来使它加黑。
|
||||
|
||||
### 添加链接
|
||||
|
||||
如果你在笔记本上有一些页面,很容易将它们联系起来。有两种方法可以做到这一点。
|
||||
|
||||
第一种方法是使用 [CamelCase][7] 来命名这些页面。假设我有个叫做 "Course Notes." 的笔记本。我可以通过输入 "AnalysisCourse." 来重命名我正在学习的数据分析课程。 当我想从笔记本的另一个页面链接到它时,我只需要输入 "AnalysisCourse" 然后按下空格键。即时超链接。
|
||||
|
||||
第二种方法是点击工具栏上的 **Insert link** 按钮。 在 **Link to** 中输入你想要链接到的页面的名称,从显示的列表中选择它,然后点击 **Link**。
|
||||
|
||||

|
||||
|
||||
我只能在同一个笔记本中的页面之间进行链接。每当我试图连接到另一个笔记本中的一个页面时,这个文件(有 .txt 的后缀名)总是在文本编辑器中被打开。
|
||||
|
||||
### 输出你的 wiki 页面
|
||||
|
||||
也许有一天你会想在别的地方使用笔记本上的信息ーー比如, 在一份文件或网页上。你可以将笔记本页面导出到以下格式中的任何一种, 而不是复制和粘贴(和丢失格式) :
|
||||
|
||||
* HTML
|
||||
* LaTeX
|
||||
* Markdown
|
||||
* ReStructuredText
|
||||
|
||||
|
||||
|
||||
为此,点击你想要导出的 wiki 页面。然后,选择 **File > Export**。决定是要导出整个笔记本还是一个页面,然后点击 **Forward**。
|
||||
|
||||

|
||||
|
||||
选择要用来保存页面或笔记本的文件格式。 使用 HTML 和 LaTeX,你可以选择一个模板。 随便看看什么最适合你。 例如, 如果你想把你的 wiki 页面变成 HTML 演示幻灯片, 你可以在 **Template** 中选择 "SlideShow s5"。 如果你想知道, 这会产生由 [S5 幻灯片框架][8]驱动的幻灯片。
|
||||
|
||||

|
||||
|
||||
点击 **Forward**,如果你在导出一个笔记本, 你可以选择将页面作为单个文件或一个文件导出。 你还可以指向要保存导出文件的文件夹。
|
||||
|
||||

|
||||
|
||||
### Zim 能做的就这些吗?
|
||||
|
||||
远远不止这些,还有一些 [插件][9] 可以扩展它的功能。它甚至包含一个内置的 Web 服务器,可以让你将你的笔记本作为静态的 HTML 文件。这对于在内部网络上分享你的页面和笔记本是非常有用的。
|
||||
|
||||
总的来说,Zim 是一个用来管理你的信息的强大而又紧凑的工具。这是我使用过的最好的桌面版 wik ,而且我一直在使用它。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/create-wiki-your-linux-desktop-zim
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
译者:[Auk7F7](https://github.com/Auk7F7)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:https://opensource.com/article/17/2/3-desktop-wikis
|
||||
[2]:http://zim-wiki.org/
|
||||
[3]:http://zim-wiki.org/downloads.html
|
||||
[4]:http://zim-wiki.org/manual/Help/Wiki_Syntax.html
|
||||
[5]:https://www.dokuwiki.org/wiki:syntax
|
||||
[6]:http://en.wikipedia.org/wiki/Wikilink
|
||||
[7]:https://en.wikipedia.org/wiki/Camel_case
|
||||
[8]:https://meyerweb.com/eric/tools/s5/
|
||||
[9]:http://zim-wiki.org/manual/Plugins.html
|
||||
@ -0,0 +1,124 @@
|
||||
通过玩命令行游戏来测试你的 BASH 技能
|
||||
=====
|
||||
|
||||
|
||||

|
||||
|
||||
如果我们经常在实际场景中使用 Linux 命令,我们倾向于更有效的学习和记忆它们。除非你经常使用 Linux 命令,否则你可能会在一段时间内忘记它们。无论你是新手还是中级用户,总会有一些令人兴奋的方法来测试你的 BASH 技能。在本教程中,我将解释如何通过玩命令行游戏来测试你的 BASH 技能。其实从技术上讲,这些并不是真正的游戏,如 Super TuxKart,NFS 或 Counterstrike 等等。这些只是 Linux 命令培训课程的游戏化版本。你将根据游戏本身的某些指示来完成一个任务。
|
||||
|
||||
现在,我们将看到几款能帮助你实时学习和练习 Linux 命令的游戏。这些游戏不是消磨时间或者令人惊诧的,这些游戏将帮助你获得终端命令的真实体验。请继续阅读:
|
||||
|
||||
### 使用 “Wargames” 来测试 BASH 技能
|
||||
|
||||
这是一个在线游戏,所以你必须和互联网保持连接。这些游戏可以帮助你以充满乐趣的游戏形式学习和练习 Linux 命令。Wargames 是 shell 游戏的集合,每款游戏有很多关卡。只有通过解决先前的关卡才能访问下一个关卡。不要担心!每个游戏都提供了有关如何进入下一关的清晰简洁说明。
|
||||
|
||||
要玩 Wargames,请点击以下链接:
|
||||
|
||||
![][2]
|
||||
|
||||
如你所见,左边列出了许多 shell 游戏。每个 shell 游戏都有自己的 SSH 端口。所以,你必须通过本地系统配置 SSH 连接到游戏,你可以在 Wargames 网站的左上角找到关于如何使用 SSH 连接到每个游戏的信息。
|
||||
|
||||
例如,让我们来玩 **Bandit** 游戏吧。为此,单击 Wargames 主页上的 Bandit 链接。在左上角,你会看到 Bandit 游戏的 SSH 信息。
|
||||
|
||||
![][3]
|
||||
|
||||
正如你在上面的屏幕截图中看到的,有很多关卡。要进入每个关卡,请单机左侧列中的相应链接。此外,右侧还有适合初学者的说明。如果你对如何玩此游戏有任何疑问,请阅读它们。
|
||||
|
||||
现在,让我们点击它进入关卡 0。在下一个屏幕中,你将获得该关卡的 SSH 信息。
|
||||
|
||||
![][4]
|
||||
|
||||
正如你在上面的屏幕截图中看到的,你需要配置 SSH 端口 2220 连接 **bandit.labs.overthewire.org**,用户名是 **bandit0**,密码是 **bandit0**。
|
||||
|
||||
让我们连接到 Bandit 游戏关卡 0。
|
||||
|
||||
输入密码 **bandit0**
|
||||
|
||||
示例输出将是:
|
||||
|
||||
![][5]
|
||||
|
||||
登录后,输入 **ls** 命令查看内容或者进入 **关卡 1 页面**,了解如何通过关卡 1 等等。建议的命令列表已在每个关卡提供。所以,你可以选择和使用任何合适的命令来解决每个关卡。
|
||||
|
||||
我必须承认,Wargames 是令人上瘾的,并且解决每个关卡是非常有趣的。 尽管有些关卡确实很具挑战性,你可能需要谷歌才能知道如何解决问题。 试一试,你会很喜欢它。
|
||||
|
||||
### 使用 “Terminus” 来测试 BASH 技能
|
||||
|
||||
这是另一个基于浏览器的在线 CLI 游戏(译注:CLI 命令行界面),可用于改进或测试你的 Linux 命令技能。要玩这个游戏,请打开你的 web 浏览器并导航到以下 URL。
|
||||
|
||||
一旦你进入游戏,你会看到有关如何玩游戏的说明。与 Wargames 不同,你不需要连接到它们的游戏服务器来玩游戏。Terminus 有一个内置的 CLI,你可以在其中找到有关如何使用它的说明。
|
||||
|
||||
你可以使用命令 **“ls”** 查看周围的环境,使用命令 **“cd LOCATION”** 移动到新的位置,返回使用命令 **“cd ..”**,与这个世界进行交互使用命令 **“less ITEM”** 等等。要知道你当前的位置,只需输入 **“pwd”**。
|
||||
|
||||
![][6]
|
||||
|
||||
### 使用 “clmystery” 来测试 BASH 技能
|
||||
|
||||
与上述游戏不同,你可以在本地玩这款游戏。你不需要连接任何远程系统,这是完全离线的游戏。
|
||||
|
||||
相信我,这是一个有趣的游戏人。按照给定的说明,你将扮演一个侦探角色来解决一个神秘案件。
|
||||
|
||||
首先,克隆仓库:
|
||||
```
|
||||
$ git clone https://github.com/veltman/clmystery.git
|
||||
|
||||
```
|
||||
|
||||
或者,从 [这里][7] 将其作为 zip 文件下载。解压缩并切换到下载文件的地方。左后,通过阅读 “instructions” 文件来解决神秘案例。
|
||||
```
|
||||
[sk@sk]: clmystery-master>$ ls
|
||||
cheatsheet.md cheatsheet.pdf encoded hint1 hint2 hint3 hint4 hint5 hint6 hint7 hint8 instructions LICENSE.md mystery README.md solution
|
||||
|
||||
```
|
||||
|
||||
这里是玩这个游戏的说明:
|
||||
|
||||
终端城发生了一起谋杀案,TCPD 需要你的帮助。你需要帮助它们弄清楚是谁犯罪了。
|
||||
|
||||
为了查明是谁干的,你需要到 **‘mystery’** 子目录并从那里开始工作。你可能需要查看犯罪现场的所有线索( **‘crimescene’** 文件)。现场的警官相当谨慎,所以他们在警官报告中写下了一切。幸运的是,警官在所有的帽子里都用了 “CLUE” 一词,并把真正的线索标记了出来。
|
||||
|
||||
如果里遇到任何问题,请打开其中一个提示文件,例如 hint1,hint2 等。你可以使用下面的 cat 命令打开提示文件。
|
||||
```
|
||||
$ cat hint1
|
||||
|
||||
$ cat hint2
|
||||
|
||||
```
|
||||
|
||||
要检查你的答案或找出解决方案,请在 clmystery 目录中打开文件 “solution”。
|
||||
```
|
||||
$ cat solution
|
||||
|
||||
```
|
||||
|
||||
要开始如何使用命令行,请参阅 **cheatsheet.md** 或 **cheatsheet.pdf** (在命令行中,你可以输入 ‘nano cheatsheet.md’)。请勿使用文本编辑器查看除说明,备忘录和提示以外的任何文件。
|
||||
|
||||
有关更多详细信息,请参阅 [**clmystery GitHub**][8] 页面。
|
||||
|
||||
**推荐阅读:**
|
||||
|
||||
而这就是我现在所能记得的。如果将来遇到任何问题,我会继续添加更多游戏。将此链接加入书签并不时访问。如果你知道其他类似的游戏,请在下面的评论部分告诉我,我将测试和更新本指南。
|
||||
|
||||
还有更多好东西,敬请关注!
|
||||
|
||||
干杯!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/test-your-bash-skills-by-playing-command-line-games/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/03/Wargames-1.png
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/03/Bandit-game.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2018/03/Bandit-level-0.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/03/Bandit-level-0-ssh-1.png
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2018/03/Terminus.png
|
||||
[7]:https://github.com/veltman/clmystery/archive/master.zip
|
||||
[8]:https://github.com/veltman/clmystery
|
||||
Loading…
Reference in New Issue
Block a user