mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-12 01:40:10 +08:00
commit
1eeaa77c19
@ -0,0 +1,69 @@
|
||||
Rowhammer:针对物理内存的攻击可以取得 Android 设备的 root 权限
|
||||
===
|
||||
|
||||
> 攻击者确实可以在物理存储单元中实现位翻转来达到侵入移动设备与计算机的目的
|
||||
|
||||

|
||||
|
||||
|
||||
研究者们发现了一种新的在不利用任何软件漏洞情况下,利用内存芯片物理设计上的弱点来侵入 Android 设备的方式。这种攻击技术同样可以影响到其它如 ARM 和 X86 架构的设备与计算机。
|
||||
|
||||
这种称之为“Rowhammer”的攻击起源于过去十多年中将更多的 DRAM(动态随机存取存储器)容量封装进越来越小的芯片中,这将导致在特定情况下存储单元电子可以从相邻两<ruby>行<rt>row</rt></ruby>的一边泄漏到另一边。(LCTT 译注:参见 https://en.wikipedia.org/wiki/Row_hammer)
|
||||
|
||||
例如,反复且快速的访问相同的物理储存位置,这种被称为 “<ruby>锤击<rt>hammering</rt></ruby>” 的行为可以导致相邻位置的位值从 0 反转成 1,或者相反。
|
||||
|
||||
虽然这样的电子干扰已经被生产商知晓并且从可靠性角度研究了一段时间了,因为内存错误能够导致系统崩溃。而研究者们现在展示了在可控方式的触发下它所存在的严重安全隐患。
|
||||
|
||||
在 2015 年 4 月,来自谷歌 Project Zero 项目的研究者公布了两份基于内存 “Rowhammer”漏洞对于 x86-64 CPU 架构的 [提权利用][7]。其中一份利用可以使代码从谷歌的 Chrome 浏览器沙盒里逃逸并且直接在系统上执行,另一份可以在 Linux 机器上获取内核级权限。
|
||||
|
||||
此后,其他的研究者进行了更深入的调查并且展示了[通过网站中 JaveScript 脚本进行利用的方式][6]甚至能够影响运行在云环境下的[虚拟服务器][5]。然而,对于这项技术是否可以应用在智能手机和移动设备大量使用的 ARM 架构中还是有疑问的。
|
||||
|
||||
现在,一队成员来自荷兰阿姆斯特丹自由大学、奥地利格拉茨技术大学和加州大学圣塔芭芭拉分校的 VUSec 小组,已经证明了 Rowhammer 不仅仅可以应用在 ARM 架构上并且甚至比在 x86 架构上更容易。
|
||||
|
||||
研究者们将他们的新攻击命名为 Drammer,代表了 Rowhammer 确实存在,并且计划于周三在维也纳举办的第 23 届 ACM 计算机与通信安全大会上展示。这种攻击建立在之前就被发现与实现的 Rowhammer 技术之上。
|
||||
|
||||
VUSec 小组的研究者已经制造了一个适用于 Android 设备的恶意应用,当它被执行的时候利用不易察觉的内存位反转在不需要任何权限的情况下就可以获取设备根权限。
|
||||
|
||||
研究者们测试了来自不同制造商的 27 款 Android 设备,21 款使用 ARMv7(32-bit)指令集架构,其它 6 款使用 ARMv8(64-bit)指令集架构。他们成功的在 17 款 ARMv7 设备和 1 款 ARMv8 设备上实现了为反转,表明了这些设备是易受攻击的。
|
||||
|
||||
此外,Drammer 能够与其它的 Android 漏洞组合使用,例如 [Stagefright][4] 或者 [BAndroid][3] 来实现无需用户手动下载恶意应用的远程攻击。
|
||||
|
||||
谷歌已经注意到了这一类型的攻击。“在研究者向谷歌漏洞奖励计划报告了这个问题之后,我们与他们进行了密切的沟通来深入理解这个问题以便我们更好的保护用户,”一位谷歌的代表在一份邮件申明中这样说到。“我们已经开发了一个缓解方案,将会包含在十一月的安全更新中。”(LCTT 译注:缓解方案,参见 https://en.wikipedia.org/wiki/Vulnerability_management)
|
||||
|
||||
VUSec 的研究者认为,谷歌的缓解方案将会使得攻击过程更为复杂,但是它不能修复潜在的问题。
|
||||
|
||||
事实上,从软件上去修复一个由硬件导致的问题是不现实的。硬件供应商正在研究相关问题并且有可能在将来的内存芯片中被修复,但是在现有设备的芯片中风险依然存在。
|
||||
|
||||
更糟的是,研究者们说,由于有许多因素会影响到攻击的成功与否并且这些因素尚未被研究透彻,因此很难去说有哪些设备会被影响到。例如,内存控制器可能会在不同的电量的情况下展现不同的行为,因此一个设备可能在满电的情况下没有风险,当它处于低电量的情况下就是有风险的。
|
||||
|
||||
同样的,在网络安全中有这样一句俗语:<ruby>攻击将变本加厉,如火如荼<rt>Attacks always get getter, they never get worse</rt></ruby>。Rowhammer 攻击已经从理论变成了现实可能,同样的,它也可能会从现在的现实可能变成确确实实的存在。这意味着今天某个设备是不被影响的,在明天就有可能被改进后的 Rowhammer 技术证明它是存在风险的。
|
||||
|
||||
Drammer 在 Android 上实现是因为研究者期望研究基于 ARM 设备的影响,但是潜在的技术可以被使用在所有的架构与操作系统上。新的攻击相较于之前建立在运气与特殊特性与特定平台之上并且十分容易失效的技术已经是一个巨大的进步了。
|
||||
|
||||
Drammer 攻击的实现依靠于被包括图形、网络、声音等大量硬件子系统所使用的 DMA(直接存储访问)缓存。Drammer 的实现采用了所有操作系统上都有的 Android 的 ION 内存分配器、接口与方法,这给我们带来的警示是该论文的主要贡献之一。
|
||||
|
||||
“破天荒的,我们成功地展示了我们可以做到,在不依赖任何特定的特性情况下完全可靠的证明了 Rowhammer”, VUSec 小组中的其中一位研究者 Cristiano Giuffrida 这样说道。“攻击所利用的内存位置并非是 Android 独有的。攻击在任何的 Linux 平台上都能工作 -- 我们甚至怀疑其它操作系统也可以 -- 因为它利用的是操作系统内核内存管理中固有的特性。”
|
||||
|
||||
“我期待我们可以看到更多针对其它平台的攻击的变种,”阿姆斯特丹自由大学的教授兼 VUSec 系统安全研究小组的领导者 Herbert Bos 补充道。
|
||||
|
||||
在他们的[论文][2]之外,研究者们也释出了一个 Android 应用来测试 Android 设备在当前所知的技术条件下受到 Rowhammer 攻击时是否会有风险。应用还没有传上谷歌应用商店,可以从 [VUSec Drammer 网站][1] 下载来手动安装。一个开源的 Rowhammer 模拟器同样能够帮助其他的研究者来更深入的研究这个问题。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:http://www.csoonline.com/article/3134726/security/physical-ram-attack-can-root-android-and-possibly-other-devices.html
|
||||
|
||||
作者:[Lucian Constantin][a]
|
||||
译者:[wcnnbdk1](https://github.com/wcnnbdk1)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.csoonline.com/author/Lucian-Constantin/
|
||||
[1]:https://www.vusec.net/projects/drammer/
|
||||
[2]:https://vvdveen.com/publications/drammer.pdf
|
||||
[3]:https://www.vusec.net/projects/bandroid/
|
||||
[4]:http://www.csoonline.com/article/3045836/security/new-stagefright-exploit-puts-millions-of-android-devices-at-risk.html
|
||||
[5]:http://www.infoworld.com/article/3105889/security/flip-feng-shui-attack-on-cloud-vms-exploits-hardware-weaknesses.html
|
||||
[6]:http://www.computerworld.com/article/2954582/security/researchers-develop-astonishing-webbased-attack-on-a-computers-dram.html
|
||||
[7]:http://www.computerworld.com/article/2895898/google-researchers-hack-computers-using-dram-electrical-leaks.html
|
||||
[8]:http://csoonline.com/newsletters/signup.html
|
||||
@ -1,68 +1,67 @@
|
||||
该死,原生移动应用的开发成本太高了!
|
||||
============================================================
|
||||
|
||||
### 一个有价值的命题
|
||||
> 一个有价值的命题
|
||||
|
||||
我们遇到了一个临界点。除去几个比较好的用例之外,使用原生框架和原生应用开发团队构建、维护移动应用再也没有意义了。
|
||||
我们遇到了一个临界点。除去少数几个特别的的用例之外,使用原生框架和原生应用开发团队构建、维护移动应用再也没有意义了。
|
||||
|
||||
|
||||
|
||||
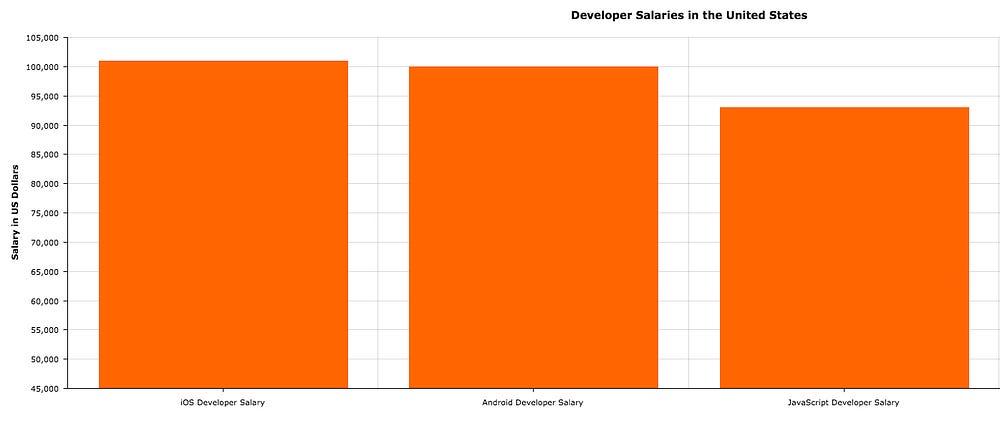
在美国,雇佣 iOS,Android,JavaScript 开发人员的平均花费([http://www.indeed.com/salary][1],[http://www.payscale.com/research/US/Skill=JavaScript/Salary][2])
|
||||
*在美国,雇佣 [iOS,Android][1],[JavaScript][2] 开发人员的平均花费*
|
||||
|
||||
在过去的几年,原生移动应用开发的费用螺旋式上升,无法控制。对没有大量资金的新创业者来说,创建原生应用、MVP 设计架构和原型的难度大大增加。现有的公司需要抓住人才,以便在现有应用上进行迭代开发或者构建一个新的应用。要尽一切努力留住最好的人才,与 [世界各地的公司][9] 拼尽全力 [争][6] 个 [高][7] [下][8]。
|
||||
在过去的几年,原生移动应用开发的费用螺旋式上升,无法控制。对没有大量资金的新创业者来说,创建原生应用、MVP 设计架构和原型的难度大大增加。现有的公司需要抓住人才,以便在现有应用上进行迭代开发或者构建一个新的应用。要尽一切努力才能留住最好的人才,与 [世界各地的公司][9] 拼尽全力[争个][6][高][7][下][8]。
|
||||
|
||||
|
||||
|
||||
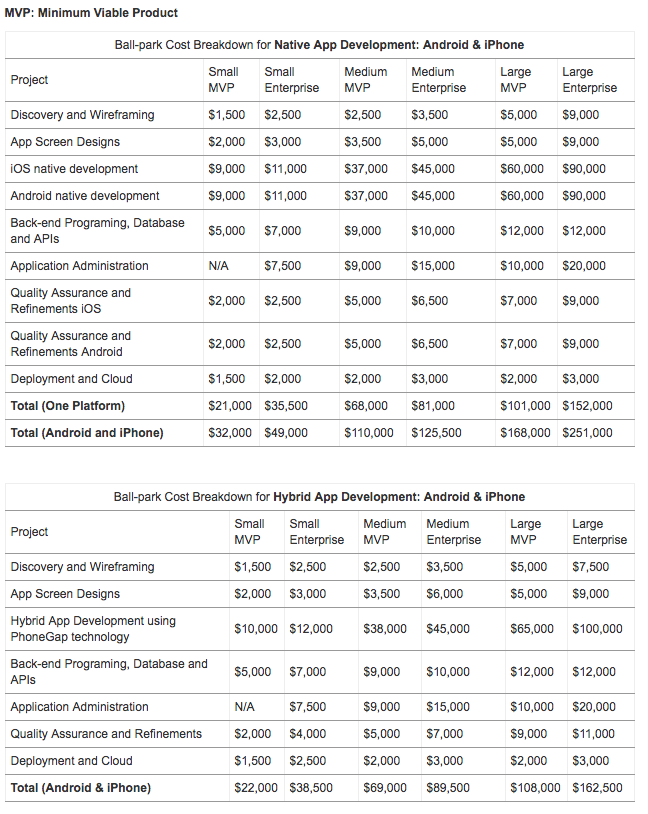
2015年初,原生方式和混合方式开发 MVP 设计架构的费用对比([Comomentum.com][3])
|
||||
*2015 年初,原生方式和混合方式开发 MVP 设计架构的费用[对比][3]*
|
||||
|
||||
### 这一切对于我们意味着什么?
|
||||
|
||||
如果你的公司很大或者有足够多的现金,旧思维是只要你在原生应用开发方面投入足够多的资金,就高枕无忧。但事实不再如此。
|
||||
|
||||
Facebook 是你最不会想到的在人才战中失败的公司(因为他们没有失败),它也遇到了原生应用方面金钱无法解决的问题。他们的移动应用庞大而又复杂,[可以看到编译它竟然需要15分钟][10]。这意味着哪怕是极小的用户界面改动,比如移动几个点,测试起来都要花费几个小时(甚至几天)。
|
||||
Facebook 是你最不会想到的在人才战中失败的公司(因为他们没有失败),它也遇到了原生应用方面金钱无法解决的问题。他们的移动应用庞大而又复杂,[他们发现编译它竟然需要 15 分钟][10]。这意味着哪怕是极小的用户界面改动,比如移动几个点,测试起来都要花费几个小时(甚至几天)。
|
||||
|
||||
除了冗长的编译时间,应用的每一个小改动在测试时都需要在两个完全不同的环境(IOS 和 Android)实施,开发团队需要使用两种语言和框架工作,这趟水更浑了。
|
||||
|
||||
Facebook 对这个问题的解决方案是 [React Native][11]。
|
||||
|
||||
### 能不能抛弃移动应用,仅面向Web呢?
|
||||
### 能不能抛弃移动应用,仅面向 Web 呢?
|
||||
|
||||
[一些人认为移动应用的末日已到。][12] 尽管我很欣赏、尊重 [Eric Elliott][13] 和他的工作,但我们还是通过考察一些近期的数据,进而讨论一下某些相反的观点:
|
||||
[一些人认为移动应用的末日已到][12]。尽管我很欣赏、尊重 [Eric Elliott][13] 和他的工作,但我们还是通过考察一些近期的数据,进而讨论一下某些相反的观点:
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
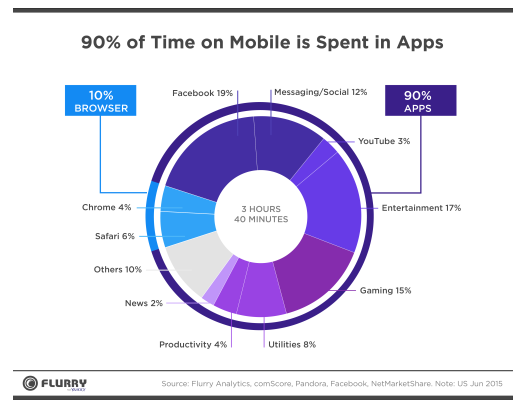
人们在移动应用上花费的时间(2016年4月,[smartinsights.com][4])
|
||||
*人们在移动应用上花费的[时间][4](2016年4月)*
|
||||
|
||||
> 人们使用 APP 的时间占使用手机总时长的 90%
|
||||
|
||||
目前世界上有 25 亿人在使用移动手机。[这个数字增长到 50 亿的速度会比我们想象的还要快。][14] 在正常情况下,丢掉 45 亿人的生意,或者抛弃有 45 亿人使用的应用程序是绝对荒唐且行不通的。
|
||||
|
||||
老问题是原生移动应用的开发成本对大多数公司来说太高了。尽管这个问题确实存在,但面向 web 的开发成本也在增加。[在美国,JavaScript 开发者的平均工资已达到 $97,000.00。][15]
|
||||
老问题是原生移动应用的开发成本对大多数公司来说太高了。然而,面向 web 的开发成本也在增加。[在美国,JavaScript 开发者的平均工资已达到 $97,000.00][15]。
|
||||
|
||||
伴随着复杂性的增加以及暴涨的高质量 web 开发需求,雇佣一个JavaScript 开发者的平均价格直逼原生应用开发者。论证 web 开发更便宜已经没用了。
|
||||
伴随着复杂性的增加以及对高质量 web 开发的需求暴涨,雇佣一个 JavaScript 开发者的平均价格直逼原生应用开发者。论证 web 开发更便宜已经没用了。
|
||||
|
||||
### 那混合开发呢?
|
||||
|
||||
混合应用是将 HTML5 应用内嵌在原生应用的容器里,并且提供实现原生平台特性所需的权限。Cordova 和 PhoneGap 就是典型的例子。
|
||||
|
||||
如果你想构建一个 MVP 设计架构、一个产品原型,或者不担心模仿原生应用的用户体验,那么混合应用会很适合你。谨记如果你最后想把它转为原生应用,整个项目都得重写。
|
||||
如果你想构建一个 MVP 设计架构、一个产品原型,或者不担心对原生应用的模仿的用户体验,那么混合应用会很适合你。但谨记如果你最后想把它转为原生应用,整个项目都得重写。
|
||||
|
||||
此领域有很多创新的东西,我最喜欢的当属 [Ionic Framework][16]。混合开发正变得越来越好,但还不如原生开发那么流畅自然。
|
||||
|
||||
有很多公司,包括最严峻的初创公司,也包括大中规模的公司,混合应用在质量上的表现似乎没有满足客户的要求,给人的感觉是活糙、不够专业。
|
||||
|
||||
[听说应用商店里的前 100 名都不是混合应用,][17]我没有证据支持这一观点。如果说有百分之零到百分之五是混合应用,我就不怀疑了。
|
||||
[听说应用商店里的前 100 名都不是混合应用][17],我没有证据支持这一观点。如果说有百分之零到百分之五是混合应用,我就不怀疑了。
|
||||
|
||||
> [我们最大的错误是在 HTML5 身上下了太多的赌注][18] — 马克 扎克伯格
|
||||
> [我们最大的错误是在 HTML5 身上下了太多的赌注][18] — 马克·扎克伯格
|
||||
|
||||
### 解决方案
|
||||
|
||||
如果你紧跟移动开发动向,那么你绝对听说过像 [NativeScript][19] 和 [React Native][20] 这样的项目。
|
||||
|
||||
通过这些项目,使用用 JavaScript 写成的基本 UI 组成块,像常规 iOS 和 Android 应用那样,就可以构建出高质量的原生移动应用。
|
||||
通过这些项目,使用由 JavaScript 写成的基本 UI 组成块,像常规 iOS 和 Android 应用那样,就可以构建出高质量的原生移动应用。
|
||||
|
||||
你可以仅用一位工程师,也可以用一个专业的工程师团队,通过 React Native 使用 [现有代码库][22] 或者 [底层技术][23] 进行跨平台移动应用开发,[原生桌面开发][21], 甚至还有 web 开发。把你的应用发布到 APP Store上, Play Store上,还有 Web 上。如此可以在保证不丧失原生应用性能和质量的同时,使成本仅占传统开发的一小部分。
|
||||
你可以仅用一位工程师,也可以用一个专业的工程师团队,通过 React Native 使用 [现有代码库][22] 或者 [底层技术][23] 进行跨平台移动应用开发、[原生桌面开发][21],甚至还有 web 开发。把你的应用发布到 APP Store 上、 Play Store 上,还有 Web 上。如此可以在保证不丧失原生应用性能和质量的同时,使成本仅占传统开发的一小部分。
|
||||
|
||||
通过 React Native 进行跨平台开发时重复使用其中 90% 的代码也不是没有的事,这个范围通常是 80% 到 90%。
|
||||
|
||||
@ -72,7 +71,7 @@ Facebook 对这个问题的解决方案是 [React Native][11]。
|
||||
|
||||
React Native 还可以使用 [Code Push][24] 和 [AppHub][25] 这样的工具来远程更新你的 JavaScript 代码。这意味着你可以向用户实时推送更新、新特性,快速修复 bug,绕过打包、发布这些工作,绕过 App Store、Google Play Store 的审核,省去了耗时 2 到 7 天的过程(App Store 一直是整个过程的痛点)。混合应用的这些优势原生应用不可能比得上。
|
||||
|
||||
如果这个领域的创新力能像刚发行时那样保持,将来你甚至可以为 [Apple Watch ][26],[Apple TV][27],和 [Tizen][28] 这样的平台开发应用。
|
||||
如果这个领域的创新力能像刚发行时那样保持,将来你甚至可以为 [Apple Watch][26]、[Apple TV][27],和 [Tizen][28] 这样的平台开发应用。
|
||||
|
||||
> NativeScript 依然是个相当年轻的框架驱动,Angular 版本 2,[上个月刚刚发布测试版][29]。但只要它保持良好的市场份额,未来就很有前途。
|
||||
|
||||
@ -84,49 +83,57 @@ React Native 还可以使用 [Code Push][24] 和 [AppHub][25] 这样的工具
|
||||
|
||||
看下面的例子,[这是一个使用 React Native 技术的著名应用列表][31]。
|
||||
|
||||
### Facebook
|
||||
#### Facebook
|
||||
|
||||

|
||||
|
||||
Facebook 公司的 React Native 应用
|
||||
*Facebook 公司的 React Native 应用*
|
||||
|
||||
Facebook 的两款应用 [Ads Manager][32] 和 [Facebook Groups][33]都在使用 React Native 技术,并且[将会应用到实现动态消息的框架上][34]。
|
||||
Facebook 的两款应用 [Ads Manager][32] 和 [Facebook Groups][33] 都在使用 React Native 技术,并且[将会应用到实现动态消息的框架上][34]。
|
||||
|
||||
Facebook 也会投入大量的资金创立和维护像 React Native 这样的开源项目,而且开源项目的开发者最近已经创建很多了不起的项目,这是很了不起的工作,像我以及全世界的业务每天都从中享受诸多好处。
|
||||
|
||||
### Instagram
|
||||
#### Instagram
|
||||
|
||||

|
||||
|
||||
Instagram
|
||||
*Instagram*
|
||||
|
||||
Instagram 应用的一部分已经使用了 React Native 技术。
|
||||
|
||||
### Airbnb
|
||||
#### Airbnb
|
||||
|
||||

|
||||
|
||||
Airbnb
|
||||
*Airbnb*
|
||||
|
||||
Airbnb 的很多东西正用 React Native 重写。(来自 [Leland Richardson][36])
|
||||
|
||||
超过 90% 的 Airbnb 旅行平台都是用 React Native 写的。(来自 [spikebrehm][37])
|
||||
|
||||
### Vogue
|
||||
#### Vogue
|
||||
|
||||

|
||||
|
||||
Vogue 是 2016 年度十佳应用之一
|
||||
*Vogue 是 2016 年度十佳应用之一*
|
||||
|
||||
Vogue 这么突出不仅仅因为它也用 React Native 写成,而是[因为它被苹果公司评为年度十佳应用之一][38]。
|
||||
|
||||
|
||||
|
||||
微软
|
||||
#### 沃尔玛
|
||||
|
||||
微软在 React Native 身上下的赌注很大
|
||||

|
||||
|
||||
它早已发布多个开源工具,包括 [Code Push][39],[React Native VS Code][40],以及 [React Native Windows][41],旨在帮助开发者向 React Native 领域转移。
|
||||
*Walmart Labs*
|
||||
|
||||
查看这篇 [Keerti](https://medium.com/@Keerti) 的[文章](https://medium.com/walmartlabs/react-native-at-walmartlabs-cdd140589560#.azpn97g8t)来了解沃尔玛是怎样看待 React Native 的优势的。
|
||||
|
||||
#### 微软
|
||||
|
||||
微软在 React Native 身上下的赌注很大。
|
||||
|
||||
它早已发布多个开源工具,包括 [Code Push][39]、[React Native VS Code][40],以及 [React Native Windows][41],旨在帮助开发者向 React Native 领域转移。
|
||||
|
||||
微软考虑的是那些已经使用 React Native 为 iOS 和 Android 开发应用的开发者,他们可以重用高达 90% 的代码,不用花费太多额外的时间和成本就可将应用发布到 Windows 上。
|
||||
|
||||
@ -136,11 +143,11 @@ Vogue 这么突出不仅仅因为它也用 React Native 写成,而是[因为
|
||||
|
||||
移动应用界面设计和移动应用开发要进行范式转变,下一步就是 React Native 以及与其相似的技术。
|
||||
|
||||
公司
|
||||
#### 公司
|
||||
|
||||
如果你的公司正想着削减成本、加快开发速度,而又不想在应用质量和性能上妥协,这是最适合使用 React Native 的时候,它能提高你的净利润。
|
||||
|
||||
开发者
|
||||
#### 开发者
|
||||
|
||||
如果你是一个开发者,想进入一个将来会快速发展的领域,我强烈推荐你把 React Native 列入你的学习清单。
|
||||
|
||||
@ -166,7 +173,7 @@ via: https://hackernoon.com/the-cost-of-native-mobile-app-development-is-too-dam
|
||||
|
||||
作者:[Nader Dabit][a]
|
||||
译者:[fuowang](https://github.com/fuowang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -9,15 +9,15 @@ GraphQL 在生产环境中似乎难以使用:虽然对于建模功能来说图
|
||||
|
||||
* 三种类型的资源(用户、博文以及评论)支持多种功能(创建用户、创建博文、给博文添加评论、关注其它用户的博文和评论,等等。)
|
||||
* 使用 PostgreSQL 作为后端数据存储(选择它因为它是一个流行的关系型数据库)。
|
||||
* 使用 Golang(开发 API 的一个流行语言)进行 API 实现。
|
||||
* 使用 Golang(开发 API 的一个流行语言)实现 API。
|
||||
|
||||
我们会比较简单的 GraphQL 实现和纯 REST 替代方案,在一种普通场景(呈现博客文章页面)下对比它们的实现复杂性和效率。
|
||||
|
||||
### 介绍
|
||||
|
||||
GraphQL 是一种 IDL(Interface Definition Language,接口定义语言),设计者定义数据类型和并把数据建模为一个图。每个顶点都是一种数据类型的一个实例,边代表了节点之间的关系。这种方式非常灵活,能适应任何业务领域。然而,问题是设计过程更加复杂,而且传统的数据存储不能很好地映射到图模型。阅读_附录1_了解更多关于这个问题的详细信息。
|
||||
GraphQL 是一种 IDL(Interface Definition Language,接口定义语言),设计者定义数据类型和并把数据建模为一个图(graph)。每个顶点都是一种数据类型的一个实例,边代表了节点之间的关系。这种方式非常灵活,能适应任何业务领域。然而,问题是设计过程更加复杂,而且传统的数据存储不能很好地映射到图模型。阅读_附录1_了解更多关于这个问题的详细信息。
|
||||
|
||||
GraphQL 在 2014 年由 Facebook 的工程师团队首次提出。尽管它的优点和功能非常有趣而且引人注目,它并没有得到大规模应用。开发者需要权衡 REST 的设计简单性、熟悉性、丰富的工具和 GraphQL 不会受限于 CRUD(LCTT 译注:Create、Read、Update、Delete) 以及网络性能(它优化了往返服务器的网络)的灵活性。
|
||||
GraphQL 在 2014 年由 Facebook 的工程师团队首次提出。尽管它的优点和功能非常有趣而且引人注目,但它并没有得到大规模应用。开发者需要权衡 REST 的设计简单性、熟悉性、丰富的工具和 GraphQL 不会受限于 CRUD(LCTT 译注:Create、Read、Update、Delete) 以及网络性能(它优化了往返服务器的网络)的灵活性。
|
||||
|
||||
大部分关于 GraphQL 的教程和指南都跳过了从数据存储获取数据以便解决查询的问题。也就是,如何使用通用目的、流行存储方案(例如关系型数据库)为 GraphQL API 设计一个支持高效数据提取的数据库。
|
||||
|
||||
@ -37,7 +37,7 @@ GraphQL 在 2014 年由 Facebook 的工程师团队首次提出。尽管它的
|
||||
|
||||
### 在 GraphQL 中建模一个博客引擎
|
||||
|
||||
_列表1_包括了博客引擎 API 的全部模式。它显示了组成图的顶点的数据类型。顶点之间的关系,也就是边,被建模为指定类型的属性。
|
||||
下述_列表1_包括了博客引擎 API 的全部模式。它显示了组成图的顶点的数据类型。顶点之间的关系,也就是边,被建模为指定类型的属性。
|
||||
|
||||
```
|
||||
type User {
|
||||
@ -86,7 +86,7 @@ type Mutation {
|
||||
|
||||
_列表1_
|
||||
|
||||
模式使用 GraphQL DSL 编写,它用于定义自定义数据类型,例如 `User`、`Post` 和 `Comment`。该语言也提供了一系列原始数据类型,例如 `String`、`Boolean` 和 `ID`(是`String` 的别名,但是有顶点唯一标识符的额外语义)。
|
||||
模式使用 GraphQL DSL 编写,它用于定义自定义数据类型,例如 `User`、`Post` 和 `Comment`。该语言也提供了一系列原始数据类型,例如 `String`、`Boolean` 和 `ID`(它是`String` 的别名,但是有顶点唯一标识符的额外语义)。
|
||||
|
||||
`Query` 和 `Mutation` 是语法解析器能识别并用于查询图的可选类型。从 GraphQL API 读取数据等同于遍历图。需要提供这样一个起始顶点;该角色通过 `Query` 类型来实现。在这种情况中,所有图的查询都要从一个由 id `user(id:ID!)` 指定的用户开始。对于写数据,定义了 `Mutation` 顶点。它提供了一系列操作,建模为能遍历(并返回)新创建顶点类型的参数化属性。_列表2_是这些查询的一些例子。
|
||||
|
||||
@ -99,7 +99,7 @@ _列表1_
|
||||
* 也可以把它们组合起来,例如 `[Comment!]!` 表示一个非空 Comment 顶点链表,其中 `[]`、`[Comment]` 是有效的,但 `null, [null], [Comment, null]` 就不是。
|
||||
|
||||
|
||||
_列表2_ 包括一系列用于博客 API 的 _curl_ 命令,它们会使用 mutation 填充图然后查询图以便获取数据。要运行它们,按照 [topliceanu/graphql-go-example][3] 仓库中的指令编译并运行服务。
|
||||
_列表2_ 包括一系列用于博客 API 的 `curl` 命令,它们会使用 mutation 填充图然后查询图以便获取数据。要运行它们,按照 [topliceanu/graphql-go-example][3] 仓库中的指令编译并运行服务。
|
||||
|
||||
```
|
||||
# 创建用户 1、2 和 3 的更改。更改和查询类似,在该情景中我们检索新创建用户的 id 和 email。
|
||||
@ -143,7 +143,10 @@ _列表2_
|
||||
|
||||
### 设计 PostgreSQL 数据库
|
||||
|
||||
关系型数据库的设计,一如以往,由避免数据冗余的需求驱动。选择该方式有两个原因:1\. 表明实现 GraphQL API 不需要定制化的数据库技术或者学习和使用新的设计技巧。2\. 表明 GraphQL API 能在现有的数据库之上创建,更具体地说,最初设计用于 REST 后端甚至传统的呈现 HTML 站点的服务器端数据库。
|
||||
关系型数据库的设计,一如以往,由避免数据冗余的需求驱动。选择该方式有两个原因:
|
||||
|
||||
1. 表明实现 GraphQL API 不需要定制化的数据库技术或者学习和使用新的设计技巧。
|
||||
2. 表明 GraphQL API 能在现有的数据库之上创建,更具体地说,最初设计用于 REST 后端甚至传统的呈现 HTML 站点的服务器端数据库。
|
||||
|
||||
阅读 _附录1_ 了解关于关系型和图数据库在构建 GraphQL API 方面的区别。_列表3_ 显示了用于创建新数据库的 SQL 命令。数据库模式和 GraphQL 模式相对应。为了支持 `follow/unfollow` 更改,需要添加 `followers` 关系。
|
||||
|
||||
@ -176,7 +179,7 @@ _列表3_
|
||||
|
||||
### Golang API 实现
|
||||
|
||||
本项目使用的用 Go 实现的 GraphQL 语法解析器是 `github.com/graphql-go/graphql`。它包括一个查询解析器,但不包括模式解析器。这要求开发者利用库提供的结构使用 Go 构建 GraphQL 模式。这和 [nodejs 实现][3] 不同,后者提供了一个模式解析器并为数据获取暴露了钩子。因此 `列表1` 中的模式只是作为指导使用,需要转化为 Golang 代码。然而,这个_“限制”_提供了与抽象级别对等的机会,并且了解模式如何和用于检索数据的图遍历模型相关。_列表4_ 显示了 `Comment` 顶点类型的实现:
|
||||
本项目使用的用 Go 实现的 GraphQL 语法解析器是 `github.com/graphql-go/graphql`。它包括一个查询解析器,但不包括模式解析器。这要求开发者利用库提供的结构使用 Go 构建 GraphQL 模式。这和 [nodejs 实现][3] 不同,后者提供了一个模式解析器并为数据获取暴露了钩子。因此 _列表1_ 中的模式只是作为指导使用,需要转化为 Golang 代码。然而,这个_“限制”_提供了与抽象级别对等的机会,并且了解模式如何和用于检索数据的图遍历模型相关。_列表4_ 显示了 `Comment` 顶点类型的实现:
|
||||
|
||||
```
|
||||
var CommentType = graphql.NewObject(graphql.ObjectConfig{
|
||||
@ -348,9 +351,9 @@ _列表5_
|
||||
|
||||
对于这种情况,对数据库的查询次数是故意相同的,但是到 API 服务器的 HTTP 请求已经减少到只有一个。我们认为在这种类型的应用程序中通过互联网的 HTTP 请求是最昂贵的。
|
||||
|
||||
为了获取 GraphQL 的优势,后端并不需要进行特别设计,从 REST 到 GraphQL 的转换可以逐步完成。这使得可以测量性能提升和优化。从这一点,API 设计者可以开始优化(潜在的合并) SQL 查询从而提高性能。缓存的机会在数据库和 API 级别都大大增加。
|
||||
为了利用 GraphQL 的优势,后端并不需要进行特别设计,从 REST 到 GraphQL 的转换可以逐步完成。这使得可以测量性能提升和优化。从这一点,API 设计者可以开始优化(潜在的合并) SQL 查询从而提高性能。缓存的机会在数据库和 API 级别都大大增加。
|
||||
|
||||
SQL 之上的抽象(例如 ORM 层)通常会和 `n+1` 问题想抵触。在 REST 事例的步骤 4 中,客户端可能不得不在单独的请求中为每个评论的作者请求关注状态。这是因为在 REST 中没有标准的方式来表达两个以上资源之间的关系,而 GraphQL 旨在通过使用嵌套查询来防止这类问题。这里我们通过获取用户的所有关注者进行欺骗。我们向客户推荐确定评论和关注作者用户的逻辑。
|
||||
SQL 之上的抽象(例如 ORM 层)通常会和 `n+1` 问题相抵触。在 REST 示例的步骤 4 中,客户端可能不得不在单独的请求中为每个评论的作者请求关注状态。这是因为在 REST 中没有标准的方式来表达两个以上资源之间的关系,而 GraphQL 旨在通过使用嵌套查询来防止这类问题。这里我们通过获取用户的所有关注者来作弊。我们向客户提出了如何确定评论并关注了作者的用户的逻辑。
|
||||
|
||||
另一个区别是获取比客户端所需更多的数据,以免破坏 REST 资源抽象。这对于用于解析和存储不需要数据的带宽消耗和电池寿命非常重要。
|
||||
|
||||
@ -358,7 +361,7 @@ SQL 之上的抽象(例如 ORM 层)通常会和 `n+1` 问题想抵触。在
|
||||
|
||||
GraphQL 是 REST 的一个可用替代方案,因为:
|
||||
|
||||
* 尽管设计 API 更加困难,该过程可以逐步完成。也是由于这个原因,从 REST 转换到 GraphQL 非常容易,两个流程可以没有任何问题地共存。
|
||||
* 尽管设计 API 更加困难,但该过程可以逐步完成。也是由于这个原因,从 REST 转换到 GraphQL 非常容易,两个流程可以没有任何问题地共存。
|
||||
* 在网络请求方面更加高效,即使是类似本博客中的简单实现。它还提供了更多查询优化和结果缓存的机会。
|
||||
* 在用于解析结果的带宽消耗和 CPU 周期方面它更加高效,因为它只返回呈现页面所需的数据。
|
||||
|
||||
@ -370,15 +373,15 @@ REST 仍然非常有用,如果:
|
||||
|
||||
### 附录1:图数据库和高效数据存储
|
||||
|
||||
尽管将应用领域数据想象为一个图非常直观,正如这篇博文介绍的那样,但是支持这种接口的高效数据存储问题仍然没有解决。
|
||||
尽管将其应用领域数据想象为一个图非常直观,正如这篇博文介绍的那样,但是支持这种接口的高效数据存储问题仍然没有解决。
|
||||
|
||||
近年来图数据库变得越来越流行。通过将 GraphQL 查询转换为特定的图数据库查询语言从而延迟解决请求的复杂性似乎是一种可行的方案。
|
||||
|
||||
问题是和关系型数据库相比图并不是一种高效的数据结构。图中一个顶点可能有到任何其它顶点的连接,访问模式比较难以预测因此提供了较少的优化机会。
|
||||
问题是和关系型数据库相比,图并不是一种高效的数据结构。图中一个顶点可能有到任何其它顶点的连接,访问模式比较难以预测因此提供了较少的优化机会。
|
||||
|
||||
例如缓存的问题,为了快速访问需要将哪些顶点保存在内存中?通用缓存算法在图遍历场景中可能没那么高效。
|
||||
|
||||
数据库分片问题:把数据库切分为更小、没有交叉的数据库并保存到独立的硬件。在学术上,最小切割的图划分问题已经得到了很好的理解,但可能是次优的而且由于病态的最坏情况可能导致高度不平衡切割。
|
||||
数据库分片问题:把数据库切分为更小、没有交叉的数据库并保存到独立的硬件。在学术上,最小切割的图划分问题已经得到了很好的理解,但可能是次优的,而且由于病态的最坏情况可能导致高度不平衡切割。
|
||||
|
||||
在关系型数据库中,数据被建模为记录(行或者元组)和列,表和数据库名称都只是简单的命名空间。大部分数据库都是面向行的,意味着每个记录都是一个连续的内存块,一个表中的所有记录在磁盘上一个接一个地整齐地打包(通常按照某个关键列排序)。这非常高效,因为这是物理存储最优的工作方式。HDD 最昂贵的操作是将磁头移动到磁盘上的另一个扇区,因此最小化此类访问非常重要。
|
||||
|
||||
@ -392,7 +395,7 @@ via: http://alexandrutopliceanu.ro/post/graphql-with-go-and-postgresql
|
||||
|
||||
作者:[Alexandru Topliceanu][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,71 +1,47 @@
|
||||
### 如何在 Linux 终端会话中使用 Asciinema 进行录制和回放
|
||||
如何在 Linux 中使用 Asciinema 进行录制和回放终端会话
|
||||
===========
|
||||
|
||||

|
||||
|
||||
内容
|
||||
|
||||
* * [1、简介][11]
|
||||
* [2、困难][12]
|
||||
* [3、惯例][13]
|
||||
* [4、标准库安装][14]
|
||||
* [4.1、在 Arch Linux 上安装][1]
|
||||
* [4.2、在 Debian 上安装][2]
|
||||
* [4.3、在 Ubuntu 上安装][3]
|
||||
* [4.4、在 Fedora 上安装][4]
|
||||
* [5、从源代码安装][15]
|
||||
* [6、前提条件][16]
|
||||
* [6.1、在 Arch Linux 上安装 ruby][5]
|
||||
* [6.2、在 Debian 上安装 ruby][6]
|
||||
* [6.3、在 Ubuntu 安装 ruby][7]
|
||||
* [6.4、在 Fedora 安装 ruby][8]
|
||||
* [6.5、在 CentOS 安装 ruby][9]
|
||||
* [7、 安装 Linuxbrew][17]
|
||||
* [8、 安装 Asciinema][18]
|
||||
* [9、录制终端会话][19]
|
||||
* [10、回放已录制终端会话][20]
|
||||
* [11、将视频嵌入 HTML][21]
|
||||
* [12、结论][22]
|
||||
* [13、 故障排除][23]
|
||||
* [13.1、在 UTF-8 环境下运行 asciinema][10]
|
||||
|
||||
### 简介
|
||||
|
||||
Asciinema 是一个轻量并且非常高效的脚本终端会话录制器的替代品。使用它可以录制、回放和分享 JSON 格式的终端会话记录。和一些桌面录制器,比如 Recordmydesktop、Simplescreenrecorder、Vokoscreen 或 Kazam 相比,Asciinema 最主要的优点是,它能够以通过 ANSI 转义码编码的 ASCII 文本录制所有的标准终端输入、输出和错误。
|
||||
Asciinema 是一个轻量并且非常高效的终端会话录制器。使用它可以录制、回放和分享 JSON 格式的终端会话记录。与一些桌面录制器,比如 Recordmydesktop、Simplescreenrecorder、Vokoscreen 或 Kazam 相比,Asciinema 最主要的优点是,它能够以通过 ASCII 文本以及 ANSI 转义码编码来录制所有的标准终端输入、输出和错误信息。
|
||||
|
||||
事实上,即使是很长的终端会话,录制出的 JSON 格式文件也非常小。另外,JSON 格式使得用户可以利用简单的文件转化器,将输出的 JSON 格式文件嵌入到 HTML 代码中,然后分享到公共网站或者使用 asciinema 账户分享到 Asciinema.org 。最后,如果你的终端会话中有一些错误,并且你还懂一些 ASCI 转义码语法,那么你可以使用任何编辑器来修改你的已录制终端会话。
|
||||
|
||||
### 困难
|
||||
**难易程度:**
|
||||
|
||||
很简单!
|
||||
|
||||
### 惯例
|
||||
**标准终端:**
|
||||
|
||||
* **#** - 给定命令需要以 root 用户权限运行或者使用 `sudo` 命令
|
||||
* **$** - 给定命令以常规权限用户运行
|
||||
|
||||
### 标准库安装
|
||||
### 从软件库安装
|
||||
|
||||
很有可能, asciinema 可以使用你的版本库进行安装。但是,如果不可以使用系统版本库进行安装或者你想安装最新的版本,那么,你可以像下面的“从源代码安装”部分所描述的那样,使用 Linuxbrew 包管理器来执行 Asciinema 安装。
|
||||
通常, asciinema 可以使用你的发行版的软件库进行安装。但是,如果不可以使用系统的软件库进行安装或者你想安装最新的版本,那么,你可以像下面的“从源代码安装”部分所描述的那样,使用 Linuxbrew 包管理器来执行 Asciinema 安装。
|
||||
|
||||
### 在 Arch Linux 上安装
|
||||
**在 Arch Linux 上安装:**
|
||||
|
||||
```
|
||||
# pacman -S asciinema
|
||||
```
|
||||
|
||||
### 在 Debian 上安装
|
||||
**在 Debian 上安装:**
|
||||
|
||||
```
|
||||
# apt install asciinema
|
||||
```
|
||||
|
||||
### 在 Ubuntu 上安装
|
||||
**在 Ubuntu 上安装:**
|
||||
|
||||
```
|
||||
$ sudo apt install asciinema
|
||||
```
|
||||
|
||||
### 在 Fedora 上安装
|
||||
**在 Fedora 上安装:**
|
||||
|
||||
```
|
||||
$ sudo dnf install asciinema
|
||||
@ -75,7 +51,7 @@ $ sudo dnf install asciinema
|
||||
|
||||
最简单并且值得推荐的方式是使用 Linuxbrew 包管理器,从源代码安装最新版本的 Asciinema 。
|
||||
|
||||
### 前提条件
|
||||
#### 前提条件
|
||||
|
||||
下面列出的前提条件是安装 Linuxbrew 和 Asciinema 需要满足的依赖关系:
|
||||
|
||||
@ -86,61 +62,69 @@ $ sudo dnf install asciinema
|
||||
|
||||
在安装 Linuxbrew 之前,请确保上面的这些包都已经安装在了你的 Linux 系统中。
|
||||
|
||||
### 在 Arch Linux 上安装 ruby
|
||||
**在 Arch Linux 上安装 ruby:**
|
||||
|
||||
```
|
||||
# pacman -S git gcc make ruby
|
||||
```
|
||||
|
||||
### 在 Debian 上安装 ruby
|
||||
**在 Debian 上安装 ruby:**
|
||||
|
||||
```
|
||||
# apt install git gcc make ruby
|
||||
```
|
||||
|
||||
### 在 Ubuntu 上安装 ruby
|
||||
**在 Ubuntu 上安装 ruby:**
|
||||
|
||||
```
|
||||
$ sudo apt install git gcc make ruby
|
||||
```
|
||||
|
||||
### 在 Fedora 上安装 ruby
|
||||
**在 Fedora 上安装 ruby:**
|
||||
|
||||
```
|
||||
$ sudo dnf install git gcc make ruby
|
||||
```
|
||||
|
||||
### 在 CentOS 上安装 ruby
|
||||
**在 CentOS 上安装 ruby:**
|
||||
|
||||
```
|
||||
# yum install git gcc make ruby
|
||||
```
|
||||
|
||||
### 安装 Linuxbrew
|
||||
#### 安装 Linuxbrew
|
||||
|
||||
Linuxbrew 包管理器是苹果的 MacOS 操作系统很受欢迎的 Homebrew 包管理器的一个复刻版本。还没发布多久,Homebrew 就以容易使用而著称。如果你想使用 Linuxbrew 来安装 Asciinema,那么,请运行下面命令在你的 Linux 版本上安装 Linuxbrew:
|
||||
|
||||
```
|
||||
$ ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Linuxbrew/install/master/install)"
|
||||
```
|
||||
|
||||
现在,Linuxbrew 已经安装到了目录 `$HOME/.linuxbrew/` 下。剩下需要做的就是使它成为可执行 `PATH` 环境变量的一部分。
|
||||
|
||||
```
|
||||
$ echo 'export PATH="$HOME/.linuxbrew/bin:$PATH"' >>~/.bash_profile
|
||||
$ . ~/.bash_profile
|
||||
```
|
||||
|
||||
为了确认 Linuxbrew 是否已经安装好,你可以使用 `brew` 命令来查看它的版本:
|
||||
|
||||
```
|
||||
$ brew --version
|
||||
Homebrew 1.1.7
|
||||
Homebrew/homebrew-core (git revision 5229; last commit 2017-02-02)
|
||||
```
|
||||
|
||||
### 安装 Asciinema
|
||||
#### 安装 Asciinema
|
||||
|
||||
安装好 Linuxbrew 以后,安装 Asciinema 就变得无比容易了:
|
||||
|
||||
```
|
||||
$ brew install asciinema
|
||||
```
|
||||
|
||||
检查 Asciinema 是否安装正确:
|
||||
|
||||
```
|
||||
$ asciinema --version
|
||||
asciinema 1.3.0
|
||||
@ -151,10 +135,13 @@ asciinema 1.3.0
|
||||
经过一番辛苦的安装工作以后,是时候来干一些有趣的事情了。Asciinema 是一个非常容易使用的软件。事实上,目前的 1.3 版本只有很少的几个可用命令行选项,其中一个是 `--help` 。
|
||||
|
||||
我们首先使用 `rec` 选项来录制终端会话。下面的命令将会开始录制终端会话,之后,你将会有一个选项来丢弃已录制记录或者把它上传到 asciinema.org 网站以便将来参考。
|
||||
|
||||
```
|
||||
$ asciinema rec
|
||||
```
|
||||
|
||||
运行上面的命令以后,你会注意到, Asciinema 已经开始录制终端会话了,你可以按下 `CTRL+D` 快捷键或执行 `exit` 命令来停止录制。如果你使用的是 Debian/Ubuntu/Mint Linux 系统,你可以像下面这样尝试进行第一次 asciinema 录制:
|
||||
|
||||
```
|
||||
$ su
|
||||
Password:
|
||||
@ -162,7 +149,9 @@ Password:
|
||||
# exit
|
||||
$ sl
|
||||
```
|
||||
|
||||
一旦输入最后一个 `exit` 命令以后,将会询问你:
|
||||
|
||||
```
|
||||
$ exit
|
||||
~ Asciicast recording finished.
|
||||
@ -170,11 +159,15 @@ $ exit
|
||||
|
||||
https://asciinema.org/a/7lw94ys68gsgr1yzdtzwijxm4
|
||||
```
|
||||
|
||||
如果你不想上传你的私密命令行技巧到 asciinema.org 网站,那么有一个选项可以把 Asciinema 记录以 JSON 格式保存为本地文件。比如,下面的 asciinema 记录将被存为 `/tmp/my_rec.json`:
|
||||
|
||||
```
|
||||
$ asciinema rec /tmp/my_rec.json
|
||||
```
|
||||
另一个非常有用的 asciinema 特性是时间微调。如果你的键盘输入速度很慢,或者你在进行多任务,输入命令和执行命令之间的时间可以延长。Asciinema 会记录你的实时按键时间,这意味着每一个停顿都将反映在最终视频的长度上。可以使用 `-w` 选项来缩短按键的时间间隔。比如,下面的命令将按键的时间间隔缩短为 0.2 秒:
|
||||
|
||||
另一个非常有用的 asciinema 特性是时间微调。如果你的键盘输入速度很慢,或者你在进行多任务,输入命令和执行命令之间的时间会比较长。Asciinema 会记录你的实时按键时间,这意味着每一个停顿都将反映在最终视频的长度上。可以使用 `-w` 选项来缩短按键的时间间隔。比如,下面的命令将按键的时间间隔缩短为 0.2 秒:
|
||||
|
||||
```
|
||||
$ asciinema rec -w 0.2
|
||||
```
|
||||
@ -182,15 +175,19 @@ $ asciinema rec -w 0.2
|
||||
### 回放已录制终端会话
|
||||
|
||||
有两种方式可以来回放已录制会话。第一种方式是直接从 asciinema.org 网站上播放终端会话。这意味着,你之前已经把录制会话上传到了 asciinema.org 网站,并且需要提供有效链接:
|
||||
|
||||
```
|
||||
$ asciinema play https://asciinema.org/a/7lw94ys68gsgr1yzdtzwijxm4
|
||||
```
|
||||
Alternatively, use your locally stored JSON file:
|
||||
|
||||
另外,你也可以使用本地存储的 JSON 文件:
|
||||
|
||||
```
|
||||
$ asciinema play /tmp/my_rec.json
|
||||
```
|
||||
|
||||
如果要使用 `wget` 命令来下载之前的上传记录,只需在链接的后面加上 `.json`:
|
||||
|
||||
```
|
||||
$ wget -q -O steam_locomotive.json https://asciinema.org/a/7lw94ys68gsgr1yzdtzwijxm4.json
|
||||
$ asciinema play steam_locomotive.json
|
||||
@ -198,7 +195,8 @@ $ asciinema play steam_locomotive.json
|
||||
|
||||
### 将视频嵌入 HTML
|
||||
|
||||
最后,Asciinema 还带有一个独立的 JavaScript 播放器。这意味者你可以很容易的在你的网站上分享终端会话记录。下面,使用一段简单的 `index.html` 代码来说明这个方法。首先,下载所有必要的东西:
|
||||
最后,asciinema 还带有一个独立的 JavaScript 播放器。这意味者你可以很容易的在你的网站上分享终端会话记录。下面,使用一段简单的 `index.html` 代码来说明这个方法。首先,下载所有必要的东西:
|
||||
|
||||
```
|
||||
$ cd /tmp/
|
||||
$ mkdir steam_locomotive
|
||||
@ -208,6 +206,7 @@ $ wget -q https://github.com/asciinema/asciinema-player/releases/download/v2.4.0
|
||||
$ wget -q https://github.com/asciinema/asciinema-player/releases/download/v2.4.0/asciinema-player.js
|
||||
```
|
||||
之后,创建一个新的包含下面这些内容的 `/tmp/steam_locomotive/index.html` 文件:
|
||||
|
||||
```
|
||||
<html>
|
||||
<head>
|
||||
@ -219,28 +218,34 @@ $ wget -q https://github.com/asciinema/asciinema-player/releases/download/v2.4.0
|
||||
</body>
|
||||
</html>
|
||||
```
|
||||
|
||||
完成以后,打开你的网页浏览器,按下 `CTRL+O` 来打开新创建的 `/tmp/steam_locomotive/index.html` 文件。
|
||||
|
||||
### 结论
|
||||
|
||||
正如前面所说的,使用 Asciinema 录制器来录制终端会话最主要的优点是它的输出文件非常小,这使得你的视频很容易分享出去。上面的例子产生了一个包含 58472 个字符的文件,它是一个只有 58 KB 大的 22 秒终端会话视频。如果我们查看输出的 JSON 文件,会发现甚至这个数字已经非常大了,这主要是因为一个 “蒸汽机车” 已经跑过了终端。这个长度的正常终端会话会产生一个更小的输出文件。
|
||||
正如前面所说的,使用 asciinema 录制器来录制终端会话最主要的优点是它的输出文件非常小,这使得你的视频很容易分享出去。上面的例子产生了一个包含 58472 个字符的文件,它是一个只有 58 KB 大 小的 22 秒终端会话视频。如果我们查看输出的 JSON 文件,会发现甚至这个数字已经非常大了,这主要是因为一个 “蒸汽机车” 已经跑过了终端。这个长度的正常终端会话一般会产生一个更小的输出文件。
|
||||
|
||||
下次,当你想要在一个论坛上询问关于 Linux 配置的问题,并且很难描述你的问题的时候,只需运行下面的命令:
|
||||
|
||||
```
|
||||
$ asciinema rec
|
||||
```
|
||||
|
||||
然后把最后的链接贴到论坛的帖子里。
|
||||
|
||||
### 故障排除
|
||||
|
||||
### 在 UTF-8 环境下运行 asciinema
|
||||
#### 在 UTF-8 环境下运行 asciinema
|
||||
|
||||
错误信息:
|
||||
|
||||
```
|
||||
asciinema 需要在 UTF-8 环境下运行。请检查 `locale` 命令的输出。
|
||||
asciinema needs a UTF-8 native locale to run. Check the output of `locale` command.
|
||||
```
|
||||
|
||||
解决方法:
|
||||
生成并导出UTF-8语言环境。例如:
|
||||
生成并导出 UTF-8 语言环境。例如:
|
||||
|
||||
```
|
||||
$ localedef -c -f UTF-8 -i en_US en_US.UTF-8
|
||||
$ export LC_ALL=en_US.UTF-8
|
||||
@ -252,7 +257,7 @@ via: https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-o
|
||||
|
||||
作者:[Lubos Rendek][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,49 @@
|
||||
甲骨文的政策更改提高了其在 AWS 上的价格
|
||||
============================================================
|
||||
|
||||
> 这种改变使在 AWS 上实施甲骨文的软件的价格翻了一番,它已经安静地生效了,而几乎没有通知用户。
|
||||
|
||||

|
||||
|
||||
之前有消息传出,甲骨文使亚马逊云上的产品价格翻了一倍。它在[如何计算 AWS 的虚拟 CPU][6] 上耍了一些花招。它这么做也没有任何宣扬。该公司的新定价政策于 1 月 23 日生效,直到 1 月 28 日都几乎没有被人注意到, 甲骨文的关注者 Tim Hall 偶然发现 Big Red 公司的 [甲骨文软件云计算环境许可][7]文件并披露了出来。
|
||||
|
||||
乍一看,这一举动似乎并不太大,因为它仅将甲骨文的 AWS 定价与 Microsoft Azure 的价格相提并论。但是 Azure 只有市场领先的 AWS 体量的三分之一,所以如果你想在云中销售许可证,AWS 是合适的地方。虽然此举可能或可能不会影响已经在 AWS 上使用甲骨文产品的用户,但是尚不清楚新规则是否适用于已在使用产品的用户 - 它肯定会让一些考虑可能使用甲骨文的用户另寻它处。
|
||||
|
||||
这个举动的主要原因是显而易见的。甲骨文希望使自己的云更具吸引力 - 这让 [The Register 观察][8]到一点:“拉里·埃里森确实承诺过甲骨文的云将会更快更便宜”。更快和更便宜仍然有待看到。如果甲骨文的 SPARC 云计划启动,并且按照广告的形式执行,那么可能会更快,但是更便宜的可能性较小。甲骨文以对其价格的强硬态度而著称。
|
||||
|
||||
随着其招牌数据库和业务栈销售的下滑,并且对 Sun 公司的 74 亿美元的投资并未能按照如期那样,甲骨文将其未来赌在云计算上。但是甲骨文来晚了,迄今为止,它的努力似乎还没有结果, 一些金融预测者并没有看到甲骨文云的光明前景。他们说,云是一个拥挤的市场,而四大公司 - 亚马逊、微软、IBM 和谷歌 - 已经有了领先优势。
|
||||
|
||||
确实如此。但是甲骨文面临的最大的障碍是,好吧,就是甲骨文。它的声誉在它之前。
|
||||
|
||||
保守地说这个公司并不是因为明星客户服务而闻名。事实上,各种新闻报道将甲骨文描绘成一个恶霸和操纵者。
|
||||
|
||||
例如,早在 2015 年,甲骨文就因为它的云并不像预期那样快速增长而越来越沮丧,开始[激活业内人士称之为的“核特权”][9]。它会审核客户的数据中心,如果客户不符合规定,将发出“违规通知” - 它通常只适用于大规模滥用情况,并命令客户在 30 天内退出使用其软件。
|
||||
|
||||
或许你能想到,大量投入在甲骨文软件平台上的大公司们绝对不能在短时间内迁移到另一个解决方案。甲骨文的违规通知将会引发灾难。
|
||||
|
||||
商业内幕人士 Julie Bort 解释到:“为了使违规通知消失 - 或者减少高额的违规罚款 - 甲骨文销售代表通常希望客户向合同中添加云额度”。
|
||||
|
||||
换句话说,甲骨文正在使用审计来扭转客户去购买它的云,而无论他们是否有需要。这种策略与最近 AWS 价格翻倍之间也可能存在联系。Hall 的文章的评论者指出,围绕价格提升的秘密背后的目的可能是触发软件审计。
|
||||
|
||||
使用这些策略的麻烦迟早会出来。消息一旦传播开来,你的客户就开始寻找其他选项。对 Big Red 而言或许是时候参考微软的做法,开始建立一个更好和更温和的甲骨文,将客户的需求放在第一位。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://windowsitpro.com/cloud/oracle-policy-change-raises-prices-aws
|
||||
|
||||
作者:[Christine Hall][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://windowsitpro.com/author/christine-hall
|
||||
[1]:http://windowsitpro.com/penton_ur/nojs/user/register?path=node%2F186491&nid=186491&source=email
|
||||
[2]:http://windowsitpro.com/author/christine-hall
|
||||
[3]:http://windowsitpro.com/author/christine-hall
|
||||
[4]:http://windowsitpro.com/cloud/oracle-policy-change-raises-prices-aws#comments
|
||||
[5]:http://windowsitpro.com/cloud/oracle-policy-change-raises-prices-aws#comments
|
||||
[6]:https://oracle-base.com/blog/2017/01/28/oracles-cloud-licensing-change-be-warned/
|
||||
[7]:http://www.oracle.com/us/corporate/pricing/cloud-licensing-070579.pdf
|
||||
[8]:https://www.theregister.co.uk/2017/01/30/oracle_effectively_doubles_licence_fees_to_run_in_aws/
|
||||
[9]:http://www.businessinsider.com/oracle-is-using-the-nuclear-option-to-sell-its-cloud-software-2015-7
|
||||
132
published/20170501 Containers running Containers.md
Normal file
132
published/20170501 Containers running Containers.md
Normal file
@ -0,0 +1,132 @@
|
||||
LinuxKit:在容器中运行容器
|
||||
============================================================
|
||||
|
||||
一些令人振奋的消息引发了我对今年 DockerCon 的兴趣,在这次会议中,无可争议的容器巨头公司 Docker 发布了一个新的操作系统:LinuxKit。
|
||||
|
||||
这家容器巨头宣布的是一个灵活的、可扩展的操作系统,而为了可移植性,系统服务也是运行在容器之中。甚至,令人惊讶的是,就连 Docker 运行时环境也是运行在容器内!
|
||||
|
||||
在本文中,我们将简要介绍一下 LinuxKit 中所承诺的内容,以及如何自己尝试一下这个不断精简、优化的容器。
|
||||
|
||||
### 少即是多
|
||||
|
||||
不可否认的是,用户一直在寻找一个可以运行他们的微服务的精简版本的 Linux 。通过容器化,你会尽可能地最小化每个应用程序,使其成为一个适合于运行在其自身容器内的独立进程。但是,由于你需要对那些驻留容器的宿主机出现的问题进行修补,因此你不断地在宿主机间移动容器。实际上,如果没有像 Kubernetes 或 Docker Swarm 这样的编排系统,容器编排几乎总是会导致停机。
|
||||
|
||||
不用说,这只是让你保持操作系统尽可能小的原因之一。
|
||||
|
||||
我曾多次在不同场合重复过的最喜爱的名言,来自荷兰的天才程序员 Wietse Zweitze,他为我们提供了重要的 Email 软件 Postfix 和 TCP Wrappers 等知名软件。
|
||||
|
||||
在 [Postfix 网站][10] 指出,即使你编码和 Wietse 一样小心,“每 1000 行[你]就会在 Postfix 中引入一个额外的 bug”。从我的专业的 DevSecOps 角度看,这里提到的“bug” 可以将其大致看做安全问题。
|
||||
|
||||
从安全的角度来看,正是由于这个原因,代码世界中“少即是多”。简单地说,使用较少的代码行有很多好处,即安全性、管理时间和性能。对于初学者来说,这意味着安全漏洞较少,更新软件包的时间更短,启动时间更快。
|
||||
|
||||
### 深入观察
|
||||
|
||||
考虑下在容器内部运行你的程序。
|
||||
|
||||
一个好的起点是 [Alpine Linux][1],它是一个苗条、精简的操作系统,通常比那些笨重的系统更受喜欢,如 Ubuntu 或 CentOS 等。Alpine 还提供了一个 miniroot 文件系统(用于容器内),最近我看到的大小是惊人的 1.8M。事实上,这个完整的 Linux 操作系统下载后有 80M。
|
||||
|
||||
如果你决定使用 Alpine Linux 作为 Docker 基础镜像,那么你可以在 Docker Hub 上[找到][2]一个, 它将其描述为:“一个基于 Alpine Linux 的最小 Docker 镜像,具有完整的包索引,大小只有5 MB!”
|
||||
|
||||
据说无处不在的 “Window 开始菜单” 文件也是大致相同的大小!我没有验证过,也不会进一步评论。
|
||||
|
||||
讲真,希望你去了解一下这个创新的类 Unix 操作系统(如 Alpine Linux)的强大功能。
|
||||
|
||||
### 锁定一切
|
||||
|
||||
再说一点,Alpine Linux 是(并不惊人)基于 [BusyBox][3],这是一套著名的打包了 Linux 命令的集合,许多人不会意识到他们的宽带路由器、智能电视,当然还有他们家庭中的物联网设备就有它。
|
||||
|
||||
Alpine Linux 站点的“[关于][4]”页面的评论中指出:
|
||||
|
||||
> “Alpine Linux 的设计考虑到安全性。内核使用 grsecurity/PaX 的非官方移植进行了修补,所有用户态二进制文件都编译为具有堆栈保护的地址无关可执行文件(PIE)。 这些主动安全特性可以防止所有类别的零日漏洞和其它漏洞利用。”
|
||||
|
||||
换句话说,这些捆绑在 Alpine Linux 中的精简二进制文件提供的功能通过了那些行业级安全工具筛选,以缓解缓冲区溢出攻击所带来的危害。
|
||||
|
||||
### 多出一只袜子
|
||||
|
||||
你可能会问,为什么当我们谈及 Docker 的新操作系统时,容器的内部结构很重要?
|
||||
|
||||
那么,你可能已经猜到,当涉及容器时,他们的目标是精简。除非绝对必要,否则不包括任何东西。所以你可以放心地清理橱柜、花园棚子、车库和袜子抽屉了。
|
||||
|
||||
Docker 的确因为它们的先见而获得声望。据报道,2 月初,Docker 聘请了 Alpine Linux 的主要推动者 Nathaniel Copa,他帮助将默认的官方镜像库从 Ubuntu 切换到 Alpine。Docker Hub 从新近精简镜像节省的带宽受到了赞誉。
|
||||
|
||||
并且最新的情况是,这项工作将与最新的基于容器的操作系统相结合:Docker 的 LinuxKit。
|
||||
|
||||
要说清楚的是 LinuxKit 注定不会代替 Alpine,而是位于容器下层,并作为一个完整的操作系统出现,你可以高兴地启动你的运行时守护程序(在这种情况下,是生成你的容器的Docker 守护程序 )。
|
||||
|
||||
### 金发女郎的 Atomic
|
||||
|
||||
经过精心调试的宿主机绝对不是一件新事物(以前提到过嵌入式 Linux 的家用设备)。在过去几十年中一直在优化 Linux 的天才在某个时候意识到底层的操作系统才是快速生产含有大量容器主机的关键。
|
||||
|
||||
例如,强大的红帽长期以来一直在出售已经贡献给 [Project Atomic][6] 的 [红帽 Atomic][5]。后者继续解释:
|
||||
|
||||
> “基于 Red Hat Enterprise Linux 或 CentOS 和 Fedora 项目的成熟技术,Atomic Host 是一个轻量级的、不可变的平台,其设计目的仅在于运行容器化应用程序。”
|
||||
|
||||
将底层的、不可变的 Atomic OS 作为红帽的 OpenShift PaaS(平台即服务)产品推荐有一个很好理由:它最小化、高性能、尖端。
|
||||
|
||||
### 特性
|
||||
|
||||
在 Docker 关于 LinuxKit 的公告中,“少即是多”的口号是显而易见的。实现 LinuxKit 愿景的项目显然是不小的事业,它由 Docker 老将和 [Unikernel][7] 的主管 Justin Cormack 指导,并与 HPE、Intel、ARM、IBM 和 Microsoft LinuxKit 合作,可以运行在从大型机到基于物联网的冰柜之中。
|
||||
|
||||
LinuxKit 的可配置性、可插拔性和可扩展性将吸引许多寻求建立其服务基准的项目。通过开源项目,Docker 明智地邀请每个人全身心地投入其功能开发,随着时间的推移,它会像好的奶酪那样成熟。
|
||||
|
||||
### 布丁作证
|
||||
|
||||
按照该发布消息中所承诺的,那些急于使用新系统的人不用再等待了。如果你准备着手 LinuxKit,你可以从 GitHub 中开始:[LinuxKit][11]。
|
||||
|
||||
在 GitHub 页面上有关于如何启动和运行一些功能的指导。
|
||||
|
||||
时间允许的话我准备更加深入研究 LinuxKit。对有争议的 Kubernetes 与 Docker Swarm 编排功能对比会是有趣的尝试。此外,我还想看到内存占用、启动时间和磁盘空间使用率的基准测试。
|
||||
|
||||
如果该承诺可靠,则作为容器运行的可插拔系统服务是构建操作系统的迷人方式。Docker 在[博客][12])中提到:“因为 LinuxKit 是原生容器,它有一个非常小的尺寸 - 35MB,引导时间非常小。所有系统服务都是容器,这意味着可以删除或替换所有的内容。”
|
||||
|
||||
我不知道你觉得怎么样,但这非常符合我的胃口。
|
||||
|
||||
### 呼叫警察
|
||||
|
||||
除了我站在 DevSecOps 角度看到的功能,我会看看其对安全的承诺。
|
||||
|
||||
Docker 在他们的博客上引用来自 NIST([国家标准与技术研究所] [8])的话:
|
||||
|
||||
> “安全性是最高目标,这与 NIST 在其《应用程序容器安全指南》草案中说明的保持一致:‘使用容器专用操作系统而不是通用操作系统来减少攻击面。当使用专用容器操作系统时,攻击面通常比通用操作系统小得多,因此攻击和危及专用容器操作系统的机会较少。’”
|
||||
|
||||
可能最重要的容器到主机和主机到容器的安全创新是将系统容器(系统服务)完全地沙箱化到自己的非特权空间中,而只给它们需要的外部访问。
|
||||
|
||||
通过<ruby>内核自我保护项目<rt>Kernel Self Protection Project</rt></ruby>([KSPP][9])的协作来实现这一功能,我很满意 Docker 开始专注于一些非常值得的东西上。对于那些不熟悉的 KSPP 的人而言,它存在理由如下:
|
||||
|
||||
> “启动这个项目的的假设是内核 bug 的存在时间很长,内核必须设计成可以防止这些缺陷的危害。”
|
||||
|
||||
KSPP 网站进一步表态:
|
||||
|
||||
> “这些努力非常重要并还在进行,但如果我们要保护我们的十亿 Android 手机、我们的汽车、国际空间站,还有其他运行 Linux 的产品,我们必须在上游的 Linux 内核中建立积极的防御性技术。我们需要内核安全地出错,而不只是安全地运行。”
|
||||
|
||||
而且,如果 Docker 最初只是在 LinuxKit 前进了一小步,那么随着时间的推移,成熟度带来的好处可能会在容器领域中取得长足的进步。
|
||||
|
||||
### 离终点还远
|
||||
|
||||
像 Docker 这样不断发展壮大的巨头无论在哪个方向上取得巨大的飞跃都将会用户和其他软件带来益处。
|
||||
|
||||
我鼓励所有对 Linux 感兴趣的人密切关注这个领域。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.devsecops.cc/devsecops/containers.html
|
||||
|
||||
作者:[Chris Binnie][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.devsecops.cc/
|
||||
[1]:https://alpinelinux.org/downloads/
|
||||
[2]:https://hub.docker.com/_/alpine
|
||||
[3]:https://busybox.net/
|
||||
[4]:https://www.alpinelinux.org/about/
|
||||
[5]:https://www.redhat.com/en/resources/red-hat-enterprise-linux-atomic-host
|
||||
[6]:http://www.projectatomic.io/
|
||||
[7]:https://en.wikipedia.org/wiki/Unikernel
|
||||
[8]:https://www.nist.gov/
|
||||
[9]:https://kernsec.org/wiki/index.php/Kernel_Self_Protection_Project
|
||||
[10]:http://www.postfix.org/TLS_README.html
|
||||
[11]:https://github.com/linuxkit/linuxkit
|
||||
[12]:https://blog.docker.com/2017/04/introducing-linuxkit-container-os-toolkit
|
||||
@ -1,354 +0,0 @@
|
||||
What I Don’t Like About Error Handling in Go, and How to Work Around It
|
||||
======================
|
||||
|
||||
More often than not, people who write Go have some sort of opinion on its error handling model. Depending on your experience with other languages, you may be used to different approaches. That’s why I’ve decided to write this article, as despite being relatively opinionated, I think drawing on my experiences can be useful in the debate. The main issues I wanted to cover are that it is difficult to force good error handling practice, that errors don’t have stack traces, and that error handling itself is too verbose. However I’ve looked at some potential workarounds for these problems which could help negate the issues somewhat.
|
||||
|
||||
### Quick Comparison to Other Languages
|
||||
|
||||
|
||||
[In Go, all errors are values][1]. Because of this, a fair amount of functions end up returning an `error`, looking something like this:
|
||||
|
||||
```
|
||||
func (s *SomeStruct) Function() (string, error)
|
||||
```
|
||||
|
||||
As a result of this, the calling code will regularly have `if` statements to check for them:
|
||||
|
||||
```
|
||||
bytes, err := someStruct.Function()
|
||||
if err != nil {
|
||||
// Process error
|
||||
}
|
||||
```
|
||||
|
||||
Another approach is the `try-catch` model that is used in other languages such as Java, C#, Javascript, Objective C, Python etc. You could see the following Java code as synonymous to the previous Go examples, declaring `throws` instead of returning an `error`:
|
||||
|
||||
```
|
||||
public String function() throws Exception
|
||||
```
|
||||
|
||||
And then doing `try-catch` instead of `if err != nil`:
|
||||
|
||||
```
|
||||
try {
|
||||
String result = someObject.function()
|
||||
// continue logic
|
||||
}
|
||||
catch (Exception e) {
|
||||
// process exception
|
||||
}
|
||||
```
|
||||
|
||||
Of course, there are more differences than this. For example, an `error` can’t crash your program, whereas an `Exception` can. There are others as well, and I want to focus on them in this article.
|
||||
|
||||
### Implementing Centralised Error Handling
|
||||
|
||||
Taking a step back, let’s look at why and how we might want to have a centralised place for handling errors.
|
||||
|
||||
An example most people would be familiar with is a web service – if some unexpected server-side error were to happen, we would generate a 5xx error. At a first pass in Go you might implement this:
|
||||
|
||||
```
|
||||
func init() {
|
||||
http.HandleFunc("/users", viewUsers)
|
||||
http.HandleFunc("/companies", viewCompanies)
|
||||
}
|
||||
|
||||
func viewUsers(w http.ResponseWriter, r *http.Request) {
|
||||
user // some code
|
||||
if err := userTemplate.Execute(w, user); err != nil {
|
||||
http.Error(w, err.Error(), 500)
|
||||
}
|
||||
}
|
||||
|
||||
func viewCompanies(w http.ResponseWriter, r *http.Request) {
|
||||
companies = // some code
|
||||
if err := companiesTemplate.Execute(w, companies); err != nil {
|
||||
http.Error(w, err.Error(), 500)
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
This isn’t a good solution, as we would have to repeat the same error handling across all of our handler functions. It would be much better to do it all in one place for maintainability purposes. Fortunately, there is [an alternative by Andrew Gerrand on the Go blog][2] which works quite nicely. We can create a Type which does http error handling:
|
||||
|
||||
```
|
||||
type appHandler func(http.ResponseWriter, *http.Request) error
|
||||
|
||||
func (fn appHandler) ServeHTTP(w http.ResponseWriter, r *http.Request) {
|
||||
if err := fn(w, r); err != nil {
|
||||
http.Error(w, err.Error(), 500)
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
And then it can be used as a wrapper to decorate our handlers:
|
||||
|
||||
```
|
||||
func init() {
|
||||
http.Handle("/users", appHandler(viewUsers))
|
||||
http.Handle("/companies", appHandler(viewCompanies))
|
||||
}
|
||||
```
|
||||
|
||||
Then all we need to do is change the signature of handler functions so they return `errors`. This works nicely, as we have been able to apply the [dry][3] principle and not re-use code unnecessarily – now we return default errors in a single place.
|
||||
|
||||
### Error Context
|
||||
|
||||
In the previous example, there are many potential errors which we could receive, all of which could be generated in many parts of the call stack. This is when things start to get tricky.
|
||||
|
||||
To demonstrate this, we can expand on our handler. It’s more likely to look like this as the template execution is not the only place where an error could occur:
|
||||
|
||||
```
|
||||
func viewUsers(w http.ResponseWriter, r *http.Request) error {
|
||||
user, err := findUser(r.formValue("id"))
|
||||
if err != nil {
|
||||
return err;
|
||||
}
|
||||
return userTemplate.Execute(w, user);
|
||||
}
|
||||
```
|
||||
|
||||
The call chain could get quite deep, and throughout it, all sorts of errors could be instantiated in different places. This post by [Russ Cox][4] explains the best practice to prevent this from being too much of a problem:
|
||||
|
||||
> Part of the intended contract for error reporting in Go is that functions include relevant available context, including the operation being attempted (such as the function name and its arguments)
|
||||
|
||||
The example given is a call to the OS package:
|
||||
|
||||
```
|
||||
err := os.Remove("/tmp/nonexist")
|
||||
fmt.Println(err)
|
||||
```
|
||||
|
||||
Which prints the output:
|
||||
|
||||
```
|
||||
remove /tmp/nonexist: no such file or directory
|
||||
```
|
||||
|
||||
To summarise, you are outputting the method called, the arguments given, and the specific thing that went wrong, immediately after doing it. When creating an `Exception` message in another language you would also follow this practice. So if we stuck to these rules in our `viewUsers` handler, it could almost always be clear what the cause of an error is.
|
||||
|
||||
The problem comes from people not following this best practice, and quite often in third party Go libraries you will see messages like:
|
||||
|
||||
```
|
||||
Oh no I broke
|
||||
```
|
||||
|
||||
Which is just not helpful – you don’t know anything about the context which makes it really hard to debug. Even worse is when these sorts of errors are ignored or returned really far back up the stack until they are handled:
|
||||
|
||||
```
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
```
|
||||
|
||||
This means that when they happened isn’t communicated.
|
||||
|
||||
It should be noted that all these mistakes can be made in an `Exception` driven model – poor error messages, swallowing exceptions etc. So why do I think that model is more helpful?
|
||||
|
||||
If we’re dealing with a poor exception message, _we are still able to know where it occurred in the call stack_. This is because of stack traces, which raises something I don’t get about Go – you have the concept of `panic` in Go which contains a stack trace, but an `error` which does not. I think the reasoning is that a `panic` can crash your program, so requires a stack trace, whereas a handled error does not as you are supposed to do something about it where it occurs.
|
||||
|
||||
So let’s go back to our previous example – a third party library with a poor error message, which just gets propagated all the way up the call chain. Do you think debugging would be easier if you had this?
|
||||
|
||||
```
|
||||
panic: Oh no I broke
|
||||
[signal 0xb code=0x1 addr=0x0 pc=0xfc90f]
|
||||
|
||||
goroutine 1103 [running]:
|
||||
panic(0x4bed00, 0xc82000c0b0)
|
||||
/usr/local/go/src/runtime/panic.go:481 +0x3e6
|
||||
github.com/Org/app/core.(_app).captureRequest(0xc820163340, 0x0, 0x55bd50, 0x0, 0x0)
|
||||
/home/ubuntu/.go_workspace/src/github.com/Org/App/core/main.go:313 +0x12cf
|
||||
github.com/Org/app/core.(_app).processRequest(0xc820163340, 0xc82064e1c0, 0xc82002aab8, 0x1)
|
||||
/home/ubuntu/.go_workspace/src/github.com/Org/App/core/main.go:203 +0xb6
|
||||
github.com/Org/app/core.NewProxy.func2(0xc82064e1c0, 0xc820bb2000, 0xc820bb2000, 0x1)
|
||||
/home/ubuntu/.go_workspace/src/github.com/Org/App/core/proxy.go:51 +0x2a
|
||||
github.com/Org/app/core/vendor/github.com/rusenask/goproxy.FuncReqHandler.Handle(0xc820da36e0, 0xc82064e1c0, 0xc820bb2000, 0xc5001, 0xc820b4a0a0)
|
||||
/home/ubuntu/.go_workspace/src/github.com/Org/app/core/vendor/github.com/rusenask/goproxy/actions.go:19 +0x30
|
||||
```
|
||||
|
||||
I think this might be something which has been overlooked in the design of Go – not that things aren’t overlooked in all languages.
|
||||
|
||||
If we use Java as an arbitrary example, one of the silliest mistakes people make is not logging the stack trace:
|
||||
|
||||
```
|
||||
LOGGER.error(ex.getMessage()) // Doesn't log stack trace
|
||||
LOGGER.error(ex.getMessage(), ex) // Does log stack trace
|
||||
```
|
||||
|
||||
But Go seems to not have this information by design.
|
||||
|
||||
In terms of getting context information – Russ also mentions the community are talking about some potential interfaces for stripping out error contexts. It would be interesting to hear more about this.
|
||||
|
||||
### Solution to the Stack Trace Problem
|
||||
|
||||
Fortunately, after doing some searching, I found this excellent [Go Errors][5] library which helps solves the problem, by adding stack traces to errors:
|
||||
|
||||
```
|
||||
if errors.Is(err, crashy.Crashed) {
|
||||
fmt.Println(err.(*errors.Error).ErrorStack())
|
||||
}
|
||||
```
|
||||
|
||||
However, I’d think it would be an improvement for this feature to have first class citizenship in the language, so you wouldn’t have to fiddle around with types. Also, if we are working with a third party library like in the previous example then it is probably not using `crashy` – we still have the same problem.
|
||||
|
||||
### What Should We Do with an Error?
|
||||
|
||||
We also have to think about what should happen when an error occurs. [It’s definitely useful that they can’t crash your program][6], and it’s also idiomatic to handle them immediately:
|
||||
|
||||
```
|
||||
err := method()
|
||||
if err != nil {
|
||||
// some logic that I must do now in the event of an error!
|
||||
}
|
||||
```
|
||||
|
||||
But what happens if we want to call lots of methods which return errors, and then handle them all in the same place? Something like this:
|
||||
|
||||
```
|
||||
err := doSomething()
|
||||
if err != nil {
|
||||
// handle the error here
|
||||
}
|
||||
|
||||
func doSomething() error {
|
||||
err := someMethod()
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
err = someOther()
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
someOtherMethod()
|
||||
}
|
||||
```
|
||||
|
||||
It feels a little verbose, whereas in other languages you can treat multiple statements that fail as a block:
|
||||
|
||||
```
|
||||
try {
|
||||
someMethod()
|
||||
someOther()
|
||||
someOtherMethod()
|
||||
}
|
||||
catch (Exception e) {
|
||||
// process exception
|
||||
}
|
||||
```
|
||||
|
||||
Or just propagate failure in the method signature:
|
||||
|
||||
```
|
||||
public void doSomething() throws SomeErrorToPropogate {
|
||||
someMethod()
|
||||
someOther()
|
||||
someOtherMethod()
|
||||
}
|
||||
```
|
||||
|
||||
Personally I think both of these example achieve the same thing, only the `Exception` model is less verbose and more flexible. If anything, I find the `if err != nil` to feel like boilerplate. Maybe there is a way that it could be cleaned up?
|
||||
|
||||
### Treating Multiple Statements That Fail as a Block
|
||||
|
||||
To begin with, I did some more reading and found a relatively pragmatic solution on the [by Rob Pike on the Go Blog.][7]
|
||||
|
||||
He defines a struct with a method which wraps errors:
|
||||
|
||||
```
|
||||
type errWriter struct {
|
||||
w io.Writer
|
||||
err error
|
||||
}
|
||||
|
||||
func (ew *errWriter) write(buf []byte) {
|
||||
if ew.err != nil {
|
||||
return
|
||||
}
|
||||
_, ew.err = ew.w.Write(buf)
|
||||
}
|
||||
```
|
||||
|
||||
This let’s us do:
|
||||
|
||||
```
|
||||
ew := &errWriter{w: fd}
|
||||
ew.write(p0[a:b])
|
||||
ew.write(p1[c:d])
|
||||
ew.write(p2[e:f])
|
||||
// and so on
|
||||
if ew.err != nil {
|
||||
return ew.err
|
||||
}
|
||||
```
|
||||
|
||||
This is also a good solution, but I still feel like something is missing – as we can’t re-use this pattern. If we wanted a method which took a string as an argument, then we’d have to change the function signature. Or what if we didn’t want to perform a write? We could try and make it more generic:
|
||||
|
||||
```
|
||||
type errWrapper struct {
|
||||
err error
|
||||
}
|
||||
```
|
||||
|
||||
```
|
||||
func (ew *errWrapper) do(f func() error) {
|
||||
if ew.err != nil {
|
||||
return
|
||||
}
|
||||
ew.err = f();
|
||||
}
|
||||
```
|
||||
|
||||
But we have the same problem that it won’t compile if we want to call functions which have different arguments. However you simply wrap those function calls:
|
||||
|
||||
```
|
||||
w := &errWrapper{}
|
||||
|
||||
w.do(func() error {
|
||||
return someFunction(1, 2);
|
||||
})
|
||||
|
||||
w.do(func() error {
|
||||
return otherFunction("foo");
|
||||
})
|
||||
|
||||
err := w.err
|
||||
|
||||
if err != nil {
|
||||
// process error here
|
||||
}
|
||||
```
|
||||
|
||||
This works, but doesn’t help too much as it ends up being more verbose than the standard `if err != nil`checks. I would be interested to hear if anyone can offer any other solutions. Maybe the language itself needs some sort of way to propagate or group errors in a less bloated fashion – but it feels like it’s been specifically designed to not do that.
|
||||
|
||||
### Conclusion
|
||||
|
||||
After reading this, you might think that by picking on `errors` I’m opposed to Go. But that’s not the case, I’m just describing how it compares to my experience with the `try catch` model. It’s a great language for systems programming, and some outstanding tools have been produced by it. To name a few there is [Kubernetes][8], [Docker][9], [Terraform][10], [Hoverfly][11] and others. There’s also the advantage of your tiny, highly performant, native binary. But `errors` have been difficult to adjust to. I hope my reasoning makes sense, and also that some of the solutions and workarounds could be of help.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Andrew is a Consultant for OpenCredo having Joined the company in 2015. Andrew has several years experience working in the across a number of industries, developing web-based enterprise applications.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
via: https://opencredo.com/why-i-dont-like-error-handling-in-go
|
||||
|
||||
作者:[Andrew Morgan][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opencredo.com/author/andrew/
|
||||
[1]:https://blog.golang.org/errors-are-values
|
||||
[2]:https://blog.golang.org/error-handling-and-go
|
||||
[3]:https://en.wikipedia.org/wiki/Don't_repeat_yourself
|
||||
[4]:https://research.swtch.com/go2017
|
||||
[5]:https://github.com/go-errors/errors
|
||||
[6]:https://davidnix.io/post/error-handling-in-go/
|
||||
[7]:https://blog.golang.org/errors-are-values
|
||||
[8]:https://kubernetes.io/
|
||||
[9]:https://www.docker.com/
|
||||
[10]:https://www.terraform.io/
|
||||
[11]:http://hoverfly.io/en/latest/
|
||||
@ -1,3 +1,5 @@
|
||||
GitFuture is translating
|
||||
|
||||
OpenGL & Go Tutorial Part 2: Drawing the Game Board
|
||||
============================================================
|
||||
|
||||
|
||||
@ -0,0 +1,97 @@
|
||||
8 ways to get started with open source hardware
|
||||
============================================================
|
||||
|
||||
### Making your own hardware is easier and less expensive than ever. Here's what you need to design, build, and test your first board.
|
||||
|
||||
|
||||

|
||||
>Image by : Thomas Hawk on [Flickr][11]. [CC BY-NC 2.0][12]. Modified by Opensource.com
|
||||
|
||||
Alan Kay, famed computer scientist, once said, "People who are really serious about software should make their own hardware." I'd argue that's as true today as it was in 1982 when he said it. However, what's changed between then and now is that hardware has gotten faster, smaller, and most importantly: cheaper. it's now possible to buy a full computer for $5.
|
||||
|
||||
With big companies driving down prices for their own products, it's grown a manufacturing ecosystem capable of producing production-grade hardware that's cheap enough and accessible enough that it is now within reach of normal individuals. This accessibility and affordability are helping drive things like crowdfunding and the maker movement, but they're also giving way to more individuals being able to participate in open source through open source hardware.
|
||||
|
||||
Explore open hardware
|
||||
|
||||
* [What is open hardware?][1]
|
||||
|
||||
* [What is Raspberry Pi?][2]
|
||||
|
||||
* [What is an Arduino?][3]
|
||||
|
||||
* [Our latest open hardware articles][4]
|
||||
|
||||
There's some pretty big differences in what is or isn't open source hardware, but the Open Source Hardware Association (OSHWA) has a definition that most folks agree with, and if you're familiar with open source software this shouldn't sound too weird:
|
||||
|
||||
> "Open source hardware (OSHW) is a term for tangible artifacts—machines, devices, or other physical things—whose design has been released to the public in such a way that anyone can make, modify, distribute, and use those things."
|
||||
|
||||
There's lots of open source hardware around; you may not have noticed the boards you already use may, in fact, be open hardware. From the humble but ever versatile [Arduino][13] and all the way up through full computers like the [BeagleBone][14] family and the [C.H.I.P.][15] computer, there are lots of examples of open hardware around, and more designs are being made all the time.
|
||||
|
||||
Hardware can be complicated, and sometimes non-obvious to beginners why a design needs something. But open source hardware gives you the ability to not only see working examples, but also the ability to change those designs or strike off and replicate the pieces you need in your own designs, and it might be as simple as copy and paste.
|
||||
|
||||
### How can I get started?
|
||||
|
||||
Let's start off by pointing out that hardware is hard, it's complicated, sometimes esoteric, and the tools you may be using are not always the most user-friendly. It's also more than likely, as anyone who's played around with a microcontroller long enough can attest: you are going to fry something and let the magic smoke out at some point. It's ok, we've all done it, some of us repeatedly because we didn't learn the lesson the first 100 times we did something, but don't let this discourage you: Lessons are learned when things go wrong, and you usually get an interesting story to tell later.
|
||||
|
||||
### Modeling
|
||||
|
||||
The first thing to do is to start modeling what you want to do with an existing board, jumper wires, a breadboard, and whatever devices you want to hook up. In many cases, the simplest thing to play with is just adding more LEDs to a board and getting them to blink in novel ways. This is a great way to prototype something, and it's a fairly common thing to do. It won't look pretty, and you may find that you wire something wrong, but these are prototypes—you just want to prove things work. When things don't work, always double check everything, and don't be afraid to ask for help—sometimes a second pair of eyes will find your oddball ground short.
|
||||
|
||||
### Design
|
||||
|
||||
When you've figured out what you want to build, it's time to start taking your idea from jumper wires and breadboards to an actual design. This is where things can get a bit daunting, but start small—in fact, it's worth starting really small just to get used to the tooling and process, so why not make a printed circuit board that has a LED and a battery on it? Seriously, this might sound overly simplistic but there's a lot of new ground to cover here.
|
||||
|
||||
1. **Find an electronic design automation (EDA) tool to use.** There are some good open source software options out there, but they aren't always the most user-friendly. [Fritzing][5], [gEDA][6], and [KiCad ][7]are all open source in ascending order of approachability. There are also some options if you want to try more commercial offerings; Eagle has a free version available with some restrictions and a lot of open source hardware designs are done in it.
|
||||
|
||||
1. **Design your board in your EDA tool.** Depending on the tool you choose, this could be fairly quick, or it could be quite the exercise in learning how things work. This is one of the reasons I suggest starting small; a circuit with an LEDaan be as simple as a battery, a resistor, and an LED. The schematic capture is pretty simple, and the layout can be small and very simple.
|
||||
|
||||
1. **Export your design for manufacturing.** This goes hand-in-hand with the next thing on the list, but it can also be a confusing process if you haven't done it before. There's a lot of knobs and dials to twist and adjust when you do the export, and things need to be exported in certain ways to make it easier on board houses to actually figure out what you want them to make.
|
||||
|
||||
1. **Find a board house.** There are lots of board houses out there that can make your design, and some are more friendly and helpful than others. One place that's particularly awesome to work with is [OSH Park][8], these guys are very friendly and supportive of open source hardware. They also have a very solid process for confirming that what you are sending them is what will get built, so they are worth checking out. There are lots of other options though; take a look at [PCB Shopper][9], which lets you compare pricing, turnaround times, etc. of a number of solid PCB manufacturers.
|
||||
|
||||
1. **Wait.** This might be the hardest part of building your own board, as it takes time to make something digital into a physical product. Plan on two weeks from when you hit "go" to getting your boards back. This is a great time to work on your next project, ensure or acquire all the parts for your current build, or generally try not to worry. On your first board it's hard—you really want it now, but be patient.
|
||||
|
||||
1. **Solder up and bring up.** Once you've got your board, it's time to make it up and then test it. If you've gone with the LED option to start, it should be fairly easy to debug, and you'll have something that works. If you went more complex, be methodical and patient; sometimes things don't work and you'll need all your debugging skills to track things down.
|
||||
|
||||
1. **Last, if you are doing open source hardware, release it.** We are talking about open source hardware, so make sure you include a license, but release it, share it, put it somewhere people can see what you've done. You may even want to write a blog post and submit it to someplace like Hackaday.
|
||||
|
||||
1. **Above all, have fun.** Frankly if you are doing something and you aren't having fun, you should stop doing it. Open source hardware can be a lot of fun, though sometimes hard and complicated. Not everything may work; heck, I've had designs where half the board wasn't working or where I (accidentally) caused 12 shorts between power and ground. Were those boards bunked boards: yup. Did I learn something in the process: A LOT, and I won't make those same mistakes again. I'll make new ones, sure, but not THOSE. (I'd point and glare at those boards and their mistakes, but they wouldn't feel bad for me glaring at them, sadly).
|
||||
|
||||
There's a lot of open source hardware out there and lots of good examples to look at, copy, and derive from and lots of information to help make building hardware easier. That's what open source hardware is: A community of people making things and sharing them so that everyone can make their own things and build the hardware that they want—not the hardware they can get.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
|
||||
作者简介:
|
||||
|
||||
John 'Warthog9' Hawley - John works for VMware in the Open Source Program Office on upstream open source projects. In a previous life he's worked on the MinnowBoard open source hardware project, led the system administration team on kernel.org, and built desktop clusters before they were cool. For fun he's built multiple star ship bridges, a replica of K-9 from a popular British TV show, done in flight computer vision processing from UAVs, designed and built a pile of his own hardware.
|
||||
|
||||
-------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/5/8-ways-get-started-open-source-hardware
|
||||
|
||||
作者:[John 'Warthog9' Hawley ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/article/17/5/8-ways-get-started-open-source-hardware
|
||||
[1]:https://opensource.com/resources/what-open-hardware?src=open_hardware_resources_menu
|
||||
[2]:https://opensource.com/resources/what-raspberry-pi?src=open_hardware_resources_menu
|
||||
[3]:https://opensource.com/resources/what-arduino?src=open_hardware_resources_menu
|
||||
[4]:https://opensource.com/tags/hardware?src=open_hardware_resources_menu
|
||||
[5]:http://fritzing.org/home/
|
||||
[6]:http://www.geda-project.org/
|
||||
[7]:http://kicad-pcb.org/
|
||||
[8]:https://oshpark.com/
|
||||
[9]:http://pcbshopper.com/
|
||||
[10]:https://opensource.com/article/17/5/8-ways-get-started-open-source-hardware?rate=jPBGDIa2vBXW6kb837X8JWdjI2V47hZ4KecI8-GJBjQ
|
||||
[11]:https://www.flickr.com/photos/thomashawk/3048157616/in/photolist-5DmB4E-BzrZ4-5aUXCN-nvBWYa-qbkwAq-fEFeDm-fuZxgC-dufA8D-oi8Npd-b6FiBp-7ChGA3-aSn7xK-7NXMyh-a9bQQr-5NG9W7-agCY7E-4QD9zm-7HLTtj-4uCiHy-bYUUtG
|
||||
[12]:https://creativecommons.org/licenses/by-nc/2.0/
|
||||
[13]:https://opensource.com/node/20751
|
||||
[14]:https://opensource.com/node/35211
|
||||
[15]:https://opensource.com/node/24891
|
||||
[16]:https://opensource.com/user/130046/feed
|
||||
[17]:https://opensource.com/users/warthog9
|
||||
@ -0,0 +1,308 @@
|
||||
4 Python libraries for building great command-line user interfaces
|
||||
============================================================
|
||||
|
||||
### In the second installment of a two-part series on terminal applications with great command-line UIs, we explore Prompt Toolkit, Click, Pygments, and Fuzzy Finder.
|
||||
|
||||
|
||||

|
||||
>Image by : [Mennonite Church USA Archives][16]. Modified by Opensource.com. [CC BY-SA 4.0][17]
|
||||
|
||||
This is the second installment in my two-part series on terminal applications with great command-line UIs. In the [first article][18], I discussed features that make a command-line application a pure joy to use. In part two, I'll look at how to implement those features in Python with the help of a few libraries. By the end of this article, readers should have a good understanding of how to use [Prompt Toolkit][19], [Click][20] (Command Line Interface Creation Kit), [Pygments][21], and [Fuzzy Finder][22] to implement an easy-to-use [REPL][23].
|
||||
|
||||
I plan to achieve this in fewer than 20 lines of Python code. Let's begin.
|
||||
|
||||
Programming and development
|
||||
|
||||
* [New Python content][1]
|
||||
|
||||
* [Our latest JavaScript articles][2]
|
||||
|
||||
* [Recent Perl posts][3]
|
||||
|
||||
* [Red Hat Developers Blog][4]
|
||||
|
||||
### Python Prompt Toolkit
|
||||
|
||||
I like to think of this library as the Swiss Army knife of command-line apps—it acts as a replacement for **[readline][5]**, **[curses][6]**, and much more. Let's install the library and get started:
|
||||
|
||||
```
|
||||
pip install prompt_toolkit
|
||||
```
|
||||
|
||||
We'll start with a simple REPL. Typically a REPL will accept user input, do an operation, and print the results. For our example, we're going to build an "echo" REPL. It merely prints back what the user typed in:
|
||||
|
||||
### REPL
|
||||
|
||||
```
|
||||
from prompt_toolkit import prompt
|
||||
|
||||
while 1:
|
||||
user_input = prompt('>')
|
||||
print(user_input)
|
||||
```
|
||||
|
||||
That is all it takes to implement a REPL. It can read user input and print out what they have entered. The **prompt** function used in this code snippet is from the **prompt_toolkit** library; it is a replacement for the **readline** library.
|
||||
|
||||
### History
|
||||
|
||||
To enhance our REPL, we can add command history:
|
||||
|
||||
```
|
||||
from prompt_toolkit import prompt
|
||||
from prompt_toolkit.history import FileHistory
|
||||
|
||||
while 1:
|
||||
user_input = prompt('>',
|
||||
history=FileHistory('history.txt'),
|
||||
)
|
||||
print(user_input)
|
||||
```
|
||||
|
||||
We've just added persistent history to our REPL. Now we can use the up/down arrow to navigate the history, and use the **Ctrl**+**R** to search the history. This satisfies the basic etiquette of a command line.
|
||||
|
||||
### Auto-suggestion
|
||||
|
||||
One of the discoverability tricks I covered in part one was the automatic suggestion of commands from the history. (We saw this feature pioneered in the **fish** shell.) Let's add that feature to our REPL:
|
||||
|
||||
```
|
||||
from prompt_toolkit import prompt
|
||||
from prompt_toolkit.history import FileHistory
|
||||
from prompt_toolkit.auto_suggest import AutoSuggestFromHistory
|
||||
|
||||
while 1:
|
||||
user_input = prompt('>',
|
||||
history=FileHistory('history.txt'),
|
||||
auto_suggest=AutoSuggestFromHistory(),
|
||||
)
|
||||
print(user_input)
|
||||
```
|
||||
|
||||
All we had to do was add a new argument to the **prompt()** API call. Now we have a REPL that has **fish**-style auto-suggestion from the history.
|
||||
|
||||
### Auto-completion
|
||||
|
||||
Now let's implement an enhancement of Tab-completion via auto-completion, which pops up possible suggestions as the user starts typing input.
|
||||
|
||||
How will our REPL know what to suggest? We supply a dictionary of possible items to suggest.
|
||||
|
||||
Let's say we're implementing a REPL for SQL. We can stock our auto-completion dictionary with SQL keywords. Let's see how to do that:
|
||||
|
||||
```
|
||||
from prompt_toolkit import prompt
|
||||
from prompt_toolkit.history import FileHistory
|
||||
from prompt_toolkit.auto_suggest import AutoSuggestFromHistory
|
||||
from prompt_toolkit.contrib.completers import WordCompleter
|
||||
|
||||
SQLCompleter = WordCompleter(['select', 'from', 'insert', 'update', 'delete', 'drop'],
|
||||
ignore_case=True)
|
||||
|
||||
while 1:
|
||||
user_input = prompt('SQL>',
|
||||
history=FileHistory('history.txt'),
|
||||
auto_suggest=AutoSuggestFromHistory(),
|
||||
completer=SQLCompleter,
|
||||
)
|
||||
print(user_input)
|
||||
```
|
||||
|
||||
Once again, we simply can use a built-in completion routine of prompt-toolkit called **WordCompleter**, which matches the user input with the dictionary of possible suggestions and offers up a list.
|
||||
|
||||
We now have a REPL that can do auto-completion, fish-style suggestions from history, and up/down traversal of history. All of that in less than 10 lines of actual code.
|
||||
|
||||
### Click
|
||||
|
||||
Click is a command-line creation toolkit that makes it easy to parse command-line options arguments and parameters for the program. This section does not talk about how to use Click as an arguments parser; instead, I'm going to look at some utilities that ship with Click.
|
||||
|
||||
Installing click is simple:
|
||||
|
||||
```
|
||||
pip install click
|
||||
```
|
||||
|
||||
### Pager
|
||||
|
||||
Pagers are Unix utilities that display long output one page at a time. Examples of pagers are **less**, **more**, **most**, etc. Displaying the output of a command via a pager is not just friendly design, but also the decent thing to do.
|
||||
|
||||
Let's take the previous example further. Instead of using the default **print()** statement, we can use **click.echo_via_pager()**. This will take care of sending the output to stdout via a pager. It is platform-agnostic, so it will work in Unix or Windows. **click.echo_via_pager()** will try to use decent defaults for the pager to be able to show color codes if necessary:
|
||||
|
||||
```
|
||||
from prompt_toolkit import prompt
|
||||
from prompt_toolkit.history import FileHistory
|
||||
from prompt_toolkit.auto_suggest import AutoSuggestFromHistory
|
||||
from prompt_toolkit.contrib.completers import WordCompleter
|
||||
import click
|
||||
|
||||
SQLCompleter = WordCompleter(['select', 'from', 'insert', 'update', 'delete', 'drop'],
|
||||
ignore_case=True)
|
||||
|
||||
while 1:
|
||||
user_input = prompt(u'SQL>',
|
||||
history=FileHistory('history.txt'),
|
||||
auto_suggest=AutoSuggestFromHistory(),
|
||||
completer=SQLCompleter,
|
||||
)
|
||||
click.echo_via_pager(user_input)
|
||||
```
|
||||
|
||||
### Editor
|
||||
|
||||
One of the niceties mentioned in my previous article was falling back to an editor when the command gets too complicated. Once again **click** has an [easy API][24] to launch an editor and return the text entered in the editor back to the application:
|
||||
|
||||
```
|
||||
import click
|
||||
message = click.edit()
|
||||
```
|
||||
|
||||
### Fuzzy Finder
|
||||
|
||||
Fuzzy Finder is a way for users to narrow down the suggestions with minimal typing. Once again, there is a library that implements Fuzzy Finder. Let's install the library:
|
||||
|
||||
```
|
||||
pip install fuzzyfinder
|
||||
```
|
||||
|
||||
The API for Fuzzy Finder is simple. You pass in the partial string and a list of possible choices, and Fuzzy Finder will return a new list that matches the partial string using the fuzzy algorithm ranked in order of relevance. For example:
|
||||
|
||||
```
|
||||
>>> from fuzzyfinder import fuzzyfinder
|
||||
|
||||
>>> suggestions = fuzzyfinder('abc', ['abcd', 'defabca', 'aagbec', 'xyz', 'qux'])
|
||||
|
||||
>>> list(suggestions)
|
||||
['abcd', 'defabca', 'aagbec']
|
||||
```
|
||||
|
||||
Now that we have our **fuzzyfinder**, let's add it into our SQL REPL. The way we do this is to define a custom completer instead of the **WordCompleter** that comes with **prompt-toolkit**. For example:
|
||||
|
||||
```
|
||||
from prompt_toolkit import prompt
|
||||
from prompt_toolkit.history import FileHistory
|
||||
from prompt_toolkit.auto_suggest import AutoSuggestFromHistory
|
||||
from prompt_toolkit.completion import Completer, Completion
|
||||
import click
|
||||
from fuzzyfinder import fuzzyfinder
|
||||
|
||||
SQLKeywords = ['select', 'from', 'insert', 'update', 'delete', 'drop']
|
||||
|
||||
class SQLCompleter(Completer):
|
||||
def get_completions(self, document, complete_event):
|
||||
word_before_cursor = document.get_word_before_cursor(WORD=True)
|
||||
matches = fuzzyfinder(word_before_cursor, SQLKeywords)
|
||||
for m in matches:
|
||||
yield Completion(m, start_position=-len(word_before_cursor))
|
||||
|
||||
while 1:
|
||||
user_input = prompt(u'SQL>',
|
||||
history=FileHistory('history.txt'),
|
||||
auto_suggest=AutoSuggestFromHistory(),
|
||||
completer=SQLCompleter(),
|
||||
)
|
||||
click.echo_via_pager(user_input)
|
||||
```
|
||||
|
||||
### Pygments
|
||||
|
||||
Now let's add syntax highlighting to the user input. We are building a SQL REPL, and having colorful SQL statements will be nice.
|
||||
|
||||
Pygments is a syntax highlighting library with built-in support for more than 300 languages. Adding syntax highlighting makes an application colorful, which helps users spot mistakes—such as typos, unmatched quotes, or brackets—in their SQL before executing it.
|
||||
|
||||
First install Pygments:
|
||||
|
||||
```
|
||||
pip install pygments
|
||||
```
|
||||
|
||||
Let's use Pygments to add color to our SQL REPL:
|
||||
|
||||
```
|
||||
from prompt_toolkit import prompt
|
||||
from prompt_toolkit.history import FileHistory
|
||||
from prompt_toolkit.auto_suggest import AutoSuggestFromHistory
|
||||
from prompt_toolkit.completion import Completer, Completion
|
||||
import click
|
||||
from fuzzyfinder import fuzzyfinder
|
||||
from pygments.lexers.sql import SqlLexer
|
||||
|
||||
SQLKeywords = ['select', 'from', 'insert', 'update', 'delete', 'drop']
|
||||
|
||||
class SQLCompleter(Completer):
|
||||
def get_completions(self, document, complete_event):
|
||||
word_before_cursor = document.get_word_before_cursor(WORD=True)
|
||||
matches = fuzzyfinder(word_before_cursor, SQLKeywords)
|
||||
for m in matches:
|
||||
yield Completion(m, start_position=-len(word_before_cursor))
|
||||
|
||||
while 1:
|
||||
user_input = prompt(u'SQL>',
|
||||
history=FileHistory('history.txt'),
|
||||
auto_suggest=AutoSuggestFromHistory(),
|
||||
completer=SQLCompleter(),
|
||||
lexer=SqlLexer,
|
||||
)
|
||||
click.echo_via_pager(user_input)
|
||||
```
|
||||
|
||||
Prompt Toolkit works well with the Pygments library. We pick **SqlLexer** supplied by **Pygments** and pass it into the **prompt** API from **prompt-toolkit**. Now all user input is treated as SQL statements and colored appropriately.
|
||||
|
||||
### Conclusion
|
||||
|
||||
That concludes our journey through the creation of a powerful REPL that has all the features of a common shell, such as history, key bindings, and user-friendly features such as auto-completion, fuzzy finding, pager support, editor support, and syntax highlighting. We achieved all of that in fewer than 20 statements of Python.
|
||||
|
||||
Wasn't that easy? Now you have no excuses not to write a stellar command-line app. These resources might help:
|
||||
|
||||
* [Click][7] (Command Line Interface Creation Kit)
|
||||
|
||||
* [Fuzzy Finder][8]
|
||||
|
||||
* [Prompt Toolkit][9]
|
||||
|
||||
* See the [Prompt Toolkit tutorial tutorial][10] and [examples][11] in the prompt-toolkit repository.
|
||||
|
||||
* [Pygments][12]
|
||||
|
||||
_Learn more in Amjith Ramanujam's [PyCon US 2017][13] talk, [Awesome Commandline Tools][14], May 20th in Portland, Oregon._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Amjith Ramanujam - Amjith Ramanujam is the creator of pgcli and mycli. People think they're pretty cool and he doesn't disagree. He likes programming in Python, Javascript and C. He likes to write simple, understandable code, sometimes he even succeeds.
|
||||
|
||||
----------------------------
|
||||
|
||||
via: https://opensource.com/article/17/5/4-practical-python-libraries
|
||||
|
||||
作者:[ Amjith Ramanujam][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/amjith
|
||||
[1]:https://opensource.com/tags/python?src=programming_resource_menu
|
||||
[2]:https://opensource.com/tags/javascript?src=programming_resource_menu
|
||||
[3]:https://opensource.com/tags/perl?src=programming_resource_menu
|
||||
[4]:https://developers.redhat.com/?intcmp=7016000000127cYAAQ&src=programming_resource_menu
|
||||
[5]:https://docs.python.org/2/library/readline.html
|
||||
[6]:https://docs.python.org/2/library/curses.html
|
||||
[7]:http://click.pocoo.org/5/
|
||||
[8]:https://pypi.python.org/pypi/fuzzyfinder
|
||||
[9]:https://python-prompt-toolkit.readthedocs.io/en/latest/
|
||||
[10]:https://github.com/jonathanslenders/python-prompt-toolkit/tree/master/examples/tutorial
|
||||
[11]:https://github.com/jonathanslenders/python-prompt-toolkit/tree/master/examples/
|
||||
[12]:http://pygments.org/
|
||||
[13]:https://us.pycon.org/2017/
|
||||
[14]:https://us.pycon.org/2017/schedule/presentation/518/
|
||||
[15]:https://opensource.com/article/17/5/4-practical-python-libraries?rate=SEw4SQN1U2QSXM7aUHJZb2ZsPwyFylPIbgcVLgC_RBg
|
||||
[16]:https://www.flickr.com/photos/mennonitechurchusa-archives/6987770030/in/photolist-bDu9zC-ovJ8gx-aecxqE-oeZerP-orVJHj-oubnD1-odmmg1-ouBNHR-otUoui-occFe4-ot7LTD-oundj9-odj4iX-9QSskz-ouaoMo-ous5V6-odJKBW-otnxbj-osXERb-iqdyJ8-ovgmPu-bDukCS-sdk9QB-5JQauY-fteJ53-ownm41-ov9Ynr-odxW52-rgqPBV-osyhxE-6QLRz9-i7ki3F-odbLQd-ownZP1-osDU6d-owrTXy-osLLXS-out7Dp-hNHsya-wPbFkS-od7yfD-ouA53c-otnzf9-ormX8L-ouTj6h-e8kAze-oya2zR-hn3B2i-aDNNqk-aDNNmR
|
||||
[17]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[18]:https://opensource.com/article/17/4/4-terminal-apps
|
||||
[19]:https://python-prompt-toolkit.readthedocs.io/en/latest/
|
||||
[20]:http://click.pocoo.org/5/
|
||||
[21]:http://pygments.org/
|
||||
[22]:https://pypi.python.org/pypi/fuzzyfinder
|
||||
[23]:https://en.wikipedia.org/wiki/Read%E2%80%93eval%E2%80%93print_loop
|
||||
[24]:http://click.pocoo.org/5/utils/#launching-editors
|
||||
[25]:https://opensource.com/user/125521/feed
|
||||
[26]:https://opensource.com/article/17/5/4-practical-python-libraries#comments
|
||||
[27]:https://opensource.com/users/amjith
|
||||
88
sources/tech/20170509 Much ado about communication.md
Normal file
88
sources/tech/20170509 Much ado about communication.md
Normal file
@ -0,0 +1,88 @@
|
||||
Much ado about communication
|
||||
============================================================
|
||||
|
||||
### One of an open source project's first challenges is determining the best way for contributors to collaborate.
|
||||
|
||||
|
||||

|
||||
>Image by : Opensource.com
|
||||
|
||||
One of the first challenges an open source project faces is how to communicate among contributors. There are a plethora of options: forums, chat channels, issues, mailing lists, pull requests, and more. How do we choose which is the right medium to use and how do we do it right?
|
||||
|
||||
Sadly and all too often, projects shy away from making a disciplined decision and instead opt for "all of the above." This results in a fragmented community: Some people sit in Slack/Mattermost/IRC, some use the forum, some use mailing lists, some live in issues, and few read all of them.
|
||||
|
||||
This is a common issue I see in organizations I'm [working with to build their internal and external communities][2]. Which of these channels do we choose and for which purposes? Also, when is it OK to say no to one of them?
|
||||
|
||||
This is what I want to dig into here.
|
||||
|
||||
### Structured and unstructured
|
||||
|
||||
I have a tiny, peanut-sized brain in my head. Because of this, I tend to break problems down into smaller pieces so I can better understand them. Likewise, I tend to break different options in a scenario down into smaller thematic pieces to better understand their purpose. I take this approach with communication channels too.
|
||||
|
||||
I believe there are two broad categories of communication channels: structured and unstructured.
|
||||
|
||||
Structured channels have a very specific focus in each individual unit of communication. An example here is a GitHub/GitLab/Jira issue. An issue is a very specific piece of information that relates to a bug or feature. The discussion that cascades after the initial issue post is typically very focused on that specific topic and finding an outcome (such as a bugfix or a final plan for a feature). The outcome is then typically reflected in a status (e.g. "FIXED," "WONTFIX," or "INVALID"). This means you can understand the beginning and end of the communication without reading the pieces in between.
|
||||
|
||||
Likewise, pull/merge requests are structured. They are focused on a specific type (typically code) of contribution. After the initial pull/merge request, the discussion is very focused on an outcome: getting the contribution in shape to merge into the wider codebase.
|
||||
|
||||
Another example here is a StackOverflow/AskBot style Q&A post. These posts start with a question and are then edited and responded to in order to provide a concise answer to the question.
|
||||
|
||||
With each of these structured mechanisms there usually is little deviation from the structure. You never see people asking others how their kids/cats/dogs/family are doing in an issue, pull request, or Q&A topic. It is socially unacceptable to veer off topic, and that is part of the power of a structured medium: It is focused and (usually) efficient.
|
||||
|
||||
The inverse, unstructured media, include chat channels and forums. In these environments there is typically a theme (such as the topic of a channel or sub-forum), but conversations are much less tied to a specific outcome or conclusion and can often be more general in nature. As an example, in a developer mailing list you will get a mix of discussions including general questions, ideas for new features, architectural challenges, and discussions that relate to the operational running of the community itself. With each of these discussions it is imperative on the participants to keep the conversation focused, on topic, and productive. As you can imagine, this is often not the case, and these kinds of discussions can veer away from a productive outcome.
|
||||
|
||||
### The impact of recording
|
||||
|
||||
Aside from the subtle differences between structured and unstructured communication, the impact of what is recorded and how it can be searched plays a large role too.
|
||||
|
||||
Typically, all structured channels are recorded. People reference old bugs, questions from StackOverflow are reused over and over again. You can search for something, and even if there is lots of discussion, the issue, pull request, or question is usually updated to reflect the ultimate conclusion.
|
||||
|
||||
This is part of the point: We want to be able to quickly and easily dig up old issues/questions/pull requests/etc., link to them, and reference them. A key component here is that we convert this content into referenceable material that can be used to educate and inform people about previous knowledge. As our community grows, our structured communication becomes a corpus of knowledge that can inform the future from lessons in the past.
|
||||
|
||||
This gets murkier with unstructured communication. On one hand, forums are generally simple and effective to search, but they are of course filled with unstructured conversation, so the thing you are looking for might be buried inside a discussion. As an example, many communities use a forum as a support tool. While this is a more than capable platform, the problem is that the answer to a question may be response #16 or response #340 in a discussion. As we are bombarded with more and more sources of information (and in smaller pieces, such as Twitter), we have become increasingly impatient to reading through large swaths of material, and this can be problematic with an unstructured medium.
|
||||
|
||||
A particularly interesting case is real-time chat. Historically, IRC has paved the way for real-time chat for many years, and for most IRC users there was little (if any) notion of recording those discussions. Sure, some projects (such as Ubuntu) record IRC logs, but this is generally not a useful resource. As my pal Jeff Atwood said to me once: "If you have to search chat for something, you have already lost."
|
||||
|
||||
While IRC is limited in recording, Slack and Mattermost are better. Conversations are archived, but the point still typically stands: Why would you want to search through large bodies of conversation to find a point that someone made? Other channels are far better for referencing previous discussions.
|
||||
|
||||
This does create an interesting opportunity though. One consistent benefit that chat exhibits over all other media is how human it is. Structured channels, and even unstructured channels such as forums and mailing lists, rarely encourage off-the-cuff social discussion. Chat does. Chat is where you ask: "How was your weekend?" "Did you see the game?" and "Are you going to see Testament, Sepultura, and Prong next week?" (OK, maybe the last one is just me.)
|
||||
|
||||
So, while real-time discussion may be less effective in our corpus of previous collaboration, it does provide a vital glue in shaping relationships.
|
||||
|
||||
### Choose your poison
|
||||
|
||||
So, back to our original question for open source communities: Which of these do we pick?
|
||||
|
||||
While this answer will vary from project to project, I tend to think of this on two levels.
|
||||
|
||||
First, you should generally prioritize structured communication. This is where tangible work gets done: in bugs/issues, pull requests, in support Q&A discussions, etc. If you are tight on resources, focus your efforts on these channels: You can more easily draw a dotted line between the investment of time and money there and productive output in the community.
|
||||
|
||||
Second, if you are passionate about building a broader community that can focus on engineering, advocacy, translations, documentation, and more, explore whether bringing in unstructured channels makes sense. Community is not just about getting stuff done, it is also about building relationships and friendships, providing support to each other in our work, and helping people grow and flourish in our communities. Unstructured communication is a helpful tool in this.
|
||||
|
||||
Of course, I am merely scratching the surface of a large topic here, but I hope this provides a little clarity in how to assess and choose the value of communication channels. Remember, less is more here: Don't be tempted to defer the decision and provide all of the above; you will get a fragmented community that's just about as inviting as an empty restaurant.
|
||||
|
||||
May the force be with you, and be sure to let me know how you get on. I am always available through my [website][3] and at [jono@jonobacon.com][4].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Jono Bacon - Jono Bacon is a leading community manager, speaker, author, and podcaster. He is the founder of Jono Bacon Consulting which provides community strategy/execution, developer workflow, and other services. He also previously served as director of community at GitHub, Canonical, XPRIZE, OpenAdvantage, and consulted and advised a range of organizations.
|
||||
|
||||
--------------------
|
||||
|
||||
via: https://opensource.com/article/17/5/much-ado-about-communication
|
||||
|
||||
作者:[ Jono Bacon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jonobacon
|
||||
[1]:https://opensource.com/article/17/5/much-ado-about-communication?rate=fBsUIx1TCGIXAFnRdYGTUqSG1pMmMCpdhYlyrFtRLS8
|
||||
[2]:http://www.jonobaconconsulting.com/
|
||||
[3]:http://www.jonobacon.com/
|
||||
[4]:mailto:jono@jonobacon.com
|
||||
[5]:https://opensource.com/user/26312/feed
|
||||
[6]:https://opensource.com/users/jonobacon
|
||||
136
sources/tech/20170516 What's the point of DevOps.md
Normal file
136
sources/tech/20170516 What's the point of DevOps.md
Normal file
@ -0,0 +1,136 @@
|
||||
What's the point of DevOps?
|
||||
============================================================
|
||||
|
||||
### True organizational culture change helps you bridge the gaps you thought were uncrossable.
|
||||
|
||||
|
||||

|
||||
>Image by : opensource.com
|
||||
|
||||
Think about the last time you tried to change a personal habit. You likely hit a point where you needed to alter the way you think and make the habit less a part of your identity. This is difficult—and you're only trying to change _your own_ ways of thinking.
|
||||
|
||||
So you may have tried to put yourself in new situations. New situations can actually help us create _new_ habits, which in turn lead to new ways of thinking.
|
||||
|
||||
That's the thing about successful change: It's as much about _outlook_ as _outcome_ . You need to know _why_ you're changing and _where_ you're headed (not just how you're going to do it), because change for its own sake is often short-lived and short-sighted.
|
||||
|
||||
Now think about the changes your IT organization needs to make. Perhaps you're thinking about adopting something like DevOps. This thing we call "DevOps" has three components: people, process, and tools. People and process are the basis for _any_ organization. Adopting DevOps, therefore, requires making fundamental changes to the core of most organizations—not just learning new tools.
|
||||
|
||||
Open Organization resources
|
||||
|
||||
* [Download the Open Organization Leaders Manual][1]
|
||||
|
||||
* [Download the Open Organization Field Guide][2]
|
||||
|
||||
* [What is an Open Organization?][3]
|
||||
|
||||
* [What is an Open Decision?][4]
|
||||
|
||||
And like any change, it can be short-sighted. If you're focused on the change as a point solution—"Get a better tool to do alerting," for example—you'll likely come up with a narrow vision of the problem. This mode of thinking may furnish a tool with more bells and whistles and a better way of handling on-call rotations. But it can't fix the fact that alerts aren't going to the right team, or that those failures remain failures since no one actually knows how to fix the service.
|
||||
|
||||
The new tool (or at least the idea of a new tool) creates a moment to have a conversation about the underlying issues that plague your team's views on monitoring. The new tool allows you to make bigger changes—changes to your beliefs and practices—which, as the foundation of your organization, are even more important.
|
||||
|
||||
Creating deeper change requires new approaches to the notion of change altogether. And to discover those approaches, we need to better understand the drive for change in the first place.
|
||||
|
||||
### Clearing the fences
|
||||
|
||||
> "In the matter of reforming things, as distinct from deforming them, there is one plain and simple principle; a principle which will probably be called a paradox. There exists in such a case a certain institution or law; let us say, for the sake of simplicity, a fence or gate erected across a road. The more modern type of reformer goes gaily up to it and says, "I don't see the use of this; let us clear it away." To which the more intelligent type of reformer will do well to answer: "If you don't see the use of it, I certainly won't let you clear it away. Go away and think. Then, when you can come back and tell me that you do see the use of it, I may allow you to destroy it."—G.K Chesterton, 1929
|
||||
|
||||
To understand the need for DevOps, which tries to recombine the traditionally "split" entities of "development" and "operations," we must first understand how the split came about. Once we "know the use of it," then we can see the split for what it really is—and dismantle it if necessary.
|
||||
|
||||
Today we have no single theory of management, but we can trace the origins of most modern management theory to Frederick Winslow Taylor. Taylor was a mechanical engineer who created a system for measuring the efficiency of workers at a steel mill. Taylor believed he could apply scientific analysis to the laborers in the mill, not only to improve individual tasks, but also to prove that there was a discoverable best method for performing _any_ task.
|
||||
|
||||
We can easily draw a historical tree with Taylor at the root. From Taylor's early efforts in the late 1880s emerged the time-motion study and other quality-improvement programs that span the 1920s all the way to today, where we see Six Sigma, Lean, and the like. Top-down, directive-style management, coupled with a methodical approach to studying process, dominates mainstream business culture today. It's primarily focused on efficiency as the primary measure of worker success.
|
||||
|
||||
>The "Dev" and "Ops" split is not the result of personality, diverging skills, or a magic hat placed on the heads of new employees; it's a byproduct of Taylorism and Sloanianism.
|
||||
|
||||
If Taylor is our root of our historical tree, then our next major fork in the trunk would be Alfred P. Sloan of General Motors in the 1920s. The structure Sloan created at GM would not only hold strong there until the 2000s, but also prove to be the major model of the corporation for much of the next 50 years.
|
||||
|
||||
In 1920, GM was experiencing a crisis of management—or rather a crisis from the lack thereof. Sloan wrote his "Organizational Study" for the board, proposing a new structure for the multitudes of GM divisions. This new structure centered on the concept of "decentralized operations with centralized control." The individual divisions, associated now with brands like Chevrolet, Cadillac, and Buick, would operate independently while providing central management the means to drive strategy and control finances.
|
||||
|
||||
Under Sloan's recommendations (and later guidance as CEO), GM rose to a dominant position in the US auto industry. Sloan's plan created a highly successful corporation from one on the brink of disaster. From the central view, the autonomous units are black boxes. Incentives and goals get set at the top levels, and the teams at the bottom drive to deliver.
|
||||
|
||||
The Taylorian idea of "best practices"—standard, interchangeable, and repeatable behaviors—still holds a place in today's management ideals, where it gets coupled with the hierarchical model of the Sloan corporate structure, which advocates rigid departmental splits and silos for maximum control.
|
||||
|
||||
We can point to several management studies that demonstrate this. But business culture isn't created and propagated only through reading books. Organizational culture is the product of _real_ people in _actual_ situations performing _concrete_ behaviors that propel cultural norms through time. That's how things like Taylorism and and Sloanianism get solidified and come to appear immovable.
|
||||
|
||||
Technology sector funding is a case in point. Here's how the cycle works: Investors only invest in those companies they believe could achieve _their_ particular view of success. This model for success doesn't necessarily originate from the company itself (and its particular goals); it comes from a board's ideas of what a successful company _should_ look like. Many investors come from companies that have survived the trials and tribulations of running a business, and as a result they have _different_ blueprints for what makes a successful company. They fund companies that can be taught to mimic their models for success. So companies wishing to acquire funding learn to mimic. In this way, the start-up incubator is a _direct_ way of reproducing a supposedly _ideal_ structure and culture.
|
||||
|
||||
The "Dev" and "Ops" split is not the result of personality, diverging skills, or a magic hat placed on the heads of new employees; it's a byproduct of Taylorism and Sloanianism. Clear and impermeable boundaries between responsibilities and personnel is a management function coupled with a focus on worker efficiency. The management split could have easily landed on product or project boundaries instead of skills, but the history of business management theory through today tells us that skills-based grouping is the "best" way to be efficient.
|
||||
|
||||
Unfortunately, those boundaries create tensions, and those tensions are a direct result of opposing goals set by different management chains with different objectives. For example:
|
||||
|
||||
|
||||
Agility ⟷ Stability
|
||||
|
||||
Drawing new users ⟷ Existing users' experience
|
||||
|
||||
Application getting features ⟷ Application available to use
|
||||
|
||||
Beating the competition ⟷ Protecting revenue
|
||||
|
||||
Fixing problems that come up ⟷ Preventing problems before they happen
|
||||
|
||||
|
||||
|
||||
Today, we can see growing recognition among organizations' top leaders that the existing business culture (and by extension the set of tensions it produces) is a serious problem. In a 2016 Gartner report, 57 percent of respondents said that culture change was one of the major challenges to the business through 2020\. The rise of new methods like Agile and DevOps as a means of affecting organizational changes reflects that recognition. The rise of "[shadow IT][7]" is the flip side of the coin; recent estimates peg nearly 30 percent of IT spend outside the control of the IT organization.
|
||||
|
||||
These are only some of the "culture concerns" that business are having. The need to change is clear, but the path ahead is still governed by the decisions of yesterday.
|
||||
|
||||
### Resistance isn't futile
|
||||
|
||||
> "Bert Lance believes he can save Uncle Sam billions if he can get the government to adopt a simple motto: 'If it ain't broke, don't fix it.' He explains: 'That's the trouble with government: Fixing things that aren't broken and not fixing things that are broken.'" — Nation's Business, May 1977
|
||||
|
||||
Typically, change is an organizational response to something gone wrong. In this sense, then, if tension (even adversity) is the normal catalyst for change, then the _resistance_ to change is an indicator of success. But overemphasis on successful paths can make organizations inflexible, hidebound, and dogmatic. Valuing policy navigation over effective results is a symptom of this growing rigidity.
|
||||
|
||||
Success in traditional IT departments has thickened the walls of the IT silo. Other departments are now "customers," not co-workers. Attempts to shift IT _away_ from being a cost-center create a new operating model that disconnects IT from the rest of the business' goals. This in turn creates resistance that limits agility, increases friction, and decreases responsiveness. Collaboration gets shelved in favor of "expert direction." The result is an isolationist view of IT can only do more harm than good.
|
||||
|
||||
And yet as "software eats the world," IT becomes more and more central to the overall success of the organization. Forward-thinking IT organizations recognize this and are already making deliberate changes to their playbooks, rather than treating change as something to fear.
|
||||
|
||||
>Change isn't just about rebuilding the organization; it's also about new ways to cross historically uncrossable gaps.
|
||||
|
||||
For instance, Facebook consulted with [anthropologist Robin Dunbar][8] on its approach to social groups, but realized the impact this had on internal groups (not just external users of the site) as the company grew. Zappos' culture has garnered so much praise that the organization created a department focused on training others in their views on core values and corporate culture. And of course, this book is a companion to _The Open Organization_ , a book that shows how open principles applied to management—transparency, participation, and community—can reinvent the organization for our fast-paced, connected era.
|
||||
|
||||
### Resolving to change
|
||||
|
||||
> "If the rate of change on the outside exceeds the rate of change on the inside, the end is near."—Jack Welch, 2004
|
||||
|
||||
A colleague once told me he could explain DevOps to a project manager using only the vocabulary of the [Information Technology Infrastructure Library][9] framework.
|
||||
|
||||
While these frameworks _appear_ to be opposed, they actually both center on risk and change management. They simply present different processes and tools for such management. This point is important to note when to talking about DevOps outside IT. Instead of emphasizing process breakdowns and failures, show how smaller changes introduce _less_ risk, and so on. This is a powerful way to highlight the benefits changing a team's culture: Focusing on the _new_ capabilities instead of the _old_ problems is an effective agent for change, especially when you adopt someone else's frame of reference.
|
||||
|
||||
Change isn't just about _rebuilding_ the organization; it's also about new ways to cross historically uncrossable gaps—resolving those tensions I mapped earlier by refusing to position things like "agility" and "stability" as mutually exclusive forces. Setting up cross-silo teams focused on _outcomes_ over _functions_ is one of the strategies in play. Bringing different teams, each of whose work relies on the others, together around a single project or goal is one of the most common approaches. Eliminating friction between these teams and improving communications yields massive improvements—even while holding to the iron silo structures of management (silos don't need to be demolished if they can be mastered). In these cases, _resistance_ to change isn't an indicator of success; an embrace of change is.
|
||||
|
||||
These aren't "best practices." They're simply a way for you to examine your own fences. Every organization has unique fences created by the people within it. And once you "know the use of it," you can decide whether it needs dismantling or mastering.
|
||||
|
||||
_This article is part of Opensource.com's forthcoming guide to open organizations and IT culture. [Register to be notified][5] when it's released._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
作者简介:
|
||||
|
||||
Matt Micene - Matt Micene is an evangelist for Linux and containers at Red Hat. He has over 15 years of experience in information technology, ranging from architecture and system design to data center design. He has a deep understanding of key technologies, such as containers, cloud computing and virtualization. His current focus is evangelizing Red Hat Enterprise Linux, and how the OS relates to the new age of compute environments.
|
||||
|
||||
------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/17/5/what-is-the-point-of-DevOps
|
||||
|
||||
作者:[Matt Micene ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/matt-micene
|
||||
[1]:https://opensource.com/open-organization/resources/leaders-manual?src=too_resource_menu
|
||||
[2]:https://opensource.com/open-organization/resources/field-guide?src=too_resource_menu
|
||||
[3]:https://opensource.com/open-organization/resources/open-org-definition?src=too_resource_menu
|
||||
[4]:https://opensource.com/open-organization/resources/open-decision-framework?src=too_resource_menu
|
||||
[5]:https://opensource.com/open-organization/resources/book-series
|
||||
[6]:https://opensource.com/open-organization/17/5/what-is-the-point-of-DevOps?rate=gOQvGqsEbNk_RSnoU0wP3PJ71E_XDYiYo7KS2HKFfP0
|
||||
[7]:https://thenewstack.io/parity-check-dont-afraid-shadow-yet/
|
||||
[8]:http://www.npr.org/2017/01/13/509358157/is-there-a-limit-to-how-many-friends-we-can-have
|
||||
[9]:https://en.wikipedia.org/wiki/ITIL
|
||||
[10]:https://opensource.com/user/18066/feed
|
||||
[11]:https://opensource.com/open-organization/17/5/what-is-the-point-of-DevOps#comments
|
||||
[12]:https://opensource.com/users/matt-micene
|
||||
244
sources/tech/20170518 Maintaining a Git Repository.md
Normal file
244
sources/tech/20170518 Maintaining a Git Repository.md
Normal file
@ -0,0 +1,244 @@
|
||||
Maintaining a Git Repository
|
||||
============================================================
|
||||
|
||||
Maintenance of your Git repository typically involves reducing a repository's size. If you imported from another version control system, you may need to clean up unnecessary files after the import. This page focuses on removing large files from a Git repo and contains the following topics:
|
||||
|
||||
* [Understanding file removal from Git history][1]
|
||||
|
||||
* [Using the BFG to rewrite history][2]
|
||||
|
||||
* [Alternatively, using git filter-branch to rewrite history][3]
|
||||
|
||||
* [Garbage collecting dead data][4]
|
||||
|
||||
Be very careful...
|
||||
|
||||
The procedure and tools on this page use advanced techniques that involve destructive operations. Make sure you read carefully and **backup your repository** before starting. The easiest way to create a backup is to clone your repository using the [--mirror][5] flag, and zip the whole clone. With the backup, if you accidentally corrupt a key element of your repo during maintenance, you can recover.
|
||||
|
||||
Keep in mind that maintenance can be disruptive to repository users. It is a good idea to communicate repository maintenance with your team or repository followers. Make sure everyone has checked in their code and have agreed to cease development during maintenance.
|
||||
|
||||
### Understanding file removal from Git history
|
||||
|
||||
Recall that cloning a repository clones the entire history — including every version of every source code file. If a user commits a huge file, such as a JAR, every clone thereafter includes this file. Even if a user ends up removing the file from the project with a subsequent commit, the file still exists in the repository history. To remove this file from your repository you must:
|
||||
|
||||
* remove the file from your project's _current_ file-tree
|
||||
|
||||
* remove the file from repository history - _rewriting_ Git history, deleting the file from **all** commits containing it
|
||||
|
||||
* remove all [reflog][6] history that refers to the _old_ commit history
|
||||
|
||||
* repack the repository, garbage-collecting the now-unused data using [git gc][7]
|
||||
|
||||
Git 'gc' (garbage collection) will remove all data from the repository that is not actually used, or in some way referenced, by any of your branches or tags. In order for that to be useful, we need to rewrite all Git repository history that contained the unwanted file, so that it no longer references it - git gc will then be able to discard the now-unused data.
|
||||
|
||||
Rewriting repository history is a tricky business, because every commit depends on it's parents, so any small change will change the commit id of every subsequent commit. There are two automated tools for doing this:
|
||||
|
||||
1. [the BFG Repo Cleaner][8] - fast, simple, easy to use. Require Java 6 or above.
|
||||
|
||||
2. [git filter-branch][9] - powerful, tricky to configure, slow on big repositories. Part of the core Git suite.
|
||||
|
||||
Remember, after you rewrite the history, whether you use the BFG or filter-branch, you will need to remove `reflog` entries that point to old history, and finally run the garbage collector to purge the old data.
|
||||
|
||||
### Using the BFG to rewrite history
|
||||
|
||||
[The BFG][11] is specifically designed for removing unwanted data like big files or passwords from Git repos, so it has a simple flag that will remove any large historical (not-in-your-current-commit) files: '--strip-blobs-bigger-than'
|
||||
|
||||
|
||||
```
|
||||
$ java -jar bfg.jar --strip-blobs-bigger-than 100M
|
||||
```
|
||||
|
||||
Any files over 100MB in size (that aren't in your _latest_ commit - because [your latest content is protected][12] by the BFG) will be removed from your Git repository's history. If you'd like to specify files by name, you can do that too:
|
||||
|
||||
|
||||
```
|
||||
$ java -jar bfg.jar --delete-files *.mp4
|
||||
```
|
||||
|
||||
The BFG is [10-1000x][13] faster than git filter-branch, and generally much easier to use - check the full [usage instructions][14] and [examples][15] for more details.
|
||||
|
||||
### Alternatively, using git filter-branch to rewrite history
|
||||
|
||||
The `filter-branch` command rewrites a Git repo's revision history, just like the BFG, but the process is slower and more manual. If you don't know _where_ the big file is, your first step will be to find it:
|
||||
|
||||
### Manually reviewing large files in your repository
|
||||
|
||||
[Antony Stubbs][16] has written a BASH script that does this very well. The script examines the contents of your packfile and lists out the large files. Before you begin removing files, do the following to obtain and install this script:
|
||||
|
||||
1. [Download the script][10] to your local system.
|
||||
|
||||
2. Put it in a well known location accessible to your Git repository.
|
||||
|
||||
3. Make the script an executable:
|
||||
|
||||
|
||||
```
|
||||
$ chmod 777 git_find_big.sh
|
||||
```
|
||||
|
||||
4. Clone the repository to your local system.
|
||||
|
||||
5. Change directory to your repository root.
|
||||
|
||||
6. Run the Git garbage collector manually.
|
||||
|
||||
|
||||
```
|
||||
git gc --auto
|
||||
```
|
||||
|
||||
7. Find out the size of the .git folder.
|
||||
|
||||
|
||||
```
|
||||
$ du -hs .git/objects
|
||||
```
|
||||
|
||||
```
|
||||
45M .git/objects
|
||||
```
|
||||
|
||||
Note this size down for later reference.
|
||||
|
||||
8. List the big files in your repo by running the `git_find_big.sh` script.
|
||||
|
||||
|
||||
```
|
||||
$ git_find_big.sh
|
||||
```
|
||||
|
||||
```
|
||||
All sizes are in kB's. The pack column is the size of the object, compressed, inside the pack file.
|
||||
```
|
||||
|
||||
```
|
||||
size pack SHA location
|
||||
```
|
||||
|
||||
```
|
||||
592 580 e3117f48bc305dd1f5ae0df3419a0ce2d9617336 media/img/emojis.jar
|
||||
```
|
||||
|
||||
```
|
||||
550 169 b594a7f59ba7ba9daebb20447a87ea4357874f43 media/js/aui/aui-dependencies.jar
|
||||
```
|
||||
|
||||
```
|
||||
518 514 22f7f9a84905aaec019dae9ea1279a9450277130 media/images/screenshots/issue-tracker-wiki.jar
|
||||
```
|
||||
|
||||
```
|
||||
337 92 1fd8ac97c9fecf74ba6246eacef8288e89b4bff5 media/js/lib/bundle.js
|
||||
```
|
||||
|
||||
```
|
||||
240 239 e0c26d9959bd583e5ef32b6206fc8abe5fea8624 media/img/featuretour/heroshot.png
|
||||
```
|
||||
|
||||
The big files are all JAR files. The pack size column is the most relevant. The `aui-dependencies.jar` compacts to 169KB but the `emojis.jar` compacts only to 580\. The `emojis.jar` is a candidate for removal.
|
||||
|
||||
### Running filter-branch
|
||||
|
||||
You can pass this command a filter for rewriting the Git index. For example, a filter can remove a file from every indexed commit. The syntax for this is the following:
|
||||
|
||||
`git filter-branch --index-filter 'git rm --cached --ignore-unmatch _pathname_ ' commitHASH`
|
||||
|
||||
The `--index-filter` option modifies a repo's staging (or index). The `--cached` option removes a file from the index not the disk. This is faster as you don't have to checkout each revision before running the filter. The -`-ignore-unmatch` option in `git rm` prevents the command from failing if the _pathname_ it is trying to remove isn't there. By specifying a commit HASH, you remove the `pathname` from every commit starting with the HASH on up. To remove from the start, leave this off or you can specify HEAD.
|
||||
|
||||
If all your large files are in different branches, you'll need to delete each file by name. If all the files are within a single branch, you can delete the branch itself.
|
||||
|
||||
### Option 1: Delete files by name
|
||||
|
||||
Use the following procedure to remove large files:
|
||||
|
||||
1. Run the following command to remove the first large file you identified:
|
||||
|
||||
|
||||
```
|
||||
git filter-branch --index-filter 'git rm --cached --ignore-unmatch filename' HEAD
|
||||
```
|
||||
|
||||
2. Repeat Step 1 for each remaining large file.
|
||||
|
||||
3. Update the references in your repository. `filter-branch` creates backups of your original refs namespaced under `refs/original/`. Once you're confident that you deleted the correct files, you can run the following command to delete the backed up refs, allowing the large objects to be garbage collected:
|
||||
|
||||
|
||||
```
|
||||
$ git for-each-ref --format="%(refname)" refs/original/ | xargs -n 1 git update-ref -d
|
||||
```
|
||||
|
||||
### Option 2: Delete just the branch
|
||||
|
||||
If all your large files are on a single branch, you can just delete the branch. Deleting the branch automatically removes all the references.
|
||||
|
||||
1. Delete the branch.
|
||||
|
||||
|
||||
```
|
||||
$ git branch -D PROJ567bugfix
|
||||
```
|
||||
|
||||
2. Prune all of the reflog references from the branch on back.
|
||||
|
||||
|
||||
```
|
||||
$ git reflog expire --expire=now PROJ567bugfix
|
||||
```
|
||||
|
||||
### Garbage collecting dead data
|
||||
|
||||
1. Prune all of the reflog references from now on back (unless you're explicitly only operating on one branch).
|
||||
|
||||
|
||||
```
|
||||
$ git reflog expire --expire=now --all
|
||||
```
|
||||
|
||||
2. Repack the repository by running the garbage collector and pruning old objects.
|
||||
|
||||
|
||||
```
|
||||
$ git gc --prune=now
|
||||
```
|
||||
|
||||
3. Push all your changes back to the Bitbucket repository.
|
||||
|
||||
|
||||
```
|
||||
$ git push --all --force
|
||||
```
|
||||
|
||||
4. Make sure all your tags are current too:
|
||||
|
||||
|
||||
```
|
||||
$ git push --tags --force
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://confluence.atlassian.com/bitbucket/maintaining-a-git-repository-321848291.html
|
||||
|
||||
作者:[atlassian.com][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://confluence.atlassian.com/bitbucket/maintaining-a-git-repository-321848291.html
|
||||
[1]:https://confluence.atlassian.com/bitbucket/maintaining-a-git-repository-321848291.html#MaintainingaGitRepository-UnderstandingfileremovalfromGithistory
|
||||
[2]:https://confluence.atlassian.com/bitbucket/maintaining-a-git-repository-321848291.html#MaintainingaGitRepository-UsingtheBFGtorewritehistory
|
||||
[3]:https://confluence.atlassian.com/bitbucket/maintaining-a-git-repository-321848291.html#MaintainingaGitRepository-Alternatively,usinggitfilter-branchtorewritehistory
|
||||
[4]:https://confluence.atlassian.com/bitbucket/maintaining-a-git-repository-321848291.html#MaintainingaGitRepository-Garbagecollectingdeaddata
|
||||
[5]:http://stackoverflow.com/questions/3959924/whats-the-difference-between-git-clone-mirror-and-git-clone-bare
|
||||
[6]:http://git-scm.com/docs/git-reflog
|
||||
[7]:http://git-scm.com/docs/git-gc
|
||||
[8]:http://rtyley.github.io/bfg-repo-cleaner/
|
||||
[9]:http://git-scm.com/docs/git-filter-branch
|
||||
[10]:https://confluence.atlassian.com/bitbucket/files/321848291/321979854/1/1360604134990/git_find_big.sh
|
||||
[11]:http://rtyley.github.io/bfg-repo-cleaner/
|
||||
[12]:http://rtyley.github.io/bfg-repo-cleaner/#protected-commits
|
||||
[13]:https://www.youtube.com/watch?v=Ir4IHzPhJuI
|
||||
[14]:http://rtyley.github.io/bfg-repo-cleaner/#usage
|
||||
[15]:http://rtyley.github.io/bfg-repo-cleaner/#examples
|
||||
[16]:https://stubbisms.wordpress.com/2009/07/10/git-script-to-show-largest-pack-objects-and-trim-your-waist-line/
|
||||
@ -1,71 +0,0 @@
|
||||
针对物理 RAM 的攻击可以取得 Android 设备的根权限,其它设备也存在这样的可能
|
||||
===
|
||||
|
||||
>攻击者确实可以在物理存储单元中实现位翻转来达到侵入(这里把 compromise 翻译成了侵入,感觉还是有点词不达意)移动设备与计算机的目的
|
||||
|
||||

|
||||
|
||||
|
||||
研究者们发现了一种新的在不利用任何软件漏洞情况下,利用 RAM 芯片物理设计上的弱点来侵入 Android 设备的方式。这种攻击技术同样可以影响到其它如 ARM 和 X86 架构的设备与计算机。
|
||||
|
||||
攻击起源于过去十多年中将更多的 DRAM(动态随机存取存储器)容量封装进越来越小的芯片中,这将导致存储单元在特定情况下电子在相邻的两行中从一边泄漏到另一边。(这里翻译的有点不太通顺,特别是这 row 的概念,只是查看了维基百科有了大致了解,结合起来看可能会更有助理解 https://en.wikipedia.org/wiki/Row_hammer)
|
||||
|
||||
例如,反复且快速的访问相同的物理储存位置 -- 一种被称为 “hammering” (这里 hammering 实在不知道该如何处理,用英文原文似乎也挺好的,在读英文内容的时候也会带来一定的便利)的行为 -- 可以导致相邻位置的位值从 0 反转成 1,或者相反。
|
||||
|
||||
虽然这样的电子干扰已经被生产商知晓并且从可靠性角度研究了一段时间了 -- 因为内存错误能够导致系统崩溃 -- 研究者展示了在可控方式的触发下它所存在的严重安全隐患。
|
||||
|
||||
在 2015 年 4 月,来自谷歌 Project Zero 项目的研究者公布了两份基于内存 “row hammer” 对于 x86-64 CPU 架构的 [提权利用][7]。其中一份利用可以使代码从谷歌的 Chrome 浏览器沙盒里逃逸并且直接在系统上执行,另一份可以在 Linux 机器上获取高级权限。(这里的 kernel-level 不太确定该如何处理,这个可以参看 https://en.wikipedia.org/wiki/Privilege_level)
|
||||
|
||||
此后,其他的研究者进行了更深入的调查并且展示了[通过网站中 JaveScript 脚本进行利用的方式][6]甚至能够影响运行在云环境下的[虚拟服务器][5]。然而,对于这项技术是否可以应用在智能手机和移动设备大量使用的 ARM 架构中还是有疑问的。
|
||||
|
||||
现在,一队成员来自荷兰阿姆斯特丹自由大学,奥地利格拉茨技术大学和加州大学圣塔芭芭拉分校的 VUSec 小组,已经证明了 Rowhammer 不仅仅可以应用在 ARM 架构上并且甚至比在 x86 架构上更容易。
|
||||
|
||||
研究者们将他们的新攻击命名为 Drammer,代表了 Rowhammer 确实存在,并且计划于周三在维也纳举办的第 23 届 ACM 计算机与通信安全大会上展示。这种攻击建立在之前就被发现与实现的 Rowhammer 技术之上。
|
||||
|
||||
VUSec 小组的研究者已经制造了一个适用于 Android 设备的恶意应用,当它被执行的时候利用不易察觉的内存位反转在不需要任何权限的情况下就可以获取设备根权限。
|
||||
|
||||
研究者们测试了来自不同制造商的 27 款 Android 设备,21 款使用 ARMv7(32-bit)指令集架构,其它 6 款使用 ARMv8(64-bit)指令集架构。他们成功的在 17 款 ARMv7 设备和 1 款 ARMv8 设备上实现了为反转,表明了这些设备是易受攻击的。
|
||||
|
||||
此外,Drammer 能够与其它的 Android 漏洞组合使用,例如 [Stagefright][4] 或者 [BAndroid][3] 来实现无需用户手动下载恶意应用的远程攻击。
|
||||
|
||||
谷歌已经注意到了这一类型的攻击。“在研究者向漏洞奖励计划(这里应该是特指谷歌的那个吧,不知道把它翻译成中文是否合适)报告了这个问题之后,我们与他们进行了密切的沟通来深入理解这个问题以便我们更好的保护用户,”一位谷歌的代表在一份邮件申明中这样说到。“我们已经开发了一个缓解方案(这里将 mitigation 翻成了缓解方案不知是否妥当,这又是一个有丰富含义的概念 https://en.wikipedia.org/wiki/Vulnerability_management)将会包含在十一月的安全更新中。”
|
||||
|
||||
VUSec 的研究者认为,谷歌的缓解方案将会使得攻击过程更为复杂,但是它不能修复潜在的问题。
|
||||
|
||||
事实上,从软件上去修复一个由硬件导致的问题是不现实的。硬件供应商正在研究相关问题并且有可能在将来的内存芯片中被修复,但是在现有设备的芯片中风险依然存在。
|
||||
|
||||
更糟的是,研究者们说,由于有许多因素会影响到攻击的成功与否并且这些因素尚未被研究透彻,因此很难去说有哪些设备会被影响到。例如,内存控制器可能会在不同的电量的情况下展现不同的行为,因此一个设备可能在满电的情况下没有风险,当它处于低电量的情况下就是有风险的。
|
||||
|
||||
同样的,在网络安全中有这样一句俗语:Attacks always get getter, they never get worse.(这里借用“道高一尺,魔高一仗。”不知是否合适)Rowhammer 攻击已经从理论变成了变成了现实,同样的他可能也会从现在的简单实现变成确确实实的存在。(这一句凭自己的理解翻的)这意味着今天某个设备是不被影响的,在明天就有可能被改进后的 Rowhammer 技术证明它是存在风险的。
|
||||
|
||||
Drammer 在 Android 上实现是因为研究者期望研究基于 ARM 设备的影响,但是潜在的技术可以被使用在所有的架构与操作系统上。新的攻击相较于之前建立在运气与特殊特性与特定平台之上并且十分容易失效的技术已经是一个巨大的进步了。
|
||||
|
||||
Drammer 依靠被大量硬件子系统所使用的 DMA(直接存储访问)缓存,其中包括了图形,网络,声音。Drammer 的实现采用了所有操作系统上都有的 Android 的 ION内存分配器,接口,与方法,这个特征(这里将 warning 翻译成了特征,纯粹是自己的理解,不知是否妥当)是文章中主要的贡献之一。
|
||||
|
||||
"破天荒的,我们成功的展示了我们可以做到,在不依赖任何特定的特性情况下完全可靠的证明了 Rowhammer,“ VUSec 小组中的其中一位研究者, Cristiano Giuffrida 这样说道。”攻击所利用的内存位置并非是 Android 独有的。攻击在任何的 Linux 平台上都能工作 -- 我们甚至怀疑其它操作系统也可以 -- 因为它利用的是操作系统内核内存管理中固有的特性。“
|
||||
|
||||
”我期待我们可以看到更多针对其它平台的攻击的变种,“阿姆斯特丹自由大学的教授兼 VUSec 系统安全研究小组的领导者,Herbert Bos 补充道。
|
||||
|
||||
在他们的[文章][2]之外,研究者们也释出了一个 Android 应用来测试 Android 设备在受到 Rowhammer 攻击时是否会有风险 -- 在当前所知的技术条件下。应用还没有传上[谷歌应用商店][Google Play],可以从 [VUSec Drammer 网站][1] 下载来手动安装。一个开源的 Rowhammer 模拟器同样能够帮助其他的研究者来更深入的研究这个问题。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:http://www.csoonline.com/article/3134726/security/physical-ram-attack-can-root-android-and-possibly-other-devices.html
|
||||
|
||||
作者:[Lucian Constantin][a]
|
||||
|
||||
译者:[wcnnbdk1](https://github.com/wcnnbdk1)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.csoonline.com/author/Lucian-Constantin/
|
||||
[1]:https://www.vusec.net/projects/drammer/
|
||||
[2]:https://vvdveen.com/publications/drammer.pdf
|
||||
[3]:https://www.vusec.net/projects/bandroid/
|
||||
[4]:http://www.csoonline.com/article/3045836/security/new-stagefright-exploit-puts-millions-of-android-devices-at-risk.html
|
||||
[5]:http://www.infoworld.com/article/3105889/security/flip-feng-shui-attack-on-cloud-vms-exploits-hardware-weaknesses.html
|
||||
[6]:http://www.computerworld.com/article/2954582/security/researchers-develop-astonishing-webbased-attack-on-a-computers-dram.html
|
||||
[7]:http://www.computerworld.com/article/2895898/google-researchers-hack-computers-using-dram-electrical-leaks.html
|
||||
[8]:http://csoonline.com/newsletters/signup.html
|
||||
@ -0,0 +1,354 @@
|
||||
我对 Go 的错误处理有哪些不满,以及我是如何处理的
|
||||
======================
|
||||
|
||||
写 Go 的人往往对它的错误处理模式有一定的看法。根据你对其他语言的经验,你可能习惯于不同的方法。这就是为什么我决定要写这篇文章,尽管有点固执己见,但我认为吸收我的经验在辩论中是有用的。 我想要解决的主要问题是,很难去强制良好的错误处理实践,错误没有堆栈追踪,并且错误处理本身太冗长。不过,我已经看到了一些潜在的解决方案或许能帮助解决一些问题。
|
||||
|
||||
### 与其他语言的快速比较
|
||||
|
||||
|
||||
[在 Go 中,所有的错误是值][1]。因为这点,相当多的函数最后会返回一个 `error`, 看起来像这样:
|
||||
|
||||
```
|
||||
func (s *SomeStruct) Function() (string, error)
|
||||
```
|
||||
|
||||
由于这点,调用代码常规上会使用 `if` 语句来检查它们:
|
||||
|
||||
```
|
||||
bytes, err := someStruct.Function()
|
||||
if err != nil {
|
||||
// Process error
|
||||
}
|
||||
```
|
||||
|
||||
另外一种是在其他语言中如 Java、C#、Javascript、Objective C、Python 等使用的 `try-catch` 模式。如下你可以看到与先前的 Go 示例类似的 Java 代码,声明 `throws` 而不是返回 `error`:
|
||||
|
||||
```
|
||||
public String function() throws Exception
|
||||
```
|
||||
|
||||
`try-catch` 而不是 `if err != nil`:
|
||||
|
||||
```
|
||||
try {
|
||||
String result = someObject.function()
|
||||
// continue logic
|
||||
}
|
||||
catch (Exception e) {
|
||||
// process exception
|
||||
}
|
||||
```
|
||||
|
||||
当然,还有其他的不同。不如,`error` 不会使你的程序崩溃,然而 `Exception` 会。还有其他的一些,我希望在在本篇中专注在这些上。
|
||||
|
||||
### 实现集中式错误处理
|
||||
|
||||
退一步,让我们看看为什么以及如何在一个集中的地方处理错误。
|
||||
|
||||
大多数人或许会熟悉的一个例子是 web 服务 - 如果出现了一些未预料的的服务端错误,我们会生成一个 5xx 错误。在 Go 中,你或许会这么实现:
|
||||
|
||||
```
|
||||
func init() {
|
||||
http.HandleFunc("/users", viewUsers)
|
||||
http.HandleFunc("/companies", viewCompanies)
|
||||
}
|
||||
|
||||
func viewUsers(w http.ResponseWriter, r *http.Request) {
|
||||
user // some code
|
||||
if err := userTemplate.Execute(w, user); err != nil {
|
||||
http.Error(w, err.Error(), 500)
|
||||
}
|
||||
}
|
||||
|
||||
func viewCompanies(w http.ResponseWriter, r *http.Request) {
|
||||
companies = // some code
|
||||
if err := companiesTemplate.Execute(w, companies); err != nil {
|
||||
http.Error(w, err.Error(), 500)
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
这并不是一个好的解决方案,因为我们不得不重复在所有的处理函数中处理错误。为了能更好地维护,最好能在一处地方处理错误。幸运的是,[在 Go 的博客中,Andrew Gerrand 提供了一个替代方法][2]可以完美地实现。我们可以错见一个处理错误的类型:
|
||||
|
||||
```
|
||||
type appHandler func(http.ResponseWriter, *http.Request) error
|
||||
|
||||
func (fn appHandler) ServeHTTP(w http.ResponseWriter, r *http.Request) {
|
||||
if err := fn(w, r); err != nil {
|
||||
http.Error(w, err.Error(), 500)
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
这可以作为一个封装器来修饰我们的处理函数:
|
||||
|
||||
```
|
||||
func init() {
|
||||
http.Handle("/users", appHandler(viewUsers))
|
||||
http.Handle("/companies", appHandler(viewCompanies))
|
||||
}
|
||||
```
|
||||
|
||||
接着我们需要做的是修改处理函数的签名来使它们返回 `errors`。这个方法很好,因为我们做到了 [dry][3] 原则,并且没有重复使用不必要的代码 - 现在我们可以在一处返回默认错误了。
|
||||
|
||||
### 错误上下文
|
||||
|
||||
在先前的例子中,我们可能会收到许多潜在的错误,它们的任何一个都可能在调用堆栈的许多部分生成。这时候事情就变得棘手了。
|
||||
|
||||
为了演示这点,我们可以扩展我们的处理函数。它可能看上去像这样,因为模板执行并不是唯一一处会发生错误的地方:
|
||||
|
||||
```
|
||||
func viewUsers(w http.ResponseWriter, r *http.Request) error {
|
||||
user, err := findUser(r.formValue("id"))
|
||||
if err != nil {
|
||||
return err;
|
||||
}
|
||||
return userTemplate.Execute(w, user);
|
||||
}
|
||||
```
|
||||
|
||||
调用链可能会相当深,在整个过程中,各种错误可能在不同的地方实例化。[Russ Cox][4]的这篇文章解释了如何避免遇到太多这类问题的最佳实践:
|
||||
|
||||
在 Go 中错误报告的部分约定是函数包含相关的上下文、包含正在尝试的操作(比如函数名和它的参数)
|
||||
|
||||
给出的例子是 OS 包中的一个调用:
|
||||
|
||||
```
|
||||
err := os.Remove("/tmp/nonexist")
|
||||
fmt.Println(err)
|
||||
```
|
||||
|
||||
它会输出:
|
||||
|
||||
```
|
||||
remove /tmp/nonexist: no such file or directory
|
||||
```
|
||||
|
||||
总结一下,执行后,输出的是被调用的函数、给定的参数、特定的出错信息。当在其他语言中创建一个 `Exception` 消息时,你也可以遵循这个实践。如果我们在 `viewUsers` 处理中坚持这点,那么几乎总是能明确错误的原因。
|
||||
|
||||
问题来自于那些不遵循这个最佳实践的人,并且你经常会在第三方的 Go 库中看到这些消息:
|
||||
|
||||
```
|
||||
Oh no I broke
|
||||
```
|
||||
|
||||
这没什么帮助 - 你无法了解上下文,这使得调试很困难。更糟糕的是,当这些错误被忽略或返回时,这些错误会被备份到堆栈中,直到它们被处理为止:
|
||||
|
||||
```
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
```
|
||||
|
||||
这意味着错误发生时它们没有交流。
|
||||
|
||||
应该注意的是,所有这些错误都可以在 `Exception` 驱动的模型中发生 - 糟糕的错误信息、隐藏异常等。那么为什么我认为该模型更有用?
|
||||
|
||||
如果我们在处理一个糟糕的异常消息,_我们仍然能够了解堆栈中发生了什么_。因为堆栈跟踪,这引发了一些我对 Go 不了解的部分 - 你知道 Go 的 `panic` 包含了堆栈追踪,但是 `error` 没有。我认为推论是 `panic` 可能会使你的程序崩溃,因此需要一个堆栈追踪,而处理错误并不会,因为它会假定你在它发生的地方做一些事。
|
||||
|
||||
所以让我们回到之前的例子 - 一个有糟糕错误信息的第三方库,它只是输出了调用链。你认为调试会更容易吗?
|
||||
|
||||
```
|
||||
panic: Oh no I broke
|
||||
[signal 0xb code=0x1 addr=0x0 pc=0xfc90f]
|
||||
|
||||
goroutine 1103 [running]:
|
||||
panic(0x4bed00, 0xc82000c0b0)
|
||||
/usr/local/go/src/runtime/panic.go:481 +0x3e6
|
||||
github.com/Org/app/core.(_app).captureRequest(0xc820163340, 0x0, 0x55bd50, 0x0, 0x0)
|
||||
/home/ubuntu/.go_workspace/src/github.com/Org/App/core/main.go:313 +0x12cf
|
||||
github.com/Org/app/core.(_app).processRequest(0xc820163340, 0xc82064e1c0, 0xc82002aab8, 0x1)
|
||||
/home/ubuntu/.go_workspace/src/github.com/Org/App/core/main.go:203 +0xb6
|
||||
github.com/Org/app/core.NewProxy.func2(0xc82064e1c0, 0xc820bb2000, 0xc820bb2000, 0x1)
|
||||
/home/ubuntu/.go_workspace/src/github.com/Org/App/core/proxy.go:51 +0x2a
|
||||
github.com/Org/app/core/vendor/github.com/rusenask/goproxy.FuncReqHandler.Handle(0xc820da36e0, 0xc82064e1c0, 0xc820bb2000, 0xc5001, 0xc820b4a0a0)
|
||||
/home/ubuntu/.go_workspace/src/github.com/Org/app/core/vendor/github.com/rusenask/goproxy/actions.go:19 +0x30
|
||||
```
|
||||
|
||||
我认为这可能是 Go 的设计中被忽略的东西 - 不是所有语言都不会忽视的。
|
||||
|
||||
如果我们使用 Java 作为一个随意的例子,其中人们犯的一个最愚蠢的错误是不记录堆栈追踪:
|
||||
|
||||
```
|
||||
LOGGER.error(ex.getMessage()) // Doesn't log stack trace
|
||||
LOGGER.error(ex.getMessage(), ex) // Does log stack trace
|
||||
```
|
||||
|
||||
但是 Go 设计中似乎没有这个信息
|
||||
|
||||
在获取上下文信息方面 - Russ 还提到了社区正在讨论一些潜在的接口用于剥离上下文错误。了解更多这点或许会很有趣。
|
||||
|
||||
### 堆栈追踪问题解决方案
|
||||
|
||||
幸运的是,在做了一些查找后,我发现了这个出色的[ Go 错误][5]库来帮助解决这个问题,来给错误添加堆栈跟踪:
|
||||
|
||||
```
|
||||
if errors.Is(err, crashy.Crashed) {
|
||||
fmt.Println(err.(*errors.Error).ErrorStack())
|
||||
}
|
||||
```
|
||||
|
||||
不过,我认为这个功能能成为语言的一等公民将是一个改进,这样你就不必对类型做一些修改了。此外,如果我们像先前的例子那样使用第三方库,那就可能不必使用 `crashy` - 我们仍有相同的问题。
|
||||
|
||||
### 我们对错误应该做什么?
|
||||
|
||||
我们还必须考虑发生错误时应该发生什么。[这一定有用,它们不会让你的程序崩溃][6],通常也会立即处理它们:
|
||||
|
||||
```
|
||||
err := method()
|
||||
if err != nil {
|
||||
// some logic that I must do now in the event of an error!
|
||||
}
|
||||
```
|
||||
|
||||
如果我们想要调用大量会返回错误的方法时会发生什么,在同一个地方处理它们么?看上去像这样:
|
||||
|
||||
```
|
||||
err := doSomething()
|
||||
if err != nil {
|
||||
// handle the error here
|
||||
}
|
||||
|
||||
func doSomething() error {
|
||||
err := someMethod()
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
err = someOther()
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
someOtherMethod()
|
||||
}
|
||||
```
|
||||
|
||||
这感觉有点冗余,然而在其他语言中你可以将多条语句作为一个整体处理。
|
||||
|
||||
```
|
||||
try {
|
||||
someMethod()
|
||||
someOther()
|
||||
someOtherMethod()
|
||||
}
|
||||
catch (Exception e) {
|
||||
// process exception
|
||||
}
|
||||
```
|
||||
|
||||
或者只要在方法签名中传递错误:
|
||||
|
||||
```
|
||||
public void doSomething() throws SomeErrorToPropogate {
|
||||
someMethod()
|
||||
someOther()
|
||||
someOtherMethod()
|
||||
}
|
||||
```
|
||||
|
||||
我个人认为这两个例子实现了一件事情,只有 `Exception` 模式更少冗余更加弹性。如果有什么,我发现 `if err!= nil` 感觉像样板。也许有一种方法可以清理?
|
||||
|
||||
### 将多条语句像一个整体那样发生错误
|
||||
|
||||
首先,我做了更多的阅读,并[在 Rob Pike 写的 Go 博客中][7]发现了一个比较务实的解决方案。
|
||||
|
||||
他定义了一个封装了错误的方法的结构体:
|
||||
|
||||
```
|
||||
type errWriter struct {
|
||||
w io.Writer
|
||||
err error
|
||||
}
|
||||
|
||||
func (ew *errWriter) write(buf []byte) {
|
||||
if ew.err != nil {
|
||||
return
|
||||
}
|
||||
_, ew.err = ew.w.Write(buf)
|
||||
}
|
||||
```
|
||||
|
||||
让我们这么做:
|
||||
|
||||
```
|
||||
ew := &errWriter{w: fd}
|
||||
ew.write(p0[a:b])
|
||||
ew.write(p1[c:d])
|
||||
ew.write(p2[e:f])
|
||||
// and so on
|
||||
if ew.err != nil {
|
||||
return ew.err
|
||||
}
|
||||
```
|
||||
|
||||
这也是一个很好的方案,但是我感觉缺少了点什么 - 因为我们不能重复使用这个模式。如果我们想要一个含有字符串参数的方法,我们就不得不改变函数签名。或者如果我们不想执行写会怎样?我们可以尝试使它更通用:
|
||||
|
||||
```
|
||||
type errWrapper struct {
|
||||
err error
|
||||
}
|
||||
```
|
||||
|
||||
```
|
||||
func (ew *errWrapper) do(f func() error) {
|
||||
if ew.err != nil {
|
||||
return
|
||||
}
|
||||
ew.err = f();
|
||||
}
|
||||
```
|
||||
|
||||
但是我们有一个相同的问题,如果我们想要调用含有不同参数的函数,它就无法编译了。然而你可以简单地封装这些函数调用:
|
||||
|
||||
```
|
||||
w := &errWrapper{}
|
||||
|
||||
w.do(func() error {
|
||||
return someFunction(1, 2);
|
||||
})
|
||||
|
||||
w.do(func() error {
|
||||
return otherFunction("foo");
|
||||
})
|
||||
|
||||
err := w.err
|
||||
|
||||
if err != nil {
|
||||
// process error here
|
||||
}
|
||||
```
|
||||
|
||||
这可以用,但是并没有帮助太大,因为它最后比标准的 `if err != nil` 检查带来了更多的冗余。我有兴趣听到有人能提供其他解决方案。或许语言本身需要一些方法来以不那么臃肿的方式的传递或者组合错误 - 但是感觉似乎是特意设计成不那么做。
|
||||
|
||||
### 总结
|
||||
|
||||
看完这些之后,你可能会认为我反对在 Go 中使用 `error`。但事实并非如此,我只是描述了如何将它与 `try catch` 模型的经验进行比较。它是一个用于系统编程很好的语言,并且已经出现了一些优秀的工具。仅举几例有 [Kubernetes][8]、[Docker][9]、[Terraform][10]、[Hoverfly][11] 等。还有小型、高性能、本地二进制的优点。但是,`error` 难以适应。 我希望我的推论是有道理的,而且一些方案和解决方法可能会有帮助。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Andrew 是 OpenCredo 的顾问,于 2015 年加入公司。Andrew 在多个行业工作多年,开发基于 Web 的企业应用程序。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
via: https://opencredo.com/why-i-dont-like-error-handling-in-go
|
||||
|
||||
作者:[Andrew Morgan][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opencredo.com/author/andrew/
|
||||
[1]:https://blog.golang.org/errors-are-values
|
||||
[2]:https://blog.golang.org/error-handling-and-go
|
||||
[3]:https://en.wikipedia.org/wiki/Don't_repeat_yourself
|
||||
[4]:https://research.swtch.com/go2017
|
||||
[5]:https://github.com/go-errors/errors
|
||||
[6]:https://davidnix.io/post/error-handling-in-go/
|
||||
[7]:https://blog.golang.org/errors-are-values
|
||||
[8]:https://kubernetes.io/
|
||||
[9]:https://www.docker.com/
|
||||
[10]:https://www.terraform.io/
|
||||
[11]:http://hoverfly.io/en/latest/
|
||||
@ -1,49 +0,0 @@
|
||||
Oracle 政策更改提高了 AWS 的价格
|
||||
============================================================
|
||||
|
||||
>这种改变使甲骨文在 AWS 上实施其软件的价格翻了一番,它已经安静地生效了,而几乎没有通知用户。
|
||||
|
||||

|
||||
|
||||
上周消息传出,甲骨文使亚马逊云上的产品价格翻了一倍。它在[如何计算 AWS 的虚拟 CPU][6]上耍了一些花招。它这么做也没有任何宣扬。该公司的新定价政策于 1 月 23 日生效,直到 1 月 28 日,几乎没有被注意到,直到 Oracle 的关注者 Tim Hall 偶然发现 Big Red 的[ Oracle 软件云计算环境许可][7]文件并揭发了出来。
|
||||
|
||||
乍一看,这一举动似乎并不太大,因为它仅将 Oracle 的 AWS 定价与 Microsoft Azure 的价格相提并论。但是 Azure 只有市场领先的 AWS 体量的三分之一,所以如果你想在云中销售许可证,AWS 是合适的地方。虽然此举可能或可能不会影响已经在 AWS 上使用 Oracle 的用户,但是尚不清楚新规则是否适用于已在使用产品的用户 - 它肯定会让一些考虑可能使用 Oracle 的用户另寻它处。
|
||||
|
||||
这个举动的主要原因是显而易见的。甲骨文希望使自己的云更具吸引力 - 这让[The Register 观察][8]到一点:“拉里·埃里森确实承诺过 Oracle 的云将会更快更便宜”。更快和更便宜仍然有待看到。如果 Oracle 的 SPARC 云计划启动,并且按照广告的形式执行,那么可能会更快,但是更便宜的可能性较小。甲骨文以对其价格的强硬态度而著称。
|
||||
|
||||
随着其签名数据库和业务栈销售的下滑,并且对 Sun 的 74 亿美元的投资并未能按照如期那样,Oracle 将其未来堵在云计算上。但是甲骨文来晚了,迄今为止, 它的努力似乎还没有结果, 一些金融预测者并没有看到 Oracle Cloud 的光明前景。他们说,云是一个拥挤的市场,而四大公司 - 亚马逊、微软、IBM 和谷歌 - 已经有了领先优势。
|
||||
|
||||
确实如此。但是 Oracle 面临的最大的障碍是,好吧,是 Oracle。它的声誉在它之前。
|
||||
|
||||
保守地说这个公司并不是因为明星客户服务而闻名。事实上, 新闻报道将甲骨文描绘成一个恶霸和操纵者。
|
||||
|
||||
例如,早在 2015 年,Oracle 就因为它的云并不像预期那样快速增长而越来越沮丧,开始[激活业内人士称之为的“核特权”][9]。它会审核客户的数据中心,如果客户不符合规定,将发出“违规通知” - 它通常只适用于大规模滥用情况,并命令客户在 30 天内退出使用其软件。
|
||||
|
||||
以防你还不知道,那么大量投资 Oracle 栈的大公司绝对不能在短时间内迁移到另一个解决方案。Oracle 的违规通知会引发灾难。
|
||||
|
||||
商业内幕人士 Julie Bort 解释到:“为了使违规通知消失 - 或者减少高额的违规罚款 - 甲骨文销售代表通常希望客户向合同中添加云额度”。
|
||||
|
||||
换句话说,Oracle 正在使用审计来扭转客户去购买它的云,而无论他们是否有需要。这种策略与最近 AWS 价格翻倍之间也可能存在联系。Hall 的文章的评论者指出,围绕价格提升的秘密背后的目的可能是触发软件审计。
|
||||
|
||||
使用这些策略的麻烦迟早会出来。消息一旦传播开来,你的客户就开始寻找其他选项。对 Big Red 而言或许是时候参考微软的做法,开始建立一个更好和更温和的 Oracle,将客户的需求放在第一位。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://windowsitpro.com/cloud/oracle-policy-change-raises-prices-aws
|
||||
|
||||
作者:[Christine Hall][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://windowsitpro.com/author/christine-hall
|
||||
[1]:http://windowsitpro.com/penton_ur/nojs/user/register?path=node%2F186491&nid=186491&source=email
|
||||
[2]:http://windowsitpro.com/author/christine-hall
|
||||
[3]:http://windowsitpro.com/author/christine-hall
|
||||
[4]:http://windowsitpro.com/cloud/oracle-policy-change-raises-prices-aws#comments
|
||||
[5]:http://windowsitpro.com/cloud/oracle-policy-change-raises-prices-aws#comments
|
||||
[6]:https://oracle-base.com/blog/2017/01/28/oracles-cloud-licensing-change-be-warned/
|
||||
[7]:http://www.oracle.com/us/corporate/pricing/cloud-licensing-070579.pdf
|
||||
[8]:https://www.theregister.co.uk/2017/01/30/oracle_effectively_doubles_licence_fees_to_run_in_aws/
|
||||
[9]:http://www.businessinsider.com/oracle-is-using-the-nuclear-option-to-sell-its-cloud-software-2015-7
|
||||
@ -1,82 +1,81 @@
|
||||
|
||||
AI正快速入侵我们生活的五个方面
|
||||
AI 正快速入侵我们生活的五个方面
|
||||
============================================================
|
||||
|
||||
> 让我们来看看我们已经被人工智能包围的五个真实存在的方面
|
||||
> 让我们来看看我们已经被人工智能包围的五个真实存在的方面。
|
||||
|
||||

|
||||
> 图片来源: opensource.com
|
||||
|
||||
开源项目[正在帮助推动][2]人工智能进步,而且随着技术的成熟,我们可以听到更多关于AI如何影响我们的生活的消息。你有没有考虑过AI是如何改变你周围的世界的?让我们来看看我们日益人为增强的宇宙,并考虑对我们的AI影响的未来做些大胆预测。
|
||||
开源项目[正在帮助推动][2]人工智能进步,而且随着技术的成熟,我们将听到更多关于 AI 如何影响我们生活的消息。你有没有考虑过 AI 是如何改变你周围的世界的?让我们来看看我们日益人为增强的世界,以及 AI 对未来影响的大胆预测。
|
||||
|
||||
### 1. AI影响你的购买决定
|
||||
### 1. AI 影响你的购买决定
|
||||
|
||||
一篇[VentureBeat][3]上的最近的新闻报道[《AI将如何帮助我们解读千禧一代》][4]"吸引了我的注意。我承认我对人工智能没有思考太多,也没有很难解读千禧一代,所以我渴望了解更多。事实证明,文章标题有点误导人;《如何卖东西给千禧一代》会是一个更准确的标题。
|
||||
最近 [VentureBeat][3] 上的一篇文章,[“AI 将如何帮助我们解读千禧一代”][4]吸引了我的注意。我承认我对人工智能没有思考太多,也没有费力尝试解读千禧一代,所以我很好奇,渴望了解更多。事实证明,文章标题有点误导;“如何卖东西给千禧一代”会是一个更准确的标题。
|
||||
|
||||
根据这篇文章,千禧一代是一个"人口统计细分,非常令人羡慕的一代人,以至于来自全世界的市场经理都在争抢他们"。通过分析网络行为——无论是购物、社交媒体或其他活动 - 机器学习可以帮助预测行为模式,这将可以变成有针对性的广告。文章接着解释如何将物联网和社交媒体平台挖掘成数据点。"使用机器学习挖掘社交媒体数据可以让公司了解千禧一代如何谈论其产品和他们对一个产品类别的看法,以及如何回应竞争对手的广告活动,还有可用于设计有针对性的广告系列的众多其他数据,"这篇文章解释。AI和千禧一代成为营销的未来并不是什么很令人吃惊的事,但是X一代和婴儿潮一代,你们也逃不掉呢!
|
||||
根据这篇文章,千禧一代是“一个年龄阶段的人群,被人觊觎,以至于来自全世界的市场经理都在争抢他们”。通过分析网络行为 —— 无论是购物、社交媒体或其他活动 - 机器学习可以帮助预测行为模式,这将可以变成有针对性的广告。文章接着解释如何对物联网和社交媒体平台进行挖掘形成数据点。“使用机器学习挖掘社交媒体数据,可以让公司了解千禧一代如何谈论其产品,他们对一个产品类别的看法,他们对竞争对手的广告活动如何响应,还可获得很多数据,用于设计有针对性的广告,"这篇文章解释说。AI 和千禧一代成为营销的未来并不是什么很令人吃惊的事,但是 X 一代和婴儿潮一代,你们也逃不掉呢!
|
||||
|
||||
> 人工智能被用来根据行为变化来定位包括城市人在内的整个人群。
|
||||
|
||||
例如, [Raconteur上][23]的一篇文章——"AI将怎样改变购买者的行为"解释说,AI在网上零售行业最大的力量是它能够迅速适应流动的情况下改变客户行为。人工智能创业公司 [Fluid AI][25]首席执行官Abhinav
|
||||
Aggarwal表示,他的公司的软件被客户用来预测客户行为,并且系统注意到在暴风雪期间发生了变化。“那些通常会忽略在一天中发送的电子邮件或应用内通知的用户现在正在打开它们,因为他们在家里没有太多的事情可做。一个小时,AI系统就适应了新的情况,并在工作时间发送更多的促销材料。"他解释说。
|
||||
例如, [Raconteur上][23]的一篇文章——"AI将怎样改变购买者的行为"解释说,AI 在网上零售行业最大的力量是它能够迅速适应流动的情况下改变客户行为。人工智能创业公司 [Fluid AI][25]首席执行官 Abhinav Aggarwal 表示,他的公司的软件被客户用来预测客户行为,并且系统注意到在暴风雪期间发生了变化。“那些通常会忽略在一天中发送的电子邮件或应用内通知的用户现在正在打开它们,因为他们在家里没有太多的事情可做。一个小时,AI 系统就适应了新的情况,并在工作时间发送更多的促销材料。"他解释说。
|
||||
|
||||
AI正在改变了我们怎样花钱和为什么花钱,但是AI是怎样改变我们挣钱的方式的呢?
|
||||
|
||||
### 2. 人工智能正在改变我们如何工作
|
||||
|
||||
[Fast公司][5]最近的一篇文章《这就是在2017年人工智能如何改变我们的生活》说道,求职者将会从人工智能中受益。作者解释说,除薪酬趋势更新之外,人工智能将被用来给求职者发送相关职位空缺信息。当你应该升职的时候,你就会得到一个升职的机会。
|
||||
[Fast 公司][5]最近的一篇文章《这就是在 2017 年人工智能如何改变我们的生活》说道,求职者将会从人工智能中受益。作者解释说,除薪酬趋势更新之外,人工智能将被用来给求职者发送相关职位空缺信息。当你应该升职的时候,你就会得到一个升职的机会。
|
||||
|
||||
人造智能也将被公司用来帮助新入职的员工。文章解释说:“许多新员工在头几天内获得了大量信息,其中大部分不会被保留。” 相反,机器人可能会随着时间的推移向一名新员工“滴滴”,因为它变得更加相关。
|
||||
|
||||
[Inc.][7]的一篇文章[《没有偏见的企业:人工智能将如何重塑招聘机制》][8]着眼于人才管理解决方案提供商[SAP SuccessFactors][9]是怎样利用人工智能作为一个工作描述偏差检查器”和检查员工赔偿金的偏差。
|
||||
[Inc.][7]的一篇文章[《没有偏见的企业:人工智能将如何重塑招聘机制》][8]着眼于人才管理解决方案提供商 [SAP SuccessFactors][9] 是怎样利用人工智能作为一个工作描述偏差检查器”和检查员工赔偿金的偏差。
|
||||
|
||||
[《Deloitte2017人力资本趋势报告》][10]显示,AI正在激励组织进行重组。Fast公司的文章[《AI是怎样改变公司组织的方式》][11]审查了这篇报告,该文章是基于全球10,000多名人力资源和商业领袖的调查结果。这篇文章解释说:"许多公司现在更注重文化和环境的适应性,而不是聘请最有资格的人来做某个具体任务,因为知道个人角色必须随AI的实施而发展 。" 为了适应不断变化的技术,组织也从自上而下的结构转向多学科团队,文章说。
|
||||
[《Deloitte 2017 人力资本趋势报告》][10]显示,AI 正在激励组织进行重组。Fast公司的文章[《AI 是怎样改变公司组织的方式》][11]审查了这篇报告,该文章是基于全球 10,000 多名人力资源和商业领袖的调查结果。这篇文章解释说:"许多公司现在更注重文化和环境的适应性,而不是聘请最有资格的人来做某个具体任务,因为知道个人角色必须随 AI 的实施而发展 。" 为了适应不断变化的技术,组织也从自上而下的结构转向多学科团队,文章说。
|
||||
|
||||
###3. AI正在改变教育
|
||||
###3. AI 正在改变教育
|
||||
|
||||
> AI将使所有教育生态系统的利益相关者受益。
|
||||
> AI 将使所有教育生态系统的利益相关者受益。
|
||||
|
||||
尽管教育的预算正在缩减,但是教室的规模却正在增长。因此利用技术的进步有助于提高教育体系的生产率和效率,并在提高教育质量和负担能力方面发挥作用。根据VentureBeat上的一篇文章[《2017年人工智能是怎样改变教育》][26],今年我们将看到AI对学生们的书面答案进行评分,机器人回答学生的答案,虚拟个人助理辅导学生等等。文章解释说:“AI将惠及教育生态系统的所有利益相关者。学生将能够通过即时的反馈和指导学习地更好,教师将获得丰富的学习分析和对个性化教学的见解,父母将以更低的成本看到他们的孩子的更好的职业前景,学校能够规模化优质的教育,政府能够向所有人提供可负担得起的教育。"
|
||||
尽管教育的预算正在缩减,但是教室的规模却正在增长。因此利用技术的进步有助于提高教育体系的生产率和效率,并在提高教育质量和负担能力方面发挥作用。根据VentureBeat上的一篇文章[《2017 年人工智能是怎样改变教育》][26],今年我们将看到 AI 对学生们的书面答案进行评分,机器人回答学生的答案,虚拟个人助理辅导学生等等。文章解释说:“AI 将惠及教育生态系统的所有利益相关者。学生将能够通过即时的反馈和指导学习地更好,教师将获得丰富的学习分析和对个性化教学的见解,父母将以更低的成本看到他们的孩子的更好的职业前景,学校能够规模化优质的教育,政府能够向所有人提供可负担得起的教育。"
|
||||
|
||||
### 4. 人工智能正在重塑医疗保健
|
||||
|
||||
2017年2月[CB Insights][12]的一篇文章挑选了106个医疗保健领域的人工智能初创公司,它们中的很多在过去几年中提高了第一次股权融资。这篇文章说:“在24家成像和诊断公司中,19家公司自2015年1月起就首次公开募股。”这份名单上了有那些从事于远程病人监测,药物发现和肿瘤学方面人工智能的公司。
|
||||
2017 年 2 月[CB Insights][12]的一篇文章挑选了 106 个医疗保健领域的人工智能初创公司,它们中的很多在过去几年中提高了第一次股权融资。这篇文章说:“在24 家成像和诊断公司中,19 家公司自 2015 年 1 月起就首次公开募股。”这份名单上了有那些从事于远程病人监测,药物发现和肿瘤学方面人工智能的公司。
|
||||
|
||||
3月16日发表在TechCrunch上的一篇关于AI进步如何重塑医疗保健的文章解释说:"一旦对人类的DNA有了更好的理解,就有机会更进一步,并能根据他们特殊的生活习性为他们提供个性化的见解"。这种趋势预示着“个性化遗传学”的新纪元,人们能够通过获得关于自己身体的前所未有的信息来充分控制自己的健康。"
|
||||
3 月 16 日发表在 TechCrunch 上的一篇关于 AI 进步如何重塑医疗保健的文章解释说:"一旦对人类的 DNA 有了更好的理解,就有机会更进一步,并能根据他们特殊的生活习性为他们提供个性化的见解"。这种趋势预示着“个性化遗传学”的新纪元,人们能够通过获得关于自己身体的前所未有的信息来充分控制自己的健康。"
|
||||
|
||||
本文接着解释说,AI和机器学习降低了研发新药的成本和时间。部分得益于广泛的测试,新药进入市场需要12年以上的时间。这篇文章说:“机器学习算法可以让计算机根据先前处理的数据来"学习"如何做出预测,或者选择(在某些情况下,甚至是产品)需要做什么实验。类似的算法还可用于预测特定化合物对人体的副作用,这样可以加快审批速度。"这篇文章指出,2015年旧金山的一个创业公司[Atomwise][15]完成了对两种可以减少一天内Ebola感染的新药物。
|
||||
本文接着解释说,AI 和机器学习降低了研发新药的成本和时间。部分得益于广泛的测试,新药进入市场需要 12年 以上的时间。这篇文章说:“机器学习算法可以让计算机根据先前处理的数据来"学习"如何做出预测,或者选择(在某些情况下,甚至是产品)需要做什么实验。类似的算法还可用于预测特定化合物对人体的副作用,这样可以加快审批速度。"这篇文章指出,2015 年旧金山的一个创业公司 [Atomwise][15] 完成了对两种可以减少一天内 Ebola 感染的新药物。
|
||||
|
||||
> AI正在帮助发现、诊断和治疗新疾病。
|
||||
> AI 正在帮助发现、诊断和治疗新疾病。
|
||||
|
||||
另外一个位于伦敦的初创公司[BenevolentAI][27]正在利用人工智能寻找科学文献中的模式。这篇文章说:"最近,这家公司找到了两种可能对Alzheimer起作用的化合物,引起了很多制药公司的关注。"
|
||||
另外一个位于伦敦的初创公司 [BenevolentAI][27] 正在利用人工智能寻找科学文献中的模式。这篇文章说:"最近,这家公司找到了两种可能对 Alzheimer 起作用的化合物,引起了很多制药公司的关注。"
|
||||
|
||||
除了有助于研发新药,AI正在帮助发现、诊断和治疗新疾病。TechCrunch上 文章解释说,过去是根据显示的症状诊断疾病,但是现在AI正在被用于检测血液中的疾病特征,并利用对数十亿例临床病例分析进行深度学习获得经验来制定治疗计划。这篇文章说:“IBM的Watson正在与纽约的Memorial Sloan Kettering合作,消化理解数十年来关于癌症患者和治疗方面的数据,为了向治疗疑难的癌症病例的医生提供和建议治疗方案。”
|
||||
除了有助于研发新药,AI正在帮助发现、诊断和治疗新疾病。TechCrunch 上 文章解释说,过去是根据显示的症状诊断疾病,但是现在 AI 正在被用于检测血液中的疾病特征,并利用对数十亿例临床病例分析进行深度学习获得经验来制定治疗计划。这篇文章说:“IBM 的 Watson 正在与纽约的 Memorial Sloan Kettering 合作,消化理解数十年来关于癌症患者和治疗方面的数据,为了向治疗疑难的癌症病例的医生提供和建议治疗方案。”
|
||||
|
||||
### 5. AI正在改变我们的爱情生活
|
||||
|
||||
有195个国家的超过5000万活跃用户通过一个在2012年推出的约会应用程序[Tinder][16]找到潜在的伴侣。在一篇[Forbes采访播客][17]中,Tinder的创始人兼董事长Sean Rad spoke与Steven Bertoni对人工智能是如何正在改变人们约会进行过讨论。在一篇[关于采访的文章][18]中,Bertoni引用了Rad说的话,他说:"可能有这样一个时刻,这时Tinder非常擅长推测你会感兴趣的人,Tinder在组织一次约会中可能会做很多跑腿的工作,对吧?"所以,这个app会向用户推荐一些附近的同伴,并更进一步,协调彼此的时间安排一次约会,而不只是向用户显示一些有可能的同伴。
|
||||
有 195 个国家的超过 5000 万活跃用户通过一个在 2012 年推出的约会应用程序 [Tinder][16] 找到潜在的伴侣。在一篇 [Forbes 采访播客][17]中,Tinder 的创始人兼董事长 Sean Rad spoke 与 Steven Bertoni 对人工智能是如何正在改变人们约会进行过讨论。在一篇[关于采访的文章][18]中,Bertoni 引用了 Rad 说的话,他说:"可能有这样一个时刻,这时 Tinder 非常擅长推测你会感兴趣的人,Tinder 在组织一次约会中可能会做很多跑腿的工作,对吧?"所以,这个 app 会向用户推荐一些附近的同伴,并更进一步,协调彼此的时间安排一次约会,而不只是向用户显示一些有可能的同伴。
|
||||
|
||||
> 我们的后代真的可能会爱上人工智能。
|
||||
|
||||
你爱上了AI吗?我们的后代真的可能会爱上人工智能。Raya Bidshahri发表在[Singularity Hub][19]的一篇文章《AI将如何重新定义爱情》说,几十年的后,我们可能会认为爱情不再受生物学的限制。
|
||||
你爱上了 AI 吗?我们的后代真的可能会爱上人工智能。Raya Bidshahri 发表在 [Singularity Hub][19] 的一篇文章《AI 将如何重新定义爱情》说,几十年的后,我们可能会认为爱情不再受生物学的限制。
|
||||
|
||||
Bidshahri解释说:"我们的技术符合摩尔定律,正在以惊人的速度增长——智能设备正在越来越多地融入我们的生活。",他补充道:"到2029年,我们将会有和人类同等智慧的AI,而到21世纪40年代,AI将会比人类聪明无数倍。许多人预测,有一天我们会与强大的机器合并,我们自己可能会变成人工智能。"他认为在这样一个世界上那些是不可避免的,人们将会接受与完全的非生物相爱。
|
||||
Bidshahri 解释说:"我们的技术符合摩尔定律,正在以惊人的速度增长——智能设备正在越来越多地融入我们的生活。",他补充道:"到 2029 年,我们将会有和人类同等智慧的 AI,而到 21 世纪 40 年代,AI 将会比人类聪明无数倍。许多人预测,有一天我们会与强大的机器合并,我们自己可能会变成人工智能。"他认为在这样一个世界上那些是不可避免的,人们将会接受与完全的非生物相爱。
|
||||
|
||||
这听起来有点怪异,但是相比较于未来机器人将统治世界,爱上AI会是一个更乐观的结果。Bidshahri说:"对AI进行编程,让他们能够感受到爱,这将使我们创造出更富有同情心的AI,这可能也是避免很多人忧虑的AI大灾难的关键。"
|
||||
|
||||
这份AI正在入侵我们生活各领域的其中五个方面的清单仅仅只是涉及到了我们身边的人工智能的表面。哪些AI创新是让你最兴奋的,或者是让你最烦恼的?大家可以在文章评论区写下你们的感受。
|
||||
这份 AI 正在入侵我们生活各领域的其中五个方面的清单仅仅只是涉及到了我们身边的人工智能的表面。哪些 AI 创新是让你最兴奋的,或者是让你最烦恼的?大家可以在文章评论区写下你们的感受。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
Rikki Endsley - Rikki Endsley是开源社区Opensource.com的管理员。在过去,她曾做过Red Hat开源和标准(OSAS)团队社区传播者;自由技术记者;USENIX协会的社区管理员;linux权威杂志ADMIN和Ubuntu User的合作出版者,还是杂志Sys Admin和UnixReview.com的主编。在Twitter上关注她:@rikkiends。
|
||||
Rikki Endsley - Rikki Endsley 是开源社区 Opensource.com 的管理员。在过去,她曾做过 Red Hat 开源和标准(OSAS)团队社区传播者;自由技术记者;USENIX 协会的社区管理员; linux 权威杂志 ADMIN 和 Ubuntu User 的合作出版者,还是杂志 Sys Admin 和 UnixReview.com 的主编。在 Twitter上关注她:@rikkiends。
|
||||
|
||||
|
||||
|
||||
via: https://opensource.com/article/17/3/5-big-ways-ai-rapidly-invading-our-lives
|
||||
|
||||
作者:[Rikki Endsley ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[zhousiyu325](https://github.com/zhousiyu325)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -1,132 +0,0 @@
|
||||
容器中运行容器
|
||||
============================================================
|
||||
|
||||
一些令人振奋的消息引发了我对今年 DockerCon 的兴趣,在会议中宣布了一个新的操作系统(OS)LinuxKit,并由无可争议的容器巨头公司 Docker 提供。
|
||||
|
||||
容器巨头已经宣布了一个灵活的、可扩展的操作系统,为了可移植性系统服务在其内运行。当你听到包括 Docker 运行时也在内时,你可能会感到惊讶。
|
||||
|
||||
在本文中,我们将简要介绍一下 LinuxKit 中承诺的内容,以及如何自己尝试并不断缩小优化容器。
|
||||
|
||||
**少即是多**
|
||||
|
||||
不可否认的是,用户一直在寻找一个被剥离版本的 Linux 来运行他们的微服务。通过容器化,你会尽可能地减少每个应用程序,使其成为一个位于其自身容器内的独立进程。但是,由于你对那些驻留容器主机的修补导致的问题,因此你不断地移动容器。实际上如果没有像 Kubernetes 或 Docker Swarm 这样的协调者,容器编排几乎总是会导致停机。
|
||||
|
||||
不用说,这只是让你保持操作系统尽可能小的原因之一。
|
||||
|
||||
我曾多次在不同场合重复过的最喜爱的名言,来自荷兰的天才程序员 Wietse Zweitze,他为我们提供了 email 中的 Postfix 和 TCP Wrappers 等知名软件。
|
||||
|
||||
Postfix 网站([Postfix TLS_README][10])指出,即使你编码和 Wietse 一样小心,“每 1000 行[你]就会在 Postfix 中引入一个额外的错误”。从我的专业的 DevSecOps 角度提到我可以被原谅的 “bug” 可以不严谨地说成安全问题。
|
||||
|
||||
从安全的角度来看,正是由于这个原因,代码世界中“少即是多”。简单地说,使用较少的代码行有很多好处,即安全性、管理时间和性能。对于初学者来说,安全漏洞较少,更新软件包的时间更短,启动时间更快。
|
||||
|
||||
**深入观察**
|
||||
|
||||
考虑下从容器内部运行你的程序。
|
||||
|
||||
一个好的起点是 Alpine Linux([https://alpinelin.org.org/downloads][1]),它是一个精简化的操作系统,通常比那些笨重的系统更受喜欢,如 Ubuntu 或 CentOS 等。Alpine 还提供了一个 miniroot 文件系统(用于容器内),最后一次检测是惊人的 1.8M。事实上,完整的 Linux 操作系统下载后有 80M。
|
||||
|
||||
如果你决定使用 Alpine Linux 作为 Docker 基础镜像,那么你可以在Docker Hub([https://hub.docker.com/_/alpine][2])上找到一个,其中 Alpine Linux 将自己描述为:“一个基于 Alpine Linux 的最小 Docker 镜像,具有完整的包索引,大小只有5 MB!”
|
||||
|
||||
据说无处不在的 “Window Start Button” 也是大致相同的大小!我不会尝试去验证,也不会进一步评论。
|
||||
|
||||
严肃地希望能让你了解创新的类 Unix 操作系统(如 Alpine Linux)的强大功能。
|
||||
|
||||
**锁定一切**
|
||||
|
||||
再说一点,Alpine Linux 是(并不惊人)基于 BusyBox([BusyBox][3]),一套著名的打包了 Linux 命令的集合,许多人不会意识到他们的宽带路由器、智能电视,当然还有他们家庭中的物联网设备就有它。
|
||||
|
||||
Alpine Linux 站点的“关于”页面([Alpine Linux][4])的评论中指出:
|
||||
|
||||
“Alpine Linux 的设计考虑到安全性。内核使用非官方的 grsecurity/PaX 移植进行修补,所有用户态二进制文件都编译为具有堆栈保护的地址无关可执行文件(PIE)。 这些主动安全特性可以防止所有类别的零日和其他漏洞利用”
|
||||
|
||||
换句话说,Alpine Linux 中的二进制文件捆绑在一起,提供了那些通过行业安全工具筛选的功能,以帮助缓解缓冲区溢出攻击。
|
||||
|
||||
**奇怪的袜子**
|
||||
|
||||
你可能会问,为什么当我们处理 Docker 的新操作系统时,容器的内部结构很重要?
|
||||
|
||||
那么,你可能已经猜到,当涉及容器时,他们的目标是精简。除非绝对必要,否则不包括任何东西。所以有信心的是,你可以在清理橱柜、花园棚子、车库和袜子抽屉后获得回报而没有惩罚。
|
||||
|
||||
Docker 的确因为它们的先见而获得声望。据报道,2 月初,Docker 聘请了 Alpine Linux 的主要推动者 Nathaniel Copa,他帮助将默认的官方镜像库从 Ubuntu 切换到 Alpine。Docker Hub 从新近精简镜像节省的带宽受到了欢迎。
|
||||
|
||||
并且最新的情况是,这项工作将与最新的基于容器的操作系统相结合:Docker 的 LinuxKit。
|
||||
|
||||
要说清楚的是 LinuxKit 不会注定代替 Alpine,而是位于容器下层,并作为一个完整的操作系统,你可以高兴地启动你的运行时守护程序(在这种情况下,在容器中产生 Docker 守护程序)。
|
||||
|
||||
**Blondie Atomic **
|
||||
|
||||
经过精心调试的主机绝对不是一件新事物(以前提到过嵌入式 Linux 的家用设备)。在过去几十年中一直在优化 Linux 的天才在某个时候意识到底层的操作系统是快速生产含有大量容器主机的关键。
|
||||
|
||||
例如,强大的红帽长期以来一直在出售已经贡献给 Project Atomic ([Project Atomic][6]) 的 Red Hat Atomic([https://www.redhat.com/en/resources/red-hat-enterprise-linux-atomic-host][5])。后者继续解释:
|
||||
|
||||
“基于 Red Hat Enterprise Linux 或 CentOS 和 Fedora 项目的成熟技术,Atomic Host 是一个轻量级的、不可变的平台,其设计目的仅在于运行容器化应用程序。
|
||||
|
||||
有一个很好理由将底层的、不可变的 Atomic OS 作为 Red Hat OpenShift PaaS(平台即服务)产品推荐。它最小化、高性能、尖端。
|
||||
|
||||
**特性**
|
||||
|
||||
在 Docker 关于 LinuxKit 的公告中,少即是多的口号是显而易见的。实现 LinuxKit 愿景的项目显然是不小的事业,它由 Docker 老将和 Unikernels([https://en.wikipedia.org/wiki/Unikernel][7])的主管 Justin Cormack 指导,并与 HPE、Intel、ARM、IBM 和 Microsoft LinuxKit 合作,可以在大型机以及基于物联网的冰柜中运行。
|
||||
|
||||
LinuxKit 的可配置、可插拔和可扩展性质将吸引许多项目寻找建立其服务的基准。通过开源项目,Docker 明智地邀请每个男人和他们的狗投入其功能开发,随着时间的推移,它会像好的奶酪那样成熟。
|
||||
|
||||
**布丁的证明**
|
||||
|
||||
有承诺称那些急于使用新系统的人不用再等待了。如果你准备着手 LinuxKit,你可以从 GitHub 中开始:[LinuxKit][11]
|
||||
|
||||
在 GitHub 页面上有关于如何启动和运行一些功能的指导。
|
||||
|
||||
时间允许的话我准备更加深入 LinuxKit。有争议的 Kubernetes 与 Docker Swarm 编排功能对比会是有趣的尝试。我还想看到内存占用、启动时间和磁盘空间使用率的基准测试。
|
||||
|
||||
如果承诺是真实的,则作为容器运行的可插拔系统服务是构建操作系统的迷人方式。Docker 在博客([https://blog.docker.com/2017/04/introducing-linuxkit-container-os-toolkit][12])中提到:“因为 LinuxKit 是原生容器,它有一个非常小的尺寸 - 35MB,引导时间非常小。所有系统服务都是容器,这意味着可以删除或替换所有的内容。“
|
||||
|
||||
我不知道你怎么样,但这非常符合我的胃口。
|
||||
|
||||
**呼叫警察**
|
||||
|
||||
除了站在我 DevSecOps 角度看到的功能,我将看到承诺的安全在现实中的面貌。
|
||||
|
||||
Docker 引用来自 NIST(国家标准与技术研究所:[https://www.nist.gov] [8]),并在他们的博客上声称:
|
||||
|
||||
安全性是最高目标,这与 NIST 在其“应用程序容器安全指南”草案中说明的保持一致:“使用容器专用操作系统而不是通用操作系统来减少攻击面。当使用专用容器操作系统时,攻击面通常比通用操作系统小得多,因此攻击和危及专用容器操作系统的机会较少。”
|
||||
|
||||
可能最重要的容器到主机和主机到容器的安全创新将是系统容器(系统服务)被完全地沙箱化到自己的非特权空间中,而只给它们需要的外部访问。
|
||||
|
||||
通过内核自我保护项目(KSPP)([https://kernsec.org/wiki/index.php/Kernel_Self_Protection_Project][9])的协作来实现这一功能,我很满意 Docker 开始专注于一些非常值得的东西上。对于那些不熟悉的 KSPP 的人而言,它存在理由如下:
|
||||
|
||||
“启动这个项目的的假设是内核 bug 的存在时间很长,内核必须设计成防止这些缺陷。”
|
||||
|
||||
KSPP 网站继续表态:
|
||||
|
||||
“这些努力非常重要并还在进行,但如果我们要保护我们的十亿 Android 手机、我们的汽车、国际空间站,还有其他运行 Linux 的产品,我们必须在上游的 Linux 内核中建立积极的防御性技术。我们需要内核安全地错误,而不只是安全地运行。”
|
||||
|
||||
而且,如果 Docker 最初只能在 LinuxKit 前进一小步,那么随着时间的推移,成熟度带来的好处可能会在容器领域中取得长足的进步。
|
||||
|
||||
**离终点还远**
|
||||
|
||||
像 Docker 这样不断发展壮大的集团无论在哪个方向上取得巨大的飞跃都将会用户和其他软件带来益处。
|
||||
|
||||
我鼓励所有对 Linux 感兴趣的人密切关注这个领域。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.devsecops.cc/devsecops/containers.html
|
||||
|
||||
作者:[Chris Binnie ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.devsecops.cc/
|
||||
[1]:https://alpinelinux.org/downloads/
|
||||
[2]:https://hub.docker.com/_/alpine
|
||||
[3]:https://busybox.net/
|
||||
[4]:https://www.alpinelinux.org/about/
|
||||
[5]:https://www.redhat.com/en/resources/red-hat-enterprise-linux-atomic-host
|
||||
[6]:http://www.projectatomic.io/
|
||||
[7]:https://en.wikipedia.org/wiki/Unikernel
|
||||
[8]:https://www.nist.gov/
|
||||
[9]:https://kernsec.org/wiki/index.php/Kernel_Self_Protection_Project
|
||||
[10]:http://www.postfix.org/TLS_README.html
|
||||
[11]:https://github.com/linuxkit/linuxkit
|
||||
[12]:https://blog.docker.com/2017/04/introducing-linuxkit-container-os-toolkit
|
||||
@ -0,0 +1,141 @@
|
||||
4 个拥有漂亮命令行 UI 的终端程序
|
||||
============================================================
|
||||
|
||||
### 我们来看几个精心设计的 CLI 程序,以及如何克服一些可发现的问题。
|
||||
|
||||

|
||||
>图片提供: opensource.com
|
||||
|
||||
在本文中,我会指出命令行界面的可见缺点以及克服这些问题的几种方法。
|
||||
|
||||
我喜欢命令行。我第一次接触命令行是在 1997 的 DOS 6.2 上。我学习了各种命令的语法,并展示了如何在目录中列出隐藏的文件(**attrib**)。我会每次仔细检查命令中的每个字符。 当我犯了一个错误,我会从头开始重新输入命令。有一天,有人向我展示了如何使用向上和向下箭头按键遍历历史,我被震惊了。
|
||||
|
||||
编程和开发
|
||||
|
||||
* [新的 Python 内容][1]
|
||||
|
||||
* [我们最新的 JavaScript 文章][2]
|
||||
|
||||
* [最近的 Perl 帖子][3]
|
||||
|
||||
* [红帽开发者博客][4]
|
||||
|
||||
后来当我被介绍 Linux 时,让我感到惊喜的是,上下箭头保留了它们遍历历史记录的能力。我仍然仔细地打字,但到现在为止,我了解如何输入,并且我能以每分钟 55 个单词的速度做的很好。接着有人向我展示了 tab 键,并再次改变了我的生活。
|
||||
|
||||
在 GUI 应用程序菜单中,工具提示和图标向用户展示功能。命令行缺乏这种能力,但有办法克服这个问题。在深入解决方案之前,我会来看看几个有问题的 CLI 程序:
|
||||
|
||||
### 1\. MySQL
|
||||
|
||||
首先我们有我们所钟爱的 MySQL REPL。我经常发现自己在输入 **SELECT * FROM** 然后按 **Tab** 的习惯。MySQL 会询问我是否想看到所有的 871 中可能性。我的数据库中绝对没有 871 张表。如果我选择 **yes**,它会显示一堆 SQL 关键字、表、函数等。
|
||||
|
||||

|
||||
|
||||
### 2\. Python
|
||||
|
||||
我们来看另一个例子,标准的 Python REPL。我开始输入命令,然后习惯按 **Tab** 键。瞧,插入了一个 **Tab** 字符,考虑到 **Tab** 在 Python 中没有作用,这是一个问题。
|
||||
|
||||

|
||||
|
||||
### 好的 UX
|
||||
|
||||
让我看下设计良好的 CLI 程序以及它们是如何克服这些可见问题的。
|
||||
|
||||
### 自动补全: bpython
|
||||
|
||||
[Bpython][15] 是对 Python REPL 的一个很好的替代。当我运行 bpython 并开始输入时,建议会立即出现。我没用通过特殊的键盘绑定触发它,甚至没有按下 **Tab** 键。
|
||||
|
||||

|
||||
|
||||
当我出于习惯按下 **Tab** 键时,它会用列表中的第一个建议补全。这是给 CLI 设计带来可见性的一个很好的例子。
|
||||
|
||||
bpython 另一方面可以展示模块和函数的文档。当我输入一个函数的名字时,它会显示函数签名以及这个函数附带的文档字符串。这是一个多么令人难以置信的周到设计啊。
|
||||
|
||||
### 上下文感知补全:mycli
|
||||
|
||||
[Mycli][16]是默认的 MySQL 客户端的现代替代品。这个工具对 MySQL 来说就像 bpython 对标准 Python REPL 做的那样。Mycli 将在你输入时自动补全关键字、表名、列和函数。
|
||||
|
||||
补全建议是上下文相关的。例如,在 **SELECT * FROM** 之后,只有来自当前数据库的表才会列出,而不是所有可能的关键字。
|
||||
|
||||

|
||||
|
||||
### 模糊搜索和在线帮助: pgcli
|
||||
|
||||
如果您正在寻找 PostgreSQL 版本的 mycli,请查看 [pgcli][17]。 与 mycli 一样,它提供了上下文感知的自动补全。菜单中的项使用模糊搜索缩小。模糊搜索允许用户输入整体字符串中的任意子字符串来尝试找到正确的匹配项。
|
||||
|
||||

|
||||
|
||||
pgcli 和 mycli 同时在 CLI 中实现了这个功能。斜杠命令的文档也作为补全菜单的一部分展示。
|
||||
|
||||
### 可发现性: fish
|
||||
|
||||
在传统的 Unix shell(Bash、zsh 等)中,有一种搜索历史记录的方法。此搜索模式由 **Ctrl-R** 触发。当在再次调用你上周运行的命令时,这是一个令人难以置信的有用的工具,例如 **ssh**或 **docker**。 一旦你知道这个功能,你会发现自己经常使用它。
|
||||
|
||||
如果这个功能是如此有用,那为什么不每次都搜索呢?这正是 [**fish** shell][18] 所做的。一旦你开始输入命令,**fish** 将开始建议与历史记录类似的命令。然后,你可以按右箭头键接受该建议。
|
||||
|
||||
### 命令行规矩
|
||||
|
||||
我已经回顾了一些创新的方法来解决可见的问题,但也有一些命令行的基础知识, 每个人都应该作为基本的 repl 功能的一部分来执行:
|
||||
|
||||
* 确保 REPL 有可通过箭头键调用的历史记录。确保会话之间的历史持续存在。
|
||||
|
||||
* 提供在编辑器中编辑命令的方法。不管你的补全是多么棒,有时用户只需要一个编辑器来制作完美的命令来删除生产环境中所有的表。
|
||||
|
||||
* 使用 pager 来管道输出。不要让用户滚动他们的终端。哦,并为 pager 使用合理的默认值。(添加选项来处理颜色代码。)
|
||||
|
||||
* 提供一种通过 **Ctrl-R** 界面或者 **fish** 样式的自动搜索来搜索历史记录的方法。
|
||||
|
||||
### 总结
|
||||
|
||||
在第 2 部分中,我将来看看 Python 中使你能够实现这些技术的特定库。同时,请查看其中一些精心设计的命令行应用程序:
|
||||
|
||||
* [bpython][5]或 [ptpython][6]:具有自动补全支持的 Python REPL。
|
||||
|
||||
* [http-prompt][7]:交互式 HTTP 客户端。
|
||||
|
||||
* [mycli][8]:MySQL、MariaDB 和 Percona 的命令行界面,具有自动补全和语法高亮。
|
||||
|
||||
* [pgcli][9]:具有自动补全和语法高亮,是对 [psql][10] 的替代工具。
|
||||
|
||||
* [wharfee][11]:用于管理 Docker 容器的 shell。
|
||||
|
||||
_在这了解 Amjith Ramanujam 更多的在 5 月 20 日在波特兰俄勒冈州举办的 [PyCon US 2017][12] 上的谈话“[令人敬畏的命令行工具][13]”。_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
作者简介:
|
||||
|
||||
Amjith Ramanujam - Amjith Ramanujam 是 pgcli 和 mycli 的创始人。人们认为它们很酷,他并不反对。他喜欢用 Python、Javascript 和 C 编程。他喜欢编写简单易懂的代码,它们有时甚至会成功。
|
||||
|
||||
-----------------------
|
||||
|
||||
via: https://opensource.com/article/17/5/4-terminal-apps
|
||||
|
||||
作者:[Amjith Ramanujam ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/amjith
|
||||
[1]:https://opensource.com/tags/python?src=programming_resource_menu
|
||||
[2]:https://opensource.com/tags/javascript?src=programming_resource_menu
|
||||
[3]:https://opensource.com/tags/perl?src=programming_resource_menu
|
||||
[4]:https://developers.redhat.com/?intcmp=7016000000127cYAAQ&src=programming_resource_menu
|
||||
[5]:http://bpython-interpreter.org/
|
||||
[6]:http://github.com/jonathanslenders/ptpython/
|
||||
[7]:https://github.com/eliangcs/http-prompt
|
||||
[8]:http://mycli.net/
|
||||
[9]:http://pgcli.com/
|
||||
[10]:https://www.postgresql.org/docs/9.2/static/app-psql.html
|
||||
[11]:http://wharfee.com/
|
||||
[12]:https://us.pycon.org/2017/
|
||||
[13]:https://us.pycon.org/2017/schedule/presentation/518/
|
||||
[14]:https://opensource.com/article/17/5/4-terminal-apps?rate=3HL0zUQ8_dkTrinonNF-V41gZvjlRP40R0RlxTJQ3G4
|
||||
[15]:https://bpython-interpreter.org/
|
||||
[16]:http://mycli.net/
|
||||
[17]:http://pgcli.com/
|
||||
[18]:https://fishshell.com/
|
||||
[19]:https://opensource.com/user/125521/feed
|
||||
[20]:https://opensource.com/article/17/5/4-terminal-apps#comments
|
||||
[21]:https://opensource.com/users/amjith
|
||||
Loading…
Reference in New Issue
Block a user