mirror of
https://github.com/LCTT/TranslateProject.git
synced 2024-12-26 21:30:55 +08:00
commit
1ed0510bbc
@ -0,0 +1,56 @@
|
||||
一周 GNOME 之旅:品味它和 KDE 的是是非非(第一节 介绍)
|
||||
================================================================================
|
||||
|
||||
*作者声明: 如果你是因为某种神迹而在没看标题的情况下点开了这篇文章,那么我想再重申一些东西……这是一篇评论文章,文中的观点都是我自己的,不代表 Phoronix 网站和 Michael 的观点。它们完全是我自己的想法。*
|
||||
|
||||
另外,没错……这可能是一篇引战的文章。我希望 KDE 和 Gnome 社团变得更好一些,因为我想发起一个讨论并反馈给他们。为此,当我想指出(我所看到的)一个瑕疵时,我会尽量地做到具体而直接。这样,相关的讨论也能做到同样的具体和直接。再次声明:本文另一可选标题为“死于成千上万的[纸割][1]”(LCTT 译注:paper cuts——纸割,被纸片割伤——指易修复但烦人的缺陷。Ubuntu 从 9.10 开始,发起了 [One Hundred Papercuts][1] 项目,用于修复那些小而烦人的易用性问题)。
|
||||
|
||||
现在,重申完毕……文章开始。
|
||||
|
||||
|
||||
|
||||
当我把[《评价 Fedora 22 KDE 》][2]一文发给 Michael 时,感觉很不是滋味。不是因为我不喜欢 KDE,或者不待见 Fedora,远非如此。事实上,我刚开始想把我的 T450s 的系统换为 Arch Linux 时,马上又决定放弃了,因为我很享受 fedora 在很多方面所带来的便捷性。
|
||||
|
||||
我感觉很不是滋味的原因是 Fedora 的开发者花费了大量的时间和精力在他们的“工作站”产品上,但是我却一点也没看到。在使用 Fedora 时,我并没用采用那些主要开发者希望用户采用的那种使用方式,因此我也就体验不到所谓的“ Fedora 体验”。它感觉就像一个人评价 Ubuntu 时用的却是 Kubuntu,评价 OS X 时用的却是 Hackintosh,或者评价 Gentoo 时用的却是 Sabayon。根据论坛里大量读者对 Michael 的说法,他们在评价各种发行版时都是使用的默认设置——我也不例外。但是我还是认为这些评价应该在“真实”配置下完成,当然我也知道在给定的情况下评论某些东西也的确是有价值的——无论是好是坏。
|
||||
|
||||
正是在怀着这种态度的情况下,我决定跳到 Gnome 这个水坑里来泡泡澡。
|
||||
|
||||
但是,我还要在此多加一个声明……我在这里所看到的 KDE 和 Gnome 都是打包在 Fedora 中的。OpenSUSE、 Kubuntu、 Arch等发行版的各个桌面可能有不同的实现方法,使得我这里所说的具体的“痛点”跟你所用的发行版有所不同。还有,虽然用了这个标题,但这篇文章将会是一篇“很 KDE”的重量级文章。之所以这样称呼,是因为我在“使用” Gnome 之后,才知道 KDE 的“纸割”到底有多么的多。
|
||||
|
||||
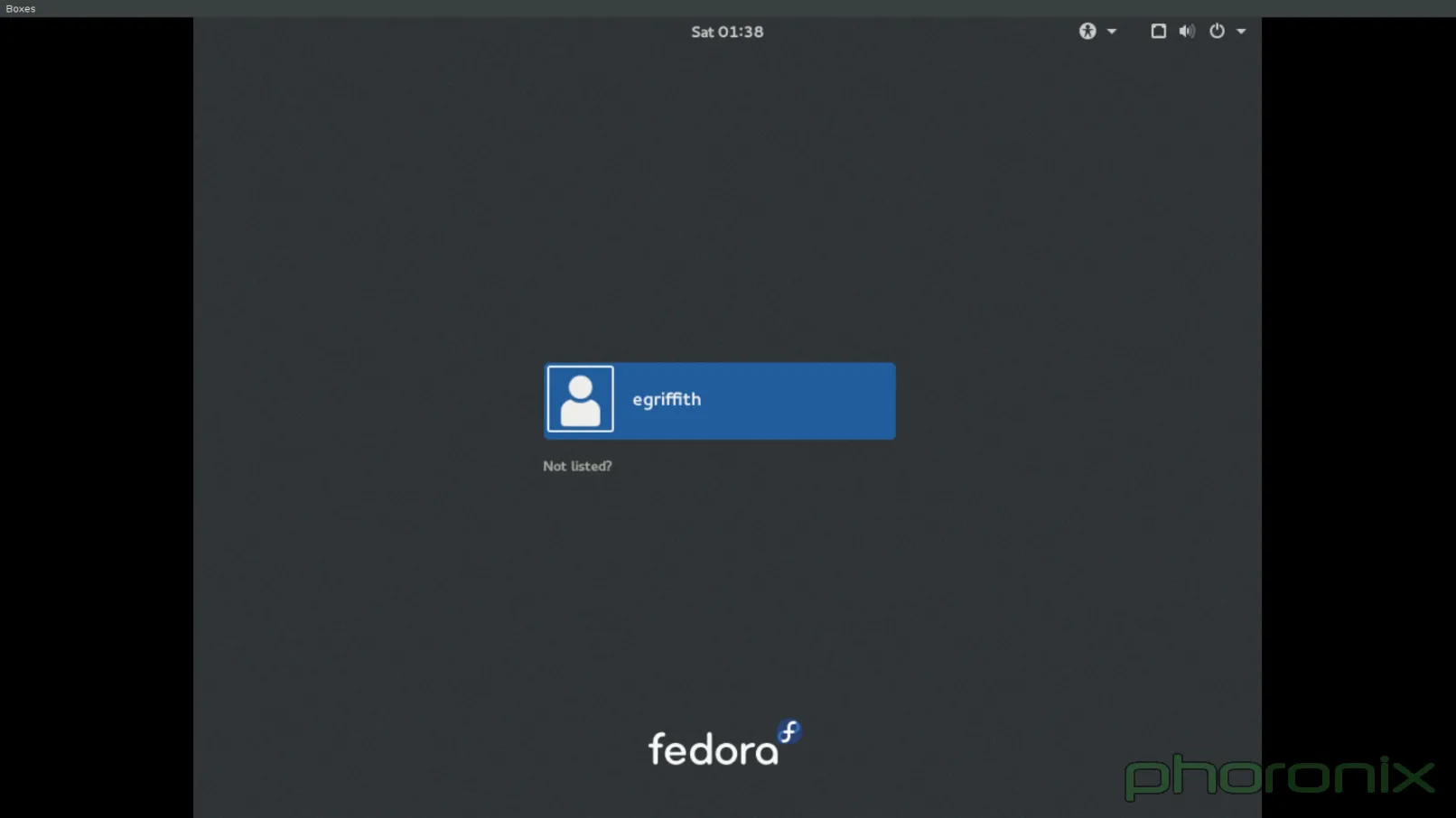
### 登录界面 ###
|
||||
|
||||
|
||||
|
||||
我一般情况下都不会介意发行版带着它们自己的特别主题,因为一般情况下桌面看起来会更好看。可我今天可算是找到了一个例外。
|
||||
|
||||
第一印象很重要,对吧?那么,GDM(LCTT 译注: Gnome Display Manage:Gnome 显示管理器。)绝对干得漂亮。它的登录界面看起来极度简洁,每一部分都应用了一致的设计风格。使用通用图标而不是文本框为它的简洁加了分。
|
||||
|
||||

|
||||
|
||||
这并不是说 Fedora 22 KDE ——现在已经是 SDDM 而不是 KDM 了——的登录界面不好看,但是看起来绝对没有它这样和谐。
|
||||
|
||||
问题到底出来在哪?顶部栏。看看 Gnome 的截图——你选择一个用户,然后用一个很小的齿轮简单地选择想登入哪个会话。设计很简洁,一点都不碍事,实话讲,如果你没注意的话可能完全会看不到它。现在看看那蓝色( LCTT 译注:blue,有忧郁之意,一语双关)的 KDE 截图,顶部栏看起来甚至不像是用同一个工具渲染出来的,它的整个位置的安排好像是某人想着:“哎哟妈呀,我们需要把这个选项扔在哪个地方……”之后决定下来的。
|
||||
|
||||
对于右上角的重启和关机选项也一样。为什么不单单用一个电源按钮,点击后会下拉出一个菜单,里面包括重启,关机,挂起的功能?按钮的颜色跟背景色不同肯定会让它更加突兀和显眼……但我可不觉得这样子有多好。同样,这看起来可真像“苦思”后的决定。
|
||||
|
||||
从实用观点来看,GDM 还要远远实用的多,再看看顶部一栏。时间被列了出来,还有一个音量控制按钮,如果你想保持周围安静,你甚至可以在登录前设置静音,还有一个可用性按钮来实现高对比度、缩放、语音转文字等功能,所有可用的功能通过简单的一个开关按钮就能得到。
|
||||
|
||||
|
||||
|
||||
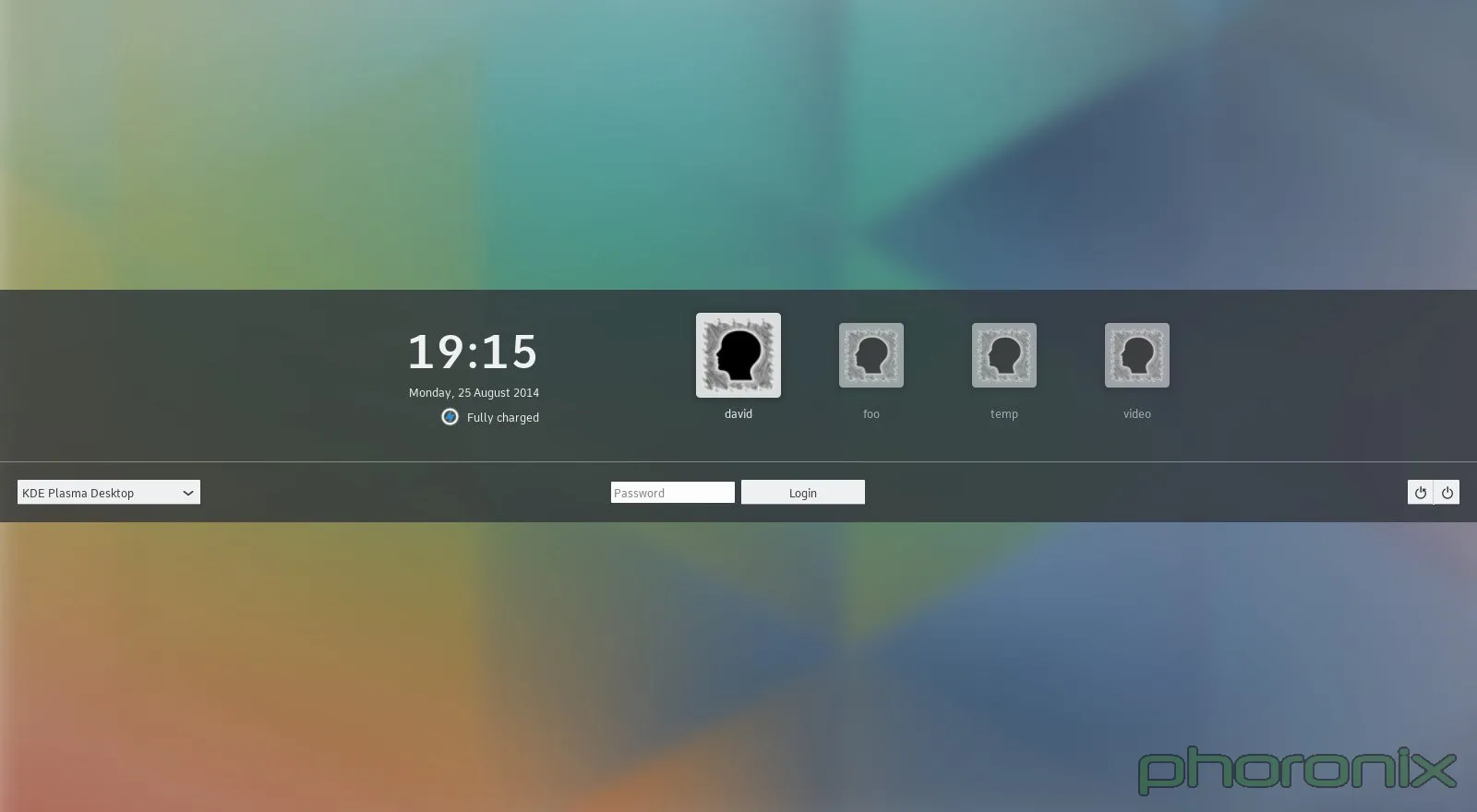
切换到上游(KDE 自带)的 Breeve 主题……突然间,我抱怨的大部分问题都被解决了。通用图标,所有东西都放在了屏幕中央,但不是那么重要的被放到了一边。因为屏幕顶部和底部都是同样的空白,在中间也就酝酿出了一种美好的和谐。还是有一个文本框来切换会话,但既然电源按钮被做成了通用图标,那么这点还算可以原谅。当前时间以一种漂亮的感觉呈现,旁边还有电量指示器。当然 gnome 还是有一些很好的附加物,例如音量小程序和可用性按钮,但 Breeze 总归要比 Fedora 的 KDE 主题进步。
|
||||
|
||||
到 Windows(Windows 8和10之前)或者 OS X 中去,你会看到类似的东西——非常简洁的,“不碍事”的锁屏与登录界面,它们都没有文本框或者其它分散视觉的小工具。这是一种有效的不分散人注意力的设计。Fedora……默认带有 Breeze 主题。VDG 在 Breeze 主题设计上干得不错。可别糟蹋了它。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.phoronix.com/scan.php?page=article&item=gnome-week-editorial&num=1
|
||||
|
||||
作者:Eric Griffith
|
||||
译者:[XLCYun](https://github.com/XLCYun)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://wiki.ubuntu.com/One%20Hundred%20Papercuts
|
||||
[2]:http://www.phoronix.com/scan.php?page=article&item=fedora-22-kde&num=1
|
||||
[3]:https://launchpad.net/hundredpapercuts
|
||||
@ -0,0 +1,32 @@
|
||||
一周 GNOME 之旅:品味它和 KDE 的是是非非(第二节 GNOME桌面)
|
||||
================================================================================
|
||||
|
||||
### 桌面 ###
|
||||
|
||||
|
||||
|
||||
在我这一周的前五天中,我都是直接手动登录进 Gnome 的——没有打开自动登录功能。在第五天的晚上,每一次都要手动登录让我觉得很厌烦,所以我就到用户管理器中打开了自动登录功能。下一次我登录的时候收到了一个提示:“你的密钥链(keychain)未解锁,请输入你的密码解锁”。在这时我才意识到了什么……Gnome 以前一直都在自动解锁我的密钥链(KDE 中叫做我的钱包),每当我通过 GDM 登录时 !当我绕开 GDM 的登录程序时,Gnome 才不得不介入让我手动解锁。
|
||||
|
||||
现在,鄙人的陋见是如果你打开了自动登录功能,那么你的密钥链也应当自动解锁——否则,这功能还有何用?无论如何,你还是需要输入你的密码,况且在 GDM 登录界面你还有机会选择要登录的会话,如果你想换的话。
|
||||
|
||||
但是,这点且不提,也就是在那一刻,我意识到要让这桌面感觉就像它在**和我**一起工作一样是多么简单的一件事。当我通过 SDDM 登录 KDE 时?甚至连启动界面都还没加载完成,就有一个窗口弹出来遮挡了启动动画(因此启动动画也就被破坏了),它提示我解锁我的 KDE 钱包或 GPG 钥匙环。
|
||||
|
||||
如果当前还没有钱包,你就会收到一个创建钱包的提醒——就不能在创建用户的时候同时为我创建一个吗?接着它又让你在两种加密模式中选择一种,甚至还暗示我们其中一种(Blowfish)是不安全的,既然是为了安全,为什么还要我选择一个不安全的东西?作者声明:如果你安装了真正的 KDE spin 版本而不是仅仅安装了被 KDE 搞过的版本,那么在创建用户时,它就会为你创建一个钱包。但很不幸的是,它不会帮你自动解锁,并且它似乎还使用了更老的 Blowfish 加密模式,而不是更新而且更安全的 GPG 模式。
|
||||
|
||||
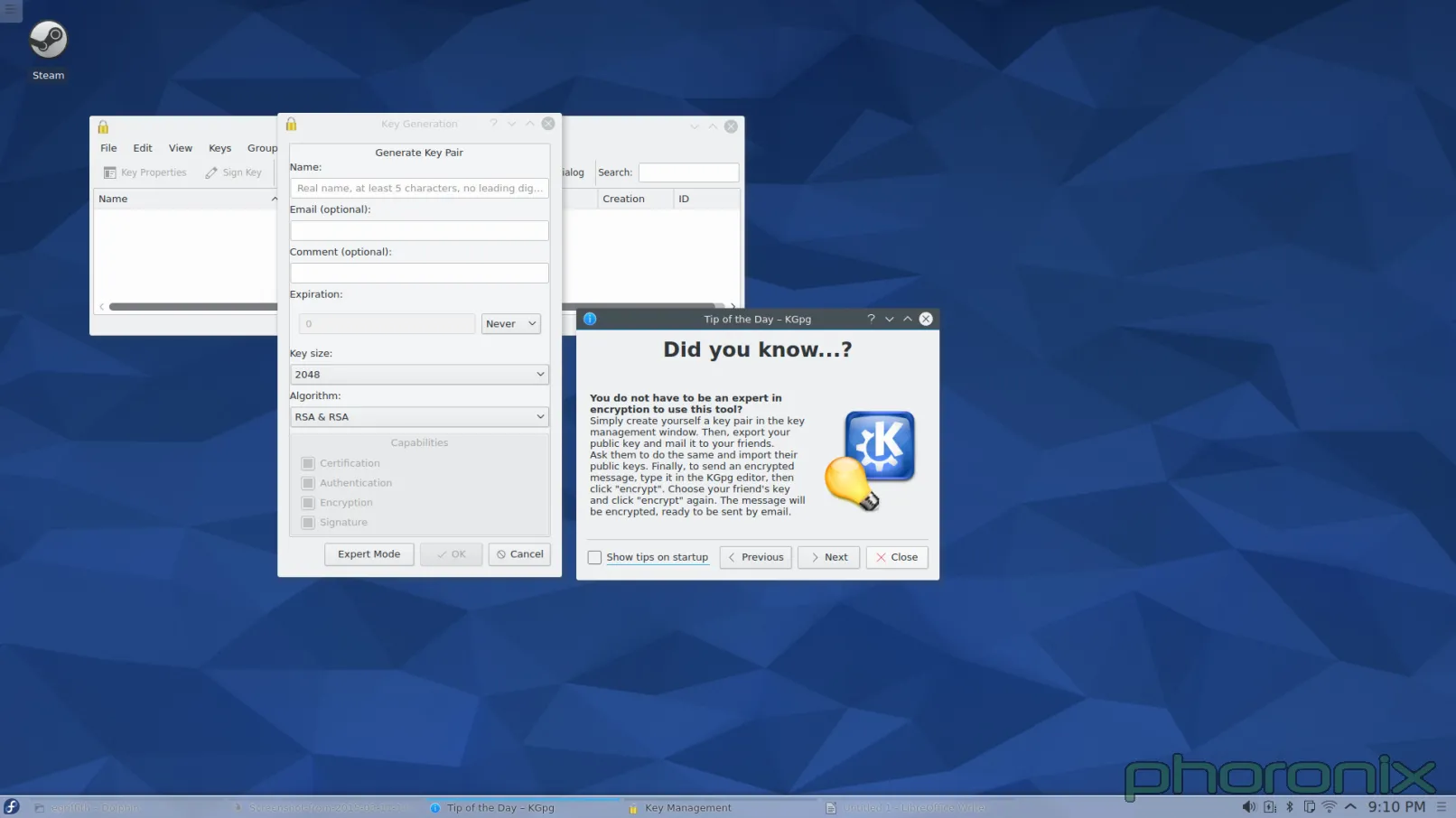
|
||||
|
||||
如果你选择了那个安全的加密模式(GPG),那么它会尝试加载 GPG 密钥……我希望你已经创建过一个了,因为如果你没有,那么你可又要被指责一番了。怎么样才能创建一个?额……它不帮你创建一个……也不告诉你怎么创建……假如你真的搞明白了你应该使用 KGpg 来创建一个密钥,接着在你就会遇到一层层的菜单和一个个的提示,而这些菜单和提示只能让新手感到困惑。为什么你要问我 GPG 的二进制文件在哪?天知道在哪!如果不止一个,你就不能为我选择一个最新的吗?如果只有一个,我再问一次,为什么你还要问我?
|
||||
|
||||
为什么你要问我要使用多大的密钥大小和加密算法?你既然默认选择了 2048 和 RSA/RSA,为什么不直接使用?如果你想让这些选项能够被修改,那就把它们扔在下面的“Expert mode(专家模式)” 按钮里去。这里不仅仅是说让配置可被用户修改的问题,而是说根本不需要默认把多余的东西扔在了用户面前。这种问题将会成为这篇文章剩下的主要内容之一……KDE 需要更理智的默认配置。配置是好的,我很喜欢在使用 KDE 时的配置,但它还需要知道什么时候应该,什么时候不应该去提示用户。而且它还需要知道“嗯,它是可配置的”不能做为默认配置做得不好的借口。用户最先接触到的就是默认配置,不好的默认配置注定要失去用户。
|
||||
|
||||
让我们抛开密钥链的问题,因为我想我已经表达出了我的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.phoronix.com/scan.php?page=article&item=gnome-week-editorial&num=2
|
||||
|
||||
作者:Eric Griffith
|
||||
译者:[XLCYun](https://github.com/XLCYun)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,66 @@
|
||||
一周 GNOME 之旅:品味它和 KDE 的是是非非(第三节 GNOME应用)
|
||||
================================================================================
|
||||
|
||||
### 应用 ###
|
||||
|
||||
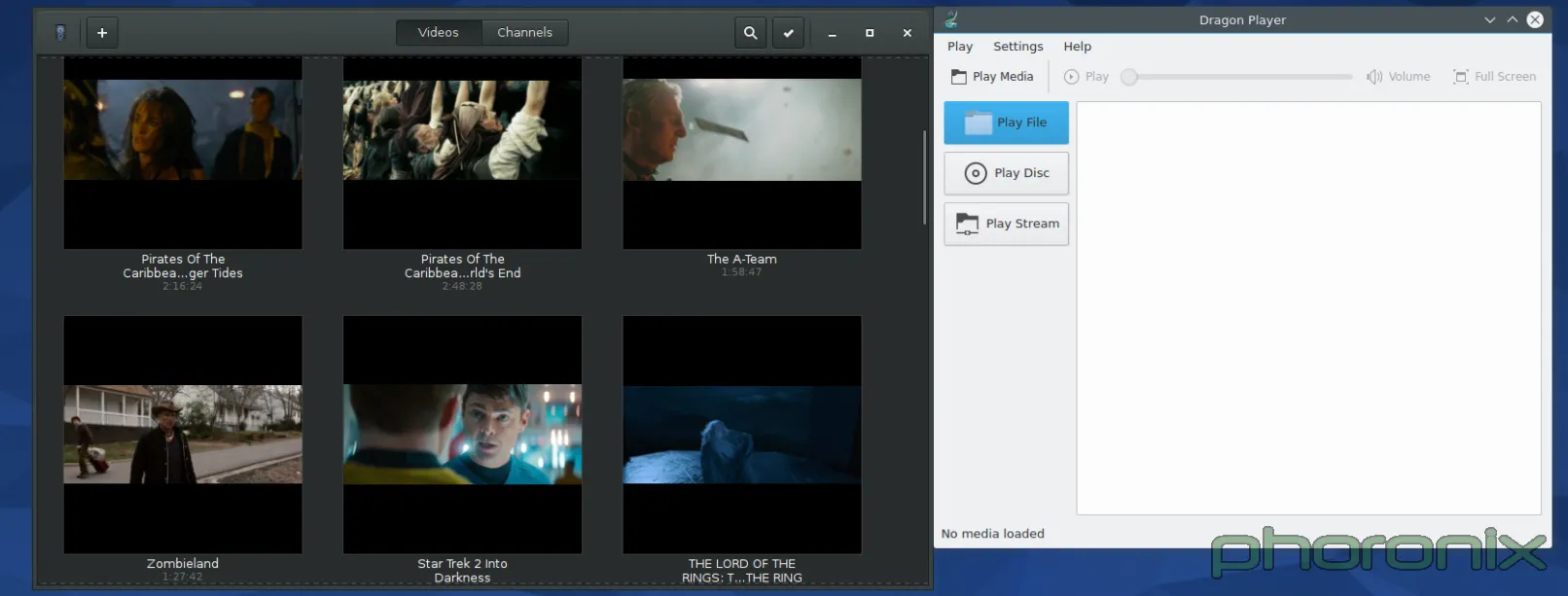
|
||||
|
||||
这是一个基本扯平的方面。每一个桌面环境都有一些非常好的应用,也有一些不怎么样的。再次强调,Gnome 把那些 KDE 完全错失的小细节给做对了。我不是想说 KDE 中有哪些应用不好。他们都能工作,但仅此而已。也就是说:它们合格了,但确实还没有达到甚至接近100分。
|
||||
|
||||
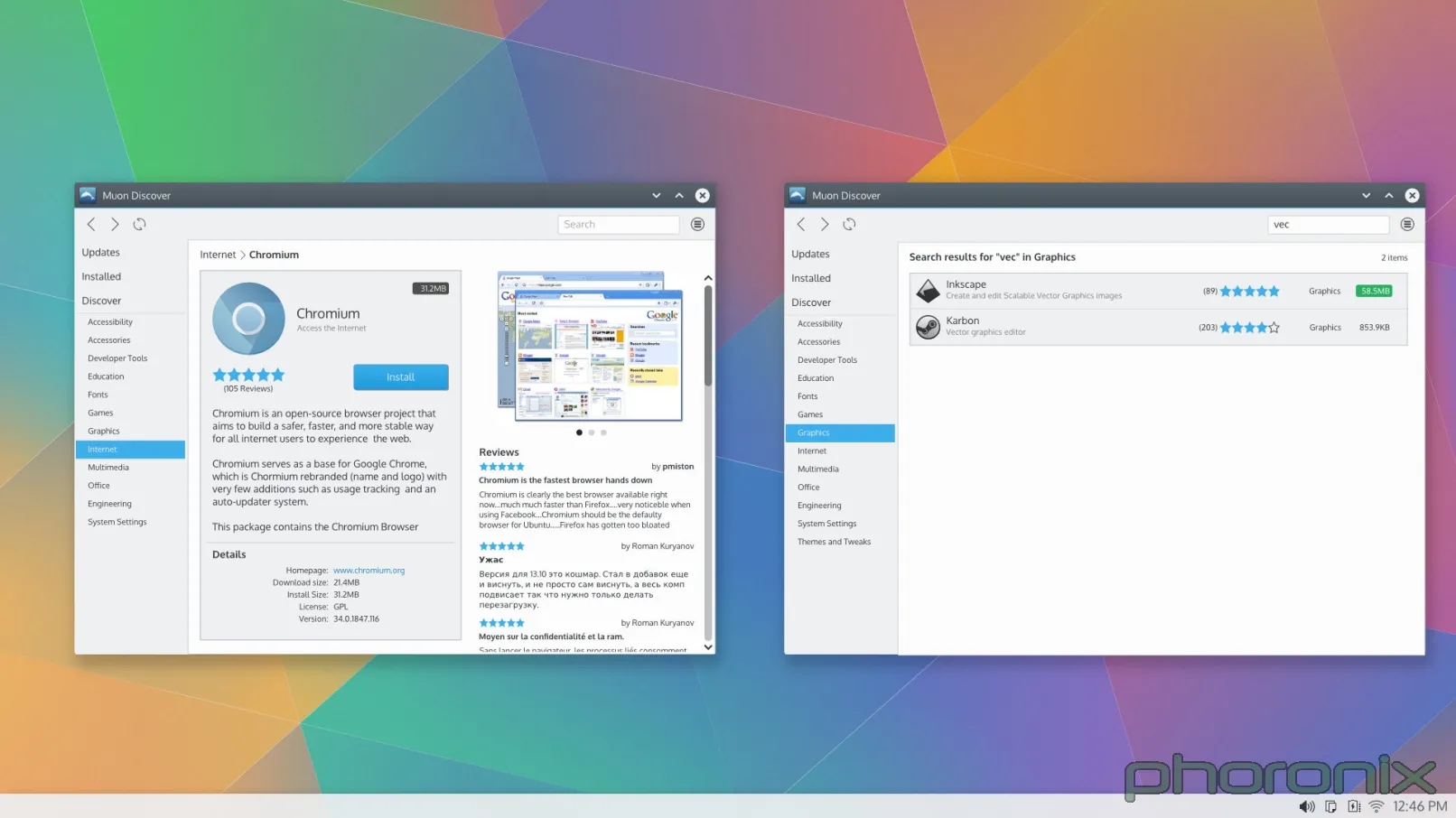
Gnome 在左,KDE 在右。Dragon 播放器运行得很好,清晰的标出了播放文件、URL或和光盘的按钮,正如你在 Gnome Videos 中能做到的一样……但是在便利的文件名和用户的友好度方面,Gnome 多走了一小步。它默认显示了在你的电脑上检测到的所有影像文件,不需要你做任何事情。KDE 有 [Baloo][](正如之前的 [Nepomuk][2],LCTT 译注:这是 KDE 中一种文件索引服务框架)为什么不使用它们?它们能列出可读取的影像文件……但却没被使用。
|
||||
|
||||
下一步……音乐播放器
|
||||
|
||||
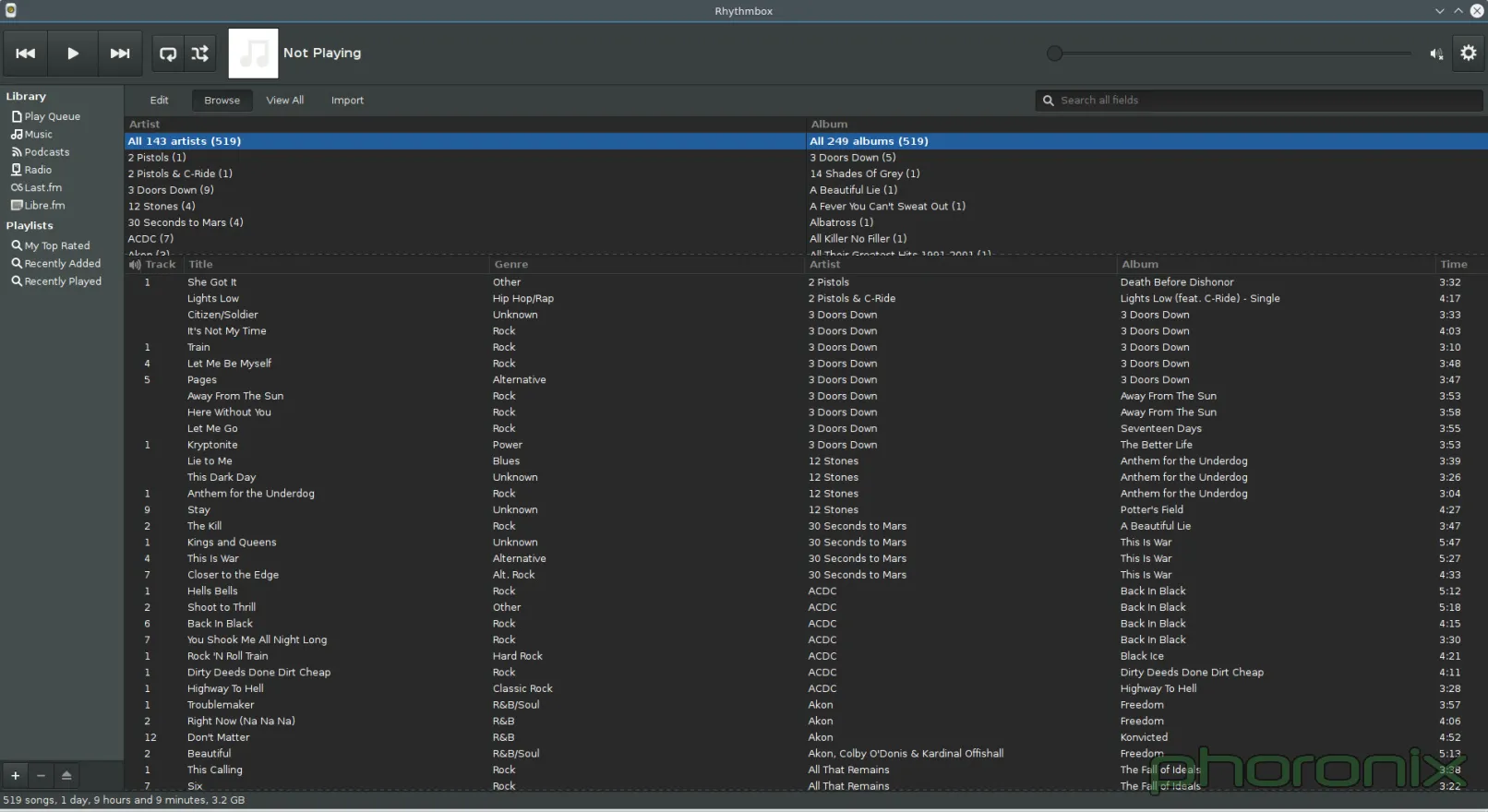
|
||||
|
||||
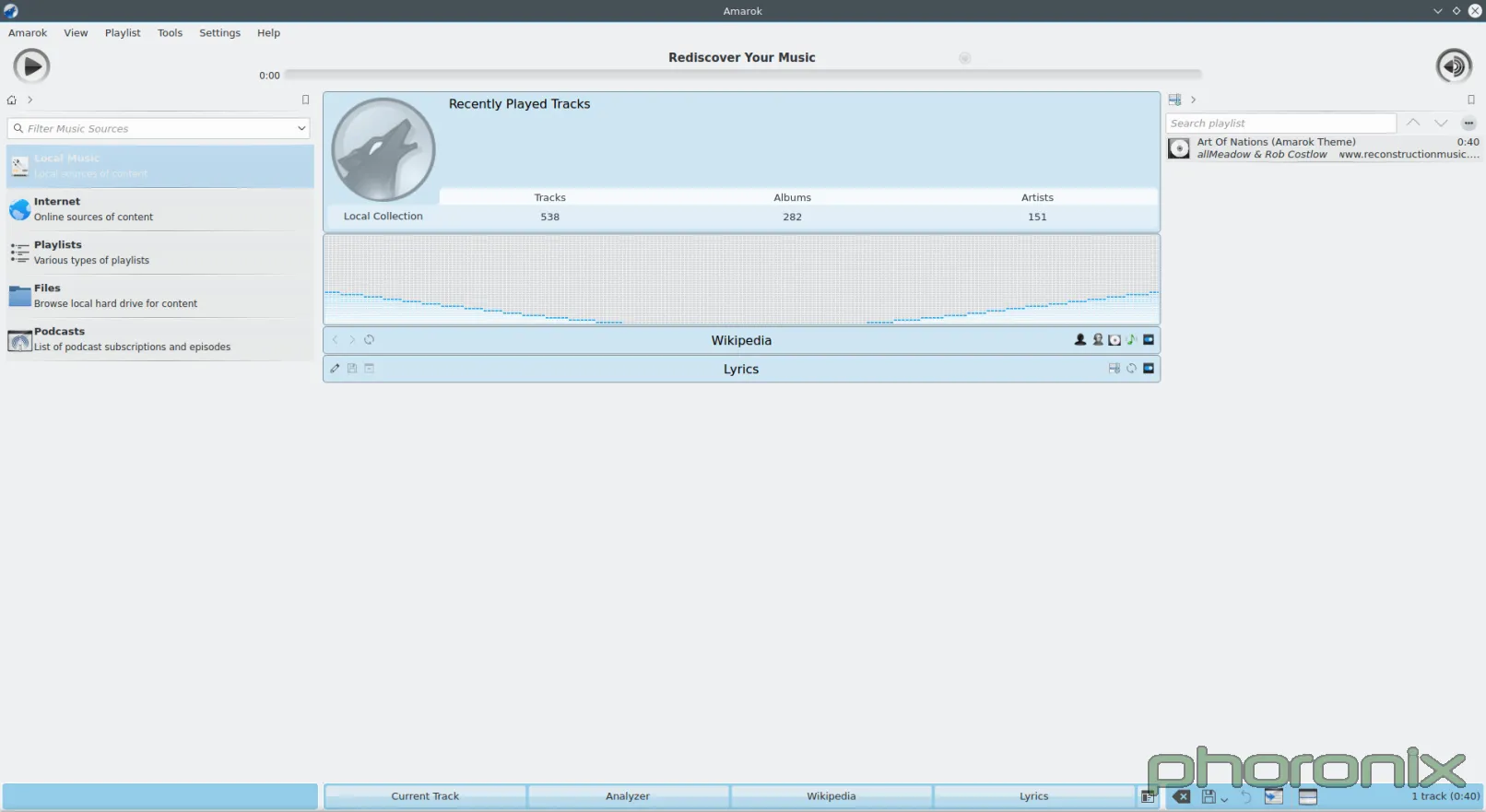
|
||||
|
||||
这两个应用,左边的是 Rhythmbox ,右边的是 Amarok,都是打开后没有做任何修改直接截屏的。看到差别了吗?Rhythmbox 看起来像个音乐播放器,直接了当,排序文件的方法也很清晰,它知道它应该是什么样的,它的工作是什么:就是播放音乐。
|
||||
|
||||
Amarok 感觉就像是某个人为了展示而把所有的扩展和选项都尽可能地塞进一个应用程序中去,而做出来的一个技术演示产品(tech demos),或者一个库演示产品(library demos)——而这些是不应该做为产品装进去的,它只应该展示其中一点东西。而 Amarok 给人的感觉却是这样的:好像是某个人想把每一个感觉可能很酷的东西都塞进一个媒体播放器里,甚至都不停下来想“我想写啥来着?一个播放音乐的应用?”
|
||||
|
||||
看看默认布局就行了。前面和中心都呈现了什么?一个可视化工具和集成了维基百科——占了整个页面最大和最显眼的区域。第二大的呢?播放列表。第三大,同时也是最小的呢?真正的音乐列表。这种默认设置对于一个核心应用来说,怎么可能称得上理智?
|
||||
|
||||
软件管理器!它在最近几年当中有很大的进步,而且接下来的几个月中,很可能只能看到它更大的进步。不幸的是,这是另一个 KDE 做得差一点点就能……但还是在终点线前以脸戗地了。
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
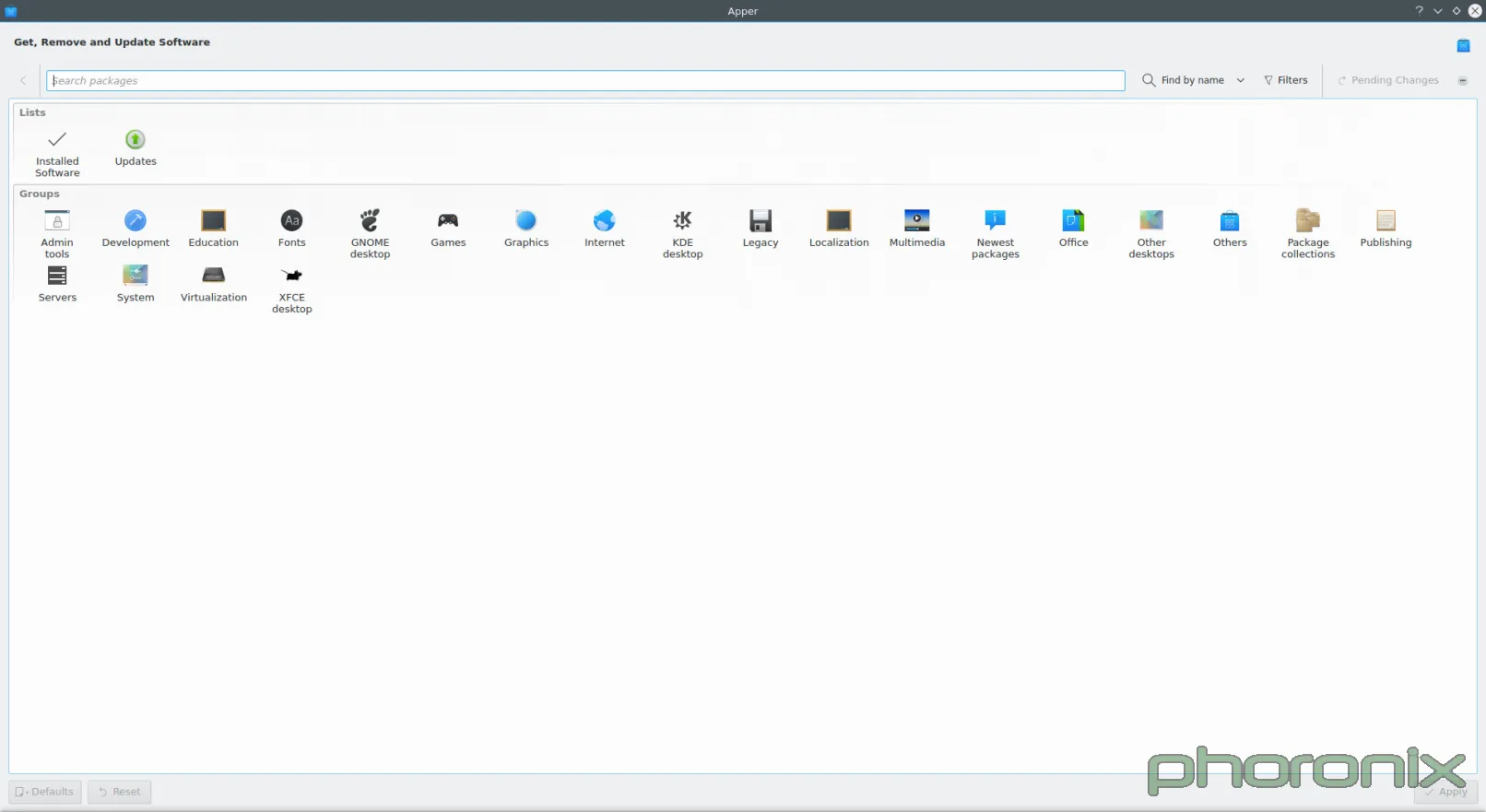
Gnome 软件中心可能是我的新的最爱的软件中心,先放下牢骚等下再发。Muon, 我想爱上你,真的。但你就是个设计上的梦魇。当 VDG 给你画设计草稿时(草图如下),你看起来真漂亮。白色空间用得很好,设计简洁,类别列表也很好,你的整个“不要分开做成两个应用程序”的设计都很不错。
|
||||
|
||||
|
||||
|
||||
接着就有人为你写代码,实现真正的UI,但是,我猜这些家伙当时一定是喝醉了。
|
||||
|
||||
我们来看看 Gnome 软件中心。正中间是什么?软件,软件截图和软件描述等等。Muon 的正中心是什么?白白浪费的大块白色空间。Gnome 软件中心还有一个贴心便利特点,那就是放了一个“运行”的按钮在那儿,以防你已经安装了这个软件。便利性和易用性很重要啊,大哥。说实话,仅仅让 Muon 把东西都居中对齐了可能看起来的效果都要好得多。
|
||||
|
||||
Gnome 软件中心沿着顶部的东西是什么,像个标签列表?所有软件,已安装软件,软件升级。语言简洁,直接,直指要点。Muon,好吧,我们有个“发现”,这个语言表达上还算差强人意,然后我们又有一个“已安装软件”,然后,就没有然后了。软件升级哪去了?
|
||||
|
||||
好吧……开发者决定把升级独立分开成一个应用程序,这样你就得打开两个应用程序才能管理你的软件——一个用来安装,一个用来升级——自从有了新立得图形软件包管理器以来,首次有这种破天荒的设计,与任何已存的软件中心的设计范例相违背。
|
||||
|
||||
我不想贴上截图给你们看,因为我不想等下还得清理我的电脑,如果你进入 Muon 安装了什么,那么它就会在屏幕下方根据安装的应用名创建一个标签,所以如果你一次性安装很多软件的话,那么下面的标签数量就会慢慢的增长,然后你就不得不手动检查清除它们,因为如果你不这样做,当标签增长到超过屏幕显示时,你就不得不一个个找过去来才能找到最近正在安装的软件。想想:在火狐浏览器中打开50个标签是什么感受。太烦人,太不方便!
|
||||
|
||||
我说过我会给 Gnome 一点打击,我是认真的。Muon 有一点做得比 Gnome 软件中心做得好。在 Muon 的设置栏下面有个“显示技术包”,即:编辑器,软件库,非图形应用程序,无 AppData 的应用等等(LCTT 译注:AppData 是软件包中的一个特殊文件,用于专门存储软件的信息)。Gnome 则没有。如果你想安装其中任何一项你必须跑到终端操作。我想这是他们做得不对的一点。我完全理解他们推行 AppData 的心情,但我想他们太急了(LCTT 译注:推行所有软件包带有 AppData 是 Gnome 软件中心的目标之一)。我是在想安装 PowerTop,而 Gnome 不显示这个软件时我才发现这点的——因为它没有 AppData,也没有“显示技术包”设置。
|
||||
|
||||
更不幸的事实是,如果你在 KDE 下你不能说“用 [Apper][3] 就行了”,因为……
|
||||
|
||||
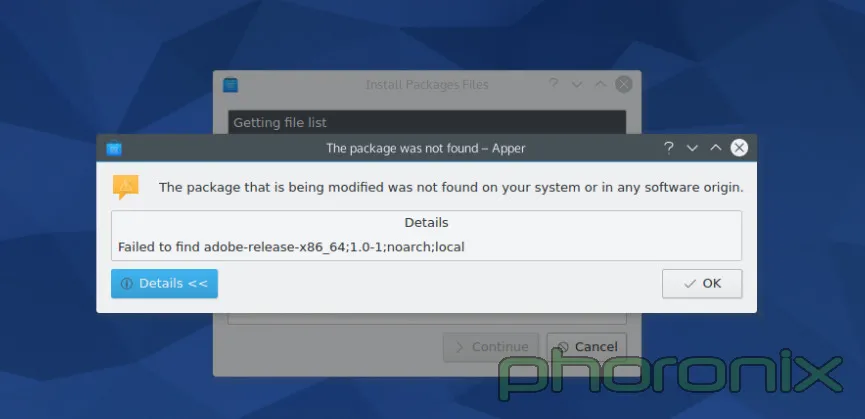
|
||||
|
||||
Apper 对安装本地软件包的支持大约在 Fedora 19 时就中止了,几乎两年了。我喜欢关注细节与质量。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.phoronix.com/scan.php?page=article&item=gnome-week-editorial&num=3
|
||||
|
||||
作者:Eric Griffith
|
||||
译者:[XLCYun](https://github.com/XLCYun)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://community.kde.org/Baloo
|
||||
[2]:http://www.ikde.org/tech/kde-tech-nepomuk/
|
||||
[3]:https://en.wikipedia.org/wiki/Apper
|
||||
@ -0,0 +1,52 @@
|
||||
一周 GNOME 之旅:品味它和 KDE 的是是非非(第四节 GNOME设置)
|
||||
================================================================================
|
||||
|
||||
### 设置 ###
|
||||
|
||||
在这我要挑一挑几个特定 KDE 控制模块的毛病,大部分原因是因为相比它们的对手GNOME来说,糟糕得太可笑,实话说,真是悲哀。
|
||||
|
||||
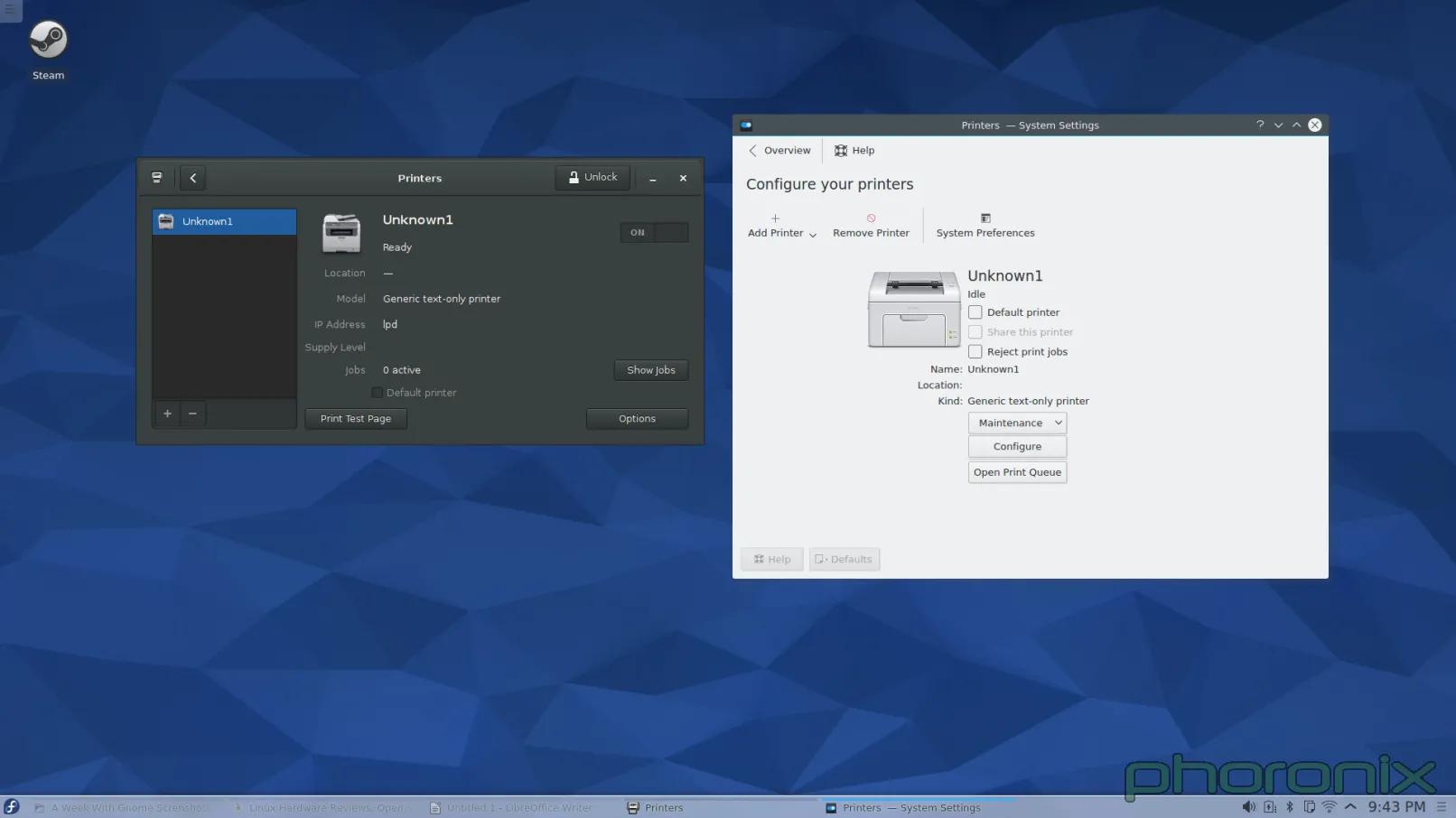
第一个接招的?打印机。
|
||||
|
||||
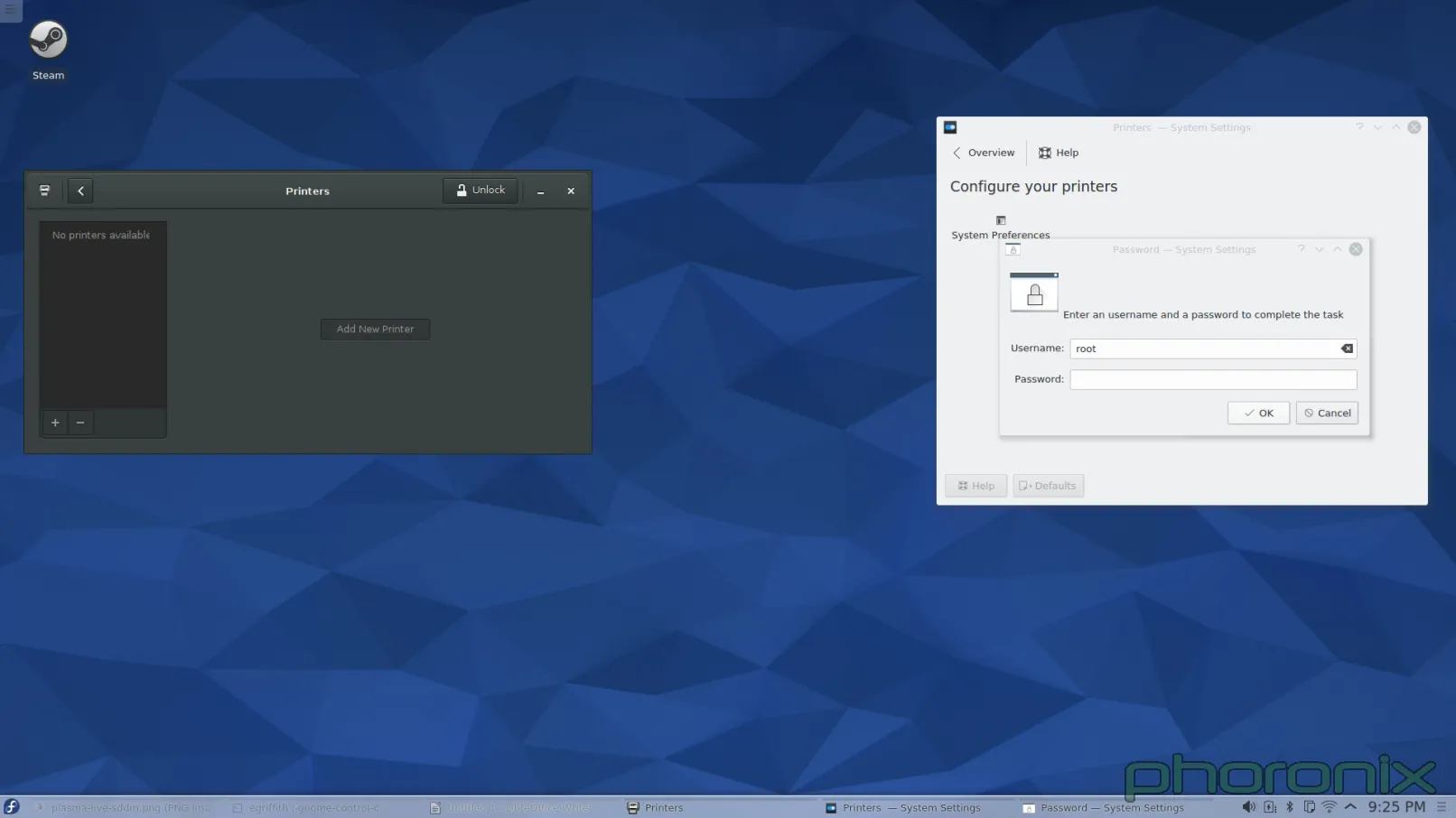
|
||||
|
||||
GNOME 在左,KDE 在右。你知道左边跟右边的打印程序有什么区别吗?当我在 GNOME 控制中心打开“打印机”时,程序窗口弹出来了,然后这样就可以使用了。而当我在 KDE 系统设置打开“打印机”时,我得到了一条密码提示。甚至我都没能看一眼打印机呢,我就必须先交出 ROOT 密码。
|
||||
|
||||
让我再重复一遍。在今天这个有了 PolicyKit 和 Logind 的日子里,对一个应该是 sudo 的操作,我依然被询问要求 ROOT 的密码。我安装系统的时候甚至都没设置 root 密码。所以我必须跑到 Konsole 去,接着运行 'sudo passwd root' 命令,这样我才能给 root 设一个密码,然后我才能回到系统设置中的打印程序,再交出 root 密码,然后仅仅是看一看哪些打印机可用。完成了这些工作后,当我点击“添加打印机”时,我再次得到请求 ROOT 密码的提示,当我解决了它后再选择一个打印机和驱动时,我再次得到请求 ROOT 密码的提示。仅仅是为了添加一个打印机到系统我就收到三次密码请求!
|
||||
|
||||
而在 GNOME 下添加打印机,在点击打印机程序中的“解锁”之前,我没有得到任何请求 SUDO 密码的提示。整个过程我只被请求过一次,仅此而已。KDE,求你了……采用 GNOME 的“解锁”模式吧。不到一定需要的时候不要发出提示。还有,不管是哪个库,只要它允许 KDE 应用程序绕过 PolicyKit/Logind(如果有的话)并直接请求 ROOT 权限……那就把它封进箱里吧。如果这是个多用户系统,那我要么必须交出 ROOT 密码,要么我必须时时刻刻待命,以免有一个用户需要升级、更改或添加一个新的打印机。而这两种情况都是完全无法接受的。
|
||||
|
||||
有还一件事……
|
||||
|
||||
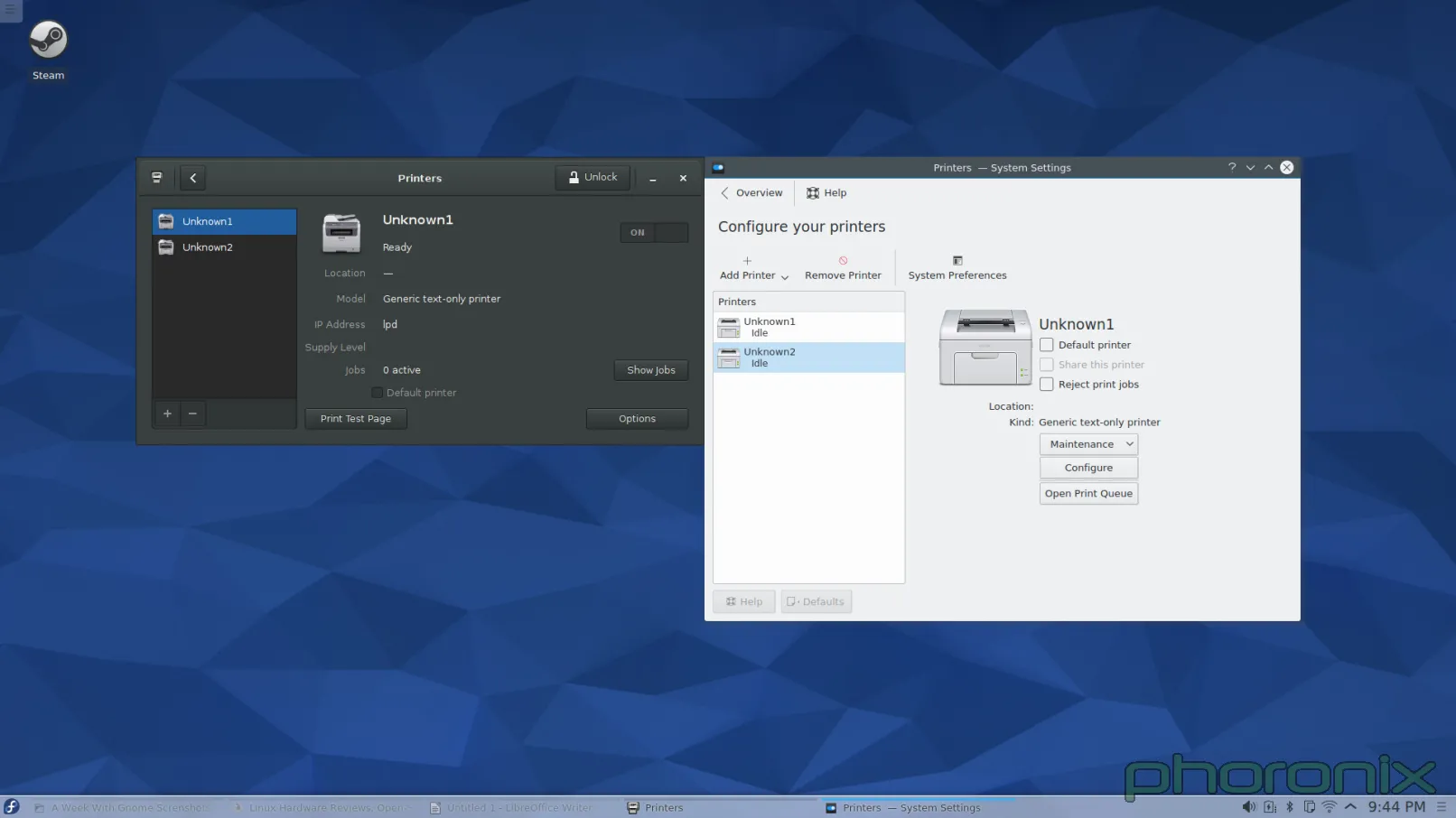
|
||||
|
||||
|
||||
|
||||
这个问题问大家:怎么样看起来更简洁?我在写这篇文章时意识到:当有任何附加的打印机准备好时,Gnome 打印机程序会把过程做得非常简洁,它们在左边上放了一个竖直栏来列出这些打印机。而我在 KDE 中添加第二台打印机时,它突然增加出一个左边栏来。而在添加之前,我脑海中已经有了一个恐怖的画面,它会像图片文件夹显示预览图一样直接在界面里插入另外一个图标。我很高兴也很惊讶的看到我是错的。但是事实是它直接“长出”另外一个从未存在的竖直栏,彻底改变了它的界面布局,而这样也称不上“好”。终究还是一种令人困惑,奇怪而又不直观的设计。
|
||||
|
||||
打印机说得够多了……下一个接受我公开石刑的 KDE 系统设置是?多媒体,即 Phonon。
|
||||
|
||||
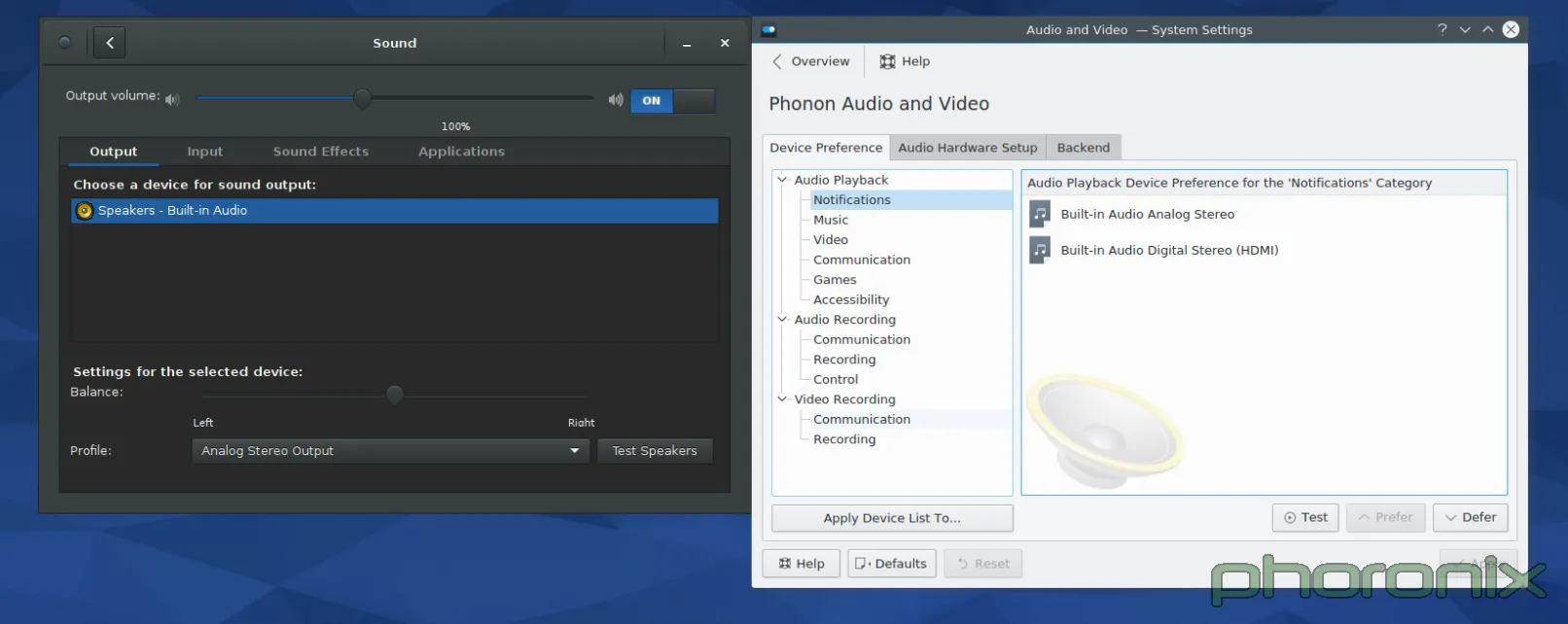
|
||||
|
||||
一如既往,GNOME 在左边,KDE 在右边。让我们先看看 GNOME 的系统设置先……眼睛移动是从左到右,从上到下,对吧?来吧,就这样做。首先:音量控制滑条。滑条中的蓝色条与空条百分百清晰地消除了哪边是“音量增加”的困惑。在音量控制条后马上就是一个 On/Off 开关,用来开关静音功能。Gnome 的再次得分在于静音后能记住当前设置的音量,而在点击音量增加按钮取消静音后能回到原来设置的音量中来。Kmixer,你个健忘的垃圾,我真的希望我能多讨论你一下。
|
||||
|
||||
继续!输入输出和应用程序的标签选项?每一个应用程序的音量随时可控?Gnome,每过一秒,我爱你越深。音量均衡选项、声音配置、和清晰地标上标志的“测试麦克风”选项。
|
||||
|
||||
我不清楚它能否以一种更干净更简洁的设计实现。是的,它只是一个 Gnome 化的 Pavucontrol,但我想这就是重要的地方。Pavucontrol 在这方面几乎完全做对了,Gnome 控制中心中的“声音”应用程序的改善使它向完美更进了一步。
|
||||
|
||||
Phonon,该你上了。但开始前我想说:我 TM 看到的是什么?!我知道我看到的是音频设备的优先级列表,但是它呈现的方式有点太坑。还有,那些用户可能关心的那些东西哪去了?拥有一个优先级列表当然很好,它也应该存在,但问题是优先级列表属于那种用户乱搞一两次之后就不会再碰的东西。它还不够重要,或者说不够常用到可以直接放在正中间位置的程度。音量控制滑块呢?对每个应用程序的音量控制功能呢?那些用户使用最频繁的东西呢?好吧,它们在 Kmix 中,一个分离的程序,拥有它自己的配置选项……而不是在系统设置下……这样真的让“系统设置”这个词变得有点用词不当。
|
||||
|
||||
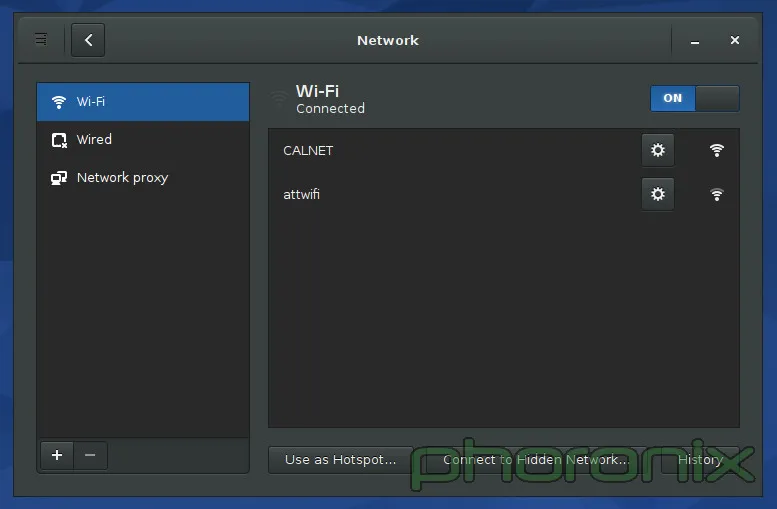
|
||||
|
||||
上面展示的 Gnome 的网络设置。KDE 的没有展示,原因就是我接下来要吐槽的内容了。如果你进入 KDE 的系统设置里,然后点击“网络”区域中三个选项中的任何一个,你会得到一大堆的选项:蓝牙设置、Samba 分享的默认用户名和密码(说真的,“连通性(Connectivity)”下面只有两个选项:SMB 的用户名和密码。TMD 怎么就配得上“连通性”这么大的词?),浏览器身份验证控制(只有 Konqueror 能用……一个已经倒闭的项目),代理设置,等等……我的 wifi 设置哪去了?它们没在这。哪去了?好吧,它们在网络应用程序的设置里面……而不是在网络设置里……
|
||||
|
||||
KDE,你这是要杀了我啊,你有“系统设置”当凶器,拿着它动手吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.phoronix.com/scan.php?page=article&item=gnome-week-editorial&num=4
|
||||
|
||||
作者:Eric Griffith
|
||||
译者:[XLCYun](https://github.com/XLCYun)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,40 @@
|
||||
一周 GNOME 之旅:品味它和 KDE 的是是非非(第三节 总结)
|
||||
================================================================================
|
||||
|
||||
### 用户体验和最后想法 ###
|
||||
|
||||
当 Gnome 2.x 和 KDE 4.x 要正面交锋时……我在它们之间左右逢源。我对它们爱恨交织,但总的来说它们使用起来还算是一种乐趣。然后 Gnome 3.x 来了,带着一场 Gnome Shell 的戏剧。那时我就放弃了 Gnome,我尽我所能的避开它。当时它对用户是不友好的,而且不直观,它打破了原有的设计典范,只为平板的统治世界做准备……而根据平板下跌的销量来看,这样的未来不可能实现。
|
||||
|
||||
在 Gnome 3 后续发布了八个版本后,奇迹发生了。Gnome 变得对对用户友好了,变得直观了。它完美吗?当然不。我还是很讨厌它想推动的那种设计范例,我讨厌它总想给我强加一种工作流(work flow),但是在付出时间和耐心后,这两都能被接受。只要你能够回头去看看 Gnome Shell 那外星人一样的界面,然后开始跟 Gnome 的其它部分(特别是控制中心)互动,你就能发现 Gnome 绝对做对了:细节,对细节的关注!
|
||||
|
||||
人们能适应新的界面设计范例,能适应新的工作流—— iPhone 和 iPad 都证明了这一点——但真正让他们操心的一直是“纸割”——那些不完美的细节。
|
||||
|
||||
它带出了 KDE 和 Gnome 之间最重要的一个区别。Gnome 感觉像一个产品,像一种非凡的体验。你用它的时候,觉得它是完整的,你要的东西都触手可及。它让人感觉就像是一个拥有 Windows 或者 OS X 那样桌面体验的 Linux 桌面版:你要的都在里面,而且它是被同一个目标一致的团队中的同一个人写出来的。天,即使是一个应用程序发出的 sudo 请求都感觉是 Gnome 下的一个特意设计的部分,就像在 Windows 下的一样。而在 KDE 下感觉就是随便一个应用程序都能创建的那种各种外观的弹窗。它不像是以系统本身这样的正式身份停下来说“嘿,有个东西要请求管理员权限!你要给它吗?”。
|
||||
|
||||
KDE 让人体验不到有凝聚力的体验。KDE 像是在没有方向地打转,感觉没有完整的体验。它就像是一堆东西往不同的的方向移动,只不过恰好它们都有一个共同享有的工具包而已。如果开发者对此很开心,那么好吧,他们开心就好,但是如果他们想提供最好体验的话,那么就需要多关注那些小地方了。用户体验跟直观应当做为每一个应用程序的设计中心,应当有一个视野,知道 KDE 要提供什么——并且——知道它看起来应该是什么样的。
|
||||
|
||||
是不是有什么原因阻止我在 KDE 下使用 Gnome 磁盘管理? Rhythmbox 呢? Evolution 呢? 没有,没有,没有。但是这样说又错过了关键。Gnome 和 KDE 都称它们自己为“桌面环境”。那么它们就应该是完整的环境,这意味着他们的各个部件应该汇集并紧密结合在一起,意味着你应该使用它们环境下的工具,因为它们说“您在一个完整的桌面中需要的任何东西,我们都支持。”说真的?只有 Gnome 看起来能符合完整的要求。KDE 在“汇集在一起”这一方面感觉就像个半成品,更不用说提供“完整体验”中你所需要的东西。Gnome 磁盘管理没有相应的对手—— kpartionmanage 要求 ROOT 权限。KDE 不运行“首次用户注册”的过程(原文:No 'First Time User' run through。可能是指系统安装过程中KDE没有创建新用户的过程,译注) ,现在也不过是在 Kubuntu 下引入了一个用户管理器。老天,Gnome 甚至提供了地图、笔记、日历和时钟应用。这些应用都是百分百要紧的吗?不,当然不了。但是正是这些应用帮助 Gnome 推动“Gnome 是一种完整丰富的体验”的想法。
|
||||
|
||||
我吐槽的 KDE 问题并非不可能解决,决对不是这样的!但是它需要人去关心它。它需要开发者为他们的作品感到自豪,而不仅仅是为它们实现的功能而感到自豪——组织的价值可大了去了。别夺走用户设置选项的能力—— GNOME 3.x 就是因为缺乏配置选项的能力而为我所诟病,但别把“好吧,你想怎么设置就怎么设置”作为借口而不提供任何理智的默认设置。默认设置是用户将看到的东西,它们是用户从打开软件的第一刻开始进行评判的关键。给用户留个好印象吧。
|
||||
|
||||
我知道 KDE 开发者们知道设计很重要,这也是为什么VDG(Visual Design Group 视觉设计组)存在的原因,但是感觉好像他们没有让 VDG 充分发挥,所以 KDE 里存在组织上的缺陷。不是 KDE 没办法完整,不是它没办法汇集整合在一起然后解决衰败问题,只是开发者们没做到。他们瞄准了靶心……但是偏了。
|
||||
|
||||
还有,在任何人说这句话之前……千万别说“欢迎给我们提交补丁啊"。因为当我开心的为某个人提交补丁时,只要开发者坚持以他们喜欢的却不直观的方式干事,更多这样的烦人事就会不断发生。这不关 Muon 有没有中心对齐。也不关 Amarok 的界面太丑。也不关每次我敲下快捷键后,弹出的音量和亮度调节窗口占用了我一大块的屏幕“地皮”(说真的,有人会把这些东西缩小)。
|
||||
|
||||
这跟心态的冷漠有关,跟开发者们在为他们的应用设计 UI 时根本就不多加思考有关。KDE 团队做的东西都工作得很好。Amarok 能播放音乐。Dragon 能播放视频。Kwin 或 Qt 和 kdelibs 似乎比 Mutter/gtk 更有力更效率(仅根据我的电池电量消耗计算。非科学性测试)。这些都很好,很重要……但是它们呈现的方式也很重要。甚至可以说,呈现方式是最重要的,因为它是用户看到的并与之交互的东西。
|
||||
|
||||
KDE 应用开发者们……让 VDG 参与进来吧。让 VDG 审查并核准每一个“核心”应用,让一个 VDG 的 UI/UX 专家来设计应用的使用模式和使用流程,以此保证其直观性。真见鬼,不管你们在开发的是啥应用,仅仅把它的模型发到 VDG 论坛寻求反馈甚至都可能都能得到一些非常好的指点跟反馈。你有这么好的资源在这,现在赶紧用吧。
|
||||
|
||||
我不想说得好像我一点都不懂感恩。我爱 KDE,我爱那些志愿者们为了给 Linux 用户一个可视化的桌面而付出的工作与努力,也爱可供选择的 Gnome。正是因为我关心我才写这篇文章。因为我想看到更好的 KDE,我想看到它走得比以前更加遥远。而这样做需要每个人继续努力,并且需要人们不再躲避批评。它需要人们对系统互动及系统崩溃的地方都保持诚实。如果我们不能直言批评,如果我们不说“这真垃圾!”,那么情况永远不会变好。
|
||||
|
||||
这周后我会继续使用 Gnome 吗?可能不。应该不。Gnome 还在试着强迫我接受其工作流,而我不想追随,也不想遵循,因为我在使用它的时候感觉变得不够高效,因为它并不遵循我的思维模式。可是对于我的朋友们,当他们问我“我该用哪种桌面环境?”我可能会推荐 Gnome,特别是那些不大懂技术,只要求“能工作”就行的朋友。根据目前 KDE 的形势来看,这可能是我能说出的最狠毒的评估了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.phoronix.com/scan.php?page=article&item=gnome-week-editorial&num=5
|
||||
|
||||
作者:Eric Griffith
|
||||
译者:[XLCYun](https://github.com/XLCYun)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,47 +1,52 @@
|
||||
|
||||
用 CD 创建 ISO,观察用户活动和检查浏览器内存的技巧
|
||||
一些 Linux 小技巧
|
||||
================================================================================
|
||||
我已经写过 [Linux 提示和技巧][1] 系列的一篇文章。写这篇文章的目的是让你知道这些小技巧可以有效地管理你的系统/服务器。
|
||||
|
||||

|
||||
|
||||
在Linux中创建 Cdrom ISO 镜像和监控用户
|
||||
*在Linux中创建 Cdrom ISO 镜像和监控用户*
|
||||
|
||||
在这篇文章中,我们将看到如何使用 CD/DVD 驱动器中加载到的内容来创建 ISO 镜像,打开随机手册页学习,看到登录用户的详细情况和查看浏览器内存使用量,而所有这些完全使用本地工具/命令无任何第三方应用程序/组件。让我们开始吧...
|
||||
在这篇文章中,我们将看到如何使用 CD/DVD 驱动器中载入的碟片来创建 ISO 镜像;打开随机手册页学习;看到登录用户的详细情况和查看浏览器内存使用量,而所有这些完全使用本地工具/命令,无需任何第三方应用程序/组件。让我们开始吧……
|
||||
|
||||
### 用 CD 中创建 ISO 映像 ###
|
||||
### 用 CD 碟片创建 ISO 映像 ###
|
||||
|
||||
我们经常需要备份/复制 CD/DVD 的内容。如果你是在 Linux 平台上,不需要任何额外的软件。所有需要的是进入 Linux 终端。
|
||||
|
||||
要从 CD/DVD 上创建 ISO 镜像,你需要做两件事。第一件事就是需要找到CD/DVD 驱动器的名称。要找到 CD/DVD 驱动器的名称,可以使用以下三种方法。
|
||||
|
||||
**1. 从终端/控制台上运行 lsblk 命令(单个驱动器).**
|
||||
**1. 从终端/控制台上运行 lsblk 命令(列出块设备)**
|
||||
|
||||
$ lsblk
|
||||
|
||||

|
||||
|
||||
找驱动器
|
||||
*找块设备*
|
||||
|
||||
**2.要查看有关 CD-ROM 的信息,可以使用以下命令。**
|
||||
从上图可以看到,sr0 就是你的 cdrom (即 /dev/sr0 )。
|
||||
|
||||
**2. 要查看有关 CD-ROM 的信息,可以使用以下命令**
|
||||
|
||||
$ less /proc/sys/dev/cdrom/info
|
||||
|
||||

|
||||
|
||||
检查 Cdrom 信息
|
||||
*检查 Cdrom 信息*
|
||||
|
||||
从上图可以看到, 设备名称是 sr0 (即 /dev/sr0)。
|
||||
|
||||
**3. 使用 [dmesg 命令][2] 也会得到相同的信息,并使用 egrep 来自定义输出。**
|
||||
|
||||
命令 ‘dmesg‘ 命令的输出/控制内核缓冲区信息。‘egrep‘ 命令输出匹配到的行。选项 -i 和 -color 与 egrep 连用时会忽略大小写,并高亮显示匹配的字符串。
|
||||
命令 ‘dmesg‘ 命令的输出/控制内核缓冲区信息。‘egrep‘ 命令输出匹配到的行。egrep 使用选项 -i 和 -color 时会忽略大小写,并高亮显示匹配的字符串。
|
||||
|
||||
$ dmesg | egrep -i --color 'cdrom|dvd|cd/rw|writer'
|
||||
|
||||

|
||||
|
||||
查找设备信息
|
||||
*查找设备信息*
|
||||
|
||||
一旦知道 CD/DVD 的名称后,在 Linux 上你可以用下面的命令来创建 ISO 镜像。
|
||||
从上图可以看到,设备名称是 sr0 (即 /dev/sr0)。
|
||||
|
||||
一旦知道 CD/DVD 的名称后,在 Linux 上你可以用下面的命令来创建 ISO 镜像(你看,只需要 cat 即可!)。
|
||||
|
||||
$ cat /dev/sr0 > /path/to/output/folder/iso_name.iso
|
||||
|
||||
@ -49,11 +54,11 @@
|
||||
|
||||

|
||||
|
||||
创建 CDROM 的 ISO 映像
|
||||
*创建 CDROM 的 ISO 映像*
|
||||
|
||||
### 随机打开一个手册页 ###
|
||||
|
||||
如果你是 Linux 新人并想学习使用命令行开关,这个修改是为你做的。把下面的代码行添加在`〜/ .bashrc`文件的末尾。
|
||||
如果你是 Linux 新人并想学习使用命令行开关,这个技巧就是给你的。把下面的代码行添加在`〜/ .bashrc`文件的末尾。
|
||||
|
||||
/use/bin/man $(ls /bin | shuf | head -1)
|
||||
|
||||
@ -63,17 +68,19 @@
|
||||
|
||||

|
||||
|
||||
LoadKeys 手册页
|
||||
*LoadKeys 手册页*
|
||||
|
||||

|
||||
|
||||
Zgrep 手册页
|
||||
*Zgrep 手册页*
|
||||
|
||||
希望你知道如何退出手册页浏览——如果你已经厌烦了每次都看到手册页,你可以删除你添加到 `.bashrc`文件中的那几行。
|
||||
|
||||
### 查看登录用户的状态 ###
|
||||
|
||||
了解其他用户正在共享服务器上做什么。
|
||||
|
||||
一般情况下,你是共享的 Linux 服务器的用户或管理员的。如果你担心自己服务器的安全并想要查看哪些用户在做什么,你可以使用命令 'w'。
|
||||
一般情况下,你是共享的 Linux 服务器的用户或管理员的。如果你担心自己服务器的安全并想要查看哪些用户在做什么,你可以使用命令 `w`。
|
||||
|
||||
这个命令可以让你知道是否有人在执行恶意代码或篡改服务器,让他停下或使用其他方法。'w' 是查看登录用户状态的首选方式。
|
||||
|
||||
@ -83,33 +90,33 @@ Zgrep 手册页
|
||||
|
||||

|
||||
|
||||
检查 Linux 用户状态
|
||||
*检查 Linux 用户状态*
|
||||
|
||||
### 查看浏览器的内存使用状况 ###
|
||||
|
||||
最近有不少谈论关于 Google-chrome 内存使用量。如果你想知道一个浏览器的内存用量,你可以列出进程名,PID 和它的使用情况。要检查浏览器的内存使用情况,只需在地址栏输入 “about:memory” 不要带引号。
|
||||
最近有不少谈论关于 Google-chrome 的内存使用量。如要检查浏览器的内存使用情况,只需在地址栏输入 “about:memory”,不要带引号。
|
||||
|
||||
我已经在 Google-Chrome 和 Mozilla 的 Firefox 网页浏览器进行了测试。你可以查看任何浏览器,如果它工作得很好,你可能会承认我们在下面的评论。你也可以杀死浏览器进程在 Linux 终端的进程/服务中。
|
||||
|
||||
在 Google Chrome 中,在地址栏输入 `about:memory`,你应该得到类似下图的东西。
|
||||
在 Google Chrome 中,在地址栏输入 `about:memory`,你应该得到类似下图的东西。
|
||||
|
||||

|
||||
|
||||
查看 Chrome 内存使用状况
|
||||
*查看 Chrome 内存使用状况*
|
||||
|
||||
在Mozilla Firefox浏览器,在地址栏输入 `about:memory`,你应该得到类似下图的东西。
|
||||
|
||||

|
||||
|
||||
查看 Firefox 内存使用状况
|
||||
*查看 Firefox 内存使用状况*
|
||||
|
||||
如果你已经了解它是什么,除了这些选项。要检查内存用量,你也可以点击最左边的 ‘Measure‘ 选项。
|
||||
|
||||

|
||||
|
||||
Firefox 主进程
|
||||
*Firefox 主进程*
|
||||
|
||||
它将通过浏览器树形展示进程内存使用量
|
||||
它将通过浏览器树形展示进程内存使用量。
|
||||
|
||||
目前为止就这样了。希望上述所有的提示将会帮助你。如果你有一个(或多个)技巧,分享给我们,将帮助 Linux 用户更有效地管理他们的 Linux 系统/服务器。
|
||||
|
||||
@ -122,7 +129,7 @@ via: http://www.tecmint.com/creating-cdrom-iso-image-watch-user-activity-in-linu
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
Linux有问必答——如何修复Linux上的“ImportError: No module named wxversion”错误
|
||||
Linux有问必答:如何修复“ImportError: No module named wxversion”错误
|
||||
================================================================================
|
||||
|
||||
> **问题** 我试着在[你的Linux发行版]上运行一个Python应用,但是我得到了这个错误"ImportError: No module named wxversion."。我怎样才能解决Python程序中的这个错误呢?
|
||||
> **问题** 我试着在[某某 Linux 发行版]上运行一个 Python 应用,但是我得到了这个错误“ImportError: No module named wxversion.”。我怎样才能解决 Python 程序中的这个错误呢?
|
||||
|
||||
Looking for python... 2.7.9 - Traceback (most recent call last):
|
||||
File "/home/dev/playonlinux/python/check_python.py", line 1, in
|
||||
@ -10,7 +10,8 @@ Linux有问必答——如何修复Linux上的“ImportError: No module named wx
|
||||
failed tests
|
||||
|
||||
该错误表明,你的Python应用是基于GUI的,依赖于一个名为wxPython的缺失模块。[wxPython][1]是一个用于wxWidgets GUI库的Python扩展模块,普遍被C++程序员用来设计GUI应用。该wxPython扩展允许Python开发者在任何Python应用中方便地设计和整合GUI。
|
||||
To solve this import error, you need to install wxPython on your Linux, as described below.
|
||||
|
||||
摇解决这个 import 错误,你需要在你的 Linux 上安装 wxPython,如下:
|
||||
|
||||
### 安装wxPython到Debian,Ubuntu或Linux Mint ###
|
||||
|
||||
@ -40,10 +41,10 @@ via: http://ask.xmodulo.com/importerror-no-module-named-wxversion.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:http://wxpython.org/
|
||||
[2]:http://xmodulo.com/how-to-set-up-epel-repository-on-centos.html
|
||||
[2]:https://linux.cn/article-2324-1.html
|
||||
@ -1,6 +1,7 @@
|
||||
Darkstat一个基于网络的流量分析器 - 在Linux中安装
|
||||
在 Linux 中安装 Darkstat:基于网页的流量分析器
|
||||
================================================================================
|
||||
Darkstat是一个简易的,基于网络的流量分析程序。它可以在主流的操作系统如Linux、Solaris、MAC、AIX上工作。它以守护进程的形式持续工作在后台并不断地嗅探网络数据并以简单易懂的形式展现在网页上。它可以为主机生成流量报告,鉴别特定主机上哪些端口打开并且兼容IPv6。让我们看下如何在Linux中安装和配置它。
|
||||
|
||||
Darkstat是一个简易的,基于网页的流量分析程序。它可以在主流的操作系统如Linux、Solaris、MAC、AIX上工作。它以守护进程的形式持续工作在后台,不断地嗅探网络数据,以简单易懂的形式展现在它的网页上。它可以为主机生成流量报告,识别特定的主机上哪些端口是打开的,它兼容IPv6。让我们看下如何在Linux中安装和配置它。
|
||||
|
||||
### 在Linux中安装配置Darkstat ###
|
||||
|
||||
@ -20,14 +21,15 @@ Darkstat是一个简易的,基于网络的流量分析程序。它可以在主
|
||||
|
||||
### 配置 Darkstat ###
|
||||
|
||||
为了正确运行这个程序,我恩需要执行一些基本的配置。运行下面的命令用gedit编辑器打开/etc/darkstat/init.cfg文件。
|
||||
为了正确运行这个程序,我们需要执行一些基本的配置。运行下面的命令用gedit编辑器打开/etc/darkstat/init.cfg文件。
|
||||
|
||||
sudo gedit /etc/darkstat/init.cfg
|
||||
|
||||

|
||||
编辑 Darkstat
|
||||
|
||||
修改START_DARKSTAT这个参数为yes,并在“INTERFACE”中提供你的网络接口。确保取消了DIR、PORT、BINDIP和LOCAL这些参数的注释。如果你希望绑定Darkstat到特定的IP,在BINDIP中提供它
|
||||
*编辑 Darkstat*
|
||||
|
||||
修改START_DARKSTAT这个参数为yes,并在“INTERFACE”中提供你的网络接口。确保取消了DIR、PORT、BINDIP和LOCAL这些参数的注释。如果你希望绑定Darkstat到特定的IP,在BINDIP参数中提供它。
|
||||
|
||||
### 启动Darkstat守护进程 ###
|
||||
|
||||
@ -47,7 +49,7 @@ Darkstat是一个简易的,基于网络的流量分析程序。它可以在主
|
||||
|
||||
### 总结 ###
|
||||
|
||||
它是一个占用很少内存的轻量级工具。这个工具流行的原因是简易、易于配置和使用。这是一个对系统管理员而言必须拥有的程序
|
||||
它是一个占用很少内存的轻量级工具。这个工具流行的原因是简易、易于配置使用。这是一个对系统管理员而言必须拥有的程序。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -55,7 +57,7 @@ via: http://linuxpitstop.com/install-darkstat-on-ubuntu-linux/
|
||||
|
||||
作者:[Aun][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,66 @@
|
||||
Ubuntu NVIDIA 显卡驱动 PPA 已经做好准备
|
||||
================================================================================
|
||||

|
||||
|
||||
加速你的帧率!
|
||||
|
||||
**嘿,各位,稍安勿躁,很快就好。**
|
||||
|
||||
就在提议开发一个[新的 PPA][1] 来给 Ubuntu 用户们提供最新的 NVIDIA 显卡驱动后不久,ubuntu 社区的人们又集结起来了,就是为了这件事。
|
||||
|
||||
顾名思义,‘**Graphics Drivers PPA**’ 包含了最新的 NVIDIA Linux 显卡驱动发布,已经打包好可供用户升级使用,没有让人头疼的二进制运行时文件!
|
||||
|
||||
这个 PPA 被设计用来让玩家们尽可能方便地在 Ubuntu 上运行最新款的游戏。
|
||||
|
||||
#### 万事俱备,只欠东风 ####
|
||||
|
||||
Jorge Castro 开发一个包含 NVIDIA 最新显卡驱动的 PPA 神器的想法得到了 Ubuntu 用户和广大游戏开发者的热烈响应。
|
||||
|
||||
就连那些致力于将“Steam平台”上的知名大作移植到 Linux 上的人们,也给了不少建议。
|
||||
|
||||
Edwin Smith,Feral Interactive 公司(‘Shadow of Mordor’) 的产品总监,对于“让用户更方便地更新驱动”的倡议表示非常欣慰。
|
||||
|
||||
### 如何使用最新的 Nvidia Drivers PPA###
|
||||
|
||||
虽然新的“显卡PPA”已经开发出来,但是现在还远远达不到成熟。开发者们提醒到:
|
||||
|
||||
> “这个 PPA 还处于测试阶段,在你使用它之前最好有一些打包的经验。请大家稍安勿躁,再等几天。”
|
||||
|
||||
将 PPA 试发布给 Ubuntu desktop 邮件列表的 Jorge,也强调说,使用现行的一些 PPA(比如 xorg-edgers)的玩家可能发现不了什么区别(因为现在的驱动只不过是把内容从其他那些现存驱动拷贝过来了)
|
||||
|
||||
“新驱动发布的时候,好戏才会上演呢,”他说。
|
||||
|
||||
截至写作本文时为止,这个 PPA 囊括了从 Ubuntu 12.04.1 到 15.10 各个版本的 Nvidia 驱动。注意这些驱动对所有的发行版都适用。
|
||||
|
||||
> **毫无疑问,除非你清楚自己在干些什么,并且知道如果出了问题应该怎么撤销,否则就不要进行下面的操作。**
|
||||
|
||||
新打开一个终端窗口,运行下面的命令加入 PPA:
|
||||
|
||||
sudo add-apt-repository ppa:graphics-drivers/ppa
|
||||
|
||||
安装或更新到最新的 Nvidia 显卡驱动:
|
||||
|
||||
sudo apt-get update && sudo apt-get install nvidia-355
|
||||
|
||||
记住:如果PPA把你的系统弄崩了,你可得自己去想办法,我们提醒过了哦。(译者注:切记!)
|
||||
|
||||
如果想要撤销对PPA的改变,使用 `ppa-purge` 命令。
|
||||
|
||||
有什么意见,想法,或者指正,就在下面的评论栏里写下来吧。(我没有 NVIDIA 的硬件来为我自己验证上面的这些东西,如果你可以验证的话,那就太感谢了。)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/08/ubuntu-nvidia-graphics-drivers-ppa-is-ready-for-action
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[DongShuaike](https://github.com/DongShuaike)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://linux.cn/article-6030-1.html
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,158 @@
|
||||
shellinabox:一款使用 AJAX 的基于 Web 的终端模拟器
|
||||
================================================================================
|
||||
|
||||
### shellinabox简介 ###
|
||||
|
||||
通常情况下,我们在访问任何远程服务器时,会使用常见的通信工具如OpenSSH和Putty等。但是,有可能我们在防火墙后面不能使用这些工具访问远程系统,或者防火墙只允许HTTPS流量才能通过。不用担心!即使你在这样的防火墙后面,我们依然有办法来访问你的远程系统。而且,你不需要安装任何类似于OpenSSH或Putty的通讯工具。你只需要有一个支持JavaScript和CSS的现代浏览器,并且你不用安装任何插件或第三方应用软件。
|
||||
|
||||
这个 **Shell In A Box**,发音是**shellinabox**,是由**Markus Gutschke**开发的一款自由开源的基于Web的Ajax的终端模拟器。它使用AJAX技术,通过Web浏览器提供了类似原生的 Shell 的外观和感受。
|
||||
|
||||
这个**shellinaboxd**守护进程实现了一个Web服务器,能够侦听指定的端口。其Web服务器可以发布一个或多个服务,这些服务显示在用 AJAX Web 应用实现的VT100模拟器中。默认情况下,端口为4200。你可以更改默认端口到任意选择的任意端口号。在你的远程服务器安装shellinabox以后,如果你想从本地系统接入,打开Web浏览器并导航到:**http://IP-Address:4200/**。输入你的用户名和密码,然后就可以开始使用你远程系统的Shell。看起来很有趣,不是吗?确实 有趣!
|
||||
|
||||
**免责声明**:
|
||||
|
||||
shellinabox不是SSH客户端或任何安全软件。它仅仅是一个应用程序,能够通过Web浏览器模拟一个远程系统的Shell。同时,它和SSH没有任何关系。这不是可靠的安全地远程控制您的系统的方式。这只是迄今为止最简单的方法之一。无论如何,你都不应该在任何公共网络上运行它。
|
||||
|
||||
### 安装shellinabox ###
|
||||
|
||||
#### 在Debian / Ubuntu系统上: ####
|
||||
|
||||
shellinabox在默认库是可用的。所以,你可以使用命令来安装它:
|
||||
|
||||
$ sudo apt-get install shellinabox
|
||||
|
||||
#### 在RHEL / CentOS系统上: ####
|
||||
|
||||
首先,使用命令安装EPEL仓库:
|
||||
|
||||
# yum install epel-release
|
||||
|
||||
然后,使用命令安装shellinabox:
|
||||
|
||||
# yum install shellinabox
|
||||
|
||||
完成!
|
||||
|
||||
### 配置shellinabox ###
|
||||
|
||||
正如我之前提到的,shellinabox侦听端口默认为**4200**。你可以将此端口更改为任意数字,以防别人猜到。
|
||||
|
||||
在Debian/Ubuntu系统上shellinabox配置文件的默认位置是**/etc/default/shellinabox**。在RHEL/CentOS/Fedora上,默认位置在**/etc/sysconfig/shellinaboxd**。
|
||||
|
||||
如果要更改默认端口,
|
||||
|
||||
在Debian / Ubuntu:
|
||||
|
||||
$ sudo vi /etc/default/shellinabox
|
||||
|
||||
在RHEL / CentOS / Fedora:
|
||||
|
||||
# vi /etc/sysconfig/shellinaboxd
|
||||
|
||||
更改你的端口到任意数字。因为我在本地网络上测试它,所以我使用默认值。
|
||||
|
||||
# Shell in a box daemon configuration
|
||||
# For details see shellinaboxd man page
|
||||
|
||||
# Basic options
|
||||
USER=shellinabox
|
||||
GROUP=shellinabox
|
||||
CERTDIR=/var/lib/shellinabox
|
||||
PORT=4200
|
||||
OPTS="--disable-ssl-menu -s /:LOGIN"
|
||||
|
||||
# Additional examples with custom options:
|
||||
|
||||
# Fancy configuration with right-click menu choice for black-on-white:
|
||||
# OPTS="--user-css Normal:+black-on-white.css,Reverse:-white-on-black.css --disable-ssl-menu -s /:LOGIN"
|
||||
|
||||
# Simple configuration for running it as an SSH console with SSL disabled:
|
||||
# OPTS="-t -s /:SSH:host.example.com"
|
||||
|
||||
重启shelinabox服务。
|
||||
|
||||
**在Debian/Ubuntu:**
|
||||
|
||||
$ sudo systemctl restart shellinabox
|
||||
|
||||
或者
|
||||
|
||||
$ sudo service shellinabox restart
|
||||
|
||||
在RHEL/CentOS系统,运行下面的命令能在每次重启时自动启动shellinaboxd服务
|
||||
|
||||
# systemctl enable shellinaboxd
|
||||
|
||||
或者
|
||||
|
||||
# chkconfig shellinaboxd on
|
||||
|
||||
如果你正在运行一个防火墙,记得要打开端口**4200**或任何你指定的端口。
|
||||
|
||||
例如,在RHEL/CentOS系统,你可以如下图所示允许端口。
|
||||
|
||||
# firewall-cmd --permanent --add-port=4200/tcp
|
||||
|
||||
----------
|
||||
|
||||
# firewall-cmd --reload
|
||||
|
||||
### 使用 ###
|
||||
|
||||
现在,在你的客户端系统,打开Web浏览器并导航到:**https://ip-address-of-remote-servers:4200**。
|
||||
|
||||
**注意**:如果你改变了端口,请填写修改后的端口。
|
||||
|
||||
你会得到一个证书问题的警告信息。接受该证书并继续。
|
||||
|
||||

|
||||
|
||||
输入远程系统的用户名和密码。现在,您就能够从浏览器本身访问远程系统的外壳。
|
||||
|
||||

|
||||
|
||||
右键点击你浏览器的空白位置。你可以得到一些有很有用的额外菜单选项。
|
||||
|
||||

|
||||
|
||||
从现在开始,你可以通过本地系统的Web浏览器在你的远程服务器随意操作。
|
||||
|
||||
当你完成工作时,记得输入`exit`退出。
|
||||
|
||||
当再次连接到远程系统时,单击**连接**按钮,然后输入远程服务器的用户名和密码。
|
||||
|
||||

|
||||
|
||||
如果想了解shellinabox更多细节,在你的终端键入下面的命令:
|
||||
|
||||
# man shellinabox
|
||||
|
||||
或者
|
||||
|
||||
# shellinaboxd -help
|
||||
|
||||
同时,参考[shellinabox 在wiki页面的介绍][1],来了解shellinabox的综合使用细节。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
正如我之前提到的,如果你在服务器运行在防火墙后面,那么基于web的SSH工具是非常有用的。有许多基于web的SSH工具,但shellinabox是非常简单而有用的工具,可以从的网络上的任何地方,模拟一个远程系统的Shell。因为它是基于浏览器的,所以你可以从任何设备访问您的远程服务器,只要你有一个支持JavaScript和CSS的浏览器。
|
||||
|
||||
就这些啦。祝你今天有个好心情!
|
||||
|
||||
#### 参考链接: ####
|
||||
|
||||
- [shellinabox website][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/shellinabox-a-web-based-ajax-terminal-emulator/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[xiaoyu33](https://github.com/xiaoyu33)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/sk/
|
||||
[1]:https://code.google.com/p/shellinabox/wiki/shellinaboxd_man
|
||||
[2]:https://code.google.com/p/shellinabox/
|
||||
@ -0,0 +1,52 @@
|
||||
Linux Without Limits: IBM Launch LinuxONE Mainframes
|
||||
================================================================================
|
||||

|
||||
|
||||
LinuxONE Emperor MainframeGood news for Ubuntu’s server team today as [IBM launch the LinuxONE][1] a Linux-only mainframe that is also able to run Ubuntu.
|
||||
|
||||
The largest of the LinuxONE systems launched by IBM is called ‘Emperor’ and can scale up to 8000 virtual machines or tens of thousands of containers – a possible record for any one single Linux system.
|
||||
|
||||
The LinuxONE is described by IBM as a ‘game changer’ that ‘unleashes the potential of Linux for business’.
|
||||
|
||||
IBM and Canonical are working together on the creation of an Ubuntu distribution for LinuxONE and other IBM z Systems. Ubuntu will join RedHat and SUSE as ‘premier Linux distributions’ on IBM z.
|
||||
|
||||
Alongside the ‘Emperor’ IBM is also offering the LinuxONE Rockhopper, a smaller mainframe for medium-sized businesses and organisations.
|
||||
|
||||
IBM is the market leader in mainframes and commands over 90% of the mainframe market.
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="750" height="422" frameborder="0" allowfullscreen="" src="https://www.youtube.com/embed/2ABfNrWs-ns?feature=oembed"></iframe>
|
||||
|
||||
### What Is a Mainframe Computer Used For? ###
|
||||
|
||||
The computer you’re reading this article on would be dwarfed by a ‘big iron’ mainframe. They are large, hulking great cabinets packed full of high-end components, custom designed technology and dizzying amounts of storage (that is data storage, not ample room for pens and rulers).
|
||||
|
||||
Mainframes computers are used by large organizations and businesses to process and store large amounts of data, crunch through statistics, and handle large-scale transaction processing.
|
||||
|
||||
### ‘World’s Fastest Processor’ ###
|
||||
|
||||
IBM has teamed up with Canonical Ltd to use Ubuntu on the LinuxONE and other IBM z Systems.
|
||||
|
||||
The LinuxONE Emperor uses the IBM z13 processor. The chip, announced back in January, is said to be the world’s fastest microprocessor. It is able to deliver transaction response times in the milliseconds.
|
||||
|
||||
But as well as being well equipped to handle for high-volume mobile transactions, the z13 inside the LinuxONE is also an ideal cloud system.
|
||||
|
||||
It can handle more than 50 virtual servers per core for a total of 8000 virtual servers, making it a cheaper, greener and more performant way to scale-out to the cloud.
|
||||
|
||||
**You don’t have to be a CIO or mainframe spotter to appreciate this announcement. The possibilities LinuxONE provides are clear enough. **
|
||||
|
||||
Source: [Reuters (h/t @popey)][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/08/ibm-linuxone-mainframe-ubuntu-partnership
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:http://www-03.ibm.com/systems/z/announcement.html
|
||||
[2]:http://www.reuters.com/article/2015/08/17/us-ibm-linuxone-idUSKCN0QM09P20150817
|
||||
@ -0,0 +1,46 @@
|
||||
Ubuntu Linux is coming to IBM mainframes
|
||||
================================================================================
|
||||
SEATTLE -- It's finally happened. At [LinuxCon][1], IBM and [Canonical][2] announced that [Ubuntu Linux][3] will soon be running on IBM mainframes.
|
||||
|
||||

|
||||
|
||||
You'll soon to be able to get your IBM mainframe in Ubuntu Linux orange
|
||||
|
||||
According to Ross Mauri, IBM's General Manager of System z, and Mark Shuttleworth, Canonical and Ubuntu's founder, this move came about because of customer demand. For over a decade, [Red Hat Enterprise Linux (RHEL)][4] and [SUSE Linux Enterprise Server (SLES)][5] were the only supported IBM mainframe Linux distributions.
|
||||
|
||||
As Ubuntu matured, more and more businesses turned to it for the enterprise Linux, and more and more of them wanted it on IBM big iron hardware. In particular, banks wanted Ubuntu there. Soon, financial CIOs will have their wish granted.
|
||||
|
||||
In an interview Shuttleworth said that Ubuntu Linux will be available on the mainframe by April 2016 in the next long-term support version of Ubuntu: Ubuntu 16.04. Canonical and IBM already took the first move in this direction in late 2014 by bringing [Ubuntu to IBM's POWER][6] architecture.
|
||||
|
||||
Before that, Canonical and IBM almost signed the dotted line to bring [Ubuntu to IBM mainframes in 2011][7] but that deal was never finalized. This time, it's happening.
|
||||
|
||||
Jane Silber, Canonical's CEO, explained in a statement, "Our [expansion of Ubuntu platform][8] support to [IBM z Systems][9] is a recognition of the number of customers that count on z Systems to run their businesses, and the maturity the hybrid cloud is reaching in the marketplace.
|
||||
|
||||
**Silber continued:**
|
||||
|
||||
> With support of z Systems, including [LinuxONE][10], Canonical is also expanding our relationship with IBM, building on our support for the POWER architecture and OpenPOWER ecosystem. Just as Power Systems clients are now benefiting from the scaleout capabilities of Ubuntu, and our agile development process which results in first to market support of new technologies such as CAPI (Coherent Accelerator Processor Interface) on POWER8, z Systems clients can expect the same rapid rollout of technology advancements, and benefit from [Juju][11] and our other cloud tools to enable faster delivery of new services to end users. In addition, our collaboration with IBM includes the enablement of scale-out deployment of many IBM software solutions with Juju Charms. Mainframe clients will delight in having a wealth of 'charmed' IBM solutions, other software provider products, and open source solutions, deployable on mainframes via Juju.
|
||||
|
||||
Shuttleworth expects Ubuntu on z to be very successful. "It's blazingly fast, and with its support for OpenStack, people who want exceptional cloud region performance will be very happy.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.zdnet.com/article/ubuntu-linux-is-coming-to-the-mainframe/#ftag=RSSbaffb68
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/
|
||||
[1]:http://events.linuxfoundation.org/events/linuxcon-north-america
|
||||
[2]:http://www.canonical.com/
|
||||
[3]:http://www.ubuntu.comj/
|
||||
[4]:http://www.redhat.com/en/technologies/linux-platforms/enterprise-linux
|
||||
[5]:https://www.suse.com/products/server/
|
||||
[6]:http://www.zdnet.com/article/ibm-doubles-down-on-linux/
|
||||
[7]:http://www.zdnet.com/article/mainframe-ubuntu-linux/
|
||||
[8]:https://insights.ubuntu.com/2015/08/17/ibm-and-canonical-plan-ubuntu-support-on-ibm-z-systems-mainframe/
|
||||
[9]:http://www-03.ibm.com/systems/uk/z/
|
||||
[10]:http://www.zdnet.com/article/linuxone-ibms-new-linux-mainframes/
|
||||
[11]:https://jujucharms.com/
|
||||
117
sources/share/20150817 Top 5 Torrent Clients For Ubuntu Linux.md
Normal file
117
sources/share/20150817 Top 5 Torrent Clients For Ubuntu Linux.md
Normal file
@ -0,0 +1,117 @@
|
||||
Top 5 Torrent Clients For Ubuntu Linux
|
||||
================================================================================
|
||||

|
||||
|
||||
Looking for the **best torrent client in Ubuntu**? Indeed there are a number of torrent clients available for desktop Linux. But which ones are the **best Ubuntu torrent clients** among them?
|
||||
|
||||
I am going to list top 5 torrent clients for Linux, which are lightweight, feature rich and have impressive GUI. Ease of installation and using is also a factor.
|
||||
|
||||
### Best torrent programs for Ubuntu ###
|
||||
|
||||
Since Ubuntu comes by default with Transmission, I am going to exclude it from the list. This doesn’t mean that Transmission doesn’t deserve to be on the list. Transmission is a good to have torrent client for Ubuntu and this is the reason why it is the default Torrent application in several Linux distributions, including Ubuntu.
|
||||
|
||||
----------
|
||||
|
||||
### Deluge ###
|
||||
|
||||

|
||||
|
||||
[Deluge][1] has been chosen as the best torrent client for Linux by Lifehacker and that speaks itself of the usefulness of Deluge. And it’s not just Lifehacker who is fan of Deluge, check out any forum and you’ll find a number of people admitting that Deluge is their favorite.
|
||||
|
||||
Fast, sleek and intuitive interface makes Deluge a hot favorite among Linux users.
|
||||
|
||||
Deluge is available in Ubuntu repositories and you can install it in Ubuntu Software Center or by using the command below:
|
||||
|
||||
sudo apt-get install deluge
|
||||
|
||||
----------
|
||||
|
||||
### qBittorrent ###
|
||||
|
||||

|
||||
|
||||
As the name suggests, [qBittorrent][2] is the Qt version of famous [Bittorrent][3] application. You’ll see an interface similar to Bittorrent client in Windows, if you ever used it. Sort of lightweight and have all the standard features of a torrent program, qBittorrent is also available in default Ubuntu repository.
|
||||
|
||||
It could be installed from Ubuntu Software Center or using the command below:
|
||||
|
||||
sudo apt-get install qbittorrent
|
||||
|
||||
----------
|
||||
|
||||
### Tixati ###
|
||||
|
||||

|
||||
|
||||
[Tixati][4] is another nice to have torrent client for Ubuntu. It has a default dark theme which might be preferred by many but not me. It has all the standard features that you can seek in a torrent client.
|
||||
|
||||
In addition to that, there are additional feature of data analysis. You can measure and analyze bandwidth and other statistics in nice charts.
|
||||
|
||||
- [Download Tixati][5]
|
||||
|
||||
----------
|
||||
|
||||
### Vuze ###
|
||||
|
||||

|
||||
|
||||
[Vuze][6] is favorite torrent application of a number of Linux as well as Windows users. Apart from the standard features, you can search for torrents directly in the application. You can also subscribe to episodic content so that you won’t have to search for new contents as you can see it in your subscription in sidebar.
|
||||
|
||||
It also comes with a video player that can play HD videos with subtitles and all. But I don’t think you would like to use it over the better video players such as VLC.
|
||||
|
||||
Vuze can be installed from Ubuntu Software Center or using the command below:
|
||||
|
||||
sudo apt-get install vuze
|
||||
|
||||
----------
|
||||
|
||||
### Frostwire ###
|
||||
|
||||

|
||||
|
||||
[Frostwire][7] is the torrent application you might want to try. It is more than just a simple torrent client. Also available for Android, you can use it to share files over WiFi.
|
||||
|
||||
You can search for torrents from within the application and play them inside the application. In addition to the downloaded files, it can browse your local media and have them organized inside the player. The same is applicable for the Android version.
|
||||
|
||||
An additional feature is that Frostwire also provides access to legal music by indi artists. You can download them and listen to it, for free, for legal.
|
||||
|
||||
- [Download Frostwire][8]
|
||||
|
||||
----------
|
||||
|
||||
### Honorable mention ###
|
||||
|
||||
On Windows, uTorrent (pronounced mu torrent) is my favorite torrent application. While uTorrent may be available for Linux, I deliberately skipped it from the list because installing and using uTorrent in Linux is neither easy nor does it provide a complete application experience (runs with in web browser).
|
||||
|
||||
You can read about uTorrent installation in Ubuntu [here][9].
|
||||
|
||||
#### Quick tip: ####
|
||||
|
||||
Most of the time, torrent applications do not start by default. You might want to change this behavior. Read this post to learn [how to manage startup applications in Ubuntu][10].
|
||||
|
||||
### What’s your favorite? ###
|
||||
|
||||
That was my opinion on the best Torrent clients in Ubuntu. What is your favorite one? Do leave a comment. You can also check the [best download managers for Ubuntu][11] in related posts. And if you use Popcorn Time, check these [Popcorn Time Tips][12].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/best-torrent-ubuntu/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://deluge-torrent.org/
|
||||
[2]:http://www.qbittorrent.org/
|
||||
[3]:http://www.bittorrent.com/
|
||||
[4]:http://www.tixati.com/
|
||||
[5]:http://www.tixati.com/download/
|
||||
[6]:http://www.vuze.com/
|
||||
[7]:http://www.frostwire.com/
|
||||
[8]:http://www.frostwire.com/downloads
|
||||
[9]:http://sysads.co.uk/2014/05/install-utorrent-3-3-ubuntu-14-04-13-10/
|
||||
[10]:http://itsfoss.com/manage-startup-applications-ubuntu/
|
||||
[11]:http://itsfoss.com/4-best-download-managers-for-linux/
|
||||
[12]:http://itsfoss.com/popcorn-time-tips/
|
||||
@ -0,0 +1,344 @@
|
||||
A Linux User Using ‘Windows 10′ After More than 8 Years – See Comparison
|
||||
================================================================================
|
||||
Windows 10 is the newest member of windows NT family of which general availability was made on July 29, 2015. It is the successor of Windows 8.1. Windows 10 is supported on Intel Architecture 32 bit, AMD64 and ARMv7 processors.
|
||||
|
||||

|
||||
|
||||
Windows 10 and Linux Comparison
|
||||
|
||||
As a Linux-user for more than 8 continuous years, I thought to test Windows 10, as it is making a lots of news these days. This article is a breakthrough of my observation. I will be seeing everything from the perspective of a Linux user so you may find it a bit biased towards Linux but with absolutely no false information.
|
||||
|
||||
1. I searched Google with the text “download windows 10” and clicked the first link.
|
||||
|
||||

|
||||
|
||||
Search Windows 10
|
||||
|
||||
You may directly go to link : [https://www.microsoft.com/en-us/software-download/windows10ISO][1]
|
||||
|
||||
2. I was supposed to select a edition from ‘windows 10‘, ‘windows 10 KN‘, ‘windows 10 N‘ and ‘windows 10 single language‘.
|
||||
|
||||

|
||||
|
||||
Select Windows 10 Edition
|
||||
|
||||
For those who want to know details of different editions of Windows 10, here is the brief details of editions.
|
||||
|
||||
- Windows 10 – Contains everything offered by Microsoft for this OS.
|
||||
- Windows 10N – This edition comes without Media-player.
|
||||
- Windows 10KN – This edition comes without media playing capabilities.
|
||||
- Windows 10 Single Language – Only one Language Pre-installed.
|
||||
|
||||
3. I selected the first option ‘Windows 10‘ and clicked ‘Confirm‘. Then I was supposed to select a product language. I choose ‘English‘.
|
||||
|
||||
I was provided with Two Download Links. One for 32-bit and other for 64-bit. I clicked 64-bit, as per my architecture.
|
||||
|
||||

|
||||
|
||||
Download Windows 10
|
||||
|
||||
With my download speed (15Mbps), it took me 3 long hours to download it. Unfortunately there were no torrent file to download the OS, which could otherwise have made the overall process smooth. The OS iso image size is 3.8 GB.
|
||||
|
||||
I could not find an image of smaller size but again the truth is there don’t exist net-installer image like things for Windows. Also there is no way to calculate hash value after the iso image has been downloaded.
|
||||
|
||||
Wonder why so ignorance from windows on such issues. To verify if the iso is downloaded correctly I need to write the image to a disk or to a USB flash drive and then boot my system and keep my finger crossed till the setup is finished.
|
||||
|
||||
Lets start. I made my USB flash drive bootable with the windows 10 iso using dd command, as:
|
||||
|
||||
# dd if=/home/avi/Downloads/Win10_English_x64.iso of=/dev/sdb1 bs=512M; sync
|
||||
|
||||
It took a few minutes to complete the process. I then rebooted the system and choose to boot from USB flash Drive in my UEFI (BIOS) settings.
|
||||
|
||||
#### System Requirements ####
|
||||
|
||||
If you are upgrading
|
||||
|
||||
- Upgrade supported only from Windows 7 SP1 or Windows 8.1
|
||||
|
||||
If you are fresh Installing
|
||||
|
||||
- Processor: 1GHz or faster
|
||||
- RAM : 1GB and Above(32-bit), 2GB and Above(64-bit)
|
||||
- HDD: 16GB and Above(32-bit), 20GB and Above(64-bit)
|
||||
- Graphic card: DirectX 9 or later + WDDM 1.0 Driver
|
||||
|
||||
### Installation of Windows 10 ###
|
||||
|
||||
1. Windows 10 boots. Yet again they changed the logo. Also no information on whats going on.
|
||||
|
||||
|
||||
|
||||
Windows 10 Logo
|
||||
|
||||
2. Selected Language to install, Time & currency format and keyboard & Input methods before clicking Next.
|
||||
|
||||

|
||||
|
||||
Select Language and Time
|
||||
|
||||
3. And then ‘Install Now‘ Menu.
|
||||
|
||||
|
||||
|
||||
Install Windows 10
|
||||
|
||||
4. The next screen is asking for Product key. I clicked ‘skip’.
|
||||
|
||||
|
||||
|
||||
Windows 10 Product Key
|
||||
|
||||
5. Choose from a listed OS. I chose ‘windows 10 pro‘.
|
||||
|
||||

|
||||
|
||||
Select Install Operating System
|
||||
|
||||
6. oh yes the license agreement. Put a check mark against ‘I accept the license terms‘ and click next.
|
||||
|
||||

|
||||
|
||||
Accept License
|
||||
|
||||
7. Next was to upgrade (to windows 10 from previous versions of windows) and Install Windows. Don’t know why custom: Windows Install only is suggested as advanced by windows. Anyway I chose to Install windows only.
|
||||
|
||||

|
||||
|
||||
Select Installation Type
|
||||
|
||||
8. Selected the file-system and clicked ‘next’.
|
||||
|
||||

|
||||
|
||||
Select Install Drive
|
||||
|
||||
9. The installer started to copy files, getting files ready for installation, installing features, installing updates and finishing up. It would be better if the installer would have shown verbose output on the action is it taking.
|
||||
|
||||

|
||||
|
||||
Installing Windows
|
||||
|
||||
10. And then windows restarted. They said reboot was needed to continue.
|
||||
|
||||

|
||||
|
||||
Windows Installation Process
|
||||
|
||||
11. And then all I got was the below screen which reads “Getting Ready”. It took 5+ minutes at this point. No idea what was going on. No output.
|
||||
|
||||

|
||||
|
||||
Windows Getting Ready
|
||||
|
||||
12. yet again, it was time to “Enter Product Key”. I clicked “Do this later” and then used expressed settings.
|
||||
|
||||

|
||||
|
||||
Enter Product Key
|
||||
|
||||

|
||||
|
||||
Select Express Settings
|
||||
|
||||
14. And then three more output screens, where I as a Linuxer expected that the Installer will tell me what it is doing but all in vain.
|
||||
|
||||

|
||||
|
||||
Loading Windows
|
||||
|
||||

|
||||
|
||||
Getting Updates
|
||||
|
||||

|
||||
|
||||
Still Loading Windows
|
||||
|
||||
15. And then the installer wanted to know who owns this machine “My organization” or I myself. Chose “I own it” and then next.
|
||||
|
||||

|
||||
|
||||
Select Organization
|
||||
|
||||
16. Installer prompted me to join “Azure Ad” or “Join a domain”, before I can click ‘continue’. I chooses the later option.
|
||||
|
||||

|
||||
|
||||
Connect Windows
|
||||
|
||||
17. The Installer wants me to create an account. So I entered user_name and clicked ‘Next‘, I was expecting an error message that I must enter a password.
|
||||
|
||||

|
||||
|
||||
Create Account
|
||||
|
||||
18. To my surprise Windows didn’t even showed warning/notification that I must create password. Such a negligence. Anyway I got my desktop.
|
||||
|
||||

|
||||
|
||||
Windows 10 Desktop
|
||||
|
||||
#### Experience of a Linux-user (Myself) till now ####
|
||||
|
||||
- No Net-installer Image
|
||||
- Image size too heavy
|
||||
- No way to check the integrity of iso downloaded (no hash check)
|
||||
- The booting and installation remains same as it was in XP, Windows 7 and 8 perhaps.
|
||||
- As usual no output on what windows Installer is doing – What file copying or what package installing.
|
||||
- Installation was straight forward and easy as compared to the installation of a Linux distribution.
|
||||
|
||||
### Windows 10 Testing ###
|
||||
|
||||
19. The default Desktop is clean. It has a recycle bin Icon on the default desktop. Search web directly from the desktop itself. Additionally icons for Task viewing, Internet browsing, folder browsing and Microsoft store is there. As usual notification bar is present on the bottom right to sum up desktop.
|
||||
|
||||

|
||||
|
||||
Deskop Shortcut Icons
|
||||
|
||||
20. Internet Explorer replaced with Microsoft Edge. Windows 10 has replace the legacy web browser Internet Explorer also known as IE with Edge aka project spartan.
|
||||
|
||||

|
||||
|
||||
Microsoft Edge Browser
|
||||
|
||||
It is fast at least as compared to IE (as it seems it testing). Familiar user Interface. The home screen contains news feed updates. There is also a search bar title that reads ‘Where to next?‘. The browser loads time is considerably low which result in improving overall speed and performance. The memory usages of Edge seems normal.
|
||||
|
||||

|
||||
|
||||
Windows Performance
|
||||
|
||||
Edge has got cortana – Intelligent Personal Assistant, Support for chrome-extension, web Note – Take notes while Browsing, Share – Right from the tab without opening any other TAB.
|
||||
|
||||
#### Experience of a Linux-user (Myself) on this point ####
|
||||
|
||||
21. Microsoft has really improved web browsing. Lets see how stable and fine it remains. It don’t lag as of now.
|
||||
|
||||
22. Though RAM usages by Edge was fine for me, a lots of users are complaining that Edge is notorious for Excessive RAM Usages.
|
||||
|
||||
23. Difficult to say at this point if Edge is ready to compete with Chrome and/or Firefox at this point of time. Lets see what future unfolds.
|
||||
|
||||
#### A few more Virtual Tour ####
|
||||
|
||||
24. Start Menu redesigned – Seems clear and effective. Metro icons make it live. Populated with most commonly applications viz., Calendar, Mail, Edge, Photos, Contact, Temperature, Companion suite, OneNote, Store, Xbox, Music, Movies & TV, Money, News, Store, etc.
|
||||
|
||||

|
||||
|
||||
Windows Look and Feel
|
||||
|
||||
In Linux on Gnome Desktop Environment, I use to search required applications simply by pressing windows key and then type the name of the application.
|
||||
|
||||

|
||||
|
||||
Search Within Desktop
|
||||
|
||||
25. File Explorer – seems clear Designing. Edges are sharp. In the left pane there is link to quick access folders.
|
||||
|
||||

|
||||
|
||||
Windows File Explorer
|
||||
|
||||
Equally clear and effective file explorer on Gnome Desktop Environment on Linux. Removed UN-necessary graphics and images from icons is a plus point.
|
||||
|
||||

|
||||
|
||||
File Browser on Gnome
|
||||
|
||||
26. Settings – Though the settings are a bit refined on Windows 10, you may compare it with the settings on a Linux Box.
|
||||
|
||||
**Settings on Windows**
|
||||
|
||||

|
||||
|
||||
Windows 10 Settings
|
||||
|
||||
**Setting on Linux Gnome**
|
||||
|
||||

|
||||
|
||||
Gnome Settings
|
||||
|
||||
27. List of Applications – List of Application on Linux is better than what they use to provide (based upon my memory, when I was a regular windows user) but still it stands low as compared to how Gnome3 list application.
|
||||
|
||||
**Application Listed by Windows**
|
||||
|
||||

|
||||
|
||||
Application List on Windows 10
|
||||
|
||||
**Application Listed by Gnome3 on Linux**
|
||||
|
||||

|
||||
|
||||
Gnome Application List on Linux
|
||||
|
||||
28. Virtual Desktop – Virtual Desktop feature of Windows 10 is one of those topic which are very much talked about these days.
|
||||
|
||||
Here is the virtual Desktop in Windows 10.
|
||||
|
||||

|
||||
|
||||
Windows Virtual Desktop
|
||||
|
||||
and the virtual Desktop on Linux we are using for more than 2 decades.
|
||||
|
||||

|
||||
|
||||
Virtual Desktop on Linux
|
||||
|
||||
#### A few other features of Windows 10 ####
|
||||
|
||||
29. Windows 10 comes with wi-fi sense. It shares your password with others. Anyone who is in the range of your wi-fi and connected to you over Skype, Outlook, Hotmail or Facebook can be granted access to your wifi network. And mind it this feature has been added as a feature by microsoft to save time and hassle-free connection.
|
||||
|
||||
In a reply to question raised by Tecmint, Microsoft said – The user has to agree to enable wifi sense, everytime on a new network. oh! What a pathetic taste as far as security is concerned. I am not convinced.
|
||||
|
||||
30. Up-gradation from Windows 7 and Windows 8.1 is free though the retail cost of Home and pro editions are approximately $119 and $199 respectively.
|
||||
|
||||
31. Microsoft released first cumulative update for windows 10, which is said to put system into endless crash loop for a few people. Windows perhaps don’t understand such problem or don’t want to work on that part don’t know why.
|
||||
|
||||
32. Microsoft’s inbuilt utility to block/hide unwanted updates don’t work in my case. This means If a update is there, there is no way to block/hide it. Sorry windows users!
|
||||
|
||||
#### A few features native to Linux that windows 10 have ####
|
||||
|
||||
Windows 10 has a lots of features that were taken directly from Linux. If Linux were not released under GNU License perhaps Microsoft would never had the below features.
|
||||
|
||||
33. Command-line package management – Yup! You heard it right. Windows 10 has a built-in package management. It works only in Windows Power Shell. OneGet is the official package manager for windows. Windows package manager in action.
|
||||
|
||||

|
||||
|
||||
Windows 10 Package Manager
|
||||
|
||||
- Border-less windows
|
||||
- Flat Icons
|
||||
- Virtual Desktop
|
||||
- One search for Online+offline search
|
||||
- Convergence of mobile and desktop OS
|
||||
|
||||
### Overall Conclusion ###
|
||||
|
||||
- Improved responsiveness
|
||||
- Well implemented Animation
|
||||
- low on resource
|
||||
- Improved battery life
|
||||
- Microsoft Edge web-browser is rock solid
|
||||
- Supported on Raspberry pi 2.
|
||||
- It is good because windows 8/8.1 was not upto mark and really bad.
|
||||
- It is a the same old wine in new bottle. Almost the same things with brushed up icons.
|
||||
|
||||
What my testing suggest is Windows 10 has improved on a few things like look and feel (as windows always did), +1 for Project spartan, Virtual Desktop, Command-line package management, one search for online and offline search. It is overall an improved product but those who thinks that Windows 10 will prove to be the last nail in the coffin of Linux are mistaken.
|
||||
|
||||
Linux is years ahead of Windows. Their approach is different. In near future windows won’t stand anywhere around Linux and there is nothing for which a Linux user need to go to Windows 10.
|
||||
|
||||
That’s all for now. Hope you liked the post. I will be here again with another interesting post you people will love to read. Provide us with your valuable feedback in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/a-linux-user-using-windows-10-after-more-than-8-years-see-comparison/
|
||||
|
||||
作者:[vishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:https://www.microsoft.com/en-us/software-download/windows10ISO
|
||||
@ -0,0 +1,109 @@
|
||||
Debian GNU/Linux Birthday : A 22 Years of Journey and Still Counting…
|
||||
================================================================================
|
||||
On 16th August 2015, the Debian project has celebrated its 22nd anniversary, making it one of the oldest popular distribution in open source world. Debian project was conceived and founded in the year 1993 by Ian Murdock. By that time Slackware had already made a remarkable presence as one of the earliest Linux Distribution.
|
||||
|
||||

|
||||
|
||||
Happy 22nd Birthday to Debian Linux
|
||||
|
||||
Ian Ashley Murdock, an American Software Engineer by profession, conceived the idea of Debian project, when he was a student of Purdue University. He named the project Debian after the name of his then-girlfriend Debra Lynn (Deb) and his name. He later married her and then got divorced in January 2008.
|
||||
|
||||

|
||||
|
||||
Debian Creator: Ian Murdock
|
||||
|
||||
Ian is currently serving as Vice President of Platform and Development Community at ExactTarget.
|
||||
|
||||
Debian (as Slackware) was the result of unavailability of up-to mark Linux Distribution, that time. Ian in an interview said – “Providing the first class Product without profit would be the sole aim of Debian Project. Even Linux was not reliable and up-to mark that time. I Remember…. Moving files between file-system and dealing with voluminous file would often result in Kernel Panic. However the project Linux was promising. The availability of Source Code freely and the potential it seemed was qualitative.”
|
||||
|
||||
I remember … like everyone else I wanted to solve problem, run something like UNIX at home, but it was not possible…neither financially nor legally, in the other sense . Then I come to know about GNU kernel Development and its non-association with any kind of legal issues, he added. He was sponsored by Free Software Foundation (FSF) in the early days when he was working on Debian, it also helped Debian to take a giant step though Ian needed to finish his degree and hence quited FSF roughly after one year of sponsorship.
|
||||
|
||||
### Debian Development History ###
|
||||
|
||||
- **Debian 0.01 – 0.09** : Released between August 1993 – December 1993.
|
||||
- **Debian 0.91 ** – Released in January 1994 with primitive package system, No dependencies.
|
||||
- **Debian 0.93 rc5** : March 1995. It is the first modern release of Debian, dpkg was used to install and maintain packages after base system installation.
|
||||
- **Debian 0.93 rc6**: Released in November 1995. It was last a.out release, deselect made an appearance for the first time – 60 developers were maintaining packages, then at that time.
|
||||
- **Debian 1.1**: Released in June 1996. Code name – Buzz, Packages count – 474, Package Manager dpkg, Kernel 2.0, ELF.
|
||||
- **Debian 1.2**: Released in December 1996. Code name – Rex, Packages count – 848, Developers Count – 120.
|
||||
- **Debian 1.3**: Released in July 1997. Code name – Bo, package count 974, Developers count – 200.
|
||||
- **Debian 2.0**: Released in July 1998. Code name: Hamm, Support for architecture – Intel i386 and Motorola 68000 series, Number of Packages: 1500+, Number of Developers: 400+, glibc included.
|
||||
- **Debian 2.1**: Released on March 09, 1999. Code name – slink, support architecture Alpha and Sparc, apt came in picture, Number of package – 2250.
|
||||
- **Debian 2.2**: Released on August 15, 2000. Code name – Potato, Supported architecture – Intel i386, Motorola 68000 series, Alpha, SUN Sparc, PowerPC and ARM architecture. Number of packages: 3900+ (binary) and 2600+ (Source), Number of Developers – 450. There were a group of people studied and came with an article called Counting potatoes, which shows – How a free software effort could lead to a modern operating system despite all the issues around it.
|
||||
- **Debian 3.0** : Released on July 19th, 2002. Code name – woody, Architecture supported increased– HP, PA_RISC, IA-64, MIPS and IBM, First release in DVD, Package Count – 8500+, Developers Count – 900+, Cryptography.
|
||||
- **Debian 3.1**: Release on June 6th, 2005. Code name – sarge, Architecture support – same as woody + AMD64 – Unofficial Port released, Kernel – 2.4 qnd 2.6 series, Number of Packages: 15000+, Number of Developers : 1500+, packages like – OpenOffice Suite, Firefox Browser, Thunderbird, Gnome 2.8, kernel 3.3 Advanced Installation Support: RAID, XFS, LVM, Modular Installer.
|
||||
- **Debian 4.0**: Released on April 8th, 2007. Code name – etch, architecture support – same as sarge, included AMD64. Number of packages: 18,200+ Developers count : 1030+, Graphical Installer.
|
||||
- **Debian 5.0**: Released on February 14th, 2009. Code name – lenny, Architecture Support – Same as before + ARM. Number of packages: 23000+, Developers Count: 1010+.
|
||||
- **Debian 6.0** : Released on July 29th, 2009. Code name – squeeze, Package included : kernel 2.6.32, Gnome 2.3. Xorg 7.5, DKMS included, Dependency-based. Architecture : Same as pervious + kfreebsd-i386 and kfreebsd-amd64, Dependency based booting.
|
||||
- **Debian 7.0**: Released on may 4, 2013. Code name: wheezy, Support for Multiarch, Tools for private cloud, Improved Installer, Third party repo need removed, full featured multimedia-codec, Kernel 3.2, Xen Hypervisor 4.1.4 Package Count: 37400+.
|
||||
- **Debian 8.0**: Released on May 25, 2015 and Code name: Jessie, Systemd as the default init system, powered by Kernel 3.16, fast booting, cgroups for services, possibility of isolating part of the services, 43000+ packages. Sysvinit init system available in Jessie.
|
||||
|
||||
**Note**: Linux Kernel initial release was on October 05, 1991 and Debian initial release was on September 15, 1993. So, Debian is there for 22 Years running Linux Kernel which is there for 24 years.
|
||||
|
||||
### Debian Facts ###
|
||||
|
||||
Year 1994 was spent on organizing and managing Debian project so that it would be easy for others to contribute. Hence no release for users were made this year however there were certain internal release.
|
||||
|
||||
Debian 1.0 was never released. A CDROM manufacturer company by mistakenly labelled an unreleased version as Debian 1.0. Hence to avoid confusion Debian 1.0 was released as Debian 1.1 and since then only the concept of official CDROM images came into existence.
|
||||
|
||||
Each release of Debian is a character of Toy Story.
|
||||
|
||||
Debian remains available in old stable, stable, testing and experimental, all the time.
|
||||
|
||||
The Debian Project continues to work on the unstable distribution (codenamed sid, after the evil kid from the Toy Story). Sid is the permanent name for the unstable distribution and is remains ‘Still In Development’. The testing release is intended to become the next stable release and is currently codenamed jessie.
|
||||
|
||||
Debian official distribution includes only Free and OpenSource Software and nothing else. However the availability of contrib and Non-free Packages makes it possible to install those packages which are free but their dependencies are not licensed free (contrib) and Packages licensed under non-free softwares.
|
||||
|
||||
Debian is the mother of a lot of Linux distribution. Some of these Includes:
|
||||
|
||||
- Damn Small Linux
|
||||
- KNOPPIX
|
||||
- Linux Advanced
|
||||
- MEPIS
|
||||
- Ubuntu
|
||||
- 64studio (No more active)
|
||||
- LMDE
|
||||
|
||||
Debian is the world’s largest non commercial Linux Distribution. It is written in C (32.1%) programming language and rest in 70 other languages.
|
||||
|
||||

|
||||
|
||||
Debian Contribution
|
||||
|
||||
Image Source: [Xmodulo][1]
|
||||
|
||||
Debian project contains 68.5 million actual loc (lines of code) + 4.5 million lines of comments and white spaces.
|
||||
|
||||
International Space station dropped Windows & Red Hat for adopting Debian – These astronauts are using one release back – now “squeeze” for stability and strength from community.
|
||||
|
||||
Thank God! Who would have heard the scream from space on Windows Metro Screen :P
|
||||
|
||||
#### The Black Wednesday ####
|
||||
|
||||
On November 20th, 2002 the University of Twente Network Operation Center (NOC) caught fire. The fire department gave up protecting the server area. NOC hosted satie.debian.org which included Security, non-US archive, New Maintainer, quality assurance, databases – Everything was turned to ashes. Later these services were re-built by debian.
|
||||
|
||||
#### The Future Distro ####
|
||||
|
||||
Next in the list is Debian 9, code name – Stretch, what it will have is yet to be revealed. The best is yet to come, Just Wait for it!
|
||||
|
||||
A lot of distribution made an appearance in Linux Distro genre and then disappeared. In most cases managing as it gets bigger was a concern. But certainly this is not the case with Debian. It has hundreds of thousands of developer and maintainer all across the globe. It is a one Distro which was there from the initial days of Linux.
|
||||
|
||||
The contribution of Debian in Linux ecosystem can’t be measured in words. If there had been no Debian, Linux would not have been so rich and user-friendly. Debian is among one of the disto which is considered highly reliable, secure and stable and a perfect choice for Web Servers.
|
||||
|
||||
That’s the beginning of Debian. It came a long way and still going. The Future is Here! The world is here! If you have not used Debian till now, What are you Waiting for. Just Download Your Image and get started, we will be here if you get into trouble.
|
||||
|
||||
- [Debian Homepage][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/happy-birthday-to-debian-gnu-linux/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://xmodulo.com/2013/08/interesting-facts-about-debian-linux.html
|
||||
[2]:https://www.debian.org/
|
||||
@ -0,0 +1,53 @@
|
||||
Docker Working on Security Components, Live Container Migration
|
||||
================================================================================
|
||||

|
||||
|
||||
**Docker developers take the stage at Containercon and discuss their work on future container innovations for security and live migration.**
|
||||
|
||||
SEATTLE—Containers are one of the hottest topics in IT today and at the Linuxcon USA event here there is a co-located event called Containercon, dedicated to this virtualization technology.
|
||||
|
||||
Docker, the lead commercial sponsor of the open-source Docker effort brought three of its top people to the keynote stage today, but not Docker founder Solomon Hykes.
|
||||
|
||||
Hykes who delivered a Linuxcon keynote in 2014 was in the audience though, as Senior Vice President of Engineering Marianna Tessel, Docker security chief Diogo Monica and Docker chief maintainer Michael Crosby presented what's new and what's coming in Docker.
|
||||
|
||||
Tessel emphasized that Docker is very real today and used in production environments at some of the largest organizations on the planet, including the U.S. Government. Docker also is working in small environments too, including the Raspberry Pi small form factor ARM computer, which now can support up to 2,300 containers on a single device.
|
||||
|
||||
"We're getting more powerful and at the same time Docker will also get simpler to use," Tessel said.
|
||||
|
||||
As a metaphor, Tessel said that the whole Docker experience is much like a cruise ship, where there is powerful and complex machinery that powers the ship, yet the experience for passengers is all smooth sailing.
|
||||
|
||||
One area that Docker is trying to make easier is security. Tessel said that security is mind-numbingly complex for most people as organizations constantly try to avoid network breaches.
|
||||
|
||||
That's where Docker Content Trust comes into play, which is a configurable feature in the recent Docker 1.8 release. Diogo Mónica, security lead for Docker joined Tessel on stage and said that security is a hard topic, which is why Docker content trust is being developed.
|
||||
|
||||
With Docker Content Trust there is a verifiable way to make sure that a given Docker application image is authentic. There also are controls to limit fraud and potential malicious code injection by verifying application freshness.
|
||||
|
||||
To prove his point, Monica did a live demonstration of what could happen if Content Trust is not enabled. In one instance, a Website update is manipulated to allow the demo Web app to be defaced. When Content Trust is enabled, the hack didn't work and was blocked.
|
||||
|
||||
"Don't let the simple demo fool you," Tessel said. "You have seen the best security possible."
|
||||
|
||||
One area where containers haven't been put to use before is for live migration, which on VMware virtual machines is a technology called vMotion. It's an area that Docker is currently working on.
|
||||
|
||||
Docker chief maintainer Michael Crosby did an onstage demonstration of a live migration of Docker containers. Crosby referred to the approach as checkpoint and restore, where a running container gets a checkpoint snapshot and is then restored to another location.
|
||||
|
||||
A container also can be cloned and then run in another location. Crosby humorously referred to his cloned container as "Dolly," a reference to the world's first cloned animal, Dolly the sheep.
|
||||
|
||||
Tessel also took time to talk about the RunC component of containers, which is now a technology component that is being developed by the Open Containers Initiative as a multi-stakeholder process. With RunC, containers expand beyond Linux to multiple operating systems including Windows and Solaris.
|
||||
|
||||
Overall, Tessel said that she can't predict the future of Docker, though she is very optimistic.
|
||||
|
||||
"I'm not sure what the future is, but I'm sure it'll be out of this world," Tessel said.
|
||||
|
||||
Sean Michael Kerner is a senior editor at eWEEK and InternetNews.com. Follow him on Twitter @TechJournalist.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.eweek.com/virtualization/docker-working-on-security-components-live-container-migration.html
|
||||
|
||||
作者:[Sean Michael Kerner][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.eweek.com/cp/bio/Sean-Michael-Kerner/
|
||||
@ -0,0 +1,49 @@
|
||||
Linuxcon: The Changing Role of the Server OS
|
||||
================================================================================
|
||||
SEATTLE - Containers might one day change the world, but it will take time and it will also change the role of the operating system. That's the message delivered during a Linuxcon keynote here today by Wim Coekaerts, SVP Linux and virtualization engineering at Oracle.
|
||||
|
||||

|
||||
|
||||
Coekaerts started his presentation by putting up a slide stating it's the year of the desktop, which generated a few laughs from the audience. Oracle Wim Coekarts Truly, though, Coekaerts said it is now apparent that 2015 is the year of the container, and more importantly the year of the application, which is what containers really are all about.
|
||||
|
||||
"What do you need an operating system for?" Coekaerts asked. "It's really just there to run an application; an operating system is there to manage hardware and resources so your app can run."
|
||||
|
||||
Coekaerts added that with Docker containers, the focus is once again on the application. At Oracle, Coekaerts said much of the focus is on how to make the app run better on the OS.
|
||||
|
||||
"Many people are used to installing apps, but many of the younger generation just click a button on their mobile device and it runs," Coekaerts said.
|
||||
|
||||
Coekaerts said that people now wonder why it's more complex in the enterprise to install software, and Docker helps to change that.
|
||||
|
||||
"The role of the operating system is changing," Coekaerts said.
|
||||
|
||||
The rise of Docker does not mean the demise of virtual machines (VMs), though. Coekaerts said it will take a very long time for things to mature in the containerization space and get used in real world.
|
||||
|
||||
During that period VMs and containers will co-exist and there will be a need for transition and migration tools between containers and VMs. For example, Coekaerts noted that Oracle's VirtualBox open-source technology is widely used on desktop systems today as a way to help users run Docker. The Docker Kitematic project makes use of VirtualBox to boot Docker on Macs today.
|
||||
|
||||
### The Open Compute Initiative and Write Once, Deploy Anywhere for Containers ###
|
||||
|
||||
A key promise that needs to be enabled for containers to truly be successful is the concept of write once, deploy anywhere. That's an area where the Linux Foundations' Open Compute Initiative (OCI) will play a key role in enabling interoperability across container runtimes.
|
||||
|
||||
"With OCI, it will make it easier to build once and run anywhere, so what you package locally you can run wherever you want," Coekaerts said.
|
||||
|
||||
Overall, though, Coekaerts said that while there is a lot of interest in moving to the container model, it's not quite ready yet. He noted Oracle is working on certifying its products to run in containers, but it's a hard process.
|
||||
|
||||
"Running the database is easy; it's everything else around it that is complex," Coekaerts said. "Containers don't behave the same as VMs, and some applications depend on low-level system configuration items that are not exposed from the host to the container."
|
||||
|
||||
Additionally, Coekaerts commented that debugging problems inside a container is different than in a VM, and there is currently a lack of mature tools for proper container app debugging.
|
||||
|
||||
Coekaerts emphasized that as containers matures it's important to not forget about the existing technology that organizations use to run and deploy applications on servers today. He said enterprises don't typically throw out everything they have just to start with new technology.
|
||||
|
||||
"Deploying new technology is hard, and you need to be able to transition from what you have," Coekaerts said. "The technology that allows you to transition easily is the technology that wins."
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.serverwatch.com/server-news/linuxcon-the-changing-role-of-the-server-os.html
|
||||
|
||||
作者:[Sean Michael Kerner][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.serverwatch.com/author/Sean-Michael-Kerner-101580.htm
|
||||
@ -0,0 +1,49 @@
|
||||
A Look at What's Next for the Linux Kernel
|
||||
================================================================================
|
||||

|
||||
|
||||
**The upcoming Linux 4.2 kernel will have more contributors than any other Linux kernel in history, according to Linux kernel developer Jonathan Corbet.**
|
||||
|
||||
SEATTLE—The Linux kernel continues to grow—both in lines of code and the number of developers that contribute to it—yet some challenges need to be addressed. That was one of the key messages from Linux kernel developer Jonathan Corbet during his annual Kernel Report session at the LinuxCon conference here.
|
||||
|
||||
The Linux 4.2 kernel is still under development, with general availability expected on Aug. 23. Corbet noted that 1,569 developers have contributed code for the Linux 4.2 kernel. Of those, 277 developers made their first contribution ever, during the Linux 4.2 development cycle.
|
||||
|
||||
Even as more developers are coming to Linux, the pace of development and releases is very fast, Corbet said. He estimates that it now takes approximately 63 days for the community to build a new Linux kernel milestone.
|
||||
|
||||
Linux 4.2 will benefit from a number of improvements that have been evolving in Linux over the last several releases. One such improvement is the introduction of OverlayFS, a new type of read-only file system that is useful because it can enable many containers to be layered on top of each other, Corbet said.
|
||||
|
||||
Linux networking also is set to improve small packet performance, which is important for areas such as high-frequency financial trading. The improvements are aimed at reducing the amount of time and power needed to process each data packet, Corbet said.
|
||||
|
||||
New drivers are always being added to Linux. On average, there are 60 to 80 new or updated drivers added in every Linux kernel development cycle, Corbet said.
|
||||
|
||||
Another key area that continues to improve is that of Live Kernel patching, first introduced in the Linux 4.0 kernel. With live kernel patching, the promise is that a system administrator can patch a live running kernel without the need to reboot a running production system. While the basic elements of live kernel patching are in the kernel already, work is under way to make the technology all work with the right level of consistency and stability, Corbet explained.
|
||||
|
||||
**Linux Security, IoT and Other Concerns**
|
||||
|
||||
Security has been a hot topic in the open-source community in the past year due to high-profile issues, including Heartbleed and Shellshock.
|
||||
|
||||
"I don't doubt there are some unpleasant surprises in the neglected Linux code at this point," Corbet said.
|
||||
|
||||
He noted that there are more than 3 millions lines of code in the Linux kernel today that have been untouched in the last decade by developers and that the Shellshock vulnerability was a flaw in 20-year-old code that hadn't been looked at in some time.
|
||||
|
||||
Another issue that concerns Corbet is the Unix 2038 issue—the Linux equivalent of the Y2K bug, which could have caused global havoc in the year 2000 if it hadn't been fixed. With the 2038 issue, there is a bug that could shut down Linux and Unix machines in the year 2038. Corbet said that while 2038 is still 23 years away, there are systems being deployed now that will be in use in the 2038.
|
||||
|
||||
Some initial work took place to fix the 2038 flaw in Linux, but much more remains to be done, Corbet said. "The time to fix this is now, not 20 years from now in a panic when we're all trying to enjoy our retirement," Corbet said.
|
||||
|
||||
The Internet of things (IoT) is another area of Linux concern for Corbet. Today, Linux is a leading embedded operating system for IoT, but that might not always be the case. Corbet is concerned that the Linux kernel's growth is making it too big in terms of memory footprint to work in future IoT devices.
|
||||
|
||||
A Linux project is now under way to minimize the size of the Linux kernel, and it's important that it gets the support it needs, Corbet said.
|
||||
|
||||
"Either Linux is suitable for IoT, or something else will come along and that something else might not be as free and open as Linux," Corbet said. "We can't assume the continued dominance of Linux in IoT. We have to earn it. We have to pay attention to stuff that makes the kernel bigger."
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.eweek.com/enterprise-apps/a-look-at-whats-next-for-the-linux-kernel.html
|
||||
|
||||
作者:[Sean Michael Kerner][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.eweek.com/cp/bio/Sean-Michael-Kerner/
|
||||
@ -0,0 +1,46 @@
|
||||
LinuxCon's surprise keynote speaker Linus Torvalds muses about open-source software
|
||||
================================================================================
|
||||
> In a broad-ranging question and answer session, Linus Torvalds, Linux's founder, shared his thoughts on the current state of open source and Linux.
|
||||
|
||||
**SEATTLE** -- [LinuxCon][1] attendees got an early Christmas present when the Wednesday morning "surprise" keynote speaker turned out to be Linux's founder, Linus Torvalds.
|
||||
|
||||

|
||||
|
||||
Jim Zemlin and Linus Torvalds shooting the breeze at LinuxCon in Seattle. -- sjvn
|
||||
|
||||
Jim Zemlin, the Linux Foundation's executive director, opened the question and answer session by quoting from a recent article about Linus, "[Torvalds may be the most influential individual economic force][2] of the past 20 years. ... Torvalds has, in effect, been as instrumental in retooling the production lines of the modern economy as Henry Ford was 100 years earlier."
|
||||
|
||||
Torvalds replied, "I don't think I'm all that powerful, but I'm glad to get all the credit for open source." For someone who's arguably been more influential on technology than Bill Gates, Steve Jobs, or Larry Ellison, Torvalds remains amusingly modest. That's probably one reason [Torvalds, who doesn't suffer fools gladly][3], remains the unchallenged leader of Linux.
|
||||
|
||||
It also helps that he doesn't take himself seriously, except when it comes to code quality. Zemlin reminded him that he was also described in the same article as being "5-feet, ho-hum tall with a paunch, ... his body type and gait resemble that of Tux, the penguin mascot of Linux." Torvald's reply was to grin and say "What is this? A roast?" He added that 5'8" was a perfectly good height.
|
||||
|
||||
More seriously, Zemlin asked Torvalds what he thought about the current excitement over containers. Indeed, at times LinuxCon has felt like DockerCon. Torvalds replied, "I'm glad that the kernel is far removed from containers and other buzzwords. We only care about just the kernel. I'm so focused on the kernel I really don't care. I don't get involved in the politics above the kernel and I'm really happy that I don't know."
|
||||
|
||||
Moving on, Zemlin asked Torvalds what he thought about the demand from the Internet of Things (IoT) for an even smaller Linux kernel. "Everyone has always wished for a smaller kernel," Torvalds said. "But, with all the modules it's still tens of MegaBytes in size. It's shocking that it used to fit into a MB. We'd like it to be mean lean, mean IT machine again."
|
||||
|
||||
But, "Torvalds continued, "It's hard to get rid of unnecessary fat. Things tend to grow. Realistically I don't think we can get down to the sizes we were 20 years ago."
|
||||
|
||||
As for security, the next topic, Torvalds said, "I'm at odds with the security community. They tend to see technology as black and white. If it's not security they don't care at all about it." The truth is "security is bugs. Most of the security issues we've had in the kernel hasn't been that big. Most of them have been really stupid and then some clever person takes advantage of it."
|
||||
|
||||
The bottom line is, "We'll never get rid of bugs so security will never be perfect. We do try to be really careful about code. With user space we have to be very strict." But, "Bugs happen and all you can do is mitigate them. Open source is doing fairly well, but anyone who thinks we'll ever be completely secure is foolish."
|
||||
|
||||
Zemlin concluded by asking Torvalds where he saw Linux ten years from now. Torvalds replied that he doesn't look at it this way. "I'm plodding, pedestrian, I look ahead six months, I don't plan 10 years ahead. I think that's insane."
|
||||
|
||||
Sure, "companies plan ten years, and their plans use open source. Their whole process is very forward thinking. But I'm not worried about 10 years ahead. I look to the next release and the release beyond that."
|
||||
|
||||
For Torvalds, who works at home where "the FedEx guy is no longer surprised to find me in my bathrobe at 2 in the afternoon," looking ahead a few months works just fine. And so do all the businesses -- both technology-based Amazon, Google, Facebook and more mainstream, WalMart, the New York Stock Exchange, and McDonalds -- that live on Linux every day.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.zdnet.com/article/linus-torvalds-muses-about-open-source-software/
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/
|
||||
[1]:http://events.linuxfoundation.org/events/linuxcon-north-america
|
||||
[2]:http://www.bloomberg.com/news/articles/2015-06-16/the-creator-of-linux-on-the-future-without-him
|
||||
[3]:http://www.zdnet.com/article/linus-torvalds-finds-gnome-3-4-to-be-a-total-user-experience-design-failure/
|
||||
@ -0,0 +1,53 @@
|
||||
Which Open Source Linux Distributions Would Presidential Hopefuls Run?
|
||||
================================================================================
|
||||

|
||||
|
||||
Republican presidential candidate Donald Trump
|
||||
|
||||
If people running for president used Linux or another open source operating system, which distribution would it be? That's a key question that the rest of the press—distracted by issues of questionable relevance such as "policy platforms" and whether it's appropriate to add an exclamation point to one's Christian name—has been ignoring. But the ignorance ends here: Read on for this sometime-journalist's take on presidential elections and Linux distributions.
|
||||
|
||||
If this sounds like a familiar topic to those of you who have been reading my drivel for years (is anyone, other than my dear editor, unfortunate enough to have actually done that?), it's because I wrote a [similar post][1] during the last presidential election cycle. Some kind readers took that article more seriously than I intended, so I'll take a moment to point out that I don't actually believe that open source software and political campaigns have anything meaningful to do with one another. I am just trying to amuse myself at the start of a new week.
|
||||
|
||||
But you can make of this what you will. You're the reader, after all.
|
||||
|
||||
### Linux Distributions of Choice: Republicans ###
|
||||
|
||||
Today, I'll cover just the Republicans. And I won't even discuss all of them, since the candidates hoping for the Republican party's nomination are too numerous to cover fully here in one post. But for starters:
|
||||
|
||||
If **Jeb (Jeb!?) Bush** ran Linux, it would be [Debian][2]. It's a relatively boring distribution designed for serious, grown-up hackers—the kind who see it as their mission to be the adults in the pack and clean up the messes that less-experienced open source fans create. Of course, this also makes Debian relatively unexciting, and its user base remains perennially small as a result.
|
||||
|
||||
**Scott Walker**, for his part, would be a [Damn Small Linux][3] (DSL) user. Requiring merely 50MB of disk space and 16MB of RAM to run, DSL can breathe new life into 20-year-old 486 computers—which is exactly what a cost-cutting guru like Walker would want. Of course, the user experience you get from DSL is damn primitive; the platform barely runs a browser. But at least you won't be wasting money on new computer hardware when the stuff you bought in 1993 can still serve you perfectly well.
|
||||
|
||||
How about **Chris Christie**? He'd obviously be clinging to [Relax-and-Recover Linux][4], which bills itself as a "setup-and-forget Linux bare metal disaster recovery solution." "Setup-and-forget" has basically been Christie's political strategy ever since that unfortunate incident on the George Washington Bridge stymied his political momentum. Disaster recovery may or may not bring back everything for Christie in the end, but at least he might succeed in recovering a confidential email or two that accidentally disappeared when his computer crashed.
|
||||
|
||||
As for **Carly Fiorina**, she'd no doubt be using software developed for "[The Machine][5]" operating system from [Hewlett-Packard][6] (HPQ), the company she led from 1999 to 2005. The Machine actually may run several different operating systems, which may or may not be based on Linux—details remain unclear—and its development began well after Fiorina's tenure at HP came to a conclusion. Still, her roots as a successful executive in the IT world form an important part of her profile today, meaning that her ties to HP have hardly been severed fully.
|
||||
|
||||
Last but not least—and you knew this was coming—there's **Donald Trump**. He'd most likely pay a team of elite hackers millions of dollars to custom-build an operating system just for him—even though he could obtain a perfectly good, ready-made operating system for free—to show off how much money he has to waste. He'd then brag about it being the best operating system ever made, though it would of course not be compliant with POSIX or anything else, because that would mean catering to the establishment. The platform would also be totally undocumented, since, if Trump explained how his operating system actually worked, he'd risk giving away all his secrets to the Islamic State—obviously.
|
||||
|
||||
Alternatively, if Trump had to go with a Linux platform already out there, [Ubuntu][7] seems like the most obvious choice. Like Trump, the Ubuntu developers have taken a we-do-what-we-want approach to building open source software by implementing their own, sometimes proprietary applications and interfaces. Free-software purists hate Ubuntu for that, but plenty of ordinary people like it a lot. Of course, whether playing purely by your own rules—in the realms of either software or politics—is sustainable in the long run remains to be seen.
|
||||
|
||||
### Stay Tuned ###
|
||||
|
||||
If you're wondering why I haven't yet mentioned the Democratic candidates, worry not. I am not leaving them out of today's writing because I like them any more or less than the Republicans. (Personally, I think the peculiar American practice of having only two viable political parties—which virtually no other functioning democracy does—is ridiculous, and I am suspicious of all of these candidates as a result.)
|
||||
|
||||
On the contrary, there's plenty to say about the Linux distributions the Democrats might use, too. And I will, in a future post. Stay tuned.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://thevarguy.com/open-source-application-software-companies/081715/which-open-source-linux-distributions-would-presidential-
|
||||
|
||||
作者:[Christopher Tozzi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://thevarguy.com/author/christopher-tozzi
|
||||
[1]:http://thevarguy.com/open-source-application-software-companies/aligning-linux-distributions-presidential-hopefuls
|
||||
[2]:http://debian.org/
|
||||
[3]:http://www.damnsmalllinux.org/
|
||||
[4]:http://relax-and-recover.org/
|
||||
[5]:http://thevarguy.com/open-source-application-software-companies/061614/hps-machine-open-source-os-truly-revolutionary
|
||||
[6]:http://hp.com/
|
||||
[7]:http://ubuntu.com/
|
||||
147
sources/talk/20150820 Why did you start using Linux.md
Normal file
147
sources/talk/20150820 Why did you start using Linux.md
Normal file
@ -0,0 +1,147 @@
|
||||
Why did you start using Linux?
|
||||
================================================================================
|
||||
> In today's open source roundup: What got you started with Linux? Plus: IBM's Linux only Mainframe. And why you should skip Windows 10 and go with Linux
|
||||
|
||||
### Why did you start using Linux? ###
|
||||
|
||||
Linux has become quite popular over the years, with many users defecting to it from OS X or Windows. But have you ever wondered what got people started with Linux? A redditor asked that question and got some very interesting answers.
|
||||
|
||||
SilverKnight asked his question on the Linux subreddit:
|
||||
|
||||
> I know this has been asked before, but I wanted to hear more from the younger generation why it is that they started using linux and what keeps them here.
|
||||
>
|
||||
> I dont want to discourage others from giving their linux origin stories, because those are usually pretty good, but I was mostly curious about our younger population since there isn't much out there from them yet.
|
||||
>
|
||||
> I myself am 27 and am a linux dabbler. I have installed quite a few different distros over the years but I haven't made the plunge to full time linux. I guess I am looking for some more reasons/inspiration to jump on the bandwagon.
|
||||
>
|
||||
> [More at Reddit][1]
|
||||
|
||||
Fellow redditors in the Linux subreddit responded with their thoughts:
|
||||
|
||||
> **DoublePlusGood**: "I started using Backtrack Linux (now Kali) at 12 because I wanted to be a "1337 haxor". I've stayed with Linux (Archlinux currently) because it lets me have the endless freedom to make my computer do what I want."
|
||||
>
|
||||
> **Zack**: "I'm a Linux user since, I think, the age of 12 or 13, I'm 15 now.
|
||||
>
|
||||
> It started when I got tired with Windows XP at 11 and the waiting, dammit am I impatient sometimes, but waiting for a basic task such as shutting down just made me tired of Windows all together.
|
||||
>
|
||||
> A few months previously I had started participating in discussions in a channel on the freenode IRC network which was about a game, and as freenode usually goes, it was open source and most of the users used Linux.
|
||||
>
|
||||
> I kept on hearing about this Linux but wasn't that interested in it at the time. However, because the channel (and most of freenode) involved quite a bit of programming I started learning Python.
|
||||
>
|
||||
> A year passed and I was attempting to install GNU/Linux (specifically Ubuntu) on my new (technically old, but I had just got it for my birthday) PC, unfortunately it continually froze, for reasons unknown (probably a bad hard drive, or a lot of dust or something else...).
|
||||
>
|
||||
> Back then I was the type to give up on things, so I just continually nagged my dad to try and install Ubuntu, he couldn't do it for the same reasons.
|
||||
>
|
||||
> After wanting Linux for a while I became determined to get Linux and ditch windows for good. So instead of Ubuntu I tried Linux Mint, being a derivative of Ubuntu(?) I didn't have high hopes, but it worked!
|
||||
>
|
||||
> I continued using it for another 6 months.
|
||||
>
|
||||
> During that time a friend on IRC gave me a virtual machine (which ran Ubuntu) on their server, I kept it for a year a bit until my dad got me my own server.
|
||||
>
|
||||
> After the 6 months I got a new PC (which I still use!) I wanted to try something different.
|
||||
>
|
||||
> I decided to install openSUSE.
|
||||
>
|
||||
> I liked it a lot, and on the same Christmas I obtained a Raspberry Pi, and stuck with Debian on it for a while due to the lack of support other distros had for it."
|
||||
>
|
||||
> **Cqz**: "Was about 9 when the Windows 98 machine handed down to me stopped working for reasons unknown. We had no Windows install disk, but Dad had one of those magazines that comes with demo programs and stuff on CDs. This one happened to have install media for Mandrake Linux, and so suddenly I was a Linux user. Had no idea what I was doing but had a lot of fun doing it, and although in following years I often dual booted with various Windows versions, the FLOSS world always felt like home. Currently only have one Windows installation, which is a virtual machine for games."
|
||||
>
|
||||
> **Tosmarcel**: "I was 15 and was really curious about this new concept called 'programming' and then I stumbled upon this Harvard course, CS50. They told users to install a Linux vm to use the command line. But then I asked myself: "Why doesn't windows have this command line?!". I googled 'linux' and Ubuntu was the top result -Ended up installing Ubuntu and deleted the windows partition accidentally... It was really hard to adapt because I knew nothing about linux. Now I'm 16 and running arch linux, never looked back and I love it!"
|
||||
>
|
||||
> **Micioonthet**: "First heard about Linux in the 5th grade when I went over to a friend's house and his laptop was running MEPIS (an old fork of Debian) instead of Windows XP.
|
||||
>
|
||||
> Turns out his dad was a socialist (in America) and their family didn't trust Microsoft. This was completely foreign to me, and I was confused as to why he would bother using an operating system that didn't support the majority of software that I knew.
|
||||
>
|
||||
> Fast forward to when I was 13 and without a laptop. Another friend of mine was complaining about how slow his laptop was, so I offered to buy it off of him so I could fix it up and use it for myself. I paid $20 and got a virus filled, unusable HP Pavilion with Windows Vista. Instead of trying to clean up the disgusting Windows install, I remembered that Linux was a thing and that it was free. I burned an Ubuntu 12.04 disc and installed it right away, and was absolutely astonished by the performance.
|
||||
>
|
||||
> Minecraft (one of the few early Linux games because it ran on Java), which could barely run at 5 FPS on Vista, ran at an entirely playable 25 FPS on a clean install of Ubuntu.
|
||||
>
|
||||
> I actually still have that old laptop and use it occasionally, because why not? Linux doesn't care how old your hardware is.
|
||||
>
|
||||
> I since converted my dad to Linux and we buy old computers at lawn sales and thrift stores for pennies and throw Linux Mint or some other lightweight distros on them."
|
||||
>
|
||||
> **Webtm**: "My dad had every computer in the house with some distribution on it, I think a couple with OpenSUSE and Debian, and his personal computer had Slackware on it. So I remember being little and playing around with Debian and not really getting into it much. So I had a Windows laptop for a few years and my dad asked me if I wanted to try out Debian. It was a fun experience and ever since then I've been using Debian and trying out distributions. I currently moved away from Linux and have been using FreeBSD for around 5 months now, and I am absolutely happy with it.
|
||||
>
|
||||
> The control over your system is fantastic. There are a lot of cool open source projects. I guess a lot of the fun was figuring out how to do the things I want by myself and tweaking those things in ways to make them do something else. Stability and performance is also a HUGE plus. Not to mention the level of privacy when switching."
|
||||
>
|
||||
> **Wyronaut**: "I'm currently 18, but I first started using Linux when I was 13. Back then my first distro was Ubuntu. The reason why I wanted to check out Linux, was because I was hosting little Minecraft game servers for myself and a couple of friends, back then Minecraft was pretty new-ish. I read that the defacto operating system for hosting servers was Linux.
|
||||
>
|
||||
> I was a big newbie when it came to command line work, so Linux scared me a little, because I had to take care of a lot of things myself. But thanks to google and a few wiki pages I managed to get up a couple of simple servers running on a few older PC's I had lying around. Great use for all that older hardware no one in the house ever uses.
|
||||
>
|
||||
> After running a few game servers I started running a few web servers as well. Experimenting with HTML, CSS and PHP. I worked with those for a year or two. Afterwards, took a look at Java. I made the terrible mistake of watching TheNewBoston video's.
|
||||
>
|
||||
> So after like a week I gave up on Java and went to pick up a book on Python instead. That book was Learn Python The Hard Way by Zed A. Shaw. After I finished that at the fast pace of two weeks, I picked up the book C++ Primer, because at the time I wanted to become a game developer. Went trough about half of the book (~500 pages) and burned out on learning. At that point I was spending a sickening amount of time behind my computer.
|
||||
>
|
||||
> After taking a bit of a break, I decided to pick up JavaScript. Read like 2 books, made like 4 different platformers and called it a day.
|
||||
>
|
||||
> Now we're arriving at the present. I had to go through the horrendous process of finding a school and deciding what job I wanted to strive for when I graduated. I ruled out anything in the gaming sector as I didn't want anything to do with graphics programming anymore, I also got completely sick of drawing and modelling. And I found this bachelor that had something to do with netsec and I instantly fell in love. I picked up a couple books on C to shred this vacation period and brushed up on some maths and I'm now waiting for the new school year to commence.
|
||||
>
|
||||
> Right now, I am having loads of fun with Arch Linux, made couple of different arrangements on different PC's and it's going great!
|
||||
>
|
||||
> In a sense Linux is what also got me into programming and ultimately into what I'm going to study in college starting this september. I probably have my future life to thank for it."
|
||||
>
|
||||
> **Linuxllc**: "You also can learn from old farts like me.
|
||||
>
|
||||
> The crutch, The crutch, The crutch. Getting rid of the crutch will inspired you and have good reason to stick with Linux.
|
||||
>
|
||||
> I got rid of my crutch(Windows XP) back in 2003. Took me only 5 days to get all my computer task back and running at a 100% workflow. Including all my peripheral devices. Minus any Windows games. I just play native Linux games."
|
||||
>
|
||||
> **Highclass**: "Hey I'm 28 not sure if this is the age group you are looking for.
|
||||
>
|
||||
> To be honest, I was always interested in computers and the thought of a free operating system was intriguing even though at the time I didn't fully grasp the free software philosophy, to me it was free as in no cost. I also did not find the CLI too intimidating as from an early age I had exposure to DOS.
|
||||
>
|
||||
> I believe my first distro was Mandrake, I was 11 or 12, I messed up the family computer on several occasions.... I ended up sticking with it always trying to push myself to the next level. Now I work in the industry with Linux everyday.
|
||||
>
|
||||
> /shrug"
|
||||
>
|
||||
> Matto: "My computer couldn't run fast enough for XP (got it at a garage sale), so I started looking for alternatives. Ubuntu came up in Google. I was maybe 15 or 16 at the time. Now I'm 23 and have a job working on a product that uses Linux internally."
|
||||
>
|
||||
> [More at Reddit][2]
|
||||
|
||||
### IBM's Linux only Mainframe ###
|
||||
|
||||
IBM has a long history with Linux, and now the company has created a Mainframe that features Ubuntu Linux. The new machine is named LinuxOne.
|
||||
|
||||
Ron Miller reports for TechCrunch:
|
||||
|
||||
> The new mainframes come in two flavors, named for penguins (Linux — penguins — get it?). The first is called Emperor and runs on the IBM z13, which we wrote about in January. The other is a smaller mainframe called the Rockhopper designed for a more “entry level” mainframe buyer.
|
||||
>
|
||||
> You may have thought that mainframes went the way of the dinosaur, but they are still alive and well and running in large institutions throughout the world. IBM as part of its broader strategy to promote the cloud, analytics and security is hoping to expand the potential market for mainframes by running Ubuntu Linux and supporting a range of popular open source enterprise software such as Apache Spark, Node.js, MongoDB, MariaDB, PostgreSQL and Chef.
|
||||
>
|
||||
> The metered mainframe will still sit inside the customer’s on-premises data center, but billing will be based on how much the customer uses the system, much like a cloud model, Mauri explained.
|
||||
>
|
||||
> ...IBM is looking for ways to increase those sales. Partnering with Canonical and encouraging use of open source tools on a mainframe gives the company a new way to attract customers to a small, but lucrative market.
|
||||
>
|
||||
> [More at TechCrunch][3]
|
||||
|
||||
### Why you should skip Windows 10 and opt for Linux ###
|
||||
|
||||
Since Windows 10 has been released there has been quite a bit of media coverage about its potential to spy on users. ZDNet has listed some reasons why you should skip Windows 10 and opt for Linux instead on your computer.
|
||||
|
||||
SJVN reports for ZDNet:
|
||||
|
||||
> You can try to turn Windows 10's data-sharing ways off, but, bad news: Windows 10 will keep sharing some of your data with Microsoft anyway. There is an alternative: Desktop Linux.
|
||||
>
|
||||
> You can do a lot to keep Windows 10 from blabbing, but you can't always stop it from talking. Cortana, Windows 10's voice activated assistant, for example, will share some data with Microsoft, even when it's disabled. That data includes a persistent computer ID to identify your PC to Microsoft.
|
||||
>
|
||||
> So, if that gives you a privacy panic attack, you can either stick with your old operating system, which is likely Windows 7, or move to Linux. Eventually, when Windows 7 is no longer supported, if you want privacy you'll have no other viable choice but Linux.
|
||||
>
|
||||
> There are other, more obscure desktop operating systems that are also desktop-based and private. These include the BSD Unix family such as FreeBSD, PCBSD, and NetBSD and eComStation, OS/2 for the 21st century. Your best choice, though, is a desktop-based Linux with a low learning curve.
|
||||
>
|
||||
> [More at ZDNet][4]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.itworld.com/article/2972587/linux/why-did-you-start-using-linux.html
|
||||
|
||||
作者:[Jim Lynch][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.itworld.com/author/Jim-Lynch/
|
||||
[1]:https://www.reddit.com/r/linux/comments/3hb2sr/question_for_younger_users_why_did_you_start/
|
||||
[2]:https://www.reddit.com/r/linux/comments/3hb2sr/question_for_younger_users_why_did_you_start/
|
||||
[3]:http://techcrunch.com/2015/08/16/ibm-teams-with-canonical-on-linux-mainframe/
|
||||
[4]:http://www.zdnet.com/article/sick-of-windows-spying-on-you-go-linux/
|
||||
@ -1,3 +1,4 @@
|
||||
wyangsun translating
|
||||
Install Strongswan - A Tool to Setup IPsec Based VPN in Linux
|
||||
================================================================================
|
||||
IPsec is a standard which provides the security at network layer. It consist of authentication header (AH) and encapsulating security payload (ESP) components. AH provides the packet Integrity and confidentiality is provided by ESP component . IPsec ensures the following security features at network layer.
|
||||
@ -110,4 +111,4 @@ via: http://linoxide.com/security/install-strongswan/
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/naveeda/
|
||||
[1]:https://www.strongswan.org/
|
||||
[1]:https://www.strongswan.org/
|
||||
|
||||
@ -1,145 +0,0 @@
|
||||
Vic020
|
||||
|
||||
Linux Tricks: Play Game in Chrome, Text-to-Speech, Schedule a Job and Watch Commands in Linux
|
||||
================================================================================
|
||||
Here again, I have compiled a list of four things under [Linux Tips and Tricks][1] series you may do to remain more productive and entertained with Linux Environment.
|
||||
|
||||

|
||||
|
||||
Linux Tips and Tricks Series
|
||||
|
||||
The topics I have covered includes Google-chrome inbuilt small game, Text-to-speech in Linux Terminal, Quick job scheduling using ‘at‘ command and watch a command at regular interval.
|
||||
|
||||
### 1. Play A Game in Google Chrome Browser ###
|
||||
|
||||
Very often when there is a power shedding or no network due to some other reason, I don’t put my Linux box into maintenance mode. I keep myself engage in a little fun game by Google Chrome. I am not a gamer and hence I have not installed third-party creepy games. Security is another concern.
|
||||
|
||||
So when there is Internet related issue and my web page seems something like this:
|
||||
|
||||

|
||||
|
||||
Unable to Connect Internet
|
||||
|
||||
You may play the Google-chrome inbuilt game simply by hitting the space-bar. There is no limitation for the number of times you can play. The best thing is you need not break a sweat installing and using it.
|
||||
|
||||
No third-party application/plugin required. It should work well on other platforms like Windows and Mac but our niche is Linux and I’ll talk about Linux only and mind it, it works well on Linux. It is a very simple game (a kind of time pass).
|
||||
|
||||
Use Space-Bar/Navigation-up-key to jump. A glimpse of the game in action.
|
||||
|
||||

|
||||
|
||||
Play Game in Google Chrome
|
||||
|
||||
### 2. Text to Speech in Linux Terminal ###
|
||||
|
||||
For those who may not be aware of espeak utility, It is a Linux command-line text to speech converter. Write anything in a variety of languages and espeak utility will read it loud for you.
|
||||
|
||||
Espeak should be installed in your system by default, however it is not installed for your system, you may do:
|
||||
|
||||
# apt-get install espeak (Debian)
|
||||
# yum install espeak (CentOS)
|
||||
# dnf install espeak (Fedora 22 onwards)
|
||||
|
||||
You may ask espeak to accept Input Interactively from standard Input device and convert it to speech for you. You may do:
|
||||
|
||||
$ espeak [Hit Return Key]
|
||||
|
||||
For detailed output you may do:
|
||||
|
||||
$ espeak --stdout | aplay [Hit Return Key][Double - Here]
|
||||
|
||||
espeak is flexible and you can ask espeak to accept input from a text file and speak it loud for you. All you need to do is:
|
||||
|
||||
$ espeak --stdout /path/to/text/file/file_name.txt | aplay [Hit Enter]
|
||||
|
||||
You may ask espeak to speak fast/slow for you. The default speed is 160 words per minute. Define your preference using switch ‘-s’.
|
||||
|
||||
To ask espeak to speak 30 words per minute, you may do:
|
||||
|
||||
$ espeak -s 30 -f /path/to/text/file/file_name.txt | aplay
|
||||
|
||||
To ask espeak to speak 200 words per minute, you may do:
|
||||
|
||||
$ espeak -s 200 -f /path/to/text/file/file_name.txt | aplay
|
||||
|
||||
To use another language say Hindi (my mother tongue), you may do:
|
||||
|
||||
$ espeak -v hindi --stdout 'टेकमिंट विश्व की एक बेहतरीन लाइंक्स आधारित वेबसाइट है|' | aplay
|
||||
|
||||
You may choose any language of your preference and ask to speak in your preferred language as suggested above. To get the list of all the languages supported by espeak, you need to run:
|
||||
|
||||
$ espeak --voices
|
||||
|
||||
### 3. Quick Schedule a Job ###
|
||||
|
||||
Most of us are already familiar with [cron][2] which is a daemon to execute scheduled commands.
|
||||
|
||||
Cron is an advanced command often used by Linux SYSAdmins to schedule a job such as Backup or practically anything at certain time/interval.
|
||||
|
||||
Are you aware of ‘at’ command in Linux which lets you schedule a job/command to run at specific time? You can tell ‘at’ what to do and when to do and everything else will be taken care by command ‘at’.
|
||||
|
||||
For an example, say you want to print the output of uptime command at 11:02 AM, All you need to do is:
|
||||
|
||||
$ at 11:02
|
||||
uptime >> /home/$USER/uptime.txt
|
||||
Ctrl+D
|
||||
|
||||

|
||||
|
||||
Schedule Job in Linux
|
||||
|
||||
To check if the command/script/job has been set or not by ‘at’ command, you may do:
|
||||
|
||||
$ at -l
|
||||
|
||||

|
||||
|
||||
View Scheduled Jobs
|
||||
|
||||
You may schedule more than one command in one go using at, simply as:
|
||||
|
||||
$ at 12:30
|
||||
Command – 1
|
||||
Command – 2
|
||||
…
|
||||
command – 50
|
||||
…
|
||||
Ctrl + D
|
||||
|
||||
### 4. Watch a Command at Specific Interval ###
|
||||
|
||||
We need to run some command for specified amount of time at regular interval. Just for example say we need to print the current time and watch the output every 3 seconds.
|
||||
|
||||
To see current time we need to run the below command in terminal.
|
||||
|
||||
$ date +"%H:%M:%S
|
||||
|
||||

|
||||
|
||||
Check Date and Time in Linux
|
||||
|
||||
and to check the output of this command every three seconds, we need to run the below command in Terminal.
|
||||
|
||||
$ watch -n 3 'date +"%H:%M:%S"'
|
||||
|
||||

|
||||
|
||||
Watch Command in Linux
|
||||
|
||||
The switch ‘-n’ in watch command is for Interval. In the above example we defined Interval to be 3 sec. You may define yours as required. Also you may pass any command/script with watch command to watch that command/script at the defined interval.
|
||||
|
||||
That’s all for now. Hope you are like this series that aims at making you more productive with Linux and that too with fun inside. All the suggestions are welcome in the comments below. Stay tuned for more such posts. Keep connected and Enjoy…
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/text-to-speech-in-terminal-schedule-a-job-and-watch-commands-in-linux/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/tag/linux-tricks/
|
||||
[2]:http://www.tecmint.com/11-cron-scheduling-task-examples-in-linux/
|
||||
@ -1,4 +1,3 @@
|
||||
translating wi-cuckoo
|
||||
Howto Run JBoss Data Virtualization GA with OData in Docker Container
|
||||
================================================================================
|
||||
Hi everyone, today we'll learn how to run JBoss Data Virtualization 6.0.0.GA with OData in a Docker Container. JBoss Data Virtualization is a data supply and integration solution platform that transforms various scatered multiple sources data, treats them as single source and delivers the required data into actionable information at business speed to any applications or users. JBoss Data Virtualization can help us easily combine and transform data into reusable business friendly data models and make unified data easily consumable through open standard interfaces. It offers comprehensive data abstraction, federation, integration, transformation, and delivery capabilities to combine data from one or multiple sources into reusable for agile data utilization and sharing.For more information about JBoss Data Virtualization, we can check out [its official page][1]. Docker is an open source platform that provides an open platform to pack, ship and run any application as a lightweight container. Running JBoss Data Virtualization with OData in Docker Container makes us easy to handle and launch.
|
||||
|
||||
@ -1,164 +0,0 @@
|
||||
DongShuaike is translating.
|
||||
|
||||
Linux and Unix Test Disk I/O Performance With dd Command
|
||||
================================================================================
|
||||
How can I use dd command on a Linux to test I/O performance of my hard disk drive? How do I check the performance of a hard drive including the read and write speed on a Linux operating systems?
|
||||
|
||||
You can use the following commands on a Linux or Unix-like systems for simple I/O performance test:
|
||||
|
||||
- **dd command** : It is used to monitor the writing performance of a disk device on a Linux and Unix-like system
|
||||
- **hdparm command** : It is used to get/set hard disk parameters including test the reading and caching performance of a disk device on a Linux based system.
|
||||
|
||||
In this tutorial you will learn how to use the dd command to test disk I/O performance.
|
||||
|
||||
### Use dd command to monitor the reading and writing performance of a disk device: ###
|
||||
|
||||
- Open a shell prompt.
|
||||
- Or login to a remote server via ssh.
|
||||
- Use the dd command to measure server throughput (write speed) `dd if=/dev/zero of=/tmp/test1.img bs=1G count=1 oflag=dsync`
|
||||
- Use the dd command to measure server latency `dd if=/dev/zero of=/tmp/test2.img bs=512 count=1000 oflag=dsync`
|
||||
|
||||
#### Understanding dd command options ####
|
||||
|
||||
In this example, I'm using RAID-10 (Adaptec 5405Z with SAS SSD) array running on a Ubuntu Linux 14.04 LTS server. The basic syntax is
|
||||
|
||||
dd if=/dev/input.file of=/path/to/output.file bs=block-size count=number-of-blocks oflag=dsync
|
||||
## GNU dd syntax ##
|
||||
dd if=/dev/zero of=/tmp/test1.img bs=1G count=1 oflag=dsync
|
||||
## OR alternate syntax for GNU/dd ##
|
||||
dd if=/dev/zero of=/tmp/testALT.img bs=1G count=1 conv=fdatasync
|
||||
|
||||
Sample outputs:
|
||||
|
||||

|
||||
Fig.01: Ubuntu Linux Server with RAID10 and testing server throughput with dd
|
||||
|
||||
Please note that one gigabyte was written for the test and 135 MB/s was server throughput for this test. Where,
|
||||
|
||||
- `if=/dev/zero (if=/dev/input.file)` : The name of the input file you want dd the read from.
|
||||
- `of=/tmp/test1.img (of=/path/to/output.file)` : The name of the output file you want dd write the input.file to.
|
||||
- `bs=1G (bs=block-size)` : Set the size of the block you want dd to use. 1 gigabyte was written for the test.
|
||||
- `count=1 (count=number-of-blocks)`: The number of blocks you want dd to read.
|
||||
- `oflag=dsync (oflag=dsync)` : Use synchronized I/O for data. Do not skip this option. This option get rid of caching and gives you good and accurate results
|
||||
- `conv=fdatasyn`: Again, this tells dd to require a complete "sync" once, right before it exits. This option is equivalent to oflag=dsync.
|
||||
|
||||
In this example, 512 bytes were written one thousand times to get RAID10 server latency time:
|
||||
|
||||
dd if=/dev/zero of=/tmp/test2.img bs=512 count=1000 oflag=dsync
|
||||
|
||||
Sample outputs:
|
||||
|
||||
1000+0 records in
|
||||
1000+0 records out
|
||||
512000 bytes (512 kB) copied, 0.60362 s, 848 kB/s
|
||||
|
||||
Please note that server throughput and latency time depends upon server/application load too. So I recommend that you run these tests on a newly rebooted server as well as peak time to get better idea about your workload. You can now compare these numbers with all your devices.
|
||||
|
||||
#### But why the server throughput and latency time are so low? ####
|
||||
|
||||
Low values does not mean you are using slow hardware. The value can be low because of the HARDWARE RAID10 controller's cache.
|
||||
|
||||
Use hdparm command to see buffered and cached disk read speed
|
||||
|
||||
I suggest you run the following commands 2 or 3 times Perform timings of device reads for benchmark and comparison purposes:
|
||||
|
||||
### Buffered disk read test for /dev/sda ##
|
||||
hdparm -t /dev/sda1
|
||||
## OR ##
|
||||
hdparm -t /dev/sda
|
||||
|
||||
To perform timings of cache reads for benchmark and comparison purposes again run the following command 2-3 times (note the -T option):
|
||||
|
||||
## Cache read benchmark for /dev/sda ###
|
||||
hdparm -T /dev/sda1
|
||||
## OR ##
|
||||
hdparm -T /dev/sda
|
||||
|
||||
OR combine both tests:
|
||||
|
||||
hdparm -Tt /dev/sda
|
||||
|
||||
Sample outputs:
|
||||
|
||||
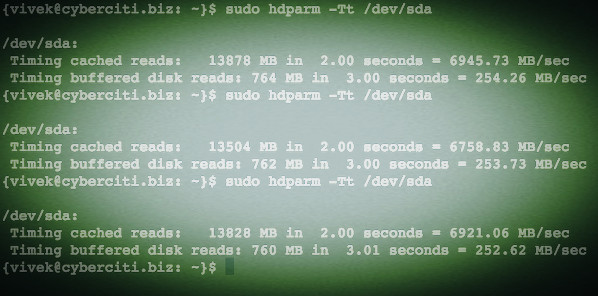
|
||||
Fig.02: Linux hdparm command to test reading and caching disk performance
|
||||
|
||||
Again note that due to filesystems caching on file operations, you will always see high read rates.
|
||||
|
||||
**Use dd command on Linux to test read speed**
|
||||
|
||||
To get accurate read test data, first discard caches before testing by running the following commands:
|
||||
|
||||
flush
|
||||
echo 3 | sudo tee /proc/sys/vm/drop_caches
|
||||
time time dd if=/path/to/bigfile of=/dev/null bs=8k
|
||||
|
||||
**Linux Laptop example**
|
||||
|
||||
Run the following command:
|
||||
|
||||
### Debian Laptop Throughput With Cache ##
|
||||
dd if=/dev/zero of=/tmp/laptop.bin bs=1G count=1 oflag=direct
|
||||
|
||||
### Deactivate the cache ###
|
||||
hdparm -W0 /dev/sda
|
||||
|
||||
### Debian Laptop Throughput Without Cache ##
|
||||
dd if=/dev/zero of=/tmp/laptop.bin bs=1G count=1 oflag=direct
|
||||
|
||||
**Apple OS X Unix (Macbook pro) example**
|
||||
|
||||
GNU dd has many more options but OS X/BSD and Unix-like dd command need to run as follows to test real disk I/O and not memory add sync option as follows:
|
||||
|
||||
## Run command 2-3 times to get good results ###
|
||||
time sh -c "dd if=/dev/zero of=/tmp/testfile bs=100k count=1k && sync"
|
||||
|
||||
Sample outputs:
|
||||
|
||||
1024+0 records in
|
||||
1024+0 records out
|
||||
104857600 bytes transferred in 0.165040 secs (635346520 bytes/sec)
|
||||
|
||||
real 0m0.241s
|
||||
user 0m0.004s
|
||||
sys 0m0.113s
|
||||
|
||||
So I'm getting 635346520 bytes (635.347 MB/s) write speed on my MBP.
|
||||
|
||||
**Not a fan of command line...?**
|
||||
|
||||
You can use disk utility (gnome-disk-utility) on a Linux or Unix based system to get the same information. The following screenshot is taken from my Fedora Linux v22 VM.
|
||||
|
||||
**Graphical method**
|
||||
|
||||
Click on the "Activities" or press the "Super" key to switch between the Activities overview and desktop. Type "Disks"
|
||||
|
||||
|
||||
Fig.03: Start the Gnome disk utility
|
||||
|
||||
Select your hard disk at left pane and click on configure button and click on "Benchmark partition":
|
||||
|
||||
|
||||
Fig.04: Benchmark disk/partition
|
||||
|
||||
Finally, click on the "Start Benchmark..." button (you may be promoted for the admin username and password):
|
||||
|
||||
|
||||
Fig.05: Final benchmark result
|
||||
|
||||
Which method and command do you recommend to use?
|
||||
|
||||
- I recommend dd command on all Unix-like systems (`time sh -c "dd if=/dev/zero of=/tmp/testfile bs=100k count=1k && sync`"
|
||||
- If you are using GNU/Linux use the dd command (`dd if=/dev/zero of=/tmp/testALT.img bs=1G count=1 conv=fdatasync`)
|
||||
- Make sure you adjust count and bs arguments as per your setup to get a good set of result.
|
||||
- The GUI method is recommended only for Linux/Unix laptop users running Gnome2 or 3 desktop.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cyberciti.biz/faq/howto-linux-unix-test-disk-performance-with-dd-command/
|
||||
|
||||
作者:Vivek Gite
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,179 @@
|
||||
How to Install OsTicket Ticketing System in Fedora 22 / Centos 7
|
||||
================================================================================
|
||||
In this article, we'll learn how to setup help desk ticketing system with osTicket in our machine or server running Fedora 22 or CentOS 7 as operating system. osTicket is a free and open source popular customer support ticketing system developed and maintained by [Enhancesoft][1] and its contributors. osTicket is the best solution for help and support ticketing system and management for better communication and support assistance with clients and customers. It has the ability to easily integrate with inquiries created via email, phone and web based forms into a beautiful multi-user web interface. osTicket makes us easy to manage, organize and log all our support requests and responses in one single place. It is a simple, lightweight, reliable, open source, web-based and easy to setup and use help desk ticketing system.
|
||||
|
||||
Here are some easy steps on how we can setup Help Desk ticketing system with osTicket in Fedora 22 or CentOS 7 operating system.
|
||||
|
||||
### 1. Installing LAMP stack ###
|
||||
|
||||
First of all, we'll need to install LAMP Stack to make osTicket working. LAMP stack is the combination of Apache web server, MySQL or MariaDB database system and PHP. To install a complete suit of LAMP stack that we need for the installation of osTicket, we'll need to run the following commands in a shell or a terminal.
|
||||
|
||||
**On Fedora 22**
|
||||
|
||||
LAMP stack is available on the official repository of Fedora 22. As the default package manager of Fedora 22 is the latest DNF package manager, we'll need to run the following command.
|
||||
|
||||
$ sudo dnf install httpd mariadb mariadb-server php php-mysql php-fpm php-cli php-xml php-common php-gd php-imap php-mbstring wget
|
||||
|
||||
**On CentOS 7**
|
||||
|
||||
As there is LAMP stack available on the official repository of CentOS 7, we'll gonna install it using yum package manager.
|
||||
|
||||
$ sudo yum install httpd mariadb mariadb-server php php-mysql php-fpm php-cli php-xml php-common php-gd php-imap php-mbstring wget
|
||||
|
||||
### 2. Starting Apache Web Server and MariaDB ###
|
||||
|
||||
Next, we'll gonna start MariaDB server and Apache Web Server to get started.
|
||||
|
||||
$ sudo systemctl start mariadb httpd
|
||||
|
||||
Then, we'll gonna enable them to start on every boot of the system.
|
||||
|
||||
$ sudo systemctl enable mariadb httpd
|
||||
|
||||
Created symlink from /etc/systemd/system/multi-user.target.wants/mariadb.service to /usr/lib/systemd/system/mariadb.service.
|
||||
Created symlink from /etc/systemd/system/multi-user.target.wants/httpd.service to /usr/lib/systemd/system/httpd.service.
|
||||
|
||||
### 3. Downloading osTicket package ###
|
||||
|
||||
Next, we'll gonna download the latest release of osTicket ie version 1.9.9 . We can download it from the official download page [http://osticket.com/download][2] or from the official github repository. [https://github.com/osTicket/osTicket-1.8/releases][3] . Here, in this tutorial we'll download the tarball of the latest release of osTicket from the github release page using wget command.
|
||||
|
||||
$ cd /tmp/
|
||||
$ wget https://github.com/osTicket/osTicket-1.8/releases/download/v1.9.9/osTicket-v1.9.9-1-gbe2f138.zip
|
||||
|
||||
--2015-07-16 09:14:23-- https://github.com/osTicket/osTicket-1.8/releases/download/v1.9.9/osTicket-v1.9.9-1-gbe2f138.zip
|
||||
Resolving github.com (github.com)... 192.30.252.131
|
||||
...
|
||||
Connecting to s3.amazonaws.com (s3.amazonaws.com)|54.231.244.4|:443... connected.
|
||||
HTTP request sent, awaiting response... 200 OK
|
||||
Length: 7150871 (6.8M) [application/octet-stream]
|
||||
Saving to: ‘osTicket-v1.9.9-1-gbe2f138.zip’
|
||||
osTicket-v1.9.9-1-gb 100%[========================>] 6.82M 1.25MB/s in 12s
|
||||
2015-07-16 09:14:37 (604 KB/s) - ‘osTicket-v1.9.9-1-gbe2f138.zip’ saved [7150871/7150871]
|
||||
|
||||
### 4. Extracting the osTicket ###
|
||||
|
||||
After we have successfully downloaded the osTicket zipped package, we'll now gonna extract the zip. As the default root directory of Apache web server is /var/www/html/ , we'll gonna create a directory called "**support**" where we'll extract the whole directory and files of the compressed zip file. To do so, we'll need to run the following commands in a terminal or a shell.
|
||||
|
||||
$ unzip osTicket-v1.9.9-1-gbe2f138.zip
|
||||
|
||||
Then, we'll move the whole extracted files to it.
|
||||
|
||||
$ sudo mv /tmp/upload /var/www/html/support
|
||||
|
||||
### 5. Fixing Ownership and Permission ###
|
||||
|
||||
Now, we'll gonna assign the ownership of the directories and files under /var/ww/html/support to apache to enable writable access to the apache process owner. To do so, we'll need to run the following command.
|
||||
|
||||
$ sudo chown apache: -R /var/www/html/support
|
||||
|
||||
Then, we'll also need to copy a sample configuration file to its default configuration file. To do so, we'll need to run the below command.
|
||||
|
||||
$ cd /var/www/html/support/
|
||||
$ sudo cp include/ost-sampleconfig.php include/ost-config.php
|
||||
$ sudo chmod 0666 include/ost-config.php
|
||||
|
||||
If you have SELinux enabled on the system, run the following command.
|
||||
|
||||
$ sudo chcon -R -t httpd_sys_content_t /var/www/html/vtigercrm
|
||||
$ sudo chcon -R -t httpd_sys_rw_content_t /var/www/html/vtigercrm
|
||||
|
||||
### 6. Configuring MariaDB ###
|
||||
|
||||
As this is the first time we're going to configure MariaDB, we'll need to create a password for the root user of mariadb so that we can use it to login and create the database for our osTicket installation. To do so, we'll need to run the following command in a terminal or a shell.
|
||||
|
||||
$ sudo mysql_secure_installation
|
||||
|
||||
...
|
||||
Enter current password for root (enter for none):
|
||||
OK, successfully used password, moving on...
|
||||
|
||||
Setting the root password ensures that nobody can log into the MariaDB
|
||||
root user without the proper authorisation.
|
||||
|
||||
Set root password? [Y/n] y
|
||||
New password:
|
||||
Re-enter new password:
|
||||
Password updated successfully!
|
||||
Reloading privilege tables..
|
||||
Success!
|
||||
...
|
||||
All done! If you've completed all of the above steps, your MariaDB
|
||||
installation should now be secure.
|
||||
|
||||
Thanks for using MariaDB!
|
||||
|
||||
Note: Above, we are asked to enter the root password of the mariadb server but as we are setting for the first time and no password has been set yet, we'll simply hit enter while asking the current mariadb root password. Then, we'll need to enter twice the new password we wanna set. Then, we can simply hit enter in every argument in order to set default configurations.
|
||||
|
||||
### 7. Creating osTicket Database ###
|
||||
|
||||
As osTicket needs a database system to store its data and information, we'll be configuring MariaDB for osTicket. So, we'll need to first login into the mariadb command environment. To do so, we'll need to run the following command.
|
||||
|
||||
$ sudo mysql -u root -p
|
||||
|
||||
Now, we'll gonna create a new database "**osticket_db**" with user "**osticket_user**" and password "osticket_password" which will be granted access to the database. To do so, we'll need to run the following commands inside the MariaDB command environment.
|
||||
|
||||
> CREATE DATABASE osticket_db;
|
||||
> CREATE USER 'osticket_user'@'localhost' IDENTIFIED BY 'osticket_password';
|
||||
> GRANT ALL PRIVILEGES on osticket_db.* TO 'osticket_user'@'localhost' ;
|
||||
> FLUSH PRIVILEGES;
|
||||
> EXIT;
|
||||
|
||||
**Note**: It is strictly recommended to replace the database name, user and password as your desire for security issue.
|
||||
|
||||
### 8. Allowing Firewall ###
|
||||
|
||||
If we are running a firewall program, we'll need to configure our firewall to allow port 80 so that the Apache web server's default port will be accessible externally. This will allow us to navigate our web browser to osTicket's web interface with the default http port 80. To do so, we'll need to run the following command.
|
||||
|
||||
$ sudo firewall-cmd --zone=public --add-port=80/tcp --permanent
|
||||
|
||||
After done, we'll need to reload our firewall service.
|
||||
|
||||
$ sudo firewall-cmd --reload
|
||||
|
||||
### 9. Web based Installation ###
|
||||
|
||||
Finally, is everything is done as described above, we'll now should be able to navigate osTicket's Installer by pointing our web browser to http://domain.com/support or http://ip-address/support . Now, we'll be shown if the dependencies required by osTicket are installed or not. As we've already installed all the necessary packages, we'll be welcomed with **green colored tick** to proceed forward.
|
||||
|
||||

|
||||
|
||||
After that, we'll be required to enter the details for our osTicket instance as shown below. We'll need to enter the database name, username, password and hostname and other important account information that we'll require while logging into the admin panel.
|
||||
|
||||

|
||||
|
||||
After the installation has been completed successfully, we'll be welcomed by a Congratulations screen. There we can see two links, one for our Admin Panel and the other for the support center as the homepage of the osTicket Support Help Desk.
|
||||
|
||||

|
||||
|
||||
If we click on http://ip-address/support or http://domain.com/support, we'll be redirected to the osTicket support page which is as shown below.
|
||||
|
||||

|
||||
|
||||
Next, to login into the admin panel, we'll need to navigate our web browser to http://ip-address/support/scp or http://domain.com/support/scp . Then, we'll need to enter the login details we had just created above while configuring the database and other information in the web installer. After successful login, we'll be able to access our dashboard and other admin sections.
|
||||
|
||||

|
||||
|
||||
### 10. Post Installation ###
|
||||
|
||||
After we have finished the web installation of osTicket, we'll now need to secure some of our configuration files. To do so, we'll need to run the following command.
|
||||
|
||||
$ sudo rm -rf /var/www/html/support/setup/
|
||||
$ sudo chmod 644 /var/www/html/support/include/ost-config.php
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
osTicket is an awesome help desk ticketing system providing several new features. It supports rich text or HTML emails, ticket filters, agent collision avoidance, auto-responder and many more features. The user interface of osTicket is very beautiful with easy to use control panel. It is a complete set of tools required for a help and support ticketing system. It is the best solution for providing customers a better way to communicate with the support team. It helps a company to make their customers happy with them regarding the support and help desk. If you have any questions, suggestions, feedback please write them in the comment box below so that we can improve or update our contents. Thank you ! Enjoy :-)
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/install-osticket-fedora-22-centos-7/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://www.enhancesoft.com/
|
||||
[2]:http://osticket.com/download
|
||||
[3]:https://github.com/osTicket/osTicket-1.8/releases
|
||||
@ -0,0 +1,62 @@
|
||||
translation by strugglingyouth
|
||||
Linux FAQs with Answers--How to fix Wireshark GUI freeze on Linux desktop
|
||||
================================================================================
|
||||
> **Question**: When I try to open a pre-recorded packet dump on Wireshark on Ubuntu, its UI suddenly freezes, and the following errors and warnings appear in the terminal where I launched Wireshark. How can I fix this problem?
|
||||
|
||||
Wireshark is a GUI-based packet capture and sniffer tool. This tool is popularly used by network administrators, network security engineers or developers for various tasks where packet-level network analysis is required, for example during network troubleshooting, vulnerability testing, application debugging, or protocol reverse engineering. Wireshark allows one to capture live packets and browse their protocol headers and payloads via a convenient GUI.
|
||||
|
||||

|
||||
|
||||
It is known that Wireshark's UI, especially run under Ubuntu desktop, sometimes hangs or freezes with the following errors, while you are scrolling up or down the packet list view, or starting to load a pre-recorded packet dump file.
|
||||
|
||||
(wireshark:3480): GLib-GObject-WARNING **: invalid unclassed pointer in cast to 'GObject'
|
||||
(wireshark:3480): GLib-GObject-CRITICAL **: g_object_set_qdata_full: assertion 'G_IS_OBJECT (object)' failed
|
||||
(wireshark:3480): GLib-GObject-WARNING **: invalid unclassed pointer in cast to 'GtkRange'
|
||||
(wireshark:3480): Gtk-CRITICAL **: gtk_range_get_adjustment: assertion 'GTK_IS_RANGE (range)' failed
|
||||
(wireshark:3480): GLib-GObject-WARNING **: invalid unclassed pointer in cast to 'GtkOrientable'
|
||||
(wireshark:3480): Gtk-CRITICAL **: gtk_orientable_get_orientation: assertion 'GTK_IS_ORIENTABLE (orientable)' failed
|
||||
(wireshark:3480): GLib-GObject-WARNING **: invalid unclassed pointer in cast to 'GtkScrollbar'
|
||||
(wireshark:3480): GLib-GObject-WARNING **: invalid unclassed pointer in cast to 'GtkWidget'
|
||||
(wireshark:3480): GLib-GObject-WARNING **: invalid unclassed pointer in cast to 'GObject'
|
||||
(wireshark:3480): GLib-GObject-CRITICAL **: g_object_get_qdata: assertion 'G_IS_OBJECT (object)' failed
|
||||
(wireshark:3480): Gtk-CRITICAL **: gtk_widget_set_name: assertion 'GTK_IS_WIDGET (widget)' failed
|
||||
|
||||
Apparently this error is caused by some incompatibility between Wireshark and overlay-scrollbar, and has not been fixed in the latest Ubuntu desktop (e.g., as of Ubuntu 15.04 Vivid Vervet).
|
||||
|
||||
A workaround to avoid this Wireshark UI freeze problem is to **temporarily disabling overlay-scrollbar**. There are two ways to disable overlay-scrollbar in Wireshark, depending on how you launch Wireshark on your desktop.
|
||||
|
||||
### Command-Line Solution ###
|
||||
|
||||
Overlay-scrollbar can be disabled by setting "**LIBOVERLAY_SCROLLBAR**" environment variable to "0".
|
||||
|
||||
So if you are launching Wireshark from the command in a terminal, you can disable overlay-scrollbar in Wireshark as follows.
|
||||
|
||||
Open your .bashrc, and define the following alias.
|
||||
|
||||
alias wireshark="LIBOVERLAY_SCROLLBAR=0 /usr/bin/wireshark"
|
||||
|
||||
### Desktop Launcher Solution ###
|
||||
|
||||
If you are launching Wireshark using a desktop launcher, you can edit its desktop launcher file.
|
||||
|
||||
$ sudo vi /usr/share/applications/wireshark.desktop
|
||||
|
||||
Look for a line that starts with "Exec", and change it as follows.
|
||||
|
||||
Exec=env LIBOVERLAY_SCROLLBAR=0 wireshark %f
|
||||
|
||||
While this solution will be beneficial for all desktop users system-wide, it will not survive Wireshark upgrade. If you want to preserve the modified .desktop file, copy it to your home directory as follows.
|
||||
|
||||
$ cp /usr/share/applications/wireshark.desktop ~/.local/share/applications/
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/fix-wireshark-gui-freeze-linux-desktop.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
@ -0,0 +1,99 @@
|
||||
How to monitor stock quotes from the command line on Linux
|
||||
================================================================================
|
||||
If you are one of those stock investors or traders, monitoring the stock market will be one of your daily routines. Most likely you will be using an online trading platform which comes with some fancy real-time charts and all sort of advanced stock analysis and tracking tools. While such sophisticated market research tools are a must for any serious stock investors to read the market, monitoring the latest stock quotes still goes a long way to build a profitable portfolio.
|
||||
|
||||
If you are a full-time system admin constantly sitting in front of terminals while trading stocks as a hobby during the day, a simple command-line tool that shows real-time stock quotes will be a blessing for you.
|
||||
|
||||
In this tutorial, let me introduce a neat command-line tool that allows you to monitor stock quotes from the command line on Linux.
|
||||
|
||||
This tool is called [Mop][1]. Written in Go, this lightweight command-line tool is extremely handy for tracking the latest stock quotes from the U.S. markets. You can easily customize the list of stocks to monitor, and it shows the latest stock quotes in ncurses-based, easy-to-read interface.
|
||||
|
||||
**Note**: Mop obtains the latest stock quotes via Yahoo! Finance API. Be aware that their stock quotes are known to be delayed by 15 minutes. So if you are looking for "real-time" stock quotes with zero delay, Mop is not a tool for you. Such "live" stock quote feeds are usually available for a fee via some proprietary closed-door interface. With that being said, let's see how you can use Mop under Linux environment.
|
||||
|
||||
### Install Mop on Linux ###
|
||||
|
||||
Since Mop is implemented in Go, you will need to install Go language first. If you don't have Go installed, follow [this guide][2] to install Go on your Linux platform. Make sure to set GOPATH environment variable as described in the guide.
|
||||
|
||||
Once Go is installed, proceed to install Mop as follows.
|
||||
|
||||
**Debian, Ubuntu or Linux Mint**
|
||||
|
||||
$ sudo apt-get install git
|
||||
$ go get github.com/michaeldv/mop
|
||||
$ cd $GOPATH/src/github.com/michaeldv/mop
|
||||
$ make install
|
||||
|
||||
Fedora, CentOS, RHEL
|
||||
|
||||
$ sudo yum install git
|
||||
$ go get github.com/michaeldv/mop
|
||||
$ cd $GOPATH/src/github.com/michaeldv/mop
|
||||
$ make install
|
||||
|
||||
The above commands will install Mop under $GOPATH/bin.
|
||||
|
||||
Now edit your .bashrc to include $GOPATH/bin in your PATH variable.
|
||||
|
||||
export PATH="$PATH:$GOPATH/bin"
|
||||
|
||||
----------
|
||||
|
||||
$ source ~/.bashrc
|
||||
|
||||
### Monitor Stock Quotes from the Command Line with Mop ###
|
||||
|
||||
To launch Mod, simply run the command called cmd.
|
||||
|
||||
$ cmd
|
||||
|
||||
At the first launch, you will see a few stock tickers which Mop comes pre-configured with.
|
||||
|
||||

|
||||
|
||||
The quotes show information like the latest price, %change, daily low/high, 52-week low/high, dividend, and annual yield. Mop obtains market overview information from [CNN][3], and individual stock quotes from [Yahoo Finance][4]. The stock quote information updates itself within the terminal periodically.
|
||||
|
||||
### Customize Stock Quotes in Mop ###
|
||||
|
||||
Let's try customizing the stock list. Mop provides easy-to-remember shortcuts for this: '+' to add a new stock, and '-' to remove a stock.
|
||||
|
||||
To add a new stock, press '+', and type a stock ticker symbol to add (e.g., MSFT). You can add more than one stock at once by typing a comma-separated list of tickers (e.g., "MSFT, AMZN, TSLA").
|
||||
|
||||

|
||||
|
||||
Removing stocks from the list can be done similarly by pressing '-'.
|
||||
|
||||
### Sort Stock Quotes in Mop ###
|
||||
|
||||
You can sort the stock quote list based on any column. To sort, press 'o', and use left/right key to choose the column to sort by. When a particular column is chosen, you can sort the list either in increasing order or in decreasing order by pressing ENTER.
|
||||
|
||||
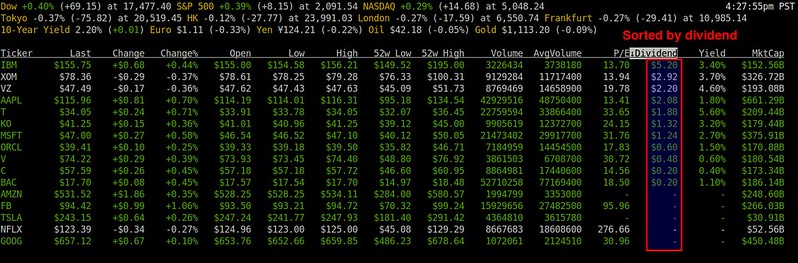
|
||||
|
||||
By pressing 'g', you can group your stocks based on whether they are advancing or declining for the day. Advancing issues are represented in green color, while declining issues are colored in white.
|
||||
|
||||

|
||||
|
||||
If you want to access help page, simply press '?'.
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
As you can see, Mop is a lightweight, yet extremely handy stock monitoring tool. Of course you can easily access stock quotes information elsewhere, from online websites, your smartphone, etc. However, if you spend a great deal of your time in a terminal environment, Mop can easily fit in to your workspace, hopefully without distracting must of your workflow. Just let it run and continuously update market date in one of your terminals, and be done with it.
|
||||
|
||||
Happy trading!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/monitor-stock-quotes-command-line-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:https://github.com/michaeldv/mop
|
||||
[2]:http://ask.xmodulo.com/install-go-language-linux.html
|
||||
[3]:http://money.cnn.com/data/markets/
|
||||
[4]:http://finance.yahoo.com/
|
||||
@ -0,0 +1,220 @@
|
||||
Part 1 - LFCS: How to use GNU ‘sed’ Command to Create, Edit, and Manipulate files in Linux
|
||||
================================================================================
|
||||
The Linux Foundation announced the LFCS (Linux Foundation Certified Sysadmin) certification, a new program that aims at helping individuals all over the world to get certified in basic to intermediate system administration tasks for Linux systems. This includes supporting running systems and services, along with first-hand troubleshooting and analysis, and smart decision-making to escalate issues to engineering teams.
|
||||
|
||||

|
||||
|
||||
Linux Foundation Certified Sysadmin – Part 1
|
||||
|
||||
Please watch the following video that demonstrates about The Linux Foundation Certification Program.
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="720" height="405" frameborder="0" allowfullscreen="allowfullscreen" src="//www.youtube.com/embed/Y29qZ71Kicg"></iframe>
|
||||
|
||||
The series will be titled Preparation for the LFCS (Linux Foundation Certified Sysadmin) Parts 1 through 10 and cover the following topics for Ubuntu, CentOS, and openSUSE:
|
||||
|
||||
- Part 1: How to use GNU ‘sed’ Command to Create, Edit, and Manipulate files in Linux
|
||||
- Part 2: How to Install and Use vi/m as a full Text Editor
|
||||
- Part 3: Archiving Files/Directories and Finding Files on the Filesystem
|
||||
- Part 4: Partitioning Storage Devices, Formatting Filesystems and Configuring Swap Partition
|
||||
- Part 5: Mount/Unmount Local and Network (Samba & NFS) Filesystems in Linux
|
||||
- Part 6: Assembling Partitions as RAID Devices – Creating & Managing System Backups
|
||||
- Part 7: Managing System Startup Process and Services (SysVinit, Systemd and Upstart
|
||||
- Part 8: Managing Users & Groups, File Permissions & Attributes and Enabling sudo Access on Accounts
|
||||
- Part 9: Linux Package Management with Yum, RPM, Apt, Dpkg, Aptitude and Zypper
|
||||
- Part 10: Learning Basic Shell Scripting and Filesystem Troubleshooting
|
||||
|
||||
|
||||
This post is Part 1 of a 10-tutorial series, which will cover the necessary domains and competencies that are required for the LFCS certification exam. That being said, fire up your terminal, and let’s start.
|
||||
|
||||
### Processing Text Streams in Linux ###
|
||||
|
||||
Linux treats the input to and the output from programs as streams (or sequences) of characters. To begin understanding redirection and pipes, we must first understand the three most important types of I/O (Input and Output) streams, which are in fact special files (by convention in UNIX and Linux, data streams and peripherals, or device files, are also treated as ordinary files).
|
||||
|
||||
The difference between > (redirection operator) and | (pipeline operator) is that while the first connects a command with a file, the latter connects the output of a command with another command.
|
||||
|
||||
# command > file
|
||||
# command1 | command2
|
||||
|
||||
Since the redirection operator creates or overwrites files silently, we must use it with extreme caution, and never mistake it with a pipeline. One advantage of pipes on Linux and UNIX systems is that there is no intermediate file involved with a pipe – the stdout of the first command is not written to a file and then read by the second command.
|
||||
|
||||
For the following practice exercises we will use the poem “A happy child” (anonymous author).
|
||||
|
||||
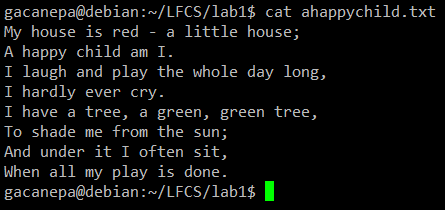
|
||||
|
||||
cat command example
|
||||
|
||||
#### Using sed ####
|
||||
|
||||
The name sed is short for stream editor. For those unfamiliar with the term, a stream editor is used to perform basic text transformations on an input stream (a file or input from a pipeline).
|
||||
|
||||
The most basic (and popular) usage of sed is the substitution of characters. We will begin by changing every occurrence of the lowercase y to UPPERCASE Y and redirecting the output to ahappychild2.txt. The g flag indicates that sed should perform the substitution for all instances of term on every line of file. If this flag is omitted, sed will replace only the first occurrence of term on each line.
|
||||
|
||||
**Basic syntax:**
|
||||
|
||||
# sed ‘s/term/replacement/flag’ file
|
||||
|
||||
**Our example:**
|
||||
|
||||
# sed ‘s/y/Y/g’ ahappychild.txt > ahappychild2.txt
|
||||
|
||||

|
||||
|
||||
sed command example
|
||||
|
||||
Should you want to search for or replace a special character (such as /, \, &) you need to escape it, in the term or replacement strings, with a backward slash.
|
||||
|
||||
For example, we will substitute the word and for an ampersand. At the same time, we will replace the word I with You when the first one is found at the beginning of a line.
|
||||
|
||||
# sed 's/and/\&/g;s/^I/You/g' ahappychild.txt
|
||||
|
||||

|
||||
|
||||
sed replace string
|
||||
|
||||
In the above command, a ^ (caret sign) is a well-known regular expression that is used to represent the beginning of a line.
|
||||
|
||||
As you can see, we can combine two or more substitution commands (and use regular expressions inside them) by separating them with a semicolon and enclosing the set inside single quotes.
|
||||
|
||||
Another use of sed is showing (or deleting) a chosen portion of a file. In the following example, we will display the first 5 lines of /var/log/messages from Jun 8.
|
||||
|
||||
# sed -n '/^Jun 8/ p' /var/log/messages | sed -n 1,5p
|
||||
|
||||
Note that by default, sed prints every line. We can override this behaviour with the -n option and then tell sed to print (indicated by p) only the part of the file (or the pipe) that matches the pattern (Jun 8 at the beginning of line in the first case and lines 1 through 5 inclusive in the second case).
|
||||
|
||||
Finally, it can be useful while inspecting scripts or configuration files to inspect the code itself and leave out comments. The following sed one-liner deletes (d) blank lines or those starting with # (the | character indicates a boolean OR between the two regular expressions).
|
||||
|
||||
# sed '/^#\|^$/d' apache2.conf
|
||||
|
||||

|
||||
|
||||
sed match string
|
||||
|
||||
#### uniq Command ####
|
||||
|
||||
The uniq command allows us to report or remove duplicate lines in a file, writing to stdout by default. We must note that uniq does not detect repeated lines unless they are adjacent. Thus, uniq is commonly used along with a preceding sort (which is used to sort lines of text files). By default, sort takes the first field (separated by spaces) as key field. To specify a different key field, we need to use the -k option.
|
||||
|
||||
**Examples**
|
||||
|
||||
The du –sch /path/to/directory/* command returns the disk space usage per subdirectories and files within the specified directory in human-readable format (also shows a total per directory), and does not order the output by size, but by subdirectory and file name. We can use the following command to sort by size.
|
||||
|
||||
# du -sch /var/* | sort –h
|
||||
|
||||
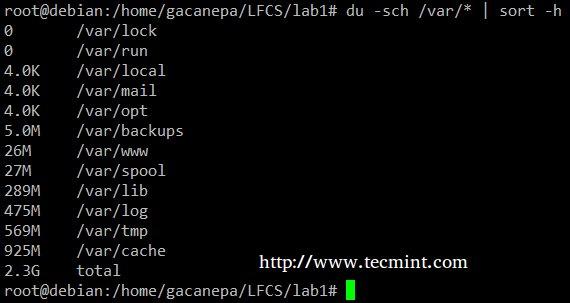
|
||||
|
||||
sort command example
|
||||
|
||||
You can count the number of events in a log by date by telling uniq to perform the comparison using the first 6 characters (-w 6) of each line (where the date is specified), and prefixing each output line by the number of occurrences (-c) with the following command.
|
||||
|
||||
# cat /var/log/mail.log | uniq -c -w 6
|
||||
|
||||

|
||||
|
||||
Count Numbers in File
|
||||
|
||||
Finally, you can combine sort and uniq (as they usually are). Consider the following file with a list of donors, donation date, and amount. Suppose we want to know how many unique donors there are. We will use the following command to cut the first field (fields are delimited by a colon), sort by name, and remove duplicate lines.
|
||||
|
||||
# cat sortuniq.txt | cut -d: -f1 | sort | uniq
|
||||
|
||||

|
||||
|
||||
Find Unique Records in File
|
||||
|
||||
- Read Also: [13 “cat” Command Examples][1]
|
||||
|
||||
#### grep Command ####
|
||||
|
||||
grep searches text files or (command output) for the occurrence of a specified regular expression and outputs any line containing a match to standard output.
|
||||
|
||||
**Examples**
|
||||
|
||||
Display the information from /etc/passwd for user gacanepa, ignoring case.
|
||||
|
||||
# grep -i gacanepa /etc/passwd
|
||||
|
||||

|
||||
|
||||
grep command example
|
||||
|
||||
Show all the contents of /etc whose name begins with rc followed by any single number.
|
||||
|
||||
# ls -l /etc | grep rc[0-9]
|
||||
|
||||

|
||||
|
||||
List Content Using grep
|
||||
|
||||
- Read Also: [12 “grep” Command Examples][2]
|
||||
|
||||
#### tr Command Usage ####
|
||||
|
||||
The tr command can be used to translate (change) or delete characters from stdin, and write the result to stdout.
|
||||
|
||||
**Examples**
|
||||
|
||||
Change all lowercase to uppercase in sortuniq.txt file.
|
||||
|
||||
# cat sortuniq.txt | tr [:lower:] [:upper:]
|
||||
|
||||

|
||||
|
||||
Sort Strings in File
|
||||
|
||||
Squeeze the delimiter in the output of ls –l to only one space.
|
||||
|
||||
# ls -l | tr -s ' '
|
||||
|
||||

|
||||
|
||||
Squeeze Delimiter
|
||||
|
||||
#### cut Command Usage ####
|
||||
|
||||
The cut command extracts portions of input lines (from stdin or files) and displays the result on standard output, based on number of bytes (-b option), characters (-c), or fields (-f). In this last case (based on fields), the default field separator is a tab, but a different delimiter can be specified by using the -d option.
|
||||
|
||||
**Examples**
|
||||
|
||||
Extract the user accounts and the default shells assigned to them from /etc/passwd (the –d option allows us to specify the field delimiter, and the –f switch indicates which field(s) will be extracted.
|
||||
|
||||
# cat /etc/passwd | cut -d: -f1,7
|
||||
|
||||

|
||||
|
||||
Extract User Accounts
|
||||
|
||||
Summing up, we will create a text stream consisting of the first and third non-blank files of the output of the last command. We will use grep as a first filter to check for sessions of user gacanepa, then squeeze delimiters to only one space (tr -s ‘ ‘). Next, we’ll extract the first and third fields with cut, and finally sort by the second field (IP addresses in this case) showing unique.
|
||||
|
||||
# last | grep gacanepa | tr -s ‘ ‘ | cut -d’ ‘ -f1,3 | sort -k2 | uniq
|
||||
|
||||

|
||||
|
||||
last command example
|
||||
|
||||
The above command shows how multiple commands and pipes can be combined so as to obtain filtered data according to our desires. Feel free to also run it by parts, to help you see the output that is pipelined from one command to the next (this can be a great learning experience, by the way!).
|
||||
|
||||
### Summary ###
|
||||
|
||||
Although this example (along with the rest of the examples in the current tutorial) may not seem very useful at first sight, they are a nice starting point to begin experimenting with commands that are used to create, edit, and manipulate files from the Linux command line. Feel free to leave your questions and comments below – they will be much appreciated!
|
||||
|
||||
#### Reference Links ####
|
||||
|
||||
- [About the LFCS][3]
|
||||
- [Why get a Linux Foundation Certification?][4]
|
||||
- [Register for the LFCS exam][5]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/sed-command-to-create-edit-and-manipulate-files-in-linux/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/13-basic-cat-command-examples-in-linux/
|
||||
[2]:http://www.tecmint.com/12-practical-examples-of-linux-grep-command/
|
||||
[3]:https://training.linuxfoundation.org/certification/LFCS
|
||||
[4]:https://training.linuxfoundation.org/certification/why-certify-with-us
|
||||
[5]:https://identity.linuxfoundation.org/user?destination=pid/1
|
||||
@ -0,0 +1,315 @@
|
||||
Part 10 - LFCS: Understanding & Learning Basic Shell Scripting and Linux Filesystem Troubleshooting
|
||||
================================================================================
|
||||
The Linux Foundation launched the LFCS certification (Linux Foundation Certified Sysadmin), a brand new initiative whose purpose is to allow individuals everywhere (and anywhere) to get certified in basic to intermediate operational support for Linux systems, which includes supporting running systems and services, along with overall monitoring and analysis, plus smart decision-making when it comes to raising issues to upper support teams.
|
||||
|
||||

|
||||
|
||||
Linux Foundation Certified Sysadmin – Part 10
|
||||
|
||||
Check out the following video that guides you an introduction to the Linux Foundation Certification Program.
|
||||
|
||||
注:youtube 视频
|
||||
|
||||
<iframe width="720" height="405" frameborder="0" allowfullscreen="allowfullscreen" src="//www.youtube.com/embed/Y29qZ71Kicg"></iframe>
|
||||
|
||||
This is the last article (Part 10) of the present 10-tutorial long series. In this article we will focus on basic shell scripting and troubleshooting Linux file systems. Both topics are required for the LFCS certification exam.
|
||||
|
||||
### Understanding Terminals and Shells ###
|
||||
|
||||
Let’s clarify a few concepts first.
|
||||
|
||||
- A shell is a program that takes commands and gives them to the operating system to be executed.
|
||||
- A terminal is a program that allows us as end users to interact with the shell. One example of a terminal is GNOME terminal, as shown in the below image.
|
||||
|
||||

|
||||
|
||||
Gnome Terminal
|
||||
|
||||
When we first start a shell, it presents a command prompt (also known as the command line), which tells us that the shell is ready to start accepting commands from its standard input device, which is usually the keyboard.
|
||||
|
||||
You may want to refer to another article in this series ([Use Command to Create, Edit, and Manipulate files – Part 1][1]) to review some useful commands.
|
||||
|
||||
Linux provides a range of options for shells, the following being the most common:
|
||||
|
||||
**bash Shell**
|
||||
|
||||
Bash stands for Bourne Again SHell and is the GNU Project’s default shell. It incorporates useful features from the Korn shell (ksh) and C shell (csh), offering several improvements at the same time. This is the default shell used by the distributions covered in the LFCS certification, and it is the shell that we will use in this tutorial.
|
||||
|
||||
**sh Shell**
|
||||
|
||||
The Bourne SHell is the oldest shell and therefore has been the default shell of many UNIX-like operating systems for many years.
|
||||
ksh Shell
|
||||
|
||||
The Korn SHell is a Unix shell which was developed by David Korn at Bell Labs in the early 1980s. It is backward-compatible with the Bourne shell and includes many features of the C shell.
|
||||
|
||||
A shell script is nothing more and nothing less than a text file turned into an executable program that combines commands that are executed by the shell one after another.
|
||||
|
||||
### Basic Shell Scripting ###
|
||||
|
||||
As mentioned earlier, a shell script is born as a plain text file. Thus, can be created and edited using our preferred text editor. You may want to consider using vi/m (refer to [Usage of vi Editor – Part 2][2] of this series), which features syntax highlighting for your convenience.
|
||||
|
||||
Type the following command to create a file named myscript.sh and press Enter.
|
||||
|
||||
# vim myscript.sh
|
||||
|
||||
The very first line of a shell script must be as follows (also known as a shebang).
|
||||
|
||||
#!/bin/bash
|
||||
|
||||
It “tells” the operating system the name of the interpreter that should be used to run the text that follows.
|
||||
|
||||
Now it’s time to add our commands. We can clarify the purpose of each command, or the entire script, by adding comments as well. Note that the shell ignores those lines beginning with a pound sign # (explanatory comments).
|
||||
|
||||
#!/bin/bash
|
||||
echo This is Part 10 of the 10-article series about the LFCS certification
|
||||
echo Today is $(date +%Y-%m-%d)
|
||||
|
||||
Once the script has been written and saved, we need to make it executable.
|
||||
|
||||
# chmod 755 myscript.sh
|
||||
|
||||
Before running our script, we need to say a few words about the $PATH environment variable. If we run,
|
||||
|
||||
echo $PATH
|
||||
|
||||
from the command line, we will see the contents of $PATH: a colon-separated list of directories that are searched when we enter the name of a executable program. It is called an environment variable because it is part of the shell environment – a set of information that becomes available for the shell and its child processes when the shell is first started.
|
||||
|
||||
When we type a command and press Enter, the shell searches in all the directories listed in the $PATH variable and executes the first instance that is found. Let’s see an example,
|
||||
|
||||

|
||||
|
||||
Environment Variables
|
||||
|
||||
If there are two executable files with the same name, one in /usr/local/bin and another in /usr/bin, the one in the first directory will be executed first, whereas the other will be disregarded.
|
||||
|
||||
If we haven’t saved our script inside one of the directories listed in the $PATH variable, we need to append ./ to the file name in order to execute it. Otherwise, we can run it just as we would do with a regular command.
|
||||
|
||||
# pwd
|
||||
# ./myscript.sh
|
||||
# cp myscript.sh ../bin
|
||||
# cd ../bin
|
||||
# pwd
|
||||
# myscript.sh
|
||||
|
||||

|
||||
|
||||
Execute Script
|
||||
|
||||
#### Conditionals ####
|
||||
|
||||
Whenever you need to specify different courses of action to be taken in a shell script, as result of the success or failure of a command, you will use the if construct to define such conditions. Its basic syntax is:
|
||||
|
||||
if CONDITION; then
|
||||
COMMANDS;
|
||||
else
|
||||
OTHER-COMMANDS
|
||||
fi
|
||||
|
||||
Where CONDITION can be one of the following (only the most frequent conditions are cited here) and evaluates to true when:
|
||||
|
||||
- [ -a file ] → file exists.
|
||||
- [ -d file ] → file exists and is a directory.
|
||||
- [ -f file ] →file exists and is a regular file.
|
||||
- [ -u file ] →file exists and its SUID (set user ID) bit is set.
|
||||
- [ -g file ] →file exists and its SGID bit is set.
|
||||
- [ -k file ] →file exists and its sticky bit is set.
|
||||
- [ -r file ] →file exists and is readable.
|
||||
- [ -s file ]→ file exists and is not empty.
|
||||
- [ -w file ]→file exists and is writable.
|
||||
- [ -x file ] is true if file exists and is executable.
|
||||
- [ string1 = string2 ] → the strings are equal.
|
||||
- [ string1 != string2 ] →the strings are not equal.
|
||||
|
||||
[ int1 op int2 ] should be part of the preceding list, while the items that follow (for example, -eq –> is true if int1 is equal to int2.) should be a “children” list of [ int1 op int2 ] where op is one of the following comparison operators.
|
||||
|
||||
- -eq –> is true if int1 is equal to int2.
|
||||
- -ne –> true if int1 is not equal to int2.
|
||||
- -lt –> true if int1 is less than int2.
|
||||
- -le –> true if int1 is less than or equal to int2.
|
||||
- -gt –> true if int1 is greater than int2.
|
||||
- -ge –> true if int1 is greater than or equal to int2.
|
||||
|
||||
#### For Loops ####
|
||||
|
||||
This loop allows to execute one or more commands for each value in a list of values. Its basic syntax is:
|
||||
|
||||
for item in SEQUENCE; do
|
||||
COMMANDS;
|
||||
done
|
||||
|
||||
Where item is a generic variable that represents each value in SEQUENCE during each iteration.
|
||||
|
||||
#### While Loops ####
|
||||
|
||||
This loop allows to execute a series of repetitive commands as long as the control command executes with an exit status equal to zero (successfully). Its basic syntax is:
|
||||
|
||||
while EVALUATION_COMMAND; do
|
||||
EXECUTE_COMMANDS;
|
||||
done
|
||||
|
||||
Where EVALUATION_COMMAND can be any command(s) that can exit with a success (0) or failure (other than 0) status, and EXECUTE_COMMANDS can be any program, script or shell construct, including other nested loops.
|
||||
|
||||
#### Putting It All Together ####
|
||||
|
||||
We will demonstrate the use of the if construct and the for loop with the following example.
|
||||
|
||||
**Determining if a service is running in a systemd-based distro**
|
||||
|
||||
Let’s create a file with a list of services that we want to monitor at a glance.
|
||||
|
||||
# cat myservices.txt
|
||||
|
||||
sshd
|
||||
mariadb
|
||||
httpd
|
||||
crond
|
||||
firewalld
|
||||
|
||||
|
||||
|
||||
Script to Monitor Linux Services
|
||||
|
||||
Our shell script should look like.
|
||||
|
||||
#!/bin/bash
|
||||
|
||||
# This script iterates over a list of services and
|
||||
# is used to determine whether they are running or not.
|
||||
|
||||
for service in $(cat myservices.txt); do
|
||||
systemctl status $service | grep --quiet "running"
|
||||
if [ $? -eq 0 ]; then
|
||||
echo $service "is [ACTIVE]"
|
||||
else
|
||||
echo $service "is [INACTIVE or NOT INSTALLED]"
|
||||
fi
|
||||
done
|
||||
|
||||
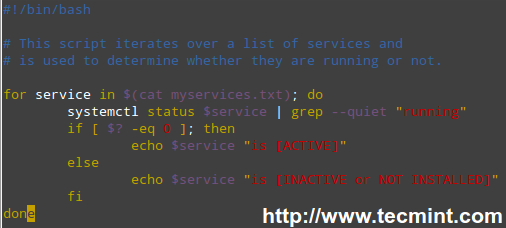
|
||||
|
||||
Linux Service Monitoring Script
|
||||
|
||||
**Let’s explain how the script works.**
|
||||
|
||||
1). The for loop reads the myservices.txt file one element of LIST at a time. That single element is denoted by the generic variable named service. The LIST is populated with the output of,
|
||||
|
||||
# cat myservices.txt
|
||||
|
||||
2). The above command is enclosed in parentheses and preceded by a dollar sign to indicate that it should be evaluated to populate the LIST that we will iterate over.
|
||||
|
||||
3). For each element of LIST (meaning every instance of the service variable), the following command will be executed.
|
||||
|
||||
# systemctl status $service | grep --quiet "running"
|
||||
|
||||
This time we need to precede our generic variable (which represents each element in LIST) with a dollar sign to indicate it’s a variable and thus its value in each iteration should be used. The output is then piped to grep.
|
||||
|
||||
The –quiet flag is used to prevent grep from displaying to the screen the lines where the word running appears. When that happens, the above command returns an exit status of 0 (represented by $? in the if construct), thus verifying that the service is running.
|
||||
|
||||
An exit status different than 0 (meaning the word running was not found in the output of systemctl status $service) indicates that the service is not running.
|
||||
|
||||

|
||||
|
||||
Services Monitoring Script
|
||||
|
||||
We could go one step further and check for the existence of myservices.txt before even attempting to enter the for loop.
|
||||
|
||||
#!/bin/bash
|
||||
|
||||
# This script iterates over a list of services and
|
||||
# is used to determine whether they are running or not.
|
||||
|
||||
if [ -f myservices.txt ]; then
|
||||
for service in $(cat myservices.txt); do
|
||||
systemctl status $service | grep --quiet "running"
|
||||
if [ $? -eq 0 ]; then
|
||||
echo $service "is [ACTIVE]"
|
||||
else
|
||||
echo $service "is [INACTIVE or NOT INSTALLED]"
|
||||
fi
|
||||
done
|
||||
else
|
||||
echo "myservices.txt is missing"
|
||||
fi
|
||||
|
||||
**Pinging a series of network or internet hosts for reply statistics**
|
||||
|
||||
You may want to maintain a list of hosts in a text file and use a script to determine every now and then whether they’re pingable or not (feel free to replace the contents of myhosts and try for yourself).
|
||||
|
||||
The read shell built-in command tells the while loop to read myhosts line by line and assigns the content of each line to variable host, which is then passed to the ping command.
|
||||
|
||||
#!/bin/bash
|
||||
|
||||
# This script is used to demonstrate the use of a while loop
|
||||
|
||||
while read host; do
|
||||
ping -c 2 $host
|
||||
done < myhosts
|
||||
|
||||
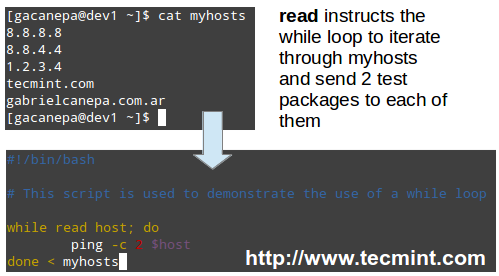
|
||||
|
||||
Script to Ping Servers
|
||||
|
||||
Read Also:
|
||||
|
||||
- [Learn Shell Scripting: A Guide from Newbies to System Administrator][3]
|
||||
- [5 Shell Scripts to Learn Shell Programming][4]
|
||||
|
||||
### Filesystem Troubleshooting ###
|
||||
|
||||
Although Linux is a very stable operating system, if it crashes for some reason (for example, due to a power outage), one (or more) of your file systems will not be unmounted properly and thus will be automatically checked for errors when Linux is restarted.
|
||||
|
||||
In addition, each time the system boots during a normal boot, it always checks the integrity of the filesystems before mounting them. In both cases this is performed using a tool named fsck (“file system check”).
|
||||
|
||||
fsck will not only check the integrity of file systems, but also attempt to repair corrupt file systems if instructed to do so. Depending on the severity of damage, fsck may succeed or not; when it does, recovered portions of files are placed in the lost+found directory, located in the root of each file system.
|
||||
|
||||
Last but not least, we must note that inconsistencies may also happen if we try to remove an USB drive when the operating system is still writing to it, and may even result in hardware damage.
|
||||
|
||||
The basic syntax of fsck is as follows:
|
||||
|
||||
# fsck [options] filesystem
|
||||
|
||||
**Checking a filesystem for errors and attempting to repair automatically**
|
||||
|
||||
In order to check a filesystem with fsck, we must first unmount it.
|
||||
|
||||
# mount | grep sdg1
|
||||
# umount /mnt
|
||||
# fsck -y /dev/sdg1
|
||||
|
||||

|
||||
|
||||
Check Filesystem Errors
|
||||
|
||||
Besides the -y flag, we can use the -a option to automatically repair the file systems without asking any questions, and force the check even when the filesystem looks clean.
|
||||
|
||||
# fsck -af /dev/sdg1
|
||||
|
||||
If we’re only interested in finding out what’s wrong (without trying to fix anything for the time being) we can run fsck with the -n option, which will output the filesystem issues to standard output.
|
||||
|
||||
# fsck -n /dev/sdg1
|
||||
|
||||
Depending on the error messages in the output of fsck, we will know whether we can try to solve the issue ourselves or escalate it to engineering teams to perform further checks on the hardware.
|
||||
|
||||
### Summary ###
|
||||
|
||||
We have arrived at the end of this 10-article series where have tried to cover the basic domain competencies required to pass the LFCS exam.
|
||||
|
||||
For obvious reasons, it is not possible to cover every single aspect of these topics in any single tutorial, and that’s why we hope that these articles have put you on the right track to try new stuff yourself and continue learning.
|
||||
|
||||
If you have any questions or comments, they are always welcome – so don’t hesitate to drop us a line via the form below!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-basic-shell-scripting-and-linux-filesystem-troubleshooting/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/sed-command-to-create-edit-and-manipulate-files-in-linux/
|
||||
[2]:http://www.tecmint.com/vi-editor-usage/
|
||||
[3]:http://www.tecmint.com/learning-shell-scripting-language-a-guide-from-newbies-to-system-administrator/
|
||||
[4]:http://www.tecmint.com/basic-shell-programming-part-ii/
|
||||
@ -0,0 +1,387 @@
|
||||
Part 2 - LFCS: How to Install and Use vi/vim as a Full Text Editor
|
||||
================================================================================
|
||||
A couple of months ago, the Linux Foundation launched the LFCS (Linux Foundation Certified Sysadmin) certification in order to help individuals from all over the world to verify they are capable of doing basic to intermediate system administration tasks on Linux systems: system support, first-hand troubleshooting and maintenance, plus intelligent decision-making to know when it’s time to raise issues to upper support teams.
|
||||
|
||||

|
||||
|
||||
Learning VI Editor in Linux
|
||||
|
||||
Please take a look at the below video that explains The Linux Foundation Certification Program.
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="720" height="405" frameborder="0" allowfullscreen="allowfullscreen" src="//www.youtube.com/embed/Y29qZ71Kicg"></iframe>
|
||||
|
||||
This post is Part 2 of a 10-tutorial series, here in this part, we will cover the basic file editing operations and understanding modes in vi/m editor, that are required for the LFCS certification exam.
|
||||
|
||||
### Perform Basic File Editing Operations Using vi/m ###
|
||||
|
||||
Vi was the first full-screen text editor written for Unix. Although it was intended to be small and simple, it can be a bit challenging for people used exclusively to GUI text editors, such as NotePad++, or gedit, to name a few examples.
|
||||
|
||||
To use Vi, we must first understand the 3 modes in which this powerful program operates, in order to begin learning later about the its powerful text-editing procedures.
|
||||
|
||||
Please note that most modern Linux distributions ship with a variant of vi known as vim (“Vi improved”), which supports more features than the original vi does. For that reason, throughout this tutorial we will use vi and vim interchangeably.
|
||||
|
||||
If your distribution does not have vim installed, you can install it as follows.
|
||||
|
||||
- Ubuntu and derivatives: aptitude update && aptitude install vim
|
||||
- Red Hat-based distributions: yum update && yum install vim
|
||||
- openSUSE: zypper update && zypper install vim
|
||||
|
||||
### Why should I want to learn vi? ###
|
||||
|
||||
There are at least 2 good reasons to learn vi.
|
||||
|
||||
1. vi is always available (no matter what distribution you’re using) since it is required by POSIX.
|
||||
|
||||
2. vi does not consume a considerable amount of system resources and allows us to perform any imaginable tasks without lifting our fingers from the keyboard.
|
||||
|
||||
In addition, vi has a very extensive built-in manual, which can be launched using the :help command right after the program is started. This built-in manual contains more information than vi/m’s man page.
|
||||
|
||||

|
||||
|
||||
vi Man Pages
|
||||
|
||||
#### Launching vi ####
|
||||
|
||||
To launch vi, type vi in your command prompt.
|
||||
|
||||

|
||||
|
||||
Start vi Editor
|
||||
|
||||
Then press i to enter Insert mode, and you can start typing. Another way to launch vi/m is.
|
||||
|
||||
# vi filename
|
||||
|
||||
Which will open a new buffer (more on buffers later) named filename, which you can later save to disk.
|
||||
|
||||
#### Understanding Vi modes ####
|
||||
|
||||
1. In command mode, vi allows the user to navigate around the file and enter vi commands, which are brief, case-sensitive combinations of one or more letters. Almost all of them can be prefixed with a number to repeat the command that number of times.
|
||||
|
||||
For example, yy (or Y) copies the entire current line, whereas 3yy (or 3Y) copies the entire current line along with the two next lines (3 lines in total). We can always enter command mode (regardless of the mode we’re working on) by pressing the Esc key. The fact that in command mode the keyboard keys are interpreted as commands instead of text tends to be confusing to beginners.
|
||||
|
||||
2. In ex mode, we can manipulate files (including saving a current file and running outside programs). To enter this mode, we must type a colon (:) from command mode, directly followed by the name of the ex-mode command that needs to be used. After that, vi returns automatically to command mode.
|
||||
|
||||
3. In insert mode (the letter i is commonly used to enter this mode), we simply enter text. Most keystrokes result in text appearing on the screen (one important exception is the Esc key, which exits insert mode and returns to command mode).
|
||||
|
||||

|
||||
|
||||
vi Insert Mode
|
||||
|
||||
#### Vi Commands ####
|
||||
|
||||
The following table shows a list of commonly used vi commands. File edition commands can be enforced by appending the exclamation sign to the command (for example, <b.:q! enforces quitting without saving).
|
||||
|
||||
注:表格
|
||||
<table cellspacing="0" border="0">
|
||||
<colgroup width="290">
|
||||
</colgroup>
|
||||
<colgroup width="781">
|
||||
</colgroup>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td bgcolor="#999999" height="19" align="LEFT" style="border: 1px solid #000000;"><b><span style="font-size: small;"> Key command</span></b></td>
|
||||
<td bgcolor="#999999" align="LEFT" style="border: 1px solid #000000;"><b><span style="font-size: small;"> Description</span></b></td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> h or left arrow</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Go one character to the left</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> j or down arrow</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Go down one line</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> k or up arrow</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Go up one line</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> l (lowercase L) or right arrow</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Go one character to the right</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> H</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Go to the top of the screen</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> L</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Go to the bottom of the screen</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> G</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Go to the end of the file</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> w</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Move one word to the right</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> b</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Move one word to the left</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> 0 (zero)</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Go to the beginning of the current line</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> ^</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Go to the first nonblank character on the current line</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> $</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Go to the end of the current line</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> Ctrl-B</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Go back one screen</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> Ctrl-F</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Go forward one screen</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> i</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Insert at the current cursor position</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> I (uppercase i)</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Insert at the beginning of the current line</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> J (uppercase j)</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Join current line with the next one (move next line up)</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> a</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Append after the current cursor position</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> o (lowercase O)</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Creates a blank line after the current line</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> O (uppercase o)</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Creates a blank line before the current line</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> r</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Replace the character at the current cursor position</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> R</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Overwrite at the current cursor position</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> x</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Delete the character at the current cursor position</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> X</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Delete the character immediately before (to the left) of the current cursor position</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> dd</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Cut (for later pasting) the entire current line</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="20" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> D</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Cut from the current cursor position to the end of the line (this command is equivalent to d$)</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="20" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> yX</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Give a movement command X, copy (yank) the appropriate number of characters, words, or lines from the current cursor position</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> yy or Y</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Yank (copy) the entire current line</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> p</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Paste after (next line) the current cursor position</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> P</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Paste before (previous line) the current cursor position</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> . (period)</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Repeat the last command</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> u</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Undo the last command</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> U</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Undo the last command in the last line. This will work as long as the cursor is still on the line.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> n</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Find the next match in a search</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> N</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Find the previous match in a search</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> :n</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Next file; when multiple files are specified for editing, this commands loads the next file.</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="20" align="LEFT" style="border: 1px solid #000000;"> :e file</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Load file in place of the current file.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="20" align="LEFT" style="border: 1px solid #000000;"> :r file</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Insert the contents of file after (next line) the current cursor position</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> :q</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Quit without saving changes.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="20" align="LEFT" style="border: 1px solid #000000;"> :w file</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Write the current buffer to file. To append to an existing file, use :w >> file.</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> :wq</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Write the contents of the current file and quit. Equivalent to x! and ZZ</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="20" align="LEFT" style="border: 1px solid #000000;"> :r! command</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Execute command and insert output after (next line) the current cursor position.</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
#### Vi Options ####
|
||||
|
||||
The following options can come in handy while running vim (we need to add them in our ~/.vimrc file).
|
||||
|
||||
# echo set number >> ~/.vimrc
|
||||
# echo syntax on >> ~/.vimrc
|
||||
# echo set tabstop=4 >> ~/.vimrc
|
||||
# echo set autoindent >> ~/.vimrc
|
||||
|
||||
|
||||
|
||||
vi Editor Options
|
||||
|
||||
- set number shows line numbers when vi opens an existing or a new file.
|
||||
- syntax on turns on syntax highlighting (for multiple file extensions) in order to make code and config files more readable.
|
||||
- set tabstop=4 sets the tab size to 4 spaces (default value is 8).
|
||||
- set autoindent carries over previous indent to the next line.
|
||||
|
||||
#### Search and replace ####
|
||||
|
||||
vi has the ability to move the cursor to a certain location (on a single line or over an entire file) based on searches. It can also perform text replacements with or without confirmation from the user.
|
||||
|
||||
a). Searching within a line: the f command searches a line and moves the cursor to the next occurrence of a specified character in the current line.
|
||||
|
||||
For example, the command fh would move the cursor to the next instance of the letter h within the current line. Note that neither the letter f nor the character you’re searching for will appear anywhere on your screen, but the character will be highlighted after you press Enter.
|
||||
|
||||
For example, this is what I get after pressing f4 in command mode.
|
||||
|
||||

|
||||
|
||||
Search String in Vi
|
||||
|
||||
b). Searching an entire file: use the / command, followed by the word or phrase to be searched for. A search may be repeated using the previous search string with the n command, or the next one (using the N command). This is the result of typing /Jane in command mode.
|
||||
|
||||
|
||||
|
||||
Vi Search String in File
|
||||
|
||||
c). vi uses a command (similar to sed’s) to perform substitution operations over a range of lines or an entire file. To change the word “old” to “young” for the entire file, we must enter the following command.
|
||||
|
||||
:%s/old/young/g
|
||||
|
||||
**Notice**: The colon at the beginning of the command.
|
||||
|
||||
|
||||
|
||||
Vi Search and Replace
|
||||
|
||||
The colon (:) starts the ex command, s in this case (for substitution), % is a shortcut meaning from the first line to the last line (the range can also be specified as n,m which means “from line n to line m”), old is the search pattern, while young is the replacement text, and g indicates that the substitution should be performed on every occurrence of the search string in the file.
|
||||
|
||||
Alternatively, a c can be added to the end of the command to ask for confirmation before performing any substitution.
|
||||
|
||||
:%s/old/young/gc
|
||||
|
||||
Before replacing the original text with the new one, vi/m will present us with the following message.
|
||||
|
||||
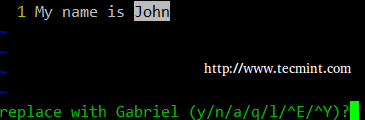
|
||||
|
||||
Replace String in Vi
|
||||
|
||||
- y: perform the substitution (yes)
|
||||
- n: skip this occurrence and go to the next one (no)
|
||||
- a: perform the substitution in this and all subsequent instances of the pattern.
|
||||
- q or Esc: quit substituting.
|
||||
- l (lowercase L): perform this substitution and quit (last).
|
||||
- Ctrl-e, Ctrl-y: Scroll down and up, respectively, to view the context of the proposed substitution.
|
||||
|
||||
#### Editing Multiple Files at a Time ####
|
||||
|
||||
Let’s type vim file1 file2 file3 in our command prompt.
|
||||
|
||||
# vim file1 file2 file3
|
||||
|
||||
First, vim will open file1. To switch to the next file (file2), we need to use the :n command. When we want to return to the previous file, :N will do the job.
|
||||
|
||||
In order to switch from file1 to file3.
|
||||
|
||||
a). The :buffers command will show a list of the file currently being edited.
|
||||
|
||||
:buffers
|
||||
|
||||
|
||||
|
||||
Edit Multiple Files
|
||||
|
||||
b). The command :buffer 3 (without the s at the end) will open file3 for editing.
|
||||
|
||||
In the image above, a pound sign (#) indicates that the file is currently open but in the background, while %a marks the file that is currently being edited. On the other hand, a blank space after the file number (3 in the above example) indicates that the file has not yet been opened.
|
||||
|
||||
#### Temporary vi buffers ####
|
||||
|
||||
To copy a couple of consecutive lines (let’s say 4, for example) into a temporary buffer named a (not associated with a file) and place those lines in another part of the file later in the current vi section, we need to…
|
||||
|
||||
1. Press the ESC key to be sure we are in vi Command mode.
|
||||
|
||||
2. Place the cursor on the first line of the text we wish to copy.
|
||||
|
||||
3. Type “a4yy to copy the current line, along with the 3 subsequent lines, into a buffer named a. We can continue editing our file – we do not need to insert the copied lines immediately.
|
||||
|
||||
4. When we reach the location for the copied lines, use “a before the p or P commands to insert the lines copied into the buffer named a:
|
||||
|
||||
- Type “ap to insert the lines copied into buffer a after the current line on which the cursor is resting.
|
||||
- Type “aP to insert the lines copied into buffer a before the current line.
|
||||
|
||||
If we wish, we can repeat the above steps to insert the contents of buffer a in multiple places in our file. A temporary buffer, as the one in this section, is disposed when the current window is closed.
|
||||
|
||||
### Summary ###
|
||||
|
||||
As we have seen, vi/m is a powerful and versatile text editor for the CLI. Feel free to share your own tricks and comments below.
|
||||
|
||||
#### Reference Links ####
|
||||
|
||||
- [About the LFCS][1]
|
||||
- [Why get a Linux Foundation Certification?][2]
|
||||
- [Register for the LFCS exam][3]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/vi-editor-usage/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:https://training.linuxfoundation.org/certification/LFCS
|
||||
[2]:https://training.linuxfoundation.org/certification/why-certify-with-us
|
||||
[3]:https://identity.linuxfoundation.org/user?destination=pid/1
|
||||
@ -0,0 +1,382 @@
|
||||
Part 3 - LFCS: How to Archive/Compress Files & Directories, Setting File Attributes and Finding Files in Linux
|
||||
================================================================================
|
||||
Recently, the Linux Foundation started the LFCS (Linux Foundation Certified Sysadmin) certification, a brand new program whose purpose is allowing individuals from all corners of the globe to have access to an exam, which if approved, certifies that the person is knowledgeable in performing basic to intermediate system administration tasks on Linux systems. This includes supporting already running systems and services, along with first-level troubleshooting and analysis, plus the ability to decide when to escalate issues to engineering teams.
|
||||
|
||||

|
||||
|
||||
Linux Foundation Certified Sysadmin – Part 3
|
||||
|
||||
Please watch the below video that gives the idea about The Linux Foundation Certification Program.
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="720" height="405" frameborder="0" allowfullscreen="allowfullscreen" src="//www.youtube.com/embed/Y29qZ71Kicg"></iframe>
|
||||
|
||||
This post is Part 3 of a 10-tutorial series, here in this part, we will cover how to archive/compress files and directories, set file attributes, and find files on the filesystem, that are required for the LFCS certification exam.
|
||||
|
||||
### Archiving and Compression Tools ###
|
||||
|
||||
A file archiving tool groups a set of files into a single standalone file that we can backup to several types of media, transfer across a network, or send via email. The most frequently used archiving utility in Linux is tar. When an archiving utility is used along with a compression tool, it allows to reduce the disk size that is needed to store the same files and information.
|
||||
|
||||
#### The tar utility ####
|
||||
|
||||
tar bundles a group of files together into a single archive (commonly called a tar file or tarball). The name originally stood for tape archiver, but we must note that we can use this tool to archive data to any kind of writeable media (not only to tapes). Tar is normally used with a compression tool such as gzip, bzip2, or xz to produce a compressed tarball.
|
||||
|
||||
**Basic syntax:**
|
||||
|
||||
# tar [options] [pathname ...]
|
||||
|
||||
Where … represents the expression used to specify which files should be acted upon.
|
||||
|
||||
#### Most commonly used tar commands ####
|
||||
|
||||
注:表格
|
||||
<table cellspacing="0" border="0">
|
||||
<colgroup width="150">
|
||||
</colgroup>
|
||||
<colgroup width="109">
|
||||
</colgroup>
|
||||
<colgroup width="351">
|
||||
</colgroup>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td bgcolor="#999999" height="18" align="CENTER" style="border: 1px solid #000001;"><b>Long option</b></td>
|
||||
<td bgcolor="#999999" align="CENTER" style="border: 1px solid #000001;"><b>Abbreviation</b></td>
|
||||
<td bgcolor="#999999" align="CENTER" style="border: 1px solid #000001;"><b>Description</b></td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000001;"> –create</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> c</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> Creates a tar archive</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000001;"> –concatenate</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> A</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> Appends tar files to an archive</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000001;"> –append</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> r</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> Appends files to the end of an archive</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000001;"> –update</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> u</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> Appends files newer than copy in archive</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="20" align="LEFT" style="border: 1px solid #000001;"> –diff or –compare</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> d</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> Find differences between archive and file system</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000001;"> –file archive</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> f</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> Use archive file or device ARCHIVE</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="20" align="LEFT" style="border: 1px solid #000001;"> –list</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> t</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> Lists the contents of a tarball</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="20" align="LEFT" style="border: 1px solid #000001;"> –extract or –get</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> x</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> Extracts files from an archive</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
#### Normally used operation modifiers ####
|
||||
|
||||
注:表格
|
||||
<table cellspacing="0" border="0">
|
||||
<colgroup width="162">
|
||||
</colgroup>
|
||||
<colgroup width="109">
|
||||
</colgroup>
|
||||
<colgroup width="743">
|
||||
</colgroup>
|
||||
<tbody>
|
||||
<tr class="alt">
|
||||
<td bgcolor="#999999" height="18" align="CENTER" style="border: 1px solid #000001;"><b><span style="font-family: Droid Sans;">Long option</span></b></td>
|
||||
<td bgcolor="#999999" align="CENTER" style="border: 1px solid #000001;"><b><span style="font-family: Droid Sans;">Abbreviation</span></b></td>
|
||||
<td bgcolor="#999999" align="CENTER" style="border: 1px solid #000001;"><b><span style="font-family: Droid Sans;">Description</span></b></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="20" align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> –directory dir</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> C</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> Changes to directory dir before performing operations</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> –same-permissions</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> p</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Droid Sans;"> Preserves original permissions</span></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="38" align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> –verbose</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> v</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> Lists all files read or extracted. When this flag is used along with –list, the file sizes, ownership, and time stamps are displayed.</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> –verify</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> W</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Droid Sans;"> Verifies the archive after writing it</span></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="20" align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> –exclude file</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> —</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> Excludes file from the archive</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> –exclude=pattern</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> X</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Droid Sans;"> Exclude files, given as a PATTERN</span></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="20" align="LEFT" style="border: 1px solid #000001;"> –gzip or –gunzip</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> z</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> Processes an archive through gzip</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="20" align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> –bzip2</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> j</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> Processes an archive through bzip2</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="20" align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> –xz</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> J</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> Processes an archive through xz</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
Gzip is the oldest compression tool and provides the least compression, while bzip2 provides improved compression. In addition, xz is the newest but (usually) provides the best compression. This advantages of best compression come at a price: the time it takes to complete the operation, and system resources used during the process.
|
||||
|
||||
Normally, tar files compressed with these utilities have .gz, .bz2, or .xz extensions, respectively. In the following examples we will be using these files: file1, file2, file3, file4, and file5.
|
||||
|
||||
**Grouping and compressing with gzip, bzip2 and xz**
|
||||
|
||||
Group all the files in the current working directory and compress the resulting bundle with gzip, bzip2, and xz (please note the use of a regular expression to specify which files should be included in the bundle – this is to prevent the archiving tool to group the tarballs created in previous steps).
|
||||
|
||||
# tar czf myfiles.tar.gz file[0-9]
|
||||
# tar cjf myfiles.tar.bz2 file[0-9]
|
||||
# tar cJf myfile.tar.xz file[0-9]
|
||||
|
||||

|
||||
|
||||
Compress Multiple Files
|
||||
|
||||
**Listing the contents of a tarball and updating / appending files to the bundle**
|
||||
|
||||
List the contents of a tarball and display the same information as a long directory listing. Note that update or append operations cannot be applied to compressed files directly (if you need to update or append a file to a compressed tarball, you need to uncompress the tar file and update / append to it, then compress again).
|
||||
|
||||
# tar tvf [tarball]
|
||||
|
||||
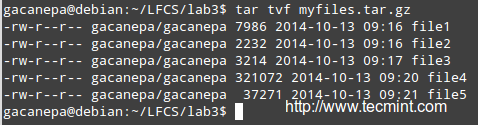
|
||||
|
||||
List Archive Content
|
||||
|
||||
Run any of the following commands:
|
||||
|
||||
# gzip -d myfiles.tar.gz [#1]
|
||||
# bzip2 -d myfiles.tar.bz2 [#2]
|
||||
# xz -d myfiles.tar.xz [#3]
|
||||
|
||||
Then
|
||||
|
||||
# tar --delete --file myfiles.tar file4 (deletes the file inside the tarball)
|
||||
# tar --update --file myfiles.tar file4 (adds the updated file)
|
||||
|
||||
and
|
||||
|
||||
# gzip myfiles.tar [ if you choose #1 above ]
|
||||
# bzip2 myfiles.tar [ if you choose #2 above ]
|
||||
# xz myfiles.tar [ if you choose #3 above ]
|
||||
|
||||
Finally,
|
||||
|
||||
# tar tvf [tarball] #again
|
||||
|
||||
and compare the modification date and time of file4 with the same information as shown earlier.
|
||||
|
||||
**Excluding file types**
|
||||
|
||||
Suppose you want to perform a backup of user’s home directories. A good sysadmin practice would be (may also be specified by company policies) to exclude all video and audio files from backups.
|
||||
|
||||
Maybe your first approach would be to exclude from the backup all files with an .mp3 or .mp4 extension (or other extensions). What if you have a clever user who can change the extension to .txt or .bkp, your approach won’t do you much good. In order to detect an audio or video file, you need to check its file type with file. The following shell script will do the job.
|
||||
|
||||
#!/bin/bash
|
||||
# Pass the directory to backup as first argument.
|
||||
DIR=$1
|
||||
# Create the tarball and compress it. Exclude files with the MPEG string in its file type.
|
||||
# -If the file type contains the string mpeg, $? (the exit status of the most recently executed command) expands to 0, and the filename is redirected to the exclude option. Otherwise, it expands to 1.
|
||||
# -If $? equals 0, add the file to the list of files to be backed up.
|
||||
tar X <(for i in $DIR/*; do file $i | grep -i mpeg; if [ $? -eq 0 ]; then echo $i; fi;done) -cjf backupfile.tar.bz2 $DIR/*
|
||||
|
||||

|
||||
|
||||
Exclude Files in tar
|
||||
|
||||
**Restoring backups with tar preserving permissions**
|
||||
|
||||
You can then restore the backup to the original user’s home directory (user_restore in this example), preserving permissions, with the following command.
|
||||
|
||||
# tar xjf backupfile.tar.bz2 --directory user_restore --same-permissions
|
||||
|
||||

|
||||
|
||||
Restore Files from Archive
|
||||
|
||||
**Read Also:**
|
||||
|
||||
- [18 tar Command Examples in Linux][1]
|
||||
- [Dtrx – An Intelligent Archive Tool for Linux][2]
|
||||
|
||||
### Using find Command to Search for Files ###
|
||||
|
||||
The find command is used to search recursively through directory trees for files or directories that match certain characteristics, and can then either print the matching files or directories or perform other operations on the matches.
|
||||
|
||||
Normally, we will search by name, owner, group, type, permissions, date, and size.
|
||||
|
||||
#### Basic syntax: ####
|
||||
|
||||
# find [directory_to_search] [expression]
|
||||
|
||||
**Finding files recursively according to Size**
|
||||
|
||||
Find all files (-f) in the current directory (.) and 2 subdirectories below (-maxdepth 3 includes the current working directory and 2 levels down) whose size (-size) is greater than 2 MB.
|
||||
|
||||
# find . -maxdepth 3 -type f -size +2M
|
||||
|
||||
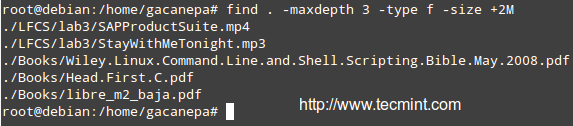
|
||||
|
||||
Find Files Based on Size
|
||||
|
||||
**Finding and deleting files that match a certain criteria**
|
||||
|
||||
Files with 777 permissions are sometimes considered an open door to external attackers. Either way, it is not safe to let anyone do anything with files. We will take a rather aggressive approach and delete them! (‘{}‘ + is used to “collect” the results of the search).
|
||||
|
||||
# find /home/user -perm 777 -exec rm '{}' +
|
||||
|
||||

|
||||
|
||||
Find Files with 777Permission
|
||||
|
||||
**Finding files per atime or mtime**
|
||||
|
||||
Search for configuration files in /etc that have been accessed (-atime) or modified (-mtime) more (+180) or less (-180) than 6 months ago or exactly 6 months ago (180).
|
||||
|
||||
Modify the following command as per the example below:
|
||||
|
||||
# find /etc -iname "*.conf" -mtime -180 -print
|
||||
|
||||

|
||||
|
||||
Find Modified Files
|
||||
|
||||
- Read Also: [35 Practical Examples of Linux ‘find’ Command][3]
|
||||
|
||||
### File Permissions and Basic Attributes ###
|
||||
|
||||
The first 10 characters in the output of ls -l are the file attributes. The first of these characters is used to indicate the file type:
|
||||
|
||||
- – : a regular file
|
||||
- -d : a directory
|
||||
- -l : a symbolic link
|
||||
- -c : a character device (which treats data as a stream of bytes, i.e. a terminal)
|
||||
- -b : a block device (which handles data in blocks, i.e. storage devices)
|
||||
|
||||
The next nine characters of the file attributes are called the file mode and represent the read (r), write (w), and execute (x) permissions of the file’s owner, the file’s group owner, and the rest of the users (commonly referred to as “the world”).
|
||||
|
||||
Whereas the read permission on a file allows the same to be opened and read, the same permission on a directory allows its contents to be listed if the execute permission is also set. In addition, the execute permission in a file allows it to be handled as a program and run, while in a directory it allows the same to be cd’ed into it.
|
||||
|
||||
File permissions are changed with the chmod command, whose basic syntax is as follows:
|
||||
|
||||
# chmod [new_mode] file
|
||||
|
||||
Where new_mode is either an octal number or an expression that specifies the new permissions.
|
||||
|
||||
The octal number can be converted from its binary equivalent, which is calculated from the desired file permissions for the owner, the group, and the world, as follows:
|
||||
|
||||
The presence of a certain permission equals a power of 2 (r=22, w=21, x=20), while its absence equates to 0. For example:
|
||||
|
||||

|
||||
|
||||
File Permissions
|
||||
|
||||
To set the file’s permissions as above in octal form, type:
|
||||
|
||||
# chmod 744 myfile
|
||||
|
||||
You can also set a file’s mode using an expression that indicates the owner’s rights with the letter u, the group owner’s rights with the letter g, and the rest with o. All of these “individuals” can be represented at the same time with the letter a. Permissions are granted (or revoked) with the + or – signs, respectively.
|
||||
|
||||
**Revoking execute permission for a shell script to all users**
|
||||
|
||||
As we explained earlier, we can revoke a certain permission prepending it with the minus sign and indicating whether it needs to be revoked for the owner, the group owner, or all users. The one-liner below can be interpreted as follows: Change mode for all (a) users, revoke (–) execute permission (x).
|
||||
|
||||
# chmod a-x backup.sh
|
||||
|
||||
Granting read, write, and execute permissions for a file to the owner and group owner, and read permissions for the world.
|
||||
|
||||
When we use a 3-digit octal number to set permissions for a file, the first digit indicates the permissions for the owner, the second digit for the group owner and the third digit for everyone else:
|
||||
|
||||
- Owner: (r=22 + w=21 + x=20 = 7)
|
||||
- Group owner: (r=22 + w=21 + x=20 = 7)
|
||||
- World: (r=22 + w=0 + x=0 = 4),
|
||||
|
||||
# chmod 774 myfile
|
||||
|
||||
In time, and with practice, you will be able to decide which method to change a file mode works best for you in each case. A long directory listing also shows the file’s owner and its group owner (which serve as a rudimentary yet effective access control to files in a system):
|
||||
|
||||

|
||||
|
||||
Linux File Listing
|
||||
|
||||
File ownership is changed with the chown command. The owner and the group owner can be changed at the same time or separately. Its basic syntax is as follows:
|
||||
|
||||
# chown user:group file
|
||||
|
||||
Where at least user or group need to be present.
|
||||
|
||||
**Few Examples**
|
||||
|
||||
Changing the owner of a file to a certain user.
|
||||
|
||||
# chown gacanepa sent
|
||||
|
||||
Changing the owner and group of a file to an specific user:group pair.
|
||||
|
||||
# chown gacanepa:gacanepa TestFile
|
||||
|
||||
Changing only the group owner of a file to a certain group. Note the colon before the group’s name.
|
||||
|
||||
# chown :gacanepa email_body.txt
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
As a sysadmin, you need to know how to create and restore backups, how to find files in your system and change their attributes, along with a few tricks that can make your life easier and will prevent you from running into future issues.
|
||||
|
||||
I hope that the tips provided in the present article will help you to achieve that goal. Feel free to add your own tips and ideas in the comments section for the benefit of the community. Thanks in advance!
|
||||
Reference Links
|
||||
|
||||
- [About the LFCS][4]
|
||||
- [Why get a Linux Foundation Certification?][5]
|
||||
- [Register for the LFCS exam][6]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/compress-files-and-finding-files-in-linux/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/18-tar-command-examples-in-linux/
|
||||
[2]:http://www.tecmint.com/dtrx-an-intelligent-archive-extraction-tar-zip-cpio-rpm-deb-rar-tool-for-linux/
|
||||
[3]:http://www.tecmint.com/35-practical-examples-of-linux-find-command/
|
||||
[4]:https://training.linuxfoundation.org/certification/LFCS
|
||||
[5]:https://training.linuxfoundation.org/certification/why-certify-with-us
|
||||
[6]:https://identity.linuxfoundation.org/user?destination=pid/1
|
||||
@ -0,0 +1,191 @@
|
||||
Part 4 - LFCS: Partitioning Storage Devices, Formatting Filesystems and Configuring Swap Partition
|
||||
================================================================================
|
||||
Last August, the Linux Foundation launched the LFCS certification (Linux Foundation Certified Sysadmin), a shiny chance for system administrators to show, through a performance-based exam, that they can perform overall operational support of Linux systems: system support, first-level diagnosing and monitoring, plus issue escalation – if needed – to other support teams.
|
||||
|
||||

|
||||
|
||||
Linux Foundation Certified Sysadmin – Part 4
|
||||
|
||||
Please aware that Linux Foundation certifications are precise, totally based on performance and available through an online portal anytime, anywhere. Thus, you no longer have to travel to a examination center to get the certifications you need to establish your skills and expertise.
|
||||
|
||||
Please watch the below video that explains The Linux Foundation Certification Program.
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="720" height="405" frameborder="0" allowfullscreen="allowfullscreen" src="//www.youtube.com/embed/Y29qZ71Kicg"></iframe>
|
||||
|
||||
This post is Part 4 of a 10-tutorial series, here in this part, we will cover the Partitioning storage devices, Formatting filesystems and Configuring swap partition, that are required for the LFCS certification exam.
|
||||
|
||||
### Partitioning Storage Devices ###
|
||||
|
||||
Partitioning is a means to divide a single hard drive into one or more parts or “slices” called partitions. A partition is a section on a drive that is treated as an independent disk and which contains a single type of file system, whereas a partition table is an index that relates those physical sections of the hard drive to partition identifications.
|
||||
|
||||
In Linux, the traditional tool for managing MBR partitions (up to ~2009) in IBM PC compatible systems is fdisk. For GPT partitions (~2010 and later) we will use gdisk. Each of these tools can be invoked by typing its name followed by a device name (such as /dev/sdb).
|
||||
|
||||
#### Managing MBR Partitions with fdisk ####
|
||||
|
||||
We will cover fdisk first.
|
||||
|
||||
# fdisk /dev/sdb
|
||||
|
||||
A prompt appears asking for the next operation. If you are unsure, you can press the ‘m‘ key to display the help contents.
|
||||
|
||||

|
||||
|
||||
fdisk Help Menu
|
||||
|
||||
In the above image, the most frequently used options are highlighted. At any moment, you can press ‘p‘ to display the current partition table.
|
||||
|
||||

|
||||
|
||||
Show Partition Table
|
||||
|
||||
The Id column shows the partition type (or partition id) that has been assigned by fdisk to the partition. A partition type serves as an indicator of the file system, the partition contains or, in simple words, the way data will be accessed in that partition.
|
||||
|
||||
Please note that a comprehensive study of each partition type is out of the scope of this tutorial – as this series is focused on the LFCS exam, which is performance-based.
|
||||
|
||||
**Some of the options used by fdisk as follows:**
|
||||
|
||||
You can list all the partition types that can be managed by fdisk by pressing the ‘l‘ option (lowercase l).
|
||||
|
||||
Press ‘d‘ to delete an existing partition. If more than one partition is found in the drive, you will be asked which one should be deleted.
|
||||
|
||||
Enter the corresponding number, and then press ‘w‘ (write modifications to partition table) to apply changes.
|
||||
|
||||
In the following example, we will delete /dev/sdb2, and then print (p) the partition table to verify the modifications.
|
||||
|
||||

|
||||
|
||||
fdisk Command Options
|
||||
|
||||
Press ‘n‘ to create a new partition, then ‘p‘ to indicate it will be a primary partition. Finally, you can accept all the default values (in which case the partition will occupy all the available space), or specify a size as follows.
|
||||
|
||||

|
||||
|
||||
Create New Partition
|
||||
|
||||
If the partition Id that fdisk chose is not the right one for our setup, we can press ‘t‘ to change it.
|
||||
|
||||

|
||||
|
||||
Change Partition Name
|
||||
|
||||
When you’re done setting up the partitions, press ‘w‘ to commit the changes to disk.
|
||||
|
||||

|
||||
|
||||
Save Partition Changes
|
||||
|
||||
#### Managing GPT Partitions with gdisk ####
|
||||
|
||||
In the following example, we will use /dev/sdb.
|
||||
|
||||
# gdisk /dev/sdb
|
||||
|
||||
We must note that gdisk can be used either to create MBR or GPT partitions.
|
||||
|
||||

|
||||
|
||||
Create GPT Partitions
|
||||
|
||||
The advantage of using GPT partitioning is that we can create up to 128 partitions in the same disk whose size can be up to the order of petabytes, whereas the maximum size for MBR partitions is 2 TB.
|
||||
|
||||
Note that most of the options in fdisk are the same in gdisk. For that reason, we will not go into detail about them, but here’s a screenshot of the process.
|
||||
|
||||

|
||||
|
||||
gdisk Command Options
|
||||
|
||||
### Formatting Filesystems ###
|
||||
|
||||
Once we have created all the necessary partitions, we must create filesystems. To find out the list of filesystems supported in your system, run.
|
||||
|
||||
# ls /sbin/mk*
|
||||
|
||||

|
||||
|
||||
Check Filesystems Type
|
||||
|
||||
The type of filesystem that you should choose depends on your requirements. You should consider the pros and cons of each filesystem and its own set of features. Two important attributes to look for in a filesystem are.
|
||||
|
||||
- Journaling support, which allows for faster data recovery in the event of a system crash.
|
||||
- Security Enhanced Linux (SELinux) support, as per the project wiki, “a security enhancement to Linux which allows users and administrators more control over access control”.
|
||||
|
||||
In our next example, we will create an ext4 filesystem (supports both journaling and SELinux) labeled Tecmint on /dev/sdb1, using mkfs, whose basic syntax is.
|
||||
|
||||
# mkfs -t [filesystem] -L [label] device
|
||||
or
|
||||
# mkfs.[filesystem] -L [label] device
|
||||
|
||||
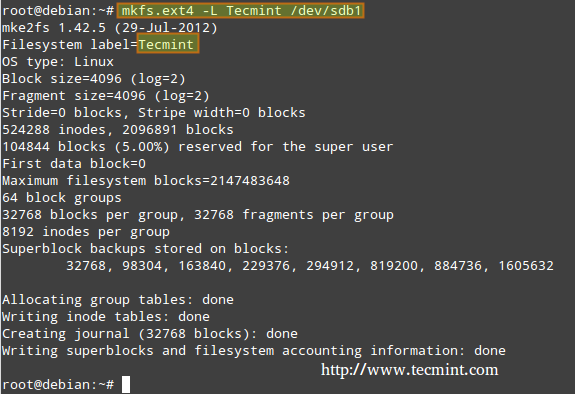
|
||||
|
||||
Create ext4 Filesystems
|
||||
|
||||
### Creating and Using Swap Partitions ###
|
||||
|
||||
Swap partitions are necessary if we need our Linux system to have access to virtual memory, which is a section of the hard disk designated for use as memory, when the main system memory (RAM) is all in use. For that reason, a swap partition may not be needed on systems with enough RAM to meet all its requirements; however, even in that case it’s up to the system administrator to decide whether to use a swap partition or not.
|
||||
|
||||
A simple rule of thumb to decide the size of a swap partition is as follows.
|
||||
|
||||
Swap should usually equal 2x physical RAM for up to 2 GB of physical RAM, and then an additional 1x physical RAM for any amount above 2 GB, but never less than 32 MB.
|
||||
|
||||
So, if:
|
||||
|
||||
M = Amount of RAM in GB, and S = Amount of swap in GB, then
|
||||
|
||||
If M < 2
|
||||
S = M *2
|
||||
Else
|
||||
S = M + 2
|
||||
|
||||
Remember this is just a formula and that only you, as a sysadmin, have the final word as to the use and size of a swap partition.
|
||||
|
||||
To configure a swap partition, create a regular partition as demonstrated earlier with the desired size. Next, we need to add the following entry to the /etc/fstab file (X can be either b or c).
|
||||
|
||||
/dev/sdX1 swap swap sw 0 0
|
||||
|
||||
Finally, let’s format and enable the swap partition.
|
||||
|
||||
# mkswap /dev/sdX1
|
||||
# swapon -v /dev/sdX1
|
||||
|
||||
To display a snapshot of the swap partition(s).
|
||||
|
||||
# cat /proc/swaps
|
||||
|
||||
To disable the swap partition.
|
||||
|
||||
# swapoff /dev/sdX1
|
||||
|
||||
For the next example, we’ll use /dev/sdc1 (=512 MB, for a system with 256 MB of RAM) to set up a partition with fdisk that we will use as swap, following the steps detailed above. Note that we will specify a fixed size in this case.
|
||||
|
||||

|
||||
|
||||
Create Swap Partition
|
||||
|
||||

|
||||
|
||||
Enable Swap Partition
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Creating partitions (including swap) and formatting filesystems are crucial in your road to Sysadminship. I hope that the tips given in this article will guide you to achieve your goals. Feel free to add your own tips & ideas in the comments section below, for the benefit of the community.
|
||||
Reference Links
|
||||
|
||||
- [About the LFCS][1]
|
||||
- [Why get a Linux Foundation Certification?][2]
|
||||
- [Register for the LFCS exam][3]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/create-partitions-and-filesystems-in-linux/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:https://training.linuxfoundation.org/certification/LFCS
|
||||
[2]:https://training.linuxfoundation.org/certification/why-certify-with-us
|
||||
[3]:https://identity.linuxfoundation.org/user?destination=pid/1
|
||||
@ -0,0 +1,232 @@
|
||||
Part 5 - LFCS: How to Mount/Unmount Local and Network (Samba & NFS) Filesystems in Linux
|
||||
================================================================================
|
||||
The Linux Foundation launched the LFCS certification (Linux Foundation Certified Sysadmin), a brand new program whose purpose is allowing individuals from all corners of the globe to get certified in basic to intermediate system administration tasks for Linux systems, which includes supporting running systems and services, along with overall monitoring and analysis, plus smart decision-making when it comes to raising issues to upper support teams.
|
||||
|
||||

|
||||
|
||||
Linux Foundation Certified Sysadmin – Part 5
|
||||
|
||||
The following video shows an introduction to The Linux Foundation Certification Program.
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="720" height="405" frameborder="0" allowfullscreen="allowfullscreen" src="//www.youtube.com/embed/Y29qZ71Kicg"></iframe>
|
||||
|
||||
This post is Part 5 of a 10-tutorial series, here in this part, we will explain How to mount/unmount local and network filesystems in linux, that are required for the LFCS certification exam.
|
||||
|
||||
### Mounting Filesystems ###
|
||||
|
||||
Once a disk has been partitioned, Linux needs some way to access the data on the partitions. Unlike DOS or Windows (where this is done by assigning a drive letter to each partition), Linux uses a unified directory tree where each partition is mounted at a mount point in that tree.
|
||||
|
||||
A mount point is a directory that is used as a way to access the filesystem on the partition, and mounting the filesystem is the process of associating a certain filesystem (a partition, for example) with a specific directory in the directory tree.
|
||||
|
||||
In other words, the first step in managing a storage device is attaching the device to the file system tree. This task can be accomplished on a one-time basis by using tools such as mount (and then unmounted with umount) or persistently across reboots by editing the /etc/fstab file.
|
||||
|
||||
The mount command (without any options or arguments) shows the currently mounted filesystems.
|
||||
|
||||
# mount
|
||||
|
||||

|
||||
|
||||
Check Mounted Filesystem
|
||||
|
||||
In addition, mount is used to mount filesystems into the filesystem tree. Its standard syntax is as follows.
|
||||
|
||||
# mount -t type device dir -o options
|
||||
|
||||
This command instructs the kernel to mount the filesystem found on device (a partition, for example, that has been formatted with a filesystem type) at the directory dir, using all options. In this form, mount does not look in /etc/fstab for instructions.
|
||||
|
||||
If only a directory or device is specified, for example.
|
||||
|
||||
# mount /dir -o options
|
||||
or
|
||||
# mount device -o options
|
||||
|
||||
mount tries to find a mount point and if it can’t find any, then searches for a device (both cases in the /etc/fstab file), and finally attempts to complete the mount operation (which usually succeeds, except for the case when either the directory or the device is already being used, or when the user invoking mount is not root).
|
||||
|
||||
You will notice that every line in the output of mount has the following format.
|
||||
|
||||
device on directory type (options)
|
||||
|
||||
For example,
|
||||
|
||||
/dev/mapper/debian-home on /home type ext4 (rw,relatime,user_xattr,barrier=1,data=ordered)
|
||||
|
||||
Reads:
|
||||
|
||||
dev/mapper/debian-home is mounted on /home, which has been formatted as ext4, with the following options: rw,relatime,user_xattr,barrier=1,data=ordered
|
||||
|
||||
**Mount Options**
|
||||
|
||||
Most frequently used mount options include.
|
||||
|
||||
- async: allows asynchronous I/O operations on the file system being mounted.
|
||||
- auto: marks the file system as enabled to be mounted automatically using mount -a. It is the opposite of noauto.
|
||||
- defaults: this option is an alias for async,auto,dev,exec,nouser,rw,suid. Note that multiple options must be separated by a comma without any spaces. If by accident you type a space between options, mount will interpret the subsequent text string as another argument.
|
||||
- loop: Mounts an image (an .iso file, for example) as a loop device. This option can be used to simulate the presence of the disk’s contents in an optical media reader.
|
||||
- noexec: prevents the execution of executable files on the particular filesystem. It is the opposite of exec.
|
||||
- nouser: prevents any users (other than root) to mount and unmount the filesystem. It is the opposite of user.
|
||||
- remount: mounts the filesystem again in case it is already mounted.
|
||||
- ro: mounts the filesystem as read only.
|
||||
- rw: mounts the file system with read and write capabilities.
|
||||
- relatime: makes access time to files be updated only if atime is earlier than mtime.
|
||||
- user_xattr: allow users to set and remote extended filesystem attributes.
|
||||
|
||||
**Mounting a device with ro and noexec options**
|
||||
|
||||
# mount -t ext4 /dev/sdg1 /mnt -o ro,noexec
|
||||
|
||||
In this case we can see that attempts to write a file to or to run a binary file located inside our mounting point fail with corresponding error messages.
|
||||
|
||||
# touch /mnt/myfile
|
||||
# /mnt/bin/echo “Hi there”
|
||||
|
||||

|
||||
|
||||
Mount Device Read Write
|
||||
|
||||
**Mounting a device with default options**
|
||||
|
||||
In the following scenario, we will try to write a file to our newly mounted device and run an executable file located within its filesystem tree using the same commands as in the previous example.
|
||||
|
||||
# mount -t ext4 /dev/sdg1 /mnt -o defaults
|
||||
|
||||

|
||||
|
||||
Mount Device
|
||||
|
||||
In this last case, it works perfectly.
|
||||
|
||||
### Unmounting Devices ###
|
||||
|
||||
Unmounting a device (with the umount command) means finish writing all the remaining “on transit” data so that it can be safely removed. Note that if you try to remove a mounted device without properly unmounting it first, you run the risk of damaging the device itself or cause data loss.
|
||||
|
||||
That being said, in order to unmount a device, you must be “standing outside” its block device descriptor or mount point. In other words, your current working directory must be something else other than the mounting point. Otherwise, you will get a message saying that the device is busy.
|
||||
|
||||
|
||||
|
||||
Unmount Device
|
||||
|
||||
An easy way to “leave” the mounting point is typing the cd command which, in lack of arguments, will take us to our current user’s home directory, as shown above.
|
||||
|
||||
### Mounting Common Networked Filesystems ###
|
||||
|
||||
The two most frequently used network file systems are SMB (which stands for “Server Message Block”) and NFS (“Network File System”). Chances are you will use NFS if you need to set up a share for Unix-like clients only, and will opt for Samba if you need to share files with Windows-based clients and perhaps other Unix-like clients as well.
|
||||
|
||||
Read Also
|
||||
|
||||
- [Setup Samba Server in RHEL/CentOS and Fedora][1]
|
||||
- [Setting up NFS (Network File System) on RHEL/CentOS/Fedora and Debian/Ubuntu][2]
|
||||
|
||||
The following steps assume that Samba and NFS shares have already been set up in the server with IP 192.168.0.10 (please note that setting up a NFS share is one of the competencies required for the LFCE exam, which we will cover after the present series).
|
||||
|
||||
#### Mounting a Samba share on Linux ####
|
||||
|
||||
Step 1: Install the samba-client samba-common and cifs-utils packages on Red Hat and Debian based distributions.
|
||||
|
||||
# yum update && yum install samba-client samba-common cifs-utils
|
||||
# aptitude update && aptitude install samba-client samba-common cifs-utils
|
||||
|
||||
Then run the following command to look for available samba shares in the server.
|
||||
|
||||
# smbclient -L 192.168.0.10
|
||||
|
||||
And enter the password for the root account in the remote machine.
|
||||
|
||||

|
||||
|
||||
Mount Samba Share
|
||||
|
||||
In the above image we have highlighted the share that is ready for mounting on our local system. You will need a valid samba username and password on the remote server in order to access it.
|
||||
|
||||
Step 2: When mounting a password-protected network share, it is not a good idea to write your credentials in the /etc/fstab file. Instead, you can store them in a hidden file somewhere with permissions set to 600, like so.
|
||||
|
||||
# mkdir /media/samba
|
||||
# echo “username=samba_username” > /media/samba/.smbcredentials
|
||||
# echo “password=samba_password” >> /media/samba/.smbcredentials
|
||||
# chmod 600 /media/samba/.smbcredentials
|
||||
|
||||
Step 3: Then add the following line to /etc/fstab file.
|
||||
|
||||
# //192.168.0.10/gacanepa /media/samba cifs credentials=/media/samba/.smbcredentials,defaults 0 0
|
||||
|
||||
Step 4: You can now mount your samba share, either manually (mount //192.168.0.10/gacanepa) or by rebooting your machine so as to apply the changes made in /etc/fstab permanently.
|
||||
|
||||

|
||||
|
||||
Mount Password Protect Samba Share
|
||||
|
||||
#### Mounting a NFS share on Linux ####
|
||||
|
||||
Step 1: Install the nfs-common and portmap packages on Red Hat and Debian based distributions.
|
||||
|
||||
# yum update && yum install nfs-utils nfs-utils-lib
|
||||
# aptitude update && aptitude install nfs-common
|
||||
|
||||
Step 2: Create a mounting point for the NFS share.
|
||||
|
||||
# mkdir /media/nfs
|
||||
|
||||
Step 3: Add the following line to /etc/fstab file.
|
||||
|
||||
192.168.0.10:/NFS-SHARE /media/nfs nfs defaults 0 0
|
||||
|
||||
Step 4: You can now mount your nfs share, either manually (mount 192.168.0.10:/NFS-SHARE) or by rebooting your machine so as to apply the changes made in /etc/fstab permanently.
|
||||
|
||||
|
||||
|
||||
Mount NFS Share
|
||||
|
||||
### Mounting Filesystems Permanently ###
|
||||
|
||||
As shown in the previous two examples, the /etc/fstab file controls how Linux provides access to disk partitions and removable media devices and consists of a series of lines that contain six fields each; the fields are separated by one or more spaces or tabs. A line that begins with a hash mark (#) is a comment and is ignored.
|
||||
|
||||
Each line has the following format.
|
||||
|
||||
<file system> <mount point> <type> <options> <dump> <pass>
|
||||
|
||||
Where:
|
||||
|
||||
- <file system>: The first column specifies the mount device. Most distributions now specify partitions by their labels or UUIDs. This practice can help reduce problems if partition numbers change.
|
||||
- <mount point>: The second column specifies the mount point.
|
||||
- <type>: The file system type code is the same as the type code used to mount a filesystem with the mount command. A file system type code of auto lets the kernel auto-detect the filesystem type, which can be a convenient option for removable media devices. Note that this option may not be available for all filesystems out there.
|
||||
- <options>: One (or more) mount option(s).
|
||||
- <dump>: You will most likely leave this to 0 (otherwise set it to 1) to disable the dump utility to backup the filesystem upon boot (The dump program was once a common backup tool, but it is much less popular today.)
|
||||
- <pass>: This column specifies whether the integrity of the filesystem should be checked at boot time with fsck. A 0 means that fsck should not check a filesystem. The higher the number, the lowest the priority. Thus, the root partition will most likely have a value of 1, while all others that should be checked should have a value of 2.
|
||||
|
||||
**Mount Examples**
|
||||
|
||||
1. To mount a partition with label TECMINT at boot time with rw and noexec attributes, you should add the following line in /etc/fstab file.
|
||||
|
||||
LABEL=TECMINT /mnt ext4 rw,noexec 0 0
|
||||
|
||||
2. If you want the contents of a disk in your DVD drive be available at boot time.
|
||||
|
||||
/dev/sr0 /media/cdrom0 iso9660 ro,user,noauto 0 0
|
||||
|
||||
Where /dev/sr0 is your DVD drive.
|
||||
|
||||
### Summary ###
|
||||
|
||||
You can rest assured that mounting and unmounting local and network filesystems from the command line will be part of your day-to-day responsibilities as sysadmin. You will also need to master /etc/fstab. I hope that you have found this article useful to help you with those tasks. Feel free to add your comments (or ask questions) below and to share this article through your network social profiles.
|
||||
Reference Links
|
||||
|
||||
- [About the LFCS][3]
|
||||
- [Why get a Linux Foundation Certification?][4]
|
||||
- [Register for the LFCS exam][5]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/mount-filesystem-in-linux/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/setup-samba-server-using-tdbsam-backend-on-rhel-centos-6-3-5-8-and-fedora-17-12/
|
||||
[2]:http://www.tecmint.com/how-to-setup-nfs-server-in-linux/
|
||||
[3]:https://training.linuxfoundation.org/certification/LFCS
|
||||
[4]:https://training.linuxfoundation.org/certification/why-certify-with-us
|
||||
[5]:https://identity.linuxfoundation.org/user?destination=pid/1
|
||||
@ -0,0 +1,276 @@
|
||||
Part 6 - LFCS: Assembling Partitions as RAID Devices – Creating & Managing System Backups
|
||||
================================================================================
|
||||
Recently, the Linux Foundation launched the LFCS (Linux Foundation Certified Sysadmin) certification, a shiny chance for system administrators everywhere to demonstrate, through a performance-based exam, that they are capable of performing overall operational support on Linux systems: system support, first-level diagnosing and monitoring, plus issue escalation, when required, to other support teams.
|
||||
|
||||

|
||||
|
||||
Linux Foundation Certified Sysadmin – Part 6
|
||||
|
||||
The following video provides an introduction to The Linux Foundation Certification Program.
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="720" height="405" frameborder="0" allowfullscreen="allowfullscreen" src="//www.youtube.com/embed/Y29qZ71Kicg"></iframe>
|
||||
|
||||
This post is Part 6 of a 10-tutorial series, here in this part, we will explain How to Assemble Partitions as RAID Devices – Creating & Managing System Backups, that are required for the LFCS certification exam.
|
||||
|
||||
### Understanding RAID ###
|
||||
|
||||
The technology known as Redundant Array of Independent Disks (RAID) is a storage solution that combines multiple hard disks into a single logical unit to provide redundancy of data and/or improve performance in read / write operations to disk.
|
||||
|
||||
However, the actual fault-tolerance and disk I/O performance lean on how the hard disks are set up to form the disk array. Depending on the available devices and the fault tolerance / performance needs, different RAID levels are defined. You can refer to the RAID series here in Tecmint.com for a more detailed explanation on each RAID level.
|
||||
|
||||
- RAID Guide: [What is RAID, Concepts of RAID and RAID Levels Explained][1]
|
||||
|
||||
Our tool of choice for creating, assembling, managing, and monitoring our software RAIDs is called mdadm (short for multiple disks admin).
|
||||
|
||||
---------------- Debian and Derivatives ----------------
|
||||
# aptitude update && aptitude install mdadm
|
||||
|
||||
----------
|
||||
|
||||
---------------- Red Hat and CentOS based Systems ----------------
|
||||
# yum update && yum install mdadm
|
||||
|
||||
----------
|
||||
|
||||
---------------- On openSUSE ----------------
|
||||
# zypper refresh && zypper install mdadm #
|
||||
|
||||
#### Assembling Partitions as RAID Devices ####
|
||||
|
||||
The process of assembling existing partitions as RAID devices consists of the following steps.
|
||||
|
||||
**1. Create the array using mdadm**
|
||||
|
||||
If one of the partitions has been formatted previously, or has been a part of another RAID array previously, you will be prompted to confirm the creation of the new array. Assuming you have taken the necessary precautions to avoid losing important data that may have resided in them, you can safely type y and press Enter.
|
||||
|
||||
# mdadm --create --verbose /dev/md0 --level=stripe --raid-devices=2 /dev/sdb1 /dev/sdc1
|
||||
|
||||

|
||||
|
||||
Creating RAID Array
|
||||
|
||||
**2. Check the array creation status**
|
||||
|
||||
After creating RAID array, you an check the status of the array using the following commands.
|
||||
|
||||
# cat /proc/mdstat
|
||||
or
|
||||
# mdadm --detail /dev/md0 [More detailed summary]
|
||||
|
||||

|
||||
|
||||
Check RAID Array Status
|
||||
|
||||
**3. Format the RAID Device**
|
||||
|
||||
Format the device with a filesystem as per your needs / requirements, as explained in [Part 4][2] of this series.
|
||||
|
||||
**4. Monitor RAID Array Service**
|
||||
|
||||
Instruct the monitoring service to “keep an eye” on the array. Add the output of mdadm –detail –scan to /etc/mdadm/mdadm.conf (Debian and derivatives) or /etc/mdadm.conf (CentOS / openSUSE), like so.
|
||||
|
||||
# mdadm --detail --scan
|
||||
|
||||

|
||||
|
||||
Monitor RAID Array
|
||||
|
||||
# mdadm --assemble --scan [Assemble the array]
|
||||
|
||||
To ensure the service starts on system boot, run the following commands as root.
|
||||
|
||||
**Debian and Derivatives**
|
||||
|
||||
Debian and derivatives, though it should start running on boot by default.
|
||||
|
||||
# update-rc.d mdadm defaults
|
||||
|
||||
Edit the /etc/default/mdadm file and add the following line.
|
||||
|
||||
AUTOSTART=true
|
||||
|
||||
**On CentOS and openSUSE (systemd-based)**
|
||||
|
||||
# systemctl start mdmonitor
|
||||
# systemctl enable mdmonitor
|
||||
|
||||
**On CentOS and openSUSE (SysVinit-based)**
|
||||
|
||||
# service mdmonitor start
|
||||
# chkconfig mdmonitor on
|
||||
|
||||
**5. Check RAID Disk Failure**
|
||||
|
||||
In RAID levels that support redundancy, replace failed drives when needed. When a device in the disk array becomes faulty, a rebuild automatically starts only if there was a spare device added when we first created the array.
|
||||
|
||||

|
||||
|
||||
Check RAID Faulty Disk
|
||||
|
||||
Otherwise, we need to manually attach an extra physical drive to our system and run.
|
||||
|
||||
# mdadm /dev/md0 --add /dev/sdX1
|
||||
|
||||
Where /dev/md0 is the array that experienced the issue and /dev/sdX1 is the new device.
|
||||
|
||||
**6. Disassemble a working array**
|
||||
|
||||
You may have to do this if you need to create a new array using the devices – (Optional Step).
|
||||
|
||||
# mdadm --stop /dev/md0 # Stop the array
|
||||
# mdadm --remove /dev/md0 # Remove the RAID device
|
||||
# mdadm --zero-superblock /dev/sdX1 # Overwrite the existing md superblock with zeroes
|
||||
|
||||
**7. Set up mail alerts**
|
||||
|
||||
You can configure a valid email address or system account to send alerts to (make sure you have this line in mdadm.conf). – (Optional Step)
|
||||
|
||||
MAILADDR root
|
||||
|
||||
In this case, all alerts that the RAID monitoring daemon collects will be sent to the local root account’s mail box. One of such alerts looks like the following.
|
||||
|
||||
**Note**: This event is related to the example in STEP 5, where a device was marked as faulty and the spare device was automatically built into the array by mdadm. Thus, we “ran out” of healthy spare devices and we got the alert.
|
||||
|
||||
|
||||
|
||||
RAID Monitoring Alerts
|
||||
|
||||
#### Understanding RAID Levels ####
|
||||
|
||||
**RAID 0**
|
||||
|
||||
The total array size is n times the size of the smallest partition, where n is the number of independent disks in the array (you will need at least two drives). Run the following command to assemble a RAID 0 array using partitions /dev/sdb1 and /dev/sdc1.
|
||||
|
||||
# mdadm --create --verbose /dev/md0 --level=stripe --raid-devices=2 /dev/sdb1 /dev/sdc1
|
||||
|
||||
Common uses: Setups that support real-time applications where performance is more important than fault-tolerance.
|
||||
|
||||
**RAID 1 (aka Mirroring)**
|
||||
|
||||
The total array size equals the size of the smallest partition (you will need at least two drives). Run the following command to assemble a RAID 1 array using partitions /dev/sdb1 and /dev/sdc1.
|
||||
|
||||
# mdadm --create --verbose /dev/md0 --level=1 --raid-devices=2 /dev/sdb1 /dev/sdc1
|
||||
|
||||
Common uses: Installation of the operating system or important subdirectories, such as /home.
|
||||
|
||||
**RAID 5 (aka drives with Parity)**
|
||||
|
||||
The total array size will be (n – 1) times the size of the smallest partition. The “lost” space in (n-1) is used for parity (redundancy) calculation (you will need at least three drives).
|
||||
|
||||
Note that you can specify a spare device (/dev/sde1 in this case) to replace a faulty part when an issue occurs. Run the following command to assemble a RAID 5 array using partitions /dev/sdb1, /dev/sdc1, /dev/sdd1, and /dev/sde1 as spare.
|
||||
|
||||
# mdadm --create --verbose /dev/md0 --level=5 --raid-devices=3 /dev/sdb1 /dev/sdc1 /dev/sdd1 --spare-devices=1 /dev/sde1
|
||||
|
||||
Common uses: Web and file servers.
|
||||
|
||||
**RAID 6 (aka drives with double Parity**
|
||||
|
||||
The total array size will be (n*s)-2*s, where n is the number of independent disks in the array and s is the size of the smallest disk. Note that you can specify a spare device (/dev/sdf1 in this case) to replace a faulty part when an issue occurs.
|
||||
|
||||
Run the following command to assemble a RAID 6 array using partitions /dev/sdb1, /dev/sdc1, /dev/sdd1, /dev/sde1, and /dev/sdf1 as spare.
|
||||
|
||||
# mdadm --create --verbose /dev/md0 --level=6 --raid-devices=4 /dev/sdb1 /dev/sdc1 /dev/sdd1 /dev/sde --spare-devices=1 /dev/sdf1
|
||||
|
||||
Common uses: File and backup servers with large capacity and high availability requirements.
|
||||
|
||||
**RAID 1+0 (aka stripe of mirrors)**
|
||||
|
||||
The total array size is computed based on the formulas for RAID 0 and RAID 1, since RAID 1+0 is a combination of both. First, calculate the size of each mirror and then the size of the stripe.
|
||||
|
||||
Note that you can specify a spare device (/dev/sdf1 in this case) to replace a faulty part when an issue occurs. Run the following command to assemble a RAID 1+0 array using partitions /dev/sdb1, /dev/sdc1, /dev/sdd1, /dev/sde1, and /dev/sdf1 as spare.
|
||||
|
||||
# mdadm --create --verbose /dev/md0 --level=10 --raid-devices=4 /dev/sd[b-e]1 --spare-devices=1 /dev/sdf1
|
||||
|
||||
Common uses: Database and application servers that require fast I/O operations.
|
||||
|
||||
#### Creating and Managing System Backups ####
|
||||
|
||||
It never hurts to remember that RAID with all its bounties IS NOT A REPLACEMENT FOR BACKUPS! Write it 1000 times on the chalkboard if you need to, but make sure you keep that idea in mind at all times. Before we begin, we must note that there is no one-size-fits-all solution for system backups, but here are some things that you do need to take into account while planning a backup strategy.
|
||||
|
||||
- What do you use your system for? (Desktop or server? If the latter case applies, what are the most critical services – whose configuration would be a real pain to lose?)
|
||||
- How often do you need to take backups of your system?
|
||||
- What is the data (e.g. files / directories / database dumps) that you want to backup? You may also want to consider if you really need to backup huge files (such as audio or video files).
|
||||
- Where (meaning physical place and media) will those backups be stored?
|
||||
|
||||
**Backing Up Your Data**
|
||||
|
||||
Method 1: Backup entire drives with dd command. You can either back up an entire hard disk or a partition by creating an exact image at any point in time. Note that this works best when the device is offline, meaning it’s not mounted and there are no processes accessing it for I/O operations.
|
||||
|
||||
The downside of this backup approach is that the image will have the same size as the disk or partition, even when the actual data occupies a small percentage of it. For example, if you want to image a partition of 20 GB that is only 10% full, the image file will still be 20 GB in size. In other words, it’s not only the actual data that gets backed up, but the entire partition itself. You may consider using this method if you need exact backups of your devices.
|
||||
|
||||
**Creating an image file out of an existing device**
|
||||
|
||||
# dd if=/dev/sda of=/system_images/sda.img
|
||||
OR
|
||||
--------------------- Alternatively, you can compress the image file ---------------------
|
||||
# dd if=/dev/sda | gzip -c > /system_images/sda.img.gz
|
||||
|
||||
**Restoring the backup from the image file**
|
||||
|
||||
# dd if=/system_images/sda.img of=/dev/sda
|
||||
OR
|
||||
|
||||
--------------------- Depending on your choice while creating the image ---------------------
|
||||
gzip -dc /system_images/sda.img.gz | dd of=/dev/sda
|
||||
|
||||
Method 2: Backup certain files / directories with tar command – already covered in [Part 3][3] of this series. You may consider using this method if you need to keep copies of specific files and directories (configuration files, users’ home directories, and so on).
|
||||
|
||||
Method 3: Synchronize files with rsync command. Rsync is a versatile remote (and local) file-copying tool. If you need to backup and synchronize your files to/from network drives, rsync is a go.
|
||||
|
||||
Whether you’re synchronizing two local directories or local < — > remote directories mounted on the local filesystem, the basic syntax is the same.
|
||||
Synchronizing two local directories or local < — > remote directories mounted on the local filesystem
|
||||
|
||||
# rsync -av source_directory destination directory
|
||||
|
||||
Where, -a recurse into subdirectories (if they exist), preserve symbolic links, timestamps, permissions, and original owner / group and -v verbose.
|
||||
|
||||
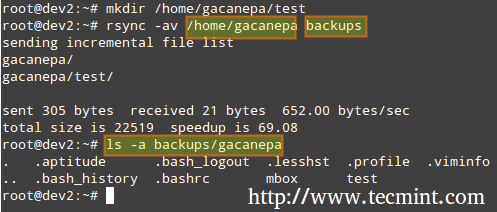
|
||||
|
||||
rsync Synchronizing Files
|
||||
|
||||
In addition, if you want to increase the security of the data transfer over the wire, you can use ssh over rsync.
|
||||
|
||||
**Synchronizing local → remote directories over ssh**
|
||||
|
||||
# rsync -avzhe ssh backups root@remote_host:/remote_directory/
|
||||
|
||||
This example will synchronize the backups directory on the local host with the contents of /root/remote_directory on the remote host.
|
||||
|
||||
Where the -h option shows file sizes in human-readable format, and the -e flag is used to indicate a ssh connection.
|
||||
|
||||

|
||||
|
||||
rsync Synchronize Remote Files
|
||||
|
||||
Synchronizing remote → local directories over ssh.
|
||||
|
||||
In this case, switch the source and destination directories from the previous example.
|
||||
|
||||
# rsync -avzhe ssh root@remote_host:/remote_directory/ backups
|
||||
|
||||
Please note that these are only 3 examples (most frequent cases you’re likely to run into) of the use of rsync. For more examples and usages of rsync commands can be found at the following article.
|
||||
|
||||
- Read Also: [10 rsync Commands to Sync Files in Linux][4]
|
||||
|
||||
### Summary ###
|
||||
|
||||
As a sysadmin, you need to ensure that your systems perform as good as possible. If you’re well prepared, and if the integrity of your data is well supported by a storage technology such as RAID and regular system backups, you’ll be safe.
|
||||
|
||||
If you have questions, comments, or further ideas on how this article can be improved, feel free to speak out below. In addition, please consider sharing this series through your social network profiles.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/creating-and-managing-raid-backups-in-linux/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/understanding-raid-setup-in-linux/
|
||||
[2]:http://www.tecmint.com/create-partitions-and-filesystems-in-linux/
|
||||
[3]:http://www.tecmint.com/compress-files-and-finding-files-in-linux/
|
||||
[4]:http://www.tecmint.com/rsync-local-remote-file-synchronization-commands/
|
||||
@ -0,0 +1,367 @@
|
||||
Part 7 - LFCS: Managing System Startup Process and Services (SysVinit, Systemd and Upstart)
|
||||
================================================================================
|
||||
A couple of months ago, the Linux Foundation announced the LFCS (Linux Foundation Certified Sysadmin) certification, an exciting new program whose aim is allowing individuals from all ends of the world to get certified in performing basic to intermediate system administration tasks on Linux systems. This includes supporting already running systems and services, along with first-hand problem-finding and analysis, plus the ability to decide when to raise issues to engineering teams.
|
||||
|
||||

|
||||
|
||||
Linux Foundation Certified Sysadmin – Part 7
|
||||
|
||||
The following video describes an brief introduction to The Linux Foundation Certification Program.
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="720" height="405" frameborder="0" allowfullscreen="allowfullscreen" src="//www.youtube.com/embed/Y29qZ71Kicg"></iframe>
|
||||
|
||||
This post is Part 7 of a 10-tutorial series, here in this part, we will explain how to Manage Linux System Startup Process and Services, that are required for the LFCS certification exam.
|
||||
|
||||
### Managing the Linux Startup Process ###
|
||||
|
||||
The boot process of a Linux system consists of several phases, each represented by a different component. The following diagram briefly summarizes the boot process and shows all the main components involved.
|
||||
|
||||

|
||||
|
||||
Linux Boot Process
|
||||
|
||||
When you press the Power button on your machine, the firmware that is stored in a EEPROM chip in the motherboard initializes the POST (Power-On Self Test) to check on the state of the system’s hardware resources. When the POST is finished, the firmware then searches and loads the 1st stage boot loader, located in the MBR or in the EFI partition of the first available disk, and gives control to it.
|
||||
|
||||
#### MBR Method ####
|
||||
|
||||
The MBR is located in the first sector of the disk marked as bootable in the BIOS settings and is 512 bytes in size.
|
||||
|
||||
- First 446 bytes: The bootloader contains both executable code and error message text.
|
||||
- Next 64 bytes: The Partition table contains a record for each of four partitions (primary or extended). Among other things, each record indicates the status (active / not active), size, and start / end sectors of each partition.
|
||||
- Last 2 bytes: The magic number serves as a validation check of the MBR.
|
||||
|
||||
The following command performs a backup of the MBR (in this example, /dev/sda is the first hard disk). The resulting file, mbr.bkp can come in handy should the partition table become corrupt, for example, rendering the system unbootable.
|
||||
|
||||
Of course, in order to use it later if the need arises, we will need to save it and store it somewhere else (like a USB drive, for example). That file will help us restore the MBR and will get us going once again if and only if we do not change the hard drive layout in the meanwhile.
|
||||
|
||||
**Backup MBR**
|
||||
|
||||
# dd if=/dev/sda of=mbr.bkp bs=512 count=1
|
||||
|
||||

|
||||
|
||||
Backup MBR in Linux
|
||||
|
||||
**Restoring MBR**
|
||||
|
||||
# dd if=mbr.bkp of=/dev/sda bs=512 count=1
|
||||
|
||||
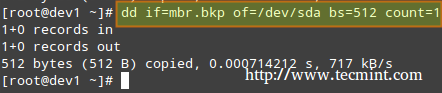
|
||||
|
||||
Restore MBR in Linux
|
||||
|
||||
#### EFI/UEFI Method ####
|
||||
|
||||
For systems using the EFI/UEFI method, the UEFI firmware reads its settings to determine which UEFI application is to be launched and from where (i.e., in which disk and partition the EFI partition is located).
|
||||
|
||||
Next, the 2nd stage boot loader (aka boot manager) is loaded and run. GRUB [GRand Unified Boot] is the most frequently used boot manager in Linux. One of two distinct versions can be found on most systems used today.
|
||||
|
||||
- GRUB legacy configuration file: /boot/grub/menu.lst (older distributions, not supported by EFI/UEFI firmwares).
|
||||
- GRUB2 configuration file: most likely, /etc/default/grub.
|
||||
|
||||
Although the objectives of the LFCS exam do not explicitly request knowledge about GRUB internals, if you’re brave and can afford to mess up your system (you may want to try it first on a virtual machine, just in case), you need to run.
|
||||
|
||||
# update-grub
|
||||
|
||||
As root after modifying GRUB’s configuration in order to apply the changes.
|
||||
|
||||
Basically, GRUB loads the default kernel and the initrd or initramfs image. In few words, initrd or initramfs help to perform the hardware detection, the kernel module loading and the device discovery necessary to get the real root filesystem mounted.
|
||||
|
||||
Once the real root filesystem is up, the kernel executes the system and service manager (init or systemd, whose process identification or PID is always 1) to begin the normal user-space boot process in order to present a user interface.
|
||||
|
||||
Both init and systemd are daemons (background processes) that manage other daemons, as the first service to start (during boot) and the last service to terminate (during shutdown).
|
||||
|
||||

|
||||
|
||||
Systemd and Init
|
||||
|
||||
### Starting Services (SysVinit) ###
|
||||
|
||||
The concept of runlevels in Linux specifies different ways to use a system by controlling which services are running. In other words, a runlevel controls what tasks can be accomplished in the current execution state = runlevel (and which ones cannot).
|
||||
|
||||
Traditionally, this startup process was performed based on conventions that originated with System V UNIX, with the system passing executing collections of scripts that start and stop services as the machine entered a specific runlevel (which, in other words, is a different mode of running the system).
|
||||
|
||||
Within each runlevel, individual services can be set to run, or to be shut down if running. Latest versions of some major distributions are moving away from the System V standard in favour of a rather new service and system manager called systemd (which stands for system daemon), but usually support sysv commands for compatibility purposes. This means that you can run most of the well-known sysv init tools in a systemd-based distribution.
|
||||
|
||||
- Read Also: [Why ‘systemd’ replaces ‘init’ in Linux][1]
|
||||
|
||||
Besides starting the system process, init looks to the /etc/inittab file to decide what runlevel must be entered.
|
||||
|
||||
注:表格
|
||||
<table cellspacing="0" border="0">
|
||||
<colgroup width="85">
|
||||
</colgroup>
|
||||
<colgroup width="1514">
|
||||
</colgroup>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000001;"><b>Runlevel</b></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><b> Description</b></td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000001;">0</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> Halt the system. Runlevel 0 is a special transitional state used to shutdown the system quickly.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="CENTER" height="20" style="border: 1px solid #000001;">1</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> Also aliased to s, or S, this runlevel is sometimes called maintenance mode. What services, if any, are started at this runlevel varies by distribution. It’s typically used for low-level system maintenance that may be impaired by normal system operation.</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000001;">2</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> Multiuser. On Debian systems and derivatives, this is the default runlevel, and includes -if available- a graphical login. On Red-Hat based systems, this is multiuser mode without networking.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000001;">3</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> On Red-Hat based systems, this is the default multiuser mode, which runs everything except the graphical environment. This runlevel and levels 4 and 5 usually are not used on Debian-based systems.</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000001;">4</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> Typically unused by default and therefore available for customization.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000001;">5</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> On Red-Hat based systems, full multiuser mode with GUI login. This runlevel is like level 3, but with a GUI login available.</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000001;">6</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> Reboot the system.</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
To switch between runlevels, we can simply issue a runlevel change using the init command: init N (where N is one of the runlevels listed above). Please note that this is not the recommended way of taking a running system to a different runlevel because it gives no warning to existing logged-in users (thus causing them to lose work and processes to terminate abnormally).
|
||||
|
||||
Instead, the shutdown command should be used to restart the system (which first sends a warning message to all logged-in users and blocks any further logins; it then signals init to switch runlevels); however, the default runlevel (the one the system will boot to) must be edited in the /etc/inittab file first.
|
||||
|
||||
For that reason, follow these steps to properly switch between runlevels, As root, look for the following line in /etc/inittab.
|
||||
|
||||
id:2:initdefault:
|
||||
|
||||
and change the number 2 for the desired runlevel with your preferred text editor, such as vim (described in [How to use vi/vim editor in Linux – Part 2][2] of this series).
|
||||
|
||||
Next, run as root.
|
||||
|
||||
# shutdown -r now
|
||||
|
||||
That last command will restart the system, causing it to start in the specified runlevel during next boot, and will run the scripts located in the /etc/rc[runlevel].d directory in order to decide which services should be started and which ones should not. For example, for runlevel 2 in the following system.
|
||||
|
||||

|
||||
|
||||
Change Runlevels in Linux
|
||||
|
||||
#### Manage Services using chkconfig ####
|
||||
|
||||
To enable or disable system services on boot, we will use [chkconfig command][3] in CentOS / openSUSE and sysv-rc-conf in Debian and derivatives. This tool can also show us what is the preconfigured state of a service for a particular runlevel.
|
||||
|
||||
- Read Also: [How to Stop and Disable Unwanted Services in Linux][4]
|
||||
|
||||
Listing the runlevel configuration for a service.
|
||||
|
||||
# chkconfig --list [service name]
|
||||
# chkconfig --list postfix
|
||||
# chkconfig --list mysqld
|
||||
|
||||

|
||||
|
||||
Listing Runlevel Configuration
|
||||
|
||||
In the above image we can see that postfix is set to start when the system enters runlevels 2 through 5, whereas mysqld will be running by default for runlevels 2 through 4. Now suppose that this is not the expected behaviour.
|
||||
|
||||
For example, we need to turn on mysqld for runlevel 5 as well, and turn off postfix for runlevels 4 and 5. Here’s what we would do in each case (run the following commands as root).
|
||||
|
||||
**Enabling a service for a particular runlevel**
|
||||
|
||||
# chkconfig --level [level(s)] service on
|
||||
# chkconfig --level 5 mysqld on
|
||||
|
||||
**Disabling a service for particular runlevels**
|
||||
|
||||
# chkconfig --level [level(s)] service off
|
||||
# chkconfig --level 45 postfix off
|
||||
|
||||
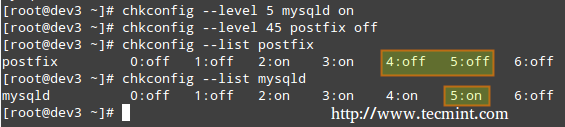
|
||||
|
||||
Enable Disable Services
|
||||
|
||||
We will now perform similar tasks in a Debian-based system using sysv-rc-conf.
|
||||
|
||||
#### Manage Services using sysv-rc-conf ####
|
||||
|
||||
Configuring a service to start automatically on a specific runlevel and prevent it from starting on all others.
|
||||
|
||||
1. Let’s use the following command to see what are the runlevels where mdadm is configured to start.
|
||||
|
||||
# ls -l /etc/rc[0-6].d | grep -E 'rc[0-6]|mdadm'
|
||||
|
||||

|
||||
|
||||
Check Runlevel of Service Running
|
||||
|
||||
2. We will use sysv-rc-conf to prevent mdadm from starting on all runlevels except 2. Just check or uncheck (with the space bar) as desired (you can move up, down, left, and right with the arrow keys).
|
||||
|
||||
# sysv-rc-conf
|
||||
|
||||

|
||||
|
||||
SysV Runlevel Config
|
||||
|
||||
Then press q to quit.
|
||||
|
||||
3. We will restart the system and run again the command from STEP 1.
|
||||
|
||||
# ls -l /etc/rc[0-6].d | grep -E 'rc[0-6]|mdadm'
|
||||
|
||||

|
||||
|
||||
Verify Service Runlevel
|
||||
|
||||
In the above image we can see that mdadm is configured to start only on runlevel 2.
|
||||
|
||||
### What About systemd? ###
|
||||
|
||||
systemd is another service and system manager that is being adopted by several major Linux distributions. It aims to allow more processing to be done in parallel during system startup (unlike sysvinit, which always tends to be slower because it starts processes one at a time, checks whether one depends on another, and waits for daemons to launch so more services can start), and to serve as a dynamic resource management to a running system.
|
||||
|
||||
Thus, services are started when needed (to avoid consuming system resources) instead of being launched without a solid reason during boot.
|
||||
|
||||
Viewing the status of all the processes running on your system, both systemd native and SysV services, run the following command.
|
||||
|
||||
# systemctl
|
||||
|
||||

|
||||
|
||||
Check All Running Processes
|
||||
|
||||
The LOAD column shows whether the unit definition (refer to the UNIT column, which shows the service or anything maintained by systemd) was properly loaded, while the ACTIVE and SUB columns show the current status of such unit.
|
||||
Displaying information about the current status of a service
|
||||
|
||||
When the ACTIVE column indicates that an unit’s status is other than active, we can check what happened using.
|
||||
|
||||
# systemctl status [unit]
|
||||
|
||||
For example, in the image above, media-samba.mount is in failed state. Let’s run.
|
||||
|
||||
# systemctl status media-samba.mount
|
||||
|
||||

|
||||
|
||||
Check Service Status
|
||||
|
||||
We can see that media-samba.mount failed because the mount process on host dev1 was unable to find the network share at //192.168.0.10/gacanepa.
|
||||
|
||||
### Starting or Stopping Services ###
|
||||
|
||||
Once the network share //192.168.0.10/gacanepa becomes available, let’s try to start, then stop, and finally restart the unit media-samba.mount. After performing each action, let’s run systemctl status media-samba.mount to check on its status.
|
||||
|
||||
# systemctl start media-samba.mount
|
||||
# systemctl status media-samba.mount
|
||||
# systemctl stop media-samba.mount
|
||||
# systemctl restart media-samba.mount
|
||||
# systemctl status media-samba.mount
|
||||
|
||||

|
||||
|
||||
Starting Stoping Services
|
||||
|
||||
**Enabling or disabling a service to start during boot**
|
||||
|
||||
Under systemd you can enable or disable a service when it boots.
|
||||
|
||||
# systemctl enable [service] # enable a service
|
||||
# systemctl disable [service] # prevent a service from starting at boot
|
||||
|
||||
The process of enabling or disabling a service to start automatically on boot consists in adding or removing symbolic links in the /etc/systemd/system/multi-user.target.wants directory.
|
||||
|
||||

|
||||
|
||||
Enabling Disabling Services
|
||||
|
||||
Alternatively, you can find out a service’s current status (enabled or disabled) with the command.
|
||||
|
||||
# systemctl is-enabled [service]
|
||||
|
||||
For example,
|
||||
|
||||
# systemctl is-enabled postfix.service
|
||||
|
||||
In addition, you can reboot or shutdown the system with.
|
||||
|
||||
# systemctl reboot
|
||||
# systemctl shutdown
|
||||
|
||||
### Upstart ###
|
||||
|
||||
Upstart is an event-based replacement for the /sbin/init daemon and was born out of the need for starting services only, when they are needed (also supervising them while they are running), and handling events as they occur, thus surpassing the classic, dependency-based sysvinit system.
|
||||
|
||||
It was originally developed for the Ubuntu distribution, but is used in Red Hat Enterprise Linux 6.0. Though it was intended to be suitable for deployment in all Linux distributions as a replacement for sysvinit, in time it was overshadowed by systemd. On February 14, 2014, Mark Shuttleworth (founder of Canonical Ltd.) announced that future releases of Ubuntu would use systemd as the default init daemon.
|
||||
|
||||
Because the SysV startup script for system has been so common for so long, a large number of software packages include SysV startup scripts. To accommodate such packages, Upstart provides a compatibility mode: It runs SysV startup scripts in the usual locations (/etc/rc.d/rc?.d, /etc/init.d/rc?.d, /etc/rc?.d, or a similar location). Thus, if we install a package that doesn’t yet include an Upstart configuration script, it should still launch in the usual way.
|
||||
|
||||
Furthermore, if we have installed utilities such as [chkconfig][5], you should be able to use them to manage your SysV-based services just as we would on sysvinit based systems.
|
||||
|
||||
Upstart scripts also support starting or stopping services based on a wider variety of actions than do SysV startup scripts; for example, Upstart can launch a service whenever a particular hardware device is attached.
|
||||
|
||||
A system that uses Upstart and its native scripts exclusively replaces the /etc/inittab file and the runlevel-specific SysV startup script directories with .conf scripts in the /etc/init directory.
|
||||
|
||||
These *.conf scripts (also known as job definitions) generally consists of the following:
|
||||
|
||||
- Description of the process.
|
||||
- Runlevels where the process should run or events that should trigger it.
|
||||
- Runlevels where process should be stopped or events that should stop it.
|
||||
- Options.
|
||||
- Command to launch the process.
|
||||
|
||||
For example,
|
||||
|
||||
# My test service - Upstart script demo description "Here goes the description of 'My test service'" author "Dave Null <dave.null@example.com>"
|
||||
# Stanzas
|
||||
|
||||
#
|
||||
# Stanzas define when and how a process is started and stopped
|
||||
# See a list of stanzas here: http://upstart.ubuntu.com/wiki/Stanzas#respawn
|
||||
# When to start the service
|
||||
start on runlevel [2345]
|
||||
# When to stop the service
|
||||
stop on runlevel [016]
|
||||
# Automatically restart process in case of crash
|
||||
respawn
|
||||
# Specify working directory
|
||||
chdir /home/dave/myfiles
|
||||
# Specify the process/command (add arguments if needed) to run
|
||||
exec bash backup.sh arg1 arg2
|
||||
|
||||
To apply changes, you will need to tell upstart to reload its configuration.
|
||||
|
||||
# initctl reload-configuration
|
||||
|
||||
Then start your job by typing the following command.
|
||||
|
||||
$ sudo start yourjobname
|
||||
|
||||
Where yourjobname is the name of the job that was added earlier with the yourjobname.conf script.
|
||||
|
||||
A more complete and detailed reference guide for Upstart is available in the project’s web site under the menu “[Cookbook][6]”.
|
||||
|
||||
### Summary ###
|
||||
|
||||
A knowledge of the Linux boot process is necessary to help you with troubleshooting tasks as well as with adapting the computer’s performance and running services to your needs.
|
||||
|
||||
In this article we have analyzed what happens from the moment when you press the Power switch to turn on the machine until you get a fully operational user interface. I hope you have learned reading it as much as I did while putting it together. Feel free to leave your comments or questions below. We always look forward to hearing from our readers!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-boot-process-and-manage-services/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/systemd-replaces-init-in-linux/
|
||||
[2]:http://www.tecmint.com/vi-editor-usage/
|
||||
[3]:http://www.tecmint.com/chkconfig-command-examples/
|
||||
[4]:http://www.tecmint.com/remove-unwanted-services-from-linux/
|
||||
[5]:http://www.tecmint.com/chkconfig-command-examples/
|
||||
[6]:http://upstart.ubuntu.com/cookbook/
|
||||
@ -0,0 +1,330 @@
|
||||
Part 8 - LFCS: Managing Users & Groups, File Permissions & Attributes and Enabling sudo Access on Accounts
|
||||
================================================================================
|
||||
Last August, the Linux Foundation started the LFCS certification (Linux Foundation Certified Sysadmin), a brand new program whose purpose is to allow individuals everywhere and anywhere take an exam in order to get certified in basic to intermediate operational support for Linux systems, which includes supporting running systems and services, along with overall monitoring and analysis, plus intelligent decision-making to be able to decide when it’s necessary to escalate issues to higher level support teams.
|
||||
|
||||

|
||||
|
||||
Linux Foundation Certified Sysadmin – Part 8
|
||||
|
||||
Please have a quick look at the following video that describes an introduction to the Linux Foundation Certification Program.
|
||||
|
||||
注:youtube视频
|
||||
<iframe width="720" height="405" frameborder="0" allowfullscreen="allowfullscreen" src="//www.youtube.com/embed/Y29qZ71Kicg"></iframe>
|
||||
|
||||
This article is Part 8 of a 10-tutorial long series, here in this section, we will guide you on how to manage users and groups permissions in Linux system, that are required for the LFCS certification exam.
|
||||
|
||||
Since Linux is a multi-user operating system (in that it allows multiple users on different computers or terminals to access a single system), you will need to know how to perform effective user management: how to add, edit, suspend, or delete user accounts, along with granting them the necessary permissions to do their assigned tasks.
|
||||
|
||||
### Adding User Accounts ###
|
||||
|
||||
To add a new user account, you can run either of the following two commands as root.
|
||||
|
||||
# adduser [new_account]
|
||||
# useradd [new_account]
|
||||
|
||||
When a new user account is added to the system, the following operations are performed.
|
||||
|
||||
1. His/her home directory is created (/home/username by default).
|
||||
|
||||
2. The following hidden files are copied into the user’s home directory, and will be used to provide environment variables for his/her user session.
|
||||
|
||||
.bash_logout
|
||||
.bash_profile
|
||||
.bashrc
|
||||
|
||||
3. A mail spool is created for the user at /var/spool/mail/username.
|
||||
|
||||
4. A group is created and given the same name as the new user account.
|
||||
|
||||
**Understanding /etc/passwd**
|
||||
|
||||
The full account information is stored in the /etc/passwd file. This file contains a record per system user account and has the following format (fields are delimited by a colon).
|
||||
|
||||
[username]:[x]:[UID]:[GID]:[Comment]:[Home directory]:[Default shell]
|
||||
|
||||
- Fields [username] and [Comment] are self explanatory.
|
||||
- The x in the second field indicates that the account is protected by a shadowed password (in /etc/shadow), which is needed to logon as [username].
|
||||
- The [UID] and [GID] fields are integers that represent the User IDentification and the primary Group IDentification to which [username] belongs, respectively.
|
||||
- The [Home directory] indicates the absolute path to [username]’s home directory, and
|
||||
- The [Default shell] is the shell that will be made available to this user when he or she logins the system.
|
||||
|
||||
**Understanding /etc/group**
|
||||
|
||||
Group information is stored in the /etc/group file. Each record has the following format.
|
||||
|
||||
[Group name]:[Group password]:[GID]:[Group members]
|
||||
|
||||
- [Group name] is the name of group.
|
||||
- An x in [Group password] indicates group passwords are not being used.
|
||||
- [GID]: same as in /etc/passwd.
|
||||
- [Group members]: a comma separated list of users who are members of [Group name].
|
||||
|
||||

|
||||
|
||||
Add User Accounts
|
||||
|
||||
After adding an account, you can edit the following information (to name a few fields) using the usermod command, whose basic syntax of usermod is as follows.
|
||||
|
||||
# usermod [options] [username]
|
||||
|
||||
**Setting the expiry date for an account**
|
||||
|
||||
Use the –expiredate flag followed by a date in YYYY-MM-DD format.
|
||||
|
||||
# usermod --expiredate 2014-10-30 tecmint
|
||||
|
||||
**Adding the user to supplementary groups**
|
||||
|
||||
Use the combined -aG, or –append –groups options, followed by a comma separated list of groups.
|
||||
|
||||
# usermod --append --groups root,users tecmint
|
||||
|
||||
**Changing the default location of the user’s home directory**
|
||||
|
||||
Use the -d, or –home options, followed by the absolute path to the new home directory.
|
||||
|
||||
# usermod --home /tmp tecmint
|
||||
|
||||
**Changing the shell the user will use by default**
|
||||
|
||||
Use –shell, followed by the path to the new shell.
|
||||
|
||||
# usermod --shell /bin/sh tecmint
|
||||
|
||||
**Displaying the groups an user is a member of**
|
||||
|
||||
# groups tecmint
|
||||
# id tecmint
|
||||
|
||||
Now let’s execute all the above commands in one go.
|
||||
|
||||
# usermod --expiredate 2014-10-30 --append --groups root,users --home /tmp --shell /bin/sh tecmint
|
||||
|
||||

|
||||
|
||||
usermod Command Examples
|
||||
|
||||
Read Also:
|
||||
|
||||
- [15 useradd Command Examples in Linux][1]
|
||||
- [15 usermod Command Examples in Linux][2]
|
||||
|
||||
For existing accounts, we can also do the following.
|
||||
|
||||
**Disabling account by locking password**
|
||||
|
||||
Use the -L (uppercase L) or the –lock option to lock a user’s password.
|
||||
|
||||
# usermod --lock tecmint
|
||||
|
||||
**Unlocking user password**
|
||||
|
||||
Use the –u or the –unlock option to unlock a user’s password that was previously blocked.
|
||||
|
||||
# usermod --unlock tecmint
|
||||
|
||||
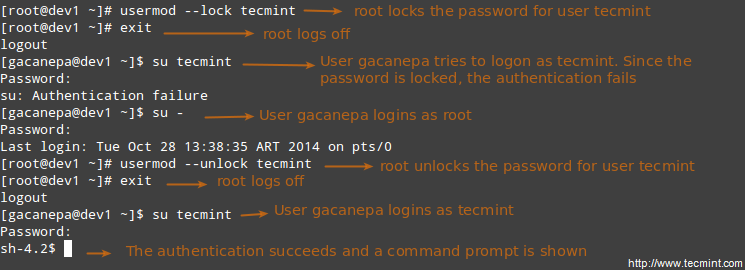
|
||||
|
||||
Lock User Accounts
|
||||
|
||||
**Creating a new group for read and write access to files that need to be accessed by several users**
|
||||
|
||||
Run the following series of commands to achieve the goal.
|
||||
|
||||
# groupadd common_group # Add a new group
|
||||
# chown :common_group common.txt # Change the group owner of common.txt to common_group
|
||||
# usermod -aG common_group user1 # Add user1 to common_group
|
||||
# usermod -aG common_group user2 # Add user2 to common_group
|
||||
# usermod -aG common_group user3 # Add user3 to common_group
|
||||
|
||||
**Deleting a group**
|
||||
|
||||
You can delete a group with the following command.
|
||||
|
||||
# groupdel [group_name]
|
||||
|
||||
If there are files owned by group_name, they will not be deleted, but the group owner will be set to the GID of the group that was deleted.
|
||||
|
||||
### Linux File Permissions ###
|
||||
|
||||
Besides the basic read, write, and execute permissions that we discussed in [Setting File Attributes – Part 3][3] of this series, there are other less used (but not less important) permission settings, sometimes referred to as “special permissions”.
|
||||
|
||||
Like the basic permissions discussed earlier, they are set using an octal file or through a letter (symbolic notation) that indicates the type of permission.
|
||||
Deleting user accounts
|
||||
|
||||
You can delete an account (along with its home directory, if it’s owned by the user, and all the files residing therein, and also the mail spool) using the userdel command with the –remove option.
|
||||
|
||||
# userdel --remove [username]
|
||||
|
||||
#### Group Management ####
|
||||
|
||||
Every time a new user account is added to the system, a group with the same name is created with the username as its only member. Other users can be added to the group later. One of the purposes of groups is to implement a simple access control to files and other system resources by setting the right permissions on those resources.
|
||||
|
||||
For example, suppose you have the following users.
|
||||
|
||||
- user1 (primary group: user1)
|
||||
- user2 (primary group: user2)
|
||||
- user3 (primary group: user3)
|
||||
|
||||
All of them need read and write access to a file called common.txt located somewhere on your local system, or maybe on a network share that user1 has created. You may be tempted to do something like,
|
||||
|
||||
# chmod 660 common.txt
|
||||
OR
|
||||
# chmod u=rw,g=rw,o= common.txt [notice the space between the last equal sign and the file name]
|
||||
|
||||
However, this will only provide read and write access to the owner of the file and to those users who are members of the group owner of the file (user1 in this case). Again, you may be tempted to add user2 and user3 to group user1, but that will also give them access to the rest of the files owned by user user1 and group user1.
|
||||
|
||||
This is where groups come in handy, and here’s what you should do in a case like this.
|
||||
|
||||
**Understanding Setuid**
|
||||
|
||||
When the setuid permission is applied to an executable file, an user running the program inherits the effective privileges of the program’s owner. Since this approach can reasonably raise security concerns, the number of files with setuid permission must be kept to a minimum. You will likely find programs with this permission set when a system user needs to access a file owned by root.
|
||||
|
||||
Summing up, it isn’t just that the user can execute the binary file, but also that he can do so with root’s privileges. For example, let’s check the permissions of /bin/passwd. This binary is used to change the password of an account, and modifies the /etc/shadow file. The superuser can change anyone’s password, but all other users should only be able to change their own.
|
||||
|
||||

|
||||
|
||||
passwd Command Examples
|
||||
|
||||
Thus, any user should have permission to run /bin/passwd, but only root will be able to specify an account. Other users can only change their corresponding passwords.
|
||||
|
||||
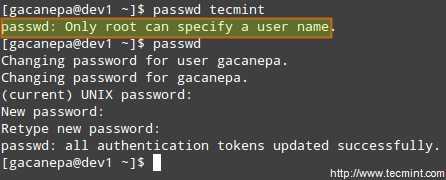
|
||||
|
||||
Change User Password
|
||||
|
||||
**Understanding Setgid**
|
||||
|
||||
When the setgid bit is set, the effective GID of the real user becomes that of the group owner. Thus, any user can access a file under the privileges granted to the group owner of such file. In addition, when the setgid bit is set on a directory, newly created files inherit the same group as the directory, and newly created subdirectories will also inherit the setgid bit of the parent directory. You will most likely use this approach whenever members of a certain group need access to all the files in a directory, regardless of the file owner’s primary group.
|
||||
|
||||
# chmod g+s [filename]
|
||||
|
||||
To set the setgid in octal form, prepend the number 2 to the current (or desired) basic permissions.
|
||||
|
||||
# chmod 2755 [directory]
|
||||
|
||||
**Setting the SETGID in a directory**
|
||||
|
||||

|
||||
|
||||
Add Setgid to Directory
|
||||
|
||||
**Understanding Sticky Bit**
|
||||
|
||||
When the “sticky bit” is set on files, Linux just ignores it, whereas for directories it has the effect of preventing users from deleting or even renaming the files it contains unless the user owns the directory, the file, or is root.
|
||||
|
||||
# chmod o+t [directory]
|
||||
|
||||
To set the sticky bit in octal form, prepend the number 1 to the current (or desired) basic permissions.
|
||||
|
||||
# chmod 1755 [directory]
|
||||
|
||||
Without the sticky bit, anyone able to write to the directory can delete or rename files. For that reason, the sticky bit is commonly found on directories, such as /tmp, that are world-writable.
|
||||
|
||||
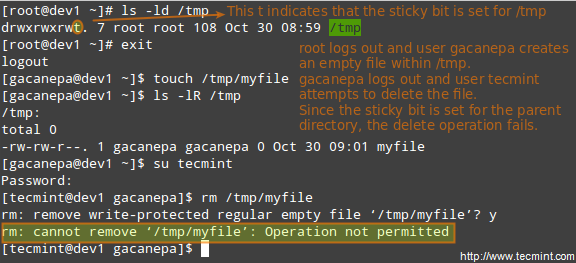
|
||||
|
||||
Add Stickybit to Directory
|
||||
|
||||
### Special Linux File Attributes ###
|
||||
|
||||
There are other attributes that enable further limits on the operations that are allowed on files. For example, prevent the file from being renamed, moved, deleted, or even modified. They are set with the [chattr command][4] and can be viewed using the lsattr tool, as follows.
|
||||
|
||||
# chattr +i file1
|
||||
# chattr +a file2
|
||||
|
||||
After executing those two commands, file1 will be immutable (which means it cannot be moved, renamed, modified or deleted) whereas file2 will enter append-only mode (can only be open in append mode for writing).
|
||||
|
||||
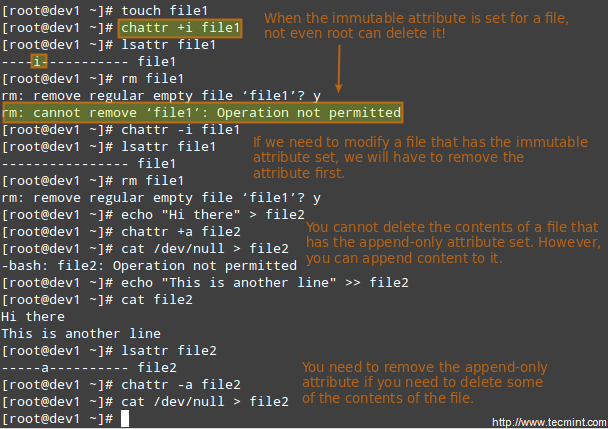
|
||||
|
||||
Chattr Command to Protect Files
|
||||
|
||||
### Accessing the root Account and Using sudo ###
|
||||
|
||||
One of the ways users can gain access to the root account is by typing.
|
||||
|
||||
$ su
|
||||
|
||||
and then entering root’s password.
|
||||
|
||||
If authentication succeeds, you will be logged on as root with the current working directory as the same as you were before. If you want to be placed in root’s home directory instead, run.
|
||||
|
||||
$ su -
|
||||
|
||||
and then enter root’s password.
|
||||
|
||||
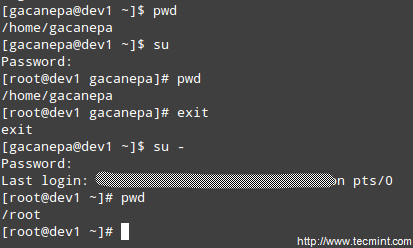
|
||||
|
||||
Enable Sudo Access on Users
|
||||
|
||||
The above procedure requires that a normal user knows root’s password, which poses a serious security risk. For that reason, the sysadmin can configure the sudo command to allow an ordinary user to execute commands as a different user (usually the superuser) in a very controlled and limited way. Thus, restrictions can be set on a user so as to enable him to run one or more specific privileged commands and no others.
|
||||
|
||||
- Read Also: [Difference Between su and sudo User][5]
|
||||
|
||||
To authenticate using sudo, the user uses his/her own password. After entering the command, we will be prompted for our password (not the superuser’s) and if the authentication succeeds (and if the user has been granted privileges to run the command), the specified command is carried out.
|
||||
|
||||
To grant access to sudo, the system administrator must edit the /etc/sudoers file. It is recommended that this file is edited using the visudo command instead of opening it directly with a text editor.
|
||||
|
||||
# visudo
|
||||
|
||||
This opens the /etc/sudoers file using vim (you can follow the instructions given in [Install and Use vim as Editor – Part 2][6] of this series to edit the file).
|
||||
|
||||
These are the most relevant lines.
|
||||
|
||||
Defaults secure_path="/usr/sbin:/usr/bin:/sbin"
|
||||
root ALL=(ALL) ALL
|
||||
tecmint ALL=/bin/yum update
|
||||
gacanepa ALL=NOPASSWD:/bin/updatedb
|
||||
%admin ALL=(ALL) ALL
|
||||
|
||||
Let’s take a closer look at them.
|
||||
|
||||
Defaults secure_path="/usr/sbin:/usr/bin:/sbin:/usr/local/bin"
|
||||
|
||||
This line lets you specify the directories that will be used for sudo, and is used to prevent using user-specific directories, which can harm the system.
|
||||
|
||||
The next lines are used to specify permissions.
|
||||
|
||||
root ALL=(ALL) ALL
|
||||
|
||||
- The first ALL keyword indicates that this rule applies to all hosts.
|
||||
- The second ALL indicates that the user in the first column can run commands with the privileges of any user.
|
||||
- The third ALL means any command can be run.
|
||||
|
||||
tecmint ALL=/bin/yum update
|
||||
|
||||
If no user is specified after the = sign, sudo assumes the root user. In this case, user tecmint will be able to run yum update as root.
|
||||
|
||||
gacanepa ALL=NOPASSWD:/bin/updatedb
|
||||
|
||||
The NOPASSWD directive allows user gacanepa to run /bin/updatedb without needing to enter his password.
|
||||
|
||||
%admin ALL=(ALL) ALL
|
||||
|
||||
The % sign indicates that this line applies to a group called “admin”. The meaning of the rest of the line is identical to that of an regular user. This means that members of the group “admin” can run all commands as any user on all hosts.
|
||||
|
||||
To see what privileges are granted to you by sudo, use the “-l” option to list them.
|
||||
|
||||

|
||||
|
||||
Sudo Access Rules
|
||||
|
||||
### Summary ###
|
||||
|
||||
Effective user and file management skills are essential tools for any system administrator. In this article we have covered the basics and hope you can use it as a good starting to point to build upon. Feel free to leave your comments or questions below, and we’ll respond quickly.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/manage-users-and-groups-in-linux/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/add-users-in-linux/
|
||||
[2]:http://www.tecmint.com/usermod-command-examples/
|
||||
[3]:http://www.tecmint.com/compress-files-and-finding-files-in-linux/
|
||||
[4]:http://www.tecmint.com/chattr-command-examples/
|
||||
[5]:http://www.tecmint.com/su-vs-sudo-and-how-to-configure-sudo-in-linux/
|
||||
[6]:http://www.tecmint.com/vi-editor-usage/
|
||||
@ -0,0 +1,229 @@
|
||||
Part 9 - LFCS: Linux Package Management with Yum, RPM, Apt, Dpkg, Aptitude and Zypper
|
||||
================================================================================
|
||||
Last August, the Linux Foundation announced the LFCS certification (Linux Foundation Certified Sysadmin), a shiny chance for system administrators everywhere to demonstrate, through a performance-based exam, that they are capable of succeeding at overall operational support for Linux systems. A Linux Foundation Certified Sysadmin has the expertise to ensure effective system support, first-level troubleshooting and monitoring, including finally issue escalation, when needed, to engineering support teams.
|
||||
|
||||

|
||||
|
||||
Linux Foundation Certified Sysadmin – Part 9
|
||||
|
||||
Watch the following video that explains about the Linux Foundation Certification Program.
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="720" height="405" frameborder="0" allowfullscreen="allowfullscreen" src="//www.youtube.com/embed/Y29qZ71Kicg"></iframe>
|
||||
|
||||
This article is a Part 9 of 10-tutorial long series, today in this article we will guide you about Linux Package Management, that are required for the LFCS certification exam.
|
||||
|
||||
### Package Management ###
|
||||
|
||||
In few words, package management is a method of installing and maintaining (which includes updating and probably removing as well) software on the system.
|
||||
|
||||
In the early days of Linux, programs were only distributed as source code, along with the required man pages, the necessary configuration files, and more. Nowadays, most Linux distributors use by default pre-built programs or sets of programs called packages, which are presented to users ready for installation on that distribution. However, one of the wonders of Linux is still the possibility to obtain source code of a program to be studied, improved, and compiled.
|
||||
|
||||
**How package management systems work**
|
||||
|
||||
If a certain package requires a certain resource such as a shared library, or another package, it is said to have a dependency. All modern package management systems provide some method of dependency resolution to ensure that when a package is installed, all of its dependencies are installed as well.
|
||||
|
||||
**Packaging Systems**
|
||||
|
||||
Almost all the software that is installed on a modern Linux system will be found on the Internet. It can either be provided by the distribution vendor through central repositories (which can contain several thousands of packages, each of which has been specifically built, tested, and maintained for the distribution) or be available in source code that can be downloaded and installed manually.
|
||||
|
||||
Because different distribution families use different packaging systems (Debian: *.deb / CentOS: *.rpm / openSUSE: *.rpm built specially for openSUSE), a package intended for one distribution will not be compatible with another distribution. However, most distributions are likely to fall into one of the three distribution families covered by the LFCS certification.
|
||||
|
||||
**High and low-level package tools**
|
||||
|
||||
In order to perform the task of package management effectively, you need to be aware that you will have two types of available utilities: low-level tools (which handle in the backend the actual installation, upgrade, and removal of package files), and high-level tools (which are in charge of ensuring that the tasks of dependency resolution and metadata searching -”data about the data”- are performed).
|
||||
|
||||
注:表格
|
||||
|
||||
<table cellspacing="0" border="0">
|
||||
<colgroup width="200">
|
||||
</colgroup>
|
||||
<colgroup width="200">
|
||||
</colgroup>
|
||||
<colgroup width="200">
|
||||
</colgroup>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td bgcolor="#AEA79F" align="CENTER" height="18" style="border: 1px solid #000001;"><b><span style="color: black;">DISTRIBUTION</span></b></td>
|
||||
<td bgcolor="#AEA79F" align="CENTER" style="border: 1px solid #000001;"><b><span style="color: black;">LOW-LEVEL TOOL</span></b></td>
|
||||
<td bgcolor="#AEA79F" align="CENTER" style="border: 1px solid #000001;"><b><span style="color: black;">HIGH-LEVEL TOOL</span></b></td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td bgcolor="#FFFFFF" align="LEFT" height="18" style="border: 1px solid #000001;"><span style="color: black;"> Debian and derivatives</span></td>
|
||||
<td bgcolor="#FFFFFF" align="LEFT" style="border: 1px solid #000001;"><span style="color: black;"> dpkg</span></td>
|
||||
<td bgcolor="#FFFFFF" align="LEFT" style="border: 1px solid #000001;"><span style="color: black;"> apt-get / aptitude</span></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td bgcolor="#FFFFFF" align="LEFT" height="18" style="border: 1px solid #000001;"><span style="color: black;"> CentOS</span></td>
|
||||
<td bgcolor="#FFFFFF" align="LEFT" style="border: 1px solid #000001;"><span style="color: black;"> rpm</span></td>
|
||||
<td bgcolor="#FFFFFF" align="LEFT" style="border: 1px solid #000001;"><span style="color: black;"> yum</span></td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td bgcolor="#FFFFFF" align="LEFT" height="18" style="border: 1px solid #000001;"><span style="color: black;"> openSUSE</span></td>
|
||||
<td bgcolor="#FFFFFF" align="LEFT" style="border: 1px solid #000001;"><span style="color: black;"> rpm</span></td>
|
||||
<td bgcolor="#FFFFFF" align="LEFT" style="border: 1px solid #000001;"><span style="color: black;"> zypper</span></td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
Let us see the descrption of the low-level and high-level tools.
|
||||
|
||||
dpkg is a low-level package manager for Debian-based systems. It can install, remove, provide information about and build *.deb packages but it can’t automatically download and install their corresponding dependencies.
|
||||
|
||||
- Read More: [15 dpkg Command Examples][1]
|
||||
|
||||
apt-get is a high-level package manager for Debian and derivatives, and provides a simple way to retrieve and install packages, including dependency resolution, from multiple sources using the command line. Unlike dpkg, apt-get does not work directly with *.deb files, but with the package proper name.
|
||||
|
||||
- Read More: [25 apt-get Command Examples][2]
|
||||
|
||||
aptitude is another high-level package manager for Debian-based systems, and can be used to perform management tasks (installing, upgrading, and removing packages, also handling dependency resolution automatically) in a fast and easy way. It provides the same functionality as apt-get and additional ones, such as offering access to several versions of a package.
|
||||
|
||||
rpm is the package management system used by Linux Standard Base (LSB)-compliant distributions for low-level handling of packages. Just like dpkg, it can query, install, verify, upgrade, and remove packages, and is more frequently used by Fedora-based distributions, such as RHEL and CentOS.
|
||||
|
||||
- Read More: [20 rpm Command Examples][3]
|
||||
|
||||
yum adds the functionality of automatic updates and package management with dependency management to RPM-based systems. As a high-level tool, like apt-get or aptitude, yum works with repositories.
|
||||
|
||||
- Read More: [20 yum Command Examples][4]
|
||||
-
|
||||
### Common Usage of Low-Level Tools ###
|
||||
|
||||
The most frequent tasks that you will do with low level tools are as follows:
|
||||
|
||||
**1. Installing a package from a compiled (*.deb or *.rpm) file**
|
||||
|
||||
The downside of this installation method is that no dependency resolution is provided. You will most likely choose to install a package from a compiled file when such package is not available in the distribution’s repositories and therefore cannot be downloaded and installed through a high-level tool. Since low-level tools do not perform dependency resolution, they will exit with an error if we try to install a package with unmet dependencies.
|
||||
|
||||
# dpkg -i file.deb [Debian and derivative]
|
||||
# rpm -i file.rpm [CentOS / openSUSE]
|
||||
|
||||
**Note**: Do not attempt to install on CentOS a *.rpm file that was built for openSUSE, or vice-versa!
|
||||
|
||||
**2. Upgrading a package from a compiled file**
|
||||
|
||||
Again, you will only upgrade an installed package manually when it is not available in the central repositories.
|
||||
|
||||
# dpkg -i file.deb [Debian and derivative]
|
||||
# rpm -U file.rpm [CentOS / openSUSE]
|
||||
|
||||
**3. Listing installed packages**
|
||||
|
||||
When you first get your hands on an already working system, chances are you’ll want to know what packages are installed.
|
||||
|
||||
# dpkg -l [Debian and derivative]
|
||||
# rpm -qa [CentOS / openSUSE]
|
||||
|
||||
If you want to know whether a specific package is installed, you can pipe the output of the above commands to grep, as explained in [manipulate files in Linux – Part 1][6] of this series. Suppose we need to verify if package mysql-common is installed on an Ubuntu system.
|
||||
|
||||
# dpkg -l | grep mysql-common
|
||||
|
||||

|
||||
|
||||
Check Installed Packages
|
||||
|
||||
Another way to determine if a package is installed.
|
||||
|
||||
# dpkg --status package_name [Debian and derivative]
|
||||
# rpm -q package_name [CentOS / openSUSE]
|
||||
|
||||
For example, let’s find out whether package sysdig is installed on our system.
|
||||
|
||||
# rpm -qa | grep sysdig
|
||||
|
||||
|
||||
|
||||
Check sysdig Package
|
||||
|
||||
**4. Finding out which package installed a file**
|
||||
|
||||
# dpkg --search file_name
|
||||
# rpm -qf file_name
|
||||
|
||||
For example, which package installed pw_dict.hwm?
|
||||
|
||||
# rpm -qf /usr/share/cracklib/pw_dict.hwm
|
||||
|
||||

|
||||
|
||||
Query File in Linux
|
||||
|
||||
### Common Usage of High-Level Tools ###
|
||||
|
||||
The most frequent tasks that you will do with high level tools are as follows.
|
||||
|
||||
**1. Searching for a package**
|
||||
|
||||
aptitude update will update the list of available packages, and aptitude search will perform the actual search for package_name.
|
||||
|
||||
# aptitude update && aptitude search package_name
|
||||
|
||||
In the search all option, yum will search for package_name not only in package names, but also in package descriptions.
|
||||
|
||||
# yum search package_name
|
||||
# yum search all package_name
|
||||
# yum whatprovides “*/package_name”
|
||||
|
||||
Let’s supposed we need a file whose name is sysdig. To know that package we will have to install, let’s run.
|
||||
|
||||
# yum whatprovides “*/sysdig”
|
||||
|
||||

|
||||
|
||||
Check Package Description
|
||||
|
||||
whatprovides tells yum to search the package the will provide a file that matches the above regular expression.
|
||||
|
||||
# zypper refresh && zypper search package_name [On openSUSE]
|
||||
|
||||
**2. Installing a package from a repository**
|
||||
|
||||
While installing a package, you may be prompted to confirm the installation after the package manager has resolved all dependencies. Note that running update or refresh (according to the package manager being used) is not strictly necessary, but keeping installed packages up to date is a good sysadmin practice for security and dependency reasons.
|
||||
|
||||
# aptitude update && aptitude install package_name [Debian and derivatives]
|
||||
# yum update && yum install package_name [CentOS]
|
||||
# zypper refresh && zypper install package_name [openSUSE]
|
||||
|
||||
**3. Removing a package**
|
||||
|
||||
The option remove will uninstall the package but leaving configuration files intact, whereas purge will erase every trace of the program from your system.
|
||||
# aptitude remove / purge package_name
|
||||
# yum erase package_name
|
||||
|
||||
---Notice the minus sign in front of the package that will be uninstalled, openSUSE ---
|
||||
|
||||
# zypper remove -package_name
|
||||
|
||||
Most (if not all) package managers will prompt you, by default, if you’re sure about proceeding with the uninstallation before actually performing it. So read the onscreen messages carefully to avoid running into unnecessary trouble!
|
||||
|
||||
**4. Displaying information about a package**
|
||||
|
||||
The following command will display information about the birthday package.
|
||||
|
||||
# aptitude show birthday
|
||||
# yum info birthday
|
||||
# zypper info birthday
|
||||
|
||||

|
||||
|
||||
Check Package Information
|
||||
|
||||
### Summary ###
|
||||
|
||||
Package management is something you just can’t sweep under the rug as a system administrator. You should be prepared to use the tools described in this article at a moment’s notice. Hope you find it useful in your preparation for the LFCS exam and for your daily tasks. Feel free to leave your comments or questions below. We will be more than glad to get back to you as soon as possible.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-package-management/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/dpkg-command-examples/
|
||||
[2]:http://www.tecmint.com/useful-basic-commands-of-apt-get-and-apt-cache-for-package-management/
|
||||
[3]:http://www.tecmint.com/20-practical-examples-of-rpm-commands-in-linux/
|
||||
[4]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
|
||||
[5]:http://www.tecmint.com/sed-command-to-create-edit-and-manipulate-files-in-linux/
|
||||
@ -1,213 +0,0 @@
|
||||
struggling 翻译中
|
||||
Setting up RAID 1 (Mirroring) using ‘Two Disks’ in Linux – Part 3
|
||||
================================================================================
|
||||
RAID Mirroring means an exact clone (or mirror) of the same data writing to two drives. A minimum two number of disks are more required in an array to create RAID1 and it’s useful only, when read performance or reliability is more precise than the data storage capacity.
|
||||
|
||||
|
||||
|
||||
Setup Raid1 in Linux
|
||||
|
||||
Mirrors are created to protect against data loss due to disk failure. Each disk in a mirror involves an exact copy of the data. When one disk fails, the same data can be retrieved from other functioning disk. However, the failed drive can be replaced from the running computer without any user interruption.
|
||||
|
||||
### Features of RAID 1 ###
|
||||
|
||||
- Mirror has Good Performance.
|
||||
- 50% of space will be lost. Means if we have two disk with 500GB size total, it will be 1TB but in Mirroring it will only show us 500GB.
|
||||
- No data loss in Mirroring if one disk fails, because we have the same content in both disks.
|
||||
- Reading will be good than writing data to drive.
|
||||
|
||||
#### Requirements ####
|
||||
|
||||
Minimum Two number of disks are allowed to create RAID 1, but you can add more disks by using twice as 2, 4, 6, 8. To add more disks, your system must have a RAID physical adapter (hardware card).
|
||||
|
||||
Here we’re using software raid not a Hardware raid, if your system has an inbuilt physical hardware raid card you can access it from it’s utility UI or using Ctrl+I key.
|
||||
|
||||
Read Also: [Basic Concepts of RAID in Linux][1]
|
||||
|
||||
#### My Server Setup ####
|
||||
|
||||
Operating System : CentOS 6.5 Final
|
||||
IP Address : 192.168.0.226
|
||||
Hostname : rd1.tecmintlocal.com
|
||||
Disk 1 [20GB] : /dev/sdb
|
||||
Disk 2 [20GB] : /dev/sdc
|
||||
|
||||
This article will guide you through a step-by-step instructions on how to setup a software RAID 1 or Mirror using mdadm (creates and manages raid) on Linux Platform. Although the same instructions also works on other Linux distributions such as RedHat, CentOS, Fedora, etc.
|
||||
|
||||
### Step 1: Installing Prerequisites and Examine Drives ###
|
||||
|
||||
1. As I said above, we’re using mdadm utility for creating and managing RAID in Linux. So, let’s install the mdadm software package on Linux using yum or apt-get package manager tool.
|
||||
|
||||
# yum install mdadm [on RedHat systems]
|
||||
# apt-get install mdadm [on Debain systems]
|
||||
|
||||
2. Once ‘mdadm‘ package has been installed, we need to examine our disk drives whether there is already any raid configured using the following command.
|
||||
|
||||
# mdadm -E /dev/sd[b-c]
|
||||
|
||||
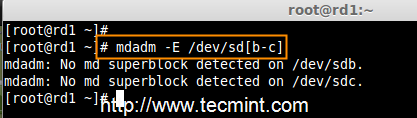
|
||||
|
||||
Check RAID on Disks
|
||||
|
||||
As you see from the above screen, that there is no any super-block detected yet, means no RAID defined.
|
||||
|
||||
### Step 2: Drive Partitioning for RAID ###
|
||||
|
||||
3. As I mentioned above, that we’re using minimum two partitions /dev/sdb and /dev/sdc for creating RAID1. Let’s create partitions on these two drives using ‘fdisk‘ command and change the type to raid during partition creation.
|
||||
|
||||
# fdisk /dev/sdb
|
||||
|
||||
Follow the below instructions
|
||||
|
||||
- Press ‘n‘ for creating new partition.
|
||||
- Then choose ‘P‘ for Primary partition.
|
||||
- Next select the partition number as 1.
|
||||
- Give the default full size by just pressing two times Enter key.
|
||||
- Next press ‘p‘ to print the defined partition.
|
||||
- Press ‘L‘ to list all available types.
|
||||
- Type ‘t‘to choose the partitions.
|
||||
- Choose ‘fd‘ for Linux raid auto and press Enter to apply.
|
||||
- Then again use ‘p‘ to print the changes what we have made.
|
||||
- Use ‘w‘ to write the changes.
|
||||
|
||||

|
||||
|
||||
Create Disk Partitions
|
||||
|
||||
After ‘/dev/sdb‘ partition has been created, next follow the same instructions to create new partition on /dev/sdc drive.
|
||||
|
||||
# fdisk /dev/sdc
|
||||
|
||||

|
||||
|
||||
Create Second Partitions
|
||||
|
||||
4. Once both the partitions are created successfully, verify the changes on both sdb & sdc drive using the same ‘mdadm‘ command and also confirm the RAID type as shown in the following screen grabs.
|
||||
|
||||
# mdadm -E /dev/sd[b-c]
|
||||
|
||||
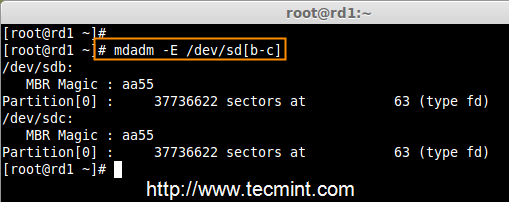
|
||||
|
||||
Verify Partitions Changes
|
||||
|
||||
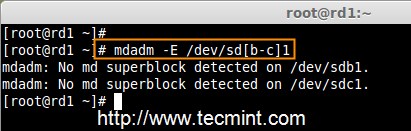
|
||||
|
||||
Check RAID Type
|
||||
|
||||
**Note**: As you see in the above picture, there is no any defined RAID on the sdb1 and sdc1 drives so far, that’s the reason we are getting as no super-blocks detected.
|
||||
|
||||
### Step 3: Creating RAID1 Devices ###
|
||||
|
||||
5. Next create RAID1 Device called ‘/dev/md0‘ using the following command and verity it.
|
||||
|
||||
# mdadm --create /dev/md0 --level=mirror --raid-devices=2 /dev/sd[b-c]1
|
||||
# cat /proc/mdstat
|
||||
|
||||

|
||||
|
||||
Create RAID Device
|
||||
|
||||
6. Next check the raid devices type and raid array using following commands.
|
||||
|
||||
# mdadm -E /dev/sd[b-c]1
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
Check RAID Device type
|
||||
|
||||

|
||||
|
||||
Check RAID Device Array
|
||||
|
||||
From the above pictures, one can easily understand that raid1 have been created and using /dev/sdb1 and /dev/sdc1 partitions and also you can see the status as resyncing.
|
||||
|
||||
### Step 4: Creating File System on RAID Device ###
|
||||
|
||||
7. Create file system using ext4 for md0 and mount under /mnt/raid1.
|
||||
|
||||
# mkfs.ext4 /dev/md0
|
||||
|
||||

|
||||
|
||||
Create RAID Device Filesystem
|
||||
|
||||
8. Next, mount the newly created filesystem under ‘/mnt/raid1‘ and create some files and verify the contents under mount point.
|
||||
|
||||
# mkdir /mnt/raid1
|
||||
# mount /dev/md0 /mnt/raid1/
|
||||
# touch /mnt/raid1/tecmint.txt
|
||||
# echo "tecmint raid setups" > /mnt/raid1/tecmint.txt
|
||||
|
||||

|
||||
|
||||
Mount Raid Device
|
||||
|
||||
9. To auto-mount RAID1 on system reboot, you need to make an entry in fstab file. Open ‘/etc/fstab‘ file and add the following line at the bottom of the file.
|
||||
|
||||
/dev/md0 /mnt/raid1 ext4 defaults 0 0
|
||||
|
||||

|
||||
|
||||
Raid Automount Device
|
||||
|
||||
10. Run ‘mount -a‘ to check whether there are any errors in fstab entry.
|
||||
|
||||
# mount -av
|
||||
|
||||
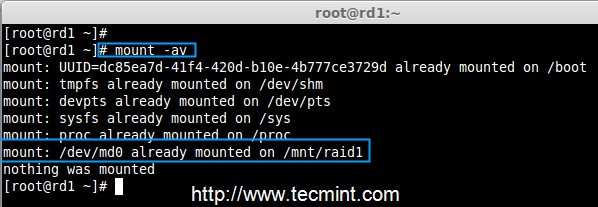
|
||||
|
||||
Check Errors in fstab
|
||||
|
||||
11. Next, save the raid configuration manually to ‘mdadm.conf‘ file using the below command.
|
||||
|
||||
# mdadm --detail --scan --verbose >> /etc/mdadm.conf
|
||||
|
||||

|
||||
|
||||
Save Raid Configuration
|
||||
|
||||
The above configuration file is read by the system at the reboots and load the RAID devices.
|
||||
|
||||
### Step 5: Verify Data After Disk Failure ###
|
||||
|
||||
12. Our main purpose is, even after any of hard disk fail or crash our data needs to be available. Let’s see what will happen when any of disk disk is unavailable in array.
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
Raid Device Verify
|
||||
|
||||
In the above image, we can see there are 2 devices available in our RAID and Active Devices are 2. Now let us see what will happen when a disk plugged out (removed sdc disk) or fails.
|
||||
|
||||
# ls -l /dev | grep sd
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
Test RAID Devices
|
||||
|
||||
Now in the above image, you can see that one of our drive is lost. I unplugged one of the drive from my Virtual machine. Now let us check our precious data.
|
||||
|
||||
# cd /mnt/raid1/
|
||||
# cat tecmint.txt
|
||||
|
||||
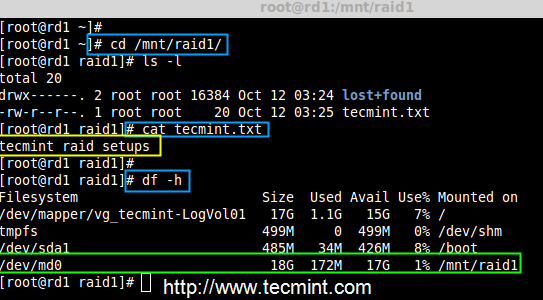
|
||||
|
||||
Verify RAID Data
|
||||
|
||||
Did you see our data is still available. From this we come to know the advantage of RAID 1 (mirror). In next article, we will see how to setup a RAID 5 striping with distributed Parity. Hope this helps you to understand how the RAID 1 (Mirror) Works.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/create-raid1-in-linux/
|
||||
|
||||
作者:[Babin Lonston][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/babinlonston/
|
||||
[1]:http://www.tecmint.com/understanding-raid-setup-in-linux/
|
||||
@ -1,286 +0,0 @@
|
||||
struggling 翻译中
|
||||
Creating RAID 5 (Striping with Distributed Parity) in Linux – Part 4
|
||||
================================================================================
|
||||
In RAID 5, data strips across multiple drives with distributed parity. The striping with distributed parity means it will split the parity information and stripe data over the multiple disks, which will have good data redundancy.
|
||||
|
||||

|
||||
|
||||
Setup Raid 5 in Linux
|
||||
|
||||
For RAID Level it should have at least three hard drives or more. RAID 5 are being used in the large scale production environment where it’s cost effective and provide performance as well as redundancy.
|
||||
|
||||
#### What is Parity? ####
|
||||
|
||||
Parity is a simplest common method of detecting errors in data storage. Parity stores information in each disks, Let’s say we have 4 disks, in 4 disks one disk space will be split to all disks to store the parity information’s. If any one of the disks fails still we can get the data by rebuilding from parity information after replacing the failed disk.
|
||||
|
||||
#### Pros and Cons of RAID 5 ####
|
||||
|
||||
- Gives better performance
|
||||
- Support Redundancy and Fault tolerance.
|
||||
- Support hot spare options.
|
||||
- Will loose a single disk capacity for using parity information.
|
||||
- No data loss if a single disk fails. We can rebuilt from parity after replacing the failed disk.
|
||||
- Suits for transaction oriented environment as the reading will be faster.
|
||||
- Due to parity overhead, writing will be slow.
|
||||
- Rebuild takes long time.
|
||||
|
||||
#### Requirements ####
|
||||
|
||||
Minimum 3 hard drives are required to create Raid 5, but you can add more disks, only if you’ve a dedicated hardware raid controller with multi ports. Here, we are using software RAID and ‘mdadm‘ package to create raid.
|
||||
|
||||
mdadm is a package which allow us to configure and manage RAID devices in Linux. By default there is no configuration file is available for RAID, we must save the configuration file after creating and configuring RAID setup in separate file called mdadm.conf.
|
||||
|
||||
Before moving further, I suggest you to go through the following articles for understanding the basics of RAID in Linux.
|
||||
|
||||
- [Basic Concepts of RAID in Linux – Part 1][1]
|
||||
- [Creating RAID 0 (Stripe) in Linux – Part 2][2]
|
||||
- [Setting up RAID 1 (Mirroring) in Linux – Part 3][3]
|
||||
|
||||
#### My Server Setup ####
|
||||
|
||||
Operating System : CentOS 6.5 Final
|
||||
IP Address : 192.168.0.227
|
||||
Hostname : rd5.tecmintlocal.com
|
||||
Disk 1 [20GB] : /dev/sdb
|
||||
Disk 2 [20GB] : /dev/sdc
|
||||
Disk 3 [20GB] : /dev/sdd
|
||||
|
||||
This article is a Part 4 of a 9-tutorial RAID series, here we are going to setup a software RAID 5 with distributed parity in Linux systems or servers using three 20GB disks named /dev/sdb, /dev/sdc and /dev/sdd.
|
||||
|
||||
### Step 1: Installing mdadm and Verify Drives ###
|
||||
|
||||
1. As we said earlier, that we’re using CentOS 6.5 Final release for this raid setup, but same steps can be followed for RAID setup in any Linux based distributions.
|
||||
|
||||
# lsb_release -a
|
||||
# ifconfig | grep inet
|
||||
|
||||

|
||||
|
||||
CentOS 6.5 Summary
|
||||
|
||||
2. If you’re following our raid series, we assume that you’ve already installed ‘mdadm‘ package, if not, use the following command according to your Linux distribution to install the package.
|
||||
|
||||
# yum install mdadm [on RedHat systems]
|
||||
# apt-get install mdadm [on Debain systems]
|
||||
|
||||
3. After the ‘mdadm‘ package installation, let’s list the three 20GB disks which we have added in our system using ‘fdisk‘ command.
|
||||
|
||||
# fdisk -l | grep sd
|
||||
|
||||
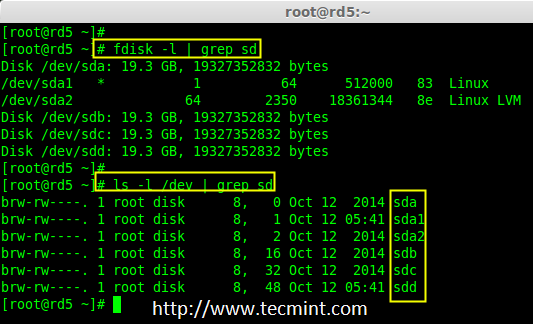
|
||||
|
||||
Install mdadm Tool
|
||||
|
||||
4. Now it’s time to examine the attached three drives for any existing RAID blocks on these drives using following command.
|
||||
|
||||
# mdadm -E /dev/sd[b-d]
|
||||
# mdadm --examine /dev/sdb /dev/sdc /dev/sdd
|
||||
|
||||
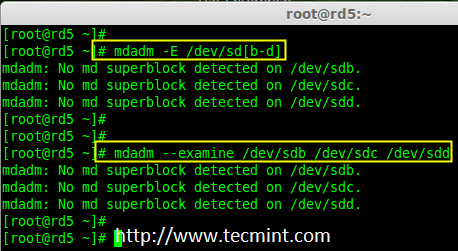
|
||||
|
||||
Examine Drives For Raid
|
||||
|
||||
**Note**: From the above image illustrated that there is no any super-block detected yet. So, there is no RAID defined in all three drives. Let us start to create one now.
|
||||
|
||||
### Step 2: Partitioning the Disks for RAID ###
|
||||
|
||||
5. First and foremost, we have to partition the disks (/dev/sdb, /dev/sdc and /dev/sdd) before adding to a RAID, So let us define the partition using ‘fdisk’ command, before forwarding to the next steps.
|
||||
|
||||
# fdisk /dev/sdb
|
||||
# fdisk /dev/sdc
|
||||
# fdisk /dev/sdd
|
||||
|
||||
#### Create /dev/sdb Partition ####
|
||||
|
||||
Please follow the below instructions to create partition on /dev/sdb drive.
|
||||
|
||||
- Press ‘n‘ for creating new partition.
|
||||
- Then choose ‘P‘ for Primary partition. Here we are choosing Primary because there is no partitions defined yet.
|
||||
- Then choose ‘1‘ to be the first partition. By default it will be 1.
|
||||
- Here for cylinder size we don’t have to choose the specified size because we need the whole partition for RAID so just Press Enter two times to choose the default full size.
|
||||
- Next press ‘p‘ to print the created partition.
|
||||
- Change the Type, If we need to know the every available types Press ‘L‘.
|
||||
- Here, we are selecting ‘fd‘ as my type is RAID.
|
||||
- Next press ‘p‘ to print the defined partition.
|
||||
- Then again use ‘p‘ to print the changes what we have made.
|
||||
- Use ‘w‘ to write the changes.
|
||||
|
||||

|
||||
|
||||
Create sdb Partition
|
||||
|
||||
**Note**: We have to follow the steps mentioned above to create partitions for sdc & sdd drives too.
|
||||
|
||||
#### Create /dev/sdc Partition ####
|
||||
|
||||
Now partition the sdc and sdd drives by following the steps given in the screenshot or you can follow above steps.
|
||||
|
||||
# fdisk /dev/sdc
|
||||
|
||||

|
||||
|
||||
Create sdc Partition
|
||||
|
||||
#### Create /dev/sdd Partition ####
|
||||
|
||||
# fdisk /dev/sdd
|
||||
|
||||

|
||||
|
||||
Create sdd Partition
|
||||
|
||||
6. After creating partitions, check for changes in all three drives sdb, sdc, & sdd.
|
||||
|
||||
# mdadm --examine /dev/sdb /dev/sdc /dev/sdd
|
||||
|
||||
or
|
||||
|
||||
# mdadm -E /dev/sd[b-c]
|
||||
|
||||
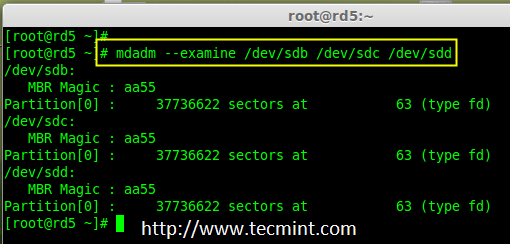
|
||||
|
||||
Check Partition Changes
|
||||
|
||||
**Note**: In the above pic. depict the type is fd i.e. for RAID.
|
||||
|
||||
7. Now Check for the RAID blocks in newly created partitions. If no super-blocks detected, than we can move forward to create a new RAID 5 setup on these drives.
|
||||
|
||||
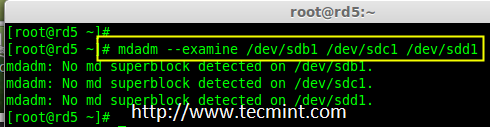
|
||||
|
||||
Check Raid on Partition
|
||||
|
||||
### Step 3: Creating md device md0 ###
|
||||
|
||||
8. Now create a Raid device ‘md0‘ (i.e. /dev/md0) and include raid level on all newly created partitions (sdb1, sdc1 and sdd1) using below command.
|
||||
|
||||
# mdadm --create /dev/md0 --level=5 --raid-devices=3 /dev/sdb1 /dev/sdc1 /dev/sdd1
|
||||
|
||||
or
|
||||
|
||||
# mdadm -C /dev/md0 -l=5 -n=3 /dev/sd[b-d]1
|
||||
|
||||
9. After creating raid device, check and verify the RAID, devices included and RAID Level from the mdstat output.
|
||||
|
||||
# cat /proc/mdstat
|
||||
|
||||

|
||||
|
||||
Verify Raid Device
|
||||
|
||||
If you want to monitor the current building process, you can use ‘watch‘ command, just pass through the ‘cat /proc/mdstat‘ with watch command which will refresh screen every 1 second.
|
||||
|
||||
# watch -n1 cat /proc/mdstat
|
||||
|
||||
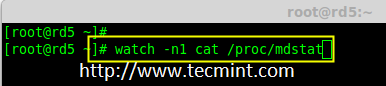
|
||||
|
||||
Monitor Raid 5 Process
|
||||
|
||||

|
||||
|
||||
Raid 5 Process Summary
|
||||
|
||||
10. After creation of raid, Verify the raid devices using the following command.
|
||||
|
||||
# mdadm -E /dev/sd[b-d]1
|
||||
|
||||

|
||||
|
||||
Verify Raid Level
|
||||
|
||||
**Note**: The Output of the above command will be little long as it prints the information of all three drives.
|
||||
|
||||
11. Next, verify the RAID array to assume that the devices which we’ve included in the RAID level are running and started to re-sync.
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
Verify Raid Array
|
||||
|
||||
### Step 4: Creating file system for md0 ###
|
||||
|
||||
12. Create a file system for ‘md0‘ device using ext4 before mounting.
|
||||
|
||||
# mkfs.ext4 /dev/md0
|
||||
|
||||

|
||||
|
||||
Create md0 Filesystem
|
||||
|
||||
13. Now create a directory under ‘/mnt‘ then mount the created filesystem under /mnt/raid5 and check the files under mount point, you will see lost+found directory.
|
||||
|
||||
# mkdir /mnt/raid5
|
||||
# mount /dev/md0 /mnt/raid5/
|
||||
# ls -l /mnt/raid5/
|
||||
|
||||
14. Create few files under mount point /mnt/raid5 and append some text in any one of the file to verify the content.
|
||||
|
||||
# touch /mnt/raid5/raid5_tecmint_{1..5}
|
||||
# ls -l /mnt/raid5/
|
||||
# echo "tecmint raid setups" > /mnt/raid5/raid5_tecmint_1
|
||||
# cat /mnt/raid5/raid5_tecmint_1
|
||||
# cat /proc/mdstat
|
||||
|
||||

|
||||
|
||||
Mount Raid Device
|
||||
|
||||
15. We need to add entry in fstab, else will not display our mount point after system reboot. To add an entry, we should edit the fstab file and append the following line as shown below. The mount point will differ according to your environment.
|
||||
|
||||
# vim /etc/fstab
|
||||
|
||||
/dev/md0 /mnt/raid5 ext4 defaults 0 0
|
||||
|
||||

|
||||
|
||||
Raid 5 Automount
|
||||
|
||||
16. Next, run ‘mount -av‘ command to check whether any errors in fstab entry.
|
||||
|
||||
# mount -av
|
||||
|
||||
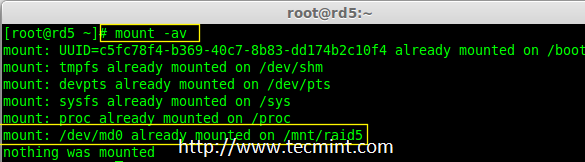
|
||||
|
||||
Check Fstab Errors
|
||||
|
||||
### Step 5: Save Raid 5 Configuration ###
|
||||
|
||||
17. As mentioned earlier in requirement section, by default RAID don’t have a config file. We have to save it manually. If this step is not followed RAID device will not be in md0, it will be in some other random number.
|
||||
|
||||
So, we must have to save the configuration before system reboot. If the configuration is saved it will be loaded to the kernel during the system reboot and RAID will also gets loaded.
|
||||
|
||||
# mdadm --detail --scan --verbose >> /etc/mdadm.conf
|
||||
|
||||

|
||||
|
||||
Save Raid 5 Configuration
|
||||
|
||||
Note: Saving the configuration will keep the RAID level stable in md0 device.
|
||||
|
||||
### Step 6: Adding Spare Drives ###
|
||||
|
||||
18. What the use of adding a spare drive? its very useful if we have a spare drive, if any one of the disk fails in our array, this spare drive will get active and rebuild the process and sync the data from other disk, so we can see a redundancy here.
|
||||
|
||||
For more instructions on how to add spare drive and check Raid 5 fault tolerance, read #Step 6 and #Step 7 in the following article.
|
||||
|
||||
- [Add Spare Drive to Raid 5 Setup][4]
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Here, in this article, we have seen how to setup a RAID 5 using three number of disks. Later in my upcoming articles, we will see how to troubleshoot when a disk fails in RAID 5 and how to replace for recovery.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/create-raid-5-in-linux/
|
||||
|
||||
作者:[Babin Lonston][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/babinlonston/
|
||||
[1]:http://www.tecmint.com/understanding-raid-setup-in-linux/
|
||||
[2]:http://www.tecmint.com/create-raid0-in-linux/
|
||||
[3]:http://www.tecmint.com/create-raid1-in-linux/
|
||||
[4]:http://www.tecmint.com/create-raid-6-in-linux/
|
||||
@ -1,183 +0,0 @@
|
||||
Translating by ictlyh
|
||||
Part 3 - How to Produce and Deliver System Activity Reports Using Linux Toolsets
|
||||
================================================================================
|
||||
As a system engineer, you will often need to produce reports that show the utilization of your system’s resources in order to make sure that: 1) they are being utilized optimally, 2) prevent bottlenecks, and 3) ensure scalability, among other reasons.
|
||||
|
||||

|
||||
|
||||
RHCE: Monitor Linux Performance Activity Reports – Part 3
|
||||
|
||||
Besides the well-known native Linux tools that are used to check disk, memory, and CPU usage – to name a few examples, Red Hat Enterprise Linux 7 provides two additional toolsets to enhance the data you can collect for your reports: sysstat and dstat.
|
||||
|
||||
In this article we will describe both, but let’s first start by reviewing the usage of the classic tools.
|
||||
|
||||
### Native Linux Tools ###
|
||||
|
||||
With df, you will be able to report disk space and inode usage of by filesystem. You need to monitor both because a lack of space will prevent you from being able to save further files (and may even cause the system to crash), just like running out of inodes will mean you can’t link further files with their corresponding data structures, thus producing the same effect: you won’t be able to save those files to disk.
|
||||
|
||||
# df -h [Display output in human-readable form]
|
||||
# df -h --total [Produce a grand total]
|
||||
|
||||
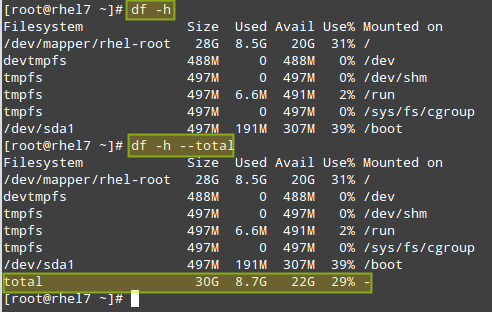
|
||||
|
||||
Check Linux Total Disk Usage
|
||||
|
||||
# df -i [Show inode count by filesystem]
|
||||
# df -i --total [Produce a grand total]
|
||||
|
||||

|
||||
|
||||
Check Linux Total inode Numbers
|
||||
|
||||
With du, you can estimate file space usage by either file, directory, or filesystem.
|
||||
|
||||
For example, let’s see how much space is used by the /home directory, which includes all of the user’s personal files. The first command will return the overall space currently used by the entire /home directory, whereas the second will also display a disaggregated list by sub-directory as well:
|
||||
|
||||
# du -sch /home
|
||||
# du -sch /home/*
|
||||
|
||||

|
||||
|
||||
Check Linux Directory Disk Size
|
||||
|
||||
Don’t Miss:
|
||||
|
||||
- [12 ‘df’ Command Examples to Check Linux Disk Space Usage][1]
|
||||
- [10 ‘du’ Command Examples to Find Disk Usage of Files/Directories][2]
|
||||
|
||||
Another utility that can’t be missing from your toolset is vmstat. It will allow you to see at a quick glance information about processes, CPU and memory usage, disk activity, and more.
|
||||
|
||||
If run without arguments, vmstat will return averages since the last reboot. While you may use this form of the command once in a while, it will be more helpful to take a certain amount of system utilization samples, one after another, with a defined time separation between samples.
|
||||
|
||||
For example,
|
||||
|
||||
# vmstat 5 10
|
||||
|
||||
will return 10 samples taken every 5 seconds:
|
||||
|
||||

|
||||
|
||||
Check Linux System Performance
|
||||
|
||||
As you can see in the above picture, the output of vmstat is divided by columns: procs (processes), memory, swap, io, system, and cpu. The meaning of each field can be found in the FIELD DESCRIPTION sections in the man page of vmstat.
|
||||
|
||||
Where can vmstat come in handy? Let’s examine the behavior of the system before and during a yum update:
|
||||
|
||||
# vmstat -a 1 5
|
||||
|
||||

|
||||
|
||||
Vmstat Linux Performance Monitoring
|
||||
|
||||
Please note that as files are being modified on disk, the amount of active memory increases and so does the number of blocks written to disk (bo) and the CPU time that is dedicated to user processes (us).
|
||||
|
||||
Or during the saving process of a large file directly to disk (caused by dsync):
|
||||
|
||||
# vmstat -a 1 5
|
||||
# dd if=/dev/zero of=dummy.out bs=1M count=1000 oflag=dsync
|
||||
|
||||

|
||||
|
||||
VmStat Linux Disk Performance Monitoring
|
||||
|
||||
In this case, we can see a yet larger number of blocks being written to disk (bo), which was to be expected, but also an increase of the amount of CPU time that it has to wait for I/O operations to complete before processing tasks (wa).
|
||||
|
||||
**Don’t Miss**: [Vmstat – Linux Performance Monitoring][3]
|
||||
|
||||
### Other Linux Tools ###
|
||||
|
||||
As mentioned in the introduction of this chapter, there are other tools that you can use to check the system status and utilization (they are not only provided by Red Hat but also by other major distributions from their officially supported repositories).
|
||||
|
||||
The sysstat package contains the following utilities:
|
||||
|
||||
- sar (collect, report, or save system activity information).
|
||||
- sadf (display data collected by sar in multiple formats).
|
||||
- mpstat (report processors related statistics).
|
||||
- iostat (report CPU statistics and I/O statistics for devices and partitions).
|
||||
- pidstat (report statistics for Linux tasks).
|
||||
- nfsiostat (report input/output statistics for NFS).
|
||||
- cifsiostat (report CIFS statistics) and
|
||||
- sa1 (collect and store binary data in the system activity daily data file.
|
||||
- sa2 (write a daily report in the /var/log/sa directory) tools.
|
||||
|
||||
whereas dstat adds some extra features to the functionality provided by those tools, along with more counters and flexibility. You can find an overall description of each tool by running yum info sysstat or yum info dstat, respectively, or checking the individual man pages after installation.
|
||||
|
||||
To install both packages:
|
||||
|
||||
# yum update && yum install sysstat dstat
|
||||
|
||||
The main configuration file for sysstat is /etc/sysconfig/sysstat. You will find the following parameters in that file:
|
||||
|
||||
# How long to keep log files (in days).
|
||||
# If value is greater than 28, then log files are kept in
|
||||
# multiple directories, one for each month.
|
||||
HISTORY=28
|
||||
# Compress (using gzip or bzip2) sa and sar files older than (in days):
|
||||
COMPRESSAFTER=31
|
||||
# Parameters for the system activity data collector (see sadc manual page)
|
||||
# which are used for the generation of log files.
|
||||
SADC_OPTIONS="-S DISK"
|
||||
# Compression program to use.
|
||||
ZIP="bzip2"
|
||||
|
||||
When sysstat is installed, two cron jobs are added and enabled in /etc/cron.d/sysstat. The first job runs the system activity accounting tool every 10 minutes and stores the reports in /var/log/sa/saXX where XX is the day of the month.
|
||||
|
||||
Thus, /var/log/sa/sa05 will contain all the system activity reports from the 5th of the month. This assumes that we are using the default value in the HISTORY variable in the configuration file above:
|
||||
|
||||
*/10 * * * * root /usr/lib64/sa/sa1 1 1
|
||||
|
||||
The second job generates a daily summary of process accounting at 11:53 pm every day and stores it in /var/log/sa/sarXX files, where XX has the same meaning as in the previous example:
|
||||
|
||||
53 23 * * * root /usr/lib64/sa/sa2 -A
|
||||
|
||||
For example, you may want to output system statistics from 9:30 am through 5:30 pm of the sixth of the month to a .csv file that can easily be viewed using LibreOffice Calc or Microsoft Excel (this approach will also allow you to create charts or graphs):
|
||||
|
||||
# sadf -s 09:30:00 -e 17:30:00 -dh /var/log/sa/sa06 -- | sed 's/;/,/g' > system_stats20150806.csv
|
||||
|
||||
You could alternatively use the -j flag instead of -d in the sadf command above to output the system stats in JSON format, which could be useful if you need to consume the data in a web application, for example.
|
||||
|
||||

|
||||
|
||||
Linux System Statistics
|
||||
|
||||
Finally, let’s see what dstat has to offer. Please note that if run without arguments, dstat assumes -cdngy by default (short for CPU, disk, network, memory pages, and system stats, respectively), and adds one line every second (execution can be interrupted anytime with Ctrl + C):
|
||||
|
||||
# dstat
|
||||
|
||||

|
||||
|
||||
Linux Disk Statistics Monitoring
|
||||
|
||||
To output the stats to a .csv file, use the –output flag followed by a file name. Let’s see how this looks on LibreOffice Calc:
|
||||
|
||||

|
||||
|
||||
Monitor Linux Statistics Output
|
||||
|
||||
I strongly advise you to check out the man page of dstat, included with this article along with the man page of sysstat in PDF format for your reading convenience. You will find several other options that will help you create custom and detailed system activity reports.
|
||||
|
||||
**Don’t Miss**: [Sysstat – Linux Usage Activity Monitoring Tool][4]
|
||||
|
||||
### Summary ###
|
||||
|
||||
In this guide we have explained how to use both native Linux tools and specific utilities provided with RHEL 7 in order to produce reports on system utilization. At one point or another, you will come to rely on these reports as best friends.
|
||||
|
||||
You will probably have used other tools that we have not covered in this tutorial. If so, feel free to share them with the rest of the community along with any other suggestions / questions / comments that you may have- using the form below.
|
||||
|
||||
We look forward to hearing from you.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-performance-monitoring-and-file-system-statistics-reports/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/how-to-check-disk-space-in-linux/
|
||||
[2]:http://www.tecmint.com/check-linux-disk-usage-of-files-and-directories/
|
||||
[3]:http://www.tecmint.com/linux-performance-monitoring-with-vmstat-and-iostat-commands/
|
||||
[4]:http://www.tecmint.com/install-sysstat-in-linux/
|
||||
@ -0,0 +1,208 @@
|
||||
ictlyh Translating
|
||||
Part 4 - Using Shell Scripting to Automate Linux System Maintenance Tasks
|
||||
================================================================================
|
||||
Some time ago I read that one of the distinguishing characteristics of an effective system administrator / engineer is laziness. It seemed a little contradictory at first but the author then proceeded to explain why:
|
||||
|
||||

|
||||
|
||||
RHCE Series: Automate Linux System Maintenance Tasks – Part 4
|
||||
|
||||
if a sysadmin spends most of his time solving issues and doing repetitive tasks, you can suspect he or she is not doing things quite right. In other words, an effective system administrator / engineer should develop a plan to perform repetitive tasks with as less action on his / her part as possible, and should foresee problems by using,
|
||||
|
||||
for example, the tools reviewed in Part 3 – [Monitor System Activity Reports Using Linux Toolsets][1] of this series. Thus, although he or she may not seem to be doing much, it’s because most of his / her responsibilities have been taken care of with the help of shell scripting, which is what we’re going to talk about in this tutorial.
|
||||
|
||||
### What is a shell script? ###
|
||||
|
||||
In few words, a shell script is nothing more and nothing less than a program that is executed step by step by a shell, which is another program that provides an interface layer between the Linux kernel and the end user.
|
||||
|
||||
By default, the shell used for user accounts in RHEL 7 is bash (/bin/bash). If you want a detailed description and some historical background, you can refer to [this Wikipedia article][2].
|
||||
|
||||
To find out more about the enormous set of features provided by this shell, you may want to check out its **man page**, which is downloaded in in PDF format at ([Bash Commands][3]). Other than that, it is assumed that you are familiar with Linux commands (if not, I strongly advise you to go through [A Guide from Newbies to SysAdmin][4] article in **Tecmint.com** before proceeding). Now let’s get started.
|
||||
|
||||
### Writing a script to display system information ###
|
||||
|
||||
For our convenience, let’s create a directory to store our shell scripts:
|
||||
|
||||
# mkdir scripts
|
||||
# cd scripts
|
||||
|
||||
And open a new text file named `system_info.sh` with your preferred text editor. We will begin by inserting a few comments at the top and some commands afterwards:
|
||||
|
||||
#!/bin/bash
|
||||
|
||||
# Sample script written for Part 4 of the RHCE series
|
||||
# This script will return the following set of system information:
|
||||
# -Hostname information:
|
||||
echo -e "\e[31;43m***** HOSTNAME INFORMATION *****\e[0m"
|
||||
hostnamectl
|
||||
echo ""
|
||||
# -File system disk space usage:
|
||||
echo -e "\e[31;43m***** FILE SYSTEM DISK SPACE USAGE *****\e[0m"
|
||||
df -h
|
||||
echo ""
|
||||
# -Free and used memory in the system:
|
||||
echo -e "\e[31;43m ***** FREE AND USED MEMORY *****\e[0m"
|
||||
free
|
||||
echo ""
|
||||
# -System uptime and load:
|
||||
echo -e "\e[31;43m***** SYSTEM UPTIME AND LOAD *****\e[0m"
|
||||
uptime
|
||||
echo ""
|
||||
# -Logged-in users:
|
||||
echo -e "\e[31;43m***** CURRENTLY LOGGED-IN USERS *****\e[0m"
|
||||
who
|
||||
echo ""
|
||||
# -Top 5 processes as far as memory usage is concerned
|
||||
echo -e "\e[31;43m***** TOP 5 MEMORY-CONSUMING PROCESSES *****\e[0m"
|
||||
ps -eo %mem,%cpu,comm --sort=-%mem | head -n 6
|
||||
echo ""
|
||||
echo -e "\e[1;32mDone.\e[0m"
|
||||
|
||||
Next, give the script execute permissions:
|
||||
|
||||
# chmod +x system_info.sh
|
||||
|
||||
and run it:
|
||||
|
||||
./system_info.sh
|
||||
|
||||
Note that the headers of each section are shown in color for better visualization:
|
||||
|
||||
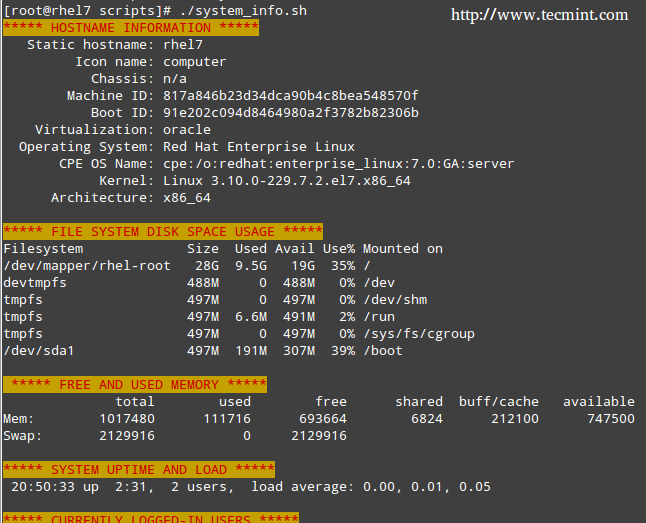
|
||||
|
||||
Server Monitoring Shell Script
|
||||
|
||||
That functionality is provided by this command:
|
||||
|
||||
echo -e "\e[COLOR1;COLOR2m<YOUR TEXT HERE>\e[0m"
|
||||
|
||||
Where COLOR1 and COLOR2 are the foreground and background colors, respectively (more info and options are explained in this entry from the [Arch Linux Wiki][5]) and <YOUR TEXT HERE> is the string that you want to show in color.
|
||||
|
||||
### Automating Tasks ###
|
||||
|
||||
The tasks that you may need to automate may vary from case to case. Thus, we cannot possibly cover all of the possible scenarios in a single article, but we will present three classic tasks that can be automated using shell scripting:
|
||||
|
||||
**1)** update the local file database, 2) find (and alternatively delete) files with 777 permissions, and 3) alert when filesystem usage surpasses a defined limit.
|
||||
|
||||
Let’s create a file named `auto_tasks.sh` in our scripts directory with the following content:
|
||||
|
||||
#!/bin/bash
|
||||
|
||||
# Sample script to automate tasks:
|
||||
# -Update local file database:
|
||||
echo -e "\e[4;32mUPDATING LOCAL FILE DATABASE\e[0m"
|
||||
updatedb
|
||||
if [ $? == 0 ]; then
|
||||
echo "The local file database was updated correctly."
|
||||
else
|
||||
echo "The local file database was not updated correctly."
|
||||
fi
|
||||
echo ""
|
||||
|
||||
# -Find and / or delete files with 777 permissions.
|
||||
echo -e "\e[4;32mLOOKING FOR FILES WITH 777 PERMISSIONS\e[0m"
|
||||
# Enable either option (comment out the other line), but not both.
|
||||
# Option 1: Delete files without prompting for confirmation. Assumes GNU version of find.
|
||||
#find -type f -perm 0777 -delete
|
||||
# Option 2: Ask for confirmation before deleting files. More portable across systems.
|
||||
find -type f -perm 0777 -exec rm -i {} +;
|
||||
echo ""
|
||||
# -Alert when file system usage surpasses a defined limit
|
||||
echo -e "\e[4;32mCHECKING FILE SYSTEM USAGE\e[0m"
|
||||
THRESHOLD=30
|
||||
while read line; do
|
||||
# This variable stores the file system path as a string
|
||||
FILESYSTEM=$(echo $line | awk '{print $1}')
|
||||
# This variable stores the use percentage (XX%)
|
||||
PERCENTAGE=$(echo $line | awk '{print $5}')
|
||||
# Use percentage without the % sign.
|
||||
USAGE=${PERCENTAGE%?}
|
||||
if [ $USAGE -gt $THRESHOLD ]; then
|
||||
echo "The remaining available space in $FILESYSTEM is critically low. Used: $PERCENTAGE"
|
||||
fi
|
||||
done < <(df -h --total | grep -vi filesystem)
|
||||
|
||||
Please note that there is a space between the two `<` signs in the last line of the script.
|
||||
|
||||

|
||||
|
||||
Shell Script to Find 777 Permissions
|
||||
|
||||
### Using Cron ###
|
||||
|
||||
To take efficiency one step further, you will not want to sit in front of your computer and run those scripts manually. Rather, you will use cron to schedule those tasks to run on a periodic basis and sends the results to a predefined list of recipients via email or save them to a file that can be viewed using a web browser.
|
||||
|
||||
The following script (filesystem_usage.sh) will run the well-known **df -h** command, format the output into a HTML table and save it in the **report.html** file:
|
||||
|
||||
#!/bin/bash
|
||||
# Sample script to demonstrate the creation of an HTML report using shell scripting
|
||||
# Web directory
|
||||
WEB_DIR=/var/www/html
|
||||
# A little CSS and table layout to make the report look a little nicer
|
||||
echo "<HTML>
|
||||
<HEAD>
|
||||
<style>
|
||||
.titulo{font-size: 1em; color: white; background:#0863CE; padding: 0.1em 0.2em;}
|
||||
table
|
||||
{
|
||||
border-collapse:collapse;
|
||||
}
|
||||
table, td, th
|
||||
{
|
||||
border:1px solid black;
|
||||
}
|
||||
</style>
|
||||
<meta http-equiv='Content-Type' content='text/html; charset=UTF-8' />
|
||||
</HEAD>
|
||||
<BODY>" > $WEB_DIR/report.html
|
||||
# View hostname and insert it at the top of the html body
|
||||
HOST=$(hostname)
|
||||
echo "Filesystem usage for host <strong>$HOST</strong><br>
|
||||
Last updated: <strong>$(date)</strong><br><br>
|
||||
<table border='1'>
|
||||
<tr><th class='titulo'>Filesystem</td>
|
||||
<th class='titulo'>Size</td>
|
||||
<th class='titulo'>Use %</td>
|
||||
</tr>" >> $WEB_DIR/report.html
|
||||
# Read the output of df -h line by line
|
||||
while read line; do
|
||||
echo "<tr><td align='center'>" >> $WEB_DIR/report.html
|
||||
echo $line | awk '{print $1}' >> $WEB_DIR/report.html
|
||||
echo "</td><td align='center'>" >> $WEB_DIR/report.html
|
||||
echo $line | awk '{print $2}' >> $WEB_DIR/report.html
|
||||
echo "</td><td align='center'>" >> $WEB_DIR/report.html
|
||||
echo $line | awk '{print $5}' >> $WEB_DIR/report.html
|
||||
echo "</td></tr>" >> $WEB_DIR/report.html
|
||||
done < <(df -h | grep -vi filesystem)
|
||||
echo "</table></BODY></HTML>" >> $WEB_DIR/report.html
|
||||
|
||||
In our **RHEL 7** server (**192.168.0.18**), this looks as follows:
|
||||
|
||||
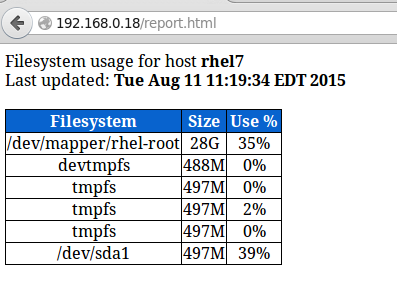
|
||||
|
||||
Server Monitoring Report
|
||||
|
||||
You can add to that report as much information as you want. To run the script every day at 1:30 pm, add the following crontab entry:
|
||||
|
||||
30 13 * * * /root/scripts/filesystem_usage.sh
|
||||
|
||||
### Summary ###
|
||||
|
||||
You will most likely think of several other tasks that you want or need to automate; as you can see, using shell scripting will greatly simplify this effort. Feel free to let us know if you find this article helpful and don't hesitate to add your own ideas or comments via the form below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/using-shell-script-to-automate-linux-system-maintenance-tasks/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/linux-performance-monitoring-and-file-system-statistics-reports/
|
||||
[2]:https://en.wikipedia.org/wiki/Bash_%28Unix_shell%29
|
||||
[3]:http://www.tecmint.com/wp-content/pdf/bash.pdf
|
||||
[4]:http://www.tecmint.com/60-commands-of-linux-a-guide-from-newbies-to-system-administrator/
|
||||
[5]:https://wiki.archlinux.org/index.php/Color_Bash_Prompt
|
||||
@ -1,218 +0,0 @@
|
||||
FSSlc translating
|
||||
|
||||
RHCSA Series: Process Management in RHEL 7: Boot, Shutdown, and Everything in Between – Part 5
|
||||
================================================================================
|
||||
We will start this article with an overall and brief revision of what happens since the moment you press the Power button to turn on your RHEL 7 server until you are presented with the login screen in a command line interface.
|
||||
|
||||

|
||||
|
||||
Linux Boot Process
|
||||
|
||||
**Please note that:**
|
||||
|
||||
1. the same basic principles apply, with perhaps minor modifications, to other Linux distributions as well, and
|
||||
2. the following description is not intended to represent an exhaustive explanation of the boot process, but only the fundamentals.
|
||||
|
||||
### Linux Boot Process ###
|
||||
|
||||
1. The POST (Power On Self Test) initializes and performs hardware checks.
|
||||
|
||||
2. When the POST finishes, the system control is passed to the first stage boot loader, which is stored on either the boot sector of one of the hard disks (for older systems using BIOS and MBR), or a dedicated (U)EFI partition.
|
||||
|
||||
3. The first stage boot loader then loads the second stage boot loader, most usually GRUB (GRand Unified Boot Loader), which resides inside /boot, which in turn loads the kernel and the initial RAM–based file system (also known as initramfs, which contains programs and binary files that perform the necessary actions needed to ultimately mount the actual root filesystem).
|
||||
|
||||
4. We are presented with a splash screen that allows us to choose an operating system and kernel to boot:
|
||||
|
||||

|
||||
|
||||
Boot Menu Screen
|
||||
|
||||
5. The kernel sets up the hardware attached to the system and once the root filesystem has been mounted, launches process with PID 1, which in turn will initialize other processes and present us with a login prompt.
|
||||
|
||||
Note: That if we wish to do so at a later time, we can examine the specifics of this process using the [dmesg command][1] and filtering its output using the tools that we have explained in previous articles of this series.
|
||||
|
||||

|
||||
|
||||
Login Screen and Process PID
|
||||
|
||||
In the example above, we used the well-known ps command to display a list of current processes whose parent process (or in other words, the process that started them) is systemd (the system and service manager that most modern Linux distributions have switched to) during system startup:
|
||||
|
||||
# ps -o ppid,pid,uname,comm --ppid=1
|
||||
|
||||
Remember that the -o flag (short for –format) allows you to present the output of ps in a customized format to suit your needs using the keywords specified in the STANDARD FORMAT SPECIFIERS section in man ps.
|
||||
|
||||
Another case in which you will want to define the output of ps instead of going with the default is when you need to find processes that are causing a significant CPU and / or memory load, and sort them accordingly:
|
||||
|
||||
# ps aux --sort=+pcpu # Sort by %CPU (ascending)
|
||||
# ps aux --sort=-pcpu # Sort by %CPU (descending)
|
||||
# ps aux --sort=+pmem # Sort by %MEM (ascending)
|
||||
# ps aux --sort=-pmem # Sort by %MEM (descending)
|
||||
# ps aux --sort=+pcpu,-pmem # Combine sort by %CPU (ascending) and %MEM (descending)
|
||||
|
||||

|
||||
|
||||
Customize ps Command Output
|
||||
|
||||
### An Introduction to SystemD ###
|
||||
|
||||
Few decisions in the Linux world have caused more controversies than the adoption of systemd by major Linux distributions. Systemd’s advocates name as its main advantages the following facts:
|
||||
|
||||
Read Also: [The Story Behind ‘init’ and ‘systemd’][2]
|
||||
|
||||
1. Systemd allows more processing to be done in parallel during system startup (as opposed to older SysVinit, which always tends to be slower because it starts processes one by one, checks if one depends on another, and then waits for daemons to launch so more services can start), and
|
||||
|
||||
2. It works as a dynamic resource management in a running system. Thus, services are started when needed (to avoid consuming system resources if they are not being used) instead of being launched without a valid reason during boot.
|
||||
|
||||
3. Backwards compatibility with SysVinit scripts.
|
||||
|
||||
Systemd is controlled by the systemctl utility. If you come from a SysVinit background, chances are you will be familiar with:
|
||||
|
||||
- the service tool, which -in those older systems- was used to manage SysVinit scripts, and
|
||||
- the chkconfig utility, which served the purpose of updating and querying runlevel information for system services.
|
||||
- shutdown, which you must have used several times to either restart or halt a running system.
|
||||
|
||||
The following table shows the similarities between the use of these legacy tools and systemctl:
|
||||
|
||||
注:表格
|
||||
<table cellspacing="0" border="0">
|
||||
<colgroup width="237"></colgroup>
|
||||
<colgroup width="256"></colgroup>
|
||||
<colgroup width="1945"></colgroup>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td align="left" height="25" bgcolor="#B7B7B7" style="border: 1px solid #000000;"><b><span style="color: black; font-family: Arial; font-size: small;">Legacy tool</span></b></td>
|
||||
<td align="left" bgcolor="#B7B7B7" style="border: 1px solid #000000;"><b><span style="color: black; font-family: Arial; font-size: small;">Systemctl equivalent</span></b></td>
|
||||
<td align="left" bgcolor="#B7B7B7" style="border: 1px solid #000000;"><b><span style="color: black; font-family: Arial; font-size: small;">Description</span></b></td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">service name start</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl start name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Start name (where name is a service)</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">service name stop</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl stop name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Stop name</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">service name condrestart</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl try-restart name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Restarts name (if it’s already running)</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">service name restart</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl restart name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Restarts name</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">service name reload</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl reload name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Reloads the configuration for name</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">service name status</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl status name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Displays the current status of name</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="23" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">service –status-all</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Arial;">Displays the status of all current services</span></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">chkconfig name on</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl enable name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Enable name to run on startup as specified in the unit file (the file to which the symlink points). The process of enabling or disabling a service to start automatically on boot consists in adding or removing symbolic links inside the /etc/systemd/system directory.</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">chkconfig name off</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl disable name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Disables name to run on startup as specified in the unit file (the file to which the symlink points)</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">chkconfig –list name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl is-enabled name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Verify whether name (a specific service) is currently enabled</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="23" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">chkconfig –list</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl –type=service</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Arial;">Displays all services and tells whether they are enabled or disabled</span></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="23" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">shutdown -h now</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl poweroff</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Arial;">Power-off the machine (halt)</span></td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="23" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">shutdown -r now</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl reboot</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Arial;">Reboot the system</span></td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
Systemd also introduced the concepts of units (which can be either a service, a mount point, a device, or a network socket) and targets (which is how systemd manages to start several related process at the same time, and can be considered -though not equal- as the equivalent of runlevels in SysVinit-based systems.
|
||||
|
||||
### Summing Up ###
|
||||
|
||||
Other tasks related with process management include, but may not be limited to, the ability to:
|
||||
|
||||
**1. Adjust the execution priority as far as the use of system resources is concerned of a process:**
|
||||
|
||||
This is accomplished through the renice utility, which alters the scheduling priority of one or more running processes. In simple terms, the scheduling priority is a feature that allows the kernel (present in versions => 2.6) to allocate system resources as per the assigned execution priority (aka niceness, in a range from -20 through 19) of a given process.
|
||||
|
||||
The basic syntax of renice is as follows:
|
||||
|
||||
# renice [-n] priority [-gpu] identifier
|
||||
|
||||
In the generic command above, the first argument is the priority value to be used, whereas the other argument can be interpreted as process IDs (which is the default setting), process group IDs, user IDs, or user names. A normal user (other than root) can only modify the scheduling priority of a process he or she owns, and only increase the niceness level (which means taking up less system resources).
|
||||
|
||||

|
||||
|
||||
Process Scheduling Priority
|
||||
|
||||
**2. Kill (or interrupt the normal execution) of a process as needed:**
|
||||
|
||||
In more precise terms, killing a process entitles sending it a signal to either finish its execution gracefully (SIGTERM=15) or immediately (SIGKILL=9) through the [kill or pkill commands][3].
|
||||
|
||||
The difference between these two tools is that the former is used to terminate a specific process or a process group altogether, while the latter allows you to do the same based on name and other attributes.
|
||||
|
||||
In addition, pkill comes bundled with pgrep, which shows you the PIDs that will be affected should pkill be used. For example, before running:
|
||||
|
||||
# pkill -u gacanepa
|
||||
|
||||
It may be useful to view at a glance which are the PIDs owned by gacanepa:
|
||||
|
||||
# pgrep -l -u gacanepa
|
||||
|
||||
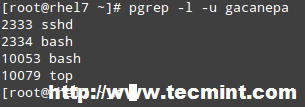
|
||||
|
||||
Find PIDs of User
|
||||
|
||||
By default, both kill and pkill send the SIGTERM signal to the process. As we mentioned above, this signal can be ignored (while the process finishes its execution or for good), so when you seriously need to stop a running process with a valid reason, you will need to specify the SIGKILL signal on the command line:
|
||||
|
||||
# kill -9 identifier # Kill a process or a process group
|
||||
# kill -s SIGNAL identifier # Idem
|
||||
# pkill -s SIGNAL identifier # Kill a process by name or other attributes
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
In this article we have explained the basics of the boot process in a RHEL 7 system, and analyzed some of the tools that are available to help you with managing processes using common utilities and systemd-specific commands.
|
||||
|
||||
Note that this list is not intended to cover all the bells and whistles of this topic, so feel free to add your own preferred tools and commands to this article using the comment form below. Questions and other comments are also welcome.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/rhcsa-exam-boot-process-and-process-management/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/dmesg-commands/
|
||||
[2]:http://www.tecmint.com/systemd-replaces-init-in-linux/
|
||||
[3]:http://www.tecmint.com/how-to-kill-a-process-in-linux/
|
||||
@ -1,269 +0,0 @@
|
||||
RHCSA Series: Using ‘Parted’ and ‘SSM’ to Configure and Encrypt System Storage – Part 6
|
||||
================================================================================
|
||||
In this article we will discuss how to set up and configure local system storage in Red Hat Enterprise Linux 7 using classic tools and introducing the System Storage Manager (also known as SSM), which greatly simplifies this task.
|
||||
|
||||

|
||||
|
||||
RHCSA: Configure and Encrypt System Storage – Part 6
|
||||
|
||||
Please note that we will present this topic in this article but will continue its description and usage on the next one (Part 7) due to vastness of the subject.
|
||||
|
||||
### Creating and Modifying Partitions in RHEL 7 ###
|
||||
|
||||
In RHEL 7, parted is the default utility to work with partitions, and will allow you to:
|
||||
|
||||
- Display the current partition table
|
||||
- Manipulate (increase or decrease the size of) existing partitions
|
||||
- Create partitions using free space or additional physical storage devices
|
||||
|
||||
It is recommended that before attempting the creation of a new partition or the modification of an existing one, you should ensure that none of the partitions on the device are in use (`umount /dev/partition`), and if you’re using part of the device as swap you need to disable it (`swapoff -v /dev/partition`) during the process.
|
||||
|
||||
The easiest way to do this is to boot RHEL in rescue mode using an installation media such as a RHEL 7 installation DVD or USB (Troubleshooting → Rescue a Red Hat Enterprise Linux system) and Select Skip when you’re prompted to choose an option to mount the existing Linux installation, and you will be presented with a command prompt where you can start typing the same commands as shown as follows during the creation of an ordinary partition in a physical device that is not being used.
|
||||
|
||||

|
||||
|
||||
RHEL 7 Rescue Mode
|
||||
|
||||
To start parted, simply type.
|
||||
|
||||
# parted /dev/sdb
|
||||
|
||||
Where `/dev/sdb` is the device where you will create the new partition; next, type print to display the current drive’s partition table:
|
||||
|
||||
|
||||
|
||||
Creat New Partition
|
||||
|
||||
As you can see, in this example we are using a virtual drive of 5 GB. We will now proceed to create a 4 GB primary partition and then format it with the xfs filesystem, which is the default in RHEL 7.
|
||||
|
||||
You can choose from a variety of file systems. You will need to manually create the partition with mkpart and then format it with mkfs.fstype as usual because mkpart does not support many modern filesystems out-of-the-box.
|
||||
|
||||
In the following example we will set a label for the device and then create a primary partition `(p)` on `/dev/sdb`, which starts at the 0% percentage of the device and ends at 4000 MB (4 GB):
|
||||
|
||||
|
||||
|
||||
Label Partition Name
|
||||
|
||||
Next, we will format the partition as xfs and print the partition table again to verify that changes were applied:
|
||||
|
||||
# mkfs.xfs /dev/sdb1
|
||||
# parted /dev/sdb print
|
||||
|
||||

|
||||
|
||||
Format Partition as XFS Filesystem
|
||||
|
||||
For older filesystems, you could use the resize command in parted to resize a partition. Unfortunately, this only applies to ext2, fat16, fat32, hfs, linux-swap, and reiserfs (if libreiserfs is installed).
|
||||
|
||||
Thus, the only way to resize a partition is by deleting it and creating it again (so make sure you have a good backup of your data!). No wonder the default partitioning scheme in RHEL 7 is based on LVM.
|
||||
|
||||
To remove a partition with parted:
|
||||
|
||||
# parted /dev/sdb print
|
||||
# parted /dev/sdb rm 1
|
||||
|
||||

|
||||
|
||||
Remove or Delete Partition
|
||||
|
||||
### The Logical Volume Manager (LVM) ###
|
||||
|
||||
Once a disk has been partitioned, it can be difficult or risky to change the partition sizes. For that reason, if we plan on resizing the partitions on our system, we should consider the possibility of using LVM instead of the classic partitioning system, where several physical devices can form a volume group that will host a defined number of logical volumes, which can be expanded or reduced without any hassle.
|
||||
|
||||
In simple terms, you may find the following diagram useful to remember the basic architecture of LVM.
|
||||
|
||||

|
||||
|
||||
Basic Architecture of LVM
|
||||
|
||||
#### Creating Physical Volumes, Volume Group and Logical Volumes ####
|
||||
|
||||
Follow these steps in order to set up LVM using classic volume management tools. Since you can expand this topic reading the [LVM series on this site][1], I will only outline the basic steps to set up LVM, and then compare them to implementing the same functionality with SSM.
|
||||
|
||||
**Note**: That we will use the whole disks `/dev/sdb` and `/dev/sdc` as PVs (Physical Volumes) but it’s entirely up to you if you want to do the same.
|
||||
|
||||
**1. Create partitions `/dev/sdb1` and `/dev/sdc1` using 100% of the available disk space in /dev/sdb and /dev/sdc:**
|
||||
|
||||
# parted /dev/sdb print
|
||||
# parted /dev/sdc print
|
||||
|
||||
|
||||
|
||||
Create New Partitions
|
||||
|
||||
**2. Create 2 physical volumes on top of /dev/sdb1 and /dev/sdc1, respectively.**
|
||||
|
||||
# pvcreate /dev/sdb1
|
||||
# pvcreate /dev/sdc1
|
||||
|
||||

|
||||
|
||||
Create Two Physical Volumes
|
||||
|
||||
Remember that you can use pvdisplay /dev/sd{b,c}1 to show information about the newly created PVs.
|
||||
|
||||
**3. Create a VG on top of the PV that you created in the previous step:**
|
||||
|
||||
# vgcreate tecmint_vg /dev/sd{b,c}1
|
||||
|
||||

|
||||
|
||||
Create Volume Group
|
||||
|
||||
Remember that you can use vgdisplay tecmint_vg to show information about the newly created VG.
|
||||
|
||||
**4. Create three logical volumes on top of VG tecmint_vg, as follows:**
|
||||
|
||||
# lvcreate -L 3G -n vol01_docs tecmint_vg [vol01_docs → 3 GB]
|
||||
# lvcreate -L 1G -n vol02_logs tecmint_vg [vol02_logs → 1 GB]
|
||||
# lvcreate -l 100%FREE -n vol03_homes tecmint_vg [vol03_homes → 6 GB]
|
||||
|
||||

|
||||
|
||||
Create Logical Volumes
|
||||
|
||||
Remember that you can use lvdisplay tecmint_vg to show information about the newly created LVs on top of VG tecmint_vg.
|
||||
|
||||
**5. Format each of the logical volumes with xfs (do NOT use xfs if you’re planning on shrinking volumes later!):**
|
||||
|
||||
# mkfs.xfs /dev/tecmint_vg/vol01_docs
|
||||
# mkfs.xfs /dev/tecmint_vg/vol02_logs
|
||||
# mkfs.xfs /dev/tecmint_vg/vol03_homes
|
||||
|
||||
**6. Finally, mount them:**
|
||||
|
||||
# mount /dev/tecmint_vg/vol01_docs /mnt/docs
|
||||
# mount /dev/tecmint_vg/vol02_logs /mnt/logs
|
||||
# mount /dev/tecmint_vg/vol03_homes /mnt/homes
|
||||
|
||||
#### Removing Logical Volumes, Volume Group and Physical Volumes ####
|
||||
|
||||
**7. Now we will reverse the LVM implementation and remove the LVs, the VG, and the PVs:**
|
||||
|
||||
# lvremove /dev/tecmint_vg/vol01_docs
|
||||
# lvremove /dev/tecmint_vg/vol02_logs
|
||||
# lvremove /dev/tecmint_vg/vol03_homes
|
||||
# vgremove /dev/tecmint_vg
|
||||
# pvremove /dev/sd{b,c}1
|
||||
|
||||
**8. Now let’s install SSM and we will see how to perform the above in ONLY 1 STEP!**
|
||||
|
||||
# yum update && yum install system-storage-manager
|
||||
|
||||
We will use the same names and sizes as before:
|
||||
|
||||
# ssm create -s 3G -n vol01_docs -p tecmint_vg --fstype ext4 /mnt/docs /dev/sd{b,c}1
|
||||
# ssm create -s 1G -n vol02_logs -p tecmint_vg --fstype ext4 /mnt/logs /dev/sd{b,c}1
|
||||
# ssm create -n vol03_homes -p tecmint_vg --fstype ext4 /mnt/homes /dev/sd{b,c}1
|
||||
|
||||
Yes! SSM will let you:
|
||||
|
||||
- initialize block devices as physical volumes
|
||||
- create a volume group
|
||||
- create logical volumes
|
||||
- format LVs, and
|
||||
- mount them using only one command
|
||||
|
||||
**9. We can now display the information about PVs, VGs, or LVs, respectively, as follows:**
|
||||
|
||||
# ssm list dev
|
||||
# ssm list pool
|
||||
# ssm list vol
|
||||
|
||||

|
||||
|
||||
Check Information of PVs, VGs, or LVs
|
||||
|
||||
**10. As we already know, one of the distinguishing features of LVM is the possibility to resize (expand or decrease) logical volumes without downtime.**
|
||||
|
||||
Say we are running out of space in vol02_logs but have plenty of space in vol03_homes. We will resize vol03_homes to 4 GB and expand vol02_logs to use the remaining space:
|
||||
|
||||
# ssm resize -s 4G /dev/tecmint_vg/vol03_homes
|
||||
|
||||
Run ssm list pool again and take note of the free space in tecmint_vg:
|
||||
|
||||
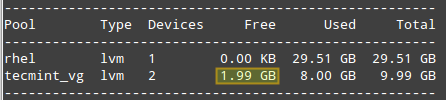
|
||||
|
||||
Check Volume Size
|
||||
|
||||
Then do:
|
||||
|
||||
# ssm resize -s+1.99 /dev/tecmint_vg/vol02_logs
|
||||
|
||||
**Note**: that the plus sign after the -s flag indicates that the specified value should be added to the present value.
|
||||
|
||||
**11. Removing logical volumes and volume groups is much easier with ssm as well. A simple,**
|
||||
|
||||
# ssm remove tecmint_vg
|
||||
|
||||
will return a prompt asking you to confirm the deletion of the VG and the LVs it contains:
|
||||
|
||||

|
||||
|
||||
Remove Logical Volume and Volume Group
|
||||
|
||||
### Managing Encrypted Volumes ###
|
||||
|
||||
SSM also provides system administrators with the capability of managing encryption for new or existing volumes. You will need the cryptsetup package installed first:
|
||||
|
||||
# yum update && yum install cryptsetup
|
||||
|
||||
Then issue the following command to create an encrypted volume. You will be prompted to enter a passphrase to maximize security:
|
||||
|
||||
# ssm create -s 3G -n vol01_docs -p tecmint_vg --fstype ext4 --encrypt luks /mnt/docs /dev/sd{b,c}1
|
||||
# ssm create -s 1G -n vol02_logs -p tecmint_vg --fstype ext4 --encrypt luks /mnt/logs /dev/sd{b,c}1
|
||||
# ssm create -n vol03_homes -p tecmint_vg --fstype ext4 --encrypt luks /mnt/homes /dev/sd{b,c}1
|
||||
|
||||
Our next task consists in adding the corresponding entries in /etc/fstab in order for those logical volumes to be available on boot. Rather than using the device identifier (/dev/something).
|
||||
|
||||
We will use each LV’s UUID (so that our devices will still be uniquely identified should we add other logical volumes or devices), which we can find out with the blkid utility:
|
||||
|
||||
# blkid -o value UUID /dev/tecmint_vg/vol01_docs
|
||||
# blkid -o value UUID /dev/tecmint_vg/vol02_logs
|
||||
# blkid -o value UUID /dev/tecmint_vg/vol03_homes
|
||||
|
||||
In our case:
|
||||
|
||||

|
||||
|
||||
Find Logical Volume UUID
|
||||
|
||||
Next, create the /etc/crypttab file with the following contents (change the UUIDs for the ones that apply to your setup):
|
||||
|
||||
docs UUID=ba77d113-f849-4ddf-8048-13860399fca8 none
|
||||
logs UUID=58f89c5a-f694-4443-83d6-2e83878e30e4 none
|
||||
homes UUID=92245af6-3f38-4e07-8dd8-787f4690d7ac none
|
||||
|
||||
And insert the following entries in /etc/fstab. Note that device_name (/dev/mapper/device_name) is the mapper identifier that appears in the first column of /etc/crypttab.
|
||||
|
||||
# Logical volume vol01_docs:
|
||||
/dev/mapper/docs /mnt/docs ext4 defaults 0 2
|
||||
# Logical volume vol02_logs
|
||||
/dev/mapper/logs /mnt/logs ext4 defaults 0 2
|
||||
# Logical volume vol03_homes
|
||||
/dev/mapper/homes /mnt/homes ext4 defaults 0 2
|
||||
|
||||
Now reboot (systemctl reboot) and you will be prompted to enter the passphrase for each LV. Afterwards you can confirm that the mount operation was successful by checking the corresponding mount points:
|
||||
|
||||

|
||||
|
||||
Verify Logical Volume Mount Points
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
In this tutorial we have started to explore how to set up and configure system storage using classic volume management tools and SSM, which also integrates filesystem and encryption capabilities in one package. This makes SSM an invaluable tool for any sysadmin.
|
||||
|
||||
Let us know if you have any questions or comments – feel free to use the form below to get in touch with us!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/rhcsa-exam-create-format-resize-delete-and-encrypt-partitions-in-linux/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/create-lvm-storage-in-linux/
|
||||
@ -1,3 +1,5 @@
|
||||
FSSlc translating
|
||||
|
||||
RHCSA Series: Using ACLs (Access Control Lists) and Mounting Samba / NFS Shares – Part 7
|
||||
================================================================================
|
||||
In the last article ([RHCSA series Part 6][1]) we started explaining how to set up and configure local system storage using parted and ssm.
|
||||
@ -209,4 +211,4 @@ via: http://www.tecmint.com/rhcsa-exam-configure-acls-and-mount-nfs-samba-shares
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/rhcsa-exam-create-format-resize-delete-and-encrypt-partitions-in-linux/
|
||||
[2]:http://www.tecmint.com/rhcsa-exam-manage-users-and-groups/
|
||||
[3]:https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/7/html/Storage_Administration_Guide/ch-acls.html
|
||||
[3]:https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/7/html/Storage_Administration_Guide/ch-acls.html
|
||||
|
||||
@ -1,55 +0,0 @@
|
||||
将GNOME作为我的Linux桌面的一周: 他们做对的与做错的 - 第一节 - 简介
|
||||
================================================================================
|
||||
*作者声明: 如果你是因为某种神迹而在没看标题的情况下点开了这篇文章,那么我想再重申一些东西...这是一篇评论文章。文中的观点都是我自己的,不代表Phoronix和Michael的观点。它们完全是我自己的想法。
|
||||
|
||||
另外,没错……这可能是一篇引战的文章。我希望社团成员们更沉稳一些,因为我确实想在KDE和Gnome的社团上发起讨论,反馈。因此当我想指出——我所看到的——一个瑕疵时,我会尽量地做到具体而直接。这样,相关的讨论也能做到同样的具体和直接。再次声明:本文另一可选标题为“被[细纸片][1]千刀万剐”(原文含paper cuts一词,指易修复但烦人的缺陷,译者注)。
|
||||
|
||||
现在,重申完毕……文章开始。
|
||||
|
||||

|
||||
|
||||
当我把[《评价Fedora 22 KDE》][2]一文发给Michael时,感觉很不是滋味。不是因为我不喜欢KDE,或者不享受Fedora,远非如此。事实上,我刚开始想把我的T450s的系统换为Arch Linux时,马上又决定放弃了,因为我很享受fedora在很多方面所带来的便捷性。
|
||||
|
||||
我感觉很不是滋味的原因是Fedora的开发者花费了大量的时间和精力在他们的“工作站”产品上,但是我却一点也没看到。在使用Fedora时,我采用的并非那些主要开发者希望用户采用的那种使用方式,因此我也就体验不到所谓的“Fedora体验”。它感觉就像一个人评价Ubuntu时用的却是Kubuntu,评价OS X时用的却是Hackintosh,或者评价Gentoo时用的却是Sabayon。根据大量Michael论坛的读者的说法,它们在评价各种发行版时使用的都是默认设置的发行版——我也不例外。但是我还是认为这些评价应该在“真实”配置下完成,当然我也知道在给定的情况下评论某些东西也的确是有价值的——无论是好是坏。
|
||||
|
||||
正是在怀着这种态度的情况下,我决定到Gnome这个水坑里来泡泡澡。
|
||||
|
||||
但是,我还要在此多加一个声明……我在这里所看到的KDE和Gnome都是打包在Fedora中的。OpenSUSE, Kubuntu, Arch等发行版的各个桌面可能有不同的实现方法,使得我这里所说的具体的“痛处”跟你所用的发行版有所不同。还有,虽然用了这个标题,但这篇文章将会是一篇很沉重的非常“KDE”的文章。之所以这样称呼这篇文章,是因为我在使用了Gnome之后,才知道KDE的“剪纸”到底有多多。
|
||||
|
||||
### 登录界面 ###
|
||||
|
||||

|
||||
|
||||
我一般情况下都不会介意发行版装载它们自己的特别主题,因为一般情况下桌面看起来会更好看。可我今天可算是找到了一个例外。
|
||||
|
||||
第一印象很重要,对吧?那么,GDM(Gnome Display Manage:Gnome显示管理器,译者注,下同。)决对干得漂亮。它的登录界面看起来极度简洁,每一部分都应用了一致的设计风格。使用通用图标而不是输入框为它的简洁加了分。
|
||||
|
||||

|
||||
|
||||
这并不是说Fedora 22 KDE——现在已经是SDDM而不是KDM了——的登录界面不好看,但是看起来决对没有它这样和谐。
|
||||
|
||||
问题到底出来在哪?顶部栏。看看Gnome的截图——你选择一个用户,然后用一个很小的齿轮简单地选择想登入哪个会话。设计很简洁,它不挡着你的道儿,实话讲,如果你没注意的话可能完全会看不到它。现在看看那蓝色( blue,有忧郁之意,一语双关,译者注)的KDE截图,顶部栏看起来甚至不像是用同一个工具渲染出来的,它的整个位置的安排好像是某人想着:“哎哟妈呀,我们需要把这个选项扔在哪个地方……”之后决定下来的。
|
||||
|
||||
对于右上角的重启和关机选项也一样。为什么不单单用一个电源按钮,点击后会下拉出一个菜单,里面包括重启,关机,挂起的功能?按钮的颜色跟背景色不同肯定会让它更加突兀和显眼……但我可不觉得这样子有多好。同样,这看起来可真像“苦思”后的决定。
|
||||
|
||||
从实用观点来看,GDM还要远远实用的多,再看看顶部一栏。时间被列了出来,还有一个音量控制按钮,如果你想保持周围安静,你甚至可以在登录前设置静音,还有一个可用的按钮来实现高对比度,缩放,语音转文字等功能,所有可用的功能通过简单的一个开关按钮就能得到。
|
||||
|
||||

|
||||
|
||||
切换到upstream的Breeve主题……突然间,我抱怨的大部分问题都被完善了。通用图标,所有东西都放在了屏幕中央,但不是那么重要的被放到了一边。因为屏幕顶部和底部都是同样的空白,在中间也就酝酿出了一种美好的和谐。还是有一个输入框来切换会话,但既然电源按钮被做成了通用图标,那么这点还算可以原谅。当然gnome还是有一些很好的附加物,例如音量小程序和可访问按钮,但Breeze总归是Fedora的KDE主题的一个进步。
|
||||
|
||||
到Windows(Windows 8和10之前)或者OS X中去,你会看到类似的东西——非常简洁的,“不挡你道”的锁屏与登录界面,它们都没有输入框或者其它分散视觉的小工具。这是一种有效的不分散人注意力的设计。Fedora……默认装有Breeze。VDG在Breeze主题设计上干得不错。可别糟蹋了它。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.phoronix.com/scan.php?page=article&item=gnome-week-editorial&num=1
|
||||
|
||||
作者:Eric Griffith
|
||||
译者:[XLCYun](https://github.com/XLCYun)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://wiki.ubuntu.com/One%20Hundred%20Papercuts
|
||||
[2]:http://www.phoronix.com/scan.php?page=article&item=fedora-22-kde&num=1
|
||||
[3]:https://launchpad.net/hundredpapercuts
|
||||
@ -1,31 +0,0 @@
|
||||
将GNOME作为我的Linux桌面的一周:他们做对的与做错的 - 第二节 - GNOME桌面
|
||||
================================================================================
|
||||
### 桌面 ###
|
||||
|
||||

|
||||
|
||||
在我这一周的前五天中,我都是直接手动登录进Gnome的——没有打开自动登录功能。在第五天的晚上,每一次都要手动登录让我觉得很厌烦,所以我就到用户管理器中打开了自动登录功能。下一次我登录的时候收到了一个提示:“你的密钥链(keychain)未解锁,请输入你的密码解锁”。在这时我才意识到了什么……每一次我通过GDM登录时——我的KDB钱包提示——Gnome以前一直都在自动解锁我的密钥链!当我绕开GDM的登录程序时,Gnome才不得不介入让我手动解锁。
|
||||
|
||||
现在,鄙人的陋见是如果你打开了自动登录功能,那么你的密钥链也应当自动解锁——否则,这功能还有何用?无论如何,你还是要输入你的密码,况且在GDM登录界面你还能有机会选择要登录的会话。
|
||||
|
||||
但是,这点且不提,也就是在那一刻,我意识到要让这桌面感觉是它在**和我**一起工作是多么简单的一件事。当我通过SDDM登录KDE时?甚至连启动界面都还没加载完成,就有一个窗口弹出来遮挡了启动动画——因此启动动画也就被破坏了——提示我解锁我的KDE钱包或GPG钥匙环。
|
||||
|
||||
如果当前不存在钱包,你就会收到一个创建钱包的提醒——就不能在创建用户的时候同时为我创建一个吗?——接着它又让你在两种加密模式中选择一种,甚至还暗示我们其中一种是不安全的(Blowfish),既然是为了安全,为什么还要我选择一个不安全的东西?作者声明:如果你安装了真正的KDE spin版本而不是仅仅安装了KDE的事后版本,那么在创建用户时,它就会为你创建一个钱包。但很不幸的是,它不会帮你解锁,并且它似乎还使用了更老的Blowfish加密模式,而不是更新而且更安全的GPG模式。
|
||||
|
||||

|
||||
|
||||
如果你选择了那个安全的加密模式(GPG),那么它会尝试加载GPG密钥……我希望你已经创建过一个了,因为如果你没有,那么你可又要被批一顿了。怎么样才能创建一个?额……它不帮你创建一个……也不告诉你怎么创建……假如你真的搞明白了你应该使用KGpg来创建一个密钥,接着在你就会遇到一层层的菜单和一个个的提示,而这些菜单和提示只能让新手感到困惑。为什么你要问我GPG的二进制文件在哪?天知道在哪!如果不止一个,你就不能为我选择一个最新的吗?如果只有一个,我再问一次,为什么你还要问我?
|
||||
|
||||
为什么你要问我要使用多大的密钥大小和加密算法?你既然默认选择了2048和RSA/RSA,为什么不直接使用?如果你想让这些选项能够被改变,那就把它们扔在下面的"Expert mode(专家模式)"按钮里去。这不仅仅关于使配置可被用户改变,而是关于默认地把多余的东西扔在了用户面前。这种问题将会成为剩下文章的主题之一……KDE需要更好更理智的默认配置。配置是好的,我很喜欢在使用KDE时的配置,但它还需要知道什么时候应该,什么时候不应该去提示用户。而且它还需要知道“嗯,它是可配置的”不能做为默认配置做得不好的借口。用户最先接触到的就是默认配置,不好的默认配置注定要失去用户。
|
||||
|
||||
让我们抛开密钥链的问题,因为我想我已经表达出了我的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.phoronix.com/scan.php?page=article&item=gnome-week-editorial&num=2
|
||||
|
||||
作者:Eric Griffith
|
||||
译者:[XLCYun](https://github.com/XLCYun)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,61 +0,0 @@
|
||||
将GNOME作为我的Linux桌面的一周: 他们做对的与做错的 - 第三节 - GNOME应用
|
||||
================================================================================
|
||||
### 应用 ###
|
||||
|
||||

|
||||
|
||||
这是一个基本上一潭死水的地方。每一个桌面环境都有一些非常好的和不怎么样的应用。再次强调,Gnome把那些KDE完全错失的小细节给做对了。我不是想说KDE中有哪些应用不好。他们都能工作。但仅此而已。也就是说:它们合格了,但确实还没有达到甚至接近100分。
|
||||
|
||||
Gnome的在左边,KDE的在右边。Dragon运行得很好,清晰的标出了播放文件、URL或和光盘的按钮,正如你在Gnome Videos中能做到的一样……但是在便利的文件名和用户的友好度方面,Gnome多走了一小步。它默认显示了在你的电脑上检测到的所有影像文件,不需要你做任何事情。KDE有Baloo——正如之前有Nepomuk——为什么不使用它们?它们能列出可读取的影像文件……但却没被使用。
|
||||
|
||||
下一步……音乐播放器
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
这两个应用,左边的Rhythmbox和右边的Amarok,都是打开后没有做任何修改直接截屏的。看到差别了吗?Rhythmbox看起来像个音乐播放器,直接了当,排序文件的方法也很清晰,它知道它应该是什么样的,它的工作是什么:就是播放音乐。
|
||||
|
||||
Amarok感觉就像是某个人为了展示而把所有的扩展和选项都尽可能地塞进一个应用程序中去而做出来的一个技术演示产品(tech demos),或者一个库演示产品(library demos)——而这些是不应该做为产品装进去的,它只应该展示一些零碎的东西。而Amarok给人的感觉却是这样的:好像是某个人想把每一个感觉可能很酷的东西都塞进一个媒体播放器里,甚至都不停下来想“我想写啥来着?一个播放音乐的应用?”
|
||||
|
||||
看看默认布局就行了。前面和中心都呈现了什么?一个可视化工具和维基集成(wikipedia integration)——占了整个页面最大和最显眼的区域。第二大的呢?播放列表。第三大,同时也是最小的呢?真正的音乐列表。这种默认设置对于一个核心应用来说,怎么可能称得上理智?
|
||||
|
||||
软件管理器!它在最近几年当中有很大的进步,而且接下来的几个月中,很可能只能看到它更大的进步。不幸的是,这是另一个地方KDE做得差一点点就能……但还是在终点线前摔了脸。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Gnome软件中心可能是我最新的最爱,先放下牢骚等下再发。Muon, 我想爱上你,真的。但你就是个设计上的梦魇。当VDG给你画设计草稿时(模型在下面),你看起来真漂亮。白色空间用得很好,设计简洁,类别列表也很好,你的整个“不要分开做成两个应用程序”的设计都很不错。
|
||||
|
||||

|
||||
|
||||
接着就有人为你写代码,实现真正的UI,但是,我猜这些家伙当时一定是喝醉了。
|
||||
|
||||
我们来看看Gnome软件中心。正中间是什么?软件,软件截图和软件描述等等。Muon的正中心是什么?白白浪费的大块白色空间。Gnome软件中心还有一个贴心便利特点,那就是放了一个“运行“的按钮在那儿,以防你已经安装了这个软件。便利性和易用性很重要啊,大哥。说实话,仅仅让Muon把东西都居中对齐了可能看起来的效果都要好得多。
|
||||
|
||||
Gnome软件中心沿着顶部的东西是什么,像个标签列表?所有软件,已安装软件,软件升级。语言简洁,直接,直指要点。Muon,好吧,我们有个”发现“,这个语言表达上还算差强人意,然后我们又有一个”已安装软件“,然后,就没有然后了。软件升级哪去了?
|
||||
|
||||
好吧……开发者决定把升级独立分开成一个应用程序,这样你就得打开两个应用程序才能管理你的软件——一个用来安装,一个用来升级——自从有了新得立图形软件包管理器以来,首次有这种破天荒的设计,与任何已存的软件中心的设计范例相违背。
|
||||
|
||||
我不想贴上截图给你们看,因为我不想等下还得清理我的电脑,如果你进入Muon安装了什么,那么它就会在屏幕下方根据安装的应用名创建一个标签,所以如果你一次性安装很多软件的话,那么下面的标签数量就会慢慢的增长,然后你就不得不手动检查清除它们,因为如果你不这样做,当标签增长到超过屏幕显示时,你就不得不一个个找过去来才能找到最近正在安装的软件。想想:在火狐浏览器打开50个标签。太烦人,太不方便!
|
||||
|
||||
我说过我会给Gnome一点打击,我是认真的。Muon有一点做得比Gnome软件中心做得好。在Muon的设置栏下面有个“显示技术包”,即:编辑器,软件库,非图形应用程序,无AppData的应用等等(AppData,软件包中的一个特殊文件,用于专门存储软件的信息,译注)。Gnome则没有。如果你想安装其中任何一项你必须跑到终端操作。我想这是他们做得不对的一点。我完全理解他们推行AppData的心情,但我想他们太急了(推行所有软件包带有AppData,是Gnome软件中心的目标之一,译注)。我是在想安装PowerTop,而Gnome不显示这个软件时我才发现这点的——没有AppData,没有“显示技术包“设置。
|
||||
|
||||
更不幸的事实是你不能“用Apper就行了”,自从……
|
||||
|
||||

|
||||
|
||||
Apper对安装本地软件包的支持大约在Fedora 19时就中止了,几乎两年了。我喜欢那种对细节与质量的关注。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.phoronix.com/scan.php?page=article&item=gnome-week-editorial&num=3
|
||||
|
||||
作者:Eric Griffith
|
||||
译者:[XLCYun](https://github.com/XLCYun)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,54 +0,0 @@
|
||||
将GNOME作为我的Linux桌面的一周: 他们做对的与做错的 - 第四节 - GNOME设置
|
||||
================================================================================
|
||||
### Settings设置 ###
|
||||
|
||||
在这我要挑一挑几个特定KDE控制模块的毛病,大部分原因是因为相比它们的对手GNOME来说,糟糕得太可笑,实话说,真是悲哀。
|
||||
|
||||
第一个接招的?打印机。
|
||||
|
||||

|
||||
|
||||
GNOME在左,KDE在右。你知道左边跟右边的打印程序有什么区别吗?当我在GNOME控制中心打开“打印机”时,程序窗口弹出来了,之后没有也没发生。而当我在KDE系统设置打开“打印机”时,我收到了一条密码提示。甚至我都没能看一眼打印机呢,我就必须先交出ROOT密码。
|
||||
|
||||
让我再重复一遍。在今天,PolicyKit和Logind的日子里,对一个应该是sudo的操作,我依然被询问要求ROOT的密码。我安装系统的时候甚至都没设置root密码。所以我必须跑到Konsole去,然后运行'sudo passwd root'命令,这样我才能给root设一个密码,这样我才能回到系统设置中的打印程序,然后交出root密码,然后仅仅是看一看哪些打印机可用。完成了这些工作后,当我点击“添加打印机”时,我再次收到请求ROOT密码的提示,当我解决了它后再选择一个打印机和驱动时,我再次收到请求ROOT密码的提示。仅仅是为了添加一个打印机到系统我就收到三次密码请求。
|
||||
|
||||
而在GNOME下添加打印机,在点击打印机程序中的”解锁“之前,我没有收到任何请求SUDO密码的提示。整个过程我只被请求过一次,仅此而已。KDE,求你了……采用GNOME的”解锁“模式吧。不到一定需要的时候不要发出提示。还有,不管是哪个库,只要它允许KDE应用程序绕过PolicyKit/Logind(如果有的话)并直接请求ROOT权限……那就把它封进箱里吧。如果这是个多用户系统,那我要么必须交出ROOT密码,要么我必须时时刻刻呆着以免有一个用户需要升级、更改或添加一个新的打印机。而这两种情况都是完全无法接受的。
|
||||
|
||||
有还一件事……
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
给论坛的问题:怎么样看起来更简洁?我在写这篇文章时意识到:当有任何的附加打印机准备好时,Gnome打印机程序会把过程做得非常简洁,它们在左边上放了一个竖直栏来列出这些打印机。而我在KDE添加第二台打印机时,它突然增加出一个左边栏来。而在添加之前,我脑海中已经有了一个恐怖的画面它会像图片文件夹显示预览图一样,直接插入另外一个图标到界面里去。我很高兴也很惊讶的看到我是错的。但是事实是它直接”长出”另外一个从末存在的竖直栏,彻底改变了它的界面布局,而这样也称不上“好”。终究还是一种令人困惑,奇怪而又不直观的设计。
|
||||
|
||||
打印机说得够多了……下一个接受我公开石刑的KDE系统设置是?多媒体,即Phonon。
|
||||
|
||||

|
||||
|
||||
一如既往,GNOME在左边,KDE在右边。让我们先看看GNOME的系统设置先……眼睛从左到右,从上到下,对吧?来吧,就这样做。首先:音量控制滑条。滑条中的蓝色条与空白条百分百清晰地消除了哪边是“音量增加”的困惑。在音量控制条后马上就是一个On/Off开关,用来开关静音功能。Gnome的再次得分在于静音后能记住当前设置的音量,而在点击音量增加按钮取消静音后能回到原来设置的音量中来。Kmixer,你个健忘的垃圾,我真的希望我能多讨论你。
|
||||
|
||||
|
||||
继续!输入输出和应用程序的标签选项?每一个应用程序的音量随时可控?Gnome,每过一秒,我爱你越深。均衡的选项设置,声音配置,和清晰地标上标志的“测试麦克风”选项。
|
||||
|
||||
|
||||
|
||||
我不清楚它能否以一种更干净更简洁的设计实现。是的,它只是一个Gnome化的Pavucontrol,但我想这就是重要的地方。Pavucontrol在这方面几乎完全做对了,Gnome控制中心中的“声音”应用程序的改善使它向完美更进了一步。
|
||||
|
||||
Phonon,该你上了。但开始前我想说:我TM看到的是什么?我知道我看到的是音频设备的权限列表,但是它呈现的方式有点太坑。还有,那些用户可能关心的那些东西哪去了?拥有一个权限列表当然很好,它也应该存在,但问题是权限列表属于那种用户乱搞一两次之后就不会再碰的东西。它还不够重要,或者说常用到可以直接放在正中间位置的程度。音量控制滑块呢?对每个应用程序的音量控制功能呢?那些用户使用最频繁的东西呢?好吧,它们在Kmix中,一个分离的程序,拥有它自己的配置选项……而不是在系统设置下……这样真的让“系统设置”这个词变得有点用词不当。
|
||||
|
||||

|
||||
|
||||
上面展示的Gnome的网络设置。KDE的没有展示,原因就是我接下来要吐槽的内容了。如果你进入KDE的系统设置里,然后点击“网络”区域中三个选项中的任何一个,你会得到一大堆的选项:蓝牙设置,Samba分享的默认用户名和密码(说真的,“连通性(Connectivity)”下面只有两个选项:SMB的用户名和密码。TMD怎么就配得上“连通性”这么大的词?),浏览器身份验证控制(只有Konqueror能用……一个已经倒闭的项目),代理设置,等等……我的wifi设置哪去了?它们没在这。哪去了?好吧,它们在网络应用程序的设置里面……而不是在网络设置里……
|
||||
|
||||
KDE,你这是要杀了我啊,你有“系统设置”当凶器,拿着它动手吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.phoronix.com/scan.php?page=article&item=gnome-week-editorial&num=4
|
||||
|
||||
作者:Eric Griffith
|
||||
译者:[XLCYun](https://github.com/XLCYun)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,39 +0,0 @@
|
||||
将GNOME作为我的Linux桌面的一周:他们做对的与做错的 - 第五节 - 总结
|
||||
================================================================================
|
||||
### 用户体验和最后想法 ###
|
||||
|
||||
当Gnome 2.x和KDE 4.x要正面交锋时……我相当开心的跳到其中。我爱的东西它们有,恨的东西也有,但总的来说它们使用起来还算是一种乐趣。然后Gnome 3.x来了,带着一场Gnome Shell的戏剧。那时我就放弃了Gnome,我尽我所能的避开它。当时它对用户是不友好的,而且不直观,它打破了原有的设计典范,只为平板的统治世界做准备……而根据平板下跌的销量来看,这样的未来不可能实现。
|
||||
|
||||
Gnome 3后续发面了八个版本后,奇迹发生了。Gnome变得对对用户友好了。变得直观了。它完美吗?当然不了。我还是很讨厌它想推动的那种设计范例,我讨厌它总想把工作流(work flow)强加给我,但是在时间和耐心的作用下,这两都能被接受。只要你能够回头去看看Gnome Shell那外星人一样的界面,然后开始跟Gnome的其它部分(特别是控制中心)互动,你就能发现Gnome绝对做对了:细节。对细节的关注!
|
||||
|
||||
人们能适应新的界面设计范例,能适应新的工作流——iPhone和iPad都证明了这一点——但真正一直让他们操心的是“纸片的割伤”(paper cuts,此处指易于修复但烦人的缺陷,译注)。
|
||||
|
||||
它带出了KDE和Gnome之间最重要的一个区别。Gnome感觉像一个产品。像一种非凡的体验。你用它的时候,觉得它是完整的,你要的东西都在你的指尖。它让人感觉就像是一个拥有windows或者OS X那样桌面体验的Linux桌面版:你要的都在里面,而且它是被同一个目标一致的团队中的同一个人写出来的。天,即使是一个应用程序发出的sudo请求都感觉是Gnome下的一个特意设计的部分,就像在Windows下的一样。而在KDE它就像是任何应用程序都能创建的那种随机外观的弹窗。它不像是以系统的一部分这样的正式身份停下来说“嘿,有个东西要请求管理员权限!你要给它吗?”。
|
||||
|
||||
KDE让人体验不到有凝聚力的体验。KDE像是在没有方向地打转,感觉没有完整的体验。它就像是一堆东西往不同的的方向移动,只不过恰好它们都有一个共同享有的工具包。如果开发者对此很开心,那么好吧,他们开心就好,但是如果他们想提供最好体验的话,那么就需要多关注那些小地方了。用户体验跟直观应当做为每一个应用程序的设计中心,应当有一个视野,知道KDE要提供什么——并且——知道它看起来应该是什么样的。
|
||||
|
||||
是不是有什么原因阻止我在KDE下使用Gnome磁盘管理? Rhythmbox? Evolution? 没有。没有。没有。但是这样说又错过了关键。Gnome和KDE都称它们为“桌面环境”。那么它们就应该是完整的环境,这意味着他们的各个部件应该汇集并紧密结合在一起,意味着你使用它们环境下的工具,因为它们说“您在一个完整的桌面中需要的任何东西,我们都支持。”说真的?只有Gnome看起来能符合完整的要求。KDE在“汇集在一起”这一方面感觉就像个半成品,更不用说提供“完整体验”中你所需要的东西。Gnome磁盘管理没有相应的对手——kpartionmanage要求ROOT权限。KDE不运行“首次用户注册”的过程(原文:No 'First Time User' run through.可能是指系统安装过程中KDE没有创建新用户的过程,译注) ,现在也不过是在Kubuntu下引入了一个用户管理器。老天,Gnome甚至提供了地图,笔记,日历和时钟应用。这些应用都是百分百要紧的吗?不,当然不了。但是正是这些应用帮助Gnome推动“Gnome是一种完整丰富的体验”的想法。
|
||||
|
||||
我吐槽的KDE问题并非不可能解决,决对不是这样的!但是它需要人去关心它。它需要开发者为他们的作品感到自豪,而不仅仅是为它们实现的功能而感到自豪——组织的价值可大了去了。别夺走用户设置选项的能力——GNOME 3.x就是因为缺乏配置选项的能力而为我所诟病,但别把“好吧,你想怎么设置就怎么设置,”作为借口而不提供任何理智的默认设置。默认设置是用户将看到的东西,它们是用户从打开软件的第一刻开始进行评判的关键。给用户留个好印象吧。
|
||||
|
||||
我知道KDE开发者们知道设计很重要,这也是为什么Visual Design Group(视觉设计团体)存在的原因,但是感觉好像他们没有让VDG充分发挥。所以KDE里存在组织上的缺陷。不是KDE没办法完整,不是它没办法汇集整合在一起然后解决衰败问题,只是开发者们没做到。他们瞄准了靶心……但是偏了。
|
||||
|
||||
还有,在任何人说这句话之前……千万别说“补丁很受欢迎啊"。因为当我开心的为个人提交补丁时,只要开发者坚持以他们喜欢的却不直观的方式干事,更多这样的烦事就会不断发生。这不关Muon有没有中心对齐。也不关Amarok的界面太丑。也不关每次我敲下快捷键后,弹出的音量和亮度调节窗口占用了我一大块的屏幕“房地产”(说真的,有人会去缩小这些东西)。
|
||||
|
||||
这跟心态的冷漠有关,跟开发者们在为他们的应用设计UI时根本就不多加思考有关。KDE团队做的东西都工作得很好。Amarok能播放音乐。Dragon能播放视频。Kwin或Qt和kdelibs似乎比Mutter/gtk更有力更效率(仅根本我的电池电量消耗计算。非科学性测试)。这些都很好,很重要……但是它们呈现的方式也很重要。甚至可以说,呈现方式是最重要的,因为它是用户看到的和与之交互的东西。
|
||||
|
||||
KDE应用开发者们……让VDG参与进来吧。让VDG审查并核准每一个”核心“应用,让一个VDG的UI/UX专家来设计应用的使用模式和使用流程,以此保证其直观性。真见鬼,不管你们在开发的是啥应用,仅仅把它的模型发到VDG论坛寻求反馈甚至都可能都能得到一些非常好的指点跟反馈。你有这么好的资源在这,现在赶紧用吧。
|
||||
|
||||
我不想说得好像我一点都不懂感恩。我爱KDE,我爱那些志愿者们为了给Linux用户一个可视化的桌面而付出的工作与努力,也爱可供选择的Gnome。正是因为我关心我才写这篇文章。因为我想看到更好的KDE,我想看到它走得比以前更加遥远。而这样做需要每个人继续努力,并且需要人们不再躲避批评。它需要人们对系统互动及系统崩溃的地方都保持诚实。如果我们不能直言批评,如果我们不说”这真垃圾!”,那么情况永远不会变好。
|
||||
|
||||
这周后我会继续使用Gnome吗?可能不,不。Gnome还在试着强迫我接受其工作流,而我不想追随,也不想遵循,因为我在使用它的时候感觉变得不够高效,因为它并不遵循我的思维模式。可是对于我的朋友们,当他们问我“我该用哪种桌面环境?”我可能会推荐Gnome,特别是那些不大懂技术,只要求“能工作”就行的朋友。根据目前KDE的形势来看,这可能是我能说出的最狠毒的评估了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.phoronix.com/scan.php?page=article&item=gnome-week-editorial&num=5
|
||||
|
||||
作者:Eric Griffith
|
||||
译者:[XLCYun](https://github.com/XLCYun)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,147 @@
|
||||
Linux小技巧:Chrome小游戏,文字说话,计划作业,重复执行命令
|
||||
================================================================================
|
||||
|
||||
重要的事情说两遍,我完成了一个[Linux提示与彩蛋][1]系列,让你的Linux获得更多创造和娱乐。
|
||||
|
||||

|
||||
|
||||
Linux提示与彩蛋系列
|
||||
|
||||
本文,我将会讲解Google-chrome内建小游戏,在终端中如何让文字说话,使用‘at’命令设置作业和使用watch命令重复执行命令。
|
||||
|
||||
### 1. Google Chrome 浏览器小游戏彩蛋 ###
|
||||
|
||||
网线脱掉或者其他什么原因连不上网时,Google Chrome就会出现一个小游戏。声明,我并不是游戏玩家,因此我的电脑上并没有安装任何第三方的恶意游戏。安全是第一位。
|
||||
|
||||
所以当Internet发生出错,会出现一个这样的界面:
|
||||
|
||||

|
||||
|
||||
不能连接到互联网
|
||||
|
||||
按下空格键来激活Google-chrome彩蛋游戏。游戏没有时间限制。并且还不需要浪费时间安装使用。
|
||||
|
||||
不需要第三方软件的支持。同样支持Windows和Mac平台,但是我的平台是Linux,我也只谈论Linux。当然在Linux,这个游戏运行很好。游戏简单,但也很花费时间。
|
||||
|
||||
使用空格/向上方向键来跳跃。请看下列截图:
|
||||
|
||||

|
||||
|
||||
Google Chrome中玩游戏
|
||||
|
||||
### 2. Linux 终端中朗读文字 ###
|
||||
|
||||
对于那些不能文字朗读的设备,有个小工具可以实现文字说话的转换器。
|
||||
espeak支持多种语言,可以及时朗读输入文字。
|
||||
|
||||
系统应该默认安装了Espeak,如果你的系统没有安装,你可以使用下列命令来安装:
|
||||
|
||||
# apt-get install espeak (Debian)
|
||||
# yum install espeak (CentOS)
|
||||
# dnf install espeak (Fedora 22 onwards)
|
||||
|
||||
You may ask espeak to accept Input Interactively from standard Input device and convert it to speech for you. You may do:
|
||||
你可以设置接受从标准输入的交互地输入并及时转换成语音朗读出来。这样设置:
|
||||
|
||||
$ espeak [按回车键]
|
||||
|
||||
更详细的输出你可以这样做:
|
||||
|
||||
$ espeak --stdout | aplay [按回车键][这里需要双击]
|
||||
|
||||
espeak设置灵活,也可以朗读文本文件。你可以这样设置:
|
||||
|
||||
$ espeak --stdout /path/to/text/file/file_name.txt | aplay [Hit Enter]
|
||||
|
||||
espeak可以设置朗读速度。默认速度是160词每分钟。使用-s参数来设置。
|
||||
|
||||
设置30词每分钟:
|
||||
|
||||
$ espeak -s 30 -f /path/to/text/file/file_name.txt | aplay
|
||||
|
||||
设置200词每分钟:
|
||||
|
||||
$ espeak -s 200 -f /path/to/text/file/file_name.txt | aplay
|
||||
|
||||
让其他语言说北印度语(作者母语),这样设置:
|
||||
|
||||
$ espeak -v hindi --stdout 'टेकमिंट विश्व की एक बेहतरीन लाइंक्स आधारित वेबसाइट है|' | aplay
|
||||
|
||||
espeak支持多种语言,支持自定义设置。使用下列命令来获得语言表:
|
||||
|
||||
$ espeak --voices
|
||||
|
||||
### 3. 快速计划作业 ###
|
||||
|
||||
我们已经非常熟悉使用[cron][2]后台执行一个计划命令。
|
||||
|
||||
Cron是一个Linux系统管理的高级命令,用于计划定时任务如备份或者指定时间或间隔的任何事情。
|
||||
|
||||
但是,你是否知道at命令可以让你计划一个作业或者命令在指定时间?at命令可以指定时间和指定内容执行作业。
|
||||
|
||||
例如,你打算在早上11点2分执行uptime命令,你只需要这样做:
|
||||
|
||||
$ at 11:02
|
||||
uptime >> /home/$USER/uptime.txt
|
||||
Ctrl+D
|
||||
|
||||

|
||||
|
||||
Linux中计划作业
|
||||
|
||||
检查at命令是否成功设置,使用:
|
||||
|
||||
$ at -l
|
||||
|
||||

|
||||
|
||||
浏览计划作业
|
||||
|
||||
at支持计划多个命令,例如:
|
||||
|
||||
$ at 12:30
|
||||
Command – 1
|
||||
Command – 2
|
||||
…
|
||||
command – 50
|
||||
…
|
||||
Ctrl + D
|
||||
|
||||
### 4. 特定时间重复执行命令 ###
|
||||
|
||||
有时,我们可以需要在指定时间间隔执行特定命令。例如,每3秒,想打印一次时间。
|
||||
|
||||
查看现在时间,使用下列命令。
|
||||
|
||||
$ date +"%H:%M:%S
|
||||
|
||||

|
||||
|
||||
Linux中查看日期和时间
|
||||
|
||||
为了查看这个命令每三秒的输出,我需要运行下列命令:
|
||||
|
||||
$ watch -n 3 'date +"%H:%M:%S"'
|
||||
|
||||

|
||||
|
||||
Linux中watch命令
|
||||
|
||||
watch命令的‘-n’开关设定时间间隔。在上诉命令中,我们定义了时间间隔为3秒。你可以按你的需求定义。同样watch
|
||||
也支持其他命令或者脚本。
|
||||
|
||||
至此。希望你喜欢这个系列的文章,让你的linux更有创造性,获得更多快乐。所有的建议欢迎评论。欢迎你也看看其他文章,谢谢。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/text-to-speech-in-terminal-schedule-a-job-and-watch-commands-in-linux/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[VicYu/Vic020](http://vicyu.net)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/tag/linux-tricks/
|
||||
[2]:http://www.tecmint.com/11-cron-scheduling-task-examples-in-linux/
|
||||
@ -0,0 +1,188 @@
|
||||
|
||||
在 Linux 中怎样将 MySQL 迁移到 MariaDB 上
|
||||
================================================================================
|
||||
|
||||
自从甲骨文收购 MySQL 后,很多 MySQL 的开发者和用户放弃了 MySQL 由于甲骨文对 MySQL 的开发和维护更多倾向于闭门的立场。在社区驱动下,促使更多人移到 MySQL 的另一个分支中,叫 MariaDB。在原有 MySQL 开发人员的带领下,MariaDB 的开发遵循开源的理念,并确保 [它的二进制格式与 MySQL 兼容][1]。Linux 发行版如 Red Hat 家族(Fedora,CentOS,RHEL),Ubuntu 和Mint,openSUSE 和 Debian 已经开始使用,并支持 MariaDB 作为 MySQL 的简易替换品。
|
||||
|
||||
如果想要将 MySQL 中的数据库迁移到 MariaDB 中,这篇文章就是你所期待的。幸运的是,由于他们的二进制兼容性,MySQL-to-MariaDB 迁移过程是非常简单的。如果你按照下面的步骤,将 MySQL 迁移到 MariaDB 会是无痛的。
|
||||
|
||||
### 准备 MySQL 数据库和表 ###
|
||||
|
||||
出于演示的目的,我们在做迁移之前在数据库中创建一个测试的 MySQL 数据库和表。如果你在 MySQL 中已经有了要迁移到 MariaDB 的数据库,跳过此步骤。否则,按以下步骤操作。
|
||||
|
||||
在终端输入 root 密码登录到 MySQL 。
|
||||
|
||||
$ mysql -u root -p
|
||||
|
||||
创建一个数据库和表。
|
||||
|
||||
mysql> create database test01;
|
||||
mysql> use test01;
|
||||
mysql> create table pet(name varchar(30), owner varchar(30), species varchar(20), sex char(1));
|
||||
|
||||
在表中添加一些数据。
|
||||
|
||||
mysql> insert into pet values('brandon','Jack','puddle','m'),('dixie','Danny','chihuahua','f');
|
||||
|
||||
退出 MySQL 数据库.
|
||||
|
||||
### 备份 MySQL 数据库 ###
|
||||
|
||||
下一步是备份现有的 MySQL 数据库。使用下面的 mysqldump 命令导出现有的数据库到文件中。运行此命令之前,请确保你的 MySQL 服务器上启用了二进制日志。如果你不知道如何启用二进制日志,请参阅结尾的教程说明。
|
||||
|
||||
$ mysqldump --all-databases --user=root --password --master-data > backupdb.sql
|
||||
|
||||
|
||||
|
||||
现在,在卸载 MySQL 之前先在系统上备份 my.cnf 文件。此步是可选的。
|
||||
|
||||
$ sudo cp /etc/mysql/my.cnf /opt/my.cnf.bak
|
||||
|
||||
### 卸载 MySQL ###
|
||||
|
||||
首先,停止 MySQL 服务。
|
||||
|
||||
$ sudo service mysql stop
|
||||
|
||||
或者:
|
||||
|
||||
$ sudo systemctl stop mysql
|
||||
|
||||
或:
|
||||
|
||||
$ sudo /etc/init.d/mysql stop
|
||||
|
||||
然后继续下一步,使用以下命令移除 MySQL 和配置文件。
|
||||
|
||||
在基于 RPM 的系统上 (例如, CentOS, Fedora 或 RHEL):
|
||||
|
||||
$ sudo yum remove mysql* mysql-server mysql-devel mysql-libs
|
||||
$ sudo rm -rf /var/lib/mysql
|
||||
|
||||
在基于 Debian 的系统上(例如, Debian, Ubuntu 或 Mint):
|
||||
|
||||
$ sudo apt-get remove mysql-server mysql-client mysql-common
|
||||
$ sudo apt-get autoremove
|
||||
$ sudo apt-get autoclean
|
||||
$ sudo deluser mysql
|
||||
$ sudo rm -rf /var/lib/mysql
|
||||
|
||||
### 安装 MariaDB ###
|
||||
|
||||
在 CentOS/RHEL 7和Ubuntu(14.04或更高版本)上,最新的 MariaDB 包含在其官方源。在 Fedora 上,自19版本后 MariaDB 已经替代了 MySQL。如果你使用的是旧版本或 LTS 类型如 Ubuntu 13.10 或更早的,你仍然可以通过添加其官方仓库来安装 MariaDB。
|
||||
|
||||
[MariaDB 网站][2] 提供了一个在线工具帮助你依据你的 Linux 发行版中来添加 MariaDB 的官方仓库。此工具为 openSUSE, Arch Linux, Mageia, Fedora, CentOS, RedHat, Mint, Ubuntu, 和 Debian 提供了 MariaDB 的官方仓库.
|
||||
|
||||

|
||||
|
||||
下面例子中,我们使用 Ubuntu 14.04 发行版和 CentOS 7 配置 MariaDB 库。
|
||||
|
||||
**Ubuntu 14.04**
|
||||
|
||||
$ sudo apt-get install software-properties-common
|
||||
$ sudo apt-key adv --recv-keys --keyserver hkp://keyserver.ubuntu.com:80 0xcbcb082a1bb943db
|
||||
$ sudo add-apt-repository 'deb http://mirror.mephi.ru/mariadb/repo/5.5/ubuntu trusty main'
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install mariadb-server
|
||||
|
||||
**CentOS 7**
|
||||
|
||||
以下为 MariaDB 创建一个自定义的 yum 仓库文件。
|
||||
|
||||
$ sudo vi /etc/yum.repos.d/MariaDB.repo
|
||||
|
||||
----------
|
||||
|
||||
[mariadb]
|
||||
name = MariaDB
|
||||
baseurl = http://yum.mariadb.org/5.5/centos7-amd64
|
||||
gpgkey=https://yum.mariadb.org/RPM-GPG-KEY-MariaDB
|
||||
gpgcheck=1
|
||||
|
||||
----------
|
||||
|
||||
$ sudo yum install MariaDB-server MariaDB-client
|
||||
|
||||
安装了所有必要的软件包后,你可能会被要求为 root 用户创建一个新密码。设置 root 的密码后,别忘了恢复备份的 my.cnf 文件。
|
||||
|
||||
$ sudo cp /opt/my.cnf /etc/mysql/
|
||||
|
||||
现在启动 MariaDB 服务。
|
||||
|
||||
$ sudo service mariadb start
|
||||
|
||||
或者:
|
||||
|
||||
$ sudo systemctl start mariadb
|
||||
|
||||
或:
|
||||
|
||||
$ sudo /etc/init.d/mariadb start
|
||||
|
||||
### 导入 MySQL 的数据库 ###
|
||||
|
||||
最后,我们将以前导出的数据库导入到 MariaDB 服务器中。
|
||||
|
||||
$ mysql -u root -p < backupdb.sql
|
||||
|
||||
输入你 MariaDB 的 root 密码,数据库导入过程将开始。导入过程完成后,将返回到命令提示符下。
|
||||
|
||||
要检查导入过程是否完全成功,请登录到 MariaDB 服务器,并查看一些样本来检查。
|
||||
|
||||
$ mysql -u root -p
|
||||
|
||||
----------
|
||||
|
||||
MariaDB [(none)]> show databases;
|
||||
MariaDB [(none)]> use test01;
|
||||
MariaDB [test01]> select * from pet;
|
||||
|
||||

|
||||
|
||||
### 结论 ###
|
||||
|
||||
如你在本教程中看到的,MySQL-to-MariaDB 的迁移并不难。MariaDB 相比 MySQL 有很多新的功能,你应该知道的。至于配置方面,在我的测试情况下,我只是将我旧的 MySQL 配置文件(my.cnf)作为 MariaDB 的配置文件,导入过程完全没有出现任何问题。对于配置文件,我建议你在迁移之前请仔细阅读MariaDB 配置选项的文件,特别是如果你正在使用 MySQL 的特殊配置。
|
||||
|
||||
如果你正在运行更复杂的配置有海量的数据库和表,包括群集或主从复制,看一看 Mozilla IT 和 Operations 团队的 [更详细的指南][3] ,或者 [官方的 MariaDB 文档][4]。
|
||||
|
||||
### 故障排除 ###
|
||||
|
||||
1.在运行 mysqldump 命令备份数据库时出现以下错误。
|
||||
|
||||
$ mysqldump --all-databases --user=root --password --master-data > backupdb.sql
|
||||
|
||||
----------
|
||||
|
||||
mysqldump: Error: Binlogging on server not active
|
||||
|
||||
通过使用 "--master-data",你要在导出的输出中包含二进制日志信息,这对于数据库的复制和恢复是有用的。但是,二进制日志未在 MySQL 服务器启用。要解决这个错误,修改 my.cnf 文件,并在 [mysqld] 部分添加下面的选项。
|
||||
|
||||
log-bin=mysql-bin
|
||||
|
||||
保存 my.cnf 文件,并重新启动 MySQL 服务:
|
||||
|
||||
$ sudo service mysql restart
|
||||
|
||||
或者:
|
||||
|
||||
$ sudo systemctl restart mysql
|
||||
|
||||
或:
|
||||
|
||||
$ sudo /etc/init.d/mysql restart
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/migrate-mysql-to-mariadb-linux.html
|
||||
|
||||
作者:[Kristophorus Hadiono][a]
|
||||
译者:[strugglingyouth](https://github.com/译者ID)
|
||||
校对:[strugglingyouth](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/kristophorus
|
||||
[1]:https://mariadb.com/kb/en/mariadb/mariadb-vs-mysql-compatibility/
|
||||
[2]:https://downloads.mariadb.org/mariadb/repositories/#mirror=aasaam
|
||||
[3]:https://blog.mozilla.org/it/2013/12/16/upgrading-from-mysql-5-1-to-mariadb-5-5/
|
||||
[4]:https://mariadb.com/kb/en/mariadb/documentation/
|
||||
@ -0,0 +1,51 @@
|
||||
|
||||
Linux 有问必答 - 如何在 Linux 中统计一个进程的线程数
|
||||
================================================================================
|
||||
> **问题**: 我正在运行一个程序,它在运行时会派生出多个线程。我想知道程序在运行时会有多少线程。在 Linux 中检查进程的线程数最简单的方法是什么?
|
||||
|
||||
如果你想看到 Linux 中每个进程的线程数,有以下几种方法可以做到这一点。
|
||||
|
||||
### 方法一: /proc ###
|
||||
|
||||
proc 伪文件系统,它驻留在 /proc 目录,这是最简单的方法来查看任何活动进程的线程数。 /proc 目录以可读文本文件形式输出,提供现有进程和系统硬件相关的信息如 CPU, interrupts, memory, disk, 等等.
|
||||
|
||||
$ cat /proc/<pid>/status
|
||||
|
||||
上面的命令将显示进程 <pid> 的详细信息,包括过程状态(例如, sleeping, running),父进程 PID,UID,GID,使用的文件描述符的数量,以及上下文切换的数量。输出也包括**进程创建的总线程数**如下所示。
|
||||
|
||||
Threads: <N>
|
||||
|
||||
例如,检查 PID 20571进程的线程数:
|
||||
|
||||
$ cat /proc/20571/status
|
||||
|
||||
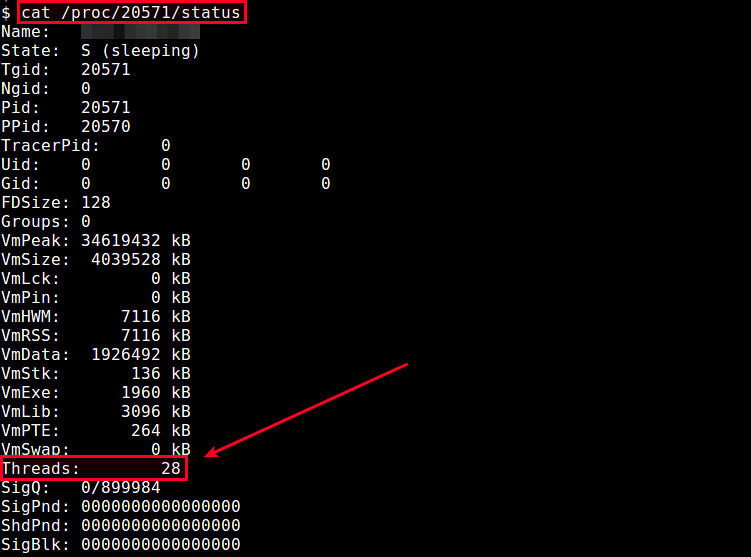
|
||||
|
||||
输出表明该进程有28个线程。
|
||||
|
||||
或者,你可以在 /proc/<pid>/task 中简单的统计目录的数量,如下所示。
|
||||
|
||||
$ ls /proc/<pid>/task | wc
|
||||
|
||||
这是因为,对于一个进程中创建的每个线程,在 /proc/<pid>/task 中会创建一个相应的目录,命名为其线程 ID。由此在 /proc/<pid>/task 中目录的总数表示在进程中线程的数目。
|
||||
|
||||
### 方法二: ps ###
|
||||
|
||||
如果你是功能强大的 ps 命令的忠实用户,这个命令也可以告诉你一个进程(用“H”选项)的线程数。下面的命令将输出进程的线程数。“h”选项需要放在前面。
|
||||
|
||||
$ ps hH p <pid> | wc -l
|
||||
|
||||
如果你想监视一个进程的不同线程消耗的硬件资源(CPU & memory),请参阅[此教程][1]。(注:此文我们翻译过)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/number-of-threads-process-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:http://ask.xmodulo.com/view-threads-process-linux.html
|
||||
@ -0,0 +1,167 @@
|
||||
使用dd命令在Linux和Unix环境下进行硬盘I/O性能检测
|
||||
================================================================================
|
||||
如何使用dd命令测试硬盘的性能?如何在linux操作系统下检测硬盘的读写能力?
|
||||
|
||||
你可以使用以下命令在一个Linux或类Unix操作系统上进行简单的I/O性能测试。
|
||||
|
||||
- **dd命令** :它被用来在Linux和类Unix系统下对硬盘设备进行写性能的检测。
|
||||
- **hparm命令**:它被用来获取或设置硬盘参数,包括测试读性能以及缓存性能等。
|
||||
|
||||
在这篇指南中,你将会学到如何使用dd命令来测试硬盘性能。
|
||||
|
||||
### 使用dd命令来监控硬盘的读写性能:###
|
||||
|
||||
- 打开shell终端(这里貌似不能翻译为终端提示符)。
|
||||
- 通过ssh登录到远程服务器。
|
||||
- 使用dd命令来测量服务器的吞吐率(写速度) `dd if=/dev/zero of=/tmp/test1.img bs=1G count=1 oflag=dsync`
|
||||
- 使用dd命令测量服务器延迟 `dd if=/dev/zero of=/tmp/test2.img bs=512 count=1000 oflag=dsync`
|
||||
|
||||
####理解dd命令的选项###
|
||||
|
||||
在这个例子当中,我将使用搭载Ubuntu Linux 14.04 LTS系统的RAID-10(配有SAS SSD的Adaptec 5405Z)服务器阵列来运行。基本语法为:
|
||||
|
||||
dd if=/dev/input.file of=/path/to/output.file bs=block-size count=number-of-blocks oflag=dsync
|
||||
## GNU dd语法 ##
|
||||
dd if=/dev/zero of=/tmp/test1.img bs=1G count=1 oflag=dsync
|
||||
##另外一种GNU dd的语法 ##
|
||||
dd if=/dev/zero of=/tmp/testALT.img bs=1G count=1 conv=fdatasync
|
||||
|
||||
输出样例:
|
||||
|
||||

|
||||
Fig.01: 使用dd命令获取的服务器吞吐率
|
||||
|
||||
请各位注意在这个实验中,我们写入一个G的数据,可以发现,服务器的吞吐率是135 MB/s,这其中
|
||||
|
||||
- `if=/dev/zero (if=/dev/input.file)` :用来设置dd命令读取的输入文件名。
|
||||
- `of=/tmp/test1.img (of=/path/to/output.file)` :dd命令将input.file写入的输出文件的名字。
|
||||
- `bs=1G (bs=block-size)` :设置dd命令读取的块的大小。例子中为1个G。
|
||||
- `count=1 (count=number-of-blocks)`: dd命令读取的块的个数。
|
||||
- `oflag=dsync (oflag=dsync)` :使用同步I/O。不要省略这个选项。这个选项能够帮助你去除caching的影响,以便呈现给你精准的结果。
|
||||
- `conv=fdatasyn`: 这个选项和`oflag=dsync`含义一样。
|
||||
|
||||
在这个例子中,一共写了1000次,每次写入512字节来获得RAID10服务器的延迟时间:
|
||||
|
||||
dd if=/dev/zero of=/tmp/test2.img bs=512 count=1000 oflag=dsync
|
||||
|
||||
输出样例:
|
||||
|
||||
1000+0 records in
|
||||
1000+0 records out
|
||||
512000 bytes (512 kB) copied, 0.60362 s, 848 kB/s
|
||||
|
||||
请注意服务器的吞吐率以及延迟时间也取决于服务器/应用的加载。所以我推荐你在一个刚刚重启过并且处于峰值时间的服务器上来运行测试,以便得到更加准确的度量。现在你可以在你的所有设备上互相比较这些测试结果了。
|
||||
|
||||
####为什么服务器的吞吐率和延迟时间都这么差?###
|
||||
|
||||
低的数值并不意味着你在使用差劲的硬件。可能是HARDWARE RAID10的控制器缓存导致的。
|
||||
|
||||
使用hdparm命令来查看硬盘缓存的读速度。
|
||||
|
||||
我建议你运行下面的命令2-3次来对设备读性能进行检测,以作为参照和相互比较:
|
||||
|
||||
### 有缓存的硬盘读性能测试——/dev/sda ###
|
||||
hdparm -t /dev/sda1
|
||||
## 或者 ##
|
||||
hdparm -t /dev/sda
|
||||
|
||||
然后运行下面这个命令2-3次来对缓存的读性能进行对照性检测:
|
||||
|
||||
## Cache读基准——/dev/sda ###
|
||||
hdparm -T /dev/sda1
|
||||
## 或者 ##
|
||||
hdparm -T /dev/sda
|
||||
|
||||
或者干脆把两个测试结合起来:
|
||||
|
||||
hdparm -Tt /dev/sda
|
||||
|
||||
输出样例:
|
||||
|
||||

|
||||
Fig.02: 检测硬盘读入以及缓存性能的Linux hdparm命令
|
||||
|
||||
请再一次注意由于文件文件操作的缓存属性,你将总是会看到很高的读速度。
|
||||
|
||||
**使用dd命令来测试读入速度**
|
||||
|
||||
为了获得精确的读测试数据,首先在测试前运行下列命令,来将缓存设置为无效:
|
||||
|
||||
flush
|
||||
echo 3 | sudo tee /proc/sys/vm/drop_caches
|
||||
time time dd if=/path/to/bigfile of=/dev/null bs=8k
|
||||
|
||||
**笔记本上的示例**
|
||||
|
||||
运行下列命令:
|
||||
|
||||
### Cache存在的Debian系统笔记本吞吐率###
|
||||
dd if=/dev/zero of=/tmp/laptop.bin bs=1G count=1 oflag=direct
|
||||
|
||||
###使cache失效###
|
||||
hdparm -W0 /dev/sda
|
||||
|
||||
###没有Cache的Debian系统笔记本吞吐率###
|
||||
dd if=/dev/zero of=/tmp/laptop.bin bs=1G count=1 oflag=direct
|
||||
|
||||
**苹果OS X Unix(Macbook pro)的例子**
|
||||
|
||||
GNU dd has many more options but OS X/BSD and Unix-like dd command need to run as follows to test real disk I/O and not memory add sync option as follows:
|
||||
GNU dd命令有其他许多选项但是在 OS X/BSD 以及类Unix中, dd命令需要像下面那样执行来检测去除掉内存地址同步的硬盘真实I/O性能:
|
||||
|
||||
## 运行这个命令2-3次来获得更好地结果 ###
|
||||
time sh -c "dd if=/dev/zero of=/tmp/testfile bs=100k count=1k && sync"
|
||||
|
||||
输出样例:
|
||||
|
||||
1024+0 records in
|
||||
1024+0 records out
|
||||
104857600 bytes transferred in 0.165040 secs (635346520 bytes/sec)
|
||||
|
||||
real 0m0.241s
|
||||
user 0m0.004s
|
||||
sys 0m0.113s
|
||||
|
||||
本人Macbook Pro的写速度是635346520字节(635.347MB/s)。
|
||||
|
||||
**不喜欢用命令行?^_^**
|
||||
|
||||
你可以在Linux或基于Unix的系统上使用disk utility(gnome-disk-utility)这款工具来得到同样的信息。下面的那个图就是在我的Fedora Linux v22 VM上截取的。
|
||||
|
||||
**图形化方法**
|
||||
|
||||
点击“Activites”或者“Super”按键来在桌面和Activites视图间切换。输入“Disks”
|
||||
|
||||

|
||||
Fig.03: 打开Gnome硬盘工具
|
||||
|
||||
在左边的面板上选择你的硬盘,点击configure按钮,然后点击“Benchmark partition”:
|
||||
|
||||

|
||||
Fig.04: 评测硬盘/分区
|
||||
|
||||
最后,点击“Start Benchmark...”按钮(你可能被要求输入管理员用户名和密码):
|
||||
|
||||

|
||||
Fig.05: 最终的评测结果
|
||||
|
||||
如果你要问,我推荐使用哪种命令和方法?
|
||||
|
||||
- 我推荐在所有的类Unix系统上使用dd命令(`time sh -c "dd if=/dev/zero of=/tmp/testfile bs=100k count=1k && sync`)
|
||||
- 如果你在使用GNU/Linux,使用dd命令 (`dd if=/dev/zero of=/tmp/testALT.img bs=1G count=1 conv=fdatasync`)
|
||||
- 确保你每次使用时,都调整了count以及bs参数以获得更好的结果。
|
||||
- GUI方法只适合桌面系统为Gnome2或Gnome3的Linux/Unix笔记本用户。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cyberciti.biz/faq/howto-linux-unix-test-disk-performance-with-dd-command/
|
||||
|
||||
作者:Vivek Gite
|
||||
译者:[DongShuaike](https://github.com/DongShuaike)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,182 @@
|
||||
RHCE 第三部分 - 如何使用 Linux 工具集产生和发送系统活动报告
|
||||
================================================================================
|
||||
作为一个系统工程师,你经常需要生成一些显示系统资源利用率的报告,以便确保:1)正最佳利用它们,2)防止出现瓶颈,3)确保可扩展性,以及其它原因。
|
||||
|
||||

|
||||
|
||||
RHCE 第三部分:监视 Linux 性能活动报告
|
||||
|
||||
除了著名的用于检测磁盘、内存和 CPU 使用率的原生 Linux 工具 - 可以给出很多例子,红帽企业版 Linux 7 还提供了两个额外的工具集用于为你的报告增加可以收集的数据:sysstat 和 dstat。
|
||||
|
||||
在这篇文章中,我们会介绍两者,但首先让我们来回顾一下传统工具的使用。
|
||||
|
||||
### 原生 Linux 工具 ###
|
||||
|
||||
使用 df,你可以报告磁盘空间以及文件系统的 inode 使用情况。你需要监视两者,因为缺少磁盘空间会阻止你保存更多文件(甚至会导致系统崩溃),就像耗尽 inode 意味着你不能将文件链接到对应的数据结构,从而导致同样的结果:你不能将那些文件保存到磁盘中。
|
||||
|
||||
# df -h [以人类可读形式显示输出]
|
||||
# df -h --total [生成总计]
|
||||
|
||||

|
||||
|
||||
检查 Linux 总的磁盘使用
|
||||
|
||||
# df -i [显示文件系统的 inode 数目]
|
||||
# df -i --total [生成总计]
|
||||
|
||||

|
||||
|
||||
检查 Linux 总的 inode 数目
|
||||
|
||||
用 du,你可以估计文件、目录或文件系统的文件空间使用。
|
||||
|
||||
举个例子,让我们来看看 /home 目录使用了多少空间,它包括了所有用户的个人文件。第一条命令会返回整个 /home 目录当前使用的所有空间,第二条命令会显示子目录的分类列表:
|
||||
|
||||
# du -sch /home
|
||||
# du -sch /home/*
|
||||
|
||||

|
||||
|
||||
检查 Linux 目录磁盘大小
|
||||
|
||||
别错过了:
|
||||
|
||||
- [检查 Linux 磁盘空间使用的 12 个 ‘df’ 命令例子][1]
|
||||
- [查看文件/目录磁盘使用的 10 个 ‘du’ 命令例子][2]
|
||||
|
||||
另一个你工具集中不容忽视的工具就是 vmstat。它允许你查看进程、CPU 和 内存使用、磁盘活动以及其它的大概信息。
|
||||
|
||||
如果不带参数运行,vmstat 会返回自从上一次启动后的平均信息。尽管你可能以这种方式使用该命令有一段时间了,再看一些系统使用率的例子会有更多帮助,例如在例子中定义了时间间隔。
|
||||
|
||||
例如
|
||||
|
||||
# vmstat 5 10
|
||||
|
||||
会每个 5 秒返回 10 个事例:
|
||||
|
||||

|
||||
|
||||
检查 Linux 系统性能
|
||||
|
||||
正如你从上面图片看到的,vmstat 的输出分为很多列:proc(process)、memory、swap、io、system、和 CPU。每个字段的意义可以在 vmstat man 手册的 FIELD DESCRIPTION 部分找到。
|
||||
|
||||
在哪里 vmstat 可以派上用场呢?让我们在 yum 升级之前和升级时检查系统行为:
|
||||
|
||||
# vmstat -a 1 5
|
||||
|
||||

|
||||
|
||||
Vmstat Linux 性能监视
|
||||
|
||||
请注意当磁盘上的文件被更改时,活跃内存的数量增加,写到磁盘的块数目(bo)和属于用户进程的 CPU 时间(us)也是这样。
|
||||
|
||||
或者一个保存大文件到磁盘时(dsync 引发):
|
||||
|
||||
# vmstat -a 1 5
|
||||
# dd if=/dev/zero of=dummy.out bs=1M count=1000 oflag=dsync
|
||||
|
||||

|
||||
|
||||
Vmstat Linux 磁盘性能监视
|
||||
|
||||
在这个例子中,我们可以看到很大数目的块被写入到磁盘(bo),这正如预期的那样,同时 CPU 处理任务之前等待 IO 操作完成的时间(wa)也增加了。
|
||||
|
||||
**别错过**: [Vmstat – Linux 性能监视][3]
|
||||
|
||||
### 其它 Linux 工具 ###
|
||||
|
||||
正如本文介绍部分提到的,这里有其它的工具你可以用来检测系统状态和利用率(不仅红帽,其它主流发行版的官方支持库中也提供了这些工具)。
|
||||
|
||||
sysstat 软件包包含以下工具:
|
||||
|
||||
- sar (收集、报告、或者保存系统活动信息)。
|
||||
- sadf (以多种方式显式 sar 收集的数据)。
|
||||
- mpstat (报告处理器相关的统计信息)。
|
||||
- iostat (报告 CPU 统计信息和设备以及分区的 IO统计信息)。
|
||||
- pidstat (报告 Linux 任务统计信息)。
|
||||
- nfsiostat (报告 NFS 的输出/输出统计信息)。
|
||||
- cifsiostat (报告 CIFS 统计信息)
|
||||
- sa1 (收集并保存系统活动日常文件的二进制数据)。
|
||||
- sa2 (在 /var/log/sa 目录写每日报告)。
|
||||
|
||||
dstat 为这些工具提供的功能添加了一些额外的特性,以及更多的计数器和更大的灵活性。你可以通过运行 yum info sysstat 或者 yum info dstat 找到每个工具完整的介绍,或者安装完成后分别查看每个工具的 man 手册。
|
||||
|
||||
安装两个软件包:
|
||||
|
||||
# yum update && yum install sysstat dstat
|
||||
|
||||
sysstat 主要的配置文件是 /etc/sysconfig/sysstat。你可以在该文件中找到下面的参数:
|
||||
|
||||
# How long to keep log files (in days).
|
||||
# If value is greater than 28, then log files are kept in
|
||||
# multiple directories, one for each month.
|
||||
HISTORY=28
|
||||
# Compress (using gzip or bzip2) sa and sar files older than (in days):
|
||||
COMPRESSAFTER=31
|
||||
# Parameters for the system activity data collector (see sadc manual page)
|
||||
# which are used for the generation of log files.
|
||||
SADC_OPTIONS="-S DISK"
|
||||
# Compression program to use.
|
||||
ZIP="bzip2"
|
||||
|
||||
sysstat 安装完成后,/etc/cron.d/sysstat 中会添加和启用两个 cron 作业。第一个作业每 10 分钟运行系统活动计数工具并在 /var/log/sa/saXX 中保存报告,其中 XX 是该月的一天。
|
||||
|
||||
因此,/var/log/sa/sa05 会包括该月份第 5 天所有的系统活动报告。这里假设我们在上面的配置文件中对 HISTORY 变量使用默认的值:
|
||||
|
||||
*/10 * * * * root /usr/lib64/sa/sa1 1 1
|
||||
|
||||
第二个作业在每天夜间 11:53 生成每日进程计数总结并把它保存到 /var/log/sa/sarXX 文件,其中 XX 和之前例子中的含义相同:
|
||||
|
||||
53 23 * * * root /usr/lib64/sa/sa2 -A
|
||||
|
||||
例如,你可能想要输出该月份第 6 天从上午 9:30 到晚上 5:30 的系统统计信息到一个 LibreOffice Calc 或 Microsoft Excel 可以查看的 .csv 文件(它也允许你创建表格和图片):
|
||||
|
||||
# sadf -s 09:30:00 -e 17:30:00 -dh /var/log/sa/sa06 -- | sed 's/;/,/g' > system_stats20150806.csv
|
||||
|
||||
你可以在上面的 sadf 命令中用 -j 标记代替 -d 以 JSON 格式输出系统统计信息,这当你在 web 应用中使用这些数据的时候非常有用。
|
||||
|
||||

|
||||
|
||||
Linux 系统统计信息
|
||||
|
||||
最后,让我们看看 dstat 提供什么功能。请注意如果不带参数运行,dstat 默认使用 -cdngy(表示 CPU、磁盘、网络、内存页、和系统统计信息),并每秒添加一行(可以在任何时候用 Ctrl + C 中断执行):
|
||||
|
||||
# dstat
|
||||
|
||||

|
||||
|
||||
Linux 磁盘统计检测
|
||||
|
||||
要输出统计信息到 .csv 文件,可以用 -output 标记后面跟一个文件名称。让我们来看看在 LibreOffice Calc 中该文件看起来是怎样的:
|
||||
|
||||

|
||||
|
||||
检测 Linux 统计信息输出
|
||||
|
||||
我强烈建议你查看 dstat 的 man 手册,为了方便你的阅读用 PDF 格式包括本文以及 sysstat 的 man 手册。你会找到其它能帮助你创建自定义的详细系统活动报告的选项。
|
||||
|
||||
**别错过**: [Sysstat – Linux 的使用活动检测工具][4]
|
||||
|
||||
### 总结 ###
|
||||
|
||||
在该指南中我们解释了如何使用 Linux 原生工具以及 RHEL 7 提供的特定工具来生成系统使用报告。在某种情况下,你可能像依赖最好的朋友那样依赖这些报告。
|
||||
|
||||
你很可能使用过这篇指南中我们没有介绍到的其它工具。如果真是这样的话,用下面的表格和社区中的其他成员一起分享吧,也可以是任何其它的建议/疑问/或者评论。
|
||||
|
||||
我们期待你的回复。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-performance-monitoring-and-file-system-statistics-reports/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/how-to-check-disk-space-in-linux/
|
||||
[2]:http://www.tecmint.com/check-linux-disk-usage-of-files-and-directories/
|
||||
[3]:http://www.tecmint.com/linux-performance-monitoring-with-vmstat-and-iostat-commands/
|
||||
[4]:http://www.tecmint.com/install-sysstat-in-linux/
|
||||
@ -0,0 +1,214 @@
|
||||
RHECSA 系列:RHEL7 中的进程管理:开机,关机,以及两者之间的所有其他事项 – Part 5
|
||||
================================================================================
|
||||
我们将概括和简要地复习从你按开机按钮来打开你的 RHEL 7 服务器到呈现出命令行界面的登录屏幕之间所发生的所有事情,以此来作为这篇文章的开始。
|
||||
|
||||

|
||||
|
||||
Linux 开机过程
|
||||
|
||||
**请注意:**
|
||||
|
||||
1. 相同的基本原则也可以应用到其他的 Linux 发行版本中,但可能需要较小的更改,并且
|
||||
2. 下面的描述并不是旨在给出开机过程的一个详尽的解释,而只是介绍一些基础的东西
|
||||
|
||||
### Linux 开机过程 ###
|
||||
|
||||
1.初始化 POST(加电自检)并执行硬件检查;
|
||||
|
||||
2.当 POST 完成后,系统的控制权将移交给启动管理器的第一阶段,它存储在一个硬盘的引导扇区(对于使用 BIOS 和 MBR 的旧式的系统)或存储在一个专门的 (U)EFI 分区上。
|
||||
|
||||
3.启动管理器的第一阶段完成后,接着进入启动管理器的第二阶段,通常大多数使用的是 GRUB(GRand Unified Boot Loader 的简称),它驻留在 `/boot` 中,反过来加载内核和驻留在 RAM 中的初始化文件系统(被称为 initramfs,它包含执行必要操作所需要的程序和二进制文件,以此来最终挂载真实的根文件系统)。
|
||||
|
||||
4.接着经历了闪屏过后,呈现在我们眼前的是类似下图的画面,它允许我们选择一个操作系统和内核来启动:
|
||||
|
||||

|
||||
|
||||
启动菜单屏幕
|
||||
|
||||
5.然后内核对挂载到系统的硬件进行设置,一旦根文件系统被挂载,接着便启动 PID 为 1 的进程,反过来这个进程将初始化其他的进程并最终呈现给我们一个登录提示符界面。
|
||||
|
||||
注意:假如我们想在后面这样做(注:这句话我总感觉不通顺,不明白它的意思,希望改一下),我们可以使用 [dmesg 命令][1](注:这篇文章已经翻译并发表了,链接是 https://linux.cn/article-3587-1.html )并使用这个系列里的上一篇文章中解释过的工具(注:即 grep)来过滤它的输出。
|
||||
|
||||

|
||||
|
||||
登录屏幕和进程的 PID
|
||||
|
||||
在上面的例子中,我们使用了众所周知的 `ps` 命令来显示在系统启动过程中的一系列当前进程的信息,它们的父进程(或者换句话说,就是那个开启这些进程的进程) 为 systemd(大多数现代的 Linux 发行版本已经切换到的系统和服务管理器):
|
||||
|
||||
# ps -o ppid,pid,uname,comm --ppid=1
|
||||
|
||||
记住 `-o`(为 -format 的简写)选项允许你以一个自定义的格式来显示 ps 的输出,以此来满足你的需求;这个自定义格式使用 man ps 里 STANDARD FORMAT SPECIFIERS 一节中的特定关键词。
|
||||
|
||||
另一个你想自定义 ps 的输出而不是使用其默认输出的情形是:当你需要找到引起 CPU 或内存消耗过多的那些进程,并按照下列方式来对它们进行排序时:
|
||||
|
||||
# ps aux --sort=+pcpu # 以 %CPU 来排序(增序)
|
||||
# ps aux --sort=-pcpu # 以 %CPU 来排序(降序)
|
||||
# ps aux --sort=+pmem # 以 %MEM 来排序(增序)
|
||||
# ps aux --sort=-pmem # 以 %MEM 来排序(降序)
|
||||
# ps aux --sort=+pcpu,-pmem # 结合 %CPU (增序) 和 %MEM (降序)来排列
|
||||
|
||||

|
||||
|
||||
自定义 ps 命令的输出
|
||||
|
||||
### systemd 的一个介绍 ###
|
||||
|
||||
在 Linux 世界中,很少有决定能够比在主流的 Linux 发行版本中采用 systemd 引起更多的争论。systemd 的倡导者根据以下事实命名其主要的优势:
|
||||
|
||||
另外请阅读: ['init' 和 'systemd' 背后的故事][2]
|
||||
|
||||
1. 在系统启动期间,systemd 允许并发地启动更多的进程(相比于先前的 SysVinit,SysVinit 似乎总是表现得更慢,因为它一个接一个地启动进程,检查一个进程是否依赖于另一个进程,然后等待守护进程去开启可以开始的更多的服务),并且
|
||||
2. 在一个运行着的系统中,它作为一个动态的资源管理器来工作。这样在开机期间,当一个服务被需要时,才启动它(以此来避免消耗系统资源)而不是在没有一个合理的原因的情况下启动额外的服务。
|
||||
3. 向后兼容 sysvinit 的脚本。
|
||||
|
||||
systemd 由 systemctl 工具控制,假如你带有 SysVinit 背景,你将会对以下的内容感到熟悉:
|
||||
|
||||
- service 工具, 在旧一点的系统中,它被用来管理 SysVinit 脚本,以及
|
||||
- chkconfig 工具, 为系统服务升级和查询运行级别信息
|
||||
- shutdown, 你一定使用过几次来重启或关闭一个运行的系统。
|
||||
|
||||
下面的表格展示了使用传统的工具和 systemctl 之间的相似之处:
|
||||
|
||||
注:表格
|
||||
<table cellspacing="0" border="0">
|
||||
<colgroup width="237"></colgroup>
|
||||
<colgroup width="256"></colgroup>
|
||||
<colgroup width="1945"></colgroup>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td align="left" height="25" bgcolor="#B7B7B7" style="border: 1px solid #000000;"><b><span style="color: black; font-family: Arial; font-size: small;">Legacy tool</span></b></td>
|
||||
<td align="left" bgcolor="#B7B7B7" style="border: 1px solid #000000;"><b><span style="color: black; font-family: Arial; font-size: small;">Systemctl equivalent</span></b></td>
|
||||
<td align="left" bgcolor="#B7B7B7" style="border: 1px solid #000000;"><b><span style="color: black; font-family: Arial; font-size: small;">Description</span></b></td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">service name start</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl start name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Start name (where name is a service)</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">service name stop</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl stop name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Stop name</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">service name condrestart</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl try-restart name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Restarts name (if it’s already running)</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">service name restart</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl restart name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Restarts name</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">service name reload</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl reload name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Reloads the configuration for name</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">service name status</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl status name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Displays the current status of name</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="23" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">service –status-all</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Arial;">Displays the status of all current services</span></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">chkconfig name on</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl enable name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Enable name to run on startup as specified in the unit file (the file to which the symlink points). The process of enabling or disabling a service to start automatically on boot consists in adding or removing symbolic links inside the /etc/systemd/system directory.</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">chkconfig name off</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl disable name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Disables name to run on startup as specified in the unit file (the file to which the symlink points)</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">chkconfig –list name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl is-enabled name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Verify whether name (a specific service) is currently enabled</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="23" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">chkconfig –list</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl –type=service</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Arial;">Displays all services and tells whether they are enabled or disabled</span></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="23" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">shutdown -h now</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl poweroff</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Arial;">Power-off the machine (halt)</span></td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="23" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">shutdown -r now</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl reboot</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Arial;">Reboot the system</span></td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
systemd 也引进了单元(它可能是一个服务,一个挂载点,一个设备或者一个网络套接字)和目标(它们定义了 systemd 如何去管理和同时开启几个相关的进程,并可认为它们与在基于 SysVinit 的系统中的运行级别等价,尽管事实上它们并不等价)。
|
||||
|
||||
### 总结归纳 ###
|
||||
|
||||
其他与进程管理相关,但并不仅限于下面所列的功能的任务有:
|
||||
|
||||
**1. 在考虑到系统资源的使用上,调整一个进程的执行优先级:**
|
||||
|
||||
这是通过 `renice` 工具来完成的,它可以改变一个或多个正在运行着的进程的调度优先级。简单来说,调度优先级是一个允许内核(当前只支持 >= 2.6 的版本)根据某个给定进程被分配的执行优先级(即优先级,从 -20 到 19)来为其分配系统资源的功能。
|
||||
|
||||
`renice` 的基本语法如下:
|
||||
|
||||
# renice [-n] priority [-gpu] identifier
|
||||
|
||||
在上面的通用命令中,第一个参数是将要使用的优先级数值,而另一个参数可以解释为进程 ID(这是默认的设定),进程组 ID,用户 ID 或者用户名。一个常规的用户(即除 root 以外的用户)只可以更改他或她所拥有的进程的调度优先级,并且只能增加优先级的层次(这意味着占用更少的系统资源)。
|
||||
|
||||

|
||||
|
||||
进程调度优先级
|
||||
|
||||
**2. 按照需要杀死一个进程(或终止其正常执行):**
|
||||
|
||||
更精确地说,杀死一个进程指的是通过 [kill 或 pkill][3]命令给该进程发送一个信号,让它优雅地(SIGTERM=15)或立即(SIGKILL=9)结束它的执行。
|
||||
|
||||
这两个工具的不同之处在于前一个被用来终止一个特定的进程或一个进程组,而后一个则允许你在进程的名称和其他属性的基础上,执行相同的动作。
|
||||
|
||||
另外, pkill 与 pgrep 相捆绑,pgrep 提供将受影响的进程的 PID 给 pkill 来使用。例如,在运行下面的命令之前:
|
||||
|
||||
# pkill -u gacanepa
|
||||
|
||||
查看一眼由 gacanepa 所拥有的 PID 或许会带来点帮助:
|
||||
|
||||
# pgrep -l -u gacanepa
|
||||
|
||||

|
||||
|
||||
找到用户拥有的 PID
|
||||
|
||||
默认情况下,kill 和 pkiill 都发送 SIGTERM 信号给进程,如我们上面提到的那样,这个信号可以被忽略(即该进程可能会终止其自身的执行或者不终止),所以当你因一个合理的理由要真正地停止一个运行着的进程,则你将需要在命令行中带上特定的 SIGKILL 信号:
|
||||
|
||||
# kill -9 identifier # 杀死一个进程或一个进程组
|
||||
# kill -s SIGNAL identifier # 同上
|
||||
# pkill -s SIGNAL identifier # 通过名称或其他属性来杀死一个进程
|
||||
|
||||
### 结论 ###
|
||||
|
||||
在这篇文章中,我们解释了在 RHEL 7 系统中,有关开机启动过程的基本知识,并分析了一些可用的工具来帮助你通过使用一般的程序和 systemd 特有的命令来管理进程。
|
||||
|
||||
请注意,这个列表并不旨在涵盖有关这个话题的所有花哨的工具,请随意使用下面的评论栏来添加你自已钟爱的工具和命令。同时欢迎你的提问和其他的评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/rhcsa-exam-boot-process-and-process-management/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/dmesg-commands/
|
||||
[2]:http://www.tecmint.com/systemd-replaces-init-in-linux/
|
||||
[3]:http://www.tecmint.com/how-to-kill-a-process-in-linux/
|
||||
@ -0,0 +1,269 @@
|
||||
RHCSA 系列:使用 'Parted' 和 'SSM' 来配置和加密系统存储 – Part 6
|
||||
================================================================================
|
||||
在本篇文章中,我们将讨论在 RHEL 7 中如何使用传统的工具来设置和配置本地系统存储,并介绍系统存储管理器(也称为 SSM),它将极大地简化上面的任务。
|
||||
|
||||

|
||||
|
||||
RHCSA: 配置和加密系统存储 – Part 6
|
||||
|
||||
请注意,我们将在这篇文章中展开这个话题,但由于该话题的宽泛性,我们将在下一期(Part 7)中继续介绍有关它的描述和使用。
|
||||
|
||||
### 在 RHEL 7 中创建和修改分区 ###
|
||||
|
||||
在 RHEL 7 中, parted 是默认的用来处理分区的程序,且它允许你:
|
||||
|
||||
- 展示当前的分区表
|
||||
- 操纵(增加或减少分区的大小)现有的分区
|
||||
- 利用空余的磁盘空间或额外的物理存储设备来创建分区
|
||||
|
||||
强烈建议你在试图增加一个新的分区或对一个现有分区进行更改前,你应当确保设备上没有任何一个分区正在使用(`umount /dev/partition`),且假如你正使用设备的一部分来作为 swap 分区,在进行上面的操作期间,你需要将它禁用(`swapoff -v /dev/partition`) 。
|
||||
|
||||
实施上面的操作的最简单的方法是使用一个安装介质例如一个 RHEL 7 安装 DVD 或 USB 以急救模式启动 RHEL(Troubleshooting → Rescue a Red Hat Enterprise Linux system),然后当让你选择一个选项来挂载现有的 Linux 安装时,选择'跳过'这个选项,接着你将看到一个命令行提示符,在其中你可以像下图显示的那样开始键入与在一个未被使用的物理设备上创建一个正常的分区时所用的相同的命令。
|
||||
|
||||

|
||||
|
||||
RHEL 7 急救模式
|
||||
|
||||
要启动 parted,只需键入:
|
||||
|
||||
# parted /dev/sdb
|
||||
|
||||
其中 `/dev/sdb` 是你将要创建新分区所在的设备;然后键入 `print` 来显示当前设备的分区表:
|
||||
|
||||

|
||||
|
||||
创建新的分区
|
||||
|
||||
正如你所看到的那样,在这个例子中,我们正在使用一个 5 GB 的虚拟光驱。现在我们将要创建一个 4 GB 的主分区,然后将它格式化为 xfs 文件系统,它是 RHEL 7 中默认的文件系统。
|
||||
|
||||
你可以从一系列的文件系统中进行选择。你将需要使用 mkpart 来手动地创建分区,接着和平常一样,用 mkfs.fstype 来对分区进行格式化,因为 mkpart 并不支持许多现代的文件系统以达到即开即用。
|
||||
|
||||
在下面的例子中,我们将为设备设定一个标记,然后在 `/dev/sdb` 上创建一个主分区 `(p)`,它从设备的 0% 开始,并在 4000MB(4 GB) 处结束。
|
||||
|
||||

|
||||
|
||||
标记分区的名称
|
||||
|
||||
接下来,我们将把分区格式化为 xfs 文件系统,然后再次打印出分区表,以此来确保更改已被应用。
|
||||
|
||||
# mkfs.xfs /dev/sdb1
|
||||
# parted /dev/sdb print
|
||||
|
||||

|
||||
|
||||
格式化分区为 XFS 文件系统
|
||||
|
||||
对于旧一点的文件系统,在 parted 中你应该使用 `resize` 命令来改变分区的大小。不幸的是,这只适用于 ext2, fat16, fat32, hfs, linux-swap, 和 reiserfs (若 libreiserfs 已被安装)。
|
||||
|
||||
因此,改变分区大小的唯一方式是删除它然后再创建它(所以确保你对你的数据做了完整的备份!)。毫无疑问,在 RHEL 7 中默认的分区方案是基于 LVM 的。
|
||||
|
||||
使用 parted 来移除一个分区,可以用:
|
||||
|
||||
# parted /dev/sdb print
|
||||
# parted /dev/sdb rm 1
|
||||
|
||||

|
||||
|
||||
移除或删除分区
|
||||
|
||||
### 逻辑卷管理(LVM) ###
|
||||
|
||||
一旦一个磁盘被分好了分区,再去更改分区的大小就是一件困难或冒险的事了。基于这个原因,假如我们计划在我们的系统上对分区的大小进行更改,我们应当考虑使用 LVM 的可能性,而不是使用传统的分区系统。这样多个物理设备可以组成一个逻辑组,以此来寄宿可自定义数目的逻辑卷,而逻辑卷的增大或减少不会带来任何麻烦。
|
||||
|
||||
简单来说,你会发现下面的示意图对记住 LVM 的基础架构或许有用。
|
||||
|
||||

|
||||
|
||||
LVM 的基本架构
|
||||
|
||||
#### 创建物理卷,卷组和逻辑卷 ####
|
||||
|
||||
遵循下面的步骤是为了使用传统的卷管理工具来设置 LVM。由于你可以通过阅读这个网站上的 LVM 系列来扩展这个话题,我将只是概要的介绍设置 LVM 的基本步骤,然后与使用 SSM 来实现相同功能做个比较。
|
||||
|
||||
**注**: 我们将使用整个磁盘 `/dev/sdb` 和 `/dev/sdc` 来作为 PVs (物理卷),但是否执行相同的操作完全取决于你。
|
||||
|
||||
**1. 使用 /dev/sdb 和 /dev/sdc 中 100% 的可用磁盘空间来创建分区 `/dev/sdb1` 和 `/dev/sdc1`:**
|
||||
|
||||
# parted /dev/sdb print
|
||||
# parted /dev/sdc print
|
||||
|
||||

|
||||
|
||||
创建新分区
|
||||
|
||||
**2. 分别在 /dev/sdb1 和 /dev/sdc1 上共创建 2 个物理卷。**
|
||||
|
||||
# pvcreate /dev/sdb1
|
||||
# pvcreate /dev/sdc1
|
||||
|
||||

|
||||
|
||||
创建两个物理卷
|
||||
|
||||
记住,你可以使用 pvdisplay /dev/sd{b,c}1 来显示有关新建的 PV 的信息。
|
||||
|
||||
**3. 在上一步中创建的 PV 之上创建一个 VG:**
|
||||
|
||||
# vgcreate tecmint_vg /dev/sd{b,c}1
|
||||
|
||||

|
||||
|
||||
创建卷组
|
||||
|
||||
记住,你可使用 vgdisplay tecmint_vg 来显示有关新建的 VG 的信息。
|
||||
|
||||
**4. 像下面那样,在 VG tecmint_vg 之上创建 3 个逻辑卷:**
|
||||
|
||||
# lvcreate -L 3G -n vol01_docs tecmint_vg [vol01_docs → 3 GB]
|
||||
# lvcreate -L 1G -n vol02_logs tecmint_vg [vol02_logs → 1 GB]
|
||||
# lvcreate -l 100%FREE -n vol03_homes tecmint_vg [vol03_homes → 6 GB]
|
||||
|
||||

|
||||
|
||||
创建逻辑卷
|
||||
|
||||
记住,你可以使用 lvdisplay tecmint_vg 来显示有关在 VG tecmint_vg 之上新建的 LV 的信息。
|
||||
|
||||
**5. 格式化每个逻辑卷为 xfs 文件系统格式(假如你计划在以后将要缩小卷的大小,请别使用 xfs 文件系统格式!):**
|
||||
|
||||
# mkfs.xfs /dev/tecmint_vg/vol01_docs
|
||||
# mkfs.xfs /dev/tecmint_vg/vol02_logs
|
||||
# mkfs.xfs /dev/tecmint_vg/vol03_homes
|
||||
|
||||
**6. 最后,挂载它们:**
|
||||
|
||||
# mount /dev/tecmint_vg/vol01_docs /mnt/docs
|
||||
# mount /dev/tecmint_vg/vol02_logs /mnt/logs
|
||||
# mount /dev/tecmint_vg/vol03_homes /mnt/homes
|
||||
|
||||
#### 移除逻辑卷,卷组和物理卷 ####
|
||||
|
||||
**7.现在我们将进行与刚才相反的操作并移除 LV,VG 和 PV:**
|
||||
|
||||
# lvremove /dev/tecmint_vg/vol01_docs
|
||||
# lvremove /dev/tecmint_vg/vol02_logs
|
||||
# lvremove /dev/tecmint_vg/vol03_homes
|
||||
# vgremove /dev/tecmint_vg
|
||||
# pvremove /dev/sd{b,c}1
|
||||
|
||||
**8. 现在,让我们来安装 SSM,我们将看到如何只用一步就完成上面所有的操作!**
|
||||
|
||||
# yum update && yum install system-storage-manager
|
||||
|
||||
我们将和上面一样,使用相同的名称和大小:
|
||||
|
||||
# ssm create -s 3G -n vol01_docs -p tecmint_vg --fstype ext4 /mnt/docs /dev/sd{b,c}1
|
||||
# ssm create -s 1G -n vol02_logs -p tecmint_vg --fstype ext4 /mnt/logs /dev/sd{b,c}1
|
||||
# ssm create -n vol03_homes -p tecmint_vg --fstype ext4 /mnt/homes /dev/sd{b,c}1
|
||||
|
||||
是的! SSM 可以让你:
|
||||
|
||||
- 初始化块设备来作为物理卷
|
||||
- 创建一个卷组
|
||||
- 创建逻辑卷
|
||||
- 格式化 LV 和
|
||||
- 只使用一个命令来挂载它们
|
||||
|
||||
**9. 现在,我们可以使用下面的命令来展示有关 PV,VG 或 LV 的信息:**
|
||||
|
||||
# ssm list dev
|
||||
# ssm list pool
|
||||
# ssm list vol
|
||||
|
||||

|
||||
|
||||
检查有关 PV, VG,或 LV 的信息
|
||||
|
||||
**10. 正如我们知道的那样, LVM 的一个显著的特点是可以在不停机的情况下更改(增大或缩小) 逻辑卷的大小:**
|
||||
|
||||
假定在 vol02_logs 上我们用尽了空间,而 vol03_homes 还留有足够的空间。我们将把 vol03_homes 的大小调整为 4 GB,并使用剩余的空间来扩展 vol02_logs:
|
||||
|
||||
# ssm resize -s 4G /dev/tecmint_vg/vol03_homes
|
||||
|
||||
再次运行 `ssm list pool`,并记录 tecmint_vg 中的剩余空间的大小:
|
||||
|
||||

|
||||
|
||||
查看卷的大小
|
||||
|
||||
然后执行:
|
||||
|
||||
# ssm resize -s+1.99 /dev/tecmint_vg/vol02_logs
|
||||
|
||||
**注**: 在 `-s` 后的加号暗示特定值应该被加到当前值上。
|
||||
|
||||
**11. 使用 ssm 来移除逻辑卷和卷组也更加简单,只需使用:**
|
||||
|
||||
# ssm remove tecmint_vg
|
||||
|
||||
这个命令将返回一个提示,询问你是否确认删除 VG 和它所包含的 LV:
|
||||
|
||||

|
||||
|
||||
移除逻辑卷和卷组
|
||||
|
||||
### 管理加密的卷 ###
|
||||
|
||||
SSM 也给系统管理员提供了为新的或现存的卷加密的能力。首先,你将需要安装 cryptsetup 软件包:
|
||||
|
||||
# yum update && yum install cryptsetup
|
||||
|
||||
然后写出下面的命令来创建一个加密卷,你将被要求输入一个密码来增强安全性:
|
||||
|
||||
# ssm create -s 3G -n vol01_docs -p tecmint_vg --fstype ext4 --encrypt luks /mnt/docs /dev/sd{b,c}1
|
||||
# ssm create -s 1G -n vol02_logs -p tecmint_vg --fstype ext4 --encrypt luks /mnt/logs /dev/sd{b,c}1
|
||||
# ssm create -n vol03_homes -p tecmint_vg --fstype ext4 --encrypt luks /mnt/homes /dev/sd{b,c}1
|
||||
|
||||
我们的下一个任务是往 /etc/fstab 中添加条目来让这些逻辑卷在启动时可用,而不是使用设备识别编号(/dev/something)。
|
||||
|
||||
我们将使用每个 LV 的 UUID (使得当我们添加其他的逻辑卷或设备后,我们的设备仍然可以被唯一的标记),而我们可以使用 blkid 应用来找到它们的 UUID:
|
||||
|
||||
# blkid -o value UUID /dev/tecmint_vg/vol01_docs
|
||||
# blkid -o value UUID /dev/tecmint_vg/vol02_logs
|
||||
# blkid -o value UUID /dev/tecmint_vg/vol03_homes
|
||||
|
||||
在我们的例子中:
|
||||
|
||||

|
||||
|
||||
找到逻辑卷的 UUID
|
||||
|
||||
接着,使用下面的内容来创建 /etc/crypttab 文件(请更改 UUID 来适用于你的设置):
|
||||
|
||||
docs UUID=ba77d113-f849-4ddf-8048-13860399fca8 none
|
||||
logs UUID=58f89c5a-f694-4443-83d6-2e83878e30e4 none
|
||||
homes UUID=92245af6-3f38-4e07-8dd8-787f4690d7ac none
|
||||
|
||||
然后在 /etc/fstab 中添加如下的条目。请注意到 device_name (/dev/mapper/device_name) 是出现在 /etc/crypttab 中第一列的映射标识:
|
||||
|
||||
# Logical volume vol01_docs:
|
||||
/dev/mapper/docs /mnt/docs ext4 defaults 0 2
|
||||
# Logical volume vol02_logs
|
||||
/dev/mapper/logs /mnt/logs ext4 defaults 0 2
|
||||
# Logical volume vol03_homes
|
||||
/dev/mapper/homes /mnt/homes ext4 defaults 0 2
|
||||
|
||||
现在重启(systemctl reboot),则你将被要求为每个 LV 输入密码。随后,你可以通过检查相应的挂载点来确保挂载操作是否成功:
|
||||
|
||||

|
||||
|
||||
确保逻辑卷挂载点
|
||||
|
||||
### 总结 ###
|
||||
|
||||
在这篇教程中,我们开始探索如何使用传统的卷管理工具和 SSM 来设置和配置系统存储,SSM 也在一个软件包中集成了文件系统和加密功能。这使得对于任何系统管理员来说,SSM 是一个非常有价值的工具。
|
||||
|
||||
假如你有任何的问题或评论,请让我们知晓 – 请随意使用下面的评论框来与我们保存联系!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/rhcsa-exam-create-format-resize-delete-and-encrypt-partitions-in-linux/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/create-lvm-storage-in-linux/
|
||||
Loading…
Reference in New Issue
Block a user