mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-19 22:51:41 +08:00
commit
1d5b33c5fb
@ -1,8 +1,7 @@
|
||||
如何在 Ubuntu16.04 中用 Apache 部署 Jenkins 自动化服务器
|
||||
============================================================
|
||||
|
||||
|
||||
Jenkins 是从 Hudson 项目衍生出来的自动化服务器。Jenkins 是一个基于服务器的应用程序,运行在 Java servlet 容器中,它支持包括 Git、SVN 以及 Mercurial 在内的多种 SCM(Source Control Management,源码控制工具)。Jenkins 提供了上百种插件帮助你的项目实现自动化。Jenkins 由 Kohsuke Kawaguchi 开发,在 2011 年使用 MIT 协议发布了第一个发行版,它是个免费软件。
|
||||
Jenkins 是从 Hudson 项目衍生出来的自动化服务器。Jenkins 是一个基于服务器的应用程序,运行在 Java servlet 容器中,它支持包括 Git、SVN 以及 Mercurial 在内的多种 SCM(Source Control Management,源码控制工具)。Jenkins 提供了上百种插件帮助你的项目实现自动化。Jenkins 由 Kohsuke Kawaguchi 开发,在 2011 年使用 MIT 协议发布了第一个发行版,它是个自由软件。
|
||||
|
||||
在这篇指南中,我会向你介绍如何在 Ubuntu 16.04 中安装最新版本的 Jenkins。我们会用自己的域名运行 Jenkins,在 apache web 服务器中安装和配置 Jenkins,而且支持反向代理。
|
||||
|
||||
@ -17,22 +16,28 @@ Jenkins 基于 Java,因此我们需要在服务器上安装 Java OpenJDK 7。
|
||||
|
||||
默认情况下,Ubuntu 16.04 没有安装用于管理 PPA 仓库的 python-software-properties 软件包,因此我们首先需要安装这个软件。使用 apt 命令安装 python-software-properties。
|
||||
|
||||
`apt-get install python-software-properties`
|
||||
```
|
||||
apt-get install python-software-properties
|
||||
```
|
||||
|
||||
下一步,添加 Java PPA 仓库到服务器中。
|
||||
|
||||
`add-apt-repository ppa:openjdk-r/ppa`
|
||||
```
|
||||
add-apt-repository ppa:openjdk-r/ppa
|
||||
```
|
||||
|
||||
输入回车键
|
||||
用 apt 命令更新 Ubuntu 仓库并安装 Java OpenJDK。
|
||||
|
||||
用 apt 命令更新 Ubuntu 仓库并安装 Java OpenJDK。`
|
||||
|
||||
`apt-get update`
|
||||
`apt-get install openjdk-7-jdk`
|
||||
```
|
||||
apt-get update
|
||||
apt-get install openjdk-7-jdk
|
||||
```
|
||||
|
||||
输入下面的命令验证安装:
|
||||
|
||||
`java -version`
|
||||
```
|
||||
java -version
|
||||
```
|
||||
|
||||
你会看到安装到服务器上的 Java 版本。
|
||||
|
||||
@ -46,21 +51,29 @@ Jenkins 给软件安装包提供了一个 Ubuntu 仓库,我们会从这个仓
|
||||
|
||||
用下面的命令添加 Jenkins 密钥和仓库到系统中。
|
||||
|
||||
`wget -q -O - https://pkg.jenkins.io/debian-stable/jenkins.io.key | sudo apt-key add -`
|
||||
`echo 'deb https://pkg.jenkins.io/debian-stable binary/' | tee -a /etc/apt/sources.list`
|
||||
```
|
||||
wget -q -O - https://pkg.jenkins.io/debian-stable/jenkins.io.key | sudo apt-key add -
|
||||
echo 'deb https://pkg.jenkins.io/debian-stable binary/' | tee -a /etc/apt/sources.list
|
||||
```
|
||||
|
||||
更新仓库并安装 Jenkins。
|
||||
|
||||
`apt-get update`
|
||||
`apt-get install jenkins`
|
||||
```
|
||||
apt-get update
|
||||
apt-get install jenkins
|
||||
```
|
||||
|
||||
安装完成后,用下面的命令启动 Jenkins。
|
||||
|
||||
`systemctl start jenkins`
|
||||
```
|
||||
systemctl start jenkins
|
||||
```
|
||||
|
||||
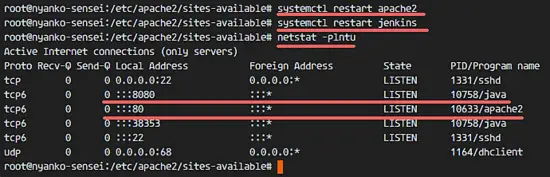
通过检查 Jenkins 默认使用的端口(端口 8080)验证 Jenkins 正在运行。我会像下面这样用 netstat 命令检测:
|
||||
通过检查 Jenkins 默认使用的端口(端口 8080)验证 Jenkins 正在运行。我会像下面这样用 `netstat` 命令检测:
|
||||
|
||||
`netstat -plntu`
|
||||
```
|
||||
netstat -plntu
|
||||
```
|
||||
|
||||
Jenkins 已经安装好了并运行在 8080 端口。
|
||||
|
||||
@ -70,23 +83,29 @@ Jenkins 已经安装好了并运行在 8080 端口。
|
||||
|
||||
### 第三步 - 为 Jenkins 安装和配置 Apache 作为反向代理
|
||||
|
||||
在这篇指南中,我们会在一个 apache web 服务器中运行 Jenkins,我们会为 Jenkins 配置 apache 作为反向代理。首先我会安装 apache 并启用一些需要的模块,然后我会为 Jenkins 用域名 my.jenkins.id 创建虚拟 host 文件。请在这里使用你自己的域名并在所有配置文件中出现的地方替换。
|
||||
在这篇指南中,我们会在一个 Apache web 服务器中运行 Jenkins,我们会为 Jenkins 配置 apache 作为反向代理。首先我会安装 apache 并启用一些需要的模块,然后我会为 Jenkins 用域名 my.jenkins.id 创建虚拟主机文件。请在这里使用你自己的域名并在所有配置文件中出现的地方替换。
|
||||
|
||||
从 Ubuntu 仓库安装 apache2 web 服务器。
|
||||
|
||||
`apt-get install apache2`
|
||||
```
|
||||
apt-get install apache2
|
||||
```
|
||||
|
||||
安装完成后,启用 proxy 和 proxy_http 模块以便将 apache 配置为 Jenkins 的前端服务器/反向代理。
|
||||
|
||||
`a2enmod proxy`
|
||||
`a2enmod proxy_http`
|
||||
```
|
||||
a2enmod proxy
|
||||
a2enmod proxy_http
|
||||
```
|
||||
|
||||
下一步,在 sites-available 目录创建新的虚拟 host 文件。
|
||||
下一步,在 `sites-available` 目录创建新的虚拟主机文件。
|
||||
|
||||
`cd /etc/apache2/sites-available/`
|
||||
`vim jenkins.conf`
|
||||
```
|
||||
cd /etc/apache2/sites-available/
|
||||
vim jenkins.conf
|
||||
```
|
||||
|
||||
粘贴下面的虚拟 host 配置。
|
||||
粘贴下面的虚拟主机配置。
|
||||
|
||||
```
|
||||
<Virtualhost *:80>
|
||||
@ -106,18 +125,24 @@ Jenkins 已经安装好了并运行在 8080 端口。
|
||||
</Virtualhost>
|
||||
```
|
||||
|
||||
保存文件。然后用 a2ensite 命令激活 Jenkins 虚拟 host。
|
||||
保存文件。然后用 `a2ensite` 命令激活 Jenkins 虚拟主机。
|
||||
|
||||
`a2ensite jenkins`
|
||||
```
|
||||
a2ensite jenkins
|
||||
```
|
||||
|
||||
重启 Apache 和 Jenkins。
|
||||
|
||||
`systemctl restart apache2`
|
||||
`systemctl restart jenkins`
|
||||
```
|
||||
systemctl restart apache2
|
||||
systemctl restart jenkins
|
||||
```
|
||||
|
||||
检查 Jenkins 和 Apache 正在使用 80 和 8080 端口。
|
||||
|
||||
`netstat -plntu`
|
||||
```
|
||||
netstat -plntu
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
@ -127,29 +152,30 @@ Jenkins 已经安装好了并运行在 8080 端口。
|
||||
|
||||
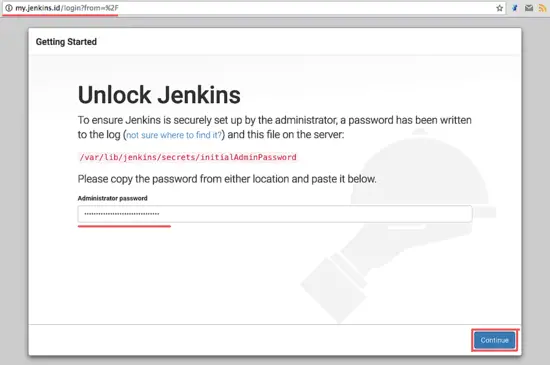
Jenkins 用域名 'my.jenkins.id' 运行。打开你的 web 浏览器然后输入 URL。你会看到要求你输入初始管理员密码的页面。Jenkins 已经生成了一个密码,因此我们只需要显示并把结果复制到密码框。
|
||||
|
||||
用 cat 命令显示 Jenkins 初始管理员密码。
|
||||
|
||||
`cat /var/lib/jenkins/secrets/initialAdminPassword`
|
||||
用 `cat` 命令显示 Jenkins 初始管理员密码。
|
||||
|
||||
```
|
||||
cat /var/lib/jenkins/secrets/initialAdminPassword
|
||||
a1789d1561bf413c938122c599cf65c9
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
将结果粘贴到密码框然后点击 ‘**Continue**’。
|
||||
将结果粘贴到密码框然后点击 Continue。
|
||||
|
||||
[
|
||||
|
||||
][13]
|
||||
|
||||
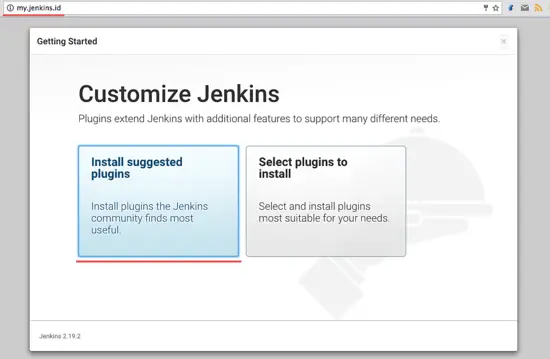
现在为了后面能比较好的使用,我们需要在 Jenkins 中安装一些插件。选择 ‘**Install Suggested Plugin**’,点击它。
|
||||
现在为了后面能比较好的使用,我们需要在 Jenkins 中安装一些插件。选择 Install Suggested Plugin,点击它。
|
||||
|
||||
[
|
||||
|
||||
][14]
|
||||
|
||||
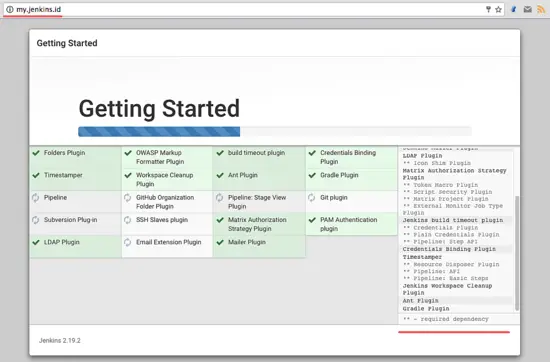
Jenkins 插件安装过程
|
||||
Jenkins 插件安装过程:
|
||||
|
||||
[
|
||||
|
||||
@ -199,27 +225,29 @@ Jenkins 在 ‘**Access Control**’ 部分提供了多种认证方法。为了
|
||||
|
||||
][21]
|
||||
|
||||
输入任务的名称,在这里我用 ‘Checking System’,选择 ‘**Freestyle Project**’ 然后点击 ‘**OK**’。
|
||||
输入任务的名称,在这里我输入 ‘Checking System’,选择 Freestyle Project 然后点击 OK。
|
||||
|
||||
[
|
||||
|
||||
][22]
|
||||
|
||||
进入 ‘**Build**’ 标签页。在 ‘**Add build step**’,选择选项 ‘**Execute shell**’。
|
||||
进入 Build 标签页。在 Add build step,选择选项 Execute shell。
|
||||
|
||||
在输入框输入下面的命令。
|
||||
|
||||
`top -b -n 1 | head -n 5`
|
||||
```
|
||||
top -b -n 1 | head -n 5
|
||||
```
|
||||
|
||||
点击 ‘**Save**’。
|
||||
点击 Save。
|
||||
|
||||
[
|
||||
|
||||
][23]
|
||||
|
||||
现在你是在任务 ‘Project checking system’的任务页。点击 ‘**Build Now**’ 执行任务 ‘checking system’。
|
||||
现在你是在任务 ‘Project checking system’ 的任务页。点击 Build Now 执行任务 ‘checking system’。
|
||||
|
||||
任务执行完成后,你会看到 ‘**Build History**’,点击第一个任务查看结果。
|
||||
任务执行完成后,你会看到 Build History,点击第一个任务查看结果。
|
||||
|
||||
下面是 Jenkins 任务执行的结果。
|
||||
|
||||
@ -233,9 +261,9 @@ Jenkins 在 ‘**Access Control**’ 部分提供了多种认证方法。为了
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-install-jenkins-with-apache-on-ubuntu-16-04/
|
||||
|
||||
作者:[Muhammad Arul ][a]
|
||||
作者:[Muhammad Arul][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
237
published/20161221 Living Android without Kotlin.md
Normal file
237
published/20161221 Living Android without Kotlin.md
Normal file
@ -0,0 +1,237 @@
|
||||
在没有 Kotlin 的世界与 Android 共舞
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
> 开始投入一件事比远离它更容易。 — Donald Rumsfeld
|
||||
|
||||
没有 Kotlin 的生活就像在触摸板上玩魔兽争霸 3。购买鼠标很简单,但如果你的新雇主不想让你在生产中使用 Kotlin,你该怎么办?
|
||||
|
||||
下面有一些选择。
|
||||
* 与你的产品负责人争取获得使用 Kotlin 的权利。
|
||||
* 使用 Kotlin 并且不告诉其他人因为你知道最好的东西是只适合你的。
|
||||
* 擦掉你的眼泪,自豪地使用 Java。
|
||||
|
||||
想象一下,你在和产品负责人的斗争中失败,作为一个专业的工程师,你不能在没有同意的情况下私自去使用那些时髦的技术。我知道这听起来非常恐怖,特别当你已经品尝到 Kotlin 的好处时,不过不要失去生活的信念。
|
||||
|
||||
在文章接下来的部分,我想简短地描述一些 Kotlin 的特征,使你通过一些知名的工具和库,可以应用到你的 Android 里的 Java 代码中去。对于 Kotlin 和 Java 的基本认识是需要的。
|
||||
|
||||
### 数据类
|
||||
|
||||
我想你肯定已经喜欢上 Kotlin 的数据类。对于你来说,得到 `equals()`、 `hashCode()`、 `toString()` 和 `copy()` 这些是很容易的。具体来说,`data` 关键字还可以按照声明顺序生成对应于属性的 `componentN()` 函数。 它们用于解构声明。
|
||||
|
||||
```
|
||||
data class Person(val name: String)
|
||||
val (riddle) = Person("Peter")
|
||||
println(riddle)
|
||||
```
|
||||
|
||||
你知道什么会被打印出来吗?确实,它不会是从 `Person` 类的 `toString()` 返回的值。这是解构声明的作用,它赋值从 `name` 到 `riddle`。使用园括号 `(riddle)` 编译器知道它必须使用解构声明机制。
|
||||
|
||||
```
|
||||
val (riddle): String = Person("Peter").component1()
|
||||
println(riddle) // prints Peter)
|
||||
```
|
||||
|
||||
> 这个代码没编译。它就是展示了构造声明怎么工作的。
|
||||
|
||||
正如你可以看到 `data` 关键字是一个超级有用的语言特性,所以你能做什么把它带到你的 Java 世界? 使用注释处理器并修改抽象语法树(Abstract Syntax Tree)。 如果你想更深入,请阅读文章末尾列出的文章(Project Lombok— Trick Explained)。
|
||||
|
||||
使用项目 Lombok 你可以实现 `data`关键字所提供的几乎相同的功能。 不幸的是,没有办法进行解构声明。
|
||||
|
||||
```
|
||||
import lombok.Data;
|
||||
|
||||
@Data class Person {
|
||||
final String name;
|
||||
}
|
||||
```
|
||||
|
||||
`@Data` 注解生成 `equals()`、`hashCode()` 和 `toString()`。 此外,它为所有字段创建 getter,为所有非最终字段创建setter,并为所有必填字段(final)创建构造函数。 值得注意的是,Lombok 仅用于编译,因此库代码不会添加到您的最终的 .apk。
|
||||
|
||||
### Lambda 表达式
|
||||
|
||||
Android 工程师有一个非常艰难的生活,因为 Android 中缺乏 Java 8 的特性,而且其中之一是 lambda 表达式。 Lambda 是很棒的,因为它们为你减少了成吨的样板。 你可以在回调和流中使用它们。 在 Kotlin 中,lambda 表达式是内置的,它们看起来比它们在 Java 中看起来好多了。 此外,lambda 的字节码可以直接插入到调用方法的字节码中,因此方法计数不会增加。 它可以使用内联函数。
|
||||
|
||||
```
|
||||
button.setOnClickListener { println("Hello World") }
|
||||
```
|
||||
|
||||
最近 Google 宣布在 Android 中支持 Java 8 的特性,由于 Jack 编译器,你可以在你的代码中使用 lambda。还要提及的是,它们在 API 23 或者更低的级别都可用。
|
||||
|
||||
```
|
||||
button.setOnClickListener(view -> System.out.println("Hello World!"));
|
||||
```
|
||||
|
||||
怎样使用它们?就只用添加下面几行到你的 `build.gradle` 文件中。
|
||||
|
||||
```
|
||||
defaultConfig {
|
||||
jackOptions {
|
||||
enabled true
|
||||
}
|
||||
}
|
||||
|
||||
compileOptions {
|
||||
sourceCompatibility JavaVersion.VERSION_1_8
|
||||
targetCompatibility JavaVersion.VERSION_1_8
|
||||
}
|
||||
```
|
||||
|
||||
如果你不喜欢用 Jack 编译器,或者你由于一些原因不能使用它,这里有一个不同的解决方案提供给你。Retrolambda 项目允许你在 Java 7,6 或者 5 上运行带有 lambda 表达式的 Java 8 代码,下面是设置过程。
|
||||
|
||||
```
|
||||
dependencies {
|
||||
classpath 'me.tatarka:gradle-retrolambda:3.4.0'
|
||||
}
|
||||
|
||||
apply plugin: 'me.tatarka.retrolambda'
|
||||
|
||||
compileOptions {
|
||||
sourceCompatibility JavaVersion.VERSION_1_8
|
||||
targetCompatibility JavaVersion.VERSION_1_8
|
||||
}
|
||||
```
|
||||
|
||||
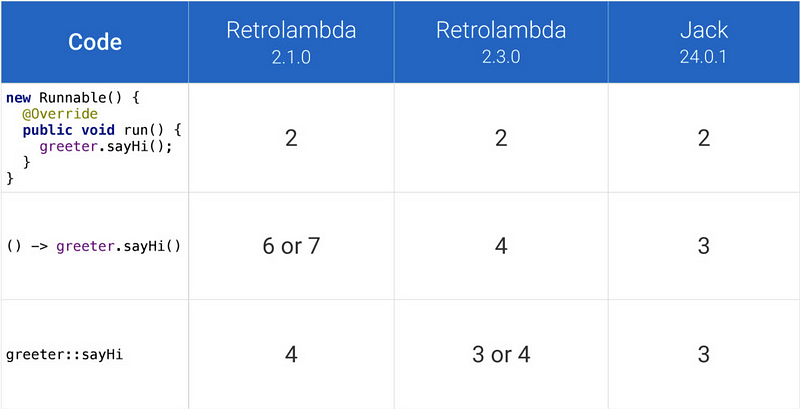
正如我前面提到的,在 Kotlin 下的 lambda 内联函数不增加方法计数,但是如何在 Jack 或者 Retrolambda 下使用它们呢? 显然,它们不是没成本的,隐藏的成本如下。
|
||||
|
||||
|
||||
|
||||
*该表展示了使用不同版本的 Retrolambda 和 Jack 编译器生成的方法数量。该比较结果来自 Jake Wharton 的“[探索 Java 的隐藏成本](http://jakewharton.com/exploring-java-hidden-costs/)” 技术讨论之中。*
|
||||
|
||||
### 数据操作
|
||||
|
||||
Kotlin 引入了高阶函数作为流的替代。 当您必须将一组数据转换为另一组数据或过滤集合时,它们非常有用。
|
||||
|
||||
```
|
||||
fun foo(persons: MutableList<Person>) {
|
||||
persons.filter { it.age >= 21 }
|
||||
.filter { it.name.startsWith("P") }
|
||||
.map { it.name }
|
||||
.sorted()
|
||||
.forEach(::println)
|
||||
}
|
||||
|
||||
data class Person(val name: String, val age: Int)
|
||||
```
|
||||
|
||||
流也由 Google 通过 Jack 编译器提供。 不幸的是,Jack 不使用 Lombok,因为它在编译代码时跳过生成中间的 `.class` 文件,而 Lombok 却依赖于这些文件。
|
||||
|
||||
```
|
||||
void foo(List<Person> persons) {
|
||||
persons.stream()
|
||||
.filter(it -> it.getAge() >= 21)
|
||||
.filter(it -> it.getName().startsWith("P"))
|
||||
.map(Person::getName)
|
||||
.sorted()
|
||||
.forEach(System.out::println);
|
||||
}
|
||||
|
||||
class Person {
|
||||
final private String name;
|
||||
final private int age;
|
||||
|
||||
public Person(String name, int age) {
|
||||
this.name = name;
|
||||
this.age = age;
|
||||
}
|
||||
|
||||
String getName() { return name; }
|
||||
int getAge() { return age; }
|
||||
}
|
||||
```
|
||||
|
||||
这简直太好了,所以 catch 在哪里? 令人悲伤的是,流从 API 24 才可用。谷歌做了好事,但哪个应用程序有用 `minSdkVersion = 24`?
|
||||
|
||||
幸运的是,Android 平台有一个很好的提供许多很棒的库的开源社区。Lightweight-Stream-API 就是其中的一个,它包含了 Java 7 及以下版本的基于迭代器的流实现。
|
||||
|
||||
```
|
||||
import lombok.Data;
|
||||
import com.annimon.stream.Stream;
|
||||
|
||||
void foo(List<Person> persons) {
|
||||
Stream.of(persons)
|
||||
.filter(it -> it.getAge() >= 21)
|
||||
.filter(it -> it.getName().startsWith("P"))
|
||||
.map(Person::getName)
|
||||
.sorted()
|
||||
.forEach(System.out::println);
|
||||
}
|
||||
|
||||
@Data class Person {
|
||||
final String name;
|
||||
final int age;
|
||||
}
|
||||
```
|
||||
|
||||
上面的例子结合了 Lombok、Retrolambda 和 Lightweight-Stream-API,它看起来几乎和 Kotlin 一样棒。使用静态工厂方法允许您将任何 Iterable 转换为流,并对其应用 lambda,就像 Java 8 流一样。 将静态调用 `Stream.of(persons)` 包装为 Iterable 类型的扩展函数是完美的,但是 Java 不支持它。
|
||||
|
||||
### 扩展函数
|
||||
|
||||
扩展机制提供了向类添加功能而无需继承它的能力。 这个众所周知的概念非常适合 Android 世界,这就是 Kotlin 在该社区很受欢迎的原因。
|
||||
|
||||
有没有技术或魔术将扩展功能添加到你的 Java 工具箱? 因 Lombok,你可以使用它们作为一个实验功能。 根据 Lombok 文档的说明,他们想把它从实验状态移出,基本上没有什么变化的话很快。 让我们重构最后一个例子,并将 `Stream.of(persons)` 包装成扩展函数。
|
||||
|
||||
```
|
||||
import lombok.Data;
|
||||
import lombok.experimental.ExtensionMethod;
|
||||
|
||||
@ExtensionMethod(Streams.class)
|
||||
public class Foo {
|
||||
void foo(List<Person> persons) {
|
||||
persons.toStream()
|
||||
.filter(it -> it.getAge() >= 21)
|
||||
.filter(it -> it.getName().startsWith("P"))
|
||||
.map(Person::getName)
|
||||
.sorted()
|
||||
.forEach(System.out::println);
|
||||
}
|
||||
}
|
||||
|
||||
@Data class Person {
|
||||
final String name;
|
||||
final int age;
|
||||
}
|
||||
|
||||
class Streams {
|
||||
static <T> Stream<T> toStream(List<T> list) {
|
||||
return Stream.of(list);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
所有的方法是 `public`、`static` 的,并且至少有一个参数的类型不是原始的,因而是扩展方法。 `@ExtensionMethod` 注解允许你指定一个包含你的扩展函数的类。 你也可以传递数组,而不是使用一个 `.class` 对象。
|
||||
|
||||
* * *
|
||||
|
||||
我完全知道我的一些想法是非常有争议的,特别是 Lombok,我也知道,有很多的库,可以使你的生活更轻松。请不要犹豫在评论里分享你的经验。干杯!
|
||||
|
||||

|
||||
|
||||
---------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Coder and professional dreamer @ Grid Dynamics
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.com/proandroiddev/living-android-without-kotlin-db7391a2b170
|
||||
|
||||
作者:[Piotr Ślesarew][a]
|
||||
译者:[DockerChen](https://github.com/DockerChen)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://hackernoon.com/@piotr.slesarew?source=post_header_lockup
|
||||
[1]:http://jakewharton.com/exploring-java-hidden-costs/
|
||||
[2]:https://medium.com/u/8ddd94878165
|
||||
[3]:https://projectlombok.org/index.html
|
||||
[4]:https://github.com/aNNiMON/Lightweight-Stream-API
|
||||
[5]:https://github.com/orfjackal/retrolambda
|
||||
[6]:http://notatube.blogspot.com/2010/11/project-lombok-trick-explained.html
|
||||
[7]:http://notatube.blogspot.com/2010/11/project-lombok-trick-explained.html
|
||||
[8]:https://twitter.com/SliskiCode
|
||||
@ -1,25 +1,20 @@
|
||||
在 Linux 上给用户赋予指定目录的读写权限
|
||||
============================================================
|
||||
|
||||
|
||||
在上篇文章中我们向您展示了如何在 Linux 上[创建一个共享目录][3]。这次,我们会为您介绍如何将 Linux 上指定目录的读写权限赋予用户。
|
||||
|
||||
|
||||
有两种方法可以实现这个目标:第一种是 [使用 ACL (访问控制列表)][4] ,第二种是[创建用户组来管理文件权限][5],下面会一一介绍。
|
||||
|
||||
|
||||
为了完成这个教程,我们将使用以下设置。
|
||||
|
||||
```
|
||||
Operating system: CentOS 7
|
||||
Test directory: /shares/project1/reports
|
||||
Test user: tecmint
|
||||
Filesystem type: Ext4
|
||||
```
|
||||
- 操作系统:CentOS 7
|
||||
- 测试目录:`/shares/project1/reports`
|
||||
- 测试用户:tecmint
|
||||
- 文件系统类型:ext4
|
||||
|
||||
请确认所有的命令都是使用 root 用户执行的,或者使用 [sudo 命令][6] 来享受与之同样的权限。
|
||||
|
||||
让我们开始吧!下面,先使用 mkdir 命令来创建一个名为 `reports` 的目录。
|
||||
让我们开始吧!下面,先使用 `mkdir` 命令来创建一个名为 `reports` 的目录。
|
||||
|
||||
```
|
||||
# mkdir -p /shares/project1/reports
|
||||
@ -27,16 +22,16 @@ Filesystem type: Ext4
|
||||
|
||||
### 使用 ACL 来为用户赋予目录的读写权限
|
||||
|
||||
重要提示:打算使用此方法的话,您需要确认您的 Linux 文件系统类型(如 Ext3 和 Ext4, NTFS, BTRFS)支持 ACL。
|
||||
重要提示:打算使用此方法的话,您需要确认您的 Linux 文件系统类型(如 ext3 和 ext4, NTFS, BTRFS)支持 ACL。
|
||||
|
||||
1. 首先, 依照以下命令在您的系统中[检查当前文件系统类型][7],并且查看内核是否支持 ACL:
|
||||
1、 首先, 依照以下命令在您的系统中[检查当前文件系统类型][7],并且查看内核是否支持 ACL:
|
||||
|
||||
```
|
||||
# df -T | awk '{print $1,$2,$NF}' | grep "^/dev"
|
||||
# grep -i acl /boot/config*
|
||||
```
|
||||
|
||||
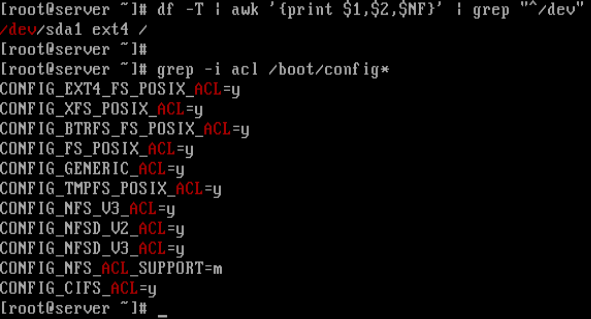
从下方的截屏可以看到,文件系统类型是 **Ext4**,并且从 **CONFIG_EXT4_FS_POSIX_ACL=y** 选项可以发现内核是支持 **POSIX ACLs** 的。
|
||||
从下方的截屏可以看到,文件系统类型是 `ext4`,并且从 `CONFIG_EXT4_FS_POSIX_ACL=y` 选项可以发现内核是支持 **POSIX ACLs** 的。
|
||||
|
||||
[
|
||||
|
||||
@ -44,7 +39,7 @@ Filesystem type: Ext4
|
||||
|
||||
*查看文件系统类型和内核的 ACL 支持。*
|
||||
|
||||
2. 接下来,查看文件系统(分区)挂载时是否使用了 ACL 选项。
|
||||
2、 接下来,查看文件系统(分区)挂载时是否使用了 ACL 选项。
|
||||
|
||||
```
|
||||
# tune2fs -l /dev/sda1 | grep acl
|
||||
@ -55,14 +50,14 @@ Filesystem type: Ext4
|
||||
|
||||
*查看分区是否支持 ACL*
|
||||
|
||||
通过上边的输出可以发现,默认的挂载项目中已经对 **ACL** 进行了支持。如果发现结果不如所愿,你可以通过以下命令对指定分区(此例中使用 **/dev/sda3**)开启 ACL 的支持。
|
||||
通过上边的输出可以发现,默认的挂载项目中已经对 **ACL** 进行了支持。如果发现结果不如所愿,你可以通过以下命令对指定分区(此例中使用 `/dev/sda3`)开启 ACL 的支持。
|
||||
|
||||
```
|
||||
# mount -o remount,acl /
|
||||
# tune2fs -o acl /dev/sda3
|
||||
```
|
||||
|
||||
3. 现在是时候指定目录 `reports` 的读写权限分配给名为 `tecmint` 的用户了,依照以下命令执行即可。
|
||||
3、 现在是时候指定目录 `reports` 的读写权限分配给名为 `tecmint` 的用户了,依照以下命令执行即可。
|
||||
|
||||
```
|
||||
# getfacl /shares/project1/reports # Check the default ACL settings for the directory
|
||||
@ -75,9 +70,9 @@ Filesystem type: Ext4
|
||||
|
||||
*通过 ACL 对指定目录赋予读写权限*
|
||||
|
||||
在上方的截屏中,通过输出结果的第二行 **getfacl** 命令可以发现,用户 `tecmint` 已经成功的被赋予了 **/shares/project1/reports** 目录的读写权限。
|
||||
在上方的截屏中,通过输出结果的第二行 `getfacl` 命令可以发现,用户 `tecmint` 已经成功的被赋予了 `/shares/project1/reports` 目录的读写权限。
|
||||
|
||||
如果想要获取ACL列表的更多信息。可以在下方查看我们的其他指南。
|
||||
如果想要获取 ACL 列表的更多信息。可以在下方查看我们的其他指南。
|
||||
|
||||
1. [如何使用访问控制列表(ACL)为用户/组设置磁盘配额][1]
|
||||
2. [如何使用访问控制列表(ACL)挂载网络共享][2]
|
||||
@ -86,7 +81,7 @@ Filesystem type: Ext4
|
||||
|
||||
### 使用用户组来为用户赋予指定目录的读写权限
|
||||
|
||||
1. 如果用户已经拥有了默认的用户组(通常组名与用户名相同),就可以简单的通过变更文件夹的所属用户组来完成。
|
||||
1、 如果用户已经拥有了默认的用户组(通常组名与用户名相同),就可以简单的通过变更文件夹的所属用户组来完成。
|
||||
|
||||
```
|
||||
# chgrp tecmint /shares/project1/reports
|
||||
@ -98,20 +93,20 @@ Filesystem type: Ext4
|
||||
# groupadd projects
|
||||
```
|
||||
|
||||
2. 接下来将用户 `tecmint` 添加到 `projects` 组中:
|
||||
2、 接下来将用户 `tecmint` 添加到 `projects` 组中:
|
||||
|
||||
```
|
||||
# usermod -aG projects tecmint # add user to projects
|
||||
# groups tecmint # check users groups
|
||||
```
|
||||
|
||||
3. 将目录的所属用户组变更为 projects:
|
||||
3、 将目录的所属用户组变更为 projects:
|
||||
|
||||
```
|
||||
# chgrp projects /shares/project1/reports
|
||||
```
|
||||
|
||||
4. 现在,给组成员设置读写权限。
|
||||
4、 现在,给组成员设置读写权限。
|
||||
|
||||
```
|
||||
# chmod -R 0760 /shares/projects/reports
|
||||
@ -141,7 +136,7 @@ via: http://www.tecmint.com/give-read-write-access-to-directory-in-linux/
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/set-access-control-lists-acls-and-disk-quotas-for-users-groups/
|
||||
[2]:http://www.tecmint.com/rhcsa-exam-configure-acls-and-mount-nfs-samba-shares/
|
||||
[3]:http://www.tecmint.com/create-a-shared-directory-in-linux/
|
||||
[3]:https://linux.cn/article-8187-1.html
|
||||
[4]:http://www.tecmint.com/secure-files-using-acls-in-linux/
|
||||
[5]:http://www.tecmint.com/manage-users-and-groups-in-linux/
|
||||
[6]:http://www.tecmint.com/sudoers-configurations-for-setting-sudo-in-linux/
|
||||
@ -1,20 +1,11 @@
|
||||
如何在 Ubuntu 上使用 pm2 和 Nginx 部署 Node.js 应用
|
||||
============================================================
|
||||
|
||||
### 导航
|
||||
|
||||
1. [第一步 - 安装 Node.js][1]
|
||||
2. [第二步 - 生成 Express 事例 App][2]
|
||||
3. [第三步- 安装 pm2][3]
|
||||
4. [第四步 - 安装配置 Nginx 作为反向代理][4]
|
||||
5. [第五步 - 测试][5]
|
||||
6. [链接][6]
|
||||
|
||||
pm2 是一个 Node.js 应用的进程管理器,它允许你让你的应用程序保持运行,还有一个内建的负载均衡器。它非常简单而且强大,你可以零间断重启或重新加载你的 node 应用,它也允许你为你的 node 应用创建集群。
|
||||
|
||||
pm2 是一个 Node.js 应用的进程管理器,它可以让你的应用程序保持运行,还有一个内建的负载均衡器。它非常简单而且强大,你可以零间断重启或重新加载你的 node 应用,它也允许你为你的 node 应用创建集群。
|
||||
|
||||
在这篇博文中,我会向你展示如何安装和配置 pm2 用于这个简单的 'Express' 应用,然后配置 Nginx 作为运行在 pm2 下的 node 应用的反向代理。
|
||||
|
||||
**前提**
|
||||
前提:
|
||||
|
||||
* Ubuntu 16.04 - 64bit
|
||||
* Root 权限
|
||||
@ -23,50 +14,64 @@ pm2 是一个 Node.js 应用的进程管理器,它允许你让你的应用程
|
||||
|
||||
在这篇指南中,我们会从零开始我们的实验。首先,我们需要在服务器上安装 Node.js。我会使用 Nodejs LTS 6.x 版本,它能从 nodesource 仓库中安装。
|
||||
|
||||
从 Ubuntu 仓库安装 '**python-software-properties**' 软件包并添加 'nodesource' Nodejs 仓库。
|
||||
从 Ubuntu 仓库安装 `python-software-properties` 软件包并添加 “nodesource” Nodejs 仓库。
|
||||
|
||||
`sudo apt-get install -y python-software-properties`
|
||||
`curl -sL https://deb.nodesource.com/setup_6.x | sudo -E bash -`
|
||||
```
|
||||
sudo apt-get install -y python-software-properties
|
||||
curl -sL https://deb.nodesource.com/setup_6.x | sudo -E bash -
|
||||
```
|
||||
|
||||
安装最新版本的 Nodejs LTS
|
||||
安装最新版本的 Nodejs LTS:
|
||||
|
||||
`sudo apt-get install -y nodejs`
|
||||
```
|
||||
sudo apt-get install -y nodejs
|
||||
```
|
||||
|
||||
安装完成后,查看 node 和 npm 版本。
|
||||
|
||||
`node -v`
|
||||
`npm -v`
|
||||
```
|
||||
node -v
|
||||
npm -v
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][10]
|
||||
|
||||
### 第二步 - 生成 Express 事例 App
|
||||
### 第二步 - 生成 Express 示例 App
|
||||
|
||||
我会使用 **express-generator**' 软件包生成的简单 web 应用框架进行事例安装。Express-generator 可以使用 npm 命令安装。
|
||||
我会使用 `express-generator` 软件包生成的简单 web 应用框架进行示例安装。`express-generator` 可以使用 `npm` 命令安装。
|
||||
|
||||
用 npm 安装 '**express-generator**':
|
||||
用 `npm `安装 `express-generator`:
|
||||
|
||||
`npm install express-generator -g`
|
||||
```
|
||||
npm install express-generator -g
|
||||
```
|
||||
|
||||
**-g:** 在系统内部安装软件包
|
||||
- `-g` : 在系统内部安装软件包。
|
||||
|
||||
我会以普通用户运行应用程序,而不是 root 或者超级用户。我们首先需要创建一个新的用户。
|
||||
|
||||
创建一个名为 '**yume**' 的用户:
|
||||
创建一个名为 `yume` 的用户:
|
||||
|
||||
`useradd -m -s /bin/bash yume`
|
||||
`passwd yume`
|
||||
```
|
||||
useradd -m -s /bin/bash yume
|
||||
passwd yume
|
||||
```
|
||||
|
||||
使用 su 命令登录到新用户:
|
||||
使用 `su` 命令登录到新用户:
|
||||
|
||||
`su - yume`
|
||||
```
|
||||
su - yume
|
||||
```
|
||||
|
||||
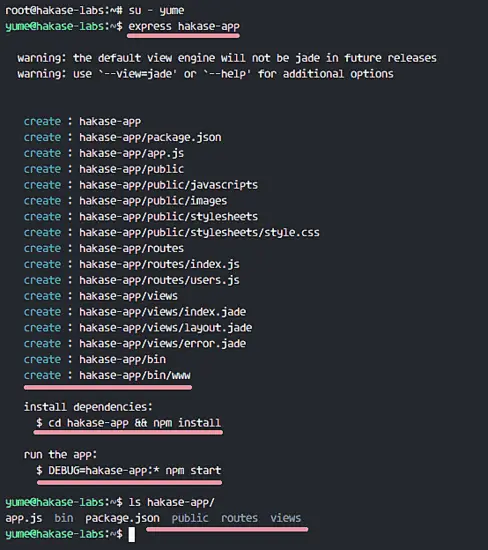
下一步,用 express 命令生成一个新的简单 web 应用程序:
|
||||
下一步,用 `express` 命令生成一个新的简单 web 应用程序:
|
||||
|
||||
`express hakase-app`
|
||||
```
|
||||
express hakase-app
|
||||
```
|
||||
|
||||
命令会创建新项目目录 '**hakase-app**'。
|
||||
命令会创建新项目目录 `hakase-app`。
|
||||
|
||||
[
|
||||
|
||||
@ -74,47 +79,59 @@ pm2 是一个 Node.js 应用的进程管理器,它允许你让你的应用程
|
||||
|
||||
进入到项目目录并安装应用需要的所有依赖。
|
||||
|
||||
`cd hakase-app`
|
||||
`npm install`
|
||||
```
|
||||
cd hakase-app
|
||||
npm install
|
||||
```
|
||||
|
||||
然后用下面的命令测试并启动一个新的简单应用程序:
|
||||
|
||||
`DEBUG=myapp:* npm start`
|
||||
```
|
||||
DEBUG=myapp:* npm start
|
||||
```
|
||||
|
||||
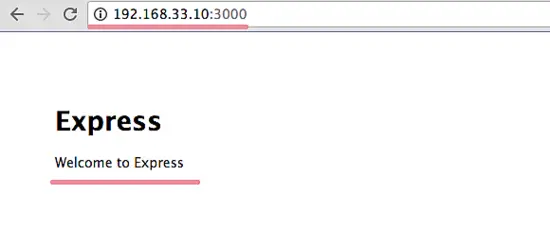
默认情况下,我们的 express 应用汇运行在 **3000** 端口。现在访问服务器的 IP 地址:[192.168.33.10:3000][12]
|
||||
默认情况下,我们的 express 应用会运行在 `3000` 端口。现在访问服务器的 IP 地址:192.168.33.10:3000 :
|
||||
|
||||
[
|
||||
|
||||
][13]
|
||||
|
||||
简单 web 应用框架以 'yume' 用户运行在 3000 端口。
|
||||
这个简单 web 应用框架现在以 'yume' 用户运行在 3000 端口。
|
||||
|
||||
### 第三步 - 安装 pm2
|
||||
|
||||
pm2 是一个 node 软件包,可以使用 npm 命令安装。让我们用 npm 命令安装吧(用 root 权限,如果你仍然以 yume 用户登录,那么运行命令 "exit" 再次成为 root 用户):
|
||||
pm2 是一个 node 软件包,可以使用 `npm` 命令安装。(用 root 权限,如果你仍然以 yume 用户登录,那么运行命令 `exit` 再次成为 root 用户):
|
||||
|
||||
`npm install pm2 -g`
|
||||
```
|
||||
npm install pm2 -g
|
||||
```
|
||||
|
||||
现在我们可以为我们的 web 应用使用 pm2 了。
|
||||
|
||||
进入应用目录 '**hakase-app**':
|
||||
进入应用目录 `hakase-app`:
|
||||
|
||||
`su - yume`
|
||||
`cd ~/hakase-app/`
|
||||
```
|
||||
su - yume
|
||||
cd ~/hakase-app/
|
||||
```
|
||||
|
||||
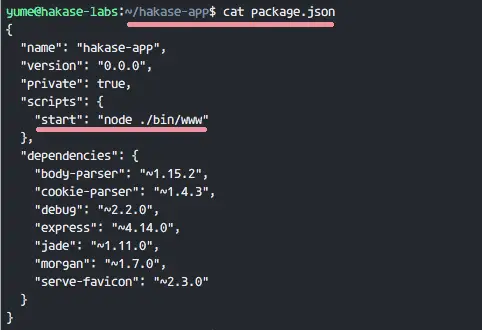
这里你可以看到一个名为 '**package.json**' 的文件,用 cat 命令显示它的内容。
|
||||
这里你可以看到一个名为 `package.json` 的文件,用 `cat` 命令显示它的内容。
|
||||
|
||||
`cat package.json`
|
||||
```
|
||||
cat package.json
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][14]
|
||||
|
||||
你可以看到 '**start**' 行有一个 nodejs 用于启动 express 应用的命令。我们会和 pm2 进程管理器一起使用这个命令。
|
||||
你可以看到 `start` 行有一个 nodejs 用于启动 express 应用的命令。我们会和 pm2 进程管理器一起使用这个命令。
|
||||
|
||||
像下面这样使用 pm2 命令运行 express 应用:
|
||||
像下面这样使用 `pm2` 命令运行 express 应用:
|
||||
|
||||
`pm2 start ./bin/www`
|
||||
```
|
||||
pm2 start ./bin/www
|
||||
```
|
||||
|
||||
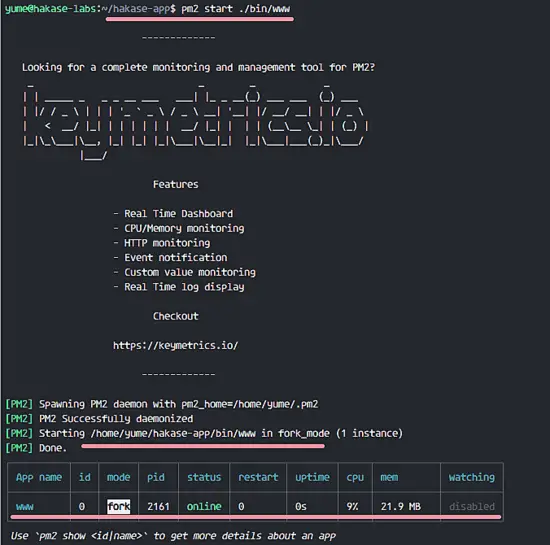
现在你可以看到像下面这样的结果:
|
||||
|
||||
@ -122,9 +139,11 @@ pm2 是一个 node 软件包,可以使用 npm 命令安装。让我们用 npm
|
||||
|
||||
][15]
|
||||
|
||||
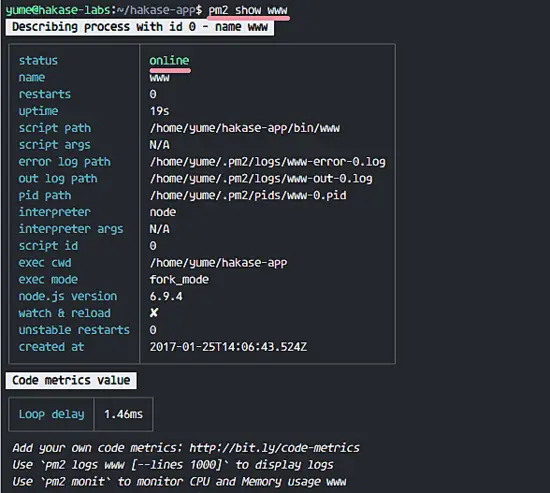
我们的 express 应用正在 pm2 中运行,名称为 '**www**',id '**0**'。你可以用 show 选项 '**show nodeid|name**' 获取更多 pm2 下运行的应用的信息。
|
||||
我们的 express 应用正在 `pm2` 中运行,名称为 `www`,id 为 `0`。你可以用 show 选项 `show nodeid|name` 获取更多 pm2 下运行的应用的信息。
|
||||
|
||||
`pm2 show www`
|
||||
```
|
||||
pm2 show www
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
@ -132,7 +151,9 @@ pm2 是一个 node 软件包,可以使用 npm 命令安装。让我们用 npm
|
||||
|
||||
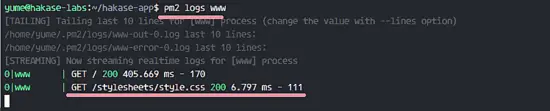
如果你想看我们应用的日志,你可以使用 logs 选项。它包括访问和错误日志,你还可以看到应用程序的 HTTP 状态。
|
||||
|
||||
`pm2 logs www`
|
||||
```
|
||||
pm2 logs www
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
@ -140,14 +161,17 @@ pm2 是一个 node 软件包,可以使用 npm 命令安装。让我们用 npm
|
||||
|
||||
你可以看到我们的程序正在运行。现在,让我们来让它开机自启动。
|
||||
|
||||
`pm2 startup systemd`
|
||||
```
|
||||
pm2 startup systemd
|
||||
```
|
||||
|
||||
**systemd**: Ubuntu 16 使用的是 systemd。
|
||||
- `systemd`: Ubuntu 16 使用的是 systemd。
|
||||
|
||||
你会看到要用 root 用户运行命令的信息。使用 "exit" 命令回到 root 用户然后运行命令。
|
||||
你会看到要用 root 用户运行命令的信息。使用 `exit` 命令回到 root 用户然后运行命令。
|
||||
|
||||
|
||||
`sudo env PATH=$PATH:/usr/bin /usr/lib/node_modules/pm2/bin/pm2 startup systemd -u yume --hp /home/yume`
|
||||
```
|
||||
sudo env PATH=$PATH:/usr/bin /usr/lib/node_modules/pm2/bin/pm2 startup systemd -u yume --hp /home/yume
|
||||
```
|
||||
|
||||
它会为启动应用程序生成 systemd 配置文件。当你重启服务器的时候,应用程序就会自动运行。
|
||||
|
||||
@ -157,66 +181,73 @@ pm2 是一个 node 软件包,可以使用 npm 命令安装。让我们用 npm
|
||||
|
||||
### 第四步 - 安装和配置 Nginx 作为反向代理
|
||||
|
||||
在这篇指南中,我们会使用 Nginx 作为 node 应用的反向代理。Ubuntu 仓库中有 Nginx,用 apt 命令安装它:
|
||||
在这篇指南中,我们会使用 Nginx 作为 node 应用的反向代理。Ubuntu 仓库中有 Nginx,用 `apt` 命令安装它:
|
||||
|
||||
`sudo apt-get install -y nginx`
|
||||
```
|
||||
sudo apt-get install -y nginx
|
||||
```
|
||||
|
||||
下一步,进入到 '**sites-available**' 目录并创建新的虚拟 host 配置文件。
|
||||
下一步,进入到 `sites-available` 目录并创建新的虚拟主机配置文件。
|
||||
|
||||
`cd /etc/nginx/sites-available/`
|
||||
`vim hakase-app`
|
||||
```
|
||||
cd /etc/nginx/sites-available/
|
||||
vim hakase-app
|
||||
```
|
||||
|
||||
粘贴下面的配置:
|
||||
|
||||
upstream hakase-app {
|
||||
# Nodejs app upstream
|
||||
server 127.0.0.1:3000;
|
||||
keepalive 64;
|
||||
}
|
||||
|
||||
# Server on port 80
|
||||
server {
|
||||
listen 80;
|
||||
server_name hakase-node.co;
|
||||
root /home/yume/hakase-app;
|
||||
|
||||
location / {
|
||||
# Proxy_pass configuration
|
||||
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
|
||||
proxy_set_header Host $http_host;
|
||||
proxy_set_header X-NginX-Proxy true;
|
||||
proxy_http_version 1.1;
|
||||
proxy_set_header Upgrade $http_upgrade;
|
||||
proxy_set_header Connection "upgrade";
|
||||
proxy_max_temp_file_size 0;
|
||||
proxy_pass http://hakase-app/;
|
||||
proxy_redirect off;
|
||||
proxy_read_timeout 240s;
|
||||
}
|
||||
}
|
||||
```
|
||||
upstream hakase-app {
|
||||
# Nodejs app upstream
|
||||
server 127.0.0.1:3000;
|
||||
keepalive 64;
|
||||
}
|
||||
|
||||
# Server on port 80
|
||||
server {
|
||||
listen 80;
|
||||
server_name hakase-node.co;
|
||||
root /home/yume/hakase-app;
|
||||
|
||||
location / {
|
||||
# Proxy_pass configuration
|
||||
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
|
||||
proxy_set_header Host $http_host;
|
||||
proxy_set_header X-NginX-Proxy true;
|
||||
proxy_http_version 1.1;
|
||||
proxy_set_header Upgrade $http_upgrade;
|
||||
proxy_set_header Connection "upgrade";
|
||||
proxy_max_temp_file_size 0;
|
||||
proxy_pass http://hakase-app/;
|
||||
proxy_redirect off;
|
||||
proxy_read_timeout 240s;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
保存文件并退出 vim。
|
||||
|
||||
在配置中:
|
||||
|
||||
* node 应用使用域名 '**hakase-node.co**' 运行。
|
||||
* 所有来自 nginx 的流量都会被转发到运行在 **3000** 端口的 node app。
|
||||
* node 应用使用域名 `hakase-node.co` 运行。
|
||||
* 所有来自 nginx 的流量都会被转发到运行在 `3000` 端口的 node app。
|
||||
|
||||
测试 Nginx 配置确保没有错误。
|
||||
|
||||
`nginx -t`
|
||||
```
|
||||
nginx -t
|
||||
```
|
||||
|
||||
启用 Nginx 并使其开机自启动。
|
||||
|
||||
`systemctl start nginx`
|
||||
`systemctl enable nginx`
|
||||
```
|
||||
systemctl start nginx
|
||||
systemctl enable nginx
|
||||
```
|
||||
|
||||
### 第五步 - 测试
|
||||
|
||||
打开你的 web 浏览器并访问域名(我的是):
|
||||
|
||||
[http://hakase-app.co][19]
|
||||
打开你的 web 浏览器并访问域名(我的是):[http://hakase-app.co][19]
|
||||
|
||||
你可以看到 express 应用正在 Nginx web 服务器中运行。
|
||||
|
||||
@ -226,13 +257,17 @@ pm2 是一个 node 软件包,可以使用 npm 命令安装。让我们用 npm
|
||||
|
||||
下一步,重启你的服务器,确保你的 node app 能开机自启动:
|
||||
|
||||
`pm2 save`
|
||||
`sudo reboot`
|
||||
```
|
||||
pm2 save
|
||||
sudo reboot
|
||||
```
|
||||
|
||||
如果你再次登录到了你的服务器,检查 node app 进程。以 '**yume**' 用户运行下面的命令。
|
||||
如果你再次登录到了你的服务器,检查 node app 进程。以 `yume` 用户运行下面的命令。
|
||||
|
||||
`su - yume`
|
||||
`pm2 status www`
|
||||
```
|
||||
su - yume
|
||||
pm2 status www
|
||||
```
|
||||
|
||||
[
|
||||
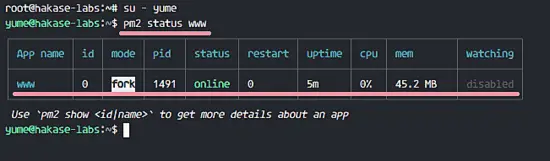
|
||||
@ -250,9 +285,9 @@ Node 应用在 pm2 中运行并使用 Nginx 作为反向代理。
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-deploy-nodejs-applications-with-pm2-and-nginx-on-ubuntu/
|
||||
|
||||
作者:[Muhammad Arul ][a]
|
||||
作者:[Muhammad Arul][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,24 +1,24 @@
|
||||
Remmina - 一个 Linux 下功能丰富的远程桌面共享工具
|
||||
Remmina:一个 Linux 下功能丰富的远程桌面共享工具
|
||||
============================================================
|
||||
|
||||
**Remmina** 是一款在 Linux 和其他类 Unix 系统下的免费开源、功能丰富、强大的远程桌面客户端,它用 GTK+ 3 编写而成。它适用于那些需要远程访问及使用许多计算机的系统管理员和在外出行人员。
|
||||
**Remmina** 是一款在 Linux 和其他类 Unix 系统下的自由开源、功能丰富、强大的远程桌面客户端,它用 GTK+ 3 编写而成。它适用于那些需要远程访问及使用许多计算机的系统管理员和在外出行人员。
|
||||
|
||||
它以简单、统一、同一性、易于使用的用户界面支持多种网络协议。
|
||||
它以简单、统一、同质、易用的用户界面支持多种网络协议。
|
||||
|
||||
#### Remmina 功能
|
||||
### Remmina 功能
|
||||
|
||||
* 支持 RDP、VNC、NX、XDMCP 和 SSH。
|
||||
* 用户能够以组的形式维护一份连接配置列表。
|
||||
* 支持用户直接输入服务器地址的快速连接。
|
||||
* 具有更高分辨率的远程桌面,可以在窗口和全屏模式下滚动/缩放。
|
||||
* 支持窗口全屏模式;当鼠标移动到屏幕边缘时,远程桌面会自动滚动。
|
||||
* 还支持全屏模式浮动工具栏;使你能够在不同模式间切换、触发键盘获取、最小化等。
|
||||
* 提供选项卡式界面,可选择由组管理。
|
||||
* 还支持全屏模式的浮动工具栏;使你能够在不同模式间切换、触发键盘获取、最小化等。
|
||||
* 提供选项卡式界面,可以按组管理。
|
||||
* 还提供托盘图标,允许你快速访问已配置的连接文件。
|
||||
|
||||
在本文中,我们将向你展示如何在 Linux 中安装 Remmina,以及使用它通过支持的不同协议实现桌面共享。
|
||||
|
||||
#### 先决条件
|
||||
### 先决条件
|
||||
|
||||
* 在远程机器上允许桌面共享(让远程机器允许远程连接)。
|
||||
* 在远程机器上设置 SSH 服务。
|
||||
@ -43,7 +43,7 @@ $ sudo dnf copr enable hubbitus/remmina-next
|
||||
$ sudo dnf upgrade --refresh 'remmina*' 'freerdp*'
|
||||
```
|
||||
|
||||
一旦安装完成后,在 Ubuntu 或 Linux Mint 菜单中搜索 **remmina**,接着运行它:
|
||||
一旦安装完成后,在 Ubuntu 或 Linux Mint 菜单中搜索 `remmina`,接着运行它:
|
||||
|
||||
[
|
||||
|
||||
@ -53,7 +53,7 @@ $ sudo dnf upgrade --refresh 'remmina*' 'freerdp*'
|
||||
|
||||
你可以通过图形界面或者编辑 `$HOME/.remmina` 或者 `$HOME/.config/remmina` 下的文件来进行配置。
|
||||
|
||||
要设置到一个新的远程服务器的连接,按下 `[Ctrl+N]` 并点击 **Connection -> New**,如下截图中配置远程连接。这是基本的设置界面。
|
||||
要设置到一个新的远程服务器的连接,按下 `Ctrl+N` 并点击 **Connection -> New**,如下截图中配置远程连接。这是基本的设置界面。
|
||||
|
||||
[
|
||||
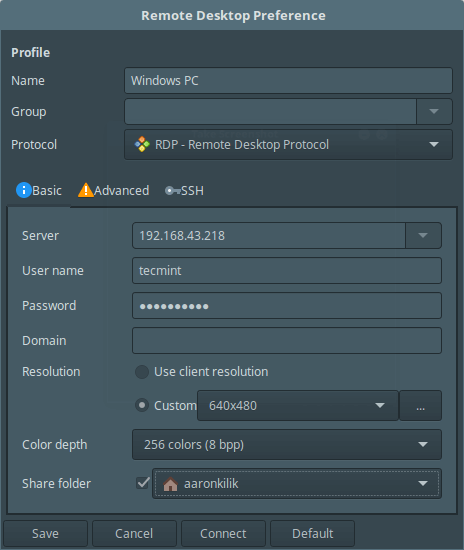
|
||||
@ -87,7 +87,7 @@ $ sudo dnf upgrade --refresh 'remmina*' 'freerdp*'
|
||||
|
||||
#### 使用 sFTP 连接到远程机器
|
||||
|
||||
选择连接配置并编辑设置,在 “**Protocols**” 下拉菜单中选择 **sFTP - 安全文件传输**。接着设置启动路径(可选),并指定 SSH 验证细节。最后点击**连接**。
|
||||
选择连接配置并编辑设置,在 “**Protocols**” 下拉菜单中选择 **sFTP - Secure File Transfer**。接着设置启动路径(可选),并指定 SSH 验证细节。最后点击**连接**。
|
||||
|
||||
[
|
||||
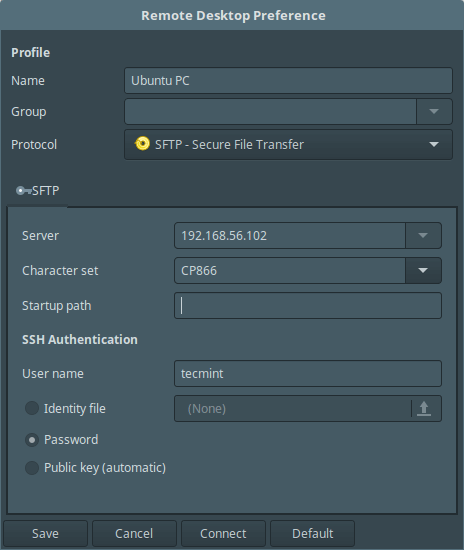
|
||||
@ -103,7 +103,7 @@ $ sudo dnf upgrade --refresh 'remmina*' 'freerdp*'
|
||||
|
||||
*输入 SSH 密码*
|
||||
|
||||
如果你看到下面的界面,那么代表 SFTP 连接成功了,你现在可以[在两台机器键传输文件了][8]。
|
||||
如果你看到下面的界面,那么代表 sFTP 连接成功了,你现在可以[在两台机器键传输文件了][8]。
|
||||
|
||||
[
|
||||
|
||||
@ -131,7 +131,7 @@ $ sudo dnf upgrade --refresh 'remmina*' 'freerdp*'
|
||||
|
||||
#### 使用 VNC 连接到远程机器
|
||||
|
||||
选择连接配置并编辑设置,在 “**Protocols**” 下拉菜单中选择 **VNC - 虚拟网络计算**。为连接配置基础、高级以及 ssh 设置,点击**连接**,接着输入用户 SSH 密码。
|
||||
选择连接配置并编辑设置,在 “**Protocols**” 下拉菜单中选择 **VNC - Virtual Network Computing**。为该连接配置基础、高级以及 ssh 设置,点击**连接**,接着输入用户 SSH 密码。
|
||||
|
||||
[
|
||||

|
||||
@ -172,7 +172,7 @@ via: http://www.tecmint.com/remmina-remote-desktop-sharing-and-ssh-client/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,8 +1,7 @@
|
||||
bd - 快速返回到父目录而不用冗余地输入 “cd ../../ ..”
|
||||
bd:快速返回某级父目录而不用冗余地输入 “cd ../../..”
|
||||
============================================================
|
||||
|
||||
|
||||
在 Linux 系统上通过命令行切换文件夹时,为了回到父目录(长路径),我们通常会重复输入[ cd 命令][1](`cd ../../..`),直到进入感兴趣的目录。
|
||||
在 Linux 系统上通过命令行切换文件夹时,为了回到父目录(长路径),我们通常会重复输入 [cd 命令][1](`cd ../../..`),直到进入感兴趣的目录。
|
||||
|
||||
对于经验丰富的 Linux 用户或需要进行各种不同任务的系统管理员而言,这可能非常乏味,因此希望在操作系统时有一个快捷方式来简化工作。
|
||||
|
||||
@ -14,7 +13,7 @@ bd 是用于切换文件夹的便利工具,它可以使你快速返回到父
|
||||
|
||||
### 如何在 Linux 中安装 bd
|
||||
|
||||
运行下面的命令,使用[ wget 命令][3]下载并安装 bd 到 `/usr/bin/` 中,添加执行权限,并在 `~/.bashrc` 中创建需要的别名:
|
||||
运行下面的命令,使用 [wget 命令][3]下载并安装 bd 到 `/usr/bin/` 中,添加执行权限,并在 `~/.bashrc` 中创建需要的别名:
|
||||
|
||||
```
|
||||
$ wget --no-check-certificate -O /usr/bin/bd https://raw.github.com/vigneshwaranr/bd/master/bd
|
||||
@ -23,7 +22,7 @@ $ echo 'alias bd=". bd -si" >> ~/.bashrc
|
||||
$ source ~/.bashrc
|
||||
```
|
||||
|
||||
注意:要启用大小写敏感的目录名匹配,在上面创建的别名中,设置 `-s` 标志而不是 `-si` 标志。
|
||||
注意:如果要启用大小写敏感的目录名匹配,请在上面创建的别名中,设置 `-s` 标志而不是 `-si` 标志。
|
||||
|
||||
要启用自动补全支持,运行这些命令:
|
||||
|
||||
@ -55,7 +54,7 @@ $ bd Data
|
||||

|
||||
][4]
|
||||
|
||||
目录间快速切换
|
||||
*目录间快速切换*
|
||||
|
||||
实际上,bd 让它变得更加直接,你要做的是输入 “bd <开头几个字母>”,比如:
|
||||
|
||||
@ -67,9 +66,9 @@ $ bd Da
|
||||

|
||||
][5]
|
||||
|
||||
快速切换目录
|
||||
*快速切换目录*
|
||||
|
||||
重要:如果层次结构中有不止一个具有相同名称的目录,bd 将会移动到最接近的目录,而不考虑最接近的父目录,如下面的例子那样。
|
||||
重要:如果层次结构中有不止一个具有相同名称的目录,bd 将会移动到最接近的目录,而不考虑最近的父目录,如下面的例子那样。
|
||||
|
||||
例如,在上面的路径中,有两个名称相同的目录 Books,如果你想移动到:
|
||||
|
||||
@ -77,7 +76,7 @@ $ bd Da
|
||||
/media/aaronkilik/Data/ComputerScience/Documents/Books/LEARN/Linux/Books
|
||||
```
|
||||
|
||||
输入 “bd Books” 会进入:
|
||||
输入 `bd Books` 会进入:
|
||||
|
||||
```
|
||||
/media/aaronkilik/Data/ComputerScience/Documents/Books
|
||||
@ -86,11 +85,11 @@ $ bd Da
|
||||

|
||||
][6]
|
||||
|
||||
快速进入 ‘Books’ 目录
|
||||
*快速进入 ‘Books’ 目录*
|
||||
|
||||
另外,在引号中使用 bd 如 ``bd <letter(s)>`` 会打印出路径而不更改当前目录,所以你可以与其他常见的 Linux 命令,如 [ls][7],[echo][8] 等一起使用 ``bd <letter(s)>` 。
|
||||
另外,在引号中使用 bd 如 ``bd <开头几个字母>`` 会打印出路径而不更改当前目录,所以你可以与其他常见的 Linux 命令,如 [ls][7],[echo][8] 等一起使用 ``bd <开头几个字母>`` 。
|
||||
|
||||
在下面的例子中,当前在 /var/www/html/internship/assets/filetree 目录中,要打印出绝对路径、详细列出内容、统计目录 html 中所有文件的大小,你不必进入它,只需要键入:
|
||||
在下面的例子中,当前在 `/var/www/html/internship/assets/filetree` 目录中,要打印出绝对路径、详细列出内容、统计目录 html 中所有文件的大小,你不必进入它,只需要键入:
|
||||
|
||||
```
|
||||
$ echo `bd ht`
|
||||
@ -101,7 +100,7 @@ $ du -cs `bd ht`
|
||||

|
||||
][9]
|
||||
|
||||
列出切换的目录
|
||||
*列出切换的目录*
|
||||
|
||||
要在 Github 上了解更多关于 bd 的信息:[https://github.com/vigneshwaranr/bd][10]
|
||||
|
||||
@ -119,15 +118,15 @@ Aaron Kili是一名 Linux 和 F.O.S.S 的爱好者,未来的 Linux 系统管
|
||||
|
||||
via: http://www.tecmint.com/bd-quickly-go-back-to-a-linux-parent-directory/
|
||||
|
||||
作者:[Aaron Kili ][a]
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/cd-command-in-linux/
|
||||
[2]:http://www.tecmint.com/autojump-a-quickest-way-to-navigate-linux-filesystem/
|
||||
[2]:https://linux.cn/article-5983-1.html
|
||||
[3]:http://www.tecmint.com/10-wget-command-examples-in-linux/
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2017/03/Switch-Between-Directories-Quickly.png
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2017/03/Quickly-Switch-Directories.png
|
||||
@ -136,7 +135,7 @@ via: http://www.tecmint.com/bd-quickly-go-back-to-a-linux-parent-directory/
|
||||
[8]:http://www.tecmint.com/echo-command-in-linux/
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2017/03/Switch-Directory-with-Listing.png
|
||||
[10]:https://github.com/vigneshwaranr/bd
|
||||
[11]:http://www.tecmint.com/autojump-a-quickest-way-to-navigate-linux-filesystem/
|
||||
[11]:https://linux.cn/article-5983-1.html
|
||||
[12]:http://www.tecmint.com/author/aaronkili/
|
||||
[13]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[14]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -1,14 +1,13 @@
|
||||
如何在 Ubuntu 中安装 Discord
|
||||
如何在 Ubuntu 中安装语音聊天工具 Discord
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
Discord 是一个非常受欢迎的文字和语音聊天程序。虽然开始时主要面向游戏玩家,但它几乎获得了所有人的了广泛青睐。
|
||||
|
||||
Discord 是一个非常受欢迎的文字和语音聊天程序。虽然开始了主要面向游戏玩家,但它几乎获得了所有人的了广泛青睐。
|
||||
Discord 不仅仅是一个很好的聊天客户端。当你安装它时,你还可以获得其强大的服务端功能,强力而自足。游戏玩家和非玩家都可以在几分钟内开启自己的私人聊天服务,这使 Discord 成为团队、公会和各种社区的明显选择。
|
||||
|
||||
Discord 不仅仅是一个很好的聊天客户端。当你安装它时,你还可以获得其强大的服务端功能,包括电池。游戏玩家和非玩家都可以在几分钟内开启自己的私人聊天服务,这使 Discord 成为团队、公会和各种社区的明显选择。
|
||||
|
||||
Linux 用户经常在游戏世界中被遗忘。但 Discord 并不是这样。它的开发人员也在 Linux 下积极构建并维护其流行聊天平台。Ubuntu 用户拥有更好的功能。Discord 捆绑在方便的 Debian/Ubuntu .deb 包中。
|
||||
Linux 用户经常被游戏世界遗忘。但 Discord 并不是这样。它的开发人员也在 Linux 下积极构建并维护其流行聊天平台。Ubuntu 用户甚至拥有更好的待遇,Discord 捆绑在方便的 Debian/Ubuntu .deb 包中。
|
||||
|
||||
### 获取并安装软件包
|
||||
|
||||
@ -46,7 +45,7 @@ sudo apt install libgconf-2-4 libappindicator1
|
||||
|
||||
### 命令行安装
|
||||
|
||||
懒惰的 Linux 熟手并不在意花哨的 GUI 工具。如果你是这个阵营的人,那么你有一个更直接的命令行选项。
|
||||
“懒惰”的 Linux 熟手并不在意花哨的 GUI 工具。如果你是这个阵营的人,那么你有一个更直接的命令行选项。
|
||||
|
||||
首先,打开一个终端并进入你的下载目录。在那里可以使用 `wget` 直接下载 .deb 包。
|
||||
|
||||
@ -55,7 +54,7 @@ cd ~/Downloads
|
||||
wget -O discord-0.0.1.deb https://discordapp.com/api/download?platform=linux&format=deb
|
||||
```
|
||||
|
||||
下载完成后,你可以使用 dpkg 直接安装 .deb 软件包。运行下面的命令:
|
||||
下载完成后,你可以使用 `dpkg` 直接安装 .deb 软件包。运行下面的命令:
|
||||
|
||||
```
|
||||
sudo dpkg -i discord-0.0.1.deb
|
||||
@ -69,19 +68,19 @@ sudo dpkg -i discord-0.0.1.deb
|
||||
|
||||

|
||||
|
||||
首次启动,你需要创建一个帐户或者登录。做任意一个你需要做的。
|
||||
首次启动,根据你需求,创建一个帐户或者登录。
|
||||
|
||||

|
||||
|
||||
登录后,你就进入 Discord 了。它会提供一些介绍教程和建议。你可以直接略过开始尝试。欢迎进入你新的 Linux 聊天体验!
|
||||
登录后,你就进入 Discord 了。它会提供一些介绍教程和建议。你可以直接略过并开始尝试。欢迎进入你新的 Linux 聊天体验!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/install-discord-ubuntu/
|
||||
|
||||
作者:[ Nick Congleton][a]
|
||||
作者:[Nick Congleton][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,164 +0,0 @@
|
||||
Translating by cposture 20161228
|
||||
# Applying the Linus Torvalds “Good Taste” Coding Requirement
|
||||
|
||||
In [a recent interview with Linus Torvalds][1], the creator of Linux, at approximately 14:20 in the interview, he made a quick point about coding with “good taste”. Good taste? The interviewer prodded him for details and Linus came prepared with illustrations.
|
||||
|
||||
He presented a code snippet. But this wasn’t “good taste” code. This snippet was an example of poor taste in order to provide some initial contrast.
|
||||
|
||||

|
||||
|
||||
It’s a function, written in C, that removes an object from a linked list. It contains 10 lines of code.
|
||||
|
||||
He called attention to the if-statement at the bottom. It was _this_ if-statement that he criticized.
|
||||
|
||||
I paused the video and studied the slide. I had recently written code very similar. Linus was effectively saying I had poor taste. I swallowed my pride and continued the video.
|
||||
|
||||
Linus explained to the audience, as I already knew, that when removing an object from a linked list, there are two cases to consider. If the object is at the start of the list there is a different process for its removal than if it is in the middle of the list. And this is the reason for the “poor taste” if-statement.
|
||||
|
||||
But if he admits it is necessary, then why is it so bad?
|
||||
|
||||
Next he revealed a second slide to the audience. This was his example of the same function, but written with “good taste”.
|
||||
|
||||

|
||||
|
||||
The original 10 lines of code had now been reduced to 4.
|
||||
|
||||
But it wasn’t the line count that mattered. It was that if-statement. It’s gone. No longer needed. The code has been refactored so that, regardless of the object’s position in the list, the same process is applied to remove it.
|
||||
|
||||
Linus explained the new code, the elimination of the edge case, and that was it. The interview then moved on to the next topic.
|
||||
|
||||
I studied the code for a moment. Linus was right. The second slide _was_better. If this was a test to determine good taste from poor taste, I would have failed. The thought that it may be possible to eliminate that conditional statement had never occurred to me. And I had written it more than once, since I commonly work with linked lists.
|
||||
|
||||
What’s good about this illustration isn’t just that it teaches you a better way to remove an item from a linked list, but that it makes you consider that the code you’ve written, the little algorithms you’ve sprinkled throughout the program, may have room for improvement in ways you’ve never considered.
|
||||
|
||||
So this was my focus as I went back and reviewed the code in my most recent project. Perhaps it was serendipitous that it also happened to be written in C.
|
||||
|
||||
To the best of my ability to discern, the crux of the “good taste” requirement is the elimination of edge cases, which tend to reveal themselves as conditional statements. The fewer conditions you test for, the better your code “_tastes”_.
|
||||
|
||||
Here is one particular example of an improvement I made that I wanted to share.
|
||||
|
||||
Initializing Grid Edges
|
||||
|
||||
Below is an algorithm I wrote to initialize the points along the edge of a grid, which is represented as a multidimensional array: grid[rows][cols].
|
||||
|
||||
Again, the purpose of this code was to only initialize the values of the points that reside on the edge of the grid — so only the top row, bottom row, left column, and right column.
|
||||
|
||||
To accomplish this I initially looped over every point in the grid and used conditionals to test for the edges. This is what it looked like:
|
||||
|
||||
```Tr
|
||||
for (r = 0; r < GRID_SIZE; ++r) {
|
||||
for (c = 0; c < GRID_SIZE; ++c) {
|
||||
```
|
||||
|
||||
```
|
||||
// Top Edge
|
||||
if (r == 0)
|
||||
grid[r][c] = 0;
|
||||
```
|
||||
|
||||
```
|
||||
// Left Edge
|
||||
if (c == 0)
|
||||
grid[r][c] = 0;
|
||||
```
|
||||
|
||||
```
|
||||
// Right Edge
|
||||
if (c == GRID_SIZE - 1)
|
||||
grid[r][c] = 0;
|
||||
```
|
||||
|
||||
```
|
||||
// Bottom Edge
|
||||
if (r == GRID_SIZE - 1)
|
||||
grid[r][c] = 0;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Even though it works, in hindsight, there are some issues with this construct.
|
||||
|
||||
1. Complexity — The use 4 conditional statements inside 2 embedded loops seems overly complex.
|
||||
2. Efficiency — Given that GRID_SIZE has a value of 64, this loop performs 4096 iterations in order to set values for only the 256 edge points.
|
||||
|
||||
Linus would probably agree, this is not very _tasty_.
|
||||
|
||||
So I did some tinkering with it. After a little bit I was able to reduce the complexity to only a single for_-_loop containing four conditionals. It was only a slight improvement in complexity, but a large improvement in performance, because it only performed 256 loop iterations, one for each point along the edge.
|
||||
|
||||
```
|
||||
for (i = 0; i < GRID_SIZE * 4; ++i) {
|
||||
```
|
||||
|
||||
```
|
||||
// Top Edge
|
||||
if (i < GRID_SIZE)
|
||||
grid[0][i] = 0;
|
||||
```
|
||||
|
||||
```
|
||||
// Right Edge
|
||||
else if (i < GRID_SIZE * 2)
|
||||
grid[i - GRID_SIZE][GRID_SIZE - 1] = 0;
|
||||
```
|
||||
|
||||
```
|
||||
// Left Edge
|
||||
else if (i < GRID_SIZE * 3)
|
||||
grid[i - (GRID_SIZE * 2)][0] = 0;
|
||||
```
|
||||
|
||||
```
|
||||
// Bottom Edge
|
||||
else
|
||||
grid[GRID_SIZE - 1][i - (GRID_SIZE * 3)] = 0;
|
||||
}
|
||||
```
|
||||
|
||||
An improvement, yes. But it looked really ugly. It’s not exactly code that is easy to follow. Based on that alone, I wasn’t satisfied.
|
||||
|
||||
I continued to tinker. Could this really be improved further? In fact, the answer was _YES_. And what I eventually came up with was so astoundingly simple and elegant that I honestly couldn’t believe it took me this long to find it.
|
||||
|
||||
Below is the final version of the code. It has _one for-loop_ and _no conditionals_. Moreover, the loop only performs 64 iterations. It vastly improves both complexity and efficiency.
|
||||
|
||||
```
|
||||
for (i = 0; i < GRID_SIZE; ++i) {
|
||||
```
|
||||
|
||||
```
|
||||
// Top Edge
|
||||
grid[0][i] = 0;
|
||||
|
||||
// Bottom Edge
|
||||
grid[GRID_SIZE - 1][i] = 0;
|
||||
```
|
||||
|
||||
```
|
||||
// Left Edge
|
||||
grid[i][0] = 0;
|
||||
```
|
||||
|
||||
```
|
||||
// Right Edge
|
||||
grid[i][GRID_SIZE - 1] = 0;
|
||||
}
|
||||
```
|
||||
|
||||
This code initializes four different edge points for each loop iteration. It’s not complex. It’s highly efficient. It’s easy to read. Compared to the original version, and even the second version, they are like night and day.
|
||||
|
||||
I was quite satisfied.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.com/@bartobri/applying-the-linus-tarvolds-good-taste-coding-requirement-99749f37684a
|
||||
|
||||
作者:[Brian Barto][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.com/@bartobri?source=post_header_lockup
|
||||
[1]:https://www.ted.com/talks/linus_torvalds_the_mind_behind_linux
|
||||
@ -1,49 +0,0 @@
|
||||
Oracle Policy Change Raises Prices on AWS
|
||||
============================================================
|
||||
|
||||
>The change, which effectively doubles Oracle's prices for implementing its software on AWS, was put in effect quietly, with little notification to users.
|
||||
|
||||

|
||||
|
||||
News came last week that Oracle has, in effect, doubled the price for running its products on Amazon's cloud. It has done so with a bit of sleight-of-hand on [how it counts AWS's virtual CPUs.][6] It also did so without fanfare. The company's new pricing policy went in effect on January 23, and pretty much went unnoticed until January 28, when Oracle follower Tim Hall stumbled on the change in Big Red's ["Licensing Oracle Software in the Cloud Computing Environment"][7] document and blew the whistle.
|
||||
|
||||
At first glance, this move might not seem to mean much, as it only puts Oracle's AWS pricing on par with its prices on Microsoft Azure. But Azure is only about a third the size of market leading AWS, so if you want to make money selling licenses in the cloud, AWS is the place to be. And while this move may or may not affect those already using Oracle on AWS -- it's not clear whether the new rules apply to those already using the products -- it will certainly push some new users who might otherwise consider Oracle to look elsewhere.
|
||||
|
||||
The main reason for this move is obvious. Oracle is hoping to make its own cloud more attractive -- which led [The Register to observe][8] with a bit of snark, "Larry Ellison did promise Oracle's cloud would be faster and cheaper." Faster and cheaper both remain to be seen. Faster maybe, if Oracle's SPARC cloud launches as planned and if it performs as advertised. Cheaper might be less likely. Oracle is known for playing hardball with its prices.
|
||||
|
||||
With declining sales of its signature database and business stack, and with its $7.4 billion dollar bet on Sun not working out as planned, Oracle is betting its future on the cloud. But Oracle came late to the party and its efforts so far seem to be returning lackluster results, with some financial forecasters not seeing a bright future for Oracle Cloud. The cloud is a crowded market, they say, and the big four -- Amazon, Microsoft, IBM and Google -- already have a commanding lead.
|
||||
|
||||
That's true. But the biggest obstacle Oracle faces in the cloud is...well, Oracle. Its reputation precedes it.
|
||||
|
||||
It's an understatement to say the company is not known for stellar customer service. Indeed, press reports paint Oracle as something of a bully and a manipulator.
|
||||
|
||||
Back in 2015, for example, Oracle, evidently growing frustrated because its cloud wasn't growing as fast as anticipated, began [activating what Business Insider called the "nuclear option."][9] It would audit a client's datacenter and if the client wasn't in compliance, it would issue a "breach notice" -- usually reserved only for cases of large scale abuse -- and order the client to quit using its software within 30 days.
|
||||
|
||||
In case you don't know, big corporations heavily invested in Oracle's stack absolutely couldn't migrate to another solution on such short notice. An Oracle breach notice spelled disaster.
|
||||
|
||||
"[T]o make the breach notice go away — or to reduce an outrageously high out-of-compliance fine — an Oracle sales rep often wants the customer to add cloud "credits" to the contract...," Business Insider's Julie Bort explained.
|
||||
|
||||
In other words, Oracle was using the audit to arm-twist clients to buy into its cloud, whether or not they had a need. There might also be a tie-in between this tactic and the recent price doubling on AWS. A commenter to Hall's article noted that the purpose behind the secrecy surrounding the price boost could possibly be to trigger software audits.
|
||||
|
||||
The trouble with employing tactics like these is that sooner or later they catch up with you. Word gets out. Your customers start looking for other options. It might be time for Big Red to take a page from Microsoft's playbook and start working to build a kinder and gentler Oracle that puts the needs of its customers first.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://windowsitpro.com/cloud/oracle-policy-change-raises-prices-aws
|
||||
|
||||
作者:[Christine Hall][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://windowsitpro.com/author/christine-hall
|
||||
[1]:http://windowsitpro.com/penton_ur/nojs/user/register?path=node%2F186491&nid=186491&source=email
|
||||
[2]:http://windowsitpro.com/author/christine-hall
|
||||
[3]:http://windowsitpro.com/author/christine-hall
|
||||
[4]:http://windowsitpro.com/cloud/oracle-policy-change-raises-prices-aws#comments
|
||||
[5]:http://windowsitpro.com/cloud/oracle-policy-change-raises-prices-aws#comments
|
||||
[6]:https://oracle-base.com/blog/2017/01/28/oracles-cloud-licensing-change-be-warned/
|
||||
[7]:http://www.oracle.com/us/corporate/pricing/cloud-licensing-070579.pdf
|
||||
[8]:https://www.theregister.co.uk/2017/01/30/oracle_effectively_doubles_licence_fees_to_run_in_aws/
|
||||
[9]:http://www.businessinsider.com/oracle-is-using-the-nuclear-option-to-sell-its-cloud-software-2015-7
|
||||
@ -1,116 +0,0 @@
|
||||
translated by zhousiyu325
|
||||
|
||||
5 big ways AI is rapidly invading our lives
|
||||
============================================================
|
||||
|
||||
> Let's look at five real ways we're already surrounded by artificial intelligence.
|
||||
|
||||
|
||||

|
||||
>Image by : opensource.com
|
||||
|
||||
Open source projects [are helping drive][2] artificial intelligence advancements, and we can expect to hear much more about how AI impacts our lives as the technologies mature. Have you considered how AI is changing the world around you already? Let's take a look at our increasingly artificially enhanced universe and consider the bold predictions about our AI-influenced future.
|
||||
|
||||
### 1\. AI influences your purchasing decisions
|
||||
|
||||
A recent story on [VentureBeat][3], "[How AI will help us decipher millennials][4]," caught my eye. I confess that I haven't given much thought to artificial intelligence—nor have I had a hard time deciphering millennials—so I was curious to learn more. As it turns out, the headline was a bit misleading; "How to sell to millennials" would have been a more accurate title.
|
||||
|
||||
According to the article, the millennial generation is a "the demographic segment so coveted that marketing managers from all over the globe are fighting over them." By analyzing online behavior—be it shopping, social media, or other activities—machine learning can help predict behavioral patterns, which can then turn into targeted advertising. The article goes on to explain how the Internet of Things and social media platforms can be mined for data points. "Using machine learning to mine social media data allows companies to determine how millennials talk about its products, what their sentiments are towards a product category, how they respond to competitors’ advertising campaigns, and a multitude of other data that can be used to design targeted advertising campaigns," the article explains. That AI and millennials are the future of marketing is no huge surprise, but Gen Xers and Baby Boomers, you're not off the hook yet.
|
||||
|
||||
>AI is being used to target entire groups—including cities—of people based on behavior changes.AI is being used to target entire groups—including cities—of people based on behavior changes.
|
||||
|
||||
For example, an article on [Raconteur][23], "[How AI will change buyer behaviour][24]," explains that the biggest strength of AI in the online retail industry is its ability to adapt quickly to fluid situations that change customer behavior. Abhinav Aggarwal, chief executive of artificial intelligence startup [Fluid AI][25], says that his company's software was being used by a client to predict customer behavior, and the system noticed a change during a snow storm. "Users who would typically ignore the e-mails or in-app notifications sent in the middle of the day were now opening them as they were stuck at home without much to do. Within an hour the AI system adapted to the new situation and started sending more promotional material during working hours," he explains.
|
||||
|
||||
AI is changing how, why, and when we spend money, but how is it changing the way we earn our paychecks?
|
||||
|
||||
### 2\. AI is changing how we work
|
||||
|
||||
A recent [Fast Company][5] article, "[This is how AI will change your work in 2017][6]," says that job seekers will benefit from artificial intelligence. The author explains that AI will be used to send job seekers alerts for relevant job openings, in addition to updates on salary trends, when you're due for a promotion, and the likelihood that you'll get one.
|
||||
|
||||
Artificial intelligence also will be used by companies to help on-board new talent. "Many new hires get a ton of information during their first couple of days on the job, much of which won't get retained," the article explains. Instead, a bot could "drip information" to a new employee over time as it becomes more relevant.
|
||||
|
||||
On [Inc.][7], "[Businesses Beyond Bias: How AI Will Reshape Hiring Practices][8]" looks at how [SAP SuccessFactors][9], a talent management solutions provider, leverages AI as a job description "bias checker" and to check for bias in employee compensation.
|
||||
|
||||
[Deloitte's 2017 Human Capital Trends Report][10] indicates that AI is motivating organizations to restructure. Fast Company's article "[How AI is changing the way companies are organized][11]" examines the report, which was based on surveys with more than 10,000 HR and business leaders around the world. "Instead of hiring the most qualified person for a specific task, many companies are now putting greater emphasis on cultural fit and adaptability, knowing that individual roles will have to evolve along with the implementation of AI," the article explains. To adapt to changing technologies, organizations are also moving away from top-down structures and to multidisciplinary teams, the article says.
|
||||
|
||||
### 3\. AI is transforming education
|
||||
|
||||
>AI will benefit all the stakeholders of the education ecosystem.
|
||||
|
||||
Education budgets are shrinking, whereas classroom sizes are growing, so leveraging technological advancements can help improve the productivity and efficiency of the education system, and play a role in improving the quality and affordability of education, according to an article on VentureBeat. "[How AI will transform education in 2017][26]" says that this year we'll see AI grading students' written answers, bots answering students' questions, virtual personal assistants tutoring students, and more. "AI will benefit all the stakeholders of the education ecosystem," the article explains. "Students would be able to learn better with instant feedback and guidance, teachers would get rich learning analytics and insights to personalize instruction, parents would see improved career prospects for their children at a reduced cost, schools would be able to scale high-quality education, and governments would be able to provide affordable education to all."
|
||||
|
||||
### 4\. AI is reshaping healthcare
|
||||
|
||||
A February 2017 article on [CB Insights][12] rounded up [106 artificial intelligence startups in healthcare][13], and many of those raised their first equity funding round within the past couple of years. "19 out of the 24 companies under imaging and diagnostics raised their first equity funding round since January 2015," the article says. Other companies on the list include those working on AI for remote patient monitoring, drug discovery, and oncology.
|
||||
|
||||
An article published on March 16 on TechCrunch that looks at [how AI advances are reshaping healthcare][14] explains, "Once a better understanding of human DNA is established, there is an opportunity to go one step further and provide personalized insights to individuals based on their idiosyncratic biological dispositions. This trend is indicative of a new era of 'personalized genetics,' whereby individuals are able to take full control of their health through access to unprecedented information about their own bodies."
|
||||
|
||||
The article goes on to explain that AI and machine learning are lowering the cost and time to discover new drugs. Thanks in part to extensive testing, new drugs can take more than 12 years to enter the market. "ML algorithms can allow computers to 'learn' how to make predictions based on the data they have previously processed or choose (and in some cases, even conduct) what experiments need to be done. Similar types of algorithms also can be used to predict the side effects of specific chemical compounds on humans, speeding up approvals," the article says. In 2015, the article notes, a San Francisco-based startup, [Atomwise][15], completed analysis on two new drugs to reduce Ebola infectivity within one day, instead of taking years.
|
||||
|
||||
>AI is helping with discovering, diagnosing, and managing new diseases.
|
||||
|
||||
Another startup, London-based [BenevolentAI][27], is harnessing AI to look for patterns in scientific literature. "Recently, the company identified two potential chemical compounds that may work on Alzheimer’s, attracting the attention of pharmaceutical companies," the article says.
|
||||
|
||||
In addition to drug discovery, AI is helping with discovering, diagnosing, and managing new diseases. The TechCrunch article explains that, historically, illnesses are diagnosed based on symptoms displayed, but AI is being used to detect disease signatures in the blood, and to develop treatment plans using deep learning insights from analyzing billions of clinical cases. "IBM's Watson is working with Memorial Sloan Kettering in New York to digest reams of data on cancer patients and treatments used over decades to present and suggest treatment options to doctors in dealing with unique cancer cases," the article says.
|
||||
|
||||
### 5\. AI is changing our love lives
|
||||
|
||||
More than 50-million active users across 195 countries swipe through potential mates with [Tinder][16], a dating app launched in 2012\. In a [Forbes Interview podcast][17], Tinder founder and chairman Sean Rad spoke with Steven Bertoni about how artificial intelligence is changing the dating game. In [an article][18] about the interview, Bertoni quotes Rad, who says, "There might be a moment when Tinder is just so good at predicting the few people that you're interested in, and Tinder might do a lot of the leg work in organizing a date, right?" So instead of presenting users with potential partners, the app would make a suggestion for a nearby partner and take it a step further, coordinate schedules, and set up a date.
|
||||
|
||||
>Future generations literally might fall in love with artificial intelligence.
|
||||
|
||||
Are you in love with AI yet? Future generations literally might fall in love with artificial intelligence. An article by Raya Bidshahri on [Singularity Hub][19], "[How AI will redefine love][20]," says that in a few decades we might be arguing that love is not limited by biology.
|
||||
|
||||
"Our technology, powered by Moore's law, is growing at a staggering rate—intelligent devices are becoming more and more integrated to our lives," Bidshahri explains, adding, "Futurist Ray Kurzweil predicts that we will have AI at a human level by 2029, and it will be a billion times more capable than humans by the 2040s. Many predict that one day we will merge with powerful machines, and we ourselves may become artificially intelligent." She argues that it's inevitable in such a world that humans would accept being in love with entirely non-biological beings.
|
||||
|
||||
That might sound a bit freaky, but falling in love with AI is a more optimistic outcome than a future in which robots take over the world. "Programming AI to have the capacity to feel love can allow us to create more compassionate AI and may be the very key to avoiding the AI apocalypse many fear," Bidshahri says.
|
||||
|
||||
This list of big ways AI is invading all areas of our lives barely scrapes the surface of the artificial intelligence bubbling up around us. Which AI innovations are most exciting—or troubling—to you? Let us know about them in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
作者简介:
|
||||
|
||||
Rikki Endsley - Rikki Endsley is a community manager for Opensource.com. In the past, she worked as the community evangelist on the Open Source and Standards (OSAS) team at Red Hat; a freelance tech journalist; community manager for the USENIX Association; associate publisher of Linux Pro Magazine, ADMIN, and Ubuntu User; and as the managing editor of Sys Admin magazine and UnixReview.com. Follow her on Twitter at: @rikkiends.
|
||||
|
||||
|
||||
-------------------
|
||||
|
||||
via: https://opensource.com/article/17/3/5-big-ways-ai-rapidly-invading-our-lives
|
||||
|
||||
作者:[Rikki Endsley ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/rikki-endsley
|
||||
[1]:https://opensource.com/article/17/3/5-big-ways-ai-rapidly-invading-our-lives?rate=ORfqhKFu9dpA9aFfg-5Za9ZWGcBcx-f0cUlf_VZNeQs
|
||||
[2]:https://www.linux.com/news/open-source-projects-are-transforming-machine-learning-and-ai
|
||||
[3]:https://twitter.com/venturebeat
|
||||
[4]:http://venturebeat.com/2017/03/16/how-ai-will-help-us-decipher-millennials/
|
||||
[5]:https://opensource.com/article/17/3/5-big-ways-ai-rapidly-invading-our-lives
|
||||
[6]:https://www.fastcompany.com/3066620/this-is-how-ai-will-change-your-work-in-2017
|
||||
[7]:https://twitter.com/Inc
|
||||
[8]:http://www.inc.com/bill-carmody/businesses-beyond-bias-how-ai-will-reshape-hiring-practices.html
|
||||
[9]:https://www.successfactors.com/en_us.html
|
||||
[10]:https://dupress.deloitte.com/dup-us-en/focus/human-capital-trends.html?id=us:2el:3pr:dup3575:awa:cons:022817:hct17
|
||||
[11]:https://www.fastcompany.com/3068492/how-ai-is-changing-the-way-companies-are-organized
|
||||
[12]:https://twitter.com/CBinsights
|
||||
[13]:https://www.cbinsights.com/blog/artificial-intelligence-startups-healthcare/
|
||||
[14]:https://techcrunch.com/2017/03/16/advances-in-ai-and-ml-are-reshaping-healthcare/
|
||||
[15]:http://www.atomwise.com/
|
||||
[16]:https://twitter.com/Tinder
|
||||
[17]:https://www.forbes.com/podcasts/the-forbes-interview/#5e962e5624e1
|
||||
[18]:https://www.forbes.com/sites/stevenbertoni/2017/02/14/tinders-sean-rad-on-how-technology-and-artificial-intelligence-will-change-dating/#4180fc2e5b99
|
||||
[19]:https://twitter.com/singularityhub
|
||||
[20]:https://singularityhub.com/2016/08/05/how-ai-will-redefine-love/
|
||||
[21]:https://opensource.com/user/23316/feed
|
||||
[22]:https://opensource.com/article/17/3/5-big-ways-ai-rapidly-invading-our-lives#comments
|
||||
[23]:https://twitter.com/raconteur
|
||||
[24]:https://www.raconteur.net/technology/how-ai-will-change-buyer-behaviour
|
||||
[25]:http://www.fluid.ai/
|
||||
[26]:http://venturebeat.com/2017/02/04/how-ai-will-transform-education-in-2017/
|
||||
[27]:https://twitter.com/benevolent_ai
|
||||
[28]:https://opensource.com/users/rikki-endsley
|
||||
@ -1,256 +0,0 @@
|
||||
rdiff-backup – A Remote Incremental Backup Tool for Linux
|
||||
============================================================
|
||||
|
||||
rdiff-backup is a powerful and easy-to-use Python script for local/remote incremental backup, which works on any POSIX operating system such as Linux, Mac OS X or [Cygwin][1]. It brings together the remarkable features of a mirror and an incremental backup.
|
||||
|
||||
Significantly, it preserves subdirectories, dev files, hard links, and critical file attributes such as permissions, uid/gid ownership, modification times, extended attributes, acls, and resource forks. It can work in a bandwidth-efficient mode over a pipe, in a similar way as the popular [rsync backup tool][2].
|
||||
|
||||
rdiff-backup backs up a single directory to another over a network using SSH, implying that the data transfer is encrypted thus secure. The target directory (on the remote system) ends up an exact copy of the source directory, however extra reverse diffs are stored in a special subdirectory in the target directory, making it possible to recover files lost some time ago.
|
||||
|
||||
#### Dependencies
|
||||
|
||||
To use rdiff-backup in Linux, you’ll need the following packages installed on your system:
|
||||
|
||||
* Python v2.2 or later
|
||||
* librsync v0.9.7 or later
|
||||
* pylibacl and pyxattr Python modules are optional but necessary for POSIX access control list(ACL) and extended attribute support respectively.
|
||||
* rdiff-backup-statistics requires Python v2.4 or later.
|
||||
|
||||
### How to Install rdiff-backup in Linux
|
||||
|
||||
Important: If you are operating over a network, you’ll have to install rdiff-backup both systems, preferably both installations of rdiff-backup will have to be the exact same version.
|
||||
|
||||
The script is already present in the official repositories of the mainstream Linux distributions, simply run the command below to install rdiff-backup as well as its dependencies:
|
||||
|
||||
#### On Debian/Ubuntu
|
||||
|
||||
```
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install librsync-dev rdiff-backup
|
||||
```
|
||||
|
||||
#### On CentOS/RHEL 7
|
||||
|
||||
```
|
||||
# wget http://dl.fedoraproject.org/pub/epel/7/x86_64/e/epel-release-7-9.noarch.rpm
|
||||
# rpm -ivh epel-release-7-9.noarch.rpm
|
||||
# yum install librsync rdiff-backup
|
||||
```
|
||||
|
||||
#### On CentOS/RHEL 6
|
||||
|
||||
```
|
||||
# wget http://download.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm
|
||||
# rpm -ivh epel-release-6-8.noarch.rpm
|
||||
# yum install librsync rdiff-backup
|
||||
```
|
||||
|
||||
#### On Fedora
|
||||
|
||||
```
|
||||
# yum install librsync rdiff-backup
|
||||
# dnf install librsync rdiff-backup [Fedora 22+]
|
||||
```
|
||||
|
||||
### How to Use rdiff-backup in Linux
|
||||
|
||||
As I mentioned before, rdiff-backup uses SSH to connect to remote machines on your network, and the default authentication in SSH is the username/password method, which normally requires human interaction.
|
||||
|
||||
However, to automate tasks such as automatic backups with scripts and beyond, you will need to configure [SSH Passwordless Login Using SSH keys][3], because SSH keys increases the trust between two Linux servers for [easy file synchronization or transfer][4].
|
||||
|
||||
Once you have setup [SSH Passwordless Login][5], you can start using the script with the following examples.
|
||||
|
||||
#### Backup Files to Different Partition
|
||||
|
||||
The example below will backup the `/etc` directory in a Backup directory on another partition:
|
||||
|
||||
```
|
||||
$ sudo rdiff-backup /etc /media/aaronkilik/Data/Backup/mint_etc.backup
|
||||
```
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
Backup Files to Different Partition
|
||||
|
||||
To exclude a particular directory as well as it’s subdirectories, you can use the `--exclude` option as follows:
|
||||
|
||||
```
|
||||
$ sudo rdiff-backup --exclude /etc/cockpit --exclude /etc/bluetooth /media/aaronkilik/Data/Backup/mint_etc.backup
|
||||
```
|
||||
|
||||
We can include all device files, fifo files, socket files, and symbolic links with the `--include-special-files` option as below:
|
||||
|
||||
```
|
||||
$ sudo rdiff-backup --include-special-files --exclude /etc/cockpit /media/aaronkilik/Data/Backup/mint_etc.backup
|
||||
```
|
||||
|
||||
There are two other important flags we can set for file selection; `--max-file-size` size which excludes files that are larger than the given size in bytes and `--min-file-size` size which excludes files that are smaller than the given size in bytes:
|
||||
|
||||
```
|
||||
$ sudo rdiff-backup --max-file-size 5M --include-special-files --exclude /etc/cockpit /media/aaronkilik/Data/Backup/mint_etc.backup
|
||||
```
|
||||
|
||||
#### Backup Remote Files on Local Linux Server
|
||||
|
||||
For the purpose of this section, we’ll use:
|
||||
|
||||
```
|
||||
Remote Server (tecmint) : 192.168.56.102
|
||||
Local Backup Server (backup) : 192.168.56.10
|
||||
```
|
||||
|
||||
As we stated before, you must install the same version of rdiff-backup on both machines, now try to check the version on both machines as follows:
|
||||
|
||||
```
|
||||
$ rdiff-backup -V
|
||||
```
|
||||
[
|
||||
|
||||
][7]
|
||||
|
||||
Check rdiff Version on Servers
|
||||
|
||||
On the backup server, create a directory which will store the backup files like so:
|
||||
|
||||
```
|
||||
# mkdir -p /backups
|
||||
```
|
||||
|
||||
Now from the backup server, run the following commands to make a backup of directories `/var/log/`and `/root` from remote Linux server 192.168.56.102 in `/backups`:
|
||||
|
||||
```
|
||||
# rdiff-backup root@192.168.56.102::/var/log/ /backups/192.168.56.102_logs.backup
|
||||
# rdiff-backup root@192.168.56.102::/root/ /backups/192.168.56.102_rootfiles.backup
|
||||
```
|
||||
|
||||
The screenshot below shows the root file on remote server 192.168.56.102 and the backed up files on the back server 192.168.56.10:
|
||||
|
||||
[
|
||||
|
||||
][8]
|
||||
|
||||
Backup Remote Directory on Local Server
|
||||
|
||||
Take note of the rdiff-backup-data directory created in the `backup` directory as seen in the screenshot, it contains vital data concerning the backup process and incremental files.
|
||||
|
||||
[
|
||||
|
||||
][9]
|
||||
|
||||
rdiff-backup – Backup Process Files
|
||||
|
||||
Now, on the server 192.168.56.102, additional files have been added to the root directory as shown below:
|
||||
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
Verify Backup Directory
|
||||
|
||||
Let’s run the backup command once more time to get the changed data, we can use the `-v[0-9]`(where the number specifies the verbosity level, default is 3 which is silent) option to set the verbosity feature:
|
||||
|
||||
```
|
||||
# rdiff-backup -v4 root@192.168.56.102::/root/ /backups/192.168.56.102_rootfiles.backup
|
||||
```
|
||||
[
|
||||
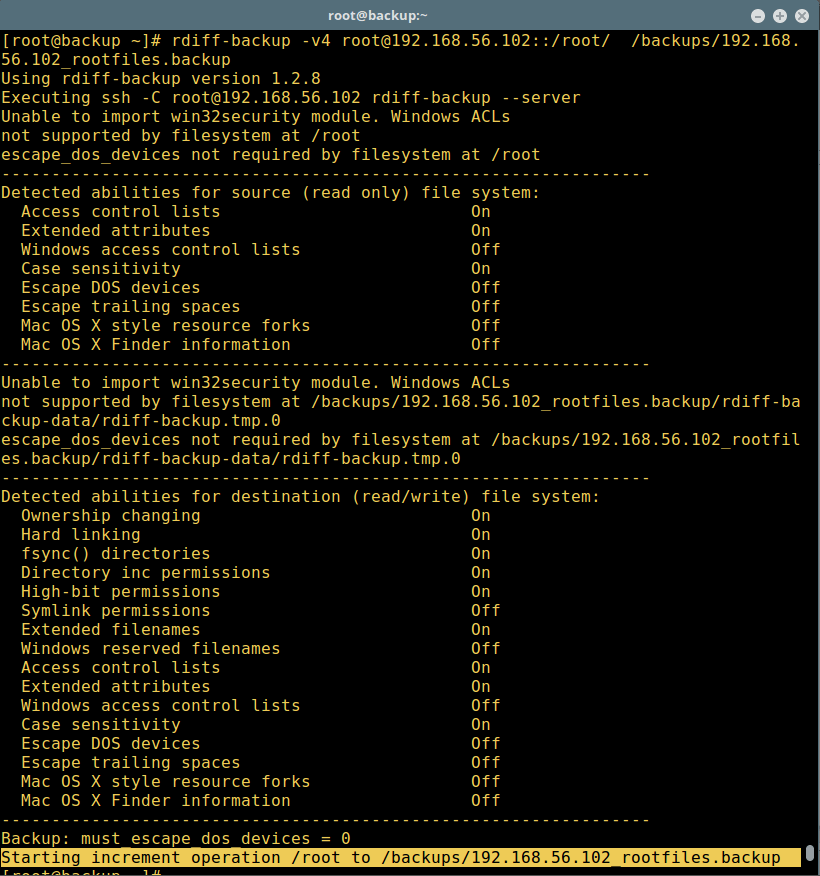
|
||||
][11]
|
||||
|
||||
Incremental Backup with Summary
|
||||
|
||||
And to list the number and date of partial incremental backups contained in the /backups/192.168.56.102_rootfiles.backup directory, we can run:
|
||||
|
||||
```
|
||||
# rdiff-backup -l /backups/192.168.56.102_rootfiles.backup/
|
||||
```
|
||||
|
||||
#### Automating rdiff-back Backup Using Cron
|
||||
|
||||
We can print summary statistics after a successful backup with the `--print-statistics`. However, if we don’t set this option, the info will still be available from the session statistics file. Read more concerning this option in the STATISTICS section of the man page.
|
||||
|
||||
And the –remote-schema flag enables us to specify an alternative method of connecting to a remote computer.
|
||||
|
||||
Now, let’s start by creating a `backup.sh` script on the backup server 192.168.56.10 as follows:
|
||||
|
||||
```
|
||||
# cd ~/bin
|
||||
# vi backup.sh
|
||||
```
|
||||
|
||||
Add the following lines to the script file.
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
#This is a rdiff-backup utility backup script
|
||||
#Backup command
|
||||
rdiff-backup --print-statistics --remote-schema 'ssh -C %s "sudo /usr/bin/rdiff-backup --server --restrict-read-only /"' root@192.168.56.102::/var/logs /backups/192.168.56.102_logs.back
|
||||
#Checking rdiff-backup command success/error
|
||||
status=$?
|
||||
if [ $status != 0 ]; then
|
||||
#append error message in ~/backup.log file
|
||||
echo "rdiff-backup exit Code: $status - Command Unsuccessful" >>~/backup.log;
|
||||
exit 1;
|
||||
fi
|
||||
#Remove incremental backup files older than one month
|
||||
rdiff-backup --force --remove-older-than 1M /backups/192.168.56.102_logs.back
|
||||
```
|
||||
|
||||
Save the file and exit, then run the following command to add the script to the crontab on the backup server 192.168.56.10:
|
||||
|
||||
```
|
||||
# crontab -e
|
||||
```
|
||||
|
||||
Add this line to run your backup script daily at midnight:
|
||||
|
||||
```
|
||||
0 0 * * * /root/bin/backup.sh > /dev/null 2>&1
|
||||
```
|
||||
|
||||
Save the crontab and close it, now we’ve successful automated the backup process. Ensure that it is working as expected.
|
||||
|
||||
Read through the rdiff-backup man page for additional info, exhaustive usage options and examples:
|
||||
|
||||
```
|
||||
# man rdiff-backup
|
||||
```
|
||||
|
||||
rdiff-backup Homepage: [http://www.nongnu.org/rdiff-backup/][12]
|
||||
|
||||
That’s it for now! In this tutorial, we showed you how to install and basically use rdiff-backup, an easy-to-use Python script for local/remote incremental backup in Linux. Do share your thoughts with us via the feedback section below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||
|
||||
|
||||
|
||||
------------
|
||||
|
||||
via: http://www.tecmint.com/rdiff-backup-remote-incremental-backup-for-linux/
|
||||
|
||||
作者:[Aaron Kili ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/install-cygwin-to-run-linux-commands-on-windows-system/
|
||||
[2]:http://www.tecmint.com/rsync-local-remote-file-synchronization-commands/
|
||||
[3]:http://www.tecmint.com/ssh-passwordless-login-using-ssh-keygen-in-5-easy-steps/
|
||||
[4]:http://www.tecmint.com/sync-new-changed-modified-files-rsync-linux/
|
||||
[5]:http://www.tecmint.com/ssh-passwordless-login-using-ssh-keygen-in-5-easy-steps/
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2017/03/Backup-Files-to-Different-Partition.png
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2017/03/check-rdif-versions-on-servers.png
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2017/03/Backup-Remote-Linux-Directory-on-Local-Server.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2017/03/rdiff-backup-data-directory-contents.png
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2017/03/additional-files-in-root-directory.png
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2017/03/incremental-backup-of-root-files.png
|
||||
[12]:http://www.nongnu.org/rdiff-backup/
|
||||
[13]:http://www.tecmint.com/author/aaronkili/
|
||||
[14]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[15]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -1,107 +1,71 @@
|
||||
GitLab工作流:概览
|
||||
GitLab 工作流概览
|
||||
======
|
||||
|
||||
GitLab是一个基于git的仓库管理程序,也是一个方便软件开发的强大完整应用。
|
||||
GitLab 是一个基于 git 的仓库管理程序,也是一个方便软件开发的强大完整应用。
|
||||
|
||||
GitLab拥有一个”用户新人友好“的界面,通过自由图形和命令行界面,使你的工作更加具有效率。GitLab不仅仅对开发者是一个有用的工具,它甚至可以被集成到你的整个团队中,使得每一个人获得一个唯一的平台。
|
||||
GitLab 拥有一个“用户新人友好”的界面,通过图形界面和命令行界面,使你的工作更加具有效率。GitLab 不仅仅对开发者是一个有用的工具,它甚至可以被集成到你的整个团队中,使得每一个人获得一个独自唯一的平台。
|
||||
|
||||
GitLab工作流逻辑符合使用者思维,使得整个平台变得更加易用。相信我,使用一次,你就离不开它了!
|
||||
|
||||
* * *
|
||||
|
||||
### 在这篇文章中
|
||||
|
||||
* [GitLab工作流][53]
|
||||
* [软件开发阶段][22]
|
||||
* [GitLab工单跟踪][52]
|
||||
* [秘密工单][21]
|
||||
* [截止日期][20]
|
||||
* [委托人][19]
|
||||
* [标签][18]
|
||||
* [工单重要性][17]
|
||||
* [GitLab工单看板][16]
|
||||
* [GitLab中的代码审查][51]
|
||||
* [第一次提交][15]
|
||||
* [合并请求][14]
|
||||
* [WIP MR][13]
|
||||
* [审查][12]
|
||||
* [建立,测试以及部署][50]
|
||||
* [Koding][11]
|
||||
* [用户案例][10]
|
||||
* [反馈: 循环分析][49]
|
||||
* [增强][48]
|
||||
* [工单 & MR模版][9]
|
||||
* [里程碑][8]
|
||||
* [高级技巧][47]
|
||||
* [对于工单 & MRs][7]
|
||||
* [订阅][3]
|
||||
* [添加 TO-DO][2]
|
||||
* [搜索你的工单 & MRs][1]
|
||||
* [转移工单][6]
|
||||
* [代码片段][5]
|
||||
* [GitLab 工作流 用户案例 梗概][46]
|
||||
* [尾声][45]
|
||||
|
||||
* * *
|
||||
GitLab 工作流逻辑符合使用者思维,使得整个平台变得更加易用。相信我,使用一次,你就离不开它了!
|
||||
|
||||
### GitLab 工作流
|
||||
|
||||
**GitLab 工作流** 使用GitLab作为平台管理你的代码,它是一系列具有逻辑可能性的过程——这个逻辑过程依据软件开发的生命周期来制定。
|
||||
**GitLab 工作流** 使用 GitLab 作为平台管理你的代码,它是一系列具有逻辑可能性的过程——这个逻辑过程依据软件开发的生命周期来制定。
|
||||
|
||||
GitLab 工作流考虑到[GitLab Flow][97],是由一系列由**基于Git**的方法和策略组成的,这些方法为版本的管理,例如**分支策略**,**Git最佳实践**等等提供了保障。
|
||||
GitLab 工作流遵循了 [GitLab Flow][97] 策略,这是由一系列由**基于 Git** 的方法和策略组成的,这些方法为版本的管理,例如**分支策略**,**Git最佳实践**等等提供了保障。
|
||||
|
||||
通过GitLab工作流,可以很方便的提升团队的工作效率以及凝聚力。这种提升,在引入一个新的项目的开始,一直到发布这个项目,成为一个产品都有所体现。这就是我们所说的“如何通过最快的速度把一个点子在10步之内变成一个产品”。
|
||||
通过 GitLab 工作流,可以很方便的[提升](https://about.gitlab.com/2016/09/13/gitlab-master-plan/)团队的工作效率以及凝聚力。这种提升,从引入一个新的项目开始,一直到发布这个项目,成为一个产品都有所体现。这就是我们所说的“如何通过最快的速度把一个点子在 10 步之内变成一个产品”。
|
||||
|
||||

|
||||
|
||||
### 软件开发阶段
|
||||
#### 软件开发阶段
|
||||
|
||||
一般情况下,软件开发经过10个主要阶段;GitLab为这10个阶段依次提供了解决方案:
|
||||
一般情况下,软件开发经过 10 个主要阶段;GitLab 为这 10 个阶段依次提供了解决方案:
|
||||
|
||||
1. **IDEA:** 每一个从点子开始的项目,通常来源于一次闲聊。在这个阶段,GitLab集成了[Mattermost][44]。
|
||||
2. **ISSUE:** 最有效的讨论一个点子的方法,就是为这个点子建立一个工单讨论。你的团队和你的合作伙伴可以帮助你去提升这个点子,通过[issue tracker][43]
|
||||
3. **PLAN:** 一旦讨论得到一致的同意,就是开始编码的时候了。但是等等!首先,我们需要优先考虑组织我们的工作流。对于此,我们可以使用[Issue Board][42]。
|
||||
4. **CODE:** 现在,当一切准备就绪,我们可以开始写代码了。
|
||||
5. **COMMIT:** 当我们为我们的草稿欢呼的时候,我们就可以在版本控制下,提交代码到功能分支了。
|
||||
6. **TEST:** 通过[GitLab CI][41],我们可以运行脚本来创建和测试我们的应用
|
||||
7. **REVIEW:** 一旦脚本成功运行,我们的创建和测试成功,我们就可以进行[code review][40]以及批准。
|
||||
8. **STAGING:** 现在是时候[将我们的代码部署到演示环境][39]来检查一下,是否一切就像我们预估的那样顺畅——或者我们可能仍然需要修改。
|
||||
9. **PRODUCTION:** 当项目已经运行的时分通畅,就是[部署到生产环境][38]的时候了!
|
||||
10. **FEEDBACK**: 现在是时候翻回去看我们能在项目中提升的部分了。我们使用[循环分析][37]来对当前项目中关键的部分进行的反馈。
|
||||
1. **IDEA**: 每一个从点子开始的项目,通常来源于一次闲聊。在这个阶段,GitLab 集成了 [Mattermost][44]。
|
||||
2. **ISSUE**: 最有效的讨论一个点子的方法,就是为这个点子建立一个工单讨论。你的团队和你的合作伙伴可以帮助你去提升这个点子,通过 [issue tracker][43]
|
||||
3. **PLAN**: 一旦讨论得到一致的同意,就是开始编码的时候了。但是等等!首先,我们需要优先考虑组织我们的工作流。对于此,我们可以使用 [Issue Board][42]。
|
||||
4. **CODE**: 现在,当一切准备就绪,我们可以开始写代码了。
|
||||
5. **COMMIT**: 当我们为我们的初步成果欢呼的时候,我们就可以在版本控制下,提交代码到功能分支了。
|
||||
6. **TEST**: 通过 [GitLab CI][41],我们可以运行脚本来创建和测试我们的应用
|
||||
7. **REVIEW**: 一旦脚本成功运行,我们测试和构建成功,我们就可以进行 [code review][40] 以及批准。
|
||||
8. **STAGING:**: 现在是时候[将我们的代码部署到演示环境][39]来检查一下,是否一切就像我们预估的那样顺畅——或者我们可能仍然需要修改。
|
||||
9. **PRODUCTION**: 当项目已经运行的十分通畅,就是[部署到生产环境][38]的时候了!
|
||||
10. **FEEDBACK**: 现在是时候翻回去看我们能在项目中提升的部分了。我们使用[循环分析][37]来对当前项目中关键的部分进行的反馈。
|
||||
|
||||
简单浏览这些步骤,我们可以发现,提供强大的工具来支持这些步骤是十分重要的。在接下来的部分,我们为GitLab的可用工具提供一个简单的概览。
|
||||
简单浏览这些步骤,我们可以发现,提供强大的工具来支持这些步骤是十分重要的。在接下来的部分,我们为 GitLab 的可用工具提供一个简单的概览。
|
||||
|
||||
### GitLab 工单追踪
|
||||
|
||||
GitLab有一个强大的工单追溯系统,在使用过程中,允许你和你的团队,以及你的合作者分享和讨论建议。
|
||||
GitLab 有一个强大的工单追溯系统,在使用过程中,允许你和你的团队,以及你的合作者分享和讨论建议。
|
||||
|
||||
|
||||
|
||||
工单是GitLab工作流的第一个重要重要特性。[以工单的讨论为开始][95]; 跟随点子的改变是一个最好的方式。
|
||||
工单是 GitLab 工作流的第一个重要重要特性。[以工单的讨论为开始][95]; 跟随点子的改变是一个最好的方式。
|
||||
|
||||
这十分有利于:
|
||||
|
||||
* 讨论点子
|
||||
* 提交功能建议
|
||||
* 提问题
|
||||
* 提交bug
|
||||
* 提交 bug
|
||||
* 获取支持
|
||||
* 精细化新代码的引入
|
||||
|
||||
对于每一个在GitLab上部署的项目都有一个工单追踪器。找到你的项目中的 **Issues** > **New issue**,来创建一个新的工单。建立一个标题来总结要被讨论的主题,并且使用[Markdown][94]来形容它。检查[pro tips][93]来加强你的工单描述。
|
||||
对于每一个在 GitLab 上部署的项目都有一个工单追踪器。找到你的项目中的 **Issues** > **New issue** 来创建一个新的工单。建立一个标题来总结要被讨论的主题,并且使用 [Markdown][94] 来形容它。看看 [pro tips][93] 来加强你的工单描述。
|
||||
|
||||
GitLab 工单追踪器代表了一个额外的实用功能,使得步骤变的更佳易于管理和考虑。下面的部分仔细描述了它。
|
||||
GitLab 工单追踪器提供了一个额外的实用功能,使得步骤变的更佳易于管理和考虑。下面的部分仔细描述了它。
|
||||
|
||||
|
||||
|
||||
### 秘密工单
|
||||
#### 秘密工单
|
||||
|
||||
无论何时,你仅仅想要在团队中讨论这个工单,你可以使用[issue confidential][92]。即使你的项目是公开的,你的工单也会被保留。当一个不是本项目成员的人,就算是[Reporter level][01],想要访问工单的地址时,浏览器也会返回一个404错误。
|
||||
无论何时,如果你仅仅想要在团队中讨论这个工单,你可以使用 [issue confidential][92]。即使你的项目是公开的,你的工单也会被保密起来。当一个不是本项目成员的人,就算是 [Reporter level][01],想要访问工单的地址时,浏览器也会返回一个 404 错误。
|
||||
|
||||
### 截止日期
|
||||
#### 截止日期
|
||||
|
||||
每一个工单允许你填写一个[截止日期][90]。有些团队以紧凑的时间表工作,并且拥有一种方式去设置一个截止日期来解决问题,是有必要的。这些都可以通过截止日期这一功能实现。
|
||||
每一个工单允许你填写一个[截止日期][90]。有些团队以紧凑的时间表工作,以某种方式去设置一个截止日期来解决问题,是有必要的。这些都可以通过截止日期这一功能实现。
|
||||
|
||||
当你有一个多任务的项目截止日期的时候——比如说,一个新的发布,项目的启动,或者追踪团体任务——你可以使用[milestones][89]。
|
||||
当你有一个多任务的项目截止日期的时候——比如说,一个新的发布、项目的启动,或者追踪团体任务——你可以使用 [milestones][89]。
|
||||
|
||||
### 受托者
|
||||
|
||||
|
||||
@ -0,0 +1,163 @@
|
||||
# 像 Linus Torvalds 学习让编出的代码具有“good taste”
|
||||
|
||||
在[最近关于 Linus Torvalds 的一个采访中][1],这位 Linux 的创始人,在采访过程中大约 14:20 的时候,快速的指出了关于代码的 "good taste"。good taste?采访者请他展示更多的细节,于是,Linus Torvalds 展示了一张提前准备好的插图。
|
||||
|
||||
这张插图中展示了一个代码片段。但这段代码并没有 “good taste”。这是一个具有 “poor taste” 的代码片段,把它作为例子,以提供一些初步的比较。
|
||||
|
||||

|
||||
|
||||
这是一个用 C 写的函数,作用是删除链表中的一个对象,它包含有 10 行代码。
|
||||
|
||||
他把注意力集中在底部的 if 语句。正是这个 if 语句受到他的批判。
|
||||
|
||||
我暂停视频,开始研究幻灯片。我发现我最近有写过和这很像的代码。Linus 不就是在说我的代码品味很差吗?我吞下自尊,继续观看视频。
|
||||
|
||||
随后, Linus 向观众解释,正如我们所知道的,当从链表中删除一个对象时,需要考虑两种可能的情况。当所需删除的对象位于链表的表头时,删除过程和位于链表中间的情况不同。这就是这个 if 语句具有 "poor taste" 的原因。
|
||||
|
||||
但既然他承认考虑这两种不同的情况是必要的,那为什么像上面那样写如此糟糕呢?
|
||||
|
||||
接下来,他又向观众展示了第二张幻灯片。这个幻灯片展示的是实现同样功能的一个函数,但这段代码具有 “goog taste” 。
|
||||
|
||||

|
||||
|
||||
原先的 10 行代码现在减少为 4 行。
|
||||
|
||||
但代码的行数并不重要,关键是 if 语句,它不见了,因为不再需要了。代码已经被重构,所以,尽管对象的地址还在列表中,但已经运用同样的操作把它删除了。
|
||||
|
||||
Linus 解释了一下新的代码,它消除了边缘情况,就是这样。然后采访转入了下一个话题。
|
||||
|
||||
我琢磨了一会这段代码。 Linus 是对的,的确,第二个函数更好。如果这是一个确定代码具有 “good taste” 还是 “bad taste” 的测试,那么很遗憾,我失败了。我从未想到过有可能能够去除条件语句。我写过不止一次这样的 if 语句,因为我经常使用链表。
|
||||
|
||||
这个例子的启发,不仅仅是教给了我们一个从链表中删除对象的更好方法,而是启发了我们去考虑自己写的代码。你通过程序实现的一个简单算法,可能还有改进的空间,只是你从来没有考虑过。
|
||||
|
||||
以这种方式,我回去审查最近正在做的项目的代码。也许是一个巧合,刚好也是用 C 写的。
|
||||
|
||||
我尽最大的能力去审查代码,“good taste” 的一个基本要求是关于边缘情况的消除方法,通常我们会使用条件语句来消除边缘情况。然而,你的测试使用的条件语句越少,你的代码就会有更好的 “tastes” 。
|
||||
|
||||
下面,我将分享一个通过审查代码进行了改进的一个特殊例子。
|
||||
|
||||
这是一个关于初始化网格边缘的算法。
|
||||
|
||||
下面所写的是一个用来初始化 grid 的网格边缘的算法,gird 表示一个二维数组:grid[行][列]
|
||||
|
||||
再次说明,这段代码的目的只是用来初始化位于 grid 边缘的点的值,所以,只需要给最上方一行、最下方一行、最左边一列以及最右边一列赋值即可。
|
||||
|
||||
为了完成这件事,我通过循环遍历 grid 中的每一个点,然后使用条件语句来测试该点是否位于边缘。代码看起来就是下面这样:
|
||||
|
||||
```Tr
|
||||
for (r = 0; r < GRID_SIZE; ++r) {
|
||||
for (c = 0; c < GRID_SIZE; ++c) {
|
||||
```
|
||||
|
||||
```
|
||||
// Top Edge
|
||||
if (r == 0)
|
||||
grid[r][c] = 0;
|
||||
```
|
||||
|
||||
```
|
||||
// Left Edge
|
||||
if (c == 0)
|
||||
grid[r][c] = 0;
|
||||
```
|
||||
|
||||
```
|
||||
// Right Edge
|
||||
if (c == GRID_SIZE - 1)
|
||||
grid[r][c] = 0;
|
||||
```
|
||||
|
||||
```
|
||||
// Bottom Edge
|
||||
if (r == GRID_SIZE - 1)
|
||||
grid[r][c] = 0;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
虽然这样做是对的,但回过头来看,这个结构存在一些问题。
|
||||
|
||||
1. 复杂性 — 在双层循环里面使用 4 个条件语句似乎过于复杂。
|
||||
2. 高效性 — 假设 GRID_SIZE 的值为 64,那么这个循环需要执行 4096 次,但需要进行赋值的只有位于边缘的 256 个点。
|
||||
|
||||
用 Linus 的眼光来看,将会认为这段代码没有 “good taste” 。
|
||||
|
||||
所以,我对上面的问题进行了一下思考。经过一番思考,我把复杂度减少为包含四个条件语句的单层循环。虽然只是稍微改进了一下复杂性,但在性能上也有了极大的提高,因为它只是沿着边缘的点进行了 256 次循环。
|
||||
|
||||
```
|
||||
for (i = 0; i < GRID_SIZE * 4; ++i) {
|
||||
```
|
||||
|
||||
```
|
||||
// Top Edge
|
||||
if (i < GRID_SIZE)
|
||||
grid[0][i] = 0;
|
||||
```
|
||||
|
||||
```
|
||||
// Right Edge
|
||||
else if (i < GRID_SIZE * 2)
|
||||
grid[i - GRID_SIZE][GRID_SIZE - 1] = 0;
|
||||
```
|
||||
|
||||
```
|
||||
// Left Edge
|
||||
else if (i < GRID_SIZE * 3)
|
||||
grid[i - (GRID_SIZE * 2)][0] = 0;
|
||||
```
|
||||
|
||||
```
|
||||
// Bottom Edge
|
||||
else
|
||||
grid[GRID_SIZE - 1][i - (GRID_SIZE * 3)] = 0;
|
||||
}
|
||||
```
|
||||
|
||||
的确是一个很大的提高。但是它看起来很丑,并不是易于遵循的代码。基于这一点,我并不满意。
|
||||
|
||||
我继续思考,是否可以进一步改进呢?事实上,答案是 YES!最后,我想出了一个非常简单且优雅的算法,老实说,我不敢相信我会花了那么长时间才发现这个算法。
|
||||
|
||||
下面是这段代码的最后版本。它只有一层循环并且没有条件语句。另外。循环只执行了 64 次迭代,极大的改善了复杂性和高效性。
|
||||
|
||||
```
|
||||
for (i = 0; i < GRID_SIZE; ++i) {
|
||||
```
|
||||
|
||||
```
|
||||
// Top Edge
|
||||
grid[0][i] = 0;
|
||||
|
||||
// Bottom Edge
|
||||
grid[GRID_SIZE - 1][i] = 0;
|
||||
```
|
||||
|
||||
```
|
||||
// Left Edge
|
||||
grid[i][0] = 0;
|
||||
```
|
||||
|
||||
```
|
||||
// Right Edge
|
||||
grid[i][GRID_SIZE - 1] = 0;
|
||||
}
|
||||
```
|
||||
|
||||
这段代码通过单层循环迭代来初始化四条边缘上的点。它并不复杂,而且非常高效,易于阅读。和原始的版本,甚至是第二个版本相比,都有天壤之别。
|
||||
|
||||
至此,我已经非常满意了。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.com/@bartobri/applying-the-linus-tarvolds-good-taste-coding-requirement-99749f37684a
|
||||
|
||||
作者:[Brian Barto][a]
|
||||
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.com/@bartobri?source=post_header_lockup
|
||||
[1]:https://www.ted.com/talks/linus_torvalds_the_mind_behind_linux
|
||||
@ -1,243 +0,0 @@
|
||||
没有Kotlin(Android)生活
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
> 开始投入一件事比远离它更容易。 — Donald Rumsfeld
|
||||
|
||||
没有Kotlin的生活就像在触摸板上玩魔兽争霸3。购买鼠标很简单,但如果你的新雇主不想让你在生产中使用Kotlin,你该怎么办?
|
||||
|
||||
下面有一些选择。
|
||||
* 与你的产品负责人争取获得使用Kotlin的权利。
|
||||
* 使用Kotlin并且不告诉其他人因为你知道最好的东西是只适合你的。
|
||||
* 擦掉你的眼泪,自豪地使用Java。
|
||||
|
||||
想象一下,你在和产品负责人的斗争中失败,作为一个专业的工程师,在没有任何人的允许下你将不会去依靠和使用时髦的技术。我知道这听起来非常恐怖,特别当你已经品尝到Kotlin的好处但是又没有失去你的希望。
|
||||
|
||||
在文章接下来的部分,我想简短地描述一些Kotlin的特征,使你通过一些知名的工具和库,可以应用到你的Android里的Java代码中去。对于Kotlin和Java一个基本的认识是需要的。
|
||||
|
||||
### 数据类
|
||||
|
||||
你真的已经喜欢上Kotlin的数据类,不是吗?对于你来说,得到`equals()`, `hashCode()`, `toString()` 和 `copy()`这些类是很容易的。具体来说,`data`关键字还会按照声明顺序生成对应于属性的`componentN()`函数。 它们用于构造声明。
|
||||
```
|
||||
data class Person(val name: String)
|
||||
val (riddle) = Person("Peter")
|
||||
println(riddle)
|
||||
```
|
||||
|
||||
你知道什么会被打印吗?确信它不会是从`Person` 类的`toString()` 返回的值。这是构造声明的作用,它赋值从`name`到`riddle`。使用园括号`(riddle)`编译器知道它必须使用构造声明机制。
|
||||
|
||||
|
||||
```
|
||||
val (riddle): String = Person("Peter").component1()
|
||||
println(riddle) // prints Peter
|
||||
view raw
|
||||
```
|
||||
|
||||
>这个代码没有编译。它就是展示了构造声明怎么工作的。
|
||||
|
||||
正如你可以看到`data`关键字是一个超级有用的语言特性,所以你能做什么把它带到你的Java世界? 使用注释处理器并修改抽象语法树。 如果你想更深入,请阅读文章末尾列出的文章(Project Lombok— Trick Explained)。
|
||||
|
||||
使用项目Lombok你可以实现几乎相同的功能,`data`关键字提供。 不幸的是,没有办法进行构造声明。
|
||||
|
||||
```
|
||||
import lombok.Data;
|
||||
|
||||
@Data class Person {
|
||||
final String name;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
`@ Data`注解生成`equals()`,`hashCode()`和`toString()`。 此外,它为所有字段创建getters,为所有非最终字段创建setters,并为所有必填字段(finalals)创建构造函数。 值得注意的是,Lombok仅用于编译,因此库代码不会添加到您的最终的.apk。
|
||||
|
||||
### Lambda表达式
|
||||
|
||||
Android工程师有一个非常艰难的生活,因为Android中缺乏Java 8的特性,而且其中之一是lambda表达式。 Lambdas是很棒的,因为它们为你减少了成吨的样板。 你可以在回调和流中使用它们。 在Kotlin中,lambda表达式是内置的,它们看起来比它们在Java中看起来好多了。 此外,lambda的字节码可以直接插入到调用方法的字节码中,因此方法计数不会增加。 它可以使用内联函数。
|
||||
|
||||
```
|
||||
button.setOnClickListener { println("Hello World") }
|
||||
```
|
||||
最近Google宣布在Android中支持Java 8的特性,由于Jack编译器,你可以在你的代码中使用lambdas。还要提及的是,它们在API 23或者更低的级别都可用。
|
||||
|
||||
```
|
||||
button.setOnClickListener(view -> System.out.println("Hello World!"));
|
||||
```
|
||||
|
||||
怎样使用它们?就只用添加下面几行到你的` build.gradle `文件中。
|
||||
|
||||
|
||||
```
|
||||
defaultConfig {
|
||||
jackOptions {
|
||||
enabled true
|
||||
}
|
||||
}
|
||||
|
||||
compileOptions {
|
||||
sourceCompatibility JavaVersion.VERSION_1_8
|
||||
targetCompatibility JavaVersion.VERSION_1_8
|
||||
}
|
||||
```
|
||||
|
||||
如果你不是一个Jack编译器的粉丝,或则你由于一些原因不能使用它,这里有一个不同的解决方案提供给你。Retrolambda项目允许你使用Java 7,6或者5上的lambda表达式来运行Java 8的代码,下面是设置过程。
|
||||
```
|
||||
dependencies {
|
||||
classpath 'me.tatarka:gradle-retrolambda:3.4.0'
|
||||
}
|
||||
|
||||
apply plugin: 'me.tatarka.retrolambda'
|
||||
|
||||
compileOptions {
|
||||
sourceCompatibility JavaVersion.VERSION_1_8
|
||||
targetCompatibility JavaVersion.VERSION_1_8
|
||||
}
|
||||
```
|
||||
正如我前面提到的,在Kotlin下的lambdas内联函数不增加方法计数,但是如何在Jack或者Retrolambda下使用它们? 显然,它们不是免费的,隐藏的成本如下。
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
### 数据操作
|
||||
|
||||
|
||||
Kotlin引入了高阶函数作为流的替代。 当您必须将一组数据转换为另一组数据或过滤集合时,它们非常有用。
|
||||
|
||||
```
|
||||
fun foo(persons: MutableList<Person>) {
|
||||
persons.filter { it.age >= 21 }
|
||||
.filter { it.name.startsWith("P") }
|
||||
.map { it.name }
|
||||
.sorted()
|
||||
.forEach(::println)
|
||||
}
|
||||
|
||||
data class Person(val name: String, val age: Int)
|
||||
```
|
||||
|
||||
Streams也由Google使用Jack编译器提供。 不幸的是,Jack不使用Lombok,因为它在编译代码时跳过生成中间的`.class`文件,而Lombok依赖于这些文件。
|
||||
|
||||
|
||||
```
|
||||
void foo(List<Person> persons) {
|
||||
persons.stream()
|
||||
.filter(it -> it.getAge() >= 21)
|
||||
.filter(it -> it.getName().startsWith("P"))
|
||||
.map(Person::getName)
|
||||
.sorted()
|
||||
.forEach(System.out::println);
|
||||
}
|
||||
|
||||
class Person {
|
||||
final private String name;
|
||||
final private int age;
|
||||
|
||||
public Person(String name, int age) {
|
||||
this.name = name;
|
||||
this.age = age;
|
||||
}
|
||||
|
||||
String getName() { return name; }
|
||||
int getAge() { return age; }
|
||||
}
|
||||
```
|
||||
|
||||
这太好了以至于不是真的,所以在哪里捉住? 悲伤的是,流从API 24 \可用。谷歌做的不错,但为什么广泛的应用程序有` minSdkVersion = 24 `?
|
||||
|
||||
幸运的是,Android平台有一个很好的开源社区提供许多很棒的库。Lightweight-Stream-API是其中的一个,它包含基于Java 7及以下版本的迭代器的流实现。
|
||||
|
||||
```
|
||||
import lombok.Data;
|
||||
import com.annimon.stream.Stream;
|
||||
|
||||
void foo(List<Person> persons) {
|
||||
Stream.of(persons)
|
||||
.filter(it -> it.getAge() >= 21)
|
||||
.filter(it -> it.getName().startsWith("P"))
|
||||
.map(Person::getName)
|
||||
.sorted()
|
||||
.forEach(System.out::println);
|
||||
}
|
||||
|
||||
@Data class Person {
|
||||
final String name;
|
||||
final int age;
|
||||
}
|
||||
```
|
||||
|
||||
上面的例子结合了Lombok,Retrolambda和Lightweight-Stream-API,它看起来几乎和Kotlin一样好,不是。 使用静态工厂方法允许您将任何Iterable转换为流,并对其应用lambdas,就像Java 8流一样。 将静态调用` Stream.of(persons) `包装为Iterable类型的扩展函数是完美的,但是Java不支持它。
|
||||
|
||||
### 扩展功能
|
||||
|
||||
扩展机制提供了向类添加功能而无需继承它的能力。 这个众所周知的概念非常适合Android世界,这就是Kotlin在社区很受欢迎的原因。
|
||||
|
||||
有没有技术或魔术将扩展功能添加到你的Java工具箱? 由于Lombok,你可以使用它们作为一个实验功能。 根据Lombok文档的说明,他们想把它从实验状态移出,没有或微小的变化很快。 让我们重构最后一个样例,并将` Stream.of(persons) `包装成扩展函数。
|
||||
|
||||
|
||||
```
|
||||
import lombok.Data;
|
||||
import lombok.experimental.ExtensionMethod;
|
||||
|
||||
@ExtensionMethod(Streams.class)
|
||||
public class Foo {
|
||||
void foo(List<Person> persons) {
|
||||
persons.toStream()
|
||||
.filter(it -> it.getAge() >= 21)
|
||||
.filter(it -> it.getName().startsWith("P"))
|
||||
.map(Person::getName)
|
||||
.sorted()
|
||||
.forEach(System.out::println);
|
||||
}
|
||||
}
|
||||
|
||||
@Data class Person {
|
||||
final String name;
|
||||
final int age;
|
||||
}
|
||||
|
||||
class Streams {
|
||||
static <T> Stream<T> toStream(List<T> list) {
|
||||
return Stream.of(list);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
所有的方法是`public`,`static`,并且至少有一个参数的类型不是原始的,被认为是扩展方法。 `@ ExtensionMethod`注解允许你指定一个包含你的扩展函数的类。 而不是使用一个`.class`对象,你也可以传递数组。
|
||||
|
||||
* * *
|
||||
|
||||
我完全知道我的一些想法是非常有争议的,特别是Lombok,我也知道,有很多的库,可以使你的生活更轻松。请不要犹豫在评论里分享你的经验。干杯!
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
---------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Coder and professional dreamer @ Grid Dynamics
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://hackernoon.com/living-android-without-kotlin-db7391a2b170#.q95i5232f
|
||||
|
||||
作者:[Piotr Ślesarew][a]
|
||||
译者:[DockerChen](https://github.com/DockerChen)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://hackernoon.com/@piotr.slesarew?source=post_header_lockup
|
||||
[1]:http://jakewharton.com/exploring-java-hidden-costs/
|
||||
[2]:https://medium.com/u/8ddd94878165
|
||||
[3]:https://projectlombok.org/index.html
|
||||
[4]:https://github.com/aNNiMON/Lightweight-Stream-API
|
||||
[5]:https://github.com/orfjackal/retrolambda
|
||||
[6]:http://notatube.blogspot.com/2010/11/project-lombok-trick-explained.html
|
||||
[7]:http://notatube.blogspot.com/2010/11/project-lombok-trick-explained.html
|
||||
[8]:https://twitter.com/SliskiCode
|
||||
@ -0,0 +1,49 @@
|
||||
Oracle 政策更改提高了 AWS 的价格
|
||||
============================================================
|
||||
|
||||
>这种改变使甲骨文在 AWS 上实施其软件的价格翻了一番,它已经安静地生效了,而几乎没有通知用户。
|
||||
|
||||

|
||||
|
||||
上周消息传出,甲骨文使亚马逊云上的产品价格翻了一倍。它在[如何计算 AWS 的虚拟 CPU][6]上耍了一些花招。它这么做也没有任何宣扬。该公司的新定价政策于 1 月 23 日生效,直到 1 月 28 日,几乎没有被注意到,直到 Oracle 的关注者 Tim Hall 偶然发现 Big Red 的[ Oracle 软件云计算环境许可][7]文件并揭发了出来。
|
||||
|
||||
乍一看,这一举动似乎并不太大,因为它仅将 Oracle 的 AWS 定价与 Microsoft Azure 的价格相提并论。但是 Azure 只有市场领先的 AWS 体量的三分之一,所以如果你想在云中销售许可证,AWS 是合适的地方。虽然此举可能或可能不会影响已经在 AWS 上使用 Oracle 的用户,但是尚不清楚新规则是否适用于已在使用产品的用户 - 它肯定会让一些考虑可能使用 Oracle 的用户另寻它处。
|
||||
|
||||
这个举动的主要原因是显而易见的。甲骨文希望使自己的云更具吸引力 - 这让[The Register 观察][8]到一点:“拉里·埃里森确实承诺过 Oracle 的云将会更快更便宜”。更快和更便宜仍然有待看到。如果 Oracle 的 SPARC 云计划启动,并且按照广告的形式执行,那么可能会更快,但是更便宜的可能性较小。甲骨文以对其价格的强硬态度而著称。
|
||||
|
||||
随着其签名数据库和业务栈销售的下滑,并且对 Sun 的 74 亿美元的投资并未能按照如期那样,Oracle 将其未来堵在云计算上。但是甲骨文来晚了,迄今为止, 它的努力似乎还没有结果, 一些金融预测者并没有看到 Oracle Cloud 的光明前景。他们说,云是一个拥挤的市场,而四大公司 - 亚马逊、微软、IBM 和谷歌 - 已经有了领先优势。
|
||||
|
||||
确实如此。但是 Oracle 面临的最大的障碍是,好吧,是 Oracle。它的声誉在它之前。
|
||||
|
||||
保守地说这个公司并不是因为明星客户服务而闻名。事实上, 新闻报道将甲骨文描绘成一个恶霸和操纵者。
|
||||
|
||||
例如,早在 2015 年,Oracle 就因为它的云并不像预期那样快速增长而越来越沮丧,开始[激活业内人士称之为的“核特权”][9]。它会审核客户的数据中心,如果客户不符合规定,将发出“违规通知” - 它通常只适用于大规模滥用情况,并命令客户在 30 天内退出使用其软件。
|
||||
|
||||
以防你还不知道,那么大量投资 Oracle 栈的大公司绝对不能在短时间内迁移到另一个解决方案。Oracle 的违规通知会引发灾难。
|
||||
|
||||
商业内幕人士 Julie Bort 解释到:“为了使违规通知消失 - 或者减少高额的违规罚款 - 甲骨文销售代表通常希望客户向合同中添加云额度”。
|
||||
|
||||
换句话说,Oracle 正在使用审计来扭转客户去购买它的云,而无论他们是否有需要。这种策略与最近 AWS 价格翻倍之间也可能存在联系。Hall 的文章的评论者指出,围绕价格提升的秘密背后的目的可能是触发软件审计。
|
||||
|
||||
使用这些策略的麻烦迟早会出来。消息一旦传播开来,你的客户就开始寻找其他选项。对 Big Red 而言或许是时候参考微软的做法,开始建立一个更好和更温和的 Oracle,将客户的需求放在第一位。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://windowsitpro.com/cloud/oracle-policy-change-raises-prices-aws
|
||||
|
||||
作者:[Christine Hall][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://windowsitpro.com/author/christine-hall
|
||||
[1]:http://windowsitpro.com/penton_ur/nojs/user/register?path=node%2F186491&nid=186491&source=email
|
||||
[2]:http://windowsitpro.com/author/christine-hall
|
||||
[3]:http://windowsitpro.com/author/christine-hall
|
||||
[4]:http://windowsitpro.com/cloud/oracle-policy-change-raises-prices-aws#comments
|
||||
[5]:http://windowsitpro.com/cloud/oracle-policy-change-raises-prices-aws#comments
|
||||
[6]:https://oracle-base.com/blog/2017/01/28/oracles-cloud-licensing-change-be-warned/
|
||||
[7]:http://www.oracle.com/us/corporate/pricing/cloud-licensing-070579.pdf
|
||||
[8]:https://www.theregister.co.uk/2017/01/30/oracle_effectively_doubles_licence_fees_to_run_in_aws/
|
||||
[9]:http://www.businessinsider.com/oracle-is-using-the-nuclear-option-to-sell-its-cloud-software-2015-7
|
||||
@ -0,0 +1,112 @@
|
||||
|
||||
AI正快速入侵我们生活的五个方面
|
||||
============================================================
|
||||
|
||||
> 让我们来看看我们已经被人工智能包围的五个真实存在的方面
|
||||
|
||||

|
||||
> 图片来源: opensource.com
|
||||
|
||||
开源项目[正在帮助推动][2]人工智能进步,而且随着技术的成熟,我们可以听到更多关于AI如何影响我们的生活的消息。你有没有考虑过AI是如何改变你周围的世界的?让我们来看看我们日益人为增强的宇宙,并考虑对我们的AI影响的未来做些大胆预测。
|
||||
|
||||
### 1. AI影响你的购买决定
|
||||
|
||||
一篇[VentureBeat][3]上的最近的新闻报道[《AI将如何帮助我们解读千禧一代》][4]"吸引了我的注意。我承认我对人工智能没有思考太多,也没有很难解读千禧一代,所以我渴望了解更多。事实证明,文章标题有点误导人;《如何卖东西给千禧一代》会是一个更准确的标题。
|
||||
|
||||
根据这篇文章,千禧一代是一个"人口统计细分,非常令人羡慕的一代人,以至于来自全世界的市场经理都在争抢他们"。通过分析网络行为——无论是购物、社交媒体或其他活动 - 机器学习可以帮助预测行为模式,这将可以变成有针对性的广告。文章接着解释如何将物联网和社交媒体平台挖掘成数据点。"使用机器学习挖掘社交媒体数据可以让公司了解千禧一代如何谈论其产品和他们对一个产品类别的看法,以及如何回应竞争对手的广告活动,还有可用于设计有针对性的广告系列的众多其他数据,"这篇文章解释。AI和千禧一代成为营销的未来并不是什么很令人吃惊的事,但是X一代和婴儿潮一代,你们也逃不掉呢!
|
||||
|
||||
> 人工智能被用来根据行为变化来定位包括城市人在内的整个人群。
|
||||
|
||||
例如, [Raconteur上][23]的一篇文章——"AI将怎样改变购买者的行为"解释说,AI在网上零售行业最大的力量是它能够迅速适应流动的情况下改变客户行为。人工智能创业公司 [Fluid AI][25]首席执行官Abhinav
|
||||
Aggarwal表示,他的公司的软件被客户用来预测客户行为,并且系统注意到在暴风雪期间发生了变化。“那些通常会忽略在一天中发送的电子邮件或应用内通知的用户现在正在打开它们,因为他们在家里没有太多的事情可做。一个小时,AI系统就适应了新的情况,并在工作时间发送更多的促销材料。"他解释说。
|
||||
|
||||
AI正在改变了我们怎样花钱和为什么花钱,但是AI是怎样改变我们挣钱的方式的呢?
|
||||
|
||||
### 2. 人工智能正在改变我们如何工作
|
||||
|
||||
[Fast公司][5]最近的一篇文章《这就是在2017年人工智能如何改变我们的生活》说道,求职者将会从人工智能中受益。作者解释说,除薪酬趋势更新之外,人工智能将被用来给求职者发送相关职位空缺信息。当你应该升职的时候,你就会得到一个升职的机会。
|
||||
|
||||
人造智能也将被公司用来帮助新入职的员工。文章解释说:“许多新员工在头几天内获得了大量信息,其中大部分不会被保留。” 相反,机器人可能会随着时间的推移向一名新员工“滴滴”,因为它变得更加相关。
|
||||
|
||||
[Inc.][7]的一篇文章[《没有偏见的企业:人工智能将如何重塑招聘机制》][8]着眼于人才管理解决方案提供商[SAP SuccessFactors][9]是怎样利用人工智能作为一个工作描述偏差检查器”和检查员工赔偿金的偏差。
|
||||
|
||||
[《Deloitte2017人力资本趋势报告》][10]显示,AI正在激励组织进行重组。Fast公司的文章[《AI是怎样改变公司组织的方式》][11]审查了这篇报告,该文章是基于全球10,000多名人力资源和商业领袖的调查结果。这篇文章解释说:"许多公司现在更注重文化和环境的适应性,而不是聘请最有资格的人来做某个具体任务,因为知道个人角色必须随AI的实施而发展 。" 为了适应不断变化的技术,组织也从自上而下的结构转向多学科团队,文章说。
|
||||
|
||||
###3. AI正在改变教育
|
||||
|
||||
> AI将使所有教育生态系统的利益相关者受益。
|
||||
|
||||
尽管教育的预算正在缩减,但是教室的规模却正在增长。因此利用技术的进步有助于提高教育体系的生产率和效率,并在提高教育质量和负担能力方面发挥作用。根据VentureBeat上的一篇文章[《2017年人工智能是怎样改变教育》][26],今年我们将看到AI对学生们的书面答案进行评分,机器人回答学生的答案,虚拟个人助理辅导学生等等。文章解释说:“AI将惠及教育生态系统的所有利益相关者。学生将能够通过即时的反馈和指导学习地更好,教师将获得丰富的学习分析和对个性化教学的见解,父母将以更低的成本看到他们的孩子的更好的职业前景,学校能够规模化优质的教育,政府能够向所有人提供可负担得起的教育。"
|
||||
|
||||
### 4. 人工智能正在重塑医疗保健
|
||||
|
||||
2017年2月[CB Insights][12]的一篇文章挑选了106个医疗保健领域的人工智能初创公司,它们中的很多在过去几年中提高了第一次股权融资。这篇文章说:“在24家成像和诊断公司中,19家公司自2015年1月起就首次公开募股。”这份名单上了有那些从事于远程病人监测,药物发现和肿瘤学方面人工智能的公司。
|
||||
|
||||
3月16日发表在TechCrunch上的一篇关于AI进步如何重塑医疗保健的文章解释说:"一旦对人类的DNA有了更好的理解,就有机会更进一步,并能根据他们特殊的生活习性为他们提供个性化的见解"。这种趋势预示着“个性化遗传学”的新纪元,人们能够通过获得关于自己身体的前所未有的信息来充分控制自己的健康。"
|
||||
|
||||
本文接着解释说,AI和机器学习降低了研发新药的成本和时间。部分得益于广泛的测试,新药进入市场需要12年以上的时间。这篇文章说:“机器学习算法可以让计算机根据先前处理的数据来"学习"如何做出预测,或者选择(在某些情况下,甚至是产品)需要做什么实验。类似的算法还可用于预测特定化合物对人体的副作用,这样可以加快审批速度。"这篇文章指出,2015年旧金山的一个创业公司[Atomwise][15]完成了对两种可以减少一天内Ebola感染的新药物。
|
||||
|
||||
> AI正在帮助发现、诊断和治疗新疾病。
|
||||
|
||||
另外一个位于伦敦的初创公司[BenevolentAI][27]正在利用人工智能寻找科学文献中的模式。这篇文章说:"最近,这家公司找到了两种可能对Alzheimer起作用的化合物,引起了很多制药公司的关注。"
|
||||
|
||||
除了有助于研发新药,AI正在帮助发现、诊断和治疗新疾病。TechCrunch上 文章解释说,过去是根据显示的症状诊断疾病,但是现在AI正在被用于检测血液中的疾病特征,并利用对数十亿例临床病例分析进行深度学习获得经验来制定治疗计划。这篇文章说:“IBM的Watson正在与纽约的Memorial Sloan Kettering合作,消化理解数十年来关于癌症患者和治疗方面的数据,为了向治疗疑难的癌症病例的医生提供和建议治疗方案。”
|
||||
|
||||
### 5. AI正在改变我们的爱情生活
|
||||
|
||||
有195个国家的超过5000万活跃用户通过一个在2012年推出的约会应用程序[Tinder][16]找到潜在的伴侣。在一篇[Forbes采访播客][17]中,Tinder的创始人兼董事长Sean Rad spoke与Steven Bertoni对人工智能是如何正在改变人们约会进行过讨论。在一篇[关于采访的文章][18]中,Bertoni引用了Rad说的话,他说:"可能有这样一个时刻,这时Tinder非常擅长推测你会感兴趣的人,Tinder在组织一次约会中可能会做很多跑腿的工作,对吧?"所以,这个app会向用户推荐一些附近的同伴,并更进一步,协调彼此的时间安排一次约会,而不只是向用户显示一些有可能的同伴。
|
||||
|
||||
> 我们的后代真的可能会爱上人工智能。
|
||||
|
||||
你爱上了AI吗?我们的后代真的可能会爱上人工智能。Raya Bidshahri发表在[Singularity Hub][19]的一篇文章《AI将如何重新定义爱情》说,几十年的后,我们可能会认为爱情不再受生物学的限制。
|
||||
|
||||
Bidshahri解释说:"我们的技术符合摩尔定律,正在以惊人的速度增长——智能设备正在越来越多地融入我们的生活。",他补充道:"到2029年,我们将会有和人类同等智慧的AI,而到21世纪40年代,AI将会比人类聪明无数倍。许多人预测,有一天我们会与强大的机器合并,我们自己可能会变成人工智能。"他认为在这样一个世界上那些是不可避免的,人们将会接受与完全的非生物相爱。
|
||||
|
||||
这听起来有点怪异,但是相比较于未来机器人将统治世界,爱上AI会是一个更乐观的结果。Bidshahri说:"对AI进行编程,让他们能够感受到爱,这将使我们创造出更富有同情心的AI,这可能也是避免很多人忧虑的AI大灾难的关键。"
|
||||
|
||||
这份AI正在入侵我们生活各领域的其中五个方面的清单仅仅只是涉及到了我们身边的人工智能的表面。哪些AI创新是让你最兴奋的,或者是让你最烦恼的?大家可以在文章评论区写下你们的感受。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
Rikki Endsley - Rikki Endsley是开源社区Opensource.com的管理员。在过去,她曾做过Red Hat开源和标准(OSAS)团队社区传播者;自由技术记者;USENIX协会的社区管理员;linux权威杂志ADMIN和Ubuntu User的合作出版者,还是杂志Sys Admin和UnixReview.com的主编。在Twitter上关注她:@rikkiends。
|
||||
|
||||
|
||||
|
||||
via: https://opensource.com/article/17/3/5-big-ways-ai-rapidly-invading-our-lives
|
||||
|
||||
作者:[Rikki Endsley ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/rikki-endsley
|
||||
[1]:https://opensource.com/article/17/3/5-big-ways-ai-rapidly-invading-our-lives?rate=ORfqhKFu9dpA9aFfg-5Za9ZWGcBcx-f0cUlf_VZNeQs
|
||||
[2]:https://www.linux.com/news/open-source-projects-are-transforming-machine-learning-and-ai
|
||||
[3]:https://twitter.com/venturebeat
|
||||
[4]:http://venturebeat.com/2017/03/16/how-ai-will-help-us-decipher-millennials/
|
||||
[5]:https://opensource.com/article/17/3/5-big-ways-ai-rapidly-invading-our-lives
|
||||
[6]:https://www.fastcompany.com/3066620/this-is-how-ai-will-change-your-work-in-2017
|
||||
[7]:https://twitter.com/Inc
|
||||
[8]:http://www.inc.com/bill-carmody/businesses-beyond-bias-how-ai-will-reshape-hiring-practices.html
|
||||
[9]:https://www.successfactors.com/en_us.html
|
||||
[10]:https://dupress.deloitte.com/dup-us-en/focus/human-capital-trends.html?id=us:2el:3pr:dup3575:awa:cons:022817:hct17
|
||||
[11]:https://www.fastcompany.com/3068492/how-ai-is-changing-the-way-companies-are-organized
|
||||
[12]:https://twitter.com/CBinsights
|
||||
[13]:https://www.cbinsights.com/blog/artificial-intelligence-startups-healthcare/
|
||||
[14]:https://techcrunch.com/2017/03/16/advances-in-ai-and-ml-are-reshaping-healthcare/
|
||||
[15]:http://www.atomwise.com/
|
||||
[16]:https://twitter.com/Tinder
|
||||
[17]:https://www.forbes.com/podcasts/the-forbes-interview/#5e962e5624e1
|
||||
[18]:https://www.forbes.com/sites/stevenbertoni/2017/02/14/tinders-sean-rad-on-how-technology-and-artificial-intelligence-will-change-dating/#4180fc2e5b99
|
||||
[19]:https://twitter.com/singularityhub
|
||||
[20]:https://singularityhub.com/2016/08/05/how-ai-will-redefine-love/
|
||||
[21]:https://opensource.com/user/23316/feed
|
||||
[22]:https://opensource.com/article/17/3/5-big-ways-ai-rapidly-invading-our-lives#comments
|
||||
[23]:https://twitter.com/raconteur
|
||||
[24]:https://www.raconteur.net/technology/how-ai-will-change-buyer-behaviour
|
||||
[25]:http://www.fluid.ai/
|
||||
[26]:http://venturebeat.com/2017/02/04/how-ai-will-transform-education-in-2017/
|
||||
[27]:https://twitter.com/benevolent_ai
|
||||
[28]:https://opensource.com/users/rikki-endsley
|
||||
|
||||
@ -0,0 +1,255 @@
|
||||
rdiff-backup - 一个 Linux 中的远程增量备份工具
|
||||
============================================================
|
||||
|
||||
rdiff-backup 是用于本地/远程增量备份的强大且易于使用的 Python 脚本,它适用于任何 POSIX 操作系统,如Linux、Mac OS X 或 [Cygwin][1]。它集合了镜像和增量备份的显著特性。
|
||||
|
||||
值得注意的是,它保留了子目录、dev文件、硬链接和关键的文件属性,如权限、uid/gid 所有权、修改时间、扩展属性、acls 以及 resource fork。它可以通过管道以高效带宽的模式工作,这与流行的[ rsync 备份工具][2]类似。
|
||||
|
||||
rdiff-backup 通过使用 SSH 将单个目录备份到另一个目录,这意味着数据传输被加密并且是安全的。目标目录(在远程系统上)最终会得到源目录的完整副本,但是额外的反向差异存储在目标目录的特殊子目录中,从而可以恢复前一段时间丢失的文件。
|
||||
|
||||
#### 依赖
|
||||
|
||||
要在 Linux 中使用 rdiff-backup,你需要在系统上安装以下软件包:
|
||||
|
||||
* Python v2.2 或更高版本
|
||||
* librsync v0.9.7 或更高版本
|
||||
* pylibacl 和 pyxattr Python 模块是可选的,但它们分别是 POSIX 访问控制列表(ACL)和扩展属性支持必需的。
|
||||
* rdiff-backup-statistics 需要 Python v2.4 或更高版本。
|
||||
|
||||
### 如何在 Linux 中安装 rdiff-backup
|
||||
|
||||
重要:如果你通过网络运行它,则必须在两个系统中都安装 rdiff-backup,两者最好是相同版本。
|
||||
|
||||
该脚本已经存在于主流 Linux 发行版的官方仓库中,只需运行以下命令来安装 rdiff-backup 及其依赖关系:
|
||||
|
||||
#### 在 Debian/Ubuntu 中
|
||||
|
||||
```
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install librsync-dev rdiff-backup
|
||||
```
|
||||
|
||||
#### 在 CentOS/RHEL 7 中
|
||||
|
||||
```
|
||||
# wget http://dl.fedoraproject.org/pub/epel/7/x86_64/e/epel-release-7-9.noarch.rpm
|
||||
# rpm -ivh epel-release-7-9.noarch.rpm
|
||||
# yum install librsync rdiff-backup
|
||||
```
|
||||
|
||||
#### 在 CentOS/RHEL 6 中
|
||||
|
||||
```
|
||||
# wget http://download.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm
|
||||
# rpm -ivh epel-release-6-8.noarch.rpm
|
||||
# yum install librsync rdiff-backup
|
||||
```
|
||||
|
||||
#### 在 Fedora 中
|
||||
|
||||
```
|
||||
# yum install librsync rdiff-backup
|
||||
# dnf install librsync rdiff-backup [Fedora 22+]
|
||||
```
|
||||
|
||||
### 如何在 Linux 中使用 rdiff-backup
|
||||
|
||||
如前所述,rdiff-backup 使用 SSH 连接到网络上的远程计算机,SSH 的默认身份验证方式是用户名/密码,这通常需要人工交互。
|
||||
|
||||
但是,要自动执行诸如脚本等自动备份之类的任务,那么你需要配置[使用 SSH 密钥无密码登录 SSH][3],因为 SSH 密钥增加了两台 Linux服务器之间的信任来[简化文件同步或传输][4]。
|
||||
|
||||
在你设置了[ SSH 无密码登录][5]后,你可以使用下面的例子开始使用该脚本。
|
||||
|
||||
#### 备份文件到不同分区
|
||||
|
||||
下面的例子会备份 `/etc` 文件夹到另外一个分区的 Backup 文件夹内:
|
||||
|
||||
```
|
||||
$ sudo rdiff-backup /etc /media/aaronkilik/Data/Backup/mint_etc.backup
|
||||
```
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
备份文件到不同分区
|
||||
|
||||
要排除一个特定文件夹和它的子目录,你可以如下使用 `--exclude` 选项:
|
||||
|
||||
```
|
||||
$ sudo rdiff-backup --exclude /etc/cockpit --exclude /etc/bluetooth /media/aaronkilik/Data/Backup/mint_etc.backup
|
||||
```
|
||||
|
||||
我们可以如下使用 `--include-special-files` 包含所有的设备文件、fifo 文件、socket 文件和链接文件:
|
||||
|
||||
```
|
||||
$ sudo rdiff-backup --include-special-files --exclude /etc/cockpit /media/aaronkilik/Data/Backup/mint_etc.backup
|
||||
```
|
||||
|
||||
还有另外两个重要标志来用于选择文件,`--max-file-size` 用来排除大于给定字节大小的文件,`--max-file-size` 用于排除小于给定字节大小的文件:
|
||||
|
||||
```
|
||||
$ sudo rdiff-backup --max-file-size 5M --include-special-files --exclude /etc/cockpit /media/aaronkilik/Data/Backup/mint_etc.backup
|
||||
```
|
||||
|
||||
#### 在本地 Linux 服务器上备份远程文件
|
||||
|
||||
要这么做,我们使用:
|
||||
|
||||
```
|
||||
Remote Server (tecmint) : 192.168.56.102
|
||||
Local Backup Server (backup) : 192.168.56.10
|
||||
```
|
||||
|
||||
如前所述,你必须在两台机器上安装相同版本的 rdiff-backup,如下所示,请尝试在两台机器上检查版本,:
|
||||
|
||||
```
|
||||
$ rdiff-backup -V
|
||||
```
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
检查服务器中 rdiff 版本
|
||||
|
||||
在备份服务器中,像这样创建一个存储备份文件的目录:
|
||||
|
||||
```
|
||||
# mkdir -p /backups
|
||||
```
|
||||
|
||||
现在在备份服务器中,运行下面的命令来将远程 Linux 服务器 192.168.56.102 中的 `/var/log/` 和 `/root` 备份到 `/backups` 中:
|
||||
|
||||
```
|
||||
# rdiff-backup root@192.168.56.102::/var/log/ /backups/192.168.56.102_logs.backup
|
||||
# rdiff-backup root@192.168.56.102::/root/ /backups/192.168.56.102_rootfiles.backup
|
||||
```
|
||||
|
||||
下面的截图展示了远程服务器 192.168.56.102 中的 root 文件夹以及 192.168.56.10 备份服务器中的已备份文件:
|
||||
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
在本地服务器备份远程目录
|
||||
|
||||
注意截图中 “backup” 目录中创建的 rdiff-backup-data 文件夹,它包含了备份过程和增量文件的重要数据。
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
rdiff-backup – 备份过程文件
|
||||
|
||||
现在,在 192.168.56.102 服务器中,如下所示 root 目录已经添加了额外的文件:
|
||||
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
验证备份目录
|
||||
|
||||
让我们再次运行备份命令以获取更改的数据,我们可以使用 `-v[0-9]`(其中数字指定详细程度级别,默认值为 3,这是静默模式)选项设置详细功能:
|
||||
|
||||
```
|
||||
# rdiff-backup -v4 root@192.168.56.102::/root/ /backups/192.168.56.102_rootfiles.backup
|
||||
```
|
||||
[
|
||||

|
||||
][11]
|
||||
|
||||
带有摘要的增量备份
|
||||
|
||||
要列出 /backups/192.168.56.102_rootfiles.backup 目录中包含的部分增量备份的数量和日期,我们可以运行:
|
||||
|
||||
```
|
||||
# rdiff-backup -l /backups/192.168.56.102_rootfiles.backup/
|
||||
```
|
||||
|
||||
#### 使用 cron 自动进行 rdiff-back 备份
|
||||
|
||||
使用 `--print-statistics` 成功备份后,我们可以打印摘要统计信息。但是,如果我们不设置此选项,我们可以仍从会话统计中获得。在手册页的 “STATISTICS” 部分中阅读有关此选项的更多信息。
|
||||
|
||||
-remote-schema 标志使我们能够指定使用替代方法连接到远程计算机。
|
||||
|
||||
现在,我们开始在备份服务器 192.168.56.10 上创建一个 `backup.sh` 脚本,如下所示:
|
||||
|
||||
```
|
||||
# cd ~/bin
|
||||
# vi backup.sh
|
||||
```
|
||||
|
||||
添加下面的行到脚本中。
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
#This is a rdiff-backup utility backup script
|
||||
#Backup command
|
||||
rdiff-backup --print-statistics --remote-schema 'ssh -C %s "sudo /usr/bin/rdiff-backup --server --restrict-read-only /"' root@192.168.56.102::/var/logs /backups/192.168.56.102_logs.back
|
||||
#Checking rdiff-backup command success/error
|
||||
status=$?
|
||||
if [ $status != 0 ]; then
|
||||
#append error message in ~/backup.log file
|
||||
echo "rdiff-backup exit Code: $status - Command Unsuccessful" >>~/backup.log;
|
||||
exit 1;
|
||||
fi
|
||||
#Remove incremental backup files older than one month
|
||||
rdiff-backup --force --remove-older-than 1M /backups/192.168.56.102_logs.back
|
||||
```
|
||||
|
||||
保存文件并退出,接着运行下面的命令在服务器 192.168.56.10 上的 crontab 中添加此脚本:
|
||||
|
||||
```
|
||||
# crontab -e
|
||||
```
|
||||
|
||||
添加此行在每天午夜运行你的备份脚本:
|
||||
|
||||
```
|
||||
0 0 * * * /root/bin/backup.sh > /dev/null 2>&1
|
||||
```
|
||||
|
||||
保存 crontab 并退出,现在我们已经成功自动化了备份过程。确保一切如希望那样工作。
|
||||
|
||||
阅读 rdiff-backup 的手册页获取更多信息、详尽的使用选项以及示例:
|
||||
|
||||
```
|
||||
# man rdiff-backup
|
||||
```
|
||||
|
||||
rdiff-backup 主页: [http://www.nongnu.org/rdiff-backup/][12]
|
||||
|
||||
就是这样了!在本教程中,我们向你展示了如何安装并基础地使用 rdiff-backup 这个易于使用的 Python 脚本,用于 Linux 中的本地/远程增量备份。 请通过下面的反馈栏与我们分享你的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili 是 Linux 和 F.O.S.S 爱好者,将来的 Linux SysAdmin 和 web 开发人员,目前是 TecMint 的内容创建者,他喜欢用电脑工作,并坚信分享知识。
|
||||
|
||||
|
||||
------------
|
||||
|
||||
via: http://www.tecmint.com/rdiff-backup-remote-incremental-backup-for-linux/
|
||||
|
||||
作者:[Aaron Kili ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/install-cygwin-to-run-linux-commands-on-windows-system/
|
||||
[2]:http://www.tecmint.com/rsync-local-remote-file-synchronization-commands/
|
||||
[3]:http://www.tecmint.com/ssh-passwordless-login-using-ssh-keygen-in-5-easy-steps/
|
||||
[4]:http://www.tecmint.com/sync-new-changed-modified-files-rsync-linux/
|
||||
[5]:http://www.tecmint.com/ssh-passwordless-login-using-ssh-keygen-in-5-easy-steps/
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2017/03/Backup-Files-to-Different-Partition.png
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2017/03/check-rdif-versions-on-servers.png
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2017/03/Backup-Remote-Linux-Directory-on-Local-Server.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2017/03/rdiff-backup-data-directory-contents.png
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2017/03/additional-files-in-root-directory.png
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2017/03/incremental-backup-of-root-files.png
|
||||
[12]:http://www.nongnu.org/rdiff-backup/
|
||||
[13]:http://www.tecmint.com/author/aaronkili/
|
||||
[14]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[15]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
Loading…
Reference in New Issue
Block a user