mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-03 23:40:14 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
1d5409ec68
@ -1,7 +1,7 @@
|
||||
netdev 第二天:从网络代码中移除“尽可能快”这个目标
|
||||
============================================================
|
||||
=======
|
||||
|
||||
嗨!今天是 netdev 会议的第 2 天,我只参加了早上的会议,但它_非常有趣_。今早会议的主角是 [Van Jacobson][1] 给出的一场名为 “从尽可能快中变化:教网卡以时间”的演讲,它的主题是 关于网络中拥塞控制的未来!!!
|
||||
嗨!今天是 netdev 会议的第 2 天,我只参加了早上的会议,但它_非常有趣_。今早会议的主角是 [Van Jacobson][1] 给出的一场名为 “从尽可能快中变化:教网卡以时间”的演讲,它的主题是关于互联网中拥塞控制的未来!!!
|
||||
|
||||
下面我将尝试着对我从这次演讲中学到的东西做总结,我几乎肯定下面的内容有些错误,但不管怎样,让我们开始吧!
|
||||
|
||||
@ -14,29 +14,27 @@ netdev 第二天:从网络代码中移除“尽可能快”这个目标
|
||||
你所能想象的最天真的发送信息包方式是:
|
||||
|
||||
1. 将你必须发送的信息包一次性发送完。
|
||||
|
||||
2. 假如你发现其中有的信息包被丢弃了,就马上重新发送这些包。
|
||||
|
||||
结果表明假如你按照上面的思路来实现 TCP,互联网将会崩溃并停止运转。我们知道它会崩溃是因为在 1986 年确实发生了崩溃的现象。为了解决这个问题,专家发明了拥塞控制算法--描述如何避免互联网的崩溃的原始论文是 Van Jacobson 于 1988 年发表的 [拥塞避免与控制][2](30 年前!)。
|
||||
结果表明假如你按照上面的思路来实现 TCP,互联网将会崩溃并停止运转。我们知道它会崩溃是因为在 1986 年确实发生了崩溃的现象。为了解决这个问题,专家发明了拥塞控制算法 —— 描述如何避免互联网的崩溃的原始论文是 Van Jacobson 于 1988 年发表的 [拥塞避免与控制][2](30 年前!)。
|
||||
|
||||
### 从 1988 年后互联网发生了什么改变?
|
||||
|
||||
在演讲中,Van Jacobson 说互联网的这些已经发生了改变:在以前的互联网上,交换机可能总是拥有比服务器更快的网卡,所以位于互联网中间层的服务器也可能比客户端更快,并且这些改变并不能对客户端发送信息包的速率有多大影响。
|
||||
在演讲中,Van Jacobson 说互联网的这些已经发生了改变:在以前的互联网上,交换机可能总是拥有比服务器更快的网卡,所以这些位于互联网中间层的服务器也可能比客户端更快,并且并不能对客户端发送信息包的速率有多大影响。
|
||||
|
||||
很显然今天已经不是这样的了!众所周知,今天的计算机相比于 5 年前的计算机在速度上并没有多大的提升(我们遇到了某些有关光速的问题)。所以我想路由器上的大型交换机并不会在速度上大幅领先于数据中心里服务器上的网卡。
|
||||
|
||||
这听起来有些糟糕,因为这意味着在中间层的客户端更容易在连接中达到饱和,而这将导致互联网变慢(而且 [缓冲膨胀][3] 将带来更高的延迟)。
|
||||
这听起来有些糟糕,因为这意味着客户端更容易在中间层的连接中达到饱和,而这将导致互联网变慢(而且 [缓冲膨胀][3] 将带来更高的延迟)。
|
||||
|
||||
所以为了提高互联网的性能且不让每个路由上的任务队列都达到饱和,客户端需要表现得更好并且在发送信息包的时候慢一点。
|
||||
|
||||
### 以更慢的速率发送更多的信息包以达到更好的性能
|
||||
|
||||
下面的结论真的让我非常意外 -- 以更慢的速率发送信息包实际上可能会带来更好的性能(即便你是在整个传输过程中,这样做的唯一的人),下面是原因:
|
||||
下面的结论真的让我非常意外 —— 以更慢的速率发送信息包实际上可能会带来更好的性能(即便你是在整个传输过程中,这样做的唯一的人),下面是原因:
|
||||
|
||||
假设你打算发送 10MB 的数据,在你和你需要连接的客户端之间有一个中间层,并且它的传输速率_非常低_,例如 1MB/s。假设你可以辨别这个慢连接(或者更多的后续中间层)的速度,那么你有 2 个选择:
|
||||
|
||||
1. 一次性将这 10MB 的数据发送完,然后看看会发生什么。
|
||||
|
||||
2. 减慢速率使得你能够以 1MB/s 的速率传给它。
|
||||
|
||||
现在,无论你选择何种方式,你可能都会发生丢包的现象。所以这样看起来,你可能需要选择一次性发送所有的信息包这种方式,对吧?不!!实际上在你的数据流的中间环节丢包要比在你的数据流的最后丢包要好得多。假如在中间环节有些包被丢弃了,你需要送往的那个客户端可以察觉到这个事情,然后再告诉你,这样你就可以再次发送那些被丢弃的包,这样便没有多大的损失。但假如信息包在最末端被丢弃,那么客户端将完全没有办法知道你一次性发送了所有的信息包!所以基本上在某个时刻被丢弃的包没有让你收到 ACK 信号时,你需要启用超时机制,并且还得重新发送它们。而超时往往意味着需要花费很长时间!
|
||||
@ -47,7 +45,7 @@ netdev 第二天:从网络代码中移除“尽可能快”这个目标
|
||||
|
||||
### 如何辨别发送数据的合适速率:BBR!
|
||||
|
||||
在上面我说过:“假设你可以辨别出位于你的终端和服务器之间慢连接的速率。。。”,那么如何做到呢?来自 Google(Jacobson 工作的地方)的某些专家已经提出了一个算法来估计瓶颈的速率!它叫做 BBR,由于本次的分享已经很长了,所以这里不做具体介绍,但你可以参考 [BBR:基于拥塞的拥塞控制][4] 和 [来自晨读论文的总结][5] 这两处链接。
|
||||
在上面我说过:“假设你可以辨别出位于你的终端和服务器之间慢连接的速率……”,那么如何做到呢?来自 Google(Jacobson 工作的地方)的某些专家已经提出了一个算法来估计瓶颈的速率!它叫做 BBR,由于本次的分享已经很长了,所以这里不做具体介绍,但你可以参考 [BBR:基于拥塞的拥塞控制][4] 和 [来自晨读论文的总结][5] 这两处链接。
|
||||
|
||||
(另外,[https://blog.acolyer.org][6] 的每日“晨读论文”总结基本上是我学习和理解计算机科学论文的唯一方式,它有可能是整个互联网上最好的博客之一!)
|
||||
|
||||
@ -56,14 +54,12 @@ netdev 第二天:从网络代码中移除“尽可能快”这个目标
|
||||
所以,假设我们相信我们想以一个更慢的速率(例如以我们连接中的瓶颈速率)来传输数据。这很好,但网络软件并不是被设计为以一个可控速率来传输数据的!下面是我所理解的大多数网络软件怎么做的:
|
||||
|
||||
1. 现在有一个队列的信息包来临;
|
||||
|
||||
2. 然后软件读取队列并尽可能快地发送信息包;
|
||||
|
||||
3. 就这样,没有了。
|
||||
|
||||
这个过程非常呆板——假设我以一个非常快的速率发送信息包,而另一端的连接却非常慢。假如我所拥有的就是一个放置所有信息包的队列,当我实际要发送数据时,我并没有办法来控制这个发送过程,所以我便不能减慢这个队列传输的速率。
|
||||
这个过程非常呆板 —— 假设我以一个非常快的速率发送信息包,而另一端的连接却非常慢。假如我所拥有的就是一个放置所有信息包的队列,当我实际要发送数据时,我并没有办法来控制这个发送过程,所以我便不能减慢这个队列传输的速率。
|
||||
|
||||
### 一个更好的方式:给每个信息包一个”最早的出发时间“
|
||||
### 一个更好的方式:给每个信息包一个“最早的出发时间”
|
||||
|
||||
BBR 协议将会修改 Linux 内核中 skb 的数据结构(这个数据结构被用来表达网络信息包),使得它有一个时间戳,这个时间戳代表着这个信息包应该被发送出去的最早时间。
|
||||
|
||||
@ -73,25 +69,23 @@ BBR 协议将会修改 Linux 内核中 skb 的数据结构(这个数据结构
|
||||
|
||||
一旦我们将时间戳打到这些信息包上,我们怎样在合适的时间将它们发送出去呢?使用_时间轮盘_!
|
||||
|
||||
在前不久的”我们喜爱的论文“活动中(这是关于这次聚会的描述的[某些好的链接][7]),有一个演讲谈论了关于时间轮盘的话题。时间轮盘是一类用来指导 Linux 的进程调度器决定何时运行进程的算法。
|
||||
在前不久的“我们喜爱的论文”活动中(这是关于这次聚会描述的[某些好的链接][7]),有一个演讲谈论了关于时间轮盘的话题。时间轮盘是一类用来指导 Linux 的进程调度器决定何时运行进程的算法。
|
||||
|
||||
Van Jacobson 说道:时间轮盘实际上比队列调度工作得更好——它们都提供常数时间的操作,但因为某些缓存机制,时间轮盘的常数要更小一些。我真的没有太明白这里他说的关于性能的解释。
|
||||
Van Jacobson 说道:时间轮盘实际上比队列调度工作得更好 —— 它们都提供常数时间的操作,但因为某些缓存机制,时间轮盘的常数要更小一些。我真的没有太明白这里他说的关于性能的解释。
|
||||
|
||||
他说道:关于时间轮盘的一个关键点是你可以很轻松地用时间轮盘实现一个队列(但反之不能!)——假如每次你增加一个新的信息包,在最开始你说我想让它_现在_就被发送走,很显然这样你就可以得到一个队列了。而这个时间轮盘方法是向后兼容的,它使得你可以更容易地实现某些更加复杂的对流量非常敏感的算法,例如让你针对不同的信息包以不同的速率去发送它们。
|
||||
他说道:关于时间轮盘的一个关键点是你可以很轻松地用时间轮盘实现一个队列(但反之不能!)—— 假如每次你增加一个新的信息包,在最开始你说我想让它_现在_就被发送走,很显然这样你就可以得到一个队列了。而这个时间轮盘方法是向后兼容的,它使得你可以更容易地实现某些更加复杂的对流量非常敏感的算法,例如让你针对不同的信息包以不同的速率去发送它们。
|
||||
|
||||
### 或许我们可以通过改善 Linux 来修复互联网!
|
||||
|
||||
对于任何影响到整个互联网规模的问题,最为棘手的问题是当你要做出改善时,例如改变互联网协议的实现,你需要面对各种不同的设备。你要面对 Linux 的机子,BSD 的机子, Windows 的机子,各种各样的手机,瞻博或者思科的路由器以及数量繁多的其他设备!
|
||||
对于任何影响到整个互联网规模的问题,最为棘手的问题是当你要做出改善时,例如改变互联网协议的实现,你需要面对各种不同的设备。你要面对 Linux 的机器、BSD 的机器、Windows 的机器、各种各样的手机、瞻博或者思科的路由器以及数量繁多的其他设备!
|
||||
|
||||
但是在网络环境中 Linux 处于某种有趣的位置上!
|
||||
|
||||
* Android 手机运行着 Linux
|
||||
|
||||
* 大多数的消费级 WiFi 路由器运行着 Linux
|
||||
|
||||
* 无数的服务器运行着 Linux
|
||||
|
||||
所以在任何给定的网络连接中,实际上很有可能在不同的终端有一台 Linux 机子(例如一个 Linux 服务器,或者一个 Linux 路由器,一台 Android 设备)。
|
||||
所以在任何给定的网络连接中,实际上很有可能在两端都有一台 Linux 机器(例如一个 Linux 服务器、或者一个 Linux 路由器、一台 Android 设备)。
|
||||
|
||||
所以重点是假如你想大幅改善互联网上的拥塞状况,只需要改变 Linux 网络栈就会大所不同(或许 iOS 网络栈也是类似的)。这也就是为什么在本次的 Linux 网络会议上有这样的一个演讲!
|
||||
|
||||
@ -99,7 +93,7 @@ Van Jacobson 说道:时间轮盘实际上比队列调度工作得更好——
|
||||
|
||||
通常我以为 TCP/IP 仍然是上世纪 80 年代的东西,所以当从这些专家口中听说这些我们正在设计的网路协议仍然有许多严重的问题时,真的是非常有趣,并且听说现在有不同的方式来设计它们。
|
||||
|
||||
当然也确实是这样——网络硬件以及和速度相关的任何设备,以及人们使用网络来干的各种事情(例如观看网飞 Netflix 的节目)等等,一直都在随着时间发生着改变,所以正因为这样,我们需要为 2018 年的互联网而不是为 1988 年的互联网设计我们不同的算法。
|
||||
当然也确实是这样 —— 网络硬件以及和速度相关的任何设备,以及人们使用网络来干的各种事情(例如观看 Netflix 的节目)等等,一直都在随着时间发生着改变,所以正因为这样,我们需要为 2018 年的互联网而不是为 1988 年的互联网设计我们不同的算法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -107,7 +101,7 @@ via: https://jvns.ca/blog/2018/07/12/netdev-day-2--moving-away-from--as-fast-as-
|
||||
|
||||
作者:[Julia Evans][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
65
published/20180803 What data is too risky for the cloud.md
Normal file
65
published/20180803 What data is too risky for the cloud.md
Normal file
@ -0,0 +1,65 @@
|
||||
什么数据对于云服务器来说风险很大
|
||||
======
|
||||
|
||||
> 在这个关于混合多云陷阱的系列文章的最后一篇当中,让我们来学习一下如何设计一个低风险的云迁移战略。
|
||||
|
||||

|
||||
|
||||
在这四篇系列文章中,我们了解到了每个组织在做云迁移的时候所应该避免的陷阱 —— 特别是混合多云的情况下。
|
||||
|
||||
[在第一部分][1],我们介绍了一些基本的定义以及我们对于混合云以及多云的观点,确保展示了两者之间的区别。[在第二部分][2],我们会对三个陷阱之一进行讨论:为什么成本并不是迁移到云端的显然的推动因素。而且,[在第三部分][3],我们考察了将所有工作向云端进行迁移的可行性。
|
||||
|
||||
最后,在这个第四部分中,我们来看看数据上云要做什么。您应该把数据向云端迁移吗?迁移多少?什么数据可以放在云端?又是什么会造成上云风险很大?
|
||||
|
||||
### 数据…数据…数据
|
||||
|
||||
影响您对云端数据的所有决策的关键因素在于确定您的带宽以及存储需求。 Gartner 预计 “数据存储在 2018 年将成为一项[$173 亿美元][4]的业务”,并且大部分资金是浪费在一些不必要的存储容量上:“但是只需要优化一下工作负载,全球的所有公司就可以节约 620 亿美元的不必要 IT 成本。”根据 Gartner 的研究,非常令人惊讶的是,全球所有的公司“为云服务器平均支付的费用比他们实际的费用多达 36% 。”
|
||||
|
||||
如果你已经阅读了本系列的前三个章节,那么你应该不会为此感到惊讶。然而令人更惊讶的是 Gartner 的结论是 “如果全球的公司将他们的服务器数据直接迁移到云端上,仅仅只有 25% 的公司能够做到省钱。”
|
||||
|
||||
等一下……工作负载是可以针对云进行优化的,但是只有一小部分公司能通过将数据向云端迁移而节省资金吗?这个又是什么意思?
|
||||
|
||||
如果你去认为云服务商会根据带宽来收取云产生的费用,那么将所有的公司内部数据移至云端很快就会成为他们的成本负担。在以下三种情况,公司才可能会觉得值得把数据放在云端中:
|
||||
|
||||
* 单个云包括存储和应用程序
|
||||
* 应用程序在云端,存储在本地
|
||||
* 应用程序在云端,而且数据缓存也在云端,存储在本地
|
||||
|
||||
在第一种情况下,通过将所有的内容都放在单个云服务商来节省带宽成本,但是这会产生一些(供应商)锁定,这个通常与 CIO 的云战略或者风险防范计划所冲突。
|
||||
|
||||
第二种方案是仅仅保留应用程序在云端所收集的数据,并且以最小的方式传输到本地存储。这就需要仔细的考虑策略,其中只有最少使用数据的应用程序部署在云端。
|
||||
|
||||
第三种情况就是将数据缓存在云端,应用程序和存储的数据被存储在本地。这也就意味着分析、人工智能、机器学习可以在内部运行而无需把数据向云服务商上传,然后处理之后再返回。缓存的数据仅仅基于应用程序对云的需求,甚至进行跨多云的部署缓存。
|
||||
|
||||
要想获得更多信息,请下载红帽[案例研究][5],其中描述了跨混合多云环境下的阿姆斯特丹的史基浦机场的数据以及云和部署策略。
|
||||
|
||||
### 数据危险
|
||||
|
||||
大多数公司都认识到了他们的数据是在其市场中的专有优势以及知识能力。因此他们会非常仔细的考虑它在云存储的地点。
|
||||
|
||||
想象一下这种情况:如果你是一个零售商,全球十大零售商之一。而且你已经计划了很长一段时间云存储战略,并且考虑使用亚马逊的云服务。但是突然间, [亚马逊收购了全食超市][6],并且准备进入你的市场。
|
||||
|
||||
一夜之间,亚马逊已经增长了 50% 的零售规模,你是否还会去信任把零售数据放到他们的云上?如果您的数据已经就在亚马逊云中,你会打算怎么做?您创建云计划时是否考虑过退出策略?虽然亚马逊可能永远不会去利用您的数据潜在价值 —— 该公司可能甚至有针对此的条款 —— 但你能相信世界上任何人的话吗?
|
||||
|
||||
### 陷阱分享,避免陷阱
|
||||
|
||||
分享我们在以前经验中看到的一些陷阱来帮助您的公司规划更安全、更持久的云端策略。了解了[成本不是显然的推动因素][2],[并非一切东西都应该在云端][3],而是你必须在云端有效管理数据才是您成功的关键所在。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
via: https://opensource.com/article/18/8/data-risky-cloud
|
||||
|
||||
作者:[Eric D.Schabell][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekmar](https://github.com/geekmar)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/eschabell
|
||||
[1]:https://opensource.com/article/18/4/pitfalls-hybrid-multi-cloud
|
||||
[2]:https://opensource.com/article/18/6/reasons-move-to-cloud
|
||||
[3]:https://opensource.com/article/18/7/why-you-cant-move-everything-cloud
|
||||
[4]:http://www.businessinsider.com/companies-waste-62-billion-on-the-cloud-by-paying-for-storage-they-dont-need-according-to-a-report-2017-11
|
||||
[5]:https://www.redhat.com/en/resources/amsterdam-airport-schiphol-case-study
|
||||
[6]:https://www.forbes.com/sites/ciocentral/2017/06/23/amazon-buys-whole-foods-now-what-the-story-behind-the-story/#33e9cc6be898
|
||||
@ -1,3 +1,5 @@
|
||||
icecoobe translating
|
||||
|
||||
A gentle introduction to FreeDOS
|
||||
======
|
||||
|
||||
|
||||
@ -1,131 +0,0 @@
|
||||
|
||||
// Copyright 2018 The Go Authors. All rights reserved.
|
||||
// Use of this source code is governed by a BSD-style
|
||||
// license that can be found in the LICENSE file.
|
||||
|
||||
## Introduction to the Go compiler
|
||||
|
||||
`cmd/compile` contains the main packages that form the Go compiler. The compiler
|
||||
may be logically split in four phases, which we will briefly describe alongside
|
||||
the list of packages that contain their code.
|
||||
|
||||
You may sometimes hear the terms "front-end" and "back-end" when referring to
|
||||
the compiler. Roughly speaking, these translate to the first two and last two
|
||||
phases we are going to list here. A third term, "middle-end", often refers to
|
||||
much of the work that happens in the second phase.
|
||||
|
||||
Note that the `go/*` family of packages, such as `go/parser` and `go/types`,
|
||||
have no relation to the compiler. Since the compiler was initially written in C,
|
||||
the `go/*` packages were developed to enable writing tools working with Go code,
|
||||
such as `gofmt` and `vet`.
|
||||
|
||||
It should be clarified that the name "gc" stands for "Go compiler", and has
|
||||
little to do with uppercase GC, which stands for garbage collection.
|
||||
|
||||
### 1. Parsing
|
||||
|
||||
* `cmd/compile/internal/syntax` (lexer, parser, syntax tree)
|
||||
|
||||
In the first phase of compilation, source code is tokenized (lexical analysis),
|
||||
parsed (syntactic analyses), and a syntax tree is constructed for each source
|
||||
file.
|
||||
|
||||
Each syntax tree is an exact representation of the respective source file, with
|
||||
nodes corresponding to the various elements of the source such as expressions,
|
||||
declarations, and statements. The syntax tree also includes position information
|
||||
which is used for error reporting and the creation of debugging information.
|
||||
|
||||
### 2. Type-checking and AST transformations
|
||||
|
||||
* `cmd/compile/internal/gc` (create compiler AST, type checking, AST transformations)
|
||||
|
||||
The gc package includes an AST definition carried over from when it was written
|
||||
in C. All of its code is written in terms of it, so the first thing that the gc
|
||||
package must do is convert the syntax package's syntax tree to the compiler's
|
||||
AST representation. This extra step may be refactored away in the future.
|
||||
|
||||
The AST is then type-checked. The first steps are name resolution and type
|
||||
inference, which determine which object belongs to which identifier, and what
|
||||
type each expression has. Type-checking includes certain extra checks, such as
|
||||
"declared and not used" as well as determining whether or not a function
|
||||
terminates.
|
||||
|
||||
Certain transformations are also done on the AST. Some nodes are refined based
|
||||
on type information, such as string additions being split from the arithmetic
|
||||
addition node type. Some other examples are dead code elimination, function call
|
||||
inlining, and escape analysis.
|
||||
|
||||
### 3. Generic SSA
|
||||
|
||||
* `cmd/compile/internal/gc` (converting to SSA)
|
||||
* `cmd/compile/internal/ssa` (SSA passes and rules)
|
||||
|
||||
|
||||
In this phase, the AST is converted into Static Single Assignment (SSA) form, a
|
||||
lower-level intermediate representation with specific properties that make it
|
||||
easier to implement optimizations and to eventually generate machine code from
|
||||
it.
|
||||
|
||||
During this conversion, function intrinsics are applied. These are special
|
||||
functions that the compiler has been taught to replace with heavily optimized
|
||||
code on a case-by-case basis.
|
||||
|
||||
Certain nodes are also lowered into simpler components during the AST to SSA
|
||||
conversion, so that the rest of the compiler can work with them. For instance,
|
||||
the copy builtin is replaced by memory moves, and range loops are rewritten into
|
||||
for loops. Some of these currently happen before the conversion to SSA due to
|
||||
historical reasons, but the long-term plan is to move all of them here.
|
||||
|
||||
Then, a series of machine-independent passes and rules are applied. These do not
|
||||
concern any single computer architecture, and thus run on all `GOARCH` variants.
|
||||
|
||||
Some examples of these generic passes include dead code elimination, removal of
|
||||
unneeded nil checks, and removal of unused branches. The generic rewrite rules
|
||||
mainly concern expressions, such as replacing some expressions with constant
|
||||
values, and optimizing multiplications and float operations.
|
||||
|
||||
### 4. Generating machine code
|
||||
|
||||
* `cmd/compile/internal/ssa` (SSA lowering and arch-specific passes)
|
||||
* `cmd/internal/obj` (machine code generation)
|
||||
|
||||
The machine-dependent phase of the compiler begins with the "lower" pass, which
|
||||
rewrites generic values into their machine-specific variants. For example, on
|
||||
amd64 memory operands are possible, so many load-store operations may be combined.
|
||||
|
||||
Note that the lower pass runs all machine-specific rewrite rules, and thus it
|
||||
currently applies lots of optimizations too.
|
||||
|
||||
Once the SSA has been "lowered" and is more specific to the target architecture,
|
||||
the final code optimization passes are run. This includes yet another dead code
|
||||
elimination pass, moving values closer to their uses, the removal of local
|
||||
variables that are never read from, and register allocation.
|
||||
|
||||
Other important pieces of work done as part of this step include stack frame
|
||||
layout, which assigns stack offsets to local variables, and pointer liveness
|
||||
analysis, which computes which on-stack pointers are live at each GC safe point.
|
||||
|
||||
At the end of the SSA generation phase, Go functions have been transformed into
|
||||
a series of obj.Prog instructions. These are passed to the assembler
|
||||
(`cmd/internal/obj`), which turns them into machine code and writes out the
|
||||
final object file. The object file will also contain reflect data, export data,
|
||||
and debugging information.
|
||||
|
||||
### Further reading
|
||||
|
||||
To dig deeper into how the SSA package works, including its passes and rules,
|
||||
head to `cmd/compile/internal/ssa/README.md`.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://github.com/golang/go/blob/master/src/cmd/compile/README.md
|
||||
|
||||
作者:[mvdan ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://github.com/mvdan
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by DavidChenLiang
|
||||
|
||||
Find If A Package Is Available For Your Linux Distribution
|
||||
======
|
||||
|
||||
|
||||
@ -19,11 +19,11 @@ Google 很快就从仅提供检索服务转向提供其他服务,其中的许
|
||||
|
||||
和许多人样,我也是 Google 开疆拓土过程中的受害者。从搜索(引擎)到电子邮件、文档、分析、再到照片,许多其他服务都建立在彼此之上,相互勾连。Google 从一家发布实用产品的公司转变成诱困用户公司,于此同时将整个互联网,转变为牟利和数据采集的设备。Google 在我们的数字生活中几乎无处不在,这种程度的存在远非其他公司可以比拟。与之相比使用其他科技巨头的产品想要抽身就相对容易。对于 Apple(苹果),你要么身处 iWorld 之中,要么是局外人。亚马逊亦是如此,甚至连 Facebook 也不过是拥有少数的几个平台,不用(Facebook)更多的是 [心理挑战][8] 实际上并没有多么困难。
|
||||
|
||||
然而,Google无处不在。 无论是笔记本电脑、智能手机或者平板电脑,我猜之中至少会有那么一个 Google 的应用程序。在大多数智能手机上,Google 就是搜索(引擎)、地图、电子邮件、浏览器和操作系统的代名词。甚至还有些应用有赖于其提供的 “[服务][9]” 和分析,比方说 Uber 便需要采用 Google Maps 来运营其乘车服务。
|
||||
然而,Google 无处不在。 无论是笔记本电脑、智能手机或者平板电脑,我猜之中至少会有那么一个 Google 的应用程序。在大多数智能手机上,Google 就是搜索(引擎)、地图、电子邮件、浏览器和操作系统的代名词。甚至还有些应用有赖于其提供的 “[服务][9]” 和分析,比方说 Uber 便需要采用 Google Maps 来运营其乘车服务。
|
||||
|
||||
Google 现在俨然已是许多语言中的单词,但彰显其超然全球统治地位的方面显然不止于此。可以说只要你不是极其注重个人隐私,那其庞大而成套的工具几乎没有多少众所周知或广泛使用的替代品。这恰好也是大家选择 Google 的原因,在很多方面能更好的替代现有的产品。但现在,使我们的难以割舍的主要原因其实是 Google 已经成为了默认选择,或者说由于其主导地位导致替代品无法对我们构成足够的吸引。
|
||||
|
||||
事实上,替代方案是存在的,这些年自爱德华·斯诺登(Edward Snowden)披露 Google 涉事 [Prism(棱镜)][10] 以来,又陆续涌现了许多替代品。我从去年年底开始着手这个项目。经过六个月的研究,测试以及大量的尝试和失败,我终于找到了所有我正在使用的 Google 产品对应的注重个人隐的私替代品。令我感到吃惊的是,其中的一些替代品比 Google 的做的还要好。
|
||||
事实上,替代方案是存在的,这些年自 Edward Snowden(爱德华·斯诺登)披露 Google 涉事 [Prism(棱镜)][10] 以来,又陆续涌现了许多替代品。我从去年年底开始着手这个项目。经过六个月的研究,测试以及大量的尝试和失败,我终于找到了所有我正在使用的 Google 产品对应的注重个人隐的私替代品。令我感到吃惊的是,其中的一些替代品比 Google 的做的还要好。
|
||||
|
||||
### 一些注意事项
|
||||
|
||||
@ -37,9 +37,9 @@ Google 现在俨然已是许多语言中的单词,但彰显其超然全球统
|
||||
|
||||
#### 搜索引擎
|
||||
|
||||
[DuckDuckGo][12] 和 [Startpage][13] 都是以保护个人隐私为中心的搜索引擎,不收集任何搜索数据。我用这两个搜索引擎来负责之前用 Google 检索的所有内容。
|
||||
[DuckDuckGo][12] 和 [startpage][13] 都是以保护个人隐私为中心的搜索引擎,不收集任何搜索数据。我用这两个搜索引擎来负责之前用 Google 检索的所有内容。
|
||||
|
||||
其他的替代方案:实际上并不多, Google 坐拥全球 74% 的市场份额时,剩下的那些主要是原因中国的封锁。不过还有 Ask.com,以及 Bing……
|
||||
其他的替代方案:实际上并不多, Google 坐拥全球 74% 的市场份额时,剩下的那些主要是因为中国的封锁。不过还有 Ask.com,以及 Bing……
|
||||
|
||||
#### Chrome
|
||||
|
||||
@ -49,15 +49,15 @@ Google 现在俨然已是许多语言中的单词,但彰显其超然全球统
|
||||
|
||||
#### Hangouts(环聊) 和 Google Chat
|
||||
|
||||
[Jitsi Meet] [17] — 一款 Google Hangouts 的开源免费替代方案。你可以直接在浏览器上使用或下载应用程序。快速,安全,几乎适用于所有平台。
|
||||
[Jitsi Meet][17] — 一款 Google Hangouts 的开源免费替代方案。你可以直接在浏览器上使用或下载应用程序。快速,安全,几乎适用于所有平台。
|
||||
|
||||
其他的替代方案:Zoom 在专业领域受到欢迎,但大部分的特性需要付费。[Signal][18],一个开源、安全的用于发消息的应用程序,可以用来打电话,不过仅限于移动设备。不推荐 Skype,既耗流量,界面还糟。
|
||||
|
||||
#### Google Maps(地图)
|
||||
|
||||
桌面端:[Here WeGo][19] — 加载速度更快,所有你能在 Google Maps 找到的你几乎都能找到。不过由于某些原因,还缺了一些国家,如日本。
|
||||
桌面端:[HERE WeGo][19] — 加载速度更快,所有你能在 Google Maps 找到的你几乎都能找到。不过由于某些原因,还缺了一些国家,如日本。
|
||||
|
||||
移动端:[Maps.me][20] — 我一开始用的就是这款地图,但是这款 APP 的导航模式有点鸡肋。Maps.me 还是相当不错的,并且具有比 Google 更好的离线功能,这对像我这样的经常旅行的人来说非常好用。
|
||||
移动端:[MAPS.ME][20] — 我一开始用的就是这款地图,但是这款 APP 的导航模式有点鸡肋。MAPS.ME 还是相当不错的,并且具有比 Google 更好的离线功能,这对像我这样的经常旅行的人来说非常好用。
|
||||
|
||||
其他的替代方案:[OpenStreetMap][21] 是我全面支持的一个项目,不过功能严重缺乏。甚至无法找到我在奥克兰的家庭住址。
|
||||
|
||||
@ -79,7 +79,7 @@ Google 现在俨然已是许多语言中的单词,但彰显其超然全球统
|
||||
|
||||
#### Calendar(日历)
|
||||
|
||||
[Fastmail][26]日历 — 这个决定异常艰难,也抛出了另一个问题。Google 的产品的存在在很多方面,可以用无处不在来形容,这导致初创公司甚至不再费心去创造替代品。在尝试了其他一些平庸的选项后,我最后还是推荐并选择 Fastmail 同时作为备用电子邮件和日历的选项。
|
||||
[Fastmail][26] 日历 — 这个决定异常艰难,也抛出了另一个问题。Google 的产品的存在在很多方面,可以用无处不在来形容,这导致初创公司甚至不再费心去创造替代品。在尝试了其他一些平庸的选项后,我最后还是推荐并选择 Fastmail 同时作为备用电子邮件和日历的选项。
|
||||
|
||||
### 进阶
|
||||
|
||||
@ -87,11 +87,11 @@ Google 现在俨然已是许多语言中的单词,但彰显其超然全球统
|
||||
|
||||
#### Google Docs(文档)、Drive(云端硬盘)、Photos(照片)和 Contacts(联系人)
|
||||
|
||||
[NextCloud][27] — 一个功能齐全、安全并且开源的云套件,具有直观、用户友好的界面。问题是你需要自己有主机才能使用 Nextcloud。我拥有一个用于部署自己网站的主机,并且能够使用 Softaculous 在我的主机的 C-Panel 上快速安装 NextCloud。你需要一个 HTTPS 证书,我从 [Let's Encrypt][28] 上免费获得了一个。不似开通 Google Drive 帐户那般容易,但也不是很难。
|
||||
[Nextcloud][27] — 一个功能齐全、安全并且开源的云套件,具有直观、用户友好的界面。问题是你需要自己有主机才能使用 Nextcloud。我拥有一个用于部署自己网站的主机,并且能够使用 Softaculous 在我的主机的 C-Panel 上快速安装 Nextcloud。你需要一个 HTTPS 证书,我从 [Let's Encrypt][28] 上免费获得了一个。不似开通 Google Drive 帐户那般容易,但也不是很难。
|
||||
|
||||
我也同时在用 Nextcloud 作为 Google 的照片存储和联系人的替代方案,然后通过 CalDev 与手机同步。
|
||||
|
||||
其他的替代方案:还有其他开源选项,如 [OwnCloud][29] 或者 [Openstack][30]。一些营利的选项也很不错,因为作为首选的 Dropbox 和 Box 也没有采用从你的数据中牟利的运营模式。
|
||||
其他的替代方案:还有其他开源选项,如 [ownCloud][29] 或者 [Openstack][30]。一些营利的选项也很不错,因为作为首选的 Dropbox 和 Box 也没有采用从你的数据中牟利的运营模式。
|
||||
|
||||
#### Google Analytics(分析)
|
||||
|
||||
@ -131,9 +131,9 @@ Google 现在俨然已是许多语言中的单词,但彰显其超然全球统
|
||||
|
||||
还有些旗鼓相当。ProtonMail 具有 Gmail 的大部分功能,但缺少一些好用的集成,例如我之前使用的 Boomerang 邮件调度程序。还缺少联系人界面,但我正在使用 Nextcloud。说到 Nextcloud,它非常适合托管文件,联系人,还包含了一个漂亮的笔记工具(以及诸多其他插件)。但它没有 Google Docs 丰富的多重编辑功能。在我的预算中,还没有找到可行的替代方案。虽然还有 Collabora Office,但这需要升级我的服务器,这对我来说不能算切实可行。
|
||||
|
||||
一些取决于位置。在一些国家(如印度尼西亚),Maps.me 实际上比 Google 地图更好用,而在另一些国家(包括美国)就差了许多。
|
||||
一些取决于位置。在一些国家(如印度尼西亚),MAPS.ME 实际上比 Google 地图更好用,而在另一些国家(包括美国)就差了许多。
|
||||
|
||||
还有些人要求使用者牺牲一些特性或功能。Piwic 是一个穷人的 Google Analytics,缺乏前者的许多详细报告和搜索功能。DuckDuckGo 适用于一般搜索,但是在特定的搜索方面还存在问题,当我搜索非英文内容时,它和 StartPage 时常都会检索失败。
|
||||
还有些人要求使用者牺牲一些特性或功能。Piwic 是一个穷人的 Google Analytics,缺乏前者的许多详细报告和搜索功能。DuckDuckGo 适用于一般搜索,但是在特定的搜索方面还存在问题,当我搜索非英文内容时,它和 startpage 时常都会检索失败。
|
||||
|
||||
### 最后,我不在心念 Google
|
||||
|
||||
@ -174,7 +174,7 @@ Nithin Coca
|
||||
via: https://medium.com/s/story/how-i-fully-quit-google-and-you-can-too-4c2f3f85793a
|
||||
|
||||
作者:[Nithin Coca][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[martin2011qi](https://github.com/martin2011qi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,40 +0,0 @@
|
||||
那些数据对于云服务器来说风险很大
|
||||
======
|
||||

|
||||
|
||||
在这系列文章中我们分四部分,我们一直在关注每个组织在做云迁移的时候应该避免的陷阱——特别是混合多云的情况下
|
||||
[在第一部分][1], 我们会介绍一些基本的定义以及我们对于混合云以及多云的看法,已确保显示两者的区别. [在第二部分][2], 我们会对三个陷阱进行讨论:第一个为什么成本并不是成为迁移云的核心明显在第一部分,我们会介绍一些基本的定义以及我们对于混合种类云以及多种类云的看法,已确保显示出两者的区别,
|
||||
动力。 而且,[在第三部分][3], 我们将对所有工作向云进行迁移的可行性。在最后,第四部分中,我们将会对如何处理云的数据做研究以及您应该怎么把数据向云端迁移吗?迁移多少?什么数据在云端起作用,又是什么会造成移动风险很大?
|
||||
### 数据...数据...数据..
|
||||
影响您对云端数据的所有决策的关键因素在于确定您的带宽以及存储需求。 Gartner预计 "2018年成为[$173亿美元]的业务[4]" 并且大部分资金是浪费在一些不必要的存储容量上:"但是只需要优化一下工作量,全球的所有公司就可以节约620亿美元的不必要IT成本。根据Gartner的研究,非常令人惊讶的是,全球所有的公司为云服务器平均支付的费用比他们实际的费用多达36%
|
||||
如果你已经阅读了本系列的前三个章节,南无你应该不会为此感到惊讶。然而令人更惊讶的是 Gartner的结论是 "如果全球的公司将他他们服务器数据直接迁移到云端上,仅仅只有25%的公司能够做到省钱。"
|
||||
等一下。。。。工作带来的负载是可以针对云进行优化的,但是可能只有一小部分公司会通过将数据向云端迁移来节省资金吗?这个又是什么意思?
|
||||
如果你去认为云服务商会根据带宽来收取云产生的费用。那么是将所有的公司内部部署的数据移至云端很快就会成为他们成本的负担。有以下三种情况。公司才可能会觉得值得把数据放在云端中:
|
||||
*具有存储和应用程序的单个云
|
||||
* 云中自带的应用程序以及内部存储
|
||||
* 云中的应用程序和缓存在云端的数据以及内部存储
|
||||
在第一种情况下,通过将所有的内容都保留在单个云服务商哪里来节省带宽成本,但是这会产生一些锁定,这个通常与CIO的云战略或者风险防范计划所冲突
|
||||
第二种方案是仅仅保留应用程序在云端所收集的数据,并且以最小值的方式传输到本地存储。这就需要仔细的考虑策略,其中只有最少使用数据的应用程序部署在云端
|
||||
第三种情况就是将数据缓存在云端,应用程序和存储数据或者是在内部的“一个事实”,这也就意味着分析人工智能学习和机器学习可以在内部运行而无需把数据向云服务商上传,然后处理之后再返回。缓存数据仅仅基于应用程序对云的需求,甚至进行跨多云的部署缓存
|
||||
要想获得更多信息,请下载红帽[案例研究][5],其中描述了跨混合多云环境下的阿姆斯特丹的史基浦机场的数据以及云和部署策略
|
||||
###数据危险
|
||||
大多数公司都认识到了他们的数据在市场中的专有优势以及智能能力。因此他们会非常仔细的考虑它在云存储的地点
|
||||
想象一下,这种情况:如果你是一个零售商,全球十大零售商之一。而且你已经计划了很长一段时间云存储战略,并且考虑使用亚马逊的云服务,但是突然间,亚马逊的 [Amazon buys Whole Foods][6],并且准备进入你的市场。一夜之间,亚马逊已经增长了50%的零售规模,你是否还回去信任此零售数据云?如果您的数据已经就在亚马逊云中,你会打算怎么做?您是否会考虑使用退出策略来进行创建云计划?虽然亚马逊可能永远不会去利用您的数据潜在的见解——该公司可能甚至有针对此计划的协议 你能相信世界上任何人的话吗?
|
||||
### 陷阱分享,避免遇到陷阱
|
||||
分享我们在以前经验中看到的一些陷阱来帮助您的公司规划更安全,更持久的云端策略 [了解成本不是明显的动力来源,][2], [并非一切东西都在云端][3], 而是你必须在云端有效管理数据才是您成功的关键所在
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
via: https://opensource.com/article/18/8/data-risky-cloud
|
||||
作者:[Eric D.Schabell][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekmar](https://github.com/geekmar)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
[a]:https://opensource.com/users/eschabell
|
||||
[1]:https://opensource.com/article/18/4/pitfalls-hybrid-multi-cloud
|
||||
[2]:https://opensource.com/article/18/6/reasons-move-to-cloud
|
||||
[3]:https://opensource.com/article/18/7/why-you-cant-move-everything-cloud
|
||||
[4]:http://www.businessinsider.com/companies-waste-62-billion-on-the-cloud-by-paying-for-storage-they-dont-need-according-to-a-report-2017-11
|
||||
[5]:https://www.redhat.com/en/resources/amsterdam-airport-schiphol-case-study
|
||||
[6]:https://www.forbes.com/sites/ciocentral/2017/06/23/amazon-buys-whole-foods-now-what-the-story-behind-the-story/#33e9cc6be898
|
||||
@ -0,0 +1,82 @@
|
||||
|
||||
// Copyright 2018 The Go Authors. All rights reserved.
|
||||
// Use of this source code is governed by a BSD-style
|
||||
// license that can be found in the LICENSE file.
|
||||
|
||||
## Go编译器介绍
|
||||
|
||||
`cmd/compile` 包含构成 Go 编译器主要的包。编译器在逻辑上可以被分为四个阶段,我们将简要介绍这几个阶段以及包含相应代码的包的列表。
|
||||
|
||||
在谈到编译器时,有时可能会听到“前端”和“后端”这两个术语。粗略地说,这些对应于我们将在此列出的前两个和后两个阶段。第三个术语“中间端”通常指的是第二阶段执行的大部分工作。
|
||||
|
||||
请注意,`go/parser` 和 `go/types` 等 `go/*` 系列包与编译器无关。由于编译器最初是用C编写的,所以这些 `go/*` 包被开发出来以便于能够写出和 `Go` 代码一起工作的工具,例如 `gofmt` 和 `vet`。
|
||||
|
||||
需要澄清的是,名称“gc”代表“Go 编译器”,与大写 GC 无关,后者代表垃圾收集。
|
||||
|
||||
### 1. 解析
|
||||
|
||||
* `cmd/compile/internal/syntax` (词法分析器、解析器、语法树)
|
||||
|
||||
在编译的第一阶段,源代码被标记化(词法分析),解析(语法分析),并为每个源文件构造语法树(译注:这里标记指token,它是一组预定义、能够识别的字符串,通常由名字和值构成,其中名字一般是词法的类别,如标识符、关键字、分隔符、操作符、文字和注释等;语法树,以及下文提到的AST,Abstract Syntax Tree,抽象语法树,是指用树来表达程序设计语言的语法结构,通常叶子节点是操作数,其它节点是操作码)。
|
||||
|
||||
每棵语法树都是相应源文件的确切表示,其中节点对应于源文件的各种元素,例如表达式,声明和语句。语法树还包括位置信息,用于错误报告和创建调试信息。
|
||||
|
||||
### 2. 类型检查和AST变形
|
||||
|
||||
* `cmd/compile/internal/gc` (创建编译器AST,类型检查,AST变形)
|
||||
|
||||
gc 包中包含一个继承自(早期)C 语言实现的版本的 AST 定义。所有代码都是基于该 AST 编写的,所以 gc 包必须做的第一件事就是将 syntax 包(定义)的语法树转换为编译器的 AST 表示法。这个额外步骤可能会在将来重构。
|
||||
|
||||
然后对 AST 进行类型检查。第一步是名字解析和类型推断,它们确定哪个对象属于哪个标识符,以及每个表达式具有的类型。类型检查包括特定的额外检查,例如“声明但未使用”以及确定函数是否会终止。
|
||||
|
||||
特定转换也基于 AST 上完成。一些节点被基于类型信息而细化,例如把字符串加法从算术加法的节点类型中拆分出来。其他一些例子是死代码消除,函数调用内联和逃逸分析(译注:逃逸分析是一种分析指针有效范围的方法)。
|
||||
|
||||
### 3. 通用SSA
|
||||
|
||||
* `cmd/compile/internal/gc` (转换成 SSA)
|
||||
|
||||
* `cmd/compile/internal/ssa` (SSA 相关的 pass 和规则)
|
||||
|
||||
(译注:许多常见高级语言的编译器无法通过一次扫描源代码或 AST 就完成所有编译工作,取而代之的做法是多次扫描,每次完成一部分工作,并将输出结果作为下次扫描的输入,直到最终产生目标代码。这里每次扫描称作一遍,即 pass;最后一遍之前所有的 pass 得到的结果都可称作中间表示法,本文中 AST、SSA 等都属于中间表示法。SSA,静态单赋值形式,是中间表示法的一种性质,它要求每个变量只被赋值一次且在使用前被定义)。
|
||||
|
||||
在此阶段,AST 将被转换为静态单赋值形式(SSA)形式,这是一种具有特定属性的低级中间表示法,可以更轻松地实现优化并最终从它生成机器代码。
|
||||
|
||||
在这个转换过程中,将完成内置函数的处理。 这些是特殊的函数,编译器被告知逐个分析这些函数并决定是否用深度优化的代码替换它们(译注:内置函数指由语言本身定义的函数,通常编译器的处理方式是使用相应实现函数的指令序列代替对函数的调用指令,有点类似内联函数)。
|
||||
|
||||
在 AST 转化成 SSA 的过程中,特定节点也被低级化为更简单的组件,以便于剩余的编译阶段可以基于它们工作。例如,内建的拷贝被替换为内存移动,range循环被改写为for循环。由于历史原因,目前这里面有些在转化到 SSA 之前发生,但长期计划则是把它们都移到这里(转化 SSA)。
|
||||
|
||||
然后,一系列机器无关的规则和pass会被执行。这些并不考虑特定计算机体系结构,因此对所有 `GOARCH` 变量的值都会运行。
|
||||
|
||||
这类通用的 pass 的一些例子包括,死代码消除,移除不必要的空指针检查,以及移除无用的分支等。通用改写规则主要考虑表达式,例如将一些表达式替换为常量,优化乘法和浮点操作。
|
||||
|
||||
### 4. 生成机器码
|
||||
|
||||
* `cmd/compile/internal/ssa` (SSA 低级化和体系结构特定的pass)
|
||||
|
||||
* `cmd/internal/obj` (机器代码生成)
|
||||
|
||||
编译器中机器相关的阶段开始于“低级”的 pass,该阶段将通用变量改写为它们的机器相关变形形式。例如,在 amd64 体系结构中操作数可以在内存中,这样许多装载-存储操作就可以被合并。
|
||||
|
||||
注意低级的 pass 运行所有机器特定的重写规则,因此它也应用了很多优化。
|
||||
|
||||
一旦 SSA 被“低级化”并且更具体地针对目标体系结构,就要运行最终代码优化的 pass 了。这包含了另外一个死代码消除的 pass,它将变量移动到更靠近它们使用的地方,移除从来没有被读过的局部变量,以及寄存器分配。
|
||||
|
||||
本步骤中完成的其它重要工作包括堆栈布局,它将指定局部变量在堆栈中的偏移位置,以及指针活性分析,后者计算每个垃圾收集安全点上的哪些堆栈上的指针仍然是活动的。
|
||||
|
||||
在 SSA 生成阶段结束时,Go 函数已被转换为一系列 obj.Prog 指令。它们被传递给汇编程序(`cmd/internal/obj`),后者将它们转换为机器代码并输出最终的目标文件。目标文件还将包含反射数据,导出数据和调试信息。
|
||||
|
||||
### 后续读物
|
||||
|
||||
要深入了解 SSA 包的工作方式,包括它的 pass 和规则,请转到 cmd/compile/internal/ssa/README.md。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://github.com/golang/go/blob/master/src/cmd/compile/README.md
|
||||
|
||||
作者:[mvdan ][a]
|
||||
译者:[stephenxs](https://github.com/stephenxs)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://github.com/mvdan
|
||||
@ -3,15 +3,15 @@
|
||||
|
||||

|
||||
|
||||
尝试找出你的机器正在运行的是什么程序,以及哪个进程耗尽了内存导致运行非常非常慢——这些都是 `top` 命令所能胜任的任务。
|
||||
尝试找出你的机器正在运行什么程序,以及哪个进程耗尽了内存导致系统非常非常慢 —— 这是 `top` 命令所能胜任的工作。
|
||||
|
||||
`top` 是一个非常有用的程序,其作用类似于 Windows 任务管理器或 MacOS 的活动监视器。在 *nix 机器上运行 `top` 将显示系统上运行的进程的实时运行视图。
|
||||
`top` 是一个非常有用的程序,其作用类似于 Windows 任务管理器或 MacOS 的活动监视器。在 \*nix 机器上运行 `top` 将实时显示系统上运行的进程的情况。
|
||||
|
||||
```
|
||||
$ top
|
||||
```
|
||||
|
||||
取决于你正在运行的 `top` 版本,你将获得如下所示的内容:
|
||||
取决于你运行的 `top` 版本,你会看到类似如下内容:
|
||||
|
||||
```
|
||||
top - 08:31:32 up 1 day, 4:09, 0 users, load average: 0.20, 0.12, 0.10
|
||||
@ -30,149 +30,146 @@ KiB Swap: 1048572 total, 0 used, 1048572 free. 1804264 cached Mem
|
||||
|
||||
### 如何阅读输出的内容
|
||||
|
||||
你可以根据输出判断您正在运行的内容,但尝试去解释结果你可能会有些困惑。
|
||||
你可以根据输出判断你正在运行的内容,但尝试去解释结果你可能会有些困惑。
|
||||
|
||||
前几行包含一堆统计信息(详细信息),后跟一个包含结果列表的表(列表)。 让我们从后者开始吧。
|
||||
前几行包含一堆统计信息(详细信息),后跟一个包含结果列的表(列)。让我们从后者开始吧。
|
||||
|
||||
### 列表
|
||||
#### 列
|
||||
|
||||
这些是正运行在系统上的进程。默认按 CPU 使用率降序排序。这意味着在列表顶部的程序正使用更多的 CPU 资源和对你的系统造成更重的负担。对于资源使用而言,这些程序是字面上的消耗最多(top)进程。你必须承认,`top` 程序名字起得很妙。
|
||||
这些是系统正在运行的进程。默认按 CPU 使用率降序排序。这意味着在列表顶部的程序正使用更多的 CPU 资源并对你的系统造成更重的负担。对于资源使用而言,这些程序是字面上的消耗资源最多的(top)进程。不得不说,`top` 这个名字起得很妙。
|
||||
|
||||
最右边的`COMMAND`一列报告进程名(你用来启动它们的命令)。在这个例子里,进程名是`bash` (一个我们正在运行 `top` 的命令解释器)、`flask`(一个 Python 写的 web 框架) 和 `top` 自身。
|
||||
最右边的 `COMMAND` 一列报告进程名(启动它们的命令)。在这个例子里,进程名是 `bash`(一个我们正在运行 `top` 的命令解释器)、`flask`(一个 Python 写的 web 框架)和 `top` 自身。
|
||||
|
||||
其他列提供了关于进程的有效信息。
|
||||
其它列提供了关于进程的有用信息:
|
||||
|
||||
* `PID`: 进程 ID,一个用来定位进程的唯一标识符
|
||||
* `USER`:运行进程的用户
|
||||
* `PR`: 任务的优先度
|
||||
* `NI`: 优先度的一个更好的表现形式
|
||||
* `VIRT`: 虚拟内存的大小 单位是 Kib(kibibytes)
|
||||
* `RES`: 常驻内存大小 单位是 KiB (物理内存和虚拟内存的一部分)
|
||||
* `SHR`: 共享内存大小 单位是 KiB(共享内存和虚拟内存的一部分)
|
||||
* `S`: 进程状态, 一般 **I** 代表空闲,**R** 代表运行,**S** 代表休眠,, **Z** 代表僵尸进程,, **T** or **t** 代表停止(还有其他更少见的选项)
|
||||
* `%CPU`: 自从上次屏幕结果更新后的 CPU 使用率
|
||||
* `%MEM`: 自从上次屏幕更新后的`RES`常驻内存使用率
|
||||
* `TIME+`: 自从程序开始后总的 CPU 使用时间
|
||||
* `COMMAND`: 启动命令,如之前描述那样
|
||||
* `PID`:进程 ID,一个用来定位进程的唯一标识符
|
||||
* `USER`:运行进程的用户
|
||||
* `PR`:任务的优先级
|
||||
* `NI`:Nice 值,优先级的一个更好的表现形式
|
||||
* `VIRT`:虚拟内存的大小,单位是 KiB(kibibytes)
|
||||
* `RES`:常驻内存大小,单位是 KiB(物理内存和虚拟内存的一部分)
|
||||
* `SHR`:共享内存大小,单位是 KiB(共享内存和虚拟内存的一部分)
|
||||
* `S`:进程状态,一般 **I** 代表空闲,**R** 代表运行,**S** 代表休眠,**Z** 代表僵尸进程,**T** 或 **t** 代表停止(还有其它更少见的选项)
|
||||
* `%CPU`:自从上次屏幕更新后的 CPU 使用率
|
||||
* `%MEM`:自从上次屏幕更新后的 `RES` 常驻内存使用率
|
||||
* `TIME+`:自从程序启动后总的 CPU 使用时间
|
||||
* `COMMAND`:启动命令,如之前描述那样
|
||||
|
||||
确切知道 `VIRT` , `RES` 和 `SHR` 值代表什么在日常操作中并不重要。重要的事情是知道`VIRT` 值最高的那个进程是那个使用最多内存的进程。如果你在用 `top` 找为什么你的电脑运行慢得就像行走在糖蜜池时,那个`VIRT` 数值最大的进程就是元凶。如果你想要知道共享内存和物理内存的确切意思,请查阅[ top 手册][1]的 Linux 内存类型。
|
||||
确切知道 `VIRT`,`RES` 和 `SHR` 值代表什么在日常操作中并不重要。重要的是要知道 `VIRT` 值最高的进程就是内存使用最多的进程。当你在用 `top` 排查为什么你的电脑运行无比卡的时候,那个 `VIRT` 数值最大的进程就是元凶。如果你想要知道共享内存和物理内存的确切意思,请查阅 [top 手册][1]的 Linux Memory Types 段落。
|
||||
|
||||
是的,我说的是 kibibytes 而不是 kilobytes。通常称为 kilobyte 的1024值实际上是 kibibyte 。 希腊语的 kilo ("χίλιοι") 意思是一千或者千(例如一千米是 1000 米,一千克是 1000 克)。Kibi 是 kilo 和 byte 的合成词,意思是 1024 字节(或者 210 )。但是,因为这个词很难说,所以很多人在说 1024 字节的时候会说 kilobyte。所有这些意味着 `top` 试图在这里使用恰当的术语,所以随它去吧。
|
||||
是的,我说的是 kibibytes 而不是 kilobytes。通常称为 kilobyte 的 1024 值实际上是 kibibyte。希腊语的 kilo(χίλιοι)意思是一千(例如一千米是 1000 米,一千克是 1000 克)。Kibi 是 kilo 和 binary 的合成词,意思是 1024 字节(或者 2^10 )。但是,因为这个词很难说,所以很多人在说 1024 字节的时候会说 kilobyte。`top` 试图在这里使用恰当的术语,所以按它说的理解就好。
|
||||
|
||||
#### 屏幕更新说明
|
||||
|
||||
实时屏幕更新是 Linux 程序可以做的 ** 非常酷 ** 的事情之一。这意味着程序能实时更新它们显示的内容,所以看起来很生动,即使它们使用的是文本。非常酷!在我们的例子里,更新之间的时间是重要的,因为我们的一些数据(`%CPU` 和 `%MEM`)是基于上次屏幕更新的数值的。
|
||||
实时屏幕更新是 Linux 程序可以做的 **非常酷** 的事之一。这意味着程序能实时更新它们显示的内容,所以看起来是动态的,即使它们用的是文本。非常酷!在我们的例子中,更新时间间隔很重要,因为一些统计数据(`%CPU` 和 `%MEM`)是基于上次屏幕更新的数值的。
|
||||
|
||||
因为我们正在运行一个持续的应用,我们能按下按键命令对设置或者配置进行实时的修改(也就是说,关闭应用,然后用一个不同的命令行标志位来再次运行该应用)。
|
||||
因为我们运行在一个持久性的程序中,我们就可以输入一些命令来实时修改配置(而不是停止应用,然后用一个不同的命令行选项再次运行)。
|
||||
|
||||
按下 `h` 调用帮助界面,界面也显示默认延迟(屏幕更新的时间间隔)。这个值默认(大约)是3秒,但是你能输入 `d` (大概是延迟 delay 的意思) 或者 `s` (可能是屏幕 screen 或者秒 seconds 的意识) 来修改这个默认值。
|
||||
按下 `h` 调用帮助界面,该界面也显示了默认延迟(屏幕更新的时间间隔)。这个值默认(大约)是 3 秒,但你可以输入 `d`(大概是 delay 的意思)或者 `s`(可能是 screen 或 seconds 的意思)来修改它。
|
||||
|
||||
#### 细节
|
||||
|
||||
在上面的进程列表里有一大堆有用的信息。有些细节看起来奇怪,令人感到困惑。但是一旦你花一些时间来逐个过一遍,你会发现,在紧要关头,这些是非常有用的数据。
|
||||
在进程列表上面有一大堆有用的信息。有些细节看起来有点儿奇怪,让人困惑。但是一旦你花点儿时间来逐个过一遍,你会发现,在紧要关头,这些是非常有用的。
|
||||
|
||||
第一行包含系统的大致信息
|
||||
第一行包含系统的大致信息:
|
||||
|
||||
* `top`:我们正在运行 `top`!你好! `top`!
|
||||
* `XX:YY:XX`: 当前时间,每次屏幕更新的时候更新
|
||||
* `up` (接下去是`X day, YY:ZZ`): 系统的 [正常运行时间][2],或者自从系统启动后已经过去了多长时间
|
||||
* `load average` (接下去是三个数字): 分别是过去 一分钟、五分钟、15分钟的 [系统负载][3]
|
||||
* `top`:我们正在运行 `top`!你好!`top`!
|
||||
* `XX:YY:XX`:当前时间,每次屏幕更新的时候更新
|
||||
* `up`(接下去是 `X day, YY:ZZ`):系统的 [uptime][2],或者自从系统启动后已经过去了多长时间
|
||||
* `load average`(后跟三个数字):分别是过去一分钟、五分钟、15 分钟的[系统负载][3]
|
||||
|
||||
第二行 (`Task`)显示了正在运行的任务的信息,不用解释。它显示了进程总数和正在运行的、休眠中的、停止的进程数和僵尸进程数。这实际上是上述 `S` (状态)列的总和。
|
||||
第二行(`Task`)显示了正在运行的任务的信息,不用解释。它显示了进程总数和正在运行的、休眠中的、停止的进程数和僵尸进程数。这实际上是上述 `S`(状态)列的总和。
|
||||
|
||||
第三行(`%Cpu(s)`)显示了按类型划分的 CPU 使用情况。数据是屏幕刷新之间的值。这些值是:
|
||||
第三行(`%Cpu(s)`)显示了按类型划分的 CPU 使用情况。数据是屏幕刷新之间的值。这些值是:
|
||||
|
||||
* `us`: 用户进程
|
||||
* `sy`: 系统进程
|
||||
* `ni`: [nice][4] 用户进程
|
||||
* `id`: CPU 的闲置时间, 高闲置时间意味着除此之外不会有太多事情发生
|
||||
* `wa`: 等待时间,或者花在等待 I/O 完成的时间
|
||||
* `hi`: 花在硬件中断的时间
|
||||
* `si`: 花在软件中断的时间
|
||||
* `st`: “虚拟机管理程序从该虚拟机窃取的时间”
|
||||
* `us`:用户进程
|
||||
* `sy`:系统进程
|
||||
* `ni`:[nice][4] 用户进程
|
||||
* `id`:CPU 的空闲时间,这个值比较高时说明系统比较空闲
|
||||
* `wa`:等待时间,或者消耗在等待 I/O 完成的时间
|
||||
* `hi`:消耗在硬件中断的时间
|
||||
* `si`:消耗在软件中断的时间
|
||||
* `st`:“虚拟机管理程序从该虚拟机窃取的时间”
|
||||
|
||||
你能通过点击`t` (触发 toggle 的意思)来展开 `Task` 和`%Cpu(s)` 列。
|
||||
你可以通过点击 `t`(toggle)来展开或折叠 `Task` 和 `%Cpu(s)` 行。
|
||||
|
||||
第四行(`Kib Mem`)和第五行(`KiB Swap`)提供了内存和交换空间的信息。这些数值是:
|
||||
|
||||
* `total`
|
||||
* `used`
|
||||
* `free`
|
||||
|
||||
还有:
|
||||
|
||||
* 总内存容量
|
||||
* 已用内存
|
||||
* 空闲内存
|
||||
* 内存的缓冲值
|
||||
* 交换空间的缓存值
|
||||
|
||||
默认它们是用 KiB 为单位展示的,但是按下 `E` (扩展内存缩放 extend memory scaling 的意思)能在不同的数值轮换:KiB 、MiB、 GiB、 TiB、 PiB、 EiB (kilobytes, megabytes, gigabytes, terabytes, petabytes, 和 exabytes,它们真正的名字)
|
||||
默认它们是用 KiB 为单位展示的,但是按下 `E`(扩展内存缩放 extend memory scaling)可以轮换不同的单位:KiB、MiB、GiB、TiB、PiB、EiB(kilobytes、megabytes、gigabytes、terabytes、petabytes 和 exabytes)
|
||||
|
||||
`top` 用户手册甚至显示了关于有效标志位和配置的更多信息。 你能运行 `man top` 来找到你系统上的文档。有不同的网页显示 [HTML 版的手册][1],但是请留意,这些手册可能是给不同 top 版本看的。
|
||||
`top` 用户手册有更多选项和配置项信息。你可以运行 `man top` 来查看你系统上的文档。还有很多 [HTML 版的 man 手册][1],但是请留意,这些手册可能是针对不同 top 版本的。
|
||||
|
||||
### 两个 top 的替代品
|
||||
|
||||
你不必总是用 `top` 来理解发生了什么。根据您的情况,其他工具可能会帮助您诊断问题,尤其是当您想要更图形化或专业的界面时。
|
||||
你不必总是用 `top` 查看系统状态。你可以根据你的情况用其它工具来协助排查问题,尤其是当你想要更图形化或更专业的界面的时候。
|
||||
|
||||
#### htop
|
||||
|
||||
`htop` 很像 `top` ,但是它给表格带来了一些非常有用的东西: CPU 和内存使用的图形表示。
|
||||
`htop` 很像 `top`,但是它带来了一些非常有用的东西:它可以以图形界面展示 CPU 和内存使用情况。
|
||||
|
||||
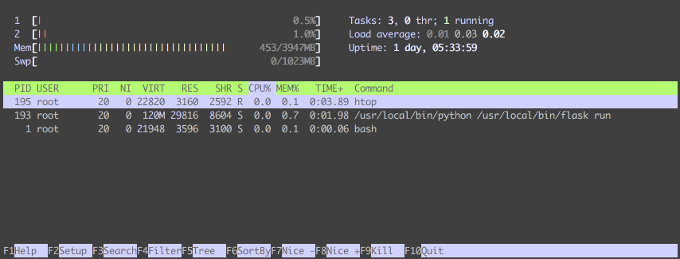
|
||||
|
||||
这就是我们在 `top` 中考察的环境在`htop` 中的样子。显示要简单得多,但仍有丰富的功能。
|
||||
这是我们在刚才运行 `top` 的同一环境中 `htop` 的样子。显示更简洁,但功能却很丰富。
|
||||
|
||||
我们的任务计数、负载、正常运行时间和进程列表仍然存在,但是我们获得了每个内核CPU使用情况的漂亮、彩色、动画视图和内存使用情况图表。
|
||||
任务统计、负载、uptime 和进程列表仍然在,但是它有了漂亮、彩色、动态的每核 CPU 使用情况,还有图形化的内存使用情况。
|
||||
|
||||
以下是不同颜色的含义(你也可以通过按“h”来获得这些信息,以获得“帮助”)。
|
||||
以下是不同颜色的含义(你也可以通过按下 `h` 来获得这些信息的帮助)。
|
||||
|
||||
CPU任务优先级或类型:
|
||||
CPU 任务优先级或类型:
|
||||
|
||||
* 蓝色:低优先级
|
||||
* 绿色:正常优先级
|
||||
* 红色:核心任务
|
||||
* 蓝色:虚拟化任务
|
||||
* 条形末尾的值是已用CPU的百分比
|
||||
* 蓝色:低优先级
|
||||
* 绿色:正常优先级
|
||||
* 红色:内核任务
|
||||
* 蓝色:虚拟任务
|
||||
* 条状图末尾的值是已用 CPU 的百分比
|
||||
|
||||
内存:
|
||||
|
||||
* 绿色:已经使用的内存
|
||||
* 蓝色:缓冲的内存
|
||||
* 黄色:缓存内存
|
||||
* 条形图末尾的值显示已用内存和总内存
|
||||
* 绿色:已经使用的内存
|
||||
* 蓝色:缓冲的内存
|
||||
* 黄色:缓存内存
|
||||
* 条状图末尾的值显示已用内存和总内存
|
||||
|
||||
如果颜色对你没用,你可以运行 `htop - C` 来禁用它们;否则,`htop` 将使用不同的符号来分隔CPU和内存类型。
|
||||
如果颜色对你没用,你可以运行 `htop -C` 来禁用它们;那样 `htop` 将使用不同的符号来展示 CPU 和内存类型。
|
||||
|
||||
在底部,有一个有效功能键的提示,你可以用它来过滤结果或改变排序顺序。 尝试一些命令,看看它们能做什么。只是尝试 `F9` 时要小心。 这将会产生一个信号列表,这些信号会杀死(即停止)一个过程。 我建议在生产环境之外探索这些选项。
|
||||
它的底部有一组激活的快捷键提示,可以用来操作过滤结果或改变排序顺序。试着按一些快捷键看看它们能做什么。不过尝试 `F9` 时要小心,它会调出一个信号列表,这些信号会杀死(即停止)一个过程。我建议在生产环境之外探索这些选项。
|
||||
|
||||
`htop` 的作者,Hisham Muhammad (是的,用 Hisham 命名的 `htop`)在二月份 的 [FOSDEM 2018][6] 就 [lightning talk][5] 做了一个展示。他解释 `htop` 是如何不仅有清晰的图形,还用更现代化的统计信息展示进程信息,这都是之前的工具 `top` 所不具备的。
|
||||
`htop` 的作者 Hisham Muhammad(是的,`htop` 的名字就是源自 Hisham 的)在二月份的 [FOSDEM 2018][6] 做了一个[简短的演讲][5]。他阐述了 `htop` 不仅有简洁的图形界面,还有更现代的进程信息统计展示方式,这都是之前的工具(如 `top`)所不具备的。
|
||||
|
||||
你可以在 [手册页面][7] 或 [htop 网站][8] 阅读更多关于 `htop` 的信息。(警告:网站包含动画背景`htop`。)
|
||||
你可以在[手册页面][7]或 [htop 网站][8]阅读更多关于 `htop` 的信息。(提示:网站背景是一个动态的 `htop`。)
|
||||
|
||||
#### docker stats
|
||||
|
||||
如果你正在用 Docker工作,你可以运行 `docker stats`来生成一个丰富的上下文来表示你的容器在做什么。
|
||||
如果你在用 Docker,你可以运行 `docker stats` 来为容器状态生成一个有丰富上下文的界面。
|
||||
|
||||
这可能比 `top` 更有帮助,因为您不是按进程分类,而是按容器分类。当容器运行缓慢时,这一点特别有用,因为查看哪个容器使用的资源最多比运行 `top` 和试图将进程映射到容器要快。
|
||||
这可能比 `top` 更有帮助,因为它不是按进程分类,而是按容器分类的。这点特别有用,当某个容器运行缓慢时,查看哪个容器耗资源最多比运行 `top` 再找到容器的进程要快。
|
||||
|
||||
上面对 `top` 和 `htop` 中首字母缩略词和描述符的解释应该会让你更容易理解 `docker stats` 中的那些。然而,[docker stats 文档] [9]对每一栏都提供了有用的描述。
|
||||
借助于上面对 `top` 和 `htop` 术语的解释,你应该会更容易理解 `docker stats` 中的那些。然而,[docker stats 文档][9]对每一列都提供了详尽的描述。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
---
|
||||
|
||||
via: https://opensource.com/article/18/8/top-tips-speed-up-computer
|
||||
|
||||
作者:[Katie McLaughlin][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[ypingcn](https://github.com/ypingcn)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[pityonline](https://github.com/pityonline)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/glasnt
|
||||
[1]:http://man7.org/linux/man-pages/man1/top.1.html
|
||||
[2]:https://en.wikipedia.org/wiki/Uptime
|
||||
[3]:https://en.wikipedia.org/wiki/Load_(computing)
|
||||
[4]:https://en.wikipedia.org/wiki/Nice_(Unix)#Etymology
|
||||
[5]:https://www.youtube.com/watch?v=L25waVhy78o
|
||||
[6]:https://fosdem.org/2018/schedule/event/htop/
|
||||
[7]:https://linux.die.net/man/1/htop
|
||||
[8]:https://hisham.hm/htop/index.php
|
||||
[9]:https://docs.docker.com/engine/reference/commandline/stats/
|
||||
[a]: https://opensource.com/users/glasnt
|
||||
[1]: http://man7.org/linux/man-pages/man1/top.1.html
|
||||
[2]: https://en.wikipedia.org/wiki/Uptime
|
||||
[3]: https://en.wikipedia.org/wiki/Load_(computing)
|
||||
[4]: https://en.wikipedia.org/wiki/Nice_(Unix)#Etymology
|
||||
[5]: https://www.youtube.com/watch?v=L25waVhy78o
|
||||
[6]: https://fosdem.org/2018/schedule/event/htop/
|
||||
[7]: https://linux.die.net/man/1/htop
|
||||
[8]: https://hisham.hm/htop/index.php
|
||||
[9]: https://docs.docker.com/engine/reference/commandline/stats/
|
||||
|
||||
Loading…
Reference in New Issue
Block a user