mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-22 23:00:57 +08:00
commit
1d378b65c6
@ -1,11 +1,11 @@
|
||||
python 是慢,但无须过度在意
|
||||
Python 是慢,但我无所谓
|
||||
=====================================
|
||||
|
||||
### 对追求生产率而牺牲性能的怒吼
|
||||
> 为牺牲性能追求生产率而呐喊
|
||||
|
||||

|
||||

|
||||
|
||||
我从关于 Python 中的 asyncio 这个标准库的讨论中休息一会,谈谈我最近正在思考的一些东西:Python 的速度。对不了解我的人说明一下,我是一个 Python 的粉丝,而且我在我能想到的所有地方都积极地使用 Python。人们对 Python 最大的抱怨之一就是它的速度比较慢,有些人甚至拒绝尝试使用 Python,因为它比其他语言速度慢。这里说说为什么我认为应该尝试使用 Python,尽管它是有点慢。
|
||||
让我从关于 Python 中的 asyncio 这个标准库的讨论中休息一会,谈谈我最近正在思考的一些东西:Python 的速度。对不了解我的人说明一下,我是一个 Python 的粉丝,而且我在我能想到的所有地方都积极地使用 Python。人们对 Python 最大的抱怨之一就是它的速度比较慢,有些人甚至拒绝尝试使用 Python,因为它比其他语言速度慢。这里说说为什么我认为应该尝试使用 Python,尽管它是有点慢。
|
||||
|
||||
### 速度不再重要
|
||||
|
||||
@ -13,126 +13,120 @@ python 是慢,但无须过度在意
|
||||
|
||||
> 优化你最贵的资源。
|
||||
|
||||
在过去,最贵的资源是计算机的运行时间。这就是导致计算机科学致力于研究不同算法的效率的原因。然而,这已经不再是正确的,因为现在硅芯片很便宜,确实很便宜。运行时间不再是你最贵的资源。公司最贵的资源现在是它的员工的时间。或者换句话说,就是你。把事情做完比快速地做事更加重要。实际上,这是相当的重要,我将把它再次放在这里,仿佛它是一个引用一样(对于那些只是粗略浏览的人):
|
||||
在过去,最贵的资源是计算机的运行时间。这就是导致计算机科学致力于研究不同算法的效率的原因。然而,这已经不再是正确的,因为现在硅芯片很便宜,确实很便宜。运行时间不再是你最贵的资源。公司最贵的资源现在是它的员工时间。或者换句话说,就是你。把事情做完比把它变快更加重要。实际上,这是相当的重要,我将把它再次放在这里,仿佛它是一个引文一样(给那些只是粗略浏览的人):
|
||||
|
||||
> 把事情做完比快速地做事更加重要。
|
||||
|
||||
你可能会说:“我的公司在意速度,我开发一个 web 应用程序,那么所有的响应时间必须少于 x 毫秒。”或者,“我们失去了客户,因为他们认为我们的 app 运行太慢了。”我并不是想说速度一点也不重要,我只是想说速度不再是最重要的东西;它不再是你最贵的资源。
|
||||
你可能会说:“我的公司在意速度,我开发一个 web 应用程序,那么所有的响应时间必须少于 x 毫秒。”或者,“我们失去了客户,因为他们认为我们的 app 运行太慢了。”我并不是想说速度一点也不重要,我只是想说速度不再是最重要的东西;它不再是你最贵的资源。
|
||||
|
||||

|
||||
|
||||
### 速度是唯一重要的东西
|
||||
|
||||
当你在编程的背景下说 _速度_ 时,你通常意味着性能,也就是 CPU 周期。当你的 CEO 在编程的背景下说 _速度_ 时,他指的是业务速度,最重要的指标是产品上市的时间。基本上,你的产品/web 程序是多么的快并不重要。它是用什么语言写的也不重要。甚至它需要花费多少钱也不重要。在一天结束时,让你的公司存活下来或者死去的唯一事物就是产品上市时间。我不只是说创业公司的想法 -- 你开始赚钱需要花费多久,更多的是“从想法到客户手中”的时间期限。企业能够存活下来的唯一方法就是比你的竞争对手更快地创新。如果在你的产品上市之前,你的竞争对手已经提前上市了,那么你想出了多少好的主意也将不再重要。你必须第一个上市,或者至少能跟上。一但你放慢了脚步,你就输了。
|
||||
当你在编程的背景下说 _速度_ 时,你通常是说性能,也就是 CPU 周期。当你的 CEO 在编程的背景下说 _速度_ 时,他指的是业务速度,最重要的指标是产品上市的时间。基本上,你的产品/web 程序是多么的快并不重要。它是用什么语言写的也不重要。甚至它需要花费多少钱也不重要。在一天结束时,让你的公司存活下来或者死去的唯一事物就是产品上市时间。我不只是说创业公司的想法 -- 你开始赚钱需要花费多久,更多的是“从想法到客户手中”的时间期限。企业能够存活下来的唯一方法就是比你的竞争对手更快地创新。如果在你的产品上市之前,你的竞争对手已经提前上市了,那么你想出了多少好的主意也将不再重要。你必须第一个上市,或者至少能跟上。一但你放慢了脚步,你就输了。
|
||||
|
||||
> 企业能够存活下来的唯一方法就是比你的竞争对手更快地创新。
|
||||
|
||||
#### 一个微服务的案例
|
||||
|
||||
像 Amazon、Google 和 Netflix 这样的公司明白快速前进的重要性。他们创建了一个业务系统,可以使用这个系统迅速地前进和快速的创新。微服务是针对他们的问题的解决方案。这篇文章不谈你是否应该使用微服务,但是至少要接受 Amazon 和 Google 认为他们应该使用微服务。
|
||||
像 Amazon、Google 和 Netflix 这样的公司明白快速前进的重要性。他们创建了一个业务系统,可以使用这个系统迅速地前进和快速的创新。微服务是针对他们的问题的解决方案。这篇文章不谈你是否应该使用微服务,但是至少要理解为什么 Amazon 和 Google 认为他们应该使用微服务。
|
||||
|
||||

|
||||

|
||||
|
||||
微服务本来就很慢。微服务的主要概念是用网络调用来打破边界。这意味着你正在使用一个函数调用(几个 cpu 周期)并将它转变为一个网络调用。没有什么比这更影响性能了。和 CPU 相比较,网络调用真的很慢。但是这些大公司仍然选择使用微服务。我所知道的架构里面没有比微服务还要慢的了。微服务最大的弊端就是它的性能,但是最大的长处就是上市的时间。通过在较小的项目和代码库上建立团队,一个公司能够以更快的速度进行迭代和创新。这恰恰表明了,非常大的公司也很在意上市时间,而不仅仅只是只有创业公司。
|
||||
微服务本来就很慢。微服务的主要概念是用网络调用来打破边界。这意味着你正在把使用的函数调用(几个 cpu 周期)转变为一个网络调用。没有什么比这更影响性能了。和 CPU 相比较,网络调用真的很慢。但是这些大公司仍然选择使用微服务。我所知道的架构里面没有比微服务还要慢的了。微服务最大的弊端就是它的性能,但是最大的长处就是上市的时间。通过在较小的项目和代码库上建立团队,一个公司能够以更快的速度进行迭代和创新。这恰恰表明了,非常大的公司也很在意上市时间,而不仅仅只是只有创业公司。
|
||||
|
||||
#### CPU 不是你的瓶颈
|
||||
|
||||

|
||||

|
||||
|
||||
如果你在写一个网络应用程序,如 web 服务器,很有可能的情况会是,CPU 时间并不是你的程序的瓶颈。当你的 web 服务器处理一个请求时,可能会进行几次网络调用,例如到数据库,或者像 Redis 这样的缓存服务器。虽然这些服务本身可能比较快速,但是对它们的网络调用却很慢。[有一篇很好的关于特定操作的速度差异的博客文章][1]。在这篇文章里,作者把 CPU 周期时间缩放到更容易理解的人类时间。如果一个单独的周期等同于 1 秒,那么一个从 California 到 New York 的网络调用将相当于 4 年。那就说明了网络调用是多少的慢。按一些粗略估计,我们可以假设在同一数据中心内的普通网络调用大约需要 3 ms。这相当于我们“人类比例” 3 个月。现在假设你的程序是高 CPU 密集型,这需要 100000 个 CPU 周期来对单一调用进行响应。这相当于刚刚超过 1 天。现在让我们假设你使用的是一种要慢 5 倍的语言,这将需要大约 5 天。很好,将那与我们 3 个月的网络调用时间相比,4 天的差异就显得并不是很重要了。如果有人为了一个包裹不得不至少等待 3 个月,我不认为额外的 4 天对他们来说真的很重要。
|
||||
如果你在写一个网络应用程序,如 web 服务器,很有可能的情况会是,CPU 时间并不是你的程序的瓶颈。当你的 web 服务器处理一个请求时,可能会进行几次网络调用,例如到数据库,或者像 Redis 这样的缓存服务器。虽然这些服务本身可能比较快速,但是对它们的网络调用却很慢。[这里有一篇很好的关于特定操作的速度差异的博客文章][1]。在这篇文章里,作者把 CPU 周期时间缩放到更容易理解的人类时间。如果一个单独的 CPU 周期等同于 **1 秒**,那么一个从 California 到 New York 的网络调用将相当于 **4 年**。那就说明了网络调用是多少的慢。按一些粗略估计,我们可以假设在同一数据中心内的普通网络调用大约需要 3 毫秒。这相当于我们“人类比例” **3 个月**。现在假设你的程序是高 CPU 密集型,这需要 100000 个 CPU 周期来对单一调用进行响应。这相当于刚刚超过 **1 天**。现在让我们假设你使用的是一种要慢 5 倍的语言,这将需要大约 **5 天**。很好,将那与我们 3 个月的网络调用时间相比,4 天的差异就显得并不是很重要了。如果有人为了一个包裹不得不至少等待 3 个月,我不认为额外的 4 天对他们来说真的很重要。
|
||||
|
||||
上面所说的终极意思是,尽管 Python 速度慢,但是这并不重要。语言的速度(或者 CPU 时间)几乎从来不是问题。实际上谷歌曾经就这一概念做过一个研究,[并且他们就此发表过一篇论文][2]。那篇论文论述了设计高吞吐量的系统。在结论里,他们说到:
|
||||
上面所说的终极意思是,尽管 Python 速度慢,但是这并不重要。语言的速度(或者 CPU 时间)几乎从来不是问题。实际上谷歌曾经就这一概念做过一个研究,[并且他们就此发表过一篇论文][2]。那篇论文论述了设计高吞吐量的系统。在结论里,他们说到:
|
||||
|
||||
> 在高吞吐量的环境中使用解释性语言似乎是矛盾的,但是我们已经发现 CPU 时间几乎不是限制因素;语言的表达性是指,大多数程序是源程序,同时花费它们的大多数时间在 I/O 读写和本机运行时代码。而且,解释性语言无论是在语言层面的轻松实验还是在允许我们在很多机器上探索分布计算的方法都是很有帮助的,
|
||||
> 在高吞吐量的环境中使用解释性语言似乎是矛盾的,但是我们已经发现 CPU 时间几乎不是限制因素;语言的表达性是指,大多数程序是源程序,同时它们的大多数时间花费在 I/O 读写和本机的运行时代码上。而且,解释性语言无论是在语言层面的轻松实验还是在允许我们在很多机器上探索分布计算的方法都是很有帮助的,
|
||||
|
||||
再次强调:
|
||||
|
||||
> CPU 时间几乎不是限制因素。
|
||||
|
||||
### 如果 CPU 时间是一个问题怎么办?
|
||||
|
||||
你可能会说,“前面说的情况真是太好了,但是我们确实有过一些问题,这些问题中 CPU 成为了我们的瓶颈,并造成了我们的 web 应用的速度十分缓慢”,或者“在服务器上 X 语言比 Y 语言需要更少的硬件资源来运行。”这些都可能是对的。关于 web 服务器有这样的美妙的事情:你可以几乎无限地负载均衡它们。换句话说,可以在 web 服务器上投入更多的硬件。当然,Python 可能会比其他语言要求更好的硬件资源,比如 c 语言。只是把硬件投入在 CPU 问题上。相比于你的时间,硬件就显得非常的便宜了。如果你在一年内节省了两周的生产力时间,那将远远多于所增加的硬件开销的回报。
|
||||
|
||||
|
||||
* * *
|
||||
|
||||

|
||||
|
||||
### 那么,Python 是更快吗?
|
||||
### 那么,Python 更快一些吗?
|
||||
|
||||
这一次我一直在谈论最重要的是开发时间。所以问题依然存在:当就开发时间而言,Python 要比其他语言更快吗?按常规惯例来看,我、[google][3] [还有][4][其他][5][几个人][6]可以告诉你 Python 是多么的[高效][7]。它为你抽象出很多东西,帮助你关注那些你真正应该编写代码的地方,而不会被困在琐碎事情的杂草里,比如你是否应该使用一个向量或者一个数组。但你可能不喜欢只是听别人说的这些话,所以让我们来看一些更多的经验数据。
|
||||
这一篇文章里面,我一直在谈论最重要的是开发时间。所以问题依然存在:当就开发时间而言,Python 要比其他语言更快吗?按常规惯例来看,我、[google][3] [还有][4][其他][5][几个人][6]可以告诉你 Python 是多么的[高效][7]。它为你抽象出很多东西,帮助你关注那些你真正应该编写代码的地方,而不会被困在琐碎事情的杂草里,比如你是否应该使用一个向量或者一个数组。但你可能不喜欢只是听别人说的这些话,所以让我们来看一些更多的经验数据。
|
||||
|
||||
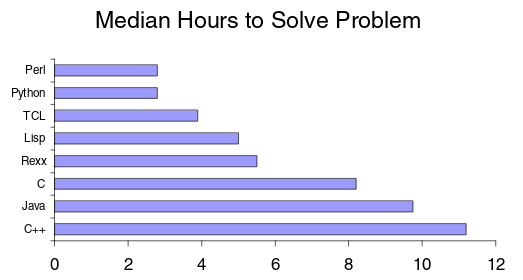
在大多数情况下,关于 python 是否是更高效语言的争论可以归结为脚本语言(或动态语言)与静态类型语言两者的争论。我认为人们普遍接受的是静态类型语言的生产力较低,但是,[这有一篇优秀的论文][8]解释了为什么不是这样。就 Python 而言,这里有一项[研究][9],它调查了不同语言编写字符串处理的代码所需要花费的时间,供参考。
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
在上述研究中,Python 的效率比 Java 高出 2 倍。有一些其他研究也显示相似的东西。 Rosetta Code 对编程语言的差异进行了[深入的研究][10]。在论文中,他们把 python 与其他脚本语言/解释性语言相比较,得出结论:
|
||||
|
||||
> Python 更简洁,即使与函数式语言相比较(平均要短 1.2 到 1.6 倍)
|
||||
>
|
||||
> Python 更简洁,即使与函数式语言相比较(平均要短 1.2 到 1.6 倍)
|
||||
|
||||
普遍的趋势似乎是 Python 中的代码行总是更少。代码行听起来可能像一个可怕的指标,但是包括上面已经提到的两项研究在内的[多项研究][11]表明,每种语言中每行代码所需要花费的时间大约是一样的。因此,限制代码行数就可以提高生产效率。甚至 codinghorror(一名 C# 程序员)本人[写了一篇关于 Python 是如何更有效率的文章][12]。
|
||||
|
||||
我认为说 Python 比其他的很多语言更加的有效率是公正的。这主要是由于 Python 有大量的自带以及第三方库。[这里是一篇讨论 Python 和其他语言间的差异的简单的文章][13]。如果你不知道为何 Python 是如此的小巧和高效,我邀请你借此机会学习一点 python,自己多实践。这儿是你的第一个程序:
|
||||
|
||||
_import __hello___
|
||||
|
||||
* * *
|
||||
```
|
||||
import __hello__
|
||||
```
|
||||
|
||||
### 但是如果速度真的重要呢?
|
||||
|
||||

|
||||
|
||||
上述论点的语气可能会让人觉得优化与速度一点也不重要。但事实是,很多时候运行时性能真的很重要。一个例子是,你有一个 web 应用程序,其中有一个特定的端点需要用很长的时间来响应。你知道这个程序需要多快,并且知道程序需要改进多少。
|
||||
上述论点的语气可能会让人觉得优化与速度一点也不重要。但事实是,很多时候运行时性能真的很重要。一个例子是,你有一个 web 应用程序,其中有一个特定的端点需要用很长的时间来响应。你知道这个程序需要多快,并且知道程序需要改进多少。
|
||||
|
||||
在我们的例子中,发生了两件事:
|
||||
|
||||
1. 我们注意到有一个端点执行缓慢。
|
||||
2. 我们承认它是缓慢,因为我们有一个可以衡量是否足够快的标准,而它要没达到那个标准。
|
||||
2. 我们承认它是缓慢,因为我们有一个可以衡量是否足够快的标准,而它没达到那个标准。
|
||||
|
||||
我们不必在应用程序中微调优化所有内容,只需要让其中每一个都“足够快”。如果一个端点花费了几秒钟来响应,你的用户可能会注意到,但是,他们并不会注意到你将响应时间由 35 毫秒降低到 25 毫秒。“足够好”就是你需要做到的所有事情。_免责声明: 我应该说有**一些**应用程序,如实时投标程序,**确实**需要细微优化,每一毫秒都相当重要。但那只是例外,而不是规则。_
|
||||
|
||||
为了明白如何对端点进行优化,你的第一步将是配置代码,并尝试找出瓶颈在哪。毕竟:
|
||||
|
||||
> 任何除了瓶颈之外的改进都是错觉。 --Gene Kim
|
||||
> <ruby>任何除了瓶颈之外的改进都是错觉。<rt>Any improvements made anywhere besides the bottleneck are an illusion.</rt></ruby> -- Gene Kim
|
||||
|
||||
如果你的优化没有触及到瓶颈,你只是浪费你的时间,并没有解决实际问题。在你优化瓶颈之前,你不会得到任何重要的改进。如果你在不知道瓶颈是什么前就尝试优化,那么你最终只会在部分代码中玩耍。在测量和确定瓶颈之前优化代码被称为“过早优化”。人们常提及 Donald Knuth 说的话,但他声称实际是他偷了别人的话:
|
||||
如果你的优化没有触及到瓶颈,你只是浪费你的时间,并没有解决实际问题。在你优化瓶颈之前,你不会得到任何重要的改进。如果你在不知道瓶颈是什么前就尝试优化,那么你最终只会在部分代码中玩耍。在测量和确定瓶颈之前优化代码被称为“过早优化”。人们常提及 Donald Knuth 说的话,但他声称这句话实际上是他从别人那里听来的:
|
||||
|
||||
> <ruby>过早优化是万恶之源<rt>Premature optimization is the root of all evil</rt></ruby>。
|
||||
|
||||
在谈到维护代码库时,来自 Donald Knuth 的更完整的引用是:
|
||||
在谈到维护代码库时,来自 Donald Knuth 的更完整的引文是:
|
||||
|
||||
> 在 97% 的时间里,我们应该忘记微不足道的效率:**过早的优化是万恶之源**。然而在关
|
||||
> 键的 3%,我们不应该错过优化的机会。 ——Donald Knuth
|
||||
> 键的 3%,我们不应该错过优化的机会。 —— Donald Knuth
|
||||
|
||||
换句话说,他所说的是,在大多数时间你应该忘记对你的代码进行优化。它几乎总是足够好。在不是足够好的情况下,我们通常只需要触及 3% 的代码路径。你的端点快了几纳秒,比如因为你使用了 if 语句而不是函数,但这并不会使你赢得任何奖项。
|
||||
换句话说,他所说的是,在大多数时间你应该忘记对你的代码进行优化。它几乎总是足够好。在不是足够好的情况下,我们通常只需要触及 3% 的代码路径。比如因为你使用了 if 语句而不是函数,你的端点快了几纳秒,但这并不会使你赢得任何奖项。
|
||||
|
||||
过早的优化包括调用某些更快的函数,或者甚至使用特定的数据结构,因为它通常更快。计算机科学认为,如果一个方法或者算法与另一个具有相同的渐近增长(或者 Big-O),那么它们是等价的,即使在实践中要慢两倍。计算机是如此之快,算法随着数据/使用增加而造成的计算增长远远超过实际速度本身。换句话说,如果你有两个 O(log n) 的函数,但是一个要慢两倍,这实际上并不重要。随着数据规模的增大,它们都以同样的速度“慢下来”。这就是过早优化是万恶之源的原因;它浪费了我们的时间,几乎从来没有真正有助于我们的性能改进。
|
||||
过早的优化包括调用某些更快的函数,或者甚至使用特定的数据结构,因为它通常更快。计算机科学认为,如果一个方法或者算法与另一个具有相同的渐近增长(或称为 Big-O),那么它们是等价的,即使在实践中要慢两倍。计算机是如此之快,算法随着数据/使用增加而造成的计算增长远远超过实际速度本身。换句话说,如果你有两个 O(log n) 的函数,但是一个要慢两倍,这实际上并不重要。随着数据规模的增大,它们都以同样的速度“慢下来”。这就是过早优化是万恶之源的原因;它浪费了我们的时间,几乎从来没有真正有助于我们的性能改进。
|
||||
|
||||
就 Big-O 而言,你可以认为对你的程序,所有的语言都是 O(n),其中 n 是代码或者指令的行数。对于同样的指令,它们以同样的速率增长。对于渐进增长,一种语言的速度快慢并不重要,所有语言都是相同的。在这个逻辑下,你可以说,为你的应用程序选择一种语言仅仅是因为它的“快速”是过早优化的最终形式。你选择某些预期快速的东西,却没有测量,也不理解瓶颈将在哪里。
|
||||
就 Big-O 而言,你可以认为对你的程序而言,所有的语言都是 O(n),其中 n 是代码或者指令的行数。对于同样的指令,它们以同样的速率增长。对于渐进增长,一种语言的速度快慢并不重要,所有语言都是相同的。在这个逻辑下,你可以说,为你的应用程序选择一种语言仅仅是因为它的“快速”是过早优化的最终形式。你选择某些预期快速的东西,却没有测量,也不理解瓶颈将在哪里。
|
||||
|
||||
> 为您的应用选择语言只是因为它的“快速”,是过早优化的最终形式。
|
||||
|
||||
* * *
|
||||
|
||||

|
||||

|
||||
|
||||
### 优化 Python
|
||||
|
||||
我最喜欢 Python 的一点是,它可以让你一次优化一点点代码。假设你有一个 Python 的方法,你发现它是你的瓶颈。你对它优化过几次,可能遵循[这里][14]和[那里][15]的一些指导,现在,你很肯定 Python 本身就是你的瓶颈。Python 有调用 C 代码的能力,这意味着,你可以用 C 重写这个方法来减少性能问题。你可以一次重写一个这样的方法。这个过程允许你用任何可以编译为 C 兼容汇编程序的语言,编写良好优化后的瓶颈方法。这让你能够在大多数时间使用 Python 编写,只在必要的时候都才用较低级的语言来写代码。
|
||||
|
||||
有一种叫做 Cython 的编程语言,它是 Python 的超集。它几乎是 Python 和 C 的合并,是一种渐进类型的语言。任何 Python 代码都是有效的 Cython 代码,Cython 代码可以编译成 C 代码。使用 Cython,你可以编写一个模块或者一个方法,并逐渐进步到越来越多的 C 类型和性能。你可以将 C 类型和 Python 的鸭子类型混在一起。使用 Cython,你可以获得混合后的完美组合,只在瓶颈处进行优化,同时在其他所有地方不失去 Python 的美丽。
|
||||
|
||||
有一种叫做 Cython 的编程语言,它是 Python 的超集。它几乎是 Python 和 C 的合并,是一种渐进类型的语言。任何 Python 代码都是有新的 Cython 代码,Cython 代码可以编译成 C 代码。使用 Cython,你可以编写一个模块或者一个方法,并逐渐进步到越来越多的 C 类型和性能。你可以将 C 类型和 Python 的鸭子类型合并在一起。使用 Cython,你可以获得混合后的完美组合,只在瓶颈处进行优化,同时在其他所有地方不失去 Python 的美丽。
|
||||

|
||||
|
||||

|
||||
*星战前夜的一幅截图:这是用 Python 编写的 space MMO 游戏。*
|
||||
|
||||
*星战前夜的一幅截图:用 Python 编写的 space MMO 游戏。*
|
||||
当您最终遇到 Python 的性能问题阻碍时,你不需要把你的整个代码库用另一种不同的语言来编写。你只需要用 Cython 重写几个函数,几乎就能得到你所需要的性能。这就是[星战前夜][16]采取的策略。这是一个大型多玩家的电脑游戏,在整个架构中使用 Python 和 Cython。它们通过优化 C/Cython 中的瓶颈来实现游戏级别的性能。如果这个策略对他们有用,那么它应该对任何人都有帮助。或者,还有其他方法来优化你的 Python。例如,[PyPy][17] 是一个 Python 的 JIT 实现,它通过使用 PyPy 替掉 CPython(这是 Python 的默认实现),为长时间运行的应用程序提供重要的运行时改进(如 web 服务器)。
|
||||
|
||||
当您最终遇到性能问题的 Python 墙时,你不需要把你的整个代码库用另一种不同的语言来编写。你只需要用 Cython 重写几个函数,几乎就能得到你所需要的性能。这就是[星战前夜][16]采取的策略。这是一个大型多玩家的电脑游戏,在整个堆栈中使用 Python 和 Cython。它们通过优化 C/Cython 中的瓶颈来实现游戏级别的性能。如果这个策略对他们有用,那么它应该对任何人都有帮助。或者,还有其他方法来优化你的 Python。例如,[PyPy][17] 是一个 Python 的 JIT 实现,它通过使用 PyPy 交换 CPython(默认实现),为长时间运行的应用程序提供重要的运行时改进(如 web server)。
|
||||

|
||||
|
||||

|
||||
|
||||
让我们回顾一下要点:
|
||||
让我们回顾一下要点:
|
||||
|
||||
* 优化你最贵的资源。那就是你,而不是计算机。
|
||||
* 选择一种语言/框架/架构来帮助你快速开发(比如 Python)。不要仅仅因为某些技术的快而选择它们。
|
||||
@ -141,17 +135,17 @@ python 是慢,但无须过度在意
|
||||
* 如果 Python 成为你的瓶颈(你已经优化过你的算法),那么可以转向热门的 Cython 或者 C。
|
||||
* 尽情享受可以快速做完事情的乐趣。
|
||||
|
||||
我希望你喜欢阅读这篇文章,就像我喜欢写这篇文章一样。如果你想说谢谢,请为我点下赞。另外,如果某个时候你想和我讨论 Python,你可以在 twitter 上艾特我(@nhumrich),或者你可以在 [Python slack channel][18] 找到我。
|
||||
我希望你喜欢阅读这篇文章,就像我喜欢写这篇文章一样。如果你想说谢谢,请为我点下赞。另外,如果某个时候你想和我讨论 Python,你可以在 twitter 上艾特我(@nhumrich),或者你可以在 [Python slack channel][18] 找到我。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
Nick Humrich -- 坚持采用持续交付的方法,并为之写了很多工具。同是还是一名 Python 黑客与技术狂热者,目前是一名 devops 工程师。
|
||||
|
||||
Nick Humrich -- 坚持采用持续交付的方法,并为之写了很多工具。同是还是一名 Python 黑客与技术狂热者,目前是一名 DevOps 工程师。
|
||||
|
||||
via: https://medium.com/hacker-daily/yes-python-is-slow-and-i-dont-care-13763980b5a1
|
||||
|
||||
作者:[Nick Humrich ][a]
|
||||
作者:[Nick Humrich][a]
|
||||
译者:[zhousiyu325](https://github.com/zhousiyu325)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
@ -1,35 +1,35 @@
|
||||
GoTTY - 在 web 中共享你的 Linux 终端(TTY)
|
||||
GoTTY:把你的 Linux 终端放到浏览器里面
|
||||
============================================================
|
||||
|
||||
|
||||
GoTTY 是一个简单的基于 Go 语言的命令行工具,它可以将你的终端 (TTY) 作为 web 程序共享。它会将命令行工具转换为 web 程序。
|
||||
GoTTY 是一个简单的基于 Go 语言的命令行工具,它可以将你的终端(TTY)作为 web 程序共享。它会将命令行工具转换为 web 程序。
|
||||
|
||||
它使用 Chrome OS 的终端仿真器(hterm)来在 Web 浏览器上执行基于 JavaScript 的终端。重要的是,GoTTY 运行了一个 Web 套接字服务器,它基本上是将 TTY 的输出传输给客户端,并从客户端接收输入(即允许客户端的输入),并将其转发给 TTY。
|
||||
|
||||
它的架构(hterm + web socket 的想法)灵感来自[ Wetty 项目][1],它使终端能够通过 HTTP 和 HTTPS 使用。
|
||||
它的架构(hterm + web socket 的想法)灵感来自 [Wetty 项目][1],它使终端能够通过 HTTP 和 HTTPS 使用。
|
||||
|
||||
#### 先决条件:
|
||||
### 先决条件
|
||||
|
||||
你需要在 Linux 中安装 [ GoLang (Go 编程语言)][2] 环境来运行 GoTTY。
|
||||
你需要在 Linux 中安装 [GoLang (Go 编程语言)][2] 环境来运行 GoTTY。
|
||||
|
||||
### 如何在 Linux 中安装 GoTTY
|
||||
|
||||
I如果你已经有一个[工作的 Go 语言环境][3],运行下面的 go get 命令来安装它:
|
||||
如果你已经有一个[可以工作的 Go 语言环境][3],运行下面的 `go get` 命令来安装它:
|
||||
|
||||
```
|
||||
# go get github.com/yudai/gotty
|
||||
```
|
||||
|
||||
上面的命令会在你的 GOBIN 环境变量中安装 GOTTY 的二进制,尝试检查下是否如此:
|
||||
上面的命令会在你的 `GOBIN` 环境变量中安装 GOTTY 的二进制,尝试检查下是否如此:
|
||||
|
||||
```
|
||||
# $GOPATH/bin/
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
检查 GOBIN 环境
|
||||
*检查 GOBIN 环境*
|
||||
|
||||
### 如何在 Linux 中使用 GoTTY
|
||||
|
||||
@ -39,13 +39,13 @@ I如果你已经有一个[工作的 Go 语言环境][3],运行下面的 go get
|
||||
# $GOBIN/gotty
|
||||
```
|
||||
|
||||
另外,要不带完整命令路径运行 GoTTY 或其他 Go 程序,使用 export 命令将 GOBIN 变量添加到 `~/.profile` 文件中的 PATH 中。
|
||||
另外,要不带完整命令路径运行 GoTTY 或其他 Go 程序,使用 `export` 命令将 `GOBIN` 变量添加到 `~/.profile` 文件中的 `PATH` 环境变量中。
|
||||
|
||||
```
|
||||
export PATH="$PATH:$GOBIN"
|
||||
```
|
||||
|
||||
保存文件并关闭。接着运行 source 来使更改生效:
|
||||
保存文件并关闭。接着运行 `source` 来使更改生效:
|
||||
|
||||
```
|
||||
# source ~/.profile
|
||||
@ -69,13 +69,13 @@ GoTTY 默认会在 8080 启动一个 Web 服务器。在浏览器中打开 URL
|
||||
|
||||
][6]
|
||||
|
||||
Gotty Linux 磁盘使用率
|
||||
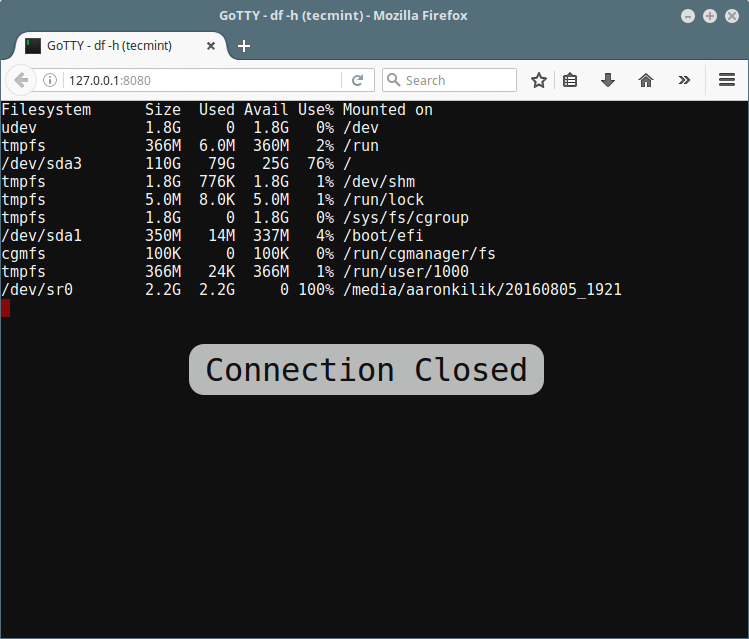
*Gotty 查看 Linux 磁盘使用率*
|
||||
|
||||
### 如何在 Linux 中自定义 GoTTY
|
||||
|
||||
你可以在 `~/.gotty` 配置文件中修改默认选项以及终端,如果存在,它会在每次启动时加载这个文件。
|
||||
你可以在 `~/.gotty` 配置文件中修改默认选项以及终端,如果该文件存在,它会在每次启动时加载这个文件。
|
||||
|
||||
这是由 getty 命令读取的主自定义文件,因此,按如下方式创建:
|
||||
这是由 getty 命令读取的主要自定义文件,因此,按如下方式创建:
|
||||
|
||||
```
|
||||
# touch ~/.gotty
|
||||
@ -96,7 +96,7 @@ background_color = "rgb(16, 16, 32)"
|
||||
}
|
||||
```
|
||||
|
||||
你可以使用命令行中的 “--html” 选项设置你自己的 index.html 文件:
|
||||
你可以使用命令行中的 `--html` 选项设置你自己的 `index.html` 文件:
|
||||
|
||||
```
|
||||
# gotty --index /path/to/index.html uptime
|
||||
@ -104,15 +104,15 @@ background_color = "rgb(16, 16, 32)"
|
||||
|
||||
### 如何在 GoTTY 中使用安全功能
|
||||
|
||||
由于 GoTTY 默认不提供可靠的安全,你需要手动使用下面说明的某些安全功能。
|
||||
由于 GoTTY 默认不提供可靠的安全保障,你需要手动使用下面说明的某些安全功能。
|
||||
|
||||
#### 允许客户端在终端中运行命令
|
||||
|
||||
请注意,默认情况下,GoTTY 不允许客户端输入到TTY中,它只能启用窗口调整。
|
||||
请注意,默认情况下,GoTTY 不允许客户端输入到TTY中,它只支持窗口缩放。
|
||||
|
||||
但是,你可以使用 `-w` 或 `--permit-write` 选项来允许客户端写入 TTY,但是并不推荐这么做因为会有安全威胁。
|
||||
|
||||
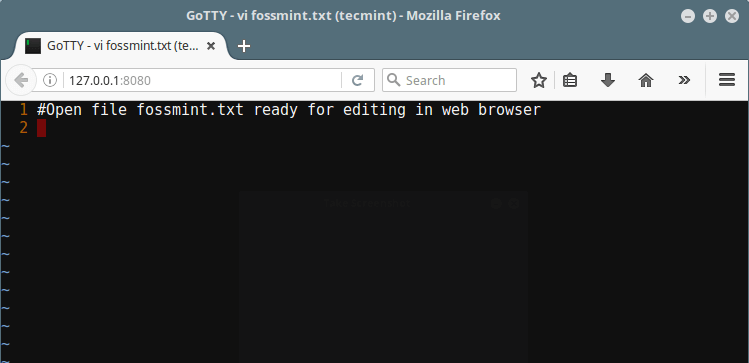
以下命令会使用[ vi 命令行编辑器][7]在 Web 浏览器中打开文件 fossmint.txt 进行编辑:
|
||||
以下命令会使用 [vi 命令行编辑器][7]在 Web 浏览器中打开文件 `fossmint.txt` 进行编辑:
|
||||
|
||||
```
|
||||
# gotty -w vi fossmint.txt
|
||||
@ -124,13 +124,13 @@ background_color = "rgb(16, 16, 32)"
|
||||
|
||||
][8]
|
||||
|
||||
Gotty Web Vi 编辑器
|
||||
*Gotty Web Vi 编辑器*
|
||||
|
||||
#### 使用基本(用户名和密码)验证运行 GoTTY
|
||||
|
||||
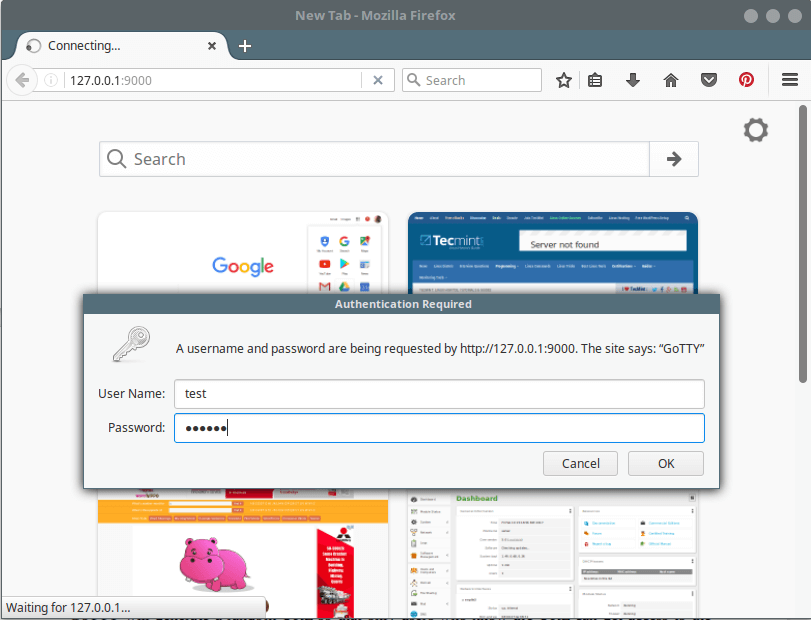
尝试激活基本身份验证机制,这样客户端将需要输入指定的用户名和密码才能连接到 GoTTY 服务器。
|
||||
|
||||
以下命令使用 `-c` 选项限制客户端访问,以向用户询问指定的凭据(用户名:test 密码:@67890):
|
||||
以下命令使用 `-c` 选项限制客户端访问,以向用户询问指定的凭据(用户名:`test` 密码:`@67890`):
|
||||
|
||||
```
|
||||
# gotty -w -p "9000" -c "test@67890" glances
|
||||
@ -139,13 +139,13 @@ Gotty Web Vi 编辑器
|
||||
|
||||
][9]
|
||||
|
||||
使用基本验证运行 GoTTY
|
||||
*使用基本验证运行 GoTTY*
|
||||
|
||||
#### Gotty 生成随机 URL
|
||||
|
||||
限制访问服务器的另一种方法是使用 `-r` 选项。GoTTY 会生成一个随机 URL,这样只有知道该 URL 的用户才可以访问该服务器。
|
||||
|
||||
还可以使用 -title-format “GoTTY – {{ .Command }} ({{ .Hostname }})” 选项来定义浏览器标题,[glances][10] 用于显示系统监控统计信息:
|
||||
还可以使用 `-title-format "GoTTY – {{ .Command }} ({{ .Hostname }})"` 选项来定义浏览器标题。[glances][10] 用于显示系统监控统计信息:
|
||||
|
||||
```
|
||||
# gotty -r --title-format "GoTTY - {{ .Command }} ({{ .Hostname }})" glances
|
||||
@ -157,19 +157,19 @@ Gotty Web Vi 编辑器
|
||||

|
||||
][11]
|
||||
|
||||
使用 Gotty 随机 URL 用于 Glances 系统监控
|
||||
*使用 Gotty 随机 URL 用于 Glances 系统监控*
|
||||
|
||||
#### 带有 SSL/TLS 使用 GoTTY
|
||||
|
||||
因为默认情况下服务器和客户端之间的所有连接都不加密,当你通过 GoTTY 发送秘密信息(如用户凭据或任何其他信息)时,你需要使用 “-t” 或 “--tls” 选项才能在会话中启用 TLS/SSL:
|
||||
因为默认情况下服务器和客户端之间的所有连接都不加密,当你通过 GoTTY 发送秘密信息(如用户凭据或任何其他信息)时,你需要使用 `-t` 或 `--tls` 选项才能在会话中启用 TLS/SSL:
|
||||
|
||||
默认情况下,GoTTY 会读取证书文件 `~/.gotty.crt` 和密钥文件 `~/.gotty.key`,因此,首先使用下面的 openssl 命令创建一个自签名的证书以及密钥( 回答问题以生成证书和密钥文件):
|
||||
默认情况下,GoTTY 会读取证书文件 `~/.gotty.crt` 和密钥文件 `~/.gotty.key`,因此,首先使用下面的 `openssl` 命令创建一个自签名的证书以及密钥( 回答问题以生成证书和密钥文件):
|
||||
|
||||
```
|
||||
# openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout ~/.gotty.key -out ~/.gotty.crt
|
||||
```
|
||||
|
||||
按如下所示,通过启用 SSL/TLS,以安全方式使用GoTTY:
|
||||
按如下所示,通过启用 SSL/TLS,以安全方式使用 GoTTY:
|
||||
|
||||
```
|
||||
# gotty -tr --title-format "GoTTY - {{ .Command }} ({{ .Hostname }})" glances
|
||||
@ -177,13 +177,13 @@ Gotty Web Vi 编辑器
|
||||
|
||||
#### 与多个客户端分享你的终端
|
||||
|
||||
你可以使用[终端复用程序][12]来与多个客户端共享一个进程,以下命令会启动一个名为 gotty 的新[ tmux 会话][13]来运行 [glances][14](确保你安装了 tmux):
|
||||
你可以使用[终端复用程序][12]来与多个客户端共享一个进程,以下命令会启动一个名为 gotty 的新 [tmux 会话][13]来运行 [glances][14](确保你安装了 tmux):
|
||||
|
||||
```
|
||||
# gotty tmux new -A -s gotty glances
|
||||
```
|
||||
|
||||
要读取不同的配置文件,像下面那样使用 –config “/path/to/file” 选项:
|
||||
要读取不同的配置文件,像下面那样使用 `–config "/path/to/file"` 选项:
|
||||
|
||||
```
|
||||
# gotty -tr --config "~/gotty_new_config" --title-format "GoTTY - {{ .Command }} ({{ .Hostname }})" glances
|
||||
@ -195,9 +195,9 @@ Gotty Web Vi 编辑器
|
||||
# gotty -v
|
||||
```
|
||||
|
||||
访问 GoTTY GitHub 仓库以查找更多使用示例:[https://github.com/yudai/gotty][15]
|
||||
访问 GoTTY GitHub 仓库以查找更多使用示例:[https://github.com/yudai/gotty][15] 。
|
||||
|
||||
就这样了!你有尝试过了吗?如何找到GoTTY?通过下面的反馈栏与我们分享你的想法。
|
||||
就这样了!你有尝试过了吗?如何知道 GoTTY 的?通过下面的反馈栏与我们分享你的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -211,9 +211,9 @@ Aaron Kili 是 Linux 和 F.O.S.S 爱好者,即将成为 Linux SysAdmin 和网
|
||||
|
||||
via: http://www.tecmint.com/gotty-share-linux-terminal-in-web-browser/
|
||||
|
||||
作者:[ Aaron Kili][a]
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,351 +0,0 @@
|
||||
YYforymj is translating.
|
||||
|
||||
[How debuggers work: Part 3 - Debugging information][25]
|
||||
============================================================
|
||||
|
||||
|
||||
This is the third part in a series of articles on how debuggers work. Make sure you read [the first][26] and [the second][27] parts before this one.
|
||||
|
||||
### In this part
|
||||
|
||||
I'm going to explain how the debugger figures out where to find the C functions and variables in the machine code it wades through, and the data it uses to map between C source code lines and machine language words.
|
||||
|
||||
### Debugging information
|
||||
|
||||
Modern compilers do a pretty good job converting your high-level code, with its nicely indented and nested control structures and arbitrarily typed variables into a big pile of bits called machine code, the sole purpose of which is to run as fast as possible on the target CPU. Most lines of C get converted into several machine code instructions. Variables are shoved all over the place - into the stack, into registers, or completely optimized away. Structures and objects don't even _exist_ in the resulting code - they're merely an abstraction that gets translated to hard-coded offsets into memory buffers.
|
||||
|
||||
So how does a debugger know where to stop when you ask it to break at the entry to some function? How does it manage to find what to show you when you ask it for the value of a variable? The answer is - debugging information.
|
||||
|
||||
Debugging information is generated by the compiler together with the machine code. It is a representation of the relationship between the executable program and the original source code. This information is encoded into a pre-defined format and stored alongside the machine code. Many such formats were invented over the years for different platforms and executable files. Since the aim of this article isn't to survey the history of these formats, but rather to show how they work, we'll have to settle on something. This something is going to be DWARF, which is almost ubiquitously used today as the debugging information format for ELF executables on Linux and other Unix-y platforms.
|
||||
|
||||
### The DWARF in the ELF
|
||||
|
||||

|
||||
|
||||
According to [its Wikipedia page][17], DWARF was designed alongside ELF, although it can in theory be embedded in other object file formats as well [[1]][18].
|
||||
|
||||
DWARF is a complex format, building on many years of experience with previous formats for various architectures and operating systems. It has to be complex, since it solves a very tricky problem - presenting debugging information from any high-level language to debuggers, providing support for arbitrary platforms and ABIs. It would take much more than this humble article to explain it fully, and to be honest I don't understand all its dark corners well enough to engage in such an endeavor anyway [[2]][19]. In this article I will take a more hands-on approach, showing just enough of DWARF to explain how debugging information works in practical terms.
|
||||
|
||||
### Debug sections in ELF files
|
||||
|
||||
First let's take a glimpse of where the DWARF info is placed inside ELF files. ELF defines arbitrary sections that may exist in each object file. A _section header table_ defines which sections exist and their names. Different tools treat various sections in special ways - for example the linker is looking for some sections, the debugger for others.
|
||||
|
||||
We'll be using an executable built from this C source for our experiments in this article, compiled into tracedprog2:
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
|
||||
void do_stuff(int my_arg)
|
||||
{
|
||||
int my_local = my_arg + 2;
|
||||
int i;
|
||||
|
||||
for (i = 0; i < my_local; ++i)
|
||||
printf("i = %d\n", i);
|
||||
}
|
||||
|
||||
int main()
|
||||
{
|
||||
do_stuff(2);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
Dumping the section headers from the ELF executable using objdump -h we'll notice several sections with names beginning with .debug_ - these are the DWARF debugging sections:
|
||||
|
||||
```
|
||||
26 .debug_aranges 00000020 00000000 00000000 00001037
|
||||
CONTENTS, READONLY, DEBUGGING
|
||||
27 .debug_pubnames 00000028 00000000 00000000 00001057
|
||||
CONTENTS, READONLY, DEBUGGING
|
||||
28 .debug_info 000000cc 00000000 00000000 0000107f
|
||||
CONTENTS, READONLY, DEBUGGING
|
||||
29 .debug_abbrev 0000008a 00000000 00000000 0000114b
|
||||
CONTENTS, READONLY, DEBUGGING
|
||||
30 .debug_line 0000006b 00000000 00000000 000011d5
|
||||
CONTENTS, READONLY, DEBUGGING
|
||||
31 .debug_frame 00000044 00000000 00000000 00001240
|
||||
CONTENTS, READONLY, DEBUGGING
|
||||
32 .debug_str 000000ae 00000000 00000000 00001284
|
||||
CONTENTS, READONLY, DEBUGGING
|
||||
33 .debug_loc 00000058 00000000 00000000 00001332
|
||||
CONTENTS, READONLY, DEBUGGING
|
||||
```
|
||||
|
||||
The first number seen for each section here is its size, and the last is the offset where it begins in the ELF file. The debugger uses this information to read the section from the executable.
|
||||
|
||||
Now let's see a few practical examples of finding useful debug information in DWARF.
|
||||
|
||||
### Finding functions
|
||||
|
||||
One of the most basic things we want to do when debugging is placing breakpoints at some function, expecting the debugger to break right at its entrance. To be able to perform this feat, the debugger must have some mapping between a function name in the high-level code and the address in the machine code where the instructions for this function begin.
|
||||
|
||||
This information can be obtained from DWARF by looking at the .debug_info section. Before we go further, a bit of background. The basic descriptive entity in DWARF is called the Debugging Information Entry (DIE). Each DIE has a tag - its type, and a set of attributes. DIEs are interlinked via sibling and child links, and values of attributes can point at other DIEs.
|
||||
|
||||
Let's run:
|
||||
|
||||
```
|
||||
objdump --dwarf=info tracedprog2
|
||||
```
|
||||
|
||||
The output is quite long, and for this example we'll just focus on these lines [[3]][20]:
|
||||
|
||||
```
|
||||
<1><71>: Abbrev Number: 5 (DW_TAG_subprogram)
|
||||
<72> DW_AT_external : 1
|
||||
<73> DW_AT_name : (...): do_stuff
|
||||
<77> DW_AT_decl_file : 1
|
||||
<78> DW_AT_decl_line : 4
|
||||
<79> DW_AT_prototyped : 1
|
||||
<7a> DW_AT_low_pc : 0x8048604
|
||||
<7e> DW_AT_high_pc : 0x804863e
|
||||
<82> DW_AT_frame_base : 0x0 (location list)
|
||||
<86> DW_AT_sibling : <0xb3>
|
||||
|
||||
<1><b3>: Abbrev Number: 9 (DW_TAG_subprogram)
|
||||
<b4> DW_AT_external : 1
|
||||
<b5> DW_AT_name : (...): main
|
||||
<b9> DW_AT_decl_file : 1
|
||||
<ba> DW_AT_decl_line : 14
|
||||
<bb> DW_AT_type : <0x4b>
|
||||
<bf> DW_AT_low_pc : 0x804863e
|
||||
<c3> DW_AT_high_pc : 0x804865a
|
||||
<c7> DW_AT_frame_base : 0x2c (location list)
|
||||
```
|
||||
|
||||
There are two entries (DIEs) tagged DW_TAG_subprogram, which is a function in DWARF's jargon. Note that there's an entry for do_stuff and an entry for main. There are several interesting attributes, but the one that interests us here is DW_AT_low_pc. This is the program-counter (EIP in x86) value for the beginning of the function. Note that it's 0x8048604 for do_stuff. Now let's see what this address is in the disassembly of the executable by running objdump -d:
|
||||
|
||||
```
|
||||
08048604 <do_stuff>:
|
||||
8048604: 55 push ebp
|
||||
8048605: 89 e5 mov ebp,esp
|
||||
8048607: 83 ec 28 sub esp,0x28
|
||||
804860a: 8b 45 08 mov eax,DWORD PTR [ebp+0x8]
|
||||
804860d: 83 c0 02 add eax,0x2
|
||||
8048610: 89 45 f4 mov DWORD PTR [ebp-0xc],eax
|
||||
8048613: c7 45 (...) mov DWORD PTR [ebp-0x10],0x0
|
||||
804861a: eb 18 jmp 8048634 <do_stuff+0x30>
|
||||
804861c: b8 20 (...) mov eax,0x8048720
|
||||
8048621: 8b 55 f0 mov edx,DWORD PTR [ebp-0x10]
|
||||
8048624: 89 54 24 04 mov DWORD PTR [esp+0x4],edx
|
||||
8048628: 89 04 24 mov DWORD PTR [esp],eax
|
||||
804862b: e8 04 (...) call 8048534 <printf@plt>
|
||||
8048630: 83 45 f0 01 add DWORD PTR [ebp-0x10],0x1
|
||||
8048634: 8b 45 f0 mov eax,DWORD PTR [ebp-0x10]
|
||||
8048637: 3b 45 f4 cmp eax,DWORD PTR [ebp-0xc]
|
||||
804863a: 7c e0 jl 804861c <do_stuff+0x18>
|
||||
804863c: c9 leave
|
||||
804863d: c3 ret
|
||||
```
|
||||
|
||||
Indeed, 0x8048604 is the beginning of do_stuff, so the debugger can have a mapping between functions and their locations in the executable.
|
||||
|
||||
### Finding variables
|
||||
|
||||
Suppose that we've indeed stopped at a breakpoint inside do_stuff. We want to ask the debugger to show us the value of the my_local variable. How does it know where to find it? Turns out this is much trickier than finding functions. Variables can be located in global storage, on the stack, and even in registers. Additionally, variables with the same name can have different values in different lexical scopes. The debugging information has to be able to reflect all these variations, and indeed DWARF does.
|
||||
|
||||
I won't cover all the possibilities, but as an example I'll demonstrate how the debugger can find my_local in do_stuff. Let's start at .debug_info and look at the entry for do_stuff again, this time also looking at a couple of its sub-entries:
|
||||
|
||||
```
|
||||
<1><71>: Abbrev Number: 5 (DW_TAG_subprogram)
|
||||
<72> DW_AT_external : 1
|
||||
<73> DW_AT_name : (...): do_stuff
|
||||
<77> DW_AT_decl_file : 1
|
||||
<78> DW_AT_decl_line : 4
|
||||
<79> DW_AT_prototyped : 1
|
||||
<7a> DW_AT_low_pc : 0x8048604
|
||||
<7e> DW_AT_high_pc : 0x804863e
|
||||
<82> DW_AT_frame_base : 0x0 (location list)
|
||||
<86> DW_AT_sibling : <0xb3>
|
||||
<2><8a>: Abbrev Number: 6 (DW_TAG_formal_parameter)
|
||||
<8b> DW_AT_name : (...): my_arg
|
||||
<8f> DW_AT_decl_file : 1
|
||||
<90> DW_AT_decl_line : 4
|
||||
<91> DW_AT_type : <0x4b>
|
||||
<95> DW_AT_location : (...) (DW_OP_fbreg: 0)
|
||||
<2><98>: Abbrev Number: 7 (DW_TAG_variable)
|
||||
<99> DW_AT_name : (...): my_local
|
||||
<9d> DW_AT_decl_file : 1
|
||||
<9e> DW_AT_decl_line : 6
|
||||
<9f> DW_AT_type : <0x4b>
|
||||
<a3> DW_AT_location : (...) (DW_OP_fbreg: -20)
|
||||
<2><a6>: Abbrev Number: 8 (DW_TAG_variable)
|
||||
<a7> DW_AT_name : i
|
||||
<a9> DW_AT_decl_file : 1
|
||||
<aa> DW_AT_decl_line : 7
|
||||
<ab> DW_AT_type : <0x4b>
|
||||
<af> DW_AT_location : (...) (DW_OP_fbreg: -24)
|
||||
```
|
||||
|
||||
Note the first number inside the angle brackets in each entry. This is the nesting level - in this example entries with <2> are children of the entry with <1>. So we know that the variable my_local (marked by the DW_TAG_variable tag) is a child of the do_stuff function. The debugger is also interested in a variable's type to be able to display it correctly. In the case of my_local the type points to another DIE - <0x4b>. If we look it up in the output of objdump we'll see it's a signed 4-byte integer.
|
||||
|
||||
To actually locate the variable in the memory image of the executing process, the debugger will look at the DW_AT_location attribute. For my_local it says DW_OP_fbreg: -20. This means that the variable is stored at offset -20 from the DW_AT_frame_base attribute of its containing function - which is the base of the frame for the function.
|
||||
|
||||
The DW_AT_frame_base attribute of do_stuff has the value 0x0 (location list), which means that this value actually has to be looked up in the location list section. Let's look at it:
|
||||
|
||||
```
|
||||
$ objdump --dwarf=loc tracedprog2
|
||||
|
||||
tracedprog2: file format elf32-i386
|
||||
|
||||
Contents of the .debug_loc section:
|
||||
|
||||
Offset Begin End Expression
|
||||
00000000 08048604 08048605 (DW_OP_breg4: 4 )
|
||||
00000000 08048605 08048607 (DW_OP_breg4: 8 )
|
||||
00000000 08048607 0804863e (DW_OP_breg5: 8 )
|
||||
00000000 <End of list>
|
||||
0000002c 0804863e 0804863f (DW_OP_breg4: 4 )
|
||||
0000002c 0804863f 08048641 (DW_OP_breg4: 8 )
|
||||
0000002c 08048641 0804865a (DW_OP_breg5: 8 )
|
||||
0000002c <End of list>
|
||||
```
|
||||
|
||||
The location information we're interested in is the first one [[4]][21]. For each address where the debugger may be, it specifies the current frame base from which offsets to variables are to be computed as an offset from a register. For x86, bpreg4 refers to esp and bpreg5 refers to ebp.
|
||||
|
||||
It's educational to look at the first several instructions of do_stuff again:
|
||||
|
||||
```
|
||||
08048604 <do_stuff>:
|
||||
8048604: 55 push ebp
|
||||
8048605: 89 e5 mov ebp,esp
|
||||
8048607: 83 ec 28 sub esp,0x28
|
||||
804860a: 8b 45 08 mov eax,DWORD PTR [ebp+0x8]
|
||||
804860d: 83 c0 02 add eax,0x2
|
||||
8048610: 89 45 f4 mov DWORD PTR [ebp-0xc],eax
|
||||
```
|
||||
|
||||
Note that ebp becomes relevant only after the second instruction is executed, and indeed for the first two addresses the base is computed from esp in the location information listed above. Once ebp is valid, it's convenient to compute offsets relative to it because it stays constant while esp keeps moving with data being pushed and popped from the stack.
|
||||
|
||||
So where does it leave us with my_local? We're only really interested in its value after the instruction at 0x8048610 (where its value is placed in memory after being computed in eax), so the debugger will be using the DW_OP_breg5: 8 frame base to find it. Now it's time to rewind a little and recall that the DW_AT_location attribute for my_local says DW_OP_fbreg: -20. Let's do the math: -20 from the frame base, which is ebp + 8. We get ebp - 12. Now look at the disassembly again and note where the data is moved from eax - indeed, ebp - 12 is where my_local is stored.
|
||||
|
||||
### Looking up line numbers
|
||||
|
||||
When we talked about finding functions in the debugging information, I was cheating a little. When we debug C source code and put a breakpoint in a function, we're usually not interested in the first _machine code_ instruction [[5]][22]. What we're _really_ interested in is the first _C code_ line of the function.
|
||||
|
||||
This is why DWARF encodes a full mapping between lines in the C source code and machine code addresses in the executable. This information is contained in the .debug_line section and can be extracted in a readable form as follows:
|
||||
|
||||
```
|
||||
$ objdump --dwarf=decodedline tracedprog2
|
||||
|
||||
tracedprog2: file format elf32-i386
|
||||
|
||||
Decoded dump of debug contents of section .debug_line:
|
||||
|
||||
CU: /home/eliben/eli/eliben-code/debugger/tracedprog2.c:
|
||||
File name Line number Starting address
|
||||
tracedprog2.c 5 0x8048604
|
||||
tracedprog2.c 6 0x804860a
|
||||
tracedprog2.c 9 0x8048613
|
||||
tracedprog2.c 10 0x804861c
|
||||
tracedprog2.c 9 0x8048630
|
||||
tracedprog2.c 11 0x804863c
|
||||
tracedprog2.c 15 0x804863e
|
||||
tracedprog2.c 16 0x8048647
|
||||
tracedprog2.c 17 0x8048653
|
||||
tracedprog2.c 18 0x8048658
|
||||
```
|
||||
|
||||
It shouldn't be hard to see the correspondence between this information, the C source code and the disassembly dump. Line number 5 points at the entry point to do_stuff - 0x8040604. The next line, 6, is where the debugger should really stop when asked to break in do_stuff, and it points at 0x804860a which is just past the prologue of the function. This line information easily allows bi-directional mapping between lines and addresses:
|
||||
|
||||
* When asked to place a breakpoint at a certain line, the debugger will use it to find which address it should put its trap on (remember our friend int 3 from the previous article?)
|
||||
* When an instruction causes a segmentation fault, the debugger will use it to find the source code line on which it happened.
|
||||
|
||||
### <tt class="docutils literal" style="font-family: Consolas, monaco, monospace; color: rgb(0, 0, 0); background-color: rgb(247, 247, 247); white-space: nowrap; border-radius: 2px; font-size: 21.6px; padding: 2px;">libdwarf - Working with DWARF programmatically
|
||||
|
||||
Employing command-line tools to access DWARF information, while useful, isn't fully satisfying. As programmers, we'd like to know how to write actual code that can read the format and extract what we need from it.
|
||||
|
||||
Naturally, one approach is to grab the DWARF specification and start hacking away. Now, remember how everyone keeps saying that you should never, ever parse HTML manually but rather use a library? Well, with DWARF it's even worse. DWARF is _much_ more complex than HTML. What I've shown here is just the tip of the iceberg, and to make things even harder, most of this information is encoded in a very compact and compressed way in the actual object file [[6]][23].
|
||||
|
||||
So we'll take another road and use a library to work with DWARF. There are two major libraries I'm aware of (plus a few less complete ones):
|
||||
|
||||
1. BFD (libbfd) is used by the [GNU binutils][11], including objdump which played a star role in this article, ld (the GNU linker) and as (the GNU assembler).
|
||||
2. libdwarf - which together with its big brother libelf are used for the tools on Solaris and FreeBSD operating systems.
|
||||
|
||||
I'm picking libdwarf over BFD because it appears less arcane to me and its license is more liberal (LGPLvs. GPL).
|
||||
|
||||
Since libdwarf is itself quite complex it requires a lot of code to operate. I'm not going to show all this code here, but [you can download][24] and run it yourself. To compile this file you'll need to have libelfand libdwarf installed, and pass the -lelf and -ldwarf flags to the linker.
|
||||
|
||||
The demonstrated program takes an executable and prints the names of functions in it, along with their entry points. Here's what it produces for the C program we've been playing with in this article:
|
||||
|
||||
```
|
||||
$ dwarf_get_func_addr tracedprog2
|
||||
DW_TAG_subprogram: 'do_stuff'
|
||||
low pc : 0x08048604
|
||||
high pc : 0x0804863e
|
||||
DW_TAG_subprogram: 'main'
|
||||
low pc : 0x0804863e
|
||||
high pc : 0x0804865a
|
||||
```
|
||||
|
||||
The documentation of libdwarf (linked in the References section of this article) is quite good, and with some effort you should have no problem pulling any other information demonstrated in this article from the DWARF sections using it.
|
||||
|
||||
### Conclusion and next steps
|
||||
|
||||
Debugging information is a simple concept in principle. The implementation details may be intricate, but in the end of the day what matters is that we now know how the debugger finds the information it needs about the original source code from which the executable it's tracing was compiled. With this information in hand, the debugger bridges between the world of the user, who thinks in terms of lines of code and data structures, and the world of the executable, which is just a bunch of machine code instructions and data in registers and memory.
|
||||
|
||||
This article, with its two predecessors, concludes an introductory series that explains the inner workings of a debugger. Using the information presented here and some programming effort, it should be possible to create a basic but functional debugger for Linux.
|
||||
|
||||
As for the next steps, I'm not sure yet. Maybe I'll end the series here, maybe I'll present some advanced topics such as backtraces, and perhaps debugging on Windows. Readers can also suggest ideas for future articles in this series or related material. Feel free to use the comments or send me an email.
|
||||
|
||||
### References
|
||||
|
||||
* objdump man page
|
||||
* Wikipedia pages for [ELF][12] and [DWARF][13].
|
||||
* [Dwarf Debugging Standard home page][14] - from here you can obtain the excellent DWARF tutorial by Michael Eager, as well as the DWARF standard itself. You'll probably want version 2 since it's what gccproduces.
|
||||
* [libdwarf home page][15] - the download package includes a comprehensive reference document for the library
|
||||
* [BFD documentation][16]
|
||||
|
||||
|
||||
[1] DWARF is an open standard, published here by the DWARF standards committee. The DWARF logo displayed above is taken from that website.
|
||||
|
||||
[2] At the end of the article I've collected some useful resources that will help you get more familiar with DWARF, if you're interested. Particularly, start with the DWARF tutorial.
|
||||
|
||||
[3] Here and in subsequent examples, I'm placing (...) instead of some longer and un-interesting information for the sake of more convenient formatting.
|
||||
|
||||
[4] Because the DW_AT_frame_base attribute of do_stuff contains offset 0x0 into the location list. Note that the same attribute for main contains the offset 0x2c which is the offset for the second set of location expressions.
|
||||
|
||||
[5] Where the function prologue is usually executed and the local variables aren't even valid yet.
|
||||
|
||||
[6] Some parts of the information (such as location data and line number data) are encoded as instructions for a specialized virtual machine. Yes, really.
|
||||
|
||||
* * *
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information
|
||||
|
||||
作者:[Eli Bendersky][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://eli.thegreenplace.net/
|
||||
[1]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id1
|
||||
[2]:http://dwarfstd.org/
|
||||
[3]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id2
|
||||
[4]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id3
|
||||
[5]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id4
|
||||
[6]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id5
|
||||
[7]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id6
|
||||
[8]:http://eli.thegreenplace.net/tag/articles
|
||||
[9]:http://eli.thegreenplace.net/tag/debuggers
|
||||
[10]:http://eli.thegreenplace.net/tag/programming
|
||||
[11]:http://www.gnu.org/software/binutils/
|
||||
[12]:http://en.wikipedia.org/wiki/Executable_and_Linkable_Format
|
||||
[13]:http://en.wikipedia.org/wiki/DWARF
|
||||
[14]:http://dwarfstd.org/
|
||||
[15]:http://reality.sgiweb.org/davea/dwarf.html
|
||||
[16]:http://sourceware.org/binutils/docs-2.21/bfd/index.html
|
||||
[17]:http://en.wikipedia.org/wiki/DWARF
|
||||
[18]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id7
|
||||
[19]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id8
|
||||
[20]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id9
|
||||
[21]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id10
|
||||
[22]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id11
|
||||
[23]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id12
|
||||
[24]:https://github.com/eliben/code-for-blog/blob/master/2011/dwarf_get_func_addr.c
|
||||
[25]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information
|
||||
[26]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1/
|
||||
[27]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints/
|
||||
@ -1,66 +0,0 @@
|
||||
[The root of all eval][1]
|
||||
============================================================
|
||||
|
||||
Ah, the `eval` function. Loved, hated. Mostly the latter.
|
||||
|
||||
```
|
||||
$ perl -E'my $program = q[say "OH HAI"]; eval $program'
|
||||
OH HAI
|
||||
```
|
||||
|
||||
I was a bit stunned when the `eval` function was renamed to `EVAL` in Perl 6 (back in 2013, after spec discussion [here][2]). I've never felt really comfortable with the rationale for doing so. I seem to be more or less alone in this opinion, though, which is fine.
|
||||
|
||||
The rationale was "the function does something really weird, so we should flag it with upper case". Like we do with `BEGIN` and the other phasers, for example. With `BEGIN` and others, the upper-casing is motivated, I agree. A phaser takes you "outside of the normal control flow". The `eval` function doesn't.
|
||||
|
||||
Other things that we upper-case are things like `.WHAT`, which look like attributes but are really specially code-generated at compile-time into something completely different. So even there the upper-casing is motivated because something outside of the normal is happening.
|
||||
|
||||
`eval` in the end is just another function. Yes, it's a function with potentially quite wide-ranging side effects, that's true. But a lot of fairly standard functions have wide-ranging side effects. (To name a few: `shell`, `die`, `exit`.) You don't see anyone clamoring to upper-case those.
|
||||
|
||||
I guess it could be argued that `eval` is very special because it hooks into the compiler and runtime in ways that normal functions don't, and maybe can't. (This is also how TimToady explained it in [the commit message][3] of the renaming commit.) But that's an argument from implementation details, which doesn't feel satisfactory. It applies with equal force to the lower-cased functions just mentioned.
|
||||
|
||||
To add insult to injury, the renamed `EVAL` is also made deliberately harder to use:
|
||||
|
||||
```
|
||||
$ perl6 -e'my $program = q[say "OH HAI"]; EVAL $program'
|
||||
===SORRY!=== Error while compiling -e
|
||||
EVAL is a very dangerous function!!! (use the MONKEY-SEE-NO-EVAL pragma to override this error,
|
||||
but only if you're VERY sure your data contains no injection attacks)
|
||||
at -e:1
|
||||
------> program = q[say "OH HAI"]; EVAL $program⏏<EOL>
|
||||
|
||||
$ perl6 -e'use MONKEY-SEE-NO-EVAL; my $program = q[say "OH HAI"]; EVAL $program'
|
||||
OH HAI
|
||||
```
|
||||
|
||||
Firstly, injection attacks are a real issue, and no laughing matter. We should educate each other and newcomers about them.
|
||||
|
||||
Secondly, that error message (`"EVAL is a very dangerous function!!!"`) is completely over-the-top in a way that damages rather than helps. I believe when we explain the dangers of code injection to people, we need to do it calmly and matter-of-factly. Not with three exclamation marks. The error message makes sense to [someone who already knows about injection attacks][4]; it provides no hints or clues for people who are unaware of the risks.
|
||||
|
||||
(The Perl 6 community is not unique in `eval`-hysteria. Yesterday I stumbled across a StackOverflow thread about how to turn a string with a type name into the corresponding constructor in JavaScript. Some unlucky soul suggested `eval`, and everybody else immediately piled on to point out how irresponsible that was. Solely as a knee-jerk reaction "because eval is bad".)
|
||||
|
||||
Thirdly, `MOKNEY-SEE-NO-EVAL`. Please, can we just... not. 😓 Random reference to monkies and the weird attempt at levity while switching on a nuclear-chainsaw function aside, I find it odd that a function that _enables_ `EVAL` is called something with `NO-EVAL`. That's not Least Surprise.
|
||||
|
||||
Anyway, the other day I realized how I can get around both the problem of the all-caps name and the problem of the necessary pragma:
|
||||
|
||||
```
|
||||
$ perl6 -e'my &eval = &EVAL; my $program = q[say "OH HAI"]; eval $program'
|
||||
OH HAI
|
||||
```
|
||||
|
||||
I was so happy to realize this that I thought I'd blog about it. Apparently the very dangerous function (`!!!`) is fine again if we just give it back its old name. 😜
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://strangelyconsistent.org/blog/the-root-of-all-eval
|
||||
|
||||
作者:[Carl Mäsak ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://strangelyconsistent.org/about
|
||||
[1]:http://strangelyconsistent.org/blog/the-root-of-all-eval
|
||||
[2]:https://github.com/perl6/specs/issues/50
|
||||
[3]:https://github.com/perl6/specs/commit/0b7df09ecc096eed5dc30f3dbdf568bbfd9de8f6
|
||||
[4]:http://bobby-tables.com/
|
||||
@ -0,0 +1,339 @@
|
||||
[调试器的工作原理: 第3篇 - 调试信息][25]
|
||||
============================================================
|
||||
|
||||
|
||||
这是调试器的工作原理系列文章的第三篇。阅读这篇文章之前应当先阅读[第一篇][26]与[第二篇][27]。
|
||||
|
||||
### 这篇文章的主要内容
|
||||
|
||||
本文将解释调试器是如何在机器码中,查找它将C语言源代码转换成机器语言代码时所需要的C语言函数、变量、与数据。
|
||||
|
||||
### 调试信息
|
||||
|
||||
|
||||
现代编译器能够将有着各种排版或嵌套的程序流程、各种数据类型的变量的高级语言代码转换为一大堆称之为机器码的 0/1 数据,这么做的唯一目的是尽可能快的在目标 CPU 上运行程序。通常来说一行C语言代码能够转换为若干条机器码。变量被分散在机器码中的各个部分,有的在堆栈中,有的在寄存器中,或者直接被优化掉了。数据结构与对象在机器码中甚至不“存在”,它们只是用于将数据按一定的结构编码存储进缓存。
|
||||
|
||||
那么调试器怎么知道,当你需要在某个函数入口处暂停时,程序要在哪停下来呢?它怎么知道当你查看某个变量值时,它怎么找到这个值?答案是,调试信息。
|
||||
|
||||
编译器在生成机器码时同时会生成相应的调试信息。调试信息代表了可执行程序与源代码之间的关系,并以一种提前定义好的格式,同机器码存放在一起。过去的数年里,人们针对不同的平台与可执行文件发明了很多种用于存储这些信息的格式。不过我们这篇文章不会讲这些格式的历史,而是将阐述这些调试信息是如何工作的,所以我们将专注于一些事情,比如 `DWARF`。`DWARF` 如今十分广泛的应用在类 `Unix` 平台上的可执行文件的调试。
|
||||
|
||||
### ELF 中的 DWARF
|
||||
|
||||

|
||||
|
||||
根据[它的维基百科][17] 所描述,虽然 `DWARF` 是同 `ELF` 一同设计的(`DWARF` 是由 `DWARF` 标准委员会推出的开放标准。上文中展示的 图标就来自这个网站。),但 `DWARF` 在理论上来说也可以嵌入到其他的可执行文件格式中。
|
||||
|
||||
`DWARF` 是一种复杂的格式,它的构建基于过去多年中许多不同的编译器与操作系统。正是因为它解决了一个为任意语言在任何平台与业务系统中产生调试信息的这样棘手的难题,它也必须很复杂。想要透彻的讲解 `DWARF` 仅仅是通过这单薄的一篇文章是远远不够的,说实话我也并没有充分地了解 `DWARF` 到每一个微小的细节,所以我也不能十分透彻的讲解 (如果你感兴趣的话,文末有一些能够帮助你的资源。建议从 `DWARF` 教程开始上手)。这篇文章中我将以浅显易懂的方式展示 `DWARF` 在实际应用中调试信息是如何工作的。
|
||||
|
||||
### ELF文件中的调试部分
|
||||
|
||||
首先让我们看看 `DWARF` 处在 ELF 文件中的什么位置。`ELF` 定义了每一个生成的目标文件中的每一部分。 _section header table_ 声明并定义了每一部分。不同的工具以不同的方式处理不同的部分,例如连接器会寻找连接器需要的部分,调试器会查找调试器需要的部分。
|
||||
|
||||
我们本文的实验会使用从这个C语言源文件构建的可执行文件,编译成 tracedprog2:
|
||||
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
|
||||
void do_stuff(int my_arg)、
|
||||
{
|
||||
int my_local = my_arg + 2;
|
||||
int i;
|
||||
|
||||
for (i = 0; i < my_local; ++i)
|
||||
printf("i = %d\n", i);
|
||||
}
|
||||
|
||||
int main()
|
||||
{
|
||||
do_stuff(2);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
使用 `objdump -h` 命令检查 `ELF` 可执行文件中的段落头,我们会看到几个以 .debug_ 开头的段落,这些就是 `DWARF` 的调试部分。
|
||||
|
||||
```
|
||||
26 .debug_aranges 00000020 00000000 00000000 00001037
|
||||
CONTENTS, READONLY, DEBUGGING
|
||||
27 .debug_pubnames 00000028 00000000 00000000 00001057
|
||||
CONTENTS, READONLY, DEBUGGING
|
||||
28 .debug_info 000000cc 00000000 00000000 0000107f
|
||||
CONTENTS, READONLY, DEBUGGING
|
||||
29 .debug_abbrev 0000008a 00000000 00000000 0000114b
|
||||
CONTENTS, READONLY, DEBUGGING
|
||||
30 .debug_line 0000006b 00000000 00000000 000011d5
|
||||
CONTENTS, READONLY, DEBUGGING
|
||||
31 .debug_frame 00000044 00000000 00000000 00001240
|
||||
CONTENTS, READONLY, DEBUGGING
|
||||
32 .debug_str 000000ae 00000000 00000000 00001284
|
||||
CONTENTS, READONLY, DEBUGGING
|
||||
33 .debug_loc 00000058 00000000 00000000 00001332
|
||||
CONTENTS, READONLY, DEBUGGING
|
||||
```
|
||||
|
||||
每个段落的第一个数字代表了这个段落的大小,最后一个数字代表了这个段落开始位置距离 `ELF` 的偏移量。调试器利用这些信息从可执行文件中读取段落。
|
||||
|
||||
现在让我们看看一些在 `DWARF` 中查找有用的调试信息的实际例子。
|
||||
|
||||
### 查找函数
|
||||
|
||||
调试器的基础任务之一,就是当我们在某个函数处设置断点时,调试器需要能够在入口处暂停。为此,必须为函数与函数在机器码地址这两者建立起某种映射关系。
|
||||
|
||||
为了获取这种映射关系,我们可以查找 `DWARF` 中的 .debug_info 段落。在我们深入之前,需要一点基础知识。`DWARF` 中每一个描述类型被称之为调试信息入口(`DIE`)。每个 `DIE` 都有关于它的属性之类的标签。`DIE` 之间通过兄弟节点或子节点连接,属性的值也可以指向其他的 `DIE`.
|
||||
|
||||
运行以下命令
|
||||
|
||||
```
|
||||
objdump --dwarf=info tracedprog2
|
||||
```
|
||||
|
||||
输出文件相当的长,为了方便举例我们只关注这些行(从这里开始,无用的冗长信息我会以 (...)代替,方便排版。):
|
||||
|
||||
```
|
||||
<1><71>: Abbrev Number: 5 (DW_TAG_subprogram)
|
||||
<72> DW_AT_external : 1
|
||||
<73> DW_AT_name : (...): do_stuff
|
||||
<77> DW_AT_decl_file : 1
|
||||
<78> DW_AT_decl_line : 4
|
||||
<79> DW_AT_prototyped : 1
|
||||
<7a> DW_AT_low_pc : 0x8048604
|
||||
<7e> DW_AT_high_pc : 0x804863e
|
||||
<82> DW_AT_frame_base : 0x0 (location list)
|
||||
<86> DW_AT_sibling : <0xb3>
|
||||
|
||||
<1><b3>: Abbrev Number: 9 (DW_TAG_subprogram)
|
||||
<b4> DW_AT_external : 1
|
||||
<b5> DW_AT_name : (...): main
|
||||
<b9> DW_AT_decl_file : 1
|
||||
<ba> DW_AT_decl_line : 14
|
||||
<bb> DW_AT_type : <0x4b>
|
||||
<bf> DW_AT_low_pc : 0x804863e
|
||||
<c3> DW_AT_high_pc : 0x804865a
|
||||
<c7> DW_AT_frame_base : 0x2c (location list)
|
||||
```
|
||||
|
||||
上面的代码中有两个带有 DW_TAG_subprogram 标签的入口,在 `DWARF` 中这是对函数的指代。注意,这是两个段落入口,其中一个是 do_stuff 函数的入口,另一个是主函数的入口。这些信息中有很多值得关注的属性,但其中最值得注意的是 DW_AT_low_pc。它代表了函数开始处程序指针的值(在x86平台上是 `EIP`)。此处 0x8048604 代表了 do_stuff 函数开始处的程序指针。下面我们将利用 `objdump -d` 命令对可执行文件进行反汇编。来看看这块地址中都有什么:
|
||||
|
||||
```
|
||||
08048604 <do_stuff>:
|
||||
8048604: 55 push ebp
|
||||
8048605: 89 e5 mov ebp,esp
|
||||
8048607: 83 ec 28 sub esp,0x28
|
||||
804860a: 8b 45 08 mov eax,DWORD PTR [ebp+0x8]
|
||||
804860d: 83 c0 02 add eax,0x2
|
||||
8048610: 89 45 f4 mov DWORD PTR [ebp-0xc],eax
|
||||
8048613: c7 45 (...) mov DWORD PTR [ebp-0x10],0x0
|
||||
804861a: eb 18 jmp 8048634 <do_stuff+0x30>
|
||||
804861c: b8 20 (...) mov eax,0x8048720
|
||||
8048621: 8b 55 f0 mov edx,DWORD PTR [ebp-0x10]
|
||||
8048624: 89 54 24 04 mov DWORD PTR [esp+0x4],edx
|
||||
8048628: 89 04 24 mov DWORD PTR [esp],eax
|
||||
804862b: e8 04 (...) call 8048534 <printf@plt>
|
||||
8048630: 83 45 f0 01 add DWORD PTR [ebp-0x10],0x1
|
||||
8048634: 8b 45 f0 mov eax,DWORD PTR [ebp-0x10]
|
||||
8048637: 3b 45 f4 cmp eax,DWORD PTR [ebp-0xc]
|
||||
804863a: 7c e0 jl 804861c <do_stuff+0x18>
|
||||
804863c: c9 leave
|
||||
804863d: c3 ret
|
||||
```
|
||||
|
||||
显然,0x8048604 是 do_stuff 的开始地址,这样一来,调试器就可以建立函数与其在可执行文件中的位置间的映射关系。
|
||||
|
||||
### 查找变量
|
||||
|
||||
假设我们当前在 do_staff 函数中某个位置上设置断点停了下来。我们想通过调试器取得 my_local 这个变量的值。调试器怎么知道在哪里去找这个值呢?很显然这要比查找函数更为困难。变量可能存储在全局存储区、堆栈、甚至是寄存器中。此外,同名变量在不同的作用域中可能有着不同的值。调试信息必须能够反映所有的这些变化,当然,`DWARF` 就能做到。
|
||||
|
||||
我不会逐一去将每一种可能的状况,但我会以调试器在 do_stuff 函数中查找 my_local 变量的过程来举个例子。下面我们再看一遍 .debug_info 中 do_stuff 的每一个入口,这次连它的子入口也要一起看。
|
||||
|
||||
```
|
||||
<1><71>: Abbrev Number: 5 (DW_TAG_subprogram)
|
||||
<72> DW_AT_external : 1
|
||||
<73> DW_AT_name : (...): do_stuff
|
||||
<77> DW_AT_decl_file : 1
|
||||
<78> DW_AT_decl_line : 4
|
||||
<79> DW_AT_prototyped : 1
|
||||
<7a> DW_AT_low_pc : 0x8048604
|
||||
<7e> DW_AT_high_pc : 0x804863e
|
||||
<82> DW_AT_frame_base : 0x0 (location list)
|
||||
<86> DW_AT_sibling : <0xb3>
|
||||
<2><8a>: Abbrev Number: 6 (DW_TAG_formal_parameter)
|
||||
<8b> DW_AT_name : (...): my_arg
|
||||
<8f> DW_AT_decl_file : 1
|
||||
<90> DW_AT_decl_line : 4
|
||||
<91> DW_AT_type : <0x4b>
|
||||
<95> DW_AT_location : (...) (DW_OP_fbreg: 0)
|
||||
<2><98>: Abbrev Number: 7 (DW_TAG_variable)
|
||||
<99> DW_AT_name : (...): my_local
|
||||
<9d> DW_AT_decl_file : 1
|
||||
<9e> DW_AT_decl_line : 6
|
||||
<9f> DW_AT_type : <0x4b>
|
||||
<a3> DW_AT_location : (...) (DW_OP_fbreg: -20)
|
||||
<2><a6>: Abbrev Number: 8 (DW_TAG_variable)
|
||||
<a7> DW_AT_name : i
|
||||
<a9> DW_AT_decl_file : 1
|
||||
<aa> DW_AT_decl_line : 7
|
||||
<ab> DW_AT_type : <0x4b>
|
||||
<af> DW_AT_location : (...) (DW_OP_fbreg: -24)
|
||||
```
|
||||
|
||||
看到每个入口处第一对尖括号中的数字了吗?这些是嵌套的等级,在上面的例子中,以 <2> 开头的入口是以 <1> 开头的子入口。因此我们得知 my_local 变量(以 DW_TAG_variable 标签标记)是 do_stuff 函数的局部变量。除此之外,调试器也需要知道变量的数据类型,这样才能正确的使用与显示变量。上面的例子中 my_local 的变量类型指向另一个 `DIE` <0x4b>。如果使用 objdump 命令查看这个 `DIE` 部分的话,我们会发现这部分代表了有符号4字节整型数据。
|
||||
|
||||
而为了在实际运行的程序内存中查找变量的值,调试器需要使用到 DW_AT_location 属性。对于 my_local 而言,是 DW_OP_fbreg: -20。这个代码段的意思是说 my_local 存储在距离它所在函数起始地址偏移量为-20的地方。
|
||||
|
||||
do_stuff 函数的 DW_AT_frame_base 属性值为 0x0 (location list)。这意味着这个属性的值需要在 location list 中查找。下面我们来一起看看。
|
||||
|
||||
```
|
||||
$ objdump --dwarf=loc tracedprog2
|
||||
|
||||
tracedprog2: file format elf32-i386
|
||||
|
||||
Contents of the .debug_loc section:
|
||||
|
||||
Offset Begin End Expression
|
||||
00000000 08048604 08048605 (DW_OP_breg4: 4 )
|
||||
00000000 08048605 08048607 (DW_OP_breg4: 8 )
|
||||
00000000 08048607 0804863e (DW_OP_breg5: 8 )
|
||||
00000000 <End of list>
|
||||
0000002c 0804863e 0804863f (DW_OP_breg4: 4 )
|
||||
0000002c 0804863f 08048641 (DW_OP_breg4: 8 )
|
||||
0000002c 08048641 0804865a (DW_OP_breg5: 8 )
|
||||
0000002c <End of list>
|
||||
```
|
||||
|
||||
我们需要关注的是第一列(do_stuff 函数的 DW_AT_frame_base 属性包含 location list 中 0x0 的偏移量。而 main 函数的相同属性包含 0x2c 的偏移量,这个偏移量是第二套地址列表的偏移量。)。对于调试器可能定位到的每一个地址,它都会指定当前栈帧到变量间的偏移量,而这个偏移就是通过寄存器来计算的。对于x86平台而言,bpreg4 指向 esp,而 bpreg5 指向 ebp。
|
||||
|
||||
让我们再看看 do_stuff 函数的头几条指令。
|
||||
|
||||
```
|
||||
08048604 <do_stuff>:
|
||||
8048604: 55 push ebp
|
||||
8048605: 89 e5 mov ebp,esp
|
||||
8048607: 83 ec 28 sub esp,0x28
|
||||
804860a: 8b 45 08 mov eax,DWORD PTR [ebp+0x8]
|
||||
804860d: 83 c0 02 add eax,0x2
|
||||
8048610: 89 45 f4 mov DWORD PTR [ebp-0xc],eax
|
||||
```
|
||||
|
||||
只有当第二条指令执行后,ebp 寄存器才真正存储了有用的值。当然,前两条指令的基址是由上面所列出来的地址信息表计算出来的。一但 ebp 确定了,计算偏移量就十分方便了,因为尽管 esp 在操作堆栈的时候需要移动,但 ebp 作为栈底并不需要移动。
|
||||
|
||||
究竟我们应该去哪里找 my_local 的值呢?在 0x8048610 这块地址后, my_local 的值经过在 eax 中的计算后被存在了内存中,从这里开始我们才需要关注 my_local 的值。调试器会利用 DW_OP_breg5: 8 这个基址来查找。我们回想下,my_local 的 DW_AT_location 属性值为 DW_OP_fbreg: -20。所以应当从基址中 -20 ,同时由于 ebp 寄存器需要 + 8,所以最终结果为 - 12。现在再次查看反汇编代码,来看看数据从 eax 中被移动到哪里了。当然,这里 my_local 应当被存储在了 ebp - 12 的地址中。
|
||||
|
||||
### 查看行号
|
||||
|
||||
当我们谈论调试信息的时候,我们利用了些技巧。当调试C语言源代码并在某个函数出放置断点的时候,我们并不关注第一条“机器码”指令(函数的调用准备工作已经完成而局部变量还没有初始化。)。我们真正关注的是函数的第一行“C代码”。
|
||||
|
||||
这就是 `DWARF` 完全覆盖映射C源代码与可执行文件中机器码地址的原因。下面是 .debug_line 段中所包含的内容,我们将其转换为可读的格式展示如下。
|
||||
|
||||
```
|
||||
$ objdump --dwarf=decodedline tracedprog2
|
||||
|
||||
tracedprog2: file format elf32-i386
|
||||
|
||||
Decoded dump of debug contents of section .debug_line:
|
||||
|
||||
CU: /home/eliben/eli/eliben-code/debugger/tracedprog2.c:
|
||||
File name Line number Starting address
|
||||
tracedprog2.c 5 0x8048604
|
||||
tracedprog2.c 6 0x804860a
|
||||
tracedprog2.c 9 0x8048613
|
||||
tracedprog2.c 10 0x804861c
|
||||
tracedprog2.c 9 0x8048630
|
||||
tracedprog2.c 11 0x804863c
|
||||
tracedprog2.c 15 0x804863e
|
||||
tracedprog2.c 16 0x8048647
|
||||
tracedprog2.c 17 0x8048653
|
||||
tracedprog2.c 18 0x8048658
|
||||
```
|
||||
|
||||
很容易就可以看出其中C源代码与反汇编代码之间的对应关系。第5行指向 do_stuff 函数的入口,0x8040604。第6行,指向 0x804860a ,正是调试器在调试 do_stuff 函数时需要停下来的地方。这里已经完成了函数调用的准备工作。上面的这些信息形成了行号与地址间的双向映射关系。
|
||||
|
||||
* 当在某一行设置断点的时候,调试器会利用这些信息去查找相应的地址来做断点工作(还记得上篇文章中的 int 3 指令吗?)
|
||||
* 当指令造成代码段错误时,调试器会利用这些信息来查看源代码中发生的状况。
|
||||
|
||||
### libdwarf - 用 DWARF 编程
|
||||
|
||||
尽管使用命令行工具来获得 `DWARF` 很有用,但这仍然不够易用。作为程序员,我们应当知道当我们需要这些调试信息时应当怎么编程来获取这些信息。
|
||||
|
||||
自然我们想到的第一种方法就是阅读 `DWARF` 规范并按规范操作阅读使用。有句话说的好,分析 HTML 应当使用库函数,永远不要手工分析。对于 `DWARF` 来说这是如此。`DWARF` 比 HTML 要复杂得多。上面所展示出来的只是冰山一角。更糟糕的是,在实际的目标文件中,大部分信息是以压缩格式存储的,分析起来更加复杂(信息中的某些部分,例如位置信息与行号信息,在某些虚拟机下是以指令的方式编码的。)。
|
||||
|
||||
所以我们要使用库函数来处理 `DWARF`。下面是两种我熟悉的主流库(还有些不完整的库这里没有写)
|
||||
|
||||
1. `BFD` (libbfd),包含了 `objdump` (对,就是这篇文章中我们一直在用的这货),`ld`(`GNU` 连接器)与 `as`(`GNU` 编译器)。`BFD` 主要用于[GNU binutils][11]。
|
||||
2. `libdwarf` ,同它的哥哥 `libelf` 一同用于 `Solaris` 与 `FreeBSD` 中的调试信息分析。
|
||||
|
||||
相比较而言我更倾向于使用 `libdwarf`,因为我对它了解的更多,并且 `libdwarf` 的开源协议更开放。
|
||||
|
||||
因为 `libdwarf` 本身相当复杂,操作起来需要相当多的代码,所以我在这不会展示所有代码。你可以在 [这里][24] 下载代码并运行试试。运行这些代码需要提前安装 `libelfand` 与 `libdwarf` ,同时在使用连接器的时候要使用参数 `-lelf` 与 `-ldwarf`。
|
||||
|
||||
这个示例程序可以接受可执行文件并打印其中的函数名称与函数入口地址。下面是我们整篇文章中使用的C程序经过示例程序处理后的输出。
|
||||
|
||||
```
|
||||
$ dwarf_get_func_addr tracedprog2
|
||||
DW_TAG_subprogram: 'do_stuff'
|
||||
low pc : 0x08048604
|
||||
high pc : 0x0804863e
|
||||
DW_TAG_subprogram: 'main'
|
||||
low pc : 0x0804863e
|
||||
high pc : 0x0804865a
|
||||
```
|
||||
|
||||
`libdwarf` 的文档很棒,如果你花些功夫,利用 `libdwarf` 获得这篇文章中所涉及到的 `DWARF` 信息应该并不困难。
|
||||
|
||||
### 结论与计划
|
||||
|
||||
原理上讲,调试信息是个很简单的概念。尽管实现细节可能比较复杂,但经过了上面的学习我想你应该了解了调试器是如何从可执行文件中获取它需要的源代码信息的了。对于程序员而言,程序只是代码段与数据结构;对可执行文件而言,程序只是一系列存储在内存或寄存器中的指令或数据。但利用调试信息,调试器就可以将这两者连接起来,从而完成调试工作。
|
||||
|
||||
此文与这系列的前两篇,一同介绍了调试器的内部工作过程。利用这里所讲到的知识,再敲些代码,应该可以完成一个 `Linux` 中最简单基础但也有一定功能的调试器。
|
||||
|
||||
下一步我并不确定要做什么,这个系列文章可能就此结束,也有可能我要讲些堆栈调用的事情,又或者讲 `Windows` 下的调试。你们有什么好的点子或者相关材料,可以直接评论或者发邮件给我。
|
||||
|
||||
### 参考
|
||||
|
||||
* objdump 参考手册
|
||||
* [ELF][12] 与 [DWARF][13]的维基百科
|
||||
* [Dwarf Debugging Standard home page][14],这里有很棒的 DWARF 教程与 DWARF 标准,作者是 Michael Eager。第二版基于 GCC 也许更能吸引你。
|
||||
* [libdwarf home page][15],这里可以下载到 libwarf 的完整库与参考手册
|
||||
* [BFD documentation][16]
|
||||
|
||||
* * *
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information
|
||||
|
||||
作者:[Eli Bendersky][a]
|
||||
译者:[YYforymj](https://github.com/YYforymj)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://eli.thegreenplace.net/
|
||||
[1]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id1
|
||||
[2]:http://dwarfstd.org/
|
||||
[3]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id2
|
||||
[4]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id3
|
||||
[5]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id4
|
||||
[6]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id5
|
||||
[7]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id6
|
||||
[8]:http://eli.thegreenplace.net/tag/articles
|
||||
[9]:http://eli.thegreenplace.net/tag/debuggers
|
||||
[10]:http://eli.thegreenplace.net/tag/programming
|
||||
[11]:http://www.gnu.org/software/binutils/
|
||||
[12]:http://en.wikipedia.org/wiki/Executable_and_Linkable_Format
|
||||
[13]:http://en.wikipedia.org/wiki/DWARF
|
||||
[14]:http://dwarfstd.org/
|
||||
[15]:http://reality.sgiweb.org/davea/dwarf.html
|
||||
[16]:http://sourceware.org/binutils/docs-2.21/bfd/index.html
|
||||
[17]:http://en.wikipedia.org/wiki/DWARF
|
||||
[18]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id7
|
||||
[19]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id8
|
||||
[20]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id9
|
||||
[21]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id10
|
||||
[22]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id11
|
||||
[23]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id12
|
||||
[24]:https://github.com/eliben/code-for-blog/blob/master/2011/dwarf_get_func_addr.c
|
||||
[25]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information
|
||||
[26]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1/
|
||||
[27]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints/
|
||||
@ -1,32 +1,31 @@
|
||||
Windows 木马黑进嵌入式设备来安装 Mirai
|
||||
============================================================
|
||||
|
||||
> 木马尝试使用出厂默认凭证对不同协议进行身份验证,如果成功则会部署 Mirai。
|
||||
> 木马尝试使用出厂默认凭证对不同协议进行身份验证,如果成功则会部署 Mirai 僵尸程序。
|
||||
|
||||

|
||||
|
||||
*图片来源: Gerd Altmann / Pixabay*
|
||||
|
||||
攻击者已经开始使用 Windows 和 Android 恶意软件入侵嵌入式设备,这消除了人们广泛认为的如果设备不直接暴露在互联网上,那么它们就不那么脆弱。
|
||||
攻击者已经开始使用 Windows 和 Android 恶意软件入侵嵌入式设备,这消除了人们广泛持有的想法,认为如果设备不直接暴露在互联网上,那么它们就不那么脆弱。
|
||||
|
||||
来自俄罗斯防病毒供应商 Doctor Web 的研究人员最近[遇到了一个 Windows 木马程序][21],它使用暴力方法访问嵌入式设备,并安装 Mirai 恶意软件。
|
||||
来自俄罗斯防病毒供应商 Doctor Web 的研究人员最近[遇到了一个 Windows 木马程序][21],它使用暴力方法访问嵌入式设备,并在其上安装 Mirai 恶意软件。
|
||||
|
||||
Mirai 是一种用在基于 Linux 的物联网设备的恶意程序,例如路由器、IP 摄像机、数字录像机等。它主要通过使用出厂设备凭据来发动分布式拒绝服务 (DDoS) 攻击并通过 Telnet 传播。
|
||||
|
||||
Mirai 的僵尸网络在过去六个月里一直被用来发起最大型的 DDoS 攻击。[它的源代码泄漏][22]之后,恶意软件被用来感染超过 50 万台设备。
|
||||
|
||||
在一台 Windows 上安装之后,Doctor Web 发现的新的木马会从命令控制服务器下载配置文件。该文件包含一系列 IP 地址,用来通过多个端口(包括 22(SSH)和 23(Telnet))尝试进行身份验证。
|
||||
Doctor Web 发现,一旦在一台 Windows 上安装之后,该新木马会从命令控制服务器下载配置文件。该文件包含一系列 IP 地址,通过多个端口,包括 22(SSH)和 23(Telnet),尝试进行身份验证。
|
||||
|
||||
#### [■ 获得你的每日安全新闻:注册 CSO 安全通讯][11]
|
||||
如果身份验证成功,恶意软件将会根据受害系统的类型。执行配置文件中指定的某些命令。在通过 Telnet 访问的 Linux 系统中,木马会下载并执行一个二进制包,然后安装 Mirai 僵尸程序。
|
||||
|
||||
如果身份验证成功,恶意软件将会根据受害系统的类型执行配置文件中指定的某些命令。在通过 Telnet 访问的 Linux 系统中,木马会下载并执行一个二进制包,然后安装 Mirari。
|
||||
|
||||
如果受影响的设备未被设计成或被配置为从 Internet 直接访问,那么许多物联网供应商会降低漏洞的严重性。这种思维方式假定局域网是信任和安全的环境。
|
||||
如果按照设计或配置,受影响的设备不会从 Internet 直接访问,那么许多物联网供应商会降低漏洞的严重性。这种思维方式假定局域网是信任和安全的环境。
|
||||
|
||||
然而事实并非如此,其他威胁如跨站点请求伪造已经出现了多年。但 Doctor Web 发现的新木马似乎是第一个专门设计用于劫持嵌入式或物联网设备的 Windows 恶意软件。
|
||||
|
||||
Doctor Web 发现的新木马被称为 [Trojan.Mirai.1][23],表明攻击者还可以使用受害的计算机来攻击不能从互联网直接访问的物联网设备。
|
||||
Doctor Web 发现的新木马被称为 [Trojan.Mirai.1][23],从它可以看到,攻击者还可以使用受害的计算机来攻击不能从互联网直接访问的物联网设备。
|
||||
|
||||
受感染的智能手机可以以类似的方式使用。卡巴斯基实验室的研究人员已经[发现了一个 Android 程序][24] 通过本地网络对路由器执行暴力密码猜测攻击。
|
||||
受感染的智能手机可以以类似的方式使用。卡巴斯基实验室的研究人员已经[发现了一个 Android 程序][24],通过本地网络对路由器执行暴力密码猜测攻击。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -49,7 +48,6 @@ via: http://www.csoonline.com/article/3168357/security/windows-trojan-hacks-into
|
||||
[8]:http://www.csoonline.com/article/3144197/security/upgraded-mirai-botnet-disrupts-deutsche-telekom-by-infecting-routers.html
|
||||
[9]:http://www.csoonline.com/video/73795/security-sessions-the-csos-role-in-active-shooter-planning
|
||||
[10]:http://www.csoonline.com/video/73795/security-sessions-the-csos-role-in-active-shooter-planning
|
||||
[11]:http://csoonline.com/newsletters/signup.html#tk.cso-infsb
|
||||
[12]:http://www.csoonline.com/author/Lucian-Constantin/
|
||||
[13]:https://twitter.com/intent/tweet?url=http%3A%2F%2Fwww.csoonline.com%2Farticle%2F3168357%2Fsecurity%2Fwindows-trojan-hacks-into-embedded-devices-to-install-mirai.html&via=csoonline&text=Windows+Trojan+hacks+into+embedded+devices+to+install+Mirai
|
||||
[14]:https://www.facebook.com/sharer/sharer.php?u=http%3A%2F%2Fwww.csoonline.com%2Farticle%2F3168357%2Fsecurity%2Fwindows-trojan-hacks-into-embedded-devices-to-install-mirai.html
|
||||
|
||||
@ -144,7 +144,7 @@ via: http://www.tecmint.com/add-new-disk-to-an-existing-linux/
|
||||
|
||||
作者:[Lakshmi Dhandapani][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
66
translated/tech/20170422 The root of all eval.md
Normal file
66
translated/tech/20170422 The root of all eval.md
Normal file
@ -0,0 +1,66 @@
|
||||
[eval 之根][1]
|
||||
============================================================
|
||||
|
||||
唉,`eval` 这个函数我又爱又恨。多数是后者。
|
||||
|
||||
```
|
||||
$ perl -E'my $program = q[say "OH HAI"]; eval $program'
|
||||
OH HAI
|
||||
```
|
||||
|
||||
当 `eval` 函数在 Perl 6 中被重命名为 `EVAL` 时,我感到有点震惊(回到 2013 年,[在这][2]讨论规范之后)。我从未对这样做的理由感到非常舒服。虽然这是个很好的意见,但是在这个意见上我似乎或多或少是孤独的。
|
||||
|
||||
理由是“这个函数真的很奇怪,所以我们应该用大写标记”。就像我们用 `BEGIN` 和其他 phaser 一样。使用 `BEGIN` 和其他 phaser,鼓励使用大写,这点我是同意的。phaser 能将程序“脱离正常控制流”。 但是 `eval` 函数并不能。
|
||||
|
||||
其他大写的地方像是 .WHAT 这样的东西,它看起来像属性,但是会在编译时将代码变成完全不同的东西。因为有常规之外的情况发生,因此大写甚至是被鼓励的。
|
||||
|
||||
`eval` 归根到底是另一个函数。是的,这是一个潜在大量副作用的函数。但是大量标准功能都有大量的副作用。(举几个例子:`shell`、 `die`、 `exit`)你没看到有人呼吁将它们大写。
|
||||
|
||||
我猜有人会争论说 `eval` ”是非常特别的,因为它以正常函数没有的方式 hook 到编译器和运行时。(这也是 TimToady 在将函数重命名的提交中的[提交消息][3]中解释的。)这位是一个来自实现细节的争论,然而这并不令人满意。这也同样适用与刚才提到的那些小写函数。
|
||||
|
||||
为了增加冒犯性的伤害,更名后 “EVAL” 也故意这么做:
|
||||
|
||||
```
|
||||
$ perl6 -e'my $program = q[say "OH HAI"]; EVAL $program'
|
||||
===SORRY!=== Error while compiling -e
|
||||
EVAL is a very dangerous function!!! (use the MONKEY-SEE-NO-EVAL pragma to override this error,
|
||||
but only if you're VERY sure your data contains no injection attacks)
|
||||
at -e:1
|
||||
------> program = q[say "OH HAI"]; EVAL $program⏏<EOL>
|
||||
|
||||
$ perl6 -e'use MONKEY-SEE-NO-EVAL; my $program = q[say "OH HAI"]; EVAL $program'
|
||||
OH HAI
|
||||
```
|
||||
|
||||
首先,注入攻击是一个真实的问题,并不是一个笑话。我们应该互相教育对方和新手。
|
||||
|
||||
其次,这个错误消息(`"EVAL is a very dangerous function!!!"`)以最明显的方式提示这会有危害而不是帮助。我相信当我们向人们解释代码注入的危险时,我们需要冷静并且切合实际。不用三个感叹号。错误信息对[已经知道注入攻击的人][4]来说是有意义的,对于那些不了解风险的人员,它不会提供任何提示或线索。
|
||||
|
||||
(Perl 6 社区并不是唯一对 `eval` 歇斯底里的,昨天我偶然发现了一个 StackOverflow 主题,关于如何将一个有类型名称的字符串转换为 JavaScript 中的相应构造函数,一些人不幸地提出了用 `eval`,而其他人立即集结起来指出这是多么不负责任,就像膝跳反射那样 “因为 eval 是坏的”)。
|
||||
|
||||
第三,“MOKNEY-SEE-NO-EVAL”。拜托,我们能不能不要这样。。。😓 在打开一个强力函数时,只是随机引用了猴子以及轻率的尝试,我奇怪地发现_启用_ `EVAL` 函数的是一个称为 `NO-EVAL` 的东西。这不是一个惊喜。
|
||||
|
||||
不管怎样,有一天,我意识到我可以同时解决名字问题和实用性问题:
|
||||
|
||||
```
|
||||
$ perl6 -e'my &eval = &EVAL; my $program = q[say "OH HAI"]; eval $program'
|
||||
OH HAI
|
||||
```
|
||||
|
||||
我很高兴我意识到这点并记录下来。显然这个非常危险的功能(`!!!`)如果我们把它的旧名字改回来,那也是好的。 😜
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://strangelyconsistent.org/blog/the-root-of-all-eval
|
||||
|
||||
作者:[Carl Mäsak ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://strangelyconsistent.org/about
|
||||
[1]:http://strangelyconsistent.org/blog/the-root-of-all-eval
|
||||
[2]:https://github.com/perl6/specs/issues/50
|
||||
[3]:https://github.com/perl6/specs/commit/0b7df09ecc096eed5dc30f3dbdf568bbfd9de8f6
|
||||
[4]:http://bobby-tables.com/
|
||||
Loading…
Reference in New Issue
Block a user