mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-21 02:10:11 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
1be4d5640b
@ -1,59 +1,58 @@
|
||||
Emacs #5: org-mode 之文档与 Presentations
|
||||
Emacs 系列(五):Org 模式之文档与演示稿
|
||||
======
|
||||
|
||||
### 1 org-mode 的输出
|
||||
这是 [Emacs 和 Org 模式系列][20]的第五篇。
|
||||
|
||||
这篇博文是由 Org 模式的源文件生成的,其有几种格式:[博客页面][21]、[演示稿][22] 和 [PDF 文档][23]。
|
||||
|
||||
### 1 Org 模式的输出
|
||||
|
||||
#### 1.1 背景
|
||||
|
||||
org-mode 不仅仅只是一个议程生成程序, 它也能输出许多不同的格式: LaTeX,PDF,Beamer,iCalendar(议程),HTML,Markdown,ODT,普通文本,帮助页面(man pages)和其它更多的复杂的格式,比如说网页文件。
|
||||
Org 模式不仅仅只是一个议程生成程序,它也能输出许多不同的格式: LaTeX、PDF、Beamer、iCalendar(议程)、HTML、Markdown、ODT、普通文本、手册页和其它更多的复杂的格式,比如说网页文件。
|
||||
|
||||
这也不只是一些事后的想法,这是 org-mode 的设计核心部分并且集成的很好。
|
||||
这也不只是一些事后的想法,这是 Org 模式的设计核心部分并且集成的很好。
|
||||
|
||||
一个文件可以同时是源代码,自动生成的输出,任务列表,文档和 presentation。
|
||||
这一个文件可以同时是源代码、自动生成的输出、任务列表、文档和展示。
|
||||
|
||||
有些人将 org-mode 作为他们首选的标记格式,甚至对于 LaTeX 文档也是如此。org-mode 手册中的 [section on exporting][13] 有更详细的介绍。
|
||||
有些人将 Org 模式作为他们首选的标记格式,甚至对于 LaTeX 文档也是如此。Org 模式手册中的 [输出一节][13] 有更详细的介绍。
|
||||
|
||||
#### 1.2 开始
|
||||
|
||||
对于任意的 org-mode 的文档,只要按下 C-c C-e键,就会弹出一个让你选择多种输出格式和选项的菜单。这些选项通常是次键选择,所以很容易设置和执行。例如:要输出一个 PDF 文档,按 C-c C-e l p,要输出 HMTL 格式的, 按 C-c C-e h h。
|
||||
对于任意的 Org 模式的文档,只要按下 `C-c C-e` 键,就会弹出一个让你选择多种输出格式和选项的菜单。这些选项通常是次键选择,所以很容易设置和执行。例如:要输出一个 PDF 文档,按 `C-c C-e l p`,要输出 HMTL 格式的, 按 `C-c C-e h h`。
|
||||
|
||||
对于所有的输出选项,都有许多可用的设置;详情参见手册。事实上,使用 LaTeX 格式相当于同时使用 LaTeX 和 HTML 模式,在不同的模式中插入任意的前言和设置等。
|
||||
|
||||
#### 1.3 第三方插件
|
||||
|
||||
[ELPA][19] 中也包含了许多额外的输出格式,详情参见 [ELPA][19].
|
||||
[ELPA][19] 中也包含了许多额外的输出格式,详情参见 [ELPA][19]。
|
||||
|
||||
### 2 org-mode 的 Beamer 演示
|
||||
### 2 Org 模式的 Beamer 演示
|
||||
|
||||
#### 2.1 关于 Beamer
|
||||
|
||||
[Beamer][14] 是一个生成 presentation 的 LaTeX 环境. 它包括了一下特性:
|
||||
[Beamer][14] 是一个生成演示稿的 LaTeX 环境. 它包括了以下特性:
|
||||
|
||||
* 在 presentation 中自动生成结构化的元素(例如 [the Marburg theme][1])。 在 presentation 时,这个特性可以为观众提供了视觉参考。
|
||||
* 在演示稿中自动生成结构化的元素(例如 [Marburg 主题][1])。 在演示稿中,这个特性可以为观众提供了视觉参考。
|
||||
* 对组织演示稿有很大的帮助。
|
||||
* 主题
|
||||
* 完全支持 LaTeX
|
||||
|
||||
* 对组织 presentation 有很大的帮助。
|
||||
#### 2.2 Org 模式中 Beamer 的优点
|
||||
|
||||
* 主题
|
||||
|
||||
* 完全支持 LaTeX
|
||||
|
||||
#### 2.2 org-mode 中 Beamer 的优点
|
||||
|
||||
在 org-mode 中用 Beamer 有很多好处,总的来说:
|
||||
|
||||
* org-mode 很简单而且对可视化支持的很好,同时改变结构可以快速的重组你的材料。
|
||||
在 Org 模式中用 Beamer 有很多好处,总的来说:
|
||||
|
||||
* Org 模式很简单而且对可视化支持的很好,同时改变结构可以快速的重组你的材料。
|
||||
* 与 org-babel 绑定在一起,实时语法高亮源码和内嵌结果。
|
||||
|
||||
* 语法通常更容易使用。
|
||||
|
||||
我已经完全用 org-mode 和 beamer 替换掉 LibreOffice/Powerpoint/GoogleDocs 的使用。事实上,当我必须使用其中一种工具时,这是相当令人沮丧的,因为它们在可视化表示结构方面远远比不上 org-mode。
|
||||
我已经完全用 Org 模式和 beamer 替换掉使用 LibreOffice/Powerpoint/GoogleDocs。事实上,当我必须使用其中一种工具时,这是相当令人沮丧的,因为它们在可视化表示演讲稿结构方面远远比不上 Org 模式。
|
||||
|
||||
#### 2.3 标题层次
|
||||
|
||||
org-mode 的 Beamer 会将你文档中的部分(文中定义了标题的)转换成幻灯片。当然,问题是:哪些部分?这是由 H [export setting][15](org-export-headline-levels)决定的。
|
||||
Org 模式的 Beamer 会将你文档中的部分(文中定义了标题的)转换成幻灯片。当然,问题是:哪些部分?这是由 H [输出设置][15](`org-export-headline-levels`)决定的。
|
||||
|
||||
针对不同的人,有许多不同的方法。我比较喜欢我的 presentation 这样:
|
||||
针对不同的人,有许多不同的方法。我比较喜欢我的演示稿这样:
|
||||
|
||||
```
|
||||
#+OPTIONS: H:2
|
||||
@ -64,7 +63,7 @@ org-mode 的 Beamer 会将你文档中的部分(文中定义了标题的)转
|
||||
|
||||
#### 2.4 主题和配置
|
||||
|
||||
你可以在 org 文件的顶部来插入几行来配置 Beamer 和 LaTeX。在本文中,例如,你可以这样定义:
|
||||
你可以在 Org 模式的文件顶部来插入几行来配置 Beamer 和 LaTeX。在本文中,例如,你可以这样定义:
|
||||
|
||||
```
|
||||
#+TITLE: Documents and presentations with org-mode
|
||||
@ -96,13 +95,13 @@ org-mode 的 Beamer 会将你文档中的部分(文中定义了标题的)转
|
||||
#+BEAMER_HEADER: \setlength{\parskip}{\smallskipamount}
|
||||
```
|
||||
|
||||
在这里, aspectratio=169 将纵横比设为 16:9, 其它部分都是标准的 LaTeX/Beamer 配置。
|
||||
在这里,`aspectratio=169` 将纵横比设为 16:9, 其它部分都是标准的 LaTeX/Beamer 配置。
|
||||
|
||||
#### 2.6 缩小 (适应屏幕)
|
||||
|
||||
有时你会遇到一些非常大的代码示例,你可能更倾向与将幻灯片缩小以适应它们。
|
||||
|
||||
只要按下 C-c C-c p 将 BEAMER_opt属性设为 shrink=15\.(或者设为更大的 shrink 值)。上一张幻灯片就用到了这个。
|
||||
只要按下 `C-c C-c p` 将 `BEAMER_opt` 属性设为 `shrink=15`\。(或者设为更大的 shrink 值)。上一张幻灯片就用到了这个。
|
||||
|
||||
#### 2.7 效果
|
||||
|
||||
@ -114,28 +113,24 @@ org-mode 的 Beamer 会将你文档中的部分(文中定义了标题的)转
|
||||
|
||||
#### 3.1 交互式的 Emacs 幻灯片
|
||||
|
||||
使用 [org-tree-slide package][17] 这个插件的话, 就可以在 Emacs 的右侧显示幻灯片了。 只要按下 M-x,然后输入 org-tree-slide-mode,回车,然后你就可以用 C-> 和 C-< 在幻灯片之间切换了。
|
||||
使用 [org-tree-slide][17] 这个插件的话,就可以在 Emacs 的右侧显示幻灯片了。 只要按下 `M-x`,然后输入 `org-tree-slide-mode`,回车,然后你就可以用 `C->` 和 `C-<` 在幻灯片之间切换了。
|
||||
|
||||
你可能会发现 C-c C-x C-v (即 org-toggle-inline-images)有助于使系统显示内嵌的图像。
|
||||
你可能会发现 `C-c C-x C-v` (即 `org-toggle-inline-images`)有助于使系统显示内嵌的图像。
|
||||
|
||||
#### 3.2 HTML 幻灯片
|
||||
|
||||
有许多方式可以将 org-mode 的 presentation 导出为 HTML,并有不同级别的 JavaScript 集成。有关详细信息,请参见 org-mode 的 wiki 中的 [non-beamer presentations section][18]。
|
||||
有许多方式可以将 Org 模式的演讲稿导出为 HTML,并有不同级别的 JavaScript 集成。有关详细信息,请参见 Org 模式的 wiki 中的 [非 beamer 演讲稿一节][18]。
|
||||
|
||||
### 4 更多
|
||||
|
||||
#### 4.1 本文中的附加资源
|
||||
|
||||
* [orgmode.org beamer tutorial][2]
|
||||
|
||||
* [LaTeX wiki][3]
|
||||
|
||||
* [Generating section title slides][4]
|
||||
|
||||
* [Shrinking content to fit on slide][5]
|
||||
|
||||
* 很棒的资源: refcard-org-beamer 详情参见其 [Github repo][6] 中的 PDF 和 .org 文件。
|
||||
|
||||
* 很棒的资源: refcard-org-beamer
|
||||
* 详情参见其 [Github repo][6] 中的 PDF 和 .org 文件。
|
||||
* 很漂亮的主题: [Theme matrix][7]
|
||||
|
||||
#### 4.2 下一个 Emacs 系列
|
||||
@ -148,9 +143,9 @@ mu4e 邮件!
|
||||
via: http://changelog.complete.org/archives/9900-emacs-5-documents-and-presentations-with-org-mode
|
||||
|
||||
作者:[John Goerzen][a]
|
||||
译者:[oneforalone](https://github.com/oneforalone)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[oneforalone](https://github.com/oneforalone)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -174,3 +169,9 @@ via: http://changelog.complete.org/archives/9900-emacs-5-documents-and-presentat
|
||||
[17]:https://orgmode.org/worg/org-tutorials/non-beamer-presentations.html#org-tree-slide
|
||||
[18]:https://orgmode.org/worg/org-tutorials/non-beamer-presentations.html
|
||||
[19]:https://www.emacswiki.org/emacs/ELPA
|
||||
[20]:https://changelog.complete.org/archives/tag/emacs2018
|
||||
[21]:https://github.com/jgoerzen/public-snippets/blob/master/emacs/emacs-org-beamer/emacs-org-beamer.org
|
||||
[22]:http://changelog.complete.org/archives/9900-emacs-5-documents-and-presentations-with-org-mode
|
||||
[23]:https://github.com/jgoerzen/public-snippets/raw/master/emacs/emacs-org-beamer/emacs-org-beamer.pdf
|
||||
[24]:https://github.com/jgoerzen/public-snippets/raw/master/emacs/emacs-org-beamer/emacs-org-beamer-document.pdf
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by qhwdw
|
||||
Know Your Storage: Block, File & Object
|
||||
======
|
||||
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (qhwdw)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -0,0 +1,54 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Patch into The Matrix at the Linux command line)
|
||||
[#]: via: (https://opensource.com/article/18/12/linux-toy-cmatrix)
|
||||
[#]: author: (Jason Baker https://opensource.com/users/jason-baker)
|
||||
|
||||
Patch into The Matrix at the Linux command line
|
||||
======
|
||||
Recreate the classic look and feel of everyone's favorite 1990s sci-fi movie code scroller with cmatrix.
|
||||
|
||||
|
||||
You've found your way to today's entry from the Linux command-line toys advent calendar. If this is your first visit to the series, you might be wondering what a command-line toy even is? It's anything that's an entertaining diversion at the terminal, be it a game, a fun utility, or a simple distraction.
|
||||
|
||||
Some of these are classics, and some are completely new (at least to me), but I hope all of you find something you enjoy in this series.
|
||||
|
||||
As we come to the close of another year, it's a good time for looking back, and looking forward. What will 2019 hold for you? What does it mean to be 2019?
|
||||
|
||||
I'm reminded that 2019 will mark the twentieth anniversary of one of my favorite science fiction movies from my teenage years, that at the time had me thinking a lot about what the future would hold: [The Matrix][1]. For a computer nerd kid like me, it was the ultimate story of a computer programmer rising up and becoming an action hero in a virtual universe by tapping into the power of his mind.
|
||||
|
||||
At the time, there was no movie that seemed more futuristic to me; both in the story itself, and in the mesmerizing special effects. Realizing that it was filmed over twenty years ago doesn't change that in my mind.
|
||||
|
||||
Bringing it back to our command-line toy for today, let's recreate the downward flowing code of the Matrix at our terminal with **cmatrix**. **cmatrix** was an easy install for me, packaged for Fedora, so installing it took simply:
|
||||
|
||||
```
|
||||
$ dnf install cmatrix
|
||||
```
|
||||
|
||||
Then, just type **cmatrix **at your terminal to run.
|
||||
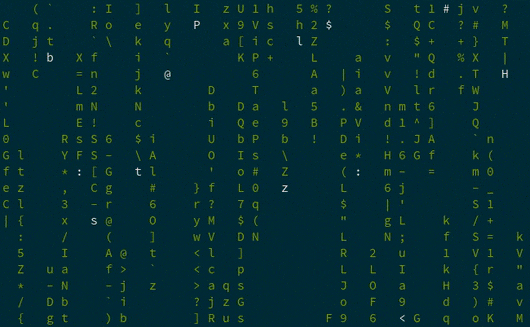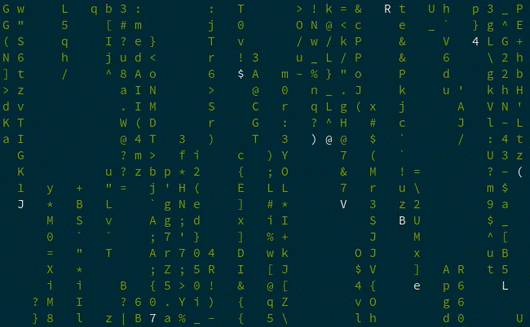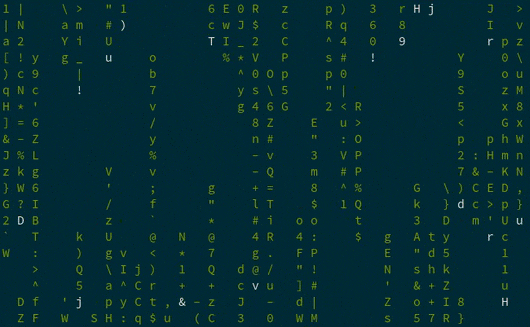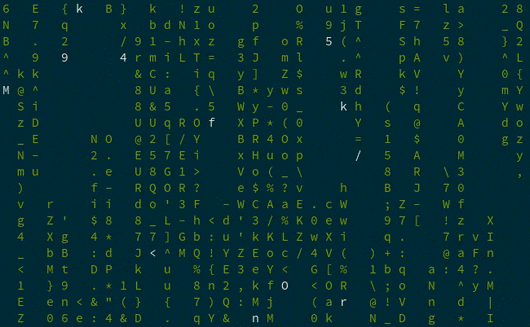
|
||||
You can find the source code for **** **cmatrix** [on GitHub][2] under a GPL license.
|
||||
|
||||
Do you have a favorite command-line toy that you think I ought to include? The calendar for this series is mostly filled out but I've got a few spots left. Let me know in the comments below, and I'll check it out. If there's space, I'll try to include it. If not, but I get some good submissions, I'll do a round-up of honorable mentions at the end.
|
||||
|
||||
Check out yesterday's toy, [Winterize your Bash prompt in Linux][3], and check back tomorrow for another!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/12/linux-toy-cmatrix
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jason-baker
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/The_Matrix
|
||||
[2]: https://github.com/abishekvashok/cmatrix
|
||||
[3]: https://opensource.com/article/18/12/linux-toy-bash-prompt
|
||||
122
sources/tech/20181212 Top 5 configuration management tools.md
Normal file
122
sources/tech/20181212 Top 5 configuration management tools.md
Normal file
@ -0,0 +1,122 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Top 5 configuration management tools)
|
||||
[#]: via: (https://opensource.com/article/18/12/configuration-management-tools)
|
||||
[#]: author: (Marco Bravo https://opensource.com/users/marcobravo)
|
||||
|
||||
Top 5 configuration management tools
|
||||
======
|
||||
Learn about configuration management tools and figure out which will work best for your DevOps organization.
|
||||

|
||||
|
||||
DevOps is evolving and gaining traction as organizations discover how it enables them to produce better applications and reduce their software products' time to market.
|
||||
|
||||
[DevOps' core values][1] are Culture, Automation, Measurement, and Sharing (CAMS), and an organization's adherence to them influences how successful it is.
|
||||
|
||||
* **Culture** brings people and processes together;
|
||||
* **Automation** creates a fabric for DevOps;
|
||||
* **Measurement** permits improvements; and
|
||||
* **Sharing** enables the feedback loop in the CAMS cycle.
|
||||
|
||||
|
||||
|
||||
Another DevOps concept is the idea that almost everything can be managed in code: servers, databases, networks, log files, application configurations, documentation, automated tests, deployment processes, and more.
|
||||
|
||||
In this article, I'll focus on one aspect of automation: Configuration management. As part of [Infrastructure as Code][2] (IaC), configuration management tools enable the use of tested and proven software development practices for managing and provisioning data centers through plaintext definition files.
|
||||
|
||||
By manipulating simple configuration files, a DevOps team can use application development best practices, such as version control, testing, small deployments, and design patterns. In short, this means code can be written to provision and manage an infrastructure as well as automate processes.
|
||||
|
||||
### Why use configuration management tools?
|
||||
|
||||
Configuration management tools enable changes and deployments to be faster, repeatable, scalable, predictable, and able to maintain the desired state, which brings controlled assets into an expected state.
|
||||
|
||||
Some advantages of using configuration management tools include:
|
||||
|
||||
* Adherence to coding conventions that make it easier to navigate code
|
||||
* Idempotency, which means that the end state remains the same, no matter how many times the code is executed
|
||||
* Distribution design to improve managing large numbers of remote servers
|
||||
|
||||
|
||||
|
||||
Some configuration management tools use a pull model, in which an agent installed on the servers runs periodically to pull the latest definitions from a central repository and apply them to the server. Other tools use a push model, where a central server triggers updates to managed servers.
|
||||
|
||||
### Top 5 configuration management tools
|
||||
|
||||
There are a variety of configuration management tools available, and each has specific features that make it better for some situations than others. Yet the top five configuration management tools, presented below in alphabetical order, have several things in common that I believe are essential for DevOps success: all have an open source license, use externalized configuration definition files, run unattended, and are scriptable. All of the descriptions are based on information from the tools' software repositories and websites.
|
||||
|
||||
#### Ansible
|
||||
|
||||
"Ansible is a radically simple IT automation platform that makes your applications and systems easier to deploy. Avoid writing scripts or custom code to deploy and update your applications—automate in a language that approaches plain English, using SSH, with no agents to install on remote systems." —[GitHub repository][3]
|
||||
|
||||
Ansible is one of my favorite tools; I started using it several years ago and fell in love with it. You can use Ansible to execute the same command for a list of servers from the command line. You can also use it to automate tasks using "playbooks" written into a YAML file, which facilitate communication between teams and non-technical people. Its main advantages are that it is simple, agentless, and easy to read (especially for non-programmers).
|
||||
|
||||
Because agents are not required, there is less overhead on servers. An SSH connection is necessary when running in push mode (which is the default), but pull mode is available if needed. [Playbooks][4] can be written with a minimal set of commands or they can be scaled for more elaborate automation tasks that could include roles, variables, and modules written by other people.
|
||||
|
||||
You can combine Ansible with other tools to create a central console to control processes. Those tools include Ansible Works (AWX), Jenkins, RunDeck, and [ARA][5], which offers [traceability when running playbooks][6].
|
||||
|
||||
### CFEngine
|
||||
|
||||
"CFEngine 3 is a popular open source configuration management system. Its primary function is to provide automated configuration and maintenance of large-scale computer systems." —[GitHub repository][7]
|
||||
|
||||
CFEngine was introduced by Mark Burgess in 1993 as a scientific approach to automated configuration management. The goal was to deal with the entropy in computer systems' configuration and resolve it with end-state "convergence." Convergence means a desired end-state and elaborates on idempotence as a capacity to reach the desired end-state. Burgess' research evolved in 2004 when he proposed the [Promise theory][8] as a model of voluntary cooperation between agents.
|
||||
|
||||
The current version of CFEngine incorporates Promise theory and uses agents running on each server that pull the configuration from a central repository. It requires some expert knowledge to deal with configurations, so it's best suited for technical people.
|
||||
|
||||
### Chef
|
||||
|
||||
"A systems integration framework, built to bring the benefits of configuration management to your entire infrastructure." —[GitHub repository][9]
|
||||
|
||||
Chef uses "recipes" written in Ruby to keep your infrastructure running up-to-date and compliant. The recipes describe a series of resources that should be in a particular state. Chef can run in client/server mode or in a standalone configuration named [chef-solo][10]. It has good integration with the major cloud providers to automatically provision and configure new machines.
|
||||
|
||||
Chef has a solid user base and provides a full toolset to allow people with different technical backgrounds and skills to interact around the recipes. But, at its base, it is more technically oriented tool.
|
||||
|
||||
### Puppet
|
||||
|
||||
"Puppet, an automated administrative engine for your Linux, Unix, and Windows systems, performs administrative tasks (such as adding users, installing packages, and updating server configurations) based on a centralized specification." —[GitHub repository][11]
|
||||
|
||||
Conceived as a tool oriented toward operations and sysadmins, Puppet has consolidated as a configuration management tool. It usually works in a client-server architecture, and an agent communicates with the server to fetch configuration instructions.
|
||||
|
||||
Puppet uses a declarative language or Ruby to describe the system configuration. It is organized in modules, and manifest files contain the desired-state goals to keep everything as required. Puppet uses the push model by default, and the pull model can be configured.
|
||||
|
||||
### Salt
|
||||
|
||||
"Software to automate the management and configuration of any infrastructure or application at scale." — [GitHub repository][12]
|
||||
|
||||
Salt was created for high-speed data collection and scale beyond tens of thousands of servers. It uses Python modules to handle configuration details and specific actions. These modules manage all of Salt's remote execution and state management behavior. Some level of technical skills are required to configure the modules.
|
||||
|
||||
Salt uses a client-server topology (with the Salt master as server and Salt minions as clients). Configurations are kept in Salt state files, which describe everything required to keep a system in the desired state.
|
||||
|
||||
### Conclusion
|
||||
|
||||
The landscape of DevOps tools is evolving all the time, and it is important to keep an eye on the changes. I hope this article will encourage you to explore these concepts and tools further. If so, the Cloud Native Computing Foundation (CNCF) maintains a good reference in the [Cloud Native Landscape Project][13].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/12/configuration-management-tools
|
||||
|
||||
作者:[Marco Bravo][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/marcobravo
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.oreilly.com/learning/why-use-terraform
|
||||
[2]: https://www.oreilly.com/library/view/infrastructure-as-code/9781491924334/ch04.html
|
||||
[3]: https://github.com/ansible/ansible
|
||||
[4]: https://opensource.com/article/18/8/ansible-playbooks-you-should-try
|
||||
[5]: https://github.com/openstack/ara
|
||||
[6]: https://opensource.com/article/18/5/analyzing-ansible-runs-using-ara
|
||||
[7]: https://github.com/cfengine/core
|
||||
[8]: https://en.wikipedia.org/wiki/Promise_theory
|
||||
[9]: https://github.com/chef/chef
|
||||
[10]: https://docs.chef.io/chef_solo.html
|
||||
[11]: https://github.com/puppetlabs/puppet
|
||||
[12]: https://github.com/saltstack/salt
|
||||
[13]: https://github.com/cncf/landscape
|
||||
@ -0,0 +1,315 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (What is PPA? Everything You Need to Know About PPA in Linux)
|
||||
[#]: via: (https://itsfoss.com/ppa-guide/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
What is PPA? Everything You Need to Know About PPA in Linux
|
||||
======
|
||||
|
||||
**Brief: An in-depth article that covers almost all the questions around using PPA in Ubuntu and other Linux distributions.**
|
||||
|
||||
If you have been using Ubuntu or some other Linux distribution based on Ubuntu such as Linux Mint, Linux Lite, Zorin OS etc, you may have come across three magical lines of this sort:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:dr-akulavich/lighttable
|
||||
sudo apt-get update
|
||||
sudo apt-get install lighttable-installer
|
||||
```
|
||||
|
||||
A number of websites suggest these kind of lines to [install applications in Ubuntu][1]. This is what is called installing an application using PPA.
|
||||
|
||||
But what is PPA? Why is it used? Is it safe to use PPA? How to properly use PPA? How to delete a PPA?
|
||||
|
||||
I’ll answer all of the above questions in this detailed guide. Even if you already know a few things about PPAs, I am sure this article will still add to your knowledge.
|
||||
|
||||
Do note that I am writing this article using Ubuntu. Therefore I’ll use the term Ubuntu almost everywhere but the explanations and steps are also applicable to other Debian/Ubuntu based distributions.
|
||||
|
||||
### What is PPA? Why is it used?
|
||||
|
||||
![Everything you need to know about PPA in Ubuntu Linux][2]
|
||||
|
||||
PPA stands for Personal Package Archive.
|
||||
|
||||
Does that make sense? Probably not.
|
||||
|
||||
Before you understand PPA, you should know the concept of repositories in Linux. I won’t go into details here though.
|
||||
|
||||
#### Concept of repositories and package management
|
||||
|
||||
A repository is a collection of files that has information about various software, their versions and some other details like the checksum. Each Ubuntu version has its own official set of four repositories:
|
||||
|
||||
* **Main** – Canonical-supported free and open-source software.
|
||||
|
||||
* **Universe** – Community-maintained free and open-source software.
|
||||
|
||||
* **Restricted** – Proprietary drivers for devices.
|
||||
|
||||
* **Multiverse** – Software restricted by copyright or legal issues.
|
||||
|
||||
|
||||
|
||||
|
||||
You can see such repositories for all Ubuntu versions [here][3]. You can browse through them and also go to the individual repositories. For example, Ubuntu 16.04 main repository can be found [here][4].
|
||||
|
||||
So basically it’s a web URL that has information about the software. How does your system know where are these repositories?
|
||||
|
||||
This information is stored in the sources.list file in the directory /etc/apt. If you look at its content, you’ll see that it has the URL of the repositories. The lines with # at the beginning are ignored.
|
||||
|
||||
Now when you run the command sudo apt update, your system uses [APT tool][5] to check against the repo and stores the information about the software and their version in a cache. When you use the command sudo apt install package_name, it uses the information to get that package from the URL where the actual software is stored.
|
||||
|
||||
If the repository doesn’t have the information about a certain package, you’ll see an error like:
|
||||
|
||||
```
|
||||
E: Unable to locate package
|
||||
```
|
||||
|
||||
At this point, I recommend reading my [guide to using apt commands][6]. This will give you a much better understanding of apt commands, update etc.
|
||||
|
||||
So this was about repositories. But what is PPA? How does it enter into the picture?
|
||||
|
||||
#### Why is PPA used?
|
||||
|
||||
As you can see, Ubuntu controls what software and more importantly which version of a software you get on your system. But imagine if a software developer releases a new version of the software.
|
||||
|
||||
Ubuntu won’t make it available immediately. There is a procedure to check if the new version of the software is compatible with the system or not. This ensures the stability of the system.
|
||||
|
||||
But this also means that it will be some weeks or in some cases, some months before it is made available by Ubuntu. Not everyone would want to wait that long to get their hands on the new version of their favorite software.
|
||||
|
||||
Similarly, suppose someone develops a software and wants Ubuntu to include that software in the official repositories. It again will take months before Ubuntu makes a decision and includes it in the official repositories.
|
||||
|
||||
Another case would be during beta testing. Even if a stable version of the software is available in the official repositories, a software developer may want some end users to test their upcoming release. How do they enable the end user to beta test the upcoming release?
|
||||
|
||||
Enter PPA!
|
||||
|
||||
### How to use PPA? How does PPA work?
|
||||
|
||||
[PPA][7], as I already told you, means Personal Package Archive. Mind the word ‘Personal’ here. That gives the hint that this is something exclusive to a developer and is not officially endorsed by the distribution.
|
||||
|
||||
Ubuntu provides a platform called Launchpad that enables software developers to create their own repositories. An end user i.e. you can add the PPA repository to your sources.list and when you update your system, your system would know about the availability of this new software and you can install it using the standard sudo apt install command like this.
|
||||
|
||||
`sudo add-apt-repository ppa:dr-akulavich/lighttable`
|
||||
`sudo apt-get update`
|
||||
`sudo apt-get install lighttable-installer`
|
||||
|
||||
To summarize:
|
||||
|
||||
* sudo add-apt-repository <PPA_info> <– This command adds the PPA repository to the list.
|
||||
* sudo apt-get update <– This command updates the list of the packages that can be installed on the system.
|
||||
* sudo apt-get install <package_in_PPA> <– This command installs the package.
|
||||
|
||||
|
||||
|
||||
You see that it is important to use the command sudo apt update or else your system will not know when a new package is available.
|
||||
|
||||
Now let’s take a look at the first command in a bit more detail.
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:dr-akulavich/lighttable
|
||||
```
|
||||
|
||||
You would notice that this command doesn’t have a URL to the repository. This is because the tool has been designed to abstract the information about URL from you.
|
||||
|
||||
Just a small note. If you add ppa:dr-akulavich/lighttable, you get Light Table. But if you add ppa:dr-akulavich, you’ll get all the repository or packages mentioned in the ‘upper repository’. It’s hierarchical.
|
||||
|
||||
Basically, when you add a PPA using add-apt-repository, it will do the same action as if you manually run these commands:
|
||||
|
||||
```
|
||||
deb http://ppa.launchpad.net/dr-akulavich/lighttable/ubuntu YOUR_UBUNTU_VERSION_HERE main
|
||||
deb-src http://ppa.launchpad.net/dr-akulavich/lighttable/ubuntu YOUR_UBUNTU_VERSION_HERE main
|
||||
```
|
||||
|
||||
The above two lines are the traditional way to add any repositories to your sources.list. But PPA does it automatically for you, without wondering about the exact repository URL and operating system version.
|
||||
|
||||
One important thing to not here is that when you use PPA, it doesn’t change your original sources.list. Instead, it creates two files in /etc/apt/sources.d directory, a list and a back up file with suffix ‘save’.
|
||||
|
||||
![Using a PPA in Ubuntu][8]PPA create separate sources.list
|
||||
|
||||
The files with suffix ‘list’ has the command that adds the information about the repository.
|
||||
|
||||
![PPA add repository information][9]Content of source.list of a PPA
|
||||
|
||||
This is a safety measure to ensure that adding PPAs don’t mess with the original sources.list. It also helps in removing the PPA.
|
||||
|
||||
#### Why PPA? Why not DEB packages?
|
||||
|
||||
You may ask why should you use PPA when it involves using command line which might not be preferred by everyone. Why not just distribute a DEB package that can be installed graphically?
|
||||
|
||||
The answer lies in the update procedure. If you install a software using a DEB package, there is no guarantee that the installed software will be updated to a newer version when you run sudo apt update && sudo apt upgrade.
|
||||
|
||||
It’s because the apt upgrade procedure relies on the sources.list. If there is no entry for a software, it doesn’t get the update via the standard software updater.
|
||||
|
||||
So does it mean software installed using DEB never gets an update? No, not really. It depends on how the package was created.
|
||||
|
||||
Some developers automatically add an entry to the sources.list and then it is updated like a regular software. Google Chrome is one such example.
|
||||
|
||||
Some software would notify you of availability of a new version when you try to run it. You’ll have to download the new DEB package and run it again to update the current software to a newer version. Oracle Virtual Box is an example in this case.
|
||||
|
||||
For the rest of the DEB packages, you’ll have to manually look for an update and this is not convenient, especially if your software is meant for beta testers. You need to add more updates frequently. This is where PPA come to the rescue.
|
||||
|
||||
#### Offical PPA vs unofficial PPA
|
||||
|
||||
You may also hear the term official PPA or unofficial PPA. What’s the difference?
|
||||
|
||||
When developers create PPA for their software, it is called the official PPA. Quite obviously because it is coming from none other than the project developers.
|
||||
|
||||
But at times, individuals create PPA of projects that were created by other developers.
|
||||
|
||||
Why would someone do that? Because many developers just provide the source code of the software and you know that [installing software from source code in Linux][10] is a pain and not everyone could or would do that.
|
||||
|
||||
This is why volunteers take it upon themselves to create a PPA from those source code so that other users can install the software easily. After all, using those 3 lines is a lot easier than battling the source code installation.
|
||||
|
||||
#### Make sure that a PPA is available for your distribution version
|
||||
|
||||
When it comes to using PPA in Ubuntu or any other Debian based distribution, there are a few things you should keep in mind.
|
||||
|
||||
Not every PPA is available for your particular version. You should know [which Ubuntu version][11] you are using. The codename of the release is important because when you go to the webpage of a certain PPA, you can see which Ubuntu versions are supported by the PPA.
|
||||
|
||||
For other Ubuntu-based distributions, you can check the content of /etc/os-release to [find out the Ubuntu version][11] information.
|
||||
|
||||
![Verify PPA availability for Ubuntu version][12]Check if PPA is available for your Ubuntu version
|
||||
|
||||
How to know the PPA url? Simply search on the internet with the PPA name like ppa:dr-akulavich/lighttable and you’ll get the first result from [Launchpad][13], the official platform for hosting PPA. You can also go to Launchpad and search for the required PPA directly there.
|
||||
|
||||
If you don’t verify and add the PPA, you may see an error like this when you try to install a software not available for your version.
|
||||
|
||||
```
|
||||
E: Unable to locate package
|
||||
```
|
||||
|
||||
What’s worse is that since it has been added to your source.list, each time you run software updater, you’ll see an error “[Failed to download repository information][14]“.
|
||||
|
||||
![Failed to download repository information Ubuntu 13.04][15]
|
||||
|
||||
If you run sudo apt update in the terminal, the error will have more details about which repository is causing the trouble. You can see something like this in the end of the output of sudo apt update:
|
||||
|
||||
```
|
||||
W: Failed to fetch http://ppa.launchpad.net/venerix/pkg/ubuntu/dists/raring/main/binary-i386/Packages 404 Not Found
|
||||
E: Some index files failed to download. They have been ignored, or old ones used instead.
|
||||
```
|
||||
|
||||
Which is self-explanatory because the system cannot find the repository for your version. Remember what we saw earlier about repository structure? APT will try to look for software information in the place <http://ppa.launchpad.net/\><PPA_NAME>/ubuntu/dists/Ubuntu_Version
|
||||
|
||||
And if the PPA for the specific version is not available, it will never be able to open the URL and you get the famous 404 error.
|
||||
|
||||
#### Why are PPAs not available for all the Ubuntu release versions?
|
||||
|
||||
It is because someone has to compile the software and create a PPA out of it on the specific versions. Considering that a new Ubuntu version is released every six months, it’s a tiresome task to update the PPA for every Ubuntu release. Not all developers have time to do that.
|
||||
|
||||
#### How to install the application if PPA is not available for your version?
|
||||
|
||||
It is possible that though the PPA is not available for your Ubuntu version, you could still download the DEB file and install the application
|
||||
|
||||
Let’s say that you go to the Light Table PPA. Using the knowledge about PPA you just learned, you realize that the PPA is not available for your specific Ubuntu release.
|
||||
|
||||
What you can do is to click on the ‘View package details’.
|
||||
|
||||
![Get DEB file from PPA][16]
|
||||
|
||||
And in here, you can click on a package to reveal more details. You’ll also find the source code and the DEB file of the package here.
|
||||
|
||||
![Download DEB file from PPA][17]
|
||||
|
||||
I advise [using Gdebi to install these DEB files][18] instead of the Software Center because Gdebi is a lot better at handling dependencies.
|
||||
|
||||
Do note that the package installed this way might not get any future updates.
|
||||
|
||||
I think you have read enough about adding PPAs. How about removing a PPA and the software installed by it?
|
||||
|
||||
### How to delete PPA?
|
||||
|
||||
I have written about [deleting PPA][19] in the past. I am going to describe the same methods here as well.
|
||||
|
||||
I advise deleting the software that you installed from a PPA before removing the PPA. If you just remove the PPA, the installed software remains in the system but it won’t get any updates. You wouldn’t want that, would you?
|
||||
|
||||
So, the question comes, how to know which application was installed by which PPA?
|
||||
|
||||
#### Find packages installed by a PPA and remove them
|
||||
|
||||
Ubuntu Software Center doesn’t help here. You’ll have to use Synaptic package manager here which has more advanced features.
|
||||
|
||||
You can install Synaptic from Software Center or use the command below:
|
||||
|
||||
```
|
||||
sudo apt install synaptic
|
||||
```
|
||||
|
||||
Once installed, start Synaptic package manager and select Origin. You’ll see various repositories added to the system. PPA entries will be labeled with prefix PPA. Click on them to see the packages that are available by the PPA. Installed software will have appropriate symbol before it.
|
||||
|
||||
![Managing PPA with Synaptic package manager][20]Find packages installed via a PPA
|
||||
|
||||
Once you have found the packages, you can delete them from Synaptic itself. Otherwise, you always have the option to use the command line:
|
||||
|
||||
```
|
||||
sudo apt remove package_name
|
||||
```
|
||||
|
||||
Once you have removed the packages installed by a PPA, you can continue to remove the PPA from your sources.list.
|
||||
|
||||
#### Remove a PPA graphically
|
||||
|
||||
Go to Software & Updates and then go to tab Other Software. Look for the PPA that you want to remove:
|
||||
|
||||
![Delete a PPA from Software Source][21]
|
||||
|
||||
You have two options here. Either you deselect the PPA or you choose the Remove option.
|
||||
|
||||
The difference is that when you deselect a PPA entry, your system will comment out the repository entry in its ppa_name.list file in /etc/apt/sources.list.d but if you choose the Remove option, it will delete the repository entry from its ppa_name.list file in /etc/apt/sources.list.d directory.
|
||||
|
||||
In both the cases, the files ppa_name.list remains in the said directory, even if it is empty.
|
||||
|
||||
### Is it safe to use PPA?
|
||||
|
||||
It is a subjective question. Purists abhor PPA because most of the time PPAs are from third-party developers. But at the same time, PPAs are popular in the Debian/Ubuntu world as they provide an easier installation option.
|
||||
|
||||
As far as the security is concerned, it’s less likely that you use a PPA and your Linux system is hacked or injected with malware. I don’t recall such an incident ever happened so far.
|
||||
|
||||
Official PPAs can be used without thinking twice. Using unofficial PPA is entirely your decision.
|
||||
|
||||
As a rule of thumb, you should avoid installing a program via a third party PPA if it the program requires sudo access to run.
|
||||
|
||||
### What do you think about using PPA?
|
||||
|
||||
I know it’s a long read but I wanted to give you a better understanding of PPA. I hope this detailed guide answered most of your questions about using PPA.
|
||||
|
||||
If you have more questions about PPA, please feel free to ask in the comment section.
|
||||
|
||||
If you notice any technical or grammatical error or if you have suggestions for improving this article, please let me know.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/ppa-guide/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/remove-install-software-ubuntu/
|
||||
[2]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/12/what-is-ppa.png?resize=800%2C450&ssl=1
|
||||
[3]: http://archive.ubuntu.com/ubuntu/dists/
|
||||
[4]: http://archive.ubuntu.com/ubuntu/dists/xenial/main/
|
||||
[5]: https://wiki.debian.org/Apt
|
||||
[6]: https://itsfoss.com/apt-command-guide/
|
||||
[7]: https://launchpad.net/ubuntu/+ppas
|
||||
[8]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2018/01/ppa-sources-list-files.png?resize=800%2C259&ssl=1
|
||||
[9]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/01/content-of-ppa-list.png?ssl=1
|
||||
[10]: https://itsfoss.com/install-software-from-source-code/
|
||||
[11]: https://itsfoss.com/how-to-know-ubuntu-unity-version/
|
||||
[12]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2017/12/verify-ppa-availibility-version.jpg?resize=800%2C481&ssl=1
|
||||
[13]: https://launchpad.net/
|
||||
[14]: https://itsfoss.com/failed-to-download-repository-information-ubuntu-13-04/
|
||||
[15]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2013/04/Failed-to-download-repository-information-Ubuntu-13.04.png?ssl=1
|
||||
[16]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2018/12/deb-from-ppa.jpg?resize=800%2C483&ssl=1
|
||||
[17]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2018/12/deb-from-ppa-2.jpg?resize=800%2C477&ssl=1
|
||||
[18]: https://itsfoss.com/gdebi-default-ubuntu-software-center/
|
||||
[19]: https://itsfoss.com/how-to-remove-or-delete-ppas-quick-tip/
|
||||
[20]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/01/ppa-synaptic-manager.jpeg?resize=800%2C394&ssl=1
|
||||
[21]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2012/08/Delete-a-PPA.jpeg?ssl=1
|
||||
@ -7,46 +7,46 @@
|
||||
[#]: author: (Sven Bösiger)
|
||||
[#]: url: ( )
|
||||
|
||||
Create a containerized machine learning model
|
||||
创建一个容器化的机器学习模型
|
||||
======
|
||||
|
||||

|
||||
|
||||
After data scientists have created a machine learning model, it has to be deployed into production. To run it on different infrastructures, using containers and exposing the model via a REST API is a common way to deploy a machine learning model. This article demonstrates how to roll out a [TensorFlow][1] machine learning model, with a REST API delivered by [Connexion][2] in a container with [Podman][3].
|
||||
数据科学家在创建机器学习模型后,必须将其部署到生产中。要在不同的基础架构上运行它,使用容器并通过 REST API 公开模型是部署机器学习模型的常用方法。本文演示了如何在 [Podman][3] 容器中使用 [Connexion][2] 推出使用 REST API 的 [TensorFlow][1] 机器学习模型。
|
||||
|
||||
### Preparation
|
||||
### 准备
|
||||
|
||||
First, install Podman with the following command:
|
||||
首先,使用以下命令安装 Podman:
|
||||
|
||||
```
|
||||
sudo dnf -y install podman
|
||||
```
|
||||
|
||||
Next, create a new folder for the container and switch to that directory.
|
||||
接下来,为容器创建一个新文件夹并切换到该目录。
|
||||
|
||||
```
|
||||
mkdir deployment_container && cd deployment_container
|
||||
```
|
||||
|
||||
### REST API for the TensorFlow model
|
||||
### TensorFlow 模型的 REST API
|
||||
|
||||
The next step is to create the REST-API for the machine learning model. This [github repository][4] contains a pretrained model, and well as the setup already configured for getting the REST API working.
|
||||
下一步是为机器学习模型创建 REST API。这个 [github 仓库][4]包含一个预训练模型,以及能让 REST API 工作的设置。
|
||||
|
||||
Clone this in the deployment_container directory with the command:
|
||||
使用以下命令在 deployment_container 目录中克隆它:
|
||||
|
||||
```
|
||||
git clone https://github.com/svenboesiger/titanic_tf_ml_model.git
|
||||
```
|
||||
|
||||
#### prediction.py & ml_model/
|
||||
#### prediction.py 和 ml_model/
|
||||
|
||||
The [prediction.py][5] file allows for a Tensorflow prediction, while the weights for the 20x20x20 neural network are located in folder [ml_model/][6].
|
||||
[prediction.py][5] 能进行 Tensorflow 预测,而 20x20x20 神经网络的权重位于文件夹 [ml_model/][6] 中。
|
||||
|
||||
#### swagger.yaml
|
||||
|
||||
The file swagger.yaml defines the API for the Connexion library using the [Swagger specification][7]. This file contains all of the information necessary to configure your server to provide input parameter validation, output response data validation, URL endpoint definition.
|
||||
swagger.yaml 使用 [Swagger规范][7] 定义 Connexion 库的 API。此文件包含让你的服务器提供输入参数验证、输出响应数据验证、URL 端点定义所需的所有信息。
|
||||
|
||||
As a bonus Connexion will provide you also with a simple but useful single page web application that demonstrates using the API with JavaScript and updating the DOM with it.
|
||||
额外地,Connexion 还将给你提供一个简单但有用的单页 Web 应用,它演示了如何使用 Javascript 调用 API 和更新 DOM。
|
||||
|
||||
```
|
||||
swagger: "2.0"
|
||||
@ -85,9 +85,9 @@ definitions:
|
||||
type: object
|
||||
```
|
||||
|
||||
#### server.py & requirements.txt
|
||||
#### server.py 和 requirements.txt
|
||||
|
||||
[server.py][8] defines an entry point to start the Connexion server.
|
||||
[server.py][8] 定义了启动 Connexion 服务器的入口点。
|
||||
|
||||
```
|
||||
import connexion
|
||||
@ -100,7 +100,7 @@ if __name__ == '__main__':
|
||||
app.run(debug=True)
|
||||
```
|
||||
|
||||
[requirements.txt][9] defines the python requirements we need to run the program.
|
||||
[requirements.txt][9] 定义了运行程序所需的 python 包。
|
||||
|
||||
```
|
||||
connexion
|
||||
@ -108,9 +108,9 @@ tensorflow
|
||||
pandas
|
||||
```
|
||||
|
||||
### Containerize!
|
||||
### 容器化!
|
||||
|
||||
For Podman to be able to build an image, create a new file called “Dockerfile” in the **deployment_container** directory created in the preparation step above:
|
||||
为了让 Podman 构建映像,请在上面的准备步骤中创建的 **deployment_container** 目录中创建一个名为 “Dockerfile” 的新文件:
|
||||
|
||||
```
|
||||
FROM fedora:28
|
||||
@ -143,25 +143,25 @@ WORKDIR /titanic_tf_ml_model
|
||||
CMD python3 server.py
|
||||
```
|
||||
|
||||
Next, build the container image with the command:
|
||||
接下来,使用以下命令构建容器镜像:
|
||||
|
||||
```
|
||||
podman build -t ml_deployment .
|
||||
```
|
||||
|
||||
### Run the container
|
||||
### 运行容器
|
||||
|
||||
With the Container image built and ready to go, you can run it locally with the command:
|
||||
随着容器镜像的构建和准备就绪,你可以使用以下命令在本地运行它:
|
||||
|
||||
```
|
||||
podman run -p 5000:5000 ml_deployment
|
||||
```
|
||||
|
||||
Navigate to [http://0.0.0.0:5000/ui][10] in your web browser to access the Swagger/Connexion UI and to test-drive the model:
|
||||
在 Web 浏览器中输入 [http://0.0.0.0:5000/ui][10] 访问 Swagger/Connexion UI 并测试模型:
|
||||
|
||||
![][11]
|
||||
|
||||
Of course you can now also access the model with your application via the REST-API.
|
||||
当然,你现在也可以在应用中通过 REST API 访问模型。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -170,7 +170,7 @@ via: https://fedoramagazine.org/create-containerized-machine-learning-model/
|
||||
|
||||
作者:[Sven Bösiger][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -187,4 +187,4 @@ via: https://fedoramagazine.org/create-containerized-machine-learning-model/
|
||||
[8]: https://github.com/svenboesiger/titanic_tf_ml_model/blob/master/server.py
|
||||
[9]: https://github.com/svenboesiger/titanic_tf_ml_model/blob/master/requirements.txt
|
||||
[10]: http://0.0.0.0:5000/
|
||||
[11]: https://fedoramagazine.org/wp-content/uploads/2018/10/Screenshot-from-2018-10-27-14-46-56-682x1024.png
|
||||
[11]: https://fedoramagazine.org/wp-content/uploads/2018/10/Screenshot-from-2018-10-27-14-46-56-682x1024.png
|
||||
Loading…
Reference in New Issue
Block a user