# zypper help install
+ install (in) [options] {capability | rpm_file_uri}
+
+ Install packages with specified capabilities or RPM files with specified
+ location. A capability is NAME[.ARCH][OP], where OP is one
+ of <, <=, =, >=, >.
+
+ Command options:
+ --from Select packages from the specified repository.
+ -r, --repo Load only the specified repository.
+ -t, --type Type of package (package, patch, pattern, product, srcpackage).
+ Default: package.
+ -n, --name Select packages by plain name, not by capability.
+ -C, --capability Select packages by capability.
+ -f, --force Install even if the item is already installed (reinstall),
+ downgraded or changes vendor or architecture.
+ --oldpackage Allow to replace a newer item with an older one.
+ Handy if you are doing a rollback. Unlike --force
+ it will not enforce a reinstall.
+ --replacefiles Install the packages even if they replace files from other,
+ already installed, packages. Default is to treat file conflicts
+ as an error. --download-as-needed disables the fileconflict check.
+ ......
+
+3. 安装之前搜索一个安转包(以 gnome-desktop 为例 )
+
+
# zypper se gnome-desktop
+
+ Retrieving repository 'openSUSE-13.2-Debug' metadata ............................................................[done]
+ Building repository 'openSUSE-13.2-Debug' cache .................................................................[done]
+ Retrieving repository 'openSUSE-13.2-Non-Oss' metadata ......................................................... [done]
+ Building repository 'openSUSE-13.2-Non-Oss' cache ...............................................................[done]
+ Retrieving repository 'openSUSE-13.2-Oss' metadata ..............................................................[done]
+ Building repository 'openSUSE-13.2-Oss' cache ...................................................................[done]
+ Retrieving repository 'openSUSE-13.2-Update' metadata ...........................................................[done]
+ Building repository 'openSUSE-13.2-Update' cache ................................................................[done]
+ Retrieving repository 'openSUSE-13.2-Update-Non-Oss' metadata ...................................................[done]
+ Building repository 'openSUSE-13.2-Update-Non-Oss' cache ........................................................[done]
+ Loading repository data...
+ Reading installed packages...
+
+ S | Name | Summary | Type
+ --+---------------------------------------+-----------------------------------------------------------+-----------
+ | gnome-desktop2-lang | Languages for package gnome-desktop2 | package
+ | gnome-desktop2 | The GNOME Desktop API Library | package
+ | libgnome-desktop-2-17 | The GNOME Desktop API Library | package
+ | libgnome-desktop-3-10 | The GNOME Desktop API Library | package
+ | libgnome-desktop-3-devel | The GNOME Desktop API Library -- Development Files | package
+ | libgnome-desktop-3_0-common | The GNOME Desktop API Library -- Common data files | package
+ | gnome-desktop-debugsource | Debug sources for package gnome-desktop | package
+ | gnome-desktop-sharp2-debugsource | Debug sources for package gnome-desktop-sharp2 | package
+ | gnome-desktop2-debugsource | Debug sources for package gnome-desktop2 | package
+ | libgnome-desktop-2-17-debuginfo | Debug information for package libgnome-desktop-2-17 | package
+ | libgnome-desktop-3-10-debuginfo | Debug information for package libgnome-desktop-3-10 | package
+ | libgnome-desktop-3_0-common-debuginfo | Debug information for package libgnome-desktop-3_0-common | package
+ | libgnome-desktop-2-17-debuginfo-32bit | Debug information for package libgnome-desktop-2-17 | package
+ | libgnome-desktop-3-10-debuginfo-32bit | Debug information for package libgnome-desktop-3-10 | package
+ | gnome-desktop-sharp2 | Mono bindings for libgnome-desktop | package
+ | libgnome-desktop-2-devel | The GNOME Desktop API Library -- Development Files | packag
+ | gnome-desktop-lang | Languages for package gnome-desktop | package
+ | libgnome-desktop-2-17-32bit | The GNOME Desktop API Library | package
+ | libgnome-desktop-3-10-32bit | The GNOME Desktop API Library | package
+ | gnome-desktop | The GNOME Desktop API Library | srcpackage
+
+4. 获取一个模式包的信息(以 lamp_server 为例)。
+
+
# zypper info -t pattern lamp_server
+
+ Loading repository data...
+ Reading installed packages...
+
+
+ Information for pattern lamp_server:
+ ------------------------------------
+ Repository: openSUSE-13.2-Update
+ Name: lamp_server
+ Version: 20141007-5.1
+ Arch: x86_64
+ Vendor: openSUSE
+ Installed: No
+ Visible to User: Yes
+ Summary: Web and LAMP Server
+ Description:
+ Software to set up a Web server that is able to serve static, dynamic, and interactive content (like a Web shop). This includes Apache HTTP Server, the database management system MySQL,
+ and scripting languages such as PHP, Python, Ruby on Rails, or Perl.
+ Contents:
+
+ S | Name | Type | Dependency
+ --+-------------------------------+---------+-----------
+ | apache2-mod_php5 | package |
+ | php5-iconv | package |
+ i | patterns-openSUSE-base | package |
+ i | apache2-prefork | package |
+ | php5-dom | package |
+ | php5-mysql | package |
+ i | apache2 | package |
+ | apache2-example-pages | package |
+ | mariadb | package |
+ | apache2-mod_perl | package |
+ | php5-ctype | package |
+ | apache2-doc | package |
+ | yast2-http-server | package |
+ | patterns-openSUSE-lamp_server | package |
# zypper ref
+ Repository 'openSUSE-13.2-0' is up to date.
+ Repository 'openSUSE-13.2-Debug' is up to date.
+ Repository 'openSUSE-13.2-Non-Oss' is up to date.
+ Repository 'openSUSE-13.2-Oss' is up to date.
+ Repository 'openSUSE-13.2-Update' is up to date.
+ Repository 'openSUSE-13.2-Update-Non-Oss' is up to date.
+ All repositories have been refreshed.
+
+10. 刷新一个指定的软件库(以 'repo-non-oss' 为例 )。
+
+
# zypper refresh repo-non-oss
+ Repository 'openSUSE-13.2-Non-Oss' is up to date.
+ Specified repositories have been refreshed.
+
+11. 强制更新一个软件库(以 'repo-non-oss' 为例 )。
+
+
# zypper ref -f repo-non-oss
+ Forcing raw metadata refresh
+ Retrieving repository 'openSUSE-13.2-Non-Oss' metadata ............................................................[done]
+ Forcing building of repository cache
+ Building repository 'openSUSE-13.2-Non-Oss' cache ............................................................[done]
+ Specified repositories have been refreshed.
# zypper mr -rk -p 85 repo-non-oss
+ Repository 'repo-non-oss' priority has been left unchanged (85)
+ Nothing to change for repository 'repo-non-oss'.
+
+15. 对所有的软件库关闭 rpm 文件缓存。
+
+
# zypper mr -Ka
+ RPM files caching has been disabled for repository 'openSUSE-13.2-0'.
+ RPM files caching has been disabled for repository 'repo-debug'.
+ RPM files caching has been disabled for repository 'repo-debug-update'.
+ RPM files caching has been disabled for repository 'repo-debug-update-non-oss'.
+ RPM files caching has been disabled for repository 'repo-non-oss'.
+ RPM files caching has been disabled for repository 'repo-oss'.
+ RPM files caching has been disabled for repository 'repo-source'.
+ RPM files caching has been disabled for repository 'repo-update'.
+ RPM files caching has been disabled for repository 'repo-update-non-oss'.
+
+16. 对所有的软件库开启 rpm 文件缓存。
+
# zypper mr -ka
+ RPM files caching has been enabled for repository 'openSUSE-13.2-0'.
+ RPM files caching has been enabled for repository 'repo-debug'.
+ RPM files caching has been enabled for repository 'repo-debug-update'.
+ RPM files caching has been enabled for repository 'repo-debug-update-non-oss'.
+ RPM files caching has been enabled for repository 'repo-non-oss'.
+ RPM files caching has been enabled for repository 'repo-oss'.
+ RPM files caching has been enabled for repository 'repo-source'.
+ RPM files caching has been enabled for repository 'repo-update'.
+ RPM files caching has been enabled for repository 'repo-update-non-oss'.
+
+17. 关闭远程库的 rpm 文件缓存
+
# zypper mr -Kt
+ RPM files caching has been disabled for repository 'repo-debug'.
+ RPM files caching has been disabled for repository 'repo-debug-update'.
+ RPM files caching has been disabled for repository 'repo-debug-update-non-oss'.
+ RPM files caching has been disabled for repository 'repo-non-oss'.
+ RPM files caching has been disabled for repository 'repo-oss'.
+ RPM files caching has been disabled for repository 'repo-source'.
+ RPM files caching has been disabled for repository 'repo-update'.
+ RPM files caching has been disabled for repository 'repo-update-non-oss'.
+
+18. 开启远程软件库的 rpm 文件缓存。
+
# zypper mr -kt
+ RPM files caching has been enabled for repository 'repo-debug'.
+ RPM files caching has been enabled for repository 'repo-debug-update'.
+ RPM files caching has been enabled for repository 'repo-debug-update-non-oss'.
+ RPM files caching has been enabled for repository 'repo-non-oss'.
+ RPM files caching has been enabled for repository 'repo-oss'.
+ RPM files caching has been enabled for repository 'repo-source'.
+ RPM files caching has been enabled for repository 'repo-update'.
+ RPM files caching has been enabled for repository 'repo-update-non-oss'.
# zypper in 'gcc<5.1'
+ Loading repository data...
+ Reading installed packages...
+ Resolving package dependencies...
+
+ The following 13 NEW packages are going to be installed:
+ cpp cpp48 gcc gcc48 libasan0 libatomic1-gcc49 libcloog-isl4 libgomp1-gcc49 libisl10 libitm1-gcc49 libmpc3 libmpfr4 libtsan0-gcc49
+
+ 13 new packages to install.
+ Overall download size: 14.5 MiB. Already cached: 0 B After the operation, additional 49.4 MiB will be used.
+ Continue? [y/n/? shows all options] (y): y
+
+24. 为特定的CPU架构安装软件包(以兼容 i586 的 gcc 为例)。
+
+
# zypper in gcc.i586
+ Loading repository data...
+ Reading installed packages...
+ Resolving package dependencies...
+
+ The following 13 NEW packages are going to be installed:
+ cpp cpp48 gcc gcc48 libasan0 libatomic1-gcc49 libcloog-isl4 libgomp1-gcc49 libisl10 libitm1-gcc49 libmpc3 libmpfr4 libtsan0-gcc49
+
+ 13 new packages to install.
+ Overall download size: 14.5 MiB. Already cached: 0 B After the operation, additional 49.4 MiB will be used.
+ Continue? [y/n/? shows all options] (y): y
+ Retrieving package libasan0-4.8.3+r212056-2.2.4.x86_64 (1/13), 74.2 KiB (166.9 KiB unpacked)
+ Retrieving: libasan0-4.8.3+r212056-2.2.4.x86_64.rpm .......................................................................................................................[done (79.2 KiB/s)]
+ Retrieving package libatomic1-gcc49-4.9.0+r211729-2.1.7.x86_64 (2/13), 14.3 KiB ( 26.1 KiB unpacked)
+ Retrieving: libatomic1-gcc49-4.9.0+r211729-2.1.7.x86_64.rpm ...............................................................................................................[done (55.3 KiB/s)]
# zypper in amarok upd:libxine1
+ Loading repository data...
+ Reading installed packages...
+ Resolving package dependencies...
+ The following 202 NEW packages are going to be installed:
+ amarok bundle-lang-kde-en clamz cups-libs enscript fontconfig gdk-pixbuf-query-loaders ghostscript-fonts-std gptfdisk gstreamer gstreamer-plugins-base hicolor-icon-theme
+ hicolor-icon-theme-branding-openSUSE htdig hunspell hunspell-tools icoutils ispell ispell-american kde4-filesystem kdebase4-runtime kdebase4-runtime-branding-openSUSE kdelibs4
+ kdelibs4-branding-openSUSE kdelibs4-core kdialog libakonadi4 l
+ .....
+
+27. 通过指定软件包的名字安装软件包。
+
+
# zypper in -n git
+ Loading repository data...
+ Reading installed packages...
+ Resolving package dependencies...
+
+ The following 35 NEW packages are going to be installed:
+ cvs cvsps fontconfig git git-core git-cvs git-email git-gui gitk git-svn git-web libserf-1-1 libsqlite3-0 libXft2 libXrender1 libXss1 perl-Authen-SASL perl-Clone perl-DBD-SQLite perl-DBI
+ perl-Error perl-IO-Socket-SSL perl-MLDBM perl-Net-Daemon perl-Net-SMTP-SSL perl-Net-SSLeay perl-Params-Util perl-PlRPC perl-SQL-Statement perl-Term-ReadKey subversion subversion-perl tcl
+ tk xhost
+
+ The following 13 recommended packages were automatically selected:
+ git-cvs git-email git-gui gitk git-svn git-web perl-Authen-SASL perl-Clone perl-MLDBM perl-Net-Daemon perl-Net-SMTP-SSL perl-PlRPC perl-SQL-Statement
+
+ The following package is suggested, but will not be installed:
+ git-daemon
+
+ 35 new packages to install.
+ Overall download size: 15.6 MiB. Already cached: 0 B After the operation, additional 56.7 MiB will be used.
+ Continue? [y/n/? shows all options] (y): y
+
+28. 通过通配符来安装软件包,例如,安装所有 php5 的软件包。
+
+
# zypper in php5*
+ Loading repository data...
+ Reading installed packages...
+ Resolving package dependencies...
+
+ Problem: php5-5.6.1-18.1.x86_64 requires smtp_daemon, but this requirement cannot be provided
+ uninstallable providers: exim-4.83-3.1.8.x86_64[openSUSE-13.2-0]
+ postfix-2.11.0-5.2.2.x86_64[openSUSE-13.2-0]
+ sendmail-8.14.9-2.2.2.x86_64[openSUSE-13.2-0]
+ exim-4.83-3.1.8.i586[repo-oss]
+ msmtp-mta-1.4.32-2.1.3.i586[repo-oss]
+ postfix-2.11.0-5.2.2.i586[repo-oss]
+ sendmail-8.14.9-2.2.2.i586[repo-oss]
+ exim-4.83-3.1.8.x86_64[repo-oss]
+ msmtp-mta-1.4.32-2.1.3.x86_64[repo-oss]
+ postfix-2.11.0-5.2.2.x86_64[repo-oss]
+ sendmail-8.14.9-2.2.2.x86_64[repo-oss]
+ postfix-2.11.3-5.5.1.i586[repo-update]
+ postfix-2.11.3-5.5.1.x86_64[repo-update]
+ Solution 1: Following actions will be done:
+ do not install php5-5.6.1-18.1.x86_64
+ do not install php5-pear-Auth_SASL-1.0.6-7.1.3.noarch
+ do not install php5-pear-Horde_Http-2.0.1-6.1.3.noarch
+ do not install php5-pear-Horde_Image-2.0.1-6.1.3.noarch
+ do not install php5-pear-Horde_Kolab_Format-2.0.1-6.1.3.noarch
+ do not install php5-pear-Horde_Ldap-2.0.1-6.1.3.noarch
+ do not install php5-pear-Horde_Memcache-2.0.1-7.1.3.noarch
+ do not install php5-pear-Horde_Mime-2.0.2-6.1.3.noarch
+ do not install php5-pear-Horde_Oauth-2.0.0-6.1.3.noarch
+ do not install php5-pear-Horde_Pdf-2.0.1-6.1.3.noarch
+ ....
+
+29. 使用模式名称(模式名称是一类软件包的名字)来批量安装软件包。
+
+
# zypper in -t pattern lamp_server
+ ading repository data...
+ Reading installed packages...
+ Resolving package dependencies...
+
+ The following 29 NEW packages are going to be installed:
+ apache2 apache2-doc apache2-example-pages apache2-mod_perl apache2-prefork patterns-openSUSE-lamp_server perl-Data-Dump perl-Encode-Locale perl-File-Listing perl-HTML-Parser
+ perl-HTML-Tagset perl-HTTP-Cookies perl-HTTP-Daemon perl-HTTP-Date perl-HTTP-Message perl-HTTP-Negotiate perl-IO-HTML perl-IO-Socket-SSL perl-libwww-perl perl-Linux-Pid
+ perl-LWP-MediaTypes perl-LWP-Protocol-https perl-Net-HTTP perl-Net-SSLeay perl-Tie-IxHash perl-TimeDate perl-URI perl-WWW-RobotRules yast2-http-server
+
+ The following NEW pattern is going to be installed:
+ lamp_server
+
+ The following 10 recommended packages were automatically selected:
+ apache2 apache2-doc apache2-example-pages apache2-mod_perl apache2-prefork perl-Data-Dump perl-IO-Socket-SSL perl-LWP-Protocol-https perl-TimeDate yast2-http-server
+
+ 29 new packages to install.
+ Overall download size: 7.2 MiB. Already cached: 1.2 MiB After the operation, additional 34.7 MiB will be used.
+ Continue? [y/n/? shows all options] (y):
+
+30. 使用一行命令安装一个软件包同时卸载另一个软件包,例如在安装 nano 的同时卸载 vi
+
+
# zypper in nano -vi
+ Loading repository data...
+ Reading installed packages...
+ '-vi' not found in package names. Trying capabilities.
+ Resolving package dependencies...
+
+ The following 2 NEW packages are going to be installed:
+ nano nano-lang
+
+ The following package is going to be REMOVED:
+ vim
+
+ The following recommended package was automatically selected:
+ nano-lang
+
+ 2 new packages to install, 1 to remove.
+ Overall download size: 550.0 KiB. Already cached: 0 B After the operation, 463.3 KiB will be freed.
+ Continue? [y/n/? shows all options] (y):
+ ...
+
+31. 使用 zypper 安装 rpm 软件包。
+
+
# zypper in teamviewer*.rpm
+ Loading repository data...
+ Reading installed packages...
+ Resolving package dependencies...
+
+ The following 24 NEW packages are going to be installed:
+ alsa-oss-32bit fontconfig-32bit libasound2-32bit libexpat1-32bit libfreetype6-32bit libgcc_s1-gcc49-32bit libICE6-32bit libjpeg62-32bit libpng12-0-32bit libpng16-16-32bit libSM6-32bit
+ libuuid1-32bit libX11-6-32bit libXau6-32bit libxcb1-32bit libXdamage1-32bit libXext6-32bit libXfixes3-32bit libXinerama1-32bit libXrandr2-32bit libXrender1-32bit libXtst6-32bit
+ libz1-32bit teamviewer
+
+ The following recommended package was automatically selected:
+ alsa-oss-32bit
+
+ 24 new packages to install.
+ Overall download size: 41.2 MiB. Already cached: 0 B After the operation, additional 119.7 MiB will be used.
+ Continue? [y/n/? shows all options] (y):
+ ..
zypper up apache2 openssh
+ Loading repository data...
+ Reading installed packages...
+ No update candidate for 'apache2-2.4.10-19.1.x86_64'. The highest available version is already installed.
+ No update candidate for 'openssh-6.6p1-5.1.3.x86_64'. The highest available version is already installed.
+ Resolving package dependencies...
+
+ Nothing to do.
+
+35. 安装一个软件库,例如 mariadb,如果该库存在则更新之。
+
+
# zypper in mariadb
+ Loading repository data...
+ Reading installed packages...
+ 'mariadb' is already installed.
+ No update candidate for 'mariadb-10.0.13-2.6.1.x86_64'. The highest available version is already installed.
+ Resolving package dependencies...
+
+ Nothing to do.
# zypper si mariadb
+ Reading installed packages...
+ Loading repository data...
+ Resolving package dependencies...
+
+ The following 36 NEW packages are going to be installed:
+ autoconf automake bison cmake cpp cpp48 gcc gcc48 gcc48-c++ gcc-c++ libaio-devel libarchive13 libasan0 libatomic1-gcc49 libcloog-isl4 libedit-devel libevent-devel libgomp1-gcc49 libisl10
+ libitm1-gcc49 libltdl7 libmpc3 libmpfr4 libopenssl-devel libstdc++48-devel libtool libtsan0-gcc49 m4 make ncurses-devel pam-devel readline-devel site-config tack tcpd-devel zlib-devel
+
+ The following source package is going to be installed:
+ mariadb
+
+ 36 new packages to install, 1 source package.
+ Overall download size: 71.5 MiB. Already cached: 129.5 KiB After the operation, additional 183.9 MiB will be used.
+ Continue? [y/n/? shows all options] (y): y
+
+37. 仅为某一个软件包安装源文件,例如 mariadb
+
+
# zypper in -D mariadb
+ Loading repository data...
+ Reading installed packages...
+ 'mariadb' is already installed.
+ No update candidate for 'mariadb-10.0.13-2.6.1.x86_64'. The highest available version is already installed.
+ Resolving package dependencies...
+
+ Nothing to do.
+
+38. 仅为某一个软件包安装依赖关系,例如 mariadb
+
+
# zypper si -d mariadb
+ Reading installed packages...
+ Loading repository data...
+ Resolving package dependencies...
+
+ The following 36 NEW packages are going to be installed:
+ autoconf automake bison cmake cpp cpp48 gcc gcc48 gcc48-c++ gcc-c++ libaio-devel libarchive13 libasan0 libatomic1-gcc49 libcloog-isl4 libedit-devel libevent-devel libgomp1-gcc49 libisl10
+ libitm1-gcc49 libltdl7 libmpc3 libmpfr4 libopenssl-devel libstdc++48-devel libtool libtsan0-gcc49 m4 make ncurses-devel pam-devel readline-devel site-config tack tcpd-devel zlib-devel
+
+ The following package is recommended, but will not be installed due to conflicts or dependency issues:
+ readline-doc
+
+ 36 new packages to install.
+ Overall download size: 33.7 MiB. Already cached: 129.5 KiB After the operation, additional 144.3 MiB will be used.
+ Continue? [y/n/? shows all options] (y): y
# zypper --non-interactive in mariadb
+ Loading repository data...
+ Reading installed packages...
+ 'mariadb' is already installed.
+ No update candidate for 'mariadb-10.0.13-2.6.1.x86_64'. The highest available version is already installed.
+ Resolving package dependencies...
+
+ Nothing to do.
+
+40. 卸载一个软件包,并且在卸载过程中跳过与用户的交互,例如 mariadb
+
+
# zypper --non-interactive rm mariadb
+ Loading repository data...
+ Reading installed packages...
+ Resolving package dependencies...
+
+ The following package is going to be REMOVED:
+ mariadb
+
+ 1 package to remove.
+ After the operation, 71.8 MiB will be freed.
+ Continue? [y/n/? shows all options] (y): y
+ (1/1) Removing mariadb-10.0.13-2.6.1 .............................................................................[done]
# zypper --quiet in mariadb
+ The following NEW package is going to be installed:
+ mariadb
+
+ 1 new package to install.
+ Overall download size: 0 B. Already cached: 7.8 MiB After the operation, additional 71.8 MiB will be used.
+ Continue? [y/n/? shows all options] (y):
+ ...
# zypper dist-upgrade
+ You are about to do a distribution upgrade with all enabled repositories. Make sure these repositories are compatible before you continue. See 'man zypper' for more information about this command.
+ Building repository 'openSUSE-13.2-0' cache .....................................................................[done]
+ Retrieving repository 'openSUSE-13.2-Debug' metadata ............................................................[done]
+ Building repository 'openSUSE-13.2-Debug' cache .................................................................[done]
+ Retrieving repository 'openSUSE-13.2-Non-Oss' metadata ..........................................................[done]
+ Building repository 'openSUSE-13.2-Non-Oss' cache ...............................................................[done]
The page you request is not present. Check the URL you have typed
"
-
-The above representation is also correct which places the string representing a usual html file.
-
-#### 4. Setting/Unsetting Apache server environment variables ####
-
-In .htaccess file you can set or unset the global environment variables that server allow to be modified by the hosters of the websites. For setting or unsetting the environment variables you need to add the following lines to your .htaccess files.
-
-**Setting the Environment variables**
-
- SetEnv OWNER “Gunjit Khera”
-
-Unsetting the Environment variables
-
- UnsetEnv OWNER
-
-#### 5. Defining different MIME types for files ####
-
-MIME (Multipurpose Internet Multimedia Extensions) are the types that are recognized by the browser by default when running any web page. You can define MIME types for your website in .htaccess files, so that different types of files as defined by you can be recognized and run by the server.
-
-
- AddType application/javascript js
- AddType application/x-font-ttf ttf ttc
-
-
-Here, mod_mime.c is the module for controlling definitions of different MIME types and if you have this module installed on your system then you can use this module to define different MIME types for different extensions used in your website so that server can understand them.
-
-#### 6. How to Limit the size of Uploads and Downloads in Apache ####
-
-.htaccess files allow you the feature to control the amount of data being uploaded or downloaded by a particular client from your website. For this you just need to append the following lines to your .htaccess file:
-
- php_value upload_max_filesize 20M
- php_value post_max_size 20M
- php_value max_execution_time 200
- php_value max_input_time 200
-
-The above lines set maximum upload size, maximum size of data being posted, maximum execution time i.e. the maximum time the a user is allowed to execute a website on his local machine, maximum time constrain within on the input time.
-
-#### 7. Making Users to download .mp3 and other files before playing on your website. ####
-
-Mostly, people play songs on websites before downloading them to check the song quality etc. Being a smart seller you can add a feature that can come in very handy for you which will not let any user play songs or videos online and users have to download them for playing. This is very useful as online playing of songs and videos consumes a lot of bandwidth.
-
-Following lines are needed to be added to be added to your .htaccess file:
-
- AddType application/octet-stream .mp3 .zip
-
-#### 8. Setting Directory Index for Website ####
-
-Most of website developers would already know that the first page that is displayed i.e. the home page of a website is named as ‘index.html’ .Many of us would have seen this also. But how is this set?
-
-.htaccess file provides a way to list a set of pages which would be scanned in order when a client requests to visit home page of the website and accordingly any one of the listed set of pages if found would be listed as the home page of the website and displayed to the user.
-
-Following line is needed to be added to produce the desired effect.
-
- DirectoryIndex index.html index.php yourpage.php
-
-The above line specifies that if any request for visiting the home page comes by any visitor then the above listed pages will be searched in order in the directory firstly: index.html which if found will be displayed as the sites home page, otherwise list will proceed to the next page i.e. index.php and so on till the last page you have entered in the list.
-
-#### 9. How to enable GZip compression for Files to save site’s bandwidth. ####
-
-This is a common observation that heavy sites generally run bit slowly than light weight sites that take less amount of space. This is just because for a heavy site it takes time to load the huge script files and images before displaying them on the client’s web browser.
-
-This is a common mechanism that when a browser requests a web page, server provides the browser with that webpage and now to locally display that web page, the browser has to download that page and then run the script inside that page.
-
-What GZip compression does here is saving the time required to serve a single customer thus increasing the bandwidth. The source files of the website on the server are kept in compressed form and when the request comes from a user then these files are transferred in compressed form which are then uncompressed and executed on the server. This improves the bandwidth constrain.
-
-Following lines can allow you to compress the source files of your website but this requires mod_deflate.c module to be installed on your server.
-
-
- AddOutputFilterByType DEFLATE text/plain
- AddOutputFilterByType DEFLATE text/html
- AddOutputFilterByType DEFLATE text/xml
- AddOutputFilterByType DEFLATE application/html
- AddOutputFilterByType DEFLATE application/javascript
- AddOutputFilterByType DEFLATE application/x-javascript
-
-
-#### 10. Playing with the File types. ####
-
-There are certain conditions that the server assumes by default. Like: .php files are run on the server, similarly .txt files say for example are meant to be displayed. Like this we can make some executable cgi-scripts or files to be simply displayed as the source code on our website instead of being executed.
-
-To do this observe the following lines from a .htaccess file.
-
- RemoveHandler cgi-script .php .pl .py
- AddType text/plain .php .pl .py
-
-These lines tell the server that .pl (perl script), .php (PHP file) and .py (Python file) are meant to just be displayed and not executed as cgi-scripts.
-
-#### 11. Setting the Time Zone for Apache server ####
-
-The power and importance of .htaccess files can be seen by the fact that this can be used to set the Time Zone of the server accordingly. This can be done by setting a global Environment variable ‘TZ’ of the list of global environment variables that are provided by the server to each of the hosted website for modification.
-
-Due to this reason only, we can see time on the websites (that display it) according to our time zone. May be some other person hosting his website on the server would have the timezone set according to the location where he lives.
-
-Following lines set the Time Zone of the Server.
-
- SetEnv TZ India/Kolkata
-
-#### 12. How to enable Cache Control on Website ####
-
-A very interesting feature of browser, most have observed is that on opening one website simultaneously more than one time, the latter one opens fast as compared to the first time. But how is this possible? Well in this case, the browser stores some frequently visited pages in its cache for faster access later on.
-
-But for how long? Well this answer depends on you i.e. on the time you set in your .htaccess file for Cache control. The .htaccess file can specify the amount of time for which the pages of website can stay in the browser’s cache and after expiration of time, it must revalidate i.e. pages would be deleted from the Cache and recreated the next time user visits the site.
-
-Following lines implement Cache Control for your website.
-
-
- Header Set Cache-Control "max-age=3600, public"
-
-
- Header Set Cache-Control "public"
- Header Set Expires "Sat, 24 Jan 2015 16:00:00 GMT"
-
-
-The above lines allow caching of the pages which are inside the directory in which .htaccess files are placed for 1 hour.
-
-#### 13. Configuring a single file, the option. ####
-
-Usually the content in .htaccess files apply to all the files and folders inside the directory in which the file is placed, but you can also provide some special permissions to a special file, like denying access to that file only or so on.
-
-For this you need to add tag to your file in a way like this:
-
-
- Order allow, deny
- Deny from 188.100.100.0
-
-
-This is a simple case of denying a file ‘conf.html’ from access by IP 188.100.100.0, but you can add any or every feature described for .htaccess file till now including the features yet to be described to the file like: Cache-control, GZip compression.
-
-This feature is used by most of the servers to secure .htaccess files which is the reason why we are not able to see the .htaccess files on the browsers. How the files are authenticated is demonstrated in subsequent heading.
-
-#### 14. Enabling CGI scripts to run outside of cgi-bin folder. ####
-
-Usually servers run CGI scripts that are located inside the cgi-bin folder but, you can enable running of CGI scripts located in your desired folder but just adding following lines to .htaccess file located in the desired folder and if not, then creating one, appending following lines:
-
- AddHandler cgi-script .cgi
- Options +ExecCGI
-
-#### 15. How to enable SSI on Website with .htaccess ####
-
-Server side includes as the name suggests would be related to something included at the server side. But what? Generally when we have many pages in our website and we have a navigation menu on our home page that displays links to other pages then, we can enable SSI (Server Size Includes) option that allows all the pages displayed in the navigation menu to be included with the home page completely.
-
-The SSI allows inclusion of multiple pages as if content they contain is a part of a single page so that any editing needed to be done is done in one file only which saves a lot of disk space. This option is by default enabled on servers but for .shtml files.
-
-In case you want to enable it for .html files you need to add following lines:
-
- AddHandler server-parsed .html
-
-After this following in the html file would lead to SSI.
-
-
-
-#### 16. How to Prevent website Directory Listing ####
-
-To prevent any client being able to list the directories of the website on the server at his local machine add following lines to the file inside the directory you don’t want to get listed.
-
- Options -Indexes
-
-#### 17. Changing Default charset and language headers. ####
-
-.htaccess files allow you to modify the character set used i.e. ASCII or UNICODE, UTF-8 etc. for your website along with the default language used for the display of content.
-
-Following server’s global environment variables allow you to achieve above feature.
-
- AddDefaultCharset UTF-8
- DefaultLanguage en-US
-
-**Re-writing URL’s: Redirection Rules**
-
-Re-writing feature simply means replacing the long and un-rememberable URL’s with short and easy to remember ones. But, before going into this topic there are some rules and some conventions for special symbols used later on in this article.
-
-**Special Symbols:**
-
- Symbol Meaning
- ^ - Start of the string
- $ - End of the String
- | - Or [a|b] – a or b
- [a-z] - Any of the letter between a to z
- + - One or more occurrence of previous letter
- * - Zero or more occurrence of previous letter
- ? - Zero or one occurrence of previous letter
-
-**Constants and their meaning:**
-
- Constant Meaning
- NC - No-case or case sensitive
- L - Last rule – stop processing further rules
- R - Temporary redirect to new URL
- R=301 - Permanent redirect to new URL
- F - Forbidden, send 403 header to the user
- P - Proxy – grab remote content in substitution section and return it
- G - Gone, no longer exists
- S=x - Skip next x rules
- T=mime-type - Force specified MIME type
- E=var:value - Set environment variable var to value
- H=handler - Set handler
- PT - Pass through – in case of URL’s with additional headers.
- QSA - Append query string from requested to substituted URL
-
-#### 18. Redirecting a non-www URL to a www URL. ####
-
-Before starting with the explanation, lets first see the lines that are needed to be added to .htaccess file to enable this feature.
-
- RewriteEngine ON
- RewriteCond %{HTTP_HOST} ^abc\.net$
- RewriteRule (.*) http://www.abc.net/$1 [R=301,L]
-
-The above lines enable the Rewrite Engine and then in second line check all those URL’s that pertain to host abc.net or have the HTTP_HOST environment variable set to “abc.net”.
-
-For all such URL’s the code permanently redirects them (as R=301 rule is enabled) to the new URL http://www.abc.net/$1 where $1 is the non-www URL having host as abc.net. The non-www URL is the one in bracket and is referred by $1.
-
-#### 19. Redirecting entire website to https. ####
-
-Following lines will help you transfer entire website to https:
-
- RewriteEngine ON
- RewriteCond %{HTTPS} !on
- RewriteRule (.*) https://%{HTTP_HOST}%{REQUEST_URI}
-
-The above lines enable the re-write engine and then check the value of HTTPS environment variable. If it is on then re-write the entire pages of the website to https.
-
-#### 20. A custom redirection example ####
-
-For example, redirect url ‘http://www.abc.net?p=100&q=20 ‘ to ‘http://www.abc.net/10020pq’.
-
- RewriteEngine ON
- RewriteRule ^http://www.abc.net/([0-9]+)([0-9]+)pq$ ^http://www.abc.net?p=$1&q=$2
-
-In above lines, $1 represents the first bracket and $2 represents the second bracket.
-
-#### 21. Renaming the htaccess file ####
-
-For preventing the .htaccess file from the intruders and other people from viewing those files you can rename that file so that it is not accessed by client’s browser. The line that does this is:
-
- AccessFileName htac.cess
-
-#### 22. How to Prevent Image Hotlinking for your Website ####
-
-Another problem that is major factor of large bandwidth consumption by the websites is the problem of hot links which are links to your websites by other websites for display of images mostly of your website which consumes your bandwidth. This problem is also called as ‘bandwidth theft’.
-
-A common observation is when a site displays the image contained in some other site due to this hot-linking your site needs to be loaded and at the stake of your site’s bandwidth, the other site’s images are displayed. To prevent this for like: images such as: .gif, .jpeg etc. following lines of code would help:
-
- RewriteEngine ON
- RewriteCond %{HTTP_REFERER} !^$
- RewriteCond %{HTTP_REFERERER} !^http://(www\.)?mydomain.com/.*$ [NC]
- RewriteRule \.(gif|jpeg|png)$ - [F].
-
-The above lines check if the HTTP_REFERER is not set to blank or not set to any of the links in your websites. If this is happening then all the images in your page are replaced by 403 forbidden.
-
-#### 23. How to Redirect Users to Maintenance Page. ####
-
-In case your website is down for maintenance and you want to notify all your clients that need to access your websites about this then for such cases you can add following lines to your .htaccess websites that allow only admin access and replace the site pages having links to any .jpg, .css, .gif, .js etc.
-
- RewriteCond %{REQUEST_URI} !^/admin/ [NC]
- RewriteCond %{REQUEST_URI} !^((.*).css|(.*).js|(.*).png|(.*).jpg) [NC]
- RewriteRule ^(.*)$ /ErrorDocs/Maintainence_Page.html
- [NC,L,U,QSA]
-
-These lines check if the Requested URL contains any request for any admin page i.e. one starting with ‘/admin/’ or any request to ‘.png, .jpg, .js, .css’ pages and for any such requests it replaces that page to ‘ErrorDocs/Maintainence_Page.html’.
-
-#### 24. Mapping IP Address to Domain Name ####
-
-Name servers are the servers that convert a specific IP Address to a domain name. This mapping can also be specified in the .htaccess files in the following manner.
-
- For Mapping L.M.N.O address to a domain name www.hellovisit.com
- RewriteCond %{HTTP_HOST} ^L\.M\.N\.O$ [NC]
- RewriteRule ^(.*)$ http://www.hellovisit.com/$1 [L,R=301]
-
-The above lines check if the host for any page is having the IP Address as: L.M.N.O and if so the page is mapped to the domain name http://www.hellovisit.com by the third line by permanent redirection.
-
-#### 25. FilesMatch Tag ####
-
-Like tag that is used to apply conditions to a single file, can be used to match to a group of files and apply some conditions to the group of files as below:
-
-
- Order Allow, Deny
- Deny from All
-
-
-### Conclusion ###
-
-The list of tricks that can be done with .htaccess files is much more. Thus, this gives us an idea how powerful this file is and how much security and dynamicity and other features it can give to your website.
-
-We’ve tried our best to cover as much as htaccess tricks in this article, but incase if we’ve missed any important trick, or you most welcome to post your htaccess ideas and tricks that you know via comments section below – we will include those in our article too…
-
---------------------------------------------------------------------------------
-
-via: http://www.tecmint.com/apache-htaccess-tricks/
-
-作者:[Gunjit Khera][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://www.tecmint.com/author/gunjitk94/
\ No newline at end of file
diff --git a/sources/tech/20150128 Docker-2 Setting up a private Docker registry.md b/sources/tech/20150128 Docker-2 Setting up a private Docker registry.md
deleted file mode 100644
index 9a9341b4b7..0000000000
--- a/sources/tech/20150128 Docker-2 Setting up a private Docker registry.md
+++ /dev/null
@@ -1,241 +0,0 @@
-Setting up a private Docker registry
-================================================================================
-
-
-[TL;DR] This is the second post in a series of 3 on how my company moved its infrastructure from PaaS to Docker based deployment.
-
-- [First part][1]: where I talk about the process we went thru before approaching Docker;
-- [Third pard][2]: where I show how to automate the entire process of building images and deploying a Rails app with Docker.
-
-----------
-
-Why would ouy want ot set up a provate registry? Well, for starters, Docker Hub only allows you to have one free private repo. Other companies are beginning to offer similar services, but they are all not very cheap. In addition, if you need to deploy production ready applications built with Docker, you might not want to publish those images on the public Docker Hub.
-
-This is a very pragmatic approach to dealing with the intricacies of setting up a private Docker registry. For the tutorial we will be using a small 512MB instance on DigitalOcean (from now on DO). I also assume you already know the basics of Docker since I will be concentrating on some more complicated stuff.
-
-### Local set up ###
-
-First of all you need to install **boot2docker** and docker CLI. If you already have your basic Docker environment up and running, you can just skip to the next section.
-
-From the terminal run the following command[1][3]:
-
- brew install boot2docker docker
-
-If everything is ok[2][4], you will now be able to start the VM inside which Docker will run with the following command:
-
- boot2docker up
-
-Follow the instructions, copy and paste the export commands that boot2docker will print in the terminal. If you now run `docker ps` you should be greeted by the following line
-
- CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
-
-Ok, Docker is ready to go. This will be enough for the moment. Let's go back to setting up the registry.
-
-### Creating the server ###
-
-Log into you DO account and create a new Droplet by selecting an image with Docker pre-installed[^n].
-
-
-
-You should receive your root credentials via email. Log into your instance and run `docker ps` to see if eveything is ok.
-
-### Setting up AWS S3 ###
-
-We are going to use Amazon Simple Storage Service (S3) as the storage layer for our registry / repository. We will need to create a bucket and user credentials to allow our docker container accessoing it.
-
-Login into your AWS account (if you don't have one you can set one up at [http://aws.amazon.com/][5]) and from the console select S3 (Simple Storage Service).
-
-
-
-Click on **Create Bucket**, enter a unique name for your bucket (and write it down, we're gonna need it later), then click on **Create**.
-
-
-
-That's it! We're done setting up the storage part.
-
-### Setup AWS access credentials ###
-
-We are now going to create a new user. Go back to your AWS console and select IAM (Identity & Access Management).
-
-
-
-In the dashboard, on the left side of the webpage, you should click on Users. Then select **Create New Users**.
-
-You should be presented with the following screen:
-
-
-
-Enter a name for your user (e.g. docker-registry) and click on Create. Write down (or download the csv file with) your Access Key and Secret Access Key that we'll need when running the Docker container. Go back to your users list and select the one you just created.
-
-Under the Permission section, click on Attach User Policy. In the next screen, you will be presented with multiple choices: select Custom Policy.
-
-
-
-Here's the content of the custom policy:
-
- {
- "Version": "2012-10-17",
- "Statement": [
- {
- "Sid": "SomeStatement",
- "Effect": "Allow",
- "Action": [
- "s3:*"
- ],
- "Resource": [
- "arn:aws:s3:::docker-registry-bucket-name/*",
- "arn:aws:s3:::docker-registry-bucket-name"
- ]
- }
- ]
- }
-
-This will allow the user (i.e. the registry) to manage (read/write) content on the bucket (make sure to use the bucket name you previously defined when setting up AWS S3). To sum it up: when you'll be pushing Docker images from your local machine to your repository, the server will be able to upload them to S3.
-
-### Installing the registry ###
-
-Now let's head back to our DO server and SSH into it. We are going to use[^n] one of the [official Docker registry images][6].
-
-Let's start our registry with the following command:
-
- docker run \
- -e SETTINGS_FLAVOR=s3 \
- -e AWS_BUCKET=bucket-name \
- -e STORAGE_PATH=/registry \
- -e AWS_KEY=your_aws_key \
- -e AWS_SECRET=your_aws_secret \
- -e SEARCH_BACKEND=sqlalchemy \
- -p 5000:5000 \
- --name registry \
- -d \
- registry
-
-Docker should pull the required fs layers from the Docker Hub and eventually start the daemonised container.
-
-### Testing the registry ###
-
-If everything worked out, you should now be able to test the registry by pinging it and by searching its content (though for the time being it's still empty).
-
-Our registry is very basic and it does not provide any means of authentication. Since there are no easy ways of adding authentication (at least none that I'm aware of that are easy enough to implment in order to justify the effort), I've decided that the easiest way of querying / pulling / pushing the registry is an unsecure (over HTTP) connection tunneled thru SSH.
-
-Opening an SSH tunnel from your local machine is straightforward:
-
- ssh -N -L 5000:localhost:5000 root@your_registry.com
-
-The command is tunnelling connections over SSH from port 5000 of the registry server (which is the one we exposed with the `docker run` command in the previous paragraph) to port 5000 on the localhost.
-
-If you now browse to the following address [http://localhost:5000/v1/_ping][7] you should get the following very simple response
-
- {}
-
-This just means that the registry is working correctly. You can also list the whole content of the registry by browsing to [http://localhost:5000/v1/search][8] that will get you a similar response:
-
- {
- "num_results": 2,
- "query": "",
- "results": [
- {
- "description": "",
- "name": "username/first-repo"
- },
- {
- "description": "",
- "name": "username/second-repo"
- }
- ]
- }
-
-### Building an image ###
-
-Let's now try and build a very simple Docker image to test our newly installed registry. On your local machine, create a Dockerfile with the following content[^n]:
-
- # Base image with ruby 2.2.0
- FROM ruby:2.2.0
-
- MAINTAINER Michelangelo Chasseur
-
-...and build it:
-
- docker build -t localhost:5000/username/repo-name .
-
-The `localhost:5000` part is especially important: the first part of the name of a Docker image will tell the `docker push` command the endpoint towards which we are trying to push our image. In our case, since we are connecting to our remote private registry via an SSH tunnel, `localhost:5000` represents exactly the reference to our registry.
-
-If everything works as expected, when the command returns, you should be able to list your newly created image with the `docker images` command. Run it and see it for yourself.
-
-### Pushing to the registry ###
-
-Now comes the trickier part. It took a me a while to realize what I'm about to describe, so just be patient if you don't get it the first time you read and try to follow along. I know that all this stuff will seem pretty complicated (and it would be if you didn't automate the process), but I promise in the end it will all make sense. In the next post I will show a couple of shell scripts and Rake tasks that will automate the whole process and will let you deploy a Rails to your registry app with a single easy command.
-
-The docker command you are running from your terminal is actually using the boot2docker VM to run the containers and do all the magic stuff. So when we run a command like `docker push some_repo` what is actually happening is that it's the boot2docker VM that is reacing out for the registry, not our localhost.
-
-This is an extremely important point to understand: in order to push the Docker image to the remote private registry, the SSH tunnel needs to be established from the boot2docker VM and not from your local machine.
-
-There are a couple of ways to go with it. I will show you the shortest one (which is not probably the easiest to understand, but it's the one that will let us automate the process with shell scripts).
-
-First of all though we need to sort one last thing with SSH.
-
-### Setting up SSH ###
-
-Let's add our boot2docker SSH key to our remote server (registry) known hosts. We can do so using the ssh-copy-id utility that you can install with the following command shouldn't you already have it:
-
- brew install ssh-copy-id
-
-Then run:
-
- ssh-copy-id -i /Users/username/.ssh/id_boot2docker root@your-registry.com
-
-Make sure to substitute `/Users/username/.ssh/id_boot2docker` with the correct path of your ssh key.
-
-This will allow us to connect via SSH to our remote registry without being prompted for the password.
-
-Finally let's test it out:
-
- boot2docker ssh "ssh -o 'StrictHostKeyChecking no' -i /Users/michelangelo/.ssh/id_boot2docker -N -L 5000:localhost:5000 root@registry.touchwa.re &" &
-
-To break things out a little bit:
-
-- `boot2docker ssh` lets you pass a command as a parameter that will be executed by the boot2docker VM;
-- the final `&` indicates that we want our command to be executed in the background;
-- `ssh -o 'StrictHostKeyChecking no' -i /Users/michelangelo/.ssh/id_boot2docker -N -L 5000:localhost:5000 root@registry.touchwa.re &` is the actual command our boot2docker VM will run;
- - the `-o 'StrictHostKeyChecking no'` will make sure that we are not prompted with security questions;
- - the `-i /Users/michelangelo/.ssh/id_boot2docker` indicates which SSH key we want our VM to use for authentication purposes (note that this should be the key you added to your remote registry in the previous step);
- - finally we are opening a tunnel on mapping port 5000 to localhost:5000.
-
-### Pulling from another server ###
-
-You should now be able to push your image to the remote registry by simply issuing the following command:
-
- docker push localhost:5000/username/repo_name
-
-In the [next post][9] we'll se how to automate some of this stuff and we'll containerize a real Rails application. Stay tuned!
-
-P.S. Please use the comments to let me know of any inconsistencies or fallacies in my tutorial. Hope you enjoyed it!
-
-1. I'm also assuming you are running on OS X.
-1. For a complete list of instructions to set up your docker environment and requirements, please visit [http://boot2docker.io/][10]
-1. Select Image > Applications > Docker 1.4.1 on 14.04 at the time of this writing.
-1. [https://github.com/docker/docker-registry/][11]
-1. This is just a stub, in the next post I will show you how to bundle a Rails application into a Docker container.
-
---------------------------------------------------------------------------------
-
-via: http://cocoahunter.com/2015/01/23/docker-2/
-
-作者:[Michelangelo Chasseur][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://cocoahunter.com/author/michelangelo/
-[1]:http://cocoahunter.com/2015/01/23/docker-1/
-[2]:http://cocoahunter.com/2015/01/23/docker-3/
-[3]:http://cocoahunter.com/2015/01/23/docker-2/#fn:1
-[4]:http://cocoahunter.com/2015/01/23/docker-2/#fn:2
-[5]:http://aws.amazon.com/
-[6]:https://registry.hub.docker.com/_/registry/
-[7]:http://localhost:5000/v1/_ping
-[8]:http://localhost:5000/v1/search
-[9]:http://cocoahunter.com/2015/01/23/docker-3/
-[10]:http://boot2docker.io/
-[11]:https://github.com/docker/docker-registry/
\ No newline at end of file
diff --git a/sources/tech/20150128 Docker-3 Automated Docker-based Rails deployments.md b/sources/tech/20150128 Docker-3 Automated Docker-based Rails deployments.md
deleted file mode 100644
index f450361a68..0000000000
--- a/sources/tech/20150128 Docker-3 Automated Docker-based Rails deployments.md
+++ /dev/null
@@ -1,253 +0,0 @@
-Automated Docker-based Rails deployments
-================================================================================
-
-
-[TL;DR] This is the third post in a series of 3 on how my company moved its infrastructure from PaaS to Docker based deployment.
-
-- [First part][1]: where I talk about the process we went thru before approaching Docker;
-- [Second part][2]: where I explain how setting up a private registry for in house secure deployments.
-
-----------
-
-In this final part we will see how to automate the whole deployment process with a real world (though very basic) example.
-
-### Basic Rails app ###
-
-Let's dive into the topic right away and bootstrap a basic Rails app. For the purpose of this demonstration I'm going to use Ruby 2.2.0 and Rails 4.1.1
-
-From the terminal run:
-
- $ rvm use 2.2.0
- $ rails new && cd docker-test
-
-Let's create a basic controller:
-
- $ rails g controller welcome index
-
-...and edit `routes.rb` so that the root of the project will point to our newly created welcome#index method:
-
- root 'welcome#index'
-
-Running `rails s` from the terminal and browsing to [http://localhost:3000][3] should bring you to the index page. We're not going to make anything fancier to the app, it's just a basic example to prove that when we'll build and deploy the container everything is working.
-
-### Setup the webserver ###
-
-We are going to use Unicorn as our webserver. Add `gem 'unicorn'` and `gem 'foreman'` to the Gemfile and bundle it up (run `bundle install` from the command line).
-
-Unicorn needs to be configured when the Rails app launches, so let's put a **unicorn.rb** file inside the **config** directory. [Here is an example][4] of a Unicorn configuration file. You can just copy & paste the content of the Gist.
-
-Let's also add a Procfile with the following content inside the root of the project so that we will be able to start the app with foreman:
-
- web: bundle exec unicorn -p $PORT -c ./config/unicorn.rb
-
-If you now try to run the app with **foreman start** everything should work as expected and you should have a running app on [http://localhost:5000][5]
-
-### Building a Docker image ###
-
-Now let's build the image inside which our app is going to live. In the root of our Rails project, create a file named **Dockerfile** and paste in it the following:
-
- # Base image with ruby 2.2.0
- FROM ruby:2.2.0
-
- # Install required libraries and dependencies
- RUN apt-get update && apt-get install -qy nodejs postgresql-client sqlite3 --no-install-recommends && rm -rf /var/lib/apt/lists/*
-
- # Set Rails version
- ENV RAILS_VERSION 4.1.1
-
- # Install Rails
- RUN gem install rails --version "$RAILS_VERSION"
-
- # Create directory from where the code will run
- RUN mkdir -p /usr/src/app
- WORKDIR /usr/src/app
-
- # Make webserver reachable to the outside world
- EXPOSE 3000
-
- # Set ENV variables
- ENV PORT=3000
-
- # Start the web app
- CMD ["foreman","start"]
-
- # Install the necessary gems
- ADD Gemfile /usr/src/app/Gemfile
- ADD Gemfile.lock /usr/src/app/Gemfile.lock
- RUN bundle install --without development test
-
- # Add rails project (from same dir as Dockerfile) to project directory
- ADD ./ /usr/src/app
-
- # Run rake tasks
- RUN RAILS_ENV=production rake db:create db:migrate
-
-Using the provided Dockerfile, let's try and build an image with the following command[1][7]:
-
- $ docker build -t localhost:5000/your_username/docker-test .
-
-And again, if everything worked out correctly, the last line of the long log output should read something like:
-
- Successfully built 82e48769506c
- $ docker images
- REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE
- localhost:5000/your_username/docker-test latest 82e48769506c About a minute ago 884.2 MB
-
-Let's try and run the container!
-
- $ docker run -d -p 3000:3000 --name docker-test localhost:5000/your_username/docker-test
-
-You should be able to reach your Rails app running inside the Docker container at port 3000 of your boot2docker VM[2][8] (in my case [http://192.168.59.103:3000][6]).
-
-### Automating with shell scripts ###
-
-Since you should already know from the previous post3 how to push your newly created image to a private regisitry and deploy it on a server, let's skip this part and go straight to automating the process.
-
-We are going to define 3 shell scripts and finally tie it all together with rake.
-
-### Clean ###
-
-Every time we build our image and deploy we are better off always clean everything. That means the following:
-
-- stop (if running) and restart boot2docker;
-- remove orphaned Docker images (images that are without tags and that are no longer used by your containers).
-
-Put the following into a **clean.sh** file in the root of your project.
-
- echo Restarting boot2docker...
- boot2docker down
- boot2docker up
-
- echo Exporting Docker variables...
- sleep 1
- export DOCKER_HOST=tcp://192.168.59.103:2376
- export DOCKER_CERT_PATH=/Users/user/.boot2docker/certs/boot2docker-vm
- export DOCKER_TLS_VERIFY=1
-
- sleep 1
- echo Removing orphaned images without tags...
- docker images | grep "" | awk '{print $3}' | xargs docker rmi
-
-Also make sure to make the script executable:
-
- $ chmod +x clean.sh
-
-### Build ###
-
-The build process basically consists in reproducing what we just did before (docker build). Create a **build.sh** script at the root of your project with the following content:
-
- docker build -t localhost:5000/your_username/docker-test .
-
-Make the script executable.
-
-### Deploy ###
-
-Finally, create a **deploy.sh** script with this content:
-
- # Open SSH connection from boot2docker to private registry
- boot2docker ssh "ssh -o 'StrictHostKeyChecking no' -i /Users/username/.ssh/id_boot2docker -N -L 5000:localhost:5000 root@your-registry.com &" &
-
- # Wait to make sure the SSH tunnel is open before pushing...
- echo Waiting 5 seconds before pushing image.
-
- echo 5...
- sleep 1
- echo 4...
- sleep 1
- echo 3...
- sleep 1
- echo 2...
- sleep 1
- echo 1...
- sleep 1
-
- # Push image onto remote registry / repo
- echo Starting push!
- docker push localhost:5000/username/docker-test
-
-If you don't understand what's going on here, please make sure you've read thoroughfully [part 2][9] of this series of posts.
-
-Make the script executable.
-
-### Tying it all together with rake ###
-
-Having 3 scripts would now require you to run them individually each time you decide to deploy your app:
-
-1. clean
-1. build
-1. deploy / push
-
-That wouldn't be much of an effort, if it weren't for the fact that developers are lazy! And lazy be it, then!
-
-The final step to wrap things up, is tying the 3 parts together with rake.
-
-To make things even simpler you can just append a bunch of lines of code to the end of the already present Rakefile in the root of your project. Open the Rakefile file - pun intended :) - and paste the following:
-
- namespace :docker do
- desc "Remove docker container"
- task :clean do
- sh './clean.sh'
- end
-
- desc "Build Docker image"
- task :build => [:clean] do
- sh './build.sh'
- end
-
- desc "Deploy Docker image"
- task :deploy => [:build] do
- sh './deploy.sh'
- end
- end
-
-Even if you don't know rake syntax (which you should, because it's pretty awesome!), it's pretty obvious what we are doing. We have declared 3 tasks inside a namespace (docker).
-
-This will create the following 3 tasks:
-
-- rake docker:clean
-- rake docker:build
-- rake docker:deploy
-
-Deploy is dependent on build, build is dependent on clean. So every time we run from the command line
-
- $ rake docker:deploy
-
-All the script will be executed in the required order.
-
-### Test it ###
-
-To see if everything is working, you just need to make a small change in the code of your app and run
-
- $ rake docker:deploy
-
-and see the magic happening. Once the image has been uploaded (and the first time it could take quite a while), you can ssh into your production server and pull (thru an SSH tunnel) the docker image onto the server and run. It's that easy!
-
-Well, maybe it takes a while to get accustomed to how everything works, but once it does, it's almost (almost) as easy as deploying with Heroku.
-
-P.S. As always, please let me have your ideas. I'm not sure this is the best, or the fastest, or the safest way of doing devops with Docker, but it certainly worked out for us.
-
-- make sure to have **boot2docker** up and running.
-- If you don't know your boot2docker VM address, just run `$ boot2docker ip`
-- if you don't, you can read it [here][10]
-
---------------------------------------------------------------------------------
-
-via: http://cocoahunter.com/2015/01/23/docker-3/
-
-作者:[Michelangelo Chasseur][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://cocoahunter.com/author/michelangelo/
-[1]:http://cocoahunter.com/docker-1
-[2]:http://cocoahunter.com/2015/01/23/docker-2/
-[3]:http://localhost:3000/
-[4]:https://gist.github.com/chasseurmic/0dad4d692ff499761b20
-[5]:http://localhost:5000/
-[6]:http://192.168.59.103:3000/
-[7]:http://cocoahunter.com/2015/01/23/docker-3/#fn:1
-[8]:http://cocoahunter.com/2015/01/23/docker-3/#fn:2
-[9]:http://cocoahunter.com/2015/01/23/docker-2/
-[10]:http://cocoahunter.com/2015/01/23/docker-2/
\ No newline at end of file
diff --git a/sources/tech/20150202 How to Bind Apache Tomcat to IPv4 in Centos or Redhat.md b/sources/tech/20150202 How to Bind Apache Tomcat to IPv4 in Centos or Redhat.md
deleted file mode 100644
index 92ac657b5a..0000000000
--- a/sources/tech/20150202 How to Bind Apache Tomcat to IPv4 in Centos or Redhat.md
+++ /dev/null
@@ -1,79 +0,0 @@
-How to Bind Apache Tomcat to IPv4 in Centos / Redhat
-================================================================================
-Hi all, today we'll learn how to bind tomcat to ipv4 in CentOS 7 Linux Distribution.
-
-**Apache Tomcat** is an open source web server and servlet container developed by the [Apache Software Foundation][1]. It implements the Java Servlet, JavaServer Pages (JSP), Java Unified Expression Language and Java WebSocket specifications from Sun Microsystems and provides a web server environment for Java code to run in.
-
-Binding Tomcat to IPv4 is necessary if we have our server not working due to the default binding of our tomcat server to IPv6. As we know IPv6 is the modern way of assigning IP address to a device and is not in complete practice these days but may come into practice in soon future. So, currently we don't need to switch our tomcat server to IPv6 due to no use and we should bind it to IPv4.
-
-Before thinking to bind to IPv4, we should make sure that we've got tomcat installed in our CentOS 7. Here's is a quick tutorial on [how to install tomcat 8 in CentOS 7.0 Server][2].
-
-### 1. Switching to user tomcat ###
-
-First of all, we'll gonna switch user to **tomcat** user. We can do that by running **su - tomcat** in a shell or terminal.
-
- # su - tomcat
-
-
-
-### 2. Finding Catalina.sh ###
-
-Now, we'll First Go to bin directory inside the directory of Apache Tomcat installation which is usually under **/usr/share/apache-tomcat-8.0.x/bin/** where x is sub version of the Apache Tomcat Release. In my case, its **/usr/share/apache-tomcat-8.0.18/bin/** as I have version 8.0.18 installed in my CentOS 7 Server.
-
- $ cd /usr/share/apache-tomcat-8.0.18/bin
-
-**Note: Please replace 8.0.18 to the version of Apache Tomcat installed in your system. **
-
-Inside the bin folder, there is a script file named catalina.sh . Thats the script file which we'll gonna edit and add a line of configuration which will bind tomcat to IPv4 . You can see that file by running **ls** into a terminal or shell.
-
- $ ls
-
-
-
-### 3. Configuring Catalina.sh ###
-
-Now, we'll add **JAVA_OPTS= "$JAVA_OPTS -Djava.net.preferIPv4Stack=true -Djava.net.preferIPv4Addresses"** to that scripting file catalina.sh at the end of the file as shown in the figure below. We can edit the file using our favorite text editing software like nano, vim, etc. Here, we'll gonna use nano.
-
- $ nano catalina.sh
-
-
-
-Then, add to the file as shown below:
-
-**JAVA_OPTS= "$JAVA_OPTS -Djava.net.preferIPv4Stack=true -Djava.net.preferIPv4Addresses"**
-
-
-
-Now, as we've added the configuration to the file, we'll now save and exit nano.
-
-### 4. Restarting ###
-
-Now, we'll restart our tomcat server to get our configuration working. We'll need to first execute shutdown.sh and then startup.sh .
-
- $ ./shutdown.sh
-
-Now, well run execute startup.sh as:
-
- $ ./startup.sh
-
-
-
-This will restart our tomcat server and the configuration will be loaded which will ultimately bind the server to IPv4.
-
-### Conclusion ###
-
-Hurray, finally we'have got our tomcat server bind to IPv4 running in our CentOS 7 Linux Distribution. Binding to IPv4 is easy and is necessary if your Tomcat server is bind to IPv6 which will infact will make your tomcat server not working as IPv6 is not used these days and may come into practice in coming future. If you have any questions, comments, feedback please do write on the comment box below and let us know what stuffs needs to be added or improved. Thank You! Enjoy :-)
-
---------------------------------------------------------------------------------
-
-via: http://linoxide.com/linux-how-to/bind-apache-tomcat-ipv4-centos/
-
-作者:[Arun Pyasi][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://linoxide.com/author/arunp/
-[1]:http://www.apache.org/
-[2]:http://linoxide.com/linux-how-to/install-tomcat-8-centos-7/
\ No newline at end of file
diff --git a/sources/tech/20150202 How to filter BGP routes in Quagga BGP router.md b/sources/tech/20150202 How to filter BGP routes in Quagga BGP router.md
deleted file mode 100644
index d92c47c774..0000000000
--- a/sources/tech/20150202 How to filter BGP routes in Quagga BGP router.md
+++ /dev/null
@@ -1,201 +0,0 @@
-How to filter BGP routes in Quagga BGP router
-================================================================================
-In the [previous tutorial][1], we demonstrated how to turn a CentOS box into a BGP router using Quagga. We also covered basic BGP peering and prefix exchange setup. In this tutorial, we will focus on how we can control incoming and outgoing BGP prefixes by using **prefix-list** and **route-map**.
-
-As described in earlier tutorials, BGP routing decisions are made based on the prefixes received/advertised. To ensure error-free routing, it is recommended that you use some sort of filtering mechanism to control these incoming and outgoing prefixes. For example, if one of your BGP neighbors starts advertising prefixes which do not belong to them, and you accept such bogus prefixes by mistake, your traffic can be sent to that wrong neighbor, and end up going nowhere (so-called "getting blackholed"). To make sure that such prefixes are not received or advertised to any neighbor, you can use prefix-list and route-map. The former is a prefix-based filtering mechanism, while the latter is a more general prefix-based policy mechanism used to fine-tune actions.
-
-We will show you how to use prefix-list and route-map in Quagga.
-
-### Topology and Requirement ###
-
-In this tutorial, we assume the following topology.
-
-
-
-Service provider A has already established an eBGP peering with service provider B, and they are exchanging routing information between them. The AS and prefix details are as stated below.
-
-- **Peering block**: 192.168.1.0/24
-- **Service provider A**: AS 100, prefix 10.10.0.0/16
-- **Service provider B**: AS 200, prefix 10.20.0.0/16
-
-In this scenario, service provider B wants to receive only prefixes 10.10.10.0/23, 10.10.10.0/24 and 10.10.11.0/24 from provider A.
-
-### Quagga Installation and BGP Peering ###
-
-In the [previous tutorial][1], we have already covered the method of installing Quagga and setting up BGP peering. So we will not go through the details here. Nonetheless, I am providing a summary of BGP configuration and prefix advertisements:
-
-
-
-The above output indicates that the BGP peering is up. Router-A is advertising multiple prefixes towards router-B. Router-B, on the other hand, is advertising a single prefix 10.20.0.0/16 to router-A. Both routers are receiving the prefixes without any problems.
-
-### Creating Prefix-List ###
-
-In a router, a prefix can be blocked with either an ACL or prefix-list. Using prefix-list is often preferred to ACLs since prefix-list is less processor intensive than ACLs. Also, prefix-list is easier to create and maintain.
-
- ip prefix-list DEMO-PRFX permit 192.168.0.0/23
-
-The above command creates prefix-list called 'DEMO-FRFX' that allows only 192.168.0.0/23.
-
-Another great feature of prefix-list is that we can specify a range of subnet mask(s). Take a look at the following example:
-
- ip prefix-list DEMO-PRFX permit 192.168.0.0/23 le 24
-
-The above command creates prefix-list called 'DEMO-PRFX' that permits prefixes between 192.168.0.0/23 and /24, which are 192.168.0.0/23, 192.168.0.0/24 and 192.168.1.0/24. The 'le' operator means less than or equal to. You can also use 'ge' operator for greater than or equal to.
-
-A single prefix-list statement can have multiple permit/deny actions. Each statement is assigned a sequence number which can be determined automatically or specified manually.
-
-Multiple prefix-list statements are parsed one by one in the increasing order of sequence numbers. When configuring prefix-list, we should keep in mind that there is always an **implicit deny** at the end of all prefix-list statements. This means that anything that is not explicitly allowed will be denied.
-
-To allow everything, we can use the following prefix-list statement which allows any prefix starting from 0.0.0.0/0 up to anything with subnet mask /32.
-
- ip prefix-list DEMO-PRFX permit 0.0.0.0/0 le 32
-
-Now that we know how to create prefix-list statements, we will create prefix-list called 'PRFX-LST' that will allow prefixes required in our scenario.
-
- router-b# conf t
- router-b(config)# ip prefix-list PRFX-LST permit 10.10.10.0/23 le 24
-
-### Creating Route-Map ###
-
-Besides prefix-list and ACLs, there is yet another mechanism called route-map, which can control prefixes in a BGP router. In fact, route-map can fine-tune possible actions more flexibly on the prefixes matched with an ACL or prefix-list.
-
-Similar to prefix-list, a route-map statement specifies permit or deny action, followed by a sequence number. Each route-map statement can have multiple permit/deny actions with it. For example:
-
- route-map DEMO-RMAP permit 10
-
-The above statement creates route-map called 'DEMO-RMAP', and adds permit action with sequence 10. Now we will use match command under sequence 10.
-
- router-a(config-route-map)# match (press ? in the keyboard)
-
-----------
-
- as-path Match BGP AS path list
- community Match BGP community list
- extcommunity Match BGP/VPN extended community list
- interface match first hop interface of route
- ip IP information
- ipv6 IPv6 information
- metric Match metric of route
- origin BGP origin code
- peer Match peer address
- probability Match portion of routes defined by percentage value
- tag Match tag of route
-
-As we can see, route-map can match many attributes. We will match a prefix in this tutorial.
-
- route-map DEMO-RMAP permit 10
- match ip address prefix-list DEMO-PRFX
-
-The match command will match the IP addresses permitted by the prefix-list 'DEMO-PRFX' created earlier (i.e., prefixes 192.168.0.0/23, 192.168.0.0/24 and 192.168.1.0/24).
-
-Next, we can modify the attributes by using the set command. The following example shows possible use cases of set.
-
- route-map DEMO-RMAP permit 10
- match ip address prefix-list DEMO-PRFX
- set (press ? in keyboard)
-
-----------
-
- aggregator BGP aggregator attribute
- as-path Transform BGP AS-path attribute
- atomic-aggregate BGP atomic aggregate attribute
- comm-list set BGP community list (for deletion)
- community BGP community attribute
- extcommunity BGP extended community attribute
- forwarding-address Forwarding Address
- ip IP information
- ipv6 IPv6 information
- local-preference BGP local preference path attribute
- metric Metric value for destination routing protocol
- metric-type Type of metric
- origin BGP origin code
- originator-id BGP originator ID attribute
- src src address for route
- tag Tag value for routing protocol
- vpnv4 VPNv4 information
- weight BGP weight for routing table
-
-As we can see, the set command can be used to change many attributes. For a demonstration purpose, we will set BGP local preference.
-
- route-map DEMO-RMAP permit 10
- match ip address prefix-list DEMO-PRFX
- set local-preference 500
-
-Just like prefix-list, there is an implicit deny at the end of all route-map statements. So we will add another permit statement in sequence number 20 to permit everything.
-
- route-map DEMO-RMAP permit 10
- match ip address prefix-list DEMO-PRFX
- set local-preference 500
- !
- route-map DEMO-RMAP permit 20
-
-The sequence number 20 does not have a specific match command, so it will, by default, match everything. Since the decision is permit, everything will be permitted by this route-map statement.
-
-If you recall, our requirement is to only allow/deny some prefixes. So in our scenario, the set command is not necessary. We will just use one permit statement as follows.
-
- router-b# conf t
- router-b(config)# route-map RMAP permit 10
- router-b(config-route-map)# match ip address prefix-list PRFX-LST
-
-This route-map statement should do the trick.
-
-### Applying Route-Map ###
-
-Keep in mind that ACLs, prefix-list and route-map are not effective unless they are applied to an interface or a BGP neighbor. Just like ACLs or prefix-list, a single route-map statement can be used with any number of interfaces or neighbors. However, any one interface or a neighbor can support only one route-map statement for inbound, and one for outbound traffic.
-
-We will apply the created route-map to the BGP configuration of router-B for neighbor 192.168.1.1 with incoming prefix advertisement.
-
- router-b# conf terminal
- router-b(config)# router bgp 200
- router-b(config-router)# neighbor 192.168.1.1 route-map RMAP in
-
-Now, we check the routes advertised and received by using the following commands.
-
-For advertised routes:
-
- show ip bgp neighbor-IP advertised-routes
-
-For received routes:
-
- show ip bgp neighbor-IP routes
-
-
-
-You can see that while router-A is advertising four prefixes towards router-B, router-B is accepting only three prefixes. If we check the range, we can see that only the prefixes that are allowed by route-map are visible on router-B. All other prefixes are discarded.
-
-**Tip**: If there is no change in the received prefixes, try resetting the BGP session using the command: "clear ip bgp neighbor-IP". In our case:
-
- clear ip bgp 192.168.1.1
-
-As we can see, the requirement has been met. We can create similar prefix-list and route-map statements in routers A and B to further control inbound and outbound prefixes.
-
-I am summarizing the configuration in one place so you can see it all at a glance.
-
- router bgp 200
- network 10.20.0.0/16
- neighbor 192.168.1.1 remote-as 100
- neighbor 192.168.1.1 route-map RMAP in
- !
- ip prefix-list PRFX-LST seq 5 permit 10.10.10.0/23 le 24
- !
- route-map RMAP permit 10
- match ip address prefix-list PRFX-LST
-
-### Summary ###
-
-In this tutorial, we showed how we can filter BGP routes in Quagga by defining prefix-list and route-map. We also demonstrated how we can combine prefix-list with route-map to fine-control incoming prefixes. You can create your own prefix-list and route-map in a similar way to match your network requirements. These tools are one of the most effective ways to protect the production network from route poisoning and advertisement of bogon routes.
-
-Hope this helps.
-
---------------------------------------------------------------------------------
-
-via: http://xmodulo.com/filter-bgp-routes-quagga-bgp-router.html
-
-作者:[Sarmed Rahman][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://xmodulo.com/author/sarmed
-[1]:http://xmodulo.com/centos-bgp-router-quagga.html
\ No newline at end of file
diff --git a/sources/tech/20150205 25 Linux Shell Scripting interview Questions & Answers.md b/sources/tech/20150205 25 Linux Shell Scripting interview Questions & Answers.md
deleted file mode 100644
index 11d5e6645a..0000000000
--- a/sources/tech/20150205 25 Linux Shell Scripting interview Questions & Answers.md
+++ /dev/null
@@ -1,378 +0,0 @@
- Vic
-25 Linux Shell Scripting interview Questions & Answers
-================================================================================
-### Q:1 What is Shell Script and why it is required ? ###
-
-Ans: A Shell Script is a text file that contains one or more commands. As a system administrator we often need to issue number of commands to accomplish the task, we can add these all commands together in a text file (Shell Script) to complete daily routine task.
-
-### Q:2 What is the default login shell and how to change default login shell for a specific user ? ###
-
-Ans: In Linux like Operating system “/bin/bash” is the default login shell which is assigned while user creation. We can change default shell using the “chsh” command . Example is shown below :
-
- # chsh -s
- # chsh linuxtechi -s /bin/sh
-
-### Q:3 What are the different type of variables used in a shell Script ? ###
-
-Ans: In a shell script we can use two types of variables :
-
-- System defined variables
-- User defined variables
-
-System defined variables are defined or created by Operating System(Linux) itself. These variables are generally defined in Capital Letters and can be viewed by “**set**” command.
-
-User defined variables are created or defined by system users and the values of variables can be viewed by using the command “`echo $`”
-
-### Q:4 How to redirect both standard output and standard error to the same location ? ###
-
-Ans: There two method to redirect std output and std error to the same location:
-
-Method:1 2>&1 (# ls /usr/share/doc > out.txt 2>&1 )
-
-Method:2 &> (# ls /usr/share/doc &> out.txt )
-
-### Q:5 What is the Syntax of “nested if statement” in shell scripting ? ###
-
-Ans : Basic Syntax is shown below :
-
- if [ Condition ]
- then
- command1
- command2
- …..
- else
- if [ condition ]
- then
- command1
- command2
- ….
- else
- command1
- command2
- …..
- fi
- fi
-
-### Q:6 What is the use of “$?” sign in shell script ? ###
-
-Ans:While writing a shell script , if you want to check whether previous command is executed successfully or not , then we can use “$?” with if statement to check the exit status of previous command. Basic example is shown below :
-
- root@localhost:~# ls /usr/bin/shar
- /usr/bin/shar
- root@localhost:~# echo $?
- 0
-
-If exit status is 0 , then command is executed successfully
-
- root@localhost:~# ls /usr/bin/share
-
- ls: cannot access /usr/bin/share: No such file or directory
- root@localhost:~# echo $?
- 2
-
-If the exit status is other than 0, then we can say command is not executed successfully.
-
-### Q:7 How to compare numbers in Linux shell Scripting ? ###
-
-Ans: test command is used to compare numbers in if-then statement. Example is shown below :
-
- #!/bin/bash
- x=10
- y=20
-
- if [ $x -gt $y ]
- then
- echo “x is greater than y”
- else
- echo “y is greater than x”
- fi
-
-### Q:8 What is the use of break command ? ###
-
-Ans: The break command is a simple way to escape out of a loop in progress. We can use the break command to exit out from any loop, including while and until loops.
-
-### Q:9 What is the use of continue command in shell scripting ? ###
-
-Ans The continue command is identical to break command except it causes the present iteration of the loop to exit, instead of the entire loop. Continue command is useful in some scenarios where error has occurred but we still want to execute the next commands of the loop.
-
-### Q:10 Tell me the Syntax of “Case statement” in Linux shell scripting ? ###
-
-Ans: The basic syntax is shown below :
-
- case word in
- value1)
- command1
- command2
- …..
- last_command
- !!
- value2)
- command1
- command2
- ……
- last_command
- ;;
- esac
-
-### Q:11 What is the basic syntax of while loop in shell scripting ? ###
-
-Ans: Like the for loop, the while loop repeats its block of commands a number of times. Unlike the for loop, however, the while loop iterates until its while condition is no longer true. The basic syntax is :
-
- while [ test_condition ]
- do
- commands…
- done
-
-### Q:12 How to make a shell script executable ? ###
-
-Ans: Using the chmod command we can make a shell script executable. Example is shown below :
-
- # chmod a+x myscript.sh
-
-### Q:13 What is the use of “#!/bin/bash” ? ###
-
-Ans: #!/bin/bash is the first of a shell script , known as shebang , where # symbol is called hash and ‘!’ is called as bang. It shows that command to be executed via /bin/bash.
-
-### Q:14 What is the syntax of for loop in shell script ? ###
-
-Ans: Basic Syntax of for loop is given below :
-
- for variables in list_of_items
- do
- command1
- command2
- ….
- last_command
- done
-
-### Q:15 How to debug a shell script ? ###
-
-Ans: A shell script can be debug if we execute the script with ‘-x’ option ( sh -x myscript.sh). Another way to debug a shell script is by using ‘-nv’ option ( sh -nv myscript.sh).
-
-### Q:16 How compare the strings in shell script ? ###
-
-Ans: test command is used to compare the text strings. The test command compares text strings by comparing each character in each string.
-
-### Q:17 What are the Special Variables set by Bourne shell for command line arguments ? ###
-
-Ans: The following table lists the special variables set by the Bourne shell for command line arguments .
-
-注:表格部分
-
-
-
-
-
-
-
-
Special Variables
-
-
-
Holds
-
-
-
-
-
$0
-
-
-
Name of the Script from the command line
-
-
-
-
-
$1
-
-
-
First Command-line argument
-
-
-
-
-
$2
-
-
-
Second Command-line argument
-
-
-
-
-
…..
-
-
-
…….
-
-
-
-
-
$9
-
-
-
Ninth Command line argument
-
-
-
-
-
$#
-
-
-
Number of Command line arguments
-
-
-
-
-
$*
-
-
-
All Command-line arguments, separated with spaces
-
-
-
-
-
-### Q:18 How to test files in a shell script ? ###
-
-Ans: test command is used to perform different test on the files. Basic test are listed below :
-
-注:表格部分
-
-
-
-
-
-
-
-
Test
-
-
-
Usage
-
-
-
-
-
-d file_name
-
-
-
Returns true if the file exists and is a directory
-
-
-
-
-
-e file_name
-
-
-
Returns true if the file exists
-
-
-
-
-
-f file_name
-
-
-
Returns true if the file exists and is a regular file
-
-
-
-
-
-r file_name
-
-
-
Returns true if the file exists and have read permissions
-
-
-
-
-
-s file_name
-
-
-
Returns true if the file exists and is not empty
-
-
-
-
-
-w file_name
-
-
-
Returns true if the file exists and have write permissions
-
-
-
-
-
-x file_name
-
-
-
Returns true if the file exists and have execute permissions
-
-
-
-
-
-### Q:19 How to put comments in your shell script ? ###
-
-Ans: Comments are the messages to yourself and for other users that describe what a script is supposed to do and how its works.To put comments in your script, start each comment line with a hash sign (#) . Example is shown below :
-
- #!/bin/bash
- # This is a command
- echo “I am logged in as $USER”
-
-### Q:20 How to get input from the terminal for shell script ? ###
-
-Ans: ‘read’ command reads in data from the terminal (using keyboard). The read command takes in whatever the user types and places the text into the variable you name. Example is shown below :
-
- # vi /tmp/test.sh
-
- #!/bin/bash
- echo ‘Please enter your name’
- read name
- echo “My Name is $name”
-
- # ./test.sh
- Please enter your name
- LinuxTechi
- My Name is LinuxTechi
-
-### Q:21 How to unset or de-assign variables ? ###
-
-Ans: ‘unset’ command is used to de-assign or unset a variable. Syntax is shown below :
-
- # unset
-
-### Q:22 How to perform arithmetic operation ? ###
-
-Ans: There are two ways to perform arithmetic operations :
-
-1. Using `expr` command (# expr 5 + 2 )
-2. using a dollar sign and square brackets ( `$[ operation ]` ) Example : test=$[16 + 4] ; test=$[16 + 4]
-
-### Q:23 Basic Syntax of do-while statement ? ###
-
-Ans: The do-while statement is similar to the while statement but performs the statements before checking the condition statement. The following is the format for the do-while statement:
-
- do
- {
- statements
- } while (condition)
-
-### Q:24 How to define functions in shell scripting ? ###
-
-Ans: A function is simply a block of of code with a name. When we give a name to a block of code, we can then call that name in our script, and that block will be executed. Example is shown below :
-
- $ diskusage () { df -h ; }
-
-### Q:25 How to use bc (bash calculator) in a shell script ? ###
-
-Ans: Use the below Syntax to use bc in shell script.
-
- variable=`echo “options; expression” | bc`
-
---------------------------------------------------------------------------------
-
-via: http://www.linuxtechi.com/linux-shell-scripting-interview-questions-answers/
-
-作者:[Pradeep Kumar][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://www.linuxtechi.com/author/pradeep/
diff --git a/sources/tech/20150205 How To Install or Configure VNC Server On CentOS 7.0.md b/sources/tech/20150205 How To Install or Configure VNC Server On CentOS 7.0.md
deleted file mode 100644
index 3eaba972f8..0000000000
--- a/sources/tech/20150205 How To Install or Configure VNC Server On CentOS 7.0.md
+++ /dev/null
@@ -1,161 +0,0 @@
-How To Install / Configure VNC Server On CentOS 7.0
-================================================================================
-Hi there, this tutorial is all about how to install or setup [VNC][1] Server on your very CentOS 7. This tutorial also works fine in RHEL 7. In this tutorial, we'll learn what is VNC and how to install or setup [VNC Server][1] on CentOS 7
-
-As we know, most of the time as a system administrator we are managing our servers over the network. It is very rare that we will need to have a physical access to any of our managed servers. In most cases all we need is to SSH remotely to do our administration tasks. In this article we will configure a GUI alternative to a remote access to our CentOS 7 server, which is VNC. VNC allows us to open a remote GUI session to our server and thus providing us with a full graphical interface accessible from any remote location.
-
-VNC server is a Free and Open Source Software which is designed for allowing remote access to the Desktop Environment of the server to the VNC Client whereas VNC viewer is used on remote computer to connect to the server .
-
-**Some Benefits of VNC server are listed below:**
-
- Remote GUI administration makes work easy & convenient.
- Clipboard sharing between host CentOS server & VNC-client machine.
- GUI tools can be installed on the host CentOS server to make the administration more powerful
- Host CentOS server can be administered through any OS having the VNC-client installed.
- More reliable over ssh graphics and RDP connections.
-
-So, now lets start our journey towards the installation of VNC Server. We need to follow the steps below to setup and to get a working VNC.
-
-First of all we'll need a working Desktop Environment (X-Windows), if we don't have a working GUI Desktop Environment (X Windows) running, we'll need to install it first.
-
-**Note: The commands below must be running under root privilege. To switch to root please execute "sudo -s" under a shell or terminal without quotes("")**
-
-### 1. Installing X-Windows ###
-
-First of all to install [X-Windows][2] we'll need to execute the below commands in a shell or terminal. It will take few minutes to install its packages.
-
- # yum check-update
- # yum groupinstall "X Window System"
-
-
-
- #yum install gnome-classic-session gnome-terminal nautilus-open-terminal control-center liberation-mono-fonts
-
-
-
- # unlink /etc/systemd/system/default.target
- # ln -sf /lib/systemd/system/graphical.target /etc/systemd/system/default.target
-
-
-
- # reboot
-
-After our machine restarts, we'll get a working CentOS 7 Desktop.
-
-Now, we'll install VNC Server on our machine.
-
-### 2. Installing VNC Server Package ###
-
-Now, we'll install VNC Server package in our CentOS 7 machine. To install VNC Server, we'll need to execute the following command.
-
- # yum install tigervnc-server -y
-
-
-
-### 3. Configuring VNC ###
-
-Then, we'll need to create a configuration file under **/etc/systemd/system/** directory. We can copy the **vncserver@:1.service** file from example file from **/lib/systemd/system/vncserver@.service**
-
- # cp /lib/systemd/system/vncserver@.service /etc/systemd/system/vncserver@:1.service
-
-
-
-Now we'll open **/etc/systemd/system/vncserver@:1.service** in our favorite text editor (here, we're gonna use **nano**). Then find the below lines of text in that file and replace with your username. Here, in my case its linoxide so I am replacing with linoxide and finally looks like below.
-
- ExecStart=/sbin/runuser -l -c "/usr/bin/vncserver %i"
- PIDFile=/home//.vnc/%H%i.pid
-
-TO
-
- ExecStart=/sbin/runuser -l linoxide -c "/usr/bin/vncserver %i"
- PIDFile=/home/linoxide/.vnc/%H%i.pid
-
-If you are creating for root user then
-
- ExecStart=/sbin/runuser -l root -c "/usr/bin/vncserver %i"
- PIDFile=/root/.vnc/%H%i.pid
-
-
-
-Now, we'll need to reload our systemd.
-
- # systemctl daemon-reload
-
-Finally, we'll create VNC password for the user . To do so, first you'll need to be sure that you have sudo access to the user, here I will login to user "linoxide" then, execute the following. To login to linoxide we'll run "**su linoxide" without quotes** .
-
- # su linoxide
- $ sudo vncpasswd
-
-
-
-**Make sure that you enter passwords more than 6 characters.**
-
-### 4. Enabling and Starting the service ###
-
-To enable service at startup ( Permanent ) execute the commands shown below.
-
- $ sudo systemctl enable vncserver@:1.service
-
-Then, start the service.
-
- $ sudo systemctl start vncserver@:1.service
-
-### 5. Allowing Firewalls ###
-
-We'll need to allow VNC services in Firewall now.
-
- $ sudo firewall-cmd --permanent --add-service vnc-server
- $ sudo systemctl restart firewalld.service
-
-
-
-Now you can able to connect VNC server using IP and Port ( Eg : ip-address:1 )
-
-### 6. Connecting the machine with VNC Client ###
-
-Finally, we are done installing VNC Server. No, we'll wanna connect the server machine and remotely access it. For that we'll need a VNC Client installed in our computer which will only enable us to remote access the server machine.
-
-
-
-You can use VNC client like [Tightvnc viewer][3] and [Realvnc viewer][4] to connect Server.
-To connect with additional users create files with different ports, please go to step 3 to configure and add a new user and port, You'll need to create **vncserver@:2.service** and replace the username in config file and continue the steps by replacing service name for different ports. **Please make sure you logged in as that particular user for creating vnc password**.
-
-VNC by itself runs on port 5900. Since each user will run their own VNC server, each user will have to connect via a separate port. The addition of a number in the file name tells VNC to run that service as a sub-port of 5900. So in our case, arun's VNC service will run on port 5901 (5900 + 1) and further will run on 5900 + x. Where, x denotes the port specified when creating config file **vncserver@:x.service for the further users**.
-
-We'll need to know the IP Address and Port of the server to connect with the client. IP addresses are the unique identity number of the machine. Here, my IP address is 96.126.120.92 and port for this user is 1. We can get the public IP address by executing the below command in a shell or terminal of the machine where VNC Server is installed.
-
- # curl -s checkip.dyndns.org|sed -e 's/.*Current IP Address: //' -e 's/<.*$//'
-
-### Conclusion ###
-
-Finally, we installed and configured VNC Server in the machine running CentOS 7 / RHEL 7 (Red Hat Enterprises Linux) . VNC is the most easy FOSS tool for the remote access and also a good alternative to Teamviewer Remote Access. VNC allows a user with VNC client installed to control the machine with VNC Server installed. Here are some commands listed below that are highly useful in VNC . Enjoy !!
-
-#### Additional Commands : ####
-
-- To stop VNC service .
-
- # systemctl stop vncserver@:1.service
-
-- To disable VNC service from startup.
-
- # systemctl disable vncserver@:1.service
-
-- To stop firewall.
-
- # systemctl stop firewalld.service
-
---------------------------------------------------------------------------------
-
-via: http://linoxide.com/linux-how-to/install-configure-vnc-server-centos-7-0/
-
-作者:[Arun Pyasi][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://linoxide.com/author/arunp/
-[1]:http://en.wikipedia.org/wiki/Virtual_Network_Computing
-[2]:http://en.wikipedia.org/wiki/X_Window_System
-[3]:http://www.tightvnc.com/
-[4]:https://www.realvnc.com/
\ No newline at end of file
diff --git a/sources/tech/20150205 How To Use Smartphones Like Weather Conky In Linux.md b/sources/tech/20150205 How To Use Smartphones Like Weather Conky In Linux.md
deleted file mode 100644
index b5bbc69a3b..0000000000
--- a/sources/tech/20150205 How To Use Smartphones Like Weather Conky In Linux.md
+++ /dev/null
@@ -1,84 +0,0 @@
-How To Use Smartphones Like Weather Conky In Linux
-================================================================================
-
-
-Smartphones have those sleek weather widgets that blend in to the display. Thanks to Flair Weather Conky, you can get **smartphone like weather display on your Linux desktop**. We will be using a GUI tool [Conky Manager to easily manage Conky in Linux][1]. Let’s first see how to install Conky Manager in Ubuntu 14.10, 14.04, Linux Mint 17 and other Linux distributions.
-
-### Install Conky Manager ###
-
-Open a terminal and use the following commands:
-
- sudo add-apt-repository ppa:teejee2008/ppa
- sudo apt-get update
- sudo apt-get install conky-manager
-
-You can read this article on [how to use Conky Manager in Linux][1].
-
-### Make sure curl is installed ###
-
-Do make sure that [curl][2] is installed. Use the following command:
-
- sudo apt-get install curl
-
-### Download Flair Weather Conky ###
-
-Get the Flair Weather Conky script from the link below:
-
-- [Download Flair Weather Conky Script][3]
-
-### Using Flair Weather Conky script in Conky Manager ###
-
-#### Step 1: ####
-
-Same as you install themes in Ubuntu 14.04, you should have a .conky directory in your Home folder. If you use command line, I don’t need to tell you how to find that. For beginners, go to your Home directory from File manager and press Ctrl+H to [show hidden files in Ubuntu][4]. Look for .conky folder here. If there is no such folder, make one.
-
-#### Step 2: ####
-
-In the .conky directory, extract the downloaded Flair Weather file. Do note that by default it is extracted to .conky directory itself. So go in this directory and get the Flair Weather folder out of it and paste it to actual .conky directory.
-
-#### Step 3: ####
-
-Flair Weather uses Yahoo and it doesn’t recognize your location automatically. You’ll need to manually edit it. Go to [Yahoo Weather][5] and get the location of id of your city by typing your city/pin code. You can get the location id from the URL.
-
-
-
-#### Step 4: ####
-
-Open Conky Manager. It should be able to read the newly installed Conky script. There are two variants, dark and light, available. You can choose whichever you prefer. You can should see the conky displayed on the desktop as soon as you select it.
-
-Default location in Flair Weather is set to Melbourne. You’ll have to manually edit the conky.
-
-
-
-#### Step 5: ####
-
-In the screenshot above, you can see the option to edit the selected conky. In the editor opened, look for location or WOEID. Change it with the location code you got in step 3. Now restart the Conky.
-
-
-
-In the same place, if you replace C by F, the unit of temperature will be changed to Fahrenheit from Celsius. Don’t forget to restart the Conky to see the changes made.
-
-#### Give it a try ####
-
-In this article we actually learned quite few things. We saw how we can use any Conky script easily, how to edit the scripts and how to use Conky Manager for various purposes. I hope you find it useful.
-
-A word of caution, Ubuntu 14.10 users might see overlapped time numerals. Please make the developer ware of any such issues.
-
-I have already shown you the screenshot of how the Flair Weather conky looked in my system. Time for you to try this and flaunt your desktop.
-
---------------------------------------------------------------------------------
-
-via: http://itsfoss.com/weather-conky-linux/
-
-作者:[Abhishek][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://itsfoss.com/author/Abhishek/
-[1]:http://itsfoss.com/conky-gui-ubuntu-1304/
-[2]:http://www.computerhope.com/unix/curl.htm
-[3]:http://speedracker.deviantart.com/art/Flair-Weather-Conky-Made-for-Conky-Manager-510130311
-[4]:http://itsfoss.com/hide-folders-and-show-hidden-files-in-ubuntu-beginner-trick/
-[5]:https://weather.yahoo.com/
\ No newline at end of file
diff --git a/sources/tech/20150205 Install Strongswan - A Tool to Setup IPsec Based VPN in Linux.md b/sources/tech/20150205 Install Strongswan - A Tool to Setup IPsec Based VPN in Linux.md
deleted file mode 100644
index ca909934fa..0000000000
--- a/sources/tech/20150205 Install Strongswan - A Tool to Setup IPsec Based VPN in Linux.md
+++ /dev/null
@@ -1,113 +0,0 @@
-Install Strongswan - A Tool to Setup IPsec Based VPN in Linux
-================================================================================
-IPsec is a standard which provides the security at network layer. It consist of authentication header (AH) and encapsulating security payload (ESP) components. AH provides the packet Integrity and confidentiality is provided by ESP component . IPsec ensures the following security features at network layer.
-
-- Confidentiality
-- Integrity of packet
-- Source Non. Repudiation
-- Replay attack protection
-
-[Strongswan][1] is an open source implementation of IPsec protocol and Strongswan stands for Strong Secure WAN (StrongS/WAN). It supports the both version of automatic keying exchange in IPsec VPN (Internet keying Exchange (IKE) V1 & V2).
-
-Strongswan basically provides the automatic keying sharing between two nodes/gateway of the VPN and after that it uses the Linux Kernel implementation of IPsec (AH & ESP). Key shared using IKE mechanism is further used in the ESP for the encryption of data. In IKE phase, strongswan uses the encryption algorithms (AES,SHA etc) of OpenSSL and other crypto libraries. However, ESP component of IPsec uses the security algorithm which are implemented in the Linux Kernel. The main features of Strongswan are given below.
-
-- 509 certificates or pre-shared keys based Authentication
-- Support of IKEv1 and IKEv2 key exchange protocols
-- Optional built-in integrity and crypto tests for plugins and libraries
-- Support of elliptic curve DH groups and ECDSA certificates
-- Storage of RSA private keys and certificates on a smartcard.
-
-It can be used in the client / server (road warrior) and gateway to gateway scenarios.
-
-### How to Install ###
-
-Almost all Linux distro’s, supports the binary package of Strongswan. In this tutorial, we will install the strongswan from binary package and also the compilation of strongswan source code with desirable features.
-
-### Using binary package ###
-
-Strongswan can be installed using following command on Ubuntu 14.04 LTS .
-
- $sudo aptitude install strongswan
-
-
-
-The global configuration (strongswan.conf) file and ipsec configuration (ipsec.conf/ipsec.secrets) files of strongswan are under /etc/ directory.
-
-### Pre-requisite for strongswan source compilation & installation ###
-
-- GMP (Mathematical/Precision Library used by strongswan)
-- OpenSSL (Crypto Algorithms from this library)
-- PKCS (1,7,8,11,12)(Certificate encoding and smart card integration with Strongswan )
-
-#### Procedure ####
-
-**1)** Go to /usr/src/ directory using following command in the terminal.
-
- $cd /usr/src
-
-**2)** Download the source code from strongswan site suing following command
-
- $sudo wget http://download.strongswan.org/strongswan-5.2.1.tar.gz
-
-(strongswan-5.2.1.tar.gz is the latest version.)
-
-
-
-**3)** Extract the downloaded software and go inside it using following command.
-
- $sudo tar –xvzf strongswan-5.2.1.tar.gz; cd strongswan-5.2.1
-
-**4)** Configure the strongswan as per desired options using configure command.
-
- ./configure --prefix=/usr/local -–enable-pkcs11 -–enable-openssl
-
-
-
-If GMP library is not installed, then configure script will generate following error.
-
-
-
-Therefore, first of all, install the GMP library using following command and then run the configure script.
-
-
-
-However, if GMP is already installed and still above error exists then create soft link of libgmp.so library at /usr/lib , /lib/, /usr/lib/x86_64-linux-gnu/ paths in Ubuntu using following command.
-
- $ sudo ln -s /usr/lib/x86_64-linux-gnu/libgmp.so.10.1.3 /usr/lib/x86_64-linux-gnu/libgmp.so
-
-
-
-After the creation of libgmp.so softlink, again run the ./configure script and it may find the gmp library. However, it may generate another error of gmp header file which is shown the following figure.
-
-
-
-Install the libgmp-dev package using following command for the solution of above error.
-
- $sudo aptitude install libgmp-dev
-
-
-
-After installation of development package of gmp library, again run the configure script and if it does not produce any error, then the following output will be displayed.
-
-
-
-Type the following commands for the compilation and installation of strongswan.
-
- $ sudo make ; sudo make install
-
-After the installation of strongswan , the Global configuration (strongswan.conf) and ipsec policy/secret configuration files (ipsec.conf/ipsec.secretes) are placed in **/usr/local/etc** directory.
-
-Strongswan can be used as tunnel or transport mode depends on our security need. It provides well known site-2-site and road warrior VPNs. It can be use easily with Cisco,Juniper devices.
-
---------------------------------------------------------------------------------
-
-via: http://linoxide.com/security/install-strongswan/
-
-作者:[nido][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://linoxide.com/author/naveeda/
-[1]:https://www.strongswan.org/
\ No newline at end of file
diff --git a/sources/tech/20150205 zBackup--A versatile deduplicating backup tool.md b/sources/tech/20150205 zBackup--A versatile deduplicating backup tool.md
deleted file mode 100644
index 62eee8521c..0000000000
--- a/sources/tech/20150205 zBackup--A versatile deduplicating backup tool.md
+++ /dev/null
@@ -1,63 +0,0 @@
-zBackup – A versatile deduplicating backup tool
-================================================================================
-zbackup is a globally-deduplicating backup tool, based on the ideas found in rsync. Feed a large .tar into it, and it will store duplicate regions of it only once, then compress and optionally encrypt the result. Feed another .tar file, and it will also re-use any data found in any previous backups. This way only new changes are stored, and as long as the files are not very different, the amount of storage required is very low. Any of the backup files stored previously can be read back in full at any time.
-
-### zBackup Features ###
-
-Parallel LZMA or LZO compression of the stored data
-Built-in AES encryption of the stored data
-Possibility to delete old backup data
-Use of a 64-bit rolling hash, keeping the amount of soft collisions to zero
-Repository consists of immutable files. No existing files are ever modified
-Written in C++ only with only modest library dependencies
-Safe to use in production
-Possibility to exchange data between repos without recompression
-
-### Install zBackup in ubuntu ###
-
-Open the terminal and run the following command
-
- sudo apt-get install zbackup
-
-### Using zBackup ###
-
-zbackup init initializes a backup repository for the backup files to be stored.
-
- zbackup init [--non-encrypted] [--password-file ~/.my_backup_password ] /my/backup/repo
-
-zbackup backup backups a tar file generated by tar c to the repository initialized using zbackup init
-
- zbackup [--password-file ~/.my_backup_password ] [--threads number_of_threads ] backup /my/backup/repo/backups/backup-`date ‘+%Y-%m-%d'`
-
-zbackup restore restores the backup file to a tar file.
-
- zbackup [--password-file ~/.my_backup_password [--cache-size cache_size_in_mb restore /my/backup/repo/backups/backup-`date ‘+%Y-%m-%d'` > /my/precious/backup-restored.tar
-
-### Available Options ###
-
-- -non-encrypted -- Do not encrypt the backup repository.
-- --password-file ~/.my_backup_password -- Use the password file specified at ~/.my_backup_password to encrypt the repository and backup file, or to decrypt the backup file.
-- --threads number_of_threads -- Limit the partial LZMA compression to number_of_threads needed. Recommended for 32-bit architectures.
-- --cache-size cache_size_in_mb -- Use the cache size provided by cache_size_in_mb to speed up the restoration process.
-
-### zBackup files ###
-
-~/.my_backup_password Used to encrypt the repository and backup file, or to decrypt the backup file. See zbackup for further details.
-
-/my/backup/repo The directory used to hold the backup repository.
-
-/my/precious/restored-tar The tar used for restoring the backup.
-
-/my/backup/repo/backups/backup-`date ‘+%Y-%m-%d'` Specifies the backup file.
-
---------------------------------------------------------------------------------
-
-via: http://www.ubuntugeek.com/zbackup-a-versatile-deduplicating-backup-tool.html
-
-作者:[ruchi][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://www.ubuntugeek.com/author/ubuntufix
\ No newline at end of file
diff --git a/sources/tech/20150209 How to access Feedly RSS feed from the command line on Linux.md b/sources/tech/20150209 How to access Feedly RSS feed from the command line on Linux.md
deleted file mode 100644
index 58a0841280..0000000000
--- a/sources/tech/20150209 How to access Feedly RSS feed from the command line on Linux.md
+++ /dev/null
@@ -1,106 +0,0 @@
-How to access Feedly RSS feed from the command line on Linux
-================================================================================
-In case you didn't know, [Feedly][1] is one of the most popular online news aggregation services. It offers seamlessly unified news reading experience across desktops, Android and iOS devices via browser extensions and mobile apps. Feedly took on the demise of Google Reader in 2013, quickly gaining a lot of then Google Reader users. I was one of them, and Feedly has remained my default RSS reader since then.
-
-While I appreciate the sleek interface of Feedly's browser extensions and mobile apps, there is yet another way to access Feedly: Linux command-line. That's right. You can access Feedly's news feed from the command line. Sounds geeky? Well, at least for system admins who live on headless servers, this can be pretty useful.
-
-Enter [Feednix][2]. This open-source software is a Feedly's unofficial command-line client written in C++. It allows you to browse Feedly's news feed in ncurses-based terminal interface. By default, Feednix is linked with a console-based browser called w3m to allow you to read articles within a terminal environment. You can choose to read from your favorite web browser though.
-
-In this tutorial, I am going to demonstrate how to install and configure Feednix to access Feedly from the command line.
-
-### Install Feednix on Linux ###
-
-You can build Feednix from the source using the following instructions. At the moment, the "Ubuntu-stable" branch of the official Github repository has the most up-to-date code. So let's use this branch to build it.
-
-As prerequisites, you will need to install a couple of development libraries, as well as w3m browser.
-
-#### Debian, Ubuntu or Linux Mint ####
-
- $ sudo apt-get install git automake g++ make libncursesw5-dev libjsoncpp-dev libcurl4-gnutls-dev w3m
- $ git clone -b Ubuntu-stable https://github.com/Jarkore/Feednix.git
- $ cd Feednix
- $ ./autogen.sh
- $ ./configure
- $ make
- $ sudo make install
-
-#### Fedora ####
-
- $ sudo yum groupinstall "C Development Tools and Libraries"
- $ sudo yum install gcc-c++ git automake make ncurses-devel jsoncpp-devel libcurl-devel w3m
- $ git clone -b Ubuntu-stable https://github.com/Jarkore/Feednix.git
- $ cd Feednix
- $ ./autogen.sh
- $ ./configure
- $ make
- $ sudo make install
-
-Arch Linux
-
-On Arch Linux, you can easily install Feednix from [AUR][3].
-
-### Configure Feednix for the First Time ###
-
-After installing it, launch Feednix as follows.
-
- $ feednix
-
-The first time you run Feednix, it will pop up a web browser window, where you need to sign up to create a Feedly's user ID and its corresponding developer access token. If you are running Feednix in a desktop-less environment, open a web browser on another computer, and go to https://feedly.com/v3/auth/dev.
-
-
-
-Once you sign in, you will see your Feedly user ID generated.
-
-
-
-To retrieve an access token, you need to follow the token link sent to your email address in your browser. Only then will you see the window showing your user ID, access token, and its expiration date. Be aware that access token is quite long (more than 200 characters). The token appears in a horizontally scrollable text box, so make sure to copy the whole access token string.
-
-
-
-Paste your user ID and access token into the Feednix' command-line prompt.
-
- [Enter User ID] >> XXXXXX
- [Enter token] >> YYYYY
-
-After successful authentication, you will see an initial Feednix screen with two panes. The left-side "Categories" pane shows a list of news categories, while the right-side "Posts" pane displays a list of news articles in the current category.
-
-
-
-### Read News in Feednix ###
-
-Here I am going to briefly describe how to access Feedly via Feednix.
-
-#### Navigate Feednix ####
-
-As I mentioned, the top screen of Feednix consists of two panes. To switch focus between the two panes, use TAB key. To move up and down the list within a pane, use 'j' and 'k' keys, respectively. These keyboard shorcuts are obviously inspired by Vim text editor.
-
-#### Read an Article ####
-
-To read a particular article, press 'o' key at the current article. It will invoke w2m browser, and load the article inside the browser. Once you are done reading, press 'q' to quit the browser, and come back to Feednix. If your environment can open a web browser, you can press 'O' to load an article on your default web browser such as Firefox.
-
-
-
-#### Subscribe to a News Feed ####
-
-You can add any arbitrary RSS news feed to your Feedly account from Feednix interface. To do so, simply press 'a' key. This will show "[ENTER FEED]:" prompt at the bottom of the screen. After typing the RSS feed, go ahead and fill in the name of the feed and its preferred category.
-
-
-
-#### Summary ####
-
-As you can see, Feednix is a quite convenient and easy-to-use command-line RSS reader. If you are a command-line junkie as well as a regular Feedly user, Feednix is definitely worth trying. I have been communicating with the creator of Feednix, Jarkore, to troubleshoot some issue. As far as I can tell, he is very active in responding to bug reports and fixing bugs. I encourage you to try out Feednix and let him know your feedback.
-
---------------------------------------------------------------------------------
-
-via: http://xmodulo.com/feedly-rss-feed-command-line-linux.html
-
-作者:[Dan Nanni][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://xmodulo.com/author/nanni
-[1]:https://feedly.com/
-[2]:https://github.com/Jarkore/Feednix
-[3]:https://aur.archlinux.org/packages/feednix/
\ No newline at end of file
diff --git a/sources/tech/20150209 How to back up a Debian system using backupninja.md b/sources/tech/20150209 How to back up a Debian system using backupninja.md
deleted file mode 100644
index edfc6150f6..0000000000
--- a/sources/tech/20150209 How to back up a Debian system using backupninja.md
+++ /dev/null
@@ -1,111 +0,0 @@
-How to back up a Debian system using backupninja
-================================================================================
-Prudence or experience by disaster can teach every [sysadmin][1] the importance of taking frequent system backups. You can do so by writing good old shell scripts, or using one (or more) of the many backup tools available for the job. Thus the more tools you become acquainted with, the better informed decisions you will make when implementing a backup solution.
-
-In this article we will present [backupninja][2], a lightweight and easy-to-configure system backup tool. With the help of programs like **rdiff-backup**, **duplicity**, **mysqlhotcopy** and **mysqldump**, Backupninja offers common backup features such as remote, secure and incremental file system backups, encrypted backup, and MySQL/MariaDB database backup. You can selectively enable status email reports, and can back up general hardware and system information as well. One key strength of backupninja is a built-in console-based wizard (called **ninjahelper**) that allows you to easily create configuration files for various backup scenarios.
-
-The downside, so to speak, is that backupninja requires other "helper" programs to be installed in order to take full advantage of all its features. While backupninja's RPM package is available for Red Hat-based distributions, backupninja's dependencies are optimized for Debian and its derivatives. Thus it is not recommended to try backupninja for Red Hat based systems.
-
-In this tutorial, we will cover the backupninja installation for Debian-based distributions.
-
-### Installing Backupninja ###
-
-Run the following command as root:
-
- # aptitude install backupninja
-
-During installation, several files and directories will be created:
-
-- **/usr/sbin/backupninja** is the main bash shell script.
-- **/etc/cron.d/backupninja**, by default, instructs cron to run the main script once per hour.
-- **/etc/logrotate.d/backupninja** rotates the logs created by the program.
-- **/etc/backup.d/** is the directory where the configuration files for backup actions reside.
-- **/etc/backupninja.conf** is the main configuration file that includes general options. It is well commented and explains each option in detail.
-- **/usr/share/backupninja** is the directory where the scripts used by backupninja are located (aka "handlers"). These are the scripts which are in charge of doing the actual work. In this directory you will also find .helper files, which are used to configure and set up ninjahelper menus.
-- **/usr/share/doc/backupninja/examples** contains templates for action configuration files (the kind of files that are created through ninjahelper).
-
-### Running Ninjahelper for the First Time ###
-
-When we try to launch ninjahelper, we can see that an internal dependency may be required. If prompted, enter "yes" and press the ENTER key to install dialog (a tool that displays user-friendly dialog boxes from shell scripts).
-
-
-
-When you press Enter after typing yes, backupninja will install dialog and present the following screen once it's done.
-
-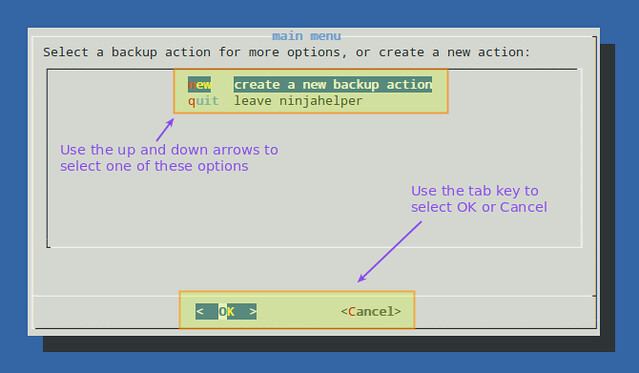
-
-#### Example 1: Back up Hardware and System Info ####
-
-After launching ninjahelper, we will create a new backup action:
-
-
-
-If necessary helper programs are not installed, we will be presented with the following screens. Disregard this step if these packages have already been installed on your system.
-
-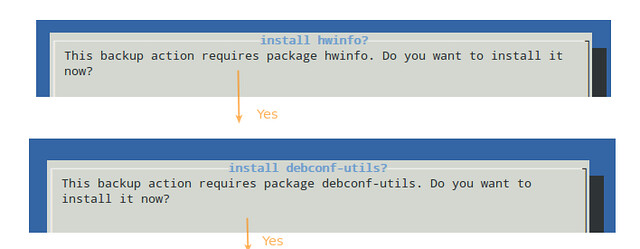
-
-The next step consists of selecting the items that you want to be a part of this backup. The first four are selected by default, but you can deselect them by pressing the spacebar.
-
-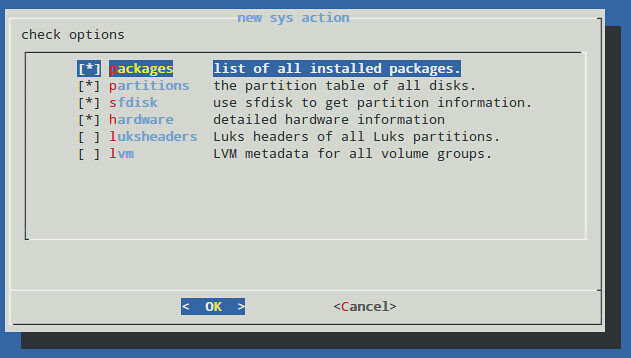
-
-Once you are done, press OK to continue. You will be able to choose whether you want to use the default configuration file for this backup action (/etc/backup.d/10.sys), or if you want to create a new one. In the latter case, a new file with the same contents as the default one will be created under the same directory but named 11.sys, and so on for future system backup actions. Note that you can edit the configuration file once it's created with your preferred text editor.
-
-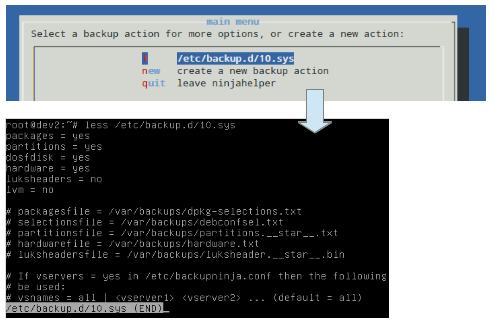
-
-#### Example 2: Incremental Rsync Pull Backup of a Remote Directory ####
-
-As you most likely know, rsync is widely used to synchronize files and folders over a network. In the following example we will discuss an approach to take incremental pull backups of a remote directory with hardlinking to save historical data and store them in our local file server. This approach will help us save space and increase security on the server side.
-
-**Step 1**: Write a custom script in the /etc/backup.d directory with the following contents and chmod it to 600. Note that this directory may contain, besides plain configuration files, scripts that you want to run when backupninja is executed, with the advantage of using variables present in the main configuration file.
-
- # REMOTE USER
- user=root
- # REMOTE HOST
- host=dev1
- # REMOTE DIRECTORY
- remotedir=/home/gacanepa/
- # LOCAL DIRECTORY
- localdir=/home/gacanepa/backup.0
- # LOCAL DIRECTORY WHERE PREVIOUS BACKUP WAS STORED
- localdirold=/home/gacanepa/backup.1
- mv $localdir $localdirold
- # RSYNC
- rsync -av --delete --recursive --link-dest=$localdirold $user@$host:$remotedir $localdir
-
-In the above configuration, the '--link-dest' option of rsync is use to hardlink unchanged files (in all attributes) from $localdir-old to the destination directory ($localdir).
-
-**Step 2**: Before backupninja is run for the first time, the parent directory (/home/gacanepa in this case) is empty. The first time we execute:
-
- # backupninja -n
-
-the backup.0 directory is created, and later in the process its name is changed to backup.1.
-
-The second time we run backupninja, backup.0 is re-created and backup.1 is kept.
-
-
-
-**Step 3**: Verify that the contents of backup.1 are hard links to the files in backup.0 by comparing the respective inode numbers and directory sizes.
-
-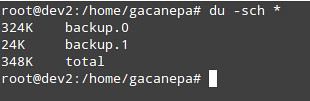
-
-### Conclusion ###
-
-Backupninja is not only a classic backup tool, but also an easy-to-configure utility. You can write your own handlers to run backupninja as per the individual configuration files located in /etc/backup.d, and you can even write helpers for ninjahelper in order to include them in its main interface.
-
-For example, if you create a handler named xmodulo in /usr/share/backupninja, it will run by default every file with the .xmodulo extension in /etc/backup.d. If you decide you want to add your xmodulo handler to ninjahelper, you can write the corresponding helper as xmodulo.helper. In addition, if you want backupninja to run an arbitrary script, just add it to /etc/backup.d and you are good to go.
-
-Feel free to leave your comments, questions, or suggestions, using the form below. we will be more than glad to hear from you.
-
---------------------------------------------------------------------------------
-
-via: http://xmodulo.com/backup-debian-system-backupninja.html
-
-作者:[Gabriel Cánepa][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://xmodulo.com/author/gabriel
-[1]:http://xmodulo.com/recommend/sysadminbook
-[2]:https://labs.riseup.net/code/projects/backupninja
\ No newline at end of file
diff --git a/sources/tech/20150209 Install OpenQRM Cloud Computing Platform In Debian.md b/sources/tech/20150209 Install OpenQRM Cloud Computing Platform In Debian.md
deleted file mode 100644
index 127f10affc..0000000000
--- a/sources/tech/20150209 Install OpenQRM Cloud Computing Platform In Debian.md
+++ /dev/null
@@ -1,149 +0,0 @@
-Install OpenQRM Cloud Computing Platform In Debian
-================================================================================
-### Introduction ###
-
-**openQRM** is a web-based open source Cloud computing and datacenter management platform that integrates flexibly with existing components in enterprise data centers.
-
-It supports the following virtualization technologies:
-
-- KVM,
-- XEN,
-- Citrix XenServer,
-- VMWare ESX,
-- LXC,
-- OpenVZ.
-
-The Hybrid Cloud Connector in openQRM supports a range of private or public cloud providers to extend your infrastructure on demand via **Amazon AWS**, **Eucalyptus** or **OpenStack**. It, also, automates provisioning, virtualization, storage and configuration management, and it takes care of high-availability. A self-service cloud portal with integrated billing system enables end-users to request new servers and application stacks on-demand.
-
-openQRM is available in two different flavours such as:
-
-- Enterprise Edition
-- Community Edition
-
-You can view the difference between both editions [here][1].
-
-### Features ###
-
-- Private/Hybrid Cloud Computing Platform;
-- Manages physical and virtualized server systems;
-- Integrates with all major open and commercial storage technologies;
-- Cross-platform: Linux, Windows, OpenSolaris, and *BSD;
-- Supports KVM, XEN, Citrix XenServer, VMWare ESX(i), lxc, OpenVZ and VirtualBox;
-- Support for Hybrid Cloud setups using additional Amazon AWS, Eucalyptus, Ubuntu UEC cloud resources;
-- Supports P2V, P2P, V2P, V2V Migrations and High-Availability;
-- Integrates with the best Open Source management tools – like puppet, nagios/Icinga or collectd;
-- Over 50 plugins for extended features and integration with your infrastructure;
-- Self-Service Portal for end-users;
-- Integrated billing system.
-
-### Installation ###
-
-Here, we will install openQRM in Ubuntu 14.04 LTS. Your server must atleast meet the following requirements.
-
-- 1 GB RAM;
-- 100 GB Hdd;
-- Optional: Virtualization enabled (VT for Intel CPUs or AMD-V for AMD CPUs) in Bios.
-
-First, install make package to compile openQRM source package.
-
- sudo apt-get update
- sudo apt-get upgrade
- sudo apt-get install make
-
-Then, run the following commands one by one to install openQRM.
-
-Download the latest available version [from here][2].
-
- wget http://sourceforge.net/projects/openqrm/files/openQRM-Community-5.1/openqrm-community-5.1.tgz
-
- tar -xvzf openqrm-community-5.1.tgz
-
- cd openqrm-community-5.1/src/
-
- sudo make
-
- sudo make install
-
- sudo make start
-
-During installation, you’ll be asked to update the php.ini file.
-
-
-
-Enter mysql root user password.
-
-
-
-Re-enter password:
-
-
-
-Select the mail server configuration type.
-
-
-
-If you’re not sure, select Local only. In our case, I go with **Local only** option.
-
-
-
-Enter your system mail name, and finally enter the Nagios administration password.
-
-
-
-The above commands will take long time depending upon your Internet connection to download all packages required to run openQRM. Be patient.
-
-Finally, you’ll get the openQRM configuration URL along with username and password.
-
-
-
-### Configuration ###
-
-After installing openQRM, open up your web browser and navigate to the URL: **http://ip-address/openqrm**.
-
-For example, in my case http://192.168.1.100/openqrm.
-
-The default username and password is: **openqrm/openqrm**.
-
-
-
-Select a network card to use for the openQRM management network.
-
-
-
-Select a database type. In our case, I selected mysql.
-
-
-
-Now, configure the database connection and initialize openQRM. Here, I use **openQRM** as database name, and user as **root** and debian as password for the database. Be mindful that you should enter the mysql root user password that you have created while installing openQRM.
-
-
-
-Congratulations!! openQRM has been installed and configured.
-
-
-
-### Update openQRM ###
-
-To update openQRM at any time run the following command:
-
- cd openqrm/src/
- make update
-
-What we have done so far is just installed and configured openQRM in our Ubuntu server. For creating, running Virtual Machines, managing Storage, integrating additional systems and running your own private Cloud, I suggest you to read the [openQRM Administrator Guide][3].
-
-That’s all now. Cheers! Happy weekend!!
-
---------------------------------------------------------------------------------
-
-via: http://www.unixmen.com/install-openqrm-cloud-computing-platform-debian/
-
-作者:[SK][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://www.unixmen.com/author/sk/
-[1]:http://www.openqrm-enterprise.com/products/edition-comparison.html
-[2]:http://sourceforge.net/projects/openqrm/files/?source=navbar
-[3]:http://www.openqrm-enterprise.com/fileadmin/Documents/Whitepaper/openQRM-Enterprise-Administrator-Guide-5.2.pdf
\ No newline at end of file
diff --git a/sources/tech/20150209 Linux FAQs with Answers--How to get the process ID (PID) of a shell script.md b/sources/tech/20150209 Linux FAQs with Answers--How to get the process ID (PID) of a shell script.md
deleted file mode 100644
index 999e3b4327..0000000000
--- a/sources/tech/20150209 Linux FAQs with Answers--How to get the process ID (PID) of a shell script.md
+++ /dev/null
@@ -1,48 +0,0 @@
-Linux FAQs with Answers--How to get the process ID (PID) of a shell script
-================================================================================
-> **Question**: I want to know the process ID (PID) of the subshell under which my shell script is running. How can I find a PID in a bash shell script?
-
-When you execute a shell script, it will launch a process known as a subshell. As a child process of the main shell, a subshell executes a list of commands in a shell script as a batch (so-called "batch processing").
-
-In some cases, you may want to know the process ID (PID) of the subshell where your shell script is running. This PID information can be used under different circumstances. For example, you can create a unique temporary file in /tmp by naming it with the shell script PID. In case a script needs to examine all running processes, it can exclude its own subshell from the process list.
-
-In bash, the **PID of a shell script's subshell process** is stored in a special variable called '$$'. This variable is read-only, and you cannot modify it in a shell script. For example:
-
- #!/bin/bash
-
- echo "PID of this script: $$"
-
-The above script will show the following output.
-
- PID of this script: 6583
-
-Besides $$, bash shell exports several other read-only variables. For example, PPID stores the process ID of the subshell's parent process (i.e., main shell). UID stores the user ID of the current user who is executing the script. For example:
-
- #!/bin/bash
-
- echo "PID of this script: $$"
- echo "PPID of this script: $PPID"
- echo "UID of this script: $UID"
-
-Its output will be:
-
- PID of this script: 6686
- PPID of this script: 4656
- UID of this script: 1000
-
-In the above, PID will keep changing every time you invoke a script. That is because each invocation of a script will create a new subshell. On the other hand, PPID will remain the same as long as you run a script inside the same shell.
-
-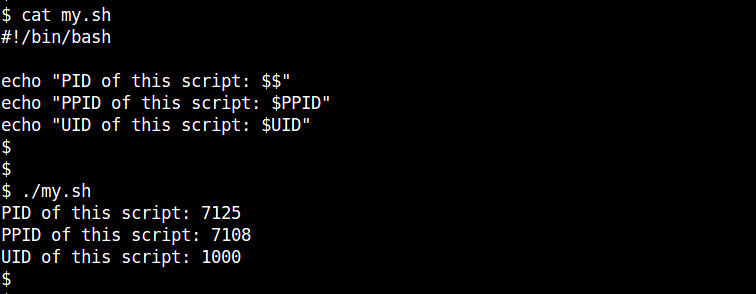
-
-For a complete list of built-in bash variables, refer to its man page.
-
- $ man bash
-
---------------------------------------------------------------------------------
-
-via: http://ask.xmodulo.com/process-id-pid-shell-script.html
-
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
\ No newline at end of file
diff --git a/sources/tech/20150211 25 Tips for Intermediate Git Users.md b/sources/tech/20150211 25 Tips for Intermediate Git Users.md
deleted file mode 100644
index a4dcb2b546..0000000000
--- a/sources/tech/20150211 25 Tips for Intermediate Git Users.md
+++ /dev/null
@@ -1,469 +0,0 @@
-25 Tips for Intermediate Git Users
-================================================================================
-I’ve been using git for about 18 months now and thought I knew it pretty well. Then we had [Scott Chacon][1] from GitHub over to do some training at [LVS, a supplier/developer of betting/gaming software][2] (where contracted until 2013) and I learnt a ton in the first day.
-
-As someone who’s always felt fairly comfortable in Git, I thought sharing some of the nuggets I learnt with the community might help someone to find an answer without needing to do lots of research.
-
-### Basic Tips ###
-
-#### 1. First Steps After Install ####
-
-After installing Git, the first thing you should do is configure your name and email, as every commit will have these details:
-
- $ git config --global user.name "Some One"
- $ git config --global user.email "someone@gmail.com"
-
-#### 2. Git is Pointer-Based ####
-
-Everything stored in git is in a file. When you create a commit it creates a file containing your commit message and associated data (name, email, date/time, previous commit, etc) and links it to a tree file. The tree file contains a list of objects or other trees. The object or blob is the actual content associated with the commit (a file, if you will, although the filename isn’t stored in the object, but in the tree). All of these files are stored with a filename of a SHA-1 hash of the object.
-
-From there branches and tags are simply files containing (basically) a SHA-1 hash which points to the commit. Using these references allows for a lot of flexibility and speed, as creating a new branch is as simple as creating a file with the name of the branch and the SHA-1 reference to the commit you’re branching from. Of course, you’d never do that as you’d use the Git command line tools (or a GUI), but it’s that simple.
-
-You may have heard references to the HEAD. This is simply a file containing the SHA-1 reference of the commit you’re currently pointing to. If you’re resolving a merge conflict and see HEAD, that’s nothing to do with a particular branch or necessarily a particular point on the branch but where you currently are.
-
-All the branch pointers are kept in .git/refs/heads, HEAD is in .git/HEAD and tags are in .git/refs/tags – feel free to have a look in there.
-
-#### 3. Two Parents – of course! ####
-
-When viewing a merge commit message in a log, you will see two parents (as opposed to the normal one for a work-based commit). The first parent is the branch you were on and the second is the one you merged in to it.
-
-#### 4. Merge Conflicts ####
-
-By now I’m sure you have had a merge conflict and had to resolve it. This is normally done by editing the file, removing the <<<<, ====, >>>> markers and the keeping the code you want to store. Sometimes it’s nice to see the code before either change, i.e. before you made the change in both branches that now conflicts. This is one command away:
-
- $ git diff --merge
- diff --cc dummy.rb
- index 5175dde,0c65895..4a00477
- --- a/dummy.rb
- +++ b/dummy.rb
- @@@ -1,5 -1,5 +1,5 @@@
- class MyFoo
- def say
- - puts "Bonjour"
- - puts "Hello world"
- ++ puts "Annyong Haseyo"
- end
- end
-
-If the file is binary, diffing files isn’t so easy… What you’ll normally want to do is to try each version of the binary file and decide which one to use (or manually copy portions over in the binary file’s editor). To pull a copy of the file from a particular branch (say you’re merging master and feature132):
-
- $ git checkout master flash/foo.fla # or...
- $ git checkout feature132 flash/foo.fla
- $ # Then...
- $ git add flash/foo.fla
-
-Another way is to cat the file from git – you can do this to another filename then copy the correct file over (when you’ve decided which it is) to the normal filename:
-
- $ git show master:flash/foo.fla > master-foo.fla
- $ git show feature132:flash/foo.fla > feature132-foo.fla
- $ # Check out master-foo.fla and feature132-foo.fla
- $ # Let's say we decide that feature132's is correct
- $ rm flash/foo.fla
- $ mv feature132-foo.fla flash/foo.fla
- $ rm master-foo.fla
- $ git add flash/foo.fla
-
-UPDATE: Thanks to Carl in the comments on the original blog post for the reminder, you can actually use “git checkout —ours flash/foo.fla” and “git checkout —theirs flash/foo.fla” to checkout a particular version without remembering which branches you merge in. Personally I prefer to be more explicit, but the option is there…
-
-Remember to add the file after resolving the merge conflict (as I do above).
-
-### Servers, Branching and Tagging ###
-
-#### 5. Remote Servers ####
-
-One of the most powerful features of Git is the ability to have more than one remote server (as well as the fact that you’re running a local repository always). You don’t always need write access either, you may have multiple servers you read from (to merge work in) and then write to another. To add a new remote server is simple:
-
- $ git remote add john git@github.com:johnsomeone/someproject.git
-
-If you want to see information about your remote servers you can do:
-
- # shows URLs of each remote server
- $ git remote -v
-
- # gives more details about each
- $ git remote show name
-
-You can always see the differences between a local branch and a remote branch:
-
- $ git diff master..john/master
-
-You can also see the changes on HEAD that aren’t on that remote branch:
-
- $ git log remote/branch..
- # Note: no final refspec after ..
-
-#### 6. Tagging ####
-
-In Git there are two types of tag – a lightweight tag and an annotated tag. Bearing in mind Tip 2 about Git being pointer based, the difference between the two is simple. A lightweight tag is simply a named pointer to a commit. You can always change it to point to another commit. An annotated tag is a name pointer to a tag object, with it’s own message and history. As it has it’s own message it can be GPG signed if required.
-
-Creating the two types of tag is easy (and one command line switch different)
-
- $ git tag to-be-tested
- $ git tag -a v1.1.0 # Prompts for a tag message
-
-#### 7. Creating Branches ####
-
-Creating branches in git is very easy (and lightning quick due to it only needing to create a less than 100 byte file). The longhand way of creating a new branch and switching to it:
-
- $ git branch feature132
- $ git checkout feature132
-
-Of course, if you know you’re going to want to switch to it straight away you can do it in one command:
-
- $ git checkout -b feature132
-
-If you want to rename a local branch it’s as easy as (the long way to show what happens):
-
- $ git checkout -b twitter-experiment feature132
- $ git branch -d feature132
-
-Update: Or you can (as Brian Palmer points out in the comments on the original blog post) just use the -m switch to “git branch” to do it in one step (as Mike points out, if you only specify one branch it renames your current branch):
-
- $ git branch -m twitter-experiment
- $ git branch -m feature132 twitter-experiment
-
-#### 8. Merging Branches ####
-
-At some point in the future, you’re going to want to merge your changes back in. There are two ways to do this:
-
- $ git checkout master
- $ git merge feature83 # Or...
- $ git rebase feature83
-
-The difference between merge and rebase is that merge tries to resolve the changes and create a new commit that blends them. Rebase tries to take your changes since you last diverged from the other branch and replay them from the HEAD of the other branch. However, don’t rebase after you’ve pushed a branch to a remote server – this can cause confusion/problems.
-
-If you aren’t sure which branches still have unique work on them – so you know which you need to merge and which ones can be removed, there are two switches to git branch that help:
-
- # Shows branches that are all merged in to your current branch
- $ git branch --merged
-
- # Shows branches that are not merged in to your current branch
- $ git branch --no-merged
-
-#### 9. Remote Branches ####
-
-If you have a local branch that you’d like to appear on a remote server, you can push it up with one command:
-
- $ git push origin twitter-experiment:refs/heads/twitter-experiment
- # Where origin is our server name and twitter-experiment is the branch
-
-Update: Thanks to Erlend in the comments on the original blog post – this is actually the same as doing `git push origin twitter-experiment` but by using the full syntax you can see that you can actually use different names on both ends (so your local can be `add-ssl-support` while your remote name can be `issue-1723`).
-
-If you want to delete a branch from the server (note the colon before the branch name):
-
- $ git push origin :twitter-experiment
-
-If you want to show the state of all remote branches you can view them like this:
-
- $ git remote show origin
-
-This may list some branches that used to exist on the server but now don’t exist. If this is the case you can easily remove them from your local checkout using:
-
- $ git remote prune
-
-Finally, if you have a remote branch that you want to track locally, the longhand way is:
-
- $ git branch --track myfeature origin/myfeature
- $ git checkout myfeature
-
-However, newer versions of Git automatically set up tracking if you use the -b flag to checkout:
-
- $ git checkout -b myfeature origin/myfeature
-
-### Storing Content in Stashes, Index and File System ###
-
-#### 10. Stashing ####
-
-In Git you can drop your current work state in to a temporary storage area stack and then re-apply it later. The simple case is as follows:
-
- $ git stash
- # Do something...
- $ git stash pop
-
-A lot of people recommend using `git stash apply` instead of pop, however if you do this you end up with a long list of stashes left hanging around. “pop” will only remove it from the stack if it applies cleanly. If you’ve used `git stash apply` you can remove the last item from the stack anyway using:
-
- $ git stash drop
-
-Git will automatically create a comment based on the current commit message. If you’d prefer to use a custom message (as it may have nothing to do with the previous commit):
-
- $ git stash save "My stash message"
-
-If you want to apply a particular stash from your list (not necessarily the last one) you can list them and apply it like this:
-
- $ git stash list
- stash@{0}: On master: Changed to German
- stash@{1}: On master: Language is now Italian
- $ git stash apply stash@{1}
-
-#### 11. Adding Interactively ####
-
-In the subversion world you change files and then just commit everything that has changed. In Git you have a LOT more power to commit just certain files or even certain patches. To commit certain files or parts of files you need to go in to interactive mode.
-
- $ git add -i
- staged unstaged path
-
-
- *** Commands ***
- 1: status 2: update 3: revert 4: add untracked
- 5: patch 6: diff 7: quit 8: help
- What now>
-
-This drops you in to a menu based interactive prompt. You can use the numbers of the commands or the highlighted letters (if you have colour highlighting turned on) to go in to that mode. Then it’s normally a matter of typing the numbers of the files you want to apply that action to (you can use formats like 1 or 1-4 or 2,4,7).
-
-If you want to go to patch mode (‘p’ or ‘5’ from interactive mode) you can also go straight in to that mode:
-
- $ git add -p
- diff --git a/dummy.rb b/dummy.rb
- index 4a00477..f856fb0 100644
- --- a/dummy.rb
- +++ b/dummy.rb
- @@ -1,5 +1,5 @@
- class MyFoo
- def say
- - puts "Annyong Haseyo"
- + puts "Guten Tag"
- end
- end
- Stage this hunk [y,n,q,a,d,/,e,?]?
-
-As you can see you then get a set of options at the bottom for choosing to add this changed part of the file, all changes from this file, etc. Using the ‘?’ command will explain the options.
-
-#### 12. Storing/Retrieving from the File System ####
-
-Some projects (the Git project itself for example) store additional files directly in the Git file system without them necessarily being a checked in file.
-
-Let’s start off by storing a random file in Git:
-
- $ echo "Foo" | git hash-object -w --stdin
- 51fc03a9bb365fae74fd2bf66517b30bf48020cb
-
-At this point the object is in the database, but if you don’t set something up to point to that object it will be garbage collected. The easiest way is to tag it:
-
- $ git tag myfile 51fc03a9bb365fae74fd2bf66517b30bf48020cb
-
-Note that here we’ve used the tag myfile. When we need to retrieve the file we can do it with:
-
- $ git cat-file blob myfile
-
-This can be useful for utility files that developers may need (passwords, gpg keys, etc) but you don’t want to actually check out on to disk every time (particularly in production).
-
-### Logging and What Changed? ###
-
-#### 13. Viewing a Log ####
-
-You can’t use Git for long without using ‘git log’ to view your recent commits. However, there are some tips on how to use it better. For example, you can view a patch of what changed in each commit with:
-
- $ git log -p
-
-Or you can just view a summary of which files changed with:
-
- $ git log --stat
-
-There’s a nice alias you can set up which shows abbreviated commits and a nice graph of branches with the messages on a single line (like gitk, but on the command line):
-
- $ git config --global alias.lol "log --pretty=oneline --abbrev-commit --graph --decorate"
- $ git lol
- * 4d2409a (master) Oops, meant that to be in Korean
- * 169b845 Hello world
-
-#### 14. Searching in the Log ####
-
-If you want to search for a particular author you can specify that:
-
- $ git log --author=Andy
-
-Update: Thanks to Johannes in the comments, I’ve cleared up some of the confusion here.
-
-Or if you have a search term that appears in the commit message:
-
- $ git log --grep="Something in the message"
-
-There’s also a more powerful command called the pickaxe command that look for the entry that removes or adds a particular piece of content (i.e. when it first appeared or was removed). This can tell you when a line was added (but not if a character on that line was later changed):
-
- $ git log -S "TODO: Check for admin status"
-
-What about if you changed a particular file, e.g. `lib/foo.rb`
-
- $ git log lib/foo.rb
-
-Let’s say you have a `feature/132` branch and a `feature/145` and you want to view the commits on those branches that aren’t on master (note the ^ meaning not):
-
- $ git log feature/132 feature/145 ^master
-
-You can also narrow it down to a date range using ActiveSupport style dates:
-
- $ git log --since=2.months.ago --until=1.day.ago
-
-By default it will use OR to combine the query, but you can easily change it to use AND (if you have more than one criteria)
-
- $ git log --since=2.months.ago --until=1.day.ago --author=andy -S "something" --all-match
-
-#### 15. Selecting Revisions to View/Change ####
-
-There are a number of items you can specify when referring to a revision, depending on what you know about it:
-
- $ git show 12a86bc38 # By revision
- $ git show v1.0.1 # By tag
- $ git show feature132 # By branch name
- $ git show 12a86bc38^ # Parent of a commit
- $ git show 12a86bc38~2 # Grandparent of a commit
- $ git show feature132@{yesterday} # Time relative
- $ git show feature132@{2.hours.ago} # Time relative
-
-Note that unlike the previous section, a caret on the end means the parent of that commit – a caret at the start means not on this branch.
-
-#### 16. Selecting a Range ####
-
-The easiest way is to use:
-
- $ git log origin/master..new
- # [old]..[new] - everything you haven't pushed yet
-
-You can also omit the [new] and it will use your current HEAD.
-
-### Rewinding Time & Fixing Mistakes ###
-
-#### 17. Resetting changes ####
-
-You can easily unstage a change if you haven’t committed it using:
-
- $ git reset HEAD lib/foo.rb
-
-Often this is aliased to ‘unstage’ as it’s a bit non-obvious.
-
- $ git config --global alias.unstage "reset HEAD"
- $ git unstage lib/foo.rb
-
-If you’ve committed the file already, you can do two things – if it’s the last commit you can just amend it:
-
- $ git commit --amend
-
-This undoes the last commit, puts your working copy back as it was with the changes staged and the commit message ready to edit/commit next time you commit.
-
-If you’ve committed more than once and just want to completely undo them, you can reset the branch back to a previous point in time.
-
- $ git checkout feature132
- $ git reset --hard HEAD~2
-
-If you actually want to bring a branch to point to a completely different SHA1 (maybe you’re bringing the HEAD of a branch to another branch, or a further commit) you can do the following to do it the long way:
-
- $ git checkout FOO
- $ git reset --hard SHA
-
-There’s actually a quicker way (as it doesn’t change your working copy back to the state of FOO first then forward to SHA):
-
- $ git update-ref refs/heads/FOO SHA
-
-#### 18. Committing to the Wrong Branch ####
-
-OK, let’s assume you committed to master but should have created a topic branch called experimental instead. To move those changes over, you can create a branch at your current point, rewind head and then checkout your new branch:
-
- $ git branch experimental # Creates a pointer to the current master state
- $ git reset --hard master~3 # Moves the master branch pointer back to 3 revisions ago
- $ git checkout experimental
-
-This can be more complex if you’ve made the changes on a branch of a branch of a branch etc. Then what you need to do is rebase the change on a branch on to somewhere else:
-
- $ git branch newtopic STARTPOINT
- $ git rebase oldtopic --onto newtopic
-
-#### 19. Interactive Rebasing ####
-
-This is a cool feature I’ve seen demoed before but never actually understood, now it’s easy. Let’s say you’ve made 3 commits but you want to re-order them or edit them (or combine them):
-
- $ git rebase -i master~3
-
-Then you get your editor pop open with some instructions. All you have to do is amend the instructions to pick/squash/edit (or remove them) commits and save/exit. Then after editing you can `git rebase —continue` to keep stepping through each of your instructions.
-
-If you choose to edit one, it will leave you in the state you were in at the time you committed that, so you need to use git commit —amend to edit it.
-
-**Note: DO NOT COMMIT DURING REBASE – only add then use —continue, —skip or —abort.**
-
-#### 20. Cleaning Up ####
-
-If you’ve committed some content to your branch (maybe you’ve imported an old repo from SVN) and you want to remove all occurrences of a file from the history:
-
- $ git filter-branch --tree-filter 'rm -f *.class' HEAD
-
-If you’ve already pushed to origin, but have committed the rubbish since then, you can also do this for your local system before pushing:
-
- $ git filter-branch --tree-filter 'rm -f *.class' origin/master..HEAD
-
-### Miscellaneous Tips ###
-
-#### 21. Previous References You’ve Viewed ####
-
-If you know you’ve previously viewed a SHA-1, but you’ve done some resetting/rewinding you can use the reflog commands to view the SHA-1s you’ve recently viewed:
-
- $ git reflog
- $ git log -g # Same as above, but shows in 'log' format
-
-#### 22. Branch Naming ####
-
-A lovely little tip – don’t forget that branch names aren’t limited to a-z and 0-9. It can be quite nice to use / and . in names for fake namespacing or versionin, for example:
-
- $ # Generate a changelog of Release 132
- $ git shortlog release/132 ^release/131
- $ # Tag this as v1.0.1
- $ git tag v1.0.1 release/132
-
-#### 23. Finding Who Dunnit ####
-
-Often it can be useful to find out who changed a line of code in a file. The simple command to do this is:
-
- $ git blame FILE
-
-Sometimes the change has come from a previous file (if you’ve combined two files, or you’ve moved a function) so you can use:
-
- $ # shows which file names the content came from
- $ git blame -C FILE
-
-Sometimes it’s nice to track this down by clicking through changes and going further and further back. There’s a nice in-built gui for this:
-
- $ git gui blame FILE
-
-#### 24. Database Maintenance ####
-
-Git doesn’t generally require a lot of maintenance, it pretty much takes care of itself. However, you can view the statistics of your database using:
-
- $ git count-objects -v
-
-If this is high you can choose to garbage collect your clone. This won’t affect pushes or other people but it can make some of your commands run much faster and take less space:
-
- $ git gc
-
-It also might be worth running a consistency check every so often:
-
- $ git fsck --full
-
-You can also add a `—auto` parameter on the end (if you’re running it frequently/daily from crontab on your server) and it will only fsck if the stats show it’s necessary.
-
-When checking, getting “dangling” or “unreachable” is fine, this is often a result of rewinding heads or rebasing. Getting “missing” or “sha1 mismatch” is bad… Get professional help!
-
-#### 25. Recovering a Lost Branch ####
-
-If you delete a branch experimental with -D you can recreate it with:
-
- $ git branch experimental SHA1_OF_HASH
-
-You can often find the SHA1 hash using git reflog if you’ve accessed it recently.
-
-Another way is to use `git fsck —lost-found`. A dangling commit here is the lost HEAD (it will only be the HEAD of the deleted branch as the HEAD^ is referred to by HEAD so it’s not dangling)
-
-### Done! ###
-
-Wow, the longest blog post I’ve ever written, I hope someone finds it useful. If you did, or if you have any questions let me know in the comments…
-
---------------------------------------------------------------------------------
-
-via: https://www.andyjeffries.co.uk/25-tips-for-intermediate-git-users/
-
-作者:[Andy Jeffries][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:https://www.andyjeffries.co.uk/author/andy-jeffries/
-[1]:http://gitcasts.com/about
-[2]:http://www.lvs.co.uk/
\ No newline at end of file
diff --git a/sources/tech/20150211 Best Known Linux Archive or Compress Tools.md b/sources/tech/20150211 Best Known Linux Archive or Compress Tools.md
deleted file mode 100644
index 3d3960cf4d..0000000000
--- a/sources/tech/20150211 Best Known Linux Archive or Compress Tools.md
+++ /dev/null
@@ -1,229 +0,0 @@
-Best Known Linux Archive / Compress Tools
-================================================================================
-Sending and receiving large files and pictures over the internet is a headache many times. Compression and decompression tools are meant to address this problem. Lets take a quick overview of a few open source tools that are available to make our jobs simpler.
-
-Tar
-gzip, gunzip
-bzip2, bunzip2
-7-Zip
-
-### Tar ###
-
-Tar is derived from 'Tape archiver' as this was initially used for archiving and storing files on magnetic tapes. It is a GNU software. It can compress a set of files (archives), extract them and manipulate those which already exist. It is useful for storing, backing up and transporting files. Tar can preserve file and directory structure while creating the archives. Files archived using tar have '.tar' extensions.
-
-Basic Usage
-
-#### a) Creating an archive (c / --create) ####
-
- tar --create --verbose --file=archive.tar file1 file2 file3
-
-OR
-
- tar cvf archive.tar file1 file2 file3
-
-
-
-creating an archive
-
-#### b) Listing an archive ( t / --list) ####
-
- tar --list archive.tar
-
-
-
-Listing the contents
-
-#### c) Extracting an archive (x / --extract) ####
-
- tar xvf archive.tar
-
- tar xvf archive.tar --wildcards '*.c' - extracts files with only *.c extension from the archive.
-
-
-
-Extracting files
-
-
-
-Extract only the required files
-
-#### d) Updating an archive ( u / --update) ####
-
- tar uvf archive.tar newfile.c - updates the archive by adding newfile.c if its version is newer than the existing one.
-
-
-
-Updating an archive
-
-#### e) Delete from an archive (--delete) ####
-
- tar--delete -f archive.tar file1.c - deletes 'file1.c' from the tar ball 'archive.tar'
-
-
-
-Deleting files
-
-Refer to [tar home page][1] for its detailed usage
-
-### Gzip / Gunzip ###
-
-Gzip stands for GNU zip. It is a compression utility that is commonly available in Linux operating system. Compressed files have an extension of '*.gz'
-
-**Basic Usage**
-
-#### a) Compressing files ####
-
- gzip file(s)
-
-Each file gets compressed individually
-
-
-
-Compress files
-
-This generally deletes the original files after compression. We can keep the original file by using the -c option.
-
- gzip -c file > file.gz
-
-
-
-Keep original files after compressing
-
-We can also compress a group of files into a single file
-
- cat file1 file2 file3 | gzip > archieve.gz
-
-
-
-Compressing a group of files
-
-#### b) Checking compression ratio ####
-
-Compression ratio of the compressed file(s) can be verified using the '-l' option.
-
- gzip -l archieve.gz
-
-
-
-Checking compression ratio
-
-#### c) Unzipping files ####
-
-Gunzip is used for unzipping files. Here also, original files are deleted after decompression. Use the -c option to retain original files.
-
- gunzip -c archieve.gz
-
-
-
-Unzipping files
-
-Using '-d' option with gzip command has the same effect of gunzip on compressed files.
-
-More details can be obtained from [gzip home page][2]
-
-### Bzip2 / Bunzip2 ###
-
-[Bzip2][3] is also a compression tool like gzip but can compress files to smaller sizes than that is possible with other traditional tools. But the drawback is that it is slower than gzip.
-
-**Basic Usage**
-
-#### a) File Compression ####
-
-Generally, no options are used for compression and the files to be compressed are passed as arguments. Each file gets compressed individually and compressed files will have the extension 'bz2'.
-
- bzip2 file1 file2 file3
-
-
-
-File Compression
-
-Use '-k' option to keep the original files after compression / decompression.
-
-
-
-Retaining original files after compression
-
-'-d' option is used for forced decompression.
-
-
-
-Delete files using -d option
-
-#### b) Decompression ####
-
- bunzip2 filename
-
-
-
-Decompressing files
-
-bunzip2 can decompress files with extensions bz2, bz, tbz2 and tbz. Files with tbz2 and tbz will end up with '.tar' extension after decompression.
-
- bzip2 -dc performs the function of decompressing files to the stdout
-
-### 7-zip ###
-
-[7-zip][4] is another open source file archiver. It uses 7z format which is a new compression format and provides high-compression ratio. Hence, it is considered to be better than the previously mentioned compression tools. It is available under Linux as p7zip package. The package includes three binaries – 7z, 7za and 7zr. Refer to the [p7zip wiki][5] for differences between these binaries. In this article, we will be using 7zr to explain the usage. Archived files will have '.7z' extension.
-
-**Basic usage**
-
-#### a) Creating an archive ####
-
- 7zr a archive-name.7z file-name(s) / directory-name(s)
-
-
-
-Creating an archive
-
-#### b) Listing an archive ####
-
- 7zr l archive-name.7z
-
-
-
-Listing an archive
-
-#### c) Extracting an archive ####
-
- 7zr e archive-name.7z
-
-
-
-Extracting an archive
-
-#### d) Updating an archive ####
-
- 7zr u archive-name.7z new-file
-
-
-
-Updating an archive
-
-#### e) Deleting files from an archive ####
-
- 7zr d archive-name.7z file-to-be-deleted
-
-
-
-Deleting files
-
-
-
-Verifying file deletion
-
---------------------------------------------------------------------------------
-
-via: http://linoxide.com/tools/linux-compress-decompress-tools/
-
-作者:[B N Poornima][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://linoxide.com/author/bnpoornima/
-[1]:http://www.gnu.org/software/tar/
-[2]:http://www.gzip.org/
-[3]:http://www.bzip.org/
-[4]:http://www.7-zip.org/
-[5]:https://wiki.archlinux.org/index.php/p7zip
\ No newline at end of file
diff --git a/sources/tech/20150211 How To Protect Ubuntu Server Against the GHOST Vulnerability.md b/sources/tech/20150211 How To Protect Ubuntu Server Against the GHOST Vulnerability.md
deleted file mode 100644
index a78b786606..0000000000
--- a/sources/tech/20150211 How To Protect Ubuntu Server Against the GHOST Vulnerability.md
+++ /dev/null
@@ -1,44 +0,0 @@
-How To Protect Ubuntu Server Against the GHOST Vulnerability
-================================================================================
-On January 27, 2015, a GNU C Library (glibc) vulnerability, referred to as the GHOST vulnerability, was announced to the general public. In summary, the vulnerability allows remote attackers to take complete control of a system by exploiting a buffer overflow bug in glibc's GetHOST functions.Check more details from [here][1]
-
-The GHOST vulnerability can be exploited on Linux systems that use versions of the GNU C Library prior to glibc-2.18. That is, systems that use an unpatched version of glibc from versions 2.2 to 2.17 are at risk.
-
-### Check System Vulnerability ###
-
-You can use the following command to check the glib version
-
- ldd --version
-
-### Output ###
-
-ldd (Ubuntu GLIBC 2.19-10ubuntu2) **2.19**
-Copyright (C) 2014 Free Software Foundation, Inc.
-This is free software; see the source for copying conditions. There is NO
-warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
-Written by Roland McGrath and Ulrich Drepper.
-
-The glib version should be above 2.17 and from the output we are running 2.19.If you are seeing glib version between 2.2 to 2.17 then you need to run the following commands
-
- sudo apt-get update
-
- sudo apt-get dist-upgrade
-
-After the installation you need to reboot the server using the following command
-
- sudo reboot
-
-After reboot use the same command again and check the glib version.
-
---------------------------------------------------------------------------------
-
-via: http://www.ubuntugeek.com/how-to-protect-ubuntu-server-against-the-ghost-vulnerability.html
-
-作者:[ruchi][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://www.ubuntugeek.com/author/ubuntufix
-[1]:http://chargen.matasano.com/chargen/2015/1/27/vulnerability-overview-ghost-cve-2015-0235.html
\ No newline at end of file
diff --git a/sources/tech/20150211 Install Linux-Dash (Web Based Monitoring tool) on Ubntu 14.10.md b/sources/tech/20150211 Install Linux-Dash (Web Based Monitoring tool) on Ubntu 14.10.md
deleted file mode 100644
index fe2432f8b3..0000000000
--- a/sources/tech/20150211 Install Linux-Dash (Web Based Monitoring tool) on Ubntu 14.10.md
+++ /dev/null
@@ -1,70 +0,0 @@
-Install Linux-Dash (Web Based Monitoring tool) on Ubntu 14.10
-================================================================================
-A low-overhead monitoring web dashboard for a GNU/Linux machine. Simply drop-in the app and go!.Linux Dash's interface provides a detailed overview of all vital aspects of your server, including RAM and disk usage, network, installed software, users, and running processes. All information is organized into sections, and you can jump to a specific section using the buttons in the main toolbar. Linux Dash is not the most advanced monitoring tool out there, but it might be a good fit for users looking for a slick, lightweight, and easy to deploy application.
-
-### Linux-Dash Features ###
-
-A beautiful web-based dashboard for monitoring server info
-
-Live, on-demand monitoring of RAM, Load, Uptime, Disk Allocation, Users and many more system stats
-
-Drop-in install for servers with Apache2/nginx + PHP
-
-Click and drag to re-arrange widgets
-
-Support for wide range of linux server flavors
-
-### List of Current Widgets ###
-
-- General info
-- Load Average
-- RAM
-- Disk Usage
-- Users
-- Software
-- IP
-- Internet Speed
-- Online
-- Processes
-- Logs
-
-### Install Linux-dash on ubuntu server 14.10 ###
-
-First you need to make sure you have [Ubuntu LAMP server 14.10][1] installed and Now you have to install the following package
-
- sudo apt-get install php5-json unzip
-
-After the installation this module will enable for apache2 so you need to restart the apache2 server using the following command
-
- sudo service apache2 restart
-
-Now you need to download the linux-dash package and install
-
- wget https://github.com/afaqurk/linux-dash/archive/master.zip
-
- unzip master.zip
-
- sudo mv linux-dash-master/ /var/www/html/linux-dash-master/
-
-Now you need to change the permissions using the following command
-
- sudo chmod 755 /var/www/html/linux-dash-master/
-
-Now you need to go to http://serverip/linux-dash-master/ you should see similar to the following output
-
-
-
-
-
---------------------------------------------------------------------------------
-
-via: http://www.ubuntugeek.com/install-linux-dash-web-based-monitoring-tool-on-ubntu-14-10.html
-
-作者:[ruchi][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://www.ubuntugeek.com/author/ubuntufix
-[1]:http://www.ubuntugeek.com/step-by-step-ubuntu-14-10-utopic-unicorn-lamp-server-setup.html
diff --git a/sources/tech/20150211 Install Mumble in Ubuntu an Opensource VoIP Apps.md b/sources/tech/20150211 Install Mumble in Ubuntu an Opensource VoIP Apps.md
deleted file mode 100644
index f49cc07c31..0000000000
--- a/sources/tech/20150211 Install Mumble in Ubuntu an Opensource VoIP Apps.md
+++ /dev/null
@@ -1,80 +0,0 @@
-translating by martin.
-
-Install Mumble in Ubuntu an Opensource VoIP Apps
-================================================================================
-Mumble is a free and open source voice over IP (VoIP) application, released under the new BSD license, primarily designed for use by gamers and it's similar to programs such as TeamSpeak and Ventrilo. It uses a server to witch people can connect with a client to talk to each other.
-
-It offers the following great features:
-
-- low latency, very important for gaming
-- offers in-game overlay so you can see who is talking and positional audio to hear the players from where they are located
-- has encrypted communications so you can stay private and secure
-- it also offers a few nice configuration interface that are easy to use
-- very stable and good on resource usage for your server
-
-### Install Mumble ###
-
-[Mumble][1] has become very popular and is now present in the software repositories of the major Linux distributions and this makes it easy to install and setup. In Ubuntu you can use the command line to install it with apt-get by running the following command:
-
- $ sudo apt-get install mumble-server
-
-
-
-This will install the server (also called Murmur) on your server.
-
-### Configuring Mumble ###
-
-To setup Mumble you will need to run the following command:
-
-$ sudo dpkg-reconfigure mumble-server
-
-The following questions will pop-up:
-
-
-
-Pick Yes to have mumble start when your server boots, next it will ask if you wish to run it in a high-priority mode that will ensure lower latency, it's a good idea to have it run it like that for the best performance:
-
-
-
-It will then require you to introduce a password for the administrator user of the new mumble server, you will need to remember this password for when you will log-in.
-
-
-
-### Installing Mumble Client ###
-
-The client can be installed on most major platforms like Windows, Mac OS X and Linux. We will cover the installation and configuration on Ubuntu Linux, to install it you can use the Software Center or run the following command:
-
- $ sudo apt-get install mumble
-
-When you first run Mumble it will present you with a wizard to help you configure your audio input and output to make the best of the client. It will first ask you what sound device and microphone to use:
-
-
-
-Then it will help you calibrate the devices:
-
-
-
-And since mumble encrypts all the communication it will ask you to also create a certificate:
-
-
-
-After you finish with the wizard you can add your first server and connect to it the dialog will look like this:
-
-
-
-First enter a label, this can be anything you wish to remember the server by, next add the address and port of the server, and finally use "SuperUser" as user and the password you used when you configured the mumble server.
-
-You can now connect to the server and enjoy all of the features while you play online or talk to your friends or partners.
-
---------------------------------------------------------------------------------
-
-via: http://linoxide.com/ubuntu-how-to/install-mumble-ubuntu/
-
-作者:[Adrian Dinu][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://linoxide.com/author/adriand/
-[1]:http://wiki.mumble.info/wiki/Main_Page
diff --git a/sources/tech/20150211 Protect Apache Against Brute Force or DDoS Attacks Using Mod_Security and Mod_evasive Modules.md b/sources/tech/20150211 Protect Apache Against Brute Force or DDoS Attacks Using Mod_Security and Mod_evasive Modules.md
deleted file mode 100644
index 29bb770e5d..0000000000
--- a/sources/tech/20150211 Protect Apache Against Brute Force or DDoS Attacks Using Mod_Security and Mod_evasive Modules.md
+++ /dev/null
@@ -1,270 +0,0 @@
-Protect Apache Against Brute Force or DDoS Attacks Using Mod_Security and Mod_evasive Modules
-================================================================================
-For those of you in the hosting business, or if you’re hosting your own servers and exposing them to the Internet, securing your systems against attackers must be a high priority.
-
-mod_security (an open source intrusion detection and prevention engine for web applications that integrates seamlessly with the web server) and mod_evasive are two very important tools that can be used to protect a web server against brute force or (D)DoS attacks.
-
-mod_evasive, as its name suggests, provides evasive capabilities while under attack, acting as an umbrella that shields web servers from such threats.
-
-
-Install Mod_Security and Mod_Evasive to Protect Apache
-
-In this article we will discuss how to install, configure, and put them into play along with Apache on RHEL/CentOS 6 and 7 as well as Fedora 21-15. In addition, we will simulate attacks in order to verify that the server reacts accordingly.
-
-This assumes that you have a LAMP server installed on your system. If not, please check this article before proceeding further.
-
-- [Install LAMP stack in RHEL/CentOS 7][1]
-
-You will also need to setup iptables as the default [firewall][2] front-end instead of firewalld if you’re running RHEL/CentOS 7 or Fedora 21. We do this in order to use the same tool in both RHEL/CentOS 7/6 and Fedora 21.
-
-### Step 1: Installing Iptables Firewall on RHEL/CentOS 7 and Fedora 21 ###
-
-To begin, stop and disable firewalld:
-
- # systemctl stop firewalld
- # systemctl disable firewalld
-
-
-Disable Firewalld Service
-
-Then install the iptables-services package before enabling iptables:
-
- # yum update && yum install iptables-services
- # systemctl enable iptables
- # systemctl start iptables
- # systemctl status iptables
-
-
-Install Iptables Firewall
-
-### Step 2: Installing Mod_Security and Mod_evasive ###
-
-In addition to having a LAMP setup already in place, you will also have to [enable the EPEL repository][3] in RHEL/CentOS 7/6 in order to install both packages. Fedora users don’t need to enable any repo, because epel is a already part of Fedora project.
-
- # yum update && yum install mod_security mod_evasive
-
-When the installation is complete, you will find the configuration files for both tools in /etc/httpd/conf.d.
-
- # ls -l /etc/httpd/conf.d
-
-
-mod_security + mod_evasive Configurations
-
-Now, in order to integrate these two modules with Apache and have it load them when it starts, make sure the following lines appear in the top level section of mod_evasive.conf and mod_security.conf, respectively:
-
- LoadModule evasive20_module modules/mod_evasive24.so
- LoadModule security2_module modules/mod_security2.so
-
-Note that modules/mod_security2.so and modules/mod_evasive24.so are the relative paths, from the /etc/httpd directory to the source file of the module. You can verify this (and change it, if needed) by listing the contents of the /etc/httpd/modules directory:
-
- # cd /etc/httpd/modules
- # pwd
- # ls -l | grep -Ei '(evasive|security)'
-
-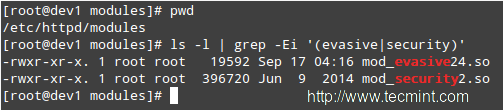
-Verify mod_security + mod_evasive Modules
-
-Then restart Apache and verify that it loads mod_evasive and mod_security:
-
- # service httpd restart [On RHEL/CentOS 6 and Fedora 20-18]
- # systemctl restart httpd [On RHEL/CentOS 7 and Fedora 21]
-
-----------
-
- [Dump a list of loaded Static and Shared Modules]
-
- # httpd -M | grep -Ei '(evasive|security)'
-
-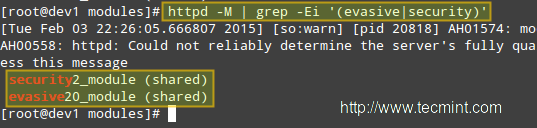
-Check mod_security + mod_evasive Modules Loaded
-
-### Step 3: Installing A Core Rule Set and Configuring Mod_Security ###
-
-In few words, a Core Rule Set (aka CRS) provides the web server with instructions on how to behave under certain conditions. The developer firm of mod_security provide a free CRS called OWASP ([Open Web Application Security Project][4]) ModSecurity CRS that can be downloaded and installed as follows.
-
-1. Download the OWASP CRS to a directory created for that purpose.
-
- # mkdir /etc/httpd/crs-tecmint
- # cd /etc/httpd/crs-tecmint
- # wget https://github.com/SpiderLabs/owasp-modsecurity-crs/tarball/master
-
-
-Download mod_security Core Rules
-
-2. Untar the CRS file and change the name of the directory for one of our convenience.
-
- # tar xzf master
- # mv SpiderLabs-owasp-modsecurity-crs-ebe8790 owasp-modsecurity-crs
-
-
-Extract mod_security Core Rules
-
-3. Now it’s time to configure mod_security. Copy the sample file with rules (owasp-modsecurity-crs/modsecurity_crs_10_setup.conf.example) into another file without the .example extension:
-
- # cp modsecurity_crs_10_setup.conf.example modsecurity_crs_10_setup.conf
-
-and tell Apache to use this file along with the module by inserting the following lines in the web server’s main configuration file /etc/httpd/conf/httpd.conf file. If you chose to unpack the tarball in another directory you will need to edit the paths following the Include directives:
-
-
- Include crs-tecmint/owasp-modsecurity-crs/modsecurity_crs_10_setup.conf
- Include crs-tecmint/owasp-modsecurity-crs/base_rules/*.conf
-
-
-Finally, it is recommended that we create our own configuration file within the /etc/httpd/modsecurity.d directory where we will place our customized directives (we will name it tecmint.conf in the following example) instead of modifying the CRS files directly. Doing so will allow for easier upgrading the CRSs as new versions are released.
-
-
- SecRuleEngine On
- SecRequestBodyAccess On
- SecResponseBodyAccess On
- SecResponseBodyMimeType text/plain text/html text/xml application/octet-stream
- SecDataDir /tmp
-
-
-You can refer to the [SpiderLabs’ ModSecurity GitHub][5] repository for a complete explanatory guide of mod_security configuration directives.
-
-### Step 4: Configuring Mod_Evasive ###
-
-mod_evasive is configured using directives in /etc/httpd/conf.d/mod_evasive.conf. Since there are no rules to update during a package upgrade, we don’t need a separate file to add customized directives, as opposed to mod_security.
-
-The default mod_evasive.conf file has the following directives enabled (note that this file is heavily commented, so we have stripped out the comments to highlight the configuration directives below):
-
-
- DOSHashTableSize 3097
- DOSPageCount 2
- DOSSiteCount 50
- DOSPageInterval 1
- DOSSiteInterval 1
- DOSBlockingPeriod 10
-
-
-Explanation of the directives:
-
-- DOSHashTableSize: This directive specifies the size of the hash table that is used to keep track of activity on a per-IP address basis. Increasing this number will provide a faster look up of the sites that the client has visited in the past, but may impact overall performance if it is set too high.
-- DOSPageCount: Legitimate number of identical requests to a specific URI (for example, any file that is being served by Apache) that can be made by a visitor over the DOSPageInterval interval.
-- DOSSiteCount: Similar to DOSPageCount, but refers to how many overall requests can be made to the entire site over the DOSSiteInterval interval.
-- DOSBlockingPeriod: If a visitor exceeds the limits set by DOSSPageCount or DOSSiteCount, his source IP address will be blacklisted during the DOSBlockingPeriod amount of time. During DOSBlockingPeriod, any requests coming from that IP address will encounter a 403 Forbidden error.
-
-Feel free to experiment with these values so that your web server will be able to handle the required amount and type of traffic.
-
-**Only a small caveat**: if these values are not set properly, you run the risk of ending up blocking legitimate visitors.
-
-You may also want to consider other useful directives:
-
-#### DOSEmailNotify ####
-
-If you have a mail server up and running, you can send out warning messages via Apache. Note that you will need to grant the apache user SELinux permission to send emails if SELinux is set to enforcing. You can do so by running
-
- # setsebool -P httpd_can_sendmail 1
-
-Next, add this directive in the mod_evasive.conf file with the rest of the other directives:
-
- DOSEmailNotify you@yourdomain.com
-
-If this value is set and your mail server is working properly, an email will be sent to the address specified whenever an IP address becomes blacklisted.
-
-#### DOSSystemCommand ####
-
-This needs a valid system command as argument,
-
- DOSSystemCommand
-
-This directive specifies a command to be executed whenever an IP address becomes blacklisted. It is often used in conjunction with a shell script that adds a firewall rule to block further connections coming from that IP address.
-
-**Write a shell script that handles IP blacklisting at the firewall level**
-
-When an IP address becomes blacklisted, we need to block future connections coming from it. We will use the following shell script that performs this job. Create a directory named scripts-tecmint (or whatever name of your choice) in /usr/local/bin and a file called ban_ip.sh in that directory.
-
- #!/bin/sh
- # IP that will be blocked, as detected by mod_evasive
- IP=$1
- # Full path to iptables
- IPTABLES="/sbin/iptables"
- # mod_evasive lock directory
- MOD_EVASIVE_LOGDIR=/var/log/mod_evasive
- # Add the following firewall rule (block all traffic coming from $IP)
- $IPTABLES -I INPUT -s $IP -j DROP
- # Remove lock file for future checks
- rm -f "$MOD_EVASIVE_LOGDIR"/dos-"$IP"
-
-Our DOSSystemCommand directive should read as follows:
-
- DOSSystemCommand "sudo /usr/local/bin/scripts-tecmint/ban_ip.sh %s"
-
-In the line above, %s represents the offending IP as detected by mod_evasive.
-
-**Add the apache user to the sudoers file**
-
-Note that all of this just won’t work unless you to give permissions to user apache to run our script (and that script only!) without a terminal and password. As usual, you can just type visudo as root to access the /etc/sudoers file and then add the following 2 lines as shown in the image below:
-
- apache ALL=NOPASSWD: /usr/local/bin/scripts-tecmint/ban_ip.sh
- Defaults:apache !requiretty
-
-
-Add Apache User to Sudoers
-
-**IMPORTANT**: As a default security policy, you can only run sudo in a terminal. Since in this case we need to use sudo without a tty, we have to comment out the line that is highlighted in the following image:
-
- #Defaults requiretty
-
-
-Disable tty for Sudo
-
-Finally, restart the web server:
-
- # service httpd restart [On RHEL/CentOS 6 and Fedora 20-18]
- # systemctl restart httpd [On RHEL/CentOS 7 and Fedora 21]
-
-### Step 4: Simulating an DDoS Attacks on Apache ###
-
-There are several tools that you can use to simulate an external attack on your server. You can just google for “tools for simulating ddos attacks” to find several of them.
-
-Note that you, and only you, will be held responsible for the results of your simulation. Do not even think of launching a simulated attack to a server that you’re not hosting within your own network.
-
-Should you want to do the same with a VPS that is hosted by someone else, you need to appropriately warn your hosting provider or ask permission for such a traffic flood to go through their networks. Tecmint.com is not, by any means, responsible for your acts!
-
-In addition, launching a simulated DoS attack from only one host does not represent a real life attack. To simulate such, you would need to target your server from several clients at the same time.
-
-Our test environment is composed of a CentOS 7 server [IP 192.168.0.17] and a Windows host from which we will launch the attack [IP 192.168.0.103]:
-
-
-Confirm Host IPAddress
-
-Please play the video below and follow the steps outlined in the indicated order to simulate a simple DoS attack:
-
-注:youtube视频,发布的时候不行做个链接吧
-
-
-Then the offending IP is blocked by iptables:
-
-
-Blocked Attacker IP
-
-### Conclusion ###
-
-With mod_security and mod_evasive enabled, the simulated attack causes the CPU and RAM to experiment a temporary usage peak for only a couple of seconds before the source IPs are blacklisted and blocked by the firewall. Without these tools, the simulation will surely knock down the server very fast and render it unusable during the duration of the attack.
-
-We would love to hear if you’re planning on using (or have used in the past) these tools. We always look forward to hearing from you, so don’t hesitate to leave your comments and questions, if any, using the form below.
-
-### Reference Links ###
-
-- [https://www.modsecurity.org/][6]
-- [http://www.zdziarski.com/blog/?page_id=442][7]
-
---------------------------------------------------------------------------------
-
-via: http://www.tecmint.com/protect-apache-using-mod_security-and-mod_evasive-on-rhel-centos-fedora/
-
-作者:[Gabriel Cánepa][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://www.tecmint.com/author/gacanepa/
-[1]:http://www.tecmint.com/install-lamp-in-centos-7/
-[2]:http://www.tecmint.com/configure-firewalld-in-centos-7/
-[3]:http://www.tecmint.com/how-to-enable-epel-repository-for-rhel-centos-6-5/
-[4]:https://www.owasp.org/index.php/Category:OWASP_ModSecurity_Core_Rule_Set_Project
-[5]:https://github.com/SpiderLabs/ModSecurity/wiki/Reference-Manual#Configuration_Directives
-[6]:https://www.modsecurity.org/
-[7]:http://www.zdziarski.com/blog/?page_id=442
\ No newline at end of file
diff --git a/sources/tech/20150211 Simple Steps Migration From MySQL To MariaDB On Linux.md b/sources/tech/20150211 Simple Steps Migration From MySQL To MariaDB On Linux.md
deleted file mode 100644
index 1588c979a4..0000000000
--- a/sources/tech/20150211 Simple Steps Migration From MySQL To MariaDB On Linux.md
+++ /dev/null
@@ -1,169 +0,0 @@
-Simple Steps Migration From MySQL To MariaDB On Linux
-================================================================================
-Hi all, this tutorial is all gonna be about how to migrate from MySQL to MariaDB on Linux Server or PC. So, you may ask why should we really migrate from MySQL to MariaDB for our database management. Here, below are the reasons why you should really need to migrate your database management system from MySQL to MariaDB.
-
-### Why should I use MariaDB instead of MySQL? ###
-
-MariaDB is an enhanced drop-in replacement and community-developed fork of the MySQL database system. It was developed by MariaDB foundation, and is being led by original developers of MySQL. Working with MariaDB is entirely same as MySQL. After Oracle bought MySQL, it is not free and open source anymore, but **MariaDB is still free and open source**. Top Websites like Google, Wikipedia, Linkedin, Mozilla and many more migrated to MariaDB. Its features are
-
-- Backwards compatible with MySQL
-- Forever open source
-- Maintained by MySQL's creator
-- More cutting edge features
-- More storage engines
-- Large websites have switched
-
-Now, lets migrate to MariaDB.
-
-**For the testing purpose**, let us create a sample database called **linoxidedb** .
-
-Log in to MySQL as root user using the following command:
-
- $ mysql -u root -p
-
-Enter the mysql root user password. You’ll be redirected to the **mysql prompt**.
-
-**Create test databases:**
-
-Enter the following commands from mysql prompt to create test databases.
-
- mysql> create database linoxidedb;
-
-To view the list of available databases, enter the following command:
-
- mysql> show databases;
-
-
-
-As see above, we have totally 5 databases including the newly created database linoxidedb .
-
- mysql> quit
-
-Now, we'll migrate the created databases from MySQL to MariaDB.
-
-Note: This tutorial is not necessary for CentOS, fedora based distribution of Linux because MariaDB is automatically installed instead of MySQL which requires no need to backup the existing databases, you just need to update mysql which will give you mariadb.
-
-### 1. Backup existing databases ###
-
-Our first important step is to create a backup of existing databases. To do that, we'll enter the following command from the **Terminal (not from MySQL prompt)**.
-
- $ mysqldump --all-databases --user=root --password --master-data > backupdatabase.sql
-
-Oops! We encountered an error. No worries, it can be fixed.
-
- $ mysqldump: Error: Binlogging on server not active
-
-
-mysqldump error
-
-To fix this error, we have to do a small modification in **my.cnf** file.
-
-Edit my.cnf file:
-
- $ sudo nano /etc/mysql/my.cnf
-
-Under [mysqld] section, add the following parameter.
-
-**log-bin=mysql-bin**
-
-
-
-Now, after done save and exit the file. Then, we'll need to restart mysql server. To do that please execute the below commands.
-
- $ sudo /etc/init.d/mysql restart
-
-Now, re-run the mysqldump command to backup all databases.
-
- $ mysqldump --all-databases --user=root --password --master-data > backupdatabase.sql
-
-
-dumping databases
-
-The above command will backup all databases, and stores them in **backupdatabase.sql** in the current directory.
-
-### 2. Uninstalling MySQL ###
-
-First of all, we'll want to **backup the my.cnf file to a safe location**.
-
-**Note**: The my.cnf file will not be deleted when uninstalling MySQL packages. We do it for the precaution. During MariaDB installation, the installer will ask us to keep the existing my.cnf(old backup) file or to use the package containers version (i.e new one).
-
-To backup the my.cnf file, please enter the following commands in a shell or terminal.
-
- $ sudo cp /etc/mysql/my.cnf my.cnf.bak
-
-To stop mysql service, enter the following command from your Terminal.
-
- $ sudo /etc/init.d/mysql stop
-
-Then, remove mysql packages.
-
- $ sudo apt-get remove mysql-server mysql-client
-
-
-
-### 3. Installing MariaDB ###
-
-Here are the commands to run to install MariaDB on your Ubuntu system:
-
- $ sudo apt-get install software-properties-common
- $ sudo apt-key adv --recv-keys --keyserver hkp://keyserver.ubuntu.com:80 0xcbcb082a1bb943db
- # sudo add-apt-repository 'deb http://mirror.mephi.ru/mariadb/repo/5.5/ubuntu trusty main'
-
-
-
-Once the key is imported and the repository added you can install MariaDB with:
-
- $ sudo apt-get update
- $ sudo apt-get install mariadb-server
-
-
-
-
-
-We should remember that during MariaDB installation, the installer will ask you either to use the existing my.cnf(old backup) file, or use the package containers version (i.e new one). You can either use the old my.cnf file or the package containers version. If you want to use the new my.cnf version, you can restore the contents of older my.cnf (We already have copied this file to safe location before) later ie my.cnf.bak . So, I will go for default which is N, we'll press N then. For other versions, please refer the [MariaDB official repositories page][2].
-
-### 4. Restoring Config File ###
-
-To restore my.cnf from my.cnf.bak, enter the following command in Terminal. We have the old as my.cnf.bak file in our current directory, so we can simply copy the file using the following command:
-
- $ sudo cp my.cnf.bak /etc/mysql/my.cnf
-
-### 5. Importing Databases ###
-
-Finally, lets import the old databases that we created before. To do that, we'll need to run the following command.
-
- $ mysql -u root -p < backupdatabase.sql
-
-That’s it. We have successfully imported the old databases.
-
-Let us check if the databases are really imported. To do that, we'll wanna log in to mysql prompt using command:
-
- $ mysql -u root -p
-
-
-
-Now, to check whether the databases are migrated to MariaDB please run "**show databases**;" command inside the MarianDB prompt without quotes("") as
-
- mariaDB> show databases;
-
-
-
-As you see in the above result all old databases including our very linoxidedb has been successfully migrated.
-
-### Conclusion ###
-
-Finally, we have successfully migrated our databases from MySQL to MariaDB Database Management System. MariaDB is far more better than MySQL. Though MySQL is still faster than MariaDB in performance but MariaDB is far more better because of its additional features and license. MariaDB is a Free and Open Source Software (FOSS) and will be FOSS forever but MySQL has many additional plugins, etc non-free and there is no proper public roadmap and won't be FOSS in future. If you have any questions, comments, feedback to us, please don't hesitate to write on the comment box below. Thank You ! And Enjoy MariaDB.
-
---------------------------------------------------------------------------------
-
-via: http://linoxide.com/linux-how-to/migrate-mysql-mariadb-linux/
-
-作者:[Arun Pyasi][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://linoxide.com/author/arunp/
-[1]:https://mariadb.org/
-[2]:https://downloads.mariadb.org/mariadb/repositories/#mirror=mephi
\ No newline at end of file
diff --git a/sources/tech/20150410 How to Install and Configure Multihomed ISC DHCP Server on Debian Linux.md b/sources/tech/20150410 How to Install and Configure Multihomed ISC DHCP Server on Debian Linux.md
new file mode 100644
index 0000000000..2a8bdb2fbd
--- /dev/null
+++ b/sources/tech/20150410 How to Install and Configure Multihomed ISC DHCP Server on Debian Linux.md
@@ -0,0 +1,159 @@
+How to Install and Configure Multihomed ISC DHCP Server on Debian Linux
+================================================================================
+Dynamic Host Control Protocol (DHCP) offers an expedited method for network administrators to provide network layer addressing to hosts on a constantly changing, or dynamic, network. One of the most common server utilities to offer DHCP functionality is ISC DHCP Server. The goal of this service is to provide hosts with the necessary network information to be able to communicate on the networks in which the host is connected. Information that is typically served by this service can include: DNS server information, network address (IP), subnet mask, default gateway information, hostname, and much more.
+
+This tutorial will cover ISC-DHCP-Server version 4.2.4 on a Debian 7.7 server that will manage multiple virtual local area networks (VLAN) but can very easily be applied to a single network setup as well.
+
+The test network that this server was setup on has traditionally relied on a Cisco router to manage the DHCP address leases. The network currently has 12 VLANs needing to be managed by one centralized server. By moving this responsibility to a dedicated server, the router can regain resources for more important tasks such as routing, access control lists, traffic inspection, and network address translation.
+
+The other benefit to moving DHCP to a dedicated server will, in a later guide, involve setting up Dynamic Domain Name Service (DDNS) so that new host’s host-names will be added to the DNS system when the host requests a DHCP address from the server.
+
+### Step 1: Installing and Configuring ISC DHCP Server ###
+
+1. To start the process of creating this multi-homed server, the ISC software needs to be installed via the Debian repositories using the ‘apt‘ utility. As with all tutorials, root or sudo access is assumed. Please make the appropriate modifications to the following commands.
+
+ # apt-get install isc-dhcp-server [Installs the ISC DHCP Server software]
+ # dpkg --get-selections isc-dhcp-server [Confirms successful installation]
+ # dpkg -s isc-dhcp-server [Alternative confirmation of installation]
+
+
+
+2. Now that the server software is confirmed installed, it is now necessary to configure the server with the network information that it will need to hand out. At the bare minimum, the administrator needs to know the following information for a basic DHCP scope:
+
+- The network addresses
+- The subnet masks
+- The range of addresses to be dynamically assigned
+
+Other useful information to have the server dynamically assign includes:
+
+- Default gateway
+- DNS server IP addresses
+- The Domain Name
+- Host name
+- Network Broadcast addresses
+
+These are merely a few of the many options that the ISC DHCP server can handle. To get a complete list as well as a description of each option, enter the following command after installing the package:
+
+ # man dhcpd.conf
+
+3. Once the administrator has concluded all the necessary information for this server to hand out it is time to configure the DHCP server as well as the necessary pools. Before creating any pools or server configurations though, the DHCP service must be configured to listen on one of the server’s interfaces.
+
+On this particular server, a NIC team has been setup and DHCP will listen on the teamed interfaces which were given the name `'bond0'`. Be sure to make the appropriate changes given the server and environment in which everything is being configured. The defaults in this file are okay for this tutorial.
+
+
+
+This line will instruct the DHCP service to listen for DHCP traffic on the specified interface(s). At this point, it is time to modify the main configuration file to enable the DHCP pools on the necessary networks. The main configuration file is located at /etc/dhcp/dhcpd.conf. Open the file with a text editor to begin:
+
+ # nano /etc/dhcp/dhcpd.conf
+
+This file is the configuration for the DHCP server specific options as well as all of the pools/hosts one wishes to configure. The top of the file starts of with a ‘ddns-update-style‘ clause and for this tutorial it will remain set to ‘none‘ however in a future article, Dynamic DNS will be covered and ISC-DHCP-Server will be integrated with BIND9 to enable host name to IP address updates.
+
+4. The next section is typically the area where and administrator can configure global network settings such as the DNS domain name, default lease time for IP addresses, subnet-masks, and much more. Again to know more about all the options be sure to read the man page for the dhcpd.conf file.
+
+ # man dhcpd.conf
+
+For this server install, there were a couple of global network options that were configured at the top of the configuration file so that they wouldn’t have to be implemented in every single pool created.
+
+
+
+Lets take a moment to explain some of these options. While they are configured globally in this example, all of them can be configured on a per pool basis as well.
+
+- option domain-name “comptech.local”; – All hosts that this DHCP server hosts, will be a member of the DNS domain name “comptech.local”
+- option domain-name-servers 172.27.10.6; DHCP will hand out DNS server IP of 172.27.10.6 to all of the hosts on all of the networks it is configured to host.
+- option subnet-mask 255.255.255.0; – The subnet mask handed out to every network will be a 255.255.255.0 or a /24
+- default-lease-time 3600; – This is the time in seconds that a lease will automatically be valid. The host can re-request the same lease if time runs out or if the host is done with the lease, they can hand the address back early.
+- max-lease-time 86400; – This is the maximum amount of time in seconds a lease can be held by a host.
+- ping-check true; – This is an extra test to ensure that the address the server wants to assign out isn’t in use by another host on the network already.
+- ping-timeout; – This is how long in second the server will wait for a response to a ping before assuming the address isn’t in use.
+- ignore client-updates; For now this option is irrelevant since DDNS has been disabled earlier in the configuration file but when DDNS is operating, this option will ignore a hosts to request to update its host-name in DNS.
+
+5. The next line in this file is the authoritative DHCP server line. This line means that if this server is to be the server that hands out addresses for the networks configured in this file, then uncomment the authoritative stanza.
+
+This server will be the only authority on all the networks it manages so the global authoritative stanza was un-commented by removing the ‘#’ in front of the keyword authoritative.
+
+
+Enable ISC Authoritative
+
+By default the server is assumed to NOT be an authority on the network. The rationale behind this is security. If someone unknowingly configures the DHCP server improperly or on a network they shouldn’t, it could cause serious connectivity issues. This line can also be used on a per network basis. This means that if the server is not the entire network’s DHCP server, the authoritative line can instead be used on a per network basis rather than in the global configuration as seen in the above screen-shot.
+
+6. The next step is to configure all of the DHCP pools/networks that this server will manage. For brevities sake, this guide will only walk through one of the pools configured. The administrator will need to have gathered all of the necessary network information (ie domain name, network addresses, how many addresses can be handed out, etc).
+
+For this pool the following information was obtained from the network administrator: network id of 172.27.60.0, subnet mask of 255.255.255.0 or a /24, the default gateway for the subnet is 172.27.60.1, and a broadcast address of 172.27.60.255.
+This information is important to building the appropriate network stanza in the dhcpd.conf file. Without further ado, let’s open the configuration file again using a text editor and then add the new network to the server. This must be done with root/sudo!
+
+ # nano /etc/dhcp/dhcpd.conf
+
+
+Configure DHCP Pools and Networks
+
+This is the sample created to hand out IP addresses to a network that is used for the creation of VMWare virtual practice servers. The first line indicates the network as well as the subnet mask for that network. Then inside the brackets are all the options that the DHCP server should provide to hosts on this network.
+
+The first stanza, range 172.27.60.50 172.27.60.254;, is the range of dynamically assignable addresses that the DHCP server can hand out to hosts on this network. Notice that the first 49 addresses aren’t in the pool and can be assigned statically to hosts if needed.
+
+The second stanza, option routers 172.27.60.1; , hands out the default gateway address for all hosts on this network.
+
+The last stanza, option broadcast-address 172.27.60.255;, indicates what the network’s broadcast address. This address SHOULD NOT be a part of the range stanza as the broadcast address can’t be assigned to a host.
+
+Some pointers, be sure to always end the option lines with a semi-colon (;) and always make sure each network created is enclosed in curly braces { }.
+
+7. If there are more networks to create, continue creating them with their appropriate options and then save the text file. Once all configurations have been completed, the ISC-DHCP-Server process will need to be restarted in order to apply the new changes. This can be accomplished with the following command:
+
+ # service isc-dhcp-server restart
+
+This will restart the DHCP service and then the administrator can check to see if the server is ready for DHCP requests several different ways. The easiest is to simply see if the server is listening on port 67 via the [lsof command][1]:
+
+ # lsof -i :67
+
+
+Check DHCP Listening Port
+
+This output indicates that the DHCPD (DHCP Server daemon) is running and listening on port 67. Port 67 in this output was actually converted to ‘bootps‘ due to a port number mapping for port 67 in /etc/services file.
+
+This is very common on most systems. At this point, the server should be ready for network connectivity and can be confirmed by connecting a machine to the network and having it request a DHCP address from the server.
+
+### Step 2: Testing Client Connectivity ###
+
+8. Most systems now-a-days are using Network Manager to maintain network connections and as such the device should be pre-configured to pull DHCP when the interface is active.
+
+However on machines that aren’t using Network Manager, it may be necessary to manually attempt to pull a DHCP address. The next few steps will show how to do this as well as how to see whether the server is handing out addresses.
+
+The ‘[ifconfig][2]‘ utility can be used to check an interface’s configuration. The machine used to test the DHCP server only has one network adapter and it is called ‘eth0‘.
+
+ # ifconfig eth0
+
+
+Check Network Interface IP Address
+
+From this output, this machine currently doesn’t have an IPv4 address, great! Let’s instruct this machine to reach out to the DHCP server and request an address. This machine has the DHCP client utility known as ‘dhclient‘ installed. The DHCP client utility may very from system to system.
+
+ # dhclient eth0
+
+
+Request IP Address from DHCP
+
+Now the `'inet addr:'` field shows an IPv4 address that falls within the scope of what was configured for the 172.27.60.0 network. Also notice that the proper broadcast address was handed out as well as subnet mask for this network.
+
+Things are looking promising but let’s check the server to see if it was actually the place where this machine received this new IP address. To accomplish this task, the server’s system log file will be consulted. While the entire log file may contain hundreds of thousands of entries, only a few are necessary for confirming that the server is working properly. Rather than using a full text editor, this time a utility known as ‘tail‘ will be used to only show the last few lines of the log file.
+
+ # tail /var/log/syslog
+
+
+Check DHCP Logs
+
+Voila! The server recorded handing out an address to this host (HRTDEBXENSRV). It is a safe assumption at this point that the server is working as intended and handing out the appropriate addresses for the networks that it is an authority. At this point the DHCP server is up and running. Configure the other networks, troubleshoot, and secure as necessary.
+
+Enjoy the newly functioning ISC-DHCP-Server and tune in later for more Debian tutorials. In the not too distant future there will be an article on Bind9 and DDNS that will tie into this article.
+
+--------------------------------------------------------------------------------
+
+via: http://www.tecmint.com/install-and-configure-multihomed-isc-dhcp-server-on-debian-linux/
+
+作者:[Rob Turner][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://www.tecmint.com/author/robturner/
+[1]:http://www.tecmint.com/10-lsof-command-examples-in-linux/
+[2]:http://www.tecmint.com/ifconfig-command-examples/
\ No newline at end of file
diff --git a/sources/tech/20150806 Installation Guide for Puppet on Ubuntu 15.04.md b/sources/tech/20150806 Installation Guide for Puppet on Ubuntu 15.04.md
new file mode 100644
index 0000000000..ae8df117ef
--- /dev/null
+++ b/sources/tech/20150806 Installation Guide for Puppet on Ubuntu 15.04.md
@@ -0,0 +1,429 @@
+Installation Guide for Puppet on Ubuntu 15.04
+================================================================================
+Hi everyone, today in this article we'll learn how to install puppet to manage your server infrastructure running ubuntu 15.04. Puppet is an open source software configuration management tool which is developed and maintained by Puppet Labs that allows us to automate the provisioning, configuration and management of a server infrastructure. Whether we're managing just a few servers or thousands of physical and virtual machines to orchestration and reporting, puppet automates tasks that system administrators often do manually which frees up time and mental space so sysadmins can work on improving other aspects of your overall setup. It ensures consistency, reliability and stability of the automated jobs processed. It facilitates closer collaboration between sysadmins and developers, enabling more efficient delivery of cleaner, better-designed code. Puppet is available in two solutions configuration management and data center automation. They are **puppet open source and puppet enterprise**. Puppet open source is a flexible, customizable solution available under the Apache 2.0 license, designed to help system administrators automate the many repetitive tasks they regularly perform. Whereas puppet enterprise edition is a proven commercial solution for diverse enterprise IT environments which lets us get all the benefits of open source puppet, plus puppet apps, commercial-only enhancements, supported modules and integrations, and the assurance of a fully supported platform. Puppet uses SSL certificates to authenticate communication between master and agent nodes.
+
+In this tutorial, we will cover how to install open source puppet in an agent and master setup running ubuntu 15.04 linux distribution. Here, Puppet master is a server from where all the configurations will be controlled and managed and all our remaining servers will be puppet agent nodes, which is configured according to the configuration of puppet master server. Here are some easy steps to install and configure puppet to manage our server infrastructure running Ubuntu 15.04.
+
+### 1. Setting up Hosts ###
+
+In this tutorial, we'll use two machines, one as puppet master server and another as puppet node agent both running ubuntu 15.04 "Vivid Vervet" in both the machines. Here is the infrastructure of the server that we're gonna use for this tutorial.
+
+puppet master server with IP 44.55.88.6 and hostname : puppetmaster
+puppet node agent with IP 45.55.86.39 and hostname : puppetnode
+
+Now we'll add the entry of the machines to /etc/hosts on both machines node agent and master server.
+
+ # nano /etc/hosts
+
+ 45.55.88.6 puppetmaster.example.com puppetmaster
+ 45.55.86.39 puppetnode.example.com puppetnode
+
+Please note that the Puppet Master server must be reachable on port 8140. So, we'll need to open port 8140 in it.
+
+### 2. Updating Time with NTP ###
+
+As puppet nodes needs to maintain accurate system time to avoid problems when it issues agent certificates. Certificates can appear to be expired if there is time difference, the time of the both the master and the node agent must be synced with each other. To sync the time, we'll update the time with NTP. To do so, here's the command below that we need to run on both master and node agent.
+
+ # ntpdate pool.ntp.org
+
+ 17 Jun 00:17:08 ntpdate[882]: adjust time server 66.175.209.17 offset -0.001938 sec
+
+Now, we'll update our local repository index and install ntp as follows.
+
+ # apt-get update && sudo apt-get -y install ntp ; service ntp restart
+
+### 3. Puppet Master Package Installation ###
+
+There are many ways to install open source puppet. In this tutorial, we'll download and install a debian binary package named as **puppetlabs-release** packaged by the Puppet Labs which will add the source of the **puppetmaster-passenger** package. The puppetmaster-passenger includes the puppet master with apache web server. So, we'll now download the Puppet Labs package.
+
+ # cd /tmp/
+ # wget https://apt.puppetlabs.com/puppetlabs-release-trusty.deb
+
+ --2015-06-17 00:19:26-- https://apt.puppetlabs.com/puppetlabs-release-trusty.deb
+ Resolving apt.puppetlabs.com (apt.puppetlabs.com)... 192.155.89.90, 2600:3c03::f03c:91ff:fedb:6b1d
+ Connecting to apt.puppetlabs.com (apt.puppetlabs.com)|192.155.89.90|:443... connected.
+ HTTP request sent, awaiting response... 200 OK
+ Length: 7384 (7.2K) [application/x-debian-package]
+ Saving to: ‘puppetlabs-release-trusty.deb’
+
+ puppetlabs-release-tr 100%[===========================>] 7.21K --.-KB/s in 0.06s
+
+ 2015-06-17 00:19:26 (130 KB/s) - ‘puppetlabs-release-trusty.deb’ saved [7384/7384]
+
+After the download has been completed, we'll wanna install the package.
+
+ # dpkg -i puppetlabs-release-trusty.deb
+
+ Selecting previously unselected package puppetlabs-release.
+ (Reading database ... 85899 files and directories currently installed.)
+ Preparing to unpack puppetlabs-release-trusty.deb ...
+ Unpacking puppetlabs-release (1.0-11) ...
+ Setting up puppetlabs-release (1.0-11) ...
+
+Then, we'll update the local respository index with the server using apt package manager.
+
+ # apt-get update
+
+Then, we'll install the puppetmaster-passenger package by running the below command.
+
+ # apt-get install puppetmaster-passenger
+
+**Note**: While installing we may get an error **Warning: Setting templatedir is deprecated. See http://links.puppetlabs.com/env-settings-deprecations (at /usr/lib/ruby/vendor_ruby/puppet/settings.rb:1139:in `issue_deprecation_warning')** but we no need to worry, we'll just simply ignore this as it says that the templatedir is deprecated so, we'll simply disbale that setting in the configuration. :)
+
+To check whether puppetmaster has been installed successfully in our Master server not not, we'll gonna try to check its version.
+
+ # puppet --version
+
+ 3.8.1
+
+We have successfully installed puppet master package in our puppet master box. As we are using passenger with apache, the puppet master process is controlled by apache server, that means it runs when apache is running.
+
+Before continuing, we'll need to stop the Puppet master by stopping the apache2 service.
+
+ # systemctl stop apache2
+
+### 4. Master version lock with Apt ###
+
+As We have puppet version as 3.8.1, we need to lock the puppet version update as this will mess up the configurations while updating the puppet. So, we'll use apt's locking feature for that. To do so, we'll need to create a new file **/etc/apt/preferences.d/00-puppet.pref** using our favorite text editor.
+
+ # nano /etc/apt/preferences.d/00-puppet.pref
+
+Then, we'll gonna add the entries in the newly created file as:
+
+ # /etc/apt/preferences.d/00-puppet.pref
+ Package: puppet puppet-common puppetmaster-passenger
+ Pin: version 3.8*
+ Pin-Priority: 501
+
+Now, it will not update the puppet while running updates in the system.
+
+### 5. Configuring Puppet Config ###
+
+Puppet master acts as a certificate authority and must generate its own certificates which is used to sign agent certificate requests. First of all, we'll need to remove any existing SSL certificates that were created during the installation of package. The default location of puppet's SSL certificates is /var/lib/puppet/ssl. So, we'll remove the entire ssl directory using rm command.
+
+ # rm -rf /var/lib/puppet/ssl
+
+Then, we'll configure the certificate. While creating the puppet master's certificate, we need to include every DNS name at which agent nodes can contact the master at. So, we'll edit the master's puppet.conf using our favorite text editor.
+
+ # nano /etc/puppet/puppet.conf
+
+The output seems as shown below.
+
+ [main]
+ logdir=/var/log/puppet
+ vardir=/var/lib/puppet
+ ssldir=/var/lib/puppet/ssl
+ rundir=/var/run/puppet
+ factpath=$vardir/lib/facter
+ templatedir=$confdir/templates
+
+ [master]
+ # These are needed when the puppetmaster is run by passenger
+ # and can safely be removed if webrick is used.
+ ssl_client_header = SSL_CLIENT_S_DN
+ ssl_client_verify_header = SSL_CLIENT_VERIFY
+
+Here, we'll need to comment the templatedir line to disable the setting as it has been already depreciated. After that, we'll add the following line at the end of the file under [main].
+
+ server = puppetmaster
+ environment = production
+ runinterval = 1h
+ strict_variables = true
+ certname = puppetmaster
+ dns_alt_names = puppetmaster, puppetmaster.example.com
+
+This configuration file has many options which might be useful in order to setup own configuration. A full description of the file is available at Puppet Labs [Main Config File (puppet.conf)][1].
+
+After editing the file, we'll wanna save that and exit.
+
+Now, we'll gonna generate a new CA certificates by running the following command.
+
+ # puppet master --verbose --no-daemonize
+
+ Info: Creating a new SSL key for ca
+ Info: Creating a new SSL certificate request for ca
+ Info: Certificate Request fingerprint (SHA256): F6:2F:69:89:BA:A5:5E:FF:7F:94:15:6B:A7:C4:20:CE:23:C7:E3:C9:63:53:E0:F2:76:D7:2E:E0:BF:BD:A6:78
+ ...
+ Notice: puppetmaster has a waiting certificate request
+ Notice: Signed certificate request for puppetmaster
+ Notice: Removing file Puppet::SSL::CertificateRequest puppetmaster at '/var/lib/puppet/ssl/ca/requests/puppetmaster.pem'
+ Notice: Removing file Puppet::SSL::CertificateRequest puppetmaster at '/var/lib/puppet/ssl/certificate_requests/puppetmaster.pem'
+ Notice: Starting Puppet master version 3.8.1
+ ^CNotice: Caught INT; storing stop
+ Notice: Processing stop
+
+Now, the certificate is being generated. Once we see **Notice: Starting Puppet master version 3.8.1**, the certificate setup is complete. Then we'll press CTRL-C to return to the shell.
+
+If we wanna look at the cert information of the certificate that was just created, we can get the list by running in the following command.
+
+ # puppet cert list -all
+
+ + "puppetmaster" (SHA256) 33:28:97:86:A1:C3:2F:73:10:D1:FB:42:DA:D5:42:69:71:84:F0:E2:8A:01:B9:58:38:90:E4:7D:B7:25:23:EC (alt names: "DNS:puppetmaster", "DNS:puppetmaster.example.com")
+
+### 6. Creating a Puppet Manifest ###
+
+The default location of the main manifest is /etc/puppet/manifests/site.pp. The main manifest file contains the definition of configuration that is used to execute in the puppet node agent. Now, we'll create the manifest file by running the following command.
+
+ # nano /etc/puppet/manifests/site.pp
+
+Then, we'll add the following lines of configuration in the file that we just opened.
+
+ # execute 'apt-get update'
+ exec { 'apt-update': # exec resource named 'apt-update'
+ command => '/usr/bin/apt-get update' # command this resource will run
+ }
+
+ # install apache2 package
+ package { 'apache2':
+ require => Exec['apt-update'], # require 'apt-update' before installing
+ ensure => installed,
+ }
+
+ # ensure apache2 service is running
+ service { 'apache2':
+ ensure => running,
+ }
+
+The above lines of configuration are responsible for the deployment of the installation of apache web server across the node agent.
+
+### 7. Starting Master Service ###
+
+We are now ready to start the puppet master. We can start it by running the apache2 service.
+
+ # systemctl start apache2
+
+Here, our puppet master is running, but it isn't managing any agent nodes yet. Now, we'll gonna add the puppet node agents to the master.
+
+**Note**: If you get an error **Job for apache2.service failed. See "systemctl status apache2.service" and "journalctl -xe" for details.** then it must be that there is some problem with the apache server. So, we can see the log what exactly has happened by running **apachectl start** under root or sudo mode. Here, while performing this tutorial, we got a misconfiguration of the certificates under **/etc/apache2/sites-enabled/puppetmaster.conf** file. We replaced **SSLCertificateFile /var/lib/puppet/ssl/certs/server.pem with SSLCertificateFile /var/lib/puppet/ssl/certs/puppetmaster.pem** and commented **SSLCertificateKeyFile** line. Then we'll need to rerun the above command to run apache server.
+
+### 8. Puppet Agent Package Installation ###
+
+Now, as we have our puppet master ready and it needs an agent to manage, we'll need to install puppet agent into the nodes. We'll need to install puppet agent in every nodes in our infrastructure we want puppet master to manage. We'll need to make sure that we have added our node agents in the DNS. Now, we'll gonna install the latest puppet agent in our agent node ie. puppetnode.example.com .
+
+We'll run the following command to download the Puppet Labs package in our puppet agent nodes.
+
+ # cd /tmp/
+ # wget https://apt.puppetlabs.com/puppetlabs-release-trusty.deb\
+
+ --2015-06-17 00:54:42-- https://apt.puppetlabs.com/puppetlabs-release-trusty.deb
+ Resolving apt.puppetlabs.com (apt.puppetlabs.com)... 192.155.89.90, 2600:3c03::f03c:91ff:fedb:6b1d
+ Connecting to apt.puppetlabs.com (apt.puppetlabs.com)|192.155.89.90|:443... connected.
+ HTTP request sent, awaiting response... 200 OK
+ Length: 7384 (7.2K) [application/x-debian-package]
+ Saving to: ‘puppetlabs-release-trusty.deb’
+
+ puppetlabs-release-tr 100%[===========================>] 7.21K --.-KB/s in 0.04s
+
+ 2015-06-17 00:54:42 (162 KB/s) - ‘puppetlabs-release-trusty.deb’ saved [7384/7384]
+
+Then, as we're running ubuntu 15.04, we'll use debian package manager to install it.
+
+ # dpkg -i puppetlabs-release-trusty.deb
+
+Now, we'll gonna update the repository index using apt-get.
+
+ # apt-get update
+
+Finally, we'll gonna install the puppet agent directly from the remote repository.
+
+ # apt-get install puppet
+
+Puppet agent is always disabled by default, so we'll need to enable it. To do so we'll need to edit /etc/default/puppet file using a text editor.
+
+ # nano /etc/default/puppet
+
+Then, we'll need to change value of **START** to "yes" as shown below.
+
+ START=yes
+
+Then, we'll need to save and exit the file.
+
+### 9. Agent Version Lock with Apt ###
+
+As We have puppet version as 3.8.1, we need to lock the puppet version update as this will mess up the configurations while updating the puppet. So, we'll use apt's locking feature for that. To do so, we'll need to create a file /etc/apt/preferences.d/00-puppet.pref using our favorite text editor.
+
+ # nano /etc/apt/preferences.d/00-puppet.pref
+
+Then, we'll gonna add the entries in the newly created file as:
+
+ # /etc/apt/preferences.d/00-puppet.pref
+ Package: puppet puppet-common
+ Pin: version 3.8*
+ Pin-Priority: 501
+
+Now, it will not update the Puppet while running updates in the system.
+
+### 10. Configuring Puppet Node Agent ###
+
+Next, We must make a few configuration changes before running the agent. To do so, we'll need to edit the agent's puppet.conf
+
+ # nano /etc/puppet/puppet.conf
+
+It will look exactly like the Puppet master's initial configuration file.
+
+This time also we'll comment the **templatedir** line. Then we'll gonna delete the [master] section, and all of the lines below it.
+
+Assuming that the puppet master is reachable at "puppet-master", the agent should be able to connect to the master. If not we'll need to use its fully qualified domain name ie. puppetmaster.example.com .
+
+ [agent]
+ server = puppetmaster.example.com
+ certname = puppetnode.example.com
+
+After adding this, it will look alike this.
+
+ [main]
+ logdir=/var/log/puppet
+ vardir=/var/lib/puppet
+ ssldir=/var/lib/puppet/ssl
+ rundir=/var/run/puppet
+ factpath=$vardir/lib/facter
+ #templatedir=$confdir/templates
+
+ [agent]
+ server = puppetmaster.example.com
+ certname = puppetnode.example.com
+
+After done with that, we'll gonna save and exit it.
+
+Next, we'll wanna start our latest puppet agent in our Ubuntu 15.04 nodes. To start our puppet agent, we'll need to run the following command.
+
+ # systemctl start puppet
+
+If everything went as expected and configured properly, we should not see any output displayed by running the above command. When we run an agent for the first time, it generates an SSL certificate and sends a request to the puppet master then if the master signs the agent's certificate, it will be able to communicate with the agent node.
+
+**Note**: If you are adding your first node, it is recommended that you attempt to sign the certificate on the puppet master before adding your other agents. Once you have verified that everything works properly, then you can go back and add the remaining agent nodes further.
+
+### 11. Signing certificate Requests on Master ###
+
+While puppet agent runs for the first time, it generates an SSL certificate and sends a request for signing to the master server. Before the master will be able to communicate and control the agent node, it must sign that specific agent node's certificate.
+
+To get the list of the certificate requests, we'll run the following command in the puppet master server.
+
+ # puppet cert list
+
+ "puppetnode.example.com" (SHA256) 31:A1:7E:23:6B:CD:7B:7D:83:98:33:8B:21:01:A6:C4:01:D5:53:3D:A0:0E:77:9A:77:AE:8F:05:4A:9A:50:B2
+
+As we just setup our first agent node, we will see one request. It will look something like the following, with the agent node's Domain name as the hostname.
+
+Note that there is no + in front of it which indicates that it has not been signed yet.
+
+Now, we'll go for signing a certification request. In order to sign a certification request, we should simply run **puppet cert sign** with the **hostname** as shown below.
+
+ # puppet cert sign puppetnode.example.com
+
+ Notice: Signed certificate request for puppetnode.example.com
+ Notice: Removing file Puppet::SSL::CertificateRequest puppetnode.example.com at '/var/lib/puppet/ssl/ca/requests/puppetnode.example.com.pem'
+
+The Puppet master can now communicate and control the node that the signed certificate belongs to.
+
+If we want to sign all of the current requests, we can use the -all option as shown below.
+
+ # puppet cert sign --all
+
+### Removing a Puppet Certificate ###
+
+If we wanna remove a host from it or wanna rebuild a host then add it back to it. In this case, we will want to revoke the host's certificate from the puppet master. To do this, we will want to use the clean action as follows.
+
+ # puppet cert clean hostname
+
+ Notice: Revoked certificate with serial 5
+ Notice: Removing file Puppet::SSL::Certificate puppetnode.example.com at '/var/lib/puppet/ssl/ca/signed/puppetnode.example.com.pem'
+ Notice: Removing file Puppet::SSL::Certificate puppetnode.example.com at '/var/lib/puppet/ssl/certs/puppetnode.example.com.pem'
+
+If we want to view all of the requests signed and unsigned, run the following command:
+
+ # puppet cert list --all
+
+ + "puppetmaster" (SHA256) 33:28:97:86:A1:C3:2F:73:10:D1:FB:42:DA:D5:42:69:71:84:F0:E2:8A:01:B9:58:38:90:E4:7D:B7:25:23:EC (alt names: "DNS:puppetmaster", "DNS:puppetmaster.example.com")
+
+### 12. Deploying a Puppet Manifest ###
+
+After we configure and complete the puppet manifest, we'll wanna deploy the manifest to the agent nodes server. To apply and load the main manifest we can simply run the following command in the agent node.
+
+ # puppet agent --test
+
+ Info: Retrieving pluginfacts
+ Info: Retrieving plugin
+ Info: Caching catalog for puppetnode.example.com
+ Info: Applying configuration version '1434563858'
+ Notice: /Stage[main]/Main/Exec[apt-update]/returns: executed successfully
+ Notice: Finished catalog run in 10.53 seconds
+
+This will show us all the processes how the main manifest will affect a single server immediately.
+
+If we wanna run a puppet manifest that is not related to the main manifest, we can simply use puppet apply followed by the manifest file path. It only applies the manifest to the node that we run the apply from.
+
+ # puppet apply /etc/puppet/manifest/test.pp
+
+### 13. Configuring Manifest for a Specific Node ###
+
+If we wanna deploy a manifest only to a specific node then we'll need to configure the manifest as follows.
+
+We'll need to edit the manifest on the master server using a text editor.
+
+ # nano /etc/puppet/manifest/site.pp
+
+Now, we'll gonna add the following lines there.
+
+ node 'puppetnode', 'puppetnode1' {
+ # execute 'apt-get update'
+ exec { 'apt-update': # exec resource named 'apt-update'
+ command => '/usr/bin/apt-get update' # command this resource will run
+ }
+
+ # install apache2 package
+ package { 'apache2':
+ require => Exec['apt-update'], # require 'apt-update' before installing
+ ensure => installed,
+ }
+
+ # ensure apache2 service is running
+ service { 'apache2':
+ ensure => running,
+ }
+ }
+
+Here, the above configuration will install and deploy the apache web server only to the two specified nodes having shortname puppetnode and puppetnode1. We can add more nodes that we need to get deployed with the manifest specifically.
+
+### 14. Configuring Manifest with a Module ###
+
+Modules are useful for grouping tasks together, they are many available in the Puppet community which anyone can contribute further.
+
+On the puppet master, we'll gonna install the **puppetlabs-apache** module using the puppet module command.
+
+ # puppet module install puppetlabs-apache
+
+**Warning**: Please do not use this module on an existing apache setup else it will purge your apache configurations that are not managed by puppet.
+
+Now we'll gonna edit the main manifest ie **site.pp** using a text editor.
+
+ # nano /etc/puppet/manifest/site.pp
+
+Now add the following lines to install apache under puppetnode.
+
+ node 'puppet-node' {
+ class { 'apache': } # use apache module
+ apache::vhost { 'example.com': # define vhost resource
+ port => '80',
+ docroot => '/var/www/html'
+ }
+ }
+
+Then we'll wanna save and exit it. Then, we'll wanna rerun the manifest to deploy the configuration to the agents for our infrastructure.
+
+### Conclusion ###
+
+Finally we have successfully installed puppet to manage our Server Infrastructure running Ubuntu 15.04 "Vivid Vervet" linux operating system. We learned how puppet works, configure a manifest configuration, communicate with nodes and deploy the manifest on the agent nodes with secure SSL certification. Controlling, managing and configuring repeated task in several N number of nodes is very easy with puppet open source software configuration management tool. If you have any questions, suggestions, feedback please write them in the comment box below so that we can improve or update our contents. Thank you ! Enjoy :-)
+
+--------------------------------------------------------------------------------
+
+via: http://linoxide.com/linux-how-to/install-puppet-ubuntu-15-04/
+
+作者:[Arun Pyasi][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://linoxide.com/author/arunp/
+[1]:https://docs.puppetlabs.com/puppet/latest/reference/config_file_main.html
diff --git a/sources/tech/20150817 How to Install OsTicket Ticketing System in Fedora 22 or Centos 7.md b/sources/tech/20150817 How to Install OsTicket Ticketing System in Fedora 22 or Centos 7.md
new file mode 100644
index 0000000000..515b15844a
--- /dev/null
+++ b/sources/tech/20150817 How to Install OsTicket Ticketing System in Fedora 22 or Centos 7.md
@@ -0,0 +1,179 @@
+How to Install OsTicket Ticketing System in Fedora 22 / Centos 7
+================================================================================
+In this article, we'll learn how to setup help desk ticketing system with osTicket in our machine or server running Fedora 22 or CentOS 7 as operating system. osTicket is a free and open source popular customer support ticketing system developed and maintained by [Enhancesoft][1] and its contributors. osTicket is the best solution for help and support ticketing system and management for better communication and support assistance with clients and customers. It has the ability to easily integrate with inquiries created via email, phone and web based forms into a beautiful multi-user web interface. osTicket makes us easy to manage, organize and log all our support requests and responses in one single place. It is a simple, lightweight, reliable, open source, web-based and easy to setup and use help desk ticketing system.
+
+Here are some easy steps on how we can setup Help Desk ticketing system with osTicket in Fedora 22 or CentOS 7 operating system.
+
+### 1. Installing LAMP stack ###
+
+First of all, we'll need to install LAMP Stack to make osTicket working. LAMP stack is the combination of Apache web server, MySQL or MariaDB database system and PHP. To install a complete suit of LAMP stack that we need for the installation of osTicket, we'll need to run the following commands in a shell or a terminal.
+
+**On Fedora 22**
+
+LAMP stack is available on the official repository of Fedora 22. As the default package manager of Fedora 22 is the latest DNF package manager, we'll need to run the following command.
+
+ $ sudo dnf install httpd mariadb mariadb-server php php-mysql php-fpm php-cli php-xml php-common php-gd php-imap php-mbstring wget
+
+**On CentOS 7**
+
+As there is LAMP stack available on the official repository of CentOS 7, we'll gonna install it using yum package manager.
+
+ $ sudo yum install httpd mariadb mariadb-server php php-mysql php-fpm php-cli php-xml php-common php-gd php-imap php-mbstring wget
+
+### 2. Starting Apache Web Server and MariaDB ###
+
+Next, we'll gonna start MariaDB server and Apache Web Server to get started.
+
+ $ sudo systemctl start mariadb httpd
+
+Then, we'll gonna enable them to start on every boot of the system.
+
+ $ sudo systemctl enable mariadb httpd
+
+ Created symlink from /etc/systemd/system/multi-user.target.wants/mariadb.service to /usr/lib/systemd/system/mariadb.service.
+ Created symlink from /etc/systemd/system/multi-user.target.wants/httpd.service to /usr/lib/systemd/system/httpd.service.
+
+### 3. Downloading osTicket package ###
+
+Next, we'll gonna download the latest release of osTicket ie version 1.9.9 . We can download it from the official download page [http://osticket.com/download][2] or from the official github repository. [https://github.com/osTicket/osTicket-1.8/releases][3] . Here, in this tutorial we'll download the tarball of the latest release of osTicket from the github release page using wget command.
+
+ $ cd /tmp/
+ $ wget https://github.com/osTicket/osTicket-1.8/releases/download/v1.9.9/osTicket-v1.9.9-1-gbe2f138.zip
+
+ --2015-07-16 09:14:23-- https://github.com/osTicket/osTicket-1.8/releases/download/v1.9.9/osTicket-v1.9.9-1-gbe2f138.zip
+ Resolving github.com (github.com)... 192.30.252.131
+ ...
+ Connecting to s3.amazonaws.com (s3.amazonaws.com)|54.231.244.4|:443... connected.
+ HTTP request sent, awaiting response... 200 OK
+ Length: 7150871 (6.8M) [application/octet-stream]
+ Saving to: ‘osTicket-v1.9.9-1-gbe2f138.zip’
+ osTicket-v1.9.9-1-gb 100%[========================>] 6.82M 1.25MB/s in 12s
+ 2015-07-16 09:14:37 (604 KB/s) - ‘osTicket-v1.9.9-1-gbe2f138.zip’ saved [7150871/7150871]
+
+### 4. Extracting the osTicket ###
+
+After we have successfully downloaded the osTicket zipped package, we'll now gonna extract the zip. As the default root directory of Apache web server is /var/www/html/ , we'll gonna create a directory called "**support**" where we'll extract the whole directory and files of the compressed zip file. To do so, we'll need to run the following commands in a terminal or a shell.
+
+ $ unzip osTicket-v1.9.9-1-gbe2f138.zip
+
+Then, we'll move the whole extracted files to it.
+
+ $ sudo mv /tmp/upload /var/www/html/support
+
+### 5. Fixing Ownership and Permission ###
+
+Now, we'll gonna assign the ownership of the directories and files under /var/ww/html/support to apache to enable writable access to the apache process owner. To do so, we'll need to run the following command.
+
+ $ sudo chown apache: -R /var/www/html/support
+
+Then, we'll also need to copy a sample configuration file to its default configuration file. To do so, we'll need to run the below command.
+
+ $ cd /var/www/html/support/
+ $ sudo cp include/ost-sampleconfig.php include/ost-config.php
+ $ sudo chmod 0666 include/ost-config.php
+
+If you have SELinux enabled on the system, run the following command.
+
+ $ sudo chcon -R -t httpd_sys_content_t /var/www/html/vtigercrm
+ $ sudo chcon -R -t httpd_sys_rw_content_t /var/www/html/vtigercrm
+
+### 6. Configuring MariaDB ###
+
+As this is the first time we're going to configure MariaDB, we'll need to create a password for the root user of mariadb so that we can use it to login and create the database for our osTicket installation. To do so, we'll need to run the following command in a terminal or a shell.
+
+ $ sudo mysql_secure_installation
+
+ ...
+ Enter current password for root (enter for none):
+ OK, successfully used password, moving on...
+
+ Setting the root password ensures that nobody can log into the MariaDB
+ root user without the proper authorisation.
+
+ Set root password? [Y/n] y
+ New password:
+ Re-enter new password:
+ Password updated successfully!
+ Reloading privilege tables..
+ Success!
+ ...
+ All done! If you've completed all of the above steps, your MariaDB
+ installation should now be secure.
+
+ Thanks for using MariaDB!
+
+Note: Above, we are asked to enter the root password of the mariadb server but as we are setting for the first time and no password has been set yet, we'll simply hit enter while asking the current mariadb root password. Then, we'll need to enter twice the new password we wanna set. Then, we can simply hit enter in every argument in order to set default configurations.
+
+### 7. Creating osTicket Database ###
+
+As osTicket needs a database system to store its data and information, we'll be configuring MariaDB for osTicket. So, we'll need to first login into the mariadb command environment. To do so, we'll need to run the following command.
+
+ $ sudo mysql -u root -p
+
+Now, we'll gonna create a new database "**osticket_db**" with user "**osticket_user**" and password "osticket_password" which will be granted access to the database. To do so, we'll need to run the following commands inside the MariaDB command environment.
+
+ > CREATE DATABASE osticket_db;
+ > CREATE USER 'osticket_user'@'localhost' IDENTIFIED BY 'osticket_password';
+ > GRANT ALL PRIVILEGES on osticket_db.* TO 'osticket_user'@'localhost' ;
+ > FLUSH PRIVILEGES;
+ > EXIT;
+
+**Note**: It is strictly recommended to replace the database name, user and password as your desire for security issue.
+
+### 8. Allowing Firewall ###
+
+If we are running a firewall program, we'll need to configure our firewall to allow port 80 so that the Apache web server's default port will be accessible externally. This will allow us to navigate our web browser to osTicket's web interface with the default http port 80. To do so, we'll need to run the following command.
+
+ $ sudo firewall-cmd --zone=public --add-port=80/tcp --permanent
+
+After done, we'll need to reload our firewall service.
+
+ $ sudo firewall-cmd --reload
+
+### 9. Web based Installation ###
+
+Finally, is everything is done as described above, we'll now should be able to navigate osTicket's Installer by pointing our web browser to http://domain.com/support or http://ip-address/support . Now, we'll be shown if the dependencies required by osTicket are installed or not. As we've already installed all the necessary packages, we'll be welcomed with **green colored tick** to proceed forward.
+
+
+
+After that, we'll be required to enter the details for our osTicket instance as shown below. We'll need to enter the database name, username, password and hostname and other important account information that we'll require while logging into the admin panel.
+
+
+
+After the installation has been completed successfully, we'll be welcomed by a Congratulations screen. There we can see two links, one for our Admin Panel and the other for the support center as the homepage of the osTicket Support Help Desk.
+
+
+
+If we click on http://ip-address/support or http://domain.com/support, we'll be redirected to the osTicket support page which is as shown below.
+
+
+
+Next, to login into the admin panel, we'll need to navigate our web browser to http://ip-address/support/scp or http://domain.com/support/scp . Then, we'll need to enter the login details we had just created above while configuring the database and other information in the web installer. After successful login, we'll be able to access our dashboard and other admin sections.
+
+
+
+### 10. Post Installation ###
+
+After we have finished the web installation of osTicket, we'll now need to secure some of our configuration files. To do so, we'll need to run the following command.
+
+ $ sudo rm -rf /var/www/html/support/setup/
+ $ sudo chmod 644 /var/www/html/support/include/ost-config.php
+
+### Conclusion ###
+
+osTicket is an awesome help desk ticketing system providing several new features. It supports rich text or HTML emails, ticket filters, agent collision avoidance, auto-responder and many more features. The user interface of osTicket is very beautiful with easy to use control panel. It is a complete set of tools required for a help and support ticketing system. It is the best solution for providing customers a better way to communicate with the support team. It helps a company to make their customers happy with them regarding the support and help desk. If you have any questions, suggestions, feedback please write them in the comment box below so that we can improve or update our contents. Thank you ! Enjoy :-)
+
+------------------------------------------------------------------------------
+
+via: http://linoxide.com/linux-how-to/install-osticket-fedora-22-centos-7/
+
+作者:[Arun Pyasi][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://linoxide.com/author/arunp/
+[1]:http://www.enhancesoft.com/
+[2]:http://osticket.com/download
+[3]:https://github.com/osTicket/osTicket-1.8/releases
\ No newline at end of file
diff --git a/sources/tech/20150906 How to Configure OpenNMS on CentOS 7.x.md b/sources/tech/20150906 How to Configure OpenNMS on CentOS 7.x.md
new file mode 100644
index 0000000000..c7810d06ef
--- /dev/null
+++ b/sources/tech/20150906 How to Configure OpenNMS on CentOS 7.x.md
@@ -0,0 +1,219 @@
+How to Configure OpenNMS on CentOS 7.x
+================================================================================
+Systems management and monitoring services are very important that provides information to view important systems management information that allow us to to make decisions based on this information. To make sure the network is running at its best and to minimize the network downtime we need to improve application performance. So, in this article we will make you understand the step by step procedure to setup OpenNMS in your IT infrastructure. OpenNMS is a free open source enterprise level network monitoring and management platform that provides information to allow us to make decisions in regards to future network and capacity planning.
+
+OpenNMS designed to manage tens of thousands of devices from a single server as well as manage unlimited devices using a cluster of servers. It includes a discovery engine to automatically configure and manage network devices without operator intervention. It is written in Java and is published under the GNU General Public License. OpenNMS is known for its scalability with its main functional areas in services monitoring, data collection using SNMP and event management and notifications.
+
+### Installing OpenNMS RPM Repository ###
+
+We will start from the installation of OpenNMS RPM for our CentOs 7.1 operating system as its available for most of the RPM-based distributions through Yum at their official link http://yum.opennms.org/ .
+
+
+
+Then open your command line interface of CentOS 7.1 and login with root credentials to run the below command with “wget” to get the required RPM.
+
+ [root@open-nms ~]# wget http://yum.opennms.org/repofiles/opennms-repo-stable-rhel7.noarch.rpm
+
+
+
+Now we need to install this repository so that the OpenNMS package information could be available through yum for installation. Let’s run the command below with same root level credentials to do so.
+
+ [root@open-nms ~]# rpm -Uvh opennms-repo-stable-rhel7.noarch.rpm
+
+
+
+### Installing Prerequisite Packages for OpenNMS ###
+
+Now before we start installation of OpenNMS, let’s make sure you’ve done the following prerequisites.
+
+**Install JDK 7**
+
+Its recommended that you install the latest stable Java 7 JDK from Oracle for the best performance to integrate JDK in our YUM repository as a fallback. Let’s go to the Oracle Java 7 SE JDK download page, accept the license if you agree, choose the platform and architecture. Once it has finished downloading, execute it from the command-line and then install the resulting JDK rpm.
+
+Else run the below command to install using the Yum from the the available system repositories.
+
+ [root@open-nms ~]# yum install java-1.7.0-openjdk-1.7.0.85-2.6.1.2.el7_1
+
+Once you have installed the Java you can confirm its installation using below command and check its installed version.
+
+ [root@open-nms ~]# java -version
+
+
+
+**Install PostgreSQL**
+
+Now we will install the PostgreSQL that is a must requirement to setup the database for OpenNMS. PostgreSQL is included in all of the major YUM-based distributions. To install, simply run the below command.
+
+ [root@open-nms ~]# yum install postgresql postgresql-server
+
+
+
+### Prepare the Database for OpenNMS ###
+
+Once you have installed PostgreSQL, now you'll need to make sure that PostgreSQL is up and active. Let’s run the below command to first initialize the database and then start its services.
+
+ [root@open-nms ~]# /sbin/service postgresql initdb
+ [root@open-nms ~]# /sbin/service postgresql start
+
+
+
+Now to confirm the status of your PostgreSQL database you can run the below command.
+
+ [root@open-nms ~]# service postgresql status
+
+
+
+To ensure that PostgreSQL will start after a reboot, use the “systemctl”command to enable start on bootup using below command.
+
+ [root@open-nms ~]# systemctl enable postgresql
+ ln -s '/usr/lib/systemd/system/postgresql.service' '/etc/systemd/system/multi-user.target.wants/postgresql.service'
+
+### Configure PostgreSQL ###
+
+Locate the Postgres “data” directory. Often this is located in /var/lib/pgsql/data directory and Open the postgresql.conf file in text editor and configure the following parameters as shown.
+
+ [root@open-nms ~]# vim /var/lib/pgsql/data/postgresql.conf
+
+----------
+
+ #------------------------------------------------------------------------------
+ # CONNECTIONS AND AUTHENTICATION
+ #------------------------------------------------------------------------------
+
+ listen_addresses = 'localhost'
+ max_connections = 256
+
+ #------------------------------------------------------------------------------
+ # RESOURCE USAGE (except WAL)
+ #------------------------------------------------------------------------------
+
+ shared_buffers = 1024MB
+
+**User Access to the Database**
+
+PostgreSQL only allows you to connect if you are logged in to the local account name that matches the PostgreSQL user. Since OpenNMS runs as root, it cannot connect as a "postgres" or "opennms" user by default, so we have to change the configuration to allow user access to the database by opening the below configuration file.
+
+ [root@open-nms ~]# vim /var/lib/pgsql/data/pg_hba.conf
+
+Update the configuration file as shown below and change the METHOD settings from "ident" to "trust"
+
+
+
+Write and quit the file to make saved changes and then restart PostgreSQL services.
+
+ [root@open-nms ~]# service postgresql restart
+
+### Starting OpenNMS Installation ###
+
+Now we are ready go with installation of OpenNMS as we have almost don with its prerequisites. Using the YUM packaging system will download and install all of the required components and their dependencies, if they are not already installed on your system.
+So let's riun th belwo command to start OpenNMS installation that will pull everything you need to have a working OpenNMS, including the OpenNMS core, web UI, and a set of common plugins.
+
+ [root@open-nms ~]# yum -y install opennms
+
+
+
+The above command will ends up with successful installation of OpenNMS and its derivative packages.
+
+### Configure JAVA for OpenNMS ###
+
+In order to integrate the default version of Java with OpenNMS we will run the below command.
+
+ [root@open-nms ~]# /opt/opennms/bin/runjava -s
+
+
+
+### Run the OpenNMS installer ###
+
+Now it's time to start the OpenNMS installer that will create and configure the OpenNMS database, while the same command will be used in case we want to update it to the latest version. To do so, we will run the following command.
+
+ [root@open-nms ~]# /opt/opennms/bin/install -dis
+
+The above install command will take many options with following mechanism.
+
+-d - to update the database
+-i - to insert any default data that belongs in the database
+-s - to create or update the stored procedures OpenNMS uses for certain kinds of data access
+
+ ==============================================================================
+ OpenNMS Installer
+ ==============================================================================
+
+ Configures PostgreSQL tables, users, and other miscellaneous settings.
+
+ DEBUG: Platform is IPv6 ready: true
+ - searching for libjicmp.so:
+ - trying to load /usr/lib64/libjicmp.so: OK
+ - searching for libjicmp6.so:
+ - trying to load /usr/lib64/libjicmp6.so: OK
+ - searching for libjrrd.so:
+ - trying to load /usr/lib64/libjrrd.so: OK
+ - using SQL directory... /opt/opennms/etc
+ - using create.sql... /opt/opennms/etc/create.sql
+ 17:27:51.178 [Main] INFO org.opennms.core.schema.Migrator - PL/PgSQL call handler exists
+ 17:27:51.180 [Main] INFO org.opennms.core.schema.Migrator - PL/PgSQL language exists
+ - checking if database "opennms" is unicode... ALREADY UNICODE
+ - Creating imports directory (/opt/opennms/etc/imports... OK
+ - Checking for old import files in /opt/opennms/etc... DONE
+ INFO 16/08/15 17:27:liquibase: Reading from databasechangelog
+ Installer completed successfully!
+
+ ==============================================================================
+ OpenNMS Upgrader
+ ==============================================================================
+
+ OpenNMS is currently stopped
+ Found upgrade task SnmpInterfaceRrdMigratorOnline
+ Found upgrade task KscReportsMigrator
+ Found upgrade task JettyConfigMigratorOffline
+ Found upgrade task DataCollectionConfigMigratorOffline
+ Processing RequisitionsMigratorOffline: Remove non-ip-snmp-primary and non-ip-interfaces from requisitions: NMS-5630, NMS-5571
+ - Running pre-execution phase
+ Backing up: /opt/opennms/etc/imports
+ - Running post-execution phase
+ Removing backup /opt/opennms/etc/datacollection.zip
+
+ Finished in 0 seconds
+
+ Upgrade completed successfully!
+
+### Firewall configurations to Allow OpenNMS ###
+
+Here we have to allow OpenNMS management interface port 8980 through firewall or router to access the management web interface from the remote systems. So use the following commands to do so.
+
+ [root@open-nms etc]# firewall-cmd --permanent --add-port=8980/tcp
+ [root@open-nms etc]# firewall-cmd --reload
+
+### Start OpenNMS and Login to Web Interface ###
+
+Let's start OpenNMS service and enable to it start at each bootup by using the below command.
+
+ [root@open-nms ~]#systemctl start opennms
+ [root@open-nms ~]#systemctl enable opennms
+
+Once the services are up are ready to go with its web management interface. Open your web browser and access it with your server's IP address and 8980 port.
+
+http://servers_ip:8980/
+
+Give the username and password where as the default username and password is admin/admin.
+
+
+
+After successful authentication with your provided username and password you will be directed towards the the Home page of OpenNMS where you can configure the new monitoring devices/nodes/services etc.
+
+
+
+### Conclusion ###
+
+Congratulations! we have successfully setup OpenNMS on CentOS 7.1. So, at the end of this tutorial, you are now able to install and configure OpenNMS with its prerequisites that included PostgreSQL and JAVA setup. So let's enjoy with the great network monitoring system with open source roots using OpenNMS that provide a bevy of features at no cost than their high-end competitors, and can scale to monitor large numbers of network nodes.
+
+--------------------------------------------------------------------------------
+
+via: http://linoxide.com/monitoring-2/install-configure-opennms-centos-7-x/
+
+作者:[Kashif Siddique][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://linoxide.com/author/kashifs/
\ No newline at end of file
diff --git a/sources/tech/20150906 How to install Suricata intrusion detection system on Linux.md b/sources/tech/20150906 How to install Suricata intrusion detection system on Linux.md
new file mode 100644
index 0000000000..fe4a784d5a
--- /dev/null
+++ b/sources/tech/20150906 How to install Suricata intrusion detection system on Linux.md
@@ -0,0 +1,197 @@
+How to install Suricata intrusion detection system on Linux
+================================================================================
+With incessant security threats, intrusion detection system (IDS) has become one of the most critical requirements in today's data center environments. However, as more and more servers upgrade their NICs to 10GB/40GB Ethernet, it is increasingly difficult to implement compute-intensive intrusion detection on commodity hardware at line rates. One approach to scaling IDS performance is **multi-threaded IDS**, where CPU-intensive deep packet inspection workload is parallelized into multiple concurrent tasks. Such parallelized inspection can exploit multi-core hardware to scale up IDS throughput easily. Two well-known open-source efforts in this area are [Suricata][1] and [Bro][2].
+
+In this tutorial, I am going to demonstrate **how to install and configure Suricata IDS on Linux server**.
+
+### Install Suricata IDS on Linux ###
+
+Let's build Suricata from the source. You first need to install several required dependencies as follows.
+
+#### Install Dependencies on Debian, Ubuntu or Linux Mint ####
+
+ $ sudo apt-get install wget build-essential libpcre3-dev libpcre3-dbg automake autoconf libtool libpcap-dev libnet1-dev libyaml-dev zlib1g-dev libcap-ng-dev libjansson-dev
+
+#### Install Dependencies on CentOS, Fedora or RHEL ####
+
+ $ sudo yum install wget libpcap-devel libnet-devel pcre-devel gcc-c++ automake autoconf libtool make libyaml-devel zlib-devel file-devel jansson-devel nss-devel
+
+Once you install all required packages, go ahead and install Suricata as follows.
+
+First, download the latest Suricata source code from [http://suricata-ids.org/download/][3], and build it. As of this writing, the latest version is 2.0.8.
+
+ $ wget http://www.openinfosecfoundation.org/download/suricata-2.0.8.tar.gz
+ $ tar -xvf suricata-2.0.8.tar.gz
+ $ cd suricata-2.0.8
+ $ ./configure --sysconfdir=/etc --localstatedir=/var
+
+Here is the example output of configuration.
+
+ Suricata Configuration:
+ AF_PACKET support: yes
+ PF_RING support: no
+ NFQueue support: no
+ NFLOG support: no
+ IPFW support: no
+ DAG enabled: no
+ Napatech enabled: no
+ Unix socket enabled: yes
+ Detection enabled: yes
+
+ libnss support: yes
+ libnspr support: yes
+ libjansson support: yes
+ Prelude support: no
+ PCRE jit: yes
+ LUA support: no
+ libluajit: no
+ libgeoip: no
+ Non-bundled htp: no
+ Old barnyard2 support: no
+ CUDA enabled: no
+
+Now compile and install it.
+
+ $ make
+ $ sudo make install
+
+Suricata source code comes with default configuration files. Let's install these default configuration files as follows.
+
+ $ sudo make install-conf
+
+As you know, Suricata is useless without IDS rule sets. Conveniently, the Makefile comes with IDS rule installation option. To install IDS rules, run the following command.
+
+ $ sudo make install-rules
+
+The above rule installation command will download the current snapshot of community rulesets available from [EmergingThreats.net][4], and store them under /etc/suricata/rules.
+
+
+
+### Configure Suricata IDS the First Time ###
+
+Now it's time to configure Suricata. The configuration file is located at **/etc/suricata/suricata.yaml**. Open the file with a text editor for editing.
+
+ $ sudo vi /etc/suricata/suricata.yaml
+
+Here are some basic setup for you to get started.
+
+The "default-log-dir" keyword should point to the location of Suricata log files.
+
+ default-log-dir: /var/log/suricata/
+
+Under "vars" section, you will find several important variables used by Suricata. "HOME_NET" should point to the local network to be inspected by Suricata. "!$HOME_NET" (assigned to EXTERNAL_NET) refers to any other networks than the local network. "XXX_PORTS" indicates the port number(s) use by different services. Note that Suricata can automatically detect HTTP traffic regardless of the port it uses. So it is not critical to specify the HTTP_PORTS variable correctly.
+
+ vars:
+ HOME_NET: "[192.168.122.0/24]"
+ EXTERNAL_NET: "!$HOME_NET"
+ HTTP_PORTS: "80"
+ SHELLCODE_PORTS: "!80"
+ SSH_PORTS: 22
+
+The "host-os-policy" section is used to defend against some well-known attacks which exploit the behavior of an operating system's network stack (e.g., TCP reassembly) to evade detection. As a counter measure, modern IDS came up with so-called "target-based" inspection, where inspection engine fine-tunes its detection algorithm based on a target operating system of the traffic. Thus, if you know what OS individual local hosts are running, you can feed that information to Suricata to potentially enhance its detection rate. This is when "host-os-policy" section is used. In this example, the default IDS policy is Linux; if no OS information is known for a particular IP address, Suricata will apply Linux-based inspection. When traffic for 192.168.122.0/28 and 192.168.122.155 is captured, Suricata will apply Windows-based inspection policy.
+
+ host-os-policy:
+ # These are Windows machines.
+ windows: [192.168.122.0/28, 192.168.122.155]
+ bsd: []
+ bsd-right: []
+ old-linux: []
+ # Make the default policy Linux.
+ linux: [0.0.0.0/0]
+ old-solaris: []
+ solaris: ["::1"]
+ hpux10: []
+ hpux11: []
+ irix: []
+ macos: []
+ vista: []
+ windows2k3: []
+
+Under "threading" section, you can specify CPU affinity for different Suricata threads. By default, [CPU affinity][5] is disabled ("set-cpu-affinity: no"), meaning that Suricata threads will be scheduled on any available CPU cores. By default, Suricata will create one "detect" thread for each CPU core. You can adjust this behavior by specifying "detect-thread-ratio: N". This will create N*M detect threads, where M is the total number of CPU cores on the host.
+
+ threading:
+ set-cpu-affinity: no
+ detect-thread-ratio: 1.5
+
+With the above threading settings, Suricata will create 1.5*M detection threads, where M is the total number of CPU cores on the system.
+
+For more information about Suricata configuration, you can read the default configuration file itself, which is heavily commented for clarity.
+
+### Perform Intrusion Detection with Suricata ###
+
+Now it's time to test-run Suricata. Before launching it, there's one more step to do.
+
+When you are using pcap capture mode, it is highly recommended to turn off any packet offloead features (e.g., LRO/GRO) on the NIC which Suricata is listening on, as those features may interfere with live packet capture.
+
+Here is how to turn off LRO/GRO on the network interface eth0:
+
+ $ sudo ethtool -K eth0 gro off lro off
+
+Note that depending on your NIC, you may see the following warning, which you can ignore. It simply means that your NIC does not support LRO.
+
+ Cannot change large-receive-offload
+
+Suricata supports a number of running modes. A runmode determines how different threads are used for IDS. The following command lists all [available runmodes][6].
+
+ $ sudo /usr/local/bin/suricata --list-runmodes
+
+
+
+The default runmode used by Suricata is autofp (which stands for "auto flow pinned load balancing"). In this mode, packets from each distinct flow are assigned to a single detect thread. Flows are assigned to threads with the lowest number of unprocessed packets.
+
+Finally, let's start Suricata, and see it in action.
+
+ $ sudo /usr/local/bin/suricata -c /etc/suricata/suricata.yaml -i eth0 --init-errors-fatal
+
+
+
+In this example, we are monitoring a network interface eth0 on a 8-core system. As shown above, Suricata creates 13 packet processing threads and 3 management threads. The packet processing threads consist of one PCAP packet capture thread, and 12 detect threads (equal to 8*1.5). This means that the packets captured by one capture thread are load-balanced to 12 detect threads for IDS. The management threads are one flow manager and two counter/stats related threads.
+
+Here is a thread-view of Suricata process (plotted by [htop][7]).
+
+
+
+Suricata detection logs are stored in /var/log/suricata directory.
+
+ $ tail -f /var/log/suricata/fast.log
+
+----------
+
+ 04/01/2015-15:47:12.559075 [**] [1:2200074:1] SURICATA TCPv4 invalid checksum [**] [Classification: (null)] [Priority: 3] {TCP} 172.16.253.158:22 -> 172.16.253.1:46997
+ 04/01/2015-15:49:06.565901 [**] [1:2200074:1] SURICATA TCPv4 invalid checksum [**] [Classification: (null)] [Priority: 3] {TCP} 172.16.253.158:22 -> 172.16.253.1:46317
+ 04/01/2015-15:49:06.566759 [**] [1:2200074:1] SURICATA TCPv4 invalid checksum [**] [Classification: (null)] [Priority: 3] {TCP} 172.16.253.158:22 -> 172.16.253.1:46317
+
+For ease of import, the log is also available in JSON format:
+
+ $ tail -f /var/log/suricata/eve.json
+
+----------
+ {"timestamp":"2015-04-01T15:49:06.565901","event_type":"alert","src_ip":"172.16.253.158","src_port":22,"dest_ip":"172.16.253.1","dest_port":46317,"proto":"TCP","alert":{"action":"allowed","gid":1,"signature_id":2200074,"rev":1,"signature":"SURICATA TCPv4 invalid checksum","category":"","severity":3}}
+ {"timestamp":"2015-04-01T15:49:06.566759","event_type":"alert","src_ip":"172.16.253.158","src_port":22,"dest_ip":"172.16.253.1","dest_port":46317,"proto":"TCP","alert":{"action":"allowed","gid":1,"signature_id":2200074,"rev":1,"signature":"SURICATA TCPv4 invalid checksum","category":"","severity":3}}
+
+### Conclusion ###
+
+In this tutorial, I demonstrated how you can set up Suricata IDS on a multi-core Linux server. Unlike single-threaded [Snort IDS][8], Suricata can easily benefit from multi-core/many-core hardware with multi-threading. There is great deal of customization in Suricata to maximize its performance and detection coverage. Suricata folks maintain [online Wiki][9] quite well, so I strongly recommend you check it out if you want to deploy Suricata in your environment.
+
+Are you currently using Suricata? If so, feel free to share your experience.
+
+--------------------------------------------------------------------------------
+
+via: http://xmodulo.com/install-suricata-intrusion-detection-system-linux.html
+
+作者:[Dan Nanni][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://xmodulo.com/author/nanni
+[1]:http://suricata-ids.org/
+[2]:https://www.bro.org/
+[3]:http://suricata-ids.org/download/
+[4]:http://rules.emergingthreats.net/
+[5]:http://xmodulo.com/run-program-process-specific-cpu-cores-linux.html
+[6]:https://redmine.openinfosecfoundation.org/projects/suricata/wiki/Runmodes
+[7]:http://ask.xmodulo.com/view-threads-process-linux.html
+[8]:http://xmodulo.com/how-to-compile-and-install-snort-from-source-code-on-ubuntu.html
+[9]:https://redmine.openinfosecfoundation.org/projects/suricata/wiki
\ No newline at end of file
diff --git a/sources/tech/20150917 A Repository with 44 Years of Unix Evolution.md b/sources/tech/20150917 A Repository with 44 Years of Unix Evolution.md
new file mode 100644
index 0000000000..807cedf01d
--- /dev/null
+++ b/sources/tech/20150917 A Repository with 44 Years of Unix Evolution.md
@@ -0,0 +1,202 @@
+A Repository with 44 Years of Unix Evolution
+================================================================================
+### Abstract ###
+
+The evolution of the Unix operating system is made available as a version-control repository, covering the period from its inception in 1972 as a five thousand line kernel, to 2015 as a widely-used 26 million line system. The repository contains 659 thousand commits and 2306 merges. The repository employs the commonly used Git system for its storage, and is hosted on the popular GitHub archive. It has been created by synthesizing with custom software 24 snapshots of systems developed at Bell Labs, Berkeley University, and the 386BSD team, two legacy repositories, and the modern repository of the open source FreeBSD system. In total, 850 individual contributors are identified, the early ones through primary research. The data set can be used for empirical research in software engineering, information systems, and software archaeology.
+
+### 1 Introduction ###
+
+The Unix operating system stands out as a major engineering breakthrough due to its exemplary design, its numerous technical contributions, its development model, and its widespread use. The design of the Unix programming environment has been characterized as one offering unusual simplicity, power, and elegance [[1][1]]. On the technical side, features that can be directly attributed to Unix or were popularized by it include [[2][2]]: the portable implementation of the kernel in a high level language; a hierarchical file system; compatible file, device, networking, and inter-process I/O; the pipes and filters architecture; virtual file systems; and the shell as a user-selectable regular process. A large community contributed software to Unix from its early days [[3][3]], [[4][4],pp. 65-72]. This community grew immensely over time and worked using what are now termed open source software development methods [[5][5],pp. 440-442]. Unix and its intellectual descendants have also helped the spread of the C and C++ programming languages, parser and lexical analyzer generators (*yacc, lex*), document preparation tools (*troff, eqn, tbl*), scripting languages (*awk, sed, Perl*), TCP/IP networking, and configuration management systems (*SCCS, RCS, Subversion, Git*), while also forming a large part of the modern internet infrastructure and the web.
+
+Luckily, important Unix material of historical importance has survived and is nowadays openly available. Although Unix was initially distributed with relatively restrictive licenses, the most significant parts of its early development have been released by one of its right-holders (Caldera International) under a liberal license. Combining these parts with software that was developed or released as open source software by the University of California, Berkeley and the FreeBSD Project provides coverage of the system's development over a period ranging from June 20th 1972 until today.
+
+Curating and processing available snapshots as well as old and modern configuration management repositories allows the reconstruction of a new synthetic Git repository that combines under a single roof most of the available data. This repository documents in a digital form the detailed evolution of an important digital artefact over a period of 44 years. The following sections describe the repository's structure and contents (Section [II][6]), the way it was created (Section [III][7]), and how it can be used (Section [IV][8]).
+
+### 2 Data Overview ###
+
+The 1GB Unix history Git repository is made available for cloning on [GitHub][9].[1][10] Currently[2][11] the repository contains 659 thousand commits and 2306 merges from about 850 contributors. The contributors include 23 from the Bell Labs staff, 158 from Berkeley's Computer Systems Research Group (CSRG), and 660 from the FreeBSD Project.
+
+The repository starts its life at a tag identified as *Epoch*, which contains only licensing information and its modern README file. Various tag and branch names identify points of significance.
+
+- *Research-VX* tags correspond to six research editions that came out of Bell Labs. These start with *Research-V1* (4768 lines of PDP-11 assembly) and end with *Research-V7* (1820 mostly C files, 324kLOC).
+- *Bell-32V* is the port of the 7th Edition Unix to the DEC/VAX architecture.
+- *BSD-X* tags correspond to 15 snapshots released from Berkeley.
+- *386BSD-X* tags correspond to two open source versions of the system, with the Intel 386 architecture kernel code mainly written by Lynne and William Jolitz.
+- *FreeBSD-release/X* tags and branches mark 116 releases coming from the FreeBSD project.
+
+In addition, branches with a *-Snapshot-Development* suffix denote commits that have been synthesized from a time-ordered sequence of a snapshot's files, while tags with a *-VCS-Development* suffix mark the point along an imported version control history branch where a particular release occurred.
+
+The repository's history includes commits from the earliest days of the system's development, such as the following.
+
+ commit c9f643f59434f14f774d61ee3856972b8c3905b1
+ Author: Dennis Ritchie
+ Date: Mon Dec 2 18:18:02 1974 -0500
+ Research V5 development
+ Work on file usr/sys/dmr/kl.c
+
+Merges between releases that happened along the system's evolution, such as the development of BSD 3 from BSD 2 and Unix 32/V, are also correctly represented in the Git repository as graph nodes with two parents.
+
+More importantly, the repository is constructed in a way that allows *git blame*, which annotates source code lines with the version, date, and author associated with their first appearance, to produce the expected code provenance results. For example, checking out the *BSD-4* tag, and running git blame on the kernel's *pipe.c* file will show lines written by Ken Thompson in 1974, 1975, and 1979, and by Bill Joy in 1980. This allows the automatic (though computationally expensive) detection of the code's provenance at any point of time.
+
+
+
+Figure 1: Code provenance across significant Unix releases.
+
+As can be seen in Figure [1][12], a modern version of Unix (FreeBSD 9) still contains visible chunks of code from BSD 4.3, BSD 4.3 Net/2, and FreeBSD 2.0. Interestingly, the Figure shows that code developed during the frantic dash to create an open source operating system out of the code released by Berkeley (386BSD and FreeBSD 1.0) does not seem to have survived. The oldest code in FreeBSD 9 appears to be an 18-line sequence in the C library file timezone.c, which can also be found in the 7th Edition Unix file with the same name and a time stamp of January 10th, 1979 - 36 years ago.
+
+### 3 Data Collection and Processing ###
+
+The goal of the project is to consolidate data concerning the evolution of Unix in a form that helps the study of the system's evolution, by entering them into a modern revision repository. This involves collecting the data, curating them, and synthesizing them into a single Git repository.
+
+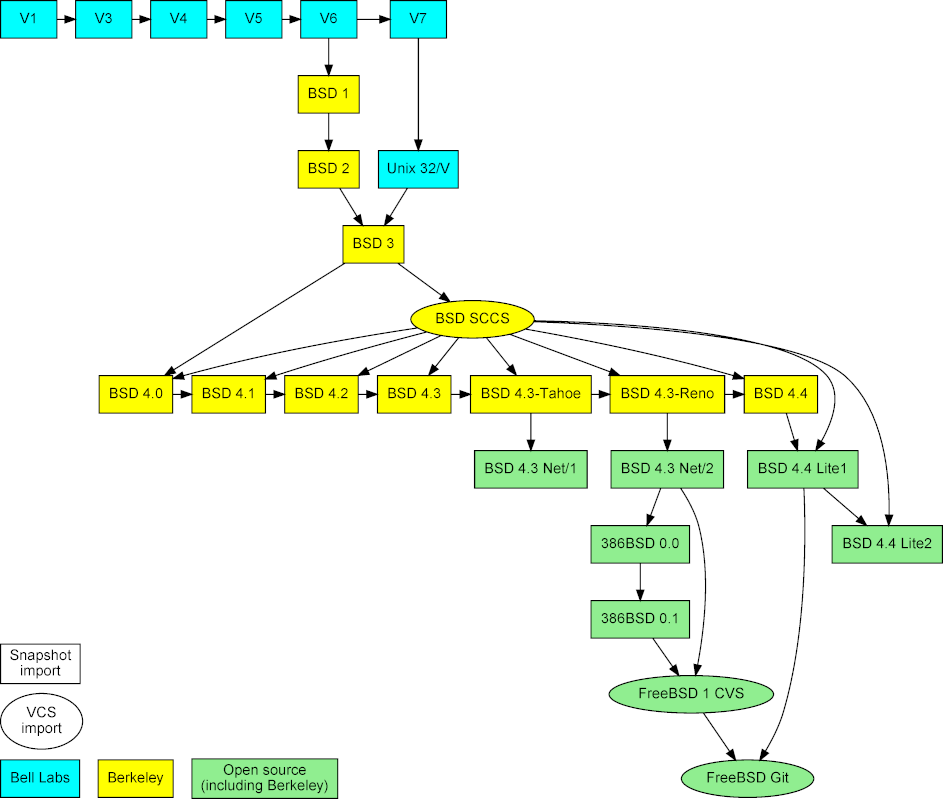
+
+Figure 2: Imported Unix snapshots, repositories, and their mergers.
+
+The project is based on three types of data (see Figure [2][13]). First, snapshots of early released versions, which were obtained from the [Unix Heritage Society archive][14],[3][15] the [CD-ROM images][16] containing the full source archives of CSRG,[4][17] the [OldLinux site][18],[5][19] and the [FreeBSD archive][20].[6][21] Second, past and current repositories, namely the CSRG SCCS [[6][22]] repository, the FreeBSD 1 CVS repository, and the [Git mirror of modern FreeBSD development][23].[7][24] The first two were obtained from the same sources as the corresponding snapshots.
+
+The last, and most labour intensive, source of data was **primary research**. The release snapshots do not provide information regarding their ancestors and the contributors of each file. Therefore, these pieces of information had to be determined through primary research. The authorship information was mainly obtained by reading author biographies, research papers, internal memos, and old documentation scans; by reading and automatically processing source code and manual page markup; by communicating via email with people who were there at the time; by posting a query on the Unix *StackExchange* site; by looking at the location of files (in early editions the kernel source code was split into `usr/sys/dmr` and `/usr/sys/ken`); and by propagating authorship from research papers and manual pages to source code and from one release to others. (Interestingly, the 1st and 2nd Research Edition manual pages have an "owner" section, listing the person (e.g. *ken*) associated with the corresponding system command, file, system call, or library function. This section was not there in the 4th Edition, and resurfaced as the "Author" section in BSD releases.) Precise details regarding the source of the authorship information are documented in the project's files that are used for mapping Unix source code files to their authors and the corresponding commit messages. Finally, information regarding merges between source code bases was obtained from a [BSD family tree maintained by the NetBSD project][25].[8][26]
+
+The software and data files that were developed as part of this project, are [available online][27],[9][28] and, with appropriate network, CPU and disk resources, they can be used to recreate the repository from scratch. The authorship information for major releases is stored in files under the project's `author-path` directory. These contain lines with a regular expressions for a file path followed by the identifier of the corresponding author. Multiple authors can also be specified. The regular expressions are processed sequentially, so that a catch-all expression at the end of the file can specify a release's default authors. To avoid repetition, a separate file with a `.au` suffix is used to map author identifiers into their names and emails. One such file has been created for every community associated with the system's evolution: Bell Labs, Berkeley, 386BSD, and FreeBSD. For the sake of authenticity, emails for the early Bell Labs releases are listed in UUCP notation (e.g. `research!ken`). The FreeBSD author identifier map, required for importing the early CVS repository, was constructed by extracting the corresponding data from the project's modern Git repository. In total the commented authorship files (828 rules) comprise 1107 lines, and there are another 640 lines mapping author identifiers to names.
+
+The curation of the project's data sources has been codified into a 168-line `Makefile`. It involves the following steps.
+
+**Fetching** Copying and cloning about 11GB of images, archives, and repositories from remote sites.
+
+**Tooling** Obtaining an archiver for old PDP-11 archives from 2.9 BSD, and adjusting it to compile under modern versions of Unix; compiling the 4.3 BSD *compress* program, which is no longer part of modern Unix systems, in order to decompress the 386BSD distributions.
+
+**Organizing** Unpacking archives using tar and *cpio*; combining three 6th Research Edition directories; unpacking all 1 BSD archives using the old PDP-11 archiver; mounting CD-ROM images so that they can be processed as file systems; combining the 8 and 62 386BSD floppy disk images into two separate files.
+
+**Cleaning** Restoring the 1st Research Edition kernel source code files, which were obtained from printouts through optical character recognition, into a format close to their original state; patching some 7th Research Edition source code files; removing metadata files and other files that were added after a release, to avoid obtaining erroneous time stamp information; patching corrupted SCCS files; processing the early FreeBSD CVS repository by removing CVS symbols assigned to multiple revisions with a custom Perl script, deleting CVS *Attic* files clashing with live ones, and converting the CVS repository into a Git one using *cvs2svn*.
+
+An interesting part of the repository representation is how snapshots are imported and linked together in a way that allows *git blame* to perform its magic. Snapshots are imported into the repository as sequential commits based on the time stamp of each file. When all files have been imported the repository is tagged with the name of the corresponding release. At that point one could delete those files, and begin the import of the next snapshot. Note that the *git blame* command works by traversing backwards a repository's history, and using heuristics to detect code moving and being copied within or across files. Consequently, deleted snapshots would create a discontinuity between them, and prevent the tracing of code between them.
+
+Instead, before the next snapshot is imported, all the files of the preceding snapshot are moved into a hidden look-aside directory named `.ref` (reference). They remain there, until all files of the next snapshot have been imported, at which point they are deleted. Because every file in the `.ref` directory matches exactly an original file, *git blame* can determine how source code moves from one version to the next via the `.ref` file, without ever displaying the `.ref` file. To further help the detection of code provenance, and to increase the representation's realism, each release is represented as a merge between the branch with the incremental file additions (*-Development*) and the preceding release.
+
+For a period in the 1980s, only a subset of the files developed at Berkeley were under SCCS version control. During that period our unified repository contains imports of both the SCCS commits, and the snapshots' incremental additions. At the point of each release, the SCCS commit with the nearest time stamp is found and is marked as a merge with the release's incremental import branch. These merges can be seen in the middle of Figure [2][29].
+
+The synthesis of the various data sources into a single repository is mainly performed by two scripts. A 780-line Perl script (`import-dir.pl`) can export the (real or synthesized) commit history from a single data source (snapshot directory, SCCS repository, or Git repository) in the *Git fast export* format. The output is a simple text format that Git tools use to import and export commits. Among other things, the script takes as arguments the mapping of files to contributors, the mapping between contributor login names and their full names, the commit(s) from which the import will be merged, which files to process and which to ignore, and the handling of "reference" files. A 450-line shell script creates the Git repository and calls the Perl script with appropriate arguments to import each one of the 27 available historical data sources. The shell script also runs 30 tests that compare the repository at specific tags against the corresponding data sources, verify the appearance and disappearance of look-aside directories, and look for regressions in the count of tree branches and merges and the output of *git blame* and *git log*. Finally, *git* is called to garbage-collect and compress the repository from its initial 6GB size down to the distributed 1GB.
+
+### 4 Data Uses ###
+
+The data set can be used for empirical research in software engineering, information systems, and software archeology. Through its unique uninterrupted coverage of a period of more than 40 years, it can inform work on software evolution and handovers across generations. With thousandfold increases in processing speed and million-fold increases in storage capacity during that time, the data set can also be used to study the co-evolution of software and hardware technology. The move of the software's development from research labs, to academia, and to the open source community can be used to study the effects of organizational culture on software development. The repository can also be used to study how notable individuals, such as Turing Award winners (Dennis Ritchie and Ken Thompson) and captains of the IT industry (Bill Joy and Eric Schmidt), actually programmed. Another phenomenon worthy of study concerns the longevity of code, either at the level of individual lines, or as complete systems that were at times distributed with Unix (Ingres, Lisp, Pascal, Ratfor, Snobol, TMG), as well as the factors that lead to code's survival or demise. Finally, because the data set stresses Git, the underlying software repository storage technology, to its limits, it can be used to drive engineering progress in the field of revision management systems.
+
+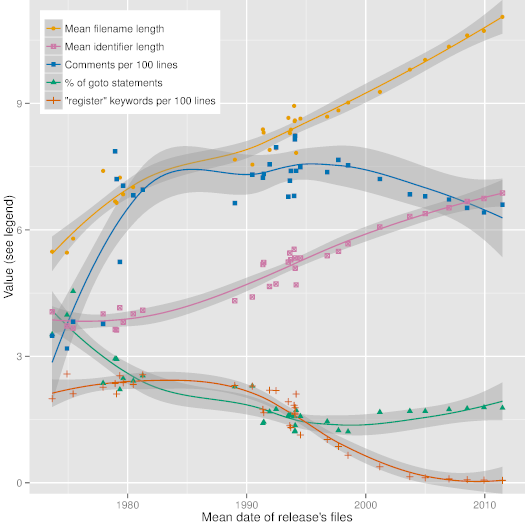
+
+Figure 3: Code style evolution along Unix releases.
+
+Figure [3][30], which depicts trend lines (obtained with R's local polynomial regression fitting function) of some interesting code metrics along 36 major releases of Unix, demonstrates the evolution of code style and programming language use over very long timescales. This evolution can be driven by software and hardware technology affordances and requirements, software construction theory, and even social forces. The dates in the Figure have been calculated as the average date of all files appearing in a given release. As can be seen in it, over the past 40 years the mean length of identifiers and file names has steadily increased from 4 and 6 characters to 7 and 11 characters, respectively. We can also see less steady increases in the number of comments and decreases in the use of the *goto* statement, as well as the virtual disappearance of the *register* type modifier.
+
+### 5 Further Work ###
+
+Many things can be done to increase the repository's faithfulness and usefulness. Given that the build process is shared as open source code, it is easy to contribute additions and fixes through GitHub pull requests. The most useful community contribution would be to increase the coverage of imported snapshot files that are attributed to a specific author. Currently, about 90 thousand files (out of a total of 160 thousand) are getting assigned an author through a default rule. Similarly, there are about 250 authors (primarily early FreeBSD ones) for which only the identifier is known. Both are listed in the build repository's unmatched directory, and contributions are welcomed. Furthermore, the BSD SCCS and the FreeBSD CVS commits that share the same author and time-stamp can be coalesced into a single Git commit. Support can be added for importing the SCCS file comment fields, in order to bring into the repository the corresponding metadata. Finally, and most importantly, more branches of open source systems can be added, such as NetBSD OpenBSD, DragonFlyBSD, and *illumos*. Ideally, current right holders of other important historical Unix releases, such as System III, System V, NeXTSTEP, and SunOS, will release their systems under a license that would allow their incorporation into this repository for study.
+
+#### Acknowledgements ####
+
+The author thanks the many individuals who contributed to the effort. Brian W. Kernighan, Doug McIlroy, and Arnold D. Robbins helped with Bell Labs login identifiers. Clem Cole, Era Eriksson, Mary Ann Horton, Kirk McKusick, Jeremy C. Reed, Ingo Schwarze, and Anatole Shaw helped with BSD login identifiers. The BSD SCCS import code is based on work by H. Merijn Brand and Jonathan Gray.
+
+This research has been co-financed by the European Union (European Social Fund - ESF) and Greek national funds through the Operational Program "Education and Lifelong Learning" of the National Strategic Reference Framework (NSRF) - Research Funding Program: Thalis - Athens University of Economics and Business - Software Engineering Research Platform.
+
+### References ###
+
+[[1]][31]
+ M. D. McIlroy, E. N. Pinson, and B. A. Tague, "UNIX time-sharing system: Foreword," *The Bell System Technical Journal*, vol. 57, no. 6, pp. 1899-1904, July-August 1978.
+
+[[2]][32]
+ D. M. Ritchie and K. Thompson, "The UNIX time-sharing system," *Bell System Technical Journal*, vol. 57, no. 6, pp. 1905-1929, July-August 1978.
+
+[[3]][33]
+ D. M. Ritchie, "The evolution of the UNIX time-sharing system," *AT&T Bell Laboratories Technical Journal*, vol. 63, no. 8, pp. 1577-1593, Oct. 1984.
+
+[[4]][34]
+ P. H. Salus, *A Quarter Century of UNIX*. Boston, MA: Addison-Wesley, 1994.
+
+[[5]][35]
+ E. S. Raymond, *The Art of Unix Programming*. Addison-Wesley, 2003.
+
+[[6]][36]
+ M. J. Rochkind, "The source code control system," *IEEE Transactions on Software Engineering*, vol. SE-1, no. 4, pp. 255-265, 1975.
+
+----------
+
+#### Footnotes: ####
+
+[1][37] - [https://github.com/dspinellis/unix-history-repo][38]
+
+[2][39] - Updates may add or modify material. To ensure replicability the repository's users are encouraged to fork it or archive it.
+
+[3][40] - [http://www.tuhs.org/archive_sites.html][41]
+
+[4][42] - [https://www.mckusick.com/csrg/][43]
+
+[5][44] - [http://www.oldlinux.org/Linux.old/distributions/386BSD][45]
+
+[6][46] - [http://ftp-archive.freebsd.org/pub/FreeBSD-Archive/old-releases/][47]
+
+[7][48] - [https://github.com/freebsd/freebsd][49]
+
+[8][50] - [http://ftp.netbsd.org/pub/NetBSD/NetBSD-current/src/share/misc/bsd-family-tree][51]
+
+[9][52] - [https://github.com/dspinellis/unix-history-make][53]
+
+--------------------------------------------------------------------------------
+
+via: http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html
+
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[1]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#MPT78
+[2]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#RT78
+[3]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#Rit84
+[4]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#Sal94
+[5]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#Ray03
+[6]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#sec:data
+[7]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#sec:dev
+[8]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#sec:use
+[9]:https://github.com/dspinellis/unix-history-repo
+[10]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAB
+[11]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAC
+[12]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#fig:provenance
+[13]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#fig:branches
+[14]:http://www.tuhs.org/archive_sites.html
+[15]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAD
+[16]:https://www.mckusick.com/csrg/
+[17]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAE
+[18]:http://www.oldlinux.org/Linux.old/distributions/386BSD
+[19]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAF
+[20]:http://ftp-archive.freebsd.org/pub/FreeBSD-Archive/old-releases/
+[21]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAG
+[22]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#SCCS
+[23]:https://github.com/freebsd/freebsd
+[24]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAH
+[25]:http://ftp.netbsd.org/pub/NetBSD/NetBSD-current/src/share/misc/bsd-family-tree
+[26]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAI
+[27]:https://github.com/dspinellis/unix-history-make
+[28]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAJ
+[29]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#fig:branches
+[30]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#fig:metrics
+[31]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#CITEMPT78
+[32]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#CITERT78
+[33]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#CITERit84
+[34]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#CITESal94
+[35]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#CITERay03
+[36]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#CITESCCS
+[37]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAB
+[38]:https://github.com/dspinellis/unix-history-repo
+[39]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAC
+[40]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAD
+[41]:http://www.tuhs.org/archive_sites.html
+[42]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAE
+[43]:https://www.mckusick.com/csrg/
+[44]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAF
+[45]:http://www.oldlinux.org/Linux.old/distributions/386BSD
+[46]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAG
+[47]:http://ftp-archive.freebsd.org/pub/FreeBSD-Archive/old-releases/
+[48]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAH
+[49]:https://github.com/freebsd/freebsd
+[50]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAI
+[51]:http://ftp.netbsd.org/pub/NetBSD/NetBSD-current/src/share/misc/bsd-family-tree
+[52]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAJ
+[53]:https://github.com/dspinellis/unix-history-make
\ No newline at end of file
diff --git a/sources/tech/20151012 Getting Started to Calico Virtual Private Networking on Docker.md b/sources/tech/20151012 Getting Started to Calico Virtual Private Networking on Docker.md
new file mode 100644
index 0000000000..27d60729e9
--- /dev/null
+++ b/sources/tech/20151012 Getting Started to Calico Virtual Private Networking on Docker.md
@@ -0,0 +1,322 @@
+Getting Started to Calico Virtual Private Networking on Docker
+================================================================================
+Calico is a free and open source software for virtual networking in data centers. It is a pure Layer 3 approach to highly scalable datacenter for cloud virtual networking. It seamlessly integrates with cloud orchestration system such as openstack, docker clusters in order to enable secure IP communication between virtual machines and containers. It implements a highly productive vRouter in each node that takes advantage of the existing Linux kernel forwarding engine. Calico works in such an awesome technology that it has the ability to peer directly with the data center’s physical fabric whether L2 or L3, without the NAT, tunnels on/off ramps, or overlays. Calico makes full utilization of docker to run its containers in the nodes which makes it multi-platform and very easy to ship, pack and deploy. Calico has the following salient features out of the box.
+
+- It can scale tens of thousands of servers and millions of workloads.
+- Calico is easy to deploy, operate and diagnose.
+- It is open source software licensed under Apache License version 2 and uses open standards.
+- It supports container, virtual machines and bare metal workloads.
+- It supports both IPv4 and IPv6 internet protocols.
+- It is designed internally to support rich, flexible and secure network policy.
+
+In this tutorial, we'll perform a virtual private networking between two nodes running Calico in them with Docker Technology. Here are some easy steps on how we can do that.
+
+### 1. Installing etcd ###
+
+To get started with the calico virtual private networking, we'll need to have a linux machine running etcd. As CoreOS comes preinstalled and preconfigured with etcd, we can use CoreOS but if we want to configure Calico in other linux distributions, then we'll need to setup it in our machine. As we are running Ubuntu 14.04 LTS, we'll need to first install and configure etcd in our machine. To install etcd in our Ubuntu box, we'll need to add the official ppa repository of Calico by running the following command in the machine which we want to run etcd server. Here, we'll be installing etcd in our 1st node.
+
+ # apt-add-repository ppa:project-calico/icehouse
+
+ The primary source of Ubuntu packages for Project Calico based on OpenStack Icehouse, an open source solution for virtual networking in cloud data centers. Find out more at http://www.projectcalico.org/
+ More info: https://launchpad.net/~project-calico/+archive/ubuntu/icehouse
+ Press [ENTER] to continue or ctrl-c to cancel adding it
+ gpg: keyring `/tmp/tmpi9zcmls1/secring.gpg' created
+ gpg: keyring `/tmp/tmpi9zcmls1/pubring.gpg' created
+ gpg: requesting key 3D40A6A7 from hkp server keyserver.ubuntu.com
+ gpg: /tmp/tmpi9zcmls1/trustdb.gpg: trustdb created
+ gpg: key 3D40A6A7: public key "Launchpad PPA for Project Calico" imported
+ gpg: Total number processed: 1
+ gpg: imported: 1 (RSA: 1)
+ OK
+
+Then, we'll need to edit /etc/apt/preferences and make changes to prefer Calico-provided packages for Nova and Neutron.
+
+ # nano /etc/apt/preferences
+
+We'll need to add the following lines into it.
+
+ Package: *
+ Pin: release o=LP-PPA-project-calico-*
+ Pin-Priority: 100
+
+
+
+Next, we'll also need to add the official BIRD PPA for Ubuntu 14.04 LTS so that bugs fixes are installed before its available on the Ubuntu repo.
+
+ # add-apt-repository ppa:cz.nic-labs/bird
+
+ The BIRD Internet Routing Daemon PPA (by upstream & .deb maintainer)
+ More info: https://launchpad.net/~cz.nic-labs/+archive/ubuntu/bird
+ Press [ENTER] to continue or ctrl-c to cancel adding it
+ gpg: keyring `/tmp/tmphxqr5hjf/secring.gpg' created
+ gpg: keyring `/tmp/tmphxqr5hjf/pubring.gpg' created
+ gpg: requesting key F9C59A45 from hkp server keyserver.ubuntu.com
+ apt-ggpg: /tmp/tmphxqr5hjf/trustdb.gpg: trustdb created
+ gpg: key F9C59A45: public key "Launchpad Datov� schr�nky" imported
+ gpg: Total number processed: 1
+ gpg: imported: 1 (RSA: 1)
+ OK
+
+Now, after the PPA jobs are done, we'll now gonna update the local repository index and then install etcd in our machine.
+
+ # apt-get update
+
+To install etcd in our ubuntu machine, we'll gonna run the following apt command.
+
+ # apt-get install etcd python-etcd
+
+### 2. Starting Etcd ###
+
+After the installation is complete, we'll now configure the etcd configuration file. Here, we'll edit **/etc/init/etcd.conf** using a text editor and append the line exec **/usr/bin/etcd** and make it look like below configuration.
+
+ # nano /etc/init/etcd.conf
+ exec /usr/bin/etcd --name="node1" \
+ --advertise-client-urls="http://10.130.65.71:2379,http://10.130.65.71:4001" \
+ --listen-client-urls="http://0.0.0.0:2379,http://0.0.0.0:4001" \
+ --listen-peer-urls "http://0.0.0.0:2380" \
+ --initial-advertise-peer-urls "http://10.130.65.71:2380" \
+ --initial-cluster-token $(uuidgen) \
+ --initial-cluster "node1=http://10.130.65.71:2380" \
+ --initial-cluster-state "new"
+
+
+
+**Note**: In the above configuration, we'll need to replace 10.130.65.71 and node-1 with the private ip address and hostname of your etcd server box. After done with editing, we'll need to save and exit the file.
+
+We can get the private ip address of our etcd server by running the following command.
+
+ # ifconfig
+
+
+
+As our etcd configuration is done, we'll now gonna start our etcd service in our Ubuntu node. To start etcd daemon, we'll gonna run the following command.
+
+ # service etcd start
+
+After done, we'll have a check if etcd is really running or not. To ensure that, we'll need to run the following command.
+
+ # service etcd status
+
+### 3. Installing Docker ###
+
+Next, we'll gonna install Docker in both of our nodes running Ubuntu. To install the latest release of docker, we'll simply need to run the following command.
+
+ # curl -sSL https://get.docker.com/ | sh
+
+
+
+After the installation is completed, we'll gonna start the docker daemon in-order to make sure that its running before we move towards Calico.
+
+ # service docker restart
+
+ docker stop/waiting
+ docker start/running, process 3056
+
+### 3. Installing Calico ###
+
+We'll now install calico in our linux machine in-order to run the calico containers. We'll need to install Calico in every node which we're wanting to connect into the Calico network. To install Calico, we'll need to run the following command under root or sudo permission.
+
+#### On 1st Node ####
+
+ # wget https://github.com/projectcalico/calico-docker/releases/download/v0.6.0/calicoctl
+
+ --2015-09-28 12:08:59-- https://github.com/projectcalico/calico-docker/releases/download/v0.6.0/calicoctl
+ Resolving github.com (github.com)... 192.30.252.129
+ Connecting to github.com (github.com)|192.30.252.129|:443... connected.
+ ...
+ Resolving github-cloud.s3.amazonaws.com (github-cloud.s3.amazonaws.com)... 54.231.9.9
+ Connecting to github-cloud.s3.amazonaws.com (github-cloud.s3.amazonaws.com)|54.231.9.9|:443... connected.
+ HTTP request sent, awaiting response... 200 OK
+ Length: 6166661 (5.9M) [application/octet-stream]
+ Saving to: 'calicoctl'
+ 100%[=========================================>] 6,166,661 1.47MB/s in 6.7s
+ 2015-09-28 12:09:08 (898 KB/s) - 'calicoctl' saved [6166661/6166661]
+
+ # chmod +x calicoctl
+
+After done with making it executable, we'll gonna make the binary calicoctl available as the command in any directory. To do so, we'll need to run the following command.
+
+ # mv calicoctl /usr/bin/
+
+#### On 2nd Node ####
+
+ # wget https://github.com/projectcalico/calico-docker/releases/download/v0.6.0/calicoctl
+
+ --2015-09-28 12:09:03-- https://github.com/projectcalico/calico-docker/releases/download/v0.6.0/calicoctl
+ Resolving github.com (github.com)... 192.30.252.131
+ Connecting to github.com (github.com)|192.30.252.131|:443... connected.
+ ...
+ Resolving github-cloud.s3.amazonaws.com (github-cloud.s3.amazonaws.com)... 54.231.8.113
+ Connecting to github-cloud.s3.amazonaws.com (github-cloud.s3.amazonaws.com)|54.231.8.113|:443... connected.
+ HTTP request sent, awaiting response... 200 OK
+ Length: 6166661 (5.9M) [application/octet-stream]
+ Saving to: 'calicoctl'
+ 100%[=========================================>] 6,166,661 1.47MB/s in 5.9s
+ 2015-09-28 12:09:11 (1022 KB/s) - 'calicoctl' saved [6166661/6166661]
+
+ # chmod +x calicoctl
+
+After done with making it executable, we'll gonna make the binary calicoctl available as the command in any directory. To do so, we'll need to run the following command.
+
+ # mv calicoctl /usr/bin/
+
+Likewise, we'll need to execute the above commands to install in every other nodes.
+
+### 4. Starting Calico services ###
+
+After we have installed calico on each of our nodes, we'll gonna start our Calico services. To start the calico services, we'll need to run the following commands.
+
+#### On 1st Node ####
+
+ # calicoctl node
+
+ WARNING: Unable to detect the xt_set module. Load with `modprobe xt_set`
+ WARNING: Unable to detect the ipip module. Load with `modprobe ipip`
+ No IP provided. Using detected IP: 10.130.61.244
+ Pulling Docker image calico/node:v0.6.0
+ Calico node is running with id: fa0ca1f26683563fa71d2ccc81d62706e02fac4bbb08f562d45009c720c24a43
+
+#### On 2nd Node ####
+
+Next, we'll gonna export a global variable in order to connect our calico nodes to the same etcd server which is hosted in node1 in our case. To do so, we'll need to run the following command in each of our nodes.
+
+ # export ETCD_AUTHORITY=10.130.61.244:2379
+
+Then, we'll gonna run calicoctl container in our every our second node.
+
+ # calicoctl node
+
+ WARNING: Unable to detect the xt_set module. Load with `modprobe xt_set`
+ WARNING: Unable to detect the ipip module. Load with `modprobe ipip`
+ No IP provided. Using detected IP: 10.130.61.245
+ Pulling Docker image calico/node:v0.6.0
+ Calico node is running with id: 70f79c746b28491277e28a8d002db4ab49f76a3e7d42e0aca8287a7178668de4
+
+This command should be executed in every nodes in which we want to start our Calico services. The above command start a container in the respective node. To check if the container is running or not, we'll gonna run the following docker command.
+
+ # docker ps
+
+
+
+If we see the output something similar to the output shown below then we can confirm that Calico containers are up and running.
+
+### 5. Starting Containers ###
+
+Next, we'll need to start few containers in each of our nodes running Calico services. We'll assign a different name to each of the containers running ubuntu. Here, workload-A, workload-B, etc has been assigned as the unique name for each of the containers. To do so, we'll need to run the following command.
+
+#### On 1st Node ####
+
+ # docker run --net=none --name workload-A -tid ubuntu
+
+ Unable to find image 'ubuntu:latest' locally
+ latest: Pulling from library/ubuntu
+ ...
+ 91e54dfb1179: Already exists
+ library/ubuntu:latest: The image you are pulling has been verified. Important: image verification is a tech preview feature and should not be relied on to provide security.
+ Digest: sha256:73fbe2308f5f5cb6e343425831b8ab44f10bbd77070ecdfbe4081daa4dbe3ed1
+ Status: Downloaded newer image for ubuntu:latest
+ a1ba9105955e9f5b32cbdad531cf6ecd9cab0647d5d3d8b33eca0093605b7a18
+
+ # docker run --net=none --name workload-B -tid ubuntu
+
+ 89dd3d00f72ac681bddee4b31835c395f14eeb1467300f2b1b9fd3e704c28b7d
+
+#### On 2nd Node ####
+
+ # docker run --net=none --name workload-C -tid ubuntu
+
+ Unable to find image 'ubuntu:latest' locally
+ latest: Pulling from library/ubuntu
+ ...
+ 91e54dfb1179: Already exists
+ library/ubuntu:latest: The image you are pulling has been verified. Important: image verification is a tech preview feature and should not be relied on to provide security.
+ Digest: sha256:73fbe2308f5f5cb6e343425831b8ab44f10bbd77070ecdfbe4081daa4dbe3ed1
+ Status: Downloaded newer image for ubuntu:latest
+ 24e2d5d7d6f3990b534b5643c0e483da5b4620a1ac2a5b921b2ba08ebf754746
+
+ # docker run --net=none --name workload-D -tid ubuntu
+
+ c6f28d1ab8f7ac1d9ccc48e6e4234972ed790205c9ca4538b506bec4dc533555
+
+Similarly, if we have more nodes, we can run ubuntu docker container into it by running the above command with assigning a different container name.
+
+### 6. Assigning IP addresses ###
+
+After we have got our docker containers running in each of our hosts, we'll go for adding a networking support to the containers. Now, we'll gonna assign a new ip address to each of the containers using calicoctl. This will add a new network interface to the containers with the assigned ip addresses. To do so, we'll need to run the following commands in the hosts running the containers.
+
+#### On 1st Node ####
+
+ # calicoctl container add workload-A 192.168.0.1
+ # calicoctl container add workload-B 192.168.0.2
+
+#### On 2nd Node ####
+
+ # calicoctl container add workload-C 192.168.0.3
+ # calicoctl container add workload-D 192.168.0.4
+
+### 7. Adding Policy Profiles ###
+
+After our containers have got networking interfaces and ip address assigned, we'll now need to add policy profiles to enable networking between the containers each other. After adding the profiles, the containers will be able to communicate to each other only if they have the common profiles assigned. That means, if they have different profiles assigned, they won't be able to communicate to eachother. So, before being able to assign. we'll need to first create some new profiles. That can be done in either of the hosts. Here, we'll run the following command in 1st Node.
+
+ # calicoctl profile add A_C
+
+ Created profile A_C
+
+ # calicoctl profile add B_D
+
+ Created profile B_D
+
+After the profile has been created, we'll simply add our workload to the required profile. Here, in this tutorial, we'll place workload A and workload C in a common profile A_C and workload B and D in a common profile B_D. To do so, we'll run the following command in our hosts.
+
+#### On 1st Node ####
+
+ # calicoctl container workload-A profile append A_C
+ # calicoctl container workload-B profile append B_D
+
+#### On 2nd Node ####
+
+ # calicoctl container workload-C profile append A_C
+ # calicoctl container workload-D profile append B_D
+
+### 8. Testing the Network ###
+
+After we've added a policy profile to each of our containers using Calicoctl, we'll now test whether our networking is working as expected or not. We'll take a node and a workload and try to communicate with the other containers running in same or different nodes. And due to the profile, we should be able to communicate only with the containers having a common profile. So, in this case, workload A should be able to communicate with only C and vice versa whereas workload A shouldn't be able to communicate with B or D. To test the network, we'll gonna ping the containers having common profiles from the 1st host running workload A and B.
+
+We'll first ping workload-C having ip 192.168.0.3 using workload-A as shown below.
+
+ # docker exec workload-A ping -c 4 192.168.0.3
+
+Then, we'll ping workload-D having ip 192.168.0.4 using workload-B as shown below.
+
+ # docker exec workload-B ping -c 4 192.168.0.4
+
+
+
+Now, we'll check if we're able to ping the containers having different profiles. We'll now ping workload-D having ip address 192.168.0.4 using workload-A.
+
+ # docker exec workload-A ping -c 4 192.168.0.4
+
+After done, we'll try to ping workload-C having ip address 192.168.0.3 using workload-B.
+
+ # docker exec workload-B ping -c 4 192.168.0.3
+
+
+
+Hence, the workloads having same profiles could ping each other whereas having different profiles couldn't ping to each other.
+
+### Conclusion ###
+
+Calico is an awesome project providing an easy way to configure a virtual network using the latest docker technology. It is considered as a great open source solution for virtual networking in cloud data centers. Calico is being experimented by people in different cloud platforms like AWS, DigitalOcean, GCE and more these days. As Calico is currently under experiment, its stable version hasn't been released yet and is still in pre-release. The project consists a well documented documentations, tutorials and manuals in their [official documentation site][2].
+
+--------------------------------------------------------------------------------
+
+via: http://linoxide.com/linux-how-to/calico-virtual-private-networking-docker/
+
+作者:[Arun Pyasi][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://linoxide.com/author/arunp/
+[1]:http://docs.projectcalico.org/
\ No newline at end of file
diff --git a/sources/tech/20151012 Remember sed and awk All Linux admins should.md b/sources/tech/20151012 Remember sed and awk All Linux admins should.md
new file mode 100644
index 0000000000..67a6641393
--- /dev/null
+++ b/sources/tech/20151012 Remember sed and awk All Linux admins should.md
@@ -0,0 +1,60 @@
+Remember sed and awk? All Linux admins should
+================================================================================
+
+
+Credit: Shutterstock
+
+**We aren’t doing the next generation of Linux and Unix admins any favors by forgetting init scripts and fundamental tools**
+
+I happened across a post on Reddit by chance, [asking about textfile manipulation][1]. It was a fairly simple request, similar to those that folks in Unix see nearly every day. In this case, it was how to remove all duplicate lines in a file, keeping one instance of each. This sounds relatively easy, but can get a bit complicated if the source file is sufficiently large and random.
+
+There are countless answers to this problem. You could write a script in nearly any language to do this, with varying levels of complexity and time investment, which I suspect is what most would do. It might take 20 or 60 minutes depending on skill level, but armed with Perl, Python, or Ruby, you could make quick work of it.
+
+Or you could use the answer stated in that thread, which warmed my heart: Just use awk.
+
+That answer is the most concise and simplest solution to the problem by far. It’s one line:
+
+ awk '!seen[$0]++' .
+
+Let’s take a look at this.
+
+In this command, there’s a lot of hidden code. Awk is a text processing language, and as such it makes a lot of assumptions. For starters, what you see here is actually the meat of a for loop. Awk assumes you want to loop through every line of the input file, so you don’t need to explicitly state it. Awk also assumes you want to print the postprocessed output, so you don’t need to state that either. Finally, Awk then assumes the loop ends when the last statement finishes, so no need to state it.
+
+The string seen in this example is the name given to an associative array. $0 is a variable that represents the entirety of the current line of the file. Thus, this command translates to “Evaluate every line in this file, and if you haven’t seen this line before, print it.” Awk does this by adding $0 to the seen array if it doesn’t already exist and incrementing the value so that it will not match the pattern the next time around and, thus, not print.
+
+Some will see this as elegant, while others may see this as obfuscation. Anyone who uses awk on a daily basis will be in the first group. Awk is designed to do this. You can write multiline programs in awk. You can even write [disturbingly complex functions in awk][2]. But at the end of the day, awk is designed to do text processing, generally within a pipe. Eliminating the extraneous cruft of loop definition is simply a shortcut for a very common use case. If you like, you could write the same thing as the following:
+
+ awk '{ if (!seen[$0]) print $0; seen[$0]++ }’
+
+It would lead to the same result.
+
+Awk is the perfect tool for this job. Nevertheless, I believe many admins -- especially newer admins -- would jump into [Bash][3] or Python to try to accomplish this task, because knowledge of awk and what it can do seems to be fading as time goes on. I think it may be an indicator of things to come, where problems that have been solved for decades suddenly emerge again, based on lack of exposure to the previous solutions.
+
+The shell, grep, sed, and awk are fundaments of Unix computing. If you’re not completely comfortable with their use, you’re artificially hamstrung because they form the basis of interaction with Unix systems via the CLI and shell scripting. One of the best ways to learn how these tools work is by observing and working with live examples, which every Unix flavor has in spades with their init systems -- or had, in the case of Linux distros that have adopted [systemd][4].
+
+Millions of Unix admins learned how shell scripting and Unix tools worked by reading, writing, modifying, and working with init scripts. Init scripts differ greatly from OS to OS, even from distribution to distribution in the case of Linux, but they are all rooted in sh, and they all use core CLI tools like sed, awk, and grep.
+
+I’ve heard many complaints that init scripts are “ancient” and “difficult,” but in fact, init scripts use the same tools that Unix admins work with every day, and thus provide an excellent way to become more familiar and comfortable with those tools. Saying that init scripts are hard to read or difficult to work with is to admit that you lack fundamental familiarity with the Unix toolset.
+
+Speaking of things found on Reddit, I also came across this question from a budding Linux sys admin, [asking whether he should bother to learn sysvinit][5]. Most of the answers in the thread are good -- yes, definitely learn sysvinit and systemd. One commenter even notes that init scripts are a great way to learn Bash, and another states that the Fortune 50 company he works for has no plans to move to a systemd-based release.
+
+But it concerns me that this is a question at all. If we continue down the path of eliminating scripts and roping off core system elements within our operating systems, we will inadvertently make it harder for new admins to learn the fundamental Unix toolset due to the lack of exposure.
+
+I’m not sure why some want to cover up Unix internals with abstraction after abstraction, but such a path may reduce a generation of Unix admins to hapless button pushers dependent on support contracts. I’m pretty sure that would not be a good development.
+
+--------------------------------------------------------------------------------
+
+via: http://www.infoworld.com/article/2985804/linux/remember-sed-awk-linux-admins-should.html
+
+作者:[Paul Venezia][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.infoworld.com/author/Paul-Venezia/
+[1]:https://www.reddit.com/r/linuxadmin/comments/3lwyko/how_do_i_remove_every_occurence_of_duplicate_line/
+[2]:http://intro-to-awk.blogspot.com/2008/08/awk-more-complex-examples.html
+[3]:http://www.infoworld.com/article/2613338/linux/linux-how-to-script-a-bash-crash-course.html
+[4]:http://www.infoworld.com/article/2608798/data-center/systemd--harbinger-of-the-linux-apocalypse.html
+[5]:https://www.reddit.com/r/linuxadmin/comments/3ltq2y/when_i_start_learning_about_linux_administration/
diff --git a/sources/tech/20151013 DFileManager--Cover Flow File Manager.md b/sources/tech/20151013 DFileManager--Cover Flow File Manager.md
new file mode 100644
index 0000000000..9c96fe9553
--- /dev/null
+++ b/sources/tech/20151013 DFileManager--Cover Flow File Manager.md
@@ -0,0 +1,63 @@
+DFileManager: Cover Flow File Manager
+================================================================================
+A real gem of a file manager absent from the standard Ubuntu repositories but sporting a unique feature. That’s DFileManager in a twitterish statement.
+
+A tricky question to answer is just how many open source Linux applications are available. Just out of curiosity, you can type at the shell:
+
+ ~$ for f in /var/lib/apt/lists/*Packages; do printf ’%5d %s\n’ $(grep ’^Package: ’ “$f” | wc -l) ${f##*/} done | sort -rn
+
+On my Ubuntu 15.04 system, it produces the following results:
+
+
+
+As the screenshot above illustrates, there are approximately 39,000 packages in the Universe repository, and around 8,500 packages in the main repository. These numbers sound a lot. But there is a smorgasbord of open source applications, utilities, and libraries that don’t have an Ubuntu team generating a package. And more importantly, there are some real treasures missing from the repositories which can only be discovered by compiling source code. DFileManager is one such utility. It is a Qt based cross-platform file manager which is in an early stage of development. Qt provides single-source portability across all major desktop operating systems.
+
+In the absence of a binary package, the user needs to compile the code. For some tools, this can be problematic, particularly if the application depends on any obscure libraries, or specific versions which may be incompatible with other software installed on a system.
+
+### Installation ###
+
+Fortunately, DFileManager is simple to compile. The installation instructions on the developer’s website provide most of the steps necessary for my creaking Ubuntu box, but a few essential packages were missing (why is it always that way however many libraries clutter up your filesystem?) To prepare my system, download the source code from GitHub and then compile the software, I entered the following commands at the shell:
+
+ ~$ sudo apt-get install qt5-default qt5-qmake libqt5x11extras5-dev
+ ~$ git clone git://git.code.sf.net/p/dfilemanager/code dfilemanager-code
+ ~$ cd dfilemananger-code
+ ~$ mkdir build
+ ~$ cd build
+ ~$ cmake ../ -DCMAKE_INSTALL_PREFIX=/usr
+ ~$ make
+ ~$ sudo make install
+
+You can then start the application by typing at the shell:
+
+ ~$ dfm
+
+Here is a screenshot of DFileManager in action, with the main attraction in full view; the Cover Flow view. This offers the ability to slide through items in the current folder with an attractive feel. It’s ideal for viewing photos. The file manager bears a resemblance to Finder (the default file manager and graphical user interface shell used on all Macintosh operating systems), which may appeal to you.
+
+
+
+### Features: ###
+
+- 4 views: Icons, Details, Columns, and Cover Flow
+- Categorised bookmarks with Places and Devices
+- Tabs
+- Simple searching and filtering
+- Customizable thumbnails for filetypes including multimedia files
+- Information bar which can be undocked
+- Open folders and files with one click
+- Option to queue IO operations
+- Remembers some view properties for each folder
+- Show hidden files
+
+DFileManager is not a replacement for KDE’s Dolphin, but do give it a go. It’s a file manager that really helps the user browse files. And don’t forget to give feedback to the developer; that’s a contribution anyone can offer.
+
+--------------------------------------------------------------------------------
+
+via: http://gofk.tumblr.com/post/131014089537/dfilemanager-cover-flow-file-manager-a-real-gem
+
+作者:[gofk][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://gofk.tumblr.com/
\ No newline at end of file
diff --git a/sources/tech/20151028 10 Tips for 10x Application Performance.md b/sources/tech/20151028 10 Tips for 10x Application Performance.md
new file mode 100644
index 0000000000..99086f1163
--- /dev/null
+++ b/sources/tech/20151028 10 Tips for 10x Application Performance.md
@@ -0,0 +1,279 @@
+translating by ezio
+
+10 Tips for 10x Application Performance
+================================================================================
+Improving web application performance is more critical than ever. The share of economic activity that’s online is growing; more than 5% of the developed world’s economy is now on the Internet (see Resources below for statistics). And our always-on, hyper-connected modern world means that user expectations are higher than ever. If your site does not respond instantly, or if your app does not work without delay, users quickly move on to your competitors.
+
+For example, a study done by Amazon almost 10 years ago proved that, even then, a 100-millisecond decrease in page-loading time translated to a 1% increase in its revenue. Another recent study highlighted the fact that that more than half of site owners surveyed said they lost revenue or customers due to poor application performance.
+
+How fast does a website need to be? For each second a page takes to load, about 4% of users abandon it. Top e-commerce sites offer a time to first interaction ranging from one to three seconds, which offers the highest conversion rate. It’s clear that the stakes for web application performance are high and likely to grow.
+
+Wanting to improve performance is easy, but actually seeing results is difficult. To help you on your journey, this blog post offers you ten tips to help you increase your website performance by as much as 10x. It’s the first in a series detailing how you can increase your application performance with the help of some well-tested optimization techniques, and with a little support from NGINX. This series also outlines potential improvements in security that you can gain along the way.
+
+### Tip #1: Accelerate and Secure Applications with a Reverse Proxy Server ###
+
+If your web application runs on a single machine, the solution to performance problems might seem obvious: just get a faster machine, with more processor, more RAM, a fast disk array, and so on. Then the new machine can run your WordPress server, Node.js application, Java application, etc., faster than before. (If your application accesses a database server, the solution might still seem simple: get two faster machines, and a faster connection between them.)
+
+Trouble is, machine speed might not be the problem. Web applications often run slowly because the computer is switching among different kinds of tasks: interacting with users on thousands of connections, accessing files from disk, and running application code, among others. The application server may be thrashing – running out of memory, swapping chunks of memory out to disk, and making many requests wait on a single task such as disk I/O.
+
+Instead of upgrading your hardware, you can take an entirely different approach: adding a reverse proxy server to offload some of these tasks. A [reverse proxy server][1] sits in front of the machine running the application and handles Internet traffic. Only the reverse proxy server is connected directly to the Internet; communication with the application servers is over a fast internal network.
+
+Using a reverse proxy server frees the application server from having to wait for users to interact with the web app and lets it concentrate on building pages for the reverse proxy server to send across the Internet. The application server, which no longer has to wait for client responses, can run at speeds close to those achieved in optimized benchmarks.
+
+Adding a reverse proxy server also adds flexibility to your web server setup. For instance, if a server of a given type is overloaded, another server of the same type can easily be added; if a server is down, it can easily be replaced.
+
+Because of the flexibility it provides, a reverse proxy server is also a prerequisite for many other performance-boosting capabilities, such as:
+
+- **Load balancing** (see [Tip #2][2]) – A load balancer runs on a reverse proxy server to share traffic evenly across a number of application servers. With a load balancer in place, you can add application servers without changing your application at all.
+- **Caching static files** (see [Tip #3][3]) – Files that are requested directly, such as image files or code files, can be stored on the reverse proxy server and sent directly to the client, which serves assets more quickly and offloads the application server, allowing the application to run faster.
+- **Securing your site** – The reverse proxy server can be configured for high security and monitored for fast recognition and response to attacks, keeping the application servers protected.
+
+NGINX software is specifically designed for use as a reverse proxy server, with the additional capabilities described above. NGINX uses an event-driven processing approach which is more efficient than traditional servers. NGINX Plus adds more advanced reverse proxy features, such as application [health checks][4], specialized request routing, advanced caching, and support.
+
+
+
+### Tip #2: Add a Load Balancer ###
+
+Adding a [load balancer][5] is a relatively easy change which can create a dramatic improvement in the performance and security of your site. Instead of making a core web server bigger and more powerful, you use a load balancer to distribute traffic across a number of servers. Even if an application is poorly written, or has problems with scaling, a load balancer can improve the user experience without any other changes.
+
+A load balancer is, first, a reverse proxy server (see [Tip #1][6]) – it receives Internet traffic and forwards requests to another server. The trick is that the load balancer supports two or more application servers, using [a choice of algorithms][7] to split requests between servers. The simplest load balancing approach is round robin, with each new request sent to the next server on the list. Other methods include sending requests to the server with the fewest active connections. NGINX Plus has [capabilities][8] for continuing a given user session on the same server, which is called session persistence.
+
+Load balancers can lead to strong improvements in performance because they prevent one server from being overloaded while other servers wait for traffic. They also make it easy to expand your web server capacity, as you can add relatively low-cost servers and be sure they’ll be put to full use.
+
+Protocols that can be load balanced include HTTP, HTTPS, SPDY, HTTP/2, WebSocket, [FastCGI][9], SCGI, uwsgi, memcached, and several other application types, including TCP-based applications and other Layer 4 protocols. Analyze your web applications to determine which you use and where performance is lagging.
+
+The same server or servers used for load balancing can also handle several other tasks, such as SSL termination, support for HTTP/1/x and HTTP/2 use by clients, and caching for static files.
+
+NGINX is often used for load balancing; to learn more, please see our [overview blog post][10], [configuration blog post][11], [ebook][12] and associated [webinar][13], and [documentation][14]. Our commercial version, [NGINX Plus][15], supports more specialized load balancing features such as load routing based on server response time and the ability to load balance on Microsoft’s NTLM protocol.
+
+### Tip #3: Cache Static and Dynamic Content ###
+
+Caching improves web application performance by delivering content to clients faster. Caching can involve several strategies: preprocessing content for fast delivery when needed, storing content on faster devices, storing content closer to the client, or a combination.
+
+There are two different types of caching to consider:
+
+- **Caching of static content**. Infrequently changing files, such as image files (JPEG, PNG) and code files (CSS, JavaScript), can be stored on an edge server for fast retrieval from memory or disk.
+- **Caching of dynamic content**. Many Web applications generate fresh HTML for each page request. By briefly caching one copy of the generated HTML for a brief period of time, you can dramatically reduce the total number of pages that have to be generated while still delivering content that’s fresh enough to meet your requirements.
+
+If a page gets ten views per second, for instance, and you cache it for one second, 90% of requests for the page will come from the cache. If you separately cache static content, even the freshly generated versions of the page might be made up largely of cached content.
+
+There are three main techniques for caching content generated by web applications:
+
+- **Moving content closer to users**. Keeping a copy of content closer to the user reduces its transmission time.
+- **Moving content to faster machines**. Content can be kept on a faster machine for faster retrieval.
+- **Moving content off of overused machines**. Machines sometimes operate much slower than their benchmark performance on a particular task because they are busy with other tasks. Caching on a different machine improves performance for the cached resources and also for non-cached resources, because the host machine is less overloaded.
+
+Caching for web applications can be implemented from the inside – the web application server – out. First, caching is used for dynamic content, to reduce the load on application servers. Then, caching is used for static content (including temporary copies of what would otherwise be dynamic content), further off-loading application servers. And caching is then moved off of application servers and onto machines that are faster and/or closer to the user, unburdening the application servers, and reducing retrieval and transmission times.
+
+Improved caching can speed up applications tremendously. For many web pages, static data, such as large image files, makes up more than half the content. It might take several seconds to retrieve and transmit such data without caching, but only fractions of a second if the data is cached locally.
+
+As an example of how caching is used in practice, NGINX and NGINX Plus use two directives to [set up caching][16]: proxy_cache_path and proxy_cache. You specify the cache location and size, the maximum time files are kept in the cache, and other parameters. Using a third (and quite popular) directive, proxy_cache_use_stale, you can even direct the cache to supply stale content when the server that supplies fresh content is busy or down, giving the client something rather than nothing. From the user’s perspective, this may strongly improves your site or application’s uptime.
+
+NGINX Plus has [advanced caching features][17], including support for [cache purging][18] and visualization of cache status on a [dashboard][19] for live activity monitoring.
+
+For more information on caching with NGINX, see the [reference documentation][20] and [NGINX Content Caching][21] in the NGINX Plus Admin Guide.
+
+**Note**: Caching crosses organizational lines between people who develop applications, people who make capital investment decisions, and people who run networks in real time. Sophisticated caching strategies, like those alluded to here, are a good example of the value of a [DevOps perspective][22], in which application developer, architectural, and operations perspectives are merged to help meet goals for site functionality, response time, security, and business results, )such as completed transactions or sales.
+
+### Tip #4: Compress Data ###
+
+Compression is a huge potential performance accelerator. There are carefully engineered and highly effective compression standards for photos (JPEG and PNG), videos (MPEG-4), and music (MP3), among others. Each of these standards reduces file size by an order of magnitude or more.
+
+Text data – including HTML (which includes plain text and HTML tags), CSS, and code such as JavaScript – is often transmitted uncompressed. Compressing this data can have a disproportionate impact on perceived web application performance, especially for clients with slow or constrained mobile connections.
+
+That’s because text data is often sufficient for a user to interact with a page, where multimedia data may be more supportive or decorative. Smart content compression can reduce the bandwidth requirements of HTML, Javascript, CSS and other text-based content, typically by 30% or more, with a corresponding reduction in load time.
+
+If you use SSL, compression reduces the amount of data that has to be SSL-encoded, which offsets some of the CPU time it takes to compress the data.
+
+Methods for compressing text data vary. For example, see the [section on HTTP/2][23] for a novel text compression scheme, adapted specifically for header data. As another example of text compression you can [turn on][24] GZIP compression in NGINX. After you [pre-compress text data][25] on your services, you can serve the compressed .gz version directly using the gzip_static directive.
+
+### Tip #5: Optimize SSL/TLS ###
+
+The Secure Sockets Layer ([SSL][26]) protocol and its successor, the Transport Layer Security (TLS) protocol, are being used on more and more websites. SSL/TLS encrypts the data transported from origin servers to users to help improve site security. Part of what may be influencing this trend is that Google now uses the presence of SSL/TLS as a positive influence on search engine rankings.
+
+Despite rising popularity, the performance hit involved in SSL/TLS is a sticking point for many sites. SSL/TLS slows website performance for two reasons:
+
+1. The initial handshake required to establish encryption keys whenever a new connection is opened. The way that browsers using HTTP/1.x establish multiple connections per server multiplies that hit.
+1. Ongoing overhead from encrypting data on the server and decrypting it on the client.
+
+To encourage the use of SSL/TLS, the authors of HTTP/2 and SPDY (described in the [next section][27]) designed these protocols so that browsers need just one connection per browser session. This greatly reduces one of the two major sources of SSL overhead. However, even more can be done today to improve the performance of applications delivered over SSL/TLS.
+
+The mechanism for optimizing SSL/TLS varies by web server. As an example, NGINX uses [OpenSSL][28], running on standard commodity hardware, to provide performance similar to dedicated hardware solutions. NGINX [SSL performance][29] is well-documented and minimizes the time and CPU penalty from performing SSL/TLS encryption and decryption.
+
+In addition, see [this blog post][30] for details on ways to increase SSL/TLS performance. To summarize briefly, the techniques are:
+
+- **Session caching**. Uses the [ssl_session_cache][31] directive to cache the parameters used when securing each new connection with SSL/TLS.
+- **Session tickets or IDs**. These store information about specific SSL/TLS sessions in a ticket or ID so a connection can be reused smoothly, without new handshaking.
+- **OCSP stapling**. Cuts handshaking time by caching SSL/TLS certificate information.
+
+NGINX and NGINX Plus can be used for SSL/TLS termination – handling encryption and decyption for client traffic, while communicating with other servers in clear text. Use [these steps][32] to set up NGINX or NGINX Plus to handle SSL/TLS termination. Also, here are [specific steps][33] for NGINX Plus when used with servers that accept TCP connections.
+
+### Tip #6: Implement HTTP/2 or SPDY ###
+
+For sites that already use SSL/TLS, HTTP/2 and SPDY are very likely to improve performance, because the single connection requires just one handshake. For sites that don’t yet use SSL/TLS, HTTP/2 and SPDY makes a move to SSL/TLS (which normally slows performance) a wash from a responsiveness point of view.
+
+Google introduced SPDY in 2012 as a way to achieve faster performance on top of HTTP/1.x. HTTP/2 is the recently approved IETF standard based on SPDY. SPDY is broadly supported, but is soon to be deprecated, replaced by HTTP/2.
+
+The key feature of SPDY and HTTP/2 is the use of a single connection rather than multiple connections. The single connection is multiplexed, so it can carry pieces of multiple requests and responses at the same time.
+
+By getting the most out of one connection, these protocols avoid the overhead of setting up and managing multiple connections, as required by the way browsers implement HTTP/1.x. The use of a single connection is especially helpful with SSL, because it minimizes the time-consuming handshaking that SSL/TLS needs to set up a secure connection.
+
+The SPDY protocol required the use of SSL/TLS; HTTP/2 does not officially require it, but all browsers so far that support HTTP/2 use it only if SSL/TLS is enabled. That is, a browser that supports HTTP/2 uses it only if the website is using SSL and its server accepts HTTP/2 traffic. Otherwise, the browser communicates over HTTP/1.x.
+
+When you implement SPDY or HTTP/2, you no longer need typical HTTP performance optimizations such as domain sharding, resource merging, and image spriting. These changes make your code and deployments simpler and easier to manage. To learn more about the changes that HTTP/2 is bringing about, read our [white paper][34].
+
+
+
+As an example of support for these protocols, NGINX has supported SPDY from early on, and [most sites][35] that use SPDY today run on NGINX. NGINX is also [pioneering support][36] for HTTP/2, with [support][37] for HTTP/2 in NGINX open source and NGINX Plus as of September 2015.
+
+Over time, we at NGINX expect most sites to fully enable SSL and to move to HTTP/2. This will lead to increased security and, as new optimizations are found and implemented, simpler code that performs better.
+
+### Tip #7: Update Software Versions ###
+
+One simple way to boost application performance is to select components for your software stack based on their reputation for stability and performance. In addition, because developers of high-quality components are likely to pursue performance enhancements and fix bugs over time, it pays to use the latest stable version of software. New releases receive more attention from developers and the user community. Newer builds also take advantage of new compiler optimizations, including tuning for new hardware.
+
+Stable new releases are typically more compatible and higher-performing than older releases. It’s also easier to keep on top of tuning optimizations, bug fixes, and security alerts when you stay on top of software updates.
+
+Staying with older software can also prevent you from taking advantage of new capabilities. For example, HTTP/2, described above, currently requires OpenSSL 1.0.1. Starting in mid-2016, HTTP/2 will require OpenSSL 1.0.2, which was released in January 2015.
+
+NGINX users can start by moving to the [[latest version of the NGINX open source software][38] or [NGINX Plus][39]; they include new capabilities such as socket sharding and thread pools (see below), and both are constantly being tuned for performance. Then look at the software deeper in your stack and move to the most recent version wherever you can.
+
+### Tip #8: Tune Linux for Performance ###
+
+Linux is the underlying operating system for most web server implementations today, and as the foundation of your infrastructure, Linux represents a significant opportunity to improve performance. By default, many Linux systems are conservatively tuned to use few resources and to match a typical desktop workload. This means that web application use cases require at least some degree of tuning for maximum performance.
+
+Linux optimizations are web server-specific. Using NGINX as an example, here are a few highlights of changes you can consider to speed up Linux:
+
+- **Backlog queue**. If you have connections that appear to be stalling, consider increasing net.core.somaxconn, the maximum number of connections that can be queued awaiting attention from NGINX. You will see error messages if the existing connection limit is too small, and you can gradually increase this parameter until the error messages stop.
+- **File descriptors**. NGINX uses up to two file descriptors for each connection. If your system is serving a lot of connections, you might need to increase sys.fs.file_max, the system-wide limit for file descriptors, and nofile, the user file descriptor limit, to support the increased load.
+- **Ephemeral ports**. When used as a proxy, NGINX creates temporary (“ephemeral”) ports for each upstream server. You can increase the range of port values, set by net.ipv4.ip_local_port_range, to increase the number of ports available. You can also reduce the timeout before an inactive port gets reused with the net.ipv4.tcp_fin_timeout setting, allowing for faster turnover.
+
+For NGINX, check out the [NGINX performance tuning guides][40] to learn how to optimize your Linux system so that it can cope with large volumes of network traffic without breaking a sweat!
+
+### Tip #9: Tune Your Web Server for Performance ###
+
+Whatever web server you use, you need to tune it for web application performance. The following recommendations apply generally to any web server, but specific settings are given for NGINX. Key optimizations include:
+
+- **Access logging**. Instead of writing a log entry for every request to disk immediately, you can buffer entries in memory and write them to disk as a group. For NGINX, add the *buffer=size* parameter to the *access_log* directive to write log entries to disk when the memory buffer fills up. If you add the **flush=time** parameter, the buffer contents are also be written to disk after the specified amount of time.
+- **Buffering**. Buffering holds part of a response in memory until the buffer fills, which can make communications with the client more efficient. Responses that don’t fit in memory are written to disk, which can slow performance. When NGINX buffering is [on][42], you use the *proxy_buffer_size* and *proxy_buffers* directives to manage it.
+- **Client keepalives**. Keepalive connections reduce overhead, especially when SSL/TLS is in use. For NGINX, you can increase the maximum number of *keepalive_requests* a client can make over a given connection from the default of 100, and you can increase the *keepalive_timeout* to allow the keepalive connection to stay open longer, resulting in faster subsequent requests.
+- **Upstream keepalives**. Upstream connections – connections to application servers, database servers, and so on – benefit from keepalive connections as well. For upstream connections, you can increase *keepalive*, the number of idle keepalive connections that remain open for each worker process. This allows for increased connection reuse, cutting down on the need to open brand new connections. For more information about keepalives, refer to this [blog post][41].
+- **Limits**. Limiting the resources that clients use can improve performance and security. For NGINX,the *limit_conn* and *limit_conn_zone* directives restrict the number of connections from a given source, while *limit_rate* constrains bandwidth. These settings can stop a legitimate user from “hogging” resources and also help prevent against attacks. The *limit_req* and *limit_req_zone* directives limit client requests. For connections to upstream servers, use the max_conns parameter to the server directive in an upstream configuration block. This limits connections to an upstream server, preventing overloading. The associated queue directive creates a queue that holds a specified number of requests for a specified length of time after the *max_conns* limit is reached.
+- **Worker processes**. Worker processes are responsible for the processing of requests. NGINX employs an event-based model and OS-dependent mechanisms to efficiently distribute requests among worker processes. The recommendation is to set the value of *worker_processes* to one per CPU. The maximum number of worker_connections (512 by default) can safely be raised on most systems if needed; experiment to find the value that works best for your system.
+- **Socket sharding**. Typically, a single socket listener distributes new connections to all worker processes. Socket sharding creates a socket listener for each worker process, with the kernel assigning connections to socket listeners as they become available. This can reduce lock contention and improve performance on multicore systems. To enable [socket sharding][43], include the reuseport parameter on the listen directive.
+- **Thread pools**. Any computer process can be held up by a single, slow operation. For web server software, disk access can hold up many faster operations, such as calculating or copying information in memory. When a thread pool is used, the slow operation is assigned to a separate set of tasks, while the main processing loop keeps running faster operations. When the disk operation completes, the results go back into the main processing loop. In NGINX, two operations – the read() system call and sendfile() – are offloaded to [thread pools][44].
+
+
+
+**Tip**. When changing settings for any operating system or supporting service, change a single setting at a time, then test performance. If the change causes problems, or if it doesn’t make your site run faster, change it back.
+
+See this [blog post][45] for more details on tuning NGINX.
+
+### Tip #10: Monitor Live Activity to Resolve Issues and Bottlenecks ###
+
+The key to a high-performance approach to application development and delivery is watching your application’s real-world performance closely and in real time. You must be able to monitor activity within specific devices and across your web infrastructure.
+
+Monitoring site activity is mostly passive – it tells you what’s going on, and leaves it to you to spot problems and fix them.
+
+Monitoring can catch several different kinds of issues. They include:
+
+- A server is down.
+- A server is limping, dropping connections.
+- A server is suffering from a high proportion of cache misses.
+- A server is not sending correct content.
+
+A global application performance monitoring tool like New Relic or Dynatrace helps you monitor page load time from remote locations, while NGINX helps you monitor the application delivery side. Application performance data tells you when your optimizations are making a real difference to your users, and when you need to consider adding capacity to your infrastructure to sustain the traffic.
+
+To help identify and resolve issues quickly, NGINX Plus adds [application-aware health checks][46] – synthetic transactions that are repeated regularly and are used to alert you to problems. NGINX Plus also has [session draining][47], which stops new connections while existing tasks complete, and a slow start capability, allowing a recovered server to come up to speed within a load-balanced group. When used effectively, health checks allow you to identify issues before they significantly impact the user experience, while session draining and slow start allow you to replace servers and ensure the process does not negatively affect perceived performance or uptime. The figure shows the built-in NGINX Plus [live activity monitoring][48] dashboard for a web infrastructure with servers, TCP connections, and caching.
+
+
+
+### Conclusion: Seeing 10x Performance Improvement ###
+
+The performance improvements that are available for any one web application vary tremendously, and actual gains depend on your budget, the time you can invest, and gaps in your existing implementation. So, how might you achieve 10x performance improvement for your own applications?
+
+To help guide you on the potential impact of each optimization, here are pointers to the improvement that may be possible with each tip detailed above, though your mileage will almost certainly vary:
+
+- **Reverse proxy server and load balancing**. No load balancing, or poor load balancing, can cause episodes of very poor performance. Adding a reverse proxy server, such as NGINX, can prevent web applications from thrashing between memory and disk. Load balancing can move processing from overburdened servers to available ones and make scaling easy. These changes can result in dramatic performance improvement, with a 10x improvement easily achieved compared to the worst moments for your current implementation, and lesser but substantial achievements available for overall performance.
+- **Caching dynamic and static content**. If you have an overburdened web server that’s doubling as your application server, 10x improvements in peak-time performance can be achieved by caching dynamic content alone. Caching for static files can improve performance by single-digit multiples as well.
+- **Compressing data**. Using media file compression such as JPEG for photos, PNG for graphics, MPEG-4 for movies, and MP3 for music files can greatly improve performance. Once these are all in use, then compressing text data (code and HTML) can improve initial page load times by a factor of two.
+- **Optimizing SSL/TLS**. Secure handshakes can have a big impact on performance, so optimizing them can lead to perhaps a 2x improvement in initial responsiveness, particularly for text-heavy sites. Optimizing media file transmission under SSL/TLS is likely to yield only small performance improvements.
+- **Implementing HTTP/2 and SPDY**. When used with SSL/TLS, these protocols are likely to result in incremental improvements for overall site performance.
+- **Tuning Linux and web server software (such as NGINX)**. Fixes such as optimizing buffering, using keepalive connections, and offloading time-intensive tasks to a separate thread pool can significantly boost performance; thread pools, for instance, can speed disk-intensive tasks by [nearly an order of magnitude][49].
+
+We hope you try out these techniques for yourself. We want to hear the kind of application performance improvements you’re able to achieve. Share your results in the comments below, or tweet your story with the hash tags #NGINX and #webperf!
+
+### Resources for Internet Statistics ###
+
+[Statista.com – Share of the internet economy in the gross domestic product in G-20 countries in 2016][50]
+
+[Load Impact – How Bad Performance Impacts Ecommerce Sales][51]
+
+[Kissmetrics – How Loading Time Affects Your Bottom Line (infographic)][52]
+
+[Econsultancy – Site speed: case studies, tips and tools for improving your conversion rate][53]
+
+--------------------------------------------------------------------------------
+
+via: https://www.nginx.com/blog/10-tips-for-10x-application-performance/?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io
+
+作者:[Floyd Smith][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.nginx.com/blog/author/floyd/
+[1]:https://www.nginx.com/resources/glossary/reverse-proxy-server
+[2]:https://www.nginx.com/blog/10-tips-for-10x-application-performance/?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io#tip2
+[3]:https://www.nginx.com/blog/10-tips-for-10x-application-performance/?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io#tip3
+[4]:https://www.nginx.com/products/application-health-checks/
+[5]:https://www.nginx.com/solutions/load-balancing/
+[6]:https://www.nginx.com/blog/10-tips-for-10x-application-performance/?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io#tip1
+[7]:https://www.nginx.com/resources/admin-guide/load-balancer/
+[8]:https://www.nginx.com/blog/load-balancing-with-nginx-plus/
+[9]:https://www.digitalocean.com/community/tutorials/understanding-and-implementing-fastcgi-proxying-in-nginx
+[10]:https://www.nginx.com/blog/five-reasons-use-software-load-balancer/
+[11]:https://www.nginx.com/blog/load-balancing-with-nginx-plus/
+[12]:https://www.nginx.com/resources/ebook/five-reasons-choose-software-load-balancer/
+[13]:https://www.nginx.com/resources/webinars/choose-software-based-load-balancer-45-min/
+[14]:https://www.nginx.com/resources/admin-guide/load-balancer/
+[15]:https://www.nginx.com/products/
+[16]:https://www.nginx.com/blog/nginx-caching-guide/
+[17]:https://www.nginx.com/products/content-caching-nginx-plus/
+[18]:http://nginx.org/en/docs/http/ngx_http_proxy_module.html?&_ga=1.95342300.1348073562.1438712874#proxy_cache_purge
+[19]:https://www.nginx.com/products/live-activity-monitoring/
+[20]:http://nginx.org/en/docs/http/ngx_http_proxy_module.html?&&&_ga=1.61156076.1348073562.1438712874#proxy_cache
+[21]:https://www.nginx.com/resources/admin-guide/content-caching
+[22]:https://www.nginx.com/blog/network-vs-devops-how-to-manage-your-control-issues/
+[23]:https://www.nginx.com/blog/10-tips-for-10x-application-performance/?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io#tip6
+[24]:https://www.nginx.com/resources/admin-guide/compression-and-decompression/
+[25]:http://nginx.org/en/docs/http/ngx_http_gzip_static_module.html
+[26]:https://www.digicert.com/ssl.htm
+[27]:https://www.nginx.com/blog/10-tips-for-10x-application-performance/?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io#tip6
+[28]:http://openssl.org/
+[29]:https://www.nginx.com/blog/nginx-ssl-performance/
+[30]:https://www.nginx.com/blog/improve-seo-https-nginx/
+[31]:http://nginx.org/en/docs/http/ngx_http_ssl_module.html#ssl_session_cache
+[32]:https://www.nginx.com/resources/admin-guide/nginx-ssl-termination/
+[33]:https://www.nginx.com/resources/admin-guide/nginx-tcp-ssl-termination/
+[34]:https://www.nginx.com/resources/datasheet/datasheet-nginx-http2-whitepaper/
+[35]:http://w3techs.com/blog/entry/25_percent_of_the_web_runs_nginx_including_46_6_percent_of_the_top_10000_sites
+[36]:https://www.nginx.com/blog/how-nginx-plans-to-support-http2/
+[37]:https://www.nginx.com/blog/nginx-plus-r7-released/
+[38]:http://nginx.org/en/download.html
+[39]:https://www.nginx.com/products/
+[40]:https://www.nginx.com/blog/tuning-nginx/
+[41]:https://www.nginx.com/blog/http-keepalives-and-web-performance/
+[42]:http://nginx.org/en/docs/http/ngx_http_proxy_module.html#proxy_buffering
+[43]:https://www.nginx.com/blog/socket-sharding-nginx-release-1-9-1/
+[44]:https://www.nginx.com/blog/thread-pools-boost-performance-9x/
+[45]:https://www.nginx.com/blog/tuning-nginx/
+[46]:https://www.nginx.com/products/application-health-checks/
+[47]:https://www.nginx.com/products/session-persistence/#session-draining
+[48]:https://www.nginx.com/products/live-activity-monitoring/
+[49]:https://www.nginx.com/blog/thread-pools-boost-performance-9x/
+[50]:http://www.statista.com/statistics/250703/forecast-of-internet-economy-as-percentage-of-gdp-in-g-20-countries/
+[51]:http://blog.loadimpact.com/blog/how-bad-performance-impacts-ecommerce-sales-part-i/
+[52]:https://blog.kissmetrics.com/loading-time/?wide=1
+[53]:https://econsultancy.com/blog/10936-site-speed-case-studies-tips-and-tools-for-improving-your-conversion-rate/
diff --git a/sources/tech/20151104 How to Install Pure-FTPd with TLS on FreeBSD 10.2.md b/sources/tech/20151104 How to Install Pure-FTPd with TLS on FreeBSD 10.2.md
new file mode 100644
index 0000000000..3d898340d8
--- /dev/null
+++ b/sources/tech/20151104 How to Install Pure-FTPd with TLS on FreeBSD 10.2.md
@@ -0,0 +1,154 @@
+How to Install Pure-FTPd with TLS on FreeBSD 10.2
+================================================================================
+FTP or File Transfer Protocol is application layer standard network protocol used to transfer file from the client to the server, after user logged in to the FTP server over the TCP-Network, such as internet. FTP has been round long time ago, much longer then P2P Program, or World Wide Web, and until this day it was a primary method for sharing file with other over the internet and it it remain very popular even today. FTP provide an secure transmission, that protect username, password and encrypt the content with SSL/TLS.
+
+Pure-FTPd is free FTP Server with strong and focus on the software security. It was great choice for you if you want to provide a fast, secure, lightweight with feature rich FTP Services. Pure-FTPd can be install on variety of Unix-like operating system, include Linux and FreeBSD. Pure-FTPd is created by Frank Dennis in 2001, based on Troll-FTPd, and until now is actively developed by a team led by Dennis.
+
+In this tutorial we will provide about installation and configuration of "**Pure-FTPd**" with Unix-like operating system FreeBSD 10.2.
+
+### Step 1 - Update system ###
+
+The first thing you must do is to install and update the freebsd repository, please connect to your server with SSH and then type command below as sudo/root :
+
+ freebsd-update fetch
+ freebsd-update install
+
+### Step 2 - Install Pure-FTPd ###
+
+You can install Pure-FTPd from the ports method, but in this tutorial we will install from the freebsd repository with "**pkg**" command. So, now let's install :
+
+ pkg install pure-ftpd
+
+Once installation is finished, please add pure-ftpd to the start at the boot time with sysrc command below :
+
+ sysrc pureftpd_enable=yes
+
+### Step 3 - Configure Pure-FTPd ###
+
+Configuration file for Pure-FTPd is located at directory "/usr/local/etc/", please go to the directory and copy the sample configuration for pure-ftpd to "**pure-ftpd.conf**".
+
+ cd /usr/local/etc/
+ cp pure-ftpd.conf.sample pure-ftpd.conf
+
+Now edit the file configuration with nano editor :
+
+ nano -c pure-ftpd.conf
+
+Note : -c option to show line number on nano.
+
+Go to line 59 and change the value of "VerboseLog" to "**yes**". This option is allow you as administrator to see the log all command used by the users.
+
+ VerboseLog yes
+
+And now look at line 126 "PureDB" for virtual-users configuration. Virtual users is a simple mechanism to store a list of users, with their password, name, uid, directory, etc. It's just like /etc/passwd. But it's not /etc/passwd. It's a different file and only for FTP. In this tutorial we will store the list of user to the file "**/usr/local/etc/pureftpd.passwd**" and "**/usr/local/etc/pureftpd.pdb**". Please uncomment that line and change the path for the file to "/usr/local/etc/pureftpd.pdb".
+
+ PureDB /usr/local/etc/pureftpd.pdb
+
+Next, uncomment on the line 336 "**CreateHomeDir**", this option make you easy to add the virtual users, allow automatically create home directories if they are missing.
+
+ CreateHomeDir yes
+
+Save and exit.
+
+Next, start pure-ftpd with service command :
+
+ service pure-ftpd start
+
+### Step 4 - Adding New Users ###
+
+At this step FTP server is started without error, but you can not log in to the FTP Server, because the default configuration of pure-ftpd is disabled for anonymous users. We need to create new users with home directory, and then give it the password for login.
+
+On thing you must do befere you add new user to pure-ftpd virtual-user is to create a system user for this, lets create new system user "**vftp**" and the default group is same as username, with home directory "**/home/vftp/**".
+
+ pw useradd vftp -s /sbin/nologin -w no -d /home/vftp \
+ -c "Virtual User Pure-FTPd" -m
+
+Now you can add the new user for the FTP Server with "**pure-pw**" command. For an example here, we will create new user named "**akari**", so please see command below :
+
+ pure-pw useradd akari -u vftp -g vftp -d /home/vftp/akari
+ Password: TYPE YOUR PASSWORD
+
+that command will create user "**akari**" and the data stored at the file "**/usr/local/etc/pureftpd.passwd**", not at /etc/passwd file, so this means is that you can easily create FTP-only accounts without messing up your system accounts.
+
+Next, you must generate the PureDB user database with this command :
+
+ pure-pw mkdb
+
+Now restart the pure-ftpd services and try connect with user "akari" :
+
+ service pure-ftpd restart
+
+Trying to connect with user akari :
+
+ ftp SERVERIP
+
+
+
+**NOTE :**
+
+If you want to add new user again, you can use "**pure-pw**" command. And if you want to delete the current user, you can use this :
+
+ pure-pw userdel useryouwanttodelete
+ pure-pw mkdb
+
+### Step 5 - Add SSL/TLS to Pure-FTPd ###
+
+Pure-FTPd supports encryption using TLS security mechanisms. To support for TLS/SSL, make sure the OpenSSL library is already installed on your freebsd system.
+
+Now you must generate new "**self-signed certificate**" on the directory "**/etc/ssl/private**". Before you generate the certificate, please create new directory there called "private".
+
+ cd /etc/ssl/
+ mkdir private
+ cd private/
+
+Now generate "self-signed certificate" with openssl command below :
+
+ openssl req -x509 -nodes -newkey rsa:2048 -sha256 -keyout \
+ /etc/ssl/private/pure-ftpd.pem \
+ -out /etc/ssl/private/pure-ftpd.pem
+
+FILL ALL WITH YOUR PERSONAL INFO.
+
+
+
+Next, change the certificate permission :
+
+ chmod 600 /etc/ssl/private/*.pem
+
+Once the certifcate is generated, Edit the pure-ftpd configuration file :
+
+ nano -c /usr/local/etc/pure-ftpd.conf
+
+Uncomment on line **423** to enable the TLS :
+
+ TLS 1
+
+And line **439** for the certificate file path :
+
+ CertFile /etc/ssl/private/pure-ftpd.pem
+
+Save and exit, then restart the pure-ftpd services :
+
+ service pure-ftpd restart
+
+Now let's test the Pure-FTPd that work with TLS/SSL. I'm here use "**FileZilla**" to connect to the FTP Server, and use user "**akari**" that have been created.
+
+
+
+Pure-FTPd with TLS on FreeBSD 10.2 successfully.
+
+### Conclusion ###
+
+FTP or File Transfer Protocol is standart protocol used to transfer file between users and the server. One of the best, lightweight and secure FTP Server Software is Pure-FTPd. It is secure and support for TLS/SSL encryption mechanism. Pure-FTPd is easy to to install and configure, you can manage the user with virtual user support, and it is make you as sysadmin is easy to manage the user if you have a much user ftp server.
+
+--------------------------------------------------------------------------------
+
+via: http://linoxide.com/linux-how-to/install-pure-ftpd-tls-freebsd-10-2/
+
+作者:[Arul][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://linoxide.com/author/arulm/
\ No newline at end of file
diff --git a/sources/tech/20151104 How to Setup Pfsense Firewall and Basic Configuration.md b/sources/tech/20151104 How to Setup Pfsense Firewall and Basic Configuration.md
new file mode 100644
index 0000000000..821937390a
--- /dev/null
+++ b/sources/tech/20151104 How to Setup Pfsense Firewall and Basic Configuration.md
@@ -0,0 +1,266 @@
+How to Setup Pfsense Firewall and Basic Configuration
+================================================================================
+In this article our focus is Pfsense setup, basic configuration and overview of features available in the security distribution of FreeBSD. In this tutorial we will run network wizard for basic setting of firewall and detailed overview of services. After the [installation process][1] following snapshot shows the IP addresses of WAN/LAN and different options for the management of Pfsense firewall.
+
+
+
+After setup , following window appear which shows the url for configuration of Pfsense.
+
+
+
+Open above given URL in the browser and login with username **admin** and password **pfsense**
+
+
+
+After successful login, following wizard appears for the basic setting of Pfsense firewall. However setup wizard option can be bypassed and user can run it from the **System** menu from the web interface.
+
+Click on the **Next** button to start basic configuration process on Pfsense firewall.
+
+
+
+Setting hostname, domain and DNS addresses is shown in the following figure.
+
+
+
+Setting time zone is shown in the below given snapshot.
+
+
+
+Next window shows setting for the WAN interface. By defaults Pfsense firewall block bogus and private networks.
+
+
+
+Setting LAN IP address which is used to access the Pfsense web interface for further configuration.
+
+
+
+By default password for web interface is "pfsense". Enter new password for admin user on the following window to access the web interface for further configuration.
+
+
+
+Click on the "reload" button which is shown below. It applies the setting and redirect firewall user to main dashboard of Pfsense.
+
+ and status of ethernet/wireless interfaces etc.
+
+
+
+### Menu detail ###
+
+PFsense consist of System, interfaces, firewall,services,vpn,status,diagnostics and help menus.
+
+
+
+### System Menu ###
+
+Sub menus of **System** is given below.
+
+
+
+In the **Advanced** sub menu user can perform following operations.
+
+1. Configuration of web interface
+1. Firewall/Nat setting
+1. Networking setting
+1. System tuneables setting
+1. Notification setting
+
+
+
+In the **Cert manager** sub menu, firewall administrator generates certificates for CA and users.
+
+
+
+In the **Firmware** sub menu, user can update Pfsense firmware manually/automatically. User can take full backup of Pfsense configurations.
+
+
+
+In the **General Setup** sub menu, user can change basic setting such as hostname and domain etc.
+
+
+
+As menu title indicates, user can enable/disable high availability feature from this sub menu.
+
+
+
+Packages sub menu provides package manager facility in the web interface for Pfsense .
+
+
+
+User can perform gateway and route management using **Routing** sub menu.
+
+
+
+**Setup Wizard** sub menu opens following window which start basic configuration of Pfsense.
+
+
+
+Management of user can be done from the **User manager** sub menu.
+
+
+
+### Interfaces Menu ###
+
+This menu is used for the assignment of interfaces (LAN/WAN), VLAN setting,wireless and GRE configuration etc.
+
+
+
+### Firewall Menu ###
+
+Firewall is the main and core part of Pfsense distribution and it provides following features.
+
+
+
+**Aliases**
+
+Aliases are defined for real hosts, networks or ports and they can be used to minimize the number of changes.
+
+
+
+**NAT (Network Address Translation)**
+
+NAT binds a specific internal address to a specific external address. Incoming traffic from the Internet to the specified IP will be directed toward the associated internal IP.
+
+
+
+**Firewall Rules**
+
+Firewall rules control what traffic is allowed to enter an interface on the firewall. After traffic is passed on the interface, it enters an entry in the state table is created.
+
+
+
+**Schedules**
+
+Firewall rules can be scheduled so that they are only active at certain times of day or on certain specific days or days of the week.
+
+
+
+**Traffic Shaper**
+
+Traffic shaping is the control of computer network traffic in order to optimize performance and lower latency.
+
+
+
+**Virtual IPs**
+
+Virtual IPs add knowledge of additional IP addresses to the firewall that are different from the firewall's real interface addresses.
+
+
+
+### Services Menu ###
+
+Services menu shows services which are provided by the Pfsense distribution along firewall.
+
+
+
+New program/software installed for some specific service is also shown in this menu such as snort. By default following services are listed in services menu.
+
+**Captive portal**
+
+The captive portal functionality in Pfsense allows securing a network by requiring a username and password entered on a portal page.
+
+
+
+**DHCP Relay**
+
+The DHCP Relay daemon will relay DHCP requests between broadcast domains for IPv4 DHCP.
+
+
+
+**DHCP Server**
+
+User can run DHCP service on the firewall for the network devices.
+
+
+
+**DNS Forwarder/Resolver/Dynamic DNS**
+
+DNS different services can be configured on the Pfsense firewall.
+
+
+
+
+
+
+
+**IGMP Proxy**
+
+User can configure IGMP on the Pfsense firewall from services menu.
+
+
+
+**Load Balancer**
+
+Load Balancing is one of the important feature which is also supported by the Pfsense firewall.
+
+
+
+**SNMP (Simple Network Management Protocol)**
+
+Pfsense supports all versions of snmp for remote management of firewall.
+
+
+
+**Wake on Lan**
+
+Using this feature packet sent to a workstation on a locally connected network which will power on a workstation.
+
+
+
+### VPN Menu ###
+
+It is one of the most important feature of Pfsense. Its supports following types of vpn configuration.
+
+**VPN IPsec**
+
+IPsec is a standard for providing security to IP protocols via encryption and/or authentication.
+
+
+
+**L2TP IPsec**
+
+L2TP/IPsec is a common VPN type that wraps L2TP, an insecure tunneling protocol, inside a secure channel built using transport mode IPsec.
+
+
+
+**OpenVPN**
+
+OpenVPN is an Open Source VPN server and client that is supported on pfSense.
+
+
+
+**Status Menu**
+
+It shows the status of services provided by Pfsense such as dhcp server, ipsec and load balancer etc.
+
+
+
+**Diagnostic Menu**
+
+This menu helps administrator/user for the rectification of Pfsense issues or problems.
+
+
+
+**Help Menu**
+
+This menu provides links for different useful resources such as FreeBSD handbook,developer wiki, paid support and pfsense book.
+
+
+
+### Conclusion ###
+
+In this article our focus was on the basic configuration and features set of Pfsense distribution. It is based on FreeBSD distribution and widely used due to security and stability features. In our future articles on Pfsense, our focus will be on the basic firewall rules setting, snort (IDS/IPS) and IPSEC VPN configuration.
+
+--------------------------------------------------------------------------------
+
+via: http://linoxide.com/firewall/pfsense-setup-basic-configuration/
+
+作者:[nido][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://linoxide.com/author/naveeda/
+[1]:http://linoxide.com/firewall/install-pfsense-firewall/
\ No newline at end of file
diff --git a/sources/tech/20151105 Linux FAQs with Answers--How to install Ubuntu desktop behind a proxy.md b/sources/tech/20151105 Linux FAQs with Answers--How to install Ubuntu desktop behind a proxy.md
new file mode 100644
index 0000000000..7ceced012d
--- /dev/null
+++ b/sources/tech/20151105 Linux FAQs with Answers--How to install Ubuntu desktop behind a proxy.md
@@ -0,0 +1,62 @@
+translation by strugglingyouth
+Linux FAQs with Answers--How to install Ubuntu desktop behind a proxy
+================================================================================
+> **Question**: My computer is connected to a corporate network sitting behind an HTTP proxy. When I try to install Ubuntu desktop on the computer from a CD-ROM drive, the installation hangs and never finishes while trying to retrieve files, which is presumably due to the proxy. However, the problem is that Ubuntu installer never asks me to configure proxy during installation procedure. Then how can I install Ubuntu desktop behind a proxy?
+
+Unlike Ubuntu server, installation of Ubuntu desktop is pretty much auto-pilot, not leaving much room for customization, such as custom disk partitioning, manual network settings, package selection, etc. While such simple, one-shot installation is considered user-friendly, it leaves much to be desired for those users looking for "advanced installation mode" to customize their Ubuntu desktop installation.
+
+In addition, one big problem of the default Ubuntu desktop installer is the absense of proxy settings. If your computer is connected behind a proxy, you will notice that Ubuntu installation gets stuck while preparing to download files.
+
+
+
+This post describes how to get around the limitation of Ubuntu **installer and install Ubuntu desktop when you are behind a proxy**.
+
+The basic idea is as follows. Instead of starting with Ubuntu installer directly, boot into live Ubuntu desktop first, configure proxy settings, and finally launch Ubuntu installer manually from live desktop. The following is the step by step procedure.
+
+After booting from Ubuntu desktop CD/DVD or USB, click on "Try Ubuntu" on the first welcome screen.
+
+
+
+Once you boot into live Ubuntu desktop, click on Settings icon in the left.
+
+
+
+Go to Network menu.
+
+
+
+Configure proxy settings manually.
+
+
+
+Next, open a terminal.
+
+
+
+Enter a root session by typing the following:
+
+ $ sudo su
+
+Finally, type the following command as the root.
+
+ # ubiquity gtk_ui
+
+This will launch GUI-based Ubuntu installer as follows.
+
+
+
+Proceed with the rest of installation.
+
+
+
+--------------------------------------------------------------------------------
+
+via: http://ask.xmodulo.com/install-ubuntu-desktop-behind-proxy.html
+
+作者:[Dan Nanni][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://ask.xmodulo.com/author/nanni
diff --git a/sources/tech/20151109 How to Configure Tripwire IDS on Debian.md b/sources/tech/20151109 How to Configure Tripwire IDS on Debian.md
new file mode 100644
index 0000000000..11e7dbad60
--- /dev/null
+++ b/sources/tech/20151109 How to Configure Tripwire IDS on Debian.md
@@ -0,0 +1,380 @@
+正在翻译:zky001
+How to Configure Tripwire IDS on Debian
+================================================================================
+This article is about Tripwire installation and configuration on Debian OS. It is a host based Intrusion detection system (IDS) for Linux environment. Prime function of tripwire IDS is to detect and report any unauthorized change (files and directories ) on linux system. After tripwire installation, baseline database created first, tripwire monitors and detects changes such as new file addition/creation, file modification and user who changed it etc. If the changes are legitimate, you can accept the changes to update tripwire database.
+
+### Installation and Configuration ###
+
+Tripwire installation on Debian VM is shown below.
+
+ # apt-get install tripwire
+
+
+
+During installation, tripwire prompt for following configuration.
+
+#### Site key Creation ####
+
+Tripwire required a site passphrase to secure the tw.cfg tripwire configuration file and tw.pol tripwire policy file. Tripewire encrypte both files using given passphrase. Site passphrase is must even for a single instance tripwire.
+
+
+
+#### Local Key passphrase ####
+
+Local passphrase is needed for the protection of tripwire database and report files . Local key used by the tripwire to avoid unauthorized modification of tripwire baseline database.
+
+
+
+#### Tripwire configuration path ####
+
+Tripwire configuration saved in the /etc/tripwire/twcfg.txt file. It is used to generate encrypted configuration file tw.cfg.
+
+
+
+**Tripwire Policy path**
+
+Tripwire saves policies in /etc/tripwire/twpol.txt file . It is used for the generation of encrypted policy file tw.pol used by the tripwire.
+
+
+
+Final installation of tripwire is shown in the following snapshot.
+
+
+
+#### Tripwire Configuration file (twcfg.txt) ####
+
+Tripwire configuration file (twcfg.txt) details is given below. Paths of encrypted policy file (tw.pol), site key (site.key) and local key (hostname-local.key) etc are given below.
+
+ ROOT =/usr/sbin
+
+ POLFILE =/etc/tripwire/tw.pol
+
+ DBFILE =/var/lib/tripwire/$(HOSTNAME).twd
+
+ REPORTFILE =/var/lib/tripwire/report/$(HOSTNAME)-$(DATE).twr
+
+ SITEKEYFILE =/etc/tripwire/site.key
+
+ LOCALKEYFILE =/etc/tripwire/$(HOSTNAME)-local.key
+
+ EDITOR =/usr/bin/editor
+
+ LATEPROMPTING =false
+
+ LOOSEDIRECTORYCHECKING =false
+
+ MAILNOVIOLATIONS =true
+
+ EMAILREPORTLEVEL =3
+
+ REPORTLEVEL =3
+
+ SYSLOGREPORTING =true
+
+ MAILMETHOD =SMTP
+
+ SMTPHOST =localhost
+
+ SMTPPORT =25
+
+ TEMPDIRECTORY =/tmp
+
+#### Tripwire Policy Configuration ####
+
+Configure tripwire configuration before generation of baseline database. It is necessary to disable few policies such as /dev , /proc ,/root/mail etc. Detailed policy file twpol.txt is given below.
+
+ @@section GLOBAL
+ TWBIN = /usr/sbin;
+ TWETC = /etc/tripwire;
+ TWVAR = /var/lib/tripwire;
+
+ #
+ # File System Definitions
+ #
+ @@section FS
+
+ #
+ # First, some variables to make configuration easier
+ #
+ SEC_CRIT = $(IgnoreNone)-SHa ; # Critical files that cannot change
+
+ SEC_BIN = $(ReadOnly) ; # Binaries that should not change
+
+ SEC_CONFIG = $(Dynamic) ; # Config files that are changed
+ # infrequently but accessed
+ # often
+
+ SEC_LOG = $(Growing) ; # Files that grow, but that
+ # should never change ownership
+
+ SEC_INVARIANT = +tpug ; # Directories that should never
+ # change permission or ownership
+
+ SIG_LOW = 33 ; # Non-critical files that are of
+ # minimal security impact
+
+ SIG_MED = 66 ; # Non-critical files that are of
+ # significant security impact
+
+ SIG_HI = 100 ; # Critical files that are
+ # significant points of
+ # vulnerability
+
+ #
+ # Tripwire Binaries
+ #
+ (
+ rulename = "Tripwire Binaries",
+ severity = $(SIG_HI)
+ )
+ {
+ $(TWBIN)/siggen -> $(SEC_BIN) ;
+ $(TWBIN)/tripwire -> $(SEC_BIN) ;
+ $(TWBIN)/twadmin -> $(SEC_BIN) ;
+ $(TWBIN)/twprint -> $(SEC_BIN) ;
+ }
+ {
+ /boot -> $(SEC_CRIT) ;
+ /lib/modules -> $(SEC_CRIT) ;
+ }
+
+ (
+ rulename = "Boot Scripts",
+ severity = $(SIG_HI)
+ )
+ {
+ /etc/init.d -> $(SEC_BIN) ;
+ #/etc/rc.boot -> $(SEC_BIN) ;
+ /etc/rcS.d -> $(SEC_BIN) ;
+ /etc/rc0.d -> $(SEC_BIN) ;
+ /etc/rc1.d -> $(SEC_BIN) ;
+ /etc/rc2.d -> $(SEC_BIN) ;
+ /etc/rc3.d -> $(SEC_BIN) ;
+ /etc/rc4.d -> $(SEC_BIN) ;
+ /etc/rc5.d -> $(SEC_BIN) ;
+ /etc/rc6.d -> $(SEC_BIN) ;
+ }
+
+ (
+ rulename = "Root file-system executables",
+ severity = $(SIG_HI)
+ )
+ {
+ /bin -> $(SEC_BIN) ;
+ /sbin -> $(SEC_BIN) ;
+ }
+
+ #
+ # Critical Libraries
+ #
+ (
+ rulename = "Root file-system libraries",
+ severity = $(SIG_HI)
+ )
+ {
+ /lib -> $(SEC_BIN) ;
+ }
+
+ #
+ # Login and Privilege Raising Programs
+ #
+ (
+ rulename = "Security Control",
+ severity = $(SIG_MED)
+ )
+ {
+ /etc/passwd -> $(SEC_CONFIG) ;
+ /etc/shadow -> $(SEC_CONFIG) ;
+ }
+ {
+ #/var/lock -> $(SEC_CONFIG) ;
+ #/var/run -> $(SEC_CONFIG) ; # daemon PIDs
+ /var/log -> $(SEC_CONFIG) ;
+ }
+
+ # These files change the behavior of the root account
+ (
+ rulename = "Root config files",
+ severity = 100
+ )
+ {
+ /root -> $(SEC_CRIT) ; # Catch all additions to /root
+ #/root/mail -> $(SEC_CONFIG) ;
+ #/root/Mail -> $(SEC_CONFIG) ;
+ /root/.xsession-errors -> $(SEC_CONFIG) ;
+ #/root/.xauth -> $(SEC_CONFIG) ;
+ #/root/.tcshrc -> $(SEC_CONFIG) ;
+ #/root/.sawfish -> $(SEC_CONFIG) ;
+ #/root/.pinerc -> $(SEC_CONFIG) ;
+ #/root/.mc -> $(SEC_CONFIG) ;
+ #/root/.gnome_private -> $(SEC_CONFIG) ;
+ #/root/.gnome-desktop -> $(SEC_CONFIG) ;
+ #/root/.gnome -> $(SEC_CONFIG) ;
+ #/root/.esd_auth -> $(SEC_CONFIG) ;
+ # /root/.elm -> $(SEC_CONFIG) ;
+ #/root/.cshrc -> $(SEC_CONFIG) ;
+ #/root/.bashrc -> $(SEC_CONFIG) ;
+ #/root/.bash_profile -> $(SEC_CONFIG) ;
+ # /root/.bash_logout -> $(SEC_CONFIG) ;
+ #/root/.bash_history -> $(SEC_CONFIG) ;
+ #/root/.amandahosts -> $(SEC_CONFIG) ;
+ #/root/.addressbook.lu -> $(SEC_CONFIG) ;
+ #/root/.addressbook -> $(SEC_CONFIG) ;
+ #/root/.Xresources -> $(SEC_CONFIG) ;
+ #/root/.Xauthority -> $(SEC_CONFIG) -i ; # Changes Inode number on login
+ /root/.ICEauthority -> $(SEC_CONFIG) ;
+ }
+
+ #
+ # Critical devices
+ #
+ (
+ rulename = "Devices & Kernel information",
+ severity = $(SIG_HI),
+ )
+ {
+ #/dev -> $(Device) ;
+ #/proc -> $(Device) ;
+ }
+
+#### Tripwire Report ####
+
+**tripwire –check** command checks the twpol.txt file and based on this file generates tripwire report which is shown below. If this is any error in the twpol.txt file, tripwire does not generate report.
+
+
+
+**Report in text form**
+
+ root@VMdebian:/home/labadmin# tripwire --check
+
+ Parsing policy file: /etc/tripwire/tw.pol
+
+ *** Processing Unix File System ***
+
+ Performing integrity check...
+
+ Wrote report file: /var/lib/tripwire/report/VMdebian-20151024-122322.twr
+
+ Open Source Tripwire(R) 2.4.2.2 Integrity Check Report
+
+ Report generated by: root
+
+ Report created on: Sat Oct 24 12:23:22 2015
+
+ Database last updated on: Never
+
+ Report Summary:
+
+ =========================================================
+
+ Host name: VMdebian
+
+ Host IP address: 127.0.1.1
+
+ Host ID: None
+
+ Policy file used: /etc/tripwire/tw.pol
+
+ Configuration file used: /etc/tripwire/tw.cfg
+
+ Database file used: /var/lib/tripwire/VMdebian.twd
+
+ Command line used: tripwire --check
+
+ =========================================================
+
+ Rule Summary:
+
+ =========================================================
+
+ -------------------------------------------------------------------------------
+
+ Section: Unix File System
+
+ -------------------------------------------------------------------------------
+
+ Rule Name Severity Level Added Removed Modified
+
+ --------- -------------- ----- ------- --------
+
+ Other binaries 66 0 0 0
+
+ Tripwire Binaries 100 0 0 0
+
+ Other libraries 66 0 0 0
+
+ Root file-system executables 100 0 0 0
+
+ Tripwire Data Files 100 0 0 0
+
+ System boot changes 100 0 0 0
+
+ (/var/log)
+
+ Root file-system libraries 100 0 0 0
+
+ (/lib)
+
+ Critical system boot files 100 0 0 0
+
+ Other configuration files 66 0 0 0
+
+ (/etc)
+
+ Boot Scripts 100 0 0 0
+
+ Security Control 66 0 0 0
+
+ Root config files 100 0 0 0
+
+ Invariant Directories 66 0 0 0
+
+ Total objects scanned: 25943
+
+ Total violations found: 0
+
+ =========================Object Summary:================================
+
+ -------------------------------------------------------------------------------
+
+ # Section: Unix File System
+
+ -------------------------------------------------------------------------------
+
+ No violations.
+
+ ===========================Error Report:=====================================
+
+ No Errors
+
+ -------------------------------------------------------------------------------
+
+ *** End of report ***
+
+ Open Source Tripwire 2.4 Portions copyright 2000 Tripwire, Inc. Tripwire is a registered
+
+ trademark of Tripwire, Inc. This software comes with ABSOLUTELY NO WARRANTY;
+
+ for details use --version. This is free software which may be redistributed
+
+ or modified only under certain conditions; see COPYING for details.
+
+ All rights reserved.
+
+ Integrity check complete.
+
+### Conclusion ###
+
+In this article, we learned installation and basic configuration of open source IDS tool Tripwire. First it generates baseline database and detects any change (file/folder) by comparing it with already generated baseline. However, tripwire is not live monitoring IDS.
+
+--------------------------------------------------------------------------------
+
+via: http://linoxide.com/security/configure-tripwire-ids-debian/
+
+作者:[nido][a]
+译者:[译者zky001](https://github.com/zky001)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://linoxide.com/author/naveeda/
diff --git a/sources/tech/20151109 How to send email notifications using Gmail SMTP server on Linux.md b/sources/tech/20151109 How to send email notifications using Gmail SMTP server on Linux.md
new file mode 100644
index 0000000000..5ffcb5aea8
--- /dev/null
+++ b/sources/tech/20151109 How to send email notifications using Gmail SMTP server on Linux.md
@@ -0,0 +1,156 @@
+How to send email notifications using Gmail SMTP server on Linux
+================================================================================
+Suppose you want to configure a Linux app to send out email messages from your server or desktop. The email messages can be part of email newsletters, status updates (e.g., [Cachet][1]), monitoring alerts (e.g., [Monit][2]), disk events (e.g., [RAID mdadm][3]), and so on. While you can set up your [own outgoing mail server][4] to deliver messages, you can alternatively rely on a freely available public SMTP server as a maintenance-free option.
+
+One of the most reliable **free SMTP servers** is from Google's Gmail service. All you have to do to send email notifications within your app is to add Gmail's SMTP server address and your credentials to the app, and you are good to go.
+
+One catch with using Gmail's SMTP server is that there are various restrictions in place, mainly to combat spammers and email marketers who often abuse the server. For example, you can send messages to no more than 100 addresses at once, and no more than 500 recipients per day. Also, if you don't want to be flagged as a spammer, you cannot send a large number of undeliverable messages. When any of these limitations is reached, your Gmail account will temporarily be locked out for a day. In short, Gmail's SMTP server is perfectly fine for your personal use, but not meant for commercial bulk emails.
+
+With that being said, let me demonstrate **how to use Gmail's SMTP server in Linux environment**.
+
+### Google Gmail SMTP Server Setting ###
+
+If you want to send emails from your app using Gmail's SMTP server, remember the following details.
+
+- **Outgoing mail server (SMTP server)**: smtp.gmail.com
+- **Use authentication**: yes
+- **Use secure connection**: yes
+- **Username**: your Gmail account ID (e.g., "alice" if your email is alice@gmail.com)
+- **Password**: your Gmail password
+- **Port**: 587
+
+Exact configuration syntax may vary depending on apps. In the rest of this tutorial, I will show you several useful examples of using Gmail SMTP server in Linux.
+
+### Send Emails from the Command Line ###
+
+As the first example, let's try the most basic email functionality: send an email from the command line using Gmail SMTP server. For this, I am going to use a command-line email client called mutt.
+
+First, install mutt:
+
+For Debian-based system:
+
+ $ sudo apt-get install mutt
+
+For Red Hat based system:
+
+ $ sudo yum install mutt
+
+Create a mutt configuration file (~/.muttrc) and specify in the file Gmail SMTP server information as follows. Replace with your own Gmail ID. Note that this configuration is for sending emails only (not receiving emails).
+
+ $ vi ~/.muttrc
+
+----------
+
+ set from = "@gmail.com"
+ set realname = "Dan Nanni"
+ set smtp_url = "smtp://@smtp.gmail.com:587/"
+ set smtp_pass = ""
+
+Now you are ready to send out an email using mutt:
+
+ $ echo "This is an email body." | mutt -s "This is an email subject" alice@yahoo.com
+
+To attach a file in an email, use "-a" option:
+
+ $ echo "This is an email body." | mutt -s "This is an email subject" alice@yahoo.com -a ~/test_attachment.jpg
+
+
+
+Using Gmail SMTP server means that the emails appear as sent from your Gmail account. In other words, a recepient will see your Gmail address as the sender's address. If you want to use your domain as the email sender, you need to use Gmail SMTP relay service instead.
+
+### Send Email Notification When a Server is Rebooted ###
+
+If you are running a [virtual private server (VPS)][5] for some critical website, one recommendation is to monitor VPS reboot activities. As a more practical example, let's consider how to set up email notifications for every reboot event on your VPS. Here I assume you are using systemd on your VPS, and show you how to create a custom systemd boot-time service for automatic email notifications.
+
+First create the following script reboot_notify.sh which takes care of email notifications.
+
+ $ sudo vi /usr/local/bin/reboot_notify.sh
+
+----------
+
+ #!/bin/sh
+
+ echo "`hostname` was rebooted on `date`" | mutt -F /etc/muttrc -s "Notification on `hostname`" alice@yahoo.com
+
+----------
+
+ $ sudo chmod +x /usr/local/bin/reboot_notify.sh
+
+In the script, I use "-F" option to specify the location of system-wide mutt configuration file. So don't forget to create /etc/muttrc file and populate Gmail SMTP information as described earlier.
+
+Now let's create a custom systemd service as follows.
+
+ $ sudo mkdir -p /usr/local/lib/systemd/system
+ $ sudo vi /usr/local/lib/systemd/system/reboot-task.service
+
+----------
+
+ [Unit]
+ Description=Send a notification email when the server gets rebooted
+ DefaultDependencies=no
+ Before=reboot.target
+
+ [Service]
+ Type=oneshot
+ ExecStart=/usr/local/bin/reboot_notify.sh
+
+ [Install]
+ WantedBy=reboot.target
+
+Once the service file is created, enable and start the service.
+
+ $ sudo systemctl enable reboot-task
+ $ sudo systemctl start reboot-task
+
+From now on, you will be receiving a notification email every time the VPS gets rebooted.
+
+
+
+### Send Email Notification from Server Usage Monitoring ###
+
+As a final example, let me present a real-world application called [Monit][6], which is a pretty useful server monitoring application. It comes with comprehensive [VPS][7] monitoring capabilities (e.g., CPU, memory, processes, file system), as well as email notification functions.
+
+If you want to receive email notifications for any event on your VPS (e.g., server overload) generated by Monit, you can add the following SMTP information to Monit configuration file.
+
+ set mailserver smtp.gmail.com port 587
+ username "" password ""
+ using tlsv12
+
+ set mail-format {
+ from: @gmail.com
+ subject: $SERVICE $EVENT at $DATE on $HOST
+ message: Monit $ACTION $SERVICE $EVENT at $DATE on $HOST : $DESCRIPTION.
+
+ Yours sincerely,
+ Monit
+ }
+
+ # the person who will receive notification emails
+ set alert alice@yahoo.com
+
+Here is the example email notification sent by Monit for excessive CPU load.
+
+
+
+### Conclusion ###
+
+As you can imagine, there will be so many different ways to take advantage of free SMTP servers like Gmail. But once again, remember that the free SMTP server is not meant for commercial usage, but only for your own personal project. If you are using Gmail SMTP server inside any app, feel free to share your use case.
+
+--------------------------------------------------------------------------------
+
+via: http://xmodulo.com/send-email-notifications-gmail-smtp-server-linux.html
+
+作者:[Dan Nanni][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://xmodulo.com/author/nanni
+[1]:http://xmodulo.com/setup-system-status-page.html
+[2]:http://xmodulo.com/server-monitoring-system-monit.html
+[3]:http://xmodulo.com/create-software-raid1-array-mdadm-linux.html
+[4]:http://xmodulo.com/mail-server-ubuntu-debian.html
+[5]:http://xmodulo.com/go/digitalocean
+[6]:http://xmodulo.com/server-monitoring-system-monit.html
+[7]:http://xmodulo.com/go/digitalocean
\ No newline at end of file
diff --git a/sources/tech/20151109 Install Android On BQ Aquaris Ubuntu Phone In Linux.md b/sources/tech/20151109 Install Android On BQ Aquaris Ubuntu Phone In Linux.md
new file mode 100644
index 0000000000..864068eb91
--- /dev/null
+++ b/sources/tech/20151109 Install Android On BQ Aquaris Ubuntu Phone In Linux.md
@@ -0,0 +1,126 @@
+zpl1025
+Install Android On BQ Aquaris Ubuntu Phone In Linux
+================================================================================
+
+
+If you happen to own the first Ubuntu phone and want to **replace Ubuntu with Android on the bq Aquaris e4.5**, this post is going to help you.
+
+There can be plenty of reasons why you might want to remove Ubuntu and use the mainstream Android OS. One of the foremost reason is that the OS itself is at an early stage and intend to target developers and enthusiasts. Whatever may be your reason, installing Android on bq Aquaris is a piece of cake, thanks to the tools provided by bq.
+
+Let’s see what to do we need to install Android on bq Aquaris.
+
+### Prerequisite ###
+
+- Working Internet connection to download Android factory image and install tools for flashing Android
+- USB data cable
+- A system running Linux
+
+This tutorial is performed using Ubuntu 15.10. But the steps should be applicable to most other Linux distributions.
+
+### Replace Ubuntu with Android in bq Aquaris e4.5 ###
+
+#### Step 1: Download Android firmware ####
+
+First step is to download the Android image for bq Aquaris e4.5. Good thing is that it is available from the bq’s support website. You can download the firmware, around 650 MB in size, from the link below:
+
+- [Download Android for bq Aquaris e4.5][1]
+
+Yes, you would get OTA updates with it. At present the firmware version is 2.0.1 which is based on Android Lolipop. Over time, there could be a new firmware based on Marshmallow and then the above link could be outdated.
+
+I suggest to check the [bq support page and download][2] the latest firmware from there.
+
+Once downloaded, extract it. In the extracted directory, look for **MT6582_Android_scatter.txt** file. We shall be using it later.
+
+#### Step 2: Download flash tool ####
+
+bq has provided its own flash tool, Herramienta MTK Flash Tool, for easier installation of Android or Ubuntu on the device. You can download the tool from the link below:
+
+- [Download MTK Flash Tool][3]
+
+Since the flash tool might be upgraded in future, you can always get the latest version of flash tool from the [bq support page][4].
+
+Once downloaded extract the downloaded file. You should see an executable file named **flash_tool** in it. We shall be using it later.
+
+#### Step 3: Remove conflicting packages (optional) ####
+
+If you are using recent version of Ubuntu or Ubuntu based Linux distributions, you may encounter “BROM ERROR : S_UNDEFINED_ERROR (1001)” later in this tutorial.
+
+To avoid this error, you’ll have to uninstall conflicting package. Use the commands below:
+
+ sudo apt-get remove modemmanager
+
+Restart udev service with the command below:
+
+ sudo service udev restart
+
+Just to check for any possible side effects on kernel module cdc_acm, run the command below:
+
+ lsmod | grep cdc_acm
+
+If the output of the above command is an empty list, you’ll have to reinstall this kernel module:
+
+ sudo modprobe cdc_acm
+
+#### Step 4: Prepare to flash Android ####
+
+Go to the downloaded and extracted flash tool directory (in step 2). Use command line for this purpose because you’ll have to use the root privileges here.
+
+Presuming that you saved it in the Downloads directory, use the command below to go to this directory (in case you do not know how to navigate between directories in command line).
+
+ cd ~/Downloads/SP_Flash*
+
+After that use the command below to run the flash tool as root:
+
+ sudo ./flash_tool
+
+You’ll see a window popped as the one below. Don’t bother about Download Agent field, it will be automatically filled. Just focus on Scatter-loading field.
+
+
+
+Remember we talked about **MT6582_Android_scatter.txt** in step 1? This text file is in the extracted directory of the Andriod firmware you downloaded in step 1. Click on Scatter-loading (in the above picture) and point to MT6582_Android_scatter.txt file.
+
+When you do that, you’ll see several green lines like the one below:
+
+
+
+#### Step 5: Flashing Android ####
+
+We are almost ready. Switch off your phone and connect it to your computer via a USB cable.
+
+Select Firmware Upgrade from the dropdown and after that click on the big download button.
+
+
+
+If everything is correct, you should see a flash status in the bottom of the tool:
+
+
+
+When the procedure is successfully completed, you’ll see a notification like this:
+
+
+
+Unplug your phone and power it on. You should see a white screen with AQUARIS written in the middle and at bottom, “powered by Android” would be displayed. It might take upto 10 minutes before you could configure and start using Android.
+
+Note: If something goes wrong in the process, Press power, volume up, volume down button together and boot in to fast boot mode. Turn off again and connect the cable again. Repeat the process of firmware upgrade. It should work.
+
+### Conclusion ###
+
+Thanks to the tools provided, it becomes easier to **flash Android on bq Ubuntu Phone**. Of course, you can use the same steps to replace Android with Ubuntu. All you need is to download Ubuntu firmware instead of Android.
+
+I hope this tutorial helped you to replace Ubuntu with Android on your bq phone. If you have questions or suggestions, feel free to ask in the comment section below.
+
+--------------------------------------------------------------------------------
+
+via: http://itsfoss.com/install-android-ubuntu-phone/
+
+作者:[Abhishek][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://itsfoss.com/author/abhishek/
+[1]:https://storage.googleapis.com/otas/2014/Smartphones/Aquaris_E4.5_L/2.0.1_20150623-1900_bq-FW.zip
+[2]:http://www.bq.com/gb/support/aquaris-e4-5
+[3]:https://storage.googleapis.com/otas/2014/Smartphones/Aquaris_E4.5/Ubuntu/Web%20version/Web%20version/SP_Flash_Tool_exe_linux_v5.1424.00.zip
+[4]:http://www.bq.com/gb/support/aquaris-e4-5-ubuntu-edition
diff --git a/sources/tech/20151114 How to Setup Drone - a Continuous Integration Service in Linux.md b/sources/tech/20151114 How to Setup Drone - a Continuous Integration Service in Linux.md
new file mode 100644
index 0000000000..bfcf1e3ae3
--- /dev/null
+++ b/sources/tech/20151114 How to Setup Drone - a Continuous Integration Service in Linux.md
@@ -0,0 +1,317 @@
+How to Setup Drone - a Continuous Integration Service in Linux
+==============================================================
+
+Are you tired of cloning, building, testing, and deploying codes time and again? If yes, switch to continuous integration. Continuous Integration aka CI is practice in software engineering of making frequent commits to the code base, building, testing and deploying as we go. CI helps to quickly integrate new codes into the existing code base. If this process is made automated, then this will speed up the development process as it reduces the time taken for the developer to build and test things manually. [Drone][1] is a free and open source project which provides an awesome environment of continuous integration service and is released under Apache License Version 2.0. It integrates with many repository providers like Github, Bitbucket and Google Code and has the ability to pull codes from the repositories enabling us to build the source code written in number of languages including PHP, Node, Ruby, Go, Dart, Python, C/C++, JAVA and more. It is made such a powerful platform cause it uses containers and docker technology for every build making users a complete control over their build environment with guaranteed isolation.
+
+### 1. Installing Docker ###
+
+First of all, we'll gonna install Docker as its the most vital element for the complete workflow of Drone. Drone does a proper utilization of docker for the purpose of building and testing application. This container technology speeds up the development of the applications. To install docker, we'll need to run the following commands with respective the distribution of linux. In this tutorial, we'll cover the steps with Ubuntu 14.04 and CentOS 7 linux distributions.
+
+#### On Ubuntu ####
+
+To install Docker in Ubuntu, we can simply run the following commands in a terminal or console.
+
+ # apt-get update
+ # apt-get install docker.io
+
+After the installation is done, we'll restart our docker engine using service command.
+
+ # service docker restart
+
+Then, we'll make docker start automatically in every system boot.
+
+ # update-rc.d docker defaults
+
+ Adding system startup for /etc/init.d/docker ...
+ /etc/rc0.d/K20docker -> ../init.d/docker
+ /etc/rc1.d/K20docker -> ../init.d/docker
+ /etc/rc6.d/K20docker -> ../init.d/docker
+ /etc/rc2.d/S20docker -> ../init.d/docker
+ /etc/rc3.d/S20docker -> ../init.d/docker
+ /etc/rc4.d/S20docker -> ../init.d/docker
+ /etc/rc5.d/S20docker -> ../init.d/docker
+
+#### On CentOS ####
+
+First, we'll gonna update every packages installed in our centos machine. We can do that by running the following command.
+
+ # sudo yum update
+
+To install docker in centos, we can simply run the following commands.
+
+ # curl -sSL https://get.docker.com/ | sh
+
+After our docker engine is installed in our centos machine, we'll simply start it by running the following systemd command as systemd is the default init system in centos 7.
+
+ # systemctl start docker
+
+Then, we'll enable docker to start automatically in every system startup.
+
+ # systemctl enable docker
+
+ ln -s '/usr/lib/systemd/system/docker.service' '/etc/systemd/system/multi-user.target.wants/docker.service'
+
+### 2. Installing SQlite Driver ###
+
+It uses SQlite3 database server for storing its data and information by default. It will automatically create a database file named drone.sqlite under /var/lib/drone/ which will handle database schema setup and migration. To setup SQlite3 drivers, we'll need to follow the below steps.
+
+#### On Ubuntu 14.04 ####
+
+As SQlite3 is available on the default respository of Ubuntu 14.04, we'll simply install it by running the following apt command.
+
+ # apt-get install libsqlite3-dev
+
+#### On CentOS 7 ####
+
+To install it on CentOS 7 machine, we'll need to run the following yum command.
+
+ # yum install sqlite-devel
+
+### 3. Installing Drone ###
+
+Finally, after we have installed those dependencies successfully, we'll now go further towards the installation of drone in our machine. In this step, we'll simply download the binary package of it from the official download link of the respective binary formats and then install them using the default package manager.
+
+#### On Ubuntu ####
+
+We'll use wget to download the debian package of drone for ubuntu from the [official Debian file download link][2]. Here is the command to download the required debian package of drone.
+
+ # wget downloads.drone.io/master/drone.deb
+
+ Resolving downloads.drone.io (downloads.drone.io)... 54.231.48.98
+ Connecting to downloads.drone.io (downloads.drone.io)|54.231.48.98|:80... connected.
+ HTTP request sent, awaiting response... 200 OK
+ Length: 7722384 (7.4M) [application/x-debian-package]
+ Saving to: 'drone.deb'
+ 100%[======================================>] 7,722,384 1.38MB/s in 17s
+ 2015-11-06 14:09:28 (456 KB/s) - 'drone.deb' saved [7722384/7722384]
+
+After its downloaded, we'll gonna install it with dpkg package manager.
+
+ # dpkg -i drone.deb
+
+ Selecting previously unselected package drone.
+ (Reading database ... 28077 files and directories currently installed.)
+ Preparing to unpack drone.deb ...
+ Unpacking drone (0.3.0-alpha-1442513246) ...
+ Setting up drone (0.3.0-alpha-1442513246) ...
+ Your system ubuntu 14: using upstart to control Drone
+ drone start/running, process 9512
+
+#### On CentOS ####
+
+In the machine running CentOS, we'll download the RPM package from the [official download link for RPM][3] using wget command as shown below.
+
+ # wget downloads.drone.io/master/drone.rpm
+
+ --2015-11-06 11:06:45-- http://downloads.drone.io/master/drone.rpm
+ Resolving downloads.drone.io (downloads.drone.io)... 54.231.114.18
+ Connecting to downloads.drone.io (downloads.drone.io)|54.231.114.18|:80... connected.
+ HTTP request sent, awaiting response... 200 OK
+ Length: 7763311 (7.4M) [application/x-redhat-package-manager]
+ Saving to: ‘drone.rpm’
+ 100%[======================================>] 7,763,311 1.18MB/s in 20s
+ 2015-11-06 11:07:06 (374 KB/s) - ‘drone.rpm’ saved [7763311/7763311]
+
+Then, we'll install the download rpm package using yum package manager.
+
+ # yum localinstall drone.rpm
+
+### 4. Configuring Port ###
+
+After the installation is completed, we'll gonna configure drone to make it workable. The configuration of drone is inside **/etc/drone/drone.toml** file. By default, drone web interface is exposed under port 80 which is the default port of http, if we wanna change it, we can change it by replacing the value under server block as shown below.
+
+ [server]
+ port=":80"
+
+### 5. Integrating Github ###
+
+In order to run Drone we must setup at least one integration points between GitHub, GitHub Enterprise, Gitlab, Gogs, Bitbucket. In this tutorial, we'll only integrate github but if we wanna integrate other we can do that from the configuration file. In order to integrate github, we'll need to create a new application in our [github settings][4].
+
+
+
+To create, we'll need to click on Register a New Application then fill out the form as shown in the following image.
+
+
+
+We should make sure that **Authorization callback URL** looks like http://drone.linoxide.com/api/auth/github.com under the configuration of the application. Then, we'll click on Register application. After done, we'll note the Client ID and Client Secret key as we'll need to configure it in our drone configuration.
+
+
+
+After thats done, we'll need to edit our drone configuration using a text editor by running the following command.
+
+ # nano /etc/drone/drone.toml
+
+Then, we'll find the [github] section and append the section with the above noted configuration as shown below.
+
+ [github]
+ client="3dd44b969709c518603c"
+ secret="4ee261abdb431bdc5e96b19cc3c498403853632a"
+ # orgs=[]
+ # open=false
+
+
+
+### 6. Configuring SMTP server ###
+
+If we wanna enable drone to send notifications via emails, then we'll need to specify the SMTP configuration of our SMTP server. If we already have an SMTP server, we can use its configuration but as we don't have an SMTP server, we'll need to install an MTA ie Postfix and then specify the SMTP configuration in the drone configuration.
+
+#### On Ubuntu ####
+
+We can install postfix in ubuntu by running the following apt command.
+
+ # apt-get install postfix
+
+#### On CentOS ####
+
+We can install postfix in CentOS by running the following yum command.
+
+ # yum install postfix
+
+After installing, we'll need to edit the configuration of our postfix configuration using a text editor.
+
+ # nano /etc/postfix/main.cf
+
+Then, we'll need to replace the value of myhostname parameter to our FQDN ie drone.linoxide.com .
+
+ myhostname = drone.linoxide.com
+
+Now, we'll gonna finally configure the SMTP section of our drone configuration file.
+
+ # nano /etc/drone/drone.toml
+
+Then, we'll find the [stmp] section and then we'll need to append the setting as follows.
+
+ [smtp]
+ host = "drone.linoxide.com"
+ port = "587"
+ from = "root@drone.linoxide.com"
+ user = "root"
+ pass = "password"
+
+
+
+Note: Here, **user** and **pass** parameters are strongly recommended to be changed according to one's user configuration.
+
+### 7. Configuring Worker ###
+
+As we know that drone utilizes docker for its building and testing task, we'll need to configure docker as the worker for our drone. To do so, we'll need to edit the [worker] section in the drone configuration file.
+
+ # nano /etc/drone/drone.toml
+
+Then, we'll uncomment the following lines and append as shown below.
+
+ [worker]
+ nodes=[
+ "unix:///var/run/docker.sock",
+ "unix:///var/run/docker.sock"
+ ]
+
+Here, we have set only 2 node which means the above configuration is capable of executing only 2 build at a time. In order to increase concurrency, we can increase the number of nodes.
+
+ [worker]
+ nodes=[
+ "unix:///var/run/docker.sock",
+ "unix:///var/run/docker.sock",
+ "unix:///var/run/docker.sock",
+ "unix:///var/run/docker.sock"
+ ]
+
+Here, in the above configuration, drone is configured to process four builds at a time, using the local docker daemon.
+
+### 8. Restarting Drone ###
+
+Finally, after everything is done regarding the installation and configuration, we'll now start our drone server in our linux machine.
+
+#### On Ubuntu ####
+
+To start drone in our Ubuntu 14.04 machine, we'll simply run service command as the default init system of Ubuntu 14.04 is SysVinit.
+
+ # service drone restart
+
+To make drone start automatically in every boot of the system, we'll run the following command.
+
+ # update-rc.d drone defaults
+
+#### On CentOS ####
+
+To start drone in CentOS machine, we'll simply run systemd command as CentOS 7 is shipped with systemd as init system.
+
+ # systemctl restart drone
+
+Then, we'll enable drone to start automatically in every system boot.
+
+ # systemctl enable drone
+
+### 9. Allowing Firewalls ###
+
+As we know drone utilizes port 80 by default and we haven't changed the port, we'll gonna configure our firewall programs to allow port 80 (http) and be accessible from other machines in the network.
+
+#### On Ubuntu 14.04 ####
+
+Iptables is a popular firewall program which is installed in the ubuntu distributions by default. We'll make iptables to expose port 80 so that we can make our Drone web interface accessible in the network.
+
+ # iptables -A INPUT -p tcp -m tcp --dport 80 -j ACCEPT
+ # /etc/init.d/iptables save
+
+#### On CentOS 7 ####
+
+As CentOS 7 has systemd installed by default, it contains firewalld running as firewall problem. In order to open the port 80 (http service) on firewalld, we'll need to execute the following commands.
+
+ # firewall-cmd --permanent --add-service=http
+
+ success
+
+ # firewall-cmd --reload
+
+ success
+
+### 10. Accessing Web Interface ###
+
+Now, we'll gonna open the web interface of drone using our favourite web browser. To do so, we'll need to point our web browser to our machine running drone in it. As the default port of drone is 80 and we have also set 80 in this tutorial, we'll simply point our browser to http://ip-address/ or http://drone.linoxide.com according to our configuration. After we have done that correctly, we'll see the first page of it having options to login into our dashboard.
+
+
+
+As we have configured Github in the above step, we'll simply select github and we'll go through the app authentication process and after its done, we'll be forwarded to our Dashboard.
+
+
+
+Here, it will synchronize all our github repository and will ask us to activate the repo which we want to build with drone.
+
+
+
+After its activated, it will ask us to add a new file named .drone.yml in our repository and define the build process and configuration in that file like which image to fetch and which command/script to run while compiling, etc.
+
+We'll need to configure our .drone.yml as shown below.
+
+ image: python
+ script:
+ - python helloworld.py
+ - echo "Build has been completed."
+
+After its done, we'll be able to build our application using the configuration YAML file .drone.yml in our drone appliation. All the commits made into the repository is synced in realtime. It automatically syncs the commit and changes made to the repository. Once the commit is made in the repository, build is automatically started in our drone application.
+
+
+
+After the build is completed, we'll be able to see the output of the build with the output console.
+
+
+
+### Conclusion ###
+
+In this article, we learned to completely setup a workable Continuous Intergration platform with Drone. If we want, we can even get started with the services provided by the official Drone.io project. We can start with free service or paid service according to our requirements. It has changed the world of Continuous integration with its beautiful web interface and powerful bunches of features. It has the ability to integrate with many third party applications and deployment platforms. If you have any questions, suggestions, feedback please write them in the comment box below so that we can improve or update our contents. Thank you !
+
+--------------------------------------------------------------------------------
+
+via: http://linoxide.com/linux-how-to/setup-drone-continuous-integration-linux/
+
+作者:[Arun Pyasi][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://linoxide.com/author/arunp/
+[1]:https://drone.io/
+[2]:http://downloads.drone.io/master/drone.deb
+[3]:http://downloads.drone.io/master/drone.rpm
+[4]:https://github.com/settings/developers
diff --git a/sources/tech/20151117 Install Android On BQ Aquaris Ubuntu Phone In Linux.md b/sources/tech/20151117 Install Android On BQ Aquaris Ubuntu Phone In Linux.md
new file mode 100644
index 0000000000..94e7ef69ce
--- /dev/null
+++ b/sources/tech/20151117 Install Android On BQ Aquaris Ubuntu Phone In Linux.md
@@ -0,0 +1,125 @@
+Install Android On BQ Aquaris Ubuntu Phone In Linux
+================================================================================
+
+
+If you happen to own the first Ubuntu phone and want to **replace Ubuntu with Android on the bq Aquaris e4.5**, this post is going to help you.
+
+There can be plenty of reasons why you might want to remove Ubuntu and use the mainstream Android OS. One of the foremost reason is that the OS itself is at an early stage and intend to target developers and enthusiasts. Whatever may be your reason, installing Android on bq Aquaris is a piece of cake, thanks to the tools provided by bq.
+
+Let’s see what to do we need to install Android on bq Aquaris.
+
+### Prerequisite ###
+
+- Working Internet connection to download Android factory image and install tools for flashing Android
+- USB data cable
+- A system running Linux
+
+This tutorial is performed using Ubuntu 15.10. But the steps should be applicable to most other Linux distributions.
+
+### Replace Ubuntu with Android in bq Aquaris e4.5 ###
+
+#### Step 1: Download Android firmware ####
+
+First step is to download the Android image for bq Aquaris e4.5. Good thing is that it is available from the bq’s support website. You can download the firmware, around 650 MB in size, from the link below:
+
+- [Download Android for bq Aquaris e4.5][1]
+
+Yes, you would get OTA updates with it. At present the firmware version is 2.0.1 which is based on Android Lolipop. Over time, there could be a new firmware based on Marshmallow and then the above link could be outdated.
+
+I suggest to check the [bq support page][2] and download the latest firmware from there.
+
+Once downloaded, extract it. In the extracted directory, look for **MT6582_Android_scatter.txt** file. We shall be using it later.
+
+#### Step 2: Download flash tool ####
+
+bq has provided its own flash tool, Herramienta MTK Flash Tool, for easier installation of Android or Ubuntu on the device. You can download the tool from the link below:
+
+- [Download MTK Flash Tool][3]
+
+Since the flash tool might be upgraded in future, you can always get the latest version of flash tool from the [bq support page][4].
+
+Once downloaded extract the downloaded file. You should see an executable file named **flash_tool** in it. We shall be using it later.
+
+#### Step 3: Remove conflicting packages (optional) ####
+
+If you are using recent version of Ubuntu or Ubuntu based Linux distributions, you may encounter “BROM ERROR : S_UNDEFINED_ERROR (1001)” later in this tutorial.
+
+To avoid this error, you’ll have to uninstall conflicting package. Use the commands below:
+
+ sudo apt-get remove modemmanager
+
+Restart udev service with the command below:
+
+ sudo service udev restart
+
+Just to check for any possible side effects on kernel module cdc_acm, run the command below:
+
+ lsmod | grep cdc_acm
+
+If the output of the above command is an empty list, you’ll have to reinstall this kernel module:
+
+ sudo modprobe cdc_acm
+
+#### Step 4: Prepare to flash Android ####
+
+Go to the downloaded and extracted flash tool directory (in step 2). Use command line for this purpose because you’ll have to use the root privileges here.
+
+Presuming that you saved it in the Downloads directory, use the command below to go to this directory (in case you do not know how to navigate between directories in command line).
+
+ cd ~/Downloads/SP_Flash*
+
+After that use the command below to run the flash tool as root:
+
+ sudo ./flash_tool
+
+You’ll see a window popped as the one below. Don’t bother about Download Agent field, it will be automatically filled. Just focus on Scatter-loading field.
+
+
+
+Remember we talked about **MT6582_Android_scatter.txt** in step 1? This text file is in the extracted directory of the Andriod firmware you downloaded in step 1. Click on Scatter-loading (in the above picture) and point to MT6582_Android_scatter.txt file.
+
+When you do that, you’ll see several green lines like the one below:
+
+
+
+#### Step 5: Flashing Android ####
+
+We are almost ready. Switch off your phone and connect it to your computer via a USB cable.
+
+Select Firmware Upgrade from the dropdown and after that click on the big download button.
+
+
+
+If everything is correct, you should see a flash status in the bottom of the tool:
+
+
+
+When the procedure is successfully completed, you’ll see a notification like this:
+
+
+
+Unplug your phone and power it on. You should see a white screen with AQUARIS written in the middle and at bottom, “powered by Android” would be displayed. It might take upto 10 minutes before you could configure and start using Android.
+
+Note: If something goes wrong in the process, Press power, volume up, volume down button together and boot in to fast boot mode. Turn off again and connect the cable again. Repeat the process of firmware upgrade. It should work.
+
+### Conclusion ###
+
+Thanks to the tools provided, it becomes easier to **flash Android on bq Ubuntu Phone**. Of course, you can use the same steps to replace Android with Ubuntu. All you need is to download Ubuntu firmware instead of Android.
+
+I hope this tutorial helped you to replace Ubuntu with Android on your bq phone. If you have questions or suggestions, feel free to ask in the comment section below.
+
+--------------------------------------------------------------------------------
+
+via: http://itsfoss.com/install-android-ubuntu-phone/
+
+作者:[Abhishek][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://itsfoss.com/author/abhishek/
+[1]:https://storage.googleapis.com/otas/2014/Smartphones/Aquaris_E4.5_L/2.0.1_20150623-1900_bq-FW.zip
+[2]:http://www.bq.com/gb/support/aquaris-e4-5
+[3]:https://storage.googleapis.com/otas/2014/Smartphones/Aquaris_E4.5/Ubuntu/Web%20version/Web%20version/SP_Flash_Tool_exe_linux_v5.1424.00.zip
+[4]:http://www.bq.com/gb/support/aquaris-e4-5-ubuntu-edition
\ No newline at end of file
diff --git a/sources/tech/20151117 Install PostgreSQL 9.4 And phpPgAdmin On Ubuntu 15.10.md b/sources/tech/20151117 Install PostgreSQL 9.4 And phpPgAdmin On Ubuntu 15.10.md
new file mode 100644
index 0000000000..de05f067b5
--- /dev/null
+++ b/sources/tech/20151117 Install PostgreSQL 9.4 And phpPgAdmin On Ubuntu 15.10.md
@@ -0,0 +1,319 @@
+ictlyh Translating
+Install PostgreSQL 9.4 And phpPgAdmin On Ubuntu 15.10
+================================================================================
+
+
+### Introduction ###
+
+[PostgreSQL][1] is a powerful, open-source object-relational database system. It runs under all major operating systems, including Linux, UNIX (AIX, BSD, HP-UX, SGI IRIX, Mac OS, Solaris, Tru64), and Windows OS.
+
+Here is what **Mark Shuttleworth**, the founder of **Ubuntu**, says about PostgreSQL.
+
+> Postgres is a truly awesome database. When we started working on Launchpad I wasn’t sure if it would be up to the job. I was so wrong. It’s been robust, fast, and professional in every regard.
+>
+> — Mark Shuttleworth.
+
+In this handy tutorial, let us see how to install PostgreSQL 9.4 on Ubuntu 15.10 server.
+
+### Install PostgreSQL ###
+
+PostgreSQL is available in the default repositories. So enter the following command from the Terminal to install it.
+
+ sudo apt-get install postgresql postgresql-contrib
+
+If you’re looking for other versions, add the PostgreSQL repository, and install it as shown below.
+
+The **PostgreSQL apt repository** supports LTS versions of Ubuntu (10.04, 12.04 and 14.04) on amd64 and i386 architectures as well as select non-LTS versions(14.10). While not fully supported, the packages often work on other non-LTS versions as well, by using the closest LTS version available.
+
+#### On Ubuntu 14.10 systems: ####
+
+Create the file **/etc/apt/sources.list.d/pgdg.list**;
+
+ sudo vi /etc/apt/sources.list.d/pgdg.list
+
+Add a line for the repository:
+
+ deb http://apt.postgresql.org/pub/repos/apt/ utopic-pgdg main
+
+**Note**: The above repository will only work on Ubuntu 14.10. It is not updated yet to Ubuntu 15.04 and 15.10.
+
+**On Ubuntu 14.04**, add the following line:
+
+ deb http://apt.postgresql.org/pub/repos/apt/ trusty-pgdg main
+
+**On Ubuntu 12.04**, add the following line:
+
+ deb http://apt.postgresql.org/pub/repos/apt/ precise-pgdg main
+
+Import the repository signing key:
+
+ wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc
+
+----------
+
+ sudo apt-key add -
+
+Update the package lists:
+
+ sudo apt-get update
+
+Then install the required version.
+
+ sudo apt-get install postgresql-9.4
+
+### Accessing PostgreSQL command prompt ###
+
+The default database name and database user are “**postgres**”. Switch to postgres user to perform postgresql related operations:
+
+ sudo -u postgres psql postgres
+
+#### Sample Output: ####
+
+ psql (9.4.5)
+ Type "help" for help.
+ postgres=#
+
+To exit from posgresql prompt, type **\q** in the **psql** prompt return back to the Terminal.
+
+### Set “postgres” user password ###
+
+Login to postgresql prompt,
+
+ sudo -u postgres psql postgres
+
+.. and set postgres password with following command:
+
+ postgres=# \password postgres
+ Enter new password:
+ Enter it again:
+ postgres=# \q
+
+To install PostgreSQL Adminpack, enter the command in postgresql prompt:
+
+ sudo -u postgres psql postgres
+
+----------
+
+ postgres=# CREATE EXTENSION adminpack;
+ CREATE EXTENSION
+
+Type **\q** in the **psql** prompt to exit from posgresql prompt, and return back to the Terminal.
+
+### Create New User and Database ###
+
+For example, let us create a new user called “**senthil**” with password “**ubuntu**”, and database called “**mydb**”.
+
+ sudo -u postgres createuser -D -A -P senthil
+
+----------
+
+ sudo -u postgres createdb -O senthil mydb
+
+### Delete Users and Databases ###
+
+To delete the database, switch to postgres user:
+
+ sudo -u postgres psql postgres
+
+Enter command:
+
+ $ drop database
+
+To delete a user, enter the following command:
+
+ $ drop user
+
+### Configure PostgreSQL-MD5 Authentication ###
+
+**MD5 authentication** requires the client to supply an MD5-encrypted password for authentication. To do that, edit **/etc/postgresql/9.4/main/pg_hba.conf** file:
+
+ sudo vi /etc/postgresql/9.4/main/pg_hba.conf
+
+Add or Modify the lines as shown below
+
+ [...]
+ # TYPE DATABASE USER ADDRESS METHOD
+ # "local" is for Unix domain socket connections only
+ local all all md5
+ # IPv4 local connections:
+ host all all 127.0.0.1/32 md5
+ host all all 192.168.1.0/24 md5
+ # IPv6 local connections:
+ host all all ::1/128 md5
+ [...]
+
+Here, 192.168.1.0/24 is my local network IP address. Replace this value with your own address.
+
+Restart postgresql service to apply the changes:
+
+ sudo systemctl restart postgresql
+
+Or,
+
+ sudo service postgresql restart
+
+### Configure PostgreSQL-Configure TCP/IP ###
+
+By default, TCP/IP connection is disabled, so that the users from another computers can’t access postgresql. To allow to connect users from another computers, Edit file **/etc/postgresql/9.4/main/postgresql.conf:**
+
+ sudo vi /etc/postgresql/9.4/main/postgresql.conf
+
+Find the lines:
+
+ [...]
+ #listen_addresses = 'localhost'
+ [...]
+ #port = 5432
+ [...]
+
+Uncomment both lines, and set the IP address of your postgresql server or set ‘*’ to listen from all clients as shown below. You should be careful to make postgreSQL to be accessible from all remote clients.
+
+ [...]
+ listen_addresses = '*'
+ [...]
+ port = 5432
+ [...]
+
+Restart postgresql service to save changes:
+
+ sudo systemctl restart postgresql
+
+Or,
+
+ sudo service postgresql restart
+
+### Manage PostgreSQL with phpPgAdmin ###
+
+[**phpPgAdmin**][2] is a web-based administration utility written in PHP for managing PosgreSQL.
+
+phpPgAdmin is available in default repositories. So, Install phpPgAdmin using command:
+
+ sudo apt-get install phppgadmin
+
+By default, you can access phppgadmin using **http://localhost/phppgadmin** from your local system’s web browser.
+
+To access remote systems, do the following.
+On Ubuntu 15.10 systems:
+
+Edit file **/etc/apache2/conf-available/phppgadmin.conf**,
+
+ sudo vi /etc/apache2/conf-available/phppgadmin.conf
+
+Find the line **Require local** and comment it by adding a **#** in front of the line.
+
+ #Require local
+
+And add the following line:
+
+ allow from all
+
+Save and exit the file.
+
+Then, restart apache service.
+
+ sudo systemctl restart apache2
+
+On Ubuntu 14.10 and previous versions:
+
+Edit file **/etc/apache2/conf.d/phppgadmin**:
+
+ sudo nano /etc/apache2/conf.d/phppgadmin
+
+Comment the following line:
+
+ [...]
+ #allow from 127.0.0.0/255.0.0.0 ::1/128
+
+Uncomment the following line to make phppgadmin from all systems.
+
+ allow from all
+
+Edit **/etc/apache2/apache2.conf**:
+
+ sudo vi /etc/apache2/apache2.conf
+
+Add the following line:
+
+ Include /etc/apache2/conf.d/phppgadmin
+
+Then, restart apache service.
+
+ sudo service apache2 restart
+
+### Configure phpPgAdmin ###
+
+Edit file **/etc/phppgadmin/config.inc.php**, and do the following changes. Most of these options are self-explanatory. Read them carefully to know why do you change these values.
+
+ sudo nano /etc/phppgadmin/config.inc.php
+
+Find the following line:
+
+ $conf['servers'][0]['host'] = '';
+
+Change it as shown below:
+
+ $conf['servers'][0]['host'] = 'localhost';
+
+And find the line:
+
+ $conf['extra_login_security'] = true;
+
+Change the value to **false**.
+
+ $conf['extra_login_security'] = false;
+
+Find the line:
+
+ $conf['owned_only'] = false;
+
+Set the value as **true**.
+
+ $conf['owned_only'] = true;
+
+Save and close the file. Restart postgresql service and Apache services.
+
+ sudo systemctl restart postgresql
+
+----------
+
+ sudo systemctl restart apache2
+
+Or,
+
+ sudo service postgresql restart
+
+ sudo service apache2 restart
+
+Now open your browser and navigate to **http://ip-address/phppgadmin**. You will see the following screen.
+
+
+
+Login with users that you’ve created earlier. I already have created a user called “**senthil**” with password “**ubuntu**” before, so I log in with user “senthil”.
+
+
+
+Now, you will be able to access the phppgadmin dashboard.
+
+
+
+Log in with postgres user:
+
+
+
+That’s it. Now you’ll able to create, delete and alter databases graphically using phppgadmin.
+
+Cheers!
+
+--------------------------------------------------------------------------------
+
+via: http://www.unixmen.com/install-postgresql-9-4-and-phppgadmin-on-ubuntu-15-10/
+
+作者:[SK][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.twitter.com/ostechnix
+[1]:http://www.postgresql.org/
+[2]:http://phppgadmin.sourceforge.net/doku.php
\ No newline at end of file
diff --git a/sources/tech/20151119 Going Beyond Hello World Containers is Hard Stuff.md b/sources/tech/20151119 Going Beyond Hello World Containers is Hard Stuff.md
new file mode 100644
index 0000000000..3a2fd08d6f
--- /dev/null
+++ b/sources/tech/20151119 Going Beyond Hello World Containers is Hard Stuff.md
@@ -0,0 +1,330 @@
+translating by ezio
+
+Going Beyond Hello World Containers is Hard Stuff
+================================================================================
+In [my previous post][1], I provided the basic concepts behind Linux container technology. I wrote as much for you as I did for me. Containers are new to me. And I figured having the opportunity to blog about the subject would provide the motivation to really learn the stuff.
+
+I intend to learn by doing. First get the concepts down, then get hands-on and write about it as I go. I assumed there must be a lot of Hello World type stuff out there to give me up to speed with the basics. Then, I could take things a bit further and build a microservice container or something.
+
+I mean, it can’t be that hard, right?
+
+Wrong.
+
+Maybe it’s easy for someone who spends significant amount of their life immersed in operations work. But for me, getting started with this stuff turned out to be hard to the point of posting my frustrations to Facebook...
+
+But, there is good news: I got it to work! And it’s always nice being able to make lemonade from lemons. So I am going to share the story of how I made my first microservice container with you. Maybe my pain will save you some time.
+
+If you've ever found yourself in a situation like this, fear not: folks like me are here to deal with the problems so you don't have to!
+
+Let’s begin.
+
+### A Thumbnail Micro Service ###
+
+The microservice I designed was simple in concept. Post a digital image in JPG or PNG format to an HTTP endpoint and get back a a 100px wide thumbnail.
+
+Here’s what that looks like:
+
+
+
+I decide to use a NodeJS for my code and version of [ImageMagick][2] to do the thumbnail transformation.
+
+I did my first version of the service, using the logic shown here:
+
+
+
+I download the [Docker Toolbox][3] which installs an the Docker Quickstart Terminal. Docker Quickstart Terminal makes creating containers easier. The terminal fires up a Linux virtual machine that has Docker installed, allowing you to run Docker commands from within a terminal.
+
+In my case, I am running on OS X. But there’s a Windows version too.
+
+I am going to use Docker Quickstart Terminal to build a container image for my microservice and run a container from that image.
+
+The Docker Quickstart Terminal runs in your regular terminal, like so:
+
+
+
+### The First Little Problem and the First Big Problem ###
+
+So I fiddled around with NodeJS and ImageMagick and I got the service to work on my local machine.
+
+Then, I created the Dockerfile, which is the configuration script Docker uses to build your container. (I’ll go more into builds and Dockerfile more later on.)
+
+Here’s the build command I ran on the Docker Quickstart Terminal:
+
+ $ docker build -t thumbnailer:0.1
+
+I got this response:
+
+ docker: "build" requires 1 argument.
+
+Huh.
+
+After 15 minutes I realized: I forgot to put a period . as the last argument!
+
+It needs to be:
+
+ $ docker build -t thumbnailer:0.1 .
+
+But this wasn’t the end of my problems.
+
+I got the image to build and then I typed [the the `run` command][4] on the Docker Quickstart Terminal to fire up a container based on the image, called `thumbnailer:0.1`:
+
+ $ docker run -d -p 3001:3000 thumbnailer:0.1
+
+The `-p 3001:3000` argument makes it so the NodeJS microservice running on port 3000 within the container binds to port 3001 on the host virtual machine.
+
+Looks so good so far, right?
+
+Wrong. Things are about to get pretty bad.
+
+I determined the IP address of the virtual machine created by Docker Quickstart Terminal by running the `docker-machine` command:
+
+ $ docker-machine ip default
+
+This returns the IP address of the default virtual machine, the one that is run under the Docker Quickstart Terminal. For me, this IP address was 192.168.99.100.
+
+I browsed to http://192.168.99.100:3001/ and got the file upload page I built:
+
+
+
+I selected a file and clicked the Upload Image button.
+
+But it didn’t work.
+
+The terminal is telling me it can’t find the `/upload` directory my microservice requires.
+
+Now, keep in mind, I had been at this for about a day—between the fiddling and research. I’m feeling a little frustrated by this point.
+
+Then, a brain spark flew. Somewhere along the line remembered reading a microservice should not do any data persistence on its own! Saving data should be the job of another service.
+
+So what if the container can’t find the `/upload` directory? The real issue is: my microservice has a fundamentally flawed design.
+
+Let’s take another look:
+
+
+
+Why am I saving a file to disk? Microservices are supposed to be fast. Why not do all my work in memory? Using memory buffers will make the "I can’t find no stickin’ directory" error go away and will increase the performance of my app dramatically.
+
+So that’s what I did. And here’s what the plan was:
+
+
+
+Here’s the NodeJS I wrote to do all the in-memory work for creating a thumbnail:
+
+ // Bind to the packages
+ var express = require('express');
+ var router = express.Router();
+ var path = require('path'); // used for file path
+ var im = require("imagemagick");
+
+ // Simple get that allows you test that you can access the thumbnail process
+ router.get('/', function (req, res, next) {
+ res.status(200).send('Thumbnailer processor is up and running');
+ });
+
+ // This is the POST handler. It will take the uploaded file and make a thumbnail from the
+ // submitted byte array. I know, it's not rocket science, but it serves a purpose
+ router.post('/', function (req, res, next) {
+ req.pipe(req.busboy);
+ req.busboy.on('file', function (fieldname, file, filename) {
+ var ext = path.extname(filename)
+
+ // Make sure that only png and jpg is allowed
+ if(ext.toLowerCase() != '.jpg' && ext.toLowerCase() != '.png'){
+ res.status(406).send("Service accepts only jpg or png files");
+ }
+
+ var bytes = [];
+
+ // put the bytes from the request into a byte array
+ file.on('data', function(data) {
+ for (var i = 0; i < data.length; ++i) {
+ bytes.push(data[i]);
+ }
+ console.log('File [' + fieldname + '] got bytes ' + bytes.length + ' bytes');
+ });
+
+ // Once the request is finished pushing the file bytes into the array, put the bytes in
+ // a buffer and process that buffer with the imagemagick resize function
+ file.on('end', function() {
+ var buffer = new Buffer(bytes,'binary');
+ console.log('Bytes got ' + bytes.length + ' bytes');
+
+ //resize
+ im.resize({
+ srcData: buffer,
+ height: 100
+ }, function(err, stdout, stderr){
+ if (err){
+ throw err;
+ }
+ // get the extension without the period
+ var typ = path.extname(filename).replace('.','');
+ res.setHeader("content-type", "image/" + typ);
+ res.status(200);
+ // send the image back as a response
+ res.send(new Buffer(stdout,'binary'));
+ });
+ });
+ });
+ });
+
+ module.exports = router;
+
+Okay, so we’re back on track and everything is hunky dory on my local machine. I go to sleep.
+
+But, before I do I test the microservice code running as standard Node app on localhost...
+
+
+
+It works fine. Now all I needed to do was get it working in a container.
+
+The next day I woke up, grabbed some coffee, and built an image—not forgetting to put in the period!
+
+ $ docker build -t thumbnailer:01 .
+
+I am building from the root directory of my thumbnailer project. The build command uses the Dockerfile that is in the root directory. That’s how it goes: put the Dockerfile in the same place you want to run build and the Dockerfile will be used by default.
+
+Here is the text of the Dockerfile I was using:
+
+ FROM ubuntu:latest
+ MAINTAINER bob@CogArtTech.com
+
+ RUN apt-get update
+ RUN apt-get install -y nodejs nodejs-legacy npm
+ RUN apt-get install imagemagick libmagickcore-dev libmagickwand-dev
+ RUN apt-get clean
+
+ COPY ./package.json src/
+
+ RUN cd src && npm install
+
+ COPY . /src
+
+ WORKDIR src/
+
+ CMD npm start
+
+What could go wrong?
+
+### The Second Big Problem ###
+
+I ran the `build` command and I got this error:
+
+ Do you want to continue? [Y/n] Abort.
+
+ The command '/bin/sh -c apt-get install imagemagick libmagickcore-dev libmagickwand-dev' returned a non-zero code: 1
+
+I figured something was wrong with the microservice. I went back to my machine, fired up the service on localhost, and uploaded a file.
+
+Then I got this error from NodeJS:
+
+ Error: spawn convert ENOENT
+
+What’s going on? This worked the other night!
+
+I searched and searched, for every permutation of the error I could think of. After about four hours of replacing different node modules here and there, I figured: why not restart the machine?
+
+I did. And guess what? The error went away!
+
+Go figure.
+
+### Putting the Genie Back in the Bottle ###
+
+So, back to the original quest: I needed to get this build working.
+
+I removed all of the containers running on the VM, using [the `rm` command][5]:
+
+ $ docker rm -f $(docker ps -a -q)
+
+The `-f` flag here force removes running images.
+
+Then I removed all of my Docker images, using [the `rmi` command][6]:
+
+ $ docker rmi if $(docker images | tail -n +2 | awk '{print $3}')
+
+I go through the whole process of rebuilding the image, installing the container and try to get the microservice running. Then after about an hour of self-doubt and accompanying frustration, I thought to myself: maybe this isn’t a problem with the microservice.
+
+So, I looked that the the error again:
+
+ Do you want to continue? [Y/n] Abort.
+
+ The command '/bin/sh -c apt-get install imagemagick libmagickcore-dev libmagickwand-dev' returned a non-zero code: 1
+
+Then it hit me: the build is looking for a Y input from the keyboard! But, this is a non-interactive Dockerfile script. There is no keyboard.
+
+I went back to the Dockerfile, and there it was:
+
+ RUN apt-get update
+ RUN apt-get install -y nodejs nodejs-legacy npm
+ RUN apt-get install imagemagick libmagickcore-dev libmagickwand-dev
+ RUN apt-get clean
+
+The second `apt-get` command is missing the `-y` flag which causes "yes" to be given automatically where usually it would be prompted for.
+
+I added the missing `-y` to the command:
+
+ RUN apt-get update
+ RUN apt-get install -y nodejs nodejs-legacy npm
+ RUN apt-get install -y imagemagick libmagickcore-dev libmagickwand-dev
+ RUN apt-get clean
+
+And guess what: after two days of trial and tribulation, it worked! Two whole days!
+
+So, I did my build:
+
+ $ docker build -t thumbnailer:0.1 .
+
+I fired up the container:
+
+ $ docker run -d -p 3001:3000 thumbnailer:0.1
+
+Got the IP address of the Virtual Machine:
+
+ $ docker-machine ip default
+
+Went to my browser and entered http://192.168.99.100:3001/ into the address bar.
+
+The upload page loaded.
+
+I selected an image, and this is what I got:
+
+
+
+It worked!
+
+Inside a container, for the first time!
+
+### So What Does It All Mean? ###
+
+A long time ago, I accepted the fact when it comes to tech, sometimes even the easy stuff is hard. Along with that, I abandoned the desire to be the smartest guy in the room. Still, the last few days trying get basic competency with containers has been, at times, a journey of self doubt.
+
+But, you wanna know something? It’s 2 AM on an early morning as I write this, and every nerve wracking hour has been worth it. Why? Because you gotta put in the time. This stuff is hard and it does not come easy for anyone. And don’t forget: you’re learning tech and tech runs the world!
+
+P.S. Check out this two part video of Hello World containers, check out [Raziel Tabib’s][7] excellent work in this video...
+
+注:youtube视频
+
+
+And don't miss part two...
+
+注:youtube视频
+
+
+--------------------------------------------------------------------------------
+
+via: https://deis.com/blog/2015/beyond-hello-world-containers-hard-stuff
+
+作者:[Bob Reselman][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://deis.com/blog
+[1]:http://deis.com/blog/2015/developer-journey-linux-containers
+[2]:https://github.com/rsms/node-imagemagick
+[3]:https://www.docker.com/toolbox
+[4]:https://docs.docker.com/reference/commandline/run/
+[5]:https://docs.docker.com/reference/commandline/rm/
+[6]:https://docs.docker.com/reference/commandline/rmi/
+[7]:http://twitter.com/RazielTabib
diff --git a/sources/tech/20151122 Doubly linked list in the Linux Kernel.md b/sources/tech/20151122 Doubly linked list in the Linux Kernel.md
new file mode 100644
index 0000000000..e6b5c97a77
--- /dev/null
+++ b/sources/tech/20151122 Doubly linked list in the Linux Kernel.md
@@ -0,0 +1,257 @@
+Data Structures in the Linux Kernel
+================================================================================
+
+Doubly linked list
+--------------------------------------------------------------------------------
+
+Linux kernel provides its own implementation of doubly linked list, which you can find in the [include/linux/list.h](https://github.com/torvalds/linux/blob/master/include/linux/list.h). We will start `Data Structures in the Linux kernel` from the doubly linked list data structure. Why? Because it is very popular in the kernel, just try to [search](http://lxr.free-electrons.com/ident?i=list_head)
+
+First of all, let's look on the main structure in the [include/linux/types.h](https://github.com/torvalds/linux/blob/master/include/linux/types.h):
+
+```C
+struct list_head {
+ struct list_head *next, *prev;
+};
+```
+
+You can note that it is different from many implementations of doubly linked list which you have seen. For example, this doubly linked list structure from the [glib](http://www.gnu.org/software/libc/) library looks like :
+
+```C
+struct GList {
+ gpointer data;
+ GList *next;
+ GList *prev;
+};
+```
+
+Usually a linked list structure contains a pointer to the item. The implementation of linked list in Linux kernel does not. So the main question is - `where does the list store the data?`. The actual implementation of linked list in the kernel is - `Intrusive list`. An intrusive linked list does not contain data in its nodes - A node just contains pointers to the next and previous node and list nodes part of the data that are added to the list. This makes the data structure generic, so it does not care about entry data type anymore.
+
+For example:
+
+```C
+struct nmi_desc {
+ spinlock_t lock;
+ struct list_head head;
+};
+```
+
+Let's look at some examples to understand how `list_head` is used in the kernel. As I already wrote about, there are many, really many different places where lists are used in the kernel. Let's look for an example in miscellaneous character drivers. Misc character drivers API from the [drivers/char/misc.c](https://github.com/torvalds/linux/blob/master/drivers/char/misc.c) is used for writing small drivers for handling simple hardware or virtual devices. Those drivers share same major number:
+
+```C
+#define MISC_MAJOR 10
+```
+
+but have their own minor number. For example you can see it with:
+
+```
+ls -l /dev | grep 10
+crw------- 1 root root 10, 235 Mar 21 12:01 autofs
+drwxr-xr-x 10 root root 200 Mar 21 12:01 cpu
+crw------- 1 root root 10, 62 Mar 21 12:01 cpu_dma_latency
+crw------- 1 root root 10, 203 Mar 21 12:01 cuse
+drwxr-xr-x 2 root root 100 Mar 21 12:01 dri
+crw-rw-rw- 1 root root 10, 229 Mar 21 12:01 fuse
+crw------- 1 root root 10, 228 Mar 21 12:01 hpet
+crw------- 1 root root 10, 183 Mar 21 12:01 hwrng
+crw-rw----+ 1 root kvm 10, 232 Mar 21 12:01 kvm
+crw-rw---- 1 root disk 10, 237 Mar 21 12:01 loop-control
+crw------- 1 root root 10, 227 Mar 21 12:01 mcelog
+crw------- 1 root root 10, 59 Mar 21 12:01 memory_bandwidth
+crw------- 1 root root 10, 61 Mar 21 12:01 network_latency
+crw------- 1 root root 10, 60 Mar 21 12:01 network_throughput
+crw-r----- 1 root kmem 10, 144 Mar 21 12:01 nvram
+brw-rw---- 1 root disk 1, 10 Mar 21 12:01 ram10
+crw--w---- 1 root tty 4, 10 Mar 21 12:01 tty10
+crw-rw---- 1 root dialout 4, 74 Mar 21 12:01 ttyS10
+crw------- 1 root root 10, 63 Mar 21 12:01 vga_arbiter
+crw------- 1 root root 10, 137 Mar 21 12:01 vhci
+```
+
+Now let's have a close look at how lists are used in the misc device drivers. First of all, let's look on `miscdevice` structure:
+
+```C
+struct miscdevice
+{
+ int minor;
+ const char *name;
+ const struct file_operations *fops;
+ struct list_head list;
+ struct device *parent;
+ struct device *this_device;
+ const char *nodename;
+ mode_t mode;
+};
+```
+
+We can see the fourth field in the `miscdevice` structure - `list` which is a list of registered devices. In the beginning of the source code file we can see the definition of misc_list:
+
+```C
+static LIST_HEAD(misc_list);
+```
+
+which expands to the definition of variables with `list_head` type:
+
+```C
+#define LIST_HEAD(name) \
+ struct list_head name = LIST_HEAD_INIT(name)
+```
+
+and initializes it with the `LIST_HEAD_INIT` macro, which sets previous and next entries with the address of variable - name:
+
+```C
+#define LIST_HEAD_INIT(name) { &(name), &(name) }
+```
+
+Now let's look on the `misc_register` function which registers a miscellaneous device. At the start it initializes `miscdevice->list` with the `INIT_LIST_HEAD` function:
+
+```C
+INIT_LIST_HEAD(&misc->list);
+```
+
+which does the same as the `LIST_HEAD_INIT` macro:
+
+```C
+static inline void INIT_LIST_HEAD(struct list_head *list)
+{
+ list->next = list;
+ list->prev = list;
+}
+```
+
+In the next step after a device is created by the `device_create` function, we add it to the miscellaneous devices list with:
+
+```
+list_add(&misc->list, &misc_list);
+```
+
+Kernel `list.h` provides this API for the addition of a new entry to the list. Let's look at its implementation:
+
+```C
+static inline void list_add(struct list_head *new, struct list_head *head)
+{
+ __list_add(new, head, head->next);
+}
+```
+
+It just calls internal function `__list_add` with the 3 given parameters:
+
+* new - new entry.
+* head - list head after which the new item will be inserted.
+* head->next - next item after list head.
+
+Implementation of the `__list_add` is pretty simple:
+
+```C
+static inline void __list_add(struct list_head *new,
+ struct list_head *prev,
+ struct list_head *next)
+{
+ next->prev = new;
+ new->next = next;
+ new->prev = prev;
+ prev->next = new;
+}
+```
+
+Here we add a new item between `prev` and `next`. So `misc` list which we defined at the start with the `LIST_HEAD_INIT` macro will contain previous and next pointers to the `miscdevice->list`.
+
+There is still one question: how to get list's entry. There is a special macro:
+
+```C
+#define list_entry(ptr, type, member) \
+ container_of(ptr, type, member)
+```
+
+which gets three parameters:
+
+* ptr - the structure list_head pointer;
+* type - structure type;
+* member - the name of the list_head within the structure;
+
+For example:
+
+```C
+const struct miscdevice *p = list_entry(v, struct miscdevice, list)
+```
+
+After this we can access to any `miscdevice` field with `p->minor` or `p->name` and etc... Let's look on the `list_entry` implementation:
+
+```C
+#define list_entry(ptr, type, member) \
+ container_of(ptr, type, member)
+```
+
+As we can see it just calls `container_of` macro with the same arguments. At first sight, the `container_of` looks strange:
+
+```C
+#define container_of(ptr, type, member) ({ \
+ const typeof( ((type *)0)->member ) *__mptr = (ptr); \
+ (type *)( (char *)__mptr - offsetof(type,member) );})
+```
+
+First of all you can note that it consists of two expressions in curly brackets. The compiler will evaluate the whole block in the curly braces and use the value of the last expression.
+
+For example:
+
+```
+#include
+
+int main() {
+ int i = 0;
+ printf("i = %d\n", ({++i; ++i;}));
+ return 0;
+}
+```
+
+will print `2`.
+
+The next point is `typeof`, it's simple. As you can understand from its name, it just returns the type of the given variable. When I first saw the implementation of the `container_of` macro, the strangest thing I found was the zero in the `((type *)0)` expression. Actually this pointer magic calculates the offset of the given field from the address of the structure, but as we have `0` here, it will be just a zero offset along with the field width. Let's look at a simple example:
+
+```C
+#include
+
+struct s {
+ int field1;
+ char field2;
+ char field3;
+};
+
+int main() {
+ printf("%p\n", &((struct s*)0)->field3);
+ return 0;
+}
+```
+
+will print `0x5`.
+
+The next `offsetof` macro calculates offset from the beginning of the structure to the given structure's field. Its implementation is very similar to the previous code:
+
+```C
+#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)
+```
+
+Let's summarize all about `container_of` macro. The `container_of` macro returns the address of the structure by the given address of the structure's field with `list_head` type, the name of the structure field with `list_head` type and type of the container structure. At the first line this macro declares the `__mptr` pointer which points to the field of the structure that `ptr` points to and assigns `ptr` to it. Now `ptr` and `__mptr` point to the same address. Technically we don't need this line but it's useful for type checking. The first line ensures that the given structure (`type` parameter) has a member called `member`. In the second line it calculates offset of the field from the structure with the `offsetof` macro and subtracts it from the structure address. That's all.
+
+Of course `list_add` and `list_entry` is not the only functions which `` provides. Implementation of the doubly linked list provides the following API:
+
+* list_add
+* list_add_tail
+* list_del
+* list_replace
+* list_move
+* list_is_last
+* list_empty
+* list_cut_position
+* list_splice
+* list_for_each
+* list_for_each_entry
+
+and many more.
+
+
+via: https://github.com/0xAX/linux-insides/edit/master/DataStructures/dlist.md
+
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/sources/tech/LFCS/Part 10 - LFCS--Understanding and Learning Basic Shell Scripting and Linux Filesystem Troubleshooting.md b/sources/tech/LFCS/Part 10 - LFCS--Understanding and Learning Basic Shell Scripting and Linux Filesystem Troubleshooting.md
new file mode 100644
index 0000000000..3ffb1dc54f
--- /dev/null
+++ b/sources/tech/LFCS/Part 10 - LFCS--Understanding and Learning Basic Shell Scripting and Linux Filesystem Troubleshooting.md
@@ -0,0 +1,315 @@
+Part 10 - LFCS: Understanding & Learning Basic Shell Scripting and Linux Filesystem Troubleshooting
+================================================================================
+The Linux Foundation launched the LFCS certification (Linux Foundation Certified Sysadmin), a brand new initiative whose purpose is to allow individuals everywhere (and anywhere) to get certified in basic to intermediate operational support for Linux systems, which includes supporting running systems and services, along with overall monitoring and analysis, plus smart decision-making when it comes to raising issues to upper support teams.
+
+
+
+Linux Foundation Certified Sysadmin – Part 10
+
+Check out the following video that guides you an introduction to the Linux Foundation Certification Program.
+
+注:youtube 视频
+
+
+
+This is the last article (Part 10) of the present 10-tutorial long series. In this article we will focus on basic shell scripting and troubleshooting Linux file systems. Both topics are required for the LFCS certification exam.
+
+### Understanding Terminals and Shells ###
+
+Let’s clarify a few concepts first.
+
+- A shell is a program that takes commands and gives them to the operating system to be executed.
+- A terminal is a program that allows us as end users to interact with the shell. One example of a terminal is GNOME terminal, as shown in the below image.
+
+
+
+Gnome Terminal
+
+When we first start a shell, it presents a command prompt (also known as the command line), which tells us that the shell is ready to start accepting commands from its standard input device, which is usually the keyboard.
+
+You may want to refer to another article in this series ([Use Command to Create, Edit, and Manipulate files – Part 1][1]) to review some useful commands.
+
+Linux provides a range of options for shells, the following being the most common:
+
+**bash Shell**
+
+Bash stands for Bourne Again SHell and is the GNU Project’s default shell. It incorporates useful features from the Korn shell (ksh) and C shell (csh), offering several improvements at the same time. This is the default shell used by the distributions covered in the LFCS certification, and it is the shell that we will use in this tutorial.
+
+**sh Shell**
+
+The Bourne SHell is the oldest shell and therefore has been the default shell of many UNIX-like operating systems for many years.
+ksh Shell
+
+The Korn SHell is a Unix shell which was developed by David Korn at Bell Labs in the early 1980s. It is backward-compatible with the Bourne shell and includes many features of the C shell.
+
+A shell script is nothing more and nothing less than a text file turned into an executable program that combines commands that are executed by the shell one after another.
+
+### Basic Shell Scripting ###
+
+As mentioned earlier, a shell script is born as a plain text file. Thus, can be created and edited using our preferred text editor. You may want to consider using vi/m (refer to [Usage of vi Editor – Part 2][2] of this series), which features syntax highlighting for your convenience.
+
+Type the following command to create a file named myscript.sh and press Enter.
+
+ # vim myscript.sh
+
+The very first line of a shell script must be as follows (also known as a shebang).
+
+ #!/bin/bash
+
+It “tells” the operating system the name of the interpreter that should be used to run the text that follows.
+
+Now it’s time to add our commands. We can clarify the purpose of each command, or the entire script, by adding comments as well. Note that the shell ignores those lines beginning with a pound sign # (explanatory comments).
+
+ #!/bin/bash
+ echo This is Part 10 of the 10-article series about the LFCS certification
+ echo Today is $(date +%Y-%m-%d)
+
+Once the script has been written and saved, we need to make it executable.
+
+ # chmod 755 myscript.sh
+
+Before running our script, we need to say a few words about the $PATH environment variable. If we run,
+
+ echo $PATH
+
+from the command line, we will see the contents of $PATH: a colon-separated list of directories that are searched when we enter the name of a executable program. It is called an environment variable because it is part of the shell environment – a set of information that becomes available for the shell and its child processes when the shell is first started.
+
+When we type a command and press Enter, the shell searches in all the directories listed in the $PATH variable and executes the first instance that is found. Let’s see an example,
+
+
+
+Environment Variables
+
+If there are two executable files with the same name, one in /usr/local/bin and another in /usr/bin, the one in the first directory will be executed first, whereas the other will be disregarded.
+
+If we haven’t saved our script inside one of the directories listed in the $PATH variable, we need to append ./ to the file name in order to execute it. Otherwise, we can run it just as we would do with a regular command.
+
+ # pwd
+ # ./myscript.sh
+ # cp myscript.sh ../bin
+ # cd ../bin
+ # pwd
+ # myscript.sh
+
+
+
+Execute Script
+
+#### Conditionals ####
+
+Whenever you need to specify different courses of action to be taken in a shell script, as result of the success or failure of a command, you will use the if construct to define such conditions. Its basic syntax is:
+
+ if CONDITION; then
+ COMMANDS;
+ else
+ OTHER-COMMANDS
+ fi
+
+Where CONDITION can be one of the following (only the most frequent conditions are cited here) and evaluates to true when:
+
+- [ -a file ] → file exists.
+- [ -d file ] → file exists and is a directory.
+- [ -f file ] →file exists and is a regular file.
+- [ -u file ] →file exists and its SUID (set user ID) bit is set.
+- [ -g file ] →file exists and its SGID bit is set.
+- [ -k file ] →file exists and its sticky bit is set.
+- [ -r file ] →file exists and is readable.
+- [ -s file ]→ file exists and is not empty.
+- [ -w file ]→file exists and is writable.
+- [ -x file ] is true if file exists and is executable.
+- [ string1 = string2 ] → the strings are equal.
+- [ string1 != string2 ] →the strings are not equal.
+
+[ int1 op int2 ] should be part of the preceding list, while the items that follow (for example, -eq –> is true if int1 is equal to int2.) should be a “children” list of [ int1 op int2 ] where op is one of the following comparison operators.
+
+- -eq –> is true if int1 is equal to int2.
+- -ne –> true if int1 is not equal to int2.
+- -lt –> true if int1 is less than int2.
+- -le –> true if int1 is less than or equal to int2.
+- -gt –> true if int1 is greater than int2.
+- -ge –> true if int1 is greater than or equal to int2.
+
+#### For Loops ####
+
+This loop allows to execute one or more commands for each value in a list of values. Its basic syntax is:
+
+ for item in SEQUENCE; do
+ COMMANDS;
+ done
+
+Where item is a generic variable that represents each value in SEQUENCE during each iteration.
+
+#### While Loops ####
+
+This loop allows to execute a series of repetitive commands as long as the control command executes with an exit status equal to zero (successfully). Its basic syntax is:
+
+ while EVALUATION_COMMAND; do
+ EXECUTE_COMMANDS;
+ done
+
+Where EVALUATION_COMMAND can be any command(s) that can exit with a success (0) or failure (other than 0) status, and EXECUTE_COMMANDS can be any program, script or shell construct, including other nested loops.
+
+#### Putting It All Together ####
+
+We will demonstrate the use of the if construct and the for loop with the following example.
+
+**Determining if a service is running in a systemd-based distro**
+
+Let’s create a file with a list of services that we want to monitor at a glance.
+
+ # cat myservices.txt
+
+ sshd
+ mariadb
+ httpd
+ crond
+ firewalld
+
+
+
+Script to Monitor Linux Services
+
+Our shell script should look like.
+
+ #!/bin/bash
+
+ # This script iterates over a list of services and
+ # is used to determine whether they are running or not.
+
+ for service in $(cat myservices.txt); do
+ systemctl status $service | grep --quiet "running"
+ if [ $? -eq 0 ]; then
+ echo $service "is [ACTIVE]"
+ else
+ echo $service "is [INACTIVE or NOT INSTALLED]"
+ fi
+ done
+
+
+
+Linux Service Monitoring Script
+
+**Let’s explain how the script works.**
+
+1). The for loop reads the myservices.txt file one element of LIST at a time. That single element is denoted by the generic variable named service. The LIST is populated with the output of,
+
+ # cat myservices.txt
+
+2). The above command is enclosed in parentheses and preceded by a dollar sign to indicate that it should be evaluated to populate the LIST that we will iterate over.
+
+3). For each element of LIST (meaning every instance of the service variable), the following command will be executed.
+
+ # systemctl status $service | grep --quiet "running"
+
+This time we need to precede our generic variable (which represents each element in LIST) with a dollar sign to indicate it’s a variable and thus its value in each iteration should be used. The output is then piped to grep.
+
+The –quiet flag is used to prevent grep from displaying to the screen the lines where the word running appears. When that happens, the above command returns an exit status of 0 (represented by $? in the if construct), thus verifying that the service is running.
+
+An exit status different than 0 (meaning the word running was not found in the output of systemctl status $service) indicates that the service is not running.
+
+
+
+Services Monitoring Script
+
+We could go one step further and check for the existence of myservices.txt before even attempting to enter the for loop.
+
+ #!/bin/bash
+
+ # This script iterates over a list of services and
+ # is used to determine whether they are running or not.
+
+ if [ -f myservices.txt ]; then
+ for service in $(cat myservices.txt); do
+ systemctl status $service | grep --quiet "running"
+ if [ $? -eq 0 ]; then
+ echo $service "is [ACTIVE]"
+ else
+ echo $service "is [INACTIVE or NOT INSTALLED]"
+ fi
+ done
+ else
+ echo "myservices.txt is missing"
+ fi
+
+**Pinging a series of network or internet hosts for reply statistics**
+
+You may want to maintain a list of hosts in a text file and use a script to determine every now and then whether they’re pingable or not (feel free to replace the contents of myhosts and try for yourself).
+
+The read shell built-in command tells the while loop to read myhosts line by line and assigns the content of each line to variable host, which is then passed to the ping command.
+
+ #!/bin/bash
+
+ # This script is used to demonstrate the use of a while loop
+
+ while read host; do
+ ping -c 2 $host
+ done < myhosts
+
+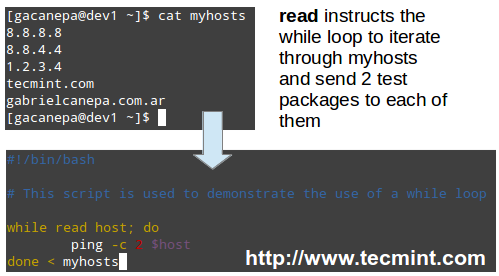
+
+Script to Ping Servers
+
+Read Also:
+
+- [Learn Shell Scripting: A Guide from Newbies to System Administrator][3]
+- [5 Shell Scripts to Learn Shell Programming][4]
+
+### Filesystem Troubleshooting ###
+
+Although Linux is a very stable operating system, if it crashes for some reason (for example, due to a power outage), one (or more) of your file systems will not be unmounted properly and thus will be automatically checked for errors when Linux is restarted.
+
+In addition, each time the system boots during a normal boot, it always checks the integrity of the filesystems before mounting them. In both cases this is performed using a tool named fsck (“file system check”).
+
+fsck will not only check the integrity of file systems, but also attempt to repair corrupt file systems if instructed to do so. Depending on the severity of damage, fsck may succeed or not; when it does, recovered portions of files are placed in the lost+found directory, located in the root of each file system.
+
+Last but not least, we must note that inconsistencies may also happen if we try to remove an USB drive when the operating system is still writing to it, and may even result in hardware damage.
+
+The basic syntax of fsck is as follows:
+
+ # fsck [options] filesystem
+
+**Checking a filesystem for errors and attempting to repair automatically**
+
+In order to check a filesystem with fsck, we must first unmount it.
+
+ # mount | grep sdg1
+ # umount /mnt
+ # fsck -y /dev/sdg1
+
+
+
+Check Filesystem Errors
+
+Besides the -y flag, we can use the -a option to automatically repair the file systems without asking any questions, and force the check even when the filesystem looks clean.
+
+ # fsck -af /dev/sdg1
+
+If we’re only interested in finding out what’s wrong (without trying to fix anything for the time being) we can run fsck with the -n option, which will output the filesystem issues to standard output.
+
+ # fsck -n /dev/sdg1
+
+Depending on the error messages in the output of fsck, we will know whether we can try to solve the issue ourselves or escalate it to engineering teams to perform further checks on the hardware.
+
+### Summary ###
+
+We have arrived at the end of this 10-article series where have tried to cover the basic domain competencies required to pass the LFCS exam.
+
+For obvious reasons, it is not possible to cover every single aspect of these topics in any single tutorial, and that’s why we hope that these articles have put you on the right track to try new stuff yourself and continue learning.
+
+If you have any questions or comments, they are always welcome – so don’t hesitate to drop us a line via the form below!
+
+--------------------------------------------------------------------------------
+
+via: http://www.tecmint.com/linux-basic-shell-scripting-and-linux-filesystem-troubleshooting/
+
+作者:[Gabriel Cánepa][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.tecmint.com/author/gacanepa/
+[1]:http://www.tecmint.com/sed-command-to-create-edit-and-manipulate-files-in-linux/
+[2]:http://www.tecmint.com/vi-editor-usage/
+[3]:http://www.tecmint.com/learning-shell-scripting-language-a-guide-from-newbies-to-system-administrator/
+[4]:http://www.tecmint.com/basic-shell-programming-part-ii/
\ No newline at end of file
diff --git a/sources/tech/LFCS/Part 2 - LFCS--How to Install and Use vi or vim as a Full Text Editor.md b/sources/tech/LFCS/Part 2 - LFCS--How to Install and Use vi or vim as a Full Text Editor.md
new file mode 100644
index 0000000000..7fe8073a77
--- /dev/null
+++ b/sources/tech/LFCS/Part 2 - LFCS--How to Install and Use vi or vim as a Full Text Editor.md
@@ -0,0 +1,387 @@
+Part 2 - LFCS: How to Install and Use vi/vim as a Full Text Editor
+================================================================================
+A couple of months ago, the Linux Foundation launched the LFCS (Linux Foundation Certified Sysadmin) certification in order to help individuals from all over the world to verify they are capable of doing basic to intermediate system administration tasks on Linux systems: system support, first-hand troubleshooting and maintenance, plus intelligent decision-making to know when it’s time to raise issues to upper support teams.
+
+
+
+Learning VI Editor in Linux
+
+Please take a look at the below video that explains The Linux Foundation Certification Program.
+
+注:youtube 视频
+
+
+This post is Part 2 of a 10-tutorial series, here in this part, we will cover the basic file editing operations and understanding modes in vi/m editor, that are required for the LFCS certification exam.
+
+### Perform Basic File Editing Operations Using vi/m ###
+
+Vi was the first full-screen text editor written for Unix. Although it was intended to be small and simple, it can be a bit challenging for people used exclusively to GUI text editors, such as NotePad++, or gedit, to name a few examples.
+
+To use Vi, we must first understand the 3 modes in which this powerful program operates, in order to begin learning later about the its powerful text-editing procedures.
+
+Please note that most modern Linux distributions ship with a variant of vi known as vim (“Vi improved”), which supports more features than the original vi does. For that reason, throughout this tutorial we will use vi and vim interchangeably.
+
+If your distribution does not have vim installed, you can install it as follows.
+
+- Ubuntu and derivatives: aptitude update && aptitude install vim
+- Red Hat-based distributions: yum update && yum install vim
+- openSUSE: zypper update && zypper install vim
+
+### Why should I want to learn vi? ###
+
+There are at least 2 good reasons to learn vi.
+
+1. vi is always available (no matter what distribution you’re using) since it is required by POSIX.
+
+2. vi does not consume a considerable amount of system resources and allows us to perform any imaginable tasks without lifting our fingers from the keyboard.
+
+In addition, vi has a very extensive built-in manual, which can be launched using the :help command right after the program is started. This built-in manual contains more information than vi/m’s man page.
+
+
+
+vi Man Pages
+
+#### Launching vi ####
+
+To launch vi, type vi in your command prompt.
+
+
+
+Start vi Editor
+
+Then press i to enter Insert mode, and you can start typing. Another way to launch vi/m is.
+
+ # vi filename
+
+Which will open a new buffer (more on buffers later) named filename, which you can later save to disk.
+
+#### Understanding Vi modes ####
+
+1. In command mode, vi allows the user to navigate around the file and enter vi commands, which are brief, case-sensitive combinations of one or more letters. Almost all of them can be prefixed with a number to repeat the command that number of times.
+
+For example, yy (or Y) copies the entire current line, whereas 3yy (or 3Y) copies the entire current line along with the two next lines (3 lines in total). We can always enter command mode (regardless of the mode we’re working on) by pressing the Esc key. The fact that in command mode the keyboard keys are interpreted as commands instead of text tends to be confusing to beginners.
+
+2. In ex mode, we can manipulate files (including saving a current file and running outside programs). To enter this mode, we must type a colon (:) from command mode, directly followed by the name of the ex-mode command that needs to be used. After that, vi returns automatically to command mode.
+
+3. In insert mode (the letter i is commonly used to enter this mode), we simply enter text. Most keystrokes result in text appearing on the screen (one important exception is the Esc key, which exits insert mode and returns to command mode).
+
+
+
+vi Insert Mode
+
+#### Vi Commands ####
+
+The following table shows a list of commonly used vi commands. File edition commands can be enforced by appending the exclamation sign to the command (for example,
+
+
+
+
+
+
+
Key command
+
Description
+
+
+
h or left arrow
+
Go one character to the left
+
+
+
j or down arrow
+
Go down one line
+
+
+
k or up arrow
+
Go up one line
+
+
+
l (lowercase L) or right arrow
+
Go one character to the right
+
+
+
H
+
Go to the top of the screen
+
+
+
L
+
Go to the bottom of the screen
+
+
+
G
+
Go to the end of the file
+
+
+
w
+
Move one word to the right
+
+
+
b
+
Move one word to the left
+
+
+
0 (zero)
+
Go to the beginning of the current line
+
+
+
^
+
Go to the first nonblank character on the current line
+
+
+
$
+
Go to the end of the current line
+
+
+
Ctrl-B
+
Go back one screen
+
+
+
Ctrl-F
+
Go forward one screen
+
+
+
i
+
Insert at the current cursor position
+
+
+
I (uppercase i)
+
Insert at the beginning of the current line
+
+
+
J (uppercase j)
+
Join current line with the next one (move next line up)
+
+
+
a
+
Append after the current cursor position
+
+
+
o (lowercase O)
+
Creates a blank line after the current line
+
+
+
O (uppercase o)
+
Creates a blank line before the current line
+
+
+
r
+
Replace the character at the current cursor position
+
+
+
R
+
Overwrite at the current cursor position
+
+
+
x
+
Delete the character at the current cursor position
+
+
+
X
+
Delete the character immediately before (to the left) of the current cursor position
+
+
+
dd
+
Cut (for later pasting) the entire current line
+
+
+
D
+
Cut from the current cursor position to the end of the line (this command is equivalent to d$)
+
+
+
yX
+
Give a movement command X, copy (yank) the appropriate number of characters, words, or lines from the current cursor position
+
+
+
yy or Y
+
Yank (copy) the entire current line
+
+
+
p
+
Paste after (next line) the current cursor position
+
+
+
P
+
Paste before (previous line) the current cursor position
+
+
+
. (period)
+
Repeat the last command
+
+
+
u
+
Undo the last command
+
+
+
U
+
Undo the last command in the last line. This will work as long as the cursor is still on the line.
+
+
+
n
+
Find the next match in a search
+
+
+
N
+
Find the previous match in a search
+
+
+
:n
+
Next file; when multiple files are specified for editing, this commands loads the next file.
+
+
+
:e file
+
Load file in place of the current file.
+
+
+
:r file
+
Insert the contents of file after (next line) the current cursor position
+
+
+
:q
+
Quit without saving changes.
+
+
+
:w file
+
Write the current buffer to file. To append to an existing file, use :w >> file.
+
+
+
:wq
+
Write the contents of the current file and quit. Equivalent to x! and ZZ
+
+
+
:r! command
+
Execute command and insert output after (next line) the current cursor position.
+
+
+
+
+#### Vi Options ####
+
+The following options can come in handy while running vim (we need to add them in our ~/.vimrc file).
+
+ # echo set number >> ~/.vimrc
+ # echo syntax on >> ~/.vimrc
+ # echo set tabstop=4 >> ~/.vimrc
+ # echo set autoindent >> ~/.vimrc
+
+
+
+vi Editor Options
+
+- set number shows line numbers when vi opens an existing or a new file.
+- syntax on turns on syntax highlighting (for multiple file extensions) in order to make code and config files more readable.
+- set tabstop=4 sets the tab size to 4 spaces (default value is 8).
+- set autoindent carries over previous indent to the next line.
+
+#### Search and replace ####
+
+vi has the ability to move the cursor to a certain location (on a single line or over an entire file) based on searches. It can also perform text replacements with or without confirmation from the user.
+
+a). Searching within a line: the f command searches a line and moves the cursor to the next occurrence of a specified character in the current line.
+
+For example, the command fh would move the cursor to the next instance of the letter h within the current line. Note that neither the letter f nor the character you’re searching for will appear anywhere on your screen, but the character will be highlighted after you press Enter.
+
+For example, this is what I get after pressing f4 in command mode.
+
+
+
+Search String in Vi
+
+b). Searching an entire file: use the / command, followed by the word or phrase to be searched for. A search may be repeated using the previous search string with the n command, or the next one (using the N command). This is the result of typing /Jane in command mode.
+
+
+
+Vi Search String in File
+
+c). vi uses a command (similar to sed’s) to perform substitution operations over a range of lines or an entire file. To change the word “old” to “young” for the entire file, we must enter the following command.
+
+ :%s/old/young/g
+
+**Notice**: The colon at the beginning of the command.
+
+
+
+Vi Search and Replace
+
+The colon (:) starts the ex command, s in this case (for substitution), % is a shortcut meaning from the first line to the last line (the range can also be specified as n,m which means “from line n to line m”), old is the search pattern, while young is the replacement text, and g indicates that the substitution should be performed on every occurrence of the search string in the file.
+
+Alternatively, a c can be added to the end of the command to ask for confirmation before performing any substitution.
+
+ :%s/old/young/gc
+
+Before replacing the original text with the new one, vi/m will present us with the following message.
+
+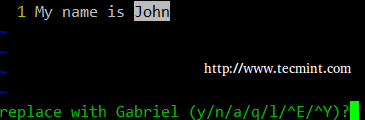
+
+Replace String in Vi
+
+- y: perform the substitution (yes)
+- n: skip this occurrence and go to the next one (no)
+- a: perform the substitution in this and all subsequent instances of the pattern.
+- q or Esc: quit substituting.
+- l (lowercase L): perform this substitution and quit (last).
+- Ctrl-e, Ctrl-y: Scroll down and up, respectively, to view the context of the proposed substitution.
+
+#### Editing Multiple Files at a Time ####
+
+Let’s type vim file1 file2 file3 in our command prompt.
+
+ # vim file1 file2 file3
+
+First, vim will open file1. To switch to the next file (file2), we need to use the :n command. When we want to return to the previous file, :N will do the job.
+
+In order to switch from file1 to file3.
+
+a). The :buffers command will show a list of the file currently being edited.
+
+ :buffers
+
+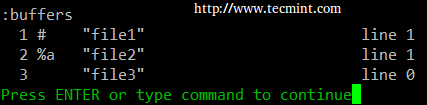
+
+Edit Multiple Files
+
+b). The command :buffer 3 (without the s at the end) will open file3 for editing.
+
+In the image above, a pound sign (#) indicates that the file is currently open but in the background, while %a marks the file that is currently being edited. On the other hand, a blank space after the file number (3 in the above example) indicates that the file has not yet been opened.
+
+#### Temporary vi buffers ####
+
+To copy a couple of consecutive lines (let’s say 4, for example) into a temporary buffer named a (not associated with a file) and place those lines in another part of the file later in the current vi section, we need to…
+
+1. Press the ESC key to be sure we are in vi Command mode.
+
+2. Place the cursor on the first line of the text we wish to copy.
+
+3. Type “a4yy to copy the current line, along with the 3 subsequent lines, into a buffer named a. We can continue editing our file – we do not need to insert the copied lines immediately.
+
+4. When we reach the location for the copied lines, use “a before the p or P commands to insert the lines copied into the buffer named a:
+
+- Type “ap to insert the lines copied into buffer a after the current line on which the cursor is resting.
+- Type “aP to insert the lines copied into buffer a before the current line.
+
+If we wish, we can repeat the above steps to insert the contents of buffer a in multiple places in our file. A temporary buffer, as the one in this section, is disposed when the current window is closed.
+
+### Summary ###
+
+As we have seen, vi/m is a powerful and versatile text editor for the CLI. Feel free to share your own tricks and comments below.
+
+#### Reference Links ####
+
+- [About the LFCS][1]
+- [Why get a Linux Foundation Certification?][2]
+- [Register for the LFCS exam][3]
+
+--------------------------------------------------------------------------------
+
+via: http://www.tecmint.com/vi-editor-usage/
+
+作者:[Gabriel Cánepa][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.tecmint.com/author/gacanepa/
+[1]:https://training.linuxfoundation.org/certification/LFCS
+[2]:https://training.linuxfoundation.org/certification/why-certify-with-us
+[3]:https://identity.linuxfoundation.org/user?destination=pid/1
\ No newline at end of file
diff --git a/sources/tech/LFCS/Part 3 - LFCS--How to Archive or Compress Files and Directories Setting File Attributes and Finding Files in Linux.md b/sources/tech/LFCS/Part 3 - LFCS--How to Archive or Compress Files and Directories Setting File Attributes and Finding Files in Linux.md
new file mode 100644
index 0000000000..82cc54a5a6
--- /dev/null
+++ b/sources/tech/LFCS/Part 3 - LFCS--How to Archive or Compress Files and Directories Setting File Attributes and Finding Files in Linux.md
@@ -0,0 +1,382 @@
+Part 3 - LFCS: How to Archive/Compress Files & Directories, Setting File Attributes and Finding Files in Linux
+================================================================================
+Recently, the Linux Foundation started the LFCS (Linux Foundation Certified Sysadmin) certification, a brand new program whose purpose is allowing individuals from all corners of the globe to have access to an exam, which if approved, certifies that the person is knowledgeable in performing basic to intermediate system administration tasks on Linux systems. This includes supporting already running systems and services, along with first-level troubleshooting and analysis, plus the ability to decide when to escalate issues to engineering teams.
+
+
+
+Linux Foundation Certified Sysadmin – Part 3
+
+Please watch the below video that gives the idea about The Linux Foundation Certification Program.
+
+注:youtube 视频
+
+
+This post is Part 3 of a 10-tutorial series, here in this part, we will cover how to archive/compress files and directories, set file attributes, and find files on the filesystem, that are required for the LFCS certification exam.
+
+### Archiving and Compression Tools ###
+
+A file archiving tool groups a set of files into a single standalone file that we can backup to several types of media, transfer across a network, or send via email. The most frequently used archiving utility in Linux is tar. When an archiving utility is used along with a compression tool, it allows to reduce the disk size that is needed to store the same files and information.
+
+#### The tar utility ####
+
+tar bundles a group of files together into a single archive (commonly called a tar file or tarball). The name originally stood for tape archiver, but we must note that we can use this tool to archive data to any kind of writeable media (not only to tapes). Tar is normally used with a compression tool such as gzip, bzip2, or xz to produce a compressed tarball.
+
+**Basic syntax:**
+
+ # tar [options] [pathname ...]
+
+Where … represents the expression used to specify which files should be acted upon.
+
+#### Most commonly used tar commands ####
+
+注:表格
+
+
+
+
+
+
+
+
+
+
Long option
+
Abbreviation
+
Description
+
+
+
–create
+
c
+
Creates a tar archive
+
+
+
–concatenate
+
A
+
Appends tar files to an archive
+
+
+
–append
+
r
+
Appends files to the end of an archive
+
+
+
–update
+
u
+
Appends files newer than copy in archive
+
+
+
–diff or –compare
+
d
+
Find differences between archive and file system
+
+
+
–file archive
+
f
+
Use archive file or device ARCHIVE
+
+
+
–list
+
t
+
Lists the contents of a tarball
+
+
+
–extract or –get
+
x
+
Extracts files from an archive
+
+
+
+
+#### Normally used operation modifiers ####
+
+注:表格
+
+
+
+
+
+
+
+
+
+
Long option
+
Abbreviation
+
Description
+
+
+
–directory dir
+
C
+
Changes to directory dir before performing operations
+
+
+
–same-permissions
+
p
+
Preserves original permissions
+
+
+
–verbose
+
v
+
Lists all files read or extracted. When this flag is used along with –list, the file sizes, ownership, and time stamps are displayed.
+
+
+
–verify
+
W
+
Verifies the archive after writing it
+
+
+
–exclude file
+
—
+
Excludes file from the archive
+
+
+
–exclude=pattern
+
X
+
Exclude files, given as a PATTERN
+
+
+
–gzip or –gunzip
+
z
+
Processes an archive through gzip
+
+
+
–bzip2
+
j
+
Processes an archive through bzip2
+
+
+
–xz
+
J
+
Processes an archive through xz
+
+
+
+
+Gzip is the oldest compression tool and provides the least compression, while bzip2 provides improved compression. In addition, xz is the newest but (usually) provides the best compression. This advantages of best compression come at a price: the time it takes to complete the operation, and system resources used during the process.
+
+Normally, tar files compressed with these utilities have .gz, .bz2, or .xz extensions, respectively. In the following examples we will be using these files: file1, file2, file3, file4, and file5.
+
+**Grouping and compressing with gzip, bzip2 and xz**
+
+Group all the files in the current working directory and compress the resulting bundle with gzip, bzip2, and xz (please note the use of a regular expression to specify which files should be included in the bundle – this is to prevent the archiving tool to group the tarballs created in previous steps).
+
+ # tar czf myfiles.tar.gz file[0-9]
+ # tar cjf myfiles.tar.bz2 file[0-9]
+ # tar cJf myfile.tar.xz file[0-9]
+
+
+
+Compress Multiple Files
+
+**Listing the contents of a tarball and updating / appending files to the bundle**
+
+List the contents of a tarball and display the same information as a long directory listing. Note that update or append operations cannot be applied to compressed files directly (if you need to update or append a file to a compressed tarball, you need to uncompress the tar file and update / append to it, then compress again).
+
+ # tar tvf [tarball]
+
+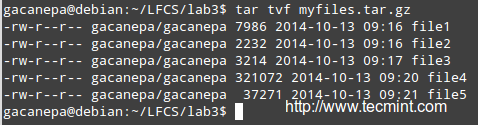
+
+List Archive Content
+
+Run any of the following commands:
+
+ # gzip -d myfiles.tar.gz [#1]
+ # bzip2 -d myfiles.tar.bz2 [#2]
+ # xz -d myfiles.tar.xz [#3]
+
+Then
+
+ # tar --delete --file myfiles.tar file4 (deletes the file inside the tarball)
+ # tar --update --file myfiles.tar file4 (adds the updated file)
+
+and
+
+ # gzip myfiles.tar [ if you choose #1 above ]
+ # bzip2 myfiles.tar [ if you choose #2 above ]
+ # xz myfiles.tar [ if you choose #3 above ]
+
+Finally,
+
+ # tar tvf [tarball] #again
+
+and compare the modification date and time of file4 with the same information as shown earlier.
+
+**Excluding file types**
+
+Suppose you want to perform a backup of user’s home directories. A good sysadmin practice would be (may also be specified by company policies) to exclude all video and audio files from backups.
+
+Maybe your first approach would be to exclude from the backup all files with an .mp3 or .mp4 extension (or other extensions). What if you have a clever user who can change the extension to .txt or .bkp, your approach won’t do you much good. In order to detect an audio or video file, you need to check its file type with file. The following shell script will do the job.
+
+ #!/bin/bash
+ # Pass the directory to backup as first argument.
+ DIR=$1
+ # Create the tarball and compress it. Exclude files with the MPEG string in its file type.
+ # -If the file type contains the string mpeg, $? (the exit status of the most recently executed command) expands to 0, and the filename is redirected to the exclude option. Otherwise, it expands to 1.
+ # -If $? equals 0, add the file to the list of files to be backed up.
+ tar X <(for i in $DIR/*; do file $i | grep -i mpeg; if [ $? -eq 0 ]; then echo $i; fi;done) -cjf backupfile.tar.bz2 $DIR/*
+
+
+
+Exclude Files in tar
+
+**Restoring backups with tar preserving permissions**
+
+You can then restore the backup to the original user’s home directory (user_restore in this example), preserving permissions, with the following command.
+
+ # tar xjf backupfile.tar.bz2 --directory user_restore --same-permissions
+
+
+
+Restore Files from Archive
+
+**Read Also:**
+
+- [18 tar Command Examples in Linux][1]
+- [Dtrx – An Intelligent Archive Tool for Linux][2]
+
+### Using find Command to Search for Files ###
+
+The find command is used to search recursively through directory trees for files or directories that match certain characteristics, and can then either print the matching files or directories or perform other operations on the matches.
+
+Normally, we will search by name, owner, group, type, permissions, date, and size.
+
+#### Basic syntax: ####
+
+# find [directory_to_search] [expression]
+
+**Finding files recursively according to Size**
+
+Find all files (-f) in the current directory (.) and 2 subdirectories below (-maxdepth 3 includes the current working directory and 2 levels down) whose size (-size) is greater than 2 MB.
+
+ # find . -maxdepth 3 -type f -size +2M
+
+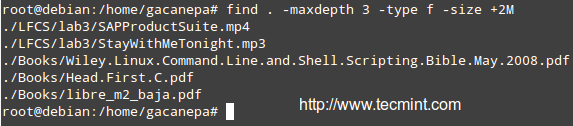
+
+Find Files Based on Size
+
+**Finding and deleting files that match a certain criteria**
+
+Files with 777 permissions are sometimes considered an open door to external attackers. Either way, it is not safe to let anyone do anything with files. We will take a rather aggressive approach and delete them! (‘{}‘ + is used to “collect” the results of the search).
+
+ # find /home/user -perm 777 -exec rm '{}' +
+
+
+
+Find Files with 777Permission
+
+**Finding files per atime or mtime**
+
+Search for configuration files in /etc that have been accessed (-atime) or modified (-mtime) more (+180) or less (-180) than 6 months ago or exactly 6 months ago (180).
+
+Modify the following command as per the example below:
+
+ # find /etc -iname "*.conf" -mtime -180 -print
+
+
+
+Find Modified Files
+
+- Read Also: [35 Practical Examples of Linux ‘find’ Command][3]
+
+### File Permissions and Basic Attributes ###
+
+The first 10 characters in the output of ls -l are the file attributes. The first of these characters is used to indicate the file type:
+
+- – : a regular file
+- -d : a directory
+- -l : a symbolic link
+- -c : a character device (which treats data as a stream of bytes, i.e. a terminal)
+- -b : a block device (which handles data in blocks, i.e. storage devices)
+
+The next nine characters of the file attributes are called the file mode and represent the read (r), write (w), and execute (x) permissions of the file’s owner, the file’s group owner, and the rest of the users (commonly referred to as “the world”).
+
+Whereas the read permission on a file allows the same to be opened and read, the same permission on a directory allows its contents to be listed if the execute permission is also set. In addition, the execute permission in a file allows it to be handled as a program and run, while in a directory it allows the same to be cd’ed into it.
+
+File permissions are changed with the chmod command, whose basic syntax is as follows:
+
+ # chmod [new_mode] file
+
+Where new_mode is either an octal number or an expression that specifies the new permissions.
+
+The octal number can be converted from its binary equivalent, which is calculated from the desired file permissions for the owner, the group, and the world, as follows:
+
+The presence of a certain permission equals a power of 2 (r=22, w=21, x=20), while its absence equates to 0. For example:
+
+
+
+File Permissions
+
+To set the file’s permissions as above in octal form, type:
+
+ # chmod 744 myfile
+
+You can also set a file’s mode using an expression that indicates the owner’s rights with the letter u, the group owner’s rights with the letter g, and the rest with o. All of these “individuals” can be represented at the same time with the letter a. Permissions are granted (or revoked) with the + or – signs, respectively.
+
+**Revoking execute permission for a shell script to all users**
+
+As we explained earlier, we can revoke a certain permission prepending it with the minus sign and indicating whether it needs to be revoked for the owner, the group owner, or all users. The one-liner below can be interpreted as follows: Change mode for all (a) users, revoke (–) execute permission (x).
+
+ # chmod a-x backup.sh
+
+Granting read, write, and execute permissions for a file to the owner and group owner, and read permissions for the world.
+
+When we use a 3-digit octal number to set permissions for a file, the first digit indicates the permissions for the owner, the second digit for the group owner and the third digit for everyone else:
+
+- Owner: (r=22 + w=21 + x=20 = 7)
+- Group owner: (r=22 + w=21 + x=20 = 7)
+- World: (r=22 + w=0 + x=0 = 4),
+
+ # chmod 774 myfile
+
+In time, and with practice, you will be able to decide which method to change a file mode works best for you in each case. A long directory listing also shows the file’s owner and its group owner (which serve as a rudimentary yet effective access control to files in a system):
+
+
+
+Linux File Listing
+
+File ownership is changed with the chown command. The owner and the group owner can be changed at the same time or separately. Its basic syntax is as follows:
+
+ # chown user:group file
+
+Where at least user or group need to be present.
+
+**Few Examples**
+
+Changing the owner of a file to a certain user.
+
+ # chown gacanepa sent
+
+Changing the owner and group of a file to an specific user:group pair.
+
+ # chown gacanepa:gacanepa TestFile
+
+Changing only the group owner of a file to a certain group. Note the colon before the group’s name.
+
+ # chown :gacanepa email_body.txt
+
+### Conclusion ###
+
+As a sysadmin, you need to know how to create and restore backups, how to find files in your system and change their attributes, along with a few tricks that can make your life easier and will prevent you from running into future issues.
+
+I hope that the tips provided in the present article will help you to achieve that goal. Feel free to add your own tips and ideas in the comments section for the benefit of the community. Thanks in advance!
+Reference Links
+
+- [About the LFCS][4]
+- [Why get a Linux Foundation Certification?][5]
+- [Register for the LFCS exam][6]
+
+--------------------------------------------------------------------------------
+
+via: http://www.tecmint.com/compress-files-and-finding-files-in-linux/
+
+作者:[Gabriel Cánepa][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.tecmint.com/author/gacanepa/
+[1]:http://www.tecmint.com/18-tar-command-examples-in-linux/
+[2]:http://www.tecmint.com/dtrx-an-intelligent-archive-extraction-tar-zip-cpio-rpm-deb-rar-tool-for-linux/
+[3]:http://www.tecmint.com/35-practical-examples-of-linux-find-command/
+[4]:https://training.linuxfoundation.org/certification/LFCS
+[5]:https://training.linuxfoundation.org/certification/why-certify-with-us
+[6]:https://identity.linuxfoundation.org/user?destination=pid/1
\ No newline at end of file
diff --git a/sources/tech/LFCS/Part 4 - LFCS--Partitioning Storage Devices Formatting Filesystems and Configuring Swap Partition.md b/sources/tech/LFCS/Part 4 - LFCS--Partitioning Storage Devices Formatting Filesystems and Configuring Swap Partition.md
new file mode 100644
index 0000000000..ada637fabb
--- /dev/null
+++ b/sources/tech/LFCS/Part 4 - LFCS--Partitioning Storage Devices Formatting Filesystems and Configuring Swap Partition.md
@@ -0,0 +1,191 @@
+Part 4 - LFCS: Partitioning Storage Devices, Formatting Filesystems and Configuring Swap Partition
+================================================================================
+Last August, the Linux Foundation launched the LFCS certification (Linux Foundation Certified Sysadmin), a shiny chance for system administrators to show, through a performance-based exam, that they can perform overall operational support of Linux systems: system support, first-level diagnosing and monitoring, plus issue escalation – if needed – to other support teams.
+
+
+
+Linux Foundation Certified Sysadmin – Part 4
+
+Please aware that Linux Foundation certifications are precise, totally based on performance and available through an online portal anytime, anywhere. Thus, you no longer have to travel to a examination center to get the certifications you need to establish your skills and expertise.
+
+Please watch the below video that explains The Linux Foundation Certification Program.
+
+注:youtube 视频
+
+
+This post is Part 4 of a 10-tutorial series, here in this part, we will cover the Partitioning storage devices, Formatting filesystems and Configuring swap partition, that are required for the LFCS certification exam.
+
+### Partitioning Storage Devices ###
+
+Partitioning is a means to divide a single hard drive into one or more parts or “slices” called partitions. A partition is a section on a drive that is treated as an independent disk and which contains a single type of file system, whereas a partition table is an index that relates those physical sections of the hard drive to partition identifications.
+
+In Linux, the traditional tool for managing MBR partitions (up to ~2009) in IBM PC compatible systems is fdisk. For GPT partitions (~2010 and later) we will use gdisk. Each of these tools can be invoked by typing its name followed by a device name (such as /dev/sdb).
+
+#### Managing MBR Partitions with fdisk ####
+
+We will cover fdisk first.
+
+ # fdisk /dev/sdb
+
+A prompt appears asking for the next operation. If you are unsure, you can press the ‘m‘ key to display the help contents.
+
+
+
+fdisk Help Menu
+
+In the above image, the most frequently used options are highlighted. At any moment, you can press ‘p‘ to display the current partition table.
+
+
+
+Show Partition Table
+
+The Id column shows the partition type (or partition id) that has been assigned by fdisk to the partition. A partition type serves as an indicator of the file system, the partition contains or, in simple words, the way data will be accessed in that partition.
+
+Please note that a comprehensive study of each partition type is out of the scope of this tutorial – as this series is focused on the LFCS exam, which is performance-based.
+
+**Some of the options used by fdisk as follows:**
+
+You can list all the partition types that can be managed by fdisk by pressing the ‘l‘ option (lowercase l).
+
+Press ‘d‘ to delete an existing partition. If more than one partition is found in the drive, you will be asked which one should be deleted.
+
+Enter the corresponding number, and then press ‘w‘ (write modifications to partition table) to apply changes.
+
+In the following example, we will delete /dev/sdb2, and then print (p) the partition table to verify the modifications.
+
+
+
+fdisk Command Options
+
+Press ‘n‘ to create a new partition, then ‘p‘ to indicate it will be a primary partition. Finally, you can accept all the default values (in which case the partition will occupy all the available space), or specify a size as follows.
+
+
+
+Create New Partition
+
+If the partition Id that fdisk chose is not the right one for our setup, we can press ‘t‘ to change it.
+
+
+
+Change Partition Name
+
+When you’re done setting up the partitions, press ‘w‘ to commit the changes to disk.
+
+
+
+Save Partition Changes
+
+#### Managing GPT Partitions with gdisk ####
+
+In the following example, we will use /dev/sdb.
+
+ # gdisk /dev/sdb
+
+We must note that gdisk can be used either to create MBR or GPT partitions.
+
+
+
+Create GPT Partitions
+
+The advantage of using GPT partitioning is that we can create up to 128 partitions in the same disk whose size can be up to the order of petabytes, whereas the maximum size for MBR partitions is 2 TB.
+
+Note that most of the options in fdisk are the same in gdisk. For that reason, we will not go into detail about them, but here’s a screenshot of the process.
+
+
+
+gdisk Command Options
+
+### Formatting Filesystems ###
+
+Once we have created all the necessary partitions, we must create filesystems. To find out the list of filesystems supported in your system, run.
+
+ # ls /sbin/mk*
+
+
+
+Check Filesystems Type
+
+The type of filesystem that you should choose depends on your requirements. You should consider the pros and cons of each filesystem and its own set of features. Two important attributes to look for in a filesystem are.
+
+- Journaling support, which allows for faster data recovery in the event of a system crash.
+- Security Enhanced Linux (SELinux) support, as per the project wiki, “a security enhancement to Linux which allows users and administrators more control over access control”.
+
+In our next example, we will create an ext4 filesystem (supports both journaling and SELinux) labeled Tecmint on /dev/sdb1, using mkfs, whose basic syntax is.
+
+ # mkfs -t [filesystem] -L [label] device
+ or
+ # mkfs.[filesystem] -L [label] device
+
+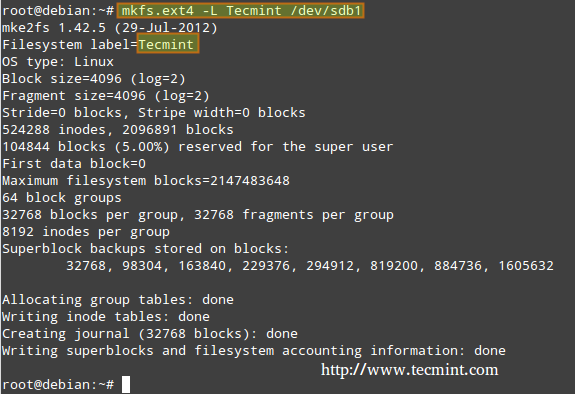
+
+Create ext4 Filesystems
+
+### Creating and Using Swap Partitions ###
+
+Swap partitions are necessary if we need our Linux system to have access to virtual memory, which is a section of the hard disk designated for use as memory, when the main system memory (RAM) is all in use. For that reason, a swap partition may not be needed on systems with enough RAM to meet all its requirements; however, even in that case it’s up to the system administrator to decide whether to use a swap partition or not.
+
+A simple rule of thumb to decide the size of a swap partition is as follows.
+
+Swap should usually equal 2x physical RAM for up to 2 GB of physical RAM, and then an additional 1x physical RAM for any amount above 2 GB, but never less than 32 MB.
+
+So, if:
+
+M = Amount of RAM in GB, and S = Amount of swap in GB, then
+
+ If M < 2
+ S = M *2
+ Else
+ S = M + 2
+
+Remember this is just a formula and that only you, as a sysadmin, have the final word as to the use and size of a swap partition.
+
+To configure a swap partition, create a regular partition as demonstrated earlier with the desired size. Next, we need to add the following entry to the /etc/fstab file (X can be either b or c).
+
+ /dev/sdX1 swap swap sw 0 0
+
+Finally, let’s format and enable the swap partition.
+
+ # mkswap /dev/sdX1
+ # swapon -v /dev/sdX1
+
+To display a snapshot of the swap partition(s).
+
+ # cat /proc/swaps
+
+To disable the swap partition.
+
+ # swapoff /dev/sdX1
+
+For the next example, we’ll use /dev/sdc1 (=512 MB, for a system with 256 MB of RAM) to set up a partition with fdisk that we will use as swap, following the steps detailed above. Note that we will specify a fixed size in this case.
+
+
+
+Create Swap Partition
+
+
+
+Enable Swap Partition
+
+### Conclusion ###
+
+Creating partitions (including swap) and formatting filesystems are crucial in your road to Sysadminship. I hope that the tips given in this article will guide you to achieve your goals. Feel free to add your own tips & ideas in the comments section below, for the benefit of the community.
+Reference Links
+
+- [About the LFCS][1]
+- [Why get a Linux Foundation Certification?][2]
+- [Register for the LFCS exam][3]
+
+--------------------------------------------------------------------------------
+
+via: http://www.tecmint.com/create-partitions-and-filesystems-in-linux/
+
+作者:[Gabriel Cánepa][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.tecmint.com/author/gacanepa/
+[1]:https://training.linuxfoundation.org/certification/LFCS
+[2]:https://training.linuxfoundation.org/certification/why-certify-with-us
+[3]:https://identity.linuxfoundation.org/user?destination=pid/1
\ No newline at end of file
diff --git a/sources/tech/LFCS/Part 5 - LFCS--How to Mount or Unmount Local and Network Samba and NFS Filesystems in Linux.md b/sources/tech/LFCS/Part 5 - LFCS--How to Mount or Unmount Local and Network Samba and NFS Filesystems in Linux.md
new file mode 100644
index 0000000000..1544a378bc
--- /dev/null
+++ b/sources/tech/LFCS/Part 5 - LFCS--How to Mount or Unmount Local and Network Samba and NFS Filesystems in Linux.md
@@ -0,0 +1,232 @@
+Part 5 - LFCS: How to Mount/Unmount Local and Network (Samba & NFS) Filesystems in Linux
+================================================================================
+The Linux Foundation launched the LFCS certification (Linux Foundation Certified Sysadmin), a brand new program whose purpose is allowing individuals from all corners of the globe to get certified in basic to intermediate system administration tasks for Linux systems, which includes supporting running systems and services, along with overall monitoring and analysis, plus smart decision-making when it comes to raising issues to upper support teams.
+
+
+
+Linux Foundation Certified Sysadmin – Part 5
+
+The following video shows an introduction to The Linux Foundation Certification Program.
+
+注:youtube 视频
+
+
+This post is Part 5 of a 10-tutorial series, here in this part, we will explain How to mount/unmount local and network filesystems in linux, that are required for the LFCS certification exam.
+
+### Mounting Filesystems ###
+
+Once a disk has been partitioned, Linux needs some way to access the data on the partitions. Unlike DOS or Windows (where this is done by assigning a drive letter to each partition), Linux uses a unified directory tree where each partition is mounted at a mount point in that tree.
+
+A mount point is a directory that is used as a way to access the filesystem on the partition, and mounting the filesystem is the process of associating a certain filesystem (a partition, for example) with a specific directory in the directory tree.
+
+In other words, the first step in managing a storage device is attaching the device to the file system tree. This task can be accomplished on a one-time basis by using tools such as mount (and then unmounted with umount) or persistently across reboots by editing the /etc/fstab file.
+
+The mount command (without any options or arguments) shows the currently mounted filesystems.
+
+ # mount
+
+
+
+Check Mounted Filesystem
+
+In addition, mount is used to mount filesystems into the filesystem tree. Its standard syntax is as follows.
+
+ # mount -t type device dir -o options
+
+This command instructs the kernel to mount the filesystem found on device (a partition, for example, that has been formatted with a filesystem type) at the directory dir, using all options. In this form, mount does not look in /etc/fstab for instructions.
+
+If only a directory or device is specified, for example.
+
+ # mount /dir -o options
+ or
+ # mount device -o options
+
+mount tries to find a mount point and if it can’t find any, then searches for a device (both cases in the /etc/fstab file), and finally attempts to complete the mount operation (which usually succeeds, except for the case when either the directory or the device is already being used, or when the user invoking mount is not root).
+
+You will notice that every line in the output of mount has the following format.
+
+ device on directory type (options)
+
+For example,
+
+ /dev/mapper/debian-home on /home type ext4 (rw,relatime,user_xattr,barrier=1,data=ordered)
+
+Reads:
+
+dev/mapper/debian-home is mounted on /home, which has been formatted as ext4, with the following options: rw,relatime,user_xattr,barrier=1,data=ordered
+
+**Mount Options**
+
+Most frequently used mount options include.
+
+- async: allows asynchronous I/O operations on the file system being mounted.
+- auto: marks the file system as enabled to be mounted automatically using mount -a. It is the opposite of noauto.
+- defaults: this option is an alias for async,auto,dev,exec,nouser,rw,suid. Note that multiple options must be separated by a comma without any spaces. If by accident you type a space between options, mount will interpret the subsequent text string as another argument.
+- loop: Mounts an image (an .iso file, for example) as a loop device. This option can be used to simulate the presence of the disk’s contents in an optical media reader.
+- noexec: prevents the execution of executable files on the particular filesystem. It is the opposite of exec.
+- nouser: prevents any users (other than root) to mount and unmount the filesystem. It is the opposite of user.
+- remount: mounts the filesystem again in case it is already mounted.
+- ro: mounts the filesystem as read only.
+- rw: mounts the file system with read and write capabilities.
+- relatime: makes access time to files be updated only if atime is earlier than mtime.
+- user_xattr: allow users to set and remote extended filesystem attributes.
+
+**Mounting a device with ro and noexec options**
+
+ # mount -t ext4 /dev/sdg1 /mnt -o ro,noexec
+
+In this case we can see that attempts to write a file to or to run a binary file located inside our mounting point fail with corresponding error messages.
+
+ # touch /mnt/myfile
+ # /mnt/bin/echo “Hi there”
+
+
+
+Mount Device Read Write
+
+**Mounting a device with default options**
+
+In the following scenario, we will try to write a file to our newly mounted device and run an executable file located within its filesystem tree using the same commands as in the previous example.
+
+ # mount -t ext4 /dev/sdg1 /mnt -o defaults
+
+
+
+Mount Device
+
+In this last case, it works perfectly.
+
+### Unmounting Devices ###
+
+Unmounting a device (with the umount command) means finish writing all the remaining “on transit” data so that it can be safely removed. Note that if you try to remove a mounted device without properly unmounting it first, you run the risk of damaging the device itself or cause data loss.
+
+That being said, in order to unmount a device, you must be “standing outside” its block device descriptor or mount point. In other words, your current working directory must be something else other than the mounting point. Otherwise, you will get a message saying that the device is busy.
+
+
+
+Unmount Device
+
+An easy way to “leave” the mounting point is typing the cd command which, in lack of arguments, will take us to our current user’s home directory, as shown above.
+
+### Mounting Common Networked Filesystems ###
+
+The two most frequently used network file systems are SMB (which stands for “Server Message Block”) and NFS (“Network File System”). Chances are you will use NFS if you need to set up a share for Unix-like clients only, and will opt for Samba if you need to share files with Windows-based clients and perhaps other Unix-like clients as well.
+
+Read Also
+
+- [Setup Samba Server in RHEL/CentOS and Fedora][1]
+- [Setting up NFS (Network File System) on RHEL/CentOS/Fedora and Debian/Ubuntu][2]
+
+The following steps assume that Samba and NFS shares have already been set up in the server with IP 192.168.0.10 (please note that setting up a NFS share is one of the competencies required for the LFCE exam, which we will cover after the present series).
+
+#### Mounting a Samba share on Linux ####
+
+Step 1: Install the samba-client samba-common and cifs-utils packages on Red Hat and Debian based distributions.
+
+ # yum update && yum install samba-client samba-common cifs-utils
+ # aptitude update && aptitude install samba-client samba-common cifs-utils
+
+Then run the following command to look for available samba shares in the server.
+
+ # smbclient -L 192.168.0.10
+
+And enter the password for the root account in the remote machine.
+
+
+
+Mount Samba Share
+
+In the above image we have highlighted the share that is ready for mounting on our local system. You will need a valid samba username and password on the remote server in order to access it.
+
+Step 2: When mounting a password-protected network share, it is not a good idea to write your credentials in the /etc/fstab file. Instead, you can store them in a hidden file somewhere with permissions set to 600, like so.
+
+ # mkdir /media/samba
+ # echo “username=samba_username” > /media/samba/.smbcredentials
+ # echo “password=samba_password” >> /media/samba/.smbcredentials
+ # chmod 600 /media/samba/.smbcredentials
+
+Step 3: Then add the following line to /etc/fstab file.
+
+ # //192.168.0.10/gacanepa /media/samba cifs credentials=/media/samba/.smbcredentials,defaults 0 0
+
+Step 4: You can now mount your samba share, either manually (mount //192.168.0.10/gacanepa) or by rebooting your machine so as to apply the changes made in /etc/fstab permanently.
+
+
+
+Mount Password Protect Samba Share
+
+#### Mounting a NFS share on Linux ####
+
+Step 1: Install the nfs-common and portmap packages on Red Hat and Debian based distributions.
+
+ # yum update && yum install nfs-utils nfs-utils-lib
+ # aptitude update && aptitude install nfs-common
+
+Step 2: Create a mounting point for the NFS share.
+
+ # mkdir /media/nfs
+
+Step 3: Add the following line to /etc/fstab file.
+
+192.168.0.10:/NFS-SHARE /media/nfs nfs defaults 0 0
+
+Step 4: You can now mount your nfs share, either manually (mount 192.168.0.10:/NFS-SHARE) or by rebooting your machine so as to apply the changes made in /etc/fstab permanently.
+
+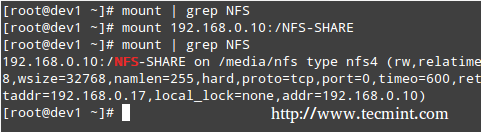
+
+Mount NFS Share
+
+### Mounting Filesystems Permanently ###
+
+As shown in the previous two examples, the /etc/fstab file controls how Linux provides access to disk partitions and removable media devices and consists of a series of lines that contain six fields each; the fields are separated by one or more spaces or tabs. A line that begins with a hash mark (#) is a comment and is ignored.
+
+Each line has the following format.
+
+
+
+Where:
+
+- : The first column specifies the mount device. Most distributions now specify partitions by their labels or UUIDs. This practice can help reduce problems if partition numbers change.
+- : The second column specifies the mount point.
+- : The file system type code is the same as the type code used to mount a filesystem with the mount command. A file system type code of auto lets the kernel auto-detect the filesystem type, which can be a convenient option for removable media devices. Note that this option may not be available for all filesystems out there.
+- : One (or more) mount option(s).
+- : You will most likely leave this to 0 (otherwise set it to 1) to disable the dump utility to backup the filesystem upon boot (The dump program was once a common backup tool, but it is much less popular today.)
+- : This column specifies whether the integrity of the filesystem should be checked at boot time with fsck. A 0 means that fsck should not check a filesystem. The higher the number, the lowest the priority. Thus, the root partition will most likely have a value of 1, while all others that should be checked should have a value of 2.
+
+**Mount Examples**
+
+1. To mount a partition with label TECMINT at boot time with rw and noexec attributes, you should add the following line in /etc/fstab file.
+
+ LABEL=TECMINT /mnt ext4 rw,noexec 0 0
+
+2. If you want the contents of a disk in your DVD drive be available at boot time.
+
+ /dev/sr0 /media/cdrom0 iso9660 ro,user,noauto 0 0
+
+Where /dev/sr0 is your DVD drive.
+
+### Summary ###
+
+You can rest assured that mounting and unmounting local and network filesystems from the command line will be part of your day-to-day responsibilities as sysadmin. You will also need to master /etc/fstab. I hope that you have found this article useful to help you with those tasks. Feel free to add your comments (or ask questions) below and to share this article through your network social profiles.
+Reference Links
+
+- [About the LFCS][3]
+- [Why get a Linux Foundation Certification?][4]
+- [Register for the LFCS exam][5]
+
+--------------------------------------------------------------------------------
+
+via: http://www.tecmint.com/mount-filesystem-in-linux/
+
+作者:[Gabriel Cánepa][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.tecmint.com/author/gacanepa/
+[1]:http://www.tecmint.com/setup-samba-server-using-tdbsam-backend-on-rhel-centos-6-3-5-8-and-fedora-17-12/
+[2]:http://www.tecmint.com/how-to-setup-nfs-server-in-linux/
+[3]:https://training.linuxfoundation.org/certification/LFCS
+[4]:https://training.linuxfoundation.org/certification/why-certify-with-us
+[5]:https://identity.linuxfoundation.org/user?destination=pid/1
\ No newline at end of file
diff --git a/sources/tech/LFCS/Part 6 - LFCS--Assembling Partitions as RAID Devices – Creating & Managing System Backups.md b/sources/tech/LFCS/Part 6 - LFCS--Assembling Partitions as RAID Devices – Creating & Managing System Backups.md
new file mode 100644
index 0000000000..fd23db110f
--- /dev/null
+++ b/sources/tech/LFCS/Part 6 - LFCS--Assembling Partitions as RAID Devices – Creating & Managing System Backups.md
@@ -0,0 +1,276 @@
+Part 6 - LFCS: Assembling Partitions as RAID Devices – Creating & Managing System Backups
+================================================================================
+Recently, the Linux Foundation launched the LFCS (Linux Foundation Certified Sysadmin) certification, a shiny chance for system administrators everywhere to demonstrate, through a performance-based exam, that they are capable of performing overall operational support on Linux systems: system support, first-level diagnosing and monitoring, plus issue escalation, when required, to other support teams.
+
+
+
+Linux Foundation Certified Sysadmin – Part 6
+
+The following video provides an introduction to The Linux Foundation Certification Program.
+
+注:youtube 视频
+
+
+This post is Part 6 of a 10-tutorial series, here in this part, we will explain How to Assemble Partitions as RAID Devices – Creating & Managing System Backups, that are required for the LFCS certification exam.
+
+### Understanding RAID ###
+
+The technology known as Redundant Array of Independent Disks (RAID) is a storage solution that combines multiple hard disks into a single logical unit to provide redundancy of data and/or improve performance in read / write operations to disk.
+
+However, the actual fault-tolerance and disk I/O performance lean on how the hard disks are set up to form the disk array. Depending on the available devices and the fault tolerance / performance needs, different RAID levels are defined. You can refer to the RAID series here in Tecmint.com for a more detailed explanation on each RAID level.
+
+- RAID Guide: [What is RAID, Concepts of RAID and RAID Levels Explained][1]
+
+Our tool of choice for creating, assembling, managing, and monitoring our software RAIDs is called mdadm (short for multiple disks admin).
+
+ ---------------- Debian and Derivatives ----------------
+ # aptitude update && aptitude install mdadm
+
+----------
+
+ ---------------- Red Hat and CentOS based Systems ----------------
+ # yum update && yum install mdadm
+
+----------
+
+ ---------------- On openSUSE ----------------
+ # zypper refresh && zypper install mdadm #
+
+#### Assembling Partitions as RAID Devices ####
+
+The process of assembling existing partitions as RAID devices consists of the following steps.
+
+**1. Create the array using mdadm**
+
+If one of the partitions has been formatted previously, or has been a part of another RAID array previously, you will be prompted to confirm the creation of the new array. Assuming you have taken the necessary precautions to avoid losing important data that may have resided in them, you can safely type y and press Enter.
+
+ # mdadm --create --verbose /dev/md0 --level=stripe --raid-devices=2 /dev/sdb1 /dev/sdc1
+
+
+
+Creating RAID Array
+
+**2. Check the array creation status**
+
+After creating RAID array, you an check the status of the array using the following commands.
+
+ # cat /proc/mdstat
+ or
+ # mdadm --detail /dev/md0 [More detailed summary]
+
+
+
+Check RAID Array Status
+
+**3. Format the RAID Device**
+
+Format the device with a filesystem as per your needs / requirements, as explained in [Part 4][2] of this series.
+
+**4. Monitor RAID Array Service**
+
+Instruct the monitoring service to “keep an eye” on the array. Add the output of mdadm –detail –scan to /etc/mdadm/mdadm.conf (Debian and derivatives) or /etc/mdadm.conf (CentOS / openSUSE), like so.
+
+ # mdadm --detail --scan
+
+
+
+Monitor RAID Array
+
+ # mdadm --assemble --scan [Assemble the array]
+
+To ensure the service starts on system boot, run the following commands as root.
+
+**Debian and Derivatives**
+
+Debian and derivatives, though it should start running on boot by default.
+
+ # update-rc.d mdadm defaults
+
+Edit the /etc/default/mdadm file and add the following line.
+
+ AUTOSTART=true
+
+**On CentOS and openSUSE (systemd-based)**
+
+ # systemctl start mdmonitor
+ # systemctl enable mdmonitor
+
+**On CentOS and openSUSE (SysVinit-based)**
+
+ # service mdmonitor start
+ # chkconfig mdmonitor on
+
+**5. Check RAID Disk Failure**
+
+In RAID levels that support redundancy, replace failed drives when needed. When a device in the disk array becomes faulty, a rebuild automatically starts only if there was a spare device added when we first created the array.
+
+
+
+Check RAID Faulty Disk
+
+Otherwise, we need to manually attach an extra physical drive to our system and run.
+
+ # mdadm /dev/md0 --add /dev/sdX1
+
+Where /dev/md0 is the array that experienced the issue and /dev/sdX1 is the new device.
+
+**6. Disassemble a working array**
+
+You may have to do this if you need to create a new array using the devices – (Optional Step).
+
+ # mdadm --stop /dev/md0 # Stop the array
+ # mdadm --remove /dev/md0 # Remove the RAID device
+ # mdadm --zero-superblock /dev/sdX1 # Overwrite the existing md superblock with zeroes
+
+**7. Set up mail alerts**
+
+You can configure a valid email address or system account to send alerts to (make sure you have this line in mdadm.conf). – (Optional Step)
+
+ MAILADDR root
+
+In this case, all alerts that the RAID monitoring daemon collects will be sent to the local root account’s mail box. One of such alerts looks like the following.
+
+**Note**: This event is related to the example in STEP 5, where a device was marked as faulty and the spare device was automatically built into the array by mdadm. Thus, we “ran out” of healthy spare devices and we got the alert.
+
+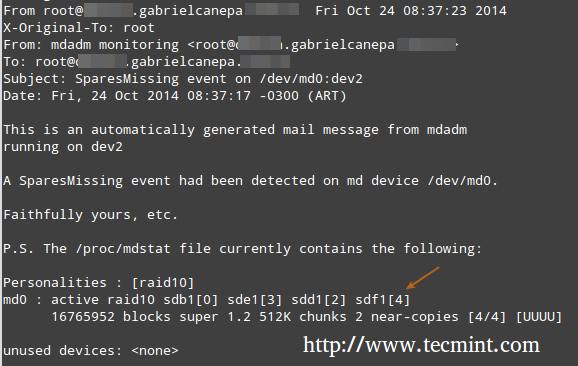
+
+RAID Monitoring Alerts
+
+#### Understanding RAID Levels ####
+
+**RAID 0**
+
+The total array size is n times the size of the smallest partition, where n is the number of independent disks in the array (you will need at least two drives). Run the following command to assemble a RAID 0 array using partitions /dev/sdb1 and /dev/sdc1.
+
+ # mdadm --create --verbose /dev/md0 --level=stripe --raid-devices=2 /dev/sdb1 /dev/sdc1
+
+Common uses: Setups that support real-time applications where performance is more important than fault-tolerance.
+
+**RAID 1 (aka Mirroring)**
+
+The total array size equals the size of the smallest partition (you will need at least two drives). Run the following command to assemble a RAID 1 array using partitions /dev/sdb1 and /dev/sdc1.
+
+ # mdadm --create --verbose /dev/md0 --level=1 --raid-devices=2 /dev/sdb1 /dev/sdc1
+
+Common uses: Installation of the operating system or important subdirectories, such as /home.
+
+**RAID 5 (aka drives with Parity)**
+
+The total array size will be (n – 1) times the size of the smallest partition. The “lost” space in (n-1) is used for parity (redundancy) calculation (you will need at least three drives).
+
+Note that you can specify a spare device (/dev/sde1 in this case) to replace a faulty part when an issue occurs. Run the following command to assemble a RAID 5 array using partitions /dev/sdb1, /dev/sdc1, /dev/sdd1, and /dev/sde1 as spare.
+
+ # mdadm --create --verbose /dev/md0 --level=5 --raid-devices=3 /dev/sdb1 /dev/sdc1 /dev/sdd1 --spare-devices=1 /dev/sde1
+
+Common uses: Web and file servers.
+
+**RAID 6 (aka drives with double Parity**
+
+The total array size will be (n*s)-2*s, where n is the number of independent disks in the array and s is the size of the smallest disk. Note that you can specify a spare device (/dev/sdf1 in this case) to replace a faulty part when an issue occurs.
+
+Run the following command to assemble a RAID 6 array using partitions /dev/sdb1, /dev/sdc1, /dev/sdd1, /dev/sde1, and /dev/sdf1 as spare.
+
+ # mdadm --create --verbose /dev/md0 --level=6 --raid-devices=4 /dev/sdb1 /dev/sdc1 /dev/sdd1 /dev/sde --spare-devices=1 /dev/sdf1
+
+Common uses: File and backup servers with large capacity and high availability requirements.
+
+**RAID 1+0 (aka stripe of mirrors)**
+
+The total array size is computed based on the formulas for RAID 0 and RAID 1, since RAID 1+0 is a combination of both. First, calculate the size of each mirror and then the size of the stripe.
+
+Note that you can specify a spare device (/dev/sdf1 in this case) to replace a faulty part when an issue occurs. Run the following command to assemble a RAID 1+0 array using partitions /dev/sdb1, /dev/sdc1, /dev/sdd1, /dev/sde1, and /dev/sdf1 as spare.
+
+ # mdadm --create --verbose /dev/md0 --level=10 --raid-devices=4 /dev/sd[b-e]1 --spare-devices=1 /dev/sdf1
+
+Common uses: Database and application servers that require fast I/O operations.
+
+#### Creating and Managing System Backups ####
+
+It never hurts to remember that RAID with all its bounties IS NOT A REPLACEMENT FOR BACKUPS! Write it 1000 times on the chalkboard if you need to, but make sure you keep that idea in mind at all times. Before we begin, we must note that there is no one-size-fits-all solution for system backups, but here are some things that you do need to take into account while planning a backup strategy.
+
+- What do you use your system for? (Desktop or server? If the latter case applies, what are the most critical services – whose configuration would be a real pain to lose?)
+- How often do you need to take backups of your system?
+- What is the data (e.g. files / directories / database dumps) that you want to backup? You may also want to consider if you really need to backup huge files (such as audio or video files).
+- Where (meaning physical place and media) will those backups be stored?
+
+**Backing Up Your Data**
+
+Method 1: Backup entire drives with dd command. You can either back up an entire hard disk or a partition by creating an exact image at any point in time. Note that this works best when the device is offline, meaning it’s not mounted and there are no processes accessing it for I/O operations.
+
+The downside of this backup approach is that the image will have the same size as the disk or partition, even when the actual data occupies a small percentage of it. For example, if you want to image a partition of 20 GB that is only 10% full, the image file will still be 20 GB in size. In other words, it’s not only the actual data that gets backed up, but the entire partition itself. You may consider using this method if you need exact backups of your devices.
+
+**Creating an image file out of an existing device**
+
+ # dd if=/dev/sda of=/system_images/sda.img
+ OR
+ --------------------- Alternatively, you can compress the image file ---------------------
+ # dd if=/dev/sda | gzip -c > /system_images/sda.img.gz
+
+**Restoring the backup from the image file**
+
+ # dd if=/system_images/sda.img of=/dev/sda
+ OR
+
+ --------------------- Depending on your choice while creating the image ---------------------
+ gzip -dc /system_images/sda.img.gz | dd of=/dev/sda
+
+Method 2: Backup certain files / directories with tar command – already covered in [Part 3][3] of this series. You may consider using this method if you need to keep copies of specific files and directories (configuration files, users’ home directories, and so on).
+
+Method 3: Synchronize files with rsync command. Rsync is a versatile remote (and local) file-copying tool. If you need to backup and synchronize your files to/from network drives, rsync is a go.
+
+Whether you’re synchronizing two local directories or local < — > remote directories mounted on the local filesystem, the basic syntax is the same.
+Synchronizing two local directories or local < — > remote directories mounted on the local filesystem
+
+ # rsync -av source_directory destination directory
+
+Where, -a recurse into subdirectories (if they exist), preserve symbolic links, timestamps, permissions, and original owner / group and -v verbose.
+
+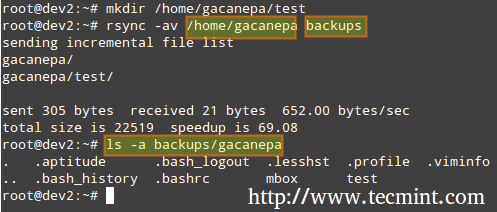
+
+rsync Synchronizing Files
+
+In addition, if you want to increase the security of the data transfer over the wire, you can use ssh over rsync.
+
+**Synchronizing local → remote directories over ssh**
+
+ # rsync -avzhe ssh backups root@remote_host:/remote_directory/
+
+This example will synchronize the backups directory on the local host with the contents of /root/remote_directory on the remote host.
+
+Where the -h option shows file sizes in human-readable format, and the -e flag is used to indicate a ssh connection.
+
+
+
+rsync Synchronize Remote Files
+
+Synchronizing remote → local directories over ssh.
+
+In this case, switch the source and destination directories from the previous example.
+
+ # rsync -avzhe ssh root@remote_host:/remote_directory/ backups
+
+Please note that these are only 3 examples (most frequent cases you’re likely to run into) of the use of rsync. For more examples and usages of rsync commands can be found at the following article.
+
+- Read Also: [10 rsync Commands to Sync Files in Linux][4]
+
+### Summary ###
+
+As a sysadmin, you need to ensure that your systems perform as good as possible. If you’re well prepared, and if the integrity of your data is well supported by a storage technology such as RAID and regular system backups, you’ll be safe.
+
+If you have questions, comments, or further ideas on how this article can be improved, feel free to speak out below. In addition, please consider sharing this series through your social network profiles.
+
+--------------------------------------------------------------------------------
+
+via: http://www.tecmint.com/creating-and-managing-raid-backups-in-linux/
+
+作者:[Gabriel Cánepa][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.tecmint.com/author/gacanepa/
+[1]:http://www.tecmint.com/understanding-raid-setup-in-linux/
+[2]:http://www.tecmint.com/create-partitions-and-filesystems-in-linux/
+[3]:http://www.tecmint.com/compress-files-and-finding-files-in-linux/
+[4]:http://www.tecmint.com/rsync-local-remote-file-synchronization-commands/
\ No newline at end of file
diff --git a/sources/tech/LFCS/Part 7 - LFCS--Managing System Startup Process and Services SysVinit Systemd and Upstart.md b/sources/tech/LFCS/Part 7 - LFCS--Managing System Startup Process and Services SysVinit Systemd and Upstart.md
new file mode 100644
index 0000000000..abf09ee523
--- /dev/null
+++ b/sources/tech/LFCS/Part 7 - LFCS--Managing System Startup Process and Services SysVinit Systemd and Upstart.md
@@ -0,0 +1,367 @@
+Part 7 - LFCS: Managing System Startup Process and Services (SysVinit, Systemd and Upstart)
+================================================================================
+A couple of months ago, the Linux Foundation announced the LFCS (Linux Foundation Certified Sysadmin) certification, an exciting new program whose aim is allowing individuals from all ends of the world to get certified in performing basic to intermediate system administration tasks on Linux systems. This includes supporting already running systems and services, along with first-hand problem-finding and analysis, plus the ability to decide when to raise issues to engineering teams.
+
+
+
+Linux Foundation Certified Sysadmin – Part 7
+
+The following video describes an brief introduction to The Linux Foundation Certification Program.
+
+注:youtube 视频
+
+
+This post is Part 7 of a 10-tutorial series, here in this part, we will explain how to Manage Linux System Startup Process and Services, that are required for the LFCS certification exam.
+
+### Managing the Linux Startup Process ###
+
+The boot process of a Linux system consists of several phases, each represented by a different component. The following diagram briefly summarizes the boot process and shows all the main components involved.
+
+
+
+Linux Boot Process
+
+When you press the Power button on your machine, the firmware that is stored in a EEPROM chip in the motherboard initializes the POST (Power-On Self Test) to check on the state of the system’s hardware resources. When the POST is finished, the firmware then searches and loads the 1st stage boot loader, located in the MBR or in the EFI partition of the first available disk, and gives control to it.
+
+#### MBR Method ####
+
+The MBR is located in the first sector of the disk marked as bootable in the BIOS settings and is 512 bytes in size.
+
+- First 446 bytes: The bootloader contains both executable code and error message text.
+- Next 64 bytes: The Partition table contains a record for each of four partitions (primary or extended). Among other things, each record indicates the status (active / not active), size, and start / end sectors of each partition.
+- Last 2 bytes: The magic number serves as a validation check of the MBR.
+
+The following command performs a backup of the MBR (in this example, /dev/sda is the first hard disk). The resulting file, mbr.bkp can come in handy should the partition table become corrupt, for example, rendering the system unbootable.
+
+Of course, in order to use it later if the need arises, we will need to save it and store it somewhere else (like a USB drive, for example). That file will help us restore the MBR and will get us going once again if and only if we do not change the hard drive layout in the meanwhile.
+
+**Backup MBR**
+
+ # dd if=/dev/sda of=mbr.bkp bs=512 count=1
+
+
+
+Backup MBR in Linux
+
+**Restoring MBR**
+
+ # dd if=mbr.bkp of=/dev/sda bs=512 count=1
+
+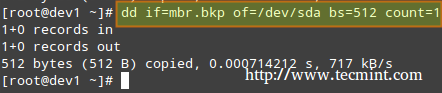
+
+Restore MBR in Linux
+
+#### EFI/UEFI Method ####
+
+For systems using the EFI/UEFI method, the UEFI firmware reads its settings to determine which UEFI application is to be launched and from where (i.e., in which disk and partition the EFI partition is located).
+
+Next, the 2nd stage boot loader (aka boot manager) is loaded and run. GRUB [GRand Unified Boot] is the most frequently used boot manager in Linux. One of two distinct versions can be found on most systems used today.
+
+- GRUB legacy configuration file: /boot/grub/menu.lst (older distributions, not supported by EFI/UEFI firmwares).
+- GRUB2 configuration file: most likely, /etc/default/grub.
+
+Although the objectives of the LFCS exam do not explicitly request knowledge about GRUB internals, if you’re brave and can afford to mess up your system (you may want to try it first on a virtual machine, just in case), you need to run.
+
+ # update-grub
+
+As root after modifying GRUB’s configuration in order to apply the changes.
+
+Basically, GRUB loads the default kernel and the initrd or initramfs image. In few words, initrd or initramfs help to perform the hardware detection, the kernel module loading and the device discovery necessary to get the real root filesystem mounted.
+
+Once the real root filesystem is up, the kernel executes the system and service manager (init or systemd, whose process identification or PID is always 1) to begin the normal user-space boot process in order to present a user interface.
+
+Both init and systemd are daemons (background processes) that manage other daemons, as the first service to start (during boot) and the last service to terminate (during shutdown).
+
+
+
+Systemd and Init
+
+### Starting Services (SysVinit) ###
+
+The concept of runlevels in Linux specifies different ways to use a system by controlling which services are running. In other words, a runlevel controls what tasks can be accomplished in the current execution state = runlevel (and which ones cannot).
+
+Traditionally, this startup process was performed based on conventions that originated with System V UNIX, with the system passing executing collections of scripts that start and stop services as the machine entered a specific runlevel (which, in other words, is a different mode of running the system).
+
+Within each runlevel, individual services can be set to run, or to be shut down if running. Latest versions of some major distributions are moving away from the System V standard in favour of a rather new service and system manager called systemd (which stands for system daemon), but usually support sysv commands for compatibility purposes. This means that you can run most of the well-known sysv init tools in a systemd-based distribution.
+
+- Read Also: [Why ‘systemd’ replaces ‘init’ in Linux][1]
+
+Besides starting the system process, init looks to the /etc/inittab file to decide what runlevel must be entered.
+
+注:表格
+
+
+
+
+
+
+
+
Runlevel
+
Description
+
+
+
0
+
Halt the system. Runlevel 0 is a special transitional state used to shutdown the system quickly.
+
+
+
1
+
Also aliased to s, or S, this runlevel is sometimes called maintenance mode. What services, if any, are started at this runlevel varies by distribution. It’s typically used for low-level system maintenance that may be impaired by normal system operation.
+
+
+
2
+
Multiuser. On Debian systems and derivatives, this is the default runlevel, and includes -if available- a graphical login. On Red-Hat based systems, this is multiuser mode without networking.
+
+
+
3
+
On Red-Hat based systems, this is the default multiuser mode, which runs everything except the graphical environment. This runlevel and levels 4 and 5 usually are not used on Debian-based systems.
+
+
+
4
+
Typically unused by default and therefore available for customization.
+
+
+
5
+
On Red-Hat based systems, full multiuser mode with GUI login. This runlevel is like level 3, but with a GUI login available.
+
+
+
6
+
Reboot the system.
+
+
+
+
+To switch between runlevels, we can simply issue a runlevel change using the init command: init N (where N is one of the runlevels listed above). Please note that this is not the recommended way of taking a running system to a different runlevel because it gives no warning to existing logged-in users (thus causing them to lose work and processes to terminate abnormally).
+
+Instead, the shutdown command should be used to restart the system (which first sends a warning message to all logged-in users and blocks any further logins; it then signals init to switch runlevels); however, the default runlevel (the one the system will boot to) must be edited in the /etc/inittab file first.
+
+For that reason, follow these steps to properly switch between runlevels, As root, look for the following line in /etc/inittab.
+
+ id:2:initdefault:
+
+and change the number 2 for the desired runlevel with your preferred text editor, such as vim (described in [How to use vi/vim editor in Linux – Part 2][2] of this series).
+
+Next, run as root.
+
+ # shutdown -r now
+
+That last command will restart the system, causing it to start in the specified runlevel during next boot, and will run the scripts located in the /etc/rc[runlevel].d directory in order to decide which services should be started and which ones should not. For example, for runlevel 2 in the following system.
+
+
+
+Change Runlevels in Linux
+
+#### Manage Services using chkconfig ####
+
+To enable or disable system services on boot, we will use [chkconfig command][3] in CentOS / openSUSE and sysv-rc-conf in Debian and derivatives. This tool can also show us what is the preconfigured state of a service for a particular runlevel.
+
+- Read Also: [How to Stop and Disable Unwanted Services in Linux][4]
+
+Listing the runlevel configuration for a service.
+
+ # chkconfig --list [service name]
+ # chkconfig --list postfix
+ # chkconfig --list mysqld
+
+
+
+Listing Runlevel Configuration
+
+In the above image we can see that postfix is set to start when the system enters runlevels 2 through 5, whereas mysqld will be running by default for runlevels 2 through 4. Now suppose that this is not the expected behaviour.
+
+For example, we need to turn on mysqld for runlevel 5 as well, and turn off postfix for runlevels 4 and 5. Here’s what we would do in each case (run the following commands as root).
+
+**Enabling a service for a particular runlevel**
+
+ # chkconfig --level [level(s)] service on
+ # chkconfig --level 5 mysqld on
+
+**Disabling a service for particular runlevels**
+
+ # chkconfig --level [level(s)] service off
+ # chkconfig --level 45 postfix off
+
+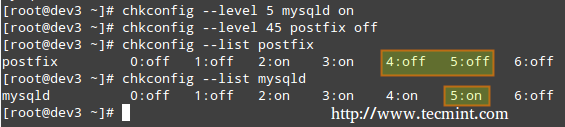
+
+Enable Disable Services
+
+We will now perform similar tasks in a Debian-based system using sysv-rc-conf.
+
+#### Manage Services using sysv-rc-conf ####
+
+Configuring a service to start automatically on a specific runlevel and prevent it from starting on all others.
+
+1. Let’s use the following command to see what are the runlevels where mdadm is configured to start.
+
+ # ls -l /etc/rc[0-6].d | grep -E 'rc[0-6]|mdadm'
+
+
+
+Check Runlevel of Service Running
+
+2. We will use sysv-rc-conf to prevent mdadm from starting on all runlevels except 2. Just check or uncheck (with the space bar) as desired (you can move up, down, left, and right with the arrow keys).
+
+ # sysv-rc-conf
+
+
+
+SysV Runlevel Config
+
+Then press q to quit.
+
+3. We will restart the system and run again the command from STEP 1.
+
+ # ls -l /etc/rc[0-6].d | grep -E 'rc[0-6]|mdadm'
+
+
+
+Verify Service Runlevel
+
+In the above image we can see that mdadm is configured to start only on runlevel 2.
+
+### What About systemd? ###
+
+systemd is another service and system manager that is being adopted by several major Linux distributions. It aims to allow more processing to be done in parallel during system startup (unlike sysvinit, which always tends to be slower because it starts processes one at a time, checks whether one depends on another, and waits for daemons to launch so more services can start), and to serve as a dynamic resource management to a running system.
+
+Thus, services are started when needed (to avoid consuming system resources) instead of being launched without a solid reason during boot.
+
+Viewing the status of all the processes running on your system, both systemd native and SysV services, run the following command.
+
+ # systemctl
+
+
+
+Check All Running Processes
+
+The LOAD column shows whether the unit definition (refer to the UNIT column, which shows the service or anything maintained by systemd) was properly loaded, while the ACTIVE and SUB columns show the current status of such unit.
+Displaying information about the current status of a service
+
+When the ACTIVE column indicates that an unit’s status is other than active, we can check what happened using.
+
+ # systemctl status [unit]
+
+For example, in the image above, media-samba.mount is in failed state. Let’s run.
+
+ # systemctl status media-samba.mount
+
+
+
+Check Service Status
+
+We can see that media-samba.mount failed because the mount process on host dev1 was unable to find the network share at //192.168.0.10/gacanepa.
+
+### Starting or Stopping Services ###
+
+Once the network share //192.168.0.10/gacanepa becomes available, let’s try to start, then stop, and finally restart the unit media-samba.mount. After performing each action, let’s run systemctl status media-samba.mount to check on its status.
+
+ # systemctl start media-samba.mount
+ # systemctl status media-samba.mount
+ # systemctl stop media-samba.mount
+ # systemctl restart media-samba.mount
+ # systemctl status media-samba.mount
+
+
+
+Starting Stoping Services
+
+**Enabling or disabling a service to start during boot**
+
+Under systemd you can enable or disable a service when it boots.
+
+ # systemctl enable [service] # enable a service
+ # systemctl disable [service] # prevent a service from starting at boot
+
+The process of enabling or disabling a service to start automatically on boot consists in adding or removing symbolic links in the /etc/systemd/system/multi-user.target.wants directory.
+
+
+
+Enabling Disabling Services
+
+Alternatively, you can find out a service’s current status (enabled or disabled) with the command.
+
+ # systemctl is-enabled [service]
+
+For example,
+
+ # systemctl is-enabled postfix.service
+
+In addition, you can reboot or shutdown the system with.
+
+ # systemctl reboot
+ # systemctl shutdown
+
+### Upstart ###
+
+Upstart is an event-based replacement for the /sbin/init daemon and was born out of the need for starting services only, when they are needed (also supervising them while they are running), and handling events as they occur, thus surpassing the classic, dependency-based sysvinit system.
+
+It was originally developed for the Ubuntu distribution, but is used in Red Hat Enterprise Linux 6.0. Though it was intended to be suitable for deployment in all Linux distributions as a replacement for sysvinit, in time it was overshadowed by systemd. On February 14, 2014, Mark Shuttleworth (founder of Canonical Ltd.) announced that future releases of Ubuntu would use systemd as the default init daemon.
+
+Because the SysV startup script for system has been so common for so long, a large number of software packages include SysV startup scripts. To accommodate such packages, Upstart provides a compatibility mode: It runs SysV startup scripts in the usual locations (/etc/rc.d/rc?.d, /etc/init.d/rc?.d, /etc/rc?.d, or a similar location). Thus, if we install a package that doesn’t yet include an Upstart configuration script, it should still launch in the usual way.
+
+Furthermore, if we have installed utilities such as [chkconfig][5], you should be able to use them to manage your SysV-based services just as we would on sysvinit based systems.
+
+Upstart scripts also support starting or stopping services based on a wider variety of actions than do SysV startup scripts; for example, Upstart can launch a service whenever a particular hardware device is attached.
+
+A system that uses Upstart and its native scripts exclusively replaces the /etc/inittab file and the runlevel-specific SysV startup script directories with .conf scripts in the /etc/init directory.
+
+These *.conf scripts (also known as job definitions) generally consists of the following:
+
+- Description of the process.
+- Runlevels where the process should run or events that should trigger it.
+- Runlevels where process should be stopped or events that should stop it.
+- Options.
+- Command to launch the process.
+
+For example,
+
+ # My test service - Upstart script demo description "Here goes the description of 'My test service'" author "Dave Null "
+ # Stanzas
+
+ #
+ # Stanzas define when and how a process is started and stopped
+ # See a list of stanzas here: http://upstart.ubuntu.com/wiki/Stanzas#respawn
+ # When to start the service
+ start on runlevel [2345]
+ # When to stop the service
+ stop on runlevel [016]
+ # Automatically restart process in case of crash
+ respawn
+ # Specify working directory
+ chdir /home/dave/myfiles
+ # Specify the process/command (add arguments if needed) to run
+ exec bash backup.sh arg1 arg2
+
+To apply changes, you will need to tell upstart to reload its configuration.
+
+ # initctl reload-configuration
+
+Then start your job by typing the following command.
+
+ $ sudo start yourjobname
+
+Where yourjobname is the name of the job that was added earlier with the yourjobname.conf script.
+
+A more complete and detailed reference guide for Upstart is available in the project’s web site under the menu “[Cookbook][6]”.
+
+### Summary ###
+
+A knowledge of the Linux boot process is necessary to help you with troubleshooting tasks as well as with adapting the computer’s performance and running services to your needs.
+
+In this article we have analyzed what happens from the moment when you press the Power switch to turn on the machine until you get a fully operational user interface. I hope you have learned reading it as much as I did while putting it together. Feel free to leave your comments or questions below. We always look forward to hearing from our readers!
+
+--------------------------------------------------------------------------------
+
+via: http://www.tecmint.com/linux-boot-process-and-manage-services/
+
+作者:[Gabriel Cánepa][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.tecmint.com/author/gacanepa/
+[1]:http://www.tecmint.com/systemd-replaces-init-in-linux/
+[2]:http://www.tecmint.com/vi-editor-usage/
+[3]:http://www.tecmint.com/chkconfig-command-examples/
+[4]:http://www.tecmint.com/remove-unwanted-services-from-linux/
+[5]:http://www.tecmint.com/chkconfig-command-examples/
+[6]:http://upstart.ubuntu.com/cookbook/
\ No newline at end of file
diff --git a/sources/tech/LFCS/Part 8 - LFCS--Managing Users and Groups File Permissions and Attributes and Enabling sudo Access on Accounts.md b/sources/tech/LFCS/Part 8 - LFCS--Managing Users and Groups File Permissions and Attributes and Enabling sudo Access on Accounts.md
new file mode 100644
index 0000000000..2cec4de4ae
--- /dev/null
+++ b/sources/tech/LFCS/Part 8 - LFCS--Managing Users and Groups File Permissions and Attributes and Enabling sudo Access on Accounts.md
@@ -0,0 +1,330 @@
+Part 8 - LFCS: Managing Users & Groups, File Permissions & Attributes and Enabling sudo Access on Accounts
+================================================================================
+Last August, the Linux Foundation started the LFCS certification (Linux Foundation Certified Sysadmin), a brand new program whose purpose is to allow individuals everywhere and anywhere take an exam in order to get certified in basic to intermediate operational support for Linux systems, which includes supporting running systems and services, along with overall monitoring and analysis, plus intelligent decision-making to be able to decide when it’s necessary to escalate issues to higher level support teams.
+
+
+
+Linux Foundation Certified Sysadmin – Part 8
+
+Please have a quick look at the following video that describes an introduction to the Linux Foundation Certification Program.
+
+注:youtube视频
+
+
+This article is Part 8 of a 10-tutorial long series, here in this section, we will guide you on how to manage users and groups permissions in Linux system, that are required for the LFCS certification exam.
+
+Since Linux is a multi-user operating system (in that it allows multiple users on different computers or terminals to access a single system), you will need to know how to perform effective user management: how to add, edit, suspend, or delete user accounts, along with granting them the necessary permissions to do their assigned tasks.
+
+### Adding User Accounts ###
+
+To add a new user account, you can run either of the following two commands as root.
+
+ # adduser [new_account]
+ # useradd [new_account]
+
+When a new user account is added to the system, the following operations are performed.
+
+1. His/her home directory is created (/home/username by default).
+
+2. The following hidden files are copied into the user’s home directory, and will be used to provide environment variables for his/her user session.
+
+ .bash_logout
+ .bash_profile
+ .bashrc
+
+3. A mail spool is created for the user at /var/spool/mail/username.
+
+4. A group is created and given the same name as the new user account.
+
+**Understanding /etc/passwd**
+
+The full account information is stored in the /etc/passwd file. This file contains a record per system user account and has the following format (fields are delimited by a colon).
+
+ [username]:[x]:[UID]:[GID]:[Comment]:[Home directory]:[Default shell]
+
+- Fields [username] and [Comment] are self explanatory.
+- The x in the second field indicates that the account is protected by a shadowed password (in /etc/shadow), which is needed to logon as [username].
+- The [UID] and [GID] fields are integers that represent the User IDentification and the primary Group IDentification to which [username] belongs, respectively.
+- The [Home directory] indicates the absolute path to [username]’s home directory, and
+- The [Default shell] is the shell that will be made available to this user when he or she logins the system.
+
+**Understanding /etc/group**
+
+Group information is stored in the /etc/group file. Each record has the following format.
+
+ [Group name]:[Group password]:[GID]:[Group members]
+
+- [Group name] is the name of group.
+- An x in [Group password] indicates group passwords are not being used.
+- [GID]: same as in /etc/passwd.
+- [Group members]: a comma separated list of users who are members of [Group name].
+
+
+
+Add User Accounts
+
+After adding an account, you can edit the following information (to name a few fields) using the usermod command, whose basic syntax of usermod is as follows.
+
+ # usermod [options] [username]
+
+**Setting the expiry date for an account**
+
+Use the –expiredate flag followed by a date in YYYY-MM-DD format.
+
+ # usermod --expiredate 2014-10-30 tecmint
+
+**Adding the user to supplementary groups**
+
+Use the combined -aG, or –append –groups options, followed by a comma separated list of groups.
+
+ # usermod --append --groups root,users tecmint
+
+**Changing the default location of the user’s home directory**
+
+Use the -d, or –home options, followed by the absolute path to the new home directory.
+
+ # usermod --home /tmp tecmint
+
+**Changing the shell the user will use by default**
+
+Use –shell, followed by the path to the new shell.
+
+ # usermod --shell /bin/sh tecmint
+
+**Displaying the groups an user is a member of**
+
+ # groups tecmint
+ # id tecmint
+
+Now let’s execute all the above commands in one go.
+
+ # usermod --expiredate 2014-10-30 --append --groups root,users --home /tmp --shell /bin/sh tecmint
+
+
+
+usermod Command Examples
+
+Read Also:
+
+- [15 useradd Command Examples in Linux][1]
+- [15 usermod Command Examples in Linux][2]
+
+For existing accounts, we can also do the following.
+
+**Disabling account by locking password**
+
+Use the -L (uppercase L) or the –lock option to lock a user’s password.
+
+ # usermod --lock tecmint
+
+**Unlocking user password**
+
+Use the –u or the –unlock option to unlock a user’s password that was previously blocked.
+
+ # usermod --unlock tecmint
+
+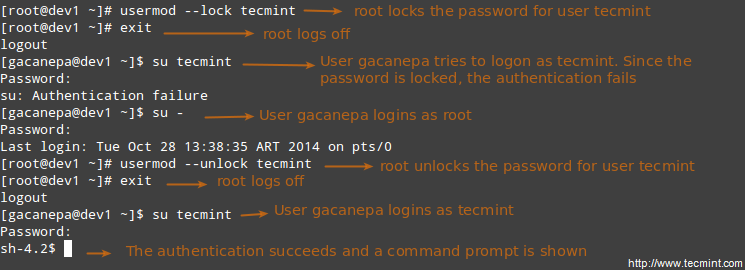
+
+Lock User Accounts
+
+**Creating a new group for read and write access to files that need to be accessed by several users**
+
+Run the following series of commands to achieve the goal.
+
+ # groupadd common_group # Add a new group
+ # chown :common_group common.txt # Change the group owner of common.txt to common_group
+ # usermod -aG common_group user1 # Add user1 to common_group
+ # usermod -aG common_group user2 # Add user2 to common_group
+ # usermod -aG common_group user3 # Add user3 to common_group
+
+**Deleting a group**
+
+You can delete a group with the following command.
+
+ # groupdel [group_name]
+
+If there are files owned by group_name, they will not be deleted, but the group owner will be set to the GID of the group that was deleted.
+
+### Linux File Permissions ###
+
+Besides the basic read, write, and execute permissions that we discussed in [Setting File Attributes – Part 3][3] of this series, there are other less used (but not less important) permission settings, sometimes referred to as “special permissions”.
+
+Like the basic permissions discussed earlier, they are set using an octal file or through a letter (symbolic notation) that indicates the type of permission.
+Deleting user accounts
+
+You can delete an account (along with its home directory, if it’s owned by the user, and all the files residing therein, and also the mail spool) using the userdel command with the –remove option.
+
+ # userdel --remove [username]
+
+#### Group Management ####
+
+Every time a new user account is added to the system, a group with the same name is created with the username as its only member. Other users can be added to the group later. One of the purposes of groups is to implement a simple access control to files and other system resources by setting the right permissions on those resources.
+
+For example, suppose you have the following users.
+
+- user1 (primary group: user1)
+- user2 (primary group: user2)
+- user3 (primary group: user3)
+
+All of them need read and write access to a file called common.txt located somewhere on your local system, or maybe on a network share that user1 has created. You may be tempted to do something like,
+
+ # chmod 660 common.txt
+ OR
+ # chmod u=rw,g=rw,o= common.txt [notice the space between the last equal sign and the file name]
+
+However, this will only provide read and write access to the owner of the file and to those users who are members of the group owner of the file (user1 in this case). Again, you may be tempted to add user2 and user3 to group user1, but that will also give them access to the rest of the files owned by user user1 and group user1.
+
+This is where groups come in handy, and here’s what you should do in a case like this.
+
+**Understanding Setuid**
+
+When the setuid permission is applied to an executable file, an user running the program inherits the effective privileges of the program’s owner. Since this approach can reasonably raise security concerns, the number of files with setuid permission must be kept to a minimum. You will likely find programs with this permission set when a system user needs to access a file owned by root.
+
+Summing up, it isn’t just that the user can execute the binary file, but also that he can do so with root’s privileges. For example, let’s check the permissions of /bin/passwd. This binary is used to change the password of an account, and modifies the /etc/shadow file. The superuser can change anyone’s password, but all other users should only be able to change their own.
+
+
+
+passwd Command Examples
+
+Thus, any user should have permission to run /bin/passwd, but only root will be able to specify an account. Other users can only change their corresponding passwords.
+
+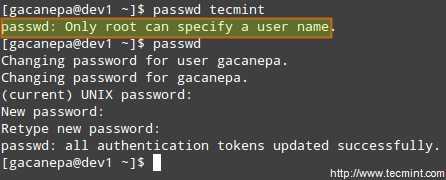
+
+Change User Password
+
+**Understanding Setgid**
+
+When the setgid bit is set, the effective GID of the real user becomes that of the group owner. Thus, any user can access a file under the privileges granted to the group owner of such file. In addition, when the setgid bit is set on a directory, newly created files inherit the same group as the directory, and newly created subdirectories will also inherit the setgid bit of the parent directory. You will most likely use this approach whenever members of a certain group need access to all the files in a directory, regardless of the file owner’s primary group.
+
+ # chmod g+s [filename]
+
+To set the setgid in octal form, prepend the number 2 to the current (or desired) basic permissions.
+
+ # chmod 2755 [directory]
+
+**Setting the SETGID in a directory**
+
+
+
+Add Setgid to Directory
+
+**Understanding Sticky Bit**
+
+When the “sticky bit” is set on files, Linux just ignores it, whereas for directories it has the effect of preventing users from deleting or even renaming the files it contains unless the user owns the directory, the file, or is root.
+
+# chmod o+t [directory]
+
+To set the sticky bit in octal form, prepend the number 1 to the current (or desired) basic permissions.
+
+# chmod 1755 [directory]
+
+Without the sticky bit, anyone able to write to the directory can delete or rename files. For that reason, the sticky bit is commonly found on directories, such as /tmp, that are world-writable.
+
+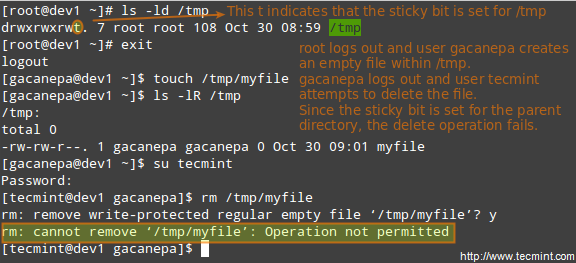
+
+Add Stickybit to Directory
+
+### Special Linux File Attributes ###
+
+There are other attributes that enable further limits on the operations that are allowed on files. For example, prevent the file from being renamed, moved, deleted, or even modified. They are set with the [chattr command][4] and can be viewed using the lsattr tool, as follows.
+
+ # chattr +i file1
+ # chattr +a file2
+
+After executing those two commands, file1 will be immutable (which means it cannot be moved, renamed, modified or deleted) whereas file2 will enter append-only mode (can only be open in append mode for writing).
+
+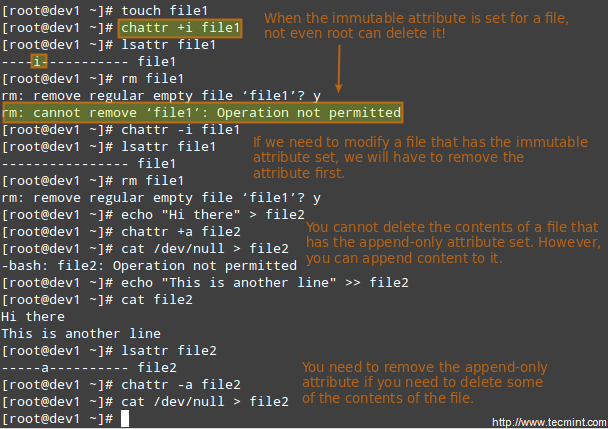
+
+Chattr Command to Protect Files
+
+### Accessing the root Account and Using sudo ###
+
+One of the ways users can gain access to the root account is by typing.
+
+ $ su
+
+and then entering root’s password.
+
+If authentication succeeds, you will be logged on as root with the current working directory as the same as you were before. If you want to be placed in root’s home directory instead, run.
+
+ $ su -
+
+and then enter root’s password.
+
+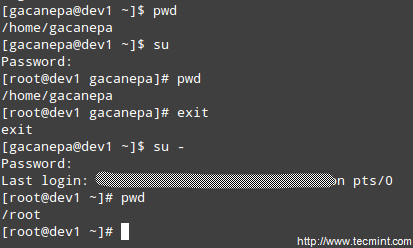
+
+Enable Sudo Access on Users
+
+The above procedure requires that a normal user knows root’s password, which poses a serious security risk. For that reason, the sysadmin can configure the sudo command to allow an ordinary user to execute commands as a different user (usually the superuser) in a very controlled and limited way. Thus, restrictions can be set on a user so as to enable him to run one or more specific privileged commands and no others.
+
+- Read Also: [Difference Between su and sudo User][5]
+
+To authenticate using sudo, the user uses his/her own password. After entering the command, we will be prompted for our password (not the superuser’s) and if the authentication succeeds (and if the user has been granted privileges to run the command), the specified command is carried out.
+
+To grant access to sudo, the system administrator must edit the /etc/sudoers file. It is recommended that this file is edited using the visudo command instead of opening it directly with a text editor.
+
+ # visudo
+
+This opens the /etc/sudoers file using vim (you can follow the instructions given in [Install and Use vim as Editor – Part 2][6] of this series to edit the file).
+
+These are the most relevant lines.
+
+ Defaults secure_path="/usr/sbin:/usr/bin:/sbin"
+ root ALL=(ALL) ALL
+ tecmint ALL=/bin/yum update
+ gacanepa ALL=NOPASSWD:/bin/updatedb
+ %admin ALL=(ALL) ALL
+
+Let’s take a closer look at them.
+
+ Defaults secure_path="/usr/sbin:/usr/bin:/sbin:/usr/local/bin"
+
+This line lets you specify the directories that will be used for sudo, and is used to prevent using user-specific directories, which can harm the system.
+
+The next lines are used to specify permissions.
+
+ root ALL=(ALL) ALL
+
+- The first ALL keyword indicates that this rule applies to all hosts.
+- The second ALL indicates that the user in the first column can run commands with the privileges of any user.
+- The third ALL means any command can be run.
+
+ tecmint ALL=/bin/yum update
+
+If no user is specified after the = sign, sudo assumes the root user. In this case, user tecmint will be able to run yum update as root.
+
+ gacanepa ALL=NOPASSWD:/bin/updatedb
+
+The NOPASSWD directive allows user gacanepa to run /bin/updatedb without needing to enter his password.
+
+ %admin ALL=(ALL) ALL
+
+The % sign indicates that this line applies to a group called “admin”. The meaning of the rest of the line is identical to that of an regular user. This means that members of the group “admin” can run all commands as any user on all hosts.
+
+To see what privileges are granted to you by sudo, use the “-l” option to list them.
+
+
+
+Sudo Access Rules
+
+### Summary ###
+
+Effective user and file management skills are essential tools for any system administrator. In this article we have covered the basics and hope you can use it as a good starting to point to build upon. Feel free to leave your comments or questions below, and we’ll respond quickly.
+
+--------------------------------------------------------------------------------
+
+via: http://www.tecmint.com/manage-users-and-groups-in-linux/
+
+作者:[Gabriel Cánepa][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.tecmint.com/author/gacanepa/
+[1]:http://www.tecmint.com/add-users-in-linux/
+[2]:http://www.tecmint.com/usermod-command-examples/
+[3]:http://www.tecmint.com/compress-files-and-finding-files-in-linux/
+[4]:http://www.tecmint.com/chattr-command-examples/
+[5]:http://www.tecmint.com/su-vs-sudo-and-how-to-configure-sudo-in-linux/
+[6]:http://www.tecmint.com/vi-editor-usage/
\ No newline at end of file
diff --git a/sources/tech/LFCS/Part 9 - LFCS--Linux Package Management with Yum RPM Apt Dpkg Aptitude and Zypper.md b/sources/tech/LFCS/Part 9 - LFCS--Linux Package Management with Yum RPM Apt Dpkg Aptitude and Zypper.md
new file mode 100644
index 0000000000..6d0f65223f
--- /dev/null
+++ b/sources/tech/LFCS/Part 9 - LFCS--Linux Package Management with Yum RPM Apt Dpkg Aptitude and Zypper.md
@@ -0,0 +1,229 @@
+Part 9 - LFCS: Linux Package Management with Yum, RPM, Apt, Dpkg, Aptitude and Zypper
+================================================================================
+Last August, the Linux Foundation announced the LFCS certification (Linux Foundation Certified Sysadmin), a shiny chance for system administrators everywhere to demonstrate, through a performance-based exam, that they are capable of succeeding at overall operational support for Linux systems. A Linux Foundation Certified Sysadmin has the expertise to ensure effective system support, first-level troubleshooting and monitoring, including finally issue escalation, when needed, to engineering support teams.
+
+
+
+Linux Foundation Certified Sysadmin – Part 9
+
+Watch the following video that explains about the Linux Foundation Certification Program.
+
+注:youtube 视频
+
+
+This article is a Part 9 of 10-tutorial long series, today in this article we will guide you about Linux Package Management, that are required for the LFCS certification exam.
+
+### Package Management ###
+
+In few words, package management is a method of installing and maintaining (which includes updating and probably removing as well) software on the system.
+
+In the early days of Linux, programs were only distributed as source code, along with the required man pages, the necessary configuration files, and more. Nowadays, most Linux distributors use by default pre-built programs or sets of programs called packages, which are presented to users ready for installation on that distribution. However, one of the wonders of Linux is still the possibility to obtain source code of a program to be studied, improved, and compiled.
+
+**How package management systems work**
+
+If a certain package requires a certain resource such as a shared library, or another package, it is said to have a dependency. All modern package management systems provide some method of dependency resolution to ensure that when a package is installed, all of its dependencies are installed as well.
+
+**Packaging Systems**
+
+Almost all the software that is installed on a modern Linux system will be found on the Internet. It can either be provided by the distribution vendor through central repositories (which can contain several thousands of packages, each of which has been specifically built, tested, and maintained for the distribution) or be available in source code that can be downloaded and installed manually.
+
+Because different distribution families use different packaging systems (Debian: *.deb / CentOS: *.rpm / openSUSE: *.rpm built specially for openSUSE), a package intended for one distribution will not be compatible with another distribution. However, most distributions are likely to fall into one of the three distribution families covered by the LFCS certification.
+
+**High and low-level package tools**
+
+In order to perform the task of package management effectively, you need to be aware that you will have two types of available utilities: low-level tools (which handle in the backend the actual installation, upgrade, and removal of package files), and high-level tools (which are in charge of ensuring that the tasks of dependency resolution and metadata searching -”data about the data”- are performed).
+
+注:表格
+
+
+
+
+
+
+
+
+
+
+
DISTRIBUTION
+
LOW-LEVEL TOOL
+
HIGH-LEVEL TOOL
+
+
+
Debian and derivatives
+
dpkg
+
apt-get / aptitude
+
+
+
CentOS
+
rpm
+
yum
+
+
+
openSUSE
+
rpm
+
zypper
+
+
+
+
+Let us see the descrption of the low-level and high-level tools.
+
+dpkg is a low-level package manager for Debian-based systems. It can install, remove, provide information about and build *.deb packages but it can’t automatically download and install their corresponding dependencies.
+
+- Read More: [15 dpkg Command Examples][1]
+
+apt-get is a high-level package manager for Debian and derivatives, and provides a simple way to retrieve and install packages, including dependency resolution, from multiple sources using the command line. Unlike dpkg, apt-get does not work directly with *.deb files, but with the package proper name.
+
+- Read More: [25 apt-get Command Examples][2]
+
+aptitude is another high-level package manager for Debian-based systems, and can be used to perform management tasks (installing, upgrading, and removing packages, also handling dependency resolution automatically) in a fast and easy way. It provides the same functionality as apt-get and additional ones, such as offering access to several versions of a package.
+
+rpm is the package management system used by Linux Standard Base (LSB)-compliant distributions for low-level handling of packages. Just like dpkg, it can query, install, verify, upgrade, and remove packages, and is more frequently used by Fedora-based distributions, such as RHEL and CentOS.
+
+- Read More: [20 rpm Command Examples][3]
+
+yum adds the functionality of automatic updates and package management with dependency management to RPM-based systems. As a high-level tool, like apt-get or aptitude, yum works with repositories.
+
+- Read More: [20 yum Command Examples][4]
+-
+### Common Usage of Low-Level Tools ###
+
+The most frequent tasks that you will do with low level tools are as follows:
+
+**1. Installing a package from a compiled (*.deb or *.rpm) file**
+
+The downside of this installation method is that no dependency resolution is provided. You will most likely choose to install a package from a compiled file when such package is not available in the distribution’s repositories and therefore cannot be downloaded and installed through a high-level tool. Since low-level tools do not perform dependency resolution, they will exit with an error if we try to install a package with unmet dependencies.
+
+ # dpkg -i file.deb [Debian and derivative]
+ # rpm -i file.rpm [CentOS / openSUSE]
+
+**Note**: Do not attempt to install on CentOS a *.rpm file that was built for openSUSE, or vice-versa!
+
+**2. Upgrading a package from a compiled file**
+
+Again, you will only upgrade an installed package manually when it is not available in the central repositories.
+
+ # dpkg -i file.deb [Debian and derivative]
+ # rpm -U file.rpm [CentOS / openSUSE]
+
+**3. Listing installed packages**
+
+When you first get your hands on an already working system, chances are you’ll want to know what packages are installed.
+
+ # dpkg -l [Debian and derivative]
+ # rpm -qa [CentOS / openSUSE]
+
+If you want to know whether a specific package is installed, you can pipe the output of the above commands to grep, as explained in [manipulate files in Linux – Part 1][6] of this series. Suppose we need to verify if package mysql-common is installed on an Ubuntu system.
+
+ # dpkg -l | grep mysql-common
+
+
+
+Check Installed Packages
+
+Another way to determine if a package is installed.
+
+ # dpkg --status package_name [Debian and derivative]
+ # rpm -q package_name [CentOS / openSUSE]
+
+For example, let’s find out whether package sysdig is installed on our system.
+
+ # rpm -qa | grep sysdig
+
+
+
+Check sysdig Package
+
+**4. Finding out which package installed a file**
+
+ # dpkg --search file_name
+ # rpm -qf file_name
+
+For example, which package installed pw_dict.hwm?
+
+ # rpm -qf /usr/share/cracklib/pw_dict.hwm
+
+
+
+Query File in Linux
+
+### Common Usage of High-Level Tools ###
+
+The most frequent tasks that you will do with high level tools are as follows.
+
+**1. Searching for a package**
+
+aptitude update will update the list of available packages, and aptitude search will perform the actual search for package_name.
+
+ # aptitude update && aptitude search package_name
+
+In the search all option, yum will search for package_name not only in package names, but also in package descriptions.
+
+ # yum search package_name
+ # yum search all package_name
+ # yum whatprovides “*/package_name”
+
+Let’s supposed we need a file whose name is sysdig. To know that package we will have to install, let’s run.
+
+ # yum whatprovides “*/sysdig”
+
+
+
+Check Package Description
+
+whatprovides tells yum to search the package the will provide a file that matches the above regular expression.
+
+ # zypper refresh && zypper search package_name [On openSUSE]
+
+**2. Installing a package from a repository**
+
+While installing a package, you may be prompted to confirm the installation after the package manager has resolved all dependencies. Note that running update or refresh (according to the package manager being used) is not strictly necessary, but keeping installed packages up to date is a good sysadmin practice for security and dependency reasons.
+
+ # aptitude update && aptitude install package_name [Debian and derivatives]
+ # yum update && yum install package_name [CentOS]
+ # zypper refresh && zypper install package_name [openSUSE]
+
+**3. Removing a package**
+
+The option remove will uninstall the package but leaving configuration files intact, whereas purge will erase every trace of the program from your system.
+# aptitude remove / purge package_name
+# yum erase package_name
+
+ ---Notice the minus sign in front of the package that will be uninstalled, openSUSE ---
+
+ # zypper remove -package_name
+
+Most (if not all) package managers will prompt you, by default, if you’re sure about proceeding with the uninstallation before actually performing it. So read the onscreen messages carefully to avoid running into unnecessary trouble!
+
+**4. Displaying information about a package**
+
+The following command will display information about the birthday package.
+
+ # aptitude show birthday
+ # yum info birthday
+ # zypper info birthday
+
+
+
+Check Package Information
+
+### Summary ###
+
+Package management is something you just can’t sweep under the rug as a system administrator. You should be prepared to use the tools described in this article at a moment’s notice. Hope you find it useful in your preparation for the LFCS exam and for your daily tasks. Feel free to leave your comments or questions below. We will be more than glad to get back to you as soon as possible.
+
+--------------------------------------------------------------------------------
+
+via: http://www.tecmint.com/linux-package-management/
+
+作者:[Gabriel Cánepa][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.tecmint.com/author/gacanepa/
+[1]:http://www.tecmint.com/dpkg-command-examples/
+[2]:http://www.tecmint.com/useful-basic-commands-of-apt-get-and-apt-cache-for-package-management/
+[3]:http://www.tecmint.com/20-practical-examples-of-rpm-commands-in-linux/
+[4]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
+[5]:http://www.tecmint.com/sed-command-to-create-edit-and-manipulate-files-in-linux/
\ No newline at end of file
diff --git a/sources/tech/Learn with Linux/Learn with Linux--Learning Music.md b/sources/tech/Learn with Linux/Learn with Linux--Learning Music.md
new file mode 100644
index 0000000000..e6467eb810
--- /dev/null
+++ b/sources/tech/Learn with Linux/Learn with Linux--Learning Music.md
@@ -0,0 +1,155 @@
+Learn with Linux: Learning Music
+================================================================================
+
+
+This article is part of the [Learn with Linux][1] series:
+
+- [Learn with Linux: Learning to Type][2]
+- [Learn with Linux: Physics Simulation][3]
+- [Learn with Linux: Learning Music][4]
+- [Learn with Linux: Two Geography Apps][5]
+- [Learn with Linux: Master Your Math with These Linux Apps][6]
+
+Linux offers great educational software and many excellent tools to aid students of all grades and ages in learning and practicing a variety of topics, often interactively. The “Learn with Linux” series of articles offers an introduction to a variety of educational apps and software.
+
+Learning music is a great pastime. Training your ears to identify scales and chords and mastering an instrument or your own voice requires lots of practise and could become difficult. Music theory is extensive. There is much to memorize, and to turn it into a “skill” you will need diligence. Linux offers exceptional software to help you along your musical journey. They will not help you become a professional musician instantly but could ease the process of learning, being a great aide and reference point.
+
+### Gnu Solfège ###
+
+[Solfège][7] is a popular music education method that is used in all levels of music education all around the world. Many popular methods (like the Kodály method) use Solfège as their basis. GNU Solfège is a great software aimed more at practising Solfège than learning it. It assumes the student has already acquired the basics and wishes to practise what they have learned.
+
+As the developer states on the GNU website:
+
+> “When you study music on high school, college, music conservatory, you usually have to do ear training. Some of the exercises, like sight singing, is easy to do alone [sic]. But often you have to be at least two people, one making questions, the other answering. […] GNU Solfège tries to help out with this. With Solfege you can practise the more simple and mechanical exercises without the need to get others to help you. Just don’t forget that this program only touches a part of the subject.”
+
+The software delivers its promise; you can practise essentially everything with audible and visual aids.
+
+GNU solfege is in the Debian (therefore Ubuntu) repositories. To get it just type the following command into a terminal:
+
+ sudo apt-get install solfege
+
+When it loads, you find yourself on a simple starting screen/
+
+
+
+The number of options is almost overwhelming. Most of the links will open sub-categories
+
+
+
+from where you can select individual exercises.
+
+
+
+There are practice sessions and tests. Both will be able to play the tones through any connected MIDI device or just your sound card’s MIDI player. The exercises often have visual notation and the ability to play back the sequence slowly.
+
+One important note about Solfège is that under Ubuntu you might not be able to hear anything with the default setup (unless you have a MIDI device connected). If that is the case, head over to “File -> Preferences,” select sound setup and choose the appropriate option for your system (choosing ALSA would probably work in most cases).
+
+
+
+Solfège could be very helpful for your daily practise. Use it regularly and you will have trained your ear before you can sing do-re-mi.
+
+### Tete (ear trainer) ###
+
+[Tete][8] (This ear trainer ‘ere) is a Java application for simple, yet efficient, [ear training][9]. It helps you identify a variety of scales by playing thhm back under various circumstances, from different roots and on different MIDI sounds. [Download it from SourceForge][10]. You then need to unzip the downloaded file.
+
+ unzip Tete-*
+
+Enter the unpacked directory:
+
+ cd Tete-*
+
+Assuming you have Java installed in your system, you can run the java file with
+
+ java -jar Tete-[your version]
+
+(To autocomplete the above command, just press the Tab key after typing “Tete-“.)
+
+Tete has a simple, one-page interface with everything on it.
+
+
+
+You can choose to play scales (see above), chords,
+
+
+
+or intervals.
+
+
+
+You can “fine tune” your experience with various options including the midi instrument’s sound, what note to start from, ascending or descending scales, and how slow/fast the playback should be. Tete’s SourceForge page includes a very useful tutorial that explains most aspects of the software.
+
+### JalMus ###
+
+Jalmus is a Java-based keyboard note reading trainer. It works with attached MIDI keyboards or with the on-screen virtual keyboard. It has many simple lessons and exercises to train in music reading. Unfortunately, its development has been discontinued since 2013, but the software appears to still be functional.
+
+To get Jalmus, head over to the [sourceforge page][11] of its last version (2.3) to get the Java installer, or just type the following command into a terminal:
+
+ wget http://garr.dl.sourceforge.net/project/jalmus/Jalmus-2.3/installjalmus23.jar
+
+Once the download finishes, load the installer with
+
+ java -jar installjalmus23.jar
+
+You will be guided through a simple Java-based installer that was made for cross-platform installation.
+
+Jalmus’s main screen is plain.
+
+
+
+You can find lessons of varying difficulty in the Lessons menu. It ranges from very simple ones, where one notes swims in from the left, and the corresponding key lights up on the on screen keyboard …
+
+
+
+… to difficult ones with many notes swimming in from the right, and you are required to repeat the sequence on your keyboard.
+
+
+
+Jalmus also includes exercises of note reading single notes, which are very similar to the lessons, only without the visual hints, where your score will be displayed after you finished. It also aids rhythm reading of varying difficulty, where the rhythm is both audible and visually marked. A metronome (audible and visual) aids in the understanding
+
+
+
+and score reading where multiple notes will be played
+
+
+
+All these options are configurable; you can switch features on and off as you like.
+
+All things considered, Jalmus probably works best for rhythm training. Although it was not necessarily its intended purpose, the software really excelled in this particular use-case.
+
+### Notable mentions ###
+
+#### TuxGuitar ####
+
+For guitarists, [TuxGuitar][12] works much like Guitar Pro on Windows (and it can also read guitar-pro files).
+PianoBooster
+
+[Piano Booster][13] can help with piano skills. It is designed to play MIDI files, which you can play along with on an attached keyboard, watching the core roll past on the screen.
+
+### Conclusion ###
+
+Linux offers many great tools for learning, and if your particular interest is music, your will not be left without software to aid your practice. Surely there are many more excellent software tools available for music students than were mentioned above. Do you know of any? Please let us know in the comments below.
+
+--------------------------------------------------------------------------------
+
+via: https://www.maketecheasier.com/linux-learning-music/
+
+作者:[Attila Orosz][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.maketecheasier.com/author/attilaorosz/
+[1]:https://www.maketecheasier.com/series/learn-with-linux/
+[2]:https://www.maketecheasier.com/learn-to-type-in-linux/
+[3]:https://www.maketecheasier.com/linux-physics-simulation/
+[4]:https://www.maketecheasier.com/linux-learning-music/
+[5]:https://www.maketecheasier.com/linux-geography-apps/
+[6]:https://www.maketecheasier.com/learn-linux-maths/
+[7]:https://en.wikipedia.org/wiki/Solf%C3%A8ge
+[8]:http://tete.sourceforge.net/index.shtml
+[9]:https://en.wikipedia.org/wiki/Ear_training
+[10]:http://sourceforge.net/projects/tete/files/latest/download
+[11]:http://sourceforge.net/projects/jalmus/files/Jalmus-2.3/
+[12]:http://tuxguitar.herac.com.ar/
+[13]:http://www.linuxlinks.com/article/20090517041840856/PianoBooster.html
\ No newline at end of file
diff --git a/sources/tech/Learn with Linux/Learn with Linux--Learning to Type.md b/sources/tech/Learn with Linux/Learn with Linux--Learning to Type.md
new file mode 100644
index 0000000000..51cef0f1a8
--- /dev/null
+++ b/sources/tech/Learn with Linux/Learn with Linux--Learning to Type.md
@@ -0,0 +1,121 @@
+Learn with Linux: Learning to Type
+================================================================================
+
+
+This article is part of the [Learn with Linux][1] series:
+
+- [Learn with Linux: Learning to Type][2]
+- [Learn with Linux: Physics Simulation][3]
+- [Learn with Linux: Learning Music][4]
+- [Learn with Linux: Two Geography Apps][5]
+- [Learn with Linux: Master Your Math with These Linux Apps][6]
+
+Linux offers great educational software and many excellent tools to aid students of all grades and ages in learning and practicing a variety of topics, often interactively. The “Learn with Linux” series of articles offers an introduction to a variety of educational apps and software.
+
+Typing is taken for granted by many people; today being keyboard savvy often comes as second nature. Yet how many of us still type with two fingers, even if ever so fast? Once typing was taught in schools, but slowly the art of ten-finger typing is giving way to two thumbs.
+
+The following two applications can help you master the keyboard so that your next thought does not get lost while your fingers catch up. They were chosen for their simplicity and ease of use. While there are some more flashy or better looking typing apps out there, the following two will get the basics covered and offer the easiest way to start out.
+
+### TuxType (or TuxTyping) ###
+
+TuxType is for children. Young students can learn how to type with ten fingers with simple lessons and practice their newly-acquired skills in fun games.
+
+Debian and derivatives (therefore all Ubuntu derivatives) should have TuxType in their standard repositories. To install simply type
+
+ sudo apt-get install tuxtype
+
+The application starts with a simple menu screen featuring Tux and some really bad midi music (Fortunately the sound can be turned off easily with the icon in the lower left corner.).
+
+
+
+The top two choices, “Fish Cascade” and “Comet Zap,” represent typing games, but to start learning you need to head over to the lessons.
+
+There are forty simple built-in lessons to choose from. Each one of these will take a letter from the keyboard and make the student practice while giving visual hints, such as which finger to use.
+
+
+
+
+
+For more advanced practice, phrase typing is also available, although for some reason this is hidden under the options menu.
+
+
+
+The games are good for speed and accuracy as the player helps Tux catch falling fish
+
+
+
+or zap incoming asteroids by typing the words written over them.
+
+
+
+Besides being a fun way to practice, these games teach spelling, speed, and eye-to-hand coordination, as you must type while also watching the screen, building a foundation for touch typing, if taken seriously.
+
+### GNU typist (gtype) ###
+
+For adults and more experienced typists, there is GNU Typist, a console-based application developed by the GNU project.
+
+GNU Typist will also be carried by most Debian derivatives’ main repos. Installing it is as easy as typing
+
+ sudo apt-get install gtype
+
+You will probably not find it in the Applications menu; insteaad you should start it from a terminal window.
+
+ gtype
+
+The main menu is simple, no-nonsense and frill-free, yet it is evident how much the software has to offer. Typing lessons of all levels are immediately accessible.
+
+
+
+The lessons are straightforward and detailed.
+
+
+
+The interactive practice sessions offer little more than highlighting your mistakes. Instead of flashy visuals you have to chance to focus on practising. At the end of each lesson you get some simple statistics of how you’ve been doing. If you make too many mistakes, you cannot proceed until you can pass the level.
+
+
+
+While the basic lessons only require you to repeat some characters, more advanced drills will have the practitioner type either whole sentences,
+
+
+
+where of course the three percent error margin means you are allowed even fewer mistakes,
+
+
+
+or some drills aiming to achieve certain goals, as in the “Balanced keyboard drill.”
+
+
+
+Simple speed drills have you type quotes,
+
+
+
+while more advanced ones will make you write longer texts taken from classics.
+
+
+
+If you’d prefer a different language, more lessons can also be loaded as command line arguments.
+
+
+
+### Conclusion ###
+
+If you care to hone your typing skills, Linux has great software to offer. The two basic, yet feature-rich, applications discussed above will cater to most aspiring typists’ needs. If you use or know of another great typing application, please don’t hesitate to let us know below in the comments.
+
+--------------------------------------------------------------------------------
+
+via: https://www.maketecheasier.com/learn-to-type-in-linux/
+
+作者:[Attila Orosz][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.maketecheasier.com/author/attilaorosz/
+[1]:https://www.maketecheasier.com/series/learn-with-linux/
+[2]:https://www.maketecheasier.com/learn-to-type-in-linux/
+[3]:https://www.maketecheasier.com/linux-physics-simulation/
+[4]:https://www.maketecheasier.com/linux-learning-music/
+[5]:https://www.maketecheasier.com/linux-geography-apps/
+[6]:https://www.maketecheasier.com/learn-linux-maths/
\ No newline at end of file
diff --git a/sources/tech/Learn with Linux/Learn with Linux--Physics Simulation.md b/sources/tech/Learn with Linux/Learn with Linux--Physics Simulation.md
new file mode 100644
index 0000000000..2a8415dda7
--- /dev/null
+++ b/sources/tech/Learn with Linux/Learn with Linux--Physics Simulation.md
@@ -0,0 +1,107 @@
+Learn with Linux: Physics Simulation
+================================================================================
+
+
+This article is part of the [Learn with Linux][1] series:
+
+- [Learn with Linux: Learning to Type][2]
+- [Learn with Linux: Physics Simulation][3]
+- [Learn with Linux: Learning Music][4]
+- [Learn with Linux: Two Geography Apps][5]
+- [Learn with Linux: Master Your Math with These Linux Apps][6]
+
+Linux offers great educational software and many excellent tools to aid students of all grades and ages in learning and practicing a variety of topics, often interactively. The “Learn with Linux” series of articles offers an introduction to a variety of educational apps and software.
+
+Physics is an interesting subject, and arguably the most enjoyable part of any Physics class/lecture are the demonstrations. It is really nice to see physics in action, yet the experiments do not need to be restricted to the classroom. While Linux offers many great tools for scientists to support or conduct experiments, this article will concern a few that would make learning physics easier or more fun.
+
+### 1. Step ###
+
+[Step][7] is an interactive physics simulator, part of [KDEEdu, the KDE Education Project][8]. Nobody could better describe what Step does than the people who made it. According to the project webpage, “[Step] works like this: you place some bodies on the scene, add some forces such as gravity or springs, then click “Simulate” and Step shows you how your scene will evolve according to the laws of physics. You can change every property of bodies/forces in your experiment (even during simulation) and see how this will change the outcome of the experiment. With Step, you can not only learn but feel how physics works!”
+
+While of course it requires Qt and loads of KDE-specific dependencies to work, projects like this (and KDEEdu itself) are part of the reason why KDE is such an awesome environment (if you don’t mind running a heavier desktop, of course).
+
+Step is in the Debian repositories; to install it on derivatives, simply type
+
+ sudo apt-get install step
+
+into a terminal. On a KDE system it should have minimal dependencies and install in seconds.
+
+Step has a simple interface, and it lets you jump right into simulations.
+
+
+
+You will find all available objects on the left-hand side. You can have different particles, gas, shaped objects, springs, and different forces in action. (1) If you select an object, a short description of it will appear on the right-hand side (2). On the right you will also see an overview of the “world” you have created (the objects it contains) (3), the properties of the currently selected object (4), and the steps you have taken so far (5).
+
+
+
+Once you have placed all you wanted on the canvas, just press “Simulate,” and watch the events unfold as the objects interact with each other.
+
+
+
+
+
+
+
+To get to know Step better you only need to press F1. The KDE Help Center offers a great and detailed Step handbook.
+
+### 2. Lightspeed ###
+
+Lightspeed is a simple GTK+ and OpenGL based simulator that is meant to demonstrate the effect of how one might observe a fast moving object. Lightspeed will simulate these effects based on Einstein’s special relativity. According to [their sourceforge page][9] “When an object accelerates to more than a few million meters per second, it begins to appear warped and discolored in strange and unusual ways, and as it approaches the speed of light (299,792,458 m/s) the effects become more and more bizarre. In addition, the manner in which the object is distorted varies drastically with the viewpoint from which it is observed.”
+
+These effects which come into play at relative velocities are:
+
+- **The Lorentz contraction** – causes the object to appear shorter
+- **The Doppler red/blue shift** – alters the hues of color observed
+- **The headlight effect** – brightens or darkens the object
+- **Optical aberration** – deforms the object in unusual ways
+
+Lightspeed is in the Debian repositories; to install it, simply type:
+
+ sudo apt-get install lightspeed
+
+The user interface is very simple. You get a shape (more can be downloaded from sourceforge) which would move along the x-axis (animation can be started by processing “A” or by selecting it from the object menu).
+
+
+
+You control the speed of its movement with the right-hand side slider and watch how it deforms.
+
+
+
+Some simple controls will allow you to add more visual elements
+
+
+
+The viewing angles can be adjusted by pressing either the left, middle or right button and dragging the mouse or from the Camera menu that also offers some other adjustments like background colour or graphics mode.
+
+### Notable mention: Physion ###
+
+Physion looks like an interesting project and a great looking software to simulate physics in a much more colorful and fun way than the above examples would allow. Unfortunately, at the time of writing, the [official website][10] was experiencing problems, and the download page was unavailable.
+
+Judging from their Youtube videos, Physion must be worth installing once a download line becomes available. Until then we can just enjoy the this video demo.
+
+注:youtube 视频
+
+
+Do you have another favorite physics simulation/demonstration/learning applications for Linux? Please share with us in the comments below.
+
+--------------------------------------------------------------------------------
+
+via: https://www.maketecheasier.com/linux-physics-simulation/
+
+作者:[Attila Orosz][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.maketecheasier.com/author/attilaorosz/
+[1]:https://www.maketecheasier.com/series/learn-with-linux/
+[2]:https://www.maketecheasier.com/learn-to-type-in-linux/
+[3]:https://www.maketecheasier.com/linux-physics-simulation/
+[4]:https://www.maketecheasier.com/linux-learning-music/
+[5]:https://www.maketecheasier.com/linux-geography-apps/
+[6]:https://www.maketecheasier.com/learn-linux-maths/
+[7]:https://edu.kde.org/applications/all/step
+[8]:https://edu.kde.org/
+[9]:http://lightspeed.sourceforge.net/
+[10]:http://www.physion.net/
\ No newline at end of file
diff --git a/sources/tech/Learn with Linux/Learn with Linux--Two Geography Apps.md b/sources/tech/Learn with Linux/Learn with Linux--Two Geography Apps.md
new file mode 100644
index 0000000000..a31e1f73b4
--- /dev/null
+++ b/sources/tech/Learn with Linux/Learn with Linux--Two Geography Apps.md
@@ -0,0 +1,103 @@
+Learn with Linux: Two Geography Apps
+================================================================================
+
+
+This article is part of the [Learn with Linux][1] series:
+
+- [Learn with Linux: Learning to Type][2]
+- [Learn with Linux: Physics Simulation][3]
+- [Learn with Linux: Learning Music][4]
+- [Learn with Linux: Two Geography Apps][5]
+- [Learn with Linux: Master Your Math with These Linux Apps][6]
+
+Linux offers great educational software and many excellent tools to aid students of all grades and ages in learning and practicing a variety of topics, often interactively. The “Learn with Linux” series of articles offers an introduction to a variety of educational apps and software.
+
+Geography is an interesting subject, used by many of us day to day, often without realizing. But when you fire up GPS, SatNav, or just Google maps, you are using the geographical data provided by this software with the maps drawn by cartographists. When you hear about a certain country in the news or hear financial data being recited, these all fall under the umbrella of geography. And you have some great Linux software to study and practice these, whether it is for school or your own improvement.
+
+### Kgeography ###
+
+There are only two geography-related applications readily available in most Linux repositories, and both of these are KDE applications, in fact part of the KDE Educatonal project. Kgeography uses simple color-coded maps of any selected country.
+
+To install kegeography just type
+
+ sudo apt-get install kgeography
+
+into a terminal window of any Ubuntu-based distribution.
+
+The interface is very basic. You are first presented with a picker menu that lets you choose an area map.
+
+
+
+On the map you can display the name and capital of any given territory by clicking on it,
+
+
+
+and test your knowledge in different quizzes.
+
+
+
+It is an interactive way to test your basic geographical knowledge and could be an excellent tool to help you prepare for exams.
+
+### Marble ###
+
+Marble is a somewhat more advanced software, offering a global view of the world without the need of 3D acceleration.
+
+
+
+To get Marble, type
+
+ sudo apt-get install marble
+
+into a terminal window of any Ubuntu-based distribution.
+
+Marble focuses on cartography, its main view being that of an atlas.
+
+
+
+You can have different projections, like Globe or Mercator displayed as defaults, with flat and other exotic views available from a drop-down menu. The surfaces include the basic Atlas view, a full-fledged offline map powered by OpenStreetMap,
+
+
+
+satellite view (by NASA),
+
+
+
+and political and even historical maps of the world, among others.
+
+
+
+Besides providing great offline maps with different skins and varying amount of data, Marble offers other types of information as well. You can switch on and off various offline info-boxes
+
+
+
+and online services from the menu.
+
+
+
+An interesting online service is Wikipedia integration. Clicking on the little Wiki logos will bring up a pop-up featuring detailed information about the selected places.
+
+
+
+The software also includes options for location tracking, route planning, and searching for locations, among other great and useful features. If you enjoy cartography, Marble offers hours of fun exploring and learning.
+
+### Conclusion ###
+
+Linux offers many great educational applications, and the subject of geography is no exception. With the above two programs you can learn a lot about our globe and test your knowledge in a fun and interactive manner.
+
+--------------------------------------------------------------------------------
+
+via: https://www.maketecheasier.com/linux-geography-apps/
+
+作者:[Attila Orosz][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.maketecheasier.com/author/attilaorosz/
+[1]:https://www.maketecheasier.com/series/learn-with-linux/
+[2]:https://www.maketecheasier.com/learn-to-type-in-linux/
+[3]:https://www.maketecheasier.com/linux-physics-simulation/
+[4]:https://www.maketecheasier.com/linux-learning-music/
+[5]:https://www.maketecheasier.com/linux-geography-apps/
+[6]:https://www.maketecheasier.com/learn-linux-maths/
\ No newline at end of file
diff --git a/translated/share/20151012 Curious about Linux Try Linux Desktop on the Cloud.md b/translated/share/20151012 Curious about Linux Try Linux Desktop on the Cloud.md
new file mode 100644
index 0000000000..016429d92d
--- /dev/null
+++ b/translated/share/20151012 Curious about Linux Try Linux Desktop on the Cloud.md
@@ -0,0 +1,43 @@
+sevenot translated
+好奇Linux?试试云端的Linux桌面
+================================================================================
+Linux在桌面操作系统市场上只占据了非常小的份额,目前调查来看,估计只有2%的市场份额;对比来看丰富多变的Windows系统占据了接近90%的市场份额。对于Linux来说要挑战Windows在桌面操作系统市场的垄断,需要一个简单的方式来让用户学习不同的操作系统。如果你相信传统的Windows用户再买一台机器来使用Linux,你就太天真了。我们只能去试想用户重新分盘,设置引导程序来使用双系统,或者跳过所有步骤回到一个最简单的方法。
+
+
+我们实验过一系列无风险的使用方法让用户试操作Linux,并且不涉及任何分区管理,包括CD/DVDs光盘、USB钥匙和桌面虚拟化软件。通过实验,我强烈推荐使用VMware的VMware Player或者Oracle VirtualBox虚拟机,对于桌面操作系统或者便携式电脑的用户,这是一种相对简单而且免费的的方法来安装运行多操作系统。每一台虚拟机和其他虚拟机相隔离,但是共享CPU,存贮,网络接口等等。但是虚拟机仍需要一定的资源来安装运行Linux,也需要一台相当强劲的主机。对于一个好奇心不大的人,这样做实在是太麻烦了。
+
+要打破用户传统的使用观念市非常困难的。很多Windows用户可以尝试使用Linux提供的免费软件,但也有太多要学习的Linux系统知识。这会花掉相当一部分时间来习惯Linux的工作方式。
+
+当然了,对于一个第一次在Linux上操作的新手,有没有一个更高效的方法呢?答案是肯定的,接着往下看看云实验平台。
+
+### LabxNow ###
+
+
+
+LabxNow提供了一个免费服务,方便广大用户通过浏览器来访问远程Liunx桌面。开发者将其加强为一个用户个人远程实验室(用户可以在系统里运行、开发任何程序),用户可以在任何地方通过互联网登入远程实验室。
+
+这项服务现在可以为个人用户提供2核处理器,4GB RAM和10GB的固态硬盘,运行在128G RAM的4 AMD 6272处理器上。
+
+#### 配置参数: ####
+
+- 系统镜像:基于Ubuntu 14.04的Xface 4.10,RHEL 6.5,CentOS(Gnome桌面),Oracle
+- 硬件: CPU - 1核或者2核; 内存: 512MB, 1GB, 2GB or 4GB
+- 超快的网络数据传输
+- 可以运行在所有流行的浏览器上
+- 可以安装任意程序,可以运行任何程序 – 这是一个非常棒的方法,可以随意做实验学你你想学的所有知识, 没有 一点风险
+- 添加、删除、管理、制定虚拟机非常方便
+- 支持虚拟机共享,远程桌面
+
+你所需要的只是一台有稳定网络的设备。不用担心虚拟专用系统(VPS)、域名、或者硬件带来的高费用。LabxNow提供了一个非常好的方法在Ubuntu、RHEL和CentOS上实验。它给Windows用户一个极好的环境,让他们探索美妙的Linux世界。说得深一点,它可以让用户随时随地在里面工作,而没有了要在每台设备上安装Linux的压力。点击下面这个链接进入[www.labxnow.org/labxweb/][1]。
+
+这里还有一些其它服务(大部分市收费服务)可以让用户在Linux使用。包括Cloudsigma环境的7天使用权和Icebergs.io(通过HTML5实现root权限)。但是现在,我推荐LabxNow。
+--------------------------------------------------------------------------------
+
+来自: http://www.linuxlinks.com/article/20151003095334682/LinuxCloud.html
+
+译者:[sevenot](https://github.com/sevenot)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[1]:https://www.labxnow.org/labxweb/
diff --git a/translated/talk/20150909 Superclass--15 of the world's best living programmers.md b/translated/talk/20150909 Superclass--15 of the world's best living programmers.md
new file mode 100644
index 0000000000..6f59aa13d9
--- /dev/null
+++ b/translated/talk/20150909 Superclass--15 of the world's best living programmers.md
@@ -0,0 +1,389 @@
+教父们: 15位举世瞩目的程序员
+================================================================================
+当开发人员讨论关于世界顶级程序员时,这些名字往往就会出现。
+
+
+
+图片来源: [tom_bullock CC BY 2.0][1]
+
+好像现在程序员有很多,其中不乏有许多优秀的程序员。但是期中哪些程序员更好呢?
+
+虽然这很难客观评价,不过在这个话题确实是开发者们乐于津道的。ITworld针对程序员社区的输入和刷新试图找出可能存在的所谓共识。事实证明,屈指可数的某些名字经常是讨论的焦点。
+
+Use the arrows above to read about 15 people commonly cited as the world’s best living programmer.下面就让我们来看看这些世界顶级的程序员吧!(没有箭头呢:P)
+
+
+
+图片来源: [NASA][2]
+
+### 玛格丽特·汉密尔顿 ###
+
+**成就: 阿波罗飞行控制软件背后的大脑**
+
+生平: 查尔斯·斯塔克·德雷珀实验室软件工程部的主任,她为首的团队负责设计和打造NASA阿波罗的板载飞行控制器软件和Skylab任务。基于阿波罗这段的工作经历,她又后续开发了[通用系统语言][5]和[开发先于事实][6]的范例。开创了[异步软件、优先调度和超可靠的软件设计][7]理念。被认为发明了“[软件工程][8]”一词。1986年获[奥古斯塔·埃达·洛夫莱斯][9]奖,[2003年获NASA杰出太空行动奖][10]。
+
+评论: “汉密尔顿发明了测试,使美国计算机工程规范了很多” [ford_beeblebrox][11]
+
+“我认为在她之前(不敬地说,包括高德纳在内的)计算机编程是(另一种形式上留存的)数学分支。然而宇宙飞船的飞行控制系统明确地将编程带入了一个崭新的领域。” [Dan Allen][12]
+
+“... 她引入了‘计算机工程’这个术语 — 并作出了最好的示范。” [David Hamilton][13]
+
+“真是个坏家伙” [Drukered][14]
+
+
+
+图片来源: [vonguard CC BY-SA 2.0][15]
+
+### 唐纳德·尔文·克努斯 ###
+
+**成就: 《计算机程序设计艺术》 作者**
+
+生平: 撰写了[编程理论的权威书籍][16]。发明了数字排版系统Tex。1971年获得[首次ACM(美国计算机协会)葛丽丝·穆雷·霍普奖][17]。1974年获ACM[图灵奖][18]奖,1979年获[国家科学奖章][19],1995年获IEEE[约翰·冯·诺依曼奖章][20]。1998年入选[计算机历史博物馆名人录][21]。
+
+评论: “... 写的计算器编程的艺术可能是有史以来计算机编程最大的贡献。”[佚名][22]
+
+“唐·克努斯的TeX是我所用过的计算机程序中唯一一个几乎没有bug的。真是让人印象深刻!” [Jaap Weel][23]
+
+“如果你要问我的话,我只能说太棒了!” [Mitch Rees-Jones][24]
+
+
+
+图片来源: [Association for Computing Machinery][25]
+
+### 肯尼斯·蓝·汤普逊 ###
+
+**成就: Unix之父**
+
+生平: 与[丹尼斯·里奇][26]共同创造了Unix。创造了[B语言][27]、[UTF-8字符编码方案][28]、[ed文本编辑器][29],同时也是Go语言的合作开发人。(同里奇)共同获得1983年的[图灵奖][30],1994年获[IEEE计算机先驱奖][31],1998年获颁[美国国家科技创新奖章][32]。在1997年入选[计算机历史博物馆名人录][33]。
+
+评论: “... 可能是有史以来最能成事的程序员了。Unix内核,Unix用具,国际象棋程序世界冠军Belle,Plan 9,Go语言。” [Pete Prokopowicz][34]
+
+“肯所做出的贡献,据我所知无人能及,是如此的根本、实用、经得住时间的考验,时至今日仍在使用。” [Jan Jannink][35]
+
+
+
+图片来源: Jiel Beaumadier CC BY-SA 3.0
+
+### 理查德·斯托曼 ###
+
+**成就: Emacs和GCC缔造者**
+
+生平: 成立了[GNU工程] [36],并创造了许多的核心工具,如[Emacs, GCC, GDB][37]和[GNU Make][38]。还创办了[自由软件基金会] [39]。1990 荣获ACM[葛丽丝·穆雷·霍普奖][40],[1998获EFF先驱奖][41].
+
+评论: “... 在Symbolics对阵LMI的战斗中,独自一人与一众Lisp黑客好手对码。” [Srinivasan Krishnan][42]
+
+“通过他在编程上的造诣与强大信念,开辟了一整套编程与计算机的亚文化。” [Dan Dunay][43]
+
+“我可以不赞同这位伟人的很多方面,但不可否认无论活着还是死去,他都已经是一位伟大的程序员了。” [Marko Poutiainen][44]
+
+“试想Linux如果没有GNU工程的前期工作。斯托曼就是这个炸弹包,哟。” [John Burnette][45]
+
+
+
+图片来源: [D.Begley CC BY 2.0][46]
+
+### 安德斯·海尔斯伯格 ###
+
+**成就: 创造了Turbo Pascal**
+
+生平: [Turbo Pascal的原作者][47],是最流行的Pascal编译器和第一个集成开发环境。而后,[领导了Delphi][48]和下一代Turbo Pascal的构建。[C#的主要设计师和架构师][49]。2001年荣获[Dr. Dobb's杰出编程奖][50]。
+
+评论: “他用汇编在主流PC操作系统day(DOS and CPM)上编写了[Pascal]的编译器。用它来编译、链接并运行仅需几秒钟而不是几分钟。” [Steve Wood][51]
+
+“我佩服他 - 他创造了我最喜欢的开发工具,陪伴着我度过了三个关键的时期直至我成为一位专业的软件工程师。” [Stefan Kiryazov][52]
+
+
+
+图片来源: [vonguard CC BY-SA 2.0][53]
+
+### Doug Cutting ###
+
+**成就: 创造了Lucene**
+
+生平: [开发了Lucene搜索引擎、Web爬虫Nutch][54]和[对于大型数据集的分布式处理套件Hadoop][55]。一位强有力的开源支持者(Lucene、Nutch以及Hadoop都是开源的)。前[Apache软件基金的理事][56]。
+
+评论: “...他就是那个即写出了优秀搜索框架(lucene/solr),又为世界开启大数据之门(hadoop)的男人。” [Rajesh Rao][57]
+
+“他在Lucene和Hadoop(及其它工程)的创造/工作中为世界创造了巨大的财富和就业...” [Amit Nithianandan][58]
+
+
+
+图片来源: [Association for Computing Machinery][59]
+
+### Sanjay Ghemawat ###
+
+**成就: 谷歌核心架构师**
+
+生平: [协助设计和实现了一些谷歌大型分布式系统的功能][60],包括MapReduce、BigTable、Spanner和谷歌文件系统。[创造了Unix的 ical][61]日历系统。2009年入选[国家工程院][62]。2012年荣获[ACM-Infosys基金计算机科学奖][63]。
+
+评论: “Jeff Dean的僚机。” [Ahmet Alp Balkan][64]
+
+
+
+图片来源: [Google][65]
+
+### Jeff Dean ###
+
+**成就: 谷歌索引搜索背后的大脑**
+
+生平: 协助设计和实现了[许多谷歌大型分布式系统的功能][66],包括网页爬虫,索引搜索,AdSense,MapReduce,BigTable和Spanner。2009年入选[国家工程院][67]。2012年荣获ACM [SIGOPS马克·维瑟奖][68]及[ACM-Infosys基金计算机科学奖][69]。
+
+评论: “... 带来的在数据挖掘(GFS、MapReduce、BigTable)上的突破。” [Natu Lauchande][70]
+
+“... 设计、构建并部署MapReduce和BigTable,和以及数不清的东西” [Erik Goldman][71]
+
+
+
+图片来源: [Krd CC BY-SA 4.0][72]
+
+### 林纳斯·托瓦兹 ###
+
+**成就: Linux缔造者**
+
+生平: 创造了[Linux内核][73]与[开源版本控制器Git][74]。收获了许多奖项和荣誉,包括有1998年的[EFF先驱奖][75],2000年荣获[英国电脑学会授予的洛夫莱斯勋章][76],2012年荣获[千禧技术奖][77]还有2014年[IEEE计算机学会授予的计算机先驱奖][78]。同样入选了2008年的[计算机历史博物馆名人录][79]与2012年的[网络名人堂][80]。
+
+评论: “他只用了几年的时间就写出了Linux内核,而GNU Hurd(GNU开发的内核)历经25年的开发却丝毫没有准备发布的意思。他的成就就是带来了希望。” [Erich Ficker][81]
+
+“托沃兹可能是程序员的程序员。” [Dan Allen][82]
+
+“他真的很棒。” [Alok Tripathy][83]
+
+
+
+图片来源: [QuakeCon CC BY 2.0][84]
+
+### 约翰·卡马克 ###
+
+**成就: 毁灭战士缔造者**
+
+生平: ID社联合创始人,打造了德军总部3D、毁灭战士和雷神之锤等所谓的即使FPS游戏。引领了[切片适配更新(adaptive tile refresh)][86], [二叉空间分割(binary space partitioning)][87],表面缓存(surface caching)等开创性的计算机图像技术。2001年入选[互动艺术与科学学会名人堂][88],2007年和2008年荣获工程技术类[艾美奖][89]并于2010年由[游戏开发者甄选奖][90]授予终生成就奖。
+
+评论: “他在写第一个渲染引擎的时候不到20岁。这家伙这是个天才。我若有他四分之一的天赋便心满意足了。” [Alex Dolinsky][91]
+
+“... 德军总部3D,、毁灭战士还有雷神之锤在那时都是革命性的,影响了一代游戏设计师。” [dniblock][92]
+
+“一个周末他几乎可以写出任何东西....” [Greg Naughton][93]
+
+“他是编程界的莫扎特... [Chris Morris][94]
+
+
+
+图片来源: [Duff][95]
+
+### 法布里斯·贝拉 ###
+
+**成就: 创造了QEMU**
+
+生平: 创造了[一系列耳熟能详的开源软件][96],其中包括硬件模拟和虚拟化的平台QEMU,用于处理多媒体数据的FFmpeg,微型C编译器和 一个可执行文件压缩软件LZEXE。2000年和2001年[C语言混乱代码大赛的获胜者][97]并在2011年荣获[Google-O'Reilly开源奖][98]。[计算Pi最多位数][99]的前世界纪录保持着。
+
+评论: “我觉得法布里斯·贝拉做的每一件事都是那么显著而又震撼。” [raphinou][100]
+
+“法布里斯·贝拉是世界上最高产的程序员...” [Pavan Yara][101]
+
+“他就像软件工程界的尼古拉·特斯拉。” [Michael Valladolid][102]
+
+“自80年代以来,他一直高产出一些列的成功作品。” [Michael Biggins][103]
+
+
+
+图片来源: [Craig Murphy CC BY 2.0][104]
+
+### Jon Skeet ###
+
+**成就: Stack Overflow传说级贡献者**
+
+生平: Google工程师[深入解析C#][105]的作者。保持着[有史以来在Stack Overflow上最高的声誉][106],平均每月解答390个问题。
+
+评论: “他根本不需要调试器,只要他盯一下代码,错误之处自会原形毕露。” [Steven A. Lowe][107]
+
+“如果他的代码没有通过编译,那编译器应该道歉。” [Dan Dyer][108]
+
+“他根本不需要什么编程规范,他的代码就是编程规范。” [Anonymous][109]
+
+
+
+图片来源: [Philip Neustrom CC BY 2.0][110]
+
+### 亚当·安捷罗 ###
+
+**成就: Quora的创办人之一**
+
+生平: 还是Facebook工程师时,[为其搭建了news feed功能的基础][111]。直至其离开并联合创始了Quora,已经成为了Facebook的CTO和工程VP。2001年以高中生的身份在[美国计算机奥林匹克上第八位完成比赛][112]。2004年ACM国际大学生编程大赛[获得银牌的团队 - 加利福尼亚技术研究所][113]的成员。2005年入围Topcoder大学生[算法编程挑战赛][114]。
+
+评论: “一位程序设计全才。” [Anonymous][115]
+
+"我做的每个好东西,他都已有了六个。" [Mark Zuckerberg][116]
+
+
+
+图片来源: [Facebook][117]
+
+### Petr Mitrechev ###
+
+**成就: 有史以来最具竞技能力的程序员之一**
+
+生平: 在国际信息学奥林匹克中[两次获得金牌][118](2000,2002)。在2006,[赢得Google Code Jam][119]同时也是[TopCoder Open算法大赛冠军][120]。也同样,两次赢得Facebook黑客杯([2011][121],[2013][122])。写这篇文章的时候,[TopCoder榜中排第二][123] (即:Petr)、在[Codeforces榜同样排第二][124]。
+
+评论: “他是竞技程序员的偶像,即使在印度也是如此...[Kavish Dwivedi][125]
+
+
+
+图片来源: [Ishandutta2007 CC BY-SA 3.0][126]
+
+### Gennady Korotkevich ###
+
+**成就: 竞技编程小神童**
+
+生平: 国际信息学奥林匹克中最小参赛者(11岁)[6次获得金牌][127] (2007-2012)。2013年ACM国际大学生编程大赛[获胜队伍][128]成员及[2014 Facebook黑客杯][129]获胜者。写这篇文章的时候,[Codeforces榜排名第一][130] (即:Tourist)、[TopCoder榜第一][131]。
+
+评论: “一个编程神童!” [Prateek Joshi][132]
+
+“Gennady真是棒,也是为什么我在白俄罗斯拥有一个强大开发团队的例证。” [Chris Howard][133]
+
+“Tourist真是天才” [Nuka Shrinivas Rao][134]
+
+--------------------------------------------------------------------------------
+
+via: http://www.itworld.com/article/2823547/enterprise-software/158256-superclass-14-of-the-world-s-best-living-programmers.html#slide1
+
+作者:[Phil Johnson][a]
+译者:[martin2011qi](https://github.com/martin2011qi)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.itworld.com/author/Phil-Johnson/
+[1]:https://www.flickr.com/photos/tombullock/15713223772
+[2]:https://commons.wikimedia.org/wiki/File:Margaret_Hamilton_in_action.jpg
+[3]:http://klabs.org/home_page/hamilton.htm
+[4]:https://www.youtube.com/watch?v=DWcITjqZtpU&feature=youtu.be&t=3m12s
+[5]:http://www.htius.com/Articles/r12ham.pdf
+[6]:http://www.htius.com/Articles/Inside_DBTF.htm
+[7]:http://www.nasa.gov/home/hqnews/2003/sep/HQ_03281_Hamilton_Honor.html
+[8]:http://www.nasa.gov/50th/50th_magazine/scientists.html
+[9]:https://books.google.com/books?id=JcmV0wfQEoYC&pg=PA321&lpg=PA321&dq=ada+lovelace+award+1986&source=bl&ots=qGdBKsUa3G&sig=bkTftPAhM1vZ_3VgPcv-38ggSNo&hl=en&sa=X&ved=0CDkQ6AEwBGoVChMI3paoxJHWxwIVA3I-Ch1whwPn#v=onepage&q=ada%20lovelace%20award%201986&f=false
+[10]:http://history.nasa.gov/alsj/a11/a11Hamilton.html
+[11]:https://www.reddit.com/r/pics/comments/2oyd1y/margaret_hamilton_with_her_code_lead_software/cmrswof
+[12]:http://qr.ae/RFEZLk
+[13]:http://qr.ae/RFEZUn
+[14]:https://www.reddit.com/r/pics/comments/2oyd1y/margaret_hamilton_with_her_code_lead_software/cmrv9u9
+[15]:https://www.flickr.com/photos/44451574@N00/5347112697
+[16]:http://cs.stanford.edu/~uno/taocp.html
+[17]:http://awards.acm.org/award_winners/knuth_1013846.cfm
+[18]:http://amturing.acm.org/award_winners/knuth_1013846.cfm
+[19]:http://www.nsf.gov/od/nms/recip_details.jsp?recip_id=198
+[20]:http://www.ieee.org/documents/von_neumann_rl.pdf
+[21]:http://www.computerhistory.org/fellowawards/hall/bios/Donald,Knuth/
+[22]:http://www.quora.com/Who-are-the-best-programmers-in-Silicon-Valley-and-why/answers/3063
+[23]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Jaap-Weel
+[24]:http://qr.ae/RFE94x
+[25]:http://amturing.acm.org/photo/thompson_4588371.cfm
+[26]:https://www.youtube.com/watch?v=JoVQTPbD6UY
+[27]:https://www.bell-labs.com/usr/dmr/www/bintro.html
+[28]:http://doc.cat-v.org/bell_labs/utf-8_history
+[29]:http://c2.com/cgi/wiki?EdIsTheStandardTextEditor
+[30]:http://amturing.acm.org/award_winners/thompson_4588371.cfm
+[31]:http://www.computer.org/portal/web/awards/cp-thompson
+[32]:http://www.uspto.gov/about/nmti/recipients/1998.jsp
+[33]:http://www.computerhistory.org/fellowawards/hall/bios/Ken,Thompson/
+[34]:http://www.quora.com/Computer-Programming/Who-is-the-best-programmer-in-the-world-right-now/answer/Pete-Prokopowicz-1
+[35]:http://qr.ae/RFEWBY
+[36]:https://groups.google.com/forum/#!msg/net.unix-wizards/8twfRPM79u0/1xlglzrWrU0J
+[37]:http://www.emacswiki.org/emacs/RichardStallman
+[38]:https://www.gnu.org/gnu/thegnuproject.html
+[39]:http://www.emacswiki.org/emacs/FreeSoftwareFoundation
+[40]:http://awards.acm.org/award_winners/stallman_9380313.cfm
+[41]:https://w2.eff.org/awards/pioneer/1998.php
+[42]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Greg-Naughton/comment/4146397
+[43]:http://qr.ae/RFEaib
+[44]:http://www.quora.com/Software-Engineering/Who-are-some-of-the-greatest-currently-active-software-architects-in-the-world/answer/Marko-Poutiainen
+[45]:http://qr.ae/RFEUqp
+[46]:https://www.flickr.com/photos/begley/2979906130
+[47]:http://www.taoyue.com/tutorials/pascal/history.html
+[48]:http://c2.com/cgi/wiki?AndersHejlsberg
+[49]:http://www.microsoft.com/about/technicalrecognition/anders-hejlsberg.aspx
+[50]:http://www.drdobbs.com/windows/dr-dobbs-excellence-in-programming-award/184404602
+[51]:http://qr.ae/RFEZrv
+[52]:http://www.quora.com/Software-Engineering/Who-are-some-of-the-greatest-currently-active-software-architects-in-the-world/answer/Stefan-Kiryazov
+[53]:https://www.flickr.com/photos/vonguard/4076389963/
+[54]:http://www.wizards-of-os.org/archiv/sprecher/a_c/doug_cutting.html
+[55]:http://hadoop.apache.org/
+[56]:https://www.linkedin.com/in/cutting
+[57]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Shalin-Shekhar-Mangar/comment/2293071
+[58]:http://www.quora.com/Who-are-the-best-programmers-in-Silicon-Valley-and-why/answer/Amit-Nithianandan
+[59]:http://awards.acm.org/award_winners/ghemawat_1482280.cfm
+[60]:http://research.google.com/pubs/SanjayGhemawat.html
+[61]:http://www.quora.com/Google/Who-is-Sanjay-Ghemawat
+[62]:http://www8.nationalacademies.org/onpinews/newsitem.aspx?RecordID=02062009
+[63]:http://awards.acm.org/award_winners/ghemawat_1482280.cfm
+[64]:http://www.quora.com/Google/Who-is-Sanjay-Ghemawat/answer/Ahmet-Alp-Balkan
+[65]:http://research.google.com/people/jeff/index.html
+[66]:http://research.google.com/people/jeff/index.html
+[67]:http://www8.nationalacademies.org/onpinews/newsitem.aspx?RecordID=02062009
+[68]:http://news.cs.washington.edu/2012/10/10/uw-cse-ph-d-alum-jeff-dean-wins-2012-sigops-mark-weiser-award/
+[69]:http://awards.acm.org/award_winners/dean_2879385.cfm
+[70]:http://www.quora.com/Computer-Programming/Who-is-the-best-programmer-in-the-world-right-now/answer/Natu-Lauchande
+[71]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Cosmin-Negruseri/comment/28399
+[72]:https://commons.wikimedia.org/wiki/File:LinuxCon_Europe_Linus_Torvalds_05.jpg
+[73]:http://www.linuxfoundation.org/about/staff#torvalds
+[74]:http://git-scm.com/book/en/Getting-Started-A-Short-History-of-Git
+[75]:https://w2.eff.org/awards/pioneer/1998.php
+[76]:http://www.bcs.org/content/ConWebDoc/14769
+[77]:http://www.zdnet.com/blog/open-source/linus-torvalds-wins-the-tech-equivalent-of-a-nobel-prize-the-millennium-technology-prize/10789
+[78]:http://www.computer.org/portal/web/pressroom/Linus-Torvalds-Named-Recipient-of-the-2014-IEEE-Computer-Society-Computer-Pioneer-Award
+[79]:http://www.computerhistory.org/fellowawards/hall/bios/Linus,Torvalds/
+[80]:http://www.internethalloffame.org/inductees/linus-torvalds
+[81]:http://qr.ae/RFEeeo
+[82]:http://qr.ae/RFEZLk
+[83]:http://www.quora.com/Software-Engineering/Who-are-some-of-the-greatest-currently-active-software-architects-in-the-world/answer/Alok-Tripathy-1
+[84]:https://www.flickr.com/photos/quakecon/9434713998
+[85]:http://doom.wikia.com/wiki/John_Carmack
+[86]:http://thegamershub.net/2012/04/gaming-gods-john-carmack/
+[87]:http://www.shamusyoung.com/twentysidedtale/?p=4759
+[88]:http://www.interactive.org/special_awards/details.asp?idSpecialAwards=6
+[89]:http://www.itworld.com/article/2951105/it-management/a-fly-named-for-bill-gates-and-9-other-unusual-honors-for-tech-s-elite.html#slide8
+[90]:http://www.gamechoiceawards.com/archive/lifetime.html
+[91]:http://qr.ae/RFEEgr
+[92]:http://www.itworld.com/answers/topic/software/question/whos-best-living-programmer#comment-424562
+[93]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Greg-Naughton
+[94]:http://money.cnn.com/2003/08/21/commentary/game_over/column_gaming/
+[95]:http://dufoli.wordpress.com/2007/06/23/ammmmaaaazing-night/
+[96]:http://bellard.org/
+[97]:http://www.ioccc.org/winners.html#B
+[98]:http://www.oscon.com/oscon2011/public/schedule/detail/21161
+[99]:http://bellard.org/pi/pi2700e9/
+[100]:https://news.ycombinator.com/item?id=7850797
+[101]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Erik-Frey/comment/1718701
+[102]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Erik-Frey/comment/2454450
+[103]:http://qr.ae/RFEjhZ
+[104]:https://www.flickr.com/photos/craigmurphy/4325516497
+[105]:http://www.amazon.co.uk/gp/product/1935182471?ie=UTF8&tag=developetutor-21&linkCode=as2&camp=1634&creative=19450&creativeASIN=1935182471
+[106]:http://stackexchange.com/leagues/1/alltime/stackoverflow
+[107]:http://meta.stackexchange.com/a/9156
+[108]:http://meta.stackexchange.com/a/9138
+[109]:http://meta.stackexchange.com/a/9182
+[110]:https://www.flickr.com/photos/philipn/5326344032
+[111]:http://www.crunchbase.com/person/adam-d-angelo
+[112]:http://www.exeter.edu/documents/Exeter_Bulletin/fall_01/oncampus.html
+[113]:http://icpc.baylor.edu/community/results-2004
+[114]:https://www.topcoder.com/tc?module=Static&d1=pressroom&d2=pr_022205
+[115]:http://qr.ae/RFfOfe
+[116]:http://www.businessinsider.com/in-new-alleged-ims-mark-zuckerberg-talks-about-adam-dangelo-2012-9#ixzz369FcQoLB
+[117]:https://www.facebook.com/hackercup/photos/a.329665040399024.91563.133954286636768/553381194694073/?type=1
+[118]:http://stats.ioinformatics.org/people/1849
+[119]:http://googlepress.blogspot.com/2006/10/google-announces-winner-of-global-code_27.html
+[120]:http://community.topcoder.com/tc?module=SimpleStats&c=coder_achievements&d1=statistics&d2=coderAchievements&cr=10574855
+[121]:https://www.facebook.com/notes/facebook-hacker-cup/facebook-hacker-cup-finals/208549245827651
+[122]:https://www.facebook.com/hackercup/photos/a.329665040399024.91563.133954286636768/553381194694073/?type=1
+[123]:http://community.topcoder.com/tc?module=AlgoRank
+[124]:http://codeforces.com/ratings
+[125]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Venkateswaran-Vicky/comment/1960855
+[126]:http://commons.wikimedia.org/wiki/File:Gennady_Korot.jpg
+[127]:http://stats.ioinformatics.org/people/804
+[128]:http://icpc.baylor.edu/regionals/finder/world-finals-2013/standings
+[129]:https://www.facebook.com/hackercup/posts/10152022955628845
+[130]:http://codeforces.com/ratings
+[131]:http://community.topcoder.com/tc?module=AlgoRank
+[132]:http://www.quora.com/Computer-Programming/Who-is-the-best-programmer-in-the-world-right-now/answer/Prateek-Joshi
+[133]:http://www.quora.com/Computer-Programming/Who-is-the-best-programmer-in-the-world-right-now/answer/Prateek-Joshi/comment/4720779
+[134]:http://www.quora.com/Computer-Programming/Who-is-the-best-programmer-in-the-world-right-now/answer/Prateek-Joshi/comment/4880549
diff --git a/translated/talk/20151012 The Brief History Of Aix HP-UX Solaris BSD And LINUX.md b/translated/talk/20151012 The Brief History Of Aix HP-UX Solaris BSD And LINUX.md
new file mode 100644
index 0000000000..921f1a57aa
--- /dev/null
+++ b/translated/talk/20151012 The Brief History Of Aix HP-UX Solaris BSD And LINUX.md
@@ -0,0 +1,101 @@
+Aix, HP-UX, Solaris, BSD, 和 LINUX 简史
+================================================================================
+
+
+要记住,当一扇门在你面前关闭的时候,另一扇门就会打开。[Ken Thompson][1] 和 [Dennis Richie][2] 两个人就是这句名言很好的实例。他们俩是 **20世纪** 最优秀的信息技术专家,因为他们创造了 **UNIX**,最具影响力和创新性的软件之一。
+
+### UNIX 系统诞生于贝尔实验室 ###
+
+**UNIX** 最开始的名字是 **UNICS** (**UN**iplexed **I**nformation and **C**omputing **S**ervice),它有一个大家庭,并不是从石头缝里蹦出来的。UNIX的祖父是 **CTSS** (**C**ompatible **T**ime **S**haring **S**ystem),它的父亲是 **Multics** (**MULT**iplexed **I**nformation and **C**omputing **S**ervice),这个系统能支持大量用户通过交互式分时使用大型机。
+
+UNIX 诞生于 **1969** 年,由 **Ken Thompson** 以及后来加入的 **Dennis Richie** 共同完成。这两位优秀的研究员和科学家一起在一个**通用电子**和**麻省理工学院**的合作项目里工作,项目目标是开发一个叫 Multics 的交互式分时系统。
+
+Multics 的目标是整合分时共享以及当时其他先进技术,允许用户在远程终端通过电话登录到主机,然后可以编辑文档,阅读电子邮件,运行计算器,等等。
+
+在之后的五年里,AT&T 公司为 Multics 项目投入了数百万美元。他们购买了 GE-645 大型机,聚集了贝尔实验室的顶级研究人员,例如 Ken Thompson, Stuart Feldman, Dennis Ritchie, M. Douglas McIlroy, Joseph F. Ossanna, 以及 Robert Morris。但是项目目标太过激进,进度严重滞后。最后,AT&T 高层决定放弃这个项目。
+
+贝尔实验室的管理层决定停止这个让许多研究人员无比纠结的操作系统上的所有遗留工作。不过要感谢 Thompson,Richie 和一些其他研究员,他们把老板的命令丢到一边,并继续在实验室里满怀热心地忘我工作,最终孵化出前无古人后无来者的 UNIX。
+
+UNIX 的第一声啼哭是在一台 PDP-7 微型机上,它是 Thompson 测试自己在操作系统设计上的点子的机器,也是 Thompson 和 Richie 一起玩 Space and Travel 游戏的模拟器。
+
+> “我们想要的不仅是一个优秀的编程环境,而是能围绕这个系统形成团体。按我们自己的经验,通过远程访问和分时共享主机实现的公共计算,本质上不只是用终端输入程序代替打孔机而已,而是鼓励密切沟通。”Dennis Richie 说。
+
+UNIX 是第一个靠近理想的系统,在这里程序员可以坐在机器前自由摆弄程序,探索各种可能性并随手测试。在 UNIX 整个生命周期里,它吸引了大量因其他操作系统限制而投身过来的高手做出无私贡献,因此它的功能模型一直保持上升趋势。
+
+UNIX 在 1970 年因为 PDP-11/20 获得了首次资金注入,之后正式更名为 UNIX 并支持在 PDP-11/20 上运行。UNIX 带来的第一次收获是在 1971 年,贝尔实验室的专利部门配备来做文字处理。
+
+### UNIX 上的 C 语言革命 ###
+
+Dennis Richie 在 1972 年发明了一种叫 “**C**” 的高级编程语言 ,之后他和 Ken Thompson 决定用 “C” 重写 UNIX 系统,来支持更好的移植性。他们在那一年里编写和调试了差不多 100,000 行代码。在使用了 “C” 语言后,系统可移植性非常好,只需要修改一小部分机器相关的代码就可以将 UNIX 移植到其他计算机平台上。
+
+UNIX 第一次公开露面是 1973 年 Dennis Ritchie 和 Ken Thompson 在操作系统原理上发表的一篇论文,然后 AT&T 发布了 UNIX 系统第 5 版,并授权给教育机构使用,然后在 1976 年第一次以 **$20.000** 的价格授权企业使用 UNIX 第 6 版。应用最广泛的是 1980 年发布的 UNIX 第 7 版,任何人都可以购买授权,只是授权条款非常有限。授权内容包括源代码,以及用 PDP-11 汇编语言写的及其相关内核。反正,各种版本 UNIX 系统完全由它的用户手册确定。
+
+### AIX 系统 ###
+
+在 **1983** 年,**Microsoft** 计划开发 **Xenix** 作为 MS-DOS 的多用户版继任者,他们在那一年花了 $8,000 搭建了一台拥有 **512 KB** 内存以及 **10 MB**硬盘并运行 Xenix 的 Altos 586。而到 1984 年为止,全世界 UNIX System V 第二版的安装数量已经超过了 100,000 。在 1986 年发布了包含因特网域名服务的 4.3BSD,而且 **IBM** 宣布 **AIX 系统**的安装数已经超过 250,000。AIX 基于 Unix System V 开发,这套系统拥有 BSD 风格的根文件系统,是两者的结合。
+
+AIX 第一次引入了 **日志文件系统 (JFS)** 以及集成逻辑卷管理器 (LVM)。IBM 在 1989 年将 AIX 移植到自己的 RS/6000 平台。2001 年发布的 5L 版是一个突破性的版本,提供了 Linux 友好性以及支持 Power4 服务器的逻辑分区。
+
+在 2004 年发布的 AIX 5.3 引入了支持 Advanced Power Virtualization (APV) 的虚拟化技术,支持对称多线程,微分区,以及可分享的处理器池。
+
+在 2007 年,IBM 同时发布 AIX 6.1 和 Power6 架构,开始加强自己的虚拟化产品。他们还将 Advanced Power Virtualization 重新包装成 PowerVM。
+
+这次改进包括被称为 WPARs 的负载分区形式,类似于 Solaris 的 zones/Containers,但是功能更强。
+
+### HP-UX 系统 ###
+
+**惠普 UNIX (HP-UX)** 源于 System V 第 3 版。这套系统一开始只支持 PA-RISC HP 9000 平台。HP-UX 第 1 版发布于 1984 年。
+
+HP-UX 第 9 版引入了 SAM,一个基于字符的图形用户界面 (GUI),用户可以用来管理整个系统。在 1995 年发布的第 10 版,调整了系统文件分布以及目录结构,变得有点类似 AT&T SVR4。
+
+第 11 版发布于 1997 年。这是 HP 第一个支持 64 位寻址的版本。不过在 2000 年重新发布成 11i,因为 HP 为特定的信息技术目的,引入了操作环境和分级应用的捆绑组。
+
+在 2001 年发布的 11.20 版宣称支持 Itanium 系统。HP-UX 是第一个使用 ACLs(访问控制列表)管理文件权限的 UNIX 系统,也是首先支持内建逻辑卷管理器的系统之一。
+
+如今,HP-UX 因为 HP 和 Veritas 的合作关系使用了 Veritas 作为主文件系统。
+
+HP-UX 目前的最新版本是 11iv3, update 4。
+
+### Solaris 系统 ###
+
+Sun 的 UNIX 版本是 **Solaris**,用来接替 1992 年创建的 **SunOS**。SunOS 一开始基于 BSD(伯克利软件发行版)风格的 UNIX,但是 SunOS 5.0 版以及之后的版本都是基于重新包装成 Solaris 的 Unix System V 第 4 版。
+
+SunOS 1.0 版于 1983 年发布,用于支持 Sun-1 和 Sun-2 平台。随后在 1985 年发布了 2.0 版。在 1987 年,Sun 和 AT&T 宣布合作一个项目以 SVR4 为基础将 System V 和 BSD 合并成一个版本。
+
+Solaris 2.4 是 Sun 发布的第一个 Sparc/x86 版本。1994 年 11 月份发布的 SunOS 4.1.4 版是最后一个版本。Solaris 7 是首个 64 位 Ultra Sparc 版本,加入了对文件系统元数据记录的原生支持。
+
+Solaris 9 发布于 2002 年,支持 Linux 特性以及 Solaris 卷管理器。之后,2005 年发布了 Solaris 10,带来许多创新,比如支持 Solaris Containers,新的 ZFS 文件系统,以及逻辑域。
+
+目前 Solaris 最新的版本是 第 10 版,最后的更新发布于 2008 年。
+
+### Linux ###
+
+到了 1991 年,用来替代商业操作系统的免费系统的需求日渐高涨。因此 **Linus Torvalds** 开始构建一个免费的操作系统,最终成为 **Linux**。Linux 最开始只有一些 “C” 文件,并且使用了阻止商业发行的授权。Linux 是一个类 UNIX 系统但又不尽相同。
+
+2015 年 发布了基于 GNU Public License 授权的 3.18 版。IBM 声称有超过 1800 万行开源代码开放给开发者。
+
+如今 GNU Public License 是应用最广泛的免费软件授权方式。根据开源软件原则,这份授权允许个人和企业自由分发、运行、通过拷贝共享、学习,以及修改软件源码。
+
+### UNIX vs. Linux: 技术概要 ###
+
+- Linux 鼓励多样性,Linux 的开发人员有更广阔的背景,有更多不同经验和意见。
+- Linux 比 UNIX 支持更多的平台和架构。
+- UNIX 商业版本的开发人员会为他们的操作系统考虑特定目标平台以及用户。
+- **Linux 比 UNIX 有更好的安全性**,更少受病毒或恶意软件攻击。Linux 上大约有 60-100 种病毒,但是没有任何一种还在传播。另一方面,UNIX 上大约有 85-120 种病毒,但是其中有一些还在传播中。
+- 通过 UNIX 命令,系统上的工具和元素很少改变,甚至很多接口和命令行参数在后续 UNIX 版本中一直沿用。
+- 有些 Linux 开发项目以自愿为基础进行资助,比如 Debian。其他项目会维护一个和商业 Linux 的社区版,比如 SUSE 的 openSUSE 以及红帽的 Fedora。
+- 传统 UNIX 是纵向扩展,而另一方面 Linux 是横向扩展。
+
+--------------------------------------------------------------------------------
+
+via: http://www.unixmen.com/brief-history-aix-hp-ux-solaris-bsd-linux/
+
+作者:[M.el Khamlichi][a]
+译者:[zpl1025](https://github.com/zpl1025)
+校对:[Caroline](https://github.com/carolinewuyan)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.unixmen.com/author/pirat9/
+[1]:http://www.unixmen.com/ken-thompson-unix-systems-father/
+[2]:http://www.unixmen.com/dennis-m-ritchie-father-c-programming-language/
diff --git a/translated/talk/The history of Android/13 - The history of Android.md b/translated/talk/The history of Android/13 - The history of Android.md
new file mode 100644
index 0000000000..8929f55064
--- /dev/null
+++ b/translated/talk/The history of Android/13 - The history of Android.md
@@ -0,0 +1,104 @@
+安卓编年史
+================================================================================
+
+
+### Android 2.1, update 1——无尽战争的开端 ###
+
+谷歌是第一代iPhone的主要合作伙伴——公司为苹果的移动操作系统提供了谷歌地图,搜索,以及Youtube。在那时,谷歌CEO埃里克·施密特是苹果的董事会成员之一。实际上,在最初的苹果发布会上,施密特是在史蒂夫·乔布斯[之后第一个登台的人][1],他还开玩笑说两家公司如此接近,都可以合并成“AppleGoo”了。
+
+当谷歌开发安卓的时候,两家公司间的关系慢慢变得充满争吵。然而,谷歌很大程度上还是通过拒iPhone关键特性于安卓门外,如双指缩放,来取悦苹果。尽管如此,Nexus One是第一部不带键盘的直板安卓旗舰机,设备被赋予了和iPhone相同的外观因素。Nexus One结合了新软件和谷歌的品牌,这是压倒苹果的最后一根稻草。根据沃尔特·艾萨克森为史蒂夫·乔布斯写的传记,2010年1月在看到了Nexus One之后,这个苹果的CEO震怒了,说道:“如果需要的话我会用尽最后一口气,以及花光苹果在银行里的400亿美元,来纠正这个错误……我要摧毁安卓,因为它完全是偷窃来的产品。我愿意为此进行核战争。”
+
+所有的这些都在秘密地发生,仅在Nexus One发布后的几年后才公诸于众。公众们最早在安卓2.1——推送给Nexus One的一个称作“[2.1 update 1][2]”的更新,发布后一个月左右捕捉到谷歌和苹果间愈演愈烈的分歧气息。这个更新添加了一个功能,正是iOS一直居于安卓之上的功能:双指缩放。
+
+尽管安卓从2.0版本开始就支持多点触控API了,默认的系统应用在乔布斯的命令下依然和这项实用的功能划清界限。在关于Nexus One的和解会议谈崩了之后,谷歌再也没有理由拒双指缩放于安卓门外了。谷歌给设备推送了更新,安卓终于补上了不足之处。
+
+随着谷歌地图,浏览器以及相册中双指缩放的全面启用,谷歌和苹果的智能手机战争也就此拉开序幕。在接下来的几年中,两家公司会变成死敌。双指缩放更新的一个月后,苹果开始了他的征途,起诉了所有使用安卓的公司。HTC,摩托罗拉以及三星都被告上法庭,直到现在都还有一些诉讼还没解决。施密特辞去了苹果董事会的职务。谷歌地图和Youtube被从iPhone中移除,苹果甚至开始打造自己的地图服务。今天,这两位选手几乎是“AppleGoo”竞赛的唯一选手,涉及领域十分广:智能手机,平板,笔记本,电影,TV秀,音乐,书籍,应用,邮件,生产力工具,浏览器,个人助理,云存储,移动广告,即时通讯,地图以及机顶盒……以及不久他们将会在汽车智能,穿戴设备,移动支付,以及客厅娱乐等进行竞争。
+
+### Android 2.2 Froyo——更快更华丽 ###
+
+[安卓2.2][3]在2010年5月,也就是2.1发布后的四个月后亮相。Froyo(冻酸奶)的亮点主要是底层优化,只为更快的速度。Froyo最大的改变是增加了JIT编译。JIT自动在运行时将java字节码转换为原生码,这会给系统全面带来显著的性能改善。
+
+浏览器同样得到了性能改善,这要感谢来自Chrome的V8 Javascript引擎的整合。这是安卓浏览器从Chrome借鉴的许多特性中的第一个,最终系统内置的浏览器会被移动版Chrome彻底替代掉。在那之前,安卓团队还是需要发布一个浏览器。从Chrome借鉴特性是条升级的捷径。
+
+在谷歌专注于让它的平台更快的同时,苹果正在让它的平台更全面。谷歌的竞争对手在一个月前发布了10英寸的iPad,先行进入了平板时代。尽管有些搭载Froyo和Gingerbread的安卓平板发布,谷歌的官方回应——安卓3.0 Honeycomb(蜂巢)以及摩托罗拉Xoom——在9个月后才来到。
+
+
+Froyo底部添加了双图标停靠栏以及全局搜索。
+Ron Amadeo供图
+
+Froyo主屏幕最大的变化是底部的新停靠栏,电话和浏览器图标填充了先前抽屉按钮左右的空白空间。这些新图标都是现有图标的定制白色版本,并且用户没办法自己设置图标。
+
+默认布局移除了所有图标,屏幕上只留下一个使用提示小部件,引导你点击启动器图标以访问你的应用。谷歌搜索小部件得到了一个谷歌logo,同时也是个按钮。点击它可以打开一个搜索界面,你可以限制搜索范围在互联网,应用或是联系人之内。
+
+
+下载页面有了“更新所有”按钮,Flash应用,一个flash驱动的一切皆有可能的网站,以及“移动到SD”按钮。
+[Ryan Paul][4]供图
+
+还有一些优秀的新功能加入了Froyo,安卓市场加入了更多的下载控制。有个新的“更新所有”按钮固定在了下载页面底部。谷歌还添加了自动更新特性,只要应用权限没有改变就能够自动安装应用;尽管如此,自动更新默认是关闭的。
+
+第二张图展示了Adobe Flash播放器,它是Froyo独占的。这个应用作为插件加入了浏览器,让浏览器能够有“完整的网络”体验。在2010年,这意味着网页充满了Flash导航和视频。Flash是安卓相比于iPhone最大的不同之一。史蒂夫·乔布斯展开了一场对抗Flash的圣战,声称它是一个被淘汰的,充满bug的软件,并且苹果不会在iOS上允许它的存在。所以安卓接纳了Flash并且让它在安卓上运行,给予用户在安卓上拥有半可用的flash实现。
+
+在那时,Flash甚至能够让桌面电脑崩溃,所以在移动设备上一直保持打开状态会带来可怕的体验。为了解决这个问题,安卓浏览器上的Flash可以设置为“按需打开”——除非用户点击Flash占位图标,否则不会加载Flash内容。对Flash的支持将会持续到安卓4.1,Adobe在那时放弃并且结束了这个项目。Flash归根到底从未在安卓上完美运行过。而Flash在iPhone这个最流行的移动设备上的缺失,推动了互联网最终放弃了这个平台。
+
+最后一张图片显示的是新增的移动应用到SD卡功能,在那个手机只有512MB内置存储的时代,这个功能十分的必要的。
+
+
+驾驶模式应用。相机现在可以旋转了。
+Ron Amadeo供图
+
+相机应用终于更新支持纵向模式了。相机设置被从抽屉中移出,变成一条半透明的按钮带,放在了快门按钮和其他控制键旁边。这个新设计看起来从Cooliris相册中获得了许多灵感,有着半透明,有弹性的聊天气泡弹出窗口。看到更现代的Cooliris风格UI设计被嫁接到皮革装饰的相机应用确实十分奇怪——从审美上来说一点都不搭。
+
+
+半残缺的Facebook应用是个常见的2x3导航页面的优秀范例。谷歌Goggles被包含了进来但同样是残缺的。
+Ron Amadeo供图
+
+不像在安卓2.0和2.1中包含的Facebook客户端,2.2版本的仍然部分能够工作并且登陆Facebook服务器。Facebook应用是个谷歌那时候设计指南的优秀范例,它建议应用拥有一个含有3x2图标方阵的导航页并作为应用主页。
+
+这是谷歌的第一个标准化尝试,将导航元素从菜单按钮里移到屏幕上,因为用户找不到它们。这个设计很实用,但它在打开应用和使用应用之间增加了额外的障碍。谷歌不久后湖意识到当用户打开一个应用,显示应用内容而不是中间导航页是个更好的主意。以Facebook为例,打开应用直接打开信息订阅会更合适。并且不久后应用设计将会把导航降级到二层位置——先是作为顶部的标签之一,后来谷歌放在了“导航抽屉”,一个含有应用所有功能位置的滑出式面板。
+
+还有个预装到Froyo的是谷歌Goggles,一个视觉搜索应用,它会尝试辨别图片上的主体。它在辨别艺术品,地标以及条形码时很实用,但差不多也就这些了。最先的两个设置屏幕,以及相机界面,这是应用里唯一现在还能运行的了。由于客户端太旧了,实际上你如今并不能完成一个搜索。应用里也没什么太多可看的,也就一个会返回搜索结果页的相机界面而已。
+
+
+Twitter应用,一个充满动画的谷歌和Twitter的合作成果。
+Ron Amadeo供图
+
+Froyo拥有第一个安卓Twitter应用,实际上它是谷歌和Twitter的合作成果。那时,一个Twitter应用是安卓应用阵容里的大缺憾。开发者们更偏爱iPhone,加上苹果占领先机和严格的设计要求,App Store里可选择的应用远比安卓的有优势。但是谷歌需要一个Twitter应用,所以它和Twitter合作组建团队让第一个版本问世。
+
+这个应用代表了谷歌的新设计语言,这以为着它有个中间导航页以及对动画要求的“技术演示”。Twitter应用甚至比Cooliris相册用的动画效果还多——所有东西一直都在动。所有页面顶部和底部的云朵以不同速度持续滚动,底部的Twitter小鸟拍动它的翅膀并且左右移动它的头。
+
+Twitter应用实际上有点Action Bar早期前身的特性,一条顶部对齐的连续控制条在安卓3.0中被引入。沿着所有屏幕的顶部有条拥有Twitter标志和像搜索,刷新和新tweet这样的按钮的蓝色横栏。它和后来的Action Bar之间大的区别在于Twitter/谷歌这里的设计的右上角缺少“上一级”按钮,实际上它在应用里用了完整的第二个栏位显示你当前所在位置。在上面的第二张图里,你可以看到整条带有“Tweets”标签的专用于显示位置的栏(当然,还有持续滚动的云朵)。第二个栏的Twitter标志扮演着另一个导航元素,有时候在当前部分显示额外的下拉区域,有时候显示整个顶级快捷方式集合。
+
+2.3Tweet流看起来和今天的并没有什么不同,除了隐藏的操作按钮(回复,转推等),都在右对齐的箭头按钮里。它们弹出来是一个聊天气泡菜单,看起来就像导航弹窗。仿action bar在新tweet页面有重要作用。它安置着twitter标志,剩余字数统计,以及添加照片,拍照,以及提到联系人按钮。
+
+Twitter应用甚至还有一对主屏幕小部件,大号的那个占据8格,给你新建栏,更新按钮,一条tweet,以及左右箭头来查看更多tweet。小号的显示一条tweet以及回复按钮。点击大号小部件的新建栏立即打开了“新Tweet”主窗口,这让“更新”按钮变得没有价值。
+
+
+Google Talk和新USB对话框。
+Ron Amadeo供图
+
+其他部分,Google Talk(以及没有截图的短信应用)从暗色主题变成了浅色主题,这让它们看起来和现在的更接近现在的,更现代的应用。USB存储界面会在你设备接入电脑的时候从一个简单的对话框进入全屏界面。这个界面现在有个一个异形安卓机器人/USB闪存盘混合体,而不是之前的纯文字设计。
+
+尽管安卓2.2在用户互动方式上没有什么新特性,但大的UI调整会在下两个版本到来。然而在所有的UI工作之前,谷歌希望先改进安卓的核心部分。
+
+----------
+
+
+
+[Ron Amadeo][a] / Ron是Ars Technica的评论编缉,专注于安卓系统和谷歌产品。他总是在追寻新鲜事物,还喜欢拆解事物看看它们到底是怎么运作的。
+
+[@RonAmadeo][t]
+
+--------------------------------------------------------------------------------
+
+via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/13/
+
+译者:[alim0x](https://github.com/alim0x) 校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[1]:http://www.youtube.com/watch?v=9hUIxyE2Ns8#t=3016
+[2]:http://arstechnica.com/gadgets/2010/02/googles-nexus-one-gets-multitouch/
+[3]:http://arstechnica.com/information-technology/2010/07/android-22-froyo/
+[4]:http://arstechnica.com/information-technology/2010/07/android-22-froyo/
+[a]:http://arstechnica.com/author/ronamadeo
+[t]:https://twitter.com/RonAmadeo
diff --git a/translated/talk/The history of Android/14 - The history of Android.md b/translated/talk/The history of Android/14 - The history of Android.md
new file mode 100644
index 0000000000..ce808f63da
--- /dev/null
+++ b/translated/talk/The history of Android/14 - The history of Android.md
@@ -0,0 +1,82 @@
+安卓编年史
+================================================================================
+### 语音操作——口袋里的超级电脑 ###
+
+2010年8月,作为语音搜索应用的一项新功能,“[语音命令][1]”登陆了安卓市场。语音命令允许用户向他们的手机发出语音命令,然后安卓会试着去理解他们并完成任务。像“导航至[地址]”这样的命令会打开谷歌地图并且开始逐向导航至你所陈述的目的地。你还可以仅仅通过语音来发送短信或电子邮件,拨打电话,打开网站,获取方向,或是在地图上查看一个地点。
+
+注:youtube视频地址
+
+
+语音命令是谷歌新应用设计哲学的顶峰。语音命令是那时候最先进的语音控制软件,秘密在于谷歌并不在设备上做任运算。一般来说,语音识别是对CPU的密集任务要求。实际上,许多语音识别程序仍然有“速度与准确性”设置,用户可以选择他们愿意为语音识别算法运行等待的时间——更多的CPU处理意味着更加准确。
+
+谷歌的创新在于没有劳烦手机上能力有限的处理器来进行语音识别运算。当说出一个命令时,用户的声音会被打包并通过互联网发送到谷歌云服务器。在那里,谷歌超算中心的超级计算机分析并解释语音,然后发送回手机。这是很长的一段旅程,但互联网最终还是有足够快的速度在一两秒内完成像这样的任务。
+
+很多人抛出词语“云计算”来表达“所有东西都被存储在服务器上”,但这才是真正的云计算。谷歌在云端进行这些巨量的运算操作,又因为在这个问题上投入了看似荒唐的CPU资源数目,所以语音识别准确性的唯一限制就是算法本身了。软件不需要由每个用户独立“训练”,因为所有使用语音操作的人无时不刻都在训练它。借助互联网的力量,安卓在你的口袋里放了一部超级电脑,同时相比于已有的解决方案,把语音识别这个工作量从口袋大小的电脑转移到房间大小的电脑上大大提高了准确性。
+
+语音识别作为谷歌的项目已经有一段时间了,它的出现都是因为一个800号码。[1-800-GOOG-411][2]是个谷歌从2007年4月起开通的免费电话信息服务。它就像411信息服务一样工作了多年——用户可以拨打这个号码询问电话号码——但是谷歌免费提供这项服务。查询过程中没有人工的干预,411服务由语音识别和文本语音转换引擎驱动。语音命令就是人们教谷歌如何去听之后三年才有实现的可能。
+
+语音识别是谷歌长远思考的极佳范例——公司并不怕在一个可能成不了商业产品的项目上投资多年。今天,语音识别驱动的产品遍布谷歌。它被用在谷歌搜索应用的输入,安卓的语音输入,以及Google.com。同时它还是Google Glass和[Android Wear][3]的默认输入界面。
+
+谷歌甚至还在输入之外的地方使用语音识别。谷歌的语音识别技术被用在了转述Youtube视频上,它能自动生成字幕供听障用户观看。生成的字幕甚至被谷歌做成了索引,所以你可以搜索某句话在视频的哪里说过。语音是许多产品的未来,并且这项长期计划将谷歌带入了屈指可数的拥有自家语音识别服务的公司行列。大部分其它的语音识别产品,像苹果的Siri和三星设备,被迫使用——并且为其支付了授权费——Nuance的语音识别。
+
+在计算机听觉系统设立运行之后,谷歌下一步将把这项策略应用到计算机视觉上。这就是为什么像Google Goggles,Google图像搜索和[Project Tango][4]这样的项目存在的原因。就像GOOG-411的那段日子,这些项目还处在早期阶段。当[谷歌的机器人部门][5]造出了机器人,它会需要看和听,谷歌的计算机视觉和听觉项目会给谷歌一个先机。
+
+
+Nexus S,第一部三星制造的Nexus手机。
+
+### Android 2.3 Gingerbread——第一次UI大变 ###
+
+Gingerbread(姜饼人)发布于2010年12月,这已是2.2发布整整七个月之后了。尽管如此,等待是值得的,因为安卓2.3整个系统的每个界面几乎都改变了。这是从安卓0.9最初的样式以来第一次重大的更新。2.3开始了一系列持续的改进,试着将安卓从丑陋的小鸭子变成能承载它自己的合适的样子——从美学角度——来对抗iPhone。
+
+说到苹果,六个月前,它发布了iPhone 4和iOS 4,新增了多任务处理和Facetime视频聊天。微软同样也终于重返这场游戏。微软在2010年11月发布了Windows Phone 7,也进入了智能手机时代。
+
+安卓2.3在界面设计上投入了很多精力,但是由于缺乏方向或设计文档,许多应用仅仅止步于获得了一个新的定制主题而已。一些应用用了更扁平的暗色主题,一些用了充满渐变,活泼的暗色主题,其他应用则是高对比度的白色和绿色组合。尽管2.3并没有做到风格统一,Gingerbread还是完成了让系统几乎每个部分变得更现代化的任务。这同样是件好事,因为下一个手机版安卓要在将近一年后才到来。
+
+Gingerbread的首发设备是Nexus S,谷歌的第二部旗舰设备,并且是第一部由三星生产的Nexus设备。尽管今天我们已经习惯了每年都有更新型号的CPU,那时候可不是这个样子。Nexus S有个1GHz Cortex A8处理器,和Nexus One是一样的。GPU从速度来说略微有所变快。Nexus S稍微比Nexus One大一点,拥有800×480分辨率的AMOLED显示屏。
+
+从参数上来说,Nexus S看起来只是个平淡无奇的升级,但他确实开了安卓的许多先河。Nexus S是谷歌第一部没有MicroSD卡槽的旗舰,板载16GB存储。Nexus One只有512MB存储空间,但它有MicroSD卡槽。移除SD卡槽为用户简化了存储管理——现在只有一个存储地点了——但是影响了高级用户的扩展能力。它是谷歌第一部带有NFC的手机,手机背面的一个特殊芯片能够在和其他NFC芯片接触时传输数据。Nexus S暂时只能读取NFC标签,而不能发送数据。
+
+托Gingerbread中一些升级的福,Nexus S是第一部不带有硬件十字方向键或轨迹球安卓手机之一。Nexus S缩减到只有电源,音量以及四个导航键。Nexus S同时还是如今[疯狂的曲面手机][6]的先驱,因为三星给Nexus S配备了一块略微有些弯曲的玻璃。
+
+
+Gingerbread更改了状态栏和壁纸,并且添加了许多新图标。
+Ron Amadeo供图
+
+升级过的“Nexus”动态壁纸作为Nexus S的独占发布。这个壁纸基本上和Nexus One的一样,带有带动画轨迹的光点。在Nexus S上,去除了方阵设计,取而代之的是波浪形的蓝/灰色背景。底部dock有了直角和彩色图标。
+
+
+新通知面板和菜单。
+Ron Amadeo供图
+
+状态栏自0.9的首次登场以来终于得到了重制。状态栏从白色渐变变成纯黑,所有图标重绘成了灰色和绿色。所有东西看起来都更加清爽和现代,这要感谢锐角图标设计和高分辨率。最奇怪的决定可能是从状态栏时钟移除了时间段显示以及信号强度那令人疑惑的灰色。尽管灰色被用在状态栏的许多图标上,而且上面截图有四格灰色信号,安卓实际上指示的是没有信号。绿色格表示信号强度,灰色格指示的是“空”信号格。
+
+Gingerbread的状态栏图标同时还作为网络连接的状态指示。如果你的设备连接到了谷歌的服务器,图标会变绿,如果没有谷歌的连接,图标会是白色的。这让你可以在外出时轻松了解你的网络连接状态。
+
+通知面板的设计从安卓1.5的设计改进而来。我们看到UI部分再次从浅色主题变为暗色主题,有个深灰色顶部,黑色背景以及在灰色底色上的黑色文本。
+
+菜单颜色同样变深了,背景从白色变成了带点透明的黑色。菜单图标和背景的对比并没有它应该有的那么强烈,因为灰色图标的颜色和它们在白色背景上的时候是一样的。要求改变颜色意味着每个开发者都得制作新的图标,所以谷歌在黑色背景上使用了先前就有的灰色。这是系统级别的改变,所以这个新菜单会出现在每个应用中。
+
+----------
+
+
+
+[Ron Amadeo][a] / Ron是Ars Technica的评论编缉,专注于安卓系统和谷歌产品。他总是在追寻新鲜事物,还喜欢拆解事物看看它们到底是怎么运作的。
+
+[@RonAmadeo][t]
+
+--------------------------------------------------------------------------------
+
+via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/14/
+
+译者:[alim0x](https://github.com/alim0x) 校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[1]:http://arstechnica.com/gadgets/2010/08/google-beefs-up-voice-search-mobile-sync/
+[2]:http://arstechnica.com/business/2007/04/google-rolls-out-free-411-service/
+[3]:http://arstechnica.com/gadgets/2014/03/in-depth-with-android-wear-googles-quantum-leap-of-a-smartwatch-os/
+[4]:http://arstechnica.com/gadgets/2014/02/googles-project-tango-is-a-smartphone-with-kinect-style-computer-vision/
+[5]:http://arstechnica.com/gadgets/2013/12/google-robots-former-android-chief-will-lead-google-robotics-division/
+[6]:http://arstechnica.com/gadgets/2013/12/lg-g-flex-review-form-over-even-basic-function/
+[a]:http://arstechnica.com/author/ronamadeo
+[t]:https://twitter.com/RonAmadeo
diff --git a/translated/talk/The history of Android/15 - The history of Android.md b/translated/talk/The history of Android/15 - The history of Android.md
new file mode 100644
index 0000000000..2bde6052a6
--- /dev/null
+++ b/translated/talk/The history of Android/15 - The history of Android.md
@@ -0,0 +1,86 @@
+安卓编年史
+================================================================================
+
+姜饼的新键盘,文本选择,边界回弹效果以及新复选框。
+Ron Amadeo 供图
+
+安卓2.3最重要的新增功能就是系统全局文本选择界面,你可以在左侧截图的谷歌搜索栏看到它。长按一个词能使其变为橙色高亮,并且出现可拖拽的小标签,长按高亮部分会弹出剪切,复制和粘贴选项。之前的方法使用的是依赖于十字方向键的控制,但现在有了触摸文本选择,Nexus S 不再需要额外的硬件控件。
+
+左侧截图右半边展示的是新的复选框设计和边界回弹效果。冻酸奶(2.2)的复选框像个灯泡——选中时显示一个绿色的勾,未选中的时候显示灰色的勾。姜饼在选项关闭的时候显示一个空的选框——这显得更有意义。姜饼是第一个拥有滚动到底发光效果的版本。当到达列表底部的时候会有一道橙色的光晕,你越往上拉光晕越明显。列表上拉滚动反弹也许最直观,但那是苹果的专利。
+
+
+新拨号界面和对话框设计。
+Ron Amadeo 供图
+
+姜饼里的拨号受到了稍微多点的照顾。它变得更暗了,并且谷歌终于解决了原本的直角,圆角以及圆形的结合问题。现在所有的边角都是直角了。所有的拨号按键被替换成了带有奇怪下划线的样式,像是用边角料拼凑的。你永远无法确定是否看到了一个按钮——我们的大脑得想象出按钮形状的剩余部分。
+
+图中的无线网络对话框可以看作是剩下的系统全局改动的样本。所有的对话框标题从灰色变为黑色,对话框,下拉框以及按钮边缘都变成了直角,各部分色调都变暗了一点。所有的这些全局变化使得姜饼看起来不像原来那样活泼,而是更加地成熟。“到处都是黑色”的外观必然不是最受欢迎的,但它无疑看起来比安卓之前的灰色和米色的配色方案好多了。
+
+
+新市场,添加了大块的绿色页面顶栏。
+Ron Amadeo 供图
+
+新版系统带来了“安卓市场 2.0”,虽然它不是姜饼独占的。主要的列表设计和原来一致,但谷歌将屏幕上部三分之一覆盖上了大块的绿色横幅,用来展示热门应用以及导航。这里主要的设计灵感也许是绿色的安卓吉祥物——它们的颜色完美匹配。在系统设计偏向暗色系的时候,霓虹灯般的绿色横幅和白色列表让市场明快得多。
+
+但是,相同的绿色背景图片被用在了不同的手机上,这意味着在低分辨率设备上,绿色横幅看起来更加的大。不少用户抱怨这浪费了屏幕空间,于是随后的更新使得绿色横幅跟随内容向上滚动。在那时,横屏模式更加糟糕——绿色横幅会填满剩下的半个屏幕。
+
+
+市场的一个带有可折叠描述的应用详情页面,“我的应用”界面,以及 Google Books 界面截图。
+Ron Amadeo供图
+
+应用详情页面经过重新设计有了可折叠部分。文本描述只截取前几行展示,向下滑动页面不用再穿过数千行的描述。简短的描述后有一个“更多”按钮可供点击来显示完整的描述。这让用户可以轻松地滑动过列表找到像是截图和“联系开发者”部分,这些部分通常在页面偏下部分。
+
+安卓主屏的其它部分明智地淡化了绿色机器人元素。市场应用的剩余部分绝大多数仅仅只是旧版市场加上新的绿色导航元素。旧有的标签界面升级成了可滑动切换标签。在姜饼右侧截图中,从右向左滑动将会从“热门付费”切换至“热门免费”,这使得导航变得更加方便。
+
+姜饼带来了将会成为 Google Play 内容商店第一位成员的应用:Google Books。这个应用是个基础的电子书阅读器,会将书籍以简单的预览图平铺展示。屏幕顶部的“获取 eBooks”链接会打开浏览器,然后加载一个你可以在上面购买电子书的移动网站。
+
+Google Books 以及市场的“我的应用”页面都是 Action Bar 的原型。就像现在的指南中写的,页面有一个带应用图标的固定置顶栏,应用内页面的名称,以及一些控件。这两个应用的布局实际上看起来十分现代,和现在的界面相似。
+
+
+新版谷歌地图。
+Ron Amadeo供图
+
+谷歌地图(再重复一次,这时候的谷歌地图是在安卓市场中的,并且不是这个安卓版本独占的)拥有了另一个操作栏原型,是一个顶部对齐的控件栏。这个早期版本的操作栏拥有许多试验性功能。功能栏主要被一个搜索框所占据,但是你永远无法向其输入内容。点击搜索框会打开安卓 1.x 版本以来的旧搜索界面,它带有完全不同的操作栏设计和活泼的按钮。2.3 版本的顶栏仅仅只是个大号的搜索按钮而已。
+
+
+从黑变白的新 business 页面。
+Ron Amadeo 供图
+
+应用抽屉里和地点一起到来的热门商家重新设计了界面。不像姜饼的其它部分,它从黑色转换成了白色。谷歌还给它保留了圆角的旧按钮。这个新版本的地图能显示商家的营业时间,并且提供高级搜索选项,比如正在营业或是通过评分或价格限定搜索范围。点评被调整到了商家详情页面,用户可以更容易地对当前商家有个直观感受。而且现在还可以从搜索结果中给某个地点加星,保存起来以后使用。
+
+
+新 YouTube 设计,神奇的是有点像旧版地图的商家页面的设计。
+Ron Amadeo供图
+
+YouTube 应用似乎完全与安卓的其它部分分离开来,就像是设计它的人完全不知道姜饼最终会是什么样子一样。高亮是红色和灰色方案,而不是绿色和橙色,而且不像扁平黑色风格的姜饼,Youtube 有着气泡状的,带有圆角并且大幅使用渐变效果的按钮,标签以及操作栏。尽管如此,新应用还是有一些正确的地方。所有的标签可以水平滑动切换,而且应用终于提供了竖屏观看视频模式。安卓在那个阶段似乎工作不是很一致。就像是有人告诉 Youtube 团队“把它做成黑色的”,然后这就是全部的指导方向一样。唯一一个与其相似的安卓实体就是旧版谷歌地图的商家页面的设计。
+
+尽管有些奇怪的设计,Youtube 应用有着最接近操作栏的顶栏设计。除了顶部操作栏的应用图标和一些按钮,最右侧还有个标着“更多”字样的按钮,点击它可以打开因为过多而无法装进操作栏的选项。在今天,这被称作“更多操作”按钮,它是个标准界面控件。
+
+
+新 Google Talk,支持语音和视频通话,以及新语音命令界面。
+Ron Amadeo供图
+
+姜饼的最后一个更新是安卓 2.3.4,它带来了新版 Google Talk。不像 Nexus One,Nexus S 带有前置摄像头——重新设计的 Google Talk 拥有语音和视频通话功能。好友列表右侧的彩色指示不仅指明在线状态,还显示了语音和视频的可用性。一个点表示仅文本信息,一个麦克风表示文本信息或语音,一个摄像机表示支持文本信息,语音以及视频。如果可用的话,点击语音或视频图标会立即向好友发起通话。
+
+姜饼是谷歌仍然提供支持的最老的安卓版本。激活一部姜饼设备并放置一会儿会收到大量更新。姜饼会拉取 Google Play 服务,它会带来许多新的 API 支持,并且会升级到最新版本的 Play 商店。打开 Play 商店并点击更新按钮,几乎每个独立谷歌应用都会被替换为更加现代的版本。我们尝试着保持这篇文章讲述的是姜饼发布时的样子,但时至今日还停留在姜饼的用户会被认为有点跟不上时代了。
+
+姜饼如今仍然能够得到支持,因为有数量可观的用户仍然在使用这个有点过时的系统。姜饼仍然存在的能量来自于它极低的系统要求,使得它成为了低端廉价设备的最佳选择。下个版本的安卓对硬件的要求变得更高了。举个例子,安卓 3.0 蜂巢不是开源的,这意味着它只能在谷歌的协助之下移植到一个设备上。同时它还是只为平板设计的,这让姜饼作为最新的手机安卓版本存在了很长一段时间。4.0 冰淇淋三明治是下一个手机版本,但它显著地提高了安卓系统要求,抛弃了低端市场。谷歌现在希望借 4.4 KitKat(奇巧巧克力)重回廉价手机市场,它的系统要求降回了 512MB 内存。时间的推移同样有所帮助——如今,就算是廉价的系统级芯片都能满足安卓 4.0 时代的系统要求。
+
+----------
+
+
+
+[Ron Amadeo][a] / Ron是Ars Technica的评论编缉,专注于安卓系统和谷歌产品。他总是在追寻新鲜事物,还喜欢拆解事物看看它们到底是怎么运作的。
+
+[@RonAmadeo][t]
+
+--------------------------------------------------------------------------------
+
+via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/15/
+
+译者:[alim0x](https://github.com/alim0x) 校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://arstechnica.com/author/ronamadeo
+[t]:https://twitter.com/RonAmadeo
diff --git a/translated/talk/The history of Android/16 - The history of Android.md b/translated/talk/The history of Android/16 - The history of Android.md
new file mode 100644
index 0000000000..53c603c7bf
--- /dev/null
+++ b/translated/talk/The history of Android/16 - The history of Android.md
@@ -0,0 +1,66 @@
+安卓编年史
+================================================================================
+### 安卓 3.0 蜂巢—平板和设计复兴 ###
+
+尽管姜饼中做了许多改变,安卓仍然是移动世界里的丑小鸭。相比于 iPhone,它的优雅程度和设计完全抬不起头。另一方面来说,为数不多的能与 iOS 的美学智慧相当的操作系统之一是 Palm 的 WebOS。WebOS 有着优秀的整体设计,创新的功能,而且被寄予期望能够从和 iPhone 的长期竞争中拯救公司。
+
+尽管如此,一年之后,Palm 资金链断裂。Palm 公司从未看到 iPhone 的到来,到 WebOS 就绪的时候已经太晚了。2010年4月,惠普花费10亿美元收购了 Palm。尽管惠普收购了一个拥有优秀用户界面的产品,界面的首席设计师,Matias Duarte,并没有加入惠普公司。2010年5月,就在惠普接手 Palm 之前,Duarte 加入了谷歌。惠普买下了面包,但谷歌雇佣了它的烘培师。
+
+
+第一部蜂巢设备,摩托罗拉 Xoom 10英寸平板。
+
+在谷歌,Duarte 被任命为安卓用户体验主管。这是第一次有人公开掌管安卓的外观。尽管 Matias 在安卓 2.2 发布时就来到了谷歌,第一个真正受他影响的安卓版本是 3.0 蜂巢,它在2011年2月发布。
+
+按谷歌自己的说法,蜂巢是匆忙问世的。10个月前,苹果发布了 iPad,让平板变得更加现代,谷歌希望能够尽快做出回应。蜂巢就是那个回应,一个运行在10英寸触摸屏上的安卓版本。悲伤的是,将这个系统推向市场是如此优先的事项,以至于边边角角都被砍去了以节省时间。
+
+新系统只用于平板——手机不能升级到蜂巢,这加大了谷歌让系统运行在差异巨大的不同尺寸屏幕上的难度。但是,仅支持平板而不支持手机使得蜂巢源码没有泄露。之前的安卓版本是开源的,这使得黑客社区能够将其最新版本移植到所有的不同设备之上。谷歌不希望应用开发者在支持不完美的蜂巢手机移植版本时感到压力,所以谷歌将源码留在自己手中,并且严格控制能够拥有蜂巢的设备。匆忙的开发还导致了软件问题。在发布时,蜂巢不是特别稳定,SD卡不能工作,Adobe Flash——安卓最大的特色之一——还不被支持。
+
+[摩托罗拉 Xoom][1]是为数不多的拥有蜂巢的设备之一,它是这个新系统的旗舰产品。Xoom 是一个10英寸,16:9 的平板,拥有 1GB 内存和 1GHz Tegra 2 双核处理器。尽管是由谷歌直接控制更新的新版安卓发布设备,它并没有被叫做“Nexus”。对此最可能的原因是谷歌对它没有足够的信心称其为旗舰。
+
+尽管如此,蜂巢是安卓的一个里程碑。在一个体验设计师的主管之下,整个安卓用户界面被重构,绝大多数奇怪的应用设计都得到改进。安卓的默认应用终于看起来像整体的一部分,不同的界面有着相似的布局和主题。然而重新设计安卓会是一个跨版本的项目——蜂巢只是将安卓塑造成型的开始。这第一份草稿为安卓未来版本的样子做了基础设计,但它也用了过多的科幻主题,谷歌将花费接下来的数个版本来淡化它。
+
+
+蜂巢和姜饼的主屏幕。
+Ron Amadeo供图
+
+姜饼只是在它的量子壁纸上试验了科幻外观,蜂巢整个系统的以电子为灵感的主题让它充满科幻意味。所有东西都是黑色的,如果你需要对比色,你可以从一些不同色调的蓝色中挑选。所有蓝色的东西还有“光晕”效果,让整个系统看起来像是外星科技创造的。默认背景是个六边形的全息方阵(一个蜂巢!明白了吗?),看起来像是一艘飞船上的传送阵的地板。
+
+蜂巢最重要的变化是增加了系统栏。摩托罗拉 Xoom 除了电源和音量键之外没有配备实体按键,所以蜂巢添加了一个大黑色底栏到屏幕底部,用于放置导航按键。这意味着默认安卓界面不再需要特别的实体按键。在这之前,安卓没有实体的返回,菜单和 Home 键就不能正常工作。现在,软件提供了所有必需的按钮,任何带有触摸屏的设备都能够运行安卓。
+
+新软件按键带来的最大的好处是灵活性。新的应用指南表明应用应不再要求实体菜单按键,需要用到的时候,蜂巢会自动检测并添加四个按钮到系统栏让应用正常工作。另一个软件按键的灵活属性是它们可以改变设备的屏幕方向。除了电源和音量键之外,Xoom 的方向实际上不是那么重要。从用户的角度来看,系统栏始终处于设备的“底部”。代价是系统栏明显占据了一些屏幕空间。为了在10英寸平板上节省空间,状态栏被合并到了系统栏中。所有的常用状态指示放在了右侧——有电源,连接状态,时间还有通知图标。
+
+主屏幕的整个布局都改变了,用户界面部件放在了设备的四个角落。屏幕底部左侧放置着之前讨论过的导航按键,右侧用于状态指示和通知,顶部左侧显示的是文本搜索和语音搜索,右侧有应用抽屉和添加小部件的按钮。
+
+
+新锁屏界面和最近应用界面。
+Ron Amadeo供图
+
+(因为 Xoom 是一部 [较重] 的10英寸,16:9平板设备,这意味着它主要是横屏使用。虽然大部分应用还支持竖屏模式,但是到目前为止,由于我们的版式限制,我们大部分使用的是竖屏模式的截图。请记住蜂巢的截图来自于10英寸的平板,而姜饼的截图来自3.7英寸的手机。二者所展现的信息密度是不能直接比较的。)
+
+解锁界面——从菜单按钮到旋转式拨号盘再到滑动解锁——移除了解锁步骤的任何精度要求,它采用了一个环状解锁盘。从中间向任意方向向外滑动就能解锁设备。就像旋转式解锁,这种解锁方式更加符合人体工程学,而不用强迫你的手指完美地遵循一条笔直的解锁路径。
+
+第二张图中略缩图条带是由新增的“最近应用”按钮打开的界面,现在处在返回和 Home 键旁边。不像姜饼中长按 Home 键显示一组最近应用的图标,蜂巢在屏幕上显示应用图标和略缩图,使得在任务间切换变得更加方便。最近应用的灵感明显来自于 Duarte 在 WebOS 中的“卡片式”多任务管理,其使用全屏略缩图来切换任务。这个设计提供和 WebOS 的任务切换一样的易识别体验,但更小的略缩图允许更多的应用一次性显示在屏幕上。
+
+尽管最近应用的实现看起来和你现在的设备很像,这个版本实际上是非常早期的。这个列表不能滚动,这意味着竖屏下只能显示七个应用,横屏下只能显示五个。任何超出范围的应用会从列表中去除。而且你也不能通过滑动略缩图来关闭应用——这只是个静态的列表。
+
+这里我们看到电子灵感影响的完整主题效果:略缩图的周围有蓝色的轮廓以及神秘的光晕。这张截图还展示软件按键的好处——上下文。返回按钮可以关闭略缩图列表,所以这里的箭头指向下方,而不是通常的样子。
+
+----------
+
+
+
+[Ron Amadeo][a] / Ron是Ars Technica的评论编缉,专注于安卓系统和谷歌产品。他总是在追寻新鲜事物,还喜欢拆解事物看看它们到底是怎么运作的。
+
+[@RonAmadeo][t]
+
+--------------------------------------------------------------------------------
+
+via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/16/
+
+译者:[alim0x](https://github.com/alim0x) 校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[1]:http://arstechnica.com/gadgets/2011/03/ars-reviews-the-motorola-xoom/
+[a]:http://arstechnica.com/author/ronamadeo
+[t]:https://twitter.com/RonAmadeo
diff --git a/translated/talk/The history of Android/17 - The history of Android.md b/translated/talk/The history of Android/17 - The history of Android.md
new file mode 100644
index 0000000000..bf86735b7c
--- /dev/null
+++ b/translated/talk/The history of Android/17 - The history of Android.md
@@ -0,0 +1,86 @@
+安卓编年史
+================================================================================
+
+蜂巢的应用列表少了很多应用。上图还展示了通知中心和新的快速设置。
+Ron Amadeo 供图
+
+默认的应用图标从32个减少到了25个,其中还有两个是第三方的游戏。因为蜂巢不是为手机设计的,而且谷歌希望默认应用都是为平板优化的,很多应用因此没有成为默认应用。被去掉的应用有亚马逊 MP3 商店,Car Home,Facebook,Google Goggles,信息,新闻与天气,电话,Twitter,谷歌语音,以及语音拨号。谷歌正在悄悄打造的音乐服务将于不久后面世,所以亚马逊 MP3 商店需要为它让路。Car Home,信息以及电话对一部不是手机的设备来说没有多大意义,Facebook 和 Twitter还没有平板版应用,Goggles,新闻与天气以及语音拨号几乎没什么人注意,就算移除了大多数人也不会想念它们的。
+
+几乎每个应用图标都是全新设计的。就像是从 G1 切换到摩托罗拉 Droid,变化的最大动力是分辨率的提高。Nexus S 有一块800×480分辨率的显示屏,姜饼重新设计了图标等资源来适应它。Xoom 巨大的1280×800 10英寸显示屏意味着几乎所有设计都要重做。但是再说一次,这次是有真正的设计师在负责,所有东西看起来更有整体性了。蜂巢的应用列表从纵向滚动变为了横向分页式。这个变化对横屏设备有意义,而对手机来说,查找一个应用还是纵向滚动列表比较快。
+
+第二张蜂巢截图展示的是新通知中心。姜饼中的灰色和黑色设计已经被抛弃了,现在是黑色面板带蓝色光晕。上面一块显示着日期时间,连接状态,电量和打开快速设置的按钮,下面是实际的通知。非持续性通知现在可以通过通知右侧的“X”来关闭。蜂巢是第一个支持通知内控制的版本。第一个(也是蜂巢发布时唯一一个)利用了此特性的应用是新的谷歌音乐,在它的通知上有上一曲,播放/暂停,下一曲按钮。这些控制可以在任何应用中访问到,这让控制音乐播放变成了一件轻而易举的事情。
+
+
+“添加到主屏幕”的缩小视图更易于组织布局。搜索界面将自动搜索建议和通用搜索分为两个面板显示。
+Ron Amadeo 供图
+
+点击主屏幕右上角的加号或长按背景空白处就会打开新的主屏幕设置界面。蜂巢会在屏幕上半部分显示所有主屏的缩小视图,下半部分分页显示的是小部件和快捷方式。小部件或快捷方式可以从下半部分的抽屉中拖动到五个主屏幕中的任意一个上。姜饼只会显示一个文本列表,而蜂巢会显示小部件完整的略缩图预览。这让你更清楚一个小部件是什么样子的,而不是像原来的“日历”一样只是一个只有应用名称的描述。
+
+摩托罗拉 Xoom 更大的屏幕让键盘的布局更加接近 PC 风格,退格,回车,shift 以及 tab 都在传统的位置上。键盘带有浅蓝色,并且键与键之间的空间更大了。谷歌还添加了一个专门的笑脸按钮。 :-)
+
+
+打开菜单的 Gmail 在蜂巢和姜饼上的效果。按钮布置在首屏更容易被发现。
+Ron Amadeo 供图
+
+Gmail 示范了蜂巢所有的用户界面概念。安卓 3.0不再把所有控制都隐藏在菜单按钮之后。屏幕的顶部现在有一条带有图标的条带,叫做 Action Bar(操作栏),它将许多常用的控制选项提升到了主屏幕上,用户直接就能看到它们。Gmail 的操作栏显示着搜索,新邮件,刷新按钮,不常用的选项比如设置,帮助,以及反馈放在了“更多”按钮中。点击复选框或选中文本的时候时整个操作栏的图标会变成和操作相关的——举个例子,选择文本会出现复制,粘贴和全选按钮。
+
+应用左上角显示的图标同时也作为称作“上一级”的导航按钮。“后退”的作用类似浏览器的后退按钮,导航到之前访问的页面,“上一级”则会导航至应用的上一层次。举例来说,如果你在安卓市场,点击“给开发者发邮件”,会打开 Gmail,“后退”会让你返回安卓市场,但是“上一级”会带你到 Gmail 的收件箱。“后退”可能会关闭当前应用,而“上一级”永远不会。应用可以控制“后退”按钮,它们往往重新定义它为“上一级”的功能。事实上,这两个按钮之间几乎没什么不同。
+
+蜂巢还引入了 “Fragments” API,允许开发者开发同时适用于平板和手机的应用。一个 “Fragments”(格子) 是一个用户界面的面板。在上图的 Gmail 中,左边的文件夹列表是一个格子,收件箱是另一个格子。手机每屏显示一个格子,而平板则可以并列显示两个。开发者可以自行定义单独每个格子的外观,安卓会根据当前的设备决定如何显示它们。
+
+
+计算器使用了常规的安卓按钮,但日历看起来像是被谁打翻了蓝墨水。
+Ron Amadeo 供图
+
+这是安卓历史上第一次计算器换上了没有特别定制的按钮,所以它看起来确实是系统的一部分。更大的屏幕有了更多空间容纳按钮,足够将计算器基本功能容纳在一个屏幕上。日历极大地受益于额外的显示空间,有了更多的空间显示事件文本和控制选项。顶部的操作栏有切换视图的按钮,显示当前时间跨度,以及常规按钮。事件块变成了白色背景,日历标识只在左上角显示。在底部(或横屏模式的侧边)显示的是月历和显示的日历列表。
+
+日历的比例同样可以调整。通过两指缩放手势,纵向的周和日视图能够在一屏内显示五到十九小时的事件。日历的背景由不均匀的蓝色斑点组成,看起来不是特别棒,在随后的版本里就被抛弃了。
+
+
+新相机界面,取景器显示的是“负片”效果。
+Ron Amadeo 供图
+
+巨大的10英寸 Xoom 平板有个摄像头,这意味着它同样有个相机应用。电子风格的重新设计终于甩掉了谷歌从安卓 1.6 以来使用的仿皮革外观。控制选项以环形排布在快门键周围,让人想起真正的相机上的圆形控制转盘。Cooliris 衍生的弹出对话气泡变成了带光晕的半透明黑色选框。蜂巢的截图显示的是新的“颜色效果”功能,它能给取景器实时加上滤镜效果。不像姜饼的相机应用,它不支持竖屏模式——它被限制在横屏状态。用10英寸的平板拍摄纵向照片没多大意义,但拍摄横向照片也没多大意义。
+
+
+时钟应用相比其它地方没受到多少关照。谷歌把它扔进一个小盒子里然后就收工了。
+Ron Amadeo 供图
+
+无数功能已经成形了,现在是时候来重制一下时钟了。整个“桌面时钟”概念被踢出门外,取而代之的是在纯黑背景上显示的简单又巨大的时间数字。打开其它应用查看天气的功能不见了,随之而去的还有显示你的壁纸的功能。当要设计平板尺寸的界面时,有时候谷歌就放弃了,就像这里,就只是把时钟界面扔到了一个小小的,居中的对话框里。
+
+
+音乐应用终于得到了一直以来都需要的完全重新设计。
+Ron Amadeo 供图
+
+尽管音乐应用之前有得到一些小的加强,但这是自安卓 0.9 以来它第一次受到正视。重新设计的亮点是一个“别叫它封面流滚动 3D 专辑封面视图”,称作“最新和最近”。导航由操作栏的下拉框解决,取代了安卓 2.1 引入的标签页导航。尽管“最新和最近”有个 3D 滚动专辑封面,“专辑”使用的是专辑略缩图的平面方阵。另一个部分也有个完全不同的设计。“歌曲”使用了垂直滚动的文本列表,“播放列表”,“年代”和“艺术家”用的是堆砌专辑显示。
+
+在几乎每个视图中,每个单独的项目有它自己单独的菜单,通常在每项的右下角有个小箭头。眼下这里只会显示“播放”和“添加到播放列表”,但这个版本的谷歌音乐是为未来搭建的。谷歌不久后就要发布音乐服务,这些独立菜单在像是在音乐商店里浏览该艺术家的其它内容,或是管理云存储和本地存储时将会是不可或缺的。
+
+正如安卓 2.1 中的 Cooliris 风格的相册,谷歌音乐会将略缩图放大作为背景图片。底部的“正在播放”栏现在显示着专辑封面,播放控制,以及播放进度条。
+
+
+新谷歌地图的一些地方真的很棒,一些却是从安卓 1.5 来的。
+Ron Amadeo 供图
+
+谷歌地图也为大屏幕进行了重新设计。这个设计将会持续一段时间,它对所有的控制选项用了一个半透明的黑色操作栏。搜索再次成为主要功能,占据了操作栏显要位置,但这回可是真的搜索栏,你可以在里面输入关键字,不像以前那个搜索栏形状的按钮会打开完全不同的界面。谷歌最终还是放弃了给缩放控件留屏幕空间,仅仅依靠手势来控制地图显示。尽管 3D 建筑轮廓这个特性已经被移植到了旧版本的地图中,蜂巢依然是拥有这个特性的第一个版本。双指在地图上向下拖放会“倾斜”地图的视角,展示建筑的侧面。你可以随意旋转,建筑同样会跟着进行调整。
+
+并不是所有部分都进行了重新设计。导航自姜饼以来就没动过,还有些界面的核心部分,像是路线,直接从安卓 1.6 的设计拿出来,放到一个小盒子里居中放置,仅此而已。
+
+----------
+
+
+
+[Ron Amadeo][a] / Ron是Ars Technica的评论编缉,专注于安卓系统和谷歌产品。他总是在追寻新鲜事物,还喜欢拆解事物看看它们到底是怎么运作的。
+
+[@RonAmadeo][t]
+
+--------------------------------------------------------------------------------
+
+via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/17/
+
+译者:[alim0x](https://github.com/alim0x) 校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://arstechnica.com/author/ronamadeo
+[t]:https://twitter.com/RonAmadeo
diff --git a/translated/talk/The history of Android/18 - The history of Android.md b/translated/talk/The history of Android/18 - The history of Android.md
new file mode 100644
index 0000000000..f4781cc621
--- /dev/null
+++ b/translated/talk/The history of Android/18 - The history of Android.md
@@ -0,0 +1,83 @@
+安卓编年史
+================================================================================
+
+安卓市场的新设计试水“卡片式”界面,这将成为谷歌的主要风格。
+Ron Amadeo 供图
+
+安卓推向市场已经有两年半时间了,安卓市场放出了它的第四版设计。这个新设计十分重要,因为它已经很接近谷歌的“卡片式”界面了。通过在小方块中显示应用或其他内容,谷歌可以使其设计在不同尺寸屏幕下无缝过渡而不受影响。内容可以像一个相册应用里的照片一样显示——给布局渲染填充一个内容块列表,加上屏幕包装,就完成了。更大的屏幕一次可以看到更多的内容块,小点的屏幕一次看到的内容就少。内容用了不一样的方式显示,谷歌还在右边新增了一个“分类”板块,顶部还有个巨大的热门应用滚动显示。
+
+虽然设计上为更容易配置界面准备好准备好了,但功能上还没有。最初发布的市场版本锁定为横屏模式,而且还是蜂巢独占的。
+
+
+应用详情页和“我的应用”界面。
+Ron Amadeo 供图
+
+新的市场不仅出售应用,还加入了书籍和电影租借。谷歌从2010年开始出售图书;之前只通过网站出售。新的市场将谷歌所有的内容销售聚合到了一处,进一步向苹果 iTunes 的主宰展开较量。虽然在“安卓市场”出售这些东西有点品牌混乱,因为大部分内容都不依赖于安卓才能使用。
+
+
+浏览器看起来非常像 Chrome,联系人使用了双面板界面。
+Ron Amadeo 供图
+
+新浏览器界面顶部添加了标签页栏。尽管这个浏览器并不是 Chrome ,它模仿了许多 Chrome 的设计和特性。除了这个探索性的顶部标签页界面,浏览器还加入了隐身标签,在浏览网页时不保存历史记录和自动补全记录。它还有个选项可以让你拥有一个 Chrome 风格的新标签页,页面上包含你最经常访问的网页略缩图。
+
+新浏览器甚至还能和 Chrome 同步。在浏览器登录后,它会下载你的 Chrome 书签并且自动登录你的谷歌账户。收藏一个页面只需点击地址栏的星形标志即可,和谷歌地图一样,浏览器抛弃了缩放按钮,完全改用手势控制。
+
+联系人应用最终从电话应用中移除,并且独立为一个应用。之前的联系人/拨号混合式设计相对于人们使用现代智能手机的方式来说,过于以电话为中心了。联系人中存有电子邮件,IM,短信,地址,生日,以及社交网络等信息,所以将它们捆绑在电话应用里的意义和将它们放进谷歌地图里差不多。抛开了电话通讯功能,联系人能够简化成没有标签页的联系人列表。蜂巢采用了双面板视图,在左侧显示完整的联系人列表,右侧是联系人详情。应用利用了 Fragments API,通过它应用可以在同一屏显示多个面板界面。
+
+蜂巢版本的联系人应用是第一个拥有快速滚动功能的版本。当按住左侧滚动条的时候,你可以快速上下拖动,应用会显示列表当前位置的首字母预览。
+
+
+新 Youtube 应用看起来像是来自黑客帝国。
+Ron Amadeo 供图
+
+谢天谢地 Youtube 终于抛弃了自安卓 2.3 以来的谷歌给予这个视频服务的“独特”设计,新界面设计与系统更加一体化。主界面是一个水平滚动的曲面墙,上面显示着最热门或者(登录之后)个人关注的视频。虽然谷歌从来没有将这个设计带到手机上,但它可以被认为是一个易于重新配置的卡片界面。操作栏在这里是个可配置的工具栏。没有登录时,操作栏由一个搜索栏填满。当你登录后,搜索缩小为一个按钮,“首页”,“浏览”和“你的频道”标签将会显示出来。
+
+
+蜂巢用一个蓝色框架的电脑界面来驱动主屏。电影工作室完全采用橙色电子风格主题。
+Ron Amadeo 供图
+
+蜂巢新增的应用“电影工作室”,这不是一个不言自明的应用,而且没有任何的解释或说明。就我们所知,你可以导入视频,剪切它们,添加文本和场景过渡。编辑视频——电脑上你可以做的最耗时,困难,以及处理器密集型任务之一——在平板上完成感觉有点野心过大了,谷歌在之后的版本里将其完全移除了。电影工作室里我们最喜欢的部分是它完全的电子风格主题。虽然系统的其它部分使用蓝色高亮,在这里是橙色的。(电影工作室是个邪恶的程序!)
+
+
+小部件!
+Ron Amadeo 供图
+
+蜂巢带来了新的部件框架,允许部件滚动,Gmail,Email 以及日历部件都升级了以支持改功能。Youtube 和书籍使用了新的部件,内容卡片可以自动滚动切换。在小部件上轻轻向上或向下滑动可以切换卡片。我们不确定你的书籍中哪些书会被显示出来,但如果你想要的话它就在那儿。尽管所有的这些小部件在10英寸屏幕上运行良好,谷歌从未将它们重新设计给手机,这让它们在安卓最流行的规格上几乎毫无用处。所有的小部件有个大块的标识标题栏,而且通常占据大半屏幕只显示很少的内容。
+
+
+安卓3.1中可滚动的最近应用以及可自定义大小的小部件。
+Ron Amadeo 供图
+
+蜂巢后续的版本修复了3.0早期的一些问题。安卓3.1在蜂巢的第一个版本之后三个月放出,并带来了一些改进。小部件自定义大小是添加的最大特性之一。长按小部件之后,一个带有拖拽按钮的蓝色外框会显示出来,拖动按钮可以改变小部件尺寸。最近应用界面现在可以垂直滚动并且承载更多应用。这个版本唯一缺失的功能是滑动关闭应用。
+
+在今天,一个0.1版本的升级是个主要更新,但是在蜂巢,那只是个小更新。除了一些界面调整,3.1添加了对游戏手柄,键盘,鼠标以及其它USB和蓝牙输入设备的支持。它还提供了更多的开发者API。
+
+
+安卓3.2的兼容性缩放和一个安卓平板上典型的展开视图应用。
+Ron Amadeo 供图
+
+安卓3.2在3.1发布后两个月放出,添加了七到八英寸的小尺寸平板支持。3.2终于启用了SD卡支持,Xoom 在生命最初的五个月像是抱着个不完整的肢体一样。
+
+蜂巢匆匆问世是为了成为一个生态系统建设者。如果应用没有平板版本,没人会想要一个安卓平板的,所以谷歌知道需要尽快将东西送到开发者手中。在这个安卓平板生态的早期阶段,应用还没有到齐。这是拥有 Xoom 的人们所面临的最大的问题。
+
+3.2添加了“兼容缩放”,给了用户一个新选项,可以将应用拉伸适应屏幕(如右侧图片显示的那样)或缩放成正常的应用布局来适应屏幕。这些选项都不是很理想,没有应用生态来支持平板,蜂巢设备销售状况惨淡。但谷歌的平板决策最终还是会得到回报。今天,安卓平板已经[取代 iOS 占据了最大的市场份额][1]。
+
+----------
+
+
+
+[Ron Amadeo][a] / Ron是Ars Technica的评论编缉,专注于安卓系统和谷歌产品。他总是在追寻新鲜事物,还喜欢拆解事物看看它们到底是怎么运作的。
+
+[@RonAmadeo][t]
+
+--------------------------------------------------------------------------------
+
+via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/18/
+
+译者:[alim0x](https://github.com/alim0x) 校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[1]:http://techcrunch.com/2014/03/03/gartner-195m-tablets-sold-in-2013-android-grabs-top-spot-from-ipad-with-62-share/
+[a]:http://arstechnica.com/author/ronamadeo
+[t]:https://twitter.com/RonAmadeo
diff --git a/translated/talk/The history of Android/19 - The history of Android.md b/translated/talk/The history of Android/19 - The history of Android.md
new file mode 100644
index 0000000000..2ea47bc778
--- /dev/null
+++ b/translated/talk/The history of Android/19 - The history of Android.md
@@ -0,0 +1,71 @@
+安卓编年史
+================================================================================
+
+姜饼上的 Google Music Beta。
+Ron Amadeo 供图
+
+### Google Music Beta —— 取代内容商店的云存储 ###
+
+尽管蜂巢改进了 Google Music 的界面,但是音乐应用的设计并没有从蜂巢直接进化到冰淇淋三明治。2011年5月,谷歌发布了“[Google Music Beta][1]”,和新的 Google Music 应用一同到来的在线音乐存储。
+
+新 Google Music 为安卓2.2及以上版本设计,借鉴了 Cooliris 相册的设计语言,但也有改变之处,背景使用了模糊处理的图片。几乎所有东西都是透明的:弹出菜单,顶部标签页,还有底部的正在播放栏。可以下载单独的歌曲或整个播放列表到设备上离线播放,这让 Google Music 成为一个让音乐同步到你所有设备的好途径。除了移动应用外,Google Music 还有一个 Web 应用,让它可以在任何一台桌面电脑上使用。
+
+谷歌和唱片公司关于内容的合约还没有谈妥,音乐商店还没准备好,所以它的权宜之计是允许用户存储音乐到线上并下载到设备上。如今谷歌除了音乐存储服务外,还有单曲购买和订阅模式。
+
+### Android 4.0, 冰淇淋三明治 —— 摩登时代 ###
+
+
+三星 Galaxy Nexus,安卓4.0的首发设备。
+
+安卓4.0,冰淇淋三明治,在2011年10月发布,系统发布回到正轨,带来定期发布的手机和平板,并且安卓再次开源。这是自姜饼以来手机设备的第一个更新,意味着最主要的安卓用户群体近乎一年没有见到更新了。4.0随处可见缩小版的蜂巢设计,还将虚拟按键,操作栏(Action Bar),全新的设计语言带到了手机上。
+
+冰淇淋三明治在三星 Galaxy Nexus 上首次亮相,也是最早带有720p显示屏的安卓手机之一。随着分辨率的提高,Galaxy Nexus 使用了更大的4.65英寸显示屏——几乎比最初的 Nexus One 大了一整英寸。这被许多批评者认为“太大了”,但如今的安卓设备甚至更大。(5英寸现在是“正常”的。)冰淇淋三明治比姜饼的性能要求更高,Galaxy Nexus 配备了一颗双核,1.2Ghz 德州仪器 OMAP 处理器和1GB的内存。
+
+在美国,Galaxy Nexus 在 Verizon 首发并且支持 LTE。不像之前的 Nexus 设备,最流行的型号——Verizon版——是在运营商的控制之下,谷歌的软件和更新在手机得到更新之前要经过 Verizon 的核准。这导致了更新的延迟以及 Verizon 不喜欢的应用被移除,即便是 Google Wallet 也不例外。
+
+多亏了冰淇淋三明治的软件改进,谷歌终于达成了移除手机上按钮的目标。有了虚拟导航键,实体电容按钮就可以移除了,最终 Galaxy Nexus 仅有电源和音量是实体按键。
+
+
+安卓4.0将很多蜂巢的设计缩小了。
+Ron Amadeo 供图
+
+电子质感的审美在蜂巢中显得有点多。于是在冰淇淋三明治中,谷歌开始减少科幻风的设计。科幻风的时钟字体从半透明折叠风格转变成纤细,优雅,看起来更加正常的字体。解锁环的水面波纹效果被去除了,蜂巢中的外星风格时钟小部件也被极简设计所取代。系统按钮也经过了重新设计,原先的蓝色轮廓,偶尔的厚边框变成了细的,设置带有白色轮廓。默认壁纸从蜂巢的蓝色太空船内部变成条纹状,破碎的彩虹,给默认布局增添了不少迟来的色彩。
+
+蜂巢的系统栏在手机上一分为二。在顶上是传统的状态栏,底部是新的系统栏,放着三个系统按钮:后退,主屏幕,最近应用。一个固定的搜索栏放置在了主屏幕顶部。该栏以和底栏一样的方式固定在屏幕上,所以在五个主屏上,它总共占据了20个图标大小的位置。在蜂巢的锁屏上,内部的小圆圈可以向大圆圈外的任意位置滑动来解锁设备。在冰淇淋三明治,你得把小圆圈移动到解锁图标上。这个新准确度要求允许谷歌向锁屏添加新的选项:一个相机快捷方式。将小圆圈拖向相机图标会直接启动相机,跳过了主屏幕。
+
+
+一个手机系统意味着更多的应用,通知面板重新回到了全屏界面。
+Ron Amadeo 供图
+
+应用抽屉还是标签页式的,但是蜂巢中的“我的应用”标签被“部件”标签页替代,这是个简单的2×3部件略缩图视图。像蜂巢里的那样,这个应用抽屉是分页的,需要水平滑动换页。(如今安卓仍在使用这个应用抽屉设计。)应用抽屉里新增的是 Google+ 应用,后来独立存在。还有一个“Messenger”快捷方式,是 Google+ 的私密信息服务。(不要混淆 “Messenger” 和已有的 “Messaging” 短信应用。)
+
+因为我们现在回到了手机上,所以短信,新闻和天气,电话,以及语音拨号都回来了,以及Cordy,一个平板的游戏,被移除了。尽管不是 Nexus 设备,我们的截图还是来自 Verizon 版的设备,可以从图上看到有像 “My Verizon Mobile” 和 “VZ Backup Assistant” 这样没用的应用。为了和冰淇淋三明治的去电子风格主题一致,日历和相机图标现在看起来更像是来自地球的东西而不是来自外星球。时钟,下载,电话,以及安卓市场同样得到了新图标,联系人“Contacts”获得了新图标,还有新名字“People”。
+
+通知面板进行了大改造,特别是和[之前姜饼中的设计][2]相比而言。面板头部有个日期,一个设置的快捷方式,以及“清除所有”按钮。虽然蜂巢的第一个版本就允许用户通过通知右边的“X”消除单个通知,但是冰淇淋三明治的实现更加优雅:只要从左向右滑动通知即可。蜂巢有着蓝色高亮,但是蓝色色调到处都是。冰淇淋三明治几乎把所有地方的蓝色统一成一个(如果你想知道确定的值,hex码是#33B5E5)。通知面板的背景是透明的,底部的“把手”变为一个简单的小蓝圈,带着不透明的黑色背景。
+
+
+安卓市场的主页背景变成了黑色。
+Ron Amadeo 供图
+
+市场获得了又一个新设计。它终于再次支持纵向模式,并且添加了音乐到商店中,你可以从中购买音乐。新的市场拓展了从蜂巢中引入的卡片概念,它还是第一个同时使用在手机和平板上的版本。主页上的卡片通常不是链接到应用的,而是指向特别的促销页面,像是“编辑精选”或季度促销。
+
+----------
+
+
+
+[Ron Amadeo][a] / Ron是Ars Technica的评论编缉,专注于安卓系统和谷歌产品。他总是在追寻新鲜事物,还喜欢拆解事物看看它们到底是怎么运作的。
+
+[@RonAmadeo][t]
+
+--------------------------------------------------------------------------------
+
+via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/19/
+
+译者:[alim0x](https://github.com/alim0x) 校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[1]:http://arstechnica.com/gadgets/2011/05/hands-on-grooving-on-the-go-with-impressive-google-music-beta/
+[2]:http://cdn.arstechnica.net/wp-content/uploads/2014/02/32.png
+[a]:http://arstechnica.com/author/ronamadeo
+[t]:https://twitter.com/RonAmadeo
diff --git a/translated/tech/20141127 dupeGuru--Find And Remove Duplicate Files Instantly From Hard Drive.md b/translated/tech/20141127 dupeGuru--Find And Remove Duplicate Files Instantly From Hard Drive.md
deleted file mode 100644
index 17da6a9508..0000000000
--- a/translated/tech/20141127 dupeGuru--Find And Remove Duplicate Files Instantly From Hard Drive.md
+++ /dev/null
@@ -1,105 +0,0 @@
-dupeGuru - 直接从硬盘中查找并移除重复文件
-================================================================================
-
-### 简介 ###
-
-对我们来说,磁盘被装满是一个较大的困扰。无论我们如何小心谨慎,我们总可能将相同的文件复制到多个不同的地方,或者在不知情的情况下,重复下载了同一个文件。因此,迟早你会看到“磁盘已满”的错误提示,若此时我们确实需要一些磁盘空间来存储重要数据,以上情形无疑是最糟糕的。假如你确信自己的系统中有重复文件,那么 **dupeGuru** 可能会帮助到你。
-
-dupeGuru 团队也开发了名为 **dupeGuru 音乐版** 的应用来移除重复的音乐文件,和名为 **dupeGuru 图片版** 的应用来移除重复的图片文件。
-
-### 1. dupeGuru (标准版) ###
-
-对于那些不熟悉 [dupeGuru][1] 的人来说,它是一个免费,开源,跨平台的应用,其用途是在系统中查找和移除重复文件。它可以在 Linux, Windows, 和 Mac OS X 等平台下使用。通过使用一个快速的模糊匹配算法,它可以在几分钟内找到重复文件。同时,你还可以调整 dupeGuru 使它去精确查找特定文件类型的重复文件,以及从你想删除的文件中,消除特定的某些文件。它支持英语、 法语、 德语、 中文 (简体)、 捷克语、 意大利语、亚美尼亚语、 俄语、乌克兰语、巴西语和越南语。
-
-#### 在 Ubuntu 14.10/14.04/13.10/13.04/12.04 中安装 dupeGuru ####
-
-dupeGuru 开发者已经构建了一个 Ubuntu PPA (Personal Package Archives)来简化安装过程。为了安装 dupeGuru,依次在终端中键入以下命令:
-
-```
-sudo apt-add-repository ppa:hsoft/ppa
-sudo apt-get update
-sudo apt-get install dupeguru-se
-```
-
-### 使用 ###
-
-使用非常简单,可从 Unity 面板或菜单中启动 dupeGuru 。
-
-
-
-点击位于底部的 `+` 按钮来添加你想扫描的文件目录。点击 `扫描` 按钮开始查找重复文件。
-
-
-
-一旦所选目录中含有重复文件,则它将在窗口中展示重复文件。正如你所看到的,在下面的截图中,我的下载目录中有一个重复文件。
-
-
-
-现在,你可以决定下一步如何操作。你可以删除这个重复的文件,或者对它进行重命名,抑或是 复制/移动 这个文件到另一个位置。为此,选定该重复文件,或 在菜单栏中选定写有“**仅显示重复**”选项 ,如果你选择了“**仅显示重复**”选项,则只有重复文件在窗口中可见,这样你便可以轻易地选择并删除这些文件。点击“操作”下拉菜单,最后选择你将执行的操作。在这里,我只想删除重复文件,所以我选择了“移动标记文件到垃圾箱”这个选项。
-
-
-
-接着,点击“继续”选项来移除重复文件。
-
-
-
-### 2. dupeGuru 音乐版 ###
-
-[dupeGuru 音乐版][2] 或 简称 dupeGuru ME ,它的功能与 dupeGuru 类似。它拥有 dupeGuru 的所有功能,但它包含更多的信息列 (如比特率,持续时间,标签等)和更多的扫描类型(如带有字段的文件名,标签以及音频内容)。同 dupeGuru 一样, dupeGuru ME 也运行在 Linux, Windows, 和 Mac OS X 中。
-
-它支持众多的格式,诸如 MP3, WMA, AAC (iTunes 格式), OGG, FLAC, 即失真率较少的 AAC 和 WMA 格式等。
-
-#### 在 Ubuntu 14.10/14.04/13.10/13.04/12.04 中安装 dupeGuru ME ####
-
-现在,我们不必再添加任何 PPA,因为在前面的步骤中,我们已经进行了添加。所以在终端中键入以下命令来安装它:
-
-```
-sudo apt-get install dupeguru-me
-```
-
-### 使用 ###
-
-你可以从 Unity 面板或菜单中启动它。dupeGuru ME 的使用方法,操作界面和外观与正常的 dupeGuru 类似。添加你想扫描的目录并选择你想执行的操作。重复的音乐文件就会被删除。
-
-
-
-### 3. dupeGuru 图片版 ###
-
-[dupeGuru 图片版][3],或简称为 duepGuru PE,是一个在你的电脑中查找重复图片的工具。它与 dupeGuru 类似,但独具匹配重复图片的功能。dupeGuru PE 可运行在 Linux, Windows, 和 Mac OS X 中。
-
-dupeGuru PE 支持 JPG, PNG, TIFF, GIF 和 BMP 等图片格式。所有的这些格式可以被同时比较。Mac OS X 版的 dupeGuru PE 还支持 PSD 和 RAW (CR2 和 NEF) 格式。
-
-#### 在 Ubuntu 14.10/14.04/13.10/13.04/12.04 中安装 dupeGuru PE ####
-
-由于我们已经添加了 PPA, 我们也不必为 dupeGuru PE 添加 PPA。只需运行如下命令来安装它。
-
-```
-sudo apt-get install dupeguru-pe
-```
-
-#### 使用 ####
-
-就使用方法,操作界面和外观而言,它与 dupeGuru ,dupeGuru ME 类似。我就纳闷为什么开发者为不同的类别开发了不同的版本。我想如果开发一个结合以上三个版本功能的应用,或许会更好。
-
-启动它,添加你想扫描的目录,并选择你想执行的操作。就这样,你的重复文件将消失。
-
-
-
-如若因为任何的安全问题而不能移除某些重复文件,请记下这些文件的位置,通过终端或文件管理器来手动删除它们。
-
-欢呼吧!
-
---------------------------------------------------------------------------------
-
-via: http://www.unixmen.com/dupeguru-find-remove-duplicate-files-instantly-hard-drive/
-
-作者:[SK][a]
-译者:[FSSlc](https://github.com/FSSlc)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://www.unixmen.com/author/sk/
-[1]:http://www.hardcoded.net/dupeguru/
-[2]:http://www.hardcoded.net/dupeguru_me/
-[3]:http://www.hardcoded.net/dupeguru_pe/
diff --git a/translated/tech/20150104 How to debug a C or C++ program with Nemiver debugger.md b/translated/tech/20150104 How to debug a C or C++ program with Nemiver debugger.md
deleted file mode 100644
index b5dc4c34a7..0000000000
--- a/translated/tech/20150104 How to debug a C or C++ program with Nemiver debugger.md
+++ /dev/null
@@ -1,126 +0,0 @@
-使用Nemiver调试器找出C/C++程序中的bug
-================================================================================
-
-如果你读过[my post on GDB][1],你就会明白我认为一个调试器对一段C/C++程序来说意味着多么的重要和有用。然而,如果一个像GDB的命令行对你而言听起来更像一个问题而不是一个解决方案,那么你也许会对Nemiver更感兴趣。[Nemiver][2] 是一款基于GTK+的独立图形化用于C/C++程序的调试器,同时它以GDB作为其后端。最令人佩服的是其速度和稳定性,Nemiver时一个非常可靠,具备许多优点的调试工具。
-
-### Nemiver的安装 ###
-
-基于Debian发行版,它的安装时非常直接简单如下:
-
- $ sudo apt-get install nemiver
-
-在Arch Linux中安装如下:
-
- $ sudo pacman -S nemiver
-
-在Fedora中安装如下:
-
- $ sudo yum install nemiver
-
-如果你选择自己变异,[GNOME website][3]中最新源码包可用。
-
-最令人欣慰的是,它能够很好地与GNOME环境像结合。
-
-### Nemiver的基本用法 ###
-
-启动Nemiver的命令:
-
- $ nemiver
-
-你也可以通过执行一下命令来启动:
-
- $ nemiver [path to executable to debug]
-
-你会注意到如果在调试模式下执行编译(-g标志表示GCC)将会更有帮助。
-
-还有一个优点是Nemiver的快速加载,所以你应该可以马上看到主屏幕的默认布局。
-
-
-
-
-
-
-
-默认情况下,断点通常位于主函数的第一行。这样就可以空出时间让你去认识调试器的基本功能:
-
-
-
-- Next line (mapped to F6)
-- Step inside a function (F7)
-- Step out of a function (Shift+F7)
-- 下一行 (映射到F6)
-- 执行内部行数(F7)
-- 执行外部函数(Shift+F7) ## 我不确定这个保留哪个都翻译出来了 ##
-
-但是由于我个人的喜好是“Run to cursor(运行至光标)”,该选项使你的程序运行精确至你光标下的行,并且默认映射到F11.
-
-下一步,断点通常是容易使用的。最快捷的方式是使用F8设置一个断点在相应的行。但是Nemiver也有一个更富在的菜单在“Debug”项,这允许你在一个特定的函数,行数,二进制位置文件的位置,或者类似一个异常,分支或者exec的事件。
-
-
-
-
-你也可以通过追踪来查看一个变量。在“Debug”选项,你可以通过命名来匹配一个表达式来检查。然后也可以通过将其添加到列表中以方便访问。这可能是最有用的一个功能虽然我从未因为浓厚的兴趣将鼠标悬停在一个变量来获取它的值。值得注意的是,将鼠标放置在相应位置时不生效的。如果想要让它更好地工作,Nemiver是可以看到结构并给所有成员的变量赋值。
-
-
-
-
-谈到方便地访问信息,我也非常欣赏这个程序的平面布局。默认情况下,代码在上个部分,标签在下半部分。这授予你访问中断输出、文本追踪、断点列表、注册地址、内存映射和变量控制。但是注意到在“Edit”“Preferences”“Layout”下你可以选择不同的布局,包括动态修改。
-
-
-
-
-
-
-自然而然,一旦你设置了所有短点,观察点和布局,您可以在“File”下很方便地保存以免你不小心关掉Nemiver。
-
-
-### Nemiver的高级用法 ###
-
-
-到目前为止,我们讨论的都是Nemiver的基本特征,例如,你马上开始喝调试一个简单的程序需要什么。如果你有更高的药求,特别是对于一些更佳复杂的程序,你应该会对接下来提到的这些特征更感兴趣。
-
-
-#### 调试一个正在运行的进程 ####
-
-
-Nemiver允许你连接到一个正在运行的进程进行调试。在“File”菜单,你可以过滤出正在运行的进程,并连接到这个进程。
-
-
-
-
-#### 通过TCP连接远程调试一个程序 ####
-
-Nemiver支持远程调试,当你在一台远程机器设置一个轻量级调试服务器,你可以通过调试服务器启动Nemiver从另一台机器去调试承载远程服务器上的目标。如果出于某些原因,你不能在远程机器上吗很好地驾驭Nemiver或者GDB,那么远程调试对于你来说将非常有用。在“File”菜单下,指定二进制文件、共享库的地址和端口。
-
-
-
-#### 使用你的GDB二进制进行调试 ####
-
-如果你想自行通过Nemiver进行编译,你可以在“Edit(编辑)”“Preferences(首选项)”“Debug(调试)”下给GDB制定一个新的位置。如果你想在Nemiver使用GDB的定制版本,那么这个选项对你来说是非常实用的。
-
-
-#### 循序一个子进程或者父进程 ####
-
-Nemiver是可以兼容一个子进程或者附近成的。想激活这个功能,请到“Debugger”下面的“Preferences(首选项)”。
-
-
-
-总而言之,Nemiver大概是我最喜欢的没有IDE的调试程序。在我看来,它甚至可以击败GDB,并且[命令行][4]程序对我本身来说更接地气。所以,如果你从未使用过的话,我会强烈推荐你使用。我只能庆祝我们团队背后给了我这么一个可靠、稳定的程序。
-
-你对Nemiver有什么见解?你是否也考虑它作为独立的调试工具?或者仍然坚持使用IDE?让我们在评论中探讨吧。
-
---------------------------------------------------------------------------------
-
-via: http://xmodulo.com/debug-program-nemiver-debugger.html
-
-作者:[Adrien Brochard][a]
-译者:[disylee](https://github.com/disylee)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://xmodulo.com/author/adrien
-[1]:http://xmodulo.com/gdb-command-line-debugger.html
-[2]:https://wiki.gnome.org/Apps/Nemiver
-[3]:https://download.gnome.org/sources/nemiver/0.9/
-[4]:http://xmodulo.com/recommend/linuxclibook
diff --git a/translated/tech/20150105 How To Install Kodi 14 (XBMC) In Ubuntu 14.04 and Linux Mint 17.md b/translated/tech/20150105 How To Install Kodi 14 (XBMC) In Ubuntu 14.04 and Linux Mint 17.md
deleted file mode 100644
index 20b6715d38..0000000000
--- a/translated/tech/20150105 How To Install Kodi 14 (XBMC) In Ubuntu 14.04 and Linux Mint 17.md
+++ /dev/null
@@ -1,51 +0,0 @@
-Ubuntu14.04或Mint17如何安装Kodi14(XBMC)
-================================================================================
-
-
-[Kodi][1],原名就是大名鼎鼎的XBMC,发布[最新版本14][2],命名为Helix。感谢官方XMBC提供的PPA,现在可以很简单地在Ubuntu14.04中安装了。
-
-Kodi是一个优秀的自由和开源的(GPL)媒体中心软件,支持所有平台,如Windows, Linux, Mac, Android等。此软件拥有全屏幕的媒体中心,可以管理所有音乐和视频,不单支持本地文件还支持网络播放,如Tube,[Netflix][3], Hulu, Amazon Prime和其他串流服务商。
-
-### Ubuntu 14.04, 14.10 和 Linux Mint 17 中安装XBMC 14 Kodi Helix ###
-
-再次感谢官方的PPA,让我们可以轻松安装Kodi 14。
-支持Ubuntu 14.04, Ubuntu 12.04, Linux Mint 17, Pinguy OS 14.04, Deepin 2014, LXLE 14.04, Linux Lite 2.0, Elementary OS and 其他基于Ubuntu的Linux 发行版。
-打开终端(Ctrl+Alt+T)然后使用下列命令。
-
- sudo add-apt-repository ppa:team-xbmc/ppa
- sudo apt-get update
- sudo apt-get install kodi
-
-需要下载大约100MB,在我的观点这不是很大。若需安装解码插件,使用下列命令:
-
- sudo apt-get install kodi-audioencoder-* kodi-pvr-*
-
-#### 从Ubuntu中移除Kodi 14 ####
-
-从系统中移除Kodi 14 ,使用下列命令:
-
- sudo apt-get remove kodi
-
-同样也应该移除PPA软件源:
-
- sudo add-apt-repository --remove ppa:team-xbmc/ppa
-
-我希望这个简单的文章可以帮助到你,在Ubuntu, Linux Mint 和其他 Linux版本中轻松安装Kodi 14。
-你怎么发现Kodi 14 Helix?
-你有没有使用其他的什么媒体中心?
-可以在下面的评论区分享你的观点。
-
---------------------------------------------------------------------------------
-
-via: http://itsfoss.com/install-kodi-14-xbmc-in-ubuntu-14-04-linux-mint-17/
-
-作者:[Abhishek][a]
-译者:[Vic020/VicYu](http://www.vicyu.net)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://itsfoss.com/author/Abhishek/
-[1]:http://kodi.tv/
-[2]:http://kodi.tv/kodi-14-0-helix-unwinds/
-[3]:http://itsfoss.com/watch-netflix-in-ubuntu-14-04/
diff --git a/translated/tech/20150105 How To Install Winusb In Ubuntu 14.04.md b/translated/tech/20150105 How To Install Winusb In Ubuntu 14.04.md
deleted file mode 100644
index b9fe775752..0000000000
--- a/translated/tech/20150105 How To Install Winusb In Ubuntu 14.04.md
+++ /dev/null
@@ -1,47 +0,0 @@
-如何在Ubuntu 14.04 中安装Winusb
-================================================================================
-
-
-[WinUSB][1]是一款简单的且有用的工具,可以让你从Windows ISO镜像或者DVD中创建USB安装盘。它结合了GUI和命令行,你可以根据你的喜好决定使用哪种。
-
-在本篇中我们会展示**如何在Ubuntu 14.04、14.10 和 Linux Mint 17 中安装WinUSB**。
-
-### 在Ubuntu 14.04、14.10 和 Linux Mint 17 中安装WinUSB ###
-
-直到Ubuntu 13.10, WinUSBu一直都在积极开发,且在官方PPA中可以找到。这个PPA还没有为Ubuntu 14.04 和14.10更新,但是二进制文件仍旧可在更新版本的Ubuntu和Linux Mint中运行。基于[基于你使用的系统是32位还是64位的][2],使用下面的命令来下载二进制文件:
-
-打开终端,并在32位的系统下使用下面的命令:
-
- wget https://launchpad.net/~colingille/+archive/freshlight/+files/winusb_1.0.11+saucy1_i386.deb
-
-对于64位的系统,使用下面的命令:
-
- wget https://launchpad.net/~colingille/+archive/freshlight/+files/winusb_1.0.11+saucy1_amd64.deb
-
-一旦你下载了正确的二进制包,你可以用下面的命令安装WinUSB:
-
- sudo dpkg -i winusb*
-
-不要担心在你安装WinUSB时看见错误。使用这条命令修复依赖:
-
- sudo apt-get -f install
-
-之后,你就可以在Unity Dash中查找WinUSB并且用它在Ubuntu 14.04 中创建Windows的live USB了。
-
-
-
-我希望这篇文章能够帮到你**在Ubuntu 14.04、14.10 和 Linux Mint 17 中安装WinUSB**。
-
---------------------------------------------------------------------------------
-
-via: http://itsfoss.com/install-winusb-in-ubuntu-14-04/
-
-作者:[Abhishek][a]
-译者:[geekpi](https://github.com/geekpi)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://itsfoss.com/author/Abhishek/
-[1]:http://en.congelli.eu/prog_info_winusb.html
-[2]:http://itsfoss.com/how-to-know-ubuntu-unity-version/
\ No newline at end of file
diff --git a/translated/tech/20150126 Improve system performance by moving your log files to RAM Using Ramlog.md b/translated/tech/20150126 Improve system performance by moving your log files to RAM Using Ramlog.md
deleted file mode 100644
index 66f5d72f87..0000000000
--- a/translated/tech/20150126 Improve system performance by moving your log files to RAM Using Ramlog.md
+++ /dev/null
@@ -1,111 +0,0 @@
-系统性能优化支招:使用Ramlog将日志文件转移到RAM
-================================================================================
-Ramlog以系统守护进程的形式存在。它系统启动的时候创建了虚拟磁盘(ramdisk),将文件从目录/var/log复制到虚拟磁盘中,同时把虚拟磁盘挂载为/var/log。接着更新虚拟磁盘上所有的日志。硬盘上的日志会保留在目录/var/log中,直到ramlog重启或停止时被更新。而关机的时候,(ramdisk上的)日志文件会重新保存到硬盘上,以确保日志一致性。Ramlog 2.x默认使用tmpfs文件系统,同时也可以支持ramfs和内核ramdisk。使用rsync(译注:Linux数据镜像备份工具)这个工具来同步日志。
-
-注意:没有保存进硬盘的日志将在断电或者内核混乱(kernel panic)的情况下丢失。
-
-如果你拥有空间足够的可用内存,而又想把日志放进虚拟磁盘,就安装ramlog吧。它是笔记本用户、UPS系统或是直接在flash中运行的系统节省写周期的优良选择。
-
-Ramlog的运行机制以及步骤:
-
-1.Ramlog在第一个守护进程(这取决于你所安装过的其它守护进程)的基础上启动。
-
-2.然后创建目录/var/log.hdd并将其硬链至/var/log。
-
-3.如果使用的是tmpfs(默认)或者ramfs之一的文件系统,将其挂载到/var/log上。
-
-而如果使用的是内核ramdisk,ramdisk将在/dev/ram9中创建,并将挂载至/var/log。默认情况下ramlog会占用所有ramdisk的内存,其大小由内核参数"ramdisk_size"指定。
-
-5.接着其它的守护进程被启动,并在ramdisk中更新日志。Logrotate(译注:Linux日志轮替工具)也是在ramdiks之上运行。
-
-6.重启(默认一天一次)ramlog时,目录/var/log.hdd将借助rsync与/var/log保持同步。日志自动保存的频率可以通过cron(译注:Linux例行性工作调度)来控制。默认情况下,ramlog文件放置在目录/etc/cron.daily下。
-
-7.系统关机时,ramlog在最后一个守护进程关闭之前关闭。
-
-在ramlog关闭期间,/var/log.hdd中的文件将被同步至/var/log,接着/var/log和/var/log.hdd都被卸载,然后删除空目录/var/log.hdd。
-
-**注意:- 此文仅面向高级用户**
-
-### 在Ubuntu中安装Ramlog ###
-
-首先需要用以下命令,从[这里][1]下载.deb安装包:
-
- wget http://www.tremende.com/ramlog/download/ramlog_2.0.0_all.deb
-
-下载ramlog_2.0.0_all.deb安装包完毕,使用以下命令进行安装:
-
- sudo dpkg -i ramlog_2.0.0_all.deb
-
-这一步会完成整个安装,现在你需要运行以下命令:
-
- sudo update-rc.d ramlog start 2 2 3 4 5 . stop 99 0 1 6 .
-
-#现在,在初始状态下升级sysklogd,使之能在ramlog停止运行前正确关闭:
-
- sudo update-rc.d -f sysklogd remove
-
- sudo update-rc.d sysklogd start 10 2 3 4 5 . stop 90 0 1 6 .
-
-然后重启系统:
-
- sudo reboot
-
-系统重启完毕,运行'ramlog getlogsize'获取/var/log的空间大小。在此基础之上多分配40%的空间,确保ramdisk有足够的空间(这整个都将作为ramdisk的空间大小)。
-
-编辑引导配置文件,如/etc/grub.conf,、/boot/grub/menu.lst 或/etc/lilo.conf(译注:具体哪个配置文件视不同引导加载程序而定),kernel参数新增项'ramdisk_size=xxx'以更新当前内核,其中xxx是ramdisk的空间大小。
-
-### 配置Ramlog ###
-
-基于deb的系统中,Ramlog的配置文件位于/etc/default/ramlog,你可以在该目录下设置以下变量:
-
-Variable (with default value):
-
-Description:
-
- RAMDISKTYPE=0
- # Values:
- # 0 -- tmpfs (can be swapped) -- default
- # 1 -- ramfs (no max size in older kernels,
- # cannot be swapped, not SELinux friendly)
- # 2 -- old kernel ramdisk
- TMPFS_RAMFS_SIZE=
- #Maximum size of memory to be used by tmpfs or ramfs.
- # The value can be percentage of total RAM or size in megabytes -- for example:
- # TMPFS_RAMFS_SIZE=40%
- # TMPFS_RAMFS_SIZE=100m
- # Empty value means default tmpfs/ramfs size which is 50% of total RAM.
- # For more options please check ‘man mount', section ‘Mount options for tmpfs'
- # (btw -- ramfs supports size limit in newer kernels
- # as well despite man says there are no mount options)
- # It has only effect if RAMDISKTYPE=0 or 1
- KERNEL_RAMDISK_SIZE=MAX
- #Kernel ramdisk size in kilobytes or MAX to use entire ramdisk.
- #It has only effect if RAMDISKTYPE=2
- LOGGING=1
- # 0=off, 1=on Logs can be found in /var/log/ramdisk
- LOGNAME=ramlog
- # name of the ramlog log file (makes sense if LOGGING=1)
- VERBOSE=1
- # 0=off, 1=on (if 1, teststartstop puts detials
- # to the logs and it is called after start or stop fails)
-
-### 在Ubuntu中卸载ramlog ###
-
-打开终端运行以下命令:
-
- sudo dpkg -P ramlog
-
-注意:如果ramlog卸载之前仍在运行,需要重启系统完成整个卸载工作。
-
---------------------------------------------------------------------------------
-
-via: http://www.ubuntugeek.com/improve-system-performance-by-moving-your-log-files-to-ram-using-ramlog.html
-
-作者:[ruchi][a]
-译者:[soooogreen](https://github.com/soooogreen)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://www.ubuntugeek.com/author/ubuntufix
-[1]:http://www.tremende.com/ramlog/download/ramlog_2.0.0_all.deb
diff --git a/translated/tech/20150824 How to Setup Zephyr Test Management Tool on CentOS 7.x.md b/translated/tech/20150824 How to Setup Zephyr Test Management Tool on CentOS 7.x.md
new file mode 100644
index 0000000000..7de8349b9c
--- /dev/null
+++ b/translated/tech/20150824 How to Setup Zephyr Test Management Tool on CentOS 7.x.md
@@ -0,0 +1,231 @@
+如何在 CentOS 7.x 上安装 Zephyr 测试管理工具
+================================================================================
+测试管理工具包括作为测试人员需要的任何东西。测试管理工具用来记录测试执行的结果、计划测试活动以及报告质量保证活动的情况。在这篇文章中我们会向你介绍如何配置 Zephyr 测试管理工具,它包括了管理测试活动需要的所有东西,不需要单独安装测试活动所需要的应用程序从而降低测试人员不必要的麻烦。一旦你安装完它,你就看可以用它跟踪 bug、缺陷,和你的团队成员协作项目任务,因为你可以轻松地共享和访问测试过程中多个项目团队的数据。
+
+### Zephyr 要求 ###
+
+安装和运行 Zephyr 要求满足以下最低条件。可以根据你的基础设施提高资源。我们会在 64 位 CentOS-7 系统上安装 Zephyr,几乎在所有的 Linux 操作系统中都有可用的 Zephyr 二进制发行版。
+
+注:表格
+
 +
+