mirror of
https://github.com/LCTT/TranslateProject.git
synced 2024-12-26 21:30:55 +08:00
translated
This commit is contained in:
parent
8a1fa8c114
commit
1ae711da22
@ -1,62 +0,0 @@
|
||||
LinuxBars Translating
|
||||
LinuxBars 翻译中
|
||||
|
||||
Baidu Takes FPGA Approach to Accelerating SQL at Scale
|
||||
===================
|
||||
|
||||

|
||||
|
||||
While much of the work at Baidu we have focused on this year has centered on the Chinese search giant’s [deep learning initiatives][1], many other critical, albeit less bleeding edge applications present true big data challenges.
|
||||
|
||||
As Baidu’s Jian Ouyang detailed this week at the Hot Chips conference, Baidu sits on over an exabyte of data, processes around 100 petabytes per day, updates 10 billion webpages daily, and handles over a petabyte of log updates every 24 hours. These numbers are on par with Google and as one might imagine, it takes a Google-like approach to problem solving at scale to get around potential bottlenecks.
|
||||
|
||||
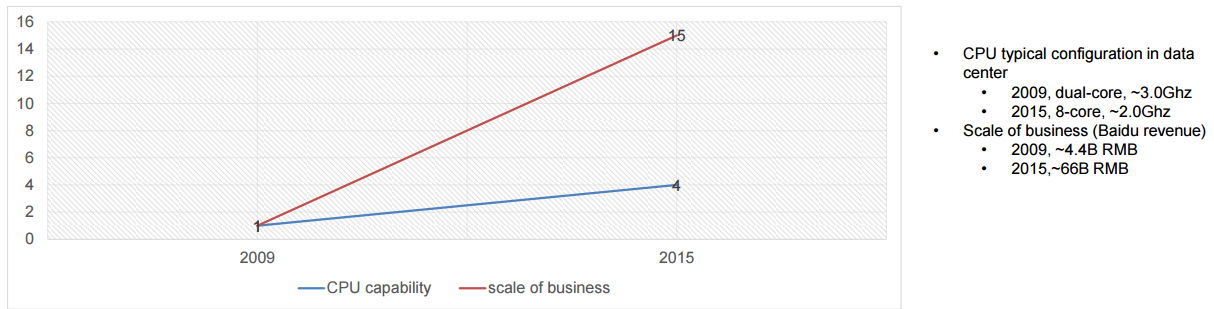
Just as we have described Google looking for any way possible to beat Moore’s Law, Baidu is on the same quest. While the exciting, sexy machine learning work is fascinating, acceleration of the core mission-critical elements of the business is as well—because it has to be. As Ouyang notes, there is a widening gap between the company’s need to deliver top-end services based on their data and what CPUs are capable of delivering.
|
||||
|
||||
|
||||
|
||||
As for Baidu’s exascale problems, on the receiving end of all of this data are a range of frameworks and platforms for data analysis; from the company’s massive knowledge graph, multimedia tools, natural language processing frameworks, recommendation engines, and click stream analytics. In short, the big problem of big data is neatly represented here—a diverse array of applications matched with overwhelming data volumes.
|
||||
|
||||
When it comes to acceleration for large-scale data analytics at Baidu, there are several challenges. Ouyang says it is difficult to abstract the computing kernels to find a comprehensive approach. “The diversity of big data applications and variable computing types makes this a challenge. It is also difficult to integrate all of this into a distributed system because there are also variable platforms and program models (MapReduce, Spark, streaming, user defined, and so on). Further there is more variance in data types and storage formats.”
|
||||
|
||||
Despite these barriers, Ouyang says teams looked for the common thread. And as it turns out, that string that ties together many of their data-intensive jobs is good old SQL. “Around 40% of our data analysis jobs are already written in SQL and rewriting others to match it can be done.” Further, he says they have the benefit of using existing SQL system that mesh with existing frameworks like Hive, Spark SQL, and Impala. The natural thing to do was to look for SQL acceleration—and Baidu found no better hardware than an FPGA.
|
||||
|
||||

|
||||
|
||||
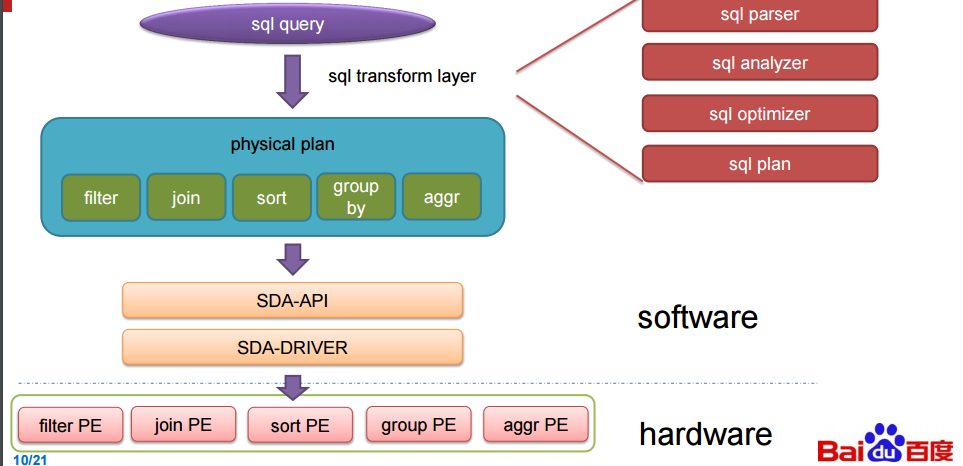
These boards, called processing elements (PE on coming slides), automatically handle key SQL functions as they come in. With that said, a disclaimer note here about what we were able to glean from the presentation. Exactly what the FPGA is talking to is a bit of a mystery and so by design. If Baidu is getting the kinds of speedups shown below in their benchmarks, this is competitive information. Still, we will share what was described. At its simplest, the FPGAs are running in the database and when it sees SQL queries coming it, the software the team designed ([and presented at Hot Chips two years ago][2] related to DNNs) kicks into gear.
|
||||
|
||||
|
||||
|
||||
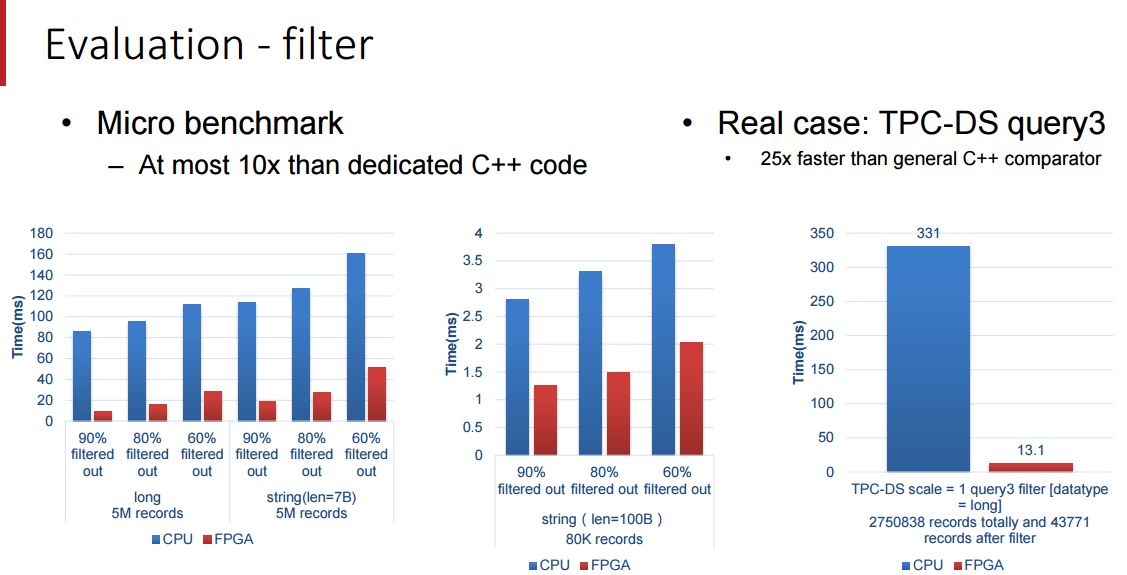
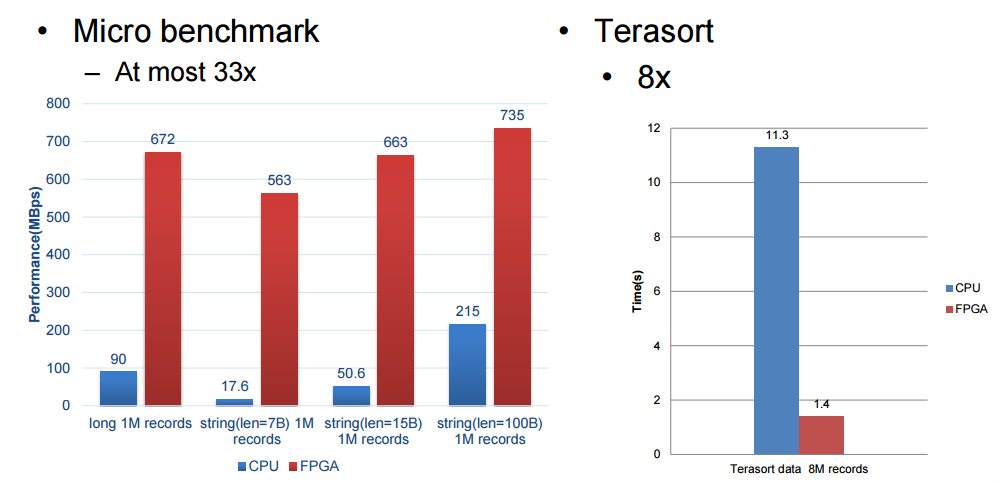
One thing Ouyang did note about the performance of their accelerator is that their performance could have been higher but they were bandwidth limited with the FPGA. In the evaluation below, Baidu setup with a 12-core 2.0 Ghz Intel E26230 X2 sporting 128 GB of memory. The SDA had five processing elements (the 300 MHzFPGA boards seen above) each of which handles core functions (filter, sort, aggregate, join and group by.).
|
||||
|
||||
To make the SQL accelerator, Baidu picked apart the TPC-DS benchmark and created special engines, called processing elements, that accelerate the five key functions in that benchmark test. These include filter, sort, aggregate, join, and group by SQL functions. (And no, we are not going to put these in all caps to shout as SQL really does.) The SDA setup employs an offload model, with the accelerator card having multiple processing elements of varying kinds shaped into the FPGA logic, with the type of SQL function and the number per card shaped by the specific workload. As these queries are being performed on Baidu’s systems, the data for the queries is pushed to the accelerator card in columnar format (which is blazingly fast for queries) and through a unified SDA API and driver, the SQL work is pushed to the right processing elements and the SQL operations are accelerated.
|
||||
|
||||
The SDA architecture uses a data flow model, and functions not supported by the processing elements are pushed back to the database systems and run natively there. More than any other factor, the performance of the SQL accelerator card developed by Baidu is limited by the memory bandwidth of the FPGA card. The accelerator works across clusters of machines, by the way, but the precise mechanism of how data and SQL operations are parsed out to multiple machines was not disclosed by Baidu.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
We’re limited in some of the details Baidu was willing to share but these benchmark results are quite impressive, particularly for Terasort. We will follow up with Baidu after Hot Chips to see if we can get more detail about how this is hooked together and how to get around the memory bandwidth bottlenecks.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.nextplatform.com/2016/08/24/baidu-takes-fpga-approach-accelerating-big-sql/?utm_source=dbweekly&utm_medium=email
|
||||
|
||||
作者:[Nicole Hemsoth][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.nextplatform.com/author/nicole/
|
||||
[1]: http://www.nextplatform.com/?s=baidu+deep+learning
|
||||
[2]: http://www.hotchips.org/wp-content/uploads/hc_archives/hc26/HC26-12-day2-epub/HC26.12-5-FPGAs-epub/HC26.12.545-Soft-Def-Acc-Ouyang-baidu-v3--baidu-v4.pdf
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,39 @@
|
||||
百度运用 FPGA 方法从规模上加速 SQL 查询
|
||||
===================================================================
|
||||
|
||||
尽管今年我们对于百度工作的焦点集中在中国搜索巨头的深度学习上,许多其他的关键的,尽管不那么前沿的应用表现出了大数据带来的挑战。
|
||||
|
||||
正如百度主任架构师在本周 Hot Chips 大会上谈论的,百度坐拥超过 1 EB 的数据,每天处理大约 100 PB 的数据,每天更新 100 亿的网页,每 24 小时更新处理超过 1 PB 的日志更新,这些数字和 Google 不分上下,正如人们所想象的。百度采用了类似 Google 的方法去处理规模上潜在的瓶颈。
|
||||
|
||||
正如刚刚我们谈到的,Google 寻找一切可能的方法去打败摩尔定律,百度也在进行相同的探索,而令人激动的,使人着迷的机器学习工作是迷人的。业务的核心关键任务的加速同样也是,因为必须如此,欧阳提到,公司基于自身的数据提供高端服务的需求和 CPU 可以承载的能力之间的差距将会逐渐增大。
|
||||
|
||||
对于百度的百亿亿级问题,在所有数据的接受端是一系列用于数据分析的框架和平台,从公司的大量的知识图,多媒体工具,自然语言处理框架,推荐引擎,和点击流分析,简而言之,大数据的首要问题就是恰当地在这里表现出一系列的和压倒一切的数据价值的应用。
|
||||
|
||||
每当谈到关于百度的大数据分析加速,这里有几个挑战,欧阳谈到提取运算核心去寻找一个广泛的方法是困难的。大数据应用和变量计算类型的多样性使得这成为一个挑战,把所有这些整合成为一个分布式系统是困难的,因为有多变的平台和编程模型(MapReduce,Spark,streaming,user defined,等等)。更进一步这里有更多的数据类型和存储格式的变化。
|
||||
|
||||
|
||||
尽管存在这些障碍,欧阳讲到团队寻找主线,而且随着不断发展,传统的 SQL 把许多数据密集型的任务连系在一起。“大约有 40% 的数据分析任务已经用 SQL 重写,重写其他的去匹配其能做的” 更进一步,他讲道他们可以享受现有的可以和已经存在的框架匹配的系统比如 Hive,Spark,SQL,和 Impala 。下一步要做的事情就是 SQL 查询加速,百度没有找到 FPGA 更好的硬件。
|
||||
|
||||
这些主板,被称为处理单元( 下图中的 PE ),自动地处理关键的 SQL 功能当他们进来,那意味着,一个放弃者在这指出我们现在所能收集到的东西,这正是 FPGA 设计神秘的地方,如果百度在基准测试中得到了下图中的加速,这是有竞争力的信息,我们还要分享所描述的东西,简单来说,FPGA 在数据库中运行,当其收到 SQL 查询的时候,团队设计的软件与之啮合。
|
||||
|
||||
欧阳提到了一件事,他们的加速器受限与 FPGA 的带宽不然性能表现本可以更高,在下面的评价中,百度安装了 2 块intl E26230 具有 12 核心,主频 2.0 GHZ,支持 128G 内存的 CPU,SDA 具有 5 个处理单元,(上图中的300MHzFPGA 主板)每个处理核心功能(过滤,排序,聚合,加入,和分组)
|
||||
|
||||
为了实现 SQL 查询加速,百度将 TPC-DS 基准拆散并且创建了特殊的引擎。叫做处理单元,在基准测试中加速 5 个关键功能,这包括过滤,排序,融合,加入和分组,(我们并没有把这些单词都大写的像 SQL 真的那样),SDA 设置使用卸载模型。和具有多个不同种类的处理单元的的加速卡在 FPGA 逻辑中形成。SQL 功能的类型和每张卡的数量由特定的工作量决定。由于这些查询在百度的系统中执行,用来查询的数据被以列 格式存储到加速卡中(这会使得查询非常快速)而且通过一个统一的 SDA API 和驱动,SQL 查询工作被分发到正确的处理单元而且 SQL 操作实现了加速。
|
||||
|
||||
SDA 架构采用一种数据流模型,加速单元不支持的操作被退回到数据库系统然后在那里本地运行,比其他任何因素,百度开发的 SQL 加速卡的性能被 FPGA 卡的内存带宽所限制。加速卡跨真个集群机器工作,顺便提一下,但是数据和 SQL 操作如何分发到多个机器的准确原理没有被百度披露。
|
||||
|
||||
我们受限与百度分享细节的意愿但是这些基准测试结果是非常感人的,尤其是传输测试,我们将跟随百度 Hot Chips 大会之后的脚步去看看我们是否能得到关于这是如何连接到一起的和如何解决内存带宽瓶颈的细节。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.nextplatform.com/2016/08/24/baidu-takes-fpga-approach-accelerating-big-sql/?utm_source=dbweekly&utm_medium=email
|
||||
|
||||
作者:[Nicole Hemsoth][a]
|
||||
译者:[LinuxBars](https://github.com/LinuxBars)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.nextplatform.com/author/nicole/
|
||||
[1]: http://www.nextplatform.com/?s=baidu+deep+learning
|
||||
[2]: http://www.hotchips.org/wp-content/uploads/hc_archives/hc26/HC26-12-day2-epub/HC26.12-5-FPGAs-epub/HC26.12.545-Soft-Def-Acc-Ouyang-baidu-v3--baidu-v4.pdf
|
||||
Loading…
Reference in New Issue
Block a user