` 加上 `div` 标签,注意生成的段落是自动缩进的。
+
+```
+
+
Vim plugins are awesome !
+
+```
+
+Vim Surround 有很多其它选项,你可以参照 [GitHub][7] 上的说明尝试它们。
+
+### 4、Vim Gitgutter
+
+[Vim Gitgutter][8] 插件对使用 Git 作为版本控制工具的人来说非常有用。它会在 Vim 的行号列旁显示 `git diff` 的差异标记。假设你有如下已提交过的代码:
+
+```
+ 1 package main
+ 2
+ 3 import "fmt"
+ 4
+ 5 func main() {
+ 6 x := true
+ 7 items := []string{"tv", "pc", "tablet"}
+ 8
+ 9 if x {
+ 10 for _, i := range items {
+ 11 fmt.Println(i)
+ 12 }
+ 13 }
+ 14 }
+```
+
+当你做出一些修改后,Vim Gitgutter 会显示如下标记:
+
+```
+ 1 package main
+ 2
+ 3 import "fmt"
+ 4
+_ 5 func main() {
+ 6 items := []string{"tv", "pc", "tablet"}
+ 7
+~ 8 if len(items) > 0 {
+ 9 for _, i := range items {
+ 10 fmt.Println(i)
++ 11 fmt.Println("------")
+ 12 }
+ 13 }
+ 14 }
+```
+
+`_` 标记表示在第 5 行和第 6 行之间删除了一行。`~` 表示第 8 行有修改,`+` 表示新增了第 11 行。
+
+另外,Vim Gitgutter 允许你用 `[c` 和 `]c` 在多个有修改的块之间跳转,甚至可以用 `Leader+hs` 来暂存某个变更集。
+
+这个插件提供了对变更的即时视觉反馈,如果你用 Git 的话,有了它简直是如虎添翼。
+
+### 5、VIM Fugitive
+
+[Vim Fugitive][9] 是另一个将 Git 工作流集成到 Vim 中的超棒插件。它对 Git 做了一些封装,可以让你在 Vim 里直接执行 Git 命令并将结果集成在 Vim 界面里。这个插件有超多的特性,更多信息请访问它的 [GitHub][10] 项目页面。
+
+这里有一个使用 Vim Fugitive 的基础 Git 工作流示例。设想我们已经对下面的 Go 代码做出修改,你可以用 `:Gblame` 调用 `git blame` 来查看每行最后的提交信息:
+
+```
+e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 1 package main
+e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 2
+e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 3 import "fmt"
+e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 4
+e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│_ 5 func main() {
+e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 6 items := []string{"tv", "pc", "tablet"}
+e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 7
+00000000 (Not Committed Yet 2018-12-05 18:55:00 -0500)│~ 8 if len(items) > 0 {
+e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 9 for _, i := range items {
+e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 10 fmt.Println(i)
+00000000 (Not Committed Yet 2018-12-05 18:55:00 -0500)│+ 11 fmt.Println("------")
+e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 12 }
+e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 13 }
+e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 14 }
+```
+
+可以看到第 8 行和第 11 行显示还未提交。用 `:Gstatus` 命令检查仓库当前的状态:
+
+```
+ 1 # On branch master
+ 2 # Your branch is up to date with 'origin/master'.
+ 3 #
+ 4 # Changes not staged for commit:
+ 5 # (use "git add
..." to update what will be committed)
+ 6 # (use "git checkout -- ..." to discard changes in working directory)
+ 7 #
+ 8 # modified: vim-5plugins/examples/test1.go
+ 9 #
+ 10 no changes added to commit (use "git add" and/or "git commit -a")
+--------------------------------------------------------------------------------------------------------
+ 1 package main
+ 2
+ 3 import "fmt"
+ 4
+_ 5 func main() {
+ 6 items := []string{"tv", "pc", "tablet"}
+ 7
+~ 8 if len(items) > 0 {
+ 9 for _, i := range items {
+ 10 fmt.Println(i)
++ 11 fmt.Println("------")
+ 12 }
+ 13 }
+ 14 }
+```
+
+Vim Fugitive 在分割的窗口里显示 `git status` 的输出结果。你可以在该行按下 `-` 键用该文件的名字暂存这个文件的提交,再按一次 `-` 可以取消暂存。这个信息会随着你的操作自动更新:
+
+```
+ 1 # On branch master
+ 2 # Your branch is up to date with 'origin/master'.
+ 3 #
+ 4 # Changes to be committed:
+ 5 # (use "git reset HEAD ..." to unstage)
+ 6 #
+ 7 # modified: vim-5plugins/examples/test1.go
+ 8 #
+--------------------------------------------------------------------------------------------------------
+ 1 package main
+ 2
+ 3 import "fmt"
+ 4
+_ 5 func main() {
+ 6 items := []string{"tv", "pc", "tablet"}
+ 7
+~ 8 if len(items) > 0 {
+ 9 for _, i := range items {
+ 10 fmt.Println(i)
++ 11 fmt.Println("------")
+ 12 }
+ 13 }
+ 14 }
+```
+
+现在你可以用 `:Gcommit` 来提交修改了。Vim Fugitive 会打开另一个分割窗口让你输入提交信息:
+
+```
+ 1 vim-5plugins: Updated test1.go example file
+ 2 # Please enter the commit message for your changes. Lines starting
+ 3 # with '#' will be ignored, and an empty message aborts the commit.
+ 4 #
+ 5 # On branch master
+ 6 # Your branch is up to date with 'origin/master'.
+ 7 #
+ 8 # Changes to be committed:
+ 9 # modified: vim-5plugins/examples/test1.go
+ 10 #
+```
+
+按 `:wq` 保存文件完成提交:
+
+```
+[master c3bf80f] vim-5plugins: Updated test1.go example file
+ 1 file changed, 2 insertions(+), 2 deletions(-)
+Press ENTER or type command to continue
+```
+
+然后你可以再用 `:Gstatus` 检查结果并用 `:Gpush` 把新的提交推送到远程。
+
+```
+ 1 # On branch master
+ 2 # Your branch is ahead of 'origin/master' by 1 commit.
+ 3 # (use "git push" to publish your local commits)
+ 4 #
+ 5 nothing to commit, working tree clean
+```
+
+Vim Fugitive 的 GitHub 项目主页有很多屏幕录像展示了它的更多功能和工作流,如果你喜欢它并想多学一些,快去看看吧。
+
+### 接下来?
+
+这些 Vim 插件都是程序开发者的神器!还有另外两类开发者常用的插件:自动完成插件和语法检查插件。它些大都是和具体的编程语言相关的,以后我会在一些文章中介绍它们。
+
+你在写代码时是否用到一些其它 Vim 插件?请在评论区留言分享。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/1/vim-plugins-developers
+
+作者:[Ricardo Gerardi][a]
+选题:[lujun9972][b]
+译者:[pityonline](https://github.com/pityonline)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/rgerardi
+[b]: https://github.com/lujun9972
+[1]: https://www.vim.org/
+[2]: https://www.vim.org/scripts/script.php?script_id=3599
+[3]: https://github.com/jiangmiao/auto-pairs
+[4]: https://github.com/scrooloose/nerdcommenter
+[5]: http://vim.wikia.com/wiki/Filetype.vim
+[6]: https://www.vim.org/scripts/script.php?script_id=1697
+[7]: https://github.com/tpope/vim-surround
+[8]: https://github.com/airblade/vim-gitgutter
+[9]: https://www.vim.org/scripts/script.php?script_id=2975
+[10]: https://github.com/tpope/vim-fugitive
diff --git a/published/201902/20190110 Toyota Motors and its Linux Journey.md b/published/201902/20190110 Toyota Motors and its Linux Journey.md
new file mode 100644
index 0000000000..d89f4f2a29
--- /dev/null
+++ b/published/201902/20190110 Toyota Motors and its Linux Journey.md
@@ -0,0 +1,61 @@
+[#]: collector: (lujun9972)
+[#]: translator: (jdh8383)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10543-1.html)
+[#]: subject: (Toyota Motors and its Linux Journey)
+[#]: via: (https://itsfoss.com/toyota-motors-linux-journey)
+[#]: author: (Malcolm Dean https://itsfoss.com/toyota-motors-linux-journey)
+
+丰田汽车的 Linux 之旅
+======
+
+我之前跟丰田汽车北美分公司的 Brian.R.Lyons(丰田发言人)聊了聊,话题是关于 Linux 在丰田和雷克萨斯汽车的信息娱乐系统上的实施方案。我了解到一些汽车制造商使用了 Automotive Grade Linux(AGL)。
+
+然后我写了一篇短文,记录了我和 Brian 的讨论内容,谈及了丰田和 Linux 的一些渊源。希望 Linux 的狂热粉丝们能够喜欢这次对话。
+
+全部的[丰田和雷克萨斯汽车都将会使用 Automotive Grade Linux(AGL)][1],主要是用于车载信息娱乐系统。这项措施对于丰田集团来说是至关重要的,因为据 Lyons 先生所说:“作为技术的引领者之一,丰田认识到,赶上科技快速进步最好的方法就是接受开源发展的理念。”
+
+丰田和众多汽车制造公司都认为,与使用非自由软件相比,采用基于 Linux 的操作系统在更新和升级方面会更加廉价和快捷。
+
+这简直太棒了!Linux 终于跟汽车结合起来了。我每天都在电脑上使用 Linux;能看到这个优秀的软件在一个完全不同的产业领域里大展拳脚真是太好了。
+
+我很好奇丰田是什么时候开始使用 [Automotive Grade Linux(AGL)][2]的。按照 Lyons 先生的说法,这要追溯到 2011 年。
+
+> “自 AGL 项目在五年前启动之始,作为活跃的会员和贡献者,丰田与其他顶级制造商和供应商展开合作,着手开发一个基于 Linux 的强大平台,并不断地增强其功能和安全性。”
+
+![丰田信息娱乐系统][3]
+
+[丰田于 2011 年加入了 Linux 基金会][4],与其他汽车制造商和软件公司就 IVI(车内信息娱乐系统)展开讨论,最终在 2012 年,Linux 基金会内部成立了 Automotive Grade Linux 工作组。
+
+丰田在 AGL 工作组里首先提出了“代码优先”的策略,这在开源领域是很常见的做法。然后丰田和其他汽车制造商、IVI 一线厂家,软件公司等各方展开对话,根据各方的技术需求详细制定了初始方向。
+
+在加入 Linux 基金会的时候,丰田就已经意识到,在一线公司之间共享软件代码将会是至关重要的。因为要维护如此复杂的软件系统,对于任何一家顶级厂商都是一笔不小的开销。丰田和它的一级供货商想把更多的资源用在开发新功能和新的用户体验上,而不是用在维护各自的代码上。
+
+各个汽车公司联合起来深入合作是一件大事。许多公司都达成了这样的共识,因为他们都发现开发维护私有软件其实更费钱。
+
+今天,在全球市场上,丰田和雷克萨斯的全部车型都使用了 AGL。
+
+身为雷克萨斯的销售人员,我认为这是一大进步。我和其他销售顾问都曾接待过很多回来找技术专员的客户,他们想更多的了解自己车上的信息娱乐系统到底都能做些什么。
+
+这件事本身对于 Linux 社区和用户是个重大利好。虽然那个我们每天都在使用的操作系统变了模样,被推到了更广阔的舞台上,但它仍然是那个 Linux,简单、包容而强大。
+
+未来将会如何发展呢?我希望它能少出差错,为消费者带来更佳的用户体验。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/toyota-motors-linux-journey
+
+作者:[Malcolm Dean][a]
+选题:[lujun9972][b]
+译者:[jdh8383](https://github.com/jdh8383)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/toyota-motors-linux-journey
+[b]: https://github.com/lujun9972
+[1]: https://www.linuxfoundation.org/press-release/2018/01/automotive-grade-linux-hits-road-globally-toyota-amazon-alexa-joins-agl-support-voice-recognition/
+[2]: https://www.automotivelinux.org/
+[3]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/toyota-interiors.jpg?resize=800%2C450&ssl=1
+[4]: https://www.linuxfoundation.org/press-release/2011/07/toyota-joins-linux-foundation/
diff --git a/published/201902/20190114 Hegemon - A Modular System And Hardware Monitoring Tool For Linux.md b/published/201902/20190114 Hegemon - A Modular System And Hardware Monitoring Tool For Linux.md
new file mode 100644
index 0000000000..873ecb8cbb
--- /dev/null
+++ b/published/201902/20190114 Hegemon - A Modular System And Hardware Monitoring Tool For Linux.md
@@ -0,0 +1,129 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10503-1.html)
+[#]: subject: (Hegemon – A Modular System And Hardware Monitoring Tool For Linux)
+[#]: via: (https://www.2daygeek.com/hegemon-a-modular-system-and-hardware-monitoring-tool-for-linux/)
+[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
+
+Hegemon:一个 Linux 的模块化系统和硬件监控工具
+======
+
+我知道每个人都更喜欢使用 [top 命令][1]来监控系统利用率。这是被 Linux 系统管理员大量使用的原生命令之一。
+
+在 Linux 中,每个包都有一个替代品。Linux 中有许多可用于此的工具,我更喜欢 [htop 命令][2]。
+
+如果你想了解其他替代方案,我建议你浏览每个链接了解更多信息。它们有 htop、CorFreq、glances、atop、Dstat、Gtop、Linux Dash、Netdata、Monit 等。
+
+所有这些只允许我们监控系统利用率而不能监控系统硬件。但是 Hegemon 允许我们在单个仪表板中监控两者。
+
+如果你正在寻找系统硬件监控软件,那么我建议你看下 [lm_sensors][3] 和 [s-tui 压力终端 UI][4]。
+
+### Hegemon 是什么?
+
+Hegemon 是一个正在开发中的模块化系统监视器,以安全的 Rust 编写。
+
+它允许用户在单个仪表板中监控两种使用情况。分别是系统利用率和硬件温度。
+
+### Hegemon 目前的特性
+
+ * 监控 CPU 和内存使用情况、温度和风扇速度
+ * 展开任何数据流以显示更详细的图表和其他信息
+ * 可调整的更新间隔
+ * 干净的 MVC 架构,具有良好的代码质量
+ * 单元测试
+
+### 计划的特性包括
+
+ * macOS 和 BSD 支持(目前仅支持 Linux)
+ * 监控磁盘和网络 I/O、GPU 使用情况(可能)等
+ * 选择并重新排序数据流
+ * 鼠标控制
+
+### 如何在 Linux 中安装 Hegemon?
+
+Hegemon 需要 Rust 1.26 或更高版本以及 libsensors 的开发文件。因此,请确保在安装 Hegemon 之前安装了这些软件包。
+
+libsensors 库在大多数发行版官方仓库中都有,因此,使用以下命令进行安装。
+
+对于 Debian/Ubuntu 系统,使用 [apt-get 命令][5] 或 [apt 命令][6] 在你的系统上安装 libsensors。
+
+```
+# apt install lm_sensors-devel
+```
+
+对于 Fedora 系统,使用 [dnf 包管理器][7]在你的系统上安装 libsensors。
+
+```
+# dnf install libsensors4-dev
+```
+
+运行以下命令安装 Rust 语言,并按照指示来做。如果你想要看 [Rust 安装][8]的方便教程,请进入该 URL。
+
+```
+$ curl https://sh.rustup.rs -sSf | sh
+```
+
+如果你已成功安装 Rust。运行以下命令安装 Hegemon。
+
+```
+$ cargo install hegemon
+```
+
+### 如何在 Linux 中启动 Hegemon?
+
+成功安装 Hegemon 包后,运行下面的命令启动。
+
+```
+$ hegemon
+```
+
+![][10]
+
+由于 libsensors.so.4 库的问题,我在启动 Hegemon 时遇到了一个问题。
+
+```
+$ hegemon
+error while loading shared libraries: libsensors.so.4: cannot open shared object file: No such file or directory manjaro
+```
+
+我使用的是 Manjaro 18.04。它存在 libsensors.so 和 libsensors.so.5 共享库,而没有 libsensors.so.4。所以,我刚刚创建了以下符号链接来解决问题。
+
+```
+$ sudo ln -s /usr/lib/libsensors.so /usr/lib/libsensors.so.4
+```
+
+这是从我的 Lenovo-Y700 笔记本中截取的示例 gif。
+
+![][11]
+
+默认它仅显示总体摘要,如果你想查看详细输出,则需要展开每个部分。如下是 Hegemon 的展开视图。
+
+![][12]
+
+--------------------------------------------------------------------------------
+
+via: https://www.2daygeek.com/hegemon-a-modular-system-and-hardware-monitoring-tool-for-linux/
+
+作者:[Magesh Maruthamuthu][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.2daygeek.com/author/magesh/
+[b]: https://github.com/lujun9972
+[1]: https://www.2daygeek.com/top-command-examples-to-monitor-server-performance/
+[2]: https://www.2daygeek.com/linux-htop-command-linux-system-performance-resource-monitoring-tool/
+[3]: https://www.2daygeek.com/view-check-cpu-hard-disk-temperature-linux/
+[4]: https://www.2daygeek.com/s-tui-stress-terminal-ui-monitor-linux-cpu-temperature-frequency/
+[5]: https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
+[6]: https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
+[7]: https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
+[8]: https://www.2daygeek.com/how-to-install-rust-programming-language-in-linux/
+[9]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
+[10]: https://www.2daygeek.com/wp-content/uploads/2019/01/hegemon-a-modular-system-and-hardware-monitoring-tool-for-linux-1.png
+[11]: https://www.2daygeek.com/wp-content/uploads/2019/01/hegemon-a-modular-system-and-hardware-monitoring-tool-for-linux-2a.gif
+[12]: https://www.2daygeek.com/wp-content/uploads/2019/01/hegemon-a-modular-system-and-hardware-monitoring-tool-for-linux-3.png
diff --git a/published/201902/20190114 Remote Working Survival Guide.md b/published/201902/20190114 Remote Working Survival Guide.md
new file mode 100644
index 0000000000..0c51a15885
--- /dev/null
+++ b/published/201902/20190114 Remote Working Survival Guide.md
@@ -0,0 +1,133 @@
+[#]: collector: (lujun9972)
+[#]: translator: (beamrolling)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10518-1.html)
+[#]: subject: (Remote Working Survival Guide)
+[#]: via: (https://www.jonobacon.com/2019/01/14/remote-working-survival/)
+[#]: author: (Jono Bacon https://www.jonobacon.com/author/admin/)
+
+远程工作生存指南
+======
+
+
+
+远程工作似乎是最近的一个热门话题。CNBC 报道称,[70% 的专业人士至少每周在家工作一次][1]。同样地,CoSo Cloud 调查发现, [77% 的人在远程工作时效率更高][2] ,而 aftercollege 的一份调查显示,[8% 的千禧一代会更多地考虑提供远程工作的公司][3]。 这看起来很合理:技术、网络以及文化似乎越来越推动了远程工作的发展。哦,自制咖啡也比以前任何时候更好喝了。
+
+目前,我准备写另一篇关于公司如何优化远程工作的文章(所以请确保你加入我们的会员以持续关注——这是免费的)。
+
+但今天,我想 **分享一些个人如何做好远程工作的建议**。不管你是全职远程工作者,或者是可以选择一周某几天在家工作的人,希望这篇文章对你有用。
+
+眼下,你需要明白,**远程工作不是万能药**。当然,穿着睡衣满屋子乱逛,听听反社会音乐,喝一大杯咖啡看起来似乎挺完美的,但这不适合每个人。
+
+有的人需要办公室的空间。有的人需要办公室的社会元素。有的人需要从家里走出来。有的人在家里缺乏保持专注的自律。有的人因为好几年未缴退税而怕政府工作人员来住处敲门。
+
+**远程工作就好像一块肌肉:如果你锻炼并且保持它,那么它能带来极大的力量和能力**。如果不这么做,结果就不一样了。
+
+在我职业生涯的大多数时间里,我在家工作。我喜欢这么做。当我在家工作的时候,我更有效率,更开心,更有能力。我并非不喜欢在办公室工作,我享受办公室的社会元素,但我更喜欢在家工作时我的“空间”。我喜欢听重金属音乐,但当整个办公室的人不想听到 [After The Burial][5] 的时候,这会引起一些问题。
+
+![][6]
+
+*“Squirrel.” [图片来源][7]*
+
+我已经学会了如何正确平衡工作、旅行以及其他元素来管理我的远程工作,以下是我的一些建议。请务必**在评论中分享一些你的建议**。
+
+### 1、你需要纪律和习惯(以及了解你的“波动”)
+
+远程工作确实是需要训练的一块肌肉。就像练出真正的肌肉一样,它需要一个明确的习惯混以健康的纪律。
+
+永远保持穿戴整齐(不要穿睡衣)。设置你一天工作的开始和结束时间(大多时候我从早上 9 点工作到下午 6 点)。选好你的午餐休息时间(我的是中午 12 点)。选好你的早晨仪式(我的是电子邮件,紧接着是全面审查客户需求)。决定你的主工作场所在哪(我的主工作场所是我家庭办公室)。决定好每天你什么时候运动(大多数时候我在下午 5 点运动)。
+
+**设计一个实际的习惯并坚持 66 天**。建立一个习惯需要很长时间,尽量不要偏离你的习惯。你越坚持这个习惯,做下去所花费的功夫越少。在这 66 天的末尾,你想都不会想,自然而然地就按习惯去做了。
+
+话虽这么说,我们又不住在真空里 ([更干净,或者别的什么][8])。我们都有自己的“波动”。
+
+“波动”是你为了改变做事的方法时,对日常做出的一些改变。举个例子,夏天的时候我通常需要更多的阳光。那时我经常会在室外的花园工作。临近假期的时候我更容易分心,所以我在上班时间会更需要呆在室内。有时候我只想要多点人际接触,因此我会在咖啡馆里工作几周。有时候我就是喜欢在厨房或者长椅上工作。你需要认识你的“波动”并倾听你的身体。 **首先养成习惯,然后在你认识到自己的“波动”的时候再对它进行适当的调整**。
+
+### 2、与你的上司及同事一起设立预期目标
+
+不是每个人都知道怎么远程工作,如果你的公司对远程工作没那么熟悉,你尤其需要和同事一起设立预期目标。
+
+这件事十分简单:**当你要设计自己的日常工作的时候,清楚地跟你的上司和团队进行交流。**让他们知道如何找到你,紧急情况下如何联系你,以及你在家的时候如何保持合作。
+
+在这里通信方式至关重要。有些远程工作者很怕离开他们的电脑,因为害怕当他们不在的时候有人给他们发消息(他们担心别人会觉得他们在边吃奇多边看 Netflix)。
+
+你需要离开一会的时间。你需要在吃午餐的时候眼睛不用一直盯着电脑屏幕。你又不是 911 接线员。**设定预期:有时候你可能不能立刻回复,但你会尽快回复**。
+
+同样地,设定你的通常可响应的时间范围的预期。举个例子,我对客户设立的预期是我一般每天早上 9 点到下午 6 点工作。当然,如果某个客户急需某样东西,我很乐意在这段时间外回应他,但作为一个一般性规则,我通常只在这段时间内工作。这对于生活的平衡是必要的。
+
+### 3、分心是你的敌人,它们需要管理
+
+我们都会分心,这是人类的本能。让你分心的事情可能是你的孩子回家了,想玩救援机器人;可能是看看Facebook、Instagram,或者 Twitter 以确保你不会错过任何不受欢迎的政治观点,或者某人的午餐图片;可能是你生活中即将到来的某件事带走了你的注意力(例如,即将举办的婚礼、活动,或者一次大旅行)。
+
+**你需要明白什么让你分心以及如何管理它**。举个例子,我知道我的电子邮件和 Twitter 会让我分心。我经常查看它们,并且每次查看都会让我脱离我正在工作的空间。拿水或者咖啡的时候我总会分心去吃零食,看 Youtube 的视频。
+
+![][9]
+
+*我的分心克星*
+
+由数字信息造成的分心有一个简单对策:**锁起来**。关闭选项卡,直到你完成了你手头的事情。有一大堆工作的时候我总这么干:我把让我分心的东西锁起来,直到做完手头的工作。这需要控制能力,但所有的一切都需要。
+
+因为别人影响而分心的元素更难解决。如果你是有家庭的人,你需要明确表示,在你工作的时候常需要独处。这也是为什么家庭办公室这么重要:你需要设一些“爸爸/妈妈正在工作”的界限。如果有急事才能进来,否则让孩子自个儿玩去。
+
+把让你分心的事锁起来有许多方法:把你的电话静音;把自己的 Facebook 状态设成“离开”;换到一个没有让你分心的事的房间(或建筑物)。再重申一次,了解是什么让你分心并控制好它。如果不这么做,你会永远被分心的事摆布。
+
+### 4、(良好的)关系需要面对面的关注
+
+有些角色比其他角色更适合远程工作。例如,我见过工程、质量保证、支持、安全以及其他团队(通常更专注于数字信息协作)的出色工作。其他团队,如设计或营销,往往在远程环境下更难熬(因为它们更注重触觉性)。
+
+但是,对于任何团队而言,建立牢固的关系至关重要,而现场讨论、协作和社交很有必要。我们的许多感官(例如肢体语言)在数字环境中被剔除,而这些在我们建立信任和关系的方式中发挥着关键作用。
+
+![][10]
+
+*火箭也很有帮助*
+
+这尤为重要,如果(a)你初来这家公司,需要建立关系;(b)对某种角色不熟悉,需要和你的团队建立关系;或者(c)你处于领导地位,构建团队融入和参与是你工作的关键部分。
+
+**解决方法是?合理搭配远程工作与面对面的时间。** 如果你的公司就在附近,可以用一部分的时间在家工作,一部分时间在公司工作。如果你的公司比较远,安排定期前往办公室(并对你的上司设定你需要这么做的预期)。例如,当我在 XPRIZE 工作的时候,我每几周就会飞往洛杉矶几天。当我在 Canonical 工作时(总部在伦敦),我们每三个月来一次冲刺。
+
+### 5、保持专注,不要松懈
+
+本文所有内容的关键在于构建一种(远程工作的)能力,并培养远程工作的肌肉。这就像建立你的日常惯例,坚持它,并认识你的“波动”和让你分心的事情以及如何管理它们一样简单。
+
+我以一种相当具体的方式来看待这个世界:**我们所做的一切都有机会得到改进和完善**。举个例子,我已经公开演讲超过 15 年,但我总是能发现新的改进方法,以及修复新的错误(说到这些,请参阅我的 [提升你公众演讲的10个方法][11])。
+
+发现新的改善方法,以及把每个绊脚石和错误视为一个开启新的不同的“啊哈!”时刻让人兴奋。远程工作和这没什么不同:寻找有助于解锁方式的模式,让你的远程工作时间更高效,更舒适,更有趣。
+
+![][12]
+
+*看看这些书。它们非常适合个人发展。参阅我的 [150 美元个人发展工具包][13] 文章*
+
+……但别为此狂热。有的人花尽他们每一分钟来寻求如何变得更好,他们经常以“做得还不够好”、“完成度不够高”等为由打击自己,无法达到他们内心关于完美的不切实际的观点。
+
+我们都是人,我们是有生命的,不是机器人。始终致力于改进,但要明白不是所有东西都是完美的。你应该有一些休息日或休息周。你也会因为压力和倦怠而挣扎。你也会遇到一些在办公室比远程工作更容易的情况。从这些时刻中学习,但不要沉迷于此。生命太短暂了。
+
+**你有什么提示,技巧和建议吗?你如何管理远程工作?我的建议中还缺少什么吗?在评论区中与我分享!**
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.jonobacon.com/2019/01/14/remote-working-survival/
+
+作者:[Jono Bacon][a]
+选题:[lujun9972][b]
+译者:[beamrolling](https://github.com/beamrolling)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.jonobacon.com/author/admin/
+[b]: https://github.com/lujun9972
+[1]: https://www.cnbc.com/2018/05/30/70-percent-of-people-globally-work-remotely-at-least-once-a-week-iwg-study.html
+[2]: http://www.cosocloud.com/press-release/connectsolutions-survey-shows-working-remotely-benefits-employers-and-employees
+[3]: https://www.aftercollege.com/cf/2015-annual-survey
+[4]: https://www.jonobacon.com/join/
+[5]: https://www.facebook.com/aftertheburial/
+[6]: https://www.jonobacon.com/wp-content/uploads/2019/01/aftertheburial2.jpg
+[7]: https://skullsnbones.com/burial-live-photos-vans-warped-tour-denver-co/
+[8]: https://www.youtube.com/watch?v=wK1PNNEKZBY
+[9]: https://www.jonobacon.com/wp-content/uploads/2019/01/IMG_20190114_102429-1024x768.jpg
+[10]: https://www.jonobacon.com/wp-content/uploads/2019/01/15381733956_3325670fda_k-1024x576.jpg
+[11]: https://www.jonobacon.com/2018/12/11/10-ways-to-up-your-public-speaking-game/
+[12]: https://www.jonobacon.com/wp-content/uploads/2019/01/DwVBxhjX4AgtJgV-1024x532.jpg
+[13]: https://www.jonobacon.com/2017/11/13/150-dollar-personal-development-kit/
diff --git a/published/201902/20190115 Comparing 3 open source databases- PostgreSQL, MariaDB, and SQLite.md b/published/201902/20190115 Comparing 3 open source databases- PostgreSQL, MariaDB, and SQLite.md
new file mode 100644
index 0000000000..c47bb62e94
--- /dev/null
+++ b/published/201902/20190115 Comparing 3 open source databases- PostgreSQL, MariaDB, and SQLite.md
@@ -0,0 +1,121 @@
+[#]: collector: (lujun9972)
+[#]: translator: (HankChow)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10512-1.html)
+[#]: subject: (Comparing 3 open source databases: PostgreSQL, MariaDB, and SQLite)
+[#]: via: (https://opensource.com/article/19/1/open-source-databases)
+[#]: author: (Sam Bocetta https://opensource.com/users/sambocetta)
+
+开源数据库 PostgreSQL、MariaDB 和 SQLite 的对比
+======
+
+> 了解如何选择最适合你的需求的开源数据库。
+
+
+
+在现代的企业级技术领域中,开源软件已经成为了一股不可忽视的重要力量。借助[开源运动][1]的东风,涌现除了许多重大的技术突破。
+
+个中原因显而易见,尽管一些基于 Linux 的开源网络标准可能不如专有厂商的那么受欢迎,但是不同制造商的智能设备之间能够互相通信,开源技术功不可没。当然也有不少人认为开源开发出来的应用比厂商提供的产品更加好,所以无论如何,使用开源数据库进行开发确实是相当有利的。
+
+和其它类型的应用软件一样,不同的开源数据库管理系统之间在功能和特性上可能会存在着比较大的差异。换言之,[不是所有的开源数据库都是平等的][2]。因此,如果要为整个组织选择一个开源数据库,那么应该重点考察数据库是否对用户友好、是否能够持续适应团队需求、是否能够提供足够安全的功能等方面的因素。
+
+出于这方面考虑,我们在这篇文章中对一些开源数据库进行了概述和优缺点对比。遗憾的是,我们必须忽略一些最常用的数据库。值得注意的是,MongoDB 最近更改了它的许可证,因此它已经不是真正的开源产品了。从商业角度来看,这个决定是很有意义的,因为 MongoDB 已经成为了数据库托管实际上的解决方案,[约 27000 家公司][3]在使用它,但这也意味着 MongoDB 已经不再被视为真正的开源产品。
+
+另外,自从 MySQL 被 Oracle 收购之后,这个产品就已经不再具有开源性质了,MySQL 可以说是数十年来首选的开源数据库。然而,这为其它真正的开源数据库解决方案提供了挑战它的空间。
+
+下面是三个值得考虑的开源数据库。
+
+### PostgreSQL
+
+没有 [PostgreSQL][4] 的开源数据库清单肯定是不完整的。PostgreSQL 一直都是各种规模企业的首选解决方案。Oracle 对 MySQL 的收购在当时来说可能具有一定的商业意义,但是随着云存储的日益壮大,[开发者对 MySQL 的依赖程度或许并不如以前那么大了][5]。
+
+尽管 PostgreSQL 不是一个最近几年才面世的新产品,但它却是借助了 [MySQL 相对衰落][6]的机会才逐渐成为最受欢迎的开源数据库之一。由于它和 MySQL 的工作方式非常相似,因此很多热衷于使用开源软件的开发者都纷纷转向 PostgreSQL。
+
+#### 优势
+
+ * 目前 PostgreSQL 最显著的优点是它的核心算法的效率,这意味着它的性能优于许多宣称更先进数据库。这一点在处理大型数据集的时候就可以很明显地体现出来了,否则 I/O 处理会成为瓶颈。
+ * PostgreSQL 也是最灵活的开源数据库之一,使用 Python、Perl、Java、Ruby、C 或者 R 都能够很方便地调用数据库。
+ * 作为最常用的几个开源数据库之中,PostgreSQL 的社区支持是做得最好的。
+
+#### 劣势
+
+ * 在数据量比较大的时候,PostgreSQL 的效率毋庸置疑是很高的,但对于数据量较小的情况,使用 PostgreSQL 就显得不如其它的一些工具快了。
+ * 尽管拥有一个很优秀的社区支持,但 PostgreSQL 的核心文档仍然需要作出改进。
+ * 如果你需要使用并行计算或者集群化等高级工具,就需要安装 PostgreSQL 的第三方插件。尽管官方有计划将这些功能逐步添加到主要版本当中,但可能会需要再等待好几年才能出现在标准版本中。
+
+### MariaDB
+
+[MariaDB][7] 是 MySQL 的真正开源的发行版本(在 [GNU GPLv2][8] 下发布)。在 Oracle 收购 MySQL 之后,MySQL 的一些核心开发人员认为 Oracle 会破坏 MySQL 的开源理念,因此建立了 MariaDB 这个独立的分支。
+
+MariaDB 在开发过程中替换了 MySQL 的几个关键组件,但仍然尽可能地保持兼容 MySQL。MariaDB 使用了 Aria 作为存储引擎,这个存储引擎既可以作为事务式引擎,也可以作为非事务式引擎。在 MariaDB 分叉出来之前,就[有一些人推测][10] Aria 会成为 MySQL 未来版本中的标准引擎。
+
+#### 优势
+
+ * 由于 MariaDB [频繁进行安全发布][11],很多用户选择使用 MariaDB 而不选择 MySQL。尽管这不一定代表 MariaDB 会比 MySQL 更加安全,但确实表明它的开发社区对安全性十分重视。
+ * 有一些人认为,MariaDB 的主要优点就是它在坚持开源的同时会与 MySQL 保持高度兼容,这就意味着从 MySQL 向 MariaDB 的迁移会非常容易。
+ * 也正是由于这种兼容性,MariaDB 也可以和其它常用于 MySQL 的语言配合使用,因此从 MySQL 迁移到 MariaDB 之后,学习和调试代码的时间成本会非常低。
+ * 你可以将 WordPress 和 MariaDB(而不是 MySQL)[配合使用][12]从而获得更好的性能和更丰富的功能。WordPress 是[最受欢迎的][13]内容管理系统(CMS),占据了一半的互联网份额,并且拥有活跃的开源开发者社区。各种第三方插件在 WordPress 和 MariaDB 配合使用时都能够正常工作。
+
+#### 劣势
+
+ * MariaDB 有时会变得比较臃肿,尤其是它的 IDX 日志文件在长期使用之后会变得非常大,最终导致性能下降。
+ * 缓存是 MariaDB 的另一个工作领域,并没有期望中那么快,这可能会让人有所失望。
+ * 尽管 MariaDB 最初承诺兼容 MySQL,但目前 MariaDB 已经不是完全兼容 MySQL。如果要从 MySQL 迁移到 MariaDB,就需要额外做一些兼容工作。
+
+### SQLite
+
+[SQLite][14] 可以说是世界上实现最多的数据库引擎,因为它被很多流行的 web 浏览器、操作系统和手机所采用。它最初是作为 MySQL 的轻量级分支所开发的。SQLite 和很多其它的数据库不同,它不采用客户端-服务端的引擎架构,而是将整个软件嵌入到每个实现当中。
+
+这样的架构让 SQLite 拥有一个强大的优势,就是在嵌入式系统或者分布式系统中,每台机器都搭载了数据库的整个实现。这样的做法减少了系统间的调用,从而大大提高了数据库的性能。
+
+#### 优势
+
+ * 如果你需要构建和实现一个小型数据库,SQLite [可能是最好的选择][15]。它小而灵活,不需要费工夫寻求各种变通方案,就可以在嵌入式系统中实现。
+ * SQLite 体积很小,因此速度极快。其它的一些高级数据库可能会使用复杂的优化方式来提高效率,但SQLite 采用了一种更简单的方法:通过减小数据库及其处理软件的大小,以使处理的数据更少。
+ * SQLite 被广泛采用也导致它可能是兼容性最高的数据库。如果你希望将应用程序集成到智能手机上,这一点尤为重要:只要是可以工作于广泛环境中的第三方应用程序,就可以原生运行于 iOS 上。
+
+#### 劣势
+
+ * SQLite 的体积小意味着它缺少了很多其它大型数据库的常见功能。例如数据加密就是[抵御黑客攻击][16]的标准功能,而 SQLite 却没有内置这个功能。
+ * SQLite 的广泛流行和源码公开使它易于使用,但是也让它更容易遭受攻击。这是它最大的劣势。SQLite 经常被发现高危的漏洞,例如最近的 [Magellan][17]。
+ * 尽管 SQLite 单文件的方式拥有速度上的优势,但是要使用它实现多用户环境却比较困难。
+
+### 哪个开源数据库才是最好的?
+
+当然,对于开源数据库的选择还是取决于业务的需求,尤其是系统的体量。对于小型数据库或者是使用量比较小的数据库,可以使用比较轻量级的解决方案,这样不仅可以加快实现的速度,而且由于系统的复杂程度不算太高,花在调试上的时间成本也不会太高。
+
+而对于大型的系统,尤其是在成长性企业中,最好还是花时间使用更复杂的数据库(例如 PostgreSQL)。这是一个磨刀不误砍柴工的选择,能够让你不至于在后期再重新选择另一款数据库。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/1/open-source-databases
+
+作者:[Sam Bocetta][a]
+选题:[lujun9972][b]
+译者:[HankChow](https://github.com/HankChow)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/sambocetta
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/article/18/2/pivotal-moments-history-open-source
+[2]: https://blog.capterra.com/free-database-software/
+[3]: https://idatalabs.com/tech/products/mongodb
+[4]: https://www.postgresql.org/
+[5]: https://www.theregister.co.uk/2018/05/31/rise_of_the_open_source_data_strategies/
+[6]: https://www.itworld.com/article/2721995/big-data/signs-of-mysql-decline-on-horizon.html
+[7]: https://mariadb.org/
+[8]: https://github.com/MariaDB/server/blob/10.4/COPYING
+[9]: https://mariadb.com/about-us/
+[10]: http://kb.askmonty.org/en/aria-faq
+[11]: https://mariadb.org/tag/security/
+[12]: https://mariadb.com/resources/blog/how-to-install-and-run-wordpress-with-mariadb/
+[13]: https://websitesetup.org/popular-cms/
+[14]: https://www.sqlite.org/index.html
+[15]: https://www.sqlite.org/aff_short.html
+[16]: https://hostingcanada.org/most-common-website-vulnerabilities/
+[17]: https://www.securitynewspaper.com/2018/12/18/critical-vulnerability-in-sqlite-you-should-update-now/
+
+
diff --git a/published/201902/20190115 Getting started with Sandstorm, an open source web app platform.md b/published/201902/20190115 Getting started with Sandstorm, an open source web app platform.md
new file mode 100644
index 0000000000..ae67f2ede2
--- /dev/null
+++ b/published/201902/20190115 Getting started with Sandstorm, an open source web app platform.md
@@ -0,0 +1,60 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10535-1.html)
+[#]: subject: (Getting started with Sandstorm, an open source web app platform)
+[#]: via: (https://opensource.com/article/19/1/productivity-tool-sandstorm)
+[#]: author: (Kevin Sonney https://opensource.com/users/ksonney (Kevin Sonney))
+
+开始使用 Sandstorm 吧,一个开源 Web 应用平台
+======
+
+> 了解 Sandstorm,这是我们在开源工具系列中的第三篇,它将在 2019 年提高你的工作效率。
+
+
+
+每年年初似乎都有疯狂的冲动想提高工作效率。新年的决心,渴望开启新的一年,当然,“抛弃旧的,拥抱新的”的态度促成了这一切。通常这时的建议严重偏向闭源和专有软件,但事实上并不用这样。
+
+这是我挑选出的 19 个新的(或者对你而言新的)开源工具中的第三个工具来帮助你在 2019 年更有效率。
+
+### Sandstorm
+
+保持高效不仅仅需要待办事项以及让事情有组织。通常它需要一组工具以使工作流程顺利进行。
+
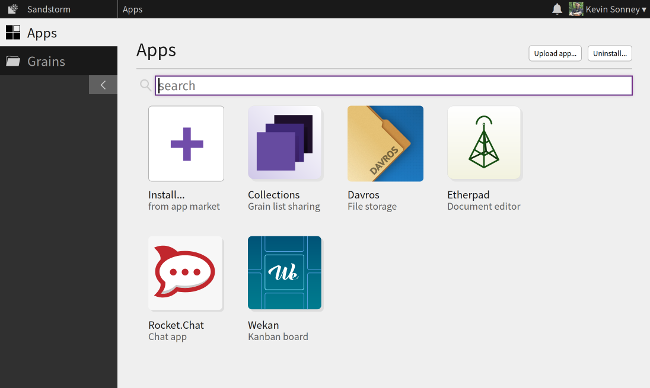
+
+
+[Sandstorm][1] 是打包的开源应用集合,它们都可从一个 Web 界面访问,也可在中央控制台进行管理。你可以自己托管或使用 [Sandstorm Oasis][2] 服务。它按用户收费。
+
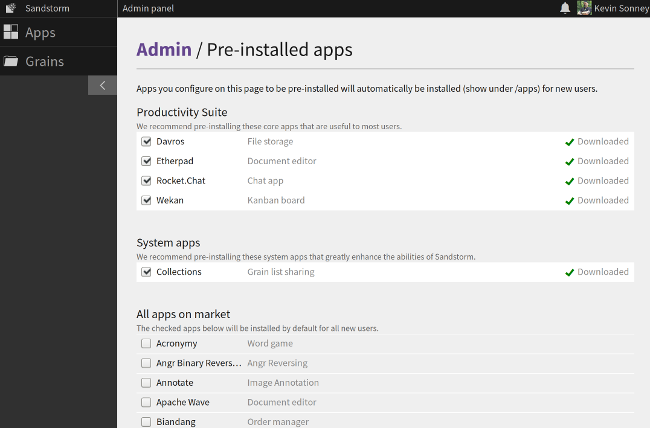
+
+
+Sandstorm 有一个市场,在这里可以轻松安装应用。应用包括效率类、财务、笔记、任务跟踪、聊天、游戏等等。你还可以按照[开发人员文档][3]中的应用打包指南打包自己的应用并上传它们。
+
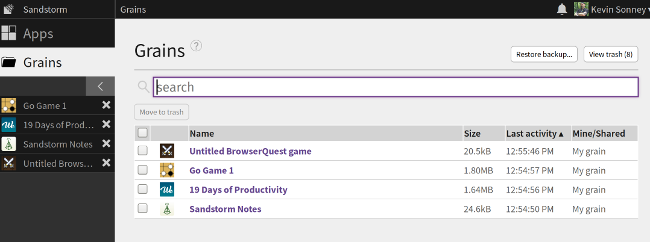
+
+
+安装后,用户可以创建 [grain][4] - 容器化后的应用数据实例。默认情况下,grain 是私有的,它可以与其他 Sandstorm 用户共享。这意味着它们默认是安全的,用户可以选择与他人共享的内容。
+
+
+
+Sandstorm 可以从几个不同的外部源进行身份验证,也可以使用无需密码的基于电子邮件的身份验证。使用外部服务意味着如果你已使用其中一种受支持的服务,那么就无需管理另一组凭据。
+
+最后,Sandstorm 使安装和使用支持的协作应用变得快速,简单和安全。
+
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/1/productivity-tool-sandstorm
+
+作者:[Kevin Sonney][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/ksonney (Kevin Sonney)
+[b]: https://github.com/lujun9972
+[1]: https://sandstorm.io/
+[2]: https://oasis.sandstorm.io
+[3]: https://docs.sandstorm.io/en/latest/developing/
+[4]: https://sandstorm.io/how-it-works
diff --git a/published/201902/20190116 The Evil-Twin Framework- A tool for improving WiFi security.md b/published/201902/20190116 The Evil-Twin Framework- A tool for improving WiFi security.md
new file mode 100644
index 0000000000..760c2ed1cf
--- /dev/null
+++ b/published/201902/20190116 The Evil-Twin Framework- A tool for improving WiFi security.md
@@ -0,0 +1,230 @@
+[#]: collector: (lujun9972)
+[#]: translator: (hopefully2333)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10568-1.html)
+[#]: subject: (The Evil-Twin Framework: A tool for improving WiFi security)
+[#]: via: (https://opensource.com/article/19/1/evil-twin-framework)
+[#]: author: (André Esser https://opensource.com/users/andreesser)
+
+Evil-Twin 框架:一个用于提升 WiFi 安全性的工具
+======
+
+> 了解一款用于对 WiFi 接入点安全进行渗透测试的工具。
+
+
+
+越来越多的设备通过无线传输的方式连接到互联网,以及,大范围可用的 WiFi 接入点为攻击者攻击用户提供了很多机会。通过欺骗用户连接到[虚假的 WiFi 接入点][1],攻击者可以完全控制用户的网络连接,这将使得攻击者可以嗅探和篡改用户的数据包,将用户的连接重定向到一个恶意的网站,并通过网络发起其他的攻击。
+
+为了保护用户并告诉他们如何避免线上的危险操作,安全审计人员和安全研究员必须评估用户的安全实践能力,用户常常在没有确认该 WiFi 接入点为安全的情况下就连接上了该网络,安全审计人员和研究员需要去了解这背后的原因。有很多工具都可以对 WiFi 的安全性进行审计,但是没有一款工具可以测试大量不同的攻击场景,也没有能和其他工具集成得很好的工具。
+
+Evil-Twin Framework(ETF)用于解决 WiFi 审计过程中的这些问题。审计者能够使用 ETF 来集成多种工具并测试该 WiFi 在不同场景下的安全性。本文会介绍 ETF 的框架和功能,然后会提供一些案例来说明该如何使用这款工具。
+
+### ETF 的架构
+
+ETF 的框架是用 [Python][2] 写的,因为这门开发语言的代码非常易读,也方便其他开发者向这个项目贡献代码。除此之外,很多 ETF 的库,比如 [Scapy][3],都是为 Python 开发的,很容易就能将它们用于 ETF。
+
+ETF 的架构(图 1)分为不同的彼此交互的模块。该框架的设置都写在一个单独的配置文件里。用户可以通过 `ConfigurationManager` 类里的用户界面来验证并修改这些配置。其他模块只能读取这些设置并根据这些设置进行运行。
+
+![Evil-Twin Framework Architecture][5]
+
+*图 1:Evil-Twin 的框架架构*
+
+ETF 支持多种与框架交互的用户界面,当前的默认界面是一个交互式控制台界面,类似于 [Metasploit][6] 那种。正在开发用于桌面/浏览器使用的图形用户界面(GUI)和命令行界面(CLI),移动端界面也是未来的一个备选项。用户可以使用交互式控制台界面来修改配置文件里的设置(最终会使用 GUI)。用户界面可以与存在于这个框架里的每个模块进行交互。
+
+WiFi 模块(AirCommunicator)用于支持多种 WiFi 功能和攻击类型。该框架确定了 Wi-Fi 通信的三个基本支柱:数据包嗅探、自定义数据包注入和创建接入点。三个主要的 WiFi 通信模块 AirScanner、AirInjector,和 AirHost,分别用于数据包嗅探、数据包注入,和接入点创建。这三个类被封装在主 WiFi 模块 AirCommunicator 中,AirCommunicator 在启动这些服务之前会先读取这些服务的配置文件。使用这些核心功能的一个或多个就可以构造任意类型的 WiFi 攻击。
+
+要使用中间人(MITM)攻击(这是一种攻击 WiFi 客户端的常见手法),ETF 有一个叫做 ETFITM(Evil-Twin Framework-in-the-Middle)的集成模块,这个模块用于创建一个 web 代理,来拦截和修改经过的 HTTP/HTTPS 数据包。
+
+许多其他的工具也可以利用 ETF 创建的 MITM。通过它的可扩展性,ETF 能够支持它们,而不必单独地调用它们,你可以通过扩展 Spawner 类来将这些工具添加到框架里。这使得开发者和安全审计人员可以使用框架里预先配置好的参数字符来调用程序。
+
+扩展 ETF 的另一种方法就是通过插件。有两类插件:WiFi 插件和 MITM 插件。MITM 插件是在 MITM 代理运行时可以执行的脚本。代理会将 HTTP(s) 请求和响应传递给可以记录和处理它们的插件。WiFi 插件遵循一个更加复杂的执行流程,但仍然会给想参与开发并且使用自己插件的贡献者提供一个相对简单的 API。WiFi 插件还可以进一步地划分为三类,其中每个对应一个核心 WiFi 通信模块。
+
+每个核心模块都有一些特定事件能触发响应的插件的执行。举个例子,AirScanner 有三个已定义的事件,可以对其响应进行编程处理。事件通常对应于服务开始运行之前的设置阶段、服务正在运行时的中间执行阶段、服务完成后的卸载或清理阶段。因为 Python 允许多重继承,所以一个插件可以继承多个插件类。
+
+上面的图 1 是框架架构的摘要。从 ConfigurationManager 指出的箭头意味着模块会从中读取信息,指向它的箭头意味着模块会写入/修改配置。
+
+### 使用 ETF 的例子
+
+ETF 可以通过多种方式对 WiFi 的网络安全或者终端用户的 WiFi 安全意识进行渗透测试。下面的例子描述了这个框架的一些渗透测试功能,例如接入点和客户端检测、对使用 WPA 和 WEP 类型协议的接入点进行攻击,和创建 evil twin 接入点。
+
+这些例子是使用 ETF 和允许进行 WiFi 数据捕获的 WiFi 卡设计的。它们也在 ETF 设置命令中使用了下面这些缩写:
+
+ * **APS** Access Point SSID
+ * **APB** Access Point BSSID
+ * **APC** Access Point Channel
+ * **CM** Client MAC address
+
+在实际的测试场景中,确保你使用了正确的信息来替换这些缩写。
+
+#### 在解除认证攻击后捕获 WPA 四次握手的数据包。
+
+这个场景(图 2)做了两个方面的考虑:解除认证攻击和捕获 WPA 四次握手数据包的可能性。这个场景从一个启用了 WPA/WPA2 的接入点开始,这个接入点有一个已经连上的客户端设备(在本例中是一台智能手机)。目的是通过常规的解除认证攻击(LCTT 译注:类似于 DoS 攻击)来让客户端断开和 WiFi 的网络,然后在客户端尝试重连的时候捕获 WPA 的握手包。重连会在断开连接后马上手动完成。
+
+![Scenario for capturing a WPA handshake after a de-authentication attack][8]
+
+*图 2:在解除认证攻击后捕获 WPA 握手包的场景*
+
+在这个例子中需要考虑的是 ETF 的可靠性。目的是确认工具是否一直都能捕获 WPA 的握手数据包。每个工具都会用来多次复现这个场景,以此来检查它们在捕获 WPA 握手数据包时的可靠性。
+
+使用 ETF 来捕获 WPA 握手数据包的方法不止一种。一种方法是使用 AirScanner 和 AirInjector 两个模块的组合;另一种方法是只使用 AirInjector。下面这个场景是使用了两个模块的组合。
+
+ETF 启用了 AirScanner 模块并分析 IEEE 802.11 数据帧来发现 WPA 握手包。然后 AirInjecto 就可以使用解除认证攻击来强制客户端断开连接,以进行重连。必须在 ETF 上执行下面这些步骤才能完成上面的目标:
+
+ 1. 进入 AirScanner 配置模式:`config airscanner`
+ 2. 设置 AirScanner 不跳信道:`config airscanner`
+ 3. 设置信道以嗅探经过 WiFi 接入点信道的数据(APC):`set fixed_sniffing_channel = `
+ 4. 使用 CredentialSniffer 插件来启动 AirScanner 模块:`start airscanner with credentialsniffer`
+ 5. 从已嗅探的接入点列表中添加目标接入点的 BSSID(APS):`add aps where ssid = `
+ 6. 启用 AirInjector 模块,在默认情况下,它会启用解除认证攻击:`start airinjector`
+
+这些简单的命令设置能让 ETF 在每次测试时执行成功且有效的解除认证攻击。ETF 也能在每次测试的时候捕获 WPA 的握手数据包。下面的代码能让我们看到 ETF 成功的执行情况。
+
+```
+███████╗████████╗███████╗
+██╔════╝╚══██╔══╝██╔════╝
+█████╗ ██║ █████╗
+██╔══╝ ██║ ██╔══╝
+███████╗ ██║ ██║
+╚══════╝ ╚═╝ ╚═╝
+
+
+[+] Do you want to load an older session? [Y/n]: n
+[+] Creating new temporary session on 02/08/2018
+[+] Enter the desired session name:
+ETF[etf/aircommunicator/]::> config airscanner
+ETF[etf/aircommunicator/airscanner]::> listargs
+ sniffing_interface = wlan1; (var)
+ probes = True; (var)
+ beacons = True; (var)
+ hop_channels = false; (var)
+fixed_sniffing_channel = 11; (var)
+ETF[etf/aircommunicator/airscanner]::> start airscanner with
+arpreplayer caffelatte credentialsniffer packetlogger selfishwifi
+ETF[etf/aircommunicator/airscanner]::> start airscanner with credentialsniffer
+[+] Successfully added credentialsniffer plugin.
+[+] Starting packet sniffer on interface 'wlan1'
+[+] Set fixed channel to 11
+ETF[etf/aircommunicator/airscanner]::> add aps where ssid = CrackWPA
+ETF[etf/aircommunicator/airscanner]::> start airinjector
+ETF[etf/aircommunicator/airscanner]::> [+] Starting deauthentication attack
+ - 1000 bursts of 1 packets
+ - 1 different packets
+[+] Injection attacks finished executing.
+[+] Starting post injection methods
+[+] Post injection methods finished
+[+] WPA Handshake found for client '70:3e:ac:bb:78:64' and network 'CrackWPA'
+```
+
+#### 使用 ARP 重放攻击并破解 WEP 无线网络
+
+下面这个场景(图 3)将关注[地址解析协议][9](ARP)重放攻击的效率和捕获包含初始化向量(IVs)的 WEP 数据包的速度。相同的网络可能需要破解不同数量的捕获的 IVs,所以这个场景的 IVs 上限是 50000。如果这个网络在首次测试期间,还未捕获到 50000 IVs 就崩溃了,那么实际捕获到的 IVs 数量会成为这个网络在接下来的测试里的新的上限。我们使用 `aircrack-ng` 对数据包进行破解。
+
+测试场景从一个使用 WEP 协议进行加密的 WiFi 接入点和一台知道其密钥的离线客户端设备开始 —— 为了测试方便,密钥使用了 12345,但它可以是更长且更复杂的密钥。一旦客户端连接到了 WEP 接入点,它会发送一个不必要的 ARP 数据包;这是要捕获和重放的数据包。一旦被捕获的包含 IVs 的数据包数量达到了设置的上限,测试就结束了。
+
+![Scenario for capturing a WPA handshake after a de-authentication attack][11]
+
+*图 3:在进行解除认证攻击后捕获 WPA 握手包的场景*
+
+ETF 使用 Python 的 Scapy 库来进行包嗅探和包注入。为了最大限度地解决 Scapy 里的已知的性能问题,ETF 微调了一些低级库,来大大加快包注入的速度。对于这个特定的场景,ETF 为了更有效率地嗅探,使用了 `tcpdump` 作为后台进程而不是 Scapy,Scapy 用于识别加密的 ARP 数据包。
+
+这个场景需要在 ETF 上执行下面这些命令和操作:
+
+ 1. 进入 AirScanner 设置模式:`config airscanner`
+ 2. 设置 AirScanner 不跳信道:`set hop_channels = false`
+ 3. 设置信道以嗅探经过接入点信道的数据(APC):`set fixed_sniffing_channel = `
+ 4. 进入 ARPReplayer 插件设置模式:`config arpreplayer`
+ 5. 设置 WEP 网络目标接入点的 BSSID(APB):`set target_ap_bssid `
+ 6. 使用 ARPReplayer 插件启动 AirScanner 模块:`start airscanner with arpreplayer`
+
+在执行完这些命令后,ETF 会正确地识别加密的 ARP 数据包,然后成功执行 ARP 重放攻击,以此破坏这个网络。
+
+#### 使用一款全能型蜜罐
+
+图 4 中的场景使用相同的 SSID 创建了多个接入点,对于那些可以探测到但是无法接入的 WiFi 网络,这个技术可以发现网络的加密类型。通过启动具有所有安全设置的多个接入点,客户端会自动连接和本地缓存的接入点信息相匹配的接入点。
+
+![Scenario for capturing a WPA handshake after a de-authentication attack][13]
+
+*图 4:在解除认证攻击后捕获 WPA 握手包数据。*
+
+使用 ETF,可以去设置 `hostapd` 配置文件,然后在后台启动该程序。`hostapd` 支持在一张无线网卡上通过设置虚拟接口开启多个接入点,并且因为它支持所有类型的安全设置,因此可以设置完整的全能蜜罐。对于使用 WEP 和 WPA(2)-PSK 的网络,使用默认密码,和对于使用 WPA(2)-EAP 的网络,配置“全部接受”策略。
+
+对于这个场景,必须在 ETF 上执行下面的命令和操作:
+
+ 1. 进入 APLauncher 设置模式:`config aplauncher`
+ 2. 设置目标接入点的 SSID(APS):`set ssid = `
+ 3. 设置 APLauncher 为全部接收的蜜罐:`set catch_all_honeypot = true`
+ 4. 启动 AirHost 模块:`start airhost`
+
+使用这些命令,ETF 可以启动一个包含所有类型安全配置的完整全能蜜罐。ETF 同样能自动启动 DHCP 和 DNS 服务器,从而让客户端能与互联网保持连接。ETF 提供了一个更好、更快、更完整的解决方案来创建全能蜜罐。下面的代码能够看到 ETF 的成功执行。
+
+```
+███████╗████████╗███████╗
+██╔════╝╚══██╔══╝██╔════╝
+█████╗ ██║ █████╗
+██╔══╝ ██║ ██╔══╝
+███████╗ ██║ ██║
+╚══════╝ ╚═╝ ╚═╝
+
+
+[+] Do you want to load an older session? [Y/n]: n
+[+] Creating ne´,cxzw temporary session on 03/08/2018
+[+] Enter the desired session name:
+ETF[etf/aircommunicator/]::> config aplauncher
+ETF[etf/aircommunicator/airhost/aplauncher]::> setconf ssid CatchMe
+ssid = CatchMe
+ETF[etf/aircommunicator/airhost/aplauncher]::> setconf catch_all_honeypot true
+catch_all_honeypot = true
+ETF[etf/aircommunicator/airhost/aplauncher]::> start airhost
+[+] Killing already started processes and restarting network services
+[+] Stopping dnsmasq and hostapd services
+[+] Access Point stopped...
+[+] Running airhost plugins pre_start
+[+] Starting hostapd background process
+[+] Starting dnsmasq service
+[+] Running airhost plugins post_start
+[+] Access Point launched successfully
+[+] Starting dnsmasq service
+```
+
+### 结论和以后的工作
+
+这些场景使用常见和众所周知的攻击方式来帮助验证 ETF 测试 WIFI 网络和客户端的能力。这个结果同样证明了该框架的架构能在平台现有功能的优势上开发新的攻击向量和功能。这会加快新的 WiFi 渗透测试工具的开发,因为很多的代码已经写好了。除此之外,将 WiFi 技术相关的东西都集成到一个单独的工具里,会使 WiFi 渗透测试更加简单高效。
+
+ETF 的目标不是取代现有的工具,而是为它们提供补充,并为安全审计人员在进行 WiFi 渗透测试和提升用户安全意识时,提供一个更好的选择。
+
+ETF 是 [GitHub][14] 上的一个开源项目,欢迎社区为它的开发做出贡献。下面是一些您可以提供帮助的方法。
+
+当前 WiFi 渗透测试的一个限制是无法在测试期间记录重要的事件。这使得报告已经识别到的漏洞更加困难且准确性更低。这个框架可以实现一个记录器,每个类都可以来访问它并创建一个渗透测试会话报告。
+
+ETF 工具的功能涵盖了 WiFi 渗透测试的方方面面。一方面,它让 WiFi 目标侦察、漏洞挖掘和攻击这些阶段变得更加容易。另一方面,它没有提供一个便于提交报告的功能。增加了会话的概念和会话报告的功能,比如在一个会话期间记录重要的事件,会极大地增加这个工具对于真实渗透测试场景的价值。
+
+另一个有价值的贡献是扩展该框架来促进 WiFi 模糊测试。IEEE 802.11 协议非常的复杂,考虑到它在客户端和接入点两方面都会有多种实现方式。可以假设这些实现都包含 bug 甚至是安全漏洞。这些 bug 可以通过对 IEEE 802.11 协议的数据帧进行模糊测试来进行发现。因为 Scapy 允许自定义的数据包创建和数据包注入,可以通过它实现一个模糊测试器。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/1/evil-twin-framework
+
+作者:[André Esser][a]
+选题:[lujun9972][b]
+译者:[hopefully2333](https://github.com/hopefully2333)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/andreesser
+[b]: https://github.com/lujun9972
+[1]: https://en.wikipedia.org/wiki/Rogue_access_point
+[2]: https://www.python.org/
+[3]: https://scapy.net
+[4]: /file/417776
+[5]: https://opensource.com/sites/default/files/uploads/pic1.png (Evil-Twin Framework Architecture)
+[6]: https://www.metasploit.com
+[7]: /file/417781
+[8]: https://opensource.com/sites/default/files/uploads/pic2.png (Scenario for capturing a WPA handshake after a de-authentication attack)
+[9]: https://en.wikipedia.org/wiki/Address_Resolution_Protocol
+[10]: /file/417786
+[11]: https://opensource.com/sites/default/files/uploads/pic3.png (Scenario for capturing a WPA handshake after a de-authentication attack)
+[12]: /file/417791
+[13]: https://opensource.com/sites/default/files/uploads/pic4.png (Scenario for capturing a WPA handshake after a de-authentication attack)
+[14]: https://github.com/Esser420/EvilTwinFramework
diff --git a/published/201902/20190117 How to Update-Change Users Password in Linux Using Different Ways.md b/published/201902/20190117 How to Update-Change Users Password in Linux Using Different Ways.md
new file mode 100644
index 0000000000..0b0b5132bd
--- /dev/null
+++ b/published/201902/20190117 How to Update-Change Users Password in Linux Using Different Ways.md
@@ -0,0 +1,246 @@
+[#]: collector: (lujun9972)
+[#]: translator: (MjSeven)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10514-1.html)
+[#]: subject: (How to Update/Change Users Password in Linux Using Different Ways)
+[#]: via: (https://www.2daygeek.com/linux-passwd-chpasswd-command-set-update-change-users-password-in-linux-using-shell-script/)
+[#]: author: (Vinoth Kumar https://www.2daygeek.com/author/vinoth/)
+
+如何使用不同的方式更改 Linux 用户密码
+======
+
+在 Linux 中创建用户账号时,设置用户密码是一件基本的事情。每个人都使用 `passwd` 命令跟上用户名,比如 `passwd USERNAME` 来为用户设置密码。
+
+确保你一定要设置一个难以猜测的密码,这可以帮助你使系统更安全。我的意思是,密码应该是字母、符号和数字的组合。此外,出于安全原因,我建议你至少每月更改一次密码。
+
+当你使用 `passwd` 命令时,它会要求你输入两次密码来设置。这是一种设置用户密码的原生方法。
+
+如果你不想两次更新密码,并希望以不同的方式进行更新,怎么办呢?当然,这可以的,有可能做到。
+
+如果你是 Linux 管理员,你可能已经多次问过下面的问题。你可能、也可能没有得到这些问题的答案。
+
+无论如何,不要担心,我们会回答你所有的问题。
+
+ * 如何用一条命令更改用户密码?
+ * 如何在 Linux 中为多个用户更改为相同的密码?
+ * 如何在 Linux 中更改多个用户的密码?
+ * 如何在 Linux 中为多个用户更改为不同的密码?
+ * 如何在多个 Linux 服务器中更改用户的密码?
+ * 如何在多个 Linux 服务器中更改多个用户的密码?
+
+### 方法-1:使用 passwd 命令
+
+`passwd` 命令是在 Linux 中为用户设置、更改密码的标准方法。以下是标准方法。
+
+```
+# passwd renu
+Changing password for user renu.
+New password:
+BAD PASSWORD: The password contains the user name in some form
+Retype new password:
+passwd: all authentication tokens updated successfully.
+```
+
+如果希望在一条命令中设置或更改密码,运行以下命令。它允许用户在一条命令中更新密码。
+
+```
+# echo "new_password" | passwd --stdin thanu
+Changing password for user thanu.
+passwd: all authentication tokens updated successfully.
+```
+
+### 方法-2:使用 chpasswd 命令
+
+`chpasswd` 是另一个命令,允许我们为 Linux 中的用户设置、更改密码。如果希望在一条命令中使用 `chpasswd` 命令更改用户密码,用以下格式。
+
+```
+# echo "thanu:new_password" | chpasswd
+```
+
+### 方法-3:如何为多个用户设置不同的密码
+
+如果你要为 Linux 中的多个用户设置、更改密码,并且使用不同的密码,使用以下脚本。
+
+为此,首先我们需要使用以下命令获取用户列表。下面的命令将列出拥有 `/home` 目录的用户,并将输出重定向到 `user-list.txt` 文件。
+
+```
+# cat /etc/passwd | grep "/home" | cut -d":" -f1 > user-list.txt
+```
+
+使用 `cat` 命令列出用户。如果你不想重置特定用户的密码,那么从列表中移除该用户。
+
+```
+# cat user-list.txt
+centos
+magi
+daygeek
+thanu
+renu
+```
+
+创建以下 shell 小脚本来实现此目的。
+
+```
+# vi password-update.sh
+
+#!/bin/sh
+for user in `more user-list.txt`
+do
+echo "[email protected]" | passwd --stdin "$user"
+chage -d 0 $user
+done
+```
+
+给 `password-update.sh` 文件设置可执行权限。
+
+```
+# chmod +x password-update.sh
+```
+
+最后运行脚本来实现这一目标。
+
+```
+# ./password-up.sh
+
+magi
+Changing password for user magi.
+passwd: all authentication tokens updated successfully.
+daygeek
+Changing password for user daygeek.
+passwd: all authentication tokens updated successfully.
+thanu
+Changing password for user thanu.
+passwd: all authentication tokens updated successfully.
+renu
+Changing password for user renu.
+passwd: all authentication tokens updated successfully.
+```
+
+### 方法-4:如何为多个用户设置相同的密码
+
+如果要在 Linux 中为多个用户设置、更改相同的密码,使用以下脚本。
+
+```
+# vi password-update.sh
+
+#!/bin/sh
+for user in `more user-list.txt`
+do
+echo "new_password" | passwd --stdin "$user"
+chage -d 0 $user
+done
+```
+
+### 方法-5:如何在多个服务器中更改用户密码
+
+如果希望更改多个服务器中的用户密码,使用以下脚本。在本例中,我们将更改 `renu` 用户的密码,确保你必须提供你希望更新密码的用户名而不是我们的用户名。
+
+确保你必须将服务器列表保存在 `server-list.txt` 文件中,每个服务器应该在单独一行中。
+
+```
+# vi password-update.sh
+
+#!/bin/bash
+for server in `cat server-list.txt`
+do
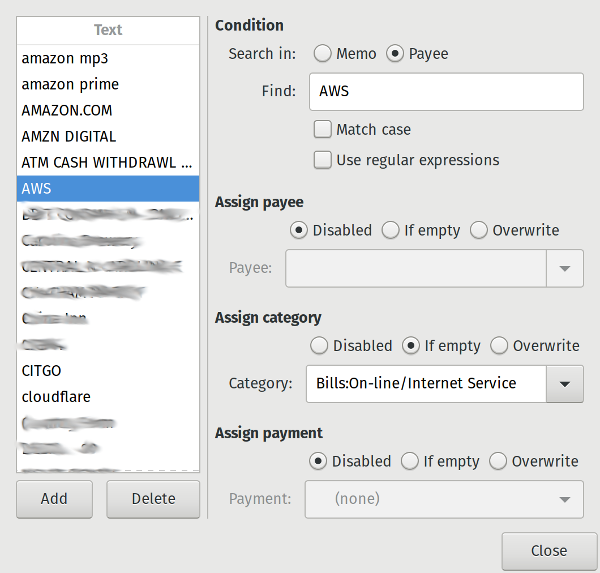
+ssh [email protected]$server 'passwd --stdin renu < Roland 可以帮你做出艰难的决定,它是我们在开源工具系列中的第七个工具,将帮助你在 2019 年提高工作效率。
+
+
+
+每年年初似乎都有疯狂的冲动想提高工作效率。新年的决心,渴望开启新的一年,当然,“抛弃旧的,拥抱新的”的态度促成了这一切。通常这时的建议严重偏向闭源和专有软件,但事实上并不用这样。
+
+这是我挑选出的 19 个新的(或者对你而言新的)开源工具中的第七个工具来帮助你在 2019 年更有效率。
+
+### Roland
+
+当一周的工作结束后,我唯一想做的就是躺到沙发上打一个周末的游戏。但即使我的职业义务在工作日结束后停止了,但我仍然需要管理我的家庭。洗衣、宠物护理、确保我孩子有他所需要的东西,以及最重要的是:决定晚餐吃什么。
+
+像许多人一样,我经常受到[决策疲劳][1]的困扰,根据速度、准备难易程度以及(坦白地说)任何让我压力最小的方式都会导致不太健康的晚餐选择。
+
+
+
+[Roland][2] 让我计划饭菜变得容易。Roland 是一款专为桌面角色扮演游戏设计的 Perl 应用。它从怪物和雇佣者等项目列表中随机挑选。从本质上讲,Roland 在命令行做的事情就像游戏管理员在桌子上掷骰子,以便在《要对玩家做的坏事全书》中找个东西一样。
+
+通过微小的修改,Roland 可以做得更多。例如,只需添加一张表,我就可以让 Roland 帮我选择晚餐。
+
+第一步是安装 Roland 及其依赖项。
+
+```
+git clone git@github.com:rjbs/Roland.git
+cpan install Getopt::Long::Descriptive Moose \
+ namespace::autoclean List:AllUtils Games::Dice \
+ Sort::ByExample Data::Bucketeer Text::Autoformat \
+ YAML::XS
+cd oland
+```
+
+接下来,创建一个名为 `dinner` 的 YAML 文档,并输入我们所有的用餐选项。
+
+```
+type: list
+pick: 1
+items:
+ - "frozen pizza"
+ - "chipotle black beans"
+ - "huevos rancheros"
+ - "nachos"
+ - "pork roast"
+ - "15 bean soup"
+ - "roast chicken"
+ - "pot roast"
+ - "grilled cheese sandwiches"
+```
+
+运行命令 `bin/roland dinner` 将读取文件并选择其中一项。
+
+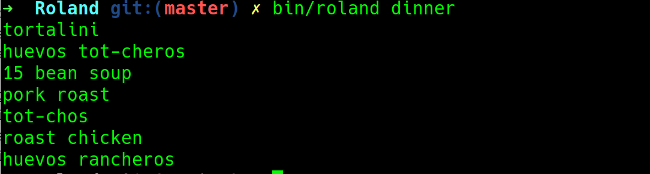
+
+我想提前计划一周,这样我可以提前购买所有食材。 `pick` 命令确定列表中要选择的物品数量,现在,`pick` 设置为 1。如果我想计划一周的晚餐菜单,我可以将 `pick: 1` 变成 `pick: 7`,它会提供一周的菜单。你还可以使用 `-m` 选项手动输入选择。
+
+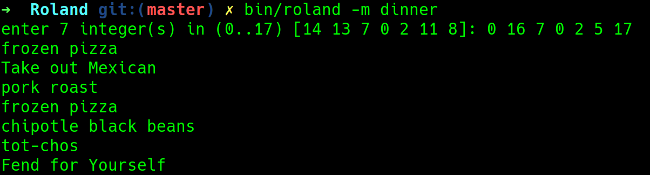
+
+你也可以用 Roland 做些有趣的事情,比如用经典短语添加一个名为 `8ball` 的文件。
+
+
+
+你可以创建各种文件来帮助做出长时间工作后看起来非常难做的常见决策。即使你不用来做这个,你仍然可以用它来为今晚的游戏设置哪个狡猾的陷阱做个决定。
+
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/1/productivity-tools-roland
+
+作者:[Kevin Sonney][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/ksonney (Kevin Sonney)
+[b]: https://github.com/lujun9972
+[1]: https://en.wikipedia.org/wiki/Decision_fatigue
+[2]: https://github.com/rjbs/Roland
diff --git a/published/201902/20190120 Get started with HomeBank, an open source personal finance app.md b/published/201902/20190120 Get started with HomeBank, an open source personal finance app.md
new file mode 100644
index 0000000000..602477dd01
--- /dev/null
+++ b/published/201902/20190120 Get started with HomeBank, an open source personal finance app.md
@@ -0,0 +1,62 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10500-1.html)
+[#]: subject: (Get started with HomeBank, an open source personal finance app)
+[#]: via: (https://opensource.com/article/19/1/productivity-tools-homebank)
+[#]: author: (Kevin Sonney https://opensource.com/users/ksonney (Kevin Sonney))
+
+开始使用 HomeBank 吧,一款开源个人财务应用
+======
+> 使用 HomeBank 跟踪你的资金流向,这是我们开源工具系列中的第八个工具,它将在 2019 年提高你的工作效率。
+
+
+
+每年年初似乎都有疯狂的冲动想提高工作效率。新年的决心,渴望开启新的一年,当然,“抛弃旧的,拥抱新的”的态度促成了这一切。通常这时的建议严重偏向闭源和专有软件,但事实上并不用这样。
+
+这是我挑选出的 19 个新的(或者对你而言新的)开源项目来帮助你在 2019 年更有效率。
+
+### HomeBank
+
+管理我的财务可能会很有压力。我不会每天查看我的银行余额,有时也很难跟踪我的钱流向哪里。我经常会花更多的时间来管理我的财务,挖掘账户和付款历史并找出我的钱去了哪里。了解我的财务状况可以帮助我保持冷静,并让我专注于其他事情。
+
+
+
+[HomeBank][1] 是一款个人财务桌面应用,帮助你轻松跟踪你的财务状况,来帮助减少此类压力。它有很好的报告可以帮助你找出你花钱的地方,允许你设置导入交易的规则,并支持大多数现代格式。
+
+HomeBank 默认可在大多数发行版上可用,因此安装它非常简单。当你第一次启动它时,它将引导你完成设置并让你创建一个帐户。之后,你可以导入任意一种支持的文件格式或开始输入交易。交易簿本身就是一个交易列表。[与其他一些应用不同][2],你不必学习[复式记账法][3]来使用 HomeBank。
+
+
+
+从银行导入文件将使用另一个分步向导进行处理,该向导提供了创建新帐户或填充现有帐户的选项。导入新帐户可节省一点时间,因为你无需在开始导入之前预先创建所有帐户。你还可以一次将多个文件导入帐户,因此不需要对每个帐户中的每个文件重复相同的步骤。
+
+
+
+我在导入和管理帐户时遇到的一个痛点是指定类别。一般而言,类别可以让你分解你的支出,看看你花钱的方式。HomeBank 与一些商业服务(以及一些商业程序)不同,它要求你手动设置所有类别。但这通常是一次性的事情,它可以在添加/导入交易时自动添加类别。还有一个按钮来分析帐户并跳过已存在的内容,这样可以加快对大量导入的分类(就像我第一次做的那样)。HomeBank 提供了大量可用的类别,你也可以添加自己的类别。
+
+HomeBank 还有预算功能,允许你计划未来几个月的开销。
+
+
+
+对我来说,最棒的功能是 HomeBank 的报告。主页面上不仅有一个图表显示你花钱的地方,而且还有许多其他报告可供你查看。如果你使用预算功能,还会有一份报告会根据预算跟踪你的支出情况。你还可以以饼图和条形图的方式查看报告。它还有趋势报告和余额报告,因此你可以回顾并查看一段时间内的变化或模式。
+
+总的来说,HomeBank 是一个非常友好,有用的程序,可以帮助你保持良好的财务状况。如果跟踪你的钱是你生活中的一件麻烦事,它使用起来很简单并且非常有用。
+
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/1/productivity-tools-homebank
+
+作者:[Kevin Sonney][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/ksonney (Kevin Sonney)
+[b]: https://github.com/lujun9972
+[1]: http://homebank.free.fr/en/index.php
+[2]: https://www.gnucash.org/
+[3]: https://en.wikipedia.org/wiki/Double-entry_bookkeeping_system
diff --git a/published/201902/20190121 Get started with TaskBoard, a lightweight kanban board.md b/published/201902/20190121 Get started with TaskBoard, a lightweight kanban board.md
new file mode 100644
index 0000000000..bff5c209c7
--- /dev/null
+++ b/published/201902/20190121 Get started with TaskBoard, a lightweight kanban board.md
@@ -0,0 +1,59 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10539-1.html)
+[#]: subject: (Get started with TaskBoard, a lightweight kanban board)
+[#]: via: (https://opensource.com/article/19/1/productivity-tool-taskboard)
+[#]: author: (Kevin Sonney https://opensource.com/users/ksonney (Kevin Sonney))
+
+开始使用 TaskBoard 吧,一款轻量级看板
+======
+
+> 了解我们在开源工具系列中的第九个工具,它将帮助你在 2019 年提高工作效率。
+
+
+
+每年年初似乎都有疯狂的冲动想提高工作效率。新年的决心,渴望开启新的一年,当然,“抛弃旧的,拥抱新的”的态度促成了这一切。通常这时的建议严重偏向闭源和专有软件,但事实上并不用这样。
+
+这是我挑选出的 19 个新的(或者对你而言新的)开源工具中的第九个工具来帮助你在 2019 年更有效率。
+
+### TaskBoard
+
+正如我在本系列的[第二篇文章][1]中所写的那样,[看板][2]现在非常受欢迎。但并非所有的看板都是相同的。[TaskBoard][3] 是一个易于在现有 Web 服务器上部署的 PHP 应用,它有一些易于使用和管理的功能。
+
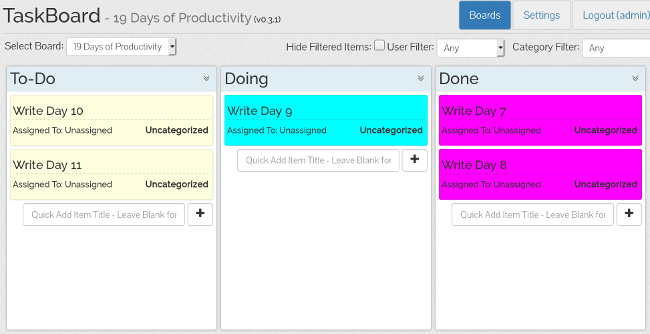
+
+
+[安装][4]它只需要解压 Web 服务器上的文件,运行一两个脚本,并确保目录可正常访问。第一次启动时,你会看到一个登录页面,然后可以就可以添加用户和制作看板了。看板创建选项包括添加要使用的列以及设置卡片的默认颜色。你还可以将用户分配给指定看板,这样每个人都只能看到他们需要查看的看板。
+
+用户管理是轻量级的,所有帐户都是服务器的本地帐户。你可以为服务器上的每个用户设置默认看板,用户也可以设置自己的默认看板。当有人在多个看板上工作时,这个选项非常有用。
+
+
+
+TaskBoard 还允许你创建自动操作,包括更改用户分配、列或卡片类别这些操作。虽然 TaskBoard 不如其他一些看板应用那么强大,但你可以设置自动操作,使看板用户更容易看到卡片、清除截止日期,并根据需要自动为人们分配新卡片。例如,在下面的截图中,如果将卡片分配给 “admin” 用户,那么它的颜色将更改为红色,并且当将卡片分配给我的用户时,其颜色将更改为蓝绿色。如果项目已添加到“待办事项”列,我还添加了一个操作来清除项目的截止日期,并在发生这种情况时自动将卡片分配给我的用户。
+
+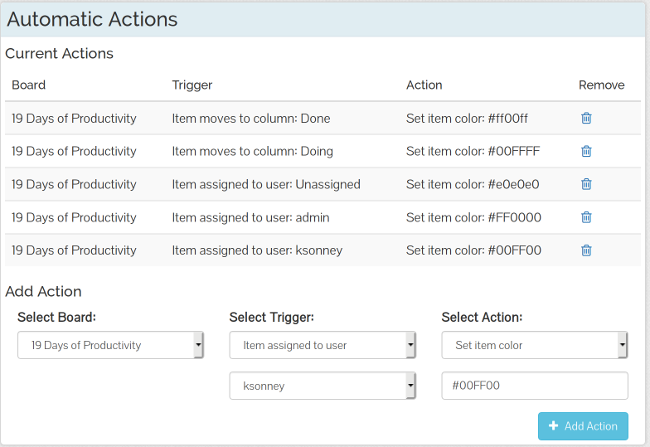
+
+卡片非常简单。虽然它们没有开始日期,但它们确实有结束日期和点数字段。点数可用于估计所需的时间、所需的工作量或仅是一般优先级。使用点数是可选的,但如果你使用 TaskBoard 进行 scrum 规划或其他敏捷技术,那么这是一个非常方便的功能。你还可以按用户和类别过滤视图。这对于正在进行多个工作流的团队非常有用,因为它允许团队负责人或经理了解进度状态或人员工作量。
+
+
+
+如果你需要一个相当轻便的看板,请看下 TaskBoard。它安装快速,有一些很好的功能,且非常、非常容易使用。它还足够的灵活性,可用于开发团队,个人任务跟踪等等。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/1/productivity-tool-taskboard
+
+作者:[Kevin Sonney][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/ksonney (Kevin Sonney)
+[b]: https://github.com/lujun9972
+[1]: https://linux.cn/article-10454-1.html
+[2]: https://en.wikipedia.org/wiki/Kanban
+[3]: https://taskboard.matthewross.me/
+[4]: https://taskboard.matthewross.me/docs/
diff --git a/published/201902/20190122 Dcp (Dat Copy) - Easy And Secure Way To Transfer Files Between Linux Systems.md b/published/201902/20190122 Dcp (Dat Copy) - Easy And Secure Way To Transfer Files Between Linux Systems.md
new file mode 100644
index 0000000000..ed9f269196
--- /dev/null
+++ b/published/201902/20190122 Dcp (Dat Copy) - Easy And Secure Way To Transfer Files Between Linux Systems.md
@@ -0,0 +1,180 @@
+[#]: collector: (lujun9972)
+[#]: translator: (dianbanjiu)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10516-1.html)
+[#]: subject: (Dcp (Dat Copy) – Easy And Secure Way To Transfer Files Between Linux Systems)
+[#]: via: (https://www.2daygeek.com/dcp-dat-copy-secure-way-to-transfer-files-between-linux-systems/)
+[#]: author: (Vinoth Kumar https://www.2daygeek.com/author/vinoth/)
+
+dcp:采用对等网络传输文件的方式
+======
+
+Linux 本就有 `scp` 和 `rsync` 可以完美地完成这个任务。然而我们今天还是想试点新东西。同时我们也想鼓励那些使用不同的理论和新技术开发新东西的开发者。
+
+我们也写过其他很多有关这个主题的文章,你可以点击下面的链接访问这些内容。
+
+它们分别是 [OnionShare][1]、[Magic Wormhole][2]、[Transfer.sh][3] 和 ffsend。
+
+### 什么是 dcp?
+
+[dcp][4] 可以在不同主机之间使用 Dat 对等网络复制文件。
+
+`dcp` 被视作一个像是 `scp` 这样工具的替代品,而无需在主机间进行 SSH 授权。
+
+这可以让你在两个主机间传输文件时,无需操心所述主机之间互相访问的细节,以及这些主机是否使用了 NAT。
+
+`dcp` 零配置、安全、快速、且是 P2P 传输。这并不是一个商用软件,使用产生的风险将由使用者自己承担。
+
+### 什么是 Dat 协议
+
+Dat 是一个 P2P 协议,是一个致力于下一代 Web 的由社区驱动的项目。
+
+### dcp 如何工作
+
+`dcp` 将会为指定的文件或者文件夹创建一个 dat 归档,并生成一个公开密钥,使用这个公开密钥可以让其他人从另外一台主机上下载上面的文件。
+
+使用网络共享的任何数据都使用该归档的公开密钥加密,也就是说文件的接收权仅限于那些拥有该公开密钥的人。
+
+### dcp 使用案例
+
+ * 向多个同事发送文件 —— 只需要告诉他们生成的公开密钥,然后他们就可以在他们的机器上收到对应的文件了。
+ * 无需设置 SSH 授权就可以在你本地网络的两个不同物理机上同步文件。
+ * 无需压缩文件并把文件上传到云端就可以轻松地发送文件。
+ * 当你有 shell 授权而没有 SSH 授权时也可以复制文件到远程服务器上。
+ * 在没有很好的 SSH 支持的 Linux/macOS 以及 Windows 系统之间分享文件。
+
+### 如何在 Linux 上安装 NodeJS & npm?
+
+`dcp` 是用 JavaScript 写成的,所以在安装 `dcp` 前,需要先安装 NodeJS。在 Linux 上使用下面的命令安装 NodeJS。
+
+Fedora 系统,使用 [DNF 命令][5] 安装 NodeJS & npm。
+
+```
+$ sudo dnf install nodejs npm
+```
+
+Debian/Ubuntu 系统,使用 [APT-GET 命令][6] 或者 [APT 命令][6] 安装 NodeJS & npm。
+
+```
+$ sudo apt install nodejs npm
+```
+
+Arch Linux 系统,使用 [Pacman 命令][8] 安装 NodeJS & npm。
+
+```
+$ sudo pacman -S nodejs npm
+```
+
+RHEL/CentOS 系统,使用 [YUM 命令][9] 安装 NodeJS & npm。
+
+```
+$ sudo yum install epel-release
+$ sudo yum install nodejs npm
+```
+
+openSUSE Leap 系统,使用 [Zypper 命令][10] 安装 NodeJS & npm。
+
+```
+$ sudo zypper nodejs6
+```
+
+### 如何在 Linux 上安装 dcp?
+
+在安装好 NodeJS 后,使用下面的 `npm` 命令安装 `dcp`。
+
+`npm` 是一个 JavaScript 的包管理器。它是 JavaScript 的运行环境 Node.js 的默认包管理器。
+
+```
+# npm i -g dat-cp
+```
+
+### 如何通过 dcp 发送文件?
+
+在 `dcp` 命令后跟你想要传输的文件或者文件夹。而且无需注明目标机器的名字。
+
+```
+# dcp [File Name Which You Want To Transfer]
+```
+
+在你运行 `dcp` 命令时将会为传送的文件生成一个 dat 归档。一旦执行完成将会在页面底部生成一个公开密钥。(LCTT 译注:此处并非非对称加密中的公钥/私钥对,而是一种公开的密钥,属于对称加密。)
+
+### 如何通过 dcp 接收文件
+
+在远程服务器上输入公开密钥即可接收对应的文件或者文件夹。
+
+```
+# dcp [Public Key]
+```
+
+以递归形式复制目录。
+
+```
+# dcp [Folder Name Which You Want To Transfer] -r
+```
+
+下面这个例子我们将会传输单个文件。
+
+![][12]
+
+上述文件传输的输出。
+
+![][13]
+
+如果你想传输不止一个文件,使用下面的格式。
+
+![][14]
+
+上述文件传输的输出。
+
+![][15]
+
+递归复制文件夹。
+
+![][16]
+
+上述文件夹传输的输出。
+
+![][17]
+
+这种方式下你只能够下载一次文件或者文件夹,不可以多次下载。这也就意味着一旦你下载了这些文件或者文件夹,这个链接就会立即失效。
+
+![][18]
+
+也可以在手册页查看更多的相关选项。
+
+```
+# dcp --help
+```
+
+--------------------------------------------------------------------------------
+
+via: https://www.2daygeek.com/dcp-dat-copy-secure-way-to-transfer-files-between-linux-systems/
+
+作者:[Vinoth Kumar][a]
+选题:[lujun9972][b]
+译者:[dianbanjiu](https://github.com/dianbanjiu)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.2daygeek.com/author/vinoth/
+[b]: https://github.com/lujun9972
+[1]: https://www.2daygeek.com/onionshare-secure-way-to-share-files-sharing-tool-linux/
+[2]: https://www.2daygeek.com/wormhole-securely-share-files-from-linux-command-line/
+[3]: https://www.2daygeek.com/transfer-sh-easy-fast-way-share-files-over-internet-from-command-line/
+[4]: https://github.com/tom-james-watson/dat-cp
+[5]: https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
+[6]: https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
+[7]: https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
+[8]: https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
+[9]: https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
+[10]: https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
+[11]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
+[12]: https://www.2daygeek.com/wp-content/uploads/2019/01/Dcp-Dat-Copy-Easy-And-Secure-Way-To-Transfer-Files-Between-Linux-Systems-1.png
+[13]: https://www.2daygeek.com/wp-content/uploads/2019/01/Dcp-Dat-Copy-Easy-And-Secure-Way-To-Transfer-Files-Between-Linux-Systems-2.png
+[14]: https://www.2daygeek.com/wp-content/uploads/2019/01/Dcp-Dat-Copy-Easy-And-Secure-Way-To-Transfer-Files-Between-Linux-Systems-3.jpg
+[15]: https://www.2daygeek.com/wp-content/uploads/2019/01/Dcp-Dat-Copy-Easy-And-Secure-Way-To-Transfer-Files-Between-Linux-Systems-4.jpg
+[16]: https://www.2daygeek.com/wp-content/uploads/2019/01/Dcp-Dat-Copy-Easy-And-Secure-Way-To-Transfer-Files-Between-Linux-Systems-6.jpg
+[17]: https://www.2daygeek.com/wp-content/uploads/2019/01/Dcp-Dat-Copy-Easy-And-Secure-Way-To-Transfer-Files-Between-Linux-Systems-7.jpg
+[18]: https://www.2daygeek.com/wp-content/uploads/2019/01/Dcp-Dat-Copy-Easy-And-Secure-Way-To-Transfer-Files-Between-Linux-Systems-5.jpg
diff --git a/published/201902/20190122 Get started with Go For It, a flexible to-do list application.md b/published/201902/20190122 Get started with Go For It, a flexible to-do list application.md
new file mode 100644
index 0000000000..e2602b216c
--- /dev/null
+++ b/published/201902/20190122 Get started with Go For It, a flexible to-do list application.md
@@ -0,0 +1,61 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10557-1.html)
+[#]: subject: (Get started with Go For It, a flexible to-do list application)
+[#]: via: (https://opensource.com/article/19/1/productivity-tool-go-for-it)
+[#]: author: (Kevin Sonney https://opensource.com/users/ksonney (Kevin Sonney))
+
+开始使用 Go For It 吧,一个灵活的待办事项列表程序
+======
+
+> Go For It,是我们开源工具系列中的第十个工具,它将使你在 2019 年更高效,它在 Todo.txt 系统的基础上构建,以帮助你完成更多工作。
+
+
+
+每年年初似乎都有疯狂的冲动想提高工作效率。新年的决心,渴望开启新的一年,当然,“抛弃旧的,拥抱新的”的态度促成了这一切。通常这时的建议严重偏向闭源和专有软件,但事实上并不用这样。
+
+这是我挑选出的 19 个新的(或者对你而言新的)开源工具中的第 10 个工具来帮助你在 2019 年更有效率。
+
+### Go For It
+
+有时,人们要高效率需要的不是一个花哨的看板或一组笔记,而是一个简单、直接的待办事项清单。像“将项目添加到列表中,在完成后检查”一样基本的东西。为此,[纯文本 Todo.txt 系统][1]可能是最容易使用的系统之一,几乎所有系统都支持它。
+
+
+
+[Go For It][2] 是一个简单易用的 Todo.txt 图形界面。如果你已经在使用 Todo.txt,它可以与现有文件一起使用,如果还没有,那么可以同时创建待办事项和完成事项。它允许拖放任务排序,允许用户按照他们想要执行的顺序组织待办事项。它还支持 [Todo.txt 格式指南][3]中所述的优先级、项目和上下文。而且,只需单击任务列表中的项目或者上下文就可通过它们过滤任务。
+
+
+
+一开始,Go For It 可能看起来与任何其他 Todo.txt 程序相同,但外观可能是骗人的。将 Go For It 与其他程序真正区分开的功能是它包含一个内置的[番茄工作法][4]计时器。选择要完成的任务,切换到“计时器”选项卡,然后单击“启动”。任务完成后,只需单击“完成”,它将自动重置计时器并选择列表中的下一个任务。你可以暂停并重新启动计时器,也可以单击“跳过”跳转到下一个任务(或中断)。在当前任务剩余 60 秒时,它会发出警告。任务的默认时间设置为 25 分钟,中断的默认时间设置为 5 分钟。你可以在“设置”页面中调整,同时还能调整 Todo.txt 和 done.txt 文件的目录的位置。
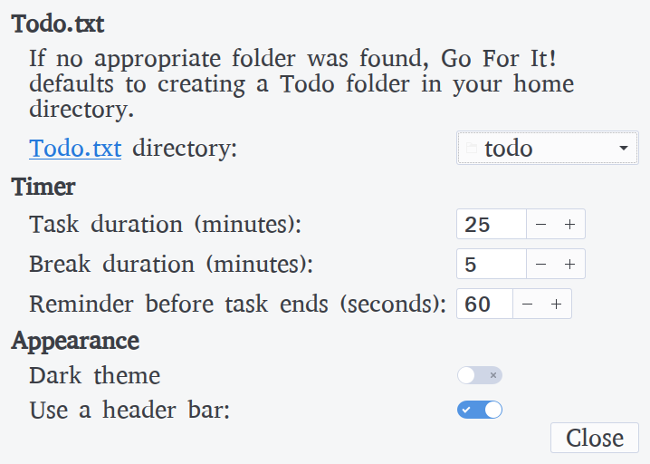
+
+
+
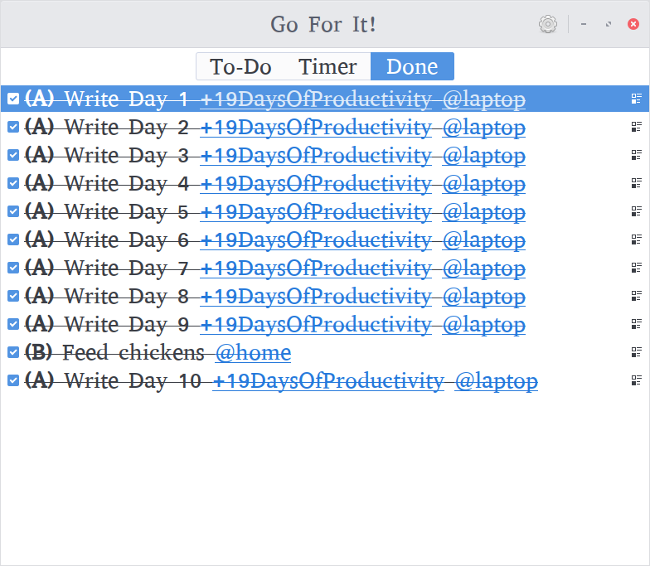
+Go For It 的第三个选项卡是“已完成”,允许你查看已完成的任务并在需要时将其清除。能够看到你已经完成的可能是非常激励的,也是一种了解你在更长的过程中进度的好方法。
+
+
+
+它还有 Todo.txt 的所有其他优点。Go For It 的列表可以被其他使用相同格式的程序访问,包括 [Todo.txt 的原始命令行工具][5]和任何已安装的[附加组件][6]。
+
+Go For It 旨在成为一个简单的工具来帮助管理你的待办事项列表并完成这些项目。如果你已经使用过 Todo.txt,那么 Go For It 是你的工具箱的绝佳补充,如果你还没有,这是一个尝试最简单、最灵活系统之一的好机会。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/1/productivity-tool-go-for-it
+
+作者:[Kevin Sonney][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/ksonney (Kevin Sonney)
+[b]: https://github.com/lujun9972
+[1]: http://todotxt.org/
+[2]: http://manuel-kehl.de/projects/go-for-it/
+[3]: https://github.com/todotxt/todo.txt
+[4]: https://en.wikipedia.org/wiki/Pomodoro_Technique
+[5]: https://github.com/todotxt/todo.txt-cli
+[6]: https://github.com/todotxt/todo.txt-cli/wiki/Todo.sh-Add-on-Directory
diff --git a/published/201902/20190122 How To Copy A File-Folder From A Local System To Remote System In Linux.md b/published/201902/20190122 How To Copy A File-Folder From A Local System To Remote System In Linux.md
new file mode 100644
index 0000000000..66407b0156
--- /dev/null
+++ b/published/201902/20190122 How To Copy A File-Folder From A Local System To Remote System In Linux.md
@@ -0,0 +1,393 @@
+[#]: collector: (lujun9972)
+[#]: translator: (luming)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10569-1.html)
+[#]: subject: (How To Copy A File/Folder From A Local System To Remote System In Linux?)
+[#]: via: (https://www.2daygeek.com/linux-scp-rsync-pscp-command-copy-files-folders-in-multiple-servers-using-shell-script/)
+[#]: author: (Prakash Subramanian https://www.2daygeek.com/author/prakash/)
+
+如何在 Linux 上复制文件/文件夹到远程系统?
+======
+
+从一个服务器复制文件到另一个服务器,或者从本地到远程复制是 Linux 管理员的日常任务之一。
+
+我觉得不会有人不同意,因为无论在哪里这都是你的日常操作之一。有很多办法都能处理这个任务,我们试着加以概括。你可以挑一个喜欢的方法。当然,看看其他命令也能在别的地方帮到你。
+
+我已经在自己的环境下测试过所有的命令和脚本了,因此你可以直接用到日常工作当中。
+
+通常大家都倾向 `scp`,因为它是文件复制的原生命令之一。但本文所列出的其它命令也很好用,建议你尝试一下。
+
+文件复制可以轻易地用以下四种方法。
+
+- `scp`:在网络上的两个主机之间复制文件,它使用 `ssh` 做文件传输,并使用相同的认证方式,具有相同的安全性。
+- `rsync`:是一个既快速又出众的多功能文件复制工具。它能本地复制、通过远程 shell 在其它主机之间复制,或者与远程的 `rsync` 守护进程 之间复制。
+- `pscp`:是一个并行复制文件到多个主机上的程序。它提供了诸多特性,例如为 `scp` 配置免密传输,保存输出到文件,以及超时控制。
+- `prsync`:也是一个并行复制文件到多个主机上的程序。它也提供了诸多特性,例如为 `ssh` 配置免密传输,保存输出到 文件,以及超时控制。
+
+### 方式 1:如何在 Linux 上使用 scp 命令从本地系统向远程系统复制文件/文件夹?
+
+`scp` 命令可以让我们从本地系统复制文件/文件夹到远程系统上。
+
+我会把 `output.txt` 文件从本地系统复制到 `2g.CentOS.com` 远程系统的 `/opt/backup` 文件夹下。
+
+```
+# scp output.txt root@2g.CentOS.com:/opt/backup
+
+output.txt 100% 2468 2.4KB/s 00:00
+```
+
+从本地系统复制两个文件 `output.txt` 和 `passwd-up.sh` 到远程系统 `2g.CentOs.com` 的 `/opt/backup` 文件夹下。
+
+```
+# scp output.txt passwd-up.sh root@2g.CentOS.com:/opt/backup
+
+output.txt 100% 2468 2.4KB/s 00:00
+passwd-up.sh 100% 877 0.9KB/s 00:00
+```
+
+从本地系统复制 `shell-script` 文件夹到远程系统 `2g.CentOs.com` 的 `/opt/back` 文件夹下。
+
+这会连同`shell-script` 文件夹下所有的文件一同复制到`/opt/back` 下。
+
+```
+# scp -r /home/daygeek/2g/shell-script/ root@:/opt/backup/
+
+output.txt 100% 2468 2.4KB/s 00:00
+ovh.sh 100% 76 0.1KB/s 00:00
+passwd-up.sh 100% 877 0.9KB/s 00:00
+passwd-up1.sh 100% 7 0.0KB/s 00:00
+server-list.txt 100% 23 0.0KB/s 00:00
+```
+
+### 方式 2:如何在 Linux 上使用 scp 命令和 Shell 脚本复制文件/文件夹到多个远程系统上?
+
+如果你想复制同一个文件到多个远程服务器上,那就需要创建一个如下面那样的小 shell 脚本。
+
+并且,需要将服务器添加进 `server-list.txt` 文件。确保添加成功后,每个服务器应当单独一行。
+
+最终,你想要的脚本就像下面这样:
+
+```
+# file-copy.sh
+
+#!/bin/sh
+for server in `more server-list.txt`
+do
+ scp /home/daygeek/2g/shell-script/output.txt root@$server:/opt/backup
+done
+```
+
+完成之后,给 `file-copy.sh` 文件设置可执行权限。
+
+```
+# chmod +x file-copy.sh
+```
+
+最后运行脚本完成复制。
+
+```
+# ./file-copy.sh
+
+output.txt 100% 2468 2.4KB/s 00:00
+output.txt 100% 2468 2.4KB/s 00:00
+```
+
+使用下面的脚本可以复制多个文件到多个远程服务器上。
+
+```
+# file-copy.sh
+
+#!/bin/sh
+for server in `more server-list.txt`
+do
+ scp /home/daygeek/2g/shell-script/output.txt passwd-up.sh root@$server:/opt/backup
+done
+```
+
+下面结果显示所有的两个文件都复制到两个服务器上。
+
+```
+# ./file-cp.sh
+
+output.txt 100% 2468 2.4KB/s 00:00
+passwd-up.sh 100% 877 0.9KB/s 00:00
+output.txt 100% 2468 2.4KB/s 00:00
+passwd-up.sh 100% 877 0.9KB/s 00:00
+```
+
+使用下面的脚本递归地复制文件夹到多个远程服务器上。
+
+```
+# file-copy.sh
+
+#!/bin/sh
+for server in `more server-list.txt`
+do
+ scp -r /home/daygeek/2g/shell-script/ root@$server:/opt/backup
+done
+```
+
+上述脚本的输出。
+
+```
+# ./file-cp.sh
+
+output.txt 100% 2468 2.4KB/s 00:00
+ovh.sh 100% 76 0.1KB/s 00:00
+passwd-up.sh 100% 877 0.9KB/s 00:00
+passwd-up1.sh 100% 7 0.0KB/s 00:00
+server-list.txt 100% 23 0.0KB/s 00:00
+
+output.txt 100% 2468 2.4KB/s 00:00
+ovh.sh 100% 76 0.1KB/s 00:00
+passwd-up.sh 100% 877 0.9KB/s 00:00
+passwd-up1.sh 100% 7 0.0KB/s 00:00
+server-list.txt 100% 23 0.0KB/s 00:00
+```
+
+### 方式 3:如何在 Linux 上使用 pscp 命令复制文件/文件夹到多个远程系统上?
+
+`pscp` 命令可以直接让我们复制文件到多个远程服务器上。
+
+使用下面的 `pscp` 命令复制单个文件到远程服务器。
+
+```
+# pscp.pssh -H 2g.CentOS.com /home/daygeek/2g/shell-script/output.txt /opt/backup
+
+[1] 18:46:11 [SUCCESS] 2g.CentOS.com
+```
+
+使用下面的 `pscp` 命令复制多个文件到远程服务器。
+
+```
+# pscp.pssh -H 2g.CentOS.com /home/daygeek/2g/shell-script/output.txt ovh.sh /opt/backup
+
+[1] 18:47:48 [SUCCESS] 2g.CentOS.com
+```
+
+使用下面的 `pscp` 命令递归地复制整个文件夹到远程服务器。
+
+```
+# pscp.pssh -H 2g.CentOS.com -r /home/daygeek/2g/shell-script/ /opt/backup
+
+[1] 18:48:46 [SUCCESS] 2g.CentOS.com
+```
+
+使用下面的 `pscp` 命令使用下面的命令复制单个文件到多个远程服务器。
+
+```
+# pscp.pssh -h server-list.txt /home/daygeek/2g/shell-script/output.txt /opt/backup
+
+[1] 18:49:48 [SUCCESS] 2g.CentOS.com
+[2] 18:49:48 [SUCCESS] 2g.Debian.com
+```
+
+使用下面的 `pscp` 命令复制多个文件到多个远程服务器。
+
+```
+# pscp.pssh -h server-list.txt /home/daygeek/2g/shell-script/output.txt passwd-up.sh /opt/backup
+
+[1] 18:50:30 [SUCCESS] 2g.Debian.com
+[2] 18:50:30 [SUCCESS] 2g.CentOS.com
+```
+
+使用下面的命令递归地复制文件夹到多个远程服务器。
+
+```
+# pscp.pssh -h server-list.txt -r /home/daygeek/2g/shell-script/ /opt/backup
+
+[1] 18:51:31 [SUCCESS] 2g.Debian.com
+[2] 18:51:31 [SUCCESS] 2g.CentOS.com
+```
+
+### 方式 4:如何在 Linux 上使用 rsync 命令复制文件/文件夹到多个远程系统上?
+
+`rsync` 是一个即快速又出众的多功能文件复制工具。它能本地复制、通过远程 shell 在其它主机之间复制,或者在远程 `rsync` 守护进程 之间复制。
+
+使用下面的 `rsync` 命令复制单个文件到远程服务器。
+
+```
+# rsync -avz /home/daygeek/2g/shell-script/output.txt root@2g.CentOS.com:/opt/backup
+
+sending incremental file list
+output.txt
+
+sent 598 bytes received 31 bytes 1258.00 bytes/sec
+total size is 2468 speedup is 3.92
+```
+
+使用下面的 `rsync` 命令复制多个文件到远程服务器。
+
+```
+# rsync -avz /home/daygeek/2g/shell-script/output.txt passwd-up.sh root@2g.CentOS.com:/opt/backup
+
+sending incremental file list
+output.txt
+passwd-up.sh
+
+sent 737 bytes received 50 bytes 1574.00 bytes/sec
+total size is 2537 speedup is 3.22
+```
+
+使用下面的 `rsync` 命令通过 `ssh` 复制单个文件到远程服务器。
+
+```
+# rsync -avzhe ssh /home/daygeek/2g/shell-script/output.txt root@2g.CentOS.com:/opt/backup
+
+sending incremental file list
+output.txt
+
+sent 598 bytes received 31 bytes 419.33 bytes/sec
+total size is 2.47K speedup is 3.92
+```
+
+使用下面的 `rsync` 命令通过 `ssh` 递归地复制文件夹到远程服务器。这种方式只复制文件不包括文件夹。
+
+```
+# rsync -avzhe ssh /home/daygeek/2g/shell-script/ root@2g.CentOS.com:/opt/backup
+
+sending incremental file list
+./
+output.txt
+ovh.sh
+passwd-up.sh
+passwd-up1.sh
+server-list.txt
+
+sent 3.85K bytes received 281 bytes 8.26K bytes/sec
+total size is 9.12K speedup is 2.21
+```
+
+### 方式 5:如何在 Linux 上使用 rsync 命令和 Shell 脚本复制文件/文件夹到多个远程系统上?
+
+如果你想复制同一个文件到多个远程服务器上,那也需要创建一个如下面那样的小 shell 脚本。
+
+```
+# file-copy.sh
+
+#!/bin/sh
+for server in `more server-list.txt`
+do
+ rsync -avzhe ssh /home/daygeek/2g/shell-script/ root@2g.CentOS.com$server:/opt/backup
+done
+```
+
+上面脚本的输出。
+
+```
+# ./file-copy.sh
+
+sending incremental file list
+./
+output.txt
+ovh.sh
+passwd-up.sh
+passwd-up1.sh
+server-list.txt
+
+sent 3.86K bytes received 281 bytes 8.28K bytes/sec
+total size is 9.13K speedup is 2.21
+
+sending incremental file list
+./
+output.txt
+ovh.sh
+passwd-up.sh
+passwd-up1.sh
+server-list.txt
+
+sent 3.86K bytes received 281 bytes 2.76K bytes/sec
+total size is 9.13K speedup is 2.21
+```
+
+### 方式 6:如何在 Linux 上使用 scp 命令和 Shell 脚本从本地系统向多个远程系统复制文件/文件夹?
+
+在上面两个 shell 脚本中,我们需要事先指定好文件和文件夹的路径,这儿我做了些小修改,让脚本可以接收文件或文件夹作为输入参数。当你每天需要多次执行复制时,这将会非常有用。
+
+```
+# file-copy.sh
+
+#!/bin/sh
+for server in `more server-list.txt`
+do
+scp -r $1 root@2g.CentOS.com$server:/opt/backup
+done
+```
+
+输入文件名并运行脚本。
+
+```
+# ./file-copy.sh output1.txt
+
+output1.txt 100% 3558 3.5KB/s 00:00
+output1.txt 100% 3558 3.5KB/s 00:00
+```
+
+### 方式 7:如何在 Linux 系统上用非标准端口复制文件/文件夹到远程系统?
+
+如果你想使用非标准端口,使用下面的 shell 脚本复制文件或文件夹。
+
+如果你使用了非标准端口,确保像下面 `scp` 命令那样指定好了端口号。
+
+```
+# file-copy-scp.sh
+
+#!/bin/sh
+for server in `more server-list.txt`
+do
+scp -P 2222 -r $1 root@2g.CentOS.com$server:/opt/backup
+done
+```
+
+运行脚本,输入文件名。
+
+```
+# ./file-copy.sh ovh.sh
+
+ovh.sh 100% 3558 3.5KB/s 00:00
+ovh.sh 100% 3558 3.5KB/s 00:00
+```
+
+如果你使用了非标准端口,确保像下面 `rsync` 命令那样指定好了端口号。
+
+```
+# file-copy-rsync.sh
+
+#!/bin/sh
+for server in `more server-list.txt`
+do
+rsync -avzhe 'ssh -p 2222' $1 root@2g.CentOS.com$server:/opt/backup
+done
+```
+
+运行脚本,输入文件名。
+
+```
+# ./file-copy-rsync.sh passwd-up.sh
+sending incremental file list
+passwd-up.sh
+
+sent 238 bytes received 35 bytes 26.00 bytes/sec
+total size is 159 speedup is 0.58
+
+sending incremental file list
+passwd-up.sh
+
+sent 238 bytes received 35 bytes 26.00 bytes/sec
+total size is 159 speedup is 0.58
+```
+
+--------------------------------------------------------------------------------
+
+via: https://www.2daygeek.com/linux-scp-rsync-pscp-command-copy-files-folders-in-multiple-servers-using-shell-script/
+
+作者:[Prakash Subramanian][a]
+选题:[lujun9972][b]
+译者:[LuuMing](https://github.com/LuuMing)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.2daygeek.com/author/prakash/
+[b]: https://github.com/lujun9972
diff --git a/published/201902/20190123 Book Review- Fundamentals of Linux.md b/published/201902/20190123 Book Review- Fundamentals of Linux.md
new file mode 100644
index 0000000000..bdde86d16e
--- /dev/null
+++ b/published/201902/20190123 Book Review- Fundamentals of Linux.md
@@ -0,0 +1,75 @@
+[#]: collector: (lujun9972)
+[#]: translator: (mySoul8012)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10565-1.html)
+[#]: subject: (Book Review: Fundamentals of Linux)
+[#]: via: (https://itsfoss.com/fundamentals-of-linux-book-review)
+[#]: author: (John Paul https://itsfoss.com/author/john/)
+
+书评:《Linux 基础》
+======
+
+介绍 Linux 的基础知识以及它的工作原理的书很多,今天,我们将会点评这样一本书。这次讨论的主题为 Oliver Pelz 所写的 《[Linux 基础][1]》,由 [PacktPub][2] 出版。
+
+[Oliver Pelz][3] 是一位拥有超过十年软件开发经验的开发者和系统管理员,拥有生物信息学学位证书。
+
+### 《Linux 基础》
+
+![Fundamental of Linux books][4]
+
+正如可以从书名中猜到那样,《Linux 基础》的目标是为读者打下一个从了解 Linux 到学习 Linux 命令行的坚实基础。这本书一共有两百多页,因此它专注于教给用户日常任务和解决经常遇到的问题。本书是为想要成为 Linux 管理员的读者而写的。
+
+第一章首先概述了虚拟化。本书作者指导了读者如何在 [VirtualBox][6] 中创建 [CentOS][5] 实例。如何克隆实例,如何使用快照。并且同时你也会学习到如何通过 SSH 命令连接到虚拟机。
+
+第二章介绍了 Linux 命令行的基础知识,包括 shell 通配符,shell 展开,如何使用包含空格和特殊字符的文件名称。如何来获取命令手册的帮助页面。如何使用 `sed`、`awk` 这两个命令。如何浏览 Linux 的文件系统。
+
+第三章更深入的介绍了 Linux 文件系统。你将了解如何在 Linux 中文件是如何链接的,以及如何搜索它们。你还将获得用户、组,以及文件权限的大概了解。由于本章的重点介绍了如何与文件进行交互。因此还将会介绍如何从命令行中读取文本文件,以及初步了解如何使用 vim 编辑器。
+
+第四章重点介绍了如何使用命令行。以及涵盖的重要命令。如 `cat`、`sort`、`awk`、`tee`、`tar`、`rsync`、`nmap`、`htop` 等。你还将会了解到进程,以及它们如何彼此通讯。这一章还介绍了 Bash shell 脚本编程。
+
+第五章同时也是本书的最后一章,将会介绍 Linux 和其他高级命令,以及网络的概念。本书的作者讨论了 Linux 是如何处理网络,并提供使用多个虚拟机的示例。同时还将会介绍如何安装新的程序,如何设置防火墙。
+
+### 关于这本书的思考
+
+Linux 的基础知识只有五章和少少的 200 来页可能看起来有些短,但是也涵盖了相当多的信息。同时也将会获得如何使用命令行所需要的知识的一切。
+
+使用本书的时候,需要注意一件事情,即,本书专注于对命令行的关注,没有任何关于如何使用图形化的用户界面的任何教程。这是因为在 Linux 中有太多不同的桌面环境,以及很多的类似的系统应用,因此很难编写一本可以涵盖所有变种的书。此外,还有部分原因还因为本书的面向的用户群体为潜在的 Linux 管理员。
+
+当我看到作者使用 Centos 教授 Linux 的时候有点惊讶。我原本以为他会使用更为常见的 Linux 的发行版本,例如 Ubuntu、Debian 或者 Fedora。原因在于 Centos 是为服务器设计的发行版本。随着时间的推移变化很小,能够为 Linux 的基础知识打下一个非常坚实的基础。
+
+我自己使用 Linux 已经操作五年了。我大部分时间都在使用桌面版本的 Linux。我有些时候会使用命令行操作。但我并没有花太多的时间在那里。我使用鼠标完成了本书中涉及到的很多操作。现在呢。我同时也知道了如何通过终端做到同样的事情。这种方式不会改变我完成任务的方式,但是会有助于自己理解幕后发生的事情。
+
+如果你刚刚使用 Linux,或者计划使用。我不会推荐你阅读这本书。这可能有点绝对化。但是如何你已经花了一些时间在 Linux 上。或者可以快速掌握某种技术语言。那么这本书很适合你。
+
+如果你认为本书适合你的学习需求。你可以从以下链接获取到该书:
+
+- [下载《Linux 基础》](https://www.packtpub.com/networking-and-servers/fundamentals-linux)
+
+我们将在未来几个月内尝试点评更多 Linux 书籍,敬请关注我们。
+
+你最喜欢的关于 Linux 的入门书籍是什么?请在下面的评论中告诉我们。
+
+如果你发现这篇文章很有趣,请花一点时间在社交媒体、Hacker News或 [Reddit][8] 上分享。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/fundamentals-of-linux-book-review
+
+作者:[John Paul][a]
+选题:[lujun9972][b]
+译者:[mySoul8012](https://github.com/mySoul8012)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/john/
+[b]: https://github.com/lujun9972
+[1]: https://www.packtpub.com/networking-and-servers/fundamentals-linux
+[2]: https://www.packtpub.com/
+[3]: http://www.oliverpelz.de/index.html
+[4]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/01/fundamentals-of-linux-book-review.jpeg?resize=800%2C450&ssl=1
+[5]: https://centos.org/
+[6]: https://www.virtualbox.org/
+[7]: https://www.centos.org/
+[8]: http://reddit.com/r/linuxusersgroup
diff --git a/published/201902/20190123 Commands to help you monitor activity on your Linux server.md b/published/201902/20190123 Commands to help you monitor activity on your Linux server.md
new file mode 100644
index 0000000000..4900629eaf
--- /dev/null
+++ b/published/201902/20190123 Commands to help you monitor activity on your Linux server.md
@@ -0,0 +1,157 @@
+[#]: collector: (lujun9972)
+[#]: translator: (dianbanjiu)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10498-1.html)
+[#]: subject: (Commands to help you monitor activity on your Linux server)
+[#]: via: (https://www.networkworld.com/article/3335200/linux/how-to-monitor-activity-on-your-linux-server.html)
+[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
+
+监控 Linux 服务器活动的几个命令
+======
+
+> `watch`、`top` 和 `ac` 命令为我们监视 Linux 服务器上的活动提供了一些十分高效的途径。
+
+
+
+为了在获取系统活动时更加轻松,Linux 系统提供了一系列相关的命令。在这篇文章中,我们就一起来看看这些对我们很有帮助的命令吧。
+
+### watch 命令
+
+`watch` 是一个用来轻松地重复检测 Linux 系统中一系列数据命令,例如用户活动、正在运行进程、登录、内存使用等。这个命令实际上是重复地运行一个特定的命令,每次都会重写之前显示的输出,它提供了一个比较方便的方式用以监测在你的系统中发生的活动。
+
+首先以一个基础且不是特别有用的命令开始,你可以运行 `watch -n 5 date`,然后你可以看到在终端中显示了当前的日期和时间,这些数据会每五秒更新一次。你可能已经猜到了,`-n 5` 选项指定了运行接下来一次命令需要等待的秒数。默认是 2 秒。这个命令将会一直运行并按照指定的时间更新显示,直到你使用 `^C` 停下它。
+
+```
+Every 5.0s: date butterfly: Wed Jan 23 15:59:14 2019
+
+Wed Jan 23 15:59:14 EST 2019
+```
+
+下面是一个更有趣的命令实例,你可以监控一个在服务器中登录用户的列表,该列表会按照指定的时间定时更新。就像下面写到的,这个命令会每 10 秒更新一次这个列表。登出的用户将会从当前显示的列表中消失,那些新登录的将会被添加到这个表格当中。如果没有用户再登录或者登出,这个表格跟之前显示的将不会有任何不同。
+
+```
+$ watch -n 10 who
+
+Every 10.0s: who butterfly: Tue Jan 23 16:02:03 2019
+
+shs :0 2019-01-23 09:45 (:0)
+dory pts/0 2019-01-23 15:50 (192.168.0.5)
+nemo pts/1 2019-01-23 16:01 (192.168.0.15)
+shark pts/3 2019-01-23 11:11 (192.168.0.27)
+```
+
+如果你只是想看有多少用户登录进来,可以通过 `watch` 调用 `uptime` 命令获取用户数和负载的平均水平,以及系统的工作状况。
+
+```
+$ watch uptime
+
+Every 2.0s: uptime butterfly: Tue Jan 23 16:25:48 2019
+
+ 16:25:48 up 22 days, 4:38, 3 users, load average: 1.15, 0.89, 1.02
+```
+
+如果你想使用 `watch` 重复一个包含了管道的命令,就需要将该命令用引号括起来,就比如下面这个每五秒显示一次有多少进程正在运行的命令。
+
+```
+$ watch -n 5 'ps -ef | wc -l'
+
+Every 5.0s: ps -ef | wc -l butterfly: Tue Jan 23 16:11:54 2019
+
+245
+```
+
+要查看内存使用,你也许会想要试一下下面的这个命令组合:
+
+```
+$ watch -n 5 free -m
+
+Every 5.0s: free -m butterfly: Tue Jan 23 16:34:09 2019
+
+Every 5.0s: free -m butterfly: Tue Jan 23 16:34:09 2019
+
+ total used free shared buff/cache available
+Mem: 5959 776 3276 12 1906 4878
+Swap: 2047 0 2047
+```
+
+你可以在 `watch` 后添加一些选项查看某个特定用户下运行的进程,不过 `top` 为此提供了更好的选择。
+
+### top 命令
+
+如果你想查看某个特定用户下的进程,`top` 命令的 `-u` 选项可以很轻松地帮你达到这个目的。
+
+```
+$ top -u nemo
+top - 16:14:33 up 2 days, 4:27, 3 users, load average: 0.00, 0.01, 0.02
+Tasks: 199 total, 1 running, 198 sleeping, 0 stopped, 0 zombie
+%Cpu(s): 0.0 us, 0.2 sy, 0.0 ni, 99.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
+MiB Mem : 5959.4 total, 3277.3 free, 776.4 used, 1905.8 buff/cache
+MiB Swap: 2048.0 total, 2048.0 free, 0.0 used. 4878.4 avail Mem
+
+ PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
+23026 nemo 20 0 46340 7820 6504 S 0.0 0.1 0:00.05 systemd
+23033 nemo 20 0 149660 3140 72 S 0.0 0.1 0:00.00 (sd-pam)
+23125 nemo 20 0 63396 5100 4092 S 0.0 0.1 0:00.00 sshd
+23128 nemo 20 0 16836 5636 4284 S 0.0 0.1 0:00.03 zsh
+```
+
+你可能不仅可以看到某个用户下的进程,还可以查看每个进程所占用的资源,以及系统总的工作状况。
+
+### ac 命令
+
+如果你想查看系统中每个用户登录的时长,可以使用 `ac` 命令。运行该命令之前首先需要安装 `acct`(Debian 等)或者 `psacct`(RHEL、Centos 等)包。
+
+`ac` 命令有一系列的选项,该命令从 `wtmp` 文件中拉取数据。这个例子展示的是最近用户登录的总小时数。
+
+```
+$ ac
+ total 1261.72
+```
+
+这个命令显示了用户登录的总的小时数:
+
+```
+$ ac -p
+ shark 5.24
+ nemo 5.52
+ shs 1251.00
+ total 1261.76
+```
+
+这个命令显示了每天登录的用户小时数:
+
+```
+$ ac -d | tail -10
+
+Jan 11 total 0.05
+Jan 12 total 1.36
+Jan 13 total 16.39
+Jan 15 total 55.33
+Jan 16 total 38.02
+Jan 17 total 28.51
+Jan 19 total 48.66
+Jan 20 total 1.37
+Jan 22 total 23.48
+Today total 9.83
+```
+
+### 总结
+
+Linux 系统上有很多命令可以用于检查系统活动。`watch` 命令允许你以重复的方式运行任何命令,并观察输出有何变化。`top` 命令是一个专注于用户进程的最佳选项,以及允许你以动态方式查看进程的变化,还可以使用 `ac` 命令检查用户连接到系统的时间。
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3335200/linux/how-to-monitor-activity-on-your-linux-server.html
+
+作者:[Sandra Henry-Stocker][a]
+选题:[lujun9972][b]
+译者:[dianbanjiu](https://github.com/dianbanjiu)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
+[b]: https://github.com/lujun9972
+[1]: https://www.facebook.com/NetworkWorld/
+[2]: https://www.linkedin.com/company/network-world
diff --git a/published/201902/20190124 Get started with LogicalDOC, an open source document management system.md b/published/201902/20190124 Get started with LogicalDOC, an open source document management system.md
new file mode 100644
index 0000000000..35e90d4839
--- /dev/null
+++ b/published/201902/20190124 Get started with LogicalDOC, an open source document management system.md
@@ -0,0 +1,63 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10561-1.html)
+[#]: subject: (Get started with LogicalDOC, an open source document management system)
+[#]: via: (https://opensource.com/article/19/1/productivity-tool-logicaldoc)
+[#]: author: (Kevin Sonney https://opensource.com/users/ksonney)
+
+开始使用 LogicalDOC 吧,一个开源文档管理系统
+======
+
+> 使用 LogicalDOC 更好地跟踪文档版本,这是我们开源工具系列中的第 12 个工具,它将使你在 2019 年更高效。
+
+
+
+每年年初似乎都有疯狂的冲动想提高工作效率。新年的决心,渴望开启新的一年,当然,“抛弃旧的,拥抱新的”的态度促成了这一切。通常这时的建议严重偏向闭源和专有软件,但事实上并不用这样。
+
+这是我挑选出的 19 个新的(或者对你而言新的)开源工具中的第 12 个工具来帮助你在 2019 年更有效率。
+
+### LogicalDOC
+
+高效部分表现在能够在你需要时找到你所需的东西。我们都看到过塞满名称类似的文件的目录,这是每次更改文档时为了跟踪所有版本而重命名这些文件而导致的。例如,我的妻子是一名作家,她在将文档发送给审稿人之前,她经常使用新名称保存文档修订版。
+
+
+
+程序员对此一个自然的解决方案是 Git 或者其他版本控制器,但这个不适用于文档作者,因为用于代码的系统通常不能很好地兼容商业文本编辑器使用的格式。之前有人说,“改变格式就行”,[这不是适合每个人的选择][1]。同样,许多版本控制工具对于非技术人员来说并不是非常友好。在大型组织中,有一些工具可以解决此问题,但它们还需要大型组织的资源来运行、管理和支持它们。
+
+
+
+[LogicalDOC CE][2] 是为解决此问题而编写的开源文档管理系统。它允许用户签入、签出、查看版本、搜索和锁定文档,并保留版本历史记录,类似于程序员使用的版本控制工具。
+
+LogicalDOC 可在 Linux、MacOS 和 Windows 上[安装][3],使用基于 Java 的安装程序。在安装时,系统将提示你提供数据库存储位置,并提供只在本地文件存储的选项。你将获得访问服务器的 URL 和默认用户名和密码,以及保存用于自动安装脚本选项。
+
+登录后,LogicalDOC 的默认页面会列出你已标记、签出的文档以及有关它们的最新说明。切换到“文档”选项卡将显示你有权访问的文件。你可以在界面中选择文件或使用拖放来上传文档。如果你上传 ZIP 文件,LogicalDOC 会解压它,并将其中的文件添加到仓库中。
+
+
+
+右键单击文件将显示一个菜单选项,包括检出文件、锁定文件以防止更改,以及执行大量其他操作。签出文件会将其下载到本地计算机以便编辑。在重新签入之前,其他任何人都无法修改签出的文件。当重新签入文件时(使用相同的菜单),用户可以向版本添加标签,并且需要备注对其执行的操作。
+
+
+
+查看早期版本只需在“版本”页面下载就行。对于某些第三方服务,它还有导入和导出选项,内置 [Dropbox][4] 支持。
+
+文档管理不仅仅是能够负担得起昂贵解决方案的大公司才能有的。LogicalDOC 可帮助你追踪文档的版本历史,并为难以管理的文档提供了安全的仓库。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/1/productivity-tool-logicaldoc
+
+作者:[Kevin Sonney][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/ksonney (Kevin Sonney)
+[b]: https://github.com/lujun9972
+[1]: http://www.antipope.org/charlie/blog-static/2013/10/why-microsoft-word-must-die.html
+[2]: https://www.logicaldoc.com/download-logicaldoc-community
+[3]: https://docs.logicaldoc.com/en/installation
+[4]: https://dropbox.com
diff --git a/published/201902/20190124 Understanding Angle Brackets in Bash.md b/published/201902/20190124 Understanding Angle Brackets in Bash.md
new file mode 100644
index 0000000000..1c8f4ffe7c
--- /dev/null
+++ b/published/201902/20190124 Understanding Angle Brackets in Bash.md
@@ -0,0 +1,154 @@
+[#]: collector: (lujun9972)
+[#]: translator: (HankChow)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10502-1.html)
+[#]: subject: (Understanding Angle Brackets in Bash)
+[#]: via: (https://www.linux.com/blog/learn/2019/1/understanding-angle-brackets-bash)
+[#]: author: (Paul Brown https://www.linux.com/users/bro66)
+
+理解 Bash 中的尖括号
+======
+
+> 为初学者介绍尖括号。
+
+
+
+[Bash][1] 内置了很多诸如 `ls`、`cd`、`mv` 这样的重要的命令,也有很多诸如 `grep`、`awk`、`sed` 这些有用的工具。但除此之外,其实 [Bash][1] 中还有很多可以[起到胶水作用][2]的标点符号,例如点号(`.`)、逗号(`,`)、括号(`<>`)、引号(`"`)之类。下面我们就来看一下可以用来进行数据转换和转移的尖括号(`<>`)。
+
+### 转移数据
+
+如果你对其它编程语言有所了解,你会知道尖括号 `<` 和 `>` 一般是作为逻辑运算符,用来比较两个值之间的大小关系。如果你还编写 HTML,尖括号作为各种标签的一部分,就更不会让你感到陌生了。
+
+在 shell 脚本语言中,尖括号可以将数据从一个地方转移到另一个地方。例如可以这样把数据存放到一个文件当中:
+
+```
+ls > dir_content.txt
+```
+
+在上面的例子中,`>` 符号让 shell 将 `ls` 命令的输出结果写入到 `dir_content.txt` 里,而不是直接显示在命令行中。需要注意的是,如果 `dir_content.txt` 这个文件不存在,Bash 会为你创建;但是如果 `dir_content.txt` 是一个已有的非空文件,它的内容就会被覆盖掉。所以执行类似的操作之前务必谨慎。
+
+你也可以不使用 `>` 而使用 `>>`,这样就可以把新的数据追加到文件的末端而不会覆盖掉文件中已有的数据了。例如:
+
+```
+ls $HOME > dir_content.txt; wc -l dir_content.txt >> dir_content.txt
+```
+
+在这串命令里,首先将家目录的内容写入到 `dir_content.txt` 文件中,然后使用 `wc -l` 计算出 `dir_content.txt` 文件的行数(也就是家目录中的文件数)并追加到 `dir_content.txt` 的末尾。
+
+在我的机器上执行上述命令之后,`dir_content.txt` 的内容会是以下这样:
+
+```
+Applications
+bin
+cloud
+Desktop
+Documents
+Downloads
+Games
+ISOs
+lib
+logs
+Music
+OpenSCAD
+Pictures
+Public
+Templates
+test_dir
+Videos
+17 dir_content.txt
+```
+
+你可以将 `>` 和 `>>` 作为箭头来理解。当然,这个箭头的指向也可以反过来。例如,Coen brothers
+(LCTT 译注:科恩兄弟,一个美国电影导演组合)的一些演员以及他们出演电影的次数保存在 `CBActors` 文件中,就像这样:
+
+```
+John Goodman 5
+John Turturro 3
+George Clooney 2
+Frances McDormand 6
+Steve Buscemi 5
+Jon Polito 4
+Tony Shalhoub 3
+James Gandolfini 1
+```
+
+你可以执行这样的命令:
+
+```
+sort < CBActors
+Frances McDormand 6 # 你会得到这样的输出
+George Clooney 2
+James Gandolfini 1
+John Goodman 5
+John Turturro 3
+Jon Polito 4
+Steve Buscemi 5
+Tony Shalhoub 3
+```
+
+就可以使用 [sort][4] 命令将这个列表按照字母顺序输出。但是,`sort` 命令本来就可以接受传入一个文件,因此在这里使用 `<` 会略显多余,直接执行 `sort CBActors` 就可以得到期望的结果。
+
+如果你想知道 Coens 最喜欢的演员是谁,你可以这样操作。首先:
+
+```
+while read name surname films; do echo $films $name $surname > filmsfirst.txt; done < CBActors
+```
+
+上面这串命令写在多行中可能会比较易读:
+
+```
+while read name surname films;\
+ do
+ echo $films $name $surname >> filmsfirst;\
+ done < CBActors
+```
+
+下面来分析一下这些命令做了什么:
+
+ * [while ...; do ... done][5] 是一个循环结构。当 `while` 后面的条件成立时,`do` 和 `done` 之间的部分会一直重复执行;
+ * [read][6] 语句会按行读入内容。`read` 会从标准输入中持续读入,直到没有内容可读入;
+ * `CBActors` 文件的内容会通过 `<` 从标准输入中读入,因此 `while` 循环会将 `CBActors` 文件逐行完整读入;
+ * `read` 命令可以按照空格将每一行内容划分为三个字段,然后分别将这三个字段赋值给 `name`、`surname` 和 `films` 三个变量,这样就可以很方便地通过 `echo $films $name $surname >> filmsfirst;\` 来重新排列几个字段的放置顺序并存放到 `filmfirst` 文件里面了。
+
+执行完以后,查看 `filmsfirst` 文件,内容会是这样的:
+
+```
+5 John Goodman
+3 John Turturro
+2 George Clooney
+6 Frances McDormand
+5 Steve Buscemi
+4 Jon Polito
+3 Tony Shalhoub
+1 James Gandolfini
+```
+
+这时候再使用 `sort` 命令:
+
+```
+sort -r filmsfirst
+```
+
+就可以看到 Coens 最喜欢的演员是 Frances McDormand 了。(`-r` 参数表示降序排列,因此 McDormand 会排在最前面)
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/blog/learn/2019/1/understanding-angle-brackets-bash
+
+作者:[Paul Brown][a]
+选题:[lujun9972][b]
+译者:[HankChow](https://github.com/HankChow)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.linux.com/users/bro66
+[b]: https://github.com/lujun9972
+[1]: https://www.linux.com/blog/2019/1/bash-shell-utility-reaches-50-milestone
+[2]: https://www.linux.com/blog/learn/2019/1/linux-tools-meaning-dot
+[3]: https://linux.die.net/man/1/wc
+[4]: https://linux.die.net/man/1/sort
+[5]: http://tldp.org/HOWTO/Bash-Prog-Intro-HOWTO-7.html
+[6]: https://linux.die.net/man/2/read
+
diff --git a/published/201902/20190125 PyGame Zero- Games without boilerplate.md b/published/201902/20190125 PyGame Zero- Games without boilerplate.md
new file mode 100644
index 0000000000..523c7e4561
--- /dev/null
+++ b/published/201902/20190125 PyGame Zero- Games without boilerplate.md
@@ -0,0 +1,101 @@
+[#]: collector: (lujun9972)
+[#]: translator: (bestony)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10532-1.html)
+[#]: subject: (PyGame Zero: Games without boilerplate)
+[#]: via: (https://opensource.com/article/19/1/pygame-zero)
+[#]: author: (Moshe Zadka https://opensource.com/users/moshez)
+
+PyGame Zero: 无需模板的游戏开发
+======
+
+> 在你的游戏开发过程中有了 PyGame Zero,和枯燥的模板说再见吧。
+
+
+
+Python 是一个很好的入门级编程语言。并且,游戏是一个很好的入门项目:它们是可视化的,自驱动的,并且可以很愉快的与朋友和家人分享。虽然,绝大多数的 Python 写就的库,比如 [PyGame][1] ,会让初学者因为忘记微小的细节很容易导致什么都没渲染而感到困扰。
+
+在理解所有部分的作用之前,他们会将其中的许多部分都视为“无意识的模板文件”——需要复制和粘贴到程序中才能使其工作的神奇段落。
+
+[PyGame Zero][2] 试图通过在 PyGame 上放置一个抽象层来弥合这一差距,因此它字面上并不需要模板。
+
+我们在说的“字面”,就是在指字面。
+
+这是一个合格的 PyGame Zero 文件:
+
+```
+# This comment is here for clarity reasons
+```
+
+我们可以将它放在一个 `game.py` 文件里,并运行:
+
+```
+$ pgzrun game.py
+```
+
+这将会展示一个窗口,并运行一个可以通过关闭窗口或按下 `CTRL-C` 中断的游戏循环。
+
+遗憾的是,这将是一场无聊的游戏。什么都没发生。
+
+为了让它更有趣一点,我们可以画一个不同的背景:
+
+```
+def draw():
+ screen.fill((255, 0, 0))
+```
+
+这将会把背景色从黑色换为红色。但是这仍是一个很无聊的游戏,什么都没发生。我们可以让它变的更有意思一点:
+
+```
+colors = [0, 0, 0]
+
+def draw():
+ screen.fill(tuple(colors))
+
+def update():
+ colors[0] = (colors[0] + 1) % 256
+```
+
+这将会让窗口从黑色开始,逐渐变亮,直到变为亮红色,再返回黑色,一遍一遍循环。
+
+`update` 函数更新了参数的值,而 `draw` 基于这些参数渲染这个游戏。
+
+即使是这样,这里也没有任何方式给玩家与这个游戏的交互的方式。让我们试试其他一些事情:
+
+```
+colors = [0, 0, 0]
+
+def draw():
+ screen.fill(tuple(colors))
+
+def update():
+ colors[0] = (colors[0] + 1) % 256
+
+def on_key_down(key, mod, unicode):
+ colors[1] = (colors[1] + 1) % 256
+```
+
+现在,按下按键来提升亮度。
+
+这些包括游戏循环的三个重要部分:响应用户输入,更新参数和重新渲染屏幕。
+
+PyGame Zero 提供了更多功能,包括绘制精灵图和播放声音片段的功能。
+
+试一试,看看你能想出什么类型的游戏!
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/1/pygame-zero
+
+作者:[Moshe Zadka][a]
+选题:[lujun9972][b]
+译者:[bestony](https://github.com/bestony)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/moshez
+[b]: https://github.com/lujun9972
+[1]: https://www.pygame.org/news
+[2]: https://pygame-zero.readthedocs.io/en/stable/
diff --git a/published/201902/20190125 Top 5 Linux Distributions for Development in 2019.md b/published/201902/20190125 Top 5 Linux Distributions for Development in 2019.md
new file mode 100644
index 0000000000..ae358bfbe0
--- /dev/null
+++ b/published/201902/20190125 Top 5 Linux Distributions for Development in 2019.md
@@ -0,0 +1,138 @@
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10534-1.html)
+[#]: subject: (Top 5 Linux Distributions for Development in 2019)
+[#]: via: (https://www.linux.com/blog/2019/1/top-5-linux-distributions-development-2019)
+[#]: author: (Jack Wallen https://www.linux.com/users/jlwallen)
+
+5 个用于开发工作的 Linux 发行版
+======
+
+> 这五个发行版用于开发工作将不会让你失望。
+
+
+
+Linux 上最受欢迎的任务之一肯定是开发。理由很充分:业务依赖于 Linux。没有 Linux,技术根本无法满足当今不断发展的世界的需求。因此,开发人员不断努力改善他们的工作环境。而进行此类改善的一种方法就是拥有合适的平台。值得庆幸的是,这就是 Linux,所以你总是有很多选择。
+
+但有时候,太多的选择本身就是一个问题。哪种发行版适合你的开发需求?当然,这取决于你正在开发的工作,但某些发行版更适合作为你的工作任务的基础。我将重点介绍我认为 2019 年最适合开发人员的五个发行版。
+
+### Ubuntu
+
+无需赘言。虽然 Linux Mint 的忠实用户无疑是一个非常忠诚的群体(这是有充分的理由的,他们选择的发行版很棒),但 Ubuntu Linux 在这里更被认可。为什么?因为有像 [AWS][1] 这样的云服务商存在,Ubuntu 成了部署最多的服务器操作系统之一。这意味着在 Ubuntu 桌面发行版上进行开发可以更轻松地转换为 Ubuntu Server。而且因为 Ubuntu 使得开发、使用和部署容器非常容易,所以你想要使用这个平台是完全合理的。而 Ubuntu 与其包含的 Snap 软件包相结合,使得这个 Canonical(Ubuntu 发行版背后的公司)的操作系统如虎添翼。
+
+但这不仅是你可以用 Ubuntu 做什么,而是你可以轻松做到。几乎对于所有的任务,Ubuntu 都是一个非常易用的发行版。而且因为 Ubuntu 如此受欢迎,所以你可以从 Ubuntu “软件” 应用的图形界面里轻松安装你想要使用的每个工具和 IDE(图 1)。
+
+![Ubuntu][3]
+
+*图 1:可以在 Ubuntu “软件”工具里面找到开发者工具。*
+
+如果你正在寻求易用、易于迁移,以及大量的工具,那么将 Ubuntu 作为开发平台就不会有错。
+
+### openSUSE
+
+我将 openSUSE 添加到此列表中有一个非常具体的原因。它不仅是一个出色的桌面发行版,它还是市场上最好的滚动发行版之一。因此,如果你希望用最新的软件开发、发布最新的软件,[openSUSE Tumbleweed][5] 应该是你的首选之一。如果你想使用最喜欢的 IDE 的最新版本,如果你总是希望确保使用最新的库和工具包进行开发,那么 Tumbleweed 就是你的平台。
+
+但 openSUSE 不仅提供滚动发布版本。如果你更愿意使用标准发行版,那么 [openSUSE Leap][6] 就是你想要的。
+
+当然,它不仅有标准版或滚动版,openSUSE 平台还有一个名为 [Kubic][7] 的 Kubernetes 特定版本,该版本基于 openSUSE MicroOS 上的 Kubernetes。但即使你没有为 Kubernetes 进行开发,你也会发现许多软件和工具可供使用。
+
+openSUSE 还提供了选择桌面环境的能力,或者你也可以选择通用桌面或服务器(图 2)。
+
+![openSUSE][9]
+
+*图 2: 正在安装 openSUSE Tumbleweed。*
+
+### Fedora
+
+使用 Fedora 作为开发平台才有意义。为什么?这个发行版本身似乎是面向开发人员的。通过定期的六个月发布周期,开发人员可以确保他们不会一直使用过时的软件。当你需要最新的工具和库时,这很重要。如果你正在开发企业级业务,Fedora 是一个理想的平台,因为它是红帽企业 Linux(RHEL)的上游。这意味着向 RHEL 的过渡应该是无痛的。这一点很重要,特别是如果你希望将你的项目带到一个更大的市场(一个比以桌面为中心的目标更深的领域)。
+
+Fedora 还提供了你将体验到的最佳 GNOME 体验之一(图 3)。换言之,这是非常稳定和快速的桌面。
+
+![GNOME][11]
+
+*图 3:Fedora 上的 GNOME 桌面。*
+
+但是如果 GNOME 不是你的菜,你还可以选择安装一个 [Fedora 花样版][12](包括 KDE、XFCE、LXQT、Mate-Compiz、Cinnamon、LXDE 和 SOAS 等桌面环境)。
+
+### Pop!_OS
+
+如果这个列表中我没有包括 [System76][13] 平台专门为他们的硬件定制的操作系统(虽然它也在其他硬件上运行良好),那我算是失职了。为什么我要包含这样的发行版,尤其是它还并未远离其所基于的 Ubuntu 平台?主要是因为如果你计划从 System76 购买台式机或笔记本电脑,那它就是你想要的发行版。但是你为什么要这样做呢(特别是考虑到 Linux 几乎适用于所有现成的硬件)?因为 System76 销售的出色硬件。随着他们的 Thelio 桌面的发布,这是你可以使用的市场上最强大的台式计算机之一。如果你正在努力开发大型应用程序(特别是那些非常依赖于非常大的数据库或需要大量处理能力进行编译的应用程序),为什么不用最好的计算机呢?而且由于 Pop!_OS 完全适用于 System76 硬件,因此这是一个明智的选择。
+
+由于 Pop!_OS 基于 Ubuntu,因此你可以轻松获得其所基于的 Ubuntu 可用的所有工具(图 4)。
+
+![Pop!_OS][15]
+
+*图 4:运行在 Pop!_OS 上的 Anjunta IDE*
+
+Pop!_OS 也会默认加密驱动器,因此你可以放心你的工作可以避免窥探(如果你的硬件落入坏人之手)。
+
+### Manjaro
+
+对于那些喜欢在 Arch Linux 上开发,但不想经历安装和使用 Arch Linux 的所有环节的人来说,那选择就是 Manjaro。Manjaro 可以轻松地启动和运行一个基于 Arch Linux 的发行版(就像安装和使用 Ubuntu 一样简单)。
+
+但是 Manjaro 对开发人员友好的原因(除了享受 Arch 式好处)是你可以下载好多种不同口味的桌面。从[Manjaro 下载页面][16] 中,你可以获得以下口味:
+
+ * GNOME
+ * XFCE
+ * KDE
+ * OpenBox
+ * Cinnamon
+ * I3
+ * Awesome
+ * Budgie
+ * Mate
+ * Xfce 开发者预览版
+ * KDE 开发者预览版
+ * GNOME 开发者预览版
+ * Architect
+ * Deepin
+
+值得注意的是它的开发者版本(面向测试人员和开发人员),Architect 版本(适用于想要从头开始构建 Manjaro 的用户)和 Awesome 版本(图 5,适用于开发人员处理日常工作的版本)。使用 Manjaro 的一个警告是,与任何滚动版本一样,你今天开发的代码可能明天无法运行。因此,你需要具备一定程度的敏捷性。当然,如果你没有为 Manjaro(或 Arch)做开发,并且你正在进行工作更多是通用的(或 Web)开发,那么只有当你使用的工具被更新了且不再适合你时,才会影响你。然而,这种情况发生的可能性很小。和大多数 Linux 发行版一样,你会发现 Manjaro 有大量的开发工具。
+
+![Manjaro][18]
+
+*图 5:Manjaro Awesome 版对于开发者来说很棒。*
+
+Manjaro 还支持 AUR(Arch User Repository —— Arch 用户的社区驱动软件库),其中包括最先进的软件和库,以及 [Unity Editor][19] 或 yEd 等专有应用程序。但是,有个关于 AUR 的警告:AUR 包含的软件中被怀疑发现了恶意软件。因此,如果你选择使用 AUR,请谨慎操作,风险自负。
+
+### 其实任何 Linux 都可以
+
+说实话,如果你是开发人员,几乎任何 Linux 发行版都可以工作。如果从命令行执行大部分开发,则尤其如此。但是如果你喜欢在可靠的桌面上运行一个好的图形界面程序,试试这些发行版中的一个,它们不会令人失望。
+
+通过 Linux 基金会和 edX 的免费[“Linux 简介”][20]课程了解有关 Linux 的更多信息。
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/blog/2019/1/top-5-linux-distributions-development-2019
+
+作者:[Jack Wallen][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.linux.com/users/jlwallen
+[b]: https://github.com/lujun9972
+[1]: https://aws.amazon.com/
+[2]: https://www.linux.com/files/images/dev1jpg
+[3]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/dev_1.jpg?itok=7QJQWBKi (Ubuntu)
+[4]: https://www.linux.com/licenses/category/used-permission
+[5]: https://en.opensuse.org/Portal:Tumbleweed
+[6]: https://en.opensuse.org/Portal:Leap
+[7]: https://software.opensuse.org/distributions/tumbleweed
+[8]: /files/images/dev2jpg
+[9]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/dev_2.jpg?itok=1GJmpr1t (openSUSE)
+[10]: /files/images/dev3jpg
+[11]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/dev_3.jpg?itok=_6Ki4EOo (GNOME)
+[12]: https://spins.fedoraproject.org/
+[13]: https://system76.com/
+[14]: /files/images/dev4jpg
+[15]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/dev_4.jpg?itok=nNG2Ax24 (Pop!_OS)
+[16]: https://manjaro.org/download/
+[17]: /files/images/dev5jpg
+[18]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/dev_5.jpg?itok=RGfF2UEi (Manjaro)
+[19]: https://unity3d.com/unity/editor
+[20]: https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/published/201902/20190126 Get started with Tint2, an open source taskbar for Linux.md b/published/201902/20190126 Get started with Tint2, an open source taskbar for Linux.md
new file mode 100644
index 0000000000..1efd095a38
--- /dev/null
+++ b/published/201902/20190126 Get started with Tint2, an open source taskbar for Linux.md
@@ -0,0 +1,59 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10511-1.html)
+[#]: subject: (Get started with Tint2, an open source taskbar for Linux)
+[#]: via: (https://opensource.com/article/19/1/productivity-tool-tint2)
+[#]: author: (Kevin Sonney https://opensource.com/users/ksonney (Kevin Sonney))
+
+开始使用 Tint2 吧,一款 Linux 中的开源任务栏
+======
+
+> Tint2 是我们在开源工具系列中的第 14 个工具,它将在 2019 年提高你的工作效率,能在任何窗口管理器中提供一致的用户体验。
+
+
+
+每年年初似乎都有疯狂的冲动想提高工作效率。新年的决心,渴望开启新的一年,当然,“抛弃旧的,拥抱新的”的态度促成了这一切。通常这时的建议严重偏向闭源和专有软件,但事实上并不用这样。
+
+这是我挑选出的 19 个新的(或者对你而言新的)开源工具中的第 14个工具来帮助你在 2019 年更有效率。
+
+### Tint2
+
+让我提高工作效率的最佳方法之一是使用尽可能不让我分心的干净界面。作为 Linux 用户,这意味着使用一种极简的窗口管理器,如 [Openbox][1]、[i3][2] 或 [Awesome][3]。它们每种都有让我更有效率的自定义选项。但让我失望的一件事是,它们都没有一致的配置,所以我不得不经常重新调整我的窗口管理器。
+
+
+
+[Tint2][4] 是一个轻量级面板和任务栏,它可以为任何窗口管理器提供一致的体验。它包含在大多数发行版中,因此它与任何其他软件包一样易于安装。
+
+它包括两个程序,Tint2 和 Tint2conf。首次启动时,Tint2 以默认布局和主题启动。默认配置包括多个 Web 浏览器、tint2conf 程序,任务栏和系统托盘。
+
+
+
+启动该配置工具能让你选择主题并自定义屏幕的顶部、底部和侧边栏。我建议从最接近你想要的主题开始,然后从那里进行自定义。
+
+
+
+在主题中,你可以自定义面板项目的位置以及面板上每个项目的背景和字体选项。你还可以在启动器中添加和删除项目。
+
+
+
+Tint2 是一个轻量级的任务栏,可以帮助你快速有效地获得所需的工具。它是高度可定制的,不显眼的 (除非用户不希望这样),并且几乎与 Linux 桌面中的任何窗口管理器兼容。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/1/productivity-tool-tint2
+
+作者:[Kevin Sonney][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/ksonney (Kevin Sonney)
+[b]: https://github.com/lujun9972
+[1]: http://openbox.org/wiki/Main_Page
+[2]: https://i3wm.org/
+[3]: https://awesomewm.org/
+[4]: https://gitlab.com/o9000/tint2
diff --git a/published/201902/20190127 Get started with eDEX-UI, a Tron-influenced terminal program for tablets and desktops.md b/published/201902/20190127 Get started with eDEX-UI, a Tron-influenced terminal program for tablets and desktops.md
new file mode 100644
index 0000000000..aa42bef0ea
--- /dev/null
+++ b/published/201902/20190127 Get started with eDEX-UI, a Tron-influenced terminal program for tablets and desktops.md
@@ -0,0 +1,57 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10525-1.html)
+[#]: subject: (Get started with eDEX-UI, a Tron-influenced terminal program for tablets and desktops)
+[#]: via: (https://opensource.com/article/19/1/productivity-tool-edex-ui)
+[#]: author: (Kevin Sonney https://opensource.com/users/ksonney (Kevin Sonney))
+
+开始使用 eDEX-UI 吧,一款受《电子世界争霸战》影响的终端程序
+======
+
+> 使用 eDEX-UI 让你的工作更有趣,这是我们开源工具系列中的第 15 个工具,它将使你在 2019 年更高效。
+
+
+
+每年年初似乎都有疯狂的冲动想提高工作效率。新年的决心,渴望开启新的一年,当然,“抛弃旧的,拥抱新的”的态度促成了这一切。通常这时的建议严重偏向闭源和专有软件,但事实上并不用这样。
+
+这是我挑选出的 19 个新的(或者对你而言新的)开源工具中的第 15 个工具来帮助你在 2019 年更有效率。
+
+### eDEX-UI
+
+当[《电子世界争霸战》][1]上映时我才 11 岁。我不能否认,尽管这部电影充满幻想,但它对我后来的职业选择产生了影响。
+
+
+
+[eDEX-UI][2] 是一款专为平板电脑和台式机设计的跨平台终端程序,它的用户界面受到《电子世界争霸战》的启发。它在选项卡式界面中有五个终端,因此可以轻松地在任务之间切换,以及显示有用的系统信息。
+
+在启动时,eDEX-UI 会启动一系列的东西,其中包含它所基于的 ElectronJS 系统的信息。启动后,eDEX-UI 会显示系统信息、文件浏览器、键盘(用于平板电脑)和主终端选项卡。其他四个选项卡(被标记为 EMPTY)没有加载任何内容,并且当你单击它时将启动一个 shell。eDEX-UI 中的默认 shell 是 Bash(如果在 Windows 上,则可能需要将其更改为 PowerShell 或 cmd.exe)。
+
+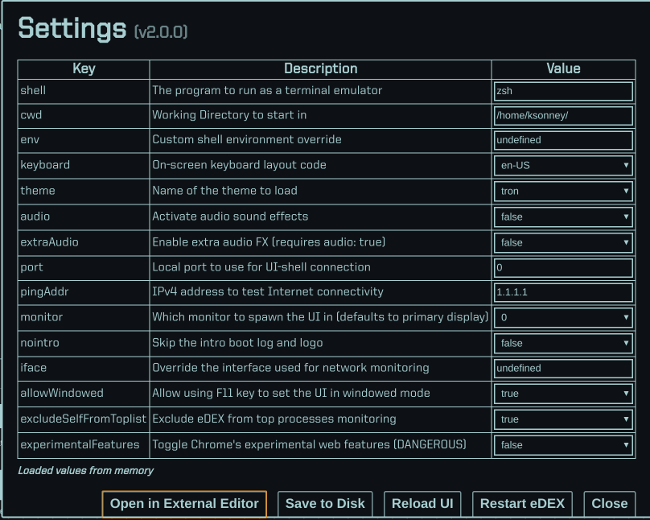
+
+更改文件浏览器中的目录也将更改活动终端中的目录,反之亦然。文件浏览器可以执行你期望的所有操作,包括在单击文件时打开关联的应用。唯一的例外是 eDEX-UI 的 `settings.json` 文件(默认在 `.config/eDEX-UI`),它会打开配置编辑器。这允许你为终端设置 shell 命令、更改主题以及修改用户界面的其他几个设置。主题也保存在配置目录中,因为它们也是 JSON 文件,所以创建自定义主题非常简单。
+
+
+
+eDEX-UI 允许你使用完全仿真运行五个终端。默认终端类型是 xterm-color,这意味着它支持全色彩。需要注意的一点是,输入时键会亮起,因此如果你在平板电脑上使用 eDEX-UI,键盘可能会在人们看见屏幕的环境中带来安全风险。因此最好在这些设备上使用没有键盘的主题,尽管在打字时看起来确实很酷。
+
+
+
+虽然 eDEX-UI 仅支持五个终端窗口,但这对我来说已经足够了。在平板电脑上,eDEX-UI 给了我网络空间感而不会影响我的效率。在桌面上,eDEX-UI 支持所有功能,并让我在我的同事面前显得很酷。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/1/productivity-tool-edex-ui
+
+作者:[Kevin Sonney][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/ksonney (Kevin Sonney)
+[b]: https://github.com/lujun9972
+[1]: https://en.wikipedia.org/wiki/Tron
+[2]: https://github.com/GitSquared/edex-ui
diff --git a/published/201902/20190128 3 simple and useful GNOME Shell extensions.md b/published/201902/20190128 3 simple and useful GNOME Shell extensions.md
new file mode 100644
index 0000000000..3125f76e71
--- /dev/null
+++ b/published/201902/20190128 3 simple and useful GNOME Shell extensions.md
@@ -0,0 +1,73 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10536-1.html)
+[#]: subject: (3 simple and useful GNOME Shell extensions)
+[#]: via: (https://fedoramagazine.org/3-simple-and-useful-gnome-shell-extensions/)
+[#]: author: (Ryan Lerch https://fedoramagazine.org/introducing-flatpak/)
+
+3 个简单实用的 GNOME Shell 扩展
+======
+
+
+Fedora 工作站的默认桌面 GNOME Shell,因其极简、整洁的用户界面而闻名,并深受许多用户的喜爱。它还以可使用扩展添加到 stock 界面的能力而闻名。在本文中,我们将介绍 GNOME Shell 的 3 个简单且有用的扩展。这三个扩展为你的桌面提供了更多的行为,可以完成你可能每天都会做的简单任务。
+
+### 安装扩展程序
+
+安装 GNOME Shell 扩展的最快捷、最简单的方法是使用“软件”应用。有关详细信息,请查看 Magazine [以前的文章](https://fedoramagazine.org/install-extensions-via-software-application/):
+
+
+
+### 可移动驱动器菜单
+
+![][1]
+
+*Fedora 29 中的 Removable Drive Menu 扩展*
+
+首先是 [Removable Drive Menu][2] 扩展。如果你的计算机中有可移动驱动器,它是一个可在系统托盘中添加一个 widget 的简单工具。它可以使你轻松打开可移动驱动器中的文件,或者快速方便地弹出驱动器以安全移除设备。
+
+![][3]
+
+*软件应用中的 Removable Drive Menu*
+
+### 扩展之扩展
+
+![][4]
+
+如果你一直在安装和尝试新扩展,那么 [Extensions][5] 扩展非常有用。它提供了所有已安装扩展的列表,允许你启用或禁用它们。此外,如果该扩展有设置,那么可以快速打开每个扩展的设置对话框。
+
+![][6]
+
+*软件中的 Extensions 扩展*
+
+### 无用的时钟移动
+
+![][7]
+
+最后的是列表中最简单的扩展。[Frippery Move Clock][8],只是将时钟位置从顶部栏的中心向右移动,位于状态区旁边。
+
+![][9]
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/3-simple-and-useful-gnome-shell-extensions/
+
+作者:[Ryan Lerch][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://fedoramagazine.org/introducing-flatpak/
+[b]: https://github.com/lujun9972
+[1]: https://fedoramagazine.org/wp-content/uploads/2019/01/removable-disk-1024x459.jpg
+[2]: https://extensions.gnome.org/extension/7/removable-drive-menu/
+[3]: https://fedoramagazine.org/wp-content/uploads/2019/01/removable-software-1024x723.png
+[4]: https://fedoramagazine.org/wp-content/uploads/2019/01/extensions-extension-1024x459.jpg
+[5]: https://extensions.gnome.org/extension/1036/extensions/
+[6]: https://fedoramagazine.org/wp-content/uploads/2019/01/extensions-software-1024x723.png
+[7]: https://fedoramagazine.org/wp-content/uploads/2019/01/move_clock-1024x189.jpg
+[8]: https://extensions.gnome.org/extension/2/move-clock/
+[9]: https://fedoramagazine.org/wp-content/uploads/2019/01/Screenshot-from-2019-01-28-21-53-18-1024x723.png
diff --git a/published/201902/20190128 Using more to view text files at the Linux command line.md b/published/201902/20190128 Using more to view text files at the Linux command line.md
new file mode 100644
index 0000000000..9929654a94
--- /dev/null
+++ b/published/201902/20190128 Using more to view text files at the Linux command line.md
@@ -0,0 +1,97 @@
+[#]: collector: (lujun9972)
+[#]: translator: (dianbanjiu)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10531-1.html)
+[#]: subject: (Using more to view text files at the Linux command line)
+[#]: via: (https://opensource.com/article/19/1/more-text-files-linux)
+[#]: author: (Scott Nesbitt https://opensource.com/users/scottnesbitt)
+
+在 Linux 命令行使用 more 查看文本文件
+======
+
+> 文本文件和 Linux 一直是携手并进的。或者说看起来如此。那你又是依靠哪些让你使用起来很舒服的工具来查看这些文本文件的呢?
+
+
+
+Linux 下有很多实用工具可以让你在终端界面查看文本文件。其中一个就是 [more][1]。
+
+`more` 跟我之前另一篇文章里写到的工具 —— [less][2] 很相似。它们之间的主要不同点在于 `more` 只允许你向前查看文件。
+
+尽管它能提供的功能看起来很有限,不过它依旧有很多有用的特性值得你去了解。下面让我们来快速浏览一下 `more` 可以做什么,以及如何使用它吧。
+
+### 基础使用
+
+假设你现在想在终端查看一个文本文件。只需打开一个终端,进入对应的目录,然后输入以下命令:
+
+```shell
+$ more
+```
+
+例如,
+
+```shell
+$ more jekyll-article.md
+```
+
+
+
+使用空格键可以向下翻页,输入 `q` 可以退出。
+
+如果你想在这个文件中搜索一些文本,输入 `/` 字符并在其后加上你想要查找的文字。例如你要查看的字段是 “terminal”,只需输入:
+
+```
+/terminal
+```
+
+
+
+搜索的内容是区分大小写的,所以输入 `/terminal` 跟 `/Terminal` 会出现不同的结果。
+
+### 和其他实用工具组合使用
+
+你可以通过管道将其他命令行工具得到的文本传输到 `more`。你问为什么这样做?因为有时这些工具获取的文本会超过终端一页可以显示的限度。
+
+想要做到这个,先输入你想要使用的完整命令,后面跟上管道符(`|`),管道符后跟 `more`。假设现在有一个有很多文件的目录。你就可以组合 `more` 跟 `ls` 命令完整查看这个目录当中的内容。
+
+```shell
+$ ls | more
+```
+
+
+
+你可以组合 `more` 和 `grep` 命令,从而实现在多个文件中找到指定的文本。下面是我在多篇文章的源文件中查找 “productivity” 的例子。
+
+```shell
+$ grep ‘productivity’ core.md Dict.md lctt2014.md lctt2016.md lctt2018.md README.md | more
+```
+
+
+
+另外一个可以和 `more` 组合的实用工具是 `ps`(列出你系统上正在运行的进程)。当你的系统上运行了很多的进程,你现在想要查看他们的时候,这个组合将会派上用场。例如你想找到一个你需要杀死的进程,只需输入下面的命令:
+
+```shell
+$ ps -u scott | more
+```
+
+注意用你的用户名替换掉 “scott”。
+
+
+
+就像我文章开篇提到的, `more` 很容易使用。尽管不如它的双胞胎兄弟 `less` 那般灵活,但是仍然值得了解一下。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/1/more-text-files-linux
+
+作者:[Scott Nesbitt][a]
+选题:[lujun9972][b]
+译者:[dianbanjiu](https://github.com/dianbanjiu)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/scottnesbitt
+[b]: https://github.com/lujun9972
+[1]: https://en.wikipedia.org/wiki/More_(command)
+[2]: https://opensource.com/article/18/4/using-less-view-text-files-command-line
diff --git a/published/201902/20190128 fdisk - Easy Way To Manage Disk Partitions In Linux.md b/published/201902/20190128 fdisk - Easy Way To Manage Disk Partitions In Linux.md
new file mode 100644
index 0000000000..5ebe7d556c
--- /dev/null
+++ b/published/201902/20190128 fdisk - Easy Way To Manage Disk Partitions In Linux.md
@@ -0,0 +1,495 @@
+[#]: collector: (lujun9972)
+[#]: translator: (zhs852)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10508-1.html)
+[#]: subject: (fdisk – Easy Way To Manage Disk Partitions In Linux)
+[#]: via: (https://www.2daygeek.com/linux-fdisk-command-to-manage-disk-partitions/)
+[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
+
+fdisk:Linux 下管理磁盘分区的利器
+======
+
+一块硬盘可以被划分成一个或多个逻辑磁盘,我们将其称作分区。我们对硬盘进行的划分信息被储存于建立在扇区 0 的分区表(MBR 或 GPT)中。
+
+Linux 需要至少一个分区来当作根文件系统,所以我们不能在没有分区的情况下安装 Linux 系统。当我们创建一个分区时,我们必须将它格式化为一个适合的文件系统,否则我们就没办法往里面储存文件了。
+
+要在 Linux 中完成分区的相关工作,我们需要一些工具。Linux 下有很多可用的相关工具,我们曾介绍过 [Parted 命令][1]。不过,今天我们的主角是 `fdisk`。
+
+人人都喜欢用 `fdisk`,它是 Linux 下管理磁盘分区的最佳利器之一。它可以操作最大 2TB 的分区。大量 Linux 管理员都喜欢使用这个工具,因为当下 LVM 和 SAN 的原因,并没有多少人会用到 2TB 以上的分区。并且这个工具被世界上许多的基础设施所使用。如果你还是想创建比 2TB 更大的分区,请使用 `parted` 命令 或 `cfdisk` 命令。
+
+对磁盘进行分区和创建文件系统是 Linux 管理员的日常。如果你在许多不同的环境中工作,你一定每天都会重复几次这项操作。
+
+### Linux 内核是如何理解硬盘的?
+
+作为人类,我们可以很轻松地理解一些事情;但是电脑就不是这样了,它们需要合适的命名才能理解这些。
+
+在 Linux 中,外围设备都位于 `/dev` 挂载点,内核通过以下的方式理解硬盘:
+
+ * `/dev/hdX[a-z]:` IDE 硬盘被命名为 hdX
+ * `/dev/sdX[a-z]:` SCSI 硬盘被命名为 sdX
+ * `/dev/xdX[a-z]:` XT 硬盘被命名为 xdX
+ * `/dev/vdX[a-z]:` 虚拟硬盘被命名为 vdX
+ * `/dev/fdN:` 软盘被命名为 fdN
+ * `/dev/scdN or /dev/srN:` CD-ROM 被命名为 `/dev/scdN` 或 `/dev/srN`
+
+### 什么是 fdisk 命令?
+
+`fdisk` 的意思是 固定磁盘 或 格式化磁盘,它是命令行下允许用户对分区进行查看、创建、调整大小、删除、移动和复制的工具。它支持 MBR、Sun、SGI、BSD 分区表,但是它不支持 GUID 分区表(GPT)。它不是为操作大分区设计的。
+
+`fdisk` 允许我们在每块硬盘上创建最多四个主分区。它们中的其中一个可以作为扩展分区,并下设多个逻辑分区。1-4 扇区作为主分区被保留,逻辑分区从扇区 5 开始。
+
+![磁盘分区结构图][3]
+
+### 如何在 Linux 下安装 fdisk?
+
+`fdisk` 作为核心组件内置于 Linux 中,所以你不必手动安装它。
+
+### 如何用 fdisk 列出可用磁盘?
+
+在执行操作之前,我们必须知道的是哪些磁盘被加入了系统。要想列出所有可用的磁盘,请执行下文的命令。这个命令将会列出磁盘名称、分区数量、分区表类型、磁盘识别代号、分区 ID 和分区类型。
+
+```shell
+$ sudo fdisk -l
+Disk /dev/sda: 30 GiB, 32212254720 bytes, 62914560 sectors
+Units: sectors of 1 * 512 = 512 bytes
+Sector size (logical/physical): 512 bytes / 512 bytes
+I/O size (minimum/optimal): 512 bytes / 512 bytes
+Disklabel type: dos
+Disk identifier: 0xeab59449
+
+Device Boot Start End Sectors Size Id Type
+/dev/sda1 * 20973568 62914559 41940992 20G 83 Linux
+
+
+Disk /dev/sdb: 10 GiB, 10737418240 bytes, 20971520 sectors
+Units: sectors of 1 * 512 = 512 bytes
+Sector size (logical/physical): 512 bytes / 512 bytes
+I/O size (minimum/optimal): 512 bytes / 512 bytes
+
+
+Disk /dev/sdc: 10 GiB, 10737418240 bytes, 20971520 sectors
+Units: sectors of 1 * 512 = 512 bytes
+Sector size (logical/physical): 512 bytes / 512 bytes
+I/O size (minimum/optimal): 512 bytes / 512 bytes
+
+
+Disk /dev/sdd: 10 GiB, 10737418240 bytes, 20971520 sectors
+Units: sectors of 1 * 512 = 512 bytes
+Sector size (logical/physical): 512 bytes / 512 bytes
+I/O size (minimum/optimal): 512 bytes / 512 bytes
+
+
+Disk /dev/sde: 10 GiB, 10737418240 bytes, 20971520 sectors
+Units: sectors of 1 * 512 = 512 bytes
+Sector size (logical/physical): 512 bytes / 512 bytes
+I/O size (minimum/optimal): 512 bytes / 512 bytes
+```
+
+### 如何使用 fdisk 列出特定分区信息?
+
+如果你希望查看指定分区的信息,请使用以下命令:
+
+```shell
+$ sudo fdisk -l /dev/sda
+Disk /dev/sda: 30 GiB, 32212254720 bytes, 62914560 sectors
+Units: sectors of 1 * 512 = 512 bytes
+Sector size (logical/physical): 512 bytes / 512 bytes
+I/O size (minimum/optimal): 512 bytes / 512 bytes
+Disklabel type: dos
+Disk identifier: 0xeab59449
+
+Device Boot Start End Sectors Size Id Type
+/dev/sda1 * 20973568 62914559 41940992 20G 83 Linux
+```
+
+### 如何列出 fdisk 所有的可用操作?
+
+在 `fdisk` 中敲击 `m`,它便会列出所有可用操作:
+
+```shell
+$ sudo fdisk /dev/sdc
+
+Welcome to fdisk (util-linux 2.30.1).
+Changes will remain in memory only, until you decide to write them.
+Be careful before using the write command.
+
+Device does not contain a recognized partition table.
+Created a new DOS disklabel with disk identifier 0xe944b373.
+
+Command (m for help): m
+
+Help:
+
+ DOS (MBR)
+ a toggle a bootable flag
+ b edit nested BSD disklabel
+ c toggle the dos compatibility flag
+
+ Generic
+ d delete a partition
+ F list free unpartitioned space
+ l list known partition types
+ n add a new partition
+ p print the partition table
+ t change a partition type
+ v verify the partition table
+ i print information about a partition
+
+ Misc
+ m print this menu
+ u change display/entry units
+ x extra functionality (experts only)
+
+ Script
+ I load disk layout from sfdisk script file
+ O dump disk layout to sfdisk script file
+
+ Save & Exit
+ w write table to disk and exit
+ q quit without saving changes
+
+ Create a new label
+ g create a new empty GPT partition table
+ G create a new empty SGI (IRIX) partition table
+ o create a new empty DOS partition table
+ s create a new empty Sun partition table
+```
+
+### 如何使用 fdisk 列出分区类型?
+
+在 `fdisk` 中敲击 `l`,它便会列出所有可用分区的类型:
+
+```shell
+$ sudo fdisk /dev/sdc
+
+Welcome to fdisk (util-linux 2.30.1).
+Changes will remain in memory only, until you decide to write them.
+Be careful before using the write command.
+
+Device does not contain a recognized partition table.
+Created a new DOS disklabel with disk identifier 0x9ffd00db.
+
+Command (m for help): l
+
+ 0 Empty 24 NEC DOS 81 Minix / old Lin bf Solaris
+ 1 FAT12 27 Hidden NTFS Win 82 Linux swap / So c1 DRDOS/sec (FAT-
+ 2 XENIX root 39 Plan 9 83 Linux c4 DRDOS/sec (FAT-
+ 3 XENIX usr 3c PartitionMagic 84 OS/2 hidden or c6 DRDOS/sec (FAT-
+ 4 FAT16 <32M 40 Venix 80286 85 Linux extended c7 Syrinx
+ 5 Extended 41 PPC PReP Boot 86 NTFS volume set da Non-FS data
+ 6 FAT16 42 SFS 87 NTFS volume set db CP/M / CTOS / .
+ 7 HPFS/NTFS/exFAT 4d QNX4.x 88 Linux plaintext de Dell Utility
+ 8 AIX 4e QNX4.x 2nd part 8e Linux LVM df BootIt
+ 9 AIX bootable 4f QNX4.x 3rd part 93 Amoeba e1 DOS access
+ a OS/2 Boot Manag 50 OnTrack DM 94 Amoeba BBT e3 DOS R/O
+ b W95 FAT32 51 OnTrack DM6 Aux 9f BSD/OS e4 SpeedStor
+ c W95 FAT32 (LBA) 52 CP/M a0 IBM Thinkpad hi ea Rufus alignment
+ e W95 FAT16 (LBA) 53 OnTrack DM6 Aux a5 FreeBSD eb BeOS fs
+ f W95 Ext'd (LBA) 54 OnTrackDM6 a6 OpenBSD ee GPT
+10 OPUS 55 EZ-Drive a7 NeXTSTEP ef EFI (FAT-12/16/
+11 Hidden FAT12 56 Golden Bow a8 Darwin UFS f0 Linux/PA-RISC b
+12 Compaq diagnost 5c Priam Edisk a9 NetBSD f1 SpeedStor
+14 Hidden FAT16 <3 61 SpeedStor ab Darwin boot f4 SpeedStor
+16 Hidden FAT16 63 GNU HURD or Sys af HFS / HFS+ f2 DOS secondary
+17 Hidden HPFS/NTF 64 Novell Netware b7 BSDI fs fb VMware VMFS
+18 AST SmartSleep 65 Novell Netware b8 BSDI swap fc VMware VMKCORE
+1b Hidden W95 FAT3 70 DiskSecure Mult bb Boot Wizard hid fd Linux raid auto
+1c Hidden W95 FAT3 75 PC/IX bc Acronis FAT32 L fe LANstep
+1e Hidden W95 FAT1 80 Old Minix be Solaris boot ff BBT
+```
+### 如何使用 fdisk 创建一个磁盘分区?
+
+如果你希望新建磁盘分区,请参考下面的步骤。比如我希望在 `/dev/sdc` 中新建四个分区(三个主分区和一个扩展分区),只需要执行下文的命令。
+
+首先,请在操作 “First sector” 的时候先按下回车,然后在 “Last sector” 中输入你希望创建分区的大小(可以在数字后面加 KB、MB、G 和 TB)。例如,你希望为这个分区扩容 1GB,就应该在 “Last sector” 中输入 `+1G`。当你创建三个分区之后,`fdisk` 默认会将分区类型设为扩展分区,如果你希望创建第四个主分区,请输入 `p` 来替代它的默认值 `e`。
+
+```shell
+$ sudo fdisk /dev/sdc
+
+Welcome to fdisk (util-linux 2.30.1).
+Changes will remain in memory only, until you decide to write them.
+Be careful before using the write command.
+
+
+Command (m for help): n
+Partition type
+ p primary (0 primary, 0 extended, 4 free)
+ e extended (container for logical partitions)
+Select (default p): Enter
+
+Using default response p.
+Partition number (1-4, default 1): Enter
+First sector (2048-20971519, default 2048): Enter
+Last sector, +sectors or +size{K,M,G,T,P} (2048-20971519, default 20971519): +1G
+
+Created a new partition 1 of type 'Linux' and of size 1 GiB.
+
+Command (m for help): p
+Disk /dev/sdc: 10 GiB, 10737418240 bytes, 20971520 sectors
+Units: sectors of 1 * 512 = 512 bytes
+Sector size (logical/physical): 512 bytes / 512 bytes
+I/O size (minimum/optimal): 512 bytes / 512 bytes
+Disklabel type: dos
+Disk identifier: 0x8cc8f9e5
+
+Device Boot Start End Sectors Size Id Type
+/dev/sdc1 2048 2099199 2097152 1G 83 Linux
+
+Command (m for help): w
+The partition table has been altered.
+Calling ioctl() to re-read partition table.
+Syncing disks.
+```
+
+### 如何使用 fdisk 创建扩展分区?
+
+请注意,创建扩展分区时,你应该使用剩下的所有空间,以便之后在扩展分区下创建逻辑分区。
+
+```shell
+$ sudo fdisk /dev/sdc
+
+Welcome to fdisk (util-linux 2.30.1).
+Changes will remain in memory only, until you decide to write them.
+Be careful before using the write command.
+
+
+Command (m for help): n
+Partition type
+ p primary (3 primary, 0 extended, 1 free)
+ e extended (container for logical partitions)
+Select (default e): Enter
+
+Using default response e.
+Selected partition 4
+First sector (6293504-20971519, default 6293504): Enter
+Last sector, +sectors or +size{K,M,G,T,P} (6293504-20971519, default 20971519): Enter
+
+Created a new partition 4 of type 'Extended' and of size 7 GiB.
+
+Command (m for help): p
+Disk /dev/sdc: 10 GiB, 10737418240 bytes, 20971520 sectors
+Units: sectors of 1 * 512 = 512 bytes
+Sector size (logical/physical): 512 bytes / 512 bytes
+I/O size (minimum/optimal): 512 bytes / 512 bytes
+Disklabel type: dos
+Disk identifier: 0x8cc8f9e5
+
+Device Boot Start End Sectors Size Id Type
+/dev/sdc1 2048 2099199 2097152 1G 83 Linux
+/dev/sdc2 2099200 4196351 2097152 1G 83 Linux
+/dev/sdc3 4196352 6293503 2097152 1G 83 Linux
+/dev/sdc4 6293504 20971519 14678016 7G 5 Extended
+
+Command (m for help): w
+The partition table has been altered.
+Calling ioctl() to re-read partition table.
+Syncing disks.
+```
+
+### 如何用 fdisk 查看未分配空间?
+
+上文中,我们总共创建了四个分区(三个主分区和一个扩展分区)。在创建逻辑分区之前,扩展分区的容量将会以未分配空间显示。
+
+使用以下命令来显示磁盘上的未分配空间,下面的示例中显示的是 7GB:
+
+```shell
+$ sudo fdisk /dev/sdc
+
+Welcome to fdisk (util-linux 2.30.1).
+Changes will remain in memory only, until you decide to write them.
+Be careful before using the write command.
+
+
+Command (m for help): F
+Unpartitioned space /dev/sdc: 7 GiB, 7515144192 bytes, 14678016 sectors
+Units: sectors of 1 * 512 = 512 bytes
+Sector size (logical/physical): 512 bytes / 512 bytes
+
+ Start End Sectors Size
+6293504 20971519 14678016 7G
+
+Command (m for help): q
+```
+
+### 如何使用 fdisk 创建逻辑分区?
+
+创建扩展分区后,请按照之前的步骤创建逻辑分区。在这里,我创建了位于 `/dev/sdc5` 的 `1GB` 逻辑分区。你可以查看分区表值来确认这点。
+
+```shell
+$ sudo fdisk /dev/sdc
+
+Welcome to fdisk (util-linux 2.30.1).
+Changes will remain in memory only, until you decide to write them.
+Be careful before using the write command.
+
+Command (m for help): n
+All primary partitions are in use.
+Adding logical partition 5
+First sector (6295552-20971519, default 6295552): Enter
+Last sector, +sectors or +size{K,M,G,T,P} (6295552-20971519, default 20971519): +1G
+
+Created a new partition 5 of type 'Linux' and of size 1 GiB.
+
+Command (m for help): p
+Disk /dev/sdc: 10 GiB, 10737418240 bytes, 20971520 sectors
+Units: sectors of 1 * 512 = 512 bytes
+Sector size (logical/physical): 512 bytes / 512 bytes
+I/O size (minimum/optimal): 512 bytes / 512 bytes
+Disklabel type: dos
+Disk identifier: 0x8cc8f9e5
+
+Device Boot Start End Sectors Size Id Type
+/dev/sdc1 2048 2099199 2097152 1G 83 Linux
+/dev/sdc2 2099200 4196351 2097152 1G 83 Linux
+/dev/sdc3 4196352 6293503 2097152 1G 83 Linux
+/dev/sdc4 6293504 20971519 14678016 7G 5 Extended
+/dev/sdc5 6295552 8392703 2097152 1G 83 Linux
+
+Command (m for help): w
+The partition table has been altered.
+Calling ioctl() to re-read partition table.
+Syncing disks.
+```
+
+### 如何使用 fdisk 命令删除分区?
+
+如果我们不再使用某个分区,请按照下面的步骤删除它。
+
+请确保你输入了正确的分区号。在这里,我准备删除 `/dev/sdc2` 分区:
+
+```shell
+$ sudo fdisk /dev/sdc
+
+Welcome to fdisk (util-linux 2.30.1).
+Changes will remain in memory only, until you decide to write them.
+Be careful before using the write command.
+
+
+Command (m for help): d
+Partition number (1-5, default 5): 2
+
+Partition 2 has been deleted.
+
+Command (m for help): p
+Disk /dev/sdc: 10 GiB, 10737418240 bytes, 20971520 sectors
+Units: sectors of 1 * 512 = 512 bytes
+Sector size (logical/physical): 512 bytes / 512 bytes
+I/O size (minimum/optimal): 512 bytes / 512 bytes
+Disklabel type: dos
+Disk identifier: 0x8cc8f9e5
+
+Device Boot Start End Sectors Size Id Type
+/dev/sdc1 2048 2099199 2097152 1G 83 Linux
+/dev/sdc3 4196352 6293503 2097152 1G 83 Linux
+/dev/sdc4 6293504 20971519 14678016 7G 5 Extended
+/dev/sdc5 6295552 8392703 2097152 1G 83 Linux
+
+Command (m for help): w
+The partition table has been altered.
+Calling ioctl() to re-read partition table.
+Syncing disks.
+```
+
+### 如何在 Linux 下格式化分区或建立文件系统?
+
+在计算时,文件系统控制了数据的储存方式,并通过 索引节点 来检索数据。如果没有文件系统,操作系统是无法找到信息储存的位置的。
+
+在此,我准备在 `/dev/sdc1` 上创建分区。有三种方式创建文件系统:
+
+```shell
+$ sudo mkfs.ext4 /dev/sdc1
+或
+$ sudo mkfs -t ext4 /dev/sdc1
+或
+$ sudo mke2fs /dev/sdc1
+
+mke2fs 1.43.5 (04-Aug-2017)
+Creating filesystem with 262144 4k blocks and 65536 inodes
+Filesystem UUID: c0a99b51-2b61-4f6a-b960-eb60915faab0
+Superblock backups stored on blocks:
+ 32768, 98304, 163840, 229376
+
+Allocating group tables: done
+Writing inode tables: done
+Creating journal (8192 blocks): done
+Writing superblocks and filesystem accounting information: done
+```
+
+当你在分区上建立文件系统时,以下重要信息会同时被创建:
+
+ * `Filesystem UUID:` UUID 代表了通用且独一无二的识别符,UUID 在 Linux 中通常用来识别设备。它 128 位长的数字代表了 32 个十六进制数。
+ * `Superblock:` 超级块储存了文件系统的元数据。如果某个文件系统的超级块被破坏,我们就无法挂载它了(也就是说无法访问其中的文件了)。
+ * `Inode:` Inode 是类 Unix 系统中文件系统的数据结构,它储存了所有除名称以外的文件信息和数据。
+ * `Journal:` 日志式文件系统包含了用来修复电脑意外关机产生下错误信息的日志。
+
+### 如何在 Linux 中挂载分区?
+
+在你创建完分区和文件系统之后,我们需要挂载它们以便使用。我们需要创建一个挂载点来挂载分区,使用 `mkdir` 来创建一个挂载点。
+
+```shell
+$ sudo mkdir -p /mnt/2g-new
+```
+
+如果你希望进行临时挂载,请使用下面的命令。在计算机重启之后,你会丢失这个挂载点。
+
+```shell
+$ sudo mount /dev/sdc1 /mnt/2g-new
+```
+
+如果你希望永久挂载某个分区,请将分区详情加入 `fstab` 文件。我们既可以输入设备名称,也可以输入 UUID。
+
+使用设备名称来进行永久挂载:
+
+```
+# vi /etc/fstab
+
+/dev/sdc1 /mnt/2g-new ext4 defaults 0 0
+```
+
+使用 UUID 来进行永久挂载(请使用 `blkid` 来获取 UUID):
+
+```
+$ sudo blkid
+/dev/sdc1: UUID="d17e3c31-e2c9-4f11-809c-94a549bc43b7" TYPE="ext2" PARTUUID="8cc8f9e5-01"
+/dev/sda1: UUID="d92fa769-e00f-4fd7-b6ed-ecf7224af7fa" TYPE="ext4" PARTUUID="eab59449-01"
+/dev/sdc3: UUID="ca307aa4-0866-49b1-8184-004025789e63" TYPE="ext4" PARTUUID="8cc8f9e5-03"
+/dev/sdc5: PARTUUID="8cc8f9e5-05"
+
+# vi /etc/fstab
+
+UUID=d17e3c31-e2c9-4f11-809c-94a549bc43b7 /mnt/2g-new ext4 defaults 0 0
+```
+
+使用 `df` 命令亦可:
+
+```
+$ df -h
+Filesystem Size Used Avail Use% Mounted on
+udev 969M 0 969M 0% /dev
+tmpfs 200M 7.0M 193M 4% /run
+/dev/sda1 20G 16G 3.0G 85% /
+tmpfs 997M 0 997M 0% /dev/shm
+tmpfs 5.0M 4.0K 5.0M 1% /run/lock
+tmpfs 997M 0 997M 0% /sys/fs/cgroup
+tmpfs 200M 28K 200M 1% /run/user/121
+tmpfs 200M 25M 176M 13% /run/user/1000
+/dev/sdc1 1008M 1.3M 956M 1% /mnt/2g-new
+```
+
+--------------------------------------------------------------------------------
+
+via: https://www.2daygeek.com/linux-fdisk-command-to-manage-disk-partitions/
+
+作者:[Magesh Maruthamuthu][a]
+选题:[lujun9972][b]
+译者:[zhs852](https://github.com/zhs852)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.2daygeek.com/author/magesh/
+[b]: https://github.com/lujun9972
+[1]: https://www.2daygeek.com/how-to-manage-disk-partitions-using-parted-command/
+[2]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
+[3]: https://www.2daygeek.com/wp-content/uploads/2019/01/linux-fdisk-command-to-manage-disk-partitions-1a.png
diff --git a/published/201902/20190129 Get started with gPodder, an open source podcast client.md b/published/201902/20190129 Get started with gPodder, an open source podcast client.md
new file mode 100644
index 0000000000..f5449a95de
--- /dev/null
+++ b/published/201902/20190129 Get started with gPodder, an open source podcast client.md
@@ -0,0 +1,65 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10567-1.html)
+[#]: subject: (Get started with gPodder, an open source podcast client)
+[#]: via: (https://opensource.com/article/19/1/productivity-tool-gpodder)
+[#]: author: (Kevin Sonney https://opensource.com/users/ksonney (Kevin Sonney))
+
+开始使用 gPodder 吧,一个开源播客客户端
+======
+
+> 使用 gPodder 将你的播客同步到你的设备上,gPodder 是我们开源工具系列中的第 17 个工具,它将在 2019 年提高你的工作效率。
+
+
+
+每年年初似乎都有疯狂的冲动想提高工作效率。新年的决心,渴望开启新的一年,当然,“抛弃旧的,拥抱新的”的态度促成了这一切。通常这时的建议严重偏向闭源和专有软件,但事实上并不用这样。
+
+这是我挑选出的 19 个新的(或者对你而言新的)开源工具中的第 17 个工具来帮助你在 2019 年更有效率。
+
+### gPodder
+
+我喜欢播客。哎呀,我非常喜欢它们,因此我录制了其中的三个(你可以在[我的个人资料][1]中找到它们的链接)。我从播客那里学到了很多东西,并在我工作时在后台播放它们。但是,如何在多台桌面和移动设备之间保持同步可能会有一些挑战。
+
+[gPodder][2] 是一个简单的跨平台播客下载器、播放器和同步工具。它支持 RSS feed、[FeedBurner][3]、[YouTube][4] 和 [SoundCloud][5],它还有一个开源的同步服务,你可以根据需要运行它。gPodder 不直接播放播客。相反,它会使用你选择的音频或视频播放器。
+
+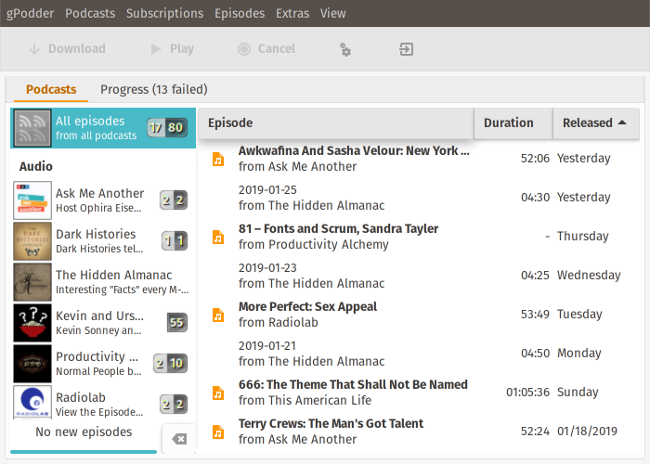
+
+安装 gPodder 非常简单。安装程序适用于 Windows 和 MacOS,同时也有用于主要的 Linux 发行版的软件包。如果你的发行版中没有它,你可以直接从 Git 下载运行。通过 “Add Podcasts via URL” 菜单,你可以输入播客的 RSS 源 URL 或其他服务的 “特殊” URL。gPodder 将获取节目列表并显示一个对话框,你可以在其中选择要下载的节目或在列表上标记旧节目。
+
+
+
+它一个更好的功能是,如果 URL 已经在你的剪贴板中,gPodder 会自动将它放入播放 URL 中,这样你就可以很容易地将新的播客添加到列表中。如果你已有播客 feed 的 OPML 文件,那么可以上传并导入它。还有一个发现选项,让你可搜索 [gPodder.net][6] 上的播客,这是由编写和维护 gPodder 的人员提供的自由及开源的播客的列表网站。
+
+
+
+[mygpo][7] 服务器在设备之间同步播客。gPodder 默认使用 [gPodder.net][8] 的服务器,但是如果你想要运行自己的服务器,那么可以在配置文件中更改它(请注意,你需要直接修改配置文件)。同步能让你在桌面和移动设备之间保持列表一致。如果你在多个设备上收听播客(例如,我在我的工作电脑、家用电脑和手机上收听),这会非常有用,因为这意味着无论你身在何处,你都拥有最近的播客和节目列表而无需一次又一次地设置。
+
+
+
+单击播客节目将显示与其关联的文本,单击“播放”将启动设备的默认音频或视频播放器。如果要使用默认之外的其他播放器,可以在 gPodder 的配置设置中更改此设置。
+
+通过 gPodder,你可以轻松查找、下载和收听播客,在设备之间同步这些播客,在易于使用的界面中访问许多其他功能。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/1/productivity-tool-gpodder
+
+作者:[Kevin Sonney][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/ksonney (Kevin Sonney)
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/users/ksonney
+[2]: https://gpodder.github.io/
+[3]: https://feedburner.google.com/
+[4]: https://youtube.com
+[5]: https://soundcloud.com/
+[6]: http://gpodder.net
+[7]: https://github.com/gpodder/mygpo
+[8]: http://gPodder.net
diff --git a/published/201902/20190129 More About Angle Brackets in Bash.md b/published/201902/20190129 More About Angle Brackets in Bash.md
new file mode 100644
index 0000000000..a34d4fc963
--- /dev/null
+++ b/published/201902/20190129 More About Angle Brackets in Bash.md
@@ -0,0 +1,89 @@
+[#]: collector: (lujun9972)
+[#]: translator: (HankChow)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10529-1.html)
+[#]: subject: (More About Angle Brackets in Bash)
+[#]: via: (https://www.linux.com/blog/learn/2019/1/more-about-angle-brackets-bash)
+[#]: author: (Paul Brown https://www.linux.com/users/bro66)
+
+Bash 中尖括号的更多用法
+======
+> 在这篇文章,我们继续来深入探讨尖括号的更多其它用法。
+
+
+
+在[上一篇文章][1]当中,我们介绍了尖括号(`<>`)以及它们的一些用法。在这篇文章,我们继续来深入探讨尖括号的更多其它用法。
+
+通过使用 `<`,可以实现“欺骗”的效果,让其它命令认为某个命令的输出是一个文件。
+
+例如,在进行备份文件的时候不确定备份是否完整,就需要去确认某个目录是否已经包含从原目录中复制过去的所有文件。你可以试一下这样操作:
+
+```
+diff <(ls /original/dir/) <(ls /backup/dir/)
+```
+
+[diff][2] 命令是一个逐行比较两个文件之间差异的工具。在上面的例子中,就使用了 `<` 让 `diff` 认为两个 `ls` 命令输出的结果都是文件,从而能够比较它们之间的差异。
+
+要注意,在 `<` 和 `(...)` 之间是没有空格的。
+
+我尝试在我的图片目录和它的备份目录执行上面的命令,输出的是以下结果:
+
+```
+diff <(ls /My/Pictures/) <(ls /My/backup/Pictures/)
+5d4 < Dv7bIIeUUAAD1Fc.jpg:large.jpg
+```
+
+输出结果中的 `<` 表示 `Dv7bIIeUUAAD1Fc.jpg:large.jpg` 这个文件存在于左边的目录(`/My/Pictures`)但不存在于右边的目录(`/My/backup/Pictures`)中。也就是说,在备份过程中可能发生了问题,导致这个文件没有被成功备份。如果 `diff` 没有显示出任何输出结果,就表明两个目录中的文件是一致的。
+
+看到这里你可能会想到,既然可以通过 `<` 将一些命令行的输出内容作为一个文件提供给一个需要接受文件格式的命令,那么在上一篇文章的“最喜欢的演员排序”例子中,就可以省去中间的一些步骤,直接对输出内容执行 `sort` 操作了。
+
+确实如此,这个例子可以简化成这样:
+
+```
+sort -r <(while read -r name surname films;do echo $films $name $surname ; done < CBactors)
+```
+
+### Here 字符串
+
+除此以外,尖括号的重定向功能还有另一种使用方式。
+
+使用 `echo` 和管道(`|`)来传递变量的用法,相信大家都不陌生。假如想要把一个字符串变量转换为全大写形式,你可以这样做:
+
+```
+myvar="Hello World" echo $myvar | tr '[:lower:]' '[:upper:]' HELLO WORLD
+```
+
+[tr][3] 命令可以将一个字符串转换为某种格式。在上面的例子中,就使用了 `tr` 将字符串中的所有小写字母都转换为大写字母。
+
+要理解的是,这个传递过程的重点不是变量,而是变量的值,也就是字符串 `Hello World`。这样的字符串叫做 HERE 字符串,含义是“这就是我们要处理的字符串”。但对于上面的例子,还可以用更直观的方式的处理,就像下面这样:
+
+```
+tr '[:lower:]' '[:upper:]' <<< $myvar
+```
+
+这种简便方式并不需要使用到 `echo` 或者管道,而是使用了我们一直在说的尖括号。
+
+### 总结
+
+使用 `<` 和 `>` 这两个简单的符号,原来可以实现这么多功能,Bash 又一次为工作的灵活性提供了很多选择。
+
+当然,我们的介绍还远远没有完结,因为还有很多别的符号可以为 Bash 命令带来更多便利。不过如果没有充分理解它们,充满符号的 Bash 命令看起来只会像是一堆乱码。接下来我会解读更多类似的 Bash 符号,下次见!
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/blog/learn/2019/1/more-about-angle-brackets-bash
+
+作者:[Paul Brown][a]
+选题:[lujun9972][b]
+译者:[HankChow](https://github.com/HankChow)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.linux.com/users/bro66
+[b]: https://github.com/lujun9972
+[1]: https://linux.cn/article-10502-1.html
+[2]: https://linux.die.net/man/1/diff
+[3]: https://linux.die.net/man/1/tr
+
diff --git a/published/201902/20190130 Get started with Budgie Desktop, a Linux environment.md b/published/201902/20190130 Get started with Budgie Desktop, a Linux environment.md
new file mode 100644
index 0000000000..58a8a6505c
--- /dev/null
+++ b/published/201902/20190130 Get started with Budgie Desktop, a Linux environment.md
@@ -0,0 +1,61 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10547-1.html)
+[#]: subject: (Get started with Budgie Desktop, a Linux environment)
+[#]: via: (https://opensource.com/article/19/1/productivity-tool-budgie-desktop)
+[#]: author: (Kevin Sonney https://opensource.com/users/ksonney (Kevin Sonney))
+
+开始使用 Budgie 吧,一款 Linux 桌面环境
+======
+
+> 使用 Budgie 按需配置你的桌面,这是我们开源工具系列中的第 18 个工具,它将在 2019 年提高你的工作效率。
+
+
+
+每年年初似乎都有疯狂的冲动想提高工作效率。新年的决心,渴望开启新的一年,当然,“抛弃旧的,拥抱新的”的态度促成了这一切。通常这时的建议严重偏向闭源和专有软件,但事实上并不用这样。
+
+这是我挑选出的 19 个新的(或者对你而言新的)开源工具中的第 18 个工具来帮助你在 2019 年更有效率。
+
+### Budgie 桌面
+
+Linux 中有许多桌面环境。从易于使用并有令人惊叹图形界面的 [GNOME 桌面][1](在大多数主要 Linux 发行版上是默认桌面)和 [KDE][2],到极简主义的 [Openbox][3],再到高度可配置的平铺化的 [i3][4],有很多选择。我要寻找的桌面环境需要速度、不引人注目和干净的用户体验。当桌面不适合你时,很难会有高效率。
+
+
+
+[Budgie 桌面][5]是 [Solus][6] Linux 发行版的默认桌面,它在大多数主要 Linux 发行版的附加软件包中提供。它基于 GNOME,并使用了许多你可能已经在计算机上使用的相同工具和库。
+
+其默认桌面非常简约,只有面板和空白桌面。Budgie 包含一个集成的侧边栏(称为 Raven),通过它可以快速访问日历、音频控件和设置菜单。Raven 还包含一个集成的通知区域,其中包含与 MacOS 类似的统一系统消息显示。
+
+
+
+点击 Raven 中的齿轮图标会显示 Budgie 的控制面板及其配置。由于 Budgie 仍处于开发阶段,与 GNOME 或 KDE 相比,它的选项有点少,我希望随着时间的推移它会有更多的选项。顶部面板选项允许用户配置顶部面板的排序、位置和内容,这很不错。
+
+
+
+Budgie 的 Welcome 应用(首次登录时展示)包含安装其他软件、面板小程序、截图和 Flatpack 软件包的选项。这些小程序有处理网络、截图、额外的时钟和计时器等等。
+
+
+
+Budgie 提供干净稳定的桌面。它响应迅速,有许多选项,允许你根据需要自定义它。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/1/productivity-tool-budgie-desktop
+
+作者:[Kevin Sonney][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/ksonney (Kevin Sonney)
+[b]: https://github.com/lujun9972
+[1]: https://www.gnome.org/
+[2]: https://www.kde.org/
+[3]: http://openbox.org/wiki/Main_Page
+[4]: https://i3wm.org/
+[5]: https://getsol.us/solus/experiences/
+[6]: https://getsol.us/home/
diff --git a/published/201902/20190130 Olive is a new Open Source Video Editor Aiming to Take On Biggies Like Final Cut Pro.md b/published/201902/20190130 Olive is a new Open Source Video Editor Aiming to Take On Biggies Like Final Cut Pro.md
new file mode 100644
index 0000000000..430b6210dd
--- /dev/null
+++ b/published/201902/20190130 Olive is a new Open Source Video Editor Aiming to Take On Biggies Like Final Cut Pro.md
@@ -0,0 +1,111 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10577-1.html)
+[#]: subject: (Olive is a new Open Source Video Editor Aiming to Take On Biggies Like Final Cut Pro)
+[#]: via: (https://itsfoss.com/olive-video-editor)
+[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
+
+Olive:一款以 Final Cut Pro 为目标的开源视频编辑器
+======
+
+[Olive][1] 是一个正在开发的新的开源视频编辑器。这个非线性视频编辑器旨在提供高端专业视频编辑软件的免费替代品。目标高么?我认为是的。
+
+如果你读过我们的 [Linux 中的最佳视频编辑器][2]这篇文章,你可能已经注意到大多数“专业级”视频编辑器(如 [Lightworks][3] 或 DaVinciResolve)既不免费也不开源。
+
+[Kdenlive][4] 和 Shotcut 也是此类,但它通常无法达到专业视频编辑的标准(这是许多 Linux 用户说的)。
+
+爱好者级和专业级的视频编辑之间的这种差距促使 Olive 的开发人员启动了这个项目。
+
+![Olive Video Editor][5]
+
+*Olive 视频编辑器界面*
+
+Libre Graphics World 中有一篇详细的[关于 Olive 的点评][6]。实际上,这是我第一次知道 Olive 的地方。如果你有兴趣了解更多信息,请阅读该文章。
+
+### 在 Linux 中安装 Olive 视频编辑器
+
+> 提醒你一下。Olive 正处于发展的早期阶段。你会发现很多 bug 和缺失/不完整的功能。你不应该把它当作你的主要视频编辑器。
+
+如果你想测试 Olive,有几种方法可以在 Linux 上安装它。
+
+#### 通过 PPA 在基于 Ubuntu 的发行版中安装 Olive
+
+你可以在 Ubuntu、Mint 和其他基于 Ubuntu 的发行版使用官方 PPA 安装 Olive。
+
+```
+sudo add-apt-repository ppa:olive-editor/olive-editor
+sudo apt-get update
+sudo apt-get install olive-editor
+```
+
+#### 通过 Snap 安装 Olive
+
+如果你的 Linux 发行版支持 Snap,则可以使用以下命令进行安装。
+
+```
+sudo snap install --edge olive-editor
+```
+
+#### 通过 Flatpak 安装 Olive
+
+如果你的 [Linux 发行版支持 Flatpak][7],你可以通过 Flatpak 安装 Olive 视频编辑器。
+
+- [Flatpak 地址](https://flathub.org/apps/details/org.olivevideoeditor.Olive)
+
+#### 通过 AppImage 使用 Olive
+
+不想安装吗?下载 [AppImage][8] 文件,将其设置为可执行文件并运行它。32 位和 64 位 AppImage 文件都有。你应该下载相应的文件。
+
+- [下载 Olive 的 AppImage](https://github.com/olive-editor/olive/releases/tag/continuous)
+
+Olive 也可用于 Windows 和 macOS。你可以从它的[下载页面][9]获得它。
+
+### 想要支持 Olive 视频编辑器的开发吗?
+
+如果你喜欢 Olive 尝试实现的功能,并且想要支持它,那么你可以通过以下几种方式。
+
+如果你在测试 Olive 时发现一些 bug,请到它们的 GitHub 仓库中报告。
+
+- [提交 bug 报告以帮助 Olive](https://github.com/olive-editor/olive/issues)
+
+如果你是程序员,请浏览 Olive 的源代码,看看你是否可以通过编码技巧帮助项目。
+
+- [Olive 的 GitHub 仓库](https://github.com/olive-editor/olive)
+
+在经济上为项目做贡献是另一种可以帮助开发开源软件的方法。你可以通过成为赞助人来支持 Olive。
+
+- [赞助 Olive](https://www.patreon.com/olivevideoeditor)
+
+如果你没有支持 Olive 的金钱或编码技能,你仍然可以帮助它。在社交媒体或你经常访问的 Linux/软件相关论坛和群组中分享这篇文章或 Olive 的网站。一点微小的口碑都能间接地帮助它。
+
+### 你如何看待 Olive?
+
+评判 Olive 还为时过早。我希望能够持续快速开发,并且在年底之前发布 Olive 的稳定版(如果我没有过于乐观的话)。
+
+你如何看待 Olive?你是否认同开发人员针对专业用户的目标?你希望 Olive 拥有哪些功能?
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/olive-video-editor
+
+作者:[Abhishek Prakash][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/abhishek/
+[b]: https://github.com/lujun9972
+[1]: https://www.olivevideoeditor.org/
+[2]: https://itsfoss.com/best-video-editing-software-linux/
+[3]: https://www.lwks.com/
+[4]: https://kdenlive.org/en/
+[5]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/olive-video-editor-interface.jpg?resize=800%2C450&ssl=1
+[6]: http://libregraphicsworld.org/blog/entry/introducing-olive-new-non-linear-video-editor
+[7]: https://itsfoss.com/flatpak-guide/
+[8]: https://itsfoss.com/use-appimage-linux/
+[9]: https://www.olivevideoeditor.org/download.php
+[10]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/olive-video-editor-interface.jpg?fit=800%2C450&ssl=1
diff --git a/published/201902/20190131 Will quantum computing break security.md b/published/201902/20190131 Will quantum computing break security.md
new file mode 100644
index 0000000000..33323796ce
--- /dev/null
+++ b/published/201902/20190131 Will quantum computing break security.md
@@ -0,0 +1,89 @@
+[#]: collector: (lujun9972)
+[#]: translator: (HankChow)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10566-1.html)
+[#]: subject: (Will quantum computing break security?)
+[#]: via: (https://opensource.com/article/19/1/will-quantum-computing-break-security)
+[#]: author: (Mike Bursell https://opensource.com/users/mikecamel)
+
+量子计算会打破现有的安全体系吗?
+======
+
+> 你会希望[某黑客][6]假冒你的银行吗?
+
+
+
+近年来,量子计算机已经出现在大众的视野当中。量子计算机被认为是第六类计算机,这六类计算机包括:
+
+1. 人力:在人造的计算工具出现之前,人类只能使用人力去进行计算。而承担计算工作的人,只能被称为“计算者”。
+2. 模拟计算工具:由人类制造的一些模拟计算过程的小工具,例如[安提凯希拉装置][1]、星盘、计算尺等等。
+3. 机械工具:在这一个类别中包括了运用到离散数学但未使用电子技术进行计算的工具,例如算盘、Charles Babbage 的差分机等等。
+4. 电子模拟计算工具:这一个类别的计算机多数用于军事方面的用途,例如炸弹瞄准器、枪炮瞄准装置等等。
+5. 电子计算机:我在这里会稍微冒险一点,我觉得 Colossus 是第一台电子计算机,[^1] :这一类几乎包含现代所有的电子设备,从移动电话到超级计算机,都在这个类别当中。
+6. 量子计算机:即将进入我们的生活,而且与之前的几类完全不同。
+
+### 什么是量子计算?
+
+量子计算的概念来源于量子力学,使用的计算方式和我们平常使用的普通计算非常不同。如果想要深入理解,建议从参考[维基百科上的定义][2]开始。对我们来说,最重要的是理解这一点:量子计算机使用量子位进行计算。在这样的前提下,对于很多数学算法和运算操作,量子计算机的计算速度会比普通计算机要快得多。
+
+这里的“快得多”是按数量级来说的“快得多”。在某些情况下,一个计算任务如果由普通计算机来执行,可能要耗费几年或者几十年才能完成,但如果由量子计算机来执行,就只需要几秒钟。这样的速度甚至令人感到可怕。因为量子计算机会非常擅长信息的加密解密计算,即使在没有密钥的情况下,也能快速完成繁重的计算任务。
+
+这意味着,如果拥有足够强大的量子计算机,那么你的所有信息都会被一览无遗,任何被加密的数据都可以被正确解密出来,甚至伪造数字签名也会成为可能。这确实是一个严重的问题。谁也不想被某个黑客冒充成自己在用的银行,更不希望自己在区块链上的交易被篡改得面目全非。
+
+### 好消息
+
+尽管上面的提到的问题非常可怕,但也不需要太担心。
+
+首先,如果要实现上面提到的能力,一台可以操作大量量子位的量子计算机是必不可少的,而这个硬件上的要求就是一个很高的门槛。[^4] 目前普遍认为,规模大得足以有效破解经典加密算法的量子计算机在最近几年还不可能出现。
+
+其次,除了攻击现有的加密算法需要大量的量子位以外,还需要很多量子位来保证容错性。
+
+还有,尽管确实有一些理论上的模型阐述了量子计算机如何对一些现有的算法作出攻击,但是要让这样的理论模型实际运作起来的难度会比我们[^5] 想象中大得多。事实上,有一些攻击手段也是未被完全确认是可行的,又或者这些攻击手段还需要继续耗费很多年的改进才能到达如斯恐怖的程度。
+
+最后,还有很多专业人士正在研究能够防御量子计算的算法(这样的算法也被称为“后量子算法”)。如果这些防御算法经过测试以后投入使用,我们就可以使用这些算法进行加密,来对抗量子计算了。
+
+总而言之,很多专家都认为,我们现有的加密方式在未来 5 年甚至未来 10 年内都是安全的,不需要过分担心。
+
+### 也有坏消息
+
+但我们也并不是高枕无忧了,以下两个问题就值得我们关注:
+
+1. 人们在设计应用系统的时候仍然没有对量子计算作出太多的考量。如果设计的系统可能会使用 10 年以上,又或者数据加密和签名的时间跨度在 10 年以上,那么就必须考虑量子计算在未来会不会对系统造成不利的影响。
+2. 新出现的防御量子计算的算法可能会是专有的。也就是说,如果基于这些防御量子计算的算法来设计系统,那么在系统落地的时候,可能会需要为此付费。尽管我是支持开源的,尤其是[开源密码学][3],但我最担心的就是无法开源这方面的内容。而且最糟糕的是,在建立新的协议标准时(不管是事实标准还是通过标准组织建立的标准),无论是故意的,还是无意忽略,或者是没有好的开源替代品,他们都很可能使用专有算法而排除使用开源算法。
+
+### 我们要怎样做?
+
+幸运的是,针对上述两个问题,我们还是有应对措施的。首先,在整个系统的设计阶段,就需要考虑到它是否会受到量子计算的影响,并作出相应的规划。当然了,不需要现在就立即采取行动,因为当前的技术水平也没法实现有效的方案,但至少也要[在加密方面保持敏捷性][4],以便在任何需要的时候为你的协议和系统更换更有效的加密算法。[^7]
+
+其次是参与开源运动。尽可能鼓励密码学方面的有识之士团结起来,支持开放标准,并投入对非专有的防御量子计算的算法研究当中去。这一点也算是当务之急,因为号召更多的人重视起来并加入研究,比研究本身更为重要。
+
+本文首发于《[Alice, Eve, and Bob][5]》,并在作者同意下重新发表。
+
+[^1]: 我认为把它称为第一台电子可编程计算机是公平的。我知道有早期的非可编程的,也有些人声称是 ENIAC,但我没有足够的空间或精力在这里争论这件事。
+[^2]: No。
+[^3]: See 2. Don't get me wrong, by the way—I grew up near Weston-super-Mare, and it's got things going for it, but it's not Mayfair.
+[^4]: 如果量子物理学家说很难,那么在我看来,就很难。
+[^5]: 而且我假设我们都不是量子物理学家或数学家。
+[^6]: I'm definitely not.
+[^7]: 而且不仅仅是出于量子计算的原因:我们现有的一些经典算法很可能会陷入其他非量子攻击,例如新的数学方法。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/1/will-quantum-computing-break-security
+
+作者:[Mike Bursell][a]
+选题:[lujun9972][b]
+译者:[HankChow](https://github.com/HankChow)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/mikecamel
+[b]: https://github.com/lujun9972
+[1]: https://en.wikipedia.org/wiki/Antikythera_mechanism
+[2]: https://en.wikipedia.org/wiki/Quantum_computing
+[3]: https://opensource.com/article/17/10/many-eyes
+[4]: https://aliceevebob.com/2017/04/04/disbelieving-the-many-eyes-hypothesis/
+[5]: https://aliceevebob.com/2019/01/08/will-quantum-computing-break-security/
+[6]: https://www.techopedia.com/definition/20225/j-random-hacker
diff --git a/published/201902/20190201 Top 5 Linux Distributions for New Users.md b/published/201902/20190201 Top 5 Linux Distributions for New Users.md
new file mode 100644
index 0000000000..5641dd8796
--- /dev/null
+++ b/published/201902/20190201 Top 5 Linux Distributions for New Users.md
@@ -0,0 +1,111 @@
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10553-1.html)
+[#]: subject: (Top 5 Linux Distributions for New Users)
+[#]: via: (https://www.linux.com/blog/learn/2019/2/top-5-linux-distributions-new-users)
+[#]: author: (Jack Wallen https://www.linux.com/users/jlwallen)
+
+5 个面向新手的 Linux 发行版
+======
+
+> 5 个可使用新用户有如归家般感觉的发行版。
+
+
+
+从最初的 Linux 到现在,Linux 已经发展了很长一段路。但是,无论你曾经多少次听说过现在使用 Linux 有多容易,仍然会有表示怀疑的人。而要真的承担得其这份声明,桌面必须足够简单,以便不熟悉 Linux 的人也能够使用它。事实上大量的桌面发行版使这成为了现实。
+
+### 无需 Linux 知识
+
+将这个清单误解为又一个“最佳用户友好型 Linux 发行版”的清单可能很简单。但这不是我们要在这里看到的。这二者之间有什么不同?就我的目的而言,定义的界限是 Linux 是否真正起到了使用的作用。换句话说,你是否可以将这个桌面操作系统放在一个用户面前,并让他们应用自如而无需懂得 Linux 知识呢?
+
+不管你相信与否,有些发行版就能做到。这里我将介绍给你 5 个这样的发行版。这些或许你全都听说过。它们或许不是你所选择的发行版,但可以向你保证它们无需过多关注,而是将用户放在眼前的。
+
+我们来看看选中的几个。
+
+### Elementary OS
+
+[Elementary OS](https://elementary.io/) 的理念主要围绕人们如何实际使用他们的桌面。开发人员和设计人员不遗余力地创建尽可能简单的桌面。在这个过程中,他们致力于去 Linux 化的 Linux。这并不是说他们已经从这个等式中删除了 Linux。不,恰恰相反,他们所做的就是创建一个与你所发现的一样的中立的操作系统。Elementary OS 是如此流畅,以确保一切都完美合理。从单个 Dock 到每个人都清晰明了的应用程序菜单,这是一个桌面,而不用提醒用户说,“你正在使用 Linux!” 事实上,其布局本身就让人联想到 Mac,但附加了一个简单的应用程序菜单(图 1)。
+
+![Elementary OS Juno][2]
+
+*图 1:Elementary OS Juno 应用菜单*
+
+将 Elementary OS 放在此列表中的另一个重要原因是它不像其他桌面发行版那样灵活。当然,有些用户会对此不以为然,但是如果桌面没有向用户扔出各种花哨的定制诱惑,那么就会形成一个非常熟悉的环境:一个既不需要也不允许大量修修补补的环境。操作系统在让新用户熟悉该平台这一方面还有很长的路要走。
+
+与任何现代 Linux 桌面发行版一样,Elementary OS 包括了应用商店,称为 AppCenter,用户可以在其中安装所需的所有应用程序,而无需触及命令行。
+
+### 深度操作系统
+
+[深度操作系统](https://www.deepin.org/)不仅得到了市场上最漂亮的台式机之一的赞誉,它也像任何桌面操作系统一样容易上手。其桌面界面非常简单,对于毫无 Linux 经验的用户来说,它的上手速度非常快。事实上,你很难找到无法立即上手使用 Deepin 桌面的用户。而这里唯一可能的障碍可能是其侧边栏控制中心(图 2)。
+
+![][5]
+
+*图 2:Deepin 的侧边栏控制编码*
+
+但即使是侧边栏控制面板,也像市场上的任何其他配置工具一样直观。任何使用过移动设备的人对于这种布局都很熟悉。至于打开应用程序,Deepin 的启动器采用了 macOS Launchpad 的方式。此按钮位于桌面底座上通常最右侧的位置,因此用户立即就可以会意,知道它可能类似于标准的“开始”菜单。
+
+与 Elementary OS(以及市场上大多数 Linux 发行版)类似,深度操作系统也包含一个应用程序商店(简称为“商店”),可以轻松安装大量应用程序。
+
+### Ubuntu
+
+你知道肯定有它。[Ubuntu](https://www.ubuntu.com/) 通常在大多数用户友好的 Linux 列表中占据首位。因为它是少数几个不需要懂得 Linux 就能使用的桌面之一。但在采用 GNOME(和 Unity 谢幕)之前,情况并非如此。因为 Unity 经常需要进行一些调整才能达到一点 Linux 知识都不需要的程度(图 3)。现在 Ubuntu 已经采用了 GNOME,并将其调整到甚至不需要懂得 GNOME 的程度,这个桌面使得对 Linux 的简单性和可用性的要求不再是迫切问题。
+
+![Ubuntu 18.04][7]
+
+*图 3:Ubuntu 18.04 桌面可使用马上熟悉起来*
+
+与 Elementary OS 不同,Ubuntu 对用户毫无阻碍。因此,任何想从桌面上获得更多信息的人都可以拥有它。但是,其开箱即用的体验对于任何类型的用户都是足够的。任何一个让用户不知道他们触手可及的力量有多少的桌面,肯定不如 Ubuntu。
+
+### Linux Mint
+
+我需要首先声明,我从来都不是 [Linux Mint](https://linuxmint.com/) 的忠实粉丝。但这并不是说我不尊重开发者的工作,而更多的是一种审美观点。我更喜欢现代化的桌面环境。但是,旧式的学校计算机桌面的隐喻(可以在默认的 Cinnamon 桌面中找到)可以让几乎每个人使用它的人都格外熟悉。Linux Mint 使用任务栏、开始按钮、系统托盘和桌面图标(图 4),提供了一个需要零学习曲线的界面。事实上,一些用户最初可能会被愚弄,以为他们正在使用 Windows 7 的克隆版。甚至是它的更新警告图标也会让用户感到非常熟悉。
+
+![Linux Mint][9]
+
+*图 4:Linux Mint 的 Cinnamon 桌面非常像 Windows 7*
+
+因为 Linux Mint 受益于其所基于的 Ubuntu,它不仅会让你马上熟悉起来,而且具有很高的可用性。无论你是否对底层平台有所了解,用户都会立即感受到宾至如归的感觉。
+
+### Ubuntu Budgie
+
+我们的列表将以这样一个发行版做结:它也能让用户忘记他们正在使用 Linux,并且使用常用工具变得简单、美观。使 Ubuntu 融合 Budgie 桌面可以构成一个令人印象深刻的易用发行版。虽然其桌面布局(图 5)可能不太一样,但毫无疑问,适应这个环境并不需要浪费时间。实际上,除了 Dock 默认居于桌面的左侧,[Ubuntu Budgie](https://ubuntubudgie.org/) 确实看起来像 Elementary OS。
+
+![Budgie][11]
+
+*图 5:Budgie 桌面既漂亮又简单*
+
+Ubuntu Budgie 中的系统托盘/通知区域提供了一些不太多见的功能,比如:快速访问 Caffeine(一种保持桌面清醒的工具)、快速笔记工具(用于记录简单笔记)、Night Lite 开关、原地下拉菜单(用于快速访问文件夹),当然还有 Raven 小程序/通知侧边栏(与深度操作系统中的控制中心侧边栏类似,但不太优雅)。Budgie 还包括一个应用程序菜单(左上角),用户可以访问所有已安装的应用程序。打开一个应用程序,该图标将出现在 Dock 中。右键单击该应用程序图标,然后选择“保留在 Dock”以便更快地访问。
+
+Ubuntu Budgie 的一切都很直观,所以几乎没有学习曲线。这种发行版既优雅又易于使用,不能再好了。
+
+### 选择一个吧
+
+至此介绍了 5 个 Linux 发行版,它们各自以自己的方式提供了让任何用户都马上熟悉的桌面体验。虽然这些可能不是你对顶级发行版的选择,但对于那些不熟悉 Linux 的用户来说,却不能否定它们的价值。
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/blog/learn/2019/2/top-5-linux-distributions-new-users
+
+作者:[Jack Wallen][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.linux.com/users/jlwallen
+[b]: https://github.com/lujun9972
+[1]: https://www.linux.com/files/images/elementaryosjpg-2
+[2]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/elementaryos_0.jpg?itok=KxgNUvMW (Elementary OS Juno)
+[3]: https://www.linux.com/licenses/category/used-permission
+[4]: https://www.linux.com/files/images/deepinjpg
+[5]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/deepin.jpg?itok=VV381a9f
+[6]: https://www.linux.com/files/images/ubuntujpg-1
+[7]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/ubuntu_1.jpg?itok=bax-_Tsg (Ubuntu 18.04)
+[8]: https://www.linux.com/files/images/linuxmintjpg
+[9]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/linuxmint.jpg?itok=8sPon0Cq (Linux Mint )
+[10]: https://www.linux.com/files/images/budgiejpg-0
+[11]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/budgie_0.jpg?itok=zcf-AHmj (Budgie)
+[12]: https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/published/201902/20190205 DNS and Root Certificates.md b/published/201902/20190205 DNS and Root Certificates.md
new file mode 100644
index 0000000000..3a921def35
--- /dev/null
+++ b/published/201902/20190205 DNS and Root Certificates.md
@@ -0,0 +1,136 @@
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10533-1.html)
+[#]: subject: (DNS and Root Certificates)
+[#]: via: (https://lushka.al/dns-and-certificates/)
+[#]: author: (Anxhelo Lushka https://lushka.al/)
+
+DNS 和根证书
+======
+
+> 关于 DNS 和根证书你需要了解的内容。
+
+由于最近发生的一些事件,我们(Privacy Today 组织)感到有必要写一篇关于此事的短文。它适用于所有读者,因此它将保持简单 —— 技术细节可能会在稍后的文章发布。
+
+### 什么是 DNS,为什么它与你有关?
+
+DNS 的意思是域名系统,你每天都会接触到它。每当你的 Web 浏览器或任何其他应用程序连接到互联网时,它就很可能会使用域名。简单来说,域名就是你键入的地址:例如 [duckduckgo.com][1]。你的计算机需要知道它所导向的地方,会向 DNS 解析器寻求帮助。而它将返回类似 [176.34.155.23][2] 这样的 IP —— 这就是连接时所需要知道的公开网络地址。 此过程称为 DNS 查找。
+
+这对你的隐私、安全以及你的自由都有一定的影响:
+
+#### 隐私
+
+由于你要求解析器获取域名的 IP,因此它会确切地知道你正在访问哪些站点,并且由于“物联网”(通常缩写为 IoT),甚至它还知道你在家中使用的是哪个设备。
+
+#### 安全
+
+你可以相信解析器返回的 IP 是正确的。有一些检查措施可以确保如此,在正常情况下这一般不是问题。但这些可能措施会被破坏,这就是写作本文的原因。如果返回的 IP 不正确,你可能会被欺骗引向了恶意的第三方 —— 甚至你都不会注意到任何差异。在这种情况下,你的隐私会受到更大的危害,因为不仅会被跟踪你访问了什么网站,甚至你访问的内容也会被跟踪。第三方可以准确地看到你正在查看的内容,收集你输入的个人信息(例如密码)等等。你的整个身份可以轻松接管。
+
+#### 自由
+
+审查通常是通过 DNS 实施的。这不是最有效的方法,但它非常普遍。即使在西方国家,它也经常被公司和政府使用。他们使用与潜在攻击者相同的方法;当你查询 IP 地址时,他们不会返回正确的 IP。他们可以表现得就好像某个域名不存在,或完全将访问指向别处。
+
+### DNS 查询的方式
+
+#### 由你的 ISP 提供的第三方 DNS 解析器
+
+大多数人都在使用由其互联网接入提供商(ISP)提供的第三方解析器。当你连接调制解调器时(LCTT 译注:或宽带路由器),这些 DNS 解析器就会被自动取出,而你可能从来没注意过它。
+
+#### 你自己选择的第三方 DNS 解析器
+
+如果你已经知道 DNS 意味着什么,那么你可能会决定使用你选择的另一个 DNS 解析器。这可能会改善这种情况,因为它使你的 ISP 更难以跟踪你,并且你可以避免某些形式的审查。尽管追踪和审查仍然是可能的,但这种方法并没有被广泛使用。
+
+#### 你自己(本地)的 DNS 解析器
+
+你可以自己动手,避免使用别人的 DNS 解析器的一些危险。如果你对此感兴趣,请告诉我们。
+
+### 根证书
+
+#### 什么是根证书?
+
+每当你访问以 https 开头的网站时,你都会使用它发送的证书与之通信。它使你的浏览器能够加密通信并确保没有人可以窥探。这就是为什么每个人都被告知在登录网站时要注意 https(而不是 http)。证书本身仅用于验证是否为某个域所生成。以及:
+
+这就是根证书的来源。可以其视为一个更高的级别,用来确保其下的级别是正确的。它验证发送给你的证书是否已由证书颁发机构授权。此权限确保创建证书的人实际上是真正的运营者。
+
+这也被称为信任链。默认情况下,你的操作系统包含一组这些根证书,以确保该信任链的存在。
+
+#### 滥用
+
+我们现在知道:
+
+* DNS 解析器在你发送域名时向你发送 IP 地址
+* 证书允许加密你的通信,并验证它们是否为你访问的域生成
+* 根证书验证该证书是否合法,并且是由真实站点运营者创建的
+
+**怎么会被滥用呢?**
+
+* 如前所述,恶意 DNS 解析器可能会向你发送错误的 IP 以进行审查。它们还可以将你导向完全不同的网站。
+* 这个网站可以向你发送假的证书。
+* 恶意的根证书可以“验证”此假证书。
+
+对你来说,这个网站看起来绝对没问题;它在网址中有 https,如果你点击它,它会说已经通过验证。就像你了解到的一样,对吗?**不对!**
+
+它现在可以接收你要发送给原站点的所有通信。这会绕过想要避免被滥用而创建的检查。你不会收到错误消息,你的浏览器也不会发觉。
+
+**而你所有的数据都会受到损害!**
+
+### 结论
+
+#### 风险
+
+* 使用恶意 DNS 解析器总是会损害你的隐私,但只要你注意 https,你的安全性就不会受到损害。
+* 使用恶意 DNS 解析程序和恶意根证书,你的隐私和安全性将完全受到损害。
+
+#### 可以采取的动作
+
+**不要安装第三方根证书!**只有非常少的例外情况才需要这样做,并且它们都不适用于一般最终用户。
+
+**不要被那些“广告拦截”、“军事级安全”或类似的东西营销噱头所吸引**。有一些方法可以自行使用 DNS 解析器来增强你的隐私,但安装第三方根证书永远不会有意义。你正在将自己置身于陷阱之中。
+
+### 实际看看
+
+**警告**
+
+有位友好的系统管理员提供了一个现场演示,你可以实时看到自己。这是真事。
+
+**千万不要输入私人数据!之后务必删除证书和该 DNS!**
+
+如果你不知道如何操作,那就不要安装它。虽然我们相信我们的朋友,但你不要随便安装随机和未知的第三方根证书。
+
+#### 实际演示
+
+链接在这里:
+
+* 设置所提供的 DNS 解析器
+* 安装所提供的根证书
+* 访问 并输入随机登录数据
+* 你的数据将显示在该网站上
+
+### 延伸信息
+
+如果你对更多技术细节感兴趣,请告诉我们。如果有足够多感兴趣的人,我们可能会写一篇文章,但是目前最重要的部分是分享基础知识,这样你就可以做出明智的决定,而不会因为营销和欺诈而陷入陷阱。请随时提出对你很关注的其他主题。
+
+这篇文章来自 [Privacy Today 频道][3]。[Privacy Today][4] 是一个关于隐私、开源、自由哲学等所有事物的组织!
+
+所有内容均根据 CC BY-NC-SA 4.0 获得许可。([署名 - 非商业性使用 - 共享 4.0 国际][5])。
+
+--------------------------------------------------------------------------------
+
+via: https://lushka.al/dns-and-certificates/
+
+作者:[Anxhelo Lushka][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://lushka.al/
+[b]: https://github.com/lujun9972
+[1]: https://duckduckgo.com
+[2]: http://176.34.155.23
+[3]: https://t.me/privacytoday
+[4]: https://t.me/joinchat/Awg5A0UW-tzOLX7zMoTDog
+[5]: https://creativecommons.org/licenses/by-nc-sa/4.0/
diff --git a/published/201902/20190205 Installing Kali Linux on VirtualBox- Quickest - Safest Way.md b/published/201902/20190205 Installing Kali Linux on VirtualBox- Quickest - Safest Way.md
new file mode 100644
index 0000000000..830ff13fd9
--- /dev/null
+++ b/published/201902/20190205 Installing Kali Linux on VirtualBox- Quickest - Safest Way.md
@@ -0,0 +1,142 @@
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10550-1.html)
+[#]: subject: (Installing Kali Linux on VirtualBox: Quickest & Safest Way)
+[#]: via: (https://itsfoss.com/install-kali-linux-virtualbox)
+[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
+
+在 VirtualBox 上安装 Kali Linux 的最安全快捷的方式
+======
+
+> 本教程将向你展示如何以最快的方式在运行于 Windows 和 Linux 上的 VirtualBox 上安装 Kali Linux。
+
+[Kali Linux][1] 是最好的[黑客][2] 和安全爱好者的 Linux 发行版之一。
+
+由于它涉及像黑客这样的敏感话题,它就像一把双刃剑。我们过去在一篇详细的 [Kali Linux 点评](https://linux.cn/article-10198-1.html)中对此进行了讨论,所以我不会再次赘述。
+
+虽然你可以通过替换现有的操作系统来安装 Kali Linux,但通过虚拟机使用它将是一个更好、更安全的选择。
+
+使用 Virtual Box,你可以将 Kali Linux 当做 Windows / Linux 系统中的常规应用程序一样,几乎就和在系统中运行 VLC 或游戏一样简单。
+
+在虚拟机中使用 Kali Linux 也是安全的。无论你在 Kali Linux 中做什么都不会影响你的“宿主机系统”(即你原来的 Windows 或 Linux 操作系统)。你的实际操作系统将不会受到影响,宿主机系统中的数据将是安全的。
+
+![Kali Linux on Virtual Box][3]
+
+### 如何在 VirtualBox 上安装 Kali Linux
+
+我将在这里使用 [VirtualBox][4]。它是一个很棒的开源虚拟化解决方案,适用于任何人(无论是专业或个人用途)。它可以免费使用。
+
+在本教程中,我们将特指 Kali Linux 的安装,但你几乎可以安装任何其他已有 ISO 文件的操作系统或预先构建好的虚拟机存储文件。
+
+**注意:**这些相同的步骤适用于运行在 Windows / Linux 上的 VirtualBox。
+
+正如我已经提到的,你可以安装 Windows 或 Linux 作为宿主机。但是,在本文中,我安装了 Windows 10(不要讨厌我!),我会尝试在 VirtualBox 中逐步安装 Kali Linux。
+
+而且,最好的是,即使你碰巧使用 Linux 发行版作为主要操作系统,相同的步骤也完全适用!
+
+想知道怎么样做吗?让我们来看看…
+
+### 在 VirtualBox 上安装 Kali Linux 的逐步指导
+
+我们将使用专为 VirtualBox 制作的定制 Kali Linux 镜像。当然,你还可以下载 Kali Linux 的 ISO 文件并创建一个新的虚拟机,但是为什么在你有一个简单的替代方案时还要这样做呢?
+
+#### 1、下载并安装 VirtualBox
+
+你需要做的第一件事是从 Oracle 官方网站下载并安装 VirtualBox。
+
+- [下载 VirtualBox](https://www.virtualbox.org/wiki/Downloads)
+
+下载了安装程序后,只需双击它即可安装 VirtualBox。在 Ubuntu / Fedora Linux 上安装 VirtualBox 也是一样的。
+
+#### 2、下载就绪的 Kali Linux 虚拟镜像
+
+VirtualBox 成功安装后,前往 [Offensive Security 的下载页面][5] 下载用于 VirtualBox 的虚拟机镜像。如果你改变主意想使用 [VMware][6],也有用于它的。
+
+![Kali Linux Virtual Box Image][7]
+
+如你所见,文件大小远远超过 3 GB,你应该使用 torrent 方式或使用 [下载管理器][8] 下载它。
+
+#### 3、在 VirtualBox 上安装 Kali Linux
+
+一旦安装了 VirtualBox 并下载了 Kali Linux 镜像,你只需将其导入 VirtualBox 即可使其正常工作。
+
+以下是如何导入 Kali Linux 的 VirtualBox 镜像:
+
+**步骤 1**:启动 VirtualBox。你会注意到有一个 “Import” 按钮,点击它。
+
+![virtualbox import][9]
+
+*点击 “Import” 按钮*
+
+**步骤 2**:接着,浏览找到你刚刚下载的文件并选择它导入(如你在下图所见)。文件名应该以 “kali linux” 开头,并以 “.ova” 扩展名结束。
+
+![virtualbox import file][10]
+
+*导入 Kali Linux 镜像*
+
+选择好之后,点击 “Next” 进行处理。
+
+**步骤 3**:现在,你将看到要导入的这个虚拟机的设置。你可以自定义它们,这是你的自由。如果你想使用默认设置,也没关系。
+
+你需要选择具有足够存储空间的路径。我永远不会在 Windows 上推荐使用 C:驱动器。
+
+![virtualbox kali linux settings][11]
+
+*以 VDI 方式导入硬盘驱动器*
+
+这里,VDI 方式的硬盘驱动器是指通过分配其存储空间设置来实际挂载该硬盘驱动器。
+
+完成设置后,点击 “Import” 并等待一段时间。
+
+**步骤 4**:你现在将看到这个虚拟机已经列出了。所以,只需点击 “Start” 即可启动它。
+
+你最初可能会因 USB 端口 2.0 控制器支持而出现错误,你可以将其禁用以解决此问题,或者只需按照屏幕上的说明安装其他软件包进行修复即可。现在就完成了!
+
+![kali linux on windows virtual box][12]
+
+*运行于 VirtualBox 中的 Kali Linux*
+
+我希望本指南可以帮助你在 VirtualBox 上轻松安装 Kali Linux。当然,Kali Linux 有很多有用的工具可用于渗透测试 —— 祝你好运!
+
+**提示**:Kali Linux 和 Ubuntu 都是基于 Debian 的。如果你在使用 Kali Linux 时遇到任何问题或错误,可以按照互联网上针对 Ubuntu 或 Debian 的教程进行操作。
+
+### 赠品:免费的 Kali Linux 指南手册
+
+如果你刚刚开始使用 Kali Linux,那么了解如何使用 Kali Linux 是一个好主意。
+
+Kali Linux 背后的公司 Offensive Security 已经创建了一本指南,介绍了 Linux 的基础知识,Kali Linux 的基础知识、配置和设置。它还有一些关于渗透测试和安全工具的章节。
+
+基本上,它拥有你开始使用 Kali Linux 时所需知道的一切。最棒的是这本书可以免费下载。
+
+- [免费下载 Kali Linux 揭秘](https://kali.training/downloads/Kali-Linux-Revealed-1st-edition.pdf)
+
+如果你遇到问题或想分享在 VirtualBox 上运行 Kali Linux 的经验,请在下面的评论中告诉我们。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/install-kali-linux-virtualbox
+
+作者:[Ankush Das][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/ankush/
+[b]: https://github.com/lujun9972
+[1]: https://www.kali.org/
+[2]: https://itsfoss.com/linux-hacking-penetration-testing/
+[3]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/kali-linux-virtual-box.png?resize=800%2C450&ssl=1
+[4]: https://www.virtualbox.org/
+[5]: https://www.offensive-security.com/kali-linux-vm-vmware-virtualbox-image-download/
+[6]: https://itsfoss.com/install-vmware-player-ubuntu-1310/
+[7]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/kali-linux-virtual-box-image.jpg?resize=800%2C347&ssl=1
+[8]: https://itsfoss.com/4-best-download-managers-for-linux/
+[9]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/vmbox-import-kali-linux.jpg?ssl=1
+[10]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/vmbox-linux-next.jpg?ssl=1
+[11]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/vmbox-kali-linux-settings.jpg?ssl=1
+[12]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/kali-linux-on-windows-virtualbox.jpg?resize=800%2C429&ssl=1
+[13]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/kali-linux-virtual-box.png?fit=800%2C450&ssl=1
diff --git a/published/201902/20190206 4 cool new projects to try in COPR for February 2019.md b/published/201902/20190206 4 cool new projects to try in COPR for February 2019.md
new file mode 100644
index 0000000000..92523ddb46
--- /dev/null
+++ b/published/201902/20190206 4 cool new projects to try in COPR for February 2019.md
@@ -0,0 +1,95 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10554-1.html)
+[#]: subject: (4 cool new projects to try in COPR for February 2019)
+[#]: via: (https://fedoramagazine.org/4-cool-new-projects-to-try-in-copr-for-february-2019/)
+[#]: author: (Dominik Turecek https://fedoramagazine.org)
+
+COPR 仓库中 4 个很酷的新软件(2019.2)
+======
+
+
+
+COPR 是个人软件仓库[集合][1],它不在 Fedora 中。这是因为某些软件不符合轻松打包的标准。或者它可能不符合其他 Fedora 标准,尽管它是自由而开源的。COPR 可以在 Fedora 套件之外提供这些项目。COPR 中的软件不被 Fedora 基础设施不支持或没有被该项目所签名。但是,这是一种尝试新的或实验性的软件的一种巧妙的方式。
+
+这是 COPR 中一组新的有趣项目。
+
+### CryFS
+
+[CryFS][2] 是一个加密文件系统。它设计与云存储一同使用,主要是 Dropbox,尽管它也可以与其他存储提供商一起使用。CryFS 不仅加密文件系统中的文件,还会加密元数据、文件大小和目录结构。
+
+#### 安装说明
+
+仓库目前为 Fedora 28 和 29 以及 EPEL 7 提供 CryFS。要安装 CryFS,请使用以下命令:
+
+```
+sudo dnf copr enable fcsm/cryfs
+sudo dnf install cryfs
+```
+
+### Cheat
+
+[Cheat][3] 是一个用于在命令行中查看各种备忘录的工具,用来提醒仅偶尔使用的程序的使用方法。对于许多 Linux 程序,`cheat` 提供了来自手册页的精简后的信息,主要关注最常用的示例。除了内置的备忘录,`cheat` 允许你编辑现有的备忘录或从头开始创建新的备忘录。
+
+![][4]
+
+#### 安装说明
+
+仓库目前为 Fedora 28、29 和 Rawhide 以及 EPEL 7 提供 `cheat`。要安装 `cheat`,请使用以下命令:
+
+```
+sudo dnf copr enable tkorbar/cheat
+sudo dnf install cheat
+```
+
+### Setconf
+
+[setconf][5] 是一个简单的程序,作为 `sed` 的替代方案,用于对配置文件进行更改。`setconf` 唯一能做的就是找到指定文件中的密钥并更改其值。`setconf` 仅提供很少的选项来更改其行为 - 例如,取消更改行的注释。
+
+#### 安装说明
+
+仓库目前为 Fedora 27、28 和 29 提供 `setconf`。要安装 `setconf`,请使用以下命令:
+
+```
+sudo dnf copr enable jamacku/setconf
+sudo dnf install setconf
+```
+
+### Reddit 终端查看器
+
+[Reddit 终端查看器][6],或称为 `rtv`,提供了从终端浏览 Reddit 的界面。它提供了 Reddit 的基本功能,因此你可以登录到你的帐户,查看 subreddits、评论、点赞和发现新主题。但是,rtv 目前不支持 Reddit 标签。
+
+![][7]
+
+#### 安装说明
+
+该仓库目前为 Fedora 29 和 Rawhide 提供 Reddit Terminal Viewer。要安装 Reddit Terminal Viewer,请使用以下命令:
+
+```
+sudo dnf copr enable tc01/rtv
+sudo dnf install rtv
+```
+
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/4-cool-new-projects-to-try-in-copr-for-february-2019/
+
+作者:[Dominik Turecek][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://fedoramagazine.org
+[b]: https://github.com/lujun9972
+[1]: https://copr.fedorainfracloud.org/
+[2]: https://www.cryfs.org/
+[3]: https://github.com/chrisallenlane/cheat
+[4]: https://fedoramagazine.org/wp-content/uploads/2019/01/cheat.png
+[5]: https://setconf.roboticoverlords.org/
+[6]: https://github.com/michael-lazar/rtv
+[7]: https://fedoramagazine.org/wp-content/uploads/2019/01/rtv.png
diff --git a/published/201902/20190207 10 Methods To Create A File In Linux.md b/published/201902/20190207 10 Methods To Create A File In Linux.md
new file mode 100644
index 0000000000..ef7d8e8228
--- /dev/null
+++ b/published/201902/20190207 10 Methods To Create A File In Linux.md
@@ -0,0 +1,315 @@
+[#]: collector: (lujun9972)
+[#]: translator: (dianbanjiu)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10549-1.html)
+[#]: subject: (10 Methods To Create A File In Linux)
+[#]: via: (https://www.2daygeek.com/linux-command-to-create-a-file/)
+[#]: author: (Vinoth Kumar https://www.2daygeek.com/author/vinoth/)
+
+在 Linux 上创建文件的 10 个方法
+======
+
+我们都知道,在 Linux 上,包括设备在内的一切都是文件。Linux 管理员每天应该会多次执行文件创建活动(可能是 20 次,50 次,甚至是更多,这依赖于他们的环境)。如果你想 [在Linux上创建一个特定大小的文件][1],查看前面的这个链接。
+
+高效创建一个文件是非常重要的能力。为什么我说高效?如果你了解一些高效进行你当前活动的方式,你就可以事半功倍。这将会节省你很多的时间。你可以把这些有用的时间用到到其他重要的事情上。
+
+我下面将会介绍多个在 Linux 上创建文件的方法。我建议你选择几个简单高效的来辅助你的工作。你不必安装下列的任何一个命令,因为它们已经作为 Linux 核心工具的一部分安装到你的系统上了。
+
+创建文件可以通过以下六个方式来完成。
+
+ * `>`:标准重定向符允许我们创建一个 0KB 的空文件。
+ * `touch`:如果文件不存在的话,`touch` 命令将会创建一个 0KB 的空文件。
+ * `echo`:通过一个参数显示文本的某行。
+ * `printf`:用于显示在终端给定的文本。
+ * `cat`:它串联并打印文件到标准输出。
+ * `vi`/`vim`:Vim 是一个向上兼容 Vi 的文本编辑器。它常用于编辑各种类型的纯文本。
+ * `nano`:是一个简小且用户友好的编辑器。它复制了 `pico` 的外观和优点,但它是自由软件。
+ * `head`:用于打印一个文件开头的一部分。
+ * `tail`:用于打印一个文件的最后一部分。
+ * `truncate`:用于缩小或者扩展文件的尺寸到指定大小。
+
+### 在 Linux 上使用重定向符(>)创建一个文件
+
+标准重定向符允许我们创建一个 0KB 的空文件。它通常用于重定向一个命令的输出到一个新文件中。在没有命令的情况下使用重定向符号时,它会创建一个文件。
+
+但是它不允许你在创建文件时向其中输入任何文本。然而它对于不是很勤劳的管理员是非常简单有用的。只需要输入重定向符后面跟着你想要的文件名。
+
+```
+$ > daygeek.txt
+```
+
+使用 `ls` 命令查看刚刚创建的文件。
+
+```
+$ ls -lh daygeek.txt
+-rw-rw-r-- 1 daygeek daygeek 0 Feb 4 02:00 daygeek.txt
+```
+
+### 在 Linux 上使用 touch 命令创建一个文件
+
+`touch` 命令常用于将每个文件的访问和修改时间更新为当前时间。
+
+如果指定的文件名不存在,将会创建一个新的文件。`touch` 不允许我们在创建文件的同时向其中输入一些文本。它默认创建一个 0KB 的空文件。
+
+```
+$ touch daygeek1.txt
+```
+
+使用 `ls` 命令查看刚刚创建的文件。
+
+```
+$ ls -lh daygeek1.txt
+-rw-rw-r-- 1 daygeek daygeek 0 Feb 4 02:02 daygeek1.txt
+```
+
+### 在 Linux 上使用 echo 命令创建一个文件
+
+`echo` 内置于大多数的操作系统中。它常用于脚本、批处理文件,以及作为插入文本的单个命令的一部分。
+
+它允许你在创建一个文件时就向其中输入一些文本。当然也允许你在之后向其中输入一些文本。
+
+```
+$ echo "2daygeek.com is a best Linux blog to learn Linux" > daygeek2.txt
+```
+
+使用 `ls` 命令查看刚刚创建的文件。
+
+```
+$ ls -lh daygeek2.txt
+-rw-rw-r-- 1 daygeek daygeek 49 Feb 4 02:04 daygeek2.txt
+```
+
+可以使用 `cat` 命令查看文件的内容。
+
+```
+$ cat daygeek2.txt
+2daygeek.com is a best Linux blog to learn Linux
+```
+
+你可以使用两个重定向符 (`>>`) 添加其他内容到同一个文件。
+
+```
+$ echo "It's FIVE years old blog" >> daygeek2.txt
+```
+
+你可以使用 `cat` 命令查看添加的内容。
+
+```
+$ cat daygeek2.txt
+2daygeek.com is a best Linux blog to learn Linux
+It's FIVE years old blog
+```
+
+### 在 Linux 上使用 printf 命令创建一个新的文件
+
+`printf` 命令也可以以类似 `echo` 的方式执行。
+
+`printf` 命令常用来显示在终端窗口给出的字符串。`printf` 可以有格式说明符、转义序列或普通字符。
+
+```
+$ printf "2daygeek.com is a best Linux blog to learn Linux\n" > daygeek3.txt
+```
+
+使用 `ls` 命令查看刚刚创建的文件。
+
+```
+$ ls -lh daygeek3.txt
+-rw-rw-r-- 1 daygeek daygeek 48 Feb 4 02:12 daygeek3.txt
+```
+
+使用 `cat` 命令查看文件的内容。
+
+```
+$ cat daygeek3.txt
+2daygeek.com is a best Linux blog to learn Linux
+```
+
+你可以使用两个重定向符 (`>>`) 添加其他的内容到同一个文件中去。
+
+```
+$ printf "It's FIVE years old blog\n" >> daygeek3.txt
+```
+
+你可以使用 `cat` 命令查看这个文件中添加的内容。
+
+```
+$ cat daygeek3.txt
+2daygeek.com is a best Linux blog to learn Linux
+It's FIVE years old blog
+```
+
+### 在 Linux 中使用 cat 创建一个文件
+
+`cat` 表示串联。在 Linux 经常用于读取一个文件中的数据。
+
+`cat` 是在类 Unix 系统中最常使用的命令之一。它提供了三个与文本文件相关的功能:显示一个文件的内容、组合多个文件的内容到一个输出以及创建一个新的文件。(LCTT 译注:如果 `cat` 命令后如果不带任何文件的话,下面的命令在回车后也不会立刻结束,回车后的操作可以按 `Ctrl-C` 或 `Ctrl-D` 来结束。)
+
+```
+$ cat > daygeek4.txt
+2daygeek.com is a best Linux blog to learn Linux
+It's FIVE years old blog
+```
+
+使用 `ls` 命令查看创建的文件。
+
+```
+$ ls -lh daygeek4.txt
+-rw-rw-r-- 1 daygeek daygeek 74 Feb 4 02:18 daygeek4.txt
+```
+
+使用 `cat` 命令查看文件的内容。
+
+```
+$ cat daygeek4.txt
+2daygeek.com is a best Linux blog to learn Linux
+It's FIVE years old blog
+```
+
+如果你想向同一个文件中添加其他内容,使用两个连接的重定向符(`>>`)。
+
+```
+$ cat >> daygeek4.txt
+This website is maintained by Magesh M, It's licensed under CC BY-NC 4.0.
+```
+
+你可以使用 `cat` 命令查看添加的内容。
+
+```
+$ cat daygeek4.txt
+2daygeek.com is a best Linux blog to learn Linux
+It's FIVE years old blog
+This website is maintained by Magesh M, It's licensed under CC BY-NC 4.0.
+```
+
+### 在 Linux 上使用 vi/vim 命令创建一个文件
+
+`vim` 是一个向上兼容 `vi` 的文本编辑器。它通常用来编辑所有种类的纯文本。在编辑程序时特别有用。
+
+`vim` 中有很多功能可以用于编辑单个文件。
+
+```
+$ vi daygeek5.txt
+
+2daygeek.com is a best Linux blog to learn Linux
+It's FIVE years old blog
+```
+
+使用 `ls` 查看刚才创建的文件。
+
+```
+$ ls -lh daygeek5.txt
+-rw-rw-r-- 1 daygeek daygeek 75 Feb 4 02:23 daygeek5.txt
+```
+
+使用 `cat` 命令查看文件的内容。
+
+```
+$ cat daygeek5.txt
+2daygeek.com is a best Linux blog to learn Linux
+It's FIVE years old blog
+```
+
+### 在 Linux 上使用 nano 命令创建一个文件
+
+`nano` 是一个编辑器,它是一个自由版本的 `pico` 克隆。`nano` 是一个小且用户友好的编辑器。它复制了 `pico` 的外观及优点,并且是一个自由软件,它添加了 `pico` 缺乏的一系列特性,像是打开多个文件、逐行滚动、撤销/重做、语法高亮、行号等等。
+
+```
+$ nano daygeek6.txt
+
+2daygeek.com is a best Linux blog to learn Linux
+It's FIVE years old blog
+This website is maintained by Magesh M, It's licensed under CC BY-NC 4.0.
+```
+
+使用 `ls` 命令查看创建的文件。
+
+```
+$ ls -lh daygeek6.txt
+-rw-rw-r-- 1 daygeek daygeek 148 Feb 4 02:26 daygeek6.txt
+```
+
+使用 `cat` 命令来查看一个文件的内容。
+
+```
+$ cat daygeek6.txt
+2daygeek.com is a best Linux blog to learn Linux
+It's FIVE years old blog
+This website is maintained by Magesh M, It's licensed under CC BY-NC 4.0.
+```
+
+### 在 Linux 上使用 head 命令创建一个文件
+
+`head` 命令通常用于输出一个文件开头的一部分。它默认会打印一个文件的开头 10 行到标准输出。如果有多个文件,则每个文件前都会有一个标题,用来表示文件名。
+
+```
+$ head -c 0K /dev/zero > daygeek7.txt
+```
+
+使用 `ls` 命令查看创建的文件。
+
+```
+$ ls -lh daygeek7.txt
+-rw-rw-r-- 1 daygeek daygeek 0 Feb 4 02:30 daygeek7.txt
+```
+
+### 在 Linux 上使用 tail 创建一个文件
+
+`tail` 命令通常用来输出一个文件最后的一部分。它默认会打印每个文件的最后 10 行到标准输出。如果有多个文件,则每个文件前都会有一个标题,用来表示文件名。
+
+```
+$ tail -c 0K /dev/zero > daygeek8.txt
+```
+
+使用 `ls` 命令查看创建的文件。
+
+```
+$ ls -lh daygeek8.txt
+-rw-rw-r-- 1 daygeek daygeek 0 Feb 4 02:31 daygeek8.txt
+```
+
+### 在 Linux 上使用 truncate 命令创建一个文件
+
+`truncate` 命令通常用作将一个文件的尺寸缩小或者扩展为某个指定的尺寸。
+
+```
+$ truncate -s 0K daygeek9.txt
+```
+
+使用 `ls` 命令检查创建的文件。
+
+```
+$ ls -lh daygeek9.txt
+-rw-rw-r-- 1 daygeek daygeek 0 Feb 4 02:37 daygeek9.txt
+```
+
+在这篇文章中,我使用这十个命令分别创建了下面的这十个文件。
+
+```
+$ ls -lh daygeek*
+-rw-rw-r-- 1 daygeek daygeek 0 Feb 4 02:02 daygeek1.txt
+-rw-rw-r-- 1 daygeek daygeek 74 Feb 4 02:07 daygeek2.txt
+-rw-rw-r-- 1 daygeek daygeek 74 Feb 4 02:15 daygeek3.txt
+-rw-rw-r-- 1 daygeek daygeek 148 Feb 4 02:20 daygeek4.txt
+-rw-rw-r-- 1 daygeek daygeek 75 Feb 4 02:23 daygeek5.txt
+-rw-rw-r-- 1 daygeek daygeek 148 Feb 4 02:26 daygeek6.txt
+-rw-rw-r-- 1 daygeek daygeek 148 Feb 4 02:32 daygeek7.txt
+-rw-rw-r-- 1 daygeek daygeek 148 Feb 4 02:32 daygeek8.txt
+-rw-rw-r-- 1 daygeek daygeek 148 Feb 4 02:38 daygeek9.txt
+-rw-rw-r-- 1 daygeek daygeek 0 Feb 4 02:00 daygeek.txt
+```
+
+--------------------------------------------------------------------------------
+
+via: https://www.2daygeek.com/linux-command-to-create-a-file/
+
+作者:[Vinoth Kumar][a]
+选题:[lujun9972][b]
+译者:[dianbanjiu](https://github.com/dianbanjiu)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.2daygeek.com/author/vinoth/
+[b]: https://github.com/lujun9972
+[1]: https://www.2daygeek.com/create-a-file-in-specific-certain-size-linux/
diff --git a/published/201902/20190207 How to determine how much memory is installed, used on Linux systems.md b/published/201902/20190207 How to determine how much memory is installed, used on Linux systems.md
new file mode 100644
index 0000000000..96b474f7e4
--- /dev/null
+++ b/published/201902/20190207 How to determine how much memory is installed, used on Linux systems.md
@@ -0,0 +1,228 @@
+[#]: collector: (lujun9972)
+[#]: translator: (leommxj)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10571-1.html)
+[#]: subject: (How to determine how much memory is installed, used on Linux systems)
+[#]: via: (https://www.networkworld.com/article/3336174/linux/how-much-memory-is-installed-and-being-used-on-your-linux-systems.html)
+[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
+
+如何在 Linux 系统中判断安装、使用了多少内存
+======
+
+> 有几个命令可以报告在 Linux 系统上安装和使用了多少内存。根据你使用的命令,你可能会被细节淹没,也可能获得快速简单的答案。
+
+
+
+在 Linux 系统中有很多种方法获取有关安装了多少内存的信息及查看多少内存正在被使用。有些命令提供了大量的细节,而其他命令提供了简洁但不一定易于理解的答案。在这篇文章中,我们将介绍一些查看内存及其使用状态的有用的工具。
+
+在我们开始之前,让我们先来回顾一些基础知识。物理内存和虚拟内存并不是一回事。后者包括配置为交换空间的磁盘空间。交换空间可能包括为此目的特意留出来的分区,以及在创建新的交换分区不可行时创建的用来增加可用交换空间的文件。有些 Linux 命令会提供关于两者的信息。
+
+当物理内存占满时,交换空间通过提供可以用来存放内存中非活动页的磁盘空间来扩展内存。
+
+`/proc/kcore` 是在内存管理中起作用的一个文件。这个文件看上去是个普通文件(虽然非常大),但它并不占用任何空间。它就像其他 `/proc` 下的文件一样是个虚拟文件。
+
+```
+$ ls -l /proc/kcore
+-r--------. 1 root root 140737477881856 Jan 28 12:59 /proc/kcore
+```
+
+有趣的是,下面查询的两个系统并没有安装相同大小的内存,但 `/proc/kcore` 的大小却是相同的。第一个系统安装了 4 GB 的内存,而第二个系统安装了 6 GB。
+
+```
+system1$ ls -l /proc/kcore
+-r--------. 1 root root 140737477881856 Jan 28 12:59 /proc/kcore
+system2$ ls -l /proc/kcore
+-r-------- 1 root root 140737477881856 Feb 5 13:00 /proc/kcore
+```
+
+一种不靠谱的解释说这个文件代表可用虚拟内存的大小(没准要加 4 KB),如果这样,这些系统的虚拟内存可就是 128TB 了!这个数字似乎代表了 64 位系统可以寻址多少内存,而不是当前系统有多少可用内存。在命令行中计算 128 TB 和这个文件大小加上 4 KB 很容易。
+
+```
+$ expr 1024 \* 1024 \* 1024 \* 1024 \* 128
+140737488355328
+$ expr 1024 \* 1024 \* 1024 \* 1024 \* 128 + 4096
+140737488359424
+```
+
+另一个用来检查内存的更人性化的命令是 `free`。它会给出一个易于理解的内存报告。
+
+```
+$ free
+ total used free shared buff/cache available
+Mem: 6102476 812244 4090752 13112 1199480 4984140
+Swap: 2097148 0 2097148
+```
+
+使用 `-g` 选项,`free` 会以 GB 为单位返回结果。
+
+```
+$ free -g
+ total used free shared buff/cache available
+Mem: 5 0 3 0 1 4
+Swap: 1 0 1
+```
+
+使用 `-t` 选项,`free` 会显示与无附加选项时相同的值(不要把 `-t` 选项理解成 TB),并额外在输出的底部添加一行总计数据。
+
+```
+$ free -t
+ total used free shared buff/cache available
+Mem: 6102476 812408 4090612 13112 1199456 4983984
+Swap: 2097148 0 2097148
+Total: 8199624 812408 6187760
+```
+
+当然,你也可以选择同时使用两个选项。
+
+```
+$ free -tg
+ total used free shared buff/cache available
+Mem: 5 0 3 0 1 4
+Swap: 1 0 1
+Total: 7 0 5
+```
+
+如果你尝试用这个报告来解释“这个系统安装了多少内存?”,你可能会感到失望。上面的报告就是在前文说的装有 6 GB 内存的系统上运行的结果。这并不是说这个结果是错的,这就是系统对其可使用的内存的看法。
+
+`free` 命令也提供了每隔 X 秒刷新显示的选项(下方示例中 X 为 10)。
+
+```
+$ free -s 10
+ total used free shared buff/cache available
+Mem: 6102476 812280 4090704 13112 1199492 4984108
+Swap: 2097148 0 2097148
+
+ total used free shared buff/cache available
+Mem: 6102476 812260 4090712 13112 1199504 4984120
+Swap: 2097148 0 2097148
+```
+
+使用 `-l` 选项,`free` 命令会提供高低内存使用信息。
+
+```
+$ free -l
+ total used free shared buff/cache available
+Mem: 6102476 812376 4090588 13112 1199512 4984000
+Low: 6102476 2011888 4090588
+High: 0 0 0
+Swap: 2097148 0 2097148
+```
+
+查看内存的另一个选择是 `/proc/meminfo` 文件。像 `/proc/kcore` 一样,这也是一个虚拟文件,它可以提供关于安装或使用了多少内存以及可用内存的报告。显然,空闲内存和可用内存并不是同一回事。`MemFree` 看起来代表未使用的 RAM。`MemAvailable` 则是对于启动新程序时可使用的内存的一个估计。
+
+```
+$ head -3 /proc/meminfo
+MemTotal: 6102476 kB
+MemFree: 4090596 kB
+MemAvailable: 4984040 kB
+```
+
+如果只想查看内存总计,可以使用下面的命令之一:
+
+```
+$ awk '/MemTotal/ {print $2}' /proc/meminfo
+6102476
+$ grep MemTotal /proc/meminfo
+MemTotal: 6102476 kB
+```
+
+`DirectMap` 将内存信息分为几类。
+
+```
+$ grep DirectMap /proc/meminfo
+DirectMap4k: 213568 kB
+DirectMap2M: 6076416 kB
+```
+
+`DirectMap4k` 代表被映射成标准 4 k 页的内存大小,`DirectMap2M` 则显示了被映射为 2 MB 的页的内存大小。
+
+`getconf` 命令将会提供比我们大多数人想要看到的更多的信息。
+
+```
+$ getconf -a | more
+LINK_MAX 65000
+_POSIX_LINK_MAX 65000
+MAX_CANON 255
+_POSIX_MAX_CANON 255
+MAX_INPUT 255
+_POSIX_MAX_INPUT 255
+NAME_MAX 255
+_POSIX_NAME_MAX 255
+PATH_MAX 4096
+_POSIX_PATH_MAX 4096
+PIPE_BUF 4096
+_POSIX_PIPE_BUF 4096
+SOCK_MAXBUF
+_POSIX_ASYNC_IO
+_POSIX_CHOWN_RESTRICTED 1
+_POSIX_NO_TRUNC 1
+_POSIX_PRIO_IO
+_POSIX_SYNC_IO
+_POSIX_VDISABLE 0
+ARG_MAX 2097152
+ATEXIT_MAX 2147483647
+CHAR_BIT 8
+CHAR_MAX 127
+--More--
+```
+
+使用类似下面的命令来将其输出精简为指定的内容,你会得到跟前文提到的其他命令相同的结果。
+
+```
+$ getconf -a | grep PAGES | awk 'BEGIN {total = 1} {if (NR == 1 || NR == 3) total *=$NF} END {print total / 1024" kB"}'
+6102476 kB
+```
+
+上面的命令通过将下方输出的第一行和最后一行的值相乘来计算内存。
+
+```
+PAGESIZE 4096 <==
+_AVPHYS_PAGES 1022511
+_PHYS_PAGES 1525619 <==
+```
+
+自己动手计算一下,我们就知道这个值是怎么来的了。
+
+```
+$ expr 4096 \* 1525619 / 1024
+6102476
+```
+
+显然值得为以上的指令之一设置个 `alias`。
+
+另一个具有非常易于理解的输出的命令是 `top` 。在 `top` 输出的前五行,你可以看到一些数字显示多少内存正被使用。
+
+```
+$ top
+top - 15:36:38 up 8 days, 2:37, 2 users, load average: 0.00, 0.00, 0.00
+Tasks: 266 total, 1 running, 265 sleeping, 0 stopped, 0 zombie
+%Cpu(s): 0.2 us, 0.4 sy, 0.0 ni, 99.4 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
+MiB Mem : 3244.8 total, 377.9 free, 1826.2 used, 1040.7 buff/cache
+MiB Swap: 3536.0 total, 3535.7 free, 0.3 used. 1126.1 avail Mem
+```
+
+最后一个命令将会以一个非常简洁的方式回答“系统安装了多少内存?”:
+
+```
+$ sudo dmidecode -t 17 | grep "Size.*MB" | awk '{s+=$2} END {print s / 1024 "GB"}'
+6GB
+```
+
+取决于你想要获取多少细节,Linux 系统提供了许多用来查看系统安装内存以及使用/空闲内存的选择。
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3336174/linux/how-much-memory-is-installed-and-being-used-on-your-linux-systems.html
+
+作者:[Sandra Henry-Stocker][a]
+选题:[lujun9972][b]
+译者:[leommxj](https://github.com/leommxj)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
+[b]: https://github.com/lujun9972
+[1]: https://www.facebook.com/NetworkWorld/
+[2]: https://www.linkedin.com/company/network-world
diff --git a/published/201902/20190208 How To Install And Use PuTTY On Linux.md b/published/201902/20190208 How To Install And Use PuTTY On Linux.md
new file mode 100644
index 0000000000..a4615d4b78
--- /dev/null
+++ b/published/201902/20190208 How To Install And Use PuTTY On Linux.md
@@ -0,0 +1,147 @@
+[#]: collector: (lujun9972)
+[#]: translator: (zhs852)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10552-1.html)
+[#]: subject: (How To Install And Use PuTTY On Linux)
+[#]: via: (https://www.ostechnix.com/how-to-install-and-use-putty-on-linux/)
+[#]: author: (SK https://www.ostechnix.com/author/sk/)
+
+在 Linux 中安装并使用 PuTTY
+======
+
+
+
+PuTTY 是一个自由开源且支持包括 SSH、Telnet 和 Rlogin 在内的多种协议的 GUI 客户端。一般来说,Windows 管理员们会把 PuTTY 当成 SSH 或 Telnet 客户端来在本地 Windows 系统和远程 Linux 服务器之间建立连接。不过,PuTTY 可不是 Windows 的独占软件。它在 Linux 用户之中也是很流行的。本篇文章将会告诉你如何在 Linux 中安装并使用 PuTTY。
+
+### 在 Linux 中安装 PuTTY
+
+PuTTY 已经包含在了许多 Linux 发行版的官方源中。举个例子,在 Arch Linux 中,我们可以通过这个命令安装 PuTTY:
+
+```shell
+$ sudo pacman -S putty
+```
+
+在 Debian、Ubuntu 或是 Linux Mint 中安装它:
+
+```shell
+$ sudo apt install putty
+```
+
+### 使用 PuTTY 访问远程 Linux 服务器
+
+在安装完 PuTTY 之后,你可以在菜单或启动器中打开它。如果你想用终端打开它,也是可以的:
+
+```shell
+$ putty
+```
+
+PuTTY 的默认界面长这个样子:
+
+
+
+如你所见,许多选项都配上了说明。在左侧面板中,你可以配置许多项目,比如:
+
+ 1. 修改 PuTTY 登录会话选项;
+ 2. 修改终端模拟器控制选项,控制各个按键的功能;
+ 3. 控制终端响铃的声音;
+ 4. 启用/禁用终端的高级功能;
+ 5. 设定 PuTTY 窗口大小;
+ 6. 控制命令回滚长度(默认是 2000 行);
+ 7. 修改 PuTTY 窗口或光标的外观;
+ 8. 调整窗口边缘;
+ 9. 调整字体;
+ 10. 保存登录信息;
+ 11. 设置代理;
+ 12. 修改各协议的控制选项;
+ 13. 以及更多。
+
+所有选项基本都有注释,相信你理解起来不难。
+
+### 使用 PuTTY 访问远程 Linux 服务器
+
+请在左侧面板点击 “Session” 选项卡,输入远程主机名(或 IP 地址)。然后,请选择连接类型(比如 Telnet、Rlogin 以及 SSH 等)。根据你选择的连接类型,PuTTY 会自动选择对应连接类型的默认端口号(比如 SSH 是 22、Telnet 是 23),如果你修改了默认端口号,别忘了手动把它输入到 “Port” 里。在这里,我用 SSH 连接到远程主机。在输入所有信息后,请点击 “Open”。
+
+
+
+如果这是你首次连接到这个远程主机,PuTTY 会显示一个安全警告,问你是否信任你连接到的远程主机。点击 “Accept” 即可将远程主机的密钥加入 PuTTY 的缓存当中:
+
+![PuTTY 安全警告][2]
+
+接下来,输入远程主机的用户名和密码。然后你就成功地连接上远程主机啦。
+
+
+
+#### 使用密钥验证访问远程主机
+
+一些 Linux 管理员可能在服务器上配置了密钥认证。举个例子,在用 PuTTY 访问 AMS 实例的时候,你需要指定密钥文件的位置。PuTTY 可以使用它自己的格式(`.ppk` 文件)来进行公钥验证。
+
+首先输入主机名或 IP。之后,在 “Category” 选项卡中,展开 “Connection”,再展开 “SSH”,然后选择 “Auth”,之后便可选择 `.ppk` 密钥文件了。
+
+![][3]
+
+点击 “Accept” 来关闭安全提示。然后,输入远程主机的密码(如果密钥被密码保护)来建立连接。
+
+#### 保存 PuTTY 会话
+
+有些时候,你可能需要多次连接到同一个远程主机,你可以保存这些会话并在之后不输入信息访问他们。
+
+请输入主机名(或 IP 地址),并提供一个会话名称,然后点击 “Save”。如果你有密钥文件,请确保你在点击 “Save” 按钮之前指定它们。
+
+![][4]
+
+现在,你可以通过选择 “Saved sessions”,然后点击 “Load”,再点击 “Open” 来启动连接。
+
+#### 使用 PuTTY 安全复制客户端(pscp)来将文件传输到远程主机中
+
+通常来说,Linux 用户和管理员会使用 `scp` 这个命令行工具来从本地往远程主机传输文件。不过 PuTTY 给我们提供了一个叫做 PuTTY 安全复制客户端(简写为 `pscp`)的工具来干这个事情。如果你的本地主机运行的是 Windows,你可能需要这个工具。PSCP 在 Windows 和 Linux 下都是可用的。
+
+使用这个命令来将 `file.txt` 从本地的 Arch Linux 拷贝到远程的 Ubuntu 上:
+
+```shell
+pscp -i test.ppk file.txt sk@192.168.225.22:/home/sk/
+```
+
+让我们来分析这个命令:
+
+ * `-i test.ppk`:访问远程主机所用的密钥文件;
+ * `file.txt`:要拷贝到远程主机的文件;
+ * `sk@192.168.225.22`:远程主机的用户名与 IP;
+ * `/home/sk/`:目标路径。
+
+要拷贝一个目录,请使用 `-r`(递归)参数:
+
+```shell
+ pscp -i test.ppk -r dir/ sk@192.168.225.22:/home/sk/
+```
+
+要使用 `pscp` 传输文件,请执行以下命令:
+
+```shell
+pscp -i test.ppk c:\documents\file.txt.txt sk@192.168.225.22:/home/sk/
+```
+
+你现在应该了解了 PuTTY 是什么,知道了如何安装它和如何使用它。同时,你也学习到了如何使用 `pscp` 程序在本地和远程主机上传输文件。
+
+以上便是所有了,希望这篇文章对你有帮助。
+
+干杯!
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/how-to-install-and-use-putty-on-linux/
+
+作者:[SK][a]
+选题:[lujun9972][b]
+译者:[zhs852](https://github.com/zhs852)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/sk/
+[b]: https://github.com/lujun9972
+[1]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
+[2]: http://www.ostechnix.com/wp-content/uploads/2019/02/putty-2.png
+[3]: http://www.ostechnix.com/wp-content/uploads/2019/02/putty-4.png
+[4]: http://www.ostechnix.com/wp-content/uploads/2019/02/putty-5.png
diff --git a/published/201902/20190214 Drinking coffee with AWK.md b/published/201902/20190214 Drinking coffee with AWK.md
new file mode 100644
index 0000000000..eb83412bbd
--- /dev/null
+++ b/published/201902/20190214 Drinking coffee with AWK.md
@@ -0,0 +1,119 @@
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10555-1.html)
+[#]: subject: (Drinking coffee with AWK)
+[#]: via: (https://opensource.com/article/19/2/drinking-coffee-awk)
+[#]: author: (Moshe Zadka https://opensource.com/users/moshez)
+
+用 AWK 喝咖啡
+======
+> 用一个简单的 AWK 程序跟踪你的同事喝咖啡的欠款。
+
+
+
+以下基于一个真实的故事,虽然一些名字和细节有所改变。
+
+> 很久以前,在一个遥远的地方,有一间~~庙~~(划掉)办公室。由于各种原因,这个办公室没有购买速溶咖啡。所以那个办公室的一些人聚在一起决定建立“咖啡角”。
+>
+> 咖啡角的一名成员会购买一些速溶咖啡,而其他成员会付给他钱。有人喝咖啡比其他人多,所以增加了“半成员”的级别:半成员每周允许喝的咖啡限量,并可以支付其它成员支付的一半。
+
+管理这事非常操心。而我刚读过《Unix 编程环境》这本书,想练习一下我的 [AWK][1] 编程技能,所以我自告奋勇创建了一个系统。
+
+第 1 步:我用一个数据库来记录成员及其应支付给咖啡角的欠款。我是以 AWK 便于处理的格式记录的,其中字段用冒号分隔:
+
+```
+member:john:1:22
+member:jane:0.5:33
+member:pratyush:0.5:17
+member:jing:1:27
+```
+
+上面的第一个字段标识了这是哪一种行(`member`)。第二个字段是成员的名字(即他们的电子邮件用户名,但没有 @ )。下一个字段是其成员级别(成员 = 1,或半会员 = 0.5)。最后一个字段是他们欠咖啡角的钱。正数表示他们欠咖啡角钱,负数表示咖啡角欠他们。
+
+第 2 步:我记录了咖啡角的收入和支出:
+
+```
+payment:jane:33
+payment:pratyush:17
+bought:john:60
+payback:john:50
+```
+
+Jane 付款 $33,Pratyush 付款 $17,John 买了价值 $60 的咖啡,而咖啡角还款给 John $50。
+
+第 3 步:我准备写一些代码,用来处理成员和付款,并生成记录了新欠账的更新的成员文件。
+
+```
+#!/usr/bin/env --split-string=awk -F: -f
+```
+
+释伴行(`#!`)需要做一些调整,我使用 `env` 命令来允许从释伴行传递多个参数:具体来说,AWK 的 `-F` 命令行参数会告诉它字段分隔符是什么。
+
+AWK 程序就是一个规则序列(也可以包含函数定义,但是对于这个咖啡角应用来说不需要)
+
+第一条规则读取该成员文件。当我运行该命令时,我总是首先给它的是成员文件,然后是付款文件。它使用 AWK 关联数组来在 `members` 数组中记录成员级别,以及在 `debt` 数组中记录当前欠账。
+
+```
+$1 == "member" {
+ members[$2]=$3
+ debt[$2]=$4
+ total_members += $3
+}
+```
+
+第二条规则在记录付款(`payment`)时减少欠账。
+
+```
+$1 == "payment" {
+ debt[$2] -= $3
+}
+```
+
+还款(`payback`)则相反:它增加欠账。这可以优雅地支持意外地给了某人太多钱的情况。
+
+```
+$1 == "payback" {
+ debt[$2] += $3
+}
+```
+
+最复杂的部分出现在有人购买(`bought`)速溶咖啡供咖啡角使用时。它被视为付款(`payment`),并且该人的债务减少了适当的金额。接下来,它计算每个会员的费用。它根据成员的级别对所有成员进行迭代并增加欠款
+
+```
+$1 == "bought" {
+ debt[$2] -= $3
+ per_member = $3/total_members
+ for (x in members) {
+ debt[x] += per_member * members[x]
+ }
+}
+```
+
+`END` 模式很特殊:当 AWK 没有更多的数据要处理时,它会一次性执行。此时,它会使用更新的欠款数生成新的成员文件。
+
+```
+END {
+ for (x in members) {
+ printf "%s:%s:%s\n", x, members[x], debt[x]
+ }
+}
+```
+
+再配合一个遍历成员文件,并向人们发送提醒电子邮件以支付他们的会费(积极清账)的脚本,这个系统管理咖啡角相当一段时间。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/2/drinking-coffee-awk
+
+作者:[Moshe Zadka][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/moshez
+[b]: https://github.com/lujun9972
+[1]: https://en.wikipedia.org/wiki/AWK
diff --git a/published/201902/20190216 How To Grant And Remove Sudo Privileges To Users On Ubuntu.md b/published/201902/20190216 How To Grant And Remove Sudo Privileges To Users On Ubuntu.md
new file mode 100644
index 0000000000..a53e354779
--- /dev/null
+++ b/published/201902/20190216 How To Grant And Remove Sudo Privileges To Users On Ubuntu.md
@@ -0,0 +1,103 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10576-1.html)
+[#]: subject: (How To Grant And Remove Sudo Privileges To Users On Ubuntu)
+[#]: via: (https://www.ostechnix.com/how-to-grant-and-remove-sudo-privileges-to-users-on-ubuntu/)
+[#]: author: (SK https://www.ostechnix.com/author/sk/)
+
+如何在 Ubuntu 上为用户授予和移除 sudo 权限
+======
+
+
+
+如你所知,用户可以在 Ubuntu 系统上使用 sudo 权限执行任何管理任务。在 Linux 机器上创建新用户时,他们无法执行任何管理任务,直到你将其加入 `sudo` 组的成员。在这个简短的教程中,我们将介绍如何将普通用户添加到 `sudo` 组以及移除给定的权限,使其成为普通用户。
+
+### 在 Linux 上向普通用户授予 sudo 权限
+
+通常,我们使用 `adduser` 命令创建新用户,如下所示。
+
+```
+$ sudo adduser ostechnix
+```
+
+如果你希望新创建的用户使用 `sudo` 执行管理任务,只需使用以下命令将它添加到 `sudo` 组:
+
+```
+$ sudo usermod -a -G sudo hduser
+```
+
+上面的命令将使名为 `ostechnix` 的用户成为 `sudo` 组的成员。
+
+你也可以使用此命令将用户添加到 `sudo` 组。
+
+```
+$ sudo adduser ostechnix sudo
+```
+
+现在,注销并以新用户身份登录,以使此更改生效。此时用户已成为管理用户。
+
+要验证它,只需在任何命令中使用 `sudo` 作为前缀。
+
+```
+$ sudo mkdir /test
+[sudo] password for ostechnix:
+```
+
+### 移除用户的 sudo 权限
+
+有时,你可能希望移除特定用户的 `sudo` 权限,而不用在 Linux 中删除它。要将任何用户设为普通用户,只需将其从 `sudo` 组中删除即可。
+
+比如说如果要从 `sudo` 组中删除名为 `ostechnix` 的用户,只需运行:
+
+```
+$ sudo deluser ostechnix sudo
+```
+
+示例输出:
+
+```
+Removing user `ostechnix' from group `sudo' ...
+Done.
+```
+
+此命令仅从 `sudo` 组中删除用户 `ostechnix`,但不会永久地从系统中删除用户。现在,它成为了普通用户,无法像 `sudo` 用户那样执行任何管理任务。
+
+此外,你可以使用以下命令撤消用户的 `sudo` 访问权限:
+
+```
+$ sudo gpasswd -d ostechnix sudo
+```
+
+从 `sudo` 组中删除用户时请小心。不要从 `sudo` 组中删除真正的管理员。
+
+使用命令验证用户 `ostechnix` 是否已从 `sudo` 组中删除:
+
+```
+$ sudo -l -U ostechnix
+User ostechnix is not allowed to run sudo on ubuntuserver.
+```
+
+是的,用户 `ostechnix` 已从 `sudo` 组中删除,他无法执行任何管理任务。
+
+从 `sudo` 组中删除用户时请小心。如果你的系统上只有一个 `sudo` 用户,并且你将他从 `sudo` 组中删除了,那么就无法执行任何管理操作,例如在系统上安装、删除和更新程序。所以,请小心。在我们的下一篇教程中,我们将解释如何恢复用户的 `sudo` 权限。
+
+就是这些了。希望这篇文章有用。还有更多好东西。敬请期待!
+
+干杯!
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/how-to-grant-and-remove-sudo-privileges-to-users-on-ubuntu/
+
+作者:[SK][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/sk/
+[b]: https://github.com/lujun9972
diff --git a/published/201902/20190219 3 tools for viewing files at the command line.md b/published/201902/20190219 3 tools for viewing files at the command line.md
new file mode 100644
index 0000000000..eb975657c2
--- /dev/null
+++ b/published/201902/20190219 3 tools for viewing files at the command line.md
@@ -0,0 +1,99 @@
+[#]: collector: (lujun9972)
+[#]: translator: (MjSeven)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10573-1.html)
+[#]: subject: (3 tools for viewing files at the command line)
+[#]: via: (https://opensource.com/article/19/2/view-files-command-line)
+[#]: author: (Scott Nesbitt https://opensource.com/users/scottnesbitt)
+
+在命令行查看文件的 3 个工具
+======
+
+> 看一下 `less`、Antiword 和 `odt2xt` 这三个实用程序,它们都可以在终端中查看文件。
+
+
+
+我常说,你不需要使用命令行也可以高效使用 Linux —— 我知道许多 Linux 用户从不打开终端窗口,并且也用的挺好。然而,即使我不认为自己是一名技术人员,我也会在命令行上花费大约 20% 的计算时间,包括操作文件、处理文本和使用实用程序。
+
+我经常在终端窗口中做的一件事是查看文件,无论是文本还是需要用到文字处理器的文件。有时使用命令行实用程序比启动文本编辑器或文字处理器更容易。
+
+下面是我在命令行中用来查看文件的三个实用程序。
+
+### less
+
+[less][1] 的美妙之处在于它易于使用,它将你正在查看的文件分解为块(或页面),这使得它们更易于阅读。你可以使用它在命令行查看文本文件,例如 README、HTML 文件、LaTeX 文件或其他任何纯文本文件。我在[上一篇文章][2]中介绍了 `less`。
+
+要使用 `less`,只需输入:
+
+```
+less file_name
+```
+
+
+
+通过按键盘上的空格键或 `PgDn` 键向下滚动文件,按 `PgUp` 键向上移动文件。要停止查看文件,按键盘上的 `Q` 键。
+
+### Antiword
+
+[Antiword][3] 是一个很好地实用小程序,你可以使用它将 Word 文档转换为纯文本。只要你想,还可以将它们转换为 [PostScript][4] 或 [PDF][5]。在本文中,让我们继续使用文本转换。
+
+Antiword 可以读取和转换 Word 2.0 到 2003 版本创建的文件(LCTT 译注:此处疑为 Word 2000,因为 Word 2.0 for DOS 发布于 1984 年,而 WinWord 2.0 发布于 1991 年,都似乎太老了)。它不能读取 DOCX 文件 —— 如果你尝试这样做,Antiword 会显示一条错误消息,表明你尝试读取的是一个 ZIP 文件。这在技术上说是正确的,但仍然令人沮丧。
+
+要使用 Antiword 查看 Word 文档,输入以下命令:
+
+```
+antiword file_name.doc
+```
+
+Antiword 将文档转换为文本并显示在终端窗口中。不幸的是,它不能在终端中将文档分解成页面。不过,你可以将 Antiword 的输出重定向到 `less` 或 [more][6] 之类的实用程序,一遍对其进行分页。通过输入以下命令来执行此操作:
+
+```
+antiword file_name.doc | less
+```
+
+如果你是命令行的新手,那么我告诉你 `|` 称为管道。这就是重定向。
+
+
+
+### odt2txt
+
+作为一个优秀的开源公民,你会希望尽可能多地使用开放格式。对于你的文字处理需求,你可能需要处理 [ODT][7] 文件(由诸如 LibreOffice Writer 和 AbiWord 等文字处理器使用)而不是 Word 文件。即使没有,也可能会遇到 ODT 文件。而且,即使你的计算机上没有安装 Writer 或 AbiWord,也很容易在命令行中查看它们。
+
+怎样做呢?用一个名叫 [odt2txt][8] 的实用小程序。正如你猜到的那样,`odt2txt` 将 ODT 文件转换为纯文本。要使用它,运行以下命令:
+
+```
+odt2txt file_name.odt
+```
+
+与 Antiword 一样,`odt2txt` 将文档转换为文本并在终端窗口中显示。和 Antiword 一样,它不会对文档进行分页。但是,你也可以使用以下命令将 `odt2txt` 的输出管道传输到 `less` 或 `more` 这样的实用程序中:
+
+```
+odt2txt file_name.odt | more
+```
+
+
+
+你有一个最喜欢的在命令行中查看文件的实用程序吗?欢迎留下评论与社区分享。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/2/view-files-command-line
+
+作者:[Scott Nesbitt][a]
+选题:[lujun9972][b]
+译者:[MjSeven](https://github.com/MjSeven)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/scottnesbitt
+[b]: https://github.com/lujun9972
+[1]: https://www.gnu.org/software/less/
+[2]: https://opensource.com/article/18/4/using-less-view-text-files-command-line
+[3]: http://www.winfield.demon.nl/
+[4]: http://en.wikipedia.org/wiki/PostScript
+[5]: http://en.wikipedia.org/wiki/Portable_Document_Format
+[6]: https://opensource.com/article/19/1/more-text-files-linux
+[7]: http://en.wikipedia.org/wiki/OpenDocument
+[8]: https://github.com/dstosberg/odt2txt
diff --git a/published/201902/20190219 How to List Installed Packages on Ubuntu and Debian -Quick Tip.md b/published/201902/20190219 How to List Installed Packages on Ubuntu and Debian -Quick Tip.md
new file mode 100644
index 0000000000..2eec9eb896
--- /dev/null
+++ b/published/201902/20190219 How to List Installed Packages on Ubuntu and Debian -Quick Tip.md
@@ -0,0 +1,200 @@
+[#]: collector: (lujun9972)
+[#]: translator: (guevaraya)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10562-1.html)
+[#]: subject: (How to List Installed Packages on Ubuntu and Debian [Quick Tip])
+[#]: via: (https://itsfoss.com/list-installed-packages-ubuntu)
+[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
+
+如何列出 Ubuntu 和 Debian 上已安装的软件包
+======
+
+当你安装了 [Ubuntu 并想好好用一用][1]。但在将来某个时候,你肯定会遇到忘记曾经安装了那些软件包。
+
+这个是完全正常。没有人要求你把系统里所有已安装的软件包都记住。但是问题是,如何才能知道已经安装了哪些软件包?如何查看安装过的软件包呢?
+
+### 列出 Ubuntu 和 Debian 上已安装的软件包
+
+![列出已安装的软件包][2]
+
+如果你经常用 [apt 命令][3],你可能觉得会有个命令像 `apt` 一样可以列出已安装的软件包。不算全错。
+
+[apt-get 命令][4] 没有类似列出已安装软件包的简单的选项,但是 `apt` 有一个这样的命令:
+
+```
+apt list --installed
+```
+
+这个会显示使用 `apt` 命令安装的所有的软件包。同时也会包含由于依赖而被安装的软件包。也就是说不仅会包含你曾经安装的程序,而且会包含大量库文件和间接安装的软件包。
+
+![用 atp 命令列出显示已安装的软件包][5]
+
+*用 atp 命令列出显示已安装的软件包*
+
+由于列出出来的已安装的软件包太多,用 `grep` 过滤特定的软件包是一个比较好的办法。
+
+```
+apt list --installed | grep program_name
+```
+
+如上命令也可以检索出使用 .deb 软件包文件安装的软件。是不是很酷?
+
+如果你阅读过 [apt 与 apt-get 对比][7]的文章,你可能已经知道 `apt` 和 `apt-get` 命令都是基于 [dpkg][8]。也就是说用 `dpkg` 命令可以列出 Debian 系统的所有已经安装的软件包。
+
+```
+dpkg-query -l
+```
+
+你可以用 `grep` 命令检索指定的软件包。
+
+![用 dpkg 命令列出显示已经安装的软件包][9]!
+
+*用 dpkg 命令列出显示已经安装的软件包*
+
+现在你可以搞定列出 Debian 的软件包管理器安装的应用了。那 Snap 和 Flatpak 这个两种应用呢?如何列出它们?因为它们不能被 `apt` 和 `dpkg` 访问。
+
+显示系统里所有已经安装的 [Snap 软件包][10],可以这个命令:
+
+```
+snap list
+```
+
+Snap 可以用绿色勾号标出哪个应用来自经过认证的发布者。
+
+![列出已经安装的 Snap 软件包][11]
+
+*列出已经安装的 Snap 软件包*
+
+显示系统里所有已安装的 [Flatpak 软件包][12],可以用这个命令:
+
+```
+flatpak list
+```
+
+让我来个汇总:
+
+
+用 `apt` 命令显示已安装软件包:
+
+```
+apt list –installed
+```
+
+用 `dpkg` 命令显示已安装软件包:
+
+```
+dpkg-query -l
+```
+
+列出系统里 Snap 已安装软件包:
+
+```
+snap list
+```
+
+列出系统里 Flatpak 已安装软件包:
+
+```
+flatpak list
+```
+
+### 显示最近安装的软件包
+
+现在你已经看过以字母顺序列出的已经安装软件包了。如何显示最近已经安装的软件包?
+
+幸运的是,Linux 系统保存了所有发生事件的日志。你可以参考最近安装软件包的日志。
+
+有两个方法可以来做。用 `dpkg` 命令的日志或者 `apt` 命令的日志。
+
+你仅仅需要用 `grep` 命令过滤已经安装的软件包日志。
+
+```
+grep " install " /var/log/dpkg.log
+```
+
+这会显示所有的软件安装包,其中包括最近安装的过程中所依赖的软件包。
+
+```
+2019-02-12 12:41:42 install ubuntu-make:all 16.11.1ubuntu1
+2019-02-13 21:03:02 install xdg-desktop-portal:amd64 0.11-1
+2019-02-13 21:03:02 install libostree-1-1:amd64 2018.8-0ubuntu0.1
+2019-02-13 21:03:02 install flatpak:amd64 1.0.6-0ubuntu0.1
+2019-02-13 21:03:02 install xdg-desktop-portal-gtk:amd64 0.11-1
+2019-02-14 11:49:10 install qml-module-qtquick-window2:amd64 5.9.5-0ubuntu1.1
+2019-02-14 11:49:10 install qml-module-qtquick2:amd64 5.9.5-0ubuntu1.1
+2019-02-14 11:49:10 install qml-module-qtgraphicaleffects:amd64 5.9.5-0ubuntu1
+```
+
+你也可以查看 `apt` 历史命令日志。这个仅会显示用 `apt` 命令安装的的程序。但不会显示被依赖安装的软件包,详细的日志在日志里可以看到。有时你只是想看看对吧?
+
+```
+grep " install " /var/log/apt/history.log
+```
+
+具体的显示如下:
+
+```
+Commandline: apt install pinta
+Commandline: apt install pinta
+Commandline: apt install tmux
+Commandline: apt install terminator
+Commandline: apt install moreutils
+Commandline: apt install ubuntu-make
+Commandline: apt install flatpak
+Commandline: apt install cool-retro-term
+Commandline: apt install ubuntu-software
+```
+
+![显示最近已安装的软件包][13]
+
+*显示最近已安装的软件包*
+
+`apt` 的历史日志非常有用。因为他显示了什么时候执行了 `apt` 命令,哪个用户执行的命令以及安装的软件包名。
+
+### 小技巧:在软件中心显示已安装的程序包名
+
+如果你觉得终端和命令行交互不友好,还有一个方法可以查看系统的程序名。
+
+可以打开软件中心,然后点击已安装标签。你可以看到系统上已经安装的程序包名
+
+![Ubuntu 软件中心显示已安装的软件包][14]
+
+*在软件中心显示已安装的软件包*
+
+这个不会显示库和其他命令行的东西,有可能你也不想看到它们,因为你的大量交互都是在 GUI。此外,你也可以用 Synaptic 软件包管理器。
+
+### 结束语
+
+我希望这个简易的教程可以帮你查看 Ubuntu 和基于 Debian 的发行版的已安装软件包。
+
+如果你对本文有什么问题或建议,请在下面留言。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/list-installed-packages-ubuntu
+
+作者:[Abhishek Prakash][a]
+选题:[lujun9972][b]
+译者:[guevaraya](https://github.com/guevaraya)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/abhishek/
+[b]: https://github.com/lujun9972
+[1]: https://itsfoss.com/getting-started-with-ubuntu/
+[2]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/list-installed-packages.png?resize=800%2C450&ssl=1
+[3]: https://itsfoss.com/apt-command-guide/
+[4]: https://itsfoss.com/apt-get-linux-guide/
+[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/02/list-installed-packages-in-ubuntu-with-apt.png?resize=800%2C407&ssl=1
+[6]: https://itsfoss.com/install-deb-files-ubuntu/
+[7]: https://itsfoss.com/apt-vs-apt-get-difference/
+[8]: https://wiki.debian.org/dpkg
+[9]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/02/list-installed-packages-with-dpkg.png?ssl=1
+[10]: https://itsfoss.com/use-snap-packages-ubuntu-16-04/
+[11]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/02/list-installed-snap-packages.png?ssl=1
+[12]: https://itsfoss.com/flatpak-guide/
+[13]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/apt-list-recently-installed-packages.png?resize=800%2C187&ssl=1
+[14]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/installed-software-ubuntu.png?ssl=1
+[15]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/list-installed-packages.png?fit=800%2C450&ssl=1
diff --git a/published/201903/20150616 Computer Laboratory - Raspberry Pi- Lesson 8 Screen03.md b/published/201903/20150616 Computer Laboratory - Raspberry Pi- Lesson 8 Screen03.md
new file mode 100644
index 0000000000..6ec24f8780
--- /dev/null
+++ b/published/201903/20150616 Computer Laboratory - Raspberry Pi- Lesson 8 Screen03.md
@@ -0,0 +1,460 @@
+[#]: collector: (lujun9972)
+[#]: translator: (qhwdw)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10585-1.html)
+[#]: subject: (Computer Laboratory – Raspberry Pi: Lesson 8 Screen03)
+[#]: via: (https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen03.html)
+[#]: author: (Alex Chadwick https://www.cl.cam.ac.uk)
+
+计算机实验室之树莓派:课程 8 屏幕03
+======
+
+屏幕03 课程基于屏幕02 课程来构建,它教你如何绘制文本,和一个操作系统命令行参数上的一个小特性。假设你已经有了[课程 7:屏幕02][1] 的操作系统代码,我们将以它为基础来构建。
+
+### 1、字符串的理论知识
+
+是的,我们的任务是为这个操作系统绘制文本。我们有几个问题需要去处理,最紧急的那个可能是如何去保存文本。令人难以置信的是,文本是迄今为止在计算机上最大的缺陷之一。原本应该是简单的数据类型却导致了操作系统的崩溃,从而削弱其他方面的加密效果,并给使用其它字母表的用户带来了许多问题。尽管如此,它仍然是极其重要的数据类型,因为它将计算机和用户很好地连接起来。文本是计算机能够理解的非常好的结构,同时人类使用它时也有足够的可读性。
+
+那么,文本是如何保存的呢?非常简单,我们使用一种方法,给每个字母分配一个唯一的编号,然后我们保存一系列的这种编号。看起来很容易吧。问题是,那个编号的数量是不固定的。一些文本段可能比其它的长。保存普通数字,我们有一些固有的限制,即:32 位,我们不能超过这个限制,我们要添加方法去使用该长度的数字等等。“文本”这个术语,我们经常也叫它“字符串”,我们希望能够写一个可用于可变长度字符串的函数,否则就需要写很多函数!对于一般的数字来说,这不是个问题,因为只有几种通用的数字格式(字节、字、半字节、双字节)。
+
+> 可变数据类型(比如文本)要求能够进行很复杂的处理。
+
+因此,如何判断字符串长度?我想显而易见的答案是存储字符串的长度,然后去存储组成字符串的字符。这称为长度前缀,因为长度位于字符串的前面。不幸的是,计算机科学家的先驱们不同意这么做。他们认为使用一个称为空终止符(`NULL`)的特殊字符(用 `\0` 表示)来表示字符串结束更有意义。这样确定简化了许多字符串算法,因为你只需要持续操作直到遇到空终止符为止。不幸的是,这成为了许多安全问题的根源。如果一个恶意用户给你一个特别长的字符串会发生什么状况?如果没有足够的空间去保存这个特别长的字符串会发生什么状况?你可以使用一个字符串复制函数来做复制,直到遇到空终止符为止,但是因为字符串特别长,而覆写了你的程序,怎么办?这看上去似乎有些较真,但是,缓冲区溢出攻击还是经常发生。长度前缀可以很容易地缓解这种问题,因为它可以很容易地推算出保存这个字符串所需要的缓冲区的长度。作为一个操作系统开发者,我留下这个问题,由你去决定如何才能更好地存储文本。
+
+> 缓冲区溢出攻击祸害计算机由来已久。最近,Wii、Xbox 和 Playstation 2、以及大型系统如 Microsoft 的 Web 和数据库服务器,都遭受到缓冲区溢出攻击。
+
+接下来的事情是,我们需要确定的是如何最好地将字符映射到数字。幸运的是,这是高度标准化的,我们有两个主要的选择,Unicode 和 ASCII。Unicode 几乎将每个有用的符号都映射为数字,作为代价,我们需要有很多很多的数字,和一个更复杂的编码方法。ASCII 为每个字符使用一个字节,因此它仅保存拉丁字母、数字、少数符号和少数特殊字符。因此,ASCII 是非常易于实现的,与之相比,Unicode 的每个字符占用的空间并不相同,这使得字符串算法更棘手。通常,操作系统上字符使用 ASCII,并不是为了显示给最终用户的(开发者和专家用户除外),给终端用户显示信息使用 Unicode,因为 Unicode 能够支持像日语字符这样的东西,并且因此可以实现本地化。
+
+幸运的是,在这里我们不需要去做选择,因为它们的前 128 个字符是完全相同的,并且编码也是完全一样的。
+
+表 1.1 ASCII/Unicode 符号 0-127
+
+| | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | a | b | c | d | e | f | |
+|----| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | ----|
+| 00 | NUL | SOH | STX | ETX | EOT | ENQ | ACK | BEL | BS | HT | LF | VT | FF | CR | SO | SI | |
+| 10 | DLE | DC1 | DC2 | DC3 | DC4 | NAK | SYN | ETB | CAN | EM | SUB | ESC | FS | GS | RS | US | |
+| 20 | ! | " | # | $ | % | & | . | ( | ) | * | + | , | - | . | / | | |
+| 30 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | < | = | > | ? | |
+| 40 | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | |
+| 50 | P | Q | R | S | T | U | V | W | X | Y | Z | [ | \ | ] | ^ | _ | |
+| 60 | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o | |
+| 70 | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ~ | DEL |
+
+这个表显示了前 128 个符号。一个符号的十六进制表示是行的值加上列的值,比如 A 是 4116。你可以惊奇地发现前两行和最后的值。这 33 个特殊字符是不可打印字符。事实上,许多人都忽略了它们。它们之所以存在是因为 ASCII 最初设计是基于计算机网络来传输数据的一种方法。因此它要发送的信息不仅仅是符号。你应该学习的重要的特殊字符是 `NUL`,它就是我们前面提到的空终止符。`HT` 水平制表符就是我们经常说的 `tab`,而 `LF` 换行符用于生成一个新行。你可能想研究和使用其它特殊字符在你的操行系统中的意义。
+
+### 2、字符
+
+到目前为止,我们已经知道了一些关于字符串的知识,我们可以开始想想它们是如何显示的。为了显示一个字符串,我们需要做的最基础的事情是能够显示一个字符。我们的第一个任务是编写一个 `DrawCharacter` 函数,给它一个要绘制的字符和一个位置,然后它将这个字符绘制出来。
+
+这就很自然地引出关于字体的讨论。我们已经知道有许多方式去按照选定的字体去显示任何给定的字母。那么字体又是如何工作的呢?在计算机科学的早期阶段,字体就是所有字母的一系列小图片而已,这种字体称为位图字体,而所有的字符绘制方法就是将图片复制到屏幕上。当人们想去调整字体大小时就出问题了。有时我们需要大的字母,而有时我们需要的是小的字母。尽管我们可以为每个字体、每种大小、每个字符都绘制新图片,但这种作法过于单调乏味。所以,发明了矢量字体。矢量字体不包含字体的图像,它包含的是如何去绘制字符的描述,即:一个 `o` 可能是最大字母高度的一半为半径绘制的圆。现代操作系统都几乎仅使用这种字体,因为这种字体在任何分辨率下都很完美。
+
+> 在许多操作系统中使用的 TrueType 字体格式是很强大的,它内置有它自己的汇编语言,以确保在任何分辨率下字母看起来都是正确的。
+
+不幸的是,虽然我很想包含一个矢量字体的格式的实现,但它的内容太多了,将占用这个网站的剩余部分。所以,我们将去实现一个位图字体,可是,如果你想去做一个像样的图形操作系统,那么矢量字体将是很有用的。
+
+在下载页面上的字体节中,我们提供了几个 `.bin` 文件。这些只是字体的原始二进制数据文件。为完成本教程,从等宽、单色、8x16 节中挑选你喜欢的字体。然后下载它并保存到 `source` 目录中并命名为 `font.bin` 文件。这些文件只是每个字母的单色图片,它们每个字母刚好是 8 x 16 个像素。所以,每个字母占用 16 字节,第一个字节是第一行,第二个字节是第二行,依此类推。
+
+
+
+这个示意图展示了等宽、单色、8x16 的字符 A 的 “Bitstream Vera Sans Mono” 字体。在这个文件中,我们可以找到,它从第 4116 × 1016 = 41016 字节开始的十六进制序列:
+
+```
+00, 00, 00, 10, 28, 28, 28, 44, 44, 7C, C6, 82, 00, 00, 00, 00
+```
+
+在这里我们将使用等宽字体,因为等宽字体的每个字符大小是相同的。不幸的是,大多数字体的复杂之处就是因为它的宽度不同,从而导致它的显示代码更复杂。在下载页面上还包含有几个其它的字体,并包含了这种字体的存储格式介绍。
+
+我们回到正题。复制下列代码到 `drawing.s` 中的 `graphicsAddress` 的 `.int 0` 之后。
+
+```assembly
+.align 4
+font:
+.incbin "font.bin"
+```
+
+> `.incbin "file"` 插入来自文件 “file” 中的二进制数据。
+
+这段代码复制文件中的字体数据到标签为 `font` 的地址。我们在这里使用了一个 `.align 4` 去确保每个字符都是从 16 字节的倍数开始,这是一个以后经常用到的用于加快访问速度的技巧。
+
+现在我们去写绘制字符的方法。我在下面给出了伪代码,你可以尝试自己去实现它。按惯例 `>>` 的意思是逻辑右移。
+
+```c
+function drawCharacter(r0 is character, r1 is x, r2 is y)
+ if character > 127 then exit
+ set charAddress to font + character × 16
+ for row = 0 to 15
+ set bits to readByte(charAddress + row)
+ for bit = 0 to 7
+ if test(bits >> bit, 0x1)
+ then setPixel(x + bit, y + row)
+ next
+ next
+ return r0 = 8, r1 = 16
+end function
+```
+
+如果直接去实现它,这显然不是个高效率的做法。像绘制字符这样的事情,效率是最重要的。因为我们要频繁使用它。我们来探索一些改善的方法,使其成为最优化的汇编代码。首先,因为我们有一个 `× 16`,你应该会马上想到它等价于逻辑左移 4 位。紧接着我们有一个变量 `row`,它只与 `charAddress` 和 `y` 相加。所以,我们可以通过增加替代变量来消除它。现在唯一的问题是如何判断我们何时完成。这时,一个很好用的 `.align 4` 上场了。我们知道,`charAddress` 将从包含 0 的低位半字节开始。这意味着我们可以通过检查低位半字节来看到进入字符数据的程度。
+
+虽然我们可以消除对 `bit` 的需求,但我们必须要引入新的变量才能实现,因此最好还是保留它。剩下唯一的改进就是去除嵌套的 `bits >> bit`。
+
+```c
+function drawCharacter(r0 is character, r1 is x, r2 is y)
+ if character > 127 then exit
+ set charAddress to font + character << 4
+ loop
+ set bits to readByte(charAddress)
+ set bit to 8
+ loop
+ set bits to bits << 1
+ set bit to bit - 1
+ if test(bits, 0x100)
+ then setPixel(x + bit, y)
+ until bit = 0
+ set y to y + 1
+ set chadAddress to chadAddress + 1
+ until charAddress AND 0b1111 = 0
+ return r0 = 8, r1 = 16
+end function
+```
+
+现在,我们已经得到了非常接近汇编代码的代码了,并且代码也是经过优化的。下面就是上述代码用汇编写出来的代码。
+
+```assembly
+.globl DrawCharacter
+DrawCharacter:
+cmp r0,#127
+movhi r0,#0
+movhi r1,#0
+movhi pc,lr
+
+push {r4,r5,r6,r7,r8,lr}
+x .req r4
+y .req r5
+charAddr .req r6
+mov x,r1
+mov y,r2
+ldr charAddr,=font
+add charAddr, r0,lsl #4
+
+lineLoop$:
+
+ bits .req r7
+ bit .req r8
+ ldrb bits,[charAddr]
+ mov bit,#8
+
+ charPixelLoop$:
+
+ subs bit,#1
+ blt charPixelLoopEnd$
+ lsl bits,#1
+ tst bits,#0x100
+ beq charPixelLoop$
+
+ add r0,x,bit
+ mov r1,y
+ bl DrawPixel
+
+ teq bit,#0
+ bne charPixelLoop$
+
+ charPixelLoopEnd$:
+ .unreq bit
+ .unreq bits
+ add y,#1
+ add charAddr,#1
+ tst charAddr,#0b1111
+ bne lineLoop$
+
+.unreq x
+.unreq y
+.unreq charAddr
+
+width .req r0
+height .req r1
+mov width,#8
+mov height,#16
+
+pop {r4,r5,r6,r7,r8,pc}
+.unreq width
+.unreq height
+```
+
+### 3、字符串
+
+现在,我们可以绘制字符了,我们可以绘制文本了。我们需要去写一个方法,给它一个字符串为输入,它通过递增位置来绘制出每个字符。为了做的更好,我们应该去实现新的行和制表符。是时候决定关于空终止符的问题了,如果你想让你的操作系统使用它们,可以按需来修改下面的代码。为避免这个问题,我将给 `DrawString` 函数传递一个字符串长度,以及字符串的地址,和 `x` 和 `y` 的坐标作为参数。
+
+```c
+function drawString(r0 is string, r1 is length, r2 is x, r3 is y)
+ set x0 to x
+ for pos = 0 to length - 1
+ set char to loadByte(string + pos)
+ set (cwidth, cheight) to DrawCharacter(char, x, y)
+ if char = '\n' then
+ set x to x0
+ set y to y + cheight
+ otherwise if char = '\t' then
+ set x1 to x
+ until x1 > x0
+ set x1 to x1 + 5 × cwidth
+ loop
+ set x to x1
+ otherwise
+ set x to x + cwidth
+ end if
+ next
+end function
+```
+
+同样,这个函数与汇编代码还有很大的差距。你可以随意去尝试实现它,即可以直接实现它,也可以简化它。我在下面给出了简化后的函数和汇编代码。
+
+很明显,写这个函数的人并不很有效率(感到奇怪吗?它就是我写的)。再说一次,我们有一个 `pos` 变量,它用于递增及与其它东西相加,这是完全没有必要的。我们可以去掉它,而同时进行长度递减,直到减到 0 为止,这样就少用了一个寄存器。除了那个烦人的乘以 5 以外,函数的其余部分还不错。在这里要做的一个重要事情是,将乘法移到循环外面;即便使用位移运算,乘法仍然是很慢的,由于我们总是加一个乘以 5 的相同的常数,因此没有必要重新计算它。实际上,在汇编代码中它可以在一个操作数中通过参数移位来实现,因此我将代码改变为下面这样。
+
+```c
+function drawString(r0 is string, r1 is length, r2 is x, r3 is y)
+ set x0 to x
+ until length = 0
+ set length to length - 1
+ set char to loadByte(string)
+ set (cwidth, cheight) to DrawCharacter(char, x, y)
+ if char = '\n' then
+ set x to x0
+ set y to y + cheight
+ otherwise if char = '\t' then
+ set x1 to x
+ set cwidth to cwidth + cwidth << 2
+ until x1 > x0
+ set x1 to x1 + cwidth
+ loop
+ set x to x1
+ otherwise
+ set x to x + cwidth
+ end if
+ set string to string + 1
+ loop
+end function
+```
+
+以下是它的汇编代码:
+
+```assembly
+.globl DrawString
+DrawString:
+x .req r4
+y .req r5
+x0 .req r6
+string .req r7
+length .req r8
+char .req r9
+push {r4,r5,r6,r7,r8,r9,lr}
+
+mov string,r0
+mov x,r2
+mov x0,x
+mov y,r3
+mov length,r1
+
+stringLoop$:
+ subs length,#1
+ blt stringLoopEnd$
+
+ ldrb char,[string]
+ add string,#1
+
+ mov r0,char
+ mov r1,x
+ mov r2,y
+ bl DrawCharacter
+ cwidth .req r0
+ cheight .req r1
+
+ teq char,#'\n'
+ moveq x,x0
+ addeq y,cheight
+ beq stringLoop$
+
+ teq char,#'\t'
+ addne x,cwidth
+ bne stringLoop$
+
+ add cwidth, cwidth,lsl #2
+ x1 .req r1
+ mov x1,x0
+
+ stringLoopTab$:
+ add x1,cwidth
+ cmp x,x1
+ bge stringLoopTab$
+ mov x,x1
+ .unreq x1
+ b stringLoop$
+stringLoopEnd$:
+.unreq cwidth
+.unreq cheight
+
+pop {r4,r5,r6,r7,r8,r9,pc}
+.unreq x
+.unreq y
+.unreq x0
+.unreq string
+.unreq length
+```
+
+这个代码中非常聪明地使用了一个新运算,`subs` 是从一个操作数中减去另一个数,保存结果,然后将结果与 0 进行比较。实现上,所有的比较都可以实现为减法后的结果与 0 进行比较,但是结果通常会丢弃。这意味着这个操作与 `cmp` 一样快。
+
+> `subs reg,#val` 从寄存器 `reg` 中减去 `val`,然后将结果与 `0` 进行比较。
+
+### 4、你的意愿是我的命令行
+
+现在,我们可以输出字符串了,而挑战是找到一个有意思的字符串去绘制。一般在这样的教程中,人们都希望去绘制 “Hello World!”,但是到目前为止,虽然我们已经能做到了,我觉得这有点“君临天下”的感觉(如果喜欢这种感觉,请随意!)。因此,作为替代,我们去继续绘制我们的命令行。
+
+有一个限制是我们所做的操作系统是用在 ARM 架构的计算机上。最关键的是,在它们引导时,给它一些信息告诉它有哪些可用资源。几乎所有的处理器都有某些方式来确定这些信息,而在 ARM 上,它是通过位于地址 10016 处的数据来确定的,这个数据的格式如下:
+
+ 1. 数据是可分解的一系列的标签。
+ 2. 这里有九种类型的标签:`core`、`mem`、`videotext`、`ramdisk`、`initrd2`、`serial`、`revision`、`videolfb`、`cmdline`。
+ 3. 每个标签只能出现一次,除了 `core` 标签是必不可少的之外,其它的都是可有可无的。
+ 4. 所有标签都依次放置在地址 `0x100` 处。
+ 5. 标签列表的结束处总是有两个字,它们全为 0。
+ 6. 每个标签的字节数都是 4 的倍数。
+ 7. 每个标签都是以标签中(以字为单位)的标签大小开始(标签包含这个数字)。
+ 8. 紧接着是包含标签编号的一个半字。编号是按上面列出的顺序,从 1 开始(`core` 是 1,`cmdline` 是 9)。
+ 9. 紧接着是一个包含 544116 的半字。
+ 10. 之后是标签的数据,它根据标签不同是可变的。数据大小(以字为单位)+ 2 的和总是与前面提到的长度相同。
+ 11. 一个 `core` 标签的长度可以是 2 个字也可以是 5 个字。如果是 2 个字,表示没有数据,如果是 5 个字,表示它有 3 个字的数据。
+ 12. 一个 `mem` 标签总是 4 个字的长度。数据是内存块的第一个地址,和内存块的长度。
+ 13. 一个 `cmdline` 标签包含一个 `null` 终止符字符串,它是个内核参数。
+
+
+在目前的树莓派版本中,只提供了 `core`、`mem` 和 `cmdline` 标签。你可以在后面找到它们的用法,更全面的参考资料在树莓派的参考页面上。现在,我们感兴趣的是 `cmdline` 标签,因为它包含一个字符串。我们继续写一些搜索这个命令行(`cmdline`)标签的代码,如果找到了,以每个条目一个新行的形式输出它。命令行只是图形处理器或用户认为操作系统应该知道的东西的一个列表。在树莓派上,这包含了 MAC 地址、序列号和屏幕分辨率。字符串本身也是一个由空格隔开的表达式(像 `key.subkey=value` 这样的)的列表。
+
+> 几乎所有的操作系统都支持一个“命令行”的程序。它的想法是为选择一个程序所期望的行为而提供一个通用的机制。
+
+我们从查找 `cmdline` 标签开始。将下列的代码复制到一个名为 `tags.s` 的新文件中。
+
+```assembly
+.section .data
+tag_core: .int 0
+tag_mem: .int 0
+tag_videotext: .int 0
+tag_ramdisk: .int 0
+tag_initrd2: .int 0
+tag_serial: .int 0
+tag_revision: .int 0
+tag_videolfb: .int 0
+tag_cmdline: .int 0
+```
+
+通过标签列表来查找是一个很慢的操作,因为这涉及到许多内存访问。因此,我们只想做一次。代码创建一些数据,用于保存每个类型的第一个标签的内存地址。接下来,用下面的伪代码就可以找到一个标签了。
+
+```c
+function FindTag(r0 is tag)
+ if tag > 9 or tag = 0 then return 0
+ set tagAddr to loadWord(tag_core + (tag - 1) × 4)
+ if not tagAddr = 0 then return tagAddr
+ if readWord(tag_core) = 0 then return 0
+ set tagAddr to 0x100
+ loop forever
+ set tagIndex to readHalfWord(tagAddr + 4)
+ if tagIndex = 0 then return FindTag(tag)
+ if readWord(tag_core+(tagIndex-1)×4) = 0
+ then storeWord(tagAddr, tag_core+(tagIndex-1)×4)
+ set tagAddr to tagAddr + loadWord(tagAddr) × 4
+ end loop
+end function
+```
+
+这段代码已经是优化过的,并且很接近汇编了。它尝试直接加载标签,第一次这样做是有些乐观的,但是除了第一次之外的其它所有情况都是可以这样做的。如果失败了,它将去检查 `core` 标签是否有地址。因为 `core` 标签是必不可少的,如果它没有地址,唯一可能的原因就是它不存在。如果它有地址,那就是我们没有找到我们要找的标签。如果没有找到,那我们就需要查找所有标签的地址。这是通过读取标签编号来做的。如果标签编号为 0,意味着已经到了标签列表的结束位置。这意味着我们已经查找了目录中所有的标签。所以,如果我们再次运行我们的函数,现在它应该能够给出一个答案。如果标签编号不为 0,我们检查这个标签类型是否已经有一个地址。如果没有,我们在目录中保存这个标签的地址。然后增加这个标签的长度(以字节为单位)到标签地址中,然后去查找下一个标签。
+
+尝试去用汇编实现这段代码。你将需要简化它。如果被卡住了,下面是我的答案。不要忘了 `.section .text`!
+
+```assembly
+.section .text
+.globl FindTag
+FindTag:
+tag .req r0
+tagList .req r1
+tagAddr .req r2
+
+sub tag,#1
+cmp tag,#8
+movhi tag,#0
+movhi pc,lr
+
+ldr tagList,=tag_core
+tagReturn$:
+add tagAddr,tagList, tag,lsl #2
+ldr tagAddr,[tagAddr]
+
+teq tagAddr,#0
+movne r0,tagAddr
+movne pc,lr
+
+ldr tagAddr,[tagList]
+teq tagAddr,#0
+movne r0,#0
+movne pc,lr
+
+mov tagAddr,#0x100
+push {r4}
+tagIndex .req r3
+oldAddr .req r4
+tagLoop$:
+ldrh tagIndex,[tagAddr,#4]
+subs tagIndex,#1
+poplt {r4}
+blt tagReturn$
+
+add tagIndex,tagList, tagIndex,lsl #2
+ldr oldAddr,[tagIndex]
+teq oldAddr,#0
+.unreq oldAddr
+streq tagAddr,[tagIndex]
+
+ldr tagIndex,[tagAddr]
+add tagAddr, tagIndex,lsl #2
+b tagLoop$
+
+.unreq tag
+.unreq tagList
+.unreq tagAddr
+.unreq tagIndex
+```
+
+### 5、Hello World
+
+现在,我们已经万事俱备了,我们可以去绘制我们的第一个字符串了。在 `main.s` 文件中删除 `bl SetGraphicsAddress` 之后的所有代码,然后将下面的代码放进去:
+
+```assembly
+mov r0,#9
+bl FindTag
+ldr r1,[r0]
+lsl r1,#2
+sub r1,#8
+add r0,#8
+mov r2,#0
+mov r3,#0
+bl DrawString
+loop$:
+b loop$
+```
+
+这段代码简单地使用了我们的 `FindTag` 方法去查找第 9 个标签(`cmdline`),然后计算它的长度,然后传递命令和长度给 `DrawString` 方法,告诉它在 `0,0` 处绘制字符串。现在可以在树莓派上测试它了。你应该会在屏幕上看到一行文本。如果没有,请查看我们的排错页面。
+
+如果一切正常,恭喜你已经能够绘制文本了。但它还有很大的改进空间。如果想去写了一个数字,或内存的一部分,或操作我们的命令行,该怎么做呢?在 [课程 9:屏幕04][2] 中,我们将学习如何操作文本和显示有用的数字和信息。
+
+--------------------------------------------------------------------------------
+
+via: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen03.html
+
+作者:[Alex Chadwick][a]
+选题:[lujun9972][b]
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.cl.cam.ac.uk
+[b]: https://github.com/lujun9972
+[1]: https://linux.cn/article-10551-1.html
+[2]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen04.html
diff --git a/published/201903/20150616 Computer Laboratory - Raspberry Pi- Lesson 9 Screen04.md b/published/201903/20150616 Computer Laboratory - Raspberry Pi- Lesson 9 Screen04.md
new file mode 100644
index 0000000000..523394f8a2
--- /dev/null
+++ b/published/201903/20150616 Computer Laboratory - Raspberry Pi- Lesson 9 Screen04.md
@@ -0,0 +1,537 @@
+[#]: collector: (lujun9972)
+[#]: translator: (qhwdw)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10605-1.html)
+[#]: subject: (Computer Laboratory – Raspberry Pi: Lesson 9 Screen04)
+[#]: via: (https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen04.html)
+[#]: author: (Alex Chadwick https://www.cl.cam.ac.uk)
+
+计算机实验室之树莓派:课程 9 屏幕04
+======
+
+屏幕04 课程基于屏幕03 课程来构建,它教你如何操作文本。假设你已经有了[课程 8:屏幕03][1] 的操作系统代码,我们将以它为基础。
+
+### 1、操作字符串
+
+能够绘制文本是极好的,但不幸的是,现在你只能绘制预先准备好的字符串。如果能够像命令行那样显示任何东西才是完美的,而理想情况下应该是,我们能够显示任何我们期望的东西。一如既往地,如果我们付出努力而写出一个非常好的函数,它能够操作我们所希望的所有字符串,而作为回报,这将使我们以后写代码更容易。曾经如此复杂的函数,在 C 语言编程中只不过是一个 `sprintf` 而已。这个函数基于给定的另一个字符串和作为描述的额外的一个参数而生成一个字符串。我们对这个函数感兴趣的地方是,这个函数是个变长函数。这意味着它可以带可变数量的参数。参数的数量取决于具体的格式字符串,因此它的参数的数量不能预先确定。
+
+> 变长函数在汇编代码中看起来似乎不好理解,然而 ,它却是非常有用和很强大的概念。
+
+这个完整的函数有许多选项,而我们在这里只列出了几个。在本教程中将要实现的选项我做了高亮处理,当然,你可以尝试去实现更多的选项。
+
+函数通过读取格式化字符串来工作,然后使用下表的意思去解释它。一旦一个参数已经使用了,就不会再次考虑它了。函数的返回值是写入的字符数。如果方法失败,将返回一个负数。
+
+表 1.1 sprintf 格式化规则
+
+| 选项 | 含义 |
+| -------------------------- | ------------------------------------------------------------ |
+| ==除了 `%` 之外的任何支付== | 复制字符到输出。 |
+| ==`%%`== | 写一个 % 字符到输出。 |
+| ==`%c`== | 将下一个参数写成字符格式。 |
+| ==`%d` 或 `%i`== | 将下一个参数写成十进制的有符号整数。 |
+| `%e` | 将下一个参数写成科学记数法,使用 eN,意思是 ×10N。 |
+| `%E` | 将下一个参数写成科学记数法,使用 EN,意思是 ×10N。 |
+| `%f` | 将下一个参数写成十进制的 IEEE 754 浮点数。 |
+| `%g` | 与 `%e` 和 `%f` 的指数表示形式相同。 |
+| `%G` | 与 `%E` 和 `%f` 的指数表示形式相同。 |
+| ==`%o`== | 将下一个参数写成八进制的无符号整数。 |
+| ==`%s`== | 下一个参数如果是一个指针,将它写成空终止符字符串。 |
+| ==`%u`== | 将下一个参数写成十进制无符号整数。 |
+| ==`%x`== | 将下一个参数写成十六进制无符号整数(使用小写的 a、b、c、d、e 和 f)。 |
+| `%X` | 将下一个参数写成十六进制的无符号整数(使用大写的 A、B、C、D、E 和 F)。 |
+| `%p` | 将下一个参数写成指针地址。 |
+| ==`%n`== | 什么也不输出。而是复制到目前为止被下一个参数在本地处理的字符个数。 |
+
+除此之外,对序列还有许多额外的处理,比如指定最小长度,符号等等。更多信息可以在 [sprintf - C++ 参考][2] 上找到。
+
+下面是调用方法和返回的结果的示例。
+
+表 1.2 sprintf 调用示例
+
+| 格式化字符串 | 参数 | 结果 |
+|---------------|-------|---------------------|
+| `"%d"` | 13 | "13" |
+| `"+%d degrees"` | 12 | "+12 degrees" |
+| `"+%x degrees"` | 24 | "+1c degrees" |
+| `"'%c' = 0%o"` | 65, 65 | "'A' = 0101" |
+| `"%d * %d%% = %d"` | 200, 40, 80 | "200 * 40% = 80" |
+| `"+%d degrees"` | -5 | "+-5 degrees" |
+| `"+%u degrees"` | -5 | "+4294967291 degrees" |
+
+希望你已经看到了这个函数是多么有用。实现它需要大量的编程工作,但给我们的回报却是一个非常有用的函数,可以用于各种用途。
+
+### 2、除法
+
+虽然这个函数看起来很强大、也很复杂。但是,处理它的许多情况的最容易的方式可能是,编写一个函数去处理一些非常常见的任务。它是个非常有用的函数,可以为任何底的一个有符号或无符号的数字生成一个字符串。那么,我们如何去实现呢?在继续阅读之前,尝试快速地设计一个算法。
+
+> 除法是非常慢的,也是非常复杂的基础数学运算。它在 ARM 汇编代码中不能直接实现,因为如果直接实现的话,它得出答案需要花费很长的时间,因此它不是个“简单的”运算。
+
+最简单的方法或许就是我在 [课程 1:OK01][3] 中提到的“除法余数法”。它的思路如下:
+
+ 1. 用当前值除以你使用的底。
+ 2. 保存余数。
+ 3. 如果得到的新值不为 0,转到第 1 步。
+ 4. 将余数反序连起来就是答案。
+
+例如:
+
+表 2.1 以 2 为底的例子
+
+转换
+
+| 值 | 新值 | 余数 |
+| ---- | ---- | ---- |
+| 137 | 68 | 1 |
+| 68 | 34 | 0 |
+| 34 | 17 | 0 |
+| 17 | 8 | 1 |
+| 8 | 4 | 0 |
+| 4 | 2 | 0 |
+| 2 | 1 | 0 |
+| 1 | 0 | 1 |
+
+因此答案是 100010012
+
+这个过程的不幸之外在于使用了除法。所以,我们必须首先要考虑二进制中的除法。
+
+我们复习一下长除法
+
+> 假如我们想把 4135 除以 17。
+>
+> ```
+> 0243 r 4
+> 17)4135
+> 0 0 × 17 = 0000
+> 4135 4135 - 0 = 4135
+> 34 200 × 17 = 3400
+> 735 4135 - 3400 = 735
+> 68 40 × 17 = 680
+> 55 735 - 680 = 55
+> 51 3 × 17 = 51
+> 4 55 - 51 = 4
+> ```
+> 答案:243 余 4
+>
+> 首先我们来看被除数的最高位。我们看到它是小于或等于除数的最小倍数,因此它是 0。我们在结果中写一个 0。
+>
+> 接下来我们看被除数倒数第二位和所有的高位。我们看到小于或等于那个数的除数的最小倍数是 34。我们在结果中写一个 2,和减去 3400。
+>
+> 接下来我们看被除数的第三位和所有高位。我们看到小于或等于那个数的除数的最小倍数是 68。我们在结果中写一个 4,和减去 680。
+>
+> 最后,我们看一下所有的余位。我们看到小于余数的除数的最小倍数是 51。我们在结果中写一个 3,减去 51。减法的结果就是我们的余数。
+>
+
+在汇编代码中做除法,我们将实现二进制的长除法。我们之所以实现它是因为,数字都是以二进制方式保存的,这让我们很容易地访问所有重要位的移位操作,并且因为在二进制中做除法比在其它高进制中做除法都要简单,因为它的数更少。
+
+```
+ 1011 r 1
+1010)1101111
+ 1010
+ 11111
+ 1010
+ 1011
+ 1010
+ 1
+```
+
+这个示例展示了如何做二进制的长除法。简单来说就是,在不超出被除数的情况下,尽可能将除数右移,根据位置输出一个 1,和减去这个数。剩下的就是余数。在这个例子中,我们展示了 11011112 ÷ 10102 = 10112 余数为 12。用十进制表示就是,111 ÷ 10 = 11 余 1。
+
+你自己尝试去实现这个长除法。你应该去写一个函数 `DivideU32` ,其中 `r0` 是被除数,而 `r1` 是除数,在 `r0` 中返回结果,在 `r1` 中返回余数。下面,我们将完成一个有效的实现。
+
+```c
+function DivideU32(r0 is dividend, r1 is divisor)
+ set shift to 31
+ set result to 0
+ while shift ≥ 0
+ if dividend ≥ (divisor << shift) then
+ set dividend to dividend - (divisor << shift)
+ set result to result + 1
+ end if
+ set result to result << 1
+ set shift to shift - 1
+ loop
+ return (result, dividend)
+end function
+```
+
+这段代码实现了我们的目标,但却不能用于汇编代码。我们出现的问题是,我们的寄存器只能保存 32 位,而 `divisor << shift` 的结果可能在一个寄存器中装不下(我们称之为溢出)。这确实是个问题。你的解决方案是否有溢出的问题呢?
+
+幸运的是,有一个称为 `clz`(计数前导零)的指令,它能计算一个二进制表示的数字的前导零的个数。这样我们就可以在溢出发生之前,可以将寄存器中的值进行相应位数的左移。你可以找出的另一个优化就是,每个循环我们计算 `divisor << shift` 了两遍。我们可以通过将除数移到开始位置来改进它,然后在每个循环结束的时候将它移下去,这样可以避免将它移到别处。
+
+我们来看一下进一步优化之后的汇编代码。
+
+```assembly
+.globl DivideU32
+DivideU32:
+result .req r0
+remainder .req r1
+shift .req r2
+current .req r3
+
+clz shift,r1
+lsl current,r1,shift
+mov remainder,r0
+mov result,#0
+
+divideU32Loop$:
+ cmp shift,#0
+ blt divideU32Return$
+ cmp remainder,current
+
+ addge result,result,#1
+ subge remainder,current
+ sub shift,#1
+ lsr current,#1
+ lsl result,#1
+ b divideU32Loop$
+divideU32Return$:
+.unreq current
+mov pc,lr
+
+.unreq result
+.unreq remainder
+.unreq shift
+```
+
+你可能毫无疑问的认为这是个非常高效的作法。它是很好,但是除法是个代价非常高的操作,并且我们的其中一个愿望就是不要经常做除法,因为如果能以任何方式提升速度就是件非常好的事情。当我们查看有循环的优化代码时,我们总是重点考虑一个问题,这个循环会运行多少次。在本案例中,在输入为 1 的情况下,这个循环最多运行 31 次。在不考虑特殊情况的时候,这很容易改进。例如,当 1 除以 1 时,不需要移位,我们将把除数移到它上面的每个位置。这可以通过简单地在被除数上使用新的 `clz` 命令并从中减去它来改进。在 `1 ÷ 1` 的案例中,这意味着移位将设置为 0,明确地表示它不需要移位。如果它设置移位为负数,表示除数大于被除数,因此我们就可以知道结果是 0,而余数是被除数。我们可以做的另一个快速检查就是,如果当前值为 0,那么它是一个整除的除法,我们就可以停止循环了。
+
+> `clz dest,src` 将第一个寄存器 `dest` 中二进制表示的值的前导零的数量,保存到第二个寄存器 `src` 中。
+
+
+```assembly
+.globl DivideU32
+DivideU32:
+result .req r0
+remainder .req r1
+shift .req r2
+current .req r3
+
+clz shift,r1
+clz r3,r0
+subs shift,r3
+lsl current,r1,shift
+mov remainder,r0
+mov result,#0
+blt divideU32Return$
+
+divideU32Loop$:
+ cmp remainder,current
+ blt divideU32LoopContinue$
+
+ add result,result,#1
+ subs remainder,current
+ lsleq result,shift
+ beq divideU32Return$
+divideU32LoopContinue$:
+ subs shift,#1
+ lsrge current,#1
+ lslge result,#1
+ bge divideU32Loop$
+
+divideU32Return$:
+.unreq current
+mov pc,lr
+
+.unreq result
+.unreq remainder
+.unreq shift
+```
+
+复制上面的代码到一个名为 `maths.s` 的文件中。
+
+### 3、数字字符串
+
+现在,我们已经可以做除法了,我们来看一下另外的一个将数字转换为字符串的实现。下列的伪代码将寄存器中的一个数字转换成以 36 为底的字符串。根据惯例,a % b 表示 a 被 b 相除之后的余数。
+
+```c
+function SignedString(r0 is value, r1 is dest, r2 is base)
+ if value ≥ 0
+ then return UnsignedString(value, dest, base)
+ otherwise
+ if dest > 0 then
+ setByte(dest, '-')
+ set dest to dest + 1
+ end if
+ return UnsignedString(-value, dest, base) + 1
+ end if
+end function
+
+function UnsignedString(r0 is value, r1 is dest, r2 is base)
+ set length to 0
+ do
+
+ set (value, rem) to DivideU32(value, base)
+ if rem > 10
+ then set rem to rem + '0'
+ otherwise set rem to rem - 10 + 'a'
+ if dest > 0
+ then setByte(dest + length, rem)
+ set length to length + 1
+
+ while value > 0
+ if dest > 0
+ then ReverseString(dest, length)
+ return length
+end function
+
+function ReverseString(r0 is string, r1 is length)
+ set end to string + length - 1
+ while end > start
+ set temp1 to readByte(start)
+ set temp2 to readByte(end)
+ setByte(start, temp2)
+ setByte(end, temp1)
+ set start to start + 1
+ set end to end - 1
+ end while
+end function
+```
+
+上述代码实现在一个名为 `text.s` 的汇编文件中。记住,如果你遇到了困难,可以在下载页面找到完整的解决方案。
+
+### 4、格式化字符串
+
+我们继续回到我们的字符串格式化方法。因为我们正在编写我们自己的操作系统,我们根据我们自己的意愿来添加或修改格式化规则。我们可以发现,添加一个 `a % b` 操作去输出一个二进制的数字比较有用,而如果你不使用空终止符字符串,那么你应该去修改 `%s` 的行为,让它从另一个参数中得到字符串的长度,或者如果你愿意,可以从长度前缀中获取。我在下面的示例中使用了一个空终止符。
+
+实现这个函数的一个主要的障碍是它的参数个数是可变的。根据 ABI 规定,额外的参数在调用方法之前以相反的顺序先推送到栈上。比如,我们使用 8 个参数 1、2、3、4、5、6、7 和 8 来调用我们的方法,我们将按下面的顺序来处理:
+
+1. 设置 r0 = 5、r1 = 6、r2 = 7、r3 = 8
+2. 推入 {r0,r1,r2,r3}
+3. 设置 r0 = 1、r1 = 2、r2 = 3、r3 = 4
+4. 调用函数
+5. 将 sp 和 #4*4 加起来
+
+现在,我们必须确定我们的函数确切需要的参数。在我的案例中,我将寄存器 `r0` 用来保存格式化字符串地址,格式化字符串长度则放在寄存器 `r1` 中,目标字符串地址放在寄存器 `r2` 中,紧接着是要求的参数列表,从寄存器 `r3` 开始和像上面描述的那样在栈上继续。如果你想去使用一个空终止符格式化字符串,在寄存器 r1 中的参数将被移除。如果你想有一个最大缓冲区长度,你可以将它保存在寄存器 `r3` 中。由于有额外的修改,我认为这样修改函数是很有用的,如果目标字符串地址为 0,意味着没有字符串被输出,但如果仍然返回一个精确的长度,意味着能够精确的判断格式化字符串的长度。
+
+如果你希望尝试实现你自己的函数,现在就可以去做了。如果不去实现你自己的,下面我将首先构建方法的伪代码,然后给出实现的汇编代码。
+
+```c
+function StringFormat(r0 is format, r1 is formatLength, r2 is dest, ...)
+ set index to 0
+ set length to 0
+ while index < formatLength
+ if readByte(format + index) = '%' then
+ set index to index + 1
+ if readByte(format + index) = '%' then
+ if dest > 0
+ then setByte(dest + length, '%')
+ set length to length + 1
+ otherwise if readByte(format + index) = 'c' then
+ if dest > 0
+ then setByte(dest + length, nextArg)
+ set length to length + 1
+ otherwise if readByte(format + index) = 'd' or 'i' then
+ set length to length + SignedString(nextArg, dest, 10)
+ otherwise if readByte(format + index) = 'o' then
+ set length to length + UnsignedString(nextArg, dest, 8)
+ otherwise if readByte(format + index) = 'u' then
+ set length to length + UnsignedString(nextArg, dest, 10)
+ otherwise if readByte(format + index) = 'b' then
+ set length to length + UnsignedString(nextArg, dest, 2)
+ otherwise if readByte(format + index) = 'x' then
+ set length to length + UnsignedString(nextArg, dest, 16)
+ otherwise if readByte(format + index) = 's' then
+ set str to nextArg
+ while getByte(str) != '\0'
+ if dest > 0
+ then setByte(dest + length, getByte(str))
+ set length to length + 1
+ set str to str + 1
+ loop
+ otherwise if readByte(format + index) = 'n' then
+ setWord(nextArg, length)
+ end if
+ otherwise
+ if dest > 0
+ then setByte(dest + length, readByte(format + index))
+ set length to length + 1
+ end if
+ set index to index + 1
+ loop
+ return length
+end function
+```
+
+虽然这个函数很大,但它还是很简单的。大多数的代码都是在检查所有各种条件,每个代码都是很简单的。此外,所有的无符号整数的大小写都是相同的(除了底以外)。因此在汇编中可以将它们汇总。下面是它的汇编代码。
+
+```assembly
+.globl FormatString
+FormatString:
+format .req r4
+formatLength .req r5
+dest .req r6
+nextArg .req r7
+argList .req r8
+length .req r9
+
+push {r4,r5,r6,r7,r8,r9,lr}
+mov format,r0
+mov formatLength,r1
+mov dest,r2
+mov nextArg,r3
+add argList,sp,#7*4
+mov length,#0
+
+formatLoop$:
+ subs formatLength,#1
+ movlt r0,length
+ poplt {r4,r5,r6,r7,r8,r9,pc}
+
+ ldrb r0,[format]
+ add format,#1
+ teq r0,#'%'
+ beq formatArg$
+
+formatChar$:
+ teq dest,#0
+ strneb r0,[dest]
+ addne dest,#1
+ add length,#1
+ b formatLoop$
+
+formatArg$:
+ subs formatLength,#1
+ movlt r0,length
+ poplt {r4,r5,r6,r7,r8,r9,pc}
+
+ ldrb r0,[format]
+ add format,#1
+ teq r0,#'%'
+ beq formatChar$
+
+ teq r0,#'c'
+ moveq r0,nextArg
+ ldreq nextArg,[argList]
+ addeq argList,#4
+ beq formatChar$
+
+ teq r0,#'s'
+ beq formatString$
+
+ teq r0,#'d'
+ beq formatSigned$
+
+ teq r0,#'u'
+ teqne r0,#'x'
+ teqne r0,#'b'
+ teqne r0,#'o'
+ beq formatUnsigned$
+
+ b formatLoop$
+
+formatString$:
+ ldrb r0,[nextArg]
+ teq r0,#0x0
+ ldreq nextArg,[argList]
+ addeq argList,#4
+ beq formatLoop$
+ add length,#1
+ teq dest,#0
+ strneb r0,[dest]
+ addne dest,#1
+ add nextArg,#1
+ b formatString$
+
+formatSigned$:
+ mov r0,nextArg
+ ldr nextArg,[argList]
+ add argList,#4
+ mov r1,dest
+ mov r2,#10
+ bl SignedString
+ teq dest,#0
+ addne dest,r0
+ add length,r0
+ b formatLoop$
+
+formatUnsigned$:
+ teq r0,#'u'
+ moveq r2,#10
+ teq r0,#'x'
+ moveq r2,#16
+ teq r0,#'b'
+ moveq r2,#2
+ teq r0,#'o'
+ moveq r2,#8
+
+ mov r0,nextArg
+ ldr nextArg,[argList]
+ add argList,#4
+ mov r1,dest
+ bl UnsignedString
+ teq dest,#0
+ addne dest,r0
+ add length,r0
+ b formatLoop$
+```
+
+### 5、一个转换操作系统
+
+你可以使用这个方法随意转换你希望的任何东西。比如,下面的代码将生成一个换算表,可以做从十进制到二进制到十六进制到八进制以及到 ASCII 的换算操作。
+
+删除 `main.s` 文件中 `bl SetGraphicsAddress` 之后的所有代码,然后粘贴以下的代码进去。
+
+```assembly
+mov r4,#0
+loop$:
+ldr r0,=format
+mov r1,#formatEnd-format
+ldr r2,=formatEnd
+lsr r3,r4,#4
+push {r3}
+push {r3}
+push {r3}
+push {r3}
+bl FormatString
+add sp,#16
+
+mov r1,r0
+ldr r0,=formatEnd
+mov r2,#0
+mov r3,r4
+
+cmp r3,#768-16
+subhi r3,#768
+addhi r2,#256
+cmp r3,#768-16
+subhi r3,#768
+addhi r2,#256
+cmp r3,#768-16
+subhi r3,#768
+addhi r2,#256
+
+bl DrawString
+
+add r4,#16
+b loop$
+
+.section .data
+format:
+.ascii "%d=0b%b=0x%x=0%o='%c'"
+formatEnd:
+```
+
+你能在测试之前推算出将发生什么吗?特别是对于 `r3 ≥ 128` 会发生什么?尝试在树莓派上运行它,看看你是否猜对了。如果不能正常运行,请查看我们的排错页面。
+
+如果一切顺利,恭喜你!你已经完成了屏幕04 教程,屏幕系列的课程结束了!我们学习了像素和帧缓冲的知识,以及如何将它们应用到树莓派上。我们学习了如何绘制简单的线条,也学习如何绘制字符,以及将数字格式化为文本的宝贵技能。我们现在已经拥有了在一个操作系统上进行图形输出的全部知识。你可以写出更多的绘制方法吗?三维绘图是什么?你能实现一个 24 位帧缓冲吗?能够从命令行上读取帧缓冲的大小吗?
+
+接下来的课程是[输入][4]系列课程,它将教我们如何使用键盘和鼠标去实现一个传统的计算机控制台。
+
+--------------------------------------------------------------------------------
+
+via: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen04.html
+
+作者:[Alex Chadwick][a]
+选题:[lujun9972][b]
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.cl.cam.ac.uk
+[b]: https://github.com/lujun9972
+[1]: https://linux.cn/article-10585-1.html
+[2]: http://www.cplusplus.com/reference/clibrary/cstdio/sprintf/
+[3]: https://linux.cn/article-10458-1.html
+[4]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/input01.html
diff --git a/published/201903/20170223 Use Emacs to create OAuth 2.0 UML sequence diagrams.md b/published/201903/20170223 Use Emacs to create OAuth 2.0 UML sequence diagrams.md
new file mode 100644
index 0000000000..23b1075f74
--- /dev/null
+++ b/published/201903/20170223 Use Emacs to create OAuth 2.0 UML sequence diagrams.md
@@ -0,0 +1,149 @@
+[#]: collector: (lujun9972)
+[#]: translator: (lujun9972)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10582-1.html)
+[#]: subject: (Use Emacs to create OAuth 2.0 UML sequence diagrams)
+[#]: via: (https://www.onwebsecurity.com/configuration/use-emacs-to-create-oauth-2-0-uml-sequence-diagrams.html)
+[#]: author: (Peter Mosmans https://www.onwebsecurity.com)
+
+使用 Emacs 创建 OAuth 2.0 的 UML 序列图
+======
+
+![OAuth 2.0 abstract protocol flow][6]
+
+看起来 [OAuth 2.0 框架][7] 已经越来越广泛地应用于 web (和 移动) 应用。太棒了!
+
+虽然协议本身并不复杂,但有很多的使用场景、流程和实现可供选择。正如生活中的大多数事物一样,魔鬼在于细节之中。
+
+在审查 OAuth 2.0 实现或编写渗透测试报告时我习惯画出 UML 图。这方便让人理解发生了什么事情,并发现潜在的问题。毕竟,一图抵千言。
+
+使用基于 GPL 开源协议 [Emacs][8] 编辑器来实现,再加上基于 GPL 开源协议的工具 [PlantUML][9] (也可以选择基于 Eclipse Public 协议的 [Graphviz][10]) 很容易做到这一点。
+
+Emacs 是世界上最万能的编辑器。在这种场景中,我们用它来编辑文本,并自动将文本转换成图片。PlantUML 是一个允许你用人类可读的文本来写 UML 并完成该转换的工具。Graphviz 是一个可视化的软件,这里我们可以用它来显示图片。
+
+下载 [预先编译好了的 PlantUML jar 文件 ][11],[Emacs][12] 还可以选择下载并安装 [Graphviz][13]。
+
+安装并启动 Emacs,然后将下面 Lisp 代码(实际上是配置)写入你的启动文件中(`~/.emacs.d/init.d`),这段代码将会:
+
+ * 配置 org 模式(一种用来组织并编辑文本文件的模式)来使用 PlantUML
+ * 将 `plantuml` 添加到可识别的 “org-babel” 语言中(这让你可以在文本文件中执行源代码)
+ * 将 PlantUML 代码标注为安全的,从而允许执行
+ * 自动显示生成的结果图片
+
+```elisp
+;; tell org-mode where to find the plantuml JAR file (specify the JAR file)
+(setq org-plantuml-jar-path (expand-file-name "~/plantuml.jar"))
+
+;; use plantuml as org-babel language
+(org-babel-do-load-languages 'org-babel-load-languages '((plantuml . t)))
+
+;; helper function
+(defun my-org-confirm-babel-evaluate (lang body)
+"Do not ask for confirmation to evaluate code for specified languages."
+(member lang '("plantuml")))
+
+;; trust certain code as being safe
+(setq org-confirm-babel-evaluate 'my-org-confirm-babel-evaluate)
+
+;; automatically show the resulting image
+(add-hook 'org-babel-after-execute-hook 'org-display-inline-images)
+```
+
+如果你还没有启动文件,那么将该代码加入到 `~/.emacs.d/init.el` 文件中然后重启 Emacs。
+
+提示:`Control-c Control-f` 可以让你创建/打开(新)文件。`Control-x Control-s` 保存文件,而 `Control-x Control-c` 退出 Emacs。
+
+这就结了!
+
+要测试该配置,可以创建/打开(`Control-c Control-f`)后缀为 `.org` 的文件,例如 `test.org`。这会让 Emacs 切换到 org 模式并识别 “org-babel” 语法。
+
+输入下面代码,然后在代码中输入 `Control-c Control-c` 来测试是否安装正常:
+
+```
+#+BEGIN_SRC plantuml :file test.png
+@startuml
+version
+@enduml
+#+END_SRC
+```
+
+一切顺利的话,你会在 Emacs 中看到文本下面显示了一张图片。
+
+> **注意:**
+
+> 要快速插入类似 `#+BEGIN_SRC` 和 `#+END_SRC` 这样的代码片段,你可以使用内置的 Easy Templates 系统:输入 ` user : request authorization
+note left
+**grant types**:
+# authorization code
+# implicit
+# password
+# client_credentials
+end note
+user --> client : authorization grant
+end
+
+group token is generated
+client -> authorization : request token\npresent authorization grant
+authorization --> client :var: access token
+note left
+**response types**:
+# code
+# token
+end note
+end group
+
+group resource can be accessed
+client -> resource : request resource\npresent token
+resource --> client : resource
+end group
+@enduml
+#+END_SRC
+```
+
+你难道会不喜欢 Emacs 和开源工具的多功能性吗?
+
+--------------------------------------------------------------------------------
+
+via: https://www.onwebsecurity.com/configuration/use-emacs-to-create-oauth-2-0-uml-sequence-diagrams.html
+
+作者:[Peter Mosmans][a]
+选题:[lujun9972][b]
+译者:[lujun9972](https://github.com/lujun9972)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.onwebsecurity.com
+[b]: https://github.com/lujun9972
+[1]: https://www.onwebsecurity.com/category/configuration.html
+[2]: https://www.onwebsecurity.com/tag/emacs.html
+[3]: https://www.onwebsecurity.com/tag/oauth2.html
+[4]: https://www.onwebsecurity.com/tag/pentesting.html
+[5]: https://www.onwebsecurity.com/tag/security.html
+[6]: https://www.onwebsecurity.com/images/oauth2-abstract-protocol-flow.png
+[7]: https://tools.ietf.org/html/rfc6749
+[8]: https://www.gnu.org/software/emacs/
+[9]: https://plantuml.com
+[10]: http://www.graphviz.org/
+[11]: http://plantuml.com/download
+[12]: https://www.gnu.org/software/emacs/download.html
+[13]: http://www.graphviz.org/Download.php
diff --git a/published/201903/20170519 zsh shell inside Emacs on Windows.md b/published/201903/20170519 zsh shell inside Emacs on Windows.md
new file mode 100644
index 0000000000..894c924416
--- /dev/null
+++ b/published/201903/20170519 zsh shell inside Emacs on Windows.md
@@ -0,0 +1,103 @@
+[#]: collector: (lujun9972)
+[#]: translator: (lujun9972)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10610-1.html)
+[#]: subject: (zsh shell inside Emacs on Windows)
+[#]: via: (https://www.onwebsecurity.com/configuration/zsh-shell-inside-emacs-on-windows.html)
+[#]: author: (Peter Mosmans https://www.onwebsecurity.com/)
+
+Windows 下 Emacs 中的 zsh shell
+======
+
+![zsh shell inside Emacs on Windows][5]
+
+运行跨平台 shell(例如 Bash 或 zsh)的最大优势在于你能在多平台上使用同样的语法和脚本。在 Windows 上设置(替换)shell 挺麻烦的,但所获得的回报远远超出这小小的付出。
+
+MSYS2 子系统允许你在 Windows 上运行 Bash 或 zsh 之类的 shell。使用 MSYS2 很重要的一点在于确保搜索路径都指向 MSYS2 子系统本身:存在太多依赖关系了。
+
+MSYS2 安装后默认的 shell 就是 Bash;zsh 则可以通过包管理器进行安装:
+
+```
+pacman -Sy zsh
+```
+
+通过修改 `etc/passwd` 文件可以设置 zsh 作为默认 shell,例如:
+
+```
+mkpasswd -c | sed -e 's/bash/zsh/' | tee -a /etc/passwd
+```
+
+这会将默认 shell 从 bash 改成 zsh。
+
+要在 Windows 上的 Emacs 中运行 zsh ,需要修改 `shell-file-name` 变量,将它指向 MSYS2 子系统中的 zsh 二进制文件。该二进制 shell 文件在 Emacs `exec-path` 变量中的某个地方。
+
+```
+(setq shell-file-name (executable-find "zsh.exe"))
+```
+
+不要忘了修改 Emacs 的 `PATH` 环境变量,因为 MSYS2 路径应该先于 Windows 路径。接上一个例子,假设 MSYS2 安装在 `c:\programs\msys2` 中,那么执行:
+
+```
+(setenv "PATH" "C:\\programs\\msys2\\mingw64\\bin;C:\\programs\\msys2\\usr\\local\\bin;C:\\programs\\msys2\\usr\\bin;C:\\Windows\\System32;C:\\Windows")
+```
+
+在 Emacs 配置文件中设置好这两个变量后,在 Emacs 中运行:
+
+```
+M-x shell
+```
+
+应该就能看到熟悉的 zsh 提示符了。
+
+Emacs 的终端设置(eterm)与 MSYS2 的标准终端设置(xterm-256color)不一样。这意味着某些插件和主题(提示符)可能不能正常工作 - 尤其在使用 oh-my-zsh 时。
+
+检测 zsh 否则在 Emacs 中运行很简单,使用变量 `$INSIDE_EMACS`。
+
+下面这段代码片段取自 `.zshrc`(当以交互式 shell 模式启动时会被加载),它会在 zsh 在 Emacs 中运行时启动 git 插件并更改主题:
+
+```
+# Disable some plugins while running in Emacs
+if [[ -n "$INSIDE_EMACS" ]]; then
+ plugins=(git)
+ ZSH_THEME="simple"
+else
+ ZSH_THEME="compact-grey"
+fi
+```
+
+通过在本地 `~/.ssh/config` 文件中将 `INSIDE_EMACS` 变量设置为 `SendEnv` 变量……
+
+```
+Host myhost
+SendEnv INSIDE_EMACS
+```
+
+……同时在 ssh 服务器的 `/etc/ssh/sshd_config` 中设置为 `AcceptEnv` 变量……
+
+```
+AcceptEnv LANG LC_* INSIDE_EMACS
+```
+
+……这使得在 Emacs shell 会话中通过 ssh 登录另一个运行着 zsh 的 ssh 服务器也能工作的很好。当在 Windows 下的 Emacs 中的 zsh 上通过 ssh 远程登录时,记得使用参数 `-t`,`-t` 参数会强制分配伪终端(之所以需要这样,时因为 Windows 下的 Emacs 并没有真正的 tty)。
+
+跨平台,开源真是个好东西……
+
+--------------------------------------------------------------------------------
+
+via: https://www.onwebsecurity.com/configuration/zsh-shell-inside-emacs-on-windows.html
+
+作者:[Peter Mosmans][a]
+选题:[lujun9972][b]
+译者:[lujun9972](https://github.com/lujun9972)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.onwebsecurity.com/
+[b]: https://github.com/lujun9972
+[1]: https://www.onwebsecurity.com/category/configuration.html
+[2]: https://www.onwebsecurity.com/tag/emacs.html
+[3]: https://www.onwebsecurity.com/tag/msys2.html
+[4]: https://www.onwebsecurity.com/tag/zsh.html
+[5]: https://www.onwebsecurity.com//images/zsh-shell-inside-emacs-on-windows.png
diff --git a/published/201903/20170721 Firefox and org-protocol URL Capture.md b/published/201903/20170721 Firefox and org-protocol URL Capture.md
new file mode 100644
index 0000000000..c9c5bba603
--- /dev/null
+++ b/published/201903/20170721 Firefox and org-protocol URL Capture.md
@@ -0,0 +1,121 @@
+[#]: collector: (lujun9972)
+[#]: translator: (lujun9972)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10586-1.html)
+[#]: subject: (Firefox and org-protocol URL Capture)
+[#]: via: (http://www.mediaonfire.com/blog/2017_07_21_org_protocol_firefox.html)
+[#]: author: (Andreas Viklund http://andreasviklund.com/)
+
+在 Firefox 上使用 Org 协议捕获 URL
+======
+
+### 介绍
+
+作为一名 Emacs 人,我尽可能让所有的工作流都在 [Org 模式][1] 上进行 —— 我比较喜欢文本。
+
+我倾向于将书签记录在 [Org 模式][1] 代办列表中,而 [Org 协议][2] 则允许外部进程利用 [Org 模式][1] 的某些功能。然而,要做到这一点配置起来很麻烦。([搜索引擎上][3])有很多教程,Firefox 也有这类 [扩展][4],然而我对它们都不太满意。
+
+因此我决定将我现在的配置记录在这篇博客中,方便其他有需要的人使用。
+
+### 配置 Emacs Org 模式
+
+启用 Org 协议:
+
+```
+(require 'org-protocol)
+```
+
+添加一个捕获模板 —— 我的配置是这样的:
+
+```
+(setq org-capture-templates
+ (quote (...
+ ("w" "org-protocol" entry (file "~/org/refile.org")
+ "* TODO Review %a\n%U\n%:initial\n" :immediate-finish)
+ ...)))
+```
+
+你可以从 [Org 模式][1] 手册中 [捕获模板][5] 章节中获取帮助。
+
+设置默认使用的模板:
+
+```
+(setq org-protocol-default-template-key "w")
+```
+
+执行这些新增配置让它们在当前 Emacs 会话中生效。
+
+### 快速测试
+
+在下一步开始前,最好测试一下配置:
+
+```
+emacsclient -n "org-protocol:///capture?url=http%3a%2f%2fduckduckgo%2ecom&title=DuckDuckGo"
+```
+
+基于的配置的模板,可能会弹出一个捕获窗口。请确保正常工作,否则后面的操作没有任何意义。如果工作不正常,检查刚才的配置并且确保你执行了这些代码块。
+
+如果你的 [Org 模式][1] 版本比较老(老于 7 版本),测试的格式会有点不同:这种 URL 编码后的格式需要改成用斜杠来分割 url 和标题。在网上搜一下很容易找出这两者的不同。
+
+### Firefox 协议
+
+现在开始设置 Firefox。浏览 `about:config`。右击配置项列表,选择 “New -> Boolean”,然后输入 `network.protocol-handler.expose.org-protocol` 作为名字并且将值设置为 `true`。
+
+有些教程说这一步是可以省略的 —— 配不配因人而异。
+
+### 添加 Desktop 文件
+
+大多数的教程都有这一步:
+
+增加一个文件 `~/.local/share/applications/org-protocol.desktop`:
+
+```
+[Desktop Entry]
+Name=org-protocol
+Exec=/path/to/emacsclient -n %u
+Type=Application
+Terminal=false
+Categories=System;
+MimeType=x-scheme-handler/org-protocol;
+```
+
+然后运行更新器。对于 i3 窗口管理器我使用下面命令(跟 gnome 一样):
+
+```
+update-desktop-database ~/.local/share/applications/
+```
+
+KDE 的方法不太一样……你可以查询其他相关教程。
+
+### 在 FireFox 中设置捕获按钮
+
+创建一个书签(我是在工具栏上创建这个书签的),地址栏输入下面内容:
+
+```
+javascript:location.href="org-protocol:///capture?url="+encodeURIComponent(location.href)+"&title="+encodeURIComponent(document.title||"[untitled page]")
+```
+
+保存该书签后,再次编辑该书签,你应该会看到其中的所有空格都被替换成了 `%20` —— 也就是空格的 URL 编码形式。
+
+现在当你点击该书签,你就会在某个 Emacs 框架中,可能是一个任意的框架中,打开一个窗口,显示你预定的模板。
+
+
+--------------------------------------------------------------------------------
+
+via: http://www.mediaonfire.com/blog/2017_07_21_org_protocol_firefox.html
+
+作者:[Andreas Viklund][a]
+选题:[lujun9972][b]
+译者:[lujun9972](https://github.com/lujun9972)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: http://andreasviklund.com/
+[b]: https://github.com/lujun9972
+[1]: http://orgmode.org/
+[2]: http://orgmode.org/worg/org-contrib/org-protocol.html
+[3]: https://duckduckgo.com/?q=org-protocol+firefox&t=ffab&ia=qa
+[4]: https://addons.mozilla.org/en-US/firefox/search/?q=org-protocol&cat=1,0&appver=53.0&platform=linux
+[5]: http://orgmode.org/manual/Capture-templates.html
diff --git a/published/201903/20171005 10 Games You Can Play on Linux with Wine.md b/published/201903/20171005 10 Games You Can Play on Linux with Wine.md
new file mode 100644
index 0000000000..4c1ad7bac8
--- /dev/null
+++ b/published/201903/20171005 10 Games You Can Play on Linux with Wine.md
@@ -0,0 +1,113 @@
+10 款你可以通过 Wine 在 Linux 上玩的游戏
+======
+
+
+
+Linux *确实* 能玩游戏,而且还能玩不少游戏。独立游戏在 Linux 平台上蓬勃发展,顶级的独立游戏也常常会在发售首日便发布 Linux 版本。然而,3A 游戏大作的开发者们却常常忽略 Linux,所以你不会很快就能玩上身边朋友们谈论正火的那些游戏。
+
+但情况还没有糟透。Wine —— 一个能使 Windows 应用在类似 Linux、BSD 和 OS X 上运行的兼容层,在支持的游戏数量和性能表现上都取得了巨大进步。很多游戏大作都可以在 Wine 的支持下运行。你不能完全释放本机性能,但还是可以跑起来游戏,运行也还算流畅,当然这也要取决与你的系统配置。下面我们来盘点一下这些可能会令你大吃一惊的可以通过 Wine 在 Linux 上玩的游戏。(LCTT 译注:本文原文发表于 2017 年,有些信息可能有所过时。)
+
+### 10、魔兽世界
+
+![World of Warcraft Wine][1]
+
+这款经典的 MMORPG 之王仍旧坚挺并保持活力。虽然这不是一款以画面见长的游戏,但想要开到全画质也需要费一些功夫。魔兽世界已经在 Wine 的支持下运行了很多年。到了最新资料片发布时,魔兽世界为它的 Mac 版本提供了 OpenGL 支持,使得游戏也可以很轻松地在 Linux 下运行。这已经不再是个问题了。
+
+你需要通过 DX9 来运行游戏并从 [Gallium Nine][2] 补丁来获得一些性能提升,不过你也可以放心大胆地在 Linux 中下副本了。
+
+### 9、上古卷轴 5:天际
+
+![Skyrim Wine][3]
+
+上古卷轴 5 已经不是款新游戏了,但它的 mod 社区依旧活跃。如果你的 Linux 系统有足够资源的话,你可以很轻松地加上很多很多 mod。需要记住的是 Wine 运行时要比游戏占用更多的系统资源,所以使用 mod 时也要考虑这一点。
+
+### 8、星际争霸 II
+
+![StarCraft II Wine][4]
+
+星际争霸 II 是成为市场上最受欢迎的 RTS 游戏之一,并且在 Wine 下运作良好。它实际上也是 Wine 下表现最好的游戏之一。
+
+考虑到这款游戏本身的竞技性,你当然希望游戏能够流畅地运行。不过不用担心,只要你的硬件够用就绝对没问题。
+
+这是一个你可以从 “staging” 补丁获益的例子,所以在你设置游戏时请继续使用它们。
+
+### 7、辐射 3 / 辐射:新维加斯
+
+![Fallout 3 Wine][5]
+
+在你提问之前,辐射 4 已经很快就准备就绪,也许就在你正读这篇文章的时候就可以玩了。就目前而言,辐射 3 和 辐射:新维加斯都能在有没有 mod 的情况下良好运行。这些游戏在 Wine 下运行地非常好,甚至还能加载大量 mod 来保持游戏的新鲜性和趣味性。在辐射 4 获得全面支持前玩这些旧作也不算是个很大的妥协。
+
+### 6、Doom (2016)
+
+![Doom Wine][6]
+
+Doom(毁灭战士)是过去几年中最刺激的射击游戏之一。在 Wine 支持下并加载 “staging” 补丁可以流畅地运行最新版本。单人模式和多人模式都有很棒的游戏体验,而且也不需要花费大量时间来配置 Wine 和调整设置。所以你想在 Linux 上体验 3A 级射击游戏的话,不妨尝试一下 Doom 。
+
+### 5、激战 2
+
+![Guild Wars 2 Wine][7]
+
+激战 2 是一款无月卡(买断制)的融合了多人和迷宫探险元素的游戏。它在市场上很受欢迎,并自称在游戏中有着很多创新。你同样可以通过 Wine 在 Linux 上玩到这款游戏。
+
+激战 2 也不算一款很老的 MMO 游戏。它试图以图像表现来保持现代风格,并具有着相当高分辨率的纹理和视觉效果。所有这些特点都能在 Wine 下顺利运行。
+
+### 4、英雄联盟
+
+![League Of Legends Wine][8]
+
+在 MOBA 游戏的世界中有两个强者:DoTA2 和英雄联盟。Valve 已经将 DoTA2 移植到 Linux 上很久了,但玩家们却从没在 Linux 上玩过英雄联盟。如果你是 Linux 的使用者并热衷英雄联盟,你还是可以通过 Wine 来玩这款你最爱的 MOBA 游戏。
+
+英雄联盟是个很有趣的例子。它的游戏本身运行良好,但安装程序却会因为需要 Adobe Air 而中断。一些安装程序脚本例如 Lutris 和 PlayOnLinux 能帮你通过这一步骤。一旦安装完毕,你就可以毫无困难地运行游戏,甚至在激烈的战况中依旧畅快玩耍。
+
+### 3、炉石传说
+
+![HearthStone Wine][9]
+
+炉石传说是一款流行且令人上瘾的免费卡牌游戏,你可在各种平台上来一局……除了 Linux。不过别担心,在 Wine 中你可以轻松玩到这款游戏。炉石并不大,所以即使在最低配置的系统里也都能玩,这是个好消息。不过由于它的竞技性所以还是要对游戏性能有一定要求。
+
+玩炉石不需要任何特殊配置和补丁,直接开玩!
+
+### 2、巫师 3
+
+![Witcher 3 Wine][10]
+
+你不是唯一一个对在这份榜单中看到了巫师 3 而感到吃惊的人。在最新版 “stage” 补丁的支持下,你终于可以在 Linux 中体验这款游戏了。尽管最初承诺会有原生版本,但 Linux 玩家还是等了很久才迎来了巫师系列的第三部。
+
+不过最好不要指望一切都能完美运行。巫师 3 *刚刚* 得到支持,有些内容可能还不会达到预期。也就是说,如果你只能用 Liux 来玩游戏,并且愿意处理一些问题。那么你也可以享受到这款完美游戏带来的初体验了。
+
+### 1、守望先锋
+
+![Overwatch Wine][11]
+
+最后,让我们来谈谈 Linux 玩家心中的另一个“白鲸”。很多人认为守望先锋会像大多数暴雪游戏一样,在发售当日就能在 Wine 上获得支持。不过情况非常不同,因为守望先锋只支持 DX11,这也正是 Wine 面临的一个痛点。
+
+守望先锋目前还不能拥有最佳性能表现,但是你还是可以通过装有特殊补丁的 Wine 和包括“staging”在内的一系列定制补丁包来运行游戏。这也说明了 Linux 玩家们真的很渴望游玩这款游戏,以至于自己开发了一套补丁来为它提供支持。
+
+这份榜单当然会遗漏一些其他游戏。大多数是由于受欢迎程度或只能从 Wine 中得到有限的支持。其他暴雪游戏,如“风暴英雄”和“暗黑破坏神 3”也能很好地运行,但这样来写就会使暴雪游戏霸占这份榜单,这不是我们想突出的重点。
+
+如果你正打算玩以上任一款游戏,请使用 Wine 的 [Gallium Nine][2] 版本并装载“staging”补丁,否则游戏可能无法正常运行。“staging”中装载的最新补丁和提升要比正式的 Wine 发行版提供的内容要早很多,使用它会令你在性能上处于领先地位。
+
+说到进步,Wine 目前在对 DirectX11 的支持有了很大进步。对于 Windows 玩家这可能不算什么,但对于 Linux 玩家来说绝对算是一件大事。大多数游戏新作支持 DX11 和 DX12,而最新版本的 Wine 仍只是支持 DX9。有了 DX11 的支持,Wine 将会让很多过去无法在 Linux 上玩的游戏运行起来。所以,定期查看你最喜欢的 Windows 游戏是否也可以开始在 Wine 上运行,你可能会非常惊喜。
+
+--------------------------------------------------------------------------------
+
+via: https://www.maketecheasier.com/games-play-on-linux-with-wine/
+
+作者:[Nick Congleton][a]
+译者:[Modrisco](https://github.com/Modrisco)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.maketecheasier.com/author/nickcongleton/
+[1]:https://www.maketecheasier.com/assets/uploads/2017/09/wow.jpg (World of Warcraft Wine)
+[2]:https://www.maketecheasier.com/install-wine-gallium-nine-linux
+[3]:https://www.maketecheasier.com/assets/uploads/2017/09/skyrim.jpg (Skyrim Wine)
+[4]:https://www.maketecheasier.com/assets/uploads/2017/09/sc2.jpg (StarCraft II Wine)
+[5]:https://www.maketecheasier.com/assets/uploads/2017/09/Fallout_3.jpg (Fallout 3 Wine)
+[6]:https://www.maketecheasier.com/assets/uploads/2017/09/doom.jpg (Doom Wine)
+[7]:https://www.maketecheasier.com/assets/uploads/2017/09/gw2.jpg (Guild Wars 2 Wine)
+[8]:https://www.maketecheasier.com/assets/uploads/2017/09/League_of_legends.jpg (League Of Legends Wine)
+[9]:https://www.maketecheasier.com/assets/uploads/2017/09/HearthStone.jpg (HearthStone Wine)
+[10]:https://www.maketecheasier.com/assets/uploads/2017/09/witcher3.jpg (Witcher 3 Wine)
+[11]:https://www.maketecheasier.com/assets/uploads/2017/09/Overwatch.jpg (Overwatch Wine)
diff --git a/published/201903/20171119 Advanced Techniques for Reducing Emacs Startup Time.md b/published/201903/20171119 Advanced Techniques for Reducing Emacs Startup Time.md
new file mode 100644
index 0000000000..b6b5819c91
--- /dev/null
+++ b/published/201903/20171119 Advanced Techniques for Reducing Emacs Startup Time.md
@@ -0,0 +1,245 @@
+[#]: collector: (lujun9972)
+[#]: translator: (lujun9972)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10625-1.html)
+[#]: subject: (Advanced Techniques for Reducing Emacs Startup Time)
+[#]: via: (https://blog.d46.us/advanced-emacs-startup/)
+[#]: author: (Joe Schafer https://blog.d46.us/)
+
+降低 Emacs 启动时间的高级技术
+======
+
+> 《[Emacs Start Up Profiler][1]》 的作者教你六项减少 Emacs 启动时间的技术。
+
+简而言之:做下面几个步骤:
+
+1. 使用 Esup 进行性能检测。
+2. 调整垃圾回收的阀值。
+3. 使用 use-package 来自动(延迟)加载所有东西。
+4. 不要使用会引起立即加载的辅助函数。
+5. 参考我的 [配置][2]。
+
+### 从 .emacs.d 的失败到现在
+
+我最近宣布了 .emacs.d 的第三次失败,并完成了第四次 Emacs 配置的迭代。演化过程为:
+
+1. 拷贝并粘贴 elisp 片段到 `~/.emacs` 中,希望它能工作。
+2. 借助 `el-get` 来以更结构化的方式来管理依赖关系。
+3. 放弃自己从零配置,以 Spacemacs 为基础。
+4. 厌倦了 Spacemacs 的复杂性,基于 `use-package` 重写配置。
+
+本文汇聚了三次重写和创建 《[Emacs Start Up Profiler][1]》过程中的技巧。非常感谢 Spacemacs、use-package 等背后的团队。没有这些无私的志愿者,这项任务将会困难得多。
+
+### 不过守护进程模式又如何呢
+
+在我们开始之前,让我反驳一下优化 Emacs 时的常见观念:“Emacs 旨在作为守护进程来运行的,因此你只需要运行一次而已。”
+
+这个观点很好,只不过:
+
+- 速度总是越快越好。
+- 配置 Emacs 时,可能会有不得不通过重启 Emacs 的情况。例如,你可能为 `post-command-hook` 添加了一个运行缓慢的 `lambda` 函数,很难删掉它。
+- 重启 Emacs 能帮你验证不同会话之间是否还能保留配置。
+
+### 1、估算当前以及最佳的启动时间
+
+第一步是测量当前的启动时间。最简单的方法就是在启动时显示后续步骤进度的信息。
+
+```
+;; Use a hook so the message doesn't get clobbered by other messages.
+(add-hook 'emacs-startup-hook
+ (lambda ()
+ (message "Emacs ready in %s with %d garbage collections."
+ (format "%.2f seconds"
+ (float-time
+ (time-subtract after-init-time before-init-time)))
+ gcs-done)))
+```
+
+第二步、测量最佳的启动速度,以便了解可能的情况。我的是 0.3 秒。
+
+```
+# -q ignores personal Emacs files but loads the site files.
+emacs -q --eval='(message "%s" (emacs-init-time))'
+
+;; For macOS users:
+open -n /Applications/Emacs.app --args -q --eval='(message "%s" (emacs-init-time))'
+```
+
+### 2、检测 Emacs 启动指标对你大有帮助
+
+《[Emacs StartUp Profiler][1]》(ESUP)将会给你顶层语句执行的详细指标。
+
+![esup.png][3]
+
+*图 1: Emacs Start Up Profiler 截图*
+
+> 警告:Spacemacs 用户需要注意,ESUP 目前与 Spacemacs 的 init.el 文件有冲突。遵照 上说的进行升级。
+
+### 3、调高启动时垃圾回收的阀值
+
+这为我节省了 **0.3 秒**。
+
+Emacs 默认值是 760kB,这在现代机器看来极其保守。真正的诀窍在于初始化完成后再把它降到合理的水平。这为我节省了 0.3 秒。
+
+```
+;; Make startup faster by reducing the frequency of garbage
+;; collection. The default is 800 kilobytes. Measured in bytes.
+(setq gc-cons-threshold (* 50 1000 1000))
+
+;; The rest of the init file.
+
+;; Make gc pauses faster by decreasing the threshold.
+(setq gc-cons-threshold (* 2 1000 1000))
+```
+
+*~/.emacs.d/init.el*
+
+### 4、不要 require 任何东西,而是使用 use-package 来自动加载
+
+让 Emacs 变坏的最好方法就是减少要做的事情。`require` 会立即加载源文件,但是很少会出现需要在启动阶段就立即需要这些功能的。
+
+在 [use-package][4] 中你只需要声明好需要哪个包中的哪个功能,`use-package` 就会帮你完成正确的事情。它看起来是这样的:
+
+```
+(use-package evil-lisp-state ; the Melpa package name
+
+ :defer t ; autoload this package
+
+ :init ; Code to run immediately.
+ (setq evil-lisp-state-global nil)
+
+ :config ; Code to run after the package is loaded.
+ (abn/define-leader-keys "k" evil-lisp-state-map))
+```
+
+可以通过查看 `features` 变量来查看 Emacs 现在加载了那些包。想要更好看的输出可以使用 [lpkg explorer][5] 或者我在 [abn-funcs-benchmark.el][6] 中的变体。输出看起来类似这样的:
+
+```
+479 features currently loaded
+ - abn-funcs-benchmark: /Users/jschaf/.dotfiles/emacs/funcs/abn-funcs-benchmark.el
+ - evil-surround: /Users/jschaf/.emacs.d/elpa/evil-surround-20170910.1952/evil-surround.elc
+ - misearch: /Applications/Emacs.app/Contents/Resources/lisp/misearch.elc
+ - multi-isearch: nil
+ -
+```
+
+### 5、不要使用辅助函数来设置模式
+
+通常,Emacs 包会建议通过运行一个辅助函数来设置键绑定。下面是一些例子:
+
+ * `(evil-escape-mode)`
+ * `(windmove-default-keybindings) ; 设置快捷键。`
+ * `(yas-global-mode 1) ; 复杂的片段配置。`
+
+可以通过 `use-package` 来对此进行重构以提高启动速度。这些辅助函数只会让你立即加载那些尚用不到的包。
+
+下面这个例子告诉你如何自动加载 `evil-escape-mode`。
+
+```
+;; The definition of evil-escape-mode.
+(define-minor-mode evil-escape-mode
+ (if evil-escape-mode
+ (add-hook 'pre-command-hook 'evil-escape-pre-command-hook)
+ (remove-hook 'pre-command-hook 'evil-escape-pre-command-hook)))
+
+;; Before:
+(evil-escape-mode)
+
+;; After:
+(use-package evil-escape
+ :defer t
+ ;; Only needed for functions without an autoload comment (;;;###autoload).
+ :commands (evil-escape-pre-command-hook)
+
+ ;; Adding to a hook won't load the function until we invoke it.
+ ;; With pre-command-hook, that means the first command we run will
+ ;; load evil-escape.
+ :init (add-hook 'pre-command-hook 'evil-escape-pre-command-hook))
+```
+
+下面来看一个关于 `org-babel` 的例子,这个例子更为复杂。我们通常的配置时这样的:
+
+```
+(org-babel-do-load-languages
+ 'org-babel-load-languages
+ '((shell . t)
+ (emacs-lisp . nil)))
+```
+
+这不是个好的配置,因为 `org-babel-do-load-languages` 定义在 `org.el` 中,而该文件有超过 2 万 4 千行的代码,需要花 0.2 秒来加载。通过查看源代码可以看到 `org-babel-do-load-languages` 仅仅只是加载 `ob-` 包而已,像这样:
+
+```
+;; From org.el in the org-babel-do-load-languages function.
+(require (intern (concat "ob-" lang)))
+```
+
+而在 `ob-.el` 文件中,我们只关心其中的两个方法 `org-babel-execute:` 和 `org-babel-expand-body:`。我们可以延时加载 org-babel 相关功能而无需调用 `org-babel-do-load-languages`,像这样:
+
+```
+;; Avoid `org-babel-do-load-languages' since it does an eager require.
+(use-package ob-python
+ :defer t
+ :ensure org-plus-contrib
+ :commands (org-babel-execute:python))
+
+(use-package ob-shell
+ :defer t
+ :ensure org-plus-contrib
+ :commands
+ (org-babel-execute:sh
+ org-babel-expand-body:sh
+
+ org-babel-execute:bash
+ org-babel-expand-body:bash))
+```
+
+### 6、使用惰性定时器来推迟加载非立即需要的包
+
+我推迟加载了 9 个包,这帮我节省了 **0.4 秒**。
+
+有些包特别有用,你希望可以很快就能使用它们,但是它们本身在 Emacs 启动过程中又不是必须的。这些软件包包括:
+
+- `recentf`:保存最近的编辑过的那些文件。
+- `saveplace`:保存访问过文件的光标位置。
+- `server`:开启 Emacs 守护进程。
+- `autorevert`:自动重载被修改过的文件。
+- `paren`:高亮匹配的括号。
+- `projectile`:项目管理工具。
+- `whitespace`:高亮行尾的空格。
+
+不要 `require` 这些软件包,**而是等到空闲 N 秒后再加载它们**。我在 1 秒后加载那些比较重要的包,在 2 秒后加载其他所有的包。
+
+```
+(use-package recentf
+ ;; Loads after 1 second of idle time.
+ :defer 1)
+
+(use-package uniquify
+ ;; Less important than recentf.
+ :defer 2)
+```
+
+### 不值得的优化
+
+不要费力把你的 Emacs 配置文件编译成字节码了。这只节省了大约 0.05 秒。把配置文件编译成字节码还可能导致源文件与编译后的文件不一致从而难以重现错误进行调试。
+
+--------------------------------------------------------------------------------
+
+via: https://blog.d46.us/advanced-emacs-startup/
+
+作者:[Joe Schafer][a]
+选题:[lujun9972][b]
+译者:[lujun9972](https://github.com/lujun9972)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://blog.d46.us/
+[b]: https://github.com/lujun9972
+[1]: https://github.com/jschaf/esup
+[2]: https://github.com/jschaf/dotfiles/blob/master/emacs/start.el
+[3]: https://blog.d46.us/images/esup.png
+[4]: https://github.com/jwiegley/use-package
+[5]: https://gist.github.com/RockyRoad29/bd4ca6fdb41196a71662986f809e2b1c
+[6]: https://github.com/jschaf/dotfiles/blob/master/emacs/funcs/abn-funcs-benchmark.el
diff --git a/published/201903/20171212 Toplip – A Very Strong File Encryption And Decryption CLI Utility.md b/published/201903/20171212 Toplip – A Very Strong File Encryption And Decryption CLI Utility.md
new file mode 100644
index 0000000000..8ae771aa28
--- /dev/null
+++ b/published/201903/20171212 Toplip – A Very Strong File Encryption And Decryption CLI Utility.md
@@ -0,0 +1,227 @@
+toplip:一款十分强大的文件加密解密 CLI 工具
+======
+
+
+在市场上能找到许多用来保护文件的文档加密工具。我们已经介绍过其中一些例如 [Cryptomater][1]、[Cryptkeeper][2]、[CryptGo][3]、[Cryptr][4]、[Tomb][5],以及 [GnuPG][6] 等加密工具。今天我们将讨论另一款叫做 “toplip” 的命令行文件加密解密工具。它是一款使用一种叫做 [AES256][7] 的强大加密方法的自由开源的加密工具。它同时也使用了 XTS-AES 设计以保护你的隐私数据。它还使用了 [Scrypt][8],一种基于密码的密钥生成函数来保护你的密码免于暴力破解。
+
+### 优秀的特性
+
+相比于其它文件加密工具,toplip 自带以下独特且杰出的特性。
+
+ * 非常强大的基于 XTS-AES256 的加密方法。
+ * 合理的推诿。
+ * 加密并嵌入文件到图片(PNG/JPG)中。
+ * 多重密码保护。
+ * 可防护直接暴力破解。
+ * 无可辨识的输出标记。
+ * 开源(GPLv3)。
+
+### 安装 toplip
+
+没有什么需要安装的。`toplip` 是独立的可执行二进制文件。你所要做的仅是从 [产品官方页面][9] 下载最新版的 `toplip` 并赋予它可执行权限。为此你只要运行:
+
+```
+chmod +x toplip
+```
+
+### 使用
+
+如果你不带任何参数运行 `toplip`,你将看到帮助页面。
+
+```
+./toplip
+```
+
+![][10]
+
+请允许我给你展示一些例子。
+
+为了达到指导目的,我建了两个文件 `file1` 和 `file2`。我同时也有 `toplip` 可执行二进制文件。我把它们全都保存进一个叫做 `test` 的目录。
+
+![][12]
+
+#### 加密/解密单个文件
+
+现在让我们加密 `file1`。为此,运行:
+
+```
+./toplip file1 > file1.encrypted
+```
+
+这行命令将让你输入密码。一旦你输入完密码,它就会加密 `file1` 的内容并将它们保存进你当前工作目录下一个叫做 `file1.encrypted` 的文件。
+
+上述命令行的示例输出将会是这样:
+
+```
+This is toplip v1.20 (C) 2015, 2016 2 Ton Digital. Author: Jeff Marrison A showcase piece for the HeavyThing library. Commercial support available Proudly made in Cooroy, Australia. More info: https://2ton.com.au/toplip file1 Passphrase #1: generating keys...Done
+Encrypting...Done
+```
+
+为了验证文件是否的确经过加密,试着打开它你会发现一些随机的字符。
+
+为了解密加密过的文件,像以下这样使用 `-d` 参数:
+
+```
+./toplip -d file1.encrypted
+```
+
+这行命令会解密提供的文档并在终端窗口显示内容。
+
+为了保存文档而不是写入到标准输出,运行:
+
+```
+./toplip -d file1.encrypted > file1.decrypted
+```
+
+输入正确的密码解密文档。`file1.encrypted` 的所有内容将会存入一个叫做 `file1.decrypted` 的文档。
+
+请不要用这种命名方法,我这样用仅仅是为了便于理解。使用其它难以预测的名字。
+
+#### 加密/解密多个文件
+
+现在我们将使用两个分别的密码加密每个文件。
+
+```
+./toplip -alt file1 file2 > file3.encrypted
+```
+
+你会被要求为每个文件输入一个密码,使用不同的密码。
+
+上述命令行的示例输出将会是这样:
+
+```
+This is toplip v1.20 (C) 2015, 2016 2 Ton Digital. Author: Jeff Marrison A showcase piece for the HeavyThing library. Commercial support available Proudly made in Cooroy, Australia. More info: https://2ton.com.au/toplip
+file2 Passphrase #1 : generating keys...Done
+file1 Passphrase #1 : generating keys...Done
+Encrypting...Done
+```
+
+上述命令所做的是加密两个文件的内容并将它们保存进一个单独的叫做 `file3.encrypted` 的文件。在保存中分别给予各自的密码。比如说如果你提供 `file1` 的密码,`toplip` 将复原 `file1`。如果你提供 `file2` 的密码,`toplip` 将复原 `file2`。
+
+每个 `toplip` 加密输出都可能包含最多四个单独的文件,并且每个文件都建有各自独特的密码。由于加密输出放在一起的方式,一下判断出是否存在多个文档不是一件容易的事。默认情况下,甚至就算确实只有一个文件是由 `toplip` 加密,随机数据都会自动加上。如果指定了多于一个文件,每个都有自己的密码,那么你可以有选择性地独立解码每个文件,以此来否认其它文件存在的可能性。这能有效地使一个用户在可控的暴露风险下打开一个加密的捆绑文件包。并且对于敌人来说,在计算上没有一种低廉的办法来确认额外的秘密数据存在。这叫做“合理的推诿”,是 toplip 著名的特性之一。
+
+为了从 `file3.encrypted` 解码 `file1`,仅需输入:
+
+```
+./toplip -d file3.encrypted > file1.encrypted
+```
+
+你将会被要求输入 `file1` 的正确密码。
+
+为了从 `file3.encrypted` 解码 `file2`,输入:
+
+```
+./toplip -d file3.encrypted > file2.encrypted
+```
+
+别忘了输入 `file2` 的正确密码。
+
+#### 使用多重密码保护
+
+这是我中意的另一个炫酷特性。在加密过程中我们可以为单个文件提供多重密码。这样可以保护密码免于暴力尝试。
+
+```
+./toplip -c 2 file1 > file1.encrypted
+```
+
+这里,`-c 2` 代表两个不同的密码。上述命令行的示例输出将会是这样:
+
+```
+This is toplip v1.20 (C) 2015, 2016 2 Ton Digital. Author: Jeff Marrison A showcase piece for the HeavyThing library. Commercial support available Proudly made in Cooroy, Australia. More info: https://2ton.com.au/toplip
+file1 Passphrase #1: generating keys...Done
+file1 Passphrase #2: generating keys...Done
+Encrypting...Done
+```
+
+正如你在上述示例中所看到的,`toplip` 要求我输入两个密码。请注意你必须提供两个不同的密码,而不是提供两遍同一个密码。
+
+为了解码这个文件,这样做:
+
+```
+$ ./toplip -c 2 -d file1.encrypted > file1.decrypted
+This is toplip v1.20 (C) 2015, 2016 2 Ton Digital. Author: Jeff Marrison A showcase piece for the HeavyThing library. Commercial support available Proudly made in Cooroy, Australia. More info: https://2ton.com.au/toplip
+file1.encrypted Passphrase #1: generating keys...Done
+file1.encrypted Passphrase #2: generating keys...Done
+Decrypting...Done
+```
+
+#### 将文件藏在图片中
+
+将一个文件、消息、图片或视频藏在另一个文件里的方法叫做隐写术。幸运的是 `toplip` 默认包含这个特性。
+
+为了将文件藏入图片中,像如下所示的样子使用 `-m` 参数。
+
+```
+$ ./toplip -m image.png file1 > image1.png
+This is toplip v1.20 (C) 2015, 2016 2 Ton Digital. Author: Jeff Marrison A showcase piece for the HeavyThing library. Commercial support available Proudly made in Cooroy, Australia. More info: https://2ton.com.au/toplip
+file1 Passphrase #1: generating keys...Done
+Encrypting...Done
+```
+
+这行命令将 `file1` 的内容藏入一张叫做 `image1.png` 的图片中。
+
+要解码,运行:
+
+```
+$ ./toplip -d image1.png > file1.decrypted This is toplip v1.20 (C) 2015, 2016 2 Ton Digital. Author: Jeff Marrison A showcase piece for the HeavyThing library. Commercial support available Proudly made in Cooroy, Australia. More info: https://2ton.com.au/toplip
+image1.png Passphrase #1: generating keys...Done
+Decrypting...Done
+```
+
+#### 增加密码复杂度
+
+为了进一步使文件变得难以破译,我们可以像以下这样增加密码复杂度:
+
+```
+./toplip -c 5 -i 0x8000 -alt file1 -c 10 -i 10 file2 > file3.encrypted
+```
+
+上述命令将会要求你为 `file1` 输入十条密码,为 `file2` 输入五条密码,并将它们存入单个叫做 `file3.encrypted` 的文件。如你所注意到的,我们在这个例子中又用了另一个 `-i` 参数。这是用来指定密钥生成循环次数。这个选项覆盖了 `scrypt` 函数初始和最终 PBKDF2 阶段的默认循环次数 1。十六进制和十进制数值都是允许的。比如说 `0x8000`、`10` 等。请注意这会大大增加计算次数。
+
+为了解码 `file1`,使用:
+
+```
+./toplip -c 5 -i 0x8000 -d file3.encrypted > file1.decrypted
+```
+
+为了解码 `file2`,使用:
+
+```
+./toplip -c 10 -i 10 -d file3.encrypted > file2.decrypted
+```
+
+参考 `toplip` [官网](https://2ton.com.au/toplip/)以了解更多关于其背后的技术信息和使用的加密方式。
+
+我个人对所有想要保护自己数据的人的建议是,别依赖单一的方法。总是使用多种工具/方法来加密文件。不要在纸上写下密码也不要将密码存入本地或云。记住密码,阅后即焚。如果你记不住,考虑使用任何了信赖的密码管理器。
+
+- [KeeWeb – An Open Source, Cross Platform Password Manager](https://www.ostechnix.com/keeweb-an-open-source-cross-platform-password-manager/)
+- [Buttercup – A Free, Secure And Cross-platform Password Manager](https://www.ostechnix.com/buttercup-a-free-secure-and-cross-platform-password-manager/)
+- [Titan – A Command line Password Manager For Linux](https://www.ostechnix.com/titan-command-line-password-manager-linux/)
+
+今天就到此为止了,更多好东西后续推出,请保持关注。
+
+顺祝时祺!
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/toplip-strong-file-encryption-decryption-cli-utility/
+
+作者:[SK][a]
+译者:[tomjlw](https://github.com/tomjlw)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.ostechnix.com/author/sk/
+[1]:https://www.ostechnix.com/cryptomator-open-source-client-side-encryption-tool-cloud/
+[2]:https://www.ostechnix.com/how-to-encrypt-your-personal-foldersdirectories-in-linux-mint-ubuntu-distros/
+[3]:https://www.ostechnix.com/cryptogo-easy-way-encrypt-password-protect-files/
+[4]:https://www.ostechnix.com/cryptr-simple-cli-utility-encrypt-decrypt-files/
+[5]:https://www.ostechnix.com/tomb-file-encryption-tool-protect-secret-files-linux/
+[6]:https://www.ostechnix.com/an-easy-way-to-encrypt-and-decrypt-files-from-commandline-in-linux/
+[7]:http://en.wikipedia.org/wiki/Advanced_Encryption_Standard
+[8]:http://en.wikipedia.org/wiki/Scrypt
+[9]:https://2ton.com.au/Products/
+[10]:https://www.ostechnix.com/wp-content/uploads/2017/12/toplip-2.png
+[12]:https://www.ostechnix.com/wp-content/uploads/2017/12/toplip-1.png
+
diff --git a/published/201903/20180122 Ick- a continuous integration system.md b/published/201903/20180122 Ick- a continuous integration system.md
new file mode 100644
index 0000000000..3c240f9545
--- /dev/null
+++ b/published/201903/20180122 Ick- a continuous integration system.md
@@ -0,0 +1,67 @@
+ick:一个持续集成系统
+======
+
+> ick 是一个持续集成(CI)系统。访问 获取更多信息。
+
+更加详细的内容如下:
+
+### 首个公开版本发行
+
+这个世界可能并不需要又一个持续集成系统(CI),但是我需要。我对我尝试过或者看过的持续集成系统感到不满意。更重要的是,有几样我感兴趣的东西比我所听说过的持续集成系统要强大得多。因此我开始编写我自己的 CI 系统。
+
+我的新个人业余项目叫做 ick。它是一个 CI 系统,这意味着它可以运行自动化的步骤来构建、测试软件。它的主页是 ,[下载][1]页面有指向源代码、.deb 包和用来安装的 Ansible 脚本的链接。
+
+我现已发布了首个公开版本,绰号 ALPHA-1,版本号 0.23。(LCTT 译注:截止至本译文发布,已经更新到 ALPHA-6)它现在是 alpha 品质,这意味着它并没拥有期望的全部特性,如果任何一个它已有的特性工作的话,那真是运气好。
+
+### 诚邀贡献
+
+ick 目前是我的个人项目。我希望能让它不仅限于此,同时我也诚邀更多贡献。访问[治理][2]页面查看章程,[入门][3]页面查看如何开始贡献的的小建议,[联系][4]页面查看如何联络。
+
+### 架构
+
+ick 拥有一个由几个通过 HTTPS 协议通信使用 RESTful API 和 JSON 处理结构化数据的部分组成的架构。访问[架构][5]页面了解细节。
+
+### 宣告
+
+持续集成(CI)是用于软件开发的强大工具。它不应枯燥、易溃或恼人。它构建起来应简单快速,除非正在测试、构建的代码中有问题,不然它应在后台安静地工作。
+
+一个持续集成系统应该简单、易用、清楚、干净、可扩展、快速、综合、透明、可靠,并推动你的生产力。构建它不应花大力气、不应需要专门为 CI 而造的硬件、不应需要频繁留意以使其保持工作、开发者永远不必思考为什么某样东西不工作。
+
+一个持续集成系统应该足够灵活以适应你的构建、测试需求。只要 CPU 架构和操作系统版本没问题,它应该支持各种操作者。
+
+同时像所有软件一样,CI 应该彻彻底底的免费,你的 CI 应由你做主。
+
+(目前的 ick 仅稍具雏形,但是它会尝试着有朝一日变得完美 —— 在最理想的情况下。)
+
+### 未来的梦想
+
+长远来看,我希望 ick 拥有像下面所描述的特性。落实全部特性可能需要一些时间。
+
+* 各种事件都可以触发构建。时间是一个明显的事件,因为项目的源代码仓库改变了。更强大的是任何依赖的改变,不管依赖是来自于 ick 构建的另一个项目,或者是包(比如说来自 Debian):ick 应当跟踪所有安装进一个项目构建环境中的包,如果任何一个包的版本改变,都应再次触发项目构建和测试。
+* ick 应该支持构建于(或针对)任何合理的目标平台,包括任何 Linux 发行版,任何自由的操作系统,以及任何一息尚存的不自由的操作系统。
+* ick 应该自己管理构建环境,并且能够执行与构建主机或网络隔离的构建。这部分工作:可以要求 ick 构建容器并在容器中运行构建。容器使用 systemd-nspawn 实现。 然而,这可以改进。(如果您认为 Docker 是唯一的出路,请为此提供支持。)
+* ick 应当不需要安装任何专门的代理,就能支持各种它能够通过 ssh 或者串口或者其它这种中性的交流管道控制的操作者。ick 不应默认它可以有比如说一个完整的 Java Runtime,如此一来,操作者就可以是一个微控制器了。
+* ick 应当能轻松掌控一大批项目。我觉得不管一个新的 Debian 源包何时上传,ick 都应该要能够跟得上在 Debian 中构建所有东西的进度。(明显这可行与否取决于是否有足够的资源确实用在构建上,但是 ick 自己不应有瓶颈。)
+* 如果有需要的话 ick 应当有选择性地补给操作者。如果所有特定种类的操作者处于忙碌中,且 ick 被设置成允许使用更多资源的话,它就应该这么做。这看起来用虚拟机、容器、云提供商等做可能会简单一些。
+* ick 应当灵活提醒感兴趣的团体,特别是关于其失败的方面。它应允许感兴趣的团体通过 IRC、Matrix、Mastodon、Twitter、email、SMS 甚至电话和语音合成来接受通知。例如“您好,感兴趣的团体。现在是四点钟您想被通知 hello 包什么时候为 RISC-V 构建好。”
+
+### 请提供反馈
+
+如果你尝试过 ick 或者甚至你仅仅是读到这,请在上面分享你的想法。在[联系][4]页面查看如何发送反馈。相比私下反馈我更偏爱公开反馈。但如果你偏爱私下反馈,那也行。
+
+--------------------------------------------------------------------------------
+
+via: https://blog.liw.fi/posts/2018/01/22/ick_a_continuous_integration_system/
+
+作者:[Lars Wirzenius][a]
+译者:[tomjlw](https://github.com/tomjlw)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://blog.liw.fi/
+[1]:http://ick.liw.fi/download/
+[2]:http://ick.liw.fi/governance/
+[3]:http://ick.liw.fi/getting-started/
+[4]:http://ick.liw.fi/contact/
+[5]:http://ick.liw.fi/architecture/
diff --git a/published/201903/20180202 Tips for success when getting started with Ansible.md b/published/201903/20180202 Tips for success when getting started with Ansible.md
new file mode 100644
index 0000000000..ab189fef6f
--- /dev/null
+++ b/published/201903/20180202 Tips for success when getting started with Ansible.md
@@ -0,0 +1,70 @@
+Ansible 入门秘诀
+======
+
+> 用 Ansible 自动化你的数据中心的关键点。
+
+
+
+Ansible 是一个开源自动化工具,可以从中央控制节点统一配置服务器、安装软件或执行各种 IT 任务。它采用一对多、无客户端的机制,从控制节点上通过 SSH 发送指令给远端的客户机来完成任务(当然除了 SSH 外也可以用别的协议)。
+
+Ansible 的主要使用群体是系统管理员,他们经常会周期性地执行一些安装、配置应用的工作。尽管如此,一些非特权用户也可以使用 Ansible,例如数据库管理员就可以通过 Ansible 用 `mysql` 这个用户来创建数据库、添加数据库用户、定义访问权限等。
+
+让我们来看一个简单的使用场景,一位系统管理员每天要配置 100 台服务器,并且必须在每台机器上执行一系列 Bash 命令,然后交付给用户。
+
+
+
+这是个简单的例子,但应该能够证明:在 yaml 文件里写好命令然后在远程服务器上运行,是一件非常轻松的事。而且如果运行环境不同,就可以加入判断条件,指明某些命令只能在特定的服务器上运行(如:只在那些不是 Ubuntu 或 Debian 的系统上运行 `yum` 命令)。
+
+Ansible 的一个重要特性是用剧本来描述一个计算机系统的最终状态,所以一个剧本可以在服务器上反复执行而不影响其最终状态(LCTT 译注:即是幂等的)。如果某个任务已经被实施过了(如,“用户 `sysman` 已经存在”),那么 Ansible 就会忽略它继续执行后续的任务。
+
+### 定义
+
+ * 任务:是工作的最小单位,它可以是个动作,比如“安装一个数据库服务”、“安装一个 web 服务器”、“创建一条防火墙规则”或者“把这个配置文件拷贝到那个服务器上去”。
+ * 动作: 由任务组成,例如,一个动作的内容是要“设置一个数据库,给 web 服务用”,这就包含了如下任务:1)安装数据库包;2)设置数据库管理员密码;3)创建数据库实例;4)为该实例分配权限。
+ * 剧本:(LCTT 译注:playbook 原指美式橄榄球队的[战术手册][5],也常指“剧本”,此处惯例采用“剧本”译名)由动作组成,一个剧本可能像这样:“设置我的网站,包含后端数据库”,其中的动作包括:1)设置数据库服务器;2)设置 web 服务器。
+ * 角色:用来保存和组织剧本,以便分享和再次使用它们。还拿上个例子来说,如果你需要一个全新的 web 服务器,就可以用别人已经写好并分享出来的角色来设置。因为角色是高度可配置的(如果编写正确的话),可以根据部署需求轻松地复用它们。
+ * [Ansible 星系][1]:是一个在线仓库,里面保存的是由社区成员上传的角色,方便彼此分享。它与 GitHub 紧密集成,因此这些角色可以先在 Git 仓库里组织好,然后通过 Ansible 星系分享出来。
+
+这些定义以及它们之间的关系可以用下图来描述:
+
+
+
+请注意上面的例子只是组织任务的方式之一,我们当然也可以把安装数据库和安装 web 服务器的剧本拆开,放到不同的角色里。Ansible 星系上最常见的角色是独立安装、配置每个应用服务,你可以参考这些安装 [mysql][2] 和 [httpd][3] 的例子。
+
+### 编写剧本的小技巧
+
+学习 Ansible 最好的资源是其[官方文档][4]。另外,像学习其他东西一样,搜索引擎是你的好朋友。我推荐你从一些简单的任务开始,比如安装应用或创建用户。下面是一些有用的指南:
+
+ * 在测试的时候少选几台服务器,这样你的动作可以执行的更快一些。如果它们在一台机器上执行成功,在其他机器上也没问题。
+ * 总是在真正运行前做一次测试,以确保所有的命令都能正确执行(要运行测试,加上 `--check-mode` 参数 )。
+ * 尽可能多做测试,别担心搞砸。任务里描述的是所需的状态,如果系统已经达到预期状态,任务会被简单地忽略掉。
+ * 确保在 `/etc/ansible/hosts` 里定义的主机名都可以被正确解析。
+ * 因为是用 SSH 与远程主机通信,主控节点必须要能接受密钥,所以你面临如下选择:1)要么在正式使用之前就做好与远程主机的密钥交换工作;2)要么在开始管理某台新的远程主机时做好准备输入 “Yes”,因为你要接受对方的 SSH 密钥交换请求(LCTT 译注:还有另一个不那么安全的选择,修改主控节点的 ssh 配置文件,将 `StrictHostKeyChecking` 设置成 “no”)。
+ * 尽管你可以在同一个剧本内把不同 Linux 发行版的任务整合到一起,但为每个发行版单独编写剧本会更明晰一些。
+
+### 总结一下
+
+Ansible 是你在数据中心里实施运维自动化的好选择,因为它:
+
+ * 无需客户端,所以比其他自动化工具更易安装。
+ * 将指令保存在 YAML 文件中(虽然也支持 JSON),比写 shell 脚本更简单。
+ * 开源,因此你也可以做出自己的贡献,让它更加强大!
+
+你是怎样使用 Ansible 让数据中心更加自动化的呢?请在评论中分享您的经验。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/2/tips-success-when-getting-started-ansible
+
+作者:[Jose Delarosa][a]
+译者:[jdh8383](https://github.com/jdh8383)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/jdelaros1
+[1]:https://galaxy.ansible.com/
+[2]:https://galaxy.ansible.com/bennojoy/mysql/
+[3]:https://galaxy.ansible.com/xcezx/httpd/
+[4]:http://docs.ansible.com/
+[5]:https://usafootball.com/football-playbook/
diff --git a/published/201903/20180206 Power(Shell) to the people.md b/published/201903/20180206 Power(Shell) to the people.md
new file mode 100644
index 0000000000..6f81e417a1
--- /dev/null
+++ b/published/201903/20180206 Power(Shell) to the people.md
@@ -0,0 +1,158 @@
+给大家安利一下 PowerShell
+======
+
+> 代码更简洁、脚本更清晰、跨平台一致性等好处是让 Linux 和 OS X 用户喜爱 PowerShell 的原因。
+
+
+
+今年(2018)早些时候,[Powershell Core][1] 以 [MIT][3] 开源协议发布了[正式可用版(GA)][2]。PowerShell 算不上是新技术。自 2006 年为 Windows 发布了第一版 PowerShell 以来,PowerShell 的创建者在[结合了][4] Unⅸ shell 的强大和灵活的同时也在弥补他们所意识到的缺点,特别是从组合命令中获取值时所要进行的文本操作。
+
+在发布了 5 个主要版本之后,PowerShell 已经可以在所有主流操作系统上(包括 OS X 和 Linux)本地运行同样创新的 shell 和命令行环境。一些人(应该说是大多数人)可能依旧在嘲弄这位诞生于 Windows 的闯入者的大胆和冒失:为那些远古以来(从千禧年开始算不算?)便存在着强大的 shell 环境的平台引荐自己。在本帖中,我希望可以将 PowerShell 的优势介绍给大家,甚至是那些经验老道的用户。
+
+### 跨平台一致性
+
+如果你计划将脚本从一个执行环境迁移到另一个平台时,你需要确保只使用了那些在两个平台下都起作用的命令和语法。比如在 GNU 系统中,你可以通过以下方式获取昨天的日期:
+
+```
+date --date="1 day ago"
+```
+
+在 BSD 系统中(比如 OS X),上述语法将没办法工作,因为 BSD 的 date 工具需要以下语法:
+
+```
+date -v -1d
+```
+
+因为 PowerShell 具有宽松的许可证,并且在所有的平台都有构建,所以你可以把 PowerShell 和你的应用一起打包。因此,当你的脚本运行在目标系统中时,它们会运行在一样的 shell 环境中,使用与你的测试环境中同样的命令实现。
+
+### 对象和结构化数据
+
+*nix 命令和工具依赖于你使用和操控非结构化数据的能力。对于那些长期活在 `sed`、 `grep` 和 `awk` 环境下的人们来说,这可能是小菜一碟,但现在有更好的选择。
+
+让我们使用 PowerShell 重写那个获取昨天日期的实例。为了获取当前日期,使用 `Get-Date` cmdlet(读作 “commandlet”):
+
+```
+> Get-Date
+
+Sunday, January 21, 2018 8:12:41 PM
+```
+
+你所看到的输出实际上并不是一个文本字符串。不如说,这是 .Net Core 对象的一个字符串表现形式。就像任何 OOP 环境中的对象一样,它具有类型以及你可以调用的方法。
+
+让我们来证明这一点:
+
+```
+> $(Get-Date).GetType().FullName
+System.DateTime
+```
+
+`$(...)` 语法就像你所期望的 POSIX shell 中那样,计算括弧中的命令然后替换整个表达式。但是在 PowerShell 中,这种表达式中的 `$` 是可选的。并且,最重要的是,结果是一个 .Net 对象,而不是文本。因此我们可以调用该对象中的 `GetType()` 方法来获取该对象类型(类似于 Java 中的 `Class` 对象),`FullName` [属性][5] 则用来获取该类型的全称。
+
+那么,这种对象导向的 shell 是如何让你的工作变得更加简单呢?
+
+首先,你可将任何对象排进 `Get-Member` cmdlet 来查看它提供的所有方法和属性。
+
+```
+> (Get-Date) | Get-Member
+PS /home/yevster/Documents/ArticlesInProgress> $(Get-Date) | Get-Member
+
+
+ TypeName: System.DateTime
+
+Name MemberType Definition
+---- ---------- ----------
+Add Method datetime Add(timespan value)
+AddDays Method datetime AddDays(double value)
+AddHours Method datetime AddHours(double value)
+AddMilliseconds Method datetime AddMilliseconds(double value)
+AddMinutes Method datetime AddMinutes(double value)
+AddMonths Method datetime AddMonths(int months)
+AddSeconds Method datetime AddSeconds(double value)
+AddTicks Method datetime AddTicks(long value)
+AddYears Method datetime AddYears(int value)
+CompareTo Method int CompareTo(System.Object value), int ...
+```
+
+你可以很快的看到 DateTime 对象具有一个 `AddDays` 方法,从而可以使用它来快速的获取昨天的日期:
+
+```
+> (Get-Date).AddDays(-1)
+
+Saturday, January 20, 2018 8:24:42 PM
+```
+
+为了做一些更刺激的事,让我们调用 Yahoo 的天气服务(因为它不需要 API 令牌)然后获取你的本地天气。
+
+```
+$city="Boston"
+$state="MA"
+$url="https://query.yahooapis.com/v1/public/yql?q=select%20*%20from%20weather.forecast%20where%20woeid%20in%20(select%20woeid%20from%20geo.places(1)%20where%20text%3D%22${city}%2C%20${state}%22)&format=json&env=store%3A%2F%2Fdatatables.org%2Falltableswithkeys"
+```
+
+现在,我们可以使用老派的方法然后直接运行 `curl $url` 来获取 JSON 二进制对象,或者……
+
+```
+$weather=(Invoke-RestMethod $url)
+```
+
+如果你查看了 `$weather` 类型(运行 `echo $weather.GetType().FullName`),你将会发现它是一个 `PSCustomObject`。这是一个用来反射 JSON 结构的动态对象。
+
+然后 PowerShell 可以通过 tab 补齐来帮助你完成命令输入。只需要输入 `$weather.`(确报包含了 `.`)然后按下 `Tab` 键。你将看到所有根级别的 JSON 键。输入其中的一个,然后跟上 `.` ,再一次按下 `Tab` 键,你将看到它所有的子键(如果有的话)。
+
+因此,你可以轻易的导航到你所想要的数据:
+
+```
+> echo $weather.query.results.channel.atmosphere.pressure
+1019.0
+
+> echo $weather.query.results.channel.wind.chill 41
+```
+
+并且如果你有非结构化的 JSON 或 CSV 数据(通过外部命令返回的),只需要将它相应的排进 `ConverFrom-Json` 或 `ConvertFrom-CSV` cmdlet,然后你可以得到一个漂亮干净的对象。
+
+### 计算 vs. 自动化
+
+我们使用 shell 用于两种目的。一个是用于计算,运行独立的命令然后手动响应它们的输出。另一个是自动化,通过写脚本执行多个命令,然后以编程的方式相应它们的输出。
+
+我们大多数人都能发现这两种目的在 shell 上的不同且互相冲突的要求。计算任务要求 shell 简洁明了。用户输入的越少越好。但如果用户输入对其他用户来说几乎难以理解,那这一点就不重要了。脚本,从另一个角度来讲是代码。可读性和可维护性是关键。这一方面,POSIX 工具通常是失败的。虽然一些命令通常会为它们的参数提供简洁明了的语法(如:`-f` 和 `--force`),但是命令名字本身就不简洁明了。
+
+PowerShell 提供了几个机制来消除这种浮士德式的平衡。
+
+首先,tab 补齐可以消除键入参数名的需要。比如:键入 `Get-Random -Mi`,按下 `Tab` 然后 PowerShell 将会为你完成参数:`Get-Random -Minimum`。但是如果你想更简洁一些,你甚至不需要按下 `Tab`。如下所示,PowerShell 可以理解:
+
+```
+Get-Random -Mi 1 -Ma 10
+```
+
+因为 `Mi` 和 `Ma` 每一个都具有独立不同的补齐。
+
+你可能已经留意到所有的 PowerShell cmdlet 名称具有动名词结构。这有助于脚本的可读性,但是你可能不想一而再、再而三的键入 `Get-`。所以并不需要!如果你之间键入了一个名词而没有动词的话,PowerShell 将查找带有该名词的 `Get-` 命令。
+
+> 小心:尽管 PowerShell 不区分大小写,但在使用 PowerShell 命令是时,名词首字母大写是一个好习惯。比如,键入 `date` 将会调用系统中的 `date` 工具。键入 `Date` 将会调用 PowerShell 的 `Get-Date` cmdlet。
+
+如果这还不够,PowerShell 还提供了别名,用来创建简单的名字。比如,如果键入 `alias -name cd`,你将会发现 `cd` 在 PowerShell 实际上时 `Set-Location` 命令的别名。
+
+所以回顾以下 —— 你可以使用强大的 tab 补全、别名,和名词补全来保持命令名词简洁、自动化和一致性参数名截断,与此同时还可以享受丰富、可读的语法格式。
+
+### 那么……你看呢?
+
+这些只是 PowerShell 的一部分优势。还有更多特性和 cmdlet,我还没讨论(如果你想弄哭 `grep` 的话,可以查看 [Where-Object][6] 或其别称 `?`)。如果你有点怀旧的话,PowerShell 可以为你加载原来的本地工具。但是给自己足够的时间来适应 PowerShell 面向对象 cmdlet 的世界,然后你将发现自己会选择忘记回去的路。
+
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/2/powershell-people
+
+作者:[Yev Bronshteyn][a]
+译者:[sanfusu](https://github.com/sanfusu)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/yevster
+[1]:https://github.com/PowerShell/PowerShell/blob/master/README.md
+[2]:https://blogs.msdn.microsoft.com/powershell/2018/01/10/powershell-core-6-0-generally-available-ga-and-supported/
+[3]:https://spdx.org/licenses/MIT
+[4]:http://www.jsnover.com/Docs/MonadManifesto.pdf
+[5]:https://docs.microsoft.com/en-us/dotnet/csharp/programming-guide/classes-and-structs/properties
+[6]:https://docs.microsoft.com/en-us/powershell/module/microsoft.powershell.core/where-object?view=powershell-6
diff --git a/published/201903/20180220 JSON vs XML vs TOML vs CSON vs YAML.md b/published/201903/20180220 JSON vs XML vs TOML vs CSON vs YAML.md
new file mode 100644
index 0000000000..23461a9493
--- /dev/null
+++ b/published/201903/20180220 JSON vs XML vs TOML vs CSON vs YAML.md
@@ -0,0 +1,209 @@
+[#]: collector: (lujun9972)
+[#]: translator: (GraveAccent)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10664-1.html)
+[#]: subject: (JSON vs XML vs TOML vs CSON vs YAML)
+[#]: via: (https://www.zionandzion.com/json-vs-xml-vs-toml-vs-cson-vs-yaml/)
+[#]: author: (Tim Anderson https://www.zionandzion.com)
+
+JSON、XML、TOML、CSON、YAML 大比拼
+======
+
+### 一段超级严肃的关于样本序列化的集合、子集和超集的文字
+
+我是一名开发者,我读代码,我写代码,我写会写代码的代码,我写会写出供其它代码读的代码的代码。这些都非常火星语,但是有其美妙之处。然而,最后一点,写会写出供其它代码读的代码的代码,可以很快变得比这段文字更费解。有很多方法可以做到这一点。一种不那么复杂而且开发者社区最爱的方式是数据序列化。对于那些不了解我刚刚抛给你的时髦词的人,数据序列化是从一个系统获取一些信息,将其转换为其它系统可以读取的格式,然后将其传递给其它系统的过程。
+
+虽然[数据序列化格式][1]多到可以埋葬哈利法塔,但它们大多分为两类:
+
+ * 易于人类读写,
+ * 易于机器读写。
+
+很难两全其美,因为人类喜欢让我们更具表现力的松散类型和灵活格式标准,而机器倾向于被确切告知一切事情而没有二义性和细节缺失,并且认为“严格规范”才是它们最爱的口味。
+
+由于我是一名 web 开发者,而且我们是一个创建网站的机构,我们将坚持使用 web 系统可以理解或不需要太多努力就能理解的特殊格式,而且对人类可读性特别有用的格式:XML、JSON、TOML、CSON 以及 YAML。每个都有各自的优缺点和适当的用例场景。
+
+### 事实最先
+
+回到互联网的早期,[一些非常聪明的家伙][2]决定整合一种让每个系统都能理解的标准语言,并创造性地将其命名为标准通用标记语言(简称 SGML)。SGML 非常灵活,发布者也很好地定义了它。它成为了 XML、SVG 和 HTML 等语言之父。所有这三个都符合 SGML 规范,可是它们都是规则更严格、灵活性更少的子集。
+
+最终,人们开始看到非常小、简洁、易读且易于生成的数据的好处,这些数据可以在系统之间以编程的方式共享,而开销很小。大约在那个时候,JSON 诞生了并且能够满足所有的需求。而另一方面,其它语言也开始出现以处理更多的专业用例,如 CSON,TOML 和 YAML。
+
+### XML:不行了
+
+原本,XML 语言非常灵活且易于编写,但它的缺点是冗长,人类难以阅读、计算机非常难以读取,并且有很多语法对于传达信息并不是完全必要的。
+
+今天,它在 web 上的数据序列化的用途已经消失了。除非你在编写 HTML 或者 SVG,否则你不太能在许多其它地方看到 XML。一些过时的系统今天仍在使用它,但是用它传递数据往往太重了。
+
+我已经可以听到 XML 老爷爷开始在它们的石碑上乱写为什么 XML 是了不起的,所以我将提供一个小小的补充:XML 可以很容易地由系统和人读写。然而,真的,我的意思是荒谬的,很难创建一个可以规范的读取它的系统。这是一个简单美观的 XML 示例:
+
+```
+
+Gambardella, Matthew
+XML Developer's Guide
+Computer
+44.95
+2000-10-01
+An in-depth look at creating applications
+with XML.
+
+```
+
+太棒了。易于阅读、理解、写入,也容易编码一个可以读写它的系统。但请考虑这个例子:
+
+```
+b"> ]>
+
+
+b b
+ d
+
+```
+
+这上面是 100% 有效的 XML。几乎不可能阅读、理解或推理。编写可以使用和理解这个的代码将花费至少 36 根头发和 248 磅咖啡渣。我们没有那么多时间或咖啡,而且我们大多数老程序员们现在都是秃头。所以,让它活在我们的记忆里,就像 [css hacks][3]、[IE 6 浏览器][4] 和[真空管][5]一样好了。
+
+### JSON:并列聚会
+
+好吧,我们都同意,XML = 差劲。那么,好的替代品是什么?JavaScript 对象表示法,简称 JSON。JSON(读起来像 Jason 这个名字) 是 Brendan Eich 发明的,并且得到了伟大而强力的 [JavaScript 意见领袖][6] Douglas Crockford 的推广。它现在几乎用在任何地方。这种格式很容易由人和机器编写,按规范中的严格规则[解析][7]也相当容易,并且灵活 —— 允许深层嵌套数据,支持所有的原始数据类型,及将集合解释为数组或对象。JSON 成为了将数据从一个系统传输到另一个系统的事实标准。几乎所有语言都有内置读写它的功能。
+
+JSON语法很简单。方括号表示数组,花括号表示记录,由冒号分隔的两个值分别表示属性或“键”(在左边)、值(在右边)。所有键必须用双引号括起来:
+
+```
+ {
+ "books": [
+ {
+ "id": "bk102",
+ "author": "Crockford, Douglas",
+ "title": "JavaScript: The Good Parts",
+ "genre": "Computer",
+ "price": 29.99,
+ "publish_date": "2008-05-01",
+ "description": "Unearthing the Excellence in JavaScript"
+ }
+ ]
+ }
+```
+
+这对你来说应该是完全有意义的。它简洁明了,并且从 XML 中删除了大量额外废话,并传达相同数量的信息。JSON 现在是王道,本文剩下的部分会介绍其它语言格式,这些格式只不过是 JSON 的简化版,尝试让其更简洁或对人类更易读,可结构还是非常相似的。
+
+### TOML: 缩短到彻底的利他主义
+
+TOML(Tom 的显而易见的最小化语言)允许以相当快捷、简洁的方式定义深层嵌套的数据结构。名字中的 Tom 是指发明者 [Tom Preston Werner][8],他是一位活跃于我们行业的创造者和软件开发人员。与 JSON 相比,语法有点尴尬,更类似 [ini 文件][9]。这不是一个糟糕的语法,但是需要一些时间适应。
+
+```
+[[books]]
+id = 'bk101'
+author = 'Crockford, Douglas'
+title = 'JavaScript: The Good Parts'
+genre = 'Computer'
+price = 29.99
+publish_date = 2008-05-01T00:00:00+00:00
+description = 'Unearthing the Excellence in JavaScript'
+```
+
+TOML 中集成了一些很棒的功能,例如多行字符串、保留字符的自动转义、日期、时间、整数、浮点数、科学记数法和“表扩展”等数据类型。最后一点是特别的,是 TOML 如此简洁的原因:
+
+```
+[a.b.c]
+d = 'Hello'
+e = 'World'
+```
+
+以上扩展到以下内容:
+
+```
+{
+ "a": {
+ "b": {
+ "c": {
+ "d": "Hello"
+ "e": "World"
+ }
+ }
+ }
+}
+```
+
+使用 TOML,你可以肯定在时间和文件长度上会节省不少。很少有系统使用它或非常类似的东西作为配置,这是它最大的缺点。根本没有很多语言或库可以用来解释 TOML。
+
+### CSON: 特定系统所包含的简单样本
+
+首先,有两个 CSON 规范。 一个代表 CoffeeScript Object Notation,另一个代表 Cursive Script Object Notation。后者不经常使用,所以我们不会关注它。我们只关注 CoffeeScript。
+
+[CSON][10] 需要一点介绍。首先,我们来谈谈 CoffeeScript。[CoffeeScript][11] 是一种通过运行编译器生成 JavaScript 的语言。它允许你以更加简洁的语法编写 JavaScript 并[转译][12]成实际的 JavaScript,然后你可以在你的 web 应用程序中使用它。CoffeeScript 通过删除 JavaScript 中必需的许多额外语法,使编写 JavaScript 变得更容易。CoffeeScript 摆脱的一个大问题是花括号 —— 不需要它们。同样,CSON 是没有大括号的 JSON。它依赖于缩进来确定数据的层次结构。CSON 非常易于读写,并且通常比 JSON 需要更少的代码行,因为没有括号。
+
+CSON 还提供一些 JSON 不提供的额外细节。多行字符串非常容易编写,你可以通过使用 `#` 符号开始一行来输入[注释][13],并且不需要用逗号分隔键值对。
+
+```
+books: [
+ id: 'bk102'
+ author: 'Crockford, Douglas'
+ title: 'JavaScript: The Good Parts'
+ genre: 'Computer'
+ price: 29.99
+ publish_date: '2008-05-01'
+ description: 'Unearthing the Excellence in JavaScript'
+]
+```
+
+这是 CSON 的大问题。它是 CoffeScript 对象表示法。也就是说你要用 CoffeeScript 解析/标记化/lex/转译或其它方式来使用 CSON。CoffeeScript 是读取数据的系统。如果数据序列化的目的是允许数据从一个系统传递到另一个系统,这里我们有一个只能由单个系统读取的数据序列化格式,这使得它与防火火柴、防水海绵或者叉匙恼人的脆弱叉子部分一样有用。
+
+如果这种格式被其它系统也采用,那它在开发者世界中可能非常有用。但到目前为止这基本上没有发生,所以在 PHP 或 JAVA 等替代语言中使用它是不行的。
+
+### YAML:年轻人的呼喊
+
+开发人员感到高兴,因为 YAML 来自[一个 Python 的贡献者][14]。YAML 具有与 CSON 相同的功能集和类似的语法,有一系列新功能,以及几乎所有 web 编程语言都可用的解析器。它还有一些额外的功能,如循环引用、软包装、多行键、类型转换标签、二进制数据、对象合并和[集合映射][15]。它具有非常好的可读性和可写性,并且是 JSON 的超集,因此你可以在 YAML 中使用完全合格的 JSON 语法并且一切正常工作。你几乎不需要引号,它可以解释大多数基本数据类型(字符串、整数、浮点数、布尔值等)。
+
+```
+books:
+ - id: bk102
+ author: Crockford, Douglas
+ title: 'JavaScript: The Good Parts'
+ genre: Computer
+ price: 29.99
+ publish_date: !!str 2008-05-01
+ description: Unearthing the Excellence in JavaScript
+```
+
+业界的年轻人正在迅速采用 YAML 作为他们首选的数据序列化和系统配置格式。他们这样做很机智。YAML 具有像 CSON 一样简洁的所有好处,以及与 JSON 一样的数据类型解释的所有功能。YAML 像加拿大人容易相处一样容易阅读。
+
+YAML 有两个问题,对我而言,第一个是大问题。在撰写本文时,YAML 解析器尚未内置于多种语言,因此你需要使用第三方库或扩展来为你选择的语言解析 .yaml 文件。这不是什么大问题,可似乎大多数为 YAML 创建解析器的开发人员都选择随机将“附加功能”放入解析器中。有些允许[标记化][16],有些允许[链引用][17],有些甚至允许内联计算。这一切都很好(某种意义上),只是这些功能都不是规范的一部分,因此很难在其他语言的其他解析器中找到。这导致系统限定,你最终遇到了与 CSON 相同的问题。如果你使用仅在一个解析器中找到的功能,则其他解析器将无法解释输入。大多数这些功能都是无意义的,不属于数据集,而是属于你的应用程序逻辑,因此最好简单地忽略它们和编写符合规范的 YAML。
+
+第二个问题是很少有解析器完全实现规范。所有的基本要素都有,但是很难找到一些更复杂和更新的东西,比如软包装、文档标记和首选语言的循环引用。我还没有看到对这些东西的刚需,所以希望它们不让你很失望。考虑到上述情况,我倾向于保持 [1.1 规范][18] 中呈现的更成熟的功能集,而避免在 [1.2 规范][19] 中找到的新东西。然而,编程是一个不断发展的怪兽,所以当你读完这篇文章时,你或许就可以使用 1.2 规范了。
+
+### 最终哲学
+
+这是最后一段话。每个序列化语言都应该以个案标准的方式评价。当涉及机器的可读性时,有些无出其右。对于人类可读性,有些名至实归,有些只是金玉其外。以下是最终细分:如果你要编写供其他代码阅读的代码,请使用 YAML。如果你正在编写能写出供其他代码读取的代码的代码,请使用 JSON。最后,如果你正在编写将代码转译为供其他代码读取的代码的代码,请重新考虑你的人生选择。
+
+--------------------------------------------------------------------------------
+
+via: https://www.zionandzion.com/json-vs-xml-vs-toml-vs-cson-vs-yaml/
+
+作者:[Tim Anderson][a]
+选题:[lujun9972][b]
+译者:[GraveAccent](https://github.com/GraveAccent)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.zionandzion.com
+[b]: https://github.com/lujun9972
+[1]: https://en.wikipedia.org/wiki/Comparison_of_data_serialization_formats
+[2]: https://en.wikipedia.org/wiki/Standard_Generalized_Markup_Language#History
+[3]: https://www.quirksmode.org/css/csshacks.html
+[4]: http://www.ie6death.com/
+[5]: https://en.wikipedia.org/wiki/Vacuum_tube
+[6]: https://twitter.com/BrendanEich/status/773403975865470976
+[7]: https://en.wikipedia.org/wiki/Parsing#Parser
+[8]: https://en.wikipedia.org/wiki/Tom_Preston-Werner
+[9]: https://en.wikipedia.org/wiki/INI_file
+[10]: https://github.com/bevry/cson#what-is-cson
+[11]: http://coffeescript.org/
+[12]: https://en.wikipedia.org/wiki/Source-to-source_compiler
+[13]: https://en.wikipedia.org/wiki/Comment_(computer_programming)
+[14]: http://clarkevans.com/
+[15]: http://exploringjs.com/es6/ch_maps-sets.html
+[16]: https://www.tutorialspoint.com/compiler_design/compiler_design_lexical_analysis.htm
+[17]: https://en.wikipedia.org/wiki/Fluent_interface
+[18]: http://yaml.org/spec/1.1/current.html
+[19]: http://www.yaml.org/spec/1.2/spec.html
diff --git a/published/201903/20180307 3 open source tools for scientific publishing.md b/published/201903/20180307 3 open source tools for scientific publishing.md
new file mode 100644
index 0000000000..40deb0ee6c
--- /dev/null
+++ b/published/201903/20180307 3 open source tools for scientific publishing.md
@@ -0,0 +1,80 @@
+3 款用于学术出版的开源工具
+======
+> 学术出版业每年的价值超过 260 亿美元。
+
+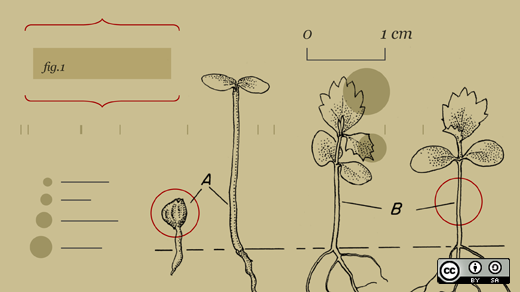
+
+有一个行业在采用数字化或开源工具方面已落后其它行业,那就是竞争与利润并存的学术出版业。根据 Stephen Buranyi 去年在 [卫报][1] 上发表的一份图表,这个估值超过 190 亿英镑(260 亿美元)的行业,即使是最重要的科学研究方面,至今其系统在选题、出版甚至分享方面仍受限于印刷媒介的诸多限制。全新的数字时代科技展现了一个巨大机遇,可以加速探索、推动科学协作而非竞争,以及将投入从基础建设导向有益于社会的研究。
+
+非盈利性的 [eLife 倡议][2] 是由研究资金赞助方建立,旨在通过使用数字或者开源技术来走出上述僵局。除了为生命科学和生物医疗方面的重大成就出版开放式获取的期刊,eLife 已将自己变成了一个在研究交流方面的实验和展示创新的平台 —— 而大部分的实验都是基于开源精神的。
+
+致力于开放出版基础设施项目给予我们加速接触、采用科学技术、提升用户体验的机会。我们认为这种机会对于推动学术出版行业是重要的。大而化之地说,开源产品的用户体验经常是有待开发的,而有时候这种情况会阻止其他人去使用它。作为我们在 OSS(开源软件)开发中投入的一部分,为了鼓励更多用户使用这些产品,我们十分注重用户体验。
+
+我们所有的代码都是开源的,并且我们也积极鼓励社区参与进我们的项目中。这对我们来说意味着更快的迭代、更多的实验、更大的透明度,同时也拓宽了我们工作的外延。
+
+我们现在参与的项目,例如 Libero (之前称作 [eLife Continuum][3])和 [可重现文档栈][4] 的开发,以及我们最近和 [Hypothesis][5] 的合作,展示了 OSS 是如何在评估、出版以及新发现的沟通方面带来正面影响的。
+
+### Libero
+
+Libero 是面向出版商的服务及应用套餐,它包括一个后期制作出版系统、整套前端用户界面样式套件、Libero 的镜头阅读器、一个 Open API 以及一个搜索及推荐引擎。
+
+去年我们采取了用户驱动的方式重新设计了 Libero 的前端,可以使用户较少地分心于网站的“陈设”,而是更多地集中关注于研究文章上。我们和 eLife 社区成员测试并迭代了该站点所有的核心功能,以确保给所有人最好的阅读体验。该网站的新 API 也为机器阅读能力提供了更简单的访问途径,其中包括文本挖掘、机器学习以及在线应用开发。
+
+我们网站上的内容以及引领新设计的样式都是开源的,以鼓励 eLife 和其它想要使用它的出版商后续的产品开发。
+
+### 可重现文档栈
+
+在与 [Substance][6] 和 [Stencila][7] 的合作下,eLife 也参与了一个项目来创建可重现文档栈(RDS)—— 一个开放式的创作、编纂以及在线出版可重现的计算型手稿的工具栈。
+
+今天越来越多的研究人员能够通过 [R Markdown][8] 和 [Python][9] 等语言记录他们的计算实验。这些可以作为实验记录的重要部分,但是尽管它们可以独立于最终的研究文章或与之一同分享,但传统出版流程经常将它们视为次级内容。为了发表论文,使用这些语言的研究人员除了将他们的计算结果用图片的形式“扁平化”提交外别无他法。但是这导致了许多实验价值和代码和计算数据可重复利用性的流失。诸如 [Jupyter][10] 这样的电子笔记本解决方案确实可以使研究员以一种可重复利用、可执行的简单形式发布,但是这种方案仍然是出版的手稿的补充,而不是不可或缺的一部分。
+
+[可重现文档栈][11] 项目旨在通过开发、发布一个可重现原稿的产品原型来解决这些挑战,该原型将代码和数据视为文档的组成部分,并展示了从创作到出版的完整端对端技术栈。它将最终允许用户以一种包含嵌入代码块和计算结果(统计结果、图表或图形)的形式提交他们的手稿,并在出版过程中保留这些可视、可执行的部分。那时出版商就可以将这些做为出版的在线文章的组成部分而保存。
+
+### 用 Hypothesis 进行开放式注解
+
+最近,我们与 [Hypothesis][12] 合作引进了开放式注解,使得我们网站的用户们可以写评语、高亮文章重要部分以及与在线阅读的群体互动。
+
+通过这样的合作,开源的 Hypothesis 软件被定制得更具有现代化的特性,如单次登录验证、用户界面定制,给予了出版商在他们自己网站上实现更多的控制。这些提升正引导着关于出版学术内容的高质量讨论。
+
+这个工具可以无缝集成到出版商的网站,学术出版平台 [PubFactory][13] 和内容解决方案供应商 [Ingenta][14] 已经利用了它优化后的特性集。[HighWire][15] 和 [Silverchair][16] 也为他们的出版商提供了实施这套方案的机会。
+
+### 其它产业和开源软件
+
+随着时间的推移,我们希望看到更多的出版商采用 Hypothesis、Libero 以及其它开源项目去帮助他们促进重要科学研究的发现以及循环利用。但是 eLife 的创新机遇也能被其它行业所利用,因为这些软件和其它 OSS 技术在其他行业也很普遍。
+
+数据科学的世界离不开高质量、良好支持的开源软件和围绕它们形成的社区;[TensorFlow][17] 就是这样一个好例子。感谢 OSS 以及其社区,AI 和机器学习的所有领域相比于计算机的其它领域的提升和发展更加迅猛。与之类似的是以 Linux 作为云端 Web 主机的爆炸性增长、接着是 Docker 容器、以及现在 GitHub 上最流行的开源项目之一的 Kubernetes 的增长。
+
+所有的这些技术使得机构们能够用更少的资源做更多的事情,并专注于创新而不是重新发明轮子上。最后,这就是 OSS 真正的好处:它使得我们从互相的失败中学习,在互相的成功中成长。
+
+我们总是在寻找与研究和科技界面方面最好的人才和想法交流的机会。你可以在 [eLife Labs][18] 上或者联系 [innovation@elifesciences.org][19] 找到更多这种交流的信息。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/3/scientific-publishing-software
+
+作者:[Paul Shanno][a]
+译者:[tomjlw](https://github.com/tomjlw)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/pshannon
+[1]:https://www.theguardian.com/science/2017/jun/27/profitable-business-scientific-publishing-bad-for-science
+[2]:https://elifesciences.org/about
+[3]:https://elifesciences.org/inside-elife/33e4127f/elife-introduces-continuum-a-new-open-source-tool-for-publishing
+[4]:https://elifesciences.org/for-the-press/e6038800/elife-supports-development-of-open-technology-stack-for-publishing-reproducible-manuscripts-online
+[5]:https://elifesciences.org/for-the-press/81d42f7d/elife-enhances-open-annotation-with-hypothesis-to-promote-scientific-discussion-online
+[6]:https://github.com/substance
+[7]:https://github.com/stencila/stencila
+[8]:https://rmarkdown.rstudio.com/
+[9]:https://www.python.org/
+[10]:http://jupyter.org/
+[11]:https://elifesciences.org/labs/7dbeb390/reproducible-document-stack-supporting-the-next-generation-research-article
+[12]:https://github.com/hypothesis
+[13]:http://www.pubfactory.com/
+[14]:http://www.ingenta.com/
+[15]:https://github.com/highwire
+[16]:https://www.silverchair.com/community/silverchair-universe/hypothesis/
+[17]:https://www.tensorflow.org/
+[18]:https://elifesciences.org/labs
+[19]:mailto:innovation@elifesciences.org
diff --git a/published/201903/20180314 Pi Day- 12 fun facts and ways to celebrate.md b/published/201903/20180314 Pi Day- 12 fun facts and ways to celebrate.md
new file mode 100644
index 0000000000..4c03a28074
--- /dev/null
+++ b/published/201903/20180314 Pi Day- 12 fun facts and ways to celebrate.md
@@ -0,0 +1,59 @@
+关于圆周率日的趣事与庆祝方式
+======
+
+> 技术团队喜欢 3 月 14 日的圆周率日:你是否知道这也是阿尔伯特·爱因斯坦的生日和 Linux 内核1.0.0 发布周年纪念日?来看一些树莓派的趣事和 DIY 项目。
+
+
+
+今天,全世界的技术团队都会为一个数字庆祝。3 月 14 日是圆周率日,人们会在这一天举行吃派比赛、披萨舞会,玩数学梗。如果这个数学领域中的重要常数不足以让 3 月 14 日成为一个节日的话,再加上爱因斯坦的生日、Linux 内核 1.0.0 发布的周年纪念日,莱伊·惠特尼在这一天申请了轧花机的专利这些原因,应该足够了吧。(LCTT译注:[轧花机](https://zh.wikipedia.org/wiki/%E8%BB%8B%E6%A3%89%E6%A9%9F)是一种快速而且简单地分开棉花纤维和种子的机器,生产力比人手分离高得多。)
+
+很荣幸,我们能在这一个特殊的日子里一起了解有关它的趣事和与 π 相关的好玩的活动。来吧,和你的团队一起庆祝圆周率日:找一两个点子来进行团队建设,或用新兴技术做一个项目。如果你有为这个大家所喜爱的无限小数庆祝的独特方式,请在评论区与大家分享。
+
+### 圆周率日的庆祝方法:
+
+ * 今天是圆周率日的第 31 次周年纪念(LCTT 译注:本文写于 2018 年的圆周率日,故在细节上存在出入。例如今天(2019 年 3 月 14 日)是圆周率日的第 31 次周年纪念)。第一次为它庆祝是在旧金山的探索博物馆由物理学家 Larry Shaw 举行。“在[第 1 次周年纪念日][1]当天,工作人员带来了水果派和茶壶来庆祝它。在 1 点 59 分(圆周率中紧接着 3.14 的数字),Shaw 在博物馆外领着队伍环馆一周。队伍中用扩音器播放着‘Pomp and Circumstance’。” 直到 21 年后,在 2009 年 3 月,圆周率正式成为了美国的法定假日。
+ * 虽然该纪念日起源于旧金山,可规模最大的庆祝活动却是在普林斯顿举行的,这个小镇举办了为期五天的[许多活动][2],包括爱因斯坦模仿比赛、掷派比赛,圆周率背诵比赛等等。其中的某些活动甚至会给获胜者提供价值 314.5 美元的奖金。
+ * 麻省理工的斯隆管理学院正在庆祝圆周率日。他们在 Twitter 上分享着关于 π 和派的圆周率日趣事,详情请关注推特话题 #PiVersusPie 。
+
+### 与圆周率有关的项目与活动:
+
+ * 如果你想锻炼你的数学技能,美国国家航空航天局(NASA)的喷气推进实验室(JPL)发布了[一系列新的数学问题][4],希望通过这些问题展现如何把圆周率用于空间探索。这也是美国国家航天局面向学生举办的第五届圆周率日挑战。
+ * 想要领略圆周率日的精神,最好的方法也许就是开展一个[树莓派][5]项目了,无论是和你的孩子还是和你的团队一起完成,都是不错的。树莓派作为一项从 2012 年开启的项目,现在已经售出了数百万块的基本型的电脑主板。事实上,它已经在[通用计算机畅销榜上排名第三][6]了。这里列举一些可能会吸引你的树莓派项目或活动:
+ * 来自谷歌的自己做 AI(AIY)项目让你自己创造一个[语音控制的数字助手][7]或者[一个图像识别设备][8]。
+ * 在树莓派上[使用 Kubernets][9]。
+ * 组装一台[怀旧游戏系统][10],目标:拯救桃子公主!
+ * 和你的团队举办一场[树莓派 Jam][11]。树莓派基金会发布了一个帮助大家顺利举办活动的[指导手册][12]。据该网站说明,树莓派 Jam 旨在“给数字创作中所有年龄段的人提供支持,让世界各地志同道合的人们汇聚起来讨论和分享他们的最新项目,举办讲习班,讨论和派相关的一切。”
+
+### 其他有关圆周率的事情:
+
+ * 当前背诵圆周率的[世界纪录保持者][13]是 Suresh Kumar Sharma,他在 2015 年 10 月花了 17 小时零 14 分钟背出了 70,030 位数字。然而,[非官方记录][14]的保持者 Akira Haraguchi 声称他可以背出 111,700 位数字。
+ * 现在,已知的圆周率数字的长度比以往都要多。在 2016 年 11 月,R&D 科学家 Peter Trueb 计算出了 22,459,157,718,361 位圆周率数字,比 2013 年的世界记录多了 [9 万亿数字][15]。据新科学家所述,“最终文件包含了圆周率的 22 万亿位数字,大小接近 9 TB。如果将其打印出来,能用数百万本 1000 页的书装满一整个图书馆。”
+
+祝你圆周率日快乐!
+
+--------------------------------------------------------------------------------
+
+via: https://enterprisersproject.com/article/2018/3/pi-day-12-fun-facts-and-ways-celebrate
+
+作者:[Carla Rudder][a]
+译者:[wwhio](https://github.com/wwhio)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://enterprisersproject.com/user/crudder
+[1]:https://www.exploratorium.edu/pi/pi-day-history
+[2]:https://princetontourcompany.com/activities/pi-day/
+[3]:https://twitter.com/MITSloan
+[4]:https://www.jpl.nasa.gov/news/news.php?feature=7074
+[5]:https://opensource.com/resources/raspberry-pi
+[6]:https://www.theverge.com/circuitbreaker/2017/3/17/14962170/raspberry-pi-sales-12-5-million-five-years-beats-commodore-64
+[7]:http://www.zdnet.com/article/raspberry-pi-this-google-kit-will-turn-your-pi-into-a-voice-controlled-digital-assistant/
+[8]:http://www.zdnet.com/article/google-offers-raspberry-pi-owners-this-new-ai-vision-kit-to-spot-cats-people-emotions/
+[9]:https://opensource.com/article/17/3/kubernetes-raspberry-pi
+[10]:https://opensource.com/article/18/1/retro-gaming
+[11]:https://opensource.com/article/17/5/how-run-raspberry-pi-meetup
+[12]:https://www.raspberrypi.org/blog/support-raspberry-jam-community/
+[13]:http://www.pi-world-ranking-list.com/index.php?page=lists&category=pi
+[14]:https://www.theguardian.com/science/alexs-adventures-in-numberland/2015/mar/13/pi-day-2015-memory-memorisation-world-record-japanese-akira-haraguchi
+[15]:https://www.newscientist.com/article/2124418-celebrate-pi-day-with-9-trillion-more-digits-than-ever-before/?utm_medium=Social&utm_campaign=Echobox&utm_source=Facebook&utm_term=Autofeed&cmpid=SOC%7CNSNS%7C2017-Echobox#link_time=1489480071
diff --git a/published/201903/20180329 Python ChatOps libraries- Opsdroid and Errbot.md b/published/201903/20180329 Python ChatOps libraries- Opsdroid and Errbot.md
new file mode 100644
index 0000000000..556eb95276
--- /dev/null
+++ b/published/201903/20180329 Python ChatOps libraries- Opsdroid and Errbot.md
@@ -0,0 +1,204 @@
+Python 的 ChatOps 库:Opsdroid 和 Errbot
+======
+
+> 学习一下 Python 世界里最广泛使用的 ChatOps 库:每个都能做什么,如何使用。
+
+
+
+ChatOps 是基于会话导向而进行的开发。其思路是你可以编写能够对聊天窗口中的某些输入进行回复的可执行代码。作为一个开发者,你能够用 ChatOps 从 Slack 合并拉取请求,自动从收到的 Facebook 消息中给某人分配支持工单,或者通过 IRC 检查开发状态。
+
+在 Python 世界,最为广泛使用的 ChatOps 库是 Opsdroid 和 Errbot。在这个月的 Python 专栏,让我们一起聊聊使用它们是怎样的体验,它们各自适用于什么方面以及如何着手使用它们。
+
+### Opsdroid
+
+[Opsdroid][2] 是一个相对年轻的(始于 2016)Python 开源聊天机器人库。它有着良好的开发文档,不错的教程,并且包含能够帮助你对接流行的聊天服务的插件。
+
+#### 它内置了什么
+
+库本身并没有自带所有你需要上手的东西,但这是故意的。轻量级的框架鼓励你去运用它现有的连接器(Opsdroid 所谓的帮你接入聊天服务的插件)或者去编写你自己的,但是它并不会因自带你所不需要的连接器而自贬身价。你可以轻松使用现有的 Opsdroid 连接器来接入:
+
++ 命令行
++ Cisco Spark
++ Facebook
++ GitHub
++ Matrix
++ Slack
++ Telegram
++ Twitter
++ Websocket
+
+Opsdroid 会调用使聊天机器人能够展现它们的“技能”的函数。这些技能其实是异步 Python 函数,并使用 Opsdroid 叫做“匹配器”的匹配装饰器。你可以设置你的 Opsdroid 项目,来使用同样从你设置文件所在的代码中的“技能”。你也可以从外面的公共或私人仓库调用这些“技能”。
+
+你同样可以启用一些现存的 Opsdroid “技能”,包括 [seen][3] —— 它会告诉你聊天机器人上次是什么时候看到某个用户的,以及 [weather][4] —— 会将天气报告给用户。
+
+最后,Opdroid 允许你使用现存的数据库模块设置数据库。现在 Opdroid 支持的数据库包括:
+
++ Mongo
++ Redis
++ SQLite
+
+你可以在你的 Opdroid 项目中的 `configuration.yaml` 文件设置数据库、技能和连接器。
+
+#### Opsdroid 的优势
+
+**Docker 支持:**从一开始 Opsdroid 就打算在 Docker 中良好运行。在 Docker 中的指导是它 [安装文档][5] 中的一部分。使用 Opsdroid 和 Docker Compose 也很简单:将 Opsdroid 设置成一种服务,当你运行 `docker-compose up` 时,你的 Opsdroid 服务将会开启你的聊天机器人也将就绪。
+
+```
+version: "3"
+
+services:
+ opsdroid:
+ container_name: opsdroid
+ build:
+ context: .
+ dockerfile: Dockerfile
+```
+
+**丰富的连接器:** Opsdroid 支持九种像 Slack 和 Github 等从外部接入的服务连接器。你所要做的一切就是在你的设置文件中启用那些连接器,然后把必须的口令或者 API 密匙传过去。比如为了启用 Opsdroid 以在一个叫做 `#updates` 的 Slack 频道发帖,你需要将以下代码加入你设置文件的 `connectors` 部分:
+
+```
+ - name: slack
+ api-token: "this-is-my-token"
+ default-room: "#updates"
+```
+
+在设置 Opsdroid 以接入 Slack 之前你需要[添加一个机器人用户][6]。
+
+如果你需要接入一个 Opsdroid 不支持的服务,在[文档][7]里有有添加你自己的连接器的教程。
+
+**相当不错的文档:** 特别是对于一个在积极开发中的新兴库来说,Opsdroid 的文档十分有帮助。这些文档包括一篇带你创建几个不同的基本技能的[教程][8]。Opsdroid 在[技能][9]、[连接器][7]、[数据库][10],以及[匹配器][11]方面的文档也十分清晰。
+
+它所支持的技能和连接器的仓库为它的技能提供了富有帮助的示范代码。
+
+**自然语言处理:** Opsdroid 的技能里面能使用正则表达式,但也同样提供了几个包括 [Dialogflow][12],[luis.ai][13],[Recast.AI][14] 以及 [wit.ai][15] 的 NLP API。
+
+#### Opsdroid 可能的不足
+
+Opsdroid 对它的一部分连接器还没有启用全部的特性。比如说,Slack API 允许你向你的消息添加颜色柱、图片以及其他的“附件”。Opsdroid Slack 连接器并没有启用“附件”特性,所以如果那些特性对你来说很重要的话,你需要编写一个自定义的 Slack 连接器。如果连接器缺少一个你需要的特性,Opsdroid 将欢迎你的[贡献][16]。文档中可以使用更多的例子,特别是对于预料到的使用场景。
+
+#### 示例用法
+
+```
+from opsdroid.matchers import match_regex
+import random
+
+
+@match_regex(r'hi|hello|hey|hallo')
+async def hello(opsdroid, config, message):
+ text = random.choice(["Hi {}", "Hello {}", "Hey {}"]).format(message.user)
+ await message.respond(text)
+```
+
+*hello/\_\_init\_\_.py*
+
+
+```
+connectors:
+ - name: websocket
+
+skills:
+ - name: hello
+ repo: "https://github.com//hello-skill"
+
+```
+
+*configuration.yaml*
+
+
+### Errbot
+
+[Errbot][17] 是一个功能齐全的开源聊天机器人。Errbot 发行于 2012 年,并且拥有人们从一个成熟的项目能期待的一切,包括良好的文档、优秀的教程以及许多帮你连入现有的流行聊天服务的插件。
+
+#### 它内置了什么
+
+不像采用了较轻量级方式的 Opsdroid,Errbot 自带了你需要可靠地创建一个自定义机器人的一切东西。
+
+Errbot 包括了对于本地 XMPP、IRC、Slack、Hipchat 以及 Telegram 服务的支持。它通过社区支持的后端列出了另外十种服务。
+
+#### Errbot 的优势
+
+**良好的文档:** Errbot 的文档成熟易读。
+
+**动态插件架构:** Errbot 允许你通过和聊天机器人交谈安全地安装、卸载、更新、启用以及禁用插件。这使得开发和添加特性十分简便。感谢 Errbot 的颗粒性授权系统,出于安全意识这所有的一切都可以被锁闭。
+
+当某个人输入 `!help`,Errbot 使用你的插件的文档字符串来为可获取的命令生成文档,这使得了解每行命令的作用更加简便。
+
+**内置的管理和安全特性:** Errbot 允许你限制拥有管理员权限的用户列表,甚至细粒度访问控制。比如说你可以限制特定用户或聊天房间访问特定命令。
+
+**额外的插件框架:** Errbot 支持钩子、回调、子命令、webhook、轮询以及其它[更多特性][18]。如果那些还不够,你甚至可以编写[动态插件][19]。当你需要基于在远程服务器上的可用命令来启用对应的聊天命令时,这个特性十分有用。
+
+**自带测试框架:** Errbot 支持 [pytest][20],同时也自带一些能使你简便测试插件的有用功能。它的“[测试你的插件][21]”的文档出于深思熟虑,并提供了足够的资料让你上手。
+
+#### Errbot 可能的不足
+
+**以 “!” 开头:** 默认情况下,Errbot 命令发出时以一个惊叹号打头(`!help` 以及 `!hello`)。一些人可能会喜欢这样,但是另一些人可能认为这让人烦恼。谢天谢地,这很容易关掉。
+
+**插件元数据** 首先,Errbot 的 [Hello World][22] 插件示例看上去易于使用。然而我无法加载我的插件,直到我进一步阅读了教程并发现我还需要一个 `.plug` 文档,这是一个 Errbot 用来加载插件的文档。这可能比较吹毛求疵了,但是在我深挖文档之前,这对我来说都不是显而易见的。
+
+### 示例用法
+
+
+```
+import random
+from errbot import BotPlugin, botcmd
+
+class Hello(BotPlugin):
+
+ @botcmd
+ def hello(self, msg, args):
+ text = random.choice(["Hi {}", "Hello {}", "Hey {}"]).format(message.user)
+ return text
+```
+
+*hello.py*
+
+```
+[Core]
+Name = Hello
+Module = hello
+
+[Python]
+Version = 2+
+
+[Documentation]
+Description = Example "Hello" plugin
+```
+
+*hello.plug*
+
+
+你用过 Errbot 或 Opsdroid 吗?如果用过请留下关于你对于这些工具印象的留言。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/3/python-chatops-libraries-opsdroid-and-errbot
+
+作者:[Jeff Triplett][a], [Lacey Williams Henschel][1]
+译者:[tomjlw](https://github.com/tomjlw)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/laceynwilliams
+[1]:https://opensource.com/users/laceynwilliams
+[2]:https://opsdroid.github.io/
+[3]:https://github.com/opsdroid/skill-seen
+[4]:https://github.com/opsdroid/skill-weather
+[5]:https://opsdroid.readthedocs.io/en/stable/#docker
+[6]:https://api.slack.com/bot-users
+[7]:https://opsdroid.readthedocs.io/en/stable/extending/connectors/
+[8]:https://opsdroid.readthedocs.io/en/stable/tutorials/introduction/
+[9]:https://opsdroid.readthedocs.io/en/stable/extending/skills/
+[10]:https://opsdroid.readthedocs.io/en/stable/extending/databases/
+[11]:https://opsdroid.readthedocs.io/en/stable/matchers/overview/
+[12]:https://opsdroid.readthedocs.io/en/stable/matchers/dialogflow/
+[13]:https://opsdroid.readthedocs.io/en/stable/matchers/luis.ai/
+[14]:https://opsdroid.readthedocs.io/en/stable/matchers/recast.ai/
+[15]:https://opsdroid.readthedocs.io/en/stable/matchers/wit.ai/
+[16]:https://opsdroid.readthedocs.io/en/stable/contributing/
+[17]:http://errbot.io/en/latest/
+[18]:http://errbot.io/en/latest/features.html#extensive-plugin-framework
+[19]:http://errbot.io/en/latest/user_guide/plugin_development/dynaplugs.html
+[20]:http://pytest.org/
+[21]:http://errbot.io/en/latest/user_guide/plugin_development/testing.html
+[22]:http://errbot.io/en/latest/index.html#simple-to-build-upon
diff --git a/published/201903/20180330 Asynchronous rsync with Emacs, dired and tramp..md b/published/201903/20180330 Asynchronous rsync with Emacs, dired and tramp..md
new file mode 100644
index 0000000000..5091e14afb
--- /dev/null
+++ b/published/201903/20180330 Asynchronous rsync with Emacs, dired and tramp..md
@@ -0,0 +1,77 @@
+[#]: collector: (lujun9972)
+[#]: translator: (lujun9972)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10639-1.html)
+[#]: subject: (Asynchronous rsync with Emacs,dired and tramp。)
+[#]: via: (https://vxlabs.com/2018/03/30/asynchronous-rsync-with-emacs-dired-and-tramp/)
+[#]: author: (cpbotha https://vxlabs.com/author/cpbotha/)
+
+在 Emacs 的 dired 和 tramp 中异步运行 rsync
+======
+
+[Trần Xuân Trường][2] 写的 [tmtxt-dired-async][1] 是一个不为人知的 Emacs 包,它可以扩展 dired(Emacs 内置的文件管理器),使之可以异步地运行 `rsync` 和其他命令 (例如压缩、解压缩和下载)。
+
+这意味着你可以拷贝上 GB 的目录而不影响 Emacs 的其他任务。
+
+它的一个功能时让你可以通过 `C-c C-a` 从不同位置添加任意多的文件到一个等待列表中,然后按下 `C-c C-v` 异步地使用 `rsync` 将整个等待列表中的文件同步到目标目录中。光这个功能就值得一试了。
+
+例如这里将 arduino 1.9 的 beta 存档同步到另一个目录中:
+
+![][4]
+
+整个进度完成后,底部的窗口会在 5 秒后自动退出。下面是异步解压上面的 arduino 存档后出现的另一个会话:
+
+![][6]
+
+这个包进一步增加了我 dired 配置的实用性。
+
+我刚刚贡献了 [一个拉取请求来允许 tmtxt-dired-async 同步到远程 tramp 目录中][7],而且我立即使用该功能来将上 GB 的新照片传输到 Linux 服务器上。
+
+若你想配置 tmtxt-dired-async,下载 [tmtxt-async-tasks.el][8](被依赖的库)以及 [tmtxt-dired-async.el][9](若你想让它支持 tramp,请确保合并使用了我的拉取请求)到 `~/.emacs.d/` 目录中,然后添加下面配置:
+
+```
+;; no MELPA packages of this, so we have to do a simple check here
+(setq dired-async-el (expand-file-name "~/.emacs.d/tmtxt-dired-async.el"))
+(when (file-exists-p dired-async-el)
+ (load (expand-file-name "~/.emacs.d/tmtxt-async-tasks.el"))
+ (load dired-async-el)
+ (define-key dired-mode-map (kbd "C-c C-r") 'tda/rsync)
+ (define-key dired-mode-map (kbd "C-c C-z") 'tda/zip)
+ (define-key dired-mode-map (kbd "C-c C-u") 'tda/unzip)
+
+ (define-key dired-mode-map (kbd "C-c C-a") 'tda/rsync-multiple-mark-file)
+ (define-key dired-mode-map (kbd "C-c C-e") 'tda/rsync-multiple-empty-list)
+ (define-key dired-mode-map (kbd "C-c C-d") 'tda/rsync-multiple-remove-item)
+ (define-key dired-mode-map (kbd "C-c C-v") 'tda/rsync-multiple)
+
+ (define-key dired-mode-map (kbd "C-c C-s") 'tda/get-files-size)
+
+ (define-key dired-mode-map (kbd "C-c C-q") 'tda/download-to-current-dir))
+```
+
+祝你开心!
+
+
+--------------------------------------------------------------------------------
+
+via: https://vxlabs.com/2018/03/30/asynchronous-rsync-with-emacs-dired-and-tramp/
+
+作者:[cpbotha][a]
+选题:[lujun9972][b]
+译者:[lujun9972](https://github.com/lujun9972)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://vxlabs.com/author/cpbotha/
+[b]: https://github.com/lujun9972
+[1]: https://truongtx.me/tmtxt-dired-async.html
+[2]: https://truongtx.me/about.html
+[3]: https://i0.wp.com/vxlabs.com/wp-content/uploads/2018/03/rsync-arduino-zip.png?resize=660%2C340&ssl=1
+[4]: https://i0.wp.com/vxlabs.com/wp-content/uploads/2018/03/rsync-arduino-zip.png?ssl=1
+[5]: https://i1.wp.com/vxlabs.com/wp-content/uploads/2018/03/progress-window-5s.png?resize=660%2C310&ssl=1
+[6]: https://i1.wp.com/vxlabs.com/wp-content/uploads/2018/03/progress-window-5s.png?ssl=1
+[7]: https://github.com/tmtxt/tmtxt-dired-async/pull/6
+[8]: https://github.com/tmtxt/tmtxt-async-tasks
+[9]: https://github.com/tmtxt/tmtxt-dired-async
diff --git a/published/201903/20180629 How To Get Flatpak Apps And Games Built With OpenGL To Work With Proprietary Nvidia Graphics Drivers.md b/published/201903/20180629 How To Get Flatpak Apps And Games Built With OpenGL To Work With Proprietary Nvidia Graphics Drivers.md
new file mode 100644
index 0000000000..9c95bb2b81
--- /dev/null
+++ b/published/201903/20180629 How To Get Flatpak Apps And Games Built With OpenGL To Work With Proprietary Nvidia Graphics Drivers.md
@@ -0,0 +1,120 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How To Get Flatpak Apps And Games Built With OpenGL To Work With Proprietary Nvidia Graphics Drivers)
+[#]: via: (https://www.linuxuprising.com/2018/06/how-to-get-flatpak-apps-and-games-built.html)
+[#]: author: (Logix https://plus.google.com/118280394805678839070)
+
+如何使得支持 OpenGL 的 Flatpak 应用和游戏在专有 Nvidia 图形驱动下工作
+======
+> 一些支持 OpenGL 并打包为 Flatpak 的应用和游戏无法使用专有 Nvidia 驱动启动。本文将介绍如何在不安装开源驱动(Nouveau)的情况下启动这些 Flatpak 应用或游戏。
+
+
+
+这有个例子。我在我的 Ubuntu 18.04 桌面上使用专有的 Nvidia 驱动程序 (`nvidia-driver-390`),当我尝试启动以 Flatpak 形式安装的最新版本 [Krita 4.1][2] (构建了 OpenGL 支持)时,显示了如下错误:
+
+```
+$ /usr/bin/flatpak run --branch=stable --arch=x86_64 --command=krita --file-forwarding org.kde.krita
+Gtk-Message: Failed to load module "canberra-gtk-module"
+Gtk-Message: Failed to load module "canberra-gtk-module"
+libGL error: No matching fbConfigs or visuals found
+libGL error: failed to load driver: swrast
+Could not initialize GLX
+```
+
+[Winepak][3] 游戏(以 Flatpak 方式打包的绑定了 Wine 的 Windows 游戏)似乎也受到了这个问题的影响,这个问题从 2016 年出现至今。
+
+要修复使用 OpenGL 和专有 Nvidia 图形驱动时无法启动的 Flatpak 游戏和应用的问题,你需要为已安装的专有驱动安装一个运行时环境。以下是步骤。
+
+1、如果尚未添加 FlatHub 仓库,请添加它。你可以在[此处][1]找到针对 Linux 发行版的说明。
+
+2、现在,你需要确定系统上安装的专有 Nvidia 驱动的确切版本。
+
+_这一步取决于你使用的 Linux 发行版,我无法涵盖所有情况。下面的说明是面向 Ubuntu(以及 Ubuntu 风格的版本),但希望你可以自己弄清楚系统上安装的 Nvidia 驱动版本。_
+
+要在 Ubuntu 中执行此操作,请打开 “软件与更新”,切换到 “附加驱动” 选项卡并记下 Nvidia 驱动包的名称。
+
+比如,你可以看到我的是 “nvidia-driver-390”:
+
+
+
+这里还没完成。我们只是找到了 Nvidia 驱动的主要版本,但我们还需要知道次要版本。要获得我们下一步所需的确切 Nvidia 驱动版本,请运行此命令(应该适用于任何基于 Debian 的 Linux 发行版,如 Ubuntu、Linux Mint 等):
+
+```
+apt-cache policy NVIDIA-PACKAGE-NAME
+```
+
+这里的 “NVIDIA-PACKAGE-NAME” 是 “软件与更新” 中列出的 Nvidia 驱动包名称。例如,要查看 “nvidia-driver-390” 包的确切安装版本,请运行以下命令:
+
+```
+$ apt-cache policy nvidia-driver-390
+nvidia-driver-390:
+ Installed: 390.48-0ubuntu3
+ Candidate: 390.48-0ubuntu3
+ Version table:
+ *** 390.48-0ubuntu3 500
+ 500 http://ro.archive.ubuntu.com/ubuntu bionic/restricted amd64 Packages
+ 100 /var/lib/dpkg/status
+```
+
+在这个命令的输出中,查找 “Installed” 部分并记下版本号(不包括 “-0ubuntu3” 之类)。现在我们知道了已安装的 Nvidia 驱动的确切版本(我例子中的是 “390.48”)。记住它,因为下一步我们需要。
+
+3、最后,你可以从 FlatHub 为你已安装的专有 Nvidia 图形驱动安装运行时环境。
+
+要列出 FlatHub 上所有可用的 Nvidia 运行时包,你可以使用以下命令:
+
+```
+flatpak remote-ls flathub | grep nvidia
+```
+
+幸运地是 FlatHub 上提供这个 Nvidia 驱动的运行时环境。你现在可以使用以下命令继续安装运行时:
+
+针对 64 位系统:
+
+```
+flatpak install flathub org.freedesktop.Platform.GL.nvidia-MAJORVERSION-MINORVERSION
+```
+
+将 “MAJORVERSION” 替换为 Nvidia 驱动的主要版本(在上面的示例中为 390),将 “MINORVERSION” 替换为次要版本(步骤2,我例子中的为 48)。
+
+例如,要为 Nvidia 图形驱动版本 390.48 安装运行时,你必须使用以下命令:
+
+```
+flatpak install flathub org.freedesktop.Platform.GL.nvidia-390-48
+```
+
+对于 32 位系统(或能够在 64 位上运行 32 位的应用或游戏),使用以下命令安装 32 位运行时:
+
+```
+flatpak install flathub org.freedesktop.Platform.GL32.nvidia-MAJORVERSION-MINORVERSION
+```
+
+再说一次,将 “MAJORVERSION” 替换为 Nvidia 驱动的主要版本(在上面的示例中为 390),将 “MINORVERSION” 替换为次要版本(步骤2,我例子中的为 48)。
+
+比如,要为 Nvidia 图形驱动版本 390.48 安装 32 位运行时,你需要使用以下命令:
+
+```
+flatpak install flathub org.freedesktop.Platform.GL32.nvidia-390-48
+```
+
+以上就是你要运行支持 OpenGL 的 Flatpak 的应用或游戏的方法。
+
+--------------------------------------------------------------------------------
+
+via: https://www.linuxuprising.com/2018/06/how-to-get-flatpak-apps-and-games-built.html
+
+作者:[Logix][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://plus.google.com/118280394805678839070
+[1]:https://flatpak.org/setup/
+[2]:https://www.linuxuprising.com/2018/06/free-painting-software-krita-410.html
+[3]:https://www.linuxuprising.com/2018/06/winepak-is-flatpak-repository-for.html
+[4]:https://github.com/winepak/applications/issues/23
+[5]:https://github.com/flatpak/flatpak/issues/138
diff --git a/published/201903/20180719 Building tiny container images.md b/published/201903/20180719 Building tiny container images.md
new file mode 100644
index 0000000000..833da1ecd0
--- /dev/null
+++ b/published/201903/20180719 Building tiny container images.md
@@ -0,0 +1,283 @@
+如何打造更小巧的容器镜像
+======
+> 五种优化 Linux 容器大小和构建更小的镜像的方法。
+
+
+
+[Docker][1] 近几年的爆炸性发展让大家逐渐了解到容器和容器镜像的概念。尽管 Linux 容器技术在很早之前就已经出现,但这项技术近来的蓬勃发展却还是要归功于 Docker 对用户友好的命令行界面以及使用 Dockerfile 格式轻松构建镜像的方式。纵然 Docker 大大降低了入门容器技术的难度,但构建一个兼具功能强大、体积小巧的容器镜像的过程中,有很多技巧需要了解。
+
+### 第一步:清理不必要的文件
+
+这一步和在普通服务器上清理文件没有太大的区别,而且要清理得更加仔细。一个小体积的容器镜像在传输方面有很大的优势,同时,在磁盘上存储不必要的数据的多个副本也是对资源的一种浪费。因此,这些技术对于容器来说应该比有大量专用内存的服务器更加需要。
+
+清理容器镜像中的缓存文件可以有效缩小镜像体积。下面的对比是使用 `dnf` 安装 [Nginx][2] 构建的镜像,分别是清理和没有清理 yum 缓存文件的结果:
+
+```
+# Dockerfile with cache
+FROM fedora:28
+LABEL maintainer Chris Collins
+
+RUN dnf install -y nginx
+
+-----
+
+# Dockerfile w/o cache
+FROM fedora:28
+LABEL maintainer Chris Collins
+
+RUN dnf install -y nginx \
+ && dnf clean all \
+ && rm -rf /var/cache/yum
+
+-----
+
+[chris@krang] $ docker build -t cache -f Dockerfile .
+[chris@krang] $ docker images --format "{{.Repository}}: {{.Size}}"
+| head -n 1
+cache: 464 MB
+
+[chris@krang] $ docker build -t no-cache -f Dockerfile-wo-cache .
+[chris@krang] $ docker images --format "{{.Repository}}: {{.Size}}" | head -n 1
+no-cache: 271 MB
+```
+
+从上面的结果来看,清理缓存文件的效果相当显著。和清除了元数据和缓存文件的容器镜像相比,不清除的镜像体积接近前者的两倍。除此以外,包管理器缓存文件、Ruby gem 的临时文件、nodejs 缓存文件,甚至是下载的源码 tarball 最好都全部清理掉。
+
+### 层:一个潜在的隐患
+
+很不幸(当你往下读,你会发现这是不幸中的万幸),根据容器中的层的概念,不能简单地向 Dockerfile 中写一句 `RUN rm -rf /var/cache/yum` 就完事儿了。因为 Dockerfile 的每一条命令都以一个层的形式存储,并一层层地叠加。所以,如果你是这样写的:
+
+```
+RUN dnf install -y nginx
+RUN dnf clean all
+RUN rm -rf /var/cache/yum
+```
+
+你的容器镜像就会包含三层,而 `RUN dnf install -y nginx` 这一层仍然会保留着那些缓存文件,然后在另外两层中被移除。但缓存实际上仍然是存在的,当你把一个文件系统挂载在另外一个文件系统之上时,文件仍然在那里,只不过你见不到也访问不到它们而已。
+
+在上一节的示例中,你会看到正确的做法是将几条命令链接起来,在产生缓存文件的同一条 Dockerfile 指令里把缓存文件清理掉:
+
+```
+RUN dnf install -y nginx \
+ && dnf clean all \
+ && rm -rf /var/cache/yum
+```
+
+这样就把几条命令连成了一条命令,在最终的镜像中只占用一个层。这样只会浪费一点缓存的好处,稍微多耗费一点点构建容器镜像的时间,但被清理掉的缓存文件就不会留存在最终的镜像中了。作为一个折衷方法,只需要把一些相关的命令(例如 `yum install` 和 `yum clean all`、下载文件、解压文件、移除 tarball 等等)连接成一个命令,就可以在最终的容器镜像中节省出大量体积,你也能够利用 Docker 的缓存加快开发速度。
+
+层还有一个更隐蔽的特性。每一层都记录了文件的更改,这里的更改并不仅仅已有的文件累加起来,而是包括文件属性在内的所有更改。因此即使是对文件使用了 `chmod` 操作也会被在新的层创建文件的副本。
+
+下面是一次 `docker images` 命令的输出内容。其中容器镜像 `layer_test_1` 是在 CentOS 基础镜像中增加了一个 1GB 大小的文件后构建出来的镜像,而容器镜像 `layer_test_2` 是使用了 `FROM layer_test_1` 语句创建出来的,除了执行一条 `chmod u+x` 命令没有做任何改变。
+
+```
+layer_test_2 latest e11b5e58e2fc 7 seconds ago 2.35 GB
+layer_test_1 latest 6eca792a4ebe 2 minutes ago 1.27 GB
+```
+
+如你所见,`layer_test_2` 镜像比 `layer_test_1` 镜像大了 1GB 以上。尽管事实上 `layer_test_1` 只是 `layer_test_2` 的前一层,但隐藏在这第二层中有一个额外的 1GB 的文件。在构建容器镜像的过程中,如果在单独一层中进行移动、更改、删除文件,都会出现类似的结果。
+
+### 专用镜像和公用镜像
+
+有这么一个亲身经历:我们部门重度依赖于 [Ruby on Rails][3],于是我们开始使用容器。一开始我们就建立了一个正式的 Ruby 的基础镜像供所有的团队使用,为了简单起见(以及在“这就是我们自己在服务器上瞎鼓捣的”想法的指导下),我们使用 [rbenv][4] 将 Ruby 最新的 4 个版本都安装到了这个镜像当中,目的是让开发人员只用这个单一的镜像就可以将使用不同版本 Ruby 的应用程序迁移到容器中。我们当时还认为这是一个虽然非常大但兼容性相当好的镜像,因为这个镜像可以同时满足各个团队的使用。
+
+实际上这是费力不讨好的。如果维护独立的、版本略微不同的镜像中,可以很轻松地实现镜像的自动化维护。同时,选择特定版本的特定镜像,还有助于在引入破坏性改变,在应用程序接近生命周期结束前提前做好预防措施,以免产生不可控的后果。庞大的公用镜像也会对资源造成浪费,当我们后来将这个庞大的镜像按照 Ruby 版本进行拆分之后,我们最终得到了共享一个基础镜像的多个镜像,如果它们都放在一个服务器上,会额外多占用一点空间,但是要比安装了多个版本的巨型镜像要小得多。
+
+这个例子也不是说构建一个灵活的镜像是没用的,但仅对于这个例子来说,从一个公共镜像创建根据用途而构建的镜像最终将节省存储资源和维护成本,而在受益于公共基础镜像的好处的同时,每个团队也能够根据需要来做定制化的配置。
+
+### 从零开始:将你需要的内容添加到空白镜像中
+
+有一些和 Dockerfile 一样易用的工具可以轻松创建非常小的兼容 Docker 的容器镜像,这些镜像甚至不需要包含一个完整的操作系统,就可以像标准的 Docker 基础镜像一样小。
+
+我曾经写过一篇[关于 Buildah 的文章][5],我想在这里再一次推荐一下这个工具。因为它足够的灵活,可以使用宿主机上的工具来操作一个空白镜像并安装打包好的应用程序,而且这些工具不会被包含到镜像当中。
+
+Buildah 取代了 `docker build` 命令。可以使用 Buildah 将容器的文件系统挂载到宿主机上并进行交互。
+
+下面来使用 Buildah 实现上文中 Nginx 的例子(现在忽略了缓存的处理):
+
+```
+#!/usr/bin/env bash
+set -o errexit
+
+# Create a container
+container=$(buildah from scratch)
+
+# Mount the container filesystem
+mountpoint=$(buildah mount $container)
+
+# Install a basic filesystem and minimal set of packages, and nginx
+dnf install --installroot $mountpoint --releasever 28 glibc-minimal-langpack nginx --setopt install_weak_deps=false -y
+
+# Save the container to an image
+buildah commit --format docker $container nginx
+
+# Cleanup
+buildah unmount $container
+
+# Push the image to the Docker daemon’s storage
+buildah push nginx:latest docker-daemon:nginx:latest
+
+```
+
+你会发现这里使用的已经不再是 Dockerfile 了,而是普通的 Bash 脚本,而且是从框架(或空白)镜像开始构建的。上面这段 Bash 脚本将容器的根文件系统挂载到了宿主机上,然后使用宿主机的命令来安装应用程序,这样的话就不需要把软件包管理器放置到容器镜像中了。
+
+这样所有无关的内容(基础镜像之外的部分,例如 `dnf`)就不再会包含在镜像中了。在这个例子当中,构建出来的镜像大小只有 304 MB,比使用 Dockerfile 构建的镜像减少了 100 MB 以上。
+
+```
+[chris@krang] $ docker images |grep nginx
+docker.io/nginx buildah 2505d3597457 4 minutes ago 304 MB
+```
+
+注:这个镜像是使用上面的构建脚本构建的,镜像名称中前缀的 `docker.io` 只是在推送到镜像仓库时加上的。
+
+对于一个 300MB 级别的容器基础镜像来说,能缩小 100MB 已经是很显著的节省了。使用软件包管理器来安装 Nginx 会带来大量的依赖项,如果能够使用宿主机直接从源代码对应用程序进行编译然后构建到容器镜像中,节省出来的空间还可以更多,因为这个时候可以精细的选用必要的依赖项,非必要的依赖项一概不构建到镜像中。
+
+[Tom Sweeney][6] 有一篇文章《[用 Buildah 构建更小的容器][7]》,如果你想在这方面做深入的优化,不妨参考一下。
+
+通过 Buildah 可以构建一个不包含完整操作系统和代码编译工具的容器镜像,大幅缩减了容器镜像的体积。对于某些类型的镜像,我们可以进一步采用这种方式,创建一个只包含应用程序本身的镜像。
+
+### 使用静态链接的二进制文件来构建镜像
+
+按照这个思路,我们甚至可以更进一步舍弃容器内部的管理和构建工具。例如,如果我们足够专业,不需要在容器中进行排错调试,是不是可以不要 Bash 了?是不是可以不要 [GNU 核心套件][8]了?是不是可以不要 Linux 基础文件系统了?如果你使用的编译型语言支持[静态链接库][9],将应用程序所需要的所有库和函数都编译成二进制文件,那么程序所需要的函数和库都可以复制和存储在二进制文件本身里面。
+
+这种做法在 [Golang][10] 社区中已经十分常见,下面我们使用由 Go 语言编写的应用程序进行展示:
+
+以下这个 Dockerfile 基于 golang:1.8 镜像构建一个小的 Hello World 应用程序镜像:
+
+```
+FROM golang:1.8
+
+ENV GOOS=linux
+ENV appdir=/go/src/gohelloworld
+
+COPY ./ /go/src/goHelloWorld
+WORKDIR /go/src/goHelloWorld
+
+RUN go get
+RUN go build -o /goHelloWorld -a
+
+CMD ["/goHelloWorld"]
+```
+
+构建出来的镜像中包含了二进制文件、源代码以及基础镜像层,一共 716MB。但对于应用程序运行唯一必要的只有编译后的二进制文件,其余内容在镜像中都是多余的。
+
+如果在编译的时候通过指定参数 `CGO_ENABLED=0` 来禁用 `cgo`,就可以在编译二进制文件的时候忽略某些函数的 C 语言库:
+
+```
+GOOS=linux CGO_ENABLED=0 go build -a goHelloWorld.go
+```
+
+编译出来的二进制文件可以加到一个空白(或框架)镜像:
+
+```
+FROM scratch
+COPY goHelloWorld /
+CMD ["/goHelloWorld"]
+```
+
+来看一下两次构建的镜像对比:
+
+```
+[ chris@krang ] $ docker images
+REPOSITORY TAG IMAGE ID CREATED SIZE
+goHello scratch a5881650d6e9 13 seconds ago 1.55 MB
+goHello builder 980290a100db 14 seconds ago 716 MB
+```
+
+从镜像体积来说简直是天差地别了。基于 golang:1.8 镜像构建出来带有 goHelloWorld 二进制的镜像(带有 `builder` 标签)体积是基于空白镜像构建的只包含该二进制文件的镜像的 460 倍!后者的整个镜像大小只有 1.55MB,也就是说,有 713MB 的数据都是非必要的。
+
+正如上面提到的,这种缩减镜像体积的方式在 Golang 社区非常流行,因此不乏这方面的文章。[Kelsey Hightower][11] 有一篇[文章][12]专门介绍了如何处理这些库的依赖关系。
+
+### 压缩镜像层
+
+除了前面几节中讲到的将多个命令链接成一个命令的技巧,还可以对镜像进行压缩。镜像压缩的实质是导出它,删除掉镜像构建过程中的所有中间层,然后保存镜像的当前状态为单个镜像层。这样可以进一步将镜像缩小到更小的体积。
+
+在 Docker 1.13 之前,压缩镜像层的的过程可能比较麻烦,需要用到 `docker-squash` 之类的工具来导出容器的内容并重新导入成一个单层的镜像。但 Docker 在 Docker 1.13 中引入了 `--squash` 参数,可以在构建过程中实现同样的功能:
+
+```
+FROM fedora:28
+LABEL maintainer Chris Collins
+
+RUN dnf install -y nginx
+RUN dnf clean all
+RUN rm -rf /var/cache/yum
+
+[chris@krang] $ docker build -t squash -f Dockerfile-squash --squash .
+[chris@krang] $ docker images --format "{{.Repository}}: {{.Size}}" | head -n 1
+squash: 271 MB
+```
+
+通过这种方式使用 Dockerfile 构建出来的镜像有 271MB 大小,和上面连接多条命令的方案构建出来的镜像体积一样,因此这个方案也是有效的,但也有一个潜在的问题,而且是另一种问题。
+
+“什么?还有另外的问题?”
+
+好吧,有点像以前一样的问题,以另一种方式引发了问题。
+
+### 过头了:过度压缩、太小太专用了
+
+容器镜像之间可以共享镜像层。基础镜像或许大小上有几 Mb,但它只需要拉取/存储一次,并且每个镜像都能复用它。所有共享基础镜像的实际镜像大小是基础镜像层加上每个特定改变的层的差异内容,因此,如果有数千个基于同一个基础镜像的容器镜像,其体积之和也有可能只比一个基础镜像大不了多少。
+
+因此,这就是过度使用压缩或专用镜像层的缺点。将不同镜像压缩成单个镜像层,各个容器镜像之间就没有可以共享的镜像层了,每个容器镜像都会占有单独的体积。如果你只需要维护少数几个容器镜像来运行很多容器,这个问题可以忽略不计;但如果你要维护的容器镜像很多,从长远来看,就会耗费大量的存储空间。
+
+回顾上面 Nginx 压缩的例子,我们能看出来这种情况并不是什么大的问题。在这个镜像中,有 Fedora 操作系统和 Nginx 应用程序,没有缓存,并且已经被压缩。但我们一般不会使用一个原始的 Nginx,而是会修改配置文件,以及引入其它代码或应用程序来配合 Nginx 使用,而要做到这些,Dockerfile 就变得更加复杂了。
+
+如果使用普通的镜像构建方式,构建出来的容器镜像就会带有 Fedora 操作系统的镜像层、一个安装了 Nginx 的镜像层(带或不带缓存)、为 Nginx 作自定义配置的其它多个镜像层,而如果有其它容器镜像需要用到 Fedora 或者 Nginx,就可以复用这个容器镜像的前两层。
+
+```
+[ App 1 Layer ( 5 MB) ] [ App 2 Layer (6 MB) ]
+[ Nginx Layer ( 21 MB) ] ------------------^
+[ Fedora Layer (249 MB) ]
+```
+
+如果使用压缩镜像层的构建方式,Fedora 操作系统会和 Nginx 以及其它配置内容都被压缩到同一层里面,如果有其它容器镜像需要使用到 Fedora,就必须重新引入 Fedora 基础镜像,这样每个容器镜像都会额外增加 249MB 的大小。
+
+```
+[ Fedora + Nginx + App 1 (275 MB)] [ Fedora + Nginx + App 2 (276 MB) ]
+```
+
+当你构建了大量在功能上趋于分化的的小型容器镜像时,这个问题就会暴露出来了。
+
+就像生活中的每一件事一样,关键是要做到适度。根据镜像层的实现原理,如果一个容器镜像变得越小、越专用化,就越难和其它容器镜像共享基础的镜像层,这样反而带来不好的效果。
+
+对于仅在基础镜像上做微小变动构建出来的多个容器镜像,可以考虑共享基础镜像层。如上所述,一个镜像层本身会带有一定的体积,但只要存在于镜像仓库中,就可以被其它容器镜像复用。这种情况下,数千个镜像也许要比单个镜像占用更少的空间。
+
+```
+[ specific app ] [ specific app 2 ]
+[ customizations ]--------------^
+[ base layer ]
+```
+
+一个容器镜像变得越小、越专用化,就越难和其它容器镜像共享基础的镜像层,最终会不必要地占用越来越多的存储空间。
+
+```
+ [ specific app 1 ] [ specific app 2 ] [ specific app 3 ]
+```
+
+### 总结
+
+减少处理容器镜像时所需的存储空间和带宽的方法有很多,其中最直接的方法就是减小容器镜像本身的大小。在使用容器的过程中,要经常留意容器镜像是否体积过大,根据不同的情况采用上述提到的清理缓存、压缩到一层、将二进制文件加入在空白镜像中等不同的方法,将容器镜像的体积缩减到一个有效的大小。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/7/building-container-images
+
+作者:[Chris Collins][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[HankChow](https://github.com/HankChow)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/clcollins
+[1]:https://www.docker.com/
+[2]:https://www.nginx.com/
+[3]:https://rubyonrails.org/
+[4]:https://github.com/rbenv/rbenv
+[5]:https://opensource.com/article/18/6/getting-started-buildah
+[6]:https://twitter.com/TSweeneyRedHat
+[7]:https://opensource.com/article/18/5/containers-buildah
+[8]:https://www.gnu.org/software/coreutils/coreutils.html
+[9]:https://en.wikipedia.org/wiki/Static_library
+[10]:https://golang.org/
+[11]:https://twitter.com/kelseyhightower
+[12]:https://medium.com/@kelseyhightower/optimizing-docker-images-for-static-binaries-b5696e26eb07
+
diff --git a/published/201903/20180826 Be productive with Org-mode.md b/published/201903/20180826 Be productive with Org-mode.md
new file mode 100644
index 0000000000..5eef4efd7b
--- /dev/null
+++ b/published/201903/20180826 Be productive with Org-mode.md
@@ -0,0 +1,194 @@
+[#]: collector: (lujun9972)
+[#]: translator: (lujun9972)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10634-1.html)
+[#]: subject: (Be productive with Org-mode)
+[#]: via: (https://www.badykov.com/emacs/2018/08/26/be-productive-with-org-mode/)
+[#]: author: (Ayrat Badykov https://www.badykov.com)
+
+高效使用 Org 模式
+======
+
+![org-mode-collage][1]
+
+### 简介
+
+在我 [前一篇关于 Emacs 的文章中][2] 我提到了 [Org 模式][3],这是一个笔记管理工具和组织工具。本文中,我将会描述一下我日常的 Org 模式使用案例。
+
+### 笔记和代办列表
+
+首先而且最重要的是,Org 模式是一个管理笔记和待办列表的工具,Org 模式的所有工具都聚焦于使用纯文本文件记录笔记。我使用 Org 模式管理多种笔记。
+
+#### 一般性笔记
+
+Org 模式最基本的应用场景就是以笔记的形式记录下你想记住的事情。比如,下面是我正在学习的笔记内容:
+
+```
+* Learn
+** Emacs LISP
+*** Plan
+
+ - [ ] Read best practices
+ - [ ] Finish reading Emacs Manual
+ - [ ] Finish Exercism Exercises
+ - [ ] Write a couple of simple plugins
+ - Notification plugin
+
+*** Resources
+
+ https://www.gnu.org/software/emacs/manual/html_node/elisp/index.html
+ http://exercism.io/languages/elisp/about
+ [[http://batsov.com/articles/2011/11/30/the-ultimate-collection-of-emacs-resources/][The Ultimate Collection of Emacs Resources]]
+
+** Rust gamedev
+*** Study [[https://github.com/SergiusIW/gate][gate]] 2d game engine with web assembly support
+*** [[ggez][https://github.com/ggez/ggez]]
+*** [[https://www.amethyst.rs/blog/release-0-8/][Amethyst 0.8 Relesed]]
+
+** Upgrade Elixir/Erlang Skills
+*** Read Erlang in Anger
+```
+
+借助 [org-bullets][4] 它看起来是这样的:
+
+![notes][5]
+
+在这个简单的例子中,你能看到 Org 模式的一些功能:
+
+- 笔记允许嵌套
+- 链接
+- 带复选框的列表
+
+#### 项目待办
+
+我在工作时时常会发现一些能够改进或修复的事情。我并不会在代码文件中留下 TODO 注释 (坏味道),相反我使用 [org-projectile][6] 来在另一个文件中记录一个 TODO 事项,并留下一个快捷方式。下面是一个该文件的例子:
+
+```
+* [[elisp:(org-projectile-open-project%20"mana")][mana]] [3/9]
+ :PROPERTIES:
+ :CATEGORY: mana
+ :END:
+** DONE [[file:~/Development/mana/apps/blockchain/lib/blockchain/contract/create_contract.ex::insufficient_gas_before_homestead%20=][fix this check using evm.configuration]]
+ CLOSED: [2018-08-08 Ср 09:14]
+ [[https://github.com/ethereum/EIPs/blob/master/EIPS/eip-2.md][eip2]]:
+ If contract creation does not have enough gas to pay for the final gas fee for
+ adding the contract code to the state, the contract creation fails (i.e. goes out-of-gas)
+ rather than leaving an empty contract.
+** DONE Upgrade Elixir to 1.7.
+ CLOSED: [2018-08-08 Ср 09:14]
+** TODO [#A] Difficulty tests
+** TODO [#C] Upgrage to OTP 21
+** DONE [#A] EIP150
+ CLOSED: [2018-08-14 Вт 21:25]
+*** DONE operation cost changes
+ CLOSED: [2018-08-08 Ср 20:31]
+*** DONE 1/64th for a call and create
+ CLOSED: [2018-08-14 Вт 21:25]
+** TODO [#C] Refactor interfaces
+** TODO [#B] Caching for storage during execution
+** TODO [#B] Removing old merkle trees
+** TODO do not calculate cost twice
+* [[elisp:(org-projectile-open-project%20".emacs.d")][.emacs.d]] [1/3]
+ :PROPERTIES:
+ :CATEGORY: .emacs.d
+ :END:
+** TODO fix flycheck issues (emacs config)
+** TODO use-package for fetching dependencies
+** DONE clean configuration
+ CLOSED: [2018-08-26 Вс 11:48]
+```
+
+它看起来是这样的:
+
+![project-todos][7]
+
+本例中你能看到更多的 Org 模式的功能:
+
+- 代办列表具有 `TODO`、`DONE` 两个状态。你还可以定义自己的状态 (`WAITING` 等)
+- 关闭的事项有 `CLOSED` 时间戳
+- 有些事项有优先级 - A、B、C
+- 链接可以指向文件内部 (`[[file:~/。..]`)
+
+#### 捕获模板
+
+正如 Org 模式的文档中所描述的,捕获可以在不怎么干扰你工作流的情况下让你快速存储笔记。
+
+我配置了许多捕获模板,可以帮我快速记录想要记住的事情。
+
+```
+ (setq org-capture-templates
+ '(("t" "Todo" entry (file+headline "~/Dropbox/org/todo.org" "Todo soon")
+ "* TODO %? \n %^t")
+ ("i" "Idea" entry (file+headline "~/Dropbox/org/ideas.org" "Ideas")
+ "* %? \n %U")
+ ("e" "Tweak" entry (file+headline "~/Dropbox/org/tweaks.org" "Tweaks")
+ "* %? \n %U")
+ ("l" "Learn" entry (file+headline "~/Dropbox/org/learn.org" "Learn")
+ "* %? \n")
+ ("w" "Work note" entry (file+headline "~/Dropbox/org/work.org" "Work")
+ "* %? \n")
+ ("m" "Check movie" entry (file+headline "~/Dropbox/org/check.org" "Movies")
+ "* %? %^g")
+ ("n" "Check book" entry (file+headline "~/Dropbox/org/check.org" "Books")
+ "* %^{book name} by %^{author} %^g")))
+```
+
+做书本记录时我需要记下它的名字和作者,做电影记录时我需要记下标签,等等。
+
+### 规划
+
+Org 模式的另一个超棒的功能是你可以用它来作日常规划。让我们来看一个例子:
+
+![schedule][8]
+
+我没有挖空心思虚构一个例子,这就是我现在真实文件的样子。它看起来内容并不多,但它有助于你花时间在在重要的事情上并且帮你对抗拖延症。
+
+#### 习惯
+
+根据 Org 模式的文档,Org 能够跟踪一种特殊的代办事情,称为 “习惯”。当我想养成新的习惯时,我会将该功能与日常规划功能一起连用:
+
+![habits][9]
+
+你可以看到,目前我在尝试每天早期并且每两天锻炼一次。另外,它也有助于让我每天阅读书籍。
+
+#### 议事日程视图
+
+最后,我还使用议事日程视图功能。待办事项可能分散在不同文件中(比如我就是日常规划和习惯分散在不同文件中),议事日程视图可以提供所有待办事项的总览:
+
+![agenda][10]
+
+### 更多 Org 模式的功能
+
++ 手机应用([Android](https://play.google.com/store/apps/details?id=com.orgzly&hl=en)、[ios](https://itunes.apple.com/app/id1238649962]))
++ [将 Org 模式文档导出为其他格式](https://orgmode.org/manual/Exporting.html)(html、markdown、pdf、latex 等)
++ 使用 [ledger](https://github.com/ledger/ledger-mode) [追踪财务状况](https://orgmode.org/worg/org-tutorials/weaving-a-budget.html)
+
+### 总结
+
+本文我描述了 Org 模式广泛功能中的一小部分,我每天都用它来提高工作效率,把时间花在重要的事情上。
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.badykov.com/emacs/2018/08/26/be-productive-with-org-mode/
+
+作者:[Ayrat Badykov][a]
+选题:[lujun9972][b]
+译者:[lujun9972](https://github.com/lujun9972)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.badykov.com
+[b]: https://github.com/lujun9972
+[1]: https://i.imgur.com/hgqCyen.jpg
+[2]: http://www.badykov.com/emacs/2018/07/31/why-emacs-is-a-great-editor/
+[3]: https://orgmode.org/
+[4]: https://github.com/sabof/org-bullets
+[5]: https://i.imgur.com/lGi60Uw.png
+[6]: https://github.com/IvanMalison/org-projectile
+[7]: https://i.imgur.com/Hbu8ilX.png
+[8]: https://i.imgur.com/z5HpuB0.png
+[9]: https://i.imgur.com/YJIp3d0.png
+[10]: https://i.imgur.com/CKX9BL9.png
diff --git a/published/201903/20180926 HTTP- Brief History of HTTP.md b/published/201903/20180926 HTTP- Brief History of HTTP.md
new file mode 100644
index 0000000000..5d95730284
--- /dev/null
+++ b/published/201903/20180926 HTTP- Brief History of HTTP.md
@@ -0,0 +1,246 @@
+[#]: collector: (lujun9972)
+[#]: translator: (MjSeven)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10621-1.html)
+[#]: subject: (HTTP: Brief History of HTTP)
+[#]: via: (https://hpbn.co/brief-history-of-http/#http-09-the-one-line-protocol)
+[#]: author: (Ilya Grigorik https://www.igvita.com/)
+
+HTTP 简史
+======
+
+译注:本文来源于 2013 年出版的《High Performance Browser Networking》的第九章,因此有些信息略有过时。事实上,现在 HTTP/2 已经有相当的不是,而新的 HTTP/3 也在设计和标准制定当中。
+
+### 介绍
+
+超文本传输协议(HTTP)是互联网上最普遍和广泛采用的应用程序协议之一。它是客户端和服务器之间的通用语言,支持现代 Web。从最初作为单个的关键字和文档路径开始,它已成为不仅仅是浏览器的首选协议,而且几乎是所有连接互联网硬件和软件应用程序的首选协议。
+
+在本文中,我们将简要回顾 HTTP 协议的发展历史。对 HTTP 不同语义的完整讨论超出了本文的范围,但理解 HTTP 的关键设计变更以及每个变更背后的动机将为我们讨论 HTTP 性能提供必要的背景,特别是在 HTTP/2 中即将进行的许多改进。
+
+### HTTP 0.9: 单行协议
+
+蒂姆·伯纳斯·李 最初的 HTTP 提案在设计时考虑到了简单性,以帮助他采用他的另一个新想法:万维网。这个策略看起来奏效了:注意,他是一个有抱负的协议设计者。
+
+1991 年,伯纳斯·李概述了这个新协议的动机,并列出了几个高级设计目标:文件传输功能、请求超文档存档索引搜索的能力,格式协商以及将客户端引用到另一个服务器的能力。为了证明该理论的实际应用,构建了一个简单原型,它实现了所提议功能的一小部分。
+
+ * 客户端请求是一个 ASCII 字符串。
+ * 客户端请求以回车符(CRLF)终止。
+ * 服务器响应是 ASCII 字符流。
+ * 服务器响应是一种超文本标记语言(HTML)。
+ * 文档传输完成后连接终止。
+
+然而,即使这听起来也比实际复杂得多。这些规则支持的是一种非常简单的,对 Telnet 友好的协议,一些 Web 服务器至今仍然支持这种协议:
+
+```
+$> telnet google.com 80
+
+Connected to 74.125.xxx.xxx
+
+GET /about/
+
+(hypertext response)
+(connection closed)
+```
+
+请求包含这样一行:`GET` 方法和请求文档的路径。响应是一个超文本文档,没有标题或任何其他元数据,只有 HTML。真的是再简单不过了。此外,由于之前的交互是预期协议的子集,因此它获得了一个非官方的 HTTP 0.9 标签。其余的,就像他们所说的,都是历史。
+
+从 1991 年这些不起眼的开始,HTTP 就有了自己的生命,并在接下来几年里迅速发展。让我们快速回顾一下 HTTP 0.9 的特性:
+
+ * 采用客户端-服务器架构,是一种请求-响应协议。
+ * 采用 ASCII 协议,运行在 TCP/IP 链路上。
+ * 旨在传输超文本文档(HTML)。
+ * 每次请求后,服务器和客户端之间的连接都将关闭。
+
+> 流行的 Web 服务器,如 Apache 和 Nginx,仍然支持 HTTP 0.9 协议,部分原因是因为它没有太多功能!如果你感兴趣,打开 Telnet 会话并尝试通过 HTTP 0.9 访问 google.com 或你最喜欢的网站,并检查早期协议的行为和限制。
+
+### HTTP/1.0: 快速增长和 Informational RFC
+
+1991 年至 1995 年期间,HTML 规范和一种称为 “web 浏览器”的新型软件快速发展,面向消费者的公共互联网基础设施也开始出现并快速增长。
+
+> **完美风暴:1990 年代初的互联网热潮**
+
+> 基于蒂姆·伯纳斯·李最初的浏览器原型,美国国家超级计算机应用中心(NCSA)的一个团队决定实现他们自己的版本。就这样,第一个流行的浏览器诞生了:NCSA Mosaic。1994 年 10 月,NCSA 团队的一名程序员 Marc Andreessen 与 Jim Clark 合作创建了 Mosaic Communications,该公司后来改名为 Netscape(网景),并于 1994 年 12 月发布了 Netscape Navigator 1.0。从这一点来说,已经很清楚了,万维网已经不仅仅是学术上的好奇心了。
+
+> 实际上,同年在瑞士日内瓦组织了第一次万维网会议,这导致万维网联盟(W3C)的成立,以帮助指导 HTML 的发展。同样,在 IETF 内部建立了一个并行的HTTP 工作组(HTTP-WG),专注于改进 HTTP 协议。后来这两个团体一直对 Web 的发展起着重要作用。
+
+> 最后,完美风暴来临,CompuServe,AOL 和 Prodigy 在 1994-1995 年的同一时间开始向公众提供拨号上网服务。凭借这股迅速的浪潮,Netscape 在 1995 年 8 月 9 日凭借其成功的 IPO 创造了历史。这预示着互联网热潮已经到来,人人都想分一杯羹!
+
+不断增长的新 Web 所需功能及其在公共网站上的应用场景很快暴露了 HTTP 0.9 的许多基础限制:我们需要一种能够提供超文本文档、提供关于请求和响应的更丰富的元数据,支持内容协商等等的协议。相应地,新兴的 Web 开发人员社区通过一个特殊的过程生成了大量实验性的 HTTP 服务器和客户端实现来回应:实现,部署,并查看其他人是否采用它。
+
+从这些急速增长的实验开始,一系列最佳实践和常见模式开始出现。1996 年 5 月,HTTP 工作组(HTTP-WG)发布了 RFC 1945,它记录了许多被广泛使用的 HTTP/1.0 实现的“常见用法”。请注意,这只是一个信息性 RFC:HTTP/1.0,如你所知的,它不是一个正式规范或 Internet 标准!
+
+话虽如此,HTTP/1.0 请求看起来应该是:
+
+```
+$> telnet website.org 80
+
+Connected to xxx.xxx.xxx.xxx
+
+GET /rfc/rfc1945.txt HTTP/1.0 ❶
+User-Agent: CERN-LineMode/2.15 libwww/2.17b3
+Accept: */*
+
+HTTP/1.0 200 OK ❷
+Content-Type: text/plain
+Content-Length: 137582
+Expires: Thu, 01 Dec 1997 16:00:00 GMT
+Last-Modified: Wed, 1 May 1996 12:45:26 GMT
+Server: Apache 0.84
+
+(plain-text response)
+(connection closed)
+```
+
+- ❶ 请求行有 HTTP 版本号,后面跟请求头
+- ❷ 响应状态,后跟响应头
+
+前面的交互并不是 HTTP/1.0 功能的详尽列表,但它确实说明了一些关键的协议更改:
+
+* 请求可能多个由换行符分隔的请求头字段组成。
+* 响应对象的前缀是响应状态行。
+* 响应对象有自己的一组由换行符分隔的响应头字段。
+* 响应对象不限于超文本。
+* 每次请求后,服务器和客户端之间的连接都将关闭。
+
+请求头和响应头都保留为 ASCII 编码,但响应对象本身可以是任何类型:HTML 文件、纯文本文件、图像或任何其他内容类型。因此,HTTP 的“超文本传输”部分在引入后不久就变成了用词不当。实际上,HTTP 已经迅速发展成为一种超媒体传输,但最初的名称没有改变。
+
+除了媒体类型协商之外,RFC 还记录了许多其他常用功能:内容编码、字符集支持、多部分类型、授权、缓存、代理行为、日期格式等。
+
+> 今天,几乎所有 Web 上的服务器都可以并且仍将使用 HTTP/1.0。不过,现在你应该更加清楚了!每个请求都需要一个新的 TCP 连接,这会对 HTTP/1.0 造成严重的性能损失。参见[三次握手][1],接着会[慢启动][2]。
+
+### HTTP/1.1: Internet 标准
+
+将 HTTP 转变为官方 IETF 互联网标准的工作与围绕 HTTP/1.0 的文档工作并行进行,并计划从 1995 年至 1999 年完成。事实上,第一个正式的 HTTP/1.1 标准定义于 RFC 2068,它在 HTTP/1.0 发布大约六个月后,即 1997 年 1 月正式发布。两年半后,即 1999 年 6 月,一些新的改进和更新被纳入标准,并作为 RFC 2616 发布。
+
+HTTP/1.1 标准解决了早期版本中发现的许多协议歧义,并引入了一些关键的性能优化:保持连接,分块编码传输,字节范围请求,附加缓存机制,传输编码和请求管道。
+
+有了这些功能,我们现在可以审视一下由任何现代 HTTP 浏览器和客户端执行的典型 HTTP/1.1 会话:
+
+```
+$> telnet website.org 80
+Connected to xxx.xxx.xxx.xxx
+
+GET /index.html HTTP/1.1 ❶
+Host: website.org
+User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_4)... (snip)
+Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
+Accept-Encoding: gzip,deflate,sdch
+Accept-Language: en-US,en;q=0.8
+Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.3
+Cookie: __qca=P0-800083390... (snip)
+
+HTTP/1.1 200 OK ❷
+Server: nginx/1.0.11
+Connection: keep-alive
+Content-Type: text/html; charset=utf-8
+Via: HTTP/1.1 GWA
+Date: Wed, 25 Jul 2012 20:23:35 GMT
+Expires: Wed, 25 Jul 2012 20:23:35 GMT
+Cache-Control: max-age=0, no-cache
+Transfer-Encoding: chunked
+
+100 ❸
+
+(snip)
+
+100
+(snip)
+
+0 ❹
+
+GET /favicon.ico HTTP/1.1 ❺
+Host: www.website.org
+User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_4)... (snip)
+Accept: */*
+Referer: http://website.org/
+Connection: close ❻
+Accept-Encoding: gzip,deflate,sdch
+Accept-Language: en-US,en;q=0.8
+Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.3
+Cookie: __qca=P0-800083390... (snip)
+
+HTTP/1.1 200 OK ❼
+Server: nginx/1.0.11
+Content-Type: image/x-icon
+Content-Length: 3638
+Connection: close
+Last-Modified: Thu, 19 Jul 2012 17:51:44 GMT
+Cache-Control: max-age=315360000
+Accept-Ranges: bytes
+Via: HTTP/1.1 GWA
+Date: Sat, 21 Jul 2012 21:35:22 GMT
+Expires: Thu, 31 Dec 2037 23:55:55 GMT
+Etag: W/PSA-GAu26oXbDi
+
+(icon data)
+(connection closed)
+```
+
+- ❶ 请求的 HTML 文件,包括编、字符集和 cookie 元数据
+- ❷ 原始 HTML 请求的分块响应
+- ❸ 以 ASCII 十六进制数字(256 字节)表示块中的八位元的数量
+- ❹ 分块流响应结束
+- ❺ 在相同的 TCP 连接上请求一个图标文件
+- ❻ 通知服务器不再重用连接
+- ❼ 图标响应后,然后关闭连接
+
+哇,这里发生了很多事情!第一个也是最明显的区别是我们有两个对象请求,一个用于 HTML 页面,另一个用于图像,它们都通过一个连接完成。这就是保持连接的实际应用,它允许我们重用现有的 TCP 连接到同一个主机的多个请求,提供一个更快的最终用户体验。参见[TCP 优化][3]。
+
+要终止持久连接,注意第二个客户端请求通过 `Connection` 请求头向服务器发送显示的 `close`。类似地,一旦传输响应,服务器就可以通知客户端关闭当前 TCP 连接。从技术上讲,任何一方都可以在没有此类信号的情况下终止 TCP 连接,但客户端和服务器应尽可能提供此类信号,以便双方都启用更好的连接重用策略。
+
+> HTTP/1.1 改变了 HTTP 协议的语义,默认情况下使用保持连接。这意味着,除非另有说明(通过 `Connection:close` 头),否则服务器应默认保持连接打开。
+
+> 但是,同样的功能也被反向移植到 HTTP/1.0 上,通过 `Connection:keep-Alive` 头启用。因此,如果你使用 HTTP/1.1,从技术上讲,你不需要 `Connection:keep-Alive` 头,但许多客户端仍然选择提供它。
+
+此外,HTTP/1.1 协议还添加了内容、编码、字符集,甚至语言协商、传输编码、缓存指令、客户端 cookie,以及可以针对每个请求协商的十几个其他功能。
+
+我们不打算详细讨论每个 HTTP/1.1 特性的语义。这个主题可以写一本专门的书了,已经有了很多很棒的书。相反,前面的示例很好地说明了 HTTP 的快速进展和演变,以及每个客户端-服务器交换的错综复杂的过程,里面发生了很多事情!
+
+> 要了解 HTTP 协议所有内部工作原理,参考 David Gourley 和 Brian Totty 共同撰写的权威指南: The Definitive Guide。
+
+### HTTP/2: 提高传输性能
+
+RFC 2616 自发布以来,已经成为互联网空前增长的基础:数十亿各种形状和大小的设备,从台式电脑到我们口袋里的小型网络设备,每天都在使用 HTTP 来传送新闻,视频,在我们生活中的数百万的其他网络应用程序都在依靠它。
+
+一开始是一个简单的,用于检索超文本的简单协议,很快演变成了一种通用的超媒体传输,现在十年过去了,它几乎可以为你所能想象到的任何用例提供支持。可以使用协议的服务器无处不在,客户端也可以使用协议,这意味着现在许多应用程序都是专门在 HTTP 之上设计和部署的。
+
+需要一个协议来控制你的咖啡壶?RFC 2324 已经涵盖了超文本咖啡壶控制协议(HTCPCP/1.0)- 它原本是 IETF 在愚人节开的一个玩笑,但在我们这个超链接的新世界中,它不仅仅意味着一个玩笑。
+
+> 超文本传输协议(HTTP)是一个应用程序级的协议,用于分布式、协作、超媒体信息系统。它是一种通用的、无状态的协议,可以通过扩展请求方法、错误码和头,用于超出超文本之外的许多任务,比如名称服务器和分布式对象管理系统。HTTP 的一个特性是数据表示的类型和协商,允许独立于传输的数据构建系统。
+>
+> RFC 2616: HTTP/1.1, June 1999
+
+HTTP 协议的简单性是它最初被采用和快速增长的原因。事实上,现在使用 HTTP 作为主要控制和数据协议的嵌入式设备(传感器,执行器和咖啡壶)并不罕见。但在其自身成功的重压下,随着我们越来越多地继续将日常互动转移到网络 —— 社交、电子邮件、新闻和视频,以及越来越多的个人和工作空间,它也开始显示出压力的迹象。用户和 Web 开发人员现在都要求 HTTP/1.1 提供近乎实时的响应能力和协议
+性能,如果不进行一些修改,就无法满足这些要求。
+
+为了应对这些新挑战,HTTP 必须继续发展,因此 HTTPbis 工作组在 2012 年初宣布了一项针对 HTTP/2 的新计划:
+
+> 已经有一个协议中出现了新的实现经验和兴趣,该协议保留了 HTTP 的语义,但是没有保留 HTTP/1.x 的消息框架和语法,这些问题已经被确定为妨碍性能和鼓励滥用底层传输。
+>
+> 工作组将使用有序的双向流中生成 HTTP 当前语义的新表达式的规范。与 HTTP/1.x 一样,主要传输目标是 TCP,但是应该可以使用其他方式传输。
+>
+> HTTP/2 charter, January 2012
+
+HTTP/2 的主要重点是提高传输性能并支持更低的延迟和更高的吞吐量。主要的版本增量听起来像是一个很大的步骤,但就性能而言,它将是一个重大的步骤,但重要的是要注意,没有任何高级协议语义收到影响:所有的 HTTP 头,值和用例是相同的。
+
+任何现有的网站或应用程序都可以并且将通过 HTTP/2 传送而无需修改。你无需修改应用程序标记来利用 HTTP/2。HTTP 服务器将来一定会使用 HTTP/2,但这对大多数用户来说应该是透明的升级。如果工作组实现目标,唯一的区别应该是我们的应用程序以更低的延迟和更好的网络连接利用率来传送数据。
+
+话虽如此,但我们不要走的太远了。在讨论新的 HTTP/2 协议功能之前,有必要回顾一下我们现有的 HTTP/1.1 部署和性能最佳实践。HTTP/2 工作组正在新规范上取得快速的进展,但即使最终标准已经完成并准备就绪,在可预见的未来,我们仍然必须支持旧的 HTTP/1.1 客户端,实际上,这得十年或更长时间。
+
+--------------------------------------------------------------------------------
+
+via: https://hpbn.co/brief-history-of-http/#http-09-the-one-line-protocol
+
+作者:[Ilya Grigorik][a]
+选题:[lujun9972][b]
+译者:[MjSeven](https://github.com/MjSeven)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.igvita.com/
+[b]: https://github.com/lujun9972
+[1]: https://hpbn.co/building-blocks-of-tcp/#three-way-handshake
+[2]: https://hpbn.co/building-blocks-of-tcp/#slow-start
+[3]: https://hpbn.co/building-blocks-of-tcp/#optimizing-for-tcp
diff --git a/published/201903/20180930 A Short History of Chaosnet.md b/published/201903/20180930 A Short History of Chaosnet.md
new file mode 100644
index 0000000000..5db6e52e7f
--- /dev/null
+++ b/published/201903/20180930 A Short History of Chaosnet.md
@@ -0,0 +1,121 @@
+Chaosnet 简史
+===
+
+如果你输入 `dig` 命令对 `google.com` 进行 DNS 查询,你会得到如下答复:
+
+```
+$ dig google.com
+
+; <<>> DiG 9.10.6 <<>> google.com
+;; global options: +cmd
+;; Got answer:
+;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 27120
+;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
+
+;; OPT PSEUDOSECTION:
+; EDNS: version: 0, flags:; udp: 512
+;; QUESTION SECTION:
+;google.com. IN A
+
+;; ANSWER SECTION:
+google.com. 194 IN A 216.58.192.206
+
+;; Query time: 23 msec
+;; SERVER: 8.8.8.8#53(8.8.8.8)
+;; WHEN: Fri Sep 21 16:14:48 CDT 2018
+;; MSG SIZE rcvd: 55
+```
+
+这个输出一部分描述了你的问题(`google.com` 的 IP 地址是什么?),另一部分则详细描述了你收到的回答。在答案区段里,`dig` 为我们找到了一个包含五个字段的记录。从左数第四个字段 `A` 定义了这个记录的类型 —— 这是一个地址记录。在 `A` 的右边,第五个字段告知我们 `google.com` 的 IP 地址是 `216.58.192.206`。第二个字段,`194` 则代表这个记录的缓存时间是 194 秒。
+
+那么,`IN` 字段告诉了我们什么呢?令人尴尬的是,在很长的一段时间里,我都认为这是一个介词。那时候我认为 DNS 记录大概是表达了“在 `A` 记录里,`google.com` 的 IP 地址是 `216.58.192.206`。”后来我才知道 `IN` 是 “internet” 的简写。`IN` 这一个部分告诉了我们这个记录分属的类别。
+
+那么,除了 “internet” 之外,DNS 记录还会有什么别的类别吗?这究竟意味着什么?你怎么去搜寻一个*不位于* internet 上的地址?看起来 `IN` 是唯一一个可能有意义的值。而且的确,如果你尝试去获得除了 `IN` 之外的,关于 `google.com` 的记录的话,DNS 服务器通常不能给出恰当的回应。以下就是我们尝试向 `8.8.8.8`(谷歌公共 DNS 服务器)询问在 `HS` 类别里 `google.com` 的 IP 地址。我们得到了状态为 `SERVFAIL` 的回复。
+
+```
+$ dig -c HS google.com
+
+; <<>> DiG 9.10.6 <<>> -c HS google.com
+;; global options: +cmd
+;; Got answer:
+;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 31517
+;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 1
+
+;; OPT PSEUDOSECTION:
+; EDNS: version: 0, flags:; udp: 512
+;; QUESTION SECTION:
+;google.com. HS A
+
+;; Query time: 34 msec
+;; SERVER: 8.8.8.8#53(8.8.8.8)
+;; WHEN: Tue Sep 25 14:48:10 CDT 2018
+;; MSG SIZE rcvd: 39
+```
+
+所以说,除了 `IN` 以外的类别没有得到广泛支持,但它们的确是存在的。除了 `IN` 之外,DNS 记录还有 `HS`(我们刚刚看到的)和 `CH` 这两个类别。`HS` 类是为一个叫做 [Hesiod][1] 的系统预留的,它可以利用 DNS 来存储并让用户访问一些文本资料。它通常在本地环境中作为 [LDAP][2] 的替代品使用。而 `CH` 这个类别,则是为 Chaosnet 预留的。
+
+如今,大家都在使用 TCP/IP 协议族。这两种协议(TCP 及 UDP)是绝大部分电脑远程连接采用的协议。不过我觉得,从互联网的垃圾堆里翻出了一个布满灰尘,绝迹已久,被人们遗忘的系统,也是一件令人愉悦的事情。那么,Chaosnet 是什么?为什么它像恐龙一样,走上了毁灭的道路呢?
+
+### 在 MIT 的机房里
+
+Chaosnet 是在 1970 年代,由 MIT 人工智能实验室的研究员们研发的。它是一个宏伟目标的一部分 —— 设计并制造一个能比其他通用电脑更高效率运行 Lisp 代码的机器。
+
+Lisp 是 MIT 教授 John McCarthy 的造物,他亦是人工智能领域的先驱者。在 1960 年发布的[一篇论文][3]中,他首次描述了 Lisp 这个语言。在 1962 年,Lisp 的编译器和解释器诞生了。Lisp 引入了非常多的新特性,这些特性在现在看来是每一门编程语言不可或缺的一部分。它是第一门拥有垃圾回收器的语言,是第一个有 REPL(Read-eval-print-loop:交互式解析器)的语言,也是第一个支持动态类型的语言。在人工智能领域工作的程序员们都十分喜爱这门语言,比如说,大名鼎鼎的 [SHRDLU][4] 就是用它写的。这个程序允许人们使用自然语言,向机器下达挪动玩具方块这样的命令。
+
+Lisp 的缺点是它太慢了。跟其它语言相比,Lisp 需要使用两倍的时间来执行相同的操作。因为 Lisp 在运行中仍会检查变量类型,而不仅是编译过程中。在 MIT 的 IBM 7090 上,它的垃圾回收器也需要长达一秒钟的时间来执行。[^1] 这个性能问题急需解决,因为 AI 研究者们试图搭建类似 SHRDLU 的应用。他们需要程序与使用者进行实时互动。因此,在 1970 年代的晚期,MIT 人工智能实验室的研究员们决定去建造一个能更高效运行 Lisp 的机器来解决这个问题。这些“Lisp 机器”们拥有更大的存储和更精简的指令集,更加适合 Lisp。类型检查由专门的电路完成,因此在 Lisp 运行速度的提升上达成了质的飞跃。跟那时流行的计算机系统不同,这些机器并不支持分时,整台电脑的资源都用来运行一个单独的 Lisp 程序。每一个用户都会得到他自己单独的 CPU。MIT 的 Lisp 机器小组在一个备忘录里提到,这些功能是如何让 Lisp 运行变得更简单的:
+
+> Lisp 机器是个人电脑。这意味着处理器和主内存并不是分时复用的,每个人都能得到单独属于自己的处理器和内存。这个个人运算系统由许多处理器组成,每个处理器都有它们自己的内存和虚拟内存。当一个用户登录时,他就会被分配一个处理器,在他的登录期间这个处理器是独属于他的。当他登出,这个处理器就会重新可用,等待被分配给下一个用户。通过采取这种方法,当前用户就不用和其他用户竞争内存的使用,他经常使用的内存页也能保存在处理器核心里,因此页面换出的情况被显著降低了。这个 Lisp 机器解决了分时 Lisp 机器的一个基本问题。[^2]
+
+这个 Lisp 机器跟我们认知的现代个人电脑有很大的不同。该小组原本希望今后用户不用直接面对 Lisp 机器,而是面对终端。那些终端会与位于别处的 Lisp 机器进行连接。虽然每个用户都有自己专属的处理器,但那些处理器在工作时会发出很大的噪音,因此它们最好是位于机房,而不是放在本应安静的办公室里。[^3] 这些处理器会通过一个“完全分布式控制”的高速本地网络共享访问一个文件系统和设备,例如打印机。[^4] 这个网络的名字就是 Chaosnet。
+
+Chaosnet 既是硬件标准也是软件协议。它的硬件标准与以太网类似,事实上 Chaosnet 软件协议是运行在以太网之上的。这个软件协议在网络层和传输层之间交互,它并不像 TCP/IP,而总是控制着本地网络。Lisp 机器小组的一个成员 David Moon 写的另一个备忘录中提到,Chaosnet “目前并不打算为低速链接、高信噪链接、多路径、长距离链接做特别的优化。” [^5] 他们专注于打造一个在小型网络里表现极佳的协议。
+
+因为 Chaosnet 连接在 Lisp 处理器和文件系统之间,所以速度十分重要。网络延迟会严重拖慢一些像打开文本文档这种简单操作的速度,为了提高速度,Chaosnet 结合了在Network Control Program网络控制程序中使用的一些改进方法,随后的 Arpanet 项目中也使用了这些方法。据 Moon 所说,“为了突破诸如在 Arpanet 中发现的速率瓶颈,很有必要采纳新的设计。目前来看,瓶颈在于由多个链接分享控制链接,而且在下一个信息发送之前,我们需要知道本次信息已经送达。” [^6] Chaosnet 协议族的批量 ACK 包跟当今 TCP 的差不多,它减少了 1/3 到一半的需要传输的包的数量。
+
+因为绝大多数 Lisp 机器使用较短的单线进行连接,所以 Chaosnet 可以使用较为简单的路由算法。Moon 在 Chaosnet 路由方案中写道“预计要适配的网络架构十分简单,很少有多个路径,而且每个节点之间的距离很短。所以我认为没有必要进行复杂的方案设计。” [^7] 因为 Chaosnet 采用的算法十分简单,所以实现它也很容易。与之对比明显,其实现程序据说只有 Arpanet 网络控制程序的一半。[^8]
+
+Chaosnet 的另一个特性是,它的地址只有 16 位,是 IPv4 地址的一半。所以这也意味着 Chaosnet 只能在局域网里工作。Chaosnet 也不会去使用端口号;当一个进程试图连接另一个机器上的另外一个进程时,需要首先初始化连接,获取一个特定的目标“联系名称”。这个联系名称一般是某个特定服务的名字。比方说,一个主机试图使用 `TELNET` 作为联系名称,连接另一个主机。我认为它的工作方式在实践中有点类似于 TCP,因为有些非常著名的服务也会拥有联系名称,比如运行在 80 端口上的 `HTTP` 服务。
+
+在 1986 年,[RFC 973][5] 通过了将 Chaosnet DNS 类别加入域名解析系统的决议。它替代了一个早先出现的类别 `CSNET`。`CSNET` 是为了支持一个名叫计算机科学网络而被制造出来的协议。我并不知道为什么 Chaosnet 能被域名解析系统另眼相待。很多别的协议族也有资格加入 DNS,但是却被忽略了。比如 DNS 的主要架构师之一 Paul Mockapetris 提到说在他原本的构想里,施乐的网络协议应该被包括在 DNS 里。[^9] 但是它并没有被加入。Chaosnet 被加入的原因大概是因为 Arpanet 项目和互联网的早期工作,有很多都在麻省剑桥的博尔特·贝拉尼克—纽曼公司,他们的雇员和 MIT 大多有紧密的联系。在这一小撮致力于发展计算机网络人中,Chaosnet 这个协议应该较为有名。
+
+Chaosnet 随着 Lisp 机器的衰落渐渐变得不那么流行。尽管在一小段时间内 Lisp 机器有实际的商业产品 —— Symbolics 和 Lisp Machines Inc 在 80 年代售卖了这些机器。但它们很快被更便宜的微型计算机替代。这些计算机没有特殊制造的回路,但也可以快速运行 Lisp。Chaosnet 被制造出来的目的之一是解决一些 Apernet 协议的原始设计缺陷,但现在 TCP/IP 协议族同样能够解决这些问题了。
+
+### 壳中幽灵
+
+非常不幸的是,在互联网中留存的关于 Chaosnet 的资料不多。RFC 675 —— TCP/IP 的初稿于 1974 年发布,而 Chasnet 于 1975 年开始开发。[^10] 但 TCP/IP 最终征服了整个互联网世界,Chaosnet 则被宣布技术性死亡。尽管 Chaosnet 有可能影响了接下来 TCP/IP 的发展,可我并没有找到能够支持这个猜测的证据。
+
+唯一一个可见的 Chaosnet 残留就是 DNS 的 `CH` 类。这个事实让我着迷。`CH` 类别是那被遗忘的幽魂 —— 在 TCP/IP 广泛部署中存在的一个替代协议 Chaosnet 的最后栖身之地。至少对于我来说,这件事情是十分让人激动。它告诉我关于 Chaosnet 的最后一丝痕迹,仍然藏在我们日常使用的网络基础架构之中。DNS 的 `CH` 类别是有趣的数码考古学遗迹。但它同时也是活生生的标识,提醒着我们互联网并非天生完整成型的,TCP/IP 不是唯一一个能够让计算机们交流的协议。“万维网”也远远不是我们这全球交流系统所能有的,最酷的名字。
+
+
+[^1]: LISP 1.5 Programmer’s Manual, The Computation Center and Research Laboratory of Electronics, 90, accessed September 30, 2018, http://www.softwarepreservation.org/projects/LISP/book/LISP%201.5%20Programmers%20Manual.pdf
+[^2]: Lisp Machine Progress Report (Artificial Intelligence Memo 444), MIT Artificial Intelligence Laboratory, August, 1977, 3, accessed September 30, 2018, https://dspace.mit.edu/bitstream/handle/1721.1/5751/AIM-444.pdf.
+[^3]: Lisp Machine Progress Report (Artificial Intelligence Memo 444), 4.
+[^4]: 同上
+[^5]: Chaosnet (Artificial Intelligence Memo 628), MIT Artificial Intelligence Laboratory, June, 1981, 1, accessed September 30, 2018, https://dspace.mit.edu/bitstream/handle/1721.1/6353/AIM-628.pdf.
+[^6]: 同上
+[^7]: Chaosnet (Artificial Intelligence Memo 628), 16.
+[^8]: Chaosnet (Artificial Intelligence Memo 628), 9.
+[^9]: Paul Mockapetris and Kevin Dunlap, “The Design of the Domain Name System,” Computer Communication Review 18, no. 4 (August 1988): 3, accessed September 30, 2018, http://www.cs.cornell.edu/people/egs/615/mockapetris.pdf.
+[^10]: Chaosnet (Artificial Intelligence Memo 628), 1.
+
+--------------------------------------------------------------------------------
+
+via: https://twobithistory.org/2018/09/30/chaosnet.html
+
+作者:[Two-Bit History][a]
+选题:[lujun9972][b]
+译者:[acyanbird](https://github.com/acyanbird)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://twobithistory.org
+[b]: https://github.com/lujun9972
+[1]: https://en.wikipedia.org/wiki/Hesiod_(name_service)
+[2]: https://en.wikipedia.org/wiki/Lightweight_Directory_Access_Protocol
+[3]: http://www-formal.stanford.edu/jmc/recursive.pdf
+[4]: https://en.wikipedia.org/wiki/SHRDLU
+[5]: https://tools.ietf.org/html/rfc973
+[6]: https://twitter.com/TwoBitHistory
+[7]: https://twobithistory.org/feed.xml
+[8]: https://twitter.com/TwoBitHistory/status/1041485204802756608?ref_src=twsrc%5Etfw
diff --git a/published/201903/20181216 Schedule a visit with the Emacs psychiatrist.md b/published/201903/20181216 Schedule a visit with the Emacs psychiatrist.md
new file mode 100644
index 0000000000..304beda2ff
--- /dev/null
+++ b/published/201903/20181216 Schedule a visit with the Emacs psychiatrist.md
@@ -0,0 +1,63 @@
+[#]: collector: (lujun9972)
+[#]: translator: (lujun9972)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10601-1.html)
+[#]: subject: (Schedule a visit with the Emacs psychiatrist)
+[#]: via: (https://opensource.com/article/18/12/linux-toy-eliza)
+[#]: author: (Jason Baker https://opensource.com/users/jason-baker)
+
+预约 Emacs 心理医生
+======
+
+> Eliza 是一个隐藏于某个 Linux 最流行文本编辑器中的自然语言处理聊天机器人。
+
+
+
+欢迎你,今天时期 24 天的 Linux 命令行玩具的又一天。如果你是第一次访问本系列,你可能会问什么是命令行玩具呢。我们将会逐步确定这个概念,但一般来说,它可能是一个游戏,或任何能让你在终端玩的开心的其他东西。
+
+可能你们已经见过了很多我们之前挑选的那些玩具,但我们依然希望对所有人来说都至少有一件新鲜事物。
+
+今天的选择是 Emacs 中的一个彩蛋:Eliza,Rogerian 心理医生,一个准备好倾听你述说一切的终端玩具。
+
+旁白:虽然这个玩具很好玩,但你的健康不是用来开玩笑的。请在假期期间照顾好你自己,无论时身体上还是精神上,若假期中的压力和焦虑对你的健康产生负面影响,请考虑找专业人士进行指导。真的有用。
+
+要启动 [Eliza][1],首先,你需要启动 Emacs。很有可能 Emacs 已经安装在你的系统中了,但若没有,它基本上也肯定在你默认的软件仓库中。
+
+由于我要求本系列的工具一定要时运行在终端内,因此使用 `-nw` 标志来启动 Emacs 让它在你的终端模拟器中运行。
+
+```
+$ emacs -nw
+```
+
+在 Emacs 中,输入 `M-x doctor` 来启动 Eliza。对于像我这样有 Vim 背景的人可能不知道这是什么意思,只需要按下 `escape`,输入 `x` 然后输入 `doctor`。然后,向它倾述所有假日的烦恼吧。
+
+Eliza 历史悠久,最早可以追溯到 1960 年代中期的 MIT 人工智能实验室。[维基百科][2] 上有它历史的详细说明。
+
+Eliza 并不是 Emacs 中唯一的娱乐工具。查看 [手册][3] 可以看到一整列好玩的玩具。
+
+![Linux toy:eliza animated][5]
+
+你有什么喜欢的命令行玩具值得推荐吗?我们时间不多了,但我还是想听听你的建议。请在下面评论中告诉我,我会查看的。另外也欢迎告诉我你们对本次玩具的想法。
+
+请一定要看看昨天的玩具,[带着这个复刻版吃豆人来到 Linux 终端游乐中心][6],然后明天再来看另一个玩具!
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/12/linux-toy-eliza
+
+作者:[Jason Baker][a]
+选题:[lujun9972][b]
+译者:[lujun9972](https://github.com/lujun9972)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/jason-baker
+[b]: https://github.com/lujun9972
+[1]: https://www.emacswiki.org/emacs/EmacsDoctor
+[2]: https://en.wikipedia.org/wiki/ELIZA
+[3]: https://www.gnu.org/software/emacs/manual/html_node/emacs/Amusements.html
+[4]: /file/417326
+[5]: https://opensource.com/sites/default/files/uploads/linux-toy-eliza-animated.gif (Linux toy: eliza animated)
+[6]: https://opensource.com/article/18/12/linux-toy-myman
diff --git a/published/201903/20181220 7 CI-CD tools for sysadmins.md b/published/201903/20181220 7 CI-CD tools for sysadmins.md
new file mode 100644
index 0000000000..64933afa4f
--- /dev/null
+++ b/published/201903/20181220 7 CI-CD tools for sysadmins.md
@@ -0,0 +1,166 @@
+[#]: collector: (lujun9972)
+[#]: translator: (jdh8383)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10578-1.html)
+[#]: subject: (7 CI/CD tools for sysadmins)
+[#]: via: (https://opensource.com/article/18/12/cicd-tools-sysadmins)
+[#]: author: (Dan Barker https://opensource.com/users/barkerd427)
+
+系统管理员的 7 个 CI/CD 工具
+======
+
+> 本文是一篇简单指南:介绍一些顶级的开源的持续集成、持续交付和持续部署(CI/CD)工具。
+
+
+
+虽然持续集成、持续交付和持续部署(CI/CD)在开发者社区里已经存在很多年,一些机构在其运维部门也有实施经验,但大多数公司并没有做这样的尝试。对于很多机构来说,让运维团队能够像他们的开发同行一样熟练操作 CI/CD 工具,已经变得十分必要了。
+
+无论是基础设施、第三方应用还是内部开发的应用,都可以开展 CI/CD 实践。尽管你会发现有很多不同的工具,但它们都有着相似的设计模型。而且可能最重要的一点是:通过带领你的公司进行这些实践,会让你在公司内部变得举足轻重,成为他人学习的榜样。
+
+一些机构在自己的基础设施上已有多年的 CI/CD 实践经验,常用的工具包括 [Ansible][1]、[Chef][2] 或者 [Puppet][3]。另一些工具,比如 [Test Kitchen][4],允许在最终要部署应用的基础设施上运行测试。事实上,如果使用更高级的配置方法,你甚至可以将应用部署到有真实负载的仿真“生产环境”上,来运行应用级别的测试。然而,单单是能够测试基础设施就是一项了不起的成就了。配置管理工具 Terraform 可以通过 Test Kitchen 来快速创建更[短暂][5]和[冥等的][6]的基础设施配置,这比它的前辈要强不少。再加上 Linux 容器和 Kubernetes,在数小时内,你就可以创建一套类似于生产环境的配置参数和系统资源,来测试整个基础设施和其上部署的应用,这在以前可能需要花费几个月的时间。而且,删除和再次创建整个测试环境也非常容易。
+
+当然,作为初学者,你也可以把网络配置和 DDL(数据定义语言)文件加入版本控制,然后开始尝试一些简单的 CI/CD 流程。虽然只能帮你检查一下语义语法或某些最佳实践,但实际上大多数开发的管道都是这样起步的。只要你把脚手架搭起来,建造就容易得多了。而一旦起步,你就会发现各种管道的使用场景。
+
+举个例子,我经常会在公司内部写新闻简报,我使用 [MJML][7] 制作邮件模板,然后把它加入版本控制。我一般会维护一个 web 版本,但是一些同事喜欢 PDF 版,于是我创建了一个[管道][8]。每当我写好一篇新闻稿,就在 Gitlab 上提交一个合并请求。这样做会自动创建一个 index.html 文件,生成这篇新闻稿的 HTML 和 PDF 版链接。HTML 和 PDF 文件也会在该管道里同时生成。除非有人来检查确认,这些文件不会被直接发布出去。使用 GitLab Pages 发布这个网站后,我就可以下载一份 HTML 版,用来发送新闻简报。未来,我会修改这个流程,当合并请求成功或者在某个审核步骤后,自动发出对应的新闻稿。这些处理逻辑并不复杂,但的确为我节省了不少时间。实际上这些工具最核心的用途就是替你节省时间。
+
+关键是要在抽象层创建出工具,这样稍加修改就可以处理不同的问题。值得留意的是,我创建的这套流程几乎不需要任何代码,除了一些[轻量级的 HTML 模板][9],一些[把 HTML 文件转换成 PDF 的 nodejs 代码][10],还有一些[生成索引页面的 nodejs 代码][11]。
+
+这其中一些东西可能看起来有点复杂,但其中大部分都源自我使用的不同工具的教学文档。而且很多开发人员也会乐意跟你合作,因为他们在完工时会发现这些东西也挺有用。上面我提供的那些代码链接是给 [DevOps KC][12](LCTT 译注:一个地方性 DevOps 组织) 发送新闻简报用的,其中大部分用来创建网站的代码来自我在内部新闻简报项目上所作的工作。
+
+下面列出的大多数工具都可以提供这种类型的交互,但是有些工具提供的模型略有不同。这一领域新兴的模型是用声明式的方法例如 YAML 来描述一个管道,其中的每个阶段都是短暂而幂等的。许多系统还会创建[有向无环图(DAG)][13],来确保管道上不同的阶段排序的正确性。
+
+这些阶段一般运行在 Linux 容器里,和普通的容器并没有区别。有一些工具,比如 [Spinnaker][14],只关注部署组件,而且提供一些其他工具没有的操作特性。[Jenkins][15] 则通常把管道配置存成 XML 格式,大部分交互都可以在图形界面里完成,但最新的方案是使用[领域专用语言(DSL)][16](如 [Groovy][17])。并且,Jenkins 的任务(job)通常运行在各个节点里,这些节点上会装一个专门的 Java 代理,还有一堆混杂的插件和预装组件。
+
+Jenkins 在自己的工具里引入了管道的概念,但使用起来却并不轻松,甚至包含一些禁区。最近,Jenkins 的创始人决定带领社区向新的方向前进,希望能为这个项目注入新的活力,把 CI/CD 真正推广开(LCTT 译注:详见后面的 Jenkins 章节)。我认为其中最有意思的想法是构建一个云原生 Jenkins,能把 Kubernetes 集群转变成 Jenkins CI/CD 平台。
+
+当你更多地了解这些工具并把实践带入你的公司和运维部门,你很快就会有追随者,因为你有办法提升自己和别人的工作效率。我们都有多年积累下来的技术债要解决,如果你能给同事们提供足够的时间来处理这些积压的工作,他们该会有多感激呢?不止如此,你的客户也会开始看到应用变得越来越稳定,管理层会把你看作得力干将,你也会在下次谈薪资待遇或参加面试时更有底气。
+
+让我们开始深入了解这些工具吧,我们将对每个工具做简短的介绍,并分享一些有用的链接。
+
+### GitLab CI
+
+- [项目主页](https://about.gitlab.com/product/continuous-integration/)
+- [源代码](https://gitlab.com/gitlab-org/gitlab-ce/)
+- 许可证:MIT
+
+GitLab 可以说是 CI/CD 领域里新登场的玩家,但它却在权威调研机构 [Forrester 的 CI 集成工具的调查报告][20]中位列第一。在一个高水平、竞争充分的领域里,这是个了不起的成就。是什么让 GitLab CI 这么成功呢?它使用 YAML 文件来描述整个管道。另有一个功能叫做 Auto DevOps,可以为较简单的项目用多种内置的测试单元自动生成管道。这套系统使用 [Herokuish buildpacks][21] 来判断语言的种类以及如何构建应用。有些语言也可以管理数据库,它真正改变了构建新应用程序和从开发的开始将它们部署到生产环境的过程。它原生集成于 Kubernetes,可以根据不同的方案将你的应用自动部署到 Kubernetes 集群,比如灰度发布、蓝绿部署等。
+
+除了它的持续集成功能,GitLab 还提供了许多补充特性,比如:将 Prometheus 和你的应用一同部署,以提供操作监控功能;通过 GitLab 提供的 Issues、Epics 和 Milestones 功能来实现项目评估和管理;管道中集成了安全检测功能,多个项目的检测结果会聚合显示;你可以通过 GitLab 提供的网页版 IDE 在线编辑代码,还可以快速查看管道的预览或执行状态。
+
+### GoCD
+
+- [项目主页](https://www.gocd.org/)
+- [源代码](https://github.com/gocd/gocd)
+- 许可证:Apache 2.0
+
+GoCD 是由老牌软件公司 Thoughtworks 出品,这已经足够证明它的能力和效率。对我而言,GoCD 最具亮点的特性是它的[价值流视图(VSM)][22]。实际上,一个管道的输出可以变成下一个管道的输入,从而把管道串联起来。这样做有助于提高不同开发团队在整个开发流程中的独立性。比如在引入 CI/CD 系统时,有些成立较久的机构希望保持他们各个团队相互隔离,这时候 VSM 就很有用了:让每个人都使用相同的工具就很容易在 VSM 中发现工作流程上的瓶颈,然后可以按图索骥调整团队或者想办法提高工作效率。
+
+为公司的每个产品配置 VSM 是非常有价值的;GoCD 可以使用 [JSON 或 YAML 格式存储配置][23],还能以可视化的方式展示数据等待时间,这让一个机构能有效减少学习它的成本。刚开始使用 GoCD 创建你自己的流程时,建议使用人工审核的方式。让每个团队也采用人工审核,这样你就可以开始收集数据并且找到可能的瓶颈点。
+
+### Travis CI
+
+- [项目主页](https://docs.travis-ci.com/)
+- [源代码](https://github.com/travis-ci/travis-ci)
+- 许可证:MIT
+
+我使用的第一个软件既服务(SaaS)类型的 CI 系统就是 Travis CI,体验很不错。管道配置以源码形式用 YAML 保存,它与 GitHub 等工具无缝整合。我印象中管道从来没有失效过,因为 Travis CI 的在线率很高。除了 SaaS 版之外,你也可以使用自行部署的版本。我还没有自行部署过,它的组件非常多,要全部安装的话,工作量就有点吓人了。我猜更简单的办法是把它部署到 Kubernetes 上,[Travis CI 提供了 Helm charts][26],这些 charts 目前不包含所有要部署的组件,但我相信以后会越来越丰富的。如果你不想处理这些细枝末节的问题,还有一个企业版可以试试。
+
+假如你在开发一个开源项目,你就能免费使用 SaaS 版的 Travis CI,享受顶尖团队提供的优质服务!这样能省去很多麻烦,你可以在一个相对通用的平台上(如 GitHub)研发开源项目,而不用找服务器来运行任何东西。
+
+### Jenkins
+
+- [项目主页](https://jenkins.io/)
+- [源代码](https://github.com/jenkinsci/jenkins)
+- 许可证:MIT
+
+Jenkins 在 CI/CD 界绝对是元老级的存在,也是事实上的标准。我强烈建议你读一读这篇文章:“[Jenkins: Shifting Gears][27]”,作者 Kohsuke 是 Jenkins 的创始人兼 CloudBees 公司 CTO。这篇文章契合了我在过去十年里对 Jenkins 及其社区的感受。他在文中阐述了一些这几年呼声很高的需求,我很乐意看到 CloudBees 引领这场变革。长期以来,Jenkins 对于非开发人员来说有点难以接受,并且一直是其管理员的重担。还好,这些问题正是他们想要着手解决的。
+
+[Jenkins 配置既代码][28](JCasC)应该可以帮助管理员解决困扰了他们多年的配置复杂性问题。与其他 CI/CD 系统类似,只需要修改一个简单的 YAML 文件就可以完成 Jenkins 主节点的配置工作。[Jenkins Evergreen][29] 的出现让配置工作变得更加轻松,它提供了很多预设的使用场景,你只管套用就可以了。这些发行版会比官方的标准版本 Jenkins 更容易维护和升级。
+
+Jenkins 2 引入了两种原生的管道功能,我在 LISA(LCTT 译注:一个系统架构和运维大会) 2017 年的研讨会上已经[讨论过了][30]。这两种功能都没有 YAML 简便,但在处理复杂任务时它们很好用。
+
+[Jenkins X][31] 是 Jenkins 的一个全新变种,用来实现云端原生 Jenkins(至少在用户看来是这样)。它会使用 JCasC 及 Evergreen,并且和 Kubernetes 整合的更加紧密。对于 Jenkins 来说这是个令人激动的时刻,我很乐意看到它在这一领域的创新,并且继续发挥领袖作用。
+
+### Concourse CI
+
+- [项目主页](https://concourse-ci.org/)
+- [源代码](https://github.com/concourse/concourse)
+- 许可证:Apache 2.0
+
+我第一次知道 Concourse 是通过 Pivotal Labs 的伙计们介绍的,当时它处于早期 beta 版本,而且那时候也很少有类似的工具。这套系统是基于微服务构建的,每个任务运行在一个容器里。它独有的一个优良特性是能够在你本地系统上运行任务,体现你本地的改动。这意味着你完全可以在本地开发(假设你已经连接到了 Concourse 的服务器),像在真实的管道构建流程一样从你本地构建项目。而且,你可以在修改过代码后从本地直接重新运行构建,来检验你的改动结果。
+
+Concourse 还有一个简单的扩展系统,它依赖于“资源”这一基础概念。基本上,你想给管道添加的每个新功能都可以用一个 Docker 镜像实现,并作为一个新的资源类型包含在你的配置中。这样可以保证每个功能都被封装在一个不可变的独立工件中,方便对其单独修改和升级,改变其中一个时不会影响其他构建。
+
+### Spinnaker
+
+- [项目主页](https://www.spinnaker.io/)
+- [源代码](https://github.com/spinnaker/spinnaker)
+- 许可证:Apache 2.0
+
+Spinnaker 出自 Netflix,它更关注持续部署而非持续集成。它可以与其他工具整合,比如 Travis 和 Jenkins,来启动测试和部署流程。它也能与 Prometheus、Datadog 这样的监控工具集成,参考它们提供的指标来决定如何部署。例如,在金丝雀发布里,我们可以根据收集到的相关监控指标来做出判断:最近的这次发布是否导致了服务降级,应该立刻回滚;还是说看起来一切 OK,应该继续执行部署。
+
+谈到持续部署,一些另类但却至关重要的问题往往被忽略掉了,说出来可能有点让人困惑:Spinnaker 可以帮助持续部署不那么“持续”。在整个应用部署流程期间,如果发生了重大问题,它可以让流程停止执行,以阻止可能发生的部署错误。但它也可以在最关键的时刻让人工审核强制通过,发布新版本上线,使整体收益最大化。实际上,CI/CD 的主要目的就是在商业模式需要调整时,能够让待更新的代码立即得到部署。
+
+### Screwdriver
+
+- [项目主页](http://screwdriver.cd/)
+- [源代码](https://github.com/screwdriver-cd/screwdriver)
+- 许可证:BSD
+
+Screwdriver 是个简单而又强大的软件。它采用微服务架构,依赖像 Nomad、Kubernetes 和 Docker 这样的工具作为执行引擎。官方有一篇很不错的[部署教学文档][34],介绍了如何将它部署到 AWS 和 Kubernetes 上,但如果正在开发中的 [Helm chart][35] 也完成的话,就更完美了。
+
+Screwdriver 也使用 YAML 来描述它的管道,并且有很多合理的默认值,这样可以有效减少各个管道重复的配置项。用配置文件可以组织起高级的工作流,来描述各个任务间复杂的依赖关系。例如,一项任务可以在另一个任务开始前或结束后运行;各个任务可以并行也可以串行执行;更赞的是你可以预先定义一项任务,只在特定的拉取请求时被触发,而且与之有依赖关系的任务并不会被执行,这能让你的管道具有一定的隔离性:什么时候被构造的工件应该被部署到生产环境,什么时候应该被审核。
+
+---
+
+以上只是我对这些 CI/CD 工具的简单介绍,它们还有许多很酷的特性等待你深入探索。而且它们都是开源软件,可以自由使用,去部署一下看看吧,究竟哪个才是最适合你的那个。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/12/cicd-tools-sysadmins
+
+作者:[Dan Barker][a]
+选题:[lujun9972][b]
+译者:[jdh8383](https://github.com/jdh8383)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/barkerd427
+[b]: https://github.com/lujun9972
+[1]: https://www.ansible.com/
+[2]: https://www.chef.io/
+[3]: https://puppet.com/
+[4]: https://github.com/test-kitchen/test-kitchen
+[5]: https://www.merriam-webster.com/dictionary/ephemeral
+[6]: https://en.wikipedia.org/wiki/Idempotence
+[7]: https://mjml.io/
+[8]: https://gitlab.com/devopskc/newsletter/blob/master/.gitlab-ci.yml
+[9]: https://gitlab.com/devopskc/newsletter/blob/master/index/index.html
+[10]: https://gitlab.com/devopskc/newsletter/blob/master/html-to-pdf.js
+[11]: https://gitlab.com/devopskc/newsletter/blob/master/populate-index.js
+[12]: https://devopskc.com/
+[13]: https://en.wikipedia.org/wiki/Directed_acyclic_graph
+[14]: https://www.spinnaker.io/
+[15]: https://jenkins.io/
+[16]: https://martinfowler.com/books/dsl.html
+[17]: http://groovy-lang.org/
+[18]: https://about.gitlab.com/product/continuous-integration/
+[19]: https://gitlab.com/gitlab-org/gitlab-ce/
+[20]: https://about.gitlab.com/2017/09/27/gitlab-leader-continuous-integration-forrester-wave/
+[21]: https://github.com/gliderlabs/herokuish
+[22]: https://www.gocd.org/getting-started/part-3/#value_stream_map
+[23]: https://docs.gocd.org/current/advanced_usage/pipelines_as_code.html
+[24]: https://docs.travis-ci.com/
+[25]: https://github.com/travis-ci/travis-ci
+[26]: https://github.com/travis-ci/kubernetes-config
+[27]: https://jenkins.io/blog/2018/08/31/shifting-gears/
+[28]: https://jenkins.io/projects/jcasc/
+[29]: https://github.com/jenkinsci/jep/blob/master/jep/300/README.adoc
+[30]: https://danbarker.codes/talk/lisa17-becoming-plumber-building-deployment-pipelines/
+[31]: https://jenkins-x.io/
+[32]: https://concourse-ci.org/
+[33]: https://github.com/concourse/concourse
+[34]: https://docs.screwdriver.cd/cluster-management/kubernetes
+[35]: https://github.com/screwdriver-cd/screwdriver-chart
diff --git a/published/201903/20190104 Midori- A Lightweight Open Source Web Browser.md b/published/201903/20190104 Midori- A Lightweight Open Source Web Browser.md
new file mode 100644
index 0000000000..e263fc38ca
--- /dev/null
+++ b/published/201903/20190104 Midori- A Lightweight Open Source Web Browser.md
@@ -0,0 +1,110 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10602-1.html)
+[#]: subject: (Midori: A Lightweight Open Source Web Browser)
+[#]: via: (https://itsfoss.com/midori-browser)
+[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
+
+Midori:轻量级开源 Web 浏览器
+======
+
+> 这是一个对再次回归的轻量级、快速、开源的 Web 浏览器 Midori 的快速回顾。
+
+如果你正在寻找一款轻量级[网络浏览器替代品][1],请试试 Midori。
+
+[Midori][2]是一款开源的网络浏览器,它更注重轻量级而不是提供大量功能。
+
+如果你从未听说过 Midori,你可能会认为它是一个新的应用程序,但实际上 Midori 首次发布于 2007 年。
+
+因为它专注于速度,所以 Midori 很快就聚集了一群爱好者,并成为了 Bodhi Linux、SilTaz 等轻量级 Linux 发行版的默认浏览器。
+
+其他发行版如 [elementary OS][3] 也使用了 Midori 作为其默认浏览器。但 Midori 的开发在 2016 年左右停滞了,它的粉丝开始怀疑 Midori 已经死了。由于这个原因,elementary OS 从最新版本中删除了它。
+
+好消息是 Midori 还没有死。经过近两年的不活跃,开发工作在 2018 年的最后一个季度恢复了。在后来的版本中添加了一些包括广告拦截器的扩展。
+
+### Midori 网络浏览器的功能
+
+![Midori web browser][4]
+
+以下是 Midori 浏览器的一些主要功能
+
+ * 使用 Vala 编写,使用 GTK+3 和 WebKit 渲染引擎。
+ * 标签、窗口和会话管理。
+ * 快速拨号。
+ * 默认保存下一个会话的选项卡。
+ * 使用 DuckDuckGo 作为默认搜索引擎。可以更改为 Google 或 Yahoo。
+ * 书签管理。
+ * 可定制和可扩展的界面。
+ * 扩展模块可以用 C 和 Vala 编写。
+ * 支持 HTML5。
+ * 少量的扩展程序包括广告拦截器、彩色标签等。没有第三方扩展程序。
+ * 表单历史。
+ * 隐私浏览。
+ * 可用于 Linux 和 Windows。
+
+小知识:Midori 是日语单词,意思是绿色。如果你因此而猜想的话,但 Midori 的开发者实际不是日本人。
+
+### 体验 Midori
+
+![Midori web browser in Ubuntu 18.04][5]
+
+这几天我一直在使用 Midori。体验基本很好。它支持 HTML5 并能快速渲染网站。广告拦截器也没问题。正如你对任何标准 Web 浏览器所期望的那样,浏览体验挺顺滑。
+
+缺少扩展一直是 Midori 的弱点,所以我不打算谈论这个。
+
+我注意到的是它不支持国际语言。我找不到添加新语言支持的方法。它根本无法渲染印地语字体,我猜对其他非[罗曼语言][6]也是一样。
+
+我也在 YouTube 中也遇到了麻烦。有些视频会抛出播放错误而其他视频没问题。
+
+Midori 没有像 Chrome 那样吃我的内存,所以这是一个很大的优势。
+
+如果你想尝试 Midori,让我们看下你该如何安装。
+
+### 在 Linux 上安装 Midori
+
+在 Ubuntu 18.04 仓库中不再提供 Midori。但是,可以使用 [Snap 包][7]轻松安装较新版本的 Midori。
+
+如果你使用的是 Ubuntu,你可以在软件中心找到 Midori(Snap 版)并从那里安装。
+
+![Midori browser is available in Ubuntu Software Center][8]
+
+对于其他 Linux 发行版,请确保你[已启用 Snap 支持][9],然后你可以使用以下命令安装 Midori:
+
+```
+sudo snap install midori
+```
+
+你可以选择从源代码编译。你可以从 Midori 的网站下载它的代码。
+
+- [下载 Midori](https://www.midori-browser.org/download/)
+
+如果你喜欢 Midori 并希望帮助这个开源项目,请向他们捐赠或[从他们的商店购买 Midori 商品][10]。
+
+你在使用 Midori 还是曾经用过么?你的体验如何?你更喜欢使用哪种其他网络浏览器?请在下面的评论栏分享你的观点。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/midori-browser
+
+作者:[Abhishek Prakash][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/abhishek/
+[b]: https://github.com/lujun9972
+[1]: https://itsfoss.com/open-source-browsers-linux/
+[2]: https://www.midori-browser.org/
+[3]: https://itsfoss.com/elementary-os-juno-features/
+[4]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/Midori-web-browser.jpeg?resize=800%2C450&ssl=1
+[5]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/01/midori-browser-linux.jpeg?resize=800%2C491&ssl=1
+[6]: https://en.wikipedia.org/wiki/Romance_languages
+[7]: https://itsfoss.com/use-snap-packages-ubuntu-16-04/
+[8]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/midori-ubuntu-software-center.jpeg?ssl=1
+[9]: https://itsfoss.com/install-snap-linux/
+[10]: https://www.midori-browser.org/shop
+[11]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/Midori-web-browser.jpeg?fit=800%2C450&ssl=1
diff --git a/published/201903/20190108 How ASLR protects Linux systems from buffer overflow attacks.md b/published/201903/20190108 How ASLR protects Linux systems from buffer overflow attacks.md
new file mode 100644
index 0000000000..08e41d60ee
--- /dev/null
+++ b/published/201903/20190108 How ASLR protects Linux systems from buffer overflow attacks.md
@@ -0,0 +1,127 @@
+[#]: collector: (lujun9972)
+[#]: translator: (leommxj)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10592-1.html)
+[#]: subject: (How ASLR protects Linux systems from buffer overflow attacks)
+[#]: via: (https://www.networkworld.com/article/3331199/linux/what-does-aslr-do-for-linux.html)
+[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
+
+ASLR 是如何保护 Linux 系统免受缓冲区溢出攻击的
+======
+
+> 地址空间随机化(ASLR)是一种内存攻击缓解技术,可以用于 Linux 和 Windows 系统。了解一下如何运行它、启用/禁用它,以及它是如何工作的。
+
+
+
+地址空间随机化(ASLR)是一种操作系统用来抵御缓冲区溢出攻击的内存保护机制。这种技术使得系统上运行的进程的内存地址无法被预测,使得与这些进程有关的漏洞变得更加难以利用。
+
+ASLR 目前在 Linux、Windows 以及 MacOS 系统上都有使用。其最早出现在 2005 的 Linux 系统上。2007 年,这项技术被 Windows 和 MacOS 部署使用。尽管 ASLR 在各个系统上都提供相同的功能,却有着不同的实现。
+
+ASLR 的有效性依赖于整个地址空间布局是否对于攻击者保持未知。此外,只有编译时作为位置无关可执行文件(PIE)的可执行程序才能得到 ASLR 技术的最大保护,因为只有这样,可执行文件的所有代码节区才会被加载在随机地址。PIE 机器码不管绝对地址是多少都可以正确执行。
+
+### ASLR 的局限性
+
+尽管 ASLR 使得对系统漏洞的利用更加困难了,但其保护系统的能力是有限的。理解关于 ASLR 的以下几点是很重要的:
+
+ * 它不能*解决*漏洞,而是增加利用漏洞的难度
+ * 并不追踪或报告漏洞
+ * 不能对编译时没有开启 ASLR 支持的二进制文件提供保护
+ * 不能避免被绕过
+
+### ASLR 是如何工作的
+
+通过对攻击者在进行缓冲区溢出攻击时所要用到的内存布局中的偏移做了随机化,ASLR 加大了攻击成功的难度,从而增强了系统的控制流完整性。
+
+通常认为 ASLR 在 64 位系统上效果更好,因为 64 位系统提供了更大的熵(可随机的地址范围)。
+
+### ASLR 是否正在你的 Linux 系统上运行?
+
+下面展示的两条命令都可以告诉你的系统是否启用了 ASLR 功能:
+
+```
+$ cat /proc/sys/kernel/randomize_va_space
+2
+$ sysctl -a --pattern randomize
+kernel.randomize_va_space = 2
+```
+
+上方指令结果中的数值(`2`)表示 ASLR 工作在全随机化模式。其可能为下面的几个数值之一:
+
+```
+0 = Disabled
+1 = Conservative Randomization
+2 = Full Randomization
+```
+
+如果你关闭了 ASLR 并且执行下面的指令,你将会注意到前后两条 `ldd` 的输出是完全一样的。`ldd` 命令会加载共享对象并显示它们在内存中的地址。
+
+```
+$ sudo sysctl -w kernel.randomize_va_space=0 <== disable
+[sudo] password for shs:
+kernel.randomize_va_space = 0
+$ ldd /bin/bash
+ linux-vdso.so.1 (0x00007ffff7fd1000) <== same addresses
+ libtinfo.so.6 => /lib/x86_64-linux-gnu/libtinfo.so.6 (0x00007ffff7c69000)
+ libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 (0x00007ffff7c63000)
+ libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007ffff7a79000)
+ /lib64/ld-linux-x86-64.so.2 (0x00007ffff7fd3000)
+$ ldd /bin/bash
+ linux-vdso.so.1 (0x00007ffff7fd1000) <== same addresses
+ libtinfo.so.6 => /lib/x86_64-linux-gnu/libtinfo.so.6 (0x00007ffff7c69000)
+ libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 (0x00007ffff7c63000)
+ libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007ffff7a79000)
+ /lib64/ld-linux-x86-64.so.2 (0x00007ffff7fd3000)
+```
+
+如果将其重新设置为 `2` 来启用 ASLR,你将会看到每次运行 `ldd`,得到的内存地址都不相同。
+
+```
+$ sudo sysctl -w kernel.randomize_va_space=2 <== enable
+[sudo] password for shs:
+kernel.randomize_va_space = 2
+$ ldd /bin/bash
+ linux-vdso.so.1 (0x00007fff47d0e000) <== first set of addresses
+ libtinfo.so.6 => /lib/x86_64-linux-gnu/libtinfo.so.6 (0x00007f1cb7ce0000)
+ libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 (0x00007f1cb7cda000)
+ libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f1cb7af0000)
+ /lib64/ld-linux-x86-64.so.2 (0x00007f1cb8045000)
+$ ldd /bin/bash
+ linux-vdso.so.1 (0x00007ffe1cbd7000) <== second set of addresses
+ libtinfo.so.6 => /lib/x86_64-linux-gnu/libtinfo.so.6 (0x00007fed59742000)
+ libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 (0x00007fed5973c000)
+ libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007fed59552000)
+ /lib64/ld-linux-x86-64.so.2 (0x00007fed59aa7000)
+```
+
+### 尝试绕过 ASLR
+
+尽管这项技术有很多优点,但绕过 ASLR 的攻击并不罕见,主要有以下几类:
+
+ * 利用地址泄露
+ * 访问与特定地址关联的数据
+ * 针对 ASLR 实现的缺陷来猜测地址,常见于系统熵过低或 ASLR 实现不完善。
+ * 利用侧信道攻击
+
+### 总结
+
+ASLR 有很大的价值,尤其是在 64 位系统上运行并被正确实现时。虽然不能避免被绕过,但这项技术的确使得利用系统漏洞变得更加困难了。这份参考资料可以提供 [在 64 位 Linux 系统上的完全 ASLR 的有效性][2] 的更多有关细节,这篇论文介绍了一种利用分支预测 [绕过 ASLR][3] 的技术。
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3331199/linux/what-does-aslr-do-for-linux.html
+
+作者:[Sandra Henry-Stocker][a]
+选题:[lujun9972][b]
+译者:[leommxj](https://github.com/leommxj)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
+[b]: https://github.com/lujun9972
+[1]: https://www.networkworld.com/article/3242170/linux/invaluable-tips-and-tricks-for-troubleshooting-linux.html
+[2]: https://cybersecurity.upv.es/attacks/offset2lib/offset2lib-paper.pdf
+[3]: http://www.cs.ucr.edu/~nael/pubs/micro16.pdf
+[4]: https://www.facebook.com/NetworkWorld/
+[5]: https://www.linkedin.com/company/network-world
diff --git a/published/201903/20190109 Configure Anaconda on Emacs - iD.md b/published/201903/20190109 Configure Anaconda on Emacs - iD.md
new file mode 100644
index 0000000000..5c6125e2e9
--- /dev/null
+++ b/published/201903/20190109 Configure Anaconda on Emacs - iD.md
@@ -0,0 +1,116 @@
+[#]: collector: (lujun9972)
+[#]: translator: (lujun9972)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10604-1.html)
+[#]: subject: (Configure Anaconda on Emacs – iD)
+[#]: via: (https://idevji.com/configure-anaconda-on-emacs/)
+[#]: author: (Devji Chhanga https://idevji.com/author/admin/)
+
+在 Emacs 上配置 Anaconda
+======
+
+也许我所追求的究极 IDE 就是 [Emacs][1] 了。我的目标是使 Emacs 成为一款全能的 Python IDE。本文描述了如何在 Emacs 上配置 Anaconda。(LCTT 译注:Anaconda 自称“世界上最流行的 Python/R 的数据分析平台”)
+
+我的配置信息:
+
+- OS:Trisquel 8.0
+- Emacs:GNU Emacs 25.3.2
+
+快捷键说明([参见完全指南][2]):
+
+```
+C-x = Ctrl + x
+M-x = Alt + x
+RET = ENTER
+```
+
+### 1、下载并安装 Anaconda
+
+#### 1.1 下载
+
+[从这儿][3] 下载 Anaconda。你应该下载 Python 3.x 的版本,因为 Python 2 在 2020 年就不再支持了。你无需预先安装 Python 3.x。这个安装脚本会自动安装它。
+
+#### 1.2 安装
+
+```
+cd ~/Downloads
+bash Anaconda3-2018.12-Linux-x86.sh
+```
+
+### 2、将 Anaconda 添加到 Emacs
+
+#### 2.1 将 MELPA 添加到 Emacs
+
+我们需要用到 `anaconda-mode` 这个 Emacs 包。该包位于 MELPA 仓库中。Emacs25 需要手工添加该仓库。
+
+- [注意:点击本文查看如何将 MELPA 添加到 Emacs][4]
+
+#### 2.2 为 Emacs 安装 anaconda-mode 包
+
+```
+M-x package-install RET
+anaconda-mode RET
+```
+
+#### 2.3 为 Emacs 配置 anaconda-mode
+
+```
+echo "(add-hook 'python-mode-hook 'anaconda-mode)" > ~/.emacs.d/init.el
+```
+
+### 3、在 Emacs 上通过 Anaconda 运行你第一个脚本
+
+#### 3.1 创建新 .py 文件
+
+```
+C-x C-f
+HelloWorld.py RET
+```
+
+#### 3.2 输入下面代码
+
+```
+print ("Hello World from Emacs")
+```
+
+#### 3.3 运行之
+
+```
+C-c C-p
+C-c C-c
+```
+
+输出为:
+
+```
+Python 3.7.1 (default, Dec 14 2018, 19:46:24)
+[GCC 7.3.0] :: Anaconda, Inc. on linux
+Type "help", "copyright", "credits" or "license" for more information.
+>>> python.el: native completion setup loaded
+>>> Hello World from Emacs
+>>>
+```
+
+我是受到 [Codingquark][5] 的影响才开始使用 Emacs 的。
+
+有任何错误和遗漏请在评论中写下。干杯!
+
+--------------------------------------------------------------------------------
+
+via: https://idevji.com/configure-anaconda-on-emacs/
+
+作者:[Devji Chhanga][a]
+选题:[lujun9972][b]
+译者:[lujun9972](https://github.com/lujun9972)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://idevji.com/author/admin/
+[b]: https://github.com/lujun9972
+[1]: https://www.gnu.org/software/emacs/
+[2]: https://www.math.uh.edu/~bgb/emacs_keys.html
+[3]: https://www.anaconda.com/download/#linux
+[4]: https://melpa.org/#/getting-started
+[5]: https://codingquark.com
diff --git a/published/201903/20190116 Get started with Cypht, an open source email client.md b/published/201903/20190116 Get started with Cypht, an open source email client.md
new file mode 100644
index 0000000000..b14eabca16
--- /dev/null
+++ b/published/201903/20190116 Get started with Cypht, an open source email client.md
@@ -0,0 +1,59 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10642-1.html)
+[#]: subject: (Get started with Cypht, an open source email client)
+[#]: via: (https://opensource.com/article/19/1/productivity-tool-cypht-email)
+[#]: author: (Kevin Sonney https://opensource.com/users/ksonney (Kevin Sonney))
+
+开始使用 Cypht 吧,一个开源的电子邮件客户端
+======
+
+> 使用 Cypht 将你的电子邮件和新闻源集成到一个界面中,这是我们 19 个开源工具系列中的第 4 个,它将使你在 2019 年更高效。
+
+
+
+每年年初似乎都有疯狂的冲动想提高工作效率。新年的决心,渴望开启新的一年,当然,“抛弃旧的,拥抱新的”的态度促成了这一切。通常这时的建议严重偏向闭源和专有软件,但事实上并不用这样。
+
+这是我挑选出的 19 个新的(或者对你而言新的)开源工具中的第 4 个工具来帮助你在 2019 年更有效率。
+
+### Cypht
+
+我们花了很多时间来处理电子邮件,有效地[管理你的电子邮件][1]可以对你的工作效率产生巨大影响。像 Thunderbird、Kontact/KMail 和 Evolution 这样的程序似乎都有一个共同点:它们试图复制 Microsoft Outlook 的功能,这在过去 10 年左右并没有真正改变。在过去十年中,甚至像 Mutt 和 Cone 这样的[著名控制台程序][2]也没有太大变化。
+
+
+
+[Cypht][3] 是一个简单、轻量级和现代的 Webmail 客户端,它将多个帐户聚合到一个界面中。除了电子邮件帐户,它还包括 Atom/RSS 源。在 “Everything” 中,不仅可以显示收件箱中的邮件,还可以显示新闻源中的最新文章,从而使得阅读不同来源的内容变得简单。
+
+
+
+它使用简化的 HTML 消息来显示邮件,或者你也可以将其设置为查看纯文本版本。由于 Cypht 不会加载远程图像(以帮助维护安全性),HTML 渲染可能有点粗糙,但它足以完成工作。你将看到包含大量富文本邮件的纯文本视图 —— 这意味着很多链接并且难以阅读。我不会说是 Cypht 的问题,因为这确实是发件人所做的,但它确实降低了阅读体验。阅读新闻源大致相同,但它们与你的电子邮件帐户集成,这意味着可以轻松获取最新的(我有时会遇到问题)。
+
+
+
+用户可以使用预配置的邮件服务器并添加他们使用的任何其他服务器。Cypht 的自定义选项包括纯文本与 HTML 邮件显示,它支持多个配置文件以及更改主题(并自行创建)。你要记得单击左侧导航栏上的“保存”按钮,否则你的自定义设置将在该会话后消失。如果你在不保存的情况下注销并重新登录,那么所有更改都将丢失,你将获得开始时的设置。因此可以轻松地实验,如果你需要重置,只需在不保存的情况下注销,那么在再次登录时就会看到之前的配置。
+
+
+
+本地[安装 Cypht][4] 非常容易。虽然它不使用容器或类似技术,但安装说明非常清晰且易于遵循,并且不需要我做任何更改。在我的笔记本上,从安装开始到首次登录大约需要 10 分钟。服务器上的共享安装使用相同的步骤,因此它应该大致相同。
+
+最后,Cypht 是桌面和基于 Web 的电子邮件客户端的绝佳替代方案,它有简单的界面,可帮助你快速有效地处理电子邮件。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/1/productivity-tool-cypht-email
+
+作者:[Kevin Sonney][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/ksonney (Kevin Sonney)
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/article/17/7/email-alternatives-thunderbird
+[2]: https://opensource.com/life/15/8/top-4-open-source-command-line-email-clients
+[3]: https://cypht.org/
+[4]: https://cypht.org/install.html
diff --git a/published/201903/20190117 Get started with CryptPad, an open source collaborative document editor.md b/published/201903/20190117 Get started with CryptPad, an open source collaborative document editor.md
new file mode 100644
index 0000000000..74430b642d
--- /dev/null
+++ b/published/201903/20190117 Get started with CryptPad, an open source collaborative document editor.md
@@ -0,0 +1,60 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10636-1.html)
+[#]: subject: (Get started with CryptPad, an open source collaborative document editor)
+[#]: via: (https://opensource.com/article/19/1/productivity-tool-cryptpad)
+[#]: author: (Kevin Sonney https://opensource.com/users/ksonney (Kevin Sonney))
+
+开始使用 CryptPad 吧,一个开源的协作文档编辑器
+======
+
+> 使用 CryptPad 安全地共享你的笔记、文档、看板等,这是我们在开源工具系列中的第 5 个工具,它将使你在 2019 年更高效。
+
+
+
+每年年初似乎都有疯狂的冲动想提高工作效率。新年的决心,渴望开启新的一年,当然,“抛弃旧的,拥抱新的”的态度促成了这一切。通常这时的建议严重偏向闭源和专有软件,但事实上并不用这样。
+
+这是我挑选出的 19 个新的(或者对你而言新的)开源工具中的第 5 个工具来帮助你在 2019 年更有效率。
+
+### CryptPad
+
+我们已经介绍过 [Joplin][1],它能很好地保存自己的笔记,但是,你可能已经注意到,它没有任何共享或协作功能。
+
+[CryptPad][2] 是一个安全、可共享的笔记应用和文档编辑器,它能够安全地协作编辑。与 Joplin 不同,它是一个 NodeJS 应用,这意味着你可以在桌面或其他服务器上运行它,并使用任何现代 Web 浏览器访问。它开箱即用,它支持富文本、Markdown、投票、白板,看板和 PPT。
+
+
+
+它支持不同的文档类型且功能齐全。它的富文本编辑器涵盖了你所期望的所有基础功能,并允许你将文件导出为 HTML。它的 Markdown 的编辑能与 Joplin 相提并论,它的看板虽然不像 [Wekan][3] 那样功能齐全,但也做得不错。其他支持的文档类型和编辑器也很不错,并且有你希望在类似应用中看到的功能,尽管投票功能显得有些粗糙。
+
+
+
+然而,CryptPad 的真正强大之处在于它的共享和协作功能。共享文档只需在“共享”选项中获取可共享 URL,CryptPad 支持使用 `