mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-04-02 02:50:11 +08:00
commit
1aa0a41995
README.md
published
20151019 Gaming On Linux--All You Need To Know.md20151202 KDE vs GNOME vs XFCE Desktop.md20151227 Upheaval in the Debian Live project.md20160204 An Introduction to SELinux.md
201604
20151028 10 Tips for 10x Application Performance.md20151109 How to Configure Tripwire IDS on Debian.md20151114 How to Setup Drone - a Continuous Integration Service in Linux.md20151119 Going Beyond Hello World Containers is Hard Stuff.md20151126 Microsoft and Linux--True Romance or Toxic Love.md20160212 How to Add New Disk in Linux CentOS 7 Without Rebooting.md20160220 Make Sudo Insult User For Each Incorrect Password Attempt.md20160223 BeeGFS Parallel File System Goes Open Source.md20160226 How to use Python to hack your Eclipse IDE.md20160405 Ubuntu Budgie Could Be the New Flavor of Ubuntu Linux, as Part of Ubuntu 16.10.md20160414 Linux Kernel 3.12 to Be Supported Until 2017 Because of SUSE Linux Enterprise 12.md
sources
news
talk
20150820 Which Open Source Linux Distributions Would Presidential Hopefuls Run.md20151227 Upheaval in the Debian Live project.md20160505 Confessions of a cross-platform developer.md
my-open-source-story
tech
20160204 An Introduction to SELinux.md20160218 7 Steps to Start Your Linux SysAdmin Career.md20160218 9 Key Trends in Hybrid Cloud Computing.md20160218 Tizen 3.0 Joins Growing List of Raspberry Pi 2 Distributions.md20160220 Convergence Becomes Real With First Ubuntu Tablet.md20160301 The Evolving Market for Commercial Software Built On Open Source.md20160429 Master OpenStack with 5 new tutorials.md20160502 The intersection of Drupal, IoT, and open hardware.md
LFCS
Part 14 - Monitor Linux Processes Resource Usage and Set Process Limits on a Per-User Basis.mdPart 7 - LFCS--Managing System Startup Process and Services SysVinit Systemd and Upstart.md
LXD
translated
talk
20151124 Review--5 memory debuggers for Linux coding.md20151202 KDE vs GNOME vs XFCE Desktop.md
my-open-source-story
tech
20151122 Doubly linked list in the Linux Kernel.md20151130 Useful Linux and Unix Tape Managements Commands For Sysadmins.md20151202 8 things to do after installing openSUSE Leap 42.1.md20151207 5 great Raspberry Pi projects for the classroom.md20160218 7 Steps to Start Your Linux SysAdmin Career.md20160218 9 Key Trends in Hybrid Cloud Computing.md20160226 How to use Python to hack your Eclipse IDE.md20160301 The Evolving Market for Commercial Software Built On Open Source.md
LFCS
LXD
76
README.md
76
README.md
@ -1,9 +1,9 @@
|
||||
简介
|
||||
-------------------------------
|
||||
|
||||
LCTT是“Linux中国”([http://linux.cn/](http://linux.cn/))的翻译组,负责从国外优秀媒体翻译Linux相关的技术、资讯、杂文等内容。
|
||||
LCTT是“Linux中国”([https://linux.cn/](https://linux.cn/))的翻译组,负责从国外优秀媒体翻译Linux相关的技术、资讯、杂文等内容。
|
||||
|
||||
LCTT已经拥有近百余名活跃成员,并欢迎更多的Linux志愿者加入我们的团队。
|
||||
LCTT已经拥有几百名活跃成员,并欢迎更多的Linux志愿者加入我们的团队。
|
||||
|
||||

|
||||
|
||||
@ -52,13 +52,15 @@ LCTT的组成
|
||||
* 2015/04/19 发起 LFS-BOOK-7.7-systemd 项目。
|
||||
* 2015/06/09 提升ictlyh和dongfengweixiao为Core Translators成员。
|
||||
* 2015/11/10 提升strugglingyouth、FSSlc、Vic020、alim0x为Core Translators成员。
|
||||
* 2016/05/09 提升PurlingNayuki为校对。
|
||||
|
||||
活跃成员
|
||||
-------------------------------
|
||||
|
||||
目前 TP 活跃成员有:
|
||||
- CORE @wxy,
|
||||
- CORE @DeadFire,
|
||||
- Leader @wxy,
|
||||
- Source @oska874,
|
||||
- Proofreader @PurlingNayuki,
|
||||
- CORE @geekpi,
|
||||
- CORE @GOLinux,
|
||||
- CORE @ictlyh,
|
||||
@ -71,6 +73,7 @@ LCTT的组成
|
||||
- CORE @Vic020,
|
||||
- CORE @dongfengweixiao,
|
||||
- CORE @alim0x,
|
||||
- Senior @DeadFire,
|
||||
- Senior @reinoir,
|
||||
- Senior @tinyeyeser,
|
||||
- Senior @vito-L,
|
||||
@ -80,41 +83,42 @@ LCTT的组成
|
||||
- ZTinoZ,
|
||||
- theo-l,
|
||||
- luoxcat,
|
||||
- disylee,
|
||||
- martin2011qi,
|
||||
- wi-cuckoo,
|
||||
- disylee,
|
||||
- haimingfg,
|
||||
- KayGuoWhu,
|
||||
- wwy-hust,
|
||||
- martin2011qi,
|
||||
- cvsher,
|
||||
- felixonmars,
|
||||
- su-kaiyao,
|
||||
- ivo-wang,
|
||||
- GHLandy,
|
||||
- cvsher,
|
||||
- wyangsun,
|
||||
- DongShuaike,
|
||||
- flsf,
|
||||
- SPccman,
|
||||
- Stevearzh
|
||||
- mr-ping,
|
||||
- Linchenguang,
|
||||
- oska874
|
||||
- Linux-pdz,
|
||||
- 2q1w2007,
|
||||
- felixonmars,
|
||||
- wyangsun,
|
||||
- MikeCoder,
|
||||
- mr-ping,
|
||||
- xiqingongzi
|
||||
- H-mudcup,
|
||||
- zhangboyue,
|
||||
- cposture,
|
||||
- xiqingongzi,
|
||||
- goreliu,
|
||||
- DongShuaike,
|
||||
- NearTan,
|
||||
- TxmszLou,
|
||||
- ZhouJ-sh,
|
||||
- wangjiezhe,
|
||||
- NearTan,
|
||||
- icybreaker,
|
||||
- shipsw,
|
||||
- johnhoow,
|
||||
- soooogreen,
|
||||
- linuhap,
|
||||
- boredivan,
|
||||
- blueabysm,
|
||||
- liaoishere,
|
||||
- boredivan,
|
||||
- name1e5s,
|
||||
- yechunxiao19,
|
||||
- l3b2w1,
|
||||
- XLCYun,
|
||||
@ -122,43 +126,55 @@ LCTT的组成
|
||||
- tenght,
|
||||
- coloka,
|
||||
- luoyutiantang,
|
||||
- yupmoon,
|
||||
- sonofelice,
|
||||
- jiajia9linuxer,
|
||||
- scusjs,
|
||||
- tnuoccalanosrep,
|
||||
- woodboow,
|
||||
- 1w2b3l,
|
||||
- JonathanKang,
|
||||
- crowner,
|
||||
- mtunique,
|
||||
- dingdongnigetou,
|
||||
- CNprober,
|
||||
- JonathanKang,
|
||||
- Medusar,
|
||||
- hyaocuk,
|
||||
- szrlee,
|
||||
- KnightJoker,
|
||||
- Xuanwo,
|
||||
- nd0104,
|
||||
- jerryling315,
|
||||
- xiaoyu33,
|
||||
- guodongxiaren,
|
||||
- zzlyzq,
|
||||
- yujianxuechuan,
|
||||
- ailurus1991,
|
||||
- ynmlml,
|
||||
- kylepeng93,
|
||||
- ggaaooppeenngg,
|
||||
- Ricky-Gong,
|
||||
- zky001,
|
||||
- Flowsnow,
|
||||
- lfzark,
|
||||
- 213edu,
|
||||
- Tanete,
|
||||
- liuaiping,
|
||||
- jerryling315,
|
||||
- bestony,
|
||||
- Timeszoro,
|
||||
- rogetfan,
|
||||
- itsang,
|
||||
- JeffDing,
|
||||
- Yuking-net,
|
||||
|
||||
- MikeCoder,
|
||||
- zhangboyue,
|
||||
- liaoishere,
|
||||
- yupmoon,
|
||||
- Medusar,
|
||||
- zzlyzq,
|
||||
- yujianxuechuan,
|
||||
- ailurus1991,
|
||||
- tomatoKiller,
|
||||
- stduolc,
|
||||
- shaohaolin,
|
||||
- Timeszoro,
|
||||
- rogetfan,
|
||||
- FineFan,
|
||||
- kingname,
|
||||
- jasminepeng,
|
||||
- JeffDing,
|
||||
- CHINAANSHE,
|
||||
|
||||
(按提交行数排名前百)
|
||||
@ -173,7 +189,7 @@ LFS 项目活跃成员有:
|
||||
- @KevinSJ
|
||||
- @Yuking-net
|
||||
|
||||
(更新于2015/11/29)
|
||||
(更新于2016/05/09)
|
||||
|
||||
谢谢大家的支持!
|
||||
|
||||
|
||||
@ -2,29 +2,29 @@ Linux上的游戏:所有你需要知道的
|
||||
================================================================================
|
||||

|
||||
|
||||
** 我能在 Linux 上玩游戏吗 ?**
|
||||
**我能在 Linux 上玩游戏吗 ?**
|
||||
|
||||
这是打算[投奔 Linux 阵营][1]的人最经常问的问题之一。毕竟,在 Linux 上面玩游戏经常被认为有点难以实现。事实上,一些人甚至考虑他们能不能在 Linux 上看电影或者听音乐。考虑到这些,关于 Linux 的平台的游戏的问题是很现实的。「
|
||||
这是打算[投奔 Linux 阵营][1]的人最经常问的问题之一。毕竟,在 Linux 上面玩游戏经常被认为有点难以实现。事实上,一些人甚至考虑他们能不能在 Linux 上看电影或者听音乐。考虑到这些,关于 Linux 的平台的游戏的问题是很现实的。
|
||||
|
||||
在本文中,我将解答大多数 Linux 新手关于在 Linux 打游戏的问题。例如 Linux 下能不能玩游戏,如果能的话,在**哪里下载游戏**或者如何获取有关游戏的信息。
|
||||
在本文中,我将解答大多数 Linux 新手关于在 Linux 中打游戏的问题。例如 Linux 下能不能玩游戏,如果能的话,在哪里**下载游戏**或者如何获取有关游戏的信息。
|
||||
|
||||
但是在此之前,我需要说明一下。我不是一个 PC 上的玩家或者说我不认为我是一个在 Linux 桌面上完游玩戏的家伙。我更喜欢在 PS4 上玩游戏并且我不关心 PC 上的游戏甚至也不关心手机上的游戏(我没有给我的任何一个朋友安利糖果传奇)。这也就是你很少在 It's FOSS 上很少看见关于 [Linux 上的游戏][2]的部分。
|
||||
但是在此之前,我需要说明一下。我不是一个 PC 上的玩家或者说我不认为我是一个在 Linux 桌面游戏玩家。我更喜欢在 PS4 上玩游戏并且我不关心 PC 上的游戏甚至也不关心手机上的游戏(我没有给我的任何一个朋友安利糖果传奇)。这也就是你很少能在 It's FOSS 上很少看见关于 [Linux 上的游戏][2]的原因。
|
||||
|
||||
所以我为什么要写这个主题?
|
||||
所以我为什么要提到这个主题?
|
||||
|
||||
因为别人问过我几次有关 Linux 上的游戏的问题并且我想要写出来一个能解答这些问题的 Linux 上的游戏指南。注意,在这里我不只是讨论 Ubuntu 上的游戏。我讨论的是在所有的 Linux 上的游戏。
|
||||
因为别人问过我几次有关 Linux 上的游戏的问题并且我想要写出来一个能解答这些问题的 Linux 游戏指南。注意,在这里我不只是讨论在 Ubuntu 上玩游戏。我讨论的是在所有的 Linux 上的游戏。
|
||||
|
||||
### 我能在 Linux 上玩游戏吗 ? ###
|
||||
|
||||
是,但不是完全是。
|
||||
|
||||
“是”,是指你能在Linux上玩游戏;“不完全是”,是指你不能在 Linux 上玩 ’所有的游戏‘。
|
||||
“是”,是指你能在Linux上玩游戏;“不完全是”,是指你不能在 Linux 上玩 ‘所有的游戏’。
|
||||
|
||||
什么?你是拒绝的?不必这样。我的意思是你能在 Linux 上玩很多流行的游戏,比如[反恐精英以及地铁:最后的曙光][3]等。但是你可能不能玩到所有在 Windows 上流行的最新游戏,比如[实况足球2015][4]。
|
||||
感到迷惑了吗?不必这样。我的意思是你能在 Linux 上玩很多流行的游戏,比如[反恐精英以及地铁:最后的曙光][3]等。但是你可能不能玩到所有在 Windows 上流行的最新游戏,比如[实况足球 2015 ][4]。
|
||||
|
||||
在我看来,造成这种情况的原因是 Linux 在桌面系统中仅占不到 2%,这占比使得大多数开发者没有在 Linux 上发布他们的游戏的打算。
|
||||
在我看来,造成这种情况的原因是 Linux 在桌面系统中仅占不到 2%,这样的占比使得大多数开发者没有开发其游戏的 Linux 版的动力。
|
||||
|
||||
这就意味指大多数近年来被提及的比较多的游戏很有可能不能在 Linux 上玩。不要灰心。我们能以某种方式在 Linux 上玩这些游戏,我们将在下面的章节中讨论这些方法。但是,在此之前,让我们看看在 Linux 上能玩的游戏的种类。
|
||||
这就意味指大多数近年来被提及的比较多的游戏很有可能不能在 Linux 上玩。不要灰心。还有别的方式在 Linux 上玩这些游戏,我们将在下面的章节中讨论这些方法。但是,在此之前,让我们看看在 Linux 上能玩的游戏的种类。
|
||||
|
||||
要我说的话,我会把那些游戏分为四类:
|
||||
|
||||
@ -33,7 +33,7 @@ Linux上的游戏:所有你需要知道的
|
||||
3. 浏览器里的游戏
|
||||
4. 终端里的游戏
|
||||
|
||||
让我们以最重要的 Linux 的原生游戏开始。
|
||||
让我们以最重要的一类, Linux 的原生游戏开始。
|
||||
|
||||
---------
|
||||
|
||||
@ -41,15 +41,15 @@ Linux上的游戏:所有你需要知道的
|
||||
|
||||
原生游戏指的是官方支持 Linux 的游戏。这些游戏有原生的 Linux 客户端并且能像在 Linux 上的其他软件一样不需要附加的步骤就能安装在 Linux 上面(我们将在下一节讨论)。
|
||||
|
||||
所以,如你所见,这里有一些为 Linux 开发的游戏,下一个问题就是在哪能找到这些游戏以及如何安装。我将列出来一些让你玩到游戏的渠道了。
|
||||
所以,如你所见,有一些为 Linux 开发的游戏,下一个问题就是在哪能找到这些游戏以及如何安装。我将列出一些让你玩到游戏的渠道。
|
||||
|
||||
#### Steam ####
|
||||
|
||||

|
||||
|
||||
“[Steam][5] 是一个游戏的分发平台。就如同 Kindle 是电子书的分发平台,iTunes 是音乐的分发平台一样,Steam 也具有那样的功能。它给了你购买和安装游戏,玩多人游戏以及在它的平台上关注其他游戏的选项。这些游戏被[ DRM ][6]所保护。”
|
||||
“[Steam][5] 是一个游戏的分发平台。就如同 Kindle 是电子书的分发平台, iTunes 是音乐的分发平台一样, Steam 也具有那样的功能。它提供购买和安装游戏,玩多人游戏以及在它的平台上关注其他游戏的选项。其上的游戏被[ DRM ][6]所保护。”
|
||||
|
||||
两年以前,游戏平台 Steam 宣布支持 Linux,这在当时是一个大新闻。这是 Linux 上玩游戏被严肃的对待的一个迹象。尽管这个决定更多地影响了他们自己的基于 Linux 游戏平台[ Steam OS][7]。这仍然是令人欣慰的事情,因为它给 Linux 带来了一大堆游戏。
|
||||
两年以前,游戏平台 Steam 宣布支持 Linux ,这在当时是一个大新闻。这是 Linux 上玩游戏被严肃对待的一个迹象。尽管这个决定更多地影响了他们自己的基于 Linux 游戏平台以及一个独立 Linux 发行版[ Steam OS][7] ,这仍然是令人欣慰的事情,因为它给 Linux 带来了一大堆游戏。
|
||||
|
||||
我已经写了一篇详细的关于安装以及使用 Steam 的文章。如果你想开始使用 Steam 的话,读读那篇文章。
|
||||
|
||||
@ -57,23 +57,23 @@ Linux上的游戏:所有你需要知道的
|
||||
|
||||
#### GOG.com ####
|
||||
|
||||
[GOG.com][9] 失灵一个与 Steam 类似的平台。与 Steam 一样,你能在这上面找到数以百计的 Linux 游戏,你可以购买和安装它们。如果游戏支持好几个平台,尼卡一在多个操作系统上安装他们。你买到你账户的游戏你可以随时玩。捏可以在你想要下载的任何时间下载。
|
||||
[GOG.com][9] 是另一个与 Steam 类似的平台。与 Steam 一样,你能在这上面找到数以百计的 Linux 游戏,并购买和安装它们。如果游戏支持好几个平台,你可以在多个操作系统上安装他们。你可以随时游玩使用你的账户购买的游戏。你也可以在任何时间下载。
|
||||
|
||||
GOG.com 与 Steam 不同的是前者仅提供没有 DRM 保护的游戏以及电影。而且,GOG.com 完全是基于网页的,所以你不需要安装类似 Steam 的客户端。你只需要用浏览器下载游戏然后安装到你的系统上。
|
||||
|
||||
#### Portable Linux Games ####
|
||||
|
||||
[Portable Linux Games][10] 是一个集聚了不少 Linux 游戏的网站。这家网站最特别以及最好的就是你能离线安装这些游戏。
|
||||
[Portable Linux Games][10] 是一个集聚了不少 Linux 游戏的网站。这家网站最特别以及最好的点就是你能离线安装这些游戏。
|
||||
|
||||
你下载到的文件包含所有的依赖(仅需 Wine 以及 Perl)并且他们也是与平台无关的。你所需要的仅仅是下载文件并且双击来启动安装程序。你也可以把文件储存起来以用于将来的安装,如果你网速不够快的话我很推荐您这样做。
|
||||
你下载到的文件包含所有的依赖(仅需 Wine 以及 Perl)并且他们也是与平台无关的。你所需要的仅仅是下载文件并且双击来启动安装程序。你也可以把文件储存起来以用于将来的安装。如果你网速不够快的话,我很推荐你这样做。
|
||||
|
||||
#### Game Drift 游戏商店 ####
|
||||
|
||||
[Game Drift][11] 是一个只专注于游戏的基于 Ubuntu 的 Linux 发行版。但是如果你不想只为游戏就去安装这个发行版的话,你也可以经常上线看哪个游戏可以在 Linux 上运行并且安装他们。
|
||||
[Game Drift][11] 是一个只专注于游戏的基于 Ubuntu 的 Linux 发行版。但是如果你不想只为游戏就去安装这个发行版的话,你也可以经常去它的在线游戏商店去看哪个游戏可以在 Linux 上运行并且安装他们。
|
||||
|
||||
#### Linux Game Database ####
|
||||
|
||||
如其名字所示,[Linux Game Database][12]是一个收集了很多 Linux 游戏的网站。你能在这里浏览诸多类型的游戏并从游戏开发者的网站下载/安装这些游戏。作为这家网站的会员,你甚至可以为游戏打分。LGDB,有点像 Linux 游戏界的 IMDB 或者 IGN.
|
||||
如其名字所示,[Linux Game Database][12]是一个收集了很多 Linux 游戏的网站。你能在这里浏览诸多类型的游戏并从游戏开发者的网站下载/安装这些游戏。作为这家网站的会员,你甚至可以为游戏打分。 LGDB 有点像 Linux 游戏界的 IMDB 或者 IGN.
|
||||
|
||||
#### Penguspy ####
|
||||
|
||||
@ -81,7 +81,7 @@ GOG.com 与 Steam 不同的是前者仅提供没有 DRM 保护的游戏以及电
|
||||
|
||||
#### 软件源 ####
|
||||
|
||||
看看你自己的发行版的软件源。那里可能有一些游戏。如果你用 Ubuntu 的话,它的软件中心里有一个游戏的分类。在一些其他的发行版里也有,比如 Liux Mint 等。
|
||||
看看你自己的发行版的软件源。其中可能有一些游戏。如果你用 Ubuntu 的话,它的软件中心里有一个游戏的分类。在一些其他的发行版里也有,比如 Linux Mint 等。
|
||||
|
||||
----------
|
||||
|
||||
@ -89,19 +89,19 @@ GOG.com 与 Steam 不同的是前者仅提供没有 DRM 保护的游戏以及电
|
||||
|
||||

|
||||
|
||||
到现在为止,我们一直在讨论 Linux 的原生游戏。但是并没有很多 Linux 上的原生游戏,或者说,火的不要不要的游戏大多不支持 Linux,但是都支持 Windows PC。所以,如何在 Linux 上玩 Wendows 的游戏?
|
||||
到现在为止,我们一直在讨论 Linux 的原生游戏。但是并没有很多 Linux 上的原生游戏,或者更准确地说,火的不要不要的游戏大多不支持 Linux,但是都支持 Windows PC 。所以,如何在 Linux 上玩 Windows 的游戏?
|
||||
|
||||
幸好,由于我们有 Wine, PlayOnLinux 和 CrossOver 等工具,我们能在 Linux 上玩不少的 Wendows 游戏。
|
||||
幸好,由于我们有 Wine 、 PlayOnLinux 和 CrossOver 等工具,我们能在 Linux 上玩不少的 Windows 游戏。
|
||||
|
||||
#### Wine ####
|
||||
|
||||
Wine 是一个能使 Wendows 应用在类似 Linux, BSD 和 OS X 上运行的兼容层。在 Wine 的帮助下,你可以在 Linux 下安装以及使用很多 Windows 下的应用。
|
||||
Wine 是一个能使 Windows 应用在类似 Linux , BSD 和 OS X 上运行的兼容层。在 Wine 的帮助下,你可以在 Linux 下安装以及使用很多 Windows 下的应用。
|
||||
|
||||
[在 Ubuntu 上安装 Wine][14]或者在其他 Linux 上安装 Wine 是很简单的,因为大多数发行版的软件源里都有它。这里也有一个很大的[ Wine 支持的应用的数据库][15]供您浏览。
|
||||
|
||||
#### CrossOver ####
|
||||
|
||||
[CrossOver][16] 是 Wine 的增强版,它给 Wine 提供了专业的技术上的支持。但是与 Wine 不同, CrossOver 不是免费的。你需要购买许可。好消息是它会把更新也贡献到 Wine 的开发者那里并且事实上加速了 Wine 的开发使得 Wine 能支持更多的 Windows 上的游戏和应用。如果你可以一年支付 48 美元,你可以购买 CrossOver 并得到他们提供的技术支持。
|
||||
[CrossOver][16] 是 Wine 的增强版,它给 Wine 提供了专业的技术上的支持。但是与 Wine 不同, CrossOver 不是免费的。你需要购买许可。好消息是它会把更新也贡献到 Wine 的开发者那里并且事实上加速了 Wine 的开发使得 Wine 能支持更多的 Windows 上的游戏和应用。如果你可以接受每年支付 48 美元,你可以购买 CrossOver 并得到他们提供的技术支持。
|
||||
|
||||
### PlayOnLinux ###
|
||||
|
||||
@ -113,9 +113,9 @@ PlayOnLinux 也基于 Wine 但是执行程序的方式略有不同。它有着
|
||||
|
||||

|
||||
|
||||
不必说你也应该知道有非常多的基于网页的游戏,这些游戏都可以在任何操作系统里运行,无论是 Windows,Linux,还是 OS X。大多数让人上瘾的手机游戏,比如[帝国之战][18]就有官方的网页版。
|
||||
不必说你也应该知道有非常多的基于网页的游戏,这些游戏都可以在任何操作系统里运行,无论是 Windows ,Linux ,还是 OS X 。大多数让人上瘾的手机游戏,比如[帝国之战][18]就有官方的网页版。
|
||||
|
||||
除了这些,还有 [Google Chrome在线商店][19],你可以在 Linux 上玩更多的这些游戏。这些 Chrome 上的游戏可以像一个单独的应用一样安装并从应用菜单中打开,一些游戏就算是离线也能运行。
|
||||
除了这些,还有 [Google Chrome 在线商店][19],你可以在 Linux 上玩更多的这些游戏。这些 Chrome 上的游戏可以像一个单独的应用一样安装并从应用菜单中打开,一些游戏就算是离线也能运行。
|
||||
|
||||
----------
|
||||
|
||||
@ -123,7 +123,7 @@ PlayOnLinux 也基于 Wine 但是执行程序的方式略有不同。它有着
|
||||
|
||||

|
||||
|
||||
使用 Linux 的一个附加优势就是可以使用命令行终端玩游戏。我知道这不是最好的玩游戏的 方法,但是在终端里玩[贪吃蛇][20]或者 [2048][21] 很有趣。在[这个博客][21]中有一些好玩的的终端游戏。你可以浏览并安装你喜欢的游戏。
|
||||
使用 Linux 的一个附加优势就是可以使用命令行终端玩游戏。我知道这不是最好的玩游戏的方法,但是在终端里玩[贪吃蛇][20]或者 [2048][21] 很有趣。在[这个博客][21]中有一些好玩的的终端游戏。你可以浏览并安装你喜欢的游戏。
|
||||
|
||||
----------
|
||||
|
||||
@ -131,21 +131,21 @@ PlayOnLinux 也基于 Wine 但是执行程序的方式略有不同。它有着
|
||||
|
||||
当你了解了不少的在 Linux 上你可以玩到的游戏以及你如何使用他们,下一个问题就是如何保持游戏的版本是最新的。对于这件事,我建议你看看下面的博客,这些博客能告诉你 Linux 游戏世界的最新消息:
|
||||
|
||||
- [Gaming on Linux][23]:我认为我把它叫做 Linux 游戏的门户并没有错误。在这你可以得到关于 Linux 的游戏的最新的传言以及新闻。最近, Gaming on Linux 有了一个由 Linux 游戏爱好者组成的漂亮的社区。
|
||||
- [Gaming on Linux][23]:我认为我把它叫做 Linux 游戏专业门户并没有错误。在这你可以得到关于 Linux 的游戏的最新的传言以及新闻。它经常更新, 还有由 Linux 游戏爱好者组成的优秀社区。
|
||||
- [Free Gamer][24]:一个专注于免费开源的游戏的博客。
|
||||
- [Linux Game News][25]:一个提供很多的 Linux 游戏的升级的 Tumbler 博客。
|
||||
|
||||
#### 还有别的要说的吗? ####
|
||||
|
||||
我认为让你知道如何开始在 Linux 上的游戏人生是一个好事。如果你仍然不能被说服。我推荐你做个[双系统][26],把 Linux 作为你的主要桌面系统,当你想玩游戏时,重启到 Windows。这是一个对游戏妥协的解决办法。
|
||||
我认为让你知道如何开始在 Linux 上的游戏人生是一个好事。如果你仍然不能被说服,我推荐你做个[双系统][26],把 Linux 作为你的主要桌面系统,当你想玩游戏时,重启到 Windows。这是一个对游戏妥协的解决办法。
|
||||
|
||||
现在,这里是你说出你自己的状况的时候了。你在 Linux 上玩游戏吗?你最喜欢什么游戏?你关注了哪些游戏博客?
|
||||
现在,这里是你说出你自己的想法的时候了。你在 Linux 上玩游戏吗?你最喜欢什么游戏?你关注了哪些游戏博客?
|
||||
|
||||
|
||||
投票项目:
|
||||
你怎样在 Linux 上玩游戏?
|
||||
|
||||
- 我玩原生 Linux 游戏,我也用 Wine 以及 PlayOnLinux 运行 Windows 游戏
|
||||
- 我玩原生 Linux 游戏,也用 Wine 以及 PlayOnLinux 运行 Windows 游戏
|
||||
- 我喜欢网页游戏
|
||||
- 我喜欢终端游戏
|
||||
- 我只玩原生 Linux 游戏
|
||||
@ -167,7 +167,7 @@ via: http://itsfoss.com/linux-gaming-guide/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[name1e5s](https://github.com/name1e5s)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[PurlingNayuki](https://github.com/PurlingNayuki)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
53
published/20151202 KDE vs GNOME vs XFCE Desktop.md
Normal file
53
published/20151202 KDE vs GNOME vs XFCE Desktop.md
Normal file
@ -0,0 +1,53 @@
|
||||
KDE、GNOME 和 XFCE 桌面比较
|
||||
================================================================================
|
||||

|
||||
|
||||
这么多年来,很多人一直都在他们的 linux 桌面端使用 KDE 或者 GNOME 桌面环境。在这两个桌面环境多年不断发展的同时,其它的桌面也在持续增加它们的用户规模。举个例子说,在轻量级桌面环境下,XFCE 一举成为了最受欢迎的桌面环境,相较于 LXDE 缺少的优美视觉效果,默认配置下的 XFCE 在这方面就可以打败前者。XFCE 提供的功能特性都能在 GNOME2 下得到,然而,在一些较老的计算机上,它的轻量级的特性却能取得更好的效果。
|
||||
|
||||
### 桌面主题定制 ###
|
||||
|
||||
用户完成安装之后,XFCE 看起来可能会有一点无趣,因为它在视觉上还缺少一些吸引力。但是,请不要误解我的话, XFCE 仍然拥有漂亮的桌面,但是对于大多数刚刚接触 XFCE 桌面环境的人来说,可能它看起来像香草一样普普通通。不过好消息是当我们想要给 XFCE 安装新的主题的时候,这会是一个十分轻松的过程,因为你能够快速的找到你喜欢的 XFCE 主题,之后你就可以将它解压到一个合适的目录中。从这一点上来说,XFCE 自带的一个放在“外观”下的重要的图形界面工具可以帮助用户更加容易的选择中意的主题,这可能是目前在 XFCE 上这方面最好用的工具了。如果用户按照上面的建议去做的话,对于想要尝试使用 XFCE 的任何用户来说都将不存在困难。
|
||||
|
||||
在 GNOME 桌面上,用户也可以按照类似上面的方法去做。不过,其中最主要的不同点就是在你做之前,用户必须手动下载并安装 GNOME Tweak Tool。当然,对于使用来说都不会有什么障碍,但是对于用户来说,使用 XFCE 安装和激活主题并不需要去额外去下载安装各种调整工具,这可能是他们无法忽略的一个优势。而在 GNOME 上,尤其是在用户已经下载并安装了 GNOME Tweak tool 之后,你仍将必须确保你已经安装了“用户主题扩展”。
|
||||
|
||||
同 XFCE 一样,用户需要去搜索并下载自己喜欢的主题,然后,用户可以再次使用 GNOME Tweak tool,并点击该工具界面左边的“外观”按钮,接着用户便可以直接查看页面底部并点击文件浏览按钮,然后浏览到那个压缩的文件夹并打开。当完成这些之后,用户将会看到一个告诉用户已经成功应用了主题的对话框,这样你的主题便已经安装完成。然后用户就可以简单的使用下拉菜单来选择他们想要的主题。和 XFCE 一样,主题激活的过程也是十分简单的,然而,对于因为要使用一个新的主题而去下载一个没有预先安装到系统里面的应用,这种情况也是需要考虑的。
|
||||
|
||||
最后,就是 KDE 桌面主题定制的过程了。和 XFCE 一样,不需要去下载额外的工具来安装主题。从这点来看,让人有种XFCE 可能要被 KDE 战胜了的感觉。不仅在 KDE 上可以完全使用图形用户界面来安装主题,而且甚至只需要用户点击获取新主题的按钮就可以找到、查看新的主题,并且最后自动安装。
|
||||
|
||||
然而,我们应该注意到 KDE 相比 XFCE 而言,是一个更加健壮完善的桌面环境。当然,对于主要以极简设计为目的的桌面来说,缺失一些更多的功能是有一定的道理的。为此,我们要为这样优秀的功能给 KDE 加分。
|
||||
|
||||
### MATE 不是一个轻量级的桌面环境 ###
|
||||
|
||||
在继续比较 XFCE、GNOME3 和 KDE 之前,对于老手我们需要澄清一下,我们没有将 MATE 桌面环境加入到我们的比较中。MATE 可被看作是 GNOME2 的另一个衍生品,但是它并没有主要作为一款轻量级或者快捷桌面出现。相反,它的主要目的是成为一款更加传统和舒适的桌面环境,并使它的用户在使用它时就像在家里一样舒适。
|
||||
|
||||
另一方面,XFCE 生来就是要实现他自己的一系列使命。XFCE 给它的用户提供了一个更轻量而仍保持吸引人的视觉体验的桌面环境。然后,对于一些认为 MATE 也是一款轻量级的桌面环境的人来说,其实 MATE 真正的目标并不是成为一款轻量级的桌面环境。这两种选择在各自安装了一款好的主题之后看起来都会让人觉得非常具有吸引力。
|
||||
|
||||
### 桌面导航 ###
|
||||
|
||||
XFCE 除了桌面,还提供了一个醒目的导航器。任何使用过传统的 Windows 或者 GNOME 2/MATE 桌面环境的用户都可以在没有任何帮助的情况下自如的使用新安装的 XFCE 桌面环境的导航器。紧接着,添加小程序到面板中也是很显眼的。就像找一个已经安装的应用程序一样,直接使用启动器并点击你想要运行的应用程序图标就行。除了 LXDE 和 MATE 之外,还没有其他的桌面的导航器可以做到如此简单。不仅如此,更好的是控制面板的使用是非常容易使用的,对于刚刚使用这个新桌面的用户来说这是一个非常大的好处。如果用户更喜欢通过老式的方法去使用他们的桌面,那么 GNOME 就不合适。通过热角而取代了最小化按钮,加上其他的应用排布方式,这可以让大多数新用户易于使用它。
|
||||
|
||||
如果用户来自类似 Windows 这样的桌面环境,那么这些用户需要摒弃这些习惯,不能简单的通过鼠标右击一下就将一个小程序添加到他们的工作空间顶部。与此相反,它可以通过使用扩展来实现。GNOME 是可以安装拓展的,并且是非常的容易,这些容易之处体现在只需要用户简单的使用位于 GNOME 扩展页面上的 on/off 开关即可。不过,用户必须知道这个东西,才能真正使用上这个功能。
|
||||
|
||||
另一方面,GNOME 正在它的外观中体现它的设计理念,即为用户提供一个直观和易用的控制面板。你可能认为那并不是什么大事,但是,在我看来,它确实是我认为值得称赞并且有必要被提及的方面。KDE 给它的用户提供了更多的传统桌面使用体验,并通过提供相似的启动器和一种更加类似的获取软件的方式的能力来迎合来自 Windows 的用户。添加小部件或者小程序到 KDE 桌面是件非常简单的事情,只需要在桌面上右击即可。唯一的问题是 KDE 中这个功能不好发现,就像 KDE 中的其它东西一样,对于用户来说好像是隐藏的。KDE 的用户可能不同意我的观点,但我仍然坚持我的说法。
|
||||
|
||||
要增加一个小部件,只要在“我的面板”上右击就可以看见面板选项,但是并不是安装小部件的一个直观的方法。你并不能看见“添加部件”,除非你选择了“面板选项”,然后才能看见“添加部件”。这对我来说不是个问题,但是对于一些用户来说,它变成了不必要的困惑。而使事情变得更复杂的是,在用户能够找到部件区域后,他们后来发现一种称为“活动”的新术语。它和部件在同一个地方,可是它在自己的区域却是另外一种行为。
|
||||
|
||||
现在请不要误解我,KDE 中的活动特性是很不错的,也是很有价值的,但是从可用性的角度看,为了不让新手感到困惑,它更加适合于放在另一个菜单项。用户各有不同,但是让新用户多测试一段时间可以让它不断改进。对“活动”的批评先放一边,KDE 添加新部件的方法的确很棒。与 KDE 的主题一样,用户不能通过使用提供的图形用户界面浏览和自动安装部件。这是一个有点神奇的功能,但是它这样也可以工作。KDE 的控制面板可能和用户希望的样子不一样,它不是足够的简单。但是有一点很清楚,这将是他们致力于改进的地方。
|
||||
|
||||
### 因此,XFCE 是最好的桌面环境,对吗? ###
|
||||
|
||||
就我自己而言,我在我的计算机上使用 GNOME、KDE,并在我的办公室和家里的电脑上使用 Xfce。我也有一些老机器在使用 Openbox 和 LXDE。每一个桌面的体验都可以给我提供一些有用的东西,可以帮助我以适合的方式使用每台机器。对我来说,Xfce 是我的心中的挚爱,因为 Xfce 是一个我使用了多年的桌面环境。但对于这篇文章,我是用我日常使用的机器来撰写的,事实上,它用的是 GNOME。
|
||||
|
||||
这篇文章的主要思想是,对于那些正在寻找稳定的、传统的、容易理解的桌面环境的用户来说,我还是觉得 Xfce 能提供好一点的用户体验。欢迎您在评论部分和我们分享你的意见。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/kde-vs-gnome-vs-xfce-desktop/
|
||||
|
||||
作者:[M.el Khamlichi][a]
|
||||
译者:[kylepeng93](https://github.com/kylepeng93)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/pirat9/
|
||||
67
published/20151227 Upheaval in the Debian Live project.md
Normal file
67
published/20151227 Upheaval in the Debian Live project.md
Normal file
@ -0,0 +1,67 @@
|
||||
Debian Live项目的剧变
|
||||
==================================================================================
|
||||
|
||||
尽管围绕 Debian Live 项目发生了很多戏剧性事件,关于 [Debian Live 项目][1]结束的[公告][2]的影响力甚至小于该项目首次出现时的公告。主要开发者的离开是最显而易见的损失,而社区对他本人及其项目的态度是很令人困惑的,但是这个项目也许还是会以其他的形式继续下去。所以 Debian 仍然会有更多的工具去创造启动光盘和其他介质。尽管是用这样一种有遗憾的方式,项目创始人 Dabiel Baumann 和 Debian CD 团队以及安装检测团队之间出现的长期争论已经被「解决」了。
|
||||
在 11 月 9 日, Baumann 发表了题为「 Debian Live 项目的突然结束」的一篇公告。在那篇短文中,他一一列举出了自从这个和他有关的[项目被发起][3]以来近 10 年间发生的不同的事件,这些事件可以表明他在 Debian Live 项目上的努力一直没有被重视或没有被足够重视。最具决定性的因素是因为在「包的含义」上存在冲突, R.Learmonth [申请][4]了新的包名,而这侵犯了在 Debian Live 上使用的命名空间。
|
||||
|
||||
考虑到最主要的 Debian Live 包之一被命名为 live-build ,而 R.Learmonth 申请的新包名却是 live-build-ng ,这简直是对 live-build 的挑战。 live-build-ng 意为一种围绕 [vmdebootstrap][5]【译者注:创造真实的和虚拟机Debian的磁盘映像】工具的外部包装,这种包装是为了创造 live 介质(光盘和USB的插入),也是 Debian Live 最需要的的部分。但是当 Baumann Learmonth [要求][6]为他的包换一个不同的名字的时候,他得到了一个「有趣」的[回复][7]:
|
||||
|
||||
```
|
||||
应该注意到, live-build 不是一个 Debian 项目,它是一个声称自己是官方 Debian 项目的外部项目,这是一个需要我们解决的问题。
|
||||
这不是命名空间的问题,我们要将以目前维护的 live-config 和 live-boot 包为基础,把它们加入到 Debian 的本地项目。如果迫不得已的话,这将会有很多分支,但是我希望它不要发生,这样的话我们就可以把这些包整合到 Debian 中并继续以一种协作的方式去开发。
|
||||
live-build 已经被 debian-cd 放弃,live-build-ng 将会取代它。至少在一个精简的 Debian 环境中,live-build 会被放弃。我们(开发团队)正在与 debian-cd 和 Debian Installer 团队合作开发 live-build-ng 。
|
||||
```
|
||||
|
||||
Debian Live 是一个「官方的」 Debian 项目(也可以是狭义的「官方」),尽管它因为思路上的不同产生过争论。除此之外, vmdebootstrap 的维护者 Neil Willians 为脱离 Debian Live 项目[提供了如下的解释][8]:
|
||||
|
||||
```
|
||||
为了更好的支持 live-build 的代替者, vmdebootstrap 肯定会被推广。为了能够用 live-build 解决目前存在的问题,这项工作会由 debian-cd 团队来负责。这些问题包括可靠性问题,以及不能很好的支持多种机器和 UEFI 等。 vmdebootstrap 也存在着这些问题,我们用来自于对 live-boot 和 live-config 的支持情况来确定 vmdebootstrap 的功能。
|
||||
```
|
||||
|
||||
这些抱怨听起来合情合理,但是它们可能已经在目前的项目中得到了解决。然而一些秘密的项目有很明显的取代 live-build 的意图。正如 Baumann [指出][9]的,这些计划没有被发布到 debian-live 的邮件列表中。人们首次从 Debian Live 项目中获知这些计划正是因为这一次的ITP事件,所以它看起来像是一个「秘密计划」——有些事情在像 Debian 这样的项目中得不到很好的安排。
|
||||
|
||||
人们可能已经猜到了,有很多帖子都支持 Baumann [重命名][10] live-build-ng 的请求,但是紧接着,人们就因为他要停止继续在 Debian Live 上工作的决定而变得沮丧。然而 Learmonth 和 Williams 却坚持认为取代 live-build 很有必要。Learmonth 给 live-build-ng 换了一个争议性也许小一些的名字: live-wrapper 。他说他的目标是为 Debian Live 项目加入新的工具(并且「把 Debian Live 项目引入 Debian 里面」),但是完成这件事还需要很大的努力。
|
||||
|
||||
```
|
||||
我向已经被 ITP 问题所困扰的每个人道歉。我们已经告知大家 live-wrapper 还不足以完全替代 live-build 且开发工作仍在进行以收集反馈。尽管有了这部分的工作,我们收到的反馈缺并不是我们所需要的。
|
||||
```
|
||||
|
||||
这种对于取代 live-build 的强烈反对或许已经被预知到了。自由软件社区的沟通和交流很关键,所以,计划去替换一个项目的核心很容易引起争议——更何况是一个一直不为人所知的计划。从 Banumann 的角度来说,他当然不是完美的,他因为上传个不合适的 [syslinux 包][11]导致了 wheezy 的延迟发布,并且从那以后他被从 Debian 开发者暂时[降级][12]为 Debian 维护者。但是这不意味着他应该受到这种对待。当然,这个项目还有其他人参与,所以不仅仅是 Baumann 受到了影响。
|
||||
|
||||
Ben Armstrong 是其他参与者中的一位,在这个事件中,他很圆滑地处理了一些事,并且想从这个事件中全身而退。他从一封邮件[13]开始,这个邮件是为了庆祝这个项目,以及他和他的团队在过去几年取得的成果。正如他所说, Debian Live 的[下游项目列表][14]是很令人振奋的。在另一封邮件中,他也[指出][15]了这个项目不是没有生命力的:
|
||||
|
||||
```
|
||||
如果 Debian CD 开发团队通过他们的努力开发出可行的、可靠的、经过完善测试替代品,以及一个合适的取代 live-build 的候选者,这对于 Debian 项目有利无害。如果他们继续做这件事,他们不会「用一个官方改良,但不可靠且几乎没有经过测试的待选者取代 live-build 」。到目前为止,我还没有看到他们那样做的迹象。其间, live-build 仍保留在存档中——它仍然处于良好状态,且没有一种经过改良的继任者来取代它,因此开发团队没有必要尽快删除它。
|
||||
```
|
||||
|
||||
11 月 24 号, Armstrong 也在[他的博客][16]上[发布][17]了一个有关 Debian Live 的新消息。它展示了从 Baumann 退出起两周内的令人高兴的进展。甚至有迹象表明 Debian Live 项目与 live-wrapper 开发者开展了合作。博客上也有了一个[计划表][18],同时不可避免地寻求更多的帮助。这让人们有理由相信围绕项目发生的戏剧性事件仅仅是一个小摩擦——也许不可避免,但绝不是像现在看起来这么糟糕。
|
||||
|
||||
---------------------------------
|
||||
|
||||
via: https://lwn.net/Articles/665839/
|
||||
|
||||
作者:Jake Edge
|
||||
译者:[vim-kakali](https://github.com/vim-kakali)
|
||||
校对:[PurlingNayuki](https://github.com/PurlingNayuki)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
[1]: https://lwn.net/Articles/666127/
|
||||
[2]: http://live.debian.net/
|
||||
[3]: https://www.debian.org/News/weekly/2006/08/
|
||||
[4]: https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=804315
|
||||
[5]: http://liw.fi/vmdebootstrap/
|
||||
[6]: https://lwn.net/Articles/666173/
|
||||
[7]: https://lwn.net/Articles/666176/
|
||||
[8]: https://lwn.net/Articles/666181/
|
||||
[9]: https://lwn.net/Articles/666208/
|
||||
[10]: https://lwn.net/Articles/666321/
|
||||
[11]: https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=699808
|
||||
[12]: https://nm.debian.org/public/process/14450
|
||||
[13]: https://lwn.net/Articles/666336/
|
||||
[14]: http://live.debian.net/project/downstream/
|
||||
[15]: https://lwn.net/Articles/666338/
|
||||
[16]: https://lwn.net/Articles/666340/
|
||||
[17]: http://syn.theti.ca/2015/11/24/debian-live-after-debian-live/
|
||||
[18]: https://wiki.debian.org/DebianLive/TODO
|
||||
127
published/20160204 An Introduction to SELinux.md
Normal file
127
published/20160204 An Introduction to SELinux.md
Normal file
@ -0,0 +1,127 @@
|
||||
SELinux 入门
|
||||
===============================
|
||||
|
||||
回到 Kernel 2.6 时代,那时候引入了一个新的安全系统,用以提供访问控制安全策略的机制。这个系统就是 [Security Enhanced Linux (SELinux)][1],它是由[美国国家安全局(NSA)][2]贡献的,它为 Linux 内核子系统引入了一个健壮的强制控制访问(Mandatory Access Control)架构。
|
||||
|
||||
如果你在之前的 Linux 生涯中都禁用或忽略了 SELinux,这篇文章就是专门为你写的:这是一篇对存在于你的 Linux 桌面或服务器之下的 SELinux 系统的介绍,它能够限制权限,甚至消除程序或守护进程的脆弱性而造成破坏的可能性。
|
||||
|
||||
在我开始之前,你应该已经了解的是 SELinux 主要是红帽 Red Hat Linux 以及它的衍生发行版上的一个工具。类似地, Ubuntu 和 SUSE(以及它们的衍生发行版)使用的是 AppArmor。SELinux 和 AppArmor 有显著的不同。你可以在 SUSE,openSUSE,Ubuntu 等等发行版上安装 SELinux,但这是项难以置信的挑战,除非你十分精通 Linux。
|
||||
|
||||
说了这么多,让我来向你介绍 SELinux。
|
||||
|
||||
### DAC vs. MAC
|
||||
|
||||
Linux 上传统的访问控制标准是自主访问控制(Discretionary Access Control,DAC)。在这种形式下,一个软件或守护进程以 User ID(UID)或 Set owner User ID(SUID)的身份运行,并且拥有该用户的目标(文件、套接字、以及其它进程)权限。这使得恶意代码很容易运行在特定权限之下,从而取得访问关键的子系统的权限。
|
||||
|
||||
另一方面,强制访问控制(Mandatory Access Control,MAC)基于保密性和完整性强制信息的隔离以限制破坏。该限制单元独立于传统的 Linux 安全机制运作,并且没有超级用户的概念。
|
||||
|
||||
### SELinux 如何工作
|
||||
|
||||
考虑一下 SELinux 的相关概念:
|
||||
|
||||
- 主体(Subjects)
|
||||
- 目标(Objects)
|
||||
- 策略(Policy)
|
||||
- 模式(Mode)
|
||||
|
||||
当一个主体(Subject,如一个程序)尝试访问一个目标(Object,如一个文件),SELinux 安全服务器(SELinux Security Server,在内核中)从策略数据库(Policy Database)中运行一个检查。基于当前的模式(mode),如果 SELinux 安全服务器授予权限,该主体就能够访问该目标。如果 SELinux 安全服务器拒绝了权限,就会在 /var/log/messages 中记录一条拒绝信息。
|
||||
|
||||
听起来相对比较简单是不是?实际上过程要更加复杂,但为了简化介绍,只列出了重要的步骤。
|
||||
|
||||
### 模式
|
||||
|
||||
SELinux 有三个模式(可以由用户设置)。这些模式将规定 SELinux 在主体请求时如何应对。这些模式是:
|
||||
|
||||
- Enforcing (强制)— SELinux 策略强制执行,基于 SELinux 策略规则授予或拒绝主体对目标的访问
|
||||
- Permissive (宽容)— SELinux 策略不强制执行,不实际拒绝访问,但会有拒绝信息写入日志
|
||||
- Disabled (禁用)— 完全禁用 SELinux
|
||||
|
||||

|
||||
|
||||
*图 1:getenforce 命令显示 SELinux 的状态是 Enforcing 启用状态。*
|
||||
|
||||
默认情况下,大部分系统的 SELinux 设置为 Enforcing。你要如何知道你的系统当前是什么模式?你可以使用一条简单的命令来查看,这条命令就是 `getenforce`。这个命令用起来难以置信的简单(因为它仅仅用来报告 SELinux 的模式)。要使用这个工具,打开一个终端窗口并执行 `getenforce` 命令。命令会返回 Enforcing、Permissive,或者 Disabled(见上方图 1)。
|
||||
|
||||
设置 SELinux 的模式实际上很简单——取决于你想设置什么模式。记住:**永远不推荐关闭 SELinux**。为什么?当你这么做了,就会出现这种可能性:你磁盘上的文件可能会被打上错误的权限标签,需要你重新标记权限才能修复。而且你无法修改一个以 Disabled 模式启动的系统的模式。你的最佳模式是 Enforcing 或者 Permissive。
|
||||
|
||||
你可以从命令行或 `/etc/selinux/config` 文件更改 SELinux 的模式。要从命令行设置模式,你可以使用 `setenforce` 工具。要设置 Enforcing 模式,按下面这么做:
|
||||
|
||||
1. 打开一个终端窗口
|
||||
2. 执行 `su` 然后输入你的管理员密码
|
||||
3. 执行 `setenforce 1`
|
||||
4. 执行 `getenforce` 确定模式已经正确设置(图 2)
|
||||
|
||||

|
||||
|
||||
*图 2:设置 SELinux 模式为 Enforcing。*
|
||||
|
||||
要设置模式为 Permissive,这么做:
|
||||
|
||||
1. 打开一个终端窗口
|
||||
2. 执行 `su` 然后输入你的管理员密码
|
||||
3. 执行 `setenforce 0`
|
||||
4. 执行 `getenforce` 确定模式已经正确设置(图 3)
|
||||
|
||||

|
||||
|
||||
*图 3:设置 SELinux 模式为 Permissive。*
|
||||
|
||||
注:通过命令行设置模式会覆盖 SELinux 配置文件中的设置。
|
||||
|
||||
如果你更愿意在 SELinux 命令文件中设置模式,用你喜欢的编辑器打开那个文件找到这一行:
|
||||
|
||||
SELINUX=permissive
|
||||
|
||||
你可以按你的偏好设置模式,然后保存文件。
|
||||
|
||||
还有第三种方法修改 SELinux 的模式(通过 bootloader),但我不推荐新用户这么做。
|
||||
|
||||
### 策略类型
|
||||
|
||||
SELinux 策略有两种:
|
||||
|
||||
- Targeted — 只有目标网络进程(dhcpd,httpd,named,nscd,ntpd,portmap,snmpd,squid,以及 syslogd)受保护
|
||||
- Strict — 对所有进程完全的 SELinux 保护
|
||||
|
||||
你可以在 `/etc/selinux/config` 文件中修改策略类型。用你喜欢的编辑器打开这个文件找到这一行:
|
||||
|
||||
SELINUXTYPE=targeted
|
||||
|
||||
修改这个选项为 targeted 或 strict 以满足你的需求。
|
||||
|
||||
### 检查完整的 SELinux 状态
|
||||
|
||||
有个方便的 SELinux 工具,你可能想要用它来获取你启用了 SELinux 的系统的详细状态报告。这个命令在终端像这样运行:
|
||||
|
||||
sestatus -v
|
||||
|
||||
你可以看到像图 4 那样的输出。
|
||||
|
||||

|
||||
|
||||
*图 4:sestatus -v 命令的输出。*
|
||||
|
||||
### 仅是皮毛
|
||||
|
||||
和你预想的一样,我只介绍了 SELinux 的一点皮毛。SELinux 的确是个复杂的系统,想要更扎实地理解它是如何工作的,以及了解如何让它更好地为你的桌面或服务器工作需要更加地深入学习。我的内容还没有覆盖到疑难解答和创建自定义 SELinux 策略。
|
||||
|
||||
SELinux 是所有 Linux 管理员都应该知道的强大工具。现在已经向你介绍了 SELinux,我强烈推荐你回到 Linux.com(当有更多关于此话题的文章发表的时候)或看看 [NSA SELinux 文档][3] 获得更加深入的指南。
|
||||
|
||||
LCTT - 相关阅读:[鸟哥的 Linux 私房菜——程序管理与 SELinux 初探][4]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/docs/ldp/883671-an-introduction-to-selinux
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/community/forums/person/93
|
||||
[1]: http://selinuxproject.org/page/Main_Page
|
||||
[2]: https://www.nsa.gov/research/selinux/
|
||||
[3]: https://www.nsa.gov/research/selinux/docs.shtml
|
||||
[4]: http://vbird.dic.ksu.edu.tw/linux_basic/0440processcontrol_5.php
|
||||
@ -1,42 +1,41 @@
|
||||
要超越Hello World 容器是件困难的事情
|
||||
从 Hello World 容器进阶是件困难的事情
|
||||
================================================================================
|
||||
|
||||
在[我的上一篇文章里][1], 我介绍了Linux 容器背后的技术的概念。我写了我知道的一切。容器对我来说也是比较新的概念。我写这篇文章的目的就是鼓励我真正的来学习这些东西。
|
||||
在[我的上一篇文章里][1], 我介绍了 Linux 容器背后的技术的概念。我写了我知道的一切。容器对我来说也是比较新的概念。我写这篇文章的目的就是鼓励我真正的来学习这些东西。
|
||||
|
||||
我打算在使用中学习。首先实践,然后上手并记录下我是怎么走过来的。我假设这里肯定有很多想"Hello World" 这种类型的知识帮助我快速的掌握基础。然后我能够更进一步,构建一个微服务容器或者其它东西。
|
||||
我打算在使用中学习。首先实践,然后上手并记录下我是怎么走过来的。我假设这里肯定有很多像 "Hello World" 这种类型的知识帮助我快速的掌握基础。然后我能够更进一步,构建一个微服务容器或者其它东西。
|
||||
|
||||
我的意思是还会比着更难吗,对吧?
|
||||
我想,它应该不会有多难的。
|
||||
|
||||
错了。
|
||||
但是我错了。
|
||||
|
||||
可能对某些人来说这很简单,因为他们会耗费大量的时间专注在操作工作上。但是对我来说实际上是很困难的,可以从我在Facebook 上的状态展示出来的挫折感就可以看出了。
|
||||
可能对某些人来说这很简单,因为他们在运维工作方面付出了大量的时间。但是对我来说实际上是很困难的,可以从我在Facebook 上的状态展示出来的挫折感就可以看出了。
|
||||
|
||||
但是还有一个好消息:我最终让它工作了。而且他工作的还不错。所以我准备分享向你分享我如何制作我的第一个微服务容器。我的痛苦可能会节省你不少时间呢。
|
||||
但是还有一个好消息:我最终搞定了。而且它工作的还不错。所以我准备分享向你分享我如何制作我的第一个微服务容器。我的痛苦可能会节省你不少时间呢。
|
||||
|
||||
如果你曾经发现或者从来都没有发现自己处在这种境地:像我这样的人在这里解决一些你不需要解决的问题。
|
||||
如果你曾经发现你也处于过这种境地,不要害怕:像我这样的人都能搞定,所以你也肯定行。
|
||||
|
||||
让我们开始吧。
|
||||
|
||||
|
||||
### 一个缩略图微服务 ###
|
||||
|
||||
我设计的微服务在理论上很简单。以JPG 或者PNG 格式在HTTP 终端发布一张数字照片,然后获得一个100像素宽的缩略图。
|
||||
我设计的微服务在理论上很简单。以 JPG 或者 PNG 格式在 HTTP 终端发布一张数字照片,然后获得一个100像素宽的缩略图。
|
||||
|
||||
下面是它实际的效果:
|
||||
下面是它的流程:
|
||||
|
||||

|
||||
|
||||
我决定使用NodeJS 作为我的开发语言,使用[ImageMagick][2] 来转换缩略图。
|
||||
我决定使用 NodeJS 作为我的开发语言,使用 [ImageMagick][2] 来转换缩略图。
|
||||
|
||||
我的服务的第一版的逻辑如下所示:
|
||||
|
||||

|
||||
|
||||
我下载了[Docker Toolbox][3],用它安装了Docker 的快速启动终端。Docker 快速启动终端使得创建容器更简单了。终端会启动一个装好了Docker 的Linux 虚拟机,它允许你在一个终端里运行Docker 命令。
|
||||
我下载了 [Docker Toolbox][3],用它安装了 Docker 的快速启动终端(Docker Quickstart Terminal)。Docker 快速启动终端使得创建容器更简单了。终端会启动一个装好了 Docker 的 Linux 虚拟机,它允许你在一个终端里运行 Docker 命令。
|
||||
|
||||
虽然在我的例子里,我的操作系统是Mac OS X。但是Windows 下也有相同的工具。
|
||||
虽然在我的例子里,我的操作系统是 Mac OS X。但是 Windows 下也有相同的工具。
|
||||
|
||||
我准备使用Docker 快速启动终端里为我的微服务创建一个容器镜像,然后从这个镜像运行容器。
|
||||
我准备使用 Docker 快速启动终端里为我的微服务创建一个容器镜像,然后从这个镜像运行容器。
|
||||
|
||||
Docker 快速启动终端就运行在你使用的普通终端里,就像这样:
|
||||
|
||||
@ -44,11 +43,11 @@ Docker 快速启动终端就运行在你使用的普通终端里,就像这样
|
||||
|
||||
### 第一个小问题和第一个大问题###
|
||||
|
||||
所以我用NodeJS 和ImageMagick 瞎搞了一通然后让我的服务在本地运行起来了。
|
||||
我用 NodeJS 和 ImageMagick 瞎搞了一通,然后让我的服务在本地运行起来了。
|
||||
|
||||
然后我创建了Dockerfile,这是Docker 用来构建容器的配置脚本。(我会在后面深入介绍构建和Dockerfile)
|
||||
然后我创建了 Dockerfile,这是 Docker 用来构建容器的配置脚本。(我会在后面深入介绍构建过程和 Dockerfile)
|
||||
|
||||
这是我运行Docker 快速启动终端的命令:
|
||||
这是我运行 Docker 快速启动终端的命令:
|
||||
|
||||
$ docker build -t thumbnailer:0.1
|
||||
|
||||
@ -58,32 +57,31 @@ Docker 快速启动终端就运行在你使用的普通终端里,就像这样
|
||||
|
||||
呃。
|
||||
|
||||
我估摸着过了15分钟:我忘记了在末尾参数输入一个点`.`。
|
||||
我估摸着过了15分钟我才反应过来:我忘记了在末尾参数输入一个点`.`。
|
||||
|
||||
正确的指令应该是这样的:
|
||||
|
||||
$ docker build -t thumbnailer:0.1 .
|
||||
|
||||
但是这不是我遇到的最后一个问题。
|
||||
|
||||
但是这不是我最后一个问题。
|
||||
|
||||
我让这个镜像构建好了,然后我Docker 快速启动终端输入了[`run` 命令][4]来启动容器,名字叫`thumbnailer:0.1`:
|
||||
我让这个镜像构建好了,然后我在 Docker 快速启动终端输入了 [`run` 命令][4]来启动容器,名字叫 `thumbnailer:0.1`:
|
||||
|
||||
$ docker run -d -p 3001:3000 thumbnailer:0.1
|
||||
|
||||
参数`-p 3001:3000` 让NodeJS 微服务在Docker 内运行在端口3000,而在主机上则是3001。
|
||||
参数 `-p 3001:3000` 让 NodeJS 微服务在 Docker 内运行在端口3000,而绑定在宿主主机上的3001。
|
||||
|
||||
到目前卡起来都很好,对吧?
|
||||
到目前看起来都很好,对吧?
|
||||
|
||||
错了。事情要马上变糟了。
|
||||
|
||||
我指定了在Docker 快速启动中端里用命令`docker-machine` 运行的Docker 虚拟机的ip地址:
|
||||
我通过运行 `docker-machine` 命令为这个 Docker 快速启动终端里创建的虚拟机指定了 ip 地址:
|
||||
|
||||
$ docker-machine ip default
|
||||
|
||||
这句话返回了默认虚拟机的IP地址,即运行docker 的虚拟机。对于我来说,这个ip 地址是192.168.99.100。
|
||||
这句话返回了默认虚拟机的 IP 地址,它运行在 Docker 快速启动终端里。在我这里,这个 ip 地址是 192.168.99.100。
|
||||
|
||||
我浏览网页http://192.168.99.100:3001/ ,然后找到了我创建的上传图片的网页:
|
||||
我浏览网页 http://192.168.99.100:3001/ ,然后找到了我创建的上传图片的网页:
|
||||
|
||||

|
||||
|
||||
@ -91,13 +89,13 @@ Docker 快速启动终端就运行在你使用的普通终端里,就像这样
|
||||
|
||||
但是它并没有工作。
|
||||
|
||||
终端告诉我他无法找到我的微服务需要的`/upload` 目录。
|
||||
终端告诉我他无法找到我的微服务需要的 `/upload` 目录。
|
||||
|
||||
现在开始记住,我已经在此耗费了将近一天的时间-从浪费时间到研究问题。我此时感到了一些挫折感。
|
||||
现在,你要知道,我已经在此耗费了将近一天的时间-从浪费时间到研究问题。我此时感到了一些挫折感。
|
||||
|
||||
然后灵光一闪。某人记起来微服务不应该自己做任何数据持久化的工作!保存数据应该是另一个服务的工作。
|
||||
|
||||
所以容器找不到目录`/upload` 的原因到底是什么?这个问题的根本就是我的微服务在基础设计上就有问题。
|
||||
所以容器找不到目录 `/upload` 的原因到底是什么?这个问题的根本就是我的微服务在基础设计上就有问题。
|
||||
|
||||
让我们看看另一幅图:
|
||||
|
||||
@ -109,7 +107,7 @@ Docker 快速启动终端就运行在你使用的普通终端里,就像这样
|
||||
|
||||

|
||||
|
||||
这是我用NodeJS 写的在内存工作、生成缩略图的代码:
|
||||
这是我用 NodeJS 写的在内存运行、生成缩略图的代码:
|
||||
|
||||
// Bind to the packages
|
||||
var express = require('express');
|
||||
@ -171,19 +169,19 @@ Docker 快速启动终端就运行在你使用的普通终端里,就像这样
|
||||
|
||||
module.exports = router;
|
||||
|
||||
好了,回到正轨,已经可以在我的本地机器正常工作了。我该去休息了。
|
||||
好了,一切回到了正轨,已经可以在我的本地机器正常工作了。我该去休息了。
|
||||
|
||||
但是,在我测试把这个微服务当作一个普通的Node 应用运行在本地时...
|
||||
但是,在我测试把这个微服务当作一个普通的 Node 应用运行在本地时...
|
||||
|
||||

|
||||
|
||||
它工作的很好。现在我要做的就是让他在容器里面工作。
|
||||
它工作的很好。现在我要做的就是让它在容器里面工作。
|
||||
|
||||
第二天我起床后喝点咖啡,然后创建一个镜像——这次没有忘记那个"."!
|
||||
|
||||
$ docker build -t thumbnailer:01 .
|
||||
|
||||
我从缩略图工程的根目录开始构建。构建命令使用了根目录下的Dockerfile。它是这样工作的:把Dockerfile 放到你想构建镜像的地方,然后系统就默认使用这个Dockerfile。
|
||||
我从缩略图项目的根目录开始构建。构建命令使用了根目录下的 Dockerfile。它是这样工作的:把 Dockerfile 放到你想构建镜像的地方,然后系统就默认使用这个 Dockerfile。
|
||||
|
||||
下面是我使用的Dockerfile 的内容:
|
||||
|
||||
@ -209,7 +207,7 @@ Docker 快速启动终端就运行在你使用的普通终端里,就像这样
|
||||
|
||||
### 第二个大问题 ###
|
||||
|
||||
我运行了`build` 命令,然后出了这个错:
|
||||
我运行了 `build` 命令,然后出了这个错:
|
||||
|
||||
Do you want to continue? [Y/n] Abort.
|
||||
|
||||
@ -217,7 +215,7 @@ Docker 快速启动终端就运行在你使用的普通终端里,就像这样
|
||||
|
||||
我猜测微服务出错了。我回到本地机器,从本机启动微服务,然后试着上传文件。
|
||||
|
||||
然后我从NodeJS 获得了这个错误:
|
||||
然后我从 NodeJS 获得了这个错误:
|
||||
|
||||
Error: spawn convert ENOENT
|
||||
|
||||
@ -225,25 +223,25 @@ Docker 快速启动终端就运行在你使用的普通终端里,就像这样
|
||||
|
||||
我搜索了我能想到的所有的错误原因。差不多4个小时后,我想:为什么不重启一下机器呢?
|
||||
|
||||
重启了,你猜猜结果?错误消失了!(译注:万能的重启)
|
||||
重启了,你猜猜结果?错误消失了!(LCTT 译注:万能的“重启试试”)
|
||||
|
||||
继续。
|
||||
|
||||
### 将精灵关进瓶子 ###
|
||||
### 将精灵关进瓶子里 ###
|
||||
|
||||
跳回正题:我需要完成构建工作。
|
||||
|
||||
我使用[`rm` 命令][5]删除了虚拟机里所有的容器。
|
||||
我使用 [`rm` 命令][5]删除了虚拟机里所有的容器。
|
||||
|
||||
$ docker rm -f $(docker ps -a -q)
|
||||
|
||||
`-f` 在这里的用处是强制删除运行中的镜像。
|
||||
|
||||
然后删除了全部Docker 镜像,用的是[命令`rmi`][6]:
|
||||
然后删除了全部 Docker 镜像,用的是[命令 `rmi`][6]:
|
||||
|
||||
$ docker rmi if $(docker images | tail -n +2 | awk '{print $3}')
|
||||
|
||||
我重新执行了命令构建镜像,安装容器,运行微服务。然后过了一个充满自我怀疑和沮丧的一个小时,我告诉我自己:这个错误可能不是微服务的原因。
|
||||
我重新执行了重新构建镜像、安装容器、运行微服务的整个过程。然后过了一个充满自我怀疑和沮丧的一个小时,我告诉我自己:这个错误可能不是微服务的原因。
|
||||
|
||||
所以我重新看到了这个错误:
|
||||
|
||||
@ -251,19 +249,17 @@ Docker 快速启动终端就运行在你使用的普通终端里,就像这样
|
||||
|
||||
The command '/bin/sh -c apt-get install imagemagick libmagickcore-dev libmagickwand-dev' returned a non-zero code: 1
|
||||
|
||||
这太打击我了:构建脚本好像需要有人从键盘输入Y! 但是,这是一个非交互的Dockerfile 脚本啊。这里并没有键盘。
|
||||
这太打击我了:构建脚本好像需要有人从键盘输入 Y! 但是,这是一个非交互的 Dockerfile 脚本啊。这里并没有键盘。
|
||||
|
||||
回到Dockerfile,脚本元来时这样的:
|
||||
回到 Dockerfile,脚本原来是这样的:
|
||||
|
||||
RUN apt-get update
|
||||
RUN apt-get install -y nodejs nodejs-legacy npm
|
||||
RUN apt-get install imagemagick libmagickcore-dev libmagickwand-dev
|
||||
RUN apt-get clean
|
||||
|
||||
The second `apt-get` command is missing the `-y` flag which causes "yes" to be given automatically where usually it would be prompted for.
|
||||
第二个`apt-get` 忘记了`-y` 标志,这才是错误的根本原因。
|
||||
第二个`apt-get` 忘记了`-y` 标志,它用于自动应答提示所需要的“yes”。这才是错误的根本原因。
|
||||
|
||||
I added the missing `-y` to the command:
|
||||
我在这条命令后面添加了`-y` :
|
||||
|
||||
RUN apt-get update
|
||||
@ -281,7 +277,6 @@ I added the missing `-y` to the command:
|
||||
|
||||
$ docker run -d -p 3001:3000 thumbnailer:0.1
|
||||
|
||||
Got the IP address of the Virtual Machine:
|
||||
获取了虚拟机的IP 地址:
|
||||
|
||||
$ docker-machine ip default
|
||||
@ -298,11 +293,11 @@ Got the IP address of the Virtual Machine:
|
||||
|
||||
在容器里面工作了,我的第一次啊!
|
||||
|
||||
### 这意味着什么? ###
|
||||
### 这让我学到了什么? ###
|
||||
|
||||
很久以前,我接受了这样一个道理:当你刚开始尝试某项技术时,即使是最简单的事情也会变得很困难。因此,我压抑了要成为房间里最聪明的人的欲望。然而最近几天尝试容器的过程就是一个充满自我怀疑的旅程。
|
||||
很久以前,我接受了这样一个道理:当你刚开始尝试某项技术时,即使是最简单的事情也会变得很困难。因此,我不会把自己当成最聪明的那个人,然而最近几天尝试容器的过程就是一个充满自我怀疑的旅程。
|
||||
|
||||
但是你想知道一些其它的事情吗?这篇文章是我在凌晨2点完成的,而每一个折磨的小时都值得了。为什么?因为这段时间你将自己全身心投入了喜欢的工作里。这件事很难,对于所有人来说都不是很容易就获得结果的。但是不要忘记:你在学习技术,运行世界的技术。
|
||||
但是你想知道一些其它的事情吗?这篇文章是我在凌晨2点完成的,而每一个受折磨的时刻都值得了。为什么?因为这段时间你将自己全身心投入了喜欢的工作里。这件事很难,对于所有人来说都不是很容易就获得结果的。但是不要忘记:你在学习技术,运行世界的技术。
|
||||
|
||||
P.S. 了解一下Hello World 容器的两段视频,这里会有 [Raziel Tabib’s][7] 的精彩工作内容。
|
||||
|
||||
@ -320,12 +315,12 @@ via: https://deis.com/blog/2015/beyond-hello-world-containers-hard-stuff
|
||||
|
||||
作者:[Bob Reselman][a]
|
||||
译者:[Ezio](https://github.com/oska874)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://deis.com/blog
|
||||
[1]:http://deis.com/blog/2015/developer-journey-linux-containers
|
||||
[1]:https://linux.cn/article-6594-1.html
|
||||
[2]:https://github.com/rsms/node-imagemagick
|
||||
[3]:https://www.docker.com/toolbox
|
||||
[4]:https://docs.docker.com/reference/commandline/run/
|
||||
@ -0,0 +1,209 @@
|
||||
用 Python 打造你的 Eclipse
|
||||
==============================================
|
||||
|
||||

|
||||
|
||||
Eclipse 高级脚本环境([EASE][1])项目虽然还在开发中,但是必须要承认它非常强大,它让我们可以快速打造自己的Eclipse 开发环境。
|
||||
|
||||
依据 Eclipse 强大的框架,可以通过其内建的插件系统全方面的扩展 Eclipse。然而,编写和部署一个新的插件还是十分麻烦,即使你只是需要一个额外的小功能。不过,现在依托于 EASE,你可以不用写任何一行 Java 代码就可以方便的做到这点。EASE 是一种使用 Python 或者 Javascript 这样的脚本语言自动实现这些功能的平台。
|
||||
|
||||
本文中,根据我在今年北美的 EclipseCon 大会上的[演讲][2],我将介绍如何用 Python 和 EASE 设置你的 Eclipse 环境,并告诉如何发挥 Python 的能量让你的 IDE 跑的飞起。
|
||||
|
||||
### 安装并运行 "Hello World"
|
||||
|
||||
本文中的例子使用 Python 的 Java 实现 Jython。你可以将 EASE 直接安装到你已有的 Eclipse IDE 中。本例中使用[Eclipse Mars][3],并安装 EASE 环境本身以及它的模块和 Jython 引擎。
|
||||
|
||||
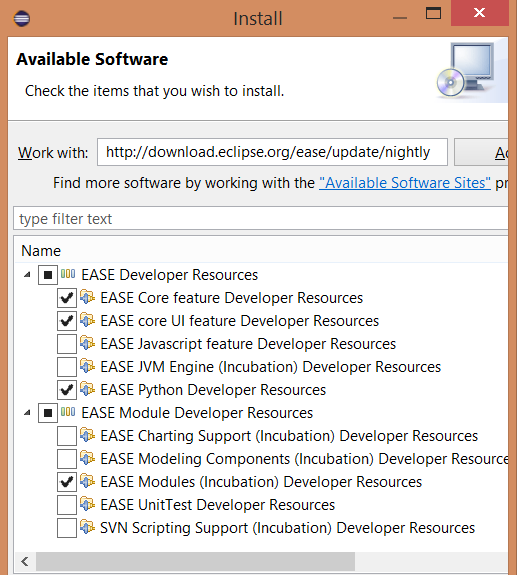
使用 Eclipse 安装对话框(`Help>Install New Software`...),安装 EASE[http://download.eclipse.org/ease/update/nightly][4],
|
||||
|
||||
选择下列组件:
|
||||
|
||||
- EASE Core feature
|
||||
- EASE core UI feature
|
||||
- EASE Python Developer Resources
|
||||
- EASE modules (Incubation)
|
||||
|
||||
这会安装 EASE 及其模块。这里我们要注意一下 Resource 模块,此模块可以访问 Eclipse 工作空间、项目和文件 API。
|
||||
|
||||
|
||||
|
||||
成功安装后,接下来安装 EASE Jython 引擎 [https://dl.bintray.com/pontesegger/ease-jython/][5] 。完成后,测试下。新建一个项目并新建一个 hello.py 文件,输入:
|
||||
|
||||
```
|
||||
print "hello world"
|
||||
```
|
||||
|
||||
选中这个文件,右击并选择“Run as -> EASE script”。这样就可以在控制台看到“Hello world”的输出。
|
||||
|
||||
现在就可以编写 Python 脚本来访问工作空间和项目了。这种方法可以用于各种定制,下面只是一些思路。
|
||||
|
||||
### 提升你的代码质量
|
||||
|
||||
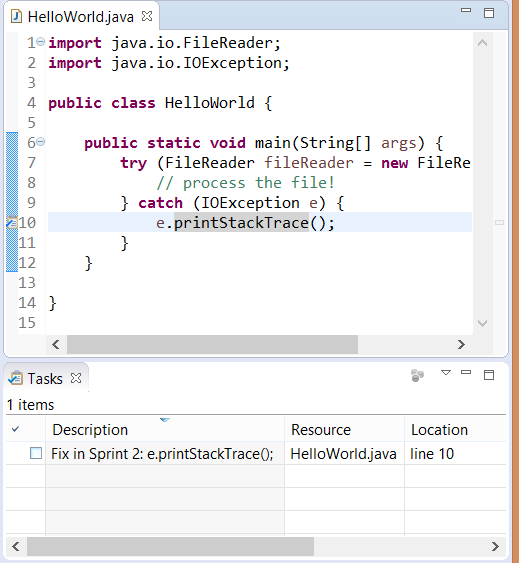
管理良好的代码质量本身是一件非常烦恼的事情,尤其是当需要处理一个大型代码库或者要许多工程师参与的时候。而这些痛苦可以通过脚本来减轻,比如批量格式化一些文件,或者[去掉文件中的 unix 式的行结束符][6]来使得在 git 之类的源代码控制系统中比较差异更加容易。另外一个更好的用途是使用脚本来生成 Eclipse markers 以高亮你可以改善的代码。这里有一些示例脚本,你可以用来在 java 文件中所有找到的“printStackTrace”方法中加入task markers 。请看[源码][7]。
|
||||
|
||||
拷贝该文件到工作空间来运行,右击并选择“Run as -> EASE script”。
|
||||
|
||||
```
|
||||
loadModule('/System/Resources')
|
||||
|
||||
from org.eclipse.core.resources import IMarker
|
||||
|
||||
for ifile in findFiles("*.java"):
|
||||
file_name = str(ifile.getLocation())
|
||||
print "Processing " + file_name
|
||||
with open(file_name) as f:
|
||||
for line_no, line in enumerate(f, start=1):
|
||||
if "printStackTrace" in line:
|
||||
marker = ifile.createMarker(IMarker.TASK)
|
||||
marker.setAttribute(IMarker.TRANSIENT, True)
|
||||
marker.setAttribute(IMarker.LINE_NUMBER, line_no)
|
||||
marker.setAttribute(IMarker.MESSAGE, "Fix in Sprint 2: " + line.strip())
|
||||
|
||||
```
|
||||
|
||||
如果你的 java 文件中包含了 printStackTraces,你就可以看见任务视图和编辑器侧边栏上自动新加的标记。
|
||||
|
||||
|
||||
|
||||
### 自动构建繁琐任务
|
||||
|
||||
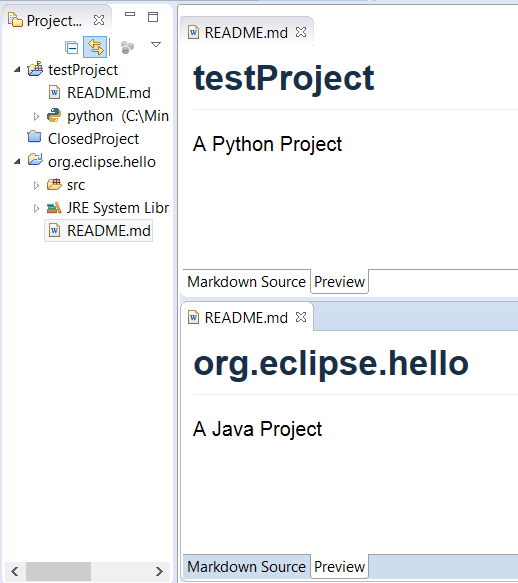
当同时工作在多个项目的时候,肯定需要完成许多繁杂、重复的任务。可能你需要在所有源文件头上加入版权信息,或者采用新框架时候自动更新文件。例如,当首次切换到 Tycho 和 Maven 的时候,我们需要 giel每个项目添加 pom.xml 文件。使用几行 Python 代码可以很轻松的完成这个任务。然后当 Tycho 支持无 pom 构建后,我们需要移除不要的 pom 文件。同样,几行代码就可以搞定这个任务,例如,这里有个脚本可以在每一个打开的工作空间项目上加入 README.md。请看源代码 [add_readme.py][8]。
|
||||
|
||||
拷贝该文件到工作空间来运行,右击并选择“Run as -> EASE script”。
|
||||
|
||||
```
|
||||
loadModule('/System/Resources')
|
||||
|
||||
for iproject in getWorkspace().getProjects():
|
||||
if not iproject.isOpen():
|
||||
continue
|
||||
|
||||
ifile = iproject.getFile("README.md")
|
||||
|
||||
if not ifile.exists():
|
||||
contents = "# " + iproject.getName() + "\n\n"
|
||||
if iproject.hasNature("org.eclipse.jdt.core.javanature"):
|
||||
contents += "A Java Project\n"
|
||||
elif iproject.hasNature("org.python.pydev.pythonNature"):
|
||||
contents += "A Python Project\n"
|
||||
writeFile(ifile, contents)
|
||||
```
|
||||
|
||||
脚本运行的结果会在每个打开的项目中加入 README.md,java 和 Python 的项目还会自动加上一行描述。
|
||||
|
||||
|
||||
|
||||
### 构建新功能
|
||||
|
||||
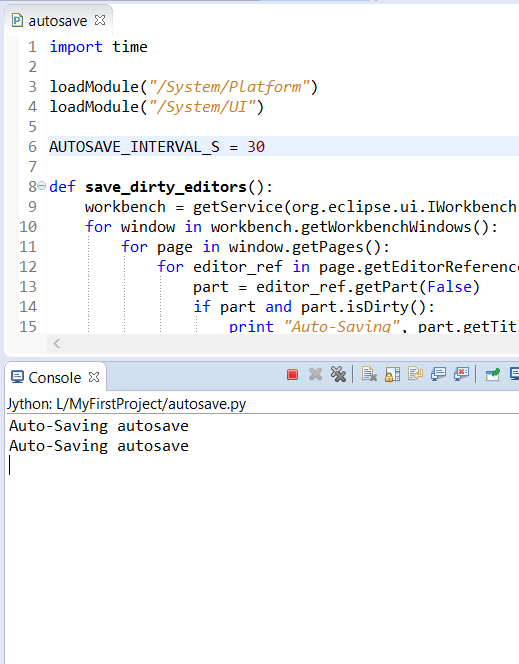
你可以使用 Python 脚本来快速构建一些急需的功能,或者做个原型给团队和用户演示你想要的功能。例如,一个 Eclipse 目前不支持的功能是自动保存你正在工作的文件。即使这个功能将会很快提供,但是你现在就可以马上拥有一个能每隔 30 秒或处于后台时自动保存的编辑器。以下是主要方法的片段。请看下列代码:[autosave.py][9]。
|
||||
|
||||
```
|
||||
def save_dirty_editors():
|
||||
workbench = getService(org.eclipse.ui.IWorkbench)
|
||||
for window in workbench.getWorkbenchWindows():
|
||||
for page in window.getPages():
|
||||
for editor_ref in page.getEditorReferences():
|
||||
part = editor_ref.getPart(False)
|
||||
if part and part.isDirty():
|
||||
print "Auto-Saving", part.getTitle()
|
||||
part.doSave(None)
|
||||
```
|
||||
|
||||
在运行脚本之前,你需要勾选 'Allow Scripts to run code in UI thread' 设定,这个设定在 Window > Preferences > Scripting 中。然后添加该脚本到工作空间,右击并选择“Run as > EASE Script”。每次编辑器自动保存时,控制台就会输出一个保存的信息。要关掉自动保存脚本,只需要点击控制台的红色方块的停止按钮即可。
|
||||
|
||||
|
||||
|
||||
### 快速扩展用户界面
|
||||
|
||||
EASE 最棒的事情是可以将你的脚本与 IDE 界面上元素(比如一个新的按钮或菜单)结合起来。不需要编写 java 代码或者安装新的插件,只需要在你的脚本前面增加几行代码。
|
||||
|
||||
下面是一个简单的脚本示例,用来创建三个新项目。
|
||||
|
||||
```
|
||||
# name : Create fruit projects
|
||||
# toolbar : Project Explorer
|
||||
# description : Create fruit projects
|
||||
|
||||
loadModule("/System/Resources")
|
||||
|
||||
for name in ["banana", "pineapple", "mango"]:
|
||||
createProject(name)
|
||||
```
|
||||
|
||||
上述注释会专门告诉 EASE 增加了一个按钮到 Project Explorer 工具条。下面这个脚本是用来增加一个删除这三个项目的按钮的。请看源码 [createProjects.py][10] 和 [deleteProjects.py][11]。
|
||||
|
||||
```
|
||||
# name :Delete fruit projects
|
||||
# toolbar : Project Explorer
|
||||
# description : Get rid of the fruit projects
|
||||
|
||||
loadModule("/System/Resources")
|
||||
|
||||
for name in ["banana", "pineapple", "mango"]:
|
||||
project = getProject(name)
|
||||
project.delete(0, None)
|
||||
```
|
||||
|
||||
为了使按钮显示出来,增加这两个脚本到一个新的项目,假如叫做 'ScriptsProject'。然后到 Windows > Preference > Scripting > Script Location,点击 'Add Workspace' 按钮并选择 ScriptProject 项目。这个项目现在会成为放置脚本的默认位置。你可以发现 Project Explorer 上出现了这两个按钮,这样你就可以通过这两个新加的按钮快速增加和删除项目。
|
||||
|
||||
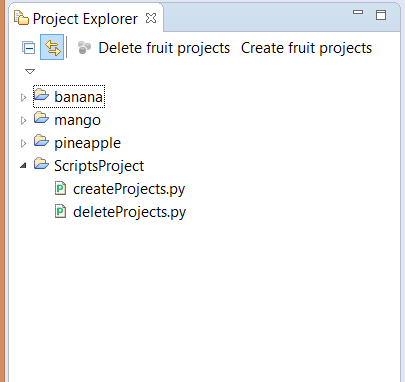
|
||||
|
||||
### 整合第三方工具
|
||||
|
||||
不管怎么说,你可能需要除了 Eclipse 生态系统以外的工具(这是真的,虽然 Eclipse 已经很丰富了,但是不是什么都有)。这些时候你会发现将他们包装在一个脚本来调用会非常方便。这里有一个简单的例子让你整合资源管理器,并将它加入到右键菜单栏,这样点击图标就可以打开资源管理器浏览当前文件。请看源码 [explorer.py][12]。
|
||||
|
||||
```
|
||||
# name : Explore from here
|
||||
# popup : enableFor(org.eclipse.core.resources.IResource)
|
||||
# description : Start a file browser using current selection
|
||||
loadModule("/System/Platform")
|
||||
loadModule('/System/UI')
|
||||
|
||||
selection = getSelection()
|
||||
if isinstance(selection, org.eclipse.jface.viewers.IStructuredSelection):
|
||||
selection = selection.getFirstElement()
|
||||
|
||||
if not isinstance(selection, org.eclipse.core.resources.IResource):
|
||||
selection = adapt(selection, org.eclipse.core.resources.IResource)
|
||||
|
||||
if isinstance(selection, org.eclipse.core.resources.IFile):
|
||||
selection = selection.getParent()
|
||||
|
||||
if isinstance(selection, org.eclipse.core.resources.IContainer):
|
||||
runProcess("explorer.exe", [selection.getLocation().toFile().toString()])
|
||||
```
|
||||
|
||||
为了让这个菜单显示出来,像之前一样将该文件加入一个新项目,比如说 'ScriptProject'。然后到 Windows > Preference > Scripting > Script Locations,点击“Add Workspace”并选择 'ScriptProject' 项目。当你在文件上右击鼠标键,你会看到弹出菜单出现了新的菜单项。点击它就会出现资源管理器。(注意,这个功能已经出现在 Eclipse 中了,但是你可以在这个例子中换成其它第三方工具。)
|
||||
|
||||
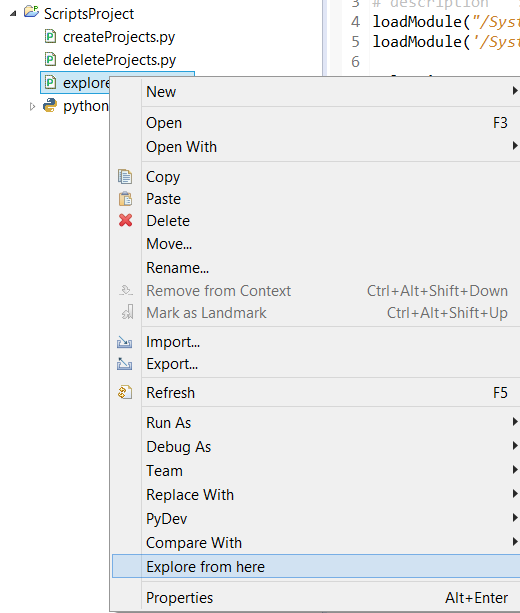
|
||||
|
||||
Eclipse 高级基本环境 (EASE)提供一套很棒的扩展功能,使得 Eclipse IDE 能使用 Python 来轻松扩展。虽然这个项目还在早期,但是[关于这个项目][13]更多更棒的功能也正在加紧开发中,如果你想为它做出贡献,请到[论坛][14]讨论。
|
||||
|
||||
我会在 2016 年的 [Eclipsecon North America][15] 会议上发布更多 EASE 细节。我的演讲 [Scripting Eclipse with Python][16] 也会不单会介绍 Jython,也包括 C-Python 和这个功能在科学领域是如何扩展的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/2/how-use-python-hack-your-ide
|
||||
|
||||
作者:[Tracy Miranda][a]
|
||||
译者:[VicYu/Vic020](http://vicyu.net)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/tracymiranda
|
||||
[1]: https://eclipse.org/ease/
|
||||
[2]: https://www.eclipsecon.org/na2016/session/scripting-eclipse-python
|
||||
[3]: https://www.eclipse.org/downloads/packages/eclipse-ide-eclipse-committers-451/mars1
|
||||
[4]: http://download.eclipse.org/ease/update/nightly
|
||||
[5]: https://dl.bintray.com/pontesegger/ease-jython/
|
||||
[6]: http://code.activestate.com/recipes/66434-change-line-endings/
|
||||
[7]: https://gist.github.com/tracymiranda/6556482e278c9afc421d
|
||||
[8]: https://gist.github.com/tracymiranda/f20f233b40f1f79b1df2
|
||||
[9]: https://gist.github.com/tracymiranda/e9588d0976c46a987463
|
||||
[10]: https://gist.github.com/tracymiranda/55995daaea9a4db584dc
|
||||
[11]: https://gist.github.com/tracymiranda/baa218fc2c1a8e898194
|
||||
[12]: https://gist.github.com/tracymiranda/8aa3f0fc4bf44f4a5cd3
|
||||
[13]: https://eclipse.org/ease/
|
||||
[14]: https://dev.eclipse.org/mailman/listinfo/ease-dev
|
||||
[15]: https://www.eclipsecon.org/na2016
|
||||
[16]: https://www.eclipsecon.org/na2016/session/scripting-eclipse-python
|
||||
@ -1,32 +0,0 @@
|
||||
ownCloud 9.0 Enterprise Edition Arrives with Extensive File Control Capabilities
|
||||
==================================================================================
|
||||
|
||||
>ownCloud, Inc. has had the great pleasure of [announcing][1] the availability of the Enterprise Edition (EE) of its powerful ownCloud 9.0 self-hosting cloud server solution.
|
||||
|
||||
Engineered exclusively for small- and medium-sized business, as well as major organizations and enterprises, [ownCloud 9.0 Enterprise Edition][2] is now available with extensive file control capabilities and all the cool new features that made the open-source version of the project famous amongst Linux users.
|
||||
|
||||
Prominent new features in ownCloud 9.0 Enterprise Edition are built-in Auto-Tagging and File Firewall apps, which have been based on some of the new features of ownCloud 9.0, such as file tags, file comments, as well as notifications and activities enhancements. This offers system administrators the ability to set rules and classifications for shared documents based on user- or system-applied tags.
|
||||
|
||||
"To illustrate how this can work, imagine working in a publicly traded company which has to be very careful not to release financial information ahead of official disclosure," reads the [announcement][3]. "While sharing this information internally it could end up in a folder which is shared through a public link. By assigning a special system tag, admins can configure the system to ensure the files are not available for download despite this mistake."
|
||||
|
||||
### Used by over 8 million people around the globe
|
||||
|
||||
ownCloud 9.0 is the best release of the open-source self-hosting cloud server software so far, which is currently used by over 8 million users around the globe. The release has brought a huge number of new features, such as code signing, as well as dozens of under-the-hood improvements and cosmetic changes. ownCloud 9.0 also got its first point release, version 9.0.1, last week, which [introduced even more enhancements][4].
|
||||
|
||||
And now, enterprises can take advantage of ownCloud 9.0's new features to differentiate between storage type and location, as well as the location of users, groups, and clients. ownCloud 9.0 Enterprise Edition gives them extensive access control, which is perfect if they have strict company guidelines or work with all sorts of regulations and rules. Below, you can see the File Firewall and Auto-Tagging apps in action.
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/owncloud-9-0-enterprise-edition-arrives-with-extensive-file-control-capabilities-502985.shtml
|
||||
|
||||
作者:[Marius Nestor][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://news.softpedia.com/editors/browse/marius-nestor
|
||||
[1]: https://owncloud.com/blog-introducing-owncloud-9-enterprise-edition/
|
||||
[2]: https://owncloud.com/
|
||||
[3]: https://owncloud.org/blog/owncloud-9-0-enterprise-edition-is-now-available/
|
||||
[4]: http://news.softpedia.com/news/owncloud-9-0-gets-its-first-point-release-over-120-improvements-introduced-502698.shtml
|
||||
@ -1,3 +1,5 @@
|
||||
vim-kakali translating
|
||||
|
||||
Which Open Source Linux Distributions Would Presidential Hopefuls Run?
|
||||
================================================================================
|
||||
![Republican presidential candidate Donald Trump
|
||||
@ -50,4 +52,4 @@ via: http://thevarguy.com/open-source-application-software-companies/081715/whic
|
||||
[4]:http://relax-and-recover.org/
|
||||
[5]:http://thevarguy.com/open-source-application-software-companies/061614/hps-machine-open-source-os-truly-revolutionary
|
||||
[6]:http://hp.com/
|
||||
[7]:http://ubuntu.com/
|
||||
[7]:http://ubuntu.com/
|
||||
|
||||
@ -1,68 +0,0 @@
|
||||
vim-kakali is translating.
|
||||
|
||||
While the event had a certain amount of drama surrounding it, the [announcement][1] of the end for the [Debian Live project][2] seems likely to have less of an impact than it first appeared. The loss of the lead developer will certainly be felt—and the treatment he and the project received seems rather baffling—but the project looks like it will continue in some form. So Debian will still have tools to create live CDs and other media going forward, but what appears to be a long-simmering dispute between project founder and leader Daniel Baumann and the Debian CD and installer teams has been "resolved", albeit in an unfortunate fashion.
|
||||
|
||||
The November 9 announcement from Baumann was titled "An abrupt End to Debian Live". In that message, he pointed to a number of different events over the nearly ten years since the [project was founded][3] that indicated to him that his efforts on Debian Live were not being valued, at least by some. The final straw, it seems, was an "intent to package" (ITP) bug [filed][4] by Iain R. Learmonth that impinged on the namespace used by Debian Live.
|
||||
|
||||
Given that one of the main Debian Live packages is called "live-build", the new package's name, "live-build-ng", was fairly confrontational in and of itself. Live-build-ng is meant to be a wrapper around the [vmdebootstrap][5] tool for creating live media (CDs and USB sticks), which is precisely the role Debian Live is filling. But when Baumann [asked][6] Learmonth to choose a different name for his package, he got an "interesting" [reply][7]:
|
||||
|
||||
```
|
||||
It is worth noting that live-build is not a Debian project, it is an external project that claims to be an official Debian project. This is something that needs to be fixed.
|
||||
There is no namespace issue, we are building on the existing live-config and live-boot packages that are maintained and bringing these into Debian as native projects. If necessary, these will be forks, but I'm hoping that won't have to happen and that we can integrate these packages into Debian and continue development in a collaborative manner.
|
||||
live-build has been deprecated by debian-cd, and live-build-ng is replacing it. In a purely Debian context at least, live-build is deprecated. live-build-ng is being developed in collaboration with debian-cd and D-I [Debian Installer].
|
||||
```
|
||||
|
||||
Whether or not Debian Live is an "official" Debian project (or even what "official" means in this context) has been disputed in the thread. Beyond that, though, Neil Williams (who is the maintainer of vmdebootstrap) [provided some][8] explanation for the switch away from Debian Live:
|
||||
|
||||
```
|
||||
vmdebootstrap is being extended explicitly to provide support for a replacement for live-build. This work is happening within the debian-cd team to be able to solve the existing problems with live-build. These problems include reliability issues, lack of multiple architecture support and lack of UEFI support. vmdebootstrap has all of these, we do use support from live-boot and live-config as these are out of the scope for vmdebootstrap.
|
||||
```
|
||||
|
||||
Those seem like legitimate complaints, but ones that could have been fixed within the existing project. Instead, though, something of a stealth project was evidently undertaken to replace live-build. As Baumann [pointed out][9], nothing was posted to the debian-live mailing list about the plans. The ITP was the first notice that anyone from the Debian Live project got about the plans, so it all looks like a "secret plan"—something that doesn't sit well in a project like Debian.
|
||||
|
||||
As might be guessed, there were multiple postings that supported Baumann's request to rename "live-build-ng", followed by many that expressed dismay at his decision to stop working on Debian Live. But Learmonth and Williams were adamant that replacing live-build is needed. Learmonth did [rename][10] live-build-ng to a perhaps less confrontational name: live-wrapper. He noted that his aim had been to add the new tool to the Debian Live project (and "bring the Debian Live project into Debian"), but things did not play out that way.
|
||||
|
||||
```
|
||||
I apologise to everyone that has been upset by the ITP bug. The software is not yet ready for use as a full replacement for live-build, and it was filed to let people know that the work was ongoing and to collect feedback. This sort of worked, but the feedback wasn't the kind I was looking for.
|
||||
```
|
||||
|
||||
The backlash could perhaps have been foreseen. Communication is a key aspect of free-software communities, so a plan to replace the guts of a project seems likely to be controversial—more so if it is kept under wraps. For his part, Baumann has certainly not been perfect—he delayed the "wheezy" release by [uploading an unsuitable syslinux package][11] and [dropped down][12] from a Debian Developer to a Debian Maintainer shortly thereafter—but that doesn't mean he deserves this kind of treatment. There are others involved in the project as well, of course, so it is not just Baumann who is affected.
|
||||
|
||||
One of those other people is Ben Armstrong, who has been something of a diplomat during the event and has tried to smooth the waters. He started with a [post][13] that celebrated the project and what Baumann and the team had accomplished over the years. As he noted, the [list of downstream projects][14] for Debian Live is quite impressive. In another post, he also [pointed out][15] that the project is not dead:
|
||||
|
||||
```
|
||||
If the Debian CD team succeeds in their efforts and produces a replacement that is viable, reliable, well-tested, and a suitable candidate to replace live-build, this can only be good for Debian. If they are doing their job, they will not "[replace live-build with] an officially improved, unreliable, little-tested alternative". I've seen no evidence so far that they operate that way. And in the meantime, live-build remains in the archive -- there is no hurry to remove it, so long as it remains in good shape, and there is not yet an improved successor to replace it.
|
||||
```
|
||||
|
||||
On November 24, Armstrong also [posted][16] an update (and to [his blog][17]) on Debian Live. It shows some good progress made in the two weeks since Baumann's exit; there are even signs of collaboration between the project and the live-wrapper developers. There is also a [to-do list][18], as well as the inevitable call for more help. That gives reason to believe that all of the drama surrounding the project was just a glitch—avoidable, perhaps, but not quite as dire as it might have seemed.
|
||||
|
||||
|
||||
---------------------------------
|
||||
|
||||
via: https://lwn.net/Articles/665839/
|
||||
|
||||
作者:Jake Edge
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
[1]: https://lwn.net/Articles/666127/
|
||||
[2]: http://live.debian.net/
|
||||
[3]: https://www.debian.org/News/weekly/2006/08/
|
||||
[4]: https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=804315
|
||||
[5]: http://liw.fi/vmdebootstrap/
|
||||
[6]: https://lwn.net/Articles/666173/
|
||||
[7]: https://lwn.net/Articles/666176/
|
||||
[8]: https://lwn.net/Articles/666181/
|
||||
[9]: https://lwn.net/Articles/666208/
|
||||
[10]: https://lwn.net/Articles/666321/
|
||||
[11]: https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=699808
|
||||
[12]: https://nm.debian.org/public/process/14450
|
||||
[13]: https://lwn.net/Articles/666336/
|
||||
[14]: http://live.debian.net/project/downstream/
|
||||
[15]: https://lwn.net/Articles/666338/
|
||||
[16]: https://lwn.net/Articles/666340/
|
||||
[17]: http://syn.theti.ca/2015/11/24/debian-live-after-debian-live/
|
||||
[18]: https://wiki.debian.org/DebianLive/TODO
|
||||
@ -0,0 +1,72 @@
|
||||
Confessions of a cross-platform developer
|
||||
=============================================
|
||||
|
||||

|
||||
|
||||
[Andreia Gaita][1] is giving a talk at this year's OSCON, titled [Confessions of a cross-platform developer][2]. She's a long-time open source and [Mono][3] contributor, and develops primarily in C#/C++. Andreia works at GitHub, where she's focused on building the GitHub Extension manager for Visual Studio.
|
||||
|
||||
I caught up with Andreia ahead of her talk to ask about cross-platform development and what she's learned in her 16 years as a cross-platform developer.
|
||||
|
||||

|
||||
|
||||
**What languages have you found easiest and hardest to develop cross-platform code for?**
|
||||
|
||||
It's less about which languages are good and more about the libraries and tooling available for those languages. The compilers/interpreters/build systems available for languages determine how easy it is to do cross-platform work with them (or whether it's even possible), and the libraries available for UI and native system access determine how deep you can integrate with the OS. With that in mind, I found C# to be the best for cross-platform work. The language itself includes features that allow fast native calls and accurate memory mapping, which you really need if you want your code to talk to the OS and native libraries. When I need very specific OS integration, I switch to C or C++.
|
||||
|
||||
**What cross-platform toolkits/abstractions have you used?**
|
||||
|
||||
Most of my cross-platform work has been developing tools, libraries and bindings for other people to develop cross-platform applications with, mostly in Mono/C# and C/C++. I don't get to use a lot of abstractions at that level, beyond glib and friends. I mostly rely on Mono for any cross-platform app that includes a UI, and Unity3D for the occasional game development. I play with Electron every now and then.
|
||||
|
||||
**What has been your approach to build systems, and how does this vary by language or platform?**
|
||||
|
||||
I try to pick the build system that is most suited for the language(s) I'm using. That way, it'll (hopefully) give me less headaches. It needs to allow for platform and architecture selection, be smart about build artifact locations (for multiple parallel builds), and be decently configurable. Most of the time I have projects combining C/C++ and C# and I want to build all the different configurations at the same time from the same source tree (Debug, Release, Windows, OSX, Linux, Android, iOS, etc, etc.), and that usually requires selecting and invoking different compilers with different flags per output build artifact. So the build system has to let me do all of this without getting (too much) in my way. I try out different build systems every now and then, just to see what's new, but in the end, I end up going back to makefiles and a combination of either shell and batch scripts or Perl scripts for driving them (because if I want users to build my things, I'd better pick a command line script language that is available everywhere).
|
||||
|
||||
**How do you balance the desire for native look and feel with the need for uniform user interfaces?**
|
||||
|
||||
Cross-platform UI is hard! I've implemented several cross-platform GUIs over the years, and it's the one thing for which I don't think there's an optimal solution. There's basically two options. You can pick a cross-platform GUI toolkit and do a UI that doesn't feel quite right in all the platforms you support, with a small codebase and low maintenance cost. Or you can choose to develop platform-specific UIs that will look and feel native and well integrated with a larger codebase and higher maintenance cost. The decision really depends on the type of app, how many features it has, how many resources you have, and how many platforms you're shipping to.
|
||||
|
||||
In the end, I think there's an increase in users' tolerance for "One UI To Rule Them All" with frameworks like Electron. I have a Chromium+C+C# framework side project that will one day hopefully allow me build Electron-style apps in C#, giving me the best of both worlds.
|
||||
|
||||
**Has building/packaging dependencies been an issue for you?**
|
||||
|
||||
I'm very conservative about my use of dependencies, having been bitten so many times by breaking ABIs, clashing symbols, and missing packages. I decide which OS version(s) I'm targeting and pick the lowest common denominator release available of a dependency to minimize issues. That usually means having five different copies of Xcode and OSX Framework libraries, five different versions of Visual Studio installed side-to-side on the same machine, multiple clang and gcc versions, and a bunch of VMs running various other distros. If I'm unsure of the state of packages in the OS I'm targeting, I will sometimes link statically and sometimes submodule dependencies to make sure they're always available. And most of all, I avoid the bleeding edge unless I really, really need something there.
|
||||
|
||||
**Do you use continuous integration, code review, and related tools?**
|
||||
|
||||
All the time! It's the only way to keep sane. The first thing I do on a project is set up cross-platform build scripts to ensure everything is automateable as early as possible. When you're targeting multiple platforms, CI is essential. It's impossible for everyone to build all the different combinations of platforms in one machine, and as soon as you're not building all of them you're going to break something without being aware of it. In a shared multi-platform codebase, different people own different platforms and features, so the only way to guarantee quality is to have cross-team code reviews combined with CI and other analysis tools. It's no different than other software projects, there's just more points of failure.
|
||||
|
||||
**Do you rely on automated build testing, or do you tend to build on each platform and test locally?**
|
||||
|
||||
For tools and libraries that don't include UIs, I can usually get away with automated build testing. If there's a UI, then I need to do both—reliable, scriptable UI automation for existing GUI toolkits is rare to non-existent, so I would have to either invest in creating UI automation tools that work across all the platforms I want to support, or I do it manually. If a project uses a custom UI toolkit (like, say, an OpenGL UI like Unity3D does), then it's fairly easy to develop scriptable automation tools and automate most of that stuff. Still, there's nothing like the human ability to break things with a couple of clicks!
|
||||
|
||||
**If you are developing cross-platform, do you support cross-editor build systems so that you can use Visual Studio on Windows, Qt Creator on Linux, and XCode on Mac? Or do you tend toward supporting one platform such as Eclipse on all platforms?**
|
||||
|
||||
I favor cross-editor build systems. I prefer generating project files for different IDEs (preferably in a way that makes it easier to add more IDEs), with build scripts that can drive builds from the IDEs for the platform they're on. Editors are the most important tool for a developer. It takes time and effort to learn them, and they're not interchangeable. I have my favorite editors and tools, and everyone else should be able to use their favorite tool, too.
|
||||
|
||||
**What is your preferred editor/development environment/IDE for cross-platform development?**
|
||||
|
||||
The cross-platform developer is cursed with having to pick the lowest common denominator editor that works across the most platforms. I love Visual Studio, but I can't rely on it for anything except Windows work (and you really don't want to make Windows your primary cross-compiling platform), so I can't make it my primary IDE. Even if I could, an essential skill of cross-platform development is to know and use as many platforms as possible. That means really knowing them—using the platform's editors and libraries, getting to know the OS and its assumptions, behaviors, and limitations, etc. To do that and keep my sanity (and my shortcut muscle memory), I have to rely on cross-platform editors. So, I use Emacs and Sublime.
|
||||
|
||||
**What are some of your favorite past and current cross-platform projects?**
|
||||
|
||||
Mono is my all-time favorite, hands down, and most of the others revolve around it in some way. Gluezilla was a Mozilla binding I did years ago to allow C# apps to embed web browser views, and that one was a doozy. At one point I had a Winforms app, built on Linux, running on Windows with an embedded GTK view in it that was running a Mozilla browser view. The CppSharp project (formerly Cxxi, formerly CppInterop) is a project I started to generate C# bindings for C++ libraries so that you could call, create instances of, and subclass C++ classes from C#. It was done in such a way that it would detect at runtime what platform you'd be running on and what compiler was used to create the native library and generate the correct C# bindings for it. That was fun!
|
||||
|
||||
**Where do you see cross-platform development heading in the future?**
|
||||
|
||||
The way we build native applications is already changing, and I feel like the visual differences between the various desktop operating systems are going to become even more blurred so that it will become easier to build cross-platform apps that integrate reasonably well without being fully native. Unfortunately, that might mean applications will be worse in terms of accessibility and less innovative when it comes to using the OS to its full potential. Cross-platform development of tools, libraries, and runtimes is something that we know how to do well, but there's still a lot of work to do with cross-platform application development.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/business/16/5/oscon-interview-andreia-gaita
|
||||
|
||||
作者:[Marcus D. Hanwell ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mhanwell
|
||||
[1]: https://twitter.com/sh4na
|
||||
[2]: http://conferences.oreilly.com/oscon/open-source-us/public/schedule/detail/48702
|
||||
[3]: http://www.mono-project.com/
|
||||
@ -0,0 +1,74 @@
|
||||
A four year, action-packed experience with Wikipedia
|
||||
=======================================================
|
||||
|
||||

|
||||
|
||||
|
||||
I consider myself to be an Odia Wikimedian. I contribute [Odia][1] knowledge (the predominant language of the Indian state of [Odisha][2]) to many Wikimedia projects, like Wikipedia and Wikisource, by writing articles and correcting mistakes in articles. I also contribute to Hindi and English Wikipedia articles.
|
||||
|
||||

|
||||
|
||||
My love for Wikimedia started while I was reading an article about the [Bangladesh Liberation war][3] on the English Wikipedia after my 10th board exam (like, an annual exam for 10th grade students in America). By mistake I clicked on a link that took me to an India Wikipedia article, and I started reading. Something was written in Odia on the lefthand side of the article, so I clicked on that, and reached a [ଭାରତ/Bhārat][4] article on the Odia Wikipedia. I was excited to find a Wikipedia article in my native language!
|
||||
|
||||

|
||||
|
||||
A banner inviting readers to be part of the 2nd Bhubaneswar workshop on April 1, 2012 sparked my curiousity. I had never contributed to Wikipedia before, only used it for research, and I wasn't familiar with open source and the community contribution process. Plus, I was only 15 years old. I registered. There were many language enthusiasts at the workshop, and all older than me. My father encouraged me to the participate despite my fear; he has played an important role—he's not a Wikimedian, like me, but his encouragement has helped me change Odia Wikipedia and participate in community activities.
|
||||
|
||||
I believe that knowledge about Odia language and literature needs to improve—there are many misconceptions and knowledge gaps—so, I help organize events and workshops for Odia Wikipedia. On my accomplished list at the point, I have:
|
||||
|
||||
* initiated three major edit-a-thons in Odia Wikipedia: Women's Day 2015, Women's Day 2016, abd [Nabakalebara edit-a-thon 2015][5]
|
||||
* initiated a photograph contest to get more [Rathyatra][6] images from all over the India
|
||||
* represented Odia Wikipedia during two events by Google ([Google I/O extended][7] and Google Dev Fest)
|
||||
* spoke at [Perception][8] 2015 and the first [Open Access India][9] meetup
|
||||
|
||||

|
||||
|
||||
I was just an editor to Wikipedia projects until last year, in January 2015, when I attended [Bengali Wikipedia's 10th anniversary conference][10] and [Vishnu][11], the director of the [Center for Internet and Society][12] at the time, invited me to attend the [Train the Trainer][13] Program. I was inspired to start doing outreach for Odia Wikipedia and hosting meetups for [GLAM]14] activities and training new Wikimedians. These experience taught me how to work with a community of contributors.
|
||||
|
||||
[Ravi][15], the director of Wikimedia India at the time, also played an important role in my journey. He trusted me and made me a part of [Wiki Loves Food][16], a public photo competition on Wikimedia Commons, and the organizing committee of [Wikiconference India 2016][17]. During Wiki Loves Food 2015, my team helped add 10,000+ CC BY-SA images on Wikimedia Commons. Ravi further solidified my commitment by sharing a lot of information with me about the Wikimedia movement, and his own journey, during [Odia Wikipedia's 13th anniversary][18].
|
||||
|
||||
Less than a year later, in December 2015, I became a Program Associate at the Center for Internet and Society's [Access to Knowledge program][19] (CIS-A2K). One of my proud moments was at a workshop in Puri, India where we helped bring 20 new Wikimedian editors to the Odia Wikimedia community. Now, I mentor Wikimedians during an informal meetup called [WikiTungi][20] Puri. I am working with this group to make Odia Wikiquotes a live project. I am also dedicated to bridging the gender gap in Odia Wikipedia. [Eight female editors][21] are now helping to organize meetups and workshops, and participate in the [Women's History month edit-a-thon][22].
|
||||
|
||||
During my brief but action-packed journey during the four years since, I have also been involved in the [Wikipedia Education Program][23], the [newsletter team][24], and two global edit-a-thons: [Art and Feminsim][25] and [Menu Challenge][26]. I look forward to the many more to come!
|
||||
|
||||
I would also like to thank [Sameer][27] and [Anna][28] (both previous members of the Wikipedia Education Program).
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/4/my-open-source-story-sailesh-patnaik
|
||||
|
||||
作者:[Sailesh Patnaik][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/saileshpat
|
||||
[1]: https://en.wikipedia.org/wiki/Odia_language
|
||||
[2]: https://en.wikipedia.org/wiki/Odisha
|
||||
[3]: https://en.wikipedia.org/wiki/Bangladesh_Liberation_War
|
||||
[4]: https://or.wikipedia.org/s/d2
|
||||
[5]: https://or.wikipedia.org/s/toq
|
||||
[6]: https://commons.wikimedia.org/wiki/Commons:The_Rathyatra_Challenge
|
||||
[7]: http://cis-india.org/openness/blog-old/odia-wikipedia-meets-google-developer-group
|
||||
[8]: http://perception.cetb.in/events/odia-wikipedia-event/
|
||||
[9]: https://opencon2015kolkata.sched.org/speaker/sailesh.patnaik007
|
||||
[10]: https://meta.wikimedia.org/wiki/Bengali_Wikipedia_10th_Anniversary_Celebration_Kolkata
|
||||
[11]: https://www.facebook.com/vishnu.vardhan.50746?fref=ts
|
||||
[12]: http://cis-india.org/
|
||||
[13]: https://meta.wikimedia.org/wiki/CIS-A2K/Events/Train_the_Trainer_Program/2015
|
||||
[14]: https://en.wikipedia.org/wiki/Wikipedia:GLAM
|
||||
[15]: https://www.facebook.com/ravidreams?fref=ts
|
||||
[16]: https://commons.wikimedia.org/wiki/Commons:Wiki_Loves_Food
|
||||
[17]: https://meta.wikimedia.org/wiki/WikiConference_India_2016
|
||||
[18]: https://or.wikipedia.org/s/sml
|
||||
[19]: https://meta.wikimedia.org/wiki/CIS-A2K
|
||||
[20]: https://or.wikipedia.org/s/xgx
|
||||
[21]: https://or.wikipedia.org/s/ysg
|
||||
[22]: https://or.wikipedia.org/s/ynj
|
||||
[23]: https://outreach.wikimedia.org/wiki/Education
|
||||
[24]: https://outreach.wikimedia.org/wiki/Talk:Education/News#Call_for_volunteers
|
||||
[25]: https://en.wikipedia.org/wiki/User_talk:Saileshpat#Barnstar_for_Art_.26_Feminism_Challenge
|
||||
[26]: https://opensource.com/life/15/11/tasty-translations-the-open-source-way
|
||||
[27]: https://www.facebook.com/samirsharbaty?fref=ts
|
||||
[28]: https://www.facebook.com/anna.koval.737?fref=ts
|
||||
@ -0,0 +1,103 @@
|
||||
translating by martin2011qi
|
||||
|
||||
Why and how I became a software engineer
|
||||
==========================================
|
||||
|
||||

|
||||
|
||||
The year was 1989. The city was Kampala, Uganda.
|
||||
|
||||
In their infinite wisdom, my parents decided that instead of all the troublemaking I was getting into at home, they would send me off to my uncle's office to learn how to use a computer. A few days later, I found myself on the 21st floor in a cramped room with six or seven other teens and a brand new computer on a desk perpendicular to the teacher's desk. It was made abundantly clear that we were not skilled enough to touch it. After three frustrating weeks of writing and perfecting DOS commands, the magic moment happened. It was my turn to type **copy doc.txt d:**.
|
||||
|
||||
The alien scratching noises that etched a simple text file onto the five-inch floppy sounded like beautiful music. For a while, that floppy disk was my most prized possession. I copied everything I could onto it. However, in 1989, Ugandans tended to take life pretty seriously, and messing around with computers, copying files, and formatting disks did not count as serious. I had to focus on my education, which led me away from computer science and into architectural engineering.
|
||||
|
||||
Like any young person of my generation, a multitude of job titles and skills acquisition filled the years in between. I taught kindergarten, taught adults how to use software, worked in a clothing store, and served as a paid usher in a church. While I earned my degree at the University of Kansas, I worked as a tech assistant to the technical administrator, which is really just a fancy title for someone who messes around with the student database.
|
||||
|
||||
By the time I graduated in 2007, technology had become inescapable. Every aspect of architectural engineering was deeply intertwined with computer science, so we all inadvertently learned simple programming skills. For me, that part was always more fascinating. But because I had to be a serious engineer, I developed a secret hobby: writing science fiction.
|
||||
|
||||
In my stories, I lived vicariously through the lives of my heroines. They were scientists with amazing programming skills who were always getting embroiled in adventures and fighting tech scallywags with technology they invented, sometimes inventing them on the spot. Sometimes the new tech I came up with was based on real-world inventions. Other times it was the stuff I read about or saw in the science fiction I consumed. This meant that I had to understand how the tech worked and my research led me to some interesting subreddits and e-zines.
|
||||
|
||||
### Open source: The ultimate goldmine
|
||||
|
||||
Throughout my experiences, the fascinating weeks I'd spent writing out DOS commands remained a prominent influence, bleeding into little side projects and occupying valuable study time. As soon as Geocities became available to all Yahoo! Users, I created a website where I published blurry pictures that I'd taken on a tiny digital camera. I created websites for free, helped friends and family fix issues they had with their computers, and created a library database for a church.
|
||||
|
||||
This meant that I was always researching and trying to find more information about how things could be made better. The Internet gods blessed me and open source fell into my lap. Suddenly, 30-day trials and restrictive licenses became a ghost of computing past. I could continue to create using GIMP, Inkscape, and OpenOffice.
|
||||
|
||||
### Time to get serious
|
||||
|
||||
I was fortunate to have a business partner who saw the magic in my stories. She too is a dreamer and visionary who imagines a better connected world that functions efficiently and conveniently. Together, we came up with several solutions to pain points we experienced in the journey to success, but implementation had been a problem. We both lacked the skills to make our products come to life, something that was made evident every time we approached investors with our ideas.
|
||||
|
||||
We needed to learn to program. So, at the end of the summer in 2015, we embarked on a journey that would lead us right to the front steps of Holberton School, a community-driven, project-based school in San Francisco.
|
||||
|
||||
My business partner came to me one morning and started a conversation the way she does when she has a new crazy idea that I'm about to get sucked into.
|
||||
|
||||
**Zee**: Gloria, I'm going to tell you something and I want you to listen first before you say no.
|
||||
|
||||
**Me**: No.
|
||||
|
||||
**Zee**: We're going to be applying to go to a school for full-stack engineers.
|
||||
|
||||
**Me**: What?
|
||||
|
||||
**Zee**: Here, look! We're going to learn how to program by applying to this school.
|
||||
|
||||
**Me**: I don't understand. We're doing online courses in Python and...
|
||||
|
||||
**Zee**: This is different. Trust me.
|
||||
|
||||
**Me**: What about the...
|
||||
|
||||
**Zee**: That's not trusting me.
|
||||
|
||||
**Me**: Fine. Show me.
|
||||
|
||||
### Removing the bias
|
||||
|
||||
What I read sounded similar to something we had seen online. It was too good to be true, but we decided to give it a try, jump in with both feet, and see what would come out of it.
|
||||
|
||||
To become students, we had to go through a four-step selection process based solely on talent and motivation, not on the basis of educational degree or programming experience. The selection process is the beginning of the curriculum, so we started learning and collaborating through it.
|
||||
|
||||
It has been my experience—and that of my business partner—that the process of applying for anything was an utter bore compared to the application process Holberton School created. It was like a game. If you completed a challenge, you got to go to the next level, where another fascinating challenge awaited. We created Twitter accounts, blogged on Medium, learned HTML and CSS in order to create a website, and created a vibrant community online even before we knew who was going to get to go.
|
||||
|
||||
The most striking thing about the online community was how varied our experience with computers was, and how our background and gender did not factor into the choices that were being made by the founders (who we secretly called "The Trinity"). We just enjoyed being together and talking to each other. We were all smart people on a journey to increasing our nerd cred by learning how to code.
|
||||
|
||||
For much of the application process, our identities were not very evident. For example, my business partner's name does not indicate her gender or race. It was during the final step, a video chat, that The Trinity even knew she was a woman of color. Thus far, only her enthusiasm and talent had propelled her through the levels. The color of her skin and her gender did not hinder nor help her. How cool is that?
|
||||
|
||||
The night we got our acceptance letters, we knew our lives were about to change in ways we had only dreamt of. On the 22nd of January 2016, we walked into 98 Battery Street to meet our fellow [Hippokampoiers][2] for the first time. It was evident then, as it had been before, that the Trinity had started something amazing. They had assembled a truly diverse collection of passionate and enthusiastic people who had dedicated themselves to become full-stack engineers.
|
||||
|
||||
The school is an experience like no other. Every day is an intense foray into some facet of programming. We're handed a project and, with a little guidance, we use every resource available to us to find the solution. The premise that [Holberton School][1] is built upon is that information is available to us in more places than we've ever had before. MOOCs, tutorials, the availability of open source software and projects, and online communities are all bursting at the seams with knowledge that shakes up some of the projects we have to complete. And with the support of the invaluable team of mentors to guide us to solutions, the school becomes more than just a school; we've become a community of learners. I would highly recommend this school for anyone who is interested in software engineering and is also interested in the learning style. The next class is in October 2016 and is accepting new applications. It's both terrifying and exhilarating, but so worth it.
|
||||
|
||||
### Open source matters
|
||||
|
||||
My earliest experience with an open source operating system was [Fedora][3], a [Red Hat][4]-sponsored project. During a panicked conversation with an IRC member, she recommended this free OS. I had never installed my own OS before, but it sparked my interest in open source and my dependence on open source software for my computing needs. We are advocates for open source contribution, creation, and use. Our projects are on GitHub where anyone can use or contribute to them. We also have the opportunity to access existing open source projects to use or contribute to in our own way. Many of the tools that we use at school are open source, such as Fedora, [Vagrant][5], [VirtualBox][6], [GCC][7], and [Discourse][8], to name a few.
|
||||
|
||||
As I continue on my journey to becoming a software engineer, I still dream of a time when I will be able to contribute to the open source community and be able to share my knowledge with others.
|
||||
|
||||
### Diversity Matters
|
||||
|
||||
Standing in the room and talking to 29 other bright-eyed learners was intoxicating. 40% of the people there were women and 44% were people of color. These numbers become very important when you are a woman of color in a field that has been famously known for its lack of diversity. It was an oasis in the tech Mecca of the world. I knew I had arrived.
|
||||
|
||||
The notion of becoming a full-stack engineer is daunting, and you may even struggle to know what that means. It is a challenging road to travel with immeasurable rewards to reap. The future is run by technology, and you are an important part of that bright future. While the media continues to trip over handling the issue of diversity in tech companies, know that whoever you are, whatever your background is, whatever your reasons might be for becoming a full-stack engineer, you can find a place to thrive.
|
||||
|
||||
But perhaps most importantly, a strong reminder of the role of women in the history of computing can help more women return to the tech world, and they can be fully engaged without hesitation due to their gender or their capabilities as women. Their talents will help shape the future not just of tech, but of the world.
|
||||
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/4/my-open-source-story-gloria-bwandungi
|
||||
|
||||
作者:[Gloria Bwandungi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/nappybrain
|
||||
[1]: https://www.holbertonschool.com/
|
||||
[2]: https://twitter.com/hippokampoiers
|
||||
[3]: https://en.wikipedia.org/wiki/Fedora_(operating_system)
|
||||
[4]: https://www.redhat.com/
|
||||
[5]: https://www.vagrantup.com/
|
||||
[6]: https://www.virtualbox.org/
|
||||
[7]: https://gcc.gnu.org/
|
||||
[8]: https://www.discourse.org/
|
||||
@ -1,136 +0,0 @@
|
||||
An Introduction to SELinux
|
||||
===============================
|
||||
|
||||

|
||||
|
||||
>Figure 1: The getenforce command reporting SELinux is set to Enforcing.
|
||||
|
||||
Way back in kernel 2.6, a new security system was introduced to provide a mechanism for supporting access control security policies. This system was [Security Enhanced Linux (SELinux)][1] and was introduced by the [National Security Administration (NSA)][2] to incorporate a strong Mandatory Access Control architecture into the subsystems of the Linux kernel.
|
||||
|
||||
If you’ve spent your entire Linux career either disabling or ignoring SELinux, this article is dedicated to you — an introduction to the system that lives “under the hood” of your Linux desktop or server to limit privilege or even eliminate the possibility of damage should programs or daemons become compromised.
|
||||
|
||||
Before I begin, you should know that SELinux is primarily a tool for Red Hat Linux and its derivatives. The likes of Ubuntu and SUSE (and their derivatives) make use of AppArmor. SELinux and AppArmor are significantly different. You can install SELinux on SUSE, openSUSE, Ubuntu, etc., but it’s an incredibly challenging task unless you’re very well versed in Linux.
|
||||
|
||||
With that said, let me introduce you to SELinux.
|
||||
|
||||
### DAC vs. MAC
|
||||
|
||||
The old-guard standard form of access control on Linux was Discretionary Access Control (DAC). With this form, an application or daemon runs under either User ID (UID) or Set owner User ID (SUID) and holds object permissions (for files, sockets, and other processes) of that user. This made it easier for malicious code to be run with a permission set that would grant it access to crucial subsystems.
|
||||
|
||||
Mandatory Access Control (MAC), on the other hand, enforces the separation of information based on both confidentiality and integrity to enable the confinement of damage. The confinement unit operates independently of the traditional Linux security mechanisms and has no concept of a superuser.
|
||||
|
||||
### How SELinux Works
|
||||
|
||||
Consider these pieces of the SELinux puzzle:
|
||||
|
||||
- Subjects
|
||||
|
||||
- Objects
|
||||
|
||||
- Policy
|
||||
|
||||
- Mode
|
||||
|
||||
When a subject (such as an application) attempts to access an object (such as a file), the SELinux Security Server (inside the kernel) runs a check against the Policy Database. Depending on the current mode, if the SELinux Security Server grants permission, the subject is given access to the object. If the SELinux Security Server denies permission, a denied message is logged in /var/log/messages.
|
||||
|
||||
Sounds relatively simple, right? There’s actually more to it than that, but for the sake of introduction, those are the important steps.
|
||||
|
||||
### The Modes
|
||||
|
||||
SELinux has three modes (which can be set by the user). These modes will dictate how SELinux acts upon subject request. The modes are:
|
||||
|
||||
- Enforcing — SELinux policy is enforced and subjects will be denied or granted access to objects based on the SELinux policy rules
|
||||
|
||||
- Permissive — SELinux policy is not enforced and does not deny access, although denials are logged
|
||||
|
||||
- Disabled — SELinux is completely disabled
|
||||
|
||||
Out of the box, most systems have SELinux set to Enforcing. How do you know what mode your system is currently running? You can use a simple command to report the mode; that command is getenforce. This command is incredibly simple to use (as it has the singular purpose of reporting the SELinux mode). To use this tool, open up a terminal window and issue the command getenforce. The report will come back with either, Enforcing, Permissive, or Disabled (see Figure 1 above).
|
||||
|
||||
Setting the SELinux mode is actually quite simple — depending upon the mode you want to set. Understand this: It is never recommended to set SELinux to Disable. Why? When you do this, you open up the possibility that files on your disk will be mislabeled and require a re-label to fix. It is also not possible to change the mode of a system when it has been booted in Disabled mode. Your best modes are either Enabled or Permissive.
|
||||
|
||||
You can change the SELinux mode from the command line or in the /etc/selinux/config file. To set the mod via command line, you use the setenforce tool. To set the mode to Enforcing, do the following:
|
||||
|
||||
1. Open up a terminal window
|
||||
|
||||
2. Issue the command su and then enter your administrator password
|
||||
|
||||
3. Issue the command setenforce 1
|
||||
|
||||
4. Issue the command getenforce to ensure the mode has been set (Figure 2)
|
||||
|
||||

|
||||
|
||||
>Figure 2: Setting the SELinux mode to Enforcing.
|
||||
|
||||
To set the mode to Permissive, do this:
|
||||
|
||||
1. Open up a terminal window
|
||||
|
||||
2. Issue the command su and then enter your administrator password
|
||||
|
||||
3. Issue the command setenforce 0
|
||||
|
||||
4. Issue the command getenforce to ensure the mode has been set (Figure 3)
|
||||
|
||||

|
||||
|
||||
>Figure 3: Setting the SELinux mode to Permissive.
|
||||
|
||||
NOTE: Setting the mode via command line overrides the setting in the SELinux config file.
|
||||
|
||||
If you’d prefer to set the mode in the SELinux command file, open up that particular file in your favorite text editor and look for the line:
|
||||
|
||||
>SELINUX=permissive
|
||||
|
||||
You can change the mode to suit your preference and then save the file.
|
||||
|
||||
There is also a third method of changing the SELinux mode (via the bootloader), but I don’t recommend it for a beginning user.
|
||||
|
||||
### Policy Type
|
||||
|
||||
There are two types of SELinux policies:
|
||||
|
||||
- Targeted — only targeted network daemons (dhcpd, httpd, named, nscd, ntpd, portmap, snmpd, squid, and syslogd) are protected
|
||||
|
||||
- Strict — full SELinux protection for all daemons
|
||||
|
||||
You can change the policy type within the /etc/selinux/config file. Open the file in your favorite text editor and look for the line:
|
||||
|
||||
>SELINUXTYPE=targeted
|
||||
|
||||
Change the option in that line to either targeted or strict to match your needs.
|
||||
|
||||
### Checking the Full SELinux Status
|
||||
|
||||
There is a handy SELinux tool you might want to know about that will display a detailed status report of your SELinux-enabled system. The command is run from a terminal window like this:
|
||||
|
||||
>sestatus -v
|
||||
|
||||
You should see output similar to that shown in Figure 4.
|
||||
|
||||

|
||||
|
||||
>Figure 4: The output of the sestatus -v command.
|
||||
|
||||
### Just Scratching the Surface
|
||||
|
||||
As you might expect, I have only scratched the surface of SELinux. It is quite a complex system and will require diving much deeper to obtain a solid understanding of how it works for you and how you can make it better work for your desktops and servers. I still have yet to cover troubleshooting and creating custom SELinux policies.
|
||||
|
||||
SELinux is a powerful tool that any Linux administrator should know. Now that you’ve been introduced, I highly recommend you return to Linux.com (when more tutorials on the subject are posted) or take a look at the [NSA SELinux documentation][3] for very in-depth tutorials.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/docs/ldp/883671-an-introduction-to-selinux
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/community/forums/person/93
|
||||
[1]: http://selinuxproject.org/page/Main_Page
|
||||
[2]: https://www.nsa.gov/research/selinux/
|
||||
[3]: https://www.nsa.gov/research/selinux/docs.shtml
|
||||
@ -1,68 +0,0 @@
|
||||
7 Steps to Start Your Linux SysAdmin Career
|
||||
===============================================
|
||||
|
||||
Linux is hot right now. Everybody is looking for Linux talent. Recruiters are knocking down the doors of anybody with Linux experience, and there are tens of thousands of jobs waiting to be filled. But what if you want to take advantage of this trend and you’re new to Linux? How do you get started?
|
||||
|
||||
1. Install Linux
|
||||
|
||||
It should almost go without saying, but the first key to learning Linux is to install Linux. Both the LFS101x and the LFS201 courses include detailed sections on installing and configuring Linux for the first time.
|
||||
|
||||
2. Take LFS101x
|
||||
|
||||
If you are completely new to Linux, the best place to start is our free [LFS101x Introduction](https://www.edx.org/course/introduction-linux-linuxfoundationx-lfs101x-2) to Linux course. This online course is hosted by edX.org, and explores the various tools and techniques commonly used by Linux system administrators and end users to achieve their day-to-day work in a Linux environment. It is designed for experienced computer users who have limited or no previous exposure to Linux, whether they are working in an individual or enterprise environment. This course will give you a good working knowledge of Linux from both a graphical and command line perspective, allowing you to easily navigate through any of the major Linux distributions.
|
||||
|
||||
3. Look into LFS201
|
||||
|
||||
Once you’ve completed LFS101x, you’re ready to start diving into the more complicated tasks in Linux that will be required of you as a professional sysadmin. To gain those skills, you’ll want to take [LFS201 Essentials of Linux System Administration](http://training.linuxfoundation.org/linux-courses/system-administration-training/essentials-of-system-administration). The course gives you in-depth explanations and instructions for each topic, along with plenty of exercises and labs to help you get real, hands-on experience with the subject matter.
|
||||
|
||||
If you would rather have a live instructor teach you or you have an employer who is interested in helping you become a Linux sysadmin, you might also be interested in LFS220 Linux System Administration. This course includes all the same topics as the LFS201 course, but is taught by an expert instructor who can guide you through the labs and answer any questions you have on the topics covered in the course.
|
||||
|
||||
4. Practice!
|
||||
|
||||
Practice makes perfect, and that’s as true for Linux as it is for any musical instrument or sport. Once you’ve installed Linux, use it regularly. Perform key tasks over and over again until you can do them easily without reference material. Learn the ins and outs of the command line as well as the GUI. This practice will ensure that you’ve got the skills and knowledge to be successful as a professional Linux sysadmin.
|
||||
|
||||
5. Get Certified
|
||||
|
||||
After you’ve taken LFS201 or LFS220 and you’ve gotten some practice, you are now ready to get certified as a system administrator. You’ll need this certification because this is how you will prove to employers that you have the necessary skills to be a professional Linux sysadmin.
|
||||
|
||||
There are several Linux certifications on the market today, and all of them have their place. However, most of these certifications are either centered on a specific distro (like Red Hat) or are purely knowledge-based and don’t demonstrate actual skill with Linux. The Linux Foundation Certified System Administrator certification is an excellent alternative for someone looking for a flexible, meaningful entry-level certification.
|
||||
|
||||
6. Get Involved
|
||||
|
||||
At this point you may also want to consider joining up with a local Linux Users Group (or LUG), if there’s one in your area. These groups are usually composed of people of all ages and experience levels, so regardless of where you are at with your Linux experience, you can find people with similar skill levels to bond with, or more advanced Linux users who can help answer questions and point you towards helpful resources. To find out if there’s a LUG near you, try looking on meetup.com, check with a nearby university, or just do a simple Internet search.
|
||||
|
||||
There are also many online communities available to you as you learn Linux. These sites and communities provide help and support to both individuals new to Linux or experienced administrators:
|
||||
|
||||
- [Linux Admin subreddit](https://www.reddit.com/r/linuxadmin)
|
||||
|
||||
- [Linux.com](http://www.linux.com/)
|
||||
|
||||
- [training.linuxfoundation.org](http://training.linuxfoundation.org/)
|
||||
|
||||
- [http://community.ubuntu.com/help-information/](http://community.ubuntu.com/help-information/)
|
||||
|
||||
- [https://forums.opensuse.org/forum.php](https://forums.opensuse.org/forum.php)
|
||||
|
||||
- [http://wiki.centos.org/Documentation](http://wiki.centos.org/Documentation)
|
||||
|
||||
7. Learn To Love The Documentation
|
||||
|
||||
Last but not least, if you ever get stuck on something within Linux, don’t forget about Linux’s included documentation. Using the commands man (for manual), info and help, you can find information on virtually every aspect of Linux, right from within the operating system. The usefulness of these built-in resources cannot be overstated, and you’ll find yourself using them throughout your career, so you might as well get familiar with them early on.
|
||||
|
||||
Interested in learning more about starting your IT career with Linux? Check out our free ebook “[A Brief Guide To Starting Your IT Career In Linux](http://training.linuxfoundation.org/sysadmin-it-career-guide).”
|
||||
|
||||
[Download Now](http://training.linuxfoundation.org/sysadmin-it-career-guide)
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linux.com/news/featured-blogs/191-linux-training/834644-7-steps-to-start-your-linux-sysadmin-career
|
||||
|
||||
作者:[linux.com][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:linux.com
|
||||
|
||||
|
||||
@ -1,74 +0,0 @@
|
||||
9 Key Trends in Hybrid Cloud Computing
|
||||
========================================
|
||||
|
||||
All three forms of cloud computing – public, private, and hybrid – have undergone considerable evolution since the concepts first gained the attention of IT years ago. Hybrid cloud is the overwhelming favorite form of the cloud, with [88% of firms surveyed](https://www.greenhousedata.com/blog/hybrid-continues-to-be-most-popular-cloud-option-adoption-accelerating) rating it as important or critical to their business.
|
||||
|
||||
The lightning-fast evolution of hybrid cloud means the conventional wisdom of a year or two back is already obsolete. So we asked several industry analysts where they saw the hybrid cloud headed in 2016 and got some interesting answers.
|
||||
|
||||
1. **2016 might be the year that we get hybrid cloud to actually work.**
|
||||
|
||||
By its very nature, hybrid cloud relies on private cloud, which has proven elusive for most enterprises. The fact is that the public cloud – Amazon, Google, Microsoft – have had much more investment and a longer head start. The private cloud has hamstrung the hybrid cloud's growth and usability.
|
||||
|
||||
There hasn't been as much investment in the private cloud because by its very nature, the private cloud means keeping and investing in your own data center. And many public cloud providers are pushing enterprises to reduce or eliminate their data center spending all together.
|
||||
|
||||
However, this year will see the private cloud start to catch up thanks to advances in OpenStack and Microsoft's Azure Stack, which is basically a private cloud in a box. The tools, infrastructures, and architectures to support hybrid cloud are also becoming much more robust.
|
||||
|
||||
2. **Containers, microservices, and unikernels will bolster the hybrid cloud.**
|
||||
|
||||
These are all cloud native technologies and will all be more or less mainstream by the end of 2016, analysts predict. They are maturing rapidly and serving as a viable alternative to virtual machines, which require more resources.
|
||||
|
||||
More importantly, they work in an on-premises scenario as well as an off-premises scenario. Containerization and orchestration allow rapid scale up, scale out, and service migration between public and private cloud, making it even easier to move your services around.
|
||||
|
||||
3. **Data and relevance take center stage**
|
||||
|
||||
The cloud, in all its forms, has been in growth mode. That makes it a technology story. But with the cloud shifting into maturity, data and relevance become more important, according to the consultancy [Avoa](http://avoa.com/2016/01/01/2016-is-the-year-of-data-and-relevance/). At first, the cloud and Big Data were all about sucking up as much data as possible. Then they worried about what to do with it.
|
||||
|
||||
In 2016, organizations will hone their craft in how data is collected and used. There is still much progress to be made in the technological and cultural aspects that must be dealt with. But 2016 should bring a renewed focus on the importance of data from all aspects and finding the most relevant information, not just lots of it.
|
||||
|
||||
4. **Cloud services move beyond just on-demand workloads**
|
||||
|
||||
AWS got its start as a place where a programmer/developer could spin up a VM real quick, get some work done, and get off. That's the essence of on-demand use, and given how much it can cost to leave those services constantly running, there is almost a disincentive to keep them running 24/7.
|
||||
|
||||
However, IT organizations are starting to act as service brokers to provide all manner of IT services to their in-house users. This can be anything from in-house IT services, public cloud infrastructure providers, platform-as-a-service, and software-as-a-service.
|
||||
|
||||
They will increasingly recognize the value of tools like cloud management platforms to provide consistent policy-based management over many of these different services. And they will see the value of technology such as containers to enhance portability. However, cloud service brokering in the sense of rapidly moving workloads between clouds for price arbitrage and related reasons will continue to be a non-starter.
|
||||
|
||||
5. **Service providers become cloud service providers**
|
||||
|
||||
Up to now, buying cloud services has been a direct sale model. The user was frequently the buyer of AWS EC2 services, either through officially recognized channels at work or through Shadow IT. But as cloud services become more comprehensive, and the menu of services more confusing, more and more people are turning to resellers and services providers to act as the purchaser of IT services for them.
|
||||
|
||||
A recent survey by 2nd Watch, a Seattle-based cloud services provider, found nearly 85 percent of IT executives in the United States would be willing to pay a small premium to buy public cloud from a channel partner if it were to make it less complex. And about four out of every five within that 85 percent would shell out an extra 15 percent or more, the survey found. One in three executives surveyed said they could use the help in buying, using, and managing public cloud services.
|
||||
|
||||
6. **IoT and cloud is to 2016 what mobile and cloud was to 2012**
|
||||
|
||||
IoT is gaining mindshare and, more importantly, it's moving from test beds to real use cases. The cloud is a vital part for IoT due to its distributed nature, and for industrial IoT, where machinery and heavy equipment talk to back-end systems, a hybrid cloud will be most natural driver because the connection, data collection, and processing will happen in a hybrid cloud environment, due to perceived benefits of the private cloud side, like security and privacy.
|
||||
|
||||
7. **The NIST definition of the cloud begins to break down**
|
||||
|
||||
In 2011, the National Institute of Standards and Technology published "[The NIST Definition of Cloud Computing](http://csrc.nist.gov/publications/nistpubs/800-145/SP800-145.pdf)" (PDF) that became the standard definitions of private, public, and hybrid cloud terms and as-a-service models.
|
||||
|
||||
Over time, though, the definitions have changed. IaaS has become much more complex, supporting things like OpenStack, [Swift](https://wiki.openstack.org/wiki/Swift) for object storage and [Neutron networking](https://wiki.openstack.org/wiki/Neutron). PaaS seems to be fading out because there's little that separates it from traditional middleware application development. And SaaS, which was just apps accessed through a browser, is losing steam because with so many cloud APIs for apps and services, you can access them through anything, not just a browser.
|
||||
|
||||
8. **Analytics becomes more important**
|
||||
|
||||
Analytics will be a huge growth opportunity for hybrid cloud because the high volume of data used in analytics is well suited to cloud, with its advantages of large scale and elasticity. For some forms of analytics, like highly sensitive data, then the private cloud will still rule. But the private cloud is part of the hybrid cloud, so either way, hybrid cloud wins.
|
||||
|
||||
9. **Security takes on a new urgency**
|
||||
|
||||
As hybrid cloud grows in 2016 and adds all kinds of new technologies, like IoT and containers, this just adds more vulnerable surface areas for data breaches. Add to it the tendency to rush into a new technology and then secure it later, which happens all the time, along with inexperienced technologists who don't think to secure the system – and you have a recipe for disaster.
|
||||
|
||||
When new technologies come out, management discipline almost always lags and we think about securing the technology later. Containers are a good example. You can download all kinds of sample containers from Docker, but do you know where it came from? Docker had to go back and add security verifications after it started letting people download and run containers without any idea what was really in it.
|
||||
|
||||
Mobile technologies like Path and Snapchat had major security problems a few years back as the smartphone market was taking off. It's inevitable that a new technology will be exploited by the bad guys. So security researchers will have their hands full trying to secure these new technologies. Probably after they get deployed.
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.datamation.com/cloud-computing/9-key-trends-in-hybrid-cloud-computing.html
|
||||
|
||||
作者:[Andy Patrizio][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.datamation.com/author/Andy-Patrizio-90720.html
|
||||
@ -1,68 +0,0 @@
|
||||
Tizen 3.0 Joins Growing List of Raspberry Pi 2 Distributions
|
||||
==============================================================
|
||||
|
||||
Last week’s news that Tizen 3.0 has been ported to the Raspberry Pi 2 Model B is the latest example of how the year-old ARMv7 version of the Pi is attracting ports from more powerful Linux distributions, most notably Fedora, Ubuntu MATE, and Snappy. The [Samsung Open Source Group’s Tizen for Pi][1] project has been underway for several years, achieving several beta releases, and now the effort has shifted to the new Tizen 3.0. It’s still in beta, but now you can create builds for the Pi 2 using tools from the [Yocto][2] Project and [OpenEmbedded project][3].
|
||||
|
||||
Tizen 3.0 offers performance and security improvements, multiple-user and 64-bit support, and an Internet of Things (IoT) framework. Samsung, the principal backer of the [Linux Foundation hosted Tizen project][4], is using the Pi port to expand the base of developers using Tizen for IoT projects, according to an [IDG News Service post][5] that reported on the port.
|
||||
|
||||
Although Samsung finally [shipped a Tizen-based][6] phone in India last summer, and Gear smartwatches continue to use Tizen, the main focus now appears to be on IoT. At CES last month, Samsung [announced][7] that all of its Tizen-based, 2016 Smart TVs will be able to act as SmartThings home automation hubs, letting users monitor the household while watching TV.
|
||||
|
||||
### The Growing List of Pi Distros
|
||||
|
||||
[Elinux.org][8] lists some 46 ARMv6-ready distributions that run on all the Raspberry Pi boards. A separate listing notes two ARMv7-only distros that require the ARMv7 Raspberry Pi 2: Ubuntu MATE, which replaces the resource-intensive Unity desktop with the Gnome 2.0 flavored MATE, and Windows 10 IoT Core. The prominent placement of a Microsoft distribution is not as controversial as one might have thought. To many younger Linux developers and casual Pi hackers, Microsoft is just another tech company, not so much the evil empire loathed by old-time Linux hackers.
|
||||
|
||||
Windows 10 IoT Core isn’t the only non-Linux distro running on the Pi. There’s also the Unix-like FreeBSD and NetBSD, as well as the revived RISC OS Pi version of the old Acorn Computers OS. Some of the 48 operating systems on the Elinux.org list are incomplete, out-of-date, or dedicated to limited niches. [DistroWatch][9] offers a more manageable list of 20.
|
||||
|
||||
The [Raspberry Pi Foundation][10] still prominently posts a download page for its homegrown, Debian-based Raspbian, in both standard and NOOBS packages. This lightweight distro is still the most popular and typically the highest rated Linux build for the Pi. The Scratch-ready distro is especially equally suited for desktop use and embedded hacking with home automation gear, robots, and other IoT gizmos. Raspbian recently [received an update][11] with an experimental OpenGL driver for doing hardware acceleration on the VideoCore IV GPU used with the Pi 2’s Broadcom BCM2836 SoC.
|
||||
|
||||
The Pi Foundation also lists several [third-party downloads][12]. In addition to Windows 10 IoT Core and and Ubuntu MATE, the list includes the lightweight, transactionally focused [Snappy Ubuntu Core][13] for the Pi 2. Canonical is aiming Snappy at those who want an app platform and cloud integration in embedded devices like drones and IoT devices. Snappy also came out last week in a version designed for [Intel NUC mini-PCs][14]. The Pi Foundation also posts images for RISC OS and the education-focused PINET. There are also two media center distros related to KODI/XBMC: OSMC and OpenElec.
|
||||
|
||||
In addition to its list of 48 released distros, Elinux.org lists several “announced” distros including Firefox OS, [openSUSE][15], Meego MER & XBMC, Puppy, RPi-Buildroot, and Aros. Missing, however, is Tizen, as well as newly announced ports such as [Manjaro-ARM][16] and the CentOS 7-based [CentOS AltArch 7][17] for the Pi 2, Banana Pi, and CubieTruck SBCs.
|
||||
|
||||
### Android Still Pi in the Sky
|
||||
|
||||
Elinux.org’s “announced” list also includes Android and a Miracast-like program called Android Transporter. People have been trying to port Android to the Pi for years; yet, even with the more suitable [Pi 2][18] shipping for a year now, Android is still pretty much a no-show. Android can run on lower-powered SoCs than the Pi 2’s quad-core, Cortex-A7, but the limited 1GB of RAM and the lack of GPU acceleration are big challenges. Perhaps Raspbian’s OpenGL driver could be ported to Android as well, although the Pi Foundation does not seem very interested in Android.
|
||||
|
||||
There are several Android-for-Pi projects in the works, but without the foundation’s backing, there is still nothing close to a complete port. Projects include an [AOSP Marshmallow][19] patch-set from Peter Yoon, as well as a [RaspAnd][20] release based on the Ubuntu-based RaspEx, which makes use of the Aptoide package manager to load some Android 5.1 apps on a Pi 2. The [Razdroid project][21], which aims to tap into the secrets of Broadcom hardware acceleration, seems to have stalled.
|
||||
|
||||
Most Rasp Pi users, however, appear more interested in [Ubuntu MATE][22], which was never optimized for ARMv6, and Fedora. For years, Pi users have run the lightweight spin-down of Fedora called Pidora, but with the Pi 2, they can now try the real thing. The Raspberry Pi Foundation has yet to post Fedora, but the recent [betas of the Pi 2 port][23] have received high marks.
|
||||
|
||||
Other Linux distributions that regularly make Top Pi distro lists include Arch Linux, which unlike most ports from mature Linux distros, works just fine on ARMv6. A recent [TechRadar Top 5 list][24] includes several more niche distros in addition to Raspbian. These include the OSMC media player environment, RetroPie for playing classic games, OpenMediaVault for turning your Pi into a NAS, and Pi MusicBox, based on the Mopidy music streaming server.
|
||||
|
||||
Beyond Ubuntu, Fedora, and Tizen, other distros, both arcane and general, are heading for the Pi 2, as well. The platform is rapidly expanding the boundaries of, as well as redefining the meaning of, desktop Linux.
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linux.com/news/embedded-mobile/mobile-linux/886126-tizen-30-joins-growing-list-of-raspberry-pi-2-distros
|
||||
|
||||
作者:[Eric Brown][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linux.com/community/forums/person/42808
|
||||
[1]:http://blogs.s-osg.org/bringing-tizen-to-a-raspberry-pi-2-near-you/
|
||||
[2]:https://www.yoctoproject.org/
|
||||
[3]:http://www.openembedded.org/wiki/Main_Page
|
||||
[4]:https://www.tizen.org/
|
||||
[5]:http://www.cio.com/article/3031812/samsung-hopes-raspberry-pi-can-spread-tizen-os-adoption.html
|
||||
[6]:http://www.linux.com/news/embedded-mobile/mobile-linux/837843-samsung-sells-a-million-tizen-phones-as-mozilla-rethinks-firefox-os
|
||||
[7]:http://www.linux.com/news/embedded-mobile/mobile-linux/877879-linux-based-drones-upstage-other-mobile-gadgets-at-ces
|
||||
[8]:http://elinux.org/RPi_Distributions
|
||||
[9]:https://distrowatch.com/search.php?category=Raspberry+Pi
|
||||
[10]:https://www.raspberrypi.org/
|
||||
[11]:http://news.softpedia.com/news/raspbian-gets-experimental-opengl-driver-gpu-now-used-for-acceleration-500152.shtml
|
||||
[12]:https://www.raspberrypi.org/downloads/
|
||||
[13]:http://www.linux.com/news/embedded-mobile/mobile-linux/804659-ubuntu-snappy-leads-mobile-linux-migration-to-iot
|
||||
[14]:https://insights.ubuntu.com/2016/02/10/ubuntu-core-is-available-for-the-intel-nuc/
|
||||
[15]:https://www.reddit.com/r/openSUSE/comments/3hxrz4/opensuse_on_a_raspberry_pi_2_armv7/
|
||||
[16]:http://www.linux-arm.info/index.php/1103-hands-on-more-adventures-with-manjaro-arm-for-the-raspberry-pi-2
|
||||
[17]:http://www.linux-arm.info/index.php/1054-centos-altarch-7-now-available-for-aarch64-powerpc64-powerpc8-le-and-armhfp
|
||||
[18]:http://www.linux.com/news/embedded-mobile/mobile-linux/807087-faster-raspberry-pi-2-says-yes-to-ubuntu-and-windows-but-wheres-android
|
||||
[19]:http://www.linux.com/news/embedded-mobile/mobile-linux/886126-tizen-30-joins-growing-list-of-raspberry-pi-2-distros#!topic/android-rpi/YW_gGr8wZkk
|
||||
[20]:https://extonlinux.wordpress.com/2015/04/05/run-android-5-1-lollipop-exton-build-on-your-raspberry-pi-2/
|
||||
[21]:https://www.raspberrypi.org/forums/viewtopic.php?f=73&t=19106
|
||||
[22]:https://ubuntu-mate.org/raspberry-pi/
|
||||
[23]:https://chisight.wordpress.com/2015/10/19/fedora-22-or-23-on-raspberry-pi-2/
|
||||
[24]:http://www.techradar.com/us/news/software/5-of-the-most-popular-raspberry-pi-distros-1292537
|
||||
@ -1,73 +0,0 @@
|
||||
Convergence Becomes Real With First Ubuntu Tablet
|
||||
====================================================
|
||||
|
||||

|
||||
|
||||
First Ubuntu tablet has been just announced. Canonical, parent company of Ubuntu, and Spanish hardware manufacturer BQ are all set to unveil the first Ubuntu tablet at Mobile World Congress, later this month.
|
||||
|
||||
BQ is also the manufacturer of the [first Ubuntu Phone](http://itsfoss.com/ubuntu-phone-specification-release-date-pricing/). The partnership between Canonical and BQ extends to the tablet as well.
|
||||
|
||||
Ubuntu has been running the [#reinvent campaign on social media](https://business.facebook.com/media/set/?set=a.656637987810305.1073741827.115098615297581&type=3) and the web ahead of the launch to generate curiosity over the tablet. But does an Ubuntu fan really need a dedicated campaign to know about such things? I think not.
|
||||
|
||||
Ahead of this launch, specifications of the Ubuntu tablet and some teasers have been released. No surprises that the main focus has been on [convergence](https://insights.ubuntu.com/2015/10/20/ubuntus-path-to-convergence/).
|
||||
|
||||
[Ubuntu Phone has demonstrated convergence](http://www.omgubuntu.co.uk/2015/02/new-video-shows-off-ubuntu-convergence-demoed-on-tablet-phone) several times in the past. Ubuntu tablet takes it to the next level. Just adding an HDMI cable makes it to a full-fledged desktop. All you need is a keyboard and a mouse.
|
||||
|
||||

|
||||
|
||||
## BQ Ubuntu tablet specification
|
||||
|
||||
BQ will be using its trusted [Aquaris M10](http://www.bq.com/es/aquaris-m10) series to launch an Ubuntu edition. This is a strategy they used earlier with Ubuntu Phone where they launched an Ubuntu edition of their Aquaris e4.5 Android smartphone.
|
||||
|
||||
Aquaris M10 boasts of a decent hardware and an enormous 10 inches screen size. A quick list of specification includes:
|
||||
|
||||
- 10.1 inch multi-touch screen
|
||||
- MediaTek Quad Core MT8163A processor up to 1.5GHz
|
||||
- High capacity Li-Po battery (7280mAh)
|
||||
- Full HD (1080p) camera for super-sharp video recording
|
||||
- 2GB RAM and 16GB internal memory
|
||||
- MicroSD slot for extra storage (up to 64GB)
|
||||
- 12 megapixel camera with autofocus and dual flash
|
||||
- Frontal speakers
|
||||
- Micro HDMI slot
|
||||
- Dimensions: 246 x 171 x 8.2mm
|
||||
- Lightweight at only 470g
|
||||
|
||||
These proposed specifications have been taken from Ubuntu’s official website which doesn’t match up with the Aquaris M10 specification on BQ website though. Ubuntu website shows a 12 MP camera while BQ website has 8 MP max.
|
||||
|
||||
As you can see, first Ubuntu tablet is not really a power horse. In 2016, 2GB of RAM doesn’t seem to be sufficient. Moreover, the closed source MediaTek processors are another let down of the first Ubuntu Phone.
|
||||
|
||||
However, a supposed price tag of Euro 260 (the Android version costs the same) is a positive factor here and considering its capability to converge into a desktop, 10 inches screen keeps it in the entry level Netbook section.
|
||||
|
||||
The 470 g weight is another plus factor.
|
||||
|
||||
## First look at Ubuntu tablet
|
||||
|
||||
While Ubuntu tablet will be officially unveiled at Mobile World Congress, you can have a glimpse of its looks and functionings in the pictures below:
|
||||
|
||||

|
||||
|
||||
## Price, availability and release date
|
||||
|
||||
BQ Aquaris M10 Ubuntu edition will go on sale in the second quarter of the year 2016. Guessing from Ubuntu Phone experience, it should be available for Europe and UK first and later in other parts of the world.
|
||||
|
||||
The price should be around 260-270 Euro. This too is an estimate based on the price of the Android version.
|
||||
|
||||
## Up for the grab?
|
||||
|
||||
I was not very convinced at the first Ubuntu Phone. However, I think Ubuntu tablet is a better device than the Ubuntu Phone. With Snappy coming in action, Ubuntu tablet has the potential to become a mobile device cum desktop.
|
||||
|
||||
What do you think of it?
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/ubuntu-tablet/
|
||||
|
||||
作者:[ABHISHEK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
|
||||
@ -1,40 +0,0 @@
|
||||
The Evolving Market for Commercial Software Built On Open Source
|
||||
=====================================================================
|
||||
|
||||

|
||||
>Attendees listen to a presentation during Structure at the UCSF Mission Bay Conference Center, where Structure Data 2016 will take place. Image credit: Structure Events.
|
||||
|
||||
It's really hard to understate the impact of open source projects on the enterprise software market these days; open source integration became the norm so quickly we could be forgiven for missing the turning point.
|
||||
|
||||
Hadoop, for example, changed more than just the world of data analysis. It gave rise to a new generation of data companies that created their own software around open source projects, tweaking and supporting that code as needed, much like how Red Hat embraced Linux in the 1990s and early 2000s. And this software is increasingly delivered over public clouds, rather than run on the buyer's own servers, enabling an amazing degree of operational flexibility but raising all sorts of new questions about licensing, support, and pricing.
|
||||
|
||||
We've been following this closely over the years when putting together the lineup for our Structure Data conference, and Structure Data 2016 is no exception. The CEOs of three of the most important companies in big data operating around Hadoop -- Hortonworks, Cloudera and MapR -- will share the stage to discuss how they sell enterprise software and services around open source projects, generating cash while giving back to that community project at the same time.
|
||||
|
||||
There was a time when making money on enterprise software was easier. Once purchased by a customer, a mega-package of software from an enterprise vendor turned into its own cash register, generating something close to lifetime income from maintenance contracts and periodic upgrades to software that became harder and harder to displace as it became the heart of a customer’s business. Customers grumbled about lock-in, but they didn't really have much of a choice if they wanted to make their workforce more productive.
|
||||
|
||||
That is no longer the case. While an awful lot of companies are still stuck running immense software packages critical to their infrastructure, new projects are being deployed on cloud servers using open source technologies. This makes it much easier to upgrade one's capabilities without having to rip out a huge software package and reinstall something else, and it also allows companies to pay as they go, rather than paying for a bunch of features they'll never use.
|
||||
|
||||
And there are a lot of customers who want to take advantage of open source projects without building and supporting a team of engineers to tweak one of those projects for their own unique needs. Those customers are willing to pay for software packages whose value is based on the delta between the open source projects and the proprietary features laid on top of that project.
|
||||
|
||||
This is especially true for infrastructure-related software. Sure, your customers could install their own tweaks to a project like Hadoop or Spark or Node.js, but there's money to be made helping those customers out with a customizable package that lets them implement some of today's vital open source technologies without having to do all of the heavy lifting themselves. Just look at Structure Data 2016 presenters such as Confluent (Kafka), Databricks (Spark), and the Cloudera-Hortonworks-MapR (Hadoop) trio.
|
||||
|
||||
There's certainly something to be said for having a vendor to yell at when things go wrong. If your engineers botch the implementation of an open source project, you've only yourself to blame. But If you contract with a company that is willing to guarantee certain performance and uptime metrics inside of a service-level agreement, you're willing to pay for support, guidance, and a chance to yell at somebody outside of your organization when inevitable problems crop up.
|
||||
|
||||
The evolving market for commercial software on top of open source projects is something we've been tracking at Structure Data for years, and we urge you to join us in San Francisco March 9 and 10 if this is a topic near and dear to your heart.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/enterprise/cloud-computing/889564-the-evolving-market-for-commercial-software-built-on-open-source-
|
||||
|
||||
作者:[Tom Krazit ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/community/forums/person/70513
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,39 @@
|
||||
Vic020
|
||||
|
||||
Master OpenStack with 5 new tutorials
|
||||
=======================================
|
||||
|
||||

|
||||
|
||||
|
||||
Returning from OpenStack Summit this week, I am reminded of just how vast the open source cloud ecosystem is and just how many different projects and concepts you need to be familiar with in order to succeed. Although, we're actually quite fortunate with the resources available for keeping up. In addition to the [official documentation][1], many great educational tools are out there, from third party training and certification, to in-person events, and many community-contributed tutorials as well.
|
||||
|
||||
To help you stay on top of things, every month we round up a collection of new tutorials, how-tos, guides, and tips created by the OpenStack community. Here are some of the great pieces published this past month.
|
||||
|
||||
- First up, if you're looking for a (reasonably) affordable home OpenStack test lab, the Intel NUC is a great platform to consider. Small in form factor, but reasonably well-powered, you can get a literal stack of them running OpenStack pretty quickly with this guide to using [TripleO to deploy OpenStack][2] on the NUC, and read about some common quirks to watch out for.
|
||||
- After you've been running OpenStack for a while, the various processes keeping your cloud alive have probably generated quite a pile of log files. While some are probably safe to purge, you still need to have a plan for managing them. Here are some [quick thoughts][3] on managing logs in Ceilometer after nine-months in to a production deployment.
|
||||
- The OpenStack infrastructure project can be an intimidating place for a newcomer just trying to land a patch. What's a gate job, what's a test, and what are all of these steps my commit is going through? Get a quick overview of the whole process from Arie Bregman in this [handy blog post][4].
|
||||
- Compute hosts fail occasionally, and whether the cause is hardware or software, the good news is that OpenStack makes it easy to migrate your running instance to another host. However, some people have found the commands to perform this migration a little confusing. Learn the difference between the migrate and evacuate commands in plain English in [this great writeup][5].
|
||||
- Network Functions Virtualization technologies require some functionality from OpenStack that are outside of what other users might be familiar with. For example, SR-IOV and PCI passthrough are ways of exposing physical hardware directly for maximizing performance. Learn the [steps involved][6] to make this happen within an OpenStack deployment.
|
||||
|
||||
That wraps up our collection for this month, but if you're still looking for more, be sure to check out our past archive of [OpenStack tutorials][7] for even more learning resources. And if there's a tutorial or guide you think we ought to include in our next roundup, be sure to let us know in the comments below.
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/business/16/4/master-openstack-new-tutorials
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jason-baker
|
||||
|
||||
[1]: http://docs.openstack.org/
|
||||
[2]: http://acksyn.org/posts/2016/03/tripleo-on-nucs/
|
||||
[3]: http://silverskysoft.com/open-stack-xwrpr/2016/03/long-term-openstack-usage-summary/
|
||||
[4]: http://abregman.com/2016/03/05/openstack-infra-jenkins-jobs/
|
||||
[5]: http://www.danplanet.com/blog/2016/03/03/evacuate-in-nova-one-command-to-confuse-us-all/
|
||||
[6]: https://trickycloud.wordpress.com/2016/03/28/openstack-for-nfv-applications-sr-iov-and-pci-passthrough/
|
||||
[7]: https://opensource.com/resources/openstack-tutorials
|
||||
@ -0,0 +1,53 @@
|
||||
zpl1025
|
||||
The intersection of Drupal, IoT, and open hardware
|
||||
=======================================================
|
||||
|
||||

|
||||
|
||||
|
||||
Meet [Amber Matz][1], a Production Manager and Trainer at [Drupalize.Me][3], a service of Lullabot Education. When she's not tinkering around with Arduinos, Raspberry Pis, and electronic wearables, you can find her wrangling presenters for the Portland Drupal User Group.
|
||||
|
||||
Coming up at [DrupalCon NOLA][3], Amber will host a session about Drupal and IoT. If you're attending and want to learn about the intersection of open hardware, IoT, and Drupal, this session is for you. If you're not able to join us in New Orleans, Amber has some pretty cool things to share. In this interview, she tells us how she got involved with Drupal, a few of her favorite open hardware projects, and what the future holds for IoT and Drupal.
|
||||
|
||||

|
||||
|
||||
**How did you get involved with the Drupal community?**
|
||||
|
||||
Back in the day, I was working at a large nonprofit in the "webmaster's office" of the marketing department and was churning out custom PHP/MySQL forms like nobody's business. I finally got weary of that and starting hunting around the web for a better way. I found Drupal 6 and starting diving in on my own. Years later, after a career shift and a move, I discovered the Portland Drupal User Group and landed a job as a full-time Drupal developer. I continued to regularly attend the meetups in Portland, which I found to be a great source of community, friendships, and professional development. Eventually, I landed a job with Lullabot as a trainer creating content for Drupalize.Me. Now, I'm managing the Drupalize.Me content pipeline, creating Drupal 8 content, and am very much involved in the Portland Drupal community. I'm this year's coordinator, finding and scheduling speakers.
|
||||
|
||||
**We have to know: What is Arduino prototyping, how did you discover it, and what's the coolest thing you've done with an Arduino?**
|
||||
|
||||
Arduino, Raspberry Pi, and wearable electronics have been these terms that I've heard thrown around for years. I found [Adafruit's Wearable Electronics][4] with Becky Stern YouTube show years ago (which, up until recently, when Becky moved on, aired every Wednesday). I was fascinated by wearables and even ordered an LED sewing kit but never did anything with it. I just didn't get it. I had no background in electronics whatsoever, and while I was fascinated by the projects I was finding, I didn't see how I could ever make anything like that. It seemed so out of reach.
|
||||
|
||||
Finally, I found a Coursera "Internet of Things" specialization. (So trendy, right?) But I was immediately hooked! I finally got an explanation of what an Arduino was, along with all these other important terms and concepts. I ordered the recommended Arduino starter kit, which came with a getting started booklet. When I made that first LED blink, it was pure delight. I had two weeks' vacation over the holidays and after Christmas, and I did nothing but make and program Arduino circuits from the getting started booklet. It was oddly so relaxing! I enjoyed it so much.
|
||||
|
||||
In January, I started creating my own prototypes. When I found out I was emceeing our company retreat's lightning talks, I created a Lightning Talk Visual Timer prototype with five LEDs and an Arduino.
|
||||
|
||||

|
||||
|
||||
It was a huge hit. I also made my first wearable project, a glowing hoodie, using the Arduino IDE compatible Gemma microcontroller, a tiny round sewable component, to which I sewed using conductive thread, a conductive slider connected to a hoodie's drawstring, which controlled the colors of five NeoPixels sewn around the inside of the hood. So that's what I mean by prototyping: Making crazy projects that are fun and maybe even a little practical.
|
||||
|
||||
**What are the biggest opportunities for Drupal and IoT?**
|
||||
|
||||
IoT isn't that much different than the web services and decoupling Drupal trends. It's the movement of data from thing one to thing two and the rendering of that data into something useful. But how does it get there? And what do you do with it? You think there are a lot of solutions, and apps, and frameworks, and APIs out there now? With IoT, that's only going to continue to increase—exponentially. What I've found is that given any device or any "thing", there is a way to connect it to the Internet—many ways. And there are plenty of code libraries out there to help makers get their data from thing one to thing two.
|
||||
|
||||
So where does Drupal fit in? Web services, for one, is going to be the first obvious place. But as a maker, I don't want to spend my time coding custom modules in Drupal. I want to plug and play! So I would love to see modules emerge that connect with IoT Cloud APIs and services like ThingSpeak and Adafruit.io and IFTTT and others. I think there's an opportunity, too, for a business to build an IoT cloud service in Drupal that allows people to send and store their sensor data, visualize it charts and graphs, and build widgets that react to certain values or thresholds. Each of these IoT Cloud API services fill a slightly different niche, and there's plenty of room for others.
|
||||
|
||||
**What are a few things you're looking forward to at DrupalCon?**
|
||||
|
||||
I love reconnecting with Drupal friends, meeting new people, and also seeing Lullabot and Drupalize.Me co-workers (we're distributed companies)! There's so much to learn with Drupal 8 and it's been overwhelming at times to put together training materials for our customers. So, I'm looking forward to attending Drupal 8-related sessions and getting up-to-speed on the latest developments. Finally, I'm really curious about New Orleans! I haven't been there since 2004 and I'm excited to see what's changed.
|
||||
|
||||
**Tell us about your DrupalCon talk Beyond the blink: Add Drupal to your IoT playground. Why should someone attend? What are the major takeaways?**
|
||||
|
||||
My session title, Beyond the blink: Add Drupal to your IoT playground, in itself is so full of assumptions that first off I'm going to get everyone up to speed and on the same page. You don't need to know anything about Arduino, the Internet of Things, or even Drupal to follow along. We'll start with making an LED blink with an Arduino, and then I want to talk about what the main takeaways have been for me: Play, learn, teach, and make. I'll show examples that have inspired me and that will hopefully inspire and encourage others in the audience to give it a try. Then, it's demo time!
|
||||
|
||||
First, thing one. Thing one is a Build Notifier Tower Light. In this demo, I'll show how I connected the Tower Light to the Internet and how I got it to respond to data received from a Cloud API service. Next, Thing two. Thing two is a "weather watch" in the form of a steampunk iPhone case. It's got small LED matrix that displays an icon of the local-to-me weather, a barometric pressure and temperature sensor, a GPS module, and a Bluetooth LE module, all connected and controlled with an Adafruit Flora microcontroller. Thing two sends weather and location data to Adafruit.io by connecting to an app on my iPhone over Bluetooth and sends it up to the cloud using an MQTT protocol! Then, on the Drupal side, I'm pulling down that data from the cloud, updating a block with the weather, and updating a map. So folks will get a taste of what you can do with web services, maps, and blocks in Drupal 8, too.
|
||||
|
||||
It's been a brain-melting adventure learning and making these demo prototypes, and I hope others will come to the session and catch a little of this contagious enthusiasm I have for this intersection of technologies! I'm very excited to share what I've discovered.
|
||||
|
||||
|
||||
|
||||
[1]: https://www.drupal.org/u/amber-himes-matz
|
||||
[2]: https://drupalize.me/
|
||||
[3]: https://events.drupal.org/neworleans2016/
|
||||
[4]: https://www.adafruit.com/beckystern
|
||||
@ -1,273 +0,0 @@
|
||||
Part 14 - Monitor Linux Processes Resource Usage and Set Process Limits on a Per-User Basis
|
||||
=============================================================================================
|
||||
|
||||
Because of the changes in the LFCS exam requirements effective Feb. 2, 2016, we are adding the necessary topics to the [LFCS series][1] published here. To prepare for this exam, your are highly encouraged to use the [LFCE series][2] as well.
|
||||
|
||||

|
||||
>Monitor Linux Processes and Set Process Limits Per User – Part 14
|
||||
|
||||
Every Linux system administrator needs to know how to verify the integrity and availability of hardware, resources, and key processes. In addition, setting resource limits on a per-user basis must also be a part of his / her skill set.
|
||||
|
||||
In this article we will explore a few ways to ensure that the system both hardware and the software is behaving correctly to avoid potential issues that may cause unexpected production downtime and money loss.
|
||||
|
||||
### Linux Reporting Processors Statistics
|
||||
|
||||
With **mpstat** you can view the activities for each processor individually or the system as a whole, both as a one-time snapshot or dynamically.
|
||||
|
||||
In order to use this tool, you will need to install **sysstat**:
|
||||
|
||||
```
|
||||
# yum update && yum install sysstat [On CentOS based systems]
|
||||
# aptitutde update && aptitude install sysstat [On Ubuntu based systems]
|
||||
# zypper update && zypper install sysstat [On openSUSE systems]
|
||||
```
|
||||
|
||||
Read more about sysstat and it’s utilities at [Learn Sysstat and Its Utilities mpstat, pidstat, iostat and sar in Linux][3]
|
||||
|
||||
Once you have installed **mpstat**, use it to generate reports of processors statistics.
|
||||
|
||||
To display **3** global reports of CPU utilization (`-u`) for all CPUs (as indicated by `-P` ALL) at a 2-second interval, do:
|
||||
|
||||
```
|
||||
# mpstat -P ALL -u 2 3
|
||||
```
|
||||
|
||||
### Sample Output
|
||||
|
||||
```
|
||||
Linux 3.19.0-32-generic (tecmint.com) Wednesday 30 March 2016 _x86_64_ (4 CPU)
|
||||
|
||||
11:41:07 IST CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
|
||||
11:41:09 IST all 5.85 0.00 1.12 0.12 0.00 0.00 0.00 0.00 0.00 92.91
|
||||
11:41:09 IST 0 4.48 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 94.53
|
||||
11:41:09 IST 1 2.50 0.00 0.50 0.00 0.00 0.00 0.00 0.00 0.00 97.00
|
||||
11:41:09 IST 2 6.44 0.00 0.99 0.00 0.00 0.00 0.00 0.00 0.00 92.57
|
||||
11:41:09 IST 3 10.45 0.00 1.99 0.00 0.00 0.00 0.00 0.00 0.00 87.56
|
||||
|
||||
11:41:09 IST CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
|
||||
11:41:11 IST all 11.60 0.12 1.12 0.50 0.00 0.00 0.00 0.00 0.00 86.66
|
||||
11:41:11 IST 0 10.50 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 88.50
|
||||
11:41:11 IST 1 14.36 0.00 1.49 2.48 0.00 0.00 0.00 0.00 0.00 81.68
|
||||
11:41:11 IST 2 2.00 0.50 1.00 0.00 0.00 0.00 0.00 0.00 0.00 96.50
|
||||
11:41:11 IST 3 19.40 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 79.60
|
||||
|
||||
11:41:11 IST CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
|
||||
11:41:13 IST all 5.69 0.00 1.24 0.00 0.00 0.00 0.00 0.00 0.00 93.07
|
||||
11:41:13 IST 0 2.97 0.00 1.49 0.00 0.00 0.00 0.00 0.00 0.00 95.54
|
||||
11:41:13 IST 1 10.78 0.00 1.47 0.00 0.00 0.00 0.00 0.00 0.00 87.75
|
||||
11:41:13 IST 2 2.00 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 97.00
|
||||
11:41:13 IST 3 6.93 0.00 0.50 0.00 0.00 0.00 0.00 0.00 0.00 92.57
|
||||
|
||||
Average: CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
|
||||
Average: all 7.71 0.04 1.16 0.21 0.00 0.00 0.00 0.00 0.00 90.89
|
||||
Average: 0 5.97 0.00 1.16 0.00 0.00 0.00 0.00 0.00 0.00 92.87
|
||||
Average: 1 9.24 0.00 1.16 0.83 0.00 0.00 0.00 0.00 0.00 88.78
|
||||
Average: 2 3.49 0.17 1.00 0.00 0.00 0.00 0.00 0.00 0.00 95.35
|
||||
Average: 3 12.25 0.00 1.16 0.00 0.00 0.00 0.00 0.00 0.00 86.59
|
||||
```
|
||||
|
||||
To view the same statistics for a specific **CPU** (**CPU 0** in the following example), use:
|
||||
|
||||
```
|
||||
# mpstat -P 0 -u 2 3
|
||||
```
|
||||
|
||||
### Sample Output
|
||||
|
||||
```
|
||||
Linux 3.19.0-32-generic (tecmint.com) Wednesday 30 March 2016 _x86_64_ (4 CPU)
|
||||
|
||||
11:42:08 IST CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
|
||||
11:42:10 IST 0 3.00 0.00 0.50 0.00 0.00 0.00 0.00 0.00 0.00 96.50
|
||||
11:42:12 IST 0 4.08 0.00 0.00 2.55 0.00 0.00 0.00 0.00 0.00 93.37
|
||||
11:42:14 IST 0 9.74 0.00 0.51 0.00 0.00 0.00 0.00 0.00 0.00 89.74
|
||||
Average: 0 5.58 0.00 0.34 0.85 0.00 0.00 0.00 0.00 0.00 93.23
|
||||
```
|
||||
|
||||
The output of the above commands shows these columns:
|
||||
|
||||
* `CPU`: Processor number as an integer, or the word all as an average for all processors.
|
||||
* `%usr`: Percentage of CPU utilization while running user level applications.
|
||||
* `%nice`: Same as `%usr`, but with nice priority.
|
||||
* `%sys`: Percentage of CPU utilization that occurred while executing kernel applications. This does not include time spent dealing with interrupts or handling hardware.
|
||||
* `%iowait`: Percentage of time when the given CPU (or all) was idle, during which there was a resource-intensive I/O operation scheduled on that CPU. A more detailed explanation (with examples) can be found [here][4].
|
||||
* `%irq`: Percentage of time spent servicing hardware interrupts.
|
||||
* `%soft`: Same as `%irq`, but with software interrupts.
|
||||
* `%steal`: Percentage of time spent in involuntary wait (steal or stolen time) when a virtual machine, as guest, is “winning” the hypervisor’s attention while competing for the CPU(s). This value should be kept as small as possible. A high value in this field means the virtual machine is stalling – or soon will be.
|
||||
* `%guest`: Percentage of time spent running a virtual processor.
|
||||
* `%idle`: percentage of time when CPU(s) were not executing any tasks. If you observe a low value in this column, that is an indication of the system being placed under a heavy load. In that case, you will need to take a closer look at the process list, as we will discuss in a minute, to determine what is causing it.
|
||||
|
||||
To put the place the processor under a somewhat high load, run the following commands and then execute mpstat (as indicated) in a separate terminal:
|
||||
|
||||
```
|
||||
# dd if=/dev/zero of=test.iso bs=1G count=1
|
||||
# mpstat -u -P 0 2 3
|
||||
# ping -f localhost # Interrupt with Ctrl + C after mpstat below completes
|
||||
# mpstat -u -P 0 2 3
|
||||
```
|
||||
|
||||
Finally, compare to the output of **mpstat** under “normal” circumstances:
|
||||
|
||||

|
||||
>Report Linux Processors Related Statistics
|
||||
|
||||
As you can see in the image above, **CPU 0** was under a heavy load during the first two examples, as indicated by the `%idle` column.
|
||||
|
||||
In the next section we will discuss how to identify these resource-hungry processes, how to obtain more information about them, and how to take appropriate action.
|
||||
|
||||
### Reporting Linux Processes
|
||||
|
||||
To list processes sorting them by CPU usage, we will use the well known `ps` command with the `-eo` (to select all processes with user-defined format) and `--sort` (to specify a custom sorting order) options, like so:
|
||||
|
||||
```
|
||||
# ps -eo pid,ppid,cmd,%cpu,%mem --sort=-%cpu
|
||||
```
|
||||
|
||||
The above command will only show the `PID`, `PPID`, the command associated with the process, and the percentage of CPU and RAM usage sorted by the percentage of CPU usage in descending order. When executed during the creation of the .iso file, here’s the first few lines of the output:
|
||||
|
||||

|
||||
>Find Linux Processes By CPU Usage
|
||||
|
||||
Once we have identified a process of interest (such as the one with `PID=2822`), we can navigate to `/proc/PID` (`/proc/2822` in this case) and do a directory listing.
|
||||
|
||||
This directory is where several files and subdirectories with detailed information about this particular process are kept while it is running.
|
||||
|
||||
#### For example:
|
||||
|
||||
* `/proc/2822/io` contains IO statistics for the process (number of characters and bytes read and written, among others, during IO operations).
|
||||
* `/proc/2822/attr/current` shows the current SELinux security attributes of the process.
|
||||
* `/proc/2822/cgroup` describes the control groups (cgroups for short) to which the process belongs if the CONFIG_CGROUPS kernel configuration option is enabled, which you can verify with:
|
||||
|
||||
```
|
||||
# cat /boot/config-$(uname -r) | grep -i cgroups
|
||||
```
|
||||
|
||||
If the option is enabled, you should see:
|
||||
|
||||
```
|
||||
CONFIG_CGROUPS=y
|
||||
```
|
||||
|
||||
Using `cgroups` you can manage the amount of allowed resource usage on a per-process basis as explained in Chapters 1 through 4 of the [Red Hat Enterprise Linux 7 Resource Management guide][5], in Chapter 9 of the [openSUSE System Analysis and Tuning guide][6], and in the [Control Groups section of the Ubuntu 14.04 Server documentation][7].
|
||||
|
||||
The `/proc/2822/fd` is a directory that contains one symbolic link for each file descriptor the process has opened. The following image shows this information for the process that was started in tty1 (the first terminal) to create the **.iso** image:
|
||||
|
||||

|
||||
>Find Linux Process Information
|
||||
|
||||
The above image shows that **stdin** (file descriptor **0**), **stdout** (file descriptor **1**), and **stderr** (file descriptor **2**) are mapped to **/dev/zero**, **/root/test.iso**, and **/dev/tty1**, respectively.
|
||||
|
||||
More information about `/proc` can be found in “The `/proc` filesystem” document kept and maintained by Kernel.org, and in the Linux Programmer’s Manual.
|
||||
|
||||
### Setting Resource Limits on a Per-User Basis in Linux
|
||||
|
||||
If you are not careful and allow any user to run an unlimited number of processes, you may eventually experience an unexpected system shutdown or get locked out as the system enters an unusable state. To prevent this from happening, you should place a limit on the number of processes users can start.
|
||||
|
||||
To do this, edit **/etc/security/limits.conf** and add the following line at the bottom of the file to set the limit:
|
||||
|
||||
```
|
||||
* hard nproc 10
|
||||
```
|
||||
|
||||
The first field can be used to indicate either a user, a group, or all of them `(*)`, whereas the second field enforces a hard limit on the number of process (nproc) to **10**. To apply changes, logging out and back in is enough.
|
||||
|
||||
Thus, let’s see what happens if a certain user other than root (either a legitimate one or not) attempts to start a shell fork bomb. If we had not implemented limits, this would initially launch two instances of a function, and then duplicate each of them in a neverending loop. Thus, it would eventually bringing your system to a crawl.
|
||||
|
||||
However, with the above restriction in place, the fork bomb does not succeed but the user will still get locked out until the system administrator kills the process associated with it:
|
||||
|
||||
|
||||
>Run Shell Fork Bomb
|
||||
|
||||
**TIP**: Other possible restrictions made possible by **ulimit** are documented in the `limits.conf` file.
|
||||
|
||||
### Linux Other Process Management Tools
|
||||
|
||||
In addition to the tools discussed previously, a system administrator may also need to:
|
||||
|
||||
**a)** Modify the execution priority (use of system resources) of a process using **renice**. This means that the kernel will allocate more or less system resources to the process based on the assigned priority (a number commonly known as “**niceness**” in a range from `-20` to `19`).
|
||||
|
||||
The lower the value, the greater the execution priority. Regular users (other than root) can only modify the niceness of processes they own to a higher value (meaning a lower execution priority), whereas root can modify this value for any process, and may increase or decrease it.
|
||||
|
||||
The basic syntax of renice is as follows:
|
||||
|
||||
```
|
||||
# renice [-n] <new priority> <UID, GID, PGID, or empty> identifier
|
||||
```
|
||||
|
||||
If the argument after the new priority value is not present (empty), it is set to PID by default. In that case, the niceness of process with **PID=identifier** is set to `<new priority>`.
|
||||
|
||||
**b)** Interrupt the normal execution of a process when needed. This is commonly known as [“killing” the process][9]. Under the hood, this means sending the process a signal to finish its execution properly and release any used resources in an orderly manner.
|
||||
|
||||
To [kill a process][10], use the **kill** command as follows:
|
||||
|
||||
```
|
||||
# kill PID
|
||||
```
|
||||
|
||||
Alternatively, you can use [pkill to terminate all processes][11] of a given owner `(-u)`, or a group owner `(-G)`, or even those processes which have a PPID in common `(-P)`. These options may be followed by the numeric representation or the actual name as identifier:
|
||||
|
||||
```
|
||||
# pkill [options] identifier
|
||||
```
|
||||
|
||||
For example,
|
||||
|
||||
```
|
||||
# pkill -G 1000
|
||||
```
|
||||
|
||||
will kill all processes owned by group with `GID=1000`.
|
||||
|
||||
And,
|
||||
|
||||
```
|
||||
# pkill -P 4993
|
||||
```
|
||||
|
||||
will kill all processes whose `PPID is 4993`.
|
||||
|
||||
Before running a `pkill`, it is a good idea to test the results with `pgrep` first, perhaps using the `-l` option as well to list the processes’ names. It takes the same options but only returns the PIDs of processes (without taking any further action) that would be killed if `pkill` is used.
|
||||
|
||||
```
|
||||
# pgrep -l -u gacanepa
|
||||
```
|
||||
|
||||
This is illustrated in the next image:
|
||||
|
||||

|
||||
>Find User Running Processes in Linux
|
||||
|
||||
### Summary
|
||||
|
||||
In this article we have explored a few ways to monitor resource usage in order to verify the integrity and availability of critical hardware and software components in a Linux system.
|
||||
|
||||
We have also learned how to take appropriate action (either by adjusting the execution priority of a given process or by terminating it) under unusual circumstances.
|
||||
|
||||
We hope the concepts explained in this tutorial have been helpful. If you have any questions or comments, feel free to reach us using the contact form below.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-basic-shell-scripting-and-linux-filesystem-troubleshooting/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/gacanepa/
|
||||
[1]: http://www.tecmint.com/sed-command-to-create-edit-and-manipulate-files-in-linux/
|
||||
[2]: http://www.tecmint.com/installing-network-services-and-configuring-services-at-system-boot/
|
||||
[3]: http://www.tecmint.com/sysstat-commands-to-monitor-linux/
|
||||
[4]: http://veithen.github.io/2013/11/18/iowait-linux.html
|
||||
[5]: https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/7/html/Resource_Management_Guide/index.html
|
||||
[6]: https://doc.opensuse.org/documentation/leap/tuning/html/book.sle.tuning/cha.tuning.cgroups.html
|
||||
[7]: https://help.ubuntu.com/lts/serverguide/cgroups.html
|
||||
[8]: http://man7.org/linux/man-pages/man5/proc.5.html
|
||||
[9]: http://www.tecmint.com/kill-processes-unresponsive-programs-in-ubuntu/
|
||||
[10]: http://www.tecmint.com/find-and-kill-running-processes-pid-in-linux/
|
||||
[11]: http://www.tecmint.com/how-to-kill-a-process-in-linux/
|
||||
@ -1,3 +1,4 @@
|
||||
ictlyh Translating
|
||||
Part 7 - LFCS: Managing System Startup Process and Services (SysVinit, Systemd and Upstart)
|
||||
================================================================================
|
||||
A couple of months ago, the Linux Foundation announced the LFCS (Linux Foundation Certified Sysadmin) certification, an exciting new program whose aim is allowing individuals from all ends of the world to get certified in performing basic to intermediate system administration tasks on Linux systems. This includes supporting already running systems and services, along with first-hand problem-finding and analysis, plus the ability to decide when to raise issues to engineering teams.
|
||||
|
||||
561
sources/tech/LXD/Part 3 - LXD 2.0--Your first LXD container.md
Normal file
561
sources/tech/LXD/Part 3 - LXD 2.0--Your first LXD container.md
Normal file
@ -0,0 +1,561 @@
|
||||
kylepeng93 is translating
|
||||
Part 3 - LXD 2.0: Your first LXD container
|
||||
==========================================
|
||||
|
||||
This is the third blog post [in this series about LXD 2.0][0].
|
||||
|
||||
As there are a lot of commands involved with managing LXD containers, this post is rather long. If you’d instead prefer a quick step-by-step tour of those same commands, you can [try our online demo instead][1]!
|
||||
|
||||

|
||||
|
||||
### Creating and starting a new container
|
||||
|
||||
As I mentioned in the previous posts, the LXD command line client comes pre-configured with a few image sources. Ubuntu is the best covered with official images for all its releases and architectures but there also are a number of unofficial images for other distributions. Those are community generated and maintained by LXC upstream contributors.
|
||||
|
||||
### Ubuntu
|
||||
|
||||
If all you want is the best supported release of Ubuntu, all you have to do is:
|
||||
|
||||
```
|
||||
lxc launch ubuntu:
|
||||
```
|
||||
|
||||
Note however that the meaning of this will change as new Ubuntu LTS releases are released. So for scripting use, you should stick to mentioning the actual release you want (see below).
|
||||
|
||||
### Ubuntu 14.04 LTS
|
||||
|
||||
To get the latest, tested, stable image of Ubuntu 14.04 LTS, you can simply run:
|
||||
|
||||
```
|
||||
lxc launch ubuntu:14.04
|
||||
```
|
||||
|
||||
In this mode, a random container name will be picked.
|
||||
If you prefer to specify your own name, you may instead do:
|
||||
|
||||
```
|
||||
lxc launch ubuntu:14.04 c1
|
||||
```
|
||||
|
||||
Should you want a specific (non-primary) architecture, say a 32bit Intel image, you can do:
|
||||
|
||||
```
|
||||
lxc launch ubuntu:14.04/i386 c2
|
||||
```
|
||||
|
||||
### Current Ubuntu development release
|
||||
|
||||
The “ubuntu:” remote used above only provides official, tested images for Ubuntu. If you instead want untested daily builds, as is appropriate for the development release, you’ll want to use the “ubuntu-daily:” remote instead.
|
||||
|
||||
```
|
||||
lxc launch ubuntu-daily:devel c3
|
||||
```
|
||||
|
||||
In this example, whatever the latest Ubuntu development release is will automatically be picked.
|
||||
|
||||
You can also be explicit, for example by using the code name:
|
||||
|
||||
```
|
||||
lxc launch ubuntu-daily:xenial c4
|
||||
```
|
||||
|
||||
### Latest Alpine Linux
|
||||
|
||||
Alpine images are available on the “images:” remote and can be launched with:
|
||||
|
||||
```
|
||||
lxc launch images:alpine/3.3/amd64 c5
|
||||
```
|
||||
|
||||
### And many more
|
||||
|
||||
A full list of the Ubuntu images can be obtained with:
|
||||
|
||||
```
|
||||
lxc image list ubuntu:
|
||||
lxc image list ubuntu-daily:
|
||||
```
|
||||
|
||||
And of all the unofficial images:
|
||||
|
||||
```
|
||||
lxc image list images:
|
||||
```
|
||||
|
||||
A list of all the aliases (friendly names) available on a given remote can also be obtained with (for the “ubuntu:” remote):
|
||||
|
||||
```
|
||||
lxc image alias list ubuntu:
|
||||
```
|
||||
|
||||
### Creating a container without starting it
|
||||
|
||||
If you want to just create a container or a batch of container but not also start them immediately, you can just replace “lxc launch” by “lxc init”. All the options are identical, the only different is that it will not start the container for you after creation.
|
||||
|
||||
```
|
||||
lxc init ubuntu:
|
||||
```
|
||||
|
||||
### Information about your containers
|
||||
|
||||
#### Listing the containers
|
||||
|
||||
To list all your containers, you can do:
|
||||
|
||||
```
|
||||
lxc list
|
||||
```
|
||||
|
||||
There are a number of options you can pass to change what columns are displayed. On systems with a lot of containers, the default columns can be a bit slow (due to having to retrieve network information from the containers), you may instead want:
|
||||
|
||||
```
|
||||
lxc list --fast
|
||||
```
|
||||
|
||||
Which shows a different set of columns that require less processing on the server side.
|
||||
|
||||
You can also filter based on name or properties:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc list security.privileged=true
|
||||
+------+---------+---------------------+-----------------------------------------------+------------+-----------+
|
||||
| NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS |
|
||||
+------+---------+---------------------+-----------------------------------------------+------------+-----------+
|
||||
| suse | RUNNING | 172.17.0.105 (eth0) | 2607:f2c0:f00f:2700:216:3eff:fef2:aff4 (eth0) | PERSISTENT | 0 |
|
||||
+------+---------+---------------------+-----------------------------------------------+------------+-----------+
|
||||
```
|
||||
|
||||
In this example, only containers that are privileged (user namespace disabled) are listed.
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc list --fast alpine
|
||||
+-------------+---------+--------------+----------------------+----------+------------+
|
||||
| NAME | STATE | ARCHITECTURE | CREATED AT | PROFILES | TYPE |
|
||||
+-------------+---------+--------------+----------------------+----------+------------+
|
||||
| alpine | RUNNING | x86_64 | 2016/03/20 02:11 UTC | default | PERSISTENT |
|
||||
+-------------+---------+--------------+----------------------+----------+------------+
|
||||
| alpine-edge | RUNNING | x86_64 | 2016/03/20 02:19 UTC | default | PERSISTENT |
|
||||
+-------------+---------+--------------+----------------------+----------+------------+
|
||||
```
|
||||
|
||||
And in this example, only the containers which have “alpine” in their names (complex regular expressions are also supported).
|
||||
|
||||
#### Getting detailed information from a container
|
||||
|
||||
As the list command obviously can’t show you everything about a container in a nicely readable way, you can query information about an individual container with:
|
||||
|
||||
```
|
||||
lxc info <container>
|
||||
```
|
||||
|
||||
For example:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc info zerotier
|
||||
Name: zerotier
|
||||
Architecture: x86_64
|
||||
Created: 2016/02/20 20:01 UTC
|
||||
Status: Running
|
||||
Type: persistent
|
||||
Profiles: default
|
||||
Pid: 31715
|
||||
Processes: 32
|
||||
Ips:
|
||||
eth0: inet 172.17.0.101
|
||||
eth0: inet6 2607:f2c0:f00f:2700:216:3eff:feec:65a8
|
||||
eth0: inet6 fe80::216:3eff:feec:65a8
|
||||
lo: inet 127.0.0.1
|
||||
lo: inet6 ::1
|
||||
lxcbr0: inet 10.0.3.1
|
||||
lxcbr0: inet6 fe80::c0a4:ceff:fe52:4d51
|
||||
zt0: inet 29.17.181.59
|
||||
zt0: inet6 fd80:56c2:e21c:0:199:9379:e711:b3e1
|
||||
zt0: inet6 fe80::79:e7ff:fe0d:5123
|
||||
Snapshots:
|
||||
zerotier/blah (taken at 2016/03/08 23:55 UTC) (stateless)
|
||||
```
|
||||
|
||||
### Life-cycle management commands
|
||||
|
||||
Those are probably the most obvious commands of any container or virtual machine manager but they still need to be covered.
|
||||
|
||||
Oh and all of them accept multiple container names for batch operation.
|
||||
|
||||
#### start
|
||||
|
||||
Starting a container is as simple as:
|
||||
|
||||
```
|
||||
lxc start <container>
|
||||
```
|
||||
|
||||
#### stop
|
||||
|
||||
Stopping a container can be done with:
|
||||
|
||||
```
|
||||
lxc stop <container>
|
||||
```
|
||||
|
||||
If the container isn’t cooperating (not responding to SIGPWR), you can force it with:
|
||||
|
||||
```
|
||||
lxc stop <container> --force
|
||||
```
|
||||
|
||||
#### restart
|
||||
|
||||
Restarting a container is done through:
|
||||
|
||||
```
|
||||
lxc restart <container>
|
||||
```
|
||||
|
||||
And if not cooperating (not responding to SIGINT), you can force it with:
|
||||
|
||||
```
|
||||
lxc restart <container> --force
|
||||
```
|
||||
|
||||
#### pause
|
||||
|
||||
You can also “pause” a container. In this mode, all the container tasks will be sent the equivalent of a SIGSTOP which means that they will still be visible and will still be using memory but they won’t get any CPU time from the scheduler.
|
||||
|
||||
This is useful if you have a CPU hungry container that takes quite a while to start but that you aren’t constantly using. You can let it start, then pause it, then start it again when needed.
|
||||
|
||||
```
|
||||
lxc pause <container>
|
||||
```
|
||||
|
||||
#### delete
|
||||
|
||||
Lastly, if you want a container to go away, you can delete it for good with:
|
||||
|
||||
```
|
||||
lxc delete <container>
|
||||
```
|
||||
|
||||
Note that you will have to pass “–force” if the container is currently running.
|
||||
|
||||
### Container configuration
|
||||
|
||||
LXD exposes quite a few container settings, including resource limitation, control of container startup and a variety of device pass-through options. The full list is far too long to cover in this post but it’s available [here][2].
|
||||
|
||||
As far as devices go, LXD currently supports the following device types:
|
||||
|
||||
- disk
|
||||
This can be a physical disk or partition being mounted into the container or a bind-mounted path from the host.
|
||||
- nic
|
||||
A network interface. It can be a bridged virtual ethernet interrface, a point to point device, an ethernet macvlan device or an actual physical interface being passed through to the container.
|
||||
- unix-block
|
||||
A UNIX block device, e.g. /dev/sda
|
||||
- unix-char
|
||||
A UNIX character device, e.g. /dev/kvm
|
||||
- none
|
||||
This special type is used to hide a device which would otherwise be inherited through profiles.
|
||||
|
||||
#### Configuration profiles
|
||||
|
||||
The list of all available profiles can be obtained with:
|
||||
|
||||
```
|
||||
lxc profile list
|
||||
```
|
||||
|
||||
To see the content of a given profile, the easiest is to use:
|
||||
|
||||
```
|
||||
lxc profile show <profile>
|
||||
```
|
||||
|
||||
And should you want to change anything inside it, use:
|
||||
|
||||
```
|
||||
lxc profile edit <profile>
|
||||
```
|
||||
|
||||
You can change the list of profiles which apply to a given container with:
|
||||
|
||||
```
|
||||
lxc profile apply <container> <profile1>,<profile2>,<profile3>,...
|
||||
```
|
||||
|
||||
#### Local configuration
|
||||
|
||||
For things that are unique to a container and so don’t make sense to put into a profile, you can just set them directly against the container:
|
||||
|
||||
```
|
||||
lxc config edit <container>
|
||||
```
|
||||
|
||||
This behaves the exact same way as “profile edit” above.
|
||||
|
||||
Instead of opening the whole thing in a text editor, you can also modify individual keys with:
|
||||
|
||||
```
|
||||
lxc config set <container> <key> <value>
|
||||
```
|
||||
Or add devices, for example:
|
||||
|
||||
```
|
||||
lxc config device add my-container kvm unix-char path=/dev/kvm
|
||||
```
|
||||
|
||||
Which will setup a /dev/kvm entry for the container named “my-container”.
|
||||
|
||||
The same can be done for a profile using “lxc profile set” and “lxc profile device add”.
|
||||
|
||||
#### Reading the configuration
|
||||
|
||||
You can read the container local configuration with:
|
||||
|
||||
```
|
||||
lxc config show <container>
|
||||
```
|
||||
|
||||
Or to get the expanded configuration (including all the profile keys):
|
||||
|
||||
```
|
||||
lxc config show --expanded <container>
|
||||
```
|
||||
|
||||
For example:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc config show --expanded zerotier
|
||||
name: zerotier
|
||||
profiles:
|
||||
- default
|
||||
config:
|
||||
security.nesting: "true"
|
||||
user.a: b
|
||||
volatile.base_image: a49d26ce5808075f5175bf31f5cb90561f5023dcd408da8ac5e834096d46b2d8
|
||||
volatile.eth0.hwaddr: 00:16:3e:ec:65:a8
|
||||
volatile.last_state.idmap: '[{"Isuid":true,"Isgid":false,"Hostid":100000,"Nsid":0,"Maprange":65536},{"Isuid":false,"Isgid":true,"Hostid":100000,"Nsid":0,"Maprange":65536}]'
|
||||
devices:
|
||||
eth0:
|
||||
name: eth0
|
||||
nictype: macvlan
|
||||
parent: eth0
|
||||
type: nic
|
||||
limits.ingress: 10Mbit
|
||||
limits.egress: 10Mbit
|
||||
root:
|
||||
path: /
|
||||
size: 30GB
|
||||
type: disk
|
||||
tun:
|
||||
path: /dev/net/tun
|
||||
type: unix-char
|
||||
ephemeral: false
|
||||
```
|
||||
|
||||
That one is very convenient to check what will actually be applied to a given container.
|
||||
|
||||
#### Live configuration update
|
||||
|
||||
Note that unless indicated in the documentation, all configuration keys and device entries are applied to affected containers live. This means that you can add and remove devices or alter the security profile of running containers without ever having to restart them.
|
||||
|
||||
### Getting a shell
|
||||
|
||||
LXD lets you execute tasks directly into the container. The most common use of this is to get a shell in the container or to run some admin tasks.
|
||||
|
||||
The benefit of this compared to SSH is that you’re not dependent on the container being reachable over the network or on any software or configuration being present inside the container.
|
||||
|
||||
Execution environment
|
||||
|
||||
One thing that’s a bit unusual with the way LXD executes commands inside the container is that it’s not itself running inside the container, which means that it can’t know what shell to use, what environment variables to set or what path to use for your home directory.
|
||||
|
||||
Commands executed through LXD will always run as the container’s root user (uid 0, gid 0) with a minimal PATH environment variable set and a HOME environment variable set to /root.
|
||||
|
||||
Additional environment variables can be passed through the command line or can be set permanently against the container through the “environment.<key>” configuration options.
|
||||
|
||||
#### Executing commands
|
||||
|
||||
Getting a shell inside a container is typically as simple as:
|
||||
|
||||
```
|
||||
lxc exec <container> bash
|
||||
```
|
||||
|
||||
That’s assuming the container does actually have bash installed.
|
||||
|
||||
|
||||
More complex commands require the use of a separator for proper argument parsing:
|
||||
|
||||
```
|
||||
lxc exec <container> -- ls -lh /
|
||||
```
|
||||
|
||||
To set or override environment variables, you can use the “–env” argument, for example:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc exec zerotier --env mykey=myvalue env | grep mykey
|
||||
mykey=myvalue
|
||||
```
|
||||
|
||||
### Managing files
|
||||
|
||||
Because LXD has direct access to the container’s file system, it can directly read and write any file inside the container. This can be very useful to pull log files or exchange files with the container.
|
||||
|
||||
#### Pulling a file from the container
|
||||
|
||||
To get a file from the container, simply run:
|
||||
|
||||
```
|
||||
lxc file pull <container>/<path> <dest>
|
||||
```
|
||||
|
||||
For example:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc file pull zerotier/etc/hosts hosts
|
||||
```
|
||||
|
||||
Or to read it to standard output:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc file pull zerotier/etc/hosts -
|
||||
127.0.0.1 localhost
|
||||
|
||||
# The following lines are desirable for IPv6 capable hosts
|
||||
::1 ip6-localhost ip6-loopback
|
||||
fe00::0 ip6-localnet
|
||||
ff00::0 ip6-mcastprefix
|
||||
ff02::1 ip6-allnodes
|
||||
ff02::2 ip6-allrouters
|
||||
ff02::3 ip6-allhosts
|
||||
```
|
||||
|
||||
#### Pushing a file to the container
|
||||
|
||||
Push simply works the other way:
|
||||
|
||||
```
|
||||
lxc file push <source> <container>/<path>
|
||||
```
|
||||
|
||||
#### Editing a file directly
|
||||
|
||||
Edit is a convenience function which simply pulls a given path, opens it in your default text editor and then pushes it back to the container when you close it:
|
||||
|
||||
```
|
||||
lxc file edit <container>/<path>
|
||||
```
|
||||
|
||||
### Snapshot management
|
||||
|
||||
LXD lets you snapshot and restore containers. Snapshots include the entirety of the container’s state (including running state if –stateful is used), which means all container configuration, container devices and the container file system.
|
||||
|
||||
#### Creating a snapshot
|
||||
|
||||
You can snapshot a container with:
|
||||
|
||||
```
|
||||
lxc snapshot <container>
|
||||
```
|
||||
|
||||
It’ll get named snapX where X is an incrementing number.
|
||||
|
||||
Alternatively, you can name your snapshot with:
|
||||
|
||||
```
|
||||
lxc snapshot <container> <snapshot name>
|
||||
```
|
||||
|
||||
#### Listing snapshots
|
||||
|
||||
The number of snapshots a container has is listed in “lxc list”, but the actual snapshot list is only visible in “lxc info”.
|
||||
|
||||
```
|
||||
lxc info <container>
|
||||
```
|
||||
|
||||
#### Restoring a snapshot
|
||||
|
||||
To restore a snapshot, simply run:
|
||||
|
||||
```
|
||||
lxc restore <container> <snapshot name>
|
||||
```
|
||||
|
||||
#### Renaming a snapshot
|
||||
|
||||
Renaming a snapshot can be done by moving it with:
|
||||
|
||||
```
|
||||
lxc move <container>/<snapshot name> <container>/<new snapshot name>
|
||||
```
|
||||
|
||||
#### Creating a new container from a snapshot
|
||||
|
||||
You can create a new container which will be identical to another container’s snapshot except for the volatile information being reset (MAC address):
|
||||
|
||||
```
|
||||
lxc copy <source container>/<snapshot name> <destination container>
|
||||
```
|
||||
|
||||
#### Deleting a snapshot
|
||||
|
||||
And finally, to delete a snapshot, just run:
|
||||
|
||||
```
|
||||
lxc delete <container>/<snapshot name>
|
||||
```
|
||||
|
||||
### Cloning and renaming
|
||||
|
||||
Getting clean distribution images is all nice and well, but sometimes you want to install a bunch of things into your container, configure it and then branch it into a bunch of other containers.
|
||||
|
||||
#### Copying a container
|
||||
|
||||
To copy a container and effectively clone it into a new one, just run:
|
||||
|
||||
```
|
||||
lxc copy <source container> <destination container>
|
||||
```
|
||||
|
||||
The destination container will be identical in every way to the source one, except it won’t have any snapshot and volatile keys (MAC address) will be reset.
|
||||
|
||||
#### Moving a container
|
||||
|
||||
LXD lets you copy and move containers between hosts, but that will get covered in a later post.
|
||||
|
||||
For now, the “move” command can be used to rename a container with:
|
||||
|
||||
```
|
||||
lxc move <old name> <new name>
|
||||
```
|
||||
|
||||
The only requirement is that the container be stopped, everything else will be kept exactly as it was, including the volatile information (MAC address and such).
|
||||
|
||||
### Conclusion
|
||||
|
||||
This pretty long post covered most of the commands you’re likely to use in day to day operation.
|
||||
|
||||
Obviously a lot of those commands have extra arguments that let you be more efficient or tweak specific aspects of your LXD containers. The best way to learn about all of those is to go through the help for those you care about (–help).
|
||||
|
||||
### Extra information
|
||||
|
||||
The main LXD website is at: <https://linuxcontainers.org/lxd>
|
||||
Development happens on Github at: <https://github.com/lxc/lxd>
|
||||
Mailing-list support happens on: <https://lists.linuxcontainers.org>
|
||||
IRC support happens in: #lxcontainers on irc.freenode.net
|
||||
|
||||
And if you don’t want or can’t install LXD on your own machine, you can always [try it online instead][1]!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.stgraber.org/2016/03/19/lxd-2-0-your-first-lxd-container-312/
|
||||
|
||||
作者:[Stéphane Graber][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.stgraber.org/author/stgraber/
|
||||
[0]: https://www.stgraber.org/2016/03/11/lxd-2-0-blog-post-series-012/
|
||||
[1]: https://linuxcontainers.org/lxd/try-it
|
||||
[2]: https://github.com/lxc/lxd/blob/master/doc/configuration.md
|
||||
405
sources/tech/LXD/Part 4 - LXD 2.0--Resource control.md
Normal file
405
sources/tech/LXD/Part 4 - LXD 2.0--Resource control.md
Normal file
@ -0,0 +1,405 @@
|
||||
Part 4 - LXD 2.0: Resource control
|
||||
======================================
|
||||
|
||||
This is the fourth blog post [in this series about LXD 2.0][0].
|
||||
|
||||
As there are a lot of commands involved with managing LXD containers, this post is rather long. If you’d instead prefer a quick step-by-step tour of those same commands, you can [try our online demo instead][1]!
|
||||
|
||||

|
||||
|
||||
### Available resource limits
|
||||
|
||||
LXD offers a variety of resource limits. Some of those are tied to the container itself, like memory quotas, CPU limits and I/O priorities. Some are tied to a particular device instead, like I/O bandwidth or disk usage limits.
|
||||
|
||||
As with all LXD configuration, resource limits can be dynamically changed while the container is running. Some may fail to apply, for example if setting a memory value smaller than the current memory usage, but LXD will try anyway and report back on failure.
|
||||
|
||||
All limits can also be inherited through profiles in which case each affected container will be constrained by that limit. That is, if you set limits.memory=256MB in the default profile, every container using the default profile (typically all of them) will have a memory limit of 256MB.
|
||||
|
||||
We don’t support resource limits pooling where a limit would be shared by a group of containers, there is simply no good way to implement something like that with the existing kernel APIs.
|
||||
|
||||
#### Disk
|
||||
|
||||
This is perhaps the most requested and obvious one. Simply setting a size limit on the container’s filesystem and have it enforced against the container.
|
||||
|
||||
And that’s exactly what LXD lets you do!
|
||||
Unfortunately this is far more complicated than it sounds. Linux doesn’t have path-based quotas, instead most filesystems only have user and group quotas which are of little use to containers.
|
||||
|
||||
This means that right now LXD only supports disk limits if you’re using the ZFS or btrfs storage backend. It may be possible to implement this feature for LVM too but this depends on the filesystem being used with it and gets tricky when combined with live updates as not all filesystems allow online growth and pretty much none of them allow online shrink.
|
||||
|
||||
#### CPU
|
||||
|
||||
When it comes to CPU limits, we support 4 different things:
|
||||
|
||||
* Just give me X CPUs
|
||||
|
||||
In this mode, you let LXD pick a bunch of cores for you and then load-balance things as more containers and CPUs go online/offline.
|
||||
|
||||
The container only sees that number of CPU.
|
||||
* Give me a specific set of CPUs (say, core 1, 3 and 5)
|
||||
|
||||
Similar to the first mode except that no load-balancing is happening, you’re stuck with those cores no matter how busy they may be.
|
||||
* Give me 20% of whatever you have
|
||||
|
||||
In this mode, you get to see all the CPUs but the scheduler will restrict you to 20% of the CPU time but only when under load! So if the system isn’t busy, your container can have as much fun as it wants. When containers next to it start using the CPU, then it gets capped.
|
||||
* Out of every measured 200ms, give me 50ms (and no more than that)
|
||||
|
||||
This mode is similar to the previous one in that you get to see all the CPUs but this time, you can only use as much CPU time as you set in the limit, no matter how idle the system may be. On a system without over-commit this lets you slice your CPU very neatly and guarantees constant performance to those containers.
|
||||
|
||||
It’s also possible to combine one of the first two with one of the last two, that is, request a set of CPUs and then further restrict how much CPU time you get on those.
|
||||
|
||||
On top of that, we also have a generic priority knob which is used to tell the scheduler who wins when you’re under load and two containers are fighting for the same resource.
|
||||
|
||||
#### Memory
|
||||
|
||||
Memory sounds pretty simple, just give me X MB of RAM!
|
||||
|
||||
And it absolutely can be that simple. We support that kind of limits as well as percentage based requests, just give me 10% of whatever the host has!
|
||||
|
||||
Then we support some extra stuff on top. For example, you can choose to turn swap on and off on a per-container basis and if it’s on, set a priority so you can choose what container will have their memory swapped out to disk first!
|
||||
|
||||
Oh and memory limits are “hard” by default. That is, when you run out of memory, the kernel out of memory killer will start having some fun with your processes.
|
||||
|
||||
Alternatively you can set the enforcement policy to “soft”, in which case you’ll be allowed to use as much memory as you want so long as nothing else is. As soon as something else wants that memory, you won’t be able to allocate anything until you’re back under your limit or until the host has memory to spare again.
|
||||
|
||||
#### Network I/O
|
||||
|
||||
Network I/O is probably our simplest looking limit, trust me, the implementation really isn’t simple though!
|
||||
|
||||
We support two things. The first is a basic bit/s limits on network interfaces. You can set a limit of ingress and egress or just set the “max” limit which then applies to both. This is only supported for “bridged” and “p2p” type interfaces.
|
||||
|
||||
The second thing is a global network I/O priority which only applies when the network interface you’re trying to talk through is saturated.
|
||||
|
||||
#### Block I/O
|
||||
|
||||
I kept the weirdest for last. It may look straightforward and feel like that to the user but there are a bunch of cases where it won’t exactly do what you think it should.
|
||||
|
||||
What we support here is basically identical to what I described in Network I/O.
|
||||
|
||||
You can set IOps or byte/s read and write limits directly on a disk device entry and there is a global block I/O priority which tells the I/O scheduler who to prefer.
|
||||
|
||||
The weirdness comes from how and where those limits are applied. Unfortunately the underlying feature we use to implement those uses full block devices. That means we can’t set per-partition I/O limits let alone per-path.
|
||||
|
||||
It also means that when using ZFS or btrfs which can use multiple block devices to back a given path (with or without RAID), we effectively don’t know what block device is providing a given path.
|
||||
|
||||
This means that it’s entirely possible, in fact likely, that a container may have multiple disk entries (bind-mounts or straight mounts) which are coming from the same underlying disk.
|
||||
|
||||
And that’s where things get weird. To make things work, LXD has logic to guess what block devices back a given path, this does include interrogating the ZFS and btrfs tools and even figures things out recursively when it finds a loop mounted file backing a filesystem.
|
||||
|
||||
That logic while not perfect, usually yields a set of block devices that should have a limit applied. LXD then records that and moves on to the next path. When it’s done looking at all the paths, it gets to the very weird part. It averages the limits you’ve set for every affected block devices and then applies those.
|
||||
|
||||
That means that “in average” you’ll be getting the right speed in the container, but it also means that you can’t have a “/fast” and a “/slow” directory both coming from the same physical disk and with differing speed limits. LXD will let you set it up but in the end, they’ll both give you the average of the two values.
|
||||
|
||||
### How does it all work?
|
||||
|
||||
Most of the limits described above are applied through the Linux kernel Cgroups API. That’s with the exception of the network limits which are applied through good old “tc”.
|
||||
|
||||
LXD at startup time detects what cgroups are enabled in your kernel and will only apply the limits which your kernel support. Should you be missing some cgroups, a warning will also be printed by the daemon which will then get logged by your init system.
|
||||
|
||||
On Ubuntu 16.04, everything is enabled by default with the exception of swap memory accounting which requires you pass the “swapaccount=1” kernel boot parameter.
|
||||
|
||||
### Applying some limits
|
||||
|
||||
All the limits described above are applied directly to the container or to one of its profiles. Container-wide limits are applied with:
|
||||
|
||||
```
|
||||
lxc config set CONTAINER KEY VALUE
|
||||
```
|
||||
|
||||
or for a profile:
|
||||
|
||||
```
|
||||
lxc profile set PROFILE KEY VALUE
|
||||
```
|
||||
|
||||
while device-specific ones are applied with:
|
||||
|
||||
```
|
||||
lxc config device set CONTAINER DEVICE KEY VALUE
|
||||
```
|
||||
|
||||
or for a profile:
|
||||
|
||||
```
|
||||
lxc profile device set PROFILE DEVICE KEY VALUE
|
||||
```
|
||||
|
||||
The complete list of valid configuration keys, device types and device keys can be [found here][1].
|
||||
|
||||
#### CPU
|
||||
|
||||
To just limit a container to any 2 CPUs, do:
|
||||
|
||||
```
|
||||
lxc config set my-container limits.cpu 2
|
||||
```
|
||||
|
||||
To pin to specific CPU cores, say the second and fourth:
|
||||
|
||||
```
|
||||
lxc config set my-container limits.cpu 1,3
|
||||
```
|
||||
|
||||
More complex pinning ranges like this works too:
|
||||
|
||||
```
|
||||
lxc config set my-container limits.cpu 0-3,7-11
|
||||
```
|
||||
|
||||
The limits are applied live, as can be seen in this example:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc exec zerotier -- cat /proc/cpuinfo | grep ^proces
|
||||
processor : 0
|
||||
processor : 1
|
||||
processor : 2
|
||||
processor : 3
|
||||
stgraber@dakara:~$ lxc config set zerotier limits.cpu 2
|
||||
stgraber@dakara:~$ lxc exec zerotier -- cat /proc/cpuinfo | grep ^proces
|
||||
processor : 0
|
||||
processor : 1
|
||||
```
|
||||
|
||||
Note that to avoid utterly confusing userspace, lxcfs arranges the /proc/cpuinfo entries so that there are no gaps.
|
||||
|
||||
As with just about everything in LXD, those settings can also be applied in profiles:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc exec snappy -- cat /proc/cpuinfo | grep ^proces
|
||||
processor : 0
|
||||
processor : 1
|
||||
processor : 2
|
||||
processor : 3
|
||||
stgraber@dakara:~$ lxc profile set default limits.cpu 3
|
||||
stgraber@dakara:~$ lxc exec snappy -- cat /proc/cpuinfo | grep ^proces
|
||||
processor : 0
|
||||
processor : 1
|
||||
processor : 2
|
||||
```
|
||||
|
||||
To limit the CPU time of a container to 10% of the total, set the CPU allowance:
|
||||
|
||||
```
|
||||
lxc config set my-container limits.cpu.allowance 10%
|
||||
```
|
||||
|
||||
Or to give it a fixed slice of CPU time:
|
||||
|
||||
```
|
||||
lxc config set my-container limits.cpu.allowance 25ms/200ms
|
||||
```
|
||||
|
||||
And lastly, to reduce the priority of a container to a minimum:
|
||||
|
||||
```
|
||||
lxc config set my-container limits.cpu.priority 0
|
||||
```
|
||||
|
||||
#### Memory
|
||||
|
||||
To apply a straightforward memory limit run:
|
||||
|
||||
```
|
||||
lxc config set my-container limits.memory 256MB
|
||||
```
|
||||
|
||||
(The supported suffixes are kB, MB, GB, TB, PB and EB)
|
||||
|
||||
To turn swap off for the container (defaults to enabled):
|
||||
|
||||
```
|
||||
lxc config set my-container limits.memory.swap false
|
||||
```
|
||||
|
||||
To tell the kernel to swap this container’s memory first:
|
||||
|
||||
```
|
||||
lxc config set my-container limits.memory.swap.priority 0
|
||||
```
|
||||
|
||||
And finally if you don’t want hard memory limit enforcement:
|
||||
|
||||
```
|
||||
lxc config set my-container limits.memory.enforce soft
|
||||
```
|
||||
|
||||
#### Disk and block I/O
|
||||
|
||||
Unlike CPU and memory, disk and I/O limits are applied to the actual device entry, so you either need to edit the original device or mask it with a more specific one.
|
||||
|
||||
To set a disk limit (requires btrfs or ZFS):
|
||||
|
||||
```
|
||||
lxc config device set my-container root size 20GB
|
||||
```
|
||||
|
||||
For example:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc exec zerotier -- df -h /
|
||||
Filesystem Size Used Avail Use% Mounted on
|
||||
encrypted/lxd/containers/zerotier 179G 542M 178G 1% /
|
||||
stgraber@dakara:~$ lxc config device set zerotier root size 20GB
|
||||
stgraber@dakara:~$ lxc exec zerotier -- df -h /
|
||||
Filesystem Size Used Avail Use% Mounted on
|
||||
encrypted/lxd/containers/zerotier 20G 542M 20G 3% /
|
||||
```
|
||||
|
||||
To restrict speed you can do the following:
|
||||
|
||||
```
|
||||
lxc config device set my-container root limits.read 30MB
|
||||
lxc config device set my-container root.limits.write 10MB
|
||||
```
|
||||
|
||||
Or to restrict IOps instead:
|
||||
|
||||
```
|
||||
lxc config device set my-container root limits.read 20Iops
|
||||
lxc config device set my-container root limits.write 10Iops
|
||||
```
|
||||
|
||||
And lastly, if you’re on a busy system with over-commit, you may want to also do:
|
||||
|
||||
```
|
||||
lxc config set my-container limits.disk.priority 10
|
||||
```
|
||||
|
||||
To increase the I/O priority for that container to the maximum.
|
||||
|
||||
#### Network I/O
|
||||
|
||||
Network I/O is basically identical to block I/O as far the knobs available.
|
||||
|
||||
For example:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc exec zerotier -- wget http://speedtest.newark.linode.com/100MB-newark.bin -O /dev/null
|
||||
--2016-03-26 22:17:34-- http://speedtest.newark.linode.com/100MB-newark.bin
|
||||
Resolving speedtest.newark.linode.com (speedtest.newark.linode.com)... 50.116.57.237, 2600:3c03::4b
|
||||
Connecting to speedtest.newark.linode.com (speedtest.newark.linode.com)|50.116.57.237|:80... connected.
|
||||
HTTP request sent, awaiting response... 200 OK
|
||||
Length: 104857600 (100M) [application/octet-stream]
|
||||
Saving to: '/dev/null'
|
||||
|
||||
/dev/null 100%[===================>] 100.00M 58.7MB/s in 1.7s
|
||||
|
||||
2016-03-26 22:17:36 (58.7 MB/s) - '/dev/null' saved [104857600/104857600]
|
||||
|
||||
stgraber@dakara:~$ lxc profile device set default eth0 limits.ingress 100Mbit
|
||||
stgraber@dakara:~$ lxc profile device set default eth0 limits.egress 100Mbit
|
||||
stgraber@dakara:~$ lxc exec zerotier -- wget http://speedtest.newark.linode.com/100MB-newark.bin -O /dev/null
|
||||
--2016-03-26 22:17:47-- http://speedtest.newark.linode.com/100MB-newark.bin
|
||||
Resolving speedtest.newark.linode.com (speedtest.newark.linode.com)... 50.116.57.237, 2600:3c03::4b
|
||||
Connecting to speedtest.newark.linode.com (speedtest.newark.linode.com)|50.116.57.237|:80... connected.
|
||||
HTTP request sent, awaiting response... 200 OK
|
||||
Length: 104857600 (100M) [application/octet-stream]
|
||||
Saving to: '/dev/null'
|
||||
|
||||
/dev/null 100%[===================>] 100.00M 11.4MB/s in 8.8s
|
||||
|
||||
2016-03-26 22:17:56 (11.4 MB/s) - '/dev/null' saved [104857600/104857600]
|
||||
```
|
||||
|
||||
And that’s how you throttle an otherwise nice gigabit connection to a mere 100Mbit/s one!
|
||||
|
||||
And as with block I/O, you can set an overall network priority with:
|
||||
|
||||
```
|
||||
lxc config set my-container limits.network.priority 5
|
||||
```
|
||||
|
||||
### Getting the current resource usage
|
||||
|
||||
The [LXD API][2] exports quite a bit of information on current container resource usage, you can get:
|
||||
|
||||
* Memory: current, peak, current swap and peak swap
|
||||
* Disk: current disk usage
|
||||
* Network: bytes and packets received and transferred for every interface
|
||||
|
||||
And now if you’re running a very recent LXD (only in git at the time of this writing), you can also get all of those in “lxc info”:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc info zerotier
|
||||
Name: zerotier
|
||||
Architecture: x86_64
|
||||
Created: 2016/02/20 20:01 UTC
|
||||
Status: Running
|
||||
Type: persistent
|
||||
Profiles: default
|
||||
Pid: 29258
|
||||
Ips:
|
||||
eth0: inet 172.17.0.101
|
||||
eth0: inet6 2607:f2c0:f00f:2700:216:3eff:feec:65a8
|
||||
eth0: inet6 fe80::216:3eff:feec:65a8
|
||||
lo: inet 127.0.0.1
|
||||
lo: inet6 ::1
|
||||
lxcbr0: inet 10.0.3.1
|
||||
lxcbr0: inet6 fe80::f0bd:55ff:feee:97a2
|
||||
zt0: inet 29.17.181.59
|
||||
zt0: inet6 fd80:56c2:e21c:0:199:9379:e711:b3e1
|
||||
zt0: inet6 fe80::79:e7ff:fe0d:5123
|
||||
Resources:
|
||||
Processes: 33
|
||||
Disk usage:
|
||||
root: 808.07MB
|
||||
Memory usage:
|
||||
Memory (current): 106.79MB
|
||||
Memory (peak): 195.51MB
|
||||
Swap (current): 124.00kB
|
||||
Swap (peak): 124.00kB
|
||||
Network usage:
|
||||
lxcbr0:
|
||||
Bytes received: 0 bytes
|
||||
Bytes sent: 570 bytes
|
||||
Packets received: 0
|
||||
Packets sent: 0
|
||||
zt0:
|
||||
Bytes received: 1.10MB
|
||||
Bytes sent: 806 bytes
|
||||
Packets received: 10957
|
||||
Packets sent: 10957
|
||||
eth0:
|
||||
Bytes received: 99.35MB
|
||||
Bytes sent: 5.88MB
|
||||
Packets received: 64481
|
||||
Packets sent: 64481
|
||||
lo:
|
||||
Bytes received: 9.57kB
|
||||
Bytes sent: 9.57kB
|
||||
Packets received: 81
|
||||
Packets sent: 81
|
||||
Snapshots:
|
||||
zerotier/blah (taken at 2016/03/08 23:55 UTC) (stateless)
|
||||
```
|
||||
|
||||
### Conclusion
|
||||
|
||||
The LXD team spent quite a few months iterating over the language we’re using for those limits. It’s meant to be as simple as it can get while remaining very powerful and specific when you want it to.
|
||||
|
||||
Live application of those limits and inheritance through profiles makes it a very powerful tool to live manage the load on your servers without impacting the running services.
|
||||
|
||||
### Extra information
|
||||
|
||||
The main LXD website is at: <https://linuxcontainers.org/lxd>
|
||||
Development happens on Github at: <https://github.com/lxc/lxd>
|
||||
Mailing-list support happens on: <https://lists.linuxcontainers.org>
|
||||
IRC support happens in: #lxcontainers on irc.freenode.net
|
||||
|
||||
And if you don’t want or can’t install LXD on your own machine, you can always [try it online instead][3]!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.stgraber.org/2016/03/26/lxd-2-0-resource-control-412/
|
||||
|
||||
作者:[Stéphane Graber][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.stgraber.org/author/stgraber/
|
||||
[0]: https://www.stgraber.org/2016/03/11/lxd-2-0-blog-post-series-012/
|
||||
[1]: https://github.com/lxc/lxd/blob/master/doc/configuration.md
|
||||
[2]: https://github.com/lxc/lxd/blob/master/doc/rest-api.md
|
||||
[3]: https://linuxcontainers.org/lxd/try-it
|
||||
458
sources/tech/LXD/Part 5 - LXD 2.0--Image management.md
Normal file
458
sources/tech/LXD/Part 5 - LXD 2.0--Image management.md
Normal file
@ -0,0 +1,458 @@
|
||||
Part 5 - LXD 2.0: Image management
|
||||
==================================
|
||||
This is the fifth blog post [in this series about LXD 2.0][0].
|
||||
|
||||
As there are a lot of commands involved with managing LXD containers, this post is rather long. If you’d instead prefer a quick step-by-step tour of those same commands, you can [try our online demo instead][1]!
|
||||
|
||||

|
||||
|
||||
### Container images
|
||||
|
||||
If you’ve used LXC before, you probably remember those LXC “templates”, basically shell scripts that spit out a container filesystem and a bit of configuration.
|
||||
|
||||
Most templates generate the filesystem by doing a full distribution bootstrapping on your local machine. This may take quite a while, won’t work for all distributions and may require significant network bandwidth.
|
||||
|
||||
Back in LXC 1.0, I wrote a “download” template which would allow users to download pre-packaged container images, generated on a central server from the usual template scripts and then heavily compressed, signed and distributed over https. A lot of our users switched from the old style container generation to using this new, much faster and much more reliable method of creating a container.
|
||||
|
||||
With LXD, we’re taking this one step further by being all-in on the image based workflow. All containers are created from an image and we have advanced image caching and pre-loading support in LXD to keep the image store up to date.
|
||||
|
||||
### Interacting with LXD images
|
||||
|
||||
Before digging deeper into the image format, lets quickly go through what LXD lets you do with those images.
|
||||
|
||||
#### Transparently importing images
|
||||
|
||||
All containers are created from an image. The image may have come from a remote image server and have been pulled using its full hash, short hash or an alias, but in the end, every LXD container is created from a local image.
|
||||
|
||||
Here are a few examples:
|
||||
|
||||
```
|
||||
lxc launch ubuntu:14.04 c1
|
||||
lxc launch ubuntu:75182b1241be475a64e68a518ce853e800e9b50397d2f152816c24f038c94d6e c2
|
||||
lxc launch ubuntu:75182b1241be c3
|
||||
```
|
||||
|
||||
All of those refer to the same remote image (at the time of this writing), the first time one of those is run, the remote image will be imported in the local LXD image store as a cached image, then the container will be created from it.
|
||||
|
||||
The next time one of those commands are run, LXD will only check that the image is still up to date (when not referring to it by its fingerprint), if it is, it will create the container without downloading anything.
|
||||
|
||||
Now that the image is cached in the local image store, you can also just start it from there without even checking if it’s up to date:
|
||||
|
||||
```
|
||||
lxc launch 75182b1241be c4
|
||||
```
|
||||
|
||||
And lastly, if you have your own local image under the name “myimage”, you can just do:
|
||||
|
||||
```
|
||||
lxc launch my-image c5
|
||||
```
|
||||
|
||||
If you want to change some of that automatic caching and expiration behavior, there are instructions in an earlier post in this series.
|
||||
|
||||
#### Manually importing images
|
||||
|
||||
##### Copying from an image server
|
||||
|
||||
If you want to copy some remote image into your local image store but not immediately create a container from it, you can use the “lxc image copy” command. It also lets you tweak some of the image flags, for example:
|
||||
|
||||
```
|
||||
lxc image copy ubuntu:14.04 local:
|
||||
```
|
||||
|
||||
This simply copies the remote image into the local image store.
|
||||
|
||||
If you want to be able to refer to your copy of the image by something easier to remember than its fingerprint, you can add an alias at the time of the copy:
|
||||
|
||||
```
|
||||
lxc image copy ubuntu:12.04 local: --alias old-ubuntu
|
||||
lxc launch old-ubuntu c6
|
||||
```
|
||||
|
||||
And if you would rather just use the aliases that were set on the source server, you can ask LXD to copy the for you:
|
||||
|
||||
lxc image copy ubuntu:15.10 local: --copy-aliases
|
||||
lxc launch 15.10 c7
|
||||
All of the copies above were one-shot copy, so copying the current version of the remote image into the local image store. If you want to have LXD keep the image up to date, as it does for the ones stored in its cache, you need to request it with the `–auto-update` flag:
|
||||
|
||||
```
|
||||
lxc image copy images:gentoo/current/amd64 local: --alias gentoo --auto-update
|
||||
```
|
||||
|
||||
##### Importing a tarball
|
||||
|
||||
If someone provides you with a LXD image as a single tarball, you can import it with:
|
||||
|
||||
```
|
||||
lxc image import <tarball>
|
||||
```
|
||||
|
||||
If you want to set an alias at import time, you can do it with:
|
||||
|
||||
```
|
||||
lxc image import <tarball> --alias random-image
|
||||
```
|
||||
|
||||
Now if you were provided with two tarballs, identify which contains the LXD metadata. Usually the tarball name gives it away, if not, pick the smallest of the two, metadata tarballs are tiny. Then import them both together with:
|
||||
|
||||
```
|
||||
lxc image import <metadata tarball> <rootfs tarball>
|
||||
```
|
||||
|
||||
##### Importing from a URL
|
||||
|
||||
“lxc image import” also works with some special URLs. If you have an https web server which serves a path with the LXD-Image-URL and LXD-Image-Hash headers set, then LXD will pull that image into its image store.
|
||||
|
||||
For example you can do:
|
||||
|
||||
```
|
||||
lxc image import https://dl.stgraber.org/lxd --alias busybox-amd64
|
||||
```
|
||||
|
||||
When pulling the image, LXD also sets some headers which the remote server could check to return an appropriate image. Those are LXD-Server-Architectures and LXD-Server-Version.
|
||||
|
||||
This is meant as a poor man’s image server. It can be made to work with any static web server and provides a user friendly way to import your image.
|
||||
|
||||
#### Managing the local image store
|
||||
|
||||
Now that we have a bunch of images in our local image store, lets see what we can do with them. We’ve already covered the most obvious, creating containers from them but there are a few more things you can do with the local image store.
|
||||
|
||||
##### Listing images
|
||||
|
||||
To get a list of all images in the store, just run “lxc image list”:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc image list
|
||||
+---------------+--------------+--------+------------------------------------------------------+--------+----------+------------------------------+
|
||||
| ALIAS | FINGERPRINT | PUBLIC | DESCRIPTION | ARCH | SIZE | UPLOAD DATE |
|
||||
+---------------+--------------+--------+------------------------------------------------------+--------+----------+------------------------------+
|
||||
| alpine-32 | 6d9c131efab3 | yes | Alpine edge (i386) (20160329_23:52) | i686 | 2.50MB | Mar 30, 2016 at 4:36am (UTC) |
|
||||
+---------------+--------------+--------+------------------------------------------------------+--------+----------+------------------------------+
|
||||
| busybox-amd64 | 74186c79ca2f | no | Busybox x86_64 | x86_64 | 0.79MB | Mar 30, 2016 at 4:33am (UTC) |
|
||||
+---------------+--------------+--------+------------------------------------------------------+--------+----------+------------------------------+
|
||||
| gentoo | 1a134c5951e0 | no | Gentoo current (amd64) (20160329_14:12) | x86_64 | 232.50MB | Mar 30, 2016 at 4:34am (UTC) |
|
||||
+---------------+--------------+--------+------------------------------------------------------+--------+----------+------------------------------+
|
||||
| my-image | c9b6e738fae7 | no | Scientific Linux 6 x86_64 (default) (20160215_02:36) | x86_64 | 625.34MB | Mar 2, 2016 at 4:56am (UTC) |
|
||||
+---------------+--------------+--------+------------------------------------------------------+--------+----------+------------------------------+
|
||||
| old-ubuntu | 4d558b08f22f | no | ubuntu 12.04 LTS amd64 (release) (20160315) | x86_64 | 155.09MB | Mar 30, 2016 at 4:30am (UTC) |
|
||||
+---------------+--------------+--------+------------------------------------------------------+--------+----------+------------------------------+
|
||||
| w (11 more) | d3703a994910 | no | ubuntu 15.10 amd64 (release) (20160315) | x86_64 | 153.35MB | Mar 30, 2016 at 4:31am (UTC) |
|
||||
+---------------+--------------+--------+------------------------------------------------------+--------+----------+------------------------------+
|
||||
| | 75182b1241be | no | ubuntu 14.04 LTS amd64 (release) (20160314) | x86_64 | 118.17MB | Mar 30, 2016 at 4:27am (UTC) |
|
||||
+---------------+--------------+--------+------------------------------------------------------+--------+----------+------------------------------+
|
||||
```
|
||||
|
||||
You can filter based on the alias or fingerprint simply by doing:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc image list amd64
|
||||
+---------------+--------------+--------+-----------------------------------------+--------+----------+------------------------------+
|
||||
| ALIAS | FINGERPRINT | PUBLIC | DESCRIPTION | ARCH | SIZE | UPLOAD DATE |
|
||||
+---------------+--------------+--------+-----------------------------------------+--------+----------+------------------------------+
|
||||
| busybox-amd64 | 74186c79ca2f | no | Busybox x86_64 | x86_64 | 0.79MB | Mar 30, 2016 at 4:33am (UTC) |
|
||||
+---------------+--------------+--------+-----------------------------------------+--------+----------+------------------------------+
|
||||
| w (11 more) | d3703a994910 | no | ubuntu 15.10 amd64 (release) (20160315) | x86_64 | 153.35MB | Mar 30, 2016 at 4:31am (UTC) |
|
||||
+---------------+--------------+--------+-----------------------------------------+--------+----------+------------------------------+
|
||||
```
|
||||
|
||||
Or by specifying a key=value filter of image properties:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc image list os=ubuntu
|
||||
+-------------+--------------+--------+---------------------------------------------+--------+----------+------------------------------+
|
||||
| ALIAS | FINGERPRINT | PUBLIC | DESCRIPTION | ARCH | SIZE | UPLOAD DATE |
|
||||
+-------------+--------------+--------+---------------------------------------------+--------+----------+------------------------------+
|
||||
| old-ubuntu | 4d558b08f22f | no | ubuntu 12.04 LTS amd64 (release) (20160315) | x86_64 | 155.09MB | Mar 30, 2016 at 4:30am (UTC) |
|
||||
+-------------+--------------+--------+---------------------------------------------+--------+----------+------------------------------+
|
||||
| w (11 more) | d3703a994910 | no | ubuntu 15.10 amd64 (release) (20160315) | x86_64 | 153.35MB | Mar 30, 2016 at 4:31am (UTC) |
|
||||
+-------------+--------------+--------+---------------------------------------------+--------+----------+------------------------------+
|
||||
| | 75182b1241be | no | ubuntu 14.04 LTS amd64 (release) (20160314) | x86_64 | 118.17MB | Mar 30, 2016 at 4:27am (UTC) |
|
||||
+-------------+--------------+--------+---------------------------------------------+--------+----------+------------------------------+
|
||||
```
|
||||
|
||||
To see everything LXD knows about a given image, you can use “lxc image info”:
|
||||
|
||||
```
|
||||
stgraber@castiana:~$ lxc image info ubuntu
|
||||
Fingerprint: e8a33ec326ae7dd02331bd72f5d22181ba25401480b8e733c247da5950a7d084
|
||||
Size: 139.43MB
|
||||
Architecture: i686
|
||||
Public: no
|
||||
Timestamps:
|
||||
Created: 2016/03/15 00:00 UTC
|
||||
Uploaded: 2016/03/16 05:50 UTC
|
||||
Expires: 2017/04/26 00:00 UTC
|
||||
Properties:
|
||||
version: 12.04
|
||||
aliases: 12.04,p,precise
|
||||
architecture: i386
|
||||
description: ubuntu 12.04 LTS i386 (release) (20160315)
|
||||
label: release
|
||||
os: ubuntu
|
||||
release: precise
|
||||
serial: 20160315
|
||||
Aliases:
|
||||
- ubuntu
|
||||
Auto update: enabled
|
||||
Source:
|
||||
Server: https://cloud-images.ubuntu.com/releases
|
||||
Protocol: simplestreams
|
||||
Alias: precise/i386
|
||||
```
|
||||
|
||||
##### Editing images
|
||||
|
||||
A convenient way to edit image properties and some of the flags is to use:
|
||||
|
||||
lxc image edit <alias or fingerprint>
|
||||
This opens up your default text editor with something like this:
|
||||
|
||||
autoupdate: true
|
||||
properties:
|
||||
aliases: 14.04,default,lts,t,trusty
|
||||
architecture: amd64
|
||||
description: ubuntu 14.04 LTS amd64 (release) (20160314)
|
||||
label: release
|
||||
os: ubuntu
|
||||
release: trusty
|
||||
serial: "20160314"
|
||||
version: "14.04"
|
||||
public: false
|
||||
You can change any property you want, turn auto-update on and off or mark an image as publicly available (more on that later).
|
||||
|
||||
##### Deleting images
|
||||
|
||||
Remove an image is a simple matter of running:
|
||||
|
||||
```
|
||||
lxc image delete <alias or fingerprint>
|
||||
```
|
||||
|
||||
Note that you don’t have to remove cached entries, those will automatically be removed by LXD after they expire (by default, after 10 days since they were last used).
|
||||
|
||||
##### Exporting images
|
||||
|
||||
If you want to get image tarballs from images currently in your image store, you can use “lxc image export”, like:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc image export old-ubuntu .
|
||||
Output is in .
|
||||
stgraber@dakara:~$ ls -lh *.tar.xz
|
||||
-rw------- 1 stgraber domain admins 656 Mar 30 00:55 meta-ubuntu-12.04-server-cloudimg-amd64-lxd.tar.xz
|
||||
-rw------- 1 stgraber domain admins 156M Mar 30 00:55 ubuntu-12.04-server-cloudimg-amd64-lxd.tar.xz
|
||||
```
|
||||
|
||||
#### Image formats
|
||||
|
||||
LXD right now supports two image layouts, unified or split. Both of those are effectively LXD-specific though the latter makes it easier to re-use the filesystem with other container or virtual machine runtimes.
|
||||
|
||||
LXD being solely focused on system containers, doesn’t support any of the application container “standard” image formats out there, nor do we plan to.
|
||||
|
||||
Our images are pretty simple, they’re made of a container filesystem, a metadata file describing things like when the image was made, when it expires, what architecture its for, … and optionally a bunch of file templates.
|
||||
|
||||
See this document for up to date details on the [image format][1].
|
||||
|
||||
##### Unified image (single tarball)
|
||||
|
||||
The unified image format is what LXD uses when generating images itself. They are a single big tarball, containing the container filesystem inside a “rootfs” directory, have the metadata.yaml file at the root of the tarball and any template goes into a “templates” directory.
|
||||
|
||||
Any compression (or none at all) can be used for that tarball. The image hash is the sha256 of the resulting compressed tarball.
|
||||
|
||||
##### Split image (two tarballs)
|
||||
|
||||
This format is most commonly used by anyone rolling their own images and who already have a compressed filesystem tarball.
|
||||
|
||||
They are made of two distinct tarball, the first contains just the metadata bits that LXD uses, so the metadata.yaml file at the root and any template in the “templates” directory.
|
||||
|
||||
The second tarball contains only the container filesystem directly at its root. Most distributions already produce such tarballs as they are common for bootstrapping new machines. This image format allows re-using them unmodified.
|
||||
|
||||
Any compression (or none at all) can be used for either tarball, they can absolutely use different compression algorithms. The image hash is the sha256 of the concatenation of the metadata and rootfs tarballs.
|
||||
|
||||
##### Image metadata
|
||||
|
||||
A typical metadata.yaml file looks something like:
|
||||
|
||||
```
|
||||
architecture: "i686"
|
||||
creation_date: 1458040200
|
||||
properties:
|
||||
architecture: "i686"
|
||||
description: "Ubuntu 12.04 LTS server (20160315)"
|
||||
os: "ubuntu"
|
||||
release: "precise"
|
||||
templates:
|
||||
/var/lib/cloud/seed/nocloud-net/meta-data:
|
||||
when:
|
||||
- start
|
||||
template: cloud-init-meta.tpl
|
||||
/var/lib/cloud/seed/nocloud-net/user-data:
|
||||
when:
|
||||
- start
|
||||
template: cloud-init-user.tpl
|
||||
properties:
|
||||
default: |
|
||||
#cloud-config
|
||||
{}
|
||||
/var/lib/cloud/seed/nocloud-net/vendor-data:
|
||||
when:
|
||||
- start
|
||||
template: cloud-init-vendor.tpl
|
||||
properties:
|
||||
default: |
|
||||
#cloud-config
|
||||
{}
|
||||
/etc/init/console.override:
|
||||
when:
|
||||
- create
|
||||
template: upstart-override.tpl
|
||||
/etc/init/tty1.override:
|
||||
when:
|
||||
- create
|
||||
template: upstart-override.tpl
|
||||
/etc/init/tty2.override:
|
||||
when:
|
||||
- create
|
||||
template: upstart-override.tpl
|
||||
/etc/init/tty3.override:
|
||||
when:
|
||||
- create
|
||||
template: upstart-override.tpl
|
||||
/etc/init/tty4.override:
|
||||
when:
|
||||
- create
|
||||
template: upstart-override.tpl
|
||||
```
|
||||
|
||||
##### Properties
|
||||
|
||||
The two only mandatory fields are the creation date (UNIX EPOCH) and the architecture. Everything else can be left unset and the image will import fine.
|
||||
|
||||
The extra properties are mainly there to help the user figure out what the image is about. The “description” property for example is what’s visible in “lxc image list”. The other properties can be used by the user to search for specific images using key/value search.
|
||||
|
||||
Those properties can then be edited by the user through “lxc image edit” in contrast, the creation date and architecture fields are immutable.
|
||||
|
||||
##### Templates
|
||||
|
||||
The template mechanism allows for some files in the container to be generated or re-generated at some point in the container lifecycle.
|
||||
|
||||
We use the pongo2 templating engine for those and we export just about everything we know about the container to the template. That way you can have custom images which use user-defined container properties or normal LXD properties to change the content of some specific files.
|
||||
|
||||
As you can see in the example above, we’re using those in Ubuntu to seed cloud-init and to turn off some init scripts.
|
||||
|
||||
### Creating your own images
|
||||
|
||||
LXD being focused on running full Linux systems means that we expect most users to just use clean distribution images and not spin their own image.
|
||||
|
||||
However there are a few cases where having your own images is useful. Such as having pre-configured images of your production servers or building your own images for a distribution or architecture that we don’t build images for.
|
||||
|
||||
#### Turning a container into an image
|
||||
|
||||
The easiest way by far to build an image with LXD is to just turn a container into an image.
|
||||
|
||||
This can be done with:
|
||||
|
||||
```
|
||||
lxc launch ubuntu:14.04 my-container
|
||||
lxc exec my-container bash
|
||||
<do whatever change you want>
|
||||
lxc publish my-container --alias my-new-image
|
||||
```
|
||||
|
||||
You can even turn a past container snapshot into a new image:
|
||||
|
||||
```
|
||||
lxc publish my-container/some-snapshot --alias some-image
|
||||
```
|
||||
|
||||
#### Manually building an image
|
||||
|
||||
Building your own image is also pretty simple.
|
||||
|
||||
1. Generate a container filesystem. This entirely depends on the distribution you’re using. For Ubuntu and Debian, it would be by using debootstrap.
|
||||
2. Configure anything that’s needed for the distribution to work properly in a container (if anything is needed).
|
||||
3. Make a tarball of that container filesystem, optionally compress it.
|
||||
4. Write a new metadata.yaml file based on the one described above.
|
||||
5. Create another tarball containing that metadata.yaml file.
|
||||
6. Import those two tarballs as a LXD image with:
|
||||
```
|
||||
lxc image import <metadata tarball> <rootfs tarball> --alias some-name
|
||||
```
|
||||
|
||||
You will probably need to go through this a few times before everything works, tweaking things here and there, possibly adding some templates and properties.
|
||||
|
||||
### Publishing your images
|
||||
|
||||
All LXD daemons act as image servers. Unless told otherwise all images loaded in the image store are marked as private and so only trusted clients can retrieve those images, but should you want to make a public image server, all you have to do is tag a few images as public and make sure you LXD daemon is listening to the network.
|
||||
|
||||
#### Just running a public LXD server
|
||||
|
||||
The easiest way to share LXD images is to run a publicly visible LXD daemon.
|
||||
|
||||
You typically do that by running:
|
||||
|
||||
```
|
||||
lxc config set core.https_address "[::]:8443"
|
||||
```
|
||||
|
||||
Remote users can then add your server as a public image server with:
|
||||
|
||||
```
|
||||
lxc remote add <some name> <IP or DNS> --public
|
||||
```
|
||||
|
||||
They can then use it just as they would any of the default image servers. As the remote server was added with “–public”, no authentication is required and the client is restricted to images which have themselves been marked as public.
|
||||
|
||||
To change what images are public, just “lxc image edit” them and set the public flag to true.
|
||||
|
||||
#### Use a static web server
|
||||
|
||||
As mentioned above, “lxc image import” supports downloading from a static http server. The requirements are basically:
|
||||
|
||||
* The server must support HTTPs with a valid certificate, TLS1.2 and EC ciphers
|
||||
* When hitting the URL provided to “lxc image import”, the server must return an answer including the LXD-Image-Hash and LXD-Image-URL HTTP headers
|
||||
|
||||
If you want to make this dynamic, you can have your server look for the LXD-Server-Architectures and LXD-Server-Version HTTP headers which LXD will provide when fetching the image. This allows you to return the right image for the server’s architecture.
|
||||
|
||||
#### Build a simplestreams server
|
||||
|
||||
The “ubuntu:” and “ubuntu-daily:” remotes aren’t using the LXD protocol (“images:” is), those are instead using a different protocol called simplestreams.
|
||||
|
||||
simplestreams is basically an image server description format, using JSON to describe a list of products and files related to those products.
|
||||
|
||||
It is used by a variety of tools like OpenStack, Juju, MAAS, … to find, download or mirror system images and LXD supports it as a native protocol for image retrieval.
|
||||
|
||||
While certainly not the easiest way to start providing LXD images, it may be worth considering if your images can also be used by some of those other tools.
|
||||
|
||||
More information can be found here.
|
||||
|
||||
### Conclusion
|
||||
|
||||
I hope this gave you a good idea of how LXD manages its images and how to build and distribute your own. The ability to have the exact same image easily available bit for bit on a bunch of globally distributed system is a big step up from the old LXC days and leads the way to more reproducible infrastructure.
|
||||
|
||||
### Extra information
|
||||
|
||||
The main LXD website is at: <https://linuxcontainers.org/lxd>
|
||||
Development happens on Github at: <https://github.com/lxc/lxd>
|
||||
Mailing-list support happens on: <https://lists.linuxcontainers.org>
|
||||
IRC support happens in: #lxcontainers on irc.freenode.net
|
||||
|
||||
And if you don’t want or can’t install LXD on your own machine, you can always [try it online instead][3]!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.stgraber.org/2016/03/30/lxd-2-0-image-management-512/
|
||||
|
||||
作者:[Stéphane Graber][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.stgraber.org/author/stgraber/
|
||||
[0]: https://www.stgraber.org/2016/03/11/lxd-2-0-blog-post-series-012/
|
||||
[1]: https://github.com/lxc/lxd/blob/master/doc/image-handling.md
|
||||
[2]: https://launchpad.net/simplestreams
|
||||
[3]: https://linuxcontainers.org/lxd/try-it
|
||||
|
||||
原文:https://www.stgraber.org/2016/03/30/lxd-2-0-image-management-512/
|
||||
@ -0,0 +1,209 @@
|
||||
Part 6 - LXD 2.0: Remote hosts and container migration
|
||||
=======================================================
|
||||
|
||||
This is the third blog post [in this series about LXD 2.0][0].
|
||||
|
||||

|
||||
|
||||
### Remote protocols
|
||||
|
||||
LXD 2.0 supports two protocols:
|
||||
|
||||
* LXD 1.0 API: That’s the REST API used between the clients and a LXD daemon as well as between LXD daemons when copying/moving images and containers.
|
||||
* Simplestreams: The Simplestreams protocol is a read-only, image-only protocol used by both the LXD client and daemon to get image information and import images from some public image servers (like the Ubuntu images).
|
||||
|
||||
Everything below will be using the first of those two.
|
||||
|
||||
### Security
|
||||
|
||||
Authentication for the LXD API is done through client certificate authentication over TLS 1.2 using recent ciphers. When two LXD daemons must exchange information directly, a temporary token is generated by the source daemon and transferred through the client to the target daemon. This token may only be used to access a particular stream and is immediately revoked so cannot be re-used.
|
||||
|
||||
To avoid Man In The Middle attacks, the client tool also sends the certificate of the source server to the target. That means that for a particular download operation, the target server is provided with the source server URL, a one-time access token for the resource it needs and the certificate that the server is supposed to be using. This prevents MITM attacks and only give temporary access to the object of the transfer.
|
||||
|
||||
### Network requirements
|
||||
|
||||
LXD 2.0 uses a model where the target of an operation (the receiving end) is connecting directly to the source to fetch the data.
|
||||
|
||||
This means that you must ensure that the target server can connect to the source directly, updating any needed firewall along the way.
|
||||
|
||||
We have [a plan][1] to allow this to be reversed and also to allow proxying through the client itself for those rare cases where draconian firewalls are preventing any communication between the two hosts.
|
||||
|
||||
### Interacting with remote hosts
|
||||
|
||||
Rather than having our users have to always provide hostname or IP addresses and then validating certificate information whenever they want to interact with a remote host, LXD is using the concept of “remotes”.
|
||||
|
||||
By default, the only real LXD remote configured is “local:” which also happens to be the default remote (so you don’t have to type its name). The local remote uses the LXD REST API to talk to the local daemon over a unix socket.
|
||||
|
||||
### Adding a remote
|
||||
|
||||
Say you have two machines with LXD installed, your local machine and a remote host that we’ll call “foo”.
|
||||
|
||||
First you need to make sure that “foo” is listening to the network and has a password set, so get a remote shell on it and run:
|
||||
|
||||
```
|
||||
lxc config set core.https_address [::]:8443
|
||||
lxc config set core.trust_password something-secure
|
||||
```
|
||||
|
||||
Now on your local LXD, we just need to make it visible to the network so we can transfer containers and images from it:
|
||||
|
||||
lxc config set core.https_address [::]:8443
|
||||
Now that the daemon configuration is done on both ends, you can add “foo” to your local client with:
|
||||
|
||||
```
|
||||
lxc remote add foo 1.2.3.4
|
||||
```
|
||||
|
||||
(replacing 1.2.3.4 by your IP address or FQDN)
|
||||
|
||||
You’ll see something like this:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc remote add foo 2607:f2c0:f00f:2770:216:3eff:fee1:bd67
|
||||
Certificate fingerprint: fdb06d909b77a5311d7437cabb6c203374462b907f3923cefc91dd5fce8d7b60
|
||||
ok (y/n)? y
|
||||
Admin password for foo:
|
||||
Client certificate stored at server: foo
|
||||
```
|
||||
|
||||
You can then list your remotes and you’ll see “foo” listed there:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc remote list
|
||||
+-----------------+-------------------------------------------------------+---------------+--------+--------+
|
||||
| NAME | URL | PROTOCOL | PUBLIC | STATIC |
|
||||
+-----------------+-------------------------------------------------------+---------------+--------+--------+
|
||||
| foo | https://[2607:f2c0:f00f:2770:216:3eff:fee1:bd67]:8443 | lxd | NO | NO |
|
||||
+-----------------+-------------------------------------------------------+---------------+--------+--------+
|
||||
| images | https://images.linuxcontainers.org:8443 | lxd | YES | NO |
|
||||
+-----------------+-------------------------------------------------------+---------------+--------+--------+
|
||||
| local (default) | unix:// | lxd | NO | YES |
|
||||
+-----------------+-------------------------------------------------------+---------------+--------+--------+
|
||||
| ubuntu | https://cloud-images.ubuntu.com/releases | simplestreams | YES | YES |
|
||||
+-----------------+-------------------------------------------------------+---------------+--------+--------+
|
||||
| ubuntu-daily | https://cloud-images.ubuntu.com/daily | simplestreams | YES | YES |
|
||||
+-----------------+-------------------------------------------------------+---------------+--------+--------+
|
||||
```
|
||||
|
||||
### Interacting with it
|
||||
|
||||
Ok, so we have a remote server defined, what can we do with it now?
|
||||
|
||||
Well, just about everything you saw in the posts until now, the only difference being that you must tell LXD what host to run against.
|
||||
|
||||
For example:
|
||||
|
||||
```
|
||||
lxc launch ubuntu:14.04 c1
|
||||
```
|
||||
|
||||
Will run on the default remote (“lxc remote get-default”) which is your local host.
|
||||
|
||||
```
|
||||
lxc launch ubuntu:14.04 foo:c1
|
||||
```
|
||||
|
||||
Will instead run on foo.
|
||||
|
||||
Listing running containers on a remote host can be done with:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc list foo:
|
||||
+------+---------+---------------------+-----------------------------------------------+------------+-----------+
|
||||
| NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS |
|
||||
+------+---------+---------------------+-----------------------------------------------+------------+-----------+
|
||||
| c1 | RUNNING | 10.245.81.95 (eth0) | 2607:f2c0:f00f:2770:216:3eff:fe43:7994 (eth0) | PERSISTENT | 0 |
|
||||
+------+---------+---------------------+-----------------------------------------------+------------+-----------+
|
||||
```
|
||||
|
||||
One thing to keep in mind is that you have to specify the remote host for both images and containers. So if you have a local image called “my-image” on “foo” and want to create a container called “c2” from it, you have to run:
|
||||
|
||||
```
|
||||
lxc launch foo:my-image foo:c2
|
||||
```
|
||||
|
||||
Finally, getting a shell into a remote container works just as you would expect:
|
||||
|
||||
```
|
||||
lxc exec foo:c1 bash
|
||||
```
|
||||
|
||||
### Copying containers
|
||||
|
||||
Copying containers between hosts is as easy as it sounds:
|
||||
|
||||
```
|
||||
lxc copy foo:c1 c2
|
||||
```
|
||||
And you’ll have a new local container called “c2” created from a copy of the remote “c1” container. This requires “c1” to be stopped first, but you could just copy a snapshot instead and do it while the source container is running:
|
||||
|
||||
```
|
||||
lxc snapshot foo:c1 current
|
||||
lxc copy foo:c1/current c3
|
||||
```
|
||||
|
||||
### Moving containers
|
||||
|
||||
Unless you’re doing live migration (which will be covered in a later post), you have to stop the source container prior to moving it, after which everything works as you’d expect.
|
||||
|
||||
```
|
||||
lxc stop foo:c1
|
||||
lxc move foo:c1 local:
|
||||
```
|
||||
|
||||
This example is functionally identical to:
|
||||
|
||||
```
|
||||
lxc stop foo:c1
|
||||
lxc move foo:c1 c1
|
||||
```
|
||||
|
||||
### How this all works
|
||||
|
||||
Interactions with remote containers work as you would expect, rather than using the REST API over a local Unix socket, LXD just uses the exact same API over a remote HTTPS transport.
|
||||
|
||||
Where it gets a bit trickier is when interaction between two daemons must occur, as is the case for copy and move.
|
||||
|
||||
In those cases the following happens:
|
||||
|
||||
1. The user runs “lxc move foo:c1 c1”.
|
||||
2. The client contacts the local: remote to check for an existing “c1” container.
|
||||
3. The client fetches container information from “foo”.
|
||||
4. The client requests a migration token from the source “foo” daemon.
|
||||
5. The client sends that migration token as well as the source URL and “foo”‘s certificate to the local LXD daemon alongside the container configuration and devices.
|
||||
6. The local LXD daemon then connects directly to “foo” using the provided token
|
||||
A. It connects to a first control websocket
|
||||
B. It negotiates the filesystem transfer protocol (zfs send/receive, btrfs send/receive or plain rsync)
|
||||
C. If available locally, it unpacks the image which was used to create the source container. This is to avoid needless data transfer.
|
||||
D. It then transfers the container and any of its snapshots as a delta.
|
||||
7. If succesful, the client then instructs “foo” to delete the source container.
|
||||
|
||||
### Try all this online
|
||||
|
||||
Don’t have two machines to try remote interactions and moving/copying containers?
|
||||
|
||||
That’s okay, you can test it all online using our [demo service][2].
|
||||
The included step-by-step walkthrough even covers it!
|
||||
|
||||
### Extra information
|
||||
|
||||
The main LXD website is at: <https://linuxcontainers.org/lxd>
|
||||
Development happens on Github at: <https://github.com/lxc/lxd>
|
||||
Mailing-list support happens on: <https://lists.linuxcontainers.org>
|
||||
IRC support happens in: #lxcontainers on irc.freenode.net
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.stgraber.org/2016/03/19/lxd-2-0-your-first-lxd-container-312/
|
||||
|
||||
作者:[Stéphane Graber][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.stgraber.org/author/stgraber/
|
||||
[0]: https://www.stgraber.org/2016/03/11/lxd-2-0-blog-post-series-012/
|
||||
[1]: https://github.com/lxc/lxd/issues/553
|
||||
[2]: https://linuxcontainers.org/lxd/try-it/
|
||||
6
sources/tech/LXD/Part 7 - LXD 2.0--Docker in LXD.md
Normal file
6
sources/tech/LXD/Part 7 - LXD 2.0--Docker in LXD.md
Normal file
@ -0,0 +1,6 @@
|
||||
Part 7 - LXD 2.0: Docker in LXD
|
||||
==================================
|
||||
|
||||
<正文待补充>
|
||||
|
||||
原文: https://www.stgraber.org/2016/04/13/lxd-2-0-docker-in-lxd-712/
|
||||
6
sources/tech/LXD/Part 8 - LXD 2.0--LXD in LXD.md
Normal file
6
sources/tech/LXD/Part 8 - LXD 2.0--LXD in LXD.md
Normal file
@ -0,0 +1,6 @@
|
||||
Part 8 - LXD 2.0: LXD in LXD
|
||||
==============================
|
||||
|
||||
<原文待补充>
|
||||
|
||||
原文:https://www.stgraber.org/2016/04/14/lxd-2-0-lxd-in-lxd-812/
|
||||
6
sources/tech/LXD/Part 9 - LXD 2.0--Live migration.md
Normal file
6
sources/tech/LXD/Part 9 - LXD 2.0--Live migration.md
Normal file
@ -0,0 +1,6 @@
|
||||
Part 9 - LXD 2.0: Live migration
|
||||
=================================
|
||||
|
||||
<正文待补充>
|
||||
|
||||
原文:https://www.stgraber.org/2016/04/25/lxd-2-0-live-migration-912/
|
||||
@ -3,11 +3,11 @@
|
||||

|
||||
Credit: [Moini][1]
|
||||
|
||||
作为一个程序员,我知道我总在犯错误——事实是,怎么可能会不犯错的!程序员也是人啊。有的错误能在编码过程中及时发现,而有些却得等到软件测试才显露出来。然而,有一类错误并不能在这两个时期被排除,从而导致软件不能正常运行,甚至是提前中止。
|
||||
作为一个程序员,我知道我总在犯错误——事实是,怎么可能会不犯错的!程序员也是人啊。有的错误能在编码过程中及时发现,而有些却得等到软件测试才显露出来。然而,还有一类错误并不能在这两个时期被排除,从而导致软件不能正常运行,甚至是提前中止。
|
||||
|
||||
想到了吗?我说的就是内存相关的错误。手动调试这些错误不仅耗时,而且很难发现并纠正。值得一提的是,这种错误非常地常见,特别是在一些软件里,这些软件是用C/C++这类允许[手动管理内存][2]的语言编写的。
|
||||
想到了吗?我说的就是内存相关的错误。手动调试这些错误不仅耗时,而且很难发现并纠正。值得一提的是,这种错误非常常见,特别是在用 C/C++ 这类允许[手动管理内存][2]的语言编写的软件里。
|
||||
|
||||
幸运的是,现行有一些编程工具能够帮你找到软件程序中这些内存相关的错误。在这些工具集中,我评定了五款Linux可用的,流行、免费并且开源的内存调试器:Dmalloc、Electric Fence、 Memcheck、 Memwatch以及Mtrace。日常编码过程中我已经把这五个调试器用了个遍,所以这些点评是建立在我的实际体验之上的。
|
||||
幸运的是,现行有一些编程工具能够帮你找到软件程序中这些内存相关的错误。在这些工具集中,我评定了五款Linux可用的,流行、免费并且开源的内存调试器: Dmalloc 、 Electric Fence 、 Memcheck 、 Memwatch 以及 Mtrace 。在日常编码中,我已经把这五个调试器用了个遍,所以这些点评是建立在我的实际体验之上的。
|
||||
|
||||
### [Dmalloc][3] ###
|
||||
|
||||
@ -15,11 +15,11 @@ Credit: [Moini][1]
|
||||
|
||||
**点评版本**:5.5.2
|
||||
|
||||
**Linux支持**:所有种类
|
||||
**支持的 Linux**:所有种类
|
||||
|
||||
**许可**:知识共享署名-相同方式共享许可证3.0
|
||||
**许可**:知识共享署名-相同方式共享许可证 3.0
|
||||
|
||||
Dmalloc是Gray Watson开发的一款内存调试工具。它实现成库,封装了标准内存管理函数如**malloc(), calloc(), free()**等,使得程序员得以检测出有问题的代码。
|
||||
Dmalloc 是 Gray Watson 开发的一款内存调试工具。它实现成库,封装了标准内存管理函数如 *malloc() , calloc() , free()* 等,使程序员得以检测出有问题的代码。
|
||||
|
||||

|
||||
Dmalloc
|
||||
@ -28,29 +28,29 @@ Dmalloc
|
||||
|
||||
#### 更新内容 ####
|
||||
|
||||
5.5.2版本是一个[bug修复发行版][6],同时修复了构建和安装的问题。
|
||||
5.5.2 版本是一个 [bug 修复发行版][6],同时修复了构建和安装的问题。
|
||||
|
||||
#### 有何优点 ####
|
||||
|
||||
Dmalloc最大的优点是可以进行任意配置。比如说,你可以配置以支持C++程序和多线程应用。Dmalloc还提供一个有用的功能:运行时可配置,这表示在Dmalloc执行时,可以轻易地使能或者禁能它提供的特性。
|
||||
Dmalloc 最大的优点就是高度可配置性。比如说,你可以配置以支持 C++ 程序和多线程应用。 Dmalloc 还提供一个有用的功能:运行时可配置,这表示在 Dmalloc 执行时,可以轻易地使能或者禁能它提供的特性。
|
||||
|
||||
你还可以配合[GNU Project Debugger (GDB)][7]来使用Dmalloc,只需要将dmalloc.gdb文件(位于Dmalloc源码包中的contrib子目录里)的内容添加到你的主目录中的.gdbinit文件里即可。
|
||||
你还可以配合 [GNU Project Debugger (GDB)][7]来使用 Dmalloc ,只需要将 *dmalloc.gdb* 文件(位于 Dmalloc 源码包中的 contrib 子目录里)的内容添加到你的主目录中的 *.gdbinit* 文件里即可。
|
||||
|
||||
另外一个优点让我对Dmalloc爱不释手的是它有大量的资料文献。前往官网的[Documentation标签][8],可以获取任何内容,有关于如何下载、安装、运行,怎样使用库,和Dmalloc所提供特性的细节描述,及其输入文件的解释。里面还有一个章节介绍了一般问题的解决方法。
|
||||
另外一个让我对 Dmalloc 爱不释手的优点是它有大量的资料文献。前往官网的 [Documentation 标签][8],可以获取所有关于如何下载、安装、运行,怎样使用库,和 Dmalloc 所提供特性的细节描述,及其输入文件的解释。其中还有一个章节介绍了一般问题的解决方法。
|
||||
|
||||
#### 注意事项 ####
|
||||
|
||||
跟Mtrace一样,Dmalloc需要程序员改动他们的源代码。比如说你可以(必须的)添加头文件**dmalloc.h**,工具就能汇报产生问题的调用的文件或行号。这个功能非常有用,因为它节省了调试的时间。
|
||||
跟 Mtrace 一样, Dmalloc 需要程序员改动他们的源代码。比如说你可以(必须的)添加头文件 *dmalloc.h* ,工具就能汇报产生问题的调用的文件或行号。这个功能非常有用,因为它节省了调试的时间。
|
||||
|
||||
除此之外,还需要在编译你的程序时,把Dmalloc库(编译源码包时产生的)链接进去。
|
||||
除此之外,还需要在编译你的程序时,把 Dmalloc 库(编译源码包时产生的)链接进去。
|
||||
|
||||
然而,还有点更麻烦的事,需要设置一个环境变量,命名为**DMALLOC_OPTION**,以供工具在运行时配置内存调试特性,以及输出文件的路径。可以手动为该环境变量分配一个值,不过初学者可能会觉得这个过程有点困难,因为你想使能的Dmalloc特性是存在于这个值之中的——表示为各自的十六进制值的累加。[这里][9]有详细介绍。
|
||||
然而,还有点更麻烦的事,需要设置一个环境变量,命名为 *DMALLOC_OPTION* ,以供工具在运行时配置内存调试特性,以及输出文件的路径。可以手动为该环境变量分配一个值,不过初学者可能会觉得这个过程有点困难,因为该值的一部分用来表示要启用的 Dmalloc 特性——表示为各自的十六进制值的累加。[这里][9]有详细介绍。
|
||||
|
||||
一个比较简单方法设置这个环境变量是使用[Dmalloc实用指令][10],这是专为这个目的设计的方法。
|
||||
一个比较简单方法设置这个环境变量是使用 [Dmalloc 实用指令][10],这是专为这个目的设计的方法。
|
||||
|
||||
#### 总结 ####
|
||||
|
||||
Dmalloc真正的优势在于它的可配置选项。而且高度可移植,曾经成功移植到多种操作系统如AIX、BSD/OS、DG/UX、Free/Net/OpenBSD、GNU/Hurd、HPUX、Irix、Linux、MS-DOG、NeXT、OSF、SCO、Solaris、SunOS、Ultrix、Unixware甚至Unicos(运行在Cray T3E主机上)。虽然Dmalloc有很多东西需要学习,但是它所提供的特性值得为之付出。
|
||||
Dmalloc 真正的优势在于它的可配置选项。而且高度可移植,曾经成功移植到多种操作系统如 AIX 、 BSD/OS 、 DG/UX 、 Free/Net/OpenBSD 、 GNU/Hurd 、 HPUX 、 Irix 、 Linux 、 MS-DOG 、 NeXT 、 OSF 、 SCO 、 Solaris 、 SunOS 、 Ultrix 、 Unixware 甚至 Unicos(运行在 Cray T3E 主机上)。虽然使用 Dmalloc 需要学习许多知识,但是它所提供的特性值得为之付出。
|
||||
|
||||
### [Electric Fence][15] ###
|
||||
|
||||
@ -58,95 +58,95 @@ Dmalloc真正的优势在于它的可配置选项。而且高度可移植,曾
|
||||
|
||||
**点评版本**:2.2.3
|
||||
|
||||
**Linux支持**:所有种类
|
||||
**支持的 Linux**:所有种类
|
||||
|
||||
**许可**:GNU 通用公共许可证 (第二版)
|
||||
|
||||
Electric Fence是Bruce Perens开发的一款内存调试工具,它以库的形式实现,你的程序需要链接它。Electric Fence能检测出[栈][11]内存溢出和访问已经释放的内存。
|
||||
Electric Fence 是 Bruce Perens 开发的一款内存调试工具,它以库的形式实现,你的程序需要链接它。Electric Fence 能检测出[栈][11]内存溢出和访问已经释放的内存。
|
||||
|
||||
|
||||
Electric Fence
|
||||
|
||||
顾名思义,Electric Fence在每个申请的缓存边界建立了fence(防护),任何非法内存访问都会导致[段错误][12]。这个调试工具同时支持C和C++编程。
|
||||
顾名思义, Electric Fence 在每个申请的缓存边界建立了 virtual fence(虚拟围栏),任何非法内存访问都会导致[段错误][12]。这个调试工具同时支持 C 和 C++ 程序。
|
||||
|
||||
|
||||
#### 更新内容 ####
|
||||
|
||||
2.2.3版本修复了工具的构建系统,使得-fno-builtin-malloc选项能真正传给[GNU Compiler Collection (GCC)][13]。
|
||||
2.2.3 版本修复了工具的构建系统,使得 `-fno-builtin-malloc` 选项能真正传给 [GNU Compiler Collection (GCC)][13]。
|
||||
|
||||
#### 有何优点 ####
|
||||
|
||||
我喜欢Electric Fence首要的一点是(Memwatch、Dmalloc和Mtrace所不具有的),这个调试工具不需要你的源码做任何的改动,你只需要在编译的时候把它的库链接进你的程序即可。
|
||||
我喜欢 Electric Fence 首要的一点是它(不同于 Memwatch 、 Dmalloc 和 Mtrace ,)不需要你的源码做任何的改动,你只需要在编译的时候把它的库链接进你的程序即可。
|
||||
|
||||
其次,Electric Fence实现一个方法,确认导致越界访问(a bounds violation)的第一个指令就是引起段错误的原因。这比在后面再发现问题要好多了。
|
||||
其次, Electric Fence 的实现保证了导致越界访问( a bounds violation )的第一个指令就是引起段错误的原因。这比在后面再发现问题要好多了。
|
||||
|
||||
不管是否有检测出错误,Electric Fence经常会在输出产生版权信息。这一点非常有用,由此可以确定你所运行的程序已经启用了Electric Fence。
|
||||
不管是否有检测出错误, Electric Fence 都会在输出产生版权信息。这一点非常有用,由此可以确定你所运行的程序已经启用了 Electric Fence 。
|
||||
|
||||
#### 注意事项 ####
|
||||
|
||||
另一方面,我对Electric Fence真正念念不忘的是它检测内存泄漏的能力。内存泄漏是C/C++软件最常见也是最难隐秘的问题之一。不过,Electric Fence不能检测出堆内存溢出,而且也不是线程安全的。
|
||||
另一方面,我对 Electric Fence 真正念念不忘的是它检测内存泄漏的能力。内存泄漏是 C/C++ 软件最常见也是最难隐秘的问题之一。不过, Electric Fence 不能检测出堆内存溢出,而且也不是线程安全的。
|
||||
|
||||
基于Electric Fence会在用户分配内存区的前后分配禁止访问的虚拟内存页,如果你过多的进行动态内存分配,将会导致你的程序消耗大量的额外内存。
|
||||
由于 Electric Fence 会在用户分配内存区的前后分配禁止访问的虚拟内存页,如果你过多的进行动态内存分配,将会导致你的程序消耗大量的额外内存。
|
||||
|
||||
Electric Fence还有一个局限是不能明确指出错误代码所在的行号。它所能做只是在监测到内存相关错误时产生段错误。想要定位行号,需要借助[The Gnu Project Debugger (GDB)][14]这样的调试工具来调试你启用了Electric Fence的程序。
|
||||
Electric Fence 还有一个局限是不能明确指出错误代码所在的行号。它所能做只是在监测到内存相关错误时产生段错误。想要定位行号,需要借助 [The Gnu Project Debugger ( GDB )][14]这样的调试工具来调试启用了 Electric Fence 的程序。
|
||||
|
||||
最后一点,Electric Fence虽然能检测出大部分的缓冲区溢出,有一个例外是,如果所申请的缓冲区大小不是系统字长的倍数,这时候溢出(即使只有几个字节)就不能被检测出来。
|
||||
最后一点,尽管 Electric Fence 能检测出大部分的缓冲区溢出,有一个例外是,如果所申请的缓冲区大小不是系统字长的倍数,这时候溢出(即使只有几个字节)就不能被检测出来。
|
||||
|
||||
#### 总结 ####
|
||||
|
||||
尽管有那么多的局限,但是Electric Fence的优点却在于它的易用性。程序只要链接工具一次,Electric Fence就可以在监测出内存相关问题的时候报警。不过,如同前面所说,Electric Fence需要配合像GDB这样的源码调试器使用。
|
||||
尽管局限性较大, Electric Fence 的易用性仍然是加分项。只要链接一次程序, Electric Fence 就可以在监测出内存相关问题的时候报警。不过,如同前面所说, Electric Fence 需要配合像 GDB 这样的源码调试器使用。
|
||||
|
||||
|
||||
### [Memcheck][16] ###
|
||||
|
||||
**开发者**:[Valgrind开发团队][17]
|
||||
**开发者**:[Valgrind 开发团队][17]
|
||||
|
||||
**点评版本**:3.10.1
|
||||
|
||||
**Linux支持**:所有种类
|
||||
**支持的 Linux**:所有种类
|
||||
|
||||
**许可**:通用公共许可证
|
||||
|
||||
[Valgrind][18]是一个提供好几款调试和Linux程序性能分析工具的套件。虽然Valgrind和编写语言各不相同(有Java、Perl、Python、Assembly code、ortran、Ada等等)的程序配合工作,但是它所提供的工具大部分都意在支持C/C++所编写的程序。
|
||||
[Valgrind][18] 是一个提供好几款调试和 Linux 程序性能分析工具的套件。虽然 Valgrind 能和编写语言各不相同(有 Java 、 Perl 、 Python 、 Assembly code 、 ortran 、 Ada等等)的程序配合工作,但是它所提供的工具主要针对用 C/C++ 所编写的程序。
|
||||
|
||||
Memcheck作为内存错误检测器,是一款最受欢迎的Memcheck工具。它能够检测出诸多问题诸如内存泄漏、无效的内存访问、未定义变量的使用以及栈内存分配和释放相关的问题等。
|
||||
Memcheck ,一款内存错误检测器,是其中最受欢迎的工具。它能够检测出如内存泄漏、无效的内存访问、未定义变量的使用以及栈内存分配和释放相关的问题等诸多问题。
|
||||
|
||||
#### 更新内容 ####
|
||||
|
||||
工具套件(3.10.1)的[发行版][19]是一个副版本,主要修复了3.10.0版本发现的bug。除此之外,从主版本backport一些包,修复了缺失的AArch64 ARMv8指令和系统调用。
|
||||
工具套件( 3.10.1 )的[发行版][19]是一个副版本,主要修复了 3.10.0 版本发现的 bug 。除此之外,从主版本向后移植(标音: backport )一些包,修复了缺失的 AArch64 ARMv8 指令和系统调用。
|
||||
|
||||
#### 有何优点 ####
|
||||
|
||||
同其它所有Valgrind工具一样,Memcheck也是基本的命令行实用程序。它的操作非常简单:通常我们会使用诸如prog arg1 arg2格式的命令来运行程序,而Memcheck只要求你多加几个值即可,就像valgrind --leak-check=full prog arg1 arg2。
|
||||
同其它所有 Valgrind 工具一样, Memcheck 也是命令行实用程序。它的操作非常简单:通常我们会使用诸如 prog arg1 arg2 格式的命令来运行程序,而 Memcheck 只要求你多加几个值即可,如 valgrind --leak-check=full prog arg1 arg2 。
|
||||
|
||||
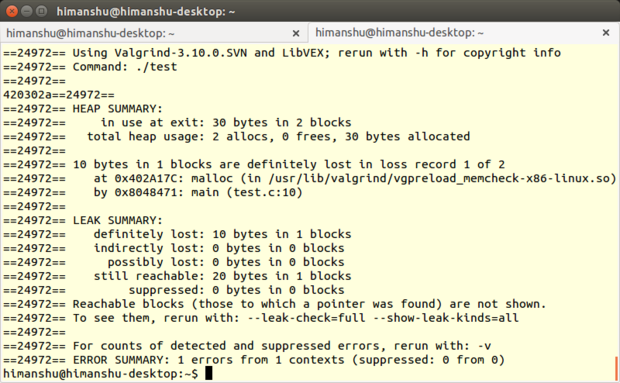
|
||||
Memcheck
|
||||
|
||||
(注意:因为Memcheck是Valgrind的默认工具所以无需提及Memcheck。但是,需要在编译程序之初带上-g参数选项,这一步会添加调试信息,使得Memcheck的错误信息会包含正确的行号。)
|
||||
(注意:因为 Memcheck 是 Valgrind 的默认工具所以无需提及 Memcheck。但是,需要在编译程序之初带上 -g 参数选项,这一步会添加调试信息,使得 Memcheck 的错误信息会包含正确的行号。)
|
||||
|
||||
我真正倾心于Memcheck的是它提供了很多命令行选项(如上所述的--leak-check选项),如此不仅能控制工具运转还可以控制它的输出。
|
||||
我真正倾心于 Memcheck 的是它提供了很多命令行选项(如上所述的 *--leak-check* 选项),如此不仅能控制工具运转还可以控制它的输出。
|
||||
|
||||
举个例子,可以开启--track-origins选项,以查看程序源码中未初始化的数据。可以开启--show-mismatched-frees选项让Memcheck匹配内存的分配和释放技术。对于C语言所写的代码,Memcheck会确保只能使用free()函数来释放内存,malloc()函数来申请内存。而对C++所写的源码,Memcheck会检查是否使用了delete或delete[]操作符来释放内存,以及new或者new[]来申请内存。
|
||||
举个例子,可以开启 *--track-origins* 选项,以查看程序源码中未初始化的数据;可以开启 *--show-mismatched-frees* 选项让 Memcheck 匹配内存的分配和释放技术。对于 C 语言所写的代码, Memcheck 会确保只能使用 *free()* 函数来释放内存, *malloc()* 函数来申请内存。而对 C++ 所写的源码, Memcheck 会检查是否使用了 *delete* 或 *delete[]* 操作符来释放内存,以及 *new* 或者*new[]* 来申请内存。
|
||||
|
||||
Memcheck最好的特点,尤其是对于初学者来说的,是它会给用户建议使用那个命令行选项能让输出更加有意义。比如说,如果你不使用基本的--leak-check选项,Memcheck会在输出时建议“使用--leak-check=full重新运行,查看更多泄漏内存细节”。如果程序有未初始化的变量,Memcheck会产生信息“使用--track-origins=yes,查看未初始化变量的定位”。
|
||||
Memcheck 最好的特点,尤其是对于初学者来说,是它会给用户建议使用哪个命令行选项能让输出更加有意义。比如说,如果你不使用基本的 *--leak-check* 选项, Memcheck 会在输出时建议“使用 --leak-check=full 重新运行以查看更多泄漏内存细节”。如果程序有未初始化的变量, Memcheck 会产生信息“使用 --track-origins=yes 以查看未初始化变量的定位”。
|
||||
|
||||
Memcheck另外一个有用的特性是它可以[创建抑制文件(suppression files)][20],由此可以忽略特定不能修正的错误,这样Memcheck运行时就不会每次都报警了。值得一提的是,Memcheck会去读取默认抑制文件来忽略系统库(比如C库)中的报错,这些错误在系统创建之前就已经存在了。可以选择创建一个新的抑制文件,或是编辑现有的(通常是/usr/lib/valgrind/default.supp)。
|
||||
Memcheck 另外一个有用的特性是它可以[创建抑制文件( suppression files )][20],由此可以忽略特定不能修正的错误,这样 Memcheck 运行时就不会每次都报警了。值得一提的是, Memcheck 会去读取默认抑制文件来忽略系统库(比如 C 库)中的报错,这些错误在系统创建之前就已经存在了。可以选择创建一个新的抑制文件,或是编辑现有的文件(通常是*/usr/lib/valgrind/default.supp*)。
|
||||
|
||||
Memcheck还有高级功能,比如可以使用[定制内存分配器][22]来[检测内存错误][21]。除此之外,Memcheck提供[监控命令][23],当用到Valgrind的内置gdbserver,以及[客户端请求][24]机制(不仅能把程序的行为告知Memcheck,还可以进行查询)时可以使用。
|
||||
Memcheck 还有高级功能,比如可以使用[定制内存分配器][22]来[检测内存错误][21]。除此之外, Memcheck 提供[监控命令][23],当用到 Valgrind 内置的 gdbserver ,以及[客户端请求][24]机制(不仅能把程序的行为告知 Memcheck ,还可以进行查询)时可以使用。
|
||||
|
||||
#### 注意事项 ####
|
||||
|
||||
毫无疑问,Memcheck可以节省很多调试时间以及省去很多麻烦。但是它使用了很多内存,导致程序执行变慢([由资料可知][25],大概花上20至30倍时间)。
|
||||
毫无疑问, Memcheck 可以节省很多调试时间以及省去很多麻烦。但是它使用了很多内存,导致程序执行变慢([由文档可知][25],大概花上 20 至 30 倍时间)。
|
||||
|
||||
除此之外,Memcheck还有其它局限。根据用户评论,Memcheck明显不是[线程安全][26]的;它不能检测出 [静态缓冲区溢出][27];还有就是,一些Linux程序如[GNU Emacs][28],目前还不能使用Memcheck。
|
||||
除此之外, Memcheck 还有其它局限。根据用户评论, Memcheck 明显不是[线程安全][26]的;它不能检测出 [静态缓冲区溢出][27];还有就是,一些 Linux 程序如 [GNU Emacs][28] 目前还不能使用 Memcheck 。
|
||||
|
||||
如果有兴趣,可以在[这里][29]查看Valgrind详尽的局限性说明。
|
||||
如果有兴趣,可以在[这里][29]查看 Valgrind 详尽的局限性说明。
|
||||
|
||||
#### 总结 ####
|
||||
|
||||
无论是对于初学者还是那些需要高级特性的人来说,Memcheck都是一款便捷的内存调试工具。如果你仅需要基本调试和错误核查,Memcheck会非常容易上手。而当你想要使用像抑制文件或者监控指令这样的特性,就需要花一些功夫学习了。
|
||||
无论是对于初学者还是那些需要高级特性的人来说, Memcheck 都是一款便捷的内存调试工具。如果你仅需要基本调试和错误核查, Memcheck 会非常容易上手。而当你想要使用像抑制文件或者监控指令这样的特性,就需要花一些功夫学习了。
|
||||
|
||||
虽然罗列了大量的局限性,但是Valgrind(包括Memcheck)在它的网站上声称全球有[成千上万程序员][30]使用了此工具。开发团队称收到来自超过30个国家的用户反馈,而这些用户的工程代码有的高达2.5千万行。
|
||||
虽然罗列了大量的局限性,但是 Valgrind(包括 Memcheck )在它的网站上声称全球有[成千上万程序员][30]使用了此工具。开发团队称收到来自超过 30 个国家的用户反馈,而这些用户的工程代码有的高达 2.5 千万行。
|
||||
|
||||
### [Memwatch][31] ###
|
||||
|
||||
@ -154,40 +154,40 @@ Memcheck还有高级功能,比如可以使用[定制内存分配器][22]来[
|
||||
|
||||
**点评版本**:2.71
|
||||
|
||||
**Linux支持**:所有种类
|
||||
**支持的 Linux**:所有种类
|
||||
|
||||
**许可**:GNU通用公共许可证
|
||||
|
||||
Memwatch是由Johan Lindh开发的内存调试工具,虽然它主要扮演内存泄漏检测器的角色,但是它也具有检测其它如[重复释放跟踪和内存错误释放][32]、缓冲区溢出和下溢、[野指针][33]写入等等内存相关问题的能力(根据网页介绍所知)。
|
||||
|
||||
Memwatch支持用C语言所编写的程序。可以在C++程序中使用它,但是这种做法并不提倡(由Memwatch源码包随附的Q&A文件中可知)。
|
||||
Memwatch 是由 Johan Lindh 开发的内存调试工具,虽然它主要扮演内存泄漏检测器的角色,但是(根据网页介绍)它也具有检测其它如[重复释放跟踪和内存错误释放][32]、缓冲区溢出和下溢、[野指针][33]写入等等内存相关问题的能力。
|
||||
|
||||
Memwatch 支持用 C 语言所编写的程序。也可以在 C++ 程序中使用它,但是这种做法并不提倡(由 Memwatch 源码包随附的 Q&A 文件中可知)。
|
||||
|
||||
#### 更新内容 ####
|
||||
|
||||
这个版本添加了ULONG_LONG_MAX以区分32位和64位程序。
|
||||
这个版本添加了 *ULONG_LONG_MAX* 以区分 32 位和 64 位程序。
|
||||
|
||||
#### 有何优点 ####
|
||||
|
||||
跟Dmalloc一样,Memwatch也有优秀的文献资料。参考USING文件,可以学习如何使用Memwatch,可以了解Memwatch是如何初始化、如何清理以及如何进行I/O操作的,等等不一而足。还有一个FAQ文件,旨在帮助用户解决使用过程遇到的一般问题。最后还有一个test.c文件提供工作案例参考。
|
||||
跟 Dmalloc 一样, Memwatch 也有优秀的文档资料。参考 USING 文件,可以学习如何使用 Memwatch ,可以了解 Memwatch 是如何初始化、如何清理以及如何进行 I/O 操作,等等。还有一个 FAQ 文件,旨在帮助用户解决使用过程遇到的一般问题。最后还有一个 *test.c* 文件提供工作案例参考。
|
||||
|
||||
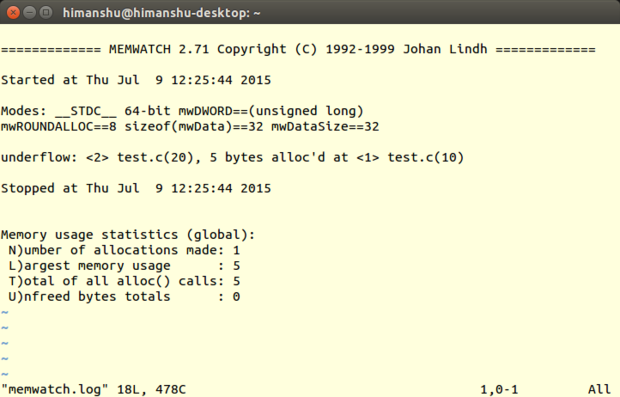
|
||||
Memwatch
|
||||
|
||||
不同于Mtrace,Memwatch的输出产生的日志文件(通常是memwatch.log)是人类可阅读格式。而且,Memwatch每次运行时总会拼接内存调试输出到此文件末尾,而不是进行覆盖(译改)。如此便可在需要之时,轻松查看之前的输出信息。
|
||||
不同于 Mtrace , Memwatch 的输出产生的日志文件(通常是 *memwatch.log* )是人类可阅读格式。而且, Memwatch 每次运行时总会拼接内存调试输出到文件末尾。如此便可在需要之时,轻松查看之前的输出信息。
|
||||
|
||||
同样值得一提的是当你执行了启用Memwatch的程序,Memwatch会在[标准输出][34]中产生一个单行输出,告知发现了错误,然后你可以在日志文件中查看输出细节。如果没有产生错误信息,就可以确保日志文件不会写入任何错误,多次运行的话能实际节省时间。
|
||||
同样值得一提的是当你执行了启用 Memwatch 的程序, Memwatch 会在[标准输出][34]中产生一个单行输出,告知发现了错误,然后你可以在日志文件中查看输出细节。如果没有产生错误信息,就可以确保日志文件不会写入任何错误,多次运行的话确实能节省时间。
|
||||
|
||||
另一个我喜欢的优点是Memwatch同样在源码中提供一个方法,你可以据此获取Memwatch的输出信息,然后任由你进行处理(参考Memwatch源码中的mwSetOutFunc()函数获取更多有关的信息)。
|
||||
另一个我喜欢的优点是 Memwatch 还提供了在源码中获取其输出信息的方式,你可以获取信息,然后任由你进行处理(参考 Memwatch 源码中的 *mwSetOutFunc()* 函数获取更多有关的信息)。
|
||||
|
||||
#### 注意事项 ####
|
||||
|
||||
跟Mtrace和Dmalloc一样,Memwatch也需要你往你的源文件里增加代码:你需要把memwatch.h这个头文件包含进你的代码。而且,编译程序的时候,你需要连同memwatch.c一块编译;或者你可以把已经编译好的目标模块包含起来,然后在命令行定义MEMWATCH和MW_STDIO变量。不用说,想要在输出中定位行号,-g编译器选项也少不了。
|
||||
跟 Mtrace 和 Dmalloc 一样, Memwatch 也需要你往你的源文件里增加代码:你需要把 *memwatch.h* 这个头文件包含进你的代码。而且,编译程序的时候,你需要连同 *memwatch.c* 一块编译;或者你可以把已经编译好的目标模块包含起来,然后在命令行定义 *MEMWATCH* 和 *MW_STDIO* 变量。不用说,想要在输出中定位行号, -g 编译器选项也少不了。
|
||||
|
||||
还有一些没有具备的特性。比如Memwatch不能检测出往一块已经被释放的内存写入操作,或是在分配的内存块之外的读取操作。而且,Memwatch也不是线程安全的。还有一点,正如我在开始时指出,在C++程序上运行Memwatch的结果是不能预料的。
|
||||
此外, Memwatch 缺少一些特性。比如 Memwatch 不能检测出往一块已经被释放的内存写入操作,或是在分配的内存块之外的读取操作。而且, Memwatch 也不是线程安全的。还有一点,正如我在开始时指出,在 C++ 程序上运行 Memwatch 的结果是不能预料的。
|
||||
|
||||
#### 总结 ####
|
||||
|
||||
Memcheck可以检测很多内存相关的问题,在处理C程序时是非常便捷的调试工具。因为源码小巧,所以可以从中了解Memcheck如何运转,有需要的话可以调试它,甚至可以根据自身需求扩展升级它的功能。
|
||||
Memcheck 可以检测很多内存相关的问题,在处理 C 程序时是非常便捷的调试工具。因为源码小巧,所以可以从中了解 Memcheck 如何运转,有需要的话可以调试它,甚至可以根据自身需求扩展升级它的功能。
|
||||
|
||||
### [Mtrace][35] ###
|
||||
|
||||
@ -195,60 +195,60 @@ Memcheck可以检测很多内存相关的问题,在处理C程序时是非常
|
||||
|
||||
**点评版本**: 2.21
|
||||
|
||||
**Linux支持**:所有种类
|
||||
**支持的 Linux**:所有种类
|
||||
|
||||
**许可**:GNU通用公共许可证
|
||||
**许可**:GNU 通用公共许可证
|
||||
|
||||
Mtrace是[GNU C库][36]中的一款内存调试工具,同时支持Linux C和C++程序,检测由malloc()和free()函数的不对等调用所引起的内存泄漏问题。
|
||||
Mtrace 是 [GNU C 库][36]中的一款内存调试工具,同时支持 Linux 上的 C 和 C++ 程序,检测由 *malloc()* 和 *free()* 函数的不对等调用所引起的内存泄漏问题。
|
||||
|
||||
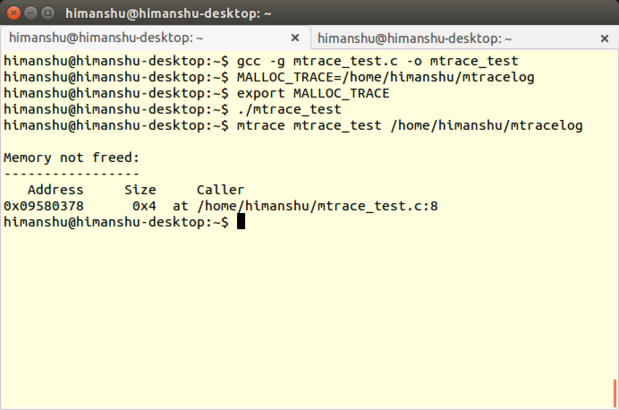
|
||||
Mtrace
|
||||
|
||||
Mtrace实现为对mtrace()函数的调用,跟踪程序中所有malloc/free调用,在用户指定的文件中记录相关信息。文件以一种机器可读的格式记录数据,所以有一个Perl脚本(同样命名为mtrace)用来把文件转换并展示为人类可读格式。
|
||||
Mtrace 实现为对 *mtrace()* 函数的调用,跟踪程序中所有 malloc/free 调用,并在用户指定的文件中记录相关信息。文件以一种机器可读的格式记录数据,所以有一个 Perl 脚本(同样命名为 mtrace )用来把文件转换并展示为人类可读格式。
|
||||
|
||||
#### 更新内容 ####
|
||||
|
||||
[Mtrace源码][37]和[Perl文件][38]同GNU C库(2.21版本)一起释出,除了更新版权日期,其它别无改动。
|
||||
[Mtrace 源码][37]和 [Perl 文件][38]同 GNU C 库( 2.21 版本)一起释出,除了更新版权日期,其它别无改动。
|
||||
|
||||
#### 有何优点 ####
|
||||
|
||||
Mtrace最优秀的特点是非常简单易学。你只需要了解在你的源码中如何以及何处添加mtrace()及其对立的muntrace()函数,还有如何使用Mtrace的Perl脚本。后者非常简单,只需要运行指令mtrace <program-executable> <log-file-generated-upon-program-execution>(例子见开头截图最后一条指令)。
|
||||
Mtrace 最优秀的特点是非常简单易学。你只需要了解在你的源码中如何以及何处添加mtrace()及其对立的muntrace()函数,还有如何使用Mtrace的Perl脚本。后者非常简单,只需要运行指令 *mtrace <program-executable> <log-file-generated-upon-program-execution>*(例子见开头截图最后一条指令)。
|
||||
|
||||
Mtrace另外一个优点是它的可收缩性,体现在,不仅可以使用它来调试完整的程序,还可以使用它来检测程序中独立模块的内存泄漏。只需在每个模块里调用mtrace()和muntrace()即可。
|
||||
Mtrace 另外一个优点是它的可收缩性,体现在,不仅可以使用它来调试完整的程序,还可以使用它来检测程序中独立模块的内存泄漏。只需在每个模块里调用 *mtrace()* 和 *muntrace()* 即可。
|
||||
|
||||
最后一点,因为Mtrace会在mtace()(在源码中添加的函数)执行时被触发,因此可以很灵活地[使用信号][39]动态地(在程序执行周期内)使能Mtrace。
|
||||
最后一点,因为 Mtrace 会在 *mtace()*(在源码中添加的函数)执行时被触发,因此可以很灵活地[使用信号][39]动态地(在程序执行周期内)使能 Mtrace 。
|
||||
|
||||
#### 注意事项 ####
|
||||
|
||||
因为mtrace()和mauntrace()函数(在mcheck.h文件中声明,所以必须在源码中包含此头文件)的调用是Mtrace运行(mauntrace()函数并非[总是必要][40])的根本,因此Mtrace要求程序员至少改动源码一次。
|
||||
因为 *mtrace()* 和 *mauntrace()* 函数(声明在 *mcheck.h* 文件中,所以必须在源码中包含此头文件)的调用是 Mtrace 运行( *mauntrace()* 函数并非[总是必要][40])的根本,因此 Mtrace 要求程序员至少改动源码一次。
|
||||
|
||||
了解需要在编译程序的时候带上-g选项([GCC][41]和[G++][42]编译器均由提供),才能使调试工具在输出展示正确的行号。除此之外,有些程序(取决于源码体积有多大)可能会花很长时间进行编译。最后,带-g选项编译会增加了可执行文件的内存(因为提供了额外的调试信息),因此记得程序需要在测试结束,不带-g选项重新进行编译。
|
||||
需要注意的是,在编译程序的时候带上 -g 选项( [GCC][41] 和 [G++][42] 编译器均有提供),才能使调试工具在输出展示正确的行号。除此之外,有些程序(取决于源码体积有多大)可能会花很长时间进行编译。最后,带 -g 选项编译会增加了可执行文件的内存(因为提供了额外的调试信息),因此记得程序需要在测试结束后,不带 -g 选项重新进行编译。
|
||||
|
||||
使用Mtrace,你需要掌握Linux环境变量的基本知识,因为在程序执行之前,需要把用户指定文件(mtrace()函数用以记载全部信息)的路径设置为环境变量MALLOC_TRACE的值。
|
||||
使用 Mtrace ,你需要掌握 Linux 环境变量的基本知识,因为在程序执行之前,需要把用户指定的文件( *mtrace()* 函数将会记录全部信息到其中)路径设置为环境变量 *MALLOC_TRACE* 的值。
|
||||
|
||||
Mtrace在检测内存泄漏和尝试释放未经过分配的内存方面存在局限。它不能检测其它内存相关问题如非法内存访问、使用未初始化内存。而且,[有人抱怨][43]Mtrace不是[线程安全][44]的。
|
||||
Mtrace 在检测内存泄漏和尝试释放未经过分配的内存方面存在局限。它不能检测其它内存相关问题如非法内存访问、使用未初始化内存。而且,[有人抱怨][43] Mtrace 不是[线程安全][44]的。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
不言自明,我在此讨论的每款内存调试器都有其优点和局限。所以,哪一款适合你取决于你所需要的特性,虽然有时候容易安装和使用也是一个决定因素。
|
||||
|
||||
要想捕获软件程序中的内存泄漏,Mtrace最适合不过了。它还可以节省时间。由于Linux系统已经预装了此工具,对于不能联网或者不可以下载第三方调试调试工具的情况,Mtrace也是极有助益的。
|
||||
要想捕获软件程序中的内存泄漏, Mtrace 最适合不过了。它还可以节省时间。由于 Linux 系统已经预装了此工具,对于不能联网或者不可以下载第三方调试调试工具的情况, Mtrace 也是极有助益的。
|
||||
|
||||
另一方面,相比Mtrace,,Dmalloc不仅能检测更多错误类型,还你呢个提供更多特性,比如运行时可配置、GDB集成。而且,Dmalloc不像这里所说的其它工具,它是线程安全的。更不用说它的详细资料了,这让Dmalloc成为初学者的理想选择。
|
||||
另一方面,相比 Mtrace , Dmalloc 不仅能检测更多错误类型,还提供更多特性,比如运行时可配置、 GDB 集成。而且, Dmalloc 不像这里所说的其它工具,它是线程安全的。更不用说它的详细资料了,这让 Dmalloc 成为初学者的理想选择。
|
||||
|
||||
虽然Memwatch的资料比Dmalloc的更加丰富,而且还能检测更多的错误种类,但是你只能在C语言写就的软件程序上使用它。一个让Memwatch脱颖而出的特性是它允许在你的程序源码中处理它的输出,这对于想要定制输出格式来说是非常有用的。
|
||||
虽然 Memwatch 的资料比 Dmalloc 的更加丰富,而且还能检测更多的错误种类,但是你只能在 C 语言写就的程序中使用它。一个让 Memwatch 脱颖而出的特性是它允许在你的程序源码中处理它的输出,这对于想要定制输出格式来说是非常有用的。
|
||||
|
||||
如果改动程序源码非你所愿,那么使用Electric Fence吧。不过,请记住,Electric Fence只能检测两种错误类型,而此二者均非内存泄漏。还有就是,需要了解GDB基础以最大程序发挥这款内存调试工具的作用。
|
||||
如果改动程序源码非你所愿,那么使用 Electric Fence 吧。不过,请记住, Electric Fence 只能检测两种错误类型,而此二者均非内存泄漏。还有就是,需要了解 GDB 基础以最大化发挥这款内存调试工具的作用。
|
||||
|
||||
Memcheck可能是这当中综合性最好的了。相比这里所说其它工具,它检测更多的错误类型,提供更多的特性,而且不需要你的源码做任何改动。但请注意,基本功能并不难上手,但是想要使用它的高级特性,就必须学习相关的专业知识了。
|
||||
Memcheck 可能是其中综合性最好的了。相比这里提及的其它工具,它能检测更多的错误类型,提供更多的特性,而且不需要你的源码做任何改动。但请注意,基本功能并不难上手,但是想要使用它的高级特性,就必须学习相关的专业知识了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.computerworld.com/article/3003957/linux/review-5-memory-debuggers-for-linux-coding.html
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[译者ID](https://github.com/soooogreen)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[soooogreen](https://github.com/soooogreen)
|
||||
校对:[PurlingNayuki](https://github.com/PurlingNayuki)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -1,47 +0,0 @@
|
||||
translating by kylepeng93
|
||||
KDE,GNOME和XFCE的较量
|
||||
================================================================================
|
||||

|
||||
这么多年来,很多人一直都在他们的linux桌面端使用KDE或者GNOME桌面环境。这两个桌面环境经过多年的发展之后仍然在继续增加他们的用户基数。然而,在轻量级桌面环境下,XFCE一举成为了最受欢迎的桌面环境,相较于LXDE缺少的优美视觉效果,默认配置下的XFCE就可以在这方面打败前者。XFCE提供了用户能在GNOME2下使用的所有功能特性。但是,必须承认,在一些太老的计算机上,它的轻量级的特性并不能得到很好的效果。
|
||||
|
||||
### 桌面主题定制 ###
|
||||
用户完成安装之后,XFCE看起来可能会有一点无聊,因为它在视觉上还缺少一些吸引力。但是,请不要误解我的话,XFCE仍然拥有漂亮的桌面,可能看起来像是用户眼中的香草,正如大多数刚刚接触XFCE桌面环境的人。好消息是当我们给XFCE安装新的主题的时候,这会是一个十分容易的过程,因为你能够快速的找到你喜欢的XFCE主题,之后,你可以将它解压到一个合适的目录中。从这一点上来说,XFCE自带的一个重要的图形界面工具可以帮助用户更加容易的选中你已经选好的主题,这可能是目前在XFCE上最好用的工具了。如果用户按照上面的指示去做的话,对于任何想要尝试使用XFCE的用户来说将不存在任何困难。
|
||||
|
||||
在GNOME桌面上,用户也可以按照上面的方法去做。不过,其中最主要的不同点就是用户必须手动下载并安装GNOME Tweak Tool,这样才能继续你想做的事。当然,对于使用任何一种方式都不会有什么障碍,但是对于用户来说,使用XFCE安装和激活主题并不需要去额外的下载并安装任何tweak tool可能是他们无法忽略的一个优势。而在GNOME上,尤其是在用户已经下载并安装了GNOME Tweak tool之后,你仍将必须确保你已经安装了用户主题拓展。
|
||||
|
||||
在XFCE一样,用户将会去搜索并下载自己喜欢的主题,然后,用户可以重新使用GNOME Tweak tool,并点击该工具界面左边的Appearance按钮,接着用户便可以简单的通过点击相应的按钮并选择自己已经下载好的主题来使用自己的主题,当一切都完成之后,用户将会看到一个告诉用户已经成功应用了主题的对话框,这样,你的主题便已经安装完成。对于这一点,用户可以简单的使用滚动条来选择他们想要的主题。和XFCE一样,主题激活的过程也是十分简单的,然而,对于因为要使用一个新的主题而下载一个不被包含的应用的需求也是需要考虑的。
|
||||
|
||||
最后,就是KDE桌面主题定制的过程了。和XFCE一样,不需要去下载额外的工具来安装主题。从这点来看,让人有种XFCE必将使KDE成为最后的赢家的感觉。不仅在KDE上可以完全使用图形用户界面来安装主题,而且甚至只需要用户点击获取新主题的按钮就可以定位,查看,并且最后自动安装新的主题。
|
||||
|
||||
然而,我们不应该认为KDE相比XFCE是一个更加稳定的桌面环境。因此,现在正是我们思考为什么一些额外的功能可能会从桌面环境中移除来达到最小化的目的。为此,我们都必须为拥有这样出色的功能而给予KDE更多的支持。
|
||||
|
||||
### MATE不是一个轻量级的桌面环境 ###
|
||||
在继续比较XFCE,GNOME3和KDE之前,必须对这方面的老手作一个事先说明,我们不会将MATE桌面环境加入到我们的比较中。MATE可被认为是GNOME2的另一个衍生品,但是它并没有声称是作为一款轻量级或者快捷桌面。相反,它的主要目的是成为一款更加传统和舒适的桌面环境,并使它的用户感觉就像在家里使用它一样。
|
||||
|
||||
另一方面,XFCE生来就是要实现他自己的一系列使命。XFCE给它的用户提供一个更加轻量级的桌面环境,至今仍然有着吸引人的桌面视觉体验。然后,对于一些认为MATE也是一款轻量级的桌面环境的人来说,其实MATE真正的目标并不是成为一款轻量级的桌面环境。这两个选择在各自安装了一款好的主题之后看起来都会让人觉得非常具有吸引力。
|
||||
|
||||
### 桌面导航 ###
|
||||
XFCE在窗口之外提供了一个显眼的导航器。任何使用过传统的windows或者GNOME 2/MATE桌面环境的用户都可以在没有任何帮助的情况下自如的使用新安装的XFCE桌面环境的导航器。紧接着,添加小程序到面板中也是很明显的。和找到已经安装的应用程序一样,直接使用启动器并点击你想要运行的应用程序图标。除了LXDE和MATE之外,还没有其他的桌面的导航器可以做到如此简单。不仅如此,更加简单的是对控制面板的使用,对于刚刚使用这个新桌面的每个用户来说这是一个非常大的好处。如果用户更喜欢通过老式的方法去使用他们的桌面,对于GNOME来说,这不是一个问题。和没有最小化按钮形成的用户关注热点一样,加上其他应用布局方法,这将使新用户更加容易习惯这个风格设计。
|
||||
|
||||
如果用户来自windows桌面环境,那么这些用户将要放弃这些习惯,因为,他们将不能简单的通过鼠标右击一下就可以将一个小程序添加到他们的工作空间的顶部。与此相反,它可以通过使用拓展来实现。GNOME中的KDE拓展是可用的,并且是非常的容易,这些容易之处体现在只需要用户简单的使用位于GNOME拓展页面上的on/off开关。用户必须清楚,只能通过访问该页面才能使用这个功能。
|
||||
|
||||
另一方面,GNOME正在它的外观中体现它的设计理念,即为用户提供一个直观和易用的控制面板。你可能认为那并不是什么大事,但是,在我看来,它确实是我认为值得称赞并且有必要被提及的方面。KDE提供给它的用户大量传统的桌面使用体验,并通过提供相似的启动器和一种更加类似的获取软件的方式的能力来迎合来自windows的用户。添加小图标或者小程序到KDE桌面是件非常简单的事情,只需要在桌面的底部右击即可。只有在KDE的使用中才会存在的的问题,对于KDE用户寻找的很多KDE的特性实际上都是隐藏的。KDE的用户可能会指责这我的观点,但我仍然坚持我的说法。
|
||||
|
||||
为了增加小部件,仅仅在我的面板上右击就可以看见面板选项,但是并不是安装小部件的一个快速的方法。通常在你选择面板选项之前你都不会看到添加的小部件,然后,就添加小部件吧。这对我来说不是个问题,但是后来对于一些用户来说,它变成了不必要的困惑。而使事情变得更加复杂,用户管理定位部件区域后,他们后来发现一种称为“Activities”的品牌新术语。在同一地区的小部件,但它是在自己的领域是什么。
|
||||
|
||||
现在请不要误解我,KDE中的活动特性是很不错的,也是很有价值的,但是从可用性的角度看,为了不让新手感到困惑,它更加适合于应用在另一个目录选项。欢迎来自用户的分歧,,但为了测试这个新手对一些长时间的可以一遍又一遍的证明它是正确的。责骂放在一边,KDE添加新部件的方法的确很棒。与KDE的主题一样,用户不能通过使用提供的图形用户界面浏览和自动安装部件。这是一个神奇的功能,也可以是这样的方式去庆祝。KDE的控制面板可能和用户希望的样子不一样,它不是足够的简单。但是有一点很清楚,这将是他们致力于改进的地方。
|
||||
|
||||
### 因此,XFCE是最好的桌面环境,对吗? ###
|
||||
我在我的计算机上使用GNOME,KDE,并在我的办公室和家里的电脑上使用Xfce。我也有一些老机器在使用Openbox和LXDE。每一个使用桌面的经验都可以给我提供一些有用的东西,可以帮助我使用每台机器,因为我认为它是合适的。对我来说,在我的心里有一个柔软的地方,因为Xfce作为一个桌面环境,我坚持使用了很多年。但在这篇文章中,我只是在写我使用电脑的日常,事实上,它是GNOME。
|
||||
这篇文章的主要思想是我还是觉得Xfce能提供好一点的用户体验,对于那些正在寻找稳定的、传统的、容易理解的桌面环境的用户来说,XFCE是理想的。欢迎您在评论部分和我们分享你的意见。
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/kde-vs-gnome-vs-xfce-desktop/
|
||||
|
||||
作者:[M.el Khamlichi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/pirat9/
|
||||
@ -0,0 +1,82 @@
|
||||
”硅谷的女儿“的天才故事
|
||||
=======================================================
|
||||
|
||||

|
||||
|
||||
在 2014 年,为了对网上一些关于女性在科技行业的缺失的评论作出回应,我的同事 [Crystal Beasley][1] 建立了一个能让在科技/信息安全方面工作的女性在网络上分享自己的“天才之路”。这篇文章就是我的故事。我把我的故事与你们分享是因为我相信榜样的力量,我也相信有一个人有很多的方式进入一个让自己满意的有挑战性的工作和一个实现了所有目标的人生。
|
||||
|
||||
### 和电脑相伴的童年
|
||||
|
||||
我,在其他的光环之下,是硅谷的女儿。我的故事不是一个观众变成舞台的主角的故事。也不是从小就为这份事业做贡献的故事。这个故事更多的是关于环境如何塑造你 — 通过它的那种已然存在的文化来改变你,如果你想要被改变的话。这不是从小就看是努力并为一个明确的目标而奋斗的故事,我知道这是关于特权的故事。
|
||||
|
||||
我出生在曼哈顿,但是我在新泽西州长大,因为我的爸爸作为一个退伍军人在那里的罗格斯大学攻读计算机科学的博士学位。当我四岁时,学校里有人问我我的爸爸干什么谋生时,我说,“他就是看电视和捕捉小虫子,但是我从没有见过那些小虫子”(译者注:小虫子,bug)。他在家里有一台哑终端,这大概与他在博尔特-贝拉尼克-纽曼公司的工作有关,他会通过早期的互联网来进行它在人工智能方面的工作。我就在旁边看着。
|
||||
|
||||
我没能玩上父亲的会抓小虫子的电视,但是我很早就接触到了技术领域,我很珍惜这个礼物。提早的熏陶对于一个未来的天才是十分必要的 — 所以,请花时间和你的小孩谈谈他以后要做什么!
|
||||
|
||||

|
||||
|
||||
>我父亲的终端和这个很类似——如果不是这个的话 CC BY-SA 4.0
|
||||
|
||||
当我六岁时,我们搬到了加州。父亲在施乐的研究中心找到了一个工作。我记得那时我认为这个城市一定有很多熊,因为在它的旗帜上都有一个熊。在1979年,帕洛阿尔托还是一个大学城,还有果园和开阔地带。
|
||||
|
||||
在帕洛阿尔托的公立学校待了一年之后,我的姐姐和我被送到了“半岛学校”,这个“模范学校”对我造成了深刻的影响。在那里,好奇心和创新意识是被推崇的,教育也是有学生自己决定的。我们很少在学校看到能叫做电脑的东西,但是在家就不同了。
|
||||
|
||||
在父亲从施乐辞职之后,他就去了苹果,在那里他帮助研发——以及带回家让我玩的第一批电脑就是:Apple II 和 LISA。我的父亲在原先的 LISA 的研发团队。我直到现在还深刻的记得他让我们一次又一次的“玩鼠标”场景,因为他想让我的 3 岁大的妹妹对这个东西感到舒服——她也确实那样。
|
||||
|
||||

|
||||
|
||||
>我们的 LISA 看起来就像这样,看到鼠标了吗?CC BY-SA 4.0
|
||||
|
||||
在学校,我的数学的概念学得不错,但是基本计算却惨不忍睹。我的第一个学校的老师告诉我的家长,还有我,说我的数学很差以及我很“笨”。虽然我在“常规的”数学项目中表现出色,能理解一个 7 岁的孩子能理解的逻辑谜题,但是我不能完成我们每天早上都要做的“练习”。她说我傻,这事我不会忘记。在那之后的十年我都没能相信自己的逻辑能力和算法的水平。不要 低估你给孩子的说的话的力量。
|
||||
|
||||
在我玩了几年爸爸的电脑之后,他从苹果跳到了 EA 又跳到了 SGI,我又体验了他带回来的新玩意。这让我们认为我们家的房子是镇里最酷的,因为我们在车库里有一个能玩 Doom 的 SGI 的机器。我不会太多的编程,但是现在我发现,在那些年里我对尝试新的科技不再恐惧。同时,我的学文学和教育的母亲,成为了一个科技行业的作家,她向我证实了一个人的职业可以改变以及科技行业的人也可以做母亲。我不是说这对她来说很简单,但是她让我认为这件是看起来很简单。你可能回想这些早期的熏陶能把我带到科技行业,但是它没有。
|
||||
|
||||
### 本科时光
|
||||
|
||||
我想我要成为一个小学教师,我就读米尔斯学院就是想要做这个。但是后来我开始研究女性,后来有研究神学,我这样做仅仅是由于我自己的一个渴求:我希望能理解人类的意志以及为更好的世界而努力。
|
||||
|
||||
同时,我也感受到了互联网的巨大力量。在 1991 年,拥有你自己的 UNIX 的账户是很令人高兴的事,这件事值得你向全世界的人吹嘘。我仅仅从在互联网中“玩”就学到了不少,从那些愿意回答我提出的问题的人那里学到的就更多了。这些学习对我的职业生涯的影响不亚于我在学校教育部之中学到的知识。没有没有用的信息。我在一个女子学院度过了影响我一生的关键时期,然后那个女子学院的一个辉煌的女人跑进了计算机院,我不忍为这是一个事故。在那个老师的权力不算太大的学院,我们不止是被允许,甚至是被鼓励去尝试很多的道路(我们能接触到很多很多的科技,还能有聪明人来供我们求助),我也确实那样做了。我十分感激当年的教育。在那个学院,我也了解了什么是极客文化。
|
||||
|
||||
之后我去了研究生院去学习 女权主义神学,但是技术行业的气息已经渗入我的灵魂。当我知道我不能成为一个教授或者一个专家时,我离开了学术圈,带着债务和很多点子回到了家。
|
||||
|
||||
### 新的开端
|
||||
|
||||
在 1995 年,我被我看见的万维网连接 人们以及分享想法和信息的能力所震惊(直到现在仍是如此)。我想要进入这个行业。看起来我好像要“女承父业”,但是我不知道我会用什么方式来这样做。我开始在硅谷做临时工,在我在太阳微系统公司得到我的第一个“技术”职位前做一些事情(为数据写最基础的数据库,技术手册印发钱的事务,备份工资单的存跟)。这些事很让人激动。(毕竟,我们是“点 com”的那个”点“)。
|
||||
|
||||
在 Sun ,我努力学习,尽可能多的尝试我新事物。我的第一个工作是网页化(啥?这是一个单独的词汇)论文以及为测试中的 Solaris 修改一些基础的服务工具(大多数是Perl写的)。在那里最终在 Open Solaris 的测试版运行时我感受到了开源的力量。
|
||||
|
||||
在那里我学到了一个很重要的事情。我发现在同样重视工程和教育的地方有一种气氛,在那里我的问题不再显得“傻”。我很庆幸我选对了导师和朋友。在决定为第二个孩子的出生产假之前,我上每一堂我能上的课程,读每一本我能读的书,尝试自学我在学校没有学习过的技术,商业以及项目管理方面的技能。
|
||||
|
||||
### 重回工作
|
||||
|
||||
当我准备重新工作时,Sun 已经不是一个值得回去的地方。所以,我收集了很多人的信息(网络是你的朋友),利用我的沟通技能最终建立了一个互联网门户(2005 年时,一切皆门户),并且开始了解 CRM,发布产品的方式,本地化,网络等知识。我这么做是基于我过去的尝试以及失败的经历所得出的教训,也是这个教训让我成功。我也认为我们需要这个方面的榜样。
|
||||
|
||||
从很多方面来看,我的职业生涯的第一部分是 我的技术上的自我教育。这事发生的时间和地点都和现在不一样——我在帮助女性和其他弱势群体的组织工作,但是我之后成为一个技术行业的女性。当时我无疑,没有看到这个行业的缺陷,现在这个行业更加的厌恶女性,而不是更加喜欢她们。
|
||||
|
||||
在这些事情之后,我还没有把自己当作一个榜样,或者一个高级技术人员。当我的一个在父母的圈子里认识极客朋友鼓励我申请一个看起来定位十分模糊且技术性很强的开源的非盈利基础设施商店(互联网系统协会,BIND,一个广泛部署的开源服务器的开发商,13 台 DNS 根域名服务器之一的运营商)的项目经理时,我很震惊。有很长一段时间,我都不知道他们为什么要雇佣我!我对 DNS ,基础设备,以及协议的开发知之甚少,但是我再次遇到了老师,并再度开始飞速发展。我花时间旅行,在关键流程攻关,搞清楚如何与高度国际化的团队合作,解决麻烦的问题,最重要的是,拥抱支持我们的开源和充满活力的社区。我几乎重新学了一切,通过试错的方式。我学习如何构思一个产品。如何通过建设开源社区,领导那些有这特定才能,技能和耐心的人,是他们给了产品价值。
|
||||
|
||||
### 成为别人的导师
|
||||
|
||||
当我在 ISC 工作时,我通过 [TechWomen 项目][2] (一个让来自中东和北非的技术行业的女性带到硅谷来接受教育的计划),我开始喜欢教学生以及支持那些女性,特别是在开源行业中奋斗的。这也就是我开始相信自己的能力的开端。我还需要学很多。
|
||||
|
||||
当我第一次读 TechWomen 的广告时,我认为那些导师甚至都不会想要和我说话!我有冒名顶替综合征。当他们邀请我成为第一批导师(以及以后 6 年的导师)时,我很震惊,但是现在我学会了相信这些都是我努力得到的待遇。冒名顶替综合征是真实的,但是它能被时间冲淡。
|
||||
|
||||
### 现在
|
||||
|
||||
最后,我不得不离开我在 ISC 的工作。幸运的是,我的工作以及我的价值让我进入了 Mozilla ,在这里我的努力和我的幸运让我在这里有着重要的作用。现在,我是一名支持多样性的包容的高级项目经理。我致力于构建一个更多样化,更有包容性的 Mozilla ,站在之前的做同样事情的巨人的肩膀上,与最聪明友善的人们一起工作。我用我的激情来让人们找到贡献一个世界需要的互联网的有意义的方式:这让我兴奋了很久。我能看见,我做到了!
|
||||
|
||||
通过对组织和个人行为的干预来用一种新的方法来改变一种文化这件事情和我的人生有着十分奇怪的联系 —— 从我的早期的学术生涯,到职业生涯再到现在。每天都是一个新的挑战,我想我最喜欢的就是在科技行业的工作,尤其是在开放互联网的工作。互联网天然的多元性是它最开始吸引我的原因,也是我还在寻求的——一个所有人都有获取的资源可能性,无论背景如何。榜样,导师,资源,以及最重要的,对不断发展的技术和开源文化的尊重能实现我相信它能实现的事 —— 包括给任何的平等的接入权和机会。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/5/my-open-source-story-larissa-shapiro
|
||||
|
||||
作者:[Larissa Shapiro][a]
|
||||
译者:[name1e5s](https://github.com/name1e5s)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/larissa-shapiro
|
||||
[1]: http://skinnywhitegirl.com/blog/my-nerd-story/1101/
|
||||
[2]: https://www.techwomen.org/mentorship/why-i-keep-coming-back-to-mentor-with-techwomen
|
||||
@ -5,7 +5,7 @@ Linux 内核里的数据结构——双向链表
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
Linux 内核自己实现了双向链表,可以在[include/linux/list.h](https://github.com/torvalds/linux/blob/master/include/linux/list.h)找到定义。我们将会从双向链表数据结构开始`内核的数据结构`。为什么?因为它在内核里使用的很广泛,你只需要在[free-electrons.com](http://lxr.free-electrons.com/ident?i=list_head) 检索一下就知道了。
|
||||
Linux 内核自己实现了双向链表,可以在[include/linux/list.h](https://github.com/torvalds/linux/blob/master/include/linux/list.h)找到定义。我们将会从双向链表数据结构开始介绍`内核里的数据结构`。为什么?因为它在内核里使用的很广泛,你只需要在[free-electrons.com](http://lxr.free-electrons.com/ident?i=list_head) 检索一下就知道了。
|
||||
|
||||
首先让我们看一下在[include/linux/types.h](https://github.com/torvalds/linux/blob/master/include/linux/types.h) 里的主结构体:
|
||||
|
||||
@ -25,7 +25,7 @@ struct GList {
|
||||
};
|
||||
```
|
||||
|
||||
通常来说一个链表会包含一个指向某个项目的指针。但是内核的实现并没有这样做。所以问题来了:`链表在哪里保存数据呢?`。实际上内核里实现的链表实际上是`侵入式链表`。侵入式链表并不在节点内保存数据-节点仅仅包含指向前后节点的指针,然后把数据是附加到链表的。这就使得这个数据结构是通用的,使用起来就不需要考虑节点数据的类型了。
|
||||
通常来说一个链表结构会包含一个指向某个项目的指针。但是Linux内核中的链表实现并没有这样做。所以问题来了:`链表在哪里保存数据呢?`。实际上,内核里实现的链表是`侵入式链表`。侵入式链表并不在节点内保存数据-它的节点仅仅包含指向前后节点的指针,以及指向链表节点数据部分的指针——数据就是这样附加在链表上的。这就使得这个数据结构是通用的,使用起来就不需要考虑节点数据的类型了。
|
||||
|
||||
比如:
|
||||
|
||||
@ -36,7 +36,7 @@ struct nmi_desc {
|
||||
};
|
||||
```
|
||||
|
||||
让我们看几个例子来理解一下在内核里是如何使用`list_head` 的。如上所述,在内核里有实在很多不同的地方用到了链表。我们来看一个在杂项字符驱动里面的使用的例子。在 [drivers/char/misc.c](https://github.com/torvalds/linux/blob/master/drivers/char/misc.c) 的杂项字符驱动API 被用来编写处理小型硬件和虚拟设备的小驱动。这些驱动共享相同的主设备号:
|
||||
让我们看几个例子来理解一下在内核里是如何使用`list_head` 的。如上所述,在内核里有很多很多不同的地方都用到了链表。我们来看一个在杂项字符驱动里面的使用的例子。在 [drivers/char/misc.c](https://github.com/torvalds/linux/blob/master/drivers/char/misc.c) 的杂项字符驱动API 被用来编写处理小型硬件或虚拟设备的小驱动。这些驱动共享相同的主设备号:
|
||||
|
||||
```C
|
||||
#define MISC_MAJOR 10
|
||||
@ -84,7 +84,7 @@ struct miscdevice
|
||||
};
|
||||
```
|
||||
|
||||
可以看到结构体的第四个变量`list` 是所有注册过的设备的链表。在源代码文件的开始可以看到这个链表的定义:
|
||||
可以看到结构体`miscdevice`的第四个变量`list` 是所有注册过的设备的链表。在源代码文件的开始可以看到这个链表的定义:
|
||||
|
||||
```C
|
||||
static LIST_HEAD(misc_list);
|
||||
@ -103,7 +103,7 @@ static LIST_HEAD(misc_list);
|
||||
#define LIST_HEAD_INIT(name) { &(name), &(name) }
|
||||
```
|
||||
|
||||
现在来看看注册杂项设备的函数`misc_register`。它在开始就用 `INIT_LIST_HEAD` 初始化了`miscdevice->list`。
|
||||
现在来看看注册杂项设备的函数`misc_register`。它在开始就用函数 `INIT_LIST_HEAD` 初始化了`miscdevice->list`。
|
||||
|
||||
```C
|
||||
INIT_LIST_HEAD(&misc->list);
|
||||
@ -119,13 +119,13 @@ static inline void INIT_LIST_HEAD(struct list_head *list)
|
||||
}
|
||||
```
|
||||
|
||||
在函数`device_create` 创建了设备后我们就用下面的语句将设备添加到设备链表:
|
||||
接下来,在函数`device_create` 创建了设备后,我们就用下面的语句将设备添加到设备链表:
|
||||
|
||||
```
|
||||
list_add(&misc->list, &misc_list);
|
||||
```
|
||||
|
||||
内核文件`list.h` 提供了项链表添加新项的API 接口。我们来看看它的实现:
|
||||
内核文件`list.h` 提供了向链表添加新项的API 接口。我们来看看它的实现:
|
||||
|
||||
|
||||
```C
|
||||
@ -138,8 +138,8 @@ static inline void list_add(struct list_head *new, struct list_head *head)
|
||||
实际上就是使用3个指定的参数来调用了内部函数`__list_add`:
|
||||
|
||||
* new - 新项。
|
||||
* head - 新项将会被添加到`head`之前.
|
||||
* head->next - `head` 之后的项。
|
||||
* head - 新项将会插在`head`的后面
|
||||
* head->next - 插入前,`head` 后面的项。
|
||||
|
||||
`__list_add`的实现非常简单:
|
||||
|
||||
@ -155,9 +155,9 @@ static inline void __list_add(struct list_head *new,
|
||||
}
|
||||
```
|
||||
|
||||
我们会在`prev`和`next` 之间添加一个新项。所以我们用宏`LIST_HEAD_INIT`定义的`misc` 链表会包含指向`miscdevice->list` 的向前指针和向后指针。
|
||||
这里,我们在`prev`和`next` 之间添加了一个新项。所以我们开始时用宏`LIST_HEAD_INIT`定义的`misc` 链表会包含指向`miscdevice->list` 的向前指针和向后指针。
|
||||
|
||||
这里有一个问题:如何得到列表的内容呢?这里有一个特殊的宏:
|
||||
这儿还有一个问题:如何得到列表的内容呢?这里有一个特殊的宏:
|
||||
|
||||
```C
|
||||
#define list_entry(ptr, type, member) \
|
||||
@ -166,7 +166,7 @@ static inline void __list_add(struct list_head *new,
|
||||
|
||||
使用了三个参数:
|
||||
|
||||
* ptr - 指向链表头的指针;
|
||||
* ptr - 指向结构 `list_head` 的指针;
|
||||
* type - 结构体类型;
|
||||
* member - 在结构体内类型为`list_head` 的变量的名字;
|
||||
|
||||
@ -207,7 +207,7 @@ int main() {
|
||||
|
||||
最终会打印`2`
|
||||
|
||||
下一点就是`typeof`,它也很简单。就如你从名字所理解的,它仅仅返回了给定变量的类型。当我第一次看到宏`container_of`的实现时,让我觉得最奇怪的就是`container_of`中的0.实际上这个指针巧妙的计算了从结构体特定变量的偏移,这里的`0`刚好就是位宽里的零偏移。让我们看一个简单的例子:
|
||||
下一点就是`typeof`,它也很简单。就如你从名字所理解的,它仅仅返回了给定变量的类型。当我第一次看到宏`container_of`的实现时,让我觉得最奇怪的就是表达式`((type *)0)`中的0.实际上这个指针巧妙的计算了从结构体特定变量的偏移,这里的`0`刚好就是位宽里的零偏移。让我们看一个简单的例子:
|
||||
|
||||
```C
|
||||
#include <stdio.h>
|
||||
@ -226,13 +226,13 @@ int main() {
|
||||
|
||||
结果显示`0x5`。
|
||||
|
||||
下一个宏`offsetof` 会计算从结构体的某个变量的相对于结构体起始地址的偏移。它的实现和上面类似:
|
||||
下一个宏`offsetof`会计算从结构体起始地址到某个给定结构字段的偏移。它的实现和上面类似:
|
||||
|
||||
```C
|
||||
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)
|
||||
```
|
||||
|
||||
现在我们来总结一下宏`container_of`。只需要知道结构体里面类型为`list_head` 的变量的名字和结构体容器的类型,它可以通过结构体的变量`list_head`获得结构体的起始地址。在宏定义的第一行,声明了一个指向结构体成员变量`ptr`的指针`__mptr`,并且把`ptr` 的地址赋给它。现在`ptr` 和`__mptr` 指向了同一个地址。从技术上讲我们并不需要这一行,但是它可以方便的进行类型检查。第一行保证了特定的结构体(参数`type`)包含成员变量`member`。第二行代码会用宏`offsetof`计算成员变量相对于结构体起始地址的偏移,然后从结构体的地址减去这个偏移,最后就得到了结构体。
|
||||
现在我们来总结一下宏`container_of`。只需给定结构体中`list_head`类型 字段的地址、名字和结构体容器的类型,它就可以返回结构体的起始地址。在宏定义的第一行,声明了一个指向结构体成员变量`ptr`的指针`__mptr`,并且把`ptr` 的地址赋给它。现在`ptr` 和`__mptr` 指向了同一个地址。从技术上讲我们并不需要这一行,但是它可以方便地进行类型检查。第一行保证了特定的结构体(参数`type`)包含成员变量`member`。第二行代码会用宏`offsetof`计算成员变量相对于结构体起始地址的偏移,然后从结构体的地址减去这个偏移,最后就得到了结构体。
|
||||
|
||||
当然了`list_add` 和 `list_entry`不是`<linux/list.h>`提供的唯一功能。双向链表的实现还提供了如下API:
|
||||
|
||||
@ -253,6 +253,6 @@ int main() {
|
||||
via: https://github.com/0xAX/linux-insides/edit/master/DataStructures/dlist.md
|
||||
|
||||
译者:[Ezio](https://github.com/oska874)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[Mr小眼儿](https://github.com/tinyeyeser)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
15条给系统管理员的实用 Linux/Unix 磁带管理命令
|
||||
给系统管理员的15条实用 Linux/Unix 磁带管理命令
|
||||
================================================================================
|
||||
磁带设备应只用于定期的文件归档或将数据从一台服务器传送至另一台。通常磁带设备与 Unix 机器连接,用 mt 或 mtx 控制。你可以将所有的数据备份到磁盘(也许是云中)和磁带设备。在这个教程中你将会了解到:
|
||||
磁带设备应只用于定期的文件归档或将数据从一台服务器传送至另一台。通常磁带设备与 Unix 机器连接,用 mt 或 mtx 控制。强烈建议您将所有的数据同时备份到磁盘(也许是云中)和磁带设备中。在本教程中你将会了解到:
|
||||
|
||||
- 磁带设备名
|
||||
- 管理磁带驱动器的基本命令
|
||||
@ -8,12 +8,13 @@
|
||||
|
||||
### 为什么备份? ###
|
||||
|
||||
一个备份设备是很重要的:
|
||||
一个备份计划对定期备份文件来说很有必要,如果你宁愿选择不备份,那么丢失重要数据的风险会大大增加。有了备份,你就有了从磁盘故障中恢复的能力。备份还可以帮助你抵御:
|
||||
|
||||
- 从磁盘故障中恢复的能力
|
||||
- 意外的文件删除
|
||||
- 文件或文件系统损坏
|
||||
- 服务器完全毁坏,包括由于火灾或其他问题导致的同盘备份毁坏
|
||||
- 硬盘或SSD崩溃
|
||||
- 病毒或勒索软件破坏或删除文件
|
||||
|
||||
你可以使用磁带归档备份整个服务器并将其离线存储。
|
||||
|
||||
@ -23,7 +24,7 @@
|
||||
|
||||
图01:磁带文件标记
|
||||
|
||||
每个磁带设备能存储多个备份文件。磁带备份文件通过 cpio,tar,dd 等命令创建。但是,磁带设备可以由各种程序打开,写入数据,并关闭。你可以存储若干备份(磁带文件)到一个物理磁带上。在每个磁带文件之间有个“磁带文件标记”。这个是用来指示一个物理磁带上磁带文件的结尾以及另一个文件的开始。你需要使用 mt 命令来定位磁带(快进,倒带和标记)。
|
||||
每个磁带设备能存储多个备份文件。磁带备份文件通过 cpio,tar,dd 等命令创建。同时,磁带设备可以由多种程序打开、写入数据、及关闭。你可以存储若干备份(磁带文件)到一个物理磁带上。在每个磁带文件之间有个“磁带文件标记”。这用来指示一个物理磁带上磁带文件的结尾以及另一个文件的开始。你需要使用 mt 命令来定位磁带(快进,倒带和标记)。
|
||||
|
||||
#### 磁带上的数据是如何存储的 ####
|
||||
|
||||
@ -87,7 +88,7 @@
|
||||
|
||||
图03:Linux 服务器上已安装的磁带设备
|
||||
|
||||
### mt 命令实例 ###
|
||||
### mt 命令示例 ###
|
||||
|
||||
在 Linux 和类Unix系统上,mt 命令用来控制磁带驱动器的操作,比如查看状态或查找磁带上的文件或写入磁带控制标记。下列大多数命令需要作为 root 用户执行。语法如下:
|
||||
|
||||
@ -111,7 +112,7 @@
|
||||
mt -f /dev/nsa0 status #FreeBSD
|
||||
mt -f /dev/rmt/1 status #Unix unity 1 也就是 tape device no. 1
|
||||
|
||||
你可以像下面一样使用 shell 循环调查系统并定位所有的磁带驱动器:
|
||||
你可以像下面一样使用 shell 循环语句遍历一个系统并定位其所有的磁带驱动器:
|
||||
|
||||
for d in 0 1 2 3 4 5
|
||||
do
|
||||
@ -133,7 +134,7 @@
|
||||
mt -f /dev/mt/0 off
|
||||
mt -f /dev/st0 eject
|
||||
|
||||
### 4:擦除磁带(倒带,在可以的情况下卸载磁带) ###
|
||||
### 4:擦除磁带(倒带,在支持的情况下卸载磁带) ###
|
||||
|
||||
mt erase
|
||||
mt -f /dev/st0 erase #Linux
|
||||
@ -179,7 +180,7 @@
|
||||
|
||||
bsfm 后退指定的文件标记数目。磁带定位在下一个文件的第一块。
|
||||
|
||||
asf The tape is positioned at the beginning of the count file. Positioning is done by first rewinding the tape and then spacing forward over count filemarks.磁带定位在
|
||||
asf 磁带定位在指定文件标记数目的开始位置。定位通过先倒带,再前进指定的文件标记数目来实现。
|
||||
|
||||
fsr 前进指定的记录数。
|
||||
|
||||
@ -413,7 +414,7 @@ via: http://www.cyberciti.biz/hardware/unix-linux-basic-tape-management-commands
|
||||
|
||||
作者:Vivek Gite
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[Mr小眼儿](https://github.com/tinyeyeser)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -1,28 +1,28 @@
|
||||
装好 openSUSE Leap 42.1 之后要做的 8 件事
|
||||
安装 openSUSE Leap 42.1 之后要做的 8 件事
|
||||
================================================================================
|
||||

|
||||
致谢:[Metropolitan Transportation/Flicrk][1]
|
||||
|
||||
> 你已经在你的电脑上安装了 openSUSE。这是你接下来要做的。
|
||||
> 你已经在你的电脑上安装了 openSUSE,这是你接下来要做的。
|
||||
|
||||
[openSUSE Leap 确实是个巨大的飞跃][2],它允许用户运行一个和 SUSE Linux 企业版拥有一样基因的发行版。和其它系统一样,在使用它之前需要做些优化设置。
|
||||
[openSUSE Leap 确实是个巨大的飞跃][2],它允许用户运行一个和 SUSE Linux 企业版拥有一样基因的发行版。和其它系统一样,为了实现最佳的使用效果,在使用它之前需要做些优化设置。
|
||||
|
||||
下面是一些我在安装 openSUSE 到我的电脑上之后做的一些事情(不适用于服务器)。这里面没有强制性要求的设置,基本安装对来说你也可能足够了。但如果你想获得更好的 openSUSE Leap 体验,那就跟着我往下看吧。
|
||||
下面是一些我在我的电脑上安装 openSUSE Leap 之后做的一些事情(不适用于服务器)。这里面没有强制性要求的设置,基本安装对你来说也可能足够了。但如果你想获得更好的 openSUSE Leap 体验,那就跟着我往下看吧。
|
||||
|
||||
### 1. 添加 Packman 仓库 ###
|
||||
|
||||
由于专利和授权等原因,openSUSE 和许多 Linux 发行版一样,不通过官方仓库(repos)提供一些软件,解码器,以及驱动等。取而代之的是通过第三方或社区仓库来提供。第一个也是最重要的仓库是“Packman”。因为这些仓库不是默认启用的,我们需要添加它们。你可以通过 YaST (openSUSE 的特色之一)或者命令行完成(如下方介绍)。
|
||||
由于专利和授权等原因,openSUSE 和许多 Linux 发行版一样,不通过官方仓库(repos)提供一些软件、解码器,以及驱动等。取而代之的是通过第三方或社区仓库来提供。第一个也是最重要的仓库是“Packman”。因为这些仓库不是默认启用的,我们需要添加它们。你可以通过 YaST(openSUSE 的特色之一)或者命令行完成(如下方介绍)。
|
||||
|
||||
|
||||
添加 Packman 仓库。
|
||||
|
||||
使用 YsST,打开软件源部分。点击“添加”按钮并选择“社区仓库(Community Repositories)”。点击“下一步”。一旦仓库列表加载出来了,选择 Packman 仓库。点击“确认”,然后点击“信任”导入信任的 GnuPG 密钥。
|
||||
使用 YaST,打开软件源部分。点击“添加”按钮并选择“社区仓库(Community Repositories)”。点击“下一步”。一旦仓库列表加载出来了,选择 Packman 仓库。点击“确认”,然后点击“信任”导入信任的 GnuPG 密钥。
|
||||
|
||||
或者在终端里使用以下命令添加并启用 Packman 仓库:
|
||||
|
||||
zypper ar -f -n packmanhttp://ftp.gwdg.de/pub/linux/misc/packman/suse/openSUSE_Leap_42.1/ packman
|
||||
|
||||
仓库添加之后,你就能接触到更多的包了。想安装任意软件或包,打开 YaST 软件管理器,搜索并安装即可。
|
||||
仓库添加之后,你就可以使用更多的包了。想安装任意软件或包,打开 YaST 软件管理器,搜索并安装即可。
|
||||
|
||||
### 2. 安装 VLC ###
|
||||
|
||||
@ -34,7 +34,7 @@ VLC 是媒体播放器里的瑞士军刀,几乎可以播放任何媒体文件
|
||||
|
||||
### 3. 安装 Handbrake ###
|
||||
|
||||
如果你需要转码或转换视频文件格式,[Handbrake 是你的不二之选][3]。Handbrake 就在我们启用的仓库中,所以只要在 YaST 中搜索并安装它。
|
||||
如果你需要转码或转换视频文件格式,[Handbrake 是你的不二之选][3]。Handbrake 就在我们启用的仓库中,所以只需要在 YaST 中搜索并安装它即可。
|
||||
|
||||
如果你用终端,运行以下命令:
|
||||
|
||||
@ -44,7 +44,7 @@ VLC 是媒体播放器里的瑞士军刀,几乎可以播放任何媒体文件
|
||||
|
||||
### 4. 安装 Chrome ###
|
||||
|
||||
openSUSE 的默认浏览器是 Firefox。但是因为 Firefox 不能胜任播放专有媒体,比如 Netflix,我推荐安装 Chrome。这需要额外的工作。首先你需要从谷歌导入信任密钥。打开终端执行“wget”命令下载密钥:
|
||||
openSUSE 的默认浏览器是 Firefox。但是因为 Firefox 不能够播放专有媒体,比如 Netflix,我推荐安装 Chrome。这需要额外的工作。首先你需要从谷歌导入信任密钥。打开终端执行“wget”命令下载密钥:
|
||||
|
||||
wget https://dl.google.com/linux/linux_signing_key.pub
|
||||
|
||||
@ -72,11 +72,11 @@ openSUSE 的默认浏览器是 Firefox。但是因为 Firefox 不能胜任播放
|
||||
|
||||
### 6. 安装媒体解码器 ###
|
||||
|
||||
你安装 VLC 之后就不需要安装媒体解码器了,但如果你要使用其它软件来播放媒体的话就需要安装了。一些开发者写了脚本/工具来简化这个过程。打开[这个页面][5]并点击合适的按钮安装完整的包。他会打开 YaST 并自动安装包(当然通常你还需要提供 root 权限密码并信任 GnuPG 密钥)。
|
||||
你安装 VLC 之后就不需要安装媒体解码器了,但如果你要使用其它软件来播放媒体的话就需要安装了。一些开发者写了脚本/工具来简化这个过程。打开[这个页面][5]并点击合适的按钮安装完整的包。它会打开 YaST 并自动安装包(当然通常你还需要提供 root 权限密码并信任 GnuPG 密钥)。
|
||||
|
||||
### 7. 安装你偏好的电子邮件客户端 ###
|
||||
### 7. 安装你喜欢的电子邮件客户端 ###
|
||||
|
||||
openSUSE 自带 Kmail 或 Evolution,这取决于你安装的桌面环境。我用的是 Plasma,自带 Kmail,这个邮件客户端还有许多地方有待改进。我建议可以试试 Thunderbird 或 Evolution。所有主要的邮件客户端都能在官方仓库找到。你还可以看看我的[精心挑选的 Linux 最佳邮件客户端][7]。
|
||||
openSUSE 自带 Kmail 或 Evolution,这取决于你安装的桌面环境。我用的是 Plasma,自带 Kmail,这个邮件客户端还有许多地方有待改进。我建议可以试试 Thunderbird 或 Evolution。所有主要的邮件客户端都能在官方仓库找到。你还可以看看我[精心挑选的 Linux 最佳邮件客户端][7]。
|
||||
|
||||
### 8. 在防火墙允许 Samba 服务 ###
|
||||
|
||||
@ -85,7 +85,7 @@ openSUSE 自带 Kmail 或 Evolution,这取决于你安装的桌面环境。我
|
||||
|
||||
在防火墙设置里允许 Samba 客户端和服务端
|
||||
|
||||
打开 YaST 并搜索 Firewall。在防火墙设置里,到“允许的服务”那里你会在“要允许的服务”下面看到一个下拉列表。选择“Samba 客户端”,然后点击“添加”。对“Samba 服务端”也一样地添加。都添加了之后,点击“下一步”,然后点击“完成”,现在你就可以通过本地网络从你的 openSUSE 分享文件以及访问其它机器了。
|
||||
打开 YaST 并搜索 Firewall。在防火墙设置里,进入到“允许的服务(Allowed Services)”,你会在“要允许的服务(Service to allow)”下面看到一个下拉列表。选择“Samba 客户端”,然后点击“添加”。同样方法添加“Samba 服务器”。都添加了之后,点击“下一步”,然后点击“完成”,现在你就可以通过本地网络从你的 openSUSE 分享文件以及访问其它机器了。
|
||||
|
||||
这差不多就是我以我喜欢的方式对我的新 openSUSE 系统做的所有设置了。如果你有任何问题,欢迎在评论区提问。
|
||||
|
||||
@ -95,7 +95,7 @@ via: http://www.itworld.com/article/3003865/open-source-tools/8-things-to-do-aft
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -0,0 +1,91 @@
|
||||
5 个很适合在课堂上演示的树莓派项目
|
||||
=====================================================
|
||||
|
||||

|
||||
|
||||
### 1. 我的世界: Pi
|
||||
|
||||
|
||||
>源于 Raspberry Pi 基金会. [CC BY-SA 4.0][1].
|
||||
|
||||
我的世界是世界上几乎每一个青少年都特别喜欢的一款游戏,而且它成功抓住了年轻人眼球,成为目前最能激发年轻人创造力的游戏之一。这个树莓派版本自带的我的世界不仅仅是一个具有创造性的建筑游戏,还是一个具有编程接口,可以通过 Python 与之交互的版本。
|
||||
|
||||
我的世界:Pi 版对于老师来说是一个教授学生解决问题和编写代码完成任务的好方式。你可以使用 Python API 创建一个房子,并且一直跟随这你的脚步移动,在所到之处建造一座桥,让天空落下熔岩雨滴,在空中显示温度,以及其它你可以想象到的一切东西。
|
||||
|
||||
详情请见 "[Getting Started with Minecraft Pi][2]."
|
||||
|
||||
### 2. 反应游戏和交通灯
|
||||
|
||||

|
||||
>源于 [Low Voltage Labs][3]. [CC BY-SA 4.0][1].
|
||||
|
||||
使用树莓派可以很轻松地进行物理计算,只需要连接几个 LED 和按钮到开发板上的 GPIO 接口,再用几行代码你就可以按下按钮来开灯。一旦你了解了如何使用代码来完成这些基本的操作,接下来就可以根据你的想象来做其它事情了。
|
||||
|
||||
如果你知道如何让一个灯闪烁,你就可以控制三个灯闪烁。挑选三个和交通灯一样颜色的 LED 灯,然后编写控制交通灯的代码。如果你知道如何使用按钮触发事件,那么你就可以模拟一个行人过马路。同时你可以参考其它已经完成的交通灯附件,比如[PI-TRAFFIC][4], [PI-STOP][5], [Traffic HAT][6],等等。
|
||||
|
||||
代码并不是全部——这只是一个演练,让你理解现实世界里系统是如何完成设计的。计算思维是一个让你终身受用的技能。
|
||||
|
||||

|
||||
>源于 Raspberry Pi 基金会. [CC BY-SA 4.0][1].
|
||||
|
||||
接下来试着接通两个按钮和 LED 灯的电源,实现一个双玩家的反应游戏 —— 让 LED 灯随机时间点亮,然后看是谁抢先按下按钮。
|
||||
|
||||
要想了解更多可以看看 [GPIO Zero recipes][7]。你所需要的资料都可以在 [CamJam EduKit 1][8] 找到。
|
||||
|
||||
### 3. Sense HAT 电子宠物
|
||||
|
||||
Astro Pi —— 一个增强版的树莓派 —— 将在 12 月问世,但是你并没有错过亲手把玩这个硬件的机会。Sense HAT 是使用在 Astro Pi 的一个传感器扩展板,现在已经开放购买了。你可以使用它来进行数据搜集、科学实验,游戏等等。可以看看下面树莓派的 Carrie Anne 拍摄的 Gurl Geek Diaries 的视频,里面演示了一种很棒的入门途径——在 Sense HAT 屏幕上自己设计一个生动的像素宠物:
|
||||
|
||||
[video](https://youtu.be/gfRDFvEVz-w)
|
||||
|
||||
>详见 "[探索 Sense HAT][9]."
|
||||
|
||||
### 4. 红外鸟笼
|
||||
|
||||

|
||||
>源于 Raspberry Pi 基金会. [CC BY-SA 4.0][1].
|
||||
|
||||
让整个班级都可以参与进来的好主意是在鸟笼里放置一个树莓派和夜视镜头,以及一些红外线灯,这样子你就可以在黑暗中看见鸟笼里的情况了,然后使用树莓派通过网络串流视频。然后就可以等待小鸟归笼了,你可以在不打扰的情况下近距离观察小窝里的它们了。
|
||||
|
||||
要了解更多有关红外线和光谱的知识,以及如何校准摄像头焦点和使用软件控制摄像头,可以访问 [Make an infrared bird box][10]。
|
||||
|
||||
|
||||
|
||||
### 5. 机器人
|
||||
|
||||

|
||||
>源于 Raspberry Pi 基金会. [CC BY-SA 4.0][1].
|
||||
|
||||
只需要一个树莓派、很少的几个电机和电机控制器,你就可以自己动手制作一个机器人。可以制作的机器人有很多种,从简单的由几个轮子和自制底盘拼凑的简单小车,到由游戏控制器驱动、具有自我意识、配备了传感器,安装了摄像头的金属种马。
|
||||
|
||||
要学习如何控制不同的电机,可以使用 RTK 电机驱动开发板入门或者使用配置了电机、轮子和传感器的 CamJam 机器人开发套件——具有很大的价值和大量的学习潜力。
|
||||
|
||||
或者,如果你还想了解更多核心内容,可以试试 PiBorg 的 [4Borg][11](£99/$150)和 [DiddyBorg][12](£180/$273),或者购买 Metal 版 DoodleBorg (£250/$380),然后构建一个最小版本的 [DoodleBorg tank][13](非卖品)。
|
||||
|
||||
详情可见 [机器人装备表][14]。
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/education/15/12/5-great-raspberry-pi-projects-classroom
|
||||
|
||||
作者:[Ben Nuttall][a]
|
||||
译者:[ezio](https://github.com/oska874)
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/bennuttall
|
||||
[1]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[2]: https://opensource.com/life/15/5/getting-started-minecraft-pi
|
||||
[3]: http://lowvoltagelabs.com/
|
||||
[4]: http://lowvoltagelabs.com/products/pi-traffic/
|
||||
[5]: http://4tronix.co.uk/store/index.php?rt=product/product&product_id=390
|
||||
[6]: https://ryanteck.uk/hats/1-traffichat-0635648607122.html
|
||||
[7]: http://pythonhosted.org/gpiozero/recipes/
|
||||
[8]: http://camjam.me/?page_id=236
|
||||
[9]: https://opensource.com/life/15/10/exploring-raspberry-pi-sense-hat
|
||||
[10]: https://www.raspberrypi.org/learning/infrared-bird-box/
|
||||
[11]: https://www.piborg.org/4borg
|
||||
[12]: https://www.piborg.org/diddyborg
|
||||
[13]: https://www.piborg.org/doodleborg
|
||||
[14]: http://camjam.me/?page_id=1035#worksheets
|
||||
@ -0,0 +1,67 @@
|
||||
七步开始你的 Linux 系统管理员生涯
|
||||
===============================================
|
||||
|
||||
|
||||
Linux 现在是个大热门。每个人都在寻求 Linux 才能。招聘人员对有 Linux 经验的人求贤若渴,还有无数的职位虚位以待。但是如果你是 Linux 新手,又想要赶上这波热潮,该从何开始下手呢?
|
||||
|
||||
1. 安装 Linux
|
||||
|
||||
这应该是不言而喻的,但学习 Linux 的第一关键就是安装 Linux。LFS101x 和 LFS201 课程都包含第一次安装和配置 Linux 的详细内容。
|
||||
|
||||
2. 完成 LFS101x 课程
|
||||
|
||||
如果你是 Linux 完完全全的新手,最佳的起点是免费的 Linux 课程 [LFS101x Introduction](https://www.edx.org/course/introduction-linux-linuxfoundationx-lfs101x-2)。这个在线课程在 edX.org,探索 Linux 系统管理员和终端用户常用的各种工具和技能以及日常 Linux 工作环境。该课程是为有一定经验但较少或没有接触过 Linux 的电脑用户设计的,不论他们是在个人还是企业环境中工作。这个课程会从图形界面和命令行教会你有用的 Linux 知识,让你能够了解主流的 Linux 发行版。
|
||||
|
||||
3. 看看 LFS201 课程
|
||||
|
||||
在你完成 LFS101x 之后,你就准备好开始进入 Linux 更加复杂的任务了,这是成为一名专业的系统管理员所必须的。为了掌握这些技能,你应该看看 [LFS201 Essentials of Linux System Administration](http://training.linuxfoundation.org/linux-courses/system-administration-training/essentials-of-system-administration) 这个课程。该课程对每个话题进行了深度的解释和介绍,还有大量的练习和实验,帮助你获得相关主题实际的上手经验。
|
||||
|
||||
如果你更愿意有个教练或者你的雇主对将你培养成 Linux 系统管理员有兴趣,你可能会对 LFS220 Linux System Administration 有兴趣。这个课程有 LFS201 中所有的主题,但是它是由专家专人教授的,帮助你进行实验以及解答你在课程主题中的问题。
|
||||
|
||||
4. 练习!
|
||||
|
||||
熟能生巧,和对任何乐器或运动适用一样,这对 Linux 来说也一样适用。在你安装 Linux 之后,经常使用它。一遍遍地练习关键任务,直到你不需要参考材料也能轻而易举地完成。练习命令行和图形界面的输入输出。这些练习能够保证你掌握成为成功的 Linux 系统管理员所必需的知识和技能。
|
||||
|
||||
5. 获得认证
|
||||
|
||||
在你完成 LFS201 或 LFS220 并且充分练习之后,你现在已经准备好获得系统管理员的认证了。你需要这个证书,因为你需要向雇主证明你拥有一名专业 Linux 系统管理员必需的技能。
|
||||
|
||||
现在有一些不同的 Linux 证书,它们有它们的独到之处。但是,它们里大部分不是在特定发行版(如红帽)上认证,就是纯粹的知识测试,没有演示 Linux 的实际技能。Linux 基金会认证系统管理员(Linux Foundation Certified System Administrator)证书对想要一个灵活的,有意义的初级证书的人来说是个优秀的替代。
|
||||
|
||||
6. 参与进来
|
||||
|
||||
如果你所在的地方有本地 Linux 用户组(Linux Users Group,LUG)的话,这时候你可能还想要考虑加入他们。这些组织通常由各种年龄和经验水平的人组成,所以不管你的 Linux 经验水平如何,你都能找到和你类似技能水平的人互助,或是更高水平的 Linux 用户来解答你的问题以及介绍有用的资源。要想知道你附近有没有 LUG,上 meet.com 看看,或是附近的大学,又或是上网搜索一下。
|
||||
|
||||
还有不少在线社区可以在你学习 Linux 的时候帮助你。这些站点和社区向 Linux 新手和有经验的管理员都能够提供帮助和支持:
|
||||
|
||||
- [Linux Admin subreddit](https://www.reddit.com/r/linuxadmin)
|
||||
|
||||
- [Linux.com](http://www.linux.com/)
|
||||
|
||||
- [training.linuxfoundation.org](http://training.linuxfoundation.org/)
|
||||
|
||||
- [http://community.ubuntu.com/help-information/](http://community.ubuntu.com/help-information/)
|
||||
|
||||
- [https://forums.opensuse.org/forum.php](https://forums.opensuse.org/forum.php)
|
||||
|
||||
- [http://wiki.centos.org/Documentation](http://wiki.centos.org/Documentation)
|
||||
|
||||
7. 学会热爱文档
|
||||
|
||||
最后但同样重要的是,如果你困在 Linux 的某些地方,别忘了 Linux 包含的文档。使用命令 man(manual,手册),info 和 help,你从系统内就可以找到 Linux 几乎所有方面的信息。这些内置资源的用处再夸大也不为过,你会发现你在生涯中始终会用到,所以你可能最好早点掌握使用它们。
|
||||
|
||||
想要了解更多开始你 Linux IT 生涯的信息?查看我们免费的电子书“[开始你 Linux IT 生涯的简短指南](http://training.linuxfoundation.org/sysadmin-it-career-guide)”。
|
||||
|
||||
[立刻下载](http://training.linuxfoundation.org/sysadmin-it-career-guide)
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linux.com/news/featured-blogs/191-linux-training/834644-7-steps-to-start-your-linux-sysadmin-career
|
||||
|
||||
作者:[linux.com][a]
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:linux.com
|
||||
@ -0,0 +1,76 @@
|
||||
混合云计算的9大关键趋势
|
||||
========================================
|
||||
|
||||
自从几年前云计算的概念受到IT界的关注以来,公有云、私有云和混合云这三种云计算方式都有了可观的演进。其中混合云计算方式是最热门的云计算方式,在接受调查的公司中,有[88%的公司](https://www.greenhousedata.com/blog/hybrid-continues-to-be-most-popular-cloud-option-adoption-accelerating)将混合云计算摆在至关重要的地位。
|
||||
|
||||
混合云计算的疾速演进意味着一两年前的传统观念已经过时了。为此,我们询问了几个行业分析师,混合云在2016年的走势将会如何,我们得到了几个比较有意思的答案。
|
||||
|
||||
1. **2016年可能是我们将混合云投入使用的一年。**
|
||||
|
||||
混合云从本质上来说依赖于私有云,这对企业来说是比较难实现的。事实上,亚马逊,谷歌和微软的公有云已经进行了大量的投资,并且起步也比较早。私有云拖了混合云发展和使用的后腿。
|
||||
|
||||
私有云没有得到这么多的投资,这是有私有云的性质决定的。私有云意味着维护和投资你自己的数据中心。许多公有云提供商正在推动企业减少或者消除他们的数据中心。
|
||||
|
||||
然而,得益于OpenStack的发展和微软的 Azure Stack ,这两者基本上就是封装在一个盒子里的私有云,我们将会看到私有云慢慢追上公有云的发展步伐。支持混合云的工具、基础设施和架构也变得更加健壮。
|
||||
|
||||
|
||||
2. **容器,微服务和unikernels将会促进混合云的发展。**
|
||||
|
||||
分析师预言,到2016年底,这些原生云技术会或多或少成为主流的。这些云技术正在快速成熟,将会成为虚拟机的一个替代品,而虚拟机需要更多的资源。
|
||||
|
||||
更重要的是,他们既能工作在在线场景,也能工作在离线场景。容器化和编排允许快速的扩大规模,进行公有云和私有云之间的服务迁移,使你能够更容易移动你的服务。
|
||||
|
||||
3. **数据和相关性占据核心舞台。**
|
||||
|
||||
所有的云计算方式都处在发展模式。这使得云计算变成了一个技术类的故事。咨询公司[Avoa](http://avoa.com/2016/01/01/2016-is-the-year-of-data-and-relevance/)称,随着云趋于成熟,数据和相关性变得越来越重要。起初,云计算和大数据都是关于怎么吸收尽可能多的数据,然后他们担心如何处理这海量的数据。
|
||||
|
||||
2016年,相关组织将会继续锤炼如何进行数据收集和使用的相关技术。在必须处理的技术和文化方面仍然有待提高。但是2016年应该重新将关注点放在从各个方面考虑的数据重要性上,发现最相关的信息,而不只是数据的数量。
|
||||
|
||||
4. **云服务将超越按需工作负载。**
|
||||
|
||||
AWS(Amazon Web Services)起初是提供给程序员或者是开发人员能够快速启动虚拟机,做一些工作然后离线的一个地方。这就是按需使用的本质。要让这些服务持续运行,几乎需要全天候工作。
|
||||
|
||||
然而,IT组织正开始作为服务代理,为内部用户提供各种IT服务。可以是内部IT服务,公有云基础架构提供商,平台服务和软件服务。
|
||||
|
||||
他们将越来越多的认识到想云管理平台这样的工具的价值。云管理平台可以提供针对不同服务的基于策略的一致性管理。他们也将看到像提高可移植性的容器等技术的价值。然而,云服务代理,在不同云之间快速移动的工作负载进行价格套利或者相关原因的意义上来讲,仍然是行不通的。
|
||||
|
||||
5. **服务提供商转变成了云服务提供商。**
|
||||
|
||||
到目前为止,购买云服务成了直销模式。AWS EC2 服务的使用者通常变成了购买者,通过官方认证渠道或者通过影子IT。但是随着云服务越来越全面,提供的服务菜单越来越复杂,越来越多的人转向了经销商,服务提供商转变成了他们IT服务的购买者。
|
||||
|
||||
2nd Watch (2nd Watch是为企业提供云管理的 AWS 的首选合作伙伴)最近的一项调查发现,在美国将近85%的IT高管愿意支付一个小的溢价从渠道商那里购买公有云服务,如果购买过程变得不再那么复杂。根据调查,这85%的高管有五分之四的愿意支付额外的15%或者更多。三分之一的受访高管表示,他们可以使用帮助来购买、使用和管理公有云服务。
|
||||
|
||||
6. **物联网和云对于2016年的意义好比移动和云对2012年的意义。**
|
||||
|
||||
物联网获得了广泛的关注,更重要的是,物联网已经从测试场景进行了实际应用。云的分布式特性使得云成为了物联网非常重要的一部分,对于工业物联网,与后端系统交互的机械和重型设备,混合云将会成为最自然的驱动者,连接,数据采集和处理将会发生在混合云环境中,这得益于私有云在安全和隐私方面的好处。
|
||||
|
||||
7. **NIST 对云的定义开始瓦解。**
|
||||
|
||||
2011年,美国国家标准与技术研究院发布了“[ NIST 对于云计算的定义](http://csrc.nist.gov/publications/nistpubs/800-145/SP800-145.pdf)”(PDF),这个定义成为了私有云、公有云、混合云和 aas模板的标准定义。
|
||||
|
||||
然而随着时间的推移,定义开始改变。Iaas变得更加复杂,开始支持OpenStack,[Swift](https://wiki.openstack.org/wiki/Swift) 对象存储和神经网络这样的项目。Paas似乎正在消退,因为Paas和传统的中间件开发几乎无异。Saas,只是通过浏览器进行访问的应用,也正在失去发展动力,因为许多app和服务提供了许多云接口,你可以通过各种手段调用接口,不仅仅通过浏览器。
|
||||
|
||||
8. **分析变得更加重要**
|
||||
|
||||
对于混合云计算来说,分析将会成为一个巨大的增长机遇,云计算具有规模大、灵活性高的优势,使得云计算非常适合需要海量数据的分析工作。对于某些分析方式,比如高度敏感的数据,私有云仍然是主导地位但是私有云也是混合云的一部分。因此,无论如何,混合云计算胜出。
|
||||
|
||||
9. **安全仍然是一个非常紧迫的问题。**
|
||||
|
||||
随着混合云计算在2016年的发展,以及对物联网和容器等新技术的引进,这同时也增加了更多的脆弱可攻破的地方从而导致数据泄露。先增加使用新技术的趋势,然后再去考虑安全性,这种问题经常发生,同时还有缺少经验的工程师不去考虑系统的安全问题,总有一天你会尝到灾难的后果的。
|
||||
|
||||
当一项新技术出来,管理规范总是落后于安全问题产生后,然后我们才考虑去保护技术。容器就是一个很鲜明的例子。你可以从Docker下周各种示例容器,但是你知道你下载的东西来自哪里么?在人们在对容器内容不知情的情况下下载并运行了容器之后,Docker不得不重新加上安全验证。
|
||||
|
||||
像Path和Snapchat这样的移动技术在智能手机市场火起来之后也出现了重大的安全问题。一项新技术被恶意利用无可避免。所以安全研究人员需要通过各种手段来保证新技术的安全性。很有可能在部署之后才会发现安全问题。
|
||||
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.datamation.com/cloud-computing/9-key-trends-in-hybrid-cloud-computing.html
|
||||
|
||||
作者:[Andy Patrizio][a]
|
||||
译者:[棣琦](https://github.com/sonofelice)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.datamation.com/author/Andy-Patrizio-90720.html
|
||||
@ -1,215 +0,0 @@
|
||||
用Python打造你的Eclipse
|
||||
==============================================
|
||||
|
||||

|
||||
|
||||
Eclipse高级脚本环境([EASE][1])项目虽然还在开发中,但是不是不得承认它非常强大,让我们可以快速打造自己的Eclipse开发环境.
|
||||
|
||||
依据Eclipse强大的框架,可以通过其内建的插件系统全方面的扩展Eclipse.然而,编写和部署一个新的插件还是十分笨重,即使只是需要一个额外的小功能。但是,现在依托EASE,可以方便实用Python或者Javascript脚本语言来扩展。
|
||||
|
||||
本文中,根据我在今年北美的EclipseCon大会上的[演讲][2],我介绍包括安装Eclipse的Python和EASE环境,并包括使用强力Python来增压你的IDE。
|
||||
|
||||
### 安装并运行 "Hello World"
|
||||
|
||||
本文中的例子使用Java实现的Python解释,Jython。Eclipse可以直接安装EASE环境。本例中使用Eclipse[Mars][3],它已经自带了EASE环境,包和Jython引擎。
|
||||
|
||||
使用Eclipse安装对话框(`Help>Install New Software`...),安装EASE[http://download.eclipse.org/ease/update/nightly][4]
|
||||
|
||||
选择下列组件:
|
||||
|
||||
- EASE Core feature
|
||||
|
||||
- EASE core UI feature
|
||||
|
||||
- EASE Python Developer Resources
|
||||
|
||||
- EASE modules (Incubation)
|
||||
|
||||
包括了EASE和模组。但是我们比较关心Resource包,此包可以访问Eclipse工作空间,项目和文件API。
|
||||
|
||||

|
||||
|
||||
|
||||
成功安装后,接下来安装Jython引擎[https://dl.bintray.com/pontesegger/ease-jython/][5].完成后,测试下。新建一个项目并新建一个hello.py文件,输入:
|
||||
|
||||
```
|
||||
print "hello world"
|
||||
```
|
||||
|
||||
选中这个文件,右击,选中'Run as -> EASE script'.这样就可以在控制台看到"Hello world"的输出.
|
||||
|
||||
配置完成,现在就可以轻松使用Python来控制工作空间和项目了.
|
||||
|
||||
### 提升你的代码质量
|
||||
|
||||
管理良好的代码质量本身是一件非常烦恼的事情,尤其是当需要处理一个大量代码库和要许多工程师参与的时候.而这些痛苦可以通过脚本来减轻,比如大量文字排版,或者[去掉文件中的unix行结束符][6]来使更容易比较.其他很棒的事情包括使用脚本让Eclipse markers高亮代码.这里有一些例子,你可以加入到task markers ,用"printStackTrace"方法在java文件中探测.请看[源码][7]
|
||||
|
||||
运行,拷贝文件到工作空间,右击运行.
|
||||
|
||||
```
|
||||
loadModule('/System/Resources')
|
||||
```
|
||||
|
||||
from org.eclipse.core.resources import IMarker
|
||||
|
||||
```
|
||||
for ifile in findFiles("*.java"):
|
||||
file_name = str(ifile.getLocation())
|
||||
print "Processing " + file_name
|
||||
with open(file_name) as f:
|
||||
for line_no, line in enumerate(f, start=1):
|
||||
if "printStackTrace" in line:
|
||||
marker = ifile.createMarker(IMarker.TASK)
|
||||
marker.setAttribute(IMarker.TRANSIENT, True)
|
||||
marker.setAttribute(IMarker.LINE_NUMBER, line_no)
|
||||
marker.setAttribute(IMarker.MESSAGE, "Fix in Sprint 2: " + line.strip())
|
||||
|
||||
```
|
||||
|
||||
如果你的任何java文件中包含了printStackTraces,你就可以看见编辑器的侧边栏上自动加上的标记.
|
||||
|
||||

|
||||
|
||||
### 自动构建繁琐任务
|
||||
|
||||
当同时工作在多个项目的时候,肯定需要需要完成许多繁杂,重复的任务.可能你需要在所有源文件头上加入CopyRight, 或者采用新框架时候自动更新文件.例如,当从Tycho迁移到Maven时候,我们给每一个项目必须添加pom.xml文件.使用Python可以很轻松的完成这个任务.只从Tycho提供无pom构建后,我们也需要移除不要的pom文件.同样,只需要几行代码就可以完成这个任务.例如,这里有个脚本可以在每一个打开的工作空间项目上加入README.md.请看源代码[add_readme.py][8].
|
||||
|
||||
拷贝文件到工作空间,右击并选择"Run as -> EASE script"
|
||||
|
||||
loadModule('/System/Resources')
|
||||
|
||||
```
|
||||
for iproject in getWorkspace().getProjects():
|
||||
if not iproject.isOpen():
|
||||
continue
|
||||
|
||||
ifile = iproject.getFile("README.md")
|
||||
|
||||
if not ifile.exists():
|
||||
contents = "# " + iproject.getName() + "\n\n"
|
||||
if iproject.hasNature("org.eclipse.jdt.core.javanature"):
|
||||
contents += "A Java Project\n"
|
||||
elif iproject.hasNature("org.python.pydev.pythonNature"):
|
||||
contents += "A Python Project\n"
|
||||
writeFile(ifile, contents)
|
||||
```
|
||||
|
||||
脚本结果会在打开的项目中加入README.md,java和Python项目还会自动加上一行描述.
|
||||
|
||||

|
||||
|
||||
### 构建新功能
|
||||
|
||||
Python脚本可以快速构建一些需要的附加功能,或者给团队和用户快速构建demo.例如,一个现在Eclipse目前不支持的功能,自动保存工作的文件.即使这个功能将会很快提供,但是你现在就可以马上拥有一个能30秒自动保存的编辑器.以下是主方法的片段.请看下列代码:[autosave.py][9]
|
||||
|
||||
```
|
||||
def save_dirty_editors():
|
||||
workbench = getService(org.eclipse.ui.IWorkbench)
|
||||
for window in workbench.getWorkbenchWindows():
|
||||
for page in window.getPages():
|
||||
for editor_ref in page.getEditorReferences():
|
||||
part = editor_ref.getPart(False)
|
||||
if part and part.isDirty():
|
||||
print "Auto-Saving", part.getTitle()
|
||||
part.doSave(None)
|
||||
```
|
||||
|
||||
在运行脚本之前,你需要勾选'Allow Scripts to run code in UI thread'设定,这个设定在Window > Preferences > Scripting中.然后添加脚本到工作空间,右击和选择"Run as > EASE Script".每10秒自动保存的信息就会在控制台输出.关掉自动保存脚本,只需要在点击控制台的红色方框.
|
||||
|
||||

|
||||
|
||||
### 快速扩展用户界面
|
||||
|
||||
EASE最棒的事情是可以通过脚本与UI元素挂钩,可以调整你的IDE,例如,在菜单中新建一个按钮.不需要编写java代码或者新的插件,只需要增加几行代码.
|
||||
|
||||
下面是一个简单的基脚本示例,用来产生三个新项目.
|
||||
|
||||
```
|
||||
# name : Create fruit projects
|
||||
# toolbar : Project Explorer
|
||||
# description : Create fruit projects
|
||||
|
||||
loadModule("/System/Resources")
|
||||
|
||||
for name in ["banana", "pineapple", "mango"]:
|
||||
createProject(name)
|
||||
```
|
||||
|
||||
上述特别的EASE增加了一个按钮到项目浏览工具条.下面这个脚本是用来删除这三个项目.请看源码[createProjects.py][10]和[deleteProjects.py][11].
|
||||
|
||||
```
|
||||
# name :Delete fruit projects
|
||||
# toolbar : Project Explorer
|
||||
# description : Get rid of the fruit projects
|
||||
|
||||
loadModule("/System/Resources")
|
||||
|
||||
for name in ["banana", "pineapple", "mango"]:
|
||||
project = getProject(name)
|
||||
project.delete(0, None)
|
||||
```
|
||||
|
||||
为了使脚本启动生效按钮,增加脚本到'ScriptsProject'文件夹.然后选择Windows > Preference > Scripting > Script 中定位到文件夹.点击'Add Workspace'按钮和选择ScriptProject项目.这个项目现在将会在启动时默认加载.你可以发现Project Explorer上出现了这两个按钮,这样你就可以通过这两个按钮快速增加删除项目.
|
||||
|
||||

|
||||
|
||||
### 整合三方工具
|
||||
|
||||
无论何时,你可能需要除了Eclipse生态系统以外的工具.这些时候你会发将他们包装在一个脚本来调用会非常方便.这里有一个简单的例子让你整合explorer.exe,并加入它到右键菜单栏,这样点击图标就可以打开浏览器浏览当前文件.请看源码[explorer.py][12]
|
||||
|
||||
```
|
||||
# name : Explore from here
|
||||
# popup : enableFor(org.eclipse.core.resources.IResource)
|
||||
# description : Start a file browser using current selection
|
||||
loadModule("/System/Platform")
|
||||
loadModule('/System/UI')
|
||||
|
||||
selection = getSelection()
|
||||
if isinstance(selection, org.eclipse.jface.viewers.IStructuredSelection):
|
||||
selection = selection.getFirstElement()
|
||||
|
||||
if not isinstance(selection, org.eclipse.core.resources.IResource):
|
||||
selection = adapt(selection, org.eclipse.core.resources.IResource)
|
||||
|
||||
if isinstance(selection, org.eclipse.core.resources.IFile):
|
||||
selection = selection.getParent()
|
||||
|
||||
if isinstance(selection, org.eclipse.core.resources.IContainer):
|
||||
runProcess("explorer.exe", [selection.getLocation().toFile().toString()])
|
||||
```
|
||||
|
||||
为了让菜单显示增加,像之前一样加入'ScriptProject'.在文件上右击,你看弹出菜单是不是出现了图标.选择Explore from here.
|
||||
|
||||

|
||||
|
||||
Eclipse高级基本环境提供一套很棒的扩展功能,使得Eclipse IDE能使用Python来轻易扩展.虽然这个项目还在婴儿期,但是[关于这个项目][13]更多更棒的功能也正在加紧开发中,如果你想为这个贡献,请到[论坛][14]讨论.
|
||||
|
||||
2016年[Eclipsecon North America][15]会议将会发布更多EASE细节.我的演讲[Scripting Eclipse with Python][16]也会不单介绍Jython,也包括C-Python和其他功能性扩展的实战例子.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/2/how-use-python-hack-your-ide
|
||||
|
||||
作者:[Tracy Miranda][a]
|
||||
译者:[VicYu/Vic020](http://vicyu.net)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/tracymiranda
|
||||
[1]: https://eclipse.org/ease/
|
||||
[2]: https://www.eclipsecon.org/na2016/session/scripting-eclipse-python
|
||||
[3]: https://www.eclipse.org/downloads/packages/eclipse-ide-eclipse-committers-451/mars1
|
||||
[4]: http://download.eclipse.org/ease/update/nightly
|
||||
[5]: https://dl.bintray.com/pontesegger/ease-jython/
|
||||
[6]: http://code.activestate.com/recipes/66434-change-line-endings/
|
||||
[7]: https://gist.github.com/tracymiranda/6556482e278c9afc421d
|
||||
[8]: https://gist.github.com/tracymiranda/f20f233b40f1f79b1df2
|
||||
[9]: https://gist.github.com/tracymiranda/e9588d0976c46a987463
|
||||
[10]: https://gist.github.com/tracymiranda/55995daaea9a4db584dc
|
||||
[11]: https://gist.github.com/tracymiranda/baa218fc2c1a8e898194
|
||||
[12]: https://gist.github.com/tracymiranda/8aa3f0fc4bf44f4a5cd3
|
||||
[13]: https://eclipse.org/ease/
|
||||
[14]: https://dev.eclipse.org/mailman/listinfo/ease-dev
|
||||
[15]: https://www.eclipsecon.org/na2016
|
||||
[16]: https://www.eclipsecon.org/na2016/session/scripting-eclipse-python
|
||||
@ -0,0 +1,36 @@
|
||||
构建在开源之上的商业软件市场持续成长
|
||||
=====================================================================
|
||||
|
||||

|
||||
> 与会者在 Structure 上听取演讲,Structure Data 2016 也将在 UCSF Mission Bay 会议中心举办。图片来源:Structure Events。
|
||||
|
||||
如今真的很难低估开源项目对于企业软件市场的影响;开源集成如此快速地形成了规范,我们没能捕捉到转折点也情有可原。
|
||||
|
||||
举个例子,Hadoop,改变的不止是数据分析的世界。它引领了新一代数据公司,它们围绕开源项目创造自己的软件,按需调整和支持那些代码,更像红帽在 90 年代和 21 世纪早期拥抱 Linux 那样。软件越来越多地通过公有云交付,而不是购买者自己的服务器,拥有了令人惊奇的操作灵活性,但同时也带来了一些关于授权,支持以及价格之类的新问题。
|
||||
|
||||
我们多年来持续追踪这个趋势,它们组成了我们的 Structure Data 会议,而 Structure Data 2016 也不例外。三家围绕 Hadoop 最重要的大数据公司——Hortonworks,Cloudera 和 MapR——的 CEO 将会共同讨论它们是如何销售他们围绕开源项目的企业软件和服务,获利的同时回报那个社区项目。
|
||||
|
||||
以前在企业软件上获利是很容易的事情。一个客户购买了之后,企业供应商的一系列大型软件就变成了它自己的收银机,从维护合同和阶段性升级中获得近乎终生的收入,软件也越来越难以被替代,因为它已经成为了客户的业务核心。客户抱怨这种绑定,但如果它们想提高工作队伍的生产力也确实没有多少选择。
|
||||
|
||||
而现在的情况不再是这样了。尽管无数的公司还陷于在他们的基础设施上运行至关重要的巨大软件包,新的项目被使用开源技术部署到云服务器上。这让升级功能不再需要去掉大量软件包再重新安装别的,同时也让公司按需付费,而不是为一堆永远用不到的特性买单。
|
||||
|
||||
有很多客户想要利用开源项目的优势,而又不想建立和支持一支工程师队伍来调整开源项目以满足自己的需求。这些客户愿意为开源项目和在这之上的专有特性之间的差异付费。
|
||||
|
||||
这对于基础设施相关的软件来说格外正确。当然,你的客户们可以安装他们自己对项目的调整,比如 Hadoop,Spark 或 Node.js,但付费可以帮助他们自定义包部署如今重要的开源技术而不用自己干这些活儿。只需看看 Structure Data 2016 的发言者就明白了,比如 Confluent(Kafka),Databricks(Spark),以及 Cloudera-Hortonworks-MapR(Hadoop)三人组。
|
||||
|
||||
当然还有一个值得提到的是在出错的时候有个供应商给你指责。如果你的工程师弄糟了开源项目的实现,那你只能怪你自己了。但是如果你和一个愿意保证在服务级别的特定性能和正常运行时间指标的公司签订了合同,你就是愿意为支持,指导,以及在突然出现不可避免的问题时朝你公司外的人发火的机会买单。
|
||||
|
||||
构建在开源之上的商业软件市场的持续成长是我们在 Structure Data 上追踪多年的内容,如果这个话题正合你意,我们鼓励你加入我们,在旧金山,3 月 9 日和 10 日。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/enterprise/cloud-computing/889564-the-evolving-market-for-commercial-software-built-on-open-source-
|
||||
|
||||
作者:[Tom Krazit ][a]
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/community/forums/person/70513
|
||||
@ -0,0 +1,275 @@
|
||||
LFCS 系列第十四讲: Linux 进程资源使用监控和基于每个用户的进程限制设置
|
||||
=============================================================================================
|
||||
|
||||
由于 2016 年 2 月 2 号开始启用了新的 LFCS 考试要求,我们在已经发表的 [LFCS 系列][1] 基础上增加了一些必要的主题。为了准备考试,同时也建议你看看 [LFCE 系列][2] 文章。
|
||||
|
||||

|
||||
>第十四讲: 监控 Linux 进程并为每个用户设置进程限制
|
||||
|
||||
每个 Linux 系统管理员都应该知道如何验证硬件、资源和主要进程的完整性和可用性。另外,基于每个用户设置资源限制也是其中一项必备技能。
|
||||
|
||||
在这篇文章中,我们会介绍一些能够确保系统硬件和软件正常工作的方法,这些方法能够避免潜在的会导致生产环境下线或钱财损失的问题发生。
|
||||
|
||||
### 报告 Linux 进程统计信息
|
||||
|
||||
你可以使用 **mpstat** 单独查看每个处理器或者系统整体的活动,可以是每次一个快照或者动态更新。
|
||||
|
||||
为了使用这个工具,你首先需要安装 **sysstat**:
|
||||
|
||||
```
|
||||
# yum update && yum install sysstat [基于 CentOS 的系统]
|
||||
# aptitutde update && aptitude install sysstat [基于 Ubuntu 的系统]
|
||||
# zypper update && zypper install sysstat [基于 openSUSE 的系统]
|
||||
```
|
||||
|
||||
你可以在 [在 Linux 中学习 Sysstat 和其中的工具 mpstat、pidstat、iostat 和 sar][3] 了解更多和 sysstat 和其中的工具相关的信息。
|
||||
|
||||
安装完 **mpstat** 之后,就可以使用它生成处理器统计信息的报告。
|
||||
|
||||
你可以使用下面的命令每隔 2 秒显示所有 CPU(用 `-P` ALL 表示) 的 CPU 利用率(`-u`),共显示 **3** 次。
|
||||
|
||||
```
|
||||
# mpstat -P ALL -u 2 3
|
||||
```
|
||||
|
||||
### 事例输出
|
||||
|
||||
```
|
||||
Linux 3.19.0-32-generic (tecmint.com) Wednesday 30 March 2016 _x86_64_ (4 CPU)
|
||||
|
||||
11:41:07 IST CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
|
||||
11:41:09 IST all 5.85 0.00 1.12 0.12 0.00 0.00 0.00 0.00 0.00 92.91
|
||||
11:41:09 IST 0 4.48 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 94.53
|
||||
11:41:09 IST 1 2.50 0.00 0.50 0.00 0.00 0.00 0.00 0.00 0.00 97.00
|
||||
11:41:09 IST 2 6.44 0.00 0.99 0.00 0.00 0.00 0.00 0.00 0.00 92.57
|
||||
11:41:09 IST 3 10.45 0.00 1.99 0.00 0.00 0.00 0.00 0.00 0.00 87.56
|
||||
|
||||
11:41:09 IST CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
|
||||
11:41:11 IST all 11.60 0.12 1.12 0.50 0.00 0.00 0.00 0.00 0.00 86.66
|
||||
11:41:11 IST 0 10.50 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 88.50
|
||||
11:41:11 IST 1 14.36 0.00 1.49 2.48 0.00 0.00 0.00 0.00 0.00 81.68
|
||||
11:41:11 IST 2 2.00 0.50 1.00 0.00 0.00 0.00 0.00 0.00 0.00 96.50
|
||||
11:41:11 IST 3 19.40 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 79.60
|
||||
|
||||
11:41:11 IST CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
|
||||
11:41:13 IST all 5.69 0.00 1.24 0.00 0.00 0.00 0.00 0.00 0.00 93.07
|
||||
11:41:13 IST 0 2.97 0.00 1.49 0.00 0.00 0.00 0.00 0.00 0.00 95.54
|
||||
11:41:13 IST 1 10.78 0.00 1.47 0.00 0.00 0.00 0.00 0.00 0.00 87.75
|
||||
11:41:13 IST 2 2.00 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 97.00
|
||||
11:41:13 IST 3 6.93 0.00 0.50 0.00 0.00 0.00 0.00 0.00 0.00 92.57
|
||||
|
||||
Average: CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
|
||||
Average: all 7.71 0.04 1.16 0.21 0.00 0.00 0.00 0.00 0.00 90.89
|
||||
Average: 0 5.97 0.00 1.16 0.00 0.00 0.00 0.00 0.00 0.00 92.87
|
||||
Average: 1 9.24 0.00 1.16 0.83 0.00 0.00 0.00 0.00 0.00 88.78
|
||||
Average: 2 3.49 0.17 1.00 0.00 0.00 0.00 0.00 0.00 0.00 95.35
|
||||
Average: 3 12.25 0.00 1.16 0.00 0.00 0.00 0.00 0.00 0.00 86.59
|
||||
```
|
||||
|
||||
要查看指定的 **CPU**(在下面的例子中是 **CPU 0**),可以使用:
|
||||
|
||||
```
|
||||
# mpstat -P 0 -u 2 3
|
||||
```
|
||||
|
||||
### 事例输出
|
||||
|
||||
```
|
||||
Linux 3.19.0-32-generic (tecmint.com) Wednesday 30 March 2016 _x86_64_ (4 CPU)
|
||||
|
||||
11:42:08 IST CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
|
||||
11:42:10 IST 0 3.00 0.00 0.50 0.00 0.00 0.00 0.00 0.00 0.00 96.50
|
||||
11:42:12 IST 0 4.08 0.00 0.00 2.55 0.00 0.00 0.00 0.00 0.00 93.37
|
||||
11:42:14 IST 0 9.74 0.00 0.51 0.00 0.00 0.00 0.00 0.00 0.00 89.74
|
||||
Average: 0 5.58 0.00 0.34 0.85 0.00 0.00 0.00 0.00 0.00 93.23
|
||||
```
|
||||
|
||||
上面命令的输出包括这些列:
|
||||
|
||||
* `CPU`: 整数表示的处理器号或者 all 表示所有处理器的平局值。
|
||||
* `%usr`: 运行在用户级别的应用的 CPU 利用率百分数。
|
||||
* `%nice`: 和 `%usr` 相同,但有 nice 优先级。
|
||||
* `%sys`: 执行内核应用的 CPU 利用率百分比。这不包括用于处理中断或者硬件请求的时间。
|
||||
* `%iowait`: 指定(或所有) CPU 的空闲时间百分比,这表示当前 CPU 处于 I/O 操作密集的状态。更详细的解释(附带示例)可以查看[这里][4]。
|
||||
* `%irq`: 用于处理硬件中断的时间所占百分比。
|
||||
* `%soft`: 和 `%irq` 相同,但是软中断。
|
||||
* `%steal`: 当一个客户虚拟机在竞争 CPU 时,非自主等待(时间片窃取)所占时间的百分比。应该保持这个值尽可能小。如果这个值很大,意味着虚拟机正在或者将要停止运转。
|
||||
* `%guest`: 运行虚拟处理器所用的时间百分比。
|
||||
* `%idle`: CPU(s) 没有运行任何任务所占时间的百分比。如果你观察到这个值很小,意味着系统负载很重。在这种情况下,你需要查看详细的进程列表、以及下面将要讨论的内容来确定这是什么原因导致的。
|
||||
|
||||
运行下面的命令使处理器处于极高负载,然后在另一个终端执行 mpstat 命令:
|
||||
|
||||
```
|
||||
# dd if=/dev/zero of=test.iso bs=1G count=1
|
||||
# mpstat -u -P 0 2 3
|
||||
# ping -f localhost # Interrupt with Ctrl + C after mpstat below completes
|
||||
# mpstat -u -P 0 2 3
|
||||
```
|
||||
|
||||
最后,和 “正常” 情况下 **mpstat** 的输出作比较:
|
||||
|
||||

|
||||
> Linux 处理器相关统计信息报告
|
||||
|
||||
正如你在上面图示中看到的,在前面两个例子中,根据 `%idle` 的值可以判断 **CPU 0** 负载很高。
|
||||
|
||||
在下一部分,我们会讨论如何识别资源饥饿型进程,如何获取更多和它们相关的信息,以及如何采取恰当的措施。
|
||||
|
||||
### Linux 进程报告
|
||||
|
||||
我们可以使用有名的 `ps` 命令,用 `-eo` 选项(根据用户定义格式选中所有进程) 和 `--sort` 选项(指定自定义排序顺序)按照 CPU 使用率排序列出进程,例如:
|
||||
|
||||
```
|
||||
# ps -eo pid,ppid,cmd,%cpu,%mem --sort=-%cpu
|
||||
```
|
||||
|
||||
上面的命令只会显示 `PID`、`PPID`、和进程相关的命令、 CPU 使用率以及 RAM 使用率,并按照 CPU 使用率降序排序。创建 .iso 文件的时候运行上面的命令,下面是输出的前面几行:
|
||||
|
||||

|
||||
>根据 CPU 使用率查找进程
|
||||
|
||||
一旦我们找到了感兴趣的进程(例如 `PID=2822` 的进程),我们就可以进入 `/proc/PID`(本例中是 `/proc/2822`) 列出目录内容。
|
||||
|
||||
这个目录就是进程运行的时候保存多个关于该进程详细信息的文件和子目录的目录。
|
||||
|
||||
#### 例如:
|
||||
|
||||
* `/proc/2822/io` 包括该进程的 IO 统计信息( IO 操作时的读写字符数)。
|
||||
* `/proc/2822/attr/current` 显示了进程当前的 SELinux 安全属性。
|
||||
* `/proc/2822/attr/current` shows the current SELinux security attributes of the process.
|
||||
* `/proc/2822/cgroup` 如果启用了 CONFIG_CGROUPS 内核设置选项,这会显示该进程所属的控制组(简称 cgroups),你可以使用下面命令验证是否启用了 CONFIG_CGROUPS:
|
||||
|
||||
```
|
||||
# cat /boot/config-$(uname -r) | grep -i cgroups
|
||||
```
|
||||
|
||||
如果启用了该选项,你应该看到:
|
||||
|
||||
```
|
||||
CONFIG_CGROUPS=y
|
||||
```
|
||||
|
||||
根据 [红帽企业版 Linux 7 资源管理指南][5] 第一到四章的内容、[openSUSE 系统分析和调优指南][6] 第九章、[Ubuntu 14.04 服务器文档 Control Groups 章节][7],你可以使用 `cgroups` 管理每个进程允许使用的资源数目。
|
||||
|
||||
`/proc/2822/fd` 这个目录包含每个打开的描述进程的文件的符号链接。下面的截图显示了 tty1(第一个终端) 中创建 **.iso** 镜像进程的相关信息:
|
||||
|
||||

|
||||
>查找 Linux 进程信息
|
||||
|
||||
上面的截图显示 **stdin**(文件描述符 **0**)、**stdout**(文件描述符 **1**)、**stderr**(文件描述符 **2**) 相应地被映射到 **/dev/zero**、 **/root/test.iso** 和 **/dev/tty1**。
|
||||
|
||||
更多关于 `/proc` 信息的可以查看 Kernel.org 维护的 “`/proc` 文件系统” 和 Linux 开发者手册。
|
||||
|
||||
### 在 Linux 中为每个用户设置资源限制
|
||||
|
||||
如果你不够小心、让任意用户使用不受限制的进程数,最终你可能会遇到意外的系统关机或者由于系统进入不可用的状态而被锁住。为了防止这种情况发生,你应该为用户可以启动的进程数目设置上限。
|
||||
|
||||
你可以在 **/etc/security/limits.conf** 文件末尾添加下面一行来设置限制:
|
||||
|
||||
```
|
||||
* hard nproc 10
|
||||
```
|
||||
|
||||
第一个字段可以用来表示一个用户、组或者所有`(*)`, 第二个字段强制限制可以使用的进程数目(nproc) 为 **10**。退出并重新登录就可以使设置生效。
|
||||
|
||||
然后,让我们来看看非 root 用户(合法用户或非法用户) 试图引起 shell fork bomb[WiKi][12] 时会发生什么。如果我们没有设置限制, shell fork bomb 会无限制地启动函数的两个实例,然后无限循环地复制任意一个实例。最终导致你的系统卡死。
|
||||
|
||||
但是,如果使用了上面的限制,fort bomb 就不会成功,但用户仍然会被锁在外面直到系统管理员杀死相关的进程。
|
||||
|
||||

|
||||
>运行 Shell Fork Bomb
|
||||
|
||||
**提示**: `limits.conf` 文件中可以查看其它 **ulimit** 可以更改的限制。
|
||||
|
||||
### 其它 Linux 进程管理工具
|
||||
|
||||
除了上面讨论的工具, 一个系统管理员还可能需要:
|
||||
|
||||
**a)** 通过使用 **renice** 调整执行优先级(系统资源使用)。这意味着内核会根据分配的优先级(众所周知的 “**niceness**”,它是一个范围从 `-20` 到 `19` 的整数)给进程分配更多或更少的系统资源。
|
||||
|
||||
这个值越小,执行优先级越高。普通用户(而非 root)只能调高他们所有的进程的 niceness 值(意味着更低的优先级),而 root 用户可以调高或调低任何进程的 niceness 值。
|
||||
|
||||
renice 命令的基本语法如下:
|
||||
|
||||
```
|
||||
# renice [-n] <new priority> <UID, GID, PGID, or empty> identifier
|
||||
```
|
||||
|
||||
如果没有 new priority 后面的参数(为空),默认就是 PID。在这种情况下, **PID=identifier** 的进程的 niceness 值会被设置为 `<new priority>`。
|
||||
|
||||
**b)** 需要的时候中断一个进程的正常执行。这也就是通常所说的 [“杀死”进程][9]。实质上,这意味着给进程发送一个信号使它恰当地结束运行并以有序的方式释放任何占用的资源。
|
||||
|
||||
按照下面的方式使用 **kill** 命令[杀死进程][10]:
|
||||
|
||||
```
|
||||
# kill PID
|
||||
```
|
||||
|
||||
另外,你也可以使用 [pkill][11] 结束指定用户`(-u)`、指定组`(-G)` 甚至有共同 PPID`(-P)` 的所有进程。这些选项后面可以使用数字或者名称表示的标识符。
|
||||
|
||||
```
|
||||
# pkill [options] identifier
|
||||
```
|
||||
|
||||
例如:
|
||||
|
||||
```
|
||||
# pkill -G 1000
|
||||
```
|
||||
|
||||
会杀死组 `GID=1000` 的所有进程。
|
||||
|
||||
而
|
||||
|
||||
```
|
||||
# pkill -P 4993
|
||||
```
|
||||
|
||||
会杀死 `PPID 是 4993` 的所有进程。
|
||||
|
||||
在运行 `pkill` 之前,先用 `pgrep` 测试结果、或者使用 `-l` 选项列出进程名称是一个很好的办法。它需要和 `pkill` 相同的参数、但是只会返回进程的 PID(而不会有其它操作),而 `pkill` 会杀死进程。
|
||||
|
||||
```
|
||||
# pgrep -l -u gacanepa
|
||||
```
|
||||
|
||||
用下面的图片说明:
|
||||
|
||||

|
||||
>在 Linux 中查找用户运行的进程
|
||||
|
||||
### 总结
|
||||
|
||||
在这篇文章中我们探讨了一些监控资源使用的方法,以便验证 Linux 系统中重要硬件和软件组件的完整性和可用性。
|
||||
|
||||
我们也学习了如何在特殊情况下采取恰当的措施(通过调整给定进程的执行优先级或者结束进程)。
|
||||
|
||||
我们希望本篇中介绍的概念能对你有所帮助。如果你有任何疑问或者评论,可以使用下面的联系方式联系我们。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-basic-shell-scripting-and-linux-filesystem-troubleshooting/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/gacanepa/
|
||||
[1]: http://www.tecmint.com/sed-command-to-create-edit-and-manipulate-files-in-linux/
|
||||
[2]: http://www.tecmint.com/installing-network-services-and-configuring-services-at-system-boot/
|
||||
[3]: http://www.tecmint.com/sysstat-commands-to-monitor-linux/
|
||||
[4]: http://veithen.github.io/2013/11/18/iowait-linux.html
|
||||
[5]: https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/7/html/Resource_Management_Guide/index.html
|
||||
[6]: https://doc.opensuse.org/documentation/leap/tuning/html/book.sle.tuning/cha.tuning.cgroups.html
|
||||
[7]: https://help.ubuntu.com/lts/serverguide/cgroups.html
|
||||
[8]: http://man7.org/linux/man-pages/man5/proc.5.html
|
||||
[9]: http://www.tecmint.com/kill-processes-unresponsive-programs-in-ubuntu/
|
||||
[10]: http://www.tecmint.com/find-and-kill-running-processes-pid-in-linux/
|
||||
[11]: http://www.tecmint.com/how-to-kill-a-process-in-linux/
|
||||
[12]: https://en.wikipedia.org/wiki/Fork_bomb
|
||||
165
translated/tech/LXD/Part 1 - LXD 2.0--Introduction to LXD.md
Normal file
165
translated/tech/LXD/Part 1 - LXD 2.0--Introduction to LXD.md
Normal file
@ -0,0 +1,165 @@
|
||||
Part 1 - LXD 2.0: LXD 入门
|
||||
======================================
|
||||
|
||||
这是 [LXD 2.0 系列介绍文章][1]的第一篇。
|
||||
|
||||

|
||||
|
||||
|
||||
### 关于 LXD 几个常见问题
|
||||
|
||||
#### 什么是 LXD ?
|
||||
|
||||
简单地说, LXD 就是一个提供了 REST API 的 LXC 容器管理器。
|
||||
|
||||
LXD 最主要的目标就是使用 Linux 容器而不是硬件虚拟化向用户提供一种接近虚拟机的使用体验。
|
||||
|
||||
#### LXD 和 Docker/Rkt 又有什么关系呢 ?
|
||||
|
||||
这是一个最常被问起的问题,现在就让我们直接指出其中的不同吧。
|
||||
|
||||
LXD 聚焦于系统容器,通常也被称为架构容器。这就是说 LXD 容器实际上如在裸机或虚拟机上运行一般运行了一个完整的 Linux 操作系统。
|
||||
|
||||
这些容器一般基于一个干净的发布镜像并会长时间运行。传统的配置管理工具和部署工具可以如在虚拟机、云和物理机器上一样与 LXD 一起使用。
|
||||
|
||||
相对的, Docker 关注于短期的、无状态的最小容器,这些容器通常并不会升级或者重新配置,而是作为一个整体被替换掉。这就使得 Docker 及类似项目更像是一种软件发布机制,而不是一个机器管理工具。
|
||||
|
||||
这两种模型并不是完全互斥的。你完全可以使用 LXD 为你的用户提供一个完整的 Linux 系统,而他们可以在 LXD 内安装 Docker 来运行他们想要的软件。
|
||||
|
||||
|
||||
#### 为什么要用 LXD?
|
||||
|
||||
我们已经持续开发并改进 LXC 好几年了。 LXC 成功的实现了它的目标,它提供了一系列很棒的用于创建和管理容器的底层工具和库。
|
||||
|
||||
然而这些底层工具的使用界面对用户并不是很友好。使用它们需要用户有很多的基础知识以理解它们的工作方式和目的。同时,向后兼容旧的容器和部署策略也使得 LXC 无法默认使用一些安全特性,这导致用户需要进行更多人工操作来实现本可以自动完成的工作。
|
||||
|
||||
我们把 LXD 作为解决这些缺陷的一个很好的机会。作为一个长时间运行的守护进程, LXD 可以绕开 LXC 的许多限制,比如动态资源限制、无法进行容器迁移和高效的在线迁移;同时,它也为创造新的默认体验提供了机会:默认开启安全特性,对用户更加友好。
|
||||
|
||||
|
||||
### LXD 的主要组件
|
||||
|
||||
LXD 是由几个主要组件构成的,这些组件都是 LXD 目录结构、命令行客户端和 API 结构体里下可见的。
|
||||
|
||||
#### 容器
|
||||
|
||||
LXD 中的容器包括以下及部分:
|
||||
|
||||
- 根文件系统
|
||||
- 设备:包括磁盘、unix 字符/块设备、网络接口
|
||||
- 一组继承而来的容器配置文件
|
||||
- 属性(容器架构,暂时的或持久的,容器名)
|
||||
- 运行时状态(当时为了记录检查点、恢复时用到了 CRIU时)
|
||||
|
||||
#### 快照
|
||||
|
||||
容器快照和容器是一回事,只不过快照是不可修改的,只能被重命名,销毁或者用来恢复系统,但是无论如何都不能被修改。
|
||||
|
||||
值得注意的是,因为我们允许用户保存容器的运行时状态,这就有效的为我们提供了“有状态”的快照的功能。这就是说我们可以使用快照回滚容器的 CPU 和内存。
|
||||
|
||||
#### 镜像
|
||||
|
||||
LXD 是基于镜像实现的,所有的 LXD 容器都是来自于镜像。容器镜像通常是一些纯净的 Linux 发行版的镜像,类似于你们在虚拟机和云实例上使用的镜像。
|
||||
|
||||
所以就可以「发布」容器:使用容器制作一个镜像并在本地或者远程 LXD 主机上使用。
|
||||
|
||||
镜像通常使用全部或部分 sha256 哈希码来区分。因为输入长长的哈希码对用户来说不好,所以镜像可以使用几个自身的属性来区分,这就使得用户在镜像商店里方便搜索镜像。别名也可以用来 1 对 1 地把对用户友好的名字映射到某个镜像的哈希码。
|
||||
|
||||
LXD 安装时已经配置好了三个远程镜像服务器(参见下面的远程一节):
|
||||
|
||||
- “ubuntu:” 提供稳定版的 Ubuntu 镜像
|
||||
- “ubuntu-daily:” 提供每天构建出来的 Ubuntu
|
||||
- “images:” 社区维护的镜像服务器,提供一系列的 Linux 发布版,使用的是上游 LXC 的模板
|
||||
|
||||
LXD 守护进程会从镜像上次被使用开始自动缓存远程镜像一段时间(默认是 10 天),超过时限后这些镜像才会失效。
|
||||
|
||||
此外, LXD 还会自动更新远程镜像(除非指明不更新),所以本地的镜像会一直是最新版的。
|
||||
|
||||
|
||||
#### 配置
|
||||
|
||||
配置文件是一种在一处定义容器配置和容器设备,然后应用到一系列容器的方法。
|
||||
|
||||
一个容器可以被应用多个配置文件。当构建最终容器配置时(即通常的扩展配置),这些配置文件都会按照他们定义顺序被应用到容器上,当有重名的配置时,新的会覆盖掉旧的。然后本地容器设置会在这些基础上应用,覆盖所有来自配置文件的选项。
|
||||
|
||||
LXD 自带两种预配置的配置文件:
|
||||
|
||||
- 「 default 」配置是自动应用在所有容器之上,除非用户提供了一系列替代的配置文件。目前这个配置文件只做一件事,为容器定义 eth0 网络设备。
|
||||
- 「 docker” 」配置是一个允许你在容器里运行 Docker 容器的配置文件。它会要求 LXD 加载一些需要的内核模块以支持容器嵌套并创建一些设备入口。
|
||||
|
||||
#### 远程
|
||||
|
||||
如我之前提到的, LXD 是一个基于网络的守护进程。附带的命令行客户端可以与多个远程 LXD 服务器、镜像服务器通信。
|
||||
|
||||
默认情况下,我们的命令行客户端会与下面几个预定义的远程服务器通信:
|
||||
|
||||
- local:(默认的远程服务器,使用 UNIX socket 和本地的 LXD 守护进程通信)
|
||||
- ubuntu:( Ubuntu 镜像服务器,提供稳定版的 Ubuntu 镜像)
|
||||
- ubuntu-daily:( Ubuntu 镜像服务器,提供每天构建出来的 Ubuntu )
|
||||
- images:( images.linuxcontainers.org 镜像服务器)
|
||||
|
||||
所有这些远程服务器的组合都可以在命令行客户端里使用。
|
||||
|
||||
你也可以添加任意数量的远程 LXD 主机来监听网络。匿名的开放镜像服务器,或者通过认证可以管理远程容器的镜像服务器,都可以添加进来。
|
||||
|
||||
正是这种远程机制使得与远程镜像服务器交互及在主机间复制、移动容器成为可能。
|
||||
|
||||
### 安全性
|
||||
|
||||
我们设计 LXD 时的一个核心要求,就是在不修改现代 Linux 发行版的前提下,使容器尽可能的安全。
|
||||
|
||||
LXD 使用的、通过使用 LXC 库实现的主要安全特性有:
|
||||
|
||||
- 内核名字空间。尤其是用户名字空间,它让容器和系统剩余部分完全分离。LXD 默认使用用户名字空间(和 LXC 相反),并允许用户在需要的时候以容器为单位打开或关闭。
|
||||
- Seccomp 系统调用。用来隔离潜在危险的系统调用。
|
||||
- AppArmor:对 mount、socket、ptrace 和文件访问提供额外的限制。特别是限制跨容器通信。
|
||||
- Capabilities。阻止容器加载内核模块,修改主机系统时间,等等。
|
||||
- CGroups。限制资源使用,防止对主机的 DoS 攻击。
|
||||
|
||||
|
||||
为了对用户友好 , LXD 构建了一个新的配置语言把大部分的这些特性都抽象封装起来,而不是如 LXC 一般直接将这些特性暴露出来。举了例子,一个用户可以告诉 LXD 把主机设备放进容器而不需要手动检查他们的主/次设备号来更新 CGroup 策略。
|
||||
|
||||
和 LXD 本身通信是基于使用 TLS 1.2 保护的链路,这些链路只允许使用有限的几个被允许的密钥。当和那些经过系统证书认证之外的主机通信时, LXD 会提示用户验证主机的远程足迹(SSH 方式),然后把足迹缓存起来以供以后使用。
|
||||
|
||||
### REST 接口
|
||||
|
||||
LXD 的工作都是通过 REST 接口实现的。在客户端和守护进程之间并没有其他的通讯手段。
|
||||
|
||||
REST 接口可以通过本地的 unix socket 访问,这只需要经过组认证,或者经过 HTTP 套接字使用客户端认证进行通信。
|
||||
|
||||
REST 接口的结构能够和上文所说的不同的组件匹配,是一种简单、直观的使用方法。
|
||||
|
||||
当需要一种复杂的通信机制时, LXD 将会进行 websocket 协商完成剩余的通信工作。这主要用于交互式终端会话、容器迁移和事件通知。
|
||||
|
||||
LXD 2.0 附带了 1.0 版的稳定 API。虽然我们在 1.0 版 API 添加了额外的特性,但是这不会在 1.0 版 API 的端点里破坏向后兼容性,因为我们会声明额外的 API 扩展使得客户端可以找到新的接口。
|
||||
|
||||
### 容器规模化
|
||||
|
||||
虽然 LXD 提供了一个很好的命令行客户端,但是这个客户端并不能管理多个主机上大量的容器。在这种使用情况下,我们可以使用 OpenStack 的 nova-lxd 插件,它可以使 OpenStack 像使用虚拟机一样使用 LXD 容器。
|
||||
|
||||
这就允许在大量的主机上部署大量的 LXD 容器,然后使用 OpenStack 的 API 来管理网络、存储以及负载均衡。
|
||||
|
||||
### 额外信息
|
||||
|
||||
LXD 的主站在: <https://linuxcontainers.org/lxd>
|
||||
|
||||
LXD 的 GitHub 仓库: <https://github.com/lxc/lxd>
|
||||
|
||||
LXD 的邮件列表: <https://lists.linuxcontainers.org>
|
||||
|
||||
LXD 的 IRC 频道: #lxcontainers on irc.freenode.net
|
||||
|
||||
如果你不想或者不能在你的机器上安装 LXD ,你可以在 web 上[试试在线版的 LXD] [2] 。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.stgraber.org/2016/03/11/lxd-2-0-introduction-to-lxd-112/
|
||||
|
||||
作者:[Stéphane Graber][a]
|
||||
译者:[ezio](https://github.com/oska874)
|
||||
校对:[PurlingNayuki](https://github.com/PurlingNayuki)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.stgraber.org/author/stgraber/
|
||||
[1]: https://www.stgraber.org/2016/03/11/lxd-2-0-blog-post-series-012/
|
||||
[2]: https://linuxcontainers.org/lxd/try-it
|
||||
@ -0,0 +1,235 @@
|
||||
translating by ezio
|
||||
|
||||
Part 2 - LXD 2.0: 安装与配置
|
||||
=================================================
|
||||
|
||||
这是 LXD 2.0 [系列介绍文章][2]的第二篇。
|
||||
|
||||

|
||||
|
||||
### 安装篇
|
||||
|
||||
获得 LXD 有很多种办法。我们推荐你是用配合最新版的 LXC 和 Linux 内核使用 LXD,这样就可以享受到它的全部特性,但是注意,我们现在也在慢慢的降低对旧版本 Linux 发布版的支持。
|
||||
|
||||
#### Ubuntu 标准版
|
||||
|
||||
所有新发布的 LXD 都会在发布几分钟后上传到 Ubuntu 开发版的安装源里。这个安装包然后就会当作种子给全部其他的安装包源,供 Ubuntu 用户使用。
|
||||
|
||||
如果使用 Ubuntu 16.04 则可以直接安装:
|
||||
|
||||
```
|
||||
sudo apt install lxd
|
||||
```
|
||||
|
||||
如果运行的是 Ubuntu 14.04,可以这样安装:
|
||||
|
||||
```
|
||||
sudo apt -t trusty-backports install lxd
|
||||
```
|
||||
|
||||
#### Ubuntu Core
|
||||
|
||||
使用Ubuntu Core 稳定版的用户可以使用下面的命令安装 LXD:
|
||||
|
||||
```
|
||||
sudo snappy install lxd.stgraber
|
||||
```
|
||||
|
||||
#### ubuntu 官方 PPA
|
||||
|
||||
是哟个其他 Ubuntu 发布版 —— 比如 Ubuntu 15.10 —— 的用户可以添加下面的 PPA (Personal Package Archive) 来安装:
|
||||
|
||||
```
|
||||
sudo apt-add-repository ppa:ubuntu-lxc/stable
|
||||
sudo apt update
|
||||
sudo apt dist-upgrade
|
||||
sudo apt install lxd
|
||||
```
|
||||
|
||||
#### Gentoo
|
||||
|
||||
Gentoo 已经有了最新的 LXD 安装包,你可以直接安装:
|
||||
|
||||
```
|
||||
sudo emerge --ask lxd
|
||||
```
|
||||
|
||||
#### 源代码
|
||||
|
||||
如果你曾经编译过 Go 工程,那么从源代码编译 LXD 并不是十分困难。然而要住你的是你需要 LXC 的开发头文件。为了运行 LXD , 你的 发布版铜须也需要使用比较新的内核(最起码是 3.13),比较新的 LXC (1.1.4 或更高版本) ,LXCFS 以及支持用户子 uid/gid 分配的 shadow 。
|
||||
|
||||
从源代码编译 LXD 的最新指令可以在[上游 README][2]里找到。
|
||||
|
||||
### ubuntu 上的网络配置
|
||||
|
||||
Ubuntu 的安装包会很方便的给你提供一个 "lxdbr0" 网桥。这个网桥默认是没有配置过的,只提供通过 HTTP 代理的 IPV6 的本地连接。
|
||||
|
||||
要配置这个网桥和添加 IPV4 、 IPV6 子网,你可以运行下面的命令:
|
||||
|
||||
```
|
||||
sudo dpkg-reconfigure -p medium lxd
|
||||
```
|
||||
|
||||
或者直接通过 LXD 初始化命令一步一步的配置:
|
||||
|
||||
```
|
||||
sudo lxd init
|
||||
```
|
||||
|
||||
### 存储系统
|
||||
|
||||
LXD 提供了集中存储后端。在开始使用 LXD 之前,你最好直到自己想要的后端,因为我们不支持在后端之间迁移已经生成的容器。
|
||||
|
||||
各个[后端特性的比较表格][3]可以在这里找到。
|
||||
|
||||
#### ZFS
|
||||
|
||||
我们的推荐是 ZFS , 因为他能支持 LXD 的全部特性,同时提供最快和最可靠的容器体验。它包括了以容器为单位的磁盘配额,直接快照和恢复,优化了的迁移(发送/接收),以及快速从镜像创建容器。它同时也被认为要比 btrfs 更成熟。
|
||||
|
||||
要和 LXD 一起使用 ZFS ,你需要首先在你的系统上安装 ZFS。
|
||||
|
||||
如果你是用的是 Ubuntu 16.04 , 你只需要简单的使用命令安装:
|
||||
|
||||
```
|
||||
sudo apt install zfsutils-linux
|
||||
```
|
||||
|
||||
在 Ubuntu 15.10 上你可以这样安装:
|
||||
|
||||
```
|
||||
sudo apt install zfsutils-linux zfs-dkms
|
||||
```
|
||||
|
||||
如果是更旧的版本,你需要这样安装:
|
||||
|
||||
```
|
||||
sudo apt-add-repository ppa:zfs-native/stable
|
||||
sudo apt update
|
||||
sudo apt install ubuntu-zfs
|
||||
```
|
||||
|
||||
配置 LXD 只需要简单的执行下面的命令:
|
||||
|
||||
```
|
||||
sudo lxd init
|
||||
```
|
||||
|
||||
这条命令接下来会想你提问一下你想要的 ZFS 的配置,然后为你配置好 ZFS 。
|
||||
|
||||
#### btrfs
|
||||
|
||||
如果 ZFS 不可用,那么 btrfs 可以提供相同级别的集成,除了不会合理的报告容器内的磁盘使用情况(虽然配额还是可以用的)。
|
||||
|
||||
btrfs 同时拥有很好的嵌套属性,而这时 ZFS 所不具有的。也就是说如果你计划在 LXD 中再使用 LXD ,那么 btrfs 就很值得你考虑一下。
|
||||
|
||||
使用 btrfs 的话,LXD 不需要进行任何的配置,你只需要保证 `/var/lib/lxd` 是保存在 btrfs 文件系统中,然后 LXD 就会自动为你使用 btrfs 了。
|
||||
|
||||
#### LVM
|
||||
|
||||
如果 ZFS 和 btrfs 都不是你想要的,你仍然可以考虑使用 LVM。 LXD 会以自动精简配置的方式使用 LVM,为每个镜像和容器创建 LV,如果需要的话也会使用 LVM 的快照功能。
|
||||
|
||||
要配置 LXD 使用 LVM,需要创建一个 LVM 的 VG ,然后运行:
|
||||
|
||||
|
||||
```
|
||||
lxc config set storage.lvm_vg_name "THE-NAME-OF-YOUR-VG"
|
||||
```
|
||||
|
||||
默认情况下 LXD 使用 ext4 作为全部 LV 的文件系统。如果你喜欢的话可以改成 XFS:
|
||||
|
||||
```
|
||||
lxc config set storage.lvm_fstype xfs
|
||||
```
|
||||
|
||||
#### 简单目录
|
||||
|
||||
如果上面全部方案你都不打算使用, LXD 还可以工作,但是不会使用任何高级特性。它只会为每个容器创建一个目录,然后在创建每个容器时解压缩镜像的压缩包,在容器拷贝和快照时会进行一次完整的文件系统拷贝。
|
||||
|
||||
除了磁盘配额以外的特性都是支持的,但是很浪费磁盘空间,并且非常慢。如果你没有其他选择,这还是可以工作的,但是你还是需要认真的考虑一下上面的几个方案。
|
||||
|
||||
### 配置篇
|
||||
|
||||
LXD 守护进程的完整配置项列表可以在[这里找到][4]。
|
||||
|
||||
#### 网络配置
|
||||
|
||||
默认情况下 LXD 不会监听网络。和它通信的唯一办法是使用本地 unix socket 通过 `/var/lib/lxd/unix.socket` 进行通信。
|
||||
|
||||
要让 LXD 监听网络,下面有两个有用的命令:
|
||||
|
||||
```
|
||||
lxc config set core.https_address [::]
|
||||
lxc config set core.trust_password some-secret-string
|
||||
```
|
||||
|
||||
第一条命令将 LXD 绑定到 IPV6 地址 “::”,也就是监听机器的所有 IPV6 地址。你可以显式的使用一个特定的 IPV4 或者 IPV6 地址替代默认地址,如果你想绑定 TCP 端口(默认是 8443)的话可以在地址后面添加端口号即可。
|
||||
|
||||
第二条命令设置了密码,可以让远程客户端用来把自己添加到 LXD 可信证书中心。如果已经给主机设置了密码,当添加 LXD 主机时会提示输入密码, LXD 守护进程会保存他们的客户端的证书以确保客户端是可信的,这样就不需要再次输入密码(可以随时设置和取消)
|
||||
|
||||
你也可以选择不设置密码,然后通过给每个客户端发送 "client.crt" (来自于 `~/.config/lxc`)文件,然后把它添加到你自己的可信中信来实现人工验证每个新客户端是否可信,可以使用下面的命令:
|
||||
|
||||
```
|
||||
lxc config trust add client.crt
|
||||
```
|
||||
|
||||
#### 代理配置
|
||||
|
||||
In most setups, you’ll want the LXD daemon to fetch images from remote servers.
|
||||
|
||||
If you are in an environment where you must go through a HTTP(s) proxy to reach the outside world, you’ll want to set a few configuration keys or alternatively make sure that the standard PROXY environment variables are set in the daemon’s environment.
|
||||
|
||||
```
|
||||
lxc config set core.proxy_http http://squid01.internal:3128
|
||||
lxc config set core.proxy_https http://squid01.internal:3128
|
||||
lxc config set core.proxy_ignore_hosts image-server.local
|
||||
```
|
||||
|
||||
With those, all transfers initiated by LXD will use the squid01.internal HTTP proxy, except for traffic to the server at image-server.local
|
||||
|
||||
#### 镜像管理
|
||||
|
||||
LXD 使用动态镜像缓存。当从远程镜像创建容器的时候,它会自动把镜像下载到本地镜像商店,同时标志为已缓存并记录来源。几天后(默认10天)如果没有再被使用,那么这个镜像就会自动被删除。每个几小时(默认是6小时) LXD 还会检查一下这个镜像是否有新版本,然后更新镜像的本地拷贝。
|
||||
|
||||
所有这些都可以通过下面的配置选项进行配置:
|
||||
|
||||
```
|
||||
lxc config set images.remote_cache_expiry 5
|
||||
lxc config set images.auto_update_interval 24
|
||||
lxc config set images.auto_update_cached false
|
||||
```
|
||||
|
||||
这些命令让 LXD 修改了它的默认属性,缓存期替换为 5 天,更新间隔为 24 小时,而且只更新那些标志为自动更新的镜像(lxc 镜像拷贝有标志 `–auto-update`)而不是 LXD 自动缓存的镜像。
|
||||
|
||||
|
||||
### 总结
|
||||
|
||||
到这里为止,你就应该有了一个可以工作的、最新版的 LXD ,现在你可以开始用 LXD 了,或者等待我们的下一条博文,那时我们会介绍如何创建第一个容器以及使用 LXD 命令行工具操作容器。
|
||||
|
||||
### 额外信息
|
||||
|
||||
LXD 的主站在: <https://linuxcontainers.org/lxd>
|
||||
|
||||
LXD 的 GitHub 仓库: <https://github.com/lxc/lxd>
|
||||
|
||||
LXD 的邮件列表: <https://lists.linuxcontainers.org>
|
||||
|
||||
LXD 的 IRC 频道: #lxcontainers on irc.freenode.net
|
||||
|
||||
如果你不想或者不能在你的机器上安装 LXD ,你可以[试试在线版的 LXD][1] 。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.stgraber.org/2016/03/15/lxd-2-0-installing-and-configuring-lxd-212/
|
||||
|
||||
作者:[Stéphane Graber][a]
|
||||
译者:[ezio](https://github.com/oska874)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.stgraber.org/author/stgraber/
|
||||
[0]: https://www.stgraber.org/2016/03/11/lxd-2-0-blog-post-series-012/
|
||||
[1]: https://linuxcontainers.org/lxd/try-it
|
||||
[2]: https://github.com/lxc/lxd/blob/master/README.md
|
||||
[3]: https://github.com/lxc/lxd/blob/master/doc/storage-backends.md
|
||||
[4]: https://github.com/lxc/lxd/blob/master/doc/configuration.md
|
||||
Loading…
Reference in New Issue
Block a user